diff --git a/.gitignore b/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..074dc911d793a167c4836e60db87dfa7a34f3fd6
--- /dev/null
+++ b/.gitignore
@@ -0,0 +1,10 @@
+*.swp
+*.swo
+
+__pycache__
+*.pyc
+
+sr_interactive_tmp
+sr_interactive_tmp_output
+
+gradio_cached_examples
diff --git a/KAIR/LICENSE b/KAIR/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..ddd784fef1443dbdf6bbd00495564e93554c7e4c
--- /dev/null
+++ b/KAIR/LICENSE
@@ -0,0 +1,9 @@
+MIT License
+
+Copyright (c) 2019 Kai Zhang
+
+Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
diff --git a/KAIR/README.md b/KAIR/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..8dd33fabc499cf4287c6deaed49f9c6b04709241
--- /dev/null
+++ b/KAIR/README.md
@@ -0,0 +1,343 @@
+## Training and testing codes for USRNet, DnCNN, FFDNet, SRMD, DPSR, MSRResNet, ESRGAN, BSRGAN, SwinIR, VRT
+[](https://github.com/cszn/KAIR/releases) 
+
+[Kai Zhang](https://cszn.github.io/)
+
+*[Computer Vision Lab](https://vision.ee.ethz.ch/the-institute.html), ETH Zurich, Switzerland*
+
+_______
+- **_News (2022-02-15)_**: We release [the training codes](https://github.com/cszn/KAIR/blob/master/docs/README_VRT.md) of [VRT ](https://github.com/JingyunLiang/VRT) for video SR, deblurring and denoising.
+
+
+  +
+  +
+  +
+
+
+
+
+- **_News (2021-12-23)_**: Our techniques are adopted in [https://www.amemori.ai/](https://www.amemori.ai/).
+- **_News (2021-12-23)_**: Our new work for practical image denoising.
+
+- 
 +- [
+- [ ](https://imgsli.com/ODczMTc)
+[
](https://imgsli.com/ODczMTc)
+[ ](https://imgsli.com/ODczMTY)
+- **_News (2021-09-09)_**: Add [main_download_pretrained_models.py](https://github.com/cszn/KAIR/blob/master/main_download_pretrained_models.py) to download pre-trained models.
+- **_News (2021-09-08)_**: Add [matlab code](https://github.com/cszn/KAIR/tree/master/matlab) to zoom local part of an image for the purpose of comparison between different results.
+- **_News (2021-09-07)_**: We upload [the training code](https://github.com/cszn/KAIR/blob/master/docs/README_SwinIR.md) of [SwinIR ](https://github.com/JingyunLiang/SwinIR) and provide an [interactive online Colob demo for real-world image SR](https://colab.research.google.com/gist/JingyunLiang/a5e3e54bc9ef8d7bf594f6fee8208533/swinir-demo-on-real-world-image-sr.ipynb). Try to super-resolve your own images on Colab!
](https://imgsli.com/ODczMTY)
+- **_News (2021-09-09)_**: Add [main_download_pretrained_models.py](https://github.com/cszn/KAIR/blob/master/main_download_pretrained_models.py) to download pre-trained models.
+- **_News (2021-09-08)_**: Add [matlab code](https://github.com/cszn/KAIR/tree/master/matlab) to zoom local part of an image for the purpose of comparison between different results.
+- **_News (2021-09-07)_**: We upload [the training code](https://github.com/cszn/KAIR/blob/master/docs/README_SwinIR.md) of [SwinIR ](https://github.com/JingyunLiang/SwinIR) and provide an [interactive online Colob demo for real-world image SR](https://colab.research.google.com/gist/JingyunLiang/a5e3e54bc9ef8d7bf594f6fee8208533/swinir-demo-on-real-world-image-sr.ipynb). Try to super-resolve your own images on Colab!  +
+|Real-World Image (x4)|[BSRGAN, ICCV2021](https://github.com/cszn/BSRGAN)|[Real-ESRGAN](https://github.com/xinntao/Real-ESRGAN)|SwinIR (ours)|
+| :--- | :---: | :-----: | :-----: |
+|
+
+|Real-World Image (x4)|[BSRGAN, ICCV2021](https://github.com/cszn/BSRGAN)|[Real-ESRGAN](https://github.com/xinntao/Real-ESRGAN)|SwinIR (ours)|
+| :--- | :---: | :-----: | :-----: |
+| |
| |
| |
| +|
+| |
| |
| |
| |
+
+- **_News (2021-08-31)_**: We upload the [training code of BSRGAN](https://github.com/cszn/BSRGAN#training).
+- **_News (2021-08-24)_**: We upload the BSRGAN degradation model.
+- **_News (2021-08-22)_**: Support multi-feature-layer VGG perceptual loss and UNet discriminator.
+- **_News (2021-08-18)_**: We upload the extended BSRGAN degradation model. It is slightly different from our published version.
+
+- **_News (2021-06-03)_**: Add testing codes of [GPEN (CVPR21)](https://github.com/yangxy/GPEN) for face image enhancement: [main_test_face_enhancement.py](https://github.com/cszn/KAIR/blob/master/main_test_face_enhancement.py)
+
+
|
+
+- **_News (2021-08-31)_**: We upload the [training code of BSRGAN](https://github.com/cszn/BSRGAN#training).
+- **_News (2021-08-24)_**: We upload the BSRGAN degradation model.
+- **_News (2021-08-22)_**: Support multi-feature-layer VGG perceptual loss and UNet discriminator.
+- **_News (2021-08-18)_**: We upload the extended BSRGAN degradation model. It is slightly different from our published version.
+
+- **_News (2021-06-03)_**: Add testing codes of [GPEN (CVPR21)](https://github.com/yangxy/GPEN) for face image enhancement: [main_test_face_enhancement.py](https://github.com/cszn/KAIR/blob/master/main_test_face_enhancement.py)
+
+ +
+ +
+ +
+ +
+ +
+ +
+
+- **_News (2021-05-13)_**: Add [PatchGAN discriminator](https://github.com/cszn/KAIR/blob/master/models/network_discriminator.py).
+
+- **_News (2021-05-12)_**: Support distributed training, see also [https://github.com/xinntao/BasicSR/blob/master/docs/TrainTest.md](https://github.com/xinntao/BasicSR/blob/master/docs/TrainTest.md).
+
+- **_News (2021-01)_**: [BSRGAN](https://github.com/cszn/BSRGAN) for blind real image super-resolution will be added.
+
+- **_Pull requests are welcome!_**
+
+- **Correction (2020-10)**: If you use multiple GPUs for GAN training, remove or comment [Line 105](https://github.com/cszn/KAIR/blob/e52a6944c6a40ba81b88430ffe38fd6517e0449e/models/model_gan.py#L105) to enable `DataParallel` for fast training
+
+- **News (2020-10)**: Add [utils_receptivefield.py](https://github.com/cszn/KAIR/blob/master/utils/utils_receptivefield.py) to calculate receptive field.
+
+- **News (2020-8)**: A `deep plug-and-play image restoration toolbox` is released at [cszn/DPIR](https://github.com/cszn/DPIR).
+
+- **Tips (2020-8)**: Use [this](https://github.com/cszn/KAIR/blob/9fd17abff001ab82a22070f7e442bb5246d2d844/main_challenge_sr.py#L147) to avoid `out of memory` issue.
+
+- **News (2020-7)**: Add [main_challenge_sr.py](https://github.com/cszn/KAIR/blob/23b0d0f717980e48fad02513ba14045d57264fe1/main_challenge_sr.py#L90) to get `FLOPs`, `#Params`, `Runtime`, `#Activations`, `#Conv`, and `Max Memory Allocated`.
+```python
+from utils.utils_modelsummary import get_model_activation, get_model_flops
+input_dim = (3, 256, 256) # set the input dimension
+activations, num_conv2d = get_model_activation(model, input_dim)
+logger.info('{:>16s} : {:<.4f} [M]'.format('#Activations', activations/10**6))
+logger.info('{:>16s} : {:16s} : {:<.4f} [G]'.format('FLOPs', flops/10**9))
+num_parameters = sum(map(lambda x: x.numel(), model.parameters()))
+logger.info('{:>16s} : {:<.4f} [M]'.format('#Params', num_parameters/10**6))
+```
+
+- **News (2020-6)**: Add [USRNet (CVPR 2020)](https://github.com/cszn/USRNet) for training and testing.
+ - [Network Architecture](https://github.com/cszn/KAIR/blob/3357aa0e54b81b1e26ceb1cee990f39add235e17/models/network_usrnet.py#L309)
+ - [Dataset](https://github.com/cszn/KAIR/blob/6c852636d3715bb281637863822a42c72739122a/data/dataset_usrnet.py#L16)
+
+
+Clone repo
+----------
+```
+git clone https://github.com/cszn/KAIR.git
+```
+```
+pip install -r requirement.txt
+```
+
+
+
+Training
+----------
+
+You should modify the json file from [options](https://github.com/cszn/KAIR/tree/master/options) first, for example,
+setting ["gpu_ids": [0,1,2,3]](https://github.com/cszn/KAIR/blob/ff80d265f64de67dfb3ffa9beff8949773c81a3d/options/train_msrresnet_psnr.json#L4) if 4 GPUs are used,
+setting ["dataroot_H": "trainsets/trainH"](https://github.com/cszn/KAIR/blob/ff80d265f64de67dfb3ffa9beff8949773c81a3d/options/train_msrresnet_psnr.json#L24) if path of the high quality dataset is `trainsets/trainH`.
+
+- Training with `DataParallel` - PSNR
+
+
+```python
+python main_train_psnr.py --opt options/train_msrresnet_psnr.json
+```
+
+- Training with `DataParallel` - GAN
+
+```python
+python main_train_gan.py --opt options/train_msrresnet_gan.json
+```
+
+- Training with `DistributedDataParallel` - PSNR - 4 GPUs
+
+```python
+python -m torch.distributed.launch --nproc_per_node=4 --master_port=1234 main_train_psnr.py --opt options/train_msrresnet_psnr.json --dist True
+```
+
+- Training with `DistributedDataParallel` - PSNR - 8 GPUs
+
+```python
+python -m torch.distributed.launch --nproc_per_node=8 --master_port=1234 main_train_psnr.py --opt options/train_msrresnet_psnr.json --dist True
+```
+
+- Training with `DistributedDataParallel` - GAN - 4 GPUs
+
+```python
+python -m torch.distributed.launch --nproc_per_node=4 --master_port=1234 main_train_gan.py --opt options/train_msrresnet_gan.json --dist True
+```
+
+- Training with `DistributedDataParallel` - GAN - 8 GPUs
+
+```python
+python -m torch.distributed.launch --nproc_per_node=8 --master_port=1234 main_train_gan.py --opt options/train_msrresnet_gan.json --dist True
+```
+
+- Kill distributed training processes of `main_train_gan.py`
+
+```python
+kill $(ps aux | grep main_train_gan.py | grep -v grep | awk '{print $2}')
+```
+
+----------
+| Method | Original Link |
+|---|---|
+| DnCNN |[https://github.com/cszn/DnCNN](https://github.com/cszn/DnCNN)|
+| FDnCNN |[https://github.com/cszn/DnCNN](https://github.com/cszn/DnCNN)|
+| FFDNet | [https://github.com/cszn/FFDNet](https://github.com/cszn/FFDNet)|
+| SRMD | [https://github.com/cszn/SRMD](https://github.com/cszn/SRMD)|
+| DPSR-SRResNet | [https://github.com/cszn/DPSR](https://github.com/cszn/DPSR)|
+| SRResNet | [https://github.com/xinntao/BasicSR](https://github.com/xinntao/BasicSR)|
+| ESRGAN | [https://github.com/xinntao/ESRGAN](https://github.com/xinntao/ESRGAN)|
+| RRDB | [https://github.com/xinntao/ESRGAN](https://github.com/xinntao/ESRGAN)|
+| IMDB | [https://github.com/Zheng222/IMDN](https://github.com/Zheng222/IMDN)|
+| USRNet | [https://github.com/cszn/USRNet](https://github.com/cszn/USRNet)|
+| DRUNet | [https://github.com/cszn/DPIR](https://github.com/cszn/DPIR)|
+| DPIR | [https://github.com/cszn/DPIR](https://github.com/cszn/DPIR)|
+| BSRGAN | [https://github.com/cszn/BSRGAN](https://github.com/cszn/BSRGAN)|
+| SwinIR | [https://github.com/JingyunLiang/SwinIR](https://github.com/JingyunLiang/SwinIR)|
+| VRT | [https://github.com/JingyunLiang/VRT](https://github.com/JingyunLiang/VRT) |
+
+Network architectures
+----------
+* [USRNet](https://github.com/cszn/USRNet)
+
+
+
+
+- **_News (2021-05-13)_**: Add [PatchGAN discriminator](https://github.com/cszn/KAIR/blob/master/models/network_discriminator.py).
+
+- **_News (2021-05-12)_**: Support distributed training, see also [https://github.com/xinntao/BasicSR/blob/master/docs/TrainTest.md](https://github.com/xinntao/BasicSR/blob/master/docs/TrainTest.md).
+
+- **_News (2021-01)_**: [BSRGAN](https://github.com/cszn/BSRGAN) for blind real image super-resolution will be added.
+
+- **_Pull requests are welcome!_**
+
+- **Correction (2020-10)**: If you use multiple GPUs for GAN training, remove or comment [Line 105](https://github.com/cszn/KAIR/blob/e52a6944c6a40ba81b88430ffe38fd6517e0449e/models/model_gan.py#L105) to enable `DataParallel` for fast training
+
+- **News (2020-10)**: Add [utils_receptivefield.py](https://github.com/cszn/KAIR/blob/master/utils/utils_receptivefield.py) to calculate receptive field.
+
+- **News (2020-8)**: A `deep plug-and-play image restoration toolbox` is released at [cszn/DPIR](https://github.com/cszn/DPIR).
+
+- **Tips (2020-8)**: Use [this](https://github.com/cszn/KAIR/blob/9fd17abff001ab82a22070f7e442bb5246d2d844/main_challenge_sr.py#L147) to avoid `out of memory` issue.
+
+- **News (2020-7)**: Add [main_challenge_sr.py](https://github.com/cszn/KAIR/blob/23b0d0f717980e48fad02513ba14045d57264fe1/main_challenge_sr.py#L90) to get `FLOPs`, `#Params`, `Runtime`, `#Activations`, `#Conv`, and `Max Memory Allocated`.
+```python
+from utils.utils_modelsummary import get_model_activation, get_model_flops
+input_dim = (3, 256, 256) # set the input dimension
+activations, num_conv2d = get_model_activation(model, input_dim)
+logger.info('{:>16s} : {:<.4f} [M]'.format('#Activations', activations/10**6))
+logger.info('{:>16s} : {:16s} : {:<.4f} [G]'.format('FLOPs', flops/10**9))
+num_parameters = sum(map(lambda x: x.numel(), model.parameters()))
+logger.info('{:>16s} : {:<.4f} [M]'.format('#Params', num_parameters/10**6))
+```
+
+- **News (2020-6)**: Add [USRNet (CVPR 2020)](https://github.com/cszn/USRNet) for training and testing.
+ - [Network Architecture](https://github.com/cszn/KAIR/blob/3357aa0e54b81b1e26ceb1cee990f39add235e17/models/network_usrnet.py#L309)
+ - [Dataset](https://github.com/cszn/KAIR/blob/6c852636d3715bb281637863822a42c72739122a/data/dataset_usrnet.py#L16)
+
+
+Clone repo
+----------
+```
+git clone https://github.com/cszn/KAIR.git
+```
+```
+pip install -r requirement.txt
+```
+
+
+
+Training
+----------
+
+You should modify the json file from [options](https://github.com/cszn/KAIR/tree/master/options) first, for example,
+setting ["gpu_ids": [0,1,2,3]](https://github.com/cszn/KAIR/blob/ff80d265f64de67dfb3ffa9beff8949773c81a3d/options/train_msrresnet_psnr.json#L4) if 4 GPUs are used,
+setting ["dataroot_H": "trainsets/trainH"](https://github.com/cszn/KAIR/blob/ff80d265f64de67dfb3ffa9beff8949773c81a3d/options/train_msrresnet_psnr.json#L24) if path of the high quality dataset is `trainsets/trainH`.
+
+- Training with `DataParallel` - PSNR
+
+
+```python
+python main_train_psnr.py --opt options/train_msrresnet_psnr.json
+```
+
+- Training with `DataParallel` - GAN
+
+```python
+python main_train_gan.py --opt options/train_msrresnet_gan.json
+```
+
+- Training with `DistributedDataParallel` - PSNR - 4 GPUs
+
+```python
+python -m torch.distributed.launch --nproc_per_node=4 --master_port=1234 main_train_psnr.py --opt options/train_msrresnet_psnr.json --dist True
+```
+
+- Training with `DistributedDataParallel` - PSNR - 8 GPUs
+
+```python
+python -m torch.distributed.launch --nproc_per_node=8 --master_port=1234 main_train_psnr.py --opt options/train_msrresnet_psnr.json --dist True
+```
+
+- Training with `DistributedDataParallel` - GAN - 4 GPUs
+
+```python
+python -m torch.distributed.launch --nproc_per_node=4 --master_port=1234 main_train_gan.py --opt options/train_msrresnet_gan.json --dist True
+```
+
+- Training with `DistributedDataParallel` - GAN - 8 GPUs
+
+```python
+python -m torch.distributed.launch --nproc_per_node=8 --master_port=1234 main_train_gan.py --opt options/train_msrresnet_gan.json --dist True
+```
+
+- Kill distributed training processes of `main_train_gan.py`
+
+```python
+kill $(ps aux | grep main_train_gan.py | grep -v grep | awk '{print $2}')
+```
+
+----------
+| Method | Original Link |
+|---|---|
+| DnCNN |[https://github.com/cszn/DnCNN](https://github.com/cszn/DnCNN)|
+| FDnCNN |[https://github.com/cszn/DnCNN](https://github.com/cszn/DnCNN)|
+| FFDNet | [https://github.com/cszn/FFDNet](https://github.com/cszn/FFDNet)|
+| SRMD | [https://github.com/cszn/SRMD](https://github.com/cszn/SRMD)|
+| DPSR-SRResNet | [https://github.com/cszn/DPSR](https://github.com/cszn/DPSR)|
+| SRResNet | [https://github.com/xinntao/BasicSR](https://github.com/xinntao/BasicSR)|
+| ESRGAN | [https://github.com/xinntao/ESRGAN](https://github.com/xinntao/ESRGAN)|
+| RRDB | [https://github.com/xinntao/ESRGAN](https://github.com/xinntao/ESRGAN)|
+| IMDB | [https://github.com/Zheng222/IMDN](https://github.com/Zheng222/IMDN)|
+| USRNet | [https://github.com/cszn/USRNet](https://github.com/cszn/USRNet)|
+| DRUNet | [https://github.com/cszn/DPIR](https://github.com/cszn/DPIR)|
+| DPIR | [https://github.com/cszn/DPIR](https://github.com/cszn/DPIR)|
+| BSRGAN | [https://github.com/cszn/BSRGAN](https://github.com/cszn/BSRGAN)|
+| SwinIR | [https://github.com/JingyunLiang/SwinIR](https://github.com/JingyunLiang/SwinIR)|
+| VRT | [https://github.com/JingyunLiang/VRT](https://github.com/JingyunLiang/VRT) |
+
+Network architectures
+----------
+* [USRNet](https://github.com/cszn/USRNet)
+
+  +
+* DnCNN
+
+
+
+* DnCNN
+
+  +
+* IRCNN denoiser
+
+
+
+* IRCNN denoiser
+
+  +
+* FFDNet
+
+
+
+* FFDNet
+
+  +
+* SRMD
+
+
+
+* SRMD
+
+  +
+* SRResNet, SRGAN, RRDB, ESRGAN
+
+
+
+* SRResNet, SRGAN, RRDB, ESRGAN
+
+  +
+* IMDN
+
+
+
+* IMDN
+
+  -----
-----  +
+
+
+Testing
+----------
+|Method | [model_zoo](model_zoo)|
+|---|---|
+| [main_test_dncnn.py](main_test_dncnn.py) |```dncnn_15.pth, dncnn_25.pth, dncnn_50.pth, dncnn_gray_blind.pth, dncnn_color_blind.pth, dncnn3.pth```|
+| [main_test_ircnn_denoiser.py](main_test_ircnn_denoiser.py) | ```ircnn_gray.pth, ircnn_color.pth```|
+| [main_test_fdncnn.py](main_test_fdncnn.py) | ```fdncnn_gray.pth, fdncnn_color.pth, fdncnn_gray_clip.pth, fdncnn_color_clip.pth```|
+| [main_test_ffdnet.py](main_test_ffdnet.py) | ```ffdnet_gray.pth, ffdnet_color.pth, ffdnet_gray_clip.pth, ffdnet_color_clip.pth```|
+| [main_test_srmd.py](main_test_srmd.py) | ```srmdnf_x2.pth, srmdnf_x3.pth, srmdnf_x4.pth, srmd_x2.pth, srmd_x3.pth, srmd_x4.pth```|
+| | **The above models are converted from MatConvNet.** |
+| [main_test_dpsr.py](main_test_dpsr.py) | ```dpsr_x2.pth, dpsr_x3.pth, dpsr_x4.pth, dpsr_x4_gan.pth```|
+| [main_test_msrresnet.py](main_test_msrresnet.py) | ```msrresnet_x4_psnr.pth, msrresnet_x4_gan.pth```|
+| [main_test_rrdb.py](main_test_rrdb.py) | ```rrdb_x4_psnr.pth, rrdb_x4_esrgan.pth```|
+| [main_test_imdn.py](main_test_imdn.py) | ```imdn_x4.pth```|
+
+[model_zoo](model_zoo)
+--------
+- download link [https://drive.google.com/drive/folders/13kfr3qny7S2xwG9h7v95F5mkWs0OmU0D](https://drive.google.com/drive/folders/13kfr3qny7S2xwG9h7v95F5mkWs0OmU0D)
+
+[trainsets](trainsets)
+----------
+- [https://github.com/xinntao/BasicSR/blob/master/docs/DatasetPreparation.md](https://github.com/xinntao/BasicSR/blob/master/docs/DatasetPreparation.md)
+- [train400](https://github.com/cszn/DnCNN/tree/master/TrainingCodes/DnCNN_TrainingCodes_v1.0/data)
+- [DIV2K](https://data.vision.ee.ethz.ch/cvl/DIV2K/)
+- [Flickr2K](https://cv.snu.ac.kr/research/EDSR/Flickr2K.tar)
+- optional: use [split_imageset(original_dataroot, taget_dataroot, n_channels=3, p_size=512, p_overlap=96, p_max=800)](https://github.com/cszn/KAIR/blob/3ee0bf3e07b90ec0b7302d97ee2adb780617e637/utils/utils_image.py#L123) to get ```trainsets/trainH``` with small images for fast data loading
+
+[testsets](testsets)
+-----------
+- [https://github.com/xinntao/BasicSR/blob/master/docs/DatasetPreparation.md](https://github.com/xinntao/BasicSR/blob/master/docs/DatasetPreparation.md)
+- [set12](https://github.com/cszn/FFDNet/tree/master/testsets)
+- [bsd68](https://github.com/cszn/FFDNet/tree/master/testsets)
+- [cbsd68](https://github.com/cszn/FFDNet/tree/master/testsets)
+- [kodak24](https://github.com/cszn/FFDNet/tree/master/testsets)
+- [srbsd68](https://github.com/cszn/DPSR/tree/master/testsets/BSD68/GT)
+- set5
+- set14
+- cbsd100
+- urban100
+- manga109
+
+
+References
+----------
+```BibTex
+@article{liang2022vrt,
+title={VRT: A Video Restoration Transformer},
+author={Liang, Jingyun and Cao, Jiezhang and Fan, Yuchen and Zhang, Kai and Ranjan, Rakesh and Li, Yawei and Timofte, Radu and Van Gool, Luc},
+journal={arXiv preprint arXiv:2022.00000},
+year={2022}
+}
+@inproceedings{liang2021swinir,
+title={SwinIR: Image Restoration Using Swin Transformer},
+author={Liang, Jingyun and Cao, Jiezhang and Sun, Guolei and Zhang, Kai and Van Gool, Luc and Timofte, Radu},
+booktitle={IEEE International Conference on Computer Vision Workshops},
+pages={1833--1844},
+year={2021}
+}
+@inproceedings{zhang2021designing,
+title={Designing a Practical Degradation Model for Deep Blind Image Super-Resolution},
+author={Zhang, Kai and Liang, Jingyun and Van Gool, Luc and Timofte, Radu},
+booktitle={IEEE International Conference on Computer Vision},
+pages={4791--4800},
+year={2021}
+}
+@article{zhang2021plug, % DPIR & DRUNet & IRCNN
+ title={Plug-and-Play Image Restoration with Deep Denoiser Prior},
+ author={Zhang, Kai and Li, Yawei and Zuo, Wangmeng and Zhang, Lei and Van Gool, Luc and Timofte, Radu},
+ journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
+ year={2021}
+}
+@inproceedings{zhang2020aim, % efficientSR_challenge
+ title={AIM 2020 Challenge on Efficient Super-Resolution: Methods and Results},
+ author={Kai Zhang and Martin Danelljan and Yawei Li and Radu Timofte and others},
+ booktitle={European Conference on Computer Vision Workshops},
+ year={2020}
+}
+@inproceedings{zhang2020deep, % USRNet
+ title={Deep unfolding network for image super-resolution},
+ author={Zhang, Kai and Van Gool, Luc and Timofte, Radu},
+ booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
+ pages={3217--3226},
+ year={2020}
+}
+@article{zhang2017beyond, % DnCNN
+ title={Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising},
+ author={Zhang, Kai and Zuo, Wangmeng and Chen, Yunjin and Meng, Deyu and Zhang, Lei},
+ journal={IEEE Transactions on Image Processing},
+ volume={26},
+ number={7},
+ pages={3142--3155},
+ year={2017}
+}
+@inproceedings{zhang2017learning, % IRCNN
+title={Learning deep CNN denoiser prior for image restoration},
+author={Zhang, Kai and Zuo, Wangmeng and Gu, Shuhang and Zhang, Lei},
+booktitle={IEEE conference on computer vision and pattern recognition},
+pages={3929--3938},
+year={2017}
+}
+@article{zhang2018ffdnet, % FFDNet, FDnCNN
+ title={FFDNet: Toward a fast and flexible solution for CNN-based image denoising},
+ author={Zhang, Kai and Zuo, Wangmeng and Zhang, Lei},
+ journal={IEEE Transactions on Image Processing},
+ volume={27},
+ number={9},
+ pages={4608--4622},
+ year={2018}
+}
+@inproceedings{zhang2018learning, % SRMD
+ title={Learning a single convolutional super-resolution network for multiple degradations},
+ author={Zhang, Kai and Zuo, Wangmeng and Zhang, Lei},
+ booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
+ pages={3262--3271},
+ year={2018}
+}
+@inproceedings{zhang2019deep, % DPSR
+ title={Deep Plug-and-Play Super-Resolution for Arbitrary Blur Kernels},
+ author={Zhang, Kai and Zuo, Wangmeng and Zhang, Lei},
+ booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
+ pages={1671--1681},
+ year={2019}
+}
+@InProceedings{wang2018esrgan, % ESRGAN, MSRResNet
+ author = {Wang, Xintao and Yu, Ke and Wu, Shixiang and Gu, Jinjin and Liu, Yihao and Dong, Chao and Qiao, Yu and Loy, Chen Change},
+ title = {ESRGAN: Enhanced super-resolution generative adversarial networks},
+ booktitle = {The European Conference on Computer Vision Workshops (ECCVW)},
+ month = {September},
+ year = {2018}
+}
+@inproceedings{hui2019lightweight, % IMDN
+ title={Lightweight Image Super-Resolution with Information Multi-distillation Network},
+ author={Hui, Zheng and Gao, Xinbo and Yang, Yunchu and Wang, Xiumei},
+ booktitle={Proceedings of the 27th ACM International Conference on Multimedia (ACM MM)},
+ pages={2024--2032},
+ year={2019}
+}
+@inproceedings{zhang2019aim, % IMDN
+ title={AIM 2019 Challenge on Constrained Super-Resolution: Methods and Results},
+ author={Kai Zhang and Shuhang Gu and Radu Timofte and others},
+ booktitle={IEEE International Conference on Computer Vision Workshops},
+ year={2019}
+}
+@inproceedings{yang2021gan,
+ title={GAN Prior Embedded Network for Blind Face Restoration in the Wild},
+ author={Tao Yang, Peiran Ren, Xuansong Xie, and Lei Zhang},
+ booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
+ year={2021}
+}
+```
diff --git a/KAIR/data/__init__.py b/KAIR/data/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..8b137891791fe96927ad78e64b0aad7bded08bdc
--- /dev/null
+++ b/KAIR/data/__init__.py
@@ -0,0 +1 @@
+
diff --git a/KAIR/data/dataset_blindsr.py b/KAIR/data/dataset_blindsr.py
new file mode 100644
index 0000000000000000000000000000000000000000..3d16ae3418b45d3550f70c43cd56ac0491fe87b6
--- /dev/null
+++ b/KAIR/data/dataset_blindsr.py
@@ -0,0 +1,92 @@
+import random
+import numpy as np
+import torch.utils.data as data
+import utils.utils_image as util
+import os
+from utils import utils_blindsr as blindsr
+
+
+class DatasetBlindSR(data.Dataset):
+ '''
+ # -----------------------------------------
+ # dataset for BSRGAN
+ # -----------------------------------------
+ '''
+ def __init__(self, opt):
+ super(DatasetBlindSR, self).__init__()
+ self.opt = opt
+ self.n_channels = opt['n_channels'] if opt['n_channels'] else 3
+ self.sf = opt['scale'] if opt['scale'] else 4
+ self.shuffle_prob = opt['shuffle_prob'] if opt['shuffle_prob'] else 0.1
+ self.use_sharp = opt['use_sharp'] if opt['use_sharp'] else False
+ self.degradation_type = opt['degradation_type'] if opt['degradation_type'] else 'bsrgan'
+ self.lq_patchsize = self.opt['lq_patchsize'] if self.opt['lq_patchsize'] else 64
+ self.patch_size = self.opt['H_size'] if self.opt['H_size'] else self.lq_patchsize*self.sf
+
+ self.paths_H = util.get_image_paths(opt['dataroot_H'])
+ print(len(self.paths_H))
+
+# for n, v in enumerate(self.paths_H):
+# if 'face' in v:
+# del self.paths_H[n]
+# time.sleep(1)
+ assert self.paths_H, 'Error: H path is empty.'
+
+ def __getitem__(self, index):
+
+ L_path = None
+
+ # ------------------------------------
+ # get H image
+ # ------------------------------------
+ H_path = self.paths_H[index]
+ img_H = util.imread_uint(H_path, self.n_channels)
+ img_name, ext = os.path.splitext(os.path.basename(H_path))
+ H, W, C = img_H.shape
+
+ if H < self.patch_size or W < self.patch_size:
+ img_H = np.tile(np.random.randint(0, 256, size=[1, 1, self.n_channels], dtype=np.uint8), (self.patch_size, self.patch_size, 1))
+
+ # ------------------------------------
+ # if train, get L/H patch pair
+ # ------------------------------------
+ if self.opt['phase'] == 'train':
+
+ H, W, C = img_H.shape
+
+ rnd_h_H = random.randint(0, max(0, H - self.patch_size))
+ rnd_w_H = random.randint(0, max(0, W - self.patch_size))
+ img_H = img_H[rnd_h_H:rnd_h_H + self.patch_size, rnd_w_H:rnd_w_H + self.patch_size, :]
+
+ if 'face' in img_name:
+ mode = random.choice([0, 4])
+ img_H = util.augment_img(img_H, mode=mode)
+ else:
+ mode = random.randint(0, 7)
+ img_H = util.augment_img(img_H, mode=mode)
+
+ img_H = util.uint2single(img_H)
+ if self.degradation_type == 'bsrgan':
+ img_L, img_H = blindsr.degradation_bsrgan(img_H, self.sf, lq_patchsize=self.lq_patchsize, isp_model=None)
+ elif self.degradation_type == 'bsrgan_plus':
+ img_L, img_H = blindsr.degradation_bsrgan_plus(img_H, self.sf, shuffle_prob=self.shuffle_prob, use_sharp=self.use_sharp, lq_patchsize=self.lq_patchsize)
+
+ else:
+ img_H = util.uint2single(img_H)
+ if self.degradation_type == 'bsrgan':
+ img_L, img_H = blindsr.degradation_bsrgan(img_H, self.sf, lq_patchsize=self.lq_patchsize, isp_model=None)
+ elif self.degradation_type == 'bsrgan_plus':
+ img_L, img_H = blindsr.degradation_bsrgan_plus(img_H, self.sf, shuffle_prob=self.shuffle_prob, use_sharp=self.use_sharp, lq_patchsize=self.lq_patchsize)
+
+ # ------------------------------------
+ # L/H pairs, HWC to CHW, numpy to tensor
+ # ------------------------------------
+ img_H, img_L = util.single2tensor3(img_H), util.single2tensor3(img_L)
+
+ if L_path is None:
+ L_path = H_path
+
+ return {'L': img_L, 'H': img_H, 'L_path': L_path, 'H_path': H_path}
+
+ def __len__(self):
+ return len(self.paths_H)
diff --git a/KAIR/data/dataset_dncnn.py b/KAIR/data/dataset_dncnn.py
new file mode 100644
index 0000000000000000000000000000000000000000..2477e253c3449fd2bf2f133c79700a7fc8be619b
--- /dev/null
+++ b/KAIR/data/dataset_dncnn.py
@@ -0,0 +1,101 @@
+import os.path
+import random
+import numpy as np
+import torch
+import torch.utils.data as data
+import utils.utils_image as util
+
+
+class DatasetDnCNN(data.Dataset):
+ """
+ # -----------------------------------------
+ # Get L/H for denosing on AWGN with fixed sigma.
+ # Only dataroot_H is needed.
+ # -----------------------------------------
+ # e.g., DnCNN
+ # -----------------------------------------
+ """
+
+ def __init__(self, opt):
+ super(DatasetDnCNN, self).__init__()
+ print('Dataset: Denosing on AWGN with fixed sigma. Only dataroot_H is needed.')
+ self.opt = opt
+ self.n_channels = opt['n_channels'] if opt['n_channels'] else 3
+ self.patch_size = opt['H_size'] if opt['H_size'] else 64
+ self.sigma = opt['sigma'] if opt['sigma'] else 25
+ self.sigma_test = opt['sigma_test'] if opt['sigma_test'] else self.sigma
+
+ # ------------------------------------
+ # get path of H
+ # return None if input is None
+ # ------------------------------------
+ self.paths_H = util.get_image_paths(opt['dataroot_H'])
+
+ def __getitem__(self, index):
+
+ # ------------------------------------
+ # get H image
+ # ------------------------------------
+ H_path = self.paths_H[index]
+ img_H = util.imread_uint(H_path, self.n_channels)
+
+ L_path = H_path
+
+ if self.opt['phase'] == 'train':
+ """
+ # --------------------------------
+ # get L/H patch pairs
+ # --------------------------------
+ """
+ H, W, _ = img_H.shape
+
+ # --------------------------------
+ # randomly crop the patch
+ # --------------------------------
+ rnd_h = random.randint(0, max(0, H - self.patch_size))
+ rnd_w = random.randint(0, max(0, W - self.patch_size))
+ patch_H = img_H[rnd_h:rnd_h + self.patch_size, rnd_w:rnd_w + self.patch_size, :]
+
+ # --------------------------------
+ # augmentation - flip, rotate
+ # --------------------------------
+ mode = random.randint(0, 7)
+ patch_H = util.augment_img(patch_H, mode=mode)
+
+ # --------------------------------
+ # HWC to CHW, numpy(uint) to tensor
+ # --------------------------------
+ img_H = util.uint2tensor3(patch_H)
+ img_L = img_H.clone()
+
+ # --------------------------------
+ # add noise
+ # --------------------------------
+ noise = torch.randn(img_L.size()).mul_(self.sigma/255.0)
+ img_L.add_(noise)
+
+ else:
+ """
+ # --------------------------------
+ # get L/H image pairs
+ # --------------------------------
+ """
+ img_H = util.uint2single(img_H)
+ img_L = np.copy(img_H)
+
+ # --------------------------------
+ # add noise
+ # --------------------------------
+ np.random.seed(seed=0)
+ img_L += np.random.normal(0, self.sigma_test/255.0, img_L.shape)
+
+ # --------------------------------
+ # HWC to CHW, numpy to tensor
+ # --------------------------------
+ img_L = util.single2tensor3(img_L)
+ img_H = util.single2tensor3(img_H)
+
+ return {'L': img_L, 'H': img_H, 'H_path': H_path, 'L_path': L_path}
+
+ def __len__(self):
+ return len(self.paths_H)
diff --git a/KAIR/data/dataset_dnpatch.py b/KAIR/data/dataset_dnpatch.py
new file mode 100644
index 0000000000000000000000000000000000000000..289f92e6f454d8246b5128f9e834de9b1678ee73
--- /dev/null
+++ b/KAIR/data/dataset_dnpatch.py
@@ -0,0 +1,133 @@
+import random
+import numpy as np
+import torch
+import torch.utils.data as data
+import utils.utils_image as util
+
+
+class DatasetDnPatch(data.Dataset):
+ """
+ # -----------------------------------------
+ # Get L/H for denosing on AWGN with fixed sigma.
+ # ****Get all H patches first****
+ # Only dataroot_H is needed.
+ # -----------------------------------------
+ # e.g., DnCNN with BSD400
+ # -----------------------------------------
+ """
+
+ def __init__(self, opt):
+ super(DatasetDnPatch, self).__init__()
+ print('Get L/H for denosing on AWGN with fixed sigma. Only dataroot_H is needed.')
+ self.opt = opt
+ self.n_channels = opt['n_channels'] if opt['n_channels'] else 3
+ self.patch_size = opt['H_size'] if opt['H_size'] else 64
+
+ self.sigma = opt['sigma'] if opt['sigma'] else 25
+ self.sigma_test = opt['sigma_test'] if opt['sigma_test'] else self.sigma
+
+ self.num_patches_per_image = opt['num_patches_per_image'] if opt['num_patches_per_image'] else 40
+ self.num_sampled = opt['num_sampled'] if opt['num_sampled'] else 3000
+
+ # ------------------------------------
+ # get paths of H
+ # ------------------------------------
+ self.paths_H = util.get_image_paths(opt['dataroot_H'])
+ assert self.paths_H, 'Error: H path is empty.'
+
+ # ------------------------------------
+ # number of sampled H images
+ # ------------------------------------
+ self.num_sampled = min(self.num_sampled, len(self.paths_H))
+
+ # ------------------------------------
+ # reserve space with zeros
+ # ------------------------------------
+ self.total_patches = self.num_sampled * self.num_patches_per_image
+ self.H_data = np.zeros([self.total_patches, self.patch_size, self.patch_size, self.n_channels], dtype=np.uint8)
+
+ # ------------------------------------
+ # update H patches
+ # ------------------------------------
+ self.update_data()
+
+ def update_data(self):
+ """
+ # ------------------------------------
+ # update whole H patches
+ # ------------------------------------
+ """
+ self.index_sampled = random.sample(range(0, len(self.paths_H), 1), self.num_sampled)
+ n_count = 0
+
+ for i in range(len(self.index_sampled)):
+ H_patches = self.get_patches(self.index_sampled[i])
+ for H_patch in H_patches:
+ self.H_data[n_count,:,:,:] = H_patch
+ n_count += 1
+
+ print('Training data updated! Total number of patches is: %5.2f X %5.2f = %5.2f\n' % (len(self.H_data)//128, 128, len(self.H_data)))
+
+ def get_patches(self, index):
+ """
+ # ------------------------------------
+ # get H patches from an H image
+ # ------------------------------------
+ """
+ H_path = self.paths_H[index]
+ img_H = util.imread_uint(H_path, self.n_channels) # uint format
+
+ H, W = img_H.shape[:2]
+
+ H_patches = []
+
+ num = self.num_patches_per_image
+ for _ in range(num):
+ rnd_h = random.randint(0, max(0, H - self.patch_size))
+ rnd_w = random.randint(0, max(0, W - self.patch_size))
+ H_patch = img_H[rnd_h:rnd_h + self.patch_size, rnd_w:rnd_w + self.patch_size, :]
+ H_patches.append(H_patch)
+
+ return H_patches
+
+ def __getitem__(self, index):
+
+ H_path = 'toy.png'
+ if self.opt['phase'] == 'train':
+
+ patch_H = self.H_data[index]
+
+ # --------------------------------
+ # augmentation - flip and/or rotate
+ # --------------------------------
+ mode = random.randint(0, 7)
+ patch_H = util.augment_img(patch_H, mode=mode)
+
+ patch_H = util.uint2tensor3(patch_H)
+ patch_L = patch_H.clone()
+
+ # ------------------------------------
+ # add noise
+ # ------------------------------------
+ noise = torch.randn(patch_L.size()).mul_(self.sigma/255.0)
+ patch_L.add_(noise)
+
+ else:
+
+ H_path = self.paths_H[index]
+ img_H = util.imread_uint(H_path, self.n_channels)
+ img_H = util.uint2single(img_H)
+ img_L = np.copy(img_H)
+
+ # ------------------------------------
+ # add noise
+ # ------------------------------------
+ np.random.seed(seed=0)
+ img_L += np.random.normal(0, self.sigma_test/255.0, img_L.shape)
+ patch_L, patch_H = util.single2tensor3(img_L), util.single2tensor3(img_H)
+
+ L_path = H_path
+ return {'L': patch_L, 'H': patch_H, 'L_path': L_path, 'H_path': H_path}
+
+ def __len__(self):
+ return len(self.H_data)
diff --git a/KAIR/data/dataset_dpsr.py b/KAIR/data/dataset_dpsr.py
new file mode 100644
index 0000000000000000000000000000000000000000..012f8283df9aae394c51e904183de1a567cc7d39
--- /dev/null
+++ b/KAIR/data/dataset_dpsr.py
@@ -0,0 +1,131 @@
+import random
+import numpy as np
+import torch
+import torch.utils.data as data
+import utils.utils_image as util
+
+
+class DatasetDPSR(data.Dataset):
+ '''
+ # -----------------------------------------
+ # Get L/H/M for noisy image SR.
+ # Only "paths_H" is needed, sythesize bicubicly downsampled L on-the-fly.
+ # -----------------------------------------
+ # e.g., SRResNet super-resolver prior for DPSR
+ # -----------------------------------------
+ '''
+
+ def __init__(self, opt):
+ super(DatasetDPSR, self).__init__()
+ self.opt = opt
+ self.n_channels = opt['n_channels'] if opt['n_channels'] else 3
+ self.sf = opt['scale'] if opt['scale'] else 4
+ self.patch_size = self.opt['H_size'] if self.opt['H_size'] else 96
+ self.L_size = self.patch_size // self.sf
+ self.sigma = opt['sigma'] if opt['sigma'] else [0, 50]
+ self.sigma_min, self.sigma_max = self.sigma[0], self.sigma[1]
+ self.sigma_test = opt['sigma_test'] if opt['sigma_test'] else 0
+
+ # ------------------------------------
+ # get paths of L/H
+ # ------------------------------------
+ self.paths_H = util.get_image_paths(opt['dataroot_H'])
+ self.paths_L = util.get_image_paths(opt['dataroot_L'])
+
+ assert self.paths_H, 'Error: H path is empty.'
+
+ def __getitem__(self, index):
+
+ # ------------------------------------
+ # get H image
+ # ------------------------------------
+ H_path = self.paths_H[index]
+ img_H = util.imread_uint(H_path, self.n_channels)
+ img_H = util.uint2single(img_H)
+
+ # ------------------------------------
+ # modcrop for SR
+ # ------------------------------------
+ img_H = util.modcrop(img_H, self.sf)
+
+ # ------------------------------------
+ # sythesize L image via matlab's bicubic
+ # ------------------------------------
+ H, W, _ = img_H.shape
+ img_L = util.imresize_np(img_H, 1 / self.sf, True)
+
+ if self.opt['phase'] == 'train':
+ """
+ # --------------------------------
+ # get L/H patch pairs
+ # --------------------------------
+ """
+ H, W, C = img_L.shape
+
+ # --------------------------------
+ # randomly crop L patch
+ # --------------------------------
+ rnd_h = random.randint(0, max(0, H - self.L_size))
+ rnd_w = random.randint(0, max(0, W - self.L_size))
+ img_L = img_L[rnd_h:rnd_h + self.L_size, rnd_w:rnd_w + self.L_size, :]
+
+ # --------------------------------
+ # crop corresponding H patch
+ # --------------------------------
+ rnd_h_H, rnd_w_H = int(rnd_h * self.sf), int(rnd_w * self.sf)
+ img_H = img_H[rnd_h_H:rnd_h_H + self.patch_size, rnd_w_H:rnd_w_H + self.patch_size, :]
+
+ # --------------------------------
+ # augmentation - flip and/or rotate
+ # --------------------------------
+ mode = random.randint(0, 7)
+ img_L, img_H = util.augment_img(img_L, mode=mode), util.augment_img(img_H, mode=mode)
+
+ # --------------------------------
+ # get patch pairs
+ # --------------------------------
+ img_H, img_L = util.single2tensor3(img_H), util.single2tensor3(img_L)
+
+ # --------------------------------
+ # select noise level and get Gaussian noise
+ # --------------------------------
+ if random.random() < 0.1:
+ noise_level = torch.zeros(1).float()
+ else:
+ noise_level = torch.FloatTensor([np.random.uniform(self.sigma_min, self.sigma_max)])/255.0
+ # noise_level = torch.rand(1)*50/255.0
+ # noise_level = torch.min(torch.from_numpy(np.float32([7*np.random.chisquare(2.5)/255.0])),torch.Tensor([50./255.]))
+
+ else:
+
+ img_H, img_L = util.single2tensor3(img_H), util.single2tensor3(img_L)
+
+ noise_level = torch.FloatTensor([self.sigma_test])
+
+ # ------------------------------------
+ # add noise
+ # ------------------------------------
+ noise = torch.randn(img_L.size()).mul_(noise_level).float()
+ img_L.add_(noise)
+
+ # ------------------------------------
+ # get noise level map M
+ # ------------------------------------
+ M_vector = noise_level.unsqueeze(1).unsqueeze(1)
+ M = M_vector.repeat(1, img_L.size()[-2], img_L.size()[-1])
+
+
+ """
+ # -------------------------------------
+ # concat L and noise level map M
+ # -------------------------------------
+ """
+ img_L = torch.cat((img_L, M), 0)
+
+
+ L_path = H_path
+
+ return {'L': img_L, 'H': img_H, 'L_path': L_path, 'H_path': H_path}
+
+ def __len__(self):
+ return len(self.paths_H)
diff --git a/KAIR/data/dataset_fdncnn.py b/KAIR/data/dataset_fdncnn.py
new file mode 100644
index 0000000000000000000000000000000000000000..632bf4783452a06cb290147b808dd48854eaabac
--- /dev/null
+++ b/KAIR/data/dataset_fdncnn.py
@@ -0,0 +1,109 @@
+import random
+import numpy as np
+import torch
+import torch.utils.data as data
+import utils.utils_image as util
+
+
+class DatasetFDnCNN(data.Dataset):
+ """
+ # -----------------------------------------
+ # Get L/H/M for denosing on AWGN with a range of sigma.
+ # Only dataroot_H is needed.
+ # -----------------------------------------
+ # e.g., FDnCNN, H = f(cat(L, M)), M is noise level map
+ # -----------------------------------------
+ """
+
+ def __init__(self, opt):
+ super(DatasetFDnCNN, self).__init__()
+ self.opt = opt
+ self.n_channels = opt['n_channels'] if opt['n_channels'] else 3
+ self.patch_size = self.opt['H_size'] if opt['H_size'] else 64
+ self.sigma = opt['sigma'] if opt['sigma'] else [0, 75]
+ self.sigma_min, self.sigma_max = self.sigma[0], self.sigma[1]
+ self.sigma_test = opt['sigma_test'] if opt['sigma_test'] else 25
+
+ # -------------------------------------
+ # get the path of H, return None if input is None
+ # -------------------------------------
+ self.paths_H = util.get_image_paths(opt['dataroot_H'])
+
+ def __getitem__(self, index):
+ # -------------------------------------
+ # get H image
+ # -------------------------------------
+ H_path = self.paths_H[index]
+ img_H = util.imread_uint(H_path, self.n_channels)
+
+ L_path = H_path
+
+ if self.opt['phase'] == 'train':
+ """
+ # --------------------------------
+ # get L/H/M patch pairs
+ # --------------------------------
+ """
+ H, W = img_H.shape[:2]
+
+ # ---------------------------------
+ # randomly crop the patch
+ # ---------------------------------
+ rnd_h = random.randint(0, max(0, H - self.patch_size))
+ rnd_w = random.randint(0, max(0, W - self.patch_size))
+ patch_H = img_H[rnd_h:rnd_h + self.patch_size, rnd_w:rnd_w + self.patch_size, :]
+
+ # ---------------------------------
+ # augmentation - flip, rotate
+ # ---------------------------------
+ mode = random.randint(0, 7)
+ patch_H = util.augment_img(patch_H, mode=mode)
+
+ # ---------------------------------
+ # HWC to CHW, numpy(uint) to tensor
+ # ---------------------------------
+ img_H = util.uint2tensor3(patch_H)
+ img_L = img_H.clone()
+
+ # ---------------------------------
+ # get noise level
+ # ---------------------------------
+ # noise_level = torch.FloatTensor([np.random.randint(self.sigma_min, self.sigma_max)])/255.0
+ noise_level = torch.FloatTensor([np.random.uniform(self.sigma_min, self.sigma_max)])/255.0
+
+ noise_level_map = torch.ones((1, img_L.size(1), img_L.size(2))).mul_(noise_level).float() # torch.full((1, img_L.size(1), img_L.size(2)), noise_level)
+
+ # ---------------------------------
+ # add noise
+ # ---------------------------------
+ noise = torch.randn(img_L.size()).mul_(noise_level).float()
+ img_L.add_(noise)
+
+ else:
+ """
+ # --------------------------------
+ # get L/H/M image pairs
+ # --------------------------------
+ """
+ img_H = util.uint2single(img_H)
+ img_L = np.copy(img_H)
+ np.random.seed(seed=0)
+ img_L += np.random.normal(0, self.sigma_test/255.0, img_L.shape)
+ noise_level_map = torch.ones((1, img_L.shape[0], img_L.shape[1])).mul_(self.sigma_test/255.0).float() # torch.full((1, img_L.size(1), img_L.size(2)), noise_level)
+
+ # ---------------------------------
+ # L/H image pairs
+ # ---------------------------------
+ img_H, img_L = util.single2tensor3(img_H), util.single2tensor3(img_L)
+
+ """
+ # -------------------------------------
+ # concat L and noise level map M
+ # -------------------------------------
+ """
+ img_L = torch.cat((img_L, noise_level_map), 0)
+
+ return {'L': img_L, 'H': img_H, 'L_path': L_path, 'H_path': H_path}
+
+ def __len__(self):
+ return len(self.paths_H)
diff --git a/KAIR/data/dataset_ffdnet.py b/KAIR/data/dataset_ffdnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..b3fd53aee5b52362bd5f80b48cc808346d7dcc80
--- /dev/null
+++ b/KAIR/data/dataset_ffdnet.py
@@ -0,0 +1,103 @@
+import random
+import numpy as np
+import torch
+import torch.utils.data as data
+import utils.utils_image as util
+
+
+class DatasetFFDNet(data.Dataset):
+ """
+ # -----------------------------------------
+ # Get L/H/M for denosing on AWGN with a range of sigma.
+ # Only dataroot_H is needed.
+ # -----------------------------------------
+ # e.g., FFDNet, H = f(L, sigma), sigma is noise level
+ # -----------------------------------------
+ """
+
+ def __init__(self, opt):
+ super(DatasetFFDNet, self).__init__()
+ self.opt = opt
+ self.n_channels = opt['n_channels'] if opt['n_channels'] else 3
+ self.patch_size = self.opt['H_size'] if opt['H_size'] else 64
+ self.sigma = opt['sigma'] if opt['sigma'] else [0, 75]
+ self.sigma_min, self.sigma_max = self.sigma[0], self.sigma[1]
+ self.sigma_test = opt['sigma_test'] if opt['sigma_test'] else 25
+
+ # -------------------------------------
+ # get the path of H, return None if input is None
+ # -------------------------------------
+ self.paths_H = util.get_image_paths(opt['dataroot_H'])
+
+ def __getitem__(self, index):
+ # -------------------------------------
+ # get H image
+ # -------------------------------------
+ H_path = self.paths_H[index]
+ img_H = util.imread_uint(H_path, self.n_channels)
+
+ L_path = H_path
+
+ if self.opt['phase'] == 'train':
+ """
+ # --------------------------------
+ # get L/H/M patch pairs
+ # --------------------------------
+ """
+ H, W = img_H.shape[:2]
+
+ # ---------------------------------
+ # randomly crop the patch
+ # ---------------------------------
+ rnd_h = random.randint(0, max(0, H - self.patch_size))
+ rnd_w = random.randint(0, max(0, W - self.patch_size))
+ patch_H = img_H[rnd_h:rnd_h + self.patch_size, rnd_w:rnd_w + self.patch_size, :]
+
+ # ---------------------------------
+ # augmentation - flip, rotate
+ # ---------------------------------
+ mode = random.randint(0, 7)
+ patch_H = util.augment_img(patch_H, mode=mode)
+
+ # ---------------------------------
+ # HWC to CHW, numpy(uint) to tensor
+ # ---------------------------------
+ img_H = util.uint2tensor3(patch_H)
+ img_L = img_H.clone()
+
+ # ---------------------------------
+ # get noise level
+ # ---------------------------------
+ # noise_level = torch.FloatTensor([np.random.randint(self.sigma_min, self.sigma_max)])/255.0
+ noise_level = torch.FloatTensor([np.random.uniform(self.sigma_min, self.sigma_max)])/255.0
+
+ # ---------------------------------
+ # add noise
+ # ---------------------------------
+ noise = torch.randn(img_L.size()).mul_(noise_level).float()
+ img_L.add_(noise)
+
+ else:
+ """
+ # --------------------------------
+ # get L/H/sigma image pairs
+ # --------------------------------
+ """
+ img_H = util.uint2single(img_H)
+ img_L = np.copy(img_H)
+ np.random.seed(seed=0)
+ img_L += np.random.normal(0, self.sigma_test/255.0, img_L.shape)
+ noise_level = torch.FloatTensor([self.sigma_test/255.0])
+
+ # ---------------------------------
+ # L/H image pairs
+ # ---------------------------------
+ img_H, img_L = util.single2tensor3(img_H), util.single2tensor3(img_L)
+
+ noise_level = noise_level.unsqueeze(1).unsqueeze(1)
+
+
+ return {'L': img_L, 'H': img_H, 'C': noise_level, 'L_path': L_path, 'H_path': H_path}
+
+ def __len__(self):
+ return len(self.paths_H)
diff --git a/KAIR/data/dataset_jpeg.py b/KAIR/data/dataset_jpeg.py
new file mode 100644
index 0000000000000000000000000000000000000000..a847f0d47e8ad86f6349459b2d244075e9f27a92
--- /dev/null
+++ b/KAIR/data/dataset_jpeg.py
@@ -0,0 +1,118 @@
+import random
+import torch.utils.data as data
+import utils.utils_image as util
+import cv2
+
+
+class DatasetJPEG(data.Dataset):
+ def __init__(self, opt):
+ super(DatasetJPEG, self).__init__()
+ print('Dataset: JPEG compression artifact reduction (deblocking) with quality factor. Only dataroot_H is needed.')
+ self.opt = opt
+ self.n_channels = opt['n_channels'] if opt['n_channels'] else 3
+ self.patch_size = self.opt['H_size'] if opt['H_size'] else 128
+
+ self.quality_factor = opt['quality_factor'] if opt['quality_factor'] else 40
+ self.quality_factor_test = opt['quality_factor_test'] if opt['quality_factor_test'] else 40
+ self.is_color = opt['is_color'] if opt['is_color'] else False
+
+ # -------------------------------------
+ # get the path of H, return None if input is None
+ # -------------------------------------
+ self.paths_H = util.get_image_paths(opt['dataroot_H'])
+
+ def __getitem__(self, index):
+
+ if self.opt['phase'] == 'train':
+ # -------------------------------------
+ # get H image
+ # -------------------------------------
+ H_path = self.paths_H[index]
+ img_H = util.imread_uint(H_path, 3)
+ L_path = H_path
+
+ H, W = img_H.shape[:2]
+ self.patch_size_plus = self.patch_size + 8
+
+ # ---------------------------------
+ # randomly crop a large patch
+ # ---------------------------------
+ rnd_h = random.randint(0, max(0, H - self.patch_size_plus))
+ rnd_w = random.randint(0, max(0, W - self.patch_size_plus))
+ patch_H = img_H[rnd_h:rnd_h + self.patch_size_plus, rnd_w:rnd_w + self.patch_size_plus, ...]
+
+ # ---------------------------------
+ # augmentation - flip, rotate
+ # ---------------------------------
+ mode = random.randint(0, 7)
+ patch_H = util.augment_img(patch_H, mode=mode)
+
+ # ---------------------------------
+ # HWC to CHW, numpy(uint) to tensor
+ # ---------------------------------
+ img_L = patch_H.copy()
+
+ # ---------------------------------
+ # set quality factor
+ # ---------------------------------
+ quality_factor = self.quality_factor
+
+ if self.is_color: # color image
+ img_H = img_L.copy()
+ img_L = cv2.cvtColor(img_L, cv2.COLOR_RGB2BGR)
+ result, encimg = cv2.imencode('.jpg', img_L, [int(cv2.IMWRITE_JPEG_QUALITY), quality_factor])
+ img_L = cv2.imdecode(encimg, 1)
+ img_L = cv2.cvtColor(img_L, cv2.COLOR_BGR2RGB)
+ else:
+ if random.random() > 0.5:
+ img_L = util.rgb2ycbcr(img_L)
+ else:
+ img_L = cv2.cvtColor(img_L, cv2.COLOR_RGB2GRAY)
+ img_H = img_L.copy()
+ result, encimg = cv2.imencode('.jpg', img_L, [int(cv2.IMWRITE_JPEG_QUALITY), quality_factor])
+ img_L = cv2.imdecode(encimg, 0)
+
+ # ---------------------------------
+ # randomly crop a patch
+ # ---------------------------------
+ H, W = img_H.shape[:2]
+ if random.random() > 0.5:
+ rnd_h = random.randint(0, max(0, H - self.patch_size))
+ rnd_w = random.randint(0, max(0, W - self.patch_size))
+ else:
+ rnd_h = 0
+ rnd_w = 0
+ img_H = img_H[rnd_h:rnd_h + self.patch_size, rnd_w:rnd_w + self.patch_size]
+ img_L = img_L[rnd_h:rnd_h + self.patch_size, rnd_w:rnd_w + self.patch_size]
+ else:
+
+ H_path = self.paths_H[index]
+ L_path = H_path
+ # ---------------------------------
+ # set quality factor
+ # ---------------------------------
+ quality_factor = self.quality_factor_test
+
+ if self.is_color: # color JPEG image deblocking
+ img_H = util.imread_uint(H_path, 3)
+ img_L = img_H.copy()
+ img_L = cv2.cvtColor(img_L, cv2.COLOR_RGB2BGR)
+ result, encimg = cv2.imencode('.jpg', img_L, [int(cv2.IMWRITE_JPEG_QUALITY), quality_factor])
+ img_L = cv2.imdecode(encimg, 1)
+ img_L = cv2.cvtColor(img_L, cv2.COLOR_BGR2RGB)
+ else:
+ img_H = cv2.imread(H_path, cv2.IMREAD_UNCHANGED)
+ is_to_ycbcr = True if img_L.ndim == 3 else False
+ if is_to_ycbcr:
+ img_H = cv2.cvtColor(img_H, cv2.COLOR_BGR2RGB)
+ img_H = util.rgb2ycbcr(img_H)
+
+ result, encimg = cv2.imencode('.jpg', img_H, [int(cv2.IMWRITE_JPEG_QUALITY), quality_factor])
+ img_L = cv2.imdecode(encimg, 0)
+
+ img_L, img_H = util.uint2tensor3(img_L), util.uint2tensor3(img_H)
+
+ return {'L': img_L, 'H': img_H, 'L_path': L_path, 'H_path': H_path}
+
+ def __len__(self):
+ return len(self.paths_H)
diff --git a/KAIR/data/dataset_l.py b/KAIR/data/dataset_l.py
new file mode 100644
index 0000000000000000000000000000000000000000..9216311b1ca526d704e1f7211ece90453b7e7cea
--- /dev/null
+++ b/KAIR/data/dataset_l.py
@@ -0,0 +1,43 @@
+import torch.utils.data as data
+import utils.utils_image as util
+
+
+class DatasetL(data.Dataset):
+ '''
+ # -----------------------------------------
+ # Get L in testing.
+ # Only "dataroot_L" is needed.
+ # -----------------------------------------
+ # -----------------------------------------
+ '''
+
+ def __init__(self, opt):
+ super(DatasetL, self).__init__()
+ print('Read L in testing. Only "dataroot_L" is needed.')
+ self.opt = opt
+ self.n_channels = opt['n_channels'] if opt['n_channels'] else 3
+
+ # ------------------------------------
+ # get the path of L
+ # ------------------------------------
+ self.paths_L = util.get_image_paths(opt['dataroot_L'])
+ assert self.paths_L, 'Error: L paths are empty.'
+
+ def __getitem__(self, index):
+ L_path = None
+
+ # ------------------------------------
+ # get L image
+ # ------------------------------------
+ L_path = self.paths_L[index]
+ img_L = util.imread_uint(L_path, self.n_channels)
+
+ # ------------------------------------
+ # HWC to CHW, numpy to tensor
+ # ------------------------------------
+ img_L = util.uint2tensor3(img_L)
+
+ return {'L': img_L, 'L_path': L_path}
+
+ def __len__(self):
+ return len(self.paths_L)
diff --git a/KAIR/data/dataset_plain.py b/KAIR/data/dataset_plain.py
new file mode 100644
index 0000000000000000000000000000000000000000..605a4e8166425f1b79f5f1985b0ef0e08cc58b00
--- /dev/null
+++ b/KAIR/data/dataset_plain.py
@@ -0,0 +1,85 @@
+import random
+import numpy as np
+import torch.utils.data as data
+import utils.utils_image as util
+
+
+class DatasetPlain(data.Dataset):
+ '''
+ # -----------------------------------------
+ # Get L/H for image-to-image mapping.
+ # Both "paths_L" and "paths_H" are needed.
+ # -----------------------------------------
+ # e.g., train denoiser with L and H
+ # -----------------------------------------
+ '''
+
+ def __init__(self, opt):
+ super(DatasetPlain, self).__init__()
+ print('Get L/H for image-to-image mapping. Both "paths_L" and "paths_H" are needed.')
+ self.opt = opt
+ self.n_channels = opt['n_channels'] if opt['n_channels'] else 3
+ self.patch_size = self.opt['H_size'] if self.opt['H_size'] else 64
+
+ # ------------------------------------
+ # get the path of L/H
+ # ------------------------------------
+ self.paths_H = util.get_image_paths(opt['dataroot_H'])
+ self.paths_L = util.get_image_paths(opt['dataroot_L'])
+
+ assert self.paths_H, 'Error: H path is empty.'
+ assert self.paths_L, 'Error: L path is empty. Plain dataset assumes both L and H are given!'
+ if self.paths_L and self.paths_H:
+ assert len(self.paths_L) == len(self.paths_H), 'L/H mismatch - {}, {}.'.format(len(self.paths_L), len(self.paths_H))
+
+ def __getitem__(self, index):
+
+ # ------------------------------------
+ # get H image
+ # ------------------------------------
+ H_path = self.paths_H[index]
+ img_H = util.imread_uint(H_path, self.n_channels)
+
+ # ------------------------------------
+ # get L image
+ # ------------------------------------
+ L_path = self.paths_L[index]
+ img_L = util.imread_uint(L_path, self.n_channels)
+
+ # ------------------------------------
+ # if train, get L/H patch pair
+ # ------------------------------------
+ if self.opt['phase'] == 'train':
+
+ H, W, _ = img_H.shape
+
+ # --------------------------------
+ # randomly crop the patch
+ # --------------------------------
+ rnd_h = random.randint(0, max(0, H - self.patch_size))
+ rnd_w = random.randint(0, max(0, W - self.patch_size))
+ patch_L = img_L[rnd_h:rnd_h + self.patch_size, rnd_w:rnd_w + self.patch_size, :]
+ patch_H = img_H[rnd_h:rnd_h + self.patch_size, rnd_w:rnd_w + self.patch_size, :]
+
+ # --------------------------------
+ # augmentation - flip and/or rotate
+ # --------------------------------
+ mode = random.randint(0, 7)
+ patch_L, patch_H = util.augment_img(patch_L, mode=mode), util.augment_img(patch_H, mode=mode)
+
+ # --------------------------------
+ # HWC to CHW, numpy(uint) to tensor
+ # --------------------------------
+ img_L, img_H = util.uint2tensor3(patch_L), util.uint2tensor3(patch_H)
+
+ else:
+
+ # --------------------------------
+ # HWC to CHW, numpy(uint) to tensor
+ # --------------------------------
+ img_L, img_H = util.uint2tensor3(img_L), util.uint2tensor3(img_H)
+
+ return {'L': img_L, 'H': img_H, 'L_path': L_path, 'H_path': H_path}
+
+ def __len__(self):
+ return len(self.paths_H)
diff --git a/KAIR/data/dataset_plainpatch.py b/KAIR/data/dataset_plainpatch.py
new file mode 100644
index 0000000000000000000000000000000000000000..2278bf00aca7f77514fe5b3a5e70b7b562baa13d
--- /dev/null
+++ b/KAIR/data/dataset_plainpatch.py
@@ -0,0 +1,131 @@
+import os.path
+import random
+import numpy as np
+import torch.utils.data as data
+import utils.utils_image as util
+
+
+
+class DatasetPlainPatch(data.Dataset):
+ '''
+ # -----------------------------------------
+ # Get L/H for image-to-image mapping.
+ # Both "paths_L" and "paths_H" are needed.
+ # -----------------------------------------
+ # e.g., train denoiser with L and H patches
+ # create a large patch dataset first
+ # -----------------------------------------
+ '''
+
+ def __init__(self, opt):
+ super(DatasetPlainPatch, self).__init__()
+ print('Get L/H for image-to-image mapping. Both "paths_L" and "paths_H" are needed.')
+ self.opt = opt
+ self.n_channels = opt['n_channels'] if opt['n_channels'] else 3
+ self.patch_size = self.opt['H_size'] if self.opt['H_size'] else 64
+
+ self.num_patches_per_image = opt['num_patches_per_image'] if opt['num_patches_per_image'] else 40
+ self.num_sampled = opt['num_sampled'] if opt['num_sampled'] else 3000
+
+ # -------------------
+ # get the path of L/H
+ # -------------------
+ self.paths_H = util.get_image_paths(opt['dataroot_H'])
+ self.paths_L = util.get_image_paths(opt['dataroot_L'])
+
+ assert self.paths_H, 'Error: H path is empty.'
+ assert self.paths_L, 'Error: L path is empty. This dataset uses L path, you can use dataset_dnpatchh'
+ if self.paths_L and self.paths_H:
+ assert len(self.paths_L) == len(self.paths_H), 'H and L datasets have different number of images - {}, {}.'.format(len(self.paths_L), len(self.paths_H))
+
+ # ------------------------------------
+ # number of sampled images
+ # ------------------------------------
+ self.num_sampled = min(self.num_sampled, len(self.paths_H))
+
+ # ------------------------------------
+ # reserve space with zeros
+ # ------------------------------------
+ self.total_patches = self.num_sampled * self.num_patches_per_image
+ self.H_data = np.zeros([self.total_patches, self.path_size, self.path_size, self.n_channels], dtype=np.uint8)
+ self.L_data = np.zeros([self.total_patches, self.path_size, self.path_size, self.n_channels], dtype=np.uint8)
+
+ # ------------------------------------
+ # update H patches
+ # ------------------------------------
+ self.update_data()
+
+
+ def update_data(self):
+ """
+ # ------------------------------------
+ # update whole L/H patches
+ # ------------------------------------
+ """
+ self.index_sampled = random.sample(range(0, len(self.paths_H), 1), self.num_sampled)
+ n_count = 0
+
+ for i in range(len(self.index_sampled)):
+ L_patches, H_patches = self.get_patches(self.index_sampled[i])
+ for (L_patch, H_patch) in zip(L_patches, H_patches):
+ self.L_data[n_count,:,:,:] = L_patch
+ self.H_data[n_count,:,:,:] = H_patch
+ n_count += 1
+
+ print('Training data updated! Total number of patches is: %5.2f X %5.2f = %5.2f\n' % (len(self.H_data)//128, 128, len(self.H_data)))
+
+ def get_patches(self, index):
+ """
+ # ------------------------------------
+ # get L/H patches from L/H images
+ # ------------------------------------
+ """
+ L_path = self.paths_L[index]
+ H_path = self.paths_H[index]
+ img_L = util.imread_uint(L_path, self.n_channels) # uint format
+ img_H = util.imread_uint(H_path, self.n_channels) # uint format
+
+ H, W = img_H.shape[:2]
+
+ L_patches, H_patches = [], []
+
+ num = self.num_patches_per_image
+ for _ in range(num):
+ rnd_h = random.randint(0, max(0, H - self.path_size))
+ rnd_w = random.randint(0, max(0, W - self.path_size))
+ L_patch = img_L[rnd_h:rnd_h + self.path_size, rnd_w:rnd_w + self.path_size, :]
+ H_patch = img_H[rnd_h:rnd_h + self.path_size, rnd_w:rnd_w + self.path_size, :]
+ L_patches.append(L_patch)
+ H_patches.append(H_patch)
+
+ return L_patches, H_patches
+
+ def __getitem__(self, index):
+
+ if self.opt['phase'] == 'train':
+
+ patch_L, patch_H = self.L_data[index], self.H_data[index]
+
+ # --------------------------------
+ # augmentation - flip and/or rotate
+ # --------------------------------
+ mode = random.randint(0, 7)
+ patch_L = util.augment_img(patch_L, mode=mode)
+ patch_H = util.augment_img(patch_H, mode=mode)
+
+ patch_L, patch_H = util.uint2tensor3(patch_L), util.uint2tensor3(patch_H)
+
+ else:
+
+ L_path, H_path = self.paths_L[index], self.paths_H[index]
+ patch_L = util.imread_uint(L_path, self.n_channels)
+ patch_H = util.imread_uint(H_path, self.n_channels)
+
+ patch_L, patch_H = util.uint2tensor3(patch_L), util.uint2tensor3(patch_H)
+
+ return {'L': patch_L, 'H': patch_H}
+
+
+ def __len__(self):
+
+ return self.total_patches
diff --git a/KAIR/data/dataset_sr.py b/KAIR/data/dataset_sr.py
new file mode 100644
index 0000000000000000000000000000000000000000..8e1c11c7bfbd7e4aecd9a9e5b44f73ad4e81bc3e
--- /dev/null
+++ b/KAIR/data/dataset_sr.py
@@ -0,0 +1,197 @@
+import math
+import numpy as np
+import random
+import torch
+import torch.utils.data as data
+import utils.utils_image as util
+from basicsr.data.degradations import circular_lowpass_kernel, random_mixed_kernels
+from basicsr.utils import DiffJPEG, USMSharp
+from numpy.typing import NDArray
+from PIL import Image
+from utils.utils_video import img2tensor
+from torch import Tensor
+
+from data.degradations import apply_real_esrgan_degradations
+
+class DatasetSR(data.Dataset):
+ '''
+ # -----------------------------------------
+ # Get L/H for SISR.
+ # If only "paths_H" is provided, sythesize bicubicly downsampled L on-the-fly.
+ # -----------------------------------------
+ # e.g., SRResNet
+ # -----------------------------------------
+ '''
+
+ def __init__(self, opt):
+ super(DatasetSR, self).__init__()
+ self.opt = opt
+ self.n_channels = opt['n_channels'] if opt['n_channels'] else 3
+ self.sf = opt['scale'] if opt['scale'] else 4
+ self.patch_size = self.opt['H_size'] if self.opt['H_size'] else 96
+ self.L_size = self.patch_size // self.sf
+
+ # ------------------------------------
+ # get paths of L/H
+ # ------------------------------------
+ self.paths_H = util.get_image_paths(opt['dataroot_H'])
+ self.paths_L = util.get_image_paths(opt['dataroot_L'])
+
+ assert self.paths_H, 'Error: H path is empty.'
+ if self.paths_L and self.paths_H:
+ assert len(self.paths_L) == len(self.paths_H), 'L/H mismatch - {}, {}.'.format(len(self.paths_L), len(self.paths_H))
+
+ self.jpeg_simulator = DiffJPEG()
+ self.usm_sharpener = USMSharp()
+
+ blur_kernel_list1 = ['iso', 'aniso', 'generalized_iso',
+ 'generalized_aniso', 'plateau_iso', 'plateau_aniso']
+ blur_kernel_list2 = ['iso', 'aniso', 'generalized_iso',
+ 'generalized_aniso', 'plateau_iso', 'plateau_aniso']
+ blur_kernel_prob1 = [0.45, 0.25, 0.12, 0.03, 0.12, 0.03]
+ blur_kernel_prob2 = [0.45, 0.25, 0.12, 0.03, 0.12, 0.03]
+ kernel_size = 21
+ blur_sigma1 = [0.05, 0.2]
+ blur_sigma2 = [0.05, 0.1]
+ betag_range1 = [0.7, 1.3]
+ betag_range2 = [0.7, 1.3]
+ betap_range1 = [0.7, 1.3]
+ betap_range2 = [0.7, 1.3]
+
+ def _decide_kernels(self) -> NDArray:
+ blur_kernel1 = random_mixed_kernels(
+ self.blur_kernel_list1,
+ self.blur_kernel_prob1,
+ self.kernel_size,
+ self.blur_sigma1,
+ self.blur_sigma1, [-math.pi, math.pi],
+ self.betag_range1,
+ self.betap_range1,
+ noise_range=None
+ )
+ blur_kernel2 = random_mixed_kernels(
+ self.blur_kernel_list2,
+ self.blur_kernel_prob2,
+ self.kernel_size,
+ self.blur_sigma2,
+ self.blur_sigma2, [-math.pi, math.pi],
+ self.betag_range2,
+ self.betap_range2,
+ noise_range=None
+ )
+ if self.kernel_size < 13:
+ omega_c = np.random.uniform(np.pi / 3, np.pi)
+ else:
+ omega_c = np.random.uniform(np.pi / 5, np.pi)
+ sinc_kernel = circular_lowpass_kernel(omega_c, self.kernel_size, pad_to=21)
+ return (blur_kernel1, blur_kernel2, sinc_kernel)
+
+ def __getitem__(self, index):
+
+ L_path = None
+ # ------------------------------------
+ # get H image
+ # ------------------------------------
+ H_path = self.paths_H[index]
+ img_H = util.imread_uint(H_path, self.n_channels)
+ img_H = util.uint2single(img_H)
+
+ # ------------------------------------
+ # modcrop
+ # ------------------------------------
+ img_H = util.modcrop(img_H, self.sf)
+
+ # ------------------------------------
+ # get L image
+ # ------------------------------------
+ if self.paths_L:
+ # --------------------------------
+ # directly load L image
+ # --------------------------------
+ L_path = self.paths_L[index]
+ img_L = util.imread_uint(L_path, self.n_channels)
+ img_L = util.uint2single(img_L)
+
+ else:
+ # --------------------------------
+ # sythesize L image via matlab's bicubic
+ # --------------------------------
+ H, W = img_H.shape[:2]
+ img_L = util.imresize_np(img_H, 1 / self.sf, True)
+
+ src_tensor = img2tensor(img_L.copy(), bgr2rgb=False,
+ float32=True).unsqueeze(0)
+
+ blur_kernel1, blur_kernel2, sinc_kernel = self._decide_kernels()
+ (img_L_2, sharp_img_L, degraded_img_L) = apply_real_esrgan_degradations(
+ src_tensor,
+ blur_kernel1=Tensor(blur_kernel1).unsqueeze(0),
+ blur_kernel2=Tensor(blur_kernel2).unsqueeze(0),
+ second_blur_prob=0.2,
+ sinc_kernel=Tensor(sinc_kernel).unsqueeze(0),
+ resize_prob1=[0.2, 0.7, 0.1],
+ resize_prob2=[0.3, 0.4, 0.3],
+ resize_range1=[0.9, 1.1],
+ resize_range2=[0.9, 1.1],
+ gray_noise_prob1=0.2,
+ gray_noise_prob2=0.2,
+ gaussian_noise_prob1=0.2,
+ gaussian_noise_prob2=0.2,
+ noise_range=[0.01, 0.2],
+ poisson_scale_range=[0.05, 0.45],
+ jpeg_compression_range1=[85, 100],
+ jpeg_compression_range2=[85, 100],
+ jpeg_simulator=self.jpeg_simulator,
+ random_crop_gt_size=256,
+ sr_upsample_scale=1,
+ usm_sharpener=self.usm_sharpener
+ )
+ # Image.fromarray((degraded_img_L[0] * 255).permute(
+ # 1, 2, 0).cpu().numpy().astype(np.uint8)).save(
+ # "/home/cll/Desktop/degraded_L.png")
+ # Image.fromarray((img_L * 255).astype(np.uint8)).save(
+ # "/home/cll/Desktop/img_L.png")
+ # Image.fromarray((img_L_2[0] * 255).permute(
+ # 1, 2, 0).cpu().numpy().astype(np.uint8)).save(
+ # "/home/cll/Desktop/img_L_2.png")
+ # exit()
+
+ # ------------------------------------
+ # if train, get L/H patch pair
+ # ------------------------------------
+ if self.opt['phase'] == 'train':
+
+ H, W, C = img_L.shape
+
+ # --------------------------------
+ # randomly crop the L patch
+ # --------------------------------
+ rnd_h = random.randint(0, max(0, H - self.L_size))
+ rnd_w = random.randint(0, max(0, W - self.L_size))
+ img_L = img_L[rnd_h:rnd_h + self.L_size, rnd_w:rnd_w + self.L_size, :]
+
+ # --------------------------------
+ # crop corresponding H patch
+ # --------------------------------
+ rnd_h_H, rnd_w_H = int(rnd_h * self.sf), int(rnd_w * self.sf)
+ img_H = img_H[rnd_h_H:rnd_h_H + self.patch_size, rnd_w_H:rnd_w_H + self.patch_size, :]
+
+ # --------------------------------
+ # augmentation - flip and/or rotate + RealESRGAN modified degradations
+ # --------------------------------
+ mode = random.randint(0, 7)
+ img_L, img_H = util.augment_img(img_L, mode=mode), util.augment_img(img_H, mode=mode)
+
+
+ # ------------------------------------
+ # L/H pairs, HWC to CHW, numpy to tensor
+ # ------------------------------------
+ img_H, img_L = util.single2tensor3(img_H), util.single2tensor3(img_L)
+
+ if L_path is None:
+ L_path = H_path
+
+ return {'L': img_L, 'H': img_H, 'L_path': L_path, 'H_path': H_path}
+
+ def __len__(self):
+ return len(self.paths_H)
diff --git a/KAIR/data/dataset_srmd.py b/KAIR/data/dataset_srmd.py
new file mode 100644
index 0000000000000000000000000000000000000000..344398a970f8b1769be95ddf9eb50d7ba3744c5e
--- /dev/null
+++ b/KAIR/data/dataset_srmd.py
@@ -0,0 +1,155 @@
+import random
+import numpy as np
+import torch
+import torch.utils.data as data
+import utils.utils_image as util
+from utils import utils_sisr
+
+
+import hdf5storage
+import os
+
+
+class DatasetSRMD(data.Dataset):
+ '''
+ # -----------------------------------------
+ # Get L/H/M for noisy image SR with Gaussian kernels.
+ # Only "paths_H" is needed, sythesize bicubicly downsampled L on-the-fly.
+ # -----------------------------------------
+ # e.g., SRMD, H = f(L, kernel, sigma), sigma is noise level
+ # -----------------------------------------
+ '''
+
+ def __init__(self, opt):
+ super(DatasetSRMD, self).__init__()
+ self.opt = opt
+ self.n_channels = opt['n_channels'] if opt['n_channels'] else 3
+ self.sf = opt['scale'] if opt['scale'] else 4
+ self.patch_size = self.opt['H_size'] if self.opt['H_size'] else 96
+ self.L_size = self.patch_size // self.sf
+ self.sigma = opt['sigma'] if opt['sigma'] else [0, 50]
+ self.sigma_min, self.sigma_max = self.sigma[0], self.sigma[1]
+ self.sigma_test = opt['sigma_test'] if opt['sigma_test'] else 0
+
+ # -------------------------------------
+ # PCA projection matrix
+ # -------------------------------------
+ self.p = hdf5storage.loadmat(os.path.join('kernels', 'srmd_pca_pytorch.mat'))['p']
+ self.ksize = int(np.sqrt(self.p.shape[-1])) # kernel size
+
+ # ------------------------------------
+ # get paths of L/H
+ # ------------------------------------
+ self.paths_H = util.get_image_paths(opt['dataroot_H'])
+ self.paths_L = util.get_image_paths(opt['dataroot_L'])
+
+ def __getitem__(self, index):
+
+ # ------------------------------------
+ # get H image
+ # ------------------------------------
+ H_path = self.paths_H[index]
+ img_H = util.imread_uint(H_path, self.n_channels)
+ img_H = util.uint2single(img_H)
+
+ # ------------------------------------
+ # modcrop for SR
+ # ------------------------------------
+ img_H = util.modcrop(img_H, self.sf)
+
+ # ------------------------------------
+ # kernel
+ # ------------------------------------
+ if self.opt['phase'] == 'train':
+ l_max = 10
+ theta = np.pi*random.random()
+ l1 = 0.1+l_max*random.random()
+ l2 = 0.1+(l1-0.1)*random.random()
+
+ kernel = utils_sisr.anisotropic_Gaussian(ksize=self.ksize, theta=theta, l1=l1, l2=l2)
+ else:
+ kernel = utils_sisr.anisotropic_Gaussian(ksize=self.ksize, theta=np.pi, l1=0.1, l2=0.1)
+
+ k = np.reshape(kernel, (-1), order="F")
+ k_reduced = np.dot(self.p, k)
+ k_reduced = torch.from_numpy(k_reduced).float()
+
+ # ------------------------------------
+ # sythesize L image via specified degradation model
+ # ------------------------------------
+ H, W, _ = img_H.shape
+ img_L = utils_sisr.srmd_degradation(img_H, kernel, self.sf)
+ img_L = np.float32(img_L)
+
+ if self.opt['phase'] == 'train':
+ """
+ # --------------------------------
+ # get L/H patch pairs
+ # --------------------------------
+ """
+ H, W, C = img_L.shape
+
+ # --------------------------------
+ # randomly crop L patch
+ # --------------------------------
+ rnd_h = random.randint(0, max(0, H - self.L_size))
+ rnd_w = random.randint(0, max(0, W - self.L_size))
+ img_L = img_L[rnd_h:rnd_h + self.L_size, rnd_w:rnd_w + self.L_size, :]
+
+ # --------------------------------
+ # crop corresponding H patch
+ # --------------------------------
+ rnd_h_H, rnd_w_H = int(rnd_h * self.sf), int(rnd_w * self.sf)
+ img_H = img_H[rnd_h_H:rnd_h_H + self.patch_size, rnd_w_H:rnd_w_H + self.patch_size, :]
+
+ # --------------------------------
+ # augmentation - flip and/or rotate
+ # --------------------------------
+ mode = random.randint(0, 7)
+ img_L, img_H = util.augment_img(img_L, mode=mode), util.augment_img(img_H, mode=mode)
+
+ # --------------------------------
+ # get patch pairs
+ # --------------------------------
+ img_H, img_L = util.single2tensor3(img_H), util.single2tensor3(img_L)
+
+ # --------------------------------
+ # select noise level and get Gaussian noise
+ # --------------------------------
+ if random.random() < 0.1:
+ noise_level = torch.zeros(1).float()
+ else:
+ noise_level = torch.FloatTensor([np.random.uniform(self.sigma_min, self.sigma_max)])/255.0
+ # noise_level = torch.rand(1)*50/255.0
+ # noise_level = torch.min(torch.from_numpy(np.float32([7*np.random.chisquare(2.5)/255.0])),torch.Tensor([50./255.]))
+
+ else:
+
+ img_H, img_L = util.single2tensor3(img_H), util.single2tensor3(img_L)
+ noise_level = noise_level = torch.FloatTensor([self.sigma_test])
+
+ # ------------------------------------
+ # add noise
+ # ------------------------------------
+ noise = torch.randn(img_L.size()).mul_(noise_level).float()
+ img_L.add_(noise)
+
+ # ------------------------------------
+ # get degradation map M
+ # ------------------------------------
+ M_vector = torch.cat((k_reduced, noise_level), 0).unsqueeze(1).unsqueeze(1)
+ M = M_vector.repeat(1, img_L.size()[-2], img_L.size()[-1])
+
+ """
+ # -------------------------------------
+ # concat L and noise level map M
+ # -------------------------------------
+ """
+
+ img_L = torch.cat((img_L, M), 0)
+ L_path = H_path
+
+ return {'L': img_L, 'H': img_H, 'L_path': L_path, 'H_path': H_path}
+
+ def __len__(self):
+ return len(self.paths_H)
diff --git a/KAIR/data/dataset_usrnet.py b/KAIR/data/dataset_usrnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..79796e0ac625b18bd3187c737ad4714e29c485f0
--- /dev/null
+++ b/KAIR/data/dataset_usrnet.py
@@ -0,0 +1,126 @@
+import random
+
+import numpy as np
+import torch
+import torch.utils.data as data
+import utils.utils_image as util
+from utils import utils_deblur
+from utils import utils_sisr
+import os
+
+from scipy import ndimage
+from scipy.io import loadmat
+# import hdf5storage
+
+
+class DatasetUSRNet(data.Dataset):
+ '''
+ # -----------------------------------------
+ # Get L/k/sf/sigma for USRNet.
+ # Only "paths_H" and kernel is needed, synthesize L on-the-fly.
+ # -----------------------------------------
+ '''
+ def __init__(self, opt):
+ super(DatasetUSRNet, self).__init__()
+ self.opt = opt
+ self.n_channels = opt['n_channels'] if opt['n_channels'] else 3
+ self.patch_size = self.opt['H_size'] if self.opt['H_size'] else 96
+ self.sigma_max = self.opt['sigma_max'] if self.opt['sigma_max'] is not None else 25
+ self.scales = opt['scales'] if opt['scales'] is not None else [1,2,3,4]
+ self.sf_validation = opt['sf_validation'] if opt['sf_validation'] is not None else 3
+ #self.kernels = hdf5storage.loadmat(os.path.join('kernels', 'kernels_12.mat'))['kernels']
+ self.kernels = loadmat(os.path.join('kernels', 'kernels_12.mat'))['kernels'] # for validation
+
+ # -------------------
+ # get the path of H
+ # -------------------
+ self.paths_H = util.get_image_paths(opt['dataroot_H']) # return None if input is None
+ self.count = 0
+
+ def __getitem__(self, index):
+
+ # -------------------
+ # get H image
+ # -------------------
+ H_path = self.paths_H[index]
+ img_H = util.imread_uint(H_path, self.n_channels)
+ L_path = H_path
+
+ if self.opt['phase'] == 'train':
+
+ # ---------------------------
+ # 1) scale factor, ensure each batch only involves one scale factor
+ # ---------------------------
+ if self.count % self.opt['dataloader_batch_size'] == 0:
+ # sf = random.choice([1,2,3,4])
+ self.sf = random.choice(self.scales)
+ # self.count = 0 # optional
+ self.count += 1
+ H, W, _ = img_H.shape
+
+ # ----------------------------
+ # randomly crop the patch
+ # ----------------------------
+ rnd_h = random.randint(0, max(0, H - self.patch_size))
+ rnd_w = random.randint(0, max(0, W - self.patch_size))
+ patch_H = img_H[rnd_h:rnd_h + self.patch_size, rnd_w:rnd_w + self.patch_size, :]
+
+ # ---------------------------
+ # augmentation - flip, rotate
+ # ---------------------------
+ mode = np.random.randint(0, 8)
+ patch_H = util.augment_img(patch_H, mode=mode)
+
+ # ---------------------------
+ # 2) kernel
+ # ---------------------------
+ r_value = random.randint(0, 7)
+ if r_value>3:
+ k = utils_deblur.blurkernel_synthesis(h=25) # motion blur
+ else:
+ sf_k = random.choice(self.scales)
+ k = utils_sisr.gen_kernel(scale_factor=np.array([sf_k, sf_k])) # Gaussian blur
+ mode_k = random.randint(0, 7)
+ k = util.augment_img(k, mode=mode_k)
+
+ # ---------------------------
+ # 3) noise level
+ # ---------------------------
+ if random.randint(0, 8) == 1:
+ noise_level = 0/255.0
+ else:
+ noise_level = np.random.randint(0, self.sigma_max)/255.0
+
+ # ---------------------------
+ # Low-quality image
+ # ---------------------------
+ img_L = ndimage.filters.convolve(patch_H, np.expand_dims(k, axis=2), mode='wrap')
+ img_L = img_L[0::self.sf, 0::self.sf, ...]
+ # add Gaussian noise
+ img_L = util.uint2single(img_L) + np.random.normal(0, noise_level, img_L.shape)
+ img_H = patch_H
+
+ else:
+
+ k = self.kernels[0, 0].astype(np.float64) # validation kernel
+ k /= np.sum(k)
+ noise_level = 0./255.0 # validation noise level
+
+ # ------------------------------------
+ # modcrop
+ # ------------------------------------
+ img_H = util.modcrop(img_H, self.sf_validation)
+
+ img_L = ndimage.filters.convolve(img_H, np.expand_dims(k, axis=2), mode='wrap') # blur
+ img_L = img_L[0::self.sf_validation, 0::self.sf_validation, ...] # downsampling
+ img_L = util.uint2single(img_L) + np.random.normal(0, noise_level, img_L.shape)
+ self.sf = self.sf_validation
+
+ k = util.single2tensor3(np.expand_dims(np.float32(k), axis=2))
+ img_H, img_L = util.uint2tensor3(img_H), util.single2tensor3(img_L)
+ noise_level = torch.FloatTensor([noise_level]).view([1,1,1])
+
+ return {'L': img_L, 'H': img_H, 'k': k, 'sigma': noise_level, 'sf': self.sf, 'L_path': L_path, 'H_path': H_path}
+
+ def __len__(self):
+ return len(self.paths_H)
diff --git a/KAIR/data/dataset_video_test.py b/KAIR/data/dataset_video_test.py
new file mode 100755
index 0000000000000000000000000000000000000000..e361441331bbae465b9e1b51f2abe39dd54f5a2f
--- /dev/null
+++ b/KAIR/data/dataset_video_test.py
@@ -0,0 +1,382 @@
+import glob
+import torch
+from os import path as osp
+import torch.utils.data as data
+
+import utils.utils_video as utils_video
+
+
+class VideoRecurrentTestDataset(data.Dataset):
+ """Video test dataset for recurrent architectures, which takes LR video
+ frames as input and output corresponding HR video frames. Modified from
+ https://github.com/xinntao/BasicSR/blob/master/basicsr/data/reds_dataset.py
+
+ Supported datasets: Vid4, REDS4, REDSofficial.
+ More generally, it supports testing dataset with following structures:
+
+ dataroot
+ ├── subfolder1
+ ├── frame000
+ ├── frame001
+ ├── ...
+ ├── subfolder1
+ ├── frame000
+ ├── frame001
+ ├── ...
+ ├── ...
+
+ For testing datasets, there is no need to prepare LMDB files.
+
+ Args:
+ opt (dict): Config for train dataset. It contains the following keys:
+ dataroot_gt (str): Data root path for gt.
+ dataroot_lq (str): Data root path for lq.
+ io_backend (dict): IO backend type and other kwarg.
+ cache_data (bool): Whether to cache testing datasets.
+ name (str): Dataset name.
+ meta_info_file (str): The path to the file storing the list of test
+ folders. If not provided, all the folders in the dataroot will
+ be used.
+ num_frame (int): Window size for input frames.
+ padding (str): Padding mode.
+ """
+
+ def __init__(self, opt):
+ super(VideoRecurrentTestDataset, self).__init__()
+ self.opt = opt
+ self.cache_data = opt['cache_data']
+ self.gt_root, self.lq_root = opt['dataroot_gt'], opt['dataroot_lq']
+ self.data_info = {'lq_path': [], 'gt_path': [], 'folder': [], 'idx': [], 'border': []}
+
+ self.imgs_lq, self.imgs_gt = {}, {}
+ if 'meta_info_file' in opt:
+ with open(opt['meta_info_file'], 'r') as fin:
+ subfolders = [line.split(' ')[0] for line in fin]
+ subfolders_lq = [osp.join(self.lq_root, key) for key in subfolders]
+ subfolders_gt = [osp.join(self.gt_root, key) for key in subfolders]
+ else:
+ subfolders_lq = sorted(glob.glob(osp.join(self.lq_root, '*')))
+ subfolders_gt = sorted(glob.glob(osp.join(self.gt_root, '*')))
+
+ for subfolder_lq, subfolder_gt in zip(subfolders_lq, subfolders_gt):
+ # get frame list for lq and gt
+ subfolder_name = osp.basename(subfolder_lq)
+ img_paths_lq = sorted(list(utils_video.scandir(subfolder_lq, full_path=True)))
+ img_paths_gt = sorted(list(utils_video.scandir(subfolder_gt, full_path=True)))
+
+ max_idx = len(img_paths_lq)
+ assert max_idx == len(img_paths_gt), (f'Different number of images in lq ({max_idx})'
+ f' and gt folders ({len(img_paths_gt)})')
+
+ self.data_info['lq_path'].extend(img_paths_lq)
+ self.data_info['gt_path'].extend(img_paths_gt)
+ self.data_info['folder'].extend([subfolder_name] * max_idx)
+ for i in range(max_idx):
+ self.data_info['idx'].append(f'{i}/{max_idx}')
+ border_l = [0] * max_idx
+ for i in range(self.opt['num_frame'] // 2):
+ border_l[i] = 1
+ border_l[max_idx - i - 1] = 1
+ self.data_info['border'].extend(border_l)
+
+ # cache data or save the frame list
+ if self.cache_data:
+ print(f'Cache {subfolder_name} for VideoTestDataset...')
+ self.imgs_lq[subfolder_name] = utils_video.read_img_seq(img_paths_lq)
+ self.imgs_gt[subfolder_name] = utils_video.read_img_seq(img_paths_gt)
+ else:
+ self.imgs_lq[subfolder_name] = img_paths_lq
+ self.imgs_gt[subfolder_name] = img_paths_gt
+
+ # Find unique folder strings
+ self.folders = sorted(list(set(self.data_info['folder'])))
+ self.sigma = opt['sigma'] / 255. if 'sigma' in opt else 0 # for non-blind video denoising
+
+ def __getitem__(self, index):
+ folder = self.folders[index]
+
+ if self.sigma:
+ # for non-blind video denoising
+ if self.cache_data:
+ imgs_gt = self.imgs_gt[folder]
+ else:
+ imgs_gt = utils_video.read_img_seq(self.imgs_gt[folder])
+
+ torch.manual_seed(0)
+ noise_level = torch.ones((1, 1, 1, 1)) * self.sigma
+ noise = torch.normal(mean=0, std=noise_level.expand_as(imgs_gt))
+ imgs_lq = imgs_gt + noise
+ t, _, h, w = imgs_lq.shape
+ imgs_lq = torch.cat([imgs_lq, noise_level.expand(t, 1, h, w)], 1)
+ else:
+ # for video sr and deblurring
+ if self.cache_data:
+ imgs_lq = self.imgs_lq[folder]
+ imgs_gt = self.imgs_gt[folder]
+ else:
+ imgs_lq = utils_video.read_img_seq(self.imgs_lq[folder])
+ imgs_gt = utils_video.read_img_seq(self.imgs_gt[folder])
+
+ return {
+ 'L': imgs_lq,
+ 'H': imgs_gt,
+ 'folder': folder,
+ 'lq_path': self.imgs_lq[folder],
+ }
+
+ def __len__(self):
+ return len(self.folders)
+
+
+class SingleVideoRecurrentTestDataset(data.Dataset):
+ """Single ideo test dataset for recurrent architectures, which takes LR video
+ frames as input and output corresponding HR video frames (only input LQ path).
+
+ More generally, it supports testing dataset with following structures:
+
+ dataroot
+ ├── subfolder1
+ ├── frame000
+ ├── frame001
+ ├── ...
+ ├── subfolder1
+ ├── frame000
+ ├── frame001
+ ├── ...
+ ├── ...
+
+ For testing datasets, there is no need to prepare LMDB files.
+
+ Args:
+ opt (dict): Config for train dataset. It contains the following keys:
+ dataroot_gt (str): Data root path for gt.
+ dataroot_lq (str): Data root path for lq.
+ io_backend (dict): IO backend type and other kwarg.
+ cache_data (bool): Whether to cache testing datasets.
+ name (str): Dataset name.
+ meta_info_file (str): The path to the file storing the list of test
+ folders. If not provided, all the folders in the dataroot will
+ be used.
+ num_frame (int): Window size for input frames.
+ padding (str): Padding mode.
+ """
+
+ def __init__(self, opt):
+ super(SingleVideoRecurrentTestDataset, self).__init__()
+ self.opt = opt
+ self.cache_data = opt['cache_data']
+ self.lq_root = opt['dataroot_lq']
+ self.data_info = {'lq_path': [], 'folder': [], 'idx': [], 'border': []}
+
+ self.imgs_lq = {}
+ if 'meta_info_file' in opt:
+ with open(opt['meta_info_file'], 'r') as fin:
+ subfolders = [line.split(' ')[0] for line in fin]
+ subfolders_lq = [osp.join(self.lq_root, key) for key in subfolders]
+ else:
+ subfolders_lq = sorted(glob.glob(osp.join(self.lq_root, '*')))
+
+ for subfolder_lq in subfolders_lq:
+ # get frame list for lq and gt
+ subfolder_name = osp.basename(subfolder_lq)
+ img_paths_lq = sorted(list(utils_video.scandir(subfolder_lq, full_path=True)))
+
+ max_idx = len(img_paths_lq)
+
+ self.data_info['lq_path'].extend(img_paths_lq)
+ self.data_info['folder'].extend([subfolder_name] * max_idx)
+ for i in range(max_idx):
+ self.data_info['idx'].append(f'{i}/{max_idx}')
+ border_l = [0] * max_idx
+ for i in range(self.opt['num_frame'] // 2):
+ border_l[i] = 1
+ border_l[max_idx - i - 1] = 1
+ self.data_info['border'].extend(border_l)
+
+ # cache data or save the frame list
+ if self.cache_data:
+ print(f'Cache {subfolder_name} for VideoTestDataset...')
+ self.imgs_lq[subfolder_name] = utils_video.read_img_seq(img_paths_lq)
+ else:
+ self.imgs_lq[subfolder_name] = img_paths_lq
+
+ # Find unique folder strings
+ self.folders = sorted(list(set(self.data_info['folder'])))
+
+ def __getitem__(self, index):
+ folder = self.folders[index]
+
+ if self.cache_data:
+ imgs_lq = self.imgs_lq[folder]
+ else:
+ imgs_lq = utils_video.read_img_seq(self.imgs_lq[folder])
+
+ return {
+ 'L': imgs_lq,
+ 'folder': folder,
+ 'lq_path': self.imgs_lq[folder],
+ }
+
+ def __len__(self):
+ return len(self.folders)
+
+
+class VideoTestVimeo90KDataset(data.Dataset):
+ """Video test dataset for Vimeo90k-Test dataset.
+
+ It only keeps the center frame for testing.
+ For testing datasets, there is no need to prepare LMDB files.
+
+ Args:
+ opt (dict): Config for train dataset. It contains the following keys:
+ dataroot_gt (str): Data root path for gt.
+ dataroot_lq (str): Data root path for lq.
+ io_backend (dict): IO backend type and other kwarg.
+ cache_data (bool): Whether to cache testing datasets.
+ name (str): Dataset name.
+ meta_info_file (str): The path to the file storing the list of test
+ folders. If not provided, all the folders in the dataroot will
+ be used.
+ num_frame (int): Window size for input frames.
+ padding (str): Padding mode.
+ """
+
+ def __init__(self, opt):
+ super(VideoTestVimeo90KDataset, self).__init__()
+ self.opt = opt
+ self.cache_data = opt['cache_data']
+ if self.cache_data:
+ raise NotImplementedError('cache_data in Vimeo90K-Test dataset is not implemented.')
+ self.gt_root, self.lq_root = opt['dataroot_gt'], opt['dataroot_lq']
+ self.data_info = {'lq_path': [], 'gt_path': [], 'folder': [], 'idx': [], 'border': []}
+ neighbor_list = [i + (9 - opt['num_frame']) // 2 for i in range(opt['num_frame'])]
+
+ with open(opt['meta_info_file'], 'r') as fin:
+ subfolders = [line.split(' ')[0] for line in fin]
+ for idx, subfolder in enumerate(subfolders):
+ gt_path = osp.join(self.gt_root, subfolder, 'im4.png')
+ self.data_info['gt_path'].append(gt_path)
+ lq_paths = [osp.join(self.lq_root, subfolder, f'im{i}.png') for i in neighbor_list]
+ self.data_info['lq_path'].append(lq_paths)
+ self.data_info['folder'].append('vimeo90k')
+ self.data_info['idx'].append(f'{idx}/{len(subfolders)}')
+ self.data_info['border'].append(0)
+
+ self.pad_sequence = opt.get('pad_sequence', False)
+
+ def __getitem__(self, index):
+ lq_path = self.data_info['lq_path'][index]
+ gt_path = self.data_info['gt_path'][index]
+ imgs_lq = utils_video.read_img_seq(lq_path)
+ img_gt = utils_video.read_img_seq([gt_path])
+ img_gt.squeeze_(0)
+
+ if self.pad_sequence: # pad the sequence: 7 frames to 8 frames
+ imgs_lq = torch.cat([imgs_lq, imgs_lq[-1:,...]], dim=0)
+
+ return {
+ 'L': imgs_lq, # (t, c, h, w)
+ 'H': img_gt, # (c, h, w)
+ 'folder': self.data_info['folder'][index], # folder name
+ 'idx': self.data_info['idx'][index], # e.g., 0/843
+ 'border': self.data_info['border'][index], # 0 for non-border
+ 'lq_path': lq_path[self.opt['num_frame'] // 2] # center frame
+ }
+
+ def __len__(self):
+ return len(self.data_info['gt_path'])
+
+
+class SingleVideoRecurrentTestDataset(data.Dataset):
+ """Single Video test dataset (only input LQ path).
+
+ Supported datasets: Vid4, REDS4, REDSofficial.
+ More generally, it supports testing dataset with following structures:
+
+ dataroot
+ ├── subfolder1
+ ├── frame000
+ ├── frame001
+ ├── ...
+ ├── subfolder1
+ ├── frame000
+ ├── frame001
+ ├── ...
+ ├── ...
+
+ For testing datasets, there is no need to prepare LMDB files.
+
+ Args:
+ opt (dict): Config for train dataset. It contains the following keys:
+ dataroot_gt (str): Data root path for gt.
+ dataroot_lq (str): Data root path for lq.
+ io_backend (dict): IO backend type and other kwarg.
+ cache_data (bool): Whether to cache testing datasets.
+ name (str): Dataset name.
+ meta_info_file (str): The path to the file storing the list of test
+ folders. If not provided, all the folders in the dataroot will
+ be used.
+ num_frame (int): Window size for input frames.
+ padding (str): Padding mode.
+ """
+
+ def __init__(self, opt):
+ super(SingleVideoRecurrentTestDataset, self).__init__()
+ self.opt = opt
+ self.cache_data = opt['cache_data']
+ self.lq_root = opt['dataroot_lq']
+ self.data_info = {'lq_path': [], 'folder': [], 'idx': [], 'border': []}
+ # file client (io backend)
+ self.file_client = None
+
+ self.imgs_lq = {}
+ if 'meta_info_file' in opt:
+ with open(opt['meta_info_file'], 'r') as fin:
+ subfolders = [line.split(' ')[0] for line in fin]
+ subfolders_lq = [osp.join(self.lq_root, key) for key in subfolders]
+ else:
+ subfolders_lq = sorted(glob.glob(osp.join(self.lq_root, '*')))
+
+ for subfolder_lq in subfolders_lq:
+ # get frame list for lq and gt
+ subfolder_name = osp.basename(subfolder_lq)
+ img_paths_lq = sorted(list(utils_video.scandir(subfolder_lq, full_path=True)))
+
+ max_idx = len(img_paths_lq)
+
+ self.data_info['lq_path'].extend(img_paths_lq)
+ self.data_info['folder'].extend([subfolder_name] * max_idx)
+ for i in range(max_idx):
+ self.data_info['idx'].append(f'{i}/{max_idx}')
+ border_l = [0] * max_idx
+ for i in range(self.opt['num_frame'] // 2):
+ border_l[i] = 1
+ border_l[max_idx - i - 1] = 1
+ self.data_info['border'].extend(border_l)
+
+ # cache data or save the frame list
+ if self.cache_data:
+ logger.info(f'Cache {subfolder_name} for VideoTestDataset...')
+ self.imgs_lq[subfolder_name] = utils_video.read_img_seq(img_paths_lq)
+ else:
+ self.imgs_lq[subfolder_name] = img_paths_lq
+
+ # Find unique folder strings
+ self.folders = sorted(list(set(self.data_info['folder'])))
+
+ def __getitem__(self, index):
+ folder = self.folders[index]
+
+ if self.cache_data:
+ imgs_lq = self.imgs_lq[folder]
+ else:
+ imgs_lq = utils_video.read_img_seq(self.imgs_lq[folder])
+
+ return {
+ 'L': imgs_lq,
+ 'folder': folder,
+ 'lq_path': self.imgs_lq[folder],
+ }
+
+ def __len__(self):
+ return len(self.folders)
diff --git a/KAIR/data/dataset_video_train.py b/KAIR/data/dataset_video_train.py
new file mode 100755
index 0000000000000000000000000000000000000000..8a14d46a84c480ff984bd7482c2d7cc357bc9b41
--- /dev/null
+++ b/KAIR/data/dataset_video_train.py
@@ -0,0 +1,390 @@
+import numpy as np
+import os
+import random
+import torch
+from pathlib import Path
+import torch.utils.data as data
+
+import utils.utils_video as utils_video
+
+
+class VideoRecurrentTrainDataset(data.Dataset):
+ """Video dataset for training recurrent networks.
+
+ The keys are generated from a meta info txt file.
+ basicsr/data/meta_info/meta_info_XXX_GT.txt
+
+ Each line contains:
+ 1. subfolder (clip) name; 2. frame number; 3. image shape, separated by
+ a white space.
+ Examples:
+ 720p_240fps_1 100 (720,1280,3)
+ 720p_240fps_3 100 (720,1280,3)
+ ...
+
+ Key examples: "720p_240fps_1/00000"
+ GT (gt): Ground-Truth;
+ LQ (lq): Low-Quality, e.g., low-resolution/blurry/noisy/compressed frames.
+
+ Args:
+ opt (dict): Config for train dataset. It contains the following keys:
+ dataroot_gt (str): Data root path for gt.
+ dataroot_lq (str): Data root path for lq.
+ dataroot_flow (str, optional): Data root path for flow.
+ meta_info_file (str): Path for meta information file.
+ val_partition (str): Validation partition types. 'REDS4' or
+ 'official'.
+ io_backend (dict): IO backend type and other kwarg.
+
+ num_frame (int): Window size for input frames.
+ gt_size (int): Cropped patched size for gt patches.
+ interval_list (list): Interval list for temporal augmentation.
+ random_reverse (bool): Random reverse input frames.
+ use_hflip (bool): Use horizontal flips.
+ use_rot (bool): Use rotation (use vertical flip and transposing h
+ and w for implementation).
+
+ scale (bool): Scale, which will be added automatically.
+ """
+
+ def __init__(self, opt):
+ super(VideoRecurrentTrainDataset, self).__init__()
+ self.opt = opt
+ self.scale = opt.get('scale', 4)
+ self.gt_size = opt.get('gt_size', 256)
+ self.gt_root, self.lq_root = Path(opt['dataroot_gt']), Path(opt['dataroot_lq'])
+ self.filename_tmpl = opt.get('filename_tmpl', '08d')
+ self.filename_ext = opt.get('filename_ext', 'png')
+ self.num_frame = opt['num_frame']
+
+ keys = []
+ total_num_frames = [] # some clips may not have 100 frames
+ start_frames = [] # some clips may not start from 00000
+ train_folders = os.listdir(self.lq_root)
+ print("TRAIN FOLDER: ", train_folders[0])
+ with open(opt['meta_info_file'], 'r') as fin:
+ for line in fin:
+ folder, frame_num, _, start_frame = line.split(' ')
+ if folder in train_folders:
+ keys.extend([f'{folder}/{i:{self.filename_tmpl}}' for i in range(int(start_frame), int(start_frame)+int(frame_num))])
+ total_num_frames.extend([int(frame_num) for i in range(int(frame_num))])
+ start_frames.extend([int(start_frame) for i in range(int(frame_num))])
+
+ # remove the video clips used in validation
+ if opt['name'] == 'REDS':
+ if opt['val_partition'] == 'REDS4':
+ val_partition = ['000', '011', '015', '020']
+ elif opt['val_partition'] == 'official':
+ val_partition = [f'{v:03d}' for v in range(240, 270)]
+ else:
+ raise ValueError(f'Wrong validation partition {opt["val_partition"]}.'
+ f"Supported ones are ['official', 'REDS4'].")
+ else:
+ val_partition = []
+
+ self.keys = []
+ self.total_num_frames = [] # some clips may not have 100 frames
+ self.start_frames = []
+ if opt['test_mode']:
+ for i, v in zip(range(len(keys)), keys):
+ if v.split('/')[0] in val_partition:
+ self.keys.append(keys[i])
+ self.total_num_frames.append(total_num_frames[i])
+ self.start_frames.append(start_frames[i])
+ else:
+ for i, v in zip(range(len(keys)), keys):
+ if v.split('/')[0] not in val_partition:
+ self.keys.append(keys[i])
+ self.total_num_frames.append(total_num_frames[i])
+ self.start_frames.append(start_frames[i])
+
+ # file client (io backend)
+ self.file_client = None
+ self.io_backend_opt = opt['io_backend']
+ self.is_lmdb = False
+ if self.io_backend_opt['type'] == 'lmdb':
+ self.is_lmdb = True
+ if hasattr(self, 'flow_root') and self.flow_root is not None:
+ self.io_backend_opt['db_paths'] = [self.lq_root, self.gt_root, self.flow_root]
+ self.io_backend_opt['client_keys'] = ['lq', 'gt', 'flow']
+ else:
+ self.io_backend_opt['db_paths'] = [self.lq_root, self.gt_root]
+ self.io_backend_opt['client_keys'] = ['lq', 'gt']
+
+ # temporal augmentation configs
+ self.interval_list = opt.get('interval_list', [1])
+ self.random_reverse = opt.get('random_reverse', False)
+ interval_str = ','.join(str(x) for x in self.interval_list)
+ print(f'Temporal augmentation interval list: [{interval_str}]; '
+ f'random reverse is {self.random_reverse}.')
+
+ def __getitem__(self, index):
+ if self.file_client is None:
+ self.file_client = utils_video.FileClient(self.io_backend_opt.pop('type'), **self.io_backend_opt)
+
+ key = self.keys[index]
+ total_num_frames = self.total_num_frames[index]
+ start_frames = self.start_frames[index]
+ clip_name, frame_name = key.split('/') # key example: 000/00000000
+
+ # determine the neighboring frames
+ interval = random.choice(self.interval_list)
+
+ # ensure not exceeding the borders
+ start_frame_idx = int(frame_name)
+ endmost_start_frame_idx = start_frames + total_num_frames - self.num_frame * interval
+ if start_frame_idx > endmost_start_frame_idx:
+ start_frame_idx = random.randint(start_frames, endmost_start_frame_idx)
+ end_frame_idx = start_frame_idx + self.num_frame * interval
+
+ neighbor_list = list(range(start_frame_idx, end_frame_idx, interval))
+
+ # random reverse
+ if self.random_reverse and random.random() < 0.5:
+ neighbor_list.reverse()
+
+ # get the neighboring LQ and GT frames
+ img_lqs = []
+ img_gts = []
+ for neighbor in neighbor_list:
+ if self.is_lmdb:
+ img_lq_path = f'{clip_name}/{neighbor:{self.filename_tmpl}}'
+ img_gt_path = f'{clip_name}/{neighbor:{self.filename_tmpl}}'
+ else:
+ img_lq_path = self.lq_root / clip_name / f'{neighbor:{self.filename_tmpl}}.{self.filename_ext}'
+ img_gt_path = self.gt_root / clip_name / f'{neighbor:{self.filename_tmpl}}.{self.filename_ext}'
+
+ # get LQ
+ img_bytes = self.file_client.get(img_lq_path, 'lq')
+ img_lq = utils_video.imfrombytes(img_bytes, float32=True)
+ img_lqs.append(img_lq)
+
+ # get GT
+ img_bytes = self.file_client.get(img_gt_path, 'gt')
+ img_gt = utils_video.imfrombytes(img_bytes, float32=True)
+ img_gts.append(img_gt)
+
+ # randomly crop
+ img_gts, img_lqs = utils_video.paired_random_crop(img_gts, img_lqs, self.gt_size, self.scale, img_gt_path)
+
+ # augmentation - flip, rotate
+ img_lqs.extend(img_gts)
+ img_results = utils_video.augment(img_lqs, self.opt['use_hflip'], self.opt['use_rot'])
+
+ img_results = utils_video.img2tensor(img_results)
+ img_gts = torch.stack(img_results[len(img_lqs) // 2:], dim=0)
+ img_lqs = torch.stack(img_results[:len(img_lqs) // 2], dim=0)
+
+ # img_lqs: (t, c, h, w)
+ # img_gts: (t, c, h, w)
+ # key: str
+ return {'L': img_lqs, 'H': img_gts, 'key': key}
+
+ def __len__(self):
+ return len(self.keys)
+
+
+class VideoRecurrentTrainNonblindDenoisingDataset(VideoRecurrentTrainDataset):
+ """Video dataset for training recurrent architectures in non-blind video denoising.
+
+ Args:
+ Same as VideoTestDataset.
+
+ """
+
+ def __init__(self, opt):
+ super(VideoRecurrentTrainNonblindDenoisingDataset, self).__init__(opt)
+ self.sigma_min = self.opt['sigma_min'] / 255.
+ self.sigma_max = self.opt['sigma_max'] / 255.
+
+ def __getitem__(self, index):
+ if self.file_client is None:
+ self.file_client = utils_video.FileClient(self.io_backend_opt.pop('type'), **self.io_backend_opt)
+
+ key = self.keys[index]
+ total_num_frames = self.total_num_frames[index]
+ start_frames = self.start_frames[index]
+ clip_name, frame_name = key.split('/') # key example: 000/00000000
+
+ # determine the neighboring frames
+ interval = random.choice(self.interval_list)
+
+ # ensure not exceeding the borders
+ start_frame_idx = int(frame_name)
+ endmost_start_frame_idx = start_frames + total_num_frames - self.num_frame * interval
+ if start_frame_idx > endmost_start_frame_idx:
+ start_frame_idx = random.randint(start_frames, endmost_start_frame_idx)
+ end_frame_idx = start_frame_idx + self.num_frame * interval
+
+ neighbor_list = list(range(start_frame_idx, end_frame_idx, interval))
+
+ # random reverse
+ if self.random_reverse and random.random() < 0.5:
+ neighbor_list.reverse()
+
+ # get the neighboring GT frames
+ img_gts = []
+ for neighbor in neighbor_list:
+ if self.is_lmdb:
+ img_gt_path = f'{clip_name}/{neighbor:{self.filename_tmpl}}'
+ else:
+ img_gt_path = self.gt_root / clip_name / f'{neighbor:{self.filename_tmpl}}.{self.filename_ext}'
+
+ # get GT
+ img_bytes = self.file_client.get(img_gt_path, 'gt')
+ img_gt = utils_video.imfrombytes(img_bytes, float32=True)
+ img_gts.append(img_gt)
+
+ # randomly crop
+ img_gts, _ = utils_video.paired_random_crop(img_gts, img_gts, self.gt_size, 1, img_gt_path)
+
+ # augmentation - flip, rotate
+ img_gts = utils_video.augment(img_gts, self.opt['use_hflip'], self.opt['use_rot'])
+
+ img_gts = utils_video.img2tensor(img_gts)
+ img_gts = torch.stack(img_gts, dim=0)
+
+ # we add noise in the network
+ noise_level = torch.empty((1, 1, 1, 1)).uniform_(self.sigma_min, self.sigma_max)
+ noise = torch.normal(mean=0, std=noise_level.expand_as(img_gts))
+ img_lqs = img_gts + noise
+
+ t, _, h, w = img_lqs.shape
+ img_lqs = torch.cat([img_lqs, noise_level.expand(t, 1, h, w)], 1)
+
+ # img_lqs: (t, c, h, w)
+ # img_gts: (t, c, h, w)
+ # key: str
+ return {'L': img_lqs, 'H': img_gts, 'key': key}
+
+
+ def __len__(self):
+ return len(self.keys)
+
+
+class VideoRecurrentTrainVimeoDataset(data.Dataset):
+ """Vimeo90K dataset for training recurrent networks.
+
+ The keys are generated from a meta info txt file.
+ basicsr/data/meta_info/meta_info_Vimeo90K_train_GT.txt
+
+ Each line contains:
+ 1. clip name; 2. frame number; 3. image shape, separated by a white space.
+ Examples:
+ 00001/0001 7 (256,448,3)
+ 00001/0002 7 (256,448,3)
+
+ Key examples: "00001/0001"
+ GT (gt): Ground-Truth;
+ LQ (lq): Low-Quality, e.g., low-resolution/blurry/noisy/compressed frames.
+
+ The neighboring frame list for different num_frame:
+ num_frame | frame list
+ 1 | 4
+ 3 | 3,4,5
+ 5 | 2,3,4,5,6
+ 7 | 1,2,3,4,5,6,7
+
+ Args:
+ opt (dict): Config for train dataset. It contains the following keys:
+ dataroot_gt (str): Data root path for gt.
+ dataroot_lq (str): Data root path for lq.
+ meta_info_file (str): Path for meta information file.
+ io_backend (dict): IO backend type and other kwarg.
+
+ num_frame (int): Window size for input frames.
+ gt_size (int): Cropped patched size for gt patches.
+ random_reverse (bool): Random reverse input frames.
+ use_hflip (bool): Use horizontal flips.
+ use_rot (bool): Use rotation (use vertical flip and transposing h
+ and w for implementation).
+
+ scale (bool): Scale, which will be added automatically.
+ """
+
+ def __init__(self, opt):
+ super(VideoRecurrentTrainVimeoDataset, self).__init__()
+ self.opt = opt
+ self.gt_root, self.lq_root = Path(opt['dataroot_gt']), Path(opt['dataroot_lq'])
+
+ with open(opt['meta_info_file'], 'r') as fin:
+ self.keys = [line.split(' ')[0] for line in fin]
+
+ # file client (io backend)
+ self.file_client = None
+ self.io_backend_opt = opt['io_backend']
+ self.is_lmdb = False
+ if self.io_backend_opt['type'] == 'lmdb':
+ self.is_lmdb = True
+ self.io_backend_opt['db_paths'] = [self.lq_root, self.gt_root]
+ self.io_backend_opt['client_keys'] = ['lq', 'gt']
+
+ # indices of input images
+ self.neighbor_list = [i + (9 - opt['num_frame']) // 2 for i in range(opt['num_frame'])]
+
+ # temporal augmentation configs
+ self.random_reverse = opt['random_reverse']
+ print(f'Random reverse is {self.random_reverse}.')
+
+ self.flip_sequence = opt.get('flip_sequence', False)
+ self.pad_sequence = opt.get('pad_sequence', False)
+ self.neighbor_list = [1, 2, 3, 4, 5, 6, 7]
+
+ def __getitem__(self, index):
+ if self.file_client is None:
+ self.file_client = utils_video.FileClient(self.io_backend_opt.pop('type'), **self.io_backend_opt)
+
+ # random reverse
+ if self.random_reverse and random.random() < 0.5:
+ self.neighbor_list.reverse()
+
+ scale = self.opt['scale']
+ gt_size = self.opt['gt_size']
+ key = self.keys[index]
+ clip, seq = key.split('/') # key example: 00001/0001
+
+ # get the neighboring LQ and GT frames
+ img_lqs = []
+ img_gts = []
+ for neighbor in self.neighbor_list:
+ if self.is_lmdb:
+ img_lq_path = f'{clip}/{seq}/im{neighbor}'
+ img_gt_path = f'{clip}/{seq}/im{neighbor}'
+ else:
+ img_lq_path = self.lq_root / clip / seq / f'im{neighbor}.png'
+ img_gt_path = self.gt_root / clip / seq / f'im{neighbor}.png'
+ # LQ
+ img_bytes = self.file_client.get(img_lq_path, 'lq')
+ img_lq = utils_video.imfrombytes(img_bytes, float32=True)
+ # GT
+ img_bytes = self.file_client.get(img_gt_path, 'gt')
+ img_gt = utils_video.imfrombytes(img_bytes, float32=True)
+
+ img_lqs.append(img_lq)
+ img_gts.append(img_gt)
+
+ # randomly crop
+ img_gts, img_lqs = utils_video.paired_random_crop(img_gts, img_lqs, gt_size, scale, img_gt_path)
+
+ # augmentation - flip, rotate
+ img_lqs.extend(img_gts)
+ img_results = utils_video.augment(img_lqs, self.opt['use_hflip'], self.opt['use_rot'])
+
+ img_results = utils_video.img2tensor(img_results)
+ img_lqs = torch.stack(img_results[:7], dim=0)
+ img_gts = torch.stack(img_results[7:], dim=0)
+
+ if self.flip_sequence: # flip the sequence: 7 frames to 14 frames
+ img_lqs = torch.cat([img_lqs, img_lqs.flip(0)], dim=0)
+ img_gts = torch.cat([img_gts, img_gts.flip(0)], dim=0)
+ elif self.pad_sequence: # pad the sequence: 7 frames to 8 frames
+ img_lqs = torch.cat([img_lqs, img_lqs[-1:,...]], dim=0)
+ img_gts = torch.cat([img_gts, img_gts[-1:,...]], dim=0)
+
+ # img_lqs: (t, c, h, w)
+ # img_gt: (c, h, w)
+ # key: str
+ return {'L': img_lqs, 'H': img_gts, 'key': key}
+
+ def __len__(self):
+ return len(self.keys)
diff --git a/KAIR/data/degradations.py b/KAIR/data/degradations.py
new file mode 100644
index 0000000000000000000000000000000000000000..77d2a87cc841d31bbc56233b8b61eda55f24827a
--- /dev/null
+++ b/KAIR/data/degradations.py
@@ -0,0 +1,145 @@
+from typing import Tuple
+
+import numpy as np
+import random
+import torch
+from numpy.typing import NDArray
+
+from basicsr.data.degradations import random_add_gaussian_noise_pt, random_add_poisson_noise_pt
+from basicsr.data.transforms import paired_random_crop
+from basicsr.utils import DiffJPEG, USMSharp
+from basicsr.utils.img_process_util import filter2D
+from torch import Tensor
+from torch.nn import functional as F
+
+
+def blur(img: Tensor, kernel: NDArray) -> Tensor:
+ return filter2D(img, kernel)
+
+
+def random_resize(
+ img: Tensor,
+ resize_prob: float,
+ resize_range: Tuple[int, int],
+ output_scale: float = 1
+) -> Tensor:
+ updown_type = random.choices(['up', 'down', 'keep'], resize_prob)[0]
+ if updown_type == 'up':
+ random_scale = np.random.uniform(1, resize_range[1])
+ elif updown_type == 'down':
+ random_scale = np.random.uniform(resize_range[0], 1)
+ else:
+ random_scale = 1
+ mode = random.choice(['area', 'bilinear', 'bicubic'])
+ out = F.interpolate(img, scale_factor=output_scale * random_scale, mode=mode)
+ return out
+
+
+def add_noise(
+ img: Tensor,
+ gray_noise_prob: float,
+ gaussian_noise_prob: float,
+ noise_range: Tuple[float, float],
+ poisson_scale_range: Tuple[float, float]
+) -> Tensor:
+ if np.random.uniform() < gaussian_noise_prob:
+ img = random_add_gaussian_noise_pt(
+ img, sigma_range=noise_range, clip=True, rounds=False,
+ gray_prob=gray_noise_prob)
+ else:
+ img = random_add_poisson_noise_pt(
+ img, scale_range=poisson_scale_range,
+ gray_prob=gray_noise_prob, clip=True, rounds=False)
+ return img
+
+
+def jpeg_compression_simulation(
+ img: Tensor,
+ jpeg_range: Tuple[float, float],
+ jpeg_simulator: DiffJPEG
+) -> Tensor:
+ jpeg_p = img.new_zeros(img.size(0)).uniform_(*jpeg_range)
+
+ # clamp to [0, 1], otherwise JPEGer will result in unpleasant artifacts
+ img = torch.clamp(img, 0, 1)
+ return jpeg_simulator(img, quality=jpeg_p)
+
+
+@torch.no_grad()
+def apply_real_esrgan_degradations(
+ gt: Tensor,
+ blur_kernel1: NDArray,
+ blur_kernel2: NDArray,
+ second_blur_prob: float,
+ sinc_kernel: NDArray,
+ resize_prob1: float,
+ resize_prob2: float,
+ resize_range1: Tuple[int, int],
+ resize_range2: Tuple[int, int],
+ gray_noise_prob1: float,
+ gray_noise_prob2: float,
+ gaussian_noise_prob1: float,
+ gaussian_noise_prob2: float,
+ noise_range: Tuple[float, float],
+ poisson_scale_range: Tuple[float, float],
+ jpeg_compression_range1: Tuple[float, float],
+ jpeg_compression_range2: Tuple[float, float],
+ jpeg_simulator: DiffJPEG,
+ random_crop_gt_size: 512,
+ sr_upsample_scale: float,
+ usm_sharpener: USMSharp
+):
+ """
+ Accept batch from batchloader, and then add two-order degradations
+ to obtain LQ images.
+
+ gt: Tensor of shape (B x C x H x W)
+ """
+ gt_usm = usm_sharpener(gt)
+ # from PIL import Image
+ # Image.fromarray((gt_usm[0].permute(1, 2, 0).cpu().numpy() * 255.).astype(np.uint8)).save(
+ # "/home/cll/Desktop/GT_USM_orig.png")
+ orig_h, orig_w = gt.size()[2:4]
+
+ # ----------------------- The first degradation process ----------------------- #
+ out = blur(gt_usm, blur_kernel1)
+ out = random_resize(out, resize_prob1, resize_range1)
+ out = add_noise(out, gray_noise_prob1, gaussian_noise_prob1, noise_range, poisson_scale_range)
+ out = jpeg_compression_simulation(out, jpeg_compression_range1, jpeg_simulator)
+
+ # ----------------------- The second degradation process ----------------------- #
+ if np.random.uniform() < second_blur_prob:
+ out = blur(out, blur_kernel2)
+ out = random_resize(out, resize_prob2, resize_range2, output_scale=(1/sr_upsample_scale))
+ out = add_noise(out, gray_noise_prob2, gaussian_noise_prob2,
+ noise_range, poisson_scale_range)
+
+ # JPEG compression + the final sinc filter
+ # We also need to resize images to desired sizes.
+ # We group [resize back + sinc filter] together
+ # as one operation.
+ # We consider two orders:
+ # 1. [resize back + sinc filter] + JPEG compression
+ # 2. JPEG compression + [resize back + sinc filter]
+ # Empirically, we find other combinations (sinc + JPEG + Resize)
+ # will introduce twisted lines.
+ if np.random.uniform() < 0.5:
+ # resize back + the final sinc filter
+ mode = random.choice(['area', 'bilinear', 'bicubic'])
+ out = F.interpolate(out, size=(orig_h // sr_upsample_scale,
+ orig_w // sr_upsample_scale), mode=mode)
+ out = blur(out, sinc_kernel)
+ out = jpeg_compression_simulation(out, jpeg_compression_range2, jpeg_simulator)
+ else:
+ out = jpeg_compression_simulation(out, jpeg_compression_range2, jpeg_simulator)
+ mode = random.choice(['area', 'bilinear', 'bicubic'])
+ out = F.interpolate(out, size=(orig_h // sr_upsample_scale,
+ orig_w // sr_upsample_scale), mode=mode)
+ out = blur(out, sinc_kernel)
+
+ # clamp and round
+ lq = torch.clamp((out * 255.0).round(), 0, 255) / 255.
+
+ (gt, gt_usm), lq = paired_random_crop([gt, gt_usm], lq, random_crop_gt_size, sr_upsample_scale)
+
+ return gt, gt_usm, lq
diff --git a/KAIR/data/select_dataset.py b/KAIR/data/select_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..bbe9986cfb1103125906db5a3349873c64024c34
--- /dev/null
+++ b/KAIR/data/select_dataset.py
@@ -0,0 +1,86 @@
+
+
+'''
+# --------------------------------------------
+# select dataset
+# --------------------------------------------
+# Kai Zhang (github: https://github.com/cszn)
+# --------------------------------------------
+'''
+
+
+def define_Dataset(dataset_opt):
+ dataset_type = dataset_opt['dataset_type'].lower()
+ if dataset_type in ['l', 'low-quality', 'input-only']:
+ from data.dataset_l import DatasetL as D
+
+ # -----------------------------------------
+ # denoising
+ # -----------------------------------------
+ elif dataset_type in ['dncnn', 'denoising']:
+ from data.dataset_dncnn import DatasetDnCNN as D
+
+ elif dataset_type in ['dnpatch']:
+ from data.dataset_dnpatch import DatasetDnPatch as D
+
+ elif dataset_type in ['ffdnet', 'denoising-noiselevel']:
+ from data.dataset_ffdnet import DatasetFFDNet as D
+
+ elif dataset_type in ['fdncnn', 'denoising-noiselevelmap']:
+ from data.dataset_fdncnn import DatasetFDnCNN as D
+
+ # -----------------------------------------
+ # super-resolution
+ # -----------------------------------------
+ elif dataset_type in ['sr', 'super-resolution']:
+ from data.dataset_sr import DatasetSR as D
+
+ elif dataset_type in ['srmd']:
+ from data.dataset_srmd import DatasetSRMD as D
+
+ elif dataset_type in ['dpsr', 'dnsr']:
+ from data.dataset_dpsr import DatasetDPSR as D
+
+ elif dataset_type in ['usrnet', 'usrgan']:
+ from data.dataset_usrnet import DatasetUSRNet as D
+
+ elif dataset_type in ['bsrnet', 'bsrgan', 'blindsr']:
+ from data.dataset_blindsr import DatasetBlindSR as D
+
+ # -------------------------------------------------
+ # JPEG compression artifact reduction (deblocking)
+ # -------------------------------------------------
+ elif dataset_type in ['jpeg']:
+ from data.dataset_jpeg import DatasetJPEG as D
+
+ # -----------------------------------------
+ # video restoration
+ # -----------------------------------------
+ elif dataset_type in ['videorecurrenttraindataset']:
+ from data.dataset_video_train import VideoRecurrentTrainDataset as D
+ elif dataset_type in ['videorecurrenttrainnonblinddenoisingdataset']:
+ from data.dataset_video_train import VideoRecurrentTrainNonblindDenoisingDataset as D
+ elif dataset_type in ['videorecurrenttrainvimeodataset']:
+ from data.dataset_video_train import VideoRecurrentTrainVimeoDataset as D
+ elif dataset_type in ['videorecurrenttestdataset']:
+ from data.dataset_video_test import VideoRecurrentTestDataset as D
+ elif dataset_type in ['singlevideorecurrenttestdataset']:
+ from data.dataset_video_test import SingleVideoRecurrentTestDataset as D
+ elif dataset_type in ['videotestvimeo90kdataset']:
+ from data.dataset_video_test import VideoTestVimeo90KDataset as D
+
+ # -----------------------------------------
+ # common
+ # -----------------------------------------
+ elif dataset_type in ['plain']:
+ from data.dataset_plain import DatasetPlain as D
+
+ elif dataset_type in ['plainpatch']:
+ from data.dataset_plainpatch import DatasetPlainPatch as D
+
+ else:
+ raise NotImplementedError('Dataset [{:s}] is not found.'.format(dataset_type))
+
+ dataset = D(dataset_opt)
+ print('Dataset [{:s} - {:s}] is created.'.format(dataset.__class__.__name__, dataset_opt['name']))
+ return dataset
diff --git a/KAIR/docs/README_SwinIR.md b/KAIR/docs/README_SwinIR.md
new file mode 100644
index 0000000000000000000000000000000000000000..52f86e58b9b743b1951b373f80422cf53d0ac3fa
--- /dev/null
+++ b/KAIR/docs/README_SwinIR.md
@@ -0,0 +1,194 @@
+# SwinIR: Image Restoration Using Shifted Window Transformer
+[paper](https://arxiv.org/abs/2108.10257)
+**|**
+[supplementary](https://github.com/JingyunLiang/SwinIR/releases/tag/v0.0)
+**|**
+[visual results](https://github.com/JingyunLiang/SwinIR/releases/tag/v0.0)
+**|**
+[original project page](https://github.com/JingyunLiang/SwinIR)
+**|**
+[online Colab demo](https://colab.research.google.com/gist/JingyunLiang/a5e3e54bc9ef8d7bf594f6fee8208533/swinir-demo-on-real-world-image-sr.ipynb)
+
+[](https://arxiv.org/abs/2108.10257)
+[](https://github.com/JingyunLiang/SwinIR)
+[](https://github.com/JingyunLiang/SwinIR/releases)
+[ ](https://colab.research.google.com/gist/JingyunLiang/a5e3e54bc9ef8d7bf594f6fee8208533/swinir-demo-on-real-world-image-sr.ipynb)
+
+> Image restoration is a long-standing low-level vision problem that aims to restore high-quality images from low-quality images (e.g., downscaled, noisy and compressed images). While state-of-the-art image restoration methods are based on convolutional neural networks, few attempts have been made with Transformers which show impressive performance on high-level vision tasks. In this paper, we propose a strong baseline model SwinIR for image restoration based on the Swin Transformer. SwinIR consists of three parts: shallow feature extraction, deep feature extraction and high-quality image reconstruction. In particular, the deep feature extraction module is composed of several residual Swin Transformer blocks (RSTB), each of which has several Swin Transformer layers together with a residual connection. We conduct experiments on three representative tasks: image super-resolution (including classical, lightweight and real-world image super-resolution), image denoising (including grayscale and color image denoising) and JPEG compression artifact reduction. Experimental results demonstrate that SwinIR outperforms state-of-the-art methods on different tasks by up to 0.14~0.45dB, while the total number of parameters can be reduced by up to 67%.
+
+
+### Dataset Preparation
+
+Training and testing sets can be downloaded as follows. Please put them in `trainsets` and `testsets` respectively.
+
+| Task | Training Set | Testing Set|
+| :--- | :---: | :---: |
+| classical/lightweight image SR | [DIV2K](https://cv.snu.ac.kr/research/EDSR/DIV2K.tar) (800 training images) or DIV2K +[Flickr2K](https://cv.snu.ac.kr/research/EDSR/Flickr2K.tar) (2650 images) | set5 + Set14 + BSD100 + Urban100 + Manga109 [download all](https://drive.google.com/drive/folders/1B3DJGQKB6eNdwuQIhdskA64qUuVKLZ9u) |
+| real-world image SR | SwinIR-M (middle size): [DIV2K](https://cv.snu.ac.kr/research/EDSR/DIV2K.tar) (800 training images) +[Flickr2K](https://cv.snu.ac.kr/research/EDSR/Flickr2K.tar) (2650 images) + [OST](https://openmmlab.oss-cn-hangzhou.aliyuncs.com/datasets/OST_dataset.zip) (10324 images, sky,water,grass,mountain,building,plant,animal)
+
+
+
+Testing
+----------
+|Method | [model_zoo](model_zoo)|
+|---|---|
+| [main_test_dncnn.py](main_test_dncnn.py) |```dncnn_15.pth, dncnn_25.pth, dncnn_50.pth, dncnn_gray_blind.pth, dncnn_color_blind.pth, dncnn3.pth```|
+| [main_test_ircnn_denoiser.py](main_test_ircnn_denoiser.py) | ```ircnn_gray.pth, ircnn_color.pth```|
+| [main_test_fdncnn.py](main_test_fdncnn.py) | ```fdncnn_gray.pth, fdncnn_color.pth, fdncnn_gray_clip.pth, fdncnn_color_clip.pth```|
+| [main_test_ffdnet.py](main_test_ffdnet.py) | ```ffdnet_gray.pth, ffdnet_color.pth, ffdnet_gray_clip.pth, ffdnet_color_clip.pth```|
+| [main_test_srmd.py](main_test_srmd.py) | ```srmdnf_x2.pth, srmdnf_x3.pth, srmdnf_x4.pth, srmd_x2.pth, srmd_x3.pth, srmd_x4.pth```|
+| | **The above models are converted from MatConvNet.** |
+| [main_test_dpsr.py](main_test_dpsr.py) | ```dpsr_x2.pth, dpsr_x3.pth, dpsr_x4.pth, dpsr_x4_gan.pth```|
+| [main_test_msrresnet.py](main_test_msrresnet.py) | ```msrresnet_x4_psnr.pth, msrresnet_x4_gan.pth```|
+| [main_test_rrdb.py](main_test_rrdb.py) | ```rrdb_x4_psnr.pth, rrdb_x4_esrgan.pth```|
+| [main_test_imdn.py](main_test_imdn.py) | ```imdn_x4.pth```|
+
+[model_zoo](model_zoo)
+--------
+- download link [https://drive.google.com/drive/folders/13kfr3qny7S2xwG9h7v95F5mkWs0OmU0D](https://drive.google.com/drive/folders/13kfr3qny7S2xwG9h7v95F5mkWs0OmU0D)
+
+[trainsets](trainsets)
+----------
+- [https://github.com/xinntao/BasicSR/blob/master/docs/DatasetPreparation.md](https://github.com/xinntao/BasicSR/blob/master/docs/DatasetPreparation.md)
+- [train400](https://github.com/cszn/DnCNN/tree/master/TrainingCodes/DnCNN_TrainingCodes_v1.0/data)
+- [DIV2K](https://data.vision.ee.ethz.ch/cvl/DIV2K/)
+- [Flickr2K](https://cv.snu.ac.kr/research/EDSR/Flickr2K.tar)
+- optional: use [split_imageset(original_dataroot, taget_dataroot, n_channels=3, p_size=512, p_overlap=96, p_max=800)](https://github.com/cszn/KAIR/blob/3ee0bf3e07b90ec0b7302d97ee2adb780617e637/utils/utils_image.py#L123) to get ```trainsets/trainH``` with small images for fast data loading
+
+[testsets](testsets)
+-----------
+- [https://github.com/xinntao/BasicSR/blob/master/docs/DatasetPreparation.md](https://github.com/xinntao/BasicSR/blob/master/docs/DatasetPreparation.md)
+- [set12](https://github.com/cszn/FFDNet/tree/master/testsets)
+- [bsd68](https://github.com/cszn/FFDNet/tree/master/testsets)
+- [cbsd68](https://github.com/cszn/FFDNet/tree/master/testsets)
+- [kodak24](https://github.com/cszn/FFDNet/tree/master/testsets)
+- [srbsd68](https://github.com/cszn/DPSR/tree/master/testsets/BSD68/GT)
+- set5
+- set14
+- cbsd100
+- urban100
+- manga109
+
+
+References
+----------
+```BibTex
+@article{liang2022vrt,
+title={VRT: A Video Restoration Transformer},
+author={Liang, Jingyun and Cao, Jiezhang and Fan, Yuchen and Zhang, Kai and Ranjan, Rakesh and Li, Yawei and Timofte, Radu and Van Gool, Luc},
+journal={arXiv preprint arXiv:2022.00000},
+year={2022}
+}
+@inproceedings{liang2021swinir,
+title={SwinIR: Image Restoration Using Swin Transformer},
+author={Liang, Jingyun and Cao, Jiezhang and Sun, Guolei and Zhang, Kai and Van Gool, Luc and Timofte, Radu},
+booktitle={IEEE International Conference on Computer Vision Workshops},
+pages={1833--1844},
+year={2021}
+}
+@inproceedings{zhang2021designing,
+title={Designing a Practical Degradation Model for Deep Blind Image Super-Resolution},
+author={Zhang, Kai and Liang, Jingyun and Van Gool, Luc and Timofte, Radu},
+booktitle={IEEE International Conference on Computer Vision},
+pages={4791--4800},
+year={2021}
+}
+@article{zhang2021plug, % DPIR & DRUNet & IRCNN
+ title={Plug-and-Play Image Restoration with Deep Denoiser Prior},
+ author={Zhang, Kai and Li, Yawei and Zuo, Wangmeng and Zhang, Lei and Van Gool, Luc and Timofte, Radu},
+ journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
+ year={2021}
+}
+@inproceedings{zhang2020aim, % efficientSR_challenge
+ title={AIM 2020 Challenge on Efficient Super-Resolution: Methods and Results},
+ author={Kai Zhang and Martin Danelljan and Yawei Li and Radu Timofte and others},
+ booktitle={European Conference on Computer Vision Workshops},
+ year={2020}
+}
+@inproceedings{zhang2020deep, % USRNet
+ title={Deep unfolding network for image super-resolution},
+ author={Zhang, Kai and Van Gool, Luc and Timofte, Radu},
+ booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
+ pages={3217--3226},
+ year={2020}
+}
+@article{zhang2017beyond, % DnCNN
+ title={Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising},
+ author={Zhang, Kai and Zuo, Wangmeng and Chen, Yunjin and Meng, Deyu and Zhang, Lei},
+ journal={IEEE Transactions on Image Processing},
+ volume={26},
+ number={7},
+ pages={3142--3155},
+ year={2017}
+}
+@inproceedings{zhang2017learning, % IRCNN
+title={Learning deep CNN denoiser prior for image restoration},
+author={Zhang, Kai and Zuo, Wangmeng and Gu, Shuhang and Zhang, Lei},
+booktitle={IEEE conference on computer vision and pattern recognition},
+pages={3929--3938},
+year={2017}
+}
+@article{zhang2018ffdnet, % FFDNet, FDnCNN
+ title={FFDNet: Toward a fast and flexible solution for CNN-based image denoising},
+ author={Zhang, Kai and Zuo, Wangmeng and Zhang, Lei},
+ journal={IEEE Transactions on Image Processing},
+ volume={27},
+ number={9},
+ pages={4608--4622},
+ year={2018}
+}
+@inproceedings{zhang2018learning, % SRMD
+ title={Learning a single convolutional super-resolution network for multiple degradations},
+ author={Zhang, Kai and Zuo, Wangmeng and Zhang, Lei},
+ booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
+ pages={3262--3271},
+ year={2018}
+}
+@inproceedings{zhang2019deep, % DPSR
+ title={Deep Plug-and-Play Super-Resolution for Arbitrary Blur Kernels},
+ author={Zhang, Kai and Zuo, Wangmeng and Zhang, Lei},
+ booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
+ pages={1671--1681},
+ year={2019}
+}
+@InProceedings{wang2018esrgan, % ESRGAN, MSRResNet
+ author = {Wang, Xintao and Yu, Ke and Wu, Shixiang and Gu, Jinjin and Liu, Yihao and Dong, Chao and Qiao, Yu and Loy, Chen Change},
+ title = {ESRGAN: Enhanced super-resolution generative adversarial networks},
+ booktitle = {The European Conference on Computer Vision Workshops (ECCVW)},
+ month = {September},
+ year = {2018}
+}
+@inproceedings{hui2019lightweight, % IMDN
+ title={Lightweight Image Super-Resolution with Information Multi-distillation Network},
+ author={Hui, Zheng and Gao, Xinbo and Yang, Yunchu and Wang, Xiumei},
+ booktitle={Proceedings of the 27th ACM International Conference on Multimedia (ACM MM)},
+ pages={2024--2032},
+ year={2019}
+}
+@inproceedings{zhang2019aim, % IMDN
+ title={AIM 2019 Challenge on Constrained Super-Resolution: Methods and Results},
+ author={Kai Zhang and Shuhang Gu and Radu Timofte and others},
+ booktitle={IEEE International Conference on Computer Vision Workshops},
+ year={2019}
+}
+@inproceedings{yang2021gan,
+ title={GAN Prior Embedded Network for Blind Face Restoration in the Wild},
+ author={Tao Yang, Peiran Ren, Xuansong Xie, and Lei Zhang},
+ booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
+ year={2021}
+}
+```
diff --git a/KAIR/data/__init__.py b/KAIR/data/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..8b137891791fe96927ad78e64b0aad7bded08bdc
--- /dev/null
+++ b/KAIR/data/__init__.py
@@ -0,0 +1 @@
+
diff --git a/KAIR/data/dataset_blindsr.py b/KAIR/data/dataset_blindsr.py
new file mode 100644
index 0000000000000000000000000000000000000000..3d16ae3418b45d3550f70c43cd56ac0491fe87b6
--- /dev/null
+++ b/KAIR/data/dataset_blindsr.py
@@ -0,0 +1,92 @@
+import random
+import numpy as np
+import torch.utils.data as data
+import utils.utils_image as util
+import os
+from utils import utils_blindsr as blindsr
+
+
+class DatasetBlindSR(data.Dataset):
+ '''
+ # -----------------------------------------
+ # dataset for BSRGAN
+ # -----------------------------------------
+ '''
+ def __init__(self, opt):
+ super(DatasetBlindSR, self).__init__()
+ self.opt = opt
+ self.n_channels = opt['n_channels'] if opt['n_channels'] else 3
+ self.sf = opt['scale'] if opt['scale'] else 4
+ self.shuffle_prob = opt['shuffle_prob'] if opt['shuffle_prob'] else 0.1
+ self.use_sharp = opt['use_sharp'] if opt['use_sharp'] else False
+ self.degradation_type = opt['degradation_type'] if opt['degradation_type'] else 'bsrgan'
+ self.lq_patchsize = self.opt['lq_patchsize'] if self.opt['lq_patchsize'] else 64
+ self.patch_size = self.opt['H_size'] if self.opt['H_size'] else self.lq_patchsize*self.sf
+
+ self.paths_H = util.get_image_paths(opt['dataroot_H'])
+ print(len(self.paths_H))
+
+# for n, v in enumerate(self.paths_H):
+# if 'face' in v:
+# del self.paths_H[n]
+# time.sleep(1)
+ assert self.paths_H, 'Error: H path is empty.'
+
+ def __getitem__(self, index):
+
+ L_path = None
+
+ # ------------------------------------
+ # get H image
+ # ------------------------------------
+ H_path = self.paths_H[index]
+ img_H = util.imread_uint(H_path, self.n_channels)
+ img_name, ext = os.path.splitext(os.path.basename(H_path))
+ H, W, C = img_H.shape
+
+ if H < self.patch_size or W < self.patch_size:
+ img_H = np.tile(np.random.randint(0, 256, size=[1, 1, self.n_channels], dtype=np.uint8), (self.patch_size, self.patch_size, 1))
+
+ # ------------------------------------
+ # if train, get L/H patch pair
+ # ------------------------------------
+ if self.opt['phase'] == 'train':
+
+ H, W, C = img_H.shape
+
+ rnd_h_H = random.randint(0, max(0, H - self.patch_size))
+ rnd_w_H = random.randint(0, max(0, W - self.patch_size))
+ img_H = img_H[rnd_h_H:rnd_h_H + self.patch_size, rnd_w_H:rnd_w_H + self.patch_size, :]
+
+ if 'face' in img_name:
+ mode = random.choice([0, 4])
+ img_H = util.augment_img(img_H, mode=mode)
+ else:
+ mode = random.randint(0, 7)
+ img_H = util.augment_img(img_H, mode=mode)
+
+ img_H = util.uint2single(img_H)
+ if self.degradation_type == 'bsrgan':
+ img_L, img_H = blindsr.degradation_bsrgan(img_H, self.sf, lq_patchsize=self.lq_patchsize, isp_model=None)
+ elif self.degradation_type == 'bsrgan_plus':
+ img_L, img_H = blindsr.degradation_bsrgan_plus(img_H, self.sf, shuffle_prob=self.shuffle_prob, use_sharp=self.use_sharp, lq_patchsize=self.lq_patchsize)
+
+ else:
+ img_H = util.uint2single(img_H)
+ if self.degradation_type == 'bsrgan':
+ img_L, img_H = blindsr.degradation_bsrgan(img_H, self.sf, lq_patchsize=self.lq_patchsize, isp_model=None)
+ elif self.degradation_type == 'bsrgan_plus':
+ img_L, img_H = blindsr.degradation_bsrgan_plus(img_H, self.sf, shuffle_prob=self.shuffle_prob, use_sharp=self.use_sharp, lq_patchsize=self.lq_patchsize)
+
+ # ------------------------------------
+ # L/H pairs, HWC to CHW, numpy to tensor
+ # ------------------------------------
+ img_H, img_L = util.single2tensor3(img_H), util.single2tensor3(img_L)
+
+ if L_path is None:
+ L_path = H_path
+
+ return {'L': img_L, 'H': img_H, 'L_path': L_path, 'H_path': H_path}
+
+ def __len__(self):
+ return len(self.paths_H)
diff --git a/KAIR/data/dataset_dncnn.py b/KAIR/data/dataset_dncnn.py
new file mode 100644
index 0000000000000000000000000000000000000000..2477e253c3449fd2bf2f133c79700a7fc8be619b
--- /dev/null
+++ b/KAIR/data/dataset_dncnn.py
@@ -0,0 +1,101 @@
+import os.path
+import random
+import numpy as np
+import torch
+import torch.utils.data as data
+import utils.utils_image as util
+
+
+class DatasetDnCNN(data.Dataset):
+ """
+ # -----------------------------------------
+ # Get L/H for denosing on AWGN with fixed sigma.
+ # Only dataroot_H is needed.
+ # -----------------------------------------
+ # e.g., DnCNN
+ # -----------------------------------------
+ """
+
+ def __init__(self, opt):
+ super(DatasetDnCNN, self).__init__()
+ print('Dataset: Denosing on AWGN with fixed sigma. Only dataroot_H is needed.')
+ self.opt = opt
+ self.n_channels = opt['n_channels'] if opt['n_channels'] else 3
+ self.patch_size = opt['H_size'] if opt['H_size'] else 64
+ self.sigma = opt['sigma'] if opt['sigma'] else 25
+ self.sigma_test = opt['sigma_test'] if opt['sigma_test'] else self.sigma
+
+ # ------------------------------------
+ # get path of H
+ # return None if input is None
+ # ------------------------------------
+ self.paths_H = util.get_image_paths(opt['dataroot_H'])
+
+ def __getitem__(self, index):
+
+ # ------------------------------------
+ # get H image
+ # ------------------------------------
+ H_path = self.paths_H[index]
+ img_H = util.imread_uint(H_path, self.n_channels)
+
+ L_path = H_path
+
+ if self.opt['phase'] == 'train':
+ """
+ # --------------------------------
+ # get L/H patch pairs
+ # --------------------------------
+ """
+ H, W, _ = img_H.shape
+
+ # --------------------------------
+ # randomly crop the patch
+ # --------------------------------
+ rnd_h = random.randint(0, max(0, H - self.patch_size))
+ rnd_w = random.randint(0, max(0, W - self.patch_size))
+ patch_H = img_H[rnd_h:rnd_h + self.patch_size, rnd_w:rnd_w + self.patch_size, :]
+
+ # --------------------------------
+ # augmentation - flip, rotate
+ # --------------------------------
+ mode = random.randint(0, 7)
+ patch_H = util.augment_img(patch_H, mode=mode)
+
+ # --------------------------------
+ # HWC to CHW, numpy(uint) to tensor
+ # --------------------------------
+ img_H = util.uint2tensor3(patch_H)
+ img_L = img_H.clone()
+
+ # --------------------------------
+ # add noise
+ # --------------------------------
+ noise = torch.randn(img_L.size()).mul_(self.sigma/255.0)
+ img_L.add_(noise)
+
+ else:
+ """
+ # --------------------------------
+ # get L/H image pairs
+ # --------------------------------
+ """
+ img_H = util.uint2single(img_H)
+ img_L = np.copy(img_H)
+
+ # --------------------------------
+ # add noise
+ # --------------------------------
+ np.random.seed(seed=0)
+ img_L += np.random.normal(0, self.sigma_test/255.0, img_L.shape)
+
+ # --------------------------------
+ # HWC to CHW, numpy to tensor
+ # --------------------------------
+ img_L = util.single2tensor3(img_L)
+ img_H = util.single2tensor3(img_H)
+
+ return {'L': img_L, 'H': img_H, 'H_path': H_path, 'L_path': L_path}
+
+ def __len__(self):
+ return len(self.paths_H)
diff --git a/KAIR/data/dataset_dnpatch.py b/KAIR/data/dataset_dnpatch.py
new file mode 100644
index 0000000000000000000000000000000000000000..289f92e6f454d8246b5128f9e834de9b1678ee73
--- /dev/null
+++ b/KAIR/data/dataset_dnpatch.py
@@ -0,0 +1,133 @@
+import random
+import numpy as np
+import torch
+import torch.utils.data as data
+import utils.utils_image as util
+
+
+class DatasetDnPatch(data.Dataset):
+ """
+ # -----------------------------------------
+ # Get L/H for denosing on AWGN with fixed sigma.
+ # ****Get all H patches first****
+ # Only dataroot_H is needed.
+ # -----------------------------------------
+ # e.g., DnCNN with BSD400
+ # -----------------------------------------
+ """
+
+ def __init__(self, opt):
+ super(DatasetDnPatch, self).__init__()
+ print('Get L/H for denosing on AWGN with fixed sigma. Only dataroot_H is needed.')
+ self.opt = opt
+ self.n_channels = opt['n_channels'] if opt['n_channels'] else 3
+ self.patch_size = opt['H_size'] if opt['H_size'] else 64
+
+ self.sigma = opt['sigma'] if opt['sigma'] else 25
+ self.sigma_test = opt['sigma_test'] if opt['sigma_test'] else self.sigma
+
+ self.num_patches_per_image = opt['num_patches_per_image'] if opt['num_patches_per_image'] else 40
+ self.num_sampled = opt['num_sampled'] if opt['num_sampled'] else 3000
+
+ # ------------------------------------
+ # get paths of H
+ # ------------------------------------
+ self.paths_H = util.get_image_paths(opt['dataroot_H'])
+ assert self.paths_H, 'Error: H path is empty.'
+
+ # ------------------------------------
+ # number of sampled H images
+ # ------------------------------------
+ self.num_sampled = min(self.num_sampled, len(self.paths_H))
+
+ # ------------------------------------
+ # reserve space with zeros
+ # ------------------------------------
+ self.total_patches = self.num_sampled * self.num_patches_per_image
+ self.H_data = np.zeros([self.total_patches, self.patch_size, self.patch_size, self.n_channels], dtype=np.uint8)
+
+ # ------------------------------------
+ # update H patches
+ # ------------------------------------
+ self.update_data()
+
+ def update_data(self):
+ """
+ # ------------------------------------
+ # update whole H patches
+ # ------------------------------------
+ """
+ self.index_sampled = random.sample(range(0, len(self.paths_H), 1), self.num_sampled)
+ n_count = 0
+
+ for i in range(len(self.index_sampled)):
+ H_patches = self.get_patches(self.index_sampled[i])
+ for H_patch in H_patches:
+ self.H_data[n_count,:,:,:] = H_patch
+ n_count += 1
+
+ print('Training data updated! Total number of patches is: %5.2f X %5.2f = %5.2f\n' % (len(self.H_data)//128, 128, len(self.H_data)))
+
+ def get_patches(self, index):
+ """
+ # ------------------------------------
+ # get H patches from an H image
+ # ------------------------------------
+ """
+ H_path = self.paths_H[index]
+ img_H = util.imread_uint(H_path, self.n_channels) # uint format
+
+ H, W = img_H.shape[:2]
+
+ H_patches = []
+
+ num = self.num_patches_per_image
+ for _ in range(num):
+ rnd_h = random.randint(0, max(0, H - self.patch_size))
+ rnd_w = random.randint(0, max(0, W - self.patch_size))
+ H_patch = img_H[rnd_h:rnd_h + self.patch_size, rnd_w:rnd_w + self.patch_size, :]
+ H_patches.append(H_patch)
+
+ return H_patches
+
+ def __getitem__(self, index):
+
+ H_path = 'toy.png'
+ if self.opt['phase'] == 'train':
+
+ patch_H = self.H_data[index]
+
+ # --------------------------------
+ # augmentation - flip and/or rotate
+ # --------------------------------
+ mode = random.randint(0, 7)
+ patch_H = util.augment_img(patch_H, mode=mode)
+
+ patch_H = util.uint2tensor3(patch_H)
+ patch_L = patch_H.clone()
+
+ # ------------------------------------
+ # add noise
+ # ------------------------------------
+ noise = torch.randn(patch_L.size()).mul_(self.sigma/255.0)
+ patch_L.add_(noise)
+
+ else:
+
+ H_path = self.paths_H[index]
+ img_H = util.imread_uint(H_path, self.n_channels)
+ img_H = util.uint2single(img_H)
+ img_L = np.copy(img_H)
+
+ # ------------------------------------
+ # add noise
+ # ------------------------------------
+ np.random.seed(seed=0)
+ img_L += np.random.normal(0, self.sigma_test/255.0, img_L.shape)
+ patch_L, patch_H = util.single2tensor3(img_L), util.single2tensor3(img_H)
+
+ L_path = H_path
+ return {'L': patch_L, 'H': patch_H, 'L_path': L_path, 'H_path': H_path}
+
+ def __len__(self):
+ return len(self.H_data)
diff --git a/KAIR/data/dataset_dpsr.py b/KAIR/data/dataset_dpsr.py
new file mode 100644
index 0000000000000000000000000000000000000000..012f8283df9aae394c51e904183de1a567cc7d39
--- /dev/null
+++ b/KAIR/data/dataset_dpsr.py
@@ -0,0 +1,131 @@
+import random
+import numpy as np
+import torch
+import torch.utils.data as data
+import utils.utils_image as util
+
+
+class DatasetDPSR(data.Dataset):
+ '''
+ # -----------------------------------------
+ # Get L/H/M for noisy image SR.
+ # Only "paths_H" is needed, sythesize bicubicly downsampled L on-the-fly.
+ # -----------------------------------------
+ # e.g., SRResNet super-resolver prior for DPSR
+ # -----------------------------------------
+ '''
+
+ def __init__(self, opt):
+ super(DatasetDPSR, self).__init__()
+ self.opt = opt
+ self.n_channels = opt['n_channels'] if opt['n_channels'] else 3
+ self.sf = opt['scale'] if opt['scale'] else 4
+ self.patch_size = self.opt['H_size'] if self.opt['H_size'] else 96
+ self.L_size = self.patch_size // self.sf
+ self.sigma = opt['sigma'] if opt['sigma'] else [0, 50]
+ self.sigma_min, self.sigma_max = self.sigma[0], self.sigma[1]
+ self.sigma_test = opt['sigma_test'] if opt['sigma_test'] else 0
+
+ # ------------------------------------
+ # get paths of L/H
+ # ------------------------------------
+ self.paths_H = util.get_image_paths(opt['dataroot_H'])
+ self.paths_L = util.get_image_paths(opt['dataroot_L'])
+
+ assert self.paths_H, 'Error: H path is empty.'
+
+ def __getitem__(self, index):
+
+ # ------------------------------------
+ # get H image
+ # ------------------------------------
+ H_path = self.paths_H[index]
+ img_H = util.imread_uint(H_path, self.n_channels)
+ img_H = util.uint2single(img_H)
+
+ # ------------------------------------
+ # modcrop for SR
+ # ------------------------------------
+ img_H = util.modcrop(img_H, self.sf)
+
+ # ------------------------------------
+ # sythesize L image via matlab's bicubic
+ # ------------------------------------
+ H, W, _ = img_H.shape
+ img_L = util.imresize_np(img_H, 1 / self.sf, True)
+
+ if self.opt['phase'] == 'train':
+ """
+ # --------------------------------
+ # get L/H patch pairs
+ # --------------------------------
+ """
+ H, W, C = img_L.shape
+
+ # --------------------------------
+ # randomly crop L patch
+ # --------------------------------
+ rnd_h = random.randint(0, max(0, H - self.L_size))
+ rnd_w = random.randint(0, max(0, W - self.L_size))
+ img_L = img_L[rnd_h:rnd_h + self.L_size, rnd_w:rnd_w + self.L_size, :]
+
+ # --------------------------------
+ # crop corresponding H patch
+ # --------------------------------
+ rnd_h_H, rnd_w_H = int(rnd_h * self.sf), int(rnd_w * self.sf)
+ img_H = img_H[rnd_h_H:rnd_h_H + self.patch_size, rnd_w_H:rnd_w_H + self.patch_size, :]
+
+ # --------------------------------
+ # augmentation - flip and/or rotate
+ # --------------------------------
+ mode = random.randint(0, 7)
+ img_L, img_H = util.augment_img(img_L, mode=mode), util.augment_img(img_H, mode=mode)
+
+ # --------------------------------
+ # get patch pairs
+ # --------------------------------
+ img_H, img_L = util.single2tensor3(img_H), util.single2tensor3(img_L)
+
+ # --------------------------------
+ # select noise level and get Gaussian noise
+ # --------------------------------
+ if random.random() < 0.1:
+ noise_level = torch.zeros(1).float()
+ else:
+ noise_level = torch.FloatTensor([np.random.uniform(self.sigma_min, self.sigma_max)])/255.0
+ # noise_level = torch.rand(1)*50/255.0
+ # noise_level = torch.min(torch.from_numpy(np.float32([7*np.random.chisquare(2.5)/255.0])),torch.Tensor([50./255.]))
+
+ else:
+
+ img_H, img_L = util.single2tensor3(img_H), util.single2tensor3(img_L)
+
+ noise_level = torch.FloatTensor([self.sigma_test])
+
+ # ------------------------------------
+ # add noise
+ # ------------------------------------
+ noise = torch.randn(img_L.size()).mul_(noise_level).float()
+ img_L.add_(noise)
+
+ # ------------------------------------
+ # get noise level map M
+ # ------------------------------------
+ M_vector = noise_level.unsqueeze(1).unsqueeze(1)
+ M = M_vector.repeat(1, img_L.size()[-2], img_L.size()[-1])
+
+
+ """
+ # -------------------------------------
+ # concat L and noise level map M
+ # -------------------------------------
+ """
+ img_L = torch.cat((img_L, M), 0)
+
+
+ L_path = H_path
+
+ return {'L': img_L, 'H': img_H, 'L_path': L_path, 'H_path': H_path}
+
+ def __len__(self):
+ return len(self.paths_H)
diff --git a/KAIR/data/dataset_fdncnn.py b/KAIR/data/dataset_fdncnn.py
new file mode 100644
index 0000000000000000000000000000000000000000..632bf4783452a06cb290147b808dd48854eaabac
--- /dev/null
+++ b/KAIR/data/dataset_fdncnn.py
@@ -0,0 +1,109 @@
+import random
+import numpy as np
+import torch
+import torch.utils.data as data
+import utils.utils_image as util
+
+
+class DatasetFDnCNN(data.Dataset):
+ """
+ # -----------------------------------------
+ # Get L/H/M for denosing on AWGN with a range of sigma.
+ # Only dataroot_H is needed.
+ # -----------------------------------------
+ # e.g., FDnCNN, H = f(cat(L, M)), M is noise level map
+ # -----------------------------------------
+ """
+
+ def __init__(self, opt):
+ super(DatasetFDnCNN, self).__init__()
+ self.opt = opt
+ self.n_channels = opt['n_channels'] if opt['n_channels'] else 3
+ self.patch_size = self.opt['H_size'] if opt['H_size'] else 64
+ self.sigma = opt['sigma'] if opt['sigma'] else [0, 75]
+ self.sigma_min, self.sigma_max = self.sigma[0], self.sigma[1]
+ self.sigma_test = opt['sigma_test'] if opt['sigma_test'] else 25
+
+ # -------------------------------------
+ # get the path of H, return None if input is None
+ # -------------------------------------
+ self.paths_H = util.get_image_paths(opt['dataroot_H'])
+
+ def __getitem__(self, index):
+ # -------------------------------------
+ # get H image
+ # -------------------------------------
+ H_path = self.paths_H[index]
+ img_H = util.imread_uint(H_path, self.n_channels)
+
+ L_path = H_path
+
+ if self.opt['phase'] == 'train':
+ """
+ # --------------------------------
+ # get L/H/M patch pairs
+ # --------------------------------
+ """
+ H, W = img_H.shape[:2]
+
+ # ---------------------------------
+ # randomly crop the patch
+ # ---------------------------------
+ rnd_h = random.randint(0, max(0, H - self.patch_size))
+ rnd_w = random.randint(0, max(0, W - self.patch_size))
+ patch_H = img_H[rnd_h:rnd_h + self.patch_size, rnd_w:rnd_w + self.patch_size, :]
+
+ # ---------------------------------
+ # augmentation - flip, rotate
+ # ---------------------------------
+ mode = random.randint(0, 7)
+ patch_H = util.augment_img(patch_H, mode=mode)
+
+ # ---------------------------------
+ # HWC to CHW, numpy(uint) to tensor
+ # ---------------------------------
+ img_H = util.uint2tensor3(patch_H)
+ img_L = img_H.clone()
+
+ # ---------------------------------
+ # get noise level
+ # ---------------------------------
+ # noise_level = torch.FloatTensor([np.random.randint(self.sigma_min, self.sigma_max)])/255.0
+ noise_level = torch.FloatTensor([np.random.uniform(self.sigma_min, self.sigma_max)])/255.0
+
+ noise_level_map = torch.ones((1, img_L.size(1), img_L.size(2))).mul_(noise_level).float() # torch.full((1, img_L.size(1), img_L.size(2)), noise_level)
+
+ # ---------------------------------
+ # add noise
+ # ---------------------------------
+ noise = torch.randn(img_L.size()).mul_(noise_level).float()
+ img_L.add_(noise)
+
+ else:
+ """
+ # --------------------------------
+ # get L/H/M image pairs
+ # --------------------------------
+ """
+ img_H = util.uint2single(img_H)
+ img_L = np.copy(img_H)
+ np.random.seed(seed=0)
+ img_L += np.random.normal(0, self.sigma_test/255.0, img_L.shape)
+ noise_level_map = torch.ones((1, img_L.shape[0], img_L.shape[1])).mul_(self.sigma_test/255.0).float() # torch.full((1, img_L.size(1), img_L.size(2)), noise_level)
+
+ # ---------------------------------
+ # L/H image pairs
+ # ---------------------------------
+ img_H, img_L = util.single2tensor3(img_H), util.single2tensor3(img_L)
+
+ """
+ # -------------------------------------
+ # concat L and noise level map M
+ # -------------------------------------
+ """
+ img_L = torch.cat((img_L, noise_level_map), 0)
+
+ return {'L': img_L, 'H': img_H, 'L_path': L_path, 'H_path': H_path}
+
+ def __len__(self):
+ return len(self.paths_H)
diff --git a/KAIR/data/dataset_ffdnet.py b/KAIR/data/dataset_ffdnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..b3fd53aee5b52362bd5f80b48cc808346d7dcc80
--- /dev/null
+++ b/KAIR/data/dataset_ffdnet.py
@@ -0,0 +1,103 @@
+import random
+import numpy as np
+import torch
+import torch.utils.data as data
+import utils.utils_image as util
+
+
+class DatasetFFDNet(data.Dataset):
+ """
+ # -----------------------------------------
+ # Get L/H/M for denosing on AWGN with a range of sigma.
+ # Only dataroot_H is needed.
+ # -----------------------------------------
+ # e.g., FFDNet, H = f(L, sigma), sigma is noise level
+ # -----------------------------------------
+ """
+
+ def __init__(self, opt):
+ super(DatasetFFDNet, self).__init__()
+ self.opt = opt
+ self.n_channels = opt['n_channels'] if opt['n_channels'] else 3
+ self.patch_size = self.opt['H_size'] if opt['H_size'] else 64
+ self.sigma = opt['sigma'] if opt['sigma'] else [0, 75]
+ self.sigma_min, self.sigma_max = self.sigma[0], self.sigma[1]
+ self.sigma_test = opt['sigma_test'] if opt['sigma_test'] else 25
+
+ # -------------------------------------
+ # get the path of H, return None if input is None
+ # -------------------------------------
+ self.paths_H = util.get_image_paths(opt['dataroot_H'])
+
+ def __getitem__(self, index):
+ # -------------------------------------
+ # get H image
+ # -------------------------------------
+ H_path = self.paths_H[index]
+ img_H = util.imread_uint(H_path, self.n_channels)
+
+ L_path = H_path
+
+ if self.opt['phase'] == 'train':
+ """
+ # --------------------------------
+ # get L/H/M patch pairs
+ # --------------------------------
+ """
+ H, W = img_H.shape[:2]
+
+ # ---------------------------------
+ # randomly crop the patch
+ # ---------------------------------
+ rnd_h = random.randint(0, max(0, H - self.patch_size))
+ rnd_w = random.randint(0, max(0, W - self.patch_size))
+ patch_H = img_H[rnd_h:rnd_h + self.patch_size, rnd_w:rnd_w + self.patch_size, :]
+
+ # ---------------------------------
+ # augmentation - flip, rotate
+ # ---------------------------------
+ mode = random.randint(0, 7)
+ patch_H = util.augment_img(patch_H, mode=mode)
+
+ # ---------------------------------
+ # HWC to CHW, numpy(uint) to tensor
+ # ---------------------------------
+ img_H = util.uint2tensor3(patch_H)
+ img_L = img_H.clone()
+
+ # ---------------------------------
+ # get noise level
+ # ---------------------------------
+ # noise_level = torch.FloatTensor([np.random.randint(self.sigma_min, self.sigma_max)])/255.0
+ noise_level = torch.FloatTensor([np.random.uniform(self.sigma_min, self.sigma_max)])/255.0
+
+ # ---------------------------------
+ # add noise
+ # ---------------------------------
+ noise = torch.randn(img_L.size()).mul_(noise_level).float()
+ img_L.add_(noise)
+
+ else:
+ """
+ # --------------------------------
+ # get L/H/sigma image pairs
+ # --------------------------------
+ """
+ img_H = util.uint2single(img_H)
+ img_L = np.copy(img_H)
+ np.random.seed(seed=0)
+ img_L += np.random.normal(0, self.sigma_test/255.0, img_L.shape)
+ noise_level = torch.FloatTensor([self.sigma_test/255.0])
+
+ # ---------------------------------
+ # L/H image pairs
+ # ---------------------------------
+ img_H, img_L = util.single2tensor3(img_H), util.single2tensor3(img_L)
+
+ noise_level = noise_level.unsqueeze(1).unsqueeze(1)
+
+
+ return {'L': img_L, 'H': img_H, 'C': noise_level, 'L_path': L_path, 'H_path': H_path}
+
+ def __len__(self):
+ return len(self.paths_H)
diff --git a/KAIR/data/dataset_jpeg.py b/KAIR/data/dataset_jpeg.py
new file mode 100644
index 0000000000000000000000000000000000000000..a847f0d47e8ad86f6349459b2d244075e9f27a92
--- /dev/null
+++ b/KAIR/data/dataset_jpeg.py
@@ -0,0 +1,118 @@
+import random
+import torch.utils.data as data
+import utils.utils_image as util
+import cv2
+
+
+class DatasetJPEG(data.Dataset):
+ def __init__(self, opt):
+ super(DatasetJPEG, self).__init__()
+ print('Dataset: JPEG compression artifact reduction (deblocking) with quality factor. Only dataroot_H is needed.')
+ self.opt = opt
+ self.n_channels = opt['n_channels'] if opt['n_channels'] else 3
+ self.patch_size = self.opt['H_size'] if opt['H_size'] else 128
+
+ self.quality_factor = opt['quality_factor'] if opt['quality_factor'] else 40
+ self.quality_factor_test = opt['quality_factor_test'] if opt['quality_factor_test'] else 40
+ self.is_color = opt['is_color'] if opt['is_color'] else False
+
+ # -------------------------------------
+ # get the path of H, return None if input is None
+ # -------------------------------------
+ self.paths_H = util.get_image_paths(opt['dataroot_H'])
+
+ def __getitem__(self, index):
+
+ if self.opt['phase'] == 'train':
+ # -------------------------------------
+ # get H image
+ # -------------------------------------
+ H_path = self.paths_H[index]
+ img_H = util.imread_uint(H_path, 3)
+ L_path = H_path
+
+ H, W = img_H.shape[:2]
+ self.patch_size_plus = self.patch_size + 8
+
+ # ---------------------------------
+ # randomly crop a large patch
+ # ---------------------------------
+ rnd_h = random.randint(0, max(0, H - self.patch_size_plus))
+ rnd_w = random.randint(0, max(0, W - self.patch_size_plus))
+ patch_H = img_H[rnd_h:rnd_h + self.patch_size_plus, rnd_w:rnd_w + self.patch_size_plus, ...]
+
+ # ---------------------------------
+ # augmentation - flip, rotate
+ # ---------------------------------
+ mode = random.randint(0, 7)
+ patch_H = util.augment_img(patch_H, mode=mode)
+
+ # ---------------------------------
+ # HWC to CHW, numpy(uint) to tensor
+ # ---------------------------------
+ img_L = patch_H.copy()
+
+ # ---------------------------------
+ # set quality factor
+ # ---------------------------------
+ quality_factor = self.quality_factor
+
+ if self.is_color: # color image
+ img_H = img_L.copy()
+ img_L = cv2.cvtColor(img_L, cv2.COLOR_RGB2BGR)
+ result, encimg = cv2.imencode('.jpg', img_L, [int(cv2.IMWRITE_JPEG_QUALITY), quality_factor])
+ img_L = cv2.imdecode(encimg, 1)
+ img_L = cv2.cvtColor(img_L, cv2.COLOR_BGR2RGB)
+ else:
+ if random.random() > 0.5:
+ img_L = util.rgb2ycbcr(img_L)
+ else:
+ img_L = cv2.cvtColor(img_L, cv2.COLOR_RGB2GRAY)
+ img_H = img_L.copy()
+ result, encimg = cv2.imencode('.jpg', img_L, [int(cv2.IMWRITE_JPEG_QUALITY), quality_factor])
+ img_L = cv2.imdecode(encimg, 0)
+
+ # ---------------------------------
+ # randomly crop a patch
+ # ---------------------------------
+ H, W = img_H.shape[:2]
+ if random.random() > 0.5:
+ rnd_h = random.randint(0, max(0, H - self.patch_size))
+ rnd_w = random.randint(0, max(0, W - self.patch_size))
+ else:
+ rnd_h = 0
+ rnd_w = 0
+ img_H = img_H[rnd_h:rnd_h + self.patch_size, rnd_w:rnd_w + self.patch_size]
+ img_L = img_L[rnd_h:rnd_h + self.patch_size, rnd_w:rnd_w + self.patch_size]
+ else:
+
+ H_path = self.paths_H[index]
+ L_path = H_path
+ # ---------------------------------
+ # set quality factor
+ # ---------------------------------
+ quality_factor = self.quality_factor_test
+
+ if self.is_color: # color JPEG image deblocking
+ img_H = util.imread_uint(H_path, 3)
+ img_L = img_H.copy()
+ img_L = cv2.cvtColor(img_L, cv2.COLOR_RGB2BGR)
+ result, encimg = cv2.imencode('.jpg', img_L, [int(cv2.IMWRITE_JPEG_QUALITY), quality_factor])
+ img_L = cv2.imdecode(encimg, 1)
+ img_L = cv2.cvtColor(img_L, cv2.COLOR_BGR2RGB)
+ else:
+ img_H = cv2.imread(H_path, cv2.IMREAD_UNCHANGED)
+ is_to_ycbcr = True if img_L.ndim == 3 else False
+ if is_to_ycbcr:
+ img_H = cv2.cvtColor(img_H, cv2.COLOR_BGR2RGB)
+ img_H = util.rgb2ycbcr(img_H)
+
+ result, encimg = cv2.imencode('.jpg', img_H, [int(cv2.IMWRITE_JPEG_QUALITY), quality_factor])
+ img_L = cv2.imdecode(encimg, 0)
+
+ img_L, img_H = util.uint2tensor3(img_L), util.uint2tensor3(img_H)
+
+ return {'L': img_L, 'H': img_H, 'L_path': L_path, 'H_path': H_path}
+
+ def __len__(self):
+ return len(self.paths_H)
diff --git a/KAIR/data/dataset_l.py b/KAIR/data/dataset_l.py
new file mode 100644
index 0000000000000000000000000000000000000000..9216311b1ca526d704e1f7211ece90453b7e7cea
--- /dev/null
+++ b/KAIR/data/dataset_l.py
@@ -0,0 +1,43 @@
+import torch.utils.data as data
+import utils.utils_image as util
+
+
+class DatasetL(data.Dataset):
+ '''
+ # -----------------------------------------
+ # Get L in testing.
+ # Only "dataroot_L" is needed.
+ # -----------------------------------------
+ # -----------------------------------------
+ '''
+
+ def __init__(self, opt):
+ super(DatasetL, self).__init__()
+ print('Read L in testing. Only "dataroot_L" is needed.')
+ self.opt = opt
+ self.n_channels = opt['n_channels'] if opt['n_channels'] else 3
+
+ # ------------------------------------
+ # get the path of L
+ # ------------------------------------
+ self.paths_L = util.get_image_paths(opt['dataroot_L'])
+ assert self.paths_L, 'Error: L paths are empty.'
+
+ def __getitem__(self, index):
+ L_path = None
+
+ # ------------------------------------
+ # get L image
+ # ------------------------------------
+ L_path = self.paths_L[index]
+ img_L = util.imread_uint(L_path, self.n_channels)
+
+ # ------------------------------------
+ # HWC to CHW, numpy to tensor
+ # ------------------------------------
+ img_L = util.uint2tensor3(img_L)
+
+ return {'L': img_L, 'L_path': L_path}
+
+ def __len__(self):
+ return len(self.paths_L)
diff --git a/KAIR/data/dataset_plain.py b/KAIR/data/dataset_plain.py
new file mode 100644
index 0000000000000000000000000000000000000000..605a4e8166425f1b79f5f1985b0ef0e08cc58b00
--- /dev/null
+++ b/KAIR/data/dataset_plain.py
@@ -0,0 +1,85 @@
+import random
+import numpy as np
+import torch.utils.data as data
+import utils.utils_image as util
+
+
+class DatasetPlain(data.Dataset):
+ '''
+ # -----------------------------------------
+ # Get L/H for image-to-image mapping.
+ # Both "paths_L" and "paths_H" are needed.
+ # -----------------------------------------
+ # e.g., train denoiser with L and H
+ # -----------------------------------------
+ '''
+
+ def __init__(self, opt):
+ super(DatasetPlain, self).__init__()
+ print('Get L/H for image-to-image mapping. Both "paths_L" and "paths_H" are needed.')
+ self.opt = opt
+ self.n_channels = opt['n_channels'] if opt['n_channels'] else 3
+ self.patch_size = self.opt['H_size'] if self.opt['H_size'] else 64
+
+ # ------------------------------------
+ # get the path of L/H
+ # ------------------------------------
+ self.paths_H = util.get_image_paths(opt['dataroot_H'])
+ self.paths_L = util.get_image_paths(opt['dataroot_L'])
+
+ assert self.paths_H, 'Error: H path is empty.'
+ assert self.paths_L, 'Error: L path is empty. Plain dataset assumes both L and H are given!'
+ if self.paths_L and self.paths_H:
+ assert len(self.paths_L) == len(self.paths_H), 'L/H mismatch - {}, {}.'.format(len(self.paths_L), len(self.paths_H))
+
+ def __getitem__(self, index):
+
+ # ------------------------------------
+ # get H image
+ # ------------------------------------
+ H_path = self.paths_H[index]
+ img_H = util.imread_uint(H_path, self.n_channels)
+
+ # ------------------------------------
+ # get L image
+ # ------------------------------------
+ L_path = self.paths_L[index]
+ img_L = util.imread_uint(L_path, self.n_channels)
+
+ # ------------------------------------
+ # if train, get L/H patch pair
+ # ------------------------------------
+ if self.opt['phase'] == 'train':
+
+ H, W, _ = img_H.shape
+
+ # --------------------------------
+ # randomly crop the patch
+ # --------------------------------
+ rnd_h = random.randint(0, max(0, H - self.patch_size))
+ rnd_w = random.randint(0, max(0, W - self.patch_size))
+ patch_L = img_L[rnd_h:rnd_h + self.patch_size, rnd_w:rnd_w + self.patch_size, :]
+ patch_H = img_H[rnd_h:rnd_h + self.patch_size, rnd_w:rnd_w + self.patch_size, :]
+
+ # --------------------------------
+ # augmentation - flip and/or rotate
+ # --------------------------------
+ mode = random.randint(0, 7)
+ patch_L, patch_H = util.augment_img(patch_L, mode=mode), util.augment_img(patch_H, mode=mode)
+
+ # --------------------------------
+ # HWC to CHW, numpy(uint) to tensor
+ # --------------------------------
+ img_L, img_H = util.uint2tensor3(patch_L), util.uint2tensor3(patch_H)
+
+ else:
+
+ # --------------------------------
+ # HWC to CHW, numpy(uint) to tensor
+ # --------------------------------
+ img_L, img_H = util.uint2tensor3(img_L), util.uint2tensor3(img_H)
+
+ return {'L': img_L, 'H': img_H, 'L_path': L_path, 'H_path': H_path}
+
+ def __len__(self):
+ return len(self.paths_H)
diff --git a/KAIR/data/dataset_plainpatch.py b/KAIR/data/dataset_plainpatch.py
new file mode 100644
index 0000000000000000000000000000000000000000..2278bf00aca7f77514fe5b3a5e70b7b562baa13d
--- /dev/null
+++ b/KAIR/data/dataset_plainpatch.py
@@ -0,0 +1,131 @@
+import os.path
+import random
+import numpy as np
+import torch.utils.data as data
+import utils.utils_image as util
+
+
+
+class DatasetPlainPatch(data.Dataset):
+ '''
+ # -----------------------------------------
+ # Get L/H for image-to-image mapping.
+ # Both "paths_L" and "paths_H" are needed.
+ # -----------------------------------------
+ # e.g., train denoiser with L and H patches
+ # create a large patch dataset first
+ # -----------------------------------------
+ '''
+
+ def __init__(self, opt):
+ super(DatasetPlainPatch, self).__init__()
+ print('Get L/H for image-to-image mapping. Both "paths_L" and "paths_H" are needed.')
+ self.opt = opt
+ self.n_channels = opt['n_channels'] if opt['n_channels'] else 3
+ self.patch_size = self.opt['H_size'] if self.opt['H_size'] else 64
+
+ self.num_patches_per_image = opt['num_patches_per_image'] if opt['num_patches_per_image'] else 40
+ self.num_sampled = opt['num_sampled'] if opt['num_sampled'] else 3000
+
+ # -------------------
+ # get the path of L/H
+ # -------------------
+ self.paths_H = util.get_image_paths(opt['dataroot_H'])
+ self.paths_L = util.get_image_paths(opt['dataroot_L'])
+
+ assert self.paths_H, 'Error: H path is empty.'
+ assert self.paths_L, 'Error: L path is empty. This dataset uses L path, you can use dataset_dnpatchh'
+ if self.paths_L and self.paths_H:
+ assert len(self.paths_L) == len(self.paths_H), 'H and L datasets have different number of images - {}, {}.'.format(len(self.paths_L), len(self.paths_H))
+
+ # ------------------------------------
+ # number of sampled images
+ # ------------------------------------
+ self.num_sampled = min(self.num_sampled, len(self.paths_H))
+
+ # ------------------------------------
+ # reserve space with zeros
+ # ------------------------------------
+ self.total_patches = self.num_sampled * self.num_patches_per_image
+ self.H_data = np.zeros([self.total_patches, self.path_size, self.path_size, self.n_channels], dtype=np.uint8)
+ self.L_data = np.zeros([self.total_patches, self.path_size, self.path_size, self.n_channels], dtype=np.uint8)
+
+ # ------------------------------------
+ # update H patches
+ # ------------------------------------
+ self.update_data()
+
+
+ def update_data(self):
+ """
+ # ------------------------------------
+ # update whole L/H patches
+ # ------------------------------------
+ """
+ self.index_sampled = random.sample(range(0, len(self.paths_H), 1), self.num_sampled)
+ n_count = 0
+
+ for i in range(len(self.index_sampled)):
+ L_patches, H_patches = self.get_patches(self.index_sampled[i])
+ for (L_patch, H_patch) in zip(L_patches, H_patches):
+ self.L_data[n_count,:,:,:] = L_patch
+ self.H_data[n_count,:,:,:] = H_patch
+ n_count += 1
+
+ print('Training data updated! Total number of patches is: %5.2f X %5.2f = %5.2f\n' % (len(self.H_data)//128, 128, len(self.H_data)))
+
+ def get_patches(self, index):
+ """
+ # ------------------------------------
+ # get L/H patches from L/H images
+ # ------------------------------------
+ """
+ L_path = self.paths_L[index]
+ H_path = self.paths_H[index]
+ img_L = util.imread_uint(L_path, self.n_channels) # uint format
+ img_H = util.imread_uint(H_path, self.n_channels) # uint format
+
+ H, W = img_H.shape[:2]
+
+ L_patches, H_patches = [], []
+
+ num = self.num_patches_per_image
+ for _ in range(num):
+ rnd_h = random.randint(0, max(0, H - self.path_size))
+ rnd_w = random.randint(0, max(0, W - self.path_size))
+ L_patch = img_L[rnd_h:rnd_h + self.path_size, rnd_w:rnd_w + self.path_size, :]
+ H_patch = img_H[rnd_h:rnd_h + self.path_size, rnd_w:rnd_w + self.path_size, :]
+ L_patches.append(L_patch)
+ H_patches.append(H_patch)
+
+ return L_patches, H_patches
+
+ def __getitem__(self, index):
+
+ if self.opt['phase'] == 'train':
+
+ patch_L, patch_H = self.L_data[index], self.H_data[index]
+
+ # --------------------------------
+ # augmentation - flip and/or rotate
+ # --------------------------------
+ mode = random.randint(0, 7)
+ patch_L = util.augment_img(patch_L, mode=mode)
+ patch_H = util.augment_img(patch_H, mode=mode)
+
+ patch_L, patch_H = util.uint2tensor3(patch_L), util.uint2tensor3(patch_H)
+
+ else:
+
+ L_path, H_path = self.paths_L[index], self.paths_H[index]
+ patch_L = util.imread_uint(L_path, self.n_channels)
+ patch_H = util.imread_uint(H_path, self.n_channels)
+
+ patch_L, patch_H = util.uint2tensor3(patch_L), util.uint2tensor3(patch_H)
+
+ return {'L': patch_L, 'H': patch_H}
+
+
+ def __len__(self):
+
+ return self.total_patches
diff --git a/KAIR/data/dataset_sr.py b/KAIR/data/dataset_sr.py
new file mode 100644
index 0000000000000000000000000000000000000000..8e1c11c7bfbd7e4aecd9a9e5b44f73ad4e81bc3e
--- /dev/null
+++ b/KAIR/data/dataset_sr.py
@@ -0,0 +1,197 @@
+import math
+import numpy as np
+import random
+import torch
+import torch.utils.data as data
+import utils.utils_image as util
+from basicsr.data.degradations import circular_lowpass_kernel, random_mixed_kernels
+from basicsr.utils import DiffJPEG, USMSharp
+from numpy.typing import NDArray
+from PIL import Image
+from utils.utils_video import img2tensor
+from torch import Tensor
+
+from data.degradations import apply_real_esrgan_degradations
+
+class DatasetSR(data.Dataset):
+ '''
+ # -----------------------------------------
+ # Get L/H for SISR.
+ # If only "paths_H" is provided, sythesize bicubicly downsampled L on-the-fly.
+ # -----------------------------------------
+ # e.g., SRResNet
+ # -----------------------------------------
+ '''
+
+ def __init__(self, opt):
+ super(DatasetSR, self).__init__()
+ self.opt = opt
+ self.n_channels = opt['n_channels'] if opt['n_channels'] else 3
+ self.sf = opt['scale'] if opt['scale'] else 4
+ self.patch_size = self.opt['H_size'] if self.opt['H_size'] else 96
+ self.L_size = self.patch_size // self.sf
+
+ # ------------------------------------
+ # get paths of L/H
+ # ------------------------------------
+ self.paths_H = util.get_image_paths(opt['dataroot_H'])
+ self.paths_L = util.get_image_paths(opt['dataroot_L'])
+
+ assert self.paths_H, 'Error: H path is empty.'
+ if self.paths_L and self.paths_H:
+ assert len(self.paths_L) == len(self.paths_H), 'L/H mismatch - {}, {}.'.format(len(self.paths_L), len(self.paths_H))
+
+ self.jpeg_simulator = DiffJPEG()
+ self.usm_sharpener = USMSharp()
+
+ blur_kernel_list1 = ['iso', 'aniso', 'generalized_iso',
+ 'generalized_aniso', 'plateau_iso', 'plateau_aniso']
+ blur_kernel_list2 = ['iso', 'aniso', 'generalized_iso',
+ 'generalized_aniso', 'plateau_iso', 'plateau_aniso']
+ blur_kernel_prob1 = [0.45, 0.25, 0.12, 0.03, 0.12, 0.03]
+ blur_kernel_prob2 = [0.45, 0.25, 0.12, 0.03, 0.12, 0.03]
+ kernel_size = 21
+ blur_sigma1 = [0.05, 0.2]
+ blur_sigma2 = [0.05, 0.1]
+ betag_range1 = [0.7, 1.3]
+ betag_range2 = [0.7, 1.3]
+ betap_range1 = [0.7, 1.3]
+ betap_range2 = [0.7, 1.3]
+
+ def _decide_kernels(self) -> NDArray:
+ blur_kernel1 = random_mixed_kernels(
+ self.blur_kernel_list1,
+ self.blur_kernel_prob1,
+ self.kernel_size,
+ self.blur_sigma1,
+ self.blur_sigma1, [-math.pi, math.pi],
+ self.betag_range1,
+ self.betap_range1,
+ noise_range=None
+ )
+ blur_kernel2 = random_mixed_kernels(
+ self.blur_kernel_list2,
+ self.blur_kernel_prob2,
+ self.kernel_size,
+ self.blur_sigma2,
+ self.blur_sigma2, [-math.pi, math.pi],
+ self.betag_range2,
+ self.betap_range2,
+ noise_range=None
+ )
+ if self.kernel_size < 13:
+ omega_c = np.random.uniform(np.pi / 3, np.pi)
+ else:
+ omega_c = np.random.uniform(np.pi / 5, np.pi)
+ sinc_kernel = circular_lowpass_kernel(omega_c, self.kernel_size, pad_to=21)
+ return (blur_kernel1, blur_kernel2, sinc_kernel)
+
+ def __getitem__(self, index):
+
+ L_path = None
+ # ------------------------------------
+ # get H image
+ # ------------------------------------
+ H_path = self.paths_H[index]
+ img_H = util.imread_uint(H_path, self.n_channels)
+ img_H = util.uint2single(img_H)
+
+ # ------------------------------------
+ # modcrop
+ # ------------------------------------
+ img_H = util.modcrop(img_H, self.sf)
+
+ # ------------------------------------
+ # get L image
+ # ------------------------------------
+ if self.paths_L:
+ # --------------------------------
+ # directly load L image
+ # --------------------------------
+ L_path = self.paths_L[index]
+ img_L = util.imread_uint(L_path, self.n_channels)
+ img_L = util.uint2single(img_L)
+
+ else:
+ # --------------------------------
+ # sythesize L image via matlab's bicubic
+ # --------------------------------
+ H, W = img_H.shape[:2]
+ img_L = util.imresize_np(img_H, 1 / self.sf, True)
+
+ src_tensor = img2tensor(img_L.copy(), bgr2rgb=False,
+ float32=True).unsqueeze(0)
+
+ blur_kernel1, blur_kernel2, sinc_kernel = self._decide_kernels()
+ (img_L_2, sharp_img_L, degraded_img_L) = apply_real_esrgan_degradations(
+ src_tensor,
+ blur_kernel1=Tensor(blur_kernel1).unsqueeze(0),
+ blur_kernel2=Tensor(blur_kernel2).unsqueeze(0),
+ second_blur_prob=0.2,
+ sinc_kernel=Tensor(sinc_kernel).unsqueeze(0),
+ resize_prob1=[0.2, 0.7, 0.1],
+ resize_prob2=[0.3, 0.4, 0.3],
+ resize_range1=[0.9, 1.1],
+ resize_range2=[0.9, 1.1],
+ gray_noise_prob1=0.2,
+ gray_noise_prob2=0.2,
+ gaussian_noise_prob1=0.2,
+ gaussian_noise_prob2=0.2,
+ noise_range=[0.01, 0.2],
+ poisson_scale_range=[0.05, 0.45],
+ jpeg_compression_range1=[85, 100],
+ jpeg_compression_range2=[85, 100],
+ jpeg_simulator=self.jpeg_simulator,
+ random_crop_gt_size=256,
+ sr_upsample_scale=1,
+ usm_sharpener=self.usm_sharpener
+ )
+ # Image.fromarray((degraded_img_L[0] * 255).permute(
+ # 1, 2, 0).cpu().numpy().astype(np.uint8)).save(
+ # "/home/cll/Desktop/degraded_L.png")
+ # Image.fromarray((img_L * 255).astype(np.uint8)).save(
+ # "/home/cll/Desktop/img_L.png")
+ # Image.fromarray((img_L_2[0] * 255).permute(
+ # 1, 2, 0).cpu().numpy().astype(np.uint8)).save(
+ # "/home/cll/Desktop/img_L_2.png")
+ # exit()
+
+ # ------------------------------------
+ # if train, get L/H patch pair
+ # ------------------------------------
+ if self.opt['phase'] == 'train':
+
+ H, W, C = img_L.shape
+
+ # --------------------------------
+ # randomly crop the L patch
+ # --------------------------------
+ rnd_h = random.randint(0, max(0, H - self.L_size))
+ rnd_w = random.randint(0, max(0, W - self.L_size))
+ img_L = img_L[rnd_h:rnd_h + self.L_size, rnd_w:rnd_w + self.L_size, :]
+
+ # --------------------------------
+ # crop corresponding H patch
+ # --------------------------------
+ rnd_h_H, rnd_w_H = int(rnd_h * self.sf), int(rnd_w * self.sf)
+ img_H = img_H[rnd_h_H:rnd_h_H + self.patch_size, rnd_w_H:rnd_w_H + self.patch_size, :]
+
+ # --------------------------------
+ # augmentation - flip and/or rotate + RealESRGAN modified degradations
+ # --------------------------------
+ mode = random.randint(0, 7)
+ img_L, img_H = util.augment_img(img_L, mode=mode), util.augment_img(img_H, mode=mode)
+
+
+ # ------------------------------------
+ # L/H pairs, HWC to CHW, numpy to tensor
+ # ------------------------------------
+ img_H, img_L = util.single2tensor3(img_H), util.single2tensor3(img_L)
+
+ if L_path is None:
+ L_path = H_path
+
+ return {'L': img_L, 'H': img_H, 'L_path': L_path, 'H_path': H_path}
+
+ def __len__(self):
+ return len(self.paths_H)
diff --git a/KAIR/data/dataset_srmd.py b/KAIR/data/dataset_srmd.py
new file mode 100644
index 0000000000000000000000000000000000000000..344398a970f8b1769be95ddf9eb50d7ba3744c5e
--- /dev/null
+++ b/KAIR/data/dataset_srmd.py
@@ -0,0 +1,155 @@
+import random
+import numpy as np
+import torch
+import torch.utils.data as data
+import utils.utils_image as util
+from utils import utils_sisr
+
+
+import hdf5storage
+import os
+
+
+class DatasetSRMD(data.Dataset):
+ '''
+ # -----------------------------------------
+ # Get L/H/M for noisy image SR with Gaussian kernels.
+ # Only "paths_H" is needed, sythesize bicubicly downsampled L on-the-fly.
+ # -----------------------------------------
+ # e.g., SRMD, H = f(L, kernel, sigma), sigma is noise level
+ # -----------------------------------------
+ '''
+
+ def __init__(self, opt):
+ super(DatasetSRMD, self).__init__()
+ self.opt = opt
+ self.n_channels = opt['n_channels'] if opt['n_channels'] else 3
+ self.sf = opt['scale'] if opt['scale'] else 4
+ self.patch_size = self.opt['H_size'] if self.opt['H_size'] else 96
+ self.L_size = self.patch_size // self.sf
+ self.sigma = opt['sigma'] if opt['sigma'] else [0, 50]
+ self.sigma_min, self.sigma_max = self.sigma[0], self.sigma[1]
+ self.sigma_test = opt['sigma_test'] if opt['sigma_test'] else 0
+
+ # -------------------------------------
+ # PCA projection matrix
+ # -------------------------------------
+ self.p = hdf5storage.loadmat(os.path.join('kernels', 'srmd_pca_pytorch.mat'))['p']
+ self.ksize = int(np.sqrt(self.p.shape[-1])) # kernel size
+
+ # ------------------------------------
+ # get paths of L/H
+ # ------------------------------------
+ self.paths_H = util.get_image_paths(opt['dataroot_H'])
+ self.paths_L = util.get_image_paths(opt['dataroot_L'])
+
+ def __getitem__(self, index):
+
+ # ------------------------------------
+ # get H image
+ # ------------------------------------
+ H_path = self.paths_H[index]
+ img_H = util.imread_uint(H_path, self.n_channels)
+ img_H = util.uint2single(img_H)
+
+ # ------------------------------------
+ # modcrop for SR
+ # ------------------------------------
+ img_H = util.modcrop(img_H, self.sf)
+
+ # ------------------------------------
+ # kernel
+ # ------------------------------------
+ if self.opt['phase'] == 'train':
+ l_max = 10
+ theta = np.pi*random.random()
+ l1 = 0.1+l_max*random.random()
+ l2 = 0.1+(l1-0.1)*random.random()
+
+ kernel = utils_sisr.anisotropic_Gaussian(ksize=self.ksize, theta=theta, l1=l1, l2=l2)
+ else:
+ kernel = utils_sisr.anisotropic_Gaussian(ksize=self.ksize, theta=np.pi, l1=0.1, l2=0.1)
+
+ k = np.reshape(kernel, (-1), order="F")
+ k_reduced = np.dot(self.p, k)
+ k_reduced = torch.from_numpy(k_reduced).float()
+
+ # ------------------------------------
+ # sythesize L image via specified degradation model
+ # ------------------------------------
+ H, W, _ = img_H.shape
+ img_L = utils_sisr.srmd_degradation(img_H, kernel, self.sf)
+ img_L = np.float32(img_L)
+
+ if self.opt['phase'] == 'train':
+ """
+ # --------------------------------
+ # get L/H patch pairs
+ # --------------------------------
+ """
+ H, W, C = img_L.shape
+
+ # --------------------------------
+ # randomly crop L patch
+ # --------------------------------
+ rnd_h = random.randint(0, max(0, H - self.L_size))
+ rnd_w = random.randint(0, max(0, W - self.L_size))
+ img_L = img_L[rnd_h:rnd_h + self.L_size, rnd_w:rnd_w + self.L_size, :]
+
+ # --------------------------------
+ # crop corresponding H patch
+ # --------------------------------
+ rnd_h_H, rnd_w_H = int(rnd_h * self.sf), int(rnd_w * self.sf)
+ img_H = img_H[rnd_h_H:rnd_h_H + self.patch_size, rnd_w_H:rnd_w_H + self.patch_size, :]
+
+ # --------------------------------
+ # augmentation - flip and/or rotate
+ # --------------------------------
+ mode = random.randint(0, 7)
+ img_L, img_H = util.augment_img(img_L, mode=mode), util.augment_img(img_H, mode=mode)
+
+ # --------------------------------
+ # get patch pairs
+ # --------------------------------
+ img_H, img_L = util.single2tensor3(img_H), util.single2tensor3(img_L)
+
+ # --------------------------------
+ # select noise level and get Gaussian noise
+ # --------------------------------
+ if random.random() < 0.1:
+ noise_level = torch.zeros(1).float()
+ else:
+ noise_level = torch.FloatTensor([np.random.uniform(self.sigma_min, self.sigma_max)])/255.0
+ # noise_level = torch.rand(1)*50/255.0
+ # noise_level = torch.min(torch.from_numpy(np.float32([7*np.random.chisquare(2.5)/255.0])),torch.Tensor([50./255.]))
+
+ else:
+
+ img_H, img_L = util.single2tensor3(img_H), util.single2tensor3(img_L)
+ noise_level = noise_level = torch.FloatTensor([self.sigma_test])
+
+ # ------------------------------------
+ # add noise
+ # ------------------------------------
+ noise = torch.randn(img_L.size()).mul_(noise_level).float()
+ img_L.add_(noise)
+
+ # ------------------------------------
+ # get degradation map M
+ # ------------------------------------
+ M_vector = torch.cat((k_reduced, noise_level), 0).unsqueeze(1).unsqueeze(1)
+ M = M_vector.repeat(1, img_L.size()[-2], img_L.size()[-1])
+
+ """
+ # -------------------------------------
+ # concat L and noise level map M
+ # -------------------------------------
+ """
+
+ img_L = torch.cat((img_L, M), 0)
+ L_path = H_path
+
+ return {'L': img_L, 'H': img_H, 'L_path': L_path, 'H_path': H_path}
+
+ def __len__(self):
+ return len(self.paths_H)
diff --git a/KAIR/data/dataset_usrnet.py b/KAIR/data/dataset_usrnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..79796e0ac625b18bd3187c737ad4714e29c485f0
--- /dev/null
+++ b/KAIR/data/dataset_usrnet.py
@@ -0,0 +1,126 @@
+import random
+
+import numpy as np
+import torch
+import torch.utils.data as data
+import utils.utils_image as util
+from utils import utils_deblur
+from utils import utils_sisr
+import os
+
+from scipy import ndimage
+from scipy.io import loadmat
+# import hdf5storage
+
+
+class DatasetUSRNet(data.Dataset):
+ '''
+ # -----------------------------------------
+ # Get L/k/sf/sigma for USRNet.
+ # Only "paths_H" and kernel is needed, synthesize L on-the-fly.
+ # -----------------------------------------
+ '''
+ def __init__(self, opt):
+ super(DatasetUSRNet, self).__init__()
+ self.opt = opt
+ self.n_channels = opt['n_channels'] if opt['n_channels'] else 3
+ self.patch_size = self.opt['H_size'] if self.opt['H_size'] else 96
+ self.sigma_max = self.opt['sigma_max'] if self.opt['sigma_max'] is not None else 25
+ self.scales = opt['scales'] if opt['scales'] is not None else [1,2,3,4]
+ self.sf_validation = opt['sf_validation'] if opt['sf_validation'] is not None else 3
+ #self.kernels = hdf5storage.loadmat(os.path.join('kernels', 'kernels_12.mat'))['kernels']
+ self.kernels = loadmat(os.path.join('kernels', 'kernels_12.mat'))['kernels'] # for validation
+
+ # -------------------
+ # get the path of H
+ # -------------------
+ self.paths_H = util.get_image_paths(opt['dataroot_H']) # return None if input is None
+ self.count = 0
+
+ def __getitem__(self, index):
+
+ # -------------------
+ # get H image
+ # -------------------
+ H_path = self.paths_H[index]
+ img_H = util.imread_uint(H_path, self.n_channels)
+ L_path = H_path
+
+ if self.opt['phase'] == 'train':
+
+ # ---------------------------
+ # 1) scale factor, ensure each batch only involves one scale factor
+ # ---------------------------
+ if self.count % self.opt['dataloader_batch_size'] == 0:
+ # sf = random.choice([1,2,3,4])
+ self.sf = random.choice(self.scales)
+ # self.count = 0 # optional
+ self.count += 1
+ H, W, _ = img_H.shape
+
+ # ----------------------------
+ # randomly crop the patch
+ # ----------------------------
+ rnd_h = random.randint(0, max(0, H - self.patch_size))
+ rnd_w = random.randint(0, max(0, W - self.patch_size))
+ patch_H = img_H[rnd_h:rnd_h + self.patch_size, rnd_w:rnd_w + self.patch_size, :]
+
+ # ---------------------------
+ # augmentation - flip, rotate
+ # ---------------------------
+ mode = np.random.randint(0, 8)
+ patch_H = util.augment_img(patch_H, mode=mode)
+
+ # ---------------------------
+ # 2) kernel
+ # ---------------------------
+ r_value = random.randint(0, 7)
+ if r_value>3:
+ k = utils_deblur.blurkernel_synthesis(h=25) # motion blur
+ else:
+ sf_k = random.choice(self.scales)
+ k = utils_sisr.gen_kernel(scale_factor=np.array([sf_k, sf_k])) # Gaussian blur
+ mode_k = random.randint(0, 7)
+ k = util.augment_img(k, mode=mode_k)
+
+ # ---------------------------
+ # 3) noise level
+ # ---------------------------
+ if random.randint(0, 8) == 1:
+ noise_level = 0/255.0
+ else:
+ noise_level = np.random.randint(0, self.sigma_max)/255.0
+
+ # ---------------------------
+ # Low-quality image
+ # ---------------------------
+ img_L = ndimage.filters.convolve(patch_H, np.expand_dims(k, axis=2), mode='wrap')
+ img_L = img_L[0::self.sf, 0::self.sf, ...]
+ # add Gaussian noise
+ img_L = util.uint2single(img_L) + np.random.normal(0, noise_level, img_L.shape)
+ img_H = patch_H
+
+ else:
+
+ k = self.kernels[0, 0].astype(np.float64) # validation kernel
+ k /= np.sum(k)
+ noise_level = 0./255.0 # validation noise level
+
+ # ------------------------------------
+ # modcrop
+ # ------------------------------------
+ img_H = util.modcrop(img_H, self.sf_validation)
+
+ img_L = ndimage.filters.convolve(img_H, np.expand_dims(k, axis=2), mode='wrap') # blur
+ img_L = img_L[0::self.sf_validation, 0::self.sf_validation, ...] # downsampling
+ img_L = util.uint2single(img_L) + np.random.normal(0, noise_level, img_L.shape)
+ self.sf = self.sf_validation
+
+ k = util.single2tensor3(np.expand_dims(np.float32(k), axis=2))
+ img_H, img_L = util.uint2tensor3(img_H), util.single2tensor3(img_L)
+ noise_level = torch.FloatTensor([noise_level]).view([1,1,1])
+
+ return {'L': img_L, 'H': img_H, 'k': k, 'sigma': noise_level, 'sf': self.sf, 'L_path': L_path, 'H_path': H_path}
+
+ def __len__(self):
+ return len(self.paths_H)
diff --git a/KAIR/data/dataset_video_test.py b/KAIR/data/dataset_video_test.py
new file mode 100755
index 0000000000000000000000000000000000000000..e361441331bbae465b9e1b51f2abe39dd54f5a2f
--- /dev/null
+++ b/KAIR/data/dataset_video_test.py
@@ -0,0 +1,382 @@
+import glob
+import torch
+from os import path as osp
+import torch.utils.data as data
+
+import utils.utils_video as utils_video
+
+
+class VideoRecurrentTestDataset(data.Dataset):
+ """Video test dataset for recurrent architectures, which takes LR video
+ frames as input and output corresponding HR video frames. Modified from
+ https://github.com/xinntao/BasicSR/blob/master/basicsr/data/reds_dataset.py
+
+ Supported datasets: Vid4, REDS4, REDSofficial.
+ More generally, it supports testing dataset with following structures:
+
+ dataroot
+ ├── subfolder1
+ ├── frame000
+ ├── frame001
+ ├── ...
+ ├── subfolder1
+ ├── frame000
+ ├── frame001
+ ├── ...
+ ├── ...
+
+ For testing datasets, there is no need to prepare LMDB files.
+
+ Args:
+ opt (dict): Config for train dataset. It contains the following keys:
+ dataroot_gt (str): Data root path for gt.
+ dataroot_lq (str): Data root path for lq.
+ io_backend (dict): IO backend type and other kwarg.
+ cache_data (bool): Whether to cache testing datasets.
+ name (str): Dataset name.
+ meta_info_file (str): The path to the file storing the list of test
+ folders. If not provided, all the folders in the dataroot will
+ be used.
+ num_frame (int): Window size for input frames.
+ padding (str): Padding mode.
+ """
+
+ def __init__(self, opt):
+ super(VideoRecurrentTestDataset, self).__init__()
+ self.opt = opt
+ self.cache_data = opt['cache_data']
+ self.gt_root, self.lq_root = opt['dataroot_gt'], opt['dataroot_lq']
+ self.data_info = {'lq_path': [], 'gt_path': [], 'folder': [], 'idx': [], 'border': []}
+
+ self.imgs_lq, self.imgs_gt = {}, {}
+ if 'meta_info_file' in opt:
+ with open(opt['meta_info_file'], 'r') as fin:
+ subfolders = [line.split(' ')[0] for line in fin]
+ subfolders_lq = [osp.join(self.lq_root, key) for key in subfolders]
+ subfolders_gt = [osp.join(self.gt_root, key) for key in subfolders]
+ else:
+ subfolders_lq = sorted(glob.glob(osp.join(self.lq_root, '*')))
+ subfolders_gt = sorted(glob.glob(osp.join(self.gt_root, '*')))
+
+ for subfolder_lq, subfolder_gt in zip(subfolders_lq, subfolders_gt):
+ # get frame list for lq and gt
+ subfolder_name = osp.basename(subfolder_lq)
+ img_paths_lq = sorted(list(utils_video.scandir(subfolder_lq, full_path=True)))
+ img_paths_gt = sorted(list(utils_video.scandir(subfolder_gt, full_path=True)))
+
+ max_idx = len(img_paths_lq)
+ assert max_idx == len(img_paths_gt), (f'Different number of images in lq ({max_idx})'
+ f' and gt folders ({len(img_paths_gt)})')
+
+ self.data_info['lq_path'].extend(img_paths_lq)
+ self.data_info['gt_path'].extend(img_paths_gt)
+ self.data_info['folder'].extend([subfolder_name] * max_idx)
+ for i in range(max_idx):
+ self.data_info['idx'].append(f'{i}/{max_idx}')
+ border_l = [0] * max_idx
+ for i in range(self.opt['num_frame'] // 2):
+ border_l[i] = 1
+ border_l[max_idx - i - 1] = 1
+ self.data_info['border'].extend(border_l)
+
+ # cache data or save the frame list
+ if self.cache_data:
+ print(f'Cache {subfolder_name} for VideoTestDataset...')
+ self.imgs_lq[subfolder_name] = utils_video.read_img_seq(img_paths_lq)
+ self.imgs_gt[subfolder_name] = utils_video.read_img_seq(img_paths_gt)
+ else:
+ self.imgs_lq[subfolder_name] = img_paths_lq
+ self.imgs_gt[subfolder_name] = img_paths_gt
+
+ # Find unique folder strings
+ self.folders = sorted(list(set(self.data_info['folder'])))
+ self.sigma = opt['sigma'] / 255. if 'sigma' in opt else 0 # for non-blind video denoising
+
+ def __getitem__(self, index):
+ folder = self.folders[index]
+
+ if self.sigma:
+ # for non-blind video denoising
+ if self.cache_data:
+ imgs_gt = self.imgs_gt[folder]
+ else:
+ imgs_gt = utils_video.read_img_seq(self.imgs_gt[folder])
+
+ torch.manual_seed(0)
+ noise_level = torch.ones((1, 1, 1, 1)) * self.sigma
+ noise = torch.normal(mean=0, std=noise_level.expand_as(imgs_gt))
+ imgs_lq = imgs_gt + noise
+ t, _, h, w = imgs_lq.shape
+ imgs_lq = torch.cat([imgs_lq, noise_level.expand(t, 1, h, w)], 1)
+ else:
+ # for video sr and deblurring
+ if self.cache_data:
+ imgs_lq = self.imgs_lq[folder]
+ imgs_gt = self.imgs_gt[folder]
+ else:
+ imgs_lq = utils_video.read_img_seq(self.imgs_lq[folder])
+ imgs_gt = utils_video.read_img_seq(self.imgs_gt[folder])
+
+ return {
+ 'L': imgs_lq,
+ 'H': imgs_gt,
+ 'folder': folder,
+ 'lq_path': self.imgs_lq[folder],
+ }
+
+ def __len__(self):
+ return len(self.folders)
+
+
+class SingleVideoRecurrentTestDataset(data.Dataset):
+ """Single ideo test dataset for recurrent architectures, which takes LR video
+ frames as input and output corresponding HR video frames (only input LQ path).
+
+ More generally, it supports testing dataset with following structures:
+
+ dataroot
+ ├── subfolder1
+ ├── frame000
+ ├── frame001
+ ├── ...
+ ├── subfolder1
+ ├── frame000
+ ├── frame001
+ ├── ...
+ ├── ...
+
+ For testing datasets, there is no need to prepare LMDB files.
+
+ Args:
+ opt (dict): Config for train dataset. It contains the following keys:
+ dataroot_gt (str): Data root path for gt.
+ dataroot_lq (str): Data root path for lq.
+ io_backend (dict): IO backend type and other kwarg.
+ cache_data (bool): Whether to cache testing datasets.
+ name (str): Dataset name.
+ meta_info_file (str): The path to the file storing the list of test
+ folders. If not provided, all the folders in the dataroot will
+ be used.
+ num_frame (int): Window size for input frames.
+ padding (str): Padding mode.
+ """
+
+ def __init__(self, opt):
+ super(SingleVideoRecurrentTestDataset, self).__init__()
+ self.opt = opt
+ self.cache_data = opt['cache_data']
+ self.lq_root = opt['dataroot_lq']
+ self.data_info = {'lq_path': [], 'folder': [], 'idx': [], 'border': []}
+
+ self.imgs_lq = {}
+ if 'meta_info_file' in opt:
+ with open(opt['meta_info_file'], 'r') as fin:
+ subfolders = [line.split(' ')[0] for line in fin]
+ subfolders_lq = [osp.join(self.lq_root, key) for key in subfolders]
+ else:
+ subfolders_lq = sorted(glob.glob(osp.join(self.lq_root, '*')))
+
+ for subfolder_lq in subfolders_lq:
+ # get frame list for lq and gt
+ subfolder_name = osp.basename(subfolder_lq)
+ img_paths_lq = sorted(list(utils_video.scandir(subfolder_lq, full_path=True)))
+
+ max_idx = len(img_paths_lq)
+
+ self.data_info['lq_path'].extend(img_paths_lq)
+ self.data_info['folder'].extend([subfolder_name] * max_idx)
+ for i in range(max_idx):
+ self.data_info['idx'].append(f'{i}/{max_idx}')
+ border_l = [0] * max_idx
+ for i in range(self.opt['num_frame'] // 2):
+ border_l[i] = 1
+ border_l[max_idx - i - 1] = 1
+ self.data_info['border'].extend(border_l)
+
+ # cache data or save the frame list
+ if self.cache_data:
+ print(f'Cache {subfolder_name} for VideoTestDataset...')
+ self.imgs_lq[subfolder_name] = utils_video.read_img_seq(img_paths_lq)
+ else:
+ self.imgs_lq[subfolder_name] = img_paths_lq
+
+ # Find unique folder strings
+ self.folders = sorted(list(set(self.data_info['folder'])))
+
+ def __getitem__(self, index):
+ folder = self.folders[index]
+
+ if self.cache_data:
+ imgs_lq = self.imgs_lq[folder]
+ else:
+ imgs_lq = utils_video.read_img_seq(self.imgs_lq[folder])
+
+ return {
+ 'L': imgs_lq,
+ 'folder': folder,
+ 'lq_path': self.imgs_lq[folder],
+ }
+
+ def __len__(self):
+ return len(self.folders)
+
+
+class VideoTestVimeo90KDataset(data.Dataset):
+ """Video test dataset for Vimeo90k-Test dataset.
+
+ It only keeps the center frame for testing.
+ For testing datasets, there is no need to prepare LMDB files.
+
+ Args:
+ opt (dict): Config for train dataset. It contains the following keys:
+ dataroot_gt (str): Data root path for gt.
+ dataroot_lq (str): Data root path for lq.
+ io_backend (dict): IO backend type and other kwarg.
+ cache_data (bool): Whether to cache testing datasets.
+ name (str): Dataset name.
+ meta_info_file (str): The path to the file storing the list of test
+ folders. If not provided, all the folders in the dataroot will
+ be used.
+ num_frame (int): Window size for input frames.
+ padding (str): Padding mode.
+ """
+
+ def __init__(self, opt):
+ super(VideoTestVimeo90KDataset, self).__init__()
+ self.opt = opt
+ self.cache_data = opt['cache_data']
+ if self.cache_data:
+ raise NotImplementedError('cache_data in Vimeo90K-Test dataset is not implemented.')
+ self.gt_root, self.lq_root = opt['dataroot_gt'], opt['dataroot_lq']
+ self.data_info = {'lq_path': [], 'gt_path': [], 'folder': [], 'idx': [], 'border': []}
+ neighbor_list = [i + (9 - opt['num_frame']) // 2 for i in range(opt['num_frame'])]
+
+ with open(opt['meta_info_file'], 'r') as fin:
+ subfolders = [line.split(' ')[0] for line in fin]
+ for idx, subfolder in enumerate(subfolders):
+ gt_path = osp.join(self.gt_root, subfolder, 'im4.png')
+ self.data_info['gt_path'].append(gt_path)
+ lq_paths = [osp.join(self.lq_root, subfolder, f'im{i}.png') for i in neighbor_list]
+ self.data_info['lq_path'].append(lq_paths)
+ self.data_info['folder'].append('vimeo90k')
+ self.data_info['idx'].append(f'{idx}/{len(subfolders)}')
+ self.data_info['border'].append(0)
+
+ self.pad_sequence = opt.get('pad_sequence', False)
+
+ def __getitem__(self, index):
+ lq_path = self.data_info['lq_path'][index]
+ gt_path = self.data_info['gt_path'][index]
+ imgs_lq = utils_video.read_img_seq(lq_path)
+ img_gt = utils_video.read_img_seq([gt_path])
+ img_gt.squeeze_(0)
+
+ if self.pad_sequence: # pad the sequence: 7 frames to 8 frames
+ imgs_lq = torch.cat([imgs_lq, imgs_lq[-1:,...]], dim=0)
+
+ return {
+ 'L': imgs_lq, # (t, c, h, w)
+ 'H': img_gt, # (c, h, w)
+ 'folder': self.data_info['folder'][index], # folder name
+ 'idx': self.data_info['idx'][index], # e.g., 0/843
+ 'border': self.data_info['border'][index], # 0 for non-border
+ 'lq_path': lq_path[self.opt['num_frame'] // 2] # center frame
+ }
+
+ def __len__(self):
+ return len(self.data_info['gt_path'])
+
+
+class SingleVideoRecurrentTestDataset(data.Dataset):
+ """Single Video test dataset (only input LQ path).
+
+ Supported datasets: Vid4, REDS4, REDSofficial.
+ More generally, it supports testing dataset with following structures:
+
+ dataroot
+ ├── subfolder1
+ ├── frame000
+ ├── frame001
+ ├── ...
+ ├── subfolder1
+ ├── frame000
+ ├── frame001
+ ├── ...
+ ├── ...
+
+ For testing datasets, there is no need to prepare LMDB files.
+
+ Args:
+ opt (dict): Config for train dataset. It contains the following keys:
+ dataroot_gt (str): Data root path for gt.
+ dataroot_lq (str): Data root path for lq.
+ io_backend (dict): IO backend type and other kwarg.
+ cache_data (bool): Whether to cache testing datasets.
+ name (str): Dataset name.
+ meta_info_file (str): The path to the file storing the list of test
+ folders. If not provided, all the folders in the dataroot will
+ be used.
+ num_frame (int): Window size for input frames.
+ padding (str): Padding mode.
+ """
+
+ def __init__(self, opt):
+ super(SingleVideoRecurrentTestDataset, self).__init__()
+ self.opt = opt
+ self.cache_data = opt['cache_data']
+ self.lq_root = opt['dataroot_lq']
+ self.data_info = {'lq_path': [], 'folder': [], 'idx': [], 'border': []}
+ # file client (io backend)
+ self.file_client = None
+
+ self.imgs_lq = {}
+ if 'meta_info_file' in opt:
+ with open(opt['meta_info_file'], 'r') as fin:
+ subfolders = [line.split(' ')[0] for line in fin]
+ subfolders_lq = [osp.join(self.lq_root, key) for key in subfolders]
+ else:
+ subfolders_lq = sorted(glob.glob(osp.join(self.lq_root, '*')))
+
+ for subfolder_lq in subfolders_lq:
+ # get frame list for lq and gt
+ subfolder_name = osp.basename(subfolder_lq)
+ img_paths_lq = sorted(list(utils_video.scandir(subfolder_lq, full_path=True)))
+
+ max_idx = len(img_paths_lq)
+
+ self.data_info['lq_path'].extend(img_paths_lq)
+ self.data_info['folder'].extend([subfolder_name] * max_idx)
+ for i in range(max_idx):
+ self.data_info['idx'].append(f'{i}/{max_idx}')
+ border_l = [0] * max_idx
+ for i in range(self.opt['num_frame'] // 2):
+ border_l[i] = 1
+ border_l[max_idx - i - 1] = 1
+ self.data_info['border'].extend(border_l)
+
+ # cache data or save the frame list
+ if self.cache_data:
+ logger.info(f'Cache {subfolder_name} for VideoTestDataset...')
+ self.imgs_lq[subfolder_name] = utils_video.read_img_seq(img_paths_lq)
+ else:
+ self.imgs_lq[subfolder_name] = img_paths_lq
+
+ # Find unique folder strings
+ self.folders = sorted(list(set(self.data_info['folder'])))
+
+ def __getitem__(self, index):
+ folder = self.folders[index]
+
+ if self.cache_data:
+ imgs_lq = self.imgs_lq[folder]
+ else:
+ imgs_lq = utils_video.read_img_seq(self.imgs_lq[folder])
+
+ return {
+ 'L': imgs_lq,
+ 'folder': folder,
+ 'lq_path': self.imgs_lq[folder],
+ }
+
+ def __len__(self):
+ return len(self.folders)
diff --git a/KAIR/data/dataset_video_train.py b/KAIR/data/dataset_video_train.py
new file mode 100755
index 0000000000000000000000000000000000000000..8a14d46a84c480ff984bd7482c2d7cc357bc9b41
--- /dev/null
+++ b/KAIR/data/dataset_video_train.py
@@ -0,0 +1,390 @@
+import numpy as np
+import os
+import random
+import torch
+from pathlib import Path
+import torch.utils.data as data
+
+import utils.utils_video as utils_video
+
+
+class VideoRecurrentTrainDataset(data.Dataset):
+ """Video dataset for training recurrent networks.
+
+ The keys are generated from a meta info txt file.
+ basicsr/data/meta_info/meta_info_XXX_GT.txt
+
+ Each line contains:
+ 1. subfolder (clip) name; 2. frame number; 3. image shape, separated by
+ a white space.
+ Examples:
+ 720p_240fps_1 100 (720,1280,3)
+ 720p_240fps_3 100 (720,1280,3)
+ ...
+
+ Key examples: "720p_240fps_1/00000"
+ GT (gt): Ground-Truth;
+ LQ (lq): Low-Quality, e.g., low-resolution/blurry/noisy/compressed frames.
+
+ Args:
+ opt (dict): Config for train dataset. It contains the following keys:
+ dataroot_gt (str): Data root path for gt.
+ dataroot_lq (str): Data root path for lq.
+ dataroot_flow (str, optional): Data root path for flow.
+ meta_info_file (str): Path for meta information file.
+ val_partition (str): Validation partition types. 'REDS4' or
+ 'official'.
+ io_backend (dict): IO backend type and other kwarg.
+
+ num_frame (int): Window size for input frames.
+ gt_size (int): Cropped patched size for gt patches.
+ interval_list (list): Interval list for temporal augmentation.
+ random_reverse (bool): Random reverse input frames.
+ use_hflip (bool): Use horizontal flips.
+ use_rot (bool): Use rotation (use vertical flip and transposing h
+ and w for implementation).
+
+ scale (bool): Scale, which will be added automatically.
+ """
+
+ def __init__(self, opt):
+ super(VideoRecurrentTrainDataset, self).__init__()
+ self.opt = opt
+ self.scale = opt.get('scale', 4)
+ self.gt_size = opt.get('gt_size', 256)
+ self.gt_root, self.lq_root = Path(opt['dataroot_gt']), Path(opt['dataroot_lq'])
+ self.filename_tmpl = opt.get('filename_tmpl', '08d')
+ self.filename_ext = opt.get('filename_ext', 'png')
+ self.num_frame = opt['num_frame']
+
+ keys = []
+ total_num_frames = [] # some clips may not have 100 frames
+ start_frames = [] # some clips may not start from 00000
+ train_folders = os.listdir(self.lq_root)
+ print("TRAIN FOLDER: ", train_folders[0])
+ with open(opt['meta_info_file'], 'r') as fin:
+ for line in fin:
+ folder, frame_num, _, start_frame = line.split(' ')
+ if folder in train_folders:
+ keys.extend([f'{folder}/{i:{self.filename_tmpl}}' for i in range(int(start_frame), int(start_frame)+int(frame_num))])
+ total_num_frames.extend([int(frame_num) for i in range(int(frame_num))])
+ start_frames.extend([int(start_frame) for i in range(int(frame_num))])
+
+ # remove the video clips used in validation
+ if opt['name'] == 'REDS':
+ if opt['val_partition'] == 'REDS4':
+ val_partition = ['000', '011', '015', '020']
+ elif opt['val_partition'] == 'official':
+ val_partition = [f'{v:03d}' for v in range(240, 270)]
+ else:
+ raise ValueError(f'Wrong validation partition {opt["val_partition"]}.'
+ f"Supported ones are ['official', 'REDS4'].")
+ else:
+ val_partition = []
+
+ self.keys = []
+ self.total_num_frames = [] # some clips may not have 100 frames
+ self.start_frames = []
+ if opt['test_mode']:
+ for i, v in zip(range(len(keys)), keys):
+ if v.split('/')[0] in val_partition:
+ self.keys.append(keys[i])
+ self.total_num_frames.append(total_num_frames[i])
+ self.start_frames.append(start_frames[i])
+ else:
+ for i, v in zip(range(len(keys)), keys):
+ if v.split('/')[0] not in val_partition:
+ self.keys.append(keys[i])
+ self.total_num_frames.append(total_num_frames[i])
+ self.start_frames.append(start_frames[i])
+
+ # file client (io backend)
+ self.file_client = None
+ self.io_backend_opt = opt['io_backend']
+ self.is_lmdb = False
+ if self.io_backend_opt['type'] == 'lmdb':
+ self.is_lmdb = True
+ if hasattr(self, 'flow_root') and self.flow_root is not None:
+ self.io_backend_opt['db_paths'] = [self.lq_root, self.gt_root, self.flow_root]
+ self.io_backend_opt['client_keys'] = ['lq', 'gt', 'flow']
+ else:
+ self.io_backend_opt['db_paths'] = [self.lq_root, self.gt_root]
+ self.io_backend_opt['client_keys'] = ['lq', 'gt']
+
+ # temporal augmentation configs
+ self.interval_list = opt.get('interval_list', [1])
+ self.random_reverse = opt.get('random_reverse', False)
+ interval_str = ','.join(str(x) for x in self.interval_list)
+ print(f'Temporal augmentation interval list: [{interval_str}]; '
+ f'random reverse is {self.random_reverse}.')
+
+ def __getitem__(self, index):
+ if self.file_client is None:
+ self.file_client = utils_video.FileClient(self.io_backend_opt.pop('type'), **self.io_backend_opt)
+
+ key = self.keys[index]
+ total_num_frames = self.total_num_frames[index]
+ start_frames = self.start_frames[index]
+ clip_name, frame_name = key.split('/') # key example: 000/00000000
+
+ # determine the neighboring frames
+ interval = random.choice(self.interval_list)
+
+ # ensure not exceeding the borders
+ start_frame_idx = int(frame_name)
+ endmost_start_frame_idx = start_frames + total_num_frames - self.num_frame * interval
+ if start_frame_idx > endmost_start_frame_idx:
+ start_frame_idx = random.randint(start_frames, endmost_start_frame_idx)
+ end_frame_idx = start_frame_idx + self.num_frame * interval
+
+ neighbor_list = list(range(start_frame_idx, end_frame_idx, interval))
+
+ # random reverse
+ if self.random_reverse and random.random() < 0.5:
+ neighbor_list.reverse()
+
+ # get the neighboring LQ and GT frames
+ img_lqs = []
+ img_gts = []
+ for neighbor in neighbor_list:
+ if self.is_lmdb:
+ img_lq_path = f'{clip_name}/{neighbor:{self.filename_tmpl}}'
+ img_gt_path = f'{clip_name}/{neighbor:{self.filename_tmpl}}'
+ else:
+ img_lq_path = self.lq_root / clip_name / f'{neighbor:{self.filename_tmpl}}.{self.filename_ext}'
+ img_gt_path = self.gt_root / clip_name / f'{neighbor:{self.filename_tmpl}}.{self.filename_ext}'
+
+ # get LQ
+ img_bytes = self.file_client.get(img_lq_path, 'lq')
+ img_lq = utils_video.imfrombytes(img_bytes, float32=True)
+ img_lqs.append(img_lq)
+
+ # get GT
+ img_bytes = self.file_client.get(img_gt_path, 'gt')
+ img_gt = utils_video.imfrombytes(img_bytes, float32=True)
+ img_gts.append(img_gt)
+
+ # randomly crop
+ img_gts, img_lqs = utils_video.paired_random_crop(img_gts, img_lqs, self.gt_size, self.scale, img_gt_path)
+
+ # augmentation - flip, rotate
+ img_lqs.extend(img_gts)
+ img_results = utils_video.augment(img_lqs, self.opt['use_hflip'], self.opt['use_rot'])
+
+ img_results = utils_video.img2tensor(img_results)
+ img_gts = torch.stack(img_results[len(img_lqs) // 2:], dim=0)
+ img_lqs = torch.stack(img_results[:len(img_lqs) // 2], dim=0)
+
+ # img_lqs: (t, c, h, w)
+ # img_gts: (t, c, h, w)
+ # key: str
+ return {'L': img_lqs, 'H': img_gts, 'key': key}
+
+ def __len__(self):
+ return len(self.keys)
+
+
+class VideoRecurrentTrainNonblindDenoisingDataset(VideoRecurrentTrainDataset):
+ """Video dataset for training recurrent architectures in non-blind video denoising.
+
+ Args:
+ Same as VideoTestDataset.
+
+ """
+
+ def __init__(self, opt):
+ super(VideoRecurrentTrainNonblindDenoisingDataset, self).__init__(opt)
+ self.sigma_min = self.opt['sigma_min'] / 255.
+ self.sigma_max = self.opt['sigma_max'] / 255.
+
+ def __getitem__(self, index):
+ if self.file_client is None:
+ self.file_client = utils_video.FileClient(self.io_backend_opt.pop('type'), **self.io_backend_opt)
+
+ key = self.keys[index]
+ total_num_frames = self.total_num_frames[index]
+ start_frames = self.start_frames[index]
+ clip_name, frame_name = key.split('/') # key example: 000/00000000
+
+ # determine the neighboring frames
+ interval = random.choice(self.interval_list)
+
+ # ensure not exceeding the borders
+ start_frame_idx = int(frame_name)
+ endmost_start_frame_idx = start_frames + total_num_frames - self.num_frame * interval
+ if start_frame_idx > endmost_start_frame_idx:
+ start_frame_idx = random.randint(start_frames, endmost_start_frame_idx)
+ end_frame_idx = start_frame_idx + self.num_frame * interval
+
+ neighbor_list = list(range(start_frame_idx, end_frame_idx, interval))
+
+ # random reverse
+ if self.random_reverse and random.random() < 0.5:
+ neighbor_list.reverse()
+
+ # get the neighboring GT frames
+ img_gts = []
+ for neighbor in neighbor_list:
+ if self.is_lmdb:
+ img_gt_path = f'{clip_name}/{neighbor:{self.filename_tmpl}}'
+ else:
+ img_gt_path = self.gt_root / clip_name / f'{neighbor:{self.filename_tmpl}}.{self.filename_ext}'
+
+ # get GT
+ img_bytes = self.file_client.get(img_gt_path, 'gt')
+ img_gt = utils_video.imfrombytes(img_bytes, float32=True)
+ img_gts.append(img_gt)
+
+ # randomly crop
+ img_gts, _ = utils_video.paired_random_crop(img_gts, img_gts, self.gt_size, 1, img_gt_path)
+
+ # augmentation - flip, rotate
+ img_gts = utils_video.augment(img_gts, self.opt['use_hflip'], self.opt['use_rot'])
+
+ img_gts = utils_video.img2tensor(img_gts)
+ img_gts = torch.stack(img_gts, dim=0)
+
+ # we add noise in the network
+ noise_level = torch.empty((1, 1, 1, 1)).uniform_(self.sigma_min, self.sigma_max)
+ noise = torch.normal(mean=0, std=noise_level.expand_as(img_gts))
+ img_lqs = img_gts + noise
+
+ t, _, h, w = img_lqs.shape
+ img_lqs = torch.cat([img_lqs, noise_level.expand(t, 1, h, w)], 1)
+
+ # img_lqs: (t, c, h, w)
+ # img_gts: (t, c, h, w)
+ # key: str
+ return {'L': img_lqs, 'H': img_gts, 'key': key}
+
+
+ def __len__(self):
+ return len(self.keys)
+
+
+class VideoRecurrentTrainVimeoDataset(data.Dataset):
+ """Vimeo90K dataset for training recurrent networks.
+
+ The keys are generated from a meta info txt file.
+ basicsr/data/meta_info/meta_info_Vimeo90K_train_GT.txt
+
+ Each line contains:
+ 1. clip name; 2. frame number; 3. image shape, separated by a white space.
+ Examples:
+ 00001/0001 7 (256,448,3)
+ 00001/0002 7 (256,448,3)
+
+ Key examples: "00001/0001"
+ GT (gt): Ground-Truth;
+ LQ (lq): Low-Quality, e.g., low-resolution/blurry/noisy/compressed frames.
+
+ The neighboring frame list for different num_frame:
+ num_frame | frame list
+ 1 | 4
+ 3 | 3,4,5
+ 5 | 2,3,4,5,6
+ 7 | 1,2,3,4,5,6,7
+
+ Args:
+ opt (dict): Config for train dataset. It contains the following keys:
+ dataroot_gt (str): Data root path for gt.
+ dataroot_lq (str): Data root path for lq.
+ meta_info_file (str): Path for meta information file.
+ io_backend (dict): IO backend type and other kwarg.
+
+ num_frame (int): Window size for input frames.
+ gt_size (int): Cropped patched size for gt patches.
+ random_reverse (bool): Random reverse input frames.
+ use_hflip (bool): Use horizontal flips.
+ use_rot (bool): Use rotation (use vertical flip and transposing h
+ and w for implementation).
+
+ scale (bool): Scale, which will be added automatically.
+ """
+
+ def __init__(self, opt):
+ super(VideoRecurrentTrainVimeoDataset, self).__init__()
+ self.opt = opt
+ self.gt_root, self.lq_root = Path(opt['dataroot_gt']), Path(opt['dataroot_lq'])
+
+ with open(opt['meta_info_file'], 'r') as fin:
+ self.keys = [line.split(' ')[0] for line in fin]
+
+ # file client (io backend)
+ self.file_client = None
+ self.io_backend_opt = opt['io_backend']
+ self.is_lmdb = False
+ if self.io_backend_opt['type'] == 'lmdb':
+ self.is_lmdb = True
+ self.io_backend_opt['db_paths'] = [self.lq_root, self.gt_root]
+ self.io_backend_opt['client_keys'] = ['lq', 'gt']
+
+ # indices of input images
+ self.neighbor_list = [i + (9 - opt['num_frame']) // 2 for i in range(opt['num_frame'])]
+
+ # temporal augmentation configs
+ self.random_reverse = opt['random_reverse']
+ print(f'Random reverse is {self.random_reverse}.')
+
+ self.flip_sequence = opt.get('flip_sequence', False)
+ self.pad_sequence = opt.get('pad_sequence', False)
+ self.neighbor_list = [1, 2, 3, 4, 5, 6, 7]
+
+ def __getitem__(self, index):
+ if self.file_client is None:
+ self.file_client = utils_video.FileClient(self.io_backend_opt.pop('type'), **self.io_backend_opt)
+
+ # random reverse
+ if self.random_reverse and random.random() < 0.5:
+ self.neighbor_list.reverse()
+
+ scale = self.opt['scale']
+ gt_size = self.opt['gt_size']
+ key = self.keys[index]
+ clip, seq = key.split('/') # key example: 00001/0001
+
+ # get the neighboring LQ and GT frames
+ img_lqs = []
+ img_gts = []
+ for neighbor in self.neighbor_list:
+ if self.is_lmdb:
+ img_lq_path = f'{clip}/{seq}/im{neighbor}'
+ img_gt_path = f'{clip}/{seq}/im{neighbor}'
+ else:
+ img_lq_path = self.lq_root / clip / seq / f'im{neighbor}.png'
+ img_gt_path = self.gt_root / clip / seq / f'im{neighbor}.png'
+ # LQ
+ img_bytes = self.file_client.get(img_lq_path, 'lq')
+ img_lq = utils_video.imfrombytes(img_bytes, float32=True)
+ # GT
+ img_bytes = self.file_client.get(img_gt_path, 'gt')
+ img_gt = utils_video.imfrombytes(img_bytes, float32=True)
+
+ img_lqs.append(img_lq)
+ img_gts.append(img_gt)
+
+ # randomly crop
+ img_gts, img_lqs = utils_video.paired_random_crop(img_gts, img_lqs, gt_size, scale, img_gt_path)
+
+ # augmentation - flip, rotate
+ img_lqs.extend(img_gts)
+ img_results = utils_video.augment(img_lqs, self.opt['use_hflip'], self.opt['use_rot'])
+
+ img_results = utils_video.img2tensor(img_results)
+ img_lqs = torch.stack(img_results[:7], dim=0)
+ img_gts = torch.stack(img_results[7:], dim=0)
+
+ if self.flip_sequence: # flip the sequence: 7 frames to 14 frames
+ img_lqs = torch.cat([img_lqs, img_lqs.flip(0)], dim=0)
+ img_gts = torch.cat([img_gts, img_gts.flip(0)], dim=0)
+ elif self.pad_sequence: # pad the sequence: 7 frames to 8 frames
+ img_lqs = torch.cat([img_lqs, img_lqs[-1:,...]], dim=0)
+ img_gts = torch.cat([img_gts, img_gts[-1:,...]], dim=0)
+
+ # img_lqs: (t, c, h, w)
+ # img_gt: (c, h, w)
+ # key: str
+ return {'L': img_lqs, 'H': img_gts, 'key': key}
+
+ def __len__(self):
+ return len(self.keys)
diff --git a/KAIR/data/degradations.py b/KAIR/data/degradations.py
new file mode 100644
index 0000000000000000000000000000000000000000..77d2a87cc841d31bbc56233b8b61eda55f24827a
--- /dev/null
+++ b/KAIR/data/degradations.py
@@ -0,0 +1,145 @@
+from typing import Tuple
+
+import numpy as np
+import random
+import torch
+from numpy.typing import NDArray
+
+from basicsr.data.degradations import random_add_gaussian_noise_pt, random_add_poisson_noise_pt
+from basicsr.data.transforms import paired_random_crop
+from basicsr.utils import DiffJPEG, USMSharp
+from basicsr.utils.img_process_util import filter2D
+from torch import Tensor
+from torch.nn import functional as F
+
+
+def blur(img: Tensor, kernel: NDArray) -> Tensor:
+ return filter2D(img, kernel)
+
+
+def random_resize(
+ img: Tensor,
+ resize_prob: float,
+ resize_range: Tuple[int, int],
+ output_scale: float = 1
+) -> Tensor:
+ updown_type = random.choices(['up', 'down', 'keep'], resize_prob)[0]
+ if updown_type == 'up':
+ random_scale = np.random.uniform(1, resize_range[1])
+ elif updown_type == 'down':
+ random_scale = np.random.uniform(resize_range[0], 1)
+ else:
+ random_scale = 1
+ mode = random.choice(['area', 'bilinear', 'bicubic'])
+ out = F.interpolate(img, scale_factor=output_scale * random_scale, mode=mode)
+ return out
+
+
+def add_noise(
+ img: Tensor,
+ gray_noise_prob: float,
+ gaussian_noise_prob: float,
+ noise_range: Tuple[float, float],
+ poisson_scale_range: Tuple[float, float]
+) -> Tensor:
+ if np.random.uniform() < gaussian_noise_prob:
+ img = random_add_gaussian_noise_pt(
+ img, sigma_range=noise_range, clip=True, rounds=False,
+ gray_prob=gray_noise_prob)
+ else:
+ img = random_add_poisson_noise_pt(
+ img, scale_range=poisson_scale_range,
+ gray_prob=gray_noise_prob, clip=True, rounds=False)
+ return img
+
+
+def jpeg_compression_simulation(
+ img: Tensor,
+ jpeg_range: Tuple[float, float],
+ jpeg_simulator: DiffJPEG
+) -> Tensor:
+ jpeg_p = img.new_zeros(img.size(0)).uniform_(*jpeg_range)
+
+ # clamp to [0, 1], otherwise JPEGer will result in unpleasant artifacts
+ img = torch.clamp(img, 0, 1)
+ return jpeg_simulator(img, quality=jpeg_p)
+
+
+@torch.no_grad()
+def apply_real_esrgan_degradations(
+ gt: Tensor,
+ blur_kernel1: NDArray,
+ blur_kernel2: NDArray,
+ second_blur_prob: float,
+ sinc_kernel: NDArray,
+ resize_prob1: float,
+ resize_prob2: float,
+ resize_range1: Tuple[int, int],
+ resize_range2: Tuple[int, int],
+ gray_noise_prob1: float,
+ gray_noise_prob2: float,
+ gaussian_noise_prob1: float,
+ gaussian_noise_prob2: float,
+ noise_range: Tuple[float, float],
+ poisson_scale_range: Tuple[float, float],
+ jpeg_compression_range1: Tuple[float, float],
+ jpeg_compression_range2: Tuple[float, float],
+ jpeg_simulator: DiffJPEG,
+ random_crop_gt_size: 512,
+ sr_upsample_scale: float,
+ usm_sharpener: USMSharp
+):
+ """
+ Accept batch from batchloader, and then add two-order degradations
+ to obtain LQ images.
+
+ gt: Tensor of shape (B x C x H x W)
+ """
+ gt_usm = usm_sharpener(gt)
+ # from PIL import Image
+ # Image.fromarray((gt_usm[0].permute(1, 2, 0).cpu().numpy() * 255.).astype(np.uint8)).save(
+ # "/home/cll/Desktop/GT_USM_orig.png")
+ orig_h, orig_w = gt.size()[2:4]
+
+ # ----------------------- The first degradation process ----------------------- #
+ out = blur(gt_usm, blur_kernel1)
+ out = random_resize(out, resize_prob1, resize_range1)
+ out = add_noise(out, gray_noise_prob1, gaussian_noise_prob1, noise_range, poisson_scale_range)
+ out = jpeg_compression_simulation(out, jpeg_compression_range1, jpeg_simulator)
+
+ # ----------------------- The second degradation process ----------------------- #
+ if np.random.uniform() < second_blur_prob:
+ out = blur(out, blur_kernel2)
+ out = random_resize(out, resize_prob2, resize_range2, output_scale=(1/sr_upsample_scale))
+ out = add_noise(out, gray_noise_prob2, gaussian_noise_prob2,
+ noise_range, poisson_scale_range)
+
+ # JPEG compression + the final sinc filter
+ # We also need to resize images to desired sizes.
+ # We group [resize back + sinc filter] together
+ # as one operation.
+ # We consider two orders:
+ # 1. [resize back + sinc filter] + JPEG compression
+ # 2. JPEG compression + [resize back + sinc filter]
+ # Empirically, we find other combinations (sinc + JPEG + Resize)
+ # will introduce twisted lines.
+ if np.random.uniform() < 0.5:
+ # resize back + the final sinc filter
+ mode = random.choice(['area', 'bilinear', 'bicubic'])
+ out = F.interpolate(out, size=(orig_h // sr_upsample_scale,
+ orig_w // sr_upsample_scale), mode=mode)
+ out = blur(out, sinc_kernel)
+ out = jpeg_compression_simulation(out, jpeg_compression_range2, jpeg_simulator)
+ else:
+ out = jpeg_compression_simulation(out, jpeg_compression_range2, jpeg_simulator)
+ mode = random.choice(['area', 'bilinear', 'bicubic'])
+ out = F.interpolate(out, size=(orig_h // sr_upsample_scale,
+ orig_w // sr_upsample_scale), mode=mode)
+ out = blur(out, sinc_kernel)
+
+ # clamp and round
+ lq = torch.clamp((out * 255.0).round(), 0, 255) / 255.
+
+ (gt, gt_usm), lq = paired_random_crop([gt, gt_usm], lq, random_crop_gt_size, sr_upsample_scale)
+
+ return gt, gt_usm, lq
diff --git a/KAIR/data/select_dataset.py b/KAIR/data/select_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..bbe9986cfb1103125906db5a3349873c64024c34
--- /dev/null
+++ b/KAIR/data/select_dataset.py
@@ -0,0 +1,86 @@
+
+
+'''
+# --------------------------------------------
+# select dataset
+# --------------------------------------------
+# Kai Zhang (github: https://github.com/cszn)
+# --------------------------------------------
+'''
+
+
+def define_Dataset(dataset_opt):
+ dataset_type = dataset_opt['dataset_type'].lower()
+ if dataset_type in ['l', 'low-quality', 'input-only']:
+ from data.dataset_l import DatasetL as D
+
+ # -----------------------------------------
+ # denoising
+ # -----------------------------------------
+ elif dataset_type in ['dncnn', 'denoising']:
+ from data.dataset_dncnn import DatasetDnCNN as D
+
+ elif dataset_type in ['dnpatch']:
+ from data.dataset_dnpatch import DatasetDnPatch as D
+
+ elif dataset_type in ['ffdnet', 'denoising-noiselevel']:
+ from data.dataset_ffdnet import DatasetFFDNet as D
+
+ elif dataset_type in ['fdncnn', 'denoising-noiselevelmap']:
+ from data.dataset_fdncnn import DatasetFDnCNN as D
+
+ # -----------------------------------------
+ # super-resolution
+ # -----------------------------------------
+ elif dataset_type in ['sr', 'super-resolution']:
+ from data.dataset_sr import DatasetSR as D
+
+ elif dataset_type in ['srmd']:
+ from data.dataset_srmd import DatasetSRMD as D
+
+ elif dataset_type in ['dpsr', 'dnsr']:
+ from data.dataset_dpsr import DatasetDPSR as D
+
+ elif dataset_type in ['usrnet', 'usrgan']:
+ from data.dataset_usrnet import DatasetUSRNet as D
+
+ elif dataset_type in ['bsrnet', 'bsrgan', 'blindsr']:
+ from data.dataset_blindsr import DatasetBlindSR as D
+
+ # -------------------------------------------------
+ # JPEG compression artifact reduction (deblocking)
+ # -------------------------------------------------
+ elif dataset_type in ['jpeg']:
+ from data.dataset_jpeg import DatasetJPEG as D
+
+ # -----------------------------------------
+ # video restoration
+ # -----------------------------------------
+ elif dataset_type in ['videorecurrenttraindataset']:
+ from data.dataset_video_train import VideoRecurrentTrainDataset as D
+ elif dataset_type in ['videorecurrenttrainnonblinddenoisingdataset']:
+ from data.dataset_video_train import VideoRecurrentTrainNonblindDenoisingDataset as D
+ elif dataset_type in ['videorecurrenttrainvimeodataset']:
+ from data.dataset_video_train import VideoRecurrentTrainVimeoDataset as D
+ elif dataset_type in ['videorecurrenttestdataset']:
+ from data.dataset_video_test import VideoRecurrentTestDataset as D
+ elif dataset_type in ['singlevideorecurrenttestdataset']:
+ from data.dataset_video_test import SingleVideoRecurrentTestDataset as D
+ elif dataset_type in ['videotestvimeo90kdataset']:
+ from data.dataset_video_test import VideoTestVimeo90KDataset as D
+
+ # -----------------------------------------
+ # common
+ # -----------------------------------------
+ elif dataset_type in ['plain']:
+ from data.dataset_plain import DatasetPlain as D
+
+ elif dataset_type in ['plainpatch']:
+ from data.dataset_plainpatch import DatasetPlainPatch as D
+
+ else:
+ raise NotImplementedError('Dataset [{:s}] is not found.'.format(dataset_type))
+
+ dataset = D(dataset_opt)
+ print('Dataset [{:s} - {:s}] is created.'.format(dataset.__class__.__name__, dataset_opt['name']))
+ return dataset
diff --git a/KAIR/docs/README_SwinIR.md b/KAIR/docs/README_SwinIR.md
new file mode 100644
index 0000000000000000000000000000000000000000..52f86e58b9b743b1951b373f80422cf53d0ac3fa
--- /dev/null
+++ b/KAIR/docs/README_SwinIR.md
@@ -0,0 +1,194 @@
+# SwinIR: Image Restoration Using Shifted Window Transformer
+[paper](https://arxiv.org/abs/2108.10257)
+**|**
+[supplementary](https://github.com/JingyunLiang/SwinIR/releases/tag/v0.0)
+**|**
+[visual results](https://github.com/JingyunLiang/SwinIR/releases/tag/v0.0)
+**|**
+[original project page](https://github.com/JingyunLiang/SwinIR)
+**|**
+[online Colab demo](https://colab.research.google.com/gist/JingyunLiang/a5e3e54bc9ef8d7bf594f6fee8208533/swinir-demo-on-real-world-image-sr.ipynb)
+
+[](https://arxiv.org/abs/2108.10257)
+[](https://github.com/JingyunLiang/SwinIR)
+[](https://github.com/JingyunLiang/SwinIR/releases)
+[ ](https://colab.research.google.com/gist/JingyunLiang/a5e3e54bc9ef8d7bf594f6fee8208533/swinir-demo-on-real-world-image-sr.ipynb)
+
+> Image restoration is a long-standing low-level vision problem that aims to restore high-quality images from low-quality images (e.g., downscaled, noisy and compressed images). While state-of-the-art image restoration methods are based on convolutional neural networks, few attempts have been made with Transformers which show impressive performance on high-level vision tasks. In this paper, we propose a strong baseline model SwinIR for image restoration based on the Swin Transformer. SwinIR consists of three parts: shallow feature extraction, deep feature extraction and high-quality image reconstruction. In particular, the deep feature extraction module is composed of several residual Swin Transformer blocks (RSTB), each of which has several Swin Transformer layers together with a residual connection. We conduct experiments on three representative tasks: image super-resolution (including classical, lightweight and real-world image super-resolution), image denoising (including grayscale and color image denoising) and JPEG compression artifact reduction. Experimental results demonstrate that SwinIR outperforms state-of-the-art methods on different tasks by up to 0.14~0.45dB, while the total number of parameters can be reduced by up to 67%.
+
+
+### Dataset Preparation
+
+Training and testing sets can be downloaded as follows. Please put them in `trainsets` and `testsets` respectively.
+
+| Task | Training Set | Testing Set|
+| :--- | :---: | :---: |
+| classical/lightweight image SR | [DIV2K](https://cv.snu.ac.kr/research/EDSR/DIV2K.tar) (800 training images) or DIV2K +[Flickr2K](https://cv.snu.ac.kr/research/EDSR/Flickr2K.tar) (2650 images) | set5 + Set14 + BSD100 + Urban100 + Manga109 [download all](https://drive.google.com/drive/folders/1B3DJGQKB6eNdwuQIhdskA64qUuVKLZ9u) |
+| real-world image SR | SwinIR-M (middle size): [DIV2K](https://cv.snu.ac.kr/research/EDSR/DIV2K.tar) (800 training images) +[Flickr2K](https://cv.snu.ac.kr/research/EDSR/Flickr2K.tar) (2650 images) + [OST](https://openmmlab.oss-cn-hangzhou.aliyuncs.com/datasets/OST_dataset.zip) (10324 images, sky,water,grass,mountain,building,plant,animal)
SwinIR-L (large size): DIV2K + Flickr2K + OST + [WED](http://ivc.uwaterloo.ca/database/WaterlooExploration/exploration_database_and_code.rar)(4744 images) + [FFHQ](https://drive.google.com/drive/folders/1tZUcXDBeOibC6jcMCtgRRz67pzrAHeHL) (first 2000 images, face) + Manga109 (manga) + [SCUT-CTW1500](https://universityofadelaide.box.com/shared/static/py5uwlfyyytbb2pxzq9czvu6fuqbjdh8.zip) (first 100 training images, texts)
***We use the first practical degradation model [BSRGAN, ICCV2021 ](https://github.com/cszn/BSRGAN) for real-world image SR** | [RealSRSet+5images](https://github.com/JingyunLiang/SwinIR/releases/download/v0.0/RealSRSet+5images.zip) |
+| color/grayscale image denoising | [DIV2K](https://cv.snu.ac.kr/research/EDSR/DIV2K.tar) (800 training images) + [Flickr2K](https://cv.snu.ac.kr/research/EDSR/Flickr2K.tar) (2650 images) + [BSD500](http://www.eecs.berkeley.edu/Research/Projects/CS/vision/grouping/BSR/BSR_bsds500.tgz) (400 training&testing images) + [WED](http://ivc.uwaterloo.ca/database/WaterlooExploration/exploration_database_and_code.rar)(4744 images) | grayscale: Set12 + BSD68 + Urban100
color: CBSD68 + Kodak24 + McMaster + Urban100 [download all](https://github.com/cszn/FFDNet/tree/master/testsets) |
+| JPEG compression artifact reduction | [DIV2K](https://cv.snu.ac.kr/research/EDSR/DIV2K.tar) (800 training images) + [Flickr2K](https://cv.snu.ac.kr/research/EDSR/Flickr2K.tar) (2650 images) + [BSD500](http://www.eecs.berkeley.edu/Research/Projects/CS/vision/grouping/BSR/BSR_bsds500.tgz) (400 training&testing images) + [WED](http://ivc.uwaterloo.ca/database/WaterlooExploration/exploration_database_and_code.rar)(4744 images) | grayscale: Classic5 +LIVE1 [download all](https://github.com/cszn/DnCNN/tree/master/testsets) |
+
+
+### Training
+To train SwinIR, run the following commands. You may need to change the `dataroot_H`, `dataroot_L`, `scale factor`, `noisel level`, `JPEG level`, `G_optimizer_lr`, `G_scheduler_milestones`, etc. in the json file for different settings.
+
+
+
+```python
+# 001 Classical Image SR (middle size)
+python -m torch.distributed.launch --nproc_per_node=8 --master_port=1234 main_train_psnr.py --opt options/swinir/train_swinir_sr_classical.json --dist True
+
+# 002 Lightweight Image SR (small size)
+python -m torch.distributed.launch --nproc_per_node=8 --master_port=1234 main_train_psnr.py --opt options/swinir/train_swinir_sr_lightweight.json --dist True
+
+# 003 Real-World Image SR (middle size)
+python -m torch.distributed.launch --nproc_per_node=8 --master_port=1234 main_train_psnr.py --opt options/swinir/train_swinir_sr_realworld_psnr.json --dist True
+# before training gan, put the PSNR-oriented model into superresolution/swinir_sr_realworld_x4_gan/models/
+python -m torch.distributed.launch --nproc_per_node=8 --master_port=1234 main_train_psnr.py --opt options/swinir/train_swinir_sr_realworld_gan.json --dist True
+
+# 004 Grayscale Image Deoising (middle size)
+python -m torch.distributed.launch --nproc_per_node=8 --master_port=1234 main_train_psnr.py --opt options/swinir/train_swinir_denoising_gray.json --dist True
+
+# 005 Color Image Deoising (middle size)
+python -m torch.distributed.launch --nproc_per_node=8 --master_port=1234 main_train_psnr.py --opt options/swinir/train_swinir_denoising_color.json --dist True
+
+# 006 JPEG Compression Artifact Reduction (middle size)
+python -m torch.distributed.launch --nproc_per_node=8 --master_port=1234 main_train_psnr.py --opt options/swinir/train_swinir_car_jpeg.json --dist True
+```
+
+You can also train above models using `DataParallel` as follows, but it will be slower.
+```python
+# 001 Classical Image SR (middle size)
+python main_train_psnr.py --opt options/swinir/train_swinir_sr_classical.json
+
+...
+```
+
+
+Note:
+
+1, We fine-tune X3/X4/X8 (or noise=25/50, or JPEG=10/20/30) models from the X2 (or noise=15, or JPEG=40) model, so that total_iteration can be halved to save training time. In this case, we halve the initial learning rate and lr_milestones accordingly. This way has similar performance as training from scratch.
+
+2, For SR, we use different kinds of `Upsampler` in classical/lightweight/real-world image SR for the purpose of fair comparison with existing works.
+
+3, We did not re-train the models after cleaning the codes. Feel free to open an issue if you meet any problems.
+
+## Testing
+Following command will download the [pretrained models](https://github.com/JingyunLiang/SwinIR/releases/tag/v0.0) and put them in `model_zoo/swinir`. All visual results of SwinIR can be downloaded [here](https://github.com/JingyunLiang/SwinIR/releases/tag/v0.0).
+
+If you are too lazy to prepare the datasets, please follow the guide in the [original project page](https://github.com/JingyunLiang/SwinIR#testing-without-preparing-datasets), where you can start testing in a minute. We also provide an [online Colab demo for real-world image SR ](https://colab.research.google.com/gist/JingyunLiang/a5e3e54bc9ef8d7bf594f6fee8208533/swinir-demo-on-real-world-image-sr.ipynb) for comparison with [the first practical degradation model BSRGAN (ICCV2021) ](https://github.com/cszn/BSRGAN) and a recent model [RealESRGAN](https://github.com/xinntao/Real-ESRGAN). Try to test your own images on Colab!
+
+```bash
+# 001 Classical Image Super-Resolution (middle size)
+# Note that --training_patch_size is just used to differentiate two different settings in Table 2 of the paper. Images are NOT tested patch by patch.
+# (setting1: when model is trained on DIV2K and with training_patch_size=48)
+python main_test_swinir.py --task classical_sr --scale 2 --training_patch_size 48 --model_path model_zoo/swinir/001_classicalSR_DIV2K_s48w8_SwinIR-M_x2.pth --folder_lq testsets/set5/LR_bicubic/X2 --folder_gt testsets/set5/HR
+python main_test_swinir.py --task classical_sr --scale 3 --training_patch_size 48 --model_path model_zoo/swinir/001_classicalSR_DIV2K_s48w8_SwinIR-M_x3.pth --folder_lq testsets/set5/LR_bicubic/X3 --folder_gt testsets/set5/HR
+python main_test_swinir.py --task classical_sr --scale 4 --training_patch_size 48 --model_path model_zoo/swinir/001_classicalSR_DIV2K_s48w8_SwinIR-M_x4.pth --folder_lq testsets/set5/LR_bicubic/X4 --folder_gt testsets/set5/HR
+python main_test_swinir.py --task classical_sr --scale 8 --training_patch_size 48 --model_path model_zoo/swinir/001_classicalSR_DIV2K_s48w8_SwinIR-M_x8.pth --folder_lq testsets/set5/LR_bicubic/X8 --folder_gt testsets/set5/HR
+
+# (setting2: when model is trained on DIV2K+Flickr2K and with training_patch_size=64)
+python main_test_swinir.py --task classical_sr --scale 2 --training_patch_size 64 --model_path model_zoo/swinir/001_classicalSR_DF2K_s64w8_SwinIR-M_x2.pth --folder_lq testsets/set5/LR_bicubic/X2 --folder_gt testsets/set5/HR
+python main_test_swinir.py --task classical_sr --scale 3 --training_patch_size 64 --model_path model_zoo/swinir/001_classicalSR_DF2K_s64w8_SwinIR-M_x3.pth --folder_lq testsets/set5/LR_bicubic/X3 --folder_gt testsets/set5/HR
+python main_test_swinir.py --task classical_sr --scale 4 --training_patch_size 64 --model_path model_zoo/swinir/001_classicalSR_DF2K_s64w8_SwinIR-M_x4.pth --folder_lq testsets/set5/LR_bicubic/X4 --folder_gt testsets/set5/HR
+python main_test_swinir.py --task classical_sr --scale 8 --training_patch_size 64 --model_path model_zoo/swinir/001_classicalSR_DF2K_s64w8_SwinIR-M_x8.pth --folder_lq testsets/set5/LR_bicubic/X8 --folder_gt testsets/set5/HR
+
+
+# 002 Lightweight Image Super-Resolution (small size)
+python main_test_swinir.py --task lightweight_sr --scale 2 --model_path model_zoo/swinir/002_lightweightSR_DIV2K_s64w8_SwinIR-S_x2.pth --folder_lq testsets/set5/LR_bicubic/X2 --folder_gt testsets/set5/HR
+python main_test_swinir.py --task lightweight_sr --scale 3 --model_path model_zoo/swinir/002_lightweightSR_DIV2K_s64w8_SwinIR-S_x3.pth --folder_lq testsets/set5/LR_bicubic/X3 --folder_gt testsets/set5/HR
+python main_test_swinir.py --task lightweight_sr --scale 4 --model_path model_zoo/swinir/002_lightweightSR_DIV2K_s64w8_SwinIR-S_x4.pth --folder_lq testsets/set5/LR_bicubic/X4 --folder_gt testsets/set5/HR
+
+
+# 003 Real-World Image Super-Resolution (use --tile 400 if you run out-of-memory)
+# (middle size)
+python main_test_swinir.py --task real_sr --scale 4 --model_path model_zoo/swinir/003_realSR_BSRGAN_DFO_s64w8_SwinIR-M_x4_GAN.pth --folder_lq testsets/RealSRSet+5images
+
+# (larger size + trained on more datasets)
+python main_test_swinir.py --task real_sr --scale 4 --large_model --model_path model_zoo/swinir/003_realSR_BSRGAN_DFOWMFC_s64w8_SwinIR-L_x4_GAN.pth --folder_lq testsets/RealSRSet+5images
+
+
+# 004 Grayscale Image Deoising (middle size)
+python main_test_swinir.py --task gray_dn --noise 15 --model_path model_zoo/swinir/004_grayDN_DFWB_s128w8_SwinIR-M_noise15.pth --folder_gt testsets/set12
+python main_test_swinir.py --task gray_dn --noise 25 --model_path model_zoo/swinir/004_grayDN_DFWB_s128w8_SwinIR-M_noise25.pth --folder_gt testsets/set12
+python main_test_swinir.py --task gray_dn --noise 50 --model_path model_zoo/swinir/004_grayDN_DFWB_s128w8_SwinIR-M_noise50.pth --folder_gt testsets/set12
+
+
+# 005 Color Image Deoising (middle size)
+python main_test_swinir.py --task color_dn --noise 15 --model_path model_zoo/swinir/005_colorDN_DFWB_s128w8_SwinIR-M_noise15.pth --folder_gt testsets/McMaster
+python main_test_swinir.py --task color_dn --noise 25 --model_path model_zoo/swinir/005_colorDN_DFWB_s128w8_SwinIR-M_noise25.pth --folder_gt testsets/McMaster
+python main_test_swinir.py --task color_dn --noise 50 --model_path model_zoo/swinir/005_colorDN_DFWB_s128w8_SwinIR-M_noise50.pth --folder_gt testsets/McMaster
+
+
+# 006 JPEG Compression Artifact Reduction (middle size, using window_size=7 because JPEG encoding uses 8x8 blocks)
+python main_test_swinir.py --task jpeg_car --jpeg 10 --model_path model_zoo/swinir/006_CAR_DFWB_s126w7_SwinIR-M_jpeg10.pth --folder_gt testsets/classic5
+python main_test_swinir.py --task jpeg_car --jpeg 20 --model_path model_zoo/swinir/006_CAR_DFWB_s126w7_SwinIR-M_jpeg20.pth --folder_gt testsets/classic5
+python main_test_swinir.py --task jpeg_car --jpeg 30 --model_path model_zoo/swinir/006_CAR_DFWB_s126w7_SwinIR-M_jpeg30.pth --folder_gt testsets/classic5
+python main_test_swinir.py --task jpeg_car --jpeg 40 --model_path model_zoo/swinir/006_CAR_DFWB_s126w7_SwinIR-M_jpeg40.pth --folder_gt testsets/classic5
+```
+
+---
+
+## Results
+
+Classical Image Super-Resolution (click me)
+
+ 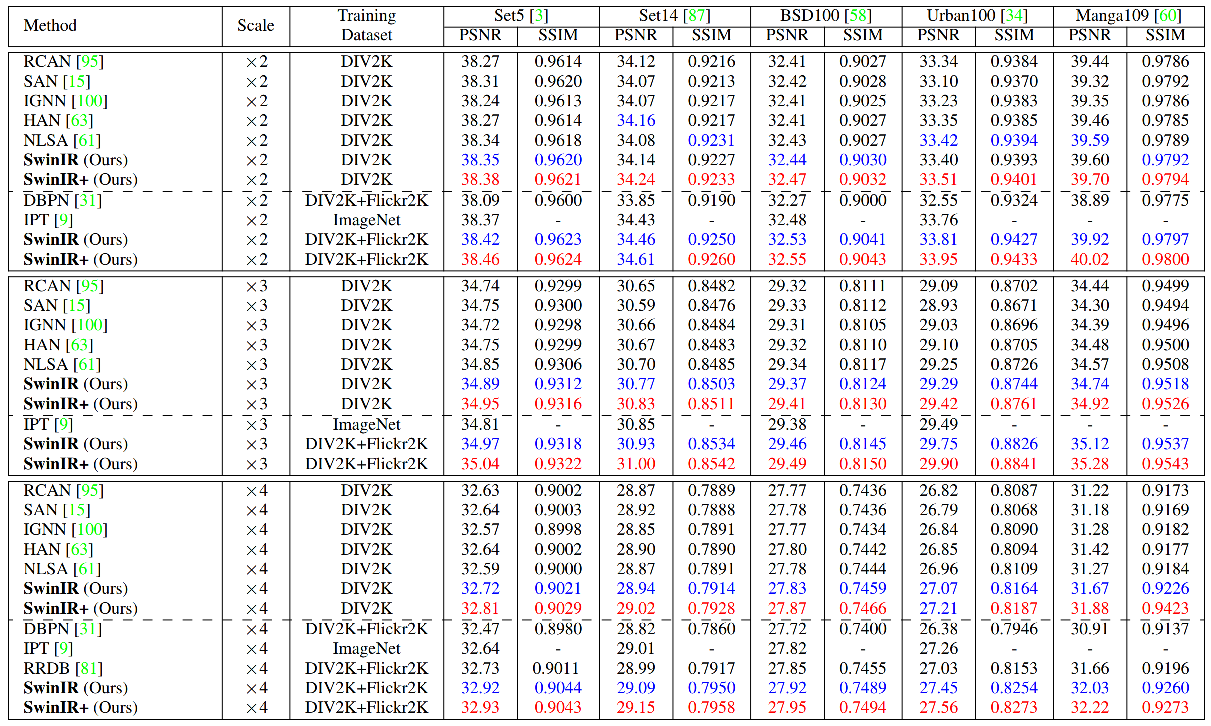 +
+  +
+
+
+
+
+Lightweight Image Super-Resolution
+
+ 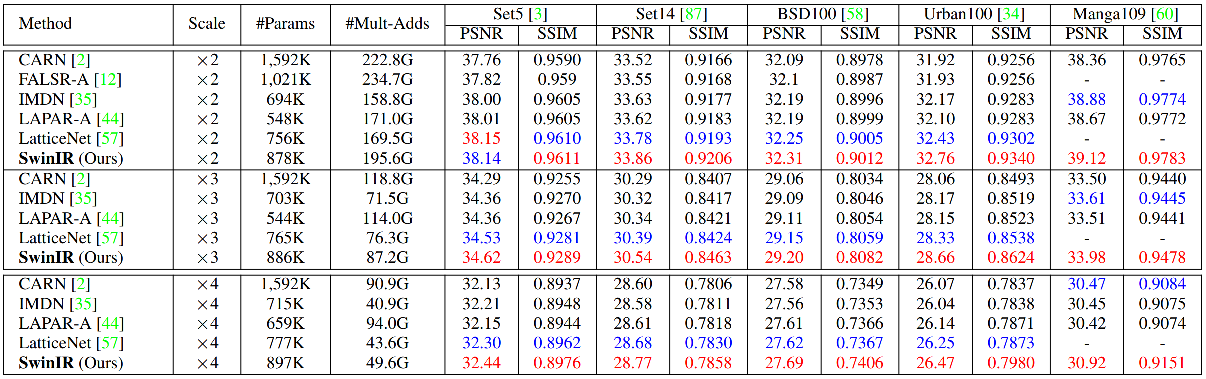 +
+
+
+
+
+Real-World Image Super-Resolution
+
+  +
+
+
+
+
+| Real-World Image (x4)|[BSRGAN, ICCV2021](https://github.com/cszn/BSRGAN)|[Real-ESRGAN](https://github.com/xinntao/Real-ESRGAN)|SwinIR (ours)|
+| :--- | :---: | :-----: | :-----: |
+||||
+|||||
+
+
+Grayscale Image Deoising
+
+  +
+
+
+
+
+Color Image Deoising
+
+ 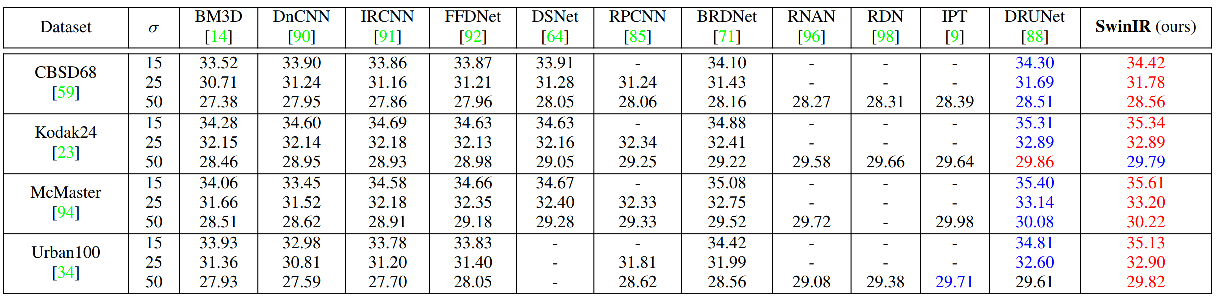 +
+
+
+
+
+JPEG Compression Artifact Reduction
+
+  +
+
+
+
+
+
+Please refer to the [paper](https://arxiv.org/abs/2108.10257) and the [original project page](https://github.com/JingyunLiang/SwinIR)
+for more results.
+
+
+## Citation
+ @article{liang2021swinir,
+ title={SwinIR: Image Restoration Using Swin Transformer},
+ author={Liang, Jingyun and Cao, Jiezhang and Sun, Guolei and Zhang, Kai and Van Gool, Luc and Timofte, Radu},
+ journal={arXiv preprint arXiv:2108.10257},
+ year={2021}
+ }
diff --git a/KAIR/docs/README_VRT.md b/KAIR/docs/README_VRT.md
new file mode 100644
index 0000000000000000000000000000000000000000..bb4e0d2853262d11ca8cfd5bb8642a3a00a5366a
--- /dev/null
+++ b/KAIR/docs/README_VRT.md
@@ -0,0 +1,191 @@
+# [VRT: A Video Restoration Transformer](https://github.com/JingyunLiang/VRT)
+[arxiv](https://arxiv.org/abs/2201.12288)
+**|**
+[supplementary](https://github.com/JingyunLiang/VRT/releases/download/v0.0/VRT_supplementary.pdf)
+**|**
+[pretrained models](https://github.com/JingyunLiang/VRT/releases)
+**|**
+[visual results](https://github.com/JingyunLiang/VRT/releases)
+**|**
+[original project page](https://github.com/JingyunLiang/VRT)
+
+[](https://arxiv.org/abs/2201.12288)
+[](https://github.com/JingyunLiang/VRT)
+[](https://github.com/JingyunLiang/VRT/releases)
+
+[ ](https://colab.research.google.com/gist/JingyunLiang/deb335792768ad9eb73854a8efca4fe0#file-vrt-demo-on-video-restoration-ipynb)
+
+This is the readme of "VRT: A Video Restoration Transformer"
+([arxiv](https://arxiv.org/pdf/2201.12288.pdf), [supp](https://github.com/JingyunLiang/VRT/releases/download/v0.0/VRT_supplementary.pdf), [pretrained models](https://github.com/JingyunLiang/VRT/releases), [visual results](https://github.com/JingyunLiang/VRT/releases)). VRT ahcieves state-of-the-art performance **(up to 2.16dB)** in
+- video SR (REDS, Vimeo90K, Vid4 and UDM10)
+- video deblurring (GoPro, DVD and REDS)
+- video denoising (DAVIS and Set8)
+
+
+
+
+
+
+
+
+
+---
+
+> Video restoration (e.g., video super-resolution) aims to restore high-quality frames from low-quality frames. Different from single image restoration, video restoration generally requires to utilize temporal information from multiple adjacent but usually misaligned video frames. Existing deep methods generally tackle with this by exploiting a sliding window strategy or a recurrent architecture, which either is restricted by frame-by-frame restoration or lacks long-range modelling ability. In this paper, we propose a Video Restoration Transformer (VRT) with parallel frame prediction and long-range temporal dependency modelling abilities. More specifically, VRT is composed of multiple scales, each of which consists of two kinds of modules: temporal mutual self attention (TMSA) and parallel warping. TMSA divides the video into small clips, on which mutual attention is applied for joint motion estimation, feature alignment and feature fusion, while self-attention is used for feature extraction. To enable cross-clip interactions, the video sequence is shifted for every other layer. Besides, parallel warping is used to further fuse information from neighboring frames by parallel feature warping. Experimental results on three tasks, including video super-resolution, video deblurring and video denoising, demonstrate that VRT outperforms the state-of-the-art methods by large margins (**up to 2.16 dB**) on nine benchmark datasets.
+
+ 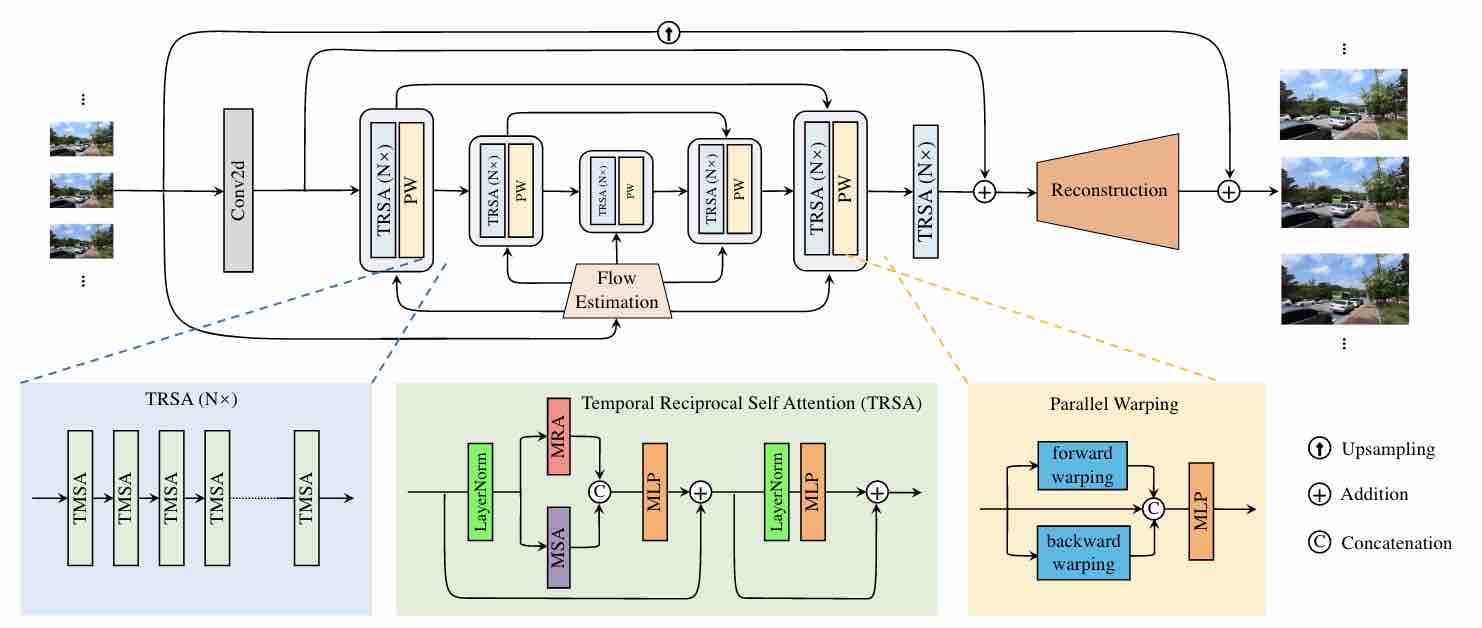 +
+
+
+#### Contents
+
+1. [Requirements](#Requirements)
+1. [Quick Testing](#Quick-Testing)
+1. [Training](#Training)
+1. [Results](#Results)
+1. [Citation](#Citation)
+1. [License and Acknowledgement](#License-and-Acknowledgement)
+
+
+## Requirements
+> - Python 3.8, PyTorch >= 1.9.1
+> - Requirements: see requirements.txt
+> - Platforms: Ubuntu 18.04, cuda-11.1
+
+## Quick Testing
+Following commands will download [pretrained models](https://github.com/JingyunLiang/VRT/releases) and [test datasets](https://github.com/JingyunLiang/VRT/releases) **automatically** (except Vimeo-90K testing set). If out-of-memory, try to reduce `--tile` at the expense of slightly decreased performance.
+
+You can also try to test it on Colab[ ](https://colab.research.google.com/gist/JingyunLiang/deb335792768ad9eb73854a8efca4fe0#file-vrt-demo-on-video-restoration-ipynb), but the results may be slightly different due to `--tile` difference.
+```bash
+# download code
+git clone https://github.com/JingyunLiang/VRT
+cd VRT
+pip install -r requirements.txt
+
+# 001, video sr trained on REDS (6 frames), tested on REDS4
+python main_test_vrt.py --task 001_VRT_videosr_bi_REDS_6frames --folder_lq testsets/REDS4/sharp_bicubic --folder_gt testsets/REDS4/GT --tile 40 128 128 --tile_overlap 2 20 20
+
+# 002, video sr trained on REDS (16 frames), tested on REDS4
+python main_test_vrt.py --task 002_VRT_videosr_bi_REDS_16frames --folder_lq testsets/REDS4/sharp_bicubic --folder_gt testsets/REDS4/GT --tile 40 128 128 --tile_overlap 2 20 20
+
+# 003, video sr trained on Vimeo (bicubic), tested on Vid4 and Vimeo
+python main_test_vrt.py --task 003_VRT_videosr_bi_Vimeo_7frames --folder_lq testsets/Vid4/BIx4 --folder_gt testsets/Vid4/GT --tile 32 128 128 --tile_overlap 2 20 20
+python main_test_vrt.py --task 003_VRT_videosr_bi_Vimeo_7frames --folder_lq testsets/vimeo90k/vimeo_septuplet_matlabLRx4/sequences --folder_gt testsets/vimeo90k/vimeo_septuplet/sequences --tile 8 0 0 --tile_overlap 0 20 20
+
+# 004, video sr trained on Vimeo (blur-downsampling), tested on Vid4, UDM10 and Vimeo
+python main_test_vrt.py --task 004_VRT_videosr_bd_Vimeo_7frames --folder_lq testsets/Vid4/BDx4 --folder_gt testsets/Vid4/GT --tile 32 128 128 --tile_overlap 2 20 20
+python main_test_vrt.py --task 004_VRT_videosr_bd_Vimeo_7frames --folder_lq testsets/UDM10/BDx4 --folder_gt testsets/UDM10/GT --tile 32 128 128 --tile_overlap 2 20 20
+python main_test_vrt.py --task 004_VRT_videosr_bd_Vimeo_7frames --folder_lq testsets/vimeo90k/vimeo_septuplet_BDLRx4/sequences --folder_gt testsets/vimeo90k/vimeo_septuplet/sequences --tile 8 0 0 --tile_overlap 0 20 20
+
+# 005, video deblurring trained and tested on DVD
+python main_test_vrt.py --task 005_VRT_videodeblurring_DVD --folder_lq testsets/DVD10/test_GT_blurred --folder_gt testsets/DVD10/test_GT --tile 12 256 256 --tile_overlap 2 20 20
+
+# 006, video deblurring trained and tested on GoPro
+python main_test_vrt.py --task 006_VRT_videodeblurring_GoPro --folder_lq testsets/GoPro11/test_GT_blurred --folder_gt testsets/GoPro11/test_GT --tile 18 192 192 --tile_overlap 2 20 20
+
+# 007, video deblurring trained on REDS, tested on REDS4
+python main_test_vrt.py --task 007_VRT_videodeblurring_REDS --folder_lq testsets/REDS4/blur --folder_gt testsets/REDS4/GT --tile 12 256 256 --tile_overlap 2 20 20
+
+# 008, video denoising trained on DAVIS (noise level 0-50) and tested on Set8 and DAVIS
+python main_test_vrt.py --task 008_VRT_videodenoising_DAVIS --sigma 10 --folder_lq testsets/Set8 --folder_gt testsets/Set8 --tile 12 256 256 --tile_overlap 2 20 20
+python main_test_vrt.py --task 008_VRT_videodenoising_DAVIS --sigma 10 --folder_lq testsets/DAVIS-test --folder_gt testsets/DAVIS-test --tile 12 256 256 --tile_overlap 2 20 20
+
+# test on your own datasets (an example)
+python main_test_vrt.py --task 001_VRT_videosr_bi_REDS_6frames --folder_lq testsets/your/own --tile 40 128 128 --tile_overlap 2 20 20
+```
+
+**All visual results of VRT can be downloaded [here](https://github.com/JingyunLiang/VRT/releases)**.
+
+
+## Training
+The training and testing sets are as follows (see the [supplementary](https://github.com/JingyunLiang/VRT/releases) for a detailed introduction of all datasets). For better I/O speed, use commands like `python scripts/data_preparation/create_lmdb.py --dataset reds` to convert `.png` datasets to `.lmdb` datasets.
+
+Note: You do **NOT need** to prepare the datasets if you just want to test the model. `main_test_vrt.py` will download the testing set automaticaly.
+
+
+| Task | Training Set | Testing Set | Pretrained Model and Visual Results of VRT |
+|:--------------------------------------------------------------|:-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------:|:----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------:| :---: |
+| video SR (setting 1, BI) | [REDS sharp & sharp_bicubic](https://seungjunnah.github.io/Datasets/reds.html) (266 videos, 266000 frames: train + val except REDS4)
*Use [regroup_reds_dataset.py](https://github.com/cszn/KAIR/tree/master/scripts/data_preparation/regroup_reds_dataset.py) to regroup and rename REDS val set | REDS4 (4 videos, 400 frames: 000, 011, 015, 020 of REDS) | [here](https://github.com/JingyunLiang/VRT/releases) |
+| video SR (setting 2 & 3, BI & BD) | [Vimeo90K](http://data.csail.mit.edu/tofu/dataset/vimeo_septuplet.zip) (64612 seven-frame videos as in `sep_trainlist.txt`)
* Use [generate_LR_Vimeo90K.m](https://github.com/cszn/KAIR/tree/master/scripts/matlab_scripts/generate_LR_Vimeo90K.m) and [generate_LR_Vimeo90K_BD.m](https://github.com/cszn/KAIR/tree/master/scripts/matlab_scripts/generate_LR_Vimeo90K_BD.m) to generate LR frames for bicubic and blur-downsampling VSR, respectively. | Vimeo90K-T (the rest 7824 7-frame videos) + [Vid4](https://drive.google.com/file/d/1ZuvNNLgR85TV_whJoHM7uVb-XW1y70DW/view) (4 videos) + [UDM10](https://www.terabox.com/web/share/link?surl=LMuQCVntRegfZSxn7s3hXw&path=%2Fproject%2Fpfnl) (10 videos)
*Use [prepare_UDM10.py](https://github.com/cszn/KAIR/tree/master/scripts/data_preparation/prepare_UDM10.py) to regroup and rename the UDM10 dataset | [here](https://github.com/JingyunLiang/VRT/releases) |
+| video deblurring (setting 1, motion blur) | [DVD](http://www.cs.ubc.ca/labs/imager/tr/2017/DeepVideoDeblurring/DeepVideoDeblurring_Dataset.zip) (61 videos, 5708 frames)
*Use [prepare_DVD.py](https://github.com/cszn/KAIR/tree/master/scripts/data_preparation/prepare_DVD.py) to regroup and rename the dataset. | DVD (10 videos, 1000 frames)
*Use [evaluate_video_deblurring.m](https://github.com/cszn/KAIR/tree/master/scripts/matlab_scripts/evaluate_video_deblurring.m) for final evaluation. | [here](https://github.com/JingyunLiang/VRT/releases) |
+| video deblurring (setting 2, motion blur) | [GoPro](http://data.cv.snu.ac.kr:8008/webdav/dataset/GOPRO/GOPRO_Large.zip) (22 videos, 2103 frames)
*Use [prepare_GoPro_as_video.py](https://github.com/cszn/KAIR/tree/master/scripts/data_preparation/prepare_GoPro_as_video.py) to regroup and rename the dataset. | GoPro (11 videos, 1111 frames)
*Use [evaluate_video_deblurring.m](https://github.com/cszn/KAIR/tree/master/scripts/matlab_scripts/evaluate_video_deblurring.m) for final evaluation. | [here](https://github.com/JingyunLiang/VRT/releases) |
+| video deblurring (setting 3, motion blur) | [REDS sharp & blur](https://seungjunnah.github.io/Datasets/reds.html) (266 videos, 266000 frames: train & val except REDS4)
*Use [regroup_reds_dataset.py](https://github.com/cszn/KAIR/tree/master/scripts/data_preparation/regroup_reds_dataset.py) to regroup and rename REDS val set. Note that it shares the same HQ frames as in VSR. | REDS4 (4 videos, 400 frames: 000, 011, 015, 020 of REDS) | [here](https://github.com/JingyunLiang/VRT/releases) |
+| video denoising (Gaussian noise) | [DAVIS-2017](https://data.vision.ee.ethz.ch/csergi/share/davis/DAVIS-2017-Unsupervised-trainval-480p.zip) (90 videos, 6208 frames)
*Use all files in DAVIS/JPEGImages/480p | [DAVIS-2017-test](https://github.com/JingyunLiang/VRT/releases) (30 videos) + [Set8](https://www.dropbox.com/sh/20n4cscqkqsfgoj/AABGftyJuJDwuCLGczL-fKvBa/test_sequences?dl=0&subfolder_nav_tracking=1) (8 videos: tractor, touchdown, park_joy and sunflower selected from DERF + hypersmooth, motorbike, rafting and snowboard from GOPRO_540P) | [here](https://github.com/JingyunLiang/VRT/releases) |
+
+Run following commands for training:
+```bash
+# download code
+git clone https://github.com/cszn/KAIR
+cd KAIR
+pip install -r requirements.txt
+
+# 001, video sr trained on REDS (6 frames), tested on REDS4
+python -m torch.distributed.launch --nproc_per_node=8 --master_port=1234 main_train_vrt.py --opt options/vrt/001_train_vrt_videosr_bi_reds_6frames.json --dist True
+
+# 002, video sr trained on REDS (16 frames), tested on REDS4
+python -m torch.distributed.launch --nproc_per_node=8 --master_port=1234 main_train_vrt.py --opt options/vrt/002_train_vrt_videosr_bi_reds_16frames.json --dist True
+
+# 003, video sr trained on Vimeo (bicubic), tested on Vid4 and Vimeo
+python -m torch.distributed.launch --nproc_per_node=8 --master_port=1234 main_train_vrt.py --opt options/vrt/003_train_vrt_videosr_bi_vimeo_7frames.json --dist True
+
+# 004, video sr trained on Vimeo (blur-downsampling), tested on Vid4, Vimeo and UDM10
+python -m torch.distributed.launch --nproc_per_node=8 --master_port=1234 main_train_vrt.py --opt options/vrt/004_train_vrt_videosr_bd_vimeo_7frames.json --dist True
+
+# 005, video deblurring trained and tested on DVD
+python -m torch.distributed.launch --nproc_per_node=8 --master_port=1234 main_train_vrt.py --opt options/vrt/005_train_vrt_videodeblurring_dvd.json --dist True
+
+# 006, video deblurring trained and tested on GoPro
+python -m torch.distributed.launch --nproc_per_node=8 --master_port=1234 main_train_vrt.py --opt options/vrt/006_train_vrt_videodeblurring_gopro.json --dist True
+
+# 007, video deblurring trained on REDS, tested on REDS4
+python -m torch.distributed.launch --nproc_per_node=8 --master_port=1234 main_train_vrt.py --opt options/vrt/007_train_vrt_videodeblurring_reds.json --dist True
+
+# 008, video denoising trained on DAVIS (noise level 0-50) and tested on Set8 and DAVIS
+python -m torch.distributed.launch --nproc_per_node=8 --master_port=1234 main_train_vrt.py --opt options/vrt/008_train_vrt_videodenoising_davis.json --dist True
+```
+Tip: The training process will terminate automatically at 20000 iteration due to a bug. Just resume training after that.
+
+Bug
+Bug: PyTorch DistributedDataParallel (DDP) does not support `torch.utils.checkpoint` well. To alleviate the problem, set `find_unused_parameters=False` when `use_checkpoint=True`. If there are other errors, make sure that unused parameters will not change during training loop and set `use_static_graph=True`.
+
+If you find a better solution, feel free to pull a request. Thank you.
+
+
+## Results
+We achieved state-of-the-art performance on video SR, video deblurring and video denoising. Detailed results can be found in the [paper](https://arxiv.org/abs/2201.12288).
+
+
+Video Super-Resolution (click me)
+
+  +
+  +
+
+
+
+
+Video Deblurring
+
+ 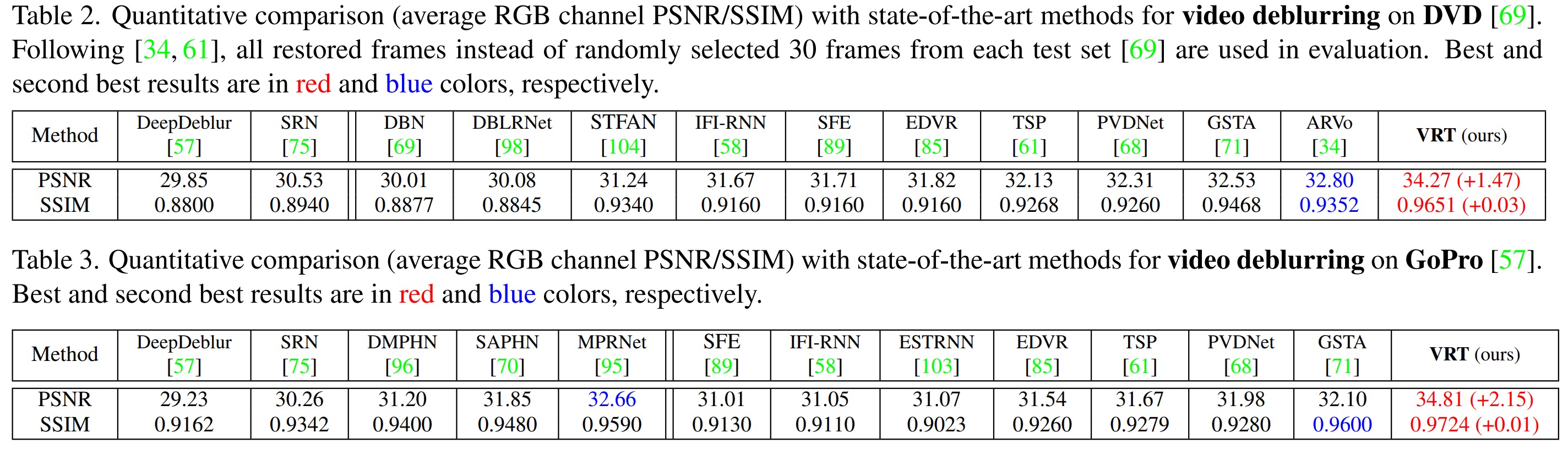 +
+  +
+ 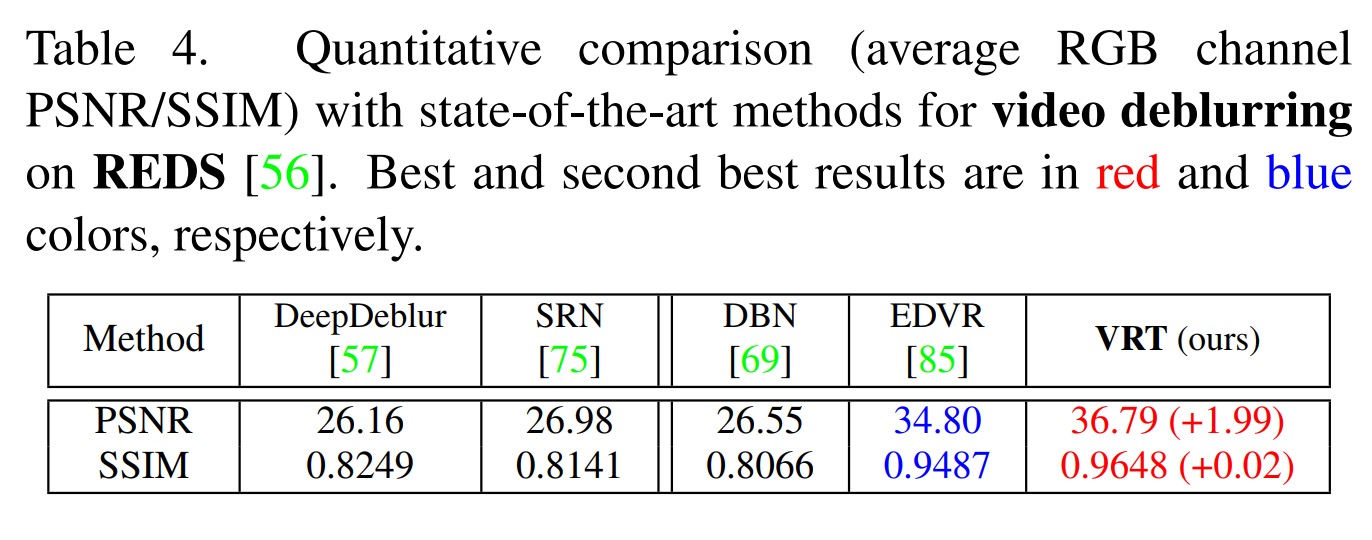 +
+
+
+
+
+Video Denoising
+
+  +
+
+
+
+
+## Citation
+ @article{liang2022vrt,
+ title={VRT: A Video Restoration Transformer},
+ author={Liang, Jingyun and Cao, Jiezhang and Fan, Yuchen and Zhang, Kai and Ranjan, Rakesh and Li, Yawei and Timofte, Radu and Van Gool, Luc},
+ journal={arXiv preprint arXiv:2201.12288},
+ year={2022}
+ }
+
+
+## License and Acknowledgement
+This project is released under the CC-BY-NC license. We refer to codes from [KAIR](https://github.com/cszn/KAIR), [BasicSR](https://github.com/xinntao/BasicSR), [Video Swin Transformer](https://github.com/SwinTransformer/Video-Swin-Transformer) and [mmediting](https://github.com/open-mmlab/mmediting). Thanks for their awesome works. The majority of VRT is licensed under CC-BY-NC, however portions of the project are available under separate license terms: KAIR is licensed under the MIT License, BasicSR, Video Swin Transformer and mmediting are licensed under the Apache 2.0 license.
\ No newline at end of file
diff --git a/KAIR/experiments/001_train_vrt_videosr_bi_reds_6frames/options/001_train_vrt_videosr_bi_reds_6frames_220311_095438.json b/KAIR/experiments/001_train_vrt_videosr_bi_reds_6frames/options/001_train_vrt_videosr_bi_reds_6frames_220311_095438.json
new file mode 100644
index 0000000000000000000000000000000000000000..14ae03db9231a29c3a12d9e44c714c709df60266
--- /dev/null
+++ b/KAIR/experiments/001_train_vrt_videosr_bi_reds_6frames/options/001_train_vrt_videosr_bi_reds_6frames_220311_095438.json
@@ -0,0 +1,201 @@
+{
+ "task": "001_train_vrt_videosr_bi_reds_6frames",
+ "model": "vrt",
+ "gpu_ids": [
+ 0,
+ 1,
+ 2,
+ 3,
+ 4,
+ 5,
+ 6,
+ 7
+ ],
+ "dist": false,
+ "find_unused_parameters": false,
+ "use_static_graph": true,
+ "scale": 4,
+ "n_channels": 3,
+ "path": {
+ "root": "experiments",
+ "pretrained_netG": null,
+ "pretrained_netE": null,
+ "task": "experiments/001_train_vrt_videosr_bi_reds_6frames",
+ "log": "experiments/001_train_vrt_videosr_bi_reds_6frames",
+ "options": "experiments/001_train_vrt_videosr_bi_reds_6frames/options",
+ "models": "experiments/001_train_vrt_videosr_bi_reds_6frames/models",
+ "images": "experiments/001_train_vrt_videosr_bi_reds_6frames/images",
+ "pretrained_optimizerG": null
+ },
+ "datasets": {
+ "train": {
+ "name": "train_dataset",
+ "dataset_type": "VideoRecurrentTrainDataset",
+ "dataroot_gt": "trainsets/REDS/train_sharp_with_val.lmdb",
+ "dataroot_lq": "trainsets/REDS/train_sharp_bicubic_with_val.lmdb",
+ "meta_info_file": "data/meta_info/meta_info_REDS_GT.txt",
+ "filename_tmpl": "08d",
+ "filename_ext": "png",
+ "val_partition": "REDS4",
+ "test_mode": false,
+ "io_backend": {
+ "type": "lmdb"
+ },
+ "num_frame": 6,
+ "gt_size": 256,
+ "interval_list": [
+ 1
+ ],
+ "random_reverse": false,
+ "use_hflip": true,
+ "use_rot": true,
+ "dataloader_shuffle": true,
+ "dataloader_num_workers": 32,
+ "dataloader_batch_size": 8,
+ "phase": "train",
+ "scale": 4,
+ "n_channels": 3
+ },
+ "test": {
+ "name": "test_dataset",
+ "dataset_type": "VideoRecurrentTestDataset",
+ "dataroot_gt": "testsets/REDS4/GT",
+ "dataroot_lq": "testsets/REDS4/sharp_bicubic",
+ "cache_data": true,
+ "io_backend": {
+ "type": "disk"
+ },
+ "num_frame": -1,
+ "phase": "test",
+ "scale": 4,
+ "n_channels": 3
+ }
+ },
+ "netG": {
+ "net_type": "vrt",
+ "upscale": 4,
+ "img_size": [
+ 6,
+ 64,
+ 64
+ ],
+ "window_size": [
+ 6,
+ 8,
+ 8
+ ],
+ "depths": [
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 4,
+ 4,
+ 4,
+ 4,
+ 4,
+ 4
+ ],
+ "indep_reconsts": [
+ 11,
+ 12
+ ],
+ "embed_dims": [
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 180,
+ 180,
+ 180,
+ 180,
+ 180,
+ 180
+ ],
+ "num_heads": [
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6
+ ],
+ "spynet_path": "model_zoo/vrt/spynet_sintel_final-3d2a1287.pth",
+ "pa_frames": 2,
+ "deformable_groups": 12,
+ "nonblind_denoising": false,
+ "use_checkpoint_attn": false,
+ "use_checkpoint_ffn": false,
+ "no_checkpoint_attn_blocks": [],
+ "no_checkpoint_ffn_blocks": [],
+ "init_type": "default",
+ "scale": 4
+ },
+ "train": {
+ "G_lossfn_type": "charbonnier",
+ "G_lossfn_weight": 1.0,
+ "G_charbonnier_eps": 1e-09,
+ "E_decay": 0,
+ "G_optimizer_type": "adam",
+ "G_optimizer_lr": 0.0004,
+ "G_optimizer_betas": [
+ 0.9,
+ 0.99
+ ],
+ "G_optimizer_wd": 0,
+ "G_optimizer_clipgrad": null,
+ "G_optimizer_reuse": true,
+ "fix_iter": 20000,
+ "fix_lr_mul": 0.125,
+ "fix_keys": [
+ "spynet",
+ "deform"
+ ],
+ "total_iter": 300000,
+ "G_scheduler_type": "CosineAnnealingWarmRestarts",
+ "G_scheduler_periods": 300000,
+ "G_scheduler_eta_min": 1e-07,
+ "G_regularizer_orthstep": null,
+ "G_regularizer_clipstep": null,
+ "G_param_strict": true,
+ "E_param_strict": true,
+ "checkpoint_test": 5000,
+ "checkpoint_save": 5000,
+ "checkpoint_print": 200,
+ "F_feature_layer": 34,
+ "F_weights": 1.0,
+ "F_lossfn_type": "l1",
+ "F_use_input_norm": true,
+ "F_use_range_norm": false,
+ "G_scheduler_restart_weights": 1
+ },
+ "val": {
+ "save_img": false,
+ "pad_seq": false,
+ "flip_seq": false,
+ "center_frame_only": false,
+ "num_frame_testing": 40,
+ "num_frame_overlapping": 2,
+ "size_patch_testing": 128
+ },
+ "opt_path": "options/vrt/001_train_vrt_videosr_bi_reds_6frames.json",
+ "is_train": true,
+ "merge_bn": false,
+ "merge_bn_startpoint": -1,
+ "num_gpu": 8,
+ "rank": 0,
+ "world_size": 1
+}
\ No newline at end of file
diff --git a/KAIR/experiments/001_train_vrt_videosr_bi_reds_6frames/options/001_train_vrt_videosr_bi_reds_6frames_220311_095450.json b/KAIR/experiments/001_train_vrt_videosr_bi_reds_6frames/options/001_train_vrt_videosr_bi_reds_6frames_220311_095450.json
new file mode 100644
index 0000000000000000000000000000000000000000..14ae03db9231a29c3a12d9e44c714c709df60266
--- /dev/null
+++ b/KAIR/experiments/001_train_vrt_videosr_bi_reds_6frames/options/001_train_vrt_videosr_bi_reds_6frames_220311_095450.json
@@ -0,0 +1,201 @@
+{
+ "task": "001_train_vrt_videosr_bi_reds_6frames",
+ "model": "vrt",
+ "gpu_ids": [
+ 0,
+ 1,
+ 2,
+ 3,
+ 4,
+ 5,
+ 6,
+ 7
+ ],
+ "dist": false,
+ "find_unused_parameters": false,
+ "use_static_graph": true,
+ "scale": 4,
+ "n_channels": 3,
+ "path": {
+ "root": "experiments",
+ "pretrained_netG": null,
+ "pretrained_netE": null,
+ "task": "experiments/001_train_vrt_videosr_bi_reds_6frames",
+ "log": "experiments/001_train_vrt_videosr_bi_reds_6frames",
+ "options": "experiments/001_train_vrt_videosr_bi_reds_6frames/options",
+ "models": "experiments/001_train_vrt_videosr_bi_reds_6frames/models",
+ "images": "experiments/001_train_vrt_videosr_bi_reds_6frames/images",
+ "pretrained_optimizerG": null
+ },
+ "datasets": {
+ "train": {
+ "name": "train_dataset",
+ "dataset_type": "VideoRecurrentTrainDataset",
+ "dataroot_gt": "trainsets/REDS/train_sharp_with_val.lmdb",
+ "dataroot_lq": "trainsets/REDS/train_sharp_bicubic_with_val.lmdb",
+ "meta_info_file": "data/meta_info/meta_info_REDS_GT.txt",
+ "filename_tmpl": "08d",
+ "filename_ext": "png",
+ "val_partition": "REDS4",
+ "test_mode": false,
+ "io_backend": {
+ "type": "lmdb"
+ },
+ "num_frame": 6,
+ "gt_size": 256,
+ "interval_list": [
+ 1
+ ],
+ "random_reverse": false,
+ "use_hflip": true,
+ "use_rot": true,
+ "dataloader_shuffle": true,
+ "dataloader_num_workers": 32,
+ "dataloader_batch_size": 8,
+ "phase": "train",
+ "scale": 4,
+ "n_channels": 3
+ },
+ "test": {
+ "name": "test_dataset",
+ "dataset_type": "VideoRecurrentTestDataset",
+ "dataroot_gt": "testsets/REDS4/GT",
+ "dataroot_lq": "testsets/REDS4/sharp_bicubic",
+ "cache_data": true,
+ "io_backend": {
+ "type": "disk"
+ },
+ "num_frame": -1,
+ "phase": "test",
+ "scale": 4,
+ "n_channels": 3
+ }
+ },
+ "netG": {
+ "net_type": "vrt",
+ "upscale": 4,
+ "img_size": [
+ 6,
+ 64,
+ 64
+ ],
+ "window_size": [
+ 6,
+ 8,
+ 8
+ ],
+ "depths": [
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 4,
+ 4,
+ 4,
+ 4,
+ 4,
+ 4
+ ],
+ "indep_reconsts": [
+ 11,
+ 12
+ ],
+ "embed_dims": [
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 180,
+ 180,
+ 180,
+ 180,
+ 180,
+ 180
+ ],
+ "num_heads": [
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6
+ ],
+ "spynet_path": "model_zoo/vrt/spynet_sintel_final-3d2a1287.pth",
+ "pa_frames": 2,
+ "deformable_groups": 12,
+ "nonblind_denoising": false,
+ "use_checkpoint_attn": false,
+ "use_checkpoint_ffn": false,
+ "no_checkpoint_attn_blocks": [],
+ "no_checkpoint_ffn_blocks": [],
+ "init_type": "default",
+ "scale": 4
+ },
+ "train": {
+ "G_lossfn_type": "charbonnier",
+ "G_lossfn_weight": 1.0,
+ "G_charbonnier_eps": 1e-09,
+ "E_decay": 0,
+ "G_optimizer_type": "adam",
+ "G_optimizer_lr": 0.0004,
+ "G_optimizer_betas": [
+ 0.9,
+ 0.99
+ ],
+ "G_optimizer_wd": 0,
+ "G_optimizer_clipgrad": null,
+ "G_optimizer_reuse": true,
+ "fix_iter": 20000,
+ "fix_lr_mul": 0.125,
+ "fix_keys": [
+ "spynet",
+ "deform"
+ ],
+ "total_iter": 300000,
+ "G_scheduler_type": "CosineAnnealingWarmRestarts",
+ "G_scheduler_periods": 300000,
+ "G_scheduler_eta_min": 1e-07,
+ "G_regularizer_orthstep": null,
+ "G_regularizer_clipstep": null,
+ "G_param_strict": true,
+ "E_param_strict": true,
+ "checkpoint_test": 5000,
+ "checkpoint_save": 5000,
+ "checkpoint_print": 200,
+ "F_feature_layer": 34,
+ "F_weights": 1.0,
+ "F_lossfn_type": "l1",
+ "F_use_input_norm": true,
+ "F_use_range_norm": false,
+ "G_scheduler_restart_weights": 1
+ },
+ "val": {
+ "save_img": false,
+ "pad_seq": false,
+ "flip_seq": false,
+ "center_frame_only": false,
+ "num_frame_testing": 40,
+ "num_frame_overlapping": 2,
+ "size_patch_testing": 128
+ },
+ "opt_path": "options/vrt/001_train_vrt_videosr_bi_reds_6frames.json",
+ "is_train": true,
+ "merge_bn": false,
+ "merge_bn_startpoint": -1,
+ "num_gpu": 8,
+ "rank": 0,
+ "world_size": 1
+}
\ No newline at end of file
diff --git a/KAIR/experiments/001_train_vrt_videosr_bi_reds_6frames/options/001_train_vrt_videosr_bi_reds_6frames_220311_095518.json b/KAIR/experiments/001_train_vrt_videosr_bi_reds_6frames/options/001_train_vrt_videosr_bi_reds_6frames_220311_095518.json
new file mode 100644
index 0000000000000000000000000000000000000000..14ae03db9231a29c3a12d9e44c714c709df60266
--- /dev/null
+++ b/KAIR/experiments/001_train_vrt_videosr_bi_reds_6frames/options/001_train_vrt_videosr_bi_reds_6frames_220311_095518.json
@@ -0,0 +1,201 @@
+{
+ "task": "001_train_vrt_videosr_bi_reds_6frames",
+ "model": "vrt",
+ "gpu_ids": [
+ 0,
+ 1,
+ 2,
+ 3,
+ 4,
+ 5,
+ 6,
+ 7
+ ],
+ "dist": false,
+ "find_unused_parameters": false,
+ "use_static_graph": true,
+ "scale": 4,
+ "n_channels": 3,
+ "path": {
+ "root": "experiments",
+ "pretrained_netG": null,
+ "pretrained_netE": null,
+ "task": "experiments/001_train_vrt_videosr_bi_reds_6frames",
+ "log": "experiments/001_train_vrt_videosr_bi_reds_6frames",
+ "options": "experiments/001_train_vrt_videosr_bi_reds_6frames/options",
+ "models": "experiments/001_train_vrt_videosr_bi_reds_6frames/models",
+ "images": "experiments/001_train_vrt_videosr_bi_reds_6frames/images",
+ "pretrained_optimizerG": null
+ },
+ "datasets": {
+ "train": {
+ "name": "train_dataset",
+ "dataset_type": "VideoRecurrentTrainDataset",
+ "dataroot_gt": "trainsets/REDS/train_sharp_with_val.lmdb",
+ "dataroot_lq": "trainsets/REDS/train_sharp_bicubic_with_val.lmdb",
+ "meta_info_file": "data/meta_info/meta_info_REDS_GT.txt",
+ "filename_tmpl": "08d",
+ "filename_ext": "png",
+ "val_partition": "REDS4",
+ "test_mode": false,
+ "io_backend": {
+ "type": "lmdb"
+ },
+ "num_frame": 6,
+ "gt_size": 256,
+ "interval_list": [
+ 1
+ ],
+ "random_reverse": false,
+ "use_hflip": true,
+ "use_rot": true,
+ "dataloader_shuffle": true,
+ "dataloader_num_workers": 32,
+ "dataloader_batch_size": 8,
+ "phase": "train",
+ "scale": 4,
+ "n_channels": 3
+ },
+ "test": {
+ "name": "test_dataset",
+ "dataset_type": "VideoRecurrentTestDataset",
+ "dataroot_gt": "testsets/REDS4/GT",
+ "dataroot_lq": "testsets/REDS4/sharp_bicubic",
+ "cache_data": true,
+ "io_backend": {
+ "type": "disk"
+ },
+ "num_frame": -1,
+ "phase": "test",
+ "scale": 4,
+ "n_channels": 3
+ }
+ },
+ "netG": {
+ "net_type": "vrt",
+ "upscale": 4,
+ "img_size": [
+ 6,
+ 64,
+ 64
+ ],
+ "window_size": [
+ 6,
+ 8,
+ 8
+ ],
+ "depths": [
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 4,
+ 4,
+ 4,
+ 4,
+ 4,
+ 4
+ ],
+ "indep_reconsts": [
+ 11,
+ 12
+ ],
+ "embed_dims": [
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 180,
+ 180,
+ 180,
+ 180,
+ 180,
+ 180
+ ],
+ "num_heads": [
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6
+ ],
+ "spynet_path": "model_zoo/vrt/spynet_sintel_final-3d2a1287.pth",
+ "pa_frames": 2,
+ "deformable_groups": 12,
+ "nonblind_denoising": false,
+ "use_checkpoint_attn": false,
+ "use_checkpoint_ffn": false,
+ "no_checkpoint_attn_blocks": [],
+ "no_checkpoint_ffn_blocks": [],
+ "init_type": "default",
+ "scale": 4
+ },
+ "train": {
+ "G_lossfn_type": "charbonnier",
+ "G_lossfn_weight": 1.0,
+ "G_charbonnier_eps": 1e-09,
+ "E_decay": 0,
+ "G_optimizer_type": "adam",
+ "G_optimizer_lr": 0.0004,
+ "G_optimizer_betas": [
+ 0.9,
+ 0.99
+ ],
+ "G_optimizer_wd": 0,
+ "G_optimizer_clipgrad": null,
+ "G_optimizer_reuse": true,
+ "fix_iter": 20000,
+ "fix_lr_mul": 0.125,
+ "fix_keys": [
+ "spynet",
+ "deform"
+ ],
+ "total_iter": 300000,
+ "G_scheduler_type": "CosineAnnealingWarmRestarts",
+ "G_scheduler_periods": 300000,
+ "G_scheduler_eta_min": 1e-07,
+ "G_regularizer_orthstep": null,
+ "G_regularizer_clipstep": null,
+ "G_param_strict": true,
+ "E_param_strict": true,
+ "checkpoint_test": 5000,
+ "checkpoint_save": 5000,
+ "checkpoint_print": 200,
+ "F_feature_layer": 34,
+ "F_weights": 1.0,
+ "F_lossfn_type": "l1",
+ "F_use_input_norm": true,
+ "F_use_range_norm": false,
+ "G_scheduler_restart_weights": 1
+ },
+ "val": {
+ "save_img": false,
+ "pad_seq": false,
+ "flip_seq": false,
+ "center_frame_only": false,
+ "num_frame_testing": 40,
+ "num_frame_overlapping": 2,
+ "size_patch_testing": 128
+ },
+ "opt_path": "options/vrt/001_train_vrt_videosr_bi_reds_6frames.json",
+ "is_train": true,
+ "merge_bn": false,
+ "merge_bn_startpoint": -1,
+ "num_gpu": 8,
+ "rank": 0,
+ "world_size": 1
+}
\ No newline at end of file
diff --git a/KAIR/experiments/001_train_vrt_videosr_bi_reds_6frames/options/001_train_vrt_videosr_bi_reds_6frames_220311_101636.json b/KAIR/experiments/001_train_vrt_videosr_bi_reds_6frames/options/001_train_vrt_videosr_bi_reds_6frames_220311_101636.json
new file mode 100644
index 0000000000000000000000000000000000000000..7a670e42eaec5e51a5e7ec54fa4f57773a190602
--- /dev/null
+++ b/KAIR/experiments/001_train_vrt_videosr_bi_reds_6frames/options/001_train_vrt_videosr_bi_reds_6frames_220311_101636.json
@@ -0,0 +1,201 @@
+{
+ "task": "001_train_vrt_videosr_bi_reds_6frames",
+ "model": "vrt",
+ "gpu_ids": [
+ 0,
+ 1,
+ 2,
+ 3,
+ 4,
+ 5,
+ 6,
+ 7
+ ],
+ "dist": false,
+ "find_unused_parameters": false,
+ "use_static_graph": true,
+ "scale": 4,
+ "n_channels": 3,
+ "path": {
+ "root": "experiments",
+ "pretrained_netG": null,
+ "pretrained_netE": null,
+ "task": "experiments/001_train_vrt_videosr_bi_reds_6frames",
+ "log": "experiments/001_train_vrt_videosr_bi_reds_6frames",
+ "options": "experiments/001_train_vrt_videosr_bi_reds_6frames/options",
+ "models": "experiments/001_train_vrt_videosr_bi_reds_6frames/models",
+ "images": "experiments/001_train_vrt_videosr_bi_reds_6frames/images",
+ "pretrained_optimizerG": null
+ },
+ "datasets": {
+ "train": {
+ "name": "train_dataset",
+ "dataset_type": "VideoRecurrentTrainDataset",
+ "dataroot_gt": "/home/cll/datasets/REDS/val/val_sharp",
+ "dataroot_lq": "/home/cll/datasets/REDS/val/val_sharp_bicubic",
+ "meta_info_file": "",
+ "filename_tmpl": "08d",
+ "filename_ext": "png",
+ "val_partition": "REDS4",
+ "test_mode": false,
+ "io_backend": {
+ "type": "disk"
+ },
+ "num_frame": 6,
+ "gt_size": 256,
+ "interval_list": [
+ 1
+ ],
+ "random_reverse": false,
+ "use_hflip": true,
+ "use_rot": true,
+ "dataloader_shuffle": true,
+ "dataloader_num_workers": 32,
+ "dataloader_batch_size": 8,
+ "phase": "train",
+ "scale": 4,
+ "n_channels": 3
+ },
+ "test": {
+ "name": "test_dataset",
+ "dataset_type": "VideoRecurrentTestDataset",
+ "dataroot_gt": "/home/cll/Desktop/REDS4/GT",
+ "dataroot_lq": "/home/cll/Desktop/REDS4/sharp_bicubic",
+ "cache_data": true,
+ "io_backend": {
+ "type": "disk"
+ },
+ "num_frame": -1,
+ "phase": "test",
+ "scale": 4,
+ "n_channels": 3
+ }
+ },
+ "netG": {
+ "net_type": "vrt",
+ "upscale": 4,
+ "img_size": [
+ 6,
+ 64,
+ 64
+ ],
+ "window_size": [
+ 6,
+ 8,
+ 8
+ ],
+ "depths": [
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 4,
+ 4,
+ 4,
+ 4,
+ 4,
+ 4
+ ],
+ "indep_reconsts": [
+ 11,
+ 12
+ ],
+ "embed_dims": [
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 180,
+ 180,
+ 180,
+ 180,
+ 180,
+ 180
+ ],
+ "num_heads": [
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6
+ ],
+ "spynet_path": "model_zoo/vrt/spynet_sintel_final-3d2a1287.pth",
+ "pa_frames": 2,
+ "deformable_groups": 12,
+ "nonblind_denoising": false,
+ "use_checkpoint_attn": false,
+ "use_checkpoint_ffn": false,
+ "no_checkpoint_attn_blocks": [],
+ "no_checkpoint_ffn_blocks": [],
+ "init_type": "default",
+ "scale": 4
+ },
+ "train": {
+ "G_lossfn_type": "charbonnier",
+ "G_lossfn_weight": 1.0,
+ "G_charbonnier_eps": 1e-09,
+ "E_decay": 0,
+ "G_optimizer_type": "adam",
+ "G_optimizer_lr": 0.0004,
+ "G_optimizer_betas": [
+ 0.9,
+ 0.99
+ ],
+ "G_optimizer_wd": 0,
+ "G_optimizer_clipgrad": null,
+ "G_optimizer_reuse": true,
+ "fix_iter": 20000,
+ "fix_lr_mul": 0.125,
+ "fix_keys": [
+ "spynet",
+ "deform"
+ ],
+ "total_iter": 300000,
+ "G_scheduler_type": "CosineAnnealingWarmRestarts",
+ "G_scheduler_periods": 300000,
+ "G_scheduler_eta_min": 1e-07,
+ "G_regularizer_orthstep": null,
+ "G_regularizer_clipstep": null,
+ "G_param_strict": true,
+ "E_param_strict": true,
+ "checkpoint_test": 5000,
+ "checkpoint_save": 5000,
+ "checkpoint_print": 200,
+ "F_feature_layer": 34,
+ "F_weights": 1.0,
+ "F_lossfn_type": "l1",
+ "F_use_input_norm": true,
+ "F_use_range_norm": false,
+ "G_scheduler_restart_weights": 1
+ },
+ "val": {
+ "save_img": false,
+ "pad_seq": false,
+ "flip_seq": false,
+ "center_frame_only": false,
+ "num_frame_testing": 40,
+ "num_frame_overlapping": 2,
+ "size_patch_testing": 128
+ },
+ "opt_path": "options/vrt/001_train_vrt_videosr_bi_reds_6frames.json",
+ "is_train": true,
+ "merge_bn": false,
+ "merge_bn_startpoint": -1,
+ "num_gpu": 8,
+ "rank": 0,
+ "world_size": 1
+}
\ No newline at end of file
diff --git a/KAIR/experiments/001_train_vrt_videosr_bi_reds_6frames/options/001_train_vrt_videosr_bi_reds_6frames_220311_101949.json b/KAIR/experiments/001_train_vrt_videosr_bi_reds_6frames/options/001_train_vrt_videosr_bi_reds_6frames_220311_101949.json
new file mode 100644
index 0000000000000000000000000000000000000000..79b3bcc93e893d21cde3f41087b8e25aa7c3a2f6
--- /dev/null
+++ b/KAIR/experiments/001_train_vrt_videosr_bi_reds_6frames/options/001_train_vrt_videosr_bi_reds_6frames_220311_101949.json
@@ -0,0 +1,201 @@
+{
+ "task": "001_train_vrt_videosr_bi_reds_6frames",
+ "model": "vrt",
+ "gpu_ids": [
+ 0,
+ 1,
+ 2,
+ 3,
+ 4,
+ 5,
+ 6,
+ 7
+ ],
+ "dist": false,
+ "find_unused_parameters": false,
+ "use_static_graph": true,
+ "scale": 4,
+ "n_channels": 3,
+ "path": {
+ "root": "experiments",
+ "pretrained_netG": "/home/cll/dev/KAIR/model_zoo/vrt/",
+ "pretrained_netE": null,
+ "task": "experiments/001_train_vrt_videosr_bi_reds_6frames",
+ "log": "experiments/001_train_vrt_videosr_bi_reds_6frames",
+ "options": "experiments/001_train_vrt_videosr_bi_reds_6frames/options",
+ "models": "experiments/001_train_vrt_videosr_bi_reds_6frames/models",
+ "images": "experiments/001_train_vrt_videosr_bi_reds_6frames/images",
+ "pretrained_optimizerG": null
+ },
+ "datasets": {
+ "train": {
+ "name": "train_dataset",
+ "dataset_type": "VideoRecurrentTrainDataset",
+ "dataroot_gt": "/home/cll/datasets/REDS/val/val_sharp",
+ "dataroot_lq": "/home/cll/datasets/REDS/val/val_sharp_bicubic",
+ "meta_info_file": "",
+ "filename_tmpl": "08d",
+ "filename_ext": "png",
+ "val_partition": "REDS4",
+ "test_mode": false,
+ "io_backend": {
+ "type": "disk"
+ },
+ "num_frame": 6,
+ "gt_size": 256,
+ "interval_list": [
+ 1
+ ],
+ "random_reverse": false,
+ "use_hflip": true,
+ "use_rot": true,
+ "dataloader_shuffle": true,
+ "dataloader_num_workers": 32,
+ "dataloader_batch_size": 8,
+ "phase": "train",
+ "scale": 4,
+ "n_channels": 3
+ },
+ "test": {
+ "name": "test_dataset",
+ "dataset_type": "VideoRecurrentTestDataset",
+ "dataroot_gt": "/home/cll/Desktop/REDS4/GT",
+ "dataroot_lq": "/home/cll/Desktop/REDS4/sharp_bicubic",
+ "cache_data": true,
+ "io_backend": {
+ "type": "disk"
+ },
+ "num_frame": -1,
+ "phase": "test",
+ "scale": 4,
+ "n_channels": 3
+ }
+ },
+ "netG": {
+ "net_type": "vrt",
+ "upscale": 4,
+ "img_size": [
+ 6,
+ 64,
+ 64
+ ],
+ "window_size": [
+ 6,
+ 8,
+ 8
+ ],
+ "depths": [
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 4,
+ 4,
+ 4,
+ 4,
+ 4,
+ 4
+ ],
+ "indep_reconsts": [
+ 11,
+ 12
+ ],
+ "embed_dims": [
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 180,
+ 180,
+ 180,
+ 180,
+ 180,
+ 180
+ ],
+ "num_heads": [
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6
+ ],
+ "spynet_path": "model_zoo/vrt/spynet_sintel_final-3d2a1287.pth",
+ "pa_frames": 2,
+ "deformable_groups": 12,
+ "nonblind_denoising": false,
+ "use_checkpoint_attn": false,
+ "use_checkpoint_ffn": false,
+ "no_checkpoint_attn_blocks": [],
+ "no_checkpoint_ffn_blocks": [],
+ "init_type": "default",
+ "scale": 4
+ },
+ "train": {
+ "G_lossfn_type": "charbonnier",
+ "G_lossfn_weight": 1.0,
+ "G_charbonnier_eps": 1e-09,
+ "E_decay": 0,
+ "G_optimizer_type": "adam",
+ "G_optimizer_lr": 0.0004,
+ "G_optimizer_betas": [
+ 0.9,
+ 0.99
+ ],
+ "G_optimizer_wd": 0,
+ "G_optimizer_clipgrad": null,
+ "G_optimizer_reuse": true,
+ "fix_iter": 20000,
+ "fix_lr_mul": 0.125,
+ "fix_keys": [
+ "spynet",
+ "deform"
+ ],
+ "total_iter": 300000,
+ "G_scheduler_type": "CosineAnnealingWarmRestarts",
+ "G_scheduler_periods": 300000,
+ "G_scheduler_eta_min": 1e-07,
+ "G_regularizer_orthstep": null,
+ "G_regularizer_clipstep": null,
+ "G_param_strict": true,
+ "E_param_strict": true,
+ "checkpoint_test": 5000,
+ "checkpoint_save": 5000,
+ "checkpoint_print": 200,
+ "F_feature_layer": 34,
+ "F_weights": 1.0,
+ "F_lossfn_type": "l1",
+ "F_use_input_norm": true,
+ "F_use_range_norm": false,
+ "G_scheduler_restart_weights": 1
+ },
+ "val": {
+ "save_img": false,
+ "pad_seq": false,
+ "flip_seq": false,
+ "center_frame_only": false,
+ "num_frame_testing": 40,
+ "num_frame_overlapping": 2,
+ "size_patch_testing": 128
+ },
+ "opt_path": "options/vrt/001_train_vrt_videosr_bi_reds_6frames.json",
+ "is_train": true,
+ "merge_bn": false,
+ "merge_bn_startpoint": -1,
+ "num_gpu": 8,
+ "rank": 0,
+ "world_size": 1
+}
\ No newline at end of file
diff --git a/KAIR/experiments/001_train_vrt_videosr_bi_reds_6frames/options/001_train_vrt_videosr_bi_reds_6frames_220311_102114.json b/KAIR/experiments/001_train_vrt_videosr_bi_reds_6frames/options/001_train_vrt_videosr_bi_reds_6frames_220311_102114.json
new file mode 100644
index 0000000000000000000000000000000000000000..69fa84f667dd8b099cede0bf9bc40408bd095d55
--- /dev/null
+++ b/KAIR/experiments/001_train_vrt_videosr_bi_reds_6frames/options/001_train_vrt_videosr_bi_reds_6frames_220311_102114.json
@@ -0,0 +1,201 @@
+{
+ "task": "001_train_vrt_videosr_bi_reds_6frames",
+ "model": "vrt",
+ "gpu_ids": [
+ 0,
+ 1,
+ 2,
+ 3,
+ 4,
+ 5,
+ 6,
+ 7
+ ],
+ "dist": false,
+ "find_unused_parameters": false,
+ "use_static_graph": true,
+ "scale": 4,
+ "n_channels": 3,
+ "path": {
+ "root": "experiments",
+ "pretrained_netG": "/home/cll/dev/KAIR/model_zoo/vrt/",
+ "pretrained_netE": null,
+ "task": "experiments/001_train_vrt_videosr_bi_reds_6frames",
+ "log": "experiments/001_train_vrt_videosr_bi_reds_6frames",
+ "options": "experiments/001_train_vrt_videosr_bi_reds_6frames/options",
+ "models": "experiments/001_train_vrt_videosr_bi_reds_6frames/models",
+ "images": "experiments/001_train_vrt_videosr_bi_reds_6frames/images",
+ "pretrained_optimizerG": null
+ },
+ "datasets": {
+ "train": {
+ "name": "train_dataset",
+ "dataset_type": "VideoRecurrentTrainDataset",
+ "dataroot_gt": "/home/cll/datasets/REDS/val/val_sharp",
+ "dataroot_lq": "/home/cll/datasets/REDS/val/val_sharp_bicubic",
+ "meta_info_file": "data/meta_info/meta_info_REDS_GT.txt",
+ "filename_tmpl": "08d",
+ "filename_ext": "png",
+ "val_partition": "REDS4",
+ "test_mode": false,
+ "io_backend": {
+ "type": "disk"
+ },
+ "num_frame": 6,
+ "gt_size": 256,
+ "interval_list": [
+ 1
+ ],
+ "random_reverse": false,
+ "use_hflip": true,
+ "use_rot": true,
+ "dataloader_shuffle": true,
+ "dataloader_num_workers": 32,
+ "dataloader_batch_size": 8,
+ "phase": "train",
+ "scale": 4,
+ "n_channels": 3
+ },
+ "test": {
+ "name": "test_dataset",
+ "dataset_type": "VideoRecurrentTestDataset",
+ "dataroot_gt": "/home/cll/Desktop/REDS4/GT",
+ "dataroot_lq": "/home/cll/Desktop/REDS4/sharp_bicubic",
+ "cache_data": true,
+ "io_backend": {
+ "type": "disk"
+ },
+ "num_frame": -1,
+ "phase": "test",
+ "scale": 4,
+ "n_channels": 3
+ }
+ },
+ "netG": {
+ "net_type": "vrt",
+ "upscale": 4,
+ "img_size": [
+ 6,
+ 64,
+ 64
+ ],
+ "window_size": [
+ 6,
+ 8,
+ 8
+ ],
+ "depths": [
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 4,
+ 4,
+ 4,
+ 4,
+ 4,
+ 4
+ ],
+ "indep_reconsts": [
+ 11,
+ 12
+ ],
+ "embed_dims": [
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 180,
+ 180,
+ 180,
+ 180,
+ 180,
+ 180
+ ],
+ "num_heads": [
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6
+ ],
+ "spynet_path": "model_zoo/vrt/spynet_sintel_final-3d2a1287.pth",
+ "pa_frames": 2,
+ "deformable_groups": 12,
+ "nonblind_denoising": false,
+ "use_checkpoint_attn": false,
+ "use_checkpoint_ffn": false,
+ "no_checkpoint_attn_blocks": [],
+ "no_checkpoint_ffn_blocks": [],
+ "init_type": "default",
+ "scale": 4
+ },
+ "train": {
+ "G_lossfn_type": "charbonnier",
+ "G_lossfn_weight": 1.0,
+ "G_charbonnier_eps": 1e-09,
+ "E_decay": 0,
+ "G_optimizer_type": "adam",
+ "G_optimizer_lr": 0.0004,
+ "G_optimizer_betas": [
+ 0.9,
+ 0.99
+ ],
+ "G_optimizer_wd": 0,
+ "G_optimizer_clipgrad": null,
+ "G_optimizer_reuse": true,
+ "fix_iter": 20000,
+ "fix_lr_mul": 0.125,
+ "fix_keys": [
+ "spynet",
+ "deform"
+ ],
+ "total_iter": 300000,
+ "G_scheduler_type": "CosineAnnealingWarmRestarts",
+ "G_scheduler_periods": 300000,
+ "G_scheduler_eta_min": 1e-07,
+ "G_regularizer_orthstep": null,
+ "G_regularizer_clipstep": null,
+ "G_param_strict": true,
+ "E_param_strict": true,
+ "checkpoint_test": 5000,
+ "checkpoint_save": 5000,
+ "checkpoint_print": 200,
+ "F_feature_layer": 34,
+ "F_weights": 1.0,
+ "F_lossfn_type": "l1",
+ "F_use_input_norm": true,
+ "F_use_range_norm": false,
+ "G_scheduler_restart_weights": 1
+ },
+ "val": {
+ "save_img": false,
+ "pad_seq": false,
+ "flip_seq": false,
+ "center_frame_only": false,
+ "num_frame_testing": 40,
+ "num_frame_overlapping": 2,
+ "size_patch_testing": 128
+ },
+ "opt_path": "options/vrt/001_train_vrt_videosr_bi_reds_6frames.json",
+ "is_train": true,
+ "merge_bn": false,
+ "merge_bn_startpoint": -1,
+ "num_gpu": 8,
+ "rank": 0,
+ "world_size": 1
+}
\ No newline at end of file
diff --git a/KAIR/experiments/001_train_vrt_videosr_bi_reds_6frames/options/001_train_vrt_videosr_bi_reds_6frames_220311_102214.json b/KAIR/experiments/001_train_vrt_videosr_bi_reds_6frames/options/001_train_vrt_videosr_bi_reds_6frames_220311_102214.json
new file mode 100644
index 0000000000000000000000000000000000000000..328a91abc5b83f6abc87be0ae22045d255b63ce5
--- /dev/null
+++ b/KAIR/experiments/001_train_vrt_videosr_bi_reds_6frames/options/001_train_vrt_videosr_bi_reds_6frames_220311_102214.json
@@ -0,0 +1,201 @@
+{
+ "task": "001_train_vrt_videosr_bi_reds_6frames",
+ "model": "vrt",
+ "gpu_ids": [
+ 0,
+ 1,
+ 2,
+ 3,
+ 4,
+ 5,
+ 6,
+ 7
+ ],
+ "dist": false,
+ "find_unused_parameters": false,
+ "use_static_graph": true,
+ "scale": 4,
+ "n_channels": 3,
+ "path": {
+ "root": "experiments",
+ "pretrained_netG": "/home/cll/dev/KAIR/model_zoo/vrt/001_VRT_videosr_bi_REDS_6frames.pth",
+ "pretrained_netE": null,
+ "task": "experiments/001_train_vrt_videosr_bi_reds_6frames",
+ "log": "experiments/001_train_vrt_videosr_bi_reds_6frames",
+ "options": "experiments/001_train_vrt_videosr_bi_reds_6frames/options",
+ "models": "experiments/001_train_vrt_videosr_bi_reds_6frames/models",
+ "images": "experiments/001_train_vrt_videosr_bi_reds_6frames/images",
+ "pretrained_optimizerG": null
+ },
+ "datasets": {
+ "train": {
+ "name": "train_dataset",
+ "dataset_type": "VideoRecurrentTrainDataset",
+ "dataroot_gt": "/home/cll/datasets/REDS/val/val_sharp",
+ "dataroot_lq": "/home/cll/datasets/REDS/val/val_sharp_bicubic",
+ "meta_info_file": "data/meta_info/meta_info_REDS_GT.txt",
+ "filename_tmpl": "08d",
+ "filename_ext": "png",
+ "val_partition": "REDS4",
+ "test_mode": false,
+ "io_backend": {
+ "type": "disk"
+ },
+ "num_frame": 6,
+ "gt_size": 256,
+ "interval_list": [
+ 1
+ ],
+ "random_reverse": false,
+ "use_hflip": true,
+ "use_rot": true,
+ "dataloader_shuffle": true,
+ "dataloader_num_workers": 32,
+ "dataloader_batch_size": 8,
+ "phase": "train",
+ "scale": 4,
+ "n_channels": 3
+ },
+ "test": {
+ "name": "test_dataset",
+ "dataset_type": "VideoRecurrentTestDataset",
+ "dataroot_gt": "/home/cll/Desktop/REDS4/GT",
+ "dataroot_lq": "/home/cll/Desktop/REDS4/sharp_bicubic",
+ "cache_data": true,
+ "io_backend": {
+ "type": "disk"
+ },
+ "num_frame": -1,
+ "phase": "test",
+ "scale": 4,
+ "n_channels": 3
+ }
+ },
+ "netG": {
+ "net_type": "vrt",
+ "upscale": 4,
+ "img_size": [
+ 6,
+ 64,
+ 64
+ ],
+ "window_size": [
+ 6,
+ 8,
+ 8
+ ],
+ "depths": [
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 4,
+ 4,
+ 4,
+ 4,
+ 4,
+ 4
+ ],
+ "indep_reconsts": [
+ 11,
+ 12
+ ],
+ "embed_dims": [
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 180,
+ 180,
+ 180,
+ 180,
+ 180,
+ 180
+ ],
+ "num_heads": [
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6
+ ],
+ "spynet_path": "model_zoo/vrt/spynet_sintel_final-3d2a1287.pth",
+ "pa_frames": 2,
+ "deformable_groups": 12,
+ "nonblind_denoising": false,
+ "use_checkpoint_attn": false,
+ "use_checkpoint_ffn": false,
+ "no_checkpoint_attn_blocks": [],
+ "no_checkpoint_ffn_blocks": [],
+ "init_type": "default",
+ "scale": 4
+ },
+ "train": {
+ "G_lossfn_type": "charbonnier",
+ "G_lossfn_weight": 1.0,
+ "G_charbonnier_eps": 1e-09,
+ "E_decay": 0,
+ "G_optimizer_type": "adam",
+ "G_optimizer_lr": 0.0004,
+ "G_optimizer_betas": [
+ 0.9,
+ 0.99
+ ],
+ "G_optimizer_wd": 0,
+ "G_optimizer_clipgrad": null,
+ "G_optimizer_reuse": true,
+ "fix_iter": 20000,
+ "fix_lr_mul": 0.125,
+ "fix_keys": [
+ "spynet",
+ "deform"
+ ],
+ "total_iter": 300000,
+ "G_scheduler_type": "CosineAnnealingWarmRestarts",
+ "G_scheduler_periods": 300000,
+ "G_scheduler_eta_min": 1e-07,
+ "G_regularizer_orthstep": null,
+ "G_regularizer_clipstep": null,
+ "G_param_strict": true,
+ "E_param_strict": true,
+ "checkpoint_test": 5000,
+ "checkpoint_save": 5000,
+ "checkpoint_print": 200,
+ "F_feature_layer": 34,
+ "F_weights": 1.0,
+ "F_lossfn_type": "l1",
+ "F_use_input_norm": true,
+ "F_use_range_norm": false,
+ "G_scheduler_restart_weights": 1
+ },
+ "val": {
+ "save_img": false,
+ "pad_seq": false,
+ "flip_seq": false,
+ "center_frame_only": false,
+ "num_frame_testing": 40,
+ "num_frame_overlapping": 2,
+ "size_patch_testing": 128
+ },
+ "opt_path": "options/vrt/001_train_vrt_videosr_bi_reds_6frames.json",
+ "is_train": true,
+ "merge_bn": false,
+ "merge_bn_startpoint": -1,
+ "num_gpu": 8,
+ "rank": 0,
+ "world_size": 1
+}
\ No newline at end of file
diff --git a/KAIR/experiments/001_train_vrt_videosr_bi_reds_6frames/options/001_train_vrt_videosr_bi_reds_6frames_220311_104612.json b/KAIR/experiments/001_train_vrt_videosr_bi_reds_6frames/options/001_train_vrt_videosr_bi_reds_6frames_220311_104612.json
new file mode 100644
index 0000000000000000000000000000000000000000..5218b3765be74502acf74d1f9c2818d5eb158b5e
--- /dev/null
+++ b/KAIR/experiments/001_train_vrt_videosr_bi_reds_6frames/options/001_train_vrt_videosr_bi_reds_6frames_220311_104612.json
@@ -0,0 +1,201 @@
+{
+ "task": "001_train_vrt_videosr_bi_reds_6frames",
+ "model": "vrt",
+ "gpu_ids": [
+ 0,
+ 1,
+ 2,
+ 3,
+ 4,
+ 5,
+ 6,
+ 7
+ ],
+ "dist": false,
+ "find_unused_parameters": false,
+ "use_static_graph": true,
+ "scale": 4,
+ "n_channels": 3,
+ "path": {
+ "root": "experiments",
+ "pretrained_netG": "/home/cll/dev/KAIR/model_zoo/vrt/001_VRT_videosr_bi_REDS_6frames.pth",
+ "pretrained_netE": null,
+ "task": "experiments/001_train_vrt_videosr_bi_reds_6frames",
+ "log": "experiments/001_train_vrt_videosr_bi_reds_6frames",
+ "options": "experiments/001_train_vrt_videosr_bi_reds_6frames/options",
+ "models": "experiments/001_train_vrt_videosr_bi_reds_6frames/models",
+ "images": "experiments/001_train_vrt_videosr_bi_reds_6frames/images",
+ "pretrained_optimizerG": null
+ },
+ "datasets": {
+ "train": {
+ "name": "train_dataset",
+ "dataset_type": "VideoRecurrentTrainDataset",
+ "dataroot_gt": "/home/cll/datasets/REDS/train/train_sharp",
+ "dataroot_lq": "/home/cll/datasets/REDS/train/train_sharp_bicubic/X4",
+ "meta_info_file": "data/meta_info/meta_info_REDS_GT.txt",
+ "filename_tmpl": "08d",
+ "filename_ext": "png",
+ "val_partition": "REDS4",
+ "test_mode": false,
+ "io_backend": {
+ "type": "disk"
+ },
+ "num_frame": 6,
+ "gt_size": 256,
+ "interval_list": [
+ 1
+ ],
+ "random_reverse": false,
+ "use_hflip": true,
+ "use_rot": true,
+ "dataloader_shuffle": true,
+ "dataloader_num_workers": 32,
+ "dataloader_batch_size": 8,
+ "phase": "train",
+ "scale": 4,
+ "n_channels": 3
+ },
+ "test": {
+ "name": "test_dataset",
+ "dataset_type": "VideoRecurrentTestDataset",
+ "dataroot_gt": "/home/cll/Desktop/REDS4/GT",
+ "dataroot_lq": "/home/cll/Desktop/REDS4/sharp_bicubic",
+ "cache_data": true,
+ "io_backend": {
+ "type": "disk"
+ },
+ "num_frame": -1,
+ "phase": "test",
+ "scale": 4,
+ "n_channels": 3
+ }
+ },
+ "netG": {
+ "net_type": "vrt",
+ "upscale": 4,
+ "img_size": [
+ 6,
+ 64,
+ 64
+ ],
+ "window_size": [
+ 6,
+ 8,
+ 8
+ ],
+ "depths": [
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 4,
+ 4,
+ 4,
+ 4,
+ 4,
+ 4
+ ],
+ "indep_reconsts": [
+ 11,
+ 12
+ ],
+ "embed_dims": [
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 180,
+ 180,
+ 180,
+ 180,
+ 180,
+ 180
+ ],
+ "num_heads": [
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6
+ ],
+ "spynet_path": "model_zoo/vrt/spynet_sintel_final-3d2a1287.pth",
+ "pa_frames": 2,
+ "deformable_groups": 12,
+ "nonblind_denoising": false,
+ "use_checkpoint_attn": false,
+ "use_checkpoint_ffn": false,
+ "no_checkpoint_attn_blocks": [],
+ "no_checkpoint_ffn_blocks": [],
+ "init_type": "default",
+ "scale": 4
+ },
+ "train": {
+ "G_lossfn_type": "charbonnier",
+ "G_lossfn_weight": 1.0,
+ "G_charbonnier_eps": 1e-09,
+ "E_decay": 0,
+ "G_optimizer_type": "adam",
+ "G_optimizer_lr": 0.0004,
+ "G_optimizer_betas": [
+ 0.9,
+ 0.99
+ ],
+ "G_optimizer_wd": 0,
+ "G_optimizer_clipgrad": null,
+ "G_optimizer_reuse": true,
+ "fix_iter": 20000,
+ "fix_lr_mul": 0.125,
+ "fix_keys": [
+ "spynet",
+ "deform"
+ ],
+ "total_iter": 300000,
+ "G_scheduler_type": "CosineAnnealingWarmRestarts",
+ "G_scheduler_periods": 300000,
+ "G_scheduler_eta_min": 1e-07,
+ "G_regularizer_orthstep": null,
+ "G_regularizer_clipstep": null,
+ "G_param_strict": true,
+ "E_param_strict": true,
+ "checkpoint_test": 5000,
+ "checkpoint_save": 5000,
+ "checkpoint_print": 200,
+ "F_feature_layer": 34,
+ "F_weights": 1.0,
+ "F_lossfn_type": "l1",
+ "F_use_input_norm": true,
+ "F_use_range_norm": false,
+ "G_scheduler_restart_weights": 1
+ },
+ "val": {
+ "save_img": false,
+ "pad_seq": false,
+ "flip_seq": false,
+ "center_frame_only": false,
+ "num_frame_testing": 40,
+ "num_frame_overlapping": 2,
+ "size_patch_testing": 128
+ },
+ "opt_path": "options/vrt/001_train_vrt_videosr_bi_reds_6frames.json",
+ "is_train": true,
+ "merge_bn": false,
+ "merge_bn_startpoint": -1,
+ "num_gpu": 8,
+ "rank": 0,
+ "world_size": 1
+}
\ No newline at end of file
diff --git a/KAIR/experiments/001_train_vrt_videosr_bi_reds_6frames/options/001_train_vrt_videosr_bi_reds_6frames_220311_105219.json b/KAIR/experiments/001_train_vrt_videosr_bi_reds_6frames/options/001_train_vrt_videosr_bi_reds_6frames_220311_105219.json
new file mode 100644
index 0000000000000000000000000000000000000000..5218b3765be74502acf74d1f9c2818d5eb158b5e
--- /dev/null
+++ b/KAIR/experiments/001_train_vrt_videosr_bi_reds_6frames/options/001_train_vrt_videosr_bi_reds_6frames_220311_105219.json
@@ -0,0 +1,201 @@
+{
+ "task": "001_train_vrt_videosr_bi_reds_6frames",
+ "model": "vrt",
+ "gpu_ids": [
+ 0,
+ 1,
+ 2,
+ 3,
+ 4,
+ 5,
+ 6,
+ 7
+ ],
+ "dist": false,
+ "find_unused_parameters": false,
+ "use_static_graph": true,
+ "scale": 4,
+ "n_channels": 3,
+ "path": {
+ "root": "experiments",
+ "pretrained_netG": "/home/cll/dev/KAIR/model_zoo/vrt/001_VRT_videosr_bi_REDS_6frames.pth",
+ "pretrained_netE": null,
+ "task": "experiments/001_train_vrt_videosr_bi_reds_6frames",
+ "log": "experiments/001_train_vrt_videosr_bi_reds_6frames",
+ "options": "experiments/001_train_vrt_videosr_bi_reds_6frames/options",
+ "models": "experiments/001_train_vrt_videosr_bi_reds_6frames/models",
+ "images": "experiments/001_train_vrt_videosr_bi_reds_6frames/images",
+ "pretrained_optimizerG": null
+ },
+ "datasets": {
+ "train": {
+ "name": "train_dataset",
+ "dataset_type": "VideoRecurrentTrainDataset",
+ "dataroot_gt": "/home/cll/datasets/REDS/train/train_sharp",
+ "dataroot_lq": "/home/cll/datasets/REDS/train/train_sharp_bicubic/X4",
+ "meta_info_file": "data/meta_info/meta_info_REDS_GT.txt",
+ "filename_tmpl": "08d",
+ "filename_ext": "png",
+ "val_partition": "REDS4",
+ "test_mode": false,
+ "io_backend": {
+ "type": "disk"
+ },
+ "num_frame": 6,
+ "gt_size": 256,
+ "interval_list": [
+ 1
+ ],
+ "random_reverse": false,
+ "use_hflip": true,
+ "use_rot": true,
+ "dataloader_shuffle": true,
+ "dataloader_num_workers": 32,
+ "dataloader_batch_size": 8,
+ "phase": "train",
+ "scale": 4,
+ "n_channels": 3
+ },
+ "test": {
+ "name": "test_dataset",
+ "dataset_type": "VideoRecurrentTestDataset",
+ "dataroot_gt": "/home/cll/Desktop/REDS4/GT",
+ "dataroot_lq": "/home/cll/Desktop/REDS4/sharp_bicubic",
+ "cache_data": true,
+ "io_backend": {
+ "type": "disk"
+ },
+ "num_frame": -1,
+ "phase": "test",
+ "scale": 4,
+ "n_channels": 3
+ }
+ },
+ "netG": {
+ "net_type": "vrt",
+ "upscale": 4,
+ "img_size": [
+ 6,
+ 64,
+ 64
+ ],
+ "window_size": [
+ 6,
+ 8,
+ 8
+ ],
+ "depths": [
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 4,
+ 4,
+ 4,
+ 4,
+ 4,
+ 4
+ ],
+ "indep_reconsts": [
+ 11,
+ 12
+ ],
+ "embed_dims": [
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 180,
+ 180,
+ 180,
+ 180,
+ 180,
+ 180
+ ],
+ "num_heads": [
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6
+ ],
+ "spynet_path": "model_zoo/vrt/spynet_sintel_final-3d2a1287.pth",
+ "pa_frames": 2,
+ "deformable_groups": 12,
+ "nonblind_denoising": false,
+ "use_checkpoint_attn": false,
+ "use_checkpoint_ffn": false,
+ "no_checkpoint_attn_blocks": [],
+ "no_checkpoint_ffn_blocks": [],
+ "init_type": "default",
+ "scale": 4
+ },
+ "train": {
+ "G_lossfn_type": "charbonnier",
+ "G_lossfn_weight": 1.0,
+ "G_charbonnier_eps": 1e-09,
+ "E_decay": 0,
+ "G_optimizer_type": "adam",
+ "G_optimizer_lr": 0.0004,
+ "G_optimizer_betas": [
+ 0.9,
+ 0.99
+ ],
+ "G_optimizer_wd": 0,
+ "G_optimizer_clipgrad": null,
+ "G_optimizer_reuse": true,
+ "fix_iter": 20000,
+ "fix_lr_mul": 0.125,
+ "fix_keys": [
+ "spynet",
+ "deform"
+ ],
+ "total_iter": 300000,
+ "G_scheduler_type": "CosineAnnealingWarmRestarts",
+ "G_scheduler_periods": 300000,
+ "G_scheduler_eta_min": 1e-07,
+ "G_regularizer_orthstep": null,
+ "G_regularizer_clipstep": null,
+ "G_param_strict": true,
+ "E_param_strict": true,
+ "checkpoint_test": 5000,
+ "checkpoint_save": 5000,
+ "checkpoint_print": 200,
+ "F_feature_layer": 34,
+ "F_weights": 1.0,
+ "F_lossfn_type": "l1",
+ "F_use_input_norm": true,
+ "F_use_range_norm": false,
+ "G_scheduler_restart_weights": 1
+ },
+ "val": {
+ "save_img": false,
+ "pad_seq": false,
+ "flip_seq": false,
+ "center_frame_only": false,
+ "num_frame_testing": 40,
+ "num_frame_overlapping": 2,
+ "size_patch_testing": 128
+ },
+ "opt_path": "options/vrt/001_train_vrt_videosr_bi_reds_6frames.json",
+ "is_train": true,
+ "merge_bn": false,
+ "merge_bn_startpoint": -1,
+ "num_gpu": 8,
+ "rank": 0,
+ "world_size": 1
+}
\ No newline at end of file
diff --git a/KAIR/experiments/001_train_vrt_videosr_bi_reds_6frames/options/001_train_vrt_videosr_bi_reds_6frames_220311_105304.json b/KAIR/experiments/001_train_vrt_videosr_bi_reds_6frames/options/001_train_vrt_videosr_bi_reds_6frames_220311_105304.json
new file mode 100644
index 0000000000000000000000000000000000000000..16699da774e5a76b6ff785a8ec65f7918070f76d
--- /dev/null
+++ b/KAIR/experiments/001_train_vrt_videosr_bi_reds_6frames/options/001_train_vrt_videosr_bi_reds_6frames_220311_105304.json
@@ -0,0 +1,201 @@
+{
+ "task": "001_train_vrt_videosr_bi_reds_6frames",
+ "model": "vrt",
+ "gpu_ids": [
+ 0,
+ 1,
+ 2,
+ 3,
+ 4,
+ 5,
+ 6,
+ 7
+ ],
+ "dist": false,
+ "find_unused_parameters": false,
+ "use_static_graph": true,
+ "scale": 4,
+ "n_channels": 3,
+ "path": {
+ "root": "experiments",
+ "pretrained_netG": "/home/cll/dev/KAIR/model_zoo/vrt/001_VRT_videosr_bi_REDS_6frames.pth",
+ "pretrained_netE": null,
+ "task": "experiments/001_train_vrt_videosr_bi_reds_6frames",
+ "log": "experiments/001_train_vrt_videosr_bi_reds_6frames",
+ "options": "experiments/001_train_vrt_videosr_bi_reds_6frames/options",
+ "models": "experiments/001_train_vrt_videosr_bi_reds_6frames/models",
+ "images": "experiments/001_train_vrt_videosr_bi_reds_6frames/images",
+ "pretrained_optimizerG": null
+ },
+ "datasets": {
+ "train": {
+ "name": "train_dataset",
+ "dataset_type": "VideoRecurrentTrainDataset",
+ "dataroot_gt": "/home/cll/datasets/REDS/train/train_sharp",
+ "dataroot_lq": "/home/cll/datasets/REDS/train/train_sharp_bicubic/X4",
+ "meta_info_file": "data/meta_info/meta_info_REDS_GT.txt",
+ "filename_tmpl": "08d",
+ "filename_ext": "png",
+ "val_partition": "REDS4",
+ "test_mode": false,
+ "io_backend": {
+ "type": "disk"
+ },
+ "num_frame": 4,
+ "gt_size": 256,
+ "interval_list": [
+ 1
+ ],
+ "random_reverse": false,
+ "use_hflip": true,
+ "use_rot": true,
+ "dataloader_shuffle": true,
+ "dataloader_num_workers": 32,
+ "dataloader_batch_size": 8,
+ "phase": "train",
+ "scale": 4,
+ "n_channels": 3
+ },
+ "test": {
+ "name": "test_dataset",
+ "dataset_type": "VideoRecurrentTestDataset",
+ "dataroot_gt": "/home/cll/Desktop/REDS4/GT",
+ "dataroot_lq": "/home/cll/Desktop/REDS4/sharp_bicubic",
+ "cache_data": true,
+ "io_backend": {
+ "type": "disk"
+ },
+ "num_frame": -1,
+ "phase": "test",
+ "scale": 4,
+ "n_channels": 3
+ }
+ },
+ "netG": {
+ "net_type": "vrt",
+ "upscale": 4,
+ "img_size": [
+ 6,
+ 64,
+ 64
+ ],
+ "window_size": [
+ 6,
+ 8,
+ 8
+ ],
+ "depths": [
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 4,
+ 4,
+ 4,
+ 4,
+ 4,
+ 4
+ ],
+ "indep_reconsts": [
+ 11,
+ 12
+ ],
+ "embed_dims": [
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 180,
+ 180,
+ 180,
+ 180,
+ 180,
+ 180
+ ],
+ "num_heads": [
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6
+ ],
+ "spynet_path": "model_zoo/vrt/spynet_sintel_final-3d2a1287.pth",
+ "pa_frames": 2,
+ "deformable_groups": 12,
+ "nonblind_denoising": false,
+ "use_checkpoint_attn": false,
+ "use_checkpoint_ffn": false,
+ "no_checkpoint_attn_blocks": [],
+ "no_checkpoint_ffn_blocks": [],
+ "init_type": "default",
+ "scale": 4
+ },
+ "train": {
+ "G_lossfn_type": "charbonnier",
+ "G_lossfn_weight": 1.0,
+ "G_charbonnier_eps": 1e-09,
+ "E_decay": 0,
+ "G_optimizer_type": "adam",
+ "G_optimizer_lr": 0.0004,
+ "G_optimizer_betas": [
+ 0.9,
+ 0.99
+ ],
+ "G_optimizer_wd": 0,
+ "G_optimizer_clipgrad": null,
+ "G_optimizer_reuse": true,
+ "fix_iter": 20000,
+ "fix_lr_mul": 0.125,
+ "fix_keys": [
+ "spynet",
+ "deform"
+ ],
+ "total_iter": 300000,
+ "G_scheduler_type": "CosineAnnealingWarmRestarts",
+ "G_scheduler_periods": 300000,
+ "G_scheduler_eta_min": 1e-07,
+ "G_regularizer_orthstep": null,
+ "G_regularizer_clipstep": null,
+ "G_param_strict": true,
+ "E_param_strict": true,
+ "checkpoint_test": 5000,
+ "checkpoint_save": 5000,
+ "checkpoint_print": 200,
+ "F_feature_layer": 34,
+ "F_weights": 1.0,
+ "F_lossfn_type": "l1",
+ "F_use_input_norm": true,
+ "F_use_range_norm": false,
+ "G_scheduler_restart_weights": 1
+ },
+ "val": {
+ "save_img": false,
+ "pad_seq": false,
+ "flip_seq": false,
+ "center_frame_only": false,
+ "num_frame_testing": 40,
+ "num_frame_overlapping": 2,
+ "size_patch_testing": 128
+ },
+ "opt_path": "options/vrt/001_train_vrt_videosr_bi_reds_6frames.json",
+ "is_train": true,
+ "merge_bn": false,
+ "merge_bn_startpoint": -1,
+ "num_gpu": 8,
+ "rank": 0,
+ "world_size": 1
+}
\ No newline at end of file
diff --git a/KAIR/experiments/001_train_vrt_videosr_bi_reds_6frames/options/001_train_vrt_videosr_bi_reds_6frames_220311_105340.json b/KAIR/experiments/001_train_vrt_videosr_bi_reds_6frames/options/001_train_vrt_videosr_bi_reds_6frames_220311_105340.json
new file mode 100644
index 0000000000000000000000000000000000000000..a94da829ded02a47ff1a4660ad786dcb95d83f84
--- /dev/null
+++ b/KAIR/experiments/001_train_vrt_videosr_bi_reds_6frames/options/001_train_vrt_videosr_bi_reds_6frames_220311_105340.json
@@ -0,0 +1,201 @@
+{
+ "task": "001_train_vrt_videosr_bi_reds_6frames",
+ "model": "vrt",
+ "gpu_ids": [
+ 0,
+ 1,
+ 2,
+ 3,
+ 4,
+ 5,
+ 6,
+ 7
+ ],
+ "dist": false,
+ "find_unused_parameters": false,
+ "use_static_graph": true,
+ "scale": 4,
+ "n_channels": 3,
+ "path": {
+ "root": "experiments",
+ "pretrained_netG": "/home/cll/dev/KAIR/model_zoo/vrt/001_VRT_videosr_bi_REDS_6frames.pth",
+ "pretrained_netE": null,
+ "task": "experiments/001_train_vrt_videosr_bi_reds_6frames",
+ "log": "experiments/001_train_vrt_videosr_bi_reds_6frames",
+ "options": "experiments/001_train_vrt_videosr_bi_reds_6frames/options",
+ "models": "experiments/001_train_vrt_videosr_bi_reds_6frames/models",
+ "images": "experiments/001_train_vrt_videosr_bi_reds_6frames/images",
+ "pretrained_optimizerG": null
+ },
+ "datasets": {
+ "train": {
+ "name": "train_dataset",
+ "dataset_type": "VideoRecurrentTrainDataset",
+ "dataroot_gt": "/home/cll/datasets/REDS/train/train_sharp",
+ "dataroot_lq": "/home/cll/datasets/REDS/train/train_sharp_bicubic/X4",
+ "meta_info_file": "data/meta_info/meta_info_REDS_GT.txt",
+ "filename_tmpl": "08d",
+ "filename_ext": "png",
+ "val_partition": "REDS4",
+ "test_mode": false,
+ "io_backend": {
+ "type": "disk"
+ },
+ "num_frame": 4,
+ "gt_size": 256,
+ "interval_list": [
+ 1
+ ],
+ "random_reverse": false,
+ "use_hflip": true,
+ "use_rot": true,
+ "dataloader_shuffle": true,
+ "dataloader_num_workers": 32,
+ "dataloader_batch_size": 8,
+ "phase": "train",
+ "scale": 4,
+ "n_channels": 3
+ },
+ "test": {
+ "name": "test_dataset",
+ "dataset_type": "VideoRecurrentTestDataset",
+ "dataroot_gt": "/home/cll/Desktop/REDS4/GT",
+ "dataroot_lq": "/home/cll/Desktop/REDS4/sharp_bicubic",
+ "cache_data": true,
+ "io_backend": {
+ "type": "disk"
+ },
+ "num_frame": -1,
+ "phase": "test",
+ "scale": 4,
+ "n_channels": 3
+ }
+ },
+ "netG": {
+ "net_type": "vrt",
+ "upscale": 4,
+ "img_size": [
+ 6,
+ 64,
+ 64
+ ],
+ "window_size": [
+ 2,
+ 8,
+ 8
+ ],
+ "depths": [
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 4,
+ 4,
+ 4,
+ 4,
+ 4,
+ 4
+ ],
+ "indep_reconsts": [
+ 11,
+ 12
+ ],
+ "embed_dims": [
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 180,
+ 180,
+ 180,
+ 180,
+ 180,
+ 180
+ ],
+ "num_heads": [
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6
+ ],
+ "spynet_path": "model_zoo/vrt/spynet_sintel_final-3d2a1287.pth",
+ "pa_frames": 2,
+ "deformable_groups": 12,
+ "nonblind_denoising": false,
+ "use_checkpoint_attn": false,
+ "use_checkpoint_ffn": false,
+ "no_checkpoint_attn_blocks": [],
+ "no_checkpoint_ffn_blocks": [],
+ "init_type": "default",
+ "scale": 4
+ },
+ "train": {
+ "G_lossfn_type": "charbonnier",
+ "G_lossfn_weight": 1.0,
+ "G_charbonnier_eps": 1e-09,
+ "E_decay": 0,
+ "G_optimizer_type": "adam",
+ "G_optimizer_lr": 0.0004,
+ "G_optimizer_betas": [
+ 0.9,
+ 0.99
+ ],
+ "G_optimizer_wd": 0,
+ "G_optimizer_clipgrad": null,
+ "G_optimizer_reuse": true,
+ "fix_iter": 20000,
+ "fix_lr_mul": 0.125,
+ "fix_keys": [
+ "spynet",
+ "deform"
+ ],
+ "total_iter": 300000,
+ "G_scheduler_type": "CosineAnnealingWarmRestarts",
+ "G_scheduler_periods": 300000,
+ "G_scheduler_eta_min": 1e-07,
+ "G_regularizer_orthstep": null,
+ "G_regularizer_clipstep": null,
+ "G_param_strict": true,
+ "E_param_strict": true,
+ "checkpoint_test": 5000,
+ "checkpoint_save": 5000,
+ "checkpoint_print": 200,
+ "F_feature_layer": 34,
+ "F_weights": 1.0,
+ "F_lossfn_type": "l1",
+ "F_use_input_norm": true,
+ "F_use_range_norm": false,
+ "G_scheduler_restart_weights": 1
+ },
+ "val": {
+ "save_img": false,
+ "pad_seq": false,
+ "flip_seq": false,
+ "center_frame_only": false,
+ "num_frame_testing": 40,
+ "num_frame_overlapping": 2,
+ "size_patch_testing": 128
+ },
+ "opt_path": "options/vrt/001_train_vrt_videosr_bi_reds_6frames.json",
+ "is_train": true,
+ "merge_bn": false,
+ "merge_bn_startpoint": -1,
+ "num_gpu": 8,
+ "rank": 0,
+ "world_size": 1
+}
\ No newline at end of file
diff --git a/KAIR/experiments/001_train_vrt_videosr_bi_reds_6frames/train.log b/KAIR/experiments/001_train_vrt_videosr_bi_reds_6frames/train.log
new file mode 100644
index 0000000000000000000000000000000000000000..3e5a233b107a1924e4a94740bb0e983de3b6c05e
--- /dev/null
+++ b/KAIR/experiments/001_train_vrt_videosr_bi_reds_6frames/train.log
@@ -0,0 +1,22331 @@
+22-03-11 09:54:38.123 : task: 001_train_vrt_videosr_bi_reds_6frames
+ model: vrt
+ gpu_ids: [0, 1, 2, 3, 4, 5, 6, 7]
+ dist: False
+ find_unused_parameters: False
+ use_static_graph: True
+ scale: 4
+ n_channels: 3
+ path:[
+ root: experiments
+ pretrained_netG: None
+ pretrained_netE: None
+ task: experiments/001_train_vrt_videosr_bi_reds_6frames
+ log: experiments/001_train_vrt_videosr_bi_reds_6frames
+ options: experiments/001_train_vrt_videosr_bi_reds_6frames/options
+ models: experiments/001_train_vrt_videosr_bi_reds_6frames/models
+ images: experiments/001_train_vrt_videosr_bi_reds_6frames/images
+ pretrained_optimizerG: None
+ ]
+ datasets:[
+ train:[
+ name: train_dataset
+ dataset_type: VideoRecurrentTrainDataset
+ dataroot_gt: trainsets/REDS/train_sharp_with_val.lmdb
+ dataroot_lq: trainsets/REDS/train_sharp_bicubic_with_val.lmdb
+ meta_info_file: data/meta_info/meta_info_REDS_GT.txt
+ filename_tmpl: 08d
+ filename_ext: png
+ val_partition: REDS4
+ test_mode: False
+ io_backend:[
+ type: lmdb
+ ]
+ num_frame: 6
+ gt_size: 256
+ interval_list: [1]
+ random_reverse: False
+ use_hflip: True
+ use_rot: True
+ dataloader_shuffle: True
+ dataloader_num_workers: 32
+ dataloader_batch_size: 8
+ phase: train
+ scale: 4
+ n_channels: 3
+ ]
+ test:[
+ name: test_dataset
+ dataset_type: VideoRecurrentTestDataset
+ dataroot_gt: testsets/REDS4/GT
+ dataroot_lq: testsets/REDS4/sharp_bicubic
+ cache_data: True
+ io_backend:[
+ type: disk
+ ]
+ num_frame: -1
+ phase: test
+ scale: 4
+ n_channels: 3
+ ]
+ ]
+ netG:[
+ net_type: vrt
+ upscale: 4
+ img_size: [6, 64, 64]
+ window_size: [6, 8, 8]
+ depths: [8, 8, 8, 8, 8, 8, 8, 4, 4, 4, 4, 4, 4]
+ indep_reconsts: [11, 12]
+ embed_dims: [120, 120, 120, 120, 120, 120, 120, 180, 180, 180, 180, 180, 180]
+ num_heads: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
+ spynet_path: model_zoo/vrt/spynet_sintel_final-3d2a1287.pth
+ pa_frames: 2
+ deformable_groups: 12
+ nonblind_denoising: False
+ use_checkpoint_attn: False
+ use_checkpoint_ffn: False
+ no_checkpoint_attn_blocks: []
+ no_checkpoint_ffn_blocks: []
+ init_type: default
+ scale: 4
+ ]
+ train:[
+ G_lossfn_type: charbonnier
+ G_lossfn_weight: 1.0
+ G_charbonnier_eps: 1e-09
+ E_decay: 0
+ G_optimizer_type: adam
+ G_optimizer_lr: 0.0004
+ G_optimizer_betas: [0.9, 0.99]
+ G_optimizer_wd: 0
+ G_optimizer_clipgrad: None
+ G_optimizer_reuse: True
+ fix_iter: 20000
+ fix_lr_mul: 0.125
+ fix_keys: ['spynet', 'deform']
+ total_iter: 300000
+ G_scheduler_type: CosineAnnealingWarmRestarts
+ G_scheduler_periods: 300000
+ G_scheduler_eta_min: 1e-07
+ G_regularizer_orthstep: None
+ G_regularizer_clipstep: None
+ G_param_strict: True
+ E_param_strict: True
+ checkpoint_test: 5000
+ checkpoint_save: 5000
+ checkpoint_print: 200
+ F_feature_layer: 34
+ F_weights: 1.0
+ F_lossfn_type: l1
+ F_use_input_norm: True
+ F_use_range_norm: False
+ G_scheduler_restart_weights: 1
+ ]
+ val:[
+ save_img: False
+ pad_seq: False
+ flip_seq: False
+ center_frame_only: False
+ num_frame_testing: 40
+ num_frame_overlapping: 2
+ size_patch_testing: 128
+ ]
+ opt_path: options/vrt/001_train_vrt_videosr_bi_reds_6frames.json
+ is_train: True
+ merge_bn: False
+ merge_bn_startpoint: -1
+ num_gpu: 8
+ rank: 0
+ world_size: 1
+
+22-03-11 09:54:38.147 : Number of train images: 27,000, iters: 3,375
+22-03-11 09:54:50.175 : task: 001_train_vrt_videosr_bi_reds_6frames
+ model: vrt
+ gpu_ids: [0, 1, 2, 3, 4, 5, 6, 7]
+ dist: False
+ find_unused_parameters: False
+ use_static_graph: True
+ scale: 4
+ n_channels: 3
+ path:[
+ root: experiments
+ pretrained_netG: None
+ pretrained_netE: None
+ task: experiments/001_train_vrt_videosr_bi_reds_6frames
+ log: experiments/001_train_vrt_videosr_bi_reds_6frames
+ options: experiments/001_train_vrt_videosr_bi_reds_6frames/options
+ models: experiments/001_train_vrt_videosr_bi_reds_6frames/models
+ images: experiments/001_train_vrt_videosr_bi_reds_6frames/images
+ pretrained_optimizerG: None
+ ]
+ datasets:[
+ train:[
+ name: train_dataset
+ dataset_type: VideoRecurrentTrainDataset
+ dataroot_gt: trainsets/REDS/train_sharp_with_val.lmdb
+ dataroot_lq: trainsets/REDS/train_sharp_bicubic_with_val.lmdb
+ meta_info_file: data/meta_info/meta_info_REDS_GT.txt
+ filename_tmpl: 08d
+ filename_ext: png
+ val_partition: REDS4
+ test_mode: False
+ io_backend:[
+ type: lmdb
+ ]
+ num_frame: 6
+ gt_size: 256
+ interval_list: [1]
+ random_reverse: False
+ use_hflip: True
+ use_rot: True
+ dataloader_shuffle: True
+ dataloader_num_workers: 32
+ dataloader_batch_size: 8
+ phase: train
+ scale: 4
+ n_channels: 3
+ ]
+ test:[
+ name: test_dataset
+ dataset_type: VideoRecurrentTestDataset
+ dataroot_gt: testsets/REDS4/GT
+ dataroot_lq: testsets/REDS4/sharp_bicubic
+ cache_data: True
+ io_backend:[
+ type: disk
+ ]
+ num_frame: -1
+ phase: test
+ scale: 4
+ n_channels: 3
+ ]
+ ]
+ netG:[
+ net_type: vrt
+ upscale: 4
+ img_size: [6, 64, 64]
+ window_size: [6, 8, 8]
+ depths: [8, 8, 8, 8, 8, 8, 8, 4, 4, 4, 4, 4, 4]
+ indep_reconsts: [11, 12]
+ embed_dims: [120, 120, 120, 120, 120, 120, 120, 180, 180, 180, 180, 180, 180]
+ num_heads: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
+ spynet_path: model_zoo/vrt/spynet_sintel_final-3d2a1287.pth
+ pa_frames: 2
+ deformable_groups: 12
+ nonblind_denoising: False
+ use_checkpoint_attn: False
+ use_checkpoint_ffn: False
+ no_checkpoint_attn_blocks: []
+ no_checkpoint_ffn_blocks: []
+ init_type: default
+ scale: 4
+ ]
+ train:[
+ G_lossfn_type: charbonnier
+ G_lossfn_weight: 1.0
+ G_charbonnier_eps: 1e-09
+ E_decay: 0
+ G_optimizer_type: adam
+ G_optimizer_lr: 0.0004
+ G_optimizer_betas: [0.9, 0.99]
+ G_optimizer_wd: 0
+ G_optimizer_clipgrad: None
+ G_optimizer_reuse: True
+ fix_iter: 20000
+ fix_lr_mul: 0.125
+ fix_keys: ['spynet', 'deform']
+ total_iter: 300000
+ G_scheduler_type: CosineAnnealingWarmRestarts
+ G_scheduler_periods: 300000
+ G_scheduler_eta_min: 1e-07
+ G_regularizer_orthstep: None
+ G_regularizer_clipstep: None
+ G_param_strict: True
+ E_param_strict: True
+ checkpoint_test: 5000
+ checkpoint_save: 5000
+ checkpoint_print: 200
+ F_feature_layer: 34
+ F_weights: 1.0
+ F_lossfn_type: l1
+ F_use_input_norm: True
+ F_use_range_norm: False
+ G_scheduler_restart_weights: 1
+ ]
+ val:[
+ save_img: False
+ pad_seq: False
+ flip_seq: False
+ center_frame_only: False
+ num_frame_testing: 40
+ num_frame_overlapping: 2
+ size_patch_testing: 128
+ ]
+ opt_path: options/vrt/001_train_vrt_videosr_bi_reds_6frames.json
+ is_train: True
+ merge_bn: False
+ merge_bn_startpoint: -1
+ num_gpu: 8
+ rank: 0
+ world_size: 1
+
+22-03-11 09:54:50.223 : Number of train images: 27,000, iters: 3,375
+22-03-11 09:54:57.597 :
+Networks name: VRT
+Params number: 30676435
+Net structure:
+VRT(
+ (conv_first): Conv3d(27, 120, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ (spynet): SpyNet(
+ (basic_module): ModuleList(
+ (0): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (1): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (2): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (3): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (4): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (5): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ )
+ )
+ (stage1): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n c d h w -> n d h w c')
+ (1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (2): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): Identity()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): Identity()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage2): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n c d (h neih) (w neiw) -> n d h w (neiw neih c)', neih=2, neiw=2)
+ (1): LayerNorm((480,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=480, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage3): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n c d (h neih) (w neiw) -> n d h w (neiw neih c)', neih=2, neiw=2)
+ (1): LayerNorm((480,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=480, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage4): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n c d (h neih) (w neiw) -> n d h w (neiw neih c)', neih=2, neiw=2)
+ (1): LayerNorm((480,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=480, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage5): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n (neiw neih c) d h w -> n d (h neih) (w neiw) c', neih=2, neiw=2)
+ (1): LayerNorm((30,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=30, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage6): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n (neiw neih c) d h w -> n d (h neih) (w neiw) c', neih=2, neiw=2)
+ (1): LayerNorm((30,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=30, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage7): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n (neiw neih c) d h w -> n d (h neih) (w neiw) c', neih=2, neiw=2)
+ (1): LayerNorm((30,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=30, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage8): ModuleList(
+ (0): Sequential(
+ (0): Rearrange('n c d h w -> n d h w c')
+ (1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=120, out_features=180, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (1): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (2): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (3): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (4): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (5): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (6): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ )
+ (norm): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (conv_after_body): Linear(in_features=180, out_features=120, bias=True)
+ (conv_before_upsample): Sequential(
+ (0): Conv3d(120, 64, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ (1): LeakyReLU(negative_slope=0.01, inplace=True)
+ )
+ (upsample): Upsample(
+ (0): Conv3d(64, 256, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ (1): Transpose_Dim12()
+ (2): PixelShuffle(upscale_factor=2)
+ (3): Transpose_Dim12()
+ (4): LeakyReLU(negative_slope=0.1, inplace=True)
+ (5): Conv3d(64, 256, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ (6): Transpose_Dim12()
+ (7): PixelShuffle(upscale_factor=2)
+ (8): Transpose_Dim12()
+ (9): LeakyReLU(negative_slope=0.1, inplace=True)
+ (10): Conv3d(64, 64, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ )
+ (conv_last): Conv3d(64, 3, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+)
+
+22-03-11 09:54:57.779 :
+ | mean | min | max | std || shape
+ | 0.000 | -0.064 | 0.064 | 0.037 | torch.Size([120, 27, 1, 3, 3]) || conv_first.weight
+ | -0.005 | -0.063 | 0.062 | 0.037 | torch.Size([120]) || conv_first.bias
+ | 0.449 | 0.406 | 0.485 | 0.040 | torch.Size([1, 3, 1, 1]) || spynet.mean
+ | 0.226 | 0.224 | 0.229 | 0.003 | torch.Size([1, 3, 1, 1]) || spynet.std
+ | -0.000 | -0.684 | 0.720 | 0.066 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.0.basic_module.0.weight
+ | -0.055 | -0.917 | 0.306 | 0.335 | torch.Size([32]) || spynet.basic_module.0.basic_module.0.bias
+ | -0.009 | -3.201 | 0.948 | 0.096 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.0.basic_module.2.weight
+ | 0.039 | -1.273 | 0.675 | 0.311 | torch.Size([64]) || spynet.basic_module.0.basic_module.2.bias
+ | -0.010 | -4.690 | 0.568 | 0.089 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.0.basic_module.4.weight
+ | 0.162 | -0.704 | 0.905 | 0.366 | torch.Size([32]) || spynet.basic_module.0.basic_module.4.bias
+ | -0.023 | -1.714 | 0.414 | 0.091 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.0.basic_module.6.weight
+ | 0.787 | -1.061 | 1.170 | 0.522 | torch.Size([16]) || spynet.basic_module.0.basic_module.6.bias
+ | 0.000 | -0.145 | 0.166 | 0.018 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.0.basic_module.8.weight
+ | -0.000 | -0.001 | 0.000 | 0.001 | torch.Size([2]) || spynet.basic_module.0.basic_module.8.bias
+ | -0.000 | -0.726 | 0.782 | 0.070 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.1.basic_module.0.weight
+ | -0.024 | -0.810 | 0.352 | 0.313 | torch.Size([32]) || spynet.basic_module.1.basic_module.0.bias
+ | -0.008 | -3.370 | 0.914 | 0.098 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.1.basic_module.2.weight
+ | 0.042 | -1.197 | 0.699 | 0.302 | torch.Size([64]) || spynet.basic_module.1.basic_module.2.bias
+ | -0.008 | -4.468 | 0.566 | 0.088 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.1.basic_module.4.weight
+ | 0.160 | -0.745 | 0.996 | 0.391 | torch.Size([32]) || spynet.basic_module.1.basic_module.4.bias
+ | -0.017 | -1.648 | 0.317 | 0.084 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.1.basic_module.6.weight
+ | 0.785 | -1.176 | 1.158 | 0.543 | torch.Size([16]) || spynet.basic_module.1.basic_module.6.bias
+ | 0.000 | -0.145 | 0.163 | 0.014 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.1.basic_module.8.weight
+ | 0.000 | -0.000 | 0.000 | 0.000 | torch.Size([2]) || spynet.basic_module.1.basic_module.8.bias
+ | 0.000 | -1.003 | 0.875 | 0.089 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.2.basic_module.0.weight
+ | -0.021 | -0.979 | 0.466 | 0.373 | torch.Size([32]) || spynet.basic_module.2.basic_module.0.bias
+ | -0.008 | -4.622 | 1.220 | 0.116 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.2.basic_module.2.weight
+ | 0.028 | -1.276 | 0.717 | 0.308 | torch.Size([64]) || spynet.basic_module.2.basic_module.2.bias
+ | -0.007 | -1.827 | 0.624 | 0.092 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.2.basic_module.4.weight
+ | 0.123 | -0.697 | 0.745 | 0.334 | torch.Size([32]) || spynet.basic_module.2.basic_module.4.bias
+ | -0.010 | -1.295 | 0.330 | 0.068 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.2.basic_module.6.weight
+ | 0.677 | -1.696 | 0.934 | 0.637 | torch.Size([16]) || spynet.basic_module.2.basic_module.6.bias
+ | 0.000 | -0.114 | 0.129 | 0.008 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.2.basic_module.8.weight
+ | -0.003 | -0.008 | 0.002 | 0.007 | torch.Size([2]) || spynet.basic_module.2.basic_module.8.bias
+ | 0.000 | -1.053 | 0.952 | 0.091 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.3.basic_module.0.weight
+ | -0.016 | -1.061 | 0.522 | 0.414 | torch.Size([32]) || spynet.basic_module.3.basic_module.0.bias
+ | -0.008 | -4.891 | 1.222 | 0.116 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.3.basic_module.2.weight
+ | 0.029 | -1.264 | 0.760 | 0.309 | torch.Size([64]) || spynet.basic_module.3.basic_module.2.bias
+ | -0.007 | -1.792 | 0.579 | 0.089 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.3.basic_module.4.weight
+ | 0.117 | -0.694 | 0.670 | 0.329 | torch.Size([32]) || spynet.basic_module.3.basic_module.4.bias
+ | -0.008 | -1.108 | 0.324 | 0.065 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.3.basic_module.6.weight
+ | 0.652 | -1.754 | 0.901 | 0.647 | torch.Size([16]) || spynet.basic_module.3.basic_module.6.bias
+ | 0.000 | -0.117 | 0.129 | 0.008 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.3.basic_module.8.weight
+ | 0.002 | -0.003 | 0.007 | 0.007 | torch.Size([2]) || spynet.basic_module.3.basic_module.8.bias
+ | -0.000 | -1.085 | 0.998 | 0.092 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.4.basic_module.0.weight
+ | 0.009 | -0.975 | 0.477 | 0.368 | torch.Size([32]) || spynet.basic_module.4.basic_module.0.bias
+ | -0.008 | -5.056 | 1.282 | 0.117 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.4.basic_module.2.weight
+ | 0.029 | -1.240 | 0.796 | 0.311 | torch.Size([64]) || spynet.basic_module.4.basic_module.2.bias
+ | -0.007 | -1.772 | 0.600 | 0.089 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.4.basic_module.4.weight
+ | 0.121 | -0.688 | 0.694 | 0.331 | torch.Size([32]) || spynet.basic_module.4.basic_module.4.bias
+ | -0.007 | -0.980 | 0.320 | 0.065 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.4.basic_module.6.weight
+ | 0.642 | -1.810 | 0.912 | 0.662 | torch.Size([16]) || spynet.basic_module.4.basic_module.6.bias
+ | 0.000 | -0.188 | 0.209 | 0.011 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.4.basic_module.8.weight
+ | -0.002 | -0.008 | 0.005 | 0.009 | torch.Size([2]) || spynet.basic_module.4.basic_module.8.bias
+ | -0.000 | -1.085 | 0.999 | 0.092 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.5.basic_module.0.weight
+ | 0.009 | -0.982 | 0.474 | 0.368 | torch.Size([32]) || spynet.basic_module.5.basic_module.0.bias
+ | -0.008 | -5.089 | 1.311 | 0.119 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.5.basic_module.2.weight
+ | 0.029 | -1.256 | 0.804 | 0.314 | torch.Size([64]) || spynet.basic_module.5.basic_module.2.bias
+ | -0.008 | -1.788 | 0.613 | 0.093 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.5.basic_module.4.weight
+ | 0.122 | -0.699 | 0.700 | 0.334 | torch.Size([32]) || spynet.basic_module.5.basic_module.4.bias
+ | -0.008 | -1.010 | 0.323 | 0.067 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.5.basic_module.6.weight
+ | 0.650 | -1.834 | 0.923 | 0.670 | torch.Size([16]) || spynet.basic_module.5.basic_module.6.bias
+ | 0.000 | -0.192 | 0.213 | 0.011 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.5.basic_module.8.weight
+ | -0.001 | -0.007 | 0.005 | 0.009 | torch.Size([2]) || spynet.basic_module.5.basic_module.8.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage1.reshape.1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage1.reshape.1.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.0.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.0.norm1.bias
+ | 0.000 | -0.065 | 0.069 | 0.020 | torch.Size([675, 6]) || stage1.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.0.attn.position_bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage1.residual_group1.blocks.0.attn.qkv_self.weight
+ | 0.003 | -0.090 | 0.091 | 0.050 | torch.Size([360]) || stage1.residual_group1.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage1.residual_group1.blocks.0.attn.proj.weight
+ | 0.005 | -0.063 | 0.064 | 0.038 | torch.Size([120]) || stage1.residual_group1.blocks.0.attn.proj.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage1.residual_group1.blocks.0.attn.qkv_mut.weight
+ | -0.004 | -0.090 | 0.091 | 0.052 | torch.Size([360]) || stage1.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.0.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.0.norm2.bias
+ | -0.001 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage1.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.002 | -0.091 | 0.091 | 0.050 | torch.Size([240]) || stage1.residual_group1.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage1.residual_group1.blocks.0.mlp.fc12.weight
+ | -0.004 | -0.089 | 0.088 | 0.052 | torch.Size([240]) || stage1.residual_group1.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage1.residual_group1.blocks.0.mlp.fc2.weight
+ | -0.003 | -0.064 | 0.064 | 0.040 | torch.Size([120]) || stage1.residual_group1.blocks.0.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.1.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.1.norm1.bias
+ | 0.000 | -0.070 | 0.070 | 0.020 | torch.Size([675, 6]) || stage1.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.1.attn.position_bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage1.residual_group1.blocks.1.attn.qkv_self.weight
+ | 0.001 | -0.091 | 0.090 | 0.053 | torch.Size([360]) || stage1.residual_group1.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage1.residual_group1.blocks.1.attn.proj.weight
+ | -0.001 | -0.064 | 0.064 | 0.038 | torch.Size([120]) || stage1.residual_group1.blocks.1.attn.proj.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage1.residual_group1.blocks.1.attn.qkv_mut.weight
+ | -0.003 | -0.091 | 0.091 | 0.053 | torch.Size([360]) || stage1.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.1.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.1.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage1.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.002 | -0.091 | 0.089 | 0.052 | torch.Size([240]) || stage1.residual_group1.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage1.residual_group1.blocks.1.mlp.fc12.weight
+ | 0.003 | -0.091 | 0.089 | 0.051 | torch.Size([240]) || stage1.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage1.residual_group1.blocks.1.mlp.fc2.weight
+ | -0.004 | -0.064 | 0.063 | 0.037 | torch.Size([120]) || stage1.residual_group1.blocks.1.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.2.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.2.norm1.bias
+ | -0.000 | -0.072 | 0.073 | 0.020 | torch.Size([675, 6]) || stage1.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.2.attn.position_bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage1.residual_group1.blocks.2.attn.qkv_self.weight
+ | 0.002 | -0.091 | 0.091 | 0.054 | torch.Size([360]) || stage1.residual_group1.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.038 | torch.Size([120, 240]) || stage1.residual_group1.blocks.2.attn.proj.weight
+ | -0.004 | -0.064 | 0.064 | 0.039 | torch.Size([120]) || stage1.residual_group1.blocks.2.attn.proj.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage1.residual_group1.blocks.2.attn.qkv_mut.weight
+ | -0.001 | -0.091 | 0.090 | 0.053 | torch.Size([360]) || stage1.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.2.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.2.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage1.residual_group1.blocks.2.mlp.fc11.weight
+ | 0.002 | -0.091 | 0.090 | 0.054 | torch.Size([240]) || stage1.residual_group1.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage1.residual_group1.blocks.2.mlp.fc12.weight
+ | -0.007 | -0.091 | 0.089 | 0.051 | torch.Size([240]) || stage1.residual_group1.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage1.residual_group1.blocks.2.mlp.fc2.weight
+ | 0.000 | -0.062 | 0.064 | 0.037 | torch.Size([120]) || stage1.residual_group1.blocks.2.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.3.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.3.norm1.bias
+ | 0.000 | -0.067 | 0.067 | 0.020 | torch.Size([675, 6]) || stage1.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.3.attn.position_bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage1.residual_group1.blocks.3.attn.qkv_self.weight
+ | 0.003 | -0.091 | 0.091 | 0.051 | torch.Size([360]) || stage1.residual_group1.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage1.residual_group1.blocks.3.attn.proj.weight
+ | -0.002 | -0.064 | 0.064 | 0.038 | torch.Size([120]) || stage1.residual_group1.blocks.3.attn.proj.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage1.residual_group1.blocks.3.attn.qkv_mut.weight
+ | 0.000 | -0.090 | 0.091 | 0.051 | torch.Size([360]) || stage1.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.3.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.3.norm2.bias
+ | -0.001 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage1.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.008 | -0.091 | 0.091 | 0.053 | torch.Size([240]) || stage1.residual_group1.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage1.residual_group1.blocks.3.mlp.fc12.weight
+ | -0.005 | -0.091 | 0.091 | 0.053 | torch.Size([240]) || stage1.residual_group1.blocks.3.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage1.residual_group1.blocks.3.mlp.fc2.weight
+ | 0.005 | -0.063 | 0.061 | 0.035 | torch.Size([120]) || stage1.residual_group1.blocks.3.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.4.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.4.norm1.bias
+ | 0.000 | -0.079 | 0.068 | 0.020 | torch.Size([675, 6]) || stage1.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.4.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage1.residual_group1.blocks.4.attn.qkv_self.weight
+ | -0.002 | -0.091 | 0.090 | 0.052 | torch.Size([360]) || stage1.residual_group1.blocks.4.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage1.residual_group1.blocks.4.attn.proj.weight
+ | 0.003 | -0.064 | 0.064 | 0.035 | torch.Size([120]) || stage1.residual_group1.blocks.4.attn.proj.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage1.residual_group1.blocks.4.attn.qkv_mut.weight
+ | -0.003 | -0.091 | 0.091 | 0.054 | torch.Size([360]) || stage1.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.4.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.4.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage1.residual_group1.blocks.4.mlp.fc11.weight
+ | 0.006 | -0.091 | 0.089 | 0.052 | torch.Size([240]) || stage1.residual_group1.blocks.4.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage1.residual_group1.blocks.4.mlp.fc12.weight
+ | 0.006 | -0.087 | 0.091 | 0.050 | torch.Size([240]) || stage1.residual_group1.blocks.4.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage1.residual_group1.blocks.4.mlp.fc2.weight
+ | -0.000 | -0.064 | 0.063 | 0.037 | torch.Size([120]) || stage1.residual_group1.blocks.4.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.5.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.5.norm1.bias
+ | 0.000 | -0.077 | 0.071 | 0.020 | torch.Size([675, 6]) || stage1.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.5.attn.position_bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage1.residual_group1.blocks.5.attn.qkv_self.weight
+ | 0.003 | -0.091 | 0.091 | 0.052 | torch.Size([360]) || stage1.residual_group1.blocks.5.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage1.residual_group1.blocks.5.attn.proj.weight
+ | -0.004 | -0.064 | 0.064 | 0.037 | torch.Size([120]) || stage1.residual_group1.blocks.5.attn.proj.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage1.residual_group1.blocks.5.attn.qkv_mut.weight
+ | 0.003 | -0.091 | 0.091 | 0.054 | torch.Size([360]) || stage1.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.5.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.5.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage1.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.000 | -0.089 | 0.089 | 0.050 | torch.Size([240]) || stage1.residual_group1.blocks.5.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage1.residual_group1.blocks.5.mlp.fc12.weight
+ | -0.004 | -0.090 | 0.091 | 0.052 | torch.Size([240]) || stage1.residual_group1.blocks.5.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage1.residual_group1.blocks.5.mlp.fc2.weight
+ | -0.003 | -0.064 | 0.063 | 0.034 | torch.Size([120]) || stage1.residual_group1.blocks.5.mlp.fc2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage1.linear1.weight
+ | -0.010 | -0.090 | 0.091 | 0.050 | torch.Size([120]) || stage1.linear1.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage1.residual_group2.blocks.0.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage1.residual_group2.blocks.0.norm1.bias
+ | 0.000 | -0.079 | 0.088 | 0.020 | torch.Size([2475, 6]) || stage1.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage1.residual_group2.blocks.0.attn.relative_position_index
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage1.residual_group2.blocks.0.attn.qkv_self.weight
+ | 0.005 | -0.091 | 0.091 | 0.050 | torch.Size([360]) || stage1.residual_group2.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage1.residual_group2.blocks.0.attn.proj.weight
+ | -0.002 | -0.090 | 0.090 | 0.054 | torch.Size([120]) || stage1.residual_group2.blocks.0.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage1.residual_group2.blocks.0.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage1.residual_group2.blocks.0.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage1.residual_group2.blocks.0.mlp.fc11.weight
+ | 0.002 | -0.091 | 0.091 | 0.051 | torch.Size([240]) || stage1.residual_group2.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage1.residual_group2.blocks.0.mlp.fc12.weight
+ | 0.001 | -0.089 | 0.091 | 0.054 | torch.Size([240]) || stage1.residual_group2.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage1.residual_group2.blocks.0.mlp.fc2.weight
+ | 0.000 | -0.064 | 0.064 | 0.038 | torch.Size([120]) || stage1.residual_group2.blocks.0.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage1.residual_group2.blocks.1.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage1.residual_group2.blocks.1.norm1.bias
+ | 0.000 | -0.078 | 0.083 | 0.020 | torch.Size([2475, 6]) || stage1.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage1.residual_group2.blocks.1.attn.relative_position_index
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage1.residual_group2.blocks.1.attn.qkv_self.weight
+ | -0.002 | -0.091 | 0.091 | 0.051 | torch.Size([360]) || stage1.residual_group2.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage1.residual_group2.blocks.1.attn.proj.weight
+ | -0.003 | -0.088 | 0.089 | 0.052 | torch.Size([120]) || stage1.residual_group2.blocks.1.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage1.residual_group2.blocks.1.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage1.residual_group2.blocks.1.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage1.residual_group2.blocks.1.mlp.fc11.weight
+ | -0.000 | -0.090 | 0.090 | 0.053 | torch.Size([240]) || stage1.residual_group2.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage1.residual_group2.blocks.1.mlp.fc12.weight
+ | -0.001 | -0.091 | 0.091 | 0.051 | torch.Size([240]) || stage1.residual_group2.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage1.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.000 | -0.064 | 0.064 | 0.038 | torch.Size([120]) || stage1.residual_group2.blocks.1.mlp.fc2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage1.linear2.weight
+ | 0.000 | -0.091 | 0.091 | 0.048 | torch.Size([120]) || stage1.linear2.bias
+ | -0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage1.pa_deform.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage1.pa_deform.bias
+ | -0.000 | -0.021 | 0.021 | 0.012 | torch.Size([120, 242, 3, 3]) || stage1.pa_deform.conv_offset.0.weight
+ | -0.001 | -0.021 | 0.021 | 0.012 | torch.Size([120]) || stage1.pa_deform.conv_offset.0.bias
+ | -0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage1.pa_deform.conv_offset.2.weight
+ | 0.000 | -0.030 | 0.030 | 0.017 | torch.Size([120]) || stage1.pa_deform.conv_offset.2.bias
+ | -0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage1.pa_deform.conv_offset.4.weight
+ | 0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120]) || stage1.pa_deform.conv_offset.4.bias
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([324, 120, 3, 3]) || stage1.pa_deform.conv_offset.6.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([324]) || stage1.pa_deform.conv_offset.6.bias
+ | 0.000 | -0.053 | 0.053 | 0.030 | torch.Size([360, 360]) || stage1.pa_fuse.fc11.weight
+ | 0.002 | -0.052 | 0.053 | 0.030 | torch.Size([360]) || stage1.pa_fuse.fc11.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([360, 360]) || stage1.pa_fuse.fc12.weight
+ | -0.001 | -0.053 | 0.053 | 0.031 | torch.Size([360]) || stage1.pa_fuse.fc12.bias
+ | 0.000 | -0.053 | 0.053 | 0.030 | torch.Size([120, 360]) || stage1.pa_fuse.fc2.weight
+ | 0.002 | -0.052 | 0.052 | 0.030 | torch.Size([120]) || stage1.pa_fuse.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([480]) || stage2.reshape.1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([480]) || stage2.reshape.1.bias
+ | 0.000 | -0.046 | 0.046 | 0.026 | torch.Size([120, 480]) || stage2.reshape.2.weight
+ | -0.001 | -0.045 | 0.045 | 0.026 | torch.Size([120]) || stage2.reshape.2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.0.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.0.norm1.bias
+ | 0.000 | -0.070 | 0.065 | 0.020 | torch.Size([675, 6]) || stage2.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.0.attn.position_bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage2.residual_group1.blocks.0.attn.qkv_self.weight
+ | -0.000 | -0.090 | 0.091 | 0.053 | torch.Size([360]) || stage2.residual_group1.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage2.residual_group1.blocks.0.attn.proj.weight
+ | 0.003 | -0.063 | 0.064 | 0.039 | torch.Size([120]) || stage2.residual_group1.blocks.0.attn.proj.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage2.residual_group1.blocks.0.attn.qkv_mut.weight
+ | 0.002 | -0.091 | 0.091 | 0.051 | torch.Size([360]) || stage2.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.0.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.0.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage2.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.004 | -0.090 | 0.090 | 0.053 | torch.Size([240]) || stage2.residual_group1.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage2.residual_group1.blocks.0.mlp.fc12.weight
+ | -0.005 | -0.090 | 0.089 | 0.055 | torch.Size([240]) || stage2.residual_group1.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage2.residual_group1.blocks.0.mlp.fc2.weight
+ | 0.003 | -0.063 | 0.064 | 0.039 | torch.Size([120]) || stage2.residual_group1.blocks.0.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.1.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.1.norm1.bias
+ | -0.000 | -0.071 | 0.066 | 0.020 | torch.Size([675, 6]) || stage2.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.1.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage2.residual_group1.blocks.1.attn.qkv_self.weight
+ | -0.001 | -0.091 | 0.091 | 0.052 | torch.Size([360]) || stage2.residual_group1.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage2.residual_group1.blocks.1.attn.proj.weight
+ | -0.002 | -0.064 | 0.060 | 0.037 | torch.Size([120]) || stage2.residual_group1.blocks.1.attn.proj.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage2.residual_group1.blocks.1.attn.qkv_mut.weight
+ | 0.003 | -0.091 | 0.091 | 0.053 | torch.Size([360]) || stage2.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.1.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.1.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage2.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.001 | -0.091 | 0.088 | 0.054 | torch.Size([240]) || stage2.residual_group1.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage2.residual_group1.blocks.1.mlp.fc12.weight
+ | -0.004 | -0.091 | 0.091 | 0.052 | torch.Size([240]) || stage2.residual_group1.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage2.residual_group1.blocks.1.mlp.fc2.weight
+ | -0.007 | -0.064 | 0.064 | 0.036 | torch.Size([120]) || stage2.residual_group1.blocks.1.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.2.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.2.norm1.bias
+ | 0.000 | -0.068 | 0.075 | 0.020 | torch.Size([675, 6]) || stage2.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.2.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage2.residual_group1.blocks.2.attn.qkv_self.weight
+ | -0.002 | -0.091 | 0.090 | 0.052 | torch.Size([360]) || stage2.residual_group1.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage2.residual_group1.blocks.2.attn.proj.weight
+ | 0.000 | -0.063 | 0.063 | 0.036 | torch.Size([120]) || stage2.residual_group1.blocks.2.attn.proj.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage2.residual_group1.blocks.2.attn.qkv_mut.weight
+ | -0.004 | -0.091 | 0.091 | 0.050 | torch.Size([360]) || stage2.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.2.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.2.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage2.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.001 | -0.091 | 0.090 | 0.053 | torch.Size([240]) || stage2.residual_group1.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage2.residual_group1.blocks.2.mlp.fc12.weight
+ | -0.008 | -0.091 | 0.091 | 0.055 | torch.Size([240]) || stage2.residual_group1.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage2.residual_group1.blocks.2.mlp.fc2.weight
+ | 0.006 | -0.063 | 0.065 | 0.038 | torch.Size([120]) || stage2.residual_group1.blocks.2.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.3.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.3.norm1.bias
+ | -0.000 | -0.095 | 0.063 | 0.020 | torch.Size([675, 6]) || stage2.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.3.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage2.residual_group1.blocks.3.attn.qkv_self.weight
+ | 0.001 | -0.091 | 0.091 | 0.052 | torch.Size([360]) || stage2.residual_group1.blocks.3.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage2.residual_group1.blocks.3.attn.proj.weight
+ | -0.007 | -0.064 | 0.064 | 0.036 | torch.Size([120]) || stage2.residual_group1.blocks.3.attn.proj.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage2.residual_group1.blocks.3.attn.qkv_mut.weight
+ | -0.003 | -0.090 | 0.091 | 0.054 | torch.Size([360]) || stage2.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.3.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.3.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage2.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.003 | -0.089 | 0.090 | 0.050 | torch.Size([240]) || stage2.residual_group1.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage2.residual_group1.blocks.3.mlp.fc12.weight
+ | -0.003 | -0.090 | 0.091 | 0.053 | torch.Size([240]) || stage2.residual_group1.blocks.3.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage2.residual_group1.blocks.3.mlp.fc2.weight
+ | -0.000 | -0.064 | 0.063 | 0.038 | torch.Size([120]) || stage2.residual_group1.blocks.3.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.4.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.4.norm1.bias
+ | -0.000 | -0.070 | 0.081 | 0.020 | torch.Size([675, 6]) || stage2.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.4.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage2.residual_group1.blocks.4.attn.qkv_self.weight
+ | -0.001 | -0.091 | 0.091 | 0.054 | torch.Size([360]) || stage2.residual_group1.blocks.4.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage2.residual_group1.blocks.4.attn.proj.weight
+ | 0.000 | -0.061 | 0.064 | 0.037 | torch.Size([120]) || stage2.residual_group1.blocks.4.attn.proj.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage2.residual_group1.blocks.4.attn.qkv_mut.weight
+ | 0.000 | -0.090 | 0.091 | 0.054 | torch.Size([360]) || stage2.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.4.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.4.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage2.residual_group1.blocks.4.mlp.fc11.weight
+ | 0.003 | -0.091 | 0.090 | 0.053 | torch.Size([240]) || stage2.residual_group1.blocks.4.mlp.fc11.bias
+ | -0.001 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage2.residual_group1.blocks.4.mlp.fc12.weight
+ | 0.003 | -0.088 | 0.091 | 0.051 | torch.Size([240]) || stage2.residual_group1.blocks.4.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage2.residual_group1.blocks.4.mlp.fc2.weight
+ | 0.000 | -0.064 | 0.062 | 0.037 | torch.Size([120]) || stage2.residual_group1.blocks.4.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.5.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.5.norm1.bias
+ | -0.000 | -0.072 | 0.077 | 0.020 | torch.Size([675, 6]) || stage2.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.5.attn.position_bias
+ | 0.000 | -0.091 | 0.091 | 0.052 | torch.Size([360, 120]) || stage2.residual_group1.blocks.5.attn.qkv_self.weight
+ | -0.005 | -0.091 | 0.089 | 0.053 | torch.Size([360]) || stage2.residual_group1.blocks.5.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage2.residual_group1.blocks.5.attn.proj.weight
+ | -0.000 | -0.063 | 0.064 | 0.039 | torch.Size([120]) || stage2.residual_group1.blocks.5.attn.proj.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage2.residual_group1.blocks.5.attn.qkv_mut.weight
+ | -0.000 | -0.091 | 0.089 | 0.054 | torch.Size([360]) || stage2.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.5.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.5.norm2.bias
+ | 0.001 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage2.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.001 | -0.091 | 0.091 | 0.052 | torch.Size([240]) || stage2.residual_group1.blocks.5.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage2.residual_group1.blocks.5.mlp.fc12.weight
+ | -0.005 | -0.091 | 0.091 | 0.055 | torch.Size([240]) || stage2.residual_group1.blocks.5.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage2.residual_group1.blocks.5.mlp.fc2.weight
+ | -0.000 | -0.063 | 0.065 | 0.039 | torch.Size([120]) || stage2.residual_group1.blocks.5.mlp.fc2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage2.linear1.weight
+ | -0.003 | -0.090 | 0.089 | 0.054 | torch.Size([120]) || stage2.linear1.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage2.residual_group2.blocks.0.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage2.residual_group2.blocks.0.norm1.bias
+ | 0.000 | -0.077 | 0.106 | 0.020 | torch.Size([2475, 6]) || stage2.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage2.residual_group2.blocks.0.attn.relative_position_index
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage2.residual_group2.blocks.0.attn.qkv_self.weight
+ | 0.005 | -0.091 | 0.091 | 0.050 | torch.Size([360]) || stage2.residual_group2.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage2.residual_group2.blocks.0.attn.proj.weight
+ | 0.005 | -0.090 | 0.090 | 0.050 | torch.Size([120]) || stage2.residual_group2.blocks.0.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage2.residual_group2.blocks.0.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage2.residual_group2.blocks.0.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage2.residual_group2.blocks.0.mlp.fc11.weight
+ | -0.002 | -0.090 | 0.091 | 0.053 | torch.Size([240]) || stage2.residual_group2.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage2.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.002 | -0.091 | 0.090 | 0.052 | torch.Size([240]) || stage2.residual_group2.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage2.residual_group2.blocks.0.mlp.fc2.weight
+ | 0.000 | -0.062 | 0.064 | 0.037 | torch.Size([120]) || stage2.residual_group2.blocks.0.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage2.residual_group2.blocks.1.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage2.residual_group2.blocks.1.norm1.bias
+ | 0.000 | -0.077 | 0.080 | 0.020 | torch.Size([2475, 6]) || stage2.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage2.residual_group2.blocks.1.attn.relative_position_index
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage2.residual_group2.blocks.1.attn.qkv_self.weight
+ | 0.002 | -0.091 | 0.090 | 0.053 | torch.Size([360]) || stage2.residual_group2.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage2.residual_group2.blocks.1.attn.proj.weight
+ | 0.013 | -0.088 | 0.090 | 0.051 | torch.Size([120]) || stage2.residual_group2.blocks.1.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage2.residual_group2.blocks.1.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage2.residual_group2.blocks.1.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage2.residual_group2.blocks.1.mlp.fc11.weight
+ | -0.002 | -0.090 | 0.091 | 0.051 | torch.Size([240]) || stage2.residual_group2.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage2.residual_group2.blocks.1.mlp.fc12.weight
+ | 0.004 | -0.091 | 0.091 | 0.055 | torch.Size([240]) || stage2.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage2.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.005 | -0.063 | 0.063 | 0.038 | torch.Size([120]) || stage2.residual_group2.blocks.1.mlp.fc2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage2.linear2.weight
+ | -0.000 | -0.088 | 0.090 | 0.053 | torch.Size([120]) || stage2.linear2.bias
+ | 0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage2.pa_deform.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage2.pa_deform.bias
+ | -0.000 | -0.021 | 0.021 | 0.012 | torch.Size([120, 242, 3, 3]) || stage2.pa_deform.conv_offset.0.weight
+ | 0.002 | -0.021 | 0.021 | 0.012 | torch.Size([120]) || stage2.pa_deform.conv_offset.0.bias
+ | 0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage2.pa_deform.conv_offset.2.weight
+ | 0.001 | -0.030 | 0.030 | 0.018 | torch.Size([120]) || stage2.pa_deform.conv_offset.2.bias
+ | -0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage2.pa_deform.conv_offset.4.weight
+ | 0.002 | -0.027 | 0.030 | 0.016 | torch.Size([120]) || stage2.pa_deform.conv_offset.4.bias
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([324, 120, 3, 3]) || stage2.pa_deform.conv_offset.6.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([324]) || stage2.pa_deform.conv_offset.6.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([360, 360]) || stage2.pa_fuse.fc11.weight
+ | 0.002 | -0.053 | 0.053 | 0.031 | torch.Size([360]) || stage2.pa_fuse.fc11.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([360, 360]) || stage2.pa_fuse.fc12.weight
+ | -0.001 | -0.053 | 0.052 | 0.030 | torch.Size([360]) || stage2.pa_fuse.fc12.bias
+ | 0.000 | -0.053 | 0.053 | 0.031 | torch.Size([120, 360]) || stage2.pa_fuse.fc2.weight
+ | -0.002 | -0.052 | 0.052 | 0.030 | torch.Size([120]) || stage2.pa_fuse.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([480]) || stage3.reshape.1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([480]) || stage3.reshape.1.bias
+ | 0.000 | -0.046 | 0.046 | 0.026 | torch.Size([120, 480]) || stage3.reshape.2.weight
+ | 0.001 | -0.045 | 0.045 | 0.027 | torch.Size([120]) || stage3.reshape.2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.0.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.0.norm1.bias
+ | 0.000 | -0.072 | 0.071 | 0.020 | torch.Size([675, 6]) || stage3.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.0.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage3.residual_group1.blocks.0.attn.qkv_self.weight
+ | 0.003 | -0.091 | 0.090 | 0.052 | torch.Size([360]) || stage3.residual_group1.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage3.residual_group1.blocks.0.attn.proj.weight
+ | -0.001 | -0.064 | 0.064 | 0.035 | torch.Size([120]) || stage3.residual_group1.blocks.0.attn.proj.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage3.residual_group1.blocks.0.attn.qkv_mut.weight
+ | 0.001 | -0.091 | 0.091 | 0.053 | torch.Size([360]) || stage3.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.0.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.0.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage3.residual_group1.blocks.0.mlp.fc11.weight
+ | 0.001 | -0.090 | 0.091 | 0.052 | torch.Size([240]) || stage3.residual_group1.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage3.residual_group1.blocks.0.mlp.fc12.weight
+ | 0.002 | -0.091 | 0.091 | 0.053 | torch.Size([240]) || stage3.residual_group1.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage3.residual_group1.blocks.0.mlp.fc2.weight
+ | 0.001 | -0.064 | 0.064 | 0.035 | torch.Size([120]) || stage3.residual_group1.blocks.0.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.1.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.1.norm1.bias
+ | -0.000 | -0.071 | 0.070 | 0.020 | torch.Size([675, 6]) || stage3.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.1.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage3.residual_group1.blocks.1.attn.qkv_self.weight
+ | 0.001 | -0.090 | 0.091 | 0.051 | torch.Size([360]) || stage3.residual_group1.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage3.residual_group1.blocks.1.attn.proj.weight
+ | 0.003 | -0.060 | 0.064 | 0.035 | torch.Size([120]) || stage3.residual_group1.blocks.1.attn.proj.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage3.residual_group1.blocks.1.attn.qkv_mut.weight
+ | -0.001 | -0.091 | 0.091 | 0.054 | torch.Size([360]) || stage3.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.1.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.1.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage3.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.004 | -0.091 | 0.091 | 0.054 | torch.Size([240]) || stage3.residual_group1.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage3.residual_group1.blocks.1.mlp.fc12.weight
+ | -0.000 | -0.090 | 0.089 | 0.053 | torch.Size([240]) || stage3.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage3.residual_group1.blocks.1.mlp.fc2.weight
+ | -0.002 | -0.064 | 0.064 | 0.037 | torch.Size([120]) || stage3.residual_group1.blocks.1.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.2.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.2.norm1.bias
+ | -0.000 | -0.076 | 0.074 | 0.020 | torch.Size([675, 6]) || stage3.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.2.attn.position_bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage3.residual_group1.blocks.2.attn.qkv_self.weight
+ | 0.005 | -0.091 | 0.091 | 0.054 | torch.Size([360]) || stage3.residual_group1.blocks.2.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage3.residual_group1.blocks.2.attn.proj.weight
+ | 0.001 | -0.064 | 0.064 | 0.037 | torch.Size([120]) || stage3.residual_group1.blocks.2.attn.proj.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage3.residual_group1.blocks.2.attn.qkv_mut.weight
+ | 0.001 | -0.091 | 0.091 | 0.051 | torch.Size([360]) || stage3.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.2.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.2.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage3.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.003 | -0.091 | 0.091 | 0.054 | torch.Size([240]) || stage3.residual_group1.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage3.residual_group1.blocks.2.mlp.fc12.weight
+ | 0.007 | -0.090 | 0.090 | 0.053 | torch.Size([240]) || stage3.residual_group1.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage3.residual_group1.blocks.2.mlp.fc2.weight
+ | -0.002 | -0.062 | 0.064 | 0.038 | torch.Size([120]) || stage3.residual_group1.blocks.2.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.3.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.3.norm1.bias
+ | -0.000 | -0.073 | 0.065 | 0.020 | torch.Size([675, 6]) || stage3.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.3.attn.position_bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage3.residual_group1.blocks.3.attn.qkv_self.weight
+ | 0.006 | -0.091 | 0.091 | 0.054 | torch.Size([360]) || stage3.residual_group1.blocks.3.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage3.residual_group1.blocks.3.attn.proj.weight
+ | 0.002 | -0.063 | 0.063 | 0.035 | torch.Size([120]) || stage3.residual_group1.blocks.3.attn.proj.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage3.residual_group1.blocks.3.attn.qkv_mut.weight
+ | 0.003 | -0.091 | 0.091 | 0.054 | torch.Size([360]) || stage3.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.3.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.3.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage3.residual_group1.blocks.3.mlp.fc11.weight
+ | 0.002 | -0.091 | 0.088 | 0.051 | torch.Size([240]) || stage3.residual_group1.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage3.residual_group1.blocks.3.mlp.fc12.weight
+ | -0.002 | -0.091 | 0.090 | 0.051 | torch.Size([240]) || stage3.residual_group1.blocks.3.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage3.residual_group1.blocks.3.mlp.fc2.weight
+ | -0.001 | -0.065 | 0.064 | 0.040 | torch.Size([120]) || stage3.residual_group1.blocks.3.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.4.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.4.norm1.bias
+ | -0.000 | -0.080 | 0.063 | 0.020 | torch.Size([675, 6]) || stage3.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.4.attn.position_bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage3.residual_group1.blocks.4.attn.qkv_self.weight
+ | -0.001 | -0.091 | 0.091 | 0.053 | torch.Size([360]) || stage3.residual_group1.blocks.4.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage3.residual_group1.blocks.4.attn.proj.weight
+ | 0.001 | -0.064 | 0.062 | 0.040 | torch.Size([120]) || stage3.residual_group1.blocks.4.attn.proj.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage3.residual_group1.blocks.4.attn.qkv_mut.weight
+ | 0.001 | -0.091 | 0.091 | 0.053 | torch.Size([360]) || stage3.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.4.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.4.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage3.residual_group1.blocks.4.mlp.fc11.weight
+ | -0.007 | -0.090 | 0.091 | 0.054 | torch.Size([240]) || stage3.residual_group1.blocks.4.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage3.residual_group1.blocks.4.mlp.fc12.weight
+ | 0.004 | -0.091 | 0.089 | 0.052 | torch.Size([240]) || stage3.residual_group1.blocks.4.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage3.residual_group1.blocks.4.mlp.fc2.weight
+ | -0.001 | -0.062 | 0.063 | 0.036 | torch.Size([120]) || stage3.residual_group1.blocks.4.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.5.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.5.norm1.bias
+ | -0.000 | -0.069 | 0.079 | 0.020 | torch.Size([675, 6]) || stage3.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.5.attn.position_bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage3.residual_group1.blocks.5.attn.qkv_self.weight
+ | -0.004 | -0.091 | 0.091 | 0.054 | torch.Size([360]) || stage3.residual_group1.blocks.5.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage3.residual_group1.blocks.5.attn.proj.weight
+ | 0.005 | -0.064 | 0.064 | 0.036 | torch.Size([120]) || stage3.residual_group1.blocks.5.attn.proj.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage3.residual_group1.blocks.5.attn.qkv_mut.weight
+ | -0.002 | -0.090 | 0.091 | 0.053 | torch.Size([360]) || stage3.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.5.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.5.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage3.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.005 | -0.090 | 0.090 | 0.055 | torch.Size([240]) || stage3.residual_group1.blocks.5.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.052 | torch.Size([240, 120]) || stage3.residual_group1.blocks.5.mlp.fc12.weight
+ | -0.000 | -0.091 | 0.089 | 0.053 | torch.Size([240]) || stage3.residual_group1.blocks.5.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage3.residual_group1.blocks.5.mlp.fc2.weight
+ | 0.004 | -0.064 | 0.064 | 0.040 | torch.Size([120]) || stage3.residual_group1.blocks.5.mlp.fc2.bias
+ | 0.000 | -0.091 | 0.091 | 0.052 | torch.Size([120, 120]) || stage3.linear1.weight
+ | 0.003 | -0.091 | 0.091 | 0.054 | torch.Size([120]) || stage3.linear1.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage3.residual_group2.blocks.0.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage3.residual_group2.blocks.0.norm1.bias
+ | -0.000 | -0.077 | 0.075 | 0.020 | torch.Size([2475, 6]) || stage3.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage3.residual_group2.blocks.0.attn.relative_position_index
+ | 0.001 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage3.residual_group2.blocks.0.attn.qkv_self.weight
+ | -0.001 | -0.091 | 0.091 | 0.054 | torch.Size([360]) || stage3.residual_group2.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage3.residual_group2.blocks.0.attn.proj.weight
+ | -0.011 | -0.091 | 0.091 | 0.053 | torch.Size([120]) || stage3.residual_group2.blocks.0.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage3.residual_group2.blocks.0.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage3.residual_group2.blocks.0.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage3.residual_group2.blocks.0.mlp.fc11.weight
+ | -0.008 | -0.091 | 0.089 | 0.052 | torch.Size([240]) || stage3.residual_group2.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.052 | torch.Size([240, 120]) || stage3.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.004 | -0.090 | 0.090 | 0.053 | torch.Size([240]) || stage3.residual_group2.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage3.residual_group2.blocks.0.mlp.fc2.weight
+ | -0.002 | -0.063 | 0.064 | 0.039 | torch.Size([120]) || stage3.residual_group2.blocks.0.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage3.residual_group2.blocks.1.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage3.residual_group2.blocks.1.norm1.bias
+ | -0.000 | -0.088 | 0.080 | 0.020 | torch.Size([2475, 6]) || stage3.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage3.residual_group2.blocks.1.attn.relative_position_index
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage3.residual_group2.blocks.1.attn.qkv_self.weight
+ | -0.002 | -0.091 | 0.091 | 0.054 | torch.Size([360]) || stage3.residual_group2.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage3.residual_group2.blocks.1.attn.proj.weight
+ | -0.003 | -0.091 | 0.089 | 0.054 | torch.Size([120]) || stage3.residual_group2.blocks.1.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage3.residual_group2.blocks.1.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage3.residual_group2.blocks.1.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage3.residual_group2.blocks.1.mlp.fc11.weight
+ | -0.000 | -0.090 | 0.090 | 0.054 | torch.Size([240]) || stage3.residual_group2.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage3.residual_group2.blocks.1.mlp.fc12.weight
+ | 0.002 | -0.089 | 0.091 | 0.051 | torch.Size([240]) || stage3.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage3.residual_group2.blocks.1.mlp.fc2.weight
+ | 0.002 | -0.061 | 0.062 | 0.034 | torch.Size([120]) || stage3.residual_group2.blocks.1.mlp.fc2.bias
+ | -0.001 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage3.linear2.weight
+ | 0.002 | -0.089 | 0.091 | 0.048 | torch.Size([120]) || stage3.linear2.bias
+ | 0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage3.pa_deform.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage3.pa_deform.bias
+ | 0.000 | -0.021 | 0.021 | 0.012 | torch.Size([120, 242, 3, 3]) || stage3.pa_deform.conv_offset.0.weight
+ | 0.000 | -0.021 | 0.021 | 0.011 | torch.Size([120]) || stage3.pa_deform.conv_offset.0.bias
+ | 0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage3.pa_deform.conv_offset.2.weight
+ | -0.002 | -0.030 | 0.030 | 0.017 | torch.Size([120]) || stage3.pa_deform.conv_offset.2.bias
+ | 0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage3.pa_deform.conv_offset.4.weight
+ | -0.001 | -0.030 | 0.030 | 0.018 | torch.Size([120]) || stage3.pa_deform.conv_offset.4.bias
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([324, 120, 3, 3]) || stage3.pa_deform.conv_offset.6.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([324]) || stage3.pa_deform.conv_offset.6.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([360, 360]) || stage3.pa_fuse.fc11.weight
+ | -0.002 | -0.053 | 0.053 | 0.029 | torch.Size([360]) || stage3.pa_fuse.fc11.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([360, 360]) || stage3.pa_fuse.fc12.weight
+ | 0.005 | -0.053 | 0.052 | 0.030 | torch.Size([360]) || stage3.pa_fuse.fc12.bias
+ | 0.000 | -0.053 | 0.053 | 0.030 | torch.Size([120, 360]) || stage3.pa_fuse.fc2.weight
+ | 0.007 | -0.052 | 0.053 | 0.029 | torch.Size([120]) || stage3.pa_fuse.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([480]) || stage4.reshape.1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([480]) || stage4.reshape.1.bias
+ | -0.000 | -0.046 | 0.046 | 0.026 | torch.Size([120, 480]) || stage4.reshape.2.weight
+ | -0.002 | -0.046 | 0.045 | 0.027 | torch.Size([120]) || stage4.reshape.2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.0.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.0.norm1.bias
+ | 0.000 | -0.065 | 0.070 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.0.attn.position_bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage4.residual_group1.blocks.0.attn.qkv_self.weight
+ | -0.003 | -0.091 | 0.091 | 0.054 | torch.Size([360]) || stage4.residual_group1.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage4.residual_group1.blocks.0.attn.proj.weight
+ | -0.002 | -0.064 | 0.064 | 0.039 | torch.Size([120]) || stage4.residual_group1.blocks.0.attn.proj.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage4.residual_group1.blocks.0.attn.qkv_mut.weight
+ | -0.004 | -0.091 | 0.090 | 0.055 | torch.Size([360]) || stage4.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.0.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.0.norm2.bias
+ | 0.001 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage4.residual_group1.blocks.0.mlp.fc11.weight
+ | 0.004 | -0.091 | 0.090 | 0.053 | torch.Size([240]) || stage4.residual_group1.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage4.residual_group1.blocks.0.mlp.fc12.weight
+ | -0.000 | -0.091 | 0.090 | 0.053 | torch.Size([240]) || stage4.residual_group1.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage4.residual_group1.blocks.0.mlp.fc2.weight
+ | 0.001 | -0.064 | 0.064 | 0.039 | torch.Size([120]) || stage4.residual_group1.blocks.0.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.1.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.1.norm1.bias
+ | 0.000 | -0.073 | 0.086 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.1.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage4.residual_group1.blocks.1.attn.qkv_self.weight
+ | -0.001 | -0.091 | 0.091 | 0.051 | torch.Size([360]) || stage4.residual_group1.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage4.residual_group1.blocks.1.attn.proj.weight
+ | 0.003 | -0.065 | 0.063 | 0.038 | torch.Size([120]) || stage4.residual_group1.blocks.1.attn.proj.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage4.residual_group1.blocks.1.attn.qkv_mut.weight
+ | -0.004 | -0.091 | 0.091 | 0.053 | torch.Size([360]) || stage4.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.1.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.1.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage4.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.003 | -0.091 | 0.089 | 0.051 | torch.Size([240]) || stage4.residual_group1.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage4.residual_group1.blocks.1.mlp.fc12.weight
+ | -0.001 | -0.091 | 0.089 | 0.053 | torch.Size([240]) || stage4.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage4.residual_group1.blocks.1.mlp.fc2.weight
+ | -0.004 | -0.064 | 0.063 | 0.037 | torch.Size([120]) || stage4.residual_group1.blocks.1.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.2.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.2.norm1.bias
+ | 0.000 | -0.064 | 0.069 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.2.attn.position_bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage4.residual_group1.blocks.2.attn.qkv_self.weight
+ | 0.002 | -0.091 | 0.091 | 0.054 | torch.Size([360]) || stage4.residual_group1.blocks.2.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage4.residual_group1.blocks.2.attn.proj.weight
+ | -0.004 | -0.063 | 0.064 | 0.038 | torch.Size([120]) || stage4.residual_group1.blocks.2.attn.proj.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage4.residual_group1.blocks.2.attn.qkv_mut.weight
+ | -0.002 | -0.091 | 0.091 | 0.053 | torch.Size([360]) || stage4.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.2.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.2.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage4.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.006 | -0.090 | 0.091 | 0.054 | torch.Size([240]) || stage4.residual_group1.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage4.residual_group1.blocks.2.mlp.fc12.weight
+ | 0.004 | -0.091 | 0.091 | 0.052 | torch.Size([240]) || stage4.residual_group1.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage4.residual_group1.blocks.2.mlp.fc2.weight
+ | 0.003 | -0.065 | 0.064 | 0.038 | torch.Size([120]) || stage4.residual_group1.blocks.2.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.3.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.3.norm1.bias
+ | -0.000 | -0.067 | 0.074 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.3.attn.position_bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage4.residual_group1.blocks.3.attn.qkv_self.weight
+ | -0.001 | -0.091 | 0.091 | 0.052 | torch.Size([360]) || stage4.residual_group1.blocks.3.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage4.residual_group1.blocks.3.attn.proj.weight
+ | 0.002 | -0.064 | 0.064 | 0.042 | torch.Size([120]) || stage4.residual_group1.blocks.3.attn.proj.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage4.residual_group1.blocks.3.attn.qkv_mut.weight
+ | 0.001 | -0.090 | 0.091 | 0.051 | torch.Size([360]) || stage4.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.3.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.3.norm2.bias
+ | -0.001 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage4.residual_group1.blocks.3.mlp.fc11.weight
+ | 0.001 | -0.091 | 0.091 | 0.051 | torch.Size([240]) || stage4.residual_group1.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage4.residual_group1.blocks.3.mlp.fc12.weight
+ | -0.001 | -0.089 | 0.091 | 0.052 | torch.Size([240]) || stage4.residual_group1.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage4.residual_group1.blocks.3.mlp.fc2.weight
+ | 0.006 | -0.064 | 0.064 | 0.036 | torch.Size([120]) || stage4.residual_group1.blocks.3.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.4.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.4.norm1.bias
+ | 0.000 | -0.074 | 0.077 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.4.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage4.residual_group1.blocks.4.attn.qkv_self.weight
+ | -0.004 | -0.090 | 0.091 | 0.053 | torch.Size([360]) || stage4.residual_group1.blocks.4.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage4.residual_group1.blocks.4.attn.proj.weight
+ | -0.003 | -0.061 | 0.064 | 0.038 | torch.Size([120]) || stage4.residual_group1.blocks.4.attn.proj.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage4.residual_group1.blocks.4.attn.qkv_mut.weight
+ | 0.003 | -0.091 | 0.091 | 0.052 | torch.Size([360]) || stage4.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.4.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.4.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage4.residual_group1.blocks.4.mlp.fc11.weight
+ | 0.000 | -0.090 | 0.089 | 0.050 | torch.Size([240]) || stage4.residual_group1.blocks.4.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage4.residual_group1.blocks.4.mlp.fc12.weight
+ | -0.001 | -0.091 | 0.090 | 0.052 | torch.Size([240]) || stage4.residual_group1.blocks.4.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage4.residual_group1.blocks.4.mlp.fc2.weight
+ | -0.002 | -0.065 | 0.063 | 0.035 | torch.Size([120]) || stage4.residual_group1.blocks.4.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.5.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.5.norm1.bias
+ | 0.000 | -0.076 | 0.074 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.5.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage4.residual_group1.blocks.5.attn.qkv_self.weight
+ | -0.000 | -0.091 | 0.091 | 0.051 | torch.Size([360]) || stage4.residual_group1.blocks.5.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage4.residual_group1.blocks.5.attn.proj.weight
+ | -0.001 | -0.063 | 0.064 | 0.036 | torch.Size([120]) || stage4.residual_group1.blocks.5.attn.proj.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage4.residual_group1.blocks.5.attn.qkv_mut.weight
+ | 0.001 | -0.091 | 0.091 | 0.051 | torch.Size([360]) || stage4.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.5.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.5.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage4.residual_group1.blocks.5.mlp.fc11.weight
+ | 0.001 | -0.091 | 0.089 | 0.052 | torch.Size([240]) || stage4.residual_group1.blocks.5.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage4.residual_group1.blocks.5.mlp.fc12.weight
+ | 0.004 | -0.091 | 0.091 | 0.051 | torch.Size([240]) || stage4.residual_group1.blocks.5.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage4.residual_group1.blocks.5.mlp.fc2.weight
+ | 0.001 | -0.064 | 0.064 | 0.035 | torch.Size([120]) || stage4.residual_group1.blocks.5.mlp.fc2.bias
+ | -0.001 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage4.linear1.weight
+ | 0.005 | -0.091 | 0.091 | 0.053 | torch.Size([120]) || stage4.linear1.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group2.blocks.0.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group2.blocks.0.norm1.bias
+ | -0.000 | -0.066 | 0.086 | 0.020 | torch.Size([2475, 6]) || stage4.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage4.residual_group2.blocks.0.attn.relative_position_index
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage4.residual_group2.blocks.0.attn.qkv_self.weight
+ | -0.001 | -0.091 | 0.091 | 0.054 | torch.Size([360]) || stage4.residual_group2.blocks.0.attn.qkv_self.bias
+ | -0.001 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage4.residual_group2.blocks.0.attn.proj.weight
+ | -0.005 | -0.089 | 0.084 | 0.053 | torch.Size([120]) || stage4.residual_group2.blocks.0.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group2.blocks.0.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group2.blocks.0.norm2.bias
+ | -0.001 | -0.091 | 0.091 | 0.052 | torch.Size([240, 120]) || stage4.residual_group2.blocks.0.mlp.fc11.weight
+ | -0.003 | -0.090 | 0.090 | 0.051 | torch.Size([240]) || stage4.residual_group2.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage4.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.006 | -0.090 | 0.089 | 0.054 | torch.Size([240]) || stage4.residual_group2.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage4.residual_group2.blocks.0.mlp.fc2.weight
+ | -0.003 | -0.064 | 0.062 | 0.037 | torch.Size([120]) || stage4.residual_group2.blocks.0.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group2.blocks.1.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group2.blocks.1.norm1.bias
+ | -0.000 | -0.074 | 0.082 | 0.020 | torch.Size([2475, 6]) || stage4.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage4.residual_group2.blocks.1.attn.relative_position_index
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage4.residual_group2.blocks.1.attn.qkv_self.weight
+ | 0.004 | -0.091 | 0.091 | 0.054 | torch.Size([360]) || stage4.residual_group2.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage4.residual_group2.blocks.1.attn.proj.weight
+ | 0.000 | -0.091 | 0.091 | 0.055 | torch.Size([120]) || stage4.residual_group2.blocks.1.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group2.blocks.1.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group2.blocks.1.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage4.residual_group2.blocks.1.mlp.fc11.weight
+ | 0.001 | -0.091 | 0.090 | 0.056 | torch.Size([240]) || stage4.residual_group2.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage4.residual_group2.blocks.1.mlp.fc12.weight
+ | -0.002 | -0.090 | 0.091 | 0.052 | torch.Size([240]) || stage4.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage4.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.004 | -0.064 | 0.062 | 0.036 | torch.Size([120]) || stage4.residual_group2.blocks.1.mlp.fc2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage4.linear2.weight
+ | 0.006 | -0.091 | 0.090 | 0.057 | torch.Size([120]) || stage4.linear2.bias
+ | 0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage4.pa_deform.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.pa_deform.bias
+ | -0.000 | -0.021 | 0.021 | 0.012 | torch.Size([120, 242, 3, 3]) || stage4.pa_deform.conv_offset.0.weight
+ | -0.000 | -0.020 | 0.021 | 0.011 | torch.Size([120]) || stage4.pa_deform.conv_offset.0.bias
+ | 0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage4.pa_deform.conv_offset.2.weight
+ | -0.003 | -0.030 | 0.030 | 0.018 | torch.Size([120]) || stage4.pa_deform.conv_offset.2.bias
+ | 0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage4.pa_deform.conv_offset.4.weight
+ | -0.001 | -0.030 | 0.030 | 0.017 | torch.Size([120]) || stage4.pa_deform.conv_offset.4.bias
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([324, 120, 3, 3]) || stage4.pa_deform.conv_offset.6.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([324]) || stage4.pa_deform.conv_offset.6.bias
+ | 0.000 | -0.053 | 0.053 | 0.030 | torch.Size([360, 360]) || stage4.pa_fuse.fc11.weight
+ | 0.000 | -0.052 | 0.053 | 0.029 | torch.Size([360]) || stage4.pa_fuse.fc11.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([360, 360]) || stage4.pa_fuse.fc12.weight
+ | -0.001 | -0.052 | 0.053 | 0.029 | torch.Size([360]) || stage4.pa_fuse.fc12.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([120, 360]) || stage4.pa_fuse.fc2.weight
+ | -0.002 | -0.053 | 0.051 | 0.029 | torch.Size([120]) || stage4.pa_fuse.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([30]) || stage5.reshape.1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([30]) || stage5.reshape.1.bias
+ | -0.002 | -0.183 | 0.182 | 0.105 | torch.Size([120, 30]) || stage5.reshape.2.weight
+ | 0.014 | -0.182 | 0.181 | 0.113 | torch.Size([120]) || stage5.reshape.2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.0.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.0.norm1.bias
+ | -0.000 | -0.073 | 0.066 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.0.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage5.residual_group1.blocks.0.attn.qkv_self.weight
+ | -0.001 | -0.090 | 0.090 | 0.050 | torch.Size([360]) || stage5.residual_group1.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage5.residual_group1.blocks.0.attn.proj.weight
+ | 0.006 | -0.062 | 0.064 | 0.039 | torch.Size([120]) || stage5.residual_group1.blocks.0.attn.proj.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage5.residual_group1.blocks.0.attn.qkv_mut.weight
+ | -0.001 | -0.091 | 0.091 | 0.054 | torch.Size([360]) || stage5.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.0.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.0.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage5.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.001 | -0.091 | 0.090 | 0.052 | torch.Size([240]) || stage5.residual_group1.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage5.residual_group1.blocks.0.mlp.fc12.weight
+ | 0.004 | -0.091 | 0.091 | 0.053 | torch.Size([240]) || stage5.residual_group1.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage5.residual_group1.blocks.0.mlp.fc2.weight
+ | 0.002 | -0.064 | 0.063 | 0.039 | torch.Size([120]) || stage5.residual_group1.blocks.0.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.1.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.1.norm1.bias
+ | 0.000 | -0.073 | 0.082 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.1.attn.position_bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage5.residual_group1.blocks.1.attn.qkv_self.weight
+ | -0.001 | -0.091 | 0.091 | 0.052 | torch.Size([360]) || stage5.residual_group1.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage5.residual_group1.blocks.1.attn.proj.weight
+ | 0.002 | -0.064 | 0.064 | 0.038 | torch.Size([120]) || stage5.residual_group1.blocks.1.attn.proj.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage5.residual_group1.blocks.1.attn.qkv_mut.weight
+ | 0.001 | -0.090 | 0.091 | 0.053 | torch.Size([360]) || stage5.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.1.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.1.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage5.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.003 | -0.090 | 0.090 | 0.053 | torch.Size([240]) || stage5.residual_group1.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage5.residual_group1.blocks.1.mlp.fc12.weight
+ | -0.001 | -0.091 | 0.091 | 0.051 | torch.Size([240]) || stage5.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage5.residual_group1.blocks.1.mlp.fc2.weight
+ | -0.000 | -0.063 | 0.062 | 0.036 | torch.Size([120]) || stage5.residual_group1.blocks.1.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.2.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.2.norm1.bias
+ | -0.000 | -0.086 | 0.069 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.2.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage5.residual_group1.blocks.2.attn.qkv_self.weight
+ | -0.004 | -0.091 | 0.091 | 0.053 | torch.Size([360]) || stage5.residual_group1.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage5.residual_group1.blocks.2.attn.proj.weight
+ | 0.004 | -0.063 | 0.064 | 0.040 | torch.Size([120]) || stage5.residual_group1.blocks.2.attn.proj.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage5.residual_group1.blocks.2.attn.qkv_mut.weight
+ | -0.004 | -0.091 | 0.090 | 0.053 | torch.Size([360]) || stage5.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.2.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.2.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage5.residual_group1.blocks.2.mlp.fc11.weight
+ | 0.005 | -0.091 | 0.090 | 0.054 | torch.Size([240]) || stage5.residual_group1.blocks.2.mlp.fc11.bias
+ | 0.001 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage5.residual_group1.blocks.2.mlp.fc12.weight
+ | 0.001 | -0.091 | 0.091 | 0.054 | torch.Size([240]) || stage5.residual_group1.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage5.residual_group1.blocks.2.mlp.fc2.weight
+ | 0.000 | -0.064 | 0.063 | 0.039 | torch.Size([120]) || stage5.residual_group1.blocks.2.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.3.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.3.norm1.bias
+ | 0.000 | -0.070 | 0.068 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.3.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage5.residual_group1.blocks.3.attn.qkv_self.weight
+ | -0.003 | -0.090 | 0.091 | 0.052 | torch.Size([360]) || stage5.residual_group1.blocks.3.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage5.residual_group1.blocks.3.attn.proj.weight
+ | 0.003 | -0.063 | 0.064 | 0.038 | torch.Size([120]) || stage5.residual_group1.blocks.3.attn.proj.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage5.residual_group1.blocks.3.attn.qkv_mut.weight
+ | 0.001 | -0.091 | 0.091 | 0.055 | torch.Size([360]) || stage5.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.3.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.3.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage5.residual_group1.blocks.3.mlp.fc11.weight
+ | 0.002 | -0.091 | 0.091 | 0.049 | torch.Size([240]) || stage5.residual_group1.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage5.residual_group1.blocks.3.mlp.fc12.weight
+ | 0.001 | -0.091 | 0.091 | 0.052 | torch.Size([240]) || stage5.residual_group1.blocks.3.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage5.residual_group1.blocks.3.mlp.fc2.weight
+ | 0.001 | -0.064 | 0.064 | 0.039 | torch.Size([120]) || stage5.residual_group1.blocks.3.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.4.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.4.norm1.bias
+ | -0.000 | -0.068 | 0.077 | 0.019 | torch.Size([675, 6]) || stage5.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.4.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.052 | torch.Size([360, 120]) || stage5.residual_group1.blocks.4.attn.qkv_self.weight
+ | -0.001 | -0.091 | 0.091 | 0.054 | torch.Size([360]) || stage5.residual_group1.blocks.4.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage5.residual_group1.blocks.4.attn.proj.weight
+ | -0.003 | -0.063 | 0.064 | 0.039 | torch.Size([120]) || stage5.residual_group1.blocks.4.attn.proj.bias
+ | 0.001 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage5.residual_group1.blocks.4.attn.qkv_mut.weight
+ | 0.003 | -0.091 | 0.091 | 0.054 | torch.Size([360]) || stage5.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.4.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.4.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage5.residual_group1.blocks.4.mlp.fc11.weight
+ | -0.002 | -0.091 | 0.091 | 0.053 | torch.Size([240]) || stage5.residual_group1.blocks.4.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage5.residual_group1.blocks.4.mlp.fc12.weight
+ | 0.002 | -0.091 | 0.091 | 0.053 | torch.Size([240]) || stage5.residual_group1.blocks.4.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage5.residual_group1.blocks.4.mlp.fc2.weight
+ | 0.001 | -0.063 | 0.063 | 0.040 | torch.Size([120]) || stage5.residual_group1.blocks.4.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.5.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.5.norm1.bias
+ | 0.000 | -0.068 | 0.075 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.5.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage5.residual_group1.blocks.5.attn.qkv_self.weight
+ | -0.003 | -0.090 | 0.091 | 0.053 | torch.Size([360]) || stage5.residual_group1.blocks.5.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage5.residual_group1.blocks.5.attn.proj.weight
+ | 0.001 | -0.063 | 0.063 | 0.034 | torch.Size([120]) || stage5.residual_group1.blocks.5.attn.proj.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage5.residual_group1.blocks.5.attn.qkv_mut.weight
+ | 0.002 | -0.090 | 0.091 | 0.053 | torch.Size([360]) || stage5.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.5.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.5.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage5.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.002 | -0.091 | 0.091 | 0.051 | torch.Size([240]) || stage5.residual_group1.blocks.5.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage5.residual_group1.blocks.5.mlp.fc12.weight
+ | -0.001 | -0.091 | 0.091 | 0.057 | torch.Size([240]) || stage5.residual_group1.blocks.5.mlp.fc12.bias
+ | -0.001 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage5.residual_group1.blocks.5.mlp.fc2.weight
+ | -0.003 | -0.064 | 0.061 | 0.038 | torch.Size([120]) || stage5.residual_group1.blocks.5.mlp.fc2.bias
+ | 0.001 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage5.linear1.weight
+ | 0.002 | -0.089 | 0.091 | 0.052 | torch.Size([120]) || stage5.linear1.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage5.residual_group2.blocks.0.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage5.residual_group2.blocks.0.norm1.bias
+ | -0.000 | -0.079 | 0.089 | 0.020 | torch.Size([2475, 6]) || stage5.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage5.residual_group2.blocks.0.attn.relative_position_index
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage5.residual_group2.blocks.0.attn.qkv_self.weight
+ | 0.002 | -0.090 | 0.090 | 0.049 | torch.Size([360]) || stage5.residual_group2.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage5.residual_group2.blocks.0.attn.proj.weight
+ | 0.000 | -0.091 | 0.090 | 0.049 | torch.Size([120]) || stage5.residual_group2.blocks.0.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage5.residual_group2.blocks.0.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage5.residual_group2.blocks.0.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage5.residual_group2.blocks.0.mlp.fc11.weight
+ | 0.000 | -0.091 | 0.089 | 0.056 | torch.Size([240]) || stage5.residual_group2.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage5.residual_group2.blocks.0.mlp.fc12.weight
+ | 0.003 | -0.091 | 0.091 | 0.055 | torch.Size([240]) || stage5.residual_group2.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage5.residual_group2.blocks.0.mlp.fc2.weight
+ | -0.006 | -0.062 | 0.062 | 0.036 | torch.Size([120]) || stage5.residual_group2.blocks.0.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage5.residual_group2.blocks.1.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage5.residual_group2.blocks.1.norm1.bias
+ | 0.000 | -0.077 | 0.082 | 0.020 | torch.Size([2475, 6]) || stage5.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage5.residual_group2.blocks.1.attn.relative_position_index
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage5.residual_group2.blocks.1.attn.qkv_self.weight
+ | -0.001 | -0.090 | 0.091 | 0.053 | torch.Size([360]) || stage5.residual_group2.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage5.residual_group2.blocks.1.attn.proj.weight
+ | -0.007 | -0.090 | 0.091 | 0.054 | torch.Size([120]) || stage5.residual_group2.blocks.1.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage5.residual_group2.blocks.1.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage5.residual_group2.blocks.1.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage5.residual_group2.blocks.1.mlp.fc11.weight
+ | 0.005 | -0.091 | 0.091 | 0.054 | torch.Size([240]) || stage5.residual_group2.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.052 | torch.Size([240, 120]) || stage5.residual_group2.blocks.1.mlp.fc12.weight
+ | -0.007 | -0.091 | 0.090 | 0.051 | torch.Size([240]) || stage5.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage5.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.001 | -0.064 | 0.062 | 0.037 | torch.Size([120]) || stage5.residual_group2.blocks.1.mlp.fc2.bias
+ | -0.001 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage5.linear2.weight
+ | 0.006 | -0.089 | 0.091 | 0.053 | torch.Size([120]) || stage5.linear2.bias
+ | -0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage5.pa_deform.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage5.pa_deform.bias
+ | 0.000 | -0.021 | 0.021 | 0.012 | torch.Size([120, 242, 3, 3]) || stage5.pa_deform.conv_offset.0.weight
+ | -0.002 | -0.021 | 0.021 | 0.013 | torch.Size([120]) || stage5.pa_deform.conv_offset.0.bias
+ | 0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage5.pa_deform.conv_offset.2.weight
+ | -0.002 | -0.030 | 0.029 | 0.017 | torch.Size([120]) || stage5.pa_deform.conv_offset.2.bias
+ | -0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage5.pa_deform.conv_offset.4.weight
+ | -0.003 | -0.029 | 0.030 | 0.017 | torch.Size([120]) || stage5.pa_deform.conv_offset.4.bias
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([324, 120, 3, 3]) || stage5.pa_deform.conv_offset.6.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([324]) || stage5.pa_deform.conv_offset.6.bias
+ | 0.000 | -0.053 | 0.053 | 0.030 | torch.Size([360, 360]) || stage5.pa_fuse.fc11.weight
+ | 0.002 | -0.052 | 0.052 | 0.030 | torch.Size([360]) || stage5.pa_fuse.fc11.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([360, 360]) || stage5.pa_fuse.fc12.weight
+ | 0.003 | -0.053 | 0.052 | 0.032 | torch.Size([360]) || stage5.pa_fuse.fc12.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([120, 360]) || stage5.pa_fuse.fc2.weight
+ | -0.001 | -0.050 | 0.051 | 0.030 | torch.Size([120]) || stage5.pa_fuse.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([30]) || stage6.reshape.1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([30]) || stage6.reshape.1.bias
+ | -0.002 | -0.183 | 0.183 | 0.107 | torch.Size([120, 30]) || stage6.reshape.2.weight
+ | -0.007 | -0.178 | 0.182 | 0.107 | torch.Size([120]) || stage6.reshape.2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.0.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.0.norm1.bias
+ | -0.000 | -0.073 | 0.070 | 0.020 | torch.Size([675, 6]) || stage6.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.0.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage6.residual_group1.blocks.0.attn.qkv_self.weight
+ | 0.003 | -0.091 | 0.091 | 0.055 | torch.Size([360]) || stage6.residual_group1.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage6.residual_group1.blocks.0.attn.proj.weight
+ | 0.000 | -0.064 | 0.063 | 0.038 | torch.Size([120]) || stage6.residual_group1.blocks.0.attn.proj.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage6.residual_group1.blocks.0.attn.qkv_mut.weight
+ | -0.002 | -0.089 | 0.091 | 0.052 | torch.Size([360]) || stage6.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.0.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.0.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage6.residual_group1.blocks.0.mlp.fc11.weight
+ | 0.001 | -0.091 | 0.090 | 0.053 | torch.Size([240]) || stage6.residual_group1.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage6.residual_group1.blocks.0.mlp.fc12.weight
+ | -0.005 | -0.091 | 0.091 | 0.054 | torch.Size([240]) || stage6.residual_group1.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage6.residual_group1.blocks.0.mlp.fc2.weight
+ | -0.001 | -0.065 | 0.064 | 0.038 | torch.Size([120]) || stage6.residual_group1.blocks.0.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.1.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.1.norm1.bias
+ | 0.000 | -0.068 | 0.071 | 0.020 | torch.Size([675, 6]) || stage6.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.1.attn.position_bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage6.residual_group1.blocks.1.attn.qkv_self.weight
+ | -0.004 | -0.091 | 0.090 | 0.052 | torch.Size([360]) || stage6.residual_group1.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage6.residual_group1.blocks.1.attn.proj.weight
+ | -0.005 | -0.064 | 0.061 | 0.037 | torch.Size([120]) || stage6.residual_group1.blocks.1.attn.proj.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage6.residual_group1.blocks.1.attn.qkv_mut.weight
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360]) || stage6.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.1.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.1.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage6.residual_group1.blocks.1.mlp.fc11.weight
+ | 0.004 | -0.091 | 0.091 | 0.054 | torch.Size([240]) || stage6.residual_group1.blocks.1.mlp.fc11.bias
+ | 0.001 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage6.residual_group1.blocks.1.mlp.fc12.weight
+ | 0.004 | -0.091 | 0.090 | 0.048 | torch.Size([240]) || stage6.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage6.residual_group1.blocks.1.mlp.fc2.weight
+ | 0.002 | -0.063 | 0.064 | 0.035 | torch.Size([120]) || stage6.residual_group1.blocks.1.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.2.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.2.norm1.bias
+ | -0.000 | -0.065 | 0.067 | 0.020 | torch.Size([675, 6]) || stage6.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.2.attn.position_bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage6.residual_group1.blocks.2.attn.qkv_self.weight
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360]) || stage6.residual_group1.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage6.residual_group1.blocks.2.attn.proj.weight
+ | -0.002 | -0.064 | 0.064 | 0.036 | torch.Size([120]) || stage6.residual_group1.blocks.2.attn.proj.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage6.residual_group1.blocks.2.attn.qkv_mut.weight
+ | 0.004 | -0.090 | 0.091 | 0.052 | torch.Size([360]) || stage6.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.2.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.2.norm2.bias
+ | -0.001 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage6.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.005 | -0.091 | 0.090 | 0.052 | torch.Size([240]) || stage6.residual_group1.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage6.residual_group1.blocks.2.mlp.fc12.weight
+ | 0.005 | -0.091 | 0.090 | 0.051 | torch.Size([240]) || stage6.residual_group1.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage6.residual_group1.blocks.2.mlp.fc2.weight
+ | 0.002 | -0.062 | 0.064 | 0.035 | torch.Size([120]) || stage6.residual_group1.blocks.2.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.3.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.3.norm1.bias
+ | -0.000 | -0.068 | 0.077 | 0.020 | torch.Size([675, 6]) || stage6.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.3.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage6.residual_group1.blocks.3.attn.qkv_self.weight
+ | 0.004 | -0.090 | 0.091 | 0.050 | torch.Size([360]) || stage6.residual_group1.blocks.3.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage6.residual_group1.blocks.3.attn.proj.weight
+ | 0.000 | -0.063 | 0.063 | 0.038 | torch.Size([120]) || stage6.residual_group1.blocks.3.attn.proj.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage6.residual_group1.blocks.3.attn.qkv_mut.weight
+ | 0.002 | -0.091 | 0.091 | 0.051 | torch.Size([360]) || stage6.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.3.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.3.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage6.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.008 | -0.091 | 0.091 | 0.053 | torch.Size([240]) || stage6.residual_group1.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage6.residual_group1.blocks.3.mlp.fc12.weight
+ | 0.002 | -0.089 | 0.089 | 0.052 | torch.Size([240]) || stage6.residual_group1.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage6.residual_group1.blocks.3.mlp.fc2.weight
+ | 0.005 | -0.063 | 0.064 | 0.037 | torch.Size([120]) || stage6.residual_group1.blocks.3.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.4.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.4.norm1.bias
+ | -0.000 | -0.086 | 0.071 | 0.020 | torch.Size([675, 6]) || stage6.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.4.attn.position_bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage6.residual_group1.blocks.4.attn.qkv_self.weight
+ | -0.001 | -0.091 | 0.091 | 0.053 | torch.Size([360]) || stage6.residual_group1.blocks.4.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage6.residual_group1.blocks.4.attn.proj.weight
+ | 0.004 | -0.063 | 0.064 | 0.038 | torch.Size([120]) || stage6.residual_group1.blocks.4.attn.proj.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage6.residual_group1.blocks.4.attn.qkv_mut.weight
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360]) || stage6.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.4.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.4.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage6.residual_group1.blocks.4.mlp.fc11.weight
+ | 0.001 | -0.091 | 0.091 | 0.054 | torch.Size([240]) || stage6.residual_group1.blocks.4.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage6.residual_group1.blocks.4.mlp.fc12.weight
+ | 0.008 | -0.088 | 0.091 | 0.055 | torch.Size([240]) || stage6.residual_group1.blocks.4.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage6.residual_group1.blocks.4.mlp.fc2.weight
+ | 0.001 | -0.063 | 0.064 | 0.037 | torch.Size([120]) || stage6.residual_group1.blocks.4.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.5.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.5.norm1.bias
+ | 0.000 | -0.074 | 0.065 | 0.020 | torch.Size([675, 6]) || stage6.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.5.attn.position_bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage6.residual_group1.blocks.5.attn.qkv_self.weight
+ | 0.001 | -0.091 | 0.091 | 0.052 | torch.Size([360]) || stage6.residual_group1.blocks.5.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage6.residual_group1.blocks.5.attn.proj.weight
+ | 0.001 | -0.065 | 0.063 | 0.039 | torch.Size([120]) || stage6.residual_group1.blocks.5.attn.proj.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage6.residual_group1.blocks.5.attn.qkv_mut.weight
+ | 0.005 | -0.091 | 0.091 | 0.055 | torch.Size([360]) || stage6.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.5.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.5.norm2.bias
+ | 0.001 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage6.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.002 | -0.091 | 0.091 | 0.051 | torch.Size([240]) || stage6.residual_group1.blocks.5.mlp.fc11.bias
+ | 0.001 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage6.residual_group1.blocks.5.mlp.fc12.weight
+ | -0.001 | -0.091 | 0.091 | 0.053 | torch.Size([240]) || stage6.residual_group1.blocks.5.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage6.residual_group1.blocks.5.mlp.fc2.weight
+ | 0.000 | -0.064 | 0.064 | 0.037 | torch.Size([120]) || stage6.residual_group1.blocks.5.mlp.fc2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage6.linear1.weight
+ | 0.001 | -0.091 | 0.090 | 0.051 | torch.Size([120]) || stage6.linear1.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage6.residual_group2.blocks.0.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage6.residual_group2.blocks.0.norm1.bias
+ | 0.000 | -0.075 | 0.086 | 0.020 | torch.Size([2475, 6]) || stage6.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage6.residual_group2.blocks.0.attn.relative_position_index
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage6.residual_group2.blocks.0.attn.qkv_self.weight
+ | -0.001 | -0.091 | 0.091 | 0.054 | torch.Size([360]) || stage6.residual_group2.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage6.residual_group2.blocks.0.attn.proj.weight
+ | -0.001 | -0.090 | 0.090 | 0.053 | torch.Size([120]) || stage6.residual_group2.blocks.0.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage6.residual_group2.blocks.0.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage6.residual_group2.blocks.0.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage6.residual_group2.blocks.0.mlp.fc11.weight
+ | -0.001 | -0.091 | 0.091 | 0.054 | torch.Size([240]) || stage6.residual_group2.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage6.residual_group2.blocks.0.mlp.fc12.weight
+ | 0.001 | -0.091 | 0.091 | 0.051 | torch.Size([240]) || stage6.residual_group2.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage6.residual_group2.blocks.0.mlp.fc2.weight
+ | -0.001 | -0.064 | 0.064 | 0.039 | torch.Size([120]) || stage6.residual_group2.blocks.0.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage6.residual_group2.blocks.1.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage6.residual_group2.blocks.1.norm1.bias
+ | -0.000 | -0.079 | 0.081 | 0.020 | torch.Size([2475, 6]) || stage6.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage6.residual_group2.blocks.1.attn.relative_position_index
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage6.residual_group2.blocks.1.attn.qkv_self.weight
+ | -0.003 | -0.091 | 0.091 | 0.052 | torch.Size([360]) || stage6.residual_group2.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage6.residual_group2.blocks.1.attn.proj.weight
+ | 0.005 | -0.089 | 0.090 | 0.054 | torch.Size([120]) || stage6.residual_group2.blocks.1.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage6.residual_group2.blocks.1.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage6.residual_group2.blocks.1.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage6.residual_group2.blocks.1.mlp.fc11.weight
+ | 0.000 | -0.091 | 0.091 | 0.054 | torch.Size([240]) || stage6.residual_group2.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage6.residual_group2.blocks.1.mlp.fc12.weight
+ | 0.000 | -0.090 | 0.090 | 0.054 | torch.Size([240]) || stage6.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage6.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.004 | -0.063 | 0.064 | 0.038 | torch.Size([120]) || stage6.residual_group2.blocks.1.mlp.fc2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage6.linear2.weight
+ | -0.004 | -0.091 | 0.091 | 0.051 | torch.Size([120]) || stage6.linear2.bias
+ | 0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage6.pa_deform.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage6.pa_deform.bias
+ | 0.000 | -0.021 | 0.021 | 0.012 | torch.Size([120, 242, 3, 3]) || stage6.pa_deform.conv_offset.0.weight
+ | 0.001 | -0.021 | 0.021 | 0.012 | torch.Size([120]) || stage6.pa_deform.conv_offset.0.bias
+ | 0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage6.pa_deform.conv_offset.2.weight
+ | -0.004 | -0.030 | 0.030 | 0.018 | torch.Size([120]) || stage6.pa_deform.conv_offset.2.bias
+ | 0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage6.pa_deform.conv_offset.4.weight
+ | 0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120]) || stage6.pa_deform.conv_offset.4.bias
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([324, 120, 3, 3]) || stage6.pa_deform.conv_offset.6.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([324]) || stage6.pa_deform.conv_offset.6.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([360, 360]) || stage6.pa_fuse.fc11.weight
+ | -0.000 | -0.053 | 0.052 | 0.032 | torch.Size([360]) || stage6.pa_fuse.fc11.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([360, 360]) || stage6.pa_fuse.fc12.weight
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([360]) || stage6.pa_fuse.fc12.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([120, 360]) || stage6.pa_fuse.fc2.weight
+ | 0.005 | -0.051 | 0.052 | 0.030 | torch.Size([120]) || stage6.pa_fuse.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([30]) || stage7.reshape.1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([30]) || stage7.reshape.1.bias
+ | -0.001 | -0.182 | 0.182 | 0.106 | torch.Size([120, 30]) || stage7.reshape.2.weight
+ | 0.005 | -0.178 | 0.181 | 0.109 | torch.Size([120]) || stage7.reshape.2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.0.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.0.norm1.bias
+ | -0.000 | -0.064 | 0.075 | 0.020 | torch.Size([675, 6]) || stage7.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.0.attn.position_bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage7.residual_group1.blocks.0.attn.qkv_self.weight
+ | -0.004 | -0.091 | 0.090 | 0.051 | torch.Size([360]) || stage7.residual_group1.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage7.residual_group1.blocks.0.attn.proj.weight
+ | 0.002 | -0.063 | 0.064 | 0.040 | torch.Size([120]) || stage7.residual_group1.blocks.0.attn.proj.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage7.residual_group1.blocks.0.attn.qkv_mut.weight
+ | 0.002 | -0.091 | 0.091 | 0.052 | torch.Size([360]) || stage7.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.0.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.0.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.052 | torch.Size([240, 120]) || stage7.residual_group1.blocks.0.mlp.fc11.weight
+ | 0.002 | -0.091 | 0.091 | 0.054 | torch.Size([240]) || stage7.residual_group1.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage7.residual_group1.blocks.0.mlp.fc12.weight
+ | -0.003 | -0.091 | 0.091 | 0.054 | torch.Size([240]) || stage7.residual_group1.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage7.residual_group1.blocks.0.mlp.fc2.weight
+ | -0.004 | -0.064 | 0.062 | 0.038 | torch.Size([120]) || stage7.residual_group1.blocks.0.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.1.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.1.norm1.bias
+ | -0.000 | -0.075 | 0.075 | 0.020 | torch.Size([675, 6]) || stage7.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.1.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage7.residual_group1.blocks.1.attn.qkv_self.weight
+ | 0.002 | -0.091 | 0.091 | 0.055 | torch.Size([360]) || stage7.residual_group1.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage7.residual_group1.blocks.1.attn.proj.weight
+ | 0.001 | -0.063 | 0.064 | 0.036 | torch.Size([120]) || stage7.residual_group1.blocks.1.attn.proj.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage7.residual_group1.blocks.1.attn.qkv_mut.weight
+ | 0.005 | -0.091 | 0.091 | 0.053 | torch.Size([360]) || stage7.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.1.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.1.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.052 | torch.Size([240, 120]) || stage7.residual_group1.blocks.1.mlp.fc11.weight
+ | 0.000 | -0.090 | 0.091 | 0.052 | torch.Size([240]) || stage7.residual_group1.blocks.1.mlp.fc11.bias
+ | -0.001 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage7.residual_group1.blocks.1.mlp.fc12.weight
+ | -0.003 | -0.091 | 0.091 | 0.052 | torch.Size([240]) || stage7.residual_group1.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage7.residual_group1.blocks.1.mlp.fc2.weight
+ | -0.004 | -0.064 | 0.062 | 0.037 | torch.Size([120]) || stage7.residual_group1.blocks.1.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.2.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.2.norm1.bias
+ | 0.000 | -0.063 | 0.092 | 0.020 | torch.Size([675, 6]) || stage7.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.2.attn.position_bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage7.residual_group1.blocks.2.attn.qkv_self.weight
+ | -0.004 | -0.090 | 0.091 | 0.053 | torch.Size([360]) || stage7.residual_group1.blocks.2.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage7.residual_group1.blocks.2.attn.proj.weight
+ | -0.000 | -0.064 | 0.062 | 0.036 | torch.Size([120]) || stage7.residual_group1.blocks.2.attn.proj.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage7.residual_group1.blocks.2.attn.qkv_mut.weight
+ | 0.000 | -0.091 | 0.091 | 0.051 | torch.Size([360]) || stage7.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.2.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.2.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage7.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.000 | -0.091 | 0.089 | 0.055 | torch.Size([240]) || stage7.residual_group1.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage7.residual_group1.blocks.2.mlp.fc12.weight
+ | -0.002 | -0.090 | 0.091 | 0.053 | torch.Size([240]) || stage7.residual_group1.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage7.residual_group1.blocks.2.mlp.fc2.weight
+ | 0.000 | -0.064 | 0.064 | 0.036 | torch.Size([120]) || stage7.residual_group1.blocks.2.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.3.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.3.norm1.bias
+ | -0.000 | -0.083 | 0.079 | 0.020 | torch.Size([675, 6]) || stage7.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.3.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage7.residual_group1.blocks.3.attn.qkv_self.weight
+ | 0.001 | -0.091 | 0.090 | 0.051 | torch.Size([360]) || stage7.residual_group1.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage7.residual_group1.blocks.3.attn.proj.weight
+ | -0.001 | -0.062 | 0.064 | 0.036 | torch.Size([120]) || stage7.residual_group1.blocks.3.attn.proj.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage7.residual_group1.blocks.3.attn.qkv_mut.weight
+ | -0.003 | -0.091 | 0.091 | 0.054 | torch.Size([360]) || stage7.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.3.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.3.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage7.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.002 | -0.091 | 0.091 | 0.052 | torch.Size([240]) || stage7.residual_group1.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage7.residual_group1.blocks.3.mlp.fc12.weight
+ | 0.001 | -0.090 | 0.091 | 0.053 | torch.Size([240]) || stage7.residual_group1.blocks.3.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage7.residual_group1.blocks.3.mlp.fc2.weight
+ | -0.003 | -0.061 | 0.064 | 0.035 | torch.Size([120]) || stage7.residual_group1.blocks.3.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.4.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.4.norm1.bias
+ | 0.000 | -0.077 | 0.084 | 0.020 | torch.Size([675, 6]) || stage7.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.4.attn.position_bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage7.residual_group1.blocks.4.attn.qkv_self.weight
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360]) || stage7.residual_group1.blocks.4.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage7.residual_group1.blocks.4.attn.proj.weight
+ | -0.005 | -0.064 | 0.063 | 0.037 | torch.Size([120]) || stage7.residual_group1.blocks.4.attn.proj.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage7.residual_group1.blocks.4.attn.qkv_mut.weight
+ | -0.000 | -0.091 | 0.090 | 0.052 | torch.Size([360]) || stage7.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.4.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.4.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage7.residual_group1.blocks.4.mlp.fc11.weight
+ | 0.001 | -0.089 | 0.090 | 0.053 | torch.Size([240]) || stage7.residual_group1.blocks.4.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage7.residual_group1.blocks.4.mlp.fc12.weight
+ | -0.003 | -0.091 | 0.091 | 0.054 | torch.Size([240]) || stage7.residual_group1.blocks.4.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage7.residual_group1.blocks.4.mlp.fc2.weight
+ | -0.001 | -0.063 | 0.062 | 0.034 | torch.Size([120]) || stage7.residual_group1.blocks.4.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.5.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.5.norm1.bias
+ | 0.000 | -0.071 | 0.078 | 0.020 | torch.Size([675, 6]) || stage7.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.5.attn.position_bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage7.residual_group1.blocks.5.attn.qkv_self.weight
+ | 0.001 | -0.091 | 0.091 | 0.055 | torch.Size([360]) || stage7.residual_group1.blocks.5.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage7.residual_group1.blocks.5.attn.proj.weight
+ | 0.004 | -0.064 | 0.064 | 0.038 | torch.Size([120]) || stage7.residual_group1.blocks.5.attn.proj.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage7.residual_group1.blocks.5.attn.qkv_mut.weight
+ | 0.011 | -0.091 | 0.091 | 0.051 | torch.Size([360]) || stage7.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.5.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.5.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage7.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.003 | -0.091 | 0.090 | 0.050 | torch.Size([240]) || stage7.residual_group1.blocks.5.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage7.residual_group1.blocks.5.mlp.fc12.weight
+ | 0.004 | -0.090 | 0.090 | 0.051 | torch.Size([240]) || stage7.residual_group1.blocks.5.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage7.residual_group1.blocks.5.mlp.fc2.weight
+ | -0.002 | -0.064 | 0.062 | 0.036 | torch.Size([120]) || stage7.residual_group1.blocks.5.mlp.fc2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage7.linear1.weight
+ | -0.005 | -0.089 | 0.090 | 0.055 | torch.Size([120]) || stage7.linear1.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage7.residual_group2.blocks.0.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage7.residual_group2.blocks.0.norm1.bias
+ | 0.000 | -0.077 | 0.074 | 0.020 | torch.Size([2475, 6]) || stage7.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage7.residual_group2.blocks.0.attn.relative_position_index
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage7.residual_group2.blocks.0.attn.qkv_self.weight
+ | -0.003 | -0.091 | 0.091 | 0.052 | torch.Size([360]) || stage7.residual_group2.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage7.residual_group2.blocks.0.attn.proj.weight
+ | 0.002 | -0.090 | 0.091 | 0.053 | torch.Size([120]) || stage7.residual_group2.blocks.0.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage7.residual_group2.blocks.0.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage7.residual_group2.blocks.0.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage7.residual_group2.blocks.0.mlp.fc11.weight
+ | 0.002 | -0.091 | 0.091 | 0.052 | torch.Size([240]) || stage7.residual_group2.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage7.residual_group2.blocks.0.mlp.fc12.weight
+ | 0.002 | -0.091 | 0.090 | 0.051 | torch.Size([240]) || stage7.residual_group2.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage7.residual_group2.blocks.0.mlp.fc2.weight
+ | 0.002 | -0.060 | 0.062 | 0.036 | torch.Size([120]) || stage7.residual_group2.blocks.0.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage7.residual_group2.blocks.1.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage7.residual_group2.blocks.1.norm1.bias
+ | -0.000 | -0.086 | 0.077 | 0.020 | torch.Size([2475, 6]) || stage7.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage7.residual_group2.blocks.1.attn.relative_position_index
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage7.residual_group2.blocks.1.attn.qkv_self.weight
+ | -0.004 | -0.091 | 0.090 | 0.052 | torch.Size([360]) || stage7.residual_group2.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage7.residual_group2.blocks.1.attn.proj.weight
+ | 0.000 | -0.089 | 0.089 | 0.053 | torch.Size([120]) || stage7.residual_group2.blocks.1.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage7.residual_group2.blocks.1.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage7.residual_group2.blocks.1.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.052 | torch.Size([240, 120]) || stage7.residual_group2.blocks.1.mlp.fc11.weight
+ | 0.005 | -0.090 | 0.091 | 0.053 | torch.Size([240]) || stage7.residual_group2.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage7.residual_group2.blocks.1.mlp.fc12.weight
+ | -0.002 | -0.090 | 0.091 | 0.054 | torch.Size([240]) || stage7.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage7.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.004 | -0.064 | 0.064 | 0.039 | torch.Size([120]) || stage7.residual_group2.blocks.1.mlp.fc2.bias
+ | 0.000 | -0.091 | 0.091 | 0.052 | torch.Size([120, 120]) || stage7.linear2.weight
+ | -0.007 | -0.090 | 0.090 | 0.051 | torch.Size([120]) || stage7.linear2.bias
+ | -0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage7.pa_deform.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage7.pa_deform.bias
+ | -0.000 | -0.021 | 0.021 | 0.012 | torch.Size([120, 242, 3, 3]) || stage7.pa_deform.conv_offset.0.weight
+ | 0.001 | -0.021 | 0.021 | 0.012 | torch.Size([120]) || stage7.pa_deform.conv_offset.0.bias
+ | -0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage7.pa_deform.conv_offset.2.weight
+ | -0.001 | -0.030 | 0.030 | 0.018 | torch.Size([120]) || stage7.pa_deform.conv_offset.2.bias
+ | -0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage7.pa_deform.conv_offset.4.weight
+ | 0.001 | -0.030 | 0.028 | 0.017 | torch.Size([120]) || stage7.pa_deform.conv_offset.4.bias
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([324, 120, 3, 3]) || stage7.pa_deform.conv_offset.6.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([324]) || stage7.pa_deform.conv_offset.6.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([360, 360]) || stage7.pa_fuse.fc11.weight
+ | 0.000 | -0.053 | 0.053 | 0.030 | torch.Size([360]) || stage7.pa_fuse.fc11.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([360, 360]) || stage7.pa_fuse.fc12.weight
+ | 0.000 | -0.053 | 0.052 | 0.031 | torch.Size([360]) || stage7.pa_fuse.fc12.bias
+ | 0.000 | -0.053 | 0.053 | 0.030 | torch.Size([120, 360]) || stage7.pa_fuse.fc2.weight
+ | 0.002 | -0.052 | 0.053 | 0.029 | torch.Size([120]) || stage7.pa_fuse.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage8.0.1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage8.0.1.bias
+ | -0.001 | -0.091 | 0.091 | 0.053 | torch.Size([180, 120]) || stage8.0.2.weight
+ | 0.005 | -0.090 | 0.090 | 0.050 | torch.Size([180]) || stage8.0.2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.1.residual_group.blocks.0.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.1.residual_group.blocks.0.norm1.bias
+ | 0.000 | -0.078 | 0.076 | 0.020 | torch.Size([2475, 6]) || stage8.1.residual_group.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.1.residual_group.blocks.0.attn.relative_position_index
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.1.residual_group.blocks.0.attn.qkv_self.weight
+ | 0.002 | -0.074 | 0.074 | 0.044 | torch.Size([540]) || stage8.1.residual_group.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.1.residual_group.blocks.0.attn.proj.weight
+ | 0.003 | -0.074 | 0.074 | 0.042 | torch.Size([180]) || stage8.1.residual_group.blocks.0.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.1.residual_group.blocks.0.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.1.residual_group.blocks.0.norm2.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.0.mlp.fc11.weight
+ | 0.002 | -0.074 | 0.075 | 0.043 | torch.Size([360]) || stage8.1.residual_group.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.0.mlp.fc12.weight
+ | 0.001 | -0.074 | 0.074 | 0.043 | torch.Size([360]) || stage8.1.residual_group.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.1.residual_group.blocks.0.mlp.fc2.weight
+ | -0.003 | -0.052 | 0.052 | 0.030 | torch.Size([180]) || stage8.1.residual_group.blocks.0.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.1.residual_group.blocks.1.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.1.residual_group.blocks.1.norm1.bias
+ | -0.000 | -0.078 | 0.075 | 0.020 | torch.Size([2475, 6]) || stage8.1.residual_group.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.1.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.1.residual_group.blocks.1.attn.qkv_self.weight
+ | -0.003 | -0.074 | 0.074 | 0.044 | torch.Size([540]) || stage8.1.residual_group.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.1.residual_group.blocks.1.attn.proj.weight
+ | 0.003 | -0.073 | 0.074 | 0.045 | torch.Size([180]) || stage8.1.residual_group.blocks.1.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.1.residual_group.blocks.1.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.1.residual_group.blocks.1.norm2.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.1.mlp.fc11.weight
+ | 0.000 | -0.075 | 0.074 | 0.044 | torch.Size([360]) || stage8.1.residual_group.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.1.mlp.fc12.weight
+ | 0.001 | -0.074 | 0.074 | 0.043 | torch.Size([360]) || stage8.1.residual_group.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.1.residual_group.blocks.1.mlp.fc2.weight
+ | 0.001 | -0.052 | 0.052 | 0.033 | torch.Size([180]) || stage8.1.residual_group.blocks.1.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.1.residual_group.blocks.2.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.1.residual_group.blocks.2.norm1.bias
+ | -0.000 | -0.081 | 0.076 | 0.020 | torch.Size([2475, 6]) || stage8.1.residual_group.blocks.2.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.1.residual_group.blocks.2.attn.relative_position_index
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.1.residual_group.blocks.2.attn.qkv_self.weight
+ | -0.002 | -0.074 | 0.074 | 0.042 | torch.Size([540]) || stage8.1.residual_group.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.1.residual_group.blocks.2.attn.proj.weight
+ | 0.002 | -0.074 | 0.074 | 0.044 | torch.Size([180]) || stage8.1.residual_group.blocks.2.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.1.residual_group.blocks.2.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.1.residual_group.blocks.2.norm2.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.2.mlp.fc11.weight
+ | -0.004 | -0.074 | 0.074 | 0.041 | torch.Size([360]) || stage8.1.residual_group.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.2.mlp.fc12.weight
+ | -0.004 | -0.074 | 0.074 | 0.043 | torch.Size([360]) || stage8.1.residual_group.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.053 | 0.053 | 0.031 | torch.Size([180, 360]) || stage8.1.residual_group.blocks.2.mlp.fc2.weight
+ | 0.000 | -0.052 | 0.052 | 0.031 | torch.Size([180]) || stage8.1.residual_group.blocks.2.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.1.residual_group.blocks.3.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.1.residual_group.blocks.3.norm1.bias
+ | 0.000 | -0.084 | 0.092 | 0.020 | torch.Size([2475, 6]) || stage8.1.residual_group.blocks.3.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.1.residual_group.blocks.3.attn.relative_position_index
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.1.residual_group.blocks.3.attn.qkv_self.weight
+ | -0.001 | -0.074 | 0.075 | 0.044 | torch.Size([540]) || stage8.1.residual_group.blocks.3.attn.qkv_self.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.1.residual_group.blocks.3.attn.proj.weight
+ | -0.003 | -0.074 | 0.074 | 0.042 | torch.Size([180]) || stage8.1.residual_group.blocks.3.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.1.residual_group.blocks.3.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.1.residual_group.blocks.3.norm2.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.3.mlp.fc11.weight
+ | -0.003 | -0.074 | 0.074 | 0.043 | torch.Size([360]) || stage8.1.residual_group.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.3.mlp.fc12.weight
+ | -0.002 | -0.074 | 0.074 | 0.044 | torch.Size([360]) || stage8.1.residual_group.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.1.residual_group.blocks.3.mlp.fc2.weight
+ | 0.003 | -0.052 | 0.052 | 0.031 | torch.Size([180]) || stage8.1.residual_group.blocks.3.mlp.fc2.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.1.linear.weight
+ | 0.002 | -0.073 | 0.074 | 0.043 | torch.Size([180]) || stage8.1.linear.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.2.residual_group.blocks.0.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.2.residual_group.blocks.0.norm1.bias
+ | -0.000 | -0.077 | 0.071 | 0.020 | torch.Size([2475, 6]) || stage8.2.residual_group.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.2.residual_group.blocks.0.attn.relative_position_index
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.2.residual_group.blocks.0.attn.qkv_self.weight
+ | -0.000 | -0.074 | 0.074 | 0.044 | torch.Size([540]) || stage8.2.residual_group.blocks.0.attn.qkv_self.bias
+ | 0.001 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.2.residual_group.blocks.0.attn.proj.weight
+ | -0.002 | -0.073 | 0.074 | 0.044 | torch.Size([180]) || stage8.2.residual_group.blocks.0.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.2.residual_group.blocks.0.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.2.residual_group.blocks.0.norm2.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.0.mlp.fc11.weight
+ | -0.000 | -0.074 | 0.074 | 0.044 | torch.Size([360]) || stage8.2.residual_group.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.0.mlp.fc12.weight
+ | -0.001 | -0.074 | 0.075 | 0.043 | torch.Size([360]) || stage8.2.residual_group.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.2.residual_group.blocks.0.mlp.fc2.weight
+ | -0.000 | -0.051 | 0.053 | 0.029 | torch.Size([180]) || stage8.2.residual_group.blocks.0.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.2.residual_group.blocks.1.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.2.residual_group.blocks.1.norm1.bias
+ | -0.000 | -0.081 | 0.079 | 0.020 | torch.Size([2475, 6]) || stage8.2.residual_group.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.2.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.2.residual_group.blocks.1.attn.qkv_self.weight
+ | -0.001 | -0.074 | 0.074 | 0.042 | torch.Size([540]) || stage8.2.residual_group.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.2.residual_group.blocks.1.attn.proj.weight
+ | 0.004 | -0.073 | 0.074 | 0.043 | torch.Size([180]) || stage8.2.residual_group.blocks.1.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.2.residual_group.blocks.1.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.2.residual_group.blocks.1.norm2.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.1.mlp.fc11.weight
+ | -0.000 | -0.074 | 0.074 | 0.044 | torch.Size([360]) || stage8.2.residual_group.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.1.mlp.fc12.weight
+ | 0.000 | -0.074 | 0.074 | 0.042 | torch.Size([360]) || stage8.2.residual_group.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.2.residual_group.blocks.1.mlp.fc2.weight
+ | 0.002 | -0.052 | 0.052 | 0.030 | torch.Size([180]) || stage8.2.residual_group.blocks.1.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.2.residual_group.blocks.2.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.2.residual_group.blocks.2.norm1.bias
+ | -0.000 | -0.081 | 0.071 | 0.020 | torch.Size([2475, 6]) || stage8.2.residual_group.blocks.2.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.2.residual_group.blocks.2.attn.relative_position_index
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.2.residual_group.blocks.2.attn.qkv_self.weight
+ | 0.000 | -0.074 | 0.073 | 0.044 | torch.Size([540]) || stage8.2.residual_group.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.2.residual_group.blocks.2.attn.proj.weight
+ | 0.001 | -0.074 | 0.074 | 0.042 | torch.Size([180]) || stage8.2.residual_group.blocks.2.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.2.residual_group.blocks.2.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.2.residual_group.blocks.2.norm2.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.2.mlp.fc11.weight
+ | -0.000 | -0.074 | 0.074 | 0.044 | torch.Size([360]) || stage8.2.residual_group.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.2.mlp.fc12.weight
+ | -0.003 | -0.075 | 0.074 | 0.045 | torch.Size([360]) || stage8.2.residual_group.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.2.residual_group.blocks.2.mlp.fc2.weight
+ | 0.002 | -0.052 | 0.051 | 0.030 | torch.Size([180]) || stage8.2.residual_group.blocks.2.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.2.residual_group.blocks.3.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.2.residual_group.blocks.3.norm1.bias
+ | 0.000 | -0.075 | 0.073 | 0.020 | torch.Size([2475, 6]) || stage8.2.residual_group.blocks.3.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.2.residual_group.blocks.3.attn.relative_position_index
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.2.residual_group.blocks.3.attn.qkv_self.weight
+ | 0.003 | -0.074 | 0.074 | 0.044 | torch.Size([540]) || stage8.2.residual_group.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.2.residual_group.blocks.3.attn.proj.weight
+ | 0.000 | -0.074 | 0.074 | 0.045 | torch.Size([180]) || stage8.2.residual_group.blocks.3.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.2.residual_group.blocks.3.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.2.residual_group.blocks.3.norm2.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.3.mlp.fc11.weight
+ | -0.001 | -0.074 | 0.074 | 0.044 | torch.Size([360]) || stage8.2.residual_group.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.3.mlp.fc12.weight
+ | -0.001 | -0.074 | 0.074 | 0.043 | torch.Size([360]) || stage8.2.residual_group.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.2.residual_group.blocks.3.mlp.fc2.weight
+ | -0.005 | -0.052 | 0.052 | 0.031 | torch.Size([180]) || stage8.2.residual_group.blocks.3.mlp.fc2.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.2.linear.weight
+ | 0.000 | -0.074 | 0.073 | 0.044 | torch.Size([180]) || stage8.2.linear.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.3.residual_group.blocks.0.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.3.residual_group.blocks.0.norm1.bias
+ | -0.000 | -0.083 | 0.080 | 0.020 | torch.Size([2475, 6]) || stage8.3.residual_group.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.3.residual_group.blocks.0.attn.relative_position_index
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.3.residual_group.blocks.0.attn.qkv_self.weight
+ | -0.005 | -0.074 | 0.074 | 0.044 | torch.Size([540]) || stage8.3.residual_group.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.3.residual_group.blocks.0.attn.proj.weight
+ | 0.004 | -0.074 | 0.074 | 0.043 | torch.Size([180]) || stage8.3.residual_group.blocks.0.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.3.residual_group.blocks.0.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.3.residual_group.blocks.0.norm2.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.0.mlp.fc11.weight
+ | -0.003 | -0.073 | 0.074 | 0.042 | torch.Size([360]) || stage8.3.residual_group.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.0.mlp.fc12.weight
+ | 0.004 | -0.074 | 0.074 | 0.044 | torch.Size([360]) || stage8.3.residual_group.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.3.residual_group.blocks.0.mlp.fc2.weight
+ | -0.001 | -0.052 | 0.052 | 0.030 | torch.Size([180]) || stage8.3.residual_group.blocks.0.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.3.residual_group.blocks.1.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.3.residual_group.blocks.1.norm1.bias
+ | -0.000 | -0.073 | 0.087 | 0.020 | torch.Size([2475, 6]) || stage8.3.residual_group.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.3.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.3.residual_group.blocks.1.attn.qkv_self.weight
+ | -0.000 | -0.074 | 0.074 | 0.043 | torch.Size([540]) || stage8.3.residual_group.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.3.residual_group.blocks.1.attn.proj.weight
+ | -0.002 | -0.074 | 0.073 | 0.042 | torch.Size([180]) || stage8.3.residual_group.blocks.1.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.3.residual_group.blocks.1.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.3.residual_group.blocks.1.norm2.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.1.mlp.fc11.weight
+ | -0.001 | -0.075 | 0.075 | 0.043 | torch.Size([360]) || stage8.3.residual_group.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.1.mlp.fc12.weight
+ | 0.002 | -0.074 | 0.074 | 0.044 | torch.Size([360]) || stage8.3.residual_group.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.3.residual_group.blocks.1.mlp.fc2.weight
+ | -0.002 | -0.052 | 0.052 | 0.030 | torch.Size([180]) || stage8.3.residual_group.blocks.1.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.3.residual_group.blocks.2.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.3.residual_group.blocks.2.norm1.bias
+ | 0.000 | -0.085 | 0.080 | 0.020 | torch.Size([2475, 6]) || stage8.3.residual_group.blocks.2.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.3.residual_group.blocks.2.attn.relative_position_index
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.3.residual_group.blocks.2.attn.qkv_self.weight
+ | -0.003 | -0.074 | 0.074 | 0.044 | torch.Size([540]) || stage8.3.residual_group.blocks.2.attn.qkv_self.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.3.residual_group.blocks.2.attn.proj.weight
+ | 0.000 | -0.074 | 0.074 | 0.042 | torch.Size([180]) || stage8.3.residual_group.blocks.2.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.3.residual_group.blocks.2.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.3.residual_group.blocks.2.norm2.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.2.mlp.fc11.weight
+ | -0.000 | -0.074 | 0.075 | 0.045 | torch.Size([360]) || stage8.3.residual_group.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.2.mlp.fc12.weight
+ | -0.003 | -0.074 | 0.074 | 0.043 | torch.Size([360]) || stage8.3.residual_group.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.3.residual_group.blocks.2.mlp.fc2.weight
+ | 0.001 | -0.051 | 0.051 | 0.030 | torch.Size([180]) || stage8.3.residual_group.blocks.2.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.3.residual_group.blocks.3.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.3.residual_group.blocks.3.norm1.bias
+ | 0.000 | -0.081 | 0.082 | 0.020 | torch.Size([2475, 6]) || stage8.3.residual_group.blocks.3.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.3.residual_group.blocks.3.attn.relative_position_index
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.3.residual_group.blocks.3.attn.qkv_self.weight
+ | -0.000 | -0.075 | 0.074 | 0.044 | torch.Size([540]) || stage8.3.residual_group.blocks.3.attn.qkv_self.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.3.residual_group.blocks.3.attn.proj.weight
+ | -0.001 | -0.074 | 0.074 | 0.045 | torch.Size([180]) || stage8.3.residual_group.blocks.3.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.3.residual_group.blocks.3.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.3.residual_group.blocks.3.norm2.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.3.mlp.fc11.weight
+ | 0.003 | -0.074 | 0.074 | 0.044 | torch.Size([360]) || stage8.3.residual_group.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.3.mlp.fc12.weight
+ | -0.000 | -0.074 | 0.075 | 0.046 | torch.Size([360]) || stage8.3.residual_group.blocks.3.mlp.fc12.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.3.residual_group.blocks.3.mlp.fc2.weight
+ | 0.001 | -0.052 | 0.052 | 0.030 | torch.Size([180]) || stage8.3.residual_group.blocks.3.mlp.fc2.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.3.linear.weight
+ | -0.001 | -0.073 | 0.074 | 0.042 | torch.Size([180]) || stage8.3.linear.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.4.residual_group.blocks.0.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.4.residual_group.blocks.0.norm1.bias
+ | -0.000 | -0.082 | 0.079 | 0.020 | torch.Size([2475, 6]) || stage8.4.residual_group.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.4.residual_group.blocks.0.attn.relative_position_index
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.4.residual_group.blocks.0.attn.qkv_self.weight
+ | 0.002 | -0.074 | 0.074 | 0.043 | torch.Size([540]) || stage8.4.residual_group.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.4.residual_group.blocks.0.attn.proj.weight
+ | 0.004 | -0.074 | 0.074 | 0.045 | torch.Size([180]) || stage8.4.residual_group.blocks.0.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.4.residual_group.blocks.0.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.4.residual_group.blocks.0.norm2.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.0.mlp.fc11.weight
+ | -0.001 | -0.074 | 0.074 | 0.041 | torch.Size([360]) || stage8.4.residual_group.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.0.mlp.fc12.weight
+ | 0.000 | -0.074 | 0.074 | 0.042 | torch.Size([360]) || stage8.4.residual_group.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.4.residual_group.blocks.0.mlp.fc2.weight
+ | -0.001 | -0.050 | 0.052 | 0.029 | torch.Size([180]) || stage8.4.residual_group.blocks.0.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.4.residual_group.blocks.1.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.4.residual_group.blocks.1.norm1.bias
+ | 0.000 | -0.083 | 0.083 | 0.020 | torch.Size([2475, 6]) || stage8.4.residual_group.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.4.residual_group.blocks.1.attn.relative_position_index
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.4.residual_group.blocks.1.attn.qkv_self.weight
+ | -0.003 | -0.074 | 0.073 | 0.043 | torch.Size([540]) || stage8.4.residual_group.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.4.residual_group.blocks.1.attn.proj.weight
+ | 0.005 | -0.073 | 0.072 | 0.041 | torch.Size([180]) || stage8.4.residual_group.blocks.1.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.4.residual_group.blocks.1.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.4.residual_group.blocks.1.norm2.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.1.mlp.fc11.weight
+ | 0.003 | -0.074 | 0.074 | 0.043 | torch.Size([360]) || stage8.4.residual_group.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.1.mlp.fc12.weight
+ | 0.001 | -0.074 | 0.074 | 0.044 | torch.Size([360]) || stage8.4.residual_group.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.4.residual_group.blocks.1.mlp.fc2.weight
+ | 0.003 | -0.052 | 0.052 | 0.031 | torch.Size([180]) || stage8.4.residual_group.blocks.1.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.4.residual_group.blocks.2.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.4.residual_group.blocks.2.norm1.bias
+ | -0.000 | -0.075 | 0.081 | 0.020 | torch.Size([2475, 6]) || stage8.4.residual_group.blocks.2.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.4.residual_group.blocks.2.attn.relative_position_index
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.4.residual_group.blocks.2.attn.qkv_self.weight
+ | -0.000 | -0.074 | 0.074 | 0.043 | torch.Size([540]) || stage8.4.residual_group.blocks.2.attn.qkv_self.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.4.residual_group.blocks.2.attn.proj.weight
+ | 0.001 | -0.074 | 0.074 | 0.044 | torch.Size([180]) || stage8.4.residual_group.blocks.2.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.4.residual_group.blocks.2.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.4.residual_group.blocks.2.norm2.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.2.mlp.fc11.weight
+ | -0.002 | -0.075 | 0.074 | 0.043 | torch.Size([360]) || stage8.4.residual_group.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.2.mlp.fc12.weight
+ | 0.001 | -0.074 | 0.074 | 0.044 | torch.Size([360]) || stage8.4.residual_group.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.4.residual_group.blocks.2.mlp.fc2.weight
+ | 0.002 | -0.053 | 0.052 | 0.031 | torch.Size([180]) || stage8.4.residual_group.blocks.2.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.4.residual_group.blocks.3.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.4.residual_group.blocks.3.norm1.bias
+ | -0.000 | -0.083 | 0.072 | 0.020 | torch.Size([2475, 6]) || stage8.4.residual_group.blocks.3.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.4.residual_group.blocks.3.attn.relative_position_index
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.4.residual_group.blocks.3.attn.qkv_self.weight
+ | -0.004 | -0.074 | 0.074 | 0.042 | torch.Size([540]) || stage8.4.residual_group.blocks.3.attn.qkv_self.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.4.residual_group.blocks.3.attn.proj.weight
+ | 0.004 | -0.074 | 0.072 | 0.045 | torch.Size([180]) || stage8.4.residual_group.blocks.3.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.4.residual_group.blocks.3.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.4.residual_group.blocks.3.norm2.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.3.mlp.fc11.weight
+ | 0.007 | -0.074 | 0.074 | 0.042 | torch.Size([360]) || stage8.4.residual_group.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.3.mlp.fc12.weight
+ | 0.001 | -0.073 | 0.075 | 0.041 | torch.Size([360]) || stage8.4.residual_group.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.4.residual_group.blocks.3.mlp.fc2.weight
+ | -0.002 | -0.052 | 0.053 | 0.031 | torch.Size([180]) || stage8.4.residual_group.blocks.3.mlp.fc2.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.4.linear.weight
+ | -0.008 | -0.075 | 0.072 | 0.039 | torch.Size([180]) || stage8.4.linear.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.5.residual_group.blocks.0.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.5.residual_group.blocks.0.norm1.bias
+ | -0.000 | -0.058 | 0.058 | 0.020 | torch.Size([225, 6]) || stage8.5.residual_group.blocks.0.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.5.residual_group.blocks.0.attn.relative_position_index
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.5.residual_group.blocks.0.attn.qkv_self.weight
+ | 0.001 | -0.073 | 0.075 | 0.042 | torch.Size([540]) || stage8.5.residual_group.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.5.residual_group.blocks.0.attn.proj.weight
+ | 0.001 | -0.074 | 0.074 | 0.044 | torch.Size([180]) || stage8.5.residual_group.blocks.0.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.5.residual_group.blocks.0.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.5.residual_group.blocks.0.norm2.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.0.mlp.fc11.weight
+ | -0.001 | -0.074 | 0.074 | 0.042 | torch.Size([360]) || stage8.5.residual_group.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.0.mlp.fc12.weight
+ | -0.000 | -0.074 | 0.074 | 0.042 | torch.Size([360]) || stage8.5.residual_group.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.5.residual_group.blocks.0.mlp.fc2.weight
+ | -0.002 | -0.051 | 0.051 | 0.031 | torch.Size([180]) || stage8.5.residual_group.blocks.0.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.5.residual_group.blocks.1.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.5.residual_group.blocks.1.norm1.bias
+ | -0.000 | -0.063 | 0.060 | 0.019 | torch.Size([225, 6]) || stage8.5.residual_group.blocks.1.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.5.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.5.residual_group.blocks.1.attn.qkv_self.weight
+ | 0.001 | -0.074 | 0.074 | 0.042 | torch.Size([540]) || stage8.5.residual_group.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.5.residual_group.blocks.1.attn.proj.weight
+ | 0.001 | -0.074 | 0.074 | 0.042 | torch.Size([180]) || stage8.5.residual_group.blocks.1.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.5.residual_group.blocks.1.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.5.residual_group.blocks.1.norm2.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.1.mlp.fc11.weight
+ | 0.001 | -0.074 | 0.074 | 0.043 | torch.Size([360]) || stage8.5.residual_group.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.1.mlp.fc12.weight
+ | 0.001 | -0.072 | 0.073 | 0.041 | torch.Size([360]) || stage8.5.residual_group.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.5.residual_group.blocks.1.mlp.fc2.weight
+ | 0.000 | -0.052 | 0.052 | 0.030 | torch.Size([180]) || stage8.5.residual_group.blocks.1.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.5.residual_group.blocks.2.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.5.residual_group.blocks.2.norm1.bias
+ | -0.000 | -0.062 | 0.058 | 0.020 | torch.Size([225, 6]) || stage8.5.residual_group.blocks.2.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.5.residual_group.blocks.2.attn.relative_position_index
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.5.residual_group.blocks.2.attn.qkv_self.weight
+ | -0.000 | -0.075 | 0.074 | 0.044 | torch.Size([540]) || stage8.5.residual_group.blocks.2.attn.qkv_self.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.5.residual_group.blocks.2.attn.proj.weight
+ | -0.001 | -0.073 | 0.074 | 0.042 | torch.Size([180]) || stage8.5.residual_group.blocks.2.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.5.residual_group.blocks.2.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.5.residual_group.blocks.2.norm2.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.2.mlp.fc11.weight
+ | 0.005 | -0.074 | 0.074 | 0.042 | torch.Size([360]) || stage8.5.residual_group.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.2.mlp.fc12.weight
+ | -0.000 | -0.074 | 0.073 | 0.043 | torch.Size([360]) || stage8.5.residual_group.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.5.residual_group.blocks.2.mlp.fc2.weight
+ | 0.005 | -0.050 | 0.053 | 0.031 | torch.Size([180]) || stage8.5.residual_group.blocks.2.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.5.residual_group.blocks.3.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.5.residual_group.blocks.3.norm1.bias
+ | 0.001 | -0.063 | 0.061 | 0.019 | torch.Size([225, 6]) || stage8.5.residual_group.blocks.3.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.5.residual_group.blocks.3.attn.relative_position_index
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.5.residual_group.blocks.3.attn.qkv_self.weight
+ | -0.004 | -0.074 | 0.075 | 0.042 | torch.Size([540]) || stage8.5.residual_group.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.5.residual_group.blocks.3.attn.proj.weight
+ | 0.004 | -0.074 | 0.074 | 0.040 | torch.Size([180]) || stage8.5.residual_group.blocks.3.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.5.residual_group.blocks.3.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.5.residual_group.blocks.3.norm2.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.3.mlp.fc11.weight
+ | 0.001 | -0.075 | 0.074 | 0.042 | torch.Size([360]) || stage8.5.residual_group.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.3.mlp.fc12.weight
+ | -0.001 | -0.074 | 0.074 | 0.043 | torch.Size([360]) || stage8.5.residual_group.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.5.residual_group.blocks.3.mlp.fc2.weight
+ | 0.003 | -0.052 | 0.052 | 0.031 | torch.Size([180]) || stage8.5.residual_group.blocks.3.mlp.fc2.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.5.linear.weight
+ | -0.001 | -0.074 | 0.074 | 0.042 | torch.Size([180]) || stage8.5.linear.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.6.residual_group.blocks.0.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.6.residual_group.blocks.0.norm1.bias
+ | -0.000 | -0.064 | 0.077 | 0.020 | torch.Size([225, 6]) || stage8.6.residual_group.blocks.0.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.6.residual_group.blocks.0.attn.relative_position_index
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.6.residual_group.blocks.0.attn.qkv_self.weight
+ | -0.001 | -0.075 | 0.074 | 0.043 | torch.Size([540]) || stage8.6.residual_group.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.6.residual_group.blocks.0.attn.proj.weight
+ | 0.002 | -0.073 | 0.074 | 0.043 | torch.Size([180]) || stage8.6.residual_group.blocks.0.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.6.residual_group.blocks.0.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.6.residual_group.blocks.0.norm2.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.0.mlp.fc11.weight
+ | -0.002 | -0.074 | 0.074 | 0.044 | torch.Size([360]) || stage8.6.residual_group.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.0.mlp.fc12.weight
+ | -0.002 | -0.074 | 0.074 | 0.043 | torch.Size([360]) || stage8.6.residual_group.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.6.residual_group.blocks.0.mlp.fc2.weight
+ | 0.002 | -0.051 | 0.052 | 0.032 | torch.Size([180]) || stage8.6.residual_group.blocks.0.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.6.residual_group.blocks.1.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.6.residual_group.blocks.1.norm1.bias
+ | 0.000 | -0.074 | 0.067 | 0.020 | torch.Size([225, 6]) || stage8.6.residual_group.blocks.1.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.6.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.6.residual_group.blocks.1.attn.qkv_self.weight
+ | -0.000 | -0.074 | 0.074 | 0.041 | torch.Size([540]) || stage8.6.residual_group.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.6.residual_group.blocks.1.attn.proj.weight
+ | -0.000 | -0.074 | 0.074 | 0.045 | torch.Size([180]) || stage8.6.residual_group.blocks.1.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.6.residual_group.blocks.1.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.6.residual_group.blocks.1.norm2.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.1.mlp.fc11.weight
+ | -0.001 | -0.074 | 0.074 | 0.042 | torch.Size([360]) || stage8.6.residual_group.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.1.mlp.fc12.weight
+ | 0.002 | -0.075 | 0.074 | 0.042 | torch.Size([360]) || stage8.6.residual_group.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.053 | 0.053 | 0.031 | torch.Size([180, 360]) || stage8.6.residual_group.blocks.1.mlp.fc2.weight
+ | -0.001 | -0.052 | 0.053 | 0.031 | torch.Size([180]) || stage8.6.residual_group.blocks.1.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.6.residual_group.blocks.2.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.6.residual_group.blocks.2.norm1.bias
+ | 0.001 | -0.071 | 0.075 | 0.020 | torch.Size([225, 6]) || stage8.6.residual_group.blocks.2.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.6.residual_group.blocks.2.attn.relative_position_index
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.6.residual_group.blocks.2.attn.qkv_self.weight
+ | 0.002 | -0.075 | 0.074 | 0.044 | torch.Size([540]) || stage8.6.residual_group.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.6.residual_group.blocks.2.attn.proj.weight
+ | 0.002 | -0.073 | 0.074 | 0.043 | torch.Size([180]) || stage8.6.residual_group.blocks.2.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.6.residual_group.blocks.2.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.6.residual_group.blocks.2.norm2.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.2.mlp.fc11.weight
+ | 0.004 | -0.074 | 0.074 | 0.044 | torch.Size([360]) || stage8.6.residual_group.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.2.mlp.fc12.weight
+ | -0.004 | -0.074 | 0.074 | 0.041 | torch.Size([360]) || stage8.6.residual_group.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.6.residual_group.blocks.2.mlp.fc2.weight
+ | -0.003 | -0.052 | 0.052 | 0.030 | torch.Size([180]) || stage8.6.residual_group.blocks.2.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.6.residual_group.blocks.3.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.6.residual_group.blocks.3.norm1.bias
+ | -0.000 | -0.060 | 0.066 | 0.021 | torch.Size([225, 6]) || stage8.6.residual_group.blocks.3.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.6.residual_group.blocks.3.attn.relative_position_index
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.6.residual_group.blocks.3.attn.qkv_self.weight
+ | -0.002 | -0.074 | 0.074 | 0.042 | torch.Size([540]) || stage8.6.residual_group.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.6.residual_group.blocks.3.attn.proj.weight
+ | -0.002 | -0.074 | 0.074 | 0.044 | torch.Size([180]) || stage8.6.residual_group.blocks.3.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.6.residual_group.blocks.3.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.6.residual_group.blocks.3.norm2.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.3.mlp.fc11.weight
+ | 0.003 | -0.074 | 0.074 | 0.044 | torch.Size([360]) || stage8.6.residual_group.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.3.mlp.fc12.weight
+ | -0.001 | -0.074 | 0.075 | 0.044 | torch.Size([360]) || stage8.6.residual_group.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.6.residual_group.blocks.3.mlp.fc2.weight
+ | 0.001 | -0.052 | 0.052 | 0.031 | torch.Size([180]) || stage8.6.residual_group.blocks.3.mlp.fc2.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.6.linear.weight
+ | -0.009 | -0.074 | 0.074 | 0.043 | torch.Size([180]) || stage8.6.linear.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || norm.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || norm.bias
+ | -0.001 | -0.075 | 0.075 | 0.043 | torch.Size([120, 180]) || conv_after_body.weight
+ | -0.002 | -0.074 | 0.074 | 0.044 | torch.Size([120]) || conv_after_body.bias
+ | -0.000 | -0.030 | 0.030 | 0.018 | torch.Size([64, 120, 1, 3, 3]) || conv_before_upsample.0.weight
+ | 0.000 | -0.029 | 0.030 | 0.016 | torch.Size([64]) || conv_before_upsample.0.bias
+ | -0.000 | -0.042 | 0.042 | 0.024 | torch.Size([256, 64, 1, 3, 3]) || upsample.0.weight
+ | 0.000 | -0.041 | 0.042 | 0.024 | torch.Size([256]) || upsample.0.bias
+ | -0.000 | -0.042 | 0.042 | 0.024 | torch.Size([256, 64, 1, 3, 3]) || upsample.5.weight
+ | 0.000 | -0.041 | 0.040 | 0.025 | torch.Size([256]) || upsample.5.bias
+ | 0.000 | -0.042 | 0.042 | 0.024 | torch.Size([64, 64, 1, 3, 3]) || upsample.10.weight
+ | 0.003 | -0.041 | 0.041 | 0.025 | torch.Size([64]) || upsample.10.bias
+ | -0.000 | -0.042 | 0.042 | 0.024 | torch.Size([3, 64, 1, 3, 3]) || conv_last.weight
+ | 0.001 | -0.039 | 0.037 | 0.038 | torch.Size([3]) || conv_last.bias
+
+22-03-11 09:55:18.025 : task: 001_train_vrt_videosr_bi_reds_6frames
+ model: vrt
+ gpu_ids: [0, 1, 2, 3, 4, 5, 6, 7]
+ dist: False
+ find_unused_parameters: False
+ use_static_graph: True
+ scale: 4
+ n_channels: 3
+ path:[
+ root: experiments
+ pretrained_netG: None
+ pretrained_netE: None
+ task: experiments/001_train_vrt_videosr_bi_reds_6frames
+ log: experiments/001_train_vrt_videosr_bi_reds_6frames
+ options: experiments/001_train_vrt_videosr_bi_reds_6frames/options
+ models: experiments/001_train_vrt_videosr_bi_reds_6frames/models
+ images: experiments/001_train_vrt_videosr_bi_reds_6frames/images
+ pretrained_optimizerG: None
+ ]
+ datasets:[
+ train:[
+ name: train_dataset
+ dataset_type: VideoRecurrentTrainDataset
+ dataroot_gt: trainsets/REDS/train_sharp_with_val.lmdb
+ dataroot_lq: trainsets/REDS/train_sharp_bicubic_with_val.lmdb
+ meta_info_file: data/meta_info/meta_info_REDS_GT.txt
+ filename_tmpl: 08d
+ filename_ext: png
+ val_partition: REDS4
+ test_mode: False
+ io_backend:[
+ type: lmdb
+ ]
+ num_frame: 6
+ gt_size: 256
+ interval_list: [1]
+ random_reverse: False
+ use_hflip: True
+ use_rot: True
+ dataloader_shuffle: True
+ dataloader_num_workers: 32
+ dataloader_batch_size: 8
+ phase: train
+ scale: 4
+ n_channels: 3
+ ]
+ test:[
+ name: test_dataset
+ dataset_type: VideoRecurrentTestDataset
+ dataroot_gt: testsets/REDS4/GT
+ dataroot_lq: testsets/REDS4/sharp_bicubic
+ cache_data: True
+ io_backend:[
+ type: disk
+ ]
+ num_frame: -1
+ phase: test
+ scale: 4
+ n_channels: 3
+ ]
+ ]
+ netG:[
+ net_type: vrt
+ upscale: 4
+ img_size: [6, 64, 64]
+ window_size: [6, 8, 8]
+ depths: [8, 8, 8, 8, 8, 8, 8, 4, 4, 4, 4, 4, 4]
+ indep_reconsts: [11, 12]
+ embed_dims: [120, 120, 120, 120, 120, 120, 120, 180, 180, 180, 180, 180, 180]
+ num_heads: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
+ spynet_path: model_zoo/vrt/spynet_sintel_final-3d2a1287.pth
+ pa_frames: 2
+ deformable_groups: 12
+ nonblind_denoising: False
+ use_checkpoint_attn: False
+ use_checkpoint_ffn: False
+ no_checkpoint_attn_blocks: []
+ no_checkpoint_ffn_blocks: []
+ init_type: default
+ scale: 4
+ ]
+ train:[
+ G_lossfn_type: charbonnier
+ G_lossfn_weight: 1.0
+ G_charbonnier_eps: 1e-09
+ E_decay: 0
+ G_optimizer_type: adam
+ G_optimizer_lr: 0.0004
+ G_optimizer_betas: [0.9, 0.99]
+ G_optimizer_wd: 0
+ G_optimizer_clipgrad: None
+ G_optimizer_reuse: True
+ fix_iter: 20000
+ fix_lr_mul: 0.125
+ fix_keys: ['spynet', 'deform']
+ total_iter: 300000
+ G_scheduler_type: CosineAnnealingWarmRestarts
+ G_scheduler_periods: 300000
+ G_scheduler_eta_min: 1e-07
+ G_regularizer_orthstep: None
+ G_regularizer_clipstep: None
+ G_param_strict: True
+ E_param_strict: True
+ checkpoint_test: 5000
+ checkpoint_save: 5000
+ checkpoint_print: 200
+ F_feature_layer: 34
+ F_weights: 1.0
+ F_lossfn_type: l1
+ F_use_input_norm: True
+ F_use_range_norm: False
+ G_scheduler_restart_weights: 1
+ ]
+ val:[
+ save_img: False
+ pad_seq: False
+ flip_seq: False
+ center_frame_only: False
+ num_frame_testing: 40
+ num_frame_overlapping: 2
+ size_patch_testing: 128
+ ]
+ opt_path: options/vrt/001_train_vrt_videosr_bi_reds_6frames.json
+ is_train: True
+ merge_bn: False
+ merge_bn_startpoint: -1
+ num_gpu: 8
+ rank: 0
+ world_size: 1
+
+22-03-11 09:55:18.071 : Number of train images: 27,000, iters: 3,375
+22-03-11 09:55:21.359 :
+Networks name: VRT
+Params number: 30676435
+Net structure:
+VRT(
+ (conv_first): Conv3d(27, 120, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ (spynet): SpyNet(
+ (basic_module): ModuleList(
+ (0): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (1): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (2): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (3): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (4): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (5): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ )
+ )
+ (stage1): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n c d h w -> n d h w c')
+ (1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (2): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): Identity()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): Identity()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage2): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n c d (h neih) (w neiw) -> n d h w (neiw neih c)', neih=2, neiw=2)
+ (1): LayerNorm((480,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=480, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage3): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n c d (h neih) (w neiw) -> n d h w (neiw neih c)', neih=2, neiw=2)
+ (1): LayerNorm((480,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=480, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage4): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n c d (h neih) (w neiw) -> n d h w (neiw neih c)', neih=2, neiw=2)
+ (1): LayerNorm((480,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=480, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage5): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n (neiw neih c) d h w -> n d (h neih) (w neiw) c', neih=2, neiw=2)
+ (1): LayerNorm((30,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=30, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage6): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n (neiw neih c) d h w -> n d (h neih) (w neiw) c', neih=2, neiw=2)
+ (1): LayerNorm((30,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=30, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage7): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n (neiw neih c) d h w -> n d (h neih) (w neiw) c', neih=2, neiw=2)
+ (1): LayerNorm((30,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=30, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage8): ModuleList(
+ (0): Sequential(
+ (0): Rearrange('n c d h w -> n d h w c')
+ (1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=120, out_features=180, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (1): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (2): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (3): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (4): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (5): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (6): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ )
+ (norm): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (conv_after_body): Linear(in_features=180, out_features=120, bias=True)
+ (conv_before_upsample): Sequential(
+ (0): Conv3d(120, 64, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ (1): LeakyReLU(negative_slope=0.01, inplace=True)
+ )
+ (upsample): Upsample(
+ (0): Conv3d(64, 256, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ (1): Transpose_Dim12()
+ (2): PixelShuffle(upscale_factor=2)
+ (3): Transpose_Dim12()
+ (4): LeakyReLU(negative_slope=0.1, inplace=True)
+ (5): Conv3d(64, 256, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ (6): Transpose_Dim12()
+ (7): PixelShuffle(upscale_factor=2)
+ (8): Transpose_Dim12()
+ (9): LeakyReLU(negative_slope=0.1, inplace=True)
+ (10): Conv3d(64, 64, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ )
+ (conv_last): Conv3d(64, 3, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+)
+
+22-03-11 09:55:21.536 :
+ | mean | min | max | std || shape
+ | 0.000 | -0.064 | 0.064 | 0.037 | torch.Size([120, 27, 1, 3, 3]) || conv_first.weight
+ | 0.000 | -0.062 | 0.064 | 0.037 | torch.Size([120]) || conv_first.bias
+ | 0.449 | 0.406 | 0.485 | 0.040 | torch.Size([1, 3, 1, 1]) || spynet.mean
+ | 0.226 | 0.224 | 0.229 | 0.003 | torch.Size([1, 3, 1, 1]) || spynet.std
+ | -0.000 | -0.684 | 0.720 | 0.066 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.0.basic_module.0.weight
+ | -0.055 | -0.917 | 0.306 | 0.335 | torch.Size([32]) || spynet.basic_module.0.basic_module.0.bias
+ | -0.009 | -3.201 | 0.948 | 0.096 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.0.basic_module.2.weight
+ | 0.039 | -1.273 | 0.675 | 0.311 | torch.Size([64]) || spynet.basic_module.0.basic_module.2.bias
+ | -0.010 | -4.690 | 0.568 | 0.089 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.0.basic_module.4.weight
+ | 0.162 | -0.704 | 0.905 | 0.366 | torch.Size([32]) || spynet.basic_module.0.basic_module.4.bias
+ | -0.023 | -1.714 | 0.414 | 0.091 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.0.basic_module.6.weight
+ | 0.787 | -1.061 | 1.170 | 0.522 | torch.Size([16]) || spynet.basic_module.0.basic_module.6.bias
+ | 0.000 | -0.145 | 0.166 | 0.018 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.0.basic_module.8.weight
+ | -0.000 | -0.001 | 0.000 | 0.001 | torch.Size([2]) || spynet.basic_module.0.basic_module.8.bias
+ | -0.000 | -0.726 | 0.782 | 0.070 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.1.basic_module.0.weight
+ | -0.024 | -0.810 | 0.352 | 0.313 | torch.Size([32]) || spynet.basic_module.1.basic_module.0.bias
+ | -0.008 | -3.370 | 0.914 | 0.098 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.1.basic_module.2.weight
+ | 0.042 | -1.197 | 0.699 | 0.302 | torch.Size([64]) || spynet.basic_module.1.basic_module.2.bias
+ | -0.008 | -4.468 | 0.566 | 0.088 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.1.basic_module.4.weight
+ | 0.160 | -0.745 | 0.996 | 0.391 | torch.Size([32]) || spynet.basic_module.1.basic_module.4.bias
+ | -0.017 | -1.648 | 0.317 | 0.084 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.1.basic_module.6.weight
+ | 0.785 | -1.176 | 1.158 | 0.543 | torch.Size([16]) || spynet.basic_module.1.basic_module.6.bias
+ | 0.000 | -0.145 | 0.163 | 0.014 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.1.basic_module.8.weight
+ | 0.000 | -0.000 | 0.000 | 0.000 | torch.Size([2]) || spynet.basic_module.1.basic_module.8.bias
+ | 0.000 | -1.003 | 0.875 | 0.089 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.2.basic_module.0.weight
+ | -0.021 | -0.979 | 0.466 | 0.373 | torch.Size([32]) || spynet.basic_module.2.basic_module.0.bias
+ | -0.008 | -4.622 | 1.220 | 0.116 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.2.basic_module.2.weight
+ | 0.028 | -1.276 | 0.717 | 0.308 | torch.Size([64]) || spynet.basic_module.2.basic_module.2.bias
+ | -0.007 | -1.827 | 0.624 | 0.092 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.2.basic_module.4.weight
+ | 0.123 | -0.697 | 0.745 | 0.334 | torch.Size([32]) || spynet.basic_module.2.basic_module.4.bias
+ | -0.010 | -1.295 | 0.330 | 0.068 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.2.basic_module.6.weight
+ | 0.677 | -1.696 | 0.934 | 0.637 | torch.Size([16]) || spynet.basic_module.2.basic_module.6.bias
+ | 0.000 | -0.114 | 0.129 | 0.008 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.2.basic_module.8.weight
+ | -0.003 | -0.008 | 0.002 | 0.007 | torch.Size([2]) || spynet.basic_module.2.basic_module.8.bias
+ | 0.000 | -1.053 | 0.952 | 0.091 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.3.basic_module.0.weight
+ | -0.016 | -1.061 | 0.522 | 0.414 | torch.Size([32]) || spynet.basic_module.3.basic_module.0.bias
+ | -0.008 | -4.891 | 1.222 | 0.116 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.3.basic_module.2.weight
+ | 0.029 | -1.264 | 0.760 | 0.309 | torch.Size([64]) || spynet.basic_module.3.basic_module.2.bias
+ | -0.007 | -1.792 | 0.579 | 0.089 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.3.basic_module.4.weight
+ | 0.117 | -0.694 | 0.670 | 0.329 | torch.Size([32]) || spynet.basic_module.3.basic_module.4.bias
+ | -0.008 | -1.108 | 0.324 | 0.065 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.3.basic_module.6.weight
+ | 0.652 | -1.754 | 0.901 | 0.647 | torch.Size([16]) || spynet.basic_module.3.basic_module.6.bias
+ | 0.000 | -0.117 | 0.129 | 0.008 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.3.basic_module.8.weight
+ | 0.002 | -0.003 | 0.007 | 0.007 | torch.Size([2]) || spynet.basic_module.3.basic_module.8.bias
+ | -0.000 | -1.085 | 0.998 | 0.092 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.4.basic_module.0.weight
+ | 0.009 | -0.975 | 0.477 | 0.368 | torch.Size([32]) || spynet.basic_module.4.basic_module.0.bias
+ | -0.008 | -5.056 | 1.282 | 0.117 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.4.basic_module.2.weight
+ | 0.029 | -1.240 | 0.796 | 0.311 | torch.Size([64]) || spynet.basic_module.4.basic_module.2.bias
+ | -0.007 | -1.772 | 0.600 | 0.089 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.4.basic_module.4.weight
+ | 0.121 | -0.688 | 0.694 | 0.331 | torch.Size([32]) || spynet.basic_module.4.basic_module.4.bias
+ | -0.007 | -0.980 | 0.320 | 0.065 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.4.basic_module.6.weight
+ | 0.642 | -1.810 | 0.912 | 0.662 | torch.Size([16]) || spynet.basic_module.4.basic_module.6.bias
+ | 0.000 | -0.188 | 0.209 | 0.011 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.4.basic_module.8.weight
+ | -0.002 | -0.008 | 0.005 | 0.009 | torch.Size([2]) || spynet.basic_module.4.basic_module.8.bias
+ | -0.000 | -1.085 | 0.999 | 0.092 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.5.basic_module.0.weight
+ | 0.009 | -0.982 | 0.474 | 0.368 | torch.Size([32]) || spynet.basic_module.5.basic_module.0.bias
+ | -0.008 | -5.089 | 1.311 | 0.119 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.5.basic_module.2.weight
+ | 0.029 | -1.256 | 0.804 | 0.314 | torch.Size([64]) || spynet.basic_module.5.basic_module.2.bias
+ | -0.008 | -1.788 | 0.613 | 0.093 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.5.basic_module.4.weight
+ | 0.122 | -0.699 | 0.700 | 0.334 | torch.Size([32]) || spynet.basic_module.5.basic_module.4.bias
+ | -0.008 | -1.010 | 0.323 | 0.067 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.5.basic_module.6.weight
+ | 0.650 | -1.834 | 0.923 | 0.670 | torch.Size([16]) || spynet.basic_module.5.basic_module.6.bias
+ | 0.000 | -0.192 | 0.213 | 0.011 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.5.basic_module.8.weight
+ | -0.001 | -0.007 | 0.005 | 0.009 | torch.Size([2]) || spynet.basic_module.5.basic_module.8.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage1.reshape.1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage1.reshape.1.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.0.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.0.norm1.bias
+ | -0.000 | -0.069 | 0.063 | 0.020 | torch.Size([675, 6]) || stage1.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.0.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage1.residual_group1.blocks.0.attn.qkv_self.weight
+ | 0.001 | -0.091 | 0.091 | 0.051 | torch.Size([360]) || stage1.residual_group1.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage1.residual_group1.blocks.0.attn.proj.weight
+ | -0.001 | -0.063 | 0.065 | 0.035 | torch.Size([120]) || stage1.residual_group1.blocks.0.attn.proj.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage1.residual_group1.blocks.0.attn.qkv_mut.weight
+ | -0.000 | -0.091 | 0.091 | 0.055 | torch.Size([360]) || stage1.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.0.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.0.norm2.bias
+ | -0.001 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage1.residual_group1.blocks.0.mlp.fc11.weight
+ | 0.003 | -0.091 | 0.091 | 0.053 | torch.Size([240]) || stage1.residual_group1.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage1.residual_group1.blocks.0.mlp.fc12.weight
+ | 0.003 | -0.090 | 0.091 | 0.054 | torch.Size([240]) || stage1.residual_group1.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage1.residual_group1.blocks.0.mlp.fc2.weight
+ | 0.004 | -0.064 | 0.064 | 0.040 | torch.Size([120]) || stage1.residual_group1.blocks.0.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.1.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.1.norm1.bias
+ | 0.000 | -0.066 | 0.076 | 0.020 | torch.Size([675, 6]) || stage1.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.1.attn.position_bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage1.residual_group1.blocks.1.attn.qkv_self.weight
+ | 0.002 | -0.091 | 0.090 | 0.052 | torch.Size([360]) || stage1.residual_group1.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage1.residual_group1.blocks.1.attn.proj.weight
+ | 0.001 | -0.065 | 0.064 | 0.037 | torch.Size([120]) || stage1.residual_group1.blocks.1.attn.proj.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage1.residual_group1.blocks.1.attn.qkv_mut.weight
+ | -0.002 | -0.091 | 0.090 | 0.052 | torch.Size([360]) || stage1.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.1.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.1.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage1.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.005 | -0.091 | 0.091 | 0.055 | torch.Size([240]) || stage1.residual_group1.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage1.residual_group1.blocks.1.mlp.fc12.weight
+ | 0.002 | -0.091 | 0.091 | 0.052 | torch.Size([240]) || stage1.residual_group1.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage1.residual_group1.blocks.1.mlp.fc2.weight
+ | -0.003 | -0.064 | 0.064 | 0.038 | torch.Size([120]) || stage1.residual_group1.blocks.1.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.2.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.2.norm1.bias
+ | -0.001 | -0.074 | 0.067 | 0.020 | torch.Size([675, 6]) || stage1.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.2.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage1.residual_group1.blocks.2.attn.qkv_self.weight
+ | -0.002 | -0.091 | 0.091 | 0.054 | torch.Size([360]) || stage1.residual_group1.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage1.residual_group1.blocks.2.attn.proj.weight
+ | 0.002 | -0.064 | 0.064 | 0.040 | torch.Size([120]) || stage1.residual_group1.blocks.2.attn.proj.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage1.residual_group1.blocks.2.attn.qkv_mut.weight
+ | -0.003 | -0.091 | 0.090 | 0.053 | torch.Size([360]) || stage1.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.2.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.2.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage1.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.004 | -0.090 | 0.091 | 0.051 | torch.Size([240]) || stage1.residual_group1.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage1.residual_group1.blocks.2.mlp.fc12.weight
+ | 0.008 | -0.091 | 0.091 | 0.053 | torch.Size([240]) || stage1.residual_group1.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage1.residual_group1.blocks.2.mlp.fc2.weight
+ | 0.000 | -0.063 | 0.062 | 0.034 | torch.Size([120]) || stage1.residual_group1.blocks.2.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.3.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.3.norm1.bias
+ | 0.000 | -0.068 | 0.072 | 0.020 | torch.Size([675, 6]) || stage1.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.3.attn.position_bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage1.residual_group1.blocks.3.attn.qkv_self.weight
+ | 0.003 | -0.091 | 0.091 | 0.051 | torch.Size([360]) || stage1.residual_group1.blocks.3.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage1.residual_group1.blocks.3.attn.proj.weight
+ | -0.005 | -0.060 | 0.063 | 0.037 | torch.Size([120]) || stage1.residual_group1.blocks.3.attn.proj.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage1.residual_group1.blocks.3.attn.qkv_mut.weight
+ | -0.000 | -0.090 | 0.091 | 0.052 | torch.Size([360]) || stage1.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.3.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.3.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage1.residual_group1.blocks.3.mlp.fc11.weight
+ | 0.004 | -0.089 | 0.091 | 0.053 | torch.Size([240]) || stage1.residual_group1.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage1.residual_group1.blocks.3.mlp.fc12.weight
+ | 0.001 | -0.090 | 0.091 | 0.055 | torch.Size([240]) || stage1.residual_group1.blocks.3.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage1.residual_group1.blocks.3.mlp.fc2.weight
+ | -0.002 | -0.062 | 0.063 | 0.034 | torch.Size([120]) || stage1.residual_group1.blocks.3.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.4.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.4.norm1.bias
+ | -0.000 | -0.080 | 0.073 | 0.020 | torch.Size([675, 6]) || stage1.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.4.attn.position_bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage1.residual_group1.blocks.4.attn.qkv_self.weight
+ | 0.000 | -0.090 | 0.091 | 0.054 | torch.Size([360]) || stage1.residual_group1.blocks.4.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage1.residual_group1.blocks.4.attn.proj.weight
+ | 0.002 | -0.064 | 0.064 | 0.038 | torch.Size([120]) || stage1.residual_group1.blocks.4.attn.proj.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage1.residual_group1.blocks.4.attn.qkv_mut.weight
+ | -0.002 | -0.091 | 0.091 | 0.054 | torch.Size([360]) || stage1.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.4.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.4.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage1.residual_group1.blocks.4.mlp.fc11.weight
+ | -0.007 | -0.090 | 0.089 | 0.048 | torch.Size([240]) || stage1.residual_group1.blocks.4.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage1.residual_group1.blocks.4.mlp.fc12.weight
+ | -0.001 | -0.091 | 0.088 | 0.055 | torch.Size([240]) || stage1.residual_group1.blocks.4.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage1.residual_group1.blocks.4.mlp.fc2.weight
+ | 0.003 | -0.063 | 0.064 | 0.037 | torch.Size([120]) || stage1.residual_group1.blocks.4.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.5.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.5.norm1.bias
+ | -0.000 | -0.066 | 0.077 | 0.020 | torch.Size([675, 6]) || stage1.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.5.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage1.residual_group1.blocks.5.attn.qkv_self.weight
+ | 0.002 | -0.091 | 0.091 | 0.053 | torch.Size([360]) || stage1.residual_group1.blocks.5.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage1.residual_group1.blocks.5.attn.proj.weight
+ | 0.005 | -0.065 | 0.064 | 0.041 | torch.Size([120]) || stage1.residual_group1.blocks.5.attn.proj.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage1.residual_group1.blocks.5.attn.qkv_mut.weight
+ | -0.001 | -0.091 | 0.091 | 0.053 | torch.Size([360]) || stage1.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.5.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage1.residual_group1.blocks.5.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage1.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.003 | -0.091 | 0.090 | 0.055 | torch.Size([240]) || stage1.residual_group1.blocks.5.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage1.residual_group1.blocks.5.mlp.fc12.weight
+ | -0.001 | -0.091 | 0.091 | 0.051 | torch.Size([240]) || stage1.residual_group1.blocks.5.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage1.residual_group1.blocks.5.mlp.fc2.weight
+ | -0.003 | -0.064 | 0.063 | 0.038 | torch.Size([120]) || stage1.residual_group1.blocks.5.mlp.fc2.bias
+ | -0.000 | -0.091 | 0.091 | 0.052 | torch.Size([120, 120]) || stage1.linear1.weight
+ | -0.001 | -0.090 | 0.091 | 0.057 | torch.Size([120]) || stage1.linear1.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage1.residual_group2.blocks.0.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage1.residual_group2.blocks.0.norm1.bias
+ | -0.000 | -0.074 | 0.073 | 0.020 | torch.Size([2475, 6]) || stage1.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage1.residual_group2.blocks.0.attn.relative_position_index
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage1.residual_group2.blocks.0.attn.qkv_self.weight
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360]) || stage1.residual_group2.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage1.residual_group2.blocks.0.attn.proj.weight
+ | 0.001 | -0.090 | 0.089 | 0.051 | torch.Size([120]) || stage1.residual_group2.blocks.0.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage1.residual_group2.blocks.0.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage1.residual_group2.blocks.0.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage1.residual_group2.blocks.0.mlp.fc11.weight
+ | 0.009 | -0.090 | 0.090 | 0.051 | torch.Size([240]) || stage1.residual_group2.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage1.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.004 | -0.091 | 0.091 | 0.054 | torch.Size([240]) || stage1.residual_group2.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage1.residual_group2.blocks.0.mlp.fc2.weight
+ | 0.001 | -0.064 | 0.063 | 0.035 | torch.Size([120]) || stage1.residual_group2.blocks.0.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage1.residual_group2.blocks.1.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage1.residual_group2.blocks.1.norm1.bias
+ | -0.000 | -0.093 | 0.079 | 0.020 | torch.Size([2475, 6]) || stage1.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage1.residual_group2.blocks.1.attn.relative_position_index
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage1.residual_group2.blocks.1.attn.qkv_self.weight
+ | 0.003 | -0.091 | 0.091 | 0.055 | torch.Size([360]) || stage1.residual_group2.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage1.residual_group2.blocks.1.attn.proj.weight
+ | -0.003 | -0.090 | 0.091 | 0.056 | torch.Size([120]) || stage1.residual_group2.blocks.1.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage1.residual_group2.blocks.1.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage1.residual_group2.blocks.1.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage1.residual_group2.blocks.1.mlp.fc11.weight
+ | 0.002 | -0.091 | 0.091 | 0.052 | torch.Size([240]) || stage1.residual_group2.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage1.residual_group2.blocks.1.mlp.fc12.weight
+ | -0.004 | -0.091 | 0.089 | 0.054 | torch.Size([240]) || stage1.residual_group2.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage1.residual_group2.blocks.1.mlp.fc2.weight
+ | 0.007 | -0.064 | 0.064 | 0.038 | torch.Size([120]) || stage1.residual_group2.blocks.1.mlp.fc2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage1.linear2.weight
+ | 0.005 | -0.091 | 0.086 | 0.052 | torch.Size([120]) || stage1.linear2.bias
+ | -0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage1.pa_deform.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage1.pa_deform.bias
+ | -0.000 | -0.021 | 0.021 | 0.012 | torch.Size([120, 242, 3, 3]) || stage1.pa_deform.conv_offset.0.weight
+ | 0.001 | -0.021 | 0.021 | 0.012 | torch.Size([120]) || stage1.pa_deform.conv_offset.0.bias
+ | 0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage1.pa_deform.conv_offset.2.weight
+ | -0.000 | -0.030 | 0.029 | 0.019 | torch.Size([120]) || stage1.pa_deform.conv_offset.2.bias
+ | 0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage1.pa_deform.conv_offset.4.weight
+ | 0.000 | -0.030 | 0.030 | 0.017 | torch.Size([120]) || stage1.pa_deform.conv_offset.4.bias
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([324, 120, 3, 3]) || stage1.pa_deform.conv_offset.6.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([324]) || stage1.pa_deform.conv_offset.6.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([360, 360]) || stage1.pa_fuse.fc11.weight
+ | -0.001 | -0.053 | 0.053 | 0.031 | torch.Size([360]) || stage1.pa_fuse.fc11.bias
+ | 0.000 | -0.053 | 0.053 | 0.030 | torch.Size([360, 360]) || stage1.pa_fuse.fc12.weight
+ | 0.001 | -0.051 | 0.053 | 0.030 | torch.Size([360]) || stage1.pa_fuse.fc12.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([120, 360]) || stage1.pa_fuse.fc2.weight
+ | 0.000 | -0.052 | 0.053 | 0.032 | torch.Size([120]) || stage1.pa_fuse.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([480]) || stage2.reshape.1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([480]) || stage2.reshape.1.bias
+ | 0.000 | -0.046 | 0.046 | 0.026 | torch.Size([120, 480]) || stage2.reshape.2.weight
+ | -0.001 | -0.044 | 0.043 | 0.026 | torch.Size([120]) || stage2.reshape.2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.0.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.0.norm1.bias
+ | -0.000 | -0.067 | 0.061 | 0.020 | torch.Size([675, 6]) || stage2.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.0.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage2.residual_group1.blocks.0.attn.qkv_self.weight
+ | 0.001 | -0.090 | 0.091 | 0.051 | torch.Size([360]) || stage2.residual_group1.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage2.residual_group1.blocks.0.attn.proj.weight
+ | 0.001 | -0.064 | 0.064 | 0.039 | torch.Size([120]) || stage2.residual_group1.blocks.0.attn.proj.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage2.residual_group1.blocks.0.attn.qkv_mut.weight
+ | 0.006 | -0.091 | 0.091 | 0.054 | torch.Size([360]) || stage2.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.0.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.0.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage2.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.009 | -0.091 | 0.090 | 0.055 | torch.Size([240]) || stage2.residual_group1.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage2.residual_group1.blocks.0.mlp.fc12.weight
+ | -0.003 | -0.090 | 0.091 | 0.052 | torch.Size([240]) || stage2.residual_group1.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage2.residual_group1.blocks.0.mlp.fc2.weight
+ | -0.001 | -0.063 | 0.062 | 0.037 | torch.Size([120]) || stage2.residual_group1.blocks.0.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.1.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.1.norm1.bias
+ | -0.001 | -0.070 | 0.072 | 0.020 | torch.Size([675, 6]) || stage2.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.1.attn.position_bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage2.residual_group1.blocks.1.attn.qkv_self.weight
+ | 0.001 | -0.091 | 0.090 | 0.052 | torch.Size([360]) || stage2.residual_group1.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage2.residual_group1.blocks.1.attn.proj.weight
+ | 0.002 | -0.064 | 0.064 | 0.036 | torch.Size([120]) || stage2.residual_group1.blocks.1.attn.proj.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage2.residual_group1.blocks.1.attn.qkv_mut.weight
+ | -0.003 | -0.091 | 0.090 | 0.050 | torch.Size([360]) || stage2.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.1.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.1.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage2.residual_group1.blocks.1.mlp.fc11.weight
+ | 0.000 | -0.091 | 0.091 | 0.054 | torch.Size([240]) || stage2.residual_group1.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.052 | torch.Size([240, 120]) || stage2.residual_group1.blocks.1.mlp.fc12.weight
+ | 0.013 | -0.090 | 0.090 | 0.052 | torch.Size([240]) || stage2.residual_group1.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage2.residual_group1.blocks.1.mlp.fc2.weight
+ | 0.001 | -0.064 | 0.064 | 0.039 | torch.Size([120]) || stage2.residual_group1.blocks.1.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.2.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.2.norm1.bias
+ | -0.000 | -0.076 | 0.073 | 0.020 | torch.Size([675, 6]) || stage2.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.2.attn.position_bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage2.residual_group1.blocks.2.attn.qkv_self.weight
+ | 0.001 | -0.091 | 0.091 | 0.053 | torch.Size([360]) || stage2.residual_group1.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage2.residual_group1.blocks.2.attn.proj.weight
+ | 0.001 | -0.063 | 0.064 | 0.039 | torch.Size([120]) || stage2.residual_group1.blocks.2.attn.proj.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage2.residual_group1.blocks.2.attn.qkv_mut.weight
+ | -0.002 | -0.091 | 0.091 | 0.054 | torch.Size([360]) || stage2.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.2.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.2.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage2.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.006 | -0.090 | 0.090 | 0.051 | torch.Size([240]) || stage2.residual_group1.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage2.residual_group1.blocks.2.mlp.fc12.weight
+ | -0.003 | -0.091 | 0.091 | 0.054 | torch.Size([240]) || stage2.residual_group1.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage2.residual_group1.blocks.2.mlp.fc2.weight
+ | -0.002 | -0.064 | 0.064 | 0.037 | torch.Size([120]) || stage2.residual_group1.blocks.2.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.3.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.3.norm1.bias
+ | -0.000 | -0.084 | 0.068 | 0.020 | torch.Size([675, 6]) || stage2.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.3.attn.position_bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage2.residual_group1.blocks.3.attn.qkv_self.weight
+ | -0.002 | -0.091 | 0.090 | 0.052 | torch.Size([360]) || stage2.residual_group1.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage2.residual_group1.blocks.3.attn.proj.weight
+ | -0.002 | -0.064 | 0.064 | 0.038 | torch.Size([120]) || stage2.residual_group1.blocks.3.attn.proj.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage2.residual_group1.blocks.3.attn.qkv_mut.weight
+ | -0.001 | -0.091 | 0.090 | 0.052 | torch.Size([360]) || stage2.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.3.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.3.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage2.residual_group1.blocks.3.mlp.fc11.weight
+ | 0.001 | -0.091 | 0.091 | 0.053 | torch.Size([240]) || stage2.residual_group1.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage2.residual_group1.blocks.3.mlp.fc12.weight
+ | 0.005 | -0.086 | 0.090 | 0.052 | torch.Size([240]) || stage2.residual_group1.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage2.residual_group1.blocks.3.mlp.fc2.weight
+ | 0.003 | -0.063 | 0.064 | 0.037 | torch.Size([120]) || stage2.residual_group1.blocks.3.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.4.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.4.norm1.bias
+ | 0.000 | -0.070 | 0.072 | 0.020 | torch.Size([675, 6]) || stage2.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.4.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage2.residual_group1.blocks.4.attn.qkv_self.weight
+ | 0.003 | -0.091 | 0.091 | 0.055 | torch.Size([360]) || stage2.residual_group1.blocks.4.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage2.residual_group1.blocks.4.attn.proj.weight
+ | 0.006 | -0.058 | 0.064 | 0.036 | torch.Size([120]) || stage2.residual_group1.blocks.4.attn.proj.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage2.residual_group1.blocks.4.attn.qkv_mut.weight
+ | -0.000 | -0.091 | 0.091 | 0.052 | torch.Size([360]) || stage2.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.4.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.4.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage2.residual_group1.blocks.4.mlp.fc11.weight
+ | 0.001 | -0.091 | 0.091 | 0.053 | torch.Size([240]) || stage2.residual_group1.blocks.4.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.052 | torch.Size([240, 120]) || stage2.residual_group1.blocks.4.mlp.fc12.weight
+ | -0.002 | -0.089 | 0.091 | 0.051 | torch.Size([240]) || stage2.residual_group1.blocks.4.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage2.residual_group1.blocks.4.mlp.fc2.weight
+ | 0.006 | -0.064 | 0.064 | 0.038 | torch.Size([120]) || stage2.residual_group1.blocks.4.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.5.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.5.norm1.bias
+ | 0.000 | -0.070 | 0.080 | 0.020 | torch.Size([675, 6]) || stage2.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.5.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage2.residual_group1.blocks.5.attn.qkv_self.weight
+ | -0.000 | -0.091 | 0.090 | 0.050 | torch.Size([360]) || stage2.residual_group1.blocks.5.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage2.residual_group1.blocks.5.attn.proj.weight
+ | -0.000 | -0.064 | 0.064 | 0.037 | torch.Size([120]) || stage2.residual_group1.blocks.5.attn.proj.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage2.residual_group1.blocks.5.attn.qkv_mut.weight
+ | 0.001 | -0.091 | 0.091 | 0.054 | torch.Size([360]) || stage2.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.5.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage2.residual_group1.blocks.5.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage2.residual_group1.blocks.5.mlp.fc11.weight
+ | 0.004 | -0.091 | 0.090 | 0.051 | torch.Size([240]) || stage2.residual_group1.blocks.5.mlp.fc11.bias
+ | -0.001 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage2.residual_group1.blocks.5.mlp.fc12.weight
+ | -0.005 | -0.090 | 0.091 | 0.053 | torch.Size([240]) || stage2.residual_group1.blocks.5.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage2.residual_group1.blocks.5.mlp.fc2.weight
+ | 0.002 | -0.064 | 0.064 | 0.036 | torch.Size([120]) || stage2.residual_group1.blocks.5.mlp.fc2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage2.linear1.weight
+ | 0.005 | -0.091 | 0.091 | 0.055 | torch.Size([120]) || stage2.linear1.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage2.residual_group2.blocks.0.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage2.residual_group2.blocks.0.norm1.bias
+ | -0.000 | -0.079 | 0.073 | 0.020 | torch.Size([2475, 6]) || stage2.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage2.residual_group2.blocks.0.attn.relative_position_index
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage2.residual_group2.blocks.0.attn.qkv_self.weight
+ | -0.002 | -0.091 | 0.091 | 0.051 | torch.Size([360]) || stage2.residual_group2.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage2.residual_group2.blocks.0.attn.proj.weight
+ | -0.002 | -0.091 | 0.088 | 0.052 | torch.Size([120]) || stage2.residual_group2.blocks.0.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage2.residual_group2.blocks.0.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage2.residual_group2.blocks.0.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage2.residual_group2.blocks.0.mlp.fc11.weight
+ | 0.000 | -0.091 | 0.091 | 0.052 | torch.Size([240]) || stage2.residual_group2.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage2.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.003 | -0.091 | 0.091 | 0.054 | torch.Size([240]) || stage2.residual_group2.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage2.residual_group2.blocks.0.mlp.fc2.weight
+ | 0.002 | -0.064 | 0.063 | 0.035 | torch.Size([120]) || stage2.residual_group2.blocks.0.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage2.residual_group2.blocks.1.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage2.residual_group2.blocks.1.norm1.bias
+ | -0.000 | -0.076 | 0.082 | 0.020 | torch.Size([2475, 6]) || stage2.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage2.residual_group2.blocks.1.attn.relative_position_index
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage2.residual_group2.blocks.1.attn.qkv_self.weight
+ | -0.002 | -0.091 | 0.091 | 0.053 | torch.Size([360]) || stage2.residual_group2.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage2.residual_group2.blocks.1.attn.proj.weight
+ | -0.001 | -0.091 | 0.091 | 0.052 | torch.Size([120]) || stage2.residual_group2.blocks.1.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage2.residual_group2.blocks.1.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage2.residual_group2.blocks.1.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage2.residual_group2.blocks.1.mlp.fc11.weight
+ | 0.002 | -0.091 | 0.091 | 0.053 | torch.Size([240]) || stage2.residual_group2.blocks.1.mlp.fc11.bias
+ | 0.001 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage2.residual_group2.blocks.1.mlp.fc12.weight
+ | -0.007 | -0.091 | 0.091 | 0.053 | torch.Size([240]) || stage2.residual_group2.blocks.1.mlp.fc12.bias
+ | 0.001 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage2.residual_group2.blocks.1.mlp.fc2.weight
+ | 0.002 | -0.065 | 0.064 | 0.037 | torch.Size([120]) || stage2.residual_group2.blocks.1.mlp.fc2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage2.linear2.weight
+ | 0.000 | -0.088 | 0.091 | 0.053 | torch.Size([120]) || stage2.linear2.bias
+ | -0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage2.pa_deform.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage2.pa_deform.bias
+ | -0.000 | -0.021 | 0.021 | 0.012 | torch.Size([120, 242, 3, 3]) || stage2.pa_deform.conv_offset.0.weight
+ | -0.001 | -0.021 | 0.021 | 0.013 | torch.Size([120]) || stage2.pa_deform.conv_offset.0.bias
+ | -0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage2.pa_deform.conv_offset.2.weight
+ | -0.002 | -0.030 | 0.029 | 0.017 | torch.Size([120]) || stage2.pa_deform.conv_offset.2.bias
+ | 0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage2.pa_deform.conv_offset.4.weight
+ | -0.001 | -0.030 | 0.030 | 0.017 | torch.Size([120]) || stage2.pa_deform.conv_offset.4.bias
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([324, 120, 3, 3]) || stage2.pa_deform.conv_offset.6.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([324]) || stage2.pa_deform.conv_offset.6.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([360, 360]) || stage2.pa_fuse.fc11.weight
+ | -0.002 | -0.053 | 0.052 | 0.030 | torch.Size([360]) || stage2.pa_fuse.fc11.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([360, 360]) || stage2.pa_fuse.fc12.weight
+ | -0.001 | -0.052 | 0.053 | 0.031 | torch.Size([360]) || stage2.pa_fuse.fc12.bias
+ | -0.000 | -0.053 | 0.053 | 0.031 | torch.Size([120, 360]) || stage2.pa_fuse.fc2.weight
+ | 0.001 | -0.045 | 0.051 | 0.029 | torch.Size([120]) || stage2.pa_fuse.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([480]) || stage3.reshape.1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([480]) || stage3.reshape.1.bias
+ | -0.000 | -0.046 | 0.046 | 0.026 | torch.Size([120, 480]) || stage3.reshape.2.weight
+ | 0.001 | -0.045 | 0.045 | 0.028 | torch.Size([120]) || stage3.reshape.2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.0.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.0.norm1.bias
+ | 0.000 | -0.075 | 0.073 | 0.020 | torch.Size([675, 6]) || stage3.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.0.attn.position_bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage3.residual_group1.blocks.0.attn.qkv_self.weight
+ | -0.003 | -0.091 | 0.091 | 0.052 | torch.Size([360]) || stage3.residual_group1.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage3.residual_group1.blocks.0.attn.proj.weight
+ | 0.003 | -0.061 | 0.063 | 0.038 | torch.Size([120]) || stage3.residual_group1.blocks.0.attn.proj.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage3.residual_group1.blocks.0.attn.qkv_mut.weight
+ | 0.001 | -0.091 | 0.091 | 0.052 | torch.Size([360]) || stage3.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.0.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.0.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage3.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.003 | -0.091 | 0.089 | 0.053 | torch.Size([240]) || stage3.residual_group1.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage3.residual_group1.blocks.0.mlp.fc12.weight
+ | -0.002 | -0.091 | 0.090 | 0.055 | torch.Size([240]) || stage3.residual_group1.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage3.residual_group1.blocks.0.mlp.fc2.weight
+ | 0.000 | -0.063 | 0.064 | 0.039 | torch.Size([120]) || stage3.residual_group1.blocks.0.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.1.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.1.norm1.bias
+ | -0.000 | -0.076 | 0.078 | 0.020 | torch.Size([675, 6]) || stage3.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.1.attn.position_bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage3.residual_group1.blocks.1.attn.qkv_self.weight
+ | 0.004 | -0.091 | 0.091 | 0.052 | torch.Size([360]) || stage3.residual_group1.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage3.residual_group1.blocks.1.attn.proj.weight
+ | 0.002 | -0.061 | 0.060 | 0.036 | torch.Size([120]) || stage3.residual_group1.blocks.1.attn.proj.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage3.residual_group1.blocks.1.attn.qkv_mut.weight
+ | 0.001 | -0.091 | 0.090 | 0.054 | torch.Size([360]) || stage3.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.1.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.1.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage3.residual_group1.blocks.1.mlp.fc11.weight
+ | 0.001 | -0.090 | 0.091 | 0.052 | torch.Size([240]) || stage3.residual_group1.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage3.residual_group1.blocks.1.mlp.fc12.weight
+ | 0.005 | -0.090 | 0.091 | 0.054 | torch.Size([240]) || stage3.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage3.residual_group1.blocks.1.mlp.fc2.weight
+ | 0.006 | -0.064 | 0.063 | 0.038 | torch.Size([120]) || stage3.residual_group1.blocks.1.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.2.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.2.norm1.bias
+ | -0.000 | -0.072 | 0.067 | 0.020 | torch.Size([675, 6]) || stage3.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.2.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage3.residual_group1.blocks.2.attn.qkv_self.weight
+ | 0.003 | -0.091 | 0.091 | 0.053 | torch.Size([360]) || stage3.residual_group1.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage3.residual_group1.blocks.2.attn.proj.weight
+ | 0.003 | -0.064 | 0.064 | 0.040 | torch.Size([120]) || stage3.residual_group1.blocks.2.attn.proj.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage3.residual_group1.blocks.2.attn.qkv_mut.weight
+ | 0.002 | -0.090 | 0.091 | 0.051 | torch.Size([360]) || stage3.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.2.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.2.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage3.residual_group1.blocks.2.mlp.fc11.weight
+ | 0.004 | -0.091 | 0.091 | 0.053 | torch.Size([240]) || stage3.residual_group1.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage3.residual_group1.blocks.2.mlp.fc12.weight
+ | 0.001 | -0.091 | 0.091 | 0.054 | torch.Size([240]) || stage3.residual_group1.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage3.residual_group1.blocks.2.mlp.fc2.weight
+ | -0.006 | -0.063 | 0.063 | 0.037 | torch.Size([120]) || stage3.residual_group1.blocks.2.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.3.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.3.norm1.bias
+ | 0.000 | -0.071 | 0.069 | 0.020 | torch.Size([675, 6]) || stage3.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.3.attn.position_bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage3.residual_group1.blocks.3.attn.qkv_self.weight
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360]) || stage3.residual_group1.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage3.residual_group1.blocks.3.attn.proj.weight
+ | 0.006 | -0.064 | 0.064 | 0.035 | torch.Size([120]) || stage3.residual_group1.blocks.3.attn.proj.bias
+ | -0.001 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage3.residual_group1.blocks.3.attn.qkv_mut.weight
+ | -0.003 | -0.091 | 0.091 | 0.052 | torch.Size([360]) || stage3.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.3.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.3.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage3.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.006 | -0.090 | 0.090 | 0.052 | torch.Size([240]) || stage3.residual_group1.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage3.residual_group1.blocks.3.mlp.fc12.weight
+ | -0.001 | -0.091 | 0.091 | 0.052 | torch.Size([240]) || stage3.residual_group1.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage3.residual_group1.blocks.3.mlp.fc2.weight
+ | 0.004 | -0.064 | 0.061 | 0.036 | torch.Size([120]) || stage3.residual_group1.blocks.3.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.4.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.4.norm1.bias
+ | -0.000 | -0.073 | 0.069 | 0.020 | torch.Size([675, 6]) || stage3.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.4.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage3.residual_group1.blocks.4.attn.qkv_self.weight
+ | -0.002 | -0.091 | 0.091 | 0.053 | torch.Size([360]) || stage3.residual_group1.blocks.4.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage3.residual_group1.blocks.4.attn.proj.weight
+ | -0.001 | -0.064 | 0.063 | 0.037 | torch.Size([120]) || stage3.residual_group1.blocks.4.attn.proj.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage3.residual_group1.blocks.4.attn.qkv_mut.weight
+ | -0.000 | -0.091 | 0.091 | 0.054 | torch.Size([360]) || stage3.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.4.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.4.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage3.residual_group1.blocks.4.mlp.fc11.weight
+ | 0.006 | -0.091 | 0.090 | 0.055 | torch.Size([240]) || stage3.residual_group1.blocks.4.mlp.fc11.bias
+ | -0.001 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage3.residual_group1.blocks.4.mlp.fc12.weight
+ | 0.001 | -0.091 | 0.091 | 0.053 | torch.Size([240]) || stage3.residual_group1.blocks.4.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage3.residual_group1.blocks.4.mlp.fc2.weight
+ | 0.001 | -0.064 | 0.064 | 0.036 | torch.Size([120]) || stage3.residual_group1.blocks.4.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.5.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.5.norm1.bias
+ | 0.000 | -0.072 | 0.077 | 0.020 | torch.Size([675, 6]) || stage3.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.5.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage3.residual_group1.blocks.5.attn.qkv_self.weight
+ | 0.001 | -0.089 | 0.090 | 0.049 | torch.Size([360]) || stage3.residual_group1.blocks.5.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage3.residual_group1.blocks.5.attn.proj.weight
+ | -0.006 | -0.064 | 0.064 | 0.039 | torch.Size([120]) || stage3.residual_group1.blocks.5.attn.proj.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage3.residual_group1.blocks.5.attn.qkv_mut.weight
+ | -0.005 | -0.090 | 0.091 | 0.054 | torch.Size([360]) || stage3.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.5.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage3.residual_group1.blocks.5.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage3.residual_group1.blocks.5.mlp.fc11.weight
+ | 0.000 | -0.091 | 0.091 | 0.054 | torch.Size([240]) || stage3.residual_group1.blocks.5.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage3.residual_group1.blocks.5.mlp.fc12.weight
+ | 0.000 | -0.090 | 0.091 | 0.052 | torch.Size([240]) || stage3.residual_group1.blocks.5.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage3.residual_group1.blocks.5.mlp.fc2.weight
+ | -0.002 | -0.064 | 0.063 | 0.036 | torch.Size([120]) || stage3.residual_group1.blocks.5.mlp.fc2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage3.linear1.weight
+ | -0.002 | -0.091 | 0.091 | 0.052 | torch.Size([120]) || stage3.linear1.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage3.residual_group2.blocks.0.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage3.residual_group2.blocks.0.norm1.bias
+ | -0.000 | -0.095 | 0.080 | 0.020 | torch.Size([2475, 6]) || stage3.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage3.residual_group2.blocks.0.attn.relative_position_index
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage3.residual_group2.blocks.0.attn.qkv_self.weight
+ | 0.002 | -0.091 | 0.091 | 0.055 | torch.Size([360]) || stage3.residual_group2.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.091 | 0.091 | 0.052 | torch.Size([120, 120]) || stage3.residual_group2.blocks.0.attn.proj.weight
+ | -0.001 | -0.090 | 0.091 | 0.049 | torch.Size([120]) || stage3.residual_group2.blocks.0.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage3.residual_group2.blocks.0.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage3.residual_group2.blocks.0.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage3.residual_group2.blocks.0.mlp.fc11.weight
+ | 0.001 | -0.091 | 0.091 | 0.052 | torch.Size([240]) || stage3.residual_group2.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage3.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.003 | -0.091 | 0.091 | 0.054 | torch.Size([240]) || stage3.residual_group2.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage3.residual_group2.blocks.0.mlp.fc2.weight
+ | -0.003 | -0.064 | 0.063 | 0.039 | torch.Size([120]) || stage3.residual_group2.blocks.0.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage3.residual_group2.blocks.1.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage3.residual_group2.blocks.1.norm1.bias
+ | -0.000 | -0.081 | 0.070 | 0.020 | torch.Size([2475, 6]) || stage3.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage3.residual_group2.blocks.1.attn.relative_position_index
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage3.residual_group2.blocks.1.attn.qkv_self.weight
+ | -0.002 | -0.091 | 0.091 | 0.052 | torch.Size([360]) || stage3.residual_group2.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.091 | 0.091 | 0.052 | torch.Size([120, 120]) || stage3.residual_group2.blocks.1.attn.proj.weight
+ | -0.000 | -0.091 | 0.091 | 0.054 | torch.Size([120]) || stage3.residual_group2.blocks.1.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage3.residual_group2.blocks.1.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage3.residual_group2.blocks.1.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage3.residual_group2.blocks.1.mlp.fc11.weight
+ | 0.004 | -0.091 | 0.091 | 0.052 | torch.Size([240]) || stage3.residual_group2.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage3.residual_group2.blocks.1.mlp.fc12.weight
+ | -0.005 | -0.090 | 0.091 | 0.054 | torch.Size([240]) || stage3.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.001 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage3.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.005 | -0.064 | 0.064 | 0.038 | torch.Size([120]) || stage3.residual_group2.blocks.1.mlp.fc2.bias
+ | -0.001 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage3.linear2.weight
+ | 0.001 | -0.089 | 0.091 | 0.051 | torch.Size([120]) || stage3.linear2.bias
+ | -0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage3.pa_deform.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage3.pa_deform.bias
+ | 0.000 | -0.021 | 0.021 | 0.012 | torch.Size([120, 242, 3, 3]) || stage3.pa_deform.conv_offset.0.weight
+ | -0.002 | -0.021 | 0.021 | 0.013 | torch.Size([120]) || stage3.pa_deform.conv_offset.0.bias
+ | -0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage3.pa_deform.conv_offset.2.weight
+ | 0.002 | -0.030 | 0.030 | 0.017 | torch.Size([120]) || stage3.pa_deform.conv_offset.2.bias
+ | -0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage3.pa_deform.conv_offset.4.weight
+ | 0.000 | -0.030 | 0.030 | 0.017 | torch.Size([120]) || stage3.pa_deform.conv_offset.4.bias
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([324, 120, 3, 3]) || stage3.pa_deform.conv_offset.6.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([324]) || stage3.pa_deform.conv_offset.6.bias
+ | 0.000 | -0.053 | 0.053 | 0.030 | torch.Size([360, 360]) || stage3.pa_fuse.fc11.weight
+ | -0.001 | -0.052 | 0.052 | 0.030 | torch.Size([360]) || stage3.pa_fuse.fc11.bias
+ | 0.000 | -0.053 | 0.053 | 0.030 | torch.Size([360, 360]) || stage3.pa_fuse.fc12.weight
+ | 0.001 | -0.052 | 0.053 | 0.030 | torch.Size([360]) || stage3.pa_fuse.fc12.bias
+ | 0.000 | -0.053 | 0.053 | 0.030 | torch.Size([120, 360]) || stage3.pa_fuse.fc2.weight
+ | 0.007 | -0.051 | 0.052 | 0.030 | torch.Size([120]) || stage3.pa_fuse.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([480]) || stage4.reshape.1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([480]) || stage4.reshape.1.bias
+ | -0.000 | -0.046 | 0.046 | 0.026 | torch.Size([120, 480]) || stage4.reshape.2.weight
+ | 0.003 | -0.045 | 0.045 | 0.028 | torch.Size([120]) || stage4.reshape.2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.0.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.0.norm1.bias
+ | -0.000 | -0.068 | 0.084 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.0.attn.position_bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage4.residual_group1.blocks.0.attn.qkv_self.weight
+ | 0.006 | -0.091 | 0.091 | 0.055 | torch.Size([360]) || stage4.residual_group1.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage4.residual_group1.blocks.0.attn.proj.weight
+ | 0.003 | -0.064 | 0.064 | 0.037 | torch.Size([120]) || stage4.residual_group1.blocks.0.attn.proj.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage4.residual_group1.blocks.0.attn.qkv_mut.weight
+ | -0.001 | -0.090 | 0.091 | 0.051 | torch.Size([360]) || stage4.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.0.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.0.norm2.bias
+ | 0.001 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage4.residual_group1.blocks.0.mlp.fc11.weight
+ | 0.004 | -0.091 | 0.091 | 0.052 | torch.Size([240]) || stage4.residual_group1.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage4.residual_group1.blocks.0.mlp.fc12.weight
+ | 0.001 | -0.090 | 0.089 | 0.052 | torch.Size([240]) || stage4.residual_group1.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage4.residual_group1.blocks.0.mlp.fc2.weight
+ | -0.002 | -0.064 | 0.063 | 0.038 | torch.Size([120]) || stage4.residual_group1.blocks.0.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.1.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.1.norm1.bias
+ | 0.000 | -0.076 | 0.082 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.1.attn.position_bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage4.residual_group1.blocks.1.attn.qkv_self.weight
+ | -0.000 | -0.091 | 0.090 | 0.052 | torch.Size([360]) || stage4.residual_group1.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage4.residual_group1.blocks.1.attn.proj.weight
+ | -0.001 | -0.064 | 0.063 | 0.038 | torch.Size([120]) || stage4.residual_group1.blocks.1.attn.proj.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage4.residual_group1.blocks.1.attn.qkv_mut.weight
+ | -0.002 | -0.091 | 0.090 | 0.052 | torch.Size([360]) || stage4.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.1.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.1.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage4.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.005 | -0.091 | 0.090 | 0.052 | torch.Size([240]) || stage4.residual_group1.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage4.residual_group1.blocks.1.mlp.fc12.weight
+ | 0.006 | -0.090 | 0.090 | 0.053 | torch.Size([240]) || stage4.residual_group1.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage4.residual_group1.blocks.1.mlp.fc2.weight
+ | 0.001 | -0.062 | 0.064 | 0.036 | torch.Size([120]) || stage4.residual_group1.blocks.1.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.2.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.2.norm1.bias
+ | -0.000 | -0.071 | 0.082 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.2.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage4.residual_group1.blocks.2.attn.qkv_self.weight
+ | 0.002 | -0.091 | 0.091 | 0.052 | torch.Size([360]) || stage4.residual_group1.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage4.residual_group1.blocks.2.attn.proj.weight
+ | 0.004 | -0.063 | 0.064 | 0.041 | torch.Size([120]) || stage4.residual_group1.blocks.2.attn.proj.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage4.residual_group1.blocks.2.attn.qkv_mut.weight
+ | 0.003 | -0.091 | 0.089 | 0.053 | torch.Size([360]) || stage4.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.2.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.2.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage4.residual_group1.blocks.2.mlp.fc11.weight
+ | 0.006 | -0.091 | 0.090 | 0.050 | torch.Size([240]) || stage4.residual_group1.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage4.residual_group1.blocks.2.mlp.fc12.weight
+ | -0.000 | -0.088 | 0.091 | 0.052 | torch.Size([240]) || stage4.residual_group1.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage4.residual_group1.blocks.2.mlp.fc2.weight
+ | -0.002 | -0.064 | 0.063 | 0.040 | torch.Size([120]) || stage4.residual_group1.blocks.2.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.3.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.3.norm1.bias
+ | 0.000 | -0.083 | 0.065 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.3.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage4.residual_group1.blocks.3.attn.qkv_self.weight
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360]) || stage4.residual_group1.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage4.residual_group1.blocks.3.attn.proj.weight
+ | 0.000 | -0.063 | 0.064 | 0.039 | torch.Size([120]) || stage4.residual_group1.blocks.3.attn.proj.bias
+ | -0.001 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage4.residual_group1.blocks.3.attn.qkv_mut.weight
+ | 0.001 | -0.091 | 0.091 | 0.054 | torch.Size([360]) || stage4.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.3.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.3.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage4.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.001 | -0.091 | 0.090 | 0.053 | torch.Size([240]) || stage4.residual_group1.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.052 | torch.Size([240, 120]) || stage4.residual_group1.blocks.3.mlp.fc12.weight
+ | -0.005 | -0.091 | 0.091 | 0.051 | torch.Size([240]) || stage4.residual_group1.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage4.residual_group1.blocks.3.mlp.fc2.weight
+ | -0.002 | -0.064 | 0.062 | 0.034 | torch.Size([120]) || stage4.residual_group1.blocks.3.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.4.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.4.norm1.bias
+ | -0.000 | -0.078 | 0.072 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.4.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage4.residual_group1.blocks.4.attn.qkv_self.weight
+ | 0.001 | -0.091 | 0.091 | 0.053 | torch.Size([360]) || stage4.residual_group1.blocks.4.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage4.residual_group1.blocks.4.attn.proj.weight
+ | -0.001 | -0.063 | 0.064 | 0.037 | torch.Size([120]) || stage4.residual_group1.blocks.4.attn.proj.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage4.residual_group1.blocks.4.attn.qkv_mut.weight
+ | 0.004 | -0.091 | 0.091 | 0.054 | torch.Size([360]) || stage4.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.4.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.4.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage4.residual_group1.blocks.4.mlp.fc11.weight
+ | 0.005 | -0.091 | 0.090 | 0.055 | torch.Size([240]) || stage4.residual_group1.blocks.4.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage4.residual_group1.blocks.4.mlp.fc12.weight
+ | -0.004 | -0.091 | 0.091 | 0.052 | torch.Size([240]) || stage4.residual_group1.blocks.4.mlp.fc12.bias
+ | -0.001 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage4.residual_group1.blocks.4.mlp.fc2.weight
+ | -0.005 | -0.064 | 0.063 | 0.037 | torch.Size([120]) || stage4.residual_group1.blocks.4.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.5.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.5.norm1.bias
+ | 0.000 | -0.079 | 0.076 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.5.attn.position_bias
+ | 0.001 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage4.residual_group1.blocks.5.attn.qkv_self.weight
+ | 0.001 | -0.091 | 0.091 | 0.050 | torch.Size([360]) || stage4.residual_group1.blocks.5.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage4.residual_group1.blocks.5.attn.proj.weight
+ | -0.002 | -0.063 | 0.064 | 0.037 | torch.Size([120]) || stage4.residual_group1.blocks.5.attn.proj.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage4.residual_group1.blocks.5.attn.qkv_mut.weight
+ | -0.001 | -0.091 | 0.091 | 0.053 | torch.Size([360]) || stage4.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.5.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.5.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage4.residual_group1.blocks.5.mlp.fc11.weight
+ | 0.005 | -0.090 | 0.089 | 0.053 | torch.Size([240]) || stage4.residual_group1.blocks.5.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage4.residual_group1.blocks.5.mlp.fc12.weight
+ | 0.002 | -0.091 | 0.091 | 0.053 | torch.Size([240]) || stage4.residual_group1.blocks.5.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage4.residual_group1.blocks.5.mlp.fc2.weight
+ | -0.003 | -0.063 | 0.063 | 0.038 | torch.Size([120]) || stage4.residual_group1.blocks.5.mlp.fc2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage4.linear1.weight
+ | 0.004 | -0.089 | 0.090 | 0.054 | torch.Size([120]) || stage4.linear1.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group2.blocks.0.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group2.blocks.0.norm1.bias
+ | -0.000 | -0.081 | 0.077 | 0.020 | torch.Size([2475, 6]) || stage4.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage4.residual_group2.blocks.0.attn.relative_position_index
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage4.residual_group2.blocks.0.attn.qkv_self.weight
+ | -0.000 | -0.091 | 0.091 | 0.052 | torch.Size([360]) || stage4.residual_group2.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage4.residual_group2.blocks.0.attn.proj.weight
+ | -0.005 | -0.090 | 0.091 | 0.051 | torch.Size([120]) || stage4.residual_group2.blocks.0.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group2.blocks.0.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group2.blocks.0.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage4.residual_group2.blocks.0.mlp.fc11.weight
+ | -0.003 | -0.088 | 0.091 | 0.052 | torch.Size([240]) || stage4.residual_group2.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage4.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.001 | -0.091 | 0.091 | 0.054 | torch.Size([240]) || stage4.residual_group2.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage4.residual_group2.blocks.0.mlp.fc2.weight
+ | -0.004 | -0.064 | 0.065 | 0.039 | torch.Size([120]) || stage4.residual_group2.blocks.0.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group2.blocks.1.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group2.blocks.1.norm1.bias
+ | 0.000 | -0.074 | 0.079 | 0.020 | torch.Size([2475, 6]) || stage4.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage4.residual_group2.blocks.1.attn.relative_position_index
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage4.residual_group2.blocks.1.attn.qkv_self.weight
+ | -0.004 | -0.091 | 0.090 | 0.050 | torch.Size([360]) || stage4.residual_group2.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage4.residual_group2.blocks.1.attn.proj.weight
+ | 0.005 | -0.090 | 0.088 | 0.053 | torch.Size([120]) || stage4.residual_group2.blocks.1.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group2.blocks.1.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group2.blocks.1.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage4.residual_group2.blocks.1.mlp.fc11.weight
+ | 0.001 | -0.091 | 0.091 | 0.054 | torch.Size([240]) || stage4.residual_group2.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage4.residual_group2.blocks.1.mlp.fc12.weight
+ | 0.003 | -0.091 | 0.090 | 0.053 | torch.Size([240]) || stage4.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage4.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.005 | -0.064 | 0.064 | 0.039 | torch.Size([120]) || stage4.residual_group2.blocks.1.mlp.fc2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage4.linear2.weight
+ | -0.001 | -0.091 | 0.087 | 0.054 | torch.Size([120]) || stage4.linear2.bias
+ | -0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage4.pa_deform.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.pa_deform.bias
+ | -0.000 | -0.021 | 0.021 | 0.012 | torch.Size([120, 242, 3, 3]) || stage4.pa_deform.conv_offset.0.weight
+ | 0.001 | -0.021 | 0.021 | 0.013 | torch.Size([120]) || stage4.pa_deform.conv_offset.0.bias
+ | 0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage4.pa_deform.conv_offset.2.weight
+ | 0.001 | -0.030 | 0.029 | 0.017 | torch.Size([120]) || stage4.pa_deform.conv_offset.2.bias
+ | 0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage4.pa_deform.conv_offset.4.weight
+ | 0.001 | -0.030 | 0.030 | 0.017 | torch.Size([120]) || stage4.pa_deform.conv_offset.4.bias
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([324, 120, 3, 3]) || stage4.pa_deform.conv_offset.6.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([324]) || stage4.pa_deform.conv_offset.6.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([360, 360]) || stage4.pa_fuse.fc11.weight
+ | -0.001 | -0.053 | 0.052 | 0.031 | torch.Size([360]) || stage4.pa_fuse.fc11.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([360, 360]) || stage4.pa_fuse.fc12.weight
+ | 0.001 | -0.053 | 0.052 | 0.031 | torch.Size([360]) || stage4.pa_fuse.fc12.bias
+ | 0.000 | -0.053 | 0.053 | 0.030 | torch.Size([120, 360]) || stage4.pa_fuse.fc2.weight
+ | 0.003 | -0.053 | 0.052 | 0.029 | torch.Size([120]) || stage4.pa_fuse.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([30]) || stage5.reshape.1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([30]) || stage5.reshape.1.bias
+ | 0.001 | -0.182 | 0.182 | 0.106 | torch.Size([120, 30]) || stage5.reshape.2.weight
+ | 0.009 | -0.178 | 0.182 | 0.107 | torch.Size([120]) || stage5.reshape.2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.0.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.0.norm1.bias
+ | 0.000 | -0.067 | 0.075 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.0.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage5.residual_group1.blocks.0.attn.qkv_self.weight
+ | 0.001 | -0.091 | 0.091 | 0.055 | torch.Size([360]) || stage5.residual_group1.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage5.residual_group1.blocks.0.attn.proj.weight
+ | 0.002 | -0.063 | 0.064 | 0.039 | torch.Size([120]) || stage5.residual_group1.blocks.0.attn.proj.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage5.residual_group1.blocks.0.attn.qkv_mut.weight
+ | -0.005 | -0.090 | 0.091 | 0.052 | torch.Size([360]) || stage5.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.0.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.0.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage5.residual_group1.blocks.0.mlp.fc11.weight
+ | 0.004 | -0.090 | 0.090 | 0.052 | torch.Size([240]) || stage5.residual_group1.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage5.residual_group1.blocks.0.mlp.fc12.weight
+ | -0.004 | -0.091 | 0.090 | 0.055 | torch.Size([240]) || stage5.residual_group1.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage5.residual_group1.blocks.0.mlp.fc2.weight
+ | 0.005 | -0.064 | 0.062 | 0.038 | torch.Size([120]) || stage5.residual_group1.blocks.0.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.1.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.1.norm1.bias
+ | 0.000 | -0.073 | 0.071 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.1.attn.position_bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage5.residual_group1.blocks.1.attn.qkv_self.weight
+ | -0.001 | -0.091 | 0.091 | 0.054 | torch.Size([360]) || stage5.residual_group1.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage5.residual_group1.blocks.1.attn.proj.weight
+ | -0.002 | -0.064 | 0.061 | 0.035 | torch.Size([120]) || stage5.residual_group1.blocks.1.attn.proj.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage5.residual_group1.blocks.1.attn.qkv_mut.weight
+ | 0.002 | -0.091 | 0.090 | 0.050 | torch.Size([360]) || stage5.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.1.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.1.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage5.residual_group1.blocks.1.mlp.fc11.weight
+ | 0.002 | -0.091 | 0.090 | 0.054 | torch.Size([240]) || stage5.residual_group1.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage5.residual_group1.blocks.1.mlp.fc12.weight
+ | 0.006 | -0.091 | 0.090 | 0.054 | torch.Size([240]) || stage5.residual_group1.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage5.residual_group1.blocks.1.mlp.fc2.weight
+ | 0.007 | -0.064 | 0.064 | 0.038 | torch.Size([120]) || stage5.residual_group1.blocks.1.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.2.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.2.norm1.bias
+ | -0.000 | -0.074 | 0.089 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.2.attn.position_bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage5.residual_group1.blocks.2.attn.qkv_self.weight
+ | 0.003 | -0.091 | 0.091 | 0.053 | torch.Size([360]) || stage5.residual_group1.blocks.2.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage5.residual_group1.blocks.2.attn.proj.weight
+ | 0.001 | -0.062 | 0.064 | 0.038 | torch.Size([120]) || stage5.residual_group1.blocks.2.attn.proj.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage5.residual_group1.blocks.2.attn.qkv_mut.weight
+ | 0.001 | -0.091 | 0.091 | 0.054 | torch.Size([360]) || stage5.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.2.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.2.norm2.bias
+ | -0.001 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage5.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.002 | -0.091 | 0.091 | 0.054 | torch.Size([240]) || stage5.residual_group1.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage5.residual_group1.blocks.2.mlp.fc12.weight
+ | 0.000 | -0.090 | 0.089 | 0.052 | torch.Size([240]) || stage5.residual_group1.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage5.residual_group1.blocks.2.mlp.fc2.weight
+ | 0.002 | -0.063 | 0.064 | 0.037 | torch.Size([120]) || stage5.residual_group1.blocks.2.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.3.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.3.norm1.bias
+ | -0.000 | -0.065 | 0.082 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.3.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage5.residual_group1.blocks.3.attn.qkv_self.weight
+ | -0.003 | -0.091 | 0.091 | 0.053 | torch.Size([360]) || stage5.residual_group1.blocks.3.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage5.residual_group1.blocks.3.attn.proj.weight
+ | 0.004 | -0.062 | 0.062 | 0.035 | torch.Size([120]) || stage5.residual_group1.blocks.3.attn.proj.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage5.residual_group1.blocks.3.attn.qkv_mut.weight
+ | 0.000 | -0.091 | 0.087 | 0.052 | torch.Size([360]) || stage5.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.3.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.3.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage5.residual_group1.blocks.3.mlp.fc11.weight
+ | 0.001 | -0.091 | 0.091 | 0.052 | torch.Size([240]) || stage5.residual_group1.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage5.residual_group1.blocks.3.mlp.fc12.weight
+ | -0.001 | -0.091 | 0.091 | 0.054 | torch.Size([240]) || stage5.residual_group1.blocks.3.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage5.residual_group1.blocks.3.mlp.fc2.weight
+ | -0.002 | -0.064 | 0.064 | 0.038 | torch.Size([120]) || stage5.residual_group1.blocks.3.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.4.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.4.norm1.bias
+ | 0.000 | -0.072 | 0.079 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.4.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage5.residual_group1.blocks.4.attn.qkv_self.weight
+ | 0.003 | -0.091 | 0.091 | 0.053 | torch.Size([360]) || stage5.residual_group1.blocks.4.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage5.residual_group1.blocks.4.attn.proj.weight
+ | -0.003 | -0.063 | 0.062 | 0.035 | torch.Size([120]) || stage5.residual_group1.blocks.4.attn.proj.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage5.residual_group1.blocks.4.attn.qkv_mut.weight
+ | 0.002 | -0.091 | 0.091 | 0.052 | torch.Size([360]) || stage5.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.4.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.4.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage5.residual_group1.blocks.4.mlp.fc11.weight
+ | 0.001 | -0.091 | 0.091 | 0.053 | torch.Size([240]) || stage5.residual_group1.blocks.4.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage5.residual_group1.blocks.4.mlp.fc12.weight
+ | 0.005 | -0.091 | 0.091 | 0.055 | torch.Size([240]) || stage5.residual_group1.blocks.4.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage5.residual_group1.blocks.4.mlp.fc2.weight
+ | -0.001 | -0.063 | 0.064 | 0.036 | torch.Size([120]) || stage5.residual_group1.blocks.4.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.5.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.5.norm1.bias
+ | 0.000 | -0.068 | 0.070 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.5.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage5.residual_group1.blocks.5.attn.qkv_self.weight
+ | -0.003 | -0.091 | 0.091 | 0.054 | torch.Size([360]) || stage5.residual_group1.blocks.5.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage5.residual_group1.blocks.5.attn.proj.weight
+ | -0.007 | -0.064 | 0.064 | 0.037 | torch.Size([120]) || stage5.residual_group1.blocks.5.attn.proj.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage5.residual_group1.blocks.5.attn.qkv_mut.weight
+ | -0.000 | -0.091 | 0.091 | 0.052 | torch.Size([360]) || stage5.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.5.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage5.residual_group1.blocks.5.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage5.residual_group1.blocks.5.mlp.fc11.weight
+ | 0.002 | -0.091 | 0.090 | 0.051 | torch.Size([240]) || stage5.residual_group1.blocks.5.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage5.residual_group1.blocks.5.mlp.fc12.weight
+ | 0.004 | -0.091 | 0.091 | 0.051 | torch.Size([240]) || stage5.residual_group1.blocks.5.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage5.residual_group1.blocks.5.mlp.fc2.weight
+ | -0.001 | -0.064 | 0.064 | 0.040 | torch.Size([120]) || stage5.residual_group1.blocks.5.mlp.fc2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage5.linear1.weight
+ | -0.002 | -0.090 | 0.091 | 0.057 | torch.Size([120]) || stage5.linear1.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage5.residual_group2.blocks.0.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage5.residual_group2.blocks.0.norm1.bias
+ | -0.000 | -0.078 | 0.101 | 0.020 | torch.Size([2475, 6]) || stage5.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage5.residual_group2.blocks.0.attn.relative_position_index
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage5.residual_group2.blocks.0.attn.qkv_self.weight
+ | 0.005 | -0.090 | 0.091 | 0.053 | torch.Size([360]) || stage5.residual_group2.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage5.residual_group2.blocks.0.attn.proj.weight
+ | 0.006 | -0.090 | 0.091 | 0.054 | torch.Size([120]) || stage5.residual_group2.blocks.0.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage5.residual_group2.blocks.0.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage5.residual_group2.blocks.0.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage5.residual_group2.blocks.0.mlp.fc11.weight
+ | -0.004 | -0.091 | 0.090 | 0.054 | torch.Size([240]) || stage5.residual_group2.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage5.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.003 | -0.091 | 0.090 | 0.050 | torch.Size([240]) || stage5.residual_group2.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage5.residual_group2.blocks.0.mlp.fc2.weight
+ | -0.001 | -0.064 | 0.063 | 0.039 | torch.Size([120]) || stage5.residual_group2.blocks.0.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage5.residual_group2.blocks.1.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage5.residual_group2.blocks.1.norm1.bias
+ | -0.000 | -0.087 | 0.084 | 0.020 | torch.Size([2475, 6]) || stage5.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage5.residual_group2.blocks.1.attn.relative_position_index
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage5.residual_group2.blocks.1.attn.qkv_self.weight
+ | 0.002 | -0.091 | 0.091 | 0.051 | torch.Size([360]) || stage5.residual_group2.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage5.residual_group2.blocks.1.attn.proj.weight
+ | 0.000 | -0.089 | 0.091 | 0.053 | torch.Size([120]) || stage5.residual_group2.blocks.1.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage5.residual_group2.blocks.1.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage5.residual_group2.blocks.1.norm2.bias
+ | 0.001 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage5.residual_group2.blocks.1.mlp.fc11.weight
+ | -0.002 | -0.091 | 0.091 | 0.050 | torch.Size([240]) || stage5.residual_group2.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.052 | torch.Size([240, 120]) || stage5.residual_group2.blocks.1.mlp.fc12.weight
+ | -0.003 | -0.090 | 0.091 | 0.052 | torch.Size([240]) || stage5.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage5.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.001 | -0.062 | 0.064 | 0.039 | torch.Size([120]) || stage5.residual_group2.blocks.1.mlp.fc2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage5.linear2.weight
+ | -0.013 | -0.088 | 0.083 | 0.050 | torch.Size([120]) || stage5.linear2.bias
+ | 0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage5.pa_deform.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage5.pa_deform.bias
+ | 0.000 | -0.021 | 0.021 | 0.012 | torch.Size([120, 242, 3, 3]) || stage5.pa_deform.conv_offset.0.weight
+ | 0.001 | -0.021 | 0.021 | 0.013 | torch.Size([120]) || stage5.pa_deform.conv_offset.0.bias
+ | 0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage5.pa_deform.conv_offset.2.weight
+ | -0.001 | -0.030 | 0.030 | 0.018 | torch.Size([120]) || stage5.pa_deform.conv_offset.2.bias
+ | -0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage5.pa_deform.conv_offset.4.weight
+ | 0.000 | -0.030 | 0.030 | 0.017 | torch.Size([120]) || stage5.pa_deform.conv_offset.4.bias
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([324, 120, 3, 3]) || stage5.pa_deform.conv_offset.6.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([324]) || stage5.pa_deform.conv_offset.6.bias
+ | 0.000 | -0.053 | 0.053 | 0.030 | torch.Size([360, 360]) || stage5.pa_fuse.fc11.weight
+ | 0.000 | -0.053 | 0.053 | 0.031 | torch.Size([360]) || stage5.pa_fuse.fc11.bias
+ | 0.000 | -0.053 | 0.053 | 0.030 | torch.Size([360, 360]) || stage5.pa_fuse.fc12.weight
+ | 0.001 | -0.053 | 0.053 | 0.030 | torch.Size([360]) || stage5.pa_fuse.fc12.bias
+ | 0.000 | -0.053 | 0.053 | 0.030 | torch.Size([120, 360]) || stage5.pa_fuse.fc2.weight
+ | -0.006 | -0.050 | 0.051 | 0.028 | torch.Size([120]) || stage5.pa_fuse.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([30]) || stage6.reshape.1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([30]) || stage6.reshape.1.bias
+ | -0.002 | -0.182 | 0.183 | 0.106 | torch.Size([120, 30]) || stage6.reshape.2.weight
+ | -0.008 | -0.181 | 0.180 | 0.110 | torch.Size([120]) || stage6.reshape.2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.0.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.0.norm1.bias
+ | -0.000 | -0.069 | 0.069 | 0.020 | torch.Size([675, 6]) || stage6.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.0.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage6.residual_group1.blocks.0.attn.qkv_self.weight
+ | 0.002 | -0.091 | 0.091 | 0.053 | torch.Size([360]) || stage6.residual_group1.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage6.residual_group1.blocks.0.attn.proj.weight
+ | -0.005 | -0.064 | 0.064 | 0.038 | torch.Size([120]) || stage6.residual_group1.blocks.0.attn.proj.bias
+ | -0.001 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage6.residual_group1.blocks.0.attn.qkv_mut.weight
+ | 0.002 | -0.091 | 0.091 | 0.054 | torch.Size([360]) || stage6.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.0.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.0.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage6.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.007 | -0.091 | 0.091 | 0.052 | torch.Size([240]) || stage6.residual_group1.blocks.0.mlp.fc11.bias
+ | -0.001 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage6.residual_group1.blocks.0.mlp.fc12.weight
+ | 0.000 | -0.091 | 0.091 | 0.052 | torch.Size([240]) || stage6.residual_group1.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage6.residual_group1.blocks.0.mlp.fc2.weight
+ | -0.001 | -0.064 | 0.064 | 0.038 | torch.Size([120]) || stage6.residual_group1.blocks.0.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.1.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.1.norm1.bias
+ | -0.000 | -0.068 | 0.074 | 0.020 | torch.Size([675, 6]) || stage6.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.1.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage6.residual_group1.blocks.1.attn.qkv_self.weight
+ | 0.004 | -0.090 | 0.091 | 0.052 | torch.Size([360]) || stage6.residual_group1.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage6.residual_group1.blocks.1.attn.proj.weight
+ | 0.000 | -0.065 | 0.062 | 0.036 | torch.Size([120]) || stage6.residual_group1.blocks.1.attn.proj.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage6.residual_group1.blocks.1.attn.qkv_mut.weight
+ | -0.001 | -0.091 | 0.091 | 0.052 | torch.Size([360]) || stage6.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.1.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.1.norm2.bias
+ | 0.001 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage6.residual_group1.blocks.1.mlp.fc11.weight
+ | 0.001 | -0.091 | 0.090 | 0.053 | torch.Size([240]) || stage6.residual_group1.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage6.residual_group1.blocks.1.mlp.fc12.weight
+ | -0.002 | -0.090 | 0.090 | 0.051 | torch.Size([240]) || stage6.residual_group1.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage6.residual_group1.blocks.1.mlp.fc2.weight
+ | 0.002 | -0.064 | 0.063 | 0.039 | torch.Size([120]) || stage6.residual_group1.blocks.1.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.2.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.2.norm1.bias
+ | 0.000 | -0.080 | 0.079 | 0.020 | torch.Size([675, 6]) || stage6.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.2.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage6.residual_group1.blocks.2.attn.qkv_self.weight
+ | 0.003 | -0.091 | 0.091 | 0.052 | torch.Size([360]) || stage6.residual_group1.blocks.2.attn.qkv_self.bias
+ | -0.001 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage6.residual_group1.blocks.2.attn.proj.weight
+ | 0.010 | -0.065 | 0.064 | 0.036 | torch.Size([120]) || stage6.residual_group1.blocks.2.attn.proj.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage6.residual_group1.blocks.2.attn.qkv_mut.weight
+ | -0.001 | -0.091 | 0.091 | 0.051 | torch.Size([360]) || stage6.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.2.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.2.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage6.residual_group1.blocks.2.mlp.fc11.weight
+ | 0.004 | -0.090 | 0.091 | 0.052 | torch.Size([240]) || stage6.residual_group1.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage6.residual_group1.blocks.2.mlp.fc12.weight
+ | 0.000 | -0.091 | 0.090 | 0.052 | torch.Size([240]) || stage6.residual_group1.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage6.residual_group1.blocks.2.mlp.fc2.weight
+ | 0.004 | -0.064 | 0.064 | 0.039 | torch.Size([120]) || stage6.residual_group1.blocks.2.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.3.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.3.norm1.bias
+ | 0.000 | -0.069 | 0.074 | 0.020 | torch.Size([675, 6]) || stage6.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.3.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage6.residual_group1.blocks.3.attn.qkv_self.weight
+ | -0.005 | -0.091 | 0.091 | 0.053 | torch.Size([360]) || stage6.residual_group1.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage6.residual_group1.blocks.3.attn.proj.weight
+ | -0.002 | -0.064 | 0.064 | 0.036 | torch.Size([120]) || stage6.residual_group1.blocks.3.attn.proj.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage6.residual_group1.blocks.3.attn.qkv_mut.weight
+ | 0.000 | -0.091 | 0.091 | 0.052 | torch.Size([360]) || stage6.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.3.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.3.norm2.bias
+ | -0.001 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage6.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.001 | -0.091 | 0.091 | 0.052 | torch.Size([240]) || stage6.residual_group1.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage6.residual_group1.blocks.3.mlp.fc12.weight
+ | -0.004 | -0.088 | 0.087 | 0.047 | torch.Size([240]) || stage6.residual_group1.blocks.3.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage6.residual_group1.blocks.3.mlp.fc2.weight
+ | -0.000 | -0.062 | 0.064 | 0.037 | torch.Size([120]) || stage6.residual_group1.blocks.3.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.4.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.4.norm1.bias
+ | 0.000 | -0.065 | 0.074 | 0.020 | torch.Size([675, 6]) || stage6.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.4.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage6.residual_group1.blocks.4.attn.qkv_self.weight
+ | -0.003 | -0.091 | 0.091 | 0.052 | torch.Size([360]) || stage6.residual_group1.blocks.4.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage6.residual_group1.blocks.4.attn.proj.weight
+ | 0.007 | -0.064 | 0.063 | 0.037 | torch.Size([120]) || stage6.residual_group1.blocks.4.attn.proj.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage6.residual_group1.blocks.4.attn.qkv_mut.weight
+ | -0.001 | -0.091 | 0.091 | 0.051 | torch.Size([360]) || stage6.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.4.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.4.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage6.residual_group1.blocks.4.mlp.fc11.weight
+ | -0.006 | -0.091 | 0.091 | 0.053 | torch.Size([240]) || stage6.residual_group1.blocks.4.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage6.residual_group1.blocks.4.mlp.fc12.weight
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240]) || stage6.residual_group1.blocks.4.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage6.residual_group1.blocks.4.mlp.fc2.weight
+ | 0.000 | -0.062 | 0.064 | 0.037 | torch.Size([120]) || stage6.residual_group1.blocks.4.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.5.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.5.norm1.bias
+ | -0.000 | -0.069 | 0.075 | 0.020 | torch.Size([675, 6]) || stage6.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.5.attn.position_bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage6.residual_group1.blocks.5.attn.qkv_self.weight
+ | 0.004 | -0.091 | 0.091 | 0.054 | torch.Size([360]) || stage6.residual_group1.blocks.5.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage6.residual_group1.blocks.5.attn.proj.weight
+ | -0.001 | -0.064 | 0.064 | 0.039 | torch.Size([120]) || stage6.residual_group1.blocks.5.attn.proj.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage6.residual_group1.blocks.5.attn.qkv_mut.weight
+ | 0.003 | -0.090 | 0.090 | 0.055 | torch.Size([360]) || stage6.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.5.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage6.residual_group1.blocks.5.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage6.residual_group1.blocks.5.mlp.fc11.weight
+ | 0.002 | -0.091 | 0.091 | 0.052 | torch.Size([240]) || stage6.residual_group1.blocks.5.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage6.residual_group1.blocks.5.mlp.fc12.weight
+ | -0.003 | -0.091 | 0.091 | 0.053 | torch.Size([240]) || stage6.residual_group1.blocks.5.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage6.residual_group1.blocks.5.mlp.fc2.weight
+ | -0.001 | -0.064 | 0.065 | 0.038 | torch.Size([120]) || stage6.residual_group1.blocks.5.mlp.fc2.bias
+ | -0.001 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage6.linear1.weight
+ | -0.005 | -0.089 | 0.091 | 0.055 | torch.Size([120]) || stage6.linear1.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage6.residual_group2.blocks.0.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage6.residual_group2.blocks.0.norm1.bias
+ | 0.000 | -0.077 | 0.081 | 0.020 | torch.Size([2475, 6]) || stage6.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage6.residual_group2.blocks.0.attn.relative_position_index
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage6.residual_group2.blocks.0.attn.qkv_self.weight
+ | 0.005 | -0.091 | 0.091 | 0.053 | torch.Size([360]) || stage6.residual_group2.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage6.residual_group2.blocks.0.attn.proj.weight
+ | 0.003 | -0.090 | 0.090 | 0.046 | torch.Size([120]) || stage6.residual_group2.blocks.0.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage6.residual_group2.blocks.0.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage6.residual_group2.blocks.0.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage6.residual_group2.blocks.0.mlp.fc11.weight
+ | -0.000 | -0.090 | 0.089 | 0.054 | torch.Size([240]) || stage6.residual_group2.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage6.residual_group2.blocks.0.mlp.fc12.weight
+ | 0.003 | -0.091 | 0.089 | 0.052 | torch.Size([240]) || stage6.residual_group2.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage6.residual_group2.blocks.0.mlp.fc2.weight
+ | -0.000 | -0.064 | 0.064 | 0.035 | torch.Size([120]) || stage6.residual_group2.blocks.0.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage6.residual_group2.blocks.1.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage6.residual_group2.blocks.1.norm1.bias
+ | -0.000 | -0.079 | 0.080 | 0.020 | torch.Size([2475, 6]) || stage6.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage6.residual_group2.blocks.1.attn.relative_position_index
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage6.residual_group2.blocks.1.attn.qkv_self.weight
+ | -0.004 | -0.091 | 0.091 | 0.052 | torch.Size([360]) || stage6.residual_group2.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage6.residual_group2.blocks.1.attn.proj.weight
+ | 0.000 | -0.091 | 0.091 | 0.055 | torch.Size([120]) || stage6.residual_group2.blocks.1.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage6.residual_group2.blocks.1.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage6.residual_group2.blocks.1.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage6.residual_group2.blocks.1.mlp.fc11.weight
+ | -0.001 | -0.091 | 0.091 | 0.054 | torch.Size([240]) || stage6.residual_group2.blocks.1.mlp.fc11.bias
+ | -0.001 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage6.residual_group2.blocks.1.mlp.fc12.weight
+ | 0.000 | -0.090 | 0.090 | 0.057 | torch.Size([240]) || stage6.residual_group2.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage6.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.000 | -0.064 | 0.064 | 0.035 | torch.Size([120]) || stage6.residual_group2.blocks.1.mlp.fc2.bias
+ | 0.001 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage6.linear2.weight
+ | 0.002 | -0.091 | 0.091 | 0.055 | torch.Size([120]) || stage6.linear2.bias
+ | 0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage6.pa_deform.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage6.pa_deform.bias
+ | 0.000 | -0.021 | 0.021 | 0.012 | torch.Size([120, 242, 3, 3]) || stage6.pa_deform.conv_offset.0.weight
+ | -0.001 | -0.021 | 0.021 | 0.013 | torch.Size([120]) || stage6.pa_deform.conv_offset.0.bias
+ | -0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage6.pa_deform.conv_offset.2.weight
+ | -0.001 | -0.030 | 0.030 | 0.019 | torch.Size([120]) || stage6.pa_deform.conv_offset.2.bias
+ | 0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage6.pa_deform.conv_offset.4.weight
+ | -0.001 | -0.029 | 0.029 | 0.017 | torch.Size([120]) || stage6.pa_deform.conv_offset.4.bias
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([324, 120, 3, 3]) || stage6.pa_deform.conv_offset.6.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([324]) || stage6.pa_deform.conv_offset.6.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([360, 360]) || stage6.pa_fuse.fc11.weight
+ | -0.001 | -0.053 | 0.053 | 0.030 | torch.Size([360]) || stage6.pa_fuse.fc11.bias
+ | 0.000 | -0.053 | 0.053 | 0.030 | torch.Size([360, 360]) || stage6.pa_fuse.fc12.weight
+ | 0.000 | -0.052 | 0.053 | 0.031 | torch.Size([360]) || stage6.pa_fuse.fc12.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([120, 360]) || stage6.pa_fuse.fc2.weight
+ | 0.000 | -0.051 | 0.052 | 0.031 | torch.Size([120]) || stage6.pa_fuse.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([30]) || stage7.reshape.1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([30]) || stage7.reshape.1.bias
+ | 0.001 | -0.183 | 0.182 | 0.106 | torch.Size([120, 30]) || stage7.reshape.2.weight
+ | -0.004 | -0.178 | 0.182 | 0.104 | torch.Size([120]) || stage7.reshape.2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.0.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.0.norm1.bias
+ | -0.000 | -0.061 | 0.074 | 0.020 | torch.Size([675, 6]) || stage7.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.0.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage7.residual_group1.blocks.0.attn.qkv_self.weight
+ | 0.003 | -0.091 | 0.091 | 0.052 | torch.Size([360]) || stage7.residual_group1.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage7.residual_group1.blocks.0.attn.proj.weight
+ | -0.002 | -0.064 | 0.064 | 0.034 | torch.Size([120]) || stage7.residual_group1.blocks.0.attn.proj.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage7.residual_group1.blocks.0.attn.qkv_mut.weight
+ | 0.001 | -0.091 | 0.091 | 0.053 | torch.Size([360]) || stage7.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.0.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.0.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage7.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.001 | -0.090 | 0.091 | 0.052 | torch.Size([240]) || stage7.residual_group1.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage7.residual_group1.blocks.0.mlp.fc12.weight
+ | -0.002 | -0.091 | 0.091 | 0.053 | torch.Size([240]) || stage7.residual_group1.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage7.residual_group1.blocks.0.mlp.fc2.weight
+ | -0.002 | -0.064 | 0.064 | 0.039 | torch.Size([120]) || stage7.residual_group1.blocks.0.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.1.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.1.norm1.bias
+ | -0.000 | -0.069 | 0.071 | 0.020 | torch.Size([675, 6]) || stage7.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.1.attn.position_bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage7.residual_group1.blocks.1.attn.qkv_self.weight
+ | -0.003 | -0.091 | 0.091 | 0.054 | torch.Size([360]) || stage7.residual_group1.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage7.residual_group1.blocks.1.attn.proj.weight
+ | -0.007 | -0.064 | 0.063 | 0.035 | torch.Size([120]) || stage7.residual_group1.blocks.1.attn.proj.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage7.residual_group1.blocks.1.attn.qkv_mut.weight
+ | -0.001 | -0.091 | 0.091 | 0.055 | torch.Size([360]) || stage7.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.1.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.1.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage7.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.003 | -0.091 | 0.091 | 0.053 | torch.Size([240]) || stage7.residual_group1.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage7.residual_group1.blocks.1.mlp.fc12.weight
+ | -0.002 | -0.091 | 0.091 | 0.054 | torch.Size([240]) || stage7.residual_group1.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage7.residual_group1.blocks.1.mlp.fc2.weight
+ | -0.006 | -0.064 | 0.059 | 0.038 | torch.Size([120]) || stage7.residual_group1.blocks.1.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.2.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.2.norm1.bias
+ | -0.000 | -0.083 | 0.070 | 0.020 | torch.Size([675, 6]) || stage7.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.2.attn.position_bias
+ | 0.001 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage7.residual_group1.blocks.2.attn.qkv_self.weight
+ | -0.001 | -0.091 | 0.091 | 0.052 | torch.Size([360]) || stage7.residual_group1.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage7.residual_group1.blocks.2.attn.proj.weight
+ | -0.001 | -0.061 | 0.064 | 0.037 | torch.Size([120]) || stage7.residual_group1.blocks.2.attn.proj.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage7.residual_group1.blocks.2.attn.qkv_mut.weight
+ | 0.006 | -0.091 | 0.091 | 0.052 | torch.Size([360]) || stage7.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.2.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.2.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage7.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.001 | -0.090 | 0.091 | 0.055 | torch.Size([240]) || stage7.residual_group1.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.052 | torch.Size([240, 120]) || stage7.residual_group1.blocks.2.mlp.fc12.weight
+ | -0.000 | -0.090 | 0.090 | 0.052 | torch.Size([240]) || stage7.residual_group1.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage7.residual_group1.blocks.2.mlp.fc2.weight
+ | -0.000 | -0.064 | 0.063 | 0.037 | torch.Size([120]) || stage7.residual_group1.blocks.2.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.3.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.3.norm1.bias
+ | -0.000 | -0.066 | 0.069 | 0.020 | torch.Size([675, 6]) || stage7.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.3.attn.position_bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage7.residual_group1.blocks.3.attn.qkv_self.weight
+ | -0.001 | -0.091 | 0.090 | 0.053 | torch.Size([360]) || stage7.residual_group1.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage7.residual_group1.blocks.3.attn.proj.weight
+ | -0.000 | -0.064 | 0.064 | 0.037 | torch.Size([120]) || stage7.residual_group1.blocks.3.attn.proj.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage7.residual_group1.blocks.3.attn.qkv_mut.weight
+ | -0.004 | -0.091 | 0.090 | 0.051 | torch.Size([360]) || stage7.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.3.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.3.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage7.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.002 | -0.090 | 0.091 | 0.053 | torch.Size([240]) || stage7.residual_group1.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage7.residual_group1.blocks.3.mlp.fc12.weight
+ | -0.003 | -0.091 | 0.090 | 0.054 | torch.Size([240]) || stage7.residual_group1.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage7.residual_group1.blocks.3.mlp.fc2.weight
+ | -0.001 | -0.064 | 0.062 | 0.039 | torch.Size([120]) || stage7.residual_group1.blocks.3.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.4.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.4.norm1.bias
+ | -0.000 | -0.081 | 0.067 | 0.020 | torch.Size([675, 6]) || stage7.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.4.attn.position_bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage7.residual_group1.blocks.4.attn.qkv_self.weight
+ | -0.002 | -0.091 | 0.089 | 0.052 | torch.Size([360]) || stage7.residual_group1.blocks.4.attn.qkv_self.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage7.residual_group1.blocks.4.attn.proj.weight
+ | -0.001 | -0.063 | 0.063 | 0.036 | torch.Size([120]) || stage7.residual_group1.blocks.4.attn.proj.bias
+ | 0.001 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage7.residual_group1.blocks.4.attn.qkv_mut.weight
+ | 0.001 | -0.090 | 0.089 | 0.054 | torch.Size([360]) || stage7.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.4.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.4.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage7.residual_group1.blocks.4.mlp.fc11.weight
+ | 0.000 | -0.091 | 0.091 | 0.052 | torch.Size([240]) || stage7.residual_group1.blocks.4.mlp.fc11.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage7.residual_group1.blocks.4.mlp.fc12.weight
+ | 0.005 | -0.090 | 0.091 | 0.051 | torch.Size([240]) || stage7.residual_group1.blocks.4.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage7.residual_group1.blocks.4.mlp.fc2.weight
+ | -0.000 | -0.063 | 0.063 | 0.037 | torch.Size([120]) || stage7.residual_group1.blocks.4.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.5.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.5.norm1.bias
+ | 0.000 | -0.070 | 0.076 | 0.020 | torch.Size([675, 6]) || stage7.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.5.attn.position_bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage7.residual_group1.blocks.5.attn.qkv_self.weight
+ | 0.004 | -0.091 | 0.090 | 0.053 | torch.Size([360]) || stage7.residual_group1.blocks.5.attn.qkv_self.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage7.residual_group1.blocks.5.attn.proj.weight
+ | 0.001 | -0.063 | 0.063 | 0.036 | torch.Size([120]) || stage7.residual_group1.blocks.5.attn.proj.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage7.residual_group1.blocks.5.attn.qkv_mut.weight
+ | -0.008 | -0.091 | 0.090 | 0.052 | torch.Size([360]) || stage7.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.5.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage7.residual_group1.blocks.5.norm2.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage7.residual_group1.blocks.5.mlp.fc11.weight
+ | 0.003 | -0.091 | 0.091 | 0.054 | torch.Size([240]) || stage7.residual_group1.blocks.5.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage7.residual_group1.blocks.5.mlp.fc12.weight
+ | -0.003 | -0.091 | 0.091 | 0.054 | torch.Size([240]) || stage7.residual_group1.blocks.5.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage7.residual_group1.blocks.5.mlp.fc2.weight
+ | -0.004 | -0.062 | 0.064 | 0.036 | torch.Size([120]) || stage7.residual_group1.blocks.5.mlp.fc2.bias
+ | 0.001 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage7.linear1.weight
+ | -0.007 | -0.091 | 0.090 | 0.051 | torch.Size([120]) || stage7.linear1.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage7.residual_group2.blocks.0.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage7.residual_group2.blocks.0.norm1.bias
+ | -0.000 | -0.078 | 0.090 | 0.020 | torch.Size([2475, 6]) || stage7.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage7.residual_group2.blocks.0.attn.relative_position_index
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage7.residual_group2.blocks.0.attn.qkv_self.weight
+ | 0.000 | -0.091 | 0.090 | 0.054 | torch.Size([360]) || stage7.residual_group2.blocks.0.attn.qkv_self.bias
+ | -0.001 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage7.residual_group2.blocks.0.attn.proj.weight
+ | 0.002 | -0.090 | 0.087 | 0.055 | torch.Size([120]) || stage7.residual_group2.blocks.0.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage7.residual_group2.blocks.0.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage7.residual_group2.blocks.0.norm2.bias
+ | 0.001 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage7.residual_group2.blocks.0.mlp.fc11.weight
+ | 0.001 | -0.091 | 0.088 | 0.051 | torch.Size([240]) || stage7.residual_group2.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage7.residual_group2.blocks.0.mlp.fc12.weight
+ | 0.001 | -0.091 | 0.091 | 0.052 | torch.Size([240]) || stage7.residual_group2.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage7.residual_group2.blocks.0.mlp.fc2.weight
+ | 0.003 | -0.063 | 0.064 | 0.038 | torch.Size([120]) || stage7.residual_group2.blocks.0.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage7.residual_group2.blocks.1.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage7.residual_group2.blocks.1.norm1.bias
+ | 0.000 | -0.079 | 0.079 | 0.020 | torch.Size([2475, 6]) || stage7.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage7.residual_group2.blocks.1.attn.relative_position_index
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([360, 120]) || stage7.residual_group2.blocks.1.attn.qkv_self.weight
+ | -0.004 | -0.091 | 0.090 | 0.052 | torch.Size([360]) || stage7.residual_group2.blocks.1.attn.qkv_self.bias
+ | 0.001 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage7.residual_group2.blocks.1.attn.proj.weight
+ | 0.007 | -0.090 | 0.090 | 0.052 | torch.Size([120]) || stage7.residual_group2.blocks.1.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage7.residual_group2.blocks.1.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage7.residual_group2.blocks.1.norm2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage7.residual_group2.blocks.1.mlp.fc11.weight
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240]) || stage7.residual_group2.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.091 | 0.091 | 0.053 | torch.Size([240, 120]) || stage7.residual_group2.blocks.1.mlp.fc12.weight
+ | 0.001 | -0.091 | 0.090 | 0.052 | torch.Size([240]) || stage7.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.065 | 0.065 | 0.037 | torch.Size([120, 240]) || stage7.residual_group2.blocks.1.mlp.fc2.weight
+ | 0.005 | -0.060 | 0.064 | 0.036 | torch.Size([120]) || stage7.residual_group2.blocks.1.mlp.fc2.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([120, 120]) || stage7.linear2.weight
+ | -0.009 | -0.087 | 0.087 | 0.048 | torch.Size([120]) || stage7.linear2.bias
+ | -0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage7.pa_deform.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage7.pa_deform.bias
+ | -0.000 | -0.021 | 0.021 | 0.012 | torch.Size([120, 242, 3, 3]) || stage7.pa_deform.conv_offset.0.weight
+ | 0.002 | -0.020 | 0.021 | 0.012 | torch.Size([120]) || stage7.pa_deform.conv_offset.0.bias
+ | -0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage7.pa_deform.conv_offset.2.weight
+ | 0.000 | -0.030 | 0.030 | 0.016 | torch.Size([120]) || stage7.pa_deform.conv_offset.2.bias
+ | 0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage7.pa_deform.conv_offset.4.weight
+ | 0.000 | -0.030 | 0.030 | 0.017 | torch.Size([120]) || stage7.pa_deform.conv_offset.4.bias
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([324, 120, 3, 3]) || stage7.pa_deform.conv_offset.6.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([324]) || stage7.pa_deform.conv_offset.6.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([360, 360]) || stage7.pa_fuse.fc11.weight
+ | 0.000 | -0.052 | 0.052 | 0.029 | torch.Size([360]) || stage7.pa_fuse.fc11.bias
+ | 0.000 | -0.053 | 0.053 | 0.030 | torch.Size([360, 360]) || stage7.pa_fuse.fc12.weight
+ | 0.002 | -0.053 | 0.053 | 0.031 | torch.Size([360]) || stage7.pa_fuse.fc12.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([120, 360]) || stage7.pa_fuse.fc2.weight
+ | 0.001 | -0.052 | 0.052 | 0.031 | torch.Size([120]) || stage7.pa_fuse.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage8.0.1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([120]) || stage8.0.1.bias
+ | 0.000 | -0.091 | 0.091 | 0.053 | torch.Size([180, 120]) || stage8.0.2.weight
+ | -0.001 | -0.090 | 0.090 | 0.053 | torch.Size([180]) || stage8.0.2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.1.residual_group.blocks.0.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.1.residual_group.blocks.0.norm1.bias
+ | 0.000 | -0.075 | 0.081 | 0.020 | torch.Size([2475, 6]) || stage8.1.residual_group.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.1.residual_group.blocks.0.attn.relative_position_index
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.1.residual_group.blocks.0.attn.qkv_self.weight
+ | -0.000 | -0.075 | 0.074 | 0.043 | torch.Size([540]) || stage8.1.residual_group.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.1.residual_group.blocks.0.attn.proj.weight
+ | 0.001 | -0.074 | 0.074 | 0.042 | torch.Size([180]) || stage8.1.residual_group.blocks.0.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.1.residual_group.blocks.0.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.1.residual_group.blocks.0.norm2.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.0.mlp.fc11.weight
+ | 0.001 | -0.075 | 0.074 | 0.042 | torch.Size([360]) || stage8.1.residual_group.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.0.mlp.fc12.weight
+ | 0.002 | -0.074 | 0.074 | 0.044 | torch.Size([360]) || stage8.1.residual_group.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.1.residual_group.blocks.0.mlp.fc2.weight
+ | -0.000 | -0.052 | 0.053 | 0.032 | torch.Size([180]) || stage8.1.residual_group.blocks.0.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.1.residual_group.blocks.1.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.1.residual_group.blocks.1.norm1.bias
+ | 0.000 | -0.073 | 0.074 | 0.020 | torch.Size([2475, 6]) || stage8.1.residual_group.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.1.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.1.residual_group.blocks.1.attn.qkv_self.weight
+ | -0.002 | -0.074 | 0.074 | 0.042 | torch.Size([540]) || stage8.1.residual_group.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.1.residual_group.blocks.1.attn.proj.weight
+ | 0.003 | -0.073 | 0.074 | 0.042 | torch.Size([180]) || stage8.1.residual_group.blocks.1.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.1.residual_group.blocks.1.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.1.residual_group.blocks.1.norm2.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.1.mlp.fc11.weight
+ | -0.000 | -0.075 | 0.074 | 0.044 | torch.Size([360]) || stage8.1.residual_group.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.1.mlp.fc12.weight
+ | -0.002 | -0.074 | 0.073 | 0.043 | torch.Size([360]) || stage8.1.residual_group.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.053 | 0.053 | 0.031 | torch.Size([180, 360]) || stage8.1.residual_group.blocks.1.mlp.fc2.weight
+ | 0.001 | -0.052 | 0.052 | 0.029 | torch.Size([180]) || stage8.1.residual_group.blocks.1.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.1.residual_group.blocks.2.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.1.residual_group.blocks.2.norm1.bias
+ | 0.000 | -0.072 | 0.078 | 0.020 | torch.Size([2475, 6]) || stage8.1.residual_group.blocks.2.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.1.residual_group.blocks.2.attn.relative_position_index
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.1.residual_group.blocks.2.attn.qkv_self.weight
+ | 0.002 | -0.074 | 0.074 | 0.043 | torch.Size([540]) || stage8.1.residual_group.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.1.residual_group.blocks.2.attn.proj.weight
+ | -0.002 | -0.074 | 0.074 | 0.043 | torch.Size([180]) || stage8.1.residual_group.blocks.2.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.1.residual_group.blocks.2.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.1.residual_group.blocks.2.norm2.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.2.mlp.fc11.weight
+ | 0.000 | -0.074 | 0.074 | 0.044 | torch.Size([360]) || stage8.1.residual_group.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.2.mlp.fc12.weight
+ | -0.001 | -0.074 | 0.073 | 0.044 | torch.Size([360]) || stage8.1.residual_group.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.1.residual_group.blocks.2.mlp.fc2.weight
+ | 0.002 | -0.049 | 0.053 | 0.030 | torch.Size([180]) || stage8.1.residual_group.blocks.2.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.1.residual_group.blocks.3.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.1.residual_group.blocks.3.norm1.bias
+ | -0.000 | -0.071 | 0.085 | 0.020 | torch.Size([2475, 6]) || stage8.1.residual_group.blocks.3.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.1.residual_group.blocks.3.attn.relative_position_index
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.1.residual_group.blocks.3.attn.qkv_self.weight
+ | -0.002 | -0.074 | 0.074 | 0.043 | torch.Size([540]) || stage8.1.residual_group.blocks.3.attn.qkv_self.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.1.residual_group.blocks.3.attn.proj.weight
+ | 0.002 | -0.074 | 0.074 | 0.042 | torch.Size([180]) || stage8.1.residual_group.blocks.3.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.1.residual_group.blocks.3.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.1.residual_group.blocks.3.norm2.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.3.mlp.fc11.weight
+ | 0.002 | -0.074 | 0.074 | 0.044 | torch.Size([360]) || stage8.1.residual_group.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.3.mlp.fc12.weight
+ | 0.000 | -0.073 | 0.074 | 0.042 | torch.Size([360]) || stage8.1.residual_group.blocks.3.mlp.fc12.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.1.residual_group.blocks.3.mlp.fc2.weight
+ | -0.005 | -0.053 | 0.052 | 0.030 | torch.Size([180]) || stage8.1.residual_group.blocks.3.mlp.fc2.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.1.linear.weight
+ | -0.002 | -0.074 | 0.074 | 0.043 | torch.Size([180]) || stage8.1.linear.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.2.residual_group.blocks.0.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.2.residual_group.blocks.0.norm1.bias
+ | 0.000 | -0.075 | 0.080 | 0.020 | torch.Size([2475, 6]) || stage8.2.residual_group.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.2.residual_group.blocks.0.attn.relative_position_index
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.2.residual_group.blocks.0.attn.qkv_self.weight
+ | -0.002 | -0.074 | 0.074 | 0.043 | torch.Size([540]) || stage8.2.residual_group.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.2.residual_group.blocks.0.attn.proj.weight
+ | 0.001 | -0.072 | 0.074 | 0.042 | torch.Size([180]) || stage8.2.residual_group.blocks.0.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.2.residual_group.blocks.0.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.2.residual_group.blocks.0.norm2.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.0.mlp.fc11.weight
+ | -0.002 | -0.074 | 0.073 | 0.043 | torch.Size([360]) || stage8.2.residual_group.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.0.mlp.fc12.weight
+ | -0.000 | -0.074 | 0.074 | 0.041 | torch.Size([360]) || stage8.2.residual_group.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.2.residual_group.blocks.0.mlp.fc2.weight
+ | -0.002 | -0.052 | 0.052 | 0.030 | torch.Size([180]) || stage8.2.residual_group.blocks.0.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.2.residual_group.blocks.1.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.2.residual_group.blocks.1.norm1.bias
+ | 0.000 | -0.084 | 0.071 | 0.020 | torch.Size([2475, 6]) || stage8.2.residual_group.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.2.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.2.residual_group.blocks.1.attn.qkv_self.weight
+ | 0.001 | -0.074 | 0.074 | 0.040 | torch.Size([540]) || stage8.2.residual_group.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.2.residual_group.blocks.1.attn.proj.weight
+ | -0.002 | -0.074 | 0.070 | 0.042 | torch.Size([180]) || stage8.2.residual_group.blocks.1.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.2.residual_group.blocks.1.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.2.residual_group.blocks.1.norm2.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.1.mlp.fc11.weight
+ | -0.000 | -0.074 | 0.074 | 0.043 | torch.Size([360]) || stage8.2.residual_group.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.1.mlp.fc12.weight
+ | -0.001 | -0.075 | 0.073 | 0.041 | torch.Size([360]) || stage8.2.residual_group.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.2.residual_group.blocks.1.mlp.fc2.weight
+ | -0.001 | -0.053 | 0.052 | 0.030 | torch.Size([180]) || stage8.2.residual_group.blocks.1.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.2.residual_group.blocks.2.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.2.residual_group.blocks.2.norm1.bias
+ | -0.000 | -0.086 | 0.076 | 0.020 | torch.Size([2475, 6]) || stage8.2.residual_group.blocks.2.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.2.residual_group.blocks.2.attn.relative_position_index
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.2.residual_group.blocks.2.attn.qkv_self.weight
+ | -0.001 | -0.074 | 0.074 | 0.043 | torch.Size([540]) || stage8.2.residual_group.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.2.residual_group.blocks.2.attn.proj.weight
+ | 0.002 | -0.073 | 0.074 | 0.041 | torch.Size([180]) || stage8.2.residual_group.blocks.2.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.2.residual_group.blocks.2.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.2.residual_group.blocks.2.norm2.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.2.mlp.fc11.weight
+ | 0.000 | -0.074 | 0.074 | 0.042 | torch.Size([360]) || stage8.2.residual_group.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.2.mlp.fc12.weight
+ | -0.002 | -0.074 | 0.074 | 0.043 | torch.Size([360]) || stage8.2.residual_group.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.053 | 0.053 | 0.031 | torch.Size([180, 360]) || stage8.2.residual_group.blocks.2.mlp.fc2.weight
+ | 0.002 | -0.053 | 0.053 | 0.031 | torch.Size([180]) || stage8.2.residual_group.blocks.2.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.2.residual_group.blocks.3.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.2.residual_group.blocks.3.norm1.bias
+ | 0.000 | -0.078 | 0.070 | 0.020 | torch.Size([2475, 6]) || stage8.2.residual_group.blocks.3.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.2.residual_group.blocks.3.attn.relative_position_index
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.2.residual_group.blocks.3.attn.qkv_self.weight
+ | 0.001 | -0.074 | 0.074 | 0.044 | torch.Size([540]) || stage8.2.residual_group.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.2.residual_group.blocks.3.attn.proj.weight
+ | -0.002 | -0.074 | 0.075 | 0.046 | torch.Size([180]) || stage8.2.residual_group.blocks.3.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.2.residual_group.blocks.3.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.2.residual_group.blocks.3.norm2.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.3.mlp.fc11.weight
+ | 0.002 | -0.074 | 0.074 | 0.042 | torch.Size([360]) || stage8.2.residual_group.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.3.mlp.fc12.weight
+ | -0.003 | -0.074 | 0.074 | 0.044 | torch.Size([360]) || stage8.2.residual_group.blocks.3.mlp.fc12.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.2.residual_group.blocks.3.mlp.fc2.weight
+ | 0.001 | -0.052 | 0.052 | 0.030 | torch.Size([180]) || stage8.2.residual_group.blocks.3.mlp.fc2.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.2.linear.weight
+ | 0.004 | -0.074 | 0.074 | 0.044 | torch.Size([180]) || stage8.2.linear.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.3.residual_group.blocks.0.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.3.residual_group.blocks.0.norm1.bias
+ | -0.000 | -0.087 | 0.074 | 0.020 | torch.Size([2475, 6]) || stage8.3.residual_group.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.3.residual_group.blocks.0.attn.relative_position_index
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.3.residual_group.blocks.0.attn.qkv_self.weight
+ | -0.001 | -0.074 | 0.075 | 0.043 | torch.Size([540]) || stage8.3.residual_group.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.3.residual_group.blocks.0.attn.proj.weight
+ | 0.004 | -0.072 | 0.074 | 0.041 | torch.Size([180]) || stage8.3.residual_group.blocks.0.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.3.residual_group.blocks.0.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.3.residual_group.blocks.0.norm2.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.0.mlp.fc11.weight
+ | 0.000 | -0.073 | 0.074 | 0.043 | torch.Size([360]) || stage8.3.residual_group.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.0.mlp.fc12.weight
+ | 0.000 | -0.074 | 0.074 | 0.043 | torch.Size([360]) || stage8.3.residual_group.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.3.residual_group.blocks.0.mlp.fc2.weight
+ | -0.000 | -0.053 | 0.052 | 0.031 | torch.Size([180]) || stage8.3.residual_group.blocks.0.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.3.residual_group.blocks.1.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.3.residual_group.blocks.1.norm1.bias
+ | 0.000 | -0.074 | 0.073 | 0.020 | torch.Size([2475, 6]) || stage8.3.residual_group.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.3.residual_group.blocks.1.attn.relative_position_index
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.3.residual_group.blocks.1.attn.qkv_self.weight
+ | 0.001 | -0.074 | 0.074 | 0.043 | torch.Size([540]) || stage8.3.residual_group.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.3.residual_group.blocks.1.attn.proj.weight
+ | 0.002 | -0.074 | 0.074 | 0.043 | torch.Size([180]) || stage8.3.residual_group.blocks.1.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.3.residual_group.blocks.1.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.3.residual_group.blocks.1.norm2.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.1.mlp.fc11.weight
+ | -0.001 | -0.074 | 0.074 | 0.042 | torch.Size([360]) || stage8.3.residual_group.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.1.mlp.fc12.weight
+ | 0.002 | -0.074 | 0.074 | 0.044 | torch.Size([360]) || stage8.3.residual_group.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.3.residual_group.blocks.1.mlp.fc2.weight
+ | -0.001 | -0.053 | 0.051 | 0.030 | torch.Size([180]) || stage8.3.residual_group.blocks.1.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.3.residual_group.blocks.2.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.3.residual_group.blocks.2.norm1.bias
+ | -0.000 | -0.085 | 0.087 | 0.020 | torch.Size([2475, 6]) || stage8.3.residual_group.blocks.2.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.3.residual_group.blocks.2.attn.relative_position_index
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.3.residual_group.blocks.2.attn.qkv_self.weight
+ | 0.002 | -0.075 | 0.074 | 0.044 | torch.Size([540]) || stage8.3.residual_group.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.3.residual_group.blocks.2.attn.proj.weight
+ | -0.005 | -0.074 | 0.074 | 0.043 | torch.Size([180]) || stage8.3.residual_group.blocks.2.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.3.residual_group.blocks.2.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.3.residual_group.blocks.2.norm2.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.2.mlp.fc11.weight
+ | 0.004 | -0.074 | 0.075 | 0.045 | torch.Size([360]) || stage8.3.residual_group.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.2.mlp.fc12.weight
+ | -0.003 | -0.074 | 0.071 | 0.042 | torch.Size([360]) || stage8.3.residual_group.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.3.residual_group.blocks.2.mlp.fc2.weight
+ | 0.001 | -0.052 | 0.053 | 0.030 | torch.Size([180]) || stage8.3.residual_group.blocks.2.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.3.residual_group.blocks.3.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.3.residual_group.blocks.3.norm1.bias
+ | -0.000 | -0.077 | 0.093 | 0.020 | torch.Size([2475, 6]) || stage8.3.residual_group.blocks.3.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.3.residual_group.blocks.3.attn.relative_position_index
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.3.residual_group.blocks.3.attn.qkv_self.weight
+ | 0.002 | -0.074 | 0.074 | 0.044 | torch.Size([540]) || stage8.3.residual_group.blocks.3.attn.qkv_self.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.3.residual_group.blocks.3.attn.proj.weight
+ | 0.002 | -0.074 | 0.074 | 0.045 | torch.Size([180]) || stage8.3.residual_group.blocks.3.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.3.residual_group.blocks.3.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.3.residual_group.blocks.3.norm2.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.3.mlp.fc11.weight
+ | -0.001 | -0.074 | 0.074 | 0.042 | torch.Size([360]) || stage8.3.residual_group.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.3.mlp.fc12.weight
+ | 0.002 | -0.074 | 0.074 | 0.043 | torch.Size([360]) || stage8.3.residual_group.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.3.residual_group.blocks.3.mlp.fc2.weight
+ | -0.001 | -0.052 | 0.053 | 0.032 | torch.Size([180]) || stage8.3.residual_group.blocks.3.mlp.fc2.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.3.linear.weight
+ | 0.002 | -0.074 | 0.073 | 0.042 | torch.Size([180]) || stage8.3.linear.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.4.residual_group.blocks.0.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.4.residual_group.blocks.0.norm1.bias
+ | 0.000 | -0.074 | 0.082 | 0.020 | torch.Size([2475, 6]) || stage8.4.residual_group.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.4.residual_group.blocks.0.attn.relative_position_index
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.4.residual_group.blocks.0.attn.qkv_self.weight
+ | -0.001 | -0.074 | 0.074 | 0.044 | torch.Size([540]) || stage8.4.residual_group.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.4.residual_group.blocks.0.attn.proj.weight
+ | 0.003 | -0.074 | 0.074 | 0.042 | torch.Size([180]) || stage8.4.residual_group.blocks.0.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.4.residual_group.blocks.0.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.4.residual_group.blocks.0.norm2.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.0.mlp.fc11.weight
+ | 0.002 | -0.074 | 0.075 | 0.045 | torch.Size([360]) || stage8.4.residual_group.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.0.mlp.fc12.weight
+ | 0.002 | -0.073 | 0.074 | 0.043 | torch.Size([360]) || stage8.4.residual_group.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.4.residual_group.blocks.0.mlp.fc2.weight
+ | -0.001 | -0.053 | 0.053 | 0.029 | torch.Size([180]) || stage8.4.residual_group.blocks.0.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.4.residual_group.blocks.1.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.4.residual_group.blocks.1.norm1.bias
+ | 0.000 | -0.077 | 0.076 | 0.020 | torch.Size([2475, 6]) || stage8.4.residual_group.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.4.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.4.residual_group.blocks.1.attn.qkv_self.weight
+ | -0.003 | -0.074 | 0.074 | 0.043 | torch.Size([540]) || stage8.4.residual_group.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.4.residual_group.blocks.1.attn.proj.weight
+ | -0.004 | -0.074 | 0.074 | 0.044 | torch.Size([180]) || stage8.4.residual_group.blocks.1.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.4.residual_group.blocks.1.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.4.residual_group.blocks.1.norm2.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.1.mlp.fc11.weight
+ | -0.001 | -0.074 | 0.074 | 0.042 | torch.Size([360]) || stage8.4.residual_group.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.1.mlp.fc12.weight
+ | -0.002 | -0.074 | 0.074 | 0.045 | torch.Size([360]) || stage8.4.residual_group.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.4.residual_group.blocks.1.mlp.fc2.weight
+ | 0.003 | -0.052 | 0.052 | 0.031 | torch.Size([180]) || stage8.4.residual_group.blocks.1.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.4.residual_group.blocks.2.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.4.residual_group.blocks.2.norm1.bias
+ | -0.000 | -0.075 | 0.073 | 0.020 | torch.Size([2475, 6]) || stage8.4.residual_group.blocks.2.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.4.residual_group.blocks.2.attn.relative_position_index
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.4.residual_group.blocks.2.attn.qkv_self.weight
+ | 0.002 | -0.074 | 0.074 | 0.042 | torch.Size([540]) || stage8.4.residual_group.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.4.residual_group.blocks.2.attn.proj.weight
+ | -0.000 | -0.074 | 0.074 | 0.045 | torch.Size([180]) || stage8.4.residual_group.blocks.2.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.4.residual_group.blocks.2.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.4.residual_group.blocks.2.norm2.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.2.mlp.fc11.weight
+ | 0.002 | -0.074 | 0.074 | 0.041 | torch.Size([360]) || stage8.4.residual_group.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.2.mlp.fc12.weight
+ | -0.001 | -0.074 | 0.073 | 0.042 | torch.Size([360]) || stage8.4.residual_group.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.4.residual_group.blocks.2.mlp.fc2.weight
+ | 0.001 | -0.053 | 0.053 | 0.030 | torch.Size([180]) || stage8.4.residual_group.blocks.2.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.4.residual_group.blocks.3.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.4.residual_group.blocks.3.norm1.bias
+ | 0.000 | -0.082 | 0.087 | 0.020 | torch.Size([2475, 6]) || stage8.4.residual_group.blocks.3.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.4.residual_group.blocks.3.attn.relative_position_index
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.4.residual_group.blocks.3.attn.qkv_self.weight
+ | 0.001 | -0.074 | 0.074 | 0.044 | torch.Size([540]) || stage8.4.residual_group.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.4.residual_group.blocks.3.attn.proj.weight
+ | 0.003 | -0.074 | 0.073 | 0.044 | torch.Size([180]) || stage8.4.residual_group.blocks.3.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.4.residual_group.blocks.3.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.4.residual_group.blocks.3.norm2.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.3.mlp.fc11.weight
+ | 0.001 | -0.074 | 0.074 | 0.043 | torch.Size([360]) || stage8.4.residual_group.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.3.mlp.fc12.weight
+ | 0.003 | -0.073 | 0.074 | 0.041 | torch.Size([360]) || stage8.4.residual_group.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.4.residual_group.blocks.3.mlp.fc2.weight
+ | -0.002 | -0.052 | 0.052 | 0.031 | torch.Size([180]) || stage8.4.residual_group.blocks.3.mlp.fc2.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.4.linear.weight
+ | 0.000 | -0.074 | 0.074 | 0.043 | torch.Size([180]) || stage8.4.linear.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.5.residual_group.blocks.0.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.5.residual_group.blocks.0.norm1.bias
+ | -0.000 | -0.060 | 0.059 | 0.019 | torch.Size([225, 6]) || stage8.5.residual_group.blocks.0.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.5.residual_group.blocks.0.attn.relative_position_index
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.5.residual_group.blocks.0.attn.qkv_self.weight
+ | -0.000 | -0.074 | 0.074 | 0.044 | torch.Size([540]) || stage8.5.residual_group.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.5.residual_group.blocks.0.attn.proj.weight
+ | -0.003 | -0.074 | 0.072 | 0.044 | torch.Size([180]) || stage8.5.residual_group.blocks.0.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.5.residual_group.blocks.0.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.5.residual_group.blocks.0.norm2.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.0.mlp.fc11.weight
+ | -0.000 | -0.074 | 0.074 | 0.042 | torch.Size([360]) || stage8.5.residual_group.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.0.mlp.fc12.weight
+ | -0.000 | -0.074 | 0.074 | 0.043 | torch.Size([360]) || stage8.5.residual_group.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.5.residual_group.blocks.0.mlp.fc2.weight
+ | -0.003 | -0.052 | 0.052 | 0.031 | torch.Size([180]) || stage8.5.residual_group.blocks.0.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.5.residual_group.blocks.1.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.5.residual_group.blocks.1.norm1.bias
+ | 0.001 | -0.059 | 0.062 | 0.020 | torch.Size([225, 6]) || stage8.5.residual_group.blocks.1.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.5.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.5.residual_group.blocks.1.attn.qkv_self.weight
+ | 0.003 | -0.075 | 0.075 | 0.044 | torch.Size([540]) || stage8.5.residual_group.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.5.residual_group.blocks.1.attn.proj.weight
+ | -0.002 | -0.074 | 0.074 | 0.041 | torch.Size([180]) || stage8.5.residual_group.blocks.1.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.5.residual_group.blocks.1.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.5.residual_group.blocks.1.norm2.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.1.mlp.fc11.weight
+ | 0.002 | -0.074 | 0.074 | 0.044 | torch.Size([360]) || stage8.5.residual_group.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.1.mlp.fc12.weight
+ | -0.005 | -0.074 | 0.074 | 0.045 | torch.Size([360]) || stage8.5.residual_group.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.5.residual_group.blocks.1.mlp.fc2.weight
+ | -0.001 | -0.053 | 0.052 | 0.031 | torch.Size([180]) || stage8.5.residual_group.blocks.1.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.5.residual_group.blocks.2.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.5.residual_group.blocks.2.norm1.bias
+ | -0.001 | -0.074 | 0.060 | 0.020 | torch.Size([225, 6]) || stage8.5.residual_group.blocks.2.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.5.residual_group.blocks.2.attn.relative_position_index
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.5.residual_group.blocks.2.attn.qkv_self.weight
+ | -0.002 | -0.074 | 0.074 | 0.043 | torch.Size([540]) || stage8.5.residual_group.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.5.residual_group.blocks.2.attn.proj.weight
+ | -0.001 | -0.073 | 0.073 | 0.045 | torch.Size([180]) || stage8.5.residual_group.blocks.2.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.5.residual_group.blocks.2.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.5.residual_group.blocks.2.norm2.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.2.mlp.fc11.weight
+ | -0.004 | -0.074 | 0.074 | 0.043 | torch.Size([360]) || stage8.5.residual_group.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.2.mlp.fc12.weight
+ | 0.001 | -0.075 | 0.075 | 0.044 | torch.Size([360]) || stage8.5.residual_group.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.5.residual_group.blocks.2.mlp.fc2.weight
+ | -0.002 | -0.053 | 0.052 | 0.031 | torch.Size([180]) || stage8.5.residual_group.blocks.2.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.5.residual_group.blocks.3.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.5.residual_group.blocks.3.norm1.bias
+ | -0.000 | -0.064 | 0.085 | 0.020 | torch.Size([225, 6]) || stage8.5.residual_group.blocks.3.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.5.residual_group.blocks.3.attn.relative_position_index
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.5.residual_group.blocks.3.attn.qkv_self.weight
+ | 0.001 | -0.074 | 0.074 | 0.044 | torch.Size([540]) || stage8.5.residual_group.blocks.3.attn.qkv_self.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.5.residual_group.blocks.3.attn.proj.weight
+ | 0.002 | -0.074 | 0.074 | 0.044 | torch.Size([180]) || stage8.5.residual_group.blocks.3.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.5.residual_group.blocks.3.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.5.residual_group.blocks.3.norm2.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.3.mlp.fc11.weight
+ | 0.000 | -0.074 | 0.074 | 0.043 | torch.Size([360]) || stage8.5.residual_group.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.3.mlp.fc12.weight
+ | -0.001 | -0.074 | 0.074 | 0.042 | torch.Size([360]) || stage8.5.residual_group.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.5.residual_group.blocks.3.mlp.fc2.weight
+ | -0.002 | -0.052 | 0.052 | 0.031 | torch.Size([180]) || stage8.5.residual_group.blocks.3.mlp.fc2.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.5.linear.weight
+ | 0.001 | -0.074 | 0.074 | 0.043 | torch.Size([180]) || stage8.5.linear.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.6.residual_group.blocks.0.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.6.residual_group.blocks.0.norm1.bias
+ | 0.000 | -0.064 | 0.057 | 0.020 | torch.Size([225, 6]) || stage8.6.residual_group.blocks.0.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.6.residual_group.blocks.0.attn.relative_position_index
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.6.residual_group.blocks.0.attn.qkv_self.weight
+ | -0.001 | -0.074 | 0.074 | 0.042 | torch.Size([540]) || stage8.6.residual_group.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.6.residual_group.blocks.0.attn.proj.weight
+ | -0.003 | -0.075 | 0.073 | 0.042 | torch.Size([180]) || stage8.6.residual_group.blocks.0.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.6.residual_group.blocks.0.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.6.residual_group.blocks.0.norm2.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.0.mlp.fc11.weight
+ | 0.001 | -0.074 | 0.074 | 0.044 | torch.Size([360]) || stage8.6.residual_group.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.0.mlp.fc12.weight
+ | -0.001 | -0.074 | 0.072 | 0.044 | torch.Size([360]) || stage8.6.residual_group.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.6.residual_group.blocks.0.mlp.fc2.weight
+ | 0.001 | -0.052 | 0.052 | 0.031 | torch.Size([180]) || stage8.6.residual_group.blocks.0.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.6.residual_group.blocks.1.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.6.residual_group.blocks.1.norm1.bias
+ | 0.001 | -0.061 | 0.074 | 0.020 | torch.Size([225, 6]) || stage8.6.residual_group.blocks.1.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.6.residual_group.blocks.1.attn.relative_position_index
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.6.residual_group.blocks.1.attn.qkv_self.weight
+ | -0.000 | -0.074 | 0.074 | 0.044 | torch.Size([540]) || stage8.6.residual_group.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.6.residual_group.blocks.1.attn.proj.weight
+ | 0.001 | -0.073 | 0.070 | 0.042 | torch.Size([180]) || stage8.6.residual_group.blocks.1.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.6.residual_group.blocks.1.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.6.residual_group.blocks.1.norm2.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.1.mlp.fc11.weight
+ | 0.002 | -0.074 | 0.074 | 0.044 | torch.Size([360]) || stage8.6.residual_group.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.1.mlp.fc12.weight
+ | 0.001 | -0.074 | 0.074 | 0.043 | torch.Size([360]) || stage8.6.residual_group.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.6.residual_group.blocks.1.mlp.fc2.weight
+ | 0.001 | -0.052 | 0.053 | 0.032 | torch.Size([180]) || stage8.6.residual_group.blocks.1.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.6.residual_group.blocks.2.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.6.residual_group.blocks.2.norm1.bias
+ | -0.000 | -0.059 | 0.058 | 0.020 | torch.Size([225, 6]) || stage8.6.residual_group.blocks.2.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.6.residual_group.blocks.2.attn.relative_position_index
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.6.residual_group.blocks.2.attn.qkv_self.weight
+ | 0.001 | -0.074 | 0.074 | 0.043 | torch.Size([540]) || stage8.6.residual_group.blocks.2.attn.qkv_self.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.6.residual_group.blocks.2.attn.proj.weight
+ | 0.004 | -0.074 | 0.074 | 0.043 | torch.Size([180]) || stage8.6.residual_group.blocks.2.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.6.residual_group.blocks.2.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.6.residual_group.blocks.2.norm2.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.2.mlp.fc11.weight
+ | 0.005 | -0.074 | 0.074 | 0.044 | torch.Size([360]) || stage8.6.residual_group.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.2.mlp.fc12.weight
+ | 0.001 | -0.074 | 0.075 | 0.044 | torch.Size([360]) || stage8.6.residual_group.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.6.residual_group.blocks.2.mlp.fc2.weight
+ | 0.001 | -0.051 | 0.051 | 0.030 | torch.Size([180]) || stage8.6.residual_group.blocks.2.mlp.fc2.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.6.residual_group.blocks.3.norm1.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.6.residual_group.blocks.3.norm1.bias
+ | 0.000 | -0.070 | 0.061 | 0.020 | torch.Size([225, 6]) || stage8.6.residual_group.blocks.3.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.6.residual_group.blocks.3.attn.relative_position_index
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([540, 180]) || stage8.6.residual_group.blocks.3.attn.qkv_self.weight
+ | 0.001 | -0.074 | 0.075 | 0.043 | torch.Size([540]) || stage8.6.residual_group.blocks.3.attn.qkv_self.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.6.residual_group.blocks.3.attn.proj.weight
+ | -0.000 | -0.072 | 0.074 | 0.044 | torch.Size([180]) || stage8.6.residual_group.blocks.3.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || stage8.6.residual_group.blocks.3.norm2.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || stage8.6.residual_group.blocks.3.norm2.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.3.mlp.fc11.weight
+ | 0.002 | -0.074 | 0.075 | 0.043 | torch.Size([360]) || stage8.6.residual_group.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.3.mlp.fc12.weight
+ | -0.002 | -0.074 | 0.074 | 0.044 | torch.Size([360]) || stage8.6.residual_group.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.053 | 0.053 | 0.030 | torch.Size([180, 360]) || stage8.6.residual_group.blocks.3.mlp.fc2.weight
+ | 0.001 | -0.052 | 0.053 | 0.031 | torch.Size([180]) || stage8.6.residual_group.blocks.3.mlp.fc2.bias
+ | -0.000 | -0.075 | 0.075 | 0.043 | torch.Size([180, 180]) || stage8.6.linear.weight
+ | 0.002 | -0.073 | 0.074 | 0.042 | torch.Size([180]) || stage8.6.linear.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([180]) || norm.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([180]) || norm.bias
+ | 0.000 | -0.075 | 0.075 | 0.043 | torch.Size([120, 180]) || conv_after_body.weight
+ | 0.004 | -0.071 | 0.072 | 0.043 | torch.Size([120]) || conv_after_body.bias
+ | -0.000 | -0.030 | 0.030 | 0.018 | torch.Size([64, 120, 1, 3, 3]) || conv_before_upsample.0.weight
+ | -0.003 | -0.029 | 0.029 | 0.018 | torch.Size([64]) || conv_before_upsample.0.bias
+ | -0.000 | -0.042 | 0.042 | 0.024 | torch.Size([256, 64, 1, 3, 3]) || upsample.0.weight
+ | -0.001 | -0.042 | 0.041 | 0.023 | torch.Size([256]) || upsample.0.bias
+ | -0.000 | -0.042 | 0.042 | 0.024 | torch.Size([256, 64, 1, 3, 3]) || upsample.5.weight
+ | -0.001 | -0.041 | 0.041 | 0.023 | torch.Size([256]) || upsample.5.bias
+ | 0.000 | -0.042 | 0.042 | 0.024 | torch.Size([64, 64, 1, 3, 3]) || upsample.10.weight
+ | 0.006 | -0.038 | 0.041 | 0.022 | torch.Size([64]) || upsample.10.bias
+ | 0.001 | -0.042 | 0.042 | 0.024 | torch.Size([3, 64, 1, 3, 3]) || conv_last.weight
+ | 0.011 | -0.006 | 0.025 | 0.016 | torch.Size([3]) || conv_last.bias
+
+22-03-11 10:16:36.045 : task: 001_train_vrt_videosr_bi_reds_6frames
+ model: vrt
+ gpu_ids: [0, 1, 2, 3, 4, 5, 6, 7]
+ dist: False
+ find_unused_parameters: False
+ use_static_graph: True
+ scale: 4
+ n_channels: 3
+ path:[
+ root: experiments
+ pretrained_netG: None
+ pretrained_netE: None
+ task: experiments/001_train_vrt_videosr_bi_reds_6frames
+ log: experiments/001_train_vrt_videosr_bi_reds_6frames
+ options: experiments/001_train_vrt_videosr_bi_reds_6frames/options
+ models: experiments/001_train_vrt_videosr_bi_reds_6frames/models
+ images: experiments/001_train_vrt_videosr_bi_reds_6frames/images
+ pretrained_optimizerG: None
+ ]
+ datasets:[
+ train:[
+ name: train_dataset
+ dataset_type: VideoRecurrentTrainDataset
+ dataroot_gt: /home/cll/datasets/REDS/val/val_sharp
+ dataroot_lq: /home/cll/datasets/REDS/val/val_sharp_bicubic
+ meta_info_file:
+ filename_tmpl: 08d
+ filename_ext: png
+ val_partition: REDS4
+ test_mode: False
+ io_backend:[
+ type: disk
+ ]
+ num_frame: 6
+ gt_size: 256
+ interval_list: [1]
+ random_reverse: False
+ use_hflip: True
+ use_rot: True
+ dataloader_shuffle: True
+ dataloader_num_workers: 32
+ dataloader_batch_size: 8
+ phase: train
+ scale: 4
+ n_channels: 3
+ ]
+ test:[
+ name: test_dataset
+ dataset_type: VideoRecurrentTestDataset
+ dataroot_gt: /home/cll/Desktop/REDS4/GT
+ dataroot_lq: /home/cll/Desktop/REDS4/sharp_bicubic
+ cache_data: True
+ io_backend:[
+ type: disk
+ ]
+ num_frame: -1
+ phase: test
+ scale: 4
+ n_channels: 3
+ ]
+ ]
+ netG:[
+ net_type: vrt
+ upscale: 4
+ img_size: [6, 64, 64]
+ window_size: [6, 8, 8]
+ depths: [8, 8, 8, 8, 8, 8, 8, 4, 4, 4, 4, 4, 4]
+ indep_reconsts: [11, 12]
+ embed_dims: [120, 120, 120, 120, 120, 120, 120, 180, 180, 180, 180, 180, 180]
+ num_heads: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
+ spynet_path: model_zoo/vrt/spynet_sintel_final-3d2a1287.pth
+ pa_frames: 2
+ deformable_groups: 12
+ nonblind_denoising: False
+ use_checkpoint_attn: False
+ use_checkpoint_ffn: False
+ no_checkpoint_attn_blocks: []
+ no_checkpoint_ffn_blocks: []
+ init_type: default
+ scale: 4
+ ]
+ train:[
+ G_lossfn_type: charbonnier
+ G_lossfn_weight: 1.0
+ G_charbonnier_eps: 1e-09
+ E_decay: 0
+ G_optimizer_type: adam
+ G_optimizer_lr: 0.0004
+ G_optimizer_betas: [0.9, 0.99]
+ G_optimizer_wd: 0
+ G_optimizer_clipgrad: None
+ G_optimizer_reuse: True
+ fix_iter: 20000
+ fix_lr_mul: 0.125
+ fix_keys: ['spynet', 'deform']
+ total_iter: 300000
+ G_scheduler_type: CosineAnnealingWarmRestarts
+ G_scheduler_periods: 300000
+ G_scheduler_eta_min: 1e-07
+ G_regularizer_orthstep: None
+ G_regularizer_clipstep: None
+ G_param_strict: True
+ E_param_strict: True
+ checkpoint_test: 5000
+ checkpoint_save: 5000
+ checkpoint_print: 200
+ F_feature_layer: 34
+ F_weights: 1.0
+ F_lossfn_type: l1
+ F_use_input_norm: True
+ F_use_range_norm: False
+ G_scheduler_restart_weights: 1
+ ]
+ val:[
+ save_img: False
+ pad_seq: False
+ flip_seq: False
+ center_frame_only: False
+ num_frame_testing: 40
+ num_frame_overlapping: 2
+ size_patch_testing: 128
+ ]
+ opt_path: options/vrt/001_train_vrt_videosr_bi_reds_6frames.json
+ is_train: True
+ merge_bn: False
+ merge_bn_startpoint: -1
+ num_gpu: 8
+ rank: 0
+ world_size: 1
+
+22-03-11 10:19:49.922 : task: 001_train_vrt_videosr_bi_reds_6frames
+ model: vrt
+ gpu_ids: [0, 1, 2, 3, 4, 5, 6, 7]
+ dist: False
+ find_unused_parameters: False
+ use_static_graph: True
+ scale: 4
+ n_channels: 3
+ path:[
+ root: experiments
+ pretrained_netG: /home/cll/dev/KAIR/model_zoo/vrt/
+ pretrained_netE: None
+ task: experiments/001_train_vrt_videosr_bi_reds_6frames
+ log: experiments/001_train_vrt_videosr_bi_reds_6frames
+ options: experiments/001_train_vrt_videosr_bi_reds_6frames/options
+ models: experiments/001_train_vrt_videosr_bi_reds_6frames/models
+ images: experiments/001_train_vrt_videosr_bi_reds_6frames/images
+ pretrained_optimizerG: None
+ ]
+ datasets:[
+ train:[
+ name: train_dataset
+ dataset_type: VideoRecurrentTrainDataset
+ dataroot_gt: /home/cll/datasets/REDS/val/val_sharp
+ dataroot_lq: /home/cll/datasets/REDS/val/val_sharp_bicubic
+ meta_info_file:
+ filename_tmpl: 08d
+ filename_ext: png
+ val_partition: REDS4
+ test_mode: False
+ io_backend:[
+ type: disk
+ ]
+ num_frame: 6
+ gt_size: 256
+ interval_list: [1]
+ random_reverse: False
+ use_hflip: True
+ use_rot: True
+ dataloader_shuffle: True
+ dataloader_num_workers: 32
+ dataloader_batch_size: 8
+ phase: train
+ scale: 4
+ n_channels: 3
+ ]
+ test:[
+ name: test_dataset
+ dataset_type: VideoRecurrentTestDataset
+ dataroot_gt: /home/cll/Desktop/REDS4/GT
+ dataroot_lq: /home/cll/Desktop/REDS4/sharp_bicubic
+ cache_data: True
+ io_backend:[
+ type: disk
+ ]
+ num_frame: -1
+ phase: test
+ scale: 4
+ n_channels: 3
+ ]
+ ]
+ netG:[
+ net_type: vrt
+ upscale: 4
+ img_size: [6, 64, 64]
+ window_size: [6, 8, 8]
+ depths: [8, 8, 8, 8, 8, 8, 8, 4, 4, 4, 4, 4, 4]
+ indep_reconsts: [11, 12]
+ embed_dims: [120, 120, 120, 120, 120, 120, 120, 180, 180, 180, 180, 180, 180]
+ num_heads: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
+ spynet_path: model_zoo/vrt/spynet_sintel_final-3d2a1287.pth
+ pa_frames: 2
+ deformable_groups: 12
+ nonblind_denoising: False
+ use_checkpoint_attn: False
+ use_checkpoint_ffn: False
+ no_checkpoint_attn_blocks: []
+ no_checkpoint_ffn_blocks: []
+ init_type: default
+ scale: 4
+ ]
+ train:[
+ G_lossfn_type: charbonnier
+ G_lossfn_weight: 1.0
+ G_charbonnier_eps: 1e-09
+ E_decay: 0
+ G_optimizer_type: adam
+ G_optimizer_lr: 0.0004
+ G_optimizer_betas: [0.9, 0.99]
+ G_optimizer_wd: 0
+ G_optimizer_clipgrad: None
+ G_optimizer_reuse: True
+ fix_iter: 20000
+ fix_lr_mul: 0.125
+ fix_keys: ['spynet', 'deform']
+ total_iter: 300000
+ G_scheduler_type: CosineAnnealingWarmRestarts
+ G_scheduler_periods: 300000
+ G_scheduler_eta_min: 1e-07
+ G_regularizer_orthstep: None
+ G_regularizer_clipstep: None
+ G_param_strict: True
+ E_param_strict: True
+ checkpoint_test: 5000
+ checkpoint_save: 5000
+ checkpoint_print: 200
+ F_feature_layer: 34
+ F_weights: 1.0
+ F_lossfn_type: l1
+ F_use_input_norm: True
+ F_use_range_norm: False
+ G_scheduler_restart_weights: 1
+ ]
+ val:[
+ save_img: False
+ pad_seq: False
+ flip_seq: False
+ center_frame_only: False
+ num_frame_testing: 40
+ num_frame_overlapping: 2
+ size_patch_testing: 128
+ ]
+ opt_path: options/vrt/001_train_vrt_videosr_bi_reds_6frames.json
+ is_train: True
+ merge_bn: False
+ merge_bn_startpoint: -1
+ num_gpu: 8
+ rank: 0
+ world_size: 1
+
+22-03-11 10:21:14.310 : task: 001_train_vrt_videosr_bi_reds_6frames
+ model: vrt
+ gpu_ids: [0, 1, 2, 3, 4, 5, 6, 7]
+ dist: False
+ find_unused_parameters: False
+ use_static_graph: True
+ scale: 4
+ n_channels: 3
+ path:[
+ root: experiments
+ pretrained_netG: /home/cll/dev/KAIR/model_zoo/vrt/
+ pretrained_netE: None
+ task: experiments/001_train_vrt_videosr_bi_reds_6frames
+ log: experiments/001_train_vrt_videosr_bi_reds_6frames
+ options: experiments/001_train_vrt_videosr_bi_reds_6frames/options
+ models: experiments/001_train_vrt_videosr_bi_reds_6frames/models
+ images: experiments/001_train_vrt_videosr_bi_reds_6frames/images
+ pretrained_optimizerG: None
+ ]
+ datasets:[
+ train:[
+ name: train_dataset
+ dataset_type: VideoRecurrentTrainDataset
+ dataroot_gt: /home/cll/datasets/REDS/val/val_sharp
+ dataroot_lq: /home/cll/datasets/REDS/val/val_sharp_bicubic
+ meta_info_file: data/meta_info/meta_info_REDS_GT.txt
+ filename_tmpl: 08d
+ filename_ext: png
+ val_partition: REDS4
+ test_mode: False
+ io_backend:[
+ type: disk
+ ]
+ num_frame: 6
+ gt_size: 256
+ interval_list: [1]
+ random_reverse: False
+ use_hflip: True
+ use_rot: True
+ dataloader_shuffle: True
+ dataloader_num_workers: 32
+ dataloader_batch_size: 8
+ phase: train
+ scale: 4
+ n_channels: 3
+ ]
+ test:[
+ name: test_dataset
+ dataset_type: VideoRecurrentTestDataset
+ dataroot_gt: /home/cll/Desktop/REDS4/GT
+ dataroot_lq: /home/cll/Desktop/REDS4/sharp_bicubic
+ cache_data: True
+ io_backend:[
+ type: disk
+ ]
+ num_frame: -1
+ phase: test
+ scale: 4
+ n_channels: 3
+ ]
+ ]
+ netG:[
+ net_type: vrt
+ upscale: 4
+ img_size: [6, 64, 64]
+ window_size: [6, 8, 8]
+ depths: [8, 8, 8, 8, 8, 8, 8, 4, 4, 4, 4, 4, 4]
+ indep_reconsts: [11, 12]
+ embed_dims: [120, 120, 120, 120, 120, 120, 120, 180, 180, 180, 180, 180, 180]
+ num_heads: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
+ spynet_path: model_zoo/vrt/spynet_sintel_final-3d2a1287.pth
+ pa_frames: 2
+ deformable_groups: 12
+ nonblind_denoising: False
+ use_checkpoint_attn: False
+ use_checkpoint_ffn: False
+ no_checkpoint_attn_blocks: []
+ no_checkpoint_ffn_blocks: []
+ init_type: default
+ scale: 4
+ ]
+ train:[
+ G_lossfn_type: charbonnier
+ G_lossfn_weight: 1.0
+ G_charbonnier_eps: 1e-09
+ E_decay: 0
+ G_optimizer_type: adam
+ G_optimizer_lr: 0.0004
+ G_optimizer_betas: [0.9, 0.99]
+ G_optimizer_wd: 0
+ G_optimizer_clipgrad: None
+ G_optimizer_reuse: True
+ fix_iter: 20000
+ fix_lr_mul: 0.125
+ fix_keys: ['spynet', 'deform']
+ total_iter: 300000
+ G_scheduler_type: CosineAnnealingWarmRestarts
+ G_scheduler_periods: 300000
+ G_scheduler_eta_min: 1e-07
+ G_regularizer_orthstep: None
+ G_regularizer_clipstep: None
+ G_param_strict: True
+ E_param_strict: True
+ checkpoint_test: 5000
+ checkpoint_save: 5000
+ checkpoint_print: 200
+ F_feature_layer: 34
+ F_weights: 1.0
+ F_lossfn_type: l1
+ F_use_input_norm: True
+ F_use_range_norm: False
+ G_scheduler_restart_weights: 1
+ ]
+ val:[
+ save_img: False
+ pad_seq: False
+ flip_seq: False
+ center_frame_only: False
+ num_frame_testing: 40
+ num_frame_overlapping: 2
+ size_patch_testing: 128
+ ]
+ opt_path: options/vrt/001_train_vrt_videosr_bi_reds_6frames.json
+ is_train: True
+ merge_bn: False
+ merge_bn_startpoint: -1
+ num_gpu: 8
+ rank: 0
+ world_size: 1
+
+22-03-11 10:21:14.354 : Number of train images: 27,000, iters: 3,375
+22-03-11 10:22:14.208 : task: 001_train_vrt_videosr_bi_reds_6frames
+ model: vrt
+ gpu_ids: [0, 1, 2, 3, 4, 5, 6, 7]
+ dist: False
+ find_unused_parameters: False
+ use_static_graph: True
+ scale: 4
+ n_channels: 3
+ path:[
+ root: experiments
+ pretrained_netG: /home/cll/dev/KAIR/model_zoo/vrt/001_VRT_videosr_bi_REDS_6frames.pth
+ pretrained_netE: None
+ task: experiments/001_train_vrt_videosr_bi_reds_6frames
+ log: experiments/001_train_vrt_videosr_bi_reds_6frames
+ options: experiments/001_train_vrt_videosr_bi_reds_6frames/options
+ models: experiments/001_train_vrt_videosr_bi_reds_6frames/models
+ images: experiments/001_train_vrt_videosr_bi_reds_6frames/images
+ pretrained_optimizerG: None
+ ]
+ datasets:[
+ train:[
+ name: train_dataset
+ dataset_type: VideoRecurrentTrainDataset
+ dataroot_gt: /home/cll/datasets/REDS/val/val_sharp
+ dataroot_lq: /home/cll/datasets/REDS/val/val_sharp_bicubic
+ meta_info_file: data/meta_info/meta_info_REDS_GT.txt
+ filename_tmpl: 08d
+ filename_ext: png
+ val_partition: REDS4
+ test_mode: False
+ io_backend:[
+ type: disk
+ ]
+ num_frame: 6
+ gt_size: 256
+ interval_list: [1]
+ random_reverse: False
+ use_hflip: True
+ use_rot: True
+ dataloader_shuffle: True
+ dataloader_num_workers: 32
+ dataloader_batch_size: 8
+ phase: train
+ scale: 4
+ n_channels: 3
+ ]
+ test:[
+ name: test_dataset
+ dataset_type: VideoRecurrentTestDataset
+ dataroot_gt: /home/cll/Desktop/REDS4/GT
+ dataroot_lq: /home/cll/Desktop/REDS4/sharp_bicubic
+ cache_data: True
+ io_backend:[
+ type: disk
+ ]
+ num_frame: -1
+ phase: test
+ scale: 4
+ n_channels: 3
+ ]
+ ]
+ netG:[
+ net_type: vrt
+ upscale: 4
+ img_size: [6, 64, 64]
+ window_size: [6, 8, 8]
+ depths: [8, 8, 8, 8, 8, 8, 8, 4, 4, 4, 4, 4, 4]
+ indep_reconsts: [11, 12]
+ embed_dims: [120, 120, 120, 120, 120, 120, 120, 180, 180, 180, 180, 180, 180]
+ num_heads: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
+ spynet_path: model_zoo/vrt/spynet_sintel_final-3d2a1287.pth
+ pa_frames: 2
+ deformable_groups: 12
+ nonblind_denoising: False
+ use_checkpoint_attn: False
+ use_checkpoint_ffn: False
+ no_checkpoint_attn_blocks: []
+ no_checkpoint_ffn_blocks: []
+ init_type: default
+ scale: 4
+ ]
+ train:[
+ G_lossfn_type: charbonnier
+ G_lossfn_weight: 1.0
+ G_charbonnier_eps: 1e-09
+ E_decay: 0
+ G_optimizer_type: adam
+ G_optimizer_lr: 0.0004
+ G_optimizer_betas: [0.9, 0.99]
+ G_optimizer_wd: 0
+ G_optimizer_clipgrad: None
+ G_optimizer_reuse: True
+ fix_iter: 20000
+ fix_lr_mul: 0.125
+ fix_keys: ['spynet', 'deform']
+ total_iter: 300000
+ G_scheduler_type: CosineAnnealingWarmRestarts
+ G_scheduler_periods: 300000
+ G_scheduler_eta_min: 1e-07
+ G_regularizer_orthstep: None
+ G_regularizer_clipstep: None
+ G_param_strict: True
+ E_param_strict: True
+ checkpoint_test: 5000
+ checkpoint_save: 5000
+ checkpoint_print: 200
+ F_feature_layer: 34
+ F_weights: 1.0
+ F_lossfn_type: l1
+ F_use_input_norm: True
+ F_use_range_norm: False
+ G_scheduler_restart_weights: 1
+ ]
+ val:[
+ save_img: False
+ pad_seq: False
+ flip_seq: False
+ center_frame_only: False
+ num_frame_testing: 40
+ num_frame_overlapping: 2
+ size_patch_testing: 128
+ ]
+ opt_path: options/vrt/001_train_vrt_videosr_bi_reds_6frames.json
+ is_train: True
+ merge_bn: False
+ merge_bn_startpoint: -1
+ num_gpu: 8
+ rank: 0
+ world_size: 1
+
+22-03-11 10:22:14.252 : Number of train images: 27,000, iters: 3,375
+22-03-11 10:22:28.605 :
+Networks name: VRT
+Params number: 30676435
+Net structure:
+VRT(
+ (conv_first): Conv3d(27, 120, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ (spynet): SpyNet(
+ (basic_module): ModuleList(
+ (0): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (1): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (2): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (3): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (4): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (5): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ )
+ )
+ (stage1): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n c d h w -> n d h w c')
+ (1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (2): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): Identity()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): Identity()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage2): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n c d (h neih) (w neiw) -> n d h w (neiw neih c)', neih=2, neiw=2)
+ (1): LayerNorm((480,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=480, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage3): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n c d (h neih) (w neiw) -> n d h w (neiw neih c)', neih=2, neiw=2)
+ (1): LayerNorm((480,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=480, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage4): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n c d (h neih) (w neiw) -> n d h w (neiw neih c)', neih=2, neiw=2)
+ (1): LayerNorm((480,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=480, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage5): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n (neiw neih c) d h w -> n d (h neih) (w neiw) c', neih=2, neiw=2)
+ (1): LayerNorm((30,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=30, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage6): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n (neiw neih c) d h w -> n d (h neih) (w neiw) c', neih=2, neiw=2)
+ (1): LayerNorm((30,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=30, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage7): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n (neiw neih c) d h w -> n d (h neih) (w neiw) c', neih=2, neiw=2)
+ (1): LayerNorm((30,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=30, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage8): ModuleList(
+ (0): Sequential(
+ (0): Rearrange('n c d h w -> n d h w c')
+ (1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=120, out_features=180, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (1): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (2): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (3): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (4): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (5): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (6): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ )
+ (norm): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (conv_after_body): Linear(in_features=180, out_features=120, bias=True)
+ (conv_before_upsample): Sequential(
+ (0): Conv3d(120, 64, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ (1): LeakyReLU(negative_slope=0.01, inplace=True)
+ )
+ (upsample): Upsample(
+ (0): Conv3d(64, 256, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ (1): Transpose_Dim12()
+ (2): PixelShuffle(upscale_factor=2)
+ (3): Transpose_Dim12()
+ (4): LeakyReLU(negative_slope=0.1, inplace=True)
+ (5): Conv3d(64, 256, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ (6): Transpose_Dim12()
+ (7): PixelShuffle(upscale_factor=2)
+ (8): Transpose_Dim12()
+ (9): LeakyReLU(negative_slope=0.1, inplace=True)
+ (10): Conv3d(64, 64, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ )
+ (conv_last): Conv3d(64, 3, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+)
+
+22-03-11 10:22:28.777 :
+ | mean | min | max | std || shape
+ | -0.000 | -1.462 | 1.580 | 0.103 | torch.Size([120, 27, 1, 3, 3]) || conv_first.weight
+ | 0.005 | -0.950 | 0.885 | 0.268 | torch.Size([120]) || conv_first.bias
+ | 0.449 | 0.406 | 0.485 | 0.040 | torch.Size([1, 3, 1, 1]) || spynet.mean
+ | 0.226 | 0.224 | 0.229 | 0.003 | torch.Size([1, 3, 1, 1]) || spynet.std
+ | -0.000 | -0.679 | 0.720 | 0.066 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.0.basic_module.0.weight
+ | -0.042 | -0.894 | 0.351 | 0.344 | torch.Size([32]) || spynet.basic_module.0.basic_module.0.bias
+ | -0.008 | -3.201 | 0.948 | 0.097 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.0.basic_module.2.weight
+ | 0.059 | -1.268 | 0.732 | 0.320 | torch.Size([64]) || spynet.basic_module.0.basic_module.2.bias
+ | -0.010 | -4.633 | 0.568 | 0.089 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.0.basic_module.4.weight
+ | 0.159 | -0.704 | 0.859 | 0.353 | torch.Size([32]) || spynet.basic_module.0.basic_module.4.bias
+ | -0.024 | -1.714 | 0.414 | 0.091 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.0.basic_module.6.weight
+ | 0.780 | -1.061 | 1.162 | 0.519 | torch.Size([16]) || spynet.basic_module.0.basic_module.6.bias
+ | 0.000 | -0.144 | 0.163 | 0.018 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.0.basic_module.8.weight
+ | 0.001 | -0.003 | 0.005 | 0.006 | torch.Size([2]) || spynet.basic_module.0.basic_module.8.bias
+ | 0.000 | -0.726 | 0.773 | 0.070 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.1.basic_module.0.weight
+ | -0.021 | -0.814 | 0.355 | 0.323 | torch.Size([32]) || spynet.basic_module.1.basic_module.0.bias
+ | -0.010 | -3.380 | 0.916 | 0.099 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.1.basic_module.2.weight
+ | 0.038 | -1.207 | 0.714 | 0.301 | torch.Size([64]) || spynet.basic_module.1.basic_module.2.bias
+ | -0.008 | -4.462 | 0.549 | 0.088 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.1.basic_module.4.weight
+ | 0.157 | -0.742 | 0.980 | 0.384 | torch.Size([32]) || spynet.basic_module.1.basic_module.4.bias
+ | -0.020 | -1.648 | 0.319 | 0.084 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.1.basic_module.6.weight
+ | 0.775 | -1.195 | 1.148 | 0.546 | torch.Size([16]) || spynet.basic_module.1.basic_module.6.bias
+ | -0.000 | -0.122 | 0.152 | 0.016 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.1.basic_module.8.weight
+ | -0.000 | -0.002 | 0.001 | 0.002 | torch.Size([2]) || spynet.basic_module.1.basic_module.8.bias
+ | 0.000 | -0.956 | 0.870 | 0.088 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.2.basic_module.0.weight
+ | -0.025 | -1.040 | 0.512 | 0.411 | torch.Size([32]) || spynet.basic_module.2.basic_module.0.bias
+ | -0.011 | -4.624 | 1.195 | 0.116 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.2.basic_module.2.weight
+ | 0.023 | -1.284 | 0.699 | 0.308 | torch.Size([64]) || spynet.basic_module.2.basic_module.2.bias
+ | -0.009 | -1.831 | 0.616 | 0.092 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.2.basic_module.4.weight
+ | 0.120 | -0.695 | 0.755 | 0.332 | torch.Size([32]) || spynet.basic_module.2.basic_module.4.bias
+ | -0.013 | -1.285 | 0.304 | 0.068 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.2.basic_module.6.weight
+ | 0.681 | -1.725 | 0.942 | 0.646 | torch.Size([16]) || spynet.basic_module.2.basic_module.6.bias
+ | 0.000 | -0.045 | 0.071 | 0.009 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.2.basic_module.8.weight
+ | -0.010 | -0.010 | -0.009 | 0.000 | torch.Size([2]) || spynet.basic_module.2.basic_module.8.bias
+ | -0.000 | -0.995 | 0.879 | 0.090 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.3.basic_module.0.weight
+ | -0.040 | -1.137 | 0.617 | 0.461 | torch.Size([32]) || spynet.basic_module.3.basic_module.0.bias
+ | -0.010 | -4.891 | 1.224 | 0.117 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.3.basic_module.2.weight
+ | 0.022 | -1.287 | 0.745 | 0.313 | torch.Size([64]) || spynet.basic_module.3.basic_module.2.bias
+ | -0.010 | -1.802 | 0.561 | 0.090 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.3.basic_module.4.weight
+ | 0.118 | -0.694 | 0.697 | 0.329 | torch.Size([32]) || spynet.basic_module.3.basic_module.4.bias
+ | -0.012 | -1.107 | 0.306 | 0.064 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.3.basic_module.6.weight
+ | 0.658 | -1.792 | 0.905 | 0.659 | torch.Size([16]) || spynet.basic_module.3.basic_module.6.bias
+ | 0.000 | -0.030 | 0.037 | 0.006 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.3.basic_module.8.weight
+ | 0.003 | -0.001 | 0.007 | 0.006 | torch.Size([2]) || spynet.basic_module.3.basic_module.8.bias
+ | -0.000 | -0.990 | 0.880 | 0.090 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.4.basic_module.0.weight
+ | -0.010 | -1.067 | 0.596 | 0.437 | torch.Size([32]) || spynet.basic_module.4.basic_module.0.bias
+ | -0.010 | -5.061 | 1.229 | 0.117 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.4.basic_module.2.weight
+ | 0.024 | -1.274 | 0.830 | 0.318 | torch.Size([64]) || spynet.basic_module.4.basic_module.2.bias
+ | -0.009 | -1.787 | 0.563 | 0.088 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.4.basic_module.4.weight
+ | 0.130 | -0.685 | 0.743 | 0.335 | torch.Size([32]) || spynet.basic_module.4.basic_module.4.bias
+ | -0.011 | -0.973 | 0.292 | 0.061 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.4.basic_module.6.weight
+ | 0.659 | -1.855 | 0.931 | 0.679 | torch.Size([16]) || spynet.basic_module.4.basic_module.6.bias
+ | 0.000 | -0.034 | 0.040 | 0.005 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.4.basic_module.8.weight
+ | -0.001 | -0.009 | 0.007 | 0.012 | torch.Size([2]) || spynet.basic_module.4.basic_module.8.bias
+ | -0.000 | -0.973 | 0.853 | 0.089 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.5.basic_module.0.weight
+ | 0.022 | -1.001 | 0.571 | 0.440 | torch.Size([32]) || spynet.basic_module.5.basic_module.0.bias
+ | -0.009 | -5.095 | 1.251 | 0.119 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.5.basic_module.2.weight
+ | 0.026 | -1.305 | 0.880 | 0.326 | torch.Size([64]) || spynet.basic_module.5.basic_module.2.bias
+ | -0.008 | -1.815 | 0.561 | 0.091 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.5.basic_module.4.weight
+ | 0.137 | -0.711 | 0.771 | 0.342 | torch.Size([32]) || spynet.basic_module.5.basic_module.4.bias
+ | -0.010 | -0.986 | 0.286 | 0.059 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.5.basic_module.6.weight
+ | 0.671 | -1.913 | 0.966 | 0.700 | torch.Size([16]) || spynet.basic_module.5.basic_module.6.bias
+ | 0.000 | -0.034 | 0.028 | 0.002 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.5.basic_module.8.weight
+ | 0.002 | -0.013 | 0.016 | 0.020 | torch.Size([2]) || spynet.basic_module.5.basic_module.8.bias
+ | 1.280 | 0.669 | 1.862 | 0.274 | torch.Size([120]) || stage1.reshape.1.weight
+ | -0.006 | -0.324 | 0.337 | 0.106 | torch.Size([120]) || stage1.reshape.1.bias
+ | 0.579 | 0.129 | 1.064 | 0.236 | torch.Size([120]) || stage1.residual_group1.blocks.0.norm1.weight
+ | -0.039 | -1.100 | 0.894 | 0.226 | torch.Size([120]) || stage1.residual_group1.blocks.0.norm1.bias
+ | -0.134 | -4.020 | 2.585 | 0.295 | torch.Size([675, 6]) || stage1.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.0.attn.position_bias
+ | -0.000 | -0.579 | 0.618 | 0.113 | torch.Size([360, 120]) || stage1.residual_group1.blocks.0.attn.qkv_self.weight
+ | 0.000 | -0.319 | 0.279 | 0.074 | torch.Size([360]) || stage1.residual_group1.blocks.0.attn.qkv_self.bias
+ | 0.001 | -0.634 | 0.686 | 0.076 | torch.Size([120, 240]) || stage1.residual_group1.blocks.0.attn.proj.weight
+ | -0.014 | -0.222 | 0.642 | 0.088 | torch.Size([120]) || stage1.residual_group1.blocks.0.attn.proj.bias
+ | -0.000 | -1.066 | 0.928 | 0.097 | torch.Size([360, 120]) || stage1.residual_group1.blocks.0.attn.qkv_mut.weight
+ | 0.000 | -0.146 | 0.190 | 0.033 | torch.Size([360]) || stage1.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.781 | 0.367 | 1.203 | 0.160 | torch.Size([120]) || stage1.residual_group1.blocks.0.norm2.weight
+ | 0.029 | -0.378 | 0.545 | 0.159 | torch.Size([120]) || stage1.residual_group1.blocks.0.norm2.bias
+ | 0.001 | -0.687 | 0.753 | 0.108 | torch.Size([240, 120]) || stage1.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.010 | -0.229 | 0.633 | 0.095 | torch.Size([240]) || stage1.residual_group1.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.674 | 0.669 | 0.117 | torch.Size([240, 120]) || stage1.residual_group1.blocks.0.mlp.fc12.weight
+ | 0.011 | -0.448 | 0.368 | 0.116 | torch.Size([240]) || stage1.residual_group1.blocks.0.mlp.fc12.bias
+ | 0.001 | -0.862 | 0.941 | 0.119 | torch.Size([120, 240]) || stage1.residual_group1.blocks.0.mlp.fc2.weight
+ | -0.004 | -0.267 | 0.594 | 0.099 | torch.Size([120]) || stage1.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.797 | 0.211 | 1.475 | 0.209 | torch.Size([120]) || stage1.residual_group1.blocks.1.norm1.weight
+ | -0.161 | -1.941 | 0.746 | 0.237 | torch.Size([120]) || stage1.residual_group1.blocks.1.norm1.bias
+ | -0.296 | -3.927 | 2.840 | 0.478 | torch.Size([675, 6]) || stage1.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.1.attn.position_bias
+ | 0.001 | -1.479 | 1.395 | 0.143 | torch.Size([360, 120]) || stage1.residual_group1.blocks.1.attn.qkv_self.weight
+ | -0.003 | -0.381 | 0.258 | 0.063 | torch.Size([360]) || stage1.residual_group1.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.526 | 0.561 | 0.079 | torch.Size([120, 240]) || stage1.residual_group1.blocks.1.attn.proj.weight
+ | -0.003 | -0.178 | 0.478 | 0.078 | torch.Size([120]) || stage1.residual_group1.blocks.1.attn.proj.bias
+ | 0.001 | -1.242 | 1.138 | 0.105 | torch.Size([360, 120]) || stage1.residual_group1.blocks.1.attn.qkv_mut.weight
+ | 0.004 | -0.213 | 0.196 | 0.050 | torch.Size([360]) || stage1.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.702 | 0.349 | 0.904 | 0.085 | torch.Size([120]) || stage1.residual_group1.blocks.1.norm2.weight
+ | 0.039 | -0.646 | 0.384 | 0.132 | torch.Size([120]) || stage1.residual_group1.blocks.1.norm2.bias
+ | 0.001 | -0.872 | 0.750 | 0.131 | torch.Size([240, 120]) || stage1.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.049 | -0.353 | 0.135 | 0.084 | torch.Size([240]) || stage1.residual_group1.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.562 | 0.580 | 0.117 | torch.Size([240, 120]) || stage1.residual_group1.blocks.1.mlp.fc12.weight
+ | 0.000 | -0.238 | 0.457 | 0.113 | torch.Size([240]) || stage1.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.828 | 0.685 | 0.123 | torch.Size([120, 240]) || stage1.residual_group1.blocks.1.mlp.fc2.weight
+ | 0.031 | -0.297 | 0.419 | 0.094 | torch.Size([120]) || stage1.residual_group1.blocks.1.mlp.fc2.bias
+ | 0.984 | 0.163 | 1.398 | 0.202 | torch.Size([120]) || stage1.residual_group1.blocks.2.norm1.weight
+ | -0.167 | -1.609 | 0.367 | 0.182 | torch.Size([120]) || stage1.residual_group1.blocks.2.norm1.bias
+ | -0.343 | -4.484 | 2.362 | 0.486 | torch.Size([675, 6]) || stage1.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.2.attn.position_bias
+ | 0.000 | -1.586 | 1.649 | 0.151 | torch.Size([360, 120]) || stage1.residual_group1.blocks.2.attn.qkv_self.weight
+ | -0.000 | -0.220 | 0.240 | 0.056 | torch.Size([360]) || stage1.residual_group1.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.378 | 0.514 | 0.086 | torch.Size([120, 240]) || stage1.residual_group1.blocks.2.attn.proj.weight
+ | -0.009 | -0.143 | 0.172 | 0.059 | torch.Size([120]) || stage1.residual_group1.blocks.2.attn.proj.bias
+ | 0.001 | -0.639 | 0.582 | 0.102 | torch.Size([360, 120]) || stage1.residual_group1.blocks.2.attn.qkv_mut.weight
+ | -0.000 | -0.141 | 0.173 | 0.035 | torch.Size([360]) || stage1.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.733 | 0.277 | 0.903 | 0.081 | torch.Size([120]) || stage1.residual_group1.blocks.2.norm2.weight
+ | 0.038 | -0.861 | 0.359 | 0.142 | torch.Size([120]) || stage1.residual_group1.blocks.2.norm2.bias
+ | 0.000 | -0.787 | 0.679 | 0.131 | torch.Size([240, 120]) || stage1.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.029 | -0.365 | 0.143 | 0.076 | torch.Size([240]) || stage1.residual_group1.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.574 | 0.539 | 0.120 | torch.Size([240, 120]) || stage1.residual_group1.blocks.2.mlp.fc12.weight
+ | -0.007 | -0.283 | 0.254 | 0.097 | torch.Size([240]) || stage1.residual_group1.blocks.2.mlp.fc12.bias
+ | 0.001 | -0.998 | 0.522 | 0.124 | torch.Size([120, 240]) || stage1.residual_group1.blocks.2.mlp.fc2.weight
+ | 0.030 | -0.169 | 0.293 | 0.095 | torch.Size([120]) || stage1.residual_group1.blocks.2.mlp.fc2.bias
+ | 1.035 | 0.143 | 1.397 | 0.196 | torch.Size([120]) || stage1.residual_group1.blocks.3.norm1.weight
+ | -0.161 | -1.413 | 0.084 | 0.154 | torch.Size([120]) || stage1.residual_group1.blocks.3.norm1.bias
+ | -0.441 | -4.685 | 3.306 | 0.529 | torch.Size([675, 6]) || stage1.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.3.attn.position_bias
+ | 0.000 | -1.590 | 1.329 | 0.155 | torch.Size([360, 120]) || stage1.residual_group1.blocks.3.attn.qkv_self.weight
+ | -0.002 | -0.266 | 0.232 | 0.049 | torch.Size([360]) || stage1.residual_group1.blocks.3.attn.qkv_self.bias
+ | -0.000 | -0.366 | 0.372 | 0.084 | torch.Size([120, 240]) || stage1.residual_group1.blocks.3.attn.proj.weight
+ | -0.011 | -0.225 | 0.171 | 0.071 | torch.Size([120]) || stage1.residual_group1.blocks.3.attn.proj.bias
+ | -0.000 | -0.660 | 0.801 | 0.100 | torch.Size([360, 120]) || stage1.residual_group1.blocks.3.attn.qkv_mut.weight
+ | -0.001 | -0.139 | 0.200 | 0.031 | torch.Size([360]) || stage1.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.724 | 0.190 | 0.911 | 0.091 | torch.Size([120]) || stage1.residual_group1.blocks.3.norm2.weight
+ | 0.038 | -0.981 | 0.285 | 0.137 | torch.Size([120]) || stage1.residual_group1.blocks.3.norm2.bias
+ | 0.001 | -0.611 | 0.598 | 0.130 | torch.Size([240, 120]) || stage1.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.035 | -0.299 | 0.221 | 0.081 | torch.Size([240]) || stage1.residual_group1.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.502 | 0.520 | 0.124 | torch.Size([240, 120]) || stage1.residual_group1.blocks.3.mlp.fc12.weight
+ | -0.002 | -0.271 | 0.215 | 0.090 | torch.Size([240]) || stage1.residual_group1.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.558 | 0.898 | 0.127 | torch.Size([120, 240]) || stage1.residual_group1.blocks.3.mlp.fc2.weight
+ | 0.010 | -0.424 | 0.190 | 0.082 | torch.Size([120]) || stage1.residual_group1.blocks.3.mlp.fc2.bias
+ | 1.085 | 0.169 | 1.400 | 0.157 | torch.Size([120]) || stage1.residual_group1.blocks.4.norm1.weight
+ | -0.086 | -1.613 | 0.150 | 0.160 | torch.Size([120]) || stage1.residual_group1.blocks.4.norm1.bias
+ | -0.541 | -3.902 | 3.728 | 0.633 | torch.Size([675, 6]) || stage1.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.4.attn.position_bias
+ | 0.001 | -1.879 | 1.832 | 0.150 | torch.Size([360, 120]) || stage1.residual_group1.blocks.4.attn.qkv_self.weight
+ | 0.001 | -0.391 | 0.444 | 0.079 | torch.Size([360]) || stage1.residual_group1.blocks.4.attn.qkv_self.bias
+ | -0.000 | -0.407 | 0.448 | 0.087 | torch.Size([120, 240]) || stage1.residual_group1.blocks.4.attn.proj.weight
+ | -0.013 | -0.302 | 0.342 | 0.104 | torch.Size([120]) || stage1.residual_group1.blocks.4.attn.proj.bias
+ | -0.001 | -0.830 | 0.863 | 0.102 | torch.Size([360, 120]) || stage1.residual_group1.blocks.4.attn.qkv_mut.weight
+ | -0.001 | -0.117 | 0.094 | 0.024 | torch.Size([360]) || stage1.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.704 | 0.195 | 0.870 | 0.079 | torch.Size([120]) || stage1.residual_group1.blocks.4.norm2.weight
+ | 0.031 | -1.069 | 0.276 | 0.140 | torch.Size([120]) || stage1.residual_group1.blocks.4.norm2.bias
+ | -0.000 | -0.656 | 0.555 | 0.130 | torch.Size([240, 120]) || stage1.residual_group1.blocks.4.mlp.fc11.weight
+ | -0.029 | -0.387 | 0.256 | 0.102 | torch.Size([240]) || stage1.residual_group1.blocks.4.mlp.fc11.bias
+ | 0.001 | -0.590 | 0.624 | 0.127 | torch.Size([240, 120]) || stage1.residual_group1.blocks.4.mlp.fc12.weight
+ | -0.011 | -0.277 | 0.303 | 0.087 | torch.Size([240]) || stage1.residual_group1.blocks.4.mlp.fc12.bias
+ | -0.000 | -1.124 | 0.539 | 0.130 | torch.Size([120, 240]) || stage1.residual_group1.blocks.4.mlp.fc2.weight
+ | -0.006 | -0.718 | 0.133 | 0.094 | torch.Size([120]) || stage1.residual_group1.blocks.4.mlp.fc2.bias
+ | 1.037 | 0.176 | 1.327 | 0.158 | torch.Size([120]) || stage1.residual_group1.blocks.5.norm1.weight
+ | -0.112 | -1.591 | 0.177 | 0.169 | torch.Size([120]) || stage1.residual_group1.blocks.5.norm1.bias
+ | -0.438 | -2.229 | 2.797 | 0.523 | torch.Size([675, 6]) || stage1.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.5.attn.position_bias
+ | -0.000 | -2.212 | 1.826 | 0.153 | torch.Size([360, 120]) || stage1.residual_group1.blocks.5.attn.qkv_self.weight
+ | 0.001 | -0.343 | 0.338 | 0.068 | torch.Size([360]) || stage1.residual_group1.blocks.5.attn.qkv_self.bias
+ | 0.000 | -0.367 | 0.451 | 0.087 | torch.Size([120, 240]) || stage1.residual_group1.blocks.5.attn.proj.weight
+ | -0.022 | -0.358 | 0.242 | 0.128 | torch.Size([120]) || stage1.residual_group1.blocks.5.attn.proj.bias
+ | 0.001 | -0.922 | 0.886 | 0.104 | torch.Size([360, 120]) || stage1.residual_group1.blocks.5.attn.qkv_mut.weight
+ | 0.002 | -0.083 | 0.089 | 0.022 | torch.Size([360]) || stage1.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.662 | 0.277 | 0.831 | 0.066 | torch.Size([120]) || stage1.residual_group1.blocks.5.norm2.weight
+ | 0.025 | -0.959 | 0.261 | 0.132 | torch.Size([120]) || stage1.residual_group1.blocks.5.norm2.bias
+ | -0.001 | -0.636 | 0.739 | 0.129 | torch.Size([240, 120]) || stage1.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.030 | -0.419 | 0.517 | 0.115 | torch.Size([240]) || stage1.residual_group1.blocks.5.mlp.fc11.bias
+ | -0.000 | -0.615 | 0.709 | 0.126 | torch.Size([240, 120]) || stage1.residual_group1.blocks.5.mlp.fc12.weight
+ | 0.002 | -0.230 | 0.457 | 0.087 | torch.Size([240]) || stage1.residual_group1.blocks.5.mlp.fc12.bias
+ | 0.001 | -1.724 | 1.186 | 0.132 | torch.Size([120, 240]) || stage1.residual_group1.blocks.5.mlp.fc2.weight
+ | -0.019 | -1.909 | 0.255 | 0.190 | torch.Size([120]) || stage1.residual_group1.blocks.5.mlp.fc2.bias
+ | -0.000 | -0.242 | 0.244 | 0.057 | torch.Size([120, 120]) || stage1.linear1.weight
+ | 0.004 | -0.221 | 0.224 | 0.083 | torch.Size([120]) || stage1.linear1.bias
+ | 0.737 | 0.334 | 1.046 | 0.119 | torch.Size([120]) || stage1.residual_group2.blocks.0.norm1.weight
+ | 0.013 | -0.911 | 0.763 | 0.193 | torch.Size([120]) || stage1.residual_group2.blocks.0.norm1.bias
+ | -0.052 | -2.462 | 2.040 | 0.273 | torch.Size([2475, 6]) || stage1.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage1.residual_group2.blocks.0.attn.relative_position_index
+ | 0.000 | -0.785 | 0.767 | 0.123 | torch.Size([360, 120]) || stage1.residual_group2.blocks.0.attn.qkv_self.weight
+ | 0.009 | -0.466 | 0.552 | 0.122 | torch.Size([360]) || stage1.residual_group2.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.431 | 0.475 | 0.091 | torch.Size([120, 120]) || stage1.residual_group2.blocks.0.attn.proj.weight
+ | -0.009 | -0.796 | 0.497 | 0.109 | torch.Size([120]) || stage1.residual_group2.blocks.0.attn.proj.bias
+ | 0.573 | 0.409 | 0.935 | 0.096 | torch.Size([120]) || stage1.residual_group2.blocks.0.norm2.weight
+ | 0.015 | -0.828 | 0.839 | 0.175 | torch.Size([120]) || stage1.residual_group2.blocks.0.norm2.bias
+ | 0.001 | -0.604 | 0.542 | 0.109 | torch.Size([240, 120]) || stage1.residual_group2.blocks.0.mlp.fc11.weight
+ | 0.037 | -0.179 | 0.273 | 0.076 | torch.Size([240]) || stage1.residual_group2.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.666 | 0.553 | 0.116 | torch.Size([240, 120]) || stage1.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.001 | -0.416 | 0.396 | 0.116 | torch.Size([240]) || stage1.residual_group2.blocks.0.mlp.fc12.bias
+ | 0.001 | -0.654 | 0.538 | 0.118 | torch.Size([120, 240]) || stage1.residual_group2.blocks.0.mlp.fc2.weight
+ | -0.002 | -0.470 | 0.310 | 0.122 | torch.Size([120]) || stage1.residual_group2.blocks.0.mlp.fc2.bias
+ | 0.951 | 0.342 | 1.189 | 0.111 | torch.Size([120]) || stage1.residual_group2.blocks.1.norm1.weight
+ | 0.010 | -0.697 | 0.802 | 0.166 | torch.Size([120]) || stage1.residual_group2.blocks.1.norm1.bias
+ | -0.098 | -2.648 | 2.410 | 0.214 | torch.Size([2475, 6]) || stage1.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage1.residual_group2.blocks.1.attn.relative_position_index
+ | -0.000 | -0.733 | 0.886 | 0.139 | torch.Size([360, 120]) || stage1.residual_group2.blocks.1.attn.qkv_self.weight
+ | -0.002 | -0.468 | 0.550 | 0.132 | torch.Size([360]) || stage1.residual_group2.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.435 | 0.377 | 0.096 | torch.Size([120, 120]) || stage1.residual_group2.blocks.1.attn.proj.weight
+ | -0.001 | -0.359 | 0.258 | 0.114 | torch.Size([120]) || stage1.residual_group2.blocks.1.attn.proj.bias
+ | 0.582 | 0.305 | 0.717 | 0.055 | torch.Size([120]) || stage1.residual_group2.blocks.1.norm2.weight
+ | 0.008 | -0.714 | 0.833 | 0.131 | torch.Size([120]) || stage1.residual_group2.blocks.1.norm2.bias
+ | 0.001 | -0.732 | 0.501 | 0.118 | torch.Size([240, 120]) || stage1.residual_group2.blocks.1.mlp.fc11.weight
+ | 0.004 | -0.306 | 0.267 | 0.091 | torch.Size([240]) || stage1.residual_group2.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.510 | 0.533 | 0.126 | torch.Size([240, 120]) || stage1.residual_group2.blocks.1.mlp.fc12.weight
+ | -0.000 | -0.315 | 0.291 | 0.090 | torch.Size([240]) || stage1.residual_group2.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.736 | 0.789 | 0.126 | torch.Size([120, 240]) || stage1.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.000 | -1.274 | 1.328 | 0.200 | torch.Size([120]) || stage1.residual_group2.blocks.1.mlp.fc2.bias
+ | -0.000 | -0.390 | 0.303 | 0.069 | torch.Size([120, 120]) || stage1.linear2.weight
+ | 0.010 | -0.219 | 0.227 | 0.087 | torch.Size([120]) || stage1.linear2.bias
+ | -0.000 | -0.095 | 0.106 | 0.024 | torch.Size([120, 120, 3, 3]) || stage1.pa_deform.weight
+ | -0.001 | -0.036 | 0.036 | 0.013 | torch.Size([120]) || stage1.pa_deform.bias
+ | -0.000 | -0.136 | 0.141 | 0.017 | torch.Size([120, 242, 3, 3]) || stage1.pa_deform.conv_offset.0.weight
+ | -0.002 | -0.028 | 0.024 | 0.013 | torch.Size([120]) || stage1.pa_deform.conv_offset.0.bias
+ | -0.001 | -0.156 | 0.104 | 0.019 | torch.Size([120, 120, 3, 3]) || stage1.pa_deform.conv_offset.2.weight
+ | -0.008 | -0.055 | 0.045 | 0.022 | torch.Size([120]) || stage1.pa_deform.conv_offset.2.bias
+ | -0.001 | -0.098 | 0.106 | 0.018 | torch.Size([120, 120, 3, 3]) || stage1.pa_deform.conv_offset.4.weight
+ | -0.000 | -0.081 | 0.070 | 0.029 | torch.Size([120]) || stage1.pa_deform.conv_offset.4.bias
+ | -0.000 | -0.375 | 0.279 | 0.027 | torch.Size([324, 120, 3, 3]) || stage1.pa_deform.conv_offset.6.weight
+ | -0.003 | -0.074 | 0.070 | 0.028 | torch.Size([324]) || stage1.pa_deform.conv_offset.6.bias
+ | -0.000 | -0.776 | 0.733 | 0.114 | torch.Size([360, 360]) || stage1.pa_fuse.fc11.weight
+ | 0.021 | -0.239 | 0.513 | 0.121 | torch.Size([360]) || stage1.pa_fuse.fc11.bias
+ | 0.001 | -1.100 | 1.143 | 0.149 | torch.Size([360, 360]) || stage1.pa_fuse.fc12.weight
+ | 0.008 | -0.405 | 0.393 | 0.136 | torch.Size([360]) || stage1.pa_fuse.fc12.bias
+ | 0.000 | -0.963 | 0.899 | 0.142 | torch.Size([120, 360]) || stage1.pa_fuse.fc2.weight
+ | -0.055 | -0.616 | 0.599 | 0.197 | torch.Size([120]) || stage1.pa_fuse.fc2.bias
+ | 1.149 | 0.345 | 1.921 | 0.289 | torch.Size([480]) || stage2.reshape.1.weight
+ | 0.017 | -0.502 | 0.663 | 0.141 | torch.Size([480]) || stage2.reshape.1.bias
+ | -0.000 | -0.609 | 0.736 | 0.146 | torch.Size([120, 480]) || stage2.reshape.2.weight
+ | 0.006 | -0.136 | 0.404 | 0.077 | torch.Size([120]) || stage2.reshape.2.bias
+ | 0.686 | 0.172 | 1.113 | 0.175 | torch.Size([120]) || stage2.residual_group1.blocks.0.norm1.weight
+ | -0.154 | -0.926 | 0.339 | 0.217 | torch.Size([120]) || stage2.residual_group1.blocks.0.norm1.bias
+ | -0.120 | -1.869 | 4.616 | 0.310 | torch.Size([675, 6]) || stage2.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.0.attn.position_bias
+ | 0.000 | -0.514 | 0.499 | 0.102 | torch.Size([360, 120]) || stage2.residual_group1.blocks.0.attn.qkv_self.weight
+ | -0.002 | -0.214 | 0.177 | 0.044 | torch.Size([360]) || stage2.residual_group1.blocks.0.attn.qkv_self.bias
+ | -0.001 | -0.499 | 0.529 | 0.093 | torch.Size([120, 240]) || stage2.residual_group1.blocks.0.attn.proj.weight
+ | -0.004 | -0.171 | 0.556 | 0.087 | torch.Size([120]) || stage2.residual_group1.blocks.0.attn.proj.bias
+ | -0.000 | -0.642 | 0.598 | 0.083 | torch.Size([360, 120]) || stage2.residual_group1.blocks.0.attn.qkv_mut.weight
+ | -0.000 | -0.141 | 0.125 | 0.027 | torch.Size([360]) || stage2.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.592 | 0.325 | 0.794 | 0.096 | torch.Size([120]) || stage2.residual_group1.blocks.0.norm2.weight
+ | 0.008 | -0.649 | 0.445 | 0.168 | torch.Size([120]) || stage2.residual_group1.blocks.0.norm2.bias
+ | 0.000 | -0.485 | 0.457 | 0.116 | torch.Size([240, 120]) || stage2.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.053 | -0.240 | 0.171 | 0.062 | torch.Size([240]) || stage2.residual_group1.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.503 | 0.462 | 0.118 | torch.Size([240, 120]) || stage2.residual_group1.blocks.0.mlp.fc12.weight
+ | 0.005 | -0.177 | 0.268 | 0.068 | torch.Size([240]) || stage2.residual_group1.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.690 | 0.498 | 0.123 | torch.Size([120, 240]) || stage2.residual_group1.blocks.0.mlp.fc2.weight
+ | -0.007 | -0.270 | 0.472 | 0.097 | torch.Size([120]) || stage2.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.864 | 0.187 | 1.221 | 0.164 | torch.Size([120]) || stage2.residual_group1.blocks.1.norm1.weight
+ | -0.146 | -1.128 | 0.299 | 0.204 | torch.Size([120]) || stage2.residual_group1.blocks.1.norm1.bias
+ | -0.241 | -1.607 | 8.958 | 0.356 | torch.Size([675, 6]) || stage2.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.1.attn.position_bias
+ | 0.000 | -0.561 | 0.538 | 0.116 | torch.Size([360, 120]) || stage2.residual_group1.blocks.1.attn.qkv_self.weight
+ | 0.001 | -0.198 | 0.222 | 0.052 | torch.Size([360]) || stage2.residual_group1.blocks.1.attn.qkv_self.bias
+ | 0.001 | -0.475 | 0.479 | 0.099 | torch.Size([120, 240]) || stage2.residual_group1.blocks.1.attn.proj.weight
+ | -0.006 | -0.295 | 0.341 | 0.101 | torch.Size([120]) || stage2.residual_group1.blocks.1.attn.proj.bias
+ | 0.001 | -0.961 | 0.789 | 0.080 | torch.Size([360, 120]) || stage2.residual_group1.blocks.1.attn.qkv_mut.weight
+ | 0.001 | -0.105 | 0.143 | 0.024 | torch.Size([360]) || stage2.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.653 | 0.401 | 0.810 | 0.063 | torch.Size([120]) || stage2.residual_group1.blocks.1.norm2.weight
+ | 0.009 | -0.767 | 0.367 | 0.154 | torch.Size([120]) || stage2.residual_group1.blocks.1.norm2.bias
+ | 0.001 | -0.486 | 0.499 | 0.117 | torch.Size([240, 120]) || stage2.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.056 | -0.185 | 0.147 | 0.058 | torch.Size([240]) || stage2.residual_group1.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.529 | 0.548 | 0.121 | torch.Size([240, 120]) || stage2.residual_group1.blocks.1.mlp.fc12.weight
+ | 0.002 | -0.231 | 0.177 | 0.071 | torch.Size([240]) || stage2.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.001 | -0.578 | 0.609 | 0.123 | torch.Size([120, 240]) || stage2.residual_group1.blocks.1.mlp.fc2.weight
+ | -0.003 | -0.350 | 0.216 | 0.098 | torch.Size([120]) || stage2.residual_group1.blocks.1.mlp.fc2.bias
+ | 0.848 | 0.172 | 1.107 | 0.144 | torch.Size([120]) || stage2.residual_group1.blocks.2.norm1.weight
+ | -0.168 | -1.123 | 0.330 | 0.178 | torch.Size([120]) || stage2.residual_group1.blocks.2.norm1.bias
+ | -0.074 | -1.239 | 4.293 | 0.247 | torch.Size([675, 6]) || stage2.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.2.attn.position_bias
+ | -0.001 | -0.643 | 0.531 | 0.117 | torch.Size([360, 120]) || stage2.residual_group1.blocks.2.attn.qkv_self.weight
+ | 0.003 | -0.220 | 0.376 | 0.047 | torch.Size([360]) || stage2.residual_group1.blocks.2.attn.qkv_self.bias
+ | 0.000 | -0.529 | 0.479 | 0.100 | torch.Size([120, 240]) || stage2.residual_group1.blocks.2.attn.proj.weight
+ | 0.002 | -0.230 | 0.295 | 0.074 | torch.Size([120]) || stage2.residual_group1.blocks.2.attn.proj.bias
+ | -0.001 | -0.726 | 0.768 | 0.091 | torch.Size([360, 120]) || stage2.residual_group1.blocks.2.attn.qkv_mut.weight
+ | 0.001 | -0.167 | 0.193 | 0.028 | torch.Size([360]) || stage2.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.695 | 0.334 | 0.833 | 0.068 | torch.Size([120]) || stage2.residual_group1.blocks.2.norm2.weight
+ | 0.012 | -0.755 | 0.517 | 0.157 | torch.Size([120]) || stage2.residual_group1.blocks.2.norm2.bias
+ | 0.001 | -0.474 | 0.480 | 0.119 | torch.Size([240, 120]) || stage2.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.049 | -0.218 | 0.148 | 0.067 | torch.Size([240]) || stage2.residual_group1.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.529 | 0.542 | 0.124 | torch.Size([240, 120]) || stage2.residual_group1.blocks.2.mlp.fc12.weight
+ | -0.006 | -0.245 | 0.239 | 0.073 | torch.Size([240]) || stage2.residual_group1.blocks.2.mlp.fc12.bias
+ | -0.001 | -0.541 | 0.485 | 0.124 | torch.Size([120, 240]) || stage2.residual_group1.blocks.2.mlp.fc2.weight
+ | 0.000 | -0.318 | 0.170 | 0.077 | torch.Size([120]) || stage2.residual_group1.blocks.2.mlp.fc2.bias
+ | 0.903 | 0.178 | 1.124 | 0.124 | torch.Size([120]) || stage2.residual_group1.blocks.3.norm1.weight
+ | -0.138 | -1.223 | 0.440 | 0.177 | torch.Size([120]) || stage2.residual_group1.blocks.3.norm1.bias
+ | -0.164 | -1.383 | 5.910 | 0.305 | torch.Size([675, 6]) || stage2.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.3.attn.position_bias
+ | -0.000 | -0.526 | 0.496 | 0.120 | torch.Size([360, 120]) || stage2.residual_group1.blocks.3.attn.qkv_self.weight
+ | 0.000 | -0.250 | 0.273 | 0.061 | torch.Size([360]) || stage2.residual_group1.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.447 | 0.524 | 0.097 | torch.Size([120, 240]) || stage2.residual_group1.blocks.3.attn.proj.weight
+ | -0.003 | -0.243 | 0.256 | 0.082 | torch.Size([120]) || stage2.residual_group1.blocks.3.attn.proj.bias
+ | -0.001 | -0.551 | 0.730 | 0.083 | torch.Size([360, 120]) || stage2.residual_group1.blocks.3.attn.qkv_mut.weight
+ | -0.001 | -0.145 | 0.126 | 0.024 | torch.Size([360]) || stage2.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.707 | 0.319 | 0.855 | 0.063 | torch.Size([120]) || stage2.residual_group1.blocks.3.norm2.weight
+ | 0.013 | -0.839 | 0.507 | 0.155 | torch.Size([120]) || stage2.residual_group1.blocks.3.norm2.bias
+ | 0.000 | -0.509 | 0.508 | 0.118 | torch.Size([240, 120]) || stage2.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.051 | -0.219 | 0.155 | 0.068 | torch.Size([240]) || stage2.residual_group1.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.475 | 0.592 | 0.124 | torch.Size([240, 120]) || stage2.residual_group1.blocks.3.mlp.fc12.weight
+ | -0.002 | -0.162 | 0.220 | 0.069 | torch.Size([240]) || stage2.residual_group1.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.465 | 0.528 | 0.124 | torch.Size([120, 240]) || stage2.residual_group1.blocks.3.mlp.fc2.weight
+ | -0.002 | -0.243 | 0.286 | 0.088 | torch.Size([120]) || stage2.residual_group1.blocks.3.mlp.fc2.bias
+ | 0.948 | 0.220 | 1.175 | 0.108 | torch.Size([120]) || stage2.residual_group1.blocks.4.norm1.weight
+ | -0.125 | -1.093 | 0.385 | 0.157 | torch.Size([120]) || stage2.residual_group1.blocks.4.norm1.bias
+ | -0.150 | -1.632 | 4.522 | 0.341 | torch.Size([675, 6]) || stage2.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.4.attn.position_bias
+ | -0.000 | -0.636 | 0.543 | 0.119 | torch.Size([360, 120]) || stage2.residual_group1.blocks.4.attn.qkv_self.weight
+ | -0.001 | -0.254 | 0.262 | 0.048 | torch.Size([360]) || stage2.residual_group1.blocks.4.attn.qkv_self.bias
+ | 0.001 | -0.632 | 0.628 | 0.112 | torch.Size([120, 240]) || stage2.residual_group1.blocks.4.attn.proj.weight
+ | -0.005 | -0.240 | 0.330 | 0.104 | torch.Size([120]) || stage2.residual_group1.blocks.4.attn.proj.bias
+ | 0.000 | -0.476 | 0.479 | 0.088 | torch.Size([360, 120]) || stage2.residual_group1.blocks.4.attn.qkv_mut.weight
+ | -0.001 | -0.112 | 0.134 | 0.020 | torch.Size([360]) || stage2.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.686 | 0.264 | 0.797 | 0.060 | torch.Size([120]) || stage2.residual_group1.blocks.4.norm2.weight
+ | 0.012 | -0.889 | 0.427 | 0.140 | torch.Size([120]) || stage2.residual_group1.blocks.4.norm2.bias
+ | 0.001 | -0.476 | 0.478 | 0.117 | torch.Size([240, 120]) || stage2.residual_group1.blocks.4.mlp.fc11.weight
+ | -0.051 | -0.267 | 0.180 | 0.071 | torch.Size([240]) || stage2.residual_group1.blocks.4.mlp.fc11.bias
+ | 0.000 | -0.506 | 0.517 | 0.127 | torch.Size([240, 120]) || stage2.residual_group1.blocks.4.mlp.fc12.weight
+ | 0.002 | -0.172 | 0.241 | 0.068 | torch.Size([240]) || stage2.residual_group1.blocks.4.mlp.fc12.bias
+ | -0.001 | -0.570 | 0.542 | 0.126 | torch.Size([120, 240]) || stage2.residual_group1.blocks.4.mlp.fc2.weight
+ | -0.003 | -0.631 | 0.395 | 0.123 | torch.Size([120]) || stage2.residual_group1.blocks.4.mlp.fc2.bias
+ | 0.912 | 0.189 | 1.122 | 0.104 | torch.Size([120]) || stage2.residual_group1.blocks.5.norm1.weight
+ | -0.114 | -1.125 | 0.188 | 0.140 | torch.Size([120]) || stage2.residual_group1.blocks.5.norm1.bias
+ | -0.099 | -1.285 | 1.708 | 0.236 | torch.Size([675, 6]) || stage2.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.5.attn.position_bias
+ | -0.000 | -0.496 | 0.540 | 0.119 | torch.Size([360, 120]) || stage2.residual_group1.blocks.5.attn.qkv_self.weight
+ | 0.003 | -0.260 | 0.228 | 0.052 | torch.Size([360]) || stage2.residual_group1.blocks.5.attn.qkv_self.bias
+ | -0.000 | -0.511 | 0.454 | 0.095 | torch.Size([120, 240]) || stage2.residual_group1.blocks.5.attn.proj.weight
+ | 0.000 | -0.711 | 0.286 | 0.115 | torch.Size([120]) || stage2.residual_group1.blocks.5.attn.proj.bias
+ | 0.000 | -0.444 | 0.454 | 0.082 | torch.Size([360, 120]) || stage2.residual_group1.blocks.5.attn.qkv_mut.weight
+ | -0.000 | -0.101 | 0.133 | 0.021 | torch.Size([360]) || stage2.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.668 | 0.312 | 0.800 | 0.056 | torch.Size([120]) || stage2.residual_group1.blocks.5.norm2.weight
+ | 0.015 | -0.778 | 0.372 | 0.111 | torch.Size([120]) || stage2.residual_group1.blocks.5.norm2.bias
+ | -0.000 | -0.485 | 0.469 | 0.115 | torch.Size([240, 120]) || stage2.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.045 | -0.294 | 0.173 | 0.083 | torch.Size([240]) || stage2.residual_group1.blocks.5.mlp.fc11.bias
+ | 0.000 | -0.554 | 0.540 | 0.129 | torch.Size([240, 120]) || stage2.residual_group1.blocks.5.mlp.fc12.weight
+ | 0.001 | -0.183 | 0.199 | 0.077 | torch.Size([240]) || stage2.residual_group1.blocks.5.mlp.fc12.bias
+ | 0.000 | -0.879 | 0.824 | 0.127 | torch.Size([120, 240]) || stage2.residual_group1.blocks.5.mlp.fc2.weight
+ | 0.001 | -1.670 | 0.358 | 0.208 | torch.Size([120]) || stage2.residual_group1.blocks.5.mlp.fc2.bias
+ | 0.001 | -0.253 | 0.346 | 0.068 | torch.Size([120, 120]) || stage2.linear1.weight
+ | 0.007 | -0.248 | 0.241 | 0.103 | torch.Size([120]) || stage2.linear1.bias
+ | 1.012 | 0.613 | 1.327 | 0.116 | torch.Size([120]) || stage2.residual_group2.blocks.0.norm1.weight
+ | 0.019 | -0.724 | 0.685 | 0.244 | torch.Size([120]) || stage2.residual_group2.blocks.0.norm1.bias
+ | 0.003 | -2.959 | 1.705 | 0.151 | torch.Size([2475, 6]) || stage2.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage2.residual_group2.blocks.0.attn.relative_position_index
+ | -0.000 | -0.636 | 0.617 | 0.125 | torch.Size([360, 120]) || stage2.residual_group2.blocks.0.attn.qkv_self.weight
+ | -0.002 | -0.291 | 0.292 | 0.085 | torch.Size([360]) || stage2.residual_group2.blocks.0.attn.qkv_self.bias
+ | -0.002 | -0.476 | 0.512 | 0.138 | torch.Size([120, 120]) || stage2.residual_group2.blocks.0.attn.proj.weight
+ | -0.002 | -0.263 | 0.398 | 0.135 | torch.Size([120]) || stage2.residual_group2.blocks.0.attn.proj.bias
+ | 0.677 | 0.521 | 0.840 | 0.063 | torch.Size([120]) || stage2.residual_group2.blocks.0.norm2.weight
+ | 0.010 | -0.710 | 0.541 | 0.173 | torch.Size([120]) || stage2.residual_group2.blocks.0.norm2.bias
+ | 0.001 | -0.540 | 0.507 | 0.112 | torch.Size([240, 120]) || stage2.residual_group2.blocks.0.mlp.fc11.weight
+ | -0.016 | -0.242 | 0.201 | 0.077 | torch.Size([240]) || stage2.residual_group2.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.519 | 0.479 | 0.122 | torch.Size([240, 120]) || stage2.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.006 | -0.162 | 0.231 | 0.071 | torch.Size([240]) || stage2.residual_group2.blocks.0.mlp.fc12.bias
+ | -0.001 | -0.449 | 0.494 | 0.121 | torch.Size([120, 240]) || stage2.residual_group2.blocks.0.mlp.fc2.weight
+ | 0.002 | -0.293 | 0.222 | 0.095 | torch.Size([120]) || stage2.residual_group2.blocks.0.mlp.fc2.bias
+ | 1.053 | 0.832 | 1.269 | 0.079 | torch.Size([120]) || stage2.residual_group2.blocks.1.norm1.weight
+ | 0.015 | -0.549 | 0.428 | 0.189 | torch.Size([120]) || stage2.residual_group2.blocks.1.norm1.bias
+ | 0.007 | -3.099 | 1.550 | 0.170 | torch.Size([2475, 6]) || stage2.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage2.residual_group2.blocks.1.attn.relative_position_index
+ | 0.000 | -0.673 | 0.604 | 0.131 | torch.Size([360, 120]) || stage2.residual_group2.blocks.1.attn.qkv_self.weight
+ | -0.001 | -0.416 | 0.391 | 0.089 | torch.Size([360]) || stage2.residual_group2.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.569 | 0.560 | 0.139 | torch.Size([120, 120]) || stage2.residual_group2.blocks.1.attn.proj.weight
+ | 0.004 | -0.613 | 0.428 | 0.158 | torch.Size([120]) || stage2.residual_group2.blocks.1.attn.proj.bias
+ | 0.762 | 0.464 | 0.954 | 0.085 | torch.Size([120]) || stage2.residual_group2.blocks.1.norm2.weight
+ | 0.005 | -0.745 | 0.381 | 0.117 | torch.Size([120]) || stage2.residual_group2.blocks.1.norm2.bias
+ | 0.000 | -0.441 | 0.448 | 0.110 | torch.Size([240, 120]) || stage2.residual_group2.blocks.1.mlp.fc11.weight
+ | 0.019 | -0.292 | 0.460 | 0.117 | torch.Size([240]) || stage2.residual_group2.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.491 | 0.490 | 0.126 | torch.Size([240, 120]) || stage2.residual_group2.blocks.1.mlp.fc12.weight
+ | -0.007 | -0.285 | 0.177 | 0.068 | torch.Size([240]) || stage2.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.535 | 0.631 | 0.125 | torch.Size([120, 240]) || stage2.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.011 | -0.765 | 0.337 | 0.142 | torch.Size([120]) || stage2.residual_group2.blocks.1.mlp.fc2.bias
+ | 0.001 | -0.367 | 0.372 | 0.074 | torch.Size([120, 120]) || stage2.linear2.weight
+ | 0.009 | -0.288 | 0.342 | 0.130 | torch.Size([120]) || stage2.linear2.bias
+ | 0.000 | -0.112 | 0.093 | 0.022 | torch.Size([120, 120, 3, 3]) || stage2.pa_deform.weight
+ | -0.002 | -0.036 | 0.035 | 0.016 | torch.Size([120]) || stage2.pa_deform.bias
+ | 0.000 | -0.068 | 0.080 | 0.016 | torch.Size([120, 242, 3, 3]) || stage2.pa_deform.conv_offset.0.weight
+ | -0.009 | -0.035 | 0.023 | 0.013 | torch.Size([120]) || stage2.pa_deform.conv_offset.0.bias
+ | 0.000 | -0.068 | 0.079 | 0.019 | torch.Size([120, 120, 3, 3]) || stage2.pa_deform.conv_offset.2.weight
+ | -0.014 | -0.061 | 0.036 | 0.021 | torch.Size([120]) || stage2.pa_deform.conv_offset.2.bias
+ | -0.001 | -0.082 | 0.079 | 0.019 | torch.Size([120, 120, 3, 3]) || stage2.pa_deform.conv_offset.4.weight
+ | -0.003 | -0.075 | 0.069 | 0.035 | torch.Size([120]) || stage2.pa_deform.conv_offset.4.bias
+ | -0.000 | -0.166 | 0.139 | 0.016 | torch.Size([324, 120, 3, 3]) || stage2.pa_deform.conv_offset.6.weight
+ | -0.015 | -0.090 | 0.050 | 0.030 | torch.Size([324]) || stage2.pa_deform.conv_offset.6.bias
+ | -0.002 | -0.642 | 0.663 | 0.127 | torch.Size([360, 360]) || stage2.pa_fuse.fc11.weight
+ | 0.130 | -0.171 | 0.480 | 0.140 | torch.Size([360]) || stage2.pa_fuse.fc11.bias
+ | -0.000 | -0.696 | 0.620 | 0.118 | torch.Size([360, 360]) || stage2.pa_fuse.fc12.weight
+ | -0.007 | -0.337 | 0.301 | 0.102 | torch.Size([360]) || stage2.pa_fuse.fc12.bias
+ | 0.000 | -0.650 | 0.657 | 0.128 | torch.Size([120, 360]) || stage2.pa_fuse.fc2.weight
+ | 0.013 | -0.507 | 0.451 | 0.215 | torch.Size([120]) || stage2.pa_fuse.fc2.bias
+ | 1.067 | 0.372 | 1.778 | 0.269 | torch.Size([480]) || stage3.reshape.1.weight
+ | -0.004 | -0.699 | 0.521 | 0.227 | torch.Size([480]) || stage3.reshape.1.bias
+ | -0.000 | -0.643 | 0.743 | 0.138 | torch.Size([120, 480]) || stage3.reshape.2.weight
+ | 0.009 | -0.176 | 0.243 | 0.079 | torch.Size([120]) || stage3.reshape.2.bias
+ | 0.785 | 0.469 | 1.029 | 0.105 | torch.Size([120]) || stage3.residual_group1.blocks.0.norm1.weight
+ | -0.102 | -0.716 | 0.311 | 0.179 | torch.Size([120]) || stage3.residual_group1.blocks.0.norm1.bias
+ | -0.001 | -0.340 | 0.163 | 0.033 | torch.Size([675, 6]) || stage3.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.0.attn.position_bias
+ | -0.000 | -0.328 | 0.302 | 0.061 | torch.Size([360, 120]) || stage3.residual_group1.blocks.0.attn.qkv_self.weight
+ | 0.004 | -0.232 | 0.189 | 0.063 | torch.Size([360]) || stage3.residual_group1.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.343 | 0.346 | 0.058 | torch.Size([120, 240]) || stage3.residual_group1.blocks.0.attn.proj.weight
+ | 0.004 | -0.335 | 0.229 | 0.102 | torch.Size([120]) || stage3.residual_group1.blocks.0.attn.proj.bias
+ | -0.000 | -0.366 | 0.325 | 0.052 | torch.Size([360, 120]) || stage3.residual_group1.blocks.0.attn.qkv_mut.weight
+ | -0.001 | -0.091 | 0.074 | 0.017 | torch.Size([360]) || stage3.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.751 | 0.517 | 0.928 | 0.083 | torch.Size([120]) || stage3.residual_group1.blocks.0.norm2.weight
+ | 0.002 | -0.271 | 0.189 | 0.101 | torch.Size([120]) || stage3.residual_group1.blocks.0.norm2.bias
+ | 0.000 | -0.371 | 0.388 | 0.096 | torch.Size([240, 120]) || stage3.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.073 | -0.203 | 0.039 | 0.046 | torch.Size([240]) || stage3.residual_group1.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.400 | 0.401 | 0.094 | torch.Size([240, 120]) || stage3.residual_group1.blocks.0.mlp.fc12.weight
+ | -0.000 | -0.178 | 0.128 | 0.052 | torch.Size([240]) || stage3.residual_group1.blocks.0.mlp.fc12.bias
+ | -0.001 | -0.410 | 0.429 | 0.098 | torch.Size([120, 240]) || stage3.residual_group1.blocks.0.mlp.fc2.weight
+ | 0.006 | -0.345 | 0.304 | 0.108 | torch.Size([120]) || stage3.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.816 | 0.469 | 1.015 | 0.110 | torch.Size([120]) || stage3.residual_group1.blocks.1.norm1.weight
+ | -0.103 | -0.647 | 0.225 | 0.140 | torch.Size([120]) || stage3.residual_group1.blocks.1.norm1.bias
+ | 0.001 | -0.464 | 0.239 | 0.034 | torch.Size([675, 6]) || stage3.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.1.attn.position_bias
+ | -0.000 | -0.304 | 0.359 | 0.061 | torch.Size([360, 120]) || stage3.residual_group1.blocks.1.attn.qkv_self.weight
+ | 0.001 | -0.173 | 0.193 | 0.047 | torch.Size([360]) || stage3.residual_group1.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.299 | 0.408 | 0.055 | torch.Size([120, 240]) || stage3.residual_group1.blocks.1.attn.proj.weight
+ | 0.007 | -0.511 | 0.239 | 0.113 | torch.Size([120]) || stage3.residual_group1.blocks.1.attn.proj.bias
+ | 0.000 | -0.288 | 0.254 | 0.049 | torch.Size([360, 120]) || stage3.residual_group1.blocks.1.attn.qkv_mut.weight
+ | 0.001 | -0.060 | 0.054 | 0.016 | torch.Size([360]) || stage3.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.796 | 0.609 | 0.971 | 0.076 | torch.Size([120]) || stage3.residual_group1.blocks.1.norm2.weight
+ | -0.002 | -0.327 | 0.247 | 0.122 | torch.Size([120]) || stage3.residual_group1.blocks.1.norm2.bias
+ | 0.001 | -0.379 | 0.407 | 0.094 | torch.Size([240, 120]) || stage3.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.077 | -0.214 | 0.034 | 0.045 | torch.Size([240]) || stage3.residual_group1.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.391 | 0.432 | 0.092 | torch.Size([240, 120]) || stage3.residual_group1.blocks.1.mlp.fc12.weight
+ | 0.005 | -0.176 | 0.112 | 0.044 | torch.Size([240]) || stage3.residual_group1.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.378 | 0.399 | 0.093 | torch.Size([120, 240]) || stage3.residual_group1.blocks.1.mlp.fc2.weight
+ | 0.009 | -0.410 | 0.306 | 0.110 | torch.Size([120]) || stage3.residual_group1.blocks.1.mlp.fc2.bias
+ | 0.854 | 0.447 | 0.995 | 0.090 | torch.Size([120]) || stage3.residual_group1.blocks.2.norm1.weight
+ | -0.086 | -0.513 | 0.198 | 0.116 | torch.Size([120]) || stage3.residual_group1.blocks.2.norm1.bias
+ | -0.001 | -0.189 | 0.292 | 0.033 | torch.Size([675, 6]) || stage3.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.2.attn.position_bias
+ | 0.000 | -0.390 | 0.367 | 0.067 | torch.Size([360, 120]) || stage3.residual_group1.blocks.2.attn.qkv_self.weight
+ | -0.002 | -0.310 | 0.284 | 0.078 | torch.Size([360]) || stage3.residual_group1.blocks.2.attn.qkv_self.bias
+ | 0.000 | -0.334 | 0.296 | 0.061 | torch.Size([120, 240]) || stage3.residual_group1.blocks.2.attn.proj.weight
+ | 0.004 | -0.356 | 0.299 | 0.096 | torch.Size([120]) || stage3.residual_group1.blocks.2.attn.proj.bias
+ | 0.000 | -0.276 | 0.315 | 0.055 | torch.Size([360, 120]) || stage3.residual_group1.blocks.2.attn.qkv_mut.weight
+ | 0.000 | -0.094 | 0.066 | 0.014 | torch.Size([360]) || stage3.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.829 | 0.673 | 1.017 | 0.074 | torch.Size([120]) || stage3.residual_group1.blocks.2.norm2.weight
+ | 0.003 | -0.259 | 0.228 | 0.098 | torch.Size([120]) || stage3.residual_group1.blocks.2.norm2.bias
+ | 0.001 | -0.410 | 0.385 | 0.091 | torch.Size([240, 120]) || stage3.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.085 | -0.200 | 0.017 | 0.044 | torch.Size([240]) || stage3.residual_group1.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.348 | 0.378 | 0.090 | torch.Size([240, 120]) || stage3.residual_group1.blocks.2.mlp.fc12.weight
+ | 0.001 | -0.130 | 0.105 | 0.042 | torch.Size([240]) || stage3.residual_group1.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.346 | 0.425 | 0.090 | torch.Size([120, 240]) || stage3.residual_group1.blocks.2.mlp.fc2.weight
+ | 0.005 | -0.363 | 0.241 | 0.094 | torch.Size([120]) || stage3.residual_group1.blocks.2.mlp.fc2.bias
+ | 0.872 | 0.554 | 1.068 | 0.102 | torch.Size([120]) || stage3.residual_group1.blocks.3.norm1.weight
+ | -0.057 | -0.402 | 0.133 | 0.087 | torch.Size([120]) || stage3.residual_group1.blocks.3.norm1.bias
+ | 0.003 | -0.365 | 0.217 | 0.050 | torch.Size([675, 6]) || stage3.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.3.attn.position_bias
+ | 0.000 | -0.359 | 0.357 | 0.065 | torch.Size([360, 120]) || stage3.residual_group1.blocks.3.attn.qkv_self.weight
+ | -0.002 | -0.265 | 0.294 | 0.062 | torch.Size([360]) || stage3.residual_group1.blocks.3.attn.qkv_self.bias
+ | -0.000 | -0.300 | 0.271 | 0.054 | torch.Size([120, 240]) || stage3.residual_group1.blocks.3.attn.proj.weight
+ | 0.002 | -0.316 | 0.215 | 0.094 | torch.Size([120]) || stage3.residual_group1.blocks.3.attn.proj.bias
+ | 0.000 | -0.370 | 0.329 | 0.039 | torch.Size([360, 120]) || stage3.residual_group1.blocks.3.attn.qkv_mut.weight
+ | 0.000 | -0.056 | 0.066 | 0.013 | torch.Size([360]) || stage3.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.842 | 0.631 | 0.989 | 0.073 | torch.Size([120]) || stage3.residual_group1.blocks.3.norm2.weight
+ | -0.001 | -0.216 | 0.263 | 0.083 | torch.Size([120]) || stage3.residual_group1.blocks.3.norm2.bias
+ | 0.001 | -0.388 | 0.391 | 0.089 | torch.Size([240, 120]) || stage3.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.087 | -0.202 | 0.032 | 0.048 | torch.Size([240]) || stage3.residual_group1.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.364 | 0.428 | 0.088 | torch.Size([240, 120]) || stage3.residual_group1.blocks.3.mlp.fc12.weight
+ | -0.000 | -0.137 | 0.106 | 0.043 | torch.Size([240]) || stage3.residual_group1.blocks.3.mlp.fc12.bias
+ | -0.001 | -0.390 | 0.339 | 0.088 | torch.Size([120, 240]) || stage3.residual_group1.blocks.3.mlp.fc2.weight
+ | 0.003 | -0.376 | 0.203 | 0.090 | torch.Size([120]) || stage3.residual_group1.blocks.3.mlp.fc2.bias
+ | 0.913 | 0.498 | 1.102 | 0.096 | torch.Size([120]) || stage3.residual_group1.blocks.4.norm1.weight
+ | -0.048 | -0.340 | 0.105 | 0.071 | torch.Size([120]) || stage3.residual_group1.blocks.4.norm1.bias
+ | 0.001 | -0.706 | 0.306 | 0.058 | torch.Size([675, 6]) || stage3.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.4.attn.position_bias
+ | 0.000 | -0.373 | 0.339 | 0.076 | torch.Size([360, 120]) || stage3.residual_group1.blocks.4.attn.qkv_self.weight
+ | -0.004 | -0.301 | 0.301 | 0.074 | torch.Size([360]) || stage3.residual_group1.blocks.4.attn.qkv_self.bias
+ | 0.000 | -0.278 | 0.277 | 0.058 | torch.Size([120, 240]) || stage3.residual_group1.blocks.4.attn.proj.weight
+ | 0.003 | -0.310 | 0.240 | 0.079 | torch.Size([120]) || stage3.residual_group1.blocks.4.attn.proj.bias
+ | -0.000 | -0.350 | 0.322 | 0.046 | torch.Size([360, 120]) || stage3.residual_group1.blocks.4.attn.qkv_mut.weight
+ | -0.000 | -0.045 | 0.064 | 0.010 | torch.Size([360]) || stage3.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.862 | 0.679 | 0.990 | 0.059 | torch.Size([120]) || stage3.residual_group1.blocks.4.norm2.weight
+ | -0.004 | -0.313 | 0.190 | 0.083 | torch.Size([120]) || stage3.residual_group1.blocks.4.norm2.bias
+ | 0.001 | -0.370 | 0.364 | 0.089 | torch.Size([240, 120]) || stage3.residual_group1.blocks.4.mlp.fc11.weight
+ | -0.092 | -0.231 | 0.129 | 0.057 | torch.Size([240]) || stage3.residual_group1.blocks.4.mlp.fc11.bias
+ | -0.000 | -0.375 | 0.511 | 0.090 | torch.Size([240, 120]) || stage3.residual_group1.blocks.4.mlp.fc12.weight
+ | 0.002 | -0.114 | 0.114 | 0.040 | torch.Size([240]) || stage3.residual_group1.blocks.4.mlp.fc12.bias
+ | -0.000 | -0.389 | 0.354 | 0.088 | torch.Size([120, 240]) || stage3.residual_group1.blocks.4.mlp.fc2.weight
+ | 0.005 | -0.258 | 0.164 | 0.073 | torch.Size([120]) || stage3.residual_group1.blocks.4.mlp.fc2.bias
+ | 0.899 | 0.480 | 1.089 | 0.103 | torch.Size([120]) || stage3.residual_group1.blocks.5.norm1.weight
+ | -0.030 | -0.257 | 0.115 | 0.056 | torch.Size([120]) || stage3.residual_group1.blocks.5.norm1.bias
+ | 0.003 | -0.462 | 0.290 | 0.069 | torch.Size([675, 6]) || stage3.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.5.attn.position_bias
+ | 0.000 | -0.391 | 0.365 | 0.069 | torch.Size([360, 120]) || stage3.residual_group1.blocks.5.attn.qkv_self.weight
+ | -0.004 | -0.232 | 0.302 | 0.064 | torch.Size([360]) || stage3.residual_group1.blocks.5.attn.qkv_self.bias
+ | -0.000 | -0.267 | 0.293 | 0.051 | torch.Size([120, 240]) || stage3.residual_group1.blocks.5.attn.proj.weight
+ | 0.000 | -0.250 | 0.182 | 0.070 | torch.Size([120]) || stage3.residual_group1.blocks.5.attn.proj.bias
+ | -0.000 | -0.238 | 0.257 | 0.033 | torch.Size([360, 120]) || stage3.residual_group1.blocks.5.attn.qkv_mut.weight
+ | -0.001 | -0.032 | 0.033 | 0.008 | torch.Size([360]) || stage3.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.864 | 0.651 | 1.029 | 0.070 | torch.Size([120]) || stage3.residual_group1.blocks.5.norm2.weight
+ | -0.003 | -0.212 | 0.175 | 0.075 | torch.Size([120]) || stage3.residual_group1.blocks.5.norm2.bias
+ | 0.000 | -0.378 | 0.379 | 0.089 | torch.Size([240, 120]) || stage3.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.097 | -0.308 | 0.026 | 0.051 | torch.Size([240]) || stage3.residual_group1.blocks.5.mlp.fc11.bias
+ | 0.000 | -0.578 | 0.401 | 0.089 | torch.Size([240, 120]) || stage3.residual_group1.blocks.5.mlp.fc12.weight
+ | -0.005 | -0.166 | 0.131 | 0.049 | torch.Size([240]) || stage3.residual_group1.blocks.5.mlp.fc12.bias
+ | 0.000 | -0.358 | 0.376 | 0.085 | torch.Size([120, 240]) || stage3.residual_group1.blocks.5.mlp.fc2.weight
+ | 0.001 | -0.262 | 0.176 | 0.072 | torch.Size([120]) || stage3.residual_group1.blocks.5.mlp.fc2.bias
+ | 0.003 | -0.284 | 0.467 | 0.071 | torch.Size([120, 120]) || stage3.linear1.weight
+ | 0.006 | -0.201 | 0.269 | 0.090 | torch.Size([120]) || stage3.linear1.bias
+ | 0.877 | 0.568 | 1.197 | 0.115 | torch.Size([120]) || stage3.residual_group2.blocks.0.norm1.weight
+ | 0.002 | -0.248 | 0.324 | 0.100 | torch.Size([120]) || stage3.residual_group2.blocks.0.norm1.bias
+ | 0.000 | -0.261 | 0.125 | 0.029 | torch.Size([2475, 6]) || stage3.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage3.residual_group2.blocks.0.attn.relative_position_index
+ | -0.000 | -0.563 | 0.552 | 0.074 | torch.Size([360, 120]) || stage3.residual_group2.blocks.0.attn.qkv_self.weight
+ | 0.005 | -0.257 | 0.302 | 0.081 | torch.Size([360]) || stage3.residual_group2.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.390 | 0.385 | 0.084 | torch.Size([120, 120]) || stage3.residual_group2.blocks.0.attn.proj.weight
+ | 0.002 | -0.450 | 0.235 | 0.125 | torch.Size([120]) || stage3.residual_group2.blocks.0.attn.proj.bias
+ | 0.986 | 0.755 | 1.165 | 0.078 | torch.Size([120]) || stage3.residual_group2.blocks.0.norm2.weight
+ | -0.000 | -0.260 | 0.169 | 0.076 | torch.Size([120]) || stage3.residual_group2.blocks.0.norm2.bias
+ | 0.000 | -0.355 | 0.397 | 0.087 | torch.Size([240, 120]) || stage3.residual_group2.blocks.0.mlp.fc11.weight
+ | -0.046 | -0.220 | 0.086 | 0.055 | torch.Size([240]) || stage3.residual_group2.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.424 | 0.368 | 0.089 | torch.Size([240, 120]) || stage3.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.006 | -0.111 | 0.122 | 0.038 | torch.Size([240]) || stage3.residual_group2.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.354 | 0.374 | 0.090 | torch.Size([120, 240]) || stage3.residual_group2.blocks.0.mlp.fc2.weight
+ | 0.001 | -0.374 | 0.272 | 0.101 | torch.Size([120]) || stage3.residual_group2.blocks.0.mlp.fc2.bias
+ | 0.919 | 0.643 | 1.132 | 0.100 | torch.Size([120]) || stage3.residual_group2.blocks.1.norm1.weight
+ | 0.000 | -0.177 | 0.181 | 0.063 | torch.Size([120]) || stage3.residual_group2.blocks.1.norm1.bias
+ | 0.000 | -0.332 | 0.131 | 0.028 | torch.Size([2475, 6]) || stage3.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage3.residual_group2.blocks.1.attn.relative_position_index
+ | -0.000 | -0.418 | 0.362 | 0.069 | torch.Size([360, 120]) || stage3.residual_group2.blocks.1.attn.qkv_self.weight
+ | -0.004 | -0.375 | 0.347 | 0.082 | torch.Size([360]) || stage3.residual_group2.blocks.1.attn.qkv_self.bias
+ | -0.001 | -0.294 | 0.354 | 0.077 | torch.Size([120, 120]) || stage3.residual_group2.blocks.1.attn.proj.weight
+ | 0.003 | -0.432 | 0.259 | 0.101 | torch.Size([120]) || stage3.residual_group2.blocks.1.attn.proj.bias
+ | 1.012 | 0.750 | 1.178 | 0.077 | torch.Size([120]) || stage3.residual_group2.blocks.1.norm2.weight
+ | -0.001 | -0.171 | 0.155 | 0.060 | torch.Size([120]) || stage3.residual_group2.blocks.1.norm2.bias
+ | 0.000 | -0.331 | 0.356 | 0.087 | torch.Size([240, 120]) || stage3.residual_group2.blocks.1.mlp.fc11.weight
+ | -0.035 | -0.207 | 0.197 | 0.065 | torch.Size([240]) || stage3.residual_group2.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.399 | 0.398 | 0.092 | torch.Size([240, 120]) || stage3.residual_group2.blocks.1.mlp.fc12.weight
+ | -0.002 | -0.111 | 0.129 | 0.041 | torch.Size([240]) || stage3.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.001 | -0.353 | 0.330 | 0.088 | torch.Size([120, 240]) || stage3.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.001 | -0.328 | 0.127 | 0.064 | torch.Size([120]) || stage3.residual_group2.blocks.1.mlp.fc2.bias
+ | 0.003 | -0.289 | 0.519 | 0.073 | torch.Size([120, 120]) || stage3.linear2.weight
+ | 0.002 | -0.318 | 0.371 | 0.144 | torch.Size([120]) || stage3.linear2.bias
+ | -0.000 | -0.086 | 0.095 | 0.022 | torch.Size([120, 120, 3, 3]) || stage3.pa_deform.weight
+ | -0.002 | -0.023 | 0.021 | 0.010 | torch.Size([120]) || stage3.pa_deform.bias
+ | -0.000 | -0.060 | 0.056 | 0.015 | torch.Size([120, 242, 3, 3]) || stage3.pa_deform.conv_offset.0.weight
+ | -0.008 | -0.035 | 0.019 | 0.013 | torch.Size([120]) || stage3.pa_deform.conv_offset.0.bias
+ | -0.001 | -0.064 | 0.062 | 0.019 | torch.Size([120, 120, 3, 3]) || stage3.pa_deform.conv_offset.2.weight
+ | -0.007 | -0.044 | 0.031 | 0.019 | torch.Size([120]) || stage3.pa_deform.conv_offset.2.bias
+ | 0.000 | -0.062 | 0.063 | 0.019 | torch.Size([120, 120, 3, 3]) || stage3.pa_deform.conv_offset.4.weight
+ | -0.006 | -0.052 | 0.043 | 0.021 | torch.Size([120]) || stage3.pa_deform.conv_offset.4.bias
+ | 0.000 | -0.081 | 0.080 | 0.011 | torch.Size([324, 120, 3, 3]) || stage3.pa_deform.conv_offset.6.weight
+ | -0.004 | -0.087 | 0.083 | 0.021 | torch.Size([324]) || stage3.pa_deform.conv_offset.6.bias
+ | -0.002 | -0.465 | 0.513 | 0.101 | torch.Size([360, 360]) || stage3.pa_fuse.fc11.weight
+ | 0.059 | -0.251 | 0.595 | 0.104 | torch.Size([360]) || stage3.pa_fuse.fc11.bias
+ | -0.000 | -0.544 | 0.531 | 0.100 | torch.Size([360, 360]) || stage3.pa_fuse.fc12.weight
+ | 0.001 | -0.589 | 0.433 | 0.106 | torch.Size([360]) || stage3.pa_fuse.fc12.bias
+ | -0.000 | -0.535 | 0.562 | 0.127 | torch.Size([120, 360]) || stage3.pa_fuse.fc2.weight
+ | -0.001 | -0.401 | 0.342 | 0.121 | torch.Size([120]) || stage3.pa_fuse.fc2.bias
+ | 0.997 | 0.921 | 1.125 | 0.028 | torch.Size([480]) || stage4.reshape.1.weight
+ | -0.000 | -0.058 | 0.059 | 0.022 | torch.Size([480]) || stage4.reshape.1.bias
+ | 0.000 | -0.155 | 0.150 | 0.031 | torch.Size([120, 480]) || stage4.reshape.2.weight
+ | 0.001 | -0.016 | 0.016 | 0.006 | torch.Size([120]) || stage4.reshape.2.bias
+ | 1.002 | 0.999 | 1.009 | 0.002 | torch.Size([120]) || stage4.residual_group1.blocks.0.norm1.weight
+ | 0.000 | -0.002 | 0.003 | 0.001 | torch.Size([120]) || stage4.residual_group1.blocks.0.norm1.bias
+ | -0.000 | -0.071 | 0.066 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.0.attn.position_bias
+ | 0.000 | -0.093 | 0.081 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.0.attn.qkv_self.weight
+ | -0.000 | -0.009 | 0.009 | 0.002 | torch.Size([360]) || stage4.residual_group1.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.080 | 0.097 | 0.021 | torch.Size([120, 240]) || stage4.residual_group1.blocks.0.attn.proj.weight
+ | 0.000 | -0.035 | 0.027 | 0.013 | torch.Size([120]) || stage4.residual_group1.blocks.0.attn.proj.bias
+ | 0.000 | -0.080 | 0.079 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.0.attn.qkv_mut.weight
+ | -0.000 | -0.007 | 0.008 | 0.002 | torch.Size([360]) || stage4.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.0.norm2.weight
+ | -0.000 | -0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.0.norm2.bias
+ | -0.000 | -0.079 | 0.085 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.0.mlp.fc11.weight
+ | 0.000 | -0.001 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.087 | 0.092 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.0.mlp.fc12.weight
+ | -0.000 | -0.001 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.080 | 0.077 | 0.020 | torch.Size([120, 240]) || stage4.residual_group1.blocks.0.mlp.fc2.weight
+ | 0.000 | -0.031 | 0.029 | 0.013 | torch.Size([120]) || stage4.residual_group1.blocks.0.mlp.fc2.bias
+ | 1.002 | 0.997 | 1.007 | 0.002 | torch.Size([120]) || stage4.residual_group1.blocks.1.norm1.weight
+ | -0.000 | -0.002 | 0.003 | 0.001 | torch.Size([120]) || stage4.residual_group1.blocks.1.norm1.bias
+ | 0.000 | -0.066 | 0.065 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.1.attn.position_bias
+ | -0.000 | -0.078 | 0.081 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.1.attn.qkv_self.weight
+ | 0.000 | -0.006 | 0.008 | 0.002 | torch.Size([360]) || stage4.residual_group1.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.080 | 0.083 | 0.021 | torch.Size([120, 240]) || stage4.residual_group1.blocks.1.attn.proj.weight
+ | -0.000 | -0.027 | 0.029 | 0.012 | torch.Size([120]) || stage4.residual_group1.blocks.1.attn.proj.bias
+ | 0.000 | -0.077 | 0.082 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.1.attn.qkv_mut.weight
+ | -0.000 | -0.006 | 0.009 | 0.001 | torch.Size([360]) || stage4.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.1.norm2.weight
+ | 0.000 | -0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.1.norm2.bias
+ | -0.000 | -0.080 | 0.078 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.000 | -0.001 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.077 | 0.085 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.1.mlp.fc12.weight
+ | 0.000 | -0.001 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.084 | 0.075 | 0.020 | torch.Size([120, 240]) || stage4.residual_group1.blocks.1.mlp.fc2.weight
+ | 0.000 | -0.034 | 0.031 | 0.013 | torch.Size([120]) || stage4.residual_group1.blocks.1.mlp.fc2.bias
+ | 1.002 | 0.996 | 1.008 | 0.002 | torch.Size([120]) || stage4.residual_group1.blocks.2.norm1.weight
+ | -0.000 | -0.003 | 0.002 | 0.001 | torch.Size([120]) || stage4.residual_group1.blocks.2.norm1.bias
+ | 0.001 | -0.070 | 0.071 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.2.attn.position_bias
+ | 0.000 | -0.091 | 0.087 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.2.attn.qkv_self.weight
+ | -0.000 | -0.007 | 0.005 | 0.001 | torch.Size([360]) || stage4.residual_group1.blocks.2.attn.qkv_self.bias
+ | 0.000 | -0.080 | 0.084 | 0.020 | torch.Size([120, 240]) || stage4.residual_group1.blocks.2.attn.proj.weight
+ | -0.000 | -0.023 | 0.026 | 0.010 | torch.Size([120]) || stage4.residual_group1.blocks.2.attn.proj.bias
+ | -0.000 | -0.107 | 0.087 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.2.attn.qkv_mut.weight
+ | 0.000 | -0.006 | 0.005 | 0.001 | torch.Size([360]) || stage4.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 1.000 | 0.999 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.2.norm2.weight
+ | 0.000 | -0.000 | 0.001 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.2.norm2.bias
+ | 0.000 | -0.076 | 0.077 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.000 | -0.005 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.2.mlp.fc11.bias
+ | -0.000 | -2.000 | 0.081 | 0.023 | torch.Size([240, 120]) || stage4.residual_group1.blocks.2.mlp.fc12.weight
+ | 0.000 | -0.001 | 0.002 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.084 | 0.077 | 0.020 | torch.Size([120, 240]) || stage4.residual_group1.blocks.2.mlp.fc2.weight
+ | 0.000 | -0.027 | 0.024 | 0.010 | torch.Size([120]) || stage4.residual_group1.blocks.2.mlp.fc2.bias
+ | 1.002 | 0.999 | 1.012 | 0.002 | torch.Size([120]) || stage4.residual_group1.blocks.3.norm1.weight
+ | -0.000 | -0.003 | 0.002 | 0.001 | torch.Size([120]) || stage4.residual_group1.blocks.3.norm1.bias
+ | 0.000 | -0.064 | 0.071 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.3.attn.position_bias
+ | 0.000 | -0.099 | 0.088 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.3.attn.qkv_self.weight
+ | 0.000 | -0.006 | 0.005 | 0.001 | torch.Size([360]) || stage4.residual_group1.blocks.3.attn.qkv_self.bias
+ | -0.000 | -0.083 | 0.084 | 0.020 | torch.Size([120, 240]) || stage4.residual_group1.blocks.3.attn.proj.weight
+ | -0.000 | -0.019 | 0.018 | 0.008 | torch.Size([120]) || stage4.residual_group1.blocks.3.attn.proj.bias
+ | 0.000 | -0.079 | 0.084 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.3.attn.qkv_mut.weight
+ | -0.000 | -0.004 | 0.004 | 0.001 | torch.Size([360]) || stage4.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.3.norm2.weight
+ | 0.000 | -0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.3.norm2.bias
+ | -0.000 | -0.078 | 0.081 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.000 | -0.001 | 0.002 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.087 | 0.076 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.3.mlp.fc12.weight
+ | -0.000 | -0.001 | 0.002 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.3.mlp.fc12.bias
+ | -0.000 | -0.079 | 0.082 | 0.020 | torch.Size([120, 240]) || stage4.residual_group1.blocks.3.mlp.fc2.weight
+ | 0.000 | -0.022 | 0.021 | 0.008 | torch.Size([120]) || stage4.residual_group1.blocks.3.mlp.fc2.bias
+ | 1.002 | 0.998 | 1.011 | 0.002 | torch.Size([120]) || stage4.residual_group1.blocks.4.norm1.weight
+ | -0.001 | -0.004 | 0.003 | 0.001 | torch.Size([120]) || stage4.residual_group1.blocks.4.norm1.bias
+ | 0.000 | -0.089 | 0.081 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.4.attn.position_bias
+ | -0.000 | -0.080 | 0.085 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.4.attn.qkv_self.weight
+ | -0.000 | -0.006 | 0.005 | 0.001 | torch.Size([360]) || stage4.residual_group1.blocks.4.attn.qkv_self.bias
+ | -0.000 | -0.075 | 0.077 | 0.020 | torch.Size([120, 240]) || stage4.residual_group1.blocks.4.attn.proj.weight
+ | -0.000 | -0.021 | 0.016 | 0.007 | torch.Size([120]) || stage4.residual_group1.blocks.4.attn.proj.bias
+ | 0.000 | -0.082 | 0.088 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.4.attn.qkv_mut.weight
+ | -0.000 | -0.004 | 0.006 | 0.001 | torch.Size([360]) || stage4.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 1.000 | 0.999 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.4.norm2.weight
+ | 0.000 | -0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.4.norm2.bias
+ | -0.000 | -0.086 | 0.080 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.4.mlp.fc11.weight
+ | 0.000 | -0.001 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.4.mlp.fc11.bias
+ | 0.000 | -0.084 | 0.083 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.4.mlp.fc12.weight
+ | 0.000 | -0.001 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.4.mlp.fc12.bias
+ | 0.000 | -0.076 | 0.081 | 0.020 | torch.Size([120, 240]) || stage4.residual_group1.blocks.4.mlp.fc2.weight
+ | -0.000 | -0.018 | 0.015 | 0.007 | torch.Size([120]) || stage4.residual_group1.blocks.4.mlp.fc2.bias
+ | 1.003 | 0.997 | 1.014 | 0.003 | torch.Size([120]) || stage4.residual_group1.blocks.5.norm1.weight
+ | -0.001 | -0.005 | 0.004 | 0.002 | torch.Size([120]) || stage4.residual_group1.blocks.5.norm1.bias
+ | -0.001 | -0.070 | 0.069 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.5.attn.position_bias
+ | -0.000 | -0.097 | 0.082 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.5.attn.qkv_self.weight
+ | 0.000 | -0.007 | 0.008 | 0.002 | torch.Size([360]) || stage4.residual_group1.blocks.5.attn.qkv_self.bias
+ | -0.000 | -0.075 | 0.089 | 0.021 | torch.Size([120, 240]) || stage4.residual_group1.blocks.5.attn.proj.weight
+ | 0.000 | -0.016 | 0.015 | 0.007 | torch.Size([120]) || stage4.residual_group1.blocks.5.attn.proj.bias
+ | 0.000 | -0.083 | 0.091 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.5.attn.qkv_mut.weight
+ | 0.000 | -0.006 | 0.006 | 0.001 | torch.Size([360]) || stage4.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 1.000 | 0.999 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.5.norm2.weight
+ | -0.000 | -0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.5.norm2.bias
+ | 0.000 | -0.093 | 0.083 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.5.mlp.fc11.weight
+ | 0.000 | -0.002 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.5.mlp.fc11.bias
+ | 0.000 | -0.086 | 0.085 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.5.mlp.fc12.weight
+ | 0.000 | -0.001 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.5.mlp.fc12.bias
+ | 0.000 | -0.079 | 0.092 | 0.020 | torch.Size([120, 240]) || stage4.residual_group1.blocks.5.mlp.fc2.weight
+ | -0.000 | -0.012 | 0.016 | 0.005 | torch.Size([120]) || stage4.residual_group1.blocks.5.mlp.fc2.bias
+ | -0.000 | -0.090 | 0.111 | 0.024 | torch.Size([120, 120]) || stage4.linear1.weight
+ | 0.001 | -0.019 | 0.029 | 0.009 | torch.Size([120]) || stage4.linear1.bias
+ | 1.000 | 0.999 | 1.003 | 0.001 | torch.Size([120]) || stage4.residual_group2.blocks.0.norm1.weight
+ | 0.000 | -0.001 | 0.001 | 0.000 | torch.Size([120]) || stage4.residual_group2.blocks.0.norm1.bias
+ | -0.000 | -0.078 | 0.075 | 0.020 | torch.Size([2475, 6]) || stage4.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage4.residual_group2.blocks.0.attn.relative_position_index
+ | 0.000 | -0.084 | 0.087 | 0.020 | torch.Size([360, 120]) || stage4.residual_group2.blocks.0.attn.qkv_self.weight
+ | 0.000 | -0.005 | 0.004 | 0.001 | torch.Size([360]) || stage4.residual_group2.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.079 | 0.080 | 0.020 | torch.Size([120, 120]) || stage4.residual_group2.blocks.0.attn.proj.weight
+ | 0.000 | -0.021 | 0.024 | 0.008 | torch.Size([120]) || stage4.residual_group2.blocks.0.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group2.blocks.0.norm2.weight
+ | -0.000 | -0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group2.blocks.0.norm2.bias
+ | -0.000 | -0.079 | 0.072 | 0.020 | torch.Size([240, 120]) || stage4.residual_group2.blocks.0.mlp.fc11.weight
+ | -0.000 | -0.001 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group2.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.077 | 0.078 | 0.020 | torch.Size([240, 120]) || stage4.residual_group2.blocks.0.mlp.fc12.weight
+ | 0.000 | -0.001 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group2.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.102 | 0.078 | 0.020 | torch.Size([120, 240]) || stage4.residual_group2.blocks.0.mlp.fc2.weight
+ | 0.000 | -0.024 | 0.020 | 0.009 | torch.Size([120]) || stage4.residual_group2.blocks.0.mlp.fc2.bias
+ | 1.001 | 0.998 | 1.003 | 0.001 | torch.Size([120]) || stage4.residual_group2.blocks.1.norm1.weight
+ | -0.000 | -0.002 | 0.002 | 0.001 | torch.Size([120]) || stage4.residual_group2.blocks.1.norm1.bias
+ | -0.000 | -0.071 | 0.079 | 0.020 | torch.Size([2475, 6]) || stage4.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage4.residual_group2.blocks.1.attn.relative_position_index
+ | 0.000 | -0.078 | 0.096 | 0.020 | torch.Size([360, 120]) || stage4.residual_group2.blocks.1.attn.qkv_self.weight
+ | 0.000 | -0.005 | 0.006 | 0.001 | torch.Size([360]) || stage4.residual_group2.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.077 | 0.080 | 0.020 | torch.Size([120, 120]) || stage4.residual_group2.blocks.1.attn.proj.weight
+ | 0.000 | -0.020 | 0.021 | 0.008 | torch.Size([120]) || stage4.residual_group2.blocks.1.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group2.blocks.1.norm2.weight
+ | -0.000 | -0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group2.blocks.1.norm2.bias
+ | -0.000 | -0.085 | 0.082 | 0.020 | torch.Size([240, 120]) || stage4.residual_group2.blocks.1.mlp.fc11.weight
+ | -0.000 | -0.001 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group2.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.083 | 0.085 | 0.020 | torch.Size([240, 120]) || stage4.residual_group2.blocks.1.mlp.fc12.weight
+ | 0.000 | -0.001 | 0.000 | 0.000 | torch.Size([240]) || stage4.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.078 | 0.078 | 0.020 | torch.Size([120, 240]) || stage4.residual_group2.blocks.1.mlp.fc2.weight
+ | 0.000 | -0.022 | 0.021 | 0.008 | torch.Size([120]) || stage4.residual_group2.blocks.1.mlp.fc2.bias
+ | 0.000 | -0.092 | 0.112 | 0.023 | torch.Size([120, 120]) || stage4.linear2.weight
+ | 0.000 | -0.032 | 0.049 | 0.015 | torch.Size([120]) || stage4.linear2.bias
+ | 0.000 | -0.036 | 0.037 | 0.018 | torch.Size([120, 120, 3, 3]) || stage4.pa_deform.weight
+ | 0.000 | -0.005 | 0.005 | 0.002 | torch.Size([120]) || stage4.pa_deform.bias
+ | -0.000 | -0.021 | 0.022 | 0.012 | torch.Size([120, 242, 3, 3]) || stage4.pa_deform.conv_offset.0.weight
+ | -0.001 | -0.021 | 0.021 | 0.012 | torch.Size([120]) || stage4.pa_deform.conv_offset.0.bias
+ | 0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage4.pa_deform.conv_offset.2.weight
+ | 0.002 | -0.030 | 0.030 | 0.018 | torch.Size([120]) || stage4.pa_deform.conv_offset.2.bias
+ | 0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage4.pa_deform.conv_offset.4.weight
+ | -0.002 | -0.030 | 0.030 | 0.017 | torch.Size([120]) || stage4.pa_deform.conv_offset.4.bias
+ | 0.000 | -0.003 | 0.002 | 0.000 | torch.Size([324, 120, 3, 3]) || stage4.pa_deform.conv_offset.6.weight
+ | 0.000 | -0.005 | 0.004 | 0.001 | torch.Size([324]) || stage4.pa_deform.conv_offset.6.bias
+ | 0.000 | -0.172 | 0.177 | 0.022 | torch.Size([360, 360]) || stage4.pa_fuse.fc11.weight
+ | 0.002 | -0.027 | 0.088 | 0.014 | torch.Size([360]) || stage4.pa_fuse.fc11.bias
+ | 0.000 | -0.212 | 0.163 | 0.022 | torch.Size([360, 360]) || stage4.pa_fuse.fc12.weight
+ | 0.000 | -0.066 | 0.081 | 0.014 | torch.Size([360]) || stage4.pa_fuse.fc12.bias
+ | 0.000 | -0.413 | 0.387 | 0.029 | torch.Size([120, 360]) || stage4.pa_fuse.fc2.weight
+ | -0.001 | -0.198 | 0.214 | 0.073 | torch.Size([120]) || stage4.pa_fuse.fc2.bias
+ | 0.979 | 0.896 | 1.076 | 0.053 | torch.Size([30]) || stage5.reshape.1.weight
+ | -0.005 | -0.074 | 0.100 | 0.043 | torch.Size([30]) || stage5.reshape.1.bias
+ | 0.000 | -0.240 | 0.249 | 0.058 | torch.Size([120, 30]) || stage5.reshape.2.weight
+ | -0.002 | -0.286 | 0.229 | 0.080 | torch.Size([120]) || stage5.reshape.2.bias
+ | 1.001 | 0.993 | 1.006 | 0.002 | torch.Size([120]) || stage5.residual_group1.blocks.0.norm1.weight
+ | -0.004 | -0.018 | 0.006 | 0.005 | torch.Size([120]) || stage5.residual_group1.blocks.0.norm1.bias
+ | -0.000 | -0.066 | 0.062 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.0.attn.position_bias
+ | -0.000 | -0.091 | 0.086 | 0.021 | torch.Size([360, 120]) || stage5.residual_group1.blocks.0.attn.qkv_self.weight
+ | -0.000 | -0.014 | 0.012 | 0.004 | torch.Size([360]) || stage5.residual_group1.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.166 | 0.172 | 0.021 | torch.Size([120, 240]) || stage5.residual_group1.blocks.0.attn.proj.weight
+ | -0.001 | -0.053 | 0.045 | 0.018 | torch.Size([120]) || stage5.residual_group1.blocks.0.attn.proj.bias
+ | -0.000 | -0.090 | 0.081 | 0.020 | torch.Size([360, 120]) || stage5.residual_group1.blocks.0.attn.qkv_mut.weight
+ | 0.000 | -0.006 | 0.006 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.999 | 0.987 | 1.001 | 0.002 | torch.Size([120]) || stage5.residual_group1.blocks.0.norm2.weight
+ | 0.000 | -0.006 | 0.006 | 0.002 | torch.Size([120]) || stage5.residual_group1.blocks.0.norm2.bias
+ | 0.000 | -0.094 | 0.079 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.0.mlp.fc11.weight
+ | 0.000 | -0.022 | 0.012 | 0.004 | torch.Size([240]) || stage5.residual_group1.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.082 | 0.083 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.0.mlp.fc12.weight
+ | 0.000 | -0.013 | 0.014 | 0.005 | torch.Size([240]) || stage5.residual_group1.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.075 | 0.083 | 0.020 | torch.Size([120, 240]) || stage5.residual_group1.blocks.0.mlp.fc2.weight
+ | 0.000 | -0.073 | 0.078 | 0.021 | torch.Size([120]) || stage5.residual_group1.blocks.0.mlp.fc2.bias
+ | 1.001 | 0.994 | 1.007 | 0.002 | torch.Size([120]) || stage5.residual_group1.blocks.1.norm1.weight
+ | -0.004 | -0.016 | 0.004 | 0.004 | torch.Size([120]) || stage5.residual_group1.blocks.1.norm1.bias
+ | 0.000 | -0.065 | 0.063 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.1.attn.position_bias
+ | -0.000 | -0.077 | 0.083 | 0.020 | torch.Size([360, 120]) || stage5.residual_group1.blocks.1.attn.qkv_self.weight
+ | 0.000 | -0.022 | 0.017 | 0.003 | torch.Size([360]) || stage5.residual_group1.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.113 | 0.098 | 0.021 | torch.Size([120, 240]) || stage5.residual_group1.blocks.1.attn.proj.weight
+ | 0.000 | -0.058 | 0.045 | 0.017 | torch.Size([120]) || stage5.residual_group1.blocks.1.attn.proj.bias
+ | 0.000 | -0.080 | 0.080 | 0.020 | torch.Size([360, 120]) || stage5.residual_group1.blocks.1.attn.qkv_mut.weight
+ | -0.000 | -0.008 | 0.007 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.999 | 0.982 | 1.001 | 0.003 | torch.Size([120]) || stage5.residual_group1.blocks.1.norm2.weight
+ | 0.000 | -0.006 | 0.005 | 0.002 | torch.Size([120]) || stage5.residual_group1.blocks.1.norm2.bias
+ | -0.000 | -0.076 | 0.083 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.1.mlp.fc11.weight
+ | 0.000 | -0.017 | 0.014 | 0.004 | torch.Size([240]) || stage5.residual_group1.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.080 | 0.086 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.1.mlp.fc12.weight
+ | -0.000 | -0.014 | 0.016 | 0.004 | torch.Size([240]) || stage5.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.096 | 0.079 | 0.020 | torch.Size([120, 240]) || stage5.residual_group1.blocks.1.mlp.fc2.weight
+ | 0.001 | -0.051 | 0.039 | 0.017 | torch.Size([120]) || stage5.residual_group1.blocks.1.mlp.fc2.bias
+ | 1.002 | 0.998 | 1.009 | 0.002 | torch.Size([120]) || stage5.residual_group1.blocks.2.norm1.weight
+ | -0.004 | -0.014 | 0.003 | 0.003 | torch.Size([120]) || stage5.residual_group1.blocks.2.norm1.bias
+ | 0.000 | -0.067 | 0.073 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.2.attn.position_bias
+ | 0.000 | -0.085 | 0.087 | 0.020 | torch.Size([360, 120]) || stage5.residual_group1.blocks.2.attn.qkv_self.weight
+ | 0.000 | -0.015 | 0.014 | 0.003 | torch.Size([360]) || stage5.residual_group1.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.108 | 0.095 | 0.020 | torch.Size([120, 240]) || stage5.residual_group1.blocks.2.attn.proj.weight
+ | -0.001 | -0.043 | 0.039 | 0.013 | torch.Size([120]) || stage5.residual_group1.blocks.2.attn.proj.bias
+ | -0.000 | -0.088 | 0.081 | 0.020 | torch.Size([360, 120]) || stage5.residual_group1.blocks.2.attn.qkv_mut.weight
+ | -0.000 | -0.009 | 0.007 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.999 | 0.978 | 1.001 | 0.003 | torch.Size([120]) || stage5.residual_group1.blocks.2.norm2.weight
+ | 0.000 | -0.003 | 0.004 | 0.002 | torch.Size([120]) || stage5.residual_group1.blocks.2.norm2.bias
+ | -0.000 | -0.076 | 0.081 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.000 | -0.012 | 0.019 | 0.004 | torch.Size([240]) || stage5.residual_group1.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.079 | 0.077 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.2.mlp.fc12.weight
+ | -0.001 | -0.014 | 0.012 | 0.004 | torch.Size([240]) || stage5.residual_group1.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.076 | 0.082 | 0.020 | torch.Size([120, 240]) || stage5.residual_group1.blocks.2.mlp.fc2.weight
+ | -0.000 | -0.047 | 0.043 | 0.017 | torch.Size([120]) || stage5.residual_group1.blocks.2.mlp.fc2.bias
+ | 1.002 | 0.978 | 1.015 | 0.005 | torch.Size([120]) || stage5.residual_group1.blocks.3.norm1.weight
+ | -0.004 | -0.013 | 0.004 | 0.003 | torch.Size([120]) || stage5.residual_group1.blocks.3.norm1.bias
+ | -0.000 | -0.084 | 0.070 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.3.attn.position_bias
+ | 0.000 | -0.078 | 0.082 | 0.020 | torch.Size([360, 120]) || stage5.residual_group1.blocks.3.attn.qkv_self.weight
+ | -0.000 | -0.014 | 0.014 | 0.003 | torch.Size([360]) || stage5.residual_group1.blocks.3.attn.qkv_self.bias
+ | -0.000 | -0.123 | 0.132 | 0.021 | torch.Size([120, 240]) || stage5.residual_group1.blocks.3.attn.proj.weight
+ | 0.001 | -0.028 | 0.044 | 0.015 | torch.Size([120]) || stage5.residual_group1.blocks.3.attn.proj.bias
+ | -0.000 | -0.082 | 0.089 | 0.020 | torch.Size([360, 120]) || stage5.residual_group1.blocks.3.attn.qkv_mut.weight
+ | -0.000 | -0.007 | 0.008 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.999 | 0.974 | 1.001 | 0.004 | torch.Size([120]) || stage5.residual_group1.blocks.3.norm2.weight
+ | 0.000 | -0.008 | 0.010 | 0.003 | torch.Size([120]) || stage5.residual_group1.blocks.3.norm2.bias
+ | 0.000 | -0.075 | 0.088 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.3.mlp.fc11.weight
+ | 0.000 | -0.014 | 0.019 | 0.005 | torch.Size([240]) || stage5.residual_group1.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.081 | 0.080 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.3.mlp.fc12.weight
+ | 0.000 | -0.031 | 0.020 | 0.006 | torch.Size([240]) || stage5.residual_group1.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.081 | 0.106 | 0.020 | torch.Size([120, 240]) || stage5.residual_group1.blocks.3.mlp.fc2.weight
+ | -0.002 | -0.046 | 0.042 | 0.017 | torch.Size([120]) || stage5.residual_group1.blocks.3.mlp.fc2.bias
+ | 1.003 | 0.944 | 1.017 | 0.009 | torch.Size([120]) || stage5.residual_group1.blocks.4.norm1.weight
+ | -0.005 | -0.015 | 0.004 | 0.004 | torch.Size([120]) || stage5.residual_group1.blocks.4.norm1.bias
+ | -0.000 | -0.071 | 0.067 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.4.attn.position_bias
+ | -0.000 | -0.085 | 0.090 | 0.021 | torch.Size([360, 120]) || stage5.residual_group1.blocks.4.attn.qkv_self.weight
+ | -0.000 | -0.021 | 0.013 | 0.004 | torch.Size([360]) || stage5.residual_group1.blocks.4.attn.qkv_self.bias
+ | 0.000 | -0.130 | 0.089 | 0.021 | torch.Size([120, 240]) || stage5.residual_group1.blocks.4.attn.proj.weight
+ | -0.001 | -0.036 | 0.024 | 0.011 | torch.Size([120]) || stage5.residual_group1.blocks.4.attn.proj.bias
+ | 0.000 | -0.086 | 0.076 | 0.020 | torch.Size([360, 120]) || stage5.residual_group1.blocks.4.attn.qkv_mut.weight
+ | 0.000 | -0.008 | 0.008 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.999 | 0.967 | 1.001 | 0.004 | torch.Size([120]) || stage5.residual_group1.blocks.4.norm2.weight
+ | 0.000 | -0.006 | 0.007 | 0.003 | torch.Size([120]) || stage5.residual_group1.blocks.4.norm2.bias
+ | 0.000 | -0.080 | 0.085 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.4.mlp.fc11.weight
+ | -0.001 | -0.015 | 0.010 | 0.004 | torch.Size([240]) || stage5.residual_group1.blocks.4.mlp.fc11.bias
+ | -0.000 | -0.081 | 0.077 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.4.mlp.fc12.weight
+ | -0.000 | -0.020 | 0.018 | 0.005 | torch.Size([240]) || stage5.residual_group1.blocks.4.mlp.fc12.bias
+ | 0.000 | -0.081 | 0.085 | 0.020 | torch.Size([120, 240]) || stage5.residual_group1.blocks.4.mlp.fc2.weight
+ | -0.001 | -0.037 | 0.050 | 0.014 | torch.Size([120]) || stage5.residual_group1.blocks.4.mlp.fc2.bias
+ | 1.004 | 0.976 | 1.039 | 0.008 | torch.Size([120]) || stage5.residual_group1.blocks.5.norm1.weight
+ | -0.005 | -0.015 | 0.005 | 0.004 | torch.Size([120]) || stage5.residual_group1.blocks.5.norm1.bias
+ | -0.000 | -0.070 | 0.076 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.5.attn.position_bias
+ | 0.000 | -0.099 | 0.097 | 0.021 | torch.Size([360, 120]) || stage5.residual_group1.blocks.5.attn.qkv_self.weight
+ | -0.000 | -0.011 | 0.012 | 0.003 | torch.Size([360]) || stage5.residual_group1.blocks.5.attn.qkv_self.bias
+ | -0.000 | -0.084 | 0.093 | 0.020 | torch.Size([120, 240]) || stage5.residual_group1.blocks.5.attn.proj.weight
+ | 0.000 | -0.038 | 0.035 | 0.012 | torch.Size([120]) || stage5.residual_group1.blocks.5.attn.proj.bias
+ | 0.000 | -0.087 | 0.082 | 0.020 | torch.Size([360, 120]) || stage5.residual_group1.blocks.5.attn.qkv_mut.weight
+ | 0.000 | -0.008 | 0.010 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.998 | 0.960 | 1.002 | 0.005 | torch.Size([120]) || stage5.residual_group1.blocks.5.norm2.weight
+ | 0.000 | -0.006 | 0.006 | 0.002 | torch.Size([120]) || stage5.residual_group1.blocks.5.norm2.bias
+ | -0.000 | -0.088 | 0.095 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.000 | -0.014 | 0.027 | 0.005 | torch.Size([240]) || stage5.residual_group1.blocks.5.mlp.fc11.bias
+ | -0.000 | -0.081 | 0.074 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.5.mlp.fc12.weight
+ | 0.000 | -0.013 | 0.025 | 0.004 | torch.Size([240]) || stage5.residual_group1.blocks.5.mlp.fc12.bias
+ | -0.000 | -0.100 | 0.086 | 0.020 | torch.Size([120, 240]) || stage5.residual_group1.blocks.5.mlp.fc2.weight
+ | 0.000 | -0.022 | 0.030 | 0.011 | torch.Size([120]) || stage5.residual_group1.blocks.5.mlp.fc2.bias
+ | -0.000 | -0.102 | 0.117 | 0.023 | torch.Size([120, 120]) || stage5.linear1.weight
+ | -0.003 | -0.297 | 0.242 | 0.084 | torch.Size([120]) || stage5.linear1.bias
+ | 0.999 | 0.971 | 1.008 | 0.005 | torch.Size([120]) || stage5.residual_group2.blocks.0.norm1.weight
+ | -0.000 | -0.035 | 0.034 | 0.011 | torch.Size([120]) || stage5.residual_group2.blocks.0.norm1.bias
+ | 0.000 | -0.079 | 0.074 | 0.020 | torch.Size([2475, 6]) || stage5.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage5.residual_group2.blocks.0.attn.relative_position_index
+ | -0.000 | -0.087 | 0.083 | 0.020 | torch.Size([360, 120]) || stage5.residual_group2.blocks.0.attn.qkv_self.weight
+ | -0.000 | -0.028 | 0.018 | 0.005 | torch.Size([360]) || stage5.residual_group2.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.079 | 0.082 | 0.021 | torch.Size([120, 120]) || stage5.residual_group2.blocks.0.attn.proj.weight
+ | -0.001 | -0.146 | 0.171 | 0.054 | torch.Size([120]) || stage5.residual_group2.blocks.0.attn.proj.bias
+ | 0.997 | 0.967 | 1.003 | 0.006 | torch.Size([120]) || stage5.residual_group2.blocks.0.norm2.weight
+ | 0.000 | -0.005 | 0.005 | 0.002 | torch.Size([120]) || stage5.residual_group2.blocks.0.norm2.bias
+ | -0.000 | -0.073 | 0.089 | 0.020 | torch.Size([240, 120]) || stage5.residual_group2.blocks.0.mlp.fc11.weight
+ | -0.002 | -0.017 | 0.008 | 0.004 | torch.Size([240]) || stage5.residual_group2.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.084 | 0.073 | 0.020 | torch.Size([240, 120]) || stage5.residual_group2.blocks.0.mlp.fc12.weight
+ | 0.000 | -0.013 | 0.011 | 0.003 | torch.Size([240]) || stage5.residual_group2.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.083 | 0.085 | 0.020 | torch.Size([120, 240]) || stage5.residual_group2.blocks.0.mlp.fc2.weight
+ | 0.000 | -0.103 | 0.140 | 0.037 | torch.Size([120]) || stage5.residual_group2.blocks.0.mlp.fc2.bias
+ | 0.999 | 0.986 | 1.010 | 0.004 | torch.Size([120]) || stage5.residual_group2.blocks.1.norm1.weight
+ | 0.000 | -0.035 | 0.034 | 0.010 | torch.Size([120]) || stage5.residual_group2.blocks.1.norm1.bias
+ | 0.000 | -0.087 | 0.074 | 0.020 | torch.Size([2475, 6]) || stage5.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage5.residual_group2.blocks.1.attn.relative_position_index
+ | -0.000 | -0.084 | 0.079 | 0.020 | torch.Size([360, 120]) || stage5.residual_group2.blocks.1.attn.qkv_self.weight
+ | 0.000 | -0.024 | 0.024 | 0.005 | torch.Size([360]) || stage5.residual_group2.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.077 | 0.078 | 0.021 | torch.Size([120, 120]) || stage5.residual_group2.blocks.1.attn.proj.weight
+ | -0.001 | -0.112 | 0.144 | 0.038 | torch.Size([120]) || stage5.residual_group2.blocks.1.attn.proj.bias
+ | 0.998 | 0.965 | 1.004 | 0.006 | torch.Size([120]) || stage5.residual_group2.blocks.1.norm2.weight
+ | 0.000 | -0.004 | 0.005 | 0.002 | torch.Size([120]) || stage5.residual_group2.blocks.1.norm2.bias
+ | 0.000 | -0.088 | 0.079 | 0.020 | torch.Size([240, 120]) || stage5.residual_group2.blocks.1.mlp.fc11.weight
+ | -0.001 | -0.012 | 0.015 | 0.004 | torch.Size([240]) || stage5.residual_group2.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.102 | 0.080 | 0.020 | torch.Size([240, 120]) || stage5.residual_group2.blocks.1.mlp.fc12.weight
+ | 0.000 | -0.012 | 0.009 | 0.004 | torch.Size([240]) || stage5.residual_group2.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.075 | 0.078 | 0.020 | torch.Size([120, 240]) || stage5.residual_group2.blocks.1.mlp.fc2.weight
+ | 0.000 | -0.105 | 0.131 | 0.042 | torch.Size([120]) || stage5.residual_group2.blocks.1.mlp.fc2.bias
+ | -0.000 | -0.220 | 0.209 | 0.035 | torch.Size([120, 120]) || stage5.linear2.weight
+ | -0.003 | -0.335 | 0.284 | 0.096 | torch.Size([120]) || stage5.linear2.bias
+ | -0.000 | -0.064 | 0.065 | 0.019 | torch.Size([120, 120, 3, 3]) || stage5.pa_deform.weight
+ | 0.001 | -0.050 | 0.050 | 0.029 | torch.Size([120]) || stage5.pa_deform.bias
+ | 0.000 | -0.119 | 0.106 | 0.013 | torch.Size([120, 242, 3, 3]) || stage5.pa_deform.conv_offset.0.weight
+ | -0.006 | -0.030 | 0.026 | 0.014 | torch.Size([120]) || stage5.pa_deform.conv_offset.0.bias
+ | -0.001 | -0.055 | 0.050 | 0.018 | torch.Size([120, 120, 3, 3]) || stage5.pa_deform.conv_offset.2.weight
+ | 0.001 | -0.033 | 0.031 | 0.018 | torch.Size([120]) || stage5.pa_deform.conv_offset.2.bias
+ | 0.001 | -0.060 | 0.050 | 0.018 | torch.Size([120, 120, 3, 3]) || stage5.pa_deform.conv_offset.4.weight
+ | -0.005 | -0.040 | 0.037 | 0.019 | torch.Size([120]) || stage5.pa_deform.conv_offset.4.bias
+ | 0.001 | -0.038 | 0.051 | 0.006 | torch.Size([324, 120, 3, 3]) || stage5.pa_deform.conv_offset.6.weight
+ | 0.000 | -0.048 | 0.050 | 0.017 | torch.Size([324]) || stage5.pa_deform.conv_offset.6.bias
+ | 0.000 | -0.334 | 0.340 | 0.036 | torch.Size([360, 360]) || stage5.pa_fuse.fc11.weight
+ | 0.037 | -0.050 | 0.294 | 0.064 | torch.Size([360]) || stage5.pa_fuse.fc11.bias
+ | -0.000 | -0.343 | 0.349 | 0.036 | torch.Size([360, 360]) || stage5.pa_fuse.fc12.weight
+ | -0.001 | -0.237 | 0.244 | 0.049 | torch.Size([360]) || stage5.pa_fuse.fc12.bias
+ | -0.000 | -0.575 | 0.591 | 0.060 | torch.Size([120, 360]) || stage5.pa_fuse.fc2.weight
+ | -0.001 | -0.404 | 0.344 | 0.122 | torch.Size([120]) || stage5.pa_fuse.fc2.bias
+ | 1.254 | 1.058 | 1.466 | 0.126 | torch.Size([30]) || stage6.reshape.1.weight
+ | -0.001 | -0.074 | 0.093 | 0.041 | torch.Size([30]) || stage6.reshape.1.bias
+ | 0.000 | -0.734 | 0.625 | 0.177 | torch.Size([120, 30]) || stage6.reshape.2.weight
+ | 0.003 | -0.269 | 0.341 | 0.108 | torch.Size([120]) || stage6.reshape.2.bias
+ | 0.815 | 0.495 | 1.118 | 0.121 | torch.Size([120]) || stage6.residual_group1.blocks.0.norm1.weight
+ | -0.071 | -0.291 | 0.263 | 0.101 | torch.Size([120]) || stage6.residual_group1.blocks.0.norm1.bias
+ | -0.000 | -0.080 | 0.087 | 0.021 | torch.Size([675, 6]) || stage6.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.0.attn.position_bias
+ | 0.000 | -0.136 | 0.134 | 0.026 | torch.Size([360, 120]) || stage6.residual_group1.blocks.0.attn.qkv_self.weight
+ | -0.000 | -0.061 | 0.037 | 0.014 | torch.Size([360]) || stage6.residual_group1.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.201 | 0.182 | 0.032 | torch.Size([120, 240]) || stage6.residual_group1.blocks.0.attn.proj.weight
+ | 0.000 | -0.223 | 0.189 | 0.090 | torch.Size([120]) || stage6.residual_group1.blocks.0.attn.proj.bias
+ | 0.000 | -0.184 | 0.211 | 0.029 | torch.Size([360, 120]) || stage6.residual_group1.blocks.0.attn.qkv_mut.weight
+ | 0.000 | -0.049 | 0.069 | 0.011 | torch.Size([360]) || stage6.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.710 | 0.556 | 0.893 | 0.072 | torch.Size([120]) || stage6.residual_group1.blocks.0.norm2.weight
+ | -0.003 | -0.172 | 0.193 | 0.070 | torch.Size([120]) || stage6.residual_group1.blocks.0.norm2.bias
+ | 0.000 | -0.217 | 0.211 | 0.033 | torch.Size([240, 120]) || stage6.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.041 | -0.158 | 0.025 | 0.036 | torch.Size([240]) || stage6.residual_group1.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.209 | 0.178 | 0.031 | torch.Size([240, 120]) || stage6.residual_group1.blocks.0.mlp.fc12.weight
+ | -0.000 | -0.141 | 0.186 | 0.031 | torch.Size([240]) || stage6.residual_group1.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.245 | 0.347 | 0.037 | torch.Size([120, 240]) || stage6.residual_group1.blocks.0.mlp.fc2.weight
+ | 0.005 | -0.161 | 0.188 | 0.079 | torch.Size([120]) || stage6.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.780 | 0.582 | 0.963 | 0.088 | torch.Size([120]) || stage6.residual_group1.blocks.1.norm1.weight
+ | -0.112 | -0.302 | 0.103 | 0.085 | torch.Size([120]) || stage6.residual_group1.blocks.1.norm1.bias
+ | 0.000 | -0.101 | 0.072 | 0.021 | torch.Size([675, 6]) || stage6.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.1.attn.position_bias
+ | 0.000 | -0.112 | 0.178 | 0.026 | torch.Size([360, 120]) || stage6.residual_group1.blocks.1.attn.qkv_self.weight
+ | -0.000 | -0.034 | 0.049 | 0.009 | torch.Size([360]) || stage6.residual_group1.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.223 | 0.242 | 0.033 | torch.Size([120, 240]) || stage6.residual_group1.blocks.1.attn.proj.weight
+ | -0.003 | -0.149 | 0.105 | 0.047 | torch.Size([120]) || stage6.residual_group1.blocks.1.attn.proj.bias
+ | 0.000 | -0.199 | 0.173 | 0.031 | torch.Size([360, 120]) || stage6.residual_group1.blocks.1.attn.qkv_mut.weight
+ | 0.000 | -0.035 | 0.056 | 0.009 | torch.Size([360]) || stage6.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.744 | 0.530 | 0.917 | 0.066 | torch.Size([120]) || stage6.residual_group1.blocks.1.norm2.weight
+ | 0.004 | -0.131 | 0.180 | 0.059 | torch.Size([120]) || stage6.residual_group1.blocks.1.norm2.bias
+ | 0.000 | -0.243 | 0.294 | 0.036 | torch.Size([240, 120]) || stage6.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.039 | -0.217 | 0.045 | 0.037 | torch.Size([240]) || stage6.residual_group1.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.206 | 0.178 | 0.033 | torch.Size([240, 120]) || stage6.residual_group1.blocks.1.mlp.fc12.weight
+ | -0.000 | -0.129 | 0.125 | 0.028 | torch.Size([240]) || stage6.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.236 | 0.276 | 0.040 | torch.Size([120, 240]) || stage6.residual_group1.blocks.1.mlp.fc2.weight
+ | 0.000 | -0.158 | 0.170 | 0.063 | torch.Size([120]) || stage6.residual_group1.blocks.1.mlp.fc2.bias
+ | 0.829 | 0.586 | 1.007 | 0.078 | torch.Size([120]) || stage6.residual_group1.blocks.2.norm1.weight
+ | -0.101 | -0.353 | 0.132 | 0.092 | torch.Size([120]) || stage6.residual_group1.blocks.2.norm1.bias
+ | -0.000 | -0.082 | 0.076 | 0.021 | torch.Size([675, 6]) || stage6.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.2.attn.position_bias
+ | 0.000 | -0.154 | 0.143 | 0.032 | torch.Size([360, 120]) || stage6.residual_group1.blocks.2.attn.qkv_self.weight
+ | 0.000 | -0.041 | 0.038 | 0.012 | torch.Size([360]) || stage6.residual_group1.blocks.2.attn.qkv_self.bias
+ | 0.000 | -0.187 | 0.202 | 0.035 | torch.Size([120, 240]) || stage6.residual_group1.blocks.2.attn.proj.weight
+ | 0.002 | -0.096 | 0.127 | 0.041 | torch.Size([120]) || stage6.residual_group1.blocks.2.attn.proj.bias
+ | -0.000 | -0.203 | 0.185 | 0.033 | torch.Size([360, 120]) || stage6.residual_group1.blocks.2.attn.qkv_mut.weight
+ | -0.000 | -0.045 | 0.049 | 0.009 | torch.Size([360]) || stage6.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.768 | 0.491 | 0.904 | 0.069 | torch.Size([120]) || stage6.residual_group1.blocks.2.norm2.weight
+ | 0.001 | -0.146 | 0.159 | 0.062 | torch.Size([120]) || stage6.residual_group1.blocks.2.norm2.bias
+ | -0.000 | -0.184 | 0.204 | 0.037 | torch.Size([240, 120]) || stage6.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.043 | -0.185 | 0.020 | 0.035 | torch.Size([240]) || stage6.residual_group1.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.188 | 0.270 | 0.035 | torch.Size([240, 120]) || stage6.residual_group1.blocks.2.mlp.fc12.weight
+ | 0.000 | -0.152 | 0.134 | 0.031 | torch.Size([240]) || stage6.residual_group1.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.222 | 0.217 | 0.042 | torch.Size([120, 240]) || stage6.residual_group1.blocks.2.mlp.fc2.weight
+ | 0.002 | -0.141 | 0.144 | 0.058 | torch.Size([120]) || stage6.residual_group1.blocks.2.mlp.fc2.bias
+ | 0.820 | 0.554 | 0.976 | 0.065 | torch.Size([120]) || stage6.residual_group1.blocks.3.norm1.weight
+ | -0.091 | -0.336 | 0.137 | 0.087 | torch.Size([120]) || stage6.residual_group1.blocks.3.norm1.bias
+ | 0.000 | -0.124 | 0.222 | 0.023 | torch.Size([675, 6]) || stage6.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.3.attn.position_bias
+ | 0.000 | -0.157 | 0.175 | 0.036 | torch.Size([360, 120]) || stage6.residual_group1.blocks.3.attn.qkv_self.weight
+ | -0.001 | -0.049 | 0.049 | 0.014 | torch.Size([360]) || stage6.residual_group1.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.238 | 0.236 | 0.036 | torch.Size([120, 240]) || stage6.residual_group1.blocks.3.attn.proj.weight
+ | -0.003 | -0.077 | 0.074 | 0.031 | torch.Size([120]) || stage6.residual_group1.blocks.3.attn.proj.bias
+ | 0.000 | -0.212 | 0.265 | 0.033 | torch.Size([360, 120]) || stage6.residual_group1.blocks.3.attn.qkv_mut.weight
+ | 0.000 | -0.028 | 0.052 | 0.009 | torch.Size([360]) || stage6.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.768 | 0.530 | 0.903 | 0.080 | torch.Size([120]) || stage6.residual_group1.blocks.3.norm2.weight
+ | 0.002 | -0.104 | 0.157 | 0.044 | torch.Size([120]) || stage6.residual_group1.blocks.3.norm2.bias
+ | -0.000 | -0.197 | 0.220 | 0.039 | torch.Size([240, 120]) || stage6.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.042 | -0.155 | 0.043 | 0.039 | torch.Size([240]) || stage6.residual_group1.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.166 | 0.199 | 0.036 | torch.Size([240, 120]) || stage6.residual_group1.blocks.3.mlp.fc12.weight
+ | 0.001 | -0.102 | 0.138 | 0.040 | torch.Size([240]) || stage6.residual_group1.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.241 | 0.256 | 0.044 | torch.Size([120, 240]) || stage6.residual_group1.blocks.3.mlp.fc2.weight
+ | 0.003 | -0.123 | 0.115 | 0.046 | torch.Size([120]) || stage6.residual_group1.blocks.3.mlp.fc2.bias
+ | 0.817 | 0.631 | 0.918 | 0.055 | torch.Size([120]) || stage6.residual_group1.blocks.4.norm1.weight
+ | -0.082 | -0.295 | 0.141 | 0.074 | torch.Size([120]) || stage6.residual_group1.blocks.4.norm1.bias
+ | -0.000 | -0.084 | 0.205 | 0.024 | torch.Size([675, 6]) || stage6.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.4.attn.position_bias
+ | -0.000 | -0.174 | 0.199 | 0.040 | torch.Size([360, 120]) || stage6.residual_group1.blocks.4.attn.qkv_self.weight
+ | -0.000 | -0.060 | 0.081 | 0.017 | torch.Size([360]) || stage6.residual_group1.blocks.4.attn.qkv_self.bias
+ | -0.000 | -0.194 | 0.191 | 0.037 | torch.Size([120, 240]) || stage6.residual_group1.blocks.4.attn.proj.weight
+ | 0.001 | -0.083 | 0.077 | 0.035 | torch.Size([120]) || stage6.residual_group1.blocks.4.attn.proj.bias
+ | -0.000 | -0.218 | 0.243 | 0.033 | torch.Size([360, 120]) || stage6.residual_group1.blocks.4.attn.qkv_mut.weight
+ | -0.000 | -0.031 | 0.024 | 0.007 | torch.Size([360]) || stage6.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.744 | 0.478 | 0.913 | 0.082 | torch.Size([120]) || stage6.residual_group1.blocks.4.norm2.weight
+ | -0.003 | -0.146 | 0.110 | 0.053 | torch.Size([120]) || stage6.residual_group1.blocks.4.norm2.bias
+ | -0.000 | -0.223 | 0.238 | 0.042 | torch.Size([240, 120]) || stage6.residual_group1.blocks.4.mlp.fc11.weight
+ | -0.046 | -0.200 | 0.071 | 0.051 | torch.Size([240]) || stage6.residual_group1.blocks.4.mlp.fc11.bias
+ | -0.000 | -0.168 | 0.201 | 0.039 | torch.Size([240, 120]) || stage6.residual_group1.blocks.4.mlp.fc12.weight
+ | 0.002 | -0.128 | 0.141 | 0.053 | torch.Size([240]) || stage6.residual_group1.blocks.4.mlp.fc12.bias
+ | -0.000 | -0.220 | 0.205 | 0.047 | torch.Size([120, 240]) || stage6.residual_group1.blocks.4.mlp.fc2.weight
+ | 0.001 | -0.086 | 0.094 | 0.034 | torch.Size([120]) || stage6.residual_group1.blocks.4.mlp.fc2.bias
+ | 0.754 | 0.353 | 0.933 | 0.056 | torch.Size([120]) || stage6.residual_group1.blocks.5.norm1.weight
+ | -0.058 | -0.246 | 0.105 | 0.060 | torch.Size([120]) || stage6.residual_group1.blocks.5.norm1.bias
+ | -0.000 | -0.113 | 0.536 | 0.030 | torch.Size([675, 6]) || stage6.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.5.attn.position_bias
+ | 0.000 | -0.261 | 0.224 | 0.044 | torch.Size([360, 120]) || stage6.residual_group1.blocks.5.attn.qkv_self.weight
+ | 0.002 | -0.050 | 0.067 | 0.018 | torch.Size([360]) || stage6.residual_group1.blocks.5.attn.qkv_self.bias
+ | 0.000 | -0.234 | 0.256 | 0.038 | torch.Size([120, 240]) || stage6.residual_group1.blocks.5.attn.proj.weight
+ | 0.002 | -0.079 | 0.076 | 0.036 | torch.Size([120]) || stage6.residual_group1.blocks.5.attn.proj.bias
+ | -0.000 | -0.211 | 0.231 | 0.029 | torch.Size([360, 120]) || stage6.residual_group1.blocks.5.attn.qkv_mut.weight
+ | 0.000 | -0.033 | 0.030 | 0.008 | torch.Size([360]) || stage6.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.677 | 0.275 | 0.833 | 0.083 | torch.Size([120]) || stage6.residual_group1.blocks.5.norm2.weight
+ | 0.001 | -0.224 | 0.306 | 0.102 | torch.Size([120]) || stage6.residual_group1.blocks.5.norm2.bias
+ | -0.000 | -0.196 | 0.211 | 0.045 | torch.Size([240, 120]) || stage6.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.061 | -0.289 | 0.136 | 0.089 | torch.Size([240]) || stage6.residual_group1.blocks.5.mlp.fc11.bias
+ | -0.000 | -0.271 | 0.312 | 0.048 | torch.Size([240, 120]) || stage6.residual_group1.blocks.5.mlp.fc12.weight
+ | 0.003 | -0.166 | 0.155 | 0.075 | torch.Size([240]) || stage6.residual_group1.blocks.5.mlp.fc12.bias
+ | 0.000 | -0.286 | 0.375 | 0.054 | torch.Size([120, 240]) || stage6.residual_group1.blocks.5.mlp.fc2.weight
+ | 0.005 | -0.054 | 0.137 | 0.031 | torch.Size([120]) || stage6.residual_group1.blocks.5.mlp.fc2.bias
+ | -0.000 | -0.174 | 0.172 | 0.039 | torch.Size([120, 120]) || stage6.linear1.weight
+ | 0.002 | -0.275 | 0.348 | 0.113 | torch.Size([120]) || stage6.linear1.bias
+ | 0.704 | 0.402 | 1.002 | 0.132 | torch.Size([120]) || stage6.residual_group2.blocks.0.norm1.weight
+ | 0.001 | -0.466 | 0.407 | 0.157 | torch.Size([120]) || stage6.residual_group2.blocks.0.norm1.bias
+ | -0.000 | -0.172 | 0.570 | 0.025 | torch.Size([2475, 6]) || stage6.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage6.residual_group2.blocks.0.attn.relative_position_index
+ | 0.000 | -0.337 | 0.378 | 0.041 | torch.Size([360, 120]) || stage6.residual_group2.blocks.0.attn.qkv_self.weight
+ | -0.000 | -0.071 | 0.068 | 0.019 | torch.Size([360]) || stage6.residual_group2.blocks.0.attn.qkv_self.bias
+ | 0.001 | -0.290 | 0.321 | 0.055 | torch.Size([120, 120]) || stage6.residual_group2.blocks.0.attn.proj.weight
+ | 0.001 | -0.255 | 0.250 | 0.104 | torch.Size([120]) || stage6.residual_group2.blocks.0.attn.proj.bias
+ | 0.695 | 0.353 | 0.966 | 0.098 | torch.Size([120]) || stage6.residual_group2.blocks.0.norm2.weight
+ | -0.001 | -0.218 | 0.165 | 0.080 | torch.Size([120]) || stage6.residual_group2.blocks.0.norm2.bias
+ | 0.000 | -0.259 | 0.255 | 0.039 | torch.Size([240, 120]) || stage6.residual_group2.blocks.0.mlp.fc11.weight
+ | -0.044 | -0.256 | 0.042 | 0.047 | torch.Size([240]) || stage6.residual_group2.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.234 | 0.214 | 0.035 | torch.Size([240, 120]) || stage6.residual_group2.blocks.0.mlp.fc12.weight
+ | 0.002 | -0.133 | 0.091 | 0.027 | torch.Size([240]) || stage6.residual_group2.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.333 | 0.296 | 0.042 | torch.Size([120, 240]) || stage6.residual_group2.blocks.0.mlp.fc2.weight
+ | 0.003 | -0.238 | 0.280 | 0.092 | torch.Size([120]) || stage6.residual_group2.blocks.0.mlp.fc2.bias
+ | 0.671 | 0.425 | 0.980 | 0.094 | torch.Size([120]) || stage6.residual_group2.blocks.1.norm1.weight
+ | 0.001 | -0.261 | 0.305 | 0.119 | torch.Size([120]) || stage6.residual_group2.blocks.1.norm1.bias
+ | -0.000 | -0.372 | 0.942 | 0.031 | torch.Size([2475, 6]) || stage6.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage6.residual_group2.blocks.1.attn.relative_position_index
+ | 0.000 | -0.450 | 0.494 | 0.045 | torch.Size([360, 120]) || stage6.residual_group2.blocks.1.attn.qkv_self.weight
+ | 0.000 | -0.133 | 0.119 | 0.029 | torch.Size([360]) || stage6.residual_group2.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.239 | 0.288 | 0.046 | torch.Size([120, 120]) || stage6.residual_group2.blocks.1.attn.proj.weight
+ | -0.001 | -0.187 | 0.157 | 0.064 | torch.Size([120]) || stage6.residual_group2.blocks.1.attn.proj.bias
+ | 0.687 | 0.160 | 0.907 | 0.128 | torch.Size([120]) || stage6.residual_group2.blocks.1.norm2.weight
+ | -0.002 | -0.192 | 0.222 | 0.084 | torch.Size([120]) || stage6.residual_group2.blocks.1.norm2.bias
+ | 0.000 | -0.257 | 0.426 | 0.042 | torch.Size([240, 120]) || stage6.residual_group2.blocks.1.mlp.fc11.weight
+ | -0.064 | -0.207 | 0.036 | 0.048 | torch.Size([240]) || stage6.residual_group2.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.269 | 0.224 | 0.038 | torch.Size([240, 120]) || stage6.residual_group2.blocks.1.mlp.fc12.weight
+ | -0.000 | -0.126 | 0.129 | 0.030 | torch.Size([240]) || stage6.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.308 | 0.298 | 0.041 | torch.Size([120, 240]) || stage6.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.004 | -0.180 | 0.192 | 0.061 | torch.Size([120]) || stage6.residual_group2.blocks.1.mlp.fc2.bias
+ | -0.000 | -0.297 | 0.368 | 0.069 | torch.Size([120, 120]) || stage6.linear2.weight
+ | 0.001 | -0.431 | 0.480 | 0.189 | torch.Size([120]) || stage6.linear2.bias
+ | 0.000 | -0.100 | 0.104 | 0.023 | torch.Size([120, 120, 3, 3]) || stage6.pa_deform.weight
+ | 0.001 | -0.018 | 0.029 | 0.010 | torch.Size([120]) || stage6.pa_deform.bias
+ | 0.000 | -0.105 | 0.111 | 0.015 | torch.Size([120, 242, 3, 3]) || stage6.pa_deform.conv_offset.0.weight
+ | -0.007 | -0.033 | 0.024 | 0.014 | torch.Size([120]) || stage6.pa_deform.conv_offset.0.bias
+ | -0.001 | -0.071 | 0.067 | 0.019 | torch.Size([120, 120, 3, 3]) || stage6.pa_deform.conv_offset.2.weight
+ | -0.003 | -0.061 | 0.043 | 0.022 | torch.Size([120]) || stage6.pa_deform.conv_offset.2.bias
+ | -0.000 | -0.074 | 0.068 | 0.019 | torch.Size([120, 120, 3, 3]) || stage6.pa_deform.conv_offset.4.weight
+ | 0.001 | -0.075 | 0.056 | 0.030 | torch.Size([120]) || stage6.pa_deform.conv_offset.4.bias
+ | 0.001 | -0.124 | 0.108 | 0.013 | torch.Size([324, 120, 3, 3]) || stage6.pa_deform.conv_offset.6.weight
+ | -0.001 | -0.113 | 0.076 | 0.021 | torch.Size([324]) || stage6.pa_deform.conv_offset.6.bias
+ | -0.001 | -0.517 | 0.524 | 0.101 | torch.Size([360, 360]) || stage6.pa_fuse.fc11.weight
+ | 0.154 | -0.305 | 0.679 | 0.180 | torch.Size([360]) || stage6.pa_fuse.fc11.bias
+ | 0.000 | -0.680 | 0.728 | 0.103 | torch.Size([360, 360]) || stage6.pa_fuse.fc12.weight
+ | 0.020 | -0.514 | 0.417 | 0.199 | torch.Size([360]) || stage6.pa_fuse.fc12.bias
+ | -0.000 | -0.587 | 0.737 | 0.135 | torch.Size([120, 360]) || stage6.pa_fuse.fc2.weight
+ | 0.015 | -0.437 | 0.490 | 0.230 | torch.Size([120]) || stage6.pa_fuse.fc2.bias
+ | 1.284 | 1.119 | 1.404 | 0.055 | torch.Size([30]) || stage7.reshape.1.weight
+ | -0.014 | -0.286 | 0.184 | 0.122 | torch.Size([30]) || stage7.reshape.1.bias
+ | -0.000 | -0.521 | 0.576 | 0.154 | torch.Size([120, 30]) || stage7.reshape.2.weight
+ | 0.004 | -0.387 | 0.738 | 0.175 | torch.Size([120]) || stage7.reshape.2.bias
+ | 0.440 | 0.099 | 0.775 | 0.141 | torch.Size([120]) || stage7.residual_group1.blocks.0.norm1.weight
+ | -0.177 | -0.670 | 0.319 | 0.183 | torch.Size([120]) || stage7.residual_group1.blocks.0.norm1.bias
+ | -0.055 | -2.159 | 1.979 | 0.240 | torch.Size([675, 6]) || stage7.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.0.attn.position_bias
+ | -0.000 | -0.535 | 0.554 | 0.104 | torch.Size([360, 120]) || stage7.residual_group1.blocks.0.attn.qkv_self.weight
+ | 0.003 | -0.193 | 0.281 | 0.053 | torch.Size([360]) || stage7.residual_group1.blocks.0.attn.qkv_self.bias
+ | -0.001 | -0.397 | 0.395 | 0.075 | torch.Size([120, 240]) || stage7.residual_group1.blocks.0.attn.proj.weight
+ | -0.001 | -0.232 | 0.692 | 0.106 | torch.Size([120]) || stage7.residual_group1.blocks.0.attn.proj.bias
+ | -0.000 | -0.899 | 1.073 | 0.091 | torch.Size([360, 120]) || stage7.residual_group1.blocks.0.attn.qkv_mut.weight
+ | -0.000 | -0.122 | 0.104 | 0.017 | torch.Size([360]) || stage7.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.310 | 0.157 | 0.440 | 0.055 | torch.Size([120]) || stage7.residual_group1.blocks.0.norm2.weight
+ | 0.006 | -0.474 | 0.266 | 0.105 | torch.Size([120]) || stage7.residual_group1.blocks.0.norm2.bias
+ | -0.000 | -0.605 | 0.490 | 0.115 | torch.Size([240, 120]) || stage7.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.101 | -0.310 | 0.126 | 0.070 | torch.Size([240]) || stage7.residual_group1.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.448 | 0.475 | 0.116 | torch.Size([240, 120]) || stage7.residual_group1.blocks.0.mlp.fc12.weight
+ | 0.006 | -0.185 | 0.215 | 0.071 | torch.Size([240]) || stage7.residual_group1.blocks.0.mlp.fc12.bias
+ | 0.001 | -0.465 | 0.512 | 0.122 | torch.Size([120, 240]) || stage7.residual_group1.blocks.0.mlp.fc2.weight
+ | 0.000 | -0.150 | 0.417 | 0.077 | torch.Size([120]) || stage7.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.577 | 0.165 | 0.829 | 0.105 | torch.Size([120]) || stage7.residual_group1.blocks.1.norm1.weight
+ | -0.136 | -0.849 | 0.206 | 0.141 | torch.Size([120]) || stage7.residual_group1.blocks.1.norm1.bias
+ | -0.143 | -3.020 | 4.621 | 0.357 | torch.Size([675, 6]) || stage7.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.1.attn.position_bias
+ | 0.000 | -0.647 | 0.640 | 0.123 | torch.Size([360, 120]) || stage7.residual_group1.blocks.1.attn.qkv_self.weight
+ | -0.002 | -0.356 | 0.382 | 0.064 | torch.Size([360]) || stage7.residual_group1.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.457 | 0.378 | 0.081 | torch.Size([120, 240]) || stage7.residual_group1.blocks.1.attn.proj.weight
+ | 0.000 | -0.250 | 0.707 | 0.108 | torch.Size([120]) || stage7.residual_group1.blocks.1.attn.proj.bias
+ | -0.001 | -1.055 | 1.091 | 0.096 | torch.Size([360, 120]) || stage7.residual_group1.blocks.1.attn.qkv_mut.weight
+ | -0.001 | -0.093 | 0.123 | 0.018 | torch.Size([360]) || stage7.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.411 | 0.265 | 0.535 | 0.044 | torch.Size([120]) || stage7.residual_group1.blocks.1.norm2.weight
+ | 0.008 | -0.630 | 0.264 | 0.121 | torch.Size([120]) || stage7.residual_group1.blocks.1.norm2.bias
+ | 0.000 | -0.501 | 0.506 | 0.119 | torch.Size([240, 120]) || stage7.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.087 | -0.341 | 0.140 | 0.073 | torch.Size([240]) || stage7.residual_group1.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.450 | 0.527 | 0.119 | torch.Size([240, 120]) || stage7.residual_group1.blocks.1.mlp.fc12.weight
+ | 0.005 | -0.188 | 0.171 | 0.063 | torch.Size([240]) || stage7.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.554 | 0.546 | 0.121 | torch.Size([120, 240]) || stage7.residual_group1.blocks.1.mlp.fc2.weight
+ | -0.000 | -0.135 | 0.220 | 0.061 | torch.Size([120]) || stage7.residual_group1.blocks.1.mlp.fc2.bias
+ | 0.655 | 0.134 | 0.896 | 0.130 | torch.Size([120]) || stage7.residual_group1.blocks.2.norm1.weight
+ | -0.139 | -0.788 | 0.181 | 0.115 | torch.Size([120]) || stage7.residual_group1.blocks.2.norm1.bias
+ | -0.062 | -3.469 | 3.276 | 0.272 | torch.Size([675, 6]) || stage7.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.2.attn.position_bias
+ | -0.000 | -0.592 | 0.650 | 0.124 | torch.Size([360, 120]) || stage7.residual_group1.blocks.2.attn.qkv_self.weight
+ | -0.000 | -0.308 | 0.218 | 0.062 | torch.Size([360]) || stage7.residual_group1.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.355 | 0.345 | 0.082 | torch.Size([120, 240]) || stage7.residual_group1.blocks.2.attn.proj.weight
+ | 0.002 | -0.213 | 0.700 | 0.097 | torch.Size([120]) || stage7.residual_group1.blocks.2.attn.proj.bias
+ | -0.001 | -1.166 | 0.942 | 0.107 | torch.Size([360, 120]) || stage7.residual_group1.blocks.2.attn.qkv_mut.weight
+ | 0.000 | -0.106 | 0.093 | 0.018 | torch.Size([360]) || stage7.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.466 | 0.317 | 0.565 | 0.042 | torch.Size([120]) || stage7.residual_group1.blocks.2.norm2.weight
+ | 0.014 | -0.657 | 0.280 | 0.118 | torch.Size([120]) || stage7.residual_group1.blocks.2.norm2.bias
+ | 0.000 | -0.541 | 0.494 | 0.118 | torch.Size([240, 120]) || stage7.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.079 | -0.335 | 0.122 | 0.080 | torch.Size([240]) || stage7.residual_group1.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.513 | 0.493 | 0.123 | torch.Size([240, 120]) || stage7.residual_group1.blocks.2.mlp.fc12.weight
+ | -0.007 | -0.180 | 0.175 | 0.066 | torch.Size([240]) || stage7.residual_group1.blocks.2.mlp.fc12.bias
+ | -0.001 | -0.509 | 0.479 | 0.123 | torch.Size([120, 240]) || stage7.residual_group1.blocks.2.mlp.fc2.weight
+ | 0.004 | -0.093 | 0.293 | 0.054 | torch.Size([120]) || stage7.residual_group1.blocks.2.mlp.fc2.bias
+ | 0.693 | 0.147 | 0.945 | 0.133 | torch.Size([120]) || stage7.residual_group1.blocks.3.norm1.weight
+ | -0.132 | -0.906 | 0.249 | 0.113 | torch.Size([120]) || stage7.residual_group1.blocks.3.norm1.bias
+ | -0.108 | -3.576 | 4.241 | 0.344 | torch.Size([675, 6]) || stage7.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.3.attn.position_bias
+ | -0.000 | -0.945 | 1.095 | 0.129 | torch.Size([360, 120]) || stage7.residual_group1.blocks.3.attn.qkv_self.weight
+ | 0.003 | -0.274 | 0.204 | 0.061 | torch.Size([360]) || stage7.residual_group1.blocks.3.attn.qkv_self.bias
+ | -0.001 | -0.379 | 0.351 | 0.081 | torch.Size([120, 240]) || stage7.residual_group1.blocks.3.attn.proj.weight
+ | 0.000 | -0.211 | 0.587 | 0.095 | torch.Size([120]) || stage7.residual_group1.blocks.3.attn.proj.bias
+ | -0.000 | -1.269 | 1.067 | 0.102 | torch.Size([360, 120]) || stage7.residual_group1.blocks.3.attn.qkv_mut.weight
+ | 0.001 | -0.091 | 0.117 | 0.021 | torch.Size([360]) || stage7.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.499 | 0.285 | 0.570 | 0.040 | torch.Size([120]) || stage7.residual_group1.blocks.3.norm2.weight
+ | 0.012 | -0.567 | 0.273 | 0.104 | torch.Size([120]) || stage7.residual_group1.blocks.3.norm2.bias
+ | 0.001 | -0.528 | 0.499 | 0.118 | torch.Size([240, 120]) || stage7.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.084 | -0.349 | 0.141 | 0.078 | torch.Size([240]) || stage7.residual_group1.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.547 | 0.592 | 0.126 | torch.Size([240, 120]) || stage7.residual_group1.blocks.3.mlp.fc12.weight
+ | 0.002 | -0.154 | 0.176 | 0.068 | torch.Size([240]) || stage7.residual_group1.blocks.3.mlp.fc12.bias
+ | 0.001 | -0.520 | 0.480 | 0.125 | torch.Size([120, 240]) || stage7.residual_group1.blocks.3.mlp.fc2.weight
+ | 0.001 | -0.150 | 0.207 | 0.065 | torch.Size([120]) || stage7.residual_group1.blocks.3.mlp.fc2.bias
+ | 0.726 | 0.137 | 1.004 | 0.160 | torch.Size([120]) || stage7.residual_group1.blocks.4.norm1.weight
+ | -0.122 | -0.907 | 0.180 | 0.103 | torch.Size([120]) || stage7.residual_group1.blocks.4.norm1.bias
+ | -0.078 | -3.824 | 4.241 | 0.297 | torch.Size([675, 6]) || stage7.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.4.attn.position_bias
+ | -0.000 | -1.188 | 0.796 | 0.127 | torch.Size([360, 120]) || stage7.residual_group1.blocks.4.attn.qkv_self.weight
+ | 0.002 | -0.248 | 0.207 | 0.056 | torch.Size([360]) || stage7.residual_group1.blocks.4.attn.qkv_self.bias
+ | -0.001 | -0.409 | 0.369 | 0.085 | torch.Size([120, 240]) || stage7.residual_group1.blocks.4.attn.proj.weight
+ | 0.002 | -0.224 | 0.322 | 0.094 | torch.Size([120]) || stage7.residual_group1.blocks.4.attn.proj.bias
+ | 0.000 | -1.744 | 1.273 | 0.110 | torch.Size([360, 120]) || stage7.residual_group1.blocks.4.attn.qkv_mut.weight
+ | 0.001 | -0.092 | 0.113 | 0.019 | torch.Size([360]) || stage7.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.514 | 0.277 | 0.614 | 0.041 | torch.Size([120]) || stage7.residual_group1.blocks.4.norm2.weight
+ | 0.016 | -0.621 | 0.286 | 0.095 | torch.Size([120]) || stage7.residual_group1.blocks.4.norm2.bias
+ | 0.001 | -0.517 | 0.453 | 0.116 | torch.Size([240, 120]) || stage7.residual_group1.blocks.4.mlp.fc11.weight
+ | -0.064 | -0.260 | 0.143 | 0.083 | torch.Size([240]) || stage7.residual_group1.blocks.4.mlp.fc11.bias
+ | 0.000 | -0.503 | 0.554 | 0.129 | torch.Size([240, 120]) || stage7.residual_group1.blocks.4.mlp.fc12.weight
+ | -0.004 | -0.232 | 0.193 | 0.075 | torch.Size([240]) || stage7.residual_group1.blocks.4.mlp.fc12.bias
+ | -0.001 | -0.595 | 0.543 | 0.128 | torch.Size([120, 240]) || stage7.residual_group1.blocks.4.mlp.fc2.weight
+ | 0.001 | -0.196 | 0.198 | 0.071 | torch.Size([120]) || stage7.residual_group1.blocks.4.mlp.fc2.bias
+ | 0.731 | 0.152 | 1.075 | 0.114 | torch.Size([120]) || stage7.residual_group1.blocks.5.norm1.weight
+ | -0.076 | -1.003 | 0.176 | 0.107 | torch.Size([120]) || stage7.residual_group1.blocks.5.norm1.bias
+ | -0.121 | -3.281 | 4.671 | 0.296 | torch.Size([675, 6]) || stage7.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.5.attn.position_bias
+ | -0.000 | -0.640 | 1.083 | 0.122 | torch.Size([360, 120]) || stage7.residual_group1.blocks.5.attn.qkv_self.weight
+ | -0.001 | -0.239 | 0.314 | 0.068 | torch.Size([360]) || stage7.residual_group1.blocks.5.attn.qkv_self.bias
+ | 0.001 | -0.344 | 0.452 | 0.078 | torch.Size([120, 240]) || stage7.residual_group1.blocks.5.attn.proj.weight
+ | 0.004 | -0.361 | 0.251 | 0.093 | torch.Size([120]) || stage7.residual_group1.blocks.5.attn.proj.bias
+ | 0.000 | -0.637 | 0.806 | 0.093 | torch.Size([360, 120]) || stage7.residual_group1.blocks.5.attn.qkv_mut.weight
+ | -0.000 | -0.088 | 0.091 | 0.017 | torch.Size([360]) || stage7.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.514 | 0.238 | 0.594 | 0.042 | torch.Size([120]) || stage7.residual_group1.blocks.5.norm2.weight
+ | 0.017 | -0.650 | 0.162 | 0.089 | torch.Size([120]) || stage7.residual_group1.blocks.5.norm2.bias
+ | 0.000 | -0.442 | 0.479 | 0.114 | torch.Size([240, 120]) || stage7.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.040 | -0.400 | 0.203 | 0.101 | torch.Size([240]) || stage7.residual_group1.blocks.5.mlp.fc11.bias
+ | -0.000 | -0.541 | 0.514 | 0.130 | torch.Size([240, 120]) || stage7.residual_group1.blocks.5.mlp.fc12.weight
+ | -0.008 | -0.319 | 0.309 | 0.092 | torch.Size([240]) || stage7.residual_group1.blocks.5.mlp.fc12.bias
+ | -0.000 | -1.018 | 1.398 | 0.130 | torch.Size([120, 240]) || stage7.residual_group1.blocks.5.mlp.fc2.weight
+ | 0.001 | -1.606 | 0.269 | 0.179 | torch.Size([120]) || stage7.residual_group1.blocks.5.mlp.fc2.bias
+ | 0.000 | -0.186 | 0.207 | 0.048 | torch.Size([120, 120]) || stage7.linear1.weight
+ | 0.010 | -0.448 | 0.437 | 0.161 | torch.Size([120]) || stage7.linear1.bias
+ | 0.703 | 0.381 | 0.856 | 0.084 | torch.Size([120]) || stage7.residual_group2.blocks.0.norm1.weight
+ | 0.014 | -0.645 | 0.486 | 0.169 | torch.Size([120]) || stage7.residual_group2.blocks.0.norm1.bias
+ | -0.007 | -4.468 | 1.008 | 0.164 | torch.Size([2475, 6]) || stage7.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage7.residual_group2.blocks.0.attn.relative_position_index
+ | -0.000 | -0.625 | 0.834 | 0.120 | torch.Size([360, 120]) || stage7.residual_group2.blocks.0.attn.qkv_self.weight
+ | -0.009 | -0.737 | 0.632 | 0.135 | torch.Size([360]) || stage7.residual_group2.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.403 | 0.406 | 0.088 | torch.Size([120, 120]) || stage7.residual_group2.blocks.0.attn.proj.weight
+ | -0.007 | -0.338 | 0.165 | 0.070 | torch.Size([120]) || stage7.residual_group2.blocks.0.attn.proj.bias
+ | 0.435 | 0.323 | 0.526 | 0.038 | torch.Size([120]) || stage7.residual_group2.blocks.0.norm2.weight
+ | 0.005 | -0.678 | 0.379 | 0.117 | torch.Size([120]) || stage7.residual_group2.blocks.0.norm2.bias
+ | 0.000 | -0.465 | 0.467 | 0.110 | torch.Size([240, 120]) || stage7.residual_group2.blocks.0.mlp.fc11.weight
+ | -0.031 | -0.236 | 0.180 | 0.077 | torch.Size([240]) || stage7.residual_group2.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.490 | 0.520 | 0.121 | torch.Size([240, 120]) || stage7.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.003 | -0.197 | 0.242 | 0.069 | torch.Size([240]) || stage7.residual_group2.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.525 | 0.501 | 0.122 | torch.Size([120, 240]) || stage7.residual_group2.blocks.0.mlp.fc2.weight
+ | -0.005 | -0.431 | 0.164 | 0.077 | torch.Size([120]) || stage7.residual_group2.blocks.0.mlp.fc2.bias
+ | 0.703 | 0.306 | 0.866 | 0.079 | torch.Size([120]) || stage7.residual_group2.blocks.1.norm1.weight
+ | 0.009 | -0.647 | 0.481 | 0.149 | torch.Size([120]) || stage7.residual_group2.blocks.1.norm1.bias
+ | -0.010 | -3.504 | 1.842 | 0.134 | torch.Size([2475, 6]) || stage7.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage7.residual_group2.blocks.1.attn.relative_position_index
+ | -0.000 | -0.639 | 0.590 | 0.122 | torch.Size([360, 120]) || stage7.residual_group2.blocks.1.attn.qkv_self.weight
+ | -0.001 | -0.613 | 0.609 | 0.148 | torch.Size([360]) || stage7.residual_group2.blocks.1.attn.qkv_self.bias
+ | 0.001 | -0.316 | 0.325 | 0.085 | torch.Size([120, 120]) || stage7.residual_group2.blocks.1.attn.proj.weight
+ | -0.004 | -0.350 | 0.145 | 0.069 | torch.Size([120]) || stage7.residual_group2.blocks.1.attn.proj.bias
+ | 0.452 | 0.309 | 0.558 | 0.037 | torch.Size([120]) || stage7.residual_group2.blocks.1.norm2.weight
+ | 0.003 | -0.661 | 0.246 | 0.091 | torch.Size([120]) || stage7.residual_group2.blocks.1.norm2.bias
+ | 0.000 | -0.580 | 0.410 | 0.108 | torch.Size([240, 120]) || stage7.residual_group2.blocks.1.mlp.fc11.weight
+ | -0.020 | -0.258 | 0.299 | 0.104 | torch.Size([240]) || stage7.residual_group2.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.529 | 0.561 | 0.126 | torch.Size([240, 120]) || stage7.residual_group2.blocks.1.mlp.fc12.weight
+ | -0.002 | -0.234 | 0.434 | 0.090 | torch.Size([240]) || stage7.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.778 | 0.581 | 0.124 | torch.Size([120, 240]) || stage7.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.001 | -0.888 | 0.286 | 0.135 | torch.Size([120]) || stage7.residual_group2.blocks.1.mlp.fc2.bias
+ | -0.001 | -0.348 | 0.237 | 0.060 | torch.Size([120, 120]) || stage7.linear2.weight
+ | 0.023 | -0.390 | 0.506 | 0.167 | torch.Size([120]) || stage7.linear2.bias
+ | -0.000 | -0.104 | 0.107 | 0.024 | torch.Size([120, 120, 3, 3]) || stage7.pa_deform.weight
+ | 0.002 | -0.041 | 0.035 | 0.016 | torch.Size([120]) || stage7.pa_deform.bias
+ | -0.000 | -0.123 | 0.109 | 0.017 | torch.Size([120, 242, 3, 3]) || stage7.pa_deform.conv_offset.0.weight
+ | -0.002 | -0.034 | 0.032 | 0.015 | torch.Size([120]) || stage7.pa_deform.conv_offset.0.bias
+ | -0.001 | -0.111 | 0.084 | 0.019 | torch.Size([120, 120, 3, 3]) || stage7.pa_deform.conv_offset.2.weight
+ | -0.008 | -0.073 | 0.081 | 0.034 | torch.Size([120]) || stage7.pa_deform.conv_offset.2.bias
+ | -0.002 | -0.154 | 0.122 | 0.018 | torch.Size([120, 120, 3, 3]) || stage7.pa_deform.conv_offset.4.weight
+ | 0.014 | -0.041 | 0.068 | 0.026 | torch.Size([120]) || stage7.pa_deform.conv_offset.4.bias
+ | -0.001 | -0.408 | 0.365 | 0.034 | torch.Size([324, 120, 3, 3]) || stage7.pa_deform.conv_offset.6.weight
+ | -0.003 | -0.057 | 0.054 | 0.024 | torch.Size([324]) || stage7.pa_deform.conv_offset.6.bias
+ | 0.000 | -0.697 | 0.606 | 0.123 | torch.Size([360, 360]) || stage7.pa_fuse.fc11.weight
+ | 0.119 | -0.211 | 0.720 | 0.177 | torch.Size([360]) || stage7.pa_fuse.fc11.bias
+ | 0.000 | -1.175 | 0.924 | 0.154 | torch.Size([360, 360]) || stage7.pa_fuse.fc12.weight
+ | -0.000 | -0.581 | 0.580 | 0.190 | torch.Size([360]) || stage7.pa_fuse.fc12.bias
+ | 0.001 | -0.786 | 0.874 | 0.135 | torch.Size([120, 360]) || stage7.pa_fuse.fc2.weight
+ | -0.053 | -0.522 | 0.577 | 0.205 | torch.Size([120]) || stage7.pa_fuse.fc2.bias
+ | 1.225 | 1.000 | 1.516 | 0.095 | torch.Size([120]) || stage8.0.1.weight
+ | -0.013 | -0.413 | 0.465 | 0.139 | torch.Size([120]) || stage8.0.1.bias
+ | 0.000 | -2.505 | 0.627 | 0.136 | torch.Size([180, 120]) || stage8.0.2.weight
+ | 0.005 | -0.397 | 0.377 | 0.107 | torch.Size([180]) || stage8.0.2.bias
+ | 0.456 | 0.123 | 0.760 | 0.129 | torch.Size([180]) || stage8.1.residual_group.blocks.0.norm1.weight
+ | -0.022 | -0.343 | 0.875 | 0.099 | torch.Size([180]) || stage8.1.residual_group.blocks.0.norm1.bias
+ | -0.014 | -1.907 | 2.592 | 0.130 | torch.Size([2475, 6]) || stage8.1.residual_group.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.1.residual_group.blocks.0.attn.relative_position_index
+ | -0.000 | -0.632 | 0.628 | 0.099 | torch.Size([540, 180]) || stage8.1.residual_group.blocks.0.attn.qkv_self.weight
+ | 0.006 | -0.567 | 0.668 | 0.148 | torch.Size([540]) || stage8.1.residual_group.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.477 | 0.447 | 0.094 | torch.Size([180, 180]) || stage8.1.residual_group.blocks.0.attn.proj.weight
+ | -0.010 | -0.460 | 0.225 | 0.085 | torch.Size([180]) || stage8.1.residual_group.blocks.0.attn.proj.bias
+ | 0.429 | 0.119 | 0.634 | 0.090 | torch.Size([180]) || stage8.1.residual_group.blocks.0.norm2.weight
+ | -0.007 | -0.338 | 0.803 | 0.086 | torch.Size([180]) || stage8.1.residual_group.blocks.0.norm2.bias
+ | -0.006 | -0.572 | 0.539 | 0.119 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.0.mlp.fc11.weight
+ | -0.060 | -0.260 | 0.185 | 0.060 | torch.Size([360]) || stage8.1.residual_group.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.461 | 0.548 | 0.113 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.0.mlp.fc12.weight
+ | 0.000 | -0.163 | 0.183 | 0.050 | torch.Size([360]) || stage8.1.residual_group.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.757 | 0.581 | 0.118 | torch.Size([180, 360]) || stage8.1.residual_group.blocks.0.mlp.fc2.weight
+ | -0.003 | -0.191 | 0.121 | 0.057 | torch.Size([180]) || stage8.1.residual_group.blocks.0.mlp.fc2.bias
+ | 0.557 | 0.086 | 0.800 | 0.112 | torch.Size([180]) || stage8.1.residual_group.blocks.1.norm1.weight
+ | -0.029 | -0.230 | 0.878 | 0.088 | torch.Size([180]) || stage8.1.residual_group.blocks.1.norm1.bias
+ | -0.016 | -2.004 | 1.711 | 0.154 | torch.Size([2475, 6]) || stage8.1.residual_group.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.1.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -0.690 | 0.575 | 0.109 | torch.Size([540, 180]) || stage8.1.residual_group.blocks.1.attn.qkv_self.weight
+ | 0.011 | -0.641 | 0.609 | 0.135 | torch.Size([540]) || stage8.1.residual_group.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.466 | 0.401 | 0.094 | torch.Size([180, 180]) || stage8.1.residual_group.blocks.1.attn.proj.weight
+ | -0.008 | -0.344 | 0.181 | 0.080 | torch.Size([180]) || stage8.1.residual_group.blocks.1.attn.proj.bias
+ | 0.503 | 0.226 | 0.742 | 0.093 | torch.Size([180]) || stage8.1.residual_group.blocks.1.norm2.weight
+ | -0.009 | -0.404 | 0.818 | 0.085 | torch.Size([180]) || stage8.1.residual_group.blocks.1.norm2.bias
+ | -0.007 | -0.595 | 0.532 | 0.121 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.1.mlp.fc11.weight
+ | -0.068 | -0.261 | 0.071 | 0.053 | torch.Size([360]) || stage8.1.residual_group.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.529 | 0.573 | 0.116 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.1.mlp.fc12.weight
+ | 0.002 | -0.129 | 0.197 | 0.046 | torch.Size([360]) || stage8.1.residual_group.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.556 | 0.582 | 0.118 | torch.Size([180, 360]) || stage8.1.residual_group.blocks.1.mlp.fc2.weight
+ | -0.003 | -0.170 | 0.145 | 0.052 | torch.Size([180]) || stage8.1.residual_group.blocks.1.mlp.fc2.bias
+ | 0.699 | 0.202 | 0.912 | 0.109 | torch.Size([180]) || stage8.1.residual_group.blocks.2.norm1.weight
+ | -0.033 | -0.253 | 0.924 | 0.091 | torch.Size([180]) || stage8.1.residual_group.blocks.2.norm1.bias
+ | -0.030 | -2.510 | 2.088 | 0.194 | torch.Size([2475, 6]) || stage8.1.residual_group.blocks.2.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.1.residual_group.blocks.2.attn.relative_position_index
+ | 0.000 | -0.637 | 0.801 | 0.116 | torch.Size([540, 180]) || stage8.1.residual_group.blocks.2.attn.qkv_self.weight
+ | 0.006 | -0.512 | 0.520 | 0.110 | torch.Size([540]) || stage8.1.residual_group.blocks.2.attn.qkv_self.bias
+ | 0.000 | -0.381 | 0.337 | 0.090 | torch.Size([180, 180]) || stage8.1.residual_group.blocks.2.attn.proj.weight
+ | -0.011 | -0.238 | 0.234 | 0.085 | torch.Size([180]) || stage8.1.residual_group.blocks.2.attn.proj.bias
+ | 0.594 | 0.150 | 0.810 | 0.108 | torch.Size([180]) || stage8.1.residual_group.blocks.2.norm2.weight
+ | -0.010 | -0.483 | 0.726 | 0.088 | torch.Size([180]) || stage8.1.residual_group.blocks.2.norm2.bias
+ | -0.006 | -0.567 | 0.499 | 0.125 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.2.mlp.fc11.weight
+ | -0.077 | -0.360 | 0.050 | 0.056 | torch.Size([360]) || stage8.1.residual_group.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.536 | 0.673 | 0.119 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.2.mlp.fc12.weight
+ | 0.001 | -0.142 | 0.186 | 0.043 | torch.Size([360]) || stage8.1.residual_group.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.536 | 0.524 | 0.119 | torch.Size([180, 360]) || stage8.1.residual_group.blocks.2.mlp.fc2.weight
+ | -0.006 | -0.147 | 0.133 | 0.051 | torch.Size([180]) || stage8.1.residual_group.blocks.2.mlp.fc2.bias
+ | 0.683 | 0.141 | 0.908 | 0.105 | torch.Size([180]) || stage8.1.residual_group.blocks.3.norm1.weight
+ | -0.033 | -0.199 | 0.878 | 0.088 | torch.Size([180]) || stage8.1.residual_group.blocks.3.norm1.bias
+ | -0.039 | -1.527 | 3.891 | 0.199 | torch.Size([2475, 6]) || stage8.1.residual_group.blocks.3.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.1.residual_group.blocks.3.attn.relative_position_index
+ | 0.000 | -0.682 | 0.693 | 0.120 | torch.Size([540, 180]) || stage8.1.residual_group.blocks.3.attn.qkv_self.weight
+ | 0.007 | -0.543 | 0.513 | 0.138 | torch.Size([540]) || stage8.1.residual_group.blocks.3.attn.qkv_self.bias
+ | -0.001 | -0.390 | 0.476 | 0.089 | torch.Size([180, 180]) || stage8.1.residual_group.blocks.3.attn.proj.weight
+ | -0.007 | -0.176 | 0.150 | 0.062 | torch.Size([180]) || stage8.1.residual_group.blocks.3.attn.proj.bias
+ | 0.640 | 0.094 | 0.853 | 0.120 | torch.Size([180]) || stage8.1.residual_group.blocks.3.norm2.weight
+ | -0.009 | -0.372 | 0.683 | 0.084 | torch.Size([180]) || stage8.1.residual_group.blocks.3.norm2.bias
+ | -0.006 | -0.628 | 0.521 | 0.126 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.3.mlp.fc11.weight
+ | -0.089 | -0.367 | 0.047 | 0.054 | torch.Size([360]) || stage8.1.residual_group.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.629 | 0.562 | 0.121 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.3.mlp.fc12.weight
+ | -0.001 | -0.186 | 0.128 | 0.042 | torch.Size([360]) || stage8.1.residual_group.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.485 | 0.499 | 0.118 | torch.Size([180, 360]) || stage8.1.residual_group.blocks.3.mlp.fc2.weight
+ | -0.007 | -0.138 | 0.209 | 0.050 | torch.Size([180]) || stage8.1.residual_group.blocks.3.mlp.fc2.bias
+ | 0.000 | -0.294 | 0.577 | 0.071 | torch.Size([180, 180]) || stage8.1.linear.weight
+ | 0.004 | -0.349 | 0.235 | 0.072 | torch.Size([180]) || stage8.1.linear.bias
+ | 0.708 | 0.242 | 1.026 | 0.136 | torch.Size([180]) || stage8.2.residual_group.blocks.0.norm1.weight
+ | -0.032 | -0.212 | 0.830 | 0.100 | torch.Size([180]) || stage8.2.residual_group.blocks.0.norm1.bias
+ | -0.039 | -1.954 | 2.394 | 0.212 | torch.Size([2475, 6]) || stage8.2.residual_group.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.2.residual_group.blocks.0.attn.relative_position_index
+ | 0.000 | -0.922 | 0.646 | 0.116 | torch.Size([540, 180]) || stage8.2.residual_group.blocks.0.attn.qkv_self.weight
+ | -0.001 | -0.429 | 0.524 | 0.101 | torch.Size([540]) || stage8.2.residual_group.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.467 | 0.453 | 0.109 | torch.Size([180, 180]) || stage8.2.residual_group.blocks.0.attn.proj.weight
+ | -0.005 | -0.339 | 0.264 | 0.095 | torch.Size([180]) || stage8.2.residual_group.blocks.0.attn.proj.bias
+ | 0.587 | 0.255 | 0.837 | 0.086 | torch.Size([180]) || stage8.2.residual_group.blocks.0.norm2.weight
+ | -0.011 | -0.285 | 0.721 | 0.083 | torch.Size([180]) || stage8.2.residual_group.blocks.0.norm2.bias
+ | -0.006 | -0.586 | 0.534 | 0.125 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.0.mlp.fc11.weight
+ | -0.075 | -0.225 | 0.066 | 0.047 | torch.Size([360]) || stage8.2.residual_group.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.493 | 0.532 | 0.123 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.0.mlp.fc12.weight
+ | 0.003 | -0.189 | 0.178 | 0.047 | torch.Size([360]) || stage8.2.residual_group.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.551 | 0.543 | 0.124 | torch.Size([180, 360]) || stage8.2.residual_group.blocks.0.mlp.fc2.weight
+ | -0.010 | -0.154 | 0.142 | 0.054 | torch.Size([180]) || stage8.2.residual_group.blocks.0.mlp.fc2.bias
+ | 0.773 | 0.210 | 1.004 | 0.113 | torch.Size([180]) || stage8.2.residual_group.blocks.1.norm1.weight
+ | -0.035 | -0.176 | 0.873 | 0.089 | torch.Size([180]) || stage8.2.residual_group.blocks.1.norm1.bias
+ | -0.027 | -2.407 | 1.736 | 0.214 | torch.Size([2475, 6]) || stage8.2.residual_group.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.2.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -0.817 | 0.977 | 0.123 | torch.Size([540, 180]) || stage8.2.residual_group.blocks.1.attn.qkv_self.weight
+ | 0.001 | -0.659 | 0.461 | 0.115 | torch.Size([540]) || stage8.2.residual_group.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.484 | 0.453 | 0.109 | torch.Size([180, 180]) || stage8.2.residual_group.blocks.1.attn.proj.weight
+ | -0.014 | -0.315 | 0.252 | 0.091 | torch.Size([180]) || stage8.2.residual_group.blocks.1.attn.proj.bias
+ | 0.641 | 0.337 | 0.810 | 0.081 | torch.Size([180]) || stage8.2.residual_group.blocks.1.norm2.weight
+ | -0.011 | -0.177 | 0.806 | 0.083 | torch.Size([180]) || stage8.2.residual_group.blocks.1.norm2.bias
+ | -0.006 | -0.569 | 0.598 | 0.125 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.1.mlp.fc11.weight
+ | -0.079 | -0.323 | 0.071 | 0.051 | torch.Size([360]) || stage8.2.residual_group.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.512 | 0.577 | 0.126 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.1.mlp.fc12.weight
+ | -0.003 | -0.142 | 0.161 | 0.050 | torch.Size([360]) || stage8.2.residual_group.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.529 | 0.572 | 0.125 | torch.Size([180, 360]) || stage8.2.residual_group.blocks.1.mlp.fc2.weight
+ | -0.010 | -0.178 | 0.159 | 0.066 | torch.Size([180]) || stage8.2.residual_group.blocks.1.mlp.fc2.bias
+ | 0.857 | 0.199 | 1.153 | 0.112 | torch.Size([180]) || stage8.2.residual_group.blocks.2.norm1.weight
+ | -0.039 | -0.189 | 0.943 | 0.089 | torch.Size([180]) || stage8.2.residual_group.blocks.2.norm1.bias
+ | -0.042 | -1.962 | 2.773 | 0.246 | torch.Size([2475, 6]) || stage8.2.residual_group.blocks.2.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.2.residual_group.blocks.2.attn.relative_position_index
+ | -0.000 | -0.783 | 0.655 | 0.123 | torch.Size([540, 180]) || stage8.2.residual_group.blocks.2.attn.qkv_self.weight
+ | 0.004 | -0.338 | 0.533 | 0.099 | torch.Size([540]) || stage8.2.residual_group.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.497 | 0.461 | 0.107 | torch.Size([180, 180]) || stage8.2.residual_group.blocks.2.attn.proj.weight
+ | -0.008 | -0.288 | 0.183 | 0.089 | torch.Size([180]) || stage8.2.residual_group.blocks.2.attn.proj.bias
+ | 0.681 | 0.327 | 0.878 | 0.085 | torch.Size([180]) || stage8.2.residual_group.blocks.2.norm2.weight
+ | -0.012 | -0.178 | 0.773 | 0.084 | torch.Size([180]) || stage8.2.residual_group.blocks.2.norm2.bias
+ | -0.006 | -0.789 | 0.546 | 0.125 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.2.mlp.fc11.weight
+ | -0.081 | -0.249 | 0.036 | 0.051 | torch.Size([360]) || stage8.2.residual_group.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.526 | 0.555 | 0.128 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.2.mlp.fc12.weight
+ | 0.000 | -0.133 | 0.191 | 0.051 | torch.Size([360]) || stage8.2.residual_group.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.572 | 0.529 | 0.126 | torch.Size([180, 360]) || stage8.2.residual_group.blocks.2.mlp.fc2.weight
+ | -0.011 | -0.164 | 0.147 | 0.065 | torch.Size([180]) || stage8.2.residual_group.blocks.2.mlp.fc2.bias
+ | 0.877 | 0.198 | 1.043 | 0.094 | torch.Size([180]) || stage8.2.residual_group.blocks.3.norm1.weight
+ | -0.038 | -0.210 | 0.916 | 0.091 | torch.Size([180]) || stage8.2.residual_group.blocks.3.norm1.bias
+ | -0.094 | -2.974 | 4.987 | 0.299 | torch.Size([2475, 6]) || stage8.2.residual_group.blocks.3.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.2.residual_group.blocks.3.attn.relative_position_index
+ | -0.000 | -0.964 | 1.011 | 0.126 | torch.Size([540, 180]) || stage8.2.residual_group.blocks.3.attn.qkv_self.weight
+ | -0.002 | -0.404 | 0.429 | 0.101 | torch.Size([540]) || stage8.2.residual_group.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.501 | 0.489 | 0.110 | torch.Size([180, 180]) || stage8.2.residual_group.blocks.3.attn.proj.weight
+ | -0.021 | -0.305 | 0.208 | 0.097 | torch.Size([180]) || stage8.2.residual_group.blocks.3.attn.proj.bias
+ | 0.697 | 0.295 | 0.894 | 0.089 | torch.Size([180]) || stage8.2.residual_group.blocks.3.norm2.weight
+ | -0.015 | -0.241 | 0.712 | 0.086 | torch.Size([180]) || stage8.2.residual_group.blocks.3.norm2.bias
+ | -0.005 | -0.562 | 0.573 | 0.125 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.3.mlp.fc11.weight
+ | -0.085 | -0.302 | 0.080 | 0.060 | torch.Size([360]) || stage8.2.residual_group.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.734 | 0.573 | 0.130 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.3.mlp.fc12.weight
+ | 0.001 | -0.150 | 0.161 | 0.054 | torch.Size([360]) || stage8.2.residual_group.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.671 | 0.623 | 0.127 | torch.Size([180, 360]) || stage8.2.residual_group.blocks.3.mlp.fc2.weight
+ | -0.023 | -0.252 | 0.317 | 0.081 | torch.Size([180]) || stage8.2.residual_group.blocks.3.mlp.fc2.bias
+ | -0.000 | -0.278 | 0.345 | 0.064 | torch.Size([180, 180]) || stage8.2.linear.weight
+ | 0.004 | -0.315 | 0.148 | 0.064 | torch.Size([180]) || stage8.2.linear.bias
+ | 0.850 | 0.326 | 1.087 | 0.122 | torch.Size([180]) || stage8.3.residual_group.blocks.0.norm1.weight
+ | -0.031 | -0.334 | 0.779 | 0.106 | torch.Size([180]) || stage8.3.residual_group.blocks.0.norm1.bias
+ | -0.012 | -2.917 | 1.476 | 0.175 | torch.Size([2475, 6]) || stage8.3.residual_group.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.3.residual_group.blocks.0.attn.relative_position_index
+ | -0.000 | -0.603 | 0.666 | 0.124 | torch.Size([540, 180]) || stage8.3.residual_group.blocks.0.attn.qkv_self.weight
+ | -0.001 | -0.374 | 0.381 | 0.086 | torch.Size([540]) || stage8.3.residual_group.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.577 | 0.605 | 0.119 | torch.Size([180, 180]) || stage8.3.residual_group.blocks.0.attn.proj.weight
+ | -0.008 | -0.394 | 0.499 | 0.134 | torch.Size([180]) || stage8.3.residual_group.blocks.0.attn.proj.bias
+ | 0.636 | 0.321 | 0.790 | 0.073 | torch.Size([180]) || stage8.3.residual_group.blocks.0.norm2.weight
+ | -0.013 | -0.294 | 0.774 | 0.090 | torch.Size([180]) || stage8.3.residual_group.blocks.0.norm2.bias
+ | -0.004 | -0.540 | 0.539 | 0.123 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.0.mlp.fc11.weight
+ | -0.065 | -0.212 | 0.047 | 0.051 | torch.Size([360]) || stage8.3.residual_group.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.608 | 0.603 | 0.130 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.0.mlp.fc12.weight
+ | -0.002 | -0.177 | 0.155 | 0.051 | torch.Size([360]) || stage8.3.residual_group.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.573 | 0.630 | 0.129 | torch.Size([180, 360]) || stage8.3.residual_group.blocks.0.mlp.fc2.weight
+ | -0.005 | -0.189 | 0.178 | 0.071 | torch.Size([180]) || stage8.3.residual_group.blocks.0.mlp.fc2.bias
+ | 0.899 | 0.275 | 1.048 | 0.099 | torch.Size([180]) || stage8.3.residual_group.blocks.1.norm1.weight
+ | -0.031 | -0.223 | 0.771 | 0.088 | torch.Size([180]) || stage8.3.residual_group.blocks.1.norm1.bias
+ | -0.003 | -3.151 | 1.718 | 0.202 | torch.Size([2475, 6]) || stage8.3.residual_group.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.3.residual_group.blocks.1.attn.relative_position_index
+ | -0.000 | -0.732 | 0.868 | 0.127 | torch.Size([540, 180]) || stage8.3.residual_group.blocks.1.attn.qkv_self.weight
+ | 0.002 | -0.412 | 0.350 | 0.093 | torch.Size([540]) || stage8.3.residual_group.blocks.1.attn.qkv_self.bias
+ | 0.001 | -0.466 | 0.487 | 0.114 | torch.Size([180, 180]) || stage8.3.residual_group.blocks.1.attn.proj.weight
+ | -0.006 | -0.388 | 0.400 | 0.129 | torch.Size([180]) || stage8.3.residual_group.blocks.1.attn.proj.bias
+ | 0.711 | 0.381 | 0.864 | 0.082 | torch.Size([180]) || stage8.3.residual_group.blocks.1.norm2.weight
+ | -0.009 | -0.240 | 0.692 | 0.090 | torch.Size([180]) || stage8.3.residual_group.blocks.1.norm2.bias
+ | -0.005 | -0.657 | 0.639 | 0.126 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.1.mlp.fc11.weight
+ | -0.077 | -0.263 | 0.047 | 0.057 | torch.Size([360]) || stage8.3.residual_group.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.673 | 0.605 | 0.134 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.1.mlp.fc12.weight
+ | 0.002 | -0.158 | 0.155 | 0.046 | torch.Size([360]) || stage8.3.residual_group.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.582 | 0.585 | 0.131 | torch.Size([180, 360]) || stage8.3.residual_group.blocks.1.mlp.fc2.weight
+ | -0.009 | -0.253 | 0.178 | 0.070 | torch.Size([180]) || stage8.3.residual_group.blocks.1.mlp.fc2.bias
+ | 0.941 | 0.262 | 1.154 | 0.094 | torch.Size([180]) || stage8.3.residual_group.blocks.2.norm1.weight
+ | -0.032 | -0.162 | 0.906 | 0.084 | torch.Size([180]) || stage8.3.residual_group.blocks.2.norm1.bias
+ | -0.005 | -3.421 | 1.350 | 0.205 | torch.Size([2475, 6]) || stage8.3.residual_group.blocks.2.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.3.residual_group.blocks.2.attn.relative_position_index
+ | -0.000 | -0.777 | 0.735 | 0.130 | torch.Size([540, 180]) || stage8.3.residual_group.blocks.2.attn.qkv_self.weight
+ | 0.000 | -0.355 | 0.421 | 0.092 | torch.Size([540]) || stage8.3.residual_group.blocks.2.attn.qkv_self.bias
+ | 0.000 | -0.479 | 0.475 | 0.115 | torch.Size([180, 180]) || stage8.3.residual_group.blocks.2.attn.proj.weight
+ | -0.013 | -0.292 | 0.345 | 0.122 | torch.Size([180]) || stage8.3.residual_group.blocks.2.attn.proj.bias
+ | 0.743 | 0.242 | 0.919 | 0.093 | torch.Size([180]) || stage8.3.residual_group.blocks.2.norm2.weight
+ | -0.011 | -0.214 | 0.691 | 0.094 | torch.Size([180]) || stage8.3.residual_group.blocks.2.norm2.bias
+ | -0.005 | -0.633 | 0.498 | 0.127 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.2.mlp.fc11.weight
+ | -0.082 | -0.346 | 0.087 | 0.062 | torch.Size([360]) || stage8.3.residual_group.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.591 | 0.670 | 0.134 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.2.mlp.fc12.weight
+ | 0.001 | -0.190 | 0.151 | 0.056 | torch.Size([360]) || stage8.3.residual_group.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.560 | 0.637 | 0.132 | torch.Size([180, 360]) || stage8.3.residual_group.blocks.2.mlp.fc2.weight
+ | -0.009 | -0.226 | 0.250 | 0.085 | torch.Size([180]) || stage8.3.residual_group.blocks.2.mlp.fc2.bias
+ | 0.950 | 0.250 | 1.103 | 0.086 | torch.Size([180]) || stage8.3.residual_group.blocks.3.norm1.weight
+ | -0.035 | -0.196 | 0.925 | 0.088 | torch.Size([180]) || stage8.3.residual_group.blocks.3.norm1.bias
+ | -0.026 | -3.591 | 5.653 | 0.236 | torch.Size([2475, 6]) || stage8.3.residual_group.blocks.3.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.3.residual_group.blocks.3.attn.relative_position_index
+ | 0.000 | -0.753 | 0.637 | 0.128 | torch.Size([540, 180]) || stage8.3.residual_group.blocks.3.attn.qkv_self.weight
+ | 0.000 | -0.333 | 0.432 | 0.081 | torch.Size([540]) || stage8.3.residual_group.blocks.3.attn.qkv_self.bias
+ | 0.001 | -0.591 | 0.591 | 0.118 | torch.Size([180, 180]) || stage8.3.residual_group.blocks.3.attn.proj.weight
+ | -0.014 | -0.348 | 0.267 | 0.122 | torch.Size([180]) || stage8.3.residual_group.blocks.3.attn.proj.bias
+ | 0.735 | 0.254 | 0.893 | 0.082 | torch.Size([180]) || stage8.3.residual_group.blocks.3.norm2.weight
+ | -0.011 | -0.241 | 0.659 | 0.093 | torch.Size([180]) || stage8.3.residual_group.blocks.3.norm2.bias
+ | -0.005 | -0.628 | 0.667 | 0.125 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.3.mlp.fc11.weight
+ | -0.076 | -0.411 | 0.113 | 0.072 | torch.Size([360]) || stage8.3.residual_group.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.662 | 0.578 | 0.135 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.3.mlp.fc12.weight
+ | -0.004 | -0.208 | 0.169 | 0.054 | torch.Size([360]) || stage8.3.residual_group.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.602 | 0.588 | 0.131 | torch.Size([180, 360]) || stage8.3.residual_group.blocks.3.mlp.fc2.weight
+ | -0.011 | -0.218 | 0.232 | 0.096 | torch.Size([180]) || stage8.3.residual_group.blocks.3.mlp.fc2.bias
+ | -0.000 | -0.343 | 0.316 | 0.065 | torch.Size([180, 180]) || stage8.3.linear.weight
+ | 0.010 | -0.297 | 0.187 | 0.061 | torch.Size([180]) || stage8.3.linear.bias
+ | 1.012 | 0.330 | 1.282 | 0.149 | torch.Size([180]) || stage8.4.residual_group.blocks.0.norm1.weight
+ | -0.030 | -0.347 | 0.800 | 0.134 | torch.Size([180]) || stage8.4.residual_group.blocks.0.norm1.bias
+ | -0.013 | -2.816 | 3.792 | 0.236 | torch.Size([2475, 6]) || stage8.4.residual_group.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.4.residual_group.blocks.0.attn.relative_position_index
+ | -0.000 | -0.807 | 0.825 | 0.131 | torch.Size([540, 180]) || stage8.4.residual_group.blocks.0.attn.qkv_self.weight
+ | -0.003 | -0.429 | 0.319 | 0.083 | torch.Size([540]) || stage8.4.residual_group.blocks.0.attn.qkv_self.bias
+ | 0.001 | -0.553 | 0.569 | 0.136 | torch.Size([180, 180]) || stage8.4.residual_group.blocks.0.attn.proj.weight
+ | -0.019 | -0.443 | 0.441 | 0.139 | torch.Size([180]) || stage8.4.residual_group.blocks.0.attn.proj.bias
+ | 0.638 | 0.420 | 0.797 | 0.063 | torch.Size([180]) || stage8.4.residual_group.blocks.0.norm2.weight
+ | -0.018 | -0.222 | 0.886 | 0.107 | torch.Size([180]) || stage8.4.residual_group.blocks.0.norm2.bias
+ | -0.002 | -0.576 | 0.510 | 0.117 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.0.mlp.fc11.weight
+ | -0.018 | -0.277 | 0.123 | 0.068 | torch.Size([360]) || stage8.4.residual_group.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.687 | 0.625 | 0.132 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.0.mlp.fc12.weight
+ | -0.007 | -0.264 | 0.267 | 0.076 | torch.Size([360]) || stage8.4.residual_group.blocks.0.mlp.fc12.bias
+ | 0.001 | -0.639 | 0.705 | 0.130 | torch.Size([180, 360]) || stage8.4.residual_group.blocks.0.mlp.fc2.weight
+ | -0.012 | -0.255 | 0.274 | 0.095 | torch.Size([180]) || stage8.4.residual_group.blocks.0.mlp.fc2.bias
+ | 1.092 | 0.475 | 1.341 | 0.115 | torch.Size([180]) || stage8.4.residual_group.blocks.1.norm1.weight
+ | -0.030 | -0.294 | 0.686 | 0.113 | torch.Size([180]) || stage8.4.residual_group.blocks.1.norm1.bias
+ | 0.018 | -3.165 | 0.990 | 0.213 | torch.Size([2475, 6]) || stage8.4.residual_group.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.4.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -0.695 | 0.699 | 0.133 | torch.Size([540, 180]) || stage8.4.residual_group.blocks.1.attn.qkv_self.weight
+ | 0.002 | -0.319 | 0.286 | 0.075 | torch.Size([540]) || stage8.4.residual_group.blocks.1.attn.qkv_self.bias
+ | -0.001 | -0.542 | 0.519 | 0.133 | torch.Size([180, 180]) || stage8.4.residual_group.blocks.1.attn.proj.weight
+ | -0.017 | -0.439 | 0.451 | 0.152 | torch.Size([180]) || stage8.4.residual_group.blocks.1.attn.proj.bias
+ | 0.664 | 0.366 | 0.835 | 0.074 | torch.Size([180]) || stage8.4.residual_group.blocks.1.norm2.weight
+ | -0.015 | -0.217 | 0.985 | 0.103 | torch.Size([180]) || stage8.4.residual_group.blocks.1.norm2.bias
+ | -0.002 | -0.641 | 0.563 | 0.117 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.1.mlp.fc11.weight
+ | -0.022 | -0.381 | 0.161 | 0.078 | torch.Size([360]) || stage8.4.residual_group.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.571 | 0.642 | 0.132 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.1.mlp.fc12.weight
+ | 0.003 | -0.279 | 0.311 | 0.087 | torch.Size([360]) || stage8.4.residual_group.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.738 | 0.633 | 0.130 | torch.Size([180, 360]) || stage8.4.residual_group.blocks.1.mlp.fc2.weight
+ | -0.007 | -0.254 | 0.261 | 0.084 | torch.Size([180]) || stage8.4.residual_group.blocks.1.mlp.fc2.bias
+ | 1.125 | 0.525 | 1.405 | 0.117 | torch.Size([180]) || stage8.4.residual_group.blocks.2.norm1.weight
+ | -0.033 | -0.186 | 0.627 | 0.082 | torch.Size([180]) || stage8.4.residual_group.blocks.2.norm1.bias
+ | 0.028 | -3.477 | 0.957 | 0.217 | torch.Size([2475, 6]) || stage8.4.residual_group.blocks.2.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.4.residual_group.blocks.2.attn.relative_position_index
+ | 0.000 | -0.663 | 0.658 | 0.130 | torch.Size([540, 180]) || stage8.4.residual_group.blocks.2.attn.qkv_self.weight
+ | -0.007 | -0.357 | 0.255 | 0.064 | torch.Size([540]) || stage8.4.residual_group.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.596 | 0.578 | 0.137 | torch.Size([180, 180]) || stage8.4.residual_group.blocks.2.attn.proj.weight
+ | -0.018 | -0.506 | 0.389 | 0.159 | torch.Size([180]) || stage8.4.residual_group.blocks.2.attn.proj.bias
+ | 0.694 | 0.319 | 0.865 | 0.084 | torch.Size([180]) || stage8.4.residual_group.blocks.2.norm2.weight
+ | -0.018 | -0.150 | 0.975 | 0.087 | torch.Size([180]) || stage8.4.residual_group.blocks.2.norm2.bias
+ | -0.002 | -0.619 | 0.565 | 0.116 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.2.mlp.fc11.weight
+ | -0.025 | -0.345 | 0.208 | 0.086 | torch.Size([360]) || stage8.4.residual_group.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.624 | 0.607 | 0.132 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.2.mlp.fc12.weight
+ | -0.003 | -0.388 | 0.290 | 0.075 | torch.Size([360]) || stage8.4.residual_group.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.927 | 0.675 | 0.130 | torch.Size([180, 360]) || stage8.4.residual_group.blocks.2.mlp.fc2.weight
+ | -0.011 | -0.325 | 0.240 | 0.096 | torch.Size([180]) || stage8.4.residual_group.blocks.2.mlp.fc2.bias
+ | 1.108 | 0.535 | 1.297 | 0.094 | torch.Size([180]) || stage8.4.residual_group.blocks.3.norm1.weight
+ | -0.035 | -0.213 | 0.546 | 0.064 | torch.Size([180]) || stage8.4.residual_group.blocks.3.norm1.bias
+ | 0.020 | -3.042 | 1.420 | 0.192 | torch.Size([2475, 6]) || stage8.4.residual_group.blocks.3.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.4.residual_group.blocks.3.attn.relative_position_index
+ | -0.000 | -0.697 | 0.700 | 0.128 | torch.Size([540, 180]) || stage8.4.residual_group.blocks.3.attn.qkv_self.weight
+ | -0.000 | -0.220 | 0.311 | 0.065 | torch.Size([540]) || stage8.4.residual_group.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.652 | 0.592 | 0.138 | torch.Size([180, 180]) || stage8.4.residual_group.blocks.3.attn.proj.weight
+ | -0.019 | -0.535 | 0.426 | 0.154 | torch.Size([180]) || stage8.4.residual_group.blocks.3.attn.proj.bias
+ | 0.685 | 0.225 | 0.893 | 0.082 | torch.Size([180]) || stage8.4.residual_group.blocks.3.norm2.weight
+ | -0.023 | -0.211 | 0.938 | 0.093 | torch.Size([180]) || stage8.4.residual_group.blocks.3.norm2.bias
+ | -0.001 | -0.501 | 0.564 | 0.113 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.3.mlp.fc11.weight
+ | -0.014 | -0.339 | 0.237 | 0.092 | torch.Size([360]) || stage8.4.residual_group.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.560 | 0.626 | 0.132 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.3.mlp.fc12.weight
+ | 0.000 | -0.231 | 0.239 | 0.075 | torch.Size([360]) || stage8.4.residual_group.blocks.3.mlp.fc12.bias
+ | -0.000 | -0.544 | 0.657 | 0.130 | torch.Size([180, 360]) || stage8.4.residual_group.blocks.3.mlp.fc2.weight
+ | -0.007 | -0.271 | 0.274 | 0.093 | torch.Size([180]) || stage8.4.residual_group.blocks.3.mlp.fc2.bias
+ | -0.001 | -0.473 | 0.481 | 0.069 | torch.Size([180, 180]) || stage8.4.linear.weight
+ | 0.029 | -0.333 | 0.194 | 0.076 | torch.Size([180]) || stage8.4.linear.bias
+ | 1.025 | 0.297 | 1.336 | 0.162 | torch.Size([180]) || stage8.5.residual_group.blocks.0.norm1.weight
+ | -0.034 | -0.429 | 0.872 | 0.141 | torch.Size([180]) || stage8.5.residual_group.blocks.0.norm1.bias
+ | -0.574 | -4.515 | 3.381 | 0.800 | torch.Size([225, 6]) || stage8.5.residual_group.blocks.0.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.5.residual_group.blocks.0.attn.relative_position_index
+ | 0.000 | -0.771 | 0.886 | 0.125 | torch.Size([540, 180]) || stage8.5.residual_group.blocks.0.attn.qkv_self.weight
+ | 0.000 | -0.356 | 0.521 | 0.085 | torch.Size([540]) || stage8.5.residual_group.blocks.0.attn.qkv_self.bias
+ | -0.001 | -0.632 | 0.656 | 0.147 | torch.Size([180, 180]) || stage8.5.residual_group.blocks.0.attn.proj.weight
+ | -0.029 | -0.329 | 0.697 | 0.127 | torch.Size([180]) || stage8.5.residual_group.blocks.0.attn.proj.bias
+ | 0.777 | 0.446 | 0.952 | 0.069 | torch.Size([180]) || stage8.5.residual_group.blocks.0.norm2.weight
+ | -0.022 | -0.335 | 0.920 | 0.121 | torch.Size([180]) || stage8.5.residual_group.blocks.0.norm2.bias
+ | -0.002 | -0.520 | 0.598 | 0.117 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.0.mlp.fc11.weight
+ | -0.013 | -0.456 | 0.200 | 0.075 | torch.Size([360]) || stage8.5.residual_group.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.677 | 0.642 | 0.137 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.0.mlp.fc12.weight
+ | 0.005 | -0.272 | 0.233 | 0.083 | torch.Size([360]) || stage8.5.residual_group.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.762 | 0.598 | 0.136 | torch.Size([180, 360]) || stage8.5.residual_group.blocks.0.mlp.fc2.weight
+ | -0.025 | -0.244 | 0.583 | 0.111 | torch.Size([180]) || stage8.5.residual_group.blocks.0.mlp.fc2.bias
+ | 1.021 | 0.261 | 1.261 | 0.133 | torch.Size([180]) || stage8.5.residual_group.blocks.1.norm1.weight
+ | -0.033 | -0.358 | 0.867 | 0.120 | torch.Size([180]) || stage8.5.residual_group.blocks.1.norm1.bias
+ | -0.550 | -3.274 | 4.406 | 0.670 | torch.Size([225, 6]) || stage8.5.residual_group.blocks.1.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.5.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -0.819 | 0.986 | 0.122 | torch.Size([540, 180]) || stage8.5.residual_group.blocks.1.attn.qkv_self.weight
+ | 0.005 | -0.510 | 0.446 | 0.084 | torch.Size([540]) || stage8.5.residual_group.blocks.1.attn.qkv_self.bias
+ | -0.003 | -0.739 | 0.682 | 0.151 | torch.Size([180, 180]) || stage8.5.residual_group.blocks.1.attn.proj.weight
+ | -0.032 | -0.318 | 0.607 | 0.133 | torch.Size([180]) || stage8.5.residual_group.blocks.1.attn.proj.bias
+ | 0.823 | 0.420 | 0.950 | 0.070 | torch.Size([180]) || stage8.5.residual_group.blocks.1.norm2.weight
+ | -0.021 | -0.274 | 0.882 | 0.111 | torch.Size([180]) || stage8.5.residual_group.blocks.1.norm2.bias
+ | -0.002 | -0.496 | 0.532 | 0.117 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.1.mlp.fc11.weight
+ | -0.028 | -0.260 | 0.194 | 0.080 | torch.Size([360]) || stage8.5.residual_group.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.620 | 0.586 | 0.139 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.1.mlp.fc12.weight
+ | 0.004 | -0.284 | 0.423 | 0.083 | torch.Size([360]) || stage8.5.residual_group.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.774 | 0.614 | 0.137 | torch.Size([180, 360]) || stage8.5.residual_group.blocks.1.mlp.fc2.weight
+ | -0.028 | -0.371 | 0.561 | 0.133 | torch.Size([180]) || stage8.5.residual_group.blocks.1.mlp.fc2.bias
+ | 1.096 | 0.377 | 1.321 | 0.110 | torch.Size([180]) || stage8.5.residual_group.blocks.2.norm1.weight
+ | -0.033 | -0.244 | 0.755 | 0.100 | torch.Size([180]) || stage8.5.residual_group.blocks.2.norm1.bias
+ | -0.441 | -3.439 | 5.870 | 0.668 | torch.Size([225, 6]) || stage8.5.residual_group.blocks.2.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.5.residual_group.blocks.2.attn.relative_position_index
+ | -0.000 | -0.710 | 0.679 | 0.123 | torch.Size([540, 180]) || stage8.5.residual_group.blocks.2.attn.qkv_self.weight
+ | 0.003 | -0.277 | 0.283 | 0.068 | torch.Size([540]) || stage8.5.residual_group.blocks.2.attn.qkv_self.bias
+ | 0.001 | -0.824 | 0.684 | 0.150 | torch.Size([180, 180]) || stage8.5.residual_group.blocks.2.attn.proj.weight
+ | -0.033 | -0.390 | 0.545 | 0.155 | torch.Size([180]) || stage8.5.residual_group.blocks.2.attn.proj.bias
+ | 0.843 | 0.390 | 0.984 | 0.076 | torch.Size([180]) || stage8.5.residual_group.blocks.2.norm2.weight
+ | -0.022 | -0.211 | 0.854 | 0.090 | torch.Size([180]) || stage8.5.residual_group.blocks.2.norm2.bias
+ | -0.002 | -0.522 | 0.503 | 0.116 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.2.mlp.fc11.weight
+ | -0.024 | -0.243 | 0.219 | 0.091 | torch.Size([360]) || stage8.5.residual_group.blocks.2.mlp.fc11.bias
+ | -0.001 | -0.638 | 0.617 | 0.139 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.2.mlp.fc12.weight
+ | -0.004 | -0.268 | 0.380 | 0.078 | torch.Size([360]) || stage8.5.residual_group.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.713 | 0.769 | 0.138 | torch.Size([180, 360]) || stage8.5.residual_group.blocks.2.mlp.fc2.weight
+ | -0.034 | -0.372 | 0.592 | 0.151 | torch.Size([180]) || stage8.5.residual_group.blocks.2.mlp.fc2.bias
+ | 1.027 | 0.318 | 1.206 | 0.094 | torch.Size([180]) || stage8.5.residual_group.blocks.3.norm1.weight
+ | -0.033 | -0.187 | 0.768 | 0.088 | torch.Size([180]) || stage8.5.residual_group.blocks.3.norm1.bias
+ | -0.347 | -2.664 | 2.684 | 0.528 | torch.Size([225, 6]) || stage8.5.residual_group.blocks.3.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.5.residual_group.blocks.3.attn.relative_position_index
+ | 0.000 | -0.677 | 0.676 | 0.127 | torch.Size([540, 180]) || stage8.5.residual_group.blocks.3.attn.qkv_self.weight
+ | 0.002 | -0.410 | 0.354 | 0.080 | torch.Size([540]) || stage8.5.residual_group.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.630 | 0.725 | 0.145 | torch.Size([180, 180]) || stage8.5.residual_group.blocks.3.attn.proj.weight
+ | -0.041 | -0.385 | 0.660 | 0.163 | torch.Size([180]) || stage8.5.residual_group.blocks.3.attn.proj.bias
+ | 0.849 | 0.390 | 0.985 | 0.070 | torch.Size([180]) || stage8.5.residual_group.blocks.3.norm2.weight
+ | -0.023 | -0.163 | 0.810 | 0.084 | torch.Size([180]) || stage8.5.residual_group.blocks.3.norm2.bias
+ | -0.002 | -0.547 | 0.536 | 0.115 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.3.mlp.fc11.weight
+ | -0.012 | -0.366 | 0.252 | 0.106 | torch.Size([360]) || stage8.5.residual_group.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.669 | 0.597 | 0.139 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.3.mlp.fc12.weight
+ | -0.002 | -0.216 | 0.202 | 0.074 | torch.Size([360]) || stage8.5.residual_group.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.700 | 0.674 | 0.139 | torch.Size([180, 360]) || stage8.5.residual_group.blocks.3.mlp.fc2.weight
+ | -0.032 | -0.376 | 0.666 | 0.134 | torch.Size([180]) || stage8.5.residual_group.blocks.3.mlp.fc2.bias
+ | -0.001 | -0.299 | 0.469 | 0.069 | torch.Size([180, 180]) || stage8.5.linear.weight
+ | 0.081 | -0.562 | 0.263 | 0.109 | torch.Size([180]) || stage8.5.linear.bias
+ | 1.111 | 0.208 | 1.434 | 0.192 | torch.Size([180]) || stage8.6.residual_group.blocks.0.norm1.weight
+ | -0.048 | -0.547 | 0.851 | 0.175 | torch.Size([180]) || stage8.6.residual_group.blocks.0.norm1.bias
+ | -0.252 | -2.157 | 6.293 | 0.490 | torch.Size([225, 6]) || stage8.6.residual_group.blocks.0.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.6.residual_group.blocks.0.attn.relative_position_index
+ | 0.000 | -0.664 | 0.631 | 0.123 | torch.Size([540, 180]) || stage8.6.residual_group.blocks.0.attn.qkv_self.weight
+ | 0.007 | -0.293 | 0.366 | 0.078 | torch.Size([540]) || stage8.6.residual_group.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.701 | 0.726 | 0.154 | torch.Size([180, 180]) || stage8.6.residual_group.blocks.0.attn.proj.weight
+ | 0.030 | -0.318 | 0.331 | 0.109 | torch.Size([180]) || stage8.6.residual_group.blocks.0.attn.proj.bias
+ | 0.959 | 0.475 | 1.322 | 0.088 | torch.Size([180]) || stage8.6.residual_group.blocks.0.norm2.weight
+ | -0.039 | -0.421 | 0.873 | 0.151 | torch.Size([180]) || stage8.6.residual_group.blocks.0.norm2.bias
+ | -0.002 | -0.550 | 0.783 | 0.116 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.0.mlp.fc11.weight
+ | 0.002 | -0.269 | 0.152 | 0.069 | torch.Size([360]) || stage8.6.residual_group.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.914 | 0.839 | 0.143 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.0.mlp.fc12.weight
+ | 0.001 | -0.340 | 0.304 | 0.075 | torch.Size([360]) || stage8.6.residual_group.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.592 | 0.713 | 0.140 | torch.Size([180, 360]) || stage8.6.residual_group.blocks.0.mlp.fc2.weight
+ | 0.002 | -0.535 | 0.384 | 0.177 | torch.Size([180]) || stage8.6.residual_group.blocks.0.mlp.fc2.bias
+ | 1.123 | 0.183 | 1.352 | 0.165 | torch.Size([180]) || stage8.6.residual_group.blocks.1.norm1.weight
+ | -0.047 | -0.513 | 0.903 | 0.168 | torch.Size([180]) || stage8.6.residual_group.blocks.1.norm1.bias
+ | -0.234 | -1.968 | 6.366 | 0.448 | torch.Size([225, 6]) || stage8.6.residual_group.blocks.1.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.6.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -0.751 | 0.759 | 0.121 | torch.Size([540, 180]) || stage8.6.residual_group.blocks.1.attn.qkv_self.weight
+ | -0.001 | -0.300 | 0.214 | 0.061 | torch.Size([540]) || stage8.6.residual_group.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.657 | 0.699 | 0.148 | torch.Size([180, 180]) || stage8.6.residual_group.blocks.1.attn.proj.weight
+ | 0.031 | -0.321 | 0.293 | 0.115 | torch.Size([180]) || stage8.6.residual_group.blocks.1.attn.proj.bias
+ | 0.986 | 0.416 | 1.360 | 0.096 | torch.Size([180]) || stage8.6.residual_group.blocks.1.norm2.weight
+ | -0.038 | -0.393 | 0.807 | 0.146 | torch.Size([180]) || stage8.6.residual_group.blocks.1.norm2.bias
+ | -0.001 | -0.589 | 0.620 | 0.116 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.1.mlp.fc11.weight
+ | 0.005 | -0.316 | 0.229 | 0.071 | torch.Size([360]) || stage8.6.residual_group.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.738 | 0.766 | 0.143 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.1.mlp.fc12.weight
+ | 0.001 | -0.252 | 0.302 | 0.072 | torch.Size([360]) || stage8.6.residual_group.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.674 | 0.629 | 0.140 | torch.Size([180, 360]) || stage8.6.residual_group.blocks.1.mlp.fc2.weight
+ | -0.001 | -0.475 | 0.441 | 0.175 | torch.Size([180]) || stage8.6.residual_group.blocks.1.mlp.fc2.bias
+ | 1.097 | 0.342 | 1.294 | 0.134 | torch.Size([180]) || stage8.6.residual_group.blocks.2.norm1.weight
+ | -0.054 | -0.639 | 0.904 | 0.186 | torch.Size([180]) || stage8.6.residual_group.blocks.2.norm1.bias
+ | -0.135 | -3.252 | 1.238 | 0.360 | torch.Size([225, 6]) || stage8.6.residual_group.blocks.2.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.6.residual_group.blocks.2.attn.relative_position_index
+ | 0.000 | -0.672 | 0.663 | 0.128 | torch.Size([540, 180]) || stage8.6.residual_group.blocks.2.attn.qkv_self.weight
+ | 0.007 | -0.170 | 0.228 | 0.046 | torch.Size([540]) || stage8.6.residual_group.blocks.2.attn.qkv_self.bias
+ | -0.001 | -0.660 | 0.651 | 0.147 | torch.Size([180, 180]) || stage8.6.residual_group.blocks.2.attn.proj.weight
+ | 0.031 | -0.360 | 0.322 | 0.126 | torch.Size([180]) || stage8.6.residual_group.blocks.2.attn.proj.bias
+ | 1.004 | 0.360 | 1.381 | 0.099 | torch.Size([180]) || stage8.6.residual_group.blocks.2.norm2.weight
+ | -0.042 | -0.447 | 0.808 | 0.157 | torch.Size([180]) || stage8.6.residual_group.blocks.2.norm2.bias
+ | -0.000 | -0.600 | 0.603 | 0.116 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.2.mlp.fc11.weight
+ | 0.022 | -0.447 | 0.249 | 0.086 | torch.Size([360]) || stage8.6.residual_group.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.666 | 0.708 | 0.143 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.2.mlp.fc12.weight
+ | -0.002 | -0.326 | 0.272 | 0.075 | torch.Size([360]) || stage8.6.residual_group.blocks.2.mlp.fc12.bias
+ | -0.001 | -0.653 | 0.719 | 0.142 | torch.Size([180, 360]) || stage8.6.residual_group.blocks.2.mlp.fc2.weight
+ | -0.011 | -0.488 | 0.321 | 0.153 | torch.Size([180]) || stage8.6.residual_group.blocks.2.mlp.fc2.bias
+ | 1.095 | 0.272 | 1.302 | 0.123 | torch.Size([180]) || stage8.6.residual_group.blocks.3.norm1.weight
+ | -0.052 | -0.557 | 1.069 | 0.192 | torch.Size([180]) || stage8.6.residual_group.blocks.3.norm1.bias
+ | -0.196 | -2.349 | 1.401 | 0.360 | torch.Size([225, 6]) || stage8.6.residual_group.blocks.3.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.6.residual_group.blocks.3.attn.relative_position_index
+ | 0.000 | -0.741 | 0.657 | 0.124 | torch.Size([540, 180]) || stage8.6.residual_group.blocks.3.attn.qkv_self.weight
+ | 0.001 | -0.186 | 0.141 | 0.040 | torch.Size([540]) || stage8.6.residual_group.blocks.3.attn.qkv_self.bias
+ | -0.001 | -0.669 | 0.671 | 0.139 | torch.Size([180, 180]) || stage8.6.residual_group.blocks.3.attn.proj.weight
+ | -0.004 | -0.323 | 0.300 | 0.124 | torch.Size([180]) || stage8.6.residual_group.blocks.3.attn.proj.bias
+ | 0.999 | 0.383 | 1.380 | 0.103 | torch.Size([180]) || stage8.6.residual_group.blocks.3.norm2.weight
+ | -0.044 | -0.392 | 0.694 | 0.163 | torch.Size([180]) || stage8.6.residual_group.blocks.3.norm2.bias
+ | 0.000 | -0.577 | 0.857 | 0.116 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.3.mlp.fc11.weight
+ | 0.041 | -0.394 | 0.238 | 0.087 | torch.Size([360]) || stage8.6.residual_group.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.924 | 0.828 | 0.143 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.3.mlp.fc12.weight
+ | -0.003 | -0.214 | 0.407 | 0.071 | torch.Size([360]) || stage8.6.residual_group.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.827 | 0.755 | 0.141 | torch.Size([180, 360]) || stage8.6.residual_group.blocks.3.mlp.fc2.weight
+ | 0.022 | -0.296 | 0.262 | 0.107 | torch.Size([180]) || stage8.6.residual_group.blocks.3.mlp.fc2.bias
+ | 0.002 | -1.059 | 1.262 | 0.089 | torch.Size([180, 180]) || stage8.6.linear.weight
+ | 0.031 | -0.789 | 0.427 | 0.120 | torch.Size([180]) || stage8.6.linear.bias
+ | 0.389 | 0.079 | 1.137 | 0.176 | torch.Size([180]) || norm.weight
+ | -0.021 | -0.669 | 0.888 | 0.127 | torch.Size([180]) || norm.bias
+ | 0.000 | -0.486 | 0.568 | 0.103 | torch.Size([120, 180]) || conv_after_body.weight
+ | -0.000 | -0.167 | 0.168 | 0.055 | torch.Size([120]) || conv_after_body.bias
+ | -0.000 | -1.782 | 1.300 | 0.109 | torch.Size([64, 120, 1, 3, 3]) || conv_before_upsample.0.weight
+ | -0.019 | -0.542 | 0.437 | 0.162 | torch.Size([64]) || conv_before_upsample.0.bias
+ | 0.001 | -1.915 | 1.372 | 0.090 | torch.Size([256, 64, 1, 3, 3]) || upsample.0.weight
+ | -0.045 | -0.281 | 0.215 | 0.097 | torch.Size([256]) || upsample.0.bias
+ | -0.006 | -4.826 | 0.582 | 0.075 | torch.Size([256, 64, 1, 3, 3]) || upsample.5.weight
+ | -0.154 | -0.441 | 0.187 | 0.100 | torch.Size([256]) || upsample.5.bias
+ | 0.000 | -0.210 | 0.246 | 0.012 | torch.Size([64, 64, 1, 3, 3]) || upsample.10.weight
+ | 0.000 | -0.013 | 0.007 | 0.003 | torch.Size([64]) || upsample.10.bias
+ | 0.000 | -0.044 | 0.042 | 0.004 | torch.Size([3, 64, 1, 3, 3]) || conv_last.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([3]) || conv_last.bias
+
+22-03-11 10:46:12.537 : task: 001_train_vrt_videosr_bi_reds_6frames
+ model: vrt
+ gpu_ids: [0, 1, 2, 3, 4, 5, 6, 7]
+ dist: False
+ find_unused_parameters: False
+ use_static_graph: True
+ scale: 4
+ n_channels: 3
+ path:[
+ root: experiments
+ pretrained_netG: /home/cll/dev/KAIR/model_zoo/vrt/001_VRT_videosr_bi_REDS_6frames.pth
+ pretrained_netE: None
+ task: experiments/001_train_vrt_videosr_bi_reds_6frames
+ log: experiments/001_train_vrt_videosr_bi_reds_6frames
+ options: experiments/001_train_vrt_videosr_bi_reds_6frames/options
+ models: experiments/001_train_vrt_videosr_bi_reds_6frames/models
+ images: experiments/001_train_vrt_videosr_bi_reds_6frames/images
+ pretrained_optimizerG: None
+ ]
+ datasets:[
+ train:[
+ name: train_dataset
+ dataset_type: VideoRecurrentTrainDataset
+ dataroot_gt: /home/cll/datasets/REDS/train/train_sharp
+ dataroot_lq: /home/cll/datasets/REDS/train/train_sharp_bicubic/X4
+ meta_info_file: data/meta_info/meta_info_REDS_GT.txt
+ filename_tmpl: 08d
+ filename_ext: png
+ val_partition: REDS4
+ test_mode: False
+ io_backend:[
+ type: disk
+ ]
+ num_frame: 6
+ gt_size: 256
+ interval_list: [1]
+ random_reverse: False
+ use_hflip: True
+ use_rot: True
+ dataloader_shuffle: True
+ dataloader_num_workers: 32
+ dataloader_batch_size: 8
+ phase: train
+ scale: 4
+ n_channels: 3
+ ]
+ test:[
+ name: test_dataset
+ dataset_type: VideoRecurrentTestDataset
+ dataroot_gt: /home/cll/Desktop/REDS4/GT
+ dataroot_lq: /home/cll/Desktop/REDS4/sharp_bicubic
+ cache_data: True
+ io_backend:[
+ type: disk
+ ]
+ num_frame: -1
+ phase: test
+ scale: 4
+ n_channels: 3
+ ]
+ ]
+ netG:[
+ net_type: vrt
+ upscale: 4
+ img_size: [6, 64, 64]
+ window_size: [6, 8, 8]
+ depths: [8, 8, 8, 8, 8, 8, 8, 4, 4, 4, 4, 4, 4]
+ indep_reconsts: [11, 12]
+ embed_dims: [120, 120, 120, 120, 120, 120, 120, 180, 180, 180, 180, 180, 180]
+ num_heads: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
+ spynet_path: model_zoo/vrt/spynet_sintel_final-3d2a1287.pth
+ pa_frames: 2
+ deformable_groups: 12
+ nonblind_denoising: False
+ use_checkpoint_attn: False
+ use_checkpoint_ffn: False
+ no_checkpoint_attn_blocks: []
+ no_checkpoint_ffn_blocks: []
+ init_type: default
+ scale: 4
+ ]
+ train:[
+ G_lossfn_type: charbonnier
+ G_lossfn_weight: 1.0
+ G_charbonnier_eps: 1e-09
+ E_decay: 0
+ G_optimizer_type: adam
+ G_optimizer_lr: 0.0004
+ G_optimizer_betas: [0.9, 0.99]
+ G_optimizer_wd: 0
+ G_optimizer_clipgrad: None
+ G_optimizer_reuse: True
+ fix_iter: 20000
+ fix_lr_mul: 0.125
+ fix_keys: ['spynet', 'deform']
+ total_iter: 300000
+ G_scheduler_type: CosineAnnealingWarmRestarts
+ G_scheduler_periods: 300000
+ G_scheduler_eta_min: 1e-07
+ G_regularizer_orthstep: None
+ G_regularizer_clipstep: None
+ G_param_strict: True
+ E_param_strict: True
+ checkpoint_test: 5000
+ checkpoint_save: 5000
+ checkpoint_print: 200
+ F_feature_layer: 34
+ F_weights: 1.0
+ F_lossfn_type: l1
+ F_use_input_norm: True
+ F_use_range_norm: False
+ G_scheduler_restart_weights: 1
+ ]
+ val:[
+ save_img: False
+ pad_seq: False
+ flip_seq: False
+ center_frame_only: False
+ num_frame_testing: 40
+ num_frame_overlapping: 2
+ size_patch_testing: 128
+ ]
+ opt_path: options/vrt/001_train_vrt_videosr_bi_reds_6frames.json
+ is_train: True
+ merge_bn: False
+ merge_bn_startpoint: -1
+ num_gpu: 8
+ rank: 0
+ world_size: 1
+
+22-03-11 10:46:12.583 : Number of train images: 27,000, iters: 3,375
+22-03-11 10:46:26.822 :
+Networks name: VRT
+Params number: 30676435
+Net structure:
+VRT(
+ (conv_first): Conv3d(27, 120, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ (spynet): SpyNet(
+ (basic_module): ModuleList(
+ (0): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (1): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (2): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (3): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (4): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (5): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ )
+ )
+ (stage1): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n c d h w -> n d h w c')
+ (1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (2): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): Identity()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): Identity()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage2): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n c d (h neih) (w neiw) -> n d h w (neiw neih c)', neih=2, neiw=2)
+ (1): LayerNorm((480,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=480, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage3): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n c d (h neih) (w neiw) -> n d h w (neiw neih c)', neih=2, neiw=2)
+ (1): LayerNorm((480,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=480, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage4): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n c d (h neih) (w neiw) -> n d h w (neiw neih c)', neih=2, neiw=2)
+ (1): LayerNorm((480,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=480, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage5): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n (neiw neih c) d h w -> n d (h neih) (w neiw) c', neih=2, neiw=2)
+ (1): LayerNorm((30,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=30, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage6): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n (neiw neih c) d h w -> n d (h neih) (w neiw) c', neih=2, neiw=2)
+ (1): LayerNorm((30,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=30, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage7): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n (neiw neih c) d h w -> n d (h neih) (w neiw) c', neih=2, neiw=2)
+ (1): LayerNorm((30,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=30, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage8): ModuleList(
+ (0): Sequential(
+ (0): Rearrange('n c d h w -> n d h w c')
+ (1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=120, out_features=180, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (1): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (2): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (3): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (4): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (5): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (6): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ )
+ (norm): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (conv_after_body): Linear(in_features=180, out_features=120, bias=True)
+ (conv_before_upsample): Sequential(
+ (0): Conv3d(120, 64, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ (1): LeakyReLU(negative_slope=0.01, inplace=True)
+ )
+ (upsample): Upsample(
+ (0): Conv3d(64, 256, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ (1): Transpose_Dim12()
+ (2): PixelShuffle(upscale_factor=2)
+ (3): Transpose_Dim12()
+ (4): LeakyReLU(negative_slope=0.1, inplace=True)
+ (5): Conv3d(64, 256, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ (6): Transpose_Dim12()
+ (7): PixelShuffle(upscale_factor=2)
+ (8): Transpose_Dim12()
+ (9): LeakyReLU(negative_slope=0.1, inplace=True)
+ (10): Conv3d(64, 64, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ )
+ (conv_last): Conv3d(64, 3, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+)
+
+22-03-11 10:46:27.000 :
+ | mean | min | max | std || shape
+ | -0.000 | -1.462 | 1.580 | 0.103 | torch.Size([120, 27, 1, 3, 3]) || conv_first.weight
+ | 0.005 | -0.950 | 0.885 | 0.268 | torch.Size([120]) || conv_first.bias
+ | 0.449 | 0.406 | 0.485 | 0.040 | torch.Size([1, 3, 1, 1]) || spynet.mean
+ | 0.226 | 0.224 | 0.229 | 0.003 | torch.Size([1, 3, 1, 1]) || spynet.std
+ | -0.000 | -0.679 | 0.720 | 0.066 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.0.basic_module.0.weight
+ | -0.042 | -0.894 | 0.351 | 0.344 | torch.Size([32]) || spynet.basic_module.0.basic_module.0.bias
+ | -0.008 | -3.201 | 0.948 | 0.097 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.0.basic_module.2.weight
+ | 0.059 | -1.268 | 0.732 | 0.320 | torch.Size([64]) || spynet.basic_module.0.basic_module.2.bias
+ | -0.010 | -4.633 | 0.568 | 0.089 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.0.basic_module.4.weight
+ | 0.159 | -0.704 | 0.859 | 0.353 | torch.Size([32]) || spynet.basic_module.0.basic_module.4.bias
+ | -0.024 | -1.714 | 0.414 | 0.091 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.0.basic_module.6.weight
+ | 0.780 | -1.061 | 1.162 | 0.519 | torch.Size([16]) || spynet.basic_module.0.basic_module.6.bias
+ | 0.000 | -0.144 | 0.163 | 0.018 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.0.basic_module.8.weight
+ | 0.001 | -0.003 | 0.005 | 0.006 | torch.Size([2]) || spynet.basic_module.0.basic_module.8.bias
+ | 0.000 | -0.726 | 0.773 | 0.070 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.1.basic_module.0.weight
+ | -0.021 | -0.814 | 0.355 | 0.323 | torch.Size([32]) || spynet.basic_module.1.basic_module.0.bias
+ | -0.010 | -3.380 | 0.916 | 0.099 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.1.basic_module.2.weight
+ | 0.038 | -1.207 | 0.714 | 0.301 | torch.Size([64]) || spynet.basic_module.1.basic_module.2.bias
+ | -0.008 | -4.462 | 0.549 | 0.088 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.1.basic_module.4.weight
+ | 0.157 | -0.742 | 0.980 | 0.384 | torch.Size([32]) || spynet.basic_module.1.basic_module.4.bias
+ | -0.020 | -1.648 | 0.319 | 0.084 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.1.basic_module.6.weight
+ | 0.775 | -1.195 | 1.148 | 0.546 | torch.Size([16]) || spynet.basic_module.1.basic_module.6.bias
+ | -0.000 | -0.122 | 0.152 | 0.016 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.1.basic_module.8.weight
+ | -0.000 | -0.002 | 0.001 | 0.002 | torch.Size([2]) || spynet.basic_module.1.basic_module.8.bias
+ | 0.000 | -0.956 | 0.870 | 0.088 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.2.basic_module.0.weight
+ | -0.025 | -1.040 | 0.512 | 0.411 | torch.Size([32]) || spynet.basic_module.2.basic_module.0.bias
+ | -0.011 | -4.624 | 1.195 | 0.116 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.2.basic_module.2.weight
+ | 0.023 | -1.284 | 0.699 | 0.308 | torch.Size([64]) || spynet.basic_module.2.basic_module.2.bias
+ | -0.009 | -1.831 | 0.616 | 0.092 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.2.basic_module.4.weight
+ | 0.120 | -0.695 | 0.755 | 0.332 | torch.Size([32]) || spynet.basic_module.2.basic_module.4.bias
+ | -0.013 | -1.285 | 0.304 | 0.068 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.2.basic_module.6.weight
+ | 0.681 | -1.725 | 0.942 | 0.646 | torch.Size([16]) || spynet.basic_module.2.basic_module.6.bias
+ | 0.000 | -0.045 | 0.071 | 0.009 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.2.basic_module.8.weight
+ | -0.010 | -0.010 | -0.009 | 0.000 | torch.Size([2]) || spynet.basic_module.2.basic_module.8.bias
+ | -0.000 | -0.995 | 0.879 | 0.090 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.3.basic_module.0.weight
+ | -0.040 | -1.137 | 0.617 | 0.461 | torch.Size([32]) || spynet.basic_module.3.basic_module.0.bias
+ | -0.010 | -4.891 | 1.224 | 0.117 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.3.basic_module.2.weight
+ | 0.022 | -1.287 | 0.745 | 0.313 | torch.Size([64]) || spynet.basic_module.3.basic_module.2.bias
+ | -0.010 | -1.802 | 0.561 | 0.090 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.3.basic_module.4.weight
+ | 0.118 | -0.694 | 0.697 | 0.329 | torch.Size([32]) || spynet.basic_module.3.basic_module.4.bias
+ | -0.012 | -1.107 | 0.306 | 0.064 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.3.basic_module.6.weight
+ | 0.658 | -1.792 | 0.905 | 0.659 | torch.Size([16]) || spynet.basic_module.3.basic_module.6.bias
+ | 0.000 | -0.030 | 0.037 | 0.006 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.3.basic_module.8.weight
+ | 0.003 | -0.001 | 0.007 | 0.006 | torch.Size([2]) || spynet.basic_module.3.basic_module.8.bias
+ | -0.000 | -0.990 | 0.880 | 0.090 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.4.basic_module.0.weight
+ | -0.010 | -1.067 | 0.596 | 0.437 | torch.Size([32]) || spynet.basic_module.4.basic_module.0.bias
+ | -0.010 | -5.061 | 1.229 | 0.117 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.4.basic_module.2.weight
+ | 0.024 | -1.274 | 0.830 | 0.318 | torch.Size([64]) || spynet.basic_module.4.basic_module.2.bias
+ | -0.009 | -1.787 | 0.563 | 0.088 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.4.basic_module.4.weight
+ | 0.130 | -0.685 | 0.743 | 0.335 | torch.Size([32]) || spynet.basic_module.4.basic_module.4.bias
+ | -0.011 | -0.973 | 0.292 | 0.061 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.4.basic_module.6.weight
+ | 0.659 | -1.855 | 0.931 | 0.679 | torch.Size([16]) || spynet.basic_module.4.basic_module.6.bias
+ | 0.000 | -0.034 | 0.040 | 0.005 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.4.basic_module.8.weight
+ | -0.001 | -0.009 | 0.007 | 0.012 | torch.Size([2]) || spynet.basic_module.4.basic_module.8.bias
+ | -0.000 | -0.973 | 0.853 | 0.089 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.5.basic_module.0.weight
+ | 0.022 | -1.001 | 0.571 | 0.440 | torch.Size([32]) || spynet.basic_module.5.basic_module.0.bias
+ | -0.009 | -5.095 | 1.251 | 0.119 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.5.basic_module.2.weight
+ | 0.026 | -1.305 | 0.880 | 0.326 | torch.Size([64]) || spynet.basic_module.5.basic_module.2.bias
+ | -0.008 | -1.815 | 0.561 | 0.091 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.5.basic_module.4.weight
+ | 0.137 | -0.711 | 0.771 | 0.342 | torch.Size([32]) || spynet.basic_module.5.basic_module.4.bias
+ | -0.010 | -0.986 | 0.286 | 0.059 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.5.basic_module.6.weight
+ | 0.671 | -1.913 | 0.966 | 0.700 | torch.Size([16]) || spynet.basic_module.5.basic_module.6.bias
+ | 0.000 | -0.034 | 0.028 | 0.002 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.5.basic_module.8.weight
+ | 0.002 | -0.013 | 0.016 | 0.020 | torch.Size([2]) || spynet.basic_module.5.basic_module.8.bias
+ | 1.280 | 0.669 | 1.862 | 0.274 | torch.Size([120]) || stage1.reshape.1.weight
+ | -0.006 | -0.324 | 0.337 | 0.106 | torch.Size([120]) || stage1.reshape.1.bias
+ | 0.579 | 0.129 | 1.064 | 0.236 | torch.Size([120]) || stage1.residual_group1.blocks.0.norm1.weight
+ | -0.039 | -1.100 | 0.894 | 0.226 | torch.Size([120]) || stage1.residual_group1.blocks.0.norm1.bias
+ | -0.134 | -4.020 | 2.585 | 0.295 | torch.Size([675, 6]) || stage1.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.0.attn.position_bias
+ | -0.000 | -0.579 | 0.618 | 0.113 | torch.Size([360, 120]) || stage1.residual_group1.blocks.0.attn.qkv_self.weight
+ | 0.000 | -0.319 | 0.279 | 0.074 | torch.Size([360]) || stage1.residual_group1.blocks.0.attn.qkv_self.bias
+ | 0.001 | -0.634 | 0.686 | 0.076 | torch.Size([120, 240]) || stage1.residual_group1.blocks.0.attn.proj.weight
+ | -0.014 | -0.222 | 0.642 | 0.088 | torch.Size([120]) || stage1.residual_group1.blocks.0.attn.proj.bias
+ | -0.000 | -1.066 | 0.928 | 0.097 | torch.Size([360, 120]) || stage1.residual_group1.blocks.0.attn.qkv_mut.weight
+ | 0.000 | -0.146 | 0.190 | 0.033 | torch.Size([360]) || stage1.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.781 | 0.367 | 1.203 | 0.160 | torch.Size([120]) || stage1.residual_group1.blocks.0.norm2.weight
+ | 0.029 | -0.378 | 0.545 | 0.159 | torch.Size([120]) || stage1.residual_group1.blocks.0.norm2.bias
+ | 0.001 | -0.687 | 0.753 | 0.108 | torch.Size([240, 120]) || stage1.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.010 | -0.229 | 0.633 | 0.095 | torch.Size([240]) || stage1.residual_group1.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.674 | 0.669 | 0.117 | torch.Size([240, 120]) || stage1.residual_group1.blocks.0.mlp.fc12.weight
+ | 0.011 | -0.448 | 0.368 | 0.116 | torch.Size([240]) || stage1.residual_group1.blocks.0.mlp.fc12.bias
+ | 0.001 | -0.862 | 0.941 | 0.119 | torch.Size([120, 240]) || stage1.residual_group1.blocks.0.mlp.fc2.weight
+ | -0.004 | -0.267 | 0.594 | 0.099 | torch.Size([120]) || stage1.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.797 | 0.211 | 1.475 | 0.209 | torch.Size([120]) || stage1.residual_group1.blocks.1.norm1.weight
+ | -0.161 | -1.941 | 0.746 | 0.237 | torch.Size([120]) || stage1.residual_group1.blocks.1.norm1.bias
+ | -0.296 | -3.927 | 2.840 | 0.478 | torch.Size([675, 6]) || stage1.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.1.attn.position_bias
+ | 0.001 | -1.479 | 1.395 | 0.143 | torch.Size([360, 120]) || stage1.residual_group1.blocks.1.attn.qkv_self.weight
+ | -0.003 | -0.381 | 0.258 | 0.063 | torch.Size([360]) || stage1.residual_group1.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.526 | 0.561 | 0.079 | torch.Size([120, 240]) || stage1.residual_group1.blocks.1.attn.proj.weight
+ | -0.003 | -0.178 | 0.478 | 0.078 | torch.Size([120]) || stage1.residual_group1.blocks.1.attn.proj.bias
+ | 0.001 | -1.242 | 1.138 | 0.105 | torch.Size([360, 120]) || stage1.residual_group1.blocks.1.attn.qkv_mut.weight
+ | 0.004 | -0.213 | 0.196 | 0.050 | torch.Size([360]) || stage1.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.702 | 0.349 | 0.904 | 0.085 | torch.Size([120]) || stage1.residual_group1.blocks.1.norm2.weight
+ | 0.039 | -0.646 | 0.384 | 0.132 | torch.Size([120]) || stage1.residual_group1.blocks.1.norm2.bias
+ | 0.001 | -0.872 | 0.750 | 0.131 | torch.Size([240, 120]) || stage1.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.049 | -0.353 | 0.135 | 0.084 | torch.Size([240]) || stage1.residual_group1.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.562 | 0.580 | 0.117 | torch.Size([240, 120]) || stage1.residual_group1.blocks.1.mlp.fc12.weight
+ | 0.000 | -0.238 | 0.457 | 0.113 | torch.Size([240]) || stage1.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.828 | 0.685 | 0.123 | torch.Size([120, 240]) || stage1.residual_group1.blocks.1.mlp.fc2.weight
+ | 0.031 | -0.297 | 0.419 | 0.094 | torch.Size([120]) || stage1.residual_group1.blocks.1.mlp.fc2.bias
+ | 0.984 | 0.163 | 1.398 | 0.202 | torch.Size([120]) || stage1.residual_group1.blocks.2.norm1.weight
+ | -0.167 | -1.609 | 0.367 | 0.182 | torch.Size([120]) || stage1.residual_group1.blocks.2.norm1.bias
+ | -0.343 | -4.484 | 2.362 | 0.486 | torch.Size([675, 6]) || stage1.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.2.attn.position_bias
+ | 0.000 | -1.586 | 1.649 | 0.151 | torch.Size([360, 120]) || stage1.residual_group1.blocks.2.attn.qkv_self.weight
+ | -0.000 | -0.220 | 0.240 | 0.056 | torch.Size([360]) || stage1.residual_group1.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.378 | 0.514 | 0.086 | torch.Size([120, 240]) || stage1.residual_group1.blocks.2.attn.proj.weight
+ | -0.009 | -0.143 | 0.172 | 0.059 | torch.Size([120]) || stage1.residual_group1.blocks.2.attn.proj.bias
+ | 0.001 | -0.639 | 0.582 | 0.102 | torch.Size([360, 120]) || stage1.residual_group1.blocks.2.attn.qkv_mut.weight
+ | -0.000 | -0.141 | 0.173 | 0.035 | torch.Size([360]) || stage1.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.733 | 0.277 | 0.903 | 0.081 | torch.Size([120]) || stage1.residual_group1.blocks.2.norm2.weight
+ | 0.038 | -0.861 | 0.359 | 0.142 | torch.Size([120]) || stage1.residual_group1.blocks.2.norm2.bias
+ | 0.000 | -0.787 | 0.679 | 0.131 | torch.Size([240, 120]) || stage1.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.029 | -0.365 | 0.143 | 0.076 | torch.Size([240]) || stage1.residual_group1.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.574 | 0.539 | 0.120 | torch.Size([240, 120]) || stage1.residual_group1.blocks.2.mlp.fc12.weight
+ | -0.007 | -0.283 | 0.254 | 0.097 | torch.Size([240]) || stage1.residual_group1.blocks.2.mlp.fc12.bias
+ | 0.001 | -0.998 | 0.522 | 0.124 | torch.Size([120, 240]) || stage1.residual_group1.blocks.2.mlp.fc2.weight
+ | 0.030 | -0.169 | 0.293 | 0.095 | torch.Size([120]) || stage1.residual_group1.blocks.2.mlp.fc2.bias
+ | 1.035 | 0.143 | 1.397 | 0.196 | torch.Size([120]) || stage1.residual_group1.blocks.3.norm1.weight
+ | -0.161 | -1.413 | 0.084 | 0.154 | torch.Size([120]) || stage1.residual_group1.blocks.3.norm1.bias
+ | -0.441 | -4.685 | 3.306 | 0.529 | torch.Size([675, 6]) || stage1.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.3.attn.position_bias
+ | 0.000 | -1.590 | 1.329 | 0.155 | torch.Size([360, 120]) || stage1.residual_group1.blocks.3.attn.qkv_self.weight
+ | -0.002 | -0.266 | 0.232 | 0.049 | torch.Size([360]) || stage1.residual_group1.blocks.3.attn.qkv_self.bias
+ | -0.000 | -0.366 | 0.372 | 0.084 | torch.Size([120, 240]) || stage1.residual_group1.blocks.3.attn.proj.weight
+ | -0.011 | -0.225 | 0.171 | 0.071 | torch.Size([120]) || stage1.residual_group1.blocks.3.attn.proj.bias
+ | -0.000 | -0.660 | 0.801 | 0.100 | torch.Size([360, 120]) || stage1.residual_group1.blocks.3.attn.qkv_mut.weight
+ | -0.001 | -0.139 | 0.200 | 0.031 | torch.Size([360]) || stage1.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.724 | 0.190 | 0.911 | 0.091 | torch.Size([120]) || stage1.residual_group1.blocks.3.norm2.weight
+ | 0.038 | -0.981 | 0.285 | 0.137 | torch.Size([120]) || stage1.residual_group1.blocks.3.norm2.bias
+ | 0.001 | -0.611 | 0.598 | 0.130 | torch.Size([240, 120]) || stage1.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.035 | -0.299 | 0.221 | 0.081 | torch.Size([240]) || stage1.residual_group1.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.502 | 0.520 | 0.124 | torch.Size([240, 120]) || stage1.residual_group1.blocks.3.mlp.fc12.weight
+ | -0.002 | -0.271 | 0.215 | 0.090 | torch.Size([240]) || stage1.residual_group1.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.558 | 0.898 | 0.127 | torch.Size([120, 240]) || stage1.residual_group1.blocks.3.mlp.fc2.weight
+ | 0.010 | -0.424 | 0.190 | 0.082 | torch.Size([120]) || stage1.residual_group1.blocks.3.mlp.fc2.bias
+ | 1.085 | 0.169 | 1.400 | 0.157 | torch.Size([120]) || stage1.residual_group1.blocks.4.norm1.weight
+ | -0.086 | -1.613 | 0.150 | 0.160 | torch.Size([120]) || stage1.residual_group1.blocks.4.norm1.bias
+ | -0.541 | -3.902 | 3.728 | 0.633 | torch.Size([675, 6]) || stage1.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.4.attn.position_bias
+ | 0.001 | -1.879 | 1.832 | 0.150 | torch.Size([360, 120]) || stage1.residual_group1.blocks.4.attn.qkv_self.weight
+ | 0.001 | -0.391 | 0.444 | 0.079 | torch.Size([360]) || stage1.residual_group1.blocks.4.attn.qkv_self.bias
+ | -0.000 | -0.407 | 0.448 | 0.087 | torch.Size([120, 240]) || stage1.residual_group1.blocks.4.attn.proj.weight
+ | -0.013 | -0.302 | 0.342 | 0.104 | torch.Size([120]) || stage1.residual_group1.blocks.4.attn.proj.bias
+ | -0.001 | -0.830 | 0.863 | 0.102 | torch.Size([360, 120]) || stage1.residual_group1.blocks.4.attn.qkv_mut.weight
+ | -0.001 | -0.117 | 0.094 | 0.024 | torch.Size([360]) || stage1.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.704 | 0.195 | 0.870 | 0.079 | torch.Size([120]) || stage1.residual_group1.blocks.4.norm2.weight
+ | 0.031 | -1.069 | 0.276 | 0.140 | torch.Size([120]) || stage1.residual_group1.blocks.4.norm2.bias
+ | -0.000 | -0.656 | 0.555 | 0.130 | torch.Size([240, 120]) || stage1.residual_group1.blocks.4.mlp.fc11.weight
+ | -0.029 | -0.387 | 0.256 | 0.102 | torch.Size([240]) || stage1.residual_group1.blocks.4.mlp.fc11.bias
+ | 0.001 | -0.590 | 0.624 | 0.127 | torch.Size([240, 120]) || stage1.residual_group1.blocks.4.mlp.fc12.weight
+ | -0.011 | -0.277 | 0.303 | 0.087 | torch.Size([240]) || stage1.residual_group1.blocks.4.mlp.fc12.bias
+ | -0.000 | -1.124 | 0.539 | 0.130 | torch.Size([120, 240]) || stage1.residual_group1.blocks.4.mlp.fc2.weight
+ | -0.006 | -0.718 | 0.133 | 0.094 | torch.Size([120]) || stage1.residual_group1.blocks.4.mlp.fc2.bias
+ | 1.037 | 0.176 | 1.327 | 0.158 | torch.Size([120]) || stage1.residual_group1.blocks.5.norm1.weight
+ | -0.112 | -1.591 | 0.177 | 0.169 | torch.Size([120]) || stage1.residual_group1.blocks.5.norm1.bias
+ | -0.438 | -2.229 | 2.797 | 0.523 | torch.Size([675, 6]) || stage1.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.5.attn.position_bias
+ | -0.000 | -2.212 | 1.826 | 0.153 | torch.Size([360, 120]) || stage1.residual_group1.blocks.5.attn.qkv_self.weight
+ | 0.001 | -0.343 | 0.338 | 0.068 | torch.Size([360]) || stage1.residual_group1.blocks.5.attn.qkv_self.bias
+ | 0.000 | -0.367 | 0.451 | 0.087 | torch.Size([120, 240]) || stage1.residual_group1.blocks.5.attn.proj.weight
+ | -0.022 | -0.358 | 0.242 | 0.128 | torch.Size([120]) || stage1.residual_group1.blocks.5.attn.proj.bias
+ | 0.001 | -0.922 | 0.886 | 0.104 | torch.Size([360, 120]) || stage1.residual_group1.blocks.5.attn.qkv_mut.weight
+ | 0.002 | -0.083 | 0.089 | 0.022 | torch.Size([360]) || stage1.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.662 | 0.277 | 0.831 | 0.066 | torch.Size([120]) || stage1.residual_group1.blocks.5.norm2.weight
+ | 0.025 | -0.959 | 0.261 | 0.132 | torch.Size([120]) || stage1.residual_group1.blocks.5.norm2.bias
+ | -0.001 | -0.636 | 0.739 | 0.129 | torch.Size([240, 120]) || stage1.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.030 | -0.419 | 0.517 | 0.115 | torch.Size([240]) || stage1.residual_group1.blocks.5.mlp.fc11.bias
+ | -0.000 | -0.615 | 0.709 | 0.126 | torch.Size([240, 120]) || stage1.residual_group1.blocks.5.mlp.fc12.weight
+ | 0.002 | -0.230 | 0.457 | 0.087 | torch.Size([240]) || stage1.residual_group1.blocks.5.mlp.fc12.bias
+ | 0.001 | -1.724 | 1.186 | 0.132 | torch.Size([120, 240]) || stage1.residual_group1.blocks.5.mlp.fc2.weight
+ | -0.019 | -1.909 | 0.255 | 0.190 | torch.Size([120]) || stage1.residual_group1.blocks.5.mlp.fc2.bias
+ | -0.000 | -0.242 | 0.244 | 0.057 | torch.Size([120, 120]) || stage1.linear1.weight
+ | 0.004 | -0.221 | 0.224 | 0.083 | torch.Size([120]) || stage1.linear1.bias
+ | 0.737 | 0.334 | 1.046 | 0.119 | torch.Size([120]) || stage1.residual_group2.blocks.0.norm1.weight
+ | 0.013 | -0.911 | 0.763 | 0.193 | torch.Size([120]) || stage1.residual_group2.blocks.0.norm1.bias
+ | -0.052 | -2.462 | 2.040 | 0.273 | torch.Size([2475, 6]) || stage1.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage1.residual_group2.blocks.0.attn.relative_position_index
+ | 0.000 | -0.785 | 0.767 | 0.123 | torch.Size([360, 120]) || stage1.residual_group2.blocks.0.attn.qkv_self.weight
+ | 0.009 | -0.466 | 0.552 | 0.122 | torch.Size([360]) || stage1.residual_group2.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.431 | 0.475 | 0.091 | torch.Size([120, 120]) || stage1.residual_group2.blocks.0.attn.proj.weight
+ | -0.009 | -0.796 | 0.497 | 0.109 | torch.Size([120]) || stage1.residual_group2.blocks.0.attn.proj.bias
+ | 0.573 | 0.409 | 0.935 | 0.096 | torch.Size([120]) || stage1.residual_group2.blocks.0.norm2.weight
+ | 0.015 | -0.828 | 0.839 | 0.175 | torch.Size([120]) || stage1.residual_group2.blocks.0.norm2.bias
+ | 0.001 | -0.604 | 0.542 | 0.109 | torch.Size([240, 120]) || stage1.residual_group2.blocks.0.mlp.fc11.weight
+ | 0.037 | -0.179 | 0.273 | 0.076 | torch.Size([240]) || stage1.residual_group2.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.666 | 0.553 | 0.116 | torch.Size([240, 120]) || stage1.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.001 | -0.416 | 0.396 | 0.116 | torch.Size([240]) || stage1.residual_group2.blocks.0.mlp.fc12.bias
+ | 0.001 | -0.654 | 0.538 | 0.118 | torch.Size([120, 240]) || stage1.residual_group2.blocks.0.mlp.fc2.weight
+ | -0.002 | -0.470 | 0.310 | 0.122 | torch.Size([120]) || stage1.residual_group2.blocks.0.mlp.fc2.bias
+ | 0.951 | 0.342 | 1.189 | 0.111 | torch.Size([120]) || stage1.residual_group2.blocks.1.norm1.weight
+ | 0.010 | -0.697 | 0.802 | 0.166 | torch.Size([120]) || stage1.residual_group2.blocks.1.norm1.bias
+ | -0.098 | -2.648 | 2.410 | 0.214 | torch.Size([2475, 6]) || stage1.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage1.residual_group2.blocks.1.attn.relative_position_index
+ | -0.000 | -0.733 | 0.886 | 0.139 | torch.Size([360, 120]) || stage1.residual_group2.blocks.1.attn.qkv_self.weight
+ | -0.002 | -0.468 | 0.550 | 0.132 | torch.Size([360]) || stage1.residual_group2.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.435 | 0.377 | 0.096 | torch.Size([120, 120]) || stage1.residual_group2.blocks.1.attn.proj.weight
+ | -0.001 | -0.359 | 0.258 | 0.114 | torch.Size([120]) || stage1.residual_group2.blocks.1.attn.proj.bias
+ | 0.582 | 0.305 | 0.717 | 0.055 | torch.Size([120]) || stage1.residual_group2.blocks.1.norm2.weight
+ | 0.008 | -0.714 | 0.833 | 0.131 | torch.Size([120]) || stage1.residual_group2.blocks.1.norm2.bias
+ | 0.001 | -0.732 | 0.501 | 0.118 | torch.Size([240, 120]) || stage1.residual_group2.blocks.1.mlp.fc11.weight
+ | 0.004 | -0.306 | 0.267 | 0.091 | torch.Size([240]) || stage1.residual_group2.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.510 | 0.533 | 0.126 | torch.Size([240, 120]) || stage1.residual_group2.blocks.1.mlp.fc12.weight
+ | -0.000 | -0.315 | 0.291 | 0.090 | torch.Size([240]) || stage1.residual_group2.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.736 | 0.789 | 0.126 | torch.Size([120, 240]) || stage1.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.000 | -1.274 | 1.328 | 0.200 | torch.Size([120]) || stage1.residual_group2.blocks.1.mlp.fc2.bias
+ | -0.000 | -0.390 | 0.303 | 0.069 | torch.Size([120, 120]) || stage1.linear2.weight
+ | 0.010 | -0.219 | 0.227 | 0.087 | torch.Size([120]) || stage1.linear2.bias
+ | -0.000 | -0.095 | 0.106 | 0.024 | torch.Size([120, 120, 3, 3]) || stage1.pa_deform.weight
+ | -0.001 | -0.036 | 0.036 | 0.013 | torch.Size([120]) || stage1.pa_deform.bias
+ | -0.000 | -0.136 | 0.141 | 0.017 | torch.Size([120, 242, 3, 3]) || stage1.pa_deform.conv_offset.0.weight
+ | -0.002 | -0.028 | 0.024 | 0.013 | torch.Size([120]) || stage1.pa_deform.conv_offset.0.bias
+ | -0.001 | -0.156 | 0.104 | 0.019 | torch.Size([120, 120, 3, 3]) || stage1.pa_deform.conv_offset.2.weight
+ | -0.008 | -0.055 | 0.045 | 0.022 | torch.Size([120]) || stage1.pa_deform.conv_offset.2.bias
+ | -0.001 | -0.098 | 0.106 | 0.018 | torch.Size([120, 120, 3, 3]) || stage1.pa_deform.conv_offset.4.weight
+ | -0.000 | -0.081 | 0.070 | 0.029 | torch.Size([120]) || stage1.pa_deform.conv_offset.4.bias
+ | -0.000 | -0.375 | 0.279 | 0.027 | torch.Size([324, 120, 3, 3]) || stage1.pa_deform.conv_offset.6.weight
+ | -0.003 | -0.074 | 0.070 | 0.028 | torch.Size([324]) || stage1.pa_deform.conv_offset.6.bias
+ | -0.000 | -0.776 | 0.733 | 0.114 | torch.Size([360, 360]) || stage1.pa_fuse.fc11.weight
+ | 0.021 | -0.239 | 0.513 | 0.121 | torch.Size([360]) || stage1.pa_fuse.fc11.bias
+ | 0.001 | -1.100 | 1.143 | 0.149 | torch.Size([360, 360]) || stage1.pa_fuse.fc12.weight
+ | 0.008 | -0.405 | 0.393 | 0.136 | torch.Size([360]) || stage1.pa_fuse.fc12.bias
+ | 0.000 | -0.963 | 0.899 | 0.142 | torch.Size([120, 360]) || stage1.pa_fuse.fc2.weight
+ | -0.055 | -0.616 | 0.599 | 0.197 | torch.Size([120]) || stage1.pa_fuse.fc2.bias
+ | 1.149 | 0.345 | 1.921 | 0.289 | torch.Size([480]) || stage2.reshape.1.weight
+ | 0.017 | -0.502 | 0.663 | 0.141 | torch.Size([480]) || stage2.reshape.1.bias
+ | -0.000 | -0.609 | 0.736 | 0.146 | torch.Size([120, 480]) || stage2.reshape.2.weight
+ | 0.006 | -0.136 | 0.404 | 0.077 | torch.Size([120]) || stage2.reshape.2.bias
+ | 0.686 | 0.172 | 1.113 | 0.175 | torch.Size([120]) || stage2.residual_group1.blocks.0.norm1.weight
+ | -0.154 | -0.926 | 0.339 | 0.217 | torch.Size([120]) || stage2.residual_group1.blocks.0.norm1.bias
+ | -0.120 | -1.869 | 4.616 | 0.310 | torch.Size([675, 6]) || stage2.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.0.attn.position_bias
+ | 0.000 | -0.514 | 0.499 | 0.102 | torch.Size([360, 120]) || stage2.residual_group1.blocks.0.attn.qkv_self.weight
+ | -0.002 | -0.214 | 0.177 | 0.044 | torch.Size([360]) || stage2.residual_group1.blocks.0.attn.qkv_self.bias
+ | -0.001 | -0.499 | 0.529 | 0.093 | torch.Size([120, 240]) || stage2.residual_group1.blocks.0.attn.proj.weight
+ | -0.004 | -0.171 | 0.556 | 0.087 | torch.Size([120]) || stage2.residual_group1.blocks.0.attn.proj.bias
+ | -0.000 | -0.642 | 0.598 | 0.083 | torch.Size([360, 120]) || stage2.residual_group1.blocks.0.attn.qkv_mut.weight
+ | -0.000 | -0.141 | 0.125 | 0.027 | torch.Size([360]) || stage2.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.592 | 0.325 | 0.794 | 0.096 | torch.Size([120]) || stage2.residual_group1.blocks.0.norm2.weight
+ | 0.008 | -0.649 | 0.445 | 0.168 | torch.Size([120]) || stage2.residual_group1.blocks.0.norm2.bias
+ | 0.000 | -0.485 | 0.457 | 0.116 | torch.Size([240, 120]) || stage2.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.053 | -0.240 | 0.171 | 0.062 | torch.Size([240]) || stage2.residual_group1.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.503 | 0.462 | 0.118 | torch.Size([240, 120]) || stage2.residual_group1.blocks.0.mlp.fc12.weight
+ | 0.005 | -0.177 | 0.268 | 0.068 | torch.Size([240]) || stage2.residual_group1.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.690 | 0.498 | 0.123 | torch.Size([120, 240]) || stage2.residual_group1.blocks.0.mlp.fc2.weight
+ | -0.007 | -0.270 | 0.472 | 0.097 | torch.Size([120]) || stage2.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.864 | 0.187 | 1.221 | 0.164 | torch.Size([120]) || stage2.residual_group1.blocks.1.norm1.weight
+ | -0.146 | -1.128 | 0.299 | 0.204 | torch.Size([120]) || stage2.residual_group1.blocks.1.norm1.bias
+ | -0.241 | -1.607 | 8.958 | 0.356 | torch.Size([675, 6]) || stage2.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.1.attn.position_bias
+ | 0.000 | -0.561 | 0.538 | 0.116 | torch.Size([360, 120]) || stage2.residual_group1.blocks.1.attn.qkv_self.weight
+ | 0.001 | -0.198 | 0.222 | 0.052 | torch.Size([360]) || stage2.residual_group1.blocks.1.attn.qkv_self.bias
+ | 0.001 | -0.475 | 0.479 | 0.099 | torch.Size([120, 240]) || stage2.residual_group1.blocks.1.attn.proj.weight
+ | -0.006 | -0.295 | 0.341 | 0.101 | torch.Size([120]) || stage2.residual_group1.blocks.1.attn.proj.bias
+ | 0.001 | -0.961 | 0.789 | 0.080 | torch.Size([360, 120]) || stage2.residual_group1.blocks.1.attn.qkv_mut.weight
+ | 0.001 | -0.105 | 0.143 | 0.024 | torch.Size([360]) || stage2.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.653 | 0.401 | 0.810 | 0.063 | torch.Size([120]) || stage2.residual_group1.blocks.1.norm2.weight
+ | 0.009 | -0.767 | 0.367 | 0.154 | torch.Size([120]) || stage2.residual_group1.blocks.1.norm2.bias
+ | 0.001 | -0.486 | 0.499 | 0.117 | torch.Size([240, 120]) || stage2.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.056 | -0.185 | 0.147 | 0.058 | torch.Size([240]) || stage2.residual_group1.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.529 | 0.548 | 0.121 | torch.Size([240, 120]) || stage2.residual_group1.blocks.1.mlp.fc12.weight
+ | 0.002 | -0.231 | 0.177 | 0.071 | torch.Size([240]) || stage2.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.001 | -0.578 | 0.609 | 0.123 | torch.Size([120, 240]) || stage2.residual_group1.blocks.1.mlp.fc2.weight
+ | -0.003 | -0.350 | 0.216 | 0.098 | torch.Size([120]) || stage2.residual_group1.blocks.1.mlp.fc2.bias
+ | 0.848 | 0.172 | 1.107 | 0.144 | torch.Size([120]) || stage2.residual_group1.blocks.2.norm1.weight
+ | -0.168 | -1.123 | 0.330 | 0.178 | torch.Size([120]) || stage2.residual_group1.blocks.2.norm1.bias
+ | -0.074 | -1.239 | 4.293 | 0.247 | torch.Size([675, 6]) || stage2.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.2.attn.position_bias
+ | -0.001 | -0.643 | 0.531 | 0.117 | torch.Size([360, 120]) || stage2.residual_group1.blocks.2.attn.qkv_self.weight
+ | 0.003 | -0.220 | 0.376 | 0.047 | torch.Size([360]) || stage2.residual_group1.blocks.2.attn.qkv_self.bias
+ | 0.000 | -0.529 | 0.479 | 0.100 | torch.Size([120, 240]) || stage2.residual_group1.blocks.2.attn.proj.weight
+ | 0.002 | -0.230 | 0.295 | 0.074 | torch.Size([120]) || stage2.residual_group1.blocks.2.attn.proj.bias
+ | -0.001 | -0.726 | 0.768 | 0.091 | torch.Size([360, 120]) || stage2.residual_group1.blocks.2.attn.qkv_mut.weight
+ | 0.001 | -0.167 | 0.193 | 0.028 | torch.Size([360]) || stage2.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.695 | 0.334 | 0.833 | 0.068 | torch.Size([120]) || stage2.residual_group1.blocks.2.norm2.weight
+ | 0.012 | -0.755 | 0.517 | 0.157 | torch.Size([120]) || stage2.residual_group1.blocks.2.norm2.bias
+ | 0.001 | -0.474 | 0.480 | 0.119 | torch.Size([240, 120]) || stage2.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.049 | -0.218 | 0.148 | 0.067 | torch.Size([240]) || stage2.residual_group1.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.529 | 0.542 | 0.124 | torch.Size([240, 120]) || stage2.residual_group1.blocks.2.mlp.fc12.weight
+ | -0.006 | -0.245 | 0.239 | 0.073 | torch.Size([240]) || stage2.residual_group1.blocks.2.mlp.fc12.bias
+ | -0.001 | -0.541 | 0.485 | 0.124 | torch.Size([120, 240]) || stage2.residual_group1.blocks.2.mlp.fc2.weight
+ | 0.000 | -0.318 | 0.170 | 0.077 | torch.Size([120]) || stage2.residual_group1.blocks.2.mlp.fc2.bias
+ | 0.903 | 0.178 | 1.124 | 0.124 | torch.Size([120]) || stage2.residual_group1.blocks.3.norm1.weight
+ | -0.138 | -1.223 | 0.440 | 0.177 | torch.Size([120]) || stage2.residual_group1.blocks.3.norm1.bias
+ | -0.164 | -1.383 | 5.910 | 0.305 | torch.Size([675, 6]) || stage2.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.3.attn.position_bias
+ | -0.000 | -0.526 | 0.496 | 0.120 | torch.Size([360, 120]) || stage2.residual_group1.blocks.3.attn.qkv_self.weight
+ | 0.000 | -0.250 | 0.273 | 0.061 | torch.Size([360]) || stage2.residual_group1.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.447 | 0.524 | 0.097 | torch.Size([120, 240]) || stage2.residual_group1.blocks.3.attn.proj.weight
+ | -0.003 | -0.243 | 0.256 | 0.082 | torch.Size([120]) || stage2.residual_group1.blocks.3.attn.proj.bias
+ | -0.001 | -0.551 | 0.730 | 0.083 | torch.Size([360, 120]) || stage2.residual_group1.blocks.3.attn.qkv_mut.weight
+ | -0.001 | -0.145 | 0.126 | 0.024 | torch.Size([360]) || stage2.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.707 | 0.319 | 0.855 | 0.063 | torch.Size([120]) || stage2.residual_group1.blocks.3.norm2.weight
+ | 0.013 | -0.839 | 0.507 | 0.155 | torch.Size([120]) || stage2.residual_group1.blocks.3.norm2.bias
+ | 0.000 | -0.509 | 0.508 | 0.118 | torch.Size([240, 120]) || stage2.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.051 | -0.219 | 0.155 | 0.068 | torch.Size([240]) || stage2.residual_group1.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.475 | 0.592 | 0.124 | torch.Size([240, 120]) || stage2.residual_group1.blocks.3.mlp.fc12.weight
+ | -0.002 | -0.162 | 0.220 | 0.069 | torch.Size([240]) || stage2.residual_group1.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.465 | 0.528 | 0.124 | torch.Size([120, 240]) || stage2.residual_group1.blocks.3.mlp.fc2.weight
+ | -0.002 | -0.243 | 0.286 | 0.088 | torch.Size([120]) || stage2.residual_group1.blocks.3.mlp.fc2.bias
+ | 0.948 | 0.220 | 1.175 | 0.108 | torch.Size([120]) || stage2.residual_group1.blocks.4.norm1.weight
+ | -0.125 | -1.093 | 0.385 | 0.157 | torch.Size([120]) || stage2.residual_group1.blocks.4.norm1.bias
+ | -0.150 | -1.632 | 4.522 | 0.341 | torch.Size([675, 6]) || stage2.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.4.attn.position_bias
+ | -0.000 | -0.636 | 0.543 | 0.119 | torch.Size([360, 120]) || stage2.residual_group1.blocks.4.attn.qkv_self.weight
+ | -0.001 | -0.254 | 0.262 | 0.048 | torch.Size([360]) || stage2.residual_group1.blocks.4.attn.qkv_self.bias
+ | 0.001 | -0.632 | 0.628 | 0.112 | torch.Size([120, 240]) || stage2.residual_group1.blocks.4.attn.proj.weight
+ | -0.005 | -0.240 | 0.330 | 0.104 | torch.Size([120]) || stage2.residual_group1.blocks.4.attn.proj.bias
+ | 0.000 | -0.476 | 0.479 | 0.088 | torch.Size([360, 120]) || stage2.residual_group1.blocks.4.attn.qkv_mut.weight
+ | -0.001 | -0.112 | 0.134 | 0.020 | torch.Size([360]) || stage2.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.686 | 0.264 | 0.797 | 0.060 | torch.Size([120]) || stage2.residual_group1.blocks.4.norm2.weight
+ | 0.012 | -0.889 | 0.427 | 0.140 | torch.Size([120]) || stage2.residual_group1.blocks.4.norm2.bias
+ | 0.001 | -0.476 | 0.478 | 0.117 | torch.Size([240, 120]) || stage2.residual_group1.blocks.4.mlp.fc11.weight
+ | -0.051 | -0.267 | 0.180 | 0.071 | torch.Size([240]) || stage2.residual_group1.blocks.4.mlp.fc11.bias
+ | 0.000 | -0.506 | 0.517 | 0.127 | torch.Size([240, 120]) || stage2.residual_group1.blocks.4.mlp.fc12.weight
+ | 0.002 | -0.172 | 0.241 | 0.068 | torch.Size([240]) || stage2.residual_group1.blocks.4.mlp.fc12.bias
+ | -0.001 | -0.570 | 0.542 | 0.126 | torch.Size([120, 240]) || stage2.residual_group1.blocks.4.mlp.fc2.weight
+ | -0.003 | -0.631 | 0.395 | 0.123 | torch.Size([120]) || stage2.residual_group1.blocks.4.mlp.fc2.bias
+ | 0.912 | 0.189 | 1.122 | 0.104 | torch.Size([120]) || stage2.residual_group1.blocks.5.norm1.weight
+ | -0.114 | -1.125 | 0.188 | 0.140 | torch.Size([120]) || stage2.residual_group1.blocks.5.norm1.bias
+ | -0.099 | -1.285 | 1.708 | 0.236 | torch.Size([675, 6]) || stage2.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.5.attn.position_bias
+ | -0.000 | -0.496 | 0.540 | 0.119 | torch.Size([360, 120]) || stage2.residual_group1.blocks.5.attn.qkv_self.weight
+ | 0.003 | -0.260 | 0.228 | 0.052 | torch.Size([360]) || stage2.residual_group1.blocks.5.attn.qkv_self.bias
+ | -0.000 | -0.511 | 0.454 | 0.095 | torch.Size([120, 240]) || stage2.residual_group1.blocks.5.attn.proj.weight
+ | 0.000 | -0.711 | 0.286 | 0.115 | torch.Size([120]) || stage2.residual_group1.blocks.5.attn.proj.bias
+ | 0.000 | -0.444 | 0.454 | 0.082 | torch.Size([360, 120]) || stage2.residual_group1.blocks.5.attn.qkv_mut.weight
+ | -0.000 | -0.101 | 0.133 | 0.021 | torch.Size([360]) || stage2.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.668 | 0.312 | 0.800 | 0.056 | torch.Size([120]) || stage2.residual_group1.blocks.5.norm2.weight
+ | 0.015 | -0.778 | 0.372 | 0.111 | torch.Size([120]) || stage2.residual_group1.blocks.5.norm2.bias
+ | -0.000 | -0.485 | 0.469 | 0.115 | torch.Size([240, 120]) || stage2.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.045 | -0.294 | 0.173 | 0.083 | torch.Size([240]) || stage2.residual_group1.blocks.5.mlp.fc11.bias
+ | 0.000 | -0.554 | 0.540 | 0.129 | torch.Size([240, 120]) || stage2.residual_group1.blocks.5.mlp.fc12.weight
+ | 0.001 | -0.183 | 0.199 | 0.077 | torch.Size([240]) || stage2.residual_group1.blocks.5.mlp.fc12.bias
+ | 0.000 | -0.879 | 0.824 | 0.127 | torch.Size([120, 240]) || stage2.residual_group1.blocks.5.mlp.fc2.weight
+ | 0.001 | -1.670 | 0.358 | 0.208 | torch.Size([120]) || stage2.residual_group1.blocks.5.mlp.fc2.bias
+ | 0.001 | -0.253 | 0.346 | 0.068 | torch.Size([120, 120]) || stage2.linear1.weight
+ | 0.007 | -0.248 | 0.241 | 0.103 | torch.Size([120]) || stage2.linear1.bias
+ | 1.012 | 0.613 | 1.327 | 0.116 | torch.Size([120]) || stage2.residual_group2.blocks.0.norm1.weight
+ | 0.019 | -0.724 | 0.685 | 0.244 | torch.Size([120]) || stage2.residual_group2.blocks.0.norm1.bias
+ | 0.003 | -2.959 | 1.705 | 0.151 | torch.Size([2475, 6]) || stage2.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage2.residual_group2.blocks.0.attn.relative_position_index
+ | -0.000 | -0.636 | 0.617 | 0.125 | torch.Size([360, 120]) || stage2.residual_group2.blocks.0.attn.qkv_self.weight
+ | -0.002 | -0.291 | 0.292 | 0.085 | torch.Size([360]) || stage2.residual_group2.blocks.0.attn.qkv_self.bias
+ | -0.002 | -0.476 | 0.512 | 0.138 | torch.Size([120, 120]) || stage2.residual_group2.blocks.0.attn.proj.weight
+ | -0.002 | -0.263 | 0.398 | 0.135 | torch.Size([120]) || stage2.residual_group2.blocks.0.attn.proj.bias
+ | 0.677 | 0.521 | 0.840 | 0.063 | torch.Size([120]) || stage2.residual_group2.blocks.0.norm2.weight
+ | 0.010 | -0.710 | 0.541 | 0.173 | torch.Size([120]) || stage2.residual_group2.blocks.0.norm2.bias
+ | 0.001 | -0.540 | 0.507 | 0.112 | torch.Size([240, 120]) || stage2.residual_group2.blocks.0.mlp.fc11.weight
+ | -0.016 | -0.242 | 0.201 | 0.077 | torch.Size([240]) || stage2.residual_group2.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.519 | 0.479 | 0.122 | torch.Size([240, 120]) || stage2.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.006 | -0.162 | 0.231 | 0.071 | torch.Size([240]) || stage2.residual_group2.blocks.0.mlp.fc12.bias
+ | -0.001 | -0.449 | 0.494 | 0.121 | torch.Size([120, 240]) || stage2.residual_group2.blocks.0.mlp.fc2.weight
+ | 0.002 | -0.293 | 0.222 | 0.095 | torch.Size([120]) || stage2.residual_group2.blocks.0.mlp.fc2.bias
+ | 1.053 | 0.832 | 1.269 | 0.079 | torch.Size([120]) || stage2.residual_group2.blocks.1.norm1.weight
+ | 0.015 | -0.549 | 0.428 | 0.189 | torch.Size([120]) || stage2.residual_group2.blocks.1.norm1.bias
+ | 0.007 | -3.099 | 1.550 | 0.170 | torch.Size([2475, 6]) || stage2.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage2.residual_group2.blocks.1.attn.relative_position_index
+ | 0.000 | -0.673 | 0.604 | 0.131 | torch.Size([360, 120]) || stage2.residual_group2.blocks.1.attn.qkv_self.weight
+ | -0.001 | -0.416 | 0.391 | 0.089 | torch.Size([360]) || stage2.residual_group2.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.569 | 0.560 | 0.139 | torch.Size([120, 120]) || stage2.residual_group2.blocks.1.attn.proj.weight
+ | 0.004 | -0.613 | 0.428 | 0.158 | torch.Size([120]) || stage2.residual_group2.blocks.1.attn.proj.bias
+ | 0.762 | 0.464 | 0.954 | 0.085 | torch.Size([120]) || stage2.residual_group2.blocks.1.norm2.weight
+ | 0.005 | -0.745 | 0.381 | 0.117 | torch.Size([120]) || stage2.residual_group2.blocks.1.norm2.bias
+ | 0.000 | -0.441 | 0.448 | 0.110 | torch.Size([240, 120]) || stage2.residual_group2.blocks.1.mlp.fc11.weight
+ | 0.019 | -0.292 | 0.460 | 0.117 | torch.Size([240]) || stage2.residual_group2.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.491 | 0.490 | 0.126 | torch.Size([240, 120]) || stage2.residual_group2.blocks.1.mlp.fc12.weight
+ | -0.007 | -0.285 | 0.177 | 0.068 | torch.Size([240]) || stage2.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.535 | 0.631 | 0.125 | torch.Size([120, 240]) || stage2.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.011 | -0.765 | 0.337 | 0.142 | torch.Size([120]) || stage2.residual_group2.blocks.1.mlp.fc2.bias
+ | 0.001 | -0.367 | 0.372 | 0.074 | torch.Size([120, 120]) || stage2.linear2.weight
+ | 0.009 | -0.288 | 0.342 | 0.130 | torch.Size([120]) || stage2.linear2.bias
+ | 0.000 | -0.112 | 0.093 | 0.022 | torch.Size([120, 120, 3, 3]) || stage2.pa_deform.weight
+ | -0.002 | -0.036 | 0.035 | 0.016 | torch.Size([120]) || stage2.pa_deform.bias
+ | 0.000 | -0.068 | 0.080 | 0.016 | torch.Size([120, 242, 3, 3]) || stage2.pa_deform.conv_offset.0.weight
+ | -0.009 | -0.035 | 0.023 | 0.013 | torch.Size([120]) || stage2.pa_deform.conv_offset.0.bias
+ | 0.000 | -0.068 | 0.079 | 0.019 | torch.Size([120, 120, 3, 3]) || stage2.pa_deform.conv_offset.2.weight
+ | -0.014 | -0.061 | 0.036 | 0.021 | torch.Size([120]) || stage2.pa_deform.conv_offset.2.bias
+ | -0.001 | -0.082 | 0.079 | 0.019 | torch.Size([120, 120, 3, 3]) || stage2.pa_deform.conv_offset.4.weight
+ | -0.003 | -0.075 | 0.069 | 0.035 | torch.Size([120]) || stage2.pa_deform.conv_offset.4.bias
+ | -0.000 | -0.166 | 0.139 | 0.016 | torch.Size([324, 120, 3, 3]) || stage2.pa_deform.conv_offset.6.weight
+ | -0.015 | -0.090 | 0.050 | 0.030 | torch.Size([324]) || stage2.pa_deform.conv_offset.6.bias
+ | -0.002 | -0.642 | 0.663 | 0.127 | torch.Size([360, 360]) || stage2.pa_fuse.fc11.weight
+ | 0.130 | -0.171 | 0.480 | 0.140 | torch.Size([360]) || stage2.pa_fuse.fc11.bias
+ | -0.000 | -0.696 | 0.620 | 0.118 | torch.Size([360, 360]) || stage2.pa_fuse.fc12.weight
+ | -0.007 | -0.337 | 0.301 | 0.102 | torch.Size([360]) || stage2.pa_fuse.fc12.bias
+ | 0.000 | -0.650 | 0.657 | 0.128 | torch.Size([120, 360]) || stage2.pa_fuse.fc2.weight
+ | 0.013 | -0.507 | 0.451 | 0.215 | torch.Size([120]) || stage2.pa_fuse.fc2.bias
+ | 1.067 | 0.372 | 1.778 | 0.269 | torch.Size([480]) || stage3.reshape.1.weight
+ | -0.004 | -0.699 | 0.521 | 0.227 | torch.Size([480]) || stage3.reshape.1.bias
+ | -0.000 | -0.643 | 0.743 | 0.138 | torch.Size([120, 480]) || stage3.reshape.2.weight
+ | 0.009 | -0.176 | 0.243 | 0.079 | torch.Size([120]) || stage3.reshape.2.bias
+ | 0.785 | 0.469 | 1.029 | 0.105 | torch.Size([120]) || stage3.residual_group1.blocks.0.norm1.weight
+ | -0.102 | -0.716 | 0.311 | 0.179 | torch.Size([120]) || stage3.residual_group1.blocks.0.norm1.bias
+ | -0.001 | -0.340 | 0.163 | 0.033 | torch.Size([675, 6]) || stage3.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.0.attn.position_bias
+ | -0.000 | -0.328 | 0.302 | 0.061 | torch.Size([360, 120]) || stage3.residual_group1.blocks.0.attn.qkv_self.weight
+ | 0.004 | -0.232 | 0.189 | 0.063 | torch.Size([360]) || stage3.residual_group1.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.343 | 0.346 | 0.058 | torch.Size([120, 240]) || stage3.residual_group1.blocks.0.attn.proj.weight
+ | 0.004 | -0.335 | 0.229 | 0.102 | torch.Size([120]) || stage3.residual_group1.blocks.0.attn.proj.bias
+ | -0.000 | -0.366 | 0.325 | 0.052 | torch.Size([360, 120]) || stage3.residual_group1.blocks.0.attn.qkv_mut.weight
+ | -0.001 | -0.091 | 0.074 | 0.017 | torch.Size([360]) || stage3.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.751 | 0.517 | 0.928 | 0.083 | torch.Size([120]) || stage3.residual_group1.blocks.0.norm2.weight
+ | 0.002 | -0.271 | 0.189 | 0.101 | torch.Size([120]) || stage3.residual_group1.blocks.0.norm2.bias
+ | 0.000 | -0.371 | 0.388 | 0.096 | torch.Size([240, 120]) || stage3.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.073 | -0.203 | 0.039 | 0.046 | torch.Size([240]) || stage3.residual_group1.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.400 | 0.401 | 0.094 | torch.Size([240, 120]) || stage3.residual_group1.blocks.0.mlp.fc12.weight
+ | -0.000 | -0.178 | 0.128 | 0.052 | torch.Size([240]) || stage3.residual_group1.blocks.0.mlp.fc12.bias
+ | -0.001 | -0.410 | 0.429 | 0.098 | torch.Size([120, 240]) || stage3.residual_group1.blocks.0.mlp.fc2.weight
+ | 0.006 | -0.345 | 0.304 | 0.108 | torch.Size([120]) || stage3.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.816 | 0.469 | 1.015 | 0.110 | torch.Size([120]) || stage3.residual_group1.blocks.1.norm1.weight
+ | -0.103 | -0.647 | 0.225 | 0.140 | torch.Size([120]) || stage3.residual_group1.blocks.1.norm1.bias
+ | 0.001 | -0.464 | 0.239 | 0.034 | torch.Size([675, 6]) || stage3.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.1.attn.position_bias
+ | -0.000 | -0.304 | 0.359 | 0.061 | torch.Size([360, 120]) || stage3.residual_group1.blocks.1.attn.qkv_self.weight
+ | 0.001 | -0.173 | 0.193 | 0.047 | torch.Size([360]) || stage3.residual_group1.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.299 | 0.408 | 0.055 | torch.Size([120, 240]) || stage3.residual_group1.blocks.1.attn.proj.weight
+ | 0.007 | -0.511 | 0.239 | 0.113 | torch.Size([120]) || stage3.residual_group1.blocks.1.attn.proj.bias
+ | 0.000 | -0.288 | 0.254 | 0.049 | torch.Size([360, 120]) || stage3.residual_group1.blocks.1.attn.qkv_mut.weight
+ | 0.001 | -0.060 | 0.054 | 0.016 | torch.Size([360]) || stage3.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.796 | 0.609 | 0.971 | 0.076 | torch.Size([120]) || stage3.residual_group1.blocks.1.norm2.weight
+ | -0.002 | -0.327 | 0.247 | 0.122 | torch.Size([120]) || stage3.residual_group1.blocks.1.norm2.bias
+ | 0.001 | -0.379 | 0.407 | 0.094 | torch.Size([240, 120]) || stage3.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.077 | -0.214 | 0.034 | 0.045 | torch.Size([240]) || stage3.residual_group1.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.391 | 0.432 | 0.092 | torch.Size([240, 120]) || stage3.residual_group1.blocks.1.mlp.fc12.weight
+ | 0.005 | -0.176 | 0.112 | 0.044 | torch.Size([240]) || stage3.residual_group1.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.378 | 0.399 | 0.093 | torch.Size([120, 240]) || stage3.residual_group1.blocks.1.mlp.fc2.weight
+ | 0.009 | -0.410 | 0.306 | 0.110 | torch.Size([120]) || stage3.residual_group1.blocks.1.mlp.fc2.bias
+ | 0.854 | 0.447 | 0.995 | 0.090 | torch.Size([120]) || stage3.residual_group1.blocks.2.norm1.weight
+ | -0.086 | -0.513 | 0.198 | 0.116 | torch.Size([120]) || stage3.residual_group1.blocks.2.norm1.bias
+ | -0.001 | -0.189 | 0.292 | 0.033 | torch.Size([675, 6]) || stage3.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.2.attn.position_bias
+ | 0.000 | -0.390 | 0.367 | 0.067 | torch.Size([360, 120]) || stage3.residual_group1.blocks.2.attn.qkv_self.weight
+ | -0.002 | -0.310 | 0.284 | 0.078 | torch.Size([360]) || stage3.residual_group1.blocks.2.attn.qkv_self.bias
+ | 0.000 | -0.334 | 0.296 | 0.061 | torch.Size([120, 240]) || stage3.residual_group1.blocks.2.attn.proj.weight
+ | 0.004 | -0.356 | 0.299 | 0.096 | torch.Size([120]) || stage3.residual_group1.blocks.2.attn.proj.bias
+ | 0.000 | -0.276 | 0.315 | 0.055 | torch.Size([360, 120]) || stage3.residual_group1.blocks.2.attn.qkv_mut.weight
+ | 0.000 | -0.094 | 0.066 | 0.014 | torch.Size([360]) || stage3.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.829 | 0.673 | 1.017 | 0.074 | torch.Size([120]) || stage3.residual_group1.blocks.2.norm2.weight
+ | 0.003 | -0.259 | 0.228 | 0.098 | torch.Size([120]) || stage3.residual_group1.blocks.2.norm2.bias
+ | 0.001 | -0.410 | 0.385 | 0.091 | torch.Size([240, 120]) || stage3.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.085 | -0.200 | 0.017 | 0.044 | torch.Size([240]) || stage3.residual_group1.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.348 | 0.378 | 0.090 | torch.Size([240, 120]) || stage3.residual_group1.blocks.2.mlp.fc12.weight
+ | 0.001 | -0.130 | 0.105 | 0.042 | torch.Size([240]) || stage3.residual_group1.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.346 | 0.425 | 0.090 | torch.Size([120, 240]) || stage3.residual_group1.blocks.2.mlp.fc2.weight
+ | 0.005 | -0.363 | 0.241 | 0.094 | torch.Size([120]) || stage3.residual_group1.blocks.2.mlp.fc2.bias
+ | 0.872 | 0.554 | 1.068 | 0.102 | torch.Size([120]) || stage3.residual_group1.blocks.3.norm1.weight
+ | -0.057 | -0.402 | 0.133 | 0.087 | torch.Size([120]) || stage3.residual_group1.blocks.3.norm1.bias
+ | 0.003 | -0.365 | 0.217 | 0.050 | torch.Size([675, 6]) || stage3.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.3.attn.position_bias
+ | 0.000 | -0.359 | 0.357 | 0.065 | torch.Size([360, 120]) || stage3.residual_group1.blocks.3.attn.qkv_self.weight
+ | -0.002 | -0.265 | 0.294 | 0.062 | torch.Size([360]) || stage3.residual_group1.blocks.3.attn.qkv_self.bias
+ | -0.000 | -0.300 | 0.271 | 0.054 | torch.Size([120, 240]) || stage3.residual_group1.blocks.3.attn.proj.weight
+ | 0.002 | -0.316 | 0.215 | 0.094 | torch.Size([120]) || stage3.residual_group1.blocks.3.attn.proj.bias
+ | 0.000 | -0.370 | 0.329 | 0.039 | torch.Size([360, 120]) || stage3.residual_group1.blocks.3.attn.qkv_mut.weight
+ | 0.000 | -0.056 | 0.066 | 0.013 | torch.Size([360]) || stage3.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.842 | 0.631 | 0.989 | 0.073 | torch.Size([120]) || stage3.residual_group1.blocks.3.norm2.weight
+ | -0.001 | -0.216 | 0.263 | 0.083 | torch.Size([120]) || stage3.residual_group1.blocks.3.norm2.bias
+ | 0.001 | -0.388 | 0.391 | 0.089 | torch.Size([240, 120]) || stage3.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.087 | -0.202 | 0.032 | 0.048 | torch.Size([240]) || stage3.residual_group1.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.364 | 0.428 | 0.088 | torch.Size([240, 120]) || stage3.residual_group1.blocks.3.mlp.fc12.weight
+ | -0.000 | -0.137 | 0.106 | 0.043 | torch.Size([240]) || stage3.residual_group1.blocks.3.mlp.fc12.bias
+ | -0.001 | -0.390 | 0.339 | 0.088 | torch.Size([120, 240]) || stage3.residual_group1.blocks.3.mlp.fc2.weight
+ | 0.003 | -0.376 | 0.203 | 0.090 | torch.Size([120]) || stage3.residual_group1.blocks.3.mlp.fc2.bias
+ | 0.913 | 0.498 | 1.102 | 0.096 | torch.Size([120]) || stage3.residual_group1.blocks.4.norm1.weight
+ | -0.048 | -0.340 | 0.105 | 0.071 | torch.Size([120]) || stage3.residual_group1.blocks.4.norm1.bias
+ | 0.001 | -0.706 | 0.306 | 0.058 | torch.Size([675, 6]) || stage3.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.4.attn.position_bias
+ | 0.000 | -0.373 | 0.339 | 0.076 | torch.Size([360, 120]) || stage3.residual_group1.blocks.4.attn.qkv_self.weight
+ | -0.004 | -0.301 | 0.301 | 0.074 | torch.Size([360]) || stage3.residual_group1.blocks.4.attn.qkv_self.bias
+ | 0.000 | -0.278 | 0.277 | 0.058 | torch.Size([120, 240]) || stage3.residual_group1.blocks.4.attn.proj.weight
+ | 0.003 | -0.310 | 0.240 | 0.079 | torch.Size([120]) || stage3.residual_group1.blocks.4.attn.proj.bias
+ | -0.000 | -0.350 | 0.322 | 0.046 | torch.Size([360, 120]) || stage3.residual_group1.blocks.4.attn.qkv_mut.weight
+ | -0.000 | -0.045 | 0.064 | 0.010 | torch.Size([360]) || stage3.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.862 | 0.679 | 0.990 | 0.059 | torch.Size([120]) || stage3.residual_group1.blocks.4.norm2.weight
+ | -0.004 | -0.313 | 0.190 | 0.083 | torch.Size([120]) || stage3.residual_group1.blocks.4.norm2.bias
+ | 0.001 | -0.370 | 0.364 | 0.089 | torch.Size([240, 120]) || stage3.residual_group1.blocks.4.mlp.fc11.weight
+ | -0.092 | -0.231 | 0.129 | 0.057 | torch.Size([240]) || stage3.residual_group1.blocks.4.mlp.fc11.bias
+ | -0.000 | -0.375 | 0.511 | 0.090 | torch.Size([240, 120]) || stage3.residual_group1.blocks.4.mlp.fc12.weight
+ | 0.002 | -0.114 | 0.114 | 0.040 | torch.Size([240]) || stage3.residual_group1.blocks.4.mlp.fc12.bias
+ | -0.000 | -0.389 | 0.354 | 0.088 | torch.Size([120, 240]) || stage3.residual_group1.blocks.4.mlp.fc2.weight
+ | 0.005 | -0.258 | 0.164 | 0.073 | torch.Size([120]) || stage3.residual_group1.blocks.4.mlp.fc2.bias
+ | 0.899 | 0.480 | 1.089 | 0.103 | torch.Size([120]) || stage3.residual_group1.blocks.5.norm1.weight
+ | -0.030 | -0.257 | 0.115 | 0.056 | torch.Size([120]) || stage3.residual_group1.blocks.5.norm1.bias
+ | 0.003 | -0.462 | 0.290 | 0.069 | torch.Size([675, 6]) || stage3.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.5.attn.position_bias
+ | 0.000 | -0.391 | 0.365 | 0.069 | torch.Size([360, 120]) || stage3.residual_group1.blocks.5.attn.qkv_self.weight
+ | -0.004 | -0.232 | 0.302 | 0.064 | torch.Size([360]) || stage3.residual_group1.blocks.5.attn.qkv_self.bias
+ | -0.000 | -0.267 | 0.293 | 0.051 | torch.Size([120, 240]) || stage3.residual_group1.blocks.5.attn.proj.weight
+ | 0.000 | -0.250 | 0.182 | 0.070 | torch.Size([120]) || stage3.residual_group1.blocks.5.attn.proj.bias
+ | -0.000 | -0.238 | 0.257 | 0.033 | torch.Size([360, 120]) || stage3.residual_group1.blocks.5.attn.qkv_mut.weight
+ | -0.001 | -0.032 | 0.033 | 0.008 | torch.Size([360]) || stage3.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.864 | 0.651 | 1.029 | 0.070 | torch.Size([120]) || stage3.residual_group1.blocks.5.norm2.weight
+ | -0.003 | -0.212 | 0.175 | 0.075 | torch.Size([120]) || stage3.residual_group1.blocks.5.norm2.bias
+ | 0.000 | -0.378 | 0.379 | 0.089 | torch.Size([240, 120]) || stage3.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.097 | -0.308 | 0.026 | 0.051 | torch.Size([240]) || stage3.residual_group1.blocks.5.mlp.fc11.bias
+ | 0.000 | -0.578 | 0.401 | 0.089 | torch.Size([240, 120]) || stage3.residual_group1.blocks.5.mlp.fc12.weight
+ | -0.005 | -0.166 | 0.131 | 0.049 | torch.Size([240]) || stage3.residual_group1.blocks.5.mlp.fc12.bias
+ | 0.000 | -0.358 | 0.376 | 0.085 | torch.Size([120, 240]) || stage3.residual_group1.blocks.5.mlp.fc2.weight
+ | 0.001 | -0.262 | 0.176 | 0.072 | torch.Size([120]) || stage3.residual_group1.blocks.5.mlp.fc2.bias
+ | 0.003 | -0.284 | 0.467 | 0.071 | torch.Size([120, 120]) || stage3.linear1.weight
+ | 0.006 | -0.201 | 0.269 | 0.090 | torch.Size([120]) || stage3.linear1.bias
+ | 0.877 | 0.568 | 1.197 | 0.115 | torch.Size([120]) || stage3.residual_group2.blocks.0.norm1.weight
+ | 0.002 | -0.248 | 0.324 | 0.100 | torch.Size([120]) || stage3.residual_group2.blocks.0.norm1.bias
+ | 0.000 | -0.261 | 0.125 | 0.029 | torch.Size([2475, 6]) || stage3.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage3.residual_group2.blocks.0.attn.relative_position_index
+ | -0.000 | -0.563 | 0.552 | 0.074 | torch.Size([360, 120]) || stage3.residual_group2.blocks.0.attn.qkv_self.weight
+ | 0.005 | -0.257 | 0.302 | 0.081 | torch.Size([360]) || stage3.residual_group2.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.390 | 0.385 | 0.084 | torch.Size([120, 120]) || stage3.residual_group2.blocks.0.attn.proj.weight
+ | 0.002 | -0.450 | 0.235 | 0.125 | torch.Size([120]) || stage3.residual_group2.blocks.0.attn.proj.bias
+ | 0.986 | 0.755 | 1.165 | 0.078 | torch.Size([120]) || stage3.residual_group2.blocks.0.norm2.weight
+ | -0.000 | -0.260 | 0.169 | 0.076 | torch.Size([120]) || stage3.residual_group2.blocks.0.norm2.bias
+ | 0.000 | -0.355 | 0.397 | 0.087 | torch.Size([240, 120]) || stage3.residual_group2.blocks.0.mlp.fc11.weight
+ | -0.046 | -0.220 | 0.086 | 0.055 | torch.Size([240]) || stage3.residual_group2.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.424 | 0.368 | 0.089 | torch.Size([240, 120]) || stage3.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.006 | -0.111 | 0.122 | 0.038 | torch.Size([240]) || stage3.residual_group2.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.354 | 0.374 | 0.090 | torch.Size([120, 240]) || stage3.residual_group2.blocks.0.mlp.fc2.weight
+ | 0.001 | -0.374 | 0.272 | 0.101 | torch.Size([120]) || stage3.residual_group2.blocks.0.mlp.fc2.bias
+ | 0.919 | 0.643 | 1.132 | 0.100 | torch.Size([120]) || stage3.residual_group2.blocks.1.norm1.weight
+ | 0.000 | -0.177 | 0.181 | 0.063 | torch.Size([120]) || stage3.residual_group2.blocks.1.norm1.bias
+ | 0.000 | -0.332 | 0.131 | 0.028 | torch.Size([2475, 6]) || stage3.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage3.residual_group2.blocks.1.attn.relative_position_index
+ | -0.000 | -0.418 | 0.362 | 0.069 | torch.Size([360, 120]) || stage3.residual_group2.blocks.1.attn.qkv_self.weight
+ | -0.004 | -0.375 | 0.347 | 0.082 | torch.Size([360]) || stage3.residual_group2.blocks.1.attn.qkv_self.bias
+ | -0.001 | -0.294 | 0.354 | 0.077 | torch.Size([120, 120]) || stage3.residual_group2.blocks.1.attn.proj.weight
+ | 0.003 | -0.432 | 0.259 | 0.101 | torch.Size([120]) || stage3.residual_group2.blocks.1.attn.proj.bias
+ | 1.012 | 0.750 | 1.178 | 0.077 | torch.Size([120]) || stage3.residual_group2.blocks.1.norm2.weight
+ | -0.001 | -0.171 | 0.155 | 0.060 | torch.Size([120]) || stage3.residual_group2.blocks.1.norm2.bias
+ | 0.000 | -0.331 | 0.356 | 0.087 | torch.Size([240, 120]) || stage3.residual_group2.blocks.1.mlp.fc11.weight
+ | -0.035 | -0.207 | 0.197 | 0.065 | torch.Size([240]) || stage3.residual_group2.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.399 | 0.398 | 0.092 | torch.Size([240, 120]) || stage3.residual_group2.blocks.1.mlp.fc12.weight
+ | -0.002 | -0.111 | 0.129 | 0.041 | torch.Size([240]) || stage3.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.001 | -0.353 | 0.330 | 0.088 | torch.Size([120, 240]) || stage3.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.001 | -0.328 | 0.127 | 0.064 | torch.Size([120]) || stage3.residual_group2.blocks.1.mlp.fc2.bias
+ | 0.003 | -0.289 | 0.519 | 0.073 | torch.Size([120, 120]) || stage3.linear2.weight
+ | 0.002 | -0.318 | 0.371 | 0.144 | torch.Size([120]) || stage3.linear2.bias
+ | -0.000 | -0.086 | 0.095 | 0.022 | torch.Size([120, 120, 3, 3]) || stage3.pa_deform.weight
+ | -0.002 | -0.023 | 0.021 | 0.010 | torch.Size([120]) || stage3.pa_deform.bias
+ | -0.000 | -0.060 | 0.056 | 0.015 | torch.Size([120, 242, 3, 3]) || stage3.pa_deform.conv_offset.0.weight
+ | -0.008 | -0.035 | 0.019 | 0.013 | torch.Size([120]) || stage3.pa_deform.conv_offset.0.bias
+ | -0.001 | -0.064 | 0.062 | 0.019 | torch.Size([120, 120, 3, 3]) || stage3.pa_deform.conv_offset.2.weight
+ | -0.007 | -0.044 | 0.031 | 0.019 | torch.Size([120]) || stage3.pa_deform.conv_offset.2.bias
+ | 0.000 | -0.062 | 0.063 | 0.019 | torch.Size([120, 120, 3, 3]) || stage3.pa_deform.conv_offset.4.weight
+ | -0.006 | -0.052 | 0.043 | 0.021 | torch.Size([120]) || stage3.pa_deform.conv_offset.4.bias
+ | 0.000 | -0.081 | 0.080 | 0.011 | torch.Size([324, 120, 3, 3]) || stage3.pa_deform.conv_offset.6.weight
+ | -0.004 | -0.087 | 0.083 | 0.021 | torch.Size([324]) || stage3.pa_deform.conv_offset.6.bias
+ | -0.002 | -0.465 | 0.513 | 0.101 | torch.Size([360, 360]) || stage3.pa_fuse.fc11.weight
+ | 0.059 | -0.251 | 0.595 | 0.104 | torch.Size([360]) || stage3.pa_fuse.fc11.bias
+ | -0.000 | -0.544 | 0.531 | 0.100 | torch.Size([360, 360]) || stage3.pa_fuse.fc12.weight
+ | 0.001 | -0.589 | 0.433 | 0.106 | torch.Size([360]) || stage3.pa_fuse.fc12.bias
+ | -0.000 | -0.535 | 0.562 | 0.127 | torch.Size([120, 360]) || stage3.pa_fuse.fc2.weight
+ | -0.001 | -0.401 | 0.342 | 0.121 | torch.Size([120]) || stage3.pa_fuse.fc2.bias
+ | 0.997 | 0.921 | 1.125 | 0.028 | torch.Size([480]) || stage4.reshape.1.weight
+ | -0.000 | -0.058 | 0.059 | 0.022 | torch.Size([480]) || stage4.reshape.1.bias
+ | 0.000 | -0.155 | 0.150 | 0.031 | torch.Size([120, 480]) || stage4.reshape.2.weight
+ | 0.001 | -0.016 | 0.016 | 0.006 | torch.Size([120]) || stage4.reshape.2.bias
+ | 1.002 | 0.999 | 1.009 | 0.002 | torch.Size([120]) || stage4.residual_group1.blocks.0.norm1.weight
+ | 0.000 | -0.002 | 0.003 | 0.001 | torch.Size([120]) || stage4.residual_group1.blocks.0.norm1.bias
+ | -0.000 | -0.071 | 0.066 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.0.attn.position_bias
+ | 0.000 | -0.093 | 0.081 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.0.attn.qkv_self.weight
+ | -0.000 | -0.009 | 0.009 | 0.002 | torch.Size([360]) || stage4.residual_group1.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.080 | 0.097 | 0.021 | torch.Size([120, 240]) || stage4.residual_group1.blocks.0.attn.proj.weight
+ | 0.000 | -0.035 | 0.027 | 0.013 | torch.Size([120]) || stage4.residual_group1.blocks.0.attn.proj.bias
+ | 0.000 | -0.080 | 0.079 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.0.attn.qkv_mut.weight
+ | -0.000 | -0.007 | 0.008 | 0.002 | torch.Size([360]) || stage4.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.0.norm2.weight
+ | -0.000 | -0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.0.norm2.bias
+ | -0.000 | -0.079 | 0.085 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.0.mlp.fc11.weight
+ | 0.000 | -0.001 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.087 | 0.092 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.0.mlp.fc12.weight
+ | -0.000 | -0.001 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.080 | 0.077 | 0.020 | torch.Size([120, 240]) || stage4.residual_group1.blocks.0.mlp.fc2.weight
+ | 0.000 | -0.031 | 0.029 | 0.013 | torch.Size([120]) || stage4.residual_group1.blocks.0.mlp.fc2.bias
+ | 1.002 | 0.997 | 1.007 | 0.002 | torch.Size([120]) || stage4.residual_group1.blocks.1.norm1.weight
+ | -0.000 | -0.002 | 0.003 | 0.001 | torch.Size([120]) || stage4.residual_group1.blocks.1.norm1.bias
+ | 0.000 | -0.066 | 0.065 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.1.attn.position_bias
+ | -0.000 | -0.078 | 0.081 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.1.attn.qkv_self.weight
+ | 0.000 | -0.006 | 0.008 | 0.002 | torch.Size([360]) || stage4.residual_group1.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.080 | 0.083 | 0.021 | torch.Size([120, 240]) || stage4.residual_group1.blocks.1.attn.proj.weight
+ | -0.000 | -0.027 | 0.029 | 0.012 | torch.Size([120]) || stage4.residual_group1.blocks.1.attn.proj.bias
+ | 0.000 | -0.077 | 0.082 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.1.attn.qkv_mut.weight
+ | -0.000 | -0.006 | 0.009 | 0.001 | torch.Size([360]) || stage4.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.1.norm2.weight
+ | 0.000 | -0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.1.norm2.bias
+ | -0.000 | -0.080 | 0.078 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.000 | -0.001 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.077 | 0.085 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.1.mlp.fc12.weight
+ | 0.000 | -0.001 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.084 | 0.075 | 0.020 | torch.Size([120, 240]) || stage4.residual_group1.blocks.1.mlp.fc2.weight
+ | 0.000 | -0.034 | 0.031 | 0.013 | torch.Size([120]) || stage4.residual_group1.blocks.1.mlp.fc2.bias
+ | 1.002 | 0.996 | 1.008 | 0.002 | torch.Size([120]) || stage4.residual_group1.blocks.2.norm1.weight
+ | -0.000 | -0.003 | 0.002 | 0.001 | torch.Size([120]) || stage4.residual_group1.blocks.2.norm1.bias
+ | 0.001 | -0.070 | 0.071 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.2.attn.position_bias
+ | 0.000 | -0.091 | 0.087 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.2.attn.qkv_self.weight
+ | -0.000 | -0.007 | 0.005 | 0.001 | torch.Size([360]) || stage4.residual_group1.blocks.2.attn.qkv_self.bias
+ | 0.000 | -0.080 | 0.084 | 0.020 | torch.Size([120, 240]) || stage4.residual_group1.blocks.2.attn.proj.weight
+ | -0.000 | -0.023 | 0.026 | 0.010 | torch.Size([120]) || stage4.residual_group1.blocks.2.attn.proj.bias
+ | -0.000 | -0.107 | 0.087 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.2.attn.qkv_mut.weight
+ | 0.000 | -0.006 | 0.005 | 0.001 | torch.Size([360]) || stage4.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 1.000 | 0.999 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.2.norm2.weight
+ | 0.000 | -0.000 | 0.001 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.2.norm2.bias
+ | 0.000 | -0.076 | 0.077 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.000 | -0.005 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.2.mlp.fc11.bias
+ | -0.000 | -2.000 | 0.081 | 0.023 | torch.Size([240, 120]) || stage4.residual_group1.blocks.2.mlp.fc12.weight
+ | 0.000 | -0.001 | 0.002 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.084 | 0.077 | 0.020 | torch.Size([120, 240]) || stage4.residual_group1.blocks.2.mlp.fc2.weight
+ | 0.000 | -0.027 | 0.024 | 0.010 | torch.Size([120]) || stage4.residual_group1.blocks.2.mlp.fc2.bias
+ | 1.002 | 0.999 | 1.012 | 0.002 | torch.Size([120]) || stage4.residual_group1.blocks.3.norm1.weight
+ | -0.000 | -0.003 | 0.002 | 0.001 | torch.Size([120]) || stage4.residual_group1.blocks.3.norm1.bias
+ | 0.000 | -0.064 | 0.071 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.3.attn.position_bias
+ | 0.000 | -0.099 | 0.088 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.3.attn.qkv_self.weight
+ | 0.000 | -0.006 | 0.005 | 0.001 | torch.Size([360]) || stage4.residual_group1.blocks.3.attn.qkv_self.bias
+ | -0.000 | -0.083 | 0.084 | 0.020 | torch.Size([120, 240]) || stage4.residual_group1.blocks.3.attn.proj.weight
+ | -0.000 | -0.019 | 0.018 | 0.008 | torch.Size([120]) || stage4.residual_group1.blocks.3.attn.proj.bias
+ | 0.000 | -0.079 | 0.084 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.3.attn.qkv_mut.weight
+ | -0.000 | -0.004 | 0.004 | 0.001 | torch.Size([360]) || stage4.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.3.norm2.weight
+ | 0.000 | -0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.3.norm2.bias
+ | -0.000 | -0.078 | 0.081 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.000 | -0.001 | 0.002 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.087 | 0.076 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.3.mlp.fc12.weight
+ | -0.000 | -0.001 | 0.002 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.3.mlp.fc12.bias
+ | -0.000 | -0.079 | 0.082 | 0.020 | torch.Size([120, 240]) || stage4.residual_group1.blocks.3.mlp.fc2.weight
+ | 0.000 | -0.022 | 0.021 | 0.008 | torch.Size([120]) || stage4.residual_group1.blocks.3.mlp.fc2.bias
+ | 1.002 | 0.998 | 1.011 | 0.002 | torch.Size([120]) || stage4.residual_group1.blocks.4.norm1.weight
+ | -0.001 | -0.004 | 0.003 | 0.001 | torch.Size([120]) || stage4.residual_group1.blocks.4.norm1.bias
+ | 0.000 | -0.089 | 0.081 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.4.attn.position_bias
+ | -0.000 | -0.080 | 0.085 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.4.attn.qkv_self.weight
+ | -0.000 | -0.006 | 0.005 | 0.001 | torch.Size([360]) || stage4.residual_group1.blocks.4.attn.qkv_self.bias
+ | -0.000 | -0.075 | 0.077 | 0.020 | torch.Size([120, 240]) || stage4.residual_group1.blocks.4.attn.proj.weight
+ | -0.000 | -0.021 | 0.016 | 0.007 | torch.Size([120]) || stage4.residual_group1.blocks.4.attn.proj.bias
+ | 0.000 | -0.082 | 0.088 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.4.attn.qkv_mut.weight
+ | -0.000 | -0.004 | 0.006 | 0.001 | torch.Size([360]) || stage4.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 1.000 | 0.999 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.4.norm2.weight
+ | 0.000 | -0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.4.norm2.bias
+ | -0.000 | -0.086 | 0.080 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.4.mlp.fc11.weight
+ | 0.000 | -0.001 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.4.mlp.fc11.bias
+ | 0.000 | -0.084 | 0.083 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.4.mlp.fc12.weight
+ | 0.000 | -0.001 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.4.mlp.fc12.bias
+ | 0.000 | -0.076 | 0.081 | 0.020 | torch.Size([120, 240]) || stage4.residual_group1.blocks.4.mlp.fc2.weight
+ | -0.000 | -0.018 | 0.015 | 0.007 | torch.Size([120]) || stage4.residual_group1.blocks.4.mlp.fc2.bias
+ | 1.003 | 0.997 | 1.014 | 0.003 | torch.Size([120]) || stage4.residual_group1.blocks.5.norm1.weight
+ | -0.001 | -0.005 | 0.004 | 0.002 | torch.Size([120]) || stage4.residual_group1.blocks.5.norm1.bias
+ | -0.001 | -0.070 | 0.069 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.5.attn.position_bias
+ | -0.000 | -0.097 | 0.082 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.5.attn.qkv_self.weight
+ | 0.000 | -0.007 | 0.008 | 0.002 | torch.Size([360]) || stage4.residual_group1.blocks.5.attn.qkv_self.bias
+ | -0.000 | -0.075 | 0.089 | 0.021 | torch.Size([120, 240]) || stage4.residual_group1.blocks.5.attn.proj.weight
+ | 0.000 | -0.016 | 0.015 | 0.007 | torch.Size([120]) || stage4.residual_group1.blocks.5.attn.proj.bias
+ | 0.000 | -0.083 | 0.091 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.5.attn.qkv_mut.weight
+ | 0.000 | -0.006 | 0.006 | 0.001 | torch.Size([360]) || stage4.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 1.000 | 0.999 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.5.norm2.weight
+ | -0.000 | -0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.5.norm2.bias
+ | 0.000 | -0.093 | 0.083 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.5.mlp.fc11.weight
+ | 0.000 | -0.002 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.5.mlp.fc11.bias
+ | 0.000 | -0.086 | 0.085 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.5.mlp.fc12.weight
+ | 0.000 | -0.001 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.5.mlp.fc12.bias
+ | 0.000 | -0.079 | 0.092 | 0.020 | torch.Size([120, 240]) || stage4.residual_group1.blocks.5.mlp.fc2.weight
+ | -0.000 | -0.012 | 0.016 | 0.005 | torch.Size([120]) || stage4.residual_group1.blocks.5.mlp.fc2.bias
+ | -0.000 | -0.090 | 0.111 | 0.024 | torch.Size([120, 120]) || stage4.linear1.weight
+ | 0.001 | -0.019 | 0.029 | 0.009 | torch.Size([120]) || stage4.linear1.bias
+ | 1.000 | 0.999 | 1.003 | 0.001 | torch.Size([120]) || stage4.residual_group2.blocks.0.norm1.weight
+ | 0.000 | -0.001 | 0.001 | 0.000 | torch.Size([120]) || stage4.residual_group2.blocks.0.norm1.bias
+ | -0.000 | -0.078 | 0.075 | 0.020 | torch.Size([2475, 6]) || stage4.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage4.residual_group2.blocks.0.attn.relative_position_index
+ | 0.000 | -0.084 | 0.087 | 0.020 | torch.Size([360, 120]) || stage4.residual_group2.blocks.0.attn.qkv_self.weight
+ | 0.000 | -0.005 | 0.004 | 0.001 | torch.Size([360]) || stage4.residual_group2.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.079 | 0.080 | 0.020 | torch.Size([120, 120]) || stage4.residual_group2.blocks.0.attn.proj.weight
+ | 0.000 | -0.021 | 0.024 | 0.008 | torch.Size([120]) || stage4.residual_group2.blocks.0.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group2.blocks.0.norm2.weight
+ | -0.000 | -0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group2.blocks.0.norm2.bias
+ | -0.000 | -0.079 | 0.072 | 0.020 | torch.Size([240, 120]) || stage4.residual_group2.blocks.0.mlp.fc11.weight
+ | -0.000 | -0.001 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group2.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.077 | 0.078 | 0.020 | torch.Size([240, 120]) || stage4.residual_group2.blocks.0.mlp.fc12.weight
+ | 0.000 | -0.001 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group2.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.102 | 0.078 | 0.020 | torch.Size([120, 240]) || stage4.residual_group2.blocks.0.mlp.fc2.weight
+ | 0.000 | -0.024 | 0.020 | 0.009 | torch.Size([120]) || stage4.residual_group2.blocks.0.mlp.fc2.bias
+ | 1.001 | 0.998 | 1.003 | 0.001 | torch.Size([120]) || stage4.residual_group2.blocks.1.norm1.weight
+ | -0.000 | -0.002 | 0.002 | 0.001 | torch.Size([120]) || stage4.residual_group2.blocks.1.norm1.bias
+ | -0.000 | -0.071 | 0.079 | 0.020 | torch.Size([2475, 6]) || stage4.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage4.residual_group2.blocks.1.attn.relative_position_index
+ | 0.000 | -0.078 | 0.096 | 0.020 | torch.Size([360, 120]) || stage4.residual_group2.blocks.1.attn.qkv_self.weight
+ | 0.000 | -0.005 | 0.006 | 0.001 | torch.Size([360]) || stage4.residual_group2.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.077 | 0.080 | 0.020 | torch.Size([120, 120]) || stage4.residual_group2.blocks.1.attn.proj.weight
+ | 0.000 | -0.020 | 0.021 | 0.008 | torch.Size([120]) || stage4.residual_group2.blocks.1.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group2.blocks.1.norm2.weight
+ | -0.000 | -0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group2.blocks.1.norm2.bias
+ | -0.000 | -0.085 | 0.082 | 0.020 | torch.Size([240, 120]) || stage4.residual_group2.blocks.1.mlp.fc11.weight
+ | -0.000 | -0.001 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group2.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.083 | 0.085 | 0.020 | torch.Size([240, 120]) || stage4.residual_group2.blocks.1.mlp.fc12.weight
+ | 0.000 | -0.001 | 0.000 | 0.000 | torch.Size([240]) || stage4.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.078 | 0.078 | 0.020 | torch.Size([120, 240]) || stage4.residual_group2.blocks.1.mlp.fc2.weight
+ | 0.000 | -0.022 | 0.021 | 0.008 | torch.Size([120]) || stage4.residual_group2.blocks.1.mlp.fc2.bias
+ | 0.000 | -0.092 | 0.112 | 0.023 | torch.Size([120, 120]) || stage4.linear2.weight
+ | 0.000 | -0.032 | 0.049 | 0.015 | torch.Size([120]) || stage4.linear2.bias
+ | 0.000 | -0.036 | 0.037 | 0.018 | torch.Size([120, 120, 3, 3]) || stage4.pa_deform.weight
+ | 0.000 | -0.005 | 0.005 | 0.002 | torch.Size([120]) || stage4.pa_deform.bias
+ | -0.000 | -0.021 | 0.022 | 0.012 | torch.Size([120, 242, 3, 3]) || stage4.pa_deform.conv_offset.0.weight
+ | -0.001 | -0.021 | 0.021 | 0.012 | torch.Size([120]) || stage4.pa_deform.conv_offset.0.bias
+ | 0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage4.pa_deform.conv_offset.2.weight
+ | 0.002 | -0.030 | 0.030 | 0.018 | torch.Size([120]) || stage4.pa_deform.conv_offset.2.bias
+ | 0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage4.pa_deform.conv_offset.4.weight
+ | -0.002 | -0.030 | 0.030 | 0.017 | torch.Size([120]) || stage4.pa_deform.conv_offset.4.bias
+ | 0.000 | -0.003 | 0.002 | 0.000 | torch.Size([324, 120, 3, 3]) || stage4.pa_deform.conv_offset.6.weight
+ | 0.000 | -0.005 | 0.004 | 0.001 | torch.Size([324]) || stage4.pa_deform.conv_offset.6.bias
+ | 0.000 | -0.172 | 0.177 | 0.022 | torch.Size([360, 360]) || stage4.pa_fuse.fc11.weight
+ | 0.002 | -0.027 | 0.088 | 0.014 | torch.Size([360]) || stage4.pa_fuse.fc11.bias
+ | 0.000 | -0.212 | 0.163 | 0.022 | torch.Size([360, 360]) || stage4.pa_fuse.fc12.weight
+ | 0.000 | -0.066 | 0.081 | 0.014 | torch.Size([360]) || stage4.pa_fuse.fc12.bias
+ | 0.000 | -0.413 | 0.387 | 0.029 | torch.Size([120, 360]) || stage4.pa_fuse.fc2.weight
+ | -0.001 | -0.198 | 0.214 | 0.073 | torch.Size([120]) || stage4.pa_fuse.fc2.bias
+ | 0.979 | 0.896 | 1.076 | 0.053 | torch.Size([30]) || stage5.reshape.1.weight
+ | -0.005 | -0.074 | 0.100 | 0.043 | torch.Size([30]) || stage5.reshape.1.bias
+ | 0.000 | -0.240 | 0.249 | 0.058 | torch.Size([120, 30]) || stage5.reshape.2.weight
+ | -0.002 | -0.286 | 0.229 | 0.080 | torch.Size([120]) || stage5.reshape.2.bias
+ | 1.001 | 0.993 | 1.006 | 0.002 | torch.Size([120]) || stage5.residual_group1.blocks.0.norm1.weight
+ | -0.004 | -0.018 | 0.006 | 0.005 | torch.Size([120]) || stage5.residual_group1.blocks.0.norm1.bias
+ | -0.000 | -0.066 | 0.062 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.0.attn.position_bias
+ | -0.000 | -0.091 | 0.086 | 0.021 | torch.Size([360, 120]) || stage5.residual_group1.blocks.0.attn.qkv_self.weight
+ | -0.000 | -0.014 | 0.012 | 0.004 | torch.Size([360]) || stage5.residual_group1.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.166 | 0.172 | 0.021 | torch.Size([120, 240]) || stage5.residual_group1.blocks.0.attn.proj.weight
+ | -0.001 | -0.053 | 0.045 | 0.018 | torch.Size([120]) || stage5.residual_group1.blocks.0.attn.proj.bias
+ | -0.000 | -0.090 | 0.081 | 0.020 | torch.Size([360, 120]) || stage5.residual_group1.blocks.0.attn.qkv_mut.weight
+ | 0.000 | -0.006 | 0.006 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.999 | 0.987 | 1.001 | 0.002 | torch.Size([120]) || stage5.residual_group1.blocks.0.norm2.weight
+ | 0.000 | -0.006 | 0.006 | 0.002 | torch.Size([120]) || stage5.residual_group1.blocks.0.norm2.bias
+ | 0.000 | -0.094 | 0.079 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.0.mlp.fc11.weight
+ | 0.000 | -0.022 | 0.012 | 0.004 | torch.Size([240]) || stage5.residual_group1.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.082 | 0.083 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.0.mlp.fc12.weight
+ | 0.000 | -0.013 | 0.014 | 0.005 | torch.Size([240]) || stage5.residual_group1.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.075 | 0.083 | 0.020 | torch.Size([120, 240]) || stage5.residual_group1.blocks.0.mlp.fc2.weight
+ | 0.000 | -0.073 | 0.078 | 0.021 | torch.Size([120]) || stage5.residual_group1.blocks.0.mlp.fc2.bias
+ | 1.001 | 0.994 | 1.007 | 0.002 | torch.Size([120]) || stage5.residual_group1.blocks.1.norm1.weight
+ | -0.004 | -0.016 | 0.004 | 0.004 | torch.Size([120]) || stage5.residual_group1.blocks.1.norm1.bias
+ | 0.000 | -0.065 | 0.063 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.1.attn.position_bias
+ | -0.000 | -0.077 | 0.083 | 0.020 | torch.Size([360, 120]) || stage5.residual_group1.blocks.1.attn.qkv_self.weight
+ | 0.000 | -0.022 | 0.017 | 0.003 | torch.Size([360]) || stage5.residual_group1.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.113 | 0.098 | 0.021 | torch.Size([120, 240]) || stage5.residual_group1.blocks.1.attn.proj.weight
+ | 0.000 | -0.058 | 0.045 | 0.017 | torch.Size([120]) || stage5.residual_group1.blocks.1.attn.proj.bias
+ | 0.000 | -0.080 | 0.080 | 0.020 | torch.Size([360, 120]) || stage5.residual_group1.blocks.1.attn.qkv_mut.weight
+ | -0.000 | -0.008 | 0.007 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.999 | 0.982 | 1.001 | 0.003 | torch.Size([120]) || stage5.residual_group1.blocks.1.norm2.weight
+ | 0.000 | -0.006 | 0.005 | 0.002 | torch.Size([120]) || stage5.residual_group1.blocks.1.norm2.bias
+ | -0.000 | -0.076 | 0.083 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.1.mlp.fc11.weight
+ | 0.000 | -0.017 | 0.014 | 0.004 | torch.Size([240]) || stage5.residual_group1.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.080 | 0.086 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.1.mlp.fc12.weight
+ | -0.000 | -0.014 | 0.016 | 0.004 | torch.Size([240]) || stage5.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.096 | 0.079 | 0.020 | torch.Size([120, 240]) || stage5.residual_group1.blocks.1.mlp.fc2.weight
+ | 0.001 | -0.051 | 0.039 | 0.017 | torch.Size([120]) || stage5.residual_group1.blocks.1.mlp.fc2.bias
+ | 1.002 | 0.998 | 1.009 | 0.002 | torch.Size([120]) || stage5.residual_group1.blocks.2.norm1.weight
+ | -0.004 | -0.014 | 0.003 | 0.003 | torch.Size([120]) || stage5.residual_group1.blocks.2.norm1.bias
+ | 0.000 | -0.067 | 0.073 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.2.attn.position_bias
+ | 0.000 | -0.085 | 0.087 | 0.020 | torch.Size([360, 120]) || stage5.residual_group1.blocks.2.attn.qkv_self.weight
+ | 0.000 | -0.015 | 0.014 | 0.003 | torch.Size([360]) || stage5.residual_group1.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.108 | 0.095 | 0.020 | torch.Size([120, 240]) || stage5.residual_group1.blocks.2.attn.proj.weight
+ | -0.001 | -0.043 | 0.039 | 0.013 | torch.Size([120]) || stage5.residual_group1.blocks.2.attn.proj.bias
+ | -0.000 | -0.088 | 0.081 | 0.020 | torch.Size([360, 120]) || stage5.residual_group1.blocks.2.attn.qkv_mut.weight
+ | -0.000 | -0.009 | 0.007 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.999 | 0.978 | 1.001 | 0.003 | torch.Size([120]) || stage5.residual_group1.blocks.2.norm2.weight
+ | 0.000 | -0.003 | 0.004 | 0.002 | torch.Size([120]) || stage5.residual_group1.blocks.2.norm2.bias
+ | -0.000 | -0.076 | 0.081 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.000 | -0.012 | 0.019 | 0.004 | torch.Size([240]) || stage5.residual_group1.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.079 | 0.077 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.2.mlp.fc12.weight
+ | -0.001 | -0.014 | 0.012 | 0.004 | torch.Size([240]) || stage5.residual_group1.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.076 | 0.082 | 0.020 | torch.Size([120, 240]) || stage5.residual_group1.blocks.2.mlp.fc2.weight
+ | -0.000 | -0.047 | 0.043 | 0.017 | torch.Size([120]) || stage5.residual_group1.blocks.2.mlp.fc2.bias
+ | 1.002 | 0.978 | 1.015 | 0.005 | torch.Size([120]) || stage5.residual_group1.blocks.3.norm1.weight
+ | -0.004 | -0.013 | 0.004 | 0.003 | torch.Size([120]) || stage5.residual_group1.blocks.3.norm1.bias
+ | -0.000 | -0.084 | 0.070 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.3.attn.position_bias
+ | 0.000 | -0.078 | 0.082 | 0.020 | torch.Size([360, 120]) || stage5.residual_group1.blocks.3.attn.qkv_self.weight
+ | -0.000 | -0.014 | 0.014 | 0.003 | torch.Size([360]) || stage5.residual_group1.blocks.3.attn.qkv_self.bias
+ | -0.000 | -0.123 | 0.132 | 0.021 | torch.Size([120, 240]) || stage5.residual_group1.blocks.3.attn.proj.weight
+ | 0.001 | -0.028 | 0.044 | 0.015 | torch.Size([120]) || stage5.residual_group1.blocks.3.attn.proj.bias
+ | -0.000 | -0.082 | 0.089 | 0.020 | torch.Size([360, 120]) || stage5.residual_group1.blocks.3.attn.qkv_mut.weight
+ | -0.000 | -0.007 | 0.008 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.999 | 0.974 | 1.001 | 0.004 | torch.Size([120]) || stage5.residual_group1.blocks.3.norm2.weight
+ | 0.000 | -0.008 | 0.010 | 0.003 | torch.Size([120]) || stage5.residual_group1.blocks.3.norm2.bias
+ | 0.000 | -0.075 | 0.088 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.3.mlp.fc11.weight
+ | 0.000 | -0.014 | 0.019 | 0.005 | torch.Size([240]) || stage5.residual_group1.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.081 | 0.080 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.3.mlp.fc12.weight
+ | 0.000 | -0.031 | 0.020 | 0.006 | torch.Size([240]) || stage5.residual_group1.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.081 | 0.106 | 0.020 | torch.Size([120, 240]) || stage5.residual_group1.blocks.3.mlp.fc2.weight
+ | -0.002 | -0.046 | 0.042 | 0.017 | torch.Size([120]) || stage5.residual_group1.blocks.3.mlp.fc2.bias
+ | 1.003 | 0.944 | 1.017 | 0.009 | torch.Size([120]) || stage5.residual_group1.blocks.4.norm1.weight
+ | -0.005 | -0.015 | 0.004 | 0.004 | torch.Size([120]) || stage5.residual_group1.blocks.4.norm1.bias
+ | -0.000 | -0.071 | 0.067 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.4.attn.position_bias
+ | -0.000 | -0.085 | 0.090 | 0.021 | torch.Size([360, 120]) || stage5.residual_group1.blocks.4.attn.qkv_self.weight
+ | -0.000 | -0.021 | 0.013 | 0.004 | torch.Size([360]) || stage5.residual_group1.blocks.4.attn.qkv_self.bias
+ | 0.000 | -0.130 | 0.089 | 0.021 | torch.Size([120, 240]) || stage5.residual_group1.blocks.4.attn.proj.weight
+ | -0.001 | -0.036 | 0.024 | 0.011 | torch.Size([120]) || stage5.residual_group1.blocks.4.attn.proj.bias
+ | 0.000 | -0.086 | 0.076 | 0.020 | torch.Size([360, 120]) || stage5.residual_group1.blocks.4.attn.qkv_mut.weight
+ | 0.000 | -0.008 | 0.008 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.999 | 0.967 | 1.001 | 0.004 | torch.Size([120]) || stage5.residual_group1.blocks.4.norm2.weight
+ | 0.000 | -0.006 | 0.007 | 0.003 | torch.Size([120]) || stage5.residual_group1.blocks.4.norm2.bias
+ | 0.000 | -0.080 | 0.085 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.4.mlp.fc11.weight
+ | -0.001 | -0.015 | 0.010 | 0.004 | torch.Size([240]) || stage5.residual_group1.blocks.4.mlp.fc11.bias
+ | -0.000 | -0.081 | 0.077 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.4.mlp.fc12.weight
+ | -0.000 | -0.020 | 0.018 | 0.005 | torch.Size([240]) || stage5.residual_group1.blocks.4.mlp.fc12.bias
+ | 0.000 | -0.081 | 0.085 | 0.020 | torch.Size([120, 240]) || stage5.residual_group1.blocks.4.mlp.fc2.weight
+ | -0.001 | -0.037 | 0.050 | 0.014 | torch.Size([120]) || stage5.residual_group1.blocks.4.mlp.fc2.bias
+ | 1.004 | 0.976 | 1.039 | 0.008 | torch.Size([120]) || stage5.residual_group1.blocks.5.norm1.weight
+ | -0.005 | -0.015 | 0.005 | 0.004 | torch.Size([120]) || stage5.residual_group1.blocks.5.norm1.bias
+ | -0.000 | -0.070 | 0.076 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.5.attn.position_bias
+ | 0.000 | -0.099 | 0.097 | 0.021 | torch.Size([360, 120]) || stage5.residual_group1.blocks.5.attn.qkv_self.weight
+ | -0.000 | -0.011 | 0.012 | 0.003 | torch.Size([360]) || stage5.residual_group1.blocks.5.attn.qkv_self.bias
+ | -0.000 | -0.084 | 0.093 | 0.020 | torch.Size([120, 240]) || stage5.residual_group1.blocks.5.attn.proj.weight
+ | 0.000 | -0.038 | 0.035 | 0.012 | torch.Size([120]) || stage5.residual_group1.blocks.5.attn.proj.bias
+ | 0.000 | -0.087 | 0.082 | 0.020 | torch.Size([360, 120]) || stage5.residual_group1.blocks.5.attn.qkv_mut.weight
+ | 0.000 | -0.008 | 0.010 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.998 | 0.960 | 1.002 | 0.005 | torch.Size([120]) || stage5.residual_group1.blocks.5.norm2.weight
+ | 0.000 | -0.006 | 0.006 | 0.002 | torch.Size([120]) || stage5.residual_group1.blocks.5.norm2.bias
+ | -0.000 | -0.088 | 0.095 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.000 | -0.014 | 0.027 | 0.005 | torch.Size([240]) || stage5.residual_group1.blocks.5.mlp.fc11.bias
+ | -0.000 | -0.081 | 0.074 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.5.mlp.fc12.weight
+ | 0.000 | -0.013 | 0.025 | 0.004 | torch.Size([240]) || stage5.residual_group1.blocks.5.mlp.fc12.bias
+ | -0.000 | -0.100 | 0.086 | 0.020 | torch.Size([120, 240]) || stage5.residual_group1.blocks.5.mlp.fc2.weight
+ | 0.000 | -0.022 | 0.030 | 0.011 | torch.Size([120]) || stage5.residual_group1.blocks.5.mlp.fc2.bias
+ | -0.000 | -0.102 | 0.117 | 0.023 | torch.Size([120, 120]) || stage5.linear1.weight
+ | -0.003 | -0.297 | 0.242 | 0.084 | torch.Size([120]) || stage5.linear1.bias
+ | 0.999 | 0.971 | 1.008 | 0.005 | torch.Size([120]) || stage5.residual_group2.blocks.0.norm1.weight
+ | -0.000 | -0.035 | 0.034 | 0.011 | torch.Size([120]) || stage5.residual_group2.blocks.0.norm1.bias
+ | 0.000 | -0.079 | 0.074 | 0.020 | torch.Size([2475, 6]) || stage5.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage5.residual_group2.blocks.0.attn.relative_position_index
+ | -0.000 | -0.087 | 0.083 | 0.020 | torch.Size([360, 120]) || stage5.residual_group2.blocks.0.attn.qkv_self.weight
+ | -0.000 | -0.028 | 0.018 | 0.005 | torch.Size([360]) || stage5.residual_group2.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.079 | 0.082 | 0.021 | torch.Size([120, 120]) || stage5.residual_group2.blocks.0.attn.proj.weight
+ | -0.001 | -0.146 | 0.171 | 0.054 | torch.Size([120]) || stage5.residual_group2.blocks.0.attn.proj.bias
+ | 0.997 | 0.967 | 1.003 | 0.006 | torch.Size([120]) || stage5.residual_group2.blocks.0.norm2.weight
+ | 0.000 | -0.005 | 0.005 | 0.002 | torch.Size([120]) || stage5.residual_group2.blocks.0.norm2.bias
+ | -0.000 | -0.073 | 0.089 | 0.020 | torch.Size([240, 120]) || stage5.residual_group2.blocks.0.mlp.fc11.weight
+ | -0.002 | -0.017 | 0.008 | 0.004 | torch.Size([240]) || stage5.residual_group2.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.084 | 0.073 | 0.020 | torch.Size([240, 120]) || stage5.residual_group2.blocks.0.mlp.fc12.weight
+ | 0.000 | -0.013 | 0.011 | 0.003 | torch.Size([240]) || stage5.residual_group2.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.083 | 0.085 | 0.020 | torch.Size([120, 240]) || stage5.residual_group2.blocks.0.mlp.fc2.weight
+ | 0.000 | -0.103 | 0.140 | 0.037 | torch.Size([120]) || stage5.residual_group2.blocks.0.mlp.fc2.bias
+ | 0.999 | 0.986 | 1.010 | 0.004 | torch.Size([120]) || stage5.residual_group2.blocks.1.norm1.weight
+ | 0.000 | -0.035 | 0.034 | 0.010 | torch.Size([120]) || stage5.residual_group2.blocks.1.norm1.bias
+ | 0.000 | -0.087 | 0.074 | 0.020 | torch.Size([2475, 6]) || stage5.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage5.residual_group2.blocks.1.attn.relative_position_index
+ | -0.000 | -0.084 | 0.079 | 0.020 | torch.Size([360, 120]) || stage5.residual_group2.blocks.1.attn.qkv_self.weight
+ | 0.000 | -0.024 | 0.024 | 0.005 | torch.Size([360]) || stage5.residual_group2.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.077 | 0.078 | 0.021 | torch.Size([120, 120]) || stage5.residual_group2.blocks.1.attn.proj.weight
+ | -0.001 | -0.112 | 0.144 | 0.038 | torch.Size([120]) || stage5.residual_group2.blocks.1.attn.proj.bias
+ | 0.998 | 0.965 | 1.004 | 0.006 | torch.Size([120]) || stage5.residual_group2.blocks.1.norm2.weight
+ | 0.000 | -0.004 | 0.005 | 0.002 | torch.Size([120]) || stage5.residual_group2.blocks.1.norm2.bias
+ | 0.000 | -0.088 | 0.079 | 0.020 | torch.Size([240, 120]) || stage5.residual_group2.blocks.1.mlp.fc11.weight
+ | -0.001 | -0.012 | 0.015 | 0.004 | torch.Size([240]) || stage5.residual_group2.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.102 | 0.080 | 0.020 | torch.Size([240, 120]) || stage5.residual_group2.blocks.1.mlp.fc12.weight
+ | 0.000 | -0.012 | 0.009 | 0.004 | torch.Size([240]) || stage5.residual_group2.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.075 | 0.078 | 0.020 | torch.Size([120, 240]) || stage5.residual_group2.blocks.1.mlp.fc2.weight
+ | 0.000 | -0.105 | 0.131 | 0.042 | torch.Size([120]) || stage5.residual_group2.blocks.1.mlp.fc2.bias
+ | -0.000 | -0.220 | 0.209 | 0.035 | torch.Size([120, 120]) || stage5.linear2.weight
+ | -0.003 | -0.335 | 0.284 | 0.096 | torch.Size([120]) || stage5.linear2.bias
+ | -0.000 | -0.064 | 0.065 | 0.019 | torch.Size([120, 120, 3, 3]) || stage5.pa_deform.weight
+ | 0.001 | -0.050 | 0.050 | 0.029 | torch.Size([120]) || stage5.pa_deform.bias
+ | 0.000 | -0.119 | 0.106 | 0.013 | torch.Size([120, 242, 3, 3]) || stage5.pa_deform.conv_offset.0.weight
+ | -0.006 | -0.030 | 0.026 | 0.014 | torch.Size([120]) || stage5.pa_deform.conv_offset.0.bias
+ | -0.001 | -0.055 | 0.050 | 0.018 | torch.Size([120, 120, 3, 3]) || stage5.pa_deform.conv_offset.2.weight
+ | 0.001 | -0.033 | 0.031 | 0.018 | torch.Size([120]) || stage5.pa_deform.conv_offset.2.bias
+ | 0.001 | -0.060 | 0.050 | 0.018 | torch.Size([120, 120, 3, 3]) || stage5.pa_deform.conv_offset.4.weight
+ | -0.005 | -0.040 | 0.037 | 0.019 | torch.Size([120]) || stage5.pa_deform.conv_offset.4.bias
+ | 0.001 | -0.038 | 0.051 | 0.006 | torch.Size([324, 120, 3, 3]) || stage5.pa_deform.conv_offset.6.weight
+ | 0.000 | -0.048 | 0.050 | 0.017 | torch.Size([324]) || stage5.pa_deform.conv_offset.6.bias
+ | 0.000 | -0.334 | 0.340 | 0.036 | torch.Size([360, 360]) || stage5.pa_fuse.fc11.weight
+ | 0.037 | -0.050 | 0.294 | 0.064 | torch.Size([360]) || stage5.pa_fuse.fc11.bias
+ | -0.000 | -0.343 | 0.349 | 0.036 | torch.Size([360, 360]) || stage5.pa_fuse.fc12.weight
+ | -0.001 | -0.237 | 0.244 | 0.049 | torch.Size([360]) || stage5.pa_fuse.fc12.bias
+ | -0.000 | -0.575 | 0.591 | 0.060 | torch.Size([120, 360]) || stage5.pa_fuse.fc2.weight
+ | -0.001 | -0.404 | 0.344 | 0.122 | torch.Size([120]) || stage5.pa_fuse.fc2.bias
+ | 1.254 | 1.058 | 1.466 | 0.126 | torch.Size([30]) || stage6.reshape.1.weight
+ | -0.001 | -0.074 | 0.093 | 0.041 | torch.Size([30]) || stage6.reshape.1.bias
+ | 0.000 | -0.734 | 0.625 | 0.177 | torch.Size([120, 30]) || stage6.reshape.2.weight
+ | 0.003 | -0.269 | 0.341 | 0.108 | torch.Size([120]) || stage6.reshape.2.bias
+ | 0.815 | 0.495 | 1.118 | 0.121 | torch.Size([120]) || stage6.residual_group1.blocks.0.norm1.weight
+ | -0.071 | -0.291 | 0.263 | 0.101 | torch.Size([120]) || stage6.residual_group1.blocks.0.norm1.bias
+ | -0.000 | -0.080 | 0.087 | 0.021 | torch.Size([675, 6]) || stage6.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.0.attn.position_bias
+ | 0.000 | -0.136 | 0.134 | 0.026 | torch.Size([360, 120]) || stage6.residual_group1.blocks.0.attn.qkv_self.weight
+ | -0.000 | -0.061 | 0.037 | 0.014 | torch.Size([360]) || stage6.residual_group1.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.201 | 0.182 | 0.032 | torch.Size([120, 240]) || stage6.residual_group1.blocks.0.attn.proj.weight
+ | 0.000 | -0.223 | 0.189 | 0.090 | torch.Size([120]) || stage6.residual_group1.blocks.0.attn.proj.bias
+ | 0.000 | -0.184 | 0.211 | 0.029 | torch.Size([360, 120]) || stage6.residual_group1.blocks.0.attn.qkv_mut.weight
+ | 0.000 | -0.049 | 0.069 | 0.011 | torch.Size([360]) || stage6.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.710 | 0.556 | 0.893 | 0.072 | torch.Size([120]) || stage6.residual_group1.blocks.0.norm2.weight
+ | -0.003 | -0.172 | 0.193 | 0.070 | torch.Size([120]) || stage6.residual_group1.blocks.0.norm2.bias
+ | 0.000 | -0.217 | 0.211 | 0.033 | torch.Size([240, 120]) || stage6.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.041 | -0.158 | 0.025 | 0.036 | torch.Size([240]) || stage6.residual_group1.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.209 | 0.178 | 0.031 | torch.Size([240, 120]) || stage6.residual_group1.blocks.0.mlp.fc12.weight
+ | -0.000 | -0.141 | 0.186 | 0.031 | torch.Size([240]) || stage6.residual_group1.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.245 | 0.347 | 0.037 | torch.Size([120, 240]) || stage6.residual_group1.blocks.0.mlp.fc2.weight
+ | 0.005 | -0.161 | 0.188 | 0.079 | torch.Size([120]) || stage6.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.780 | 0.582 | 0.963 | 0.088 | torch.Size([120]) || stage6.residual_group1.blocks.1.norm1.weight
+ | -0.112 | -0.302 | 0.103 | 0.085 | torch.Size([120]) || stage6.residual_group1.blocks.1.norm1.bias
+ | 0.000 | -0.101 | 0.072 | 0.021 | torch.Size([675, 6]) || stage6.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.1.attn.position_bias
+ | 0.000 | -0.112 | 0.178 | 0.026 | torch.Size([360, 120]) || stage6.residual_group1.blocks.1.attn.qkv_self.weight
+ | -0.000 | -0.034 | 0.049 | 0.009 | torch.Size([360]) || stage6.residual_group1.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.223 | 0.242 | 0.033 | torch.Size([120, 240]) || stage6.residual_group1.blocks.1.attn.proj.weight
+ | -0.003 | -0.149 | 0.105 | 0.047 | torch.Size([120]) || stage6.residual_group1.blocks.1.attn.proj.bias
+ | 0.000 | -0.199 | 0.173 | 0.031 | torch.Size([360, 120]) || stage6.residual_group1.blocks.1.attn.qkv_mut.weight
+ | 0.000 | -0.035 | 0.056 | 0.009 | torch.Size([360]) || stage6.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.744 | 0.530 | 0.917 | 0.066 | torch.Size([120]) || stage6.residual_group1.blocks.1.norm2.weight
+ | 0.004 | -0.131 | 0.180 | 0.059 | torch.Size([120]) || stage6.residual_group1.blocks.1.norm2.bias
+ | 0.000 | -0.243 | 0.294 | 0.036 | torch.Size([240, 120]) || stage6.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.039 | -0.217 | 0.045 | 0.037 | torch.Size([240]) || stage6.residual_group1.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.206 | 0.178 | 0.033 | torch.Size([240, 120]) || stage6.residual_group1.blocks.1.mlp.fc12.weight
+ | -0.000 | -0.129 | 0.125 | 0.028 | torch.Size([240]) || stage6.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.236 | 0.276 | 0.040 | torch.Size([120, 240]) || stage6.residual_group1.blocks.1.mlp.fc2.weight
+ | 0.000 | -0.158 | 0.170 | 0.063 | torch.Size([120]) || stage6.residual_group1.blocks.1.mlp.fc2.bias
+ | 0.829 | 0.586 | 1.007 | 0.078 | torch.Size([120]) || stage6.residual_group1.blocks.2.norm1.weight
+ | -0.101 | -0.353 | 0.132 | 0.092 | torch.Size([120]) || stage6.residual_group1.blocks.2.norm1.bias
+ | -0.000 | -0.082 | 0.076 | 0.021 | torch.Size([675, 6]) || stage6.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.2.attn.position_bias
+ | 0.000 | -0.154 | 0.143 | 0.032 | torch.Size([360, 120]) || stage6.residual_group1.blocks.2.attn.qkv_self.weight
+ | 0.000 | -0.041 | 0.038 | 0.012 | torch.Size([360]) || stage6.residual_group1.blocks.2.attn.qkv_self.bias
+ | 0.000 | -0.187 | 0.202 | 0.035 | torch.Size([120, 240]) || stage6.residual_group1.blocks.2.attn.proj.weight
+ | 0.002 | -0.096 | 0.127 | 0.041 | torch.Size([120]) || stage6.residual_group1.blocks.2.attn.proj.bias
+ | -0.000 | -0.203 | 0.185 | 0.033 | torch.Size([360, 120]) || stage6.residual_group1.blocks.2.attn.qkv_mut.weight
+ | -0.000 | -0.045 | 0.049 | 0.009 | torch.Size([360]) || stage6.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.768 | 0.491 | 0.904 | 0.069 | torch.Size([120]) || stage6.residual_group1.blocks.2.norm2.weight
+ | 0.001 | -0.146 | 0.159 | 0.062 | torch.Size([120]) || stage6.residual_group1.blocks.2.norm2.bias
+ | -0.000 | -0.184 | 0.204 | 0.037 | torch.Size([240, 120]) || stage6.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.043 | -0.185 | 0.020 | 0.035 | torch.Size([240]) || stage6.residual_group1.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.188 | 0.270 | 0.035 | torch.Size([240, 120]) || stage6.residual_group1.blocks.2.mlp.fc12.weight
+ | 0.000 | -0.152 | 0.134 | 0.031 | torch.Size([240]) || stage6.residual_group1.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.222 | 0.217 | 0.042 | torch.Size([120, 240]) || stage6.residual_group1.blocks.2.mlp.fc2.weight
+ | 0.002 | -0.141 | 0.144 | 0.058 | torch.Size([120]) || stage6.residual_group1.blocks.2.mlp.fc2.bias
+ | 0.820 | 0.554 | 0.976 | 0.065 | torch.Size([120]) || stage6.residual_group1.blocks.3.norm1.weight
+ | -0.091 | -0.336 | 0.137 | 0.087 | torch.Size([120]) || stage6.residual_group1.blocks.3.norm1.bias
+ | 0.000 | -0.124 | 0.222 | 0.023 | torch.Size([675, 6]) || stage6.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.3.attn.position_bias
+ | 0.000 | -0.157 | 0.175 | 0.036 | torch.Size([360, 120]) || stage6.residual_group1.blocks.3.attn.qkv_self.weight
+ | -0.001 | -0.049 | 0.049 | 0.014 | torch.Size([360]) || stage6.residual_group1.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.238 | 0.236 | 0.036 | torch.Size([120, 240]) || stage6.residual_group1.blocks.3.attn.proj.weight
+ | -0.003 | -0.077 | 0.074 | 0.031 | torch.Size([120]) || stage6.residual_group1.blocks.3.attn.proj.bias
+ | 0.000 | -0.212 | 0.265 | 0.033 | torch.Size([360, 120]) || stage6.residual_group1.blocks.3.attn.qkv_mut.weight
+ | 0.000 | -0.028 | 0.052 | 0.009 | torch.Size([360]) || stage6.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.768 | 0.530 | 0.903 | 0.080 | torch.Size([120]) || stage6.residual_group1.blocks.3.norm2.weight
+ | 0.002 | -0.104 | 0.157 | 0.044 | torch.Size([120]) || stage6.residual_group1.blocks.3.norm2.bias
+ | -0.000 | -0.197 | 0.220 | 0.039 | torch.Size([240, 120]) || stage6.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.042 | -0.155 | 0.043 | 0.039 | torch.Size([240]) || stage6.residual_group1.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.166 | 0.199 | 0.036 | torch.Size([240, 120]) || stage6.residual_group1.blocks.3.mlp.fc12.weight
+ | 0.001 | -0.102 | 0.138 | 0.040 | torch.Size([240]) || stage6.residual_group1.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.241 | 0.256 | 0.044 | torch.Size([120, 240]) || stage6.residual_group1.blocks.3.mlp.fc2.weight
+ | 0.003 | -0.123 | 0.115 | 0.046 | torch.Size([120]) || stage6.residual_group1.blocks.3.mlp.fc2.bias
+ | 0.817 | 0.631 | 0.918 | 0.055 | torch.Size([120]) || stage6.residual_group1.blocks.4.norm1.weight
+ | -0.082 | -0.295 | 0.141 | 0.074 | torch.Size([120]) || stage6.residual_group1.blocks.4.norm1.bias
+ | -0.000 | -0.084 | 0.205 | 0.024 | torch.Size([675, 6]) || stage6.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.4.attn.position_bias
+ | -0.000 | -0.174 | 0.199 | 0.040 | torch.Size([360, 120]) || stage6.residual_group1.blocks.4.attn.qkv_self.weight
+ | -0.000 | -0.060 | 0.081 | 0.017 | torch.Size([360]) || stage6.residual_group1.blocks.4.attn.qkv_self.bias
+ | -0.000 | -0.194 | 0.191 | 0.037 | torch.Size([120, 240]) || stage6.residual_group1.blocks.4.attn.proj.weight
+ | 0.001 | -0.083 | 0.077 | 0.035 | torch.Size([120]) || stage6.residual_group1.blocks.4.attn.proj.bias
+ | -0.000 | -0.218 | 0.243 | 0.033 | torch.Size([360, 120]) || stage6.residual_group1.blocks.4.attn.qkv_mut.weight
+ | -0.000 | -0.031 | 0.024 | 0.007 | torch.Size([360]) || stage6.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.744 | 0.478 | 0.913 | 0.082 | torch.Size([120]) || stage6.residual_group1.blocks.4.norm2.weight
+ | -0.003 | -0.146 | 0.110 | 0.053 | torch.Size([120]) || stage6.residual_group1.blocks.4.norm2.bias
+ | -0.000 | -0.223 | 0.238 | 0.042 | torch.Size([240, 120]) || stage6.residual_group1.blocks.4.mlp.fc11.weight
+ | -0.046 | -0.200 | 0.071 | 0.051 | torch.Size([240]) || stage6.residual_group1.blocks.4.mlp.fc11.bias
+ | -0.000 | -0.168 | 0.201 | 0.039 | torch.Size([240, 120]) || stage6.residual_group1.blocks.4.mlp.fc12.weight
+ | 0.002 | -0.128 | 0.141 | 0.053 | torch.Size([240]) || stage6.residual_group1.blocks.4.mlp.fc12.bias
+ | -0.000 | -0.220 | 0.205 | 0.047 | torch.Size([120, 240]) || stage6.residual_group1.blocks.4.mlp.fc2.weight
+ | 0.001 | -0.086 | 0.094 | 0.034 | torch.Size([120]) || stage6.residual_group1.blocks.4.mlp.fc2.bias
+ | 0.754 | 0.353 | 0.933 | 0.056 | torch.Size([120]) || stage6.residual_group1.blocks.5.norm1.weight
+ | -0.058 | -0.246 | 0.105 | 0.060 | torch.Size([120]) || stage6.residual_group1.blocks.5.norm1.bias
+ | -0.000 | -0.113 | 0.536 | 0.030 | torch.Size([675, 6]) || stage6.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.5.attn.position_bias
+ | 0.000 | -0.261 | 0.224 | 0.044 | torch.Size([360, 120]) || stage6.residual_group1.blocks.5.attn.qkv_self.weight
+ | 0.002 | -0.050 | 0.067 | 0.018 | torch.Size([360]) || stage6.residual_group1.blocks.5.attn.qkv_self.bias
+ | 0.000 | -0.234 | 0.256 | 0.038 | torch.Size([120, 240]) || stage6.residual_group1.blocks.5.attn.proj.weight
+ | 0.002 | -0.079 | 0.076 | 0.036 | torch.Size([120]) || stage6.residual_group1.blocks.5.attn.proj.bias
+ | -0.000 | -0.211 | 0.231 | 0.029 | torch.Size([360, 120]) || stage6.residual_group1.blocks.5.attn.qkv_mut.weight
+ | 0.000 | -0.033 | 0.030 | 0.008 | torch.Size([360]) || stage6.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.677 | 0.275 | 0.833 | 0.083 | torch.Size([120]) || stage6.residual_group1.blocks.5.norm2.weight
+ | 0.001 | -0.224 | 0.306 | 0.102 | torch.Size([120]) || stage6.residual_group1.blocks.5.norm2.bias
+ | -0.000 | -0.196 | 0.211 | 0.045 | torch.Size([240, 120]) || stage6.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.061 | -0.289 | 0.136 | 0.089 | torch.Size([240]) || stage6.residual_group1.blocks.5.mlp.fc11.bias
+ | -0.000 | -0.271 | 0.312 | 0.048 | torch.Size([240, 120]) || stage6.residual_group1.blocks.5.mlp.fc12.weight
+ | 0.003 | -0.166 | 0.155 | 0.075 | torch.Size([240]) || stage6.residual_group1.blocks.5.mlp.fc12.bias
+ | 0.000 | -0.286 | 0.375 | 0.054 | torch.Size([120, 240]) || stage6.residual_group1.blocks.5.mlp.fc2.weight
+ | 0.005 | -0.054 | 0.137 | 0.031 | torch.Size([120]) || stage6.residual_group1.blocks.5.mlp.fc2.bias
+ | -0.000 | -0.174 | 0.172 | 0.039 | torch.Size([120, 120]) || stage6.linear1.weight
+ | 0.002 | -0.275 | 0.348 | 0.113 | torch.Size([120]) || stage6.linear1.bias
+ | 0.704 | 0.402 | 1.002 | 0.132 | torch.Size([120]) || stage6.residual_group2.blocks.0.norm1.weight
+ | 0.001 | -0.466 | 0.407 | 0.157 | torch.Size([120]) || stage6.residual_group2.blocks.0.norm1.bias
+ | -0.000 | -0.172 | 0.570 | 0.025 | torch.Size([2475, 6]) || stage6.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage6.residual_group2.blocks.0.attn.relative_position_index
+ | 0.000 | -0.337 | 0.378 | 0.041 | torch.Size([360, 120]) || stage6.residual_group2.blocks.0.attn.qkv_self.weight
+ | -0.000 | -0.071 | 0.068 | 0.019 | torch.Size([360]) || stage6.residual_group2.blocks.0.attn.qkv_self.bias
+ | 0.001 | -0.290 | 0.321 | 0.055 | torch.Size([120, 120]) || stage6.residual_group2.blocks.0.attn.proj.weight
+ | 0.001 | -0.255 | 0.250 | 0.104 | torch.Size([120]) || stage6.residual_group2.blocks.0.attn.proj.bias
+ | 0.695 | 0.353 | 0.966 | 0.098 | torch.Size([120]) || stage6.residual_group2.blocks.0.norm2.weight
+ | -0.001 | -0.218 | 0.165 | 0.080 | torch.Size([120]) || stage6.residual_group2.blocks.0.norm2.bias
+ | 0.000 | -0.259 | 0.255 | 0.039 | torch.Size([240, 120]) || stage6.residual_group2.blocks.0.mlp.fc11.weight
+ | -0.044 | -0.256 | 0.042 | 0.047 | torch.Size([240]) || stage6.residual_group2.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.234 | 0.214 | 0.035 | torch.Size([240, 120]) || stage6.residual_group2.blocks.0.mlp.fc12.weight
+ | 0.002 | -0.133 | 0.091 | 0.027 | torch.Size([240]) || stage6.residual_group2.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.333 | 0.296 | 0.042 | torch.Size([120, 240]) || stage6.residual_group2.blocks.0.mlp.fc2.weight
+ | 0.003 | -0.238 | 0.280 | 0.092 | torch.Size([120]) || stage6.residual_group2.blocks.0.mlp.fc2.bias
+ | 0.671 | 0.425 | 0.980 | 0.094 | torch.Size([120]) || stage6.residual_group2.blocks.1.norm1.weight
+ | 0.001 | -0.261 | 0.305 | 0.119 | torch.Size([120]) || stage6.residual_group2.blocks.1.norm1.bias
+ | -0.000 | -0.372 | 0.942 | 0.031 | torch.Size([2475, 6]) || stage6.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage6.residual_group2.blocks.1.attn.relative_position_index
+ | 0.000 | -0.450 | 0.494 | 0.045 | torch.Size([360, 120]) || stage6.residual_group2.blocks.1.attn.qkv_self.weight
+ | 0.000 | -0.133 | 0.119 | 0.029 | torch.Size([360]) || stage6.residual_group2.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.239 | 0.288 | 0.046 | torch.Size([120, 120]) || stage6.residual_group2.blocks.1.attn.proj.weight
+ | -0.001 | -0.187 | 0.157 | 0.064 | torch.Size([120]) || stage6.residual_group2.blocks.1.attn.proj.bias
+ | 0.687 | 0.160 | 0.907 | 0.128 | torch.Size([120]) || stage6.residual_group2.blocks.1.norm2.weight
+ | -0.002 | -0.192 | 0.222 | 0.084 | torch.Size([120]) || stage6.residual_group2.blocks.1.norm2.bias
+ | 0.000 | -0.257 | 0.426 | 0.042 | torch.Size([240, 120]) || stage6.residual_group2.blocks.1.mlp.fc11.weight
+ | -0.064 | -0.207 | 0.036 | 0.048 | torch.Size([240]) || stage6.residual_group2.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.269 | 0.224 | 0.038 | torch.Size([240, 120]) || stage6.residual_group2.blocks.1.mlp.fc12.weight
+ | -0.000 | -0.126 | 0.129 | 0.030 | torch.Size([240]) || stage6.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.308 | 0.298 | 0.041 | torch.Size([120, 240]) || stage6.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.004 | -0.180 | 0.192 | 0.061 | torch.Size([120]) || stage6.residual_group2.blocks.1.mlp.fc2.bias
+ | -0.000 | -0.297 | 0.368 | 0.069 | torch.Size([120, 120]) || stage6.linear2.weight
+ | 0.001 | -0.431 | 0.480 | 0.189 | torch.Size([120]) || stage6.linear2.bias
+ | 0.000 | -0.100 | 0.104 | 0.023 | torch.Size([120, 120, 3, 3]) || stage6.pa_deform.weight
+ | 0.001 | -0.018 | 0.029 | 0.010 | torch.Size([120]) || stage6.pa_deform.bias
+ | 0.000 | -0.105 | 0.111 | 0.015 | torch.Size([120, 242, 3, 3]) || stage6.pa_deform.conv_offset.0.weight
+ | -0.007 | -0.033 | 0.024 | 0.014 | torch.Size([120]) || stage6.pa_deform.conv_offset.0.bias
+ | -0.001 | -0.071 | 0.067 | 0.019 | torch.Size([120, 120, 3, 3]) || stage6.pa_deform.conv_offset.2.weight
+ | -0.003 | -0.061 | 0.043 | 0.022 | torch.Size([120]) || stage6.pa_deform.conv_offset.2.bias
+ | -0.000 | -0.074 | 0.068 | 0.019 | torch.Size([120, 120, 3, 3]) || stage6.pa_deform.conv_offset.4.weight
+ | 0.001 | -0.075 | 0.056 | 0.030 | torch.Size([120]) || stage6.pa_deform.conv_offset.4.bias
+ | 0.001 | -0.124 | 0.108 | 0.013 | torch.Size([324, 120, 3, 3]) || stage6.pa_deform.conv_offset.6.weight
+ | -0.001 | -0.113 | 0.076 | 0.021 | torch.Size([324]) || stage6.pa_deform.conv_offset.6.bias
+ | -0.001 | -0.517 | 0.524 | 0.101 | torch.Size([360, 360]) || stage6.pa_fuse.fc11.weight
+ | 0.154 | -0.305 | 0.679 | 0.180 | torch.Size([360]) || stage6.pa_fuse.fc11.bias
+ | 0.000 | -0.680 | 0.728 | 0.103 | torch.Size([360, 360]) || stage6.pa_fuse.fc12.weight
+ | 0.020 | -0.514 | 0.417 | 0.199 | torch.Size([360]) || stage6.pa_fuse.fc12.bias
+ | -0.000 | -0.587 | 0.737 | 0.135 | torch.Size([120, 360]) || stage6.pa_fuse.fc2.weight
+ | 0.015 | -0.437 | 0.490 | 0.230 | torch.Size([120]) || stage6.pa_fuse.fc2.bias
+ | 1.284 | 1.119 | 1.404 | 0.055 | torch.Size([30]) || stage7.reshape.1.weight
+ | -0.014 | -0.286 | 0.184 | 0.122 | torch.Size([30]) || stage7.reshape.1.bias
+ | -0.000 | -0.521 | 0.576 | 0.154 | torch.Size([120, 30]) || stage7.reshape.2.weight
+ | 0.004 | -0.387 | 0.738 | 0.175 | torch.Size([120]) || stage7.reshape.2.bias
+ | 0.440 | 0.099 | 0.775 | 0.141 | torch.Size([120]) || stage7.residual_group1.blocks.0.norm1.weight
+ | -0.177 | -0.670 | 0.319 | 0.183 | torch.Size([120]) || stage7.residual_group1.blocks.0.norm1.bias
+ | -0.055 | -2.159 | 1.979 | 0.240 | torch.Size([675, 6]) || stage7.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.0.attn.position_bias
+ | -0.000 | -0.535 | 0.554 | 0.104 | torch.Size([360, 120]) || stage7.residual_group1.blocks.0.attn.qkv_self.weight
+ | 0.003 | -0.193 | 0.281 | 0.053 | torch.Size([360]) || stage7.residual_group1.blocks.0.attn.qkv_self.bias
+ | -0.001 | -0.397 | 0.395 | 0.075 | torch.Size([120, 240]) || stage7.residual_group1.blocks.0.attn.proj.weight
+ | -0.001 | -0.232 | 0.692 | 0.106 | torch.Size([120]) || stage7.residual_group1.blocks.0.attn.proj.bias
+ | -0.000 | -0.899 | 1.073 | 0.091 | torch.Size([360, 120]) || stage7.residual_group1.blocks.0.attn.qkv_mut.weight
+ | -0.000 | -0.122 | 0.104 | 0.017 | torch.Size([360]) || stage7.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.310 | 0.157 | 0.440 | 0.055 | torch.Size([120]) || stage7.residual_group1.blocks.0.norm2.weight
+ | 0.006 | -0.474 | 0.266 | 0.105 | torch.Size([120]) || stage7.residual_group1.blocks.0.norm2.bias
+ | -0.000 | -0.605 | 0.490 | 0.115 | torch.Size([240, 120]) || stage7.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.101 | -0.310 | 0.126 | 0.070 | torch.Size([240]) || stage7.residual_group1.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.448 | 0.475 | 0.116 | torch.Size([240, 120]) || stage7.residual_group1.blocks.0.mlp.fc12.weight
+ | 0.006 | -0.185 | 0.215 | 0.071 | torch.Size([240]) || stage7.residual_group1.blocks.0.mlp.fc12.bias
+ | 0.001 | -0.465 | 0.512 | 0.122 | torch.Size([120, 240]) || stage7.residual_group1.blocks.0.mlp.fc2.weight
+ | 0.000 | -0.150 | 0.417 | 0.077 | torch.Size([120]) || stage7.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.577 | 0.165 | 0.829 | 0.105 | torch.Size([120]) || stage7.residual_group1.blocks.1.norm1.weight
+ | -0.136 | -0.849 | 0.206 | 0.141 | torch.Size([120]) || stage7.residual_group1.blocks.1.norm1.bias
+ | -0.143 | -3.020 | 4.621 | 0.357 | torch.Size([675, 6]) || stage7.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.1.attn.position_bias
+ | 0.000 | -0.647 | 0.640 | 0.123 | torch.Size([360, 120]) || stage7.residual_group1.blocks.1.attn.qkv_self.weight
+ | -0.002 | -0.356 | 0.382 | 0.064 | torch.Size([360]) || stage7.residual_group1.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.457 | 0.378 | 0.081 | torch.Size([120, 240]) || stage7.residual_group1.blocks.1.attn.proj.weight
+ | 0.000 | -0.250 | 0.707 | 0.108 | torch.Size([120]) || stage7.residual_group1.blocks.1.attn.proj.bias
+ | -0.001 | -1.055 | 1.091 | 0.096 | torch.Size([360, 120]) || stage7.residual_group1.blocks.1.attn.qkv_mut.weight
+ | -0.001 | -0.093 | 0.123 | 0.018 | torch.Size([360]) || stage7.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.411 | 0.265 | 0.535 | 0.044 | torch.Size([120]) || stage7.residual_group1.blocks.1.norm2.weight
+ | 0.008 | -0.630 | 0.264 | 0.121 | torch.Size([120]) || stage7.residual_group1.blocks.1.norm2.bias
+ | 0.000 | -0.501 | 0.506 | 0.119 | torch.Size([240, 120]) || stage7.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.087 | -0.341 | 0.140 | 0.073 | torch.Size([240]) || stage7.residual_group1.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.450 | 0.527 | 0.119 | torch.Size([240, 120]) || stage7.residual_group1.blocks.1.mlp.fc12.weight
+ | 0.005 | -0.188 | 0.171 | 0.063 | torch.Size([240]) || stage7.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.554 | 0.546 | 0.121 | torch.Size([120, 240]) || stage7.residual_group1.blocks.1.mlp.fc2.weight
+ | -0.000 | -0.135 | 0.220 | 0.061 | torch.Size([120]) || stage7.residual_group1.blocks.1.mlp.fc2.bias
+ | 0.655 | 0.134 | 0.896 | 0.130 | torch.Size([120]) || stage7.residual_group1.blocks.2.norm1.weight
+ | -0.139 | -0.788 | 0.181 | 0.115 | torch.Size([120]) || stage7.residual_group1.blocks.2.norm1.bias
+ | -0.062 | -3.469 | 3.276 | 0.272 | torch.Size([675, 6]) || stage7.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.2.attn.position_bias
+ | -0.000 | -0.592 | 0.650 | 0.124 | torch.Size([360, 120]) || stage7.residual_group1.blocks.2.attn.qkv_self.weight
+ | -0.000 | -0.308 | 0.218 | 0.062 | torch.Size([360]) || stage7.residual_group1.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.355 | 0.345 | 0.082 | torch.Size([120, 240]) || stage7.residual_group1.blocks.2.attn.proj.weight
+ | 0.002 | -0.213 | 0.700 | 0.097 | torch.Size([120]) || stage7.residual_group1.blocks.2.attn.proj.bias
+ | -0.001 | -1.166 | 0.942 | 0.107 | torch.Size([360, 120]) || stage7.residual_group1.blocks.2.attn.qkv_mut.weight
+ | 0.000 | -0.106 | 0.093 | 0.018 | torch.Size([360]) || stage7.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.466 | 0.317 | 0.565 | 0.042 | torch.Size([120]) || stage7.residual_group1.blocks.2.norm2.weight
+ | 0.014 | -0.657 | 0.280 | 0.118 | torch.Size([120]) || stage7.residual_group1.blocks.2.norm2.bias
+ | 0.000 | -0.541 | 0.494 | 0.118 | torch.Size([240, 120]) || stage7.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.079 | -0.335 | 0.122 | 0.080 | torch.Size([240]) || stage7.residual_group1.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.513 | 0.493 | 0.123 | torch.Size([240, 120]) || stage7.residual_group1.blocks.2.mlp.fc12.weight
+ | -0.007 | -0.180 | 0.175 | 0.066 | torch.Size([240]) || stage7.residual_group1.blocks.2.mlp.fc12.bias
+ | -0.001 | -0.509 | 0.479 | 0.123 | torch.Size([120, 240]) || stage7.residual_group1.blocks.2.mlp.fc2.weight
+ | 0.004 | -0.093 | 0.293 | 0.054 | torch.Size([120]) || stage7.residual_group1.blocks.2.mlp.fc2.bias
+ | 0.693 | 0.147 | 0.945 | 0.133 | torch.Size([120]) || stage7.residual_group1.blocks.3.norm1.weight
+ | -0.132 | -0.906 | 0.249 | 0.113 | torch.Size([120]) || stage7.residual_group1.blocks.3.norm1.bias
+ | -0.108 | -3.576 | 4.241 | 0.344 | torch.Size([675, 6]) || stage7.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.3.attn.position_bias
+ | -0.000 | -0.945 | 1.095 | 0.129 | torch.Size([360, 120]) || stage7.residual_group1.blocks.3.attn.qkv_self.weight
+ | 0.003 | -0.274 | 0.204 | 0.061 | torch.Size([360]) || stage7.residual_group1.blocks.3.attn.qkv_self.bias
+ | -0.001 | -0.379 | 0.351 | 0.081 | torch.Size([120, 240]) || stage7.residual_group1.blocks.3.attn.proj.weight
+ | 0.000 | -0.211 | 0.587 | 0.095 | torch.Size([120]) || stage7.residual_group1.blocks.3.attn.proj.bias
+ | -0.000 | -1.269 | 1.067 | 0.102 | torch.Size([360, 120]) || stage7.residual_group1.blocks.3.attn.qkv_mut.weight
+ | 0.001 | -0.091 | 0.117 | 0.021 | torch.Size([360]) || stage7.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.499 | 0.285 | 0.570 | 0.040 | torch.Size([120]) || stage7.residual_group1.blocks.3.norm2.weight
+ | 0.012 | -0.567 | 0.273 | 0.104 | torch.Size([120]) || stage7.residual_group1.blocks.3.norm2.bias
+ | 0.001 | -0.528 | 0.499 | 0.118 | torch.Size([240, 120]) || stage7.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.084 | -0.349 | 0.141 | 0.078 | torch.Size([240]) || stage7.residual_group1.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.547 | 0.592 | 0.126 | torch.Size([240, 120]) || stage7.residual_group1.blocks.3.mlp.fc12.weight
+ | 0.002 | -0.154 | 0.176 | 0.068 | torch.Size([240]) || stage7.residual_group1.blocks.3.mlp.fc12.bias
+ | 0.001 | -0.520 | 0.480 | 0.125 | torch.Size([120, 240]) || stage7.residual_group1.blocks.3.mlp.fc2.weight
+ | 0.001 | -0.150 | 0.207 | 0.065 | torch.Size([120]) || stage7.residual_group1.blocks.3.mlp.fc2.bias
+ | 0.726 | 0.137 | 1.004 | 0.160 | torch.Size([120]) || stage7.residual_group1.blocks.4.norm1.weight
+ | -0.122 | -0.907 | 0.180 | 0.103 | torch.Size([120]) || stage7.residual_group1.blocks.4.norm1.bias
+ | -0.078 | -3.824 | 4.241 | 0.297 | torch.Size([675, 6]) || stage7.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.4.attn.position_bias
+ | -0.000 | -1.188 | 0.796 | 0.127 | torch.Size([360, 120]) || stage7.residual_group1.blocks.4.attn.qkv_self.weight
+ | 0.002 | -0.248 | 0.207 | 0.056 | torch.Size([360]) || stage7.residual_group1.blocks.4.attn.qkv_self.bias
+ | -0.001 | -0.409 | 0.369 | 0.085 | torch.Size([120, 240]) || stage7.residual_group1.blocks.4.attn.proj.weight
+ | 0.002 | -0.224 | 0.322 | 0.094 | torch.Size([120]) || stage7.residual_group1.blocks.4.attn.proj.bias
+ | 0.000 | -1.744 | 1.273 | 0.110 | torch.Size([360, 120]) || stage7.residual_group1.blocks.4.attn.qkv_mut.weight
+ | 0.001 | -0.092 | 0.113 | 0.019 | torch.Size([360]) || stage7.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.514 | 0.277 | 0.614 | 0.041 | torch.Size([120]) || stage7.residual_group1.blocks.4.norm2.weight
+ | 0.016 | -0.621 | 0.286 | 0.095 | torch.Size([120]) || stage7.residual_group1.blocks.4.norm2.bias
+ | 0.001 | -0.517 | 0.453 | 0.116 | torch.Size([240, 120]) || stage7.residual_group1.blocks.4.mlp.fc11.weight
+ | -0.064 | -0.260 | 0.143 | 0.083 | torch.Size([240]) || stage7.residual_group1.blocks.4.mlp.fc11.bias
+ | 0.000 | -0.503 | 0.554 | 0.129 | torch.Size([240, 120]) || stage7.residual_group1.blocks.4.mlp.fc12.weight
+ | -0.004 | -0.232 | 0.193 | 0.075 | torch.Size([240]) || stage7.residual_group1.blocks.4.mlp.fc12.bias
+ | -0.001 | -0.595 | 0.543 | 0.128 | torch.Size([120, 240]) || stage7.residual_group1.blocks.4.mlp.fc2.weight
+ | 0.001 | -0.196 | 0.198 | 0.071 | torch.Size([120]) || stage7.residual_group1.blocks.4.mlp.fc2.bias
+ | 0.731 | 0.152 | 1.075 | 0.114 | torch.Size([120]) || stage7.residual_group1.blocks.5.norm1.weight
+ | -0.076 | -1.003 | 0.176 | 0.107 | torch.Size([120]) || stage7.residual_group1.blocks.5.norm1.bias
+ | -0.121 | -3.281 | 4.671 | 0.296 | torch.Size([675, 6]) || stage7.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.5.attn.position_bias
+ | -0.000 | -0.640 | 1.083 | 0.122 | torch.Size([360, 120]) || stage7.residual_group1.blocks.5.attn.qkv_self.weight
+ | -0.001 | -0.239 | 0.314 | 0.068 | torch.Size([360]) || stage7.residual_group1.blocks.5.attn.qkv_self.bias
+ | 0.001 | -0.344 | 0.452 | 0.078 | torch.Size([120, 240]) || stage7.residual_group1.blocks.5.attn.proj.weight
+ | 0.004 | -0.361 | 0.251 | 0.093 | torch.Size([120]) || stage7.residual_group1.blocks.5.attn.proj.bias
+ | 0.000 | -0.637 | 0.806 | 0.093 | torch.Size([360, 120]) || stage7.residual_group1.blocks.5.attn.qkv_mut.weight
+ | -0.000 | -0.088 | 0.091 | 0.017 | torch.Size([360]) || stage7.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.514 | 0.238 | 0.594 | 0.042 | torch.Size([120]) || stage7.residual_group1.blocks.5.norm2.weight
+ | 0.017 | -0.650 | 0.162 | 0.089 | torch.Size([120]) || stage7.residual_group1.blocks.5.norm2.bias
+ | 0.000 | -0.442 | 0.479 | 0.114 | torch.Size([240, 120]) || stage7.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.040 | -0.400 | 0.203 | 0.101 | torch.Size([240]) || stage7.residual_group1.blocks.5.mlp.fc11.bias
+ | -0.000 | -0.541 | 0.514 | 0.130 | torch.Size([240, 120]) || stage7.residual_group1.blocks.5.mlp.fc12.weight
+ | -0.008 | -0.319 | 0.309 | 0.092 | torch.Size([240]) || stage7.residual_group1.blocks.5.mlp.fc12.bias
+ | -0.000 | -1.018 | 1.398 | 0.130 | torch.Size([120, 240]) || stage7.residual_group1.blocks.5.mlp.fc2.weight
+ | 0.001 | -1.606 | 0.269 | 0.179 | torch.Size([120]) || stage7.residual_group1.blocks.5.mlp.fc2.bias
+ | 0.000 | -0.186 | 0.207 | 0.048 | torch.Size([120, 120]) || stage7.linear1.weight
+ | 0.010 | -0.448 | 0.437 | 0.161 | torch.Size([120]) || stage7.linear1.bias
+ | 0.703 | 0.381 | 0.856 | 0.084 | torch.Size([120]) || stage7.residual_group2.blocks.0.norm1.weight
+ | 0.014 | -0.645 | 0.486 | 0.169 | torch.Size([120]) || stage7.residual_group2.blocks.0.norm1.bias
+ | -0.007 | -4.468 | 1.008 | 0.164 | torch.Size([2475, 6]) || stage7.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage7.residual_group2.blocks.0.attn.relative_position_index
+ | -0.000 | -0.625 | 0.834 | 0.120 | torch.Size([360, 120]) || stage7.residual_group2.blocks.0.attn.qkv_self.weight
+ | -0.009 | -0.737 | 0.632 | 0.135 | torch.Size([360]) || stage7.residual_group2.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.403 | 0.406 | 0.088 | torch.Size([120, 120]) || stage7.residual_group2.blocks.0.attn.proj.weight
+ | -0.007 | -0.338 | 0.165 | 0.070 | torch.Size([120]) || stage7.residual_group2.blocks.0.attn.proj.bias
+ | 0.435 | 0.323 | 0.526 | 0.038 | torch.Size([120]) || stage7.residual_group2.blocks.0.norm2.weight
+ | 0.005 | -0.678 | 0.379 | 0.117 | torch.Size([120]) || stage7.residual_group2.blocks.0.norm2.bias
+ | 0.000 | -0.465 | 0.467 | 0.110 | torch.Size([240, 120]) || stage7.residual_group2.blocks.0.mlp.fc11.weight
+ | -0.031 | -0.236 | 0.180 | 0.077 | torch.Size([240]) || stage7.residual_group2.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.490 | 0.520 | 0.121 | torch.Size([240, 120]) || stage7.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.003 | -0.197 | 0.242 | 0.069 | torch.Size([240]) || stage7.residual_group2.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.525 | 0.501 | 0.122 | torch.Size([120, 240]) || stage7.residual_group2.blocks.0.mlp.fc2.weight
+ | -0.005 | -0.431 | 0.164 | 0.077 | torch.Size([120]) || stage7.residual_group2.blocks.0.mlp.fc2.bias
+ | 0.703 | 0.306 | 0.866 | 0.079 | torch.Size([120]) || stage7.residual_group2.blocks.1.norm1.weight
+ | 0.009 | -0.647 | 0.481 | 0.149 | torch.Size([120]) || stage7.residual_group2.blocks.1.norm1.bias
+ | -0.010 | -3.504 | 1.842 | 0.134 | torch.Size([2475, 6]) || stage7.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage7.residual_group2.blocks.1.attn.relative_position_index
+ | -0.000 | -0.639 | 0.590 | 0.122 | torch.Size([360, 120]) || stage7.residual_group2.blocks.1.attn.qkv_self.weight
+ | -0.001 | -0.613 | 0.609 | 0.148 | torch.Size([360]) || stage7.residual_group2.blocks.1.attn.qkv_self.bias
+ | 0.001 | -0.316 | 0.325 | 0.085 | torch.Size([120, 120]) || stage7.residual_group2.blocks.1.attn.proj.weight
+ | -0.004 | -0.350 | 0.145 | 0.069 | torch.Size([120]) || stage7.residual_group2.blocks.1.attn.proj.bias
+ | 0.452 | 0.309 | 0.558 | 0.037 | torch.Size([120]) || stage7.residual_group2.blocks.1.norm2.weight
+ | 0.003 | -0.661 | 0.246 | 0.091 | torch.Size([120]) || stage7.residual_group2.blocks.1.norm2.bias
+ | 0.000 | -0.580 | 0.410 | 0.108 | torch.Size([240, 120]) || stage7.residual_group2.blocks.1.mlp.fc11.weight
+ | -0.020 | -0.258 | 0.299 | 0.104 | torch.Size([240]) || stage7.residual_group2.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.529 | 0.561 | 0.126 | torch.Size([240, 120]) || stage7.residual_group2.blocks.1.mlp.fc12.weight
+ | -0.002 | -0.234 | 0.434 | 0.090 | torch.Size([240]) || stage7.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.778 | 0.581 | 0.124 | torch.Size([120, 240]) || stage7.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.001 | -0.888 | 0.286 | 0.135 | torch.Size([120]) || stage7.residual_group2.blocks.1.mlp.fc2.bias
+ | -0.001 | -0.348 | 0.237 | 0.060 | torch.Size([120, 120]) || stage7.linear2.weight
+ | 0.023 | -0.390 | 0.506 | 0.167 | torch.Size([120]) || stage7.linear2.bias
+ | -0.000 | -0.104 | 0.107 | 0.024 | torch.Size([120, 120, 3, 3]) || stage7.pa_deform.weight
+ | 0.002 | -0.041 | 0.035 | 0.016 | torch.Size([120]) || stage7.pa_deform.bias
+ | -0.000 | -0.123 | 0.109 | 0.017 | torch.Size([120, 242, 3, 3]) || stage7.pa_deform.conv_offset.0.weight
+ | -0.002 | -0.034 | 0.032 | 0.015 | torch.Size([120]) || stage7.pa_deform.conv_offset.0.bias
+ | -0.001 | -0.111 | 0.084 | 0.019 | torch.Size([120, 120, 3, 3]) || stage7.pa_deform.conv_offset.2.weight
+ | -0.008 | -0.073 | 0.081 | 0.034 | torch.Size([120]) || stage7.pa_deform.conv_offset.2.bias
+ | -0.002 | -0.154 | 0.122 | 0.018 | torch.Size([120, 120, 3, 3]) || stage7.pa_deform.conv_offset.4.weight
+ | 0.014 | -0.041 | 0.068 | 0.026 | torch.Size([120]) || stage7.pa_deform.conv_offset.4.bias
+ | -0.001 | -0.408 | 0.365 | 0.034 | torch.Size([324, 120, 3, 3]) || stage7.pa_deform.conv_offset.6.weight
+ | -0.003 | -0.057 | 0.054 | 0.024 | torch.Size([324]) || stage7.pa_deform.conv_offset.6.bias
+ | 0.000 | -0.697 | 0.606 | 0.123 | torch.Size([360, 360]) || stage7.pa_fuse.fc11.weight
+ | 0.119 | -0.211 | 0.720 | 0.177 | torch.Size([360]) || stage7.pa_fuse.fc11.bias
+ | 0.000 | -1.175 | 0.924 | 0.154 | torch.Size([360, 360]) || stage7.pa_fuse.fc12.weight
+ | -0.000 | -0.581 | 0.580 | 0.190 | torch.Size([360]) || stage7.pa_fuse.fc12.bias
+ | 0.001 | -0.786 | 0.874 | 0.135 | torch.Size([120, 360]) || stage7.pa_fuse.fc2.weight
+ | -0.053 | -0.522 | 0.577 | 0.205 | torch.Size([120]) || stage7.pa_fuse.fc2.bias
+ | 1.225 | 1.000 | 1.516 | 0.095 | torch.Size([120]) || stage8.0.1.weight
+ | -0.013 | -0.413 | 0.465 | 0.139 | torch.Size([120]) || stage8.0.1.bias
+ | 0.000 | -2.505 | 0.627 | 0.136 | torch.Size([180, 120]) || stage8.0.2.weight
+ | 0.005 | -0.397 | 0.377 | 0.107 | torch.Size([180]) || stage8.0.2.bias
+ | 0.456 | 0.123 | 0.760 | 0.129 | torch.Size([180]) || stage8.1.residual_group.blocks.0.norm1.weight
+ | -0.022 | -0.343 | 0.875 | 0.099 | torch.Size([180]) || stage8.1.residual_group.blocks.0.norm1.bias
+ | -0.014 | -1.907 | 2.592 | 0.130 | torch.Size([2475, 6]) || stage8.1.residual_group.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.1.residual_group.blocks.0.attn.relative_position_index
+ | -0.000 | -0.632 | 0.628 | 0.099 | torch.Size([540, 180]) || stage8.1.residual_group.blocks.0.attn.qkv_self.weight
+ | 0.006 | -0.567 | 0.668 | 0.148 | torch.Size([540]) || stage8.1.residual_group.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.477 | 0.447 | 0.094 | torch.Size([180, 180]) || stage8.1.residual_group.blocks.0.attn.proj.weight
+ | -0.010 | -0.460 | 0.225 | 0.085 | torch.Size([180]) || stage8.1.residual_group.blocks.0.attn.proj.bias
+ | 0.429 | 0.119 | 0.634 | 0.090 | torch.Size([180]) || stage8.1.residual_group.blocks.0.norm2.weight
+ | -0.007 | -0.338 | 0.803 | 0.086 | torch.Size([180]) || stage8.1.residual_group.blocks.0.norm2.bias
+ | -0.006 | -0.572 | 0.539 | 0.119 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.0.mlp.fc11.weight
+ | -0.060 | -0.260 | 0.185 | 0.060 | torch.Size([360]) || stage8.1.residual_group.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.461 | 0.548 | 0.113 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.0.mlp.fc12.weight
+ | 0.000 | -0.163 | 0.183 | 0.050 | torch.Size([360]) || stage8.1.residual_group.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.757 | 0.581 | 0.118 | torch.Size([180, 360]) || stage8.1.residual_group.blocks.0.mlp.fc2.weight
+ | -0.003 | -0.191 | 0.121 | 0.057 | torch.Size([180]) || stage8.1.residual_group.blocks.0.mlp.fc2.bias
+ | 0.557 | 0.086 | 0.800 | 0.112 | torch.Size([180]) || stage8.1.residual_group.blocks.1.norm1.weight
+ | -0.029 | -0.230 | 0.878 | 0.088 | torch.Size([180]) || stage8.1.residual_group.blocks.1.norm1.bias
+ | -0.016 | -2.004 | 1.711 | 0.154 | torch.Size([2475, 6]) || stage8.1.residual_group.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.1.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -0.690 | 0.575 | 0.109 | torch.Size([540, 180]) || stage8.1.residual_group.blocks.1.attn.qkv_self.weight
+ | 0.011 | -0.641 | 0.609 | 0.135 | torch.Size([540]) || stage8.1.residual_group.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.466 | 0.401 | 0.094 | torch.Size([180, 180]) || stage8.1.residual_group.blocks.1.attn.proj.weight
+ | -0.008 | -0.344 | 0.181 | 0.080 | torch.Size([180]) || stage8.1.residual_group.blocks.1.attn.proj.bias
+ | 0.503 | 0.226 | 0.742 | 0.093 | torch.Size([180]) || stage8.1.residual_group.blocks.1.norm2.weight
+ | -0.009 | -0.404 | 0.818 | 0.085 | torch.Size([180]) || stage8.1.residual_group.blocks.1.norm2.bias
+ | -0.007 | -0.595 | 0.532 | 0.121 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.1.mlp.fc11.weight
+ | -0.068 | -0.261 | 0.071 | 0.053 | torch.Size([360]) || stage8.1.residual_group.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.529 | 0.573 | 0.116 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.1.mlp.fc12.weight
+ | 0.002 | -0.129 | 0.197 | 0.046 | torch.Size([360]) || stage8.1.residual_group.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.556 | 0.582 | 0.118 | torch.Size([180, 360]) || stage8.1.residual_group.blocks.1.mlp.fc2.weight
+ | -0.003 | -0.170 | 0.145 | 0.052 | torch.Size([180]) || stage8.1.residual_group.blocks.1.mlp.fc2.bias
+ | 0.699 | 0.202 | 0.912 | 0.109 | torch.Size([180]) || stage8.1.residual_group.blocks.2.norm1.weight
+ | -0.033 | -0.253 | 0.924 | 0.091 | torch.Size([180]) || stage8.1.residual_group.blocks.2.norm1.bias
+ | -0.030 | -2.510 | 2.088 | 0.194 | torch.Size([2475, 6]) || stage8.1.residual_group.blocks.2.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.1.residual_group.blocks.2.attn.relative_position_index
+ | 0.000 | -0.637 | 0.801 | 0.116 | torch.Size([540, 180]) || stage8.1.residual_group.blocks.2.attn.qkv_self.weight
+ | 0.006 | -0.512 | 0.520 | 0.110 | torch.Size([540]) || stage8.1.residual_group.blocks.2.attn.qkv_self.bias
+ | 0.000 | -0.381 | 0.337 | 0.090 | torch.Size([180, 180]) || stage8.1.residual_group.blocks.2.attn.proj.weight
+ | -0.011 | -0.238 | 0.234 | 0.085 | torch.Size([180]) || stage8.1.residual_group.blocks.2.attn.proj.bias
+ | 0.594 | 0.150 | 0.810 | 0.108 | torch.Size([180]) || stage8.1.residual_group.blocks.2.norm2.weight
+ | -0.010 | -0.483 | 0.726 | 0.088 | torch.Size([180]) || stage8.1.residual_group.blocks.2.norm2.bias
+ | -0.006 | -0.567 | 0.499 | 0.125 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.2.mlp.fc11.weight
+ | -0.077 | -0.360 | 0.050 | 0.056 | torch.Size([360]) || stage8.1.residual_group.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.536 | 0.673 | 0.119 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.2.mlp.fc12.weight
+ | 0.001 | -0.142 | 0.186 | 0.043 | torch.Size([360]) || stage8.1.residual_group.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.536 | 0.524 | 0.119 | torch.Size([180, 360]) || stage8.1.residual_group.blocks.2.mlp.fc2.weight
+ | -0.006 | -0.147 | 0.133 | 0.051 | torch.Size([180]) || stage8.1.residual_group.blocks.2.mlp.fc2.bias
+ | 0.683 | 0.141 | 0.908 | 0.105 | torch.Size([180]) || stage8.1.residual_group.blocks.3.norm1.weight
+ | -0.033 | -0.199 | 0.878 | 0.088 | torch.Size([180]) || stage8.1.residual_group.blocks.3.norm1.bias
+ | -0.039 | -1.527 | 3.891 | 0.199 | torch.Size([2475, 6]) || stage8.1.residual_group.blocks.3.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.1.residual_group.blocks.3.attn.relative_position_index
+ | 0.000 | -0.682 | 0.693 | 0.120 | torch.Size([540, 180]) || stage8.1.residual_group.blocks.3.attn.qkv_self.weight
+ | 0.007 | -0.543 | 0.513 | 0.138 | torch.Size([540]) || stage8.1.residual_group.blocks.3.attn.qkv_self.bias
+ | -0.001 | -0.390 | 0.476 | 0.089 | torch.Size([180, 180]) || stage8.1.residual_group.blocks.3.attn.proj.weight
+ | -0.007 | -0.176 | 0.150 | 0.062 | torch.Size([180]) || stage8.1.residual_group.blocks.3.attn.proj.bias
+ | 0.640 | 0.094 | 0.853 | 0.120 | torch.Size([180]) || stage8.1.residual_group.blocks.3.norm2.weight
+ | -0.009 | -0.372 | 0.683 | 0.084 | torch.Size([180]) || stage8.1.residual_group.blocks.3.norm2.bias
+ | -0.006 | -0.628 | 0.521 | 0.126 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.3.mlp.fc11.weight
+ | -0.089 | -0.367 | 0.047 | 0.054 | torch.Size([360]) || stage8.1.residual_group.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.629 | 0.562 | 0.121 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.3.mlp.fc12.weight
+ | -0.001 | -0.186 | 0.128 | 0.042 | torch.Size([360]) || stage8.1.residual_group.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.485 | 0.499 | 0.118 | torch.Size([180, 360]) || stage8.1.residual_group.blocks.3.mlp.fc2.weight
+ | -0.007 | -0.138 | 0.209 | 0.050 | torch.Size([180]) || stage8.1.residual_group.blocks.3.mlp.fc2.bias
+ | 0.000 | -0.294 | 0.577 | 0.071 | torch.Size([180, 180]) || stage8.1.linear.weight
+ | 0.004 | -0.349 | 0.235 | 0.072 | torch.Size([180]) || stage8.1.linear.bias
+ | 0.708 | 0.242 | 1.026 | 0.136 | torch.Size([180]) || stage8.2.residual_group.blocks.0.norm1.weight
+ | -0.032 | -0.212 | 0.830 | 0.100 | torch.Size([180]) || stage8.2.residual_group.blocks.0.norm1.bias
+ | -0.039 | -1.954 | 2.394 | 0.212 | torch.Size([2475, 6]) || stage8.2.residual_group.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.2.residual_group.blocks.0.attn.relative_position_index
+ | 0.000 | -0.922 | 0.646 | 0.116 | torch.Size([540, 180]) || stage8.2.residual_group.blocks.0.attn.qkv_self.weight
+ | -0.001 | -0.429 | 0.524 | 0.101 | torch.Size([540]) || stage8.2.residual_group.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.467 | 0.453 | 0.109 | torch.Size([180, 180]) || stage8.2.residual_group.blocks.0.attn.proj.weight
+ | -0.005 | -0.339 | 0.264 | 0.095 | torch.Size([180]) || stage8.2.residual_group.blocks.0.attn.proj.bias
+ | 0.587 | 0.255 | 0.837 | 0.086 | torch.Size([180]) || stage8.2.residual_group.blocks.0.norm2.weight
+ | -0.011 | -0.285 | 0.721 | 0.083 | torch.Size([180]) || stage8.2.residual_group.blocks.0.norm2.bias
+ | -0.006 | -0.586 | 0.534 | 0.125 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.0.mlp.fc11.weight
+ | -0.075 | -0.225 | 0.066 | 0.047 | torch.Size([360]) || stage8.2.residual_group.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.493 | 0.532 | 0.123 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.0.mlp.fc12.weight
+ | 0.003 | -0.189 | 0.178 | 0.047 | torch.Size([360]) || stage8.2.residual_group.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.551 | 0.543 | 0.124 | torch.Size([180, 360]) || stage8.2.residual_group.blocks.0.mlp.fc2.weight
+ | -0.010 | -0.154 | 0.142 | 0.054 | torch.Size([180]) || stage8.2.residual_group.blocks.0.mlp.fc2.bias
+ | 0.773 | 0.210 | 1.004 | 0.113 | torch.Size([180]) || stage8.2.residual_group.blocks.1.norm1.weight
+ | -0.035 | -0.176 | 0.873 | 0.089 | torch.Size([180]) || stage8.2.residual_group.blocks.1.norm1.bias
+ | -0.027 | -2.407 | 1.736 | 0.214 | torch.Size([2475, 6]) || stage8.2.residual_group.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.2.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -0.817 | 0.977 | 0.123 | torch.Size([540, 180]) || stage8.2.residual_group.blocks.1.attn.qkv_self.weight
+ | 0.001 | -0.659 | 0.461 | 0.115 | torch.Size([540]) || stage8.2.residual_group.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.484 | 0.453 | 0.109 | torch.Size([180, 180]) || stage8.2.residual_group.blocks.1.attn.proj.weight
+ | -0.014 | -0.315 | 0.252 | 0.091 | torch.Size([180]) || stage8.2.residual_group.blocks.1.attn.proj.bias
+ | 0.641 | 0.337 | 0.810 | 0.081 | torch.Size([180]) || stage8.2.residual_group.blocks.1.norm2.weight
+ | -0.011 | -0.177 | 0.806 | 0.083 | torch.Size([180]) || stage8.2.residual_group.blocks.1.norm2.bias
+ | -0.006 | -0.569 | 0.598 | 0.125 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.1.mlp.fc11.weight
+ | -0.079 | -0.323 | 0.071 | 0.051 | torch.Size([360]) || stage8.2.residual_group.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.512 | 0.577 | 0.126 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.1.mlp.fc12.weight
+ | -0.003 | -0.142 | 0.161 | 0.050 | torch.Size([360]) || stage8.2.residual_group.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.529 | 0.572 | 0.125 | torch.Size([180, 360]) || stage8.2.residual_group.blocks.1.mlp.fc2.weight
+ | -0.010 | -0.178 | 0.159 | 0.066 | torch.Size([180]) || stage8.2.residual_group.blocks.1.mlp.fc2.bias
+ | 0.857 | 0.199 | 1.153 | 0.112 | torch.Size([180]) || stage8.2.residual_group.blocks.2.norm1.weight
+ | -0.039 | -0.189 | 0.943 | 0.089 | torch.Size([180]) || stage8.2.residual_group.blocks.2.norm1.bias
+ | -0.042 | -1.962 | 2.773 | 0.246 | torch.Size([2475, 6]) || stage8.2.residual_group.blocks.2.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.2.residual_group.blocks.2.attn.relative_position_index
+ | -0.000 | -0.783 | 0.655 | 0.123 | torch.Size([540, 180]) || stage8.2.residual_group.blocks.2.attn.qkv_self.weight
+ | 0.004 | -0.338 | 0.533 | 0.099 | torch.Size([540]) || stage8.2.residual_group.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.497 | 0.461 | 0.107 | torch.Size([180, 180]) || stage8.2.residual_group.blocks.2.attn.proj.weight
+ | -0.008 | -0.288 | 0.183 | 0.089 | torch.Size([180]) || stage8.2.residual_group.blocks.2.attn.proj.bias
+ | 0.681 | 0.327 | 0.878 | 0.085 | torch.Size([180]) || stage8.2.residual_group.blocks.2.norm2.weight
+ | -0.012 | -0.178 | 0.773 | 0.084 | torch.Size([180]) || stage8.2.residual_group.blocks.2.norm2.bias
+ | -0.006 | -0.789 | 0.546 | 0.125 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.2.mlp.fc11.weight
+ | -0.081 | -0.249 | 0.036 | 0.051 | torch.Size([360]) || stage8.2.residual_group.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.526 | 0.555 | 0.128 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.2.mlp.fc12.weight
+ | 0.000 | -0.133 | 0.191 | 0.051 | torch.Size([360]) || stage8.2.residual_group.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.572 | 0.529 | 0.126 | torch.Size([180, 360]) || stage8.2.residual_group.blocks.2.mlp.fc2.weight
+ | -0.011 | -0.164 | 0.147 | 0.065 | torch.Size([180]) || stage8.2.residual_group.blocks.2.mlp.fc2.bias
+ | 0.877 | 0.198 | 1.043 | 0.094 | torch.Size([180]) || stage8.2.residual_group.blocks.3.norm1.weight
+ | -0.038 | -0.210 | 0.916 | 0.091 | torch.Size([180]) || stage8.2.residual_group.blocks.3.norm1.bias
+ | -0.094 | -2.974 | 4.987 | 0.299 | torch.Size([2475, 6]) || stage8.2.residual_group.blocks.3.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.2.residual_group.blocks.3.attn.relative_position_index
+ | -0.000 | -0.964 | 1.011 | 0.126 | torch.Size([540, 180]) || stage8.2.residual_group.blocks.3.attn.qkv_self.weight
+ | -0.002 | -0.404 | 0.429 | 0.101 | torch.Size([540]) || stage8.2.residual_group.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.501 | 0.489 | 0.110 | torch.Size([180, 180]) || stage8.2.residual_group.blocks.3.attn.proj.weight
+ | -0.021 | -0.305 | 0.208 | 0.097 | torch.Size([180]) || stage8.2.residual_group.blocks.3.attn.proj.bias
+ | 0.697 | 0.295 | 0.894 | 0.089 | torch.Size([180]) || stage8.2.residual_group.blocks.3.norm2.weight
+ | -0.015 | -0.241 | 0.712 | 0.086 | torch.Size([180]) || stage8.2.residual_group.blocks.3.norm2.bias
+ | -0.005 | -0.562 | 0.573 | 0.125 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.3.mlp.fc11.weight
+ | -0.085 | -0.302 | 0.080 | 0.060 | torch.Size([360]) || stage8.2.residual_group.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.734 | 0.573 | 0.130 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.3.mlp.fc12.weight
+ | 0.001 | -0.150 | 0.161 | 0.054 | torch.Size([360]) || stage8.2.residual_group.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.671 | 0.623 | 0.127 | torch.Size([180, 360]) || stage8.2.residual_group.blocks.3.mlp.fc2.weight
+ | -0.023 | -0.252 | 0.317 | 0.081 | torch.Size([180]) || stage8.2.residual_group.blocks.3.mlp.fc2.bias
+ | -0.000 | -0.278 | 0.345 | 0.064 | torch.Size([180, 180]) || stage8.2.linear.weight
+ | 0.004 | -0.315 | 0.148 | 0.064 | torch.Size([180]) || stage8.2.linear.bias
+ | 0.850 | 0.326 | 1.087 | 0.122 | torch.Size([180]) || stage8.3.residual_group.blocks.0.norm1.weight
+ | -0.031 | -0.334 | 0.779 | 0.106 | torch.Size([180]) || stage8.3.residual_group.blocks.0.norm1.bias
+ | -0.012 | -2.917 | 1.476 | 0.175 | torch.Size([2475, 6]) || stage8.3.residual_group.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.3.residual_group.blocks.0.attn.relative_position_index
+ | -0.000 | -0.603 | 0.666 | 0.124 | torch.Size([540, 180]) || stage8.3.residual_group.blocks.0.attn.qkv_self.weight
+ | -0.001 | -0.374 | 0.381 | 0.086 | torch.Size([540]) || stage8.3.residual_group.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.577 | 0.605 | 0.119 | torch.Size([180, 180]) || stage8.3.residual_group.blocks.0.attn.proj.weight
+ | -0.008 | -0.394 | 0.499 | 0.134 | torch.Size([180]) || stage8.3.residual_group.blocks.0.attn.proj.bias
+ | 0.636 | 0.321 | 0.790 | 0.073 | torch.Size([180]) || stage8.3.residual_group.blocks.0.norm2.weight
+ | -0.013 | -0.294 | 0.774 | 0.090 | torch.Size([180]) || stage8.3.residual_group.blocks.0.norm2.bias
+ | -0.004 | -0.540 | 0.539 | 0.123 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.0.mlp.fc11.weight
+ | -0.065 | -0.212 | 0.047 | 0.051 | torch.Size([360]) || stage8.3.residual_group.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.608 | 0.603 | 0.130 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.0.mlp.fc12.weight
+ | -0.002 | -0.177 | 0.155 | 0.051 | torch.Size([360]) || stage8.3.residual_group.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.573 | 0.630 | 0.129 | torch.Size([180, 360]) || stage8.3.residual_group.blocks.0.mlp.fc2.weight
+ | -0.005 | -0.189 | 0.178 | 0.071 | torch.Size([180]) || stage8.3.residual_group.blocks.0.mlp.fc2.bias
+ | 0.899 | 0.275 | 1.048 | 0.099 | torch.Size([180]) || stage8.3.residual_group.blocks.1.norm1.weight
+ | -0.031 | -0.223 | 0.771 | 0.088 | torch.Size([180]) || stage8.3.residual_group.blocks.1.norm1.bias
+ | -0.003 | -3.151 | 1.718 | 0.202 | torch.Size([2475, 6]) || stage8.3.residual_group.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.3.residual_group.blocks.1.attn.relative_position_index
+ | -0.000 | -0.732 | 0.868 | 0.127 | torch.Size([540, 180]) || stage8.3.residual_group.blocks.1.attn.qkv_self.weight
+ | 0.002 | -0.412 | 0.350 | 0.093 | torch.Size([540]) || stage8.3.residual_group.blocks.1.attn.qkv_self.bias
+ | 0.001 | -0.466 | 0.487 | 0.114 | torch.Size([180, 180]) || stage8.3.residual_group.blocks.1.attn.proj.weight
+ | -0.006 | -0.388 | 0.400 | 0.129 | torch.Size([180]) || stage8.3.residual_group.blocks.1.attn.proj.bias
+ | 0.711 | 0.381 | 0.864 | 0.082 | torch.Size([180]) || stage8.3.residual_group.blocks.1.norm2.weight
+ | -0.009 | -0.240 | 0.692 | 0.090 | torch.Size([180]) || stage8.3.residual_group.blocks.1.norm2.bias
+ | -0.005 | -0.657 | 0.639 | 0.126 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.1.mlp.fc11.weight
+ | -0.077 | -0.263 | 0.047 | 0.057 | torch.Size([360]) || stage8.3.residual_group.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.673 | 0.605 | 0.134 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.1.mlp.fc12.weight
+ | 0.002 | -0.158 | 0.155 | 0.046 | torch.Size([360]) || stage8.3.residual_group.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.582 | 0.585 | 0.131 | torch.Size([180, 360]) || stage8.3.residual_group.blocks.1.mlp.fc2.weight
+ | -0.009 | -0.253 | 0.178 | 0.070 | torch.Size([180]) || stage8.3.residual_group.blocks.1.mlp.fc2.bias
+ | 0.941 | 0.262 | 1.154 | 0.094 | torch.Size([180]) || stage8.3.residual_group.blocks.2.norm1.weight
+ | -0.032 | -0.162 | 0.906 | 0.084 | torch.Size([180]) || stage8.3.residual_group.blocks.2.norm1.bias
+ | -0.005 | -3.421 | 1.350 | 0.205 | torch.Size([2475, 6]) || stage8.3.residual_group.blocks.2.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.3.residual_group.blocks.2.attn.relative_position_index
+ | -0.000 | -0.777 | 0.735 | 0.130 | torch.Size([540, 180]) || stage8.3.residual_group.blocks.2.attn.qkv_self.weight
+ | 0.000 | -0.355 | 0.421 | 0.092 | torch.Size([540]) || stage8.3.residual_group.blocks.2.attn.qkv_self.bias
+ | 0.000 | -0.479 | 0.475 | 0.115 | torch.Size([180, 180]) || stage8.3.residual_group.blocks.2.attn.proj.weight
+ | -0.013 | -0.292 | 0.345 | 0.122 | torch.Size([180]) || stage8.3.residual_group.blocks.2.attn.proj.bias
+ | 0.743 | 0.242 | 0.919 | 0.093 | torch.Size([180]) || stage8.3.residual_group.blocks.2.norm2.weight
+ | -0.011 | -0.214 | 0.691 | 0.094 | torch.Size([180]) || stage8.3.residual_group.blocks.2.norm2.bias
+ | -0.005 | -0.633 | 0.498 | 0.127 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.2.mlp.fc11.weight
+ | -0.082 | -0.346 | 0.087 | 0.062 | torch.Size([360]) || stage8.3.residual_group.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.591 | 0.670 | 0.134 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.2.mlp.fc12.weight
+ | 0.001 | -0.190 | 0.151 | 0.056 | torch.Size([360]) || stage8.3.residual_group.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.560 | 0.637 | 0.132 | torch.Size([180, 360]) || stage8.3.residual_group.blocks.2.mlp.fc2.weight
+ | -0.009 | -0.226 | 0.250 | 0.085 | torch.Size([180]) || stage8.3.residual_group.blocks.2.mlp.fc2.bias
+ | 0.950 | 0.250 | 1.103 | 0.086 | torch.Size([180]) || stage8.3.residual_group.blocks.3.norm1.weight
+ | -0.035 | -0.196 | 0.925 | 0.088 | torch.Size([180]) || stage8.3.residual_group.blocks.3.norm1.bias
+ | -0.026 | -3.591 | 5.653 | 0.236 | torch.Size([2475, 6]) || stage8.3.residual_group.blocks.3.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.3.residual_group.blocks.3.attn.relative_position_index
+ | 0.000 | -0.753 | 0.637 | 0.128 | torch.Size([540, 180]) || stage8.3.residual_group.blocks.3.attn.qkv_self.weight
+ | 0.000 | -0.333 | 0.432 | 0.081 | torch.Size([540]) || stage8.3.residual_group.blocks.3.attn.qkv_self.bias
+ | 0.001 | -0.591 | 0.591 | 0.118 | torch.Size([180, 180]) || stage8.3.residual_group.blocks.3.attn.proj.weight
+ | -0.014 | -0.348 | 0.267 | 0.122 | torch.Size([180]) || stage8.3.residual_group.blocks.3.attn.proj.bias
+ | 0.735 | 0.254 | 0.893 | 0.082 | torch.Size([180]) || stage8.3.residual_group.blocks.3.norm2.weight
+ | -0.011 | -0.241 | 0.659 | 0.093 | torch.Size([180]) || stage8.3.residual_group.blocks.3.norm2.bias
+ | -0.005 | -0.628 | 0.667 | 0.125 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.3.mlp.fc11.weight
+ | -0.076 | -0.411 | 0.113 | 0.072 | torch.Size([360]) || stage8.3.residual_group.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.662 | 0.578 | 0.135 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.3.mlp.fc12.weight
+ | -0.004 | -0.208 | 0.169 | 0.054 | torch.Size([360]) || stage8.3.residual_group.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.602 | 0.588 | 0.131 | torch.Size([180, 360]) || stage8.3.residual_group.blocks.3.mlp.fc2.weight
+ | -0.011 | -0.218 | 0.232 | 0.096 | torch.Size([180]) || stage8.3.residual_group.blocks.3.mlp.fc2.bias
+ | -0.000 | -0.343 | 0.316 | 0.065 | torch.Size([180, 180]) || stage8.3.linear.weight
+ | 0.010 | -0.297 | 0.187 | 0.061 | torch.Size([180]) || stage8.3.linear.bias
+ | 1.012 | 0.330 | 1.282 | 0.149 | torch.Size([180]) || stage8.4.residual_group.blocks.0.norm1.weight
+ | -0.030 | -0.347 | 0.800 | 0.134 | torch.Size([180]) || stage8.4.residual_group.blocks.0.norm1.bias
+ | -0.013 | -2.816 | 3.792 | 0.236 | torch.Size([2475, 6]) || stage8.4.residual_group.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.4.residual_group.blocks.0.attn.relative_position_index
+ | -0.000 | -0.807 | 0.825 | 0.131 | torch.Size([540, 180]) || stage8.4.residual_group.blocks.0.attn.qkv_self.weight
+ | -0.003 | -0.429 | 0.319 | 0.083 | torch.Size([540]) || stage8.4.residual_group.blocks.0.attn.qkv_self.bias
+ | 0.001 | -0.553 | 0.569 | 0.136 | torch.Size([180, 180]) || stage8.4.residual_group.blocks.0.attn.proj.weight
+ | -0.019 | -0.443 | 0.441 | 0.139 | torch.Size([180]) || stage8.4.residual_group.blocks.0.attn.proj.bias
+ | 0.638 | 0.420 | 0.797 | 0.063 | torch.Size([180]) || stage8.4.residual_group.blocks.0.norm2.weight
+ | -0.018 | -0.222 | 0.886 | 0.107 | torch.Size([180]) || stage8.4.residual_group.blocks.0.norm2.bias
+ | -0.002 | -0.576 | 0.510 | 0.117 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.0.mlp.fc11.weight
+ | -0.018 | -0.277 | 0.123 | 0.068 | torch.Size([360]) || stage8.4.residual_group.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.687 | 0.625 | 0.132 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.0.mlp.fc12.weight
+ | -0.007 | -0.264 | 0.267 | 0.076 | torch.Size([360]) || stage8.4.residual_group.blocks.0.mlp.fc12.bias
+ | 0.001 | -0.639 | 0.705 | 0.130 | torch.Size([180, 360]) || stage8.4.residual_group.blocks.0.mlp.fc2.weight
+ | -0.012 | -0.255 | 0.274 | 0.095 | torch.Size([180]) || stage8.4.residual_group.blocks.0.mlp.fc2.bias
+ | 1.092 | 0.475 | 1.341 | 0.115 | torch.Size([180]) || stage8.4.residual_group.blocks.1.norm1.weight
+ | -0.030 | -0.294 | 0.686 | 0.113 | torch.Size([180]) || stage8.4.residual_group.blocks.1.norm1.bias
+ | 0.018 | -3.165 | 0.990 | 0.213 | torch.Size([2475, 6]) || stage8.4.residual_group.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.4.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -0.695 | 0.699 | 0.133 | torch.Size([540, 180]) || stage8.4.residual_group.blocks.1.attn.qkv_self.weight
+ | 0.002 | -0.319 | 0.286 | 0.075 | torch.Size([540]) || stage8.4.residual_group.blocks.1.attn.qkv_self.bias
+ | -0.001 | -0.542 | 0.519 | 0.133 | torch.Size([180, 180]) || stage8.4.residual_group.blocks.1.attn.proj.weight
+ | -0.017 | -0.439 | 0.451 | 0.152 | torch.Size([180]) || stage8.4.residual_group.blocks.1.attn.proj.bias
+ | 0.664 | 0.366 | 0.835 | 0.074 | torch.Size([180]) || stage8.4.residual_group.blocks.1.norm2.weight
+ | -0.015 | -0.217 | 0.985 | 0.103 | torch.Size([180]) || stage8.4.residual_group.blocks.1.norm2.bias
+ | -0.002 | -0.641 | 0.563 | 0.117 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.1.mlp.fc11.weight
+ | -0.022 | -0.381 | 0.161 | 0.078 | torch.Size([360]) || stage8.4.residual_group.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.571 | 0.642 | 0.132 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.1.mlp.fc12.weight
+ | 0.003 | -0.279 | 0.311 | 0.087 | torch.Size([360]) || stage8.4.residual_group.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.738 | 0.633 | 0.130 | torch.Size([180, 360]) || stage8.4.residual_group.blocks.1.mlp.fc2.weight
+ | -0.007 | -0.254 | 0.261 | 0.084 | torch.Size([180]) || stage8.4.residual_group.blocks.1.mlp.fc2.bias
+ | 1.125 | 0.525 | 1.405 | 0.117 | torch.Size([180]) || stage8.4.residual_group.blocks.2.norm1.weight
+ | -0.033 | -0.186 | 0.627 | 0.082 | torch.Size([180]) || stage8.4.residual_group.blocks.2.norm1.bias
+ | 0.028 | -3.477 | 0.957 | 0.217 | torch.Size([2475, 6]) || stage8.4.residual_group.blocks.2.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.4.residual_group.blocks.2.attn.relative_position_index
+ | 0.000 | -0.663 | 0.658 | 0.130 | torch.Size([540, 180]) || stage8.4.residual_group.blocks.2.attn.qkv_self.weight
+ | -0.007 | -0.357 | 0.255 | 0.064 | torch.Size([540]) || stage8.4.residual_group.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.596 | 0.578 | 0.137 | torch.Size([180, 180]) || stage8.4.residual_group.blocks.2.attn.proj.weight
+ | -0.018 | -0.506 | 0.389 | 0.159 | torch.Size([180]) || stage8.4.residual_group.blocks.2.attn.proj.bias
+ | 0.694 | 0.319 | 0.865 | 0.084 | torch.Size([180]) || stage8.4.residual_group.blocks.2.norm2.weight
+ | -0.018 | -0.150 | 0.975 | 0.087 | torch.Size([180]) || stage8.4.residual_group.blocks.2.norm2.bias
+ | -0.002 | -0.619 | 0.565 | 0.116 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.2.mlp.fc11.weight
+ | -0.025 | -0.345 | 0.208 | 0.086 | torch.Size([360]) || stage8.4.residual_group.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.624 | 0.607 | 0.132 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.2.mlp.fc12.weight
+ | -0.003 | -0.388 | 0.290 | 0.075 | torch.Size([360]) || stage8.4.residual_group.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.927 | 0.675 | 0.130 | torch.Size([180, 360]) || stage8.4.residual_group.blocks.2.mlp.fc2.weight
+ | -0.011 | -0.325 | 0.240 | 0.096 | torch.Size([180]) || stage8.4.residual_group.blocks.2.mlp.fc2.bias
+ | 1.108 | 0.535 | 1.297 | 0.094 | torch.Size([180]) || stage8.4.residual_group.blocks.3.norm1.weight
+ | -0.035 | -0.213 | 0.546 | 0.064 | torch.Size([180]) || stage8.4.residual_group.blocks.3.norm1.bias
+ | 0.020 | -3.042 | 1.420 | 0.192 | torch.Size([2475, 6]) || stage8.4.residual_group.blocks.3.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.4.residual_group.blocks.3.attn.relative_position_index
+ | -0.000 | -0.697 | 0.700 | 0.128 | torch.Size([540, 180]) || stage8.4.residual_group.blocks.3.attn.qkv_self.weight
+ | -0.000 | -0.220 | 0.311 | 0.065 | torch.Size([540]) || stage8.4.residual_group.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.652 | 0.592 | 0.138 | torch.Size([180, 180]) || stage8.4.residual_group.blocks.3.attn.proj.weight
+ | -0.019 | -0.535 | 0.426 | 0.154 | torch.Size([180]) || stage8.4.residual_group.blocks.3.attn.proj.bias
+ | 0.685 | 0.225 | 0.893 | 0.082 | torch.Size([180]) || stage8.4.residual_group.blocks.3.norm2.weight
+ | -0.023 | -0.211 | 0.938 | 0.093 | torch.Size([180]) || stage8.4.residual_group.blocks.3.norm2.bias
+ | -0.001 | -0.501 | 0.564 | 0.113 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.3.mlp.fc11.weight
+ | -0.014 | -0.339 | 0.237 | 0.092 | torch.Size([360]) || stage8.4.residual_group.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.560 | 0.626 | 0.132 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.3.mlp.fc12.weight
+ | 0.000 | -0.231 | 0.239 | 0.075 | torch.Size([360]) || stage8.4.residual_group.blocks.3.mlp.fc12.bias
+ | -0.000 | -0.544 | 0.657 | 0.130 | torch.Size([180, 360]) || stage8.4.residual_group.blocks.3.mlp.fc2.weight
+ | -0.007 | -0.271 | 0.274 | 0.093 | torch.Size([180]) || stage8.4.residual_group.blocks.3.mlp.fc2.bias
+ | -0.001 | -0.473 | 0.481 | 0.069 | torch.Size([180, 180]) || stage8.4.linear.weight
+ | 0.029 | -0.333 | 0.194 | 0.076 | torch.Size([180]) || stage8.4.linear.bias
+ | 1.025 | 0.297 | 1.336 | 0.162 | torch.Size([180]) || stage8.5.residual_group.blocks.0.norm1.weight
+ | -0.034 | -0.429 | 0.872 | 0.141 | torch.Size([180]) || stage8.5.residual_group.blocks.0.norm1.bias
+ | -0.574 | -4.515 | 3.381 | 0.800 | torch.Size([225, 6]) || stage8.5.residual_group.blocks.0.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.5.residual_group.blocks.0.attn.relative_position_index
+ | 0.000 | -0.771 | 0.886 | 0.125 | torch.Size([540, 180]) || stage8.5.residual_group.blocks.0.attn.qkv_self.weight
+ | 0.000 | -0.356 | 0.521 | 0.085 | torch.Size([540]) || stage8.5.residual_group.blocks.0.attn.qkv_self.bias
+ | -0.001 | -0.632 | 0.656 | 0.147 | torch.Size([180, 180]) || stage8.5.residual_group.blocks.0.attn.proj.weight
+ | -0.029 | -0.329 | 0.697 | 0.127 | torch.Size([180]) || stage8.5.residual_group.blocks.0.attn.proj.bias
+ | 0.777 | 0.446 | 0.952 | 0.069 | torch.Size([180]) || stage8.5.residual_group.blocks.0.norm2.weight
+ | -0.022 | -0.335 | 0.920 | 0.121 | torch.Size([180]) || stage8.5.residual_group.blocks.0.norm2.bias
+ | -0.002 | -0.520 | 0.598 | 0.117 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.0.mlp.fc11.weight
+ | -0.013 | -0.456 | 0.200 | 0.075 | torch.Size([360]) || stage8.5.residual_group.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.677 | 0.642 | 0.137 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.0.mlp.fc12.weight
+ | 0.005 | -0.272 | 0.233 | 0.083 | torch.Size([360]) || stage8.5.residual_group.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.762 | 0.598 | 0.136 | torch.Size([180, 360]) || stage8.5.residual_group.blocks.0.mlp.fc2.weight
+ | -0.025 | -0.244 | 0.583 | 0.111 | torch.Size([180]) || stage8.5.residual_group.blocks.0.mlp.fc2.bias
+ | 1.021 | 0.261 | 1.261 | 0.133 | torch.Size([180]) || stage8.5.residual_group.blocks.1.norm1.weight
+ | -0.033 | -0.358 | 0.867 | 0.120 | torch.Size([180]) || stage8.5.residual_group.blocks.1.norm1.bias
+ | -0.550 | -3.274 | 4.406 | 0.670 | torch.Size([225, 6]) || stage8.5.residual_group.blocks.1.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.5.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -0.819 | 0.986 | 0.122 | torch.Size([540, 180]) || stage8.5.residual_group.blocks.1.attn.qkv_self.weight
+ | 0.005 | -0.510 | 0.446 | 0.084 | torch.Size([540]) || stage8.5.residual_group.blocks.1.attn.qkv_self.bias
+ | -0.003 | -0.739 | 0.682 | 0.151 | torch.Size([180, 180]) || stage8.5.residual_group.blocks.1.attn.proj.weight
+ | -0.032 | -0.318 | 0.607 | 0.133 | torch.Size([180]) || stage8.5.residual_group.blocks.1.attn.proj.bias
+ | 0.823 | 0.420 | 0.950 | 0.070 | torch.Size([180]) || stage8.5.residual_group.blocks.1.norm2.weight
+ | -0.021 | -0.274 | 0.882 | 0.111 | torch.Size([180]) || stage8.5.residual_group.blocks.1.norm2.bias
+ | -0.002 | -0.496 | 0.532 | 0.117 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.1.mlp.fc11.weight
+ | -0.028 | -0.260 | 0.194 | 0.080 | torch.Size([360]) || stage8.5.residual_group.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.620 | 0.586 | 0.139 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.1.mlp.fc12.weight
+ | 0.004 | -0.284 | 0.423 | 0.083 | torch.Size([360]) || stage8.5.residual_group.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.774 | 0.614 | 0.137 | torch.Size([180, 360]) || stage8.5.residual_group.blocks.1.mlp.fc2.weight
+ | -0.028 | -0.371 | 0.561 | 0.133 | torch.Size([180]) || stage8.5.residual_group.blocks.1.mlp.fc2.bias
+ | 1.096 | 0.377 | 1.321 | 0.110 | torch.Size([180]) || stage8.5.residual_group.blocks.2.norm1.weight
+ | -0.033 | -0.244 | 0.755 | 0.100 | torch.Size([180]) || stage8.5.residual_group.blocks.2.norm1.bias
+ | -0.441 | -3.439 | 5.870 | 0.668 | torch.Size([225, 6]) || stage8.5.residual_group.blocks.2.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.5.residual_group.blocks.2.attn.relative_position_index
+ | -0.000 | -0.710 | 0.679 | 0.123 | torch.Size([540, 180]) || stage8.5.residual_group.blocks.2.attn.qkv_self.weight
+ | 0.003 | -0.277 | 0.283 | 0.068 | torch.Size([540]) || stage8.5.residual_group.blocks.2.attn.qkv_self.bias
+ | 0.001 | -0.824 | 0.684 | 0.150 | torch.Size([180, 180]) || stage8.5.residual_group.blocks.2.attn.proj.weight
+ | -0.033 | -0.390 | 0.545 | 0.155 | torch.Size([180]) || stage8.5.residual_group.blocks.2.attn.proj.bias
+ | 0.843 | 0.390 | 0.984 | 0.076 | torch.Size([180]) || stage8.5.residual_group.blocks.2.norm2.weight
+ | -0.022 | -0.211 | 0.854 | 0.090 | torch.Size([180]) || stage8.5.residual_group.blocks.2.norm2.bias
+ | -0.002 | -0.522 | 0.503 | 0.116 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.2.mlp.fc11.weight
+ | -0.024 | -0.243 | 0.219 | 0.091 | torch.Size([360]) || stage8.5.residual_group.blocks.2.mlp.fc11.bias
+ | -0.001 | -0.638 | 0.617 | 0.139 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.2.mlp.fc12.weight
+ | -0.004 | -0.268 | 0.380 | 0.078 | torch.Size([360]) || stage8.5.residual_group.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.713 | 0.769 | 0.138 | torch.Size([180, 360]) || stage8.5.residual_group.blocks.2.mlp.fc2.weight
+ | -0.034 | -0.372 | 0.592 | 0.151 | torch.Size([180]) || stage8.5.residual_group.blocks.2.mlp.fc2.bias
+ | 1.027 | 0.318 | 1.206 | 0.094 | torch.Size([180]) || stage8.5.residual_group.blocks.3.norm1.weight
+ | -0.033 | -0.187 | 0.768 | 0.088 | torch.Size([180]) || stage8.5.residual_group.blocks.3.norm1.bias
+ | -0.347 | -2.664 | 2.684 | 0.528 | torch.Size([225, 6]) || stage8.5.residual_group.blocks.3.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.5.residual_group.blocks.3.attn.relative_position_index
+ | 0.000 | -0.677 | 0.676 | 0.127 | torch.Size([540, 180]) || stage8.5.residual_group.blocks.3.attn.qkv_self.weight
+ | 0.002 | -0.410 | 0.354 | 0.080 | torch.Size([540]) || stage8.5.residual_group.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.630 | 0.725 | 0.145 | torch.Size([180, 180]) || stage8.5.residual_group.blocks.3.attn.proj.weight
+ | -0.041 | -0.385 | 0.660 | 0.163 | torch.Size([180]) || stage8.5.residual_group.blocks.3.attn.proj.bias
+ | 0.849 | 0.390 | 0.985 | 0.070 | torch.Size([180]) || stage8.5.residual_group.blocks.3.norm2.weight
+ | -0.023 | -0.163 | 0.810 | 0.084 | torch.Size([180]) || stage8.5.residual_group.blocks.3.norm2.bias
+ | -0.002 | -0.547 | 0.536 | 0.115 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.3.mlp.fc11.weight
+ | -0.012 | -0.366 | 0.252 | 0.106 | torch.Size([360]) || stage8.5.residual_group.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.669 | 0.597 | 0.139 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.3.mlp.fc12.weight
+ | -0.002 | -0.216 | 0.202 | 0.074 | torch.Size([360]) || stage8.5.residual_group.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.700 | 0.674 | 0.139 | torch.Size([180, 360]) || stage8.5.residual_group.blocks.3.mlp.fc2.weight
+ | -0.032 | -0.376 | 0.666 | 0.134 | torch.Size([180]) || stage8.5.residual_group.blocks.3.mlp.fc2.bias
+ | -0.001 | -0.299 | 0.469 | 0.069 | torch.Size([180, 180]) || stage8.5.linear.weight
+ | 0.081 | -0.562 | 0.263 | 0.109 | torch.Size([180]) || stage8.5.linear.bias
+ | 1.111 | 0.208 | 1.434 | 0.192 | torch.Size([180]) || stage8.6.residual_group.blocks.0.norm1.weight
+ | -0.048 | -0.547 | 0.851 | 0.175 | torch.Size([180]) || stage8.6.residual_group.blocks.0.norm1.bias
+ | -0.252 | -2.157 | 6.293 | 0.490 | torch.Size([225, 6]) || stage8.6.residual_group.blocks.0.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.6.residual_group.blocks.0.attn.relative_position_index
+ | 0.000 | -0.664 | 0.631 | 0.123 | torch.Size([540, 180]) || stage8.6.residual_group.blocks.0.attn.qkv_self.weight
+ | 0.007 | -0.293 | 0.366 | 0.078 | torch.Size([540]) || stage8.6.residual_group.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.701 | 0.726 | 0.154 | torch.Size([180, 180]) || stage8.6.residual_group.blocks.0.attn.proj.weight
+ | 0.030 | -0.318 | 0.331 | 0.109 | torch.Size([180]) || stage8.6.residual_group.blocks.0.attn.proj.bias
+ | 0.959 | 0.475 | 1.322 | 0.088 | torch.Size([180]) || stage8.6.residual_group.blocks.0.norm2.weight
+ | -0.039 | -0.421 | 0.873 | 0.151 | torch.Size([180]) || stage8.6.residual_group.blocks.0.norm2.bias
+ | -0.002 | -0.550 | 0.783 | 0.116 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.0.mlp.fc11.weight
+ | 0.002 | -0.269 | 0.152 | 0.069 | torch.Size([360]) || stage8.6.residual_group.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.914 | 0.839 | 0.143 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.0.mlp.fc12.weight
+ | 0.001 | -0.340 | 0.304 | 0.075 | torch.Size([360]) || stage8.6.residual_group.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.592 | 0.713 | 0.140 | torch.Size([180, 360]) || stage8.6.residual_group.blocks.0.mlp.fc2.weight
+ | 0.002 | -0.535 | 0.384 | 0.177 | torch.Size([180]) || stage8.6.residual_group.blocks.0.mlp.fc2.bias
+ | 1.123 | 0.183 | 1.352 | 0.165 | torch.Size([180]) || stage8.6.residual_group.blocks.1.norm1.weight
+ | -0.047 | -0.513 | 0.903 | 0.168 | torch.Size([180]) || stage8.6.residual_group.blocks.1.norm1.bias
+ | -0.234 | -1.968 | 6.366 | 0.448 | torch.Size([225, 6]) || stage8.6.residual_group.blocks.1.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.6.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -0.751 | 0.759 | 0.121 | torch.Size([540, 180]) || stage8.6.residual_group.blocks.1.attn.qkv_self.weight
+ | -0.001 | -0.300 | 0.214 | 0.061 | torch.Size([540]) || stage8.6.residual_group.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.657 | 0.699 | 0.148 | torch.Size([180, 180]) || stage8.6.residual_group.blocks.1.attn.proj.weight
+ | 0.031 | -0.321 | 0.293 | 0.115 | torch.Size([180]) || stage8.6.residual_group.blocks.1.attn.proj.bias
+ | 0.986 | 0.416 | 1.360 | 0.096 | torch.Size([180]) || stage8.6.residual_group.blocks.1.norm2.weight
+ | -0.038 | -0.393 | 0.807 | 0.146 | torch.Size([180]) || stage8.6.residual_group.blocks.1.norm2.bias
+ | -0.001 | -0.589 | 0.620 | 0.116 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.1.mlp.fc11.weight
+ | 0.005 | -0.316 | 0.229 | 0.071 | torch.Size([360]) || stage8.6.residual_group.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.738 | 0.766 | 0.143 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.1.mlp.fc12.weight
+ | 0.001 | -0.252 | 0.302 | 0.072 | torch.Size([360]) || stage8.6.residual_group.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.674 | 0.629 | 0.140 | torch.Size([180, 360]) || stage8.6.residual_group.blocks.1.mlp.fc2.weight
+ | -0.001 | -0.475 | 0.441 | 0.175 | torch.Size([180]) || stage8.6.residual_group.blocks.1.mlp.fc2.bias
+ | 1.097 | 0.342 | 1.294 | 0.134 | torch.Size([180]) || stage8.6.residual_group.blocks.2.norm1.weight
+ | -0.054 | -0.639 | 0.904 | 0.186 | torch.Size([180]) || stage8.6.residual_group.blocks.2.norm1.bias
+ | -0.135 | -3.252 | 1.238 | 0.360 | torch.Size([225, 6]) || stage8.6.residual_group.blocks.2.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.6.residual_group.blocks.2.attn.relative_position_index
+ | 0.000 | -0.672 | 0.663 | 0.128 | torch.Size([540, 180]) || stage8.6.residual_group.blocks.2.attn.qkv_self.weight
+ | 0.007 | -0.170 | 0.228 | 0.046 | torch.Size([540]) || stage8.6.residual_group.blocks.2.attn.qkv_self.bias
+ | -0.001 | -0.660 | 0.651 | 0.147 | torch.Size([180, 180]) || stage8.6.residual_group.blocks.2.attn.proj.weight
+ | 0.031 | -0.360 | 0.322 | 0.126 | torch.Size([180]) || stage8.6.residual_group.blocks.2.attn.proj.bias
+ | 1.004 | 0.360 | 1.381 | 0.099 | torch.Size([180]) || stage8.6.residual_group.blocks.2.norm2.weight
+ | -0.042 | -0.447 | 0.808 | 0.157 | torch.Size([180]) || stage8.6.residual_group.blocks.2.norm2.bias
+ | -0.000 | -0.600 | 0.603 | 0.116 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.2.mlp.fc11.weight
+ | 0.022 | -0.447 | 0.249 | 0.086 | torch.Size([360]) || stage8.6.residual_group.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.666 | 0.708 | 0.143 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.2.mlp.fc12.weight
+ | -0.002 | -0.326 | 0.272 | 0.075 | torch.Size([360]) || stage8.6.residual_group.blocks.2.mlp.fc12.bias
+ | -0.001 | -0.653 | 0.719 | 0.142 | torch.Size([180, 360]) || stage8.6.residual_group.blocks.2.mlp.fc2.weight
+ | -0.011 | -0.488 | 0.321 | 0.153 | torch.Size([180]) || stage8.6.residual_group.blocks.2.mlp.fc2.bias
+ | 1.095 | 0.272 | 1.302 | 0.123 | torch.Size([180]) || stage8.6.residual_group.blocks.3.norm1.weight
+ | -0.052 | -0.557 | 1.069 | 0.192 | torch.Size([180]) || stage8.6.residual_group.blocks.3.norm1.bias
+ | -0.196 | -2.349 | 1.401 | 0.360 | torch.Size([225, 6]) || stage8.6.residual_group.blocks.3.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.6.residual_group.blocks.3.attn.relative_position_index
+ | 0.000 | -0.741 | 0.657 | 0.124 | torch.Size([540, 180]) || stage8.6.residual_group.blocks.3.attn.qkv_self.weight
+ | 0.001 | -0.186 | 0.141 | 0.040 | torch.Size([540]) || stage8.6.residual_group.blocks.3.attn.qkv_self.bias
+ | -0.001 | -0.669 | 0.671 | 0.139 | torch.Size([180, 180]) || stage8.6.residual_group.blocks.3.attn.proj.weight
+ | -0.004 | -0.323 | 0.300 | 0.124 | torch.Size([180]) || stage8.6.residual_group.blocks.3.attn.proj.bias
+ | 0.999 | 0.383 | 1.380 | 0.103 | torch.Size([180]) || stage8.6.residual_group.blocks.3.norm2.weight
+ | -0.044 | -0.392 | 0.694 | 0.163 | torch.Size([180]) || stage8.6.residual_group.blocks.3.norm2.bias
+ | 0.000 | -0.577 | 0.857 | 0.116 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.3.mlp.fc11.weight
+ | 0.041 | -0.394 | 0.238 | 0.087 | torch.Size([360]) || stage8.6.residual_group.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.924 | 0.828 | 0.143 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.3.mlp.fc12.weight
+ | -0.003 | -0.214 | 0.407 | 0.071 | torch.Size([360]) || stage8.6.residual_group.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.827 | 0.755 | 0.141 | torch.Size([180, 360]) || stage8.6.residual_group.blocks.3.mlp.fc2.weight
+ | 0.022 | -0.296 | 0.262 | 0.107 | torch.Size([180]) || stage8.6.residual_group.blocks.3.mlp.fc2.bias
+ | 0.002 | -1.059 | 1.262 | 0.089 | torch.Size([180, 180]) || stage8.6.linear.weight
+ | 0.031 | -0.789 | 0.427 | 0.120 | torch.Size([180]) || stage8.6.linear.bias
+ | 0.389 | 0.079 | 1.137 | 0.176 | torch.Size([180]) || norm.weight
+ | -0.021 | -0.669 | 0.888 | 0.127 | torch.Size([180]) || norm.bias
+ | 0.000 | -0.486 | 0.568 | 0.103 | torch.Size([120, 180]) || conv_after_body.weight
+ | -0.000 | -0.167 | 0.168 | 0.055 | torch.Size([120]) || conv_after_body.bias
+ | -0.000 | -1.782 | 1.300 | 0.109 | torch.Size([64, 120, 1, 3, 3]) || conv_before_upsample.0.weight
+ | -0.019 | -0.542 | 0.437 | 0.162 | torch.Size([64]) || conv_before_upsample.0.bias
+ | 0.001 | -1.915 | 1.372 | 0.090 | torch.Size([256, 64, 1, 3, 3]) || upsample.0.weight
+ | -0.045 | -0.281 | 0.215 | 0.097 | torch.Size([256]) || upsample.0.bias
+ | -0.006 | -4.826 | 0.582 | 0.075 | torch.Size([256, 64, 1, 3, 3]) || upsample.5.weight
+ | -0.154 | -0.441 | 0.187 | 0.100 | torch.Size([256]) || upsample.5.bias
+ | 0.000 | -0.210 | 0.246 | 0.012 | torch.Size([64, 64, 1, 3, 3]) || upsample.10.weight
+ | 0.000 | -0.013 | 0.007 | 0.003 | torch.Size([64]) || upsample.10.bias
+ | 0.000 | -0.044 | 0.042 | 0.004 | torch.Size([3, 64, 1, 3, 3]) || conv_last.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([3]) || conv_last.bias
+
+22-03-11 10:52:19.525 : task: 001_train_vrt_videosr_bi_reds_6frames
+ model: vrt
+ gpu_ids: [0, 1, 2, 3, 4, 5, 6, 7]
+ dist: False
+ find_unused_parameters: False
+ use_static_graph: True
+ scale: 4
+ n_channels: 3
+ path:[
+ root: experiments
+ pretrained_netG: /home/cll/dev/KAIR/model_zoo/vrt/001_VRT_videosr_bi_REDS_6frames.pth
+ pretrained_netE: None
+ task: experiments/001_train_vrt_videosr_bi_reds_6frames
+ log: experiments/001_train_vrt_videosr_bi_reds_6frames
+ options: experiments/001_train_vrt_videosr_bi_reds_6frames/options
+ models: experiments/001_train_vrt_videosr_bi_reds_6frames/models
+ images: experiments/001_train_vrt_videosr_bi_reds_6frames/images
+ pretrained_optimizerG: None
+ ]
+ datasets:[
+ train:[
+ name: train_dataset
+ dataset_type: VideoRecurrentTrainDataset
+ dataroot_gt: /home/cll/datasets/REDS/train/train_sharp
+ dataroot_lq: /home/cll/datasets/REDS/train/train_sharp_bicubic/X4
+ meta_info_file: data/meta_info/meta_info_REDS_GT.txt
+ filename_tmpl: 08d
+ filename_ext: png
+ val_partition: REDS4
+ test_mode: False
+ io_backend:[
+ type: disk
+ ]
+ num_frame: 6
+ gt_size: 256
+ interval_list: [1]
+ random_reverse: False
+ use_hflip: True
+ use_rot: True
+ dataloader_shuffle: True
+ dataloader_num_workers: 32
+ dataloader_batch_size: 8
+ phase: train
+ scale: 4
+ n_channels: 3
+ ]
+ test:[
+ name: test_dataset
+ dataset_type: VideoRecurrentTestDataset
+ dataroot_gt: /home/cll/Desktop/REDS4/GT
+ dataroot_lq: /home/cll/Desktop/REDS4/sharp_bicubic
+ cache_data: True
+ io_backend:[
+ type: disk
+ ]
+ num_frame: -1
+ phase: test
+ scale: 4
+ n_channels: 3
+ ]
+ ]
+ netG:[
+ net_type: vrt
+ upscale: 4
+ img_size: [6, 64, 64]
+ window_size: [6, 8, 8]
+ depths: [8, 8, 8, 8, 8, 8, 8, 4, 4, 4, 4, 4, 4]
+ indep_reconsts: [11, 12]
+ embed_dims: [120, 120, 120, 120, 120, 120, 120, 180, 180, 180, 180, 180, 180]
+ num_heads: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
+ spynet_path: model_zoo/vrt/spynet_sintel_final-3d2a1287.pth
+ pa_frames: 2
+ deformable_groups: 12
+ nonblind_denoising: False
+ use_checkpoint_attn: False
+ use_checkpoint_ffn: False
+ no_checkpoint_attn_blocks: []
+ no_checkpoint_ffn_blocks: []
+ init_type: default
+ scale: 4
+ ]
+ train:[
+ G_lossfn_type: charbonnier
+ G_lossfn_weight: 1.0
+ G_charbonnier_eps: 1e-09
+ E_decay: 0
+ G_optimizer_type: adam
+ G_optimizer_lr: 0.0004
+ G_optimizer_betas: [0.9, 0.99]
+ G_optimizer_wd: 0
+ G_optimizer_clipgrad: None
+ G_optimizer_reuse: True
+ fix_iter: 20000
+ fix_lr_mul: 0.125
+ fix_keys: ['spynet', 'deform']
+ total_iter: 300000
+ G_scheduler_type: CosineAnnealingWarmRestarts
+ G_scheduler_periods: 300000
+ G_scheduler_eta_min: 1e-07
+ G_regularizer_orthstep: None
+ G_regularizer_clipstep: None
+ G_param_strict: True
+ E_param_strict: True
+ checkpoint_test: 5000
+ checkpoint_save: 5000
+ checkpoint_print: 200
+ F_feature_layer: 34
+ F_weights: 1.0
+ F_lossfn_type: l1
+ F_use_input_norm: True
+ F_use_range_norm: False
+ G_scheduler_restart_weights: 1
+ ]
+ val:[
+ save_img: False
+ pad_seq: False
+ flip_seq: False
+ center_frame_only: False
+ num_frame_testing: 40
+ num_frame_overlapping: 2
+ size_patch_testing: 128
+ ]
+ opt_path: options/vrt/001_train_vrt_videosr_bi_reds_6frames.json
+ is_train: True
+ merge_bn: False
+ merge_bn_startpoint: -1
+ num_gpu: 8
+ rank: 0
+ world_size: 1
+
+22-03-11 10:52:19.571 : Number of train images: 24,000, iters: 3,000
+22-03-11 10:52:33.932 :
+Networks name: VRT
+Params number: 30676435
+Net structure:
+VRT(
+ (conv_first): Conv3d(27, 120, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ (spynet): SpyNet(
+ (basic_module): ModuleList(
+ (0): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (1): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (2): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (3): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (4): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (5): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ )
+ )
+ (stage1): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n c d h w -> n d h w c')
+ (1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (2): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): Identity()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): Identity()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage2): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n c d (h neih) (w neiw) -> n d h w (neiw neih c)', neih=2, neiw=2)
+ (1): LayerNorm((480,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=480, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage3): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n c d (h neih) (w neiw) -> n d h w (neiw neih c)', neih=2, neiw=2)
+ (1): LayerNorm((480,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=480, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage4): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n c d (h neih) (w neiw) -> n d h w (neiw neih c)', neih=2, neiw=2)
+ (1): LayerNorm((480,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=480, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage5): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n (neiw neih c) d h w -> n d (h neih) (w neiw) c', neih=2, neiw=2)
+ (1): LayerNorm((30,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=30, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage6): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n (neiw neih c) d h w -> n d (h neih) (w neiw) c', neih=2, neiw=2)
+ (1): LayerNorm((30,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=30, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage7): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n (neiw neih c) d h w -> n d (h neih) (w neiw) c', neih=2, neiw=2)
+ (1): LayerNorm((30,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=30, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage8): ModuleList(
+ (0): Sequential(
+ (0): Rearrange('n c d h w -> n d h w c')
+ (1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=120, out_features=180, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (1): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (2): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (3): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (4): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (5): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (6): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ )
+ (norm): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (conv_after_body): Linear(in_features=180, out_features=120, bias=True)
+ (conv_before_upsample): Sequential(
+ (0): Conv3d(120, 64, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ (1): LeakyReLU(negative_slope=0.01, inplace=True)
+ )
+ (upsample): Upsample(
+ (0): Conv3d(64, 256, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ (1): Transpose_Dim12()
+ (2): PixelShuffle(upscale_factor=2)
+ (3): Transpose_Dim12()
+ (4): LeakyReLU(negative_slope=0.1, inplace=True)
+ (5): Conv3d(64, 256, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ (6): Transpose_Dim12()
+ (7): PixelShuffle(upscale_factor=2)
+ (8): Transpose_Dim12()
+ (9): LeakyReLU(negative_slope=0.1, inplace=True)
+ (10): Conv3d(64, 64, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ )
+ (conv_last): Conv3d(64, 3, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+)
+
+22-03-11 10:52:34.115 :
+ | mean | min | max | std || shape
+ | -0.000 | -1.462 | 1.580 | 0.103 | torch.Size([120, 27, 1, 3, 3]) || conv_first.weight
+ | 0.005 | -0.950 | 0.885 | 0.268 | torch.Size([120]) || conv_first.bias
+ | 0.449 | 0.406 | 0.485 | 0.040 | torch.Size([1, 3, 1, 1]) || spynet.mean
+ | 0.226 | 0.224 | 0.229 | 0.003 | torch.Size([1, 3, 1, 1]) || spynet.std
+ | -0.000 | -0.679 | 0.720 | 0.066 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.0.basic_module.0.weight
+ | -0.042 | -0.894 | 0.351 | 0.344 | torch.Size([32]) || spynet.basic_module.0.basic_module.0.bias
+ | -0.008 | -3.201 | 0.948 | 0.097 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.0.basic_module.2.weight
+ | 0.059 | -1.268 | 0.732 | 0.320 | torch.Size([64]) || spynet.basic_module.0.basic_module.2.bias
+ | -0.010 | -4.633 | 0.568 | 0.089 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.0.basic_module.4.weight
+ | 0.159 | -0.704 | 0.859 | 0.353 | torch.Size([32]) || spynet.basic_module.0.basic_module.4.bias
+ | -0.024 | -1.714 | 0.414 | 0.091 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.0.basic_module.6.weight
+ | 0.780 | -1.061 | 1.162 | 0.519 | torch.Size([16]) || spynet.basic_module.0.basic_module.6.bias
+ | 0.000 | -0.144 | 0.163 | 0.018 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.0.basic_module.8.weight
+ | 0.001 | -0.003 | 0.005 | 0.006 | torch.Size([2]) || spynet.basic_module.0.basic_module.8.bias
+ | 0.000 | -0.726 | 0.773 | 0.070 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.1.basic_module.0.weight
+ | -0.021 | -0.814 | 0.355 | 0.323 | torch.Size([32]) || spynet.basic_module.1.basic_module.0.bias
+ | -0.010 | -3.380 | 0.916 | 0.099 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.1.basic_module.2.weight
+ | 0.038 | -1.207 | 0.714 | 0.301 | torch.Size([64]) || spynet.basic_module.1.basic_module.2.bias
+ | -0.008 | -4.462 | 0.549 | 0.088 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.1.basic_module.4.weight
+ | 0.157 | -0.742 | 0.980 | 0.384 | torch.Size([32]) || spynet.basic_module.1.basic_module.4.bias
+ | -0.020 | -1.648 | 0.319 | 0.084 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.1.basic_module.6.weight
+ | 0.775 | -1.195 | 1.148 | 0.546 | torch.Size([16]) || spynet.basic_module.1.basic_module.6.bias
+ | -0.000 | -0.122 | 0.152 | 0.016 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.1.basic_module.8.weight
+ | -0.000 | -0.002 | 0.001 | 0.002 | torch.Size([2]) || spynet.basic_module.1.basic_module.8.bias
+ | 0.000 | -0.956 | 0.870 | 0.088 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.2.basic_module.0.weight
+ | -0.025 | -1.040 | 0.512 | 0.411 | torch.Size([32]) || spynet.basic_module.2.basic_module.0.bias
+ | -0.011 | -4.624 | 1.195 | 0.116 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.2.basic_module.2.weight
+ | 0.023 | -1.284 | 0.699 | 0.308 | torch.Size([64]) || spynet.basic_module.2.basic_module.2.bias
+ | -0.009 | -1.831 | 0.616 | 0.092 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.2.basic_module.4.weight
+ | 0.120 | -0.695 | 0.755 | 0.332 | torch.Size([32]) || spynet.basic_module.2.basic_module.4.bias
+ | -0.013 | -1.285 | 0.304 | 0.068 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.2.basic_module.6.weight
+ | 0.681 | -1.725 | 0.942 | 0.646 | torch.Size([16]) || spynet.basic_module.2.basic_module.6.bias
+ | 0.000 | -0.045 | 0.071 | 0.009 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.2.basic_module.8.weight
+ | -0.010 | -0.010 | -0.009 | 0.000 | torch.Size([2]) || spynet.basic_module.2.basic_module.8.bias
+ | -0.000 | -0.995 | 0.879 | 0.090 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.3.basic_module.0.weight
+ | -0.040 | -1.137 | 0.617 | 0.461 | torch.Size([32]) || spynet.basic_module.3.basic_module.0.bias
+ | -0.010 | -4.891 | 1.224 | 0.117 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.3.basic_module.2.weight
+ | 0.022 | -1.287 | 0.745 | 0.313 | torch.Size([64]) || spynet.basic_module.3.basic_module.2.bias
+ | -0.010 | -1.802 | 0.561 | 0.090 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.3.basic_module.4.weight
+ | 0.118 | -0.694 | 0.697 | 0.329 | torch.Size([32]) || spynet.basic_module.3.basic_module.4.bias
+ | -0.012 | -1.107 | 0.306 | 0.064 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.3.basic_module.6.weight
+ | 0.658 | -1.792 | 0.905 | 0.659 | torch.Size([16]) || spynet.basic_module.3.basic_module.6.bias
+ | 0.000 | -0.030 | 0.037 | 0.006 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.3.basic_module.8.weight
+ | 0.003 | -0.001 | 0.007 | 0.006 | torch.Size([2]) || spynet.basic_module.3.basic_module.8.bias
+ | -0.000 | -0.990 | 0.880 | 0.090 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.4.basic_module.0.weight
+ | -0.010 | -1.067 | 0.596 | 0.437 | torch.Size([32]) || spynet.basic_module.4.basic_module.0.bias
+ | -0.010 | -5.061 | 1.229 | 0.117 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.4.basic_module.2.weight
+ | 0.024 | -1.274 | 0.830 | 0.318 | torch.Size([64]) || spynet.basic_module.4.basic_module.2.bias
+ | -0.009 | -1.787 | 0.563 | 0.088 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.4.basic_module.4.weight
+ | 0.130 | -0.685 | 0.743 | 0.335 | torch.Size([32]) || spynet.basic_module.4.basic_module.4.bias
+ | -0.011 | -0.973 | 0.292 | 0.061 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.4.basic_module.6.weight
+ | 0.659 | -1.855 | 0.931 | 0.679 | torch.Size([16]) || spynet.basic_module.4.basic_module.6.bias
+ | 0.000 | -0.034 | 0.040 | 0.005 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.4.basic_module.8.weight
+ | -0.001 | -0.009 | 0.007 | 0.012 | torch.Size([2]) || spynet.basic_module.4.basic_module.8.bias
+ | -0.000 | -0.973 | 0.853 | 0.089 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.5.basic_module.0.weight
+ | 0.022 | -1.001 | 0.571 | 0.440 | torch.Size([32]) || spynet.basic_module.5.basic_module.0.bias
+ | -0.009 | -5.095 | 1.251 | 0.119 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.5.basic_module.2.weight
+ | 0.026 | -1.305 | 0.880 | 0.326 | torch.Size([64]) || spynet.basic_module.5.basic_module.2.bias
+ | -0.008 | -1.815 | 0.561 | 0.091 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.5.basic_module.4.weight
+ | 0.137 | -0.711 | 0.771 | 0.342 | torch.Size([32]) || spynet.basic_module.5.basic_module.4.bias
+ | -0.010 | -0.986 | 0.286 | 0.059 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.5.basic_module.6.weight
+ | 0.671 | -1.913 | 0.966 | 0.700 | torch.Size([16]) || spynet.basic_module.5.basic_module.6.bias
+ | 0.000 | -0.034 | 0.028 | 0.002 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.5.basic_module.8.weight
+ | 0.002 | -0.013 | 0.016 | 0.020 | torch.Size([2]) || spynet.basic_module.5.basic_module.8.bias
+ | 1.280 | 0.669 | 1.862 | 0.274 | torch.Size([120]) || stage1.reshape.1.weight
+ | -0.006 | -0.324 | 0.337 | 0.106 | torch.Size([120]) || stage1.reshape.1.bias
+ | 0.579 | 0.129 | 1.064 | 0.236 | torch.Size([120]) || stage1.residual_group1.blocks.0.norm1.weight
+ | -0.039 | -1.100 | 0.894 | 0.226 | torch.Size([120]) || stage1.residual_group1.blocks.0.norm1.bias
+ | -0.134 | -4.020 | 2.585 | 0.295 | torch.Size([675, 6]) || stage1.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.0.attn.position_bias
+ | -0.000 | -0.579 | 0.618 | 0.113 | torch.Size([360, 120]) || stage1.residual_group1.blocks.0.attn.qkv_self.weight
+ | 0.000 | -0.319 | 0.279 | 0.074 | torch.Size([360]) || stage1.residual_group1.blocks.0.attn.qkv_self.bias
+ | 0.001 | -0.634 | 0.686 | 0.076 | torch.Size([120, 240]) || stage1.residual_group1.blocks.0.attn.proj.weight
+ | -0.014 | -0.222 | 0.642 | 0.088 | torch.Size([120]) || stage1.residual_group1.blocks.0.attn.proj.bias
+ | -0.000 | -1.066 | 0.928 | 0.097 | torch.Size([360, 120]) || stage1.residual_group1.blocks.0.attn.qkv_mut.weight
+ | 0.000 | -0.146 | 0.190 | 0.033 | torch.Size([360]) || stage1.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.781 | 0.367 | 1.203 | 0.160 | torch.Size([120]) || stage1.residual_group1.blocks.0.norm2.weight
+ | 0.029 | -0.378 | 0.545 | 0.159 | torch.Size([120]) || stage1.residual_group1.blocks.0.norm2.bias
+ | 0.001 | -0.687 | 0.753 | 0.108 | torch.Size([240, 120]) || stage1.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.010 | -0.229 | 0.633 | 0.095 | torch.Size([240]) || stage1.residual_group1.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.674 | 0.669 | 0.117 | torch.Size([240, 120]) || stage1.residual_group1.blocks.0.mlp.fc12.weight
+ | 0.011 | -0.448 | 0.368 | 0.116 | torch.Size([240]) || stage1.residual_group1.blocks.0.mlp.fc12.bias
+ | 0.001 | -0.862 | 0.941 | 0.119 | torch.Size([120, 240]) || stage1.residual_group1.blocks.0.mlp.fc2.weight
+ | -0.004 | -0.267 | 0.594 | 0.099 | torch.Size([120]) || stage1.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.797 | 0.211 | 1.475 | 0.209 | torch.Size([120]) || stage1.residual_group1.blocks.1.norm1.weight
+ | -0.161 | -1.941 | 0.746 | 0.237 | torch.Size([120]) || stage1.residual_group1.blocks.1.norm1.bias
+ | -0.296 | -3.927 | 2.840 | 0.478 | torch.Size([675, 6]) || stage1.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.1.attn.position_bias
+ | 0.001 | -1.479 | 1.395 | 0.143 | torch.Size([360, 120]) || stage1.residual_group1.blocks.1.attn.qkv_self.weight
+ | -0.003 | -0.381 | 0.258 | 0.063 | torch.Size([360]) || stage1.residual_group1.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.526 | 0.561 | 0.079 | torch.Size([120, 240]) || stage1.residual_group1.blocks.1.attn.proj.weight
+ | -0.003 | -0.178 | 0.478 | 0.078 | torch.Size([120]) || stage1.residual_group1.blocks.1.attn.proj.bias
+ | 0.001 | -1.242 | 1.138 | 0.105 | torch.Size([360, 120]) || stage1.residual_group1.blocks.1.attn.qkv_mut.weight
+ | 0.004 | -0.213 | 0.196 | 0.050 | torch.Size([360]) || stage1.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.702 | 0.349 | 0.904 | 0.085 | torch.Size([120]) || stage1.residual_group1.blocks.1.norm2.weight
+ | 0.039 | -0.646 | 0.384 | 0.132 | torch.Size([120]) || stage1.residual_group1.blocks.1.norm2.bias
+ | 0.001 | -0.872 | 0.750 | 0.131 | torch.Size([240, 120]) || stage1.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.049 | -0.353 | 0.135 | 0.084 | torch.Size([240]) || stage1.residual_group1.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.562 | 0.580 | 0.117 | torch.Size([240, 120]) || stage1.residual_group1.blocks.1.mlp.fc12.weight
+ | 0.000 | -0.238 | 0.457 | 0.113 | torch.Size([240]) || stage1.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.828 | 0.685 | 0.123 | torch.Size([120, 240]) || stage1.residual_group1.blocks.1.mlp.fc2.weight
+ | 0.031 | -0.297 | 0.419 | 0.094 | torch.Size([120]) || stage1.residual_group1.blocks.1.mlp.fc2.bias
+ | 0.984 | 0.163 | 1.398 | 0.202 | torch.Size([120]) || stage1.residual_group1.blocks.2.norm1.weight
+ | -0.167 | -1.609 | 0.367 | 0.182 | torch.Size([120]) || stage1.residual_group1.blocks.2.norm1.bias
+ | -0.343 | -4.484 | 2.362 | 0.486 | torch.Size([675, 6]) || stage1.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.2.attn.position_bias
+ | 0.000 | -1.586 | 1.649 | 0.151 | torch.Size([360, 120]) || stage1.residual_group1.blocks.2.attn.qkv_self.weight
+ | -0.000 | -0.220 | 0.240 | 0.056 | torch.Size([360]) || stage1.residual_group1.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.378 | 0.514 | 0.086 | torch.Size([120, 240]) || stage1.residual_group1.blocks.2.attn.proj.weight
+ | -0.009 | -0.143 | 0.172 | 0.059 | torch.Size([120]) || stage1.residual_group1.blocks.2.attn.proj.bias
+ | 0.001 | -0.639 | 0.582 | 0.102 | torch.Size([360, 120]) || stage1.residual_group1.blocks.2.attn.qkv_mut.weight
+ | -0.000 | -0.141 | 0.173 | 0.035 | torch.Size([360]) || stage1.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.733 | 0.277 | 0.903 | 0.081 | torch.Size([120]) || stage1.residual_group1.blocks.2.norm2.weight
+ | 0.038 | -0.861 | 0.359 | 0.142 | torch.Size([120]) || stage1.residual_group1.blocks.2.norm2.bias
+ | 0.000 | -0.787 | 0.679 | 0.131 | torch.Size([240, 120]) || stage1.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.029 | -0.365 | 0.143 | 0.076 | torch.Size([240]) || stage1.residual_group1.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.574 | 0.539 | 0.120 | torch.Size([240, 120]) || stage1.residual_group1.blocks.2.mlp.fc12.weight
+ | -0.007 | -0.283 | 0.254 | 0.097 | torch.Size([240]) || stage1.residual_group1.blocks.2.mlp.fc12.bias
+ | 0.001 | -0.998 | 0.522 | 0.124 | torch.Size([120, 240]) || stage1.residual_group1.blocks.2.mlp.fc2.weight
+ | 0.030 | -0.169 | 0.293 | 0.095 | torch.Size([120]) || stage1.residual_group1.blocks.2.mlp.fc2.bias
+ | 1.035 | 0.143 | 1.397 | 0.196 | torch.Size([120]) || stage1.residual_group1.blocks.3.norm1.weight
+ | -0.161 | -1.413 | 0.084 | 0.154 | torch.Size([120]) || stage1.residual_group1.blocks.3.norm1.bias
+ | -0.441 | -4.685 | 3.306 | 0.529 | torch.Size([675, 6]) || stage1.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.3.attn.position_bias
+ | 0.000 | -1.590 | 1.329 | 0.155 | torch.Size([360, 120]) || stage1.residual_group1.blocks.3.attn.qkv_self.weight
+ | -0.002 | -0.266 | 0.232 | 0.049 | torch.Size([360]) || stage1.residual_group1.blocks.3.attn.qkv_self.bias
+ | -0.000 | -0.366 | 0.372 | 0.084 | torch.Size([120, 240]) || stage1.residual_group1.blocks.3.attn.proj.weight
+ | -0.011 | -0.225 | 0.171 | 0.071 | torch.Size([120]) || stage1.residual_group1.blocks.3.attn.proj.bias
+ | -0.000 | -0.660 | 0.801 | 0.100 | torch.Size([360, 120]) || stage1.residual_group1.blocks.3.attn.qkv_mut.weight
+ | -0.001 | -0.139 | 0.200 | 0.031 | torch.Size([360]) || stage1.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.724 | 0.190 | 0.911 | 0.091 | torch.Size([120]) || stage1.residual_group1.blocks.3.norm2.weight
+ | 0.038 | -0.981 | 0.285 | 0.137 | torch.Size([120]) || stage1.residual_group1.blocks.3.norm2.bias
+ | 0.001 | -0.611 | 0.598 | 0.130 | torch.Size([240, 120]) || stage1.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.035 | -0.299 | 0.221 | 0.081 | torch.Size([240]) || stage1.residual_group1.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.502 | 0.520 | 0.124 | torch.Size([240, 120]) || stage1.residual_group1.blocks.3.mlp.fc12.weight
+ | -0.002 | -0.271 | 0.215 | 0.090 | torch.Size([240]) || stage1.residual_group1.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.558 | 0.898 | 0.127 | torch.Size([120, 240]) || stage1.residual_group1.blocks.3.mlp.fc2.weight
+ | 0.010 | -0.424 | 0.190 | 0.082 | torch.Size([120]) || stage1.residual_group1.blocks.3.mlp.fc2.bias
+ | 1.085 | 0.169 | 1.400 | 0.157 | torch.Size([120]) || stage1.residual_group1.blocks.4.norm1.weight
+ | -0.086 | -1.613 | 0.150 | 0.160 | torch.Size([120]) || stage1.residual_group1.blocks.4.norm1.bias
+ | -0.541 | -3.902 | 3.728 | 0.633 | torch.Size([675, 6]) || stage1.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.4.attn.position_bias
+ | 0.001 | -1.879 | 1.832 | 0.150 | torch.Size([360, 120]) || stage1.residual_group1.blocks.4.attn.qkv_self.weight
+ | 0.001 | -0.391 | 0.444 | 0.079 | torch.Size([360]) || stage1.residual_group1.blocks.4.attn.qkv_self.bias
+ | -0.000 | -0.407 | 0.448 | 0.087 | torch.Size([120, 240]) || stage1.residual_group1.blocks.4.attn.proj.weight
+ | -0.013 | -0.302 | 0.342 | 0.104 | torch.Size([120]) || stage1.residual_group1.blocks.4.attn.proj.bias
+ | -0.001 | -0.830 | 0.863 | 0.102 | torch.Size([360, 120]) || stage1.residual_group1.blocks.4.attn.qkv_mut.weight
+ | -0.001 | -0.117 | 0.094 | 0.024 | torch.Size([360]) || stage1.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.704 | 0.195 | 0.870 | 0.079 | torch.Size([120]) || stage1.residual_group1.blocks.4.norm2.weight
+ | 0.031 | -1.069 | 0.276 | 0.140 | torch.Size([120]) || stage1.residual_group1.blocks.4.norm2.bias
+ | -0.000 | -0.656 | 0.555 | 0.130 | torch.Size([240, 120]) || stage1.residual_group1.blocks.4.mlp.fc11.weight
+ | -0.029 | -0.387 | 0.256 | 0.102 | torch.Size([240]) || stage1.residual_group1.blocks.4.mlp.fc11.bias
+ | 0.001 | -0.590 | 0.624 | 0.127 | torch.Size([240, 120]) || stage1.residual_group1.blocks.4.mlp.fc12.weight
+ | -0.011 | -0.277 | 0.303 | 0.087 | torch.Size([240]) || stage1.residual_group1.blocks.4.mlp.fc12.bias
+ | -0.000 | -1.124 | 0.539 | 0.130 | torch.Size([120, 240]) || stage1.residual_group1.blocks.4.mlp.fc2.weight
+ | -0.006 | -0.718 | 0.133 | 0.094 | torch.Size([120]) || stage1.residual_group1.blocks.4.mlp.fc2.bias
+ | 1.037 | 0.176 | 1.327 | 0.158 | torch.Size([120]) || stage1.residual_group1.blocks.5.norm1.weight
+ | -0.112 | -1.591 | 0.177 | 0.169 | torch.Size([120]) || stage1.residual_group1.blocks.5.norm1.bias
+ | -0.438 | -2.229 | 2.797 | 0.523 | torch.Size([675, 6]) || stage1.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.5.attn.position_bias
+ | -0.000 | -2.212 | 1.826 | 0.153 | torch.Size([360, 120]) || stage1.residual_group1.blocks.5.attn.qkv_self.weight
+ | 0.001 | -0.343 | 0.338 | 0.068 | torch.Size([360]) || stage1.residual_group1.blocks.5.attn.qkv_self.bias
+ | 0.000 | -0.367 | 0.451 | 0.087 | torch.Size([120, 240]) || stage1.residual_group1.blocks.5.attn.proj.weight
+ | -0.022 | -0.358 | 0.242 | 0.128 | torch.Size([120]) || stage1.residual_group1.blocks.5.attn.proj.bias
+ | 0.001 | -0.922 | 0.886 | 0.104 | torch.Size([360, 120]) || stage1.residual_group1.blocks.5.attn.qkv_mut.weight
+ | 0.002 | -0.083 | 0.089 | 0.022 | torch.Size([360]) || stage1.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.662 | 0.277 | 0.831 | 0.066 | torch.Size([120]) || stage1.residual_group1.blocks.5.norm2.weight
+ | 0.025 | -0.959 | 0.261 | 0.132 | torch.Size([120]) || stage1.residual_group1.blocks.5.norm2.bias
+ | -0.001 | -0.636 | 0.739 | 0.129 | torch.Size([240, 120]) || stage1.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.030 | -0.419 | 0.517 | 0.115 | torch.Size([240]) || stage1.residual_group1.blocks.5.mlp.fc11.bias
+ | -0.000 | -0.615 | 0.709 | 0.126 | torch.Size([240, 120]) || stage1.residual_group1.blocks.5.mlp.fc12.weight
+ | 0.002 | -0.230 | 0.457 | 0.087 | torch.Size([240]) || stage1.residual_group1.blocks.5.mlp.fc12.bias
+ | 0.001 | -1.724 | 1.186 | 0.132 | torch.Size([120, 240]) || stage1.residual_group1.blocks.5.mlp.fc2.weight
+ | -0.019 | -1.909 | 0.255 | 0.190 | torch.Size([120]) || stage1.residual_group1.blocks.5.mlp.fc2.bias
+ | -0.000 | -0.242 | 0.244 | 0.057 | torch.Size([120, 120]) || stage1.linear1.weight
+ | 0.004 | -0.221 | 0.224 | 0.083 | torch.Size([120]) || stage1.linear1.bias
+ | 0.737 | 0.334 | 1.046 | 0.119 | torch.Size([120]) || stage1.residual_group2.blocks.0.norm1.weight
+ | 0.013 | -0.911 | 0.763 | 0.193 | torch.Size([120]) || stage1.residual_group2.blocks.0.norm1.bias
+ | -0.052 | -2.462 | 2.040 | 0.273 | torch.Size([2475, 6]) || stage1.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage1.residual_group2.blocks.0.attn.relative_position_index
+ | 0.000 | -0.785 | 0.767 | 0.123 | torch.Size([360, 120]) || stage1.residual_group2.blocks.0.attn.qkv_self.weight
+ | 0.009 | -0.466 | 0.552 | 0.122 | torch.Size([360]) || stage1.residual_group2.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.431 | 0.475 | 0.091 | torch.Size([120, 120]) || stage1.residual_group2.blocks.0.attn.proj.weight
+ | -0.009 | -0.796 | 0.497 | 0.109 | torch.Size([120]) || stage1.residual_group2.blocks.0.attn.proj.bias
+ | 0.573 | 0.409 | 0.935 | 0.096 | torch.Size([120]) || stage1.residual_group2.blocks.0.norm2.weight
+ | 0.015 | -0.828 | 0.839 | 0.175 | torch.Size([120]) || stage1.residual_group2.blocks.0.norm2.bias
+ | 0.001 | -0.604 | 0.542 | 0.109 | torch.Size([240, 120]) || stage1.residual_group2.blocks.0.mlp.fc11.weight
+ | 0.037 | -0.179 | 0.273 | 0.076 | torch.Size([240]) || stage1.residual_group2.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.666 | 0.553 | 0.116 | torch.Size([240, 120]) || stage1.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.001 | -0.416 | 0.396 | 0.116 | torch.Size([240]) || stage1.residual_group2.blocks.0.mlp.fc12.bias
+ | 0.001 | -0.654 | 0.538 | 0.118 | torch.Size([120, 240]) || stage1.residual_group2.blocks.0.mlp.fc2.weight
+ | -0.002 | -0.470 | 0.310 | 0.122 | torch.Size([120]) || stage1.residual_group2.blocks.0.mlp.fc2.bias
+ | 0.951 | 0.342 | 1.189 | 0.111 | torch.Size([120]) || stage1.residual_group2.blocks.1.norm1.weight
+ | 0.010 | -0.697 | 0.802 | 0.166 | torch.Size([120]) || stage1.residual_group2.blocks.1.norm1.bias
+ | -0.098 | -2.648 | 2.410 | 0.214 | torch.Size([2475, 6]) || stage1.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage1.residual_group2.blocks.1.attn.relative_position_index
+ | -0.000 | -0.733 | 0.886 | 0.139 | torch.Size([360, 120]) || stage1.residual_group2.blocks.1.attn.qkv_self.weight
+ | -0.002 | -0.468 | 0.550 | 0.132 | torch.Size([360]) || stage1.residual_group2.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.435 | 0.377 | 0.096 | torch.Size([120, 120]) || stage1.residual_group2.blocks.1.attn.proj.weight
+ | -0.001 | -0.359 | 0.258 | 0.114 | torch.Size([120]) || stage1.residual_group2.blocks.1.attn.proj.bias
+ | 0.582 | 0.305 | 0.717 | 0.055 | torch.Size([120]) || stage1.residual_group2.blocks.1.norm2.weight
+ | 0.008 | -0.714 | 0.833 | 0.131 | torch.Size([120]) || stage1.residual_group2.blocks.1.norm2.bias
+ | 0.001 | -0.732 | 0.501 | 0.118 | torch.Size([240, 120]) || stage1.residual_group2.blocks.1.mlp.fc11.weight
+ | 0.004 | -0.306 | 0.267 | 0.091 | torch.Size([240]) || stage1.residual_group2.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.510 | 0.533 | 0.126 | torch.Size([240, 120]) || stage1.residual_group2.blocks.1.mlp.fc12.weight
+ | -0.000 | -0.315 | 0.291 | 0.090 | torch.Size([240]) || stage1.residual_group2.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.736 | 0.789 | 0.126 | torch.Size([120, 240]) || stage1.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.000 | -1.274 | 1.328 | 0.200 | torch.Size([120]) || stage1.residual_group2.blocks.1.mlp.fc2.bias
+ | -0.000 | -0.390 | 0.303 | 0.069 | torch.Size([120, 120]) || stage1.linear2.weight
+ | 0.010 | -0.219 | 0.227 | 0.087 | torch.Size([120]) || stage1.linear2.bias
+ | -0.000 | -0.095 | 0.106 | 0.024 | torch.Size([120, 120, 3, 3]) || stage1.pa_deform.weight
+ | -0.001 | -0.036 | 0.036 | 0.013 | torch.Size([120]) || stage1.pa_deform.bias
+ | -0.000 | -0.136 | 0.141 | 0.017 | torch.Size([120, 242, 3, 3]) || stage1.pa_deform.conv_offset.0.weight
+ | -0.002 | -0.028 | 0.024 | 0.013 | torch.Size([120]) || stage1.pa_deform.conv_offset.0.bias
+ | -0.001 | -0.156 | 0.104 | 0.019 | torch.Size([120, 120, 3, 3]) || stage1.pa_deform.conv_offset.2.weight
+ | -0.008 | -0.055 | 0.045 | 0.022 | torch.Size([120]) || stage1.pa_deform.conv_offset.2.bias
+ | -0.001 | -0.098 | 0.106 | 0.018 | torch.Size([120, 120, 3, 3]) || stage1.pa_deform.conv_offset.4.weight
+ | -0.000 | -0.081 | 0.070 | 0.029 | torch.Size([120]) || stage1.pa_deform.conv_offset.4.bias
+ | -0.000 | -0.375 | 0.279 | 0.027 | torch.Size([324, 120, 3, 3]) || stage1.pa_deform.conv_offset.6.weight
+ | -0.003 | -0.074 | 0.070 | 0.028 | torch.Size([324]) || stage1.pa_deform.conv_offset.6.bias
+ | -0.000 | -0.776 | 0.733 | 0.114 | torch.Size([360, 360]) || stage1.pa_fuse.fc11.weight
+ | 0.021 | -0.239 | 0.513 | 0.121 | torch.Size([360]) || stage1.pa_fuse.fc11.bias
+ | 0.001 | -1.100 | 1.143 | 0.149 | torch.Size([360, 360]) || stage1.pa_fuse.fc12.weight
+ | 0.008 | -0.405 | 0.393 | 0.136 | torch.Size([360]) || stage1.pa_fuse.fc12.bias
+ | 0.000 | -0.963 | 0.899 | 0.142 | torch.Size([120, 360]) || stage1.pa_fuse.fc2.weight
+ | -0.055 | -0.616 | 0.599 | 0.197 | torch.Size([120]) || stage1.pa_fuse.fc2.bias
+ | 1.149 | 0.345 | 1.921 | 0.289 | torch.Size([480]) || stage2.reshape.1.weight
+ | 0.017 | -0.502 | 0.663 | 0.141 | torch.Size([480]) || stage2.reshape.1.bias
+ | -0.000 | -0.609 | 0.736 | 0.146 | torch.Size([120, 480]) || stage2.reshape.2.weight
+ | 0.006 | -0.136 | 0.404 | 0.077 | torch.Size([120]) || stage2.reshape.2.bias
+ | 0.686 | 0.172 | 1.113 | 0.175 | torch.Size([120]) || stage2.residual_group1.blocks.0.norm1.weight
+ | -0.154 | -0.926 | 0.339 | 0.217 | torch.Size([120]) || stage2.residual_group1.blocks.0.norm1.bias
+ | -0.120 | -1.869 | 4.616 | 0.310 | torch.Size([675, 6]) || stage2.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.0.attn.position_bias
+ | 0.000 | -0.514 | 0.499 | 0.102 | torch.Size([360, 120]) || stage2.residual_group1.blocks.0.attn.qkv_self.weight
+ | -0.002 | -0.214 | 0.177 | 0.044 | torch.Size([360]) || stage2.residual_group1.blocks.0.attn.qkv_self.bias
+ | -0.001 | -0.499 | 0.529 | 0.093 | torch.Size([120, 240]) || stage2.residual_group1.blocks.0.attn.proj.weight
+ | -0.004 | -0.171 | 0.556 | 0.087 | torch.Size([120]) || stage2.residual_group1.blocks.0.attn.proj.bias
+ | -0.000 | -0.642 | 0.598 | 0.083 | torch.Size([360, 120]) || stage2.residual_group1.blocks.0.attn.qkv_mut.weight
+ | -0.000 | -0.141 | 0.125 | 0.027 | torch.Size([360]) || stage2.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.592 | 0.325 | 0.794 | 0.096 | torch.Size([120]) || stage2.residual_group1.blocks.0.norm2.weight
+ | 0.008 | -0.649 | 0.445 | 0.168 | torch.Size([120]) || stage2.residual_group1.blocks.0.norm2.bias
+ | 0.000 | -0.485 | 0.457 | 0.116 | torch.Size([240, 120]) || stage2.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.053 | -0.240 | 0.171 | 0.062 | torch.Size([240]) || stage2.residual_group1.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.503 | 0.462 | 0.118 | torch.Size([240, 120]) || stage2.residual_group1.blocks.0.mlp.fc12.weight
+ | 0.005 | -0.177 | 0.268 | 0.068 | torch.Size([240]) || stage2.residual_group1.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.690 | 0.498 | 0.123 | torch.Size([120, 240]) || stage2.residual_group1.blocks.0.mlp.fc2.weight
+ | -0.007 | -0.270 | 0.472 | 0.097 | torch.Size([120]) || stage2.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.864 | 0.187 | 1.221 | 0.164 | torch.Size([120]) || stage2.residual_group1.blocks.1.norm1.weight
+ | -0.146 | -1.128 | 0.299 | 0.204 | torch.Size([120]) || stage2.residual_group1.blocks.1.norm1.bias
+ | -0.241 | -1.607 | 8.958 | 0.356 | torch.Size([675, 6]) || stage2.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.1.attn.position_bias
+ | 0.000 | -0.561 | 0.538 | 0.116 | torch.Size([360, 120]) || stage2.residual_group1.blocks.1.attn.qkv_self.weight
+ | 0.001 | -0.198 | 0.222 | 0.052 | torch.Size([360]) || stage2.residual_group1.blocks.1.attn.qkv_self.bias
+ | 0.001 | -0.475 | 0.479 | 0.099 | torch.Size([120, 240]) || stage2.residual_group1.blocks.1.attn.proj.weight
+ | -0.006 | -0.295 | 0.341 | 0.101 | torch.Size([120]) || stage2.residual_group1.blocks.1.attn.proj.bias
+ | 0.001 | -0.961 | 0.789 | 0.080 | torch.Size([360, 120]) || stage2.residual_group1.blocks.1.attn.qkv_mut.weight
+ | 0.001 | -0.105 | 0.143 | 0.024 | torch.Size([360]) || stage2.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.653 | 0.401 | 0.810 | 0.063 | torch.Size([120]) || stage2.residual_group1.blocks.1.norm2.weight
+ | 0.009 | -0.767 | 0.367 | 0.154 | torch.Size([120]) || stage2.residual_group1.blocks.1.norm2.bias
+ | 0.001 | -0.486 | 0.499 | 0.117 | torch.Size([240, 120]) || stage2.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.056 | -0.185 | 0.147 | 0.058 | torch.Size([240]) || stage2.residual_group1.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.529 | 0.548 | 0.121 | torch.Size([240, 120]) || stage2.residual_group1.blocks.1.mlp.fc12.weight
+ | 0.002 | -0.231 | 0.177 | 0.071 | torch.Size([240]) || stage2.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.001 | -0.578 | 0.609 | 0.123 | torch.Size([120, 240]) || stage2.residual_group1.blocks.1.mlp.fc2.weight
+ | -0.003 | -0.350 | 0.216 | 0.098 | torch.Size([120]) || stage2.residual_group1.blocks.1.mlp.fc2.bias
+ | 0.848 | 0.172 | 1.107 | 0.144 | torch.Size([120]) || stage2.residual_group1.blocks.2.norm1.weight
+ | -0.168 | -1.123 | 0.330 | 0.178 | torch.Size([120]) || stage2.residual_group1.blocks.2.norm1.bias
+ | -0.074 | -1.239 | 4.293 | 0.247 | torch.Size([675, 6]) || stage2.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.2.attn.position_bias
+ | -0.001 | -0.643 | 0.531 | 0.117 | torch.Size([360, 120]) || stage2.residual_group1.blocks.2.attn.qkv_self.weight
+ | 0.003 | -0.220 | 0.376 | 0.047 | torch.Size([360]) || stage2.residual_group1.blocks.2.attn.qkv_self.bias
+ | 0.000 | -0.529 | 0.479 | 0.100 | torch.Size([120, 240]) || stage2.residual_group1.blocks.2.attn.proj.weight
+ | 0.002 | -0.230 | 0.295 | 0.074 | torch.Size([120]) || stage2.residual_group1.blocks.2.attn.proj.bias
+ | -0.001 | -0.726 | 0.768 | 0.091 | torch.Size([360, 120]) || stage2.residual_group1.blocks.2.attn.qkv_mut.weight
+ | 0.001 | -0.167 | 0.193 | 0.028 | torch.Size([360]) || stage2.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.695 | 0.334 | 0.833 | 0.068 | torch.Size([120]) || stage2.residual_group1.blocks.2.norm2.weight
+ | 0.012 | -0.755 | 0.517 | 0.157 | torch.Size([120]) || stage2.residual_group1.blocks.2.norm2.bias
+ | 0.001 | -0.474 | 0.480 | 0.119 | torch.Size([240, 120]) || stage2.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.049 | -0.218 | 0.148 | 0.067 | torch.Size([240]) || stage2.residual_group1.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.529 | 0.542 | 0.124 | torch.Size([240, 120]) || stage2.residual_group1.blocks.2.mlp.fc12.weight
+ | -0.006 | -0.245 | 0.239 | 0.073 | torch.Size([240]) || stage2.residual_group1.blocks.2.mlp.fc12.bias
+ | -0.001 | -0.541 | 0.485 | 0.124 | torch.Size([120, 240]) || stage2.residual_group1.blocks.2.mlp.fc2.weight
+ | 0.000 | -0.318 | 0.170 | 0.077 | torch.Size([120]) || stage2.residual_group1.blocks.2.mlp.fc2.bias
+ | 0.903 | 0.178 | 1.124 | 0.124 | torch.Size([120]) || stage2.residual_group1.blocks.3.norm1.weight
+ | -0.138 | -1.223 | 0.440 | 0.177 | torch.Size([120]) || stage2.residual_group1.blocks.3.norm1.bias
+ | -0.164 | -1.383 | 5.910 | 0.305 | torch.Size([675, 6]) || stage2.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.3.attn.position_bias
+ | -0.000 | -0.526 | 0.496 | 0.120 | torch.Size([360, 120]) || stage2.residual_group1.blocks.3.attn.qkv_self.weight
+ | 0.000 | -0.250 | 0.273 | 0.061 | torch.Size([360]) || stage2.residual_group1.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.447 | 0.524 | 0.097 | torch.Size([120, 240]) || stage2.residual_group1.blocks.3.attn.proj.weight
+ | -0.003 | -0.243 | 0.256 | 0.082 | torch.Size([120]) || stage2.residual_group1.blocks.3.attn.proj.bias
+ | -0.001 | -0.551 | 0.730 | 0.083 | torch.Size([360, 120]) || stage2.residual_group1.blocks.3.attn.qkv_mut.weight
+ | -0.001 | -0.145 | 0.126 | 0.024 | torch.Size([360]) || stage2.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.707 | 0.319 | 0.855 | 0.063 | torch.Size([120]) || stage2.residual_group1.blocks.3.norm2.weight
+ | 0.013 | -0.839 | 0.507 | 0.155 | torch.Size([120]) || stage2.residual_group1.blocks.3.norm2.bias
+ | 0.000 | -0.509 | 0.508 | 0.118 | torch.Size([240, 120]) || stage2.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.051 | -0.219 | 0.155 | 0.068 | torch.Size([240]) || stage2.residual_group1.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.475 | 0.592 | 0.124 | torch.Size([240, 120]) || stage2.residual_group1.blocks.3.mlp.fc12.weight
+ | -0.002 | -0.162 | 0.220 | 0.069 | torch.Size([240]) || stage2.residual_group1.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.465 | 0.528 | 0.124 | torch.Size([120, 240]) || stage2.residual_group1.blocks.3.mlp.fc2.weight
+ | -0.002 | -0.243 | 0.286 | 0.088 | torch.Size([120]) || stage2.residual_group1.blocks.3.mlp.fc2.bias
+ | 0.948 | 0.220 | 1.175 | 0.108 | torch.Size([120]) || stage2.residual_group1.blocks.4.norm1.weight
+ | -0.125 | -1.093 | 0.385 | 0.157 | torch.Size([120]) || stage2.residual_group1.blocks.4.norm1.bias
+ | -0.150 | -1.632 | 4.522 | 0.341 | torch.Size([675, 6]) || stage2.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.4.attn.position_bias
+ | -0.000 | -0.636 | 0.543 | 0.119 | torch.Size([360, 120]) || stage2.residual_group1.blocks.4.attn.qkv_self.weight
+ | -0.001 | -0.254 | 0.262 | 0.048 | torch.Size([360]) || stage2.residual_group1.blocks.4.attn.qkv_self.bias
+ | 0.001 | -0.632 | 0.628 | 0.112 | torch.Size([120, 240]) || stage2.residual_group1.blocks.4.attn.proj.weight
+ | -0.005 | -0.240 | 0.330 | 0.104 | torch.Size([120]) || stage2.residual_group1.blocks.4.attn.proj.bias
+ | 0.000 | -0.476 | 0.479 | 0.088 | torch.Size([360, 120]) || stage2.residual_group1.blocks.4.attn.qkv_mut.weight
+ | -0.001 | -0.112 | 0.134 | 0.020 | torch.Size([360]) || stage2.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.686 | 0.264 | 0.797 | 0.060 | torch.Size([120]) || stage2.residual_group1.blocks.4.norm2.weight
+ | 0.012 | -0.889 | 0.427 | 0.140 | torch.Size([120]) || stage2.residual_group1.blocks.4.norm2.bias
+ | 0.001 | -0.476 | 0.478 | 0.117 | torch.Size([240, 120]) || stage2.residual_group1.blocks.4.mlp.fc11.weight
+ | -0.051 | -0.267 | 0.180 | 0.071 | torch.Size([240]) || stage2.residual_group1.blocks.4.mlp.fc11.bias
+ | 0.000 | -0.506 | 0.517 | 0.127 | torch.Size([240, 120]) || stage2.residual_group1.blocks.4.mlp.fc12.weight
+ | 0.002 | -0.172 | 0.241 | 0.068 | torch.Size([240]) || stage2.residual_group1.blocks.4.mlp.fc12.bias
+ | -0.001 | -0.570 | 0.542 | 0.126 | torch.Size([120, 240]) || stage2.residual_group1.blocks.4.mlp.fc2.weight
+ | -0.003 | -0.631 | 0.395 | 0.123 | torch.Size([120]) || stage2.residual_group1.blocks.4.mlp.fc2.bias
+ | 0.912 | 0.189 | 1.122 | 0.104 | torch.Size([120]) || stage2.residual_group1.blocks.5.norm1.weight
+ | -0.114 | -1.125 | 0.188 | 0.140 | torch.Size([120]) || stage2.residual_group1.blocks.5.norm1.bias
+ | -0.099 | -1.285 | 1.708 | 0.236 | torch.Size([675, 6]) || stage2.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.5.attn.position_bias
+ | -0.000 | -0.496 | 0.540 | 0.119 | torch.Size([360, 120]) || stage2.residual_group1.blocks.5.attn.qkv_self.weight
+ | 0.003 | -0.260 | 0.228 | 0.052 | torch.Size([360]) || stage2.residual_group1.blocks.5.attn.qkv_self.bias
+ | -0.000 | -0.511 | 0.454 | 0.095 | torch.Size([120, 240]) || stage2.residual_group1.blocks.5.attn.proj.weight
+ | 0.000 | -0.711 | 0.286 | 0.115 | torch.Size([120]) || stage2.residual_group1.blocks.5.attn.proj.bias
+ | 0.000 | -0.444 | 0.454 | 0.082 | torch.Size([360, 120]) || stage2.residual_group1.blocks.5.attn.qkv_mut.weight
+ | -0.000 | -0.101 | 0.133 | 0.021 | torch.Size([360]) || stage2.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.668 | 0.312 | 0.800 | 0.056 | torch.Size([120]) || stage2.residual_group1.blocks.5.norm2.weight
+ | 0.015 | -0.778 | 0.372 | 0.111 | torch.Size([120]) || stage2.residual_group1.blocks.5.norm2.bias
+ | -0.000 | -0.485 | 0.469 | 0.115 | torch.Size([240, 120]) || stage2.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.045 | -0.294 | 0.173 | 0.083 | torch.Size([240]) || stage2.residual_group1.blocks.5.mlp.fc11.bias
+ | 0.000 | -0.554 | 0.540 | 0.129 | torch.Size([240, 120]) || stage2.residual_group1.blocks.5.mlp.fc12.weight
+ | 0.001 | -0.183 | 0.199 | 0.077 | torch.Size([240]) || stage2.residual_group1.blocks.5.mlp.fc12.bias
+ | 0.000 | -0.879 | 0.824 | 0.127 | torch.Size([120, 240]) || stage2.residual_group1.blocks.5.mlp.fc2.weight
+ | 0.001 | -1.670 | 0.358 | 0.208 | torch.Size([120]) || stage2.residual_group1.blocks.5.mlp.fc2.bias
+ | 0.001 | -0.253 | 0.346 | 0.068 | torch.Size([120, 120]) || stage2.linear1.weight
+ | 0.007 | -0.248 | 0.241 | 0.103 | torch.Size([120]) || stage2.linear1.bias
+ | 1.012 | 0.613 | 1.327 | 0.116 | torch.Size([120]) || stage2.residual_group2.blocks.0.norm1.weight
+ | 0.019 | -0.724 | 0.685 | 0.244 | torch.Size([120]) || stage2.residual_group2.blocks.0.norm1.bias
+ | 0.003 | -2.959 | 1.705 | 0.151 | torch.Size([2475, 6]) || stage2.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage2.residual_group2.blocks.0.attn.relative_position_index
+ | -0.000 | -0.636 | 0.617 | 0.125 | torch.Size([360, 120]) || stage2.residual_group2.blocks.0.attn.qkv_self.weight
+ | -0.002 | -0.291 | 0.292 | 0.085 | torch.Size([360]) || stage2.residual_group2.blocks.0.attn.qkv_self.bias
+ | -0.002 | -0.476 | 0.512 | 0.138 | torch.Size([120, 120]) || stage2.residual_group2.blocks.0.attn.proj.weight
+ | -0.002 | -0.263 | 0.398 | 0.135 | torch.Size([120]) || stage2.residual_group2.blocks.0.attn.proj.bias
+ | 0.677 | 0.521 | 0.840 | 0.063 | torch.Size([120]) || stage2.residual_group2.blocks.0.norm2.weight
+ | 0.010 | -0.710 | 0.541 | 0.173 | torch.Size([120]) || stage2.residual_group2.blocks.0.norm2.bias
+ | 0.001 | -0.540 | 0.507 | 0.112 | torch.Size([240, 120]) || stage2.residual_group2.blocks.0.mlp.fc11.weight
+ | -0.016 | -0.242 | 0.201 | 0.077 | torch.Size([240]) || stage2.residual_group2.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.519 | 0.479 | 0.122 | torch.Size([240, 120]) || stage2.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.006 | -0.162 | 0.231 | 0.071 | torch.Size([240]) || stage2.residual_group2.blocks.0.mlp.fc12.bias
+ | -0.001 | -0.449 | 0.494 | 0.121 | torch.Size([120, 240]) || stage2.residual_group2.blocks.0.mlp.fc2.weight
+ | 0.002 | -0.293 | 0.222 | 0.095 | torch.Size([120]) || stage2.residual_group2.blocks.0.mlp.fc2.bias
+ | 1.053 | 0.832 | 1.269 | 0.079 | torch.Size([120]) || stage2.residual_group2.blocks.1.norm1.weight
+ | 0.015 | -0.549 | 0.428 | 0.189 | torch.Size([120]) || stage2.residual_group2.blocks.1.norm1.bias
+ | 0.007 | -3.099 | 1.550 | 0.170 | torch.Size([2475, 6]) || stage2.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage2.residual_group2.blocks.1.attn.relative_position_index
+ | 0.000 | -0.673 | 0.604 | 0.131 | torch.Size([360, 120]) || stage2.residual_group2.blocks.1.attn.qkv_self.weight
+ | -0.001 | -0.416 | 0.391 | 0.089 | torch.Size([360]) || stage2.residual_group2.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.569 | 0.560 | 0.139 | torch.Size([120, 120]) || stage2.residual_group2.blocks.1.attn.proj.weight
+ | 0.004 | -0.613 | 0.428 | 0.158 | torch.Size([120]) || stage2.residual_group2.blocks.1.attn.proj.bias
+ | 0.762 | 0.464 | 0.954 | 0.085 | torch.Size([120]) || stage2.residual_group2.blocks.1.norm2.weight
+ | 0.005 | -0.745 | 0.381 | 0.117 | torch.Size([120]) || stage2.residual_group2.blocks.1.norm2.bias
+ | 0.000 | -0.441 | 0.448 | 0.110 | torch.Size([240, 120]) || stage2.residual_group2.blocks.1.mlp.fc11.weight
+ | 0.019 | -0.292 | 0.460 | 0.117 | torch.Size([240]) || stage2.residual_group2.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.491 | 0.490 | 0.126 | torch.Size([240, 120]) || stage2.residual_group2.blocks.1.mlp.fc12.weight
+ | -0.007 | -0.285 | 0.177 | 0.068 | torch.Size([240]) || stage2.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.535 | 0.631 | 0.125 | torch.Size([120, 240]) || stage2.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.011 | -0.765 | 0.337 | 0.142 | torch.Size([120]) || stage2.residual_group2.blocks.1.mlp.fc2.bias
+ | 0.001 | -0.367 | 0.372 | 0.074 | torch.Size([120, 120]) || stage2.linear2.weight
+ | 0.009 | -0.288 | 0.342 | 0.130 | torch.Size([120]) || stage2.linear2.bias
+ | 0.000 | -0.112 | 0.093 | 0.022 | torch.Size([120, 120, 3, 3]) || stage2.pa_deform.weight
+ | -0.002 | -0.036 | 0.035 | 0.016 | torch.Size([120]) || stage2.pa_deform.bias
+ | 0.000 | -0.068 | 0.080 | 0.016 | torch.Size([120, 242, 3, 3]) || stage2.pa_deform.conv_offset.0.weight
+ | -0.009 | -0.035 | 0.023 | 0.013 | torch.Size([120]) || stage2.pa_deform.conv_offset.0.bias
+ | 0.000 | -0.068 | 0.079 | 0.019 | torch.Size([120, 120, 3, 3]) || stage2.pa_deform.conv_offset.2.weight
+ | -0.014 | -0.061 | 0.036 | 0.021 | torch.Size([120]) || stage2.pa_deform.conv_offset.2.bias
+ | -0.001 | -0.082 | 0.079 | 0.019 | torch.Size([120, 120, 3, 3]) || stage2.pa_deform.conv_offset.4.weight
+ | -0.003 | -0.075 | 0.069 | 0.035 | torch.Size([120]) || stage2.pa_deform.conv_offset.4.bias
+ | -0.000 | -0.166 | 0.139 | 0.016 | torch.Size([324, 120, 3, 3]) || stage2.pa_deform.conv_offset.6.weight
+ | -0.015 | -0.090 | 0.050 | 0.030 | torch.Size([324]) || stage2.pa_deform.conv_offset.6.bias
+ | -0.002 | -0.642 | 0.663 | 0.127 | torch.Size([360, 360]) || stage2.pa_fuse.fc11.weight
+ | 0.130 | -0.171 | 0.480 | 0.140 | torch.Size([360]) || stage2.pa_fuse.fc11.bias
+ | -0.000 | -0.696 | 0.620 | 0.118 | torch.Size([360, 360]) || stage2.pa_fuse.fc12.weight
+ | -0.007 | -0.337 | 0.301 | 0.102 | torch.Size([360]) || stage2.pa_fuse.fc12.bias
+ | 0.000 | -0.650 | 0.657 | 0.128 | torch.Size([120, 360]) || stage2.pa_fuse.fc2.weight
+ | 0.013 | -0.507 | 0.451 | 0.215 | torch.Size([120]) || stage2.pa_fuse.fc2.bias
+ | 1.067 | 0.372 | 1.778 | 0.269 | torch.Size([480]) || stage3.reshape.1.weight
+ | -0.004 | -0.699 | 0.521 | 0.227 | torch.Size([480]) || stage3.reshape.1.bias
+ | -0.000 | -0.643 | 0.743 | 0.138 | torch.Size([120, 480]) || stage3.reshape.2.weight
+ | 0.009 | -0.176 | 0.243 | 0.079 | torch.Size([120]) || stage3.reshape.2.bias
+ | 0.785 | 0.469 | 1.029 | 0.105 | torch.Size([120]) || stage3.residual_group1.blocks.0.norm1.weight
+ | -0.102 | -0.716 | 0.311 | 0.179 | torch.Size([120]) || stage3.residual_group1.blocks.0.norm1.bias
+ | -0.001 | -0.340 | 0.163 | 0.033 | torch.Size([675, 6]) || stage3.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.0.attn.position_bias
+ | -0.000 | -0.328 | 0.302 | 0.061 | torch.Size([360, 120]) || stage3.residual_group1.blocks.0.attn.qkv_self.weight
+ | 0.004 | -0.232 | 0.189 | 0.063 | torch.Size([360]) || stage3.residual_group1.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.343 | 0.346 | 0.058 | torch.Size([120, 240]) || stage3.residual_group1.blocks.0.attn.proj.weight
+ | 0.004 | -0.335 | 0.229 | 0.102 | torch.Size([120]) || stage3.residual_group1.blocks.0.attn.proj.bias
+ | -0.000 | -0.366 | 0.325 | 0.052 | torch.Size([360, 120]) || stage3.residual_group1.blocks.0.attn.qkv_mut.weight
+ | -0.001 | -0.091 | 0.074 | 0.017 | torch.Size([360]) || stage3.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.751 | 0.517 | 0.928 | 0.083 | torch.Size([120]) || stage3.residual_group1.blocks.0.norm2.weight
+ | 0.002 | -0.271 | 0.189 | 0.101 | torch.Size([120]) || stage3.residual_group1.blocks.0.norm2.bias
+ | 0.000 | -0.371 | 0.388 | 0.096 | torch.Size([240, 120]) || stage3.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.073 | -0.203 | 0.039 | 0.046 | torch.Size([240]) || stage3.residual_group1.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.400 | 0.401 | 0.094 | torch.Size([240, 120]) || stage3.residual_group1.blocks.0.mlp.fc12.weight
+ | -0.000 | -0.178 | 0.128 | 0.052 | torch.Size([240]) || stage3.residual_group1.blocks.0.mlp.fc12.bias
+ | -0.001 | -0.410 | 0.429 | 0.098 | torch.Size([120, 240]) || stage3.residual_group1.blocks.0.mlp.fc2.weight
+ | 0.006 | -0.345 | 0.304 | 0.108 | torch.Size([120]) || stage3.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.816 | 0.469 | 1.015 | 0.110 | torch.Size([120]) || stage3.residual_group1.blocks.1.norm1.weight
+ | -0.103 | -0.647 | 0.225 | 0.140 | torch.Size([120]) || stage3.residual_group1.blocks.1.norm1.bias
+ | 0.001 | -0.464 | 0.239 | 0.034 | torch.Size([675, 6]) || stage3.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.1.attn.position_bias
+ | -0.000 | -0.304 | 0.359 | 0.061 | torch.Size([360, 120]) || stage3.residual_group1.blocks.1.attn.qkv_self.weight
+ | 0.001 | -0.173 | 0.193 | 0.047 | torch.Size([360]) || stage3.residual_group1.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.299 | 0.408 | 0.055 | torch.Size([120, 240]) || stage3.residual_group1.blocks.1.attn.proj.weight
+ | 0.007 | -0.511 | 0.239 | 0.113 | torch.Size([120]) || stage3.residual_group1.blocks.1.attn.proj.bias
+ | 0.000 | -0.288 | 0.254 | 0.049 | torch.Size([360, 120]) || stage3.residual_group1.blocks.1.attn.qkv_mut.weight
+ | 0.001 | -0.060 | 0.054 | 0.016 | torch.Size([360]) || stage3.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.796 | 0.609 | 0.971 | 0.076 | torch.Size([120]) || stage3.residual_group1.blocks.1.norm2.weight
+ | -0.002 | -0.327 | 0.247 | 0.122 | torch.Size([120]) || stage3.residual_group1.blocks.1.norm2.bias
+ | 0.001 | -0.379 | 0.407 | 0.094 | torch.Size([240, 120]) || stage3.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.077 | -0.214 | 0.034 | 0.045 | torch.Size([240]) || stage3.residual_group1.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.391 | 0.432 | 0.092 | torch.Size([240, 120]) || stage3.residual_group1.blocks.1.mlp.fc12.weight
+ | 0.005 | -0.176 | 0.112 | 0.044 | torch.Size([240]) || stage3.residual_group1.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.378 | 0.399 | 0.093 | torch.Size([120, 240]) || stage3.residual_group1.blocks.1.mlp.fc2.weight
+ | 0.009 | -0.410 | 0.306 | 0.110 | torch.Size([120]) || stage3.residual_group1.blocks.1.mlp.fc2.bias
+ | 0.854 | 0.447 | 0.995 | 0.090 | torch.Size([120]) || stage3.residual_group1.blocks.2.norm1.weight
+ | -0.086 | -0.513 | 0.198 | 0.116 | torch.Size([120]) || stage3.residual_group1.blocks.2.norm1.bias
+ | -0.001 | -0.189 | 0.292 | 0.033 | torch.Size([675, 6]) || stage3.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.2.attn.position_bias
+ | 0.000 | -0.390 | 0.367 | 0.067 | torch.Size([360, 120]) || stage3.residual_group1.blocks.2.attn.qkv_self.weight
+ | -0.002 | -0.310 | 0.284 | 0.078 | torch.Size([360]) || stage3.residual_group1.blocks.2.attn.qkv_self.bias
+ | 0.000 | -0.334 | 0.296 | 0.061 | torch.Size([120, 240]) || stage3.residual_group1.blocks.2.attn.proj.weight
+ | 0.004 | -0.356 | 0.299 | 0.096 | torch.Size([120]) || stage3.residual_group1.blocks.2.attn.proj.bias
+ | 0.000 | -0.276 | 0.315 | 0.055 | torch.Size([360, 120]) || stage3.residual_group1.blocks.2.attn.qkv_mut.weight
+ | 0.000 | -0.094 | 0.066 | 0.014 | torch.Size([360]) || stage3.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.829 | 0.673 | 1.017 | 0.074 | torch.Size([120]) || stage3.residual_group1.blocks.2.norm2.weight
+ | 0.003 | -0.259 | 0.228 | 0.098 | torch.Size([120]) || stage3.residual_group1.blocks.2.norm2.bias
+ | 0.001 | -0.410 | 0.385 | 0.091 | torch.Size([240, 120]) || stage3.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.085 | -0.200 | 0.017 | 0.044 | torch.Size([240]) || stage3.residual_group1.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.348 | 0.378 | 0.090 | torch.Size([240, 120]) || stage3.residual_group1.blocks.2.mlp.fc12.weight
+ | 0.001 | -0.130 | 0.105 | 0.042 | torch.Size([240]) || stage3.residual_group1.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.346 | 0.425 | 0.090 | torch.Size([120, 240]) || stage3.residual_group1.blocks.2.mlp.fc2.weight
+ | 0.005 | -0.363 | 0.241 | 0.094 | torch.Size([120]) || stage3.residual_group1.blocks.2.mlp.fc2.bias
+ | 0.872 | 0.554 | 1.068 | 0.102 | torch.Size([120]) || stage3.residual_group1.blocks.3.norm1.weight
+ | -0.057 | -0.402 | 0.133 | 0.087 | torch.Size([120]) || stage3.residual_group1.blocks.3.norm1.bias
+ | 0.003 | -0.365 | 0.217 | 0.050 | torch.Size([675, 6]) || stage3.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.3.attn.position_bias
+ | 0.000 | -0.359 | 0.357 | 0.065 | torch.Size([360, 120]) || stage3.residual_group1.blocks.3.attn.qkv_self.weight
+ | -0.002 | -0.265 | 0.294 | 0.062 | torch.Size([360]) || stage3.residual_group1.blocks.3.attn.qkv_self.bias
+ | -0.000 | -0.300 | 0.271 | 0.054 | torch.Size([120, 240]) || stage3.residual_group1.blocks.3.attn.proj.weight
+ | 0.002 | -0.316 | 0.215 | 0.094 | torch.Size([120]) || stage3.residual_group1.blocks.3.attn.proj.bias
+ | 0.000 | -0.370 | 0.329 | 0.039 | torch.Size([360, 120]) || stage3.residual_group1.blocks.3.attn.qkv_mut.weight
+ | 0.000 | -0.056 | 0.066 | 0.013 | torch.Size([360]) || stage3.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.842 | 0.631 | 0.989 | 0.073 | torch.Size([120]) || stage3.residual_group1.blocks.3.norm2.weight
+ | -0.001 | -0.216 | 0.263 | 0.083 | torch.Size([120]) || stage3.residual_group1.blocks.3.norm2.bias
+ | 0.001 | -0.388 | 0.391 | 0.089 | torch.Size([240, 120]) || stage3.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.087 | -0.202 | 0.032 | 0.048 | torch.Size([240]) || stage3.residual_group1.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.364 | 0.428 | 0.088 | torch.Size([240, 120]) || stage3.residual_group1.blocks.3.mlp.fc12.weight
+ | -0.000 | -0.137 | 0.106 | 0.043 | torch.Size([240]) || stage3.residual_group1.blocks.3.mlp.fc12.bias
+ | -0.001 | -0.390 | 0.339 | 0.088 | torch.Size([120, 240]) || stage3.residual_group1.blocks.3.mlp.fc2.weight
+ | 0.003 | -0.376 | 0.203 | 0.090 | torch.Size([120]) || stage3.residual_group1.blocks.3.mlp.fc2.bias
+ | 0.913 | 0.498 | 1.102 | 0.096 | torch.Size([120]) || stage3.residual_group1.blocks.4.norm1.weight
+ | -0.048 | -0.340 | 0.105 | 0.071 | torch.Size([120]) || stage3.residual_group1.blocks.4.norm1.bias
+ | 0.001 | -0.706 | 0.306 | 0.058 | torch.Size([675, 6]) || stage3.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.4.attn.position_bias
+ | 0.000 | -0.373 | 0.339 | 0.076 | torch.Size([360, 120]) || stage3.residual_group1.blocks.4.attn.qkv_self.weight
+ | -0.004 | -0.301 | 0.301 | 0.074 | torch.Size([360]) || stage3.residual_group1.blocks.4.attn.qkv_self.bias
+ | 0.000 | -0.278 | 0.277 | 0.058 | torch.Size([120, 240]) || stage3.residual_group1.blocks.4.attn.proj.weight
+ | 0.003 | -0.310 | 0.240 | 0.079 | torch.Size([120]) || stage3.residual_group1.blocks.4.attn.proj.bias
+ | -0.000 | -0.350 | 0.322 | 0.046 | torch.Size([360, 120]) || stage3.residual_group1.blocks.4.attn.qkv_mut.weight
+ | -0.000 | -0.045 | 0.064 | 0.010 | torch.Size([360]) || stage3.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.862 | 0.679 | 0.990 | 0.059 | torch.Size([120]) || stage3.residual_group1.blocks.4.norm2.weight
+ | -0.004 | -0.313 | 0.190 | 0.083 | torch.Size([120]) || stage3.residual_group1.blocks.4.norm2.bias
+ | 0.001 | -0.370 | 0.364 | 0.089 | torch.Size([240, 120]) || stage3.residual_group1.blocks.4.mlp.fc11.weight
+ | -0.092 | -0.231 | 0.129 | 0.057 | torch.Size([240]) || stage3.residual_group1.blocks.4.mlp.fc11.bias
+ | -0.000 | -0.375 | 0.511 | 0.090 | torch.Size([240, 120]) || stage3.residual_group1.blocks.4.mlp.fc12.weight
+ | 0.002 | -0.114 | 0.114 | 0.040 | torch.Size([240]) || stage3.residual_group1.blocks.4.mlp.fc12.bias
+ | -0.000 | -0.389 | 0.354 | 0.088 | torch.Size([120, 240]) || stage3.residual_group1.blocks.4.mlp.fc2.weight
+ | 0.005 | -0.258 | 0.164 | 0.073 | torch.Size([120]) || stage3.residual_group1.blocks.4.mlp.fc2.bias
+ | 0.899 | 0.480 | 1.089 | 0.103 | torch.Size([120]) || stage3.residual_group1.blocks.5.norm1.weight
+ | -0.030 | -0.257 | 0.115 | 0.056 | torch.Size([120]) || stage3.residual_group1.blocks.5.norm1.bias
+ | 0.003 | -0.462 | 0.290 | 0.069 | torch.Size([675, 6]) || stage3.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.5.attn.position_bias
+ | 0.000 | -0.391 | 0.365 | 0.069 | torch.Size([360, 120]) || stage3.residual_group1.blocks.5.attn.qkv_self.weight
+ | -0.004 | -0.232 | 0.302 | 0.064 | torch.Size([360]) || stage3.residual_group1.blocks.5.attn.qkv_self.bias
+ | -0.000 | -0.267 | 0.293 | 0.051 | torch.Size([120, 240]) || stage3.residual_group1.blocks.5.attn.proj.weight
+ | 0.000 | -0.250 | 0.182 | 0.070 | torch.Size([120]) || stage3.residual_group1.blocks.5.attn.proj.bias
+ | -0.000 | -0.238 | 0.257 | 0.033 | torch.Size([360, 120]) || stage3.residual_group1.blocks.5.attn.qkv_mut.weight
+ | -0.001 | -0.032 | 0.033 | 0.008 | torch.Size([360]) || stage3.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.864 | 0.651 | 1.029 | 0.070 | torch.Size([120]) || stage3.residual_group1.blocks.5.norm2.weight
+ | -0.003 | -0.212 | 0.175 | 0.075 | torch.Size([120]) || stage3.residual_group1.blocks.5.norm2.bias
+ | 0.000 | -0.378 | 0.379 | 0.089 | torch.Size([240, 120]) || stage3.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.097 | -0.308 | 0.026 | 0.051 | torch.Size([240]) || stage3.residual_group1.blocks.5.mlp.fc11.bias
+ | 0.000 | -0.578 | 0.401 | 0.089 | torch.Size([240, 120]) || stage3.residual_group1.blocks.5.mlp.fc12.weight
+ | -0.005 | -0.166 | 0.131 | 0.049 | torch.Size([240]) || stage3.residual_group1.blocks.5.mlp.fc12.bias
+ | 0.000 | -0.358 | 0.376 | 0.085 | torch.Size([120, 240]) || stage3.residual_group1.blocks.5.mlp.fc2.weight
+ | 0.001 | -0.262 | 0.176 | 0.072 | torch.Size([120]) || stage3.residual_group1.blocks.5.mlp.fc2.bias
+ | 0.003 | -0.284 | 0.467 | 0.071 | torch.Size([120, 120]) || stage3.linear1.weight
+ | 0.006 | -0.201 | 0.269 | 0.090 | torch.Size([120]) || stage3.linear1.bias
+ | 0.877 | 0.568 | 1.197 | 0.115 | torch.Size([120]) || stage3.residual_group2.blocks.0.norm1.weight
+ | 0.002 | -0.248 | 0.324 | 0.100 | torch.Size([120]) || stage3.residual_group2.blocks.0.norm1.bias
+ | 0.000 | -0.261 | 0.125 | 0.029 | torch.Size([2475, 6]) || stage3.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage3.residual_group2.blocks.0.attn.relative_position_index
+ | -0.000 | -0.563 | 0.552 | 0.074 | torch.Size([360, 120]) || stage3.residual_group2.blocks.0.attn.qkv_self.weight
+ | 0.005 | -0.257 | 0.302 | 0.081 | torch.Size([360]) || stage3.residual_group2.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.390 | 0.385 | 0.084 | torch.Size([120, 120]) || stage3.residual_group2.blocks.0.attn.proj.weight
+ | 0.002 | -0.450 | 0.235 | 0.125 | torch.Size([120]) || stage3.residual_group2.blocks.0.attn.proj.bias
+ | 0.986 | 0.755 | 1.165 | 0.078 | torch.Size([120]) || stage3.residual_group2.blocks.0.norm2.weight
+ | -0.000 | -0.260 | 0.169 | 0.076 | torch.Size([120]) || stage3.residual_group2.blocks.0.norm2.bias
+ | 0.000 | -0.355 | 0.397 | 0.087 | torch.Size([240, 120]) || stage3.residual_group2.blocks.0.mlp.fc11.weight
+ | -0.046 | -0.220 | 0.086 | 0.055 | torch.Size([240]) || stage3.residual_group2.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.424 | 0.368 | 0.089 | torch.Size([240, 120]) || stage3.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.006 | -0.111 | 0.122 | 0.038 | torch.Size([240]) || stage3.residual_group2.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.354 | 0.374 | 0.090 | torch.Size([120, 240]) || stage3.residual_group2.blocks.0.mlp.fc2.weight
+ | 0.001 | -0.374 | 0.272 | 0.101 | torch.Size([120]) || stage3.residual_group2.blocks.0.mlp.fc2.bias
+ | 0.919 | 0.643 | 1.132 | 0.100 | torch.Size([120]) || stage3.residual_group2.blocks.1.norm1.weight
+ | 0.000 | -0.177 | 0.181 | 0.063 | torch.Size([120]) || stage3.residual_group2.blocks.1.norm1.bias
+ | 0.000 | -0.332 | 0.131 | 0.028 | torch.Size([2475, 6]) || stage3.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage3.residual_group2.blocks.1.attn.relative_position_index
+ | -0.000 | -0.418 | 0.362 | 0.069 | torch.Size([360, 120]) || stage3.residual_group2.blocks.1.attn.qkv_self.weight
+ | -0.004 | -0.375 | 0.347 | 0.082 | torch.Size([360]) || stage3.residual_group2.blocks.1.attn.qkv_self.bias
+ | -0.001 | -0.294 | 0.354 | 0.077 | torch.Size([120, 120]) || stage3.residual_group2.blocks.1.attn.proj.weight
+ | 0.003 | -0.432 | 0.259 | 0.101 | torch.Size([120]) || stage3.residual_group2.blocks.1.attn.proj.bias
+ | 1.012 | 0.750 | 1.178 | 0.077 | torch.Size([120]) || stage3.residual_group2.blocks.1.norm2.weight
+ | -0.001 | -0.171 | 0.155 | 0.060 | torch.Size([120]) || stage3.residual_group2.blocks.1.norm2.bias
+ | 0.000 | -0.331 | 0.356 | 0.087 | torch.Size([240, 120]) || stage3.residual_group2.blocks.1.mlp.fc11.weight
+ | -0.035 | -0.207 | 0.197 | 0.065 | torch.Size([240]) || stage3.residual_group2.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.399 | 0.398 | 0.092 | torch.Size([240, 120]) || stage3.residual_group2.blocks.1.mlp.fc12.weight
+ | -0.002 | -0.111 | 0.129 | 0.041 | torch.Size([240]) || stage3.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.001 | -0.353 | 0.330 | 0.088 | torch.Size([120, 240]) || stage3.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.001 | -0.328 | 0.127 | 0.064 | torch.Size([120]) || stage3.residual_group2.blocks.1.mlp.fc2.bias
+ | 0.003 | -0.289 | 0.519 | 0.073 | torch.Size([120, 120]) || stage3.linear2.weight
+ | 0.002 | -0.318 | 0.371 | 0.144 | torch.Size([120]) || stage3.linear2.bias
+ | -0.000 | -0.086 | 0.095 | 0.022 | torch.Size([120, 120, 3, 3]) || stage3.pa_deform.weight
+ | -0.002 | -0.023 | 0.021 | 0.010 | torch.Size([120]) || stage3.pa_deform.bias
+ | -0.000 | -0.060 | 0.056 | 0.015 | torch.Size([120, 242, 3, 3]) || stage3.pa_deform.conv_offset.0.weight
+ | -0.008 | -0.035 | 0.019 | 0.013 | torch.Size([120]) || stage3.pa_deform.conv_offset.0.bias
+ | -0.001 | -0.064 | 0.062 | 0.019 | torch.Size([120, 120, 3, 3]) || stage3.pa_deform.conv_offset.2.weight
+ | -0.007 | -0.044 | 0.031 | 0.019 | torch.Size([120]) || stage3.pa_deform.conv_offset.2.bias
+ | 0.000 | -0.062 | 0.063 | 0.019 | torch.Size([120, 120, 3, 3]) || stage3.pa_deform.conv_offset.4.weight
+ | -0.006 | -0.052 | 0.043 | 0.021 | torch.Size([120]) || stage3.pa_deform.conv_offset.4.bias
+ | 0.000 | -0.081 | 0.080 | 0.011 | torch.Size([324, 120, 3, 3]) || stage3.pa_deform.conv_offset.6.weight
+ | -0.004 | -0.087 | 0.083 | 0.021 | torch.Size([324]) || stage3.pa_deform.conv_offset.6.bias
+ | -0.002 | -0.465 | 0.513 | 0.101 | torch.Size([360, 360]) || stage3.pa_fuse.fc11.weight
+ | 0.059 | -0.251 | 0.595 | 0.104 | torch.Size([360]) || stage3.pa_fuse.fc11.bias
+ | -0.000 | -0.544 | 0.531 | 0.100 | torch.Size([360, 360]) || stage3.pa_fuse.fc12.weight
+ | 0.001 | -0.589 | 0.433 | 0.106 | torch.Size([360]) || stage3.pa_fuse.fc12.bias
+ | -0.000 | -0.535 | 0.562 | 0.127 | torch.Size([120, 360]) || stage3.pa_fuse.fc2.weight
+ | -0.001 | -0.401 | 0.342 | 0.121 | torch.Size([120]) || stage3.pa_fuse.fc2.bias
+ | 0.997 | 0.921 | 1.125 | 0.028 | torch.Size([480]) || stage4.reshape.1.weight
+ | -0.000 | -0.058 | 0.059 | 0.022 | torch.Size([480]) || stage4.reshape.1.bias
+ | 0.000 | -0.155 | 0.150 | 0.031 | torch.Size([120, 480]) || stage4.reshape.2.weight
+ | 0.001 | -0.016 | 0.016 | 0.006 | torch.Size([120]) || stage4.reshape.2.bias
+ | 1.002 | 0.999 | 1.009 | 0.002 | torch.Size([120]) || stage4.residual_group1.blocks.0.norm1.weight
+ | 0.000 | -0.002 | 0.003 | 0.001 | torch.Size([120]) || stage4.residual_group1.blocks.0.norm1.bias
+ | -0.000 | -0.071 | 0.066 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.0.attn.position_bias
+ | 0.000 | -0.093 | 0.081 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.0.attn.qkv_self.weight
+ | -0.000 | -0.009 | 0.009 | 0.002 | torch.Size([360]) || stage4.residual_group1.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.080 | 0.097 | 0.021 | torch.Size([120, 240]) || stage4.residual_group1.blocks.0.attn.proj.weight
+ | 0.000 | -0.035 | 0.027 | 0.013 | torch.Size([120]) || stage4.residual_group1.blocks.0.attn.proj.bias
+ | 0.000 | -0.080 | 0.079 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.0.attn.qkv_mut.weight
+ | -0.000 | -0.007 | 0.008 | 0.002 | torch.Size([360]) || stage4.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.0.norm2.weight
+ | -0.000 | -0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.0.norm2.bias
+ | -0.000 | -0.079 | 0.085 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.0.mlp.fc11.weight
+ | 0.000 | -0.001 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.087 | 0.092 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.0.mlp.fc12.weight
+ | -0.000 | -0.001 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.080 | 0.077 | 0.020 | torch.Size([120, 240]) || stage4.residual_group1.blocks.0.mlp.fc2.weight
+ | 0.000 | -0.031 | 0.029 | 0.013 | torch.Size([120]) || stage4.residual_group1.blocks.0.mlp.fc2.bias
+ | 1.002 | 0.997 | 1.007 | 0.002 | torch.Size([120]) || stage4.residual_group1.blocks.1.norm1.weight
+ | -0.000 | -0.002 | 0.003 | 0.001 | torch.Size([120]) || stage4.residual_group1.blocks.1.norm1.bias
+ | 0.000 | -0.066 | 0.065 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.1.attn.position_bias
+ | -0.000 | -0.078 | 0.081 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.1.attn.qkv_self.weight
+ | 0.000 | -0.006 | 0.008 | 0.002 | torch.Size([360]) || stage4.residual_group1.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.080 | 0.083 | 0.021 | torch.Size([120, 240]) || stage4.residual_group1.blocks.1.attn.proj.weight
+ | -0.000 | -0.027 | 0.029 | 0.012 | torch.Size([120]) || stage4.residual_group1.blocks.1.attn.proj.bias
+ | 0.000 | -0.077 | 0.082 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.1.attn.qkv_mut.weight
+ | -0.000 | -0.006 | 0.009 | 0.001 | torch.Size([360]) || stage4.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.1.norm2.weight
+ | 0.000 | -0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.1.norm2.bias
+ | -0.000 | -0.080 | 0.078 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.000 | -0.001 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.077 | 0.085 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.1.mlp.fc12.weight
+ | 0.000 | -0.001 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.084 | 0.075 | 0.020 | torch.Size([120, 240]) || stage4.residual_group1.blocks.1.mlp.fc2.weight
+ | 0.000 | -0.034 | 0.031 | 0.013 | torch.Size([120]) || stage4.residual_group1.blocks.1.mlp.fc2.bias
+ | 1.002 | 0.996 | 1.008 | 0.002 | torch.Size([120]) || stage4.residual_group1.blocks.2.norm1.weight
+ | -0.000 | -0.003 | 0.002 | 0.001 | torch.Size([120]) || stage4.residual_group1.blocks.2.norm1.bias
+ | 0.001 | -0.070 | 0.071 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.2.attn.position_bias
+ | 0.000 | -0.091 | 0.087 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.2.attn.qkv_self.weight
+ | -0.000 | -0.007 | 0.005 | 0.001 | torch.Size([360]) || stage4.residual_group1.blocks.2.attn.qkv_self.bias
+ | 0.000 | -0.080 | 0.084 | 0.020 | torch.Size([120, 240]) || stage4.residual_group1.blocks.2.attn.proj.weight
+ | -0.000 | -0.023 | 0.026 | 0.010 | torch.Size([120]) || stage4.residual_group1.blocks.2.attn.proj.bias
+ | -0.000 | -0.107 | 0.087 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.2.attn.qkv_mut.weight
+ | 0.000 | -0.006 | 0.005 | 0.001 | torch.Size([360]) || stage4.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 1.000 | 0.999 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.2.norm2.weight
+ | 0.000 | -0.000 | 0.001 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.2.norm2.bias
+ | 0.000 | -0.076 | 0.077 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.000 | -0.005 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.2.mlp.fc11.bias
+ | -0.000 | -2.000 | 0.081 | 0.023 | torch.Size([240, 120]) || stage4.residual_group1.blocks.2.mlp.fc12.weight
+ | 0.000 | -0.001 | 0.002 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.084 | 0.077 | 0.020 | torch.Size([120, 240]) || stage4.residual_group1.blocks.2.mlp.fc2.weight
+ | 0.000 | -0.027 | 0.024 | 0.010 | torch.Size([120]) || stage4.residual_group1.blocks.2.mlp.fc2.bias
+ | 1.002 | 0.999 | 1.012 | 0.002 | torch.Size([120]) || stage4.residual_group1.blocks.3.norm1.weight
+ | -0.000 | -0.003 | 0.002 | 0.001 | torch.Size([120]) || stage4.residual_group1.blocks.3.norm1.bias
+ | 0.000 | -0.064 | 0.071 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.3.attn.position_bias
+ | 0.000 | -0.099 | 0.088 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.3.attn.qkv_self.weight
+ | 0.000 | -0.006 | 0.005 | 0.001 | torch.Size([360]) || stage4.residual_group1.blocks.3.attn.qkv_self.bias
+ | -0.000 | -0.083 | 0.084 | 0.020 | torch.Size([120, 240]) || stage4.residual_group1.blocks.3.attn.proj.weight
+ | -0.000 | -0.019 | 0.018 | 0.008 | torch.Size([120]) || stage4.residual_group1.blocks.3.attn.proj.bias
+ | 0.000 | -0.079 | 0.084 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.3.attn.qkv_mut.weight
+ | -0.000 | -0.004 | 0.004 | 0.001 | torch.Size([360]) || stage4.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.3.norm2.weight
+ | 0.000 | -0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.3.norm2.bias
+ | -0.000 | -0.078 | 0.081 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.000 | -0.001 | 0.002 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.087 | 0.076 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.3.mlp.fc12.weight
+ | -0.000 | -0.001 | 0.002 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.3.mlp.fc12.bias
+ | -0.000 | -0.079 | 0.082 | 0.020 | torch.Size([120, 240]) || stage4.residual_group1.blocks.3.mlp.fc2.weight
+ | 0.000 | -0.022 | 0.021 | 0.008 | torch.Size([120]) || stage4.residual_group1.blocks.3.mlp.fc2.bias
+ | 1.002 | 0.998 | 1.011 | 0.002 | torch.Size([120]) || stage4.residual_group1.blocks.4.norm1.weight
+ | -0.001 | -0.004 | 0.003 | 0.001 | torch.Size([120]) || stage4.residual_group1.blocks.4.norm1.bias
+ | 0.000 | -0.089 | 0.081 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.4.attn.position_bias
+ | -0.000 | -0.080 | 0.085 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.4.attn.qkv_self.weight
+ | -0.000 | -0.006 | 0.005 | 0.001 | torch.Size([360]) || stage4.residual_group1.blocks.4.attn.qkv_self.bias
+ | -0.000 | -0.075 | 0.077 | 0.020 | torch.Size([120, 240]) || stage4.residual_group1.blocks.4.attn.proj.weight
+ | -0.000 | -0.021 | 0.016 | 0.007 | torch.Size([120]) || stage4.residual_group1.blocks.4.attn.proj.bias
+ | 0.000 | -0.082 | 0.088 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.4.attn.qkv_mut.weight
+ | -0.000 | -0.004 | 0.006 | 0.001 | torch.Size([360]) || stage4.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 1.000 | 0.999 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.4.norm2.weight
+ | 0.000 | -0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.4.norm2.bias
+ | -0.000 | -0.086 | 0.080 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.4.mlp.fc11.weight
+ | 0.000 | -0.001 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.4.mlp.fc11.bias
+ | 0.000 | -0.084 | 0.083 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.4.mlp.fc12.weight
+ | 0.000 | -0.001 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.4.mlp.fc12.bias
+ | 0.000 | -0.076 | 0.081 | 0.020 | torch.Size([120, 240]) || stage4.residual_group1.blocks.4.mlp.fc2.weight
+ | -0.000 | -0.018 | 0.015 | 0.007 | torch.Size([120]) || stage4.residual_group1.blocks.4.mlp.fc2.bias
+ | 1.003 | 0.997 | 1.014 | 0.003 | torch.Size([120]) || stage4.residual_group1.blocks.5.norm1.weight
+ | -0.001 | -0.005 | 0.004 | 0.002 | torch.Size([120]) || stage4.residual_group1.blocks.5.norm1.bias
+ | -0.001 | -0.070 | 0.069 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.5.attn.position_bias
+ | -0.000 | -0.097 | 0.082 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.5.attn.qkv_self.weight
+ | 0.000 | -0.007 | 0.008 | 0.002 | torch.Size([360]) || stage4.residual_group1.blocks.5.attn.qkv_self.bias
+ | -0.000 | -0.075 | 0.089 | 0.021 | torch.Size([120, 240]) || stage4.residual_group1.blocks.5.attn.proj.weight
+ | 0.000 | -0.016 | 0.015 | 0.007 | torch.Size([120]) || stage4.residual_group1.blocks.5.attn.proj.bias
+ | 0.000 | -0.083 | 0.091 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.5.attn.qkv_mut.weight
+ | 0.000 | -0.006 | 0.006 | 0.001 | torch.Size([360]) || stage4.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 1.000 | 0.999 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.5.norm2.weight
+ | -0.000 | -0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.5.norm2.bias
+ | 0.000 | -0.093 | 0.083 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.5.mlp.fc11.weight
+ | 0.000 | -0.002 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.5.mlp.fc11.bias
+ | 0.000 | -0.086 | 0.085 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.5.mlp.fc12.weight
+ | 0.000 | -0.001 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.5.mlp.fc12.bias
+ | 0.000 | -0.079 | 0.092 | 0.020 | torch.Size([120, 240]) || stage4.residual_group1.blocks.5.mlp.fc2.weight
+ | -0.000 | -0.012 | 0.016 | 0.005 | torch.Size([120]) || stage4.residual_group1.blocks.5.mlp.fc2.bias
+ | -0.000 | -0.090 | 0.111 | 0.024 | torch.Size([120, 120]) || stage4.linear1.weight
+ | 0.001 | -0.019 | 0.029 | 0.009 | torch.Size([120]) || stage4.linear1.bias
+ | 1.000 | 0.999 | 1.003 | 0.001 | torch.Size([120]) || stage4.residual_group2.blocks.0.norm1.weight
+ | 0.000 | -0.001 | 0.001 | 0.000 | torch.Size([120]) || stage4.residual_group2.blocks.0.norm1.bias
+ | -0.000 | -0.078 | 0.075 | 0.020 | torch.Size([2475, 6]) || stage4.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage4.residual_group2.blocks.0.attn.relative_position_index
+ | 0.000 | -0.084 | 0.087 | 0.020 | torch.Size([360, 120]) || stage4.residual_group2.blocks.0.attn.qkv_self.weight
+ | 0.000 | -0.005 | 0.004 | 0.001 | torch.Size([360]) || stage4.residual_group2.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.079 | 0.080 | 0.020 | torch.Size([120, 120]) || stage4.residual_group2.blocks.0.attn.proj.weight
+ | 0.000 | -0.021 | 0.024 | 0.008 | torch.Size([120]) || stage4.residual_group2.blocks.0.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group2.blocks.0.norm2.weight
+ | -0.000 | -0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group2.blocks.0.norm2.bias
+ | -0.000 | -0.079 | 0.072 | 0.020 | torch.Size([240, 120]) || stage4.residual_group2.blocks.0.mlp.fc11.weight
+ | -0.000 | -0.001 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group2.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.077 | 0.078 | 0.020 | torch.Size([240, 120]) || stage4.residual_group2.blocks.0.mlp.fc12.weight
+ | 0.000 | -0.001 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group2.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.102 | 0.078 | 0.020 | torch.Size([120, 240]) || stage4.residual_group2.blocks.0.mlp.fc2.weight
+ | 0.000 | -0.024 | 0.020 | 0.009 | torch.Size([120]) || stage4.residual_group2.blocks.0.mlp.fc2.bias
+ | 1.001 | 0.998 | 1.003 | 0.001 | torch.Size([120]) || stage4.residual_group2.blocks.1.norm1.weight
+ | -0.000 | -0.002 | 0.002 | 0.001 | torch.Size([120]) || stage4.residual_group2.blocks.1.norm1.bias
+ | -0.000 | -0.071 | 0.079 | 0.020 | torch.Size([2475, 6]) || stage4.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage4.residual_group2.blocks.1.attn.relative_position_index
+ | 0.000 | -0.078 | 0.096 | 0.020 | torch.Size([360, 120]) || stage4.residual_group2.blocks.1.attn.qkv_self.weight
+ | 0.000 | -0.005 | 0.006 | 0.001 | torch.Size([360]) || stage4.residual_group2.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.077 | 0.080 | 0.020 | torch.Size([120, 120]) || stage4.residual_group2.blocks.1.attn.proj.weight
+ | 0.000 | -0.020 | 0.021 | 0.008 | torch.Size([120]) || stage4.residual_group2.blocks.1.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group2.blocks.1.norm2.weight
+ | -0.000 | -0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group2.blocks.1.norm2.bias
+ | -0.000 | -0.085 | 0.082 | 0.020 | torch.Size([240, 120]) || stage4.residual_group2.blocks.1.mlp.fc11.weight
+ | -0.000 | -0.001 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group2.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.083 | 0.085 | 0.020 | torch.Size([240, 120]) || stage4.residual_group2.blocks.1.mlp.fc12.weight
+ | 0.000 | -0.001 | 0.000 | 0.000 | torch.Size([240]) || stage4.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.078 | 0.078 | 0.020 | torch.Size([120, 240]) || stage4.residual_group2.blocks.1.mlp.fc2.weight
+ | 0.000 | -0.022 | 0.021 | 0.008 | torch.Size([120]) || stage4.residual_group2.blocks.1.mlp.fc2.bias
+ | 0.000 | -0.092 | 0.112 | 0.023 | torch.Size([120, 120]) || stage4.linear2.weight
+ | 0.000 | -0.032 | 0.049 | 0.015 | torch.Size([120]) || stage4.linear2.bias
+ | 0.000 | -0.036 | 0.037 | 0.018 | torch.Size([120, 120, 3, 3]) || stage4.pa_deform.weight
+ | 0.000 | -0.005 | 0.005 | 0.002 | torch.Size([120]) || stage4.pa_deform.bias
+ | -0.000 | -0.021 | 0.022 | 0.012 | torch.Size([120, 242, 3, 3]) || stage4.pa_deform.conv_offset.0.weight
+ | -0.001 | -0.021 | 0.021 | 0.012 | torch.Size([120]) || stage4.pa_deform.conv_offset.0.bias
+ | 0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage4.pa_deform.conv_offset.2.weight
+ | 0.002 | -0.030 | 0.030 | 0.018 | torch.Size([120]) || stage4.pa_deform.conv_offset.2.bias
+ | 0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage4.pa_deform.conv_offset.4.weight
+ | -0.002 | -0.030 | 0.030 | 0.017 | torch.Size([120]) || stage4.pa_deform.conv_offset.4.bias
+ | 0.000 | -0.003 | 0.002 | 0.000 | torch.Size([324, 120, 3, 3]) || stage4.pa_deform.conv_offset.6.weight
+ | 0.000 | -0.005 | 0.004 | 0.001 | torch.Size([324]) || stage4.pa_deform.conv_offset.6.bias
+ | 0.000 | -0.172 | 0.177 | 0.022 | torch.Size([360, 360]) || stage4.pa_fuse.fc11.weight
+ | 0.002 | -0.027 | 0.088 | 0.014 | torch.Size([360]) || stage4.pa_fuse.fc11.bias
+ | 0.000 | -0.212 | 0.163 | 0.022 | torch.Size([360, 360]) || stage4.pa_fuse.fc12.weight
+ | 0.000 | -0.066 | 0.081 | 0.014 | torch.Size([360]) || stage4.pa_fuse.fc12.bias
+ | 0.000 | -0.413 | 0.387 | 0.029 | torch.Size([120, 360]) || stage4.pa_fuse.fc2.weight
+ | -0.001 | -0.198 | 0.214 | 0.073 | torch.Size([120]) || stage4.pa_fuse.fc2.bias
+ | 0.979 | 0.896 | 1.076 | 0.053 | torch.Size([30]) || stage5.reshape.1.weight
+ | -0.005 | -0.074 | 0.100 | 0.043 | torch.Size([30]) || stage5.reshape.1.bias
+ | 0.000 | -0.240 | 0.249 | 0.058 | torch.Size([120, 30]) || stage5.reshape.2.weight
+ | -0.002 | -0.286 | 0.229 | 0.080 | torch.Size([120]) || stage5.reshape.2.bias
+ | 1.001 | 0.993 | 1.006 | 0.002 | torch.Size([120]) || stage5.residual_group1.blocks.0.norm1.weight
+ | -0.004 | -0.018 | 0.006 | 0.005 | torch.Size([120]) || stage5.residual_group1.blocks.0.norm1.bias
+ | -0.000 | -0.066 | 0.062 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.0.attn.position_bias
+ | -0.000 | -0.091 | 0.086 | 0.021 | torch.Size([360, 120]) || stage5.residual_group1.blocks.0.attn.qkv_self.weight
+ | -0.000 | -0.014 | 0.012 | 0.004 | torch.Size([360]) || stage5.residual_group1.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.166 | 0.172 | 0.021 | torch.Size([120, 240]) || stage5.residual_group1.blocks.0.attn.proj.weight
+ | -0.001 | -0.053 | 0.045 | 0.018 | torch.Size([120]) || stage5.residual_group1.blocks.0.attn.proj.bias
+ | -0.000 | -0.090 | 0.081 | 0.020 | torch.Size([360, 120]) || stage5.residual_group1.blocks.0.attn.qkv_mut.weight
+ | 0.000 | -0.006 | 0.006 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.999 | 0.987 | 1.001 | 0.002 | torch.Size([120]) || stage5.residual_group1.blocks.0.norm2.weight
+ | 0.000 | -0.006 | 0.006 | 0.002 | torch.Size([120]) || stage5.residual_group1.blocks.0.norm2.bias
+ | 0.000 | -0.094 | 0.079 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.0.mlp.fc11.weight
+ | 0.000 | -0.022 | 0.012 | 0.004 | torch.Size([240]) || stage5.residual_group1.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.082 | 0.083 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.0.mlp.fc12.weight
+ | 0.000 | -0.013 | 0.014 | 0.005 | torch.Size([240]) || stage5.residual_group1.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.075 | 0.083 | 0.020 | torch.Size([120, 240]) || stage5.residual_group1.blocks.0.mlp.fc2.weight
+ | 0.000 | -0.073 | 0.078 | 0.021 | torch.Size([120]) || stage5.residual_group1.blocks.0.mlp.fc2.bias
+ | 1.001 | 0.994 | 1.007 | 0.002 | torch.Size([120]) || stage5.residual_group1.blocks.1.norm1.weight
+ | -0.004 | -0.016 | 0.004 | 0.004 | torch.Size([120]) || stage5.residual_group1.blocks.1.norm1.bias
+ | 0.000 | -0.065 | 0.063 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.1.attn.position_bias
+ | -0.000 | -0.077 | 0.083 | 0.020 | torch.Size([360, 120]) || stage5.residual_group1.blocks.1.attn.qkv_self.weight
+ | 0.000 | -0.022 | 0.017 | 0.003 | torch.Size([360]) || stage5.residual_group1.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.113 | 0.098 | 0.021 | torch.Size([120, 240]) || stage5.residual_group1.blocks.1.attn.proj.weight
+ | 0.000 | -0.058 | 0.045 | 0.017 | torch.Size([120]) || stage5.residual_group1.blocks.1.attn.proj.bias
+ | 0.000 | -0.080 | 0.080 | 0.020 | torch.Size([360, 120]) || stage5.residual_group1.blocks.1.attn.qkv_mut.weight
+ | -0.000 | -0.008 | 0.007 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.999 | 0.982 | 1.001 | 0.003 | torch.Size([120]) || stage5.residual_group1.blocks.1.norm2.weight
+ | 0.000 | -0.006 | 0.005 | 0.002 | torch.Size([120]) || stage5.residual_group1.blocks.1.norm2.bias
+ | -0.000 | -0.076 | 0.083 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.1.mlp.fc11.weight
+ | 0.000 | -0.017 | 0.014 | 0.004 | torch.Size([240]) || stage5.residual_group1.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.080 | 0.086 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.1.mlp.fc12.weight
+ | -0.000 | -0.014 | 0.016 | 0.004 | torch.Size([240]) || stage5.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.096 | 0.079 | 0.020 | torch.Size([120, 240]) || stage5.residual_group1.blocks.1.mlp.fc2.weight
+ | 0.001 | -0.051 | 0.039 | 0.017 | torch.Size([120]) || stage5.residual_group1.blocks.1.mlp.fc2.bias
+ | 1.002 | 0.998 | 1.009 | 0.002 | torch.Size([120]) || stage5.residual_group1.blocks.2.norm1.weight
+ | -0.004 | -0.014 | 0.003 | 0.003 | torch.Size([120]) || stage5.residual_group1.blocks.2.norm1.bias
+ | 0.000 | -0.067 | 0.073 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.2.attn.position_bias
+ | 0.000 | -0.085 | 0.087 | 0.020 | torch.Size([360, 120]) || stage5.residual_group1.blocks.2.attn.qkv_self.weight
+ | 0.000 | -0.015 | 0.014 | 0.003 | torch.Size([360]) || stage5.residual_group1.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.108 | 0.095 | 0.020 | torch.Size([120, 240]) || stage5.residual_group1.blocks.2.attn.proj.weight
+ | -0.001 | -0.043 | 0.039 | 0.013 | torch.Size([120]) || stage5.residual_group1.blocks.2.attn.proj.bias
+ | -0.000 | -0.088 | 0.081 | 0.020 | torch.Size([360, 120]) || stage5.residual_group1.blocks.2.attn.qkv_mut.weight
+ | -0.000 | -0.009 | 0.007 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.999 | 0.978 | 1.001 | 0.003 | torch.Size([120]) || stage5.residual_group1.blocks.2.norm2.weight
+ | 0.000 | -0.003 | 0.004 | 0.002 | torch.Size([120]) || stage5.residual_group1.blocks.2.norm2.bias
+ | -0.000 | -0.076 | 0.081 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.000 | -0.012 | 0.019 | 0.004 | torch.Size([240]) || stage5.residual_group1.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.079 | 0.077 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.2.mlp.fc12.weight
+ | -0.001 | -0.014 | 0.012 | 0.004 | torch.Size([240]) || stage5.residual_group1.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.076 | 0.082 | 0.020 | torch.Size([120, 240]) || stage5.residual_group1.blocks.2.mlp.fc2.weight
+ | -0.000 | -0.047 | 0.043 | 0.017 | torch.Size([120]) || stage5.residual_group1.blocks.2.mlp.fc2.bias
+ | 1.002 | 0.978 | 1.015 | 0.005 | torch.Size([120]) || stage5.residual_group1.blocks.3.norm1.weight
+ | -0.004 | -0.013 | 0.004 | 0.003 | torch.Size([120]) || stage5.residual_group1.blocks.3.norm1.bias
+ | -0.000 | -0.084 | 0.070 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.3.attn.position_bias
+ | 0.000 | -0.078 | 0.082 | 0.020 | torch.Size([360, 120]) || stage5.residual_group1.blocks.3.attn.qkv_self.weight
+ | -0.000 | -0.014 | 0.014 | 0.003 | torch.Size([360]) || stage5.residual_group1.blocks.3.attn.qkv_self.bias
+ | -0.000 | -0.123 | 0.132 | 0.021 | torch.Size([120, 240]) || stage5.residual_group1.blocks.3.attn.proj.weight
+ | 0.001 | -0.028 | 0.044 | 0.015 | torch.Size([120]) || stage5.residual_group1.blocks.3.attn.proj.bias
+ | -0.000 | -0.082 | 0.089 | 0.020 | torch.Size([360, 120]) || stage5.residual_group1.blocks.3.attn.qkv_mut.weight
+ | -0.000 | -0.007 | 0.008 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.999 | 0.974 | 1.001 | 0.004 | torch.Size([120]) || stage5.residual_group1.blocks.3.norm2.weight
+ | 0.000 | -0.008 | 0.010 | 0.003 | torch.Size([120]) || stage5.residual_group1.blocks.3.norm2.bias
+ | 0.000 | -0.075 | 0.088 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.3.mlp.fc11.weight
+ | 0.000 | -0.014 | 0.019 | 0.005 | torch.Size([240]) || stage5.residual_group1.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.081 | 0.080 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.3.mlp.fc12.weight
+ | 0.000 | -0.031 | 0.020 | 0.006 | torch.Size([240]) || stage5.residual_group1.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.081 | 0.106 | 0.020 | torch.Size([120, 240]) || stage5.residual_group1.blocks.3.mlp.fc2.weight
+ | -0.002 | -0.046 | 0.042 | 0.017 | torch.Size([120]) || stage5.residual_group1.blocks.3.mlp.fc2.bias
+ | 1.003 | 0.944 | 1.017 | 0.009 | torch.Size([120]) || stage5.residual_group1.blocks.4.norm1.weight
+ | -0.005 | -0.015 | 0.004 | 0.004 | torch.Size([120]) || stage5.residual_group1.blocks.4.norm1.bias
+ | -0.000 | -0.071 | 0.067 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.4.attn.position_bias
+ | -0.000 | -0.085 | 0.090 | 0.021 | torch.Size([360, 120]) || stage5.residual_group1.blocks.4.attn.qkv_self.weight
+ | -0.000 | -0.021 | 0.013 | 0.004 | torch.Size([360]) || stage5.residual_group1.blocks.4.attn.qkv_self.bias
+ | 0.000 | -0.130 | 0.089 | 0.021 | torch.Size([120, 240]) || stage5.residual_group1.blocks.4.attn.proj.weight
+ | -0.001 | -0.036 | 0.024 | 0.011 | torch.Size([120]) || stage5.residual_group1.blocks.4.attn.proj.bias
+ | 0.000 | -0.086 | 0.076 | 0.020 | torch.Size([360, 120]) || stage5.residual_group1.blocks.4.attn.qkv_mut.weight
+ | 0.000 | -0.008 | 0.008 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.999 | 0.967 | 1.001 | 0.004 | torch.Size([120]) || stage5.residual_group1.blocks.4.norm2.weight
+ | 0.000 | -0.006 | 0.007 | 0.003 | torch.Size([120]) || stage5.residual_group1.blocks.4.norm2.bias
+ | 0.000 | -0.080 | 0.085 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.4.mlp.fc11.weight
+ | -0.001 | -0.015 | 0.010 | 0.004 | torch.Size([240]) || stage5.residual_group1.blocks.4.mlp.fc11.bias
+ | -0.000 | -0.081 | 0.077 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.4.mlp.fc12.weight
+ | -0.000 | -0.020 | 0.018 | 0.005 | torch.Size([240]) || stage5.residual_group1.blocks.4.mlp.fc12.bias
+ | 0.000 | -0.081 | 0.085 | 0.020 | torch.Size([120, 240]) || stage5.residual_group1.blocks.4.mlp.fc2.weight
+ | -0.001 | -0.037 | 0.050 | 0.014 | torch.Size([120]) || stage5.residual_group1.blocks.4.mlp.fc2.bias
+ | 1.004 | 0.976 | 1.039 | 0.008 | torch.Size([120]) || stage5.residual_group1.blocks.5.norm1.weight
+ | -0.005 | -0.015 | 0.005 | 0.004 | torch.Size([120]) || stage5.residual_group1.blocks.5.norm1.bias
+ | -0.000 | -0.070 | 0.076 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.5.attn.position_bias
+ | 0.000 | -0.099 | 0.097 | 0.021 | torch.Size([360, 120]) || stage5.residual_group1.blocks.5.attn.qkv_self.weight
+ | -0.000 | -0.011 | 0.012 | 0.003 | torch.Size([360]) || stage5.residual_group1.blocks.5.attn.qkv_self.bias
+ | -0.000 | -0.084 | 0.093 | 0.020 | torch.Size([120, 240]) || stage5.residual_group1.blocks.5.attn.proj.weight
+ | 0.000 | -0.038 | 0.035 | 0.012 | torch.Size([120]) || stage5.residual_group1.blocks.5.attn.proj.bias
+ | 0.000 | -0.087 | 0.082 | 0.020 | torch.Size([360, 120]) || stage5.residual_group1.blocks.5.attn.qkv_mut.weight
+ | 0.000 | -0.008 | 0.010 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.998 | 0.960 | 1.002 | 0.005 | torch.Size([120]) || stage5.residual_group1.blocks.5.norm2.weight
+ | 0.000 | -0.006 | 0.006 | 0.002 | torch.Size([120]) || stage5.residual_group1.blocks.5.norm2.bias
+ | -0.000 | -0.088 | 0.095 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.000 | -0.014 | 0.027 | 0.005 | torch.Size([240]) || stage5.residual_group1.blocks.5.mlp.fc11.bias
+ | -0.000 | -0.081 | 0.074 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.5.mlp.fc12.weight
+ | 0.000 | -0.013 | 0.025 | 0.004 | torch.Size([240]) || stage5.residual_group1.blocks.5.mlp.fc12.bias
+ | -0.000 | -0.100 | 0.086 | 0.020 | torch.Size([120, 240]) || stage5.residual_group1.blocks.5.mlp.fc2.weight
+ | 0.000 | -0.022 | 0.030 | 0.011 | torch.Size([120]) || stage5.residual_group1.blocks.5.mlp.fc2.bias
+ | -0.000 | -0.102 | 0.117 | 0.023 | torch.Size([120, 120]) || stage5.linear1.weight
+ | -0.003 | -0.297 | 0.242 | 0.084 | torch.Size([120]) || stage5.linear1.bias
+ | 0.999 | 0.971 | 1.008 | 0.005 | torch.Size([120]) || stage5.residual_group2.blocks.0.norm1.weight
+ | -0.000 | -0.035 | 0.034 | 0.011 | torch.Size([120]) || stage5.residual_group2.blocks.0.norm1.bias
+ | 0.000 | -0.079 | 0.074 | 0.020 | torch.Size([2475, 6]) || stage5.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage5.residual_group2.blocks.0.attn.relative_position_index
+ | -0.000 | -0.087 | 0.083 | 0.020 | torch.Size([360, 120]) || stage5.residual_group2.blocks.0.attn.qkv_self.weight
+ | -0.000 | -0.028 | 0.018 | 0.005 | torch.Size([360]) || stage5.residual_group2.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.079 | 0.082 | 0.021 | torch.Size([120, 120]) || stage5.residual_group2.blocks.0.attn.proj.weight
+ | -0.001 | -0.146 | 0.171 | 0.054 | torch.Size([120]) || stage5.residual_group2.blocks.0.attn.proj.bias
+ | 0.997 | 0.967 | 1.003 | 0.006 | torch.Size([120]) || stage5.residual_group2.blocks.0.norm2.weight
+ | 0.000 | -0.005 | 0.005 | 0.002 | torch.Size([120]) || stage5.residual_group2.blocks.0.norm2.bias
+ | -0.000 | -0.073 | 0.089 | 0.020 | torch.Size([240, 120]) || stage5.residual_group2.blocks.0.mlp.fc11.weight
+ | -0.002 | -0.017 | 0.008 | 0.004 | torch.Size([240]) || stage5.residual_group2.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.084 | 0.073 | 0.020 | torch.Size([240, 120]) || stage5.residual_group2.blocks.0.mlp.fc12.weight
+ | 0.000 | -0.013 | 0.011 | 0.003 | torch.Size([240]) || stage5.residual_group2.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.083 | 0.085 | 0.020 | torch.Size([120, 240]) || stage5.residual_group2.blocks.0.mlp.fc2.weight
+ | 0.000 | -0.103 | 0.140 | 0.037 | torch.Size([120]) || stage5.residual_group2.blocks.0.mlp.fc2.bias
+ | 0.999 | 0.986 | 1.010 | 0.004 | torch.Size([120]) || stage5.residual_group2.blocks.1.norm1.weight
+ | 0.000 | -0.035 | 0.034 | 0.010 | torch.Size([120]) || stage5.residual_group2.blocks.1.norm1.bias
+ | 0.000 | -0.087 | 0.074 | 0.020 | torch.Size([2475, 6]) || stage5.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage5.residual_group2.blocks.1.attn.relative_position_index
+ | -0.000 | -0.084 | 0.079 | 0.020 | torch.Size([360, 120]) || stage5.residual_group2.blocks.1.attn.qkv_self.weight
+ | 0.000 | -0.024 | 0.024 | 0.005 | torch.Size([360]) || stage5.residual_group2.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.077 | 0.078 | 0.021 | torch.Size([120, 120]) || stage5.residual_group2.blocks.1.attn.proj.weight
+ | -0.001 | -0.112 | 0.144 | 0.038 | torch.Size([120]) || stage5.residual_group2.blocks.1.attn.proj.bias
+ | 0.998 | 0.965 | 1.004 | 0.006 | torch.Size([120]) || stage5.residual_group2.blocks.1.norm2.weight
+ | 0.000 | -0.004 | 0.005 | 0.002 | torch.Size([120]) || stage5.residual_group2.blocks.1.norm2.bias
+ | 0.000 | -0.088 | 0.079 | 0.020 | torch.Size([240, 120]) || stage5.residual_group2.blocks.1.mlp.fc11.weight
+ | -0.001 | -0.012 | 0.015 | 0.004 | torch.Size([240]) || stage5.residual_group2.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.102 | 0.080 | 0.020 | torch.Size([240, 120]) || stage5.residual_group2.blocks.1.mlp.fc12.weight
+ | 0.000 | -0.012 | 0.009 | 0.004 | torch.Size([240]) || stage5.residual_group2.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.075 | 0.078 | 0.020 | torch.Size([120, 240]) || stage5.residual_group2.blocks.1.mlp.fc2.weight
+ | 0.000 | -0.105 | 0.131 | 0.042 | torch.Size([120]) || stage5.residual_group2.blocks.1.mlp.fc2.bias
+ | -0.000 | -0.220 | 0.209 | 0.035 | torch.Size([120, 120]) || stage5.linear2.weight
+ | -0.003 | -0.335 | 0.284 | 0.096 | torch.Size([120]) || stage5.linear2.bias
+ | -0.000 | -0.064 | 0.065 | 0.019 | torch.Size([120, 120, 3, 3]) || stage5.pa_deform.weight
+ | 0.001 | -0.050 | 0.050 | 0.029 | torch.Size([120]) || stage5.pa_deform.bias
+ | 0.000 | -0.119 | 0.106 | 0.013 | torch.Size([120, 242, 3, 3]) || stage5.pa_deform.conv_offset.0.weight
+ | -0.006 | -0.030 | 0.026 | 0.014 | torch.Size([120]) || stage5.pa_deform.conv_offset.0.bias
+ | -0.001 | -0.055 | 0.050 | 0.018 | torch.Size([120, 120, 3, 3]) || stage5.pa_deform.conv_offset.2.weight
+ | 0.001 | -0.033 | 0.031 | 0.018 | torch.Size([120]) || stage5.pa_deform.conv_offset.2.bias
+ | 0.001 | -0.060 | 0.050 | 0.018 | torch.Size([120, 120, 3, 3]) || stage5.pa_deform.conv_offset.4.weight
+ | -0.005 | -0.040 | 0.037 | 0.019 | torch.Size([120]) || stage5.pa_deform.conv_offset.4.bias
+ | 0.001 | -0.038 | 0.051 | 0.006 | torch.Size([324, 120, 3, 3]) || stage5.pa_deform.conv_offset.6.weight
+ | 0.000 | -0.048 | 0.050 | 0.017 | torch.Size([324]) || stage5.pa_deform.conv_offset.6.bias
+ | 0.000 | -0.334 | 0.340 | 0.036 | torch.Size([360, 360]) || stage5.pa_fuse.fc11.weight
+ | 0.037 | -0.050 | 0.294 | 0.064 | torch.Size([360]) || stage5.pa_fuse.fc11.bias
+ | -0.000 | -0.343 | 0.349 | 0.036 | torch.Size([360, 360]) || stage5.pa_fuse.fc12.weight
+ | -0.001 | -0.237 | 0.244 | 0.049 | torch.Size([360]) || stage5.pa_fuse.fc12.bias
+ | -0.000 | -0.575 | 0.591 | 0.060 | torch.Size([120, 360]) || stage5.pa_fuse.fc2.weight
+ | -0.001 | -0.404 | 0.344 | 0.122 | torch.Size([120]) || stage5.pa_fuse.fc2.bias
+ | 1.254 | 1.058 | 1.466 | 0.126 | torch.Size([30]) || stage6.reshape.1.weight
+ | -0.001 | -0.074 | 0.093 | 0.041 | torch.Size([30]) || stage6.reshape.1.bias
+ | 0.000 | -0.734 | 0.625 | 0.177 | torch.Size([120, 30]) || stage6.reshape.2.weight
+ | 0.003 | -0.269 | 0.341 | 0.108 | torch.Size([120]) || stage6.reshape.2.bias
+ | 0.815 | 0.495 | 1.118 | 0.121 | torch.Size([120]) || stage6.residual_group1.blocks.0.norm1.weight
+ | -0.071 | -0.291 | 0.263 | 0.101 | torch.Size([120]) || stage6.residual_group1.blocks.0.norm1.bias
+ | -0.000 | -0.080 | 0.087 | 0.021 | torch.Size([675, 6]) || stage6.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.0.attn.position_bias
+ | 0.000 | -0.136 | 0.134 | 0.026 | torch.Size([360, 120]) || stage6.residual_group1.blocks.0.attn.qkv_self.weight
+ | -0.000 | -0.061 | 0.037 | 0.014 | torch.Size([360]) || stage6.residual_group1.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.201 | 0.182 | 0.032 | torch.Size([120, 240]) || stage6.residual_group1.blocks.0.attn.proj.weight
+ | 0.000 | -0.223 | 0.189 | 0.090 | torch.Size([120]) || stage6.residual_group1.blocks.0.attn.proj.bias
+ | 0.000 | -0.184 | 0.211 | 0.029 | torch.Size([360, 120]) || stage6.residual_group1.blocks.0.attn.qkv_mut.weight
+ | 0.000 | -0.049 | 0.069 | 0.011 | torch.Size([360]) || stage6.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.710 | 0.556 | 0.893 | 0.072 | torch.Size([120]) || stage6.residual_group1.blocks.0.norm2.weight
+ | -0.003 | -0.172 | 0.193 | 0.070 | torch.Size([120]) || stage6.residual_group1.blocks.0.norm2.bias
+ | 0.000 | -0.217 | 0.211 | 0.033 | torch.Size([240, 120]) || stage6.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.041 | -0.158 | 0.025 | 0.036 | torch.Size([240]) || stage6.residual_group1.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.209 | 0.178 | 0.031 | torch.Size([240, 120]) || stage6.residual_group1.blocks.0.mlp.fc12.weight
+ | -0.000 | -0.141 | 0.186 | 0.031 | torch.Size([240]) || stage6.residual_group1.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.245 | 0.347 | 0.037 | torch.Size([120, 240]) || stage6.residual_group1.blocks.0.mlp.fc2.weight
+ | 0.005 | -0.161 | 0.188 | 0.079 | torch.Size([120]) || stage6.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.780 | 0.582 | 0.963 | 0.088 | torch.Size([120]) || stage6.residual_group1.blocks.1.norm1.weight
+ | -0.112 | -0.302 | 0.103 | 0.085 | torch.Size([120]) || stage6.residual_group1.blocks.1.norm1.bias
+ | 0.000 | -0.101 | 0.072 | 0.021 | torch.Size([675, 6]) || stage6.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.1.attn.position_bias
+ | 0.000 | -0.112 | 0.178 | 0.026 | torch.Size([360, 120]) || stage6.residual_group1.blocks.1.attn.qkv_self.weight
+ | -0.000 | -0.034 | 0.049 | 0.009 | torch.Size([360]) || stage6.residual_group1.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.223 | 0.242 | 0.033 | torch.Size([120, 240]) || stage6.residual_group1.blocks.1.attn.proj.weight
+ | -0.003 | -0.149 | 0.105 | 0.047 | torch.Size([120]) || stage6.residual_group1.blocks.1.attn.proj.bias
+ | 0.000 | -0.199 | 0.173 | 0.031 | torch.Size([360, 120]) || stage6.residual_group1.blocks.1.attn.qkv_mut.weight
+ | 0.000 | -0.035 | 0.056 | 0.009 | torch.Size([360]) || stage6.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.744 | 0.530 | 0.917 | 0.066 | torch.Size([120]) || stage6.residual_group1.blocks.1.norm2.weight
+ | 0.004 | -0.131 | 0.180 | 0.059 | torch.Size([120]) || stage6.residual_group1.blocks.1.norm2.bias
+ | 0.000 | -0.243 | 0.294 | 0.036 | torch.Size([240, 120]) || stage6.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.039 | -0.217 | 0.045 | 0.037 | torch.Size([240]) || stage6.residual_group1.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.206 | 0.178 | 0.033 | torch.Size([240, 120]) || stage6.residual_group1.blocks.1.mlp.fc12.weight
+ | -0.000 | -0.129 | 0.125 | 0.028 | torch.Size([240]) || stage6.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.236 | 0.276 | 0.040 | torch.Size([120, 240]) || stage6.residual_group1.blocks.1.mlp.fc2.weight
+ | 0.000 | -0.158 | 0.170 | 0.063 | torch.Size([120]) || stage6.residual_group1.blocks.1.mlp.fc2.bias
+ | 0.829 | 0.586 | 1.007 | 0.078 | torch.Size([120]) || stage6.residual_group1.blocks.2.norm1.weight
+ | -0.101 | -0.353 | 0.132 | 0.092 | torch.Size([120]) || stage6.residual_group1.blocks.2.norm1.bias
+ | -0.000 | -0.082 | 0.076 | 0.021 | torch.Size([675, 6]) || stage6.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.2.attn.position_bias
+ | 0.000 | -0.154 | 0.143 | 0.032 | torch.Size([360, 120]) || stage6.residual_group1.blocks.2.attn.qkv_self.weight
+ | 0.000 | -0.041 | 0.038 | 0.012 | torch.Size([360]) || stage6.residual_group1.blocks.2.attn.qkv_self.bias
+ | 0.000 | -0.187 | 0.202 | 0.035 | torch.Size([120, 240]) || stage6.residual_group1.blocks.2.attn.proj.weight
+ | 0.002 | -0.096 | 0.127 | 0.041 | torch.Size([120]) || stage6.residual_group1.blocks.2.attn.proj.bias
+ | -0.000 | -0.203 | 0.185 | 0.033 | torch.Size([360, 120]) || stage6.residual_group1.blocks.2.attn.qkv_mut.weight
+ | -0.000 | -0.045 | 0.049 | 0.009 | torch.Size([360]) || stage6.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.768 | 0.491 | 0.904 | 0.069 | torch.Size([120]) || stage6.residual_group1.blocks.2.norm2.weight
+ | 0.001 | -0.146 | 0.159 | 0.062 | torch.Size([120]) || stage6.residual_group1.blocks.2.norm2.bias
+ | -0.000 | -0.184 | 0.204 | 0.037 | torch.Size([240, 120]) || stage6.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.043 | -0.185 | 0.020 | 0.035 | torch.Size([240]) || stage6.residual_group1.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.188 | 0.270 | 0.035 | torch.Size([240, 120]) || stage6.residual_group1.blocks.2.mlp.fc12.weight
+ | 0.000 | -0.152 | 0.134 | 0.031 | torch.Size([240]) || stage6.residual_group1.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.222 | 0.217 | 0.042 | torch.Size([120, 240]) || stage6.residual_group1.blocks.2.mlp.fc2.weight
+ | 0.002 | -0.141 | 0.144 | 0.058 | torch.Size([120]) || stage6.residual_group1.blocks.2.mlp.fc2.bias
+ | 0.820 | 0.554 | 0.976 | 0.065 | torch.Size([120]) || stage6.residual_group1.blocks.3.norm1.weight
+ | -0.091 | -0.336 | 0.137 | 0.087 | torch.Size([120]) || stage6.residual_group1.blocks.3.norm1.bias
+ | 0.000 | -0.124 | 0.222 | 0.023 | torch.Size([675, 6]) || stage6.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.3.attn.position_bias
+ | 0.000 | -0.157 | 0.175 | 0.036 | torch.Size([360, 120]) || stage6.residual_group1.blocks.3.attn.qkv_self.weight
+ | -0.001 | -0.049 | 0.049 | 0.014 | torch.Size([360]) || stage6.residual_group1.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.238 | 0.236 | 0.036 | torch.Size([120, 240]) || stage6.residual_group1.blocks.3.attn.proj.weight
+ | -0.003 | -0.077 | 0.074 | 0.031 | torch.Size([120]) || stage6.residual_group1.blocks.3.attn.proj.bias
+ | 0.000 | -0.212 | 0.265 | 0.033 | torch.Size([360, 120]) || stage6.residual_group1.blocks.3.attn.qkv_mut.weight
+ | 0.000 | -0.028 | 0.052 | 0.009 | torch.Size([360]) || stage6.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.768 | 0.530 | 0.903 | 0.080 | torch.Size([120]) || stage6.residual_group1.blocks.3.norm2.weight
+ | 0.002 | -0.104 | 0.157 | 0.044 | torch.Size([120]) || stage6.residual_group1.blocks.3.norm2.bias
+ | -0.000 | -0.197 | 0.220 | 0.039 | torch.Size([240, 120]) || stage6.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.042 | -0.155 | 0.043 | 0.039 | torch.Size([240]) || stage6.residual_group1.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.166 | 0.199 | 0.036 | torch.Size([240, 120]) || stage6.residual_group1.blocks.3.mlp.fc12.weight
+ | 0.001 | -0.102 | 0.138 | 0.040 | torch.Size([240]) || stage6.residual_group1.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.241 | 0.256 | 0.044 | torch.Size([120, 240]) || stage6.residual_group1.blocks.3.mlp.fc2.weight
+ | 0.003 | -0.123 | 0.115 | 0.046 | torch.Size([120]) || stage6.residual_group1.blocks.3.mlp.fc2.bias
+ | 0.817 | 0.631 | 0.918 | 0.055 | torch.Size([120]) || stage6.residual_group1.blocks.4.norm1.weight
+ | -0.082 | -0.295 | 0.141 | 0.074 | torch.Size([120]) || stage6.residual_group1.blocks.4.norm1.bias
+ | -0.000 | -0.084 | 0.205 | 0.024 | torch.Size([675, 6]) || stage6.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.4.attn.position_bias
+ | -0.000 | -0.174 | 0.199 | 0.040 | torch.Size([360, 120]) || stage6.residual_group1.blocks.4.attn.qkv_self.weight
+ | -0.000 | -0.060 | 0.081 | 0.017 | torch.Size([360]) || stage6.residual_group1.blocks.4.attn.qkv_self.bias
+ | -0.000 | -0.194 | 0.191 | 0.037 | torch.Size([120, 240]) || stage6.residual_group1.blocks.4.attn.proj.weight
+ | 0.001 | -0.083 | 0.077 | 0.035 | torch.Size([120]) || stage6.residual_group1.blocks.4.attn.proj.bias
+ | -0.000 | -0.218 | 0.243 | 0.033 | torch.Size([360, 120]) || stage6.residual_group1.blocks.4.attn.qkv_mut.weight
+ | -0.000 | -0.031 | 0.024 | 0.007 | torch.Size([360]) || stage6.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.744 | 0.478 | 0.913 | 0.082 | torch.Size([120]) || stage6.residual_group1.blocks.4.norm2.weight
+ | -0.003 | -0.146 | 0.110 | 0.053 | torch.Size([120]) || stage6.residual_group1.blocks.4.norm2.bias
+ | -0.000 | -0.223 | 0.238 | 0.042 | torch.Size([240, 120]) || stage6.residual_group1.blocks.4.mlp.fc11.weight
+ | -0.046 | -0.200 | 0.071 | 0.051 | torch.Size([240]) || stage6.residual_group1.blocks.4.mlp.fc11.bias
+ | -0.000 | -0.168 | 0.201 | 0.039 | torch.Size([240, 120]) || stage6.residual_group1.blocks.4.mlp.fc12.weight
+ | 0.002 | -0.128 | 0.141 | 0.053 | torch.Size([240]) || stage6.residual_group1.blocks.4.mlp.fc12.bias
+ | -0.000 | -0.220 | 0.205 | 0.047 | torch.Size([120, 240]) || stage6.residual_group1.blocks.4.mlp.fc2.weight
+ | 0.001 | -0.086 | 0.094 | 0.034 | torch.Size([120]) || stage6.residual_group1.blocks.4.mlp.fc2.bias
+ | 0.754 | 0.353 | 0.933 | 0.056 | torch.Size([120]) || stage6.residual_group1.blocks.5.norm1.weight
+ | -0.058 | -0.246 | 0.105 | 0.060 | torch.Size([120]) || stage6.residual_group1.blocks.5.norm1.bias
+ | -0.000 | -0.113 | 0.536 | 0.030 | torch.Size([675, 6]) || stage6.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.5.attn.position_bias
+ | 0.000 | -0.261 | 0.224 | 0.044 | torch.Size([360, 120]) || stage6.residual_group1.blocks.5.attn.qkv_self.weight
+ | 0.002 | -0.050 | 0.067 | 0.018 | torch.Size([360]) || stage6.residual_group1.blocks.5.attn.qkv_self.bias
+ | 0.000 | -0.234 | 0.256 | 0.038 | torch.Size([120, 240]) || stage6.residual_group1.blocks.5.attn.proj.weight
+ | 0.002 | -0.079 | 0.076 | 0.036 | torch.Size([120]) || stage6.residual_group1.blocks.5.attn.proj.bias
+ | -0.000 | -0.211 | 0.231 | 0.029 | torch.Size([360, 120]) || stage6.residual_group1.blocks.5.attn.qkv_mut.weight
+ | 0.000 | -0.033 | 0.030 | 0.008 | torch.Size([360]) || stage6.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.677 | 0.275 | 0.833 | 0.083 | torch.Size([120]) || stage6.residual_group1.blocks.5.norm2.weight
+ | 0.001 | -0.224 | 0.306 | 0.102 | torch.Size([120]) || stage6.residual_group1.blocks.5.norm2.bias
+ | -0.000 | -0.196 | 0.211 | 0.045 | torch.Size([240, 120]) || stage6.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.061 | -0.289 | 0.136 | 0.089 | torch.Size([240]) || stage6.residual_group1.blocks.5.mlp.fc11.bias
+ | -0.000 | -0.271 | 0.312 | 0.048 | torch.Size([240, 120]) || stage6.residual_group1.blocks.5.mlp.fc12.weight
+ | 0.003 | -0.166 | 0.155 | 0.075 | torch.Size([240]) || stage6.residual_group1.blocks.5.mlp.fc12.bias
+ | 0.000 | -0.286 | 0.375 | 0.054 | torch.Size([120, 240]) || stage6.residual_group1.blocks.5.mlp.fc2.weight
+ | 0.005 | -0.054 | 0.137 | 0.031 | torch.Size([120]) || stage6.residual_group1.blocks.5.mlp.fc2.bias
+ | -0.000 | -0.174 | 0.172 | 0.039 | torch.Size([120, 120]) || stage6.linear1.weight
+ | 0.002 | -0.275 | 0.348 | 0.113 | torch.Size([120]) || stage6.linear1.bias
+ | 0.704 | 0.402 | 1.002 | 0.132 | torch.Size([120]) || stage6.residual_group2.blocks.0.norm1.weight
+ | 0.001 | -0.466 | 0.407 | 0.157 | torch.Size([120]) || stage6.residual_group2.blocks.0.norm1.bias
+ | -0.000 | -0.172 | 0.570 | 0.025 | torch.Size([2475, 6]) || stage6.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage6.residual_group2.blocks.0.attn.relative_position_index
+ | 0.000 | -0.337 | 0.378 | 0.041 | torch.Size([360, 120]) || stage6.residual_group2.blocks.0.attn.qkv_self.weight
+ | -0.000 | -0.071 | 0.068 | 0.019 | torch.Size([360]) || stage6.residual_group2.blocks.0.attn.qkv_self.bias
+ | 0.001 | -0.290 | 0.321 | 0.055 | torch.Size([120, 120]) || stage6.residual_group2.blocks.0.attn.proj.weight
+ | 0.001 | -0.255 | 0.250 | 0.104 | torch.Size([120]) || stage6.residual_group2.blocks.0.attn.proj.bias
+ | 0.695 | 0.353 | 0.966 | 0.098 | torch.Size([120]) || stage6.residual_group2.blocks.0.norm2.weight
+ | -0.001 | -0.218 | 0.165 | 0.080 | torch.Size([120]) || stage6.residual_group2.blocks.0.norm2.bias
+ | 0.000 | -0.259 | 0.255 | 0.039 | torch.Size([240, 120]) || stage6.residual_group2.blocks.0.mlp.fc11.weight
+ | -0.044 | -0.256 | 0.042 | 0.047 | torch.Size([240]) || stage6.residual_group2.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.234 | 0.214 | 0.035 | torch.Size([240, 120]) || stage6.residual_group2.blocks.0.mlp.fc12.weight
+ | 0.002 | -0.133 | 0.091 | 0.027 | torch.Size([240]) || stage6.residual_group2.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.333 | 0.296 | 0.042 | torch.Size([120, 240]) || stage6.residual_group2.blocks.0.mlp.fc2.weight
+ | 0.003 | -0.238 | 0.280 | 0.092 | torch.Size([120]) || stage6.residual_group2.blocks.0.mlp.fc2.bias
+ | 0.671 | 0.425 | 0.980 | 0.094 | torch.Size([120]) || stage6.residual_group2.blocks.1.norm1.weight
+ | 0.001 | -0.261 | 0.305 | 0.119 | torch.Size([120]) || stage6.residual_group2.blocks.1.norm1.bias
+ | -0.000 | -0.372 | 0.942 | 0.031 | torch.Size([2475, 6]) || stage6.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage6.residual_group2.blocks.1.attn.relative_position_index
+ | 0.000 | -0.450 | 0.494 | 0.045 | torch.Size([360, 120]) || stage6.residual_group2.blocks.1.attn.qkv_self.weight
+ | 0.000 | -0.133 | 0.119 | 0.029 | torch.Size([360]) || stage6.residual_group2.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.239 | 0.288 | 0.046 | torch.Size([120, 120]) || stage6.residual_group2.blocks.1.attn.proj.weight
+ | -0.001 | -0.187 | 0.157 | 0.064 | torch.Size([120]) || stage6.residual_group2.blocks.1.attn.proj.bias
+ | 0.687 | 0.160 | 0.907 | 0.128 | torch.Size([120]) || stage6.residual_group2.blocks.1.norm2.weight
+ | -0.002 | -0.192 | 0.222 | 0.084 | torch.Size([120]) || stage6.residual_group2.blocks.1.norm2.bias
+ | 0.000 | -0.257 | 0.426 | 0.042 | torch.Size([240, 120]) || stage6.residual_group2.blocks.1.mlp.fc11.weight
+ | -0.064 | -0.207 | 0.036 | 0.048 | torch.Size([240]) || stage6.residual_group2.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.269 | 0.224 | 0.038 | torch.Size([240, 120]) || stage6.residual_group2.blocks.1.mlp.fc12.weight
+ | -0.000 | -0.126 | 0.129 | 0.030 | torch.Size([240]) || stage6.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.308 | 0.298 | 0.041 | torch.Size([120, 240]) || stage6.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.004 | -0.180 | 0.192 | 0.061 | torch.Size([120]) || stage6.residual_group2.blocks.1.mlp.fc2.bias
+ | -0.000 | -0.297 | 0.368 | 0.069 | torch.Size([120, 120]) || stage6.linear2.weight
+ | 0.001 | -0.431 | 0.480 | 0.189 | torch.Size([120]) || stage6.linear2.bias
+ | 0.000 | -0.100 | 0.104 | 0.023 | torch.Size([120, 120, 3, 3]) || stage6.pa_deform.weight
+ | 0.001 | -0.018 | 0.029 | 0.010 | torch.Size([120]) || stage6.pa_deform.bias
+ | 0.000 | -0.105 | 0.111 | 0.015 | torch.Size([120, 242, 3, 3]) || stage6.pa_deform.conv_offset.0.weight
+ | -0.007 | -0.033 | 0.024 | 0.014 | torch.Size([120]) || stage6.pa_deform.conv_offset.0.bias
+ | -0.001 | -0.071 | 0.067 | 0.019 | torch.Size([120, 120, 3, 3]) || stage6.pa_deform.conv_offset.2.weight
+ | -0.003 | -0.061 | 0.043 | 0.022 | torch.Size([120]) || stage6.pa_deform.conv_offset.2.bias
+ | -0.000 | -0.074 | 0.068 | 0.019 | torch.Size([120, 120, 3, 3]) || stage6.pa_deform.conv_offset.4.weight
+ | 0.001 | -0.075 | 0.056 | 0.030 | torch.Size([120]) || stage6.pa_deform.conv_offset.4.bias
+ | 0.001 | -0.124 | 0.108 | 0.013 | torch.Size([324, 120, 3, 3]) || stage6.pa_deform.conv_offset.6.weight
+ | -0.001 | -0.113 | 0.076 | 0.021 | torch.Size([324]) || stage6.pa_deform.conv_offset.6.bias
+ | -0.001 | -0.517 | 0.524 | 0.101 | torch.Size([360, 360]) || stage6.pa_fuse.fc11.weight
+ | 0.154 | -0.305 | 0.679 | 0.180 | torch.Size([360]) || stage6.pa_fuse.fc11.bias
+ | 0.000 | -0.680 | 0.728 | 0.103 | torch.Size([360, 360]) || stage6.pa_fuse.fc12.weight
+ | 0.020 | -0.514 | 0.417 | 0.199 | torch.Size([360]) || stage6.pa_fuse.fc12.bias
+ | -0.000 | -0.587 | 0.737 | 0.135 | torch.Size([120, 360]) || stage6.pa_fuse.fc2.weight
+ | 0.015 | -0.437 | 0.490 | 0.230 | torch.Size([120]) || stage6.pa_fuse.fc2.bias
+ | 1.284 | 1.119 | 1.404 | 0.055 | torch.Size([30]) || stage7.reshape.1.weight
+ | -0.014 | -0.286 | 0.184 | 0.122 | torch.Size([30]) || stage7.reshape.1.bias
+ | -0.000 | -0.521 | 0.576 | 0.154 | torch.Size([120, 30]) || stage7.reshape.2.weight
+ | 0.004 | -0.387 | 0.738 | 0.175 | torch.Size([120]) || stage7.reshape.2.bias
+ | 0.440 | 0.099 | 0.775 | 0.141 | torch.Size([120]) || stage7.residual_group1.blocks.0.norm1.weight
+ | -0.177 | -0.670 | 0.319 | 0.183 | torch.Size([120]) || stage7.residual_group1.blocks.0.norm1.bias
+ | -0.055 | -2.159 | 1.979 | 0.240 | torch.Size([675, 6]) || stage7.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.0.attn.position_bias
+ | -0.000 | -0.535 | 0.554 | 0.104 | torch.Size([360, 120]) || stage7.residual_group1.blocks.0.attn.qkv_self.weight
+ | 0.003 | -0.193 | 0.281 | 0.053 | torch.Size([360]) || stage7.residual_group1.blocks.0.attn.qkv_self.bias
+ | -0.001 | -0.397 | 0.395 | 0.075 | torch.Size([120, 240]) || stage7.residual_group1.blocks.0.attn.proj.weight
+ | -0.001 | -0.232 | 0.692 | 0.106 | torch.Size([120]) || stage7.residual_group1.blocks.0.attn.proj.bias
+ | -0.000 | -0.899 | 1.073 | 0.091 | torch.Size([360, 120]) || stage7.residual_group1.blocks.0.attn.qkv_mut.weight
+ | -0.000 | -0.122 | 0.104 | 0.017 | torch.Size([360]) || stage7.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.310 | 0.157 | 0.440 | 0.055 | torch.Size([120]) || stage7.residual_group1.blocks.0.norm2.weight
+ | 0.006 | -0.474 | 0.266 | 0.105 | torch.Size([120]) || stage7.residual_group1.blocks.0.norm2.bias
+ | -0.000 | -0.605 | 0.490 | 0.115 | torch.Size([240, 120]) || stage7.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.101 | -0.310 | 0.126 | 0.070 | torch.Size([240]) || stage7.residual_group1.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.448 | 0.475 | 0.116 | torch.Size([240, 120]) || stage7.residual_group1.blocks.0.mlp.fc12.weight
+ | 0.006 | -0.185 | 0.215 | 0.071 | torch.Size([240]) || stage7.residual_group1.blocks.0.mlp.fc12.bias
+ | 0.001 | -0.465 | 0.512 | 0.122 | torch.Size([120, 240]) || stage7.residual_group1.blocks.0.mlp.fc2.weight
+ | 0.000 | -0.150 | 0.417 | 0.077 | torch.Size([120]) || stage7.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.577 | 0.165 | 0.829 | 0.105 | torch.Size([120]) || stage7.residual_group1.blocks.1.norm1.weight
+ | -0.136 | -0.849 | 0.206 | 0.141 | torch.Size([120]) || stage7.residual_group1.blocks.1.norm1.bias
+ | -0.143 | -3.020 | 4.621 | 0.357 | torch.Size([675, 6]) || stage7.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.1.attn.position_bias
+ | 0.000 | -0.647 | 0.640 | 0.123 | torch.Size([360, 120]) || stage7.residual_group1.blocks.1.attn.qkv_self.weight
+ | -0.002 | -0.356 | 0.382 | 0.064 | torch.Size([360]) || stage7.residual_group1.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.457 | 0.378 | 0.081 | torch.Size([120, 240]) || stage7.residual_group1.blocks.1.attn.proj.weight
+ | 0.000 | -0.250 | 0.707 | 0.108 | torch.Size([120]) || stage7.residual_group1.blocks.1.attn.proj.bias
+ | -0.001 | -1.055 | 1.091 | 0.096 | torch.Size([360, 120]) || stage7.residual_group1.blocks.1.attn.qkv_mut.weight
+ | -0.001 | -0.093 | 0.123 | 0.018 | torch.Size([360]) || stage7.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.411 | 0.265 | 0.535 | 0.044 | torch.Size([120]) || stage7.residual_group1.blocks.1.norm2.weight
+ | 0.008 | -0.630 | 0.264 | 0.121 | torch.Size([120]) || stage7.residual_group1.blocks.1.norm2.bias
+ | 0.000 | -0.501 | 0.506 | 0.119 | torch.Size([240, 120]) || stage7.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.087 | -0.341 | 0.140 | 0.073 | torch.Size([240]) || stage7.residual_group1.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.450 | 0.527 | 0.119 | torch.Size([240, 120]) || stage7.residual_group1.blocks.1.mlp.fc12.weight
+ | 0.005 | -0.188 | 0.171 | 0.063 | torch.Size([240]) || stage7.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.554 | 0.546 | 0.121 | torch.Size([120, 240]) || stage7.residual_group1.blocks.1.mlp.fc2.weight
+ | -0.000 | -0.135 | 0.220 | 0.061 | torch.Size([120]) || stage7.residual_group1.blocks.1.mlp.fc2.bias
+ | 0.655 | 0.134 | 0.896 | 0.130 | torch.Size([120]) || stage7.residual_group1.blocks.2.norm1.weight
+ | -0.139 | -0.788 | 0.181 | 0.115 | torch.Size([120]) || stage7.residual_group1.blocks.2.norm1.bias
+ | -0.062 | -3.469 | 3.276 | 0.272 | torch.Size([675, 6]) || stage7.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.2.attn.position_bias
+ | -0.000 | -0.592 | 0.650 | 0.124 | torch.Size([360, 120]) || stage7.residual_group1.blocks.2.attn.qkv_self.weight
+ | -0.000 | -0.308 | 0.218 | 0.062 | torch.Size([360]) || stage7.residual_group1.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.355 | 0.345 | 0.082 | torch.Size([120, 240]) || stage7.residual_group1.blocks.2.attn.proj.weight
+ | 0.002 | -0.213 | 0.700 | 0.097 | torch.Size([120]) || stage7.residual_group1.blocks.2.attn.proj.bias
+ | -0.001 | -1.166 | 0.942 | 0.107 | torch.Size([360, 120]) || stage7.residual_group1.blocks.2.attn.qkv_mut.weight
+ | 0.000 | -0.106 | 0.093 | 0.018 | torch.Size([360]) || stage7.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.466 | 0.317 | 0.565 | 0.042 | torch.Size([120]) || stage7.residual_group1.blocks.2.norm2.weight
+ | 0.014 | -0.657 | 0.280 | 0.118 | torch.Size([120]) || stage7.residual_group1.blocks.2.norm2.bias
+ | 0.000 | -0.541 | 0.494 | 0.118 | torch.Size([240, 120]) || stage7.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.079 | -0.335 | 0.122 | 0.080 | torch.Size([240]) || stage7.residual_group1.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.513 | 0.493 | 0.123 | torch.Size([240, 120]) || stage7.residual_group1.blocks.2.mlp.fc12.weight
+ | -0.007 | -0.180 | 0.175 | 0.066 | torch.Size([240]) || stage7.residual_group1.blocks.2.mlp.fc12.bias
+ | -0.001 | -0.509 | 0.479 | 0.123 | torch.Size([120, 240]) || stage7.residual_group1.blocks.2.mlp.fc2.weight
+ | 0.004 | -0.093 | 0.293 | 0.054 | torch.Size([120]) || stage7.residual_group1.blocks.2.mlp.fc2.bias
+ | 0.693 | 0.147 | 0.945 | 0.133 | torch.Size([120]) || stage7.residual_group1.blocks.3.norm1.weight
+ | -0.132 | -0.906 | 0.249 | 0.113 | torch.Size([120]) || stage7.residual_group1.blocks.3.norm1.bias
+ | -0.108 | -3.576 | 4.241 | 0.344 | torch.Size([675, 6]) || stage7.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.3.attn.position_bias
+ | -0.000 | -0.945 | 1.095 | 0.129 | torch.Size([360, 120]) || stage7.residual_group1.blocks.3.attn.qkv_self.weight
+ | 0.003 | -0.274 | 0.204 | 0.061 | torch.Size([360]) || stage7.residual_group1.blocks.3.attn.qkv_self.bias
+ | -0.001 | -0.379 | 0.351 | 0.081 | torch.Size([120, 240]) || stage7.residual_group1.blocks.3.attn.proj.weight
+ | 0.000 | -0.211 | 0.587 | 0.095 | torch.Size([120]) || stage7.residual_group1.blocks.3.attn.proj.bias
+ | -0.000 | -1.269 | 1.067 | 0.102 | torch.Size([360, 120]) || stage7.residual_group1.blocks.3.attn.qkv_mut.weight
+ | 0.001 | -0.091 | 0.117 | 0.021 | torch.Size([360]) || stage7.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.499 | 0.285 | 0.570 | 0.040 | torch.Size([120]) || stage7.residual_group1.blocks.3.norm2.weight
+ | 0.012 | -0.567 | 0.273 | 0.104 | torch.Size([120]) || stage7.residual_group1.blocks.3.norm2.bias
+ | 0.001 | -0.528 | 0.499 | 0.118 | torch.Size([240, 120]) || stage7.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.084 | -0.349 | 0.141 | 0.078 | torch.Size([240]) || stage7.residual_group1.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.547 | 0.592 | 0.126 | torch.Size([240, 120]) || stage7.residual_group1.blocks.3.mlp.fc12.weight
+ | 0.002 | -0.154 | 0.176 | 0.068 | torch.Size([240]) || stage7.residual_group1.blocks.3.mlp.fc12.bias
+ | 0.001 | -0.520 | 0.480 | 0.125 | torch.Size([120, 240]) || stage7.residual_group1.blocks.3.mlp.fc2.weight
+ | 0.001 | -0.150 | 0.207 | 0.065 | torch.Size([120]) || stage7.residual_group1.blocks.3.mlp.fc2.bias
+ | 0.726 | 0.137 | 1.004 | 0.160 | torch.Size([120]) || stage7.residual_group1.blocks.4.norm1.weight
+ | -0.122 | -0.907 | 0.180 | 0.103 | torch.Size([120]) || stage7.residual_group1.blocks.4.norm1.bias
+ | -0.078 | -3.824 | 4.241 | 0.297 | torch.Size([675, 6]) || stage7.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.4.attn.position_bias
+ | -0.000 | -1.188 | 0.796 | 0.127 | torch.Size([360, 120]) || stage7.residual_group1.blocks.4.attn.qkv_self.weight
+ | 0.002 | -0.248 | 0.207 | 0.056 | torch.Size([360]) || stage7.residual_group1.blocks.4.attn.qkv_self.bias
+ | -0.001 | -0.409 | 0.369 | 0.085 | torch.Size([120, 240]) || stage7.residual_group1.blocks.4.attn.proj.weight
+ | 0.002 | -0.224 | 0.322 | 0.094 | torch.Size([120]) || stage7.residual_group1.blocks.4.attn.proj.bias
+ | 0.000 | -1.744 | 1.273 | 0.110 | torch.Size([360, 120]) || stage7.residual_group1.blocks.4.attn.qkv_mut.weight
+ | 0.001 | -0.092 | 0.113 | 0.019 | torch.Size([360]) || stage7.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.514 | 0.277 | 0.614 | 0.041 | torch.Size([120]) || stage7.residual_group1.blocks.4.norm2.weight
+ | 0.016 | -0.621 | 0.286 | 0.095 | torch.Size([120]) || stage7.residual_group1.blocks.4.norm2.bias
+ | 0.001 | -0.517 | 0.453 | 0.116 | torch.Size([240, 120]) || stage7.residual_group1.blocks.4.mlp.fc11.weight
+ | -0.064 | -0.260 | 0.143 | 0.083 | torch.Size([240]) || stage7.residual_group1.blocks.4.mlp.fc11.bias
+ | 0.000 | -0.503 | 0.554 | 0.129 | torch.Size([240, 120]) || stage7.residual_group1.blocks.4.mlp.fc12.weight
+ | -0.004 | -0.232 | 0.193 | 0.075 | torch.Size([240]) || stage7.residual_group1.blocks.4.mlp.fc12.bias
+ | -0.001 | -0.595 | 0.543 | 0.128 | torch.Size([120, 240]) || stage7.residual_group1.blocks.4.mlp.fc2.weight
+ | 0.001 | -0.196 | 0.198 | 0.071 | torch.Size([120]) || stage7.residual_group1.blocks.4.mlp.fc2.bias
+ | 0.731 | 0.152 | 1.075 | 0.114 | torch.Size([120]) || stage7.residual_group1.blocks.5.norm1.weight
+ | -0.076 | -1.003 | 0.176 | 0.107 | torch.Size([120]) || stage7.residual_group1.blocks.5.norm1.bias
+ | -0.121 | -3.281 | 4.671 | 0.296 | torch.Size([675, 6]) || stage7.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.5.attn.position_bias
+ | -0.000 | -0.640 | 1.083 | 0.122 | torch.Size([360, 120]) || stage7.residual_group1.blocks.5.attn.qkv_self.weight
+ | -0.001 | -0.239 | 0.314 | 0.068 | torch.Size([360]) || stage7.residual_group1.blocks.5.attn.qkv_self.bias
+ | 0.001 | -0.344 | 0.452 | 0.078 | torch.Size([120, 240]) || stage7.residual_group1.blocks.5.attn.proj.weight
+ | 0.004 | -0.361 | 0.251 | 0.093 | torch.Size([120]) || stage7.residual_group1.blocks.5.attn.proj.bias
+ | 0.000 | -0.637 | 0.806 | 0.093 | torch.Size([360, 120]) || stage7.residual_group1.blocks.5.attn.qkv_mut.weight
+ | -0.000 | -0.088 | 0.091 | 0.017 | torch.Size([360]) || stage7.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.514 | 0.238 | 0.594 | 0.042 | torch.Size([120]) || stage7.residual_group1.blocks.5.norm2.weight
+ | 0.017 | -0.650 | 0.162 | 0.089 | torch.Size([120]) || stage7.residual_group1.blocks.5.norm2.bias
+ | 0.000 | -0.442 | 0.479 | 0.114 | torch.Size([240, 120]) || stage7.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.040 | -0.400 | 0.203 | 0.101 | torch.Size([240]) || stage7.residual_group1.blocks.5.mlp.fc11.bias
+ | -0.000 | -0.541 | 0.514 | 0.130 | torch.Size([240, 120]) || stage7.residual_group1.blocks.5.mlp.fc12.weight
+ | -0.008 | -0.319 | 0.309 | 0.092 | torch.Size([240]) || stage7.residual_group1.blocks.5.mlp.fc12.bias
+ | -0.000 | -1.018 | 1.398 | 0.130 | torch.Size([120, 240]) || stage7.residual_group1.blocks.5.mlp.fc2.weight
+ | 0.001 | -1.606 | 0.269 | 0.179 | torch.Size([120]) || stage7.residual_group1.blocks.5.mlp.fc2.bias
+ | 0.000 | -0.186 | 0.207 | 0.048 | torch.Size([120, 120]) || stage7.linear1.weight
+ | 0.010 | -0.448 | 0.437 | 0.161 | torch.Size([120]) || stage7.linear1.bias
+ | 0.703 | 0.381 | 0.856 | 0.084 | torch.Size([120]) || stage7.residual_group2.blocks.0.norm1.weight
+ | 0.014 | -0.645 | 0.486 | 0.169 | torch.Size([120]) || stage7.residual_group2.blocks.0.norm1.bias
+ | -0.007 | -4.468 | 1.008 | 0.164 | torch.Size([2475, 6]) || stage7.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage7.residual_group2.blocks.0.attn.relative_position_index
+ | -0.000 | -0.625 | 0.834 | 0.120 | torch.Size([360, 120]) || stage7.residual_group2.blocks.0.attn.qkv_self.weight
+ | -0.009 | -0.737 | 0.632 | 0.135 | torch.Size([360]) || stage7.residual_group2.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.403 | 0.406 | 0.088 | torch.Size([120, 120]) || stage7.residual_group2.blocks.0.attn.proj.weight
+ | -0.007 | -0.338 | 0.165 | 0.070 | torch.Size([120]) || stage7.residual_group2.blocks.0.attn.proj.bias
+ | 0.435 | 0.323 | 0.526 | 0.038 | torch.Size([120]) || stage7.residual_group2.blocks.0.norm2.weight
+ | 0.005 | -0.678 | 0.379 | 0.117 | torch.Size([120]) || stage7.residual_group2.blocks.0.norm2.bias
+ | 0.000 | -0.465 | 0.467 | 0.110 | torch.Size([240, 120]) || stage7.residual_group2.blocks.0.mlp.fc11.weight
+ | -0.031 | -0.236 | 0.180 | 0.077 | torch.Size([240]) || stage7.residual_group2.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.490 | 0.520 | 0.121 | torch.Size([240, 120]) || stage7.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.003 | -0.197 | 0.242 | 0.069 | torch.Size([240]) || stage7.residual_group2.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.525 | 0.501 | 0.122 | torch.Size([120, 240]) || stage7.residual_group2.blocks.0.mlp.fc2.weight
+ | -0.005 | -0.431 | 0.164 | 0.077 | torch.Size([120]) || stage7.residual_group2.blocks.0.mlp.fc2.bias
+ | 0.703 | 0.306 | 0.866 | 0.079 | torch.Size([120]) || stage7.residual_group2.blocks.1.norm1.weight
+ | 0.009 | -0.647 | 0.481 | 0.149 | torch.Size([120]) || stage7.residual_group2.blocks.1.norm1.bias
+ | -0.010 | -3.504 | 1.842 | 0.134 | torch.Size([2475, 6]) || stage7.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage7.residual_group2.blocks.1.attn.relative_position_index
+ | -0.000 | -0.639 | 0.590 | 0.122 | torch.Size([360, 120]) || stage7.residual_group2.blocks.1.attn.qkv_self.weight
+ | -0.001 | -0.613 | 0.609 | 0.148 | torch.Size([360]) || stage7.residual_group2.blocks.1.attn.qkv_self.bias
+ | 0.001 | -0.316 | 0.325 | 0.085 | torch.Size([120, 120]) || stage7.residual_group2.blocks.1.attn.proj.weight
+ | -0.004 | -0.350 | 0.145 | 0.069 | torch.Size([120]) || stage7.residual_group2.blocks.1.attn.proj.bias
+ | 0.452 | 0.309 | 0.558 | 0.037 | torch.Size([120]) || stage7.residual_group2.blocks.1.norm2.weight
+ | 0.003 | -0.661 | 0.246 | 0.091 | torch.Size([120]) || stage7.residual_group2.blocks.1.norm2.bias
+ | 0.000 | -0.580 | 0.410 | 0.108 | torch.Size([240, 120]) || stage7.residual_group2.blocks.1.mlp.fc11.weight
+ | -0.020 | -0.258 | 0.299 | 0.104 | torch.Size([240]) || stage7.residual_group2.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.529 | 0.561 | 0.126 | torch.Size([240, 120]) || stage7.residual_group2.blocks.1.mlp.fc12.weight
+ | -0.002 | -0.234 | 0.434 | 0.090 | torch.Size([240]) || stage7.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.778 | 0.581 | 0.124 | torch.Size([120, 240]) || stage7.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.001 | -0.888 | 0.286 | 0.135 | torch.Size([120]) || stage7.residual_group2.blocks.1.mlp.fc2.bias
+ | -0.001 | -0.348 | 0.237 | 0.060 | torch.Size([120, 120]) || stage7.linear2.weight
+ | 0.023 | -0.390 | 0.506 | 0.167 | torch.Size([120]) || stage7.linear2.bias
+ | -0.000 | -0.104 | 0.107 | 0.024 | torch.Size([120, 120, 3, 3]) || stage7.pa_deform.weight
+ | 0.002 | -0.041 | 0.035 | 0.016 | torch.Size([120]) || stage7.pa_deform.bias
+ | -0.000 | -0.123 | 0.109 | 0.017 | torch.Size([120, 242, 3, 3]) || stage7.pa_deform.conv_offset.0.weight
+ | -0.002 | -0.034 | 0.032 | 0.015 | torch.Size([120]) || stage7.pa_deform.conv_offset.0.bias
+ | -0.001 | -0.111 | 0.084 | 0.019 | torch.Size([120, 120, 3, 3]) || stage7.pa_deform.conv_offset.2.weight
+ | -0.008 | -0.073 | 0.081 | 0.034 | torch.Size([120]) || stage7.pa_deform.conv_offset.2.bias
+ | -0.002 | -0.154 | 0.122 | 0.018 | torch.Size([120, 120, 3, 3]) || stage7.pa_deform.conv_offset.4.weight
+ | 0.014 | -0.041 | 0.068 | 0.026 | torch.Size([120]) || stage7.pa_deform.conv_offset.4.bias
+ | -0.001 | -0.408 | 0.365 | 0.034 | torch.Size([324, 120, 3, 3]) || stage7.pa_deform.conv_offset.6.weight
+ | -0.003 | -0.057 | 0.054 | 0.024 | torch.Size([324]) || stage7.pa_deform.conv_offset.6.bias
+ | 0.000 | -0.697 | 0.606 | 0.123 | torch.Size([360, 360]) || stage7.pa_fuse.fc11.weight
+ | 0.119 | -0.211 | 0.720 | 0.177 | torch.Size([360]) || stage7.pa_fuse.fc11.bias
+ | 0.000 | -1.175 | 0.924 | 0.154 | torch.Size([360, 360]) || stage7.pa_fuse.fc12.weight
+ | -0.000 | -0.581 | 0.580 | 0.190 | torch.Size([360]) || stage7.pa_fuse.fc12.bias
+ | 0.001 | -0.786 | 0.874 | 0.135 | torch.Size([120, 360]) || stage7.pa_fuse.fc2.weight
+ | -0.053 | -0.522 | 0.577 | 0.205 | torch.Size([120]) || stage7.pa_fuse.fc2.bias
+ | 1.225 | 1.000 | 1.516 | 0.095 | torch.Size([120]) || stage8.0.1.weight
+ | -0.013 | -0.413 | 0.465 | 0.139 | torch.Size([120]) || stage8.0.1.bias
+ | 0.000 | -2.505 | 0.627 | 0.136 | torch.Size([180, 120]) || stage8.0.2.weight
+ | 0.005 | -0.397 | 0.377 | 0.107 | torch.Size([180]) || stage8.0.2.bias
+ | 0.456 | 0.123 | 0.760 | 0.129 | torch.Size([180]) || stage8.1.residual_group.blocks.0.norm1.weight
+ | -0.022 | -0.343 | 0.875 | 0.099 | torch.Size([180]) || stage8.1.residual_group.blocks.0.norm1.bias
+ | -0.014 | -1.907 | 2.592 | 0.130 | torch.Size([2475, 6]) || stage8.1.residual_group.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.1.residual_group.blocks.0.attn.relative_position_index
+ | -0.000 | -0.632 | 0.628 | 0.099 | torch.Size([540, 180]) || stage8.1.residual_group.blocks.0.attn.qkv_self.weight
+ | 0.006 | -0.567 | 0.668 | 0.148 | torch.Size([540]) || stage8.1.residual_group.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.477 | 0.447 | 0.094 | torch.Size([180, 180]) || stage8.1.residual_group.blocks.0.attn.proj.weight
+ | -0.010 | -0.460 | 0.225 | 0.085 | torch.Size([180]) || stage8.1.residual_group.blocks.0.attn.proj.bias
+ | 0.429 | 0.119 | 0.634 | 0.090 | torch.Size([180]) || stage8.1.residual_group.blocks.0.norm2.weight
+ | -0.007 | -0.338 | 0.803 | 0.086 | torch.Size([180]) || stage8.1.residual_group.blocks.0.norm2.bias
+ | -0.006 | -0.572 | 0.539 | 0.119 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.0.mlp.fc11.weight
+ | -0.060 | -0.260 | 0.185 | 0.060 | torch.Size([360]) || stage8.1.residual_group.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.461 | 0.548 | 0.113 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.0.mlp.fc12.weight
+ | 0.000 | -0.163 | 0.183 | 0.050 | torch.Size([360]) || stage8.1.residual_group.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.757 | 0.581 | 0.118 | torch.Size([180, 360]) || stage8.1.residual_group.blocks.0.mlp.fc2.weight
+ | -0.003 | -0.191 | 0.121 | 0.057 | torch.Size([180]) || stage8.1.residual_group.blocks.0.mlp.fc2.bias
+ | 0.557 | 0.086 | 0.800 | 0.112 | torch.Size([180]) || stage8.1.residual_group.blocks.1.norm1.weight
+ | -0.029 | -0.230 | 0.878 | 0.088 | torch.Size([180]) || stage8.1.residual_group.blocks.1.norm1.bias
+ | -0.016 | -2.004 | 1.711 | 0.154 | torch.Size([2475, 6]) || stage8.1.residual_group.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.1.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -0.690 | 0.575 | 0.109 | torch.Size([540, 180]) || stage8.1.residual_group.blocks.1.attn.qkv_self.weight
+ | 0.011 | -0.641 | 0.609 | 0.135 | torch.Size([540]) || stage8.1.residual_group.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.466 | 0.401 | 0.094 | torch.Size([180, 180]) || stage8.1.residual_group.blocks.1.attn.proj.weight
+ | -0.008 | -0.344 | 0.181 | 0.080 | torch.Size([180]) || stage8.1.residual_group.blocks.1.attn.proj.bias
+ | 0.503 | 0.226 | 0.742 | 0.093 | torch.Size([180]) || stage8.1.residual_group.blocks.1.norm2.weight
+ | -0.009 | -0.404 | 0.818 | 0.085 | torch.Size([180]) || stage8.1.residual_group.blocks.1.norm2.bias
+ | -0.007 | -0.595 | 0.532 | 0.121 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.1.mlp.fc11.weight
+ | -0.068 | -0.261 | 0.071 | 0.053 | torch.Size([360]) || stage8.1.residual_group.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.529 | 0.573 | 0.116 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.1.mlp.fc12.weight
+ | 0.002 | -0.129 | 0.197 | 0.046 | torch.Size([360]) || stage8.1.residual_group.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.556 | 0.582 | 0.118 | torch.Size([180, 360]) || stage8.1.residual_group.blocks.1.mlp.fc2.weight
+ | -0.003 | -0.170 | 0.145 | 0.052 | torch.Size([180]) || stage8.1.residual_group.blocks.1.mlp.fc2.bias
+ | 0.699 | 0.202 | 0.912 | 0.109 | torch.Size([180]) || stage8.1.residual_group.blocks.2.norm1.weight
+ | -0.033 | -0.253 | 0.924 | 0.091 | torch.Size([180]) || stage8.1.residual_group.blocks.2.norm1.bias
+ | -0.030 | -2.510 | 2.088 | 0.194 | torch.Size([2475, 6]) || stage8.1.residual_group.blocks.2.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.1.residual_group.blocks.2.attn.relative_position_index
+ | 0.000 | -0.637 | 0.801 | 0.116 | torch.Size([540, 180]) || stage8.1.residual_group.blocks.2.attn.qkv_self.weight
+ | 0.006 | -0.512 | 0.520 | 0.110 | torch.Size([540]) || stage8.1.residual_group.blocks.2.attn.qkv_self.bias
+ | 0.000 | -0.381 | 0.337 | 0.090 | torch.Size([180, 180]) || stage8.1.residual_group.blocks.2.attn.proj.weight
+ | -0.011 | -0.238 | 0.234 | 0.085 | torch.Size([180]) || stage8.1.residual_group.blocks.2.attn.proj.bias
+ | 0.594 | 0.150 | 0.810 | 0.108 | torch.Size([180]) || stage8.1.residual_group.blocks.2.norm2.weight
+ | -0.010 | -0.483 | 0.726 | 0.088 | torch.Size([180]) || stage8.1.residual_group.blocks.2.norm2.bias
+ | -0.006 | -0.567 | 0.499 | 0.125 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.2.mlp.fc11.weight
+ | -0.077 | -0.360 | 0.050 | 0.056 | torch.Size([360]) || stage8.1.residual_group.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.536 | 0.673 | 0.119 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.2.mlp.fc12.weight
+ | 0.001 | -0.142 | 0.186 | 0.043 | torch.Size([360]) || stage8.1.residual_group.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.536 | 0.524 | 0.119 | torch.Size([180, 360]) || stage8.1.residual_group.blocks.2.mlp.fc2.weight
+ | -0.006 | -0.147 | 0.133 | 0.051 | torch.Size([180]) || stage8.1.residual_group.blocks.2.mlp.fc2.bias
+ | 0.683 | 0.141 | 0.908 | 0.105 | torch.Size([180]) || stage8.1.residual_group.blocks.3.norm1.weight
+ | -0.033 | -0.199 | 0.878 | 0.088 | torch.Size([180]) || stage8.1.residual_group.blocks.3.norm1.bias
+ | -0.039 | -1.527 | 3.891 | 0.199 | torch.Size([2475, 6]) || stage8.1.residual_group.blocks.3.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.1.residual_group.blocks.3.attn.relative_position_index
+ | 0.000 | -0.682 | 0.693 | 0.120 | torch.Size([540, 180]) || stage8.1.residual_group.blocks.3.attn.qkv_self.weight
+ | 0.007 | -0.543 | 0.513 | 0.138 | torch.Size([540]) || stage8.1.residual_group.blocks.3.attn.qkv_self.bias
+ | -0.001 | -0.390 | 0.476 | 0.089 | torch.Size([180, 180]) || stage8.1.residual_group.blocks.3.attn.proj.weight
+ | -0.007 | -0.176 | 0.150 | 0.062 | torch.Size([180]) || stage8.1.residual_group.blocks.3.attn.proj.bias
+ | 0.640 | 0.094 | 0.853 | 0.120 | torch.Size([180]) || stage8.1.residual_group.blocks.3.norm2.weight
+ | -0.009 | -0.372 | 0.683 | 0.084 | torch.Size([180]) || stage8.1.residual_group.blocks.3.norm2.bias
+ | -0.006 | -0.628 | 0.521 | 0.126 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.3.mlp.fc11.weight
+ | -0.089 | -0.367 | 0.047 | 0.054 | torch.Size([360]) || stage8.1.residual_group.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.629 | 0.562 | 0.121 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.3.mlp.fc12.weight
+ | -0.001 | -0.186 | 0.128 | 0.042 | torch.Size([360]) || stage8.1.residual_group.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.485 | 0.499 | 0.118 | torch.Size([180, 360]) || stage8.1.residual_group.blocks.3.mlp.fc2.weight
+ | -0.007 | -0.138 | 0.209 | 0.050 | torch.Size([180]) || stage8.1.residual_group.blocks.3.mlp.fc2.bias
+ | 0.000 | -0.294 | 0.577 | 0.071 | torch.Size([180, 180]) || stage8.1.linear.weight
+ | 0.004 | -0.349 | 0.235 | 0.072 | torch.Size([180]) || stage8.1.linear.bias
+ | 0.708 | 0.242 | 1.026 | 0.136 | torch.Size([180]) || stage8.2.residual_group.blocks.0.norm1.weight
+ | -0.032 | -0.212 | 0.830 | 0.100 | torch.Size([180]) || stage8.2.residual_group.blocks.0.norm1.bias
+ | -0.039 | -1.954 | 2.394 | 0.212 | torch.Size([2475, 6]) || stage8.2.residual_group.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.2.residual_group.blocks.0.attn.relative_position_index
+ | 0.000 | -0.922 | 0.646 | 0.116 | torch.Size([540, 180]) || stage8.2.residual_group.blocks.0.attn.qkv_self.weight
+ | -0.001 | -0.429 | 0.524 | 0.101 | torch.Size([540]) || stage8.2.residual_group.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.467 | 0.453 | 0.109 | torch.Size([180, 180]) || stage8.2.residual_group.blocks.0.attn.proj.weight
+ | -0.005 | -0.339 | 0.264 | 0.095 | torch.Size([180]) || stage8.2.residual_group.blocks.0.attn.proj.bias
+ | 0.587 | 0.255 | 0.837 | 0.086 | torch.Size([180]) || stage8.2.residual_group.blocks.0.norm2.weight
+ | -0.011 | -0.285 | 0.721 | 0.083 | torch.Size([180]) || stage8.2.residual_group.blocks.0.norm2.bias
+ | -0.006 | -0.586 | 0.534 | 0.125 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.0.mlp.fc11.weight
+ | -0.075 | -0.225 | 0.066 | 0.047 | torch.Size([360]) || stage8.2.residual_group.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.493 | 0.532 | 0.123 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.0.mlp.fc12.weight
+ | 0.003 | -0.189 | 0.178 | 0.047 | torch.Size([360]) || stage8.2.residual_group.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.551 | 0.543 | 0.124 | torch.Size([180, 360]) || stage8.2.residual_group.blocks.0.mlp.fc2.weight
+ | -0.010 | -0.154 | 0.142 | 0.054 | torch.Size([180]) || stage8.2.residual_group.blocks.0.mlp.fc2.bias
+ | 0.773 | 0.210 | 1.004 | 0.113 | torch.Size([180]) || stage8.2.residual_group.blocks.1.norm1.weight
+ | -0.035 | -0.176 | 0.873 | 0.089 | torch.Size([180]) || stage8.2.residual_group.blocks.1.norm1.bias
+ | -0.027 | -2.407 | 1.736 | 0.214 | torch.Size([2475, 6]) || stage8.2.residual_group.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.2.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -0.817 | 0.977 | 0.123 | torch.Size([540, 180]) || stage8.2.residual_group.blocks.1.attn.qkv_self.weight
+ | 0.001 | -0.659 | 0.461 | 0.115 | torch.Size([540]) || stage8.2.residual_group.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.484 | 0.453 | 0.109 | torch.Size([180, 180]) || stage8.2.residual_group.blocks.1.attn.proj.weight
+ | -0.014 | -0.315 | 0.252 | 0.091 | torch.Size([180]) || stage8.2.residual_group.blocks.1.attn.proj.bias
+ | 0.641 | 0.337 | 0.810 | 0.081 | torch.Size([180]) || stage8.2.residual_group.blocks.1.norm2.weight
+ | -0.011 | -0.177 | 0.806 | 0.083 | torch.Size([180]) || stage8.2.residual_group.blocks.1.norm2.bias
+ | -0.006 | -0.569 | 0.598 | 0.125 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.1.mlp.fc11.weight
+ | -0.079 | -0.323 | 0.071 | 0.051 | torch.Size([360]) || stage8.2.residual_group.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.512 | 0.577 | 0.126 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.1.mlp.fc12.weight
+ | -0.003 | -0.142 | 0.161 | 0.050 | torch.Size([360]) || stage8.2.residual_group.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.529 | 0.572 | 0.125 | torch.Size([180, 360]) || stage8.2.residual_group.blocks.1.mlp.fc2.weight
+ | -0.010 | -0.178 | 0.159 | 0.066 | torch.Size([180]) || stage8.2.residual_group.blocks.1.mlp.fc2.bias
+ | 0.857 | 0.199 | 1.153 | 0.112 | torch.Size([180]) || stage8.2.residual_group.blocks.2.norm1.weight
+ | -0.039 | -0.189 | 0.943 | 0.089 | torch.Size([180]) || stage8.2.residual_group.blocks.2.norm1.bias
+ | -0.042 | -1.962 | 2.773 | 0.246 | torch.Size([2475, 6]) || stage8.2.residual_group.blocks.2.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.2.residual_group.blocks.2.attn.relative_position_index
+ | -0.000 | -0.783 | 0.655 | 0.123 | torch.Size([540, 180]) || stage8.2.residual_group.blocks.2.attn.qkv_self.weight
+ | 0.004 | -0.338 | 0.533 | 0.099 | torch.Size([540]) || stage8.2.residual_group.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.497 | 0.461 | 0.107 | torch.Size([180, 180]) || stage8.2.residual_group.blocks.2.attn.proj.weight
+ | -0.008 | -0.288 | 0.183 | 0.089 | torch.Size([180]) || stage8.2.residual_group.blocks.2.attn.proj.bias
+ | 0.681 | 0.327 | 0.878 | 0.085 | torch.Size([180]) || stage8.2.residual_group.blocks.2.norm2.weight
+ | -0.012 | -0.178 | 0.773 | 0.084 | torch.Size([180]) || stage8.2.residual_group.blocks.2.norm2.bias
+ | -0.006 | -0.789 | 0.546 | 0.125 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.2.mlp.fc11.weight
+ | -0.081 | -0.249 | 0.036 | 0.051 | torch.Size([360]) || stage8.2.residual_group.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.526 | 0.555 | 0.128 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.2.mlp.fc12.weight
+ | 0.000 | -0.133 | 0.191 | 0.051 | torch.Size([360]) || stage8.2.residual_group.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.572 | 0.529 | 0.126 | torch.Size([180, 360]) || stage8.2.residual_group.blocks.2.mlp.fc2.weight
+ | -0.011 | -0.164 | 0.147 | 0.065 | torch.Size([180]) || stage8.2.residual_group.blocks.2.mlp.fc2.bias
+ | 0.877 | 0.198 | 1.043 | 0.094 | torch.Size([180]) || stage8.2.residual_group.blocks.3.norm1.weight
+ | -0.038 | -0.210 | 0.916 | 0.091 | torch.Size([180]) || stage8.2.residual_group.blocks.3.norm1.bias
+ | -0.094 | -2.974 | 4.987 | 0.299 | torch.Size([2475, 6]) || stage8.2.residual_group.blocks.3.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.2.residual_group.blocks.3.attn.relative_position_index
+ | -0.000 | -0.964 | 1.011 | 0.126 | torch.Size([540, 180]) || stage8.2.residual_group.blocks.3.attn.qkv_self.weight
+ | -0.002 | -0.404 | 0.429 | 0.101 | torch.Size([540]) || stage8.2.residual_group.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.501 | 0.489 | 0.110 | torch.Size([180, 180]) || stage8.2.residual_group.blocks.3.attn.proj.weight
+ | -0.021 | -0.305 | 0.208 | 0.097 | torch.Size([180]) || stage8.2.residual_group.blocks.3.attn.proj.bias
+ | 0.697 | 0.295 | 0.894 | 0.089 | torch.Size([180]) || stage8.2.residual_group.blocks.3.norm2.weight
+ | -0.015 | -0.241 | 0.712 | 0.086 | torch.Size([180]) || stage8.2.residual_group.blocks.3.norm2.bias
+ | -0.005 | -0.562 | 0.573 | 0.125 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.3.mlp.fc11.weight
+ | -0.085 | -0.302 | 0.080 | 0.060 | torch.Size([360]) || stage8.2.residual_group.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.734 | 0.573 | 0.130 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.3.mlp.fc12.weight
+ | 0.001 | -0.150 | 0.161 | 0.054 | torch.Size([360]) || stage8.2.residual_group.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.671 | 0.623 | 0.127 | torch.Size([180, 360]) || stage8.2.residual_group.blocks.3.mlp.fc2.weight
+ | -0.023 | -0.252 | 0.317 | 0.081 | torch.Size([180]) || stage8.2.residual_group.blocks.3.mlp.fc2.bias
+ | -0.000 | -0.278 | 0.345 | 0.064 | torch.Size([180, 180]) || stage8.2.linear.weight
+ | 0.004 | -0.315 | 0.148 | 0.064 | torch.Size([180]) || stage8.2.linear.bias
+ | 0.850 | 0.326 | 1.087 | 0.122 | torch.Size([180]) || stage8.3.residual_group.blocks.0.norm1.weight
+ | -0.031 | -0.334 | 0.779 | 0.106 | torch.Size([180]) || stage8.3.residual_group.blocks.0.norm1.bias
+ | -0.012 | -2.917 | 1.476 | 0.175 | torch.Size([2475, 6]) || stage8.3.residual_group.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.3.residual_group.blocks.0.attn.relative_position_index
+ | -0.000 | -0.603 | 0.666 | 0.124 | torch.Size([540, 180]) || stage8.3.residual_group.blocks.0.attn.qkv_self.weight
+ | -0.001 | -0.374 | 0.381 | 0.086 | torch.Size([540]) || stage8.3.residual_group.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.577 | 0.605 | 0.119 | torch.Size([180, 180]) || stage8.3.residual_group.blocks.0.attn.proj.weight
+ | -0.008 | -0.394 | 0.499 | 0.134 | torch.Size([180]) || stage8.3.residual_group.blocks.0.attn.proj.bias
+ | 0.636 | 0.321 | 0.790 | 0.073 | torch.Size([180]) || stage8.3.residual_group.blocks.0.norm2.weight
+ | -0.013 | -0.294 | 0.774 | 0.090 | torch.Size([180]) || stage8.3.residual_group.blocks.0.norm2.bias
+ | -0.004 | -0.540 | 0.539 | 0.123 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.0.mlp.fc11.weight
+ | -0.065 | -0.212 | 0.047 | 0.051 | torch.Size([360]) || stage8.3.residual_group.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.608 | 0.603 | 0.130 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.0.mlp.fc12.weight
+ | -0.002 | -0.177 | 0.155 | 0.051 | torch.Size([360]) || stage8.3.residual_group.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.573 | 0.630 | 0.129 | torch.Size([180, 360]) || stage8.3.residual_group.blocks.0.mlp.fc2.weight
+ | -0.005 | -0.189 | 0.178 | 0.071 | torch.Size([180]) || stage8.3.residual_group.blocks.0.mlp.fc2.bias
+ | 0.899 | 0.275 | 1.048 | 0.099 | torch.Size([180]) || stage8.3.residual_group.blocks.1.norm1.weight
+ | -0.031 | -0.223 | 0.771 | 0.088 | torch.Size([180]) || stage8.3.residual_group.blocks.1.norm1.bias
+ | -0.003 | -3.151 | 1.718 | 0.202 | torch.Size([2475, 6]) || stage8.3.residual_group.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.3.residual_group.blocks.1.attn.relative_position_index
+ | -0.000 | -0.732 | 0.868 | 0.127 | torch.Size([540, 180]) || stage8.3.residual_group.blocks.1.attn.qkv_self.weight
+ | 0.002 | -0.412 | 0.350 | 0.093 | torch.Size([540]) || stage8.3.residual_group.blocks.1.attn.qkv_self.bias
+ | 0.001 | -0.466 | 0.487 | 0.114 | torch.Size([180, 180]) || stage8.3.residual_group.blocks.1.attn.proj.weight
+ | -0.006 | -0.388 | 0.400 | 0.129 | torch.Size([180]) || stage8.3.residual_group.blocks.1.attn.proj.bias
+ | 0.711 | 0.381 | 0.864 | 0.082 | torch.Size([180]) || stage8.3.residual_group.blocks.1.norm2.weight
+ | -0.009 | -0.240 | 0.692 | 0.090 | torch.Size([180]) || stage8.3.residual_group.blocks.1.norm2.bias
+ | -0.005 | -0.657 | 0.639 | 0.126 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.1.mlp.fc11.weight
+ | -0.077 | -0.263 | 0.047 | 0.057 | torch.Size([360]) || stage8.3.residual_group.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.673 | 0.605 | 0.134 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.1.mlp.fc12.weight
+ | 0.002 | -0.158 | 0.155 | 0.046 | torch.Size([360]) || stage8.3.residual_group.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.582 | 0.585 | 0.131 | torch.Size([180, 360]) || stage8.3.residual_group.blocks.1.mlp.fc2.weight
+ | -0.009 | -0.253 | 0.178 | 0.070 | torch.Size([180]) || stage8.3.residual_group.blocks.1.mlp.fc2.bias
+ | 0.941 | 0.262 | 1.154 | 0.094 | torch.Size([180]) || stage8.3.residual_group.blocks.2.norm1.weight
+ | -0.032 | -0.162 | 0.906 | 0.084 | torch.Size([180]) || stage8.3.residual_group.blocks.2.norm1.bias
+ | -0.005 | -3.421 | 1.350 | 0.205 | torch.Size([2475, 6]) || stage8.3.residual_group.blocks.2.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.3.residual_group.blocks.2.attn.relative_position_index
+ | -0.000 | -0.777 | 0.735 | 0.130 | torch.Size([540, 180]) || stage8.3.residual_group.blocks.2.attn.qkv_self.weight
+ | 0.000 | -0.355 | 0.421 | 0.092 | torch.Size([540]) || stage8.3.residual_group.blocks.2.attn.qkv_self.bias
+ | 0.000 | -0.479 | 0.475 | 0.115 | torch.Size([180, 180]) || stage8.3.residual_group.blocks.2.attn.proj.weight
+ | -0.013 | -0.292 | 0.345 | 0.122 | torch.Size([180]) || stage8.3.residual_group.blocks.2.attn.proj.bias
+ | 0.743 | 0.242 | 0.919 | 0.093 | torch.Size([180]) || stage8.3.residual_group.blocks.2.norm2.weight
+ | -0.011 | -0.214 | 0.691 | 0.094 | torch.Size([180]) || stage8.3.residual_group.blocks.2.norm2.bias
+ | -0.005 | -0.633 | 0.498 | 0.127 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.2.mlp.fc11.weight
+ | -0.082 | -0.346 | 0.087 | 0.062 | torch.Size([360]) || stage8.3.residual_group.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.591 | 0.670 | 0.134 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.2.mlp.fc12.weight
+ | 0.001 | -0.190 | 0.151 | 0.056 | torch.Size([360]) || stage8.3.residual_group.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.560 | 0.637 | 0.132 | torch.Size([180, 360]) || stage8.3.residual_group.blocks.2.mlp.fc2.weight
+ | -0.009 | -0.226 | 0.250 | 0.085 | torch.Size([180]) || stage8.3.residual_group.blocks.2.mlp.fc2.bias
+ | 0.950 | 0.250 | 1.103 | 0.086 | torch.Size([180]) || stage8.3.residual_group.blocks.3.norm1.weight
+ | -0.035 | -0.196 | 0.925 | 0.088 | torch.Size([180]) || stage8.3.residual_group.blocks.3.norm1.bias
+ | -0.026 | -3.591 | 5.653 | 0.236 | torch.Size([2475, 6]) || stage8.3.residual_group.blocks.3.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.3.residual_group.blocks.3.attn.relative_position_index
+ | 0.000 | -0.753 | 0.637 | 0.128 | torch.Size([540, 180]) || stage8.3.residual_group.blocks.3.attn.qkv_self.weight
+ | 0.000 | -0.333 | 0.432 | 0.081 | torch.Size([540]) || stage8.3.residual_group.blocks.3.attn.qkv_self.bias
+ | 0.001 | -0.591 | 0.591 | 0.118 | torch.Size([180, 180]) || stage8.3.residual_group.blocks.3.attn.proj.weight
+ | -0.014 | -0.348 | 0.267 | 0.122 | torch.Size([180]) || stage8.3.residual_group.blocks.3.attn.proj.bias
+ | 0.735 | 0.254 | 0.893 | 0.082 | torch.Size([180]) || stage8.3.residual_group.blocks.3.norm2.weight
+ | -0.011 | -0.241 | 0.659 | 0.093 | torch.Size([180]) || stage8.3.residual_group.blocks.3.norm2.bias
+ | -0.005 | -0.628 | 0.667 | 0.125 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.3.mlp.fc11.weight
+ | -0.076 | -0.411 | 0.113 | 0.072 | torch.Size([360]) || stage8.3.residual_group.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.662 | 0.578 | 0.135 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.3.mlp.fc12.weight
+ | -0.004 | -0.208 | 0.169 | 0.054 | torch.Size([360]) || stage8.3.residual_group.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.602 | 0.588 | 0.131 | torch.Size([180, 360]) || stage8.3.residual_group.blocks.3.mlp.fc2.weight
+ | -0.011 | -0.218 | 0.232 | 0.096 | torch.Size([180]) || stage8.3.residual_group.blocks.3.mlp.fc2.bias
+ | -0.000 | -0.343 | 0.316 | 0.065 | torch.Size([180, 180]) || stage8.3.linear.weight
+ | 0.010 | -0.297 | 0.187 | 0.061 | torch.Size([180]) || stage8.3.linear.bias
+ | 1.012 | 0.330 | 1.282 | 0.149 | torch.Size([180]) || stage8.4.residual_group.blocks.0.norm1.weight
+ | -0.030 | -0.347 | 0.800 | 0.134 | torch.Size([180]) || stage8.4.residual_group.blocks.0.norm1.bias
+ | -0.013 | -2.816 | 3.792 | 0.236 | torch.Size([2475, 6]) || stage8.4.residual_group.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.4.residual_group.blocks.0.attn.relative_position_index
+ | -0.000 | -0.807 | 0.825 | 0.131 | torch.Size([540, 180]) || stage8.4.residual_group.blocks.0.attn.qkv_self.weight
+ | -0.003 | -0.429 | 0.319 | 0.083 | torch.Size([540]) || stage8.4.residual_group.blocks.0.attn.qkv_self.bias
+ | 0.001 | -0.553 | 0.569 | 0.136 | torch.Size([180, 180]) || stage8.4.residual_group.blocks.0.attn.proj.weight
+ | -0.019 | -0.443 | 0.441 | 0.139 | torch.Size([180]) || stage8.4.residual_group.blocks.0.attn.proj.bias
+ | 0.638 | 0.420 | 0.797 | 0.063 | torch.Size([180]) || stage8.4.residual_group.blocks.0.norm2.weight
+ | -0.018 | -0.222 | 0.886 | 0.107 | torch.Size([180]) || stage8.4.residual_group.blocks.0.norm2.bias
+ | -0.002 | -0.576 | 0.510 | 0.117 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.0.mlp.fc11.weight
+ | -0.018 | -0.277 | 0.123 | 0.068 | torch.Size([360]) || stage8.4.residual_group.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.687 | 0.625 | 0.132 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.0.mlp.fc12.weight
+ | -0.007 | -0.264 | 0.267 | 0.076 | torch.Size([360]) || stage8.4.residual_group.blocks.0.mlp.fc12.bias
+ | 0.001 | -0.639 | 0.705 | 0.130 | torch.Size([180, 360]) || stage8.4.residual_group.blocks.0.mlp.fc2.weight
+ | -0.012 | -0.255 | 0.274 | 0.095 | torch.Size([180]) || stage8.4.residual_group.blocks.0.mlp.fc2.bias
+ | 1.092 | 0.475 | 1.341 | 0.115 | torch.Size([180]) || stage8.4.residual_group.blocks.1.norm1.weight
+ | -0.030 | -0.294 | 0.686 | 0.113 | torch.Size([180]) || stage8.4.residual_group.blocks.1.norm1.bias
+ | 0.018 | -3.165 | 0.990 | 0.213 | torch.Size([2475, 6]) || stage8.4.residual_group.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.4.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -0.695 | 0.699 | 0.133 | torch.Size([540, 180]) || stage8.4.residual_group.blocks.1.attn.qkv_self.weight
+ | 0.002 | -0.319 | 0.286 | 0.075 | torch.Size([540]) || stage8.4.residual_group.blocks.1.attn.qkv_self.bias
+ | -0.001 | -0.542 | 0.519 | 0.133 | torch.Size([180, 180]) || stage8.4.residual_group.blocks.1.attn.proj.weight
+ | -0.017 | -0.439 | 0.451 | 0.152 | torch.Size([180]) || stage8.4.residual_group.blocks.1.attn.proj.bias
+ | 0.664 | 0.366 | 0.835 | 0.074 | torch.Size([180]) || stage8.4.residual_group.blocks.1.norm2.weight
+ | -0.015 | -0.217 | 0.985 | 0.103 | torch.Size([180]) || stage8.4.residual_group.blocks.1.norm2.bias
+ | -0.002 | -0.641 | 0.563 | 0.117 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.1.mlp.fc11.weight
+ | -0.022 | -0.381 | 0.161 | 0.078 | torch.Size([360]) || stage8.4.residual_group.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.571 | 0.642 | 0.132 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.1.mlp.fc12.weight
+ | 0.003 | -0.279 | 0.311 | 0.087 | torch.Size([360]) || stage8.4.residual_group.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.738 | 0.633 | 0.130 | torch.Size([180, 360]) || stage8.4.residual_group.blocks.1.mlp.fc2.weight
+ | -0.007 | -0.254 | 0.261 | 0.084 | torch.Size([180]) || stage8.4.residual_group.blocks.1.mlp.fc2.bias
+ | 1.125 | 0.525 | 1.405 | 0.117 | torch.Size([180]) || stage8.4.residual_group.blocks.2.norm1.weight
+ | -0.033 | -0.186 | 0.627 | 0.082 | torch.Size([180]) || stage8.4.residual_group.blocks.2.norm1.bias
+ | 0.028 | -3.477 | 0.957 | 0.217 | torch.Size([2475, 6]) || stage8.4.residual_group.blocks.2.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.4.residual_group.blocks.2.attn.relative_position_index
+ | 0.000 | -0.663 | 0.658 | 0.130 | torch.Size([540, 180]) || stage8.4.residual_group.blocks.2.attn.qkv_self.weight
+ | -0.007 | -0.357 | 0.255 | 0.064 | torch.Size([540]) || stage8.4.residual_group.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.596 | 0.578 | 0.137 | torch.Size([180, 180]) || stage8.4.residual_group.blocks.2.attn.proj.weight
+ | -0.018 | -0.506 | 0.389 | 0.159 | torch.Size([180]) || stage8.4.residual_group.blocks.2.attn.proj.bias
+ | 0.694 | 0.319 | 0.865 | 0.084 | torch.Size([180]) || stage8.4.residual_group.blocks.2.norm2.weight
+ | -0.018 | -0.150 | 0.975 | 0.087 | torch.Size([180]) || stage8.4.residual_group.blocks.2.norm2.bias
+ | -0.002 | -0.619 | 0.565 | 0.116 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.2.mlp.fc11.weight
+ | -0.025 | -0.345 | 0.208 | 0.086 | torch.Size([360]) || stage8.4.residual_group.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.624 | 0.607 | 0.132 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.2.mlp.fc12.weight
+ | -0.003 | -0.388 | 0.290 | 0.075 | torch.Size([360]) || stage8.4.residual_group.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.927 | 0.675 | 0.130 | torch.Size([180, 360]) || stage8.4.residual_group.blocks.2.mlp.fc2.weight
+ | -0.011 | -0.325 | 0.240 | 0.096 | torch.Size([180]) || stage8.4.residual_group.blocks.2.mlp.fc2.bias
+ | 1.108 | 0.535 | 1.297 | 0.094 | torch.Size([180]) || stage8.4.residual_group.blocks.3.norm1.weight
+ | -0.035 | -0.213 | 0.546 | 0.064 | torch.Size([180]) || stage8.4.residual_group.blocks.3.norm1.bias
+ | 0.020 | -3.042 | 1.420 | 0.192 | torch.Size([2475, 6]) || stage8.4.residual_group.blocks.3.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.4.residual_group.blocks.3.attn.relative_position_index
+ | -0.000 | -0.697 | 0.700 | 0.128 | torch.Size([540, 180]) || stage8.4.residual_group.blocks.3.attn.qkv_self.weight
+ | -0.000 | -0.220 | 0.311 | 0.065 | torch.Size([540]) || stage8.4.residual_group.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.652 | 0.592 | 0.138 | torch.Size([180, 180]) || stage8.4.residual_group.blocks.3.attn.proj.weight
+ | -0.019 | -0.535 | 0.426 | 0.154 | torch.Size([180]) || stage8.4.residual_group.blocks.3.attn.proj.bias
+ | 0.685 | 0.225 | 0.893 | 0.082 | torch.Size([180]) || stage8.4.residual_group.blocks.3.norm2.weight
+ | -0.023 | -0.211 | 0.938 | 0.093 | torch.Size([180]) || stage8.4.residual_group.blocks.3.norm2.bias
+ | -0.001 | -0.501 | 0.564 | 0.113 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.3.mlp.fc11.weight
+ | -0.014 | -0.339 | 0.237 | 0.092 | torch.Size([360]) || stage8.4.residual_group.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.560 | 0.626 | 0.132 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.3.mlp.fc12.weight
+ | 0.000 | -0.231 | 0.239 | 0.075 | torch.Size([360]) || stage8.4.residual_group.blocks.3.mlp.fc12.bias
+ | -0.000 | -0.544 | 0.657 | 0.130 | torch.Size([180, 360]) || stage8.4.residual_group.blocks.3.mlp.fc2.weight
+ | -0.007 | -0.271 | 0.274 | 0.093 | torch.Size([180]) || stage8.4.residual_group.blocks.3.mlp.fc2.bias
+ | -0.001 | -0.473 | 0.481 | 0.069 | torch.Size([180, 180]) || stage8.4.linear.weight
+ | 0.029 | -0.333 | 0.194 | 0.076 | torch.Size([180]) || stage8.4.linear.bias
+ | 1.025 | 0.297 | 1.336 | 0.162 | torch.Size([180]) || stage8.5.residual_group.blocks.0.norm1.weight
+ | -0.034 | -0.429 | 0.872 | 0.141 | torch.Size([180]) || stage8.5.residual_group.blocks.0.norm1.bias
+ | -0.574 | -4.515 | 3.381 | 0.800 | torch.Size([225, 6]) || stage8.5.residual_group.blocks.0.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.5.residual_group.blocks.0.attn.relative_position_index
+ | 0.000 | -0.771 | 0.886 | 0.125 | torch.Size([540, 180]) || stage8.5.residual_group.blocks.0.attn.qkv_self.weight
+ | 0.000 | -0.356 | 0.521 | 0.085 | torch.Size([540]) || stage8.5.residual_group.blocks.0.attn.qkv_self.bias
+ | -0.001 | -0.632 | 0.656 | 0.147 | torch.Size([180, 180]) || stage8.5.residual_group.blocks.0.attn.proj.weight
+ | -0.029 | -0.329 | 0.697 | 0.127 | torch.Size([180]) || stage8.5.residual_group.blocks.0.attn.proj.bias
+ | 0.777 | 0.446 | 0.952 | 0.069 | torch.Size([180]) || stage8.5.residual_group.blocks.0.norm2.weight
+ | -0.022 | -0.335 | 0.920 | 0.121 | torch.Size([180]) || stage8.5.residual_group.blocks.0.norm2.bias
+ | -0.002 | -0.520 | 0.598 | 0.117 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.0.mlp.fc11.weight
+ | -0.013 | -0.456 | 0.200 | 0.075 | torch.Size([360]) || stage8.5.residual_group.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.677 | 0.642 | 0.137 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.0.mlp.fc12.weight
+ | 0.005 | -0.272 | 0.233 | 0.083 | torch.Size([360]) || stage8.5.residual_group.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.762 | 0.598 | 0.136 | torch.Size([180, 360]) || stage8.5.residual_group.blocks.0.mlp.fc2.weight
+ | -0.025 | -0.244 | 0.583 | 0.111 | torch.Size([180]) || stage8.5.residual_group.blocks.0.mlp.fc2.bias
+ | 1.021 | 0.261 | 1.261 | 0.133 | torch.Size([180]) || stage8.5.residual_group.blocks.1.norm1.weight
+ | -0.033 | -0.358 | 0.867 | 0.120 | torch.Size([180]) || stage8.5.residual_group.blocks.1.norm1.bias
+ | -0.550 | -3.274 | 4.406 | 0.670 | torch.Size([225, 6]) || stage8.5.residual_group.blocks.1.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.5.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -0.819 | 0.986 | 0.122 | torch.Size([540, 180]) || stage8.5.residual_group.blocks.1.attn.qkv_self.weight
+ | 0.005 | -0.510 | 0.446 | 0.084 | torch.Size([540]) || stage8.5.residual_group.blocks.1.attn.qkv_self.bias
+ | -0.003 | -0.739 | 0.682 | 0.151 | torch.Size([180, 180]) || stage8.5.residual_group.blocks.1.attn.proj.weight
+ | -0.032 | -0.318 | 0.607 | 0.133 | torch.Size([180]) || stage8.5.residual_group.blocks.1.attn.proj.bias
+ | 0.823 | 0.420 | 0.950 | 0.070 | torch.Size([180]) || stage8.5.residual_group.blocks.1.norm2.weight
+ | -0.021 | -0.274 | 0.882 | 0.111 | torch.Size([180]) || stage8.5.residual_group.blocks.1.norm2.bias
+ | -0.002 | -0.496 | 0.532 | 0.117 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.1.mlp.fc11.weight
+ | -0.028 | -0.260 | 0.194 | 0.080 | torch.Size([360]) || stage8.5.residual_group.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.620 | 0.586 | 0.139 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.1.mlp.fc12.weight
+ | 0.004 | -0.284 | 0.423 | 0.083 | torch.Size([360]) || stage8.5.residual_group.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.774 | 0.614 | 0.137 | torch.Size([180, 360]) || stage8.5.residual_group.blocks.1.mlp.fc2.weight
+ | -0.028 | -0.371 | 0.561 | 0.133 | torch.Size([180]) || stage8.5.residual_group.blocks.1.mlp.fc2.bias
+ | 1.096 | 0.377 | 1.321 | 0.110 | torch.Size([180]) || stage8.5.residual_group.blocks.2.norm1.weight
+ | -0.033 | -0.244 | 0.755 | 0.100 | torch.Size([180]) || stage8.5.residual_group.blocks.2.norm1.bias
+ | -0.441 | -3.439 | 5.870 | 0.668 | torch.Size([225, 6]) || stage8.5.residual_group.blocks.2.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.5.residual_group.blocks.2.attn.relative_position_index
+ | -0.000 | -0.710 | 0.679 | 0.123 | torch.Size([540, 180]) || stage8.5.residual_group.blocks.2.attn.qkv_self.weight
+ | 0.003 | -0.277 | 0.283 | 0.068 | torch.Size([540]) || stage8.5.residual_group.blocks.2.attn.qkv_self.bias
+ | 0.001 | -0.824 | 0.684 | 0.150 | torch.Size([180, 180]) || stage8.5.residual_group.blocks.2.attn.proj.weight
+ | -0.033 | -0.390 | 0.545 | 0.155 | torch.Size([180]) || stage8.5.residual_group.blocks.2.attn.proj.bias
+ | 0.843 | 0.390 | 0.984 | 0.076 | torch.Size([180]) || stage8.5.residual_group.blocks.2.norm2.weight
+ | -0.022 | -0.211 | 0.854 | 0.090 | torch.Size([180]) || stage8.5.residual_group.blocks.2.norm2.bias
+ | -0.002 | -0.522 | 0.503 | 0.116 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.2.mlp.fc11.weight
+ | -0.024 | -0.243 | 0.219 | 0.091 | torch.Size([360]) || stage8.5.residual_group.blocks.2.mlp.fc11.bias
+ | -0.001 | -0.638 | 0.617 | 0.139 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.2.mlp.fc12.weight
+ | -0.004 | -0.268 | 0.380 | 0.078 | torch.Size([360]) || stage8.5.residual_group.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.713 | 0.769 | 0.138 | torch.Size([180, 360]) || stage8.5.residual_group.blocks.2.mlp.fc2.weight
+ | -0.034 | -0.372 | 0.592 | 0.151 | torch.Size([180]) || stage8.5.residual_group.blocks.2.mlp.fc2.bias
+ | 1.027 | 0.318 | 1.206 | 0.094 | torch.Size([180]) || stage8.5.residual_group.blocks.3.norm1.weight
+ | -0.033 | -0.187 | 0.768 | 0.088 | torch.Size([180]) || stage8.5.residual_group.blocks.3.norm1.bias
+ | -0.347 | -2.664 | 2.684 | 0.528 | torch.Size([225, 6]) || stage8.5.residual_group.blocks.3.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.5.residual_group.blocks.3.attn.relative_position_index
+ | 0.000 | -0.677 | 0.676 | 0.127 | torch.Size([540, 180]) || stage8.5.residual_group.blocks.3.attn.qkv_self.weight
+ | 0.002 | -0.410 | 0.354 | 0.080 | torch.Size([540]) || stage8.5.residual_group.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.630 | 0.725 | 0.145 | torch.Size([180, 180]) || stage8.5.residual_group.blocks.3.attn.proj.weight
+ | -0.041 | -0.385 | 0.660 | 0.163 | torch.Size([180]) || stage8.5.residual_group.blocks.3.attn.proj.bias
+ | 0.849 | 0.390 | 0.985 | 0.070 | torch.Size([180]) || stage8.5.residual_group.blocks.3.norm2.weight
+ | -0.023 | -0.163 | 0.810 | 0.084 | torch.Size([180]) || stage8.5.residual_group.blocks.3.norm2.bias
+ | -0.002 | -0.547 | 0.536 | 0.115 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.3.mlp.fc11.weight
+ | -0.012 | -0.366 | 0.252 | 0.106 | torch.Size([360]) || stage8.5.residual_group.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.669 | 0.597 | 0.139 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.3.mlp.fc12.weight
+ | -0.002 | -0.216 | 0.202 | 0.074 | torch.Size([360]) || stage8.5.residual_group.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.700 | 0.674 | 0.139 | torch.Size([180, 360]) || stage8.5.residual_group.blocks.3.mlp.fc2.weight
+ | -0.032 | -0.376 | 0.666 | 0.134 | torch.Size([180]) || stage8.5.residual_group.blocks.3.mlp.fc2.bias
+ | -0.001 | -0.299 | 0.469 | 0.069 | torch.Size([180, 180]) || stage8.5.linear.weight
+ | 0.081 | -0.562 | 0.263 | 0.109 | torch.Size([180]) || stage8.5.linear.bias
+ | 1.111 | 0.208 | 1.434 | 0.192 | torch.Size([180]) || stage8.6.residual_group.blocks.0.norm1.weight
+ | -0.048 | -0.547 | 0.851 | 0.175 | torch.Size([180]) || stage8.6.residual_group.blocks.0.norm1.bias
+ | -0.252 | -2.157 | 6.293 | 0.490 | torch.Size([225, 6]) || stage8.6.residual_group.blocks.0.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.6.residual_group.blocks.0.attn.relative_position_index
+ | 0.000 | -0.664 | 0.631 | 0.123 | torch.Size([540, 180]) || stage8.6.residual_group.blocks.0.attn.qkv_self.weight
+ | 0.007 | -0.293 | 0.366 | 0.078 | torch.Size([540]) || stage8.6.residual_group.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.701 | 0.726 | 0.154 | torch.Size([180, 180]) || stage8.6.residual_group.blocks.0.attn.proj.weight
+ | 0.030 | -0.318 | 0.331 | 0.109 | torch.Size([180]) || stage8.6.residual_group.blocks.0.attn.proj.bias
+ | 0.959 | 0.475 | 1.322 | 0.088 | torch.Size([180]) || stage8.6.residual_group.blocks.0.norm2.weight
+ | -0.039 | -0.421 | 0.873 | 0.151 | torch.Size([180]) || stage8.6.residual_group.blocks.0.norm2.bias
+ | -0.002 | -0.550 | 0.783 | 0.116 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.0.mlp.fc11.weight
+ | 0.002 | -0.269 | 0.152 | 0.069 | torch.Size([360]) || stage8.6.residual_group.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.914 | 0.839 | 0.143 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.0.mlp.fc12.weight
+ | 0.001 | -0.340 | 0.304 | 0.075 | torch.Size([360]) || stage8.6.residual_group.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.592 | 0.713 | 0.140 | torch.Size([180, 360]) || stage8.6.residual_group.blocks.0.mlp.fc2.weight
+ | 0.002 | -0.535 | 0.384 | 0.177 | torch.Size([180]) || stage8.6.residual_group.blocks.0.mlp.fc2.bias
+ | 1.123 | 0.183 | 1.352 | 0.165 | torch.Size([180]) || stage8.6.residual_group.blocks.1.norm1.weight
+ | -0.047 | -0.513 | 0.903 | 0.168 | torch.Size([180]) || stage8.6.residual_group.blocks.1.norm1.bias
+ | -0.234 | -1.968 | 6.366 | 0.448 | torch.Size([225, 6]) || stage8.6.residual_group.blocks.1.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.6.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -0.751 | 0.759 | 0.121 | torch.Size([540, 180]) || stage8.6.residual_group.blocks.1.attn.qkv_self.weight
+ | -0.001 | -0.300 | 0.214 | 0.061 | torch.Size([540]) || stage8.6.residual_group.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.657 | 0.699 | 0.148 | torch.Size([180, 180]) || stage8.6.residual_group.blocks.1.attn.proj.weight
+ | 0.031 | -0.321 | 0.293 | 0.115 | torch.Size([180]) || stage8.6.residual_group.blocks.1.attn.proj.bias
+ | 0.986 | 0.416 | 1.360 | 0.096 | torch.Size([180]) || stage8.6.residual_group.blocks.1.norm2.weight
+ | -0.038 | -0.393 | 0.807 | 0.146 | torch.Size([180]) || stage8.6.residual_group.blocks.1.norm2.bias
+ | -0.001 | -0.589 | 0.620 | 0.116 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.1.mlp.fc11.weight
+ | 0.005 | -0.316 | 0.229 | 0.071 | torch.Size([360]) || stage8.6.residual_group.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.738 | 0.766 | 0.143 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.1.mlp.fc12.weight
+ | 0.001 | -0.252 | 0.302 | 0.072 | torch.Size([360]) || stage8.6.residual_group.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.674 | 0.629 | 0.140 | torch.Size([180, 360]) || stage8.6.residual_group.blocks.1.mlp.fc2.weight
+ | -0.001 | -0.475 | 0.441 | 0.175 | torch.Size([180]) || stage8.6.residual_group.blocks.1.mlp.fc2.bias
+ | 1.097 | 0.342 | 1.294 | 0.134 | torch.Size([180]) || stage8.6.residual_group.blocks.2.norm1.weight
+ | -0.054 | -0.639 | 0.904 | 0.186 | torch.Size([180]) || stage8.6.residual_group.blocks.2.norm1.bias
+ | -0.135 | -3.252 | 1.238 | 0.360 | torch.Size([225, 6]) || stage8.6.residual_group.blocks.2.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.6.residual_group.blocks.2.attn.relative_position_index
+ | 0.000 | -0.672 | 0.663 | 0.128 | torch.Size([540, 180]) || stage8.6.residual_group.blocks.2.attn.qkv_self.weight
+ | 0.007 | -0.170 | 0.228 | 0.046 | torch.Size([540]) || stage8.6.residual_group.blocks.2.attn.qkv_self.bias
+ | -0.001 | -0.660 | 0.651 | 0.147 | torch.Size([180, 180]) || stage8.6.residual_group.blocks.2.attn.proj.weight
+ | 0.031 | -0.360 | 0.322 | 0.126 | torch.Size([180]) || stage8.6.residual_group.blocks.2.attn.proj.bias
+ | 1.004 | 0.360 | 1.381 | 0.099 | torch.Size([180]) || stage8.6.residual_group.blocks.2.norm2.weight
+ | -0.042 | -0.447 | 0.808 | 0.157 | torch.Size([180]) || stage8.6.residual_group.blocks.2.norm2.bias
+ | -0.000 | -0.600 | 0.603 | 0.116 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.2.mlp.fc11.weight
+ | 0.022 | -0.447 | 0.249 | 0.086 | torch.Size([360]) || stage8.6.residual_group.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.666 | 0.708 | 0.143 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.2.mlp.fc12.weight
+ | -0.002 | -0.326 | 0.272 | 0.075 | torch.Size([360]) || stage8.6.residual_group.blocks.2.mlp.fc12.bias
+ | -0.001 | -0.653 | 0.719 | 0.142 | torch.Size([180, 360]) || stage8.6.residual_group.blocks.2.mlp.fc2.weight
+ | -0.011 | -0.488 | 0.321 | 0.153 | torch.Size([180]) || stage8.6.residual_group.blocks.2.mlp.fc2.bias
+ | 1.095 | 0.272 | 1.302 | 0.123 | torch.Size([180]) || stage8.6.residual_group.blocks.3.norm1.weight
+ | -0.052 | -0.557 | 1.069 | 0.192 | torch.Size([180]) || stage8.6.residual_group.blocks.3.norm1.bias
+ | -0.196 | -2.349 | 1.401 | 0.360 | torch.Size([225, 6]) || stage8.6.residual_group.blocks.3.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.6.residual_group.blocks.3.attn.relative_position_index
+ | 0.000 | -0.741 | 0.657 | 0.124 | torch.Size([540, 180]) || stage8.6.residual_group.blocks.3.attn.qkv_self.weight
+ | 0.001 | -0.186 | 0.141 | 0.040 | torch.Size([540]) || stage8.6.residual_group.blocks.3.attn.qkv_self.bias
+ | -0.001 | -0.669 | 0.671 | 0.139 | torch.Size([180, 180]) || stage8.6.residual_group.blocks.3.attn.proj.weight
+ | -0.004 | -0.323 | 0.300 | 0.124 | torch.Size([180]) || stage8.6.residual_group.blocks.3.attn.proj.bias
+ | 0.999 | 0.383 | 1.380 | 0.103 | torch.Size([180]) || stage8.6.residual_group.blocks.3.norm2.weight
+ | -0.044 | -0.392 | 0.694 | 0.163 | torch.Size([180]) || stage8.6.residual_group.blocks.3.norm2.bias
+ | 0.000 | -0.577 | 0.857 | 0.116 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.3.mlp.fc11.weight
+ | 0.041 | -0.394 | 0.238 | 0.087 | torch.Size([360]) || stage8.6.residual_group.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.924 | 0.828 | 0.143 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.3.mlp.fc12.weight
+ | -0.003 | -0.214 | 0.407 | 0.071 | torch.Size([360]) || stage8.6.residual_group.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.827 | 0.755 | 0.141 | torch.Size([180, 360]) || stage8.6.residual_group.blocks.3.mlp.fc2.weight
+ | 0.022 | -0.296 | 0.262 | 0.107 | torch.Size([180]) || stage8.6.residual_group.blocks.3.mlp.fc2.bias
+ | 0.002 | -1.059 | 1.262 | 0.089 | torch.Size([180, 180]) || stage8.6.linear.weight
+ | 0.031 | -0.789 | 0.427 | 0.120 | torch.Size([180]) || stage8.6.linear.bias
+ | 0.389 | 0.079 | 1.137 | 0.176 | torch.Size([180]) || norm.weight
+ | -0.021 | -0.669 | 0.888 | 0.127 | torch.Size([180]) || norm.bias
+ | 0.000 | -0.486 | 0.568 | 0.103 | torch.Size([120, 180]) || conv_after_body.weight
+ | -0.000 | -0.167 | 0.168 | 0.055 | torch.Size([120]) || conv_after_body.bias
+ | -0.000 | -1.782 | 1.300 | 0.109 | torch.Size([64, 120, 1, 3, 3]) || conv_before_upsample.0.weight
+ | -0.019 | -0.542 | 0.437 | 0.162 | torch.Size([64]) || conv_before_upsample.0.bias
+ | 0.001 | -1.915 | 1.372 | 0.090 | torch.Size([256, 64, 1, 3, 3]) || upsample.0.weight
+ | -0.045 | -0.281 | 0.215 | 0.097 | torch.Size([256]) || upsample.0.bias
+ | -0.006 | -4.826 | 0.582 | 0.075 | torch.Size([256, 64, 1, 3, 3]) || upsample.5.weight
+ | -0.154 | -0.441 | 0.187 | 0.100 | torch.Size([256]) || upsample.5.bias
+ | 0.000 | -0.210 | 0.246 | 0.012 | torch.Size([64, 64, 1, 3, 3]) || upsample.10.weight
+ | 0.000 | -0.013 | 0.007 | 0.003 | torch.Size([64]) || upsample.10.bias
+ | 0.000 | -0.044 | 0.042 | 0.004 | torch.Size([3, 64, 1, 3, 3]) || conv_last.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([3]) || conv_last.bias
+
+22-03-11 10:53:04.972 : task: 001_train_vrt_videosr_bi_reds_6frames
+ model: vrt
+ gpu_ids: [0, 1, 2, 3, 4, 5, 6, 7]
+ dist: False
+ find_unused_parameters: False
+ use_static_graph: True
+ scale: 4
+ n_channels: 3
+ path:[
+ root: experiments
+ pretrained_netG: /home/cll/dev/KAIR/model_zoo/vrt/001_VRT_videosr_bi_REDS_6frames.pth
+ pretrained_netE: None
+ task: experiments/001_train_vrt_videosr_bi_reds_6frames
+ log: experiments/001_train_vrt_videosr_bi_reds_6frames
+ options: experiments/001_train_vrt_videosr_bi_reds_6frames/options
+ models: experiments/001_train_vrt_videosr_bi_reds_6frames/models
+ images: experiments/001_train_vrt_videosr_bi_reds_6frames/images
+ pretrained_optimizerG: None
+ ]
+ datasets:[
+ train:[
+ name: train_dataset
+ dataset_type: VideoRecurrentTrainDataset
+ dataroot_gt: /home/cll/datasets/REDS/train/train_sharp
+ dataroot_lq: /home/cll/datasets/REDS/train/train_sharp_bicubic/X4
+ meta_info_file: data/meta_info/meta_info_REDS_GT.txt
+ filename_tmpl: 08d
+ filename_ext: png
+ val_partition: REDS4
+ test_mode: False
+ io_backend:[
+ type: disk
+ ]
+ num_frame: 4
+ gt_size: 256
+ interval_list: [1]
+ random_reverse: False
+ use_hflip: True
+ use_rot: True
+ dataloader_shuffle: True
+ dataloader_num_workers: 32
+ dataloader_batch_size: 8
+ phase: train
+ scale: 4
+ n_channels: 3
+ ]
+ test:[
+ name: test_dataset
+ dataset_type: VideoRecurrentTestDataset
+ dataroot_gt: /home/cll/Desktop/REDS4/GT
+ dataroot_lq: /home/cll/Desktop/REDS4/sharp_bicubic
+ cache_data: True
+ io_backend:[
+ type: disk
+ ]
+ num_frame: -1
+ phase: test
+ scale: 4
+ n_channels: 3
+ ]
+ ]
+ netG:[
+ net_type: vrt
+ upscale: 4
+ img_size: [6, 64, 64]
+ window_size: [6, 8, 8]
+ depths: [8, 8, 8, 8, 8, 8, 8, 4, 4, 4, 4, 4, 4]
+ indep_reconsts: [11, 12]
+ embed_dims: [120, 120, 120, 120, 120, 120, 120, 180, 180, 180, 180, 180, 180]
+ num_heads: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
+ spynet_path: model_zoo/vrt/spynet_sintel_final-3d2a1287.pth
+ pa_frames: 2
+ deformable_groups: 12
+ nonblind_denoising: False
+ use_checkpoint_attn: False
+ use_checkpoint_ffn: False
+ no_checkpoint_attn_blocks: []
+ no_checkpoint_ffn_blocks: []
+ init_type: default
+ scale: 4
+ ]
+ train:[
+ G_lossfn_type: charbonnier
+ G_lossfn_weight: 1.0
+ G_charbonnier_eps: 1e-09
+ E_decay: 0
+ G_optimizer_type: adam
+ G_optimizer_lr: 0.0004
+ G_optimizer_betas: [0.9, 0.99]
+ G_optimizer_wd: 0
+ G_optimizer_clipgrad: None
+ G_optimizer_reuse: True
+ fix_iter: 20000
+ fix_lr_mul: 0.125
+ fix_keys: ['spynet', 'deform']
+ total_iter: 300000
+ G_scheduler_type: CosineAnnealingWarmRestarts
+ G_scheduler_periods: 300000
+ G_scheduler_eta_min: 1e-07
+ G_regularizer_orthstep: None
+ G_regularizer_clipstep: None
+ G_param_strict: True
+ E_param_strict: True
+ checkpoint_test: 5000
+ checkpoint_save: 5000
+ checkpoint_print: 200
+ F_feature_layer: 34
+ F_weights: 1.0
+ F_lossfn_type: l1
+ F_use_input_norm: True
+ F_use_range_norm: False
+ G_scheduler_restart_weights: 1
+ ]
+ val:[
+ save_img: False
+ pad_seq: False
+ flip_seq: False
+ center_frame_only: False
+ num_frame_testing: 40
+ num_frame_overlapping: 2
+ size_patch_testing: 128
+ ]
+ opt_path: options/vrt/001_train_vrt_videosr_bi_reds_6frames.json
+ is_train: True
+ merge_bn: False
+ merge_bn_startpoint: -1
+ num_gpu: 8
+ rank: 0
+ world_size: 1
+
+22-03-11 10:53:05.016 : Number of train images: 24,000, iters: 3,000
+22-03-11 10:53:19.424 :
+Networks name: VRT
+Params number: 30676435
+Net structure:
+VRT(
+ (conv_first): Conv3d(27, 120, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ (spynet): SpyNet(
+ (basic_module): ModuleList(
+ (0): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (1): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (2): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (3): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (4): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (5): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ )
+ )
+ (stage1): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n c d h w -> n d h w c')
+ (1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (2): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): Identity()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): Identity()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage2): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n c d (h neih) (w neiw) -> n d h w (neiw neih c)', neih=2, neiw=2)
+ (1): LayerNorm((480,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=480, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage3): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n c d (h neih) (w neiw) -> n d h w (neiw neih c)', neih=2, neiw=2)
+ (1): LayerNorm((480,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=480, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage4): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n c d (h neih) (w neiw) -> n d h w (neiw neih c)', neih=2, neiw=2)
+ (1): LayerNorm((480,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=480, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage5): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n (neiw neih c) d h w -> n d (h neih) (w neiw) c', neih=2, neiw=2)
+ (1): LayerNorm((30,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=30, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage6): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n (neiw neih c) d h w -> n d (h neih) (w neiw) c', neih=2, neiw=2)
+ (1): LayerNorm((30,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=30, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage7): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n (neiw neih c) d h w -> n d (h neih) (w neiw) c', neih=2, neiw=2)
+ (1): LayerNorm((30,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=30, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(242, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 324, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage8): ModuleList(
+ (0): Sequential(
+ (0): Rearrange('n c d h w -> n d h w c')
+ (1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=120, out_features=180, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (1): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (2): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (3): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (4): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (5): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (6): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ )
+ (norm): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (conv_after_body): Linear(in_features=180, out_features=120, bias=True)
+ (conv_before_upsample): Sequential(
+ (0): Conv3d(120, 64, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ (1): LeakyReLU(negative_slope=0.01, inplace=True)
+ )
+ (upsample): Upsample(
+ (0): Conv3d(64, 256, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ (1): Transpose_Dim12()
+ (2): PixelShuffle(upscale_factor=2)
+ (3): Transpose_Dim12()
+ (4): LeakyReLU(negative_slope=0.1, inplace=True)
+ (5): Conv3d(64, 256, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ (6): Transpose_Dim12()
+ (7): PixelShuffle(upscale_factor=2)
+ (8): Transpose_Dim12()
+ (9): LeakyReLU(negative_slope=0.1, inplace=True)
+ (10): Conv3d(64, 64, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ )
+ (conv_last): Conv3d(64, 3, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+)
+
+22-03-11 10:53:19.603 :
+ | mean | min | max | std || shape
+ | -0.000 | -1.462 | 1.580 | 0.103 | torch.Size([120, 27, 1, 3, 3]) || conv_first.weight
+ | 0.005 | -0.950 | 0.885 | 0.268 | torch.Size([120]) || conv_first.bias
+ | 0.449 | 0.406 | 0.485 | 0.040 | torch.Size([1, 3, 1, 1]) || spynet.mean
+ | 0.226 | 0.224 | 0.229 | 0.003 | torch.Size([1, 3, 1, 1]) || spynet.std
+ | -0.000 | -0.679 | 0.720 | 0.066 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.0.basic_module.0.weight
+ | -0.042 | -0.894 | 0.351 | 0.344 | torch.Size([32]) || spynet.basic_module.0.basic_module.0.bias
+ | -0.008 | -3.201 | 0.948 | 0.097 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.0.basic_module.2.weight
+ | 0.059 | -1.268 | 0.732 | 0.320 | torch.Size([64]) || spynet.basic_module.0.basic_module.2.bias
+ | -0.010 | -4.633 | 0.568 | 0.089 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.0.basic_module.4.weight
+ | 0.159 | -0.704 | 0.859 | 0.353 | torch.Size([32]) || spynet.basic_module.0.basic_module.4.bias
+ | -0.024 | -1.714 | 0.414 | 0.091 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.0.basic_module.6.weight
+ | 0.780 | -1.061 | 1.162 | 0.519 | torch.Size([16]) || spynet.basic_module.0.basic_module.6.bias
+ | 0.000 | -0.144 | 0.163 | 0.018 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.0.basic_module.8.weight
+ | 0.001 | -0.003 | 0.005 | 0.006 | torch.Size([2]) || spynet.basic_module.0.basic_module.8.bias
+ | 0.000 | -0.726 | 0.773 | 0.070 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.1.basic_module.0.weight
+ | -0.021 | -0.814 | 0.355 | 0.323 | torch.Size([32]) || spynet.basic_module.1.basic_module.0.bias
+ | -0.010 | -3.380 | 0.916 | 0.099 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.1.basic_module.2.weight
+ | 0.038 | -1.207 | 0.714 | 0.301 | torch.Size([64]) || spynet.basic_module.1.basic_module.2.bias
+ | -0.008 | -4.462 | 0.549 | 0.088 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.1.basic_module.4.weight
+ | 0.157 | -0.742 | 0.980 | 0.384 | torch.Size([32]) || spynet.basic_module.1.basic_module.4.bias
+ | -0.020 | -1.648 | 0.319 | 0.084 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.1.basic_module.6.weight
+ | 0.775 | -1.195 | 1.148 | 0.546 | torch.Size([16]) || spynet.basic_module.1.basic_module.6.bias
+ | -0.000 | -0.122 | 0.152 | 0.016 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.1.basic_module.8.weight
+ | -0.000 | -0.002 | 0.001 | 0.002 | torch.Size([2]) || spynet.basic_module.1.basic_module.8.bias
+ | 0.000 | -0.956 | 0.870 | 0.088 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.2.basic_module.0.weight
+ | -0.025 | -1.040 | 0.512 | 0.411 | torch.Size([32]) || spynet.basic_module.2.basic_module.0.bias
+ | -0.011 | -4.624 | 1.195 | 0.116 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.2.basic_module.2.weight
+ | 0.023 | -1.284 | 0.699 | 0.308 | torch.Size([64]) || spynet.basic_module.2.basic_module.2.bias
+ | -0.009 | -1.831 | 0.616 | 0.092 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.2.basic_module.4.weight
+ | 0.120 | -0.695 | 0.755 | 0.332 | torch.Size([32]) || spynet.basic_module.2.basic_module.4.bias
+ | -0.013 | -1.285 | 0.304 | 0.068 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.2.basic_module.6.weight
+ | 0.681 | -1.725 | 0.942 | 0.646 | torch.Size([16]) || spynet.basic_module.2.basic_module.6.bias
+ | 0.000 | -0.045 | 0.071 | 0.009 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.2.basic_module.8.weight
+ | -0.010 | -0.010 | -0.009 | 0.000 | torch.Size([2]) || spynet.basic_module.2.basic_module.8.bias
+ | -0.000 | -0.995 | 0.879 | 0.090 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.3.basic_module.0.weight
+ | -0.040 | -1.137 | 0.617 | 0.461 | torch.Size([32]) || spynet.basic_module.3.basic_module.0.bias
+ | -0.010 | -4.891 | 1.224 | 0.117 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.3.basic_module.2.weight
+ | 0.022 | -1.287 | 0.745 | 0.313 | torch.Size([64]) || spynet.basic_module.3.basic_module.2.bias
+ | -0.010 | -1.802 | 0.561 | 0.090 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.3.basic_module.4.weight
+ | 0.118 | -0.694 | 0.697 | 0.329 | torch.Size([32]) || spynet.basic_module.3.basic_module.4.bias
+ | -0.012 | -1.107 | 0.306 | 0.064 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.3.basic_module.6.weight
+ | 0.658 | -1.792 | 0.905 | 0.659 | torch.Size([16]) || spynet.basic_module.3.basic_module.6.bias
+ | 0.000 | -0.030 | 0.037 | 0.006 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.3.basic_module.8.weight
+ | 0.003 | -0.001 | 0.007 | 0.006 | torch.Size([2]) || spynet.basic_module.3.basic_module.8.bias
+ | -0.000 | -0.990 | 0.880 | 0.090 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.4.basic_module.0.weight
+ | -0.010 | -1.067 | 0.596 | 0.437 | torch.Size([32]) || spynet.basic_module.4.basic_module.0.bias
+ | -0.010 | -5.061 | 1.229 | 0.117 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.4.basic_module.2.weight
+ | 0.024 | -1.274 | 0.830 | 0.318 | torch.Size([64]) || spynet.basic_module.4.basic_module.2.bias
+ | -0.009 | -1.787 | 0.563 | 0.088 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.4.basic_module.4.weight
+ | 0.130 | -0.685 | 0.743 | 0.335 | torch.Size([32]) || spynet.basic_module.4.basic_module.4.bias
+ | -0.011 | -0.973 | 0.292 | 0.061 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.4.basic_module.6.weight
+ | 0.659 | -1.855 | 0.931 | 0.679 | torch.Size([16]) || spynet.basic_module.4.basic_module.6.bias
+ | 0.000 | -0.034 | 0.040 | 0.005 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.4.basic_module.8.weight
+ | -0.001 | -0.009 | 0.007 | 0.012 | torch.Size([2]) || spynet.basic_module.4.basic_module.8.bias
+ | -0.000 | -0.973 | 0.853 | 0.089 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.5.basic_module.0.weight
+ | 0.022 | -1.001 | 0.571 | 0.440 | torch.Size([32]) || spynet.basic_module.5.basic_module.0.bias
+ | -0.009 | -5.095 | 1.251 | 0.119 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.5.basic_module.2.weight
+ | 0.026 | -1.305 | 0.880 | 0.326 | torch.Size([64]) || spynet.basic_module.5.basic_module.2.bias
+ | -0.008 | -1.815 | 0.561 | 0.091 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.5.basic_module.4.weight
+ | 0.137 | -0.711 | 0.771 | 0.342 | torch.Size([32]) || spynet.basic_module.5.basic_module.4.bias
+ | -0.010 | -0.986 | 0.286 | 0.059 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.5.basic_module.6.weight
+ | 0.671 | -1.913 | 0.966 | 0.700 | torch.Size([16]) || spynet.basic_module.5.basic_module.6.bias
+ | 0.000 | -0.034 | 0.028 | 0.002 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.5.basic_module.8.weight
+ | 0.002 | -0.013 | 0.016 | 0.020 | torch.Size([2]) || spynet.basic_module.5.basic_module.8.bias
+ | 1.280 | 0.669 | 1.862 | 0.274 | torch.Size([120]) || stage1.reshape.1.weight
+ | -0.006 | -0.324 | 0.337 | 0.106 | torch.Size([120]) || stage1.reshape.1.bias
+ | 0.579 | 0.129 | 1.064 | 0.236 | torch.Size([120]) || stage1.residual_group1.blocks.0.norm1.weight
+ | -0.039 | -1.100 | 0.894 | 0.226 | torch.Size([120]) || stage1.residual_group1.blocks.0.norm1.bias
+ | -0.134 | -4.020 | 2.585 | 0.295 | torch.Size([675, 6]) || stage1.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.0.attn.position_bias
+ | -0.000 | -0.579 | 0.618 | 0.113 | torch.Size([360, 120]) || stage1.residual_group1.blocks.0.attn.qkv_self.weight
+ | 0.000 | -0.319 | 0.279 | 0.074 | torch.Size([360]) || stage1.residual_group1.blocks.0.attn.qkv_self.bias
+ | 0.001 | -0.634 | 0.686 | 0.076 | torch.Size([120, 240]) || stage1.residual_group1.blocks.0.attn.proj.weight
+ | -0.014 | -0.222 | 0.642 | 0.088 | torch.Size([120]) || stage1.residual_group1.blocks.0.attn.proj.bias
+ | -0.000 | -1.066 | 0.928 | 0.097 | torch.Size([360, 120]) || stage1.residual_group1.blocks.0.attn.qkv_mut.weight
+ | 0.000 | -0.146 | 0.190 | 0.033 | torch.Size([360]) || stage1.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.781 | 0.367 | 1.203 | 0.160 | torch.Size([120]) || stage1.residual_group1.blocks.0.norm2.weight
+ | 0.029 | -0.378 | 0.545 | 0.159 | torch.Size([120]) || stage1.residual_group1.blocks.0.norm2.bias
+ | 0.001 | -0.687 | 0.753 | 0.108 | torch.Size([240, 120]) || stage1.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.010 | -0.229 | 0.633 | 0.095 | torch.Size([240]) || stage1.residual_group1.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.674 | 0.669 | 0.117 | torch.Size([240, 120]) || stage1.residual_group1.blocks.0.mlp.fc12.weight
+ | 0.011 | -0.448 | 0.368 | 0.116 | torch.Size([240]) || stage1.residual_group1.blocks.0.mlp.fc12.bias
+ | 0.001 | -0.862 | 0.941 | 0.119 | torch.Size([120, 240]) || stage1.residual_group1.blocks.0.mlp.fc2.weight
+ | -0.004 | -0.267 | 0.594 | 0.099 | torch.Size([120]) || stage1.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.797 | 0.211 | 1.475 | 0.209 | torch.Size([120]) || stage1.residual_group1.blocks.1.norm1.weight
+ | -0.161 | -1.941 | 0.746 | 0.237 | torch.Size([120]) || stage1.residual_group1.blocks.1.norm1.bias
+ | -0.296 | -3.927 | 2.840 | 0.478 | torch.Size([675, 6]) || stage1.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.1.attn.position_bias
+ | 0.001 | -1.479 | 1.395 | 0.143 | torch.Size([360, 120]) || stage1.residual_group1.blocks.1.attn.qkv_self.weight
+ | -0.003 | -0.381 | 0.258 | 0.063 | torch.Size([360]) || stage1.residual_group1.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.526 | 0.561 | 0.079 | torch.Size([120, 240]) || stage1.residual_group1.blocks.1.attn.proj.weight
+ | -0.003 | -0.178 | 0.478 | 0.078 | torch.Size([120]) || stage1.residual_group1.blocks.1.attn.proj.bias
+ | 0.001 | -1.242 | 1.138 | 0.105 | torch.Size([360, 120]) || stage1.residual_group1.blocks.1.attn.qkv_mut.weight
+ | 0.004 | -0.213 | 0.196 | 0.050 | torch.Size([360]) || stage1.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.702 | 0.349 | 0.904 | 0.085 | torch.Size([120]) || stage1.residual_group1.blocks.1.norm2.weight
+ | 0.039 | -0.646 | 0.384 | 0.132 | torch.Size([120]) || stage1.residual_group1.blocks.1.norm2.bias
+ | 0.001 | -0.872 | 0.750 | 0.131 | torch.Size([240, 120]) || stage1.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.049 | -0.353 | 0.135 | 0.084 | torch.Size([240]) || stage1.residual_group1.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.562 | 0.580 | 0.117 | torch.Size([240, 120]) || stage1.residual_group1.blocks.1.mlp.fc12.weight
+ | 0.000 | -0.238 | 0.457 | 0.113 | torch.Size([240]) || stage1.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.828 | 0.685 | 0.123 | torch.Size([120, 240]) || stage1.residual_group1.blocks.1.mlp.fc2.weight
+ | 0.031 | -0.297 | 0.419 | 0.094 | torch.Size([120]) || stage1.residual_group1.blocks.1.mlp.fc2.bias
+ | 0.984 | 0.163 | 1.398 | 0.202 | torch.Size([120]) || stage1.residual_group1.blocks.2.norm1.weight
+ | -0.167 | -1.609 | 0.367 | 0.182 | torch.Size([120]) || stage1.residual_group1.blocks.2.norm1.bias
+ | -0.343 | -4.484 | 2.362 | 0.486 | torch.Size([675, 6]) || stage1.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.2.attn.position_bias
+ | 0.000 | -1.586 | 1.649 | 0.151 | torch.Size([360, 120]) || stage1.residual_group1.blocks.2.attn.qkv_self.weight
+ | -0.000 | -0.220 | 0.240 | 0.056 | torch.Size([360]) || stage1.residual_group1.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.378 | 0.514 | 0.086 | torch.Size([120, 240]) || stage1.residual_group1.blocks.2.attn.proj.weight
+ | -0.009 | -0.143 | 0.172 | 0.059 | torch.Size([120]) || stage1.residual_group1.blocks.2.attn.proj.bias
+ | 0.001 | -0.639 | 0.582 | 0.102 | torch.Size([360, 120]) || stage1.residual_group1.blocks.2.attn.qkv_mut.weight
+ | -0.000 | -0.141 | 0.173 | 0.035 | torch.Size([360]) || stage1.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.733 | 0.277 | 0.903 | 0.081 | torch.Size([120]) || stage1.residual_group1.blocks.2.norm2.weight
+ | 0.038 | -0.861 | 0.359 | 0.142 | torch.Size([120]) || stage1.residual_group1.blocks.2.norm2.bias
+ | 0.000 | -0.787 | 0.679 | 0.131 | torch.Size([240, 120]) || stage1.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.029 | -0.365 | 0.143 | 0.076 | torch.Size([240]) || stage1.residual_group1.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.574 | 0.539 | 0.120 | torch.Size([240, 120]) || stage1.residual_group1.blocks.2.mlp.fc12.weight
+ | -0.007 | -0.283 | 0.254 | 0.097 | torch.Size([240]) || stage1.residual_group1.blocks.2.mlp.fc12.bias
+ | 0.001 | -0.998 | 0.522 | 0.124 | torch.Size([120, 240]) || stage1.residual_group1.blocks.2.mlp.fc2.weight
+ | 0.030 | -0.169 | 0.293 | 0.095 | torch.Size([120]) || stage1.residual_group1.blocks.2.mlp.fc2.bias
+ | 1.035 | 0.143 | 1.397 | 0.196 | torch.Size([120]) || stage1.residual_group1.blocks.3.norm1.weight
+ | -0.161 | -1.413 | 0.084 | 0.154 | torch.Size([120]) || stage1.residual_group1.blocks.3.norm1.bias
+ | -0.441 | -4.685 | 3.306 | 0.529 | torch.Size([675, 6]) || stage1.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.3.attn.position_bias
+ | 0.000 | -1.590 | 1.329 | 0.155 | torch.Size([360, 120]) || stage1.residual_group1.blocks.3.attn.qkv_self.weight
+ | -0.002 | -0.266 | 0.232 | 0.049 | torch.Size([360]) || stage1.residual_group1.blocks.3.attn.qkv_self.bias
+ | -0.000 | -0.366 | 0.372 | 0.084 | torch.Size([120, 240]) || stage1.residual_group1.blocks.3.attn.proj.weight
+ | -0.011 | -0.225 | 0.171 | 0.071 | torch.Size([120]) || stage1.residual_group1.blocks.3.attn.proj.bias
+ | -0.000 | -0.660 | 0.801 | 0.100 | torch.Size([360, 120]) || stage1.residual_group1.blocks.3.attn.qkv_mut.weight
+ | -0.001 | -0.139 | 0.200 | 0.031 | torch.Size([360]) || stage1.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.724 | 0.190 | 0.911 | 0.091 | torch.Size([120]) || stage1.residual_group1.blocks.3.norm2.weight
+ | 0.038 | -0.981 | 0.285 | 0.137 | torch.Size([120]) || stage1.residual_group1.blocks.3.norm2.bias
+ | 0.001 | -0.611 | 0.598 | 0.130 | torch.Size([240, 120]) || stage1.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.035 | -0.299 | 0.221 | 0.081 | torch.Size([240]) || stage1.residual_group1.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.502 | 0.520 | 0.124 | torch.Size([240, 120]) || stage1.residual_group1.blocks.3.mlp.fc12.weight
+ | -0.002 | -0.271 | 0.215 | 0.090 | torch.Size([240]) || stage1.residual_group1.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.558 | 0.898 | 0.127 | torch.Size([120, 240]) || stage1.residual_group1.blocks.3.mlp.fc2.weight
+ | 0.010 | -0.424 | 0.190 | 0.082 | torch.Size([120]) || stage1.residual_group1.blocks.3.mlp.fc2.bias
+ | 1.085 | 0.169 | 1.400 | 0.157 | torch.Size([120]) || stage1.residual_group1.blocks.4.norm1.weight
+ | -0.086 | -1.613 | 0.150 | 0.160 | torch.Size([120]) || stage1.residual_group1.blocks.4.norm1.bias
+ | -0.541 | -3.902 | 3.728 | 0.633 | torch.Size([675, 6]) || stage1.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.4.attn.position_bias
+ | 0.001 | -1.879 | 1.832 | 0.150 | torch.Size([360, 120]) || stage1.residual_group1.blocks.4.attn.qkv_self.weight
+ | 0.001 | -0.391 | 0.444 | 0.079 | torch.Size([360]) || stage1.residual_group1.blocks.4.attn.qkv_self.bias
+ | -0.000 | -0.407 | 0.448 | 0.087 | torch.Size([120, 240]) || stage1.residual_group1.blocks.4.attn.proj.weight
+ | -0.013 | -0.302 | 0.342 | 0.104 | torch.Size([120]) || stage1.residual_group1.blocks.4.attn.proj.bias
+ | -0.001 | -0.830 | 0.863 | 0.102 | torch.Size([360, 120]) || stage1.residual_group1.blocks.4.attn.qkv_mut.weight
+ | -0.001 | -0.117 | 0.094 | 0.024 | torch.Size([360]) || stage1.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.704 | 0.195 | 0.870 | 0.079 | torch.Size([120]) || stage1.residual_group1.blocks.4.norm2.weight
+ | 0.031 | -1.069 | 0.276 | 0.140 | torch.Size([120]) || stage1.residual_group1.blocks.4.norm2.bias
+ | -0.000 | -0.656 | 0.555 | 0.130 | torch.Size([240, 120]) || stage1.residual_group1.blocks.4.mlp.fc11.weight
+ | -0.029 | -0.387 | 0.256 | 0.102 | torch.Size([240]) || stage1.residual_group1.blocks.4.mlp.fc11.bias
+ | 0.001 | -0.590 | 0.624 | 0.127 | torch.Size([240, 120]) || stage1.residual_group1.blocks.4.mlp.fc12.weight
+ | -0.011 | -0.277 | 0.303 | 0.087 | torch.Size([240]) || stage1.residual_group1.blocks.4.mlp.fc12.bias
+ | -0.000 | -1.124 | 0.539 | 0.130 | torch.Size([120, 240]) || stage1.residual_group1.blocks.4.mlp.fc2.weight
+ | -0.006 | -0.718 | 0.133 | 0.094 | torch.Size([120]) || stage1.residual_group1.blocks.4.mlp.fc2.bias
+ | 1.037 | 0.176 | 1.327 | 0.158 | torch.Size([120]) || stage1.residual_group1.blocks.5.norm1.weight
+ | -0.112 | -1.591 | 0.177 | 0.169 | torch.Size([120]) || stage1.residual_group1.blocks.5.norm1.bias
+ | -0.438 | -2.229 | 2.797 | 0.523 | torch.Size([675, 6]) || stage1.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.5.attn.position_bias
+ | -0.000 | -2.212 | 1.826 | 0.153 | torch.Size([360, 120]) || stage1.residual_group1.blocks.5.attn.qkv_self.weight
+ | 0.001 | -0.343 | 0.338 | 0.068 | torch.Size([360]) || stage1.residual_group1.blocks.5.attn.qkv_self.bias
+ | 0.000 | -0.367 | 0.451 | 0.087 | torch.Size([120, 240]) || stage1.residual_group1.blocks.5.attn.proj.weight
+ | -0.022 | -0.358 | 0.242 | 0.128 | torch.Size([120]) || stage1.residual_group1.blocks.5.attn.proj.bias
+ | 0.001 | -0.922 | 0.886 | 0.104 | torch.Size([360, 120]) || stage1.residual_group1.blocks.5.attn.qkv_mut.weight
+ | 0.002 | -0.083 | 0.089 | 0.022 | torch.Size([360]) || stage1.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.662 | 0.277 | 0.831 | 0.066 | torch.Size([120]) || stage1.residual_group1.blocks.5.norm2.weight
+ | 0.025 | -0.959 | 0.261 | 0.132 | torch.Size([120]) || stage1.residual_group1.blocks.5.norm2.bias
+ | -0.001 | -0.636 | 0.739 | 0.129 | torch.Size([240, 120]) || stage1.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.030 | -0.419 | 0.517 | 0.115 | torch.Size([240]) || stage1.residual_group1.blocks.5.mlp.fc11.bias
+ | -0.000 | -0.615 | 0.709 | 0.126 | torch.Size([240, 120]) || stage1.residual_group1.blocks.5.mlp.fc12.weight
+ | 0.002 | -0.230 | 0.457 | 0.087 | torch.Size([240]) || stage1.residual_group1.blocks.5.mlp.fc12.bias
+ | 0.001 | -1.724 | 1.186 | 0.132 | torch.Size([120, 240]) || stage1.residual_group1.blocks.5.mlp.fc2.weight
+ | -0.019 | -1.909 | 0.255 | 0.190 | torch.Size([120]) || stage1.residual_group1.blocks.5.mlp.fc2.bias
+ | -0.000 | -0.242 | 0.244 | 0.057 | torch.Size([120, 120]) || stage1.linear1.weight
+ | 0.004 | -0.221 | 0.224 | 0.083 | torch.Size([120]) || stage1.linear1.bias
+ | 0.737 | 0.334 | 1.046 | 0.119 | torch.Size([120]) || stage1.residual_group2.blocks.0.norm1.weight
+ | 0.013 | -0.911 | 0.763 | 0.193 | torch.Size([120]) || stage1.residual_group2.blocks.0.norm1.bias
+ | -0.052 | -2.462 | 2.040 | 0.273 | torch.Size([2475, 6]) || stage1.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage1.residual_group2.blocks.0.attn.relative_position_index
+ | 0.000 | -0.785 | 0.767 | 0.123 | torch.Size([360, 120]) || stage1.residual_group2.blocks.0.attn.qkv_self.weight
+ | 0.009 | -0.466 | 0.552 | 0.122 | torch.Size([360]) || stage1.residual_group2.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.431 | 0.475 | 0.091 | torch.Size([120, 120]) || stage1.residual_group2.blocks.0.attn.proj.weight
+ | -0.009 | -0.796 | 0.497 | 0.109 | torch.Size([120]) || stage1.residual_group2.blocks.0.attn.proj.bias
+ | 0.573 | 0.409 | 0.935 | 0.096 | torch.Size([120]) || stage1.residual_group2.blocks.0.norm2.weight
+ | 0.015 | -0.828 | 0.839 | 0.175 | torch.Size([120]) || stage1.residual_group2.blocks.0.norm2.bias
+ | 0.001 | -0.604 | 0.542 | 0.109 | torch.Size([240, 120]) || stage1.residual_group2.blocks.0.mlp.fc11.weight
+ | 0.037 | -0.179 | 0.273 | 0.076 | torch.Size([240]) || stage1.residual_group2.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.666 | 0.553 | 0.116 | torch.Size([240, 120]) || stage1.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.001 | -0.416 | 0.396 | 0.116 | torch.Size([240]) || stage1.residual_group2.blocks.0.mlp.fc12.bias
+ | 0.001 | -0.654 | 0.538 | 0.118 | torch.Size([120, 240]) || stage1.residual_group2.blocks.0.mlp.fc2.weight
+ | -0.002 | -0.470 | 0.310 | 0.122 | torch.Size([120]) || stage1.residual_group2.blocks.0.mlp.fc2.bias
+ | 0.951 | 0.342 | 1.189 | 0.111 | torch.Size([120]) || stage1.residual_group2.blocks.1.norm1.weight
+ | 0.010 | -0.697 | 0.802 | 0.166 | torch.Size([120]) || stage1.residual_group2.blocks.1.norm1.bias
+ | -0.098 | -2.648 | 2.410 | 0.214 | torch.Size([2475, 6]) || stage1.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage1.residual_group2.blocks.1.attn.relative_position_index
+ | -0.000 | -0.733 | 0.886 | 0.139 | torch.Size([360, 120]) || stage1.residual_group2.blocks.1.attn.qkv_self.weight
+ | -0.002 | -0.468 | 0.550 | 0.132 | torch.Size([360]) || stage1.residual_group2.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.435 | 0.377 | 0.096 | torch.Size([120, 120]) || stage1.residual_group2.blocks.1.attn.proj.weight
+ | -0.001 | -0.359 | 0.258 | 0.114 | torch.Size([120]) || stage1.residual_group2.blocks.1.attn.proj.bias
+ | 0.582 | 0.305 | 0.717 | 0.055 | torch.Size([120]) || stage1.residual_group2.blocks.1.norm2.weight
+ | 0.008 | -0.714 | 0.833 | 0.131 | torch.Size([120]) || stage1.residual_group2.blocks.1.norm2.bias
+ | 0.001 | -0.732 | 0.501 | 0.118 | torch.Size([240, 120]) || stage1.residual_group2.blocks.1.mlp.fc11.weight
+ | 0.004 | -0.306 | 0.267 | 0.091 | torch.Size([240]) || stage1.residual_group2.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.510 | 0.533 | 0.126 | torch.Size([240, 120]) || stage1.residual_group2.blocks.1.mlp.fc12.weight
+ | -0.000 | -0.315 | 0.291 | 0.090 | torch.Size([240]) || stage1.residual_group2.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.736 | 0.789 | 0.126 | torch.Size([120, 240]) || stage1.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.000 | -1.274 | 1.328 | 0.200 | torch.Size([120]) || stage1.residual_group2.blocks.1.mlp.fc2.bias
+ | -0.000 | -0.390 | 0.303 | 0.069 | torch.Size([120, 120]) || stage1.linear2.weight
+ | 0.010 | -0.219 | 0.227 | 0.087 | torch.Size([120]) || stage1.linear2.bias
+ | -0.000 | -0.095 | 0.106 | 0.024 | torch.Size([120, 120, 3, 3]) || stage1.pa_deform.weight
+ | -0.001 | -0.036 | 0.036 | 0.013 | torch.Size([120]) || stage1.pa_deform.bias
+ | -0.000 | -0.136 | 0.141 | 0.017 | torch.Size([120, 242, 3, 3]) || stage1.pa_deform.conv_offset.0.weight
+ | -0.002 | -0.028 | 0.024 | 0.013 | torch.Size([120]) || stage1.pa_deform.conv_offset.0.bias
+ | -0.001 | -0.156 | 0.104 | 0.019 | torch.Size([120, 120, 3, 3]) || stage1.pa_deform.conv_offset.2.weight
+ | -0.008 | -0.055 | 0.045 | 0.022 | torch.Size([120]) || stage1.pa_deform.conv_offset.2.bias
+ | -0.001 | -0.098 | 0.106 | 0.018 | torch.Size([120, 120, 3, 3]) || stage1.pa_deform.conv_offset.4.weight
+ | -0.000 | -0.081 | 0.070 | 0.029 | torch.Size([120]) || stage1.pa_deform.conv_offset.4.bias
+ | -0.000 | -0.375 | 0.279 | 0.027 | torch.Size([324, 120, 3, 3]) || stage1.pa_deform.conv_offset.6.weight
+ | -0.003 | -0.074 | 0.070 | 0.028 | torch.Size([324]) || stage1.pa_deform.conv_offset.6.bias
+ | -0.000 | -0.776 | 0.733 | 0.114 | torch.Size([360, 360]) || stage1.pa_fuse.fc11.weight
+ | 0.021 | -0.239 | 0.513 | 0.121 | torch.Size([360]) || stage1.pa_fuse.fc11.bias
+ | 0.001 | -1.100 | 1.143 | 0.149 | torch.Size([360, 360]) || stage1.pa_fuse.fc12.weight
+ | 0.008 | -0.405 | 0.393 | 0.136 | torch.Size([360]) || stage1.pa_fuse.fc12.bias
+ | 0.000 | -0.963 | 0.899 | 0.142 | torch.Size([120, 360]) || stage1.pa_fuse.fc2.weight
+ | -0.055 | -0.616 | 0.599 | 0.197 | torch.Size([120]) || stage1.pa_fuse.fc2.bias
+ | 1.149 | 0.345 | 1.921 | 0.289 | torch.Size([480]) || stage2.reshape.1.weight
+ | 0.017 | -0.502 | 0.663 | 0.141 | torch.Size([480]) || stage2.reshape.1.bias
+ | -0.000 | -0.609 | 0.736 | 0.146 | torch.Size([120, 480]) || stage2.reshape.2.weight
+ | 0.006 | -0.136 | 0.404 | 0.077 | torch.Size([120]) || stage2.reshape.2.bias
+ | 0.686 | 0.172 | 1.113 | 0.175 | torch.Size([120]) || stage2.residual_group1.blocks.0.norm1.weight
+ | -0.154 | -0.926 | 0.339 | 0.217 | torch.Size([120]) || stage2.residual_group1.blocks.0.norm1.bias
+ | -0.120 | -1.869 | 4.616 | 0.310 | torch.Size([675, 6]) || stage2.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.0.attn.position_bias
+ | 0.000 | -0.514 | 0.499 | 0.102 | torch.Size([360, 120]) || stage2.residual_group1.blocks.0.attn.qkv_self.weight
+ | -0.002 | -0.214 | 0.177 | 0.044 | torch.Size([360]) || stage2.residual_group1.blocks.0.attn.qkv_self.bias
+ | -0.001 | -0.499 | 0.529 | 0.093 | torch.Size([120, 240]) || stage2.residual_group1.blocks.0.attn.proj.weight
+ | -0.004 | -0.171 | 0.556 | 0.087 | torch.Size([120]) || stage2.residual_group1.blocks.0.attn.proj.bias
+ | -0.000 | -0.642 | 0.598 | 0.083 | torch.Size([360, 120]) || stage2.residual_group1.blocks.0.attn.qkv_mut.weight
+ | -0.000 | -0.141 | 0.125 | 0.027 | torch.Size([360]) || stage2.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.592 | 0.325 | 0.794 | 0.096 | torch.Size([120]) || stage2.residual_group1.blocks.0.norm2.weight
+ | 0.008 | -0.649 | 0.445 | 0.168 | torch.Size([120]) || stage2.residual_group1.blocks.0.norm2.bias
+ | 0.000 | -0.485 | 0.457 | 0.116 | torch.Size([240, 120]) || stage2.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.053 | -0.240 | 0.171 | 0.062 | torch.Size([240]) || stage2.residual_group1.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.503 | 0.462 | 0.118 | torch.Size([240, 120]) || stage2.residual_group1.blocks.0.mlp.fc12.weight
+ | 0.005 | -0.177 | 0.268 | 0.068 | torch.Size([240]) || stage2.residual_group1.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.690 | 0.498 | 0.123 | torch.Size([120, 240]) || stage2.residual_group1.blocks.0.mlp.fc2.weight
+ | -0.007 | -0.270 | 0.472 | 0.097 | torch.Size([120]) || stage2.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.864 | 0.187 | 1.221 | 0.164 | torch.Size([120]) || stage2.residual_group1.blocks.1.norm1.weight
+ | -0.146 | -1.128 | 0.299 | 0.204 | torch.Size([120]) || stage2.residual_group1.blocks.1.norm1.bias
+ | -0.241 | -1.607 | 8.958 | 0.356 | torch.Size([675, 6]) || stage2.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.1.attn.position_bias
+ | 0.000 | -0.561 | 0.538 | 0.116 | torch.Size([360, 120]) || stage2.residual_group1.blocks.1.attn.qkv_self.weight
+ | 0.001 | -0.198 | 0.222 | 0.052 | torch.Size([360]) || stage2.residual_group1.blocks.1.attn.qkv_self.bias
+ | 0.001 | -0.475 | 0.479 | 0.099 | torch.Size([120, 240]) || stage2.residual_group1.blocks.1.attn.proj.weight
+ | -0.006 | -0.295 | 0.341 | 0.101 | torch.Size([120]) || stage2.residual_group1.blocks.1.attn.proj.bias
+ | 0.001 | -0.961 | 0.789 | 0.080 | torch.Size([360, 120]) || stage2.residual_group1.blocks.1.attn.qkv_mut.weight
+ | 0.001 | -0.105 | 0.143 | 0.024 | torch.Size([360]) || stage2.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.653 | 0.401 | 0.810 | 0.063 | torch.Size([120]) || stage2.residual_group1.blocks.1.norm2.weight
+ | 0.009 | -0.767 | 0.367 | 0.154 | torch.Size([120]) || stage2.residual_group1.blocks.1.norm2.bias
+ | 0.001 | -0.486 | 0.499 | 0.117 | torch.Size([240, 120]) || stage2.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.056 | -0.185 | 0.147 | 0.058 | torch.Size([240]) || stage2.residual_group1.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.529 | 0.548 | 0.121 | torch.Size([240, 120]) || stage2.residual_group1.blocks.1.mlp.fc12.weight
+ | 0.002 | -0.231 | 0.177 | 0.071 | torch.Size([240]) || stage2.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.001 | -0.578 | 0.609 | 0.123 | torch.Size([120, 240]) || stage2.residual_group1.blocks.1.mlp.fc2.weight
+ | -0.003 | -0.350 | 0.216 | 0.098 | torch.Size([120]) || stage2.residual_group1.blocks.1.mlp.fc2.bias
+ | 0.848 | 0.172 | 1.107 | 0.144 | torch.Size([120]) || stage2.residual_group1.blocks.2.norm1.weight
+ | -0.168 | -1.123 | 0.330 | 0.178 | torch.Size([120]) || stage2.residual_group1.blocks.2.norm1.bias
+ | -0.074 | -1.239 | 4.293 | 0.247 | torch.Size([675, 6]) || stage2.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.2.attn.position_bias
+ | -0.001 | -0.643 | 0.531 | 0.117 | torch.Size([360, 120]) || stage2.residual_group1.blocks.2.attn.qkv_self.weight
+ | 0.003 | -0.220 | 0.376 | 0.047 | torch.Size([360]) || stage2.residual_group1.blocks.2.attn.qkv_self.bias
+ | 0.000 | -0.529 | 0.479 | 0.100 | torch.Size([120, 240]) || stage2.residual_group1.blocks.2.attn.proj.weight
+ | 0.002 | -0.230 | 0.295 | 0.074 | torch.Size([120]) || stage2.residual_group1.blocks.2.attn.proj.bias
+ | -0.001 | -0.726 | 0.768 | 0.091 | torch.Size([360, 120]) || stage2.residual_group1.blocks.2.attn.qkv_mut.weight
+ | 0.001 | -0.167 | 0.193 | 0.028 | torch.Size([360]) || stage2.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.695 | 0.334 | 0.833 | 0.068 | torch.Size([120]) || stage2.residual_group1.blocks.2.norm2.weight
+ | 0.012 | -0.755 | 0.517 | 0.157 | torch.Size([120]) || stage2.residual_group1.blocks.2.norm2.bias
+ | 0.001 | -0.474 | 0.480 | 0.119 | torch.Size([240, 120]) || stage2.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.049 | -0.218 | 0.148 | 0.067 | torch.Size([240]) || stage2.residual_group1.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.529 | 0.542 | 0.124 | torch.Size([240, 120]) || stage2.residual_group1.blocks.2.mlp.fc12.weight
+ | -0.006 | -0.245 | 0.239 | 0.073 | torch.Size([240]) || stage2.residual_group1.blocks.2.mlp.fc12.bias
+ | -0.001 | -0.541 | 0.485 | 0.124 | torch.Size([120, 240]) || stage2.residual_group1.blocks.2.mlp.fc2.weight
+ | 0.000 | -0.318 | 0.170 | 0.077 | torch.Size([120]) || stage2.residual_group1.blocks.2.mlp.fc2.bias
+ | 0.903 | 0.178 | 1.124 | 0.124 | torch.Size([120]) || stage2.residual_group1.blocks.3.norm1.weight
+ | -0.138 | -1.223 | 0.440 | 0.177 | torch.Size([120]) || stage2.residual_group1.blocks.3.norm1.bias
+ | -0.164 | -1.383 | 5.910 | 0.305 | torch.Size([675, 6]) || stage2.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.3.attn.position_bias
+ | -0.000 | -0.526 | 0.496 | 0.120 | torch.Size([360, 120]) || stage2.residual_group1.blocks.3.attn.qkv_self.weight
+ | 0.000 | -0.250 | 0.273 | 0.061 | torch.Size([360]) || stage2.residual_group1.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.447 | 0.524 | 0.097 | torch.Size([120, 240]) || stage2.residual_group1.blocks.3.attn.proj.weight
+ | -0.003 | -0.243 | 0.256 | 0.082 | torch.Size([120]) || stage2.residual_group1.blocks.3.attn.proj.bias
+ | -0.001 | -0.551 | 0.730 | 0.083 | torch.Size([360, 120]) || stage2.residual_group1.blocks.3.attn.qkv_mut.weight
+ | -0.001 | -0.145 | 0.126 | 0.024 | torch.Size([360]) || stage2.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.707 | 0.319 | 0.855 | 0.063 | torch.Size([120]) || stage2.residual_group1.blocks.3.norm2.weight
+ | 0.013 | -0.839 | 0.507 | 0.155 | torch.Size([120]) || stage2.residual_group1.blocks.3.norm2.bias
+ | 0.000 | -0.509 | 0.508 | 0.118 | torch.Size([240, 120]) || stage2.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.051 | -0.219 | 0.155 | 0.068 | torch.Size([240]) || stage2.residual_group1.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.475 | 0.592 | 0.124 | torch.Size([240, 120]) || stage2.residual_group1.blocks.3.mlp.fc12.weight
+ | -0.002 | -0.162 | 0.220 | 0.069 | torch.Size([240]) || stage2.residual_group1.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.465 | 0.528 | 0.124 | torch.Size([120, 240]) || stage2.residual_group1.blocks.3.mlp.fc2.weight
+ | -0.002 | -0.243 | 0.286 | 0.088 | torch.Size([120]) || stage2.residual_group1.blocks.3.mlp.fc2.bias
+ | 0.948 | 0.220 | 1.175 | 0.108 | torch.Size([120]) || stage2.residual_group1.blocks.4.norm1.weight
+ | -0.125 | -1.093 | 0.385 | 0.157 | torch.Size([120]) || stage2.residual_group1.blocks.4.norm1.bias
+ | -0.150 | -1.632 | 4.522 | 0.341 | torch.Size([675, 6]) || stage2.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.4.attn.position_bias
+ | -0.000 | -0.636 | 0.543 | 0.119 | torch.Size([360, 120]) || stage2.residual_group1.blocks.4.attn.qkv_self.weight
+ | -0.001 | -0.254 | 0.262 | 0.048 | torch.Size([360]) || stage2.residual_group1.blocks.4.attn.qkv_self.bias
+ | 0.001 | -0.632 | 0.628 | 0.112 | torch.Size([120, 240]) || stage2.residual_group1.blocks.4.attn.proj.weight
+ | -0.005 | -0.240 | 0.330 | 0.104 | torch.Size([120]) || stage2.residual_group1.blocks.4.attn.proj.bias
+ | 0.000 | -0.476 | 0.479 | 0.088 | torch.Size([360, 120]) || stage2.residual_group1.blocks.4.attn.qkv_mut.weight
+ | -0.001 | -0.112 | 0.134 | 0.020 | torch.Size([360]) || stage2.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.686 | 0.264 | 0.797 | 0.060 | torch.Size([120]) || stage2.residual_group1.blocks.4.norm2.weight
+ | 0.012 | -0.889 | 0.427 | 0.140 | torch.Size([120]) || stage2.residual_group1.blocks.4.norm2.bias
+ | 0.001 | -0.476 | 0.478 | 0.117 | torch.Size([240, 120]) || stage2.residual_group1.blocks.4.mlp.fc11.weight
+ | -0.051 | -0.267 | 0.180 | 0.071 | torch.Size([240]) || stage2.residual_group1.blocks.4.mlp.fc11.bias
+ | 0.000 | -0.506 | 0.517 | 0.127 | torch.Size([240, 120]) || stage2.residual_group1.blocks.4.mlp.fc12.weight
+ | 0.002 | -0.172 | 0.241 | 0.068 | torch.Size([240]) || stage2.residual_group1.blocks.4.mlp.fc12.bias
+ | -0.001 | -0.570 | 0.542 | 0.126 | torch.Size([120, 240]) || stage2.residual_group1.blocks.4.mlp.fc2.weight
+ | -0.003 | -0.631 | 0.395 | 0.123 | torch.Size([120]) || stage2.residual_group1.blocks.4.mlp.fc2.bias
+ | 0.912 | 0.189 | 1.122 | 0.104 | torch.Size([120]) || stage2.residual_group1.blocks.5.norm1.weight
+ | -0.114 | -1.125 | 0.188 | 0.140 | torch.Size([120]) || stage2.residual_group1.blocks.5.norm1.bias
+ | -0.099 | -1.285 | 1.708 | 0.236 | torch.Size([675, 6]) || stage2.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.5.attn.position_bias
+ | -0.000 | -0.496 | 0.540 | 0.119 | torch.Size([360, 120]) || stage2.residual_group1.blocks.5.attn.qkv_self.weight
+ | 0.003 | -0.260 | 0.228 | 0.052 | torch.Size([360]) || stage2.residual_group1.blocks.5.attn.qkv_self.bias
+ | -0.000 | -0.511 | 0.454 | 0.095 | torch.Size([120, 240]) || stage2.residual_group1.blocks.5.attn.proj.weight
+ | 0.000 | -0.711 | 0.286 | 0.115 | torch.Size([120]) || stage2.residual_group1.blocks.5.attn.proj.bias
+ | 0.000 | -0.444 | 0.454 | 0.082 | torch.Size([360, 120]) || stage2.residual_group1.blocks.5.attn.qkv_mut.weight
+ | -0.000 | -0.101 | 0.133 | 0.021 | torch.Size([360]) || stage2.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.668 | 0.312 | 0.800 | 0.056 | torch.Size([120]) || stage2.residual_group1.blocks.5.norm2.weight
+ | 0.015 | -0.778 | 0.372 | 0.111 | torch.Size([120]) || stage2.residual_group1.blocks.5.norm2.bias
+ | -0.000 | -0.485 | 0.469 | 0.115 | torch.Size([240, 120]) || stage2.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.045 | -0.294 | 0.173 | 0.083 | torch.Size([240]) || stage2.residual_group1.blocks.5.mlp.fc11.bias
+ | 0.000 | -0.554 | 0.540 | 0.129 | torch.Size([240, 120]) || stage2.residual_group1.blocks.5.mlp.fc12.weight
+ | 0.001 | -0.183 | 0.199 | 0.077 | torch.Size([240]) || stage2.residual_group1.blocks.5.mlp.fc12.bias
+ | 0.000 | -0.879 | 0.824 | 0.127 | torch.Size([120, 240]) || stage2.residual_group1.blocks.5.mlp.fc2.weight
+ | 0.001 | -1.670 | 0.358 | 0.208 | torch.Size([120]) || stage2.residual_group1.blocks.5.mlp.fc2.bias
+ | 0.001 | -0.253 | 0.346 | 0.068 | torch.Size([120, 120]) || stage2.linear1.weight
+ | 0.007 | -0.248 | 0.241 | 0.103 | torch.Size([120]) || stage2.linear1.bias
+ | 1.012 | 0.613 | 1.327 | 0.116 | torch.Size([120]) || stage2.residual_group2.blocks.0.norm1.weight
+ | 0.019 | -0.724 | 0.685 | 0.244 | torch.Size([120]) || stage2.residual_group2.blocks.0.norm1.bias
+ | 0.003 | -2.959 | 1.705 | 0.151 | torch.Size([2475, 6]) || stage2.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage2.residual_group2.blocks.0.attn.relative_position_index
+ | -0.000 | -0.636 | 0.617 | 0.125 | torch.Size([360, 120]) || stage2.residual_group2.blocks.0.attn.qkv_self.weight
+ | -0.002 | -0.291 | 0.292 | 0.085 | torch.Size([360]) || stage2.residual_group2.blocks.0.attn.qkv_self.bias
+ | -0.002 | -0.476 | 0.512 | 0.138 | torch.Size([120, 120]) || stage2.residual_group2.blocks.0.attn.proj.weight
+ | -0.002 | -0.263 | 0.398 | 0.135 | torch.Size([120]) || stage2.residual_group2.blocks.0.attn.proj.bias
+ | 0.677 | 0.521 | 0.840 | 0.063 | torch.Size([120]) || stage2.residual_group2.blocks.0.norm2.weight
+ | 0.010 | -0.710 | 0.541 | 0.173 | torch.Size([120]) || stage2.residual_group2.blocks.0.norm2.bias
+ | 0.001 | -0.540 | 0.507 | 0.112 | torch.Size([240, 120]) || stage2.residual_group2.blocks.0.mlp.fc11.weight
+ | -0.016 | -0.242 | 0.201 | 0.077 | torch.Size([240]) || stage2.residual_group2.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.519 | 0.479 | 0.122 | torch.Size([240, 120]) || stage2.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.006 | -0.162 | 0.231 | 0.071 | torch.Size([240]) || stage2.residual_group2.blocks.0.mlp.fc12.bias
+ | -0.001 | -0.449 | 0.494 | 0.121 | torch.Size([120, 240]) || stage2.residual_group2.blocks.0.mlp.fc2.weight
+ | 0.002 | -0.293 | 0.222 | 0.095 | torch.Size([120]) || stage2.residual_group2.blocks.0.mlp.fc2.bias
+ | 1.053 | 0.832 | 1.269 | 0.079 | torch.Size([120]) || stage2.residual_group2.blocks.1.norm1.weight
+ | 0.015 | -0.549 | 0.428 | 0.189 | torch.Size([120]) || stage2.residual_group2.blocks.1.norm1.bias
+ | 0.007 | -3.099 | 1.550 | 0.170 | torch.Size([2475, 6]) || stage2.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage2.residual_group2.blocks.1.attn.relative_position_index
+ | 0.000 | -0.673 | 0.604 | 0.131 | torch.Size([360, 120]) || stage2.residual_group2.blocks.1.attn.qkv_self.weight
+ | -0.001 | -0.416 | 0.391 | 0.089 | torch.Size([360]) || stage2.residual_group2.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.569 | 0.560 | 0.139 | torch.Size([120, 120]) || stage2.residual_group2.blocks.1.attn.proj.weight
+ | 0.004 | -0.613 | 0.428 | 0.158 | torch.Size([120]) || stage2.residual_group2.blocks.1.attn.proj.bias
+ | 0.762 | 0.464 | 0.954 | 0.085 | torch.Size([120]) || stage2.residual_group2.blocks.1.norm2.weight
+ | 0.005 | -0.745 | 0.381 | 0.117 | torch.Size([120]) || stage2.residual_group2.blocks.1.norm2.bias
+ | 0.000 | -0.441 | 0.448 | 0.110 | torch.Size([240, 120]) || stage2.residual_group2.blocks.1.mlp.fc11.weight
+ | 0.019 | -0.292 | 0.460 | 0.117 | torch.Size([240]) || stage2.residual_group2.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.491 | 0.490 | 0.126 | torch.Size([240, 120]) || stage2.residual_group2.blocks.1.mlp.fc12.weight
+ | -0.007 | -0.285 | 0.177 | 0.068 | torch.Size([240]) || stage2.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.535 | 0.631 | 0.125 | torch.Size([120, 240]) || stage2.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.011 | -0.765 | 0.337 | 0.142 | torch.Size([120]) || stage2.residual_group2.blocks.1.mlp.fc2.bias
+ | 0.001 | -0.367 | 0.372 | 0.074 | torch.Size([120, 120]) || stage2.linear2.weight
+ | 0.009 | -0.288 | 0.342 | 0.130 | torch.Size([120]) || stage2.linear2.bias
+ | 0.000 | -0.112 | 0.093 | 0.022 | torch.Size([120, 120, 3, 3]) || stage2.pa_deform.weight
+ | -0.002 | -0.036 | 0.035 | 0.016 | torch.Size([120]) || stage2.pa_deform.bias
+ | 0.000 | -0.068 | 0.080 | 0.016 | torch.Size([120, 242, 3, 3]) || stage2.pa_deform.conv_offset.0.weight
+ | -0.009 | -0.035 | 0.023 | 0.013 | torch.Size([120]) || stage2.pa_deform.conv_offset.0.bias
+ | 0.000 | -0.068 | 0.079 | 0.019 | torch.Size([120, 120, 3, 3]) || stage2.pa_deform.conv_offset.2.weight
+ | -0.014 | -0.061 | 0.036 | 0.021 | torch.Size([120]) || stage2.pa_deform.conv_offset.2.bias
+ | -0.001 | -0.082 | 0.079 | 0.019 | torch.Size([120, 120, 3, 3]) || stage2.pa_deform.conv_offset.4.weight
+ | -0.003 | -0.075 | 0.069 | 0.035 | torch.Size([120]) || stage2.pa_deform.conv_offset.4.bias
+ | -0.000 | -0.166 | 0.139 | 0.016 | torch.Size([324, 120, 3, 3]) || stage2.pa_deform.conv_offset.6.weight
+ | -0.015 | -0.090 | 0.050 | 0.030 | torch.Size([324]) || stage2.pa_deform.conv_offset.6.bias
+ | -0.002 | -0.642 | 0.663 | 0.127 | torch.Size([360, 360]) || stage2.pa_fuse.fc11.weight
+ | 0.130 | -0.171 | 0.480 | 0.140 | torch.Size([360]) || stage2.pa_fuse.fc11.bias
+ | -0.000 | -0.696 | 0.620 | 0.118 | torch.Size([360, 360]) || stage2.pa_fuse.fc12.weight
+ | -0.007 | -0.337 | 0.301 | 0.102 | torch.Size([360]) || stage2.pa_fuse.fc12.bias
+ | 0.000 | -0.650 | 0.657 | 0.128 | torch.Size([120, 360]) || stage2.pa_fuse.fc2.weight
+ | 0.013 | -0.507 | 0.451 | 0.215 | torch.Size([120]) || stage2.pa_fuse.fc2.bias
+ | 1.067 | 0.372 | 1.778 | 0.269 | torch.Size([480]) || stage3.reshape.1.weight
+ | -0.004 | -0.699 | 0.521 | 0.227 | torch.Size([480]) || stage3.reshape.1.bias
+ | -0.000 | -0.643 | 0.743 | 0.138 | torch.Size([120, 480]) || stage3.reshape.2.weight
+ | 0.009 | -0.176 | 0.243 | 0.079 | torch.Size([120]) || stage3.reshape.2.bias
+ | 0.785 | 0.469 | 1.029 | 0.105 | torch.Size([120]) || stage3.residual_group1.blocks.0.norm1.weight
+ | -0.102 | -0.716 | 0.311 | 0.179 | torch.Size([120]) || stage3.residual_group1.blocks.0.norm1.bias
+ | -0.001 | -0.340 | 0.163 | 0.033 | torch.Size([675, 6]) || stage3.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.0.attn.position_bias
+ | -0.000 | -0.328 | 0.302 | 0.061 | torch.Size([360, 120]) || stage3.residual_group1.blocks.0.attn.qkv_self.weight
+ | 0.004 | -0.232 | 0.189 | 0.063 | torch.Size([360]) || stage3.residual_group1.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.343 | 0.346 | 0.058 | torch.Size([120, 240]) || stage3.residual_group1.blocks.0.attn.proj.weight
+ | 0.004 | -0.335 | 0.229 | 0.102 | torch.Size([120]) || stage3.residual_group1.blocks.0.attn.proj.bias
+ | -0.000 | -0.366 | 0.325 | 0.052 | torch.Size([360, 120]) || stage3.residual_group1.blocks.0.attn.qkv_mut.weight
+ | -0.001 | -0.091 | 0.074 | 0.017 | torch.Size([360]) || stage3.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.751 | 0.517 | 0.928 | 0.083 | torch.Size([120]) || stage3.residual_group1.blocks.0.norm2.weight
+ | 0.002 | -0.271 | 0.189 | 0.101 | torch.Size([120]) || stage3.residual_group1.blocks.0.norm2.bias
+ | 0.000 | -0.371 | 0.388 | 0.096 | torch.Size([240, 120]) || stage3.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.073 | -0.203 | 0.039 | 0.046 | torch.Size([240]) || stage3.residual_group1.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.400 | 0.401 | 0.094 | torch.Size([240, 120]) || stage3.residual_group1.blocks.0.mlp.fc12.weight
+ | -0.000 | -0.178 | 0.128 | 0.052 | torch.Size([240]) || stage3.residual_group1.blocks.0.mlp.fc12.bias
+ | -0.001 | -0.410 | 0.429 | 0.098 | torch.Size([120, 240]) || stage3.residual_group1.blocks.0.mlp.fc2.weight
+ | 0.006 | -0.345 | 0.304 | 0.108 | torch.Size([120]) || stage3.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.816 | 0.469 | 1.015 | 0.110 | torch.Size([120]) || stage3.residual_group1.blocks.1.norm1.weight
+ | -0.103 | -0.647 | 0.225 | 0.140 | torch.Size([120]) || stage3.residual_group1.blocks.1.norm1.bias
+ | 0.001 | -0.464 | 0.239 | 0.034 | torch.Size([675, 6]) || stage3.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.1.attn.position_bias
+ | -0.000 | -0.304 | 0.359 | 0.061 | torch.Size([360, 120]) || stage3.residual_group1.blocks.1.attn.qkv_self.weight
+ | 0.001 | -0.173 | 0.193 | 0.047 | torch.Size([360]) || stage3.residual_group1.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.299 | 0.408 | 0.055 | torch.Size([120, 240]) || stage3.residual_group1.blocks.1.attn.proj.weight
+ | 0.007 | -0.511 | 0.239 | 0.113 | torch.Size([120]) || stage3.residual_group1.blocks.1.attn.proj.bias
+ | 0.000 | -0.288 | 0.254 | 0.049 | torch.Size([360, 120]) || stage3.residual_group1.blocks.1.attn.qkv_mut.weight
+ | 0.001 | -0.060 | 0.054 | 0.016 | torch.Size([360]) || stage3.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.796 | 0.609 | 0.971 | 0.076 | torch.Size([120]) || stage3.residual_group1.blocks.1.norm2.weight
+ | -0.002 | -0.327 | 0.247 | 0.122 | torch.Size([120]) || stage3.residual_group1.blocks.1.norm2.bias
+ | 0.001 | -0.379 | 0.407 | 0.094 | torch.Size([240, 120]) || stage3.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.077 | -0.214 | 0.034 | 0.045 | torch.Size([240]) || stage3.residual_group1.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.391 | 0.432 | 0.092 | torch.Size([240, 120]) || stage3.residual_group1.blocks.1.mlp.fc12.weight
+ | 0.005 | -0.176 | 0.112 | 0.044 | torch.Size([240]) || stage3.residual_group1.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.378 | 0.399 | 0.093 | torch.Size([120, 240]) || stage3.residual_group1.blocks.1.mlp.fc2.weight
+ | 0.009 | -0.410 | 0.306 | 0.110 | torch.Size([120]) || stage3.residual_group1.blocks.1.mlp.fc2.bias
+ | 0.854 | 0.447 | 0.995 | 0.090 | torch.Size([120]) || stage3.residual_group1.blocks.2.norm1.weight
+ | -0.086 | -0.513 | 0.198 | 0.116 | torch.Size([120]) || stage3.residual_group1.blocks.2.norm1.bias
+ | -0.001 | -0.189 | 0.292 | 0.033 | torch.Size([675, 6]) || stage3.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.2.attn.position_bias
+ | 0.000 | -0.390 | 0.367 | 0.067 | torch.Size([360, 120]) || stage3.residual_group1.blocks.2.attn.qkv_self.weight
+ | -0.002 | -0.310 | 0.284 | 0.078 | torch.Size([360]) || stage3.residual_group1.blocks.2.attn.qkv_self.bias
+ | 0.000 | -0.334 | 0.296 | 0.061 | torch.Size([120, 240]) || stage3.residual_group1.blocks.2.attn.proj.weight
+ | 0.004 | -0.356 | 0.299 | 0.096 | torch.Size([120]) || stage3.residual_group1.blocks.2.attn.proj.bias
+ | 0.000 | -0.276 | 0.315 | 0.055 | torch.Size([360, 120]) || stage3.residual_group1.blocks.2.attn.qkv_mut.weight
+ | 0.000 | -0.094 | 0.066 | 0.014 | torch.Size([360]) || stage3.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.829 | 0.673 | 1.017 | 0.074 | torch.Size([120]) || stage3.residual_group1.blocks.2.norm2.weight
+ | 0.003 | -0.259 | 0.228 | 0.098 | torch.Size([120]) || stage3.residual_group1.blocks.2.norm2.bias
+ | 0.001 | -0.410 | 0.385 | 0.091 | torch.Size([240, 120]) || stage3.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.085 | -0.200 | 0.017 | 0.044 | torch.Size([240]) || stage3.residual_group1.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.348 | 0.378 | 0.090 | torch.Size([240, 120]) || stage3.residual_group1.blocks.2.mlp.fc12.weight
+ | 0.001 | -0.130 | 0.105 | 0.042 | torch.Size([240]) || stage3.residual_group1.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.346 | 0.425 | 0.090 | torch.Size([120, 240]) || stage3.residual_group1.blocks.2.mlp.fc2.weight
+ | 0.005 | -0.363 | 0.241 | 0.094 | torch.Size([120]) || stage3.residual_group1.blocks.2.mlp.fc2.bias
+ | 0.872 | 0.554 | 1.068 | 0.102 | torch.Size([120]) || stage3.residual_group1.blocks.3.norm1.weight
+ | -0.057 | -0.402 | 0.133 | 0.087 | torch.Size([120]) || stage3.residual_group1.blocks.3.norm1.bias
+ | 0.003 | -0.365 | 0.217 | 0.050 | torch.Size([675, 6]) || stage3.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.3.attn.position_bias
+ | 0.000 | -0.359 | 0.357 | 0.065 | torch.Size([360, 120]) || stage3.residual_group1.blocks.3.attn.qkv_self.weight
+ | -0.002 | -0.265 | 0.294 | 0.062 | torch.Size([360]) || stage3.residual_group1.blocks.3.attn.qkv_self.bias
+ | -0.000 | -0.300 | 0.271 | 0.054 | torch.Size([120, 240]) || stage3.residual_group1.blocks.3.attn.proj.weight
+ | 0.002 | -0.316 | 0.215 | 0.094 | torch.Size([120]) || stage3.residual_group1.blocks.3.attn.proj.bias
+ | 0.000 | -0.370 | 0.329 | 0.039 | torch.Size([360, 120]) || stage3.residual_group1.blocks.3.attn.qkv_mut.weight
+ | 0.000 | -0.056 | 0.066 | 0.013 | torch.Size([360]) || stage3.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.842 | 0.631 | 0.989 | 0.073 | torch.Size([120]) || stage3.residual_group1.blocks.3.norm2.weight
+ | -0.001 | -0.216 | 0.263 | 0.083 | torch.Size([120]) || stage3.residual_group1.blocks.3.norm2.bias
+ | 0.001 | -0.388 | 0.391 | 0.089 | torch.Size([240, 120]) || stage3.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.087 | -0.202 | 0.032 | 0.048 | torch.Size([240]) || stage3.residual_group1.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.364 | 0.428 | 0.088 | torch.Size([240, 120]) || stage3.residual_group1.blocks.3.mlp.fc12.weight
+ | -0.000 | -0.137 | 0.106 | 0.043 | torch.Size([240]) || stage3.residual_group1.blocks.3.mlp.fc12.bias
+ | -0.001 | -0.390 | 0.339 | 0.088 | torch.Size([120, 240]) || stage3.residual_group1.blocks.3.mlp.fc2.weight
+ | 0.003 | -0.376 | 0.203 | 0.090 | torch.Size([120]) || stage3.residual_group1.blocks.3.mlp.fc2.bias
+ | 0.913 | 0.498 | 1.102 | 0.096 | torch.Size([120]) || stage3.residual_group1.blocks.4.norm1.weight
+ | -0.048 | -0.340 | 0.105 | 0.071 | torch.Size([120]) || stage3.residual_group1.blocks.4.norm1.bias
+ | 0.001 | -0.706 | 0.306 | 0.058 | torch.Size([675, 6]) || stage3.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.4.attn.position_bias
+ | 0.000 | -0.373 | 0.339 | 0.076 | torch.Size([360, 120]) || stage3.residual_group1.blocks.4.attn.qkv_self.weight
+ | -0.004 | -0.301 | 0.301 | 0.074 | torch.Size([360]) || stage3.residual_group1.blocks.4.attn.qkv_self.bias
+ | 0.000 | -0.278 | 0.277 | 0.058 | torch.Size([120, 240]) || stage3.residual_group1.blocks.4.attn.proj.weight
+ | 0.003 | -0.310 | 0.240 | 0.079 | torch.Size([120]) || stage3.residual_group1.blocks.4.attn.proj.bias
+ | -0.000 | -0.350 | 0.322 | 0.046 | torch.Size([360, 120]) || stage3.residual_group1.blocks.4.attn.qkv_mut.weight
+ | -0.000 | -0.045 | 0.064 | 0.010 | torch.Size([360]) || stage3.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.862 | 0.679 | 0.990 | 0.059 | torch.Size([120]) || stage3.residual_group1.blocks.4.norm2.weight
+ | -0.004 | -0.313 | 0.190 | 0.083 | torch.Size([120]) || stage3.residual_group1.blocks.4.norm2.bias
+ | 0.001 | -0.370 | 0.364 | 0.089 | torch.Size([240, 120]) || stage3.residual_group1.blocks.4.mlp.fc11.weight
+ | -0.092 | -0.231 | 0.129 | 0.057 | torch.Size([240]) || stage3.residual_group1.blocks.4.mlp.fc11.bias
+ | -0.000 | -0.375 | 0.511 | 0.090 | torch.Size([240, 120]) || stage3.residual_group1.blocks.4.mlp.fc12.weight
+ | 0.002 | -0.114 | 0.114 | 0.040 | torch.Size([240]) || stage3.residual_group1.blocks.4.mlp.fc12.bias
+ | -0.000 | -0.389 | 0.354 | 0.088 | torch.Size([120, 240]) || stage3.residual_group1.blocks.4.mlp.fc2.weight
+ | 0.005 | -0.258 | 0.164 | 0.073 | torch.Size([120]) || stage3.residual_group1.blocks.4.mlp.fc2.bias
+ | 0.899 | 0.480 | 1.089 | 0.103 | torch.Size([120]) || stage3.residual_group1.blocks.5.norm1.weight
+ | -0.030 | -0.257 | 0.115 | 0.056 | torch.Size([120]) || stage3.residual_group1.blocks.5.norm1.bias
+ | 0.003 | -0.462 | 0.290 | 0.069 | torch.Size([675, 6]) || stage3.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.5.attn.position_bias
+ | 0.000 | -0.391 | 0.365 | 0.069 | torch.Size([360, 120]) || stage3.residual_group1.blocks.5.attn.qkv_self.weight
+ | -0.004 | -0.232 | 0.302 | 0.064 | torch.Size([360]) || stage3.residual_group1.blocks.5.attn.qkv_self.bias
+ | -0.000 | -0.267 | 0.293 | 0.051 | torch.Size([120, 240]) || stage3.residual_group1.blocks.5.attn.proj.weight
+ | 0.000 | -0.250 | 0.182 | 0.070 | torch.Size([120]) || stage3.residual_group1.blocks.5.attn.proj.bias
+ | -0.000 | -0.238 | 0.257 | 0.033 | torch.Size([360, 120]) || stage3.residual_group1.blocks.5.attn.qkv_mut.weight
+ | -0.001 | -0.032 | 0.033 | 0.008 | torch.Size([360]) || stage3.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.864 | 0.651 | 1.029 | 0.070 | torch.Size([120]) || stage3.residual_group1.blocks.5.norm2.weight
+ | -0.003 | -0.212 | 0.175 | 0.075 | torch.Size([120]) || stage3.residual_group1.blocks.5.norm2.bias
+ | 0.000 | -0.378 | 0.379 | 0.089 | torch.Size([240, 120]) || stage3.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.097 | -0.308 | 0.026 | 0.051 | torch.Size([240]) || stage3.residual_group1.blocks.5.mlp.fc11.bias
+ | 0.000 | -0.578 | 0.401 | 0.089 | torch.Size([240, 120]) || stage3.residual_group1.blocks.5.mlp.fc12.weight
+ | -0.005 | -0.166 | 0.131 | 0.049 | torch.Size([240]) || stage3.residual_group1.blocks.5.mlp.fc12.bias
+ | 0.000 | -0.358 | 0.376 | 0.085 | torch.Size([120, 240]) || stage3.residual_group1.blocks.5.mlp.fc2.weight
+ | 0.001 | -0.262 | 0.176 | 0.072 | torch.Size([120]) || stage3.residual_group1.blocks.5.mlp.fc2.bias
+ | 0.003 | -0.284 | 0.467 | 0.071 | torch.Size([120, 120]) || stage3.linear1.weight
+ | 0.006 | -0.201 | 0.269 | 0.090 | torch.Size([120]) || stage3.linear1.bias
+ | 0.877 | 0.568 | 1.197 | 0.115 | torch.Size([120]) || stage3.residual_group2.blocks.0.norm1.weight
+ | 0.002 | -0.248 | 0.324 | 0.100 | torch.Size([120]) || stage3.residual_group2.blocks.0.norm1.bias
+ | 0.000 | -0.261 | 0.125 | 0.029 | torch.Size([2475, 6]) || stage3.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage3.residual_group2.blocks.0.attn.relative_position_index
+ | -0.000 | -0.563 | 0.552 | 0.074 | torch.Size([360, 120]) || stage3.residual_group2.blocks.0.attn.qkv_self.weight
+ | 0.005 | -0.257 | 0.302 | 0.081 | torch.Size([360]) || stage3.residual_group2.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.390 | 0.385 | 0.084 | torch.Size([120, 120]) || stage3.residual_group2.blocks.0.attn.proj.weight
+ | 0.002 | -0.450 | 0.235 | 0.125 | torch.Size([120]) || stage3.residual_group2.blocks.0.attn.proj.bias
+ | 0.986 | 0.755 | 1.165 | 0.078 | torch.Size([120]) || stage3.residual_group2.blocks.0.norm2.weight
+ | -0.000 | -0.260 | 0.169 | 0.076 | torch.Size([120]) || stage3.residual_group2.blocks.0.norm2.bias
+ | 0.000 | -0.355 | 0.397 | 0.087 | torch.Size([240, 120]) || stage3.residual_group2.blocks.0.mlp.fc11.weight
+ | -0.046 | -0.220 | 0.086 | 0.055 | torch.Size([240]) || stage3.residual_group2.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.424 | 0.368 | 0.089 | torch.Size([240, 120]) || stage3.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.006 | -0.111 | 0.122 | 0.038 | torch.Size([240]) || stage3.residual_group2.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.354 | 0.374 | 0.090 | torch.Size([120, 240]) || stage3.residual_group2.blocks.0.mlp.fc2.weight
+ | 0.001 | -0.374 | 0.272 | 0.101 | torch.Size([120]) || stage3.residual_group2.blocks.0.mlp.fc2.bias
+ | 0.919 | 0.643 | 1.132 | 0.100 | torch.Size([120]) || stage3.residual_group2.blocks.1.norm1.weight
+ | 0.000 | -0.177 | 0.181 | 0.063 | torch.Size([120]) || stage3.residual_group2.blocks.1.norm1.bias
+ | 0.000 | -0.332 | 0.131 | 0.028 | torch.Size([2475, 6]) || stage3.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage3.residual_group2.blocks.1.attn.relative_position_index
+ | -0.000 | -0.418 | 0.362 | 0.069 | torch.Size([360, 120]) || stage3.residual_group2.blocks.1.attn.qkv_self.weight
+ | -0.004 | -0.375 | 0.347 | 0.082 | torch.Size([360]) || stage3.residual_group2.blocks.1.attn.qkv_self.bias
+ | -0.001 | -0.294 | 0.354 | 0.077 | torch.Size([120, 120]) || stage3.residual_group2.blocks.1.attn.proj.weight
+ | 0.003 | -0.432 | 0.259 | 0.101 | torch.Size([120]) || stage3.residual_group2.blocks.1.attn.proj.bias
+ | 1.012 | 0.750 | 1.178 | 0.077 | torch.Size([120]) || stage3.residual_group2.blocks.1.norm2.weight
+ | -0.001 | -0.171 | 0.155 | 0.060 | torch.Size([120]) || stage3.residual_group2.blocks.1.norm2.bias
+ | 0.000 | -0.331 | 0.356 | 0.087 | torch.Size([240, 120]) || stage3.residual_group2.blocks.1.mlp.fc11.weight
+ | -0.035 | -0.207 | 0.197 | 0.065 | torch.Size([240]) || stage3.residual_group2.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.399 | 0.398 | 0.092 | torch.Size([240, 120]) || stage3.residual_group2.blocks.1.mlp.fc12.weight
+ | -0.002 | -0.111 | 0.129 | 0.041 | torch.Size([240]) || stage3.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.001 | -0.353 | 0.330 | 0.088 | torch.Size([120, 240]) || stage3.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.001 | -0.328 | 0.127 | 0.064 | torch.Size([120]) || stage3.residual_group2.blocks.1.mlp.fc2.bias
+ | 0.003 | -0.289 | 0.519 | 0.073 | torch.Size([120, 120]) || stage3.linear2.weight
+ | 0.002 | -0.318 | 0.371 | 0.144 | torch.Size([120]) || stage3.linear2.bias
+ | -0.000 | -0.086 | 0.095 | 0.022 | torch.Size([120, 120, 3, 3]) || stage3.pa_deform.weight
+ | -0.002 | -0.023 | 0.021 | 0.010 | torch.Size([120]) || stage3.pa_deform.bias
+ | -0.000 | -0.060 | 0.056 | 0.015 | torch.Size([120, 242, 3, 3]) || stage3.pa_deform.conv_offset.0.weight
+ | -0.008 | -0.035 | 0.019 | 0.013 | torch.Size([120]) || stage3.pa_deform.conv_offset.0.bias
+ | -0.001 | -0.064 | 0.062 | 0.019 | torch.Size([120, 120, 3, 3]) || stage3.pa_deform.conv_offset.2.weight
+ | -0.007 | -0.044 | 0.031 | 0.019 | torch.Size([120]) || stage3.pa_deform.conv_offset.2.bias
+ | 0.000 | -0.062 | 0.063 | 0.019 | torch.Size([120, 120, 3, 3]) || stage3.pa_deform.conv_offset.4.weight
+ | -0.006 | -0.052 | 0.043 | 0.021 | torch.Size([120]) || stage3.pa_deform.conv_offset.4.bias
+ | 0.000 | -0.081 | 0.080 | 0.011 | torch.Size([324, 120, 3, 3]) || stage3.pa_deform.conv_offset.6.weight
+ | -0.004 | -0.087 | 0.083 | 0.021 | torch.Size([324]) || stage3.pa_deform.conv_offset.6.bias
+ | -0.002 | -0.465 | 0.513 | 0.101 | torch.Size([360, 360]) || stage3.pa_fuse.fc11.weight
+ | 0.059 | -0.251 | 0.595 | 0.104 | torch.Size([360]) || stage3.pa_fuse.fc11.bias
+ | -0.000 | -0.544 | 0.531 | 0.100 | torch.Size([360, 360]) || stage3.pa_fuse.fc12.weight
+ | 0.001 | -0.589 | 0.433 | 0.106 | torch.Size([360]) || stage3.pa_fuse.fc12.bias
+ | -0.000 | -0.535 | 0.562 | 0.127 | torch.Size([120, 360]) || stage3.pa_fuse.fc2.weight
+ | -0.001 | -0.401 | 0.342 | 0.121 | torch.Size([120]) || stage3.pa_fuse.fc2.bias
+ | 0.997 | 0.921 | 1.125 | 0.028 | torch.Size([480]) || stage4.reshape.1.weight
+ | -0.000 | -0.058 | 0.059 | 0.022 | torch.Size([480]) || stage4.reshape.1.bias
+ | 0.000 | -0.155 | 0.150 | 0.031 | torch.Size([120, 480]) || stage4.reshape.2.weight
+ | 0.001 | -0.016 | 0.016 | 0.006 | torch.Size([120]) || stage4.reshape.2.bias
+ | 1.002 | 0.999 | 1.009 | 0.002 | torch.Size([120]) || stage4.residual_group1.blocks.0.norm1.weight
+ | 0.000 | -0.002 | 0.003 | 0.001 | torch.Size([120]) || stage4.residual_group1.blocks.0.norm1.bias
+ | -0.000 | -0.071 | 0.066 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.0.attn.position_bias
+ | 0.000 | -0.093 | 0.081 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.0.attn.qkv_self.weight
+ | -0.000 | -0.009 | 0.009 | 0.002 | torch.Size([360]) || stage4.residual_group1.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.080 | 0.097 | 0.021 | torch.Size([120, 240]) || stage4.residual_group1.blocks.0.attn.proj.weight
+ | 0.000 | -0.035 | 0.027 | 0.013 | torch.Size([120]) || stage4.residual_group1.blocks.0.attn.proj.bias
+ | 0.000 | -0.080 | 0.079 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.0.attn.qkv_mut.weight
+ | -0.000 | -0.007 | 0.008 | 0.002 | torch.Size([360]) || stage4.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.0.norm2.weight
+ | -0.000 | -0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.0.norm2.bias
+ | -0.000 | -0.079 | 0.085 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.0.mlp.fc11.weight
+ | 0.000 | -0.001 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.087 | 0.092 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.0.mlp.fc12.weight
+ | -0.000 | -0.001 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.080 | 0.077 | 0.020 | torch.Size([120, 240]) || stage4.residual_group1.blocks.0.mlp.fc2.weight
+ | 0.000 | -0.031 | 0.029 | 0.013 | torch.Size([120]) || stage4.residual_group1.blocks.0.mlp.fc2.bias
+ | 1.002 | 0.997 | 1.007 | 0.002 | torch.Size([120]) || stage4.residual_group1.blocks.1.norm1.weight
+ | -0.000 | -0.002 | 0.003 | 0.001 | torch.Size([120]) || stage4.residual_group1.blocks.1.norm1.bias
+ | 0.000 | -0.066 | 0.065 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.1.attn.position_bias
+ | -0.000 | -0.078 | 0.081 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.1.attn.qkv_self.weight
+ | 0.000 | -0.006 | 0.008 | 0.002 | torch.Size([360]) || stage4.residual_group1.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.080 | 0.083 | 0.021 | torch.Size([120, 240]) || stage4.residual_group1.blocks.1.attn.proj.weight
+ | -0.000 | -0.027 | 0.029 | 0.012 | torch.Size([120]) || stage4.residual_group1.blocks.1.attn.proj.bias
+ | 0.000 | -0.077 | 0.082 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.1.attn.qkv_mut.weight
+ | -0.000 | -0.006 | 0.009 | 0.001 | torch.Size([360]) || stage4.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.1.norm2.weight
+ | 0.000 | -0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.1.norm2.bias
+ | -0.000 | -0.080 | 0.078 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.000 | -0.001 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.077 | 0.085 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.1.mlp.fc12.weight
+ | 0.000 | -0.001 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.084 | 0.075 | 0.020 | torch.Size([120, 240]) || stage4.residual_group1.blocks.1.mlp.fc2.weight
+ | 0.000 | -0.034 | 0.031 | 0.013 | torch.Size([120]) || stage4.residual_group1.blocks.1.mlp.fc2.bias
+ | 1.002 | 0.996 | 1.008 | 0.002 | torch.Size([120]) || stage4.residual_group1.blocks.2.norm1.weight
+ | -0.000 | -0.003 | 0.002 | 0.001 | torch.Size([120]) || stage4.residual_group1.blocks.2.norm1.bias
+ | 0.001 | -0.070 | 0.071 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.2.attn.position_bias
+ | 0.000 | -0.091 | 0.087 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.2.attn.qkv_self.weight
+ | -0.000 | -0.007 | 0.005 | 0.001 | torch.Size([360]) || stage4.residual_group1.blocks.2.attn.qkv_self.bias
+ | 0.000 | -0.080 | 0.084 | 0.020 | torch.Size([120, 240]) || stage4.residual_group1.blocks.2.attn.proj.weight
+ | -0.000 | -0.023 | 0.026 | 0.010 | torch.Size([120]) || stage4.residual_group1.blocks.2.attn.proj.bias
+ | -0.000 | -0.107 | 0.087 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.2.attn.qkv_mut.weight
+ | 0.000 | -0.006 | 0.005 | 0.001 | torch.Size([360]) || stage4.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 1.000 | 0.999 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.2.norm2.weight
+ | 0.000 | -0.000 | 0.001 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.2.norm2.bias
+ | 0.000 | -0.076 | 0.077 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.000 | -0.005 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.2.mlp.fc11.bias
+ | -0.000 | -2.000 | 0.081 | 0.023 | torch.Size([240, 120]) || stage4.residual_group1.blocks.2.mlp.fc12.weight
+ | 0.000 | -0.001 | 0.002 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.084 | 0.077 | 0.020 | torch.Size([120, 240]) || stage4.residual_group1.blocks.2.mlp.fc2.weight
+ | 0.000 | -0.027 | 0.024 | 0.010 | torch.Size([120]) || stage4.residual_group1.blocks.2.mlp.fc2.bias
+ | 1.002 | 0.999 | 1.012 | 0.002 | torch.Size([120]) || stage4.residual_group1.blocks.3.norm1.weight
+ | -0.000 | -0.003 | 0.002 | 0.001 | torch.Size([120]) || stage4.residual_group1.blocks.3.norm1.bias
+ | 0.000 | -0.064 | 0.071 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.3.attn.position_bias
+ | 0.000 | -0.099 | 0.088 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.3.attn.qkv_self.weight
+ | 0.000 | -0.006 | 0.005 | 0.001 | torch.Size([360]) || stage4.residual_group1.blocks.3.attn.qkv_self.bias
+ | -0.000 | -0.083 | 0.084 | 0.020 | torch.Size([120, 240]) || stage4.residual_group1.blocks.3.attn.proj.weight
+ | -0.000 | -0.019 | 0.018 | 0.008 | torch.Size([120]) || stage4.residual_group1.blocks.3.attn.proj.bias
+ | 0.000 | -0.079 | 0.084 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.3.attn.qkv_mut.weight
+ | -0.000 | -0.004 | 0.004 | 0.001 | torch.Size([360]) || stage4.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.3.norm2.weight
+ | 0.000 | -0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.3.norm2.bias
+ | -0.000 | -0.078 | 0.081 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.000 | -0.001 | 0.002 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.087 | 0.076 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.3.mlp.fc12.weight
+ | -0.000 | -0.001 | 0.002 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.3.mlp.fc12.bias
+ | -0.000 | -0.079 | 0.082 | 0.020 | torch.Size([120, 240]) || stage4.residual_group1.blocks.3.mlp.fc2.weight
+ | 0.000 | -0.022 | 0.021 | 0.008 | torch.Size([120]) || stage4.residual_group1.blocks.3.mlp.fc2.bias
+ | 1.002 | 0.998 | 1.011 | 0.002 | torch.Size([120]) || stage4.residual_group1.blocks.4.norm1.weight
+ | -0.001 | -0.004 | 0.003 | 0.001 | torch.Size([120]) || stage4.residual_group1.blocks.4.norm1.bias
+ | 0.000 | -0.089 | 0.081 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.4.attn.position_bias
+ | -0.000 | -0.080 | 0.085 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.4.attn.qkv_self.weight
+ | -0.000 | -0.006 | 0.005 | 0.001 | torch.Size([360]) || stage4.residual_group1.blocks.4.attn.qkv_self.bias
+ | -0.000 | -0.075 | 0.077 | 0.020 | torch.Size([120, 240]) || stage4.residual_group1.blocks.4.attn.proj.weight
+ | -0.000 | -0.021 | 0.016 | 0.007 | torch.Size([120]) || stage4.residual_group1.blocks.4.attn.proj.bias
+ | 0.000 | -0.082 | 0.088 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.4.attn.qkv_mut.weight
+ | -0.000 | -0.004 | 0.006 | 0.001 | torch.Size([360]) || stage4.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 1.000 | 0.999 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.4.norm2.weight
+ | 0.000 | -0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.4.norm2.bias
+ | -0.000 | -0.086 | 0.080 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.4.mlp.fc11.weight
+ | 0.000 | -0.001 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.4.mlp.fc11.bias
+ | 0.000 | -0.084 | 0.083 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.4.mlp.fc12.weight
+ | 0.000 | -0.001 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.4.mlp.fc12.bias
+ | 0.000 | -0.076 | 0.081 | 0.020 | torch.Size([120, 240]) || stage4.residual_group1.blocks.4.mlp.fc2.weight
+ | -0.000 | -0.018 | 0.015 | 0.007 | torch.Size([120]) || stage4.residual_group1.blocks.4.mlp.fc2.bias
+ | 1.003 | 0.997 | 1.014 | 0.003 | torch.Size([120]) || stage4.residual_group1.blocks.5.norm1.weight
+ | -0.001 | -0.005 | 0.004 | 0.002 | torch.Size([120]) || stage4.residual_group1.blocks.5.norm1.bias
+ | -0.001 | -0.070 | 0.069 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.5.attn.position_bias
+ | -0.000 | -0.097 | 0.082 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.5.attn.qkv_self.weight
+ | 0.000 | -0.007 | 0.008 | 0.002 | torch.Size([360]) || stage4.residual_group1.blocks.5.attn.qkv_self.bias
+ | -0.000 | -0.075 | 0.089 | 0.021 | torch.Size([120, 240]) || stage4.residual_group1.blocks.5.attn.proj.weight
+ | 0.000 | -0.016 | 0.015 | 0.007 | torch.Size([120]) || stage4.residual_group1.blocks.5.attn.proj.bias
+ | 0.000 | -0.083 | 0.091 | 0.020 | torch.Size([360, 120]) || stage4.residual_group1.blocks.5.attn.qkv_mut.weight
+ | 0.000 | -0.006 | 0.006 | 0.001 | torch.Size([360]) || stage4.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 1.000 | 0.999 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.5.norm2.weight
+ | -0.000 | -0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group1.blocks.5.norm2.bias
+ | 0.000 | -0.093 | 0.083 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.5.mlp.fc11.weight
+ | 0.000 | -0.002 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.5.mlp.fc11.bias
+ | 0.000 | -0.086 | 0.085 | 0.020 | torch.Size([240, 120]) || stage4.residual_group1.blocks.5.mlp.fc12.weight
+ | 0.000 | -0.001 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group1.blocks.5.mlp.fc12.bias
+ | 0.000 | -0.079 | 0.092 | 0.020 | torch.Size([120, 240]) || stage4.residual_group1.blocks.5.mlp.fc2.weight
+ | -0.000 | -0.012 | 0.016 | 0.005 | torch.Size([120]) || stage4.residual_group1.blocks.5.mlp.fc2.bias
+ | -0.000 | -0.090 | 0.111 | 0.024 | torch.Size([120, 120]) || stage4.linear1.weight
+ | 0.001 | -0.019 | 0.029 | 0.009 | torch.Size([120]) || stage4.linear1.bias
+ | 1.000 | 0.999 | 1.003 | 0.001 | torch.Size([120]) || stage4.residual_group2.blocks.0.norm1.weight
+ | 0.000 | -0.001 | 0.001 | 0.000 | torch.Size([120]) || stage4.residual_group2.blocks.0.norm1.bias
+ | -0.000 | -0.078 | 0.075 | 0.020 | torch.Size([2475, 6]) || stage4.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage4.residual_group2.blocks.0.attn.relative_position_index
+ | 0.000 | -0.084 | 0.087 | 0.020 | torch.Size([360, 120]) || stage4.residual_group2.blocks.0.attn.qkv_self.weight
+ | 0.000 | -0.005 | 0.004 | 0.001 | torch.Size([360]) || stage4.residual_group2.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.079 | 0.080 | 0.020 | torch.Size([120, 120]) || stage4.residual_group2.blocks.0.attn.proj.weight
+ | 0.000 | -0.021 | 0.024 | 0.008 | torch.Size([120]) || stage4.residual_group2.blocks.0.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group2.blocks.0.norm2.weight
+ | -0.000 | -0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group2.blocks.0.norm2.bias
+ | -0.000 | -0.079 | 0.072 | 0.020 | torch.Size([240, 120]) || stage4.residual_group2.blocks.0.mlp.fc11.weight
+ | -0.000 | -0.001 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group2.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.077 | 0.078 | 0.020 | torch.Size([240, 120]) || stage4.residual_group2.blocks.0.mlp.fc12.weight
+ | 0.000 | -0.001 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group2.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.102 | 0.078 | 0.020 | torch.Size([120, 240]) || stage4.residual_group2.blocks.0.mlp.fc2.weight
+ | 0.000 | -0.024 | 0.020 | 0.009 | torch.Size([120]) || stage4.residual_group2.blocks.0.mlp.fc2.bias
+ | 1.001 | 0.998 | 1.003 | 0.001 | torch.Size([120]) || stage4.residual_group2.blocks.1.norm1.weight
+ | -0.000 | -0.002 | 0.002 | 0.001 | torch.Size([120]) || stage4.residual_group2.blocks.1.norm1.bias
+ | -0.000 | -0.071 | 0.079 | 0.020 | torch.Size([2475, 6]) || stage4.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage4.residual_group2.blocks.1.attn.relative_position_index
+ | 0.000 | -0.078 | 0.096 | 0.020 | torch.Size([360, 120]) || stage4.residual_group2.blocks.1.attn.qkv_self.weight
+ | 0.000 | -0.005 | 0.006 | 0.001 | torch.Size([360]) || stage4.residual_group2.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.077 | 0.080 | 0.020 | torch.Size([120, 120]) || stage4.residual_group2.blocks.1.attn.proj.weight
+ | 0.000 | -0.020 | 0.021 | 0.008 | torch.Size([120]) || stage4.residual_group2.blocks.1.attn.proj.bias
+ | 1.000 | 1.000 | 1.000 | 0.000 | torch.Size([120]) || stage4.residual_group2.blocks.1.norm2.weight
+ | -0.000 | -0.000 | 0.000 | 0.000 | torch.Size([120]) || stage4.residual_group2.blocks.1.norm2.bias
+ | -0.000 | -0.085 | 0.082 | 0.020 | torch.Size([240, 120]) || stage4.residual_group2.blocks.1.mlp.fc11.weight
+ | -0.000 | -0.001 | 0.001 | 0.000 | torch.Size([240]) || stage4.residual_group2.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.083 | 0.085 | 0.020 | torch.Size([240, 120]) || stage4.residual_group2.blocks.1.mlp.fc12.weight
+ | 0.000 | -0.001 | 0.000 | 0.000 | torch.Size([240]) || stage4.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.078 | 0.078 | 0.020 | torch.Size([120, 240]) || stage4.residual_group2.blocks.1.mlp.fc2.weight
+ | 0.000 | -0.022 | 0.021 | 0.008 | torch.Size([120]) || stage4.residual_group2.blocks.1.mlp.fc2.bias
+ | 0.000 | -0.092 | 0.112 | 0.023 | torch.Size([120, 120]) || stage4.linear2.weight
+ | 0.000 | -0.032 | 0.049 | 0.015 | torch.Size([120]) || stage4.linear2.bias
+ | 0.000 | -0.036 | 0.037 | 0.018 | torch.Size([120, 120, 3, 3]) || stage4.pa_deform.weight
+ | 0.000 | -0.005 | 0.005 | 0.002 | torch.Size([120]) || stage4.pa_deform.bias
+ | -0.000 | -0.021 | 0.022 | 0.012 | torch.Size([120, 242, 3, 3]) || stage4.pa_deform.conv_offset.0.weight
+ | -0.001 | -0.021 | 0.021 | 0.012 | torch.Size([120]) || stage4.pa_deform.conv_offset.0.bias
+ | 0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage4.pa_deform.conv_offset.2.weight
+ | 0.002 | -0.030 | 0.030 | 0.018 | torch.Size([120]) || stage4.pa_deform.conv_offset.2.bias
+ | 0.000 | -0.030 | 0.030 | 0.018 | torch.Size([120, 120, 3, 3]) || stage4.pa_deform.conv_offset.4.weight
+ | -0.002 | -0.030 | 0.030 | 0.017 | torch.Size([120]) || stage4.pa_deform.conv_offset.4.bias
+ | 0.000 | -0.003 | 0.002 | 0.000 | torch.Size([324, 120, 3, 3]) || stage4.pa_deform.conv_offset.6.weight
+ | 0.000 | -0.005 | 0.004 | 0.001 | torch.Size([324]) || stage4.pa_deform.conv_offset.6.bias
+ | 0.000 | -0.172 | 0.177 | 0.022 | torch.Size([360, 360]) || stage4.pa_fuse.fc11.weight
+ | 0.002 | -0.027 | 0.088 | 0.014 | torch.Size([360]) || stage4.pa_fuse.fc11.bias
+ | 0.000 | -0.212 | 0.163 | 0.022 | torch.Size([360, 360]) || stage4.pa_fuse.fc12.weight
+ | 0.000 | -0.066 | 0.081 | 0.014 | torch.Size([360]) || stage4.pa_fuse.fc12.bias
+ | 0.000 | -0.413 | 0.387 | 0.029 | torch.Size([120, 360]) || stage4.pa_fuse.fc2.weight
+ | -0.001 | -0.198 | 0.214 | 0.073 | torch.Size([120]) || stage4.pa_fuse.fc2.bias
+ | 0.979 | 0.896 | 1.076 | 0.053 | torch.Size([30]) || stage5.reshape.1.weight
+ | -0.005 | -0.074 | 0.100 | 0.043 | torch.Size([30]) || stage5.reshape.1.bias
+ | 0.000 | -0.240 | 0.249 | 0.058 | torch.Size([120, 30]) || stage5.reshape.2.weight
+ | -0.002 | -0.286 | 0.229 | 0.080 | torch.Size([120]) || stage5.reshape.2.bias
+ | 1.001 | 0.993 | 1.006 | 0.002 | torch.Size([120]) || stage5.residual_group1.blocks.0.norm1.weight
+ | -0.004 | -0.018 | 0.006 | 0.005 | torch.Size([120]) || stage5.residual_group1.blocks.0.norm1.bias
+ | -0.000 | -0.066 | 0.062 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.0.attn.position_bias
+ | -0.000 | -0.091 | 0.086 | 0.021 | torch.Size([360, 120]) || stage5.residual_group1.blocks.0.attn.qkv_self.weight
+ | -0.000 | -0.014 | 0.012 | 0.004 | torch.Size([360]) || stage5.residual_group1.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.166 | 0.172 | 0.021 | torch.Size([120, 240]) || stage5.residual_group1.blocks.0.attn.proj.weight
+ | -0.001 | -0.053 | 0.045 | 0.018 | torch.Size([120]) || stage5.residual_group1.blocks.0.attn.proj.bias
+ | -0.000 | -0.090 | 0.081 | 0.020 | torch.Size([360, 120]) || stage5.residual_group1.blocks.0.attn.qkv_mut.weight
+ | 0.000 | -0.006 | 0.006 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.999 | 0.987 | 1.001 | 0.002 | torch.Size([120]) || stage5.residual_group1.blocks.0.norm2.weight
+ | 0.000 | -0.006 | 0.006 | 0.002 | torch.Size([120]) || stage5.residual_group1.blocks.0.norm2.bias
+ | 0.000 | -0.094 | 0.079 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.0.mlp.fc11.weight
+ | 0.000 | -0.022 | 0.012 | 0.004 | torch.Size([240]) || stage5.residual_group1.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.082 | 0.083 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.0.mlp.fc12.weight
+ | 0.000 | -0.013 | 0.014 | 0.005 | torch.Size([240]) || stage5.residual_group1.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.075 | 0.083 | 0.020 | torch.Size([120, 240]) || stage5.residual_group1.blocks.0.mlp.fc2.weight
+ | 0.000 | -0.073 | 0.078 | 0.021 | torch.Size([120]) || stage5.residual_group1.blocks.0.mlp.fc2.bias
+ | 1.001 | 0.994 | 1.007 | 0.002 | torch.Size([120]) || stage5.residual_group1.blocks.1.norm1.weight
+ | -0.004 | -0.016 | 0.004 | 0.004 | torch.Size([120]) || stage5.residual_group1.blocks.1.norm1.bias
+ | 0.000 | -0.065 | 0.063 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.1.attn.position_bias
+ | -0.000 | -0.077 | 0.083 | 0.020 | torch.Size([360, 120]) || stage5.residual_group1.blocks.1.attn.qkv_self.weight
+ | 0.000 | -0.022 | 0.017 | 0.003 | torch.Size([360]) || stage5.residual_group1.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.113 | 0.098 | 0.021 | torch.Size([120, 240]) || stage5.residual_group1.blocks.1.attn.proj.weight
+ | 0.000 | -0.058 | 0.045 | 0.017 | torch.Size([120]) || stage5.residual_group1.blocks.1.attn.proj.bias
+ | 0.000 | -0.080 | 0.080 | 0.020 | torch.Size([360, 120]) || stage5.residual_group1.blocks.1.attn.qkv_mut.weight
+ | -0.000 | -0.008 | 0.007 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.999 | 0.982 | 1.001 | 0.003 | torch.Size([120]) || stage5.residual_group1.blocks.1.norm2.weight
+ | 0.000 | -0.006 | 0.005 | 0.002 | torch.Size([120]) || stage5.residual_group1.blocks.1.norm2.bias
+ | -0.000 | -0.076 | 0.083 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.1.mlp.fc11.weight
+ | 0.000 | -0.017 | 0.014 | 0.004 | torch.Size([240]) || stage5.residual_group1.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.080 | 0.086 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.1.mlp.fc12.weight
+ | -0.000 | -0.014 | 0.016 | 0.004 | torch.Size([240]) || stage5.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.096 | 0.079 | 0.020 | torch.Size([120, 240]) || stage5.residual_group1.blocks.1.mlp.fc2.weight
+ | 0.001 | -0.051 | 0.039 | 0.017 | torch.Size([120]) || stage5.residual_group1.blocks.1.mlp.fc2.bias
+ | 1.002 | 0.998 | 1.009 | 0.002 | torch.Size([120]) || stage5.residual_group1.blocks.2.norm1.weight
+ | -0.004 | -0.014 | 0.003 | 0.003 | torch.Size([120]) || stage5.residual_group1.blocks.2.norm1.bias
+ | 0.000 | -0.067 | 0.073 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.2.attn.position_bias
+ | 0.000 | -0.085 | 0.087 | 0.020 | torch.Size([360, 120]) || stage5.residual_group1.blocks.2.attn.qkv_self.weight
+ | 0.000 | -0.015 | 0.014 | 0.003 | torch.Size([360]) || stage5.residual_group1.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.108 | 0.095 | 0.020 | torch.Size([120, 240]) || stage5.residual_group1.blocks.2.attn.proj.weight
+ | -0.001 | -0.043 | 0.039 | 0.013 | torch.Size([120]) || stage5.residual_group1.blocks.2.attn.proj.bias
+ | -0.000 | -0.088 | 0.081 | 0.020 | torch.Size([360, 120]) || stage5.residual_group1.blocks.2.attn.qkv_mut.weight
+ | -0.000 | -0.009 | 0.007 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.999 | 0.978 | 1.001 | 0.003 | torch.Size([120]) || stage5.residual_group1.blocks.2.norm2.weight
+ | 0.000 | -0.003 | 0.004 | 0.002 | torch.Size([120]) || stage5.residual_group1.blocks.2.norm2.bias
+ | -0.000 | -0.076 | 0.081 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.000 | -0.012 | 0.019 | 0.004 | torch.Size([240]) || stage5.residual_group1.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.079 | 0.077 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.2.mlp.fc12.weight
+ | -0.001 | -0.014 | 0.012 | 0.004 | torch.Size([240]) || stage5.residual_group1.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.076 | 0.082 | 0.020 | torch.Size([120, 240]) || stage5.residual_group1.blocks.2.mlp.fc2.weight
+ | -0.000 | -0.047 | 0.043 | 0.017 | torch.Size([120]) || stage5.residual_group1.blocks.2.mlp.fc2.bias
+ | 1.002 | 0.978 | 1.015 | 0.005 | torch.Size([120]) || stage5.residual_group1.blocks.3.norm1.weight
+ | -0.004 | -0.013 | 0.004 | 0.003 | torch.Size([120]) || stage5.residual_group1.blocks.3.norm1.bias
+ | -0.000 | -0.084 | 0.070 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.3.attn.position_bias
+ | 0.000 | -0.078 | 0.082 | 0.020 | torch.Size([360, 120]) || stage5.residual_group1.blocks.3.attn.qkv_self.weight
+ | -0.000 | -0.014 | 0.014 | 0.003 | torch.Size([360]) || stage5.residual_group1.blocks.3.attn.qkv_self.bias
+ | -0.000 | -0.123 | 0.132 | 0.021 | torch.Size([120, 240]) || stage5.residual_group1.blocks.3.attn.proj.weight
+ | 0.001 | -0.028 | 0.044 | 0.015 | torch.Size([120]) || stage5.residual_group1.blocks.3.attn.proj.bias
+ | -0.000 | -0.082 | 0.089 | 0.020 | torch.Size([360, 120]) || stage5.residual_group1.blocks.3.attn.qkv_mut.weight
+ | -0.000 | -0.007 | 0.008 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.999 | 0.974 | 1.001 | 0.004 | torch.Size([120]) || stage5.residual_group1.blocks.3.norm2.weight
+ | 0.000 | -0.008 | 0.010 | 0.003 | torch.Size([120]) || stage5.residual_group1.blocks.3.norm2.bias
+ | 0.000 | -0.075 | 0.088 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.3.mlp.fc11.weight
+ | 0.000 | -0.014 | 0.019 | 0.005 | torch.Size([240]) || stage5.residual_group1.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.081 | 0.080 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.3.mlp.fc12.weight
+ | 0.000 | -0.031 | 0.020 | 0.006 | torch.Size([240]) || stage5.residual_group1.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.081 | 0.106 | 0.020 | torch.Size([120, 240]) || stage5.residual_group1.blocks.3.mlp.fc2.weight
+ | -0.002 | -0.046 | 0.042 | 0.017 | torch.Size([120]) || stage5.residual_group1.blocks.3.mlp.fc2.bias
+ | 1.003 | 0.944 | 1.017 | 0.009 | torch.Size([120]) || stage5.residual_group1.blocks.4.norm1.weight
+ | -0.005 | -0.015 | 0.004 | 0.004 | torch.Size([120]) || stage5.residual_group1.blocks.4.norm1.bias
+ | -0.000 | -0.071 | 0.067 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.4.attn.position_bias
+ | -0.000 | -0.085 | 0.090 | 0.021 | torch.Size([360, 120]) || stage5.residual_group1.blocks.4.attn.qkv_self.weight
+ | -0.000 | -0.021 | 0.013 | 0.004 | torch.Size([360]) || stage5.residual_group1.blocks.4.attn.qkv_self.bias
+ | 0.000 | -0.130 | 0.089 | 0.021 | torch.Size([120, 240]) || stage5.residual_group1.blocks.4.attn.proj.weight
+ | -0.001 | -0.036 | 0.024 | 0.011 | torch.Size([120]) || stage5.residual_group1.blocks.4.attn.proj.bias
+ | 0.000 | -0.086 | 0.076 | 0.020 | torch.Size([360, 120]) || stage5.residual_group1.blocks.4.attn.qkv_mut.weight
+ | 0.000 | -0.008 | 0.008 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.999 | 0.967 | 1.001 | 0.004 | torch.Size([120]) || stage5.residual_group1.blocks.4.norm2.weight
+ | 0.000 | -0.006 | 0.007 | 0.003 | torch.Size([120]) || stage5.residual_group1.blocks.4.norm2.bias
+ | 0.000 | -0.080 | 0.085 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.4.mlp.fc11.weight
+ | -0.001 | -0.015 | 0.010 | 0.004 | torch.Size([240]) || stage5.residual_group1.blocks.4.mlp.fc11.bias
+ | -0.000 | -0.081 | 0.077 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.4.mlp.fc12.weight
+ | -0.000 | -0.020 | 0.018 | 0.005 | torch.Size([240]) || stage5.residual_group1.blocks.4.mlp.fc12.bias
+ | 0.000 | -0.081 | 0.085 | 0.020 | torch.Size([120, 240]) || stage5.residual_group1.blocks.4.mlp.fc2.weight
+ | -0.001 | -0.037 | 0.050 | 0.014 | torch.Size([120]) || stage5.residual_group1.blocks.4.mlp.fc2.bias
+ | 1.004 | 0.976 | 1.039 | 0.008 | torch.Size([120]) || stage5.residual_group1.blocks.5.norm1.weight
+ | -0.005 | -0.015 | 0.005 | 0.004 | torch.Size([120]) || stage5.residual_group1.blocks.5.norm1.bias
+ | -0.000 | -0.070 | 0.076 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.5.attn.position_bias
+ | 0.000 | -0.099 | 0.097 | 0.021 | torch.Size([360, 120]) || stage5.residual_group1.blocks.5.attn.qkv_self.weight
+ | -0.000 | -0.011 | 0.012 | 0.003 | torch.Size([360]) || stage5.residual_group1.blocks.5.attn.qkv_self.bias
+ | -0.000 | -0.084 | 0.093 | 0.020 | torch.Size([120, 240]) || stage5.residual_group1.blocks.5.attn.proj.weight
+ | 0.000 | -0.038 | 0.035 | 0.012 | torch.Size([120]) || stage5.residual_group1.blocks.5.attn.proj.bias
+ | 0.000 | -0.087 | 0.082 | 0.020 | torch.Size([360, 120]) || stage5.residual_group1.blocks.5.attn.qkv_mut.weight
+ | 0.000 | -0.008 | 0.010 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.998 | 0.960 | 1.002 | 0.005 | torch.Size([120]) || stage5.residual_group1.blocks.5.norm2.weight
+ | 0.000 | -0.006 | 0.006 | 0.002 | torch.Size([120]) || stage5.residual_group1.blocks.5.norm2.bias
+ | -0.000 | -0.088 | 0.095 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.000 | -0.014 | 0.027 | 0.005 | torch.Size([240]) || stage5.residual_group1.blocks.5.mlp.fc11.bias
+ | -0.000 | -0.081 | 0.074 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.5.mlp.fc12.weight
+ | 0.000 | -0.013 | 0.025 | 0.004 | torch.Size([240]) || stage5.residual_group1.blocks.5.mlp.fc12.bias
+ | -0.000 | -0.100 | 0.086 | 0.020 | torch.Size([120, 240]) || stage5.residual_group1.blocks.5.mlp.fc2.weight
+ | 0.000 | -0.022 | 0.030 | 0.011 | torch.Size([120]) || stage5.residual_group1.blocks.5.mlp.fc2.bias
+ | -0.000 | -0.102 | 0.117 | 0.023 | torch.Size([120, 120]) || stage5.linear1.weight
+ | -0.003 | -0.297 | 0.242 | 0.084 | torch.Size([120]) || stage5.linear1.bias
+ | 0.999 | 0.971 | 1.008 | 0.005 | torch.Size([120]) || stage5.residual_group2.blocks.0.norm1.weight
+ | -0.000 | -0.035 | 0.034 | 0.011 | torch.Size([120]) || stage5.residual_group2.blocks.0.norm1.bias
+ | 0.000 | -0.079 | 0.074 | 0.020 | torch.Size([2475, 6]) || stage5.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage5.residual_group2.blocks.0.attn.relative_position_index
+ | -0.000 | -0.087 | 0.083 | 0.020 | torch.Size([360, 120]) || stage5.residual_group2.blocks.0.attn.qkv_self.weight
+ | -0.000 | -0.028 | 0.018 | 0.005 | torch.Size([360]) || stage5.residual_group2.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.079 | 0.082 | 0.021 | torch.Size([120, 120]) || stage5.residual_group2.blocks.0.attn.proj.weight
+ | -0.001 | -0.146 | 0.171 | 0.054 | torch.Size([120]) || stage5.residual_group2.blocks.0.attn.proj.bias
+ | 0.997 | 0.967 | 1.003 | 0.006 | torch.Size([120]) || stage5.residual_group2.blocks.0.norm2.weight
+ | 0.000 | -0.005 | 0.005 | 0.002 | torch.Size([120]) || stage5.residual_group2.blocks.0.norm2.bias
+ | -0.000 | -0.073 | 0.089 | 0.020 | torch.Size([240, 120]) || stage5.residual_group2.blocks.0.mlp.fc11.weight
+ | -0.002 | -0.017 | 0.008 | 0.004 | torch.Size([240]) || stage5.residual_group2.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.084 | 0.073 | 0.020 | torch.Size([240, 120]) || stage5.residual_group2.blocks.0.mlp.fc12.weight
+ | 0.000 | -0.013 | 0.011 | 0.003 | torch.Size([240]) || stage5.residual_group2.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.083 | 0.085 | 0.020 | torch.Size([120, 240]) || stage5.residual_group2.blocks.0.mlp.fc2.weight
+ | 0.000 | -0.103 | 0.140 | 0.037 | torch.Size([120]) || stage5.residual_group2.blocks.0.mlp.fc2.bias
+ | 0.999 | 0.986 | 1.010 | 0.004 | torch.Size([120]) || stage5.residual_group2.blocks.1.norm1.weight
+ | 0.000 | -0.035 | 0.034 | 0.010 | torch.Size([120]) || stage5.residual_group2.blocks.1.norm1.bias
+ | 0.000 | -0.087 | 0.074 | 0.020 | torch.Size([2475, 6]) || stage5.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage5.residual_group2.blocks.1.attn.relative_position_index
+ | -0.000 | -0.084 | 0.079 | 0.020 | torch.Size([360, 120]) || stage5.residual_group2.blocks.1.attn.qkv_self.weight
+ | 0.000 | -0.024 | 0.024 | 0.005 | torch.Size([360]) || stage5.residual_group2.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.077 | 0.078 | 0.021 | torch.Size([120, 120]) || stage5.residual_group2.blocks.1.attn.proj.weight
+ | -0.001 | -0.112 | 0.144 | 0.038 | torch.Size([120]) || stage5.residual_group2.blocks.1.attn.proj.bias
+ | 0.998 | 0.965 | 1.004 | 0.006 | torch.Size([120]) || stage5.residual_group2.blocks.1.norm2.weight
+ | 0.000 | -0.004 | 0.005 | 0.002 | torch.Size([120]) || stage5.residual_group2.blocks.1.norm2.bias
+ | 0.000 | -0.088 | 0.079 | 0.020 | torch.Size([240, 120]) || stage5.residual_group2.blocks.1.mlp.fc11.weight
+ | -0.001 | -0.012 | 0.015 | 0.004 | torch.Size([240]) || stage5.residual_group2.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.102 | 0.080 | 0.020 | torch.Size([240, 120]) || stage5.residual_group2.blocks.1.mlp.fc12.weight
+ | 0.000 | -0.012 | 0.009 | 0.004 | torch.Size([240]) || stage5.residual_group2.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.075 | 0.078 | 0.020 | torch.Size([120, 240]) || stage5.residual_group2.blocks.1.mlp.fc2.weight
+ | 0.000 | -0.105 | 0.131 | 0.042 | torch.Size([120]) || stage5.residual_group2.blocks.1.mlp.fc2.bias
+ | -0.000 | -0.220 | 0.209 | 0.035 | torch.Size([120, 120]) || stage5.linear2.weight
+ | -0.003 | -0.335 | 0.284 | 0.096 | torch.Size([120]) || stage5.linear2.bias
+ | -0.000 | -0.064 | 0.065 | 0.019 | torch.Size([120, 120, 3, 3]) || stage5.pa_deform.weight
+ | 0.001 | -0.050 | 0.050 | 0.029 | torch.Size([120]) || stage5.pa_deform.bias
+ | 0.000 | -0.119 | 0.106 | 0.013 | torch.Size([120, 242, 3, 3]) || stage5.pa_deform.conv_offset.0.weight
+ | -0.006 | -0.030 | 0.026 | 0.014 | torch.Size([120]) || stage5.pa_deform.conv_offset.0.bias
+ | -0.001 | -0.055 | 0.050 | 0.018 | torch.Size([120, 120, 3, 3]) || stage5.pa_deform.conv_offset.2.weight
+ | 0.001 | -0.033 | 0.031 | 0.018 | torch.Size([120]) || stage5.pa_deform.conv_offset.2.bias
+ | 0.001 | -0.060 | 0.050 | 0.018 | torch.Size([120, 120, 3, 3]) || stage5.pa_deform.conv_offset.4.weight
+ | -0.005 | -0.040 | 0.037 | 0.019 | torch.Size([120]) || stage5.pa_deform.conv_offset.4.bias
+ | 0.001 | -0.038 | 0.051 | 0.006 | torch.Size([324, 120, 3, 3]) || stage5.pa_deform.conv_offset.6.weight
+ | 0.000 | -0.048 | 0.050 | 0.017 | torch.Size([324]) || stage5.pa_deform.conv_offset.6.bias
+ | 0.000 | -0.334 | 0.340 | 0.036 | torch.Size([360, 360]) || stage5.pa_fuse.fc11.weight
+ | 0.037 | -0.050 | 0.294 | 0.064 | torch.Size([360]) || stage5.pa_fuse.fc11.bias
+ | -0.000 | -0.343 | 0.349 | 0.036 | torch.Size([360, 360]) || stage5.pa_fuse.fc12.weight
+ | -0.001 | -0.237 | 0.244 | 0.049 | torch.Size([360]) || stage5.pa_fuse.fc12.bias
+ | -0.000 | -0.575 | 0.591 | 0.060 | torch.Size([120, 360]) || stage5.pa_fuse.fc2.weight
+ | -0.001 | -0.404 | 0.344 | 0.122 | torch.Size([120]) || stage5.pa_fuse.fc2.bias
+ | 1.254 | 1.058 | 1.466 | 0.126 | torch.Size([30]) || stage6.reshape.1.weight
+ | -0.001 | -0.074 | 0.093 | 0.041 | torch.Size([30]) || stage6.reshape.1.bias
+ | 0.000 | -0.734 | 0.625 | 0.177 | torch.Size([120, 30]) || stage6.reshape.2.weight
+ | 0.003 | -0.269 | 0.341 | 0.108 | torch.Size([120]) || stage6.reshape.2.bias
+ | 0.815 | 0.495 | 1.118 | 0.121 | torch.Size([120]) || stage6.residual_group1.blocks.0.norm1.weight
+ | -0.071 | -0.291 | 0.263 | 0.101 | torch.Size([120]) || stage6.residual_group1.blocks.0.norm1.bias
+ | -0.000 | -0.080 | 0.087 | 0.021 | torch.Size([675, 6]) || stage6.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.0.attn.position_bias
+ | 0.000 | -0.136 | 0.134 | 0.026 | torch.Size([360, 120]) || stage6.residual_group1.blocks.0.attn.qkv_self.weight
+ | -0.000 | -0.061 | 0.037 | 0.014 | torch.Size([360]) || stage6.residual_group1.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.201 | 0.182 | 0.032 | torch.Size([120, 240]) || stage6.residual_group1.blocks.0.attn.proj.weight
+ | 0.000 | -0.223 | 0.189 | 0.090 | torch.Size([120]) || stage6.residual_group1.blocks.0.attn.proj.bias
+ | 0.000 | -0.184 | 0.211 | 0.029 | torch.Size([360, 120]) || stage6.residual_group1.blocks.0.attn.qkv_mut.weight
+ | 0.000 | -0.049 | 0.069 | 0.011 | torch.Size([360]) || stage6.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.710 | 0.556 | 0.893 | 0.072 | torch.Size([120]) || stage6.residual_group1.blocks.0.norm2.weight
+ | -0.003 | -0.172 | 0.193 | 0.070 | torch.Size([120]) || stage6.residual_group1.blocks.0.norm2.bias
+ | 0.000 | -0.217 | 0.211 | 0.033 | torch.Size([240, 120]) || stage6.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.041 | -0.158 | 0.025 | 0.036 | torch.Size([240]) || stage6.residual_group1.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.209 | 0.178 | 0.031 | torch.Size([240, 120]) || stage6.residual_group1.blocks.0.mlp.fc12.weight
+ | -0.000 | -0.141 | 0.186 | 0.031 | torch.Size([240]) || stage6.residual_group1.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.245 | 0.347 | 0.037 | torch.Size([120, 240]) || stage6.residual_group1.blocks.0.mlp.fc2.weight
+ | 0.005 | -0.161 | 0.188 | 0.079 | torch.Size([120]) || stage6.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.780 | 0.582 | 0.963 | 0.088 | torch.Size([120]) || stage6.residual_group1.blocks.1.norm1.weight
+ | -0.112 | -0.302 | 0.103 | 0.085 | torch.Size([120]) || stage6.residual_group1.blocks.1.norm1.bias
+ | 0.000 | -0.101 | 0.072 | 0.021 | torch.Size([675, 6]) || stage6.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.1.attn.position_bias
+ | 0.000 | -0.112 | 0.178 | 0.026 | torch.Size([360, 120]) || stage6.residual_group1.blocks.1.attn.qkv_self.weight
+ | -0.000 | -0.034 | 0.049 | 0.009 | torch.Size([360]) || stage6.residual_group1.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.223 | 0.242 | 0.033 | torch.Size([120, 240]) || stage6.residual_group1.blocks.1.attn.proj.weight
+ | -0.003 | -0.149 | 0.105 | 0.047 | torch.Size([120]) || stage6.residual_group1.blocks.1.attn.proj.bias
+ | 0.000 | -0.199 | 0.173 | 0.031 | torch.Size([360, 120]) || stage6.residual_group1.blocks.1.attn.qkv_mut.weight
+ | 0.000 | -0.035 | 0.056 | 0.009 | torch.Size([360]) || stage6.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.744 | 0.530 | 0.917 | 0.066 | torch.Size([120]) || stage6.residual_group1.blocks.1.norm2.weight
+ | 0.004 | -0.131 | 0.180 | 0.059 | torch.Size([120]) || stage6.residual_group1.blocks.1.norm2.bias
+ | 0.000 | -0.243 | 0.294 | 0.036 | torch.Size([240, 120]) || stage6.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.039 | -0.217 | 0.045 | 0.037 | torch.Size([240]) || stage6.residual_group1.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.206 | 0.178 | 0.033 | torch.Size([240, 120]) || stage6.residual_group1.blocks.1.mlp.fc12.weight
+ | -0.000 | -0.129 | 0.125 | 0.028 | torch.Size([240]) || stage6.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.236 | 0.276 | 0.040 | torch.Size([120, 240]) || stage6.residual_group1.blocks.1.mlp.fc2.weight
+ | 0.000 | -0.158 | 0.170 | 0.063 | torch.Size([120]) || stage6.residual_group1.blocks.1.mlp.fc2.bias
+ | 0.829 | 0.586 | 1.007 | 0.078 | torch.Size([120]) || stage6.residual_group1.blocks.2.norm1.weight
+ | -0.101 | -0.353 | 0.132 | 0.092 | torch.Size([120]) || stage6.residual_group1.blocks.2.norm1.bias
+ | -0.000 | -0.082 | 0.076 | 0.021 | torch.Size([675, 6]) || stage6.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.2.attn.position_bias
+ | 0.000 | -0.154 | 0.143 | 0.032 | torch.Size([360, 120]) || stage6.residual_group1.blocks.2.attn.qkv_self.weight
+ | 0.000 | -0.041 | 0.038 | 0.012 | torch.Size([360]) || stage6.residual_group1.blocks.2.attn.qkv_self.bias
+ | 0.000 | -0.187 | 0.202 | 0.035 | torch.Size([120, 240]) || stage6.residual_group1.blocks.2.attn.proj.weight
+ | 0.002 | -0.096 | 0.127 | 0.041 | torch.Size([120]) || stage6.residual_group1.blocks.2.attn.proj.bias
+ | -0.000 | -0.203 | 0.185 | 0.033 | torch.Size([360, 120]) || stage6.residual_group1.blocks.2.attn.qkv_mut.weight
+ | -0.000 | -0.045 | 0.049 | 0.009 | torch.Size([360]) || stage6.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.768 | 0.491 | 0.904 | 0.069 | torch.Size([120]) || stage6.residual_group1.blocks.2.norm2.weight
+ | 0.001 | -0.146 | 0.159 | 0.062 | torch.Size([120]) || stage6.residual_group1.blocks.2.norm2.bias
+ | -0.000 | -0.184 | 0.204 | 0.037 | torch.Size([240, 120]) || stage6.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.043 | -0.185 | 0.020 | 0.035 | torch.Size([240]) || stage6.residual_group1.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.188 | 0.270 | 0.035 | torch.Size([240, 120]) || stage6.residual_group1.blocks.2.mlp.fc12.weight
+ | 0.000 | -0.152 | 0.134 | 0.031 | torch.Size([240]) || stage6.residual_group1.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.222 | 0.217 | 0.042 | torch.Size([120, 240]) || stage6.residual_group1.blocks.2.mlp.fc2.weight
+ | 0.002 | -0.141 | 0.144 | 0.058 | torch.Size([120]) || stage6.residual_group1.blocks.2.mlp.fc2.bias
+ | 0.820 | 0.554 | 0.976 | 0.065 | torch.Size([120]) || stage6.residual_group1.blocks.3.norm1.weight
+ | -0.091 | -0.336 | 0.137 | 0.087 | torch.Size([120]) || stage6.residual_group1.blocks.3.norm1.bias
+ | 0.000 | -0.124 | 0.222 | 0.023 | torch.Size([675, 6]) || stage6.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.3.attn.position_bias
+ | 0.000 | -0.157 | 0.175 | 0.036 | torch.Size([360, 120]) || stage6.residual_group1.blocks.3.attn.qkv_self.weight
+ | -0.001 | -0.049 | 0.049 | 0.014 | torch.Size([360]) || stage6.residual_group1.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.238 | 0.236 | 0.036 | torch.Size([120, 240]) || stage6.residual_group1.blocks.3.attn.proj.weight
+ | -0.003 | -0.077 | 0.074 | 0.031 | torch.Size([120]) || stage6.residual_group1.blocks.3.attn.proj.bias
+ | 0.000 | -0.212 | 0.265 | 0.033 | torch.Size([360, 120]) || stage6.residual_group1.blocks.3.attn.qkv_mut.weight
+ | 0.000 | -0.028 | 0.052 | 0.009 | torch.Size([360]) || stage6.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.768 | 0.530 | 0.903 | 0.080 | torch.Size([120]) || stage6.residual_group1.blocks.3.norm2.weight
+ | 0.002 | -0.104 | 0.157 | 0.044 | torch.Size([120]) || stage6.residual_group1.blocks.3.norm2.bias
+ | -0.000 | -0.197 | 0.220 | 0.039 | torch.Size([240, 120]) || stage6.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.042 | -0.155 | 0.043 | 0.039 | torch.Size([240]) || stage6.residual_group1.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.166 | 0.199 | 0.036 | torch.Size([240, 120]) || stage6.residual_group1.blocks.3.mlp.fc12.weight
+ | 0.001 | -0.102 | 0.138 | 0.040 | torch.Size([240]) || stage6.residual_group1.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.241 | 0.256 | 0.044 | torch.Size([120, 240]) || stage6.residual_group1.blocks.3.mlp.fc2.weight
+ | 0.003 | -0.123 | 0.115 | 0.046 | torch.Size([120]) || stage6.residual_group1.blocks.3.mlp.fc2.bias
+ | 0.817 | 0.631 | 0.918 | 0.055 | torch.Size([120]) || stage6.residual_group1.blocks.4.norm1.weight
+ | -0.082 | -0.295 | 0.141 | 0.074 | torch.Size([120]) || stage6.residual_group1.blocks.4.norm1.bias
+ | -0.000 | -0.084 | 0.205 | 0.024 | torch.Size([675, 6]) || stage6.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.4.attn.position_bias
+ | -0.000 | -0.174 | 0.199 | 0.040 | torch.Size([360, 120]) || stage6.residual_group1.blocks.4.attn.qkv_self.weight
+ | -0.000 | -0.060 | 0.081 | 0.017 | torch.Size([360]) || stage6.residual_group1.blocks.4.attn.qkv_self.bias
+ | -0.000 | -0.194 | 0.191 | 0.037 | torch.Size([120, 240]) || stage6.residual_group1.blocks.4.attn.proj.weight
+ | 0.001 | -0.083 | 0.077 | 0.035 | torch.Size([120]) || stage6.residual_group1.blocks.4.attn.proj.bias
+ | -0.000 | -0.218 | 0.243 | 0.033 | torch.Size([360, 120]) || stage6.residual_group1.blocks.4.attn.qkv_mut.weight
+ | -0.000 | -0.031 | 0.024 | 0.007 | torch.Size([360]) || stage6.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.744 | 0.478 | 0.913 | 0.082 | torch.Size([120]) || stage6.residual_group1.blocks.4.norm2.weight
+ | -0.003 | -0.146 | 0.110 | 0.053 | torch.Size([120]) || stage6.residual_group1.blocks.4.norm2.bias
+ | -0.000 | -0.223 | 0.238 | 0.042 | torch.Size([240, 120]) || stage6.residual_group1.blocks.4.mlp.fc11.weight
+ | -0.046 | -0.200 | 0.071 | 0.051 | torch.Size([240]) || stage6.residual_group1.blocks.4.mlp.fc11.bias
+ | -0.000 | -0.168 | 0.201 | 0.039 | torch.Size([240, 120]) || stage6.residual_group1.blocks.4.mlp.fc12.weight
+ | 0.002 | -0.128 | 0.141 | 0.053 | torch.Size([240]) || stage6.residual_group1.blocks.4.mlp.fc12.bias
+ | -0.000 | -0.220 | 0.205 | 0.047 | torch.Size([120, 240]) || stage6.residual_group1.blocks.4.mlp.fc2.weight
+ | 0.001 | -0.086 | 0.094 | 0.034 | torch.Size([120]) || stage6.residual_group1.blocks.4.mlp.fc2.bias
+ | 0.754 | 0.353 | 0.933 | 0.056 | torch.Size([120]) || stage6.residual_group1.blocks.5.norm1.weight
+ | -0.058 | -0.246 | 0.105 | 0.060 | torch.Size([120]) || stage6.residual_group1.blocks.5.norm1.bias
+ | -0.000 | -0.113 | 0.536 | 0.030 | torch.Size([675, 6]) || stage6.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.5.attn.position_bias
+ | 0.000 | -0.261 | 0.224 | 0.044 | torch.Size([360, 120]) || stage6.residual_group1.blocks.5.attn.qkv_self.weight
+ | 0.002 | -0.050 | 0.067 | 0.018 | torch.Size([360]) || stage6.residual_group1.blocks.5.attn.qkv_self.bias
+ | 0.000 | -0.234 | 0.256 | 0.038 | torch.Size([120, 240]) || stage6.residual_group1.blocks.5.attn.proj.weight
+ | 0.002 | -0.079 | 0.076 | 0.036 | torch.Size([120]) || stage6.residual_group1.blocks.5.attn.proj.bias
+ | -0.000 | -0.211 | 0.231 | 0.029 | torch.Size([360, 120]) || stage6.residual_group1.blocks.5.attn.qkv_mut.weight
+ | 0.000 | -0.033 | 0.030 | 0.008 | torch.Size([360]) || stage6.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.677 | 0.275 | 0.833 | 0.083 | torch.Size([120]) || stage6.residual_group1.blocks.5.norm2.weight
+ | 0.001 | -0.224 | 0.306 | 0.102 | torch.Size([120]) || stage6.residual_group1.blocks.5.norm2.bias
+ | -0.000 | -0.196 | 0.211 | 0.045 | torch.Size([240, 120]) || stage6.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.061 | -0.289 | 0.136 | 0.089 | torch.Size([240]) || stage6.residual_group1.blocks.5.mlp.fc11.bias
+ | -0.000 | -0.271 | 0.312 | 0.048 | torch.Size([240, 120]) || stage6.residual_group1.blocks.5.mlp.fc12.weight
+ | 0.003 | -0.166 | 0.155 | 0.075 | torch.Size([240]) || stage6.residual_group1.blocks.5.mlp.fc12.bias
+ | 0.000 | -0.286 | 0.375 | 0.054 | torch.Size([120, 240]) || stage6.residual_group1.blocks.5.mlp.fc2.weight
+ | 0.005 | -0.054 | 0.137 | 0.031 | torch.Size([120]) || stage6.residual_group1.blocks.5.mlp.fc2.bias
+ | -0.000 | -0.174 | 0.172 | 0.039 | torch.Size([120, 120]) || stage6.linear1.weight
+ | 0.002 | -0.275 | 0.348 | 0.113 | torch.Size([120]) || stage6.linear1.bias
+ | 0.704 | 0.402 | 1.002 | 0.132 | torch.Size([120]) || stage6.residual_group2.blocks.0.norm1.weight
+ | 0.001 | -0.466 | 0.407 | 0.157 | torch.Size([120]) || stage6.residual_group2.blocks.0.norm1.bias
+ | -0.000 | -0.172 | 0.570 | 0.025 | torch.Size([2475, 6]) || stage6.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage6.residual_group2.blocks.0.attn.relative_position_index
+ | 0.000 | -0.337 | 0.378 | 0.041 | torch.Size([360, 120]) || stage6.residual_group2.blocks.0.attn.qkv_self.weight
+ | -0.000 | -0.071 | 0.068 | 0.019 | torch.Size([360]) || stage6.residual_group2.blocks.0.attn.qkv_self.bias
+ | 0.001 | -0.290 | 0.321 | 0.055 | torch.Size([120, 120]) || stage6.residual_group2.blocks.0.attn.proj.weight
+ | 0.001 | -0.255 | 0.250 | 0.104 | torch.Size([120]) || stage6.residual_group2.blocks.0.attn.proj.bias
+ | 0.695 | 0.353 | 0.966 | 0.098 | torch.Size([120]) || stage6.residual_group2.blocks.0.norm2.weight
+ | -0.001 | -0.218 | 0.165 | 0.080 | torch.Size([120]) || stage6.residual_group2.blocks.0.norm2.bias
+ | 0.000 | -0.259 | 0.255 | 0.039 | torch.Size([240, 120]) || stage6.residual_group2.blocks.0.mlp.fc11.weight
+ | -0.044 | -0.256 | 0.042 | 0.047 | torch.Size([240]) || stage6.residual_group2.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.234 | 0.214 | 0.035 | torch.Size([240, 120]) || stage6.residual_group2.blocks.0.mlp.fc12.weight
+ | 0.002 | -0.133 | 0.091 | 0.027 | torch.Size([240]) || stage6.residual_group2.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.333 | 0.296 | 0.042 | torch.Size([120, 240]) || stage6.residual_group2.blocks.0.mlp.fc2.weight
+ | 0.003 | -0.238 | 0.280 | 0.092 | torch.Size([120]) || stage6.residual_group2.blocks.0.mlp.fc2.bias
+ | 0.671 | 0.425 | 0.980 | 0.094 | torch.Size([120]) || stage6.residual_group2.blocks.1.norm1.weight
+ | 0.001 | -0.261 | 0.305 | 0.119 | torch.Size([120]) || stage6.residual_group2.blocks.1.norm1.bias
+ | -0.000 | -0.372 | 0.942 | 0.031 | torch.Size([2475, 6]) || stage6.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage6.residual_group2.blocks.1.attn.relative_position_index
+ | 0.000 | -0.450 | 0.494 | 0.045 | torch.Size([360, 120]) || stage6.residual_group2.blocks.1.attn.qkv_self.weight
+ | 0.000 | -0.133 | 0.119 | 0.029 | torch.Size([360]) || stage6.residual_group2.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.239 | 0.288 | 0.046 | torch.Size([120, 120]) || stage6.residual_group2.blocks.1.attn.proj.weight
+ | -0.001 | -0.187 | 0.157 | 0.064 | torch.Size([120]) || stage6.residual_group2.blocks.1.attn.proj.bias
+ | 0.687 | 0.160 | 0.907 | 0.128 | torch.Size([120]) || stage6.residual_group2.blocks.1.norm2.weight
+ | -0.002 | -0.192 | 0.222 | 0.084 | torch.Size([120]) || stage6.residual_group2.blocks.1.norm2.bias
+ | 0.000 | -0.257 | 0.426 | 0.042 | torch.Size([240, 120]) || stage6.residual_group2.blocks.1.mlp.fc11.weight
+ | -0.064 | -0.207 | 0.036 | 0.048 | torch.Size([240]) || stage6.residual_group2.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.269 | 0.224 | 0.038 | torch.Size([240, 120]) || stage6.residual_group2.blocks.1.mlp.fc12.weight
+ | -0.000 | -0.126 | 0.129 | 0.030 | torch.Size([240]) || stage6.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.308 | 0.298 | 0.041 | torch.Size([120, 240]) || stage6.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.004 | -0.180 | 0.192 | 0.061 | torch.Size([120]) || stage6.residual_group2.blocks.1.mlp.fc2.bias
+ | -0.000 | -0.297 | 0.368 | 0.069 | torch.Size([120, 120]) || stage6.linear2.weight
+ | 0.001 | -0.431 | 0.480 | 0.189 | torch.Size([120]) || stage6.linear2.bias
+ | 0.000 | -0.100 | 0.104 | 0.023 | torch.Size([120, 120, 3, 3]) || stage6.pa_deform.weight
+ | 0.001 | -0.018 | 0.029 | 0.010 | torch.Size([120]) || stage6.pa_deform.bias
+ | 0.000 | -0.105 | 0.111 | 0.015 | torch.Size([120, 242, 3, 3]) || stage6.pa_deform.conv_offset.0.weight
+ | -0.007 | -0.033 | 0.024 | 0.014 | torch.Size([120]) || stage6.pa_deform.conv_offset.0.bias
+ | -0.001 | -0.071 | 0.067 | 0.019 | torch.Size([120, 120, 3, 3]) || stage6.pa_deform.conv_offset.2.weight
+ | -0.003 | -0.061 | 0.043 | 0.022 | torch.Size([120]) || stage6.pa_deform.conv_offset.2.bias
+ | -0.000 | -0.074 | 0.068 | 0.019 | torch.Size([120, 120, 3, 3]) || stage6.pa_deform.conv_offset.4.weight
+ | 0.001 | -0.075 | 0.056 | 0.030 | torch.Size([120]) || stage6.pa_deform.conv_offset.4.bias
+ | 0.001 | -0.124 | 0.108 | 0.013 | torch.Size([324, 120, 3, 3]) || stage6.pa_deform.conv_offset.6.weight
+ | -0.001 | -0.113 | 0.076 | 0.021 | torch.Size([324]) || stage6.pa_deform.conv_offset.6.bias
+ | -0.001 | -0.517 | 0.524 | 0.101 | torch.Size([360, 360]) || stage6.pa_fuse.fc11.weight
+ | 0.154 | -0.305 | 0.679 | 0.180 | torch.Size([360]) || stage6.pa_fuse.fc11.bias
+ | 0.000 | -0.680 | 0.728 | 0.103 | torch.Size([360, 360]) || stage6.pa_fuse.fc12.weight
+ | 0.020 | -0.514 | 0.417 | 0.199 | torch.Size([360]) || stage6.pa_fuse.fc12.bias
+ | -0.000 | -0.587 | 0.737 | 0.135 | torch.Size([120, 360]) || stage6.pa_fuse.fc2.weight
+ | 0.015 | -0.437 | 0.490 | 0.230 | torch.Size([120]) || stage6.pa_fuse.fc2.bias
+ | 1.284 | 1.119 | 1.404 | 0.055 | torch.Size([30]) || stage7.reshape.1.weight
+ | -0.014 | -0.286 | 0.184 | 0.122 | torch.Size([30]) || stage7.reshape.1.bias
+ | -0.000 | -0.521 | 0.576 | 0.154 | torch.Size([120, 30]) || stage7.reshape.2.weight
+ | 0.004 | -0.387 | 0.738 | 0.175 | torch.Size([120]) || stage7.reshape.2.bias
+ | 0.440 | 0.099 | 0.775 | 0.141 | torch.Size([120]) || stage7.residual_group1.blocks.0.norm1.weight
+ | -0.177 | -0.670 | 0.319 | 0.183 | torch.Size([120]) || stage7.residual_group1.blocks.0.norm1.bias
+ | -0.055 | -2.159 | 1.979 | 0.240 | torch.Size([675, 6]) || stage7.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.0.attn.position_bias
+ | -0.000 | -0.535 | 0.554 | 0.104 | torch.Size([360, 120]) || stage7.residual_group1.blocks.0.attn.qkv_self.weight
+ | 0.003 | -0.193 | 0.281 | 0.053 | torch.Size([360]) || stage7.residual_group1.blocks.0.attn.qkv_self.bias
+ | -0.001 | -0.397 | 0.395 | 0.075 | torch.Size([120, 240]) || stage7.residual_group1.blocks.0.attn.proj.weight
+ | -0.001 | -0.232 | 0.692 | 0.106 | torch.Size([120]) || stage7.residual_group1.blocks.0.attn.proj.bias
+ | -0.000 | -0.899 | 1.073 | 0.091 | torch.Size([360, 120]) || stage7.residual_group1.blocks.0.attn.qkv_mut.weight
+ | -0.000 | -0.122 | 0.104 | 0.017 | torch.Size([360]) || stage7.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.310 | 0.157 | 0.440 | 0.055 | torch.Size([120]) || stage7.residual_group1.blocks.0.norm2.weight
+ | 0.006 | -0.474 | 0.266 | 0.105 | torch.Size([120]) || stage7.residual_group1.blocks.0.norm2.bias
+ | -0.000 | -0.605 | 0.490 | 0.115 | torch.Size([240, 120]) || stage7.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.101 | -0.310 | 0.126 | 0.070 | torch.Size([240]) || stage7.residual_group1.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.448 | 0.475 | 0.116 | torch.Size([240, 120]) || stage7.residual_group1.blocks.0.mlp.fc12.weight
+ | 0.006 | -0.185 | 0.215 | 0.071 | torch.Size([240]) || stage7.residual_group1.blocks.0.mlp.fc12.bias
+ | 0.001 | -0.465 | 0.512 | 0.122 | torch.Size([120, 240]) || stage7.residual_group1.blocks.0.mlp.fc2.weight
+ | 0.000 | -0.150 | 0.417 | 0.077 | torch.Size([120]) || stage7.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.577 | 0.165 | 0.829 | 0.105 | torch.Size([120]) || stage7.residual_group1.blocks.1.norm1.weight
+ | -0.136 | -0.849 | 0.206 | 0.141 | torch.Size([120]) || stage7.residual_group1.blocks.1.norm1.bias
+ | -0.143 | -3.020 | 4.621 | 0.357 | torch.Size([675, 6]) || stage7.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.1.attn.position_bias
+ | 0.000 | -0.647 | 0.640 | 0.123 | torch.Size([360, 120]) || stage7.residual_group1.blocks.1.attn.qkv_self.weight
+ | -0.002 | -0.356 | 0.382 | 0.064 | torch.Size([360]) || stage7.residual_group1.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.457 | 0.378 | 0.081 | torch.Size([120, 240]) || stage7.residual_group1.blocks.1.attn.proj.weight
+ | 0.000 | -0.250 | 0.707 | 0.108 | torch.Size([120]) || stage7.residual_group1.blocks.1.attn.proj.bias
+ | -0.001 | -1.055 | 1.091 | 0.096 | torch.Size([360, 120]) || stage7.residual_group1.blocks.1.attn.qkv_mut.weight
+ | -0.001 | -0.093 | 0.123 | 0.018 | torch.Size([360]) || stage7.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.411 | 0.265 | 0.535 | 0.044 | torch.Size([120]) || stage7.residual_group1.blocks.1.norm2.weight
+ | 0.008 | -0.630 | 0.264 | 0.121 | torch.Size([120]) || stage7.residual_group1.blocks.1.norm2.bias
+ | 0.000 | -0.501 | 0.506 | 0.119 | torch.Size([240, 120]) || stage7.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.087 | -0.341 | 0.140 | 0.073 | torch.Size([240]) || stage7.residual_group1.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.450 | 0.527 | 0.119 | torch.Size([240, 120]) || stage7.residual_group1.blocks.1.mlp.fc12.weight
+ | 0.005 | -0.188 | 0.171 | 0.063 | torch.Size([240]) || stage7.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.554 | 0.546 | 0.121 | torch.Size([120, 240]) || stage7.residual_group1.blocks.1.mlp.fc2.weight
+ | -0.000 | -0.135 | 0.220 | 0.061 | torch.Size([120]) || stage7.residual_group1.blocks.1.mlp.fc2.bias
+ | 0.655 | 0.134 | 0.896 | 0.130 | torch.Size([120]) || stage7.residual_group1.blocks.2.norm1.weight
+ | -0.139 | -0.788 | 0.181 | 0.115 | torch.Size([120]) || stage7.residual_group1.blocks.2.norm1.bias
+ | -0.062 | -3.469 | 3.276 | 0.272 | torch.Size([675, 6]) || stage7.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.2.attn.position_bias
+ | -0.000 | -0.592 | 0.650 | 0.124 | torch.Size([360, 120]) || stage7.residual_group1.blocks.2.attn.qkv_self.weight
+ | -0.000 | -0.308 | 0.218 | 0.062 | torch.Size([360]) || stage7.residual_group1.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.355 | 0.345 | 0.082 | torch.Size([120, 240]) || stage7.residual_group1.blocks.2.attn.proj.weight
+ | 0.002 | -0.213 | 0.700 | 0.097 | torch.Size([120]) || stage7.residual_group1.blocks.2.attn.proj.bias
+ | -0.001 | -1.166 | 0.942 | 0.107 | torch.Size([360, 120]) || stage7.residual_group1.blocks.2.attn.qkv_mut.weight
+ | 0.000 | -0.106 | 0.093 | 0.018 | torch.Size([360]) || stage7.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.466 | 0.317 | 0.565 | 0.042 | torch.Size([120]) || stage7.residual_group1.blocks.2.norm2.weight
+ | 0.014 | -0.657 | 0.280 | 0.118 | torch.Size([120]) || stage7.residual_group1.blocks.2.norm2.bias
+ | 0.000 | -0.541 | 0.494 | 0.118 | torch.Size([240, 120]) || stage7.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.079 | -0.335 | 0.122 | 0.080 | torch.Size([240]) || stage7.residual_group1.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.513 | 0.493 | 0.123 | torch.Size([240, 120]) || stage7.residual_group1.blocks.2.mlp.fc12.weight
+ | -0.007 | -0.180 | 0.175 | 0.066 | torch.Size([240]) || stage7.residual_group1.blocks.2.mlp.fc12.bias
+ | -0.001 | -0.509 | 0.479 | 0.123 | torch.Size([120, 240]) || stage7.residual_group1.blocks.2.mlp.fc2.weight
+ | 0.004 | -0.093 | 0.293 | 0.054 | torch.Size([120]) || stage7.residual_group1.blocks.2.mlp.fc2.bias
+ | 0.693 | 0.147 | 0.945 | 0.133 | torch.Size([120]) || stage7.residual_group1.blocks.3.norm1.weight
+ | -0.132 | -0.906 | 0.249 | 0.113 | torch.Size([120]) || stage7.residual_group1.blocks.3.norm1.bias
+ | -0.108 | -3.576 | 4.241 | 0.344 | torch.Size([675, 6]) || stage7.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.3.attn.position_bias
+ | -0.000 | -0.945 | 1.095 | 0.129 | torch.Size([360, 120]) || stage7.residual_group1.blocks.3.attn.qkv_self.weight
+ | 0.003 | -0.274 | 0.204 | 0.061 | torch.Size([360]) || stage7.residual_group1.blocks.3.attn.qkv_self.bias
+ | -0.001 | -0.379 | 0.351 | 0.081 | torch.Size([120, 240]) || stage7.residual_group1.blocks.3.attn.proj.weight
+ | 0.000 | -0.211 | 0.587 | 0.095 | torch.Size([120]) || stage7.residual_group1.blocks.3.attn.proj.bias
+ | -0.000 | -1.269 | 1.067 | 0.102 | torch.Size([360, 120]) || stage7.residual_group1.blocks.3.attn.qkv_mut.weight
+ | 0.001 | -0.091 | 0.117 | 0.021 | torch.Size([360]) || stage7.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.499 | 0.285 | 0.570 | 0.040 | torch.Size([120]) || stage7.residual_group1.blocks.3.norm2.weight
+ | 0.012 | -0.567 | 0.273 | 0.104 | torch.Size([120]) || stage7.residual_group1.blocks.3.norm2.bias
+ | 0.001 | -0.528 | 0.499 | 0.118 | torch.Size([240, 120]) || stage7.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.084 | -0.349 | 0.141 | 0.078 | torch.Size([240]) || stage7.residual_group1.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.547 | 0.592 | 0.126 | torch.Size([240, 120]) || stage7.residual_group1.blocks.3.mlp.fc12.weight
+ | 0.002 | -0.154 | 0.176 | 0.068 | torch.Size([240]) || stage7.residual_group1.blocks.3.mlp.fc12.bias
+ | 0.001 | -0.520 | 0.480 | 0.125 | torch.Size([120, 240]) || stage7.residual_group1.blocks.3.mlp.fc2.weight
+ | 0.001 | -0.150 | 0.207 | 0.065 | torch.Size([120]) || stage7.residual_group1.blocks.3.mlp.fc2.bias
+ | 0.726 | 0.137 | 1.004 | 0.160 | torch.Size([120]) || stage7.residual_group1.blocks.4.norm1.weight
+ | -0.122 | -0.907 | 0.180 | 0.103 | torch.Size([120]) || stage7.residual_group1.blocks.4.norm1.bias
+ | -0.078 | -3.824 | 4.241 | 0.297 | torch.Size([675, 6]) || stage7.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.4.attn.position_bias
+ | -0.000 | -1.188 | 0.796 | 0.127 | torch.Size([360, 120]) || stage7.residual_group1.blocks.4.attn.qkv_self.weight
+ | 0.002 | -0.248 | 0.207 | 0.056 | torch.Size([360]) || stage7.residual_group1.blocks.4.attn.qkv_self.bias
+ | -0.001 | -0.409 | 0.369 | 0.085 | torch.Size([120, 240]) || stage7.residual_group1.blocks.4.attn.proj.weight
+ | 0.002 | -0.224 | 0.322 | 0.094 | torch.Size([120]) || stage7.residual_group1.blocks.4.attn.proj.bias
+ | 0.000 | -1.744 | 1.273 | 0.110 | torch.Size([360, 120]) || stage7.residual_group1.blocks.4.attn.qkv_mut.weight
+ | 0.001 | -0.092 | 0.113 | 0.019 | torch.Size([360]) || stage7.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.514 | 0.277 | 0.614 | 0.041 | torch.Size([120]) || stage7.residual_group1.blocks.4.norm2.weight
+ | 0.016 | -0.621 | 0.286 | 0.095 | torch.Size([120]) || stage7.residual_group1.blocks.4.norm2.bias
+ | 0.001 | -0.517 | 0.453 | 0.116 | torch.Size([240, 120]) || stage7.residual_group1.blocks.4.mlp.fc11.weight
+ | -0.064 | -0.260 | 0.143 | 0.083 | torch.Size([240]) || stage7.residual_group1.blocks.4.mlp.fc11.bias
+ | 0.000 | -0.503 | 0.554 | 0.129 | torch.Size([240, 120]) || stage7.residual_group1.blocks.4.mlp.fc12.weight
+ | -0.004 | -0.232 | 0.193 | 0.075 | torch.Size([240]) || stage7.residual_group1.blocks.4.mlp.fc12.bias
+ | -0.001 | -0.595 | 0.543 | 0.128 | torch.Size([120, 240]) || stage7.residual_group1.blocks.4.mlp.fc2.weight
+ | 0.001 | -0.196 | 0.198 | 0.071 | torch.Size([120]) || stage7.residual_group1.blocks.4.mlp.fc2.bias
+ | 0.731 | 0.152 | 1.075 | 0.114 | torch.Size([120]) || stage7.residual_group1.blocks.5.norm1.weight
+ | -0.076 | -1.003 | 0.176 | 0.107 | torch.Size([120]) || stage7.residual_group1.blocks.5.norm1.bias
+ | -0.121 | -3.281 | 4.671 | 0.296 | torch.Size([675, 6]) || stage7.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.5.attn.position_bias
+ | -0.000 | -0.640 | 1.083 | 0.122 | torch.Size([360, 120]) || stage7.residual_group1.blocks.5.attn.qkv_self.weight
+ | -0.001 | -0.239 | 0.314 | 0.068 | torch.Size([360]) || stage7.residual_group1.blocks.5.attn.qkv_self.bias
+ | 0.001 | -0.344 | 0.452 | 0.078 | torch.Size([120, 240]) || stage7.residual_group1.blocks.5.attn.proj.weight
+ | 0.004 | -0.361 | 0.251 | 0.093 | torch.Size([120]) || stage7.residual_group1.blocks.5.attn.proj.bias
+ | 0.000 | -0.637 | 0.806 | 0.093 | torch.Size([360, 120]) || stage7.residual_group1.blocks.5.attn.qkv_mut.weight
+ | -0.000 | -0.088 | 0.091 | 0.017 | torch.Size([360]) || stage7.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.514 | 0.238 | 0.594 | 0.042 | torch.Size([120]) || stage7.residual_group1.blocks.5.norm2.weight
+ | 0.017 | -0.650 | 0.162 | 0.089 | torch.Size([120]) || stage7.residual_group1.blocks.5.norm2.bias
+ | 0.000 | -0.442 | 0.479 | 0.114 | torch.Size([240, 120]) || stage7.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.040 | -0.400 | 0.203 | 0.101 | torch.Size([240]) || stage7.residual_group1.blocks.5.mlp.fc11.bias
+ | -0.000 | -0.541 | 0.514 | 0.130 | torch.Size([240, 120]) || stage7.residual_group1.blocks.5.mlp.fc12.weight
+ | -0.008 | -0.319 | 0.309 | 0.092 | torch.Size([240]) || stage7.residual_group1.blocks.5.mlp.fc12.bias
+ | -0.000 | -1.018 | 1.398 | 0.130 | torch.Size([120, 240]) || stage7.residual_group1.blocks.5.mlp.fc2.weight
+ | 0.001 | -1.606 | 0.269 | 0.179 | torch.Size([120]) || stage7.residual_group1.blocks.5.mlp.fc2.bias
+ | 0.000 | -0.186 | 0.207 | 0.048 | torch.Size([120, 120]) || stage7.linear1.weight
+ | 0.010 | -0.448 | 0.437 | 0.161 | torch.Size([120]) || stage7.linear1.bias
+ | 0.703 | 0.381 | 0.856 | 0.084 | torch.Size([120]) || stage7.residual_group2.blocks.0.norm1.weight
+ | 0.014 | -0.645 | 0.486 | 0.169 | torch.Size([120]) || stage7.residual_group2.blocks.0.norm1.bias
+ | -0.007 | -4.468 | 1.008 | 0.164 | torch.Size([2475, 6]) || stage7.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage7.residual_group2.blocks.0.attn.relative_position_index
+ | -0.000 | -0.625 | 0.834 | 0.120 | torch.Size([360, 120]) || stage7.residual_group2.blocks.0.attn.qkv_self.weight
+ | -0.009 | -0.737 | 0.632 | 0.135 | torch.Size([360]) || stage7.residual_group2.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.403 | 0.406 | 0.088 | torch.Size([120, 120]) || stage7.residual_group2.blocks.0.attn.proj.weight
+ | -0.007 | -0.338 | 0.165 | 0.070 | torch.Size([120]) || stage7.residual_group2.blocks.0.attn.proj.bias
+ | 0.435 | 0.323 | 0.526 | 0.038 | torch.Size([120]) || stage7.residual_group2.blocks.0.norm2.weight
+ | 0.005 | -0.678 | 0.379 | 0.117 | torch.Size([120]) || stage7.residual_group2.blocks.0.norm2.bias
+ | 0.000 | -0.465 | 0.467 | 0.110 | torch.Size([240, 120]) || stage7.residual_group2.blocks.0.mlp.fc11.weight
+ | -0.031 | -0.236 | 0.180 | 0.077 | torch.Size([240]) || stage7.residual_group2.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.490 | 0.520 | 0.121 | torch.Size([240, 120]) || stage7.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.003 | -0.197 | 0.242 | 0.069 | torch.Size([240]) || stage7.residual_group2.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.525 | 0.501 | 0.122 | torch.Size([120, 240]) || stage7.residual_group2.blocks.0.mlp.fc2.weight
+ | -0.005 | -0.431 | 0.164 | 0.077 | torch.Size([120]) || stage7.residual_group2.blocks.0.mlp.fc2.bias
+ | 0.703 | 0.306 | 0.866 | 0.079 | torch.Size([120]) || stage7.residual_group2.blocks.1.norm1.weight
+ | 0.009 | -0.647 | 0.481 | 0.149 | torch.Size([120]) || stage7.residual_group2.blocks.1.norm1.bias
+ | -0.010 | -3.504 | 1.842 | 0.134 | torch.Size([2475, 6]) || stage7.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage7.residual_group2.blocks.1.attn.relative_position_index
+ | -0.000 | -0.639 | 0.590 | 0.122 | torch.Size([360, 120]) || stage7.residual_group2.blocks.1.attn.qkv_self.weight
+ | -0.001 | -0.613 | 0.609 | 0.148 | torch.Size([360]) || stage7.residual_group2.blocks.1.attn.qkv_self.bias
+ | 0.001 | -0.316 | 0.325 | 0.085 | torch.Size([120, 120]) || stage7.residual_group2.blocks.1.attn.proj.weight
+ | -0.004 | -0.350 | 0.145 | 0.069 | torch.Size([120]) || stage7.residual_group2.blocks.1.attn.proj.bias
+ | 0.452 | 0.309 | 0.558 | 0.037 | torch.Size([120]) || stage7.residual_group2.blocks.1.norm2.weight
+ | 0.003 | -0.661 | 0.246 | 0.091 | torch.Size([120]) || stage7.residual_group2.blocks.1.norm2.bias
+ | 0.000 | -0.580 | 0.410 | 0.108 | torch.Size([240, 120]) || stage7.residual_group2.blocks.1.mlp.fc11.weight
+ | -0.020 | -0.258 | 0.299 | 0.104 | torch.Size([240]) || stage7.residual_group2.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.529 | 0.561 | 0.126 | torch.Size([240, 120]) || stage7.residual_group2.blocks.1.mlp.fc12.weight
+ | -0.002 | -0.234 | 0.434 | 0.090 | torch.Size([240]) || stage7.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.778 | 0.581 | 0.124 | torch.Size([120, 240]) || stage7.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.001 | -0.888 | 0.286 | 0.135 | torch.Size([120]) || stage7.residual_group2.blocks.1.mlp.fc2.bias
+ | -0.001 | -0.348 | 0.237 | 0.060 | torch.Size([120, 120]) || stage7.linear2.weight
+ | 0.023 | -0.390 | 0.506 | 0.167 | torch.Size([120]) || stage7.linear2.bias
+ | -0.000 | -0.104 | 0.107 | 0.024 | torch.Size([120, 120, 3, 3]) || stage7.pa_deform.weight
+ | 0.002 | -0.041 | 0.035 | 0.016 | torch.Size([120]) || stage7.pa_deform.bias
+ | -0.000 | -0.123 | 0.109 | 0.017 | torch.Size([120, 242, 3, 3]) || stage7.pa_deform.conv_offset.0.weight
+ | -0.002 | -0.034 | 0.032 | 0.015 | torch.Size([120]) || stage7.pa_deform.conv_offset.0.bias
+ | -0.001 | -0.111 | 0.084 | 0.019 | torch.Size([120, 120, 3, 3]) || stage7.pa_deform.conv_offset.2.weight
+ | -0.008 | -0.073 | 0.081 | 0.034 | torch.Size([120]) || stage7.pa_deform.conv_offset.2.bias
+ | -0.002 | -0.154 | 0.122 | 0.018 | torch.Size([120, 120, 3, 3]) || stage7.pa_deform.conv_offset.4.weight
+ | 0.014 | -0.041 | 0.068 | 0.026 | torch.Size([120]) || stage7.pa_deform.conv_offset.4.bias
+ | -0.001 | -0.408 | 0.365 | 0.034 | torch.Size([324, 120, 3, 3]) || stage7.pa_deform.conv_offset.6.weight
+ | -0.003 | -0.057 | 0.054 | 0.024 | torch.Size([324]) || stage7.pa_deform.conv_offset.6.bias
+ | 0.000 | -0.697 | 0.606 | 0.123 | torch.Size([360, 360]) || stage7.pa_fuse.fc11.weight
+ | 0.119 | -0.211 | 0.720 | 0.177 | torch.Size([360]) || stage7.pa_fuse.fc11.bias
+ | 0.000 | -1.175 | 0.924 | 0.154 | torch.Size([360, 360]) || stage7.pa_fuse.fc12.weight
+ | -0.000 | -0.581 | 0.580 | 0.190 | torch.Size([360]) || stage7.pa_fuse.fc12.bias
+ | 0.001 | -0.786 | 0.874 | 0.135 | torch.Size([120, 360]) || stage7.pa_fuse.fc2.weight
+ | -0.053 | -0.522 | 0.577 | 0.205 | torch.Size([120]) || stage7.pa_fuse.fc2.bias
+ | 1.225 | 1.000 | 1.516 | 0.095 | torch.Size([120]) || stage8.0.1.weight
+ | -0.013 | -0.413 | 0.465 | 0.139 | torch.Size([120]) || stage8.0.1.bias
+ | 0.000 | -2.505 | 0.627 | 0.136 | torch.Size([180, 120]) || stage8.0.2.weight
+ | 0.005 | -0.397 | 0.377 | 0.107 | torch.Size([180]) || stage8.0.2.bias
+ | 0.456 | 0.123 | 0.760 | 0.129 | torch.Size([180]) || stage8.1.residual_group.blocks.0.norm1.weight
+ | -0.022 | -0.343 | 0.875 | 0.099 | torch.Size([180]) || stage8.1.residual_group.blocks.0.norm1.bias
+ | -0.014 | -1.907 | 2.592 | 0.130 | torch.Size([2475, 6]) || stage8.1.residual_group.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.1.residual_group.blocks.0.attn.relative_position_index
+ | -0.000 | -0.632 | 0.628 | 0.099 | torch.Size([540, 180]) || stage8.1.residual_group.blocks.0.attn.qkv_self.weight
+ | 0.006 | -0.567 | 0.668 | 0.148 | torch.Size([540]) || stage8.1.residual_group.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.477 | 0.447 | 0.094 | torch.Size([180, 180]) || stage8.1.residual_group.blocks.0.attn.proj.weight
+ | -0.010 | -0.460 | 0.225 | 0.085 | torch.Size([180]) || stage8.1.residual_group.blocks.0.attn.proj.bias
+ | 0.429 | 0.119 | 0.634 | 0.090 | torch.Size([180]) || stage8.1.residual_group.blocks.0.norm2.weight
+ | -0.007 | -0.338 | 0.803 | 0.086 | torch.Size([180]) || stage8.1.residual_group.blocks.0.norm2.bias
+ | -0.006 | -0.572 | 0.539 | 0.119 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.0.mlp.fc11.weight
+ | -0.060 | -0.260 | 0.185 | 0.060 | torch.Size([360]) || stage8.1.residual_group.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.461 | 0.548 | 0.113 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.0.mlp.fc12.weight
+ | 0.000 | -0.163 | 0.183 | 0.050 | torch.Size([360]) || stage8.1.residual_group.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.757 | 0.581 | 0.118 | torch.Size([180, 360]) || stage8.1.residual_group.blocks.0.mlp.fc2.weight
+ | -0.003 | -0.191 | 0.121 | 0.057 | torch.Size([180]) || stage8.1.residual_group.blocks.0.mlp.fc2.bias
+ | 0.557 | 0.086 | 0.800 | 0.112 | torch.Size([180]) || stage8.1.residual_group.blocks.1.norm1.weight
+ | -0.029 | -0.230 | 0.878 | 0.088 | torch.Size([180]) || stage8.1.residual_group.blocks.1.norm1.bias
+ | -0.016 | -2.004 | 1.711 | 0.154 | torch.Size([2475, 6]) || stage8.1.residual_group.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.1.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -0.690 | 0.575 | 0.109 | torch.Size([540, 180]) || stage8.1.residual_group.blocks.1.attn.qkv_self.weight
+ | 0.011 | -0.641 | 0.609 | 0.135 | torch.Size([540]) || stage8.1.residual_group.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.466 | 0.401 | 0.094 | torch.Size([180, 180]) || stage8.1.residual_group.blocks.1.attn.proj.weight
+ | -0.008 | -0.344 | 0.181 | 0.080 | torch.Size([180]) || stage8.1.residual_group.blocks.1.attn.proj.bias
+ | 0.503 | 0.226 | 0.742 | 0.093 | torch.Size([180]) || stage8.1.residual_group.blocks.1.norm2.weight
+ | -0.009 | -0.404 | 0.818 | 0.085 | torch.Size([180]) || stage8.1.residual_group.blocks.1.norm2.bias
+ | -0.007 | -0.595 | 0.532 | 0.121 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.1.mlp.fc11.weight
+ | -0.068 | -0.261 | 0.071 | 0.053 | torch.Size([360]) || stage8.1.residual_group.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.529 | 0.573 | 0.116 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.1.mlp.fc12.weight
+ | 0.002 | -0.129 | 0.197 | 0.046 | torch.Size([360]) || stage8.1.residual_group.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.556 | 0.582 | 0.118 | torch.Size([180, 360]) || stage8.1.residual_group.blocks.1.mlp.fc2.weight
+ | -0.003 | -0.170 | 0.145 | 0.052 | torch.Size([180]) || stage8.1.residual_group.blocks.1.mlp.fc2.bias
+ | 0.699 | 0.202 | 0.912 | 0.109 | torch.Size([180]) || stage8.1.residual_group.blocks.2.norm1.weight
+ | -0.033 | -0.253 | 0.924 | 0.091 | torch.Size([180]) || stage8.1.residual_group.blocks.2.norm1.bias
+ | -0.030 | -2.510 | 2.088 | 0.194 | torch.Size([2475, 6]) || stage8.1.residual_group.blocks.2.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.1.residual_group.blocks.2.attn.relative_position_index
+ | 0.000 | -0.637 | 0.801 | 0.116 | torch.Size([540, 180]) || stage8.1.residual_group.blocks.2.attn.qkv_self.weight
+ | 0.006 | -0.512 | 0.520 | 0.110 | torch.Size([540]) || stage8.1.residual_group.blocks.2.attn.qkv_self.bias
+ | 0.000 | -0.381 | 0.337 | 0.090 | torch.Size([180, 180]) || stage8.1.residual_group.blocks.2.attn.proj.weight
+ | -0.011 | -0.238 | 0.234 | 0.085 | torch.Size([180]) || stage8.1.residual_group.blocks.2.attn.proj.bias
+ | 0.594 | 0.150 | 0.810 | 0.108 | torch.Size([180]) || stage8.1.residual_group.blocks.2.norm2.weight
+ | -0.010 | -0.483 | 0.726 | 0.088 | torch.Size([180]) || stage8.1.residual_group.blocks.2.norm2.bias
+ | -0.006 | -0.567 | 0.499 | 0.125 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.2.mlp.fc11.weight
+ | -0.077 | -0.360 | 0.050 | 0.056 | torch.Size([360]) || stage8.1.residual_group.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.536 | 0.673 | 0.119 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.2.mlp.fc12.weight
+ | 0.001 | -0.142 | 0.186 | 0.043 | torch.Size([360]) || stage8.1.residual_group.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.536 | 0.524 | 0.119 | torch.Size([180, 360]) || stage8.1.residual_group.blocks.2.mlp.fc2.weight
+ | -0.006 | -0.147 | 0.133 | 0.051 | torch.Size([180]) || stage8.1.residual_group.blocks.2.mlp.fc2.bias
+ | 0.683 | 0.141 | 0.908 | 0.105 | torch.Size([180]) || stage8.1.residual_group.blocks.3.norm1.weight
+ | -0.033 | -0.199 | 0.878 | 0.088 | torch.Size([180]) || stage8.1.residual_group.blocks.3.norm1.bias
+ | -0.039 | -1.527 | 3.891 | 0.199 | torch.Size([2475, 6]) || stage8.1.residual_group.blocks.3.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.1.residual_group.blocks.3.attn.relative_position_index
+ | 0.000 | -0.682 | 0.693 | 0.120 | torch.Size([540, 180]) || stage8.1.residual_group.blocks.3.attn.qkv_self.weight
+ | 0.007 | -0.543 | 0.513 | 0.138 | torch.Size([540]) || stage8.1.residual_group.blocks.3.attn.qkv_self.bias
+ | -0.001 | -0.390 | 0.476 | 0.089 | torch.Size([180, 180]) || stage8.1.residual_group.blocks.3.attn.proj.weight
+ | -0.007 | -0.176 | 0.150 | 0.062 | torch.Size([180]) || stage8.1.residual_group.blocks.3.attn.proj.bias
+ | 0.640 | 0.094 | 0.853 | 0.120 | torch.Size([180]) || stage8.1.residual_group.blocks.3.norm2.weight
+ | -0.009 | -0.372 | 0.683 | 0.084 | torch.Size([180]) || stage8.1.residual_group.blocks.3.norm2.bias
+ | -0.006 | -0.628 | 0.521 | 0.126 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.3.mlp.fc11.weight
+ | -0.089 | -0.367 | 0.047 | 0.054 | torch.Size([360]) || stage8.1.residual_group.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.629 | 0.562 | 0.121 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.3.mlp.fc12.weight
+ | -0.001 | -0.186 | 0.128 | 0.042 | torch.Size([360]) || stage8.1.residual_group.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.485 | 0.499 | 0.118 | torch.Size([180, 360]) || stage8.1.residual_group.blocks.3.mlp.fc2.weight
+ | -0.007 | -0.138 | 0.209 | 0.050 | torch.Size([180]) || stage8.1.residual_group.blocks.3.mlp.fc2.bias
+ | 0.000 | -0.294 | 0.577 | 0.071 | torch.Size([180, 180]) || stage8.1.linear.weight
+ | 0.004 | -0.349 | 0.235 | 0.072 | torch.Size([180]) || stage8.1.linear.bias
+ | 0.708 | 0.242 | 1.026 | 0.136 | torch.Size([180]) || stage8.2.residual_group.blocks.0.norm1.weight
+ | -0.032 | -0.212 | 0.830 | 0.100 | torch.Size([180]) || stage8.2.residual_group.blocks.0.norm1.bias
+ | -0.039 | -1.954 | 2.394 | 0.212 | torch.Size([2475, 6]) || stage8.2.residual_group.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.2.residual_group.blocks.0.attn.relative_position_index
+ | 0.000 | -0.922 | 0.646 | 0.116 | torch.Size([540, 180]) || stage8.2.residual_group.blocks.0.attn.qkv_self.weight
+ | -0.001 | -0.429 | 0.524 | 0.101 | torch.Size([540]) || stage8.2.residual_group.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.467 | 0.453 | 0.109 | torch.Size([180, 180]) || stage8.2.residual_group.blocks.0.attn.proj.weight
+ | -0.005 | -0.339 | 0.264 | 0.095 | torch.Size([180]) || stage8.2.residual_group.blocks.0.attn.proj.bias
+ | 0.587 | 0.255 | 0.837 | 0.086 | torch.Size([180]) || stage8.2.residual_group.blocks.0.norm2.weight
+ | -0.011 | -0.285 | 0.721 | 0.083 | torch.Size([180]) || stage8.2.residual_group.blocks.0.norm2.bias
+ | -0.006 | -0.586 | 0.534 | 0.125 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.0.mlp.fc11.weight
+ | -0.075 | -0.225 | 0.066 | 0.047 | torch.Size([360]) || stage8.2.residual_group.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.493 | 0.532 | 0.123 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.0.mlp.fc12.weight
+ | 0.003 | -0.189 | 0.178 | 0.047 | torch.Size([360]) || stage8.2.residual_group.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.551 | 0.543 | 0.124 | torch.Size([180, 360]) || stage8.2.residual_group.blocks.0.mlp.fc2.weight
+ | -0.010 | -0.154 | 0.142 | 0.054 | torch.Size([180]) || stage8.2.residual_group.blocks.0.mlp.fc2.bias
+ | 0.773 | 0.210 | 1.004 | 0.113 | torch.Size([180]) || stage8.2.residual_group.blocks.1.norm1.weight
+ | -0.035 | -0.176 | 0.873 | 0.089 | torch.Size([180]) || stage8.2.residual_group.blocks.1.norm1.bias
+ | -0.027 | -2.407 | 1.736 | 0.214 | torch.Size([2475, 6]) || stage8.2.residual_group.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.2.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -0.817 | 0.977 | 0.123 | torch.Size([540, 180]) || stage8.2.residual_group.blocks.1.attn.qkv_self.weight
+ | 0.001 | -0.659 | 0.461 | 0.115 | torch.Size([540]) || stage8.2.residual_group.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.484 | 0.453 | 0.109 | torch.Size([180, 180]) || stage8.2.residual_group.blocks.1.attn.proj.weight
+ | -0.014 | -0.315 | 0.252 | 0.091 | torch.Size([180]) || stage8.2.residual_group.blocks.1.attn.proj.bias
+ | 0.641 | 0.337 | 0.810 | 0.081 | torch.Size([180]) || stage8.2.residual_group.blocks.1.norm2.weight
+ | -0.011 | -0.177 | 0.806 | 0.083 | torch.Size([180]) || stage8.2.residual_group.blocks.1.norm2.bias
+ | -0.006 | -0.569 | 0.598 | 0.125 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.1.mlp.fc11.weight
+ | -0.079 | -0.323 | 0.071 | 0.051 | torch.Size([360]) || stage8.2.residual_group.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.512 | 0.577 | 0.126 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.1.mlp.fc12.weight
+ | -0.003 | -0.142 | 0.161 | 0.050 | torch.Size([360]) || stage8.2.residual_group.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.529 | 0.572 | 0.125 | torch.Size([180, 360]) || stage8.2.residual_group.blocks.1.mlp.fc2.weight
+ | -0.010 | -0.178 | 0.159 | 0.066 | torch.Size([180]) || stage8.2.residual_group.blocks.1.mlp.fc2.bias
+ | 0.857 | 0.199 | 1.153 | 0.112 | torch.Size([180]) || stage8.2.residual_group.blocks.2.norm1.weight
+ | -0.039 | -0.189 | 0.943 | 0.089 | torch.Size([180]) || stage8.2.residual_group.blocks.2.norm1.bias
+ | -0.042 | -1.962 | 2.773 | 0.246 | torch.Size([2475, 6]) || stage8.2.residual_group.blocks.2.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.2.residual_group.blocks.2.attn.relative_position_index
+ | -0.000 | -0.783 | 0.655 | 0.123 | torch.Size([540, 180]) || stage8.2.residual_group.blocks.2.attn.qkv_self.weight
+ | 0.004 | -0.338 | 0.533 | 0.099 | torch.Size([540]) || stage8.2.residual_group.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.497 | 0.461 | 0.107 | torch.Size([180, 180]) || stage8.2.residual_group.blocks.2.attn.proj.weight
+ | -0.008 | -0.288 | 0.183 | 0.089 | torch.Size([180]) || stage8.2.residual_group.blocks.2.attn.proj.bias
+ | 0.681 | 0.327 | 0.878 | 0.085 | torch.Size([180]) || stage8.2.residual_group.blocks.2.norm2.weight
+ | -0.012 | -0.178 | 0.773 | 0.084 | torch.Size([180]) || stage8.2.residual_group.blocks.2.norm2.bias
+ | -0.006 | -0.789 | 0.546 | 0.125 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.2.mlp.fc11.weight
+ | -0.081 | -0.249 | 0.036 | 0.051 | torch.Size([360]) || stage8.2.residual_group.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.526 | 0.555 | 0.128 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.2.mlp.fc12.weight
+ | 0.000 | -0.133 | 0.191 | 0.051 | torch.Size([360]) || stage8.2.residual_group.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.572 | 0.529 | 0.126 | torch.Size([180, 360]) || stage8.2.residual_group.blocks.2.mlp.fc2.weight
+ | -0.011 | -0.164 | 0.147 | 0.065 | torch.Size([180]) || stage8.2.residual_group.blocks.2.mlp.fc2.bias
+ | 0.877 | 0.198 | 1.043 | 0.094 | torch.Size([180]) || stage8.2.residual_group.blocks.3.norm1.weight
+ | -0.038 | -0.210 | 0.916 | 0.091 | torch.Size([180]) || stage8.2.residual_group.blocks.3.norm1.bias
+ | -0.094 | -2.974 | 4.987 | 0.299 | torch.Size([2475, 6]) || stage8.2.residual_group.blocks.3.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.2.residual_group.blocks.3.attn.relative_position_index
+ | -0.000 | -0.964 | 1.011 | 0.126 | torch.Size([540, 180]) || stage8.2.residual_group.blocks.3.attn.qkv_self.weight
+ | -0.002 | -0.404 | 0.429 | 0.101 | torch.Size([540]) || stage8.2.residual_group.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.501 | 0.489 | 0.110 | torch.Size([180, 180]) || stage8.2.residual_group.blocks.3.attn.proj.weight
+ | -0.021 | -0.305 | 0.208 | 0.097 | torch.Size([180]) || stage8.2.residual_group.blocks.3.attn.proj.bias
+ | 0.697 | 0.295 | 0.894 | 0.089 | torch.Size([180]) || stage8.2.residual_group.blocks.3.norm2.weight
+ | -0.015 | -0.241 | 0.712 | 0.086 | torch.Size([180]) || stage8.2.residual_group.blocks.3.norm2.bias
+ | -0.005 | -0.562 | 0.573 | 0.125 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.3.mlp.fc11.weight
+ | -0.085 | -0.302 | 0.080 | 0.060 | torch.Size([360]) || stage8.2.residual_group.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.734 | 0.573 | 0.130 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.3.mlp.fc12.weight
+ | 0.001 | -0.150 | 0.161 | 0.054 | torch.Size([360]) || stage8.2.residual_group.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.671 | 0.623 | 0.127 | torch.Size([180, 360]) || stage8.2.residual_group.blocks.3.mlp.fc2.weight
+ | -0.023 | -0.252 | 0.317 | 0.081 | torch.Size([180]) || stage8.2.residual_group.blocks.3.mlp.fc2.bias
+ | -0.000 | -0.278 | 0.345 | 0.064 | torch.Size([180, 180]) || stage8.2.linear.weight
+ | 0.004 | -0.315 | 0.148 | 0.064 | torch.Size([180]) || stage8.2.linear.bias
+ | 0.850 | 0.326 | 1.087 | 0.122 | torch.Size([180]) || stage8.3.residual_group.blocks.0.norm1.weight
+ | -0.031 | -0.334 | 0.779 | 0.106 | torch.Size([180]) || stage8.3.residual_group.blocks.0.norm1.bias
+ | -0.012 | -2.917 | 1.476 | 0.175 | torch.Size([2475, 6]) || stage8.3.residual_group.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.3.residual_group.blocks.0.attn.relative_position_index
+ | -0.000 | -0.603 | 0.666 | 0.124 | torch.Size([540, 180]) || stage8.3.residual_group.blocks.0.attn.qkv_self.weight
+ | -0.001 | -0.374 | 0.381 | 0.086 | torch.Size([540]) || stage8.3.residual_group.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.577 | 0.605 | 0.119 | torch.Size([180, 180]) || stage8.3.residual_group.blocks.0.attn.proj.weight
+ | -0.008 | -0.394 | 0.499 | 0.134 | torch.Size([180]) || stage8.3.residual_group.blocks.0.attn.proj.bias
+ | 0.636 | 0.321 | 0.790 | 0.073 | torch.Size([180]) || stage8.3.residual_group.blocks.0.norm2.weight
+ | -0.013 | -0.294 | 0.774 | 0.090 | torch.Size([180]) || stage8.3.residual_group.blocks.0.norm2.bias
+ | -0.004 | -0.540 | 0.539 | 0.123 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.0.mlp.fc11.weight
+ | -0.065 | -0.212 | 0.047 | 0.051 | torch.Size([360]) || stage8.3.residual_group.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.608 | 0.603 | 0.130 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.0.mlp.fc12.weight
+ | -0.002 | -0.177 | 0.155 | 0.051 | torch.Size([360]) || stage8.3.residual_group.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.573 | 0.630 | 0.129 | torch.Size([180, 360]) || stage8.3.residual_group.blocks.0.mlp.fc2.weight
+ | -0.005 | -0.189 | 0.178 | 0.071 | torch.Size([180]) || stage8.3.residual_group.blocks.0.mlp.fc2.bias
+ | 0.899 | 0.275 | 1.048 | 0.099 | torch.Size([180]) || stage8.3.residual_group.blocks.1.norm1.weight
+ | -0.031 | -0.223 | 0.771 | 0.088 | torch.Size([180]) || stage8.3.residual_group.blocks.1.norm1.bias
+ | -0.003 | -3.151 | 1.718 | 0.202 | torch.Size([2475, 6]) || stage8.3.residual_group.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.3.residual_group.blocks.1.attn.relative_position_index
+ | -0.000 | -0.732 | 0.868 | 0.127 | torch.Size([540, 180]) || stage8.3.residual_group.blocks.1.attn.qkv_self.weight
+ | 0.002 | -0.412 | 0.350 | 0.093 | torch.Size([540]) || stage8.3.residual_group.blocks.1.attn.qkv_self.bias
+ | 0.001 | -0.466 | 0.487 | 0.114 | torch.Size([180, 180]) || stage8.3.residual_group.blocks.1.attn.proj.weight
+ | -0.006 | -0.388 | 0.400 | 0.129 | torch.Size([180]) || stage8.3.residual_group.blocks.1.attn.proj.bias
+ | 0.711 | 0.381 | 0.864 | 0.082 | torch.Size([180]) || stage8.3.residual_group.blocks.1.norm2.weight
+ | -0.009 | -0.240 | 0.692 | 0.090 | torch.Size([180]) || stage8.3.residual_group.blocks.1.norm2.bias
+ | -0.005 | -0.657 | 0.639 | 0.126 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.1.mlp.fc11.weight
+ | -0.077 | -0.263 | 0.047 | 0.057 | torch.Size([360]) || stage8.3.residual_group.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.673 | 0.605 | 0.134 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.1.mlp.fc12.weight
+ | 0.002 | -0.158 | 0.155 | 0.046 | torch.Size([360]) || stage8.3.residual_group.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.582 | 0.585 | 0.131 | torch.Size([180, 360]) || stage8.3.residual_group.blocks.1.mlp.fc2.weight
+ | -0.009 | -0.253 | 0.178 | 0.070 | torch.Size([180]) || stage8.3.residual_group.blocks.1.mlp.fc2.bias
+ | 0.941 | 0.262 | 1.154 | 0.094 | torch.Size([180]) || stage8.3.residual_group.blocks.2.norm1.weight
+ | -0.032 | -0.162 | 0.906 | 0.084 | torch.Size([180]) || stage8.3.residual_group.blocks.2.norm1.bias
+ | -0.005 | -3.421 | 1.350 | 0.205 | torch.Size([2475, 6]) || stage8.3.residual_group.blocks.2.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.3.residual_group.blocks.2.attn.relative_position_index
+ | -0.000 | -0.777 | 0.735 | 0.130 | torch.Size([540, 180]) || stage8.3.residual_group.blocks.2.attn.qkv_self.weight
+ | 0.000 | -0.355 | 0.421 | 0.092 | torch.Size([540]) || stage8.3.residual_group.blocks.2.attn.qkv_self.bias
+ | 0.000 | -0.479 | 0.475 | 0.115 | torch.Size([180, 180]) || stage8.3.residual_group.blocks.2.attn.proj.weight
+ | -0.013 | -0.292 | 0.345 | 0.122 | torch.Size([180]) || stage8.3.residual_group.blocks.2.attn.proj.bias
+ | 0.743 | 0.242 | 0.919 | 0.093 | torch.Size([180]) || stage8.3.residual_group.blocks.2.norm2.weight
+ | -0.011 | -0.214 | 0.691 | 0.094 | torch.Size([180]) || stage8.3.residual_group.blocks.2.norm2.bias
+ | -0.005 | -0.633 | 0.498 | 0.127 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.2.mlp.fc11.weight
+ | -0.082 | -0.346 | 0.087 | 0.062 | torch.Size([360]) || stage8.3.residual_group.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.591 | 0.670 | 0.134 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.2.mlp.fc12.weight
+ | 0.001 | -0.190 | 0.151 | 0.056 | torch.Size([360]) || stage8.3.residual_group.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.560 | 0.637 | 0.132 | torch.Size([180, 360]) || stage8.3.residual_group.blocks.2.mlp.fc2.weight
+ | -0.009 | -0.226 | 0.250 | 0.085 | torch.Size([180]) || stage8.3.residual_group.blocks.2.mlp.fc2.bias
+ | 0.950 | 0.250 | 1.103 | 0.086 | torch.Size([180]) || stage8.3.residual_group.blocks.3.norm1.weight
+ | -0.035 | -0.196 | 0.925 | 0.088 | torch.Size([180]) || stage8.3.residual_group.blocks.3.norm1.bias
+ | -0.026 | -3.591 | 5.653 | 0.236 | torch.Size([2475, 6]) || stage8.3.residual_group.blocks.3.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.3.residual_group.blocks.3.attn.relative_position_index
+ | 0.000 | -0.753 | 0.637 | 0.128 | torch.Size([540, 180]) || stage8.3.residual_group.blocks.3.attn.qkv_self.weight
+ | 0.000 | -0.333 | 0.432 | 0.081 | torch.Size([540]) || stage8.3.residual_group.blocks.3.attn.qkv_self.bias
+ | 0.001 | -0.591 | 0.591 | 0.118 | torch.Size([180, 180]) || stage8.3.residual_group.blocks.3.attn.proj.weight
+ | -0.014 | -0.348 | 0.267 | 0.122 | torch.Size([180]) || stage8.3.residual_group.blocks.3.attn.proj.bias
+ | 0.735 | 0.254 | 0.893 | 0.082 | torch.Size([180]) || stage8.3.residual_group.blocks.3.norm2.weight
+ | -0.011 | -0.241 | 0.659 | 0.093 | torch.Size([180]) || stage8.3.residual_group.blocks.3.norm2.bias
+ | -0.005 | -0.628 | 0.667 | 0.125 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.3.mlp.fc11.weight
+ | -0.076 | -0.411 | 0.113 | 0.072 | torch.Size([360]) || stage8.3.residual_group.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.662 | 0.578 | 0.135 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.3.mlp.fc12.weight
+ | -0.004 | -0.208 | 0.169 | 0.054 | torch.Size([360]) || stage8.3.residual_group.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.602 | 0.588 | 0.131 | torch.Size([180, 360]) || stage8.3.residual_group.blocks.3.mlp.fc2.weight
+ | -0.011 | -0.218 | 0.232 | 0.096 | torch.Size([180]) || stage8.3.residual_group.blocks.3.mlp.fc2.bias
+ | -0.000 | -0.343 | 0.316 | 0.065 | torch.Size([180, 180]) || stage8.3.linear.weight
+ | 0.010 | -0.297 | 0.187 | 0.061 | torch.Size([180]) || stage8.3.linear.bias
+ | 1.012 | 0.330 | 1.282 | 0.149 | torch.Size([180]) || stage8.4.residual_group.blocks.0.norm1.weight
+ | -0.030 | -0.347 | 0.800 | 0.134 | torch.Size([180]) || stage8.4.residual_group.blocks.0.norm1.bias
+ | -0.013 | -2.816 | 3.792 | 0.236 | torch.Size([2475, 6]) || stage8.4.residual_group.blocks.0.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.4.residual_group.blocks.0.attn.relative_position_index
+ | -0.000 | -0.807 | 0.825 | 0.131 | torch.Size([540, 180]) || stage8.4.residual_group.blocks.0.attn.qkv_self.weight
+ | -0.003 | -0.429 | 0.319 | 0.083 | torch.Size([540]) || stage8.4.residual_group.blocks.0.attn.qkv_self.bias
+ | 0.001 | -0.553 | 0.569 | 0.136 | torch.Size([180, 180]) || stage8.4.residual_group.blocks.0.attn.proj.weight
+ | -0.019 | -0.443 | 0.441 | 0.139 | torch.Size([180]) || stage8.4.residual_group.blocks.0.attn.proj.bias
+ | 0.638 | 0.420 | 0.797 | 0.063 | torch.Size([180]) || stage8.4.residual_group.blocks.0.norm2.weight
+ | -0.018 | -0.222 | 0.886 | 0.107 | torch.Size([180]) || stage8.4.residual_group.blocks.0.norm2.bias
+ | -0.002 | -0.576 | 0.510 | 0.117 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.0.mlp.fc11.weight
+ | -0.018 | -0.277 | 0.123 | 0.068 | torch.Size([360]) || stage8.4.residual_group.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.687 | 0.625 | 0.132 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.0.mlp.fc12.weight
+ | -0.007 | -0.264 | 0.267 | 0.076 | torch.Size([360]) || stage8.4.residual_group.blocks.0.mlp.fc12.bias
+ | 0.001 | -0.639 | 0.705 | 0.130 | torch.Size([180, 360]) || stage8.4.residual_group.blocks.0.mlp.fc2.weight
+ | -0.012 | -0.255 | 0.274 | 0.095 | torch.Size([180]) || stage8.4.residual_group.blocks.0.mlp.fc2.bias
+ | 1.092 | 0.475 | 1.341 | 0.115 | torch.Size([180]) || stage8.4.residual_group.blocks.1.norm1.weight
+ | -0.030 | -0.294 | 0.686 | 0.113 | torch.Size([180]) || stage8.4.residual_group.blocks.1.norm1.bias
+ | 0.018 | -3.165 | 0.990 | 0.213 | torch.Size([2475, 6]) || stage8.4.residual_group.blocks.1.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.4.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -0.695 | 0.699 | 0.133 | torch.Size([540, 180]) || stage8.4.residual_group.blocks.1.attn.qkv_self.weight
+ | 0.002 | -0.319 | 0.286 | 0.075 | torch.Size([540]) || stage8.4.residual_group.blocks.1.attn.qkv_self.bias
+ | -0.001 | -0.542 | 0.519 | 0.133 | torch.Size([180, 180]) || stage8.4.residual_group.blocks.1.attn.proj.weight
+ | -0.017 | -0.439 | 0.451 | 0.152 | torch.Size([180]) || stage8.4.residual_group.blocks.1.attn.proj.bias
+ | 0.664 | 0.366 | 0.835 | 0.074 | torch.Size([180]) || stage8.4.residual_group.blocks.1.norm2.weight
+ | -0.015 | -0.217 | 0.985 | 0.103 | torch.Size([180]) || stage8.4.residual_group.blocks.1.norm2.bias
+ | -0.002 | -0.641 | 0.563 | 0.117 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.1.mlp.fc11.weight
+ | -0.022 | -0.381 | 0.161 | 0.078 | torch.Size([360]) || stage8.4.residual_group.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.571 | 0.642 | 0.132 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.1.mlp.fc12.weight
+ | 0.003 | -0.279 | 0.311 | 0.087 | torch.Size([360]) || stage8.4.residual_group.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.738 | 0.633 | 0.130 | torch.Size([180, 360]) || stage8.4.residual_group.blocks.1.mlp.fc2.weight
+ | -0.007 | -0.254 | 0.261 | 0.084 | torch.Size([180]) || stage8.4.residual_group.blocks.1.mlp.fc2.bias
+ | 1.125 | 0.525 | 1.405 | 0.117 | torch.Size([180]) || stage8.4.residual_group.blocks.2.norm1.weight
+ | -0.033 | -0.186 | 0.627 | 0.082 | torch.Size([180]) || stage8.4.residual_group.blocks.2.norm1.bias
+ | 0.028 | -3.477 | 0.957 | 0.217 | torch.Size([2475, 6]) || stage8.4.residual_group.blocks.2.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.4.residual_group.blocks.2.attn.relative_position_index
+ | 0.000 | -0.663 | 0.658 | 0.130 | torch.Size([540, 180]) || stage8.4.residual_group.blocks.2.attn.qkv_self.weight
+ | -0.007 | -0.357 | 0.255 | 0.064 | torch.Size([540]) || stage8.4.residual_group.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.596 | 0.578 | 0.137 | torch.Size([180, 180]) || stage8.4.residual_group.blocks.2.attn.proj.weight
+ | -0.018 | -0.506 | 0.389 | 0.159 | torch.Size([180]) || stage8.4.residual_group.blocks.2.attn.proj.bias
+ | 0.694 | 0.319 | 0.865 | 0.084 | torch.Size([180]) || stage8.4.residual_group.blocks.2.norm2.weight
+ | -0.018 | -0.150 | 0.975 | 0.087 | torch.Size([180]) || stage8.4.residual_group.blocks.2.norm2.bias
+ | -0.002 | -0.619 | 0.565 | 0.116 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.2.mlp.fc11.weight
+ | -0.025 | -0.345 | 0.208 | 0.086 | torch.Size([360]) || stage8.4.residual_group.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.624 | 0.607 | 0.132 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.2.mlp.fc12.weight
+ | -0.003 | -0.388 | 0.290 | 0.075 | torch.Size([360]) || stage8.4.residual_group.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.927 | 0.675 | 0.130 | torch.Size([180, 360]) || stage8.4.residual_group.blocks.2.mlp.fc2.weight
+ | -0.011 | -0.325 | 0.240 | 0.096 | torch.Size([180]) || stage8.4.residual_group.blocks.2.mlp.fc2.bias
+ | 1.108 | 0.535 | 1.297 | 0.094 | torch.Size([180]) || stage8.4.residual_group.blocks.3.norm1.weight
+ | -0.035 | -0.213 | 0.546 | 0.064 | torch.Size([180]) || stage8.4.residual_group.blocks.3.norm1.bias
+ | 0.020 | -3.042 | 1.420 | 0.192 | torch.Size([2475, 6]) || stage8.4.residual_group.blocks.3.attn.relative_position_bias_table
+ | 1237.000 | 0.000 | 2474.000 | 545.607 | torch.Size([384, 384]) || stage8.4.residual_group.blocks.3.attn.relative_position_index
+ | -0.000 | -0.697 | 0.700 | 0.128 | torch.Size([540, 180]) || stage8.4.residual_group.blocks.3.attn.qkv_self.weight
+ | -0.000 | -0.220 | 0.311 | 0.065 | torch.Size([540]) || stage8.4.residual_group.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.652 | 0.592 | 0.138 | torch.Size([180, 180]) || stage8.4.residual_group.blocks.3.attn.proj.weight
+ | -0.019 | -0.535 | 0.426 | 0.154 | torch.Size([180]) || stage8.4.residual_group.blocks.3.attn.proj.bias
+ | 0.685 | 0.225 | 0.893 | 0.082 | torch.Size([180]) || stage8.4.residual_group.blocks.3.norm2.weight
+ | -0.023 | -0.211 | 0.938 | 0.093 | torch.Size([180]) || stage8.4.residual_group.blocks.3.norm2.bias
+ | -0.001 | -0.501 | 0.564 | 0.113 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.3.mlp.fc11.weight
+ | -0.014 | -0.339 | 0.237 | 0.092 | torch.Size([360]) || stage8.4.residual_group.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.560 | 0.626 | 0.132 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.3.mlp.fc12.weight
+ | 0.000 | -0.231 | 0.239 | 0.075 | torch.Size([360]) || stage8.4.residual_group.blocks.3.mlp.fc12.bias
+ | -0.000 | -0.544 | 0.657 | 0.130 | torch.Size([180, 360]) || stage8.4.residual_group.blocks.3.mlp.fc2.weight
+ | -0.007 | -0.271 | 0.274 | 0.093 | torch.Size([180]) || stage8.4.residual_group.blocks.3.mlp.fc2.bias
+ | -0.001 | -0.473 | 0.481 | 0.069 | torch.Size([180, 180]) || stage8.4.linear.weight
+ | 0.029 | -0.333 | 0.194 | 0.076 | torch.Size([180]) || stage8.4.linear.bias
+ | 1.025 | 0.297 | 1.336 | 0.162 | torch.Size([180]) || stage8.5.residual_group.blocks.0.norm1.weight
+ | -0.034 | -0.429 | 0.872 | 0.141 | torch.Size([180]) || stage8.5.residual_group.blocks.0.norm1.bias
+ | -0.574 | -4.515 | 3.381 | 0.800 | torch.Size([225, 6]) || stage8.5.residual_group.blocks.0.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.5.residual_group.blocks.0.attn.relative_position_index
+ | 0.000 | -0.771 | 0.886 | 0.125 | torch.Size([540, 180]) || stage8.5.residual_group.blocks.0.attn.qkv_self.weight
+ | 0.000 | -0.356 | 0.521 | 0.085 | torch.Size([540]) || stage8.5.residual_group.blocks.0.attn.qkv_self.bias
+ | -0.001 | -0.632 | 0.656 | 0.147 | torch.Size([180, 180]) || stage8.5.residual_group.blocks.0.attn.proj.weight
+ | -0.029 | -0.329 | 0.697 | 0.127 | torch.Size([180]) || stage8.5.residual_group.blocks.0.attn.proj.bias
+ | 0.777 | 0.446 | 0.952 | 0.069 | torch.Size([180]) || stage8.5.residual_group.blocks.0.norm2.weight
+ | -0.022 | -0.335 | 0.920 | 0.121 | torch.Size([180]) || stage8.5.residual_group.blocks.0.norm2.bias
+ | -0.002 | -0.520 | 0.598 | 0.117 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.0.mlp.fc11.weight
+ | -0.013 | -0.456 | 0.200 | 0.075 | torch.Size([360]) || stage8.5.residual_group.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.677 | 0.642 | 0.137 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.0.mlp.fc12.weight
+ | 0.005 | -0.272 | 0.233 | 0.083 | torch.Size([360]) || stage8.5.residual_group.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.762 | 0.598 | 0.136 | torch.Size([180, 360]) || stage8.5.residual_group.blocks.0.mlp.fc2.weight
+ | -0.025 | -0.244 | 0.583 | 0.111 | torch.Size([180]) || stage8.5.residual_group.blocks.0.mlp.fc2.bias
+ | 1.021 | 0.261 | 1.261 | 0.133 | torch.Size([180]) || stage8.5.residual_group.blocks.1.norm1.weight
+ | -0.033 | -0.358 | 0.867 | 0.120 | torch.Size([180]) || stage8.5.residual_group.blocks.1.norm1.bias
+ | -0.550 | -3.274 | 4.406 | 0.670 | torch.Size([225, 6]) || stage8.5.residual_group.blocks.1.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.5.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -0.819 | 0.986 | 0.122 | torch.Size([540, 180]) || stage8.5.residual_group.blocks.1.attn.qkv_self.weight
+ | 0.005 | -0.510 | 0.446 | 0.084 | torch.Size([540]) || stage8.5.residual_group.blocks.1.attn.qkv_self.bias
+ | -0.003 | -0.739 | 0.682 | 0.151 | torch.Size([180, 180]) || stage8.5.residual_group.blocks.1.attn.proj.weight
+ | -0.032 | -0.318 | 0.607 | 0.133 | torch.Size([180]) || stage8.5.residual_group.blocks.1.attn.proj.bias
+ | 0.823 | 0.420 | 0.950 | 0.070 | torch.Size([180]) || stage8.5.residual_group.blocks.1.norm2.weight
+ | -0.021 | -0.274 | 0.882 | 0.111 | torch.Size([180]) || stage8.5.residual_group.blocks.1.norm2.bias
+ | -0.002 | -0.496 | 0.532 | 0.117 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.1.mlp.fc11.weight
+ | -0.028 | -0.260 | 0.194 | 0.080 | torch.Size([360]) || stage8.5.residual_group.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.620 | 0.586 | 0.139 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.1.mlp.fc12.weight
+ | 0.004 | -0.284 | 0.423 | 0.083 | torch.Size([360]) || stage8.5.residual_group.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.774 | 0.614 | 0.137 | torch.Size([180, 360]) || stage8.5.residual_group.blocks.1.mlp.fc2.weight
+ | -0.028 | -0.371 | 0.561 | 0.133 | torch.Size([180]) || stage8.5.residual_group.blocks.1.mlp.fc2.bias
+ | 1.096 | 0.377 | 1.321 | 0.110 | torch.Size([180]) || stage8.5.residual_group.blocks.2.norm1.weight
+ | -0.033 | -0.244 | 0.755 | 0.100 | torch.Size([180]) || stage8.5.residual_group.blocks.2.norm1.bias
+ | -0.441 | -3.439 | 5.870 | 0.668 | torch.Size([225, 6]) || stage8.5.residual_group.blocks.2.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.5.residual_group.blocks.2.attn.relative_position_index
+ | -0.000 | -0.710 | 0.679 | 0.123 | torch.Size([540, 180]) || stage8.5.residual_group.blocks.2.attn.qkv_self.weight
+ | 0.003 | -0.277 | 0.283 | 0.068 | torch.Size([540]) || stage8.5.residual_group.blocks.2.attn.qkv_self.bias
+ | 0.001 | -0.824 | 0.684 | 0.150 | torch.Size([180, 180]) || stage8.5.residual_group.blocks.2.attn.proj.weight
+ | -0.033 | -0.390 | 0.545 | 0.155 | torch.Size([180]) || stage8.5.residual_group.blocks.2.attn.proj.bias
+ | 0.843 | 0.390 | 0.984 | 0.076 | torch.Size([180]) || stage8.5.residual_group.blocks.2.norm2.weight
+ | -0.022 | -0.211 | 0.854 | 0.090 | torch.Size([180]) || stage8.5.residual_group.blocks.2.norm2.bias
+ | -0.002 | -0.522 | 0.503 | 0.116 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.2.mlp.fc11.weight
+ | -0.024 | -0.243 | 0.219 | 0.091 | torch.Size([360]) || stage8.5.residual_group.blocks.2.mlp.fc11.bias
+ | -0.001 | -0.638 | 0.617 | 0.139 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.2.mlp.fc12.weight
+ | -0.004 | -0.268 | 0.380 | 0.078 | torch.Size([360]) || stage8.5.residual_group.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.713 | 0.769 | 0.138 | torch.Size([180, 360]) || stage8.5.residual_group.blocks.2.mlp.fc2.weight
+ | -0.034 | -0.372 | 0.592 | 0.151 | torch.Size([180]) || stage8.5.residual_group.blocks.2.mlp.fc2.bias
+ | 1.027 | 0.318 | 1.206 | 0.094 | torch.Size([180]) || stage8.5.residual_group.blocks.3.norm1.weight
+ | -0.033 | -0.187 | 0.768 | 0.088 | torch.Size([180]) || stage8.5.residual_group.blocks.3.norm1.bias
+ | -0.347 | -2.664 | 2.684 | 0.528 | torch.Size([225, 6]) || stage8.5.residual_group.blocks.3.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.5.residual_group.blocks.3.attn.relative_position_index
+ | 0.000 | -0.677 | 0.676 | 0.127 | torch.Size([540, 180]) || stage8.5.residual_group.blocks.3.attn.qkv_self.weight
+ | 0.002 | -0.410 | 0.354 | 0.080 | torch.Size([540]) || stage8.5.residual_group.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.630 | 0.725 | 0.145 | torch.Size([180, 180]) || stage8.5.residual_group.blocks.3.attn.proj.weight
+ | -0.041 | -0.385 | 0.660 | 0.163 | torch.Size([180]) || stage8.5.residual_group.blocks.3.attn.proj.bias
+ | 0.849 | 0.390 | 0.985 | 0.070 | torch.Size([180]) || stage8.5.residual_group.blocks.3.norm2.weight
+ | -0.023 | -0.163 | 0.810 | 0.084 | torch.Size([180]) || stage8.5.residual_group.blocks.3.norm2.bias
+ | -0.002 | -0.547 | 0.536 | 0.115 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.3.mlp.fc11.weight
+ | -0.012 | -0.366 | 0.252 | 0.106 | torch.Size([360]) || stage8.5.residual_group.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.669 | 0.597 | 0.139 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.3.mlp.fc12.weight
+ | -0.002 | -0.216 | 0.202 | 0.074 | torch.Size([360]) || stage8.5.residual_group.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.700 | 0.674 | 0.139 | torch.Size([180, 360]) || stage8.5.residual_group.blocks.3.mlp.fc2.weight
+ | -0.032 | -0.376 | 0.666 | 0.134 | torch.Size([180]) || stage8.5.residual_group.blocks.3.mlp.fc2.bias
+ | -0.001 | -0.299 | 0.469 | 0.069 | torch.Size([180, 180]) || stage8.5.linear.weight
+ | 0.081 | -0.562 | 0.263 | 0.109 | torch.Size([180]) || stage8.5.linear.bias
+ | 1.111 | 0.208 | 1.434 | 0.192 | torch.Size([180]) || stage8.6.residual_group.blocks.0.norm1.weight
+ | -0.048 | -0.547 | 0.851 | 0.175 | torch.Size([180]) || stage8.6.residual_group.blocks.0.norm1.bias
+ | -0.252 | -2.157 | 6.293 | 0.490 | torch.Size([225, 6]) || stage8.6.residual_group.blocks.0.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.6.residual_group.blocks.0.attn.relative_position_index
+ | 0.000 | -0.664 | 0.631 | 0.123 | torch.Size([540, 180]) || stage8.6.residual_group.blocks.0.attn.qkv_self.weight
+ | 0.007 | -0.293 | 0.366 | 0.078 | torch.Size([540]) || stage8.6.residual_group.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.701 | 0.726 | 0.154 | torch.Size([180, 180]) || stage8.6.residual_group.blocks.0.attn.proj.weight
+ | 0.030 | -0.318 | 0.331 | 0.109 | torch.Size([180]) || stage8.6.residual_group.blocks.0.attn.proj.bias
+ | 0.959 | 0.475 | 1.322 | 0.088 | torch.Size([180]) || stage8.6.residual_group.blocks.0.norm2.weight
+ | -0.039 | -0.421 | 0.873 | 0.151 | torch.Size([180]) || stage8.6.residual_group.blocks.0.norm2.bias
+ | -0.002 | -0.550 | 0.783 | 0.116 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.0.mlp.fc11.weight
+ | 0.002 | -0.269 | 0.152 | 0.069 | torch.Size([360]) || stage8.6.residual_group.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.914 | 0.839 | 0.143 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.0.mlp.fc12.weight
+ | 0.001 | -0.340 | 0.304 | 0.075 | torch.Size([360]) || stage8.6.residual_group.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.592 | 0.713 | 0.140 | torch.Size([180, 360]) || stage8.6.residual_group.blocks.0.mlp.fc2.weight
+ | 0.002 | -0.535 | 0.384 | 0.177 | torch.Size([180]) || stage8.6.residual_group.blocks.0.mlp.fc2.bias
+ | 1.123 | 0.183 | 1.352 | 0.165 | torch.Size([180]) || stage8.6.residual_group.blocks.1.norm1.weight
+ | -0.047 | -0.513 | 0.903 | 0.168 | torch.Size([180]) || stage8.6.residual_group.blocks.1.norm1.bias
+ | -0.234 | -1.968 | 6.366 | 0.448 | torch.Size([225, 6]) || stage8.6.residual_group.blocks.1.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.6.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -0.751 | 0.759 | 0.121 | torch.Size([540, 180]) || stage8.6.residual_group.blocks.1.attn.qkv_self.weight
+ | -0.001 | -0.300 | 0.214 | 0.061 | torch.Size([540]) || stage8.6.residual_group.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.657 | 0.699 | 0.148 | torch.Size([180, 180]) || stage8.6.residual_group.blocks.1.attn.proj.weight
+ | 0.031 | -0.321 | 0.293 | 0.115 | torch.Size([180]) || stage8.6.residual_group.blocks.1.attn.proj.bias
+ | 0.986 | 0.416 | 1.360 | 0.096 | torch.Size([180]) || stage8.6.residual_group.blocks.1.norm2.weight
+ | -0.038 | -0.393 | 0.807 | 0.146 | torch.Size([180]) || stage8.6.residual_group.blocks.1.norm2.bias
+ | -0.001 | -0.589 | 0.620 | 0.116 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.1.mlp.fc11.weight
+ | 0.005 | -0.316 | 0.229 | 0.071 | torch.Size([360]) || stage8.6.residual_group.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.738 | 0.766 | 0.143 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.1.mlp.fc12.weight
+ | 0.001 | -0.252 | 0.302 | 0.072 | torch.Size([360]) || stage8.6.residual_group.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.674 | 0.629 | 0.140 | torch.Size([180, 360]) || stage8.6.residual_group.blocks.1.mlp.fc2.weight
+ | -0.001 | -0.475 | 0.441 | 0.175 | torch.Size([180]) || stage8.6.residual_group.blocks.1.mlp.fc2.bias
+ | 1.097 | 0.342 | 1.294 | 0.134 | torch.Size([180]) || stage8.6.residual_group.blocks.2.norm1.weight
+ | -0.054 | -0.639 | 0.904 | 0.186 | torch.Size([180]) || stage8.6.residual_group.blocks.2.norm1.bias
+ | -0.135 | -3.252 | 1.238 | 0.360 | torch.Size([225, 6]) || stage8.6.residual_group.blocks.2.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.6.residual_group.blocks.2.attn.relative_position_index
+ | 0.000 | -0.672 | 0.663 | 0.128 | torch.Size([540, 180]) || stage8.6.residual_group.blocks.2.attn.qkv_self.weight
+ | 0.007 | -0.170 | 0.228 | 0.046 | torch.Size([540]) || stage8.6.residual_group.blocks.2.attn.qkv_self.bias
+ | -0.001 | -0.660 | 0.651 | 0.147 | torch.Size([180, 180]) || stage8.6.residual_group.blocks.2.attn.proj.weight
+ | 0.031 | -0.360 | 0.322 | 0.126 | torch.Size([180]) || stage8.6.residual_group.blocks.2.attn.proj.bias
+ | 1.004 | 0.360 | 1.381 | 0.099 | torch.Size([180]) || stage8.6.residual_group.blocks.2.norm2.weight
+ | -0.042 | -0.447 | 0.808 | 0.157 | torch.Size([180]) || stage8.6.residual_group.blocks.2.norm2.bias
+ | -0.000 | -0.600 | 0.603 | 0.116 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.2.mlp.fc11.weight
+ | 0.022 | -0.447 | 0.249 | 0.086 | torch.Size([360]) || stage8.6.residual_group.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.666 | 0.708 | 0.143 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.2.mlp.fc12.weight
+ | -0.002 | -0.326 | 0.272 | 0.075 | torch.Size([360]) || stage8.6.residual_group.blocks.2.mlp.fc12.bias
+ | -0.001 | -0.653 | 0.719 | 0.142 | torch.Size([180, 360]) || stage8.6.residual_group.blocks.2.mlp.fc2.weight
+ | -0.011 | -0.488 | 0.321 | 0.153 | torch.Size([180]) || stage8.6.residual_group.blocks.2.mlp.fc2.bias
+ | 1.095 | 0.272 | 1.302 | 0.123 | torch.Size([180]) || stage8.6.residual_group.blocks.3.norm1.weight
+ | -0.052 | -0.557 | 1.069 | 0.192 | torch.Size([180]) || stage8.6.residual_group.blocks.3.norm1.bias
+ | -0.196 | -2.349 | 1.401 | 0.360 | torch.Size([225, 6]) || stage8.6.residual_group.blocks.3.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.6.residual_group.blocks.3.attn.relative_position_index
+ | 0.000 | -0.741 | 0.657 | 0.124 | torch.Size([540, 180]) || stage8.6.residual_group.blocks.3.attn.qkv_self.weight
+ | 0.001 | -0.186 | 0.141 | 0.040 | torch.Size([540]) || stage8.6.residual_group.blocks.3.attn.qkv_self.bias
+ | -0.001 | -0.669 | 0.671 | 0.139 | torch.Size([180, 180]) || stage8.6.residual_group.blocks.3.attn.proj.weight
+ | -0.004 | -0.323 | 0.300 | 0.124 | torch.Size([180]) || stage8.6.residual_group.blocks.3.attn.proj.bias
+ | 0.999 | 0.383 | 1.380 | 0.103 | torch.Size([180]) || stage8.6.residual_group.blocks.3.norm2.weight
+ | -0.044 | -0.392 | 0.694 | 0.163 | torch.Size([180]) || stage8.6.residual_group.blocks.3.norm2.bias
+ | 0.000 | -0.577 | 0.857 | 0.116 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.3.mlp.fc11.weight
+ | 0.041 | -0.394 | 0.238 | 0.087 | torch.Size([360]) || stage8.6.residual_group.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.924 | 0.828 | 0.143 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.3.mlp.fc12.weight
+ | -0.003 | -0.214 | 0.407 | 0.071 | torch.Size([360]) || stage8.6.residual_group.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.827 | 0.755 | 0.141 | torch.Size([180, 360]) || stage8.6.residual_group.blocks.3.mlp.fc2.weight
+ | 0.022 | -0.296 | 0.262 | 0.107 | torch.Size([180]) || stage8.6.residual_group.blocks.3.mlp.fc2.bias
+ | 0.002 | -1.059 | 1.262 | 0.089 | torch.Size([180, 180]) || stage8.6.linear.weight
+ | 0.031 | -0.789 | 0.427 | 0.120 | torch.Size([180]) || stage8.6.linear.bias
+ | 0.389 | 0.079 | 1.137 | 0.176 | torch.Size([180]) || norm.weight
+ | -0.021 | -0.669 | 0.888 | 0.127 | torch.Size([180]) || norm.bias
+ | 0.000 | -0.486 | 0.568 | 0.103 | torch.Size([120, 180]) || conv_after_body.weight
+ | -0.000 | -0.167 | 0.168 | 0.055 | torch.Size([120]) || conv_after_body.bias
+ | -0.000 | -1.782 | 1.300 | 0.109 | torch.Size([64, 120, 1, 3, 3]) || conv_before_upsample.0.weight
+ | -0.019 | -0.542 | 0.437 | 0.162 | torch.Size([64]) || conv_before_upsample.0.bias
+ | 0.001 | -1.915 | 1.372 | 0.090 | torch.Size([256, 64, 1, 3, 3]) || upsample.0.weight
+ | -0.045 | -0.281 | 0.215 | 0.097 | torch.Size([256]) || upsample.0.bias
+ | -0.006 | -4.826 | 0.582 | 0.075 | torch.Size([256, 64, 1, 3, 3]) || upsample.5.weight
+ | -0.154 | -0.441 | 0.187 | 0.100 | torch.Size([256]) || upsample.5.bias
+ | 0.000 | -0.210 | 0.246 | 0.012 | torch.Size([64, 64, 1, 3, 3]) || upsample.10.weight
+ | 0.000 | -0.013 | 0.007 | 0.003 | torch.Size([64]) || upsample.10.bias
+ | 0.000 | -0.044 | 0.042 | 0.004 | torch.Size([3, 64, 1, 3, 3]) || conv_last.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([3]) || conv_last.bias
+
+22-03-11 10:53:40.924 : task: 001_train_vrt_videosr_bi_reds_6frames
+ model: vrt
+ gpu_ids: [0, 1, 2, 3, 4, 5, 6, 7]
+ dist: False
+ find_unused_parameters: False
+ use_static_graph: True
+ scale: 4
+ n_channels: 3
+ path:[
+ root: experiments
+ pretrained_netG: /home/cll/dev/KAIR/model_zoo/vrt/001_VRT_videosr_bi_REDS_6frames.pth
+ pretrained_netE: None
+ task: experiments/001_train_vrt_videosr_bi_reds_6frames
+ log: experiments/001_train_vrt_videosr_bi_reds_6frames
+ options: experiments/001_train_vrt_videosr_bi_reds_6frames/options
+ models: experiments/001_train_vrt_videosr_bi_reds_6frames/models
+ images: experiments/001_train_vrt_videosr_bi_reds_6frames/images
+ pretrained_optimizerG: None
+ ]
+ datasets:[
+ train:[
+ name: train_dataset
+ dataset_type: VideoRecurrentTrainDataset
+ dataroot_gt: /home/cll/datasets/REDS/train/train_sharp
+ dataroot_lq: /home/cll/datasets/REDS/train/train_sharp_bicubic/X4
+ meta_info_file: data/meta_info/meta_info_REDS_GT.txt
+ filename_tmpl: 08d
+ filename_ext: png
+ val_partition: REDS4
+ test_mode: False
+ io_backend:[
+ type: disk
+ ]
+ num_frame: 4
+ gt_size: 256
+ interval_list: [1]
+ random_reverse: False
+ use_hflip: True
+ use_rot: True
+ dataloader_shuffle: True
+ dataloader_num_workers: 32
+ dataloader_batch_size: 8
+ phase: train
+ scale: 4
+ n_channels: 3
+ ]
+ test:[
+ name: test_dataset
+ dataset_type: VideoRecurrentTestDataset
+ dataroot_gt: /home/cll/Desktop/REDS4/GT
+ dataroot_lq: /home/cll/Desktop/REDS4/sharp_bicubic
+ cache_data: True
+ io_backend:[
+ type: disk
+ ]
+ num_frame: -1
+ phase: test
+ scale: 4
+ n_channels: 3
+ ]
+ ]
+ netG:[
+ net_type: vrt
+ upscale: 4
+ img_size: [6, 64, 64]
+ window_size: [2, 8, 8]
+ depths: [8, 8, 8, 8, 8, 8, 8, 4, 4, 4, 4, 4, 4]
+ indep_reconsts: [11, 12]
+ embed_dims: [120, 120, 120, 120, 120, 120, 120, 180, 180, 180, 180, 180, 180]
+ num_heads: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
+ spynet_path: model_zoo/vrt/spynet_sintel_final-3d2a1287.pth
+ pa_frames: 2
+ deformable_groups: 12
+ nonblind_denoising: False
+ use_checkpoint_attn: False
+ use_checkpoint_ffn: False
+ no_checkpoint_attn_blocks: []
+ no_checkpoint_ffn_blocks: []
+ init_type: default
+ scale: 4
+ ]
+ train:[
+ G_lossfn_type: charbonnier
+ G_lossfn_weight: 1.0
+ G_charbonnier_eps: 1e-09
+ E_decay: 0
+ G_optimizer_type: adam
+ G_optimizer_lr: 0.0004
+ G_optimizer_betas: [0.9, 0.99]
+ G_optimizer_wd: 0
+ G_optimizer_clipgrad: None
+ G_optimizer_reuse: True
+ fix_iter: 20000
+ fix_lr_mul: 0.125
+ fix_keys: ['spynet', 'deform']
+ total_iter: 300000
+ G_scheduler_type: CosineAnnealingWarmRestarts
+ G_scheduler_periods: 300000
+ G_scheduler_eta_min: 1e-07
+ G_regularizer_orthstep: None
+ G_regularizer_clipstep: None
+ G_param_strict: True
+ E_param_strict: True
+ checkpoint_test: 5000
+ checkpoint_save: 5000
+ checkpoint_print: 200
+ F_feature_layer: 34
+ F_weights: 1.0
+ F_lossfn_type: l1
+ F_use_input_norm: True
+ F_use_range_norm: False
+ G_scheduler_restart_weights: 1
+ ]
+ val:[
+ save_img: False
+ pad_seq: False
+ flip_seq: False
+ center_frame_only: False
+ num_frame_testing: 40
+ num_frame_overlapping: 2
+ size_patch_testing: 128
+ ]
+ opt_path: options/vrt/001_train_vrt_videosr_bi_reds_6frames.json
+ is_train: True
+ merge_bn: False
+ merge_bn_startpoint: -1
+ num_gpu: 8
+ rank: 0
+ world_size: 1
+
+22-03-11 10:53:40.969 : Number of train images: 24,000, iters: 3,000
diff --git a/KAIR/experiments/003_train_vrt_videosr_bi_vimeo_7frames/options/003_train_vrt_videosr_bi_vimeo_7frames_220311_095626.json b/KAIR/experiments/003_train_vrt_videosr_bi_vimeo_7frames/options/003_train_vrt_videosr_bi_vimeo_7frames_220311_095626.json
new file mode 100644
index 0000000000000000000000000000000000000000..954edfedc2074f76c4112f05508420e2c185d3ad
--- /dev/null
+++ b/KAIR/experiments/003_train_vrt_videosr_bi_vimeo_7frames/options/003_train_vrt_videosr_bi_vimeo_7frames_220311_095626.json
@@ -0,0 +1,198 @@
+{
+ "task": "003_train_vrt_videosr_bi_vimeo_7frames",
+ "model": "vrt",
+ "gpu_ids": [
+ 0,
+ 1,
+ 2,
+ 3,
+ 4,
+ 5,
+ 6,
+ 7
+ ],
+ "dist": false,
+ "find_unused_parameters": false,
+ "use_static_graph": true,
+ "scale": 4,
+ "n_channels": 3,
+ "path": {
+ "root": "experiments",
+ "pretrained_netG": "model_zoo/vrt/002_VRT_videosr_bi_REDS_16frames.pth",
+ "pretrained_netE": null,
+ "task": "experiments/003_train_vrt_videosr_bi_vimeo_7frames",
+ "log": "experiments/003_train_vrt_videosr_bi_vimeo_7frames",
+ "options": "experiments/003_train_vrt_videosr_bi_vimeo_7frames/options",
+ "models": "experiments/003_train_vrt_videosr_bi_vimeo_7frames/models",
+ "images": "experiments/003_train_vrt_videosr_bi_vimeo_7frames/images",
+ "pretrained_optimizerG": null
+ },
+ "datasets": {
+ "train": {
+ "name": "train_dataset",
+ "dataset_type": "VideoRecurrentTrainVimeoDataset",
+ "dataroot_gt": "trainsets/vimeo90k",
+ "dataroot_lq": "trainsets/vimeo90k",
+ "meta_info_file": "data/meta_info/meta_info_Vimeo90K_train_GT.txt",
+ "io_backend": {
+ "type": "file"
+ },
+ "num_frame": -1,
+ "gt_size": 256,
+ "interval_list": [
+ 1
+ ],
+ "random_reverse": true,
+ "use_hflip": true,
+ "use_rot": true,
+ "pad_sequence": true,
+ "dataloader_shuffle": true,
+ "dataloader_num_workers": 32,
+ "dataloader_batch_size": 8,
+ "phase": "train",
+ "scale": 4,
+ "n_channels": 3
+ },
+ "test": {
+ "name": "test_dataset",
+ "dataset_type": "VideoRecurrentTestDataset",
+ "dataroot_gt": "testsets/Vid4/GT",
+ "dataroot_lq": "testsets/Vid4/BIx4",
+ "cache_data": true,
+ "io_backend": {
+ "type": "disk"
+ },
+ "num_frame": -1,
+ "phase": "test",
+ "scale": 4,
+ "n_channels": 3
+ }
+ },
+ "netG": {
+ "net_type": "vrt",
+ "upscale": 4,
+ "img_size": [
+ 8,
+ 64,
+ 64
+ ],
+ "window_size": [
+ 8,
+ 8,
+ 8
+ ],
+ "depths": [
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 4,
+ 4,
+ 4,
+ 4,
+ 4,
+ 4
+ ],
+ "indep_reconsts": [
+ 11,
+ 12
+ ],
+ "embed_dims": [
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 180,
+ 180,
+ 180,
+ 180,
+ 180,
+ 180
+ ],
+ "num_heads": [
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6
+ ],
+ "spynet_path": "model_zoo/vrt/spynet_sintel_final-3d2a1287.pth",
+ "pa_frames": 4,
+ "deformable_groups": 16,
+ "nonblind_denoising": false,
+ "use_checkpoint_attn": false,
+ "use_checkpoint_ffn": false,
+ "no_checkpoint_attn_blocks": [],
+ "no_checkpoint_ffn_blocks": [],
+ "init_type": "default",
+ "scale": 4
+ },
+ "train": {
+ "G_lossfn_type": "charbonnier",
+ "G_lossfn_weight": 1.0,
+ "G_charbonnier_eps": 1e-09,
+ "E_decay": 0,
+ "G_optimizer_type": "adam",
+ "G_optimizer_lr": 0.0004,
+ "G_optimizer_betas": [
+ 0.9,
+ 0.99
+ ],
+ "G_optimizer_wd": 0,
+ "G_optimizer_clipgrad": null,
+ "G_optimizer_reuse": true,
+ "fix_iter": 20000,
+ "fix_lr_mul": 0.125,
+ "fix_keys": [
+ "spynet",
+ "deform"
+ ],
+ "total_iter": 300000,
+ "G_scheduler_type": "CosineAnnealingWarmRestarts",
+ "G_scheduler_periods": 300000,
+ "G_scheduler_eta_min": 1e-07,
+ "G_regularizer_orthstep": null,
+ "G_regularizer_clipstep": null,
+ "G_param_strict": false,
+ "E_param_strict": true,
+ "checkpoint_test": 5000,
+ "checkpoint_save": 5000,
+ "checkpoint_print": 200,
+ "F_feature_layer": 34,
+ "F_weights": 1.0,
+ "F_lossfn_type": "l1",
+ "F_use_input_norm": true,
+ "F_use_range_norm": false,
+ "G_scheduler_restart_weights": 1
+ },
+ "val": {
+ "save_img": false,
+ "pad_seq": false,
+ "flip_seq": false,
+ "center_frame_only": false,
+ "num_frame_testing": 32,
+ "num_frame_overlapping": 2,
+ "size_patch_testing": 128
+ },
+ "opt_path": "options/vrt/003_train_vrt_videosr_bi_vimeo_7frames.json",
+ "is_train": true,
+ "merge_bn": false,
+ "merge_bn_startpoint": -1,
+ "num_gpu": 8,
+ "rank": 0,
+ "world_size": 1
+}
\ No newline at end of file
diff --git a/KAIR/experiments/003_train_vrt_videosr_bi_vimeo_7frames/options/003_train_vrt_videosr_bi_vimeo_7frames_220311_101027.json b/KAIR/experiments/003_train_vrt_videosr_bi_vimeo_7frames/options/003_train_vrt_videosr_bi_vimeo_7frames_220311_101027.json
new file mode 100644
index 0000000000000000000000000000000000000000..954edfedc2074f76c4112f05508420e2c185d3ad
--- /dev/null
+++ b/KAIR/experiments/003_train_vrt_videosr_bi_vimeo_7frames/options/003_train_vrt_videosr_bi_vimeo_7frames_220311_101027.json
@@ -0,0 +1,198 @@
+{
+ "task": "003_train_vrt_videosr_bi_vimeo_7frames",
+ "model": "vrt",
+ "gpu_ids": [
+ 0,
+ 1,
+ 2,
+ 3,
+ 4,
+ 5,
+ 6,
+ 7
+ ],
+ "dist": false,
+ "find_unused_parameters": false,
+ "use_static_graph": true,
+ "scale": 4,
+ "n_channels": 3,
+ "path": {
+ "root": "experiments",
+ "pretrained_netG": "model_zoo/vrt/002_VRT_videosr_bi_REDS_16frames.pth",
+ "pretrained_netE": null,
+ "task": "experiments/003_train_vrt_videosr_bi_vimeo_7frames",
+ "log": "experiments/003_train_vrt_videosr_bi_vimeo_7frames",
+ "options": "experiments/003_train_vrt_videosr_bi_vimeo_7frames/options",
+ "models": "experiments/003_train_vrt_videosr_bi_vimeo_7frames/models",
+ "images": "experiments/003_train_vrt_videosr_bi_vimeo_7frames/images",
+ "pretrained_optimizerG": null
+ },
+ "datasets": {
+ "train": {
+ "name": "train_dataset",
+ "dataset_type": "VideoRecurrentTrainVimeoDataset",
+ "dataroot_gt": "trainsets/vimeo90k",
+ "dataroot_lq": "trainsets/vimeo90k",
+ "meta_info_file": "data/meta_info/meta_info_Vimeo90K_train_GT.txt",
+ "io_backend": {
+ "type": "file"
+ },
+ "num_frame": -1,
+ "gt_size": 256,
+ "interval_list": [
+ 1
+ ],
+ "random_reverse": true,
+ "use_hflip": true,
+ "use_rot": true,
+ "pad_sequence": true,
+ "dataloader_shuffle": true,
+ "dataloader_num_workers": 32,
+ "dataloader_batch_size": 8,
+ "phase": "train",
+ "scale": 4,
+ "n_channels": 3
+ },
+ "test": {
+ "name": "test_dataset",
+ "dataset_type": "VideoRecurrentTestDataset",
+ "dataroot_gt": "testsets/Vid4/GT",
+ "dataroot_lq": "testsets/Vid4/BIx4",
+ "cache_data": true,
+ "io_backend": {
+ "type": "disk"
+ },
+ "num_frame": -1,
+ "phase": "test",
+ "scale": 4,
+ "n_channels": 3
+ }
+ },
+ "netG": {
+ "net_type": "vrt",
+ "upscale": 4,
+ "img_size": [
+ 8,
+ 64,
+ 64
+ ],
+ "window_size": [
+ 8,
+ 8,
+ 8
+ ],
+ "depths": [
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 4,
+ 4,
+ 4,
+ 4,
+ 4,
+ 4
+ ],
+ "indep_reconsts": [
+ 11,
+ 12
+ ],
+ "embed_dims": [
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 180,
+ 180,
+ 180,
+ 180,
+ 180,
+ 180
+ ],
+ "num_heads": [
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6
+ ],
+ "spynet_path": "model_zoo/vrt/spynet_sintel_final-3d2a1287.pth",
+ "pa_frames": 4,
+ "deformable_groups": 16,
+ "nonblind_denoising": false,
+ "use_checkpoint_attn": false,
+ "use_checkpoint_ffn": false,
+ "no_checkpoint_attn_blocks": [],
+ "no_checkpoint_ffn_blocks": [],
+ "init_type": "default",
+ "scale": 4
+ },
+ "train": {
+ "G_lossfn_type": "charbonnier",
+ "G_lossfn_weight": 1.0,
+ "G_charbonnier_eps": 1e-09,
+ "E_decay": 0,
+ "G_optimizer_type": "adam",
+ "G_optimizer_lr": 0.0004,
+ "G_optimizer_betas": [
+ 0.9,
+ 0.99
+ ],
+ "G_optimizer_wd": 0,
+ "G_optimizer_clipgrad": null,
+ "G_optimizer_reuse": true,
+ "fix_iter": 20000,
+ "fix_lr_mul": 0.125,
+ "fix_keys": [
+ "spynet",
+ "deform"
+ ],
+ "total_iter": 300000,
+ "G_scheduler_type": "CosineAnnealingWarmRestarts",
+ "G_scheduler_periods": 300000,
+ "G_scheduler_eta_min": 1e-07,
+ "G_regularizer_orthstep": null,
+ "G_regularizer_clipstep": null,
+ "G_param_strict": false,
+ "E_param_strict": true,
+ "checkpoint_test": 5000,
+ "checkpoint_save": 5000,
+ "checkpoint_print": 200,
+ "F_feature_layer": 34,
+ "F_weights": 1.0,
+ "F_lossfn_type": "l1",
+ "F_use_input_norm": true,
+ "F_use_range_norm": false,
+ "G_scheduler_restart_weights": 1
+ },
+ "val": {
+ "save_img": false,
+ "pad_seq": false,
+ "flip_seq": false,
+ "center_frame_only": false,
+ "num_frame_testing": 32,
+ "num_frame_overlapping": 2,
+ "size_patch_testing": 128
+ },
+ "opt_path": "options/vrt/003_train_vrt_videosr_bi_vimeo_7frames.json",
+ "is_train": true,
+ "merge_bn": false,
+ "merge_bn_startpoint": -1,
+ "num_gpu": 8,
+ "rank": 0,
+ "world_size": 1
+}
\ No newline at end of file
diff --git a/KAIR/experiments/003_train_vrt_videosr_bi_vimeo_7frames/options/003_train_vrt_videosr_bi_vimeo_7frames_220311_101042.json b/KAIR/experiments/003_train_vrt_videosr_bi_vimeo_7frames/options/003_train_vrt_videosr_bi_vimeo_7frames_220311_101042.json
new file mode 100644
index 0000000000000000000000000000000000000000..2a2d2c10cec4274f211bef5c67ba92f551dd18d4
--- /dev/null
+++ b/KAIR/experiments/003_train_vrt_videosr_bi_vimeo_7frames/options/003_train_vrt_videosr_bi_vimeo_7frames_220311_101042.json
@@ -0,0 +1,198 @@
+{
+ "task": "003_train_vrt_videosr_bi_vimeo_7frames",
+ "model": "vrt",
+ "gpu_ids": [
+ 0,
+ 1,
+ 2,
+ 3,
+ 4,
+ 5,
+ 6,
+ 7
+ ],
+ "dist": false,
+ "find_unused_parameters": false,
+ "use_static_graph": true,
+ "scale": 4,
+ "n_channels": 3,
+ "path": {
+ "root": "experiments",
+ "pretrained_netG": "model_zoo/vrt/002_VRT_videosr_bi_REDS_16frames.pth",
+ "pretrained_netE": null,
+ "task": "experiments/003_train_vrt_videosr_bi_vimeo_7frames",
+ "log": "experiments/003_train_vrt_videosr_bi_vimeo_7frames",
+ "options": "experiments/003_train_vrt_videosr_bi_vimeo_7frames/options",
+ "models": "experiments/003_train_vrt_videosr_bi_vimeo_7frames/models",
+ "images": "experiments/003_train_vrt_videosr_bi_vimeo_7frames/images",
+ "pretrained_optimizerG": null
+ },
+ "datasets": {
+ "train": {
+ "name": "train_dataset",
+ "dataset_type": "VideoRecurrentTrainVimeoDataset",
+ "dataroot_gt": "trainsets/vimeo90k",
+ "dataroot_lq": "trainsets/vimeo90k",
+ "meta_info_file": "data/meta_info/meta_info_Vimeo90K_train_GT.txt",
+ "io_backend": {
+ "type": "disk"
+ },
+ "num_frame": -1,
+ "gt_size": 256,
+ "interval_list": [
+ 1
+ ],
+ "random_reverse": true,
+ "use_hflip": true,
+ "use_rot": true,
+ "pad_sequence": true,
+ "dataloader_shuffle": true,
+ "dataloader_num_workers": 32,
+ "dataloader_batch_size": 8,
+ "phase": "train",
+ "scale": 4,
+ "n_channels": 3
+ },
+ "test": {
+ "name": "test_dataset",
+ "dataset_type": "VideoRecurrentTestDataset",
+ "dataroot_gt": "testsets/Vid4/GT",
+ "dataroot_lq": "testsets/Vid4/BIx4",
+ "cache_data": true,
+ "io_backend": {
+ "type": "disk"
+ },
+ "num_frame": -1,
+ "phase": "test",
+ "scale": 4,
+ "n_channels": 3
+ }
+ },
+ "netG": {
+ "net_type": "vrt",
+ "upscale": 4,
+ "img_size": [
+ 8,
+ 64,
+ 64
+ ],
+ "window_size": [
+ 8,
+ 8,
+ 8
+ ],
+ "depths": [
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 4,
+ 4,
+ 4,
+ 4,
+ 4,
+ 4
+ ],
+ "indep_reconsts": [
+ 11,
+ 12
+ ],
+ "embed_dims": [
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 180,
+ 180,
+ 180,
+ 180,
+ 180,
+ 180
+ ],
+ "num_heads": [
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6
+ ],
+ "spynet_path": "model_zoo/vrt/spynet_sintel_final-3d2a1287.pth",
+ "pa_frames": 4,
+ "deformable_groups": 16,
+ "nonblind_denoising": false,
+ "use_checkpoint_attn": false,
+ "use_checkpoint_ffn": false,
+ "no_checkpoint_attn_blocks": [],
+ "no_checkpoint_ffn_blocks": [],
+ "init_type": "default",
+ "scale": 4
+ },
+ "train": {
+ "G_lossfn_type": "charbonnier",
+ "G_lossfn_weight": 1.0,
+ "G_charbonnier_eps": 1e-09,
+ "E_decay": 0,
+ "G_optimizer_type": "adam",
+ "G_optimizer_lr": 0.0004,
+ "G_optimizer_betas": [
+ 0.9,
+ 0.99
+ ],
+ "G_optimizer_wd": 0,
+ "G_optimizer_clipgrad": null,
+ "G_optimizer_reuse": true,
+ "fix_iter": 20000,
+ "fix_lr_mul": 0.125,
+ "fix_keys": [
+ "spynet",
+ "deform"
+ ],
+ "total_iter": 300000,
+ "G_scheduler_type": "CosineAnnealingWarmRestarts",
+ "G_scheduler_periods": 300000,
+ "G_scheduler_eta_min": 1e-07,
+ "G_regularizer_orthstep": null,
+ "G_regularizer_clipstep": null,
+ "G_param_strict": false,
+ "E_param_strict": true,
+ "checkpoint_test": 5000,
+ "checkpoint_save": 5000,
+ "checkpoint_print": 200,
+ "F_feature_layer": 34,
+ "F_weights": 1.0,
+ "F_lossfn_type": "l1",
+ "F_use_input_norm": true,
+ "F_use_range_norm": false,
+ "G_scheduler_restart_weights": 1
+ },
+ "val": {
+ "save_img": false,
+ "pad_seq": false,
+ "flip_seq": false,
+ "center_frame_only": false,
+ "num_frame_testing": 32,
+ "num_frame_overlapping": 2,
+ "size_patch_testing": 128
+ },
+ "opt_path": "options/vrt/003_train_vrt_videosr_bi_vimeo_7frames.json",
+ "is_train": true,
+ "merge_bn": false,
+ "merge_bn_startpoint": -1,
+ "num_gpu": 8,
+ "rank": 0,
+ "world_size": 1
+}
\ No newline at end of file
diff --git a/KAIR/experiments/003_train_vrt_videosr_bi_vimeo_7frames/options/003_train_vrt_videosr_bi_vimeo_7frames_220311_101058.json b/KAIR/experiments/003_train_vrt_videosr_bi_vimeo_7frames/options/003_train_vrt_videosr_bi_vimeo_7frames_220311_101058.json
new file mode 100644
index 0000000000000000000000000000000000000000..2a2d2c10cec4274f211bef5c67ba92f551dd18d4
--- /dev/null
+++ b/KAIR/experiments/003_train_vrt_videosr_bi_vimeo_7frames/options/003_train_vrt_videosr_bi_vimeo_7frames_220311_101058.json
@@ -0,0 +1,198 @@
+{
+ "task": "003_train_vrt_videosr_bi_vimeo_7frames",
+ "model": "vrt",
+ "gpu_ids": [
+ 0,
+ 1,
+ 2,
+ 3,
+ 4,
+ 5,
+ 6,
+ 7
+ ],
+ "dist": false,
+ "find_unused_parameters": false,
+ "use_static_graph": true,
+ "scale": 4,
+ "n_channels": 3,
+ "path": {
+ "root": "experiments",
+ "pretrained_netG": "model_zoo/vrt/002_VRT_videosr_bi_REDS_16frames.pth",
+ "pretrained_netE": null,
+ "task": "experiments/003_train_vrt_videosr_bi_vimeo_7frames",
+ "log": "experiments/003_train_vrt_videosr_bi_vimeo_7frames",
+ "options": "experiments/003_train_vrt_videosr_bi_vimeo_7frames/options",
+ "models": "experiments/003_train_vrt_videosr_bi_vimeo_7frames/models",
+ "images": "experiments/003_train_vrt_videosr_bi_vimeo_7frames/images",
+ "pretrained_optimizerG": null
+ },
+ "datasets": {
+ "train": {
+ "name": "train_dataset",
+ "dataset_type": "VideoRecurrentTrainVimeoDataset",
+ "dataroot_gt": "trainsets/vimeo90k",
+ "dataroot_lq": "trainsets/vimeo90k",
+ "meta_info_file": "data/meta_info/meta_info_Vimeo90K_train_GT.txt",
+ "io_backend": {
+ "type": "disk"
+ },
+ "num_frame": -1,
+ "gt_size": 256,
+ "interval_list": [
+ 1
+ ],
+ "random_reverse": true,
+ "use_hflip": true,
+ "use_rot": true,
+ "pad_sequence": true,
+ "dataloader_shuffle": true,
+ "dataloader_num_workers": 32,
+ "dataloader_batch_size": 8,
+ "phase": "train",
+ "scale": 4,
+ "n_channels": 3
+ },
+ "test": {
+ "name": "test_dataset",
+ "dataset_type": "VideoRecurrentTestDataset",
+ "dataroot_gt": "testsets/Vid4/GT",
+ "dataroot_lq": "testsets/Vid4/BIx4",
+ "cache_data": true,
+ "io_backend": {
+ "type": "disk"
+ },
+ "num_frame": -1,
+ "phase": "test",
+ "scale": 4,
+ "n_channels": 3
+ }
+ },
+ "netG": {
+ "net_type": "vrt",
+ "upscale": 4,
+ "img_size": [
+ 8,
+ 64,
+ 64
+ ],
+ "window_size": [
+ 8,
+ 8,
+ 8
+ ],
+ "depths": [
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 8,
+ 4,
+ 4,
+ 4,
+ 4,
+ 4,
+ 4
+ ],
+ "indep_reconsts": [
+ 11,
+ 12
+ ],
+ "embed_dims": [
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 120,
+ 180,
+ 180,
+ 180,
+ 180,
+ 180,
+ 180
+ ],
+ "num_heads": [
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6,
+ 6
+ ],
+ "spynet_path": "model_zoo/vrt/spynet_sintel_final-3d2a1287.pth",
+ "pa_frames": 4,
+ "deformable_groups": 16,
+ "nonblind_denoising": false,
+ "use_checkpoint_attn": false,
+ "use_checkpoint_ffn": false,
+ "no_checkpoint_attn_blocks": [],
+ "no_checkpoint_ffn_blocks": [],
+ "init_type": "default",
+ "scale": 4
+ },
+ "train": {
+ "G_lossfn_type": "charbonnier",
+ "G_lossfn_weight": 1.0,
+ "G_charbonnier_eps": 1e-09,
+ "E_decay": 0,
+ "G_optimizer_type": "adam",
+ "G_optimizer_lr": 0.0004,
+ "G_optimizer_betas": [
+ 0.9,
+ 0.99
+ ],
+ "G_optimizer_wd": 0,
+ "G_optimizer_clipgrad": null,
+ "G_optimizer_reuse": true,
+ "fix_iter": 20000,
+ "fix_lr_mul": 0.125,
+ "fix_keys": [
+ "spynet",
+ "deform"
+ ],
+ "total_iter": 300000,
+ "G_scheduler_type": "CosineAnnealingWarmRestarts",
+ "G_scheduler_periods": 300000,
+ "G_scheduler_eta_min": 1e-07,
+ "G_regularizer_orthstep": null,
+ "G_regularizer_clipstep": null,
+ "G_param_strict": false,
+ "E_param_strict": true,
+ "checkpoint_test": 5000,
+ "checkpoint_save": 5000,
+ "checkpoint_print": 200,
+ "F_feature_layer": 34,
+ "F_weights": 1.0,
+ "F_lossfn_type": "l1",
+ "F_use_input_norm": true,
+ "F_use_range_norm": false,
+ "G_scheduler_restart_weights": 1
+ },
+ "val": {
+ "save_img": false,
+ "pad_seq": false,
+ "flip_seq": false,
+ "center_frame_only": false,
+ "num_frame_testing": 32,
+ "num_frame_overlapping": 2,
+ "size_patch_testing": 128
+ },
+ "opt_path": "options/vrt/003_train_vrt_videosr_bi_vimeo_7frames.json",
+ "is_train": true,
+ "merge_bn": false,
+ "merge_bn_startpoint": -1,
+ "num_gpu": 8,
+ "rank": 0,
+ "world_size": 1
+}
\ No newline at end of file
diff --git a/KAIR/experiments/003_train_vrt_videosr_bi_vimeo_7frames/train.log b/KAIR/experiments/003_train_vrt_videosr_bi_vimeo_7frames/train.log
new file mode 100644
index 0000000000000000000000000000000000000000..ab743dbb2ddd627891d4f61ce1eb1a2f033b2916
--- /dev/null
+++ b/KAIR/experiments/003_train_vrt_videosr_bi_vimeo_7frames/train.log
@@ -0,0 +1,10958 @@
+22-03-11 09:56:26.486 : task: 003_train_vrt_videosr_bi_vimeo_7frames
+ model: vrt
+ gpu_ids: [0, 1, 2, 3, 4, 5, 6, 7]
+ dist: False
+ find_unused_parameters: False
+ use_static_graph: True
+ scale: 4
+ n_channels: 3
+ path:[
+ root: experiments
+ pretrained_netG: model_zoo/vrt/002_VRT_videosr_bi_REDS_16frames.pth
+ pretrained_netE: None
+ task: experiments/003_train_vrt_videosr_bi_vimeo_7frames
+ log: experiments/003_train_vrt_videosr_bi_vimeo_7frames
+ options: experiments/003_train_vrt_videosr_bi_vimeo_7frames/options
+ models: experiments/003_train_vrt_videosr_bi_vimeo_7frames/models
+ images: experiments/003_train_vrt_videosr_bi_vimeo_7frames/images
+ pretrained_optimizerG: None
+ ]
+ datasets:[
+ train:[
+ name: train_dataset
+ dataset_type: VideoRecurrentTrainVimeoDataset
+ dataroot_gt: trainsets/vimeo90k
+ dataroot_lq: trainsets/vimeo90k
+ meta_info_file: data/meta_info/meta_info_Vimeo90K_train_GT.txt
+ io_backend:[
+ type: file
+ ]
+ num_frame: -1
+ gt_size: 256
+ interval_list: [1]
+ random_reverse: True
+ use_hflip: True
+ use_rot: True
+ pad_sequence: True
+ dataloader_shuffle: True
+ dataloader_num_workers: 32
+ dataloader_batch_size: 8
+ phase: train
+ scale: 4
+ n_channels: 3
+ ]
+ test:[
+ name: test_dataset
+ dataset_type: VideoRecurrentTestDataset
+ dataroot_gt: testsets/Vid4/GT
+ dataroot_lq: testsets/Vid4/BIx4
+ cache_data: True
+ io_backend:[
+ type: disk
+ ]
+ num_frame: -1
+ phase: test
+ scale: 4
+ n_channels: 3
+ ]
+ ]
+ netG:[
+ net_type: vrt
+ upscale: 4
+ img_size: [8, 64, 64]
+ window_size: [8, 8, 8]
+ depths: [8, 8, 8, 8, 8, 8, 8, 4, 4, 4, 4, 4, 4]
+ indep_reconsts: [11, 12]
+ embed_dims: [120, 120, 120, 120, 120, 120, 120, 180, 180, 180, 180, 180, 180]
+ num_heads: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
+ spynet_path: model_zoo/vrt/spynet_sintel_final-3d2a1287.pth
+ pa_frames: 4
+ deformable_groups: 16
+ nonblind_denoising: False
+ use_checkpoint_attn: False
+ use_checkpoint_ffn: False
+ no_checkpoint_attn_blocks: []
+ no_checkpoint_ffn_blocks: []
+ init_type: default
+ scale: 4
+ ]
+ train:[
+ G_lossfn_type: charbonnier
+ G_lossfn_weight: 1.0
+ G_charbonnier_eps: 1e-09
+ E_decay: 0
+ G_optimizer_type: adam
+ G_optimizer_lr: 0.0004
+ G_optimizer_betas: [0.9, 0.99]
+ G_optimizer_wd: 0
+ G_optimizer_clipgrad: None
+ G_optimizer_reuse: True
+ fix_iter: 20000
+ fix_lr_mul: 0.125
+ fix_keys: ['spynet', 'deform']
+ total_iter: 300000
+ G_scheduler_type: CosineAnnealingWarmRestarts
+ G_scheduler_periods: 300000
+ G_scheduler_eta_min: 1e-07
+ G_regularizer_orthstep: None
+ G_regularizer_clipstep: None
+ G_param_strict: False
+ E_param_strict: True
+ checkpoint_test: 5000
+ checkpoint_save: 5000
+ checkpoint_print: 200
+ F_feature_layer: 34
+ F_weights: 1.0
+ F_lossfn_type: l1
+ F_use_input_norm: True
+ F_use_range_norm: False
+ G_scheduler_restart_weights: 1
+ ]
+ val:[
+ save_img: False
+ pad_seq: False
+ flip_seq: False
+ center_frame_only: False
+ num_frame_testing: 32
+ num_frame_overlapping: 2
+ size_patch_testing: 128
+ ]
+ opt_path: options/vrt/003_train_vrt_videosr_bi_vimeo_7frames.json
+ is_train: True
+ merge_bn: False
+ merge_bn_startpoint: -1
+ num_gpu: 8
+ rank: 0
+ world_size: 1
+
+22-03-11 09:56:26.522 : Number of train images: 64,612, iters: 8,077
+22-03-11 10:10:27.405 : task: 003_train_vrt_videosr_bi_vimeo_7frames
+ model: vrt
+ gpu_ids: [0, 1, 2, 3, 4, 5, 6, 7]
+ dist: False
+ find_unused_parameters: False
+ use_static_graph: True
+ scale: 4
+ n_channels: 3
+ path:[
+ root: experiments
+ pretrained_netG: model_zoo/vrt/002_VRT_videosr_bi_REDS_16frames.pth
+ pretrained_netE: None
+ task: experiments/003_train_vrt_videosr_bi_vimeo_7frames
+ log: experiments/003_train_vrt_videosr_bi_vimeo_7frames
+ options: experiments/003_train_vrt_videosr_bi_vimeo_7frames/options
+ models: experiments/003_train_vrt_videosr_bi_vimeo_7frames/models
+ images: experiments/003_train_vrt_videosr_bi_vimeo_7frames/images
+ pretrained_optimizerG: None
+ ]
+ datasets:[
+ train:[
+ name: train_dataset
+ dataset_type: VideoRecurrentTrainVimeoDataset
+ dataroot_gt: trainsets/vimeo90k
+ dataroot_lq: trainsets/vimeo90k
+ meta_info_file: data/meta_info/meta_info_Vimeo90K_train_GT.txt
+ io_backend:[
+ type: file
+ ]
+ num_frame: -1
+ gt_size: 256
+ interval_list: [1]
+ random_reverse: True
+ use_hflip: True
+ use_rot: True
+ pad_sequence: True
+ dataloader_shuffle: True
+ dataloader_num_workers: 32
+ dataloader_batch_size: 8
+ phase: train
+ scale: 4
+ n_channels: 3
+ ]
+ test:[
+ name: test_dataset
+ dataset_type: VideoRecurrentTestDataset
+ dataroot_gt: testsets/Vid4/GT
+ dataroot_lq: testsets/Vid4/BIx4
+ cache_data: True
+ io_backend:[
+ type: disk
+ ]
+ num_frame: -1
+ phase: test
+ scale: 4
+ n_channels: 3
+ ]
+ ]
+ netG:[
+ net_type: vrt
+ upscale: 4
+ img_size: [8, 64, 64]
+ window_size: [8, 8, 8]
+ depths: [8, 8, 8, 8, 8, 8, 8, 4, 4, 4, 4, 4, 4]
+ indep_reconsts: [11, 12]
+ embed_dims: [120, 120, 120, 120, 120, 120, 120, 180, 180, 180, 180, 180, 180]
+ num_heads: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
+ spynet_path: model_zoo/vrt/spynet_sintel_final-3d2a1287.pth
+ pa_frames: 4
+ deformable_groups: 16
+ nonblind_denoising: False
+ use_checkpoint_attn: False
+ use_checkpoint_ffn: False
+ no_checkpoint_attn_blocks: []
+ no_checkpoint_ffn_blocks: []
+ init_type: default
+ scale: 4
+ ]
+ train:[
+ G_lossfn_type: charbonnier
+ G_lossfn_weight: 1.0
+ G_charbonnier_eps: 1e-09
+ E_decay: 0
+ G_optimizer_type: adam
+ G_optimizer_lr: 0.0004
+ G_optimizer_betas: [0.9, 0.99]
+ G_optimizer_wd: 0
+ G_optimizer_clipgrad: None
+ G_optimizer_reuse: True
+ fix_iter: 20000
+ fix_lr_mul: 0.125
+ fix_keys: ['spynet', 'deform']
+ total_iter: 300000
+ G_scheduler_type: CosineAnnealingWarmRestarts
+ G_scheduler_periods: 300000
+ G_scheduler_eta_min: 1e-07
+ G_regularizer_orthstep: None
+ G_regularizer_clipstep: None
+ G_param_strict: False
+ E_param_strict: True
+ checkpoint_test: 5000
+ checkpoint_save: 5000
+ checkpoint_print: 200
+ F_feature_layer: 34
+ F_weights: 1.0
+ F_lossfn_type: l1
+ F_use_input_norm: True
+ F_use_range_norm: False
+ G_scheduler_restart_weights: 1
+ ]
+ val:[
+ save_img: False
+ pad_seq: False
+ flip_seq: False
+ center_frame_only: False
+ num_frame_testing: 32
+ num_frame_overlapping: 2
+ size_patch_testing: 128
+ ]
+ opt_path: options/vrt/003_train_vrt_videosr_bi_vimeo_7frames.json
+ is_train: True
+ merge_bn: False
+ merge_bn_startpoint: -1
+ num_gpu: 8
+ rank: 0
+ world_size: 1
+
+22-03-11 10:10:27.440 : Number of train images: 64,612, iters: 8,077
+22-03-11 10:10:31.005 :
+Networks name: VRT
+Params number: 32577991
+Net structure:
+VRT(
+ (conv_first): Conv3d(27, 120, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ (spynet): SpyNet(
+ (basic_module): ModuleList(
+ (0): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (1): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (2): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (3): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (4): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (5): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ )
+ )
+ (stage1): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n c d h w -> n d h w c')
+ (1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (2): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): Identity()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): Identity()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(364, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 432, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage2): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n c d (h neih) (w neiw) -> n d h w (neiw neih c)', neih=2, neiw=2)
+ (1): LayerNorm((480,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=480, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(364, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 432, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage3): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n c d (h neih) (w neiw) -> n d h w (neiw neih c)', neih=2, neiw=2)
+ (1): LayerNorm((480,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=480, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(364, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 432, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage4): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n c d (h neih) (w neiw) -> n d h w (neiw neih c)', neih=2, neiw=2)
+ (1): LayerNorm((480,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=480, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(364, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 432, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage5): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n (neiw neih c) d h w -> n d (h neih) (w neiw) c', neih=2, neiw=2)
+ (1): LayerNorm((30,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=30, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(364, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 432, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage6): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n (neiw neih c) d h w -> n d (h neih) (w neiw) c', neih=2, neiw=2)
+ (1): LayerNorm((30,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=30, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(364, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 432, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage7): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n (neiw neih c) d h w -> n d (h neih) (w neiw) c', neih=2, neiw=2)
+ (1): LayerNorm((30,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=30, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(364, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 432, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage8): ModuleList(
+ (0): Sequential(
+ (0): Rearrange('n c d h w -> n d h w c')
+ (1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=120, out_features=180, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (1): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (2): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (3): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (4): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (5): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (6): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ )
+ (norm): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (conv_after_body): Linear(in_features=180, out_features=120, bias=True)
+ (conv_before_upsample): Sequential(
+ (0): Conv3d(120, 64, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ (1): LeakyReLU(negative_slope=0.01, inplace=True)
+ )
+ (upsample): Upsample(
+ (0): Conv3d(64, 256, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ (1): Transpose_Dim12()
+ (2): PixelShuffle(upscale_factor=2)
+ (3): Transpose_Dim12()
+ (4): LeakyReLU(negative_slope=0.1, inplace=True)
+ (5): Conv3d(64, 256, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ (6): Transpose_Dim12()
+ (7): PixelShuffle(upscale_factor=2)
+ (8): Transpose_Dim12()
+ (9): LeakyReLU(negative_slope=0.1, inplace=True)
+ (10): Conv3d(64, 64, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ )
+ (conv_last): Conv3d(64, 3, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+)
+
+22-03-11 10:10:31.165 :
+ | mean | min | max | std || shape
+ | 0.000 | -1.496 | 1.623 | 0.115 | torch.Size([120, 27, 1, 3, 3]) || conv_first.weight
+ | -0.005 | -1.075 | 0.916 | 0.274 | torch.Size([120]) || conv_first.bias
+ | 0.449 | 0.406 | 0.485 | 0.040 | torch.Size([1, 3, 1, 1]) || spynet.mean
+ | 0.226 | 0.224 | 0.229 | 0.003 | torch.Size([1, 3, 1, 1]) || spynet.std
+ | -0.000 | -0.656 | 0.699 | 0.067 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.0.basic_module.0.weight
+ | -0.037 | -0.877 | 0.359 | 0.346 | torch.Size([32]) || spynet.basic_module.0.basic_module.0.bias
+ | -0.007 | -3.201 | 0.948 | 0.097 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.0.basic_module.2.weight
+ | 0.063 | -1.264 | 0.752 | 0.323 | torch.Size([64]) || spynet.basic_module.0.basic_module.2.bias
+ | -0.010 | -4.633 | 0.568 | 0.089 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.0.basic_module.4.weight
+ | 0.158 | -0.704 | 0.861 | 0.357 | torch.Size([32]) || spynet.basic_module.0.basic_module.4.bias
+ | -0.024 | -1.714 | 0.414 | 0.091 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.0.basic_module.6.weight
+ | 0.779 | -1.061 | 1.164 | 0.519 | torch.Size([16]) || spynet.basic_module.0.basic_module.6.bias
+ | 0.000 | -0.148 | 0.161 | 0.018 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.0.basic_module.8.weight
+ | 0.002 | -0.000 | 0.004 | 0.003 | torch.Size([2]) || spynet.basic_module.0.basic_module.8.bias
+ | 0.000 | -0.745 | 0.760 | 0.070 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.1.basic_module.0.weight
+ | -0.019 | -0.848 | 0.359 | 0.331 | torch.Size([32]) || spynet.basic_module.1.basic_module.0.bias
+ | -0.010 | -3.373 | 0.916 | 0.099 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.1.basic_module.2.weight
+ | 0.037 | -1.227 | 0.720 | 0.303 | torch.Size([64]) || spynet.basic_module.1.basic_module.2.bias
+ | -0.009 | -4.425 | 0.539 | 0.088 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.1.basic_module.4.weight
+ | 0.158 | -0.758 | 0.988 | 0.386 | torch.Size([32]) || spynet.basic_module.1.basic_module.4.bias
+ | -0.020 | -1.647 | 0.319 | 0.084 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.1.basic_module.6.weight
+ | 0.777 | -1.211 | 1.152 | 0.550 | torch.Size([16]) || spynet.basic_module.1.basic_module.6.bias
+ | 0.000 | -0.126 | 0.144 | 0.017 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.1.basic_module.8.weight
+ | 0.004 | 0.001 | 0.008 | 0.005 | torch.Size([2]) || spynet.basic_module.1.basic_module.8.bias
+ | 0.000 | -0.938 | 0.872 | 0.088 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.2.basic_module.0.weight
+ | -0.028 | -1.086 | 0.552 | 0.435 | torch.Size([32]) || spynet.basic_module.2.basic_module.0.bias
+ | -0.011 | -4.624 | 1.203 | 0.116 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.2.basic_module.2.weight
+ | 0.022 | -1.298 | 0.715 | 0.312 | torch.Size([64]) || spynet.basic_module.2.basic_module.2.bias
+ | -0.010 | -1.806 | 0.627 | 0.092 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.2.basic_module.4.weight
+ | 0.118 | -0.698 | 0.750 | 0.332 | torch.Size([32]) || spynet.basic_module.2.basic_module.4.bias
+ | -0.014 | -1.277 | 0.337 | 0.067 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.2.basic_module.6.weight
+ | 0.684 | -1.730 | 0.954 | 0.648 | torch.Size([16]) || spynet.basic_module.2.basic_module.6.bias
+ | 0.000 | -0.031 | 0.042 | 0.009 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.2.basic_module.8.weight
+ | -0.010 | -0.010 | -0.010 | 0.000 | torch.Size([2]) || spynet.basic_module.2.basic_module.8.bias
+ | -0.000 | -0.956 | 0.847 | 0.089 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.3.basic_module.0.weight
+ | -0.049 | -1.175 | 0.652 | 0.477 | torch.Size([32]) || spynet.basic_module.3.basic_module.0.bias
+ | -0.010 | -4.892 | 1.180 | 0.117 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.3.basic_module.2.weight
+ | 0.021 | -1.294 | 0.764 | 0.316 | torch.Size([64]) || spynet.basic_module.3.basic_module.2.bias
+ | -0.010 | -1.793 | 0.556 | 0.089 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.3.basic_module.4.weight
+ | 0.123 | -0.717 | 0.737 | 0.335 | torch.Size([32]) || spynet.basic_module.3.basic_module.4.bias
+ | -0.012 | -1.102 | 0.291 | 0.061 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.3.basic_module.6.weight
+ | 0.650 | -1.838 | 0.913 | 0.669 | torch.Size([16]) || spynet.basic_module.3.basic_module.6.bias
+ | 0.000 | -0.032 | 0.039 | 0.006 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.3.basic_module.8.weight
+ | 0.000 | -0.012 | 0.012 | 0.017 | torch.Size([2]) || spynet.basic_module.3.basic_module.8.bias
+ | -0.000 | -0.953 | 0.855 | 0.089 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.4.basic_module.0.weight
+ | -0.009 | -1.001 | 0.584 | 0.427 | torch.Size([32]) || spynet.basic_module.4.basic_module.0.bias
+ | -0.010 | -5.054 | 1.223 | 0.116 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.4.basic_module.2.weight
+ | 0.023 | -1.315 | 0.884 | 0.326 | torch.Size([64]) || spynet.basic_module.4.basic_module.2.bias
+ | -0.009 | -1.786 | 0.534 | 0.088 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.4.basic_module.4.weight
+ | 0.142 | -0.698 | 0.780 | 0.342 | torch.Size([32]) || spynet.basic_module.4.basic_module.4.bias
+ | -0.011 | -0.957 | 0.276 | 0.057 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.4.basic_module.6.weight
+ | 0.653 | -1.854 | 0.943 | 0.677 | torch.Size([16]) || spynet.basic_module.4.basic_module.6.bias
+ | 0.000 | -0.034 | 0.035 | 0.005 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.4.basic_module.8.weight
+ | -0.001 | -0.010 | 0.008 | 0.012 | torch.Size([2]) || spynet.basic_module.4.basic_module.8.bias
+ | -0.000 | -0.918 | 0.865 | 0.087 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.5.basic_module.0.weight
+ | 0.047 | -0.824 | 0.510 | 0.392 | torch.Size([32]) || spynet.basic_module.5.basic_module.0.bias
+ | -0.009 | -5.094 | 1.213 | 0.118 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.5.basic_module.2.weight
+ | 0.029 | -1.319 | 0.938 | 0.330 | torch.Size([64]) || spynet.basic_module.5.basic_module.2.bias
+ | -0.007 | -1.794 | 0.519 | 0.088 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.5.basic_module.4.weight
+ | 0.145 | -0.725 | 0.830 | 0.349 | torch.Size([32]) || spynet.basic_module.5.basic_module.4.bias
+ | -0.008 | -0.766 | 0.275 | 0.052 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.5.basic_module.6.weight
+ | 0.659 | -1.945 | 0.999 | 0.706 | torch.Size([16]) || spynet.basic_module.5.basic_module.6.bias
+ | 0.000 | -0.025 | 0.026 | 0.002 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.5.basic_module.8.weight
+ | 0.014 | 0.001 | 0.027 | 0.018 | torch.Size([2]) || spynet.basic_module.5.basic_module.8.bias
+ | 1.335 | 0.614 | 2.324 | 0.313 | torch.Size([120]) || stage1.reshape.1.weight
+ | -0.007 | -0.451 | 0.392 | 0.149 | torch.Size([120]) || stage1.reshape.1.bias
+ | 0.640 | 0.164 | 1.487 | 0.258 | torch.Size([120]) || stage1.residual_group1.blocks.0.norm1.weight
+ | -0.072 | -1.225 | 0.558 | 0.260 | torch.Size([120]) || stage1.residual_group1.blocks.0.norm1.bias
+ | -0.295 | -4.200 | 2.891 | 0.402 | torch.Size([675, 6]) || stage1.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.0.attn.position_bias
+ | 0.001 | -0.736 | 0.771 | 0.143 | torch.Size([360, 120]) || stage1.residual_group1.blocks.0.attn.qkv_self.weight
+ | -0.002 | -0.412 | 0.503 | 0.106 | torch.Size([360]) || stage1.residual_group1.blocks.0.attn.qkv_self.bias
+ | 0.001 | -0.711 | 0.595 | 0.091 | torch.Size([120, 240]) || stage1.residual_group1.blocks.0.attn.proj.weight
+ | -0.006 | -0.195 | 0.530 | 0.097 | torch.Size([120]) || stage1.residual_group1.blocks.0.attn.proj.bias
+ | -0.000 | -1.076 | 1.181 | 0.133 | torch.Size([360, 120]) || stage1.residual_group1.blocks.0.attn.qkv_mut.weight
+ | 0.000 | -0.228 | 0.294 | 0.059 | torch.Size([360]) || stage1.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.836 | 0.408 | 1.248 | 0.162 | torch.Size([120]) || stage1.residual_group1.blocks.0.norm2.weight
+ | 0.042 | -0.494 | 0.495 | 0.159 | torch.Size([120]) || stage1.residual_group1.blocks.0.norm2.bias
+ | 0.003 | -0.889 | 0.982 | 0.142 | torch.Size([240, 120]) || stage1.residual_group1.blocks.0.mlp.fc11.weight
+ | 0.041 | -0.364 | 0.458 | 0.117 | torch.Size([240]) || stage1.residual_group1.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.757 | 0.882 | 0.140 | torch.Size([240, 120]) || stage1.residual_group1.blocks.0.mlp.fc12.weight
+ | 0.011 | -0.400 | 0.470 | 0.157 | torch.Size([240]) || stage1.residual_group1.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.852 | 1.093 | 0.139 | torch.Size([120, 240]) || stage1.residual_group1.blocks.0.mlp.fc2.weight
+ | 0.022 | -0.265 | 0.384 | 0.096 | torch.Size([120]) || stage1.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.894 | 0.195 | 1.588 | 0.211 | torch.Size([120]) || stage1.residual_group1.blocks.1.norm1.weight
+ | -0.156 | -1.734 | 0.260 | 0.208 | torch.Size([120]) || stage1.residual_group1.blocks.1.norm1.bias
+ | -0.433 | -4.335 | 2.455 | 0.555 | torch.Size([675, 6]) || stage1.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.1.attn.position_bias
+ | -0.001 | -1.631 | 1.615 | 0.174 | torch.Size([360, 120]) || stage1.residual_group1.blocks.1.attn.qkv_self.weight
+ | 0.005 | -0.246 | 0.392 | 0.072 | torch.Size([360]) || stage1.residual_group1.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.697 | 0.574 | 0.098 | torch.Size([120, 240]) || stage1.residual_group1.blocks.1.attn.proj.weight
+ | 0.011 | -0.191 | 0.529 | 0.104 | torch.Size([120]) || stage1.residual_group1.blocks.1.attn.proj.bias
+ | -0.001 | -1.260 | 1.186 | 0.133 | torch.Size([360, 120]) || stage1.residual_group1.blocks.1.attn.qkv_mut.weight
+ | -0.002 | -0.207 | 0.162 | 0.050 | torch.Size([360]) || stage1.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.725 | 0.421 | 0.899 | 0.072 | torch.Size([120]) || stage1.residual_group1.blocks.1.norm2.weight
+ | 0.043 | -0.750 | 0.403 | 0.161 | torch.Size([120]) || stage1.residual_group1.blocks.1.norm2.bias
+ | -0.001 | -0.950 | 0.899 | 0.146 | torch.Size([240, 120]) || stage1.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.001 | -0.381 | 0.301 | 0.092 | torch.Size([240]) || stage1.residual_group1.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.615 | 0.630 | 0.142 | torch.Size([240, 120]) || stage1.residual_group1.blocks.1.mlp.fc12.weight
+ | 0.009 | -0.473 | 0.647 | 0.131 | torch.Size([240]) || stage1.residual_group1.blocks.1.mlp.fc12.bias
+ | 0.001 | -0.789 | 0.813 | 0.146 | torch.Size([120, 240]) || stage1.residual_group1.blocks.1.mlp.fc2.weight
+ | -0.041 | -0.335 | 0.331 | 0.119 | torch.Size([120]) || stage1.residual_group1.blocks.1.mlp.fc2.bias
+ | 1.087 | 0.163 | 1.663 | 0.218 | torch.Size([120]) || stage1.residual_group1.blocks.2.norm1.weight
+ | -0.188 | -1.539 | 0.134 | 0.175 | torch.Size([120]) || stage1.residual_group1.blocks.2.norm1.bias
+ | -0.505 | -4.230 | 3.070 | 0.545 | torch.Size([675, 6]) || stage1.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.2.attn.position_bias
+ | -0.000 | -1.348 | 1.453 | 0.171 | torch.Size([360, 120]) || stage1.residual_group1.blocks.2.attn.qkv_self.weight
+ | 0.007 | -0.394 | 0.633 | 0.080 | torch.Size([360]) || stage1.residual_group1.blocks.2.attn.qkv_self.bias
+ | 0.001 | -0.561 | 0.466 | 0.108 | torch.Size([120, 240]) || stage1.residual_group1.blocks.2.attn.proj.weight
+ | 0.028 | -0.263 | 0.277 | 0.111 | torch.Size([120]) || stage1.residual_group1.blocks.2.attn.proj.bias
+ | -0.000 | -0.982 | 1.268 | 0.124 | torch.Size([360, 120]) || stage1.residual_group1.blocks.2.attn.qkv_mut.weight
+ | 0.001 | -0.139 | 0.149 | 0.035 | torch.Size([360]) || stage1.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.743 | 0.234 | 0.925 | 0.092 | torch.Size([120]) || stage1.residual_group1.blocks.2.norm2.weight
+ | 0.030 | -1.015 | 0.440 | 0.156 | torch.Size([120]) || stage1.residual_group1.blocks.2.norm2.bias
+ | -0.002 | -0.956 | 1.234 | 0.155 | torch.Size([240, 120]) || stage1.residual_group1.blocks.2.mlp.fc11.weight
+ | 0.003 | -0.419 | 0.302 | 0.108 | torch.Size([240]) || stage1.residual_group1.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.723 | 0.609 | 0.143 | torch.Size([240, 120]) || stage1.residual_group1.blocks.2.mlp.fc12.weight
+ | -0.007 | -0.362 | 0.529 | 0.129 | torch.Size([240]) || stage1.residual_group1.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.768 | 0.645 | 0.147 | torch.Size([120, 240]) || stage1.residual_group1.blocks.2.mlp.fc2.weight
+ | -0.033 | -0.281 | 0.244 | 0.100 | torch.Size([120]) || stage1.residual_group1.blocks.2.mlp.fc2.bias
+ | 1.076 | 0.178 | 1.503 | 0.199 | torch.Size([120]) || stage1.residual_group1.blocks.3.norm1.weight
+ | -0.153 | -1.699 | 0.096 | 0.171 | torch.Size([120]) || stage1.residual_group1.blocks.3.norm1.bias
+ | -0.815 | -4.386 | 4.546 | 0.797 | torch.Size([675, 6]) || stage1.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.3.attn.position_bias
+ | 0.001 | -2.332 | 2.215 | 0.164 | torch.Size([360, 120]) || stage1.residual_group1.blocks.3.attn.qkv_self.weight
+ | -0.004 | -0.455 | 0.400 | 0.070 | torch.Size([360]) || stage1.residual_group1.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.504 | 0.556 | 0.108 | torch.Size([120, 240]) || stage1.residual_group1.blocks.3.attn.proj.weight
+ | -0.006 | -0.339 | 0.365 | 0.137 | torch.Size([120]) || stage1.residual_group1.blocks.3.attn.proj.bias
+ | 0.000 | -1.444 | 1.191 | 0.122 | torch.Size([360, 120]) || stage1.residual_group1.blocks.3.attn.qkv_mut.weight
+ | -0.001 | -0.162 | 0.140 | 0.029 | torch.Size([360]) || stage1.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.715 | 0.229 | 0.865 | 0.078 | torch.Size([120]) || stage1.residual_group1.blocks.3.norm2.weight
+ | 0.026 | -1.011 | 0.287 | 0.151 | torch.Size([120]) || stage1.residual_group1.blocks.3.norm2.bias
+ | -0.003 | -0.761 | 0.828 | 0.148 | torch.Size([240, 120]) || stage1.residual_group1.blocks.3.mlp.fc11.weight
+ | 0.014 | -0.337 | 0.418 | 0.135 | torch.Size([240]) || stage1.residual_group1.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.716 | 0.712 | 0.149 | torch.Size([240, 120]) || stage1.residual_group1.blocks.3.mlp.fc12.weight
+ | 0.003 | -0.427 | 0.369 | 0.124 | torch.Size([240]) || stage1.residual_group1.blocks.3.mlp.fc12.bias
+ | 0.001 | -0.719 | 0.640 | 0.151 | torch.Size([120, 240]) || stage1.residual_group1.blocks.3.mlp.fc2.weight
+ | -0.010 | -0.557 | 0.227 | 0.103 | torch.Size([120]) || stage1.residual_group1.blocks.3.mlp.fc2.bias
+ | 1.161 | 0.188 | 1.556 | 0.179 | torch.Size([120]) || stage1.residual_group1.blocks.4.norm1.weight
+ | -0.165 | -1.773 | 0.054 | 0.186 | torch.Size([120]) || stage1.residual_group1.blocks.4.norm1.bias
+ | -0.575 | -3.741 | 5.261 | 0.767 | torch.Size([675, 6]) || stage1.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.4.attn.position_bias
+ | 0.000 | -2.020 | 2.251 | 0.173 | torch.Size([360, 120]) || stage1.residual_group1.blocks.4.attn.qkv_self.weight
+ | 0.000 | -0.318 | 0.312 | 0.071 | torch.Size([360]) || stage1.residual_group1.blocks.4.attn.qkv_self.bias
+ | 0.000 | -0.463 | 0.456 | 0.112 | torch.Size([120, 240]) || stage1.residual_group1.blocks.4.attn.proj.weight
+ | 0.002 | -0.406 | 0.393 | 0.154 | torch.Size([120]) || stage1.residual_group1.blocks.4.attn.proj.bias
+ | -0.001 | -0.968 | 1.330 | 0.123 | torch.Size([360, 120]) || stage1.residual_group1.blocks.4.attn.qkv_mut.weight
+ | 0.001 | -0.152 | 0.176 | 0.030 | torch.Size([360]) || stage1.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.699 | 0.230 | 0.850 | 0.073 | torch.Size([120]) || stage1.residual_group1.blocks.4.norm2.weight
+ | 0.029 | -1.033 | 0.300 | 0.149 | torch.Size([120]) || stage1.residual_group1.blocks.4.norm2.bias
+ | -0.002 | -0.718 | 0.803 | 0.145 | torch.Size([240, 120]) || stage1.residual_group1.blocks.4.mlp.fc11.weight
+ | 0.002 | -0.389 | 0.405 | 0.139 | torch.Size([240]) || stage1.residual_group1.blocks.4.mlp.fc11.bias
+ | -0.001 | -0.582 | 0.624 | 0.151 | torch.Size([240, 120]) || stage1.residual_group1.blocks.4.mlp.fc12.weight
+ | 0.003 | -0.385 | 0.386 | 0.118 | torch.Size([240]) || stage1.residual_group1.blocks.4.mlp.fc12.bias
+ | 0.000 | -0.677 | 0.737 | 0.153 | torch.Size([120, 240]) || stage1.residual_group1.blocks.4.mlp.fc2.weight
+ | 0.003 | -0.671 | 0.208 | 0.108 | torch.Size([120]) || stage1.residual_group1.blocks.4.mlp.fc2.bias
+ | 1.067 | 0.173 | 1.473 | 0.179 | torch.Size([120]) || stage1.residual_group1.blocks.5.norm1.weight
+ | -0.129 | -1.487 | 0.138 | 0.166 | torch.Size([120]) || stage1.residual_group1.blocks.5.norm1.bias
+ | -0.530 | -3.629 | 3.705 | 0.621 | torch.Size([675, 6]) || stage1.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.5.attn.position_bias
+ | 0.000 | -2.344 | 1.768 | 0.157 | torch.Size([360, 120]) || stage1.residual_group1.blocks.5.attn.qkv_self.weight
+ | -0.001 | -0.428 | 0.265 | 0.082 | torch.Size([360]) || stage1.residual_group1.blocks.5.attn.qkv_self.bias
+ | -0.001 | -0.541 | 0.559 | 0.120 | torch.Size([120, 240]) || stage1.residual_group1.blocks.5.attn.proj.weight
+ | 0.031 | -0.324 | 0.379 | 0.133 | torch.Size([120]) || stage1.residual_group1.blocks.5.attn.proj.bias
+ | -0.001 | -1.380 | 0.992 | 0.120 | torch.Size([360, 120]) || stage1.residual_group1.blocks.5.attn.qkv_mut.weight
+ | 0.000 | -0.100 | 0.111 | 0.027 | torch.Size([360]) || stage1.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.637 | 0.273 | 0.780 | 0.064 | torch.Size([120]) || stage1.residual_group1.blocks.5.norm2.weight
+ | 0.022 | -1.160 | 0.338 | 0.149 | torch.Size([120]) || stage1.residual_group1.blocks.5.norm2.bias
+ | -0.002 | -0.696 | 0.638 | 0.139 | torch.Size([240, 120]) || stage1.residual_group1.blocks.5.mlp.fc11.weight
+ | 0.007 | -0.366 | 0.364 | 0.134 | torch.Size([240]) || stage1.residual_group1.blocks.5.mlp.fc11.bias
+ | -0.001 | -0.581 | 0.657 | 0.151 | torch.Size([240, 120]) || stage1.residual_group1.blocks.5.mlp.fc12.weight
+ | -0.004 | -0.366 | 0.244 | 0.105 | torch.Size([240]) || stage1.residual_group1.blocks.5.mlp.fc12.bias
+ | 0.000 | -1.143 | 0.787 | 0.154 | torch.Size([120, 240]) || stage1.residual_group1.blocks.5.mlp.fc2.weight
+ | 0.023 | -1.254 | 0.407 | 0.160 | torch.Size([120]) || stage1.residual_group1.blocks.5.mlp.fc2.bias
+ | 0.001 | -0.293 | 0.270 | 0.065 | torch.Size([120, 120]) || stage1.linear1.weight
+ | 0.006 | -0.209 | 0.382 | 0.093 | torch.Size([120]) || stage1.linear1.bias
+ | 0.811 | 0.432 | 1.092 | 0.108 | torch.Size([120]) || stage1.residual_group2.blocks.0.norm1.weight
+ | 0.033 | -0.763 | 0.477 | 0.200 | torch.Size([120]) || stage1.residual_group2.blocks.0.norm1.bias
+ | -0.049 | -2.996 | 1.734 | 0.246 | torch.Size([3375, 6]) || stage1.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage1.residual_group2.blocks.0.attn.relative_position_index
+ | -0.000 | -0.847 | 1.215 | 0.150 | torch.Size([360, 120]) || stage1.residual_group2.blocks.0.attn.qkv_self.weight
+ | -0.000 | -0.542 | 0.581 | 0.147 | torch.Size([360]) || stage1.residual_group2.blocks.0.attn.qkv_self.bias
+ | 0.001 | -0.536 | 0.569 | 0.124 | torch.Size([120, 120]) || stage1.residual_group2.blocks.0.attn.proj.weight
+ | -0.004 | -0.195 | 0.602 | 0.102 | torch.Size([120]) || stage1.residual_group2.blocks.0.attn.proj.bias
+ | 0.568 | 0.438 | 0.872 | 0.074 | torch.Size([120]) || stage1.residual_group2.blocks.0.norm2.weight
+ | 0.025 | -0.782 | 0.342 | 0.164 | torch.Size([120]) || stage1.residual_group2.blocks.0.norm2.bias
+ | 0.003 | -0.601 | 0.699 | 0.126 | torch.Size([240, 120]) || stage1.residual_group2.blocks.0.mlp.fc11.weight
+ | 0.068 | -0.329 | 0.446 | 0.095 | torch.Size([240]) || stage1.residual_group2.blocks.0.mlp.fc11.bias
+ | 0.001 | -0.807 | 0.710 | 0.143 | torch.Size([240, 120]) || stage1.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.002 | -0.585 | 0.392 | 0.117 | torch.Size([240]) || stage1.residual_group2.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.779 | 0.575 | 0.142 | torch.Size([120, 240]) || stage1.residual_group2.blocks.0.mlp.fc2.weight
+ | 0.008 | -0.377 | 0.374 | 0.159 | torch.Size([120]) || stage1.residual_group2.blocks.0.mlp.fc2.bias
+ | 0.942 | 0.411 | 1.171 | 0.093 | torch.Size([120]) || stage1.residual_group2.blocks.1.norm1.weight
+ | 0.038 | -0.837 | 0.321 | 0.152 | torch.Size([120]) || stage1.residual_group2.blocks.1.norm1.bias
+ | -0.077 | -2.150 | 2.175 | 0.237 | torch.Size([3375, 6]) || stage1.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage1.residual_group2.blocks.1.attn.relative_position_index
+ | -0.000 | -0.750 | 0.771 | 0.159 | torch.Size([360, 120]) || stage1.residual_group2.blocks.1.attn.qkv_self.weight
+ | -0.004 | -0.589 | 0.559 | 0.145 | torch.Size([360]) || stage1.residual_group2.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.478 | 0.525 | 0.125 | torch.Size([120, 120]) || stage1.residual_group2.blocks.1.attn.proj.weight
+ | 0.009 | -0.338 | 0.449 | 0.154 | torch.Size([120]) || stage1.residual_group2.blocks.1.attn.proj.bias
+ | 0.597 | 0.429 | 0.741 | 0.044 | torch.Size([120]) || stage1.residual_group2.blocks.1.norm2.weight
+ | 0.038 | -0.697 | 0.195 | 0.103 | torch.Size([120]) || stage1.residual_group2.blocks.1.norm2.bias
+ | 0.003 | -0.671 | 0.636 | 0.135 | torch.Size([240, 120]) || stage1.residual_group2.blocks.1.mlp.fc11.weight
+ | 0.057 | -0.519 | 0.422 | 0.139 | torch.Size([240]) || stage1.residual_group2.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.629 | 0.607 | 0.153 | torch.Size([240, 120]) || stage1.residual_group2.blocks.1.mlp.fc12.weight
+ | -0.007 | -0.279 | 0.403 | 0.083 | torch.Size([240]) || stage1.residual_group2.blocks.1.mlp.fc12.bias
+ | 0.001 | -0.620 | 0.712 | 0.150 | torch.Size([120, 240]) || stage1.residual_group2.blocks.1.mlp.fc2.weight
+ | 0.014 | -0.721 | 0.333 | 0.163 | torch.Size([120]) || stage1.residual_group2.blocks.1.mlp.fc2.bias
+ | 0.000 | -0.504 | 0.343 | 0.079 | torch.Size([120, 120]) || stage1.linear2.weight
+ | 0.015 | -0.276 | 0.353 | 0.122 | torch.Size([120]) || stage1.linear2.bias
+ | -0.000 | -0.151 | 0.136 | 0.025 | torch.Size([120, 120, 3, 3]) || stage1.pa_deform.weight
+ | -0.001 | -0.087 | 0.103 | 0.030 | torch.Size([120]) || stage1.pa_deform.bias
+ | -0.000 | -0.017 | 0.017 | 0.010 | torch.Size([120, 364, 3, 3]) || stage1.pa_deform.conv_offset.0.weight
+ | -0.004 | -0.024 | 0.040 | 0.013 | torch.Size([120]) || stage1.pa_deform.conv_offset.0.bias
+ | -0.001 | -0.122 | 0.123 | 0.017 | torch.Size([120, 120, 3, 3]) || stage1.pa_deform.conv_offset.2.weight
+ | -0.009 | -0.068 | 0.068 | 0.028 | torch.Size([120]) || stage1.pa_deform.conv_offset.2.bias
+ | -0.001 | -0.175 | 0.114 | 0.015 | torch.Size([120, 120, 3, 3]) || stage1.pa_deform.conv_offset.4.weight
+ | 0.019 | -0.059 | 0.110 | 0.042 | torch.Size([120]) || stage1.pa_deform.conv_offset.4.bias
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432, 120, 3, 3]) || stage1.pa_deform.conv_offset.6.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432]) || stage1.pa_deform.conv_offset.6.bias
+ | -0.001 | -1.034 | 1.208 | 0.150 | torch.Size([360, 360]) || stage1.pa_fuse.fc11.weight
+ | 0.085 | -0.220 | 0.682 | 0.164 | torch.Size([360]) || stage1.pa_fuse.fc11.bias
+ | 0.001 | -1.305 | 1.408 | 0.167 | torch.Size([360, 360]) || stage1.pa_fuse.fc12.weight
+ | 0.005 | -0.474 | 0.521 | 0.147 | torch.Size([360]) || stage1.pa_fuse.fc12.bias
+ | 0.000 | -0.941 | 0.939 | 0.158 | torch.Size([120, 360]) || stage1.pa_fuse.fc2.weight
+ | 0.019 | -0.993 | 0.852 | 0.371 | torch.Size([120]) || stage1.pa_fuse.fc2.bias
+ | 1.099 | 0.165 | 1.669 | 0.285 | torch.Size([480]) || stage2.reshape.1.weight
+ | -0.009 | -0.723 | 0.825 | 0.237 | torch.Size([480]) || stage2.reshape.1.bias
+ | -0.000 | -0.767 | 0.672 | 0.163 | torch.Size([120, 480]) || stage2.reshape.2.weight
+ | -0.007 | -0.473 | 0.285 | 0.116 | torch.Size([120]) || stage2.reshape.2.bias
+ | 0.665 | 0.267 | 1.019 | 0.157 | torch.Size([120]) || stage2.residual_group1.blocks.0.norm1.weight
+ | -0.152 | -0.897 | 0.303 | 0.218 | torch.Size([120]) || stage2.residual_group1.blocks.0.norm1.bias
+ | -0.208 | -1.940 | 4.459 | 0.383 | torch.Size([675, 6]) || stage2.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.0.attn.position_bias
+ | -0.000 | -0.653 | 0.613 | 0.127 | torch.Size([360, 120]) || stage2.residual_group1.blocks.0.attn.qkv_self.weight
+ | 0.003 | -0.263 | 0.270 | 0.066 | torch.Size([360]) || stage2.residual_group1.blocks.0.attn.qkv_self.bias
+ | 0.002 | -0.796 | 0.596 | 0.108 | torch.Size([120, 240]) || stage2.residual_group1.blocks.0.attn.proj.weight
+ | -0.008 | -0.955 | 0.285 | 0.127 | torch.Size([120]) || stage2.residual_group1.blocks.0.attn.proj.bias
+ | 0.000 | -1.099 | 0.979 | 0.109 | torch.Size([360, 120]) || stage2.residual_group1.blocks.0.attn.qkv_mut.weight
+ | -0.000 | -0.131 | 0.090 | 0.022 | torch.Size([360]) || stage2.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.548 | 0.301 | 0.671 | 0.063 | torch.Size([120]) || stage2.residual_group1.blocks.0.norm2.weight
+ | 0.003 | -0.744 | 0.803 | 0.231 | torch.Size([120]) || stage2.residual_group1.blocks.0.norm2.bias
+ | 0.001 | -0.645 | 0.555 | 0.133 | torch.Size([240, 120]) || stage2.residual_group1.blocks.0.mlp.fc11.weight
+ | 0.013 | -0.406 | 0.272 | 0.097 | torch.Size([240]) || stage2.residual_group1.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.622 | 0.666 | 0.147 | torch.Size([240, 120]) || stage2.residual_group1.blocks.0.mlp.fc12.weight
+ | 0.002 | -0.228 | 0.307 | 0.085 | torch.Size([240]) || stage2.residual_group1.blocks.0.mlp.fc12.bias
+ | 0.001 | -0.834 | 0.822 | 0.149 | torch.Size([120, 240]) || stage2.residual_group1.blocks.0.mlp.fc2.weight
+ | -0.009 | -0.948 | 0.446 | 0.159 | torch.Size([120]) || stage2.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.777 | 0.311 | 1.104 | 0.161 | torch.Size([120]) || stage2.residual_group1.blocks.1.norm1.weight
+ | -0.178 | -0.966 | 0.822 | 0.247 | torch.Size([120]) || stage2.residual_group1.blocks.1.norm1.bias
+ | -0.387 | -2.000 | 5.826 | 0.443 | torch.Size([675, 6]) || stage2.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.1.attn.position_bias
+ | 0.000 | -0.662 | 0.706 | 0.132 | torch.Size([360, 120]) || stage2.residual_group1.blocks.1.attn.qkv_self.weight
+ | -0.006 | -0.348 | 0.306 | 0.079 | torch.Size([360]) || stage2.residual_group1.blocks.1.attn.qkv_self.bias
+ | -0.001 | -0.595 | 0.730 | 0.112 | torch.Size([120, 240]) || stage2.residual_group1.blocks.1.attn.proj.weight
+ | -0.001 | -0.811 | 0.531 | 0.167 | torch.Size([120]) || stage2.residual_group1.blocks.1.attn.proj.bias
+ | -0.000 | -1.007 | 1.002 | 0.105 | torch.Size([360, 120]) || stage2.residual_group1.blocks.1.attn.qkv_mut.weight
+ | -0.002 | -0.180 | 0.108 | 0.024 | torch.Size([360]) || stage2.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.599 | 0.282 | 0.730 | 0.059 | torch.Size([120]) || stage2.residual_group1.blocks.1.norm2.weight
+ | -0.004 | -0.671 | 0.938 | 0.218 | torch.Size([120]) || stage2.residual_group1.blocks.1.norm2.bias
+ | 0.000 | -0.536 | 0.570 | 0.134 | torch.Size([240, 120]) || stage2.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.022 | -0.540 | 0.226 | 0.107 | torch.Size([240]) || stage2.residual_group1.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.646 | 0.589 | 0.149 | torch.Size([240, 120]) || stage2.residual_group1.blocks.1.mlp.fc12.weight
+ | 0.008 | -0.203 | 0.282 | 0.092 | torch.Size([240]) || stage2.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.000 | -1.052 | 0.649 | 0.150 | torch.Size([120, 240]) || stage2.residual_group1.blocks.1.mlp.fc2.weight
+ | -0.007 | -0.581 | 0.467 | 0.137 | torch.Size([120]) || stage2.residual_group1.blocks.1.mlp.fc2.bias
+ | 0.780 | 0.134 | 1.161 | 0.193 | torch.Size([120]) || stage2.residual_group1.blocks.2.norm1.weight
+ | -0.152 | -0.996 | 1.042 | 0.227 | torch.Size([120]) || stage2.residual_group1.blocks.2.norm1.bias
+ | -0.186 | -2.565 | 4.152 | 0.428 | torch.Size([675, 6]) || stage2.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.2.attn.position_bias
+ | 0.001 | -0.856 | 0.814 | 0.151 | torch.Size([360, 120]) || stage2.residual_group1.blocks.2.attn.qkv_self.weight
+ | -0.002 | -0.367 | 0.317 | 0.074 | torch.Size([360]) || stage2.residual_group1.blocks.2.attn.qkv_self.bias
+ | -0.001 | -0.656 | 0.730 | 0.131 | torch.Size([120, 240]) || stage2.residual_group1.blocks.2.attn.proj.weight
+ | -0.003 | -0.555 | 0.620 | 0.163 | torch.Size([120]) || stage2.residual_group1.blocks.2.attn.proj.bias
+ | 0.001 | -2.191 | 2.575 | 0.137 | torch.Size([360, 120]) || stage2.residual_group1.blocks.2.attn.qkv_mut.weight
+ | 0.000 | -0.121 | 0.139 | 0.023 | torch.Size([360]) || stage2.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.640 | 0.297 | 0.797 | 0.064 | torch.Size([120]) || stage2.residual_group1.blocks.2.norm2.weight
+ | -0.013 | -0.584 | 0.934 | 0.217 | torch.Size([120]) || stage2.residual_group1.blocks.2.norm2.bias
+ | 0.000 | -0.523 | 0.556 | 0.136 | torch.Size([240, 120]) || stage2.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.035 | -0.490 | 0.217 | 0.117 | torch.Size([240]) || stage2.residual_group1.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.679 | 0.601 | 0.152 | torch.Size([240, 120]) || stage2.residual_group1.blocks.2.mlp.fc12.weight
+ | 0.005 | -0.287 | 0.308 | 0.098 | torch.Size([240]) || stage2.residual_group1.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.576 | 0.584 | 0.151 | torch.Size([120, 240]) || stage2.residual_group1.blocks.2.mlp.fc2.weight
+ | -0.006 | -0.423 | 0.376 | 0.121 | torch.Size([120]) || stage2.residual_group1.blocks.2.mlp.fc2.bias
+ | 0.776 | 0.134 | 1.030 | 0.164 | torch.Size([120]) || stage2.residual_group1.blocks.3.norm1.weight
+ | -0.167 | -0.870 | 1.066 | 0.204 | torch.Size([120]) || stage2.residual_group1.blocks.3.norm1.bias
+ | -0.259 | -1.735 | 5.189 | 0.366 | torch.Size([675, 6]) || stage2.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.3.attn.position_bias
+ | 0.000 | -1.292 | 1.255 | 0.149 | torch.Size([360, 120]) || stage2.residual_group1.blocks.3.attn.qkv_self.weight
+ | 0.000 | -0.493 | 0.445 | 0.101 | torch.Size([360]) || stage2.residual_group1.blocks.3.attn.qkv_self.bias
+ | 0.001 | -0.618 | 0.582 | 0.122 | torch.Size([120, 240]) || stage2.residual_group1.blocks.3.attn.proj.weight
+ | -0.001 | -0.543 | 0.420 | 0.166 | torch.Size([120]) || stage2.residual_group1.blocks.3.attn.proj.bias
+ | 0.002 | -2.296 | 2.630 | 0.162 | torch.Size([360, 120]) || stage2.residual_group1.blocks.3.attn.qkv_mut.weight
+ | -0.001 | -0.130 | 0.149 | 0.028 | torch.Size([360]) || stage2.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.625 | 0.301 | 0.772 | 0.060 | torch.Size([120]) || stage2.residual_group1.blocks.3.norm2.weight
+ | -0.015 | -0.498 | 0.992 | 0.198 | torch.Size([120]) || stage2.residual_group1.blocks.3.norm2.bias
+ | -0.000 | -0.620 | 0.681 | 0.130 | torch.Size([240, 120]) || stage2.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.006 | -0.391 | 0.256 | 0.113 | torch.Size([240]) || stage2.residual_group1.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.575 | 0.669 | 0.152 | torch.Size([240, 120]) || stage2.residual_group1.blocks.3.mlp.fc12.weight
+ | -0.000 | -0.225 | 0.333 | 0.088 | torch.Size([240]) || stage2.residual_group1.blocks.3.mlp.fc12.bias
+ | 0.001 | -0.680 | 0.639 | 0.151 | torch.Size([120, 240]) || stage2.residual_group1.blocks.3.mlp.fc2.weight
+ | -0.011 | -0.549 | 0.259 | 0.139 | torch.Size([120]) || stage2.residual_group1.blocks.3.mlp.fc2.bias
+ | 0.933 | 0.310 | 1.186 | 0.121 | torch.Size([120]) || stage2.residual_group1.blocks.4.norm1.weight
+ | -0.180 | -0.736 | 1.168 | 0.204 | torch.Size([120]) || stage2.residual_group1.blocks.4.norm1.bias
+ | -0.164 | -2.965 | 4.145 | 0.437 | torch.Size([675, 6]) || stage2.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.4.attn.position_bias
+ | 0.000 | -0.860 | 0.749 | 0.136 | torch.Size([360, 120]) || stage2.residual_group1.blocks.4.attn.qkv_self.weight
+ | 0.005 | -0.274 | 0.308 | 0.080 | torch.Size([360]) || stage2.residual_group1.blocks.4.attn.qkv_self.bias
+ | 0.001 | -0.648 | 0.681 | 0.129 | torch.Size([120, 240]) || stage2.residual_group1.blocks.4.attn.proj.weight
+ | 0.002 | -0.547 | 0.295 | 0.149 | torch.Size([120]) || stage2.residual_group1.blocks.4.attn.proj.bias
+ | -0.000 | -0.647 | 0.577 | 0.105 | torch.Size([360, 120]) || stage2.residual_group1.blocks.4.attn.qkv_mut.weight
+ | -0.001 | -0.138 | 0.125 | 0.023 | torch.Size([360]) || stage2.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.635 | 0.329 | 0.748 | 0.049 | torch.Size([120]) || stage2.residual_group1.blocks.4.norm2.weight
+ | -0.018 | -0.375 | 0.891 | 0.157 | torch.Size([120]) || stage2.residual_group1.blocks.4.norm2.bias
+ | -0.000 | -0.603 | 0.497 | 0.130 | torch.Size([240, 120]) || stage2.residual_group1.blocks.4.mlp.fc11.weight
+ | -0.010 | -0.345 | 0.297 | 0.113 | torch.Size([240]) || stage2.residual_group1.blocks.4.mlp.fc11.bias
+ | -0.000 | -0.680 | 0.679 | 0.153 | torch.Size([240, 120]) || stage2.residual_group1.blocks.4.mlp.fc12.weight
+ | -0.000 | -0.200 | 0.251 | 0.086 | torch.Size([240]) || stage2.residual_group1.blocks.4.mlp.fc12.bias
+ | -0.001 | -0.568 | 0.614 | 0.152 | torch.Size([120, 240]) || stage2.residual_group1.blocks.4.mlp.fc2.weight
+ | -0.009 | -0.375 | 0.493 | 0.135 | torch.Size([120]) || stage2.residual_group1.blocks.4.mlp.fc2.bias
+ | 0.870 | 0.315 | 1.059 | 0.096 | torch.Size([120]) || stage2.residual_group1.blocks.5.norm1.weight
+ | -0.139 | -0.657 | 1.107 | 0.163 | torch.Size([120]) || stage2.residual_group1.blocks.5.norm1.bias
+ | -0.156 | -4.167 | 4.651 | 0.340 | torch.Size([675, 6]) || stage2.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.5.attn.position_bias
+ | 0.000 | -0.701 | 0.871 | 0.134 | torch.Size([360, 120]) || stage2.residual_group1.blocks.5.attn.qkv_self.weight
+ | -0.000 | -0.427 | 0.471 | 0.099 | torch.Size([360]) || stage2.residual_group1.blocks.5.attn.qkv_self.bias
+ | -0.000 | -0.520 | 0.546 | 0.113 | torch.Size([120, 240]) || stage2.residual_group1.blocks.5.attn.proj.weight
+ | -0.008 | -0.360 | 0.350 | 0.137 | torch.Size([120]) || stage2.residual_group1.blocks.5.attn.proj.bias
+ | 0.001 | -0.510 | 0.502 | 0.100 | torch.Size([360, 120]) || stage2.residual_group1.blocks.5.attn.qkv_mut.weight
+ | 0.001 | -0.092 | 0.125 | 0.021 | torch.Size([360]) || stage2.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.597 | 0.345 | 0.691 | 0.044 | torch.Size([120]) || stage2.residual_group1.blocks.5.norm2.weight
+ | -0.015 | -0.367 | 0.987 | 0.132 | torch.Size([120]) || stage2.residual_group1.blocks.5.norm2.bias
+ | 0.001 | -0.552 | 0.532 | 0.128 | torch.Size([240, 120]) || stage2.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.009 | -0.336 | 0.253 | 0.107 | torch.Size([240]) || stage2.residual_group1.blocks.5.mlp.fc11.bias
+ | 0.000 | -0.644 | 0.758 | 0.154 | torch.Size([240, 120]) || stage2.residual_group1.blocks.5.mlp.fc12.weight
+ | -0.001 | -0.243 | 0.264 | 0.088 | torch.Size([240]) || stage2.residual_group1.blocks.5.mlp.fc12.bias
+ | -0.001 | -0.667 | 0.621 | 0.152 | torch.Size([120, 240]) || stage2.residual_group1.blocks.5.mlp.fc2.weight
+ | -0.002 | -0.447 | 1.139 | 0.183 | torch.Size([120]) || stage2.residual_group1.blocks.5.mlp.fc2.bias
+ | 0.002 | -0.268 | 0.331 | 0.066 | torch.Size([120, 120]) || stage2.linear1.weight
+ | 0.005 | -0.338 | 0.589 | 0.128 | torch.Size([120]) || stage2.linear1.bias
+ | 0.939 | 0.517 | 1.207 | 0.113 | torch.Size([120]) || stage2.residual_group2.blocks.0.norm1.weight
+ | 0.023 | -0.770 | 0.614 | 0.238 | torch.Size([120]) || stage2.residual_group2.blocks.0.norm1.bias
+ | 0.004 | -3.112 | 1.341 | 0.140 | torch.Size([3375, 6]) || stage2.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage2.residual_group2.blocks.0.attn.relative_position_index
+ | 0.000 | -0.605 | 0.580 | 0.136 | torch.Size([360, 120]) || stage2.residual_group2.blocks.0.attn.qkv_self.weight
+ | 0.001 | -0.591 | 0.477 | 0.112 | torch.Size([360]) || stage2.residual_group2.blocks.0.attn.qkv_self.bias
+ | 0.001 | -0.645 | 0.613 | 0.150 | torch.Size([120, 120]) || stage2.residual_group2.blocks.0.attn.proj.weight
+ | -0.031 | -0.422 | 0.330 | 0.138 | torch.Size([120]) || stage2.residual_group2.blocks.0.attn.proj.bias
+ | 0.684 | 0.501 | 0.807 | 0.061 | torch.Size([120]) || stage2.residual_group2.blocks.0.norm2.weight
+ | 0.018 | -0.693 | 0.412 | 0.181 | torch.Size([120]) || stage2.residual_group2.blocks.0.norm2.bias
+ | 0.001 | -0.559 | 0.715 | 0.125 | torch.Size([240, 120]) || stage2.residual_group2.blocks.0.mlp.fc11.weight
+ | 0.031 | -0.346 | 0.273 | 0.108 | torch.Size([240]) || stage2.residual_group2.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.744 | 0.559 | 0.146 | torch.Size([240, 120]) || stage2.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.005 | -0.239 | 0.270 | 0.080 | torch.Size([240]) || stage2.residual_group2.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.603 | 0.871 | 0.144 | torch.Size([120, 240]) || stage2.residual_group2.blocks.0.mlp.fc2.weight
+ | -0.003 | -0.317 | 0.303 | 0.122 | torch.Size([120]) || stage2.residual_group2.blocks.0.mlp.fc2.bias
+ | 0.974 | 0.575 | 1.211 | 0.095 | torch.Size([120]) || stage2.residual_group2.blocks.1.norm1.weight
+ | 0.023 | -0.703 | 0.556 | 0.208 | torch.Size([120]) || stage2.residual_group2.blocks.1.norm1.bias
+ | 0.012 | -2.867 | 1.552 | 0.185 | torch.Size([3375, 6]) || stage2.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage2.residual_group2.blocks.1.attn.relative_position_index
+ | 0.000 | -0.743 | 0.663 | 0.142 | torch.Size([360, 120]) || stage2.residual_group2.blocks.1.attn.qkv_self.weight
+ | 0.002 | -0.647 | 0.654 | 0.141 | torch.Size([360]) || stage2.residual_group2.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.610 | 0.648 | 0.151 | torch.Size([120, 120]) || stage2.residual_group2.blocks.1.attn.proj.weight
+ | -0.028 | -0.565 | 0.416 | 0.167 | torch.Size([120]) || stage2.residual_group2.blocks.1.attn.proj.bias
+ | 0.742 | 0.522 | 0.891 | 0.076 | torch.Size([120]) || stage2.residual_group2.blocks.1.norm2.weight
+ | 0.020 | -0.506 | 0.335 | 0.138 | torch.Size([120]) || stage2.residual_group2.blocks.1.norm2.bias
+ | 0.001 | -0.486 | 0.512 | 0.123 | torch.Size([240, 120]) || stage2.residual_group2.blocks.1.mlp.fc11.weight
+ | 0.094 | -0.405 | 0.617 | 0.174 | torch.Size([240]) || stage2.residual_group2.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.618 | 0.596 | 0.149 | torch.Size([240, 120]) || stage2.residual_group2.blocks.1.mlp.fc12.weight
+ | -0.001 | -0.276 | 0.202 | 0.077 | torch.Size([240]) || stage2.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.668 | 0.769 | 0.148 | torch.Size([120, 240]) || stage2.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.014 | -0.729 | 0.410 | 0.187 | torch.Size([120]) || stage2.residual_group2.blocks.1.mlp.fc2.bias
+ | 0.001 | -0.309 | 0.381 | 0.079 | torch.Size([120, 120]) || stage2.linear2.weight
+ | 0.017 | -0.403 | 0.399 | 0.133 | torch.Size([120]) || stage2.linear2.bias
+ | -0.000 | -0.111 | 0.126 | 0.024 | torch.Size([120, 120, 3, 3]) || stage2.pa_deform.weight
+ | 0.001 | -0.031 | 0.055 | 0.017 | torch.Size([120]) || stage2.pa_deform.bias
+ | -0.000 | -0.017 | 0.017 | 0.010 | torch.Size([120, 364, 3, 3]) || stage2.pa_deform.conv_offset.0.weight
+ | -0.010 | -0.038 | 0.021 | 0.012 | torch.Size([120]) || stage2.pa_deform.conv_offset.0.bias
+ | -0.001 | -0.113 | 0.096 | 0.020 | torch.Size([120, 120, 3, 3]) || stage2.pa_deform.conv_offset.2.weight
+ | -0.010 | -0.089 | 0.087 | 0.032 | torch.Size([120]) || stage2.pa_deform.conv_offset.2.bias
+ | -0.001 | -0.079 | 0.087 | 0.019 | torch.Size([120, 120, 3, 3]) || stage2.pa_deform.conv_offset.4.weight
+ | -0.015 | -0.134 | 0.121 | 0.058 | torch.Size([120]) || stage2.pa_deform.conv_offset.4.bias
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432, 120, 3, 3]) || stage2.pa_deform.conv_offset.6.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432]) || stage2.pa_deform.conv_offset.6.bias
+ | 0.004 | -1.011 | 1.138 | 0.150 | torch.Size([360, 360]) || stage2.pa_fuse.fc11.weight
+ | 0.151 | -0.228 | 0.674 | 0.167 | torch.Size([360]) || stage2.pa_fuse.fc11.bias
+ | 0.001 | -0.988 | 1.066 | 0.144 | torch.Size([360, 360]) || stage2.pa_fuse.fc12.weight
+ | 0.009 | -0.418 | 0.533 | 0.127 | torch.Size([360]) || stage2.pa_fuse.fc12.bias
+ | 0.000 | -0.784 | 0.831 | 0.151 | torch.Size([120, 360]) || stage2.pa_fuse.fc2.weight
+ | 0.007 | -0.581 | 0.470 | 0.257 | torch.Size([120]) || stage2.pa_fuse.fc2.bias
+ | 1.105 | 0.504 | 1.774 | 0.248 | torch.Size([480]) || stage3.reshape.1.weight
+ | -0.006 | -0.633 | 0.736 | 0.296 | torch.Size([480]) || stage3.reshape.1.bias
+ | -0.000 | -0.682 | 0.687 | 0.168 | torch.Size([120, 480]) || stage3.reshape.2.weight
+ | -0.004 | -0.207 | 0.227 | 0.086 | torch.Size([120]) || stage3.reshape.2.bias
+ | 0.735 | 0.431 | 0.997 | 0.127 | torch.Size([120]) || stage3.residual_group1.blocks.0.norm1.weight
+ | -0.162 | -0.753 | 0.303 | 0.198 | torch.Size([120]) || stage3.residual_group1.blocks.0.norm1.bias
+ | -0.001 | -0.490 | 0.344 | 0.037 | torch.Size([675, 6]) || stage3.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.0.attn.position_bias
+ | 0.000 | -0.333 | 0.350 | 0.061 | torch.Size([360, 120]) || stage3.residual_group1.blocks.0.attn.qkv_self.weight
+ | -0.004 | -0.195 | 0.128 | 0.039 | torch.Size([360]) || stage3.residual_group1.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.359 | 0.365 | 0.067 | torch.Size([120, 240]) || stage3.residual_group1.blocks.0.attn.proj.weight
+ | -0.002 | -0.216 | 0.262 | 0.084 | torch.Size([120]) || stage3.residual_group1.blocks.0.attn.proj.bias
+ | 0.000 | -0.597 | 0.657 | 0.058 | torch.Size([360, 120]) || stage3.residual_group1.blocks.0.attn.qkv_mut.weight
+ | 0.001 | -0.115 | 0.118 | 0.020 | torch.Size([360]) || stage3.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.594 | 0.414 | 0.775 | 0.069 | torch.Size([120]) || stage3.residual_group1.blocks.0.norm2.weight
+ | 0.003 | -0.260 | 0.315 | 0.105 | torch.Size([120]) || stage3.residual_group1.blocks.0.norm2.bias
+ | 0.001 | -0.446 | 0.536 | 0.116 | torch.Size([240, 120]) || stage3.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.077 | -0.361 | 0.145 | 0.072 | torch.Size([240]) || stage3.residual_group1.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.507 | 0.503 | 0.124 | torch.Size([240, 120]) || stage3.residual_group1.blocks.0.mlp.fc12.weight
+ | 0.005 | -0.225 | 0.207 | 0.062 | torch.Size([240]) || stage3.residual_group1.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.553 | 0.493 | 0.129 | torch.Size([120, 240]) || stage3.residual_group1.blocks.0.mlp.fc2.weight
+ | -0.006 | -0.268 | 0.158 | 0.085 | torch.Size([120]) || stage3.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.716 | 0.376 | 0.965 | 0.119 | torch.Size([120]) || stage3.residual_group1.blocks.1.norm1.weight
+ | -0.185 | -0.732 | 0.209 | 0.179 | torch.Size([120]) || stage3.residual_group1.blocks.1.norm1.bias
+ | -0.002 | -0.462 | 1.414 | 0.064 | torch.Size([675, 6]) || stage3.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.1.attn.position_bias
+ | 0.000 | -0.383 | 0.438 | 0.060 | torch.Size([360, 120]) || stage3.residual_group1.blocks.1.attn.qkv_self.weight
+ | -0.002 | -0.229 | 0.157 | 0.044 | torch.Size([360]) || stage3.residual_group1.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.357 | 0.478 | 0.065 | torch.Size([120, 240]) || stage3.residual_group1.blocks.1.attn.proj.weight
+ | -0.004 | -0.280 | 0.216 | 0.101 | torch.Size([120]) || stage3.residual_group1.blocks.1.attn.proj.bias
+ | 0.000 | -0.471 | 0.517 | 0.063 | torch.Size([360, 120]) || stage3.residual_group1.blocks.1.attn.qkv_mut.weight
+ | -0.000 | -0.112 | 0.131 | 0.022 | torch.Size([360]) || stage3.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.633 | 0.486 | 0.778 | 0.057 | torch.Size([120]) || stage3.residual_group1.blocks.1.norm2.weight
+ | 0.004 | -0.350 | 0.280 | 0.107 | torch.Size([120]) || stage3.residual_group1.blocks.1.norm2.bias
+ | 0.001 | -0.513 | 0.512 | 0.118 | torch.Size([240, 120]) || stage3.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.081 | -0.274 | 0.096 | 0.071 | torch.Size([240]) || stage3.residual_group1.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.548 | 0.533 | 0.126 | torch.Size([240, 120]) || stage3.residual_group1.blocks.1.mlp.fc12.weight
+ | -0.003 | -0.181 | 0.194 | 0.059 | torch.Size([240]) || stage3.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.499 | 0.534 | 0.128 | torch.Size([120, 240]) || stage3.residual_group1.blocks.1.mlp.fc2.weight
+ | -0.007 | -0.282 | 0.152 | 0.083 | torch.Size([120]) || stage3.residual_group1.blocks.1.mlp.fc2.bias
+ | 0.796 | 0.469 | 1.007 | 0.111 | torch.Size([120]) || stage3.residual_group1.blocks.2.norm1.weight
+ | -0.109 | -0.638 | 0.181 | 0.146 | torch.Size([120]) || stage3.residual_group1.blocks.2.norm1.bias
+ | -0.004 | -1.009 | 1.155 | 0.105 | torch.Size([675, 6]) || stage3.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.2.attn.position_bias
+ | -0.000 | -0.378 | 0.375 | 0.081 | torch.Size([360, 120]) || stage3.residual_group1.blocks.2.attn.qkv_self.weight
+ | 0.003 | -0.263 | 0.331 | 0.066 | torch.Size([360]) || stage3.residual_group1.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.485 | 0.366 | 0.074 | torch.Size([120, 240]) || stage3.residual_group1.blocks.2.attn.proj.weight
+ | -0.001 | -0.249 | 0.145 | 0.080 | torch.Size([120]) || stage3.residual_group1.blocks.2.attn.proj.bias
+ | -0.001 | -0.332 | 0.421 | 0.063 | torch.Size([360, 120]) || stage3.residual_group1.blocks.2.attn.qkv_mut.weight
+ | -0.001 | -0.098 | 0.083 | 0.016 | torch.Size([360]) || stage3.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.657 | 0.507 | 0.776 | 0.053 | torch.Size([120]) || stage3.residual_group1.blocks.2.norm2.weight
+ | 0.003 | -0.270 | 0.280 | 0.104 | torch.Size([120]) || stage3.residual_group1.blocks.2.norm2.bias
+ | 0.000 | -0.445 | 0.556 | 0.117 | torch.Size([240, 120]) || stage3.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.097 | -0.295 | 0.100 | 0.070 | torch.Size([240]) || stage3.residual_group1.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.480 | 0.501 | 0.126 | torch.Size([240, 120]) || stage3.residual_group1.blocks.2.mlp.fc12.weight
+ | 0.005 | -0.148 | 0.191 | 0.060 | torch.Size([240]) || stage3.residual_group1.blocks.2.mlp.fc12.bias
+ | 0.001 | -0.569 | 0.484 | 0.126 | torch.Size([120, 240]) || stage3.residual_group1.blocks.2.mlp.fc2.weight
+ | -0.006 | -0.246 | 0.161 | 0.082 | torch.Size([120]) || stage3.residual_group1.blocks.2.mlp.fc2.bias
+ | 0.814 | 0.482 | 1.048 | 0.109 | torch.Size([120]) || stage3.residual_group1.blocks.3.norm1.weight
+ | -0.138 | -0.585 | 0.128 | 0.129 | torch.Size([120]) || stage3.residual_group1.blocks.3.norm1.bias
+ | -0.008 | -1.801 | 4.148 | 0.110 | torch.Size([675, 6]) || stage3.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.3.attn.position_bias
+ | -0.001 | -0.364 | 0.546 | 0.076 | torch.Size([360, 120]) || stage3.residual_group1.blocks.3.attn.qkv_self.weight
+ | 0.003 | -0.179 | 0.182 | 0.046 | torch.Size([360]) || stage3.residual_group1.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.378 | 0.385 | 0.070 | torch.Size([120, 240]) || stage3.residual_group1.blocks.3.attn.proj.weight
+ | -0.005 | -0.368 | 0.175 | 0.101 | torch.Size([120]) || stage3.residual_group1.blocks.3.attn.proj.bias
+ | 0.000 | -0.338 | 0.461 | 0.062 | torch.Size([360, 120]) || stage3.residual_group1.blocks.3.attn.qkv_mut.weight
+ | 0.000 | -0.098 | 0.082 | 0.019 | torch.Size([360]) || stage3.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.676 | 0.526 | 0.799 | 0.056 | torch.Size([120]) || stage3.residual_group1.blocks.3.norm2.weight
+ | 0.002 | -0.269 | 0.242 | 0.090 | torch.Size([120]) || stage3.residual_group1.blocks.3.norm2.bias
+ | 0.000 | -0.474 | 0.505 | 0.118 | torch.Size([240, 120]) || stage3.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.095 | -0.247 | 0.071 | 0.063 | torch.Size([240]) || stage3.residual_group1.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.518 | 0.502 | 0.126 | torch.Size([240, 120]) || stage3.residual_group1.blocks.3.mlp.fc12.weight
+ | -0.003 | -0.194 | 0.228 | 0.068 | torch.Size([240]) || stage3.residual_group1.blocks.3.mlp.fc12.bias
+ | -0.001 | -0.502 | 0.499 | 0.124 | torch.Size([120, 240]) || stage3.residual_group1.blocks.3.mlp.fc2.weight
+ | -0.007 | -0.248 | 0.207 | 0.098 | torch.Size([120]) || stage3.residual_group1.blocks.3.mlp.fc2.bias
+ | 0.843 | 0.498 | 1.046 | 0.099 | torch.Size([120]) || stage3.residual_group1.blocks.4.norm1.weight
+ | -0.082 | -0.456 | 0.195 | 0.111 | torch.Size([120]) || stage3.residual_group1.blocks.4.norm1.bias
+ | -0.012 | -3.133 | 2.263 | 0.177 | torch.Size([675, 6]) || stage3.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.4.attn.position_bias
+ | 0.001 | -0.494 | 0.443 | 0.096 | torch.Size([360, 120]) || stage3.residual_group1.blocks.4.attn.qkv_self.weight
+ | -0.004 | -0.492 | 0.329 | 0.088 | torch.Size([360]) || stage3.residual_group1.blocks.4.attn.qkv_self.bias
+ | -0.000 | -0.464 | 0.391 | 0.080 | torch.Size([120, 240]) || stage3.residual_group1.blocks.4.attn.proj.weight
+ | -0.003 | -0.420 | 0.332 | 0.124 | torch.Size([120]) || stage3.residual_group1.blocks.4.attn.proj.bias
+ | 0.001 | -0.469 | 0.518 | 0.068 | torch.Size([360, 120]) || stage3.residual_group1.blocks.4.attn.qkv_mut.weight
+ | 0.001 | -0.068 | 0.099 | 0.014 | torch.Size([360]) || stage3.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.705 | 0.598 | 0.823 | 0.047 | torch.Size([120]) || stage3.residual_group1.blocks.4.norm2.weight
+ | 0.001 | -0.161 | 0.155 | 0.065 | torch.Size([120]) || stage3.residual_group1.blocks.4.norm2.bias
+ | 0.000 | -0.526 | 0.442 | 0.119 | torch.Size([240, 120]) || stage3.residual_group1.blocks.4.mlp.fc11.weight
+ | -0.102 | -0.319 | 0.054 | 0.072 | torch.Size([240]) || stage3.residual_group1.blocks.4.mlp.fc11.bias
+ | 0.000 | -0.555 | 0.499 | 0.126 | torch.Size([240, 120]) || stage3.residual_group1.blocks.4.mlp.fc12.weight
+ | -0.003 | -0.201 | 0.135 | 0.065 | torch.Size([240]) || stage3.residual_group1.blocks.4.mlp.fc12.bias
+ | 0.001 | -0.454 | 0.522 | 0.122 | torch.Size([120, 240]) || stage3.residual_group1.blocks.4.mlp.fc2.weight
+ | -0.011 | -0.379 | 0.195 | 0.091 | torch.Size([120]) || stage3.residual_group1.blocks.4.mlp.fc2.bias
+ | 0.856 | 0.618 | 1.073 | 0.095 | torch.Size([120]) || stage3.residual_group1.blocks.5.norm1.weight
+ | -0.059 | -0.368 | 0.153 | 0.095 | torch.Size([120]) || stage3.residual_group1.blocks.5.norm1.bias
+ | -0.006 | -1.747 | 1.724 | 0.133 | torch.Size([675, 6]) || stage3.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.5.attn.position_bias
+ | -0.000 | -0.399 | 0.417 | 0.090 | torch.Size([360, 120]) || stage3.residual_group1.blocks.5.attn.qkv_self.weight
+ | 0.009 | -0.294 | 0.398 | 0.079 | torch.Size([360]) || stage3.residual_group1.blocks.5.attn.qkv_self.bias
+ | 0.001 | -0.345 | 0.341 | 0.067 | torch.Size([120, 240]) || stage3.residual_group1.blocks.5.attn.proj.weight
+ | -0.004 | -0.435 | 0.326 | 0.113 | torch.Size([120]) || stage3.residual_group1.blocks.5.attn.proj.bias
+ | -0.000 | -0.370 | 0.339 | 0.052 | torch.Size([360, 120]) || stage3.residual_group1.blocks.5.attn.qkv_mut.weight
+ | -0.000 | -0.059 | 0.060 | 0.012 | torch.Size([360]) || stage3.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.707 | 0.600 | 0.832 | 0.051 | torch.Size([120]) || stage3.residual_group1.blocks.5.norm2.weight
+ | -0.001 | -0.157 | 0.140 | 0.063 | torch.Size([120]) || stage3.residual_group1.blocks.5.norm2.bias
+ | 0.001 | -0.473 | 0.464 | 0.117 | torch.Size([240, 120]) || stage3.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.091 | -0.291 | 0.092 | 0.073 | torch.Size([240]) || stage3.residual_group1.blocks.5.mlp.fc11.bias
+ | -0.000 | -0.479 | 0.477 | 0.124 | torch.Size([240, 120]) || stage3.residual_group1.blocks.5.mlp.fc12.weight
+ | 0.004 | -0.197 | 0.180 | 0.063 | torch.Size([240]) || stage3.residual_group1.blocks.5.mlp.fc12.bias
+ | -0.001 | -0.504 | 0.440 | 0.118 | torch.Size([120, 240]) || stage3.residual_group1.blocks.5.mlp.fc2.weight
+ | -0.008 | -0.449 | 0.421 | 0.135 | torch.Size([120]) || stage3.residual_group1.blocks.5.mlp.fc2.bias
+ | 0.003 | -0.331 | 0.524 | 0.083 | torch.Size([120, 120]) || stage3.linear1.weight
+ | -0.001 | -0.270 | 0.250 | 0.116 | torch.Size([120]) || stage3.linear1.bias
+ | 0.883 | 0.354 | 1.107 | 0.120 | torch.Size([120]) || stage3.residual_group2.blocks.0.norm1.weight
+ | 0.011 | -0.416 | 0.299 | 0.131 | torch.Size([120]) || stage3.residual_group2.blocks.0.norm1.bias
+ | 0.000 | -0.322 | 0.139 | 0.028 | torch.Size([3375, 6]) || stage3.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage3.residual_group2.blocks.0.attn.relative_position_index
+ | 0.000 | -0.470 | 0.455 | 0.097 | torch.Size([360, 120]) || stage3.residual_group2.blocks.0.attn.qkv_self.weight
+ | 0.007 | -0.384 | 0.374 | 0.125 | torch.Size([360]) || stage3.residual_group2.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.467 | 0.428 | 0.109 | torch.Size([120, 120]) || stage3.residual_group2.blocks.0.attn.proj.weight
+ | -0.009 | -0.348 | 0.279 | 0.126 | torch.Size([120]) || stage3.residual_group2.blocks.0.attn.proj.bias
+ | 0.873 | 0.618 | 1.060 | 0.070 | torch.Size([120]) || stage3.residual_group2.blocks.0.norm2.weight
+ | 0.005 | -0.242 | 0.278 | 0.098 | torch.Size([120]) || stage3.residual_group2.blocks.0.norm2.bias
+ | 0.000 | -0.549 | 0.437 | 0.115 | torch.Size([240, 120]) || stage3.residual_group2.blocks.0.mlp.fc11.weight
+ | -0.053 | -0.174 | 0.127 | 0.058 | torch.Size([240]) || stage3.residual_group2.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.469 | 0.517 | 0.124 | torch.Size([240, 120]) || stage3.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.002 | -0.133 | 0.187 | 0.052 | torch.Size([240]) || stage3.residual_group2.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.548 | 0.557 | 0.125 | torch.Size([120, 240]) || stage3.residual_group2.blocks.0.mlp.fc2.weight
+ | -0.011 | -0.339 | 0.303 | 0.116 | torch.Size([120]) || stage3.residual_group2.blocks.0.mlp.fc2.bias
+ | 0.960 | 0.744 | 1.153 | 0.095 | torch.Size([120]) || stage3.residual_group2.blocks.1.norm1.weight
+ | 0.004 | -0.302 | 0.238 | 0.099 | torch.Size([120]) || stage3.residual_group2.blocks.1.norm1.bias
+ | 0.000 | -0.567 | 0.133 | 0.032 | torch.Size([3375, 6]) || stage3.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage3.residual_group2.blocks.1.attn.relative_position_index
+ | 0.000 | -0.425 | 0.414 | 0.087 | torch.Size([360, 120]) || stage3.residual_group2.blocks.1.attn.qkv_self.weight
+ | 0.001 | -0.419 | 0.485 | 0.116 | torch.Size([360]) || stage3.residual_group2.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.429 | 0.385 | 0.095 | torch.Size([120, 120]) || stage3.residual_group2.blocks.1.attn.proj.weight
+ | -0.011 | -0.398 | 0.287 | 0.123 | torch.Size([120]) || stage3.residual_group2.blocks.1.attn.proj.bias
+ | 0.909 | 0.770 | 1.090 | 0.066 | torch.Size([120]) || stage3.residual_group2.blocks.1.norm2.weight
+ | -0.000 | -0.204 | 0.175 | 0.073 | torch.Size([120]) || stage3.residual_group2.blocks.1.norm2.bias
+ | 0.000 | -0.451 | 0.462 | 0.115 | torch.Size([240, 120]) || stage3.residual_group2.blocks.1.mlp.fc11.weight
+ | -0.069 | -0.268 | 0.143 | 0.077 | torch.Size([240]) || stage3.residual_group2.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.488 | 0.602 | 0.126 | torch.Size([240, 120]) || stage3.residual_group2.blocks.1.mlp.fc12.weight
+ | -0.004 | -0.179 | 0.114 | 0.050 | torch.Size([240]) || stage3.residual_group2.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.480 | 0.466 | 0.118 | torch.Size([120, 240]) || stage3.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.007 | -0.358 | 0.225 | 0.102 | torch.Size([120]) || stage3.residual_group2.blocks.1.mlp.fc2.bias
+ | 0.003 | -0.274 | 0.457 | 0.073 | torch.Size([120, 120]) || stage3.linear2.weight
+ | 0.002 | -0.532 | 0.438 | 0.200 | torch.Size([120]) || stage3.linear2.bias
+ | -0.000 | -0.098 | 0.115 | 0.025 | torch.Size([120, 120, 3, 3]) || stage3.pa_deform.weight
+ | 0.002 | -0.033 | 0.041 | 0.015 | torch.Size([120]) || stage3.pa_deform.bias
+ | 0.000 | -0.017 | 0.017 | 0.010 | torch.Size([120, 364, 3, 3]) || stage3.pa_deform.conv_offset.0.weight
+ | -0.010 | -0.030 | 0.017 | 0.010 | torch.Size([120]) || stage3.pa_deform.conv_offset.0.bias
+ | -0.000 | -0.078 | 0.069 | 0.020 | torch.Size([120, 120, 3, 3]) || stage3.pa_deform.conv_offset.2.weight
+ | -0.006 | -0.055 | 0.067 | 0.026 | torch.Size([120]) || stage3.pa_deform.conv_offset.2.bias
+ | -0.001 | -0.071 | 0.067 | 0.020 | torch.Size([120, 120, 3, 3]) || stage3.pa_deform.conv_offset.4.weight
+ | 0.004 | -0.070 | 0.113 | 0.042 | torch.Size([120]) || stage3.pa_deform.conv_offset.4.bias
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432, 120, 3, 3]) || stage3.pa_deform.conv_offset.6.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432]) || stage3.pa_deform.conv_offset.6.bias
+ | 0.004 | -0.623 | 0.669 | 0.126 | torch.Size([360, 360]) || stage3.pa_fuse.fc11.weight
+ | 0.092 | -0.221 | 0.676 | 0.151 | torch.Size([360]) || stage3.pa_fuse.fc11.bias
+ | 0.000 | -0.604 | 0.689 | 0.125 | torch.Size([360, 360]) || stage3.pa_fuse.fc12.weight
+ | 0.008 | -0.544 | 0.379 | 0.118 | torch.Size([360]) || stage3.pa_fuse.fc12.bias
+ | 0.000 | -0.669 | 0.719 | 0.151 | torch.Size([120, 360]) || stage3.pa_fuse.fc2.weight
+ | -0.005 | -0.411 | 0.443 | 0.155 | torch.Size([120]) || stage3.pa_fuse.fc2.bias
+ | 1.005 | 0.488 | 1.503 | 0.166 | torch.Size([480]) || stage4.reshape.1.weight
+ | 0.001 | -0.316 | 0.358 | 0.118 | torch.Size([480]) || stage4.reshape.1.bias
+ | 0.000 | -0.486 | 0.450 | 0.084 | torch.Size([120, 480]) || stage4.reshape.2.weight
+ | -0.007 | -0.139 | 0.092 | 0.043 | torch.Size([120]) || stage4.reshape.2.bias
+ | 0.996 | 0.831 | 1.101 | 0.039 | torch.Size([120]) || stage4.residual_group1.blocks.0.norm1.weight
+ | -0.014 | -0.109 | 0.112 | 0.040 | torch.Size([120]) || stage4.residual_group1.blocks.0.norm1.bias
+ | 0.000 | -0.064 | 0.064 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.0.attn.position_bias
+ | -0.000 | -0.109 | 0.107 | 0.023 | torch.Size([360, 120]) || stage4.residual_group1.blocks.0.attn.qkv_self.weight
+ | -0.001 | -0.033 | 0.029 | 0.009 | torch.Size([360]) || stage4.residual_group1.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.256 | 0.235 | 0.030 | torch.Size([120, 240]) || stage4.residual_group1.blocks.0.attn.proj.weight
+ | 0.007 | -0.099 | 0.227 | 0.051 | torch.Size([120]) || stage4.residual_group1.blocks.0.attn.proj.bias
+ | -0.000 | -0.129 | 0.142 | 0.025 | torch.Size([360, 120]) || stage4.residual_group1.blocks.0.attn.qkv_mut.weight
+ | -0.000 | -0.035 | 0.029 | 0.006 | torch.Size([360]) || stage4.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.966 | 0.869 | 1.089 | 0.041 | torch.Size([120]) || stage4.residual_group1.blocks.0.norm2.weight
+ | 0.000 | -0.155 | 0.152 | 0.058 | torch.Size([120]) || stage4.residual_group1.blocks.0.norm2.bias
+ | -0.000 | -0.248 | 0.221 | 0.024 | torch.Size([240, 120]) || stage4.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.002 | -0.066 | 0.012 | 0.007 | torch.Size([240]) || stage4.residual_group1.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.287 | 0.219 | 0.024 | torch.Size([240, 120]) || stage4.residual_group1.blocks.0.mlp.fc12.weight
+ | 0.000 | -0.085 | 0.067 | 0.010 | torch.Size([240]) || stage4.residual_group1.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.256 | 0.235 | 0.025 | torch.Size([120, 240]) || stage4.residual_group1.blocks.0.mlp.fc2.weight
+ | 0.009 | -0.123 | 0.254 | 0.058 | torch.Size([120]) || stage4.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.988 | 0.825 | 1.079 | 0.043 | torch.Size([120]) || stage4.residual_group1.blocks.1.norm1.weight
+ | -0.013 | -0.123 | 0.105 | 0.047 | torch.Size([120]) || stage4.residual_group1.blocks.1.norm1.bias
+ | -0.000 | -0.081 | 0.078 | 0.021 | torch.Size([675, 6]) || stage4.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.1.attn.position_bias
+ | 0.000 | -0.133 | 0.170 | 0.025 | torch.Size([360, 120]) || stage4.residual_group1.blocks.1.attn.qkv_self.weight
+ | -0.000 | -0.053 | 0.048 | 0.014 | torch.Size([360]) || stage4.residual_group1.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.177 | 0.174 | 0.031 | torch.Size([120, 240]) || stage4.residual_group1.blocks.1.attn.proj.weight
+ | 0.008 | -0.099 | 0.204 | 0.048 | torch.Size([120]) || stage4.residual_group1.blocks.1.attn.proj.bias
+ | 0.000 | -0.138 | 0.130 | 0.026 | torch.Size([360, 120]) || stage4.residual_group1.blocks.1.attn.qkv_mut.weight
+ | 0.000 | -0.061 | 0.059 | 0.010 | torch.Size([360]) || stage4.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.996 | 0.943 | 1.081 | 0.026 | torch.Size([120]) || stage4.residual_group1.blocks.1.norm2.weight
+ | 0.001 | -0.064 | 0.051 | 0.027 | torch.Size([120]) || stage4.residual_group1.blocks.1.norm2.bias
+ | -0.000 | -0.336 | 0.268 | 0.024 | torch.Size([240, 120]) || stage4.residual_group1.blocks.1.mlp.fc11.weight
+ | 0.000 | -0.029 | 0.028 | 0.006 | torch.Size([240]) || stage4.residual_group1.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.223 | 0.272 | 0.024 | torch.Size([240, 120]) || stage4.residual_group1.blocks.1.mlp.fc12.weight
+ | -0.001 | -0.084 | 0.037 | 0.009 | torch.Size([240]) || stage4.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.207 | 0.216 | 0.024 | torch.Size([120, 240]) || stage4.residual_group1.blocks.1.mlp.fc2.weight
+ | 0.007 | -0.140 | 0.216 | 0.058 | torch.Size([120]) || stage4.residual_group1.blocks.1.mlp.fc2.bias
+ | 0.994 | 0.855 | 1.108 | 0.038 | torch.Size([120]) || stage4.residual_group1.blocks.2.norm1.weight
+ | -0.019 | -0.115 | 0.091 | 0.028 | torch.Size([120]) || stage4.residual_group1.blocks.2.norm1.bias
+ | 0.000 | -0.063 | 0.076 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.2.attn.position_bias
+ | -0.000 | -0.190 | 0.179 | 0.027 | torch.Size([360, 120]) || stage4.residual_group1.blocks.2.attn.qkv_self.weight
+ | -0.001 | -0.043 | 0.039 | 0.011 | torch.Size([360]) || stage4.residual_group1.blocks.2.attn.qkv_self.bias
+ | 0.000 | -0.158 | 0.161 | 0.030 | torch.Size([120, 240]) || stage4.residual_group1.blocks.2.attn.proj.weight
+ | 0.008 | -0.118 | 0.164 | 0.050 | torch.Size([120]) || stage4.residual_group1.blocks.2.attn.proj.bias
+ | -0.000 | -0.213 | 0.211 | 0.029 | torch.Size([360, 120]) || stage4.residual_group1.blocks.2.attn.qkv_mut.weight
+ | -0.000 | -0.043 | 0.040 | 0.010 | torch.Size([360]) || stage4.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.993 | 0.903 | 1.099 | 0.028 | torch.Size([120]) || stage4.residual_group1.blocks.2.norm2.weight
+ | 0.003 | -0.097 | 0.106 | 0.044 | torch.Size([120]) || stage4.residual_group1.blocks.2.norm2.bias
+ | 0.000 | -0.186 | 0.177 | 0.024 | torch.Size([240, 120]) || stage4.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.000 | -0.068 | 0.045 | 0.010 | torch.Size([240]) || stage4.residual_group1.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.307 | 0.185 | 0.024 | torch.Size([240, 120]) || stage4.residual_group1.blocks.2.mlp.fc12.weight
+ | -0.000 | -0.081 | 0.061 | 0.010 | torch.Size([240]) || stage4.residual_group1.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.195 | 0.216 | 0.024 | torch.Size([120, 240]) || stage4.residual_group1.blocks.2.mlp.fc2.weight
+ | 0.008 | -0.115 | 0.161 | 0.050 | torch.Size([120]) || stage4.residual_group1.blocks.2.mlp.fc2.bias
+ | 0.997 | 0.893 | 1.071 | 0.032 | torch.Size([120]) || stage4.residual_group1.blocks.3.norm1.weight
+ | -0.019 | -0.083 | 0.047 | 0.024 | torch.Size([120]) || stage4.residual_group1.blocks.3.norm1.bias
+ | 0.001 | -0.076 | 0.073 | 0.021 | torch.Size([675, 6]) || stage4.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.3.attn.position_bias
+ | 0.000 | -0.275 | 0.259 | 0.029 | torch.Size([360, 120]) || stage4.residual_group1.blocks.3.attn.qkv_self.weight
+ | -0.001 | -0.071 | 0.066 | 0.017 | torch.Size([360]) || stage4.residual_group1.blocks.3.attn.qkv_self.bias
+ | -0.000 | -0.166 | 0.157 | 0.028 | torch.Size([120, 240]) || stage4.residual_group1.blocks.3.attn.proj.weight
+ | 0.008 | -0.105 | 0.149 | 0.043 | torch.Size([120]) || stage4.residual_group1.blocks.3.attn.proj.bias
+ | 0.000 | -0.184 | 0.197 | 0.028 | torch.Size([360, 120]) || stage4.residual_group1.blocks.3.attn.qkv_mut.weight
+ | 0.001 | -0.042 | 0.050 | 0.008 | torch.Size([360]) || stage4.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 1.001 | 0.971 | 1.136 | 0.022 | torch.Size([120]) || stage4.residual_group1.blocks.3.norm2.weight
+ | -0.002 | -0.054 | 0.050 | 0.023 | torch.Size([120]) || stage4.residual_group1.blocks.3.norm2.bias
+ | 0.000 | -0.329 | 0.210 | 0.023 | torch.Size([240, 120]) || stage4.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.000 | -0.078 | 0.029 | 0.009 | torch.Size([240]) || stage4.residual_group1.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.234 | 0.241 | 0.023 | torch.Size([240, 120]) || stage4.residual_group1.blocks.3.mlp.fc12.weight
+ | 0.000 | -0.031 | 0.024 | 0.006 | torch.Size([240]) || stage4.residual_group1.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.169 | 0.164 | 0.023 | torch.Size([120, 240]) || stage4.residual_group1.blocks.3.mlp.fc2.weight
+ | 0.007 | -0.085 | 0.114 | 0.043 | torch.Size([120]) || stage4.residual_group1.blocks.3.mlp.fc2.bias
+ | 1.003 | 0.901 | 1.099 | 0.044 | torch.Size([120]) || stage4.residual_group1.blocks.4.norm1.weight
+ | -0.034 | -0.095 | 0.039 | 0.030 | torch.Size([120]) || stage4.residual_group1.blocks.4.norm1.bias
+ | 0.000 | -0.071 | 0.090 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.4.attn.position_bias
+ | -0.000 | -0.238 | 0.268 | 0.034 | torch.Size([360, 120]) || stage4.residual_group1.blocks.4.attn.qkv_self.weight
+ | -0.002 | -0.199 | 0.144 | 0.030 | torch.Size([360]) || stage4.residual_group1.blocks.4.attn.qkv_self.bias
+ | -0.000 | -0.167 | 0.218 | 0.029 | torch.Size([120, 240]) || stage4.residual_group1.blocks.4.attn.proj.weight
+ | 0.008 | -0.089 | 0.140 | 0.039 | torch.Size([120]) || stage4.residual_group1.blocks.4.attn.proj.bias
+ | 0.000 | -0.267 | 0.253 | 0.031 | torch.Size([360, 120]) || stage4.residual_group1.blocks.4.attn.qkv_mut.weight
+ | 0.001 | -0.067 | 0.069 | 0.009 | torch.Size([360]) || stage4.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 1.004 | 0.953 | 1.056 | 0.014 | torch.Size([120]) || stage4.residual_group1.blocks.4.norm2.weight
+ | -0.001 | -0.056 | 0.077 | 0.021 | torch.Size([120]) || stage4.residual_group1.blocks.4.norm2.bias
+ | -0.000 | -0.170 | 0.184 | 0.023 | torch.Size([240, 120]) || stage4.residual_group1.blocks.4.mlp.fc11.weight
+ | 0.001 | -0.037 | 0.027 | 0.007 | torch.Size([240]) || stage4.residual_group1.blocks.4.mlp.fc11.bias
+ | 0.000 | -0.149 | 0.202 | 0.023 | torch.Size([240, 120]) || stage4.residual_group1.blocks.4.mlp.fc12.weight
+ | 0.000 | -0.059 | 0.095 | 0.010 | torch.Size([240]) || stage4.residual_group1.blocks.4.mlp.fc12.bias
+ | -0.000 | -0.145 | 0.181 | 0.023 | torch.Size([120, 240]) || stage4.residual_group1.blocks.4.mlp.fc2.weight
+ | 0.006 | -0.086 | 0.117 | 0.036 | torch.Size([120]) || stage4.residual_group1.blocks.4.mlp.fc2.bias
+ | 0.996 | 0.859 | 1.077 | 0.047 | torch.Size([120]) || stage4.residual_group1.blocks.5.norm1.weight
+ | -0.058 | -0.153 | 0.009 | 0.038 | torch.Size([120]) || stage4.residual_group1.blocks.5.norm1.bias
+ | 0.000 | -0.087 | 0.083 | 0.021 | torch.Size([675, 6]) || stage4.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.5.attn.position_bias
+ | -0.000 | -0.249 | 0.266 | 0.033 | torch.Size([360, 120]) || stage4.residual_group1.blocks.5.attn.qkv_self.weight
+ | -0.001 | -0.199 | 0.168 | 0.031 | torch.Size([360]) || stage4.residual_group1.blocks.5.attn.qkv_self.bias
+ | 0.000 | -0.156 | 0.142 | 0.027 | torch.Size([120, 240]) || stage4.residual_group1.blocks.5.attn.proj.weight
+ | 0.004 | -0.102 | 0.145 | 0.045 | torch.Size([120]) || stage4.residual_group1.blocks.5.attn.proj.bias
+ | 0.000 | -0.299 | 0.376 | 0.033 | torch.Size([360, 120]) || stage4.residual_group1.blocks.5.attn.qkv_mut.weight
+ | 0.000 | -0.034 | 0.066 | 0.007 | torch.Size([360]) || stage4.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.992 | 0.924 | 1.097 | 0.025 | torch.Size([120]) || stage4.residual_group1.blocks.5.norm2.weight
+ | -0.002 | -0.089 | 0.074 | 0.038 | torch.Size([120]) || stage4.residual_group1.blocks.5.norm2.bias
+ | -0.000 | -0.192 | 0.208 | 0.023 | torch.Size([240, 120]) || stage4.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.002 | -0.064 | 0.021 | 0.009 | torch.Size([240]) || stage4.residual_group1.blocks.5.mlp.fc11.bias
+ | -0.000 | -0.240 | 0.191 | 0.023 | torch.Size([240, 120]) || stage4.residual_group1.blocks.5.mlp.fc12.weight
+ | 0.000 | -0.040 | 0.044 | 0.008 | torch.Size([240]) || stage4.residual_group1.blocks.5.mlp.fc12.bias
+ | -0.000 | -0.141 | 0.155 | 0.022 | torch.Size([120, 240]) || stage4.residual_group1.blocks.5.mlp.fc2.weight
+ | 0.005 | -0.107 | 0.103 | 0.045 | torch.Size([120]) || stage4.residual_group1.blocks.5.mlp.fc2.bias
+ | 0.001 | -0.286 | 0.303 | 0.059 | torch.Size([120, 120]) || stage4.linear1.weight
+ | -0.012 | -0.311 | 0.190 | 0.090 | torch.Size([120]) || stage4.linear1.bias
+ | 1.009 | 0.926 | 1.101 | 0.028 | torch.Size([120]) || stage4.residual_group2.blocks.0.norm1.weight
+ | -0.001 | -0.036 | 0.048 | 0.015 | torch.Size([120]) || stage4.residual_group2.blocks.0.norm1.bias
+ | 0.000 | -0.071 | 0.076 | 0.020 | torch.Size([3375, 6]) || stage4.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage4.residual_group2.blocks.0.attn.relative_position_index
+ | -0.000 | -0.135 | 0.141 | 0.023 | torch.Size([360, 120]) || stage4.residual_group2.blocks.0.attn.qkv_self.weight
+ | 0.001 | -0.023 | 0.021 | 0.007 | torch.Size([360]) || stage4.residual_group2.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.115 | 0.121 | 0.025 | torch.Size([120, 120]) || stage4.residual_group2.blocks.0.attn.proj.weight
+ | -0.007 | -0.200 | 0.098 | 0.043 | torch.Size([120]) || stage4.residual_group2.blocks.0.attn.proj.bias
+ | 1.002 | 0.999 | 1.016 | 0.002 | torch.Size([120]) || stage4.residual_group2.blocks.0.norm2.weight
+ | 0.000 | -0.003 | 0.004 | 0.001 | torch.Size([120]) || stage4.residual_group2.blocks.0.norm2.bias
+ | 0.000 | -0.082 | 0.094 | 0.020 | torch.Size([240, 120]) || stage4.residual_group2.blocks.0.mlp.fc11.weight
+ | 0.000 | -0.005 | 0.017 | 0.002 | torch.Size([240]) || stage4.residual_group2.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.088 | 0.079 | 0.020 | torch.Size([240, 120]) || stage4.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.000 | -0.010 | 0.008 | 0.002 | torch.Size([240]) || stage4.residual_group2.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.090 | 0.105 | 0.020 | torch.Size([120, 240]) || stage4.residual_group2.blocks.0.mlp.fc2.weight
+ | -0.006 | -0.181 | 0.096 | 0.041 | torch.Size([120]) || stage4.residual_group2.blocks.0.mlp.fc2.bias
+ | 1.006 | 0.923 | 1.098 | 0.025 | torch.Size([120]) || stage4.residual_group2.blocks.1.norm1.weight
+ | -0.001 | -0.045 | 0.053 | 0.019 | torch.Size([120]) || stage4.residual_group2.blocks.1.norm1.bias
+ | -0.000 | -0.083 | 0.085 | 0.020 | torch.Size([3375, 6]) || stage4.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage4.residual_group2.blocks.1.attn.relative_position_index
+ | -0.000 | -0.132 | 0.133 | 0.023 | torch.Size([360, 120]) || stage4.residual_group2.blocks.1.attn.qkv_self.weight
+ | -0.000 | -0.030 | 0.035 | 0.009 | torch.Size([360]) || stage4.residual_group2.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.129 | 0.094 | 0.024 | torch.Size([120, 120]) || stage4.residual_group2.blocks.1.attn.proj.weight
+ | -0.008 | -0.218 | 0.116 | 0.048 | torch.Size([120]) || stage4.residual_group2.blocks.1.attn.proj.bias
+ | 1.003 | 0.999 | 1.024 | 0.003 | torch.Size([120]) || stage4.residual_group2.blocks.1.norm2.weight
+ | -0.000 | -0.004 | 0.005 | 0.002 | torch.Size([120]) || stage4.residual_group2.blocks.1.norm2.bias
+ | -0.000 | -0.126 | 0.080 | 0.021 | torch.Size([240, 120]) || stage4.residual_group2.blocks.1.mlp.fc11.weight
+ | 0.001 | -0.006 | 0.016 | 0.003 | torch.Size([240]) || stage4.residual_group2.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.092 | 0.076 | 0.020 | torch.Size([240, 120]) || stage4.residual_group2.blocks.1.mlp.fc12.weight
+ | 0.000 | -0.015 | 0.013 | 0.003 | torch.Size([240]) || stage4.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.091 | 0.115 | 0.020 | torch.Size([120, 240]) || stage4.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.006 | -0.196 | 0.090 | 0.041 | torch.Size([120]) || stage4.residual_group2.blocks.1.mlp.fc2.bias
+ | 0.001 | -0.291 | 0.416 | 0.059 | torch.Size([120, 120]) || stage4.linear2.weight
+ | -0.009 | -0.269 | 0.198 | 0.094 | torch.Size([120]) || stage4.linear2.bias
+ | 0.000 | -0.053 | 0.057 | 0.019 | torch.Size([120, 120, 3, 3]) || stage4.pa_deform.weight
+ | -0.001 | -0.021 | 0.021 | 0.009 | torch.Size([120]) || stage4.pa_deform.bias
+ | -0.000 | -0.017 | 0.017 | 0.010 | torch.Size([120, 364, 3, 3]) || stage4.pa_deform.conv_offset.0.weight
+ | -0.000 | -0.015 | 0.015 | 0.009 | torch.Size([120]) || stage4.pa_deform.conv_offset.0.bias
+ | -0.000 | -0.039 | 0.041 | 0.018 | torch.Size([120, 120, 3, 3]) || stage4.pa_deform.conv_offset.2.weight
+ | 0.000 | -0.030 | 0.029 | 0.018 | torch.Size([120]) || stage4.pa_deform.conv_offset.2.bias
+ | -0.000 | -0.045 | 0.041 | 0.018 | torch.Size([120, 120, 3, 3]) || stage4.pa_deform.conv_offset.4.weight
+ | -0.002 | -0.031 | 0.030 | 0.016 | torch.Size([120]) || stage4.pa_deform.conv_offset.4.bias
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432, 120, 3, 3]) || stage4.pa_deform.conv_offset.6.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432]) || stage4.pa_deform.conv_offset.6.bias
+ | -0.000 | -0.356 | 0.435 | 0.035 | torch.Size([360, 360]) || stage4.pa_fuse.fc11.weight
+ | 0.003 | -0.080 | 0.304 | 0.033 | torch.Size([360]) || stage4.pa_fuse.fc11.bias
+ | 0.000 | -0.361 | 0.436 | 0.035 | torch.Size([360, 360]) || stage4.pa_fuse.fc12.weight
+ | -0.001 | -0.166 | 0.299 | 0.032 | torch.Size([360]) || stage4.pa_fuse.fc12.bias
+ | -0.000 | -0.748 | 0.752 | 0.056 | torch.Size([120, 360]) || stage4.pa_fuse.fc2.weight
+ | -0.000 | -0.262 | 0.270 | 0.086 | torch.Size([120]) || stage4.pa_fuse.fc2.bias
+ | 0.980 | 0.710 | 1.274 | 0.146 | torch.Size([30]) || stage5.reshape.1.weight
+ | -0.002 | -0.062 | 0.057 | 0.036 | torch.Size([30]) || stage5.reshape.1.bias
+ | 0.001 | -0.530 | 0.432 | 0.092 | torch.Size([120, 30]) || stage5.reshape.2.weight
+ | 0.021 | -0.305 | 0.337 | 0.080 | torch.Size([120]) || stage5.reshape.2.bias
+ | 0.994 | 0.934 | 1.012 | 0.016 | torch.Size([120]) || stage5.residual_group1.blocks.0.norm1.weight
+ | -0.014 | -0.040 | 0.038 | 0.014 | torch.Size([120]) || stage5.residual_group1.blocks.0.norm1.bias
+ | 0.000 | -0.082 | 0.072 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.0.attn.position_bias
+ | -0.000 | -0.078 | 0.101 | 0.021 | torch.Size([360, 120]) || stage5.residual_group1.blocks.0.attn.qkv_self.weight
+ | -0.000 | -0.022 | 0.023 | 0.005 | torch.Size([360]) || stage5.residual_group1.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.198 | 0.237 | 0.022 | torch.Size([120, 240]) || stage5.residual_group1.blocks.0.attn.proj.weight
+ | -0.003 | -0.067 | 0.082 | 0.027 | torch.Size([120]) || stage5.residual_group1.blocks.0.attn.proj.bias
+ | 0.000 | -0.103 | 0.092 | 0.021 | torch.Size([360, 120]) || stage5.residual_group1.blocks.0.attn.qkv_mut.weight
+ | -0.000 | -0.007 | 0.006 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.991 | 0.929 | 1.004 | 0.011 | torch.Size([120]) || stage5.residual_group1.blocks.0.norm2.weight
+ | 0.001 | -0.009 | 0.014 | 0.004 | torch.Size([120]) || stage5.residual_group1.blocks.0.norm2.bias
+ | -0.000 | -0.112 | 0.093 | 0.021 | torch.Size([240, 120]) || stage5.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.001 | -0.033 | 0.027 | 0.008 | torch.Size([240]) || stage5.residual_group1.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.098 | 0.085 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.0.mlp.fc12.weight
+ | -0.000 | -0.033 | 0.026 | 0.009 | torch.Size([240]) || stage5.residual_group1.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.163 | 0.140 | 0.021 | torch.Size([120, 240]) || stage5.residual_group1.blocks.0.mlp.fc2.weight
+ | 0.003 | -0.060 | 0.110 | 0.032 | torch.Size([120]) || stage5.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.992 | 0.872 | 1.010 | 0.018 | torch.Size([120]) || stage5.residual_group1.blocks.1.norm1.weight
+ | -0.015 | -0.039 | 0.031 | 0.010 | torch.Size([120]) || stage5.residual_group1.blocks.1.norm1.bias
+ | -0.000 | -0.078 | 0.078 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.1.attn.position_bias
+ | 0.000 | -0.088 | 0.099 | 0.021 | torch.Size([360, 120]) || stage5.residual_group1.blocks.1.attn.qkv_self.weight
+ | 0.000 | -0.030 | 0.030 | 0.006 | torch.Size([360]) || stage5.residual_group1.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.151 | 0.185 | 0.022 | torch.Size([120, 240]) || stage5.residual_group1.blocks.1.attn.proj.weight
+ | -0.005 | -0.073 | 0.061 | 0.024 | torch.Size([120]) || stage5.residual_group1.blocks.1.attn.proj.bias
+ | 0.000 | -0.093 | 0.089 | 0.021 | torch.Size([360, 120]) || stage5.residual_group1.blocks.1.attn.qkv_mut.weight
+ | 0.000 | -0.009 | 0.007 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.997 | 0.923 | 1.003 | 0.008 | torch.Size([120]) || stage5.residual_group1.blocks.1.norm2.weight
+ | 0.000 | -0.008 | 0.009 | 0.004 | torch.Size([120]) || stage5.residual_group1.blocks.1.norm2.bias
+ | -0.000 | -0.082 | 0.092 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.000 | -0.023 | 0.021 | 0.007 | torch.Size([240]) || stage5.residual_group1.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.082 | 0.078 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.1.mlp.fc12.weight
+ | -0.001 | -0.028 | 0.025 | 0.008 | torch.Size([240]) || stage5.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.097 | 0.090 | 0.020 | torch.Size([120, 240]) || stage5.residual_group1.blocks.1.mlp.fc2.weight
+ | 0.000 | -0.062 | 0.102 | 0.028 | torch.Size([120]) || stage5.residual_group1.blocks.1.mlp.fc2.bias
+ | 0.994 | 0.845 | 1.015 | 0.018 | torch.Size([120]) || stage5.residual_group1.blocks.2.norm1.weight
+ | -0.018 | -0.045 | 0.016 | 0.008 | torch.Size([120]) || stage5.residual_group1.blocks.2.norm1.bias
+ | 0.000 | -0.065 | 0.068 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.2.attn.position_bias
+ | -0.000 | -0.088 | 0.113 | 0.021 | torch.Size([360, 120]) || stage5.residual_group1.blocks.2.attn.qkv_self.weight
+ | 0.000 | -0.022 | 0.020 | 0.005 | torch.Size([360]) || stage5.residual_group1.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.124 | 0.124 | 0.021 | torch.Size([120, 240]) || stage5.residual_group1.blocks.2.attn.proj.weight
+ | -0.001 | -0.061 | 0.049 | 0.020 | torch.Size([120]) || stage5.residual_group1.blocks.2.attn.proj.bias
+ | -0.000 | -0.088 | 0.087 | 0.021 | torch.Size([360, 120]) || stage5.residual_group1.blocks.2.attn.qkv_mut.weight
+ | -0.000 | -0.008 | 0.005 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.993 | 0.847 | 1.012 | 0.016 | torch.Size([120]) || stage5.residual_group1.blocks.2.norm2.weight
+ | 0.000 | -0.014 | 0.015 | 0.007 | torch.Size([120]) || stage5.residual_group1.blocks.2.norm2.bias
+ | 0.000 | -0.096 | 0.096 | 0.021 | torch.Size([240, 120]) || stage5.residual_group1.blocks.2.mlp.fc11.weight
+ | 0.001 | -0.038 | 0.027 | 0.009 | torch.Size([240]) || stage5.residual_group1.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.090 | 0.095 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.2.mlp.fc12.weight
+ | 0.000 | -0.045 | 0.039 | 0.011 | torch.Size([240]) || stage5.residual_group1.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.153 | 0.130 | 0.021 | torch.Size([120, 240]) || stage5.residual_group1.blocks.2.mlp.fc2.weight
+ | -0.006 | -0.097 | 0.083 | 0.028 | torch.Size([120]) || stage5.residual_group1.blocks.2.mlp.fc2.bias
+ | 0.984 | 0.798 | 1.006 | 0.023 | torch.Size([120]) || stage5.residual_group1.blocks.3.norm1.weight
+ | -0.018 | -0.042 | 0.003 | 0.010 | torch.Size([120]) || stage5.residual_group1.blocks.3.norm1.bias
+ | 0.000 | -0.074 | 0.214 | 0.021 | torch.Size([675, 6]) || stage5.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.3.attn.position_bias
+ | 0.000 | -0.133 | 0.132 | 0.022 | torch.Size([360, 120]) || stage5.residual_group1.blocks.3.attn.qkv_self.weight
+ | -0.000 | -0.035 | 0.037 | 0.008 | torch.Size([360]) || stage5.residual_group1.blocks.3.attn.qkv_self.bias
+ | -0.000 | -0.121 | 0.123 | 0.020 | torch.Size([120, 240]) || stage5.residual_group1.blocks.3.attn.proj.weight
+ | -0.002 | -0.043 | 0.049 | 0.016 | torch.Size([120]) || stage5.residual_group1.blocks.3.attn.proj.bias
+ | 0.000 | -0.082 | 0.093 | 0.021 | torch.Size([360, 120]) || stage5.residual_group1.blocks.3.attn.qkv_mut.weight
+ | -0.000 | -0.007 | 0.007 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.993 | 0.809 | 1.008 | 0.018 | torch.Size([120]) || stage5.residual_group1.blocks.3.norm2.weight
+ | 0.001 | -0.018 | 0.013 | 0.006 | torch.Size([120]) || stage5.residual_group1.blocks.3.norm2.bias
+ | -0.000 | -0.100 | 0.097 | 0.021 | torch.Size([240, 120]) || stage5.residual_group1.blocks.3.mlp.fc11.weight
+ | 0.001 | -0.038 | 0.045 | 0.009 | torch.Size([240]) || stage5.residual_group1.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.104 | 0.095 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.3.mlp.fc12.weight
+ | -0.000 | -0.043 | 0.040 | 0.011 | torch.Size([240]) || stage5.residual_group1.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.108 | 0.121 | 0.021 | torch.Size([120, 240]) || stage5.residual_group1.blocks.3.mlp.fc2.weight
+ | 0.002 | -0.066 | 0.048 | 0.023 | torch.Size([120]) || stage5.residual_group1.blocks.3.mlp.fc2.bias
+ | 0.988 | 0.835 | 1.035 | 0.019 | torch.Size([120]) || stage5.residual_group1.blocks.4.norm1.weight
+ | -0.022 | -0.052 | 0.003 | 0.013 | torch.Size([120]) || stage5.residual_group1.blocks.4.norm1.bias
+ | -0.000 | -0.086 | 0.118 | 0.021 | torch.Size([675, 6]) || stage5.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.4.attn.position_bias
+ | 0.000 | -0.199 | 0.223 | 0.023 | torch.Size([360, 120]) || stage5.residual_group1.blocks.4.attn.qkv_self.weight
+ | -0.000 | -0.045 | 0.028 | 0.009 | torch.Size([360]) || stage5.residual_group1.blocks.4.attn.qkv_self.bias
+ | 0.000 | -0.114 | 0.143 | 0.021 | torch.Size([120, 240]) || stage5.residual_group1.blocks.4.attn.proj.weight
+ | -0.003 | -0.060 | 0.047 | 0.021 | torch.Size([120]) || stage5.residual_group1.blocks.4.attn.proj.bias
+ | -0.000 | -0.117 | 0.102 | 0.021 | torch.Size([360, 120]) || stage5.residual_group1.blocks.4.attn.qkv_mut.weight
+ | 0.000 | -0.008 | 0.010 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.994 | 0.774 | 1.007 | 0.021 | torch.Size([120]) || stage5.residual_group1.blocks.4.norm2.weight
+ | 0.001 | -0.023 | 0.027 | 0.010 | torch.Size([120]) || stage5.residual_group1.blocks.4.norm2.bias
+ | -0.000 | -0.085 | 0.107 | 0.021 | torch.Size([240, 120]) || stage5.residual_group1.blocks.4.mlp.fc11.weight
+ | 0.003 | -0.044 | 0.042 | 0.013 | torch.Size([240]) || stage5.residual_group1.blocks.4.mlp.fc11.bias
+ | -0.000 | -0.103 | 0.080 | 0.021 | torch.Size([240, 120]) || stage5.residual_group1.blocks.4.mlp.fc12.weight
+ | 0.000 | -0.067 | 0.058 | 0.015 | torch.Size([240]) || stage5.residual_group1.blocks.4.mlp.fc12.bias
+ | 0.000 | -0.096 | 0.103 | 0.021 | torch.Size([120, 240]) || stage5.residual_group1.blocks.4.mlp.fc2.weight
+ | -0.000 | -0.045 | 0.054 | 0.023 | torch.Size([120]) || stage5.residual_group1.blocks.4.mlp.fc2.bias
+ | 0.985 | 0.552 | 1.092 | 0.044 | torch.Size([120]) || stage5.residual_group1.blocks.5.norm1.weight
+ | -0.023 | -0.073 | 0.024 | 0.019 | torch.Size([120]) || stage5.residual_group1.blocks.5.norm1.bias
+ | -0.000 | -0.080 | 0.121 | 0.021 | torch.Size([675, 6]) || stage5.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.5.attn.position_bias
+ | -0.000 | -1.776 | 0.186 | 0.026 | torch.Size([360, 120]) || stage5.residual_group1.blocks.5.attn.qkv_self.weight
+ | -0.000 | -0.070 | 0.065 | 0.015 | torch.Size([360]) || stage5.residual_group1.blocks.5.attn.qkv_self.bias
+ | 0.000 | -0.230 | 0.359 | 0.022 | torch.Size([120, 240]) || stage5.residual_group1.blocks.5.attn.proj.weight
+ | -0.001 | -0.062 | 0.079 | 0.028 | torch.Size([120]) || stage5.residual_group1.blocks.5.attn.proj.bias
+ | -0.000 | -0.086 | 0.104 | 0.021 | torch.Size([360, 120]) || stage5.residual_group1.blocks.5.attn.qkv_mut.weight
+ | -0.000 | -0.007 | 0.008 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.976 | 0.863 | 0.995 | 0.015 | torch.Size([120]) || stage5.residual_group1.blocks.5.norm2.weight
+ | -0.001 | -0.037 | 0.053 | 0.018 | torch.Size([120]) || stage5.residual_group1.blocks.5.norm2.bias
+ | -0.000 | -0.121 | 0.100 | 0.021 | torch.Size([240, 120]) || stage5.residual_group1.blocks.5.mlp.fc11.weight
+ | 0.009 | -0.074 | 0.101 | 0.021 | torch.Size([240]) || stage5.residual_group1.blocks.5.mlp.fc11.bias
+ | 0.000 | -0.102 | 0.101 | 0.021 | torch.Size([240, 120]) || stage5.residual_group1.blocks.5.mlp.fc12.weight
+ | 0.001 | -0.092 | 0.082 | 0.028 | torch.Size([240]) || stage5.residual_group1.blocks.5.mlp.fc12.bias
+ | -0.000 | -0.148 | 0.202 | 0.022 | torch.Size([120, 240]) || stage5.residual_group1.blocks.5.mlp.fc2.weight
+ | 0.001 | -0.056 | 0.054 | 0.025 | torch.Size([120]) || stage5.residual_group1.blocks.5.mlp.fc2.bias
+ | -0.000 | -0.139 | 0.123 | 0.024 | torch.Size([120, 120]) || stage5.linear1.weight
+ | 0.022 | -0.317 | 0.336 | 0.081 | torch.Size([120]) || stage5.linear1.bias
+ | 0.963 | 0.765 | 1.026 | 0.058 | torch.Size([120]) || stage5.residual_group2.blocks.0.norm1.weight
+ | -0.001 | -0.315 | 0.286 | 0.078 | torch.Size([120]) || stage5.residual_group2.blocks.0.norm1.bias
+ | 0.000 | -0.077 | 0.080 | 0.020 | torch.Size([3375, 6]) || stage5.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage5.residual_group2.blocks.0.attn.relative_position_index
+ | -0.000 | -0.159 | 0.119 | 0.022 | torch.Size([360, 120]) || stage5.residual_group2.blocks.0.attn.qkv_self.weight
+ | 0.000 | -0.038 | 0.044 | 0.013 | torch.Size([360]) || stage5.residual_group2.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.134 | 0.126 | 0.024 | torch.Size([120, 120]) || stage5.residual_group2.blocks.0.attn.proj.weight
+ | -0.005 | -0.263 | 0.230 | 0.060 | torch.Size([120]) || stage5.residual_group2.blocks.0.attn.proj.bias
+ | 0.990 | 0.913 | 1.001 | 0.017 | torch.Size([120]) || stage5.residual_group2.blocks.0.norm2.weight
+ | 0.000 | -0.009 | 0.010 | 0.004 | torch.Size([120]) || stage5.residual_group2.blocks.0.norm2.bias
+ | -0.000 | -0.077 | 0.089 | 0.020 | torch.Size([240, 120]) || stage5.residual_group2.blocks.0.mlp.fc11.weight
+ | -0.004 | -0.025 | 0.016 | 0.007 | torch.Size([240]) || stage5.residual_group2.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.073 | 0.090 | 0.020 | torch.Size([240, 120]) || stage5.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.000 | -0.018 | 0.018 | 0.007 | torch.Size([240]) || stage5.residual_group2.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.084 | 0.083 | 0.020 | torch.Size([120, 240]) || stage5.residual_group2.blocks.0.mlp.fc2.weight
+ | -0.006 | -0.264 | 0.273 | 0.056 | torch.Size([120]) || stage5.residual_group2.blocks.0.mlp.fc2.bias
+ | 0.976 | 0.733 | 1.048 | 0.053 | torch.Size([120]) || stage5.residual_group2.blocks.1.norm1.weight
+ | -0.001 | -0.265 | 0.241 | 0.061 | torch.Size([120]) || stage5.residual_group2.blocks.1.norm1.bias
+ | -0.000 | -0.079 | 0.081 | 0.020 | torch.Size([3375, 6]) || stage5.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage5.residual_group2.blocks.1.attn.relative_position_index
+ | -0.000 | -0.145 | 0.145 | 0.023 | torch.Size([360, 120]) || stage5.residual_group2.blocks.1.attn.qkv_self.weight
+ | -0.000 | -0.031 | 0.051 | 0.009 | torch.Size([360]) || stage5.residual_group2.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.114 | 0.103 | 0.025 | torch.Size([120, 120]) || stage5.residual_group2.blocks.1.attn.proj.weight
+ | -0.011 | -0.166 | 0.119 | 0.032 | torch.Size([120]) || stage5.residual_group2.blocks.1.attn.proj.bias
+ | 0.993 | 0.939 | 1.001 | 0.012 | torch.Size([120]) || stage5.residual_group2.blocks.1.norm2.weight
+ | 0.000 | -0.011 | 0.008 | 0.004 | torch.Size([120]) || stage5.residual_group2.blocks.1.norm2.bias
+ | -0.000 | -0.090 | 0.081 | 0.020 | torch.Size([240, 120]) || stage5.residual_group2.blocks.1.mlp.fc11.weight
+ | -0.002 | -0.026 | 0.020 | 0.007 | torch.Size([240]) || stage5.residual_group2.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.092 | 0.078 | 0.020 | torch.Size([240, 120]) || stage5.residual_group2.blocks.1.mlp.fc12.weight
+ | 0.000 | -0.020 | 0.021 | 0.007 | torch.Size([240]) || stage5.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.097 | 0.093 | 0.020 | torch.Size([120, 240]) || stage5.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.016 | -0.224 | 0.158 | 0.041 | torch.Size([120]) || stage5.residual_group2.blocks.1.mlp.fc2.bias
+ | -0.000 | -0.244 | 0.248 | 0.044 | torch.Size([120, 120]) || stage5.linear2.weight
+ | 0.022 | -0.367 | 0.377 | 0.103 | torch.Size([120]) || stage5.linear2.bias
+ | -0.000 | -0.153 | 0.112 | 0.022 | torch.Size([120, 120, 3, 3]) || stage5.pa_deform.weight
+ | -0.004 | -0.061 | 0.053 | 0.023 | torch.Size([120]) || stage5.pa_deform.bias
+ | -0.000 | -0.017 | 0.017 | 0.010 | torch.Size([120, 364, 3, 3]) || stage5.pa_deform.conv_offset.0.weight
+ | -0.010 | -0.038 | 0.022 | 0.013 | torch.Size([120]) || stage5.pa_deform.conv_offset.0.bias
+ | -0.001 | -0.081 | 0.076 | 0.020 | torch.Size([120, 120, 3, 3]) || stage5.pa_deform.conv_offset.2.weight
+ | -0.008 | -0.062 | 0.031 | 0.021 | torch.Size([120]) || stage5.pa_deform.conv_offset.2.bias
+ | -0.000 | -0.080 | 0.079 | 0.019 | torch.Size([120, 120, 3, 3]) || stage5.pa_deform.conv_offset.4.weight
+ | -0.005 | -0.057 | 0.035 | 0.020 | torch.Size([120]) || stage5.pa_deform.conv_offset.4.bias
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432, 120, 3, 3]) || stage5.pa_deform.conv_offset.6.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432]) || stage5.pa_deform.conv_offset.6.bias
+ | 0.000 | -0.590 | 0.536 | 0.063 | torch.Size([360, 360]) || stage5.pa_fuse.fc11.weight
+ | 0.075 | -0.075 | 0.431 | 0.094 | torch.Size([360]) || stage5.pa_fuse.fc11.bias
+ | 0.000 | -0.704 | 0.718 | 0.064 | torch.Size([360, 360]) || stage5.pa_fuse.fc12.weight
+ | 0.005 | -0.308 | 0.337 | 0.073 | torch.Size([360]) || stage5.pa_fuse.fc12.bias
+ | 0.000 | -0.702 | 0.735 | 0.101 | torch.Size([120, 360]) || stage5.pa_fuse.fc2.weight
+ | -0.005 | -0.422 | 0.451 | 0.157 | torch.Size([120]) || stage5.pa_fuse.fc2.bias
+ | 1.444 | 1.141 | 1.615 | 0.121 | torch.Size([30]) || stage6.reshape.1.weight
+ | -0.003 | -0.150 | 0.115 | 0.074 | torch.Size([30]) || stage6.reshape.1.bias
+ | 0.001 | -0.848 | 0.822 | 0.232 | torch.Size([120, 30]) || stage6.reshape.2.weight
+ | 0.004 | -0.514 | 0.640 | 0.181 | torch.Size([120]) || stage6.reshape.2.bias
+ | 0.557 | 0.119 | 0.895 | 0.153 | torch.Size([120]) || stage6.residual_group1.blocks.0.norm1.weight
+ | -0.070 | -0.374 | 0.181 | 0.100 | torch.Size([120]) || stage6.residual_group1.blocks.0.norm1.bias
+ | 0.001 | -0.438 | 0.141 | 0.054 | torch.Size([675, 6]) || stage6.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.0.attn.position_bias
+ | 0.000 | -0.339 | 0.306 | 0.051 | torch.Size([360, 120]) || stage6.residual_group1.blocks.0.attn.qkv_self.weight
+ | -0.005 | -0.318 | 0.257 | 0.059 | torch.Size([360]) || stage6.residual_group1.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.473 | 0.491 | 0.061 | torch.Size([120, 240]) || stage6.residual_group1.blocks.0.attn.proj.weight
+ | -0.001 | -0.330 | 0.253 | 0.125 | torch.Size([120]) || stage6.residual_group1.blocks.0.attn.proj.bias
+ | 0.000 | -0.361 | 0.307 | 0.045 | torch.Size([360, 120]) || stage6.residual_group1.blocks.0.attn.qkv_mut.weight
+ | -0.000 | -0.044 | 0.053 | 0.010 | torch.Size([360]) || stage6.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.521 | 0.121 | 0.882 | 0.143 | torch.Size([120]) || stage6.residual_group1.blocks.0.norm2.weight
+ | 0.003 | -0.212 | 0.271 | 0.104 | torch.Size([120]) || stage6.residual_group1.blocks.0.norm2.bias
+ | -0.000 | -0.360 | 0.360 | 0.075 | torch.Size([240, 120]) || stage6.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.095 | -0.280 | 0.021 | 0.059 | torch.Size([240]) || stage6.residual_group1.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.354 | 0.331 | 0.069 | torch.Size([240, 120]) || stage6.residual_group1.blocks.0.mlp.fc12.weight
+ | -0.005 | -0.196 | 0.129 | 0.048 | torch.Size([240]) || stage6.residual_group1.blocks.0.mlp.fc12.bias
+ | 0.001 | -0.486 | 0.379 | 0.080 | torch.Size([120, 240]) || stage6.residual_group1.blocks.0.mlp.fc2.weight
+ | 0.001 | -0.154 | 0.154 | 0.069 | torch.Size([120]) || stage6.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.587 | 0.200 | 0.865 | 0.122 | torch.Size([120]) || stage6.residual_group1.blocks.1.norm1.weight
+ | -0.118 | -0.374 | 0.082 | 0.089 | torch.Size([120]) || stage6.residual_group1.blocks.1.norm1.bias
+ | 0.001 | -0.423 | 0.140 | 0.050 | torch.Size([675, 6]) || stage6.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.1.attn.position_bias
+ | 0.000 | -0.315 | 0.354 | 0.057 | torch.Size([360, 120]) || stage6.residual_group1.blocks.1.attn.qkv_self.weight
+ | 0.001 | -0.184 | 0.148 | 0.047 | torch.Size([360]) || stage6.residual_group1.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.626 | 0.422 | 0.060 | torch.Size([120, 240]) || stage6.residual_group1.blocks.1.attn.proj.weight
+ | 0.004 | -0.234 | 0.187 | 0.087 | torch.Size([120]) || stage6.residual_group1.blocks.1.attn.proj.bias
+ | -0.000 | -0.692 | 0.743 | 0.058 | torch.Size([360, 120]) || stage6.residual_group1.blocks.1.attn.qkv_mut.weight
+ | -0.000 | -0.038 | 0.041 | 0.009 | torch.Size([360]) || stage6.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.590 | 0.287 | 0.942 | 0.125 | torch.Size([120]) || stage6.residual_group1.blocks.1.norm2.weight
+ | -0.006 | -0.196 | 0.203 | 0.076 | torch.Size([120]) || stage6.residual_group1.blocks.1.norm2.bias
+ | 0.000 | -0.427 | 0.431 | 0.075 | torch.Size([240, 120]) || stage6.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.080 | -0.242 | 0.033 | 0.053 | torch.Size([240]) || stage6.residual_group1.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.293 | 0.362 | 0.069 | torch.Size([240, 120]) || stage6.residual_group1.blocks.1.mlp.fc12.weight
+ | 0.001 | -0.171 | 0.207 | 0.047 | torch.Size([240]) || stage6.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.423 | 0.467 | 0.077 | torch.Size([120, 240]) || stage6.residual_group1.blocks.1.mlp.fc2.weight
+ | 0.000 | -0.152 | 0.184 | 0.057 | torch.Size([120]) || stage6.residual_group1.blocks.1.mlp.fc2.bias
+ | 0.703 | 0.255 | 1.008 | 0.132 | torch.Size([120]) || stage6.residual_group1.blocks.2.norm1.weight
+ | -0.125 | -0.342 | 0.042 | 0.078 | torch.Size([120]) || stage6.residual_group1.blocks.2.norm1.bias
+ | 0.000 | -0.381 | 0.350 | 0.052 | torch.Size([675, 6]) || stage6.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.2.attn.position_bias
+ | 0.000 | -0.426 | 0.500 | 0.058 | torch.Size([360, 120]) || stage6.residual_group1.blocks.2.attn.qkv_self.weight
+ | -0.003 | -0.262 | 0.226 | 0.054 | torch.Size([360]) || stage6.residual_group1.blocks.2.attn.qkv_self.bias
+ | -0.001 | -0.299 | 0.325 | 0.055 | torch.Size([120, 240]) || stage6.residual_group1.blocks.2.attn.proj.weight
+ | -0.001 | -0.149 | 0.096 | 0.061 | torch.Size([120]) || stage6.residual_group1.blocks.2.attn.proj.bias
+ | 0.000 | -0.406 | 0.391 | 0.055 | torch.Size([360, 120]) || stage6.residual_group1.blocks.2.attn.qkv_mut.weight
+ | 0.001 | -0.055 | 0.085 | 0.015 | torch.Size([360]) || stage6.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.666 | 0.308 | 0.942 | 0.118 | torch.Size([120]) || stage6.residual_group1.blocks.2.norm2.weight
+ | -0.005 | -0.203 | 0.265 | 0.086 | torch.Size([120]) || stage6.residual_group1.blocks.2.norm2.bias
+ | -0.000 | -0.349 | 0.494 | 0.072 | torch.Size([240, 120]) || stage6.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.071 | -0.213 | 0.071 | 0.053 | torch.Size([240]) || stage6.residual_group1.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.294 | 0.408 | 0.066 | torch.Size([240, 120]) || stage6.residual_group1.blocks.2.mlp.fc12.weight
+ | -0.003 | -0.120 | 0.147 | 0.049 | torch.Size([240]) || stage6.residual_group1.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.303 | 0.304 | 0.073 | torch.Size([120, 240]) || stage6.residual_group1.blocks.2.mlp.fc2.weight
+ | -0.005 | -0.150 | 0.129 | 0.063 | torch.Size([120]) || stage6.residual_group1.blocks.2.mlp.fc2.bias
+ | 0.702 | 0.307 | 0.960 | 0.129 | torch.Size([120]) || stage6.residual_group1.blocks.3.norm1.weight
+ | -0.100 | -0.262 | 0.057 | 0.070 | torch.Size([120]) || stage6.residual_group1.blocks.3.norm1.bias
+ | 0.001 | -0.501 | 0.290 | 0.062 | torch.Size([675, 6]) || stage6.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.3.attn.position_bias
+ | -0.000 | -0.349 | 0.336 | 0.061 | torch.Size([360, 120]) || stage6.residual_group1.blocks.3.attn.qkv_self.weight
+ | 0.001 | -0.287 | 0.202 | 0.053 | torch.Size([360]) || stage6.residual_group1.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.322 | 0.401 | 0.056 | torch.Size([120, 240]) || stage6.residual_group1.blocks.3.attn.proj.weight
+ | -0.004 | -0.182 | 0.151 | 0.062 | torch.Size([120]) || stage6.residual_group1.blocks.3.attn.proj.bias
+ | 0.000 | -0.441 | 0.444 | 0.054 | torch.Size([360, 120]) || stage6.residual_group1.blocks.3.attn.qkv_mut.weight
+ | 0.000 | -0.038 | 0.033 | 0.009 | torch.Size([360]) || stage6.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.666 | 0.317 | 0.970 | 0.117 | torch.Size([120]) || stage6.residual_group1.blocks.3.norm2.weight
+ | -0.003 | -0.173 | 0.168 | 0.067 | torch.Size([120]) || stage6.residual_group1.blocks.3.norm2.bias
+ | -0.000 | -0.354 | 0.408 | 0.070 | torch.Size([240, 120]) || stage6.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.072 | -0.297 | 0.067 | 0.065 | torch.Size([240]) || stage6.residual_group1.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.299 | 0.335 | 0.066 | torch.Size([240, 120]) || stage6.residual_group1.blocks.3.mlp.fc12.weight
+ | -0.004 | -0.191 | 0.136 | 0.060 | torch.Size([240]) || stage6.residual_group1.blocks.3.mlp.fc12.bias
+ | -0.000 | -0.400 | 0.590 | 0.071 | torch.Size([120, 240]) || stage6.residual_group1.blocks.3.mlp.fc2.weight
+ | -0.005 | -0.159 | 0.142 | 0.061 | torch.Size([120]) || stage6.residual_group1.blocks.3.mlp.fc2.bias
+ | 0.730 | 0.334 | 0.963 | 0.118 | torch.Size([120]) || stage6.residual_group1.blocks.4.norm1.weight
+ | -0.064 | -0.201 | 0.064 | 0.055 | torch.Size([120]) || stage6.residual_group1.blocks.4.norm1.bias
+ | -0.000 | -0.702 | 1.180 | 0.086 | torch.Size([675, 6]) || stage6.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.4.attn.position_bias
+ | -0.000 | -0.483 | 0.398 | 0.073 | torch.Size([360, 120]) || stage6.residual_group1.blocks.4.attn.qkv_self.weight
+ | 0.004 | -0.480 | 0.514 | 0.080 | torch.Size([360]) || stage6.residual_group1.blocks.4.attn.qkv_self.bias
+ | 0.000 | -0.331 | 0.390 | 0.056 | torch.Size([120, 240]) || stage6.residual_group1.blocks.4.attn.proj.weight
+ | -0.004 | -0.141 | 0.167 | 0.050 | torch.Size([120]) || stage6.residual_group1.blocks.4.attn.proj.bias
+ | 0.000 | -0.387 | 0.470 | 0.048 | torch.Size([360, 120]) || stage6.residual_group1.blocks.4.attn.qkv_mut.weight
+ | 0.001 | -0.065 | 0.039 | 0.010 | torch.Size([360]) || stage6.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.656 | 0.235 | 0.874 | 0.105 | torch.Size([120]) || stage6.residual_group1.blocks.4.norm2.weight
+ | -0.005 | -0.237 | 0.171 | 0.074 | torch.Size([120]) || stage6.residual_group1.blocks.4.norm2.bias
+ | -0.000 | -0.440 | 0.483 | 0.075 | torch.Size([240, 120]) || stage6.residual_group1.blocks.4.mlp.fc11.weight
+ | -0.076 | -0.347 | 0.110 | 0.076 | torch.Size([240]) || stage6.residual_group1.blocks.4.mlp.fc11.bias
+ | 0.000 | -0.286 | 0.348 | 0.070 | torch.Size([240, 120]) || stage6.residual_group1.blocks.4.mlp.fc12.weight
+ | 0.001 | -0.189 | 0.169 | 0.069 | torch.Size([240]) || stage6.residual_group1.blocks.4.mlp.fc12.bias
+ | 0.000 | -0.398 | 0.336 | 0.075 | torch.Size([120, 240]) || stage6.residual_group1.blocks.4.mlp.fc2.weight
+ | -0.004 | -0.127 | 0.137 | 0.052 | torch.Size([120]) || stage6.residual_group1.blocks.4.mlp.fc2.bias
+ | 0.691 | 0.178 | 0.975 | 0.116 | torch.Size([120]) || stage6.residual_group1.blocks.5.norm1.weight
+ | -0.042 | -0.137 | 0.099 | 0.037 | torch.Size([120]) || stage6.residual_group1.blocks.5.norm1.bias
+ | -0.001 | -0.662 | 1.078 | 0.078 | torch.Size([675, 6]) || stage6.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.5.attn.position_bias
+ | -0.000 | -0.359 | 0.531 | 0.072 | torch.Size([360, 120]) || stage6.residual_group1.blocks.5.attn.qkv_self.weight
+ | 0.002 | -0.293 | 0.311 | 0.075 | torch.Size([360]) || stage6.residual_group1.blocks.5.attn.qkv_self.bias
+ | 0.000 | -0.426 | 0.488 | 0.055 | torch.Size([120, 240]) || stage6.residual_group1.blocks.5.attn.proj.weight
+ | -0.006 | -0.103 | 0.159 | 0.044 | torch.Size([120]) || stage6.residual_group1.blocks.5.attn.proj.bias
+ | 0.000 | -0.401 | 0.385 | 0.044 | torch.Size([360, 120]) || stage6.residual_group1.blocks.5.attn.qkv_mut.weight
+ | 0.001 | -0.039 | 0.043 | 0.009 | torch.Size([360]) || stage6.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.607 | 0.210 | 0.802 | 0.094 | torch.Size([120]) || stage6.residual_group1.blocks.5.norm2.weight
+ | -0.004 | -0.178 | 0.199 | 0.068 | torch.Size([120]) || stage6.residual_group1.blocks.5.norm2.bias
+ | -0.000 | -0.377 | 0.541 | 0.079 | torch.Size([240, 120]) || stage6.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.069 | -0.429 | 0.280 | 0.096 | torch.Size([240]) || stage6.residual_group1.blocks.5.mlp.fc11.bias
+ | -0.000 | -0.394 | 0.344 | 0.077 | torch.Size([240, 120]) || stage6.residual_group1.blocks.5.mlp.fc12.weight
+ | 0.000 | -0.241 | 0.223 | 0.085 | torch.Size([240]) || stage6.residual_group1.blocks.5.mlp.fc12.bias
+ | -0.000 | -0.527 | 0.647 | 0.077 | torch.Size([120, 240]) || stage6.residual_group1.blocks.5.mlp.fc2.weight
+ | -0.006 | -0.126 | 0.157 | 0.047 | torch.Size([120]) || stage6.residual_group1.blocks.5.mlp.fc2.bias
+ | -0.001 | -0.294 | 0.287 | 0.060 | torch.Size([120, 120]) || stage6.linear1.weight
+ | 0.006 | -0.543 | 0.664 | 0.193 | torch.Size([120]) || stage6.linear1.bias
+ | 0.674 | 0.222 | 1.065 | 0.154 | torch.Size([120]) || stage6.residual_group2.blocks.0.norm1.weight
+ | 0.002 | -0.480 | 0.311 | 0.128 | torch.Size([120]) || stage6.residual_group2.blocks.0.norm1.bias
+ | 0.000 | -0.629 | 0.461 | 0.041 | torch.Size([3375, 6]) || stage6.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage6.residual_group2.blocks.0.attn.relative_position_index
+ | 0.000 | -0.495 | 0.440 | 0.085 | torch.Size([360, 120]) || stage6.residual_group2.blocks.0.attn.qkv_self.weight
+ | -0.001 | -0.516 | 0.468 | 0.114 | torch.Size([360]) || stage6.residual_group2.blocks.0.attn.qkv_self.bias
+ | 0.001 | -0.369 | 0.377 | 0.085 | torch.Size([120, 120]) || stage6.residual_group2.blocks.0.attn.proj.weight
+ | -0.003 | -0.297 | 0.292 | 0.113 | torch.Size([120]) || stage6.residual_group2.blocks.0.attn.proj.bias
+ | 0.644 | 0.181 | 1.104 | 0.153 | torch.Size([120]) || stage6.residual_group2.blocks.0.norm2.weight
+ | 0.003 | -0.167 | 0.185 | 0.070 | torch.Size([120]) || stage6.residual_group2.blocks.0.norm2.bias
+ | -0.000 | -0.383 | 0.534 | 0.087 | torch.Size([240, 120]) || stage6.residual_group2.blocks.0.mlp.fc11.weight
+ | -0.101 | -0.214 | 0.048 | 0.051 | torch.Size([240]) || stage6.residual_group2.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.350 | 0.560 | 0.085 | torch.Size([240, 120]) || stage6.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.005 | -0.159 | 0.138 | 0.047 | torch.Size([240]) || stage6.residual_group2.blocks.0.mlp.fc12.bias
+ | -0.001 | -0.374 | 0.488 | 0.091 | torch.Size([120, 240]) || stage6.residual_group2.blocks.0.mlp.fc2.weight
+ | -0.006 | -0.271 | 0.252 | 0.096 | torch.Size([120]) || stage6.residual_group2.blocks.0.mlp.fc2.bias
+ | 0.663 | 0.353 | 0.959 | 0.106 | torch.Size([120]) || stage6.residual_group2.blocks.1.norm1.weight
+ | 0.001 | -0.314 | 0.289 | 0.089 | torch.Size([120]) || stage6.residual_group2.blocks.1.norm1.bias
+ | 0.000 | -0.772 | 0.763 | 0.041 | torch.Size([3375, 6]) || stage6.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage6.residual_group2.blocks.1.attn.relative_position_index
+ | -0.000 | -0.495 | 0.604 | 0.086 | torch.Size([360, 120]) || stage6.residual_group2.blocks.1.attn.qkv_self.weight
+ | 0.005 | -0.491 | 0.401 | 0.097 | torch.Size([360]) || stage6.residual_group2.blocks.1.attn.qkv_self.bias
+ | 0.001 | -0.380 | 0.376 | 0.076 | torch.Size([120, 120]) || stage6.residual_group2.blocks.1.attn.proj.weight
+ | -0.007 | -0.321 | 0.234 | 0.096 | torch.Size([120]) || stage6.residual_group2.blocks.1.attn.proj.bias
+ | 0.666 | 0.226 | 1.153 | 0.138 | torch.Size([120]) || stage6.residual_group2.blocks.1.norm2.weight
+ | 0.001 | -0.178 | 0.220 | 0.069 | torch.Size([120]) || stage6.residual_group2.blocks.1.norm2.bias
+ | 0.000 | -0.514 | 0.608 | 0.090 | torch.Size([240, 120]) || stage6.residual_group2.blocks.1.mlp.fc11.weight
+ | -0.132 | -0.313 | 0.023 | 0.059 | torch.Size([240]) || stage6.residual_group2.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.423 | 0.488 | 0.088 | torch.Size([240, 120]) || stage6.residual_group2.blocks.1.mlp.fc12.weight
+ | -0.002 | -0.153 | 0.122 | 0.053 | torch.Size([240]) || stage6.residual_group2.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.399 | 0.435 | 0.087 | torch.Size([120, 240]) || stage6.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.001 | -0.285 | 0.241 | 0.093 | torch.Size([120]) || stage6.residual_group2.blocks.1.mlp.fc2.bias
+ | 0.000 | -0.308 | 0.365 | 0.070 | torch.Size([120, 120]) || stage6.linear2.weight
+ | -0.002 | -0.699 | 0.757 | 0.303 | torch.Size([120]) || stage6.linear2.bias
+ | 0.000 | -0.130 | 0.129 | 0.027 | torch.Size([120, 120, 3, 3]) || stage6.pa_deform.weight
+ | -0.001 | -0.051 | 0.045 | 0.018 | torch.Size([120]) || stage6.pa_deform.bias
+ | 0.000 | -0.017 | 0.017 | 0.010 | torch.Size([120, 364, 3, 3]) || stage6.pa_deform.conv_offset.0.weight
+ | -0.007 | -0.049 | 0.026 | 0.012 | torch.Size([120]) || stage6.pa_deform.conv_offset.0.bias
+ | -0.001 | -0.090 | 0.114 | 0.020 | torch.Size([120, 120, 3, 3]) || stage6.pa_deform.conv_offset.2.weight
+ | -0.008 | -0.070 | 0.060 | 0.030 | torch.Size([120]) || stage6.pa_deform.conv_offset.2.bias
+ | -0.001 | -0.097 | 0.101 | 0.020 | torch.Size([120, 120, 3, 3]) || stage6.pa_deform.conv_offset.4.weight
+ | 0.006 | -0.096 | 0.114 | 0.044 | torch.Size([120]) || stage6.pa_deform.conv_offset.4.bias
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432, 120, 3, 3]) || stage6.pa_deform.conv_offset.6.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432]) || stage6.pa_deform.conv_offset.6.bias
+ | -0.002 | -0.822 | 0.740 | 0.127 | torch.Size([360, 360]) || stage6.pa_fuse.fc11.weight
+ | 0.212 | -0.394 | 0.913 | 0.216 | torch.Size([360]) || stage6.pa_fuse.fc11.bias
+ | -0.000 | -0.948 | 0.848 | 0.131 | torch.Size([360, 360]) || stage6.pa_fuse.fc12.weight
+ | 0.001 | -0.657 | 0.605 | 0.279 | torch.Size([360]) || stage6.pa_fuse.fc12.bias
+ | -0.000 | -0.678 | 0.823 | 0.158 | torch.Size([120, 360]) || stage6.pa_fuse.fc2.weight
+ | 0.009 | -0.616 | 0.477 | 0.283 | torch.Size([120]) || stage6.pa_fuse.fc2.bias
+ | 1.363 | 1.278 | 1.458 | 0.048 | torch.Size([30]) || stage7.reshape.1.weight
+ | -0.001 | -0.247 | 0.227 | 0.139 | torch.Size([30]) || stage7.reshape.1.bias
+ | -0.000 | -0.590 | 0.587 | 0.179 | torch.Size([120, 30]) || stage7.reshape.2.weight
+ | -0.029 | -0.525 | 0.546 | 0.231 | torch.Size([120]) || stage7.reshape.2.bias
+ | 0.406 | 0.101 | 0.864 | 0.138 | torch.Size([120]) || stage7.residual_group1.blocks.0.norm1.weight
+ | -0.159 | -0.667 | 0.525 | 0.161 | torch.Size([120]) || stage7.residual_group1.blocks.0.norm1.bias
+ | -0.174 | -2.385 | 4.798 | 0.381 | torch.Size([675, 6]) || stage7.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.0.attn.position_bias
+ | -0.000 | -0.809 | 0.687 | 0.111 | torch.Size([360, 120]) || stage7.residual_group1.blocks.0.attn.qkv_self.weight
+ | 0.001 | -0.275 | 0.262 | 0.057 | torch.Size([360]) || stage7.residual_group1.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.416 | 0.438 | 0.096 | torch.Size([120, 240]) || stage7.residual_group1.blocks.0.attn.proj.weight
+ | 0.008 | -0.499 | 0.295 | 0.131 | torch.Size([120]) || stage7.residual_group1.blocks.0.attn.proj.bias
+ | -0.000 | -1.494 | 1.378 | 0.106 | torch.Size([360, 120]) || stage7.residual_group1.blocks.0.attn.qkv_mut.weight
+ | -0.000 | -0.123 | 0.106 | 0.015 | torch.Size([360]) || stage7.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.284 | 0.172 | 0.377 | 0.040 | torch.Size([120]) || stage7.residual_group1.blocks.0.norm2.weight
+ | -0.003 | -0.502 | 0.588 | 0.124 | torch.Size([120]) || stage7.residual_group1.blocks.0.norm2.bias
+ | 0.000 | -0.597 | 0.567 | 0.132 | torch.Size([240, 120]) || stage7.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.061 | -0.420 | 0.409 | 0.104 | torch.Size([240]) || stage7.residual_group1.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.606 | 0.601 | 0.144 | torch.Size([240, 120]) || stage7.residual_group1.blocks.0.mlp.fc12.weight
+ | -0.003 | -0.306 | 0.261 | 0.101 | torch.Size([240]) || stage7.residual_group1.blocks.0.mlp.fc12.bias
+ | -0.001 | -0.572 | 0.609 | 0.149 | torch.Size([120, 240]) || stage7.residual_group1.blocks.0.mlp.fc2.weight
+ | -0.008 | -0.373 | 0.306 | 0.099 | torch.Size([120]) || stage7.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.538 | 0.114 | 0.809 | 0.125 | torch.Size([120]) || stage7.residual_group1.blocks.1.norm1.weight
+ | -0.129 | -0.865 | 0.532 | 0.163 | torch.Size([120]) || stage7.residual_group1.blocks.1.norm1.bias
+ | -0.281 | -2.710 | 4.413 | 0.432 | torch.Size([675, 6]) || stage7.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.1.attn.position_bias
+ | 0.000 | -0.646 | 0.655 | 0.135 | torch.Size([360, 120]) || stage7.residual_group1.blocks.1.attn.qkv_self.weight
+ | -0.000 | -0.301 | 0.303 | 0.068 | torch.Size([360]) || stage7.residual_group1.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.479 | 0.463 | 0.100 | torch.Size([120, 240]) || stage7.residual_group1.blocks.1.attn.proj.weight
+ | 0.016 | -0.460 | 0.313 | 0.135 | torch.Size([120]) || stage7.residual_group1.blocks.1.attn.proj.bias
+ | 0.000 | -2.205 | 2.065 | 0.127 | torch.Size([360, 120]) || stage7.residual_group1.blocks.1.attn.qkv_mut.weight
+ | -0.000 | -0.074 | 0.085 | 0.017 | torch.Size([360]) || stage7.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.353 | 0.243 | 0.425 | 0.034 | torch.Size([120]) || stage7.residual_group1.blocks.1.norm2.weight
+ | -0.008 | -0.643 | 0.628 | 0.146 | torch.Size([120]) || stage7.residual_group1.blocks.1.norm2.bias
+ | 0.000 | -0.535 | 0.617 | 0.135 | torch.Size([240, 120]) || stage7.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.054 | -0.348 | 0.244 | 0.109 | torch.Size([240]) || stage7.residual_group1.blocks.1.mlp.fc11.bias
+ | -0.001 | -0.671 | 0.611 | 0.148 | torch.Size([240, 120]) || stage7.residual_group1.blocks.1.mlp.fc12.weight
+ | 0.004 | -0.272 | 0.292 | 0.098 | torch.Size([240]) || stage7.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.672 | 0.595 | 0.149 | torch.Size([120, 240]) || stage7.residual_group1.blocks.1.mlp.fc2.weight
+ | -0.003 | -0.398 | 0.273 | 0.088 | torch.Size([120]) || stage7.residual_group1.blocks.1.mlp.fc2.bias
+ | 0.581 | 0.093 | 0.791 | 0.147 | torch.Size([120]) || stage7.residual_group1.blocks.2.norm1.weight
+ | -0.143 | -1.023 | 0.481 | 0.167 | torch.Size([120]) || stage7.residual_group1.blocks.2.norm1.bias
+ | -0.098 | -2.171 | 4.402 | 0.287 | torch.Size([675, 6]) || stage7.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.2.attn.position_bias
+ | 0.000 | -0.640 | 0.701 | 0.147 | torch.Size([360, 120]) || stage7.residual_group1.blocks.2.attn.qkv_self.weight
+ | -0.005 | -0.328 | 0.408 | 0.072 | torch.Size([360]) || stage7.residual_group1.blocks.2.attn.qkv_self.bias
+ | -0.001 | -0.417 | 0.441 | 0.101 | torch.Size([120, 240]) || stage7.residual_group1.blocks.2.attn.proj.weight
+ | 0.007 | -0.508 | 0.265 | 0.127 | torch.Size([120]) || stage7.residual_group1.blocks.2.attn.proj.bias
+ | -0.001 | -2.511 | 2.484 | 0.143 | torch.Size([360, 120]) || stage7.residual_group1.blocks.2.attn.qkv_mut.weight
+ | -0.000 | -0.093 | 0.104 | 0.019 | torch.Size([360]) || stage7.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.392 | 0.276 | 0.487 | 0.034 | torch.Size([120]) || stage7.residual_group1.blocks.2.norm2.weight
+ | -0.016 | -0.555 | 0.581 | 0.143 | torch.Size([120]) || stage7.residual_group1.blocks.2.norm2.bias
+ | -0.000 | -0.630 | 0.674 | 0.135 | torch.Size([240, 120]) || stage7.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.072 | -0.420 | 0.173 | 0.115 | torch.Size([240]) || stage7.residual_group1.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.654 | 0.793 | 0.152 | torch.Size([240, 120]) || stage7.residual_group1.blocks.2.mlp.fc12.weight
+ | -0.003 | -0.303 | 0.263 | 0.098 | torch.Size([240]) || stage7.residual_group1.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.603 | 0.658 | 0.150 | torch.Size([120, 240]) || stage7.residual_group1.blocks.2.mlp.fc2.weight
+ | 0.003 | -0.301 | 0.247 | 0.081 | torch.Size([120]) || stage7.residual_group1.blocks.2.mlp.fc2.bias
+ | 0.611 | 0.127 | 0.811 | 0.134 | torch.Size([120]) || stage7.residual_group1.blocks.3.norm1.weight
+ | -0.137 | -0.781 | 0.684 | 0.164 | torch.Size([120]) || stage7.residual_group1.blocks.3.norm1.bias
+ | -0.109 | -4.577 | 4.527 | 0.332 | torch.Size([675, 6]) || stage7.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.3.attn.position_bias
+ | 0.000 | -0.757 | 0.743 | 0.146 | torch.Size([360, 120]) || stage7.residual_group1.blocks.3.attn.qkv_self.weight
+ | 0.001 | -0.358 | 0.342 | 0.083 | torch.Size([360]) || stage7.residual_group1.blocks.3.attn.qkv_self.bias
+ | 0.001 | -0.465 | 0.447 | 0.097 | torch.Size([120, 240]) || stage7.residual_group1.blocks.3.attn.proj.weight
+ | 0.002 | -0.389 | 0.233 | 0.113 | torch.Size([120]) || stage7.residual_group1.blocks.3.attn.proj.bias
+ | -0.001 | -1.947 | 1.928 | 0.127 | torch.Size([360, 120]) || stage7.residual_group1.blocks.3.attn.qkv_mut.weight
+ | 0.000 | -0.106 | 0.070 | 0.018 | torch.Size([360]) || stage7.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.410 | 0.283 | 0.489 | 0.035 | torch.Size([120]) || stage7.residual_group1.blocks.3.norm2.weight
+ | -0.014 | -0.442 | 0.639 | 0.147 | torch.Size([120]) || stage7.residual_group1.blocks.3.norm2.bias
+ | -0.000 | -0.542 | 0.585 | 0.132 | torch.Size([240, 120]) || stage7.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.069 | -0.463 | 0.214 | 0.122 | torch.Size([240]) || stage7.residual_group1.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.689 | 0.605 | 0.154 | torch.Size([240, 120]) || stage7.residual_group1.blocks.3.mlp.fc12.weight
+ | -0.008 | -0.307 | 0.279 | 0.096 | torch.Size([240]) || stage7.residual_group1.blocks.3.mlp.fc12.bias
+ | -0.000 | -0.593 | 0.603 | 0.152 | torch.Size([120, 240]) || stage7.residual_group1.blocks.3.mlp.fc2.weight
+ | 0.010 | -0.269 | 0.270 | 0.094 | torch.Size([120]) || stage7.residual_group1.blocks.3.mlp.fc2.bias
+ | 0.652 | 0.132 | 0.859 | 0.133 | torch.Size([120]) || stage7.residual_group1.blocks.4.norm1.weight
+ | -0.131 | -0.662 | 0.729 | 0.163 | torch.Size([120]) || stage7.residual_group1.blocks.4.norm1.bias
+ | -0.092 | -4.521 | 3.027 | 0.337 | torch.Size([675, 6]) || stage7.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.4.attn.position_bias
+ | -0.000 | -0.694 | 0.828 | 0.148 | torch.Size([360, 120]) || stage7.residual_group1.blocks.4.attn.qkv_self.weight
+ | 0.002 | -0.328 | 0.361 | 0.078 | torch.Size([360]) || stage7.residual_group1.blocks.4.attn.qkv_self.bias
+ | 0.000 | -0.430 | 0.483 | 0.100 | torch.Size([120, 240]) || stage7.residual_group1.blocks.4.attn.proj.weight
+ | -0.003 | -0.368 | 0.250 | 0.103 | torch.Size([120]) || stage7.residual_group1.blocks.4.attn.proj.bias
+ | -0.000 | -1.506 | 1.779 | 0.122 | torch.Size([360, 120]) || stage7.residual_group1.blocks.4.attn.qkv_mut.weight
+ | 0.000 | -0.090 | 0.112 | 0.020 | torch.Size([360]) || stage7.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.435 | 0.347 | 0.536 | 0.033 | torch.Size([120]) || stage7.residual_group1.blocks.4.norm2.weight
+ | -0.018 | -0.345 | 0.609 | 0.136 | torch.Size([120]) || stage7.residual_group1.blocks.4.norm2.bias
+ | -0.001 | -0.580 | 0.558 | 0.132 | torch.Size([240, 120]) || stage7.residual_group1.blocks.4.mlp.fc11.weight
+ | -0.066 | -0.392 | 0.239 | 0.128 | torch.Size([240]) || stage7.residual_group1.blocks.4.mlp.fc11.bias
+ | -0.000 | -0.608 | 0.667 | 0.157 | torch.Size([240, 120]) || stage7.residual_group1.blocks.4.mlp.fc12.weight
+ | -0.001 | -0.276 | 0.296 | 0.105 | torch.Size([240]) || stage7.residual_group1.blocks.4.mlp.fc12.bias
+ | 0.000 | -0.666 | 0.775 | 0.155 | torch.Size([120, 240]) || stage7.residual_group1.blocks.4.mlp.fc2.weight
+ | 0.001 | -0.380 | 0.360 | 0.101 | torch.Size([120]) || stage7.residual_group1.blocks.4.mlp.fc2.bias
+ | 0.648 | 0.269 | 0.885 | 0.109 | torch.Size([120]) || stage7.residual_group1.blocks.5.norm1.weight
+ | -0.116 | -0.436 | 0.749 | 0.144 | torch.Size([120]) || stage7.residual_group1.blocks.5.norm1.bias
+ | -0.130 | -3.976 | 4.665 | 0.318 | torch.Size([675, 6]) || stage7.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.5.attn.position_bias
+ | -0.000 | -0.702 | 0.671 | 0.140 | torch.Size([360, 120]) || stage7.residual_group1.blocks.5.attn.qkv_self.weight
+ | 0.000 | -0.346 | 0.340 | 0.078 | torch.Size([360]) || stage7.residual_group1.blocks.5.attn.qkv_self.bias
+ | -0.000 | -0.410 | 0.394 | 0.091 | torch.Size([120, 240]) || stage7.residual_group1.blocks.5.attn.proj.weight
+ | 0.006 | -0.286 | 0.244 | 0.100 | torch.Size([120]) || stage7.residual_group1.blocks.5.attn.proj.bias
+ | 0.001 | -0.870 | 0.885 | 0.109 | torch.Size([360, 120]) || stage7.residual_group1.blocks.5.attn.qkv_mut.weight
+ | 0.001 | -0.120 | 0.096 | 0.018 | torch.Size([360]) || stage7.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.445 | 0.326 | 0.595 | 0.034 | torch.Size([120]) || stage7.residual_group1.blocks.5.norm2.weight
+ | -0.016 | -0.233 | 0.558 | 0.110 | torch.Size([120]) || stage7.residual_group1.blocks.5.norm2.bias
+ | -0.001 | -0.576 | 0.577 | 0.129 | torch.Size([240, 120]) || stage7.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.038 | -0.525 | 0.269 | 0.139 | torch.Size([240]) || stage7.residual_group1.blocks.5.mlp.fc11.bias
+ | -0.000 | -0.672 | 0.671 | 0.158 | torch.Size([240, 120]) || stage7.residual_group1.blocks.5.mlp.fc12.weight
+ | 0.003 | -0.400 | 0.281 | 0.116 | torch.Size([240]) || stage7.residual_group1.blocks.5.mlp.fc12.bias
+ | 0.000 | -0.937 | 0.714 | 0.156 | torch.Size([120, 240]) || stage7.residual_group1.blocks.5.mlp.fc2.weight
+ | 0.007 | -0.435 | 0.876 | 0.188 | torch.Size([120]) || stage7.residual_group1.blocks.5.mlp.fc2.bias
+ | -0.000 | -0.234 | 0.212 | 0.056 | torch.Size([120, 120]) || stage7.linear1.weight
+ | -0.033 | -0.655 | 0.586 | 0.242 | torch.Size([120]) || stage7.linear1.bias
+ | 0.684 | 0.257 | 0.867 | 0.090 | torch.Size([120]) || stage7.residual_group2.blocks.0.norm1.weight
+ | -0.003 | -0.857 | 0.829 | 0.193 | torch.Size([120]) || stage7.residual_group2.blocks.0.norm1.bias
+ | -0.005 | -5.628 | 1.358 | 0.121 | torch.Size([3375, 6]) || stage7.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage7.residual_group2.blocks.0.attn.relative_position_index
+ | 0.000 | -0.699 | 0.827 | 0.137 | torch.Size([360, 120]) || stage7.residual_group2.blocks.0.attn.qkv_self.weight
+ | 0.001 | -0.821 | 0.662 | 0.143 | torch.Size([360]) || stage7.residual_group2.blocks.0.attn.qkv_self.bias
+ | 0.001 | -0.392 | 0.418 | 0.106 | torch.Size([120, 120]) || stage7.residual_group2.blocks.0.attn.proj.weight
+ | 0.003 | -0.147 | 0.171 | 0.052 | torch.Size([120]) || stage7.residual_group2.blocks.0.attn.proj.bias
+ | 0.431 | 0.316 | 0.521 | 0.036 | torch.Size([120]) || stage7.residual_group2.blocks.0.norm2.weight
+ | -0.003 | -0.595 | 0.673 | 0.129 | torch.Size([120]) || stage7.residual_group2.blocks.0.norm2.bias
+ | -0.000 | -0.701 | 0.542 | 0.119 | torch.Size([240, 120]) || stage7.residual_group2.blocks.0.mlp.fc11.weight
+ | 0.017 | -0.290 | 0.421 | 0.117 | torch.Size([240]) || stage7.residual_group2.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.603 | 0.637 | 0.145 | torch.Size([240, 120]) || stage7.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.006 | -0.394 | 0.426 | 0.098 | torch.Size([240]) || stage7.residual_group2.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.602 | 0.607 | 0.144 | torch.Size([120, 240]) || stage7.residual_group2.blocks.0.mlp.fc2.weight
+ | -0.003 | -0.460 | 0.272 | 0.112 | torch.Size([120]) || stage7.residual_group2.blocks.0.mlp.fc2.bias
+ | 0.655 | 0.251 | 0.779 | 0.074 | torch.Size([120]) || stage7.residual_group2.blocks.1.norm1.weight
+ | -0.004 | -0.718 | 0.811 | 0.153 | torch.Size([120]) || stage7.residual_group2.blocks.1.norm1.bias
+ | -0.007 | -3.104 | 1.224 | 0.101 | torch.Size([3375, 6]) || stage7.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage7.residual_group2.blocks.1.attn.relative_position_index
+ | -0.000 | -0.664 | 0.647 | 0.137 | torch.Size([360, 120]) || stage7.residual_group2.blocks.1.attn.qkv_self.weight
+ | 0.002 | -0.532 | 0.746 | 0.150 | torch.Size([360]) || stage7.residual_group2.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.428 | 0.360 | 0.100 | torch.Size([120, 120]) || stage7.residual_group2.blocks.1.attn.proj.weight
+ | 0.009 | -0.244 | 0.242 | 0.063 | torch.Size([120]) || stage7.residual_group2.blocks.1.attn.proj.bias
+ | 0.442 | 0.284 | 0.530 | 0.038 | torch.Size([120]) || stage7.residual_group2.blocks.1.norm2.weight
+ | -0.004 | -0.421 | 0.664 | 0.106 | torch.Size([120]) || stage7.residual_group2.blocks.1.norm2.bias
+ | -0.001 | -0.604 | 0.583 | 0.119 | torch.Size([240, 120]) || stage7.residual_group2.blocks.1.mlp.fc11.weight
+ | 0.028 | -0.389 | 0.406 | 0.134 | torch.Size([240]) || stage7.residual_group2.blocks.1.mlp.fc11.bias
+ | -0.001 | -0.681 | 0.818 | 0.148 | torch.Size([240, 120]) || stage7.residual_group2.blocks.1.mlp.fc12.weight
+ | 0.003 | -0.247 | 0.361 | 0.096 | torch.Size([240]) || stage7.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.783 | 0.835 | 0.146 | torch.Size([120, 240]) || stage7.residual_group2.blocks.1.mlp.fc2.weight
+ | 0.008 | -0.529 | 0.922 | 0.144 | torch.Size([120]) || stage7.residual_group2.blocks.1.mlp.fc2.bias
+ | -0.001 | -0.353 | 0.277 | 0.071 | torch.Size([120, 120]) || stage7.linear2.weight
+ | -0.026 | -0.905 | 0.749 | 0.262 | torch.Size([120]) || stage7.linear2.bias
+ | -0.000 | -0.125 | 0.138 | 0.027 | torch.Size([120, 120, 3, 3]) || stage7.pa_deform.weight
+ | -0.003 | -0.091 | 0.071 | 0.030 | torch.Size([120]) || stage7.pa_deform.bias
+ | 0.000 | -0.017 | 0.017 | 0.010 | torch.Size([120, 364, 3, 3]) || stage7.pa_deform.conv_offset.0.weight
+ | -0.000 | -0.028 | 0.054 | 0.015 | torch.Size([120]) || stage7.pa_deform.conv_offset.0.bias
+ | -0.001 | -0.130 | 0.111 | 0.017 | torch.Size([120, 120, 3, 3]) || stage7.pa_deform.conv_offset.2.weight
+ | -0.004 | -0.105 | 0.094 | 0.040 | torch.Size([120]) || stage7.pa_deform.conv_offset.2.bias
+ | -0.002 | -0.203 | 0.124 | 0.016 | torch.Size([120, 120, 3, 3]) || stage7.pa_deform.conv_offset.4.weight
+ | 0.027 | -0.097 | 0.151 | 0.048 | torch.Size([120]) || stage7.pa_deform.conv_offset.4.bias
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432, 120, 3, 3]) || stage7.pa_deform.conv_offset.6.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432]) || stage7.pa_deform.conv_offset.6.bias
+ | -0.002 | -0.997 | 1.031 | 0.156 | torch.Size([360, 360]) || stage7.pa_fuse.fc11.weight
+ | 0.219 | -0.261 | 0.769 | 0.213 | torch.Size([360]) || stage7.pa_fuse.fc11.bias
+ | 0.001 | -1.119 | 1.206 | 0.175 | torch.Size([360, 360]) || stage7.pa_fuse.fc12.weight
+ | -0.011 | -0.547 | 0.598 | 0.195 | torch.Size([360]) || stage7.pa_fuse.fc12.bias
+ | 0.000 | -0.860 | 0.957 | 0.160 | torch.Size([120, 360]) || stage7.pa_fuse.fc2.weight
+ | 0.018 | -1.017 | 0.731 | 0.363 | torch.Size([120]) || stage7.pa_fuse.fc2.bias
+ | 1.491 | 1.080 | 1.847 | 0.135 | torch.Size([120]) || stage8.0.1.weight
+ | -0.012 | -0.370 | 0.414 | 0.140 | torch.Size([120]) || stage8.0.1.bias
+ | -0.000 | -0.882 | 1.114 | 0.177 | torch.Size([180, 120]) || stage8.0.2.weight
+ | -0.005 | -1.101 | 0.699 | 0.167 | torch.Size([180]) || stage8.0.2.bias
+ | 0.622 | 0.186 | 1.009 | 0.188 | torch.Size([180]) || stage8.1.residual_group.blocks.0.norm1.weight
+ | -0.006 | -0.884 | 1.056 | 0.212 | torch.Size([180]) || stage8.1.residual_group.blocks.0.norm1.bias
+ | -0.003 | -2.578 | 2.238 | 0.223 | torch.Size([3375, 6]) || stage8.1.residual_group.blocks.0.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.1.residual_group.blocks.0.attn.relative_position_index
+ | 0.000 | -1.042 | 1.335 | 0.152 | torch.Size([540, 180]) || stage8.1.residual_group.blocks.0.attn.qkv_self.weight
+ | -0.007 | -0.992 | 0.938 | 0.208 | torch.Size([540]) || stage8.1.residual_group.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.692 | 0.565 | 0.129 | torch.Size([180, 180]) || stage8.1.residual_group.blocks.0.attn.proj.weight
+ | 0.009 | -1.288 | 0.895 | 0.185 | torch.Size([180]) || stage8.1.residual_group.blocks.0.attn.proj.bias
+ | 0.415 | 0.180 | 0.539 | 0.066 | torch.Size([180]) || stage8.1.residual_group.blocks.0.norm2.weight
+ | -0.006 | -0.634 | 0.818 | 0.145 | torch.Size([180]) || stage8.1.residual_group.blocks.0.norm2.bias
+ | 0.001 | -0.969 | 0.867 | 0.145 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.0.mlp.fc11.weight
+ | -0.055 | -0.545 | 0.271 | 0.110 | torch.Size([360]) || stage8.1.residual_group.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.698 | 0.845 | 0.153 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.0.mlp.fc12.weight
+ | 0.007 | -0.526 | 0.444 | 0.126 | torch.Size([360]) || stage8.1.residual_group.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.812 | 0.874 | 0.155 | torch.Size([180, 360]) || stage8.1.residual_group.blocks.0.mlp.fc2.weight
+ | 0.009 | -0.468 | 0.864 | 0.160 | torch.Size([180]) || stage8.1.residual_group.blocks.0.mlp.fc2.bias
+ | 0.724 | 0.198 | 0.915 | 0.128 | torch.Size([180]) || stage8.1.residual_group.blocks.1.norm1.weight
+ | -0.003 | -1.026 | 0.953 | 0.209 | torch.Size([180]) || stage8.1.residual_group.blocks.1.norm1.bias
+ | 0.030 | -3.042 | 1.112 | 0.227 | torch.Size([3375, 6]) || stage8.1.residual_group.blocks.1.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.1.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -1.192 | 0.952 | 0.169 | torch.Size([540, 180]) || stage8.1.residual_group.blocks.1.attn.qkv_self.weight
+ | -0.009 | -1.186 | 0.822 | 0.191 | torch.Size([540]) || stage8.1.residual_group.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.500 | 0.647 | 0.121 | torch.Size([180, 180]) || stage8.1.residual_group.blocks.1.attn.proj.weight
+ | 0.004 | -0.892 | 1.020 | 0.208 | torch.Size([180]) || stage8.1.residual_group.blocks.1.attn.proj.bias
+ | 0.492 | 0.230 | 0.628 | 0.064 | torch.Size([180]) || stage8.1.residual_group.blocks.1.norm2.weight
+ | -0.006 | -0.853 | 0.872 | 0.165 | torch.Size([180]) || stage8.1.residual_group.blocks.1.norm2.bias
+ | 0.001 | -0.748 | 0.701 | 0.150 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.1.mlp.fc11.weight
+ | -0.055 | -0.409 | 0.305 | 0.096 | torch.Size([360]) || stage8.1.residual_group.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.806 | 0.662 | 0.155 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.1.mlp.fc12.weight
+ | 0.001 | -0.304 | 0.419 | 0.096 | torch.Size([360]) || stage8.1.residual_group.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.841 | 0.781 | 0.154 | torch.Size([180, 360]) || stage8.1.residual_group.blocks.1.mlp.fc2.weight
+ | 0.005 | -0.280 | 0.641 | 0.119 | torch.Size([180]) || stage8.1.residual_group.blocks.1.mlp.fc2.bias
+ | 0.803 | 0.314 | 1.038 | 0.110 | torch.Size([180]) || stage8.1.residual_group.blocks.2.norm1.weight
+ | -0.006 | -1.202 | 1.119 | 0.207 | torch.Size([180]) || stage8.1.residual_group.blocks.2.norm1.bias
+ | -0.002 | -2.783 | 1.481 | 0.236 | torch.Size([3375, 6]) || stage8.1.residual_group.blocks.2.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.1.residual_group.blocks.2.attn.relative_position_index
+ | 0.000 | -0.957 | 0.943 | 0.162 | torch.Size([540, 180]) || stage8.1.residual_group.blocks.2.attn.qkv_self.weight
+ | 0.002 | -0.519 | 0.526 | 0.136 | torch.Size([540]) || stage8.1.residual_group.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.543 | 0.516 | 0.117 | torch.Size([180, 180]) || stage8.1.residual_group.blocks.2.attn.proj.weight
+ | 0.005 | -0.711 | 0.838 | 0.184 | torch.Size([180]) || stage8.1.residual_group.blocks.2.attn.proj.bias
+ | 0.549 | 0.206 | 0.679 | 0.078 | torch.Size([180]) || stage8.1.residual_group.blocks.2.norm2.weight
+ | -0.005 | -0.888 | 0.879 | 0.154 | torch.Size([180]) || stage8.1.residual_group.blocks.2.norm2.bias
+ | 0.000 | -0.748 | 0.896 | 0.148 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.2.mlp.fc11.weight
+ | -0.073 | -0.478 | 0.193 | 0.098 | torch.Size([360]) || stage8.1.residual_group.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.628 | 0.674 | 0.157 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.2.mlp.fc12.weight
+ | -0.001 | -0.331 | 0.230 | 0.082 | torch.Size([360]) || stage8.1.residual_group.blocks.2.mlp.fc12.bias
+ | 0.001 | -0.677 | 0.673 | 0.154 | torch.Size([180, 360]) || stage8.1.residual_group.blocks.2.mlp.fc2.weight
+ | 0.004 | -0.294 | 0.745 | 0.112 | torch.Size([180]) || stage8.1.residual_group.blocks.2.mlp.fc2.bias
+ | 0.843 | 0.308 | 0.966 | 0.094 | torch.Size([180]) || stage8.1.residual_group.blocks.3.norm1.weight
+ | -0.002 | -1.222 | 1.324 | 0.192 | torch.Size([180]) || stage8.1.residual_group.blocks.3.norm1.bias
+ | 0.001 | -2.899 | 2.240 | 0.272 | torch.Size([3375, 6]) || stage8.1.residual_group.blocks.3.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.1.residual_group.blocks.3.attn.relative_position_index
+ | -0.000 | -0.999 | 0.935 | 0.167 | torch.Size([540, 180]) || stage8.1.residual_group.blocks.3.attn.qkv_self.weight
+ | -0.001 | -0.612 | 0.531 | 0.127 | torch.Size([540]) || stage8.1.residual_group.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.591 | 0.537 | 0.112 | torch.Size([180, 180]) || stage8.1.residual_group.blocks.3.attn.proj.weight
+ | -0.005 | -0.476 | 1.034 | 0.188 | torch.Size([180]) || stage8.1.residual_group.blocks.3.attn.proj.bias
+ | 0.534 | 0.198 | 0.660 | 0.074 | torch.Size([180]) || stage8.1.residual_group.blocks.3.norm2.weight
+ | -0.006 | -0.845 | 0.869 | 0.130 | torch.Size([180]) || stage8.1.residual_group.blocks.3.norm2.bias
+ | 0.001 | -0.649 | 0.677 | 0.147 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.3.mlp.fc11.weight
+ | -0.080 | -0.378 | 0.228 | 0.109 | torch.Size([360]) || stage8.1.residual_group.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.628 | 0.683 | 0.157 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.3.mlp.fc12.weight
+ | -0.005 | -0.300 | 0.222 | 0.083 | torch.Size([360]) || stage8.1.residual_group.blocks.3.mlp.fc12.bias
+ | 0.001 | -0.959 | 0.733 | 0.153 | torch.Size([180, 360]) || stage8.1.residual_group.blocks.3.mlp.fc2.weight
+ | 0.003 | -0.915 | 0.961 | 0.165 | torch.Size([180]) || stage8.1.residual_group.blocks.3.mlp.fc2.bias
+ | 0.001 | -0.411 | 0.533 | 0.070 | torch.Size([180, 180]) || stage8.1.linear.weight
+ | -0.004 | -0.907 | 0.257 | 0.135 | torch.Size([180]) || stage8.1.linear.bias
+ | 0.890 | 0.143 | 1.178 | 0.177 | torch.Size([180]) || stage8.2.residual_group.blocks.0.norm1.weight
+ | -0.034 | -0.781 | 0.959 | 0.177 | torch.Size([180]) || stage8.2.residual_group.blocks.0.norm1.bias
+ | 0.001 | -2.545 | 1.182 | 0.186 | torch.Size([3375, 6]) || stage8.2.residual_group.blocks.0.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.2.residual_group.blocks.0.attn.relative_position_index
+ | 0.000 | -1.151 | 1.199 | 0.158 | torch.Size([540, 180]) || stage8.2.residual_group.blocks.0.attn.qkv_self.weight
+ | -0.001 | -0.731 | 0.744 | 0.155 | torch.Size([540]) || stage8.2.residual_group.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.522 | 0.577 | 0.131 | torch.Size([180, 180]) || stage8.2.residual_group.blocks.0.attn.proj.weight
+ | 0.003 | -0.537 | 0.895 | 0.164 | torch.Size([180]) || stage8.2.residual_group.blocks.0.attn.proj.bias
+ | 0.599 | 0.203 | 0.779 | 0.101 | torch.Size([180]) || stage8.2.residual_group.blocks.0.norm2.weight
+ | -0.021 | -0.429 | 1.016 | 0.143 | torch.Size([180]) || stage8.2.residual_group.blocks.0.norm2.bias
+ | -0.000 | -0.914 | 0.736 | 0.145 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.0.mlp.fc11.weight
+ | -0.054 | -0.545 | 0.183 | 0.106 | torch.Size([360]) || stage8.2.residual_group.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.716 | 0.750 | 0.155 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.0.mlp.fc12.weight
+ | 0.003 | -0.254 | 0.408 | 0.085 | torch.Size([360]) || stage8.2.residual_group.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.842 | 0.706 | 0.153 | torch.Size([180, 360]) || stage8.2.residual_group.blocks.0.mlp.fc2.weight
+ | 0.001 | -0.277 | 0.365 | 0.093 | torch.Size([180]) || stage8.2.residual_group.blocks.0.mlp.fc2.bias
+ | 0.910 | 0.151 | 1.164 | 0.152 | torch.Size([180]) || stage8.2.residual_group.blocks.1.norm1.weight
+ | -0.032 | -0.801 | 1.151 | 0.191 | torch.Size([180]) || stage8.2.residual_group.blocks.1.norm1.bias
+ | -0.069 | -2.776 | 5.771 | 0.290 | torch.Size([3375, 6]) || stage8.2.residual_group.blocks.1.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.2.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -1.359 | 1.101 | 0.156 | torch.Size([540, 180]) || stage8.2.residual_group.blocks.1.attn.qkv_self.weight
+ | 0.009 | -0.624 | 0.654 | 0.155 | torch.Size([540]) || stage8.2.residual_group.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.565 | 0.575 | 0.134 | torch.Size([180, 180]) || stage8.2.residual_group.blocks.1.attn.proj.weight
+ | -0.004 | -0.671 | 0.566 | 0.171 | torch.Size([180]) || stage8.2.residual_group.blocks.1.attn.proj.bias
+ | 0.609 | 0.206 | 0.818 | 0.109 | torch.Size([180]) || stage8.2.residual_group.blocks.1.norm2.weight
+ | -0.022 | -0.474 | 1.079 | 0.147 | torch.Size([180]) || stage8.2.residual_group.blocks.1.norm2.bias
+ | 0.000 | -0.760 | 0.819 | 0.143 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.1.mlp.fc11.weight
+ | -0.045 | -0.414 | 0.277 | 0.106 | torch.Size([360]) || stage8.2.residual_group.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.831 | 0.809 | 0.155 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.1.mlp.fc12.weight
+ | -0.002 | -0.544 | 0.244 | 0.082 | torch.Size([360]) || stage8.2.residual_group.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.749 | 0.962 | 0.151 | torch.Size([180, 360]) || stage8.2.residual_group.blocks.1.mlp.fc2.weight
+ | 0.011 | -0.275 | 0.294 | 0.101 | torch.Size([180]) || stage8.2.residual_group.blocks.1.mlp.fc2.bias
+ | 0.990 | 0.168 | 1.270 | 0.152 | torch.Size([180]) || stage8.2.residual_group.blocks.2.norm1.weight
+ | -0.034 | -0.773 | 1.134 | 0.182 | torch.Size([180]) || stage8.2.residual_group.blocks.2.norm1.bias
+ | -0.070 | -2.190 | 5.577 | 0.255 | torch.Size([3375, 6]) || stage8.2.residual_group.blocks.2.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.2.residual_group.blocks.2.attn.relative_position_index
+ | -0.000 | -1.004 | 1.113 | 0.152 | torch.Size([540, 180]) || stage8.2.residual_group.blocks.2.attn.qkv_self.weight
+ | 0.000 | -0.781 | 0.551 | 0.137 | torch.Size([540]) || stage8.2.residual_group.blocks.2.attn.qkv_self.bias
+ | 0.001 | -0.580 | 0.572 | 0.141 | torch.Size([180, 180]) || stage8.2.residual_group.blocks.2.attn.proj.weight
+ | -0.001 | -0.554 | 0.820 | 0.177 | torch.Size([180]) || stage8.2.residual_group.blocks.2.attn.proj.bias
+ | 0.642 | 0.178 | 0.852 | 0.111 | torch.Size([180]) || stage8.2.residual_group.blocks.2.norm2.weight
+ | -0.025 | -0.413 | 0.853 | 0.124 | torch.Size([180]) || stage8.2.residual_group.blocks.2.norm2.bias
+ | -0.000 | -0.780 | 1.141 | 0.143 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.2.mlp.fc11.weight
+ | -0.067 | -0.860 | 0.177 | 0.114 | torch.Size([360]) || stage8.2.residual_group.blocks.2.mlp.fc11.bias
+ | -0.000 | -1.067 | 0.859 | 0.155 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.2.mlp.fc12.weight
+ | 0.002 | -0.298 | 0.225 | 0.072 | torch.Size([360]) || stage8.2.residual_group.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.726 | 0.809 | 0.151 | torch.Size([180, 360]) || stage8.2.residual_group.blocks.2.mlp.fc2.weight
+ | 0.001 | -0.394 | 0.292 | 0.112 | torch.Size([180]) || stage8.2.residual_group.blocks.2.mlp.fc2.bias
+ | 0.990 | 0.219 | 1.226 | 0.130 | torch.Size([180]) || stage8.2.residual_group.blocks.3.norm1.weight
+ | -0.032 | -0.837 | 1.156 | 0.168 | torch.Size([180]) || stage8.2.residual_group.blocks.3.norm1.bias
+ | -0.005 | -4.045 | 1.695 | 0.178 | torch.Size([3375, 6]) || stage8.2.residual_group.blocks.3.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.2.residual_group.blocks.3.attn.relative_position_index
+ | 0.000 | -0.855 | 1.101 | 0.153 | torch.Size([540, 180]) || stage8.2.residual_group.blocks.3.attn.qkv_self.weight
+ | -0.002 | -0.706 | 0.841 | 0.123 | torch.Size([540]) || stage8.2.residual_group.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.586 | 0.699 | 0.134 | torch.Size([180, 180]) || stage8.2.residual_group.blocks.3.attn.proj.weight
+ | 0.001 | -0.402 | 0.842 | 0.173 | torch.Size([180]) || stage8.2.residual_group.blocks.3.attn.proj.bias
+ | 0.613 | 0.196 | 0.800 | 0.102 | torch.Size([180]) || stage8.2.residual_group.blocks.3.norm2.weight
+ | -0.021 | -0.404 | 0.907 | 0.115 | torch.Size([180]) || stage8.2.residual_group.blocks.3.norm2.bias
+ | 0.000 | -0.718 | 0.654 | 0.138 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.3.mlp.fc11.weight
+ | -0.064 | -0.568 | 0.205 | 0.115 | torch.Size([360]) || stage8.2.residual_group.blocks.3.mlp.fc11.bias
+ | -0.001 | -0.674 | 0.596 | 0.155 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.3.mlp.fc12.weight
+ | -0.012 | -0.279 | 0.171 | 0.073 | torch.Size([360]) || stage8.2.residual_group.blocks.3.mlp.fc12.bias
+ | -0.000 | -0.634 | 0.692 | 0.150 | torch.Size([180, 360]) || stage8.2.residual_group.blocks.3.mlp.fc2.weight
+ | 0.010 | -0.528 | 1.331 | 0.175 | torch.Size([180]) || stage8.2.residual_group.blocks.3.mlp.fc2.bias
+ | -0.000 | -0.361 | 0.549 | 0.078 | torch.Size([180, 180]) || stage8.2.linear.weight
+ | -0.001 | -0.682 | 0.349 | 0.142 | torch.Size([180]) || stage8.2.linear.bias
+ | 1.018 | 0.177 | 1.365 | 0.177 | torch.Size([180]) || stage8.3.residual_group.blocks.0.norm1.weight
+ | -0.033 | -0.673 | 0.916 | 0.166 | torch.Size([180]) || stage8.3.residual_group.blocks.0.norm1.bias
+ | 0.003 | -2.963 | 1.620 | 0.138 | torch.Size([3375, 6]) || stage8.3.residual_group.blocks.0.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.3.residual_group.blocks.0.attn.relative_position_index
+ | -0.000 | -1.095 | 0.939 | 0.152 | torch.Size([540, 180]) || stage8.3.residual_group.blocks.0.attn.qkv_self.weight
+ | 0.004 | -0.725 | 0.682 | 0.135 | torch.Size([540]) || stage8.3.residual_group.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.731 | 0.755 | 0.149 | torch.Size([180, 180]) || stage8.3.residual_group.blocks.0.attn.proj.weight
+ | 0.013 | -0.457 | 0.481 | 0.158 | torch.Size([180]) || stage8.3.residual_group.blocks.0.attn.proj.bias
+ | 0.703 | 0.276 | 0.865 | 0.096 | torch.Size([180]) || stage8.3.residual_group.blocks.0.norm2.weight
+ | -0.024 | -0.449 | 0.966 | 0.132 | torch.Size([180]) || stage8.3.residual_group.blocks.0.norm2.bias
+ | -0.001 | -0.873 | 0.665 | 0.138 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.0.mlp.fc11.weight
+ | -0.052 | -0.479 | 0.198 | 0.104 | torch.Size([360]) || stage8.3.residual_group.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.787 | 0.699 | 0.155 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.0.mlp.fc12.weight
+ | -0.003 | -0.436 | 0.264 | 0.081 | torch.Size([360]) || stage8.3.residual_group.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.675 | 0.689 | 0.153 | torch.Size([180, 360]) || stage8.3.residual_group.blocks.0.mlp.fc2.weight
+ | 0.004 | -0.265 | 0.254 | 0.106 | torch.Size([180]) || stage8.3.residual_group.blocks.0.mlp.fc2.bias
+ | 0.956 | 0.184 | 1.255 | 0.167 | torch.Size([180]) || stage8.3.residual_group.blocks.1.norm1.weight
+ | -0.036 | -0.699 | 0.965 | 0.155 | torch.Size([180]) || stage8.3.residual_group.blocks.1.norm1.bias
+ | -0.038 | -3.913 | 4.625 | 0.210 | torch.Size([3375, 6]) || stage8.3.residual_group.blocks.1.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.3.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -1.142 | 0.934 | 0.147 | torch.Size([540, 180]) || stage8.3.residual_group.blocks.1.attn.qkv_self.weight
+ | 0.000 | -0.708 | 0.560 | 0.117 | torch.Size([540]) || stage8.3.residual_group.blocks.1.attn.qkv_self.bias
+ | -0.002 | -0.746 | 0.626 | 0.149 | torch.Size([180, 180]) || stage8.3.residual_group.blocks.1.attn.proj.weight
+ | 0.021 | -0.378 | 0.376 | 0.127 | torch.Size([180]) || stage8.3.residual_group.blocks.1.attn.proj.bias
+ | 0.741 | 0.282 | 0.933 | 0.107 | torch.Size([180]) || stage8.3.residual_group.blocks.1.norm2.weight
+ | -0.028 | -0.425 | 0.898 | 0.115 | torch.Size([180]) || stage8.3.residual_group.blocks.1.norm2.bias
+ | -0.001 | -0.761 | 0.822 | 0.139 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.1.mlp.fc11.weight
+ | -0.057 | -0.502 | 0.219 | 0.100 | torch.Size([360]) || stage8.3.residual_group.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.829 | 0.872 | 0.156 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.1.mlp.fc12.weight
+ | 0.004 | -0.262 | 0.226 | 0.077 | torch.Size([360]) || stage8.3.residual_group.blocks.1.mlp.fc12.bias
+ | -0.001 | -0.797 | 0.765 | 0.153 | torch.Size([180, 360]) || stage8.3.residual_group.blocks.1.mlp.fc2.weight
+ | -0.002 | -0.360 | 0.289 | 0.109 | torch.Size([180]) || stage8.3.residual_group.blocks.1.mlp.fc2.bias
+ | 1.068 | 0.207 | 1.335 | 0.160 | torch.Size([180]) || stage8.3.residual_group.blocks.2.norm1.weight
+ | -0.034 | -0.784 | 1.005 | 0.163 | torch.Size([180]) || stage8.3.residual_group.blocks.2.norm1.bias
+ | -0.004 | -2.897 | 1.185 | 0.143 | torch.Size([3375, 6]) || stage8.3.residual_group.blocks.2.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.3.residual_group.blocks.2.attn.relative_position_index
+ | 0.000 | -1.055 | 0.899 | 0.151 | torch.Size([540, 180]) || stage8.3.residual_group.blocks.2.attn.qkv_self.weight
+ | -0.000 | -0.572 | 0.670 | 0.120 | torch.Size([540]) || stage8.3.residual_group.blocks.2.attn.qkv_self.bias
+ | -0.001 | -0.729 | 0.798 | 0.156 | torch.Size([180, 180]) || stage8.3.residual_group.blocks.2.attn.proj.weight
+ | 0.025 | -0.570 | 0.501 | 0.166 | torch.Size([180]) || stage8.3.residual_group.blocks.2.attn.proj.bias
+ | 0.759 | 0.228 | 0.969 | 0.115 | torch.Size([180]) || stage8.3.residual_group.blocks.2.norm2.weight
+ | -0.025 | -0.394 | 0.791 | 0.103 | torch.Size([180]) || stage8.3.residual_group.blocks.2.norm2.bias
+ | -0.001 | -0.962 | 0.903 | 0.137 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.2.mlp.fc11.weight
+ | -0.064 | -0.587 | 0.209 | 0.108 | torch.Size([360]) || stage8.3.residual_group.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.966 | 0.925 | 0.156 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.2.mlp.fc12.weight
+ | 0.004 | -0.366 | 0.239 | 0.074 | torch.Size([360]) || stage8.3.residual_group.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.782 | 0.817 | 0.152 | torch.Size([180, 360]) || stage8.3.residual_group.blocks.2.mlp.fc2.weight
+ | 0.003 | -0.321 | 0.340 | 0.117 | torch.Size([180]) || stage8.3.residual_group.blocks.2.mlp.fc2.bias
+ | 1.082 | 0.237 | 1.309 | 0.144 | torch.Size([180]) || stage8.3.residual_group.blocks.3.norm1.weight
+ | -0.031 | -0.726 | 0.933 | 0.149 | torch.Size([180]) || stage8.3.residual_group.blocks.3.norm1.bias
+ | 0.005 | -3.023 | 1.093 | 0.142 | torch.Size([3375, 6]) || stage8.3.residual_group.blocks.3.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.3.residual_group.blocks.3.attn.relative_position_index
+ | -0.000 | -0.830 | 0.867 | 0.151 | torch.Size([540, 180]) || stage8.3.residual_group.blocks.3.attn.qkv_self.weight
+ | -0.001 | -0.487 | 0.710 | 0.107 | torch.Size([540]) || stage8.3.residual_group.blocks.3.attn.qkv_self.bias
+ | -0.001 | -0.940 | 0.725 | 0.157 | torch.Size([180, 180]) || stage8.3.residual_group.blocks.3.attn.proj.weight
+ | 0.027 | -0.522 | 0.807 | 0.170 | torch.Size([180]) || stage8.3.residual_group.blocks.3.attn.proj.bias
+ | 0.705 | 0.249 | 0.868 | 0.095 | torch.Size([180]) || stage8.3.residual_group.blocks.3.norm2.weight
+ | -0.023 | -0.426 | 0.826 | 0.108 | torch.Size([180]) || stage8.3.residual_group.blocks.3.norm2.bias
+ | -0.000 | -0.814 | 0.927 | 0.131 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.3.mlp.fc11.weight
+ | -0.043 | -0.613 | 0.209 | 0.116 | torch.Size([360]) || stage8.3.residual_group.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.709 | 0.851 | 0.154 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.3.mlp.fc12.weight
+ | -0.004 | -0.225 | 0.241 | 0.078 | torch.Size([360]) || stage8.3.residual_group.blocks.3.mlp.fc12.bias
+ | -0.000 | -0.857 | 0.845 | 0.151 | torch.Size([180, 360]) || stage8.3.residual_group.blocks.3.mlp.fc2.weight
+ | 0.016 | -0.441 | 1.206 | 0.183 | torch.Size([180]) || stage8.3.residual_group.blocks.3.mlp.fc2.bias
+ | -0.002 | -0.437 | 0.634 | 0.077 | torch.Size([180, 180]) || stage8.3.linear.weight
+ | -0.003 | -0.564 | 0.338 | 0.145 | torch.Size([180]) || stage8.3.linear.bias
+ | 1.164 | 0.238 | 1.496 | 0.205 | torch.Size([180]) || stage8.4.residual_group.blocks.0.norm1.weight
+ | -0.033 | -0.667 | 0.780 | 0.170 | torch.Size([180]) || stage8.4.residual_group.blocks.0.norm1.bias
+ | -0.002 | -3.025 | 1.339 | 0.130 | torch.Size([3375, 6]) || stage8.4.residual_group.blocks.0.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.4.residual_group.blocks.0.attn.relative_position_index
+ | -0.000 | -0.736 | 0.735 | 0.147 | torch.Size([540, 180]) || stage8.4.residual_group.blocks.0.attn.qkv_self.weight
+ | -0.007 | -0.468 | 0.575 | 0.112 | torch.Size([540]) || stage8.4.residual_group.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.725 | 0.750 | 0.162 | torch.Size([180, 180]) || stage8.4.residual_group.blocks.0.attn.proj.weight
+ | -0.004 | -0.461 | 0.540 | 0.163 | torch.Size([180]) || stage8.4.residual_group.blocks.0.attn.proj.bias
+ | 0.804 | 0.361 | 0.962 | 0.091 | torch.Size([180]) || stage8.4.residual_group.blocks.0.norm2.weight
+ | -0.025 | -0.421 | 0.837 | 0.127 | torch.Size([180]) || stage8.4.residual_group.blocks.0.norm2.bias
+ | -0.002 | -0.664 | 0.869 | 0.129 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.0.mlp.fc11.weight
+ | -0.028 | -0.519 | 0.180 | 0.098 | torch.Size([360]) || stage8.4.residual_group.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.793 | 0.821 | 0.156 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.0.mlp.fc12.weight
+ | 0.001 | -0.235 | 0.329 | 0.081 | torch.Size([360]) || stage8.4.residual_group.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.758 | 0.730 | 0.153 | torch.Size([180, 360]) || stage8.4.residual_group.blocks.0.mlp.fc2.weight
+ | 0.010 | -0.332 | 0.306 | 0.118 | torch.Size([180]) || stage8.4.residual_group.blocks.0.mlp.fc2.bias
+ | 1.097 | 0.202 | 1.361 | 0.200 | torch.Size([180]) || stage8.4.residual_group.blocks.1.norm1.weight
+ | -0.034 | -0.597 | 0.687 | 0.147 | torch.Size([180]) || stage8.4.residual_group.blocks.1.norm1.bias
+ | 0.007 | -4.645 | 1.140 | 0.130 | torch.Size([3375, 6]) || stage8.4.residual_group.blocks.1.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.4.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -1.002 | 0.810 | 0.144 | torch.Size([540, 180]) || stage8.4.residual_group.blocks.1.attn.qkv_self.weight
+ | 0.005 | -0.407 | 0.438 | 0.108 | torch.Size([540]) || stage8.4.residual_group.blocks.1.attn.qkv_self.bias
+ | -0.001 | -0.646 | 0.678 | 0.154 | torch.Size([180, 180]) || stage8.4.residual_group.blocks.1.attn.proj.weight
+ | 0.004 | -0.418 | 0.415 | 0.139 | torch.Size([180]) || stage8.4.residual_group.blocks.1.attn.proj.bias
+ | 0.836 | 0.316 | 1.026 | 0.106 | torch.Size([180]) || stage8.4.residual_group.blocks.1.norm2.weight
+ | -0.024 | -0.364 | 0.851 | 0.117 | torch.Size([180]) || stage8.4.residual_group.blocks.1.norm2.bias
+ | -0.002 | -0.690 | 0.848 | 0.128 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.1.mlp.fc11.weight
+ | -0.032 | -0.484 | 0.195 | 0.101 | torch.Size([360]) || stage8.4.residual_group.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.863 | 0.768 | 0.155 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.1.mlp.fc12.weight
+ | -0.001 | -0.319 | 0.409 | 0.078 | torch.Size([360]) || stage8.4.residual_group.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.836 | 0.822 | 0.154 | torch.Size([180, 360]) || stage8.4.residual_group.blocks.1.mlp.fc2.weight
+ | 0.019 | -0.356 | 0.374 | 0.129 | torch.Size([180]) || stage8.4.residual_group.blocks.1.mlp.fc2.bias
+ | 1.151 | 0.229 | 1.393 | 0.176 | torch.Size([180]) || stage8.4.residual_group.blocks.2.norm1.weight
+ | -0.028 | -0.649 | 0.925 | 0.149 | torch.Size([180]) || stage8.4.residual_group.blocks.2.norm1.bias
+ | -0.005 | -3.864 | 1.138 | 0.140 | torch.Size([3375, 6]) || stage8.4.residual_group.blocks.2.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.4.residual_group.blocks.2.attn.relative_position_index
+ | -0.000 | -1.813 | 0.897 | 0.146 | torch.Size([540, 180]) || stage8.4.residual_group.blocks.2.attn.qkv_self.weight
+ | -0.001 | -0.449 | 0.486 | 0.103 | torch.Size([540]) || stage8.4.residual_group.blocks.2.attn.qkv_self.bias
+ | -0.001 | -0.739 | 0.710 | 0.175 | torch.Size([180, 180]) || stage8.4.residual_group.blocks.2.attn.proj.weight
+ | -0.000 | -0.542 | 0.407 | 0.162 | torch.Size([180]) || stage8.4.residual_group.blocks.2.attn.proj.bias
+ | 0.820 | 0.329 | 0.989 | 0.094 | torch.Size([180]) || stage8.4.residual_group.blocks.2.norm2.weight
+ | -0.025 | -0.461 | 0.753 | 0.106 | torch.Size([180]) || stage8.4.residual_group.blocks.2.norm2.bias
+ | -0.001 | -0.648 | 0.788 | 0.125 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.2.mlp.fc11.weight
+ | -0.015 | -0.501 | 0.248 | 0.101 | torch.Size([360]) || stage8.4.residual_group.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.745 | 0.796 | 0.155 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.2.mlp.fc12.weight
+ | 0.007 | -0.244 | 0.231 | 0.080 | torch.Size([360]) || stage8.4.residual_group.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.771 | 1.049 | 0.154 | torch.Size([180, 360]) || stage8.4.residual_group.blocks.2.mlp.fc2.weight
+ | 0.018 | -0.360 | 0.336 | 0.143 | torch.Size([180]) || stage8.4.residual_group.blocks.2.mlp.fc2.bias
+ | 1.177 | 0.269 | 1.385 | 0.163 | torch.Size([180]) || stage8.4.residual_group.blocks.3.norm1.weight
+ | -0.028 | -0.700 | 0.877 | 0.145 | torch.Size([180]) || stage8.4.residual_group.blocks.3.norm1.bias
+ | -0.005 | -2.684 | 0.830 | 0.097 | torch.Size([3375, 6]) || stage8.4.residual_group.blocks.3.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.4.residual_group.blocks.3.attn.relative_position_index
+ | -0.000 | -0.996 | 0.727 | 0.142 | torch.Size([540, 180]) || stage8.4.residual_group.blocks.3.attn.qkv_self.weight
+ | 0.004 | -0.326 | 0.449 | 0.101 | torch.Size([540]) || stage8.4.residual_group.blocks.3.attn.qkv_self.bias
+ | -0.001 | -0.777 | 0.785 | 0.170 | torch.Size([180, 180]) || stage8.4.residual_group.blocks.3.attn.proj.weight
+ | 0.004 | -0.396 | 0.449 | 0.158 | torch.Size([180]) || stage8.4.residual_group.blocks.3.attn.proj.bias
+ | 0.790 | 0.392 | 1.005 | 0.078 | torch.Size([180]) || stage8.4.residual_group.blocks.3.norm2.weight
+ | -0.030 | -0.481 | 0.719 | 0.110 | torch.Size([180]) || stage8.4.residual_group.blocks.3.norm2.bias
+ | -0.001 | -0.569 | 0.732 | 0.121 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.3.mlp.fc11.weight
+ | 0.020 | -0.670 | 0.335 | 0.125 | torch.Size([360]) || stage8.4.residual_group.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.822 | 0.831 | 0.155 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.3.mlp.fc12.weight
+ | -0.003 | -0.282 | 0.296 | 0.089 | torch.Size([360]) || stage8.4.residual_group.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.856 | 0.886 | 0.155 | torch.Size([180, 360]) || stage8.4.residual_group.blocks.3.mlp.fc2.weight
+ | 0.029 | -0.390 | 0.437 | 0.161 | torch.Size([180]) || stage8.4.residual_group.blocks.3.mlp.fc2.bias
+ | -0.002 | -0.490 | 0.625 | 0.079 | torch.Size([180, 180]) || stage8.4.linear.weight
+ | -0.002 | -0.573 | 0.398 | 0.168 | torch.Size([180]) || stage8.4.linear.bias
+ | 1.337 | 0.163 | 1.694 | 0.268 | torch.Size([180]) || stage8.5.residual_group.blocks.0.norm1.weight
+ | -0.025 | -0.727 | 1.008 | 0.186 | torch.Size([180]) || stage8.5.residual_group.blocks.0.norm1.bias
+ | -0.738 | -2.885 | 5.812 | 0.748 | torch.Size([225, 6]) || stage8.5.residual_group.blocks.0.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.5.residual_group.blocks.0.attn.relative_position_index
+ | -0.000 | -0.852 | 0.854 | 0.135 | torch.Size([540, 180]) || stage8.5.residual_group.blocks.0.attn.qkv_self.weight
+ | -0.005 | -0.546 | 0.550 | 0.112 | torch.Size([540]) || stage8.5.residual_group.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.901 | 0.781 | 0.195 | torch.Size([180, 180]) || stage8.5.residual_group.blocks.0.attn.proj.weight
+ | -0.020 | -0.545 | 0.469 | 0.173 | torch.Size([180]) || stage8.5.residual_group.blocks.0.attn.proj.bias
+ | 0.956 | 0.367 | 1.185 | 0.129 | torch.Size([180]) || stage8.5.residual_group.blocks.0.norm2.weight
+ | -0.033 | -0.519 | 0.833 | 0.147 | torch.Size([180]) || stage8.5.residual_group.blocks.0.norm2.bias
+ | -0.001 | -0.832 | 0.580 | 0.119 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.0.mlp.fc11.weight
+ | 0.055 | -0.256 | 0.378 | 0.097 | torch.Size([360]) || stage8.5.residual_group.blocks.0.mlp.fc11.bias
+ | 0.000 | -1.058 | 0.859 | 0.154 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.0.mlp.fc12.weight
+ | 0.006 | -0.377 | 0.318 | 0.093 | torch.Size([360]) || stage8.5.residual_group.blocks.0.mlp.fc12.bias
+ | -0.001 | -0.751 | 0.766 | 0.156 | torch.Size([180, 360]) || stage8.5.residual_group.blocks.0.mlp.fc2.weight
+ | -0.011 | -0.316 | 0.323 | 0.132 | torch.Size([180]) || stage8.5.residual_group.blocks.0.mlp.fc2.bias
+ | 1.346 | 0.151 | 1.746 | 0.272 | torch.Size([180]) || stage8.5.residual_group.blocks.1.norm1.weight
+ | -0.023 | -0.691 | 0.993 | 0.169 | torch.Size([180]) || stage8.5.residual_group.blocks.1.norm1.bias
+ | -0.705 | -2.997 | 4.745 | 0.748 | torch.Size([225, 6]) || stage8.5.residual_group.blocks.1.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.5.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -0.911 | 0.984 | 0.141 | torch.Size([540, 180]) || stage8.5.residual_group.blocks.1.attn.qkv_self.weight
+ | -0.011 | -0.405 | 0.288 | 0.095 | torch.Size([540]) || stage8.5.residual_group.blocks.1.attn.qkv_self.bias
+ | 0.001 | -0.853 | 0.977 | 0.210 | torch.Size([180, 180]) || stage8.5.residual_group.blocks.1.attn.proj.weight
+ | -0.008 | -0.516 | 0.596 | 0.170 | torch.Size([180]) || stage8.5.residual_group.blocks.1.attn.proj.bias
+ | 1.021 | 0.333 | 1.268 | 0.154 | torch.Size([180]) || stage8.5.residual_group.blocks.1.norm2.weight
+ | -0.034 | -0.512 | 0.812 | 0.134 | torch.Size([180]) || stage8.5.residual_group.blocks.1.norm2.bias
+ | 0.000 | -0.561 | 0.546 | 0.120 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.1.mlp.fc11.weight
+ | 0.050 | -0.450 | 0.320 | 0.100 | torch.Size([360]) || stage8.5.residual_group.blocks.1.mlp.fc11.bias
+ | 0.001 | -0.907 | 0.752 | 0.157 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.1.mlp.fc12.weight
+ | -0.008 | -0.306 | 0.343 | 0.091 | torch.Size([360]) || stage8.5.residual_group.blocks.1.mlp.fc12.bias
+ | -0.001 | -0.891 | 0.741 | 0.158 | torch.Size([180, 360]) || stage8.5.residual_group.blocks.1.mlp.fc2.weight
+ | -0.014 | -0.407 | 0.478 | 0.168 | torch.Size([180]) || stage8.5.residual_group.blocks.1.mlp.fc2.bias
+ | 1.266 | 0.195 | 1.640 | 0.251 | torch.Size([180]) || stage8.5.residual_group.blocks.2.norm1.weight
+ | -0.028 | -0.680 | 0.987 | 0.162 | torch.Size([180]) || stage8.5.residual_group.blocks.2.norm1.bias
+ | -0.515 | -2.839 | 4.668 | 0.636 | torch.Size([225, 6]) || stage8.5.residual_group.blocks.2.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.5.residual_group.blocks.2.attn.relative_position_index
+ | 0.001 | -0.968 | 0.890 | 0.144 | torch.Size([540, 180]) || stage8.5.residual_group.blocks.2.attn.qkv_self.weight
+ | -0.001 | -0.372 | 0.390 | 0.095 | torch.Size([540]) || stage8.5.residual_group.blocks.2.attn.qkv_self.bias
+ | -0.000 | -1.001 | 0.995 | 0.221 | torch.Size([180, 180]) || stage8.5.residual_group.blocks.2.attn.proj.weight
+ | -0.012 | -0.576 | 0.456 | 0.172 | torch.Size([180]) || stage8.5.residual_group.blocks.2.attn.proj.bias
+ | 1.046 | 0.311 | 1.264 | 0.147 | torch.Size([180]) || stage8.5.residual_group.blocks.2.norm2.weight
+ | -0.033 | -0.519 | 0.785 | 0.123 | torch.Size([180]) || stage8.5.residual_group.blocks.2.norm2.bias
+ | 0.000 | -0.533 | 0.563 | 0.119 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.2.mlp.fc11.weight
+ | 0.053 | -0.314 | 0.364 | 0.109 | torch.Size([360]) || stage8.5.residual_group.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.862 | 0.822 | 0.158 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.2.mlp.fc12.weight
+ | -0.004 | -0.266 | 0.289 | 0.084 | torch.Size([360]) || stage8.5.residual_group.blocks.2.mlp.fc12.bias
+ | 0.001 | -0.787 | 0.886 | 0.161 | torch.Size([180, 360]) || stage8.5.residual_group.blocks.2.mlp.fc2.weight
+ | -0.007 | -0.421 | 0.503 | 0.171 | torch.Size([180]) || stage8.5.residual_group.blocks.2.mlp.fc2.bias
+ | 1.226 | 0.277 | 1.561 | 0.208 | torch.Size([180]) || stage8.5.residual_group.blocks.3.norm1.weight
+ | -0.032 | -0.670 | 1.030 | 0.168 | torch.Size([180]) || stage8.5.residual_group.blocks.3.norm1.bias
+ | -0.401 | -1.953 | 3.930 | 0.598 | torch.Size([225, 6]) || stage8.5.residual_group.blocks.3.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.5.residual_group.blocks.3.attn.relative_position_index
+ | -0.000 | -0.857 | 0.754 | 0.139 | torch.Size([540, 180]) || stage8.5.residual_group.blocks.3.attn.qkv_self.weight
+ | 0.004 | -0.317 | 0.278 | 0.081 | torch.Size([540]) || stage8.5.residual_group.blocks.3.attn.qkv_self.bias
+ | -0.002 | -1.022 | 0.999 | 0.200 | torch.Size([180, 180]) || stage8.5.residual_group.blocks.3.attn.proj.weight
+ | -0.009 | -0.384 | 0.393 | 0.165 | torch.Size([180]) || stage8.5.residual_group.blocks.3.attn.proj.bias
+ | 1.038 | 0.340 | 1.216 | 0.128 | torch.Size([180]) || stage8.5.residual_group.blocks.3.norm2.weight
+ | -0.034 | -0.574 | 0.775 | 0.124 | torch.Size([180]) || stage8.5.residual_group.blocks.3.norm2.bias
+ | 0.001 | -0.588 | 0.613 | 0.119 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.3.mlp.fc11.weight
+ | 0.063 | -0.447 | 0.307 | 0.111 | torch.Size([360]) || stage8.5.residual_group.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.873 | 0.775 | 0.159 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.3.mlp.fc12.weight
+ | 0.001 | -0.456 | 0.435 | 0.092 | torch.Size([360]) || stage8.5.residual_group.blocks.3.mlp.fc12.bias
+ | -0.000 | -0.819 | 0.772 | 0.160 | torch.Size([180, 360]) || stage8.5.residual_group.blocks.3.mlp.fc2.weight
+ | -0.018 | -0.319 | 0.340 | 0.131 | torch.Size([180]) || stage8.5.residual_group.blocks.3.mlp.fc2.bias
+ | -0.000 | -0.562 | 0.471 | 0.080 | torch.Size([180, 180]) || stage8.5.linear.weight
+ | 0.024 | -0.609 | 0.488 | 0.184 | torch.Size([180]) || stage8.5.linear.bias
+ | 1.369 | 0.171 | 1.961 | 0.355 | torch.Size([180]) || stage8.6.residual_group.blocks.0.norm1.weight
+ | -0.028 | -0.642 | 0.733 | 0.196 | torch.Size([180]) || stage8.6.residual_group.blocks.0.norm1.bias
+ | -0.029 | -1.759 | 1.624 | 0.312 | torch.Size([225, 6]) || stage8.6.residual_group.blocks.0.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.6.residual_group.blocks.0.attn.relative_position_index
+ | -0.000 | -0.686 | 0.691 | 0.113 | torch.Size([540, 180]) || stage8.6.residual_group.blocks.0.attn.qkv_self.weight
+ | -0.003 | -0.261 | 0.301 | 0.081 | torch.Size([540]) || stage8.6.residual_group.blocks.0.attn.qkv_self.bias
+ | 0.001 | -0.736 | 0.637 | 0.149 | torch.Size([180, 180]) || stage8.6.residual_group.blocks.0.attn.proj.weight
+ | -0.006 | -0.293 | 0.300 | 0.106 | torch.Size([180]) || stage8.6.residual_group.blocks.0.attn.proj.bias
+ | 1.302 | 0.401 | 1.613 | 0.192 | torch.Size([180]) || stage8.6.residual_group.blocks.0.norm2.weight
+ | -0.029 | -0.475 | 0.696 | 0.159 | torch.Size([180]) || stage8.6.residual_group.blocks.0.norm2.bias
+ | -0.001 | -0.649 | 0.564 | 0.119 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.0.mlp.fc11.weight
+ | 0.036 | -0.275 | 0.218 | 0.071 | torch.Size([360]) || stage8.6.residual_group.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.717 | 0.831 | 0.148 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.0.mlp.fc12.weight
+ | 0.006 | -0.231 | 0.270 | 0.074 | torch.Size([360]) || stage8.6.residual_group.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.833 | 0.791 | 0.150 | torch.Size([180, 360]) || stage8.6.residual_group.blocks.0.mlp.fc2.weight
+ | 0.004 | -0.364 | 0.324 | 0.134 | torch.Size([180]) || stage8.6.residual_group.blocks.0.mlp.fc2.bias
+ | 1.450 | 0.218 | 1.962 | 0.354 | torch.Size([180]) || stage8.6.residual_group.blocks.1.norm1.weight
+ | -0.025 | -0.716 | 0.851 | 0.206 | torch.Size([180]) || stage8.6.residual_group.blocks.1.norm1.bias
+ | -0.045 | -1.549 | 2.100 | 0.321 | torch.Size([225, 6]) || stage8.6.residual_group.blocks.1.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.6.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -0.759 | 0.636 | 0.110 | torch.Size([540, 180]) || stage8.6.residual_group.blocks.1.attn.qkv_self.weight
+ | -0.001 | -0.235 | 0.269 | 0.070 | torch.Size([540]) || stage8.6.residual_group.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.691 | 0.657 | 0.145 | torch.Size([180, 180]) || stage8.6.residual_group.blocks.1.attn.proj.weight
+ | -0.007 | -0.375 | 0.328 | 0.116 | torch.Size([180]) || stage8.6.residual_group.blocks.1.attn.proj.bias
+ | 1.326 | 0.335 | 1.596 | 0.186 | torch.Size([180]) || stage8.6.residual_group.blocks.1.norm2.weight
+ | -0.029 | -0.566 | 0.748 | 0.160 | torch.Size([180]) || stage8.6.residual_group.blocks.1.norm2.bias
+ | -0.002 | -0.667 | 0.591 | 0.121 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.1.mlp.fc11.weight
+ | 0.042 | -0.387 | 0.373 | 0.078 | torch.Size([360]) || stage8.6.residual_group.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.685 | 0.894 | 0.147 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.1.mlp.fc12.weight
+ | 0.000 | -0.353 | 0.326 | 0.092 | torch.Size([360]) || stage8.6.residual_group.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.801 | 0.692 | 0.149 | torch.Size([180, 360]) || stage8.6.residual_group.blocks.1.mlp.fc2.weight
+ | -0.007 | -0.331 | 0.273 | 0.127 | torch.Size([180]) || stage8.6.residual_group.blocks.1.mlp.fc2.bias
+ | 1.416 | 0.215 | 1.819 | 0.303 | torch.Size([180]) || stage8.6.residual_group.blocks.2.norm1.weight
+ | -0.024 | -0.596 | 0.869 | 0.211 | torch.Size([180]) || stage8.6.residual_group.blocks.2.norm1.bias
+ | -0.038 | -2.355 | 1.330 | 0.286 | torch.Size([225, 6]) || stage8.6.residual_group.blocks.2.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.6.residual_group.blocks.2.attn.relative_position_index
+ | -0.000 | -0.964 | 0.732 | 0.112 | torch.Size([540, 180]) || stage8.6.residual_group.blocks.2.attn.qkv_self.weight
+ | 0.002 | -0.192 | 0.251 | 0.052 | torch.Size([540]) || stage8.6.residual_group.blocks.2.attn.qkv_self.bias
+ | 0.001 | -0.736 | 0.624 | 0.138 | torch.Size([180, 180]) || stage8.6.residual_group.blocks.2.attn.proj.weight
+ | -0.008 | -0.376 | 0.254 | 0.119 | torch.Size([180]) || stage8.6.residual_group.blocks.2.attn.proj.bias
+ | 1.352 | 0.217 | 1.546 | 0.187 | torch.Size([180]) || stage8.6.residual_group.blocks.2.norm2.weight
+ | -0.023 | -0.627 | 0.881 | 0.164 | torch.Size([180]) || stage8.6.residual_group.blocks.2.norm2.bias
+ | -0.001 | -0.616 | 0.688 | 0.122 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.2.mlp.fc11.weight
+ | 0.040 | -0.332 | 0.242 | 0.083 | torch.Size([360]) || stage8.6.residual_group.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.970 | 0.669 | 0.148 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.2.mlp.fc12.weight
+ | 0.006 | -0.333 | 0.371 | 0.092 | torch.Size([360]) || stage8.6.residual_group.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.849 | 0.824 | 0.150 | torch.Size([180, 360]) || stage8.6.residual_group.blocks.2.mlp.fc2.weight
+ | -0.007 | -0.282 | 0.333 | 0.111 | torch.Size([180]) || stage8.6.residual_group.blocks.2.mlp.fc2.bias
+ | 1.346 | 0.206 | 1.798 | 0.286 | torch.Size([180]) || stage8.6.residual_group.blocks.3.norm1.weight
+ | -0.022 | -0.742 | 0.797 | 0.196 | torch.Size([180]) || stage8.6.residual_group.blocks.3.norm1.bias
+ | -0.056 | -1.296 | 2.098 | 0.311 | torch.Size([225, 6]) || stage8.6.residual_group.blocks.3.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.6.residual_group.blocks.3.attn.relative_position_index
+ | -0.000 | -0.693 | 0.597 | 0.103 | torch.Size([540, 180]) || stage8.6.residual_group.blocks.3.attn.qkv_self.weight
+ | -0.003 | -0.211 | 0.161 | 0.055 | torch.Size([540]) || stage8.6.residual_group.blocks.3.attn.qkv_self.bias
+ | -0.000 | -0.767 | 0.663 | 0.127 | torch.Size([180, 180]) || stage8.6.residual_group.blocks.3.attn.proj.weight
+ | -0.011 | -0.269 | 0.169 | 0.072 | torch.Size([180]) || stage8.6.residual_group.blocks.3.attn.proj.bias
+ | 1.329 | 0.247 | 1.544 | 0.183 | torch.Size([180]) || stage8.6.residual_group.blocks.3.norm2.weight
+ | -0.023 | -0.619 | 0.881 | 0.171 | torch.Size([180]) || stage8.6.residual_group.blocks.3.norm2.bias
+ | -0.001 | -0.670 | 0.594 | 0.124 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.3.mlp.fc11.weight
+ | 0.052 | -0.262 | 0.275 | 0.073 | torch.Size([360]) || stage8.6.residual_group.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.899 | 0.808 | 0.149 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.3.mlp.fc12.weight
+ | -0.009 | -0.273 | 0.326 | 0.090 | torch.Size([360]) || stage8.6.residual_group.blocks.3.mlp.fc12.bias
+ | 0.001 | -0.773 | 0.930 | 0.150 | torch.Size([180, 360]) || stage8.6.residual_group.blocks.3.mlp.fc2.weight
+ | -0.001 | -0.264 | 0.261 | 0.088 | torch.Size([180]) || stage8.6.residual_group.blocks.3.mlp.fc2.bias
+ | -0.001 | -1.128 | 1.483 | 0.100 | torch.Size([180, 180]) || stage8.6.linear.weight
+ | 0.014 | -0.757 | 0.769 | 0.160 | torch.Size([180]) || stage8.6.linear.bias
+ | 0.387 | 0.109 | 1.033 | 0.194 | torch.Size([180]) || norm.weight
+ | -0.006 | -0.754 | 0.773 | 0.142 | torch.Size([180]) || norm.bias
+ | 0.001 | -0.596 | 0.563 | 0.121 | torch.Size([120, 180]) || conv_after_body.weight
+ | -0.016 | -0.251 | 0.121 | 0.061 | torch.Size([120]) || conv_after_body.bias
+ | 0.003 | -1.347 | 1.476 | 0.161 | torch.Size([64, 120, 1, 3, 3]) || conv_before_upsample.0.weight
+ | -0.090 | -0.847 | 0.182 | 0.193 | torch.Size([64]) || conv_before_upsample.0.bias
+ | 0.002 | -1.602 | 0.994 | 0.114 | torch.Size([256, 64, 1, 3, 3]) || upsample.0.weight
+ | -0.059 | -0.461 | 0.137 | 0.098 | torch.Size([256]) || upsample.0.bias
+ | -0.005 | -4.099 | 0.822 | 0.076 | torch.Size([256, 64, 1, 3, 3]) || upsample.5.weight
+ | -0.137 | -0.426 | 0.152 | 0.097 | torch.Size([256]) || upsample.5.bias
+ | -0.000 | -0.377 | 0.324 | 0.014 | torch.Size([64, 64, 1, 3, 3]) || upsample.10.weight
+ | -0.000 | -0.016 | 0.014 | 0.003 | torch.Size([64]) || upsample.10.bias
+ | -0.000 | -0.043 | 0.040 | 0.004 | torch.Size([3, 64, 1, 3, 3]) || conv_last.weight
+ | -0.000 | -0.000 | 0.000 | 0.000 | torch.Size([3]) || conv_last.bias
+
+22-03-11 10:10:42.661 : task: 003_train_vrt_videosr_bi_vimeo_7frames
+ model: vrt
+ gpu_ids: [0, 1, 2, 3, 4, 5, 6, 7]
+ dist: False
+ find_unused_parameters: False
+ use_static_graph: True
+ scale: 4
+ n_channels: 3
+ path:[
+ root: experiments
+ pretrained_netG: model_zoo/vrt/002_VRT_videosr_bi_REDS_16frames.pth
+ pretrained_netE: None
+ task: experiments/003_train_vrt_videosr_bi_vimeo_7frames
+ log: experiments/003_train_vrt_videosr_bi_vimeo_7frames
+ options: experiments/003_train_vrt_videosr_bi_vimeo_7frames/options
+ models: experiments/003_train_vrt_videosr_bi_vimeo_7frames/models
+ images: experiments/003_train_vrt_videosr_bi_vimeo_7frames/images
+ pretrained_optimizerG: None
+ ]
+ datasets:[
+ train:[
+ name: train_dataset
+ dataset_type: VideoRecurrentTrainVimeoDataset
+ dataroot_gt: trainsets/vimeo90k
+ dataroot_lq: trainsets/vimeo90k
+ meta_info_file: data/meta_info/meta_info_Vimeo90K_train_GT.txt
+ io_backend:[
+ type: disk
+ ]
+ num_frame: -1
+ gt_size: 256
+ interval_list: [1]
+ random_reverse: True
+ use_hflip: True
+ use_rot: True
+ pad_sequence: True
+ dataloader_shuffle: True
+ dataloader_num_workers: 32
+ dataloader_batch_size: 8
+ phase: train
+ scale: 4
+ n_channels: 3
+ ]
+ test:[
+ name: test_dataset
+ dataset_type: VideoRecurrentTestDataset
+ dataroot_gt: testsets/Vid4/GT
+ dataroot_lq: testsets/Vid4/BIx4
+ cache_data: True
+ io_backend:[
+ type: disk
+ ]
+ num_frame: -1
+ phase: test
+ scale: 4
+ n_channels: 3
+ ]
+ ]
+ netG:[
+ net_type: vrt
+ upscale: 4
+ img_size: [8, 64, 64]
+ window_size: [8, 8, 8]
+ depths: [8, 8, 8, 8, 8, 8, 8, 4, 4, 4, 4, 4, 4]
+ indep_reconsts: [11, 12]
+ embed_dims: [120, 120, 120, 120, 120, 120, 120, 180, 180, 180, 180, 180, 180]
+ num_heads: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
+ spynet_path: model_zoo/vrt/spynet_sintel_final-3d2a1287.pth
+ pa_frames: 4
+ deformable_groups: 16
+ nonblind_denoising: False
+ use_checkpoint_attn: False
+ use_checkpoint_ffn: False
+ no_checkpoint_attn_blocks: []
+ no_checkpoint_ffn_blocks: []
+ init_type: default
+ scale: 4
+ ]
+ train:[
+ G_lossfn_type: charbonnier
+ G_lossfn_weight: 1.0
+ G_charbonnier_eps: 1e-09
+ E_decay: 0
+ G_optimizer_type: adam
+ G_optimizer_lr: 0.0004
+ G_optimizer_betas: [0.9, 0.99]
+ G_optimizer_wd: 0
+ G_optimizer_clipgrad: None
+ G_optimizer_reuse: True
+ fix_iter: 20000
+ fix_lr_mul: 0.125
+ fix_keys: ['spynet', 'deform']
+ total_iter: 300000
+ G_scheduler_type: CosineAnnealingWarmRestarts
+ G_scheduler_periods: 300000
+ G_scheduler_eta_min: 1e-07
+ G_regularizer_orthstep: None
+ G_regularizer_clipstep: None
+ G_param_strict: False
+ E_param_strict: True
+ checkpoint_test: 5000
+ checkpoint_save: 5000
+ checkpoint_print: 200
+ F_feature_layer: 34
+ F_weights: 1.0
+ F_lossfn_type: l1
+ F_use_input_norm: True
+ F_use_range_norm: False
+ G_scheduler_restart_weights: 1
+ ]
+ val:[
+ save_img: False
+ pad_seq: False
+ flip_seq: False
+ center_frame_only: False
+ num_frame_testing: 32
+ num_frame_overlapping: 2
+ size_patch_testing: 128
+ ]
+ opt_path: options/vrt/003_train_vrt_videosr_bi_vimeo_7frames.json
+ is_train: True
+ merge_bn: False
+ merge_bn_startpoint: -1
+ num_gpu: 8
+ rank: 0
+ world_size: 1
+
+22-03-11 10:10:42.695 : Number of train images: 64,612, iters: 8,077
+22-03-11 10:10:46.280 :
+Networks name: VRT
+Params number: 32577991
+Net structure:
+VRT(
+ (conv_first): Conv3d(27, 120, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ (spynet): SpyNet(
+ (basic_module): ModuleList(
+ (0): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (1): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (2): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (3): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (4): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (5): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ )
+ )
+ (stage1): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n c d h w -> n d h w c')
+ (1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (2): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): Identity()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): Identity()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(364, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 432, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage2): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n c d (h neih) (w neiw) -> n d h w (neiw neih c)', neih=2, neiw=2)
+ (1): LayerNorm((480,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=480, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(364, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 432, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage3): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n c d (h neih) (w neiw) -> n d h w (neiw neih c)', neih=2, neiw=2)
+ (1): LayerNorm((480,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=480, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(364, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 432, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage4): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n c d (h neih) (w neiw) -> n d h w (neiw neih c)', neih=2, neiw=2)
+ (1): LayerNorm((480,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=480, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(364, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 432, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage5): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n (neiw neih c) d h w -> n d (h neih) (w neiw) c', neih=2, neiw=2)
+ (1): LayerNorm((30,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=30, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(364, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 432, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage6): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n (neiw neih c) d h w -> n d (h neih) (w neiw) c', neih=2, neiw=2)
+ (1): LayerNorm((30,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=30, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(364, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 432, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage7): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n (neiw neih c) d h w -> n d (h neih) (w neiw) c', neih=2, neiw=2)
+ (1): LayerNorm((30,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=30, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(364, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 432, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage8): ModuleList(
+ (0): Sequential(
+ (0): Rearrange('n c d h w -> n d h w c')
+ (1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=120, out_features=180, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (1): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (2): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (3): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (4): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (5): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (6): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ )
+ (norm): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (conv_after_body): Linear(in_features=180, out_features=120, bias=True)
+ (conv_before_upsample): Sequential(
+ (0): Conv3d(120, 64, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ (1): LeakyReLU(negative_slope=0.01, inplace=True)
+ )
+ (upsample): Upsample(
+ (0): Conv3d(64, 256, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ (1): Transpose_Dim12()
+ (2): PixelShuffle(upscale_factor=2)
+ (3): Transpose_Dim12()
+ (4): LeakyReLU(negative_slope=0.1, inplace=True)
+ (5): Conv3d(64, 256, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ (6): Transpose_Dim12()
+ (7): PixelShuffle(upscale_factor=2)
+ (8): Transpose_Dim12()
+ (9): LeakyReLU(negative_slope=0.1, inplace=True)
+ (10): Conv3d(64, 64, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ )
+ (conv_last): Conv3d(64, 3, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+)
+
+22-03-11 10:10:46.456 :
+ | mean | min | max | std || shape
+ | 0.000 | -1.496 | 1.623 | 0.115 | torch.Size([120, 27, 1, 3, 3]) || conv_first.weight
+ | -0.005 | -1.075 | 0.916 | 0.274 | torch.Size([120]) || conv_first.bias
+ | 0.449 | 0.406 | 0.485 | 0.040 | torch.Size([1, 3, 1, 1]) || spynet.mean
+ | 0.226 | 0.224 | 0.229 | 0.003 | torch.Size([1, 3, 1, 1]) || spynet.std
+ | -0.000 | -0.656 | 0.699 | 0.067 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.0.basic_module.0.weight
+ | -0.037 | -0.877 | 0.359 | 0.346 | torch.Size([32]) || spynet.basic_module.0.basic_module.0.bias
+ | -0.007 | -3.201 | 0.948 | 0.097 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.0.basic_module.2.weight
+ | 0.063 | -1.264 | 0.752 | 0.323 | torch.Size([64]) || spynet.basic_module.0.basic_module.2.bias
+ | -0.010 | -4.633 | 0.568 | 0.089 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.0.basic_module.4.weight
+ | 0.158 | -0.704 | 0.861 | 0.357 | torch.Size([32]) || spynet.basic_module.0.basic_module.4.bias
+ | -0.024 | -1.714 | 0.414 | 0.091 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.0.basic_module.6.weight
+ | 0.779 | -1.061 | 1.164 | 0.519 | torch.Size([16]) || spynet.basic_module.0.basic_module.6.bias
+ | 0.000 | -0.148 | 0.161 | 0.018 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.0.basic_module.8.weight
+ | 0.002 | -0.000 | 0.004 | 0.003 | torch.Size([2]) || spynet.basic_module.0.basic_module.8.bias
+ | 0.000 | -0.745 | 0.760 | 0.070 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.1.basic_module.0.weight
+ | -0.019 | -0.848 | 0.359 | 0.331 | torch.Size([32]) || spynet.basic_module.1.basic_module.0.bias
+ | -0.010 | -3.373 | 0.916 | 0.099 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.1.basic_module.2.weight
+ | 0.037 | -1.227 | 0.720 | 0.303 | torch.Size([64]) || spynet.basic_module.1.basic_module.2.bias
+ | -0.009 | -4.425 | 0.539 | 0.088 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.1.basic_module.4.weight
+ | 0.158 | -0.758 | 0.988 | 0.386 | torch.Size([32]) || spynet.basic_module.1.basic_module.4.bias
+ | -0.020 | -1.647 | 0.319 | 0.084 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.1.basic_module.6.weight
+ | 0.777 | -1.211 | 1.152 | 0.550 | torch.Size([16]) || spynet.basic_module.1.basic_module.6.bias
+ | 0.000 | -0.126 | 0.144 | 0.017 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.1.basic_module.8.weight
+ | 0.004 | 0.001 | 0.008 | 0.005 | torch.Size([2]) || spynet.basic_module.1.basic_module.8.bias
+ | 0.000 | -0.938 | 0.872 | 0.088 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.2.basic_module.0.weight
+ | -0.028 | -1.086 | 0.552 | 0.435 | torch.Size([32]) || spynet.basic_module.2.basic_module.0.bias
+ | -0.011 | -4.624 | 1.203 | 0.116 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.2.basic_module.2.weight
+ | 0.022 | -1.298 | 0.715 | 0.312 | torch.Size([64]) || spynet.basic_module.2.basic_module.2.bias
+ | -0.010 | -1.806 | 0.627 | 0.092 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.2.basic_module.4.weight
+ | 0.118 | -0.698 | 0.750 | 0.332 | torch.Size([32]) || spynet.basic_module.2.basic_module.4.bias
+ | -0.014 | -1.277 | 0.337 | 0.067 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.2.basic_module.6.weight
+ | 0.684 | -1.730 | 0.954 | 0.648 | torch.Size([16]) || spynet.basic_module.2.basic_module.6.bias
+ | 0.000 | -0.031 | 0.042 | 0.009 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.2.basic_module.8.weight
+ | -0.010 | -0.010 | -0.010 | 0.000 | torch.Size([2]) || spynet.basic_module.2.basic_module.8.bias
+ | -0.000 | -0.956 | 0.847 | 0.089 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.3.basic_module.0.weight
+ | -0.049 | -1.175 | 0.652 | 0.477 | torch.Size([32]) || spynet.basic_module.3.basic_module.0.bias
+ | -0.010 | -4.892 | 1.180 | 0.117 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.3.basic_module.2.weight
+ | 0.021 | -1.294 | 0.764 | 0.316 | torch.Size([64]) || spynet.basic_module.3.basic_module.2.bias
+ | -0.010 | -1.793 | 0.556 | 0.089 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.3.basic_module.4.weight
+ | 0.123 | -0.717 | 0.737 | 0.335 | torch.Size([32]) || spynet.basic_module.3.basic_module.4.bias
+ | -0.012 | -1.102 | 0.291 | 0.061 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.3.basic_module.6.weight
+ | 0.650 | -1.838 | 0.913 | 0.669 | torch.Size([16]) || spynet.basic_module.3.basic_module.6.bias
+ | 0.000 | -0.032 | 0.039 | 0.006 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.3.basic_module.8.weight
+ | 0.000 | -0.012 | 0.012 | 0.017 | torch.Size([2]) || spynet.basic_module.3.basic_module.8.bias
+ | -0.000 | -0.953 | 0.855 | 0.089 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.4.basic_module.0.weight
+ | -0.009 | -1.001 | 0.584 | 0.427 | torch.Size([32]) || spynet.basic_module.4.basic_module.0.bias
+ | -0.010 | -5.054 | 1.223 | 0.116 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.4.basic_module.2.weight
+ | 0.023 | -1.315 | 0.884 | 0.326 | torch.Size([64]) || spynet.basic_module.4.basic_module.2.bias
+ | -0.009 | -1.786 | 0.534 | 0.088 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.4.basic_module.4.weight
+ | 0.142 | -0.698 | 0.780 | 0.342 | torch.Size([32]) || spynet.basic_module.4.basic_module.4.bias
+ | -0.011 | -0.957 | 0.276 | 0.057 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.4.basic_module.6.weight
+ | 0.653 | -1.854 | 0.943 | 0.677 | torch.Size([16]) || spynet.basic_module.4.basic_module.6.bias
+ | 0.000 | -0.034 | 0.035 | 0.005 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.4.basic_module.8.weight
+ | -0.001 | -0.010 | 0.008 | 0.012 | torch.Size([2]) || spynet.basic_module.4.basic_module.8.bias
+ | -0.000 | -0.918 | 0.865 | 0.087 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.5.basic_module.0.weight
+ | 0.047 | -0.824 | 0.510 | 0.392 | torch.Size([32]) || spynet.basic_module.5.basic_module.0.bias
+ | -0.009 | -5.094 | 1.213 | 0.118 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.5.basic_module.2.weight
+ | 0.029 | -1.319 | 0.938 | 0.330 | torch.Size([64]) || spynet.basic_module.5.basic_module.2.bias
+ | -0.007 | -1.794 | 0.519 | 0.088 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.5.basic_module.4.weight
+ | 0.145 | -0.725 | 0.830 | 0.349 | torch.Size([32]) || spynet.basic_module.5.basic_module.4.bias
+ | -0.008 | -0.766 | 0.275 | 0.052 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.5.basic_module.6.weight
+ | 0.659 | -1.945 | 0.999 | 0.706 | torch.Size([16]) || spynet.basic_module.5.basic_module.6.bias
+ | 0.000 | -0.025 | 0.026 | 0.002 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.5.basic_module.8.weight
+ | 0.014 | 0.001 | 0.027 | 0.018 | torch.Size([2]) || spynet.basic_module.5.basic_module.8.bias
+ | 1.335 | 0.614 | 2.324 | 0.313 | torch.Size([120]) || stage1.reshape.1.weight
+ | -0.007 | -0.451 | 0.392 | 0.149 | torch.Size([120]) || stage1.reshape.1.bias
+ | 0.640 | 0.164 | 1.487 | 0.258 | torch.Size([120]) || stage1.residual_group1.blocks.0.norm1.weight
+ | -0.072 | -1.225 | 0.558 | 0.260 | torch.Size([120]) || stage1.residual_group1.blocks.0.norm1.bias
+ | -0.295 | -4.200 | 2.891 | 0.402 | torch.Size([675, 6]) || stage1.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.0.attn.position_bias
+ | 0.001 | -0.736 | 0.771 | 0.143 | torch.Size([360, 120]) || stage1.residual_group1.blocks.0.attn.qkv_self.weight
+ | -0.002 | -0.412 | 0.503 | 0.106 | torch.Size([360]) || stage1.residual_group1.blocks.0.attn.qkv_self.bias
+ | 0.001 | -0.711 | 0.595 | 0.091 | torch.Size([120, 240]) || stage1.residual_group1.blocks.0.attn.proj.weight
+ | -0.006 | -0.195 | 0.530 | 0.097 | torch.Size([120]) || stage1.residual_group1.blocks.0.attn.proj.bias
+ | -0.000 | -1.076 | 1.181 | 0.133 | torch.Size([360, 120]) || stage1.residual_group1.blocks.0.attn.qkv_mut.weight
+ | 0.000 | -0.228 | 0.294 | 0.059 | torch.Size([360]) || stage1.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.836 | 0.408 | 1.248 | 0.162 | torch.Size([120]) || stage1.residual_group1.blocks.0.norm2.weight
+ | 0.042 | -0.494 | 0.495 | 0.159 | torch.Size([120]) || stage1.residual_group1.blocks.0.norm2.bias
+ | 0.003 | -0.889 | 0.982 | 0.142 | torch.Size([240, 120]) || stage1.residual_group1.blocks.0.mlp.fc11.weight
+ | 0.041 | -0.364 | 0.458 | 0.117 | torch.Size([240]) || stage1.residual_group1.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.757 | 0.882 | 0.140 | torch.Size([240, 120]) || stage1.residual_group1.blocks.0.mlp.fc12.weight
+ | 0.011 | -0.400 | 0.470 | 0.157 | torch.Size([240]) || stage1.residual_group1.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.852 | 1.093 | 0.139 | torch.Size([120, 240]) || stage1.residual_group1.blocks.0.mlp.fc2.weight
+ | 0.022 | -0.265 | 0.384 | 0.096 | torch.Size([120]) || stage1.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.894 | 0.195 | 1.588 | 0.211 | torch.Size([120]) || stage1.residual_group1.blocks.1.norm1.weight
+ | -0.156 | -1.734 | 0.260 | 0.208 | torch.Size([120]) || stage1.residual_group1.blocks.1.norm1.bias
+ | -0.433 | -4.335 | 2.455 | 0.555 | torch.Size([675, 6]) || stage1.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.1.attn.position_bias
+ | -0.001 | -1.631 | 1.615 | 0.174 | torch.Size([360, 120]) || stage1.residual_group1.blocks.1.attn.qkv_self.weight
+ | 0.005 | -0.246 | 0.392 | 0.072 | torch.Size([360]) || stage1.residual_group1.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.697 | 0.574 | 0.098 | torch.Size([120, 240]) || stage1.residual_group1.blocks.1.attn.proj.weight
+ | 0.011 | -0.191 | 0.529 | 0.104 | torch.Size([120]) || stage1.residual_group1.blocks.1.attn.proj.bias
+ | -0.001 | -1.260 | 1.186 | 0.133 | torch.Size([360, 120]) || stage1.residual_group1.blocks.1.attn.qkv_mut.weight
+ | -0.002 | -0.207 | 0.162 | 0.050 | torch.Size([360]) || stage1.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.725 | 0.421 | 0.899 | 0.072 | torch.Size([120]) || stage1.residual_group1.blocks.1.norm2.weight
+ | 0.043 | -0.750 | 0.403 | 0.161 | torch.Size([120]) || stage1.residual_group1.blocks.1.norm2.bias
+ | -0.001 | -0.950 | 0.899 | 0.146 | torch.Size([240, 120]) || stage1.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.001 | -0.381 | 0.301 | 0.092 | torch.Size([240]) || stage1.residual_group1.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.615 | 0.630 | 0.142 | torch.Size([240, 120]) || stage1.residual_group1.blocks.1.mlp.fc12.weight
+ | 0.009 | -0.473 | 0.647 | 0.131 | torch.Size([240]) || stage1.residual_group1.blocks.1.mlp.fc12.bias
+ | 0.001 | -0.789 | 0.813 | 0.146 | torch.Size([120, 240]) || stage1.residual_group1.blocks.1.mlp.fc2.weight
+ | -0.041 | -0.335 | 0.331 | 0.119 | torch.Size([120]) || stage1.residual_group1.blocks.1.mlp.fc2.bias
+ | 1.087 | 0.163 | 1.663 | 0.218 | torch.Size([120]) || stage1.residual_group1.blocks.2.norm1.weight
+ | -0.188 | -1.539 | 0.134 | 0.175 | torch.Size([120]) || stage1.residual_group1.blocks.2.norm1.bias
+ | -0.505 | -4.230 | 3.070 | 0.545 | torch.Size([675, 6]) || stage1.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.2.attn.position_bias
+ | -0.000 | -1.348 | 1.453 | 0.171 | torch.Size([360, 120]) || stage1.residual_group1.blocks.2.attn.qkv_self.weight
+ | 0.007 | -0.394 | 0.633 | 0.080 | torch.Size([360]) || stage1.residual_group1.blocks.2.attn.qkv_self.bias
+ | 0.001 | -0.561 | 0.466 | 0.108 | torch.Size([120, 240]) || stage1.residual_group1.blocks.2.attn.proj.weight
+ | 0.028 | -0.263 | 0.277 | 0.111 | torch.Size([120]) || stage1.residual_group1.blocks.2.attn.proj.bias
+ | -0.000 | -0.982 | 1.268 | 0.124 | torch.Size([360, 120]) || stage1.residual_group1.blocks.2.attn.qkv_mut.weight
+ | 0.001 | -0.139 | 0.149 | 0.035 | torch.Size([360]) || stage1.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.743 | 0.234 | 0.925 | 0.092 | torch.Size([120]) || stage1.residual_group1.blocks.2.norm2.weight
+ | 0.030 | -1.015 | 0.440 | 0.156 | torch.Size([120]) || stage1.residual_group1.blocks.2.norm2.bias
+ | -0.002 | -0.956 | 1.234 | 0.155 | torch.Size([240, 120]) || stage1.residual_group1.blocks.2.mlp.fc11.weight
+ | 0.003 | -0.419 | 0.302 | 0.108 | torch.Size([240]) || stage1.residual_group1.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.723 | 0.609 | 0.143 | torch.Size([240, 120]) || stage1.residual_group1.blocks.2.mlp.fc12.weight
+ | -0.007 | -0.362 | 0.529 | 0.129 | torch.Size([240]) || stage1.residual_group1.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.768 | 0.645 | 0.147 | torch.Size([120, 240]) || stage1.residual_group1.blocks.2.mlp.fc2.weight
+ | -0.033 | -0.281 | 0.244 | 0.100 | torch.Size([120]) || stage1.residual_group1.blocks.2.mlp.fc2.bias
+ | 1.076 | 0.178 | 1.503 | 0.199 | torch.Size([120]) || stage1.residual_group1.blocks.3.norm1.weight
+ | -0.153 | -1.699 | 0.096 | 0.171 | torch.Size([120]) || stage1.residual_group1.blocks.3.norm1.bias
+ | -0.815 | -4.386 | 4.546 | 0.797 | torch.Size([675, 6]) || stage1.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.3.attn.position_bias
+ | 0.001 | -2.332 | 2.215 | 0.164 | torch.Size([360, 120]) || stage1.residual_group1.blocks.3.attn.qkv_self.weight
+ | -0.004 | -0.455 | 0.400 | 0.070 | torch.Size([360]) || stage1.residual_group1.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.504 | 0.556 | 0.108 | torch.Size([120, 240]) || stage1.residual_group1.blocks.3.attn.proj.weight
+ | -0.006 | -0.339 | 0.365 | 0.137 | torch.Size([120]) || stage1.residual_group1.blocks.3.attn.proj.bias
+ | 0.000 | -1.444 | 1.191 | 0.122 | torch.Size([360, 120]) || stage1.residual_group1.blocks.3.attn.qkv_mut.weight
+ | -0.001 | -0.162 | 0.140 | 0.029 | torch.Size([360]) || stage1.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.715 | 0.229 | 0.865 | 0.078 | torch.Size([120]) || stage1.residual_group1.blocks.3.norm2.weight
+ | 0.026 | -1.011 | 0.287 | 0.151 | torch.Size([120]) || stage1.residual_group1.blocks.3.norm2.bias
+ | -0.003 | -0.761 | 0.828 | 0.148 | torch.Size([240, 120]) || stage1.residual_group1.blocks.3.mlp.fc11.weight
+ | 0.014 | -0.337 | 0.418 | 0.135 | torch.Size([240]) || stage1.residual_group1.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.716 | 0.712 | 0.149 | torch.Size([240, 120]) || stage1.residual_group1.blocks.3.mlp.fc12.weight
+ | 0.003 | -0.427 | 0.369 | 0.124 | torch.Size([240]) || stage1.residual_group1.blocks.3.mlp.fc12.bias
+ | 0.001 | -0.719 | 0.640 | 0.151 | torch.Size([120, 240]) || stage1.residual_group1.blocks.3.mlp.fc2.weight
+ | -0.010 | -0.557 | 0.227 | 0.103 | torch.Size([120]) || stage1.residual_group1.blocks.3.mlp.fc2.bias
+ | 1.161 | 0.188 | 1.556 | 0.179 | torch.Size([120]) || stage1.residual_group1.blocks.4.norm1.weight
+ | -0.165 | -1.773 | 0.054 | 0.186 | torch.Size([120]) || stage1.residual_group1.blocks.4.norm1.bias
+ | -0.575 | -3.741 | 5.261 | 0.767 | torch.Size([675, 6]) || stage1.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.4.attn.position_bias
+ | 0.000 | -2.020 | 2.251 | 0.173 | torch.Size([360, 120]) || stage1.residual_group1.blocks.4.attn.qkv_self.weight
+ | 0.000 | -0.318 | 0.312 | 0.071 | torch.Size([360]) || stage1.residual_group1.blocks.4.attn.qkv_self.bias
+ | 0.000 | -0.463 | 0.456 | 0.112 | torch.Size([120, 240]) || stage1.residual_group1.blocks.4.attn.proj.weight
+ | 0.002 | -0.406 | 0.393 | 0.154 | torch.Size([120]) || stage1.residual_group1.blocks.4.attn.proj.bias
+ | -0.001 | -0.968 | 1.330 | 0.123 | torch.Size([360, 120]) || stage1.residual_group1.blocks.4.attn.qkv_mut.weight
+ | 0.001 | -0.152 | 0.176 | 0.030 | torch.Size([360]) || stage1.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.699 | 0.230 | 0.850 | 0.073 | torch.Size([120]) || stage1.residual_group1.blocks.4.norm2.weight
+ | 0.029 | -1.033 | 0.300 | 0.149 | torch.Size([120]) || stage1.residual_group1.blocks.4.norm2.bias
+ | -0.002 | -0.718 | 0.803 | 0.145 | torch.Size([240, 120]) || stage1.residual_group1.blocks.4.mlp.fc11.weight
+ | 0.002 | -0.389 | 0.405 | 0.139 | torch.Size([240]) || stage1.residual_group1.blocks.4.mlp.fc11.bias
+ | -0.001 | -0.582 | 0.624 | 0.151 | torch.Size([240, 120]) || stage1.residual_group1.blocks.4.mlp.fc12.weight
+ | 0.003 | -0.385 | 0.386 | 0.118 | torch.Size([240]) || stage1.residual_group1.blocks.4.mlp.fc12.bias
+ | 0.000 | -0.677 | 0.737 | 0.153 | torch.Size([120, 240]) || stage1.residual_group1.blocks.4.mlp.fc2.weight
+ | 0.003 | -0.671 | 0.208 | 0.108 | torch.Size([120]) || stage1.residual_group1.blocks.4.mlp.fc2.bias
+ | 1.067 | 0.173 | 1.473 | 0.179 | torch.Size([120]) || stage1.residual_group1.blocks.5.norm1.weight
+ | -0.129 | -1.487 | 0.138 | 0.166 | torch.Size([120]) || stage1.residual_group1.blocks.5.norm1.bias
+ | -0.530 | -3.629 | 3.705 | 0.621 | torch.Size([675, 6]) || stage1.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.5.attn.position_bias
+ | 0.000 | -2.344 | 1.768 | 0.157 | torch.Size([360, 120]) || stage1.residual_group1.blocks.5.attn.qkv_self.weight
+ | -0.001 | -0.428 | 0.265 | 0.082 | torch.Size([360]) || stage1.residual_group1.blocks.5.attn.qkv_self.bias
+ | -0.001 | -0.541 | 0.559 | 0.120 | torch.Size([120, 240]) || stage1.residual_group1.blocks.5.attn.proj.weight
+ | 0.031 | -0.324 | 0.379 | 0.133 | torch.Size([120]) || stage1.residual_group1.blocks.5.attn.proj.bias
+ | -0.001 | -1.380 | 0.992 | 0.120 | torch.Size([360, 120]) || stage1.residual_group1.blocks.5.attn.qkv_mut.weight
+ | 0.000 | -0.100 | 0.111 | 0.027 | torch.Size([360]) || stage1.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.637 | 0.273 | 0.780 | 0.064 | torch.Size([120]) || stage1.residual_group1.blocks.5.norm2.weight
+ | 0.022 | -1.160 | 0.338 | 0.149 | torch.Size([120]) || stage1.residual_group1.blocks.5.norm2.bias
+ | -0.002 | -0.696 | 0.638 | 0.139 | torch.Size([240, 120]) || stage1.residual_group1.blocks.5.mlp.fc11.weight
+ | 0.007 | -0.366 | 0.364 | 0.134 | torch.Size([240]) || stage1.residual_group1.blocks.5.mlp.fc11.bias
+ | -0.001 | -0.581 | 0.657 | 0.151 | torch.Size([240, 120]) || stage1.residual_group1.blocks.5.mlp.fc12.weight
+ | -0.004 | -0.366 | 0.244 | 0.105 | torch.Size([240]) || stage1.residual_group1.blocks.5.mlp.fc12.bias
+ | 0.000 | -1.143 | 0.787 | 0.154 | torch.Size([120, 240]) || stage1.residual_group1.blocks.5.mlp.fc2.weight
+ | 0.023 | -1.254 | 0.407 | 0.160 | torch.Size([120]) || stage1.residual_group1.blocks.5.mlp.fc2.bias
+ | 0.001 | -0.293 | 0.270 | 0.065 | torch.Size([120, 120]) || stage1.linear1.weight
+ | 0.006 | -0.209 | 0.382 | 0.093 | torch.Size([120]) || stage1.linear1.bias
+ | 0.811 | 0.432 | 1.092 | 0.108 | torch.Size([120]) || stage1.residual_group2.blocks.0.norm1.weight
+ | 0.033 | -0.763 | 0.477 | 0.200 | torch.Size([120]) || stage1.residual_group2.blocks.0.norm1.bias
+ | -0.049 | -2.996 | 1.734 | 0.246 | torch.Size([3375, 6]) || stage1.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage1.residual_group2.blocks.0.attn.relative_position_index
+ | -0.000 | -0.847 | 1.215 | 0.150 | torch.Size([360, 120]) || stage1.residual_group2.blocks.0.attn.qkv_self.weight
+ | -0.000 | -0.542 | 0.581 | 0.147 | torch.Size([360]) || stage1.residual_group2.blocks.0.attn.qkv_self.bias
+ | 0.001 | -0.536 | 0.569 | 0.124 | torch.Size([120, 120]) || stage1.residual_group2.blocks.0.attn.proj.weight
+ | -0.004 | -0.195 | 0.602 | 0.102 | torch.Size([120]) || stage1.residual_group2.blocks.0.attn.proj.bias
+ | 0.568 | 0.438 | 0.872 | 0.074 | torch.Size([120]) || stage1.residual_group2.blocks.0.norm2.weight
+ | 0.025 | -0.782 | 0.342 | 0.164 | torch.Size([120]) || stage1.residual_group2.blocks.0.norm2.bias
+ | 0.003 | -0.601 | 0.699 | 0.126 | torch.Size([240, 120]) || stage1.residual_group2.blocks.0.mlp.fc11.weight
+ | 0.068 | -0.329 | 0.446 | 0.095 | torch.Size([240]) || stage1.residual_group2.blocks.0.mlp.fc11.bias
+ | 0.001 | -0.807 | 0.710 | 0.143 | torch.Size([240, 120]) || stage1.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.002 | -0.585 | 0.392 | 0.117 | torch.Size([240]) || stage1.residual_group2.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.779 | 0.575 | 0.142 | torch.Size([120, 240]) || stage1.residual_group2.blocks.0.mlp.fc2.weight
+ | 0.008 | -0.377 | 0.374 | 0.159 | torch.Size([120]) || stage1.residual_group2.blocks.0.mlp.fc2.bias
+ | 0.942 | 0.411 | 1.171 | 0.093 | torch.Size([120]) || stage1.residual_group2.blocks.1.norm1.weight
+ | 0.038 | -0.837 | 0.321 | 0.152 | torch.Size([120]) || stage1.residual_group2.blocks.1.norm1.bias
+ | -0.077 | -2.150 | 2.175 | 0.237 | torch.Size([3375, 6]) || stage1.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage1.residual_group2.blocks.1.attn.relative_position_index
+ | -0.000 | -0.750 | 0.771 | 0.159 | torch.Size([360, 120]) || stage1.residual_group2.blocks.1.attn.qkv_self.weight
+ | -0.004 | -0.589 | 0.559 | 0.145 | torch.Size([360]) || stage1.residual_group2.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.478 | 0.525 | 0.125 | torch.Size([120, 120]) || stage1.residual_group2.blocks.1.attn.proj.weight
+ | 0.009 | -0.338 | 0.449 | 0.154 | torch.Size([120]) || stage1.residual_group2.blocks.1.attn.proj.bias
+ | 0.597 | 0.429 | 0.741 | 0.044 | torch.Size([120]) || stage1.residual_group2.blocks.1.norm2.weight
+ | 0.038 | -0.697 | 0.195 | 0.103 | torch.Size([120]) || stage1.residual_group2.blocks.1.norm2.bias
+ | 0.003 | -0.671 | 0.636 | 0.135 | torch.Size([240, 120]) || stage1.residual_group2.blocks.1.mlp.fc11.weight
+ | 0.057 | -0.519 | 0.422 | 0.139 | torch.Size([240]) || stage1.residual_group2.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.629 | 0.607 | 0.153 | torch.Size([240, 120]) || stage1.residual_group2.blocks.1.mlp.fc12.weight
+ | -0.007 | -0.279 | 0.403 | 0.083 | torch.Size([240]) || stage1.residual_group2.blocks.1.mlp.fc12.bias
+ | 0.001 | -0.620 | 0.712 | 0.150 | torch.Size([120, 240]) || stage1.residual_group2.blocks.1.mlp.fc2.weight
+ | 0.014 | -0.721 | 0.333 | 0.163 | torch.Size([120]) || stage1.residual_group2.blocks.1.mlp.fc2.bias
+ | 0.000 | -0.504 | 0.343 | 0.079 | torch.Size([120, 120]) || stage1.linear2.weight
+ | 0.015 | -0.276 | 0.353 | 0.122 | torch.Size([120]) || stage1.linear2.bias
+ | -0.000 | -0.151 | 0.136 | 0.025 | torch.Size([120, 120, 3, 3]) || stage1.pa_deform.weight
+ | -0.001 | -0.087 | 0.103 | 0.030 | torch.Size([120]) || stage1.pa_deform.bias
+ | -0.000 | -0.017 | 0.017 | 0.010 | torch.Size([120, 364, 3, 3]) || stage1.pa_deform.conv_offset.0.weight
+ | -0.004 | -0.024 | 0.040 | 0.013 | torch.Size([120]) || stage1.pa_deform.conv_offset.0.bias
+ | -0.001 | -0.122 | 0.123 | 0.017 | torch.Size([120, 120, 3, 3]) || stage1.pa_deform.conv_offset.2.weight
+ | -0.009 | -0.068 | 0.068 | 0.028 | torch.Size([120]) || stage1.pa_deform.conv_offset.2.bias
+ | -0.001 | -0.175 | 0.114 | 0.015 | torch.Size([120, 120, 3, 3]) || stage1.pa_deform.conv_offset.4.weight
+ | 0.019 | -0.059 | 0.110 | 0.042 | torch.Size([120]) || stage1.pa_deform.conv_offset.4.bias
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432, 120, 3, 3]) || stage1.pa_deform.conv_offset.6.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432]) || stage1.pa_deform.conv_offset.6.bias
+ | -0.001 | -1.034 | 1.208 | 0.150 | torch.Size([360, 360]) || stage1.pa_fuse.fc11.weight
+ | 0.085 | -0.220 | 0.682 | 0.164 | torch.Size([360]) || stage1.pa_fuse.fc11.bias
+ | 0.001 | -1.305 | 1.408 | 0.167 | torch.Size([360, 360]) || stage1.pa_fuse.fc12.weight
+ | 0.005 | -0.474 | 0.521 | 0.147 | torch.Size([360]) || stage1.pa_fuse.fc12.bias
+ | 0.000 | -0.941 | 0.939 | 0.158 | torch.Size([120, 360]) || stage1.pa_fuse.fc2.weight
+ | 0.019 | -0.993 | 0.852 | 0.371 | torch.Size([120]) || stage1.pa_fuse.fc2.bias
+ | 1.099 | 0.165 | 1.669 | 0.285 | torch.Size([480]) || stage2.reshape.1.weight
+ | -0.009 | -0.723 | 0.825 | 0.237 | torch.Size([480]) || stage2.reshape.1.bias
+ | -0.000 | -0.767 | 0.672 | 0.163 | torch.Size([120, 480]) || stage2.reshape.2.weight
+ | -0.007 | -0.473 | 0.285 | 0.116 | torch.Size([120]) || stage2.reshape.2.bias
+ | 0.665 | 0.267 | 1.019 | 0.157 | torch.Size([120]) || stage2.residual_group1.blocks.0.norm1.weight
+ | -0.152 | -0.897 | 0.303 | 0.218 | torch.Size([120]) || stage2.residual_group1.blocks.0.norm1.bias
+ | -0.208 | -1.940 | 4.459 | 0.383 | torch.Size([675, 6]) || stage2.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.0.attn.position_bias
+ | -0.000 | -0.653 | 0.613 | 0.127 | torch.Size([360, 120]) || stage2.residual_group1.blocks.0.attn.qkv_self.weight
+ | 0.003 | -0.263 | 0.270 | 0.066 | torch.Size([360]) || stage2.residual_group1.blocks.0.attn.qkv_self.bias
+ | 0.002 | -0.796 | 0.596 | 0.108 | torch.Size([120, 240]) || stage2.residual_group1.blocks.0.attn.proj.weight
+ | -0.008 | -0.955 | 0.285 | 0.127 | torch.Size([120]) || stage2.residual_group1.blocks.0.attn.proj.bias
+ | 0.000 | -1.099 | 0.979 | 0.109 | torch.Size([360, 120]) || stage2.residual_group1.blocks.0.attn.qkv_mut.weight
+ | -0.000 | -0.131 | 0.090 | 0.022 | torch.Size([360]) || stage2.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.548 | 0.301 | 0.671 | 0.063 | torch.Size([120]) || stage2.residual_group1.blocks.0.norm2.weight
+ | 0.003 | -0.744 | 0.803 | 0.231 | torch.Size([120]) || stage2.residual_group1.blocks.0.norm2.bias
+ | 0.001 | -0.645 | 0.555 | 0.133 | torch.Size([240, 120]) || stage2.residual_group1.blocks.0.mlp.fc11.weight
+ | 0.013 | -0.406 | 0.272 | 0.097 | torch.Size([240]) || stage2.residual_group1.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.622 | 0.666 | 0.147 | torch.Size([240, 120]) || stage2.residual_group1.blocks.0.mlp.fc12.weight
+ | 0.002 | -0.228 | 0.307 | 0.085 | torch.Size([240]) || stage2.residual_group1.blocks.0.mlp.fc12.bias
+ | 0.001 | -0.834 | 0.822 | 0.149 | torch.Size([120, 240]) || stage2.residual_group1.blocks.0.mlp.fc2.weight
+ | -0.009 | -0.948 | 0.446 | 0.159 | torch.Size([120]) || stage2.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.777 | 0.311 | 1.104 | 0.161 | torch.Size([120]) || stage2.residual_group1.blocks.1.norm1.weight
+ | -0.178 | -0.966 | 0.822 | 0.247 | torch.Size([120]) || stage2.residual_group1.blocks.1.norm1.bias
+ | -0.387 | -2.000 | 5.826 | 0.443 | torch.Size([675, 6]) || stage2.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.1.attn.position_bias
+ | 0.000 | -0.662 | 0.706 | 0.132 | torch.Size([360, 120]) || stage2.residual_group1.blocks.1.attn.qkv_self.weight
+ | -0.006 | -0.348 | 0.306 | 0.079 | torch.Size([360]) || stage2.residual_group1.blocks.1.attn.qkv_self.bias
+ | -0.001 | -0.595 | 0.730 | 0.112 | torch.Size([120, 240]) || stage2.residual_group1.blocks.1.attn.proj.weight
+ | -0.001 | -0.811 | 0.531 | 0.167 | torch.Size([120]) || stage2.residual_group1.blocks.1.attn.proj.bias
+ | -0.000 | -1.007 | 1.002 | 0.105 | torch.Size([360, 120]) || stage2.residual_group1.blocks.1.attn.qkv_mut.weight
+ | -0.002 | -0.180 | 0.108 | 0.024 | torch.Size([360]) || stage2.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.599 | 0.282 | 0.730 | 0.059 | torch.Size([120]) || stage2.residual_group1.blocks.1.norm2.weight
+ | -0.004 | -0.671 | 0.938 | 0.218 | torch.Size([120]) || stage2.residual_group1.blocks.1.norm2.bias
+ | 0.000 | -0.536 | 0.570 | 0.134 | torch.Size([240, 120]) || stage2.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.022 | -0.540 | 0.226 | 0.107 | torch.Size([240]) || stage2.residual_group1.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.646 | 0.589 | 0.149 | torch.Size([240, 120]) || stage2.residual_group1.blocks.1.mlp.fc12.weight
+ | 0.008 | -0.203 | 0.282 | 0.092 | torch.Size([240]) || stage2.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.000 | -1.052 | 0.649 | 0.150 | torch.Size([120, 240]) || stage2.residual_group1.blocks.1.mlp.fc2.weight
+ | -0.007 | -0.581 | 0.467 | 0.137 | torch.Size([120]) || stage2.residual_group1.blocks.1.mlp.fc2.bias
+ | 0.780 | 0.134 | 1.161 | 0.193 | torch.Size([120]) || stage2.residual_group1.blocks.2.norm1.weight
+ | -0.152 | -0.996 | 1.042 | 0.227 | torch.Size([120]) || stage2.residual_group1.blocks.2.norm1.bias
+ | -0.186 | -2.565 | 4.152 | 0.428 | torch.Size([675, 6]) || stage2.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.2.attn.position_bias
+ | 0.001 | -0.856 | 0.814 | 0.151 | torch.Size([360, 120]) || stage2.residual_group1.blocks.2.attn.qkv_self.weight
+ | -0.002 | -0.367 | 0.317 | 0.074 | torch.Size([360]) || stage2.residual_group1.blocks.2.attn.qkv_self.bias
+ | -0.001 | -0.656 | 0.730 | 0.131 | torch.Size([120, 240]) || stage2.residual_group1.blocks.2.attn.proj.weight
+ | -0.003 | -0.555 | 0.620 | 0.163 | torch.Size([120]) || stage2.residual_group1.blocks.2.attn.proj.bias
+ | 0.001 | -2.191 | 2.575 | 0.137 | torch.Size([360, 120]) || stage2.residual_group1.blocks.2.attn.qkv_mut.weight
+ | 0.000 | -0.121 | 0.139 | 0.023 | torch.Size([360]) || stage2.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.640 | 0.297 | 0.797 | 0.064 | torch.Size([120]) || stage2.residual_group1.blocks.2.norm2.weight
+ | -0.013 | -0.584 | 0.934 | 0.217 | torch.Size([120]) || stage2.residual_group1.blocks.2.norm2.bias
+ | 0.000 | -0.523 | 0.556 | 0.136 | torch.Size([240, 120]) || stage2.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.035 | -0.490 | 0.217 | 0.117 | torch.Size([240]) || stage2.residual_group1.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.679 | 0.601 | 0.152 | torch.Size([240, 120]) || stage2.residual_group1.blocks.2.mlp.fc12.weight
+ | 0.005 | -0.287 | 0.308 | 0.098 | torch.Size([240]) || stage2.residual_group1.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.576 | 0.584 | 0.151 | torch.Size([120, 240]) || stage2.residual_group1.blocks.2.mlp.fc2.weight
+ | -0.006 | -0.423 | 0.376 | 0.121 | torch.Size([120]) || stage2.residual_group1.blocks.2.mlp.fc2.bias
+ | 0.776 | 0.134 | 1.030 | 0.164 | torch.Size([120]) || stage2.residual_group1.blocks.3.norm1.weight
+ | -0.167 | -0.870 | 1.066 | 0.204 | torch.Size([120]) || stage2.residual_group1.blocks.3.norm1.bias
+ | -0.259 | -1.735 | 5.189 | 0.366 | torch.Size([675, 6]) || stage2.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.3.attn.position_bias
+ | 0.000 | -1.292 | 1.255 | 0.149 | torch.Size([360, 120]) || stage2.residual_group1.blocks.3.attn.qkv_self.weight
+ | 0.000 | -0.493 | 0.445 | 0.101 | torch.Size([360]) || stage2.residual_group1.blocks.3.attn.qkv_self.bias
+ | 0.001 | -0.618 | 0.582 | 0.122 | torch.Size([120, 240]) || stage2.residual_group1.blocks.3.attn.proj.weight
+ | -0.001 | -0.543 | 0.420 | 0.166 | torch.Size([120]) || stage2.residual_group1.blocks.3.attn.proj.bias
+ | 0.002 | -2.296 | 2.630 | 0.162 | torch.Size([360, 120]) || stage2.residual_group1.blocks.3.attn.qkv_mut.weight
+ | -0.001 | -0.130 | 0.149 | 0.028 | torch.Size([360]) || stage2.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.625 | 0.301 | 0.772 | 0.060 | torch.Size([120]) || stage2.residual_group1.blocks.3.norm2.weight
+ | -0.015 | -0.498 | 0.992 | 0.198 | torch.Size([120]) || stage2.residual_group1.blocks.3.norm2.bias
+ | -0.000 | -0.620 | 0.681 | 0.130 | torch.Size([240, 120]) || stage2.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.006 | -0.391 | 0.256 | 0.113 | torch.Size([240]) || stage2.residual_group1.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.575 | 0.669 | 0.152 | torch.Size([240, 120]) || stage2.residual_group1.blocks.3.mlp.fc12.weight
+ | -0.000 | -0.225 | 0.333 | 0.088 | torch.Size([240]) || stage2.residual_group1.blocks.3.mlp.fc12.bias
+ | 0.001 | -0.680 | 0.639 | 0.151 | torch.Size([120, 240]) || stage2.residual_group1.blocks.3.mlp.fc2.weight
+ | -0.011 | -0.549 | 0.259 | 0.139 | torch.Size([120]) || stage2.residual_group1.blocks.3.mlp.fc2.bias
+ | 0.933 | 0.310 | 1.186 | 0.121 | torch.Size([120]) || stage2.residual_group1.blocks.4.norm1.weight
+ | -0.180 | -0.736 | 1.168 | 0.204 | torch.Size([120]) || stage2.residual_group1.blocks.4.norm1.bias
+ | -0.164 | -2.965 | 4.145 | 0.437 | torch.Size([675, 6]) || stage2.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.4.attn.position_bias
+ | 0.000 | -0.860 | 0.749 | 0.136 | torch.Size([360, 120]) || stage2.residual_group1.blocks.4.attn.qkv_self.weight
+ | 0.005 | -0.274 | 0.308 | 0.080 | torch.Size([360]) || stage2.residual_group1.blocks.4.attn.qkv_self.bias
+ | 0.001 | -0.648 | 0.681 | 0.129 | torch.Size([120, 240]) || stage2.residual_group1.blocks.4.attn.proj.weight
+ | 0.002 | -0.547 | 0.295 | 0.149 | torch.Size([120]) || stage2.residual_group1.blocks.4.attn.proj.bias
+ | -0.000 | -0.647 | 0.577 | 0.105 | torch.Size([360, 120]) || stage2.residual_group1.blocks.4.attn.qkv_mut.weight
+ | -0.001 | -0.138 | 0.125 | 0.023 | torch.Size([360]) || stage2.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.635 | 0.329 | 0.748 | 0.049 | torch.Size([120]) || stage2.residual_group1.blocks.4.norm2.weight
+ | -0.018 | -0.375 | 0.891 | 0.157 | torch.Size([120]) || stage2.residual_group1.blocks.4.norm2.bias
+ | -0.000 | -0.603 | 0.497 | 0.130 | torch.Size([240, 120]) || stage2.residual_group1.blocks.4.mlp.fc11.weight
+ | -0.010 | -0.345 | 0.297 | 0.113 | torch.Size([240]) || stage2.residual_group1.blocks.4.mlp.fc11.bias
+ | -0.000 | -0.680 | 0.679 | 0.153 | torch.Size([240, 120]) || stage2.residual_group1.blocks.4.mlp.fc12.weight
+ | -0.000 | -0.200 | 0.251 | 0.086 | torch.Size([240]) || stage2.residual_group1.blocks.4.mlp.fc12.bias
+ | -0.001 | -0.568 | 0.614 | 0.152 | torch.Size([120, 240]) || stage2.residual_group1.blocks.4.mlp.fc2.weight
+ | -0.009 | -0.375 | 0.493 | 0.135 | torch.Size([120]) || stage2.residual_group1.blocks.4.mlp.fc2.bias
+ | 0.870 | 0.315 | 1.059 | 0.096 | torch.Size([120]) || stage2.residual_group1.blocks.5.norm1.weight
+ | -0.139 | -0.657 | 1.107 | 0.163 | torch.Size([120]) || stage2.residual_group1.blocks.5.norm1.bias
+ | -0.156 | -4.167 | 4.651 | 0.340 | torch.Size([675, 6]) || stage2.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.5.attn.position_bias
+ | 0.000 | -0.701 | 0.871 | 0.134 | torch.Size([360, 120]) || stage2.residual_group1.blocks.5.attn.qkv_self.weight
+ | -0.000 | -0.427 | 0.471 | 0.099 | torch.Size([360]) || stage2.residual_group1.blocks.5.attn.qkv_self.bias
+ | -0.000 | -0.520 | 0.546 | 0.113 | torch.Size([120, 240]) || stage2.residual_group1.blocks.5.attn.proj.weight
+ | -0.008 | -0.360 | 0.350 | 0.137 | torch.Size([120]) || stage2.residual_group1.blocks.5.attn.proj.bias
+ | 0.001 | -0.510 | 0.502 | 0.100 | torch.Size([360, 120]) || stage2.residual_group1.blocks.5.attn.qkv_mut.weight
+ | 0.001 | -0.092 | 0.125 | 0.021 | torch.Size([360]) || stage2.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.597 | 0.345 | 0.691 | 0.044 | torch.Size([120]) || stage2.residual_group1.blocks.5.norm2.weight
+ | -0.015 | -0.367 | 0.987 | 0.132 | torch.Size([120]) || stage2.residual_group1.blocks.5.norm2.bias
+ | 0.001 | -0.552 | 0.532 | 0.128 | torch.Size([240, 120]) || stage2.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.009 | -0.336 | 0.253 | 0.107 | torch.Size([240]) || stage2.residual_group1.blocks.5.mlp.fc11.bias
+ | 0.000 | -0.644 | 0.758 | 0.154 | torch.Size([240, 120]) || stage2.residual_group1.blocks.5.mlp.fc12.weight
+ | -0.001 | -0.243 | 0.264 | 0.088 | torch.Size([240]) || stage2.residual_group1.blocks.5.mlp.fc12.bias
+ | -0.001 | -0.667 | 0.621 | 0.152 | torch.Size([120, 240]) || stage2.residual_group1.blocks.5.mlp.fc2.weight
+ | -0.002 | -0.447 | 1.139 | 0.183 | torch.Size([120]) || stage2.residual_group1.blocks.5.mlp.fc2.bias
+ | 0.002 | -0.268 | 0.331 | 0.066 | torch.Size([120, 120]) || stage2.linear1.weight
+ | 0.005 | -0.338 | 0.589 | 0.128 | torch.Size([120]) || stage2.linear1.bias
+ | 0.939 | 0.517 | 1.207 | 0.113 | torch.Size([120]) || stage2.residual_group2.blocks.0.norm1.weight
+ | 0.023 | -0.770 | 0.614 | 0.238 | torch.Size([120]) || stage2.residual_group2.blocks.0.norm1.bias
+ | 0.004 | -3.112 | 1.341 | 0.140 | torch.Size([3375, 6]) || stage2.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage2.residual_group2.blocks.0.attn.relative_position_index
+ | 0.000 | -0.605 | 0.580 | 0.136 | torch.Size([360, 120]) || stage2.residual_group2.blocks.0.attn.qkv_self.weight
+ | 0.001 | -0.591 | 0.477 | 0.112 | torch.Size([360]) || stage2.residual_group2.blocks.0.attn.qkv_self.bias
+ | 0.001 | -0.645 | 0.613 | 0.150 | torch.Size([120, 120]) || stage2.residual_group2.blocks.0.attn.proj.weight
+ | -0.031 | -0.422 | 0.330 | 0.138 | torch.Size([120]) || stage2.residual_group2.blocks.0.attn.proj.bias
+ | 0.684 | 0.501 | 0.807 | 0.061 | torch.Size([120]) || stage2.residual_group2.blocks.0.norm2.weight
+ | 0.018 | -0.693 | 0.412 | 0.181 | torch.Size([120]) || stage2.residual_group2.blocks.0.norm2.bias
+ | 0.001 | -0.559 | 0.715 | 0.125 | torch.Size([240, 120]) || stage2.residual_group2.blocks.0.mlp.fc11.weight
+ | 0.031 | -0.346 | 0.273 | 0.108 | torch.Size([240]) || stage2.residual_group2.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.744 | 0.559 | 0.146 | torch.Size([240, 120]) || stage2.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.005 | -0.239 | 0.270 | 0.080 | torch.Size([240]) || stage2.residual_group2.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.603 | 0.871 | 0.144 | torch.Size([120, 240]) || stage2.residual_group2.blocks.0.mlp.fc2.weight
+ | -0.003 | -0.317 | 0.303 | 0.122 | torch.Size([120]) || stage2.residual_group2.blocks.0.mlp.fc2.bias
+ | 0.974 | 0.575 | 1.211 | 0.095 | torch.Size([120]) || stage2.residual_group2.blocks.1.norm1.weight
+ | 0.023 | -0.703 | 0.556 | 0.208 | torch.Size([120]) || stage2.residual_group2.blocks.1.norm1.bias
+ | 0.012 | -2.867 | 1.552 | 0.185 | torch.Size([3375, 6]) || stage2.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage2.residual_group2.blocks.1.attn.relative_position_index
+ | 0.000 | -0.743 | 0.663 | 0.142 | torch.Size([360, 120]) || stage2.residual_group2.blocks.1.attn.qkv_self.weight
+ | 0.002 | -0.647 | 0.654 | 0.141 | torch.Size([360]) || stage2.residual_group2.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.610 | 0.648 | 0.151 | torch.Size([120, 120]) || stage2.residual_group2.blocks.1.attn.proj.weight
+ | -0.028 | -0.565 | 0.416 | 0.167 | torch.Size([120]) || stage2.residual_group2.blocks.1.attn.proj.bias
+ | 0.742 | 0.522 | 0.891 | 0.076 | torch.Size([120]) || stage2.residual_group2.blocks.1.norm2.weight
+ | 0.020 | -0.506 | 0.335 | 0.138 | torch.Size([120]) || stage2.residual_group2.blocks.1.norm2.bias
+ | 0.001 | -0.486 | 0.512 | 0.123 | torch.Size([240, 120]) || stage2.residual_group2.blocks.1.mlp.fc11.weight
+ | 0.094 | -0.405 | 0.617 | 0.174 | torch.Size([240]) || stage2.residual_group2.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.618 | 0.596 | 0.149 | torch.Size([240, 120]) || stage2.residual_group2.blocks.1.mlp.fc12.weight
+ | -0.001 | -0.276 | 0.202 | 0.077 | torch.Size([240]) || stage2.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.668 | 0.769 | 0.148 | torch.Size([120, 240]) || stage2.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.014 | -0.729 | 0.410 | 0.187 | torch.Size([120]) || stage2.residual_group2.blocks.1.mlp.fc2.bias
+ | 0.001 | -0.309 | 0.381 | 0.079 | torch.Size([120, 120]) || stage2.linear2.weight
+ | 0.017 | -0.403 | 0.399 | 0.133 | torch.Size([120]) || stage2.linear2.bias
+ | -0.000 | -0.111 | 0.126 | 0.024 | torch.Size([120, 120, 3, 3]) || stage2.pa_deform.weight
+ | 0.001 | -0.031 | 0.055 | 0.017 | torch.Size([120]) || stage2.pa_deform.bias
+ | -0.000 | -0.017 | 0.017 | 0.010 | torch.Size([120, 364, 3, 3]) || stage2.pa_deform.conv_offset.0.weight
+ | -0.010 | -0.038 | 0.021 | 0.012 | torch.Size([120]) || stage2.pa_deform.conv_offset.0.bias
+ | -0.001 | -0.113 | 0.096 | 0.020 | torch.Size([120, 120, 3, 3]) || stage2.pa_deform.conv_offset.2.weight
+ | -0.010 | -0.089 | 0.087 | 0.032 | torch.Size([120]) || stage2.pa_deform.conv_offset.2.bias
+ | -0.001 | -0.079 | 0.087 | 0.019 | torch.Size([120, 120, 3, 3]) || stage2.pa_deform.conv_offset.4.weight
+ | -0.015 | -0.134 | 0.121 | 0.058 | torch.Size([120]) || stage2.pa_deform.conv_offset.4.bias
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432, 120, 3, 3]) || stage2.pa_deform.conv_offset.6.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432]) || stage2.pa_deform.conv_offset.6.bias
+ | 0.004 | -1.011 | 1.138 | 0.150 | torch.Size([360, 360]) || stage2.pa_fuse.fc11.weight
+ | 0.151 | -0.228 | 0.674 | 0.167 | torch.Size([360]) || stage2.pa_fuse.fc11.bias
+ | 0.001 | -0.988 | 1.066 | 0.144 | torch.Size([360, 360]) || stage2.pa_fuse.fc12.weight
+ | 0.009 | -0.418 | 0.533 | 0.127 | torch.Size([360]) || stage2.pa_fuse.fc12.bias
+ | 0.000 | -0.784 | 0.831 | 0.151 | torch.Size([120, 360]) || stage2.pa_fuse.fc2.weight
+ | 0.007 | -0.581 | 0.470 | 0.257 | torch.Size([120]) || stage2.pa_fuse.fc2.bias
+ | 1.105 | 0.504 | 1.774 | 0.248 | torch.Size([480]) || stage3.reshape.1.weight
+ | -0.006 | -0.633 | 0.736 | 0.296 | torch.Size([480]) || stage3.reshape.1.bias
+ | -0.000 | -0.682 | 0.687 | 0.168 | torch.Size([120, 480]) || stage3.reshape.2.weight
+ | -0.004 | -0.207 | 0.227 | 0.086 | torch.Size([120]) || stage3.reshape.2.bias
+ | 0.735 | 0.431 | 0.997 | 0.127 | torch.Size([120]) || stage3.residual_group1.blocks.0.norm1.weight
+ | -0.162 | -0.753 | 0.303 | 0.198 | torch.Size([120]) || stage3.residual_group1.blocks.0.norm1.bias
+ | -0.001 | -0.490 | 0.344 | 0.037 | torch.Size([675, 6]) || stage3.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.0.attn.position_bias
+ | 0.000 | -0.333 | 0.350 | 0.061 | torch.Size([360, 120]) || stage3.residual_group1.blocks.0.attn.qkv_self.weight
+ | -0.004 | -0.195 | 0.128 | 0.039 | torch.Size([360]) || stage3.residual_group1.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.359 | 0.365 | 0.067 | torch.Size([120, 240]) || stage3.residual_group1.blocks.0.attn.proj.weight
+ | -0.002 | -0.216 | 0.262 | 0.084 | torch.Size([120]) || stage3.residual_group1.blocks.0.attn.proj.bias
+ | 0.000 | -0.597 | 0.657 | 0.058 | torch.Size([360, 120]) || stage3.residual_group1.blocks.0.attn.qkv_mut.weight
+ | 0.001 | -0.115 | 0.118 | 0.020 | torch.Size([360]) || stage3.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.594 | 0.414 | 0.775 | 0.069 | torch.Size([120]) || stage3.residual_group1.blocks.0.norm2.weight
+ | 0.003 | -0.260 | 0.315 | 0.105 | torch.Size([120]) || stage3.residual_group1.blocks.0.norm2.bias
+ | 0.001 | -0.446 | 0.536 | 0.116 | torch.Size([240, 120]) || stage3.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.077 | -0.361 | 0.145 | 0.072 | torch.Size([240]) || stage3.residual_group1.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.507 | 0.503 | 0.124 | torch.Size([240, 120]) || stage3.residual_group1.blocks.0.mlp.fc12.weight
+ | 0.005 | -0.225 | 0.207 | 0.062 | torch.Size([240]) || stage3.residual_group1.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.553 | 0.493 | 0.129 | torch.Size([120, 240]) || stage3.residual_group1.blocks.0.mlp.fc2.weight
+ | -0.006 | -0.268 | 0.158 | 0.085 | torch.Size([120]) || stage3.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.716 | 0.376 | 0.965 | 0.119 | torch.Size([120]) || stage3.residual_group1.blocks.1.norm1.weight
+ | -0.185 | -0.732 | 0.209 | 0.179 | torch.Size([120]) || stage3.residual_group1.blocks.1.norm1.bias
+ | -0.002 | -0.462 | 1.414 | 0.064 | torch.Size([675, 6]) || stage3.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.1.attn.position_bias
+ | 0.000 | -0.383 | 0.438 | 0.060 | torch.Size([360, 120]) || stage3.residual_group1.blocks.1.attn.qkv_self.weight
+ | -0.002 | -0.229 | 0.157 | 0.044 | torch.Size([360]) || stage3.residual_group1.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.357 | 0.478 | 0.065 | torch.Size([120, 240]) || stage3.residual_group1.blocks.1.attn.proj.weight
+ | -0.004 | -0.280 | 0.216 | 0.101 | torch.Size([120]) || stage3.residual_group1.blocks.1.attn.proj.bias
+ | 0.000 | -0.471 | 0.517 | 0.063 | torch.Size([360, 120]) || stage3.residual_group1.blocks.1.attn.qkv_mut.weight
+ | -0.000 | -0.112 | 0.131 | 0.022 | torch.Size([360]) || stage3.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.633 | 0.486 | 0.778 | 0.057 | torch.Size([120]) || stage3.residual_group1.blocks.1.norm2.weight
+ | 0.004 | -0.350 | 0.280 | 0.107 | torch.Size([120]) || stage3.residual_group1.blocks.1.norm2.bias
+ | 0.001 | -0.513 | 0.512 | 0.118 | torch.Size([240, 120]) || stage3.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.081 | -0.274 | 0.096 | 0.071 | torch.Size([240]) || stage3.residual_group1.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.548 | 0.533 | 0.126 | torch.Size([240, 120]) || stage3.residual_group1.blocks.1.mlp.fc12.weight
+ | -0.003 | -0.181 | 0.194 | 0.059 | torch.Size([240]) || stage3.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.499 | 0.534 | 0.128 | torch.Size([120, 240]) || stage3.residual_group1.blocks.1.mlp.fc2.weight
+ | -0.007 | -0.282 | 0.152 | 0.083 | torch.Size([120]) || stage3.residual_group1.blocks.1.mlp.fc2.bias
+ | 0.796 | 0.469 | 1.007 | 0.111 | torch.Size([120]) || stage3.residual_group1.blocks.2.norm1.weight
+ | -0.109 | -0.638 | 0.181 | 0.146 | torch.Size([120]) || stage3.residual_group1.blocks.2.norm1.bias
+ | -0.004 | -1.009 | 1.155 | 0.105 | torch.Size([675, 6]) || stage3.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.2.attn.position_bias
+ | -0.000 | -0.378 | 0.375 | 0.081 | torch.Size([360, 120]) || stage3.residual_group1.blocks.2.attn.qkv_self.weight
+ | 0.003 | -0.263 | 0.331 | 0.066 | torch.Size([360]) || stage3.residual_group1.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.485 | 0.366 | 0.074 | torch.Size([120, 240]) || stage3.residual_group1.blocks.2.attn.proj.weight
+ | -0.001 | -0.249 | 0.145 | 0.080 | torch.Size([120]) || stage3.residual_group1.blocks.2.attn.proj.bias
+ | -0.001 | -0.332 | 0.421 | 0.063 | torch.Size([360, 120]) || stage3.residual_group1.blocks.2.attn.qkv_mut.weight
+ | -0.001 | -0.098 | 0.083 | 0.016 | torch.Size([360]) || stage3.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.657 | 0.507 | 0.776 | 0.053 | torch.Size([120]) || stage3.residual_group1.blocks.2.norm2.weight
+ | 0.003 | -0.270 | 0.280 | 0.104 | torch.Size([120]) || stage3.residual_group1.blocks.2.norm2.bias
+ | 0.000 | -0.445 | 0.556 | 0.117 | torch.Size([240, 120]) || stage3.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.097 | -0.295 | 0.100 | 0.070 | torch.Size([240]) || stage3.residual_group1.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.480 | 0.501 | 0.126 | torch.Size([240, 120]) || stage3.residual_group1.blocks.2.mlp.fc12.weight
+ | 0.005 | -0.148 | 0.191 | 0.060 | torch.Size([240]) || stage3.residual_group1.blocks.2.mlp.fc12.bias
+ | 0.001 | -0.569 | 0.484 | 0.126 | torch.Size([120, 240]) || stage3.residual_group1.blocks.2.mlp.fc2.weight
+ | -0.006 | -0.246 | 0.161 | 0.082 | torch.Size([120]) || stage3.residual_group1.blocks.2.mlp.fc2.bias
+ | 0.814 | 0.482 | 1.048 | 0.109 | torch.Size([120]) || stage3.residual_group1.blocks.3.norm1.weight
+ | -0.138 | -0.585 | 0.128 | 0.129 | torch.Size([120]) || stage3.residual_group1.blocks.3.norm1.bias
+ | -0.008 | -1.801 | 4.148 | 0.110 | torch.Size([675, 6]) || stage3.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.3.attn.position_bias
+ | -0.001 | -0.364 | 0.546 | 0.076 | torch.Size([360, 120]) || stage3.residual_group1.blocks.3.attn.qkv_self.weight
+ | 0.003 | -0.179 | 0.182 | 0.046 | torch.Size([360]) || stage3.residual_group1.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.378 | 0.385 | 0.070 | torch.Size([120, 240]) || stage3.residual_group1.blocks.3.attn.proj.weight
+ | -0.005 | -0.368 | 0.175 | 0.101 | torch.Size([120]) || stage3.residual_group1.blocks.3.attn.proj.bias
+ | 0.000 | -0.338 | 0.461 | 0.062 | torch.Size([360, 120]) || stage3.residual_group1.blocks.3.attn.qkv_mut.weight
+ | 0.000 | -0.098 | 0.082 | 0.019 | torch.Size([360]) || stage3.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.676 | 0.526 | 0.799 | 0.056 | torch.Size([120]) || stage3.residual_group1.blocks.3.norm2.weight
+ | 0.002 | -0.269 | 0.242 | 0.090 | torch.Size([120]) || stage3.residual_group1.blocks.3.norm2.bias
+ | 0.000 | -0.474 | 0.505 | 0.118 | torch.Size([240, 120]) || stage3.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.095 | -0.247 | 0.071 | 0.063 | torch.Size([240]) || stage3.residual_group1.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.518 | 0.502 | 0.126 | torch.Size([240, 120]) || stage3.residual_group1.blocks.3.mlp.fc12.weight
+ | -0.003 | -0.194 | 0.228 | 0.068 | torch.Size([240]) || stage3.residual_group1.blocks.3.mlp.fc12.bias
+ | -0.001 | -0.502 | 0.499 | 0.124 | torch.Size([120, 240]) || stage3.residual_group1.blocks.3.mlp.fc2.weight
+ | -0.007 | -0.248 | 0.207 | 0.098 | torch.Size([120]) || stage3.residual_group1.blocks.3.mlp.fc2.bias
+ | 0.843 | 0.498 | 1.046 | 0.099 | torch.Size([120]) || stage3.residual_group1.blocks.4.norm1.weight
+ | -0.082 | -0.456 | 0.195 | 0.111 | torch.Size([120]) || stage3.residual_group1.blocks.4.norm1.bias
+ | -0.012 | -3.133 | 2.263 | 0.177 | torch.Size([675, 6]) || stage3.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.4.attn.position_bias
+ | 0.001 | -0.494 | 0.443 | 0.096 | torch.Size([360, 120]) || stage3.residual_group1.blocks.4.attn.qkv_self.weight
+ | -0.004 | -0.492 | 0.329 | 0.088 | torch.Size([360]) || stage3.residual_group1.blocks.4.attn.qkv_self.bias
+ | -0.000 | -0.464 | 0.391 | 0.080 | torch.Size([120, 240]) || stage3.residual_group1.blocks.4.attn.proj.weight
+ | -0.003 | -0.420 | 0.332 | 0.124 | torch.Size([120]) || stage3.residual_group1.blocks.4.attn.proj.bias
+ | 0.001 | -0.469 | 0.518 | 0.068 | torch.Size([360, 120]) || stage3.residual_group1.blocks.4.attn.qkv_mut.weight
+ | 0.001 | -0.068 | 0.099 | 0.014 | torch.Size([360]) || stage3.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.705 | 0.598 | 0.823 | 0.047 | torch.Size([120]) || stage3.residual_group1.blocks.4.norm2.weight
+ | 0.001 | -0.161 | 0.155 | 0.065 | torch.Size([120]) || stage3.residual_group1.blocks.4.norm2.bias
+ | 0.000 | -0.526 | 0.442 | 0.119 | torch.Size([240, 120]) || stage3.residual_group1.blocks.4.mlp.fc11.weight
+ | -0.102 | -0.319 | 0.054 | 0.072 | torch.Size([240]) || stage3.residual_group1.blocks.4.mlp.fc11.bias
+ | 0.000 | -0.555 | 0.499 | 0.126 | torch.Size([240, 120]) || stage3.residual_group1.blocks.4.mlp.fc12.weight
+ | -0.003 | -0.201 | 0.135 | 0.065 | torch.Size([240]) || stage3.residual_group1.blocks.4.mlp.fc12.bias
+ | 0.001 | -0.454 | 0.522 | 0.122 | torch.Size([120, 240]) || stage3.residual_group1.blocks.4.mlp.fc2.weight
+ | -0.011 | -0.379 | 0.195 | 0.091 | torch.Size([120]) || stage3.residual_group1.blocks.4.mlp.fc2.bias
+ | 0.856 | 0.618 | 1.073 | 0.095 | torch.Size([120]) || stage3.residual_group1.blocks.5.norm1.weight
+ | -0.059 | -0.368 | 0.153 | 0.095 | torch.Size([120]) || stage3.residual_group1.blocks.5.norm1.bias
+ | -0.006 | -1.747 | 1.724 | 0.133 | torch.Size([675, 6]) || stage3.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.5.attn.position_bias
+ | -0.000 | -0.399 | 0.417 | 0.090 | torch.Size([360, 120]) || stage3.residual_group1.blocks.5.attn.qkv_self.weight
+ | 0.009 | -0.294 | 0.398 | 0.079 | torch.Size([360]) || stage3.residual_group1.blocks.5.attn.qkv_self.bias
+ | 0.001 | -0.345 | 0.341 | 0.067 | torch.Size([120, 240]) || stage3.residual_group1.blocks.5.attn.proj.weight
+ | -0.004 | -0.435 | 0.326 | 0.113 | torch.Size([120]) || stage3.residual_group1.blocks.5.attn.proj.bias
+ | -0.000 | -0.370 | 0.339 | 0.052 | torch.Size([360, 120]) || stage3.residual_group1.blocks.5.attn.qkv_mut.weight
+ | -0.000 | -0.059 | 0.060 | 0.012 | torch.Size([360]) || stage3.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.707 | 0.600 | 0.832 | 0.051 | torch.Size([120]) || stage3.residual_group1.blocks.5.norm2.weight
+ | -0.001 | -0.157 | 0.140 | 0.063 | torch.Size([120]) || stage3.residual_group1.blocks.5.norm2.bias
+ | 0.001 | -0.473 | 0.464 | 0.117 | torch.Size([240, 120]) || stage3.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.091 | -0.291 | 0.092 | 0.073 | torch.Size([240]) || stage3.residual_group1.blocks.5.mlp.fc11.bias
+ | -0.000 | -0.479 | 0.477 | 0.124 | torch.Size([240, 120]) || stage3.residual_group1.blocks.5.mlp.fc12.weight
+ | 0.004 | -0.197 | 0.180 | 0.063 | torch.Size([240]) || stage3.residual_group1.blocks.5.mlp.fc12.bias
+ | -0.001 | -0.504 | 0.440 | 0.118 | torch.Size([120, 240]) || stage3.residual_group1.blocks.5.mlp.fc2.weight
+ | -0.008 | -0.449 | 0.421 | 0.135 | torch.Size([120]) || stage3.residual_group1.blocks.5.mlp.fc2.bias
+ | 0.003 | -0.331 | 0.524 | 0.083 | torch.Size([120, 120]) || stage3.linear1.weight
+ | -0.001 | -0.270 | 0.250 | 0.116 | torch.Size([120]) || stage3.linear1.bias
+ | 0.883 | 0.354 | 1.107 | 0.120 | torch.Size([120]) || stage3.residual_group2.blocks.0.norm1.weight
+ | 0.011 | -0.416 | 0.299 | 0.131 | torch.Size([120]) || stage3.residual_group2.blocks.0.norm1.bias
+ | 0.000 | -0.322 | 0.139 | 0.028 | torch.Size([3375, 6]) || stage3.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage3.residual_group2.blocks.0.attn.relative_position_index
+ | 0.000 | -0.470 | 0.455 | 0.097 | torch.Size([360, 120]) || stage3.residual_group2.blocks.0.attn.qkv_self.weight
+ | 0.007 | -0.384 | 0.374 | 0.125 | torch.Size([360]) || stage3.residual_group2.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.467 | 0.428 | 0.109 | torch.Size([120, 120]) || stage3.residual_group2.blocks.0.attn.proj.weight
+ | -0.009 | -0.348 | 0.279 | 0.126 | torch.Size([120]) || stage3.residual_group2.blocks.0.attn.proj.bias
+ | 0.873 | 0.618 | 1.060 | 0.070 | torch.Size([120]) || stage3.residual_group2.blocks.0.norm2.weight
+ | 0.005 | -0.242 | 0.278 | 0.098 | torch.Size([120]) || stage3.residual_group2.blocks.0.norm2.bias
+ | 0.000 | -0.549 | 0.437 | 0.115 | torch.Size([240, 120]) || stage3.residual_group2.blocks.0.mlp.fc11.weight
+ | -0.053 | -0.174 | 0.127 | 0.058 | torch.Size([240]) || stage3.residual_group2.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.469 | 0.517 | 0.124 | torch.Size([240, 120]) || stage3.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.002 | -0.133 | 0.187 | 0.052 | torch.Size([240]) || stage3.residual_group2.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.548 | 0.557 | 0.125 | torch.Size([120, 240]) || stage3.residual_group2.blocks.0.mlp.fc2.weight
+ | -0.011 | -0.339 | 0.303 | 0.116 | torch.Size([120]) || stage3.residual_group2.blocks.0.mlp.fc2.bias
+ | 0.960 | 0.744 | 1.153 | 0.095 | torch.Size([120]) || stage3.residual_group2.blocks.1.norm1.weight
+ | 0.004 | -0.302 | 0.238 | 0.099 | torch.Size([120]) || stage3.residual_group2.blocks.1.norm1.bias
+ | 0.000 | -0.567 | 0.133 | 0.032 | torch.Size([3375, 6]) || stage3.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage3.residual_group2.blocks.1.attn.relative_position_index
+ | 0.000 | -0.425 | 0.414 | 0.087 | torch.Size([360, 120]) || stage3.residual_group2.blocks.1.attn.qkv_self.weight
+ | 0.001 | -0.419 | 0.485 | 0.116 | torch.Size([360]) || stage3.residual_group2.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.429 | 0.385 | 0.095 | torch.Size([120, 120]) || stage3.residual_group2.blocks.1.attn.proj.weight
+ | -0.011 | -0.398 | 0.287 | 0.123 | torch.Size([120]) || stage3.residual_group2.blocks.1.attn.proj.bias
+ | 0.909 | 0.770 | 1.090 | 0.066 | torch.Size([120]) || stage3.residual_group2.blocks.1.norm2.weight
+ | -0.000 | -0.204 | 0.175 | 0.073 | torch.Size([120]) || stage3.residual_group2.blocks.1.norm2.bias
+ | 0.000 | -0.451 | 0.462 | 0.115 | torch.Size([240, 120]) || stage3.residual_group2.blocks.1.mlp.fc11.weight
+ | -0.069 | -0.268 | 0.143 | 0.077 | torch.Size([240]) || stage3.residual_group2.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.488 | 0.602 | 0.126 | torch.Size([240, 120]) || stage3.residual_group2.blocks.1.mlp.fc12.weight
+ | -0.004 | -0.179 | 0.114 | 0.050 | torch.Size([240]) || stage3.residual_group2.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.480 | 0.466 | 0.118 | torch.Size([120, 240]) || stage3.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.007 | -0.358 | 0.225 | 0.102 | torch.Size([120]) || stage3.residual_group2.blocks.1.mlp.fc2.bias
+ | 0.003 | -0.274 | 0.457 | 0.073 | torch.Size([120, 120]) || stage3.linear2.weight
+ | 0.002 | -0.532 | 0.438 | 0.200 | torch.Size([120]) || stage3.linear2.bias
+ | -0.000 | -0.098 | 0.115 | 0.025 | torch.Size([120, 120, 3, 3]) || stage3.pa_deform.weight
+ | 0.002 | -0.033 | 0.041 | 0.015 | torch.Size([120]) || stage3.pa_deform.bias
+ | 0.000 | -0.017 | 0.017 | 0.010 | torch.Size([120, 364, 3, 3]) || stage3.pa_deform.conv_offset.0.weight
+ | -0.010 | -0.030 | 0.017 | 0.010 | torch.Size([120]) || stage3.pa_deform.conv_offset.0.bias
+ | -0.000 | -0.078 | 0.069 | 0.020 | torch.Size([120, 120, 3, 3]) || stage3.pa_deform.conv_offset.2.weight
+ | -0.006 | -0.055 | 0.067 | 0.026 | torch.Size([120]) || stage3.pa_deform.conv_offset.2.bias
+ | -0.001 | -0.071 | 0.067 | 0.020 | torch.Size([120, 120, 3, 3]) || stage3.pa_deform.conv_offset.4.weight
+ | 0.004 | -0.070 | 0.113 | 0.042 | torch.Size([120]) || stage3.pa_deform.conv_offset.4.bias
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432, 120, 3, 3]) || stage3.pa_deform.conv_offset.6.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432]) || stage3.pa_deform.conv_offset.6.bias
+ | 0.004 | -0.623 | 0.669 | 0.126 | torch.Size([360, 360]) || stage3.pa_fuse.fc11.weight
+ | 0.092 | -0.221 | 0.676 | 0.151 | torch.Size([360]) || stage3.pa_fuse.fc11.bias
+ | 0.000 | -0.604 | 0.689 | 0.125 | torch.Size([360, 360]) || stage3.pa_fuse.fc12.weight
+ | 0.008 | -0.544 | 0.379 | 0.118 | torch.Size([360]) || stage3.pa_fuse.fc12.bias
+ | 0.000 | -0.669 | 0.719 | 0.151 | torch.Size([120, 360]) || stage3.pa_fuse.fc2.weight
+ | -0.005 | -0.411 | 0.443 | 0.155 | torch.Size([120]) || stage3.pa_fuse.fc2.bias
+ | 1.005 | 0.488 | 1.503 | 0.166 | torch.Size([480]) || stage4.reshape.1.weight
+ | 0.001 | -0.316 | 0.358 | 0.118 | torch.Size([480]) || stage4.reshape.1.bias
+ | 0.000 | -0.486 | 0.450 | 0.084 | torch.Size([120, 480]) || stage4.reshape.2.weight
+ | -0.007 | -0.139 | 0.092 | 0.043 | torch.Size([120]) || stage4.reshape.2.bias
+ | 0.996 | 0.831 | 1.101 | 0.039 | torch.Size([120]) || stage4.residual_group1.blocks.0.norm1.weight
+ | -0.014 | -0.109 | 0.112 | 0.040 | torch.Size([120]) || stage4.residual_group1.blocks.0.norm1.bias
+ | 0.000 | -0.064 | 0.064 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.0.attn.position_bias
+ | -0.000 | -0.109 | 0.107 | 0.023 | torch.Size([360, 120]) || stage4.residual_group1.blocks.0.attn.qkv_self.weight
+ | -0.001 | -0.033 | 0.029 | 0.009 | torch.Size([360]) || stage4.residual_group1.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.256 | 0.235 | 0.030 | torch.Size([120, 240]) || stage4.residual_group1.blocks.0.attn.proj.weight
+ | 0.007 | -0.099 | 0.227 | 0.051 | torch.Size([120]) || stage4.residual_group1.blocks.0.attn.proj.bias
+ | -0.000 | -0.129 | 0.142 | 0.025 | torch.Size([360, 120]) || stage4.residual_group1.blocks.0.attn.qkv_mut.weight
+ | -0.000 | -0.035 | 0.029 | 0.006 | torch.Size([360]) || stage4.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.966 | 0.869 | 1.089 | 0.041 | torch.Size([120]) || stage4.residual_group1.blocks.0.norm2.weight
+ | 0.000 | -0.155 | 0.152 | 0.058 | torch.Size([120]) || stage4.residual_group1.blocks.0.norm2.bias
+ | -0.000 | -0.248 | 0.221 | 0.024 | torch.Size([240, 120]) || stage4.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.002 | -0.066 | 0.012 | 0.007 | torch.Size([240]) || stage4.residual_group1.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.287 | 0.219 | 0.024 | torch.Size([240, 120]) || stage4.residual_group1.blocks.0.mlp.fc12.weight
+ | 0.000 | -0.085 | 0.067 | 0.010 | torch.Size([240]) || stage4.residual_group1.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.256 | 0.235 | 0.025 | torch.Size([120, 240]) || stage4.residual_group1.blocks.0.mlp.fc2.weight
+ | 0.009 | -0.123 | 0.254 | 0.058 | torch.Size([120]) || stage4.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.988 | 0.825 | 1.079 | 0.043 | torch.Size([120]) || stage4.residual_group1.blocks.1.norm1.weight
+ | -0.013 | -0.123 | 0.105 | 0.047 | torch.Size([120]) || stage4.residual_group1.blocks.1.norm1.bias
+ | -0.000 | -0.081 | 0.078 | 0.021 | torch.Size([675, 6]) || stage4.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.1.attn.position_bias
+ | 0.000 | -0.133 | 0.170 | 0.025 | torch.Size([360, 120]) || stage4.residual_group1.blocks.1.attn.qkv_self.weight
+ | -0.000 | -0.053 | 0.048 | 0.014 | torch.Size([360]) || stage4.residual_group1.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.177 | 0.174 | 0.031 | torch.Size([120, 240]) || stage4.residual_group1.blocks.1.attn.proj.weight
+ | 0.008 | -0.099 | 0.204 | 0.048 | torch.Size([120]) || stage4.residual_group1.blocks.1.attn.proj.bias
+ | 0.000 | -0.138 | 0.130 | 0.026 | torch.Size([360, 120]) || stage4.residual_group1.blocks.1.attn.qkv_mut.weight
+ | 0.000 | -0.061 | 0.059 | 0.010 | torch.Size([360]) || stage4.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.996 | 0.943 | 1.081 | 0.026 | torch.Size([120]) || stage4.residual_group1.blocks.1.norm2.weight
+ | 0.001 | -0.064 | 0.051 | 0.027 | torch.Size([120]) || stage4.residual_group1.blocks.1.norm2.bias
+ | -0.000 | -0.336 | 0.268 | 0.024 | torch.Size([240, 120]) || stage4.residual_group1.blocks.1.mlp.fc11.weight
+ | 0.000 | -0.029 | 0.028 | 0.006 | torch.Size([240]) || stage4.residual_group1.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.223 | 0.272 | 0.024 | torch.Size([240, 120]) || stage4.residual_group1.blocks.1.mlp.fc12.weight
+ | -0.001 | -0.084 | 0.037 | 0.009 | torch.Size([240]) || stage4.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.207 | 0.216 | 0.024 | torch.Size([120, 240]) || stage4.residual_group1.blocks.1.mlp.fc2.weight
+ | 0.007 | -0.140 | 0.216 | 0.058 | torch.Size([120]) || stage4.residual_group1.blocks.1.mlp.fc2.bias
+ | 0.994 | 0.855 | 1.108 | 0.038 | torch.Size([120]) || stage4.residual_group1.blocks.2.norm1.weight
+ | -0.019 | -0.115 | 0.091 | 0.028 | torch.Size([120]) || stage4.residual_group1.blocks.2.norm1.bias
+ | 0.000 | -0.063 | 0.076 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.2.attn.position_bias
+ | -0.000 | -0.190 | 0.179 | 0.027 | torch.Size([360, 120]) || stage4.residual_group1.blocks.2.attn.qkv_self.weight
+ | -0.001 | -0.043 | 0.039 | 0.011 | torch.Size([360]) || stage4.residual_group1.blocks.2.attn.qkv_self.bias
+ | 0.000 | -0.158 | 0.161 | 0.030 | torch.Size([120, 240]) || stage4.residual_group1.blocks.2.attn.proj.weight
+ | 0.008 | -0.118 | 0.164 | 0.050 | torch.Size([120]) || stage4.residual_group1.blocks.2.attn.proj.bias
+ | -0.000 | -0.213 | 0.211 | 0.029 | torch.Size([360, 120]) || stage4.residual_group1.blocks.2.attn.qkv_mut.weight
+ | -0.000 | -0.043 | 0.040 | 0.010 | torch.Size([360]) || stage4.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.993 | 0.903 | 1.099 | 0.028 | torch.Size([120]) || stage4.residual_group1.blocks.2.norm2.weight
+ | 0.003 | -0.097 | 0.106 | 0.044 | torch.Size([120]) || stage4.residual_group1.blocks.2.norm2.bias
+ | 0.000 | -0.186 | 0.177 | 0.024 | torch.Size([240, 120]) || stage4.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.000 | -0.068 | 0.045 | 0.010 | torch.Size([240]) || stage4.residual_group1.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.307 | 0.185 | 0.024 | torch.Size([240, 120]) || stage4.residual_group1.blocks.2.mlp.fc12.weight
+ | -0.000 | -0.081 | 0.061 | 0.010 | torch.Size([240]) || stage4.residual_group1.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.195 | 0.216 | 0.024 | torch.Size([120, 240]) || stage4.residual_group1.blocks.2.mlp.fc2.weight
+ | 0.008 | -0.115 | 0.161 | 0.050 | torch.Size([120]) || stage4.residual_group1.blocks.2.mlp.fc2.bias
+ | 0.997 | 0.893 | 1.071 | 0.032 | torch.Size([120]) || stage4.residual_group1.blocks.3.norm1.weight
+ | -0.019 | -0.083 | 0.047 | 0.024 | torch.Size([120]) || stage4.residual_group1.blocks.3.norm1.bias
+ | 0.001 | -0.076 | 0.073 | 0.021 | torch.Size([675, 6]) || stage4.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.3.attn.position_bias
+ | 0.000 | -0.275 | 0.259 | 0.029 | torch.Size([360, 120]) || stage4.residual_group1.blocks.3.attn.qkv_self.weight
+ | -0.001 | -0.071 | 0.066 | 0.017 | torch.Size([360]) || stage4.residual_group1.blocks.3.attn.qkv_self.bias
+ | -0.000 | -0.166 | 0.157 | 0.028 | torch.Size([120, 240]) || stage4.residual_group1.blocks.3.attn.proj.weight
+ | 0.008 | -0.105 | 0.149 | 0.043 | torch.Size([120]) || stage4.residual_group1.blocks.3.attn.proj.bias
+ | 0.000 | -0.184 | 0.197 | 0.028 | torch.Size([360, 120]) || stage4.residual_group1.blocks.3.attn.qkv_mut.weight
+ | 0.001 | -0.042 | 0.050 | 0.008 | torch.Size([360]) || stage4.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 1.001 | 0.971 | 1.136 | 0.022 | torch.Size([120]) || stage4.residual_group1.blocks.3.norm2.weight
+ | -0.002 | -0.054 | 0.050 | 0.023 | torch.Size([120]) || stage4.residual_group1.blocks.3.norm2.bias
+ | 0.000 | -0.329 | 0.210 | 0.023 | torch.Size([240, 120]) || stage4.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.000 | -0.078 | 0.029 | 0.009 | torch.Size([240]) || stage4.residual_group1.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.234 | 0.241 | 0.023 | torch.Size([240, 120]) || stage4.residual_group1.blocks.3.mlp.fc12.weight
+ | 0.000 | -0.031 | 0.024 | 0.006 | torch.Size([240]) || stage4.residual_group1.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.169 | 0.164 | 0.023 | torch.Size([120, 240]) || stage4.residual_group1.blocks.3.mlp.fc2.weight
+ | 0.007 | -0.085 | 0.114 | 0.043 | torch.Size([120]) || stage4.residual_group1.blocks.3.mlp.fc2.bias
+ | 1.003 | 0.901 | 1.099 | 0.044 | torch.Size([120]) || stage4.residual_group1.blocks.4.norm1.weight
+ | -0.034 | -0.095 | 0.039 | 0.030 | torch.Size([120]) || stage4.residual_group1.blocks.4.norm1.bias
+ | 0.000 | -0.071 | 0.090 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.4.attn.position_bias
+ | -0.000 | -0.238 | 0.268 | 0.034 | torch.Size([360, 120]) || stage4.residual_group1.blocks.4.attn.qkv_self.weight
+ | -0.002 | -0.199 | 0.144 | 0.030 | torch.Size([360]) || stage4.residual_group1.blocks.4.attn.qkv_self.bias
+ | -0.000 | -0.167 | 0.218 | 0.029 | torch.Size([120, 240]) || stage4.residual_group1.blocks.4.attn.proj.weight
+ | 0.008 | -0.089 | 0.140 | 0.039 | torch.Size([120]) || stage4.residual_group1.blocks.4.attn.proj.bias
+ | 0.000 | -0.267 | 0.253 | 0.031 | torch.Size([360, 120]) || stage4.residual_group1.blocks.4.attn.qkv_mut.weight
+ | 0.001 | -0.067 | 0.069 | 0.009 | torch.Size([360]) || stage4.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 1.004 | 0.953 | 1.056 | 0.014 | torch.Size([120]) || stage4.residual_group1.blocks.4.norm2.weight
+ | -0.001 | -0.056 | 0.077 | 0.021 | torch.Size([120]) || stage4.residual_group1.blocks.4.norm2.bias
+ | -0.000 | -0.170 | 0.184 | 0.023 | torch.Size([240, 120]) || stage4.residual_group1.blocks.4.mlp.fc11.weight
+ | 0.001 | -0.037 | 0.027 | 0.007 | torch.Size([240]) || stage4.residual_group1.blocks.4.mlp.fc11.bias
+ | 0.000 | -0.149 | 0.202 | 0.023 | torch.Size([240, 120]) || stage4.residual_group1.blocks.4.mlp.fc12.weight
+ | 0.000 | -0.059 | 0.095 | 0.010 | torch.Size([240]) || stage4.residual_group1.blocks.4.mlp.fc12.bias
+ | -0.000 | -0.145 | 0.181 | 0.023 | torch.Size([120, 240]) || stage4.residual_group1.blocks.4.mlp.fc2.weight
+ | 0.006 | -0.086 | 0.117 | 0.036 | torch.Size([120]) || stage4.residual_group1.blocks.4.mlp.fc2.bias
+ | 0.996 | 0.859 | 1.077 | 0.047 | torch.Size([120]) || stage4.residual_group1.blocks.5.norm1.weight
+ | -0.058 | -0.153 | 0.009 | 0.038 | torch.Size([120]) || stage4.residual_group1.blocks.5.norm1.bias
+ | 0.000 | -0.087 | 0.083 | 0.021 | torch.Size([675, 6]) || stage4.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.5.attn.position_bias
+ | -0.000 | -0.249 | 0.266 | 0.033 | torch.Size([360, 120]) || stage4.residual_group1.blocks.5.attn.qkv_self.weight
+ | -0.001 | -0.199 | 0.168 | 0.031 | torch.Size([360]) || stage4.residual_group1.blocks.5.attn.qkv_self.bias
+ | 0.000 | -0.156 | 0.142 | 0.027 | torch.Size([120, 240]) || stage4.residual_group1.blocks.5.attn.proj.weight
+ | 0.004 | -0.102 | 0.145 | 0.045 | torch.Size([120]) || stage4.residual_group1.blocks.5.attn.proj.bias
+ | 0.000 | -0.299 | 0.376 | 0.033 | torch.Size([360, 120]) || stage4.residual_group1.blocks.5.attn.qkv_mut.weight
+ | 0.000 | -0.034 | 0.066 | 0.007 | torch.Size([360]) || stage4.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.992 | 0.924 | 1.097 | 0.025 | torch.Size([120]) || stage4.residual_group1.blocks.5.norm2.weight
+ | -0.002 | -0.089 | 0.074 | 0.038 | torch.Size([120]) || stage4.residual_group1.blocks.5.norm2.bias
+ | -0.000 | -0.192 | 0.208 | 0.023 | torch.Size([240, 120]) || stage4.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.002 | -0.064 | 0.021 | 0.009 | torch.Size([240]) || stage4.residual_group1.blocks.5.mlp.fc11.bias
+ | -0.000 | -0.240 | 0.191 | 0.023 | torch.Size([240, 120]) || stage4.residual_group1.blocks.5.mlp.fc12.weight
+ | 0.000 | -0.040 | 0.044 | 0.008 | torch.Size([240]) || stage4.residual_group1.blocks.5.mlp.fc12.bias
+ | -0.000 | -0.141 | 0.155 | 0.022 | torch.Size([120, 240]) || stage4.residual_group1.blocks.5.mlp.fc2.weight
+ | 0.005 | -0.107 | 0.103 | 0.045 | torch.Size([120]) || stage4.residual_group1.blocks.5.mlp.fc2.bias
+ | 0.001 | -0.286 | 0.303 | 0.059 | torch.Size([120, 120]) || stage4.linear1.weight
+ | -0.012 | -0.311 | 0.190 | 0.090 | torch.Size([120]) || stage4.linear1.bias
+ | 1.009 | 0.926 | 1.101 | 0.028 | torch.Size([120]) || stage4.residual_group2.blocks.0.norm1.weight
+ | -0.001 | -0.036 | 0.048 | 0.015 | torch.Size([120]) || stage4.residual_group2.blocks.0.norm1.bias
+ | 0.000 | -0.071 | 0.076 | 0.020 | torch.Size([3375, 6]) || stage4.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage4.residual_group2.blocks.0.attn.relative_position_index
+ | -0.000 | -0.135 | 0.141 | 0.023 | torch.Size([360, 120]) || stage4.residual_group2.blocks.0.attn.qkv_self.weight
+ | 0.001 | -0.023 | 0.021 | 0.007 | torch.Size([360]) || stage4.residual_group2.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.115 | 0.121 | 0.025 | torch.Size([120, 120]) || stage4.residual_group2.blocks.0.attn.proj.weight
+ | -0.007 | -0.200 | 0.098 | 0.043 | torch.Size([120]) || stage4.residual_group2.blocks.0.attn.proj.bias
+ | 1.002 | 0.999 | 1.016 | 0.002 | torch.Size([120]) || stage4.residual_group2.blocks.0.norm2.weight
+ | 0.000 | -0.003 | 0.004 | 0.001 | torch.Size([120]) || stage4.residual_group2.blocks.0.norm2.bias
+ | 0.000 | -0.082 | 0.094 | 0.020 | torch.Size([240, 120]) || stage4.residual_group2.blocks.0.mlp.fc11.weight
+ | 0.000 | -0.005 | 0.017 | 0.002 | torch.Size([240]) || stage4.residual_group2.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.088 | 0.079 | 0.020 | torch.Size([240, 120]) || stage4.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.000 | -0.010 | 0.008 | 0.002 | torch.Size([240]) || stage4.residual_group2.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.090 | 0.105 | 0.020 | torch.Size([120, 240]) || stage4.residual_group2.blocks.0.mlp.fc2.weight
+ | -0.006 | -0.181 | 0.096 | 0.041 | torch.Size([120]) || stage4.residual_group2.blocks.0.mlp.fc2.bias
+ | 1.006 | 0.923 | 1.098 | 0.025 | torch.Size([120]) || stage4.residual_group2.blocks.1.norm1.weight
+ | -0.001 | -0.045 | 0.053 | 0.019 | torch.Size([120]) || stage4.residual_group2.blocks.1.norm1.bias
+ | -0.000 | -0.083 | 0.085 | 0.020 | torch.Size([3375, 6]) || stage4.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage4.residual_group2.blocks.1.attn.relative_position_index
+ | -0.000 | -0.132 | 0.133 | 0.023 | torch.Size([360, 120]) || stage4.residual_group2.blocks.1.attn.qkv_self.weight
+ | -0.000 | -0.030 | 0.035 | 0.009 | torch.Size([360]) || stage4.residual_group2.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.129 | 0.094 | 0.024 | torch.Size([120, 120]) || stage4.residual_group2.blocks.1.attn.proj.weight
+ | -0.008 | -0.218 | 0.116 | 0.048 | torch.Size([120]) || stage4.residual_group2.blocks.1.attn.proj.bias
+ | 1.003 | 0.999 | 1.024 | 0.003 | torch.Size([120]) || stage4.residual_group2.blocks.1.norm2.weight
+ | -0.000 | -0.004 | 0.005 | 0.002 | torch.Size([120]) || stage4.residual_group2.blocks.1.norm2.bias
+ | -0.000 | -0.126 | 0.080 | 0.021 | torch.Size([240, 120]) || stage4.residual_group2.blocks.1.mlp.fc11.weight
+ | 0.001 | -0.006 | 0.016 | 0.003 | torch.Size([240]) || stage4.residual_group2.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.092 | 0.076 | 0.020 | torch.Size([240, 120]) || stage4.residual_group2.blocks.1.mlp.fc12.weight
+ | 0.000 | -0.015 | 0.013 | 0.003 | torch.Size([240]) || stage4.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.091 | 0.115 | 0.020 | torch.Size([120, 240]) || stage4.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.006 | -0.196 | 0.090 | 0.041 | torch.Size([120]) || stage4.residual_group2.blocks.1.mlp.fc2.bias
+ | 0.001 | -0.291 | 0.416 | 0.059 | torch.Size([120, 120]) || stage4.linear2.weight
+ | -0.009 | -0.269 | 0.198 | 0.094 | torch.Size([120]) || stage4.linear2.bias
+ | 0.000 | -0.053 | 0.057 | 0.019 | torch.Size([120, 120, 3, 3]) || stage4.pa_deform.weight
+ | -0.001 | -0.021 | 0.021 | 0.009 | torch.Size([120]) || stage4.pa_deform.bias
+ | 0.000 | -0.017 | 0.017 | 0.010 | torch.Size([120, 364, 3, 3]) || stage4.pa_deform.conv_offset.0.weight
+ | -0.000 | -0.015 | 0.015 | 0.009 | torch.Size([120]) || stage4.pa_deform.conv_offset.0.bias
+ | -0.000 | -0.039 | 0.041 | 0.018 | torch.Size([120, 120, 3, 3]) || stage4.pa_deform.conv_offset.2.weight
+ | 0.000 | -0.030 | 0.029 | 0.018 | torch.Size([120]) || stage4.pa_deform.conv_offset.2.bias
+ | -0.000 | -0.045 | 0.041 | 0.018 | torch.Size([120, 120, 3, 3]) || stage4.pa_deform.conv_offset.4.weight
+ | -0.002 | -0.031 | 0.030 | 0.016 | torch.Size([120]) || stage4.pa_deform.conv_offset.4.bias
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432, 120, 3, 3]) || stage4.pa_deform.conv_offset.6.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432]) || stage4.pa_deform.conv_offset.6.bias
+ | -0.000 | -0.356 | 0.435 | 0.035 | torch.Size([360, 360]) || stage4.pa_fuse.fc11.weight
+ | 0.003 | -0.080 | 0.304 | 0.033 | torch.Size([360]) || stage4.pa_fuse.fc11.bias
+ | 0.000 | -0.361 | 0.436 | 0.035 | torch.Size([360, 360]) || stage4.pa_fuse.fc12.weight
+ | -0.001 | -0.166 | 0.299 | 0.032 | torch.Size([360]) || stage4.pa_fuse.fc12.bias
+ | -0.000 | -0.748 | 0.752 | 0.056 | torch.Size([120, 360]) || stage4.pa_fuse.fc2.weight
+ | -0.000 | -0.262 | 0.270 | 0.086 | torch.Size([120]) || stage4.pa_fuse.fc2.bias
+ | 0.980 | 0.710 | 1.274 | 0.146 | torch.Size([30]) || stage5.reshape.1.weight
+ | -0.002 | -0.062 | 0.057 | 0.036 | torch.Size([30]) || stage5.reshape.1.bias
+ | 0.001 | -0.530 | 0.432 | 0.092 | torch.Size([120, 30]) || stage5.reshape.2.weight
+ | 0.021 | -0.305 | 0.337 | 0.080 | torch.Size([120]) || stage5.reshape.2.bias
+ | 0.994 | 0.934 | 1.012 | 0.016 | torch.Size([120]) || stage5.residual_group1.blocks.0.norm1.weight
+ | -0.014 | -0.040 | 0.038 | 0.014 | torch.Size([120]) || stage5.residual_group1.blocks.0.norm1.bias
+ | 0.000 | -0.082 | 0.072 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.0.attn.position_bias
+ | -0.000 | -0.078 | 0.101 | 0.021 | torch.Size([360, 120]) || stage5.residual_group1.blocks.0.attn.qkv_self.weight
+ | -0.000 | -0.022 | 0.023 | 0.005 | torch.Size([360]) || stage5.residual_group1.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.198 | 0.237 | 0.022 | torch.Size([120, 240]) || stage5.residual_group1.blocks.0.attn.proj.weight
+ | -0.003 | -0.067 | 0.082 | 0.027 | torch.Size([120]) || stage5.residual_group1.blocks.0.attn.proj.bias
+ | 0.000 | -0.103 | 0.092 | 0.021 | torch.Size([360, 120]) || stage5.residual_group1.blocks.0.attn.qkv_mut.weight
+ | -0.000 | -0.007 | 0.006 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.991 | 0.929 | 1.004 | 0.011 | torch.Size([120]) || stage5.residual_group1.blocks.0.norm2.weight
+ | 0.001 | -0.009 | 0.014 | 0.004 | torch.Size([120]) || stage5.residual_group1.blocks.0.norm2.bias
+ | -0.000 | -0.112 | 0.093 | 0.021 | torch.Size([240, 120]) || stage5.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.001 | -0.033 | 0.027 | 0.008 | torch.Size([240]) || stage5.residual_group1.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.098 | 0.085 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.0.mlp.fc12.weight
+ | -0.000 | -0.033 | 0.026 | 0.009 | torch.Size([240]) || stage5.residual_group1.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.163 | 0.140 | 0.021 | torch.Size([120, 240]) || stage5.residual_group1.blocks.0.mlp.fc2.weight
+ | 0.003 | -0.060 | 0.110 | 0.032 | torch.Size([120]) || stage5.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.992 | 0.872 | 1.010 | 0.018 | torch.Size([120]) || stage5.residual_group1.blocks.1.norm1.weight
+ | -0.015 | -0.039 | 0.031 | 0.010 | torch.Size([120]) || stage5.residual_group1.blocks.1.norm1.bias
+ | -0.000 | -0.078 | 0.078 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.1.attn.position_bias
+ | 0.000 | -0.088 | 0.099 | 0.021 | torch.Size([360, 120]) || stage5.residual_group1.blocks.1.attn.qkv_self.weight
+ | 0.000 | -0.030 | 0.030 | 0.006 | torch.Size([360]) || stage5.residual_group1.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.151 | 0.185 | 0.022 | torch.Size([120, 240]) || stage5.residual_group1.blocks.1.attn.proj.weight
+ | -0.005 | -0.073 | 0.061 | 0.024 | torch.Size([120]) || stage5.residual_group1.blocks.1.attn.proj.bias
+ | 0.000 | -0.093 | 0.089 | 0.021 | torch.Size([360, 120]) || stage5.residual_group1.blocks.1.attn.qkv_mut.weight
+ | 0.000 | -0.009 | 0.007 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.997 | 0.923 | 1.003 | 0.008 | torch.Size([120]) || stage5.residual_group1.blocks.1.norm2.weight
+ | 0.000 | -0.008 | 0.009 | 0.004 | torch.Size([120]) || stage5.residual_group1.blocks.1.norm2.bias
+ | -0.000 | -0.082 | 0.092 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.000 | -0.023 | 0.021 | 0.007 | torch.Size([240]) || stage5.residual_group1.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.082 | 0.078 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.1.mlp.fc12.weight
+ | -0.001 | -0.028 | 0.025 | 0.008 | torch.Size([240]) || stage5.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.097 | 0.090 | 0.020 | torch.Size([120, 240]) || stage5.residual_group1.blocks.1.mlp.fc2.weight
+ | 0.000 | -0.062 | 0.102 | 0.028 | torch.Size([120]) || stage5.residual_group1.blocks.1.mlp.fc2.bias
+ | 0.994 | 0.845 | 1.015 | 0.018 | torch.Size([120]) || stage5.residual_group1.blocks.2.norm1.weight
+ | -0.018 | -0.045 | 0.016 | 0.008 | torch.Size([120]) || stage5.residual_group1.blocks.2.norm1.bias
+ | 0.000 | -0.065 | 0.068 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.2.attn.position_bias
+ | -0.000 | -0.088 | 0.113 | 0.021 | torch.Size([360, 120]) || stage5.residual_group1.blocks.2.attn.qkv_self.weight
+ | 0.000 | -0.022 | 0.020 | 0.005 | torch.Size([360]) || stage5.residual_group1.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.124 | 0.124 | 0.021 | torch.Size([120, 240]) || stage5.residual_group1.blocks.2.attn.proj.weight
+ | -0.001 | -0.061 | 0.049 | 0.020 | torch.Size([120]) || stage5.residual_group1.blocks.2.attn.proj.bias
+ | -0.000 | -0.088 | 0.087 | 0.021 | torch.Size([360, 120]) || stage5.residual_group1.blocks.2.attn.qkv_mut.weight
+ | -0.000 | -0.008 | 0.005 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.993 | 0.847 | 1.012 | 0.016 | torch.Size([120]) || stage5.residual_group1.blocks.2.norm2.weight
+ | 0.000 | -0.014 | 0.015 | 0.007 | torch.Size([120]) || stage5.residual_group1.blocks.2.norm2.bias
+ | 0.000 | -0.096 | 0.096 | 0.021 | torch.Size([240, 120]) || stage5.residual_group1.blocks.2.mlp.fc11.weight
+ | 0.001 | -0.038 | 0.027 | 0.009 | torch.Size([240]) || stage5.residual_group1.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.090 | 0.095 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.2.mlp.fc12.weight
+ | 0.000 | -0.045 | 0.039 | 0.011 | torch.Size([240]) || stage5.residual_group1.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.153 | 0.130 | 0.021 | torch.Size([120, 240]) || stage5.residual_group1.blocks.2.mlp.fc2.weight
+ | -0.006 | -0.097 | 0.083 | 0.028 | torch.Size([120]) || stage5.residual_group1.blocks.2.mlp.fc2.bias
+ | 0.984 | 0.798 | 1.006 | 0.023 | torch.Size([120]) || stage5.residual_group1.blocks.3.norm1.weight
+ | -0.018 | -0.042 | 0.003 | 0.010 | torch.Size([120]) || stage5.residual_group1.blocks.3.norm1.bias
+ | 0.000 | -0.074 | 0.214 | 0.021 | torch.Size([675, 6]) || stage5.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.3.attn.position_bias
+ | 0.000 | -0.133 | 0.132 | 0.022 | torch.Size([360, 120]) || stage5.residual_group1.blocks.3.attn.qkv_self.weight
+ | -0.000 | -0.035 | 0.037 | 0.008 | torch.Size([360]) || stage5.residual_group1.blocks.3.attn.qkv_self.bias
+ | -0.000 | -0.121 | 0.123 | 0.020 | torch.Size([120, 240]) || stage5.residual_group1.blocks.3.attn.proj.weight
+ | -0.002 | -0.043 | 0.049 | 0.016 | torch.Size([120]) || stage5.residual_group1.blocks.3.attn.proj.bias
+ | 0.000 | -0.082 | 0.093 | 0.021 | torch.Size([360, 120]) || stage5.residual_group1.blocks.3.attn.qkv_mut.weight
+ | -0.000 | -0.007 | 0.007 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.993 | 0.809 | 1.008 | 0.018 | torch.Size([120]) || stage5.residual_group1.blocks.3.norm2.weight
+ | 0.001 | -0.018 | 0.013 | 0.006 | torch.Size([120]) || stage5.residual_group1.blocks.3.norm2.bias
+ | -0.000 | -0.100 | 0.097 | 0.021 | torch.Size([240, 120]) || stage5.residual_group1.blocks.3.mlp.fc11.weight
+ | 0.001 | -0.038 | 0.045 | 0.009 | torch.Size([240]) || stage5.residual_group1.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.104 | 0.095 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.3.mlp.fc12.weight
+ | -0.000 | -0.043 | 0.040 | 0.011 | torch.Size([240]) || stage5.residual_group1.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.108 | 0.121 | 0.021 | torch.Size([120, 240]) || stage5.residual_group1.blocks.3.mlp.fc2.weight
+ | 0.002 | -0.066 | 0.048 | 0.023 | torch.Size([120]) || stage5.residual_group1.blocks.3.mlp.fc2.bias
+ | 0.988 | 0.835 | 1.035 | 0.019 | torch.Size([120]) || stage5.residual_group1.blocks.4.norm1.weight
+ | -0.022 | -0.052 | 0.003 | 0.013 | torch.Size([120]) || stage5.residual_group1.blocks.4.norm1.bias
+ | -0.000 | -0.086 | 0.118 | 0.021 | torch.Size([675, 6]) || stage5.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.4.attn.position_bias
+ | 0.000 | -0.199 | 0.223 | 0.023 | torch.Size([360, 120]) || stage5.residual_group1.blocks.4.attn.qkv_self.weight
+ | -0.000 | -0.045 | 0.028 | 0.009 | torch.Size([360]) || stage5.residual_group1.blocks.4.attn.qkv_self.bias
+ | 0.000 | -0.114 | 0.143 | 0.021 | torch.Size([120, 240]) || stage5.residual_group1.blocks.4.attn.proj.weight
+ | -0.003 | -0.060 | 0.047 | 0.021 | torch.Size([120]) || stage5.residual_group1.blocks.4.attn.proj.bias
+ | -0.000 | -0.117 | 0.102 | 0.021 | torch.Size([360, 120]) || stage5.residual_group1.blocks.4.attn.qkv_mut.weight
+ | 0.000 | -0.008 | 0.010 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.994 | 0.774 | 1.007 | 0.021 | torch.Size([120]) || stage5.residual_group1.blocks.4.norm2.weight
+ | 0.001 | -0.023 | 0.027 | 0.010 | torch.Size([120]) || stage5.residual_group1.blocks.4.norm2.bias
+ | -0.000 | -0.085 | 0.107 | 0.021 | torch.Size([240, 120]) || stage5.residual_group1.blocks.4.mlp.fc11.weight
+ | 0.003 | -0.044 | 0.042 | 0.013 | torch.Size([240]) || stage5.residual_group1.blocks.4.mlp.fc11.bias
+ | -0.000 | -0.103 | 0.080 | 0.021 | torch.Size([240, 120]) || stage5.residual_group1.blocks.4.mlp.fc12.weight
+ | 0.000 | -0.067 | 0.058 | 0.015 | torch.Size([240]) || stage5.residual_group1.blocks.4.mlp.fc12.bias
+ | 0.000 | -0.096 | 0.103 | 0.021 | torch.Size([120, 240]) || stage5.residual_group1.blocks.4.mlp.fc2.weight
+ | -0.000 | -0.045 | 0.054 | 0.023 | torch.Size([120]) || stage5.residual_group1.blocks.4.mlp.fc2.bias
+ | 0.985 | 0.552 | 1.092 | 0.044 | torch.Size([120]) || stage5.residual_group1.blocks.5.norm1.weight
+ | -0.023 | -0.073 | 0.024 | 0.019 | torch.Size([120]) || stage5.residual_group1.blocks.5.norm1.bias
+ | -0.000 | -0.080 | 0.121 | 0.021 | torch.Size([675, 6]) || stage5.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.5.attn.position_bias
+ | -0.000 | -1.776 | 0.186 | 0.026 | torch.Size([360, 120]) || stage5.residual_group1.blocks.5.attn.qkv_self.weight
+ | -0.000 | -0.070 | 0.065 | 0.015 | torch.Size([360]) || stage5.residual_group1.blocks.5.attn.qkv_self.bias
+ | 0.000 | -0.230 | 0.359 | 0.022 | torch.Size([120, 240]) || stage5.residual_group1.blocks.5.attn.proj.weight
+ | -0.001 | -0.062 | 0.079 | 0.028 | torch.Size([120]) || stage5.residual_group1.blocks.5.attn.proj.bias
+ | -0.000 | -0.086 | 0.104 | 0.021 | torch.Size([360, 120]) || stage5.residual_group1.blocks.5.attn.qkv_mut.weight
+ | -0.000 | -0.007 | 0.008 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.976 | 0.863 | 0.995 | 0.015 | torch.Size([120]) || stage5.residual_group1.blocks.5.norm2.weight
+ | -0.001 | -0.037 | 0.053 | 0.018 | torch.Size([120]) || stage5.residual_group1.blocks.5.norm2.bias
+ | -0.000 | -0.121 | 0.100 | 0.021 | torch.Size([240, 120]) || stage5.residual_group1.blocks.5.mlp.fc11.weight
+ | 0.009 | -0.074 | 0.101 | 0.021 | torch.Size([240]) || stage5.residual_group1.blocks.5.mlp.fc11.bias
+ | 0.000 | -0.102 | 0.101 | 0.021 | torch.Size([240, 120]) || stage5.residual_group1.blocks.5.mlp.fc12.weight
+ | 0.001 | -0.092 | 0.082 | 0.028 | torch.Size([240]) || stage5.residual_group1.blocks.5.mlp.fc12.bias
+ | -0.000 | -0.148 | 0.202 | 0.022 | torch.Size([120, 240]) || stage5.residual_group1.blocks.5.mlp.fc2.weight
+ | 0.001 | -0.056 | 0.054 | 0.025 | torch.Size([120]) || stage5.residual_group1.blocks.5.mlp.fc2.bias
+ | -0.000 | -0.139 | 0.123 | 0.024 | torch.Size([120, 120]) || stage5.linear1.weight
+ | 0.022 | -0.317 | 0.336 | 0.081 | torch.Size([120]) || stage5.linear1.bias
+ | 0.963 | 0.765 | 1.026 | 0.058 | torch.Size([120]) || stage5.residual_group2.blocks.0.norm1.weight
+ | -0.001 | -0.315 | 0.286 | 0.078 | torch.Size([120]) || stage5.residual_group2.blocks.0.norm1.bias
+ | 0.000 | -0.077 | 0.080 | 0.020 | torch.Size([3375, 6]) || stage5.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage5.residual_group2.blocks.0.attn.relative_position_index
+ | -0.000 | -0.159 | 0.119 | 0.022 | torch.Size([360, 120]) || stage5.residual_group2.blocks.0.attn.qkv_self.weight
+ | 0.000 | -0.038 | 0.044 | 0.013 | torch.Size([360]) || stage5.residual_group2.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.134 | 0.126 | 0.024 | torch.Size([120, 120]) || stage5.residual_group2.blocks.0.attn.proj.weight
+ | -0.005 | -0.263 | 0.230 | 0.060 | torch.Size([120]) || stage5.residual_group2.blocks.0.attn.proj.bias
+ | 0.990 | 0.913 | 1.001 | 0.017 | torch.Size([120]) || stage5.residual_group2.blocks.0.norm2.weight
+ | 0.000 | -0.009 | 0.010 | 0.004 | torch.Size([120]) || stage5.residual_group2.blocks.0.norm2.bias
+ | -0.000 | -0.077 | 0.089 | 0.020 | torch.Size([240, 120]) || stage5.residual_group2.blocks.0.mlp.fc11.weight
+ | -0.004 | -0.025 | 0.016 | 0.007 | torch.Size([240]) || stage5.residual_group2.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.073 | 0.090 | 0.020 | torch.Size([240, 120]) || stage5.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.000 | -0.018 | 0.018 | 0.007 | torch.Size([240]) || stage5.residual_group2.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.084 | 0.083 | 0.020 | torch.Size([120, 240]) || stage5.residual_group2.blocks.0.mlp.fc2.weight
+ | -0.006 | -0.264 | 0.273 | 0.056 | torch.Size([120]) || stage5.residual_group2.blocks.0.mlp.fc2.bias
+ | 0.976 | 0.733 | 1.048 | 0.053 | torch.Size([120]) || stage5.residual_group2.blocks.1.norm1.weight
+ | -0.001 | -0.265 | 0.241 | 0.061 | torch.Size([120]) || stage5.residual_group2.blocks.1.norm1.bias
+ | -0.000 | -0.079 | 0.081 | 0.020 | torch.Size([3375, 6]) || stage5.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage5.residual_group2.blocks.1.attn.relative_position_index
+ | -0.000 | -0.145 | 0.145 | 0.023 | torch.Size([360, 120]) || stage5.residual_group2.blocks.1.attn.qkv_self.weight
+ | -0.000 | -0.031 | 0.051 | 0.009 | torch.Size([360]) || stage5.residual_group2.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.114 | 0.103 | 0.025 | torch.Size([120, 120]) || stage5.residual_group2.blocks.1.attn.proj.weight
+ | -0.011 | -0.166 | 0.119 | 0.032 | torch.Size([120]) || stage5.residual_group2.blocks.1.attn.proj.bias
+ | 0.993 | 0.939 | 1.001 | 0.012 | torch.Size([120]) || stage5.residual_group2.blocks.1.norm2.weight
+ | 0.000 | -0.011 | 0.008 | 0.004 | torch.Size([120]) || stage5.residual_group2.blocks.1.norm2.bias
+ | -0.000 | -0.090 | 0.081 | 0.020 | torch.Size([240, 120]) || stage5.residual_group2.blocks.1.mlp.fc11.weight
+ | -0.002 | -0.026 | 0.020 | 0.007 | torch.Size([240]) || stage5.residual_group2.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.092 | 0.078 | 0.020 | torch.Size([240, 120]) || stage5.residual_group2.blocks.1.mlp.fc12.weight
+ | 0.000 | -0.020 | 0.021 | 0.007 | torch.Size([240]) || stage5.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.097 | 0.093 | 0.020 | torch.Size([120, 240]) || stage5.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.016 | -0.224 | 0.158 | 0.041 | torch.Size([120]) || stage5.residual_group2.blocks.1.mlp.fc2.bias
+ | -0.000 | -0.244 | 0.248 | 0.044 | torch.Size([120, 120]) || stage5.linear2.weight
+ | 0.022 | -0.367 | 0.377 | 0.103 | torch.Size([120]) || stage5.linear2.bias
+ | -0.000 | -0.153 | 0.112 | 0.022 | torch.Size([120, 120, 3, 3]) || stage5.pa_deform.weight
+ | -0.004 | -0.061 | 0.053 | 0.023 | torch.Size([120]) || stage5.pa_deform.bias
+ | 0.000 | -0.017 | 0.017 | 0.010 | torch.Size([120, 364, 3, 3]) || stage5.pa_deform.conv_offset.0.weight
+ | -0.010 | -0.038 | 0.022 | 0.013 | torch.Size([120]) || stage5.pa_deform.conv_offset.0.bias
+ | -0.001 | -0.081 | 0.076 | 0.020 | torch.Size([120, 120, 3, 3]) || stage5.pa_deform.conv_offset.2.weight
+ | -0.008 | -0.062 | 0.031 | 0.021 | torch.Size([120]) || stage5.pa_deform.conv_offset.2.bias
+ | -0.000 | -0.080 | 0.079 | 0.019 | torch.Size([120, 120, 3, 3]) || stage5.pa_deform.conv_offset.4.weight
+ | -0.005 | -0.057 | 0.035 | 0.020 | torch.Size([120]) || stage5.pa_deform.conv_offset.4.bias
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432, 120, 3, 3]) || stage5.pa_deform.conv_offset.6.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432]) || stage5.pa_deform.conv_offset.6.bias
+ | 0.000 | -0.590 | 0.536 | 0.063 | torch.Size([360, 360]) || stage5.pa_fuse.fc11.weight
+ | 0.075 | -0.075 | 0.431 | 0.094 | torch.Size([360]) || stage5.pa_fuse.fc11.bias
+ | 0.000 | -0.704 | 0.718 | 0.064 | torch.Size([360, 360]) || stage5.pa_fuse.fc12.weight
+ | 0.005 | -0.308 | 0.337 | 0.073 | torch.Size([360]) || stage5.pa_fuse.fc12.bias
+ | 0.000 | -0.702 | 0.735 | 0.101 | torch.Size([120, 360]) || stage5.pa_fuse.fc2.weight
+ | -0.005 | -0.422 | 0.451 | 0.157 | torch.Size([120]) || stage5.pa_fuse.fc2.bias
+ | 1.444 | 1.141 | 1.615 | 0.121 | torch.Size([30]) || stage6.reshape.1.weight
+ | -0.003 | -0.150 | 0.115 | 0.074 | torch.Size([30]) || stage6.reshape.1.bias
+ | 0.001 | -0.848 | 0.822 | 0.232 | torch.Size([120, 30]) || stage6.reshape.2.weight
+ | 0.004 | -0.514 | 0.640 | 0.181 | torch.Size([120]) || stage6.reshape.2.bias
+ | 0.557 | 0.119 | 0.895 | 0.153 | torch.Size([120]) || stage6.residual_group1.blocks.0.norm1.weight
+ | -0.070 | -0.374 | 0.181 | 0.100 | torch.Size([120]) || stage6.residual_group1.blocks.0.norm1.bias
+ | 0.001 | -0.438 | 0.141 | 0.054 | torch.Size([675, 6]) || stage6.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.0.attn.position_bias
+ | 0.000 | -0.339 | 0.306 | 0.051 | torch.Size([360, 120]) || stage6.residual_group1.blocks.0.attn.qkv_self.weight
+ | -0.005 | -0.318 | 0.257 | 0.059 | torch.Size([360]) || stage6.residual_group1.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.473 | 0.491 | 0.061 | torch.Size([120, 240]) || stage6.residual_group1.blocks.0.attn.proj.weight
+ | -0.001 | -0.330 | 0.253 | 0.125 | torch.Size([120]) || stage6.residual_group1.blocks.0.attn.proj.bias
+ | 0.000 | -0.361 | 0.307 | 0.045 | torch.Size([360, 120]) || stage6.residual_group1.blocks.0.attn.qkv_mut.weight
+ | -0.000 | -0.044 | 0.053 | 0.010 | torch.Size([360]) || stage6.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.521 | 0.121 | 0.882 | 0.143 | torch.Size([120]) || stage6.residual_group1.blocks.0.norm2.weight
+ | 0.003 | -0.212 | 0.271 | 0.104 | torch.Size([120]) || stage6.residual_group1.blocks.0.norm2.bias
+ | -0.000 | -0.360 | 0.360 | 0.075 | torch.Size([240, 120]) || stage6.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.095 | -0.280 | 0.021 | 0.059 | torch.Size([240]) || stage6.residual_group1.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.354 | 0.331 | 0.069 | torch.Size([240, 120]) || stage6.residual_group1.blocks.0.mlp.fc12.weight
+ | -0.005 | -0.196 | 0.129 | 0.048 | torch.Size([240]) || stage6.residual_group1.blocks.0.mlp.fc12.bias
+ | 0.001 | -0.486 | 0.379 | 0.080 | torch.Size([120, 240]) || stage6.residual_group1.blocks.0.mlp.fc2.weight
+ | 0.001 | -0.154 | 0.154 | 0.069 | torch.Size([120]) || stage6.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.587 | 0.200 | 0.865 | 0.122 | torch.Size([120]) || stage6.residual_group1.blocks.1.norm1.weight
+ | -0.118 | -0.374 | 0.082 | 0.089 | torch.Size([120]) || stage6.residual_group1.blocks.1.norm1.bias
+ | 0.001 | -0.423 | 0.140 | 0.050 | torch.Size([675, 6]) || stage6.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.1.attn.position_bias
+ | 0.000 | -0.315 | 0.354 | 0.057 | torch.Size([360, 120]) || stage6.residual_group1.blocks.1.attn.qkv_self.weight
+ | 0.001 | -0.184 | 0.148 | 0.047 | torch.Size([360]) || stage6.residual_group1.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.626 | 0.422 | 0.060 | torch.Size([120, 240]) || stage6.residual_group1.blocks.1.attn.proj.weight
+ | 0.004 | -0.234 | 0.187 | 0.087 | torch.Size([120]) || stage6.residual_group1.blocks.1.attn.proj.bias
+ | -0.000 | -0.692 | 0.743 | 0.058 | torch.Size([360, 120]) || stage6.residual_group1.blocks.1.attn.qkv_mut.weight
+ | -0.000 | -0.038 | 0.041 | 0.009 | torch.Size([360]) || stage6.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.590 | 0.287 | 0.942 | 0.125 | torch.Size([120]) || stage6.residual_group1.blocks.1.norm2.weight
+ | -0.006 | -0.196 | 0.203 | 0.076 | torch.Size([120]) || stage6.residual_group1.blocks.1.norm2.bias
+ | 0.000 | -0.427 | 0.431 | 0.075 | torch.Size([240, 120]) || stage6.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.080 | -0.242 | 0.033 | 0.053 | torch.Size([240]) || stage6.residual_group1.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.293 | 0.362 | 0.069 | torch.Size([240, 120]) || stage6.residual_group1.blocks.1.mlp.fc12.weight
+ | 0.001 | -0.171 | 0.207 | 0.047 | torch.Size([240]) || stage6.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.423 | 0.467 | 0.077 | torch.Size([120, 240]) || stage6.residual_group1.blocks.1.mlp.fc2.weight
+ | 0.000 | -0.152 | 0.184 | 0.057 | torch.Size([120]) || stage6.residual_group1.blocks.1.mlp.fc2.bias
+ | 0.703 | 0.255 | 1.008 | 0.132 | torch.Size([120]) || stage6.residual_group1.blocks.2.norm1.weight
+ | -0.125 | -0.342 | 0.042 | 0.078 | torch.Size([120]) || stage6.residual_group1.blocks.2.norm1.bias
+ | 0.000 | -0.381 | 0.350 | 0.052 | torch.Size([675, 6]) || stage6.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.2.attn.position_bias
+ | 0.000 | -0.426 | 0.500 | 0.058 | torch.Size([360, 120]) || stage6.residual_group1.blocks.2.attn.qkv_self.weight
+ | -0.003 | -0.262 | 0.226 | 0.054 | torch.Size([360]) || stage6.residual_group1.blocks.2.attn.qkv_self.bias
+ | -0.001 | -0.299 | 0.325 | 0.055 | torch.Size([120, 240]) || stage6.residual_group1.blocks.2.attn.proj.weight
+ | -0.001 | -0.149 | 0.096 | 0.061 | torch.Size([120]) || stage6.residual_group1.blocks.2.attn.proj.bias
+ | 0.000 | -0.406 | 0.391 | 0.055 | torch.Size([360, 120]) || stage6.residual_group1.blocks.2.attn.qkv_mut.weight
+ | 0.001 | -0.055 | 0.085 | 0.015 | torch.Size([360]) || stage6.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.666 | 0.308 | 0.942 | 0.118 | torch.Size([120]) || stage6.residual_group1.blocks.2.norm2.weight
+ | -0.005 | -0.203 | 0.265 | 0.086 | torch.Size([120]) || stage6.residual_group1.blocks.2.norm2.bias
+ | -0.000 | -0.349 | 0.494 | 0.072 | torch.Size([240, 120]) || stage6.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.071 | -0.213 | 0.071 | 0.053 | torch.Size([240]) || stage6.residual_group1.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.294 | 0.408 | 0.066 | torch.Size([240, 120]) || stage6.residual_group1.blocks.2.mlp.fc12.weight
+ | -0.003 | -0.120 | 0.147 | 0.049 | torch.Size([240]) || stage6.residual_group1.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.303 | 0.304 | 0.073 | torch.Size([120, 240]) || stage6.residual_group1.blocks.2.mlp.fc2.weight
+ | -0.005 | -0.150 | 0.129 | 0.063 | torch.Size([120]) || stage6.residual_group1.blocks.2.mlp.fc2.bias
+ | 0.702 | 0.307 | 0.960 | 0.129 | torch.Size([120]) || stage6.residual_group1.blocks.3.norm1.weight
+ | -0.100 | -0.262 | 0.057 | 0.070 | torch.Size([120]) || stage6.residual_group1.blocks.3.norm1.bias
+ | 0.001 | -0.501 | 0.290 | 0.062 | torch.Size([675, 6]) || stage6.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.3.attn.position_bias
+ | -0.000 | -0.349 | 0.336 | 0.061 | torch.Size([360, 120]) || stage6.residual_group1.blocks.3.attn.qkv_self.weight
+ | 0.001 | -0.287 | 0.202 | 0.053 | torch.Size([360]) || stage6.residual_group1.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.322 | 0.401 | 0.056 | torch.Size([120, 240]) || stage6.residual_group1.blocks.3.attn.proj.weight
+ | -0.004 | -0.182 | 0.151 | 0.062 | torch.Size([120]) || stage6.residual_group1.blocks.3.attn.proj.bias
+ | 0.000 | -0.441 | 0.444 | 0.054 | torch.Size([360, 120]) || stage6.residual_group1.blocks.3.attn.qkv_mut.weight
+ | 0.000 | -0.038 | 0.033 | 0.009 | torch.Size([360]) || stage6.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.666 | 0.317 | 0.970 | 0.117 | torch.Size([120]) || stage6.residual_group1.blocks.3.norm2.weight
+ | -0.003 | -0.173 | 0.168 | 0.067 | torch.Size([120]) || stage6.residual_group1.blocks.3.norm2.bias
+ | -0.000 | -0.354 | 0.408 | 0.070 | torch.Size([240, 120]) || stage6.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.072 | -0.297 | 0.067 | 0.065 | torch.Size([240]) || stage6.residual_group1.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.299 | 0.335 | 0.066 | torch.Size([240, 120]) || stage6.residual_group1.blocks.3.mlp.fc12.weight
+ | -0.004 | -0.191 | 0.136 | 0.060 | torch.Size([240]) || stage6.residual_group1.blocks.3.mlp.fc12.bias
+ | -0.000 | -0.400 | 0.590 | 0.071 | torch.Size([120, 240]) || stage6.residual_group1.blocks.3.mlp.fc2.weight
+ | -0.005 | -0.159 | 0.142 | 0.061 | torch.Size([120]) || stage6.residual_group1.blocks.3.mlp.fc2.bias
+ | 0.730 | 0.334 | 0.963 | 0.118 | torch.Size([120]) || stage6.residual_group1.blocks.4.norm1.weight
+ | -0.064 | -0.201 | 0.064 | 0.055 | torch.Size([120]) || stage6.residual_group1.blocks.4.norm1.bias
+ | -0.000 | -0.702 | 1.180 | 0.086 | torch.Size([675, 6]) || stage6.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.4.attn.position_bias
+ | -0.000 | -0.483 | 0.398 | 0.073 | torch.Size([360, 120]) || stage6.residual_group1.blocks.4.attn.qkv_self.weight
+ | 0.004 | -0.480 | 0.514 | 0.080 | torch.Size([360]) || stage6.residual_group1.blocks.4.attn.qkv_self.bias
+ | 0.000 | -0.331 | 0.390 | 0.056 | torch.Size([120, 240]) || stage6.residual_group1.blocks.4.attn.proj.weight
+ | -0.004 | -0.141 | 0.167 | 0.050 | torch.Size([120]) || stage6.residual_group1.blocks.4.attn.proj.bias
+ | 0.000 | -0.387 | 0.470 | 0.048 | torch.Size([360, 120]) || stage6.residual_group1.blocks.4.attn.qkv_mut.weight
+ | 0.001 | -0.065 | 0.039 | 0.010 | torch.Size([360]) || stage6.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.656 | 0.235 | 0.874 | 0.105 | torch.Size([120]) || stage6.residual_group1.blocks.4.norm2.weight
+ | -0.005 | -0.237 | 0.171 | 0.074 | torch.Size([120]) || stage6.residual_group1.blocks.4.norm2.bias
+ | -0.000 | -0.440 | 0.483 | 0.075 | torch.Size([240, 120]) || stage6.residual_group1.blocks.4.mlp.fc11.weight
+ | -0.076 | -0.347 | 0.110 | 0.076 | torch.Size([240]) || stage6.residual_group1.blocks.4.mlp.fc11.bias
+ | 0.000 | -0.286 | 0.348 | 0.070 | torch.Size([240, 120]) || stage6.residual_group1.blocks.4.mlp.fc12.weight
+ | 0.001 | -0.189 | 0.169 | 0.069 | torch.Size([240]) || stage6.residual_group1.blocks.4.mlp.fc12.bias
+ | 0.000 | -0.398 | 0.336 | 0.075 | torch.Size([120, 240]) || stage6.residual_group1.blocks.4.mlp.fc2.weight
+ | -0.004 | -0.127 | 0.137 | 0.052 | torch.Size([120]) || stage6.residual_group1.blocks.4.mlp.fc2.bias
+ | 0.691 | 0.178 | 0.975 | 0.116 | torch.Size([120]) || stage6.residual_group1.blocks.5.norm1.weight
+ | -0.042 | -0.137 | 0.099 | 0.037 | torch.Size([120]) || stage6.residual_group1.blocks.5.norm1.bias
+ | -0.001 | -0.662 | 1.078 | 0.078 | torch.Size([675, 6]) || stage6.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.5.attn.position_bias
+ | -0.000 | -0.359 | 0.531 | 0.072 | torch.Size([360, 120]) || stage6.residual_group1.blocks.5.attn.qkv_self.weight
+ | 0.002 | -0.293 | 0.311 | 0.075 | torch.Size([360]) || stage6.residual_group1.blocks.5.attn.qkv_self.bias
+ | 0.000 | -0.426 | 0.488 | 0.055 | torch.Size([120, 240]) || stage6.residual_group1.blocks.5.attn.proj.weight
+ | -0.006 | -0.103 | 0.159 | 0.044 | torch.Size([120]) || stage6.residual_group1.blocks.5.attn.proj.bias
+ | 0.000 | -0.401 | 0.385 | 0.044 | torch.Size([360, 120]) || stage6.residual_group1.blocks.5.attn.qkv_mut.weight
+ | 0.001 | -0.039 | 0.043 | 0.009 | torch.Size([360]) || stage6.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.607 | 0.210 | 0.802 | 0.094 | torch.Size([120]) || stage6.residual_group1.blocks.5.norm2.weight
+ | -0.004 | -0.178 | 0.199 | 0.068 | torch.Size([120]) || stage6.residual_group1.blocks.5.norm2.bias
+ | -0.000 | -0.377 | 0.541 | 0.079 | torch.Size([240, 120]) || stage6.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.069 | -0.429 | 0.280 | 0.096 | torch.Size([240]) || stage6.residual_group1.blocks.5.mlp.fc11.bias
+ | -0.000 | -0.394 | 0.344 | 0.077 | torch.Size([240, 120]) || stage6.residual_group1.blocks.5.mlp.fc12.weight
+ | 0.000 | -0.241 | 0.223 | 0.085 | torch.Size([240]) || stage6.residual_group1.blocks.5.mlp.fc12.bias
+ | -0.000 | -0.527 | 0.647 | 0.077 | torch.Size([120, 240]) || stage6.residual_group1.blocks.5.mlp.fc2.weight
+ | -0.006 | -0.126 | 0.157 | 0.047 | torch.Size([120]) || stage6.residual_group1.blocks.5.mlp.fc2.bias
+ | -0.001 | -0.294 | 0.287 | 0.060 | torch.Size([120, 120]) || stage6.linear1.weight
+ | 0.006 | -0.543 | 0.664 | 0.193 | torch.Size([120]) || stage6.linear1.bias
+ | 0.674 | 0.222 | 1.065 | 0.154 | torch.Size([120]) || stage6.residual_group2.blocks.0.norm1.weight
+ | 0.002 | -0.480 | 0.311 | 0.128 | torch.Size([120]) || stage6.residual_group2.blocks.0.norm1.bias
+ | 0.000 | -0.629 | 0.461 | 0.041 | torch.Size([3375, 6]) || stage6.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage6.residual_group2.blocks.0.attn.relative_position_index
+ | 0.000 | -0.495 | 0.440 | 0.085 | torch.Size([360, 120]) || stage6.residual_group2.blocks.0.attn.qkv_self.weight
+ | -0.001 | -0.516 | 0.468 | 0.114 | torch.Size([360]) || stage6.residual_group2.blocks.0.attn.qkv_self.bias
+ | 0.001 | -0.369 | 0.377 | 0.085 | torch.Size([120, 120]) || stage6.residual_group2.blocks.0.attn.proj.weight
+ | -0.003 | -0.297 | 0.292 | 0.113 | torch.Size([120]) || stage6.residual_group2.blocks.0.attn.proj.bias
+ | 0.644 | 0.181 | 1.104 | 0.153 | torch.Size([120]) || stage6.residual_group2.blocks.0.norm2.weight
+ | 0.003 | -0.167 | 0.185 | 0.070 | torch.Size([120]) || stage6.residual_group2.blocks.0.norm2.bias
+ | -0.000 | -0.383 | 0.534 | 0.087 | torch.Size([240, 120]) || stage6.residual_group2.blocks.0.mlp.fc11.weight
+ | -0.101 | -0.214 | 0.048 | 0.051 | torch.Size([240]) || stage6.residual_group2.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.350 | 0.560 | 0.085 | torch.Size([240, 120]) || stage6.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.005 | -0.159 | 0.138 | 0.047 | torch.Size([240]) || stage6.residual_group2.blocks.0.mlp.fc12.bias
+ | -0.001 | -0.374 | 0.488 | 0.091 | torch.Size([120, 240]) || stage6.residual_group2.blocks.0.mlp.fc2.weight
+ | -0.006 | -0.271 | 0.252 | 0.096 | torch.Size([120]) || stage6.residual_group2.blocks.0.mlp.fc2.bias
+ | 0.663 | 0.353 | 0.959 | 0.106 | torch.Size([120]) || stage6.residual_group2.blocks.1.norm1.weight
+ | 0.001 | -0.314 | 0.289 | 0.089 | torch.Size([120]) || stage6.residual_group2.blocks.1.norm1.bias
+ | 0.000 | -0.772 | 0.763 | 0.041 | torch.Size([3375, 6]) || stage6.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage6.residual_group2.blocks.1.attn.relative_position_index
+ | -0.000 | -0.495 | 0.604 | 0.086 | torch.Size([360, 120]) || stage6.residual_group2.blocks.1.attn.qkv_self.weight
+ | 0.005 | -0.491 | 0.401 | 0.097 | torch.Size([360]) || stage6.residual_group2.blocks.1.attn.qkv_self.bias
+ | 0.001 | -0.380 | 0.376 | 0.076 | torch.Size([120, 120]) || stage6.residual_group2.blocks.1.attn.proj.weight
+ | -0.007 | -0.321 | 0.234 | 0.096 | torch.Size([120]) || stage6.residual_group2.blocks.1.attn.proj.bias
+ | 0.666 | 0.226 | 1.153 | 0.138 | torch.Size([120]) || stage6.residual_group2.blocks.1.norm2.weight
+ | 0.001 | -0.178 | 0.220 | 0.069 | torch.Size([120]) || stage6.residual_group2.blocks.1.norm2.bias
+ | 0.000 | -0.514 | 0.608 | 0.090 | torch.Size([240, 120]) || stage6.residual_group2.blocks.1.mlp.fc11.weight
+ | -0.132 | -0.313 | 0.023 | 0.059 | torch.Size([240]) || stage6.residual_group2.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.423 | 0.488 | 0.088 | torch.Size([240, 120]) || stage6.residual_group2.blocks.1.mlp.fc12.weight
+ | -0.002 | -0.153 | 0.122 | 0.053 | torch.Size([240]) || stage6.residual_group2.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.399 | 0.435 | 0.087 | torch.Size([120, 240]) || stage6.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.001 | -0.285 | 0.241 | 0.093 | torch.Size([120]) || stage6.residual_group2.blocks.1.mlp.fc2.bias
+ | 0.000 | -0.308 | 0.365 | 0.070 | torch.Size([120, 120]) || stage6.linear2.weight
+ | -0.002 | -0.699 | 0.757 | 0.303 | torch.Size([120]) || stage6.linear2.bias
+ | 0.000 | -0.130 | 0.129 | 0.027 | torch.Size([120, 120, 3, 3]) || stage6.pa_deform.weight
+ | -0.001 | -0.051 | 0.045 | 0.018 | torch.Size([120]) || stage6.pa_deform.bias
+ | -0.000 | -0.017 | 0.017 | 0.010 | torch.Size([120, 364, 3, 3]) || stage6.pa_deform.conv_offset.0.weight
+ | -0.007 | -0.049 | 0.026 | 0.012 | torch.Size([120]) || stage6.pa_deform.conv_offset.0.bias
+ | -0.001 | -0.090 | 0.114 | 0.020 | torch.Size([120, 120, 3, 3]) || stage6.pa_deform.conv_offset.2.weight
+ | -0.008 | -0.070 | 0.060 | 0.030 | torch.Size([120]) || stage6.pa_deform.conv_offset.2.bias
+ | -0.001 | -0.097 | 0.101 | 0.020 | torch.Size([120, 120, 3, 3]) || stage6.pa_deform.conv_offset.4.weight
+ | 0.006 | -0.096 | 0.114 | 0.044 | torch.Size([120]) || stage6.pa_deform.conv_offset.4.bias
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432, 120, 3, 3]) || stage6.pa_deform.conv_offset.6.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432]) || stage6.pa_deform.conv_offset.6.bias
+ | -0.002 | -0.822 | 0.740 | 0.127 | torch.Size([360, 360]) || stage6.pa_fuse.fc11.weight
+ | 0.212 | -0.394 | 0.913 | 0.216 | torch.Size([360]) || stage6.pa_fuse.fc11.bias
+ | -0.000 | -0.948 | 0.848 | 0.131 | torch.Size([360, 360]) || stage6.pa_fuse.fc12.weight
+ | 0.001 | -0.657 | 0.605 | 0.279 | torch.Size([360]) || stage6.pa_fuse.fc12.bias
+ | -0.000 | -0.678 | 0.823 | 0.158 | torch.Size([120, 360]) || stage6.pa_fuse.fc2.weight
+ | 0.009 | -0.616 | 0.477 | 0.283 | torch.Size([120]) || stage6.pa_fuse.fc2.bias
+ | 1.363 | 1.278 | 1.458 | 0.048 | torch.Size([30]) || stage7.reshape.1.weight
+ | -0.001 | -0.247 | 0.227 | 0.139 | torch.Size([30]) || stage7.reshape.1.bias
+ | -0.000 | -0.590 | 0.587 | 0.179 | torch.Size([120, 30]) || stage7.reshape.2.weight
+ | -0.029 | -0.525 | 0.546 | 0.231 | torch.Size([120]) || stage7.reshape.2.bias
+ | 0.406 | 0.101 | 0.864 | 0.138 | torch.Size([120]) || stage7.residual_group1.blocks.0.norm1.weight
+ | -0.159 | -0.667 | 0.525 | 0.161 | torch.Size([120]) || stage7.residual_group1.blocks.0.norm1.bias
+ | -0.174 | -2.385 | 4.798 | 0.381 | torch.Size([675, 6]) || stage7.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.0.attn.position_bias
+ | -0.000 | -0.809 | 0.687 | 0.111 | torch.Size([360, 120]) || stage7.residual_group1.blocks.0.attn.qkv_self.weight
+ | 0.001 | -0.275 | 0.262 | 0.057 | torch.Size([360]) || stage7.residual_group1.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.416 | 0.438 | 0.096 | torch.Size([120, 240]) || stage7.residual_group1.blocks.0.attn.proj.weight
+ | 0.008 | -0.499 | 0.295 | 0.131 | torch.Size([120]) || stage7.residual_group1.blocks.0.attn.proj.bias
+ | -0.000 | -1.494 | 1.378 | 0.106 | torch.Size([360, 120]) || stage7.residual_group1.blocks.0.attn.qkv_mut.weight
+ | -0.000 | -0.123 | 0.106 | 0.015 | torch.Size([360]) || stage7.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.284 | 0.172 | 0.377 | 0.040 | torch.Size([120]) || stage7.residual_group1.blocks.0.norm2.weight
+ | -0.003 | -0.502 | 0.588 | 0.124 | torch.Size([120]) || stage7.residual_group1.blocks.0.norm2.bias
+ | 0.000 | -0.597 | 0.567 | 0.132 | torch.Size([240, 120]) || stage7.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.061 | -0.420 | 0.409 | 0.104 | torch.Size([240]) || stage7.residual_group1.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.606 | 0.601 | 0.144 | torch.Size([240, 120]) || stage7.residual_group1.blocks.0.mlp.fc12.weight
+ | -0.003 | -0.306 | 0.261 | 0.101 | torch.Size([240]) || stage7.residual_group1.blocks.0.mlp.fc12.bias
+ | -0.001 | -0.572 | 0.609 | 0.149 | torch.Size([120, 240]) || stage7.residual_group1.blocks.0.mlp.fc2.weight
+ | -0.008 | -0.373 | 0.306 | 0.099 | torch.Size([120]) || stage7.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.538 | 0.114 | 0.809 | 0.125 | torch.Size([120]) || stage7.residual_group1.blocks.1.norm1.weight
+ | -0.129 | -0.865 | 0.532 | 0.163 | torch.Size([120]) || stage7.residual_group1.blocks.1.norm1.bias
+ | -0.281 | -2.710 | 4.413 | 0.432 | torch.Size([675, 6]) || stage7.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.1.attn.position_bias
+ | 0.000 | -0.646 | 0.655 | 0.135 | torch.Size([360, 120]) || stage7.residual_group1.blocks.1.attn.qkv_self.weight
+ | -0.000 | -0.301 | 0.303 | 0.068 | torch.Size([360]) || stage7.residual_group1.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.479 | 0.463 | 0.100 | torch.Size([120, 240]) || stage7.residual_group1.blocks.1.attn.proj.weight
+ | 0.016 | -0.460 | 0.313 | 0.135 | torch.Size([120]) || stage7.residual_group1.blocks.1.attn.proj.bias
+ | 0.000 | -2.205 | 2.065 | 0.127 | torch.Size([360, 120]) || stage7.residual_group1.blocks.1.attn.qkv_mut.weight
+ | -0.000 | -0.074 | 0.085 | 0.017 | torch.Size([360]) || stage7.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.353 | 0.243 | 0.425 | 0.034 | torch.Size([120]) || stage7.residual_group1.blocks.1.norm2.weight
+ | -0.008 | -0.643 | 0.628 | 0.146 | torch.Size([120]) || stage7.residual_group1.blocks.1.norm2.bias
+ | 0.000 | -0.535 | 0.617 | 0.135 | torch.Size([240, 120]) || stage7.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.054 | -0.348 | 0.244 | 0.109 | torch.Size([240]) || stage7.residual_group1.blocks.1.mlp.fc11.bias
+ | -0.001 | -0.671 | 0.611 | 0.148 | torch.Size([240, 120]) || stage7.residual_group1.blocks.1.mlp.fc12.weight
+ | 0.004 | -0.272 | 0.292 | 0.098 | torch.Size([240]) || stage7.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.672 | 0.595 | 0.149 | torch.Size([120, 240]) || stage7.residual_group1.blocks.1.mlp.fc2.weight
+ | -0.003 | -0.398 | 0.273 | 0.088 | torch.Size([120]) || stage7.residual_group1.blocks.1.mlp.fc2.bias
+ | 0.581 | 0.093 | 0.791 | 0.147 | torch.Size([120]) || stage7.residual_group1.blocks.2.norm1.weight
+ | -0.143 | -1.023 | 0.481 | 0.167 | torch.Size([120]) || stage7.residual_group1.blocks.2.norm1.bias
+ | -0.098 | -2.171 | 4.402 | 0.287 | torch.Size([675, 6]) || stage7.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.2.attn.position_bias
+ | 0.000 | -0.640 | 0.701 | 0.147 | torch.Size([360, 120]) || stage7.residual_group1.blocks.2.attn.qkv_self.weight
+ | -0.005 | -0.328 | 0.408 | 0.072 | torch.Size([360]) || stage7.residual_group1.blocks.2.attn.qkv_self.bias
+ | -0.001 | -0.417 | 0.441 | 0.101 | torch.Size([120, 240]) || stage7.residual_group1.blocks.2.attn.proj.weight
+ | 0.007 | -0.508 | 0.265 | 0.127 | torch.Size([120]) || stage7.residual_group1.blocks.2.attn.proj.bias
+ | -0.001 | -2.511 | 2.484 | 0.143 | torch.Size([360, 120]) || stage7.residual_group1.blocks.2.attn.qkv_mut.weight
+ | -0.000 | -0.093 | 0.104 | 0.019 | torch.Size([360]) || stage7.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.392 | 0.276 | 0.487 | 0.034 | torch.Size([120]) || stage7.residual_group1.blocks.2.norm2.weight
+ | -0.016 | -0.555 | 0.581 | 0.143 | torch.Size([120]) || stage7.residual_group1.blocks.2.norm2.bias
+ | -0.000 | -0.630 | 0.674 | 0.135 | torch.Size([240, 120]) || stage7.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.072 | -0.420 | 0.173 | 0.115 | torch.Size([240]) || stage7.residual_group1.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.654 | 0.793 | 0.152 | torch.Size([240, 120]) || stage7.residual_group1.blocks.2.mlp.fc12.weight
+ | -0.003 | -0.303 | 0.263 | 0.098 | torch.Size([240]) || stage7.residual_group1.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.603 | 0.658 | 0.150 | torch.Size([120, 240]) || stage7.residual_group1.blocks.2.mlp.fc2.weight
+ | 0.003 | -0.301 | 0.247 | 0.081 | torch.Size([120]) || stage7.residual_group1.blocks.2.mlp.fc2.bias
+ | 0.611 | 0.127 | 0.811 | 0.134 | torch.Size([120]) || stage7.residual_group1.blocks.3.norm1.weight
+ | -0.137 | -0.781 | 0.684 | 0.164 | torch.Size([120]) || stage7.residual_group1.blocks.3.norm1.bias
+ | -0.109 | -4.577 | 4.527 | 0.332 | torch.Size([675, 6]) || stage7.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.3.attn.position_bias
+ | 0.000 | -0.757 | 0.743 | 0.146 | torch.Size([360, 120]) || stage7.residual_group1.blocks.3.attn.qkv_self.weight
+ | 0.001 | -0.358 | 0.342 | 0.083 | torch.Size([360]) || stage7.residual_group1.blocks.3.attn.qkv_self.bias
+ | 0.001 | -0.465 | 0.447 | 0.097 | torch.Size([120, 240]) || stage7.residual_group1.blocks.3.attn.proj.weight
+ | 0.002 | -0.389 | 0.233 | 0.113 | torch.Size([120]) || stage7.residual_group1.blocks.3.attn.proj.bias
+ | -0.001 | -1.947 | 1.928 | 0.127 | torch.Size([360, 120]) || stage7.residual_group1.blocks.3.attn.qkv_mut.weight
+ | 0.000 | -0.106 | 0.070 | 0.018 | torch.Size([360]) || stage7.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.410 | 0.283 | 0.489 | 0.035 | torch.Size([120]) || stage7.residual_group1.blocks.3.norm2.weight
+ | -0.014 | -0.442 | 0.639 | 0.147 | torch.Size([120]) || stage7.residual_group1.blocks.3.norm2.bias
+ | -0.000 | -0.542 | 0.585 | 0.132 | torch.Size([240, 120]) || stage7.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.069 | -0.463 | 0.214 | 0.122 | torch.Size([240]) || stage7.residual_group1.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.689 | 0.605 | 0.154 | torch.Size([240, 120]) || stage7.residual_group1.blocks.3.mlp.fc12.weight
+ | -0.008 | -0.307 | 0.279 | 0.096 | torch.Size([240]) || stage7.residual_group1.blocks.3.mlp.fc12.bias
+ | -0.000 | -0.593 | 0.603 | 0.152 | torch.Size([120, 240]) || stage7.residual_group1.blocks.3.mlp.fc2.weight
+ | 0.010 | -0.269 | 0.270 | 0.094 | torch.Size([120]) || stage7.residual_group1.blocks.3.mlp.fc2.bias
+ | 0.652 | 0.132 | 0.859 | 0.133 | torch.Size([120]) || stage7.residual_group1.blocks.4.norm1.weight
+ | -0.131 | -0.662 | 0.729 | 0.163 | torch.Size([120]) || stage7.residual_group1.blocks.4.norm1.bias
+ | -0.092 | -4.521 | 3.027 | 0.337 | torch.Size([675, 6]) || stage7.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.4.attn.position_bias
+ | -0.000 | -0.694 | 0.828 | 0.148 | torch.Size([360, 120]) || stage7.residual_group1.blocks.4.attn.qkv_self.weight
+ | 0.002 | -0.328 | 0.361 | 0.078 | torch.Size([360]) || stage7.residual_group1.blocks.4.attn.qkv_self.bias
+ | 0.000 | -0.430 | 0.483 | 0.100 | torch.Size([120, 240]) || stage7.residual_group1.blocks.4.attn.proj.weight
+ | -0.003 | -0.368 | 0.250 | 0.103 | torch.Size([120]) || stage7.residual_group1.blocks.4.attn.proj.bias
+ | -0.000 | -1.506 | 1.779 | 0.122 | torch.Size([360, 120]) || stage7.residual_group1.blocks.4.attn.qkv_mut.weight
+ | 0.000 | -0.090 | 0.112 | 0.020 | torch.Size([360]) || stage7.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.435 | 0.347 | 0.536 | 0.033 | torch.Size([120]) || stage7.residual_group1.blocks.4.norm2.weight
+ | -0.018 | -0.345 | 0.609 | 0.136 | torch.Size([120]) || stage7.residual_group1.blocks.4.norm2.bias
+ | -0.001 | -0.580 | 0.558 | 0.132 | torch.Size([240, 120]) || stage7.residual_group1.blocks.4.mlp.fc11.weight
+ | -0.066 | -0.392 | 0.239 | 0.128 | torch.Size([240]) || stage7.residual_group1.blocks.4.mlp.fc11.bias
+ | -0.000 | -0.608 | 0.667 | 0.157 | torch.Size([240, 120]) || stage7.residual_group1.blocks.4.mlp.fc12.weight
+ | -0.001 | -0.276 | 0.296 | 0.105 | torch.Size([240]) || stage7.residual_group1.blocks.4.mlp.fc12.bias
+ | 0.000 | -0.666 | 0.775 | 0.155 | torch.Size([120, 240]) || stage7.residual_group1.blocks.4.mlp.fc2.weight
+ | 0.001 | -0.380 | 0.360 | 0.101 | torch.Size([120]) || stage7.residual_group1.blocks.4.mlp.fc2.bias
+ | 0.648 | 0.269 | 0.885 | 0.109 | torch.Size([120]) || stage7.residual_group1.blocks.5.norm1.weight
+ | -0.116 | -0.436 | 0.749 | 0.144 | torch.Size([120]) || stage7.residual_group1.blocks.5.norm1.bias
+ | -0.130 | -3.976 | 4.665 | 0.318 | torch.Size([675, 6]) || stage7.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.5.attn.position_bias
+ | -0.000 | -0.702 | 0.671 | 0.140 | torch.Size([360, 120]) || stage7.residual_group1.blocks.5.attn.qkv_self.weight
+ | 0.000 | -0.346 | 0.340 | 0.078 | torch.Size([360]) || stage7.residual_group1.blocks.5.attn.qkv_self.bias
+ | -0.000 | -0.410 | 0.394 | 0.091 | torch.Size([120, 240]) || stage7.residual_group1.blocks.5.attn.proj.weight
+ | 0.006 | -0.286 | 0.244 | 0.100 | torch.Size([120]) || stage7.residual_group1.blocks.5.attn.proj.bias
+ | 0.001 | -0.870 | 0.885 | 0.109 | torch.Size([360, 120]) || stage7.residual_group1.blocks.5.attn.qkv_mut.weight
+ | 0.001 | -0.120 | 0.096 | 0.018 | torch.Size([360]) || stage7.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.445 | 0.326 | 0.595 | 0.034 | torch.Size([120]) || stage7.residual_group1.blocks.5.norm2.weight
+ | -0.016 | -0.233 | 0.558 | 0.110 | torch.Size([120]) || stage7.residual_group1.blocks.5.norm2.bias
+ | -0.001 | -0.576 | 0.577 | 0.129 | torch.Size([240, 120]) || stage7.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.038 | -0.525 | 0.269 | 0.139 | torch.Size([240]) || stage7.residual_group1.blocks.5.mlp.fc11.bias
+ | -0.000 | -0.672 | 0.671 | 0.158 | torch.Size([240, 120]) || stage7.residual_group1.blocks.5.mlp.fc12.weight
+ | 0.003 | -0.400 | 0.281 | 0.116 | torch.Size([240]) || stage7.residual_group1.blocks.5.mlp.fc12.bias
+ | 0.000 | -0.937 | 0.714 | 0.156 | torch.Size([120, 240]) || stage7.residual_group1.blocks.5.mlp.fc2.weight
+ | 0.007 | -0.435 | 0.876 | 0.188 | torch.Size([120]) || stage7.residual_group1.blocks.5.mlp.fc2.bias
+ | -0.000 | -0.234 | 0.212 | 0.056 | torch.Size([120, 120]) || stage7.linear1.weight
+ | -0.033 | -0.655 | 0.586 | 0.242 | torch.Size([120]) || stage7.linear1.bias
+ | 0.684 | 0.257 | 0.867 | 0.090 | torch.Size([120]) || stage7.residual_group2.blocks.0.norm1.weight
+ | -0.003 | -0.857 | 0.829 | 0.193 | torch.Size([120]) || stage7.residual_group2.blocks.0.norm1.bias
+ | -0.005 | -5.628 | 1.358 | 0.121 | torch.Size([3375, 6]) || stage7.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage7.residual_group2.blocks.0.attn.relative_position_index
+ | 0.000 | -0.699 | 0.827 | 0.137 | torch.Size([360, 120]) || stage7.residual_group2.blocks.0.attn.qkv_self.weight
+ | 0.001 | -0.821 | 0.662 | 0.143 | torch.Size([360]) || stage7.residual_group2.blocks.0.attn.qkv_self.bias
+ | 0.001 | -0.392 | 0.418 | 0.106 | torch.Size([120, 120]) || stage7.residual_group2.blocks.0.attn.proj.weight
+ | 0.003 | -0.147 | 0.171 | 0.052 | torch.Size([120]) || stage7.residual_group2.blocks.0.attn.proj.bias
+ | 0.431 | 0.316 | 0.521 | 0.036 | torch.Size([120]) || stage7.residual_group2.blocks.0.norm2.weight
+ | -0.003 | -0.595 | 0.673 | 0.129 | torch.Size([120]) || stage7.residual_group2.blocks.0.norm2.bias
+ | -0.000 | -0.701 | 0.542 | 0.119 | torch.Size([240, 120]) || stage7.residual_group2.blocks.0.mlp.fc11.weight
+ | 0.017 | -0.290 | 0.421 | 0.117 | torch.Size([240]) || stage7.residual_group2.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.603 | 0.637 | 0.145 | torch.Size([240, 120]) || stage7.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.006 | -0.394 | 0.426 | 0.098 | torch.Size([240]) || stage7.residual_group2.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.602 | 0.607 | 0.144 | torch.Size([120, 240]) || stage7.residual_group2.blocks.0.mlp.fc2.weight
+ | -0.003 | -0.460 | 0.272 | 0.112 | torch.Size([120]) || stage7.residual_group2.blocks.0.mlp.fc2.bias
+ | 0.655 | 0.251 | 0.779 | 0.074 | torch.Size([120]) || stage7.residual_group2.blocks.1.norm1.weight
+ | -0.004 | -0.718 | 0.811 | 0.153 | torch.Size([120]) || stage7.residual_group2.blocks.1.norm1.bias
+ | -0.007 | -3.104 | 1.224 | 0.101 | torch.Size([3375, 6]) || stage7.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage7.residual_group2.blocks.1.attn.relative_position_index
+ | -0.000 | -0.664 | 0.647 | 0.137 | torch.Size([360, 120]) || stage7.residual_group2.blocks.1.attn.qkv_self.weight
+ | 0.002 | -0.532 | 0.746 | 0.150 | torch.Size([360]) || stage7.residual_group2.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.428 | 0.360 | 0.100 | torch.Size([120, 120]) || stage7.residual_group2.blocks.1.attn.proj.weight
+ | 0.009 | -0.244 | 0.242 | 0.063 | torch.Size([120]) || stage7.residual_group2.blocks.1.attn.proj.bias
+ | 0.442 | 0.284 | 0.530 | 0.038 | torch.Size([120]) || stage7.residual_group2.blocks.1.norm2.weight
+ | -0.004 | -0.421 | 0.664 | 0.106 | torch.Size([120]) || stage7.residual_group2.blocks.1.norm2.bias
+ | -0.001 | -0.604 | 0.583 | 0.119 | torch.Size([240, 120]) || stage7.residual_group2.blocks.1.mlp.fc11.weight
+ | 0.028 | -0.389 | 0.406 | 0.134 | torch.Size([240]) || stage7.residual_group2.blocks.1.mlp.fc11.bias
+ | -0.001 | -0.681 | 0.818 | 0.148 | torch.Size([240, 120]) || stage7.residual_group2.blocks.1.mlp.fc12.weight
+ | 0.003 | -0.247 | 0.361 | 0.096 | torch.Size([240]) || stage7.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.783 | 0.835 | 0.146 | torch.Size([120, 240]) || stage7.residual_group2.blocks.1.mlp.fc2.weight
+ | 0.008 | -0.529 | 0.922 | 0.144 | torch.Size([120]) || stage7.residual_group2.blocks.1.mlp.fc2.bias
+ | -0.001 | -0.353 | 0.277 | 0.071 | torch.Size([120, 120]) || stage7.linear2.weight
+ | -0.026 | -0.905 | 0.749 | 0.262 | torch.Size([120]) || stage7.linear2.bias
+ | -0.000 | -0.125 | 0.138 | 0.027 | torch.Size([120, 120, 3, 3]) || stage7.pa_deform.weight
+ | -0.003 | -0.091 | 0.071 | 0.030 | torch.Size([120]) || stage7.pa_deform.bias
+ | -0.000 | -0.017 | 0.017 | 0.010 | torch.Size([120, 364, 3, 3]) || stage7.pa_deform.conv_offset.0.weight
+ | -0.000 | -0.028 | 0.054 | 0.015 | torch.Size([120]) || stage7.pa_deform.conv_offset.0.bias
+ | -0.001 | -0.130 | 0.111 | 0.017 | torch.Size([120, 120, 3, 3]) || stage7.pa_deform.conv_offset.2.weight
+ | -0.004 | -0.105 | 0.094 | 0.040 | torch.Size([120]) || stage7.pa_deform.conv_offset.2.bias
+ | -0.002 | -0.203 | 0.124 | 0.016 | torch.Size([120, 120, 3, 3]) || stage7.pa_deform.conv_offset.4.weight
+ | 0.027 | -0.097 | 0.151 | 0.048 | torch.Size([120]) || stage7.pa_deform.conv_offset.4.bias
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432, 120, 3, 3]) || stage7.pa_deform.conv_offset.6.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432]) || stage7.pa_deform.conv_offset.6.bias
+ | -0.002 | -0.997 | 1.031 | 0.156 | torch.Size([360, 360]) || stage7.pa_fuse.fc11.weight
+ | 0.219 | -0.261 | 0.769 | 0.213 | torch.Size([360]) || stage7.pa_fuse.fc11.bias
+ | 0.001 | -1.119 | 1.206 | 0.175 | torch.Size([360, 360]) || stage7.pa_fuse.fc12.weight
+ | -0.011 | -0.547 | 0.598 | 0.195 | torch.Size([360]) || stage7.pa_fuse.fc12.bias
+ | 0.000 | -0.860 | 0.957 | 0.160 | torch.Size([120, 360]) || stage7.pa_fuse.fc2.weight
+ | 0.018 | -1.017 | 0.731 | 0.363 | torch.Size([120]) || stage7.pa_fuse.fc2.bias
+ | 1.491 | 1.080 | 1.847 | 0.135 | torch.Size([120]) || stage8.0.1.weight
+ | -0.012 | -0.370 | 0.414 | 0.140 | torch.Size([120]) || stage8.0.1.bias
+ | -0.000 | -0.882 | 1.114 | 0.177 | torch.Size([180, 120]) || stage8.0.2.weight
+ | -0.005 | -1.101 | 0.699 | 0.167 | torch.Size([180]) || stage8.0.2.bias
+ | 0.622 | 0.186 | 1.009 | 0.188 | torch.Size([180]) || stage8.1.residual_group.blocks.0.norm1.weight
+ | -0.006 | -0.884 | 1.056 | 0.212 | torch.Size([180]) || stage8.1.residual_group.blocks.0.norm1.bias
+ | -0.003 | -2.578 | 2.238 | 0.223 | torch.Size([3375, 6]) || stage8.1.residual_group.blocks.0.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.1.residual_group.blocks.0.attn.relative_position_index
+ | 0.000 | -1.042 | 1.335 | 0.152 | torch.Size([540, 180]) || stage8.1.residual_group.blocks.0.attn.qkv_self.weight
+ | -0.007 | -0.992 | 0.938 | 0.208 | torch.Size([540]) || stage8.1.residual_group.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.692 | 0.565 | 0.129 | torch.Size([180, 180]) || stage8.1.residual_group.blocks.0.attn.proj.weight
+ | 0.009 | -1.288 | 0.895 | 0.185 | torch.Size([180]) || stage8.1.residual_group.blocks.0.attn.proj.bias
+ | 0.415 | 0.180 | 0.539 | 0.066 | torch.Size([180]) || stage8.1.residual_group.blocks.0.norm2.weight
+ | -0.006 | -0.634 | 0.818 | 0.145 | torch.Size([180]) || stage8.1.residual_group.blocks.0.norm2.bias
+ | 0.001 | -0.969 | 0.867 | 0.145 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.0.mlp.fc11.weight
+ | -0.055 | -0.545 | 0.271 | 0.110 | torch.Size([360]) || stage8.1.residual_group.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.698 | 0.845 | 0.153 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.0.mlp.fc12.weight
+ | 0.007 | -0.526 | 0.444 | 0.126 | torch.Size([360]) || stage8.1.residual_group.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.812 | 0.874 | 0.155 | torch.Size([180, 360]) || stage8.1.residual_group.blocks.0.mlp.fc2.weight
+ | 0.009 | -0.468 | 0.864 | 0.160 | torch.Size([180]) || stage8.1.residual_group.blocks.0.mlp.fc2.bias
+ | 0.724 | 0.198 | 0.915 | 0.128 | torch.Size([180]) || stage8.1.residual_group.blocks.1.norm1.weight
+ | -0.003 | -1.026 | 0.953 | 0.209 | torch.Size([180]) || stage8.1.residual_group.blocks.1.norm1.bias
+ | 0.030 | -3.042 | 1.112 | 0.227 | torch.Size([3375, 6]) || stage8.1.residual_group.blocks.1.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.1.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -1.192 | 0.952 | 0.169 | torch.Size([540, 180]) || stage8.1.residual_group.blocks.1.attn.qkv_self.weight
+ | -0.009 | -1.186 | 0.822 | 0.191 | torch.Size([540]) || stage8.1.residual_group.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.500 | 0.647 | 0.121 | torch.Size([180, 180]) || stage8.1.residual_group.blocks.1.attn.proj.weight
+ | 0.004 | -0.892 | 1.020 | 0.208 | torch.Size([180]) || stage8.1.residual_group.blocks.1.attn.proj.bias
+ | 0.492 | 0.230 | 0.628 | 0.064 | torch.Size([180]) || stage8.1.residual_group.blocks.1.norm2.weight
+ | -0.006 | -0.853 | 0.872 | 0.165 | torch.Size([180]) || stage8.1.residual_group.blocks.1.norm2.bias
+ | 0.001 | -0.748 | 0.701 | 0.150 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.1.mlp.fc11.weight
+ | -0.055 | -0.409 | 0.305 | 0.096 | torch.Size([360]) || stage8.1.residual_group.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.806 | 0.662 | 0.155 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.1.mlp.fc12.weight
+ | 0.001 | -0.304 | 0.419 | 0.096 | torch.Size([360]) || stage8.1.residual_group.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.841 | 0.781 | 0.154 | torch.Size([180, 360]) || stage8.1.residual_group.blocks.1.mlp.fc2.weight
+ | 0.005 | -0.280 | 0.641 | 0.119 | torch.Size([180]) || stage8.1.residual_group.blocks.1.mlp.fc2.bias
+ | 0.803 | 0.314 | 1.038 | 0.110 | torch.Size([180]) || stage8.1.residual_group.blocks.2.norm1.weight
+ | -0.006 | -1.202 | 1.119 | 0.207 | torch.Size([180]) || stage8.1.residual_group.blocks.2.norm1.bias
+ | -0.002 | -2.783 | 1.481 | 0.236 | torch.Size([3375, 6]) || stage8.1.residual_group.blocks.2.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.1.residual_group.blocks.2.attn.relative_position_index
+ | 0.000 | -0.957 | 0.943 | 0.162 | torch.Size([540, 180]) || stage8.1.residual_group.blocks.2.attn.qkv_self.weight
+ | 0.002 | -0.519 | 0.526 | 0.136 | torch.Size([540]) || stage8.1.residual_group.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.543 | 0.516 | 0.117 | torch.Size([180, 180]) || stage8.1.residual_group.blocks.2.attn.proj.weight
+ | 0.005 | -0.711 | 0.838 | 0.184 | torch.Size([180]) || stage8.1.residual_group.blocks.2.attn.proj.bias
+ | 0.549 | 0.206 | 0.679 | 0.078 | torch.Size([180]) || stage8.1.residual_group.blocks.2.norm2.weight
+ | -0.005 | -0.888 | 0.879 | 0.154 | torch.Size([180]) || stage8.1.residual_group.blocks.2.norm2.bias
+ | 0.000 | -0.748 | 0.896 | 0.148 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.2.mlp.fc11.weight
+ | -0.073 | -0.478 | 0.193 | 0.098 | torch.Size([360]) || stage8.1.residual_group.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.628 | 0.674 | 0.157 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.2.mlp.fc12.weight
+ | -0.001 | -0.331 | 0.230 | 0.082 | torch.Size([360]) || stage8.1.residual_group.blocks.2.mlp.fc12.bias
+ | 0.001 | -0.677 | 0.673 | 0.154 | torch.Size([180, 360]) || stage8.1.residual_group.blocks.2.mlp.fc2.weight
+ | 0.004 | -0.294 | 0.745 | 0.112 | torch.Size([180]) || stage8.1.residual_group.blocks.2.mlp.fc2.bias
+ | 0.843 | 0.308 | 0.966 | 0.094 | torch.Size([180]) || stage8.1.residual_group.blocks.3.norm1.weight
+ | -0.002 | -1.222 | 1.324 | 0.192 | torch.Size([180]) || stage8.1.residual_group.blocks.3.norm1.bias
+ | 0.001 | -2.899 | 2.240 | 0.272 | torch.Size([3375, 6]) || stage8.1.residual_group.blocks.3.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.1.residual_group.blocks.3.attn.relative_position_index
+ | -0.000 | -0.999 | 0.935 | 0.167 | torch.Size([540, 180]) || stage8.1.residual_group.blocks.3.attn.qkv_self.weight
+ | -0.001 | -0.612 | 0.531 | 0.127 | torch.Size([540]) || stage8.1.residual_group.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.591 | 0.537 | 0.112 | torch.Size([180, 180]) || stage8.1.residual_group.blocks.3.attn.proj.weight
+ | -0.005 | -0.476 | 1.034 | 0.188 | torch.Size([180]) || stage8.1.residual_group.blocks.3.attn.proj.bias
+ | 0.534 | 0.198 | 0.660 | 0.074 | torch.Size([180]) || stage8.1.residual_group.blocks.3.norm2.weight
+ | -0.006 | -0.845 | 0.869 | 0.130 | torch.Size([180]) || stage8.1.residual_group.blocks.3.norm2.bias
+ | 0.001 | -0.649 | 0.677 | 0.147 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.3.mlp.fc11.weight
+ | -0.080 | -0.378 | 0.228 | 0.109 | torch.Size([360]) || stage8.1.residual_group.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.628 | 0.683 | 0.157 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.3.mlp.fc12.weight
+ | -0.005 | -0.300 | 0.222 | 0.083 | torch.Size([360]) || stage8.1.residual_group.blocks.3.mlp.fc12.bias
+ | 0.001 | -0.959 | 0.733 | 0.153 | torch.Size([180, 360]) || stage8.1.residual_group.blocks.3.mlp.fc2.weight
+ | 0.003 | -0.915 | 0.961 | 0.165 | torch.Size([180]) || stage8.1.residual_group.blocks.3.mlp.fc2.bias
+ | 0.001 | -0.411 | 0.533 | 0.070 | torch.Size([180, 180]) || stage8.1.linear.weight
+ | -0.004 | -0.907 | 0.257 | 0.135 | torch.Size([180]) || stage8.1.linear.bias
+ | 0.890 | 0.143 | 1.178 | 0.177 | torch.Size([180]) || stage8.2.residual_group.blocks.0.norm1.weight
+ | -0.034 | -0.781 | 0.959 | 0.177 | torch.Size([180]) || stage8.2.residual_group.blocks.0.norm1.bias
+ | 0.001 | -2.545 | 1.182 | 0.186 | torch.Size([3375, 6]) || stage8.2.residual_group.blocks.0.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.2.residual_group.blocks.0.attn.relative_position_index
+ | 0.000 | -1.151 | 1.199 | 0.158 | torch.Size([540, 180]) || stage8.2.residual_group.blocks.0.attn.qkv_self.weight
+ | -0.001 | -0.731 | 0.744 | 0.155 | torch.Size([540]) || stage8.2.residual_group.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.522 | 0.577 | 0.131 | torch.Size([180, 180]) || stage8.2.residual_group.blocks.0.attn.proj.weight
+ | 0.003 | -0.537 | 0.895 | 0.164 | torch.Size([180]) || stage8.2.residual_group.blocks.0.attn.proj.bias
+ | 0.599 | 0.203 | 0.779 | 0.101 | torch.Size([180]) || stage8.2.residual_group.blocks.0.norm2.weight
+ | -0.021 | -0.429 | 1.016 | 0.143 | torch.Size([180]) || stage8.2.residual_group.blocks.0.norm2.bias
+ | -0.000 | -0.914 | 0.736 | 0.145 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.0.mlp.fc11.weight
+ | -0.054 | -0.545 | 0.183 | 0.106 | torch.Size([360]) || stage8.2.residual_group.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.716 | 0.750 | 0.155 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.0.mlp.fc12.weight
+ | 0.003 | -0.254 | 0.408 | 0.085 | torch.Size([360]) || stage8.2.residual_group.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.842 | 0.706 | 0.153 | torch.Size([180, 360]) || stage8.2.residual_group.blocks.0.mlp.fc2.weight
+ | 0.001 | -0.277 | 0.365 | 0.093 | torch.Size([180]) || stage8.2.residual_group.blocks.0.mlp.fc2.bias
+ | 0.910 | 0.151 | 1.164 | 0.152 | torch.Size([180]) || stage8.2.residual_group.blocks.1.norm1.weight
+ | -0.032 | -0.801 | 1.151 | 0.191 | torch.Size([180]) || stage8.2.residual_group.blocks.1.norm1.bias
+ | -0.069 | -2.776 | 5.771 | 0.290 | torch.Size([3375, 6]) || stage8.2.residual_group.blocks.1.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.2.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -1.359 | 1.101 | 0.156 | torch.Size([540, 180]) || stage8.2.residual_group.blocks.1.attn.qkv_self.weight
+ | 0.009 | -0.624 | 0.654 | 0.155 | torch.Size([540]) || stage8.2.residual_group.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.565 | 0.575 | 0.134 | torch.Size([180, 180]) || stage8.2.residual_group.blocks.1.attn.proj.weight
+ | -0.004 | -0.671 | 0.566 | 0.171 | torch.Size([180]) || stage8.2.residual_group.blocks.1.attn.proj.bias
+ | 0.609 | 0.206 | 0.818 | 0.109 | torch.Size([180]) || stage8.2.residual_group.blocks.1.norm2.weight
+ | -0.022 | -0.474 | 1.079 | 0.147 | torch.Size([180]) || stage8.2.residual_group.blocks.1.norm2.bias
+ | 0.000 | -0.760 | 0.819 | 0.143 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.1.mlp.fc11.weight
+ | -0.045 | -0.414 | 0.277 | 0.106 | torch.Size([360]) || stage8.2.residual_group.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.831 | 0.809 | 0.155 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.1.mlp.fc12.weight
+ | -0.002 | -0.544 | 0.244 | 0.082 | torch.Size([360]) || stage8.2.residual_group.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.749 | 0.962 | 0.151 | torch.Size([180, 360]) || stage8.2.residual_group.blocks.1.mlp.fc2.weight
+ | 0.011 | -0.275 | 0.294 | 0.101 | torch.Size([180]) || stage8.2.residual_group.blocks.1.mlp.fc2.bias
+ | 0.990 | 0.168 | 1.270 | 0.152 | torch.Size([180]) || stage8.2.residual_group.blocks.2.norm1.weight
+ | -0.034 | -0.773 | 1.134 | 0.182 | torch.Size([180]) || stage8.2.residual_group.blocks.2.norm1.bias
+ | -0.070 | -2.190 | 5.577 | 0.255 | torch.Size([3375, 6]) || stage8.2.residual_group.blocks.2.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.2.residual_group.blocks.2.attn.relative_position_index
+ | -0.000 | -1.004 | 1.113 | 0.152 | torch.Size([540, 180]) || stage8.2.residual_group.blocks.2.attn.qkv_self.weight
+ | 0.000 | -0.781 | 0.551 | 0.137 | torch.Size([540]) || stage8.2.residual_group.blocks.2.attn.qkv_self.bias
+ | 0.001 | -0.580 | 0.572 | 0.141 | torch.Size([180, 180]) || stage8.2.residual_group.blocks.2.attn.proj.weight
+ | -0.001 | -0.554 | 0.820 | 0.177 | torch.Size([180]) || stage8.2.residual_group.blocks.2.attn.proj.bias
+ | 0.642 | 0.178 | 0.852 | 0.111 | torch.Size([180]) || stage8.2.residual_group.blocks.2.norm2.weight
+ | -0.025 | -0.413 | 0.853 | 0.124 | torch.Size([180]) || stage8.2.residual_group.blocks.2.norm2.bias
+ | -0.000 | -0.780 | 1.141 | 0.143 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.2.mlp.fc11.weight
+ | -0.067 | -0.860 | 0.177 | 0.114 | torch.Size([360]) || stage8.2.residual_group.blocks.2.mlp.fc11.bias
+ | -0.000 | -1.067 | 0.859 | 0.155 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.2.mlp.fc12.weight
+ | 0.002 | -0.298 | 0.225 | 0.072 | torch.Size([360]) || stage8.2.residual_group.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.726 | 0.809 | 0.151 | torch.Size([180, 360]) || stage8.2.residual_group.blocks.2.mlp.fc2.weight
+ | 0.001 | -0.394 | 0.292 | 0.112 | torch.Size([180]) || stage8.2.residual_group.blocks.2.mlp.fc2.bias
+ | 0.990 | 0.219 | 1.226 | 0.130 | torch.Size([180]) || stage8.2.residual_group.blocks.3.norm1.weight
+ | -0.032 | -0.837 | 1.156 | 0.168 | torch.Size([180]) || stage8.2.residual_group.blocks.3.norm1.bias
+ | -0.005 | -4.045 | 1.695 | 0.178 | torch.Size([3375, 6]) || stage8.2.residual_group.blocks.3.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.2.residual_group.blocks.3.attn.relative_position_index
+ | 0.000 | -0.855 | 1.101 | 0.153 | torch.Size([540, 180]) || stage8.2.residual_group.blocks.3.attn.qkv_self.weight
+ | -0.002 | -0.706 | 0.841 | 0.123 | torch.Size([540]) || stage8.2.residual_group.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.586 | 0.699 | 0.134 | torch.Size([180, 180]) || stage8.2.residual_group.blocks.3.attn.proj.weight
+ | 0.001 | -0.402 | 0.842 | 0.173 | torch.Size([180]) || stage8.2.residual_group.blocks.3.attn.proj.bias
+ | 0.613 | 0.196 | 0.800 | 0.102 | torch.Size([180]) || stage8.2.residual_group.blocks.3.norm2.weight
+ | -0.021 | -0.404 | 0.907 | 0.115 | torch.Size([180]) || stage8.2.residual_group.blocks.3.norm2.bias
+ | 0.000 | -0.718 | 0.654 | 0.138 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.3.mlp.fc11.weight
+ | -0.064 | -0.568 | 0.205 | 0.115 | torch.Size([360]) || stage8.2.residual_group.blocks.3.mlp.fc11.bias
+ | -0.001 | -0.674 | 0.596 | 0.155 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.3.mlp.fc12.weight
+ | -0.012 | -0.279 | 0.171 | 0.073 | torch.Size([360]) || stage8.2.residual_group.blocks.3.mlp.fc12.bias
+ | -0.000 | -0.634 | 0.692 | 0.150 | torch.Size([180, 360]) || stage8.2.residual_group.blocks.3.mlp.fc2.weight
+ | 0.010 | -0.528 | 1.331 | 0.175 | torch.Size([180]) || stage8.2.residual_group.blocks.3.mlp.fc2.bias
+ | -0.000 | -0.361 | 0.549 | 0.078 | torch.Size([180, 180]) || stage8.2.linear.weight
+ | -0.001 | -0.682 | 0.349 | 0.142 | torch.Size([180]) || stage8.2.linear.bias
+ | 1.018 | 0.177 | 1.365 | 0.177 | torch.Size([180]) || stage8.3.residual_group.blocks.0.norm1.weight
+ | -0.033 | -0.673 | 0.916 | 0.166 | torch.Size([180]) || stage8.3.residual_group.blocks.0.norm1.bias
+ | 0.003 | -2.963 | 1.620 | 0.138 | torch.Size([3375, 6]) || stage8.3.residual_group.blocks.0.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.3.residual_group.blocks.0.attn.relative_position_index
+ | -0.000 | -1.095 | 0.939 | 0.152 | torch.Size([540, 180]) || stage8.3.residual_group.blocks.0.attn.qkv_self.weight
+ | 0.004 | -0.725 | 0.682 | 0.135 | torch.Size([540]) || stage8.3.residual_group.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.731 | 0.755 | 0.149 | torch.Size([180, 180]) || stage8.3.residual_group.blocks.0.attn.proj.weight
+ | 0.013 | -0.457 | 0.481 | 0.158 | torch.Size([180]) || stage8.3.residual_group.blocks.0.attn.proj.bias
+ | 0.703 | 0.276 | 0.865 | 0.096 | torch.Size([180]) || stage8.3.residual_group.blocks.0.norm2.weight
+ | -0.024 | -0.449 | 0.966 | 0.132 | torch.Size([180]) || stage8.3.residual_group.blocks.0.norm2.bias
+ | -0.001 | -0.873 | 0.665 | 0.138 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.0.mlp.fc11.weight
+ | -0.052 | -0.479 | 0.198 | 0.104 | torch.Size([360]) || stage8.3.residual_group.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.787 | 0.699 | 0.155 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.0.mlp.fc12.weight
+ | -0.003 | -0.436 | 0.264 | 0.081 | torch.Size([360]) || stage8.3.residual_group.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.675 | 0.689 | 0.153 | torch.Size([180, 360]) || stage8.3.residual_group.blocks.0.mlp.fc2.weight
+ | 0.004 | -0.265 | 0.254 | 0.106 | torch.Size([180]) || stage8.3.residual_group.blocks.0.mlp.fc2.bias
+ | 0.956 | 0.184 | 1.255 | 0.167 | torch.Size([180]) || stage8.3.residual_group.blocks.1.norm1.weight
+ | -0.036 | -0.699 | 0.965 | 0.155 | torch.Size([180]) || stage8.3.residual_group.blocks.1.norm1.bias
+ | -0.038 | -3.913 | 4.625 | 0.210 | torch.Size([3375, 6]) || stage8.3.residual_group.blocks.1.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.3.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -1.142 | 0.934 | 0.147 | torch.Size([540, 180]) || stage8.3.residual_group.blocks.1.attn.qkv_self.weight
+ | 0.000 | -0.708 | 0.560 | 0.117 | torch.Size([540]) || stage8.3.residual_group.blocks.1.attn.qkv_self.bias
+ | -0.002 | -0.746 | 0.626 | 0.149 | torch.Size([180, 180]) || stage8.3.residual_group.blocks.1.attn.proj.weight
+ | 0.021 | -0.378 | 0.376 | 0.127 | torch.Size([180]) || stage8.3.residual_group.blocks.1.attn.proj.bias
+ | 0.741 | 0.282 | 0.933 | 0.107 | torch.Size([180]) || stage8.3.residual_group.blocks.1.norm2.weight
+ | -0.028 | -0.425 | 0.898 | 0.115 | torch.Size([180]) || stage8.3.residual_group.blocks.1.norm2.bias
+ | -0.001 | -0.761 | 0.822 | 0.139 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.1.mlp.fc11.weight
+ | -0.057 | -0.502 | 0.219 | 0.100 | torch.Size([360]) || stage8.3.residual_group.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.829 | 0.872 | 0.156 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.1.mlp.fc12.weight
+ | 0.004 | -0.262 | 0.226 | 0.077 | torch.Size([360]) || stage8.3.residual_group.blocks.1.mlp.fc12.bias
+ | -0.001 | -0.797 | 0.765 | 0.153 | torch.Size([180, 360]) || stage8.3.residual_group.blocks.1.mlp.fc2.weight
+ | -0.002 | -0.360 | 0.289 | 0.109 | torch.Size([180]) || stage8.3.residual_group.blocks.1.mlp.fc2.bias
+ | 1.068 | 0.207 | 1.335 | 0.160 | torch.Size([180]) || stage8.3.residual_group.blocks.2.norm1.weight
+ | -0.034 | -0.784 | 1.005 | 0.163 | torch.Size([180]) || stage8.3.residual_group.blocks.2.norm1.bias
+ | -0.004 | -2.897 | 1.185 | 0.143 | torch.Size([3375, 6]) || stage8.3.residual_group.blocks.2.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.3.residual_group.blocks.2.attn.relative_position_index
+ | 0.000 | -1.055 | 0.899 | 0.151 | torch.Size([540, 180]) || stage8.3.residual_group.blocks.2.attn.qkv_self.weight
+ | -0.000 | -0.572 | 0.670 | 0.120 | torch.Size([540]) || stage8.3.residual_group.blocks.2.attn.qkv_self.bias
+ | -0.001 | -0.729 | 0.798 | 0.156 | torch.Size([180, 180]) || stage8.3.residual_group.blocks.2.attn.proj.weight
+ | 0.025 | -0.570 | 0.501 | 0.166 | torch.Size([180]) || stage8.3.residual_group.blocks.2.attn.proj.bias
+ | 0.759 | 0.228 | 0.969 | 0.115 | torch.Size([180]) || stage8.3.residual_group.blocks.2.norm2.weight
+ | -0.025 | -0.394 | 0.791 | 0.103 | torch.Size([180]) || stage8.3.residual_group.blocks.2.norm2.bias
+ | -0.001 | -0.962 | 0.903 | 0.137 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.2.mlp.fc11.weight
+ | -0.064 | -0.587 | 0.209 | 0.108 | torch.Size([360]) || stage8.3.residual_group.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.966 | 0.925 | 0.156 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.2.mlp.fc12.weight
+ | 0.004 | -0.366 | 0.239 | 0.074 | torch.Size([360]) || stage8.3.residual_group.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.782 | 0.817 | 0.152 | torch.Size([180, 360]) || stage8.3.residual_group.blocks.2.mlp.fc2.weight
+ | 0.003 | -0.321 | 0.340 | 0.117 | torch.Size([180]) || stage8.3.residual_group.blocks.2.mlp.fc2.bias
+ | 1.082 | 0.237 | 1.309 | 0.144 | torch.Size([180]) || stage8.3.residual_group.blocks.3.norm1.weight
+ | -0.031 | -0.726 | 0.933 | 0.149 | torch.Size([180]) || stage8.3.residual_group.blocks.3.norm1.bias
+ | 0.005 | -3.023 | 1.093 | 0.142 | torch.Size([3375, 6]) || stage8.3.residual_group.blocks.3.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.3.residual_group.blocks.3.attn.relative_position_index
+ | -0.000 | -0.830 | 0.867 | 0.151 | torch.Size([540, 180]) || stage8.3.residual_group.blocks.3.attn.qkv_self.weight
+ | -0.001 | -0.487 | 0.710 | 0.107 | torch.Size([540]) || stage8.3.residual_group.blocks.3.attn.qkv_self.bias
+ | -0.001 | -0.940 | 0.725 | 0.157 | torch.Size([180, 180]) || stage8.3.residual_group.blocks.3.attn.proj.weight
+ | 0.027 | -0.522 | 0.807 | 0.170 | torch.Size([180]) || stage8.3.residual_group.blocks.3.attn.proj.bias
+ | 0.705 | 0.249 | 0.868 | 0.095 | torch.Size([180]) || stage8.3.residual_group.blocks.3.norm2.weight
+ | -0.023 | -0.426 | 0.826 | 0.108 | torch.Size([180]) || stage8.3.residual_group.blocks.3.norm2.bias
+ | -0.000 | -0.814 | 0.927 | 0.131 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.3.mlp.fc11.weight
+ | -0.043 | -0.613 | 0.209 | 0.116 | torch.Size([360]) || stage8.3.residual_group.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.709 | 0.851 | 0.154 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.3.mlp.fc12.weight
+ | -0.004 | -0.225 | 0.241 | 0.078 | torch.Size([360]) || stage8.3.residual_group.blocks.3.mlp.fc12.bias
+ | -0.000 | -0.857 | 0.845 | 0.151 | torch.Size([180, 360]) || stage8.3.residual_group.blocks.3.mlp.fc2.weight
+ | 0.016 | -0.441 | 1.206 | 0.183 | torch.Size([180]) || stage8.3.residual_group.blocks.3.mlp.fc2.bias
+ | -0.002 | -0.437 | 0.634 | 0.077 | torch.Size([180, 180]) || stage8.3.linear.weight
+ | -0.003 | -0.564 | 0.338 | 0.145 | torch.Size([180]) || stage8.3.linear.bias
+ | 1.164 | 0.238 | 1.496 | 0.205 | torch.Size([180]) || stage8.4.residual_group.blocks.0.norm1.weight
+ | -0.033 | -0.667 | 0.780 | 0.170 | torch.Size([180]) || stage8.4.residual_group.blocks.0.norm1.bias
+ | -0.002 | -3.025 | 1.339 | 0.130 | torch.Size([3375, 6]) || stage8.4.residual_group.blocks.0.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.4.residual_group.blocks.0.attn.relative_position_index
+ | -0.000 | -0.736 | 0.735 | 0.147 | torch.Size([540, 180]) || stage8.4.residual_group.blocks.0.attn.qkv_self.weight
+ | -0.007 | -0.468 | 0.575 | 0.112 | torch.Size([540]) || stage8.4.residual_group.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.725 | 0.750 | 0.162 | torch.Size([180, 180]) || stage8.4.residual_group.blocks.0.attn.proj.weight
+ | -0.004 | -0.461 | 0.540 | 0.163 | torch.Size([180]) || stage8.4.residual_group.blocks.0.attn.proj.bias
+ | 0.804 | 0.361 | 0.962 | 0.091 | torch.Size([180]) || stage8.4.residual_group.blocks.0.norm2.weight
+ | -0.025 | -0.421 | 0.837 | 0.127 | torch.Size([180]) || stage8.4.residual_group.blocks.0.norm2.bias
+ | -0.002 | -0.664 | 0.869 | 0.129 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.0.mlp.fc11.weight
+ | -0.028 | -0.519 | 0.180 | 0.098 | torch.Size([360]) || stage8.4.residual_group.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.793 | 0.821 | 0.156 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.0.mlp.fc12.weight
+ | 0.001 | -0.235 | 0.329 | 0.081 | torch.Size([360]) || stage8.4.residual_group.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.758 | 0.730 | 0.153 | torch.Size([180, 360]) || stage8.4.residual_group.blocks.0.mlp.fc2.weight
+ | 0.010 | -0.332 | 0.306 | 0.118 | torch.Size([180]) || stage8.4.residual_group.blocks.0.mlp.fc2.bias
+ | 1.097 | 0.202 | 1.361 | 0.200 | torch.Size([180]) || stage8.4.residual_group.blocks.1.norm1.weight
+ | -0.034 | -0.597 | 0.687 | 0.147 | torch.Size([180]) || stage8.4.residual_group.blocks.1.norm1.bias
+ | 0.007 | -4.645 | 1.140 | 0.130 | torch.Size([3375, 6]) || stage8.4.residual_group.blocks.1.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.4.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -1.002 | 0.810 | 0.144 | torch.Size([540, 180]) || stage8.4.residual_group.blocks.1.attn.qkv_self.weight
+ | 0.005 | -0.407 | 0.438 | 0.108 | torch.Size([540]) || stage8.4.residual_group.blocks.1.attn.qkv_self.bias
+ | -0.001 | -0.646 | 0.678 | 0.154 | torch.Size([180, 180]) || stage8.4.residual_group.blocks.1.attn.proj.weight
+ | 0.004 | -0.418 | 0.415 | 0.139 | torch.Size([180]) || stage8.4.residual_group.blocks.1.attn.proj.bias
+ | 0.836 | 0.316 | 1.026 | 0.106 | torch.Size([180]) || stage8.4.residual_group.blocks.1.norm2.weight
+ | -0.024 | -0.364 | 0.851 | 0.117 | torch.Size([180]) || stage8.4.residual_group.blocks.1.norm2.bias
+ | -0.002 | -0.690 | 0.848 | 0.128 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.1.mlp.fc11.weight
+ | -0.032 | -0.484 | 0.195 | 0.101 | torch.Size([360]) || stage8.4.residual_group.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.863 | 0.768 | 0.155 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.1.mlp.fc12.weight
+ | -0.001 | -0.319 | 0.409 | 0.078 | torch.Size([360]) || stage8.4.residual_group.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.836 | 0.822 | 0.154 | torch.Size([180, 360]) || stage8.4.residual_group.blocks.1.mlp.fc2.weight
+ | 0.019 | -0.356 | 0.374 | 0.129 | torch.Size([180]) || stage8.4.residual_group.blocks.1.mlp.fc2.bias
+ | 1.151 | 0.229 | 1.393 | 0.176 | torch.Size([180]) || stage8.4.residual_group.blocks.2.norm1.weight
+ | -0.028 | -0.649 | 0.925 | 0.149 | torch.Size([180]) || stage8.4.residual_group.blocks.2.norm1.bias
+ | -0.005 | -3.864 | 1.138 | 0.140 | torch.Size([3375, 6]) || stage8.4.residual_group.blocks.2.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.4.residual_group.blocks.2.attn.relative_position_index
+ | -0.000 | -1.813 | 0.897 | 0.146 | torch.Size([540, 180]) || stage8.4.residual_group.blocks.2.attn.qkv_self.weight
+ | -0.001 | -0.449 | 0.486 | 0.103 | torch.Size([540]) || stage8.4.residual_group.blocks.2.attn.qkv_self.bias
+ | -0.001 | -0.739 | 0.710 | 0.175 | torch.Size([180, 180]) || stage8.4.residual_group.blocks.2.attn.proj.weight
+ | -0.000 | -0.542 | 0.407 | 0.162 | torch.Size([180]) || stage8.4.residual_group.blocks.2.attn.proj.bias
+ | 0.820 | 0.329 | 0.989 | 0.094 | torch.Size([180]) || stage8.4.residual_group.blocks.2.norm2.weight
+ | -0.025 | -0.461 | 0.753 | 0.106 | torch.Size([180]) || stage8.4.residual_group.blocks.2.norm2.bias
+ | -0.001 | -0.648 | 0.788 | 0.125 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.2.mlp.fc11.weight
+ | -0.015 | -0.501 | 0.248 | 0.101 | torch.Size([360]) || stage8.4.residual_group.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.745 | 0.796 | 0.155 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.2.mlp.fc12.weight
+ | 0.007 | -0.244 | 0.231 | 0.080 | torch.Size([360]) || stage8.4.residual_group.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.771 | 1.049 | 0.154 | torch.Size([180, 360]) || stage8.4.residual_group.blocks.2.mlp.fc2.weight
+ | 0.018 | -0.360 | 0.336 | 0.143 | torch.Size([180]) || stage8.4.residual_group.blocks.2.mlp.fc2.bias
+ | 1.177 | 0.269 | 1.385 | 0.163 | torch.Size([180]) || stage8.4.residual_group.blocks.3.norm1.weight
+ | -0.028 | -0.700 | 0.877 | 0.145 | torch.Size([180]) || stage8.4.residual_group.blocks.3.norm1.bias
+ | -0.005 | -2.684 | 0.830 | 0.097 | torch.Size([3375, 6]) || stage8.4.residual_group.blocks.3.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.4.residual_group.blocks.3.attn.relative_position_index
+ | -0.000 | -0.996 | 0.727 | 0.142 | torch.Size([540, 180]) || stage8.4.residual_group.blocks.3.attn.qkv_self.weight
+ | 0.004 | -0.326 | 0.449 | 0.101 | torch.Size([540]) || stage8.4.residual_group.blocks.3.attn.qkv_self.bias
+ | -0.001 | -0.777 | 0.785 | 0.170 | torch.Size([180, 180]) || stage8.4.residual_group.blocks.3.attn.proj.weight
+ | 0.004 | -0.396 | 0.449 | 0.158 | torch.Size([180]) || stage8.4.residual_group.blocks.3.attn.proj.bias
+ | 0.790 | 0.392 | 1.005 | 0.078 | torch.Size([180]) || stage8.4.residual_group.blocks.3.norm2.weight
+ | -0.030 | -0.481 | 0.719 | 0.110 | torch.Size([180]) || stage8.4.residual_group.blocks.3.norm2.bias
+ | -0.001 | -0.569 | 0.732 | 0.121 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.3.mlp.fc11.weight
+ | 0.020 | -0.670 | 0.335 | 0.125 | torch.Size([360]) || stage8.4.residual_group.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.822 | 0.831 | 0.155 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.3.mlp.fc12.weight
+ | -0.003 | -0.282 | 0.296 | 0.089 | torch.Size([360]) || stage8.4.residual_group.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.856 | 0.886 | 0.155 | torch.Size([180, 360]) || stage8.4.residual_group.blocks.3.mlp.fc2.weight
+ | 0.029 | -0.390 | 0.437 | 0.161 | torch.Size([180]) || stage8.4.residual_group.blocks.3.mlp.fc2.bias
+ | -0.002 | -0.490 | 0.625 | 0.079 | torch.Size([180, 180]) || stage8.4.linear.weight
+ | -0.002 | -0.573 | 0.398 | 0.168 | torch.Size([180]) || stage8.4.linear.bias
+ | 1.337 | 0.163 | 1.694 | 0.268 | torch.Size([180]) || stage8.5.residual_group.blocks.0.norm1.weight
+ | -0.025 | -0.727 | 1.008 | 0.186 | torch.Size([180]) || stage8.5.residual_group.blocks.0.norm1.bias
+ | -0.738 | -2.885 | 5.812 | 0.748 | torch.Size([225, 6]) || stage8.5.residual_group.blocks.0.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.5.residual_group.blocks.0.attn.relative_position_index
+ | -0.000 | -0.852 | 0.854 | 0.135 | torch.Size([540, 180]) || stage8.5.residual_group.blocks.0.attn.qkv_self.weight
+ | -0.005 | -0.546 | 0.550 | 0.112 | torch.Size([540]) || stage8.5.residual_group.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.901 | 0.781 | 0.195 | torch.Size([180, 180]) || stage8.5.residual_group.blocks.0.attn.proj.weight
+ | -0.020 | -0.545 | 0.469 | 0.173 | torch.Size([180]) || stage8.5.residual_group.blocks.0.attn.proj.bias
+ | 0.956 | 0.367 | 1.185 | 0.129 | torch.Size([180]) || stage8.5.residual_group.blocks.0.norm2.weight
+ | -0.033 | -0.519 | 0.833 | 0.147 | torch.Size([180]) || stage8.5.residual_group.blocks.0.norm2.bias
+ | -0.001 | -0.832 | 0.580 | 0.119 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.0.mlp.fc11.weight
+ | 0.055 | -0.256 | 0.378 | 0.097 | torch.Size([360]) || stage8.5.residual_group.blocks.0.mlp.fc11.bias
+ | 0.000 | -1.058 | 0.859 | 0.154 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.0.mlp.fc12.weight
+ | 0.006 | -0.377 | 0.318 | 0.093 | torch.Size([360]) || stage8.5.residual_group.blocks.0.mlp.fc12.bias
+ | -0.001 | -0.751 | 0.766 | 0.156 | torch.Size([180, 360]) || stage8.5.residual_group.blocks.0.mlp.fc2.weight
+ | -0.011 | -0.316 | 0.323 | 0.132 | torch.Size([180]) || stage8.5.residual_group.blocks.0.mlp.fc2.bias
+ | 1.346 | 0.151 | 1.746 | 0.272 | torch.Size([180]) || stage8.5.residual_group.blocks.1.norm1.weight
+ | -0.023 | -0.691 | 0.993 | 0.169 | torch.Size([180]) || stage8.5.residual_group.blocks.1.norm1.bias
+ | -0.705 | -2.997 | 4.745 | 0.748 | torch.Size([225, 6]) || stage8.5.residual_group.blocks.1.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.5.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -0.911 | 0.984 | 0.141 | torch.Size([540, 180]) || stage8.5.residual_group.blocks.1.attn.qkv_self.weight
+ | -0.011 | -0.405 | 0.288 | 0.095 | torch.Size([540]) || stage8.5.residual_group.blocks.1.attn.qkv_self.bias
+ | 0.001 | -0.853 | 0.977 | 0.210 | torch.Size([180, 180]) || stage8.5.residual_group.blocks.1.attn.proj.weight
+ | -0.008 | -0.516 | 0.596 | 0.170 | torch.Size([180]) || stage8.5.residual_group.blocks.1.attn.proj.bias
+ | 1.021 | 0.333 | 1.268 | 0.154 | torch.Size([180]) || stage8.5.residual_group.blocks.1.norm2.weight
+ | -0.034 | -0.512 | 0.812 | 0.134 | torch.Size([180]) || stage8.5.residual_group.blocks.1.norm2.bias
+ | 0.000 | -0.561 | 0.546 | 0.120 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.1.mlp.fc11.weight
+ | 0.050 | -0.450 | 0.320 | 0.100 | torch.Size([360]) || stage8.5.residual_group.blocks.1.mlp.fc11.bias
+ | 0.001 | -0.907 | 0.752 | 0.157 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.1.mlp.fc12.weight
+ | -0.008 | -0.306 | 0.343 | 0.091 | torch.Size([360]) || stage8.5.residual_group.blocks.1.mlp.fc12.bias
+ | -0.001 | -0.891 | 0.741 | 0.158 | torch.Size([180, 360]) || stage8.5.residual_group.blocks.1.mlp.fc2.weight
+ | -0.014 | -0.407 | 0.478 | 0.168 | torch.Size([180]) || stage8.5.residual_group.blocks.1.mlp.fc2.bias
+ | 1.266 | 0.195 | 1.640 | 0.251 | torch.Size([180]) || stage8.5.residual_group.blocks.2.norm1.weight
+ | -0.028 | -0.680 | 0.987 | 0.162 | torch.Size([180]) || stage8.5.residual_group.blocks.2.norm1.bias
+ | -0.515 | -2.839 | 4.668 | 0.636 | torch.Size([225, 6]) || stage8.5.residual_group.blocks.2.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.5.residual_group.blocks.2.attn.relative_position_index
+ | 0.001 | -0.968 | 0.890 | 0.144 | torch.Size([540, 180]) || stage8.5.residual_group.blocks.2.attn.qkv_self.weight
+ | -0.001 | -0.372 | 0.390 | 0.095 | torch.Size([540]) || stage8.5.residual_group.blocks.2.attn.qkv_self.bias
+ | -0.000 | -1.001 | 0.995 | 0.221 | torch.Size([180, 180]) || stage8.5.residual_group.blocks.2.attn.proj.weight
+ | -0.012 | -0.576 | 0.456 | 0.172 | torch.Size([180]) || stage8.5.residual_group.blocks.2.attn.proj.bias
+ | 1.046 | 0.311 | 1.264 | 0.147 | torch.Size([180]) || stage8.5.residual_group.blocks.2.norm2.weight
+ | -0.033 | -0.519 | 0.785 | 0.123 | torch.Size([180]) || stage8.5.residual_group.blocks.2.norm2.bias
+ | 0.000 | -0.533 | 0.563 | 0.119 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.2.mlp.fc11.weight
+ | 0.053 | -0.314 | 0.364 | 0.109 | torch.Size([360]) || stage8.5.residual_group.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.862 | 0.822 | 0.158 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.2.mlp.fc12.weight
+ | -0.004 | -0.266 | 0.289 | 0.084 | torch.Size([360]) || stage8.5.residual_group.blocks.2.mlp.fc12.bias
+ | 0.001 | -0.787 | 0.886 | 0.161 | torch.Size([180, 360]) || stage8.5.residual_group.blocks.2.mlp.fc2.weight
+ | -0.007 | -0.421 | 0.503 | 0.171 | torch.Size([180]) || stage8.5.residual_group.blocks.2.mlp.fc2.bias
+ | 1.226 | 0.277 | 1.561 | 0.208 | torch.Size([180]) || stage8.5.residual_group.blocks.3.norm1.weight
+ | -0.032 | -0.670 | 1.030 | 0.168 | torch.Size([180]) || stage8.5.residual_group.blocks.3.norm1.bias
+ | -0.401 | -1.953 | 3.930 | 0.598 | torch.Size([225, 6]) || stage8.5.residual_group.blocks.3.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.5.residual_group.blocks.3.attn.relative_position_index
+ | -0.000 | -0.857 | 0.754 | 0.139 | torch.Size([540, 180]) || stage8.5.residual_group.blocks.3.attn.qkv_self.weight
+ | 0.004 | -0.317 | 0.278 | 0.081 | torch.Size([540]) || stage8.5.residual_group.blocks.3.attn.qkv_self.bias
+ | -0.002 | -1.022 | 0.999 | 0.200 | torch.Size([180, 180]) || stage8.5.residual_group.blocks.3.attn.proj.weight
+ | -0.009 | -0.384 | 0.393 | 0.165 | torch.Size([180]) || stage8.5.residual_group.blocks.3.attn.proj.bias
+ | 1.038 | 0.340 | 1.216 | 0.128 | torch.Size([180]) || stage8.5.residual_group.blocks.3.norm2.weight
+ | -0.034 | -0.574 | 0.775 | 0.124 | torch.Size([180]) || stage8.5.residual_group.blocks.3.norm2.bias
+ | 0.001 | -0.588 | 0.613 | 0.119 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.3.mlp.fc11.weight
+ | 0.063 | -0.447 | 0.307 | 0.111 | torch.Size([360]) || stage8.5.residual_group.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.873 | 0.775 | 0.159 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.3.mlp.fc12.weight
+ | 0.001 | -0.456 | 0.435 | 0.092 | torch.Size([360]) || stage8.5.residual_group.blocks.3.mlp.fc12.bias
+ | -0.000 | -0.819 | 0.772 | 0.160 | torch.Size([180, 360]) || stage8.5.residual_group.blocks.3.mlp.fc2.weight
+ | -0.018 | -0.319 | 0.340 | 0.131 | torch.Size([180]) || stage8.5.residual_group.blocks.3.mlp.fc2.bias
+ | -0.000 | -0.562 | 0.471 | 0.080 | torch.Size([180, 180]) || stage8.5.linear.weight
+ | 0.024 | -0.609 | 0.488 | 0.184 | torch.Size([180]) || stage8.5.linear.bias
+ | 1.369 | 0.171 | 1.961 | 0.355 | torch.Size([180]) || stage8.6.residual_group.blocks.0.norm1.weight
+ | -0.028 | -0.642 | 0.733 | 0.196 | torch.Size([180]) || stage8.6.residual_group.blocks.0.norm1.bias
+ | -0.029 | -1.759 | 1.624 | 0.312 | torch.Size([225, 6]) || stage8.6.residual_group.blocks.0.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.6.residual_group.blocks.0.attn.relative_position_index
+ | -0.000 | -0.686 | 0.691 | 0.113 | torch.Size([540, 180]) || stage8.6.residual_group.blocks.0.attn.qkv_self.weight
+ | -0.003 | -0.261 | 0.301 | 0.081 | torch.Size([540]) || stage8.6.residual_group.blocks.0.attn.qkv_self.bias
+ | 0.001 | -0.736 | 0.637 | 0.149 | torch.Size([180, 180]) || stage8.6.residual_group.blocks.0.attn.proj.weight
+ | -0.006 | -0.293 | 0.300 | 0.106 | torch.Size([180]) || stage8.6.residual_group.blocks.0.attn.proj.bias
+ | 1.302 | 0.401 | 1.613 | 0.192 | torch.Size([180]) || stage8.6.residual_group.blocks.0.norm2.weight
+ | -0.029 | -0.475 | 0.696 | 0.159 | torch.Size([180]) || stage8.6.residual_group.blocks.0.norm2.bias
+ | -0.001 | -0.649 | 0.564 | 0.119 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.0.mlp.fc11.weight
+ | 0.036 | -0.275 | 0.218 | 0.071 | torch.Size([360]) || stage8.6.residual_group.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.717 | 0.831 | 0.148 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.0.mlp.fc12.weight
+ | 0.006 | -0.231 | 0.270 | 0.074 | torch.Size([360]) || stage8.6.residual_group.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.833 | 0.791 | 0.150 | torch.Size([180, 360]) || stage8.6.residual_group.blocks.0.mlp.fc2.weight
+ | 0.004 | -0.364 | 0.324 | 0.134 | torch.Size([180]) || stage8.6.residual_group.blocks.0.mlp.fc2.bias
+ | 1.450 | 0.218 | 1.962 | 0.354 | torch.Size([180]) || stage8.6.residual_group.blocks.1.norm1.weight
+ | -0.025 | -0.716 | 0.851 | 0.206 | torch.Size([180]) || stage8.6.residual_group.blocks.1.norm1.bias
+ | -0.045 | -1.549 | 2.100 | 0.321 | torch.Size([225, 6]) || stage8.6.residual_group.blocks.1.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.6.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -0.759 | 0.636 | 0.110 | torch.Size([540, 180]) || stage8.6.residual_group.blocks.1.attn.qkv_self.weight
+ | -0.001 | -0.235 | 0.269 | 0.070 | torch.Size([540]) || stage8.6.residual_group.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.691 | 0.657 | 0.145 | torch.Size([180, 180]) || stage8.6.residual_group.blocks.1.attn.proj.weight
+ | -0.007 | -0.375 | 0.328 | 0.116 | torch.Size([180]) || stage8.6.residual_group.blocks.1.attn.proj.bias
+ | 1.326 | 0.335 | 1.596 | 0.186 | torch.Size([180]) || stage8.6.residual_group.blocks.1.norm2.weight
+ | -0.029 | -0.566 | 0.748 | 0.160 | torch.Size([180]) || stage8.6.residual_group.blocks.1.norm2.bias
+ | -0.002 | -0.667 | 0.591 | 0.121 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.1.mlp.fc11.weight
+ | 0.042 | -0.387 | 0.373 | 0.078 | torch.Size([360]) || stage8.6.residual_group.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.685 | 0.894 | 0.147 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.1.mlp.fc12.weight
+ | 0.000 | -0.353 | 0.326 | 0.092 | torch.Size([360]) || stage8.6.residual_group.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.801 | 0.692 | 0.149 | torch.Size([180, 360]) || stage8.6.residual_group.blocks.1.mlp.fc2.weight
+ | -0.007 | -0.331 | 0.273 | 0.127 | torch.Size([180]) || stage8.6.residual_group.blocks.1.mlp.fc2.bias
+ | 1.416 | 0.215 | 1.819 | 0.303 | torch.Size([180]) || stage8.6.residual_group.blocks.2.norm1.weight
+ | -0.024 | -0.596 | 0.869 | 0.211 | torch.Size([180]) || stage8.6.residual_group.blocks.2.norm1.bias
+ | -0.038 | -2.355 | 1.330 | 0.286 | torch.Size([225, 6]) || stage8.6.residual_group.blocks.2.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.6.residual_group.blocks.2.attn.relative_position_index
+ | -0.000 | -0.964 | 0.732 | 0.112 | torch.Size([540, 180]) || stage8.6.residual_group.blocks.2.attn.qkv_self.weight
+ | 0.002 | -0.192 | 0.251 | 0.052 | torch.Size([540]) || stage8.6.residual_group.blocks.2.attn.qkv_self.bias
+ | 0.001 | -0.736 | 0.624 | 0.138 | torch.Size([180, 180]) || stage8.6.residual_group.blocks.2.attn.proj.weight
+ | -0.008 | -0.376 | 0.254 | 0.119 | torch.Size([180]) || stage8.6.residual_group.blocks.2.attn.proj.bias
+ | 1.352 | 0.217 | 1.546 | 0.187 | torch.Size([180]) || stage8.6.residual_group.blocks.2.norm2.weight
+ | -0.023 | -0.627 | 0.881 | 0.164 | torch.Size([180]) || stage8.6.residual_group.blocks.2.norm2.bias
+ | -0.001 | -0.616 | 0.688 | 0.122 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.2.mlp.fc11.weight
+ | 0.040 | -0.332 | 0.242 | 0.083 | torch.Size([360]) || stage8.6.residual_group.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.970 | 0.669 | 0.148 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.2.mlp.fc12.weight
+ | 0.006 | -0.333 | 0.371 | 0.092 | torch.Size([360]) || stage8.6.residual_group.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.849 | 0.824 | 0.150 | torch.Size([180, 360]) || stage8.6.residual_group.blocks.2.mlp.fc2.weight
+ | -0.007 | -0.282 | 0.333 | 0.111 | torch.Size([180]) || stage8.6.residual_group.blocks.2.mlp.fc2.bias
+ | 1.346 | 0.206 | 1.798 | 0.286 | torch.Size([180]) || stage8.6.residual_group.blocks.3.norm1.weight
+ | -0.022 | -0.742 | 0.797 | 0.196 | torch.Size([180]) || stage8.6.residual_group.blocks.3.norm1.bias
+ | -0.056 | -1.296 | 2.098 | 0.311 | torch.Size([225, 6]) || stage8.6.residual_group.blocks.3.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.6.residual_group.blocks.3.attn.relative_position_index
+ | -0.000 | -0.693 | 0.597 | 0.103 | torch.Size([540, 180]) || stage8.6.residual_group.blocks.3.attn.qkv_self.weight
+ | -0.003 | -0.211 | 0.161 | 0.055 | torch.Size([540]) || stage8.6.residual_group.blocks.3.attn.qkv_self.bias
+ | -0.000 | -0.767 | 0.663 | 0.127 | torch.Size([180, 180]) || stage8.6.residual_group.blocks.3.attn.proj.weight
+ | -0.011 | -0.269 | 0.169 | 0.072 | torch.Size([180]) || stage8.6.residual_group.blocks.3.attn.proj.bias
+ | 1.329 | 0.247 | 1.544 | 0.183 | torch.Size([180]) || stage8.6.residual_group.blocks.3.norm2.weight
+ | -0.023 | -0.619 | 0.881 | 0.171 | torch.Size([180]) || stage8.6.residual_group.blocks.3.norm2.bias
+ | -0.001 | -0.670 | 0.594 | 0.124 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.3.mlp.fc11.weight
+ | 0.052 | -0.262 | 0.275 | 0.073 | torch.Size([360]) || stage8.6.residual_group.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.899 | 0.808 | 0.149 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.3.mlp.fc12.weight
+ | -0.009 | -0.273 | 0.326 | 0.090 | torch.Size([360]) || stage8.6.residual_group.blocks.3.mlp.fc12.bias
+ | 0.001 | -0.773 | 0.930 | 0.150 | torch.Size([180, 360]) || stage8.6.residual_group.blocks.3.mlp.fc2.weight
+ | -0.001 | -0.264 | 0.261 | 0.088 | torch.Size([180]) || stage8.6.residual_group.blocks.3.mlp.fc2.bias
+ | -0.001 | -1.128 | 1.483 | 0.100 | torch.Size([180, 180]) || stage8.6.linear.weight
+ | 0.014 | -0.757 | 0.769 | 0.160 | torch.Size([180]) || stage8.6.linear.bias
+ | 0.387 | 0.109 | 1.033 | 0.194 | torch.Size([180]) || norm.weight
+ | -0.006 | -0.754 | 0.773 | 0.142 | torch.Size([180]) || norm.bias
+ | 0.001 | -0.596 | 0.563 | 0.121 | torch.Size([120, 180]) || conv_after_body.weight
+ | -0.016 | -0.251 | 0.121 | 0.061 | torch.Size([120]) || conv_after_body.bias
+ | 0.003 | -1.347 | 1.476 | 0.161 | torch.Size([64, 120, 1, 3, 3]) || conv_before_upsample.0.weight
+ | -0.090 | -0.847 | 0.182 | 0.193 | torch.Size([64]) || conv_before_upsample.0.bias
+ | 0.002 | -1.602 | 0.994 | 0.114 | torch.Size([256, 64, 1, 3, 3]) || upsample.0.weight
+ | -0.059 | -0.461 | 0.137 | 0.098 | torch.Size([256]) || upsample.0.bias
+ | -0.005 | -4.099 | 0.822 | 0.076 | torch.Size([256, 64, 1, 3, 3]) || upsample.5.weight
+ | -0.137 | -0.426 | 0.152 | 0.097 | torch.Size([256]) || upsample.5.bias
+ | -0.000 | -0.377 | 0.324 | 0.014 | torch.Size([64, 64, 1, 3, 3]) || upsample.10.weight
+ | -0.000 | -0.016 | 0.014 | 0.003 | torch.Size([64]) || upsample.10.bias
+ | -0.000 | -0.043 | 0.040 | 0.004 | torch.Size([3, 64, 1, 3, 3]) || conv_last.weight
+ | -0.000 | -0.000 | 0.000 | 0.000 | torch.Size([3]) || conv_last.bias
+
+22-03-11 10:10:58.452 : task: 003_train_vrt_videosr_bi_vimeo_7frames
+ model: vrt
+ gpu_ids: [0, 1, 2, 3, 4, 5, 6, 7]
+ dist: False
+ find_unused_parameters: False
+ use_static_graph: True
+ scale: 4
+ n_channels: 3
+ path:[
+ root: experiments
+ pretrained_netG: model_zoo/vrt/002_VRT_videosr_bi_REDS_16frames.pth
+ pretrained_netE: None
+ task: experiments/003_train_vrt_videosr_bi_vimeo_7frames
+ log: experiments/003_train_vrt_videosr_bi_vimeo_7frames
+ options: experiments/003_train_vrt_videosr_bi_vimeo_7frames/options
+ models: experiments/003_train_vrt_videosr_bi_vimeo_7frames/models
+ images: experiments/003_train_vrt_videosr_bi_vimeo_7frames/images
+ pretrained_optimizerG: None
+ ]
+ datasets:[
+ train:[
+ name: train_dataset
+ dataset_type: VideoRecurrentTrainVimeoDataset
+ dataroot_gt: trainsets/vimeo90k
+ dataroot_lq: trainsets/vimeo90k
+ meta_info_file: data/meta_info/meta_info_Vimeo90K_train_GT.txt
+ io_backend:[
+ type: disk
+ ]
+ num_frame: -1
+ gt_size: 256
+ interval_list: [1]
+ random_reverse: True
+ use_hflip: True
+ use_rot: True
+ pad_sequence: True
+ dataloader_shuffle: True
+ dataloader_num_workers: 32
+ dataloader_batch_size: 8
+ phase: train
+ scale: 4
+ n_channels: 3
+ ]
+ test:[
+ name: test_dataset
+ dataset_type: VideoRecurrentTestDataset
+ dataroot_gt: testsets/Vid4/GT
+ dataroot_lq: testsets/Vid4/BIx4
+ cache_data: True
+ io_backend:[
+ type: disk
+ ]
+ num_frame: -1
+ phase: test
+ scale: 4
+ n_channels: 3
+ ]
+ ]
+ netG:[
+ net_type: vrt
+ upscale: 4
+ img_size: [8, 64, 64]
+ window_size: [8, 8, 8]
+ depths: [8, 8, 8, 8, 8, 8, 8, 4, 4, 4, 4, 4, 4]
+ indep_reconsts: [11, 12]
+ embed_dims: [120, 120, 120, 120, 120, 120, 120, 180, 180, 180, 180, 180, 180]
+ num_heads: [6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]
+ spynet_path: model_zoo/vrt/spynet_sintel_final-3d2a1287.pth
+ pa_frames: 4
+ deformable_groups: 16
+ nonblind_denoising: False
+ use_checkpoint_attn: False
+ use_checkpoint_ffn: False
+ no_checkpoint_attn_blocks: []
+ no_checkpoint_ffn_blocks: []
+ init_type: default
+ scale: 4
+ ]
+ train:[
+ G_lossfn_type: charbonnier
+ G_lossfn_weight: 1.0
+ G_charbonnier_eps: 1e-09
+ E_decay: 0
+ G_optimizer_type: adam
+ G_optimizer_lr: 0.0004
+ G_optimizer_betas: [0.9, 0.99]
+ G_optimizer_wd: 0
+ G_optimizer_clipgrad: None
+ G_optimizer_reuse: True
+ fix_iter: 20000
+ fix_lr_mul: 0.125
+ fix_keys: ['spynet', 'deform']
+ total_iter: 300000
+ G_scheduler_type: CosineAnnealingWarmRestarts
+ G_scheduler_periods: 300000
+ G_scheduler_eta_min: 1e-07
+ G_regularizer_orthstep: None
+ G_regularizer_clipstep: None
+ G_param_strict: False
+ E_param_strict: True
+ checkpoint_test: 5000
+ checkpoint_save: 5000
+ checkpoint_print: 200
+ F_feature_layer: 34
+ F_weights: 1.0
+ F_lossfn_type: l1
+ F_use_input_norm: True
+ F_use_range_norm: False
+ G_scheduler_restart_weights: 1
+ ]
+ val:[
+ save_img: False
+ pad_seq: False
+ flip_seq: False
+ center_frame_only: False
+ num_frame_testing: 32
+ num_frame_overlapping: 2
+ size_patch_testing: 128
+ ]
+ opt_path: options/vrt/003_train_vrt_videosr_bi_vimeo_7frames.json
+ is_train: True
+ merge_bn: False
+ merge_bn_startpoint: -1
+ num_gpu: 8
+ rank: 0
+ world_size: 1
+
+22-03-11 10:10:58.485 : Number of train images: 64,612, iters: 8,077
+22-03-11 10:11:02.029 :
+Networks name: VRT
+Params number: 32577991
+Net structure:
+VRT(
+ (conv_first): Conv3d(27, 120, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ (spynet): SpyNet(
+ (basic_module): ModuleList(
+ (0): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (1): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (2): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (3): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (4): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ (5): BasicModule(
+ (basic_module): Sequential(
+ (0): Conv2d(8, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (1): ReLU()
+ (2): Conv2d(32, 64, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (3): ReLU()
+ (4): Conv2d(64, 32, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (5): ReLU()
+ (6): Conv2d(32, 16, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ (7): ReLU()
+ (8): Conv2d(16, 2, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3))
+ )
+ )
+ )
+ )
+ (stage1): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n c d h w -> n d h w c')
+ (1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (2): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): Identity()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): Identity()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(364, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 432, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage2): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n c d (h neih) (w neiw) -> n d h w (neiw neih c)', neih=2, neiw=2)
+ (1): LayerNorm((480,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=480, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(364, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 432, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage3): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n c d (h neih) (w neiw) -> n d h w (neiw neih c)', neih=2, neiw=2)
+ (1): LayerNorm((480,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=480, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(364, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 432, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage4): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n c d (h neih) (w neiw) -> n d h w (neiw neih c)', neih=2, neiw=2)
+ (1): LayerNorm((480,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=480, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(364, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 432, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage5): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n (neiw neih c) d h w -> n d (h neih) (w neiw) c', neih=2, neiw=2)
+ (1): LayerNorm((30,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=30, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(364, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 432, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage6): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n (neiw neih c) d h w -> n d (h neih) (w neiw) c', neih=2, neiw=2)
+ (1): LayerNorm((30,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=30, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(364, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 432, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage7): Stage(
+ (reshape): Sequential(
+ (0): Rearrange('n (neiw neih c) d h w -> n d (h neih) (w neiw) c', neih=2, neiw=2)
+ (1): LayerNorm((30,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=30, out_features=120, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (residual_group1): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (4): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (5): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=240, out_features=120, bias=True)
+ (qkv_mut): Linear(in_features=120, out_features=360, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear1): Linear(in_features=120, out_features=120, bias=True)
+ (residual_group2): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=120, out_features=360, bias=True)
+ (proj): Linear(in_features=120, out_features=120, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=120, out_features=240, bias=True)
+ (fc12): Linear(in_features=120, out_features=240, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=240, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear2): Linear(in_features=120, out_features=120, bias=True)
+ (pa_deform): DCNv2PackFlowGuided(
+ (conv_offset): Sequential(
+ (0): Conv2d(364, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): LeakyReLU(negative_slope=0.1, inplace=True)
+ (2): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): LeakyReLU(negative_slope=0.1, inplace=True)
+ (4): Conv2d(120, 120, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (5): LeakyReLU(negative_slope=0.1, inplace=True)
+ (6): Conv2d(120, 432, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ )
+ )
+ (pa_fuse): Mlp_GEGLU(
+ (fc11): Linear(in_features=360, out_features=360, bias=True)
+ (fc12): Linear(in_features=360, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=120, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (stage8): ModuleList(
+ (0): Sequential(
+ (0): Rearrange('n c d h w -> n d h w c')
+ (1): LayerNorm((120,), eps=1e-05, elementwise_affine=True)
+ (2): Linear(in_features=120, out_features=180, bias=True)
+ (3): Rearrange('n d h w c -> n c d h w')
+ )
+ (1): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (2): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (3): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (4): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (5): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ (6): RTMSA(
+ (residual_group): TMSAG(
+ (blocks): ModuleList(
+ (0): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (1): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (2): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ (3): TMSA(
+ (norm1): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (attn): WindowAttention(
+ (qkv_self): Linear(in_features=180, out_features=540, bias=True)
+ (proj): Linear(in_features=180, out_features=180, bias=True)
+ (softmax): Softmax(dim=-1)
+ )
+ (drop_path): DropPath()
+ (norm2): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (mlp): Mlp_GEGLU(
+ (fc11): Linear(in_features=180, out_features=360, bias=True)
+ (fc12): Linear(in_features=180, out_features=360, bias=True)
+ (act): GELU()
+ (fc2): Linear(in_features=360, out_features=180, bias=True)
+ (drop): Dropout(p=0.0, inplace=False)
+ )
+ )
+ )
+ )
+ (linear): Linear(in_features=180, out_features=180, bias=True)
+ )
+ )
+ (norm): LayerNorm((180,), eps=1e-05, elementwise_affine=True)
+ (conv_after_body): Linear(in_features=180, out_features=120, bias=True)
+ (conv_before_upsample): Sequential(
+ (0): Conv3d(120, 64, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ (1): LeakyReLU(negative_slope=0.01, inplace=True)
+ )
+ (upsample): Upsample(
+ (0): Conv3d(64, 256, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ (1): Transpose_Dim12()
+ (2): PixelShuffle(upscale_factor=2)
+ (3): Transpose_Dim12()
+ (4): LeakyReLU(negative_slope=0.1, inplace=True)
+ (5): Conv3d(64, 256, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ (6): Transpose_Dim12()
+ (7): PixelShuffle(upscale_factor=2)
+ (8): Transpose_Dim12()
+ (9): LeakyReLU(negative_slope=0.1, inplace=True)
+ (10): Conv3d(64, 64, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+ )
+ (conv_last): Conv3d(64, 3, kernel_size=(1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1))
+)
+
+22-03-11 10:11:02.191 :
+ | mean | min | max | std || shape
+ | 0.000 | -1.496 | 1.623 | 0.115 | torch.Size([120, 27, 1, 3, 3]) || conv_first.weight
+ | -0.005 | -1.075 | 0.916 | 0.274 | torch.Size([120]) || conv_first.bias
+ | 0.449 | 0.406 | 0.485 | 0.040 | torch.Size([1, 3, 1, 1]) || spynet.mean
+ | 0.226 | 0.224 | 0.229 | 0.003 | torch.Size([1, 3, 1, 1]) || spynet.std
+ | -0.000 | -0.656 | 0.699 | 0.067 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.0.basic_module.0.weight
+ | -0.037 | -0.877 | 0.359 | 0.346 | torch.Size([32]) || spynet.basic_module.0.basic_module.0.bias
+ | -0.007 | -3.201 | 0.948 | 0.097 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.0.basic_module.2.weight
+ | 0.063 | -1.264 | 0.752 | 0.323 | torch.Size([64]) || spynet.basic_module.0.basic_module.2.bias
+ | -0.010 | -4.633 | 0.568 | 0.089 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.0.basic_module.4.weight
+ | 0.158 | -0.704 | 0.861 | 0.357 | torch.Size([32]) || spynet.basic_module.0.basic_module.4.bias
+ | -0.024 | -1.714 | 0.414 | 0.091 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.0.basic_module.6.weight
+ | 0.779 | -1.061 | 1.164 | 0.519 | torch.Size([16]) || spynet.basic_module.0.basic_module.6.bias
+ | 0.000 | -0.148 | 0.161 | 0.018 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.0.basic_module.8.weight
+ | 0.002 | -0.000 | 0.004 | 0.003 | torch.Size([2]) || spynet.basic_module.0.basic_module.8.bias
+ | 0.000 | -0.745 | 0.760 | 0.070 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.1.basic_module.0.weight
+ | -0.019 | -0.848 | 0.359 | 0.331 | torch.Size([32]) || spynet.basic_module.1.basic_module.0.bias
+ | -0.010 | -3.373 | 0.916 | 0.099 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.1.basic_module.2.weight
+ | 0.037 | -1.227 | 0.720 | 0.303 | torch.Size([64]) || spynet.basic_module.1.basic_module.2.bias
+ | -0.009 | -4.425 | 0.539 | 0.088 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.1.basic_module.4.weight
+ | 0.158 | -0.758 | 0.988 | 0.386 | torch.Size([32]) || spynet.basic_module.1.basic_module.4.bias
+ | -0.020 | -1.647 | 0.319 | 0.084 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.1.basic_module.6.weight
+ | 0.777 | -1.211 | 1.152 | 0.550 | torch.Size([16]) || spynet.basic_module.1.basic_module.6.bias
+ | 0.000 | -0.126 | 0.144 | 0.017 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.1.basic_module.8.weight
+ | 0.004 | 0.001 | 0.008 | 0.005 | torch.Size([2]) || spynet.basic_module.1.basic_module.8.bias
+ | 0.000 | -0.938 | 0.872 | 0.088 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.2.basic_module.0.weight
+ | -0.028 | -1.086 | 0.552 | 0.435 | torch.Size([32]) || spynet.basic_module.2.basic_module.0.bias
+ | -0.011 | -4.624 | 1.203 | 0.116 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.2.basic_module.2.weight
+ | 0.022 | -1.298 | 0.715 | 0.312 | torch.Size([64]) || spynet.basic_module.2.basic_module.2.bias
+ | -0.010 | -1.806 | 0.627 | 0.092 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.2.basic_module.4.weight
+ | 0.118 | -0.698 | 0.750 | 0.332 | torch.Size([32]) || spynet.basic_module.2.basic_module.4.bias
+ | -0.014 | -1.277 | 0.337 | 0.067 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.2.basic_module.6.weight
+ | 0.684 | -1.730 | 0.954 | 0.648 | torch.Size([16]) || spynet.basic_module.2.basic_module.6.bias
+ | 0.000 | -0.031 | 0.042 | 0.009 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.2.basic_module.8.weight
+ | -0.010 | -0.010 | -0.010 | 0.000 | torch.Size([2]) || spynet.basic_module.2.basic_module.8.bias
+ | -0.000 | -0.956 | 0.847 | 0.089 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.3.basic_module.0.weight
+ | -0.049 | -1.175 | 0.652 | 0.477 | torch.Size([32]) || spynet.basic_module.3.basic_module.0.bias
+ | -0.010 | -4.892 | 1.180 | 0.117 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.3.basic_module.2.weight
+ | 0.021 | -1.294 | 0.764 | 0.316 | torch.Size([64]) || spynet.basic_module.3.basic_module.2.bias
+ | -0.010 | -1.793 | 0.556 | 0.089 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.3.basic_module.4.weight
+ | 0.123 | -0.717 | 0.737 | 0.335 | torch.Size([32]) || spynet.basic_module.3.basic_module.4.bias
+ | -0.012 | -1.102 | 0.291 | 0.061 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.3.basic_module.6.weight
+ | 0.650 | -1.838 | 0.913 | 0.669 | torch.Size([16]) || spynet.basic_module.3.basic_module.6.bias
+ | 0.000 | -0.032 | 0.039 | 0.006 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.3.basic_module.8.weight
+ | 0.000 | -0.012 | 0.012 | 0.017 | torch.Size([2]) || spynet.basic_module.3.basic_module.8.bias
+ | -0.000 | -0.953 | 0.855 | 0.089 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.4.basic_module.0.weight
+ | -0.009 | -1.001 | 0.584 | 0.427 | torch.Size([32]) || spynet.basic_module.4.basic_module.0.bias
+ | -0.010 | -5.054 | 1.223 | 0.116 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.4.basic_module.2.weight
+ | 0.023 | -1.315 | 0.884 | 0.326 | torch.Size([64]) || spynet.basic_module.4.basic_module.2.bias
+ | -0.009 | -1.786 | 0.534 | 0.088 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.4.basic_module.4.weight
+ | 0.142 | -0.698 | 0.780 | 0.342 | torch.Size([32]) || spynet.basic_module.4.basic_module.4.bias
+ | -0.011 | -0.957 | 0.276 | 0.057 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.4.basic_module.6.weight
+ | 0.653 | -1.854 | 0.943 | 0.677 | torch.Size([16]) || spynet.basic_module.4.basic_module.6.bias
+ | 0.000 | -0.034 | 0.035 | 0.005 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.4.basic_module.8.weight
+ | -0.001 | -0.010 | 0.008 | 0.012 | torch.Size([2]) || spynet.basic_module.4.basic_module.8.bias
+ | -0.000 | -0.918 | 0.865 | 0.087 | torch.Size([32, 8, 7, 7]) || spynet.basic_module.5.basic_module.0.weight
+ | 0.047 | -0.824 | 0.510 | 0.392 | torch.Size([32]) || spynet.basic_module.5.basic_module.0.bias
+ | -0.009 | -5.094 | 1.213 | 0.118 | torch.Size([64, 32, 7, 7]) || spynet.basic_module.5.basic_module.2.weight
+ | 0.029 | -1.319 | 0.938 | 0.330 | torch.Size([64]) || spynet.basic_module.5.basic_module.2.bias
+ | -0.007 | -1.794 | 0.519 | 0.088 | torch.Size([32, 64, 7, 7]) || spynet.basic_module.5.basic_module.4.weight
+ | 0.145 | -0.725 | 0.830 | 0.349 | torch.Size([32]) || spynet.basic_module.5.basic_module.4.bias
+ | -0.008 | -0.766 | 0.275 | 0.052 | torch.Size([16, 32, 7, 7]) || spynet.basic_module.5.basic_module.6.weight
+ | 0.659 | -1.945 | 0.999 | 0.706 | torch.Size([16]) || spynet.basic_module.5.basic_module.6.bias
+ | 0.000 | -0.025 | 0.026 | 0.002 | torch.Size([2, 16, 7, 7]) || spynet.basic_module.5.basic_module.8.weight
+ | 0.014 | 0.001 | 0.027 | 0.018 | torch.Size([2]) || spynet.basic_module.5.basic_module.8.bias
+ | 1.335 | 0.614 | 2.324 | 0.313 | torch.Size([120]) || stage1.reshape.1.weight
+ | -0.007 | -0.451 | 0.392 | 0.149 | torch.Size([120]) || stage1.reshape.1.bias
+ | 0.640 | 0.164 | 1.487 | 0.258 | torch.Size([120]) || stage1.residual_group1.blocks.0.norm1.weight
+ | -0.072 | -1.225 | 0.558 | 0.260 | torch.Size([120]) || stage1.residual_group1.blocks.0.norm1.bias
+ | -0.295 | -4.200 | 2.891 | 0.402 | torch.Size([675, 6]) || stage1.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.0.attn.position_bias
+ | 0.001 | -0.736 | 0.771 | 0.143 | torch.Size([360, 120]) || stage1.residual_group1.blocks.0.attn.qkv_self.weight
+ | -0.002 | -0.412 | 0.503 | 0.106 | torch.Size([360]) || stage1.residual_group1.blocks.0.attn.qkv_self.bias
+ | 0.001 | -0.711 | 0.595 | 0.091 | torch.Size([120, 240]) || stage1.residual_group1.blocks.0.attn.proj.weight
+ | -0.006 | -0.195 | 0.530 | 0.097 | torch.Size([120]) || stage1.residual_group1.blocks.0.attn.proj.bias
+ | -0.000 | -1.076 | 1.181 | 0.133 | torch.Size([360, 120]) || stage1.residual_group1.blocks.0.attn.qkv_mut.weight
+ | 0.000 | -0.228 | 0.294 | 0.059 | torch.Size([360]) || stage1.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.836 | 0.408 | 1.248 | 0.162 | torch.Size([120]) || stage1.residual_group1.blocks.0.norm2.weight
+ | 0.042 | -0.494 | 0.495 | 0.159 | torch.Size([120]) || stage1.residual_group1.blocks.0.norm2.bias
+ | 0.003 | -0.889 | 0.982 | 0.142 | torch.Size([240, 120]) || stage1.residual_group1.blocks.0.mlp.fc11.weight
+ | 0.041 | -0.364 | 0.458 | 0.117 | torch.Size([240]) || stage1.residual_group1.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.757 | 0.882 | 0.140 | torch.Size([240, 120]) || stage1.residual_group1.blocks.0.mlp.fc12.weight
+ | 0.011 | -0.400 | 0.470 | 0.157 | torch.Size([240]) || stage1.residual_group1.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.852 | 1.093 | 0.139 | torch.Size([120, 240]) || stage1.residual_group1.blocks.0.mlp.fc2.weight
+ | 0.022 | -0.265 | 0.384 | 0.096 | torch.Size([120]) || stage1.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.894 | 0.195 | 1.588 | 0.211 | torch.Size([120]) || stage1.residual_group1.blocks.1.norm1.weight
+ | -0.156 | -1.734 | 0.260 | 0.208 | torch.Size([120]) || stage1.residual_group1.blocks.1.norm1.bias
+ | -0.433 | -4.335 | 2.455 | 0.555 | torch.Size([675, 6]) || stage1.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.1.attn.position_bias
+ | -0.001 | -1.631 | 1.615 | 0.174 | torch.Size([360, 120]) || stage1.residual_group1.blocks.1.attn.qkv_self.weight
+ | 0.005 | -0.246 | 0.392 | 0.072 | torch.Size([360]) || stage1.residual_group1.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.697 | 0.574 | 0.098 | torch.Size([120, 240]) || stage1.residual_group1.blocks.1.attn.proj.weight
+ | 0.011 | -0.191 | 0.529 | 0.104 | torch.Size([120]) || stage1.residual_group1.blocks.1.attn.proj.bias
+ | -0.001 | -1.260 | 1.186 | 0.133 | torch.Size([360, 120]) || stage1.residual_group1.blocks.1.attn.qkv_mut.weight
+ | -0.002 | -0.207 | 0.162 | 0.050 | torch.Size([360]) || stage1.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.725 | 0.421 | 0.899 | 0.072 | torch.Size([120]) || stage1.residual_group1.blocks.1.norm2.weight
+ | 0.043 | -0.750 | 0.403 | 0.161 | torch.Size([120]) || stage1.residual_group1.blocks.1.norm2.bias
+ | -0.001 | -0.950 | 0.899 | 0.146 | torch.Size([240, 120]) || stage1.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.001 | -0.381 | 0.301 | 0.092 | torch.Size([240]) || stage1.residual_group1.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.615 | 0.630 | 0.142 | torch.Size([240, 120]) || stage1.residual_group1.blocks.1.mlp.fc12.weight
+ | 0.009 | -0.473 | 0.647 | 0.131 | torch.Size([240]) || stage1.residual_group1.blocks.1.mlp.fc12.bias
+ | 0.001 | -0.789 | 0.813 | 0.146 | torch.Size([120, 240]) || stage1.residual_group1.blocks.1.mlp.fc2.weight
+ | -0.041 | -0.335 | 0.331 | 0.119 | torch.Size([120]) || stage1.residual_group1.blocks.1.mlp.fc2.bias
+ | 1.087 | 0.163 | 1.663 | 0.218 | torch.Size([120]) || stage1.residual_group1.blocks.2.norm1.weight
+ | -0.188 | -1.539 | 0.134 | 0.175 | torch.Size([120]) || stage1.residual_group1.blocks.2.norm1.bias
+ | -0.505 | -4.230 | 3.070 | 0.545 | torch.Size([675, 6]) || stage1.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.2.attn.position_bias
+ | -0.000 | -1.348 | 1.453 | 0.171 | torch.Size([360, 120]) || stage1.residual_group1.blocks.2.attn.qkv_self.weight
+ | 0.007 | -0.394 | 0.633 | 0.080 | torch.Size([360]) || stage1.residual_group1.blocks.2.attn.qkv_self.bias
+ | 0.001 | -0.561 | 0.466 | 0.108 | torch.Size([120, 240]) || stage1.residual_group1.blocks.2.attn.proj.weight
+ | 0.028 | -0.263 | 0.277 | 0.111 | torch.Size([120]) || stage1.residual_group1.blocks.2.attn.proj.bias
+ | -0.000 | -0.982 | 1.268 | 0.124 | torch.Size([360, 120]) || stage1.residual_group1.blocks.2.attn.qkv_mut.weight
+ | 0.001 | -0.139 | 0.149 | 0.035 | torch.Size([360]) || stage1.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.743 | 0.234 | 0.925 | 0.092 | torch.Size([120]) || stage1.residual_group1.blocks.2.norm2.weight
+ | 0.030 | -1.015 | 0.440 | 0.156 | torch.Size([120]) || stage1.residual_group1.blocks.2.norm2.bias
+ | -0.002 | -0.956 | 1.234 | 0.155 | torch.Size([240, 120]) || stage1.residual_group1.blocks.2.mlp.fc11.weight
+ | 0.003 | -0.419 | 0.302 | 0.108 | torch.Size([240]) || stage1.residual_group1.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.723 | 0.609 | 0.143 | torch.Size([240, 120]) || stage1.residual_group1.blocks.2.mlp.fc12.weight
+ | -0.007 | -0.362 | 0.529 | 0.129 | torch.Size([240]) || stage1.residual_group1.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.768 | 0.645 | 0.147 | torch.Size([120, 240]) || stage1.residual_group1.blocks.2.mlp.fc2.weight
+ | -0.033 | -0.281 | 0.244 | 0.100 | torch.Size([120]) || stage1.residual_group1.blocks.2.mlp.fc2.bias
+ | 1.076 | 0.178 | 1.503 | 0.199 | torch.Size([120]) || stage1.residual_group1.blocks.3.norm1.weight
+ | -0.153 | -1.699 | 0.096 | 0.171 | torch.Size([120]) || stage1.residual_group1.blocks.3.norm1.bias
+ | -0.815 | -4.386 | 4.546 | 0.797 | torch.Size([675, 6]) || stage1.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.3.attn.position_bias
+ | 0.001 | -2.332 | 2.215 | 0.164 | torch.Size([360, 120]) || stage1.residual_group1.blocks.3.attn.qkv_self.weight
+ | -0.004 | -0.455 | 0.400 | 0.070 | torch.Size([360]) || stage1.residual_group1.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.504 | 0.556 | 0.108 | torch.Size([120, 240]) || stage1.residual_group1.blocks.3.attn.proj.weight
+ | -0.006 | -0.339 | 0.365 | 0.137 | torch.Size([120]) || stage1.residual_group1.blocks.3.attn.proj.bias
+ | 0.000 | -1.444 | 1.191 | 0.122 | torch.Size([360, 120]) || stage1.residual_group1.blocks.3.attn.qkv_mut.weight
+ | -0.001 | -0.162 | 0.140 | 0.029 | torch.Size([360]) || stage1.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.715 | 0.229 | 0.865 | 0.078 | torch.Size([120]) || stage1.residual_group1.blocks.3.norm2.weight
+ | 0.026 | -1.011 | 0.287 | 0.151 | torch.Size([120]) || stage1.residual_group1.blocks.3.norm2.bias
+ | -0.003 | -0.761 | 0.828 | 0.148 | torch.Size([240, 120]) || stage1.residual_group1.blocks.3.mlp.fc11.weight
+ | 0.014 | -0.337 | 0.418 | 0.135 | torch.Size([240]) || stage1.residual_group1.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.716 | 0.712 | 0.149 | torch.Size([240, 120]) || stage1.residual_group1.blocks.3.mlp.fc12.weight
+ | 0.003 | -0.427 | 0.369 | 0.124 | torch.Size([240]) || stage1.residual_group1.blocks.3.mlp.fc12.bias
+ | 0.001 | -0.719 | 0.640 | 0.151 | torch.Size([120, 240]) || stage1.residual_group1.blocks.3.mlp.fc2.weight
+ | -0.010 | -0.557 | 0.227 | 0.103 | torch.Size([120]) || stage1.residual_group1.blocks.3.mlp.fc2.bias
+ | 1.161 | 0.188 | 1.556 | 0.179 | torch.Size([120]) || stage1.residual_group1.blocks.4.norm1.weight
+ | -0.165 | -1.773 | 0.054 | 0.186 | torch.Size([120]) || stage1.residual_group1.blocks.4.norm1.bias
+ | -0.575 | -3.741 | 5.261 | 0.767 | torch.Size([675, 6]) || stage1.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.4.attn.position_bias
+ | 0.000 | -2.020 | 2.251 | 0.173 | torch.Size([360, 120]) || stage1.residual_group1.blocks.4.attn.qkv_self.weight
+ | 0.000 | -0.318 | 0.312 | 0.071 | torch.Size([360]) || stage1.residual_group1.blocks.4.attn.qkv_self.bias
+ | 0.000 | -0.463 | 0.456 | 0.112 | torch.Size([120, 240]) || stage1.residual_group1.blocks.4.attn.proj.weight
+ | 0.002 | -0.406 | 0.393 | 0.154 | torch.Size([120]) || stage1.residual_group1.blocks.4.attn.proj.bias
+ | -0.001 | -0.968 | 1.330 | 0.123 | torch.Size([360, 120]) || stage1.residual_group1.blocks.4.attn.qkv_mut.weight
+ | 0.001 | -0.152 | 0.176 | 0.030 | torch.Size([360]) || stage1.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.699 | 0.230 | 0.850 | 0.073 | torch.Size([120]) || stage1.residual_group1.blocks.4.norm2.weight
+ | 0.029 | -1.033 | 0.300 | 0.149 | torch.Size([120]) || stage1.residual_group1.blocks.4.norm2.bias
+ | -0.002 | -0.718 | 0.803 | 0.145 | torch.Size([240, 120]) || stage1.residual_group1.blocks.4.mlp.fc11.weight
+ | 0.002 | -0.389 | 0.405 | 0.139 | torch.Size([240]) || stage1.residual_group1.blocks.4.mlp.fc11.bias
+ | -0.001 | -0.582 | 0.624 | 0.151 | torch.Size([240, 120]) || stage1.residual_group1.blocks.4.mlp.fc12.weight
+ | 0.003 | -0.385 | 0.386 | 0.118 | torch.Size([240]) || stage1.residual_group1.blocks.4.mlp.fc12.bias
+ | 0.000 | -0.677 | 0.737 | 0.153 | torch.Size([120, 240]) || stage1.residual_group1.blocks.4.mlp.fc2.weight
+ | 0.003 | -0.671 | 0.208 | 0.108 | torch.Size([120]) || stage1.residual_group1.blocks.4.mlp.fc2.bias
+ | 1.067 | 0.173 | 1.473 | 0.179 | torch.Size([120]) || stage1.residual_group1.blocks.5.norm1.weight
+ | -0.129 | -1.487 | 0.138 | 0.166 | torch.Size([120]) || stage1.residual_group1.blocks.5.norm1.bias
+ | -0.530 | -3.629 | 3.705 | 0.621 | torch.Size([675, 6]) || stage1.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage1.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage1.residual_group1.blocks.5.attn.position_bias
+ | 0.000 | -2.344 | 1.768 | 0.157 | torch.Size([360, 120]) || stage1.residual_group1.blocks.5.attn.qkv_self.weight
+ | -0.001 | -0.428 | 0.265 | 0.082 | torch.Size([360]) || stage1.residual_group1.blocks.5.attn.qkv_self.bias
+ | -0.001 | -0.541 | 0.559 | 0.120 | torch.Size([120, 240]) || stage1.residual_group1.blocks.5.attn.proj.weight
+ | 0.031 | -0.324 | 0.379 | 0.133 | torch.Size([120]) || stage1.residual_group1.blocks.5.attn.proj.bias
+ | -0.001 | -1.380 | 0.992 | 0.120 | torch.Size([360, 120]) || stage1.residual_group1.blocks.5.attn.qkv_mut.weight
+ | 0.000 | -0.100 | 0.111 | 0.027 | torch.Size([360]) || stage1.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.637 | 0.273 | 0.780 | 0.064 | torch.Size([120]) || stage1.residual_group1.blocks.5.norm2.weight
+ | 0.022 | -1.160 | 0.338 | 0.149 | torch.Size([120]) || stage1.residual_group1.blocks.5.norm2.bias
+ | -0.002 | -0.696 | 0.638 | 0.139 | torch.Size([240, 120]) || stage1.residual_group1.blocks.5.mlp.fc11.weight
+ | 0.007 | -0.366 | 0.364 | 0.134 | torch.Size([240]) || stage1.residual_group1.blocks.5.mlp.fc11.bias
+ | -0.001 | -0.581 | 0.657 | 0.151 | torch.Size([240, 120]) || stage1.residual_group1.blocks.5.mlp.fc12.weight
+ | -0.004 | -0.366 | 0.244 | 0.105 | torch.Size([240]) || stage1.residual_group1.blocks.5.mlp.fc12.bias
+ | 0.000 | -1.143 | 0.787 | 0.154 | torch.Size([120, 240]) || stage1.residual_group1.blocks.5.mlp.fc2.weight
+ | 0.023 | -1.254 | 0.407 | 0.160 | torch.Size([120]) || stage1.residual_group1.blocks.5.mlp.fc2.bias
+ | 0.001 | -0.293 | 0.270 | 0.065 | torch.Size([120, 120]) || stage1.linear1.weight
+ | 0.006 | -0.209 | 0.382 | 0.093 | torch.Size([120]) || stage1.linear1.bias
+ | 0.811 | 0.432 | 1.092 | 0.108 | torch.Size([120]) || stage1.residual_group2.blocks.0.norm1.weight
+ | 0.033 | -0.763 | 0.477 | 0.200 | torch.Size([120]) || stage1.residual_group2.blocks.0.norm1.bias
+ | -0.049 | -2.996 | 1.734 | 0.246 | torch.Size([3375, 6]) || stage1.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage1.residual_group2.blocks.0.attn.relative_position_index
+ | -0.000 | -0.847 | 1.215 | 0.150 | torch.Size([360, 120]) || stage1.residual_group2.blocks.0.attn.qkv_self.weight
+ | -0.000 | -0.542 | 0.581 | 0.147 | torch.Size([360]) || stage1.residual_group2.blocks.0.attn.qkv_self.bias
+ | 0.001 | -0.536 | 0.569 | 0.124 | torch.Size([120, 120]) || stage1.residual_group2.blocks.0.attn.proj.weight
+ | -0.004 | -0.195 | 0.602 | 0.102 | torch.Size([120]) || stage1.residual_group2.blocks.0.attn.proj.bias
+ | 0.568 | 0.438 | 0.872 | 0.074 | torch.Size([120]) || stage1.residual_group2.blocks.0.norm2.weight
+ | 0.025 | -0.782 | 0.342 | 0.164 | torch.Size([120]) || stage1.residual_group2.blocks.0.norm2.bias
+ | 0.003 | -0.601 | 0.699 | 0.126 | torch.Size([240, 120]) || stage1.residual_group2.blocks.0.mlp.fc11.weight
+ | 0.068 | -0.329 | 0.446 | 0.095 | torch.Size([240]) || stage1.residual_group2.blocks.0.mlp.fc11.bias
+ | 0.001 | -0.807 | 0.710 | 0.143 | torch.Size([240, 120]) || stage1.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.002 | -0.585 | 0.392 | 0.117 | torch.Size([240]) || stage1.residual_group2.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.779 | 0.575 | 0.142 | torch.Size([120, 240]) || stage1.residual_group2.blocks.0.mlp.fc2.weight
+ | 0.008 | -0.377 | 0.374 | 0.159 | torch.Size([120]) || stage1.residual_group2.blocks.0.mlp.fc2.bias
+ | 0.942 | 0.411 | 1.171 | 0.093 | torch.Size([120]) || stage1.residual_group2.blocks.1.norm1.weight
+ | 0.038 | -0.837 | 0.321 | 0.152 | torch.Size([120]) || stage1.residual_group2.blocks.1.norm1.bias
+ | -0.077 | -2.150 | 2.175 | 0.237 | torch.Size([3375, 6]) || stage1.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage1.residual_group2.blocks.1.attn.relative_position_index
+ | -0.000 | -0.750 | 0.771 | 0.159 | torch.Size([360, 120]) || stage1.residual_group2.blocks.1.attn.qkv_self.weight
+ | -0.004 | -0.589 | 0.559 | 0.145 | torch.Size([360]) || stage1.residual_group2.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.478 | 0.525 | 0.125 | torch.Size([120, 120]) || stage1.residual_group2.blocks.1.attn.proj.weight
+ | 0.009 | -0.338 | 0.449 | 0.154 | torch.Size([120]) || stage1.residual_group2.blocks.1.attn.proj.bias
+ | 0.597 | 0.429 | 0.741 | 0.044 | torch.Size([120]) || stage1.residual_group2.blocks.1.norm2.weight
+ | 0.038 | -0.697 | 0.195 | 0.103 | torch.Size([120]) || stage1.residual_group2.blocks.1.norm2.bias
+ | 0.003 | -0.671 | 0.636 | 0.135 | torch.Size([240, 120]) || stage1.residual_group2.blocks.1.mlp.fc11.weight
+ | 0.057 | -0.519 | 0.422 | 0.139 | torch.Size([240]) || stage1.residual_group2.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.629 | 0.607 | 0.153 | torch.Size([240, 120]) || stage1.residual_group2.blocks.1.mlp.fc12.weight
+ | -0.007 | -0.279 | 0.403 | 0.083 | torch.Size([240]) || stage1.residual_group2.blocks.1.mlp.fc12.bias
+ | 0.001 | -0.620 | 0.712 | 0.150 | torch.Size([120, 240]) || stage1.residual_group2.blocks.1.mlp.fc2.weight
+ | 0.014 | -0.721 | 0.333 | 0.163 | torch.Size([120]) || stage1.residual_group2.blocks.1.mlp.fc2.bias
+ | 0.000 | -0.504 | 0.343 | 0.079 | torch.Size([120, 120]) || stage1.linear2.weight
+ | 0.015 | -0.276 | 0.353 | 0.122 | torch.Size([120]) || stage1.linear2.bias
+ | -0.000 | -0.151 | 0.136 | 0.025 | torch.Size([120, 120, 3, 3]) || stage1.pa_deform.weight
+ | -0.001 | -0.087 | 0.103 | 0.030 | torch.Size([120]) || stage1.pa_deform.bias
+ | 0.000 | -0.017 | 0.017 | 0.010 | torch.Size([120, 364, 3, 3]) || stage1.pa_deform.conv_offset.0.weight
+ | -0.004 | -0.024 | 0.040 | 0.013 | torch.Size([120]) || stage1.pa_deform.conv_offset.0.bias
+ | -0.001 | -0.122 | 0.123 | 0.017 | torch.Size([120, 120, 3, 3]) || stage1.pa_deform.conv_offset.2.weight
+ | -0.009 | -0.068 | 0.068 | 0.028 | torch.Size([120]) || stage1.pa_deform.conv_offset.2.bias
+ | -0.001 | -0.175 | 0.114 | 0.015 | torch.Size([120, 120, 3, 3]) || stage1.pa_deform.conv_offset.4.weight
+ | 0.019 | -0.059 | 0.110 | 0.042 | torch.Size([120]) || stage1.pa_deform.conv_offset.4.bias
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432, 120, 3, 3]) || stage1.pa_deform.conv_offset.6.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432]) || stage1.pa_deform.conv_offset.6.bias
+ | -0.001 | -1.034 | 1.208 | 0.150 | torch.Size([360, 360]) || stage1.pa_fuse.fc11.weight
+ | 0.085 | -0.220 | 0.682 | 0.164 | torch.Size([360]) || stage1.pa_fuse.fc11.bias
+ | 0.001 | -1.305 | 1.408 | 0.167 | torch.Size([360, 360]) || stage1.pa_fuse.fc12.weight
+ | 0.005 | -0.474 | 0.521 | 0.147 | torch.Size([360]) || stage1.pa_fuse.fc12.bias
+ | 0.000 | -0.941 | 0.939 | 0.158 | torch.Size([120, 360]) || stage1.pa_fuse.fc2.weight
+ | 0.019 | -0.993 | 0.852 | 0.371 | torch.Size([120]) || stage1.pa_fuse.fc2.bias
+ | 1.099 | 0.165 | 1.669 | 0.285 | torch.Size([480]) || stage2.reshape.1.weight
+ | -0.009 | -0.723 | 0.825 | 0.237 | torch.Size([480]) || stage2.reshape.1.bias
+ | -0.000 | -0.767 | 0.672 | 0.163 | torch.Size([120, 480]) || stage2.reshape.2.weight
+ | -0.007 | -0.473 | 0.285 | 0.116 | torch.Size([120]) || stage2.reshape.2.bias
+ | 0.665 | 0.267 | 1.019 | 0.157 | torch.Size([120]) || stage2.residual_group1.blocks.0.norm1.weight
+ | -0.152 | -0.897 | 0.303 | 0.218 | torch.Size([120]) || stage2.residual_group1.blocks.0.norm1.bias
+ | -0.208 | -1.940 | 4.459 | 0.383 | torch.Size([675, 6]) || stage2.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.0.attn.position_bias
+ | -0.000 | -0.653 | 0.613 | 0.127 | torch.Size([360, 120]) || stage2.residual_group1.blocks.0.attn.qkv_self.weight
+ | 0.003 | -0.263 | 0.270 | 0.066 | torch.Size([360]) || stage2.residual_group1.blocks.0.attn.qkv_self.bias
+ | 0.002 | -0.796 | 0.596 | 0.108 | torch.Size([120, 240]) || stage2.residual_group1.blocks.0.attn.proj.weight
+ | -0.008 | -0.955 | 0.285 | 0.127 | torch.Size([120]) || stage2.residual_group1.blocks.0.attn.proj.bias
+ | 0.000 | -1.099 | 0.979 | 0.109 | torch.Size([360, 120]) || stage2.residual_group1.blocks.0.attn.qkv_mut.weight
+ | -0.000 | -0.131 | 0.090 | 0.022 | torch.Size([360]) || stage2.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.548 | 0.301 | 0.671 | 0.063 | torch.Size([120]) || stage2.residual_group1.blocks.0.norm2.weight
+ | 0.003 | -0.744 | 0.803 | 0.231 | torch.Size([120]) || stage2.residual_group1.blocks.0.norm2.bias
+ | 0.001 | -0.645 | 0.555 | 0.133 | torch.Size([240, 120]) || stage2.residual_group1.blocks.0.mlp.fc11.weight
+ | 0.013 | -0.406 | 0.272 | 0.097 | torch.Size([240]) || stage2.residual_group1.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.622 | 0.666 | 0.147 | torch.Size([240, 120]) || stage2.residual_group1.blocks.0.mlp.fc12.weight
+ | 0.002 | -0.228 | 0.307 | 0.085 | torch.Size([240]) || stage2.residual_group1.blocks.0.mlp.fc12.bias
+ | 0.001 | -0.834 | 0.822 | 0.149 | torch.Size([120, 240]) || stage2.residual_group1.blocks.0.mlp.fc2.weight
+ | -0.009 | -0.948 | 0.446 | 0.159 | torch.Size([120]) || stage2.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.777 | 0.311 | 1.104 | 0.161 | torch.Size([120]) || stage2.residual_group1.blocks.1.norm1.weight
+ | -0.178 | -0.966 | 0.822 | 0.247 | torch.Size([120]) || stage2.residual_group1.blocks.1.norm1.bias
+ | -0.387 | -2.000 | 5.826 | 0.443 | torch.Size([675, 6]) || stage2.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.1.attn.position_bias
+ | 0.000 | -0.662 | 0.706 | 0.132 | torch.Size([360, 120]) || stage2.residual_group1.blocks.1.attn.qkv_self.weight
+ | -0.006 | -0.348 | 0.306 | 0.079 | torch.Size([360]) || stage2.residual_group1.blocks.1.attn.qkv_self.bias
+ | -0.001 | -0.595 | 0.730 | 0.112 | torch.Size([120, 240]) || stage2.residual_group1.blocks.1.attn.proj.weight
+ | -0.001 | -0.811 | 0.531 | 0.167 | torch.Size([120]) || stage2.residual_group1.blocks.1.attn.proj.bias
+ | -0.000 | -1.007 | 1.002 | 0.105 | torch.Size([360, 120]) || stage2.residual_group1.blocks.1.attn.qkv_mut.weight
+ | -0.002 | -0.180 | 0.108 | 0.024 | torch.Size([360]) || stage2.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.599 | 0.282 | 0.730 | 0.059 | torch.Size([120]) || stage2.residual_group1.blocks.1.norm2.weight
+ | -0.004 | -0.671 | 0.938 | 0.218 | torch.Size([120]) || stage2.residual_group1.blocks.1.norm2.bias
+ | 0.000 | -0.536 | 0.570 | 0.134 | torch.Size([240, 120]) || stage2.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.022 | -0.540 | 0.226 | 0.107 | torch.Size([240]) || stage2.residual_group1.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.646 | 0.589 | 0.149 | torch.Size([240, 120]) || stage2.residual_group1.blocks.1.mlp.fc12.weight
+ | 0.008 | -0.203 | 0.282 | 0.092 | torch.Size([240]) || stage2.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.000 | -1.052 | 0.649 | 0.150 | torch.Size([120, 240]) || stage2.residual_group1.blocks.1.mlp.fc2.weight
+ | -0.007 | -0.581 | 0.467 | 0.137 | torch.Size([120]) || stage2.residual_group1.blocks.1.mlp.fc2.bias
+ | 0.780 | 0.134 | 1.161 | 0.193 | torch.Size([120]) || stage2.residual_group1.blocks.2.norm1.weight
+ | -0.152 | -0.996 | 1.042 | 0.227 | torch.Size([120]) || stage2.residual_group1.blocks.2.norm1.bias
+ | -0.186 | -2.565 | 4.152 | 0.428 | torch.Size([675, 6]) || stage2.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.2.attn.position_bias
+ | 0.001 | -0.856 | 0.814 | 0.151 | torch.Size([360, 120]) || stage2.residual_group1.blocks.2.attn.qkv_self.weight
+ | -0.002 | -0.367 | 0.317 | 0.074 | torch.Size([360]) || stage2.residual_group1.blocks.2.attn.qkv_self.bias
+ | -0.001 | -0.656 | 0.730 | 0.131 | torch.Size([120, 240]) || stage2.residual_group1.blocks.2.attn.proj.weight
+ | -0.003 | -0.555 | 0.620 | 0.163 | torch.Size([120]) || stage2.residual_group1.blocks.2.attn.proj.bias
+ | 0.001 | -2.191 | 2.575 | 0.137 | torch.Size([360, 120]) || stage2.residual_group1.blocks.2.attn.qkv_mut.weight
+ | 0.000 | -0.121 | 0.139 | 0.023 | torch.Size([360]) || stage2.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.640 | 0.297 | 0.797 | 0.064 | torch.Size([120]) || stage2.residual_group1.blocks.2.norm2.weight
+ | -0.013 | -0.584 | 0.934 | 0.217 | torch.Size([120]) || stage2.residual_group1.blocks.2.norm2.bias
+ | 0.000 | -0.523 | 0.556 | 0.136 | torch.Size([240, 120]) || stage2.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.035 | -0.490 | 0.217 | 0.117 | torch.Size([240]) || stage2.residual_group1.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.679 | 0.601 | 0.152 | torch.Size([240, 120]) || stage2.residual_group1.blocks.2.mlp.fc12.weight
+ | 0.005 | -0.287 | 0.308 | 0.098 | torch.Size([240]) || stage2.residual_group1.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.576 | 0.584 | 0.151 | torch.Size([120, 240]) || stage2.residual_group1.blocks.2.mlp.fc2.weight
+ | -0.006 | -0.423 | 0.376 | 0.121 | torch.Size([120]) || stage2.residual_group1.blocks.2.mlp.fc2.bias
+ | 0.776 | 0.134 | 1.030 | 0.164 | torch.Size([120]) || stage2.residual_group1.blocks.3.norm1.weight
+ | -0.167 | -0.870 | 1.066 | 0.204 | torch.Size([120]) || stage2.residual_group1.blocks.3.norm1.bias
+ | -0.259 | -1.735 | 5.189 | 0.366 | torch.Size([675, 6]) || stage2.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.3.attn.position_bias
+ | 0.000 | -1.292 | 1.255 | 0.149 | torch.Size([360, 120]) || stage2.residual_group1.blocks.3.attn.qkv_self.weight
+ | 0.000 | -0.493 | 0.445 | 0.101 | torch.Size([360]) || stage2.residual_group1.blocks.3.attn.qkv_self.bias
+ | 0.001 | -0.618 | 0.582 | 0.122 | torch.Size([120, 240]) || stage2.residual_group1.blocks.3.attn.proj.weight
+ | -0.001 | -0.543 | 0.420 | 0.166 | torch.Size([120]) || stage2.residual_group1.blocks.3.attn.proj.bias
+ | 0.002 | -2.296 | 2.630 | 0.162 | torch.Size([360, 120]) || stage2.residual_group1.blocks.3.attn.qkv_mut.weight
+ | -0.001 | -0.130 | 0.149 | 0.028 | torch.Size([360]) || stage2.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.625 | 0.301 | 0.772 | 0.060 | torch.Size([120]) || stage2.residual_group1.blocks.3.norm2.weight
+ | -0.015 | -0.498 | 0.992 | 0.198 | torch.Size([120]) || stage2.residual_group1.blocks.3.norm2.bias
+ | -0.000 | -0.620 | 0.681 | 0.130 | torch.Size([240, 120]) || stage2.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.006 | -0.391 | 0.256 | 0.113 | torch.Size([240]) || stage2.residual_group1.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.575 | 0.669 | 0.152 | torch.Size([240, 120]) || stage2.residual_group1.blocks.3.mlp.fc12.weight
+ | -0.000 | -0.225 | 0.333 | 0.088 | torch.Size([240]) || stage2.residual_group1.blocks.3.mlp.fc12.bias
+ | 0.001 | -0.680 | 0.639 | 0.151 | torch.Size([120, 240]) || stage2.residual_group1.blocks.3.mlp.fc2.weight
+ | -0.011 | -0.549 | 0.259 | 0.139 | torch.Size([120]) || stage2.residual_group1.blocks.3.mlp.fc2.bias
+ | 0.933 | 0.310 | 1.186 | 0.121 | torch.Size([120]) || stage2.residual_group1.blocks.4.norm1.weight
+ | -0.180 | -0.736 | 1.168 | 0.204 | torch.Size([120]) || stage2.residual_group1.blocks.4.norm1.bias
+ | -0.164 | -2.965 | 4.145 | 0.437 | torch.Size([675, 6]) || stage2.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.4.attn.position_bias
+ | 0.000 | -0.860 | 0.749 | 0.136 | torch.Size([360, 120]) || stage2.residual_group1.blocks.4.attn.qkv_self.weight
+ | 0.005 | -0.274 | 0.308 | 0.080 | torch.Size([360]) || stage2.residual_group1.blocks.4.attn.qkv_self.bias
+ | 0.001 | -0.648 | 0.681 | 0.129 | torch.Size([120, 240]) || stage2.residual_group1.blocks.4.attn.proj.weight
+ | 0.002 | -0.547 | 0.295 | 0.149 | torch.Size([120]) || stage2.residual_group1.blocks.4.attn.proj.bias
+ | -0.000 | -0.647 | 0.577 | 0.105 | torch.Size([360, 120]) || stage2.residual_group1.blocks.4.attn.qkv_mut.weight
+ | -0.001 | -0.138 | 0.125 | 0.023 | torch.Size([360]) || stage2.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.635 | 0.329 | 0.748 | 0.049 | torch.Size([120]) || stage2.residual_group1.blocks.4.norm2.weight
+ | -0.018 | -0.375 | 0.891 | 0.157 | torch.Size([120]) || stage2.residual_group1.blocks.4.norm2.bias
+ | -0.000 | -0.603 | 0.497 | 0.130 | torch.Size([240, 120]) || stage2.residual_group1.blocks.4.mlp.fc11.weight
+ | -0.010 | -0.345 | 0.297 | 0.113 | torch.Size([240]) || stage2.residual_group1.blocks.4.mlp.fc11.bias
+ | -0.000 | -0.680 | 0.679 | 0.153 | torch.Size([240, 120]) || stage2.residual_group1.blocks.4.mlp.fc12.weight
+ | -0.000 | -0.200 | 0.251 | 0.086 | torch.Size([240]) || stage2.residual_group1.blocks.4.mlp.fc12.bias
+ | -0.001 | -0.568 | 0.614 | 0.152 | torch.Size([120, 240]) || stage2.residual_group1.blocks.4.mlp.fc2.weight
+ | -0.009 | -0.375 | 0.493 | 0.135 | torch.Size([120]) || stage2.residual_group1.blocks.4.mlp.fc2.bias
+ | 0.870 | 0.315 | 1.059 | 0.096 | torch.Size([120]) || stage2.residual_group1.blocks.5.norm1.weight
+ | -0.139 | -0.657 | 1.107 | 0.163 | torch.Size([120]) || stage2.residual_group1.blocks.5.norm1.bias
+ | -0.156 | -4.167 | 4.651 | 0.340 | torch.Size([675, 6]) || stage2.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage2.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage2.residual_group1.blocks.5.attn.position_bias
+ | 0.000 | -0.701 | 0.871 | 0.134 | torch.Size([360, 120]) || stage2.residual_group1.blocks.5.attn.qkv_self.weight
+ | -0.000 | -0.427 | 0.471 | 0.099 | torch.Size([360]) || stage2.residual_group1.blocks.5.attn.qkv_self.bias
+ | -0.000 | -0.520 | 0.546 | 0.113 | torch.Size([120, 240]) || stage2.residual_group1.blocks.5.attn.proj.weight
+ | -0.008 | -0.360 | 0.350 | 0.137 | torch.Size([120]) || stage2.residual_group1.blocks.5.attn.proj.bias
+ | 0.001 | -0.510 | 0.502 | 0.100 | torch.Size([360, 120]) || stage2.residual_group1.blocks.5.attn.qkv_mut.weight
+ | 0.001 | -0.092 | 0.125 | 0.021 | torch.Size([360]) || stage2.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.597 | 0.345 | 0.691 | 0.044 | torch.Size([120]) || stage2.residual_group1.blocks.5.norm2.weight
+ | -0.015 | -0.367 | 0.987 | 0.132 | torch.Size([120]) || stage2.residual_group1.blocks.5.norm2.bias
+ | 0.001 | -0.552 | 0.532 | 0.128 | torch.Size([240, 120]) || stage2.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.009 | -0.336 | 0.253 | 0.107 | torch.Size([240]) || stage2.residual_group1.blocks.5.mlp.fc11.bias
+ | 0.000 | -0.644 | 0.758 | 0.154 | torch.Size([240, 120]) || stage2.residual_group1.blocks.5.mlp.fc12.weight
+ | -0.001 | -0.243 | 0.264 | 0.088 | torch.Size([240]) || stage2.residual_group1.blocks.5.mlp.fc12.bias
+ | -0.001 | -0.667 | 0.621 | 0.152 | torch.Size([120, 240]) || stage2.residual_group1.blocks.5.mlp.fc2.weight
+ | -0.002 | -0.447 | 1.139 | 0.183 | torch.Size([120]) || stage2.residual_group1.blocks.5.mlp.fc2.bias
+ | 0.002 | -0.268 | 0.331 | 0.066 | torch.Size([120, 120]) || stage2.linear1.weight
+ | 0.005 | -0.338 | 0.589 | 0.128 | torch.Size([120]) || stage2.linear1.bias
+ | 0.939 | 0.517 | 1.207 | 0.113 | torch.Size([120]) || stage2.residual_group2.blocks.0.norm1.weight
+ | 0.023 | -0.770 | 0.614 | 0.238 | torch.Size([120]) || stage2.residual_group2.blocks.0.norm1.bias
+ | 0.004 | -3.112 | 1.341 | 0.140 | torch.Size([3375, 6]) || stage2.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage2.residual_group2.blocks.0.attn.relative_position_index
+ | 0.000 | -0.605 | 0.580 | 0.136 | torch.Size([360, 120]) || stage2.residual_group2.blocks.0.attn.qkv_self.weight
+ | 0.001 | -0.591 | 0.477 | 0.112 | torch.Size([360]) || stage2.residual_group2.blocks.0.attn.qkv_self.bias
+ | 0.001 | -0.645 | 0.613 | 0.150 | torch.Size([120, 120]) || stage2.residual_group2.blocks.0.attn.proj.weight
+ | -0.031 | -0.422 | 0.330 | 0.138 | torch.Size([120]) || stage2.residual_group2.blocks.0.attn.proj.bias
+ | 0.684 | 0.501 | 0.807 | 0.061 | torch.Size([120]) || stage2.residual_group2.blocks.0.norm2.weight
+ | 0.018 | -0.693 | 0.412 | 0.181 | torch.Size([120]) || stage2.residual_group2.blocks.0.norm2.bias
+ | 0.001 | -0.559 | 0.715 | 0.125 | torch.Size([240, 120]) || stage2.residual_group2.blocks.0.mlp.fc11.weight
+ | 0.031 | -0.346 | 0.273 | 0.108 | torch.Size([240]) || stage2.residual_group2.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.744 | 0.559 | 0.146 | torch.Size([240, 120]) || stage2.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.005 | -0.239 | 0.270 | 0.080 | torch.Size([240]) || stage2.residual_group2.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.603 | 0.871 | 0.144 | torch.Size([120, 240]) || stage2.residual_group2.blocks.0.mlp.fc2.weight
+ | -0.003 | -0.317 | 0.303 | 0.122 | torch.Size([120]) || stage2.residual_group2.blocks.0.mlp.fc2.bias
+ | 0.974 | 0.575 | 1.211 | 0.095 | torch.Size([120]) || stage2.residual_group2.blocks.1.norm1.weight
+ | 0.023 | -0.703 | 0.556 | 0.208 | torch.Size([120]) || stage2.residual_group2.blocks.1.norm1.bias
+ | 0.012 | -2.867 | 1.552 | 0.185 | torch.Size([3375, 6]) || stage2.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage2.residual_group2.blocks.1.attn.relative_position_index
+ | 0.000 | -0.743 | 0.663 | 0.142 | torch.Size([360, 120]) || stage2.residual_group2.blocks.1.attn.qkv_self.weight
+ | 0.002 | -0.647 | 0.654 | 0.141 | torch.Size([360]) || stage2.residual_group2.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.610 | 0.648 | 0.151 | torch.Size([120, 120]) || stage2.residual_group2.blocks.1.attn.proj.weight
+ | -0.028 | -0.565 | 0.416 | 0.167 | torch.Size([120]) || stage2.residual_group2.blocks.1.attn.proj.bias
+ | 0.742 | 0.522 | 0.891 | 0.076 | torch.Size([120]) || stage2.residual_group2.blocks.1.norm2.weight
+ | 0.020 | -0.506 | 0.335 | 0.138 | torch.Size([120]) || stage2.residual_group2.blocks.1.norm2.bias
+ | 0.001 | -0.486 | 0.512 | 0.123 | torch.Size([240, 120]) || stage2.residual_group2.blocks.1.mlp.fc11.weight
+ | 0.094 | -0.405 | 0.617 | 0.174 | torch.Size([240]) || stage2.residual_group2.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.618 | 0.596 | 0.149 | torch.Size([240, 120]) || stage2.residual_group2.blocks.1.mlp.fc12.weight
+ | -0.001 | -0.276 | 0.202 | 0.077 | torch.Size([240]) || stage2.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.668 | 0.769 | 0.148 | torch.Size([120, 240]) || stage2.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.014 | -0.729 | 0.410 | 0.187 | torch.Size([120]) || stage2.residual_group2.blocks.1.mlp.fc2.bias
+ | 0.001 | -0.309 | 0.381 | 0.079 | torch.Size([120, 120]) || stage2.linear2.weight
+ | 0.017 | -0.403 | 0.399 | 0.133 | torch.Size([120]) || stage2.linear2.bias
+ | -0.000 | -0.111 | 0.126 | 0.024 | torch.Size([120, 120, 3, 3]) || stage2.pa_deform.weight
+ | 0.001 | -0.031 | 0.055 | 0.017 | torch.Size([120]) || stage2.pa_deform.bias
+ | 0.000 | -0.017 | 0.017 | 0.010 | torch.Size([120, 364, 3, 3]) || stage2.pa_deform.conv_offset.0.weight
+ | -0.010 | -0.038 | 0.021 | 0.012 | torch.Size([120]) || stage2.pa_deform.conv_offset.0.bias
+ | -0.001 | -0.113 | 0.096 | 0.020 | torch.Size([120, 120, 3, 3]) || stage2.pa_deform.conv_offset.2.weight
+ | -0.010 | -0.089 | 0.087 | 0.032 | torch.Size([120]) || stage2.pa_deform.conv_offset.2.bias
+ | -0.001 | -0.079 | 0.087 | 0.019 | torch.Size([120, 120, 3, 3]) || stage2.pa_deform.conv_offset.4.weight
+ | -0.015 | -0.134 | 0.121 | 0.058 | torch.Size([120]) || stage2.pa_deform.conv_offset.4.bias
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432, 120, 3, 3]) || stage2.pa_deform.conv_offset.6.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432]) || stage2.pa_deform.conv_offset.6.bias
+ | 0.004 | -1.011 | 1.138 | 0.150 | torch.Size([360, 360]) || stage2.pa_fuse.fc11.weight
+ | 0.151 | -0.228 | 0.674 | 0.167 | torch.Size([360]) || stage2.pa_fuse.fc11.bias
+ | 0.001 | -0.988 | 1.066 | 0.144 | torch.Size([360, 360]) || stage2.pa_fuse.fc12.weight
+ | 0.009 | -0.418 | 0.533 | 0.127 | torch.Size([360]) || stage2.pa_fuse.fc12.bias
+ | 0.000 | -0.784 | 0.831 | 0.151 | torch.Size([120, 360]) || stage2.pa_fuse.fc2.weight
+ | 0.007 | -0.581 | 0.470 | 0.257 | torch.Size([120]) || stage2.pa_fuse.fc2.bias
+ | 1.105 | 0.504 | 1.774 | 0.248 | torch.Size([480]) || stage3.reshape.1.weight
+ | -0.006 | -0.633 | 0.736 | 0.296 | torch.Size([480]) || stage3.reshape.1.bias
+ | -0.000 | -0.682 | 0.687 | 0.168 | torch.Size([120, 480]) || stage3.reshape.2.weight
+ | -0.004 | -0.207 | 0.227 | 0.086 | torch.Size([120]) || stage3.reshape.2.bias
+ | 0.735 | 0.431 | 0.997 | 0.127 | torch.Size([120]) || stage3.residual_group1.blocks.0.norm1.weight
+ | -0.162 | -0.753 | 0.303 | 0.198 | torch.Size([120]) || stage3.residual_group1.blocks.0.norm1.bias
+ | -0.001 | -0.490 | 0.344 | 0.037 | torch.Size([675, 6]) || stage3.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.0.attn.position_bias
+ | 0.000 | -0.333 | 0.350 | 0.061 | torch.Size([360, 120]) || stage3.residual_group1.blocks.0.attn.qkv_self.weight
+ | -0.004 | -0.195 | 0.128 | 0.039 | torch.Size([360]) || stage3.residual_group1.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.359 | 0.365 | 0.067 | torch.Size([120, 240]) || stage3.residual_group1.blocks.0.attn.proj.weight
+ | -0.002 | -0.216 | 0.262 | 0.084 | torch.Size([120]) || stage3.residual_group1.blocks.0.attn.proj.bias
+ | 0.000 | -0.597 | 0.657 | 0.058 | torch.Size([360, 120]) || stage3.residual_group1.blocks.0.attn.qkv_mut.weight
+ | 0.001 | -0.115 | 0.118 | 0.020 | torch.Size([360]) || stage3.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.594 | 0.414 | 0.775 | 0.069 | torch.Size([120]) || stage3.residual_group1.blocks.0.norm2.weight
+ | 0.003 | -0.260 | 0.315 | 0.105 | torch.Size([120]) || stage3.residual_group1.blocks.0.norm2.bias
+ | 0.001 | -0.446 | 0.536 | 0.116 | torch.Size([240, 120]) || stage3.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.077 | -0.361 | 0.145 | 0.072 | torch.Size([240]) || stage3.residual_group1.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.507 | 0.503 | 0.124 | torch.Size([240, 120]) || stage3.residual_group1.blocks.0.mlp.fc12.weight
+ | 0.005 | -0.225 | 0.207 | 0.062 | torch.Size([240]) || stage3.residual_group1.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.553 | 0.493 | 0.129 | torch.Size([120, 240]) || stage3.residual_group1.blocks.0.mlp.fc2.weight
+ | -0.006 | -0.268 | 0.158 | 0.085 | torch.Size([120]) || stage3.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.716 | 0.376 | 0.965 | 0.119 | torch.Size([120]) || stage3.residual_group1.blocks.1.norm1.weight
+ | -0.185 | -0.732 | 0.209 | 0.179 | torch.Size([120]) || stage3.residual_group1.blocks.1.norm1.bias
+ | -0.002 | -0.462 | 1.414 | 0.064 | torch.Size([675, 6]) || stage3.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.1.attn.position_bias
+ | 0.000 | -0.383 | 0.438 | 0.060 | torch.Size([360, 120]) || stage3.residual_group1.blocks.1.attn.qkv_self.weight
+ | -0.002 | -0.229 | 0.157 | 0.044 | torch.Size([360]) || stage3.residual_group1.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.357 | 0.478 | 0.065 | torch.Size([120, 240]) || stage3.residual_group1.blocks.1.attn.proj.weight
+ | -0.004 | -0.280 | 0.216 | 0.101 | torch.Size([120]) || stage3.residual_group1.blocks.1.attn.proj.bias
+ | 0.000 | -0.471 | 0.517 | 0.063 | torch.Size([360, 120]) || stage3.residual_group1.blocks.1.attn.qkv_mut.weight
+ | -0.000 | -0.112 | 0.131 | 0.022 | torch.Size([360]) || stage3.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.633 | 0.486 | 0.778 | 0.057 | torch.Size([120]) || stage3.residual_group1.blocks.1.norm2.weight
+ | 0.004 | -0.350 | 0.280 | 0.107 | torch.Size([120]) || stage3.residual_group1.blocks.1.norm2.bias
+ | 0.001 | -0.513 | 0.512 | 0.118 | torch.Size([240, 120]) || stage3.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.081 | -0.274 | 0.096 | 0.071 | torch.Size([240]) || stage3.residual_group1.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.548 | 0.533 | 0.126 | torch.Size([240, 120]) || stage3.residual_group1.blocks.1.mlp.fc12.weight
+ | -0.003 | -0.181 | 0.194 | 0.059 | torch.Size([240]) || stage3.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.499 | 0.534 | 0.128 | torch.Size([120, 240]) || stage3.residual_group1.blocks.1.mlp.fc2.weight
+ | -0.007 | -0.282 | 0.152 | 0.083 | torch.Size([120]) || stage3.residual_group1.blocks.1.mlp.fc2.bias
+ | 0.796 | 0.469 | 1.007 | 0.111 | torch.Size([120]) || stage3.residual_group1.blocks.2.norm1.weight
+ | -0.109 | -0.638 | 0.181 | 0.146 | torch.Size([120]) || stage3.residual_group1.blocks.2.norm1.bias
+ | -0.004 | -1.009 | 1.155 | 0.105 | torch.Size([675, 6]) || stage3.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.2.attn.position_bias
+ | -0.000 | -0.378 | 0.375 | 0.081 | torch.Size([360, 120]) || stage3.residual_group1.blocks.2.attn.qkv_self.weight
+ | 0.003 | -0.263 | 0.331 | 0.066 | torch.Size([360]) || stage3.residual_group1.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.485 | 0.366 | 0.074 | torch.Size([120, 240]) || stage3.residual_group1.blocks.2.attn.proj.weight
+ | -0.001 | -0.249 | 0.145 | 0.080 | torch.Size([120]) || stage3.residual_group1.blocks.2.attn.proj.bias
+ | -0.001 | -0.332 | 0.421 | 0.063 | torch.Size([360, 120]) || stage3.residual_group1.blocks.2.attn.qkv_mut.weight
+ | -0.001 | -0.098 | 0.083 | 0.016 | torch.Size([360]) || stage3.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.657 | 0.507 | 0.776 | 0.053 | torch.Size([120]) || stage3.residual_group1.blocks.2.norm2.weight
+ | 0.003 | -0.270 | 0.280 | 0.104 | torch.Size([120]) || stage3.residual_group1.blocks.2.norm2.bias
+ | 0.000 | -0.445 | 0.556 | 0.117 | torch.Size([240, 120]) || stage3.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.097 | -0.295 | 0.100 | 0.070 | torch.Size([240]) || stage3.residual_group1.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.480 | 0.501 | 0.126 | torch.Size([240, 120]) || stage3.residual_group1.blocks.2.mlp.fc12.weight
+ | 0.005 | -0.148 | 0.191 | 0.060 | torch.Size([240]) || stage3.residual_group1.blocks.2.mlp.fc12.bias
+ | 0.001 | -0.569 | 0.484 | 0.126 | torch.Size([120, 240]) || stage3.residual_group1.blocks.2.mlp.fc2.weight
+ | -0.006 | -0.246 | 0.161 | 0.082 | torch.Size([120]) || stage3.residual_group1.blocks.2.mlp.fc2.bias
+ | 0.814 | 0.482 | 1.048 | 0.109 | torch.Size([120]) || stage3.residual_group1.blocks.3.norm1.weight
+ | -0.138 | -0.585 | 0.128 | 0.129 | torch.Size([120]) || stage3.residual_group1.blocks.3.norm1.bias
+ | -0.008 | -1.801 | 4.148 | 0.110 | torch.Size([675, 6]) || stage3.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.3.attn.position_bias
+ | -0.001 | -0.364 | 0.546 | 0.076 | torch.Size([360, 120]) || stage3.residual_group1.blocks.3.attn.qkv_self.weight
+ | 0.003 | -0.179 | 0.182 | 0.046 | torch.Size([360]) || stage3.residual_group1.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.378 | 0.385 | 0.070 | torch.Size([120, 240]) || stage3.residual_group1.blocks.3.attn.proj.weight
+ | -0.005 | -0.368 | 0.175 | 0.101 | torch.Size([120]) || stage3.residual_group1.blocks.3.attn.proj.bias
+ | 0.000 | -0.338 | 0.461 | 0.062 | torch.Size([360, 120]) || stage3.residual_group1.blocks.3.attn.qkv_mut.weight
+ | 0.000 | -0.098 | 0.082 | 0.019 | torch.Size([360]) || stage3.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.676 | 0.526 | 0.799 | 0.056 | torch.Size([120]) || stage3.residual_group1.blocks.3.norm2.weight
+ | 0.002 | -0.269 | 0.242 | 0.090 | torch.Size([120]) || stage3.residual_group1.blocks.3.norm2.bias
+ | 0.000 | -0.474 | 0.505 | 0.118 | torch.Size([240, 120]) || stage3.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.095 | -0.247 | 0.071 | 0.063 | torch.Size([240]) || stage3.residual_group1.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.518 | 0.502 | 0.126 | torch.Size([240, 120]) || stage3.residual_group1.blocks.3.mlp.fc12.weight
+ | -0.003 | -0.194 | 0.228 | 0.068 | torch.Size([240]) || stage3.residual_group1.blocks.3.mlp.fc12.bias
+ | -0.001 | -0.502 | 0.499 | 0.124 | torch.Size([120, 240]) || stage3.residual_group1.blocks.3.mlp.fc2.weight
+ | -0.007 | -0.248 | 0.207 | 0.098 | torch.Size([120]) || stage3.residual_group1.blocks.3.mlp.fc2.bias
+ | 0.843 | 0.498 | 1.046 | 0.099 | torch.Size([120]) || stage3.residual_group1.blocks.4.norm1.weight
+ | -0.082 | -0.456 | 0.195 | 0.111 | torch.Size([120]) || stage3.residual_group1.blocks.4.norm1.bias
+ | -0.012 | -3.133 | 2.263 | 0.177 | torch.Size([675, 6]) || stage3.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.4.attn.position_bias
+ | 0.001 | -0.494 | 0.443 | 0.096 | torch.Size([360, 120]) || stage3.residual_group1.blocks.4.attn.qkv_self.weight
+ | -0.004 | -0.492 | 0.329 | 0.088 | torch.Size([360]) || stage3.residual_group1.blocks.4.attn.qkv_self.bias
+ | -0.000 | -0.464 | 0.391 | 0.080 | torch.Size([120, 240]) || stage3.residual_group1.blocks.4.attn.proj.weight
+ | -0.003 | -0.420 | 0.332 | 0.124 | torch.Size([120]) || stage3.residual_group1.blocks.4.attn.proj.bias
+ | 0.001 | -0.469 | 0.518 | 0.068 | torch.Size([360, 120]) || stage3.residual_group1.blocks.4.attn.qkv_mut.weight
+ | 0.001 | -0.068 | 0.099 | 0.014 | torch.Size([360]) || stage3.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.705 | 0.598 | 0.823 | 0.047 | torch.Size([120]) || stage3.residual_group1.blocks.4.norm2.weight
+ | 0.001 | -0.161 | 0.155 | 0.065 | torch.Size([120]) || stage3.residual_group1.blocks.4.norm2.bias
+ | 0.000 | -0.526 | 0.442 | 0.119 | torch.Size([240, 120]) || stage3.residual_group1.blocks.4.mlp.fc11.weight
+ | -0.102 | -0.319 | 0.054 | 0.072 | torch.Size([240]) || stage3.residual_group1.blocks.4.mlp.fc11.bias
+ | 0.000 | -0.555 | 0.499 | 0.126 | torch.Size([240, 120]) || stage3.residual_group1.blocks.4.mlp.fc12.weight
+ | -0.003 | -0.201 | 0.135 | 0.065 | torch.Size([240]) || stage3.residual_group1.blocks.4.mlp.fc12.bias
+ | 0.001 | -0.454 | 0.522 | 0.122 | torch.Size([120, 240]) || stage3.residual_group1.blocks.4.mlp.fc2.weight
+ | -0.011 | -0.379 | 0.195 | 0.091 | torch.Size([120]) || stage3.residual_group1.blocks.4.mlp.fc2.bias
+ | 0.856 | 0.618 | 1.073 | 0.095 | torch.Size([120]) || stage3.residual_group1.blocks.5.norm1.weight
+ | -0.059 | -0.368 | 0.153 | 0.095 | torch.Size([120]) || stage3.residual_group1.blocks.5.norm1.bias
+ | -0.006 | -1.747 | 1.724 | 0.133 | torch.Size([675, 6]) || stage3.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage3.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage3.residual_group1.blocks.5.attn.position_bias
+ | -0.000 | -0.399 | 0.417 | 0.090 | torch.Size([360, 120]) || stage3.residual_group1.blocks.5.attn.qkv_self.weight
+ | 0.009 | -0.294 | 0.398 | 0.079 | torch.Size([360]) || stage3.residual_group1.blocks.5.attn.qkv_self.bias
+ | 0.001 | -0.345 | 0.341 | 0.067 | torch.Size([120, 240]) || stage3.residual_group1.blocks.5.attn.proj.weight
+ | -0.004 | -0.435 | 0.326 | 0.113 | torch.Size([120]) || stage3.residual_group1.blocks.5.attn.proj.bias
+ | -0.000 | -0.370 | 0.339 | 0.052 | torch.Size([360, 120]) || stage3.residual_group1.blocks.5.attn.qkv_mut.weight
+ | -0.000 | -0.059 | 0.060 | 0.012 | torch.Size([360]) || stage3.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.707 | 0.600 | 0.832 | 0.051 | torch.Size([120]) || stage3.residual_group1.blocks.5.norm2.weight
+ | -0.001 | -0.157 | 0.140 | 0.063 | torch.Size([120]) || stage3.residual_group1.blocks.5.norm2.bias
+ | 0.001 | -0.473 | 0.464 | 0.117 | torch.Size([240, 120]) || stage3.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.091 | -0.291 | 0.092 | 0.073 | torch.Size([240]) || stage3.residual_group1.blocks.5.mlp.fc11.bias
+ | -0.000 | -0.479 | 0.477 | 0.124 | torch.Size([240, 120]) || stage3.residual_group1.blocks.5.mlp.fc12.weight
+ | 0.004 | -0.197 | 0.180 | 0.063 | torch.Size([240]) || stage3.residual_group1.blocks.5.mlp.fc12.bias
+ | -0.001 | -0.504 | 0.440 | 0.118 | torch.Size([120, 240]) || stage3.residual_group1.blocks.5.mlp.fc2.weight
+ | -0.008 | -0.449 | 0.421 | 0.135 | torch.Size([120]) || stage3.residual_group1.blocks.5.mlp.fc2.bias
+ | 0.003 | -0.331 | 0.524 | 0.083 | torch.Size([120, 120]) || stage3.linear1.weight
+ | -0.001 | -0.270 | 0.250 | 0.116 | torch.Size([120]) || stage3.linear1.bias
+ | 0.883 | 0.354 | 1.107 | 0.120 | torch.Size([120]) || stage3.residual_group2.blocks.0.norm1.weight
+ | 0.011 | -0.416 | 0.299 | 0.131 | torch.Size([120]) || stage3.residual_group2.blocks.0.norm1.bias
+ | 0.000 | -0.322 | 0.139 | 0.028 | torch.Size([3375, 6]) || stage3.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage3.residual_group2.blocks.0.attn.relative_position_index
+ | 0.000 | -0.470 | 0.455 | 0.097 | torch.Size([360, 120]) || stage3.residual_group2.blocks.0.attn.qkv_self.weight
+ | 0.007 | -0.384 | 0.374 | 0.125 | torch.Size([360]) || stage3.residual_group2.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.467 | 0.428 | 0.109 | torch.Size([120, 120]) || stage3.residual_group2.blocks.0.attn.proj.weight
+ | -0.009 | -0.348 | 0.279 | 0.126 | torch.Size([120]) || stage3.residual_group2.blocks.0.attn.proj.bias
+ | 0.873 | 0.618 | 1.060 | 0.070 | torch.Size([120]) || stage3.residual_group2.blocks.0.norm2.weight
+ | 0.005 | -0.242 | 0.278 | 0.098 | torch.Size([120]) || stage3.residual_group2.blocks.0.norm2.bias
+ | 0.000 | -0.549 | 0.437 | 0.115 | torch.Size([240, 120]) || stage3.residual_group2.blocks.0.mlp.fc11.weight
+ | -0.053 | -0.174 | 0.127 | 0.058 | torch.Size([240]) || stage3.residual_group2.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.469 | 0.517 | 0.124 | torch.Size([240, 120]) || stage3.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.002 | -0.133 | 0.187 | 0.052 | torch.Size([240]) || stage3.residual_group2.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.548 | 0.557 | 0.125 | torch.Size([120, 240]) || stage3.residual_group2.blocks.0.mlp.fc2.weight
+ | -0.011 | -0.339 | 0.303 | 0.116 | torch.Size([120]) || stage3.residual_group2.blocks.0.mlp.fc2.bias
+ | 0.960 | 0.744 | 1.153 | 0.095 | torch.Size([120]) || stage3.residual_group2.blocks.1.norm1.weight
+ | 0.004 | -0.302 | 0.238 | 0.099 | torch.Size([120]) || stage3.residual_group2.blocks.1.norm1.bias
+ | 0.000 | -0.567 | 0.133 | 0.032 | torch.Size([3375, 6]) || stage3.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage3.residual_group2.blocks.1.attn.relative_position_index
+ | 0.000 | -0.425 | 0.414 | 0.087 | torch.Size([360, 120]) || stage3.residual_group2.blocks.1.attn.qkv_self.weight
+ | 0.001 | -0.419 | 0.485 | 0.116 | torch.Size([360]) || stage3.residual_group2.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.429 | 0.385 | 0.095 | torch.Size([120, 120]) || stage3.residual_group2.blocks.1.attn.proj.weight
+ | -0.011 | -0.398 | 0.287 | 0.123 | torch.Size([120]) || stage3.residual_group2.blocks.1.attn.proj.bias
+ | 0.909 | 0.770 | 1.090 | 0.066 | torch.Size([120]) || stage3.residual_group2.blocks.1.norm2.weight
+ | -0.000 | -0.204 | 0.175 | 0.073 | torch.Size([120]) || stage3.residual_group2.blocks.1.norm2.bias
+ | 0.000 | -0.451 | 0.462 | 0.115 | torch.Size([240, 120]) || stage3.residual_group2.blocks.1.mlp.fc11.weight
+ | -0.069 | -0.268 | 0.143 | 0.077 | torch.Size([240]) || stage3.residual_group2.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.488 | 0.602 | 0.126 | torch.Size([240, 120]) || stage3.residual_group2.blocks.1.mlp.fc12.weight
+ | -0.004 | -0.179 | 0.114 | 0.050 | torch.Size([240]) || stage3.residual_group2.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.480 | 0.466 | 0.118 | torch.Size([120, 240]) || stage3.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.007 | -0.358 | 0.225 | 0.102 | torch.Size([120]) || stage3.residual_group2.blocks.1.mlp.fc2.bias
+ | 0.003 | -0.274 | 0.457 | 0.073 | torch.Size([120, 120]) || stage3.linear2.weight
+ | 0.002 | -0.532 | 0.438 | 0.200 | torch.Size([120]) || stage3.linear2.bias
+ | -0.000 | -0.098 | 0.115 | 0.025 | torch.Size([120, 120, 3, 3]) || stage3.pa_deform.weight
+ | 0.002 | -0.033 | 0.041 | 0.015 | torch.Size([120]) || stage3.pa_deform.bias
+ | -0.000 | -0.017 | 0.017 | 0.010 | torch.Size([120, 364, 3, 3]) || stage3.pa_deform.conv_offset.0.weight
+ | -0.010 | -0.030 | 0.017 | 0.010 | torch.Size([120]) || stage3.pa_deform.conv_offset.0.bias
+ | -0.000 | -0.078 | 0.069 | 0.020 | torch.Size([120, 120, 3, 3]) || stage3.pa_deform.conv_offset.2.weight
+ | -0.006 | -0.055 | 0.067 | 0.026 | torch.Size([120]) || stage3.pa_deform.conv_offset.2.bias
+ | -0.001 | -0.071 | 0.067 | 0.020 | torch.Size([120, 120, 3, 3]) || stage3.pa_deform.conv_offset.4.weight
+ | 0.004 | -0.070 | 0.113 | 0.042 | torch.Size([120]) || stage3.pa_deform.conv_offset.4.bias
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432, 120, 3, 3]) || stage3.pa_deform.conv_offset.6.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432]) || stage3.pa_deform.conv_offset.6.bias
+ | 0.004 | -0.623 | 0.669 | 0.126 | torch.Size([360, 360]) || stage3.pa_fuse.fc11.weight
+ | 0.092 | -0.221 | 0.676 | 0.151 | torch.Size([360]) || stage3.pa_fuse.fc11.bias
+ | 0.000 | -0.604 | 0.689 | 0.125 | torch.Size([360, 360]) || stage3.pa_fuse.fc12.weight
+ | 0.008 | -0.544 | 0.379 | 0.118 | torch.Size([360]) || stage3.pa_fuse.fc12.bias
+ | 0.000 | -0.669 | 0.719 | 0.151 | torch.Size([120, 360]) || stage3.pa_fuse.fc2.weight
+ | -0.005 | -0.411 | 0.443 | 0.155 | torch.Size([120]) || stage3.pa_fuse.fc2.bias
+ | 1.005 | 0.488 | 1.503 | 0.166 | torch.Size([480]) || stage4.reshape.1.weight
+ | 0.001 | -0.316 | 0.358 | 0.118 | torch.Size([480]) || stage4.reshape.1.bias
+ | 0.000 | -0.486 | 0.450 | 0.084 | torch.Size([120, 480]) || stage4.reshape.2.weight
+ | -0.007 | -0.139 | 0.092 | 0.043 | torch.Size([120]) || stage4.reshape.2.bias
+ | 0.996 | 0.831 | 1.101 | 0.039 | torch.Size([120]) || stage4.residual_group1.blocks.0.norm1.weight
+ | -0.014 | -0.109 | 0.112 | 0.040 | torch.Size([120]) || stage4.residual_group1.blocks.0.norm1.bias
+ | 0.000 | -0.064 | 0.064 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.0.attn.position_bias
+ | -0.000 | -0.109 | 0.107 | 0.023 | torch.Size([360, 120]) || stage4.residual_group1.blocks.0.attn.qkv_self.weight
+ | -0.001 | -0.033 | 0.029 | 0.009 | torch.Size([360]) || stage4.residual_group1.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.256 | 0.235 | 0.030 | torch.Size([120, 240]) || stage4.residual_group1.blocks.0.attn.proj.weight
+ | 0.007 | -0.099 | 0.227 | 0.051 | torch.Size([120]) || stage4.residual_group1.blocks.0.attn.proj.bias
+ | -0.000 | -0.129 | 0.142 | 0.025 | torch.Size([360, 120]) || stage4.residual_group1.blocks.0.attn.qkv_mut.weight
+ | -0.000 | -0.035 | 0.029 | 0.006 | torch.Size([360]) || stage4.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.966 | 0.869 | 1.089 | 0.041 | torch.Size([120]) || stage4.residual_group1.blocks.0.norm2.weight
+ | 0.000 | -0.155 | 0.152 | 0.058 | torch.Size([120]) || stage4.residual_group1.blocks.0.norm2.bias
+ | -0.000 | -0.248 | 0.221 | 0.024 | torch.Size([240, 120]) || stage4.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.002 | -0.066 | 0.012 | 0.007 | torch.Size([240]) || stage4.residual_group1.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.287 | 0.219 | 0.024 | torch.Size([240, 120]) || stage4.residual_group1.blocks.0.mlp.fc12.weight
+ | 0.000 | -0.085 | 0.067 | 0.010 | torch.Size([240]) || stage4.residual_group1.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.256 | 0.235 | 0.025 | torch.Size([120, 240]) || stage4.residual_group1.blocks.0.mlp.fc2.weight
+ | 0.009 | -0.123 | 0.254 | 0.058 | torch.Size([120]) || stage4.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.988 | 0.825 | 1.079 | 0.043 | torch.Size([120]) || stage4.residual_group1.blocks.1.norm1.weight
+ | -0.013 | -0.123 | 0.105 | 0.047 | torch.Size([120]) || stage4.residual_group1.blocks.1.norm1.bias
+ | -0.000 | -0.081 | 0.078 | 0.021 | torch.Size([675, 6]) || stage4.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.1.attn.position_bias
+ | 0.000 | -0.133 | 0.170 | 0.025 | torch.Size([360, 120]) || stage4.residual_group1.blocks.1.attn.qkv_self.weight
+ | -0.000 | -0.053 | 0.048 | 0.014 | torch.Size([360]) || stage4.residual_group1.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.177 | 0.174 | 0.031 | torch.Size([120, 240]) || stage4.residual_group1.blocks.1.attn.proj.weight
+ | 0.008 | -0.099 | 0.204 | 0.048 | torch.Size([120]) || stage4.residual_group1.blocks.1.attn.proj.bias
+ | 0.000 | -0.138 | 0.130 | 0.026 | torch.Size([360, 120]) || stage4.residual_group1.blocks.1.attn.qkv_mut.weight
+ | 0.000 | -0.061 | 0.059 | 0.010 | torch.Size([360]) || stage4.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.996 | 0.943 | 1.081 | 0.026 | torch.Size([120]) || stage4.residual_group1.blocks.1.norm2.weight
+ | 0.001 | -0.064 | 0.051 | 0.027 | torch.Size([120]) || stage4.residual_group1.blocks.1.norm2.bias
+ | -0.000 | -0.336 | 0.268 | 0.024 | torch.Size([240, 120]) || stage4.residual_group1.blocks.1.mlp.fc11.weight
+ | 0.000 | -0.029 | 0.028 | 0.006 | torch.Size([240]) || stage4.residual_group1.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.223 | 0.272 | 0.024 | torch.Size([240, 120]) || stage4.residual_group1.blocks.1.mlp.fc12.weight
+ | -0.001 | -0.084 | 0.037 | 0.009 | torch.Size([240]) || stage4.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.207 | 0.216 | 0.024 | torch.Size([120, 240]) || stage4.residual_group1.blocks.1.mlp.fc2.weight
+ | 0.007 | -0.140 | 0.216 | 0.058 | torch.Size([120]) || stage4.residual_group1.blocks.1.mlp.fc2.bias
+ | 0.994 | 0.855 | 1.108 | 0.038 | torch.Size([120]) || stage4.residual_group1.blocks.2.norm1.weight
+ | -0.019 | -0.115 | 0.091 | 0.028 | torch.Size([120]) || stage4.residual_group1.blocks.2.norm1.bias
+ | 0.000 | -0.063 | 0.076 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.2.attn.position_bias
+ | -0.000 | -0.190 | 0.179 | 0.027 | torch.Size([360, 120]) || stage4.residual_group1.blocks.2.attn.qkv_self.weight
+ | -0.001 | -0.043 | 0.039 | 0.011 | torch.Size([360]) || stage4.residual_group1.blocks.2.attn.qkv_self.bias
+ | 0.000 | -0.158 | 0.161 | 0.030 | torch.Size([120, 240]) || stage4.residual_group1.blocks.2.attn.proj.weight
+ | 0.008 | -0.118 | 0.164 | 0.050 | torch.Size([120]) || stage4.residual_group1.blocks.2.attn.proj.bias
+ | -0.000 | -0.213 | 0.211 | 0.029 | torch.Size([360, 120]) || stage4.residual_group1.blocks.2.attn.qkv_mut.weight
+ | -0.000 | -0.043 | 0.040 | 0.010 | torch.Size([360]) || stage4.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.993 | 0.903 | 1.099 | 0.028 | torch.Size([120]) || stage4.residual_group1.blocks.2.norm2.weight
+ | 0.003 | -0.097 | 0.106 | 0.044 | torch.Size([120]) || stage4.residual_group1.blocks.2.norm2.bias
+ | 0.000 | -0.186 | 0.177 | 0.024 | torch.Size([240, 120]) || stage4.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.000 | -0.068 | 0.045 | 0.010 | torch.Size([240]) || stage4.residual_group1.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.307 | 0.185 | 0.024 | torch.Size([240, 120]) || stage4.residual_group1.blocks.2.mlp.fc12.weight
+ | -0.000 | -0.081 | 0.061 | 0.010 | torch.Size([240]) || stage4.residual_group1.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.195 | 0.216 | 0.024 | torch.Size([120, 240]) || stage4.residual_group1.blocks.2.mlp.fc2.weight
+ | 0.008 | -0.115 | 0.161 | 0.050 | torch.Size([120]) || stage4.residual_group1.blocks.2.mlp.fc2.bias
+ | 0.997 | 0.893 | 1.071 | 0.032 | torch.Size([120]) || stage4.residual_group1.blocks.3.norm1.weight
+ | -0.019 | -0.083 | 0.047 | 0.024 | torch.Size([120]) || stage4.residual_group1.blocks.3.norm1.bias
+ | 0.001 | -0.076 | 0.073 | 0.021 | torch.Size([675, 6]) || stage4.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.3.attn.position_bias
+ | 0.000 | -0.275 | 0.259 | 0.029 | torch.Size([360, 120]) || stage4.residual_group1.blocks.3.attn.qkv_self.weight
+ | -0.001 | -0.071 | 0.066 | 0.017 | torch.Size([360]) || stage4.residual_group1.blocks.3.attn.qkv_self.bias
+ | -0.000 | -0.166 | 0.157 | 0.028 | torch.Size([120, 240]) || stage4.residual_group1.blocks.3.attn.proj.weight
+ | 0.008 | -0.105 | 0.149 | 0.043 | torch.Size([120]) || stage4.residual_group1.blocks.3.attn.proj.bias
+ | 0.000 | -0.184 | 0.197 | 0.028 | torch.Size([360, 120]) || stage4.residual_group1.blocks.3.attn.qkv_mut.weight
+ | 0.001 | -0.042 | 0.050 | 0.008 | torch.Size([360]) || stage4.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 1.001 | 0.971 | 1.136 | 0.022 | torch.Size([120]) || stage4.residual_group1.blocks.3.norm2.weight
+ | -0.002 | -0.054 | 0.050 | 0.023 | torch.Size([120]) || stage4.residual_group1.blocks.3.norm2.bias
+ | 0.000 | -0.329 | 0.210 | 0.023 | torch.Size([240, 120]) || stage4.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.000 | -0.078 | 0.029 | 0.009 | torch.Size([240]) || stage4.residual_group1.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.234 | 0.241 | 0.023 | torch.Size([240, 120]) || stage4.residual_group1.blocks.3.mlp.fc12.weight
+ | 0.000 | -0.031 | 0.024 | 0.006 | torch.Size([240]) || stage4.residual_group1.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.169 | 0.164 | 0.023 | torch.Size([120, 240]) || stage4.residual_group1.blocks.3.mlp.fc2.weight
+ | 0.007 | -0.085 | 0.114 | 0.043 | torch.Size([120]) || stage4.residual_group1.blocks.3.mlp.fc2.bias
+ | 1.003 | 0.901 | 1.099 | 0.044 | torch.Size([120]) || stage4.residual_group1.blocks.4.norm1.weight
+ | -0.034 | -0.095 | 0.039 | 0.030 | torch.Size([120]) || stage4.residual_group1.blocks.4.norm1.bias
+ | 0.000 | -0.071 | 0.090 | 0.020 | torch.Size([675, 6]) || stage4.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.4.attn.position_bias
+ | -0.000 | -0.238 | 0.268 | 0.034 | torch.Size([360, 120]) || stage4.residual_group1.blocks.4.attn.qkv_self.weight
+ | -0.002 | -0.199 | 0.144 | 0.030 | torch.Size([360]) || stage4.residual_group1.blocks.4.attn.qkv_self.bias
+ | -0.000 | -0.167 | 0.218 | 0.029 | torch.Size([120, 240]) || stage4.residual_group1.blocks.4.attn.proj.weight
+ | 0.008 | -0.089 | 0.140 | 0.039 | torch.Size([120]) || stage4.residual_group1.blocks.4.attn.proj.bias
+ | 0.000 | -0.267 | 0.253 | 0.031 | torch.Size([360, 120]) || stage4.residual_group1.blocks.4.attn.qkv_mut.weight
+ | 0.001 | -0.067 | 0.069 | 0.009 | torch.Size([360]) || stage4.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 1.004 | 0.953 | 1.056 | 0.014 | torch.Size([120]) || stage4.residual_group1.blocks.4.norm2.weight
+ | -0.001 | -0.056 | 0.077 | 0.021 | torch.Size([120]) || stage4.residual_group1.blocks.4.norm2.bias
+ | -0.000 | -0.170 | 0.184 | 0.023 | torch.Size([240, 120]) || stage4.residual_group1.blocks.4.mlp.fc11.weight
+ | 0.001 | -0.037 | 0.027 | 0.007 | torch.Size([240]) || stage4.residual_group1.blocks.4.mlp.fc11.bias
+ | 0.000 | -0.149 | 0.202 | 0.023 | torch.Size([240, 120]) || stage4.residual_group1.blocks.4.mlp.fc12.weight
+ | 0.000 | -0.059 | 0.095 | 0.010 | torch.Size([240]) || stage4.residual_group1.blocks.4.mlp.fc12.bias
+ | -0.000 | -0.145 | 0.181 | 0.023 | torch.Size([120, 240]) || stage4.residual_group1.blocks.4.mlp.fc2.weight
+ | 0.006 | -0.086 | 0.117 | 0.036 | torch.Size([120]) || stage4.residual_group1.blocks.4.mlp.fc2.bias
+ | 0.996 | 0.859 | 1.077 | 0.047 | torch.Size([120]) || stage4.residual_group1.blocks.5.norm1.weight
+ | -0.058 | -0.153 | 0.009 | 0.038 | torch.Size([120]) || stage4.residual_group1.blocks.5.norm1.bias
+ | 0.000 | -0.087 | 0.083 | 0.021 | torch.Size([675, 6]) || stage4.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage4.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage4.residual_group1.blocks.5.attn.position_bias
+ | -0.000 | -0.249 | 0.266 | 0.033 | torch.Size([360, 120]) || stage4.residual_group1.blocks.5.attn.qkv_self.weight
+ | -0.001 | -0.199 | 0.168 | 0.031 | torch.Size([360]) || stage4.residual_group1.blocks.5.attn.qkv_self.bias
+ | 0.000 | -0.156 | 0.142 | 0.027 | torch.Size([120, 240]) || stage4.residual_group1.blocks.5.attn.proj.weight
+ | 0.004 | -0.102 | 0.145 | 0.045 | torch.Size([120]) || stage4.residual_group1.blocks.5.attn.proj.bias
+ | 0.000 | -0.299 | 0.376 | 0.033 | torch.Size([360, 120]) || stage4.residual_group1.blocks.5.attn.qkv_mut.weight
+ | 0.000 | -0.034 | 0.066 | 0.007 | torch.Size([360]) || stage4.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.992 | 0.924 | 1.097 | 0.025 | torch.Size([120]) || stage4.residual_group1.blocks.5.norm2.weight
+ | -0.002 | -0.089 | 0.074 | 0.038 | torch.Size([120]) || stage4.residual_group1.blocks.5.norm2.bias
+ | -0.000 | -0.192 | 0.208 | 0.023 | torch.Size([240, 120]) || stage4.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.002 | -0.064 | 0.021 | 0.009 | torch.Size([240]) || stage4.residual_group1.blocks.5.mlp.fc11.bias
+ | -0.000 | -0.240 | 0.191 | 0.023 | torch.Size([240, 120]) || stage4.residual_group1.blocks.5.mlp.fc12.weight
+ | 0.000 | -0.040 | 0.044 | 0.008 | torch.Size([240]) || stage4.residual_group1.blocks.5.mlp.fc12.bias
+ | -0.000 | -0.141 | 0.155 | 0.022 | torch.Size([120, 240]) || stage4.residual_group1.blocks.5.mlp.fc2.weight
+ | 0.005 | -0.107 | 0.103 | 0.045 | torch.Size([120]) || stage4.residual_group1.blocks.5.mlp.fc2.bias
+ | 0.001 | -0.286 | 0.303 | 0.059 | torch.Size([120, 120]) || stage4.linear1.weight
+ | -0.012 | -0.311 | 0.190 | 0.090 | torch.Size([120]) || stage4.linear1.bias
+ | 1.009 | 0.926 | 1.101 | 0.028 | torch.Size([120]) || stage4.residual_group2.blocks.0.norm1.weight
+ | -0.001 | -0.036 | 0.048 | 0.015 | torch.Size([120]) || stage4.residual_group2.blocks.0.norm1.bias
+ | 0.000 | -0.071 | 0.076 | 0.020 | torch.Size([3375, 6]) || stage4.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage4.residual_group2.blocks.0.attn.relative_position_index
+ | -0.000 | -0.135 | 0.141 | 0.023 | torch.Size([360, 120]) || stage4.residual_group2.blocks.0.attn.qkv_self.weight
+ | 0.001 | -0.023 | 0.021 | 0.007 | torch.Size([360]) || stage4.residual_group2.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.115 | 0.121 | 0.025 | torch.Size([120, 120]) || stage4.residual_group2.blocks.0.attn.proj.weight
+ | -0.007 | -0.200 | 0.098 | 0.043 | torch.Size([120]) || stage4.residual_group2.blocks.0.attn.proj.bias
+ | 1.002 | 0.999 | 1.016 | 0.002 | torch.Size([120]) || stage4.residual_group2.blocks.0.norm2.weight
+ | 0.000 | -0.003 | 0.004 | 0.001 | torch.Size([120]) || stage4.residual_group2.blocks.0.norm2.bias
+ | 0.000 | -0.082 | 0.094 | 0.020 | torch.Size([240, 120]) || stage4.residual_group2.blocks.0.mlp.fc11.weight
+ | 0.000 | -0.005 | 0.017 | 0.002 | torch.Size([240]) || stage4.residual_group2.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.088 | 0.079 | 0.020 | torch.Size([240, 120]) || stage4.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.000 | -0.010 | 0.008 | 0.002 | torch.Size([240]) || stage4.residual_group2.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.090 | 0.105 | 0.020 | torch.Size([120, 240]) || stage4.residual_group2.blocks.0.mlp.fc2.weight
+ | -0.006 | -0.181 | 0.096 | 0.041 | torch.Size([120]) || stage4.residual_group2.blocks.0.mlp.fc2.bias
+ | 1.006 | 0.923 | 1.098 | 0.025 | torch.Size([120]) || stage4.residual_group2.blocks.1.norm1.weight
+ | -0.001 | -0.045 | 0.053 | 0.019 | torch.Size([120]) || stage4.residual_group2.blocks.1.norm1.bias
+ | -0.000 | -0.083 | 0.085 | 0.020 | torch.Size([3375, 6]) || stage4.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage4.residual_group2.blocks.1.attn.relative_position_index
+ | -0.000 | -0.132 | 0.133 | 0.023 | torch.Size([360, 120]) || stage4.residual_group2.blocks.1.attn.qkv_self.weight
+ | -0.000 | -0.030 | 0.035 | 0.009 | torch.Size([360]) || stage4.residual_group2.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.129 | 0.094 | 0.024 | torch.Size([120, 120]) || stage4.residual_group2.blocks.1.attn.proj.weight
+ | -0.008 | -0.218 | 0.116 | 0.048 | torch.Size([120]) || stage4.residual_group2.blocks.1.attn.proj.bias
+ | 1.003 | 0.999 | 1.024 | 0.003 | torch.Size([120]) || stage4.residual_group2.blocks.1.norm2.weight
+ | -0.000 | -0.004 | 0.005 | 0.002 | torch.Size([120]) || stage4.residual_group2.blocks.1.norm2.bias
+ | -0.000 | -0.126 | 0.080 | 0.021 | torch.Size([240, 120]) || stage4.residual_group2.blocks.1.mlp.fc11.weight
+ | 0.001 | -0.006 | 0.016 | 0.003 | torch.Size([240]) || stage4.residual_group2.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.092 | 0.076 | 0.020 | torch.Size([240, 120]) || stage4.residual_group2.blocks.1.mlp.fc12.weight
+ | 0.000 | -0.015 | 0.013 | 0.003 | torch.Size([240]) || stage4.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.091 | 0.115 | 0.020 | torch.Size([120, 240]) || stage4.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.006 | -0.196 | 0.090 | 0.041 | torch.Size([120]) || stage4.residual_group2.blocks.1.mlp.fc2.bias
+ | 0.001 | -0.291 | 0.416 | 0.059 | torch.Size([120, 120]) || stage4.linear2.weight
+ | -0.009 | -0.269 | 0.198 | 0.094 | torch.Size([120]) || stage4.linear2.bias
+ | 0.000 | -0.053 | 0.057 | 0.019 | torch.Size([120, 120, 3, 3]) || stage4.pa_deform.weight
+ | -0.001 | -0.021 | 0.021 | 0.009 | torch.Size([120]) || stage4.pa_deform.bias
+ | -0.000 | -0.017 | 0.017 | 0.010 | torch.Size([120, 364, 3, 3]) || stage4.pa_deform.conv_offset.0.weight
+ | -0.000 | -0.015 | 0.015 | 0.009 | torch.Size([120]) || stage4.pa_deform.conv_offset.0.bias
+ | -0.000 | -0.039 | 0.041 | 0.018 | torch.Size([120, 120, 3, 3]) || stage4.pa_deform.conv_offset.2.weight
+ | 0.000 | -0.030 | 0.029 | 0.018 | torch.Size([120]) || stage4.pa_deform.conv_offset.2.bias
+ | -0.000 | -0.045 | 0.041 | 0.018 | torch.Size([120, 120, 3, 3]) || stage4.pa_deform.conv_offset.4.weight
+ | -0.002 | -0.031 | 0.030 | 0.016 | torch.Size([120]) || stage4.pa_deform.conv_offset.4.bias
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432, 120, 3, 3]) || stage4.pa_deform.conv_offset.6.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432]) || stage4.pa_deform.conv_offset.6.bias
+ | -0.000 | -0.356 | 0.435 | 0.035 | torch.Size([360, 360]) || stage4.pa_fuse.fc11.weight
+ | 0.003 | -0.080 | 0.304 | 0.033 | torch.Size([360]) || stage4.pa_fuse.fc11.bias
+ | 0.000 | -0.361 | 0.436 | 0.035 | torch.Size([360, 360]) || stage4.pa_fuse.fc12.weight
+ | -0.001 | -0.166 | 0.299 | 0.032 | torch.Size([360]) || stage4.pa_fuse.fc12.bias
+ | -0.000 | -0.748 | 0.752 | 0.056 | torch.Size([120, 360]) || stage4.pa_fuse.fc2.weight
+ | -0.000 | -0.262 | 0.270 | 0.086 | torch.Size([120]) || stage4.pa_fuse.fc2.bias
+ | 0.980 | 0.710 | 1.274 | 0.146 | torch.Size([30]) || stage5.reshape.1.weight
+ | -0.002 | -0.062 | 0.057 | 0.036 | torch.Size([30]) || stage5.reshape.1.bias
+ | 0.001 | -0.530 | 0.432 | 0.092 | torch.Size([120, 30]) || stage5.reshape.2.weight
+ | 0.021 | -0.305 | 0.337 | 0.080 | torch.Size([120]) || stage5.reshape.2.bias
+ | 0.994 | 0.934 | 1.012 | 0.016 | torch.Size([120]) || stage5.residual_group1.blocks.0.norm1.weight
+ | -0.014 | -0.040 | 0.038 | 0.014 | torch.Size([120]) || stage5.residual_group1.blocks.0.norm1.bias
+ | 0.000 | -0.082 | 0.072 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.0.attn.position_bias
+ | -0.000 | -0.078 | 0.101 | 0.021 | torch.Size([360, 120]) || stage5.residual_group1.blocks.0.attn.qkv_self.weight
+ | -0.000 | -0.022 | 0.023 | 0.005 | torch.Size([360]) || stage5.residual_group1.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.198 | 0.237 | 0.022 | torch.Size([120, 240]) || stage5.residual_group1.blocks.0.attn.proj.weight
+ | -0.003 | -0.067 | 0.082 | 0.027 | torch.Size([120]) || stage5.residual_group1.blocks.0.attn.proj.bias
+ | 0.000 | -0.103 | 0.092 | 0.021 | torch.Size([360, 120]) || stage5.residual_group1.blocks.0.attn.qkv_mut.weight
+ | -0.000 | -0.007 | 0.006 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.991 | 0.929 | 1.004 | 0.011 | torch.Size([120]) || stage5.residual_group1.blocks.0.norm2.weight
+ | 0.001 | -0.009 | 0.014 | 0.004 | torch.Size([120]) || stage5.residual_group1.blocks.0.norm2.bias
+ | -0.000 | -0.112 | 0.093 | 0.021 | torch.Size([240, 120]) || stage5.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.001 | -0.033 | 0.027 | 0.008 | torch.Size([240]) || stage5.residual_group1.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.098 | 0.085 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.0.mlp.fc12.weight
+ | -0.000 | -0.033 | 0.026 | 0.009 | torch.Size([240]) || stage5.residual_group1.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.163 | 0.140 | 0.021 | torch.Size([120, 240]) || stage5.residual_group1.blocks.0.mlp.fc2.weight
+ | 0.003 | -0.060 | 0.110 | 0.032 | torch.Size([120]) || stage5.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.992 | 0.872 | 1.010 | 0.018 | torch.Size([120]) || stage5.residual_group1.blocks.1.norm1.weight
+ | -0.015 | -0.039 | 0.031 | 0.010 | torch.Size([120]) || stage5.residual_group1.blocks.1.norm1.bias
+ | -0.000 | -0.078 | 0.078 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.1.attn.position_bias
+ | 0.000 | -0.088 | 0.099 | 0.021 | torch.Size([360, 120]) || stage5.residual_group1.blocks.1.attn.qkv_self.weight
+ | 0.000 | -0.030 | 0.030 | 0.006 | torch.Size([360]) || stage5.residual_group1.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.151 | 0.185 | 0.022 | torch.Size([120, 240]) || stage5.residual_group1.blocks.1.attn.proj.weight
+ | -0.005 | -0.073 | 0.061 | 0.024 | torch.Size([120]) || stage5.residual_group1.blocks.1.attn.proj.bias
+ | 0.000 | -0.093 | 0.089 | 0.021 | torch.Size([360, 120]) || stage5.residual_group1.blocks.1.attn.qkv_mut.weight
+ | 0.000 | -0.009 | 0.007 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.997 | 0.923 | 1.003 | 0.008 | torch.Size([120]) || stage5.residual_group1.blocks.1.norm2.weight
+ | 0.000 | -0.008 | 0.009 | 0.004 | torch.Size([120]) || stage5.residual_group1.blocks.1.norm2.bias
+ | -0.000 | -0.082 | 0.092 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.000 | -0.023 | 0.021 | 0.007 | torch.Size([240]) || stage5.residual_group1.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.082 | 0.078 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.1.mlp.fc12.weight
+ | -0.001 | -0.028 | 0.025 | 0.008 | torch.Size([240]) || stage5.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.097 | 0.090 | 0.020 | torch.Size([120, 240]) || stage5.residual_group1.blocks.1.mlp.fc2.weight
+ | 0.000 | -0.062 | 0.102 | 0.028 | torch.Size([120]) || stage5.residual_group1.blocks.1.mlp.fc2.bias
+ | 0.994 | 0.845 | 1.015 | 0.018 | torch.Size([120]) || stage5.residual_group1.blocks.2.norm1.weight
+ | -0.018 | -0.045 | 0.016 | 0.008 | torch.Size([120]) || stage5.residual_group1.blocks.2.norm1.bias
+ | 0.000 | -0.065 | 0.068 | 0.020 | torch.Size([675, 6]) || stage5.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.2.attn.position_bias
+ | -0.000 | -0.088 | 0.113 | 0.021 | torch.Size([360, 120]) || stage5.residual_group1.blocks.2.attn.qkv_self.weight
+ | 0.000 | -0.022 | 0.020 | 0.005 | torch.Size([360]) || stage5.residual_group1.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.124 | 0.124 | 0.021 | torch.Size([120, 240]) || stage5.residual_group1.blocks.2.attn.proj.weight
+ | -0.001 | -0.061 | 0.049 | 0.020 | torch.Size([120]) || stage5.residual_group1.blocks.2.attn.proj.bias
+ | -0.000 | -0.088 | 0.087 | 0.021 | torch.Size([360, 120]) || stage5.residual_group1.blocks.2.attn.qkv_mut.weight
+ | -0.000 | -0.008 | 0.005 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.993 | 0.847 | 1.012 | 0.016 | torch.Size([120]) || stage5.residual_group1.blocks.2.norm2.weight
+ | 0.000 | -0.014 | 0.015 | 0.007 | torch.Size([120]) || stage5.residual_group1.blocks.2.norm2.bias
+ | 0.000 | -0.096 | 0.096 | 0.021 | torch.Size([240, 120]) || stage5.residual_group1.blocks.2.mlp.fc11.weight
+ | 0.001 | -0.038 | 0.027 | 0.009 | torch.Size([240]) || stage5.residual_group1.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.090 | 0.095 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.2.mlp.fc12.weight
+ | 0.000 | -0.045 | 0.039 | 0.011 | torch.Size([240]) || stage5.residual_group1.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.153 | 0.130 | 0.021 | torch.Size([120, 240]) || stage5.residual_group1.blocks.2.mlp.fc2.weight
+ | -0.006 | -0.097 | 0.083 | 0.028 | torch.Size([120]) || stage5.residual_group1.blocks.2.mlp.fc2.bias
+ | 0.984 | 0.798 | 1.006 | 0.023 | torch.Size([120]) || stage5.residual_group1.blocks.3.norm1.weight
+ | -0.018 | -0.042 | 0.003 | 0.010 | torch.Size([120]) || stage5.residual_group1.blocks.3.norm1.bias
+ | 0.000 | -0.074 | 0.214 | 0.021 | torch.Size([675, 6]) || stage5.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.3.attn.position_bias
+ | 0.000 | -0.133 | 0.132 | 0.022 | torch.Size([360, 120]) || stage5.residual_group1.blocks.3.attn.qkv_self.weight
+ | -0.000 | -0.035 | 0.037 | 0.008 | torch.Size([360]) || stage5.residual_group1.blocks.3.attn.qkv_self.bias
+ | -0.000 | -0.121 | 0.123 | 0.020 | torch.Size([120, 240]) || stage5.residual_group1.blocks.3.attn.proj.weight
+ | -0.002 | -0.043 | 0.049 | 0.016 | torch.Size([120]) || stage5.residual_group1.blocks.3.attn.proj.bias
+ | 0.000 | -0.082 | 0.093 | 0.021 | torch.Size([360, 120]) || stage5.residual_group1.blocks.3.attn.qkv_mut.weight
+ | -0.000 | -0.007 | 0.007 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.993 | 0.809 | 1.008 | 0.018 | torch.Size([120]) || stage5.residual_group1.blocks.3.norm2.weight
+ | 0.001 | -0.018 | 0.013 | 0.006 | torch.Size([120]) || stage5.residual_group1.blocks.3.norm2.bias
+ | -0.000 | -0.100 | 0.097 | 0.021 | torch.Size([240, 120]) || stage5.residual_group1.blocks.3.mlp.fc11.weight
+ | 0.001 | -0.038 | 0.045 | 0.009 | torch.Size([240]) || stage5.residual_group1.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.104 | 0.095 | 0.020 | torch.Size([240, 120]) || stage5.residual_group1.blocks.3.mlp.fc12.weight
+ | -0.000 | -0.043 | 0.040 | 0.011 | torch.Size([240]) || stage5.residual_group1.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.108 | 0.121 | 0.021 | torch.Size([120, 240]) || stage5.residual_group1.blocks.3.mlp.fc2.weight
+ | 0.002 | -0.066 | 0.048 | 0.023 | torch.Size([120]) || stage5.residual_group1.blocks.3.mlp.fc2.bias
+ | 0.988 | 0.835 | 1.035 | 0.019 | torch.Size([120]) || stage5.residual_group1.blocks.4.norm1.weight
+ | -0.022 | -0.052 | 0.003 | 0.013 | torch.Size([120]) || stage5.residual_group1.blocks.4.norm1.bias
+ | -0.000 | -0.086 | 0.118 | 0.021 | torch.Size([675, 6]) || stage5.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.4.attn.position_bias
+ | 0.000 | -0.199 | 0.223 | 0.023 | torch.Size([360, 120]) || stage5.residual_group1.blocks.4.attn.qkv_self.weight
+ | -0.000 | -0.045 | 0.028 | 0.009 | torch.Size([360]) || stage5.residual_group1.blocks.4.attn.qkv_self.bias
+ | 0.000 | -0.114 | 0.143 | 0.021 | torch.Size([120, 240]) || stage5.residual_group1.blocks.4.attn.proj.weight
+ | -0.003 | -0.060 | 0.047 | 0.021 | torch.Size([120]) || stage5.residual_group1.blocks.4.attn.proj.bias
+ | -0.000 | -0.117 | 0.102 | 0.021 | torch.Size([360, 120]) || stage5.residual_group1.blocks.4.attn.qkv_mut.weight
+ | 0.000 | -0.008 | 0.010 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.994 | 0.774 | 1.007 | 0.021 | torch.Size([120]) || stage5.residual_group1.blocks.4.norm2.weight
+ | 0.001 | -0.023 | 0.027 | 0.010 | torch.Size([120]) || stage5.residual_group1.blocks.4.norm2.bias
+ | -0.000 | -0.085 | 0.107 | 0.021 | torch.Size([240, 120]) || stage5.residual_group1.blocks.4.mlp.fc11.weight
+ | 0.003 | -0.044 | 0.042 | 0.013 | torch.Size([240]) || stage5.residual_group1.blocks.4.mlp.fc11.bias
+ | -0.000 | -0.103 | 0.080 | 0.021 | torch.Size([240, 120]) || stage5.residual_group1.blocks.4.mlp.fc12.weight
+ | 0.000 | -0.067 | 0.058 | 0.015 | torch.Size([240]) || stage5.residual_group1.blocks.4.mlp.fc12.bias
+ | 0.000 | -0.096 | 0.103 | 0.021 | torch.Size([120, 240]) || stage5.residual_group1.blocks.4.mlp.fc2.weight
+ | -0.000 | -0.045 | 0.054 | 0.023 | torch.Size([120]) || stage5.residual_group1.blocks.4.mlp.fc2.bias
+ | 0.985 | 0.552 | 1.092 | 0.044 | torch.Size([120]) || stage5.residual_group1.blocks.5.norm1.weight
+ | -0.023 | -0.073 | 0.024 | 0.019 | torch.Size([120]) || stage5.residual_group1.blocks.5.norm1.bias
+ | -0.000 | -0.080 | 0.121 | 0.021 | torch.Size([675, 6]) || stage5.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage5.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage5.residual_group1.blocks.5.attn.position_bias
+ | -0.000 | -1.776 | 0.186 | 0.026 | torch.Size([360, 120]) || stage5.residual_group1.blocks.5.attn.qkv_self.weight
+ | -0.000 | -0.070 | 0.065 | 0.015 | torch.Size([360]) || stage5.residual_group1.blocks.5.attn.qkv_self.bias
+ | 0.000 | -0.230 | 0.359 | 0.022 | torch.Size([120, 240]) || stage5.residual_group1.blocks.5.attn.proj.weight
+ | -0.001 | -0.062 | 0.079 | 0.028 | torch.Size([120]) || stage5.residual_group1.blocks.5.attn.proj.bias
+ | -0.000 | -0.086 | 0.104 | 0.021 | torch.Size([360, 120]) || stage5.residual_group1.blocks.5.attn.qkv_mut.weight
+ | -0.000 | -0.007 | 0.008 | 0.002 | torch.Size([360]) || stage5.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.976 | 0.863 | 0.995 | 0.015 | torch.Size([120]) || stage5.residual_group1.blocks.5.norm2.weight
+ | -0.001 | -0.037 | 0.053 | 0.018 | torch.Size([120]) || stage5.residual_group1.blocks.5.norm2.bias
+ | -0.000 | -0.121 | 0.100 | 0.021 | torch.Size([240, 120]) || stage5.residual_group1.blocks.5.mlp.fc11.weight
+ | 0.009 | -0.074 | 0.101 | 0.021 | torch.Size([240]) || stage5.residual_group1.blocks.5.mlp.fc11.bias
+ | 0.000 | -0.102 | 0.101 | 0.021 | torch.Size([240, 120]) || stage5.residual_group1.blocks.5.mlp.fc12.weight
+ | 0.001 | -0.092 | 0.082 | 0.028 | torch.Size([240]) || stage5.residual_group1.blocks.5.mlp.fc12.bias
+ | -0.000 | -0.148 | 0.202 | 0.022 | torch.Size([120, 240]) || stage5.residual_group1.blocks.5.mlp.fc2.weight
+ | 0.001 | -0.056 | 0.054 | 0.025 | torch.Size([120]) || stage5.residual_group1.blocks.5.mlp.fc2.bias
+ | -0.000 | -0.139 | 0.123 | 0.024 | torch.Size([120, 120]) || stage5.linear1.weight
+ | 0.022 | -0.317 | 0.336 | 0.081 | torch.Size([120]) || stage5.linear1.bias
+ | 0.963 | 0.765 | 1.026 | 0.058 | torch.Size([120]) || stage5.residual_group2.blocks.0.norm1.weight
+ | -0.001 | -0.315 | 0.286 | 0.078 | torch.Size([120]) || stage5.residual_group2.blocks.0.norm1.bias
+ | 0.000 | -0.077 | 0.080 | 0.020 | torch.Size([3375, 6]) || stage5.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage5.residual_group2.blocks.0.attn.relative_position_index
+ | -0.000 | -0.159 | 0.119 | 0.022 | torch.Size([360, 120]) || stage5.residual_group2.blocks.0.attn.qkv_self.weight
+ | 0.000 | -0.038 | 0.044 | 0.013 | torch.Size([360]) || stage5.residual_group2.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.134 | 0.126 | 0.024 | torch.Size([120, 120]) || stage5.residual_group2.blocks.0.attn.proj.weight
+ | -0.005 | -0.263 | 0.230 | 0.060 | torch.Size([120]) || stage5.residual_group2.blocks.0.attn.proj.bias
+ | 0.990 | 0.913 | 1.001 | 0.017 | torch.Size([120]) || stage5.residual_group2.blocks.0.norm2.weight
+ | 0.000 | -0.009 | 0.010 | 0.004 | torch.Size([120]) || stage5.residual_group2.blocks.0.norm2.bias
+ | -0.000 | -0.077 | 0.089 | 0.020 | torch.Size([240, 120]) || stage5.residual_group2.blocks.0.mlp.fc11.weight
+ | -0.004 | -0.025 | 0.016 | 0.007 | torch.Size([240]) || stage5.residual_group2.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.073 | 0.090 | 0.020 | torch.Size([240, 120]) || stage5.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.000 | -0.018 | 0.018 | 0.007 | torch.Size([240]) || stage5.residual_group2.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.084 | 0.083 | 0.020 | torch.Size([120, 240]) || stage5.residual_group2.blocks.0.mlp.fc2.weight
+ | -0.006 | -0.264 | 0.273 | 0.056 | torch.Size([120]) || stage5.residual_group2.blocks.0.mlp.fc2.bias
+ | 0.976 | 0.733 | 1.048 | 0.053 | torch.Size([120]) || stage5.residual_group2.blocks.1.norm1.weight
+ | -0.001 | -0.265 | 0.241 | 0.061 | torch.Size([120]) || stage5.residual_group2.blocks.1.norm1.bias
+ | -0.000 | -0.079 | 0.081 | 0.020 | torch.Size([3375, 6]) || stage5.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage5.residual_group2.blocks.1.attn.relative_position_index
+ | -0.000 | -0.145 | 0.145 | 0.023 | torch.Size([360, 120]) || stage5.residual_group2.blocks.1.attn.qkv_self.weight
+ | -0.000 | -0.031 | 0.051 | 0.009 | torch.Size([360]) || stage5.residual_group2.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.114 | 0.103 | 0.025 | torch.Size([120, 120]) || stage5.residual_group2.blocks.1.attn.proj.weight
+ | -0.011 | -0.166 | 0.119 | 0.032 | torch.Size([120]) || stage5.residual_group2.blocks.1.attn.proj.bias
+ | 0.993 | 0.939 | 1.001 | 0.012 | torch.Size([120]) || stage5.residual_group2.blocks.1.norm2.weight
+ | 0.000 | -0.011 | 0.008 | 0.004 | torch.Size([120]) || stage5.residual_group2.blocks.1.norm2.bias
+ | -0.000 | -0.090 | 0.081 | 0.020 | torch.Size([240, 120]) || stage5.residual_group2.blocks.1.mlp.fc11.weight
+ | -0.002 | -0.026 | 0.020 | 0.007 | torch.Size([240]) || stage5.residual_group2.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.092 | 0.078 | 0.020 | torch.Size([240, 120]) || stage5.residual_group2.blocks.1.mlp.fc12.weight
+ | 0.000 | -0.020 | 0.021 | 0.007 | torch.Size([240]) || stage5.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.097 | 0.093 | 0.020 | torch.Size([120, 240]) || stage5.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.016 | -0.224 | 0.158 | 0.041 | torch.Size([120]) || stage5.residual_group2.blocks.1.mlp.fc2.bias
+ | -0.000 | -0.244 | 0.248 | 0.044 | torch.Size([120, 120]) || stage5.linear2.weight
+ | 0.022 | -0.367 | 0.377 | 0.103 | torch.Size([120]) || stage5.linear2.bias
+ | -0.000 | -0.153 | 0.112 | 0.022 | torch.Size([120, 120, 3, 3]) || stage5.pa_deform.weight
+ | -0.004 | -0.061 | 0.053 | 0.023 | torch.Size([120]) || stage5.pa_deform.bias
+ | 0.000 | -0.017 | 0.017 | 0.010 | torch.Size([120, 364, 3, 3]) || stage5.pa_deform.conv_offset.0.weight
+ | -0.010 | -0.038 | 0.022 | 0.013 | torch.Size([120]) || stage5.pa_deform.conv_offset.0.bias
+ | -0.001 | -0.081 | 0.076 | 0.020 | torch.Size([120, 120, 3, 3]) || stage5.pa_deform.conv_offset.2.weight
+ | -0.008 | -0.062 | 0.031 | 0.021 | torch.Size([120]) || stage5.pa_deform.conv_offset.2.bias
+ | -0.000 | -0.080 | 0.079 | 0.019 | torch.Size([120, 120, 3, 3]) || stage5.pa_deform.conv_offset.4.weight
+ | -0.005 | -0.057 | 0.035 | 0.020 | torch.Size([120]) || stage5.pa_deform.conv_offset.4.bias
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432, 120, 3, 3]) || stage5.pa_deform.conv_offset.6.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432]) || stage5.pa_deform.conv_offset.6.bias
+ | 0.000 | -0.590 | 0.536 | 0.063 | torch.Size([360, 360]) || stage5.pa_fuse.fc11.weight
+ | 0.075 | -0.075 | 0.431 | 0.094 | torch.Size([360]) || stage5.pa_fuse.fc11.bias
+ | 0.000 | -0.704 | 0.718 | 0.064 | torch.Size([360, 360]) || stage5.pa_fuse.fc12.weight
+ | 0.005 | -0.308 | 0.337 | 0.073 | torch.Size([360]) || stage5.pa_fuse.fc12.bias
+ | 0.000 | -0.702 | 0.735 | 0.101 | torch.Size([120, 360]) || stage5.pa_fuse.fc2.weight
+ | -0.005 | -0.422 | 0.451 | 0.157 | torch.Size([120]) || stage5.pa_fuse.fc2.bias
+ | 1.444 | 1.141 | 1.615 | 0.121 | torch.Size([30]) || stage6.reshape.1.weight
+ | -0.003 | -0.150 | 0.115 | 0.074 | torch.Size([30]) || stage6.reshape.1.bias
+ | 0.001 | -0.848 | 0.822 | 0.232 | torch.Size([120, 30]) || stage6.reshape.2.weight
+ | 0.004 | -0.514 | 0.640 | 0.181 | torch.Size([120]) || stage6.reshape.2.bias
+ | 0.557 | 0.119 | 0.895 | 0.153 | torch.Size([120]) || stage6.residual_group1.blocks.0.norm1.weight
+ | -0.070 | -0.374 | 0.181 | 0.100 | torch.Size([120]) || stage6.residual_group1.blocks.0.norm1.bias
+ | 0.001 | -0.438 | 0.141 | 0.054 | torch.Size([675, 6]) || stage6.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.0.attn.position_bias
+ | 0.000 | -0.339 | 0.306 | 0.051 | torch.Size([360, 120]) || stage6.residual_group1.blocks.0.attn.qkv_self.weight
+ | -0.005 | -0.318 | 0.257 | 0.059 | torch.Size([360]) || stage6.residual_group1.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.473 | 0.491 | 0.061 | torch.Size([120, 240]) || stage6.residual_group1.blocks.0.attn.proj.weight
+ | -0.001 | -0.330 | 0.253 | 0.125 | torch.Size([120]) || stage6.residual_group1.blocks.0.attn.proj.bias
+ | 0.000 | -0.361 | 0.307 | 0.045 | torch.Size([360, 120]) || stage6.residual_group1.blocks.0.attn.qkv_mut.weight
+ | -0.000 | -0.044 | 0.053 | 0.010 | torch.Size([360]) || stage6.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.521 | 0.121 | 0.882 | 0.143 | torch.Size([120]) || stage6.residual_group1.blocks.0.norm2.weight
+ | 0.003 | -0.212 | 0.271 | 0.104 | torch.Size([120]) || stage6.residual_group1.blocks.0.norm2.bias
+ | -0.000 | -0.360 | 0.360 | 0.075 | torch.Size([240, 120]) || stage6.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.095 | -0.280 | 0.021 | 0.059 | torch.Size([240]) || stage6.residual_group1.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.354 | 0.331 | 0.069 | torch.Size([240, 120]) || stage6.residual_group1.blocks.0.mlp.fc12.weight
+ | -0.005 | -0.196 | 0.129 | 0.048 | torch.Size([240]) || stage6.residual_group1.blocks.0.mlp.fc12.bias
+ | 0.001 | -0.486 | 0.379 | 0.080 | torch.Size([120, 240]) || stage6.residual_group1.blocks.0.mlp.fc2.weight
+ | 0.001 | -0.154 | 0.154 | 0.069 | torch.Size([120]) || stage6.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.587 | 0.200 | 0.865 | 0.122 | torch.Size([120]) || stage6.residual_group1.blocks.1.norm1.weight
+ | -0.118 | -0.374 | 0.082 | 0.089 | torch.Size([120]) || stage6.residual_group1.blocks.1.norm1.bias
+ | 0.001 | -0.423 | 0.140 | 0.050 | torch.Size([675, 6]) || stage6.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.1.attn.position_bias
+ | 0.000 | -0.315 | 0.354 | 0.057 | torch.Size([360, 120]) || stage6.residual_group1.blocks.1.attn.qkv_self.weight
+ | 0.001 | -0.184 | 0.148 | 0.047 | torch.Size([360]) || stage6.residual_group1.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.626 | 0.422 | 0.060 | torch.Size([120, 240]) || stage6.residual_group1.blocks.1.attn.proj.weight
+ | 0.004 | -0.234 | 0.187 | 0.087 | torch.Size([120]) || stage6.residual_group1.blocks.1.attn.proj.bias
+ | -0.000 | -0.692 | 0.743 | 0.058 | torch.Size([360, 120]) || stage6.residual_group1.blocks.1.attn.qkv_mut.weight
+ | -0.000 | -0.038 | 0.041 | 0.009 | torch.Size([360]) || stage6.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.590 | 0.287 | 0.942 | 0.125 | torch.Size([120]) || stage6.residual_group1.blocks.1.norm2.weight
+ | -0.006 | -0.196 | 0.203 | 0.076 | torch.Size([120]) || stage6.residual_group1.blocks.1.norm2.bias
+ | 0.000 | -0.427 | 0.431 | 0.075 | torch.Size([240, 120]) || stage6.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.080 | -0.242 | 0.033 | 0.053 | torch.Size([240]) || stage6.residual_group1.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.293 | 0.362 | 0.069 | torch.Size([240, 120]) || stage6.residual_group1.blocks.1.mlp.fc12.weight
+ | 0.001 | -0.171 | 0.207 | 0.047 | torch.Size([240]) || stage6.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.423 | 0.467 | 0.077 | torch.Size([120, 240]) || stage6.residual_group1.blocks.1.mlp.fc2.weight
+ | 0.000 | -0.152 | 0.184 | 0.057 | torch.Size([120]) || stage6.residual_group1.blocks.1.mlp.fc2.bias
+ | 0.703 | 0.255 | 1.008 | 0.132 | torch.Size([120]) || stage6.residual_group1.blocks.2.norm1.weight
+ | -0.125 | -0.342 | 0.042 | 0.078 | torch.Size([120]) || stage6.residual_group1.blocks.2.norm1.bias
+ | 0.000 | -0.381 | 0.350 | 0.052 | torch.Size([675, 6]) || stage6.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.2.attn.position_bias
+ | 0.000 | -0.426 | 0.500 | 0.058 | torch.Size([360, 120]) || stage6.residual_group1.blocks.2.attn.qkv_self.weight
+ | -0.003 | -0.262 | 0.226 | 0.054 | torch.Size([360]) || stage6.residual_group1.blocks.2.attn.qkv_self.bias
+ | -0.001 | -0.299 | 0.325 | 0.055 | torch.Size([120, 240]) || stage6.residual_group1.blocks.2.attn.proj.weight
+ | -0.001 | -0.149 | 0.096 | 0.061 | torch.Size([120]) || stage6.residual_group1.blocks.2.attn.proj.bias
+ | 0.000 | -0.406 | 0.391 | 0.055 | torch.Size([360, 120]) || stage6.residual_group1.blocks.2.attn.qkv_mut.weight
+ | 0.001 | -0.055 | 0.085 | 0.015 | torch.Size([360]) || stage6.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.666 | 0.308 | 0.942 | 0.118 | torch.Size([120]) || stage6.residual_group1.blocks.2.norm2.weight
+ | -0.005 | -0.203 | 0.265 | 0.086 | torch.Size([120]) || stage6.residual_group1.blocks.2.norm2.bias
+ | -0.000 | -0.349 | 0.494 | 0.072 | torch.Size([240, 120]) || stage6.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.071 | -0.213 | 0.071 | 0.053 | torch.Size([240]) || stage6.residual_group1.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.294 | 0.408 | 0.066 | torch.Size([240, 120]) || stage6.residual_group1.blocks.2.mlp.fc12.weight
+ | -0.003 | -0.120 | 0.147 | 0.049 | torch.Size([240]) || stage6.residual_group1.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.303 | 0.304 | 0.073 | torch.Size([120, 240]) || stage6.residual_group1.blocks.2.mlp.fc2.weight
+ | -0.005 | -0.150 | 0.129 | 0.063 | torch.Size([120]) || stage6.residual_group1.blocks.2.mlp.fc2.bias
+ | 0.702 | 0.307 | 0.960 | 0.129 | torch.Size([120]) || stage6.residual_group1.blocks.3.norm1.weight
+ | -0.100 | -0.262 | 0.057 | 0.070 | torch.Size([120]) || stage6.residual_group1.blocks.3.norm1.bias
+ | 0.001 | -0.501 | 0.290 | 0.062 | torch.Size([675, 6]) || stage6.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.3.attn.position_bias
+ | -0.000 | -0.349 | 0.336 | 0.061 | torch.Size([360, 120]) || stage6.residual_group1.blocks.3.attn.qkv_self.weight
+ | 0.001 | -0.287 | 0.202 | 0.053 | torch.Size([360]) || stage6.residual_group1.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.322 | 0.401 | 0.056 | torch.Size([120, 240]) || stage6.residual_group1.blocks.3.attn.proj.weight
+ | -0.004 | -0.182 | 0.151 | 0.062 | torch.Size([120]) || stage6.residual_group1.blocks.3.attn.proj.bias
+ | 0.000 | -0.441 | 0.444 | 0.054 | torch.Size([360, 120]) || stage6.residual_group1.blocks.3.attn.qkv_mut.weight
+ | 0.000 | -0.038 | 0.033 | 0.009 | torch.Size([360]) || stage6.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.666 | 0.317 | 0.970 | 0.117 | torch.Size([120]) || stage6.residual_group1.blocks.3.norm2.weight
+ | -0.003 | -0.173 | 0.168 | 0.067 | torch.Size([120]) || stage6.residual_group1.blocks.3.norm2.bias
+ | -0.000 | -0.354 | 0.408 | 0.070 | torch.Size([240, 120]) || stage6.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.072 | -0.297 | 0.067 | 0.065 | torch.Size([240]) || stage6.residual_group1.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.299 | 0.335 | 0.066 | torch.Size([240, 120]) || stage6.residual_group1.blocks.3.mlp.fc12.weight
+ | -0.004 | -0.191 | 0.136 | 0.060 | torch.Size([240]) || stage6.residual_group1.blocks.3.mlp.fc12.bias
+ | -0.000 | -0.400 | 0.590 | 0.071 | torch.Size([120, 240]) || stage6.residual_group1.blocks.3.mlp.fc2.weight
+ | -0.005 | -0.159 | 0.142 | 0.061 | torch.Size([120]) || stage6.residual_group1.blocks.3.mlp.fc2.bias
+ | 0.730 | 0.334 | 0.963 | 0.118 | torch.Size([120]) || stage6.residual_group1.blocks.4.norm1.weight
+ | -0.064 | -0.201 | 0.064 | 0.055 | torch.Size([120]) || stage6.residual_group1.blocks.4.norm1.bias
+ | -0.000 | -0.702 | 1.180 | 0.086 | torch.Size([675, 6]) || stage6.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.4.attn.position_bias
+ | -0.000 | -0.483 | 0.398 | 0.073 | torch.Size([360, 120]) || stage6.residual_group1.blocks.4.attn.qkv_self.weight
+ | 0.004 | -0.480 | 0.514 | 0.080 | torch.Size([360]) || stage6.residual_group1.blocks.4.attn.qkv_self.bias
+ | 0.000 | -0.331 | 0.390 | 0.056 | torch.Size([120, 240]) || stage6.residual_group1.blocks.4.attn.proj.weight
+ | -0.004 | -0.141 | 0.167 | 0.050 | torch.Size([120]) || stage6.residual_group1.blocks.4.attn.proj.bias
+ | 0.000 | -0.387 | 0.470 | 0.048 | torch.Size([360, 120]) || stage6.residual_group1.blocks.4.attn.qkv_mut.weight
+ | 0.001 | -0.065 | 0.039 | 0.010 | torch.Size([360]) || stage6.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.656 | 0.235 | 0.874 | 0.105 | torch.Size([120]) || stage6.residual_group1.blocks.4.norm2.weight
+ | -0.005 | -0.237 | 0.171 | 0.074 | torch.Size([120]) || stage6.residual_group1.blocks.4.norm2.bias
+ | -0.000 | -0.440 | 0.483 | 0.075 | torch.Size([240, 120]) || stage6.residual_group1.blocks.4.mlp.fc11.weight
+ | -0.076 | -0.347 | 0.110 | 0.076 | torch.Size([240]) || stage6.residual_group1.blocks.4.mlp.fc11.bias
+ | 0.000 | -0.286 | 0.348 | 0.070 | torch.Size([240, 120]) || stage6.residual_group1.blocks.4.mlp.fc12.weight
+ | 0.001 | -0.189 | 0.169 | 0.069 | torch.Size([240]) || stage6.residual_group1.blocks.4.mlp.fc12.bias
+ | 0.000 | -0.398 | 0.336 | 0.075 | torch.Size([120, 240]) || stage6.residual_group1.blocks.4.mlp.fc2.weight
+ | -0.004 | -0.127 | 0.137 | 0.052 | torch.Size([120]) || stage6.residual_group1.blocks.4.mlp.fc2.bias
+ | 0.691 | 0.178 | 0.975 | 0.116 | torch.Size([120]) || stage6.residual_group1.blocks.5.norm1.weight
+ | -0.042 | -0.137 | 0.099 | 0.037 | torch.Size([120]) || stage6.residual_group1.blocks.5.norm1.bias
+ | -0.001 | -0.662 | 1.078 | 0.078 | torch.Size([675, 6]) || stage6.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage6.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage6.residual_group1.blocks.5.attn.position_bias
+ | -0.000 | -0.359 | 0.531 | 0.072 | torch.Size([360, 120]) || stage6.residual_group1.blocks.5.attn.qkv_self.weight
+ | 0.002 | -0.293 | 0.311 | 0.075 | torch.Size([360]) || stage6.residual_group1.blocks.5.attn.qkv_self.bias
+ | 0.000 | -0.426 | 0.488 | 0.055 | torch.Size([120, 240]) || stage6.residual_group1.blocks.5.attn.proj.weight
+ | -0.006 | -0.103 | 0.159 | 0.044 | torch.Size([120]) || stage6.residual_group1.blocks.5.attn.proj.bias
+ | 0.000 | -0.401 | 0.385 | 0.044 | torch.Size([360, 120]) || stage6.residual_group1.blocks.5.attn.qkv_mut.weight
+ | 0.001 | -0.039 | 0.043 | 0.009 | torch.Size([360]) || stage6.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.607 | 0.210 | 0.802 | 0.094 | torch.Size([120]) || stage6.residual_group1.blocks.5.norm2.weight
+ | -0.004 | -0.178 | 0.199 | 0.068 | torch.Size([120]) || stage6.residual_group1.blocks.5.norm2.bias
+ | -0.000 | -0.377 | 0.541 | 0.079 | torch.Size([240, 120]) || stage6.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.069 | -0.429 | 0.280 | 0.096 | torch.Size([240]) || stage6.residual_group1.blocks.5.mlp.fc11.bias
+ | -0.000 | -0.394 | 0.344 | 0.077 | torch.Size([240, 120]) || stage6.residual_group1.blocks.5.mlp.fc12.weight
+ | 0.000 | -0.241 | 0.223 | 0.085 | torch.Size([240]) || stage6.residual_group1.blocks.5.mlp.fc12.bias
+ | -0.000 | -0.527 | 0.647 | 0.077 | torch.Size([120, 240]) || stage6.residual_group1.blocks.5.mlp.fc2.weight
+ | -0.006 | -0.126 | 0.157 | 0.047 | torch.Size([120]) || stage6.residual_group1.blocks.5.mlp.fc2.bias
+ | -0.001 | -0.294 | 0.287 | 0.060 | torch.Size([120, 120]) || stage6.linear1.weight
+ | 0.006 | -0.543 | 0.664 | 0.193 | torch.Size([120]) || stage6.linear1.bias
+ | 0.674 | 0.222 | 1.065 | 0.154 | torch.Size([120]) || stage6.residual_group2.blocks.0.norm1.weight
+ | 0.002 | -0.480 | 0.311 | 0.128 | torch.Size([120]) || stage6.residual_group2.blocks.0.norm1.bias
+ | 0.000 | -0.629 | 0.461 | 0.041 | torch.Size([3375, 6]) || stage6.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage6.residual_group2.blocks.0.attn.relative_position_index
+ | 0.000 | -0.495 | 0.440 | 0.085 | torch.Size([360, 120]) || stage6.residual_group2.blocks.0.attn.qkv_self.weight
+ | -0.001 | -0.516 | 0.468 | 0.114 | torch.Size([360]) || stage6.residual_group2.blocks.0.attn.qkv_self.bias
+ | 0.001 | -0.369 | 0.377 | 0.085 | torch.Size([120, 120]) || stage6.residual_group2.blocks.0.attn.proj.weight
+ | -0.003 | -0.297 | 0.292 | 0.113 | torch.Size([120]) || stage6.residual_group2.blocks.0.attn.proj.bias
+ | 0.644 | 0.181 | 1.104 | 0.153 | torch.Size([120]) || stage6.residual_group2.blocks.0.norm2.weight
+ | 0.003 | -0.167 | 0.185 | 0.070 | torch.Size([120]) || stage6.residual_group2.blocks.0.norm2.bias
+ | -0.000 | -0.383 | 0.534 | 0.087 | torch.Size([240, 120]) || stage6.residual_group2.blocks.0.mlp.fc11.weight
+ | -0.101 | -0.214 | 0.048 | 0.051 | torch.Size([240]) || stage6.residual_group2.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.350 | 0.560 | 0.085 | torch.Size([240, 120]) || stage6.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.005 | -0.159 | 0.138 | 0.047 | torch.Size([240]) || stage6.residual_group2.blocks.0.mlp.fc12.bias
+ | -0.001 | -0.374 | 0.488 | 0.091 | torch.Size([120, 240]) || stage6.residual_group2.blocks.0.mlp.fc2.weight
+ | -0.006 | -0.271 | 0.252 | 0.096 | torch.Size([120]) || stage6.residual_group2.blocks.0.mlp.fc2.bias
+ | 0.663 | 0.353 | 0.959 | 0.106 | torch.Size([120]) || stage6.residual_group2.blocks.1.norm1.weight
+ | 0.001 | -0.314 | 0.289 | 0.089 | torch.Size([120]) || stage6.residual_group2.blocks.1.norm1.bias
+ | 0.000 | -0.772 | 0.763 | 0.041 | torch.Size([3375, 6]) || stage6.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage6.residual_group2.blocks.1.attn.relative_position_index
+ | -0.000 | -0.495 | 0.604 | 0.086 | torch.Size([360, 120]) || stage6.residual_group2.blocks.1.attn.qkv_self.weight
+ | 0.005 | -0.491 | 0.401 | 0.097 | torch.Size([360]) || stage6.residual_group2.blocks.1.attn.qkv_self.bias
+ | 0.001 | -0.380 | 0.376 | 0.076 | torch.Size([120, 120]) || stage6.residual_group2.blocks.1.attn.proj.weight
+ | -0.007 | -0.321 | 0.234 | 0.096 | torch.Size([120]) || stage6.residual_group2.blocks.1.attn.proj.bias
+ | 0.666 | 0.226 | 1.153 | 0.138 | torch.Size([120]) || stage6.residual_group2.blocks.1.norm2.weight
+ | 0.001 | -0.178 | 0.220 | 0.069 | torch.Size([120]) || stage6.residual_group2.blocks.1.norm2.bias
+ | 0.000 | -0.514 | 0.608 | 0.090 | torch.Size([240, 120]) || stage6.residual_group2.blocks.1.mlp.fc11.weight
+ | -0.132 | -0.313 | 0.023 | 0.059 | torch.Size([240]) || stage6.residual_group2.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.423 | 0.488 | 0.088 | torch.Size([240, 120]) || stage6.residual_group2.blocks.1.mlp.fc12.weight
+ | -0.002 | -0.153 | 0.122 | 0.053 | torch.Size([240]) || stage6.residual_group2.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.399 | 0.435 | 0.087 | torch.Size([120, 240]) || stage6.residual_group2.blocks.1.mlp.fc2.weight
+ | -0.001 | -0.285 | 0.241 | 0.093 | torch.Size([120]) || stage6.residual_group2.blocks.1.mlp.fc2.bias
+ | 0.000 | -0.308 | 0.365 | 0.070 | torch.Size([120, 120]) || stage6.linear2.weight
+ | -0.002 | -0.699 | 0.757 | 0.303 | torch.Size([120]) || stage6.linear2.bias
+ | 0.000 | -0.130 | 0.129 | 0.027 | torch.Size([120, 120, 3, 3]) || stage6.pa_deform.weight
+ | -0.001 | -0.051 | 0.045 | 0.018 | torch.Size([120]) || stage6.pa_deform.bias
+ | -0.000 | -0.017 | 0.017 | 0.010 | torch.Size([120, 364, 3, 3]) || stage6.pa_deform.conv_offset.0.weight
+ | -0.007 | -0.049 | 0.026 | 0.012 | torch.Size([120]) || stage6.pa_deform.conv_offset.0.bias
+ | -0.001 | -0.090 | 0.114 | 0.020 | torch.Size([120, 120, 3, 3]) || stage6.pa_deform.conv_offset.2.weight
+ | -0.008 | -0.070 | 0.060 | 0.030 | torch.Size([120]) || stage6.pa_deform.conv_offset.2.bias
+ | -0.001 | -0.097 | 0.101 | 0.020 | torch.Size([120, 120, 3, 3]) || stage6.pa_deform.conv_offset.4.weight
+ | 0.006 | -0.096 | 0.114 | 0.044 | torch.Size([120]) || stage6.pa_deform.conv_offset.4.bias
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432, 120, 3, 3]) || stage6.pa_deform.conv_offset.6.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432]) || stage6.pa_deform.conv_offset.6.bias
+ | -0.002 | -0.822 | 0.740 | 0.127 | torch.Size([360, 360]) || stage6.pa_fuse.fc11.weight
+ | 0.212 | -0.394 | 0.913 | 0.216 | torch.Size([360]) || stage6.pa_fuse.fc11.bias
+ | -0.000 | -0.948 | 0.848 | 0.131 | torch.Size([360, 360]) || stage6.pa_fuse.fc12.weight
+ | 0.001 | -0.657 | 0.605 | 0.279 | torch.Size([360]) || stage6.pa_fuse.fc12.bias
+ | -0.000 | -0.678 | 0.823 | 0.158 | torch.Size([120, 360]) || stage6.pa_fuse.fc2.weight
+ | 0.009 | -0.616 | 0.477 | 0.283 | torch.Size([120]) || stage6.pa_fuse.fc2.bias
+ | 1.363 | 1.278 | 1.458 | 0.048 | torch.Size([30]) || stage7.reshape.1.weight
+ | -0.001 | -0.247 | 0.227 | 0.139 | torch.Size([30]) || stage7.reshape.1.bias
+ | -0.000 | -0.590 | 0.587 | 0.179 | torch.Size([120, 30]) || stage7.reshape.2.weight
+ | -0.029 | -0.525 | 0.546 | 0.231 | torch.Size([120]) || stage7.reshape.2.bias
+ | 0.406 | 0.101 | 0.864 | 0.138 | torch.Size([120]) || stage7.residual_group1.blocks.0.norm1.weight
+ | -0.159 | -0.667 | 0.525 | 0.161 | torch.Size([120]) || stage7.residual_group1.blocks.0.norm1.bias
+ | -0.174 | -2.385 | 4.798 | 0.381 | torch.Size([675, 6]) || stage7.residual_group1.blocks.0.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.0.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.0.attn.position_bias
+ | -0.000 | -0.809 | 0.687 | 0.111 | torch.Size([360, 120]) || stage7.residual_group1.blocks.0.attn.qkv_self.weight
+ | 0.001 | -0.275 | 0.262 | 0.057 | torch.Size([360]) || stage7.residual_group1.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.416 | 0.438 | 0.096 | torch.Size([120, 240]) || stage7.residual_group1.blocks.0.attn.proj.weight
+ | 0.008 | -0.499 | 0.295 | 0.131 | torch.Size([120]) || stage7.residual_group1.blocks.0.attn.proj.bias
+ | -0.000 | -1.494 | 1.378 | 0.106 | torch.Size([360, 120]) || stage7.residual_group1.blocks.0.attn.qkv_mut.weight
+ | -0.000 | -0.123 | 0.106 | 0.015 | torch.Size([360]) || stage7.residual_group1.blocks.0.attn.qkv_mut.bias
+ | 0.284 | 0.172 | 0.377 | 0.040 | torch.Size([120]) || stage7.residual_group1.blocks.0.norm2.weight
+ | -0.003 | -0.502 | 0.588 | 0.124 | torch.Size([120]) || stage7.residual_group1.blocks.0.norm2.bias
+ | 0.000 | -0.597 | 0.567 | 0.132 | torch.Size([240, 120]) || stage7.residual_group1.blocks.0.mlp.fc11.weight
+ | -0.061 | -0.420 | 0.409 | 0.104 | torch.Size([240]) || stage7.residual_group1.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.606 | 0.601 | 0.144 | torch.Size([240, 120]) || stage7.residual_group1.blocks.0.mlp.fc12.weight
+ | -0.003 | -0.306 | 0.261 | 0.101 | torch.Size([240]) || stage7.residual_group1.blocks.0.mlp.fc12.bias
+ | -0.001 | -0.572 | 0.609 | 0.149 | torch.Size([120, 240]) || stage7.residual_group1.blocks.0.mlp.fc2.weight
+ | -0.008 | -0.373 | 0.306 | 0.099 | torch.Size([120]) || stage7.residual_group1.blocks.0.mlp.fc2.bias
+ | 0.538 | 0.114 | 0.809 | 0.125 | torch.Size([120]) || stage7.residual_group1.blocks.1.norm1.weight
+ | -0.129 | -0.865 | 0.532 | 0.163 | torch.Size([120]) || stage7.residual_group1.blocks.1.norm1.bias
+ | -0.281 | -2.710 | 4.413 | 0.432 | torch.Size([675, 6]) || stage7.residual_group1.blocks.1.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.1.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.1.attn.position_bias
+ | 0.000 | -0.646 | 0.655 | 0.135 | torch.Size([360, 120]) || stage7.residual_group1.blocks.1.attn.qkv_self.weight
+ | -0.000 | -0.301 | 0.303 | 0.068 | torch.Size([360]) || stage7.residual_group1.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.479 | 0.463 | 0.100 | torch.Size([120, 240]) || stage7.residual_group1.blocks.1.attn.proj.weight
+ | 0.016 | -0.460 | 0.313 | 0.135 | torch.Size([120]) || stage7.residual_group1.blocks.1.attn.proj.bias
+ | 0.000 | -2.205 | 2.065 | 0.127 | torch.Size([360, 120]) || stage7.residual_group1.blocks.1.attn.qkv_mut.weight
+ | -0.000 | -0.074 | 0.085 | 0.017 | torch.Size([360]) || stage7.residual_group1.blocks.1.attn.qkv_mut.bias
+ | 0.353 | 0.243 | 0.425 | 0.034 | torch.Size([120]) || stage7.residual_group1.blocks.1.norm2.weight
+ | -0.008 | -0.643 | 0.628 | 0.146 | torch.Size([120]) || stage7.residual_group1.blocks.1.norm2.bias
+ | 0.000 | -0.535 | 0.617 | 0.135 | torch.Size([240, 120]) || stage7.residual_group1.blocks.1.mlp.fc11.weight
+ | -0.054 | -0.348 | 0.244 | 0.109 | torch.Size([240]) || stage7.residual_group1.blocks.1.mlp.fc11.bias
+ | -0.001 | -0.671 | 0.611 | 0.148 | torch.Size([240, 120]) || stage7.residual_group1.blocks.1.mlp.fc12.weight
+ | 0.004 | -0.272 | 0.292 | 0.098 | torch.Size([240]) || stage7.residual_group1.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.672 | 0.595 | 0.149 | torch.Size([120, 240]) || stage7.residual_group1.blocks.1.mlp.fc2.weight
+ | -0.003 | -0.398 | 0.273 | 0.088 | torch.Size([120]) || stage7.residual_group1.blocks.1.mlp.fc2.bias
+ | 0.581 | 0.093 | 0.791 | 0.147 | torch.Size([120]) || stage7.residual_group1.blocks.2.norm1.weight
+ | -0.143 | -1.023 | 0.481 | 0.167 | torch.Size([120]) || stage7.residual_group1.blocks.2.norm1.bias
+ | -0.098 | -2.171 | 4.402 | 0.287 | torch.Size([675, 6]) || stage7.residual_group1.blocks.2.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.2.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.2.attn.position_bias
+ | 0.000 | -0.640 | 0.701 | 0.147 | torch.Size([360, 120]) || stage7.residual_group1.blocks.2.attn.qkv_self.weight
+ | -0.005 | -0.328 | 0.408 | 0.072 | torch.Size([360]) || stage7.residual_group1.blocks.2.attn.qkv_self.bias
+ | -0.001 | -0.417 | 0.441 | 0.101 | torch.Size([120, 240]) || stage7.residual_group1.blocks.2.attn.proj.weight
+ | 0.007 | -0.508 | 0.265 | 0.127 | torch.Size([120]) || stage7.residual_group1.blocks.2.attn.proj.bias
+ | -0.001 | -2.511 | 2.484 | 0.143 | torch.Size([360, 120]) || stage7.residual_group1.blocks.2.attn.qkv_mut.weight
+ | -0.000 | -0.093 | 0.104 | 0.019 | torch.Size([360]) || stage7.residual_group1.blocks.2.attn.qkv_mut.bias
+ | 0.392 | 0.276 | 0.487 | 0.034 | torch.Size([120]) || stage7.residual_group1.blocks.2.norm2.weight
+ | -0.016 | -0.555 | 0.581 | 0.143 | torch.Size([120]) || stage7.residual_group1.blocks.2.norm2.bias
+ | -0.000 | -0.630 | 0.674 | 0.135 | torch.Size([240, 120]) || stage7.residual_group1.blocks.2.mlp.fc11.weight
+ | -0.072 | -0.420 | 0.173 | 0.115 | torch.Size([240]) || stage7.residual_group1.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.654 | 0.793 | 0.152 | torch.Size([240, 120]) || stage7.residual_group1.blocks.2.mlp.fc12.weight
+ | -0.003 | -0.303 | 0.263 | 0.098 | torch.Size([240]) || stage7.residual_group1.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.603 | 0.658 | 0.150 | torch.Size([120, 240]) || stage7.residual_group1.blocks.2.mlp.fc2.weight
+ | 0.003 | -0.301 | 0.247 | 0.081 | torch.Size([120]) || stage7.residual_group1.blocks.2.mlp.fc2.bias
+ | 0.611 | 0.127 | 0.811 | 0.134 | torch.Size([120]) || stage7.residual_group1.blocks.3.norm1.weight
+ | -0.137 | -0.781 | 0.684 | 0.164 | torch.Size([120]) || stage7.residual_group1.blocks.3.norm1.bias
+ | -0.109 | -4.577 | 4.527 | 0.332 | torch.Size([675, 6]) || stage7.residual_group1.blocks.3.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.3.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.3.attn.position_bias
+ | 0.000 | -0.757 | 0.743 | 0.146 | torch.Size([360, 120]) || stage7.residual_group1.blocks.3.attn.qkv_self.weight
+ | 0.001 | -0.358 | 0.342 | 0.083 | torch.Size([360]) || stage7.residual_group1.blocks.3.attn.qkv_self.bias
+ | 0.001 | -0.465 | 0.447 | 0.097 | torch.Size([120, 240]) || stage7.residual_group1.blocks.3.attn.proj.weight
+ | 0.002 | -0.389 | 0.233 | 0.113 | torch.Size([120]) || stage7.residual_group1.blocks.3.attn.proj.bias
+ | -0.001 | -1.947 | 1.928 | 0.127 | torch.Size([360, 120]) || stage7.residual_group1.blocks.3.attn.qkv_mut.weight
+ | 0.000 | -0.106 | 0.070 | 0.018 | torch.Size([360]) || stage7.residual_group1.blocks.3.attn.qkv_mut.bias
+ | 0.410 | 0.283 | 0.489 | 0.035 | torch.Size([120]) || stage7.residual_group1.blocks.3.norm2.weight
+ | -0.014 | -0.442 | 0.639 | 0.147 | torch.Size([120]) || stage7.residual_group1.blocks.3.norm2.bias
+ | -0.000 | -0.542 | 0.585 | 0.132 | torch.Size([240, 120]) || stage7.residual_group1.blocks.3.mlp.fc11.weight
+ | -0.069 | -0.463 | 0.214 | 0.122 | torch.Size([240]) || stage7.residual_group1.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.689 | 0.605 | 0.154 | torch.Size([240, 120]) || stage7.residual_group1.blocks.3.mlp.fc12.weight
+ | -0.008 | -0.307 | 0.279 | 0.096 | torch.Size([240]) || stage7.residual_group1.blocks.3.mlp.fc12.bias
+ | -0.000 | -0.593 | 0.603 | 0.152 | torch.Size([120, 240]) || stage7.residual_group1.blocks.3.mlp.fc2.weight
+ | 0.010 | -0.269 | 0.270 | 0.094 | torch.Size([120]) || stage7.residual_group1.blocks.3.mlp.fc2.bias
+ | 0.652 | 0.132 | 0.859 | 0.133 | torch.Size([120]) || stage7.residual_group1.blocks.4.norm1.weight
+ | -0.131 | -0.662 | 0.729 | 0.163 | torch.Size([120]) || stage7.residual_group1.blocks.4.norm1.bias
+ | -0.092 | -4.521 | 3.027 | 0.337 | torch.Size([675, 6]) || stage7.residual_group1.blocks.4.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.4.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.4.attn.position_bias
+ | -0.000 | -0.694 | 0.828 | 0.148 | torch.Size([360, 120]) || stage7.residual_group1.blocks.4.attn.qkv_self.weight
+ | 0.002 | -0.328 | 0.361 | 0.078 | torch.Size([360]) || stage7.residual_group1.blocks.4.attn.qkv_self.bias
+ | 0.000 | -0.430 | 0.483 | 0.100 | torch.Size([120, 240]) || stage7.residual_group1.blocks.4.attn.proj.weight
+ | -0.003 | -0.368 | 0.250 | 0.103 | torch.Size([120]) || stage7.residual_group1.blocks.4.attn.proj.bias
+ | -0.000 | -1.506 | 1.779 | 0.122 | torch.Size([360, 120]) || stage7.residual_group1.blocks.4.attn.qkv_mut.weight
+ | 0.000 | -0.090 | 0.112 | 0.020 | torch.Size([360]) || stage7.residual_group1.blocks.4.attn.qkv_mut.bias
+ | 0.435 | 0.347 | 0.536 | 0.033 | torch.Size([120]) || stage7.residual_group1.blocks.4.norm2.weight
+ | -0.018 | -0.345 | 0.609 | 0.136 | torch.Size([120]) || stage7.residual_group1.blocks.4.norm2.bias
+ | -0.001 | -0.580 | 0.558 | 0.132 | torch.Size([240, 120]) || stage7.residual_group1.blocks.4.mlp.fc11.weight
+ | -0.066 | -0.392 | 0.239 | 0.128 | torch.Size([240]) || stage7.residual_group1.blocks.4.mlp.fc11.bias
+ | -0.000 | -0.608 | 0.667 | 0.157 | torch.Size([240, 120]) || stage7.residual_group1.blocks.4.mlp.fc12.weight
+ | -0.001 | -0.276 | 0.296 | 0.105 | torch.Size([240]) || stage7.residual_group1.blocks.4.mlp.fc12.bias
+ | 0.000 | -0.666 | 0.775 | 0.155 | torch.Size([120, 240]) || stage7.residual_group1.blocks.4.mlp.fc2.weight
+ | 0.001 | -0.380 | 0.360 | 0.101 | torch.Size([120]) || stage7.residual_group1.blocks.4.mlp.fc2.bias
+ | 0.648 | 0.269 | 0.885 | 0.109 | torch.Size([120]) || stage7.residual_group1.blocks.5.norm1.weight
+ | -0.116 | -0.436 | 0.749 | 0.144 | torch.Size([120]) || stage7.residual_group1.blocks.5.norm1.bias
+ | -0.130 | -3.976 | 4.665 | 0.318 | torch.Size([675, 6]) || stage7.residual_group1.blocks.5.attn.relative_position_bias_table
+ | 337.000 | 0.000 | 674.000 | 166.395 | torch.Size([128, 128]) || stage7.residual_group1.blocks.5.attn.relative_position_index
+ | 0.487 | -1.000 | 1.000 | 0.512 | torch.Size([1, 64, 120]) || stage7.residual_group1.blocks.5.attn.position_bias
+ | -0.000 | -0.702 | 0.671 | 0.140 | torch.Size([360, 120]) || stage7.residual_group1.blocks.5.attn.qkv_self.weight
+ | 0.000 | -0.346 | 0.340 | 0.078 | torch.Size([360]) || stage7.residual_group1.blocks.5.attn.qkv_self.bias
+ | -0.000 | -0.410 | 0.394 | 0.091 | torch.Size([120, 240]) || stage7.residual_group1.blocks.5.attn.proj.weight
+ | 0.006 | -0.286 | 0.244 | 0.100 | torch.Size([120]) || stage7.residual_group1.blocks.5.attn.proj.bias
+ | 0.001 | -0.870 | 0.885 | 0.109 | torch.Size([360, 120]) || stage7.residual_group1.blocks.5.attn.qkv_mut.weight
+ | 0.001 | -0.120 | 0.096 | 0.018 | torch.Size([360]) || stage7.residual_group1.blocks.5.attn.qkv_mut.bias
+ | 0.445 | 0.326 | 0.595 | 0.034 | torch.Size([120]) || stage7.residual_group1.blocks.5.norm2.weight
+ | -0.016 | -0.233 | 0.558 | 0.110 | torch.Size([120]) || stage7.residual_group1.blocks.5.norm2.bias
+ | -0.001 | -0.576 | 0.577 | 0.129 | torch.Size([240, 120]) || stage7.residual_group1.blocks.5.mlp.fc11.weight
+ | -0.038 | -0.525 | 0.269 | 0.139 | torch.Size([240]) || stage7.residual_group1.blocks.5.mlp.fc11.bias
+ | -0.000 | -0.672 | 0.671 | 0.158 | torch.Size([240, 120]) || stage7.residual_group1.blocks.5.mlp.fc12.weight
+ | 0.003 | -0.400 | 0.281 | 0.116 | torch.Size([240]) || stage7.residual_group1.blocks.5.mlp.fc12.bias
+ | 0.000 | -0.937 | 0.714 | 0.156 | torch.Size([120, 240]) || stage7.residual_group1.blocks.5.mlp.fc2.weight
+ | 0.007 | -0.435 | 0.876 | 0.188 | torch.Size([120]) || stage7.residual_group1.blocks.5.mlp.fc2.bias
+ | -0.000 | -0.234 | 0.212 | 0.056 | torch.Size([120, 120]) || stage7.linear1.weight
+ | -0.033 | -0.655 | 0.586 | 0.242 | torch.Size([120]) || stage7.linear1.bias
+ | 0.684 | 0.257 | 0.867 | 0.090 | torch.Size([120]) || stage7.residual_group2.blocks.0.norm1.weight
+ | -0.003 | -0.857 | 0.829 | 0.193 | torch.Size([120]) || stage7.residual_group2.blocks.0.norm1.bias
+ | -0.005 | -5.628 | 1.358 | 0.121 | torch.Size([3375, 6]) || stage7.residual_group2.blocks.0.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage7.residual_group2.blocks.0.attn.relative_position_index
+ | 0.000 | -0.699 | 0.827 | 0.137 | torch.Size([360, 120]) || stage7.residual_group2.blocks.0.attn.qkv_self.weight
+ | 0.001 | -0.821 | 0.662 | 0.143 | torch.Size([360]) || stage7.residual_group2.blocks.0.attn.qkv_self.bias
+ | 0.001 | -0.392 | 0.418 | 0.106 | torch.Size([120, 120]) || stage7.residual_group2.blocks.0.attn.proj.weight
+ | 0.003 | -0.147 | 0.171 | 0.052 | torch.Size([120]) || stage7.residual_group2.blocks.0.attn.proj.bias
+ | 0.431 | 0.316 | 0.521 | 0.036 | torch.Size([120]) || stage7.residual_group2.blocks.0.norm2.weight
+ | -0.003 | -0.595 | 0.673 | 0.129 | torch.Size([120]) || stage7.residual_group2.blocks.0.norm2.bias
+ | -0.000 | -0.701 | 0.542 | 0.119 | torch.Size([240, 120]) || stage7.residual_group2.blocks.0.mlp.fc11.weight
+ | 0.017 | -0.290 | 0.421 | 0.117 | torch.Size([240]) || stage7.residual_group2.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.603 | 0.637 | 0.145 | torch.Size([240, 120]) || stage7.residual_group2.blocks.0.mlp.fc12.weight
+ | -0.006 | -0.394 | 0.426 | 0.098 | torch.Size([240]) || stage7.residual_group2.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.602 | 0.607 | 0.144 | torch.Size([120, 240]) || stage7.residual_group2.blocks.0.mlp.fc2.weight
+ | -0.003 | -0.460 | 0.272 | 0.112 | torch.Size([120]) || stage7.residual_group2.blocks.0.mlp.fc2.bias
+ | 0.655 | 0.251 | 0.779 | 0.074 | torch.Size([120]) || stage7.residual_group2.blocks.1.norm1.weight
+ | -0.004 | -0.718 | 0.811 | 0.153 | torch.Size([120]) || stage7.residual_group2.blocks.1.norm1.bias
+ | -0.007 | -3.104 | 1.224 | 0.101 | torch.Size([3375, 6]) || stage7.residual_group2.blocks.1.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage7.residual_group2.blocks.1.attn.relative_position_index
+ | -0.000 | -0.664 | 0.647 | 0.137 | torch.Size([360, 120]) || stage7.residual_group2.blocks.1.attn.qkv_self.weight
+ | 0.002 | -0.532 | 0.746 | 0.150 | torch.Size([360]) || stage7.residual_group2.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.428 | 0.360 | 0.100 | torch.Size([120, 120]) || stage7.residual_group2.blocks.1.attn.proj.weight
+ | 0.009 | -0.244 | 0.242 | 0.063 | torch.Size([120]) || stage7.residual_group2.blocks.1.attn.proj.bias
+ | 0.442 | 0.284 | 0.530 | 0.038 | torch.Size([120]) || stage7.residual_group2.blocks.1.norm2.weight
+ | -0.004 | -0.421 | 0.664 | 0.106 | torch.Size([120]) || stage7.residual_group2.blocks.1.norm2.bias
+ | -0.001 | -0.604 | 0.583 | 0.119 | torch.Size([240, 120]) || stage7.residual_group2.blocks.1.mlp.fc11.weight
+ | 0.028 | -0.389 | 0.406 | 0.134 | torch.Size([240]) || stage7.residual_group2.blocks.1.mlp.fc11.bias
+ | -0.001 | -0.681 | 0.818 | 0.148 | torch.Size([240, 120]) || stage7.residual_group2.blocks.1.mlp.fc12.weight
+ | 0.003 | -0.247 | 0.361 | 0.096 | torch.Size([240]) || stage7.residual_group2.blocks.1.mlp.fc12.bias
+ | -0.000 | -0.783 | 0.835 | 0.146 | torch.Size([120, 240]) || stage7.residual_group2.blocks.1.mlp.fc2.weight
+ | 0.008 | -0.529 | 0.922 | 0.144 | torch.Size([120]) || stage7.residual_group2.blocks.1.mlp.fc2.bias
+ | -0.001 | -0.353 | 0.277 | 0.071 | torch.Size([120, 120]) || stage7.linear2.weight
+ | -0.026 | -0.905 | 0.749 | 0.262 | torch.Size([120]) || stage7.linear2.bias
+ | -0.000 | -0.125 | 0.138 | 0.027 | torch.Size([120, 120, 3, 3]) || stage7.pa_deform.weight
+ | -0.003 | -0.091 | 0.071 | 0.030 | torch.Size([120]) || stage7.pa_deform.bias
+ | 0.000 | -0.017 | 0.017 | 0.010 | torch.Size([120, 364, 3, 3]) || stage7.pa_deform.conv_offset.0.weight
+ | -0.000 | -0.028 | 0.054 | 0.015 | torch.Size([120]) || stage7.pa_deform.conv_offset.0.bias
+ | -0.001 | -0.130 | 0.111 | 0.017 | torch.Size([120, 120, 3, 3]) || stage7.pa_deform.conv_offset.2.weight
+ | -0.004 | -0.105 | 0.094 | 0.040 | torch.Size([120]) || stage7.pa_deform.conv_offset.2.bias
+ | -0.002 | -0.203 | 0.124 | 0.016 | torch.Size([120, 120, 3, 3]) || stage7.pa_deform.conv_offset.4.weight
+ | 0.027 | -0.097 | 0.151 | 0.048 | torch.Size([120]) || stage7.pa_deform.conv_offset.4.bias
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432, 120, 3, 3]) || stage7.pa_deform.conv_offset.6.weight
+ | 0.000 | 0.000 | 0.000 | 0.000 | torch.Size([432]) || stage7.pa_deform.conv_offset.6.bias
+ | -0.002 | -0.997 | 1.031 | 0.156 | torch.Size([360, 360]) || stage7.pa_fuse.fc11.weight
+ | 0.219 | -0.261 | 0.769 | 0.213 | torch.Size([360]) || stage7.pa_fuse.fc11.bias
+ | 0.001 | -1.119 | 1.206 | 0.175 | torch.Size([360, 360]) || stage7.pa_fuse.fc12.weight
+ | -0.011 | -0.547 | 0.598 | 0.195 | torch.Size([360]) || stage7.pa_fuse.fc12.bias
+ | 0.000 | -0.860 | 0.957 | 0.160 | torch.Size([120, 360]) || stage7.pa_fuse.fc2.weight
+ | 0.018 | -1.017 | 0.731 | 0.363 | torch.Size([120]) || stage7.pa_fuse.fc2.bias
+ | 1.491 | 1.080 | 1.847 | 0.135 | torch.Size([120]) || stage8.0.1.weight
+ | -0.012 | -0.370 | 0.414 | 0.140 | torch.Size([120]) || stage8.0.1.bias
+ | -0.000 | -0.882 | 1.114 | 0.177 | torch.Size([180, 120]) || stage8.0.2.weight
+ | -0.005 | -1.101 | 0.699 | 0.167 | torch.Size([180]) || stage8.0.2.bias
+ | 0.622 | 0.186 | 1.009 | 0.188 | torch.Size([180]) || stage8.1.residual_group.blocks.0.norm1.weight
+ | -0.006 | -0.884 | 1.056 | 0.212 | torch.Size([180]) || stage8.1.residual_group.blocks.0.norm1.bias
+ | -0.003 | -2.578 | 2.238 | 0.223 | torch.Size([3375, 6]) || stage8.1.residual_group.blocks.0.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.1.residual_group.blocks.0.attn.relative_position_index
+ | 0.000 | -1.042 | 1.335 | 0.152 | torch.Size([540, 180]) || stage8.1.residual_group.blocks.0.attn.qkv_self.weight
+ | -0.007 | -0.992 | 0.938 | 0.208 | torch.Size([540]) || stage8.1.residual_group.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.692 | 0.565 | 0.129 | torch.Size([180, 180]) || stage8.1.residual_group.blocks.0.attn.proj.weight
+ | 0.009 | -1.288 | 0.895 | 0.185 | torch.Size([180]) || stage8.1.residual_group.blocks.0.attn.proj.bias
+ | 0.415 | 0.180 | 0.539 | 0.066 | torch.Size([180]) || stage8.1.residual_group.blocks.0.norm2.weight
+ | -0.006 | -0.634 | 0.818 | 0.145 | torch.Size([180]) || stage8.1.residual_group.blocks.0.norm2.bias
+ | 0.001 | -0.969 | 0.867 | 0.145 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.0.mlp.fc11.weight
+ | -0.055 | -0.545 | 0.271 | 0.110 | torch.Size([360]) || stage8.1.residual_group.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.698 | 0.845 | 0.153 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.0.mlp.fc12.weight
+ | 0.007 | -0.526 | 0.444 | 0.126 | torch.Size([360]) || stage8.1.residual_group.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.812 | 0.874 | 0.155 | torch.Size([180, 360]) || stage8.1.residual_group.blocks.0.mlp.fc2.weight
+ | 0.009 | -0.468 | 0.864 | 0.160 | torch.Size([180]) || stage8.1.residual_group.blocks.0.mlp.fc2.bias
+ | 0.724 | 0.198 | 0.915 | 0.128 | torch.Size([180]) || stage8.1.residual_group.blocks.1.norm1.weight
+ | -0.003 | -1.026 | 0.953 | 0.209 | torch.Size([180]) || stage8.1.residual_group.blocks.1.norm1.bias
+ | 0.030 | -3.042 | 1.112 | 0.227 | torch.Size([3375, 6]) || stage8.1.residual_group.blocks.1.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.1.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -1.192 | 0.952 | 0.169 | torch.Size([540, 180]) || stage8.1.residual_group.blocks.1.attn.qkv_self.weight
+ | -0.009 | -1.186 | 0.822 | 0.191 | torch.Size([540]) || stage8.1.residual_group.blocks.1.attn.qkv_self.bias
+ | -0.000 | -0.500 | 0.647 | 0.121 | torch.Size([180, 180]) || stage8.1.residual_group.blocks.1.attn.proj.weight
+ | 0.004 | -0.892 | 1.020 | 0.208 | torch.Size([180]) || stage8.1.residual_group.blocks.1.attn.proj.bias
+ | 0.492 | 0.230 | 0.628 | 0.064 | torch.Size([180]) || stage8.1.residual_group.blocks.1.norm2.weight
+ | -0.006 | -0.853 | 0.872 | 0.165 | torch.Size([180]) || stage8.1.residual_group.blocks.1.norm2.bias
+ | 0.001 | -0.748 | 0.701 | 0.150 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.1.mlp.fc11.weight
+ | -0.055 | -0.409 | 0.305 | 0.096 | torch.Size([360]) || stage8.1.residual_group.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.806 | 0.662 | 0.155 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.1.mlp.fc12.weight
+ | 0.001 | -0.304 | 0.419 | 0.096 | torch.Size([360]) || stage8.1.residual_group.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.841 | 0.781 | 0.154 | torch.Size([180, 360]) || stage8.1.residual_group.blocks.1.mlp.fc2.weight
+ | 0.005 | -0.280 | 0.641 | 0.119 | torch.Size([180]) || stage8.1.residual_group.blocks.1.mlp.fc2.bias
+ | 0.803 | 0.314 | 1.038 | 0.110 | torch.Size([180]) || stage8.1.residual_group.blocks.2.norm1.weight
+ | -0.006 | -1.202 | 1.119 | 0.207 | torch.Size([180]) || stage8.1.residual_group.blocks.2.norm1.bias
+ | -0.002 | -2.783 | 1.481 | 0.236 | torch.Size([3375, 6]) || stage8.1.residual_group.blocks.2.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.1.residual_group.blocks.2.attn.relative_position_index
+ | 0.000 | -0.957 | 0.943 | 0.162 | torch.Size([540, 180]) || stage8.1.residual_group.blocks.2.attn.qkv_self.weight
+ | 0.002 | -0.519 | 0.526 | 0.136 | torch.Size([540]) || stage8.1.residual_group.blocks.2.attn.qkv_self.bias
+ | -0.000 | -0.543 | 0.516 | 0.117 | torch.Size([180, 180]) || stage8.1.residual_group.blocks.2.attn.proj.weight
+ | 0.005 | -0.711 | 0.838 | 0.184 | torch.Size([180]) || stage8.1.residual_group.blocks.2.attn.proj.bias
+ | 0.549 | 0.206 | 0.679 | 0.078 | torch.Size([180]) || stage8.1.residual_group.blocks.2.norm2.weight
+ | -0.005 | -0.888 | 0.879 | 0.154 | torch.Size([180]) || stage8.1.residual_group.blocks.2.norm2.bias
+ | 0.000 | -0.748 | 0.896 | 0.148 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.2.mlp.fc11.weight
+ | -0.073 | -0.478 | 0.193 | 0.098 | torch.Size([360]) || stage8.1.residual_group.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.628 | 0.674 | 0.157 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.2.mlp.fc12.weight
+ | -0.001 | -0.331 | 0.230 | 0.082 | torch.Size([360]) || stage8.1.residual_group.blocks.2.mlp.fc12.bias
+ | 0.001 | -0.677 | 0.673 | 0.154 | torch.Size([180, 360]) || stage8.1.residual_group.blocks.2.mlp.fc2.weight
+ | 0.004 | -0.294 | 0.745 | 0.112 | torch.Size([180]) || stage8.1.residual_group.blocks.2.mlp.fc2.bias
+ | 0.843 | 0.308 | 0.966 | 0.094 | torch.Size([180]) || stage8.1.residual_group.blocks.3.norm1.weight
+ | -0.002 | -1.222 | 1.324 | 0.192 | torch.Size([180]) || stage8.1.residual_group.blocks.3.norm1.bias
+ | 0.001 | -2.899 | 2.240 | 0.272 | torch.Size([3375, 6]) || stage8.1.residual_group.blocks.3.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.1.residual_group.blocks.3.attn.relative_position_index
+ | -0.000 | -0.999 | 0.935 | 0.167 | torch.Size([540, 180]) || stage8.1.residual_group.blocks.3.attn.qkv_self.weight
+ | -0.001 | -0.612 | 0.531 | 0.127 | torch.Size([540]) || stage8.1.residual_group.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.591 | 0.537 | 0.112 | torch.Size([180, 180]) || stage8.1.residual_group.blocks.3.attn.proj.weight
+ | -0.005 | -0.476 | 1.034 | 0.188 | torch.Size([180]) || stage8.1.residual_group.blocks.3.attn.proj.bias
+ | 0.534 | 0.198 | 0.660 | 0.074 | torch.Size([180]) || stage8.1.residual_group.blocks.3.norm2.weight
+ | -0.006 | -0.845 | 0.869 | 0.130 | torch.Size([180]) || stage8.1.residual_group.blocks.3.norm2.bias
+ | 0.001 | -0.649 | 0.677 | 0.147 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.3.mlp.fc11.weight
+ | -0.080 | -0.378 | 0.228 | 0.109 | torch.Size([360]) || stage8.1.residual_group.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.628 | 0.683 | 0.157 | torch.Size([360, 180]) || stage8.1.residual_group.blocks.3.mlp.fc12.weight
+ | -0.005 | -0.300 | 0.222 | 0.083 | torch.Size([360]) || stage8.1.residual_group.blocks.3.mlp.fc12.bias
+ | 0.001 | -0.959 | 0.733 | 0.153 | torch.Size([180, 360]) || stage8.1.residual_group.blocks.3.mlp.fc2.weight
+ | 0.003 | -0.915 | 0.961 | 0.165 | torch.Size([180]) || stage8.1.residual_group.blocks.3.mlp.fc2.bias
+ | 0.001 | -0.411 | 0.533 | 0.070 | torch.Size([180, 180]) || stage8.1.linear.weight
+ | -0.004 | -0.907 | 0.257 | 0.135 | torch.Size([180]) || stage8.1.linear.bias
+ | 0.890 | 0.143 | 1.178 | 0.177 | torch.Size([180]) || stage8.2.residual_group.blocks.0.norm1.weight
+ | -0.034 | -0.781 | 0.959 | 0.177 | torch.Size([180]) || stage8.2.residual_group.blocks.0.norm1.bias
+ | 0.001 | -2.545 | 1.182 | 0.186 | torch.Size([3375, 6]) || stage8.2.residual_group.blocks.0.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.2.residual_group.blocks.0.attn.relative_position_index
+ | 0.000 | -1.151 | 1.199 | 0.158 | torch.Size([540, 180]) || stage8.2.residual_group.blocks.0.attn.qkv_self.weight
+ | -0.001 | -0.731 | 0.744 | 0.155 | torch.Size([540]) || stage8.2.residual_group.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.522 | 0.577 | 0.131 | torch.Size([180, 180]) || stage8.2.residual_group.blocks.0.attn.proj.weight
+ | 0.003 | -0.537 | 0.895 | 0.164 | torch.Size([180]) || stage8.2.residual_group.blocks.0.attn.proj.bias
+ | 0.599 | 0.203 | 0.779 | 0.101 | torch.Size([180]) || stage8.2.residual_group.blocks.0.norm2.weight
+ | -0.021 | -0.429 | 1.016 | 0.143 | torch.Size([180]) || stage8.2.residual_group.blocks.0.norm2.bias
+ | -0.000 | -0.914 | 0.736 | 0.145 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.0.mlp.fc11.weight
+ | -0.054 | -0.545 | 0.183 | 0.106 | torch.Size([360]) || stage8.2.residual_group.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.716 | 0.750 | 0.155 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.0.mlp.fc12.weight
+ | 0.003 | -0.254 | 0.408 | 0.085 | torch.Size([360]) || stage8.2.residual_group.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.842 | 0.706 | 0.153 | torch.Size([180, 360]) || stage8.2.residual_group.blocks.0.mlp.fc2.weight
+ | 0.001 | -0.277 | 0.365 | 0.093 | torch.Size([180]) || stage8.2.residual_group.blocks.0.mlp.fc2.bias
+ | 0.910 | 0.151 | 1.164 | 0.152 | torch.Size([180]) || stage8.2.residual_group.blocks.1.norm1.weight
+ | -0.032 | -0.801 | 1.151 | 0.191 | torch.Size([180]) || stage8.2.residual_group.blocks.1.norm1.bias
+ | -0.069 | -2.776 | 5.771 | 0.290 | torch.Size([3375, 6]) || stage8.2.residual_group.blocks.1.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.2.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -1.359 | 1.101 | 0.156 | torch.Size([540, 180]) || stage8.2.residual_group.blocks.1.attn.qkv_self.weight
+ | 0.009 | -0.624 | 0.654 | 0.155 | torch.Size([540]) || stage8.2.residual_group.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.565 | 0.575 | 0.134 | torch.Size([180, 180]) || stage8.2.residual_group.blocks.1.attn.proj.weight
+ | -0.004 | -0.671 | 0.566 | 0.171 | torch.Size([180]) || stage8.2.residual_group.blocks.1.attn.proj.bias
+ | 0.609 | 0.206 | 0.818 | 0.109 | torch.Size([180]) || stage8.2.residual_group.blocks.1.norm2.weight
+ | -0.022 | -0.474 | 1.079 | 0.147 | torch.Size([180]) || stage8.2.residual_group.blocks.1.norm2.bias
+ | 0.000 | -0.760 | 0.819 | 0.143 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.1.mlp.fc11.weight
+ | -0.045 | -0.414 | 0.277 | 0.106 | torch.Size([360]) || stage8.2.residual_group.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.831 | 0.809 | 0.155 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.1.mlp.fc12.weight
+ | -0.002 | -0.544 | 0.244 | 0.082 | torch.Size([360]) || stage8.2.residual_group.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.749 | 0.962 | 0.151 | torch.Size([180, 360]) || stage8.2.residual_group.blocks.1.mlp.fc2.weight
+ | 0.011 | -0.275 | 0.294 | 0.101 | torch.Size([180]) || stage8.2.residual_group.blocks.1.mlp.fc2.bias
+ | 0.990 | 0.168 | 1.270 | 0.152 | torch.Size([180]) || stage8.2.residual_group.blocks.2.norm1.weight
+ | -0.034 | -0.773 | 1.134 | 0.182 | torch.Size([180]) || stage8.2.residual_group.blocks.2.norm1.bias
+ | -0.070 | -2.190 | 5.577 | 0.255 | torch.Size([3375, 6]) || stage8.2.residual_group.blocks.2.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.2.residual_group.blocks.2.attn.relative_position_index
+ | -0.000 | -1.004 | 1.113 | 0.152 | torch.Size([540, 180]) || stage8.2.residual_group.blocks.2.attn.qkv_self.weight
+ | 0.000 | -0.781 | 0.551 | 0.137 | torch.Size([540]) || stage8.2.residual_group.blocks.2.attn.qkv_self.bias
+ | 0.001 | -0.580 | 0.572 | 0.141 | torch.Size([180, 180]) || stage8.2.residual_group.blocks.2.attn.proj.weight
+ | -0.001 | -0.554 | 0.820 | 0.177 | torch.Size([180]) || stage8.2.residual_group.blocks.2.attn.proj.bias
+ | 0.642 | 0.178 | 0.852 | 0.111 | torch.Size([180]) || stage8.2.residual_group.blocks.2.norm2.weight
+ | -0.025 | -0.413 | 0.853 | 0.124 | torch.Size([180]) || stage8.2.residual_group.blocks.2.norm2.bias
+ | -0.000 | -0.780 | 1.141 | 0.143 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.2.mlp.fc11.weight
+ | -0.067 | -0.860 | 0.177 | 0.114 | torch.Size([360]) || stage8.2.residual_group.blocks.2.mlp.fc11.bias
+ | -0.000 | -1.067 | 0.859 | 0.155 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.2.mlp.fc12.weight
+ | 0.002 | -0.298 | 0.225 | 0.072 | torch.Size([360]) || stage8.2.residual_group.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.726 | 0.809 | 0.151 | torch.Size([180, 360]) || stage8.2.residual_group.blocks.2.mlp.fc2.weight
+ | 0.001 | -0.394 | 0.292 | 0.112 | torch.Size([180]) || stage8.2.residual_group.blocks.2.mlp.fc2.bias
+ | 0.990 | 0.219 | 1.226 | 0.130 | torch.Size([180]) || stage8.2.residual_group.blocks.3.norm1.weight
+ | -0.032 | -0.837 | 1.156 | 0.168 | torch.Size([180]) || stage8.2.residual_group.blocks.3.norm1.bias
+ | -0.005 | -4.045 | 1.695 | 0.178 | torch.Size([3375, 6]) || stage8.2.residual_group.blocks.3.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.2.residual_group.blocks.3.attn.relative_position_index
+ | 0.000 | -0.855 | 1.101 | 0.153 | torch.Size([540, 180]) || stage8.2.residual_group.blocks.3.attn.qkv_self.weight
+ | -0.002 | -0.706 | 0.841 | 0.123 | torch.Size([540]) || stage8.2.residual_group.blocks.3.attn.qkv_self.bias
+ | 0.000 | -0.586 | 0.699 | 0.134 | torch.Size([180, 180]) || stage8.2.residual_group.blocks.3.attn.proj.weight
+ | 0.001 | -0.402 | 0.842 | 0.173 | torch.Size([180]) || stage8.2.residual_group.blocks.3.attn.proj.bias
+ | 0.613 | 0.196 | 0.800 | 0.102 | torch.Size([180]) || stage8.2.residual_group.blocks.3.norm2.weight
+ | -0.021 | -0.404 | 0.907 | 0.115 | torch.Size([180]) || stage8.2.residual_group.blocks.3.norm2.bias
+ | 0.000 | -0.718 | 0.654 | 0.138 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.3.mlp.fc11.weight
+ | -0.064 | -0.568 | 0.205 | 0.115 | torch.Size([360]) || stage8.2.residual_group.blocks.3.mlp.fc11.bias
+ | -0.001 | -0.674 | 0.596 | 0.155 | torch.Size([360, 180]) || stage8.2.residual_group.blocks.3.mlp.fc12.weight
+ | -0.012 | -0.279 | 0.171 | 0.073 | torch.Size([360]) || stage8.2.residual_group.blocks.3.mlp.fc12.bias
+ | -0.000 | -0.634 | 0.692 | 0.150 | torch.Size([180, 360]) || stage8.2.residual_group.blocks.3.mlp.fc2.weight
+ | 0.010 | -0.528 | 1.331 | 0.175 | torch.Size([180]) || stage8.2.residual_group.blocks.3.mlp.fc2.bias
+ | -0.000 | -0.361 | 0.549 | 0.078 | torch.Size([180, 180]) || stage8.2.linear.weight
+ | -0.001 | -0.682 | 0.349 | 0.142 | torch.Size([180]) || stage8.2.linear.bias
+ | 1.018 | 0.177 | 1.365 | 0.177 | torch.Size([180]) || stage8.3.residual_group.blocks.0.norm1.weight
+ | -0.033 | -0.673 | 0.916 | 0.166 | torch.Size([180]) || stage8.3.residual_group.blocks.0.norm1.bias
+ | 0.003 | -2.963 | 1.620 | 0.138 | torch.Size([3375, 6]) || stage8.3.residual_group.blocks.0.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.3.residual_group.blocks.0.attn.relative_position_index
+ | -0.000 | -1.095 | 0.939 | 0.152 | torch.Size([540, 180]) || stage8.3.residual_group.blocks.0.attn.qkv_self.weight
+ | 0.004 | -0.725 | 0.682 | 0.135 | torch.Size([540]) || stage8.3.residual_group.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.731 | 0.755 | 0.149 | torch.Size([180, 180]) || stage8.3.residual_group.blocks.0.attn.proj.weight
+ | 0.013 | -0.457 | 0.481 | 0.158 | torch.Size([180]) || stage8.3.residual_group.blocks.0.attn.proj.bias
+ | 0.703 | 0.276 | 0.865 | 0.096 | torch.Size([180]) || stage8.3.residual_group.blocks.0.norm2.weight
+ | -0.024 | -0.449 | 0.966 | 0.132 | torch.Size([180]) || stage8.3.residual_group.blocks.0.norm2.bias
+ | -0.001 | -0.873 | 0.665 | 0.138 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.0.mlp.fc11.weight
+ | -0.052 | -0.479 | 0.198 | 0.104 | torch.Size([360]) || stage8.3.residual_group.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.787 | 0.699 | 0.155 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.0.mlp.fc12.weight
+ | -0.003 | -0.436 | 0.264 | 0.081 | torch.Size([360]) || stage8.3.residual_group.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.675 | 0.689 | 0.153 | torch.Size([180, 360]) || stage8.3.residual_group.blocks.0.mlp.fc2.weight
+ | 0.004 | -0.265 | 0.254 | 0.106 | torch.Size([180]) || stage8.3.residual_group.blocks.0.mlp.fc2.bias
+ | 0.956 | 0.184 | 1.255 | 0.167 | torch.Size([180]) || stage8.3.residual_group.blocks.1.norm1.weight
+ | -0.036 | -0.699 | 0.965 | 0.155 | torch.Size([180]) || stage8.3.residual_group.blocks.1.norm1.bias
+ | -0.038 | -3.913 | 4.625 | 0.210 | torch.Size([3375, 6]) || stage8.3.residual_group.blocks.1.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.3.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -1.142 | 0.934 | 0.147 | torch.Size([540, 180]) || stage8.3.residual_group.blocks.1.attn.qkv_self.weight
+ | 0.000 | -0.708 | 0.560 | 0.117 | torch.Size([540]) || stage8.3.residual_group.blocks.1.attn.qkv_self.bias
+ | -0.002 | -0.746 | 0.626 | 0.149 | torch.Size([180, 180]) || stage8.3.residual_group.blocks.1.attn.proj.weight
+ | 0.021 | -0.378 | 0.376 | 0.127 | torch.Size([180]) || stage8.3.residual_group.blocks.1.attn.proj.bias
+ | 0.741 | 0.282 | 0.933 | 0.107 | torch.Size([180]) || stage8.3.residual_group.blocks.1.norm2.weight
+ | -0.028 | -0.425 | 0.898 | 0.115 | torch.Size([180]) || stage8.3.residual_group.blocks.1.norm2.bias
+ | -0.001 | -0.761 | 0.822 | 0.139 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.1.mlp.fc11.weight
+ | -0.057 | -0.502 | 0.219 | 0.100 | torch.Size([360]) || stage8.3.residual_group.blocks.1.mlp.fc11.bias
+ | 0.000 | -0.829 | 0.872 | 0.156 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.1.mlp.fc12.weight
+ | 0.004 | -0.262 | 0.226 | 0.077 | torch.Size([360]) || stage8.3.residual_group.blocks.1.mlp.fc12.bias
+ | -0.001 | -0.797 | 0.765 | 0.153 | torch.Size([180, 360]) || stage8.3.residual_group.blocks.1.mlp.fc2.weight
+ | -0.002 | -0.360 | 0.289 | 0.109 | torch.Size([180]) || stage8.3.residual_group.blocks.1.mlp.fc2.bias
+ | 1.068 | 0.207 | 1.335 | 0.160 | torch.Size([180]) || stage8.3.residual_group.blocks.2.norm1.weight
+ | -0.034 | -0.784 | 1.005 | 0.163 | torch.Size([180]) || stage8.3.residual_group.blocks.2.norm1.bias
+ | -0.004 | -2.897 | 1.185 | 0.143 | torch.Size([3375, 6]) || stage8.3.residual_group.blocks.2.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.3.residual_group.blocks.2.attn.relative_position_index
+ | 0.000 | -1.055 | 0.899 | 0.151 | torch.Size([540, 180]) || stage8.3.residual_group.blocks.2.attn.qkv_self.weight
+ | -0.000 | -0.572 | 0.670 | 0.120 | torch.Size([540]) || stage8.3.residual_group.blocks.2.attn.qkv_self.bias
+ | -0.001 | -0.729 | 0.798 | 0.156 | torch.Size([180, 180]) || stage8.3.residual_group.blocks.2.attn.proj.weight
+ | 0.025 | -0.570 | 0.501 | 0.166 | torch.Size([180]) || stage8.3.residual_group.blocks.2.attn.proj.bias
+ | 0.759 | 0.228 | 0.969 | 0.115 | torch.Size([180]) || stage8.3.residual_group.blocks.2.norm2.weight
+ | -0.025 | -0.394 | 0.791 | 0.103 | torch.Size([180]) || stage8.3.residual_group.blocks.2.norm2.bias
+ | -0.001 | -0.962 | 0.903 | 0.137 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.2.mlp.fc11.weight
+ | -0.064 | -0.587 | 0.209 | 0.108 | torch.Size([360]) || stage8.3.residual_group.blocks.2.mlp.fc11.bias
+ | -0.000 | -0.966 | 0.925 | 0.156 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.2.mlp.fc12.weight
+ | 0.004 | -0.366 | 0.239 | 0.074 | torch.Size([360]) || stage8.3.residual_group.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.782 | 0.817 | 0.152 | torch.Size([180, 360]) || stage8.3.residual_group.blocks.2.mlp.fc2.weight
+ | 0.003 | -0.321 | 0.340 | 0.117 | torch.Size([180]) || stage8.3.residual_group.blocks.2.mlp.fc2.bias
+ | 1.082 | 0.237 | 1.309 | 0.144 | torch.Size([180]) || stage8.3.residual_group.blocks.3.norm1.weight
+ | -0.031 | -0.726 | 0.933 | 0.149 | torch.Size([180]) || stage8.3.residual_group.blocks.3.norm1.bias
+ | 0.005 | -3.023 | 1.093 | 0.142 | torch.Size([3375, 6]) || stage8.3.residual_group.blocks.3.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.3.residual_group.blocks.3.attn.relative_position_index
+ | -0.000 | -0.830 | 0.867 | 0.151 | torch.Size([540, 180]) || stage8.3.residual_group.blocks.3.attn.qkv_self.weight
+ | -0.001 | -0.487 | 0.710 | 0.107 | torch.Size([540]) || stage8.3.residual_group.blocks.3.attn.qkv_self.bias
+ | -0.001 | -0.940 | 0.725 | 0.157 | torch.Size([180, 180]) || stage8.3.residual_group.blocks.3.attn.proj.weight
+ | 0.027 | -0.522 | 0.807 | 0.170 | torch.Size([180]) || stage8.3.residual_group.blocks.3.attn.proj.bias
+ | 0.705 | 0.249 | 0.868 | 0.095 | torch.Size([180]) || stage8.3.residual_group.blocks.3.norm2.weight
+ | -0.023 | -0.426 | 0.826 | 0.108 | torch.Size([180]) || stage8.3.residual_group.blocks.3.norm2.bias
+ | -0.000 | -0.814 | 0.927 | 0.131 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.3.mlp.fc11.weight
+ | -0.043 | -0.613 | 0.209 | 0.116 | torch.Size([360]) || stage8.3.residual_group.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.709 | 0.851 | 0.154 | torch.Size([360, 180]) || stage8.3.residual_group.blocks.3.mlp.fc12.weight
+ | -0.004 | -0.225 | 0.241 | 0.078 | torch.Size([360]) || stage8.3.residual_group.blocks.3.mlp.fc12.bias
+ | -0.000 | -0.857 | 0.845 | 0.151 | torch.Size([180, 360]) || stage8.3.residual_group.blocks.3.mlp.fc2.weight
+ | 0.016 | -0.441 | 1.206 | 0.183 | torch.Size([180]) || stage8.3.residual_group.blocks.3.mlp.fc2.bias
+ | -0.002 | -0.437 | 0.634 | 0.077 | torch.Size([180, 180]) || stage8.3.linear.weight
+ | -0.003 | -0.564 | 0.338 | 0.145 | torch.Size([180]) || stage8.3.linear.bias
+ | 1.164 | 0.238 | 1.496 | 0.205 | torch.Size([180]) || stage8.4.residual_group.blocks.0.norm1.weight
+ | -0.033 | -0.667 | 0.780 | 0.170 | torch.Size([180]) || stage8.4.residual_group.blocks.0.norm1.bias
+ | -0.002 | -3.025 | 1.339 | 0.130 | torch.Size([3375, 6]) || stage8.4.residual_group.blocks.0.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.4.residual_group.blocks.0.attn.relative_position_index
+ | -0.000 | -0.736 | 0.735 | 0.147 | torch.Size([540, 180]) || stage8.4.residual_group.blocks.0.attn.qkv_self.weight
+ | -0.007 | -0.468 | 0.575 | 0.112 | torch.Size([540]) || stage8.4.residual_group.blocks.0.attn.qkv_self.bias
+ | -0.000 | -0.725 | 0.750 | 0.162 | torch.Size([180, 180]) || stage8.4.residual_group.blocks.0.attn.proj.weight
+ | -0.004 | -0.461 | 0.540 | 0.163 | torch.Size([180]) || stage8.4.residual_group.blocks.0.attn.proj.bias
+ | 0.804 | 0.361 | 0.962 | 0.091 | torch.Size([180]) || stage8.4.residual_group.blocks.0.norm2.weight
+ | -0.025 | -0.421 | 0.837 | 0.127 | torch.Size([180]) || stage8.4.residual_group.blocks.0.norm2.bias
+ | -0.002 | -0.664 | 0.869 | 0.129 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.0.mlp.fc11.weight
+ | -0.028 | -0.519 | 0.180 | 0.098 | torch.Size([360]) || stage8.4.residual_group.blocks.0.mlp.fc11.bias
+ | -0.000 | -0.793 | 0.821 | 0.156 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.0.mlp.fc12.weight
+ | 0.001 | -0.235 | 0.329 | 0.081 | torch.Size([360]) || stage8.4.residual_group.blocks.0.mlp.fc12.bias
+ | -0.000 | -0.758 | 0.730 | 0.153 | torch.Size([180, 360]) || stage8.4.residual_group.blocks.0.mlp.fc2.weight
+ | 0.010 | -0.332 | 0.306 | 0.118 | torch.Size([180]) || stage8.4.residual_group.blocks.0.mlp.fc2.bias
+ | 1.097 | 0.202 | 1.361 | 0.200 | torch.Size([180]) || stage8.4.residual_group.blocks.1.norm1.weight
+ | -0.034 | -0.597 | 0.687 | 0.147 | torch.Size([180]) || stage8.4.residual_group.blocks.1.norm1.bias
+ | 0.007 | -4.645 | 1.140 | 0.130 | torch.Size([3375, 6]) || stage8.4.residual_group.blocks.1.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.4.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -1.002 | 0.810 | 0.144 | torch.Size([540, 180]) || stage8.4.residual_group.blocks.1.attn.qkv_self.weight
+ | 0.005 | -0.407 | 0.438 | 0.108 | torch.Size([540]) || stage8.4.residual_group.blocks.1.attn.qkv_self.bias
+ | -0.001 | -0.646 | 0.678 | 0.154 | torch.Size([180, 180]) || stage8.4.residual_group.blocks.1.attn.proj.weight
+ | 0.004 | -0.418 | 0.415 | 0.139 | torch.Size([180]) || stage8.4.residual_group.blocks.1.attn.proj.bias
+ | 0.836 | 0.316 | 1.026 | 0.106 | torch.Size([180]) || stage8.4.residual_group.blocks.1.norm2.weight
+ | -0.024 | -0.364 | 0.851 | 0.117 | torch.Size([180]) || stage8.4.residual_group.blocks.1.norm2.bias
+ | -0.002 | -0.690 | 0.848 | 0.128 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.1.mlp.fc11.weight
+ | -0.032 | -0.484 | 0.195 | 0.101 | torch.Size([360]) || stage8.4.residual_group.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.863 | 0.768 | 0.155 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.1.mlp.fc12.weight
+ | -0.001 | -0.319 | 0.409 | 0.078 | torch.Size([360]) || stage8.4.residual_group.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.836 | 0.822 | 0.154 | torch.Size([180, 360]) || stage8.4.residual_group.blocks.1.mlp.fc2.weight
+ | 0.019 | -0.356 | 0.374 | 0.129 | torch.Size([180]) || stage8.4.residual_group.blocks.1.mlp.fc2.bias
+ | 1.151 | 0.229 | 1.393 | 0.176 | torch.Size([180]) || stage8.4.residual_group.blocks.2.norm1.weight
+ | -0.028 | -0.649 | 0.925 | 0.149 | torch.Size([180]) || stage8.4.residual_group.blocks.2.norm1.bias
+ | -0.005 | -3.864 | 1.138 | 0.140 | torch.Size([3375, 6]) || stage8.4.residual_group.blocks.2.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.4.residual_group.blocks.2.attn.relative_position_index
+ | -0.000 | -1.813 | 0.897 | 0.146 | torch.Size([540, 180]) || stage8.4.residual_group.blocks.2.attn.qkv_self.weight
+ | -0.001 | -0.449 | 0.486 | 0.103 | torch.Size([540]) || stage8.4.residual_group.blocks.2.attn.qkv_self.bias
+ | -0.001 | -0.739 | 0.710 | 0.175 | torch.Size([180, 180]) || stage8.4.residual_group.blocks.2.attn.proj.weight
+ | -0.000 | -0.542 | 0.407 | 0.162 | torch.Size([180]) || stage8.4.residual_group.blocks.2.attn.proj.bias
+ | 0.820 | 0.329 | 0.989 | 0.094 | torch.Size([180]) || stage8.4.residual_group.blocks.2.norm2.weight
+ | -0.025 | -0.461 | 0.753 | 0.106 | torch.Size([180]) || stage8.4.residual_group.blocks.2.norm2.bias
+ | -0.001 | -0.648 | 0.788 | 0.125 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.2.mlp.fc11.weight
+ | -0.015 | -0.501 | 0.248 | 0.101 | torch.Size([360]) || stage8.4.residual_group.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.745 | 0.796 | 0.155 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.2.mlp.fc12.weight
+ | 0.007 | -0.244 | 0.231 | 0.080 | torch.Size([360]) || stage8.4.residual_group.blocks.2.mlp.fc12.bias
+ | -0.000 | -0.771 | 1.049 | 0.154 | torch.Size([180, 360]) || stage8.4.residual_group.blocks.2.mlp.fc2.weight
+ | 0.018 | -0.360 | 0.336 | 0.143 | torch.Size([180]) || stage8.4.residual_group.blocks.2.mlp.fc2.bias
+ | 1.177 | 0.269 | 1.385 | 0.163 | torch.Size([180]) || stage8.4.residual_group.blocks.3.norm1.weight
+ | -0.028 | -0.700 | 0.877 | 0.145 | torch.Size([180]) || stage8.4.residual_group.blocks.3.norm1.bias
+ | -0.005 | -2.684 | 0.830 | 0.097 | torch.Size([3375, 6]) || stage8.4.residual_group.blocks.3.attn.relative_position_bias_table
+ | 1687.000 | 0.000 | 3374.000 | 730.710 | torch.Size([512, 512]) || stage8.4.residual_group.blocks.3.attn.relative_position_index
+ | -0.000 | -0.996 | 0.727 | 0.142 | torch.Size([540, 180]) || stage8.4.residual_group.blocks.3.attn.qkv_self.weight
+ | 0.004 | -0.326 | 0.449 | 0.101 | torch.Size([540]) || stage8.4.residual_group.blocks.3.attn.qkv_self.bias
+ | -0.001 | -0.777 | 0.785 | 0.170 | torch.Size([180, 180]) || stage8.4.residual_group.blocks.3.attn.proj.weight
+ | 0.004 | -0.396 | 0.449 | 0.158 | torch.Size([180]) || stage8.4.residual_group.blocks.3.attn.proj.bias
+ | 0.790 | 0.392 | 1.005 | 0.078 | torch.Size([180]) || stage8.4.residual_group.blocks.3.norm2.weight
+ | -0.030 | -0.481 | 0.719 | 0.110 | torch.Size([180]) || stage8.4.residual_group.blocks.3.norm2.bias
+ | -0.001 | -0.569 | 0.732 | 0.121 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.3.mlp.fc11.weight
+ | 0.020 | -0.670 | 0.335 | 0.125 | torch.Size([360]) || stage8.4.residual_group.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.822 | 0.831 | 0.155 | torch.Size([360, 180]) || stage8.4.residual_group.blocks.3.mlp.fc12.weight
+ | -0.003 | -0.282 | 0.296 | 0.089 | torch.Size([360]) || stage8.4.residual_group.blocks.3.mlp.fc12.bias
+ | 0.000 | -0.856 | 0.886 | 0.155 | torch.Size([180, 360]) || stage8.4.residual_group.blocks.3.mlp.fc2.weight
+ | 0.029 | -0.390 | 0.437 | 0.161 | torch.Size([180]) || stage8.4.residual_group.blocks.3.mlp.fc2.bias
+ | -0.002 | -0.490 | 0.625 | 0.079 | torch.Size([180, 180]) || stage8.4.linear.weight
+ | -0.002 | -0.573 | 0.398 | 0.168 | torch.Size([180]) || stage8.4.linear.bias
+ | 1.337 | 0.163 | 1.694 | 0.268 | torch.Size([180]) || stage8.5.residual_group.blocks.0.norm1.weight
+ | -0.025 | -0.727 | 1.008 | 0.186 | torch.Size([180]) || stage8.5.residual_group.blocks.0.norm1.bias
+ | -0.738 | -2.885 | 5.812 | 0.748 | torch.Size([225, 6]) || stage8.5.residual_group.blocks.0.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.5.residual_group.blocks.0.attn.relative_position_index
+ | -0.000 | -0.852 | 0.854 | 0.135 | torch.Size([540, 180]) || stage8.5.residual_group.blocks.0.attn.qkv_self.weight
+ | -0.005 | -0.546 | 0.550 | 0.112 | torch.Size([540]) || stage8.5.residual_group.blocks.0.attn.qkv_self.bias
+ | 0.000 | -0.901 | 0.781 | 0.195 | torch.Size([180, 180]) || stage8.5.residual_group.blocks.0.attn.proj.weight
+ | -0.020 | -0.545 | 0.469 | 0.173 | torch.Size([180]) || stage8.5.residual_group.blocks.0.attn.proj.bias
+ | 0.956 | 0.367 | 1.185 | 0.129 | torch.Size([180]) || stage8.5.residual_group.blocks.0.norm2.weight
+ | -0.033 | -0.519 | 0.833 | 0.147 | torch.Size([180]) || stage8.5.residual_group.blocks.0.norm2.bias
+ | -0.001 | -0.832 | 0.580 | 0.119 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.0.mlp.fc11.weight
+ | 0.055 | -0.256 | 0.378 | 0.097 | torch.Size([360]) || stage8.5.residual_group.blocks.0.mlp.fc11.bias
+ | 0.000 | -1.058 | 0.859 | 0.154 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.0.mlp.fc12.weight
+ | 0.006 | -0.377 | 0.318 | 0.093 | torch.Size([360]) || stage8.5.residual_group.blocks.0.mlp.fc12.bias
+ | -0.001 | -0.751 | 0.766 | 0.156 | torch.Size([180, 360]) || stage8.5.residual_group.blocks.0.mlp.fc2.weight
+ | -0.011 | -0.316 | 0.323 | 0.132 | torch.Size([180]) || stage8.5.residual_group.blocks.0.mlp.fc2.bias
+ | 1.346 | 0.151 | 1.746 | 0.272 | torch.Size([180]) || stage8.5.residual_group.blocks.1.norm1.weight
+ | -0.023 | -0.691 | 0.993 | 0.169 | torch.Size([180]) || stage8.5.residual_group.blocks.1.norm1.bias
+ | -0.705 | -2.997 | 4.745 | 0.748 | torch.Size([225, 6]) || stage8.5.residual_group.blocks.1.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.5.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -0.911 | 0.984 | 0.141 | torch.Size([540, 180]) || stage8.5.residual_group.blocks.1.attn.qkv_self.weight
+ | -0.011 | -0.405 | 0.288 | 0.095 | torch.Size([540]) || stage8.5.residual_group.blocks.1.attn.qkv_self.bias
+ | 0.001 | -0.853 | 0.977 | 0.210 | torch.Size([180, 180]) || stage8.5.residual_group.blocks.1.attn.proj.weight
+ | -0.008 | -0.516 | 0.596 | 0.170 | torch.Size([180]) || stage8.5.residual_group.blocks.1.attn.proj.bias
+ | 1.021 | 0.333 | 1.268 | 0.154 | torch.Size([180]) || stage8.5.residual_group.blocks.1.norm2.weight
+ | -0.034 | -0.512 | 0.812 | 0.134 | torch.Size([180]) || stage8.5.residual_group.blocks.1.norm2.bias
+ | 0.000 | -0.561 | 0.546 | 0.120 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.1.mlp.fc11.weight
+ | 0.050 | -0.450 | 0.320 | 0.100 | torch.Size([360]) || stage8.5.residual_group.blocks.1.mlp.fc11.bias
+ | 0.001 | -0.907 | 0.752 | 0.157 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.1.mlp.fc12.weight
+ | -0.008 | -0.306 | 0.343 | 0.091 | torch.Size([360]) || stage8.5.residual_group.blocks.1.mlp.fc12.bias
+ | -0.001 | -0.891 | 0.741 | 0.158 | torch.Size([180, 360]) || stage8.5.residual_group.blocks.1.mlp.fc2.weight
+ | -0.014 | -0.407 | 0.478 | 0.168 | torch.Size([180]) || stage8.5.residual_group.blocks.1.mlp.fc2.bias
+ | 1.266 | 0.195 | 1.640 | 0.251 | torch.Size([180]) || stage8.5.residual_group.blocks.2.norm1.weight
+ | -0.028 | -0.680 | 0.987 | 0.162 | torch.Size([180]) || stage8.5.residual_group.blocks.2.norm1.bias
+ | -0.515 | -2.839 | 4.668 | 0.636 | torch.Size([225, 6]) || stage8.5.residual_group.blocks.2.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.5.residual_group.blocks.2.attn.relative_position_index
+ | 0.001 | -0.968 | 0.890 | 0.144 | torch.Size([540, 180]) || stage8.5.residual_group.blocks.2.attn.qkv_self.weight
+ | -0.001 | -0.372 | 0.390 | 0.095 | torch.Size([540]) || stage8.5.residual_group.blocks.2.attn.qkv_self.bias
+ | -0.000 | -1.001 | 0.995 | 0.221 | torch.Size([180, 180]) || stage8.5.residual_group.blocks.2.attn.proj.weight
+ | -0.012 | -0.576 | 0.456 | 0.172 | torch.Size([180]) || stage8.5.residual_group.blocks.2.attn.proj.bias
+ | 1.046 | 0.311 | 1.264 | 0.147 | torch.Size([180]) || stage8.5.residual_group.blocks.2.norm2.weight
+ | -0.033 | -0.519 | 0.785 | 0.123 | torch.Size([180]) || stage8.5.residual_group.blocks.2.norm2.bias
+ | 0.000 | -0.533 | 0.563 | 0.119 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.2.mlp.fc11.weight
+ | 0.053 | -0.314 | 0.364 | 0.109 | torch.Size([360]) || stage8.5.residual_group.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.862 | 0.822 | 0.158 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.2.mlp.fc12.weight
+ | -0.004 | -0.266 | 0.289 | 0.084 | torch.Size([360]) || stage8.5.residual_group.blocks.2.mlp.fc12.bias
+ | 0.001 | -0.787 | 0.886 | 0.161 | torch.Size([180, 360]) || stage8.5.residual_group.blocks.2.mlp.fc2.weight
+ | -0.007 | -0.421 | 0.503 | 0.171 | torch.Size([180]) || stage8.5.residual_group.blocks.2.mlp.fc2.bias
+ | 1.226 | 0.277 | 1.561 | 0.208 | torch.Size([180]) || stage8.5.residual_group.blocks.3.norm1.weight
+ | -0.032 | -0.670 | 1.030 | 0.168 | torch.Size([180]) || stage8.5.residual_group.blocks.3.norm1.bias
+ | -0.401 | -1.953 | 3.930 | 0.598 | torch.Size([225, 6]) || stage8.5.residual_group.blocks.3.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.5.residual_group.blocks.3.attn.relative_position_index
+ | -0.000 | -0.857 | 0.754 | 0.139 | torch.Size([540, 180]) || stage8.5.residual_group.blocks.3.attn.qkv_self.weight
+ | 0.004 | -0.317 | 0.278 | 0.081 | torch.Size([540]) || stage8.5.residual_group.blocks.3.attn.qkv_self.bias
+ | -0.002 | -1.022 | 0.999 | 0.200 | torch.Size([180, 180]) || stage8.5.residual_group.blocks.3.attn.proj.weight
+ | -0.009 | -0.384 | 0.393 | 0.165 | torch.Size([180]) || stage8.5.residual_group.blocks.3.attn.proj.bias
+ | 1.038 | 0.340 | 1.216 | 0.128 | torch.Size([180]) || stage8.5.residual_group.blocks.3.norm2.weight
+ | -0.034 | -0.574 | 0.775 | 0.124 | torch.Size([180]) || stage8.5.residual_group.blocks.3.norm2.bias
+ | 0.001 | -0.588 | 0.613 | 0.119 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.3.mlp.fc11.weight
+ | 0.063 | -0.447 | 0.307 | 0.111 | torch.Size([360]) || stage8.5.residual_group.blocks.3.mlp.fc11.bias
+ | -0.000 | -0.873 | 0.775 | 0.159 | torch.Size([360, 180]) || stage8.5.residual_group.blocks.3.mlp.fc12.weight
+ | 0.001 | -0.456 | 0.435 | 0.092 | torch.Size([360]) || stage8.5.residual_group.blocks.3.mlp.fc12.bias
+ | -0.000 | -0.819 | 0.772 | 0.160 | torch.Size([180, 360]) || stage8.5.residual_group.blocks.3.mlp.fc2.weight
+ | -0.018 | -0.319 | 0.340 | 0.131 | torch.Size([180]) || stage8.5.residual_group.blocks.3.mlp.fc2.bias
+ | -0.000 | -0.562 | 0.471 | 0.080 | torch.Size([180, 180]) || stage8.5.linear.weight
+ | 0.024 | -0.609 | 0.488 | 0.184 | torch.Size([180]) || stage8.5.linear.bias
+ | 1.369 | 0.171 | 1.961 | 0.355 | torch.Size([180]) || stage8.6.residual_group.blocks.0.norm1.weight
+ | -0.028 | -0.642 | 0.733 | 0.196 | torch.Size([180]) || stage8.6.residual_group.blocks.0.norm1.bias
+ | -0.029 | -1.759 | 1.624 | 0.312 | torch.Size([225, 6]) || stage8.6.residual_group.blocks.0.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.6.residual_group.blocks.0.attn.relative_position_index
+ | -0.000 | -0.686 | 0.691 | 0.113 | torch.Size([540, 180]) || stage8.6.residual_group.blocks.0.attn.qkv_self.weight
+ | -0.003 | -0.261 | 0.301 | 0.081 | torch.Size([540]) || stage8.6.residual_group.blocks.0.attn.qkv_self.bias
+ | 0.001 | -0.736 | 0.637 | 0.149 | torch.Size([180, 180]) || stage8.6.residual_group.blocks.0.attn.proj.weight
+ | -0.006 | -0.293 | 0.300 | 0.106 | torch.Size([180]) || stage8.6.residual_group.blocks.0.attn.proj.bias
+ | 1.302 | 0.401 | 1.613 | 0.192 | torch.Size([180]) || stage8.6.residual_group.blocks.0.norm2.weight
+ | -0.029 | -0.475 | 0.696 | 0.159 | torch.Size([180]) || stage8.6.residual_group.blocks.0.norm2.bias
+ | -0.001 | -0.649 | 0.564 | 0.119 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.0.mlp.fc11.weight
+ | 0.036 | -0.275 | 0.218 | 0.071 | torch.Size([360]) || stage8.6.residual_group.blocks.0.mlp.fc11.bias
+ | 0.000 | -0.717 | 0.831 | 0.148 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.0.mlp.fc12.weight
+ | 0.006 | -0.231 | 0.270 | 0.074 | torch.Size([360]) || stage8.6.residual_group.blocks.0.mlp.fc12.bias
+ | 0.000 | -0.833 | 0.791 | 0.150 | torch.Size([180, 360]) || stage8.6.residual_group.blocks.0.mlp.fc2.weight
+ | 0.004 | -0.364 | 0.324 | 0.134 | torch.Size([180]) || stage8.6.residual_group.blocks.0.mlp.fc2.bias
+ | 1.450 | 0.218 | 1.962 | 0.354 | torch.Size([180]) || stage8.6.residual_group.blocks.1.norm1.weight
+ | -0.025 | -0.716 | 0.851 | 0.206 | torch.Size([180]) || stage8.6.residual_group.blocks.1.norm1.bias
+ | -0.045 | -1.549 | 2.100 | 0.321 | torch.Size([225, 6]) || stage8.6.residual_group.blocks.1.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.6.residual_group.blocks.1.attn.relative_position_index
+ | 0.000 | -0.759 | 0.636 | 0.110 | torch.Size([540, 180]) || stage8.6.residual_group.blocks.1.attn.qkv_self.weight
+ | -0.001 | -0.235 | 0.269 | 0.070 | torch.Size([540]) || stage8.6.residual_group.blocks.1.attn.qkv_self.bias
+ | 0.000 | -0.691 | 0.657 | 0.145 | torch.Size([180, 180]) || stage8.6.residual_group.blocks.1.attn.proj.weight
+ | -0.007 | -0.375 | 0.328 | 0.116 | torch.Size([180]) || stage8.6.residual_group.blocks.1.attn.proj.bias
+ | 1.326 | 0.335 | 1.596 | 0.186 | torch.Size([180]) || stage8.6.residual_group.blocks.1.norm2.weight
+ | -0.029 | -0.566 | 0.748 | 0.160 | torch.Size([180]) || stage8.6.residual_group.blocks.1.norm2.bias
+ | -0.002 | -0.667 | 0.591 | 0.121 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.1.mlp.fc11.weight
+ | 0.042 | -0.387 | 0.373 | 0.078 | torch.Size([360]) || stage8.6.residual_group.blocks.1.mlp.fc11.bias
+ | -0.000 | -0.685 | 0.894 | 0.147 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.1.mlp.fc12.weight
+ | 0.000 | -0.353 | 0.326 | 0.092 | torch.Size([360]) || stage8.6.residual_group.blocks.1.mlp.fc12.bias
+ | 0.000 | -0.801 | 0.692 | 0.149 | torch.Size([180, 360]) || stage8.6.residual_group.blocks.1.mlp.fc2.weight
+ | -0.007 | -0.331 | 0.273 | 0.127 | torch.Size([180]) || stage8.6.residual_group.blocks.1.mlp.fc2.bias
+ | 1.416 | 0.215 | 1.819 | 0.303 | torch.Size([180]) || stage8.6.residual_group.blocks.2.norm1.weight
+ | -0.024 | -0.596 | 0.869 | 0.211 | torch.Size([180]) || stage8.6.residual_group.blocks.2.norm1.bias
+ | -0.038 | -2.355 | 1.330 | 0.286 | torch.Size([225, 6]) || stage8.6.residual_group.blocks.2.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.6.residual_group.blocks.2.attn.relative_position_index
+ | -0.000 | -0.964 | 0.732 | 0.112 | torch.Size([540, 180]) || stage8.6.residual_group.blocks.2.attn.qkv_self.weight
+ | 0.002 | -0.192 | 0.251 | 0.052 | torch.Size([540]) || stage8.6.residual_group.blocks.2.attn.qkv_self.bias
+ | 0.001 | -0.736 | 0.624 | 0.138 | torch.Size([180, 180]) || stage8.6.residual_group.blocks.2.attn.proj.weight
+ | -0.008 | -0.376 | 0.254 | 0.119 | torch.Size([180]) || stage8.6.residual_group.blocks.2.attn.proj.bias
+ | 1.352 | 0.217 | 1.546 | 0.187 | torch.Size([180]) || stage8.6.residual_group.blocks.2.norm2.weight
+ | -0.023 | -0.627 | 0.881 | 0.164 | torch.Size([180]) || stage8.6.residual_group.blocks.2.norm2.bias
+ | -0.001 | -0.616 | 0.688 | 0.122 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.2.mlp.fc11.weight
+ | 0.040 | -0.332 | 0.242 | 0.083 | torch.Size([360]) || stage8.6.residual_group.blocks.2.mlp.fc11.bias
+ | 0.000 | -0.970 | 0.669 | 0.148 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.2.mlp.fc12.weight
+ | 0.006 | -0.333 | 0.371 | 0.092 | torch.Size([360]) || stage8.6.residual_group.blocks.2.mlp.fc12.bias
+ | 0.000 | -0.849 | 0.824 | 0.150 | torch.Size([180, 360]) || stage8.6.residual_group.blocks.2.mlp.fc2.weight
+ | -0.007 | -0.282 | 0.333 | 0.111 | torch.Size([180]) || stage8.6.residual_group.blocks.2.mlp.fc2.bias
+ | 1.346 | 0.206 | 1.798 | 0.286 | torch.Size([180]) || stage8.6.residual_group.blocks.3.norm1.weight
+ | -0.022 | -0.742 | 0.797 | 0.196 | torch.Size([180]) || stage8.6.residual_group.blocks.3.norm1.bias
+ | -0.056 | -1.296 | 2.098 | 0.311 | torch.Size([225, 6]) || stage8.6.residual_group.blocks.3.attn.relative_position_bias_table
+ | 112.000 | 0.000 | 224.000 | 48.719 | torch.Size([64, 64]) || stage8.6.residual_group.blocks.3.attn.relative_position_index
+ | -0.000 | -0.693 | 0.597 | 0.103 | torch.Size([540, 180]) || stage8.6.residual_group.blocks.3.attn.qkv_self.weight
+ | -0.003 | -0.211 | 0.161 | 0.055 | torch.Size([540]) || stage8.6.residual_group.blocks.3.attn.qkv_self.bias
+ | -0.000 | -0.767 | 0.663 | 0.127 | torch.Size([180, 180]) || stage8.6.residual_group.blocks.3.attn.proj.weight
+ | -0.011 | -0.269 | 0.169 | 0.072 | torch.Size([180]) || stage8.6.residual_group.blocks.3.attn.proj.bias
+ | 1.329 | 0.247 | 1.544 | 0.183 | torch.Size([180]) || stage8.6.residual_group.blocks.3.norm2.weight
+ | -0.023 | -0.619 | 0.881 | 0.171 | torch.Size([180]) || stage8.6.residual_group.blocks.3.norm2.bias
+ | -0.001 | -0.670 | 0.594 | 0.124 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.3.mlp.fc11.weight
+ | 0.052 | -0.262 | 0.275 | 0.073 | torch.Size([360]) || stage8.6.residual_group.blocks.3.mlp.fc11.bias
+ | 0.000 | -0.899 | 0.808 | 0.149 | torch.Size([360, 180]) || stage8.6.residual_group.blocks.3.mlp.fc12.weight
+ | -0.009 | -0.273 | 0.326 | 0.090 | torch.Size([360]) || stage8.6.residual_group.blocks.3.mlp.fc12.bias
+ | 0.001 | -0.773 | 0.930 | 0.150 | torch.Size([180, 360]) || stage8.6.residual_group.blocks.3.mlp.fc2.weight
+ | -0.001 | -0.264 | 0.261 | 0.088 | torch.Size([180]) || stage8.6.residual_group.blocks.3.mlp.fc2.bias
+ | -0.001 | -1.128 | 1.483 | 0.100 | torch.Size([180, 180]) || stage8.6.linear.weight
+ | 0.014 | -0.757 | 0.769 | 0.160 | torch.Size([180]) || stage8.6.linear.bias
+ | 0.387 | 0.109 | 1.033 | 0.194 | torch.Size([180]) || norm.weight
+ | -0.006 | -0.754 | 0.773 | 0.142 | torch.Size([180]) || norm.bias
+ | 0.001 | -0.596 | 0.563 | 0.121 | torch.Size([120, 180]) || conv_after_body.weight
+ | -0.016 | -0.251 | 0.121 | 0.061 | torch.Size([120]) || conv_after_body.bias
+ | 0.003 | -1.347 | 1.476 | 0.161 | torch.Size([64, 120, 1, 3, 3]) || conv_before_upsample.0.weight
+ | -0.090 | -0.847 | 0.182 | 0.193 | torch.Size([64]) || conv_before_upsample.0.bias
+ | 0.002 | -1.602 | 0.994 | 0.114 | torch.Size([256, 64, 1, 3, 3]) || upsample.0.weight
+ | -0.059 | -0.461 | 0.137 | 0.098 | torch.Size([256]) || upsample.0.bias
+ | -0.005 | -4.099 | 0.822 | 0.076 | torch.Size([256, 64, 1, 3, 3]) || upsample.5.weight
+ | -0.137 | -0.426 | 0.152 | 0.097 | torch.Size([256]) || upsample.5.bias
+ | -0.000 | -0.377 | 0.324 | 0.014 | torch.Size([64, 64, 1, 3, 3]) || upsample.10.weight
+ | -0.000 | -0.016 | 0.014 | 0.003 | torch.Size([64]) || upsample.10.bias
+ | -0.000 | -0.043 | 0.040 | 0.004 | torch.Size([3, 64, 1, 3, 3]) || conv_last.weight
+ | -0.000 | -0.000 | 0.000 | 0.000 | torch.Size([3]) || conv_last.bias
+
diff --git a/KAIR/image_degradation.py b/KAIR/image_degradation.py
new file mode 100644
index 0000000000000000000000000000000000000000..ad3562840f5b1203b1cb21842f1ca3e977e72830
--- /dev/null
+++ b/KAIR/image_degradation.py
@@ -0,0 +1,106 @@
+import math
+import os
+
+import numpy as np
+from basicsr.data.degradations import circular_lowpass_kernel, random_mixed_kernels
+from basicsr.utils import DiffJPEG, USMSharp
+from numpy.typing import NDArray
+from PIL import Image
+from torch import Tensor
+from torch.nn import functional as F
+
+from data.degradations import apply_real_esrgan_degradations
+from utils.utils_video import img2tensor
+
+
+blur_kernel_list1 = ['iso', 'aniso', 'generalized_iso',
+ 'generalized_aniso', 'plateau_iso', 'plateau_aniso']
+blur_kernel_list2 = ['iso', 'aniso', 'generalized_iso',
+ 'generalized_aniso', 'plateau_iso', 'plateau_aniso']
+blur_kernel_prob1 = [0.45, 0.25, 0.12, 0.03, 0.12, 0.03]
+blur_kernel_prob2 = [0.45, 0.25, 0.12, 0.03, 0.12, 0.03]
+kernel_size = 21
+blur_sigma1 = [0.05, 0.2]
+blur_sigma2 = [0.05, 0.1]
+betag_range1 = [0.7, 1.3]
+betag_range2 = [0.7, 1.3]
+betap_range1 = [0.7, 1.3]
+betap_range2 = [0.7, 1.3]
+
+
+
+
+def degrade_imgs(src_folder: str, dst_folder: str, degrade_scale: float, start_size: int) -> None:
+ src_img_filenames = os.listdir(src_folder)
+ jpeg_simulator = DiffJPEG()
+ usm_sharpener = USMSharp()
+ for src_img_filename in src_img_filenames:
+ src_img = Image.open(os.path.join(src_folder, src_img_filename))
+
+ src_tensor = img2tensor(np.array(src_img), bgr2rgb=False,
+ float32=True).unsqueeze(0) / 255.0
+ orig_h, orig_w = src_tensor.size()[2:4]
+ print("SRC TENSOR orig size: ", src_tensor.size())
+ if orig_h != start_size or orig_w != start_size:
+ src_tensor = F.interpolate(src_tensor, size=(start_size, start_size), mode='bicubic')
+ print("SRC TENSOR new size: ", src_tensor.size())
+
+ blur_kernel1, blur_kernel2, sinc_kernel = _decide_kernels()
+ (src, src_sharp, degraded_img) = apply_real_esrgan_degradations(
+ src_tensor,
+ blur_kernel1=Tensor(blur_kernel1).unsqueeze(0),
+ blur_kernel2=Tensor(blur_kernel2).unsqueeze(0),
+ second_blur_prob=0.4,
+ sinc_kernel=Tensor(sinc_kernel).unsqueeze(0),
+ resize_prob1=[0.2, 0.7, 0.1],
+ resize_prob2=[0.3, 0.4, 0.3],
+ resize_range1=[0.9, 1.1],
+ resize_range2=[0.9, 1.1],
+ gray_noise_prob1=0.2,
+ gray_noise_prob2=0.2,
+ gaussian_noise_prob1=0.2,
+ gaussian_noise_prob2=0.2,
+ noise_range=[0.01, 0.2],
+ poisson_scale_range=[0.05, 0.45],
+ jpeg_compression_range1=[85, 100],
+ jpeg_compression_range2=[85, 100],
+ jpeg_simulator=jpeg_simulator,
+ random_crop_gt_size=start_size,
+ sr_upsample_scale=1,
+ usm_sharpener=usm_sharpener
+ )
+
+ # print(src.size())
+ # print(src_sharp.size())
+ # print(degraded_img.size())
+ # print(torch.max(src))
+ # print(torch.max(src_sharp))
+ # print(torch.max(degraded_img))
+ # print(torch.min(src))
+ # print(torch.min(src_sharp))
+ # print(torch.min(degraded_img))
+ # Image.fromarray((src[0] * 255.0).permute(1, 2, 0).cpu().numpy().astype(np.uint8)).save(
+ # "/home/cll/Desktop/TEST_IMAGE1.png")
+ # Image.fromarray((src_sharp[0] * 255.0).permute(
+ # 1, 2, 0).cpu().numpy().astype(np.uint8)).save(
+ # "/home/cll/Desktop/TEST_IMAGE2.png")
+
+ Image.fromarray((degraded_img[0] * 255.0).permute(
+ 1, 2, 0).cpu().numpy().astype(np.uint8)).save(
+ os.path.join(dst_folder, src_img_filename))
+ print("SAVED %s: " % src_img_filename)
+
+ # Image.fromarray((src_tensor[0] * 255.0).permute(
+ # 1, 2, 0).cpu().numpy().astype(np.uint8)).save(
+ # os.path.join(dst_folder, src_img_filename))
+ # print("SAVED %s: " % src_img_filename)
+
+
+if __name__ == "__main__":
+ SRC_FOLDER = "/home/cll/Desktop/sr_test_GT_HQ"
+ OUTPUT_RESOLUTION_SCALE = 1
+ DST_FOLDER = "/home/cll/Desktop/sr_test_degraded_LQ_512"
+ # DST_FOLDER = "/home/cll/Desktop/sr_test_GT_512"
+ os.makedirs(DST_FOLDER, exist_ok=True)
+
+ degrade_imgs(SRC_FOLDER, DST_FOLDER, OUTPUT_RESOLUTION_SCALE, 512)
diff --git a/KAIR/kernels/Levin09.mat b/KAIR/kernels/Levin09.mat
new file mode 100644
index 0000000000000000000000000000000000000000..d2adbd35e387aef5190a67091980ee8d4c080a73
Binary files /dev/null and b/KAIR/kernels/Levin09.mat differ
diff --git a/KAIR/kernels/k_large_1.png b/KAIR/kernels/k_large_1.png
new file mode 100644
index 0000000000000000000000000000000000000000..479d4d3c5955f2696b7133230626b7cffbcd1e4a
Binary files /dev/null and b/KAIR/kernels/k_large_1.png differ
diff --git a/KAIR/kernels/k_large_2.png b/KAIR/kernels/k_large_2.png
new file mode 100644
index 0000000000000000000000000000000000000000..e47e6783818e688e4403665ba8533d631a0790ff
Binary files /dev/null and b/KAIR/kernels/k_large_2.png differ
diff --git a/KAIR/kernels/kernels_12.mat b/KAIR/kernels/kernels_12.mat
new file mode 100644
index 0000000000000000000000000000000000000000..afedf2c22847d5f6f9e81a30963af387b9644be8
Binary files /dev/null and b/KAIR/kernels/kernels_12.mat differ
diff --git a/KAIR/kernels/kernels_bicubicx234.mat b/KAIR/kernels/kernels_bicubicx234.mat
new file mode 100644
index 0000000000000000000000000000000000000000..0d88b86c60e073df4fdbea32249782ff16069d7f
Binary files /dev/null and b/KAIR/kernels/kernels_bicubicx234.mat differ
diff --git a/KAIR/kernels/srmd_pca_matlab.mat b/KAIR/kernels/srmd_pca_matlab.mat
new file mode 100644
index 0000000000000000000000000000000000000000..8fb2f8c128c9d14b540f99f350797a1d39606e8d
Binary files /dev/null and b/KAIR/kernels/srmd_pca_matlab.mat differ
diff --git a/KAIR/main_challenge_sr.py b/KAIR/main_challenge_sr.py
new file mode 100644
index 0000000000000000000000000000000000000000..0798dd31904adf647f0834a8ce4873438fad037f
--- /dev/null
+++ b/KAIR/main_challenge_sr.py
@@ -0,0 +1,174 @@
+import os.path
+import logging
+import time
+from collections import OrderedDict
+import torch
+
+from utils import utils_logger
+from utils import utils_image as util
+# from utils import utils_model
+
+
+'''
+This code can help you to calculate:
+`FLOPs`, `#Params`, `Runtime`, `#Activations`, `#Conv`, and `Max Memory Allocated`.
+
+- `#Params' denotes the total number of parameters.
+- `FLOPs' is the abbreviation for floating point operations.
+- `#Activations' measures the number of elements of all outputs of convolutional layers.
+- `Memory' represents maximum GPU memory consumption according to the PyTorch function torch.cuda.max_memory_allocated().
+- `#Conv' represents the number of convolutional layers.
+- `FLOPs', `#Activations', and `Memory' are tested on an LR image of size 256x256.
+
+For more information, please refer to ECCVW paper "AIM 2020 Challenge on Efficient Super-Resolution: Methods and Results".
+
+# If you use this code, please consider the following citations:
+
+@inproceedings{zhang2020aim,
+ title={AIM 2020 Challenge on Efficient Super-Resolution: Methods and Results},
+ author={Kai Zhang and Martin Danelljan and Yawei Li and Radu Timofte and others},
+ booktitle={European Conference on Computer Vision Workshops},
+ year={2020}
+}
+@inproceedings{zhang2019aim,
+ title={AIM 2019 Challenge on Constrained Super-Resolution: Methods and Results},
+ author={Kai Zhang and Shuhang Gu and Radu Timofte and others},
+ booktitle={IEEE International Conference on Computer Vision Workshops},
+ year={2019}
+}
+
+CuDNN (https://developer.nvidia.com/rdp/cudnn-archive) should be installed.
+
+For `Memery` and `Runtime`, set 'print_modelsummary = False' and 'save_results = False'.
+'''
+
+
+
+
+def main():
+
+ utils_logger.logger_info('efficientsr_challenge', log_path='efficientsr_challenge.log')
+ logger = logging.getLogger('efficientsr_challenge')
+
+# print(torch.__version__) # pytorch version
+# print(torch.version.cuda) # cuda version
+# print(torch.backends.cudnn.version()) # cudnn version
+
+ # --------------------------------
+ # basic settings
+ # --------------------------------
+ model_names = ['msrresnet', 'imdn']
+ model_id = 1 # set the model name
+ sf = 4
+ model_name = model_names[model_id]
+ logger.info('{:>16s} : {:s}'.format('Model Name', model_name))
+
+ testsets = 'testsets' # set path of testsets
+ testset_L = 'DIV2K_valid_LR' # set current testing dataset; 'DIV2K_test_LR'
+ testset_L = 'set12'
+
+ save_results = True
+ print_modelsummary = True # set False when calculating `Max Memery` and `Runtime`
+
+ torch.cuda.set_device(0) # set GPU ID
+ logger.info('{:>16s} : {:16s} : {:<.4f} [M]'.format('#Activations', activations/10**6))
+ logger.info('{:>16s} : {:16s} : {:<.4f} [G]'.format('FLOPs', flops/10**9))
+
+ num_parameters = sum(map(lambda x: x.numel(), model.parameters()))
+ logger.info('{:>16s} : {:<.4f} [M]'.format('#Params', num_parameters/10**6))
+
+ # --------------------------------
+ # read image
+ # --------------------------------
+ L_path = os.path.join(testsets, testset_L)
+ E_path = os.path.join(testsets, testset_L+'_'+model_name)
+ util.mkdir(E_path)
+
+ # record runtime
+ test_results = OrderedDict()
+ test_results['runtime'] = []
+
+ logger.info('{:>16s} : {:s}'.format('Input Path', L_path))
+ logger.info('{:>16s} : {:s}'.format('Output Path', E_path))
+ idx = 0
+
+ start = torch.cuda.Event(enable_timing=True)
+ end = torch.cuda.Event(enable_timing=True)
+
+ for img in util.get_image_paths(L_path):
+
+ # --------------------------------
+ # (1) img_L
+ # --------------------------------
+ idx += 1
+ img_name, ext = os.path.splitext(os.path.basename(img))
+ logger.info('{:->4d}--> {:>10s}'.format(idx, img_name+ext))
+
+ img_L = util.imread_uint(img, n_channels=3)
+ img_L = util.uint2tensor4(img_L)
+ torch.cuda.empty_cache()
+ img_L = img_L.to(device)
+
+ start.record()
+ img_E = model(img_L)
+ # img_E = utils_model.test_mode(model, img_L, mode=2, min_size=480, sf=sf) # use this to avoid 'out of memory' issue.
+ # logger.info('{:>16s} : {:<.3f} [M]'.format('Max Memery', torch.cuda.max_memory_allocated(torch.cuda.current_device())/1024**2)) # Memery
+ end.record()
+ torch.cuda.synchronize()
+ test_results['runtime'].append(start.elapsed_time(end)) # milliseconds
+
+
+# torch.cuda.synchronize()
+# start = time.time()
+# img_E = model(img_L)
+# torch.cuda.synchronize()
+# end = time.time()
+# test_results['runtime'].append(end-start) # seconds
+
+ # --------------------------------
+ # (2) img_E
+ # --------------------------------
+ img_E = util.tensor2uint(img_E)
+
+ if save_results:
+ util.imsave(img_E, os.path.join(E_path, img_name+ext))
+ ave_runtime = sum(test_results['runtime']) / len(test_results['runtime']) / 1000.0
+ logger.info('------> Average runtime of ({}) is : {:.6f} seconds'.format(L_path, ave_runtime))
+
+
+if __name__ == '__main__':
+
+ main()
diff --git a/KAIR/main_download_pretrained_models.py b/KAIR/main_download_pretrained_models.py
new file mode 100644
index 0000000000000000000000000000000000000000..02a067a173f0c4e1898ce2272af1117260524a5e
--- /dev/null
+++ b/KAIR/main_download_pretrained_models.py
@@ -0,0 +1,141 @@
+import argparse
+import os
+import requests
+import re
+
+
+"""
+How to use:
+download all the models:
+ python main_download_pretrained_models.py --models "all" --model_dir "model_zoo"
+
+download DnCNN models:
+ python main_download_pretrained_models.py --models "DnCNN" --model_dir "model_zoo"
+
+download SRMD models:
+ python main_download_pretrained_models.py --models "SRMD" --model_dir "model_zoo"
+
+download BSRGAN models:
+ python main_download_pretrained_models.py --models "BSRGAN" --model_dir "model_zoo"
+
+download FFDNet models:
+ python main_download_pretrained_models.py --models "FFDNet" --model_dir "model_zoo"
+
+download DPSR models:
+ python main_download_pretrained_models.py --models "DPSR" --model_dir "model_zoo"
+
+download SwinIR models:
+ python main_download_pretrained_models.py --models "SwinIR" --model_dir "model_zoo"
+
+download VRT models:
+ python main_download_pretrained_models.py --models "VRT" --model_dir "model_zoo"
+
+download other models:
+ python main_download_pretrained_models.py --models "others" --model_dir "model_zoo"
+
+------------------------------------------------------------------
+
+download 'dncnn_15.pth' and 'dncnn_50.pth'
+ python main_download_pretrained_models.py --models "dncnn_15.pth dncnn_50.pth" --model_dir "model_zoo"
+
+------------------------------------------------------------------
+
+download DnCNN models and 'BSRGAN.pth'
+ python main_download_pretrained_models.py --models "DnCNN BSRGAN.pth" --model_dir "model_zoo"
+
+"""
+
+
+def download_pretrained_model(model_dir='model_zoo', model_name='dncnn3.pth'):
+ if os.path.exists(os.path.join(model_dir, model_name)):
+ print(f'already exists, skip downloading [{model_name}]')
+ else:
+ os.makedirs(model_dir, exist_ok=True)
+ if 'SwinIR' in model_name:
+ url = 'https://github.com/JingyunLiang/SwinIR/releases/download/v0.0/{}'.format(model_name)
+ elif 'VRT' in model_name:
+ url = 'https://github.com/JingyunLiang/VRT/releases/download/v0.0/{}'.format(model_name)
+ else:
+ url = 'https://github.com/cszn/KAIR/releases/download/v1.0/{}'.format(model_name)
+ r = requests.get(url, allow_redirects=True)
+ print(f'downloading [{model_dir}/{model_name}] ...')
+ open(os.path.join(model_dir, model_name), 'wb').write(r.content)
+ print('done!')
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--models',
+ type=lambda s: re.split(' |, ', s),
+ default = "dncnn3.pth",
+ help='comma or space delimited list of characters, e.g., "DnCNN", "DnCNN BSRGAN.pth", "dncnn_15.pth dncnn_50.pth"')
+ parser.add_argument('--model_dir', type=str, default='model_zoo', help='path of model_zoo')
+ args = parser.parse_args()
+
+ print(f'trying to download {args.models}')
+
+ method_model_zoo = {'DnCNN': ['dncnn_15.pth', 'dncnn_25.pth', 'dncnn_50.pth', 'dncnn3.pth', 'dncnn_color_blind.pth', 'dncnn_gray_blind.pth'],
+ 'SRMD': ['srmdnf_x2.pth', 'srmdnf_x3.pth', 'srmdnf_x4.pth', 'srmd_x2.pth', 'srmd_x3.pth', 'srmd_x4.pth'],
+ 'DPSR': ['dpsr_x2.pth', 'dpsr_x3.pth', 'dpsr_x4.pth', 'dpsr_x4_gan.pth'],
+ 'FFDNet': ['ffdnet_color.pth', 'ffdnet_gray.pth', 'ffdnet_color_clip.pth', 'ffdnet_gray_clip.pth'],
+ 'USRNet': ['usrgan.pth', 'usrgan_tiny.pth', 'usrnet.pth', 'usrnet_tiny.pth'],
+ 'DPIR': ['drunet_gray.pth', 'drunet_color.pth', 'drunet_deblocking_color.pth', 'drunet_deblocking_grayscale.pth'],
+ 'BSRGAN': ['BSRGAN.pth', 'BSRNet.pth', 'BSRGANx2.pth'],
+ 'IRCNN': ['ircnn_color.pth', 'ircnn_gray.pth'],
+ 'SwinIR': ['001_classicalSR_DF2K_s64w8_SwinIR-M_x2.pth', '001_classicalSR_DF2K_s64w8_SwinIR-M_x3.pth',
+ '001_classicalSR_DF2K_s64w8_SwinIR-M_x4.pth', '001_classicalSR_DF2K_s64w8_SwinIR-M_x8.pth',
+ '001_classicalSR_DIV2K_s48w8_SwinIR-M_x2.pth', '001_classicalSR_DIV2K_s48w8_SwinIR-M_x3.pth',
+ '001_classicalSR_DIV2K_s48w8_SwinIR-M_x4.pth', '001_classicalSR_DIV2K_s48w8_SwinIR-M_x8.pth',
+ '002_lightweightSR_DIV2K_s64w8_SwinIR-S_x2.pth', '002_lightweightSR_DIV2K_s64w8_SwinIR-S_x3.pth',
+ '002_lightweightSR_DIV2K_s64w8_SwinIR-S_x4.pth', '003_realSR_BSRGAN_DFO_s64w8_SwinIR-M_x4_GAN.pth',
+ '003_realSR_BSRGAN_DFO_s64w8_SwinIR-M_x4_PSNR.pth', '004_grayDN_DFWB_s128w8_SwinIR-M_noise15.pth',
+ '004_grayDN_DFWB_s128w8_SwinIR-M_noise25.pth', '004_grayDN_DFWB_s128w8_SwinIR-M_noise50.pth',
+ '005_colorDN_DFWB_s128w8_SwinIR-M_noise15.pth', '005_colorDN_DFWB_s128w8_SwinIR-M_noise25.pth',
+ '005_colorDN_DFWB_s128w8_SwinIR-M_noise50.pth', '006_CAR_DFWB_s126w7_SwinIR-M_jpeg10.pth',
+ '006_CAR_DFWB_s126w7_SwinIR-M_jpeg20.pth', '006_CAR_DFWB_s126w7_SwinIR-M_jpeg30.pth',
+ '006_CAR_DFWB_s126w7_SwinIR-M_jpeg40.pth'],
+ 'VRT': ['001_VRT_videosr_bi_REDS_6frames.pth', '002_VRT_videosr_bi_REDS_16frames.pth',
+ '003_VRT_videosr_bi_Vimeo_7frames.pth', '004_VRT_videosr_bd_Vimeo_7frames.pth',
+ '005_VRT_videodeblurring_DVD.pth', '006_VRT_videodeblurring_GoPro.pth',
+ '007_VRT_videodeblurring_REDS.pth', '008_VRT_videodenoising_DAVIS.pth'],
+ 'others': ['msrresnet_x4_psnr.pth', 'msrresnet_x4_gan.pth', 'imdn_x4.pth', 'RRDB.pth', 'ESRGAN.pth',
+ 'FSSR_DPED.pth', 'FSSR_JPEG.pth', 'RealSR_DPED.pth', 'RealSR_JPEG.pth']
+ }
+
+ method_zoo = list(method_model_zoo.keys())
+ model_zoo = []
+ for b in list(method_model_zoo.values()):
+ model_zoo += b
+
+ if 'all' in args.models:
+ for method in method_zoo:
+ for model_name in method_model_zoo[method]:
+ download_pretrained_model(args.model_dir, model_name)
+ else:
+ for method_model in args.models:
+ if method_model in method_zoo: # method, need for loop
+ for model_name in method_model_zoo[method_model]:
+ if 'SwinIR' in model_name:
+ download_pretrained_model(os.path.join(args.model_dir, 'swinir'), model_name)
+ elif 'VRT' in model_name:
+ download_pretrained_model(os.path.join(args.model_dir, 'vrt'), model_name)
+ else:
+ download_pretrained_model(args.model_dir, model_name)
+ elif method_model in model_zoo: # model, do not need for loop
+ if 'SwinIR' in method_model:
+ download_pretrained_model(os.path.join(args.model_dir, 'swinir'), method_model)
+ elif 'VRT' in method_model:
+ download_pretrained_model(os.path.join(args.model_dir, 'vrt'), method_model)
+ else:
+ download_pretrained_model(args.model_dir, method_model)
+ else:
+ print(f'Do not find {method_model} from the pre-trained model zoo!')
+
+
+
+
+
+
+
+
+
diff --git a/KAIR/main_test_dncnn.py b/KAIR/main_test_dncnn.py
new file mode 100644
index 0000000000000000000000000000000000000000..d4fccb5b2ff41f5aa0c5de0b55f8ef2d7941f720
--- /dev/null
+++ b/KAIR/main_test_dncnn.py
@@ -0,0 +1,203 @@
+import os.path
+import logging
+import argparse
+
+import numpy as np
+from datetime import datetime
+from collections import OrderedDict
+# from scipy.io import loadmat
+
+import torch
+
+from utils import utils_logger
+from utils import utils_model
+from utils import utils_image as util
+
+
+'''
+Spyder (Python 3.6)
+PyTorch 1.1.0
+Windows 10 or Linux
+
+Kai Zhang (cskaizhang@gmail.com)
+github: https://github.com/cszn/KAIR
+ https://github.com/cszn/DnCNN
+
+@article{zhang2017beyond,
+ title={Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising},
+ author={Zhang, Kai and Zuo, Wangmeng and Chen, Yunjin and Meng, Deyu and Zhang, Lei},
+ journal={IEEE Transactions on Image Processing},
+ volume={26},
+ number={7},
+ pages={3142--3155},
+ year={2017},
+ publisher={IEEE}
+}
+
+% If you have any question, please feel free to contact with me.
+% Kai Zhang (e-mail: cskaizhang@gmail.com; github: https://github.com/cszn)
+
+by Kai Zhang (12/Dec./2019)
+'''
+
+"""
+# --------------------------------------------
+|--model_zoo # model_zoo
+ |--dncnn_15 # model_name
+ |--dncnn_25
+ |--dncnn_50
+ |--dncnn_gray_blind
+ |--dncnn_color_blind
+ |--dncnn3
+|--testset # testsets
+ |--set12 # testset_name
+ |--bsd68
+ |--cbsd68
+|--results # results
+ |--set12_dncnn_15 # result_name = testset_name + '_' + model_name
+ |--set12_dncnn_25
+ |--bsd68_dncnn_15
+# --------------------------------------------
+"""
+
+
+def main():
+
+ # ----------------------------------------
+ # Preparation
+ # ----------------------------------------
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--model_name', type=str, default='dncnn_25', help='dncnn_15, dncnn_25, dncnn_50, dncnn_gray_blind, dncnn_color_blind, dncnn3')
+ parser.add_argument('--testset_name', type=str, default='set12', help='test set, bsd68 | set12')
+ parser.add_argument('--noise_level_img', type=int, default=15, help='noise level: 15, 25, 50')
+ parser.add_argument('--x8', type=bool, default=False, help='x8 to boost performance')
+ parser.add_argument('--show_img', type=bool, default=False, help='show the image')
+ parser.add_argument('--model_pool', type=str, default='model_zoo', help='path of model_zoo')
+ parser.add_argument('--testsets', type=str, default='testsets', help='path of testing folder')
+ parser.add_argument('--results', type=str, default='results', help='path of results')
+ parser.add_argument('--need_degradation', type=bool, default=True, help='add noise or not')
+ parser.add_argument('--task_current', type=str, default='dn', help='dn for denoising, fixed!')
+ parser.add_argument('--sf', type=int, default=1, help='unused for denoising')
+ args = parser.parse_args()
+
+ if 'color' in args.model_name:
+ n_channels = 3 # fixed, 1 for grayscale image, 3 for color image
+ else:
+ n_channels = 1 # fixed for grayscale image
+ if args.model_name in ['dncnn_gray_blind', 'dncnn_color_blind', 'dncnn3']:
+ nb = 20 # fixed
+ else:
+ nb = 17 # fixed
+
+ result_name = args.testset_name + '_' + args.model_name # fixed
+ border = args.sf if args.task_current == 'sr' else 0 # shave boader to calculate PSNR and SSIM
+ model_path = os.path.join(args.model_pool, args.model_name+'.pth')
+
+ # ----------------------------------------
+ # L_path, E_path, H_path
+ # ----------------------------------------
+
+ L_path = os.path.join(args.testsets, args.testset_name) # L_path, for Low-quality images
+ H_path = L_path # H_path, for High-quality images
+ E_path = os.path.join(args.results, result_name) # E_path, for Estimated images
+ util.mkdir(E_path)
+
+ if H_path == L_path:
+ args.need_degradation = True
+ logger_name = result_name
+ utils_logger.logger_info(logger_name, log_path=os.path.join(E_path, logger_name+'.log'))
+ logger = logging.getLogger(logger_name)
+
+ need_H = True if H_path is not None else False
+ device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
+
+ # ----------------------------------------
+ # load model
+ # ----------------------------------------
+
+ from models.network_dncnn import DnCNN as net
+ model = net(in_nc=n_channels, out_nc=n_channels, nc=64, nb=nb, act_mode='R')
+ # model = net(in_nc=n_channels, out_nc=n_channels, nc=64, nb=nb, act_mode='BR') # use this if BN is not merged by utils_bnorm.merge_bn(model)
+ model.load_state_dict(torch.load(model_path), strict=True)
+ model.eval()
+ for k, v in model.named_parameters():
+ v.requires_grad = False
+ model = model.to(device)
+ logger.info('Model path: {:s}'.format(model_path))
+ number_parameters = sum(map(lambda x: x.numel(), model.parameters()))
+ logger.info('Params number: {}'.format(number_parameters))
+
+ test_results = OrderedDict()
+ test_results['psnr'] = []
+ test_results['ssim'] = []
+
+ logger.info('model_name:{}, image sigma:{}'.format(args.model_name, args.noise_level_img))
+ logger.info(L_path)
+ L_paths = util.get_image_paths(L_path)
+ H_paths = util.get_image_paths(H_path) if need_H else None
+
+ for idx, img in enumerate(L_paths):
+
+ # ------------------------------------
+ # (1) img_L
+ # ------------------------------------
+
+ img_name, ext = os.path.splitext(os.path.basename(img))
+ # logger.info('{:->4d}--> {:>10s}'.format(idx+1, img_name+ext))
+ img_L = util.imread_uint(img, n_channels=n_channels)
+ img_L = util.uint2single(img_L)
+
+ if args.need_degradation: # degradation process
+ np.random.seed(seed=0) # for reproducibility
+ img_L += np.random.normal(0, args.noise_level_img/255., img_L.shape)
+
+ util.imshow(util.single2uint(img_L), title='Noisy image with noise level {}'.format(args.noise_level_img)) if args.show_img else None
+
+ img_L = util.single2tensor4(img_L)
+ img_L = img_L.to(device)
+
+ # ------------------------------------
+ # (2) img_E
+ # ------------------------------------
+
+ if not args.x8:
+ img_E = model(img_L)
+ else:
+ img_E = utils_model.test_mode(model, img_L, mode=3)
+
+ img_E = util.tensor2uint(img_E)
+
+ if need_H:
+
+ # --------------------------------
+ # (3) img_H
+ # --------------------------------
+
+ img_H = util.imread_uint(H_paths[idx], n_channels=n_channels)
+ img_H = img_H.squeeze()
+
+ # --------------------------------
+ # PSNR and SSIM
+ # --------------------------------
+
+ psnr = util.calculate_psnr(img_E, img_H, border=border)
+ ssim = util.calculate_ssim(img_E, img_H, border=border)
+ test_results['psnr'].append(psnr)
+ test_results['ssim'].append(ssim)
+ logger.info('{:s} - PSNR: {:.2f} dB; SSIM: {:.4f}.'.format(img_name+ext, psnr, ssim))
+ util.imshow(np.concatenate([img_E, img_H], axis=1), title='Recovered / Ground-truth') if args.show_img else None
+
+ # ------------------------------------
+ # save results
+ # ------------------------------------
+
+ util.imsave(img_E, os.path.join(E_path, img_name+ext))
+
+ if need_H:
+ ave_psnr = sum(test_results['psnr']) / len(test_results['psnr'])
+ ave_ssim = sum(test_results['ssim']) / len(test_results['ssim'])
+ logger.info('Average PSNR/SSIM(RGB) - {} - PSNR: {:.2f} dB; SSIM: {:.4f}'.format(result_name, ave_psnr, ave_ssim))
+
+if __name__ == '__main__':
+
+ main()
diff --git a/KAIR/main_test_dncnn3_deblocking.py b/KAIR/main_test_dncnn3_deblocking.py
new file mode 100644
index 0000000000000000000000000000000000000000..0b117b919dd2507db21aeaabca06b2a50b69e96d
--- /dev/null
+++ b/KAIR/main_test_dncnn3_deblocking.py
@@ -0,0 +1,140 @@
+import os.path
+import logging
+
+import numpy as np
+from datetime import datetime
+from collections import OrderedDict
+
+import torch
+
+from utils import utils_logger
+from utils import utils_model
+from utils import utils_image as util
+#import os
+#os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
+
+
+'''
+Spyder (Python 3.6)
+PyTorch 1.1.0
+Windows 10 or Linux
+
+Kai Zhang (cskaizhang@gmail.com)
+github: https://github.com/cszn/KAIR
+ https://github.com/cszn/DnCNN
+
+@article{zhang2017beyond,
+ title={Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising},
+ author={Zhang, Kai and Zuo, Wangmeng and Chen, Yunjin and Meng, Deyu and Zhang, Lei},
+ journal={IEEE Transactions on Image Processing},
+ volume={26},
+ number={7},
+ pages={3142--3155},
+ year={2017},
+ publisher={IEEE}
+}
+
+% If you have any question, please feel free to contact with me.
+% Kai Zhang (e-mail: cskaizhang@gmail.com; github: https://github.com/cszn)
+
+by Kai Zhang (12/Dec./2019)
+'''
+
+"""
+# --------------------------------------------
+|--model_zoo # model_zoo
+ |--dncnn3 # model_name
+|--testset # testsets
+ |--set12 # testset_name
+ |--bsd68
+|--results # results
+ |--set12_dncnn3 # result_name = testset_name + '_' + model_name
+# --------------------------------------------
+"""
+
+
+def main():
+
+ # ----------------------------------------
+ # Preparation
+ # ----------------------------------------
+
+ model_name = 'dncnn3' # 'dncnn3'- can be used for blind Gaussian denoising, JPEG deblocking (quality factor 5-100) and super-resolution (x234)
+
+ # important!
+ testset_name = 'bsd68' # test set, low-quality grayscale/color JPEG images
+ n_channels = 1 # set 1 for grayscale image, set 3 for color image
+
+
+ x8 = False # default: False, x8 to boost performance
+ testsets = 'testsets' # fixed
+ results = 'results' # fixed
+ result_name = testset_name + '_' + model_name # fixed
+ L_path = os.path.join(testsets, testset_name) # L_path, for Low-quality grayscale/Y-channel JPEG images
+ E_path = os.path.join(results, result_name) # E_path, for Estimated images
+ util.mkdir(E_path)
+
+ model_pool = 'model_zoo' # fixed
+ model_path = os.path.join(model_pool, model_name+'.pth')
+ logger_name = result_name
+ utils_logger.logger_info(logger_name, log_path=os.path.join(E_path, logger_name+'.log'))
+ logger = logging.getLogger(logger_name)
+
+ device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
+
+ # ----------------------------------------
+ # load model
+ # ----------------------------------------
+
+ from models.network_dncnn import DnCNN as net
+ model = net(in_nc=1, out_nc=1, nc=64, nb=20, act_mode='R')
+ model.load_state_dict(torch.load(model_path), strict=True)
+ model.eval()
+ for k, v in model.named_parameters():
+ v.requires_grad = False
+ model = model.to(device)
+ logger.info('Model path: {:s}'.format(model_path))
+ number_parameters = sum(map(lambda x: x.numel(), model.parameters()))
+ logger.info('Params number: {}'.format(number_parameters))
+
+ logger.info(L_path)
+ L_paths = util.get_image_paths(L_path)
+
+ for idx, img in enumerate(L_paths):
+
+ # ------------------------------------
+ # (1) img_L
+ # ------------------------------------
+ img_name, ext = os.path.splitext(os.path.basename(img))
+ logger.info('{:->4d}--> {:>10s}'.format(idx+1, img_name+ext))
+ img_L = util.imread_uint(img, n_channels=n_channels)
+ img_L = util.uint2single(img_L)
+ if n_channels == 3:
+ ycbcr = util.rgb2ycbcr(img_L, False)
+ img_L = ycbcr[..., 0:1]
+ img_L = util.single2tensor4(img_L)
+ img_L = img_L.to(device)
+
+ # ------------------------------------
+ # (2) img_E
+ # ------------------------------------
+ if not x8:
+ img_E = model(img_L)
+ else:
+ img_E = utils_model.test_mode(model, img_L, mode=3)
+
+ img_E = util.tensor2single(img_E)
+ if n_channels == 3:
+ ycbcr[..., 0] = img_E
+ img_E = util.ycbcr2rgb(ycbcr)
+ img_E = util.single2uint(img_E)
+
+ # ------------------------------------
+ # save results
+ # ------------------------------------
+ util.imsave(img_E, os.path.join(E_path, img_name+'.png'))
+
+
+if __name__ == '__main__':
+
+ main()
diff --git a/KAIR/main_test_dpsr.py b/KAIR/main_test_dpsr.py
new file mode 100644
index 0000000000000000000000000000000000000000..15c106bc26e346fb415a720cc5a85423b7ceadc6
--- /dev/null
+++ b/KAIR/main_test_dpsr.py
@@ -0,0 +1,214 @@
+import os.path
+import logging
+import re
+
+import numpy as np
+from collections import OrderedDict
+
+import torch
+
+from utils import utils_logger
+from utils import utils_image as util
+from utils import utils_model
+
+
+'''
+Spyder (Python 3.6)
+PyTorch 1.1.0
+Windows 10 or Linux
+
+Kai Zhang (cskaizhang@gmail.com)
+github: https://github.com/cszn/KAIR
+ https://github.com/cszn/DPSR
+
+@inproceedings{zhang2019deep,
+ title={Deep Plug-and-Play Super-Resolution for Arbitrary Blur Kernels},
+ author={Zhang, Kai and Zuo, Wangmeng and Zhang, Lei},
+ booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
+ pages={1671--1681},
+ year={2019}
+}
+
+% If you have any question, please feel free to contact with me.
+% Kai Zhang (e-mail: cskaizhang@gmail.com; github: https://github.com/cszn)
+
+by Kai Zhang (12/Dec./2019)
+'''
+
+"""
+# --------------------------------------------
+testing code for the super-resolver prior of DPSR
+# --------------------------------------------
+|--model_zoo # model_zoo
+ |--dpsr_x2 # model_name, optimized for PSNR
+ |--dpsr_x3
+ |--dpsr_x4
+ |--dpsr_x4_gan # model_name, optimized for perceptual quality
+|--testset # testsets
+ |--set5 # testset_name
+ |--srbsd68
+|--results # results
+ |--set5_dpsr_x2 # result_name = testset_name + '_' + model_name
+ |--set5_dpsr_x3
+ |--set5_dpsr_x4
+ |--set5_dpsr_x4_gan
+ |--srbsd68_dpsr_x4_gan
+# --------------------------------------------
+"""
+
+
+def main():
+
+ # ----------------------------------------
+ # Preparation
+ # ----------------------------------------
+
+ noise_level_img = 0 # default: 0, noise level for LR image
+ noise_level_model = noise_level_img # noise level for model
+ model_name = 'dpsr_x4_gan' # 'dpsr_x2' | 'dpsr_x3' | 'dpsr_x4' | 'dpsr_x4_gan'
+ testset_name = 'set5' # test set, 'set5' | 'srbsd68'
+ need_degradation = True # default: True
+ x8 = False # default: False, x8 to boost performance
+ sf = [int(s) for s in re.findall(r'\d+', model_name)][0] # scale factor
+ show_img = False # default: False
+
+
+
+ task_current = 'sr' # 'dn' for denoising | 'sr' for super-resolution
+ n_channels = 3 # fixed
+ nc = 96 # fixed, number of channels
+ nb = 16 # fixed, number of conv layers
+ model_pool = 'model_zoo' # fixed
+ testsets = 'testsets' # fixed
+ results = 'results' # fixed
+ result_name = testset_name + '_' + model_name
+ border = sf if task_current == 'sr' else 0 # shave boader to calculate PSNR and SSIM
+ model_path = os.path.join(model_pool, model_name+'.pth')
+
+ # ----------------------------------------
+ # L_path, E_path, H_path
+ # ----------------------------------------
+
+ L_path = os.path.join(testsets, testset_name) # L_path, for Low-quality images
+ H_path = L_path # H_path, for High-quality images
+ E_path = os.path.join(results, result_name) # E_path, for Estimated images
+ util.mkdir(E_path)
+
+ if H_path == L_path:
+ need_degradation = True
+ logger_name = result_name
+ utils_logger.logger_info(logger_name, log_path=os.path.join(E_path, logger_name+'.log'))
+ logger = logging.getLogger(logger_name)
+
+ need_H = True if H_path is not None else False
+ device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
+
+ # ----------------------------------------
+ # load model
+ # ----------------------------------------
+
+ from models.network_dpsr import MSRResNet_prior as net
+ model = net(in_nc=n_channels+1, out_nc=n_channels, nc=nc, nb=nb, upscale=sf, act_mode='R', upsample_mode='pixelshuffle')
+ model.load_state_dict(torch.load(model_path), strict=False)
+ model.eval()
+ for k, v in model.named_parameters():
+ v.requires_grad = False
+ model = model.to(device)
+ logger.info('Model path: {:s}'.format(model_path))
+ number_parameters = sum(map(lambda x: x.numel(), model.parameters()))
+ logger.info('Params number: {}'.format(number_parameters))
+
+ test_results = OrderedDict()
+ test_results['psnr'] = []
+ test_results['ssim'] = []
+ test_results['psnr_y'] = []
+ test_results['ssim_y'] = []
+
+ logger.info('model_name:{}, model sigma:{}, image sigma:{}'.format(model_name, noise_level_img, noise_level_model))
+ logger.info(L_path)
+ L_paths = util.get_image_paths(L_path)
+ H_paths = util.get_image_paths(H_path) if need_H else None
+
+ for idx, img in enumerate(L_paths):
+
+ # ------------------------------------
+ # (1) img_L
+ # ------------------------------------
+
+ img_name, ext = os.path.splitext(os.path.basename(img))
+ # logger.info('{:->4d}--> {:>10s}'.format(idx+1, img_name+ext))
+ img_L = util.imread_uint(img, n_channels=n_channels)
+ img_L = util.uint2single(img_L)
+
+ # degradation process, bicubic downsampling + Gaussian noise
+ if need_degradation:
+ img_L = util.modcrop(img_L, sf)
+ img_L = util.imresize_np(img_L, 1/sf)
+ np.random.seed(seed=0) # for reproducibility
+ img_L += np.random.normal(0, noise_level_img/255., img_L.shape)
+
+ util.imshow(util.single2uint(img_L), title='LR image with noise level {}'.format(noise_level_img)) if show_img else None
+
+ img_L = util.single2tensor4(img_L)
+ noise_level_map = torch.full((1, 1, img_L.size(2), img_L.size(3)), noise_level_model/255.).type_as(img_L)
+ img_L = torch.cat((img_L, noise_level_map), dim=1)
+ img_L = img_L.to(device)
+
+ # ------------------------------------
+ # (2) img_E
+ # ------------------------------------
+
+ if not x8:
+ img_E = model(img_L)
+ else:
+ img_E = utils_model.test_mode(model, img_L, mode=3, sf=sf)
+
+ img_E = util.tensor2uint(img_E)
+
+ if need_H:
+
+ # --------------------------------
+ # (3) img_H
+ # --------------------------------
+
+ img_H = util.imread_uint(H_paths[idx], n_channels=n_channels)
+ img_H = img_H.squeeze()
+ img_H = util.modcrop(img_H, sf)
+
+ # --------------------------------
+ # PSNR and SSIM
+ # --------------------------------
+
+ psnr = util.calculate_psnr(img_E, img_H, border=border)
+ ssim = util.calculate_ssim(img_E, img_H, border=border)
+ test_results['psnr'].append(psnr)
+ test_results['ssim'].append(ssim)
+ logger.info('{:s} - PSNR: {:.2f} dB; SSIM: {:.4f}.'.format(img_name+ext, psnr, ssim))
+ util.imshow(np.concatenate([img_E, img_H], axis=1), title='Recovered / Ground-truth') if show_img else None
+
+ if np.ndim(img_H) == 3: # RGB image
+ img_E_y = util.rgb2ycbcr(img_E, only_y=True)
+ img_H_y = util.rgb2ycbcr(img_H, only_y=True)
+ psnr_y = util.calculate_psnr(img_E_y, img_H_y, border=border)
+ ssim_y = util.calculate_ssim(img_E_y, img_H_y, border=border)
+ test_results['psnr_y'].append(psnr_y)
+ test_results['ssim_y'].append(ssim_y)
+
+ # ------------------------------------
+ # save results
+ # ------------------------------------
+
+ util.imsave(img_E, os.path.join(E_path, img_name+'.png'))
+
+ if need_H:
+ ave_psnr = sum(test_results['psnr']) / len(test_results['psnr'])
+ ave_ssim = sum(test_results['ssim']) / len(test_results['ssim'])
+ logger.info('Average PSNR/SSIM(RGB) - {} - x{} --PSNR: {:.2f} dB; SSIM: {:.4f}'.format(result_name, sf, ave_psnr, ave_ssim))
+ if np.ndim(img_H) == 3:
+ ave_psnr_y = sum(test_results['psnr_y']) / len(test_results['psnr_y'])
+ ave_ssim_y = sum(test_results['ssim_y']) / len(test_results['ssim_y'])
+ logger.info('Average PSNR/SSIM( Y ) - {} - x{} - PSNR: {:.2f} dB; SSIM: {:.4f}'.format(result_name, sf, ave_psnr_y, ave_ssim_y))
+
+if __name__ == '__main__':
+
+ main()
diff --git a/KAIR/main_test_face_enhancement.py b/KAIR/main_test_face_enhancement.py
new file mode 100644
index 0000000000000000000000000000000000000000..ed9e0aad09736ded3cf6a9fb6b92b69d7b7b5b68
--- /dev/null
+++ b/KAIR/main_test_face_enhancement.py
@@ -0,0 +1,172 @@
+'''
+@paper: GAN Prior Embedded Network for Blind Face Restoration in the Wild (CVPR2021)
+@author: yangxy (yangtao9009@gmail.com)
+https://github.com/yangxy/GPEN
+@inproceedings{Yang2021GPEN,
+ title={GAN Prior Embedded Network for Blind Face Restoration in the Wild},
+ author={Tao Yang, Peiran Ren, Xuansong Xie, and Lei Zhang},
+ booktitle={IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
+ year={2021}
+}
+© Alibaba, 2021. For academic and non-commercial use only.
+==================================================
+slightly modified by Kai Zhang (2021-06-03)
+https://github.com/cszn/KAIR
+
+How to run:
+
+step 1: Download model and model and put them into `model_zoo`.
+RetinaFace-R50.pth: https://public-vigen-video.oss-cn-shanghai.aliyuncs.com/robin/models/RetinaFace-R50.pth
+GPEN-512.pth: https://public-vigen-video.oss-cn-shanghai.aliyuncs.com/robin/models/GPEN-512.pth
+
+step 2: Install ninja by `pip install ninja`; set for your own testing images
+
+step 3: `python main_test_face_enhancement.py`
+==================================================
+'''
+
+
+import os
+import cv2
+import glob
+import numpy as np
+import torch
+
+from utils.utils_alignfaces import warp_and_crop_face, get_reference_facial_points
+from utils import utils_image as util
+
+from retinaface.retinaface_detection import RetinaFaceDetection
+from models.network_faceenhancer import FullGenerator as enhancer_net
+
+
+class faceenhancer(object):
+ def __init__(self, model_path='model_zoo/GPEN-512.pth', size=512, channel_multiplier=2):
+ self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
+ self.model_path = model_path
+ self.size = size
+ self.model = enhancer_net(self.size, 512, 8, channel_multiplier).to(self.device)
+ self.model.load_state_dict(torch.load(self.model_path))
+ self.model.eval()
+
+ def process(self, img):
+ '''
+ img: uint8 RGB image, (W, H, 3)
+ out: uint8 RGB image, (W, H, 3)
+ '''
+ img = cv2.resize(img, (self.size, self.size))
+ img = util.uint2tensor4(img)
+ img = (img - 0.5) / 0.5
+ img = img.to(self.device)
+
+ with torch.no_grad():
+ out, __ = self.model(img)
+
+ out = util.tensor2uint(out * 0.5 + 0.5)
+ return out
+
+
+class faceenhancer_with_detection_alignment(object):
+ def __init__(self, model_path, size=512, channel_multiplier=2):
+ self.facedetector = RetinaFaceDetection('model_zoo/RetinaFace-R50.pth')
+ self.faceenhancer = faceenhancer(model_path, size, channel_multiplier)
+ self.size = size
+ self.threshold = 0.9
+
+ self.mask = np.zeros((512, 512), np.float32)
+ cv2.rectangle(self.mask, (26, 26), (486, 486), (1, 1, 1), -1, cv2.LINE_AA)
+ self.mask = cv2.GaussianBlur(self.mask, (101, 101), 11)
+ self.mask = cv2.GaussianBlur(self.mask, (101, 101), 11)
+
+ self.kernel = np.array((
+ [0.0625, 0.125, 0.0625],
+ [0.125, 0.25, 0.125],
+ [0.0625, 0.125, 0.0625]), dtype="float32")
+
+ # get the reference 5 landmarks position in the crop settings
+ default_square = True
+ inner_padding_factor = 0.25
+ outer_padding = (0, 0)
+ self.reference_5pts = get_reference_facial_points(
+ (self.size, self.size), inner_padding_factor, outer_padding, default_square)
+
+ def process(self, img):
+ '''
+ img: uint8 RGB image, (W, H, 3)
+ img, orig_faces, enhanced_faces: uint8 RGB image / cropped face images
+ '''
+ img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
+ facebs, landms = self.facedetector.detect(img)
+
+ orig_faces, enhanced_faces = [], []
+ height, width = img.shape[:2]
+ full_mask = np.zeros((height, width), dtype=np.float32)
+ full_img = np.zeros(img.shape, dtype=np.uint8)
+
+ for i, (faceb, facial5points) in enumerate(zip(facebs, landms)):
+ if faceb[4]0)] = tmp_mask[np.where(mask>0)]
+ full_img[np.where(mask>0)] = tmp_img[np.where(mask>0)]
+
+ full_mask = full_mask[:, :, np.newaxis]
+ img = cv2.convertScaleAbs(img*(1-full_mask) + full_img*full_mask)
+
+ return img, orig_faces, enhanced_faces
+
+
+if __name__=='__main__':
+
+ inputdir = os.path.join('testsets', 'real_faces')
+ outdir = os.path.join('testsets', 'real_faces_results')
+ os.makedirs(outdir, exist_ok=True)
+
+ # whether use the face detection&alignment or not
+ need_face_detection = True
+
+ if need_face_detection:
+ enhancer = faceenhancer_with_detection_alignment(model_path=os.path.join('model_zoo','GPEN-512.pth'), size=512, channel_multiplier=2)
+ else:
+ enhancer = faceenhancer(model_path=os.path.join('model_zoo','GPEN-512.pth'), size=512, channel_multiplier=2)
+
+ for idx, img_file in enumerate(util.get_image_paths(inputdir)):
+ img_name, ext = os.path.splitext(os.path.basename(img_file))
+ img_L = util.imread_uint(img_file, n_channels=3)
+
+ print('{:->4d} --> {:4d}--> {:>10s}'.format(idx+1, img_name+ext))
+ img_L = util.imread_uint(img, n_channels=n_channels)
+ img_L = util.uint2single(img_L)
+
+ if need_degradation: # degradation process
+ np.random.seed(seed=0) # for reproducibility
+ img_L += np.random.normal(0, noise_level_img/255., img_L.shape)
+ if use_clip:
+ img_L = util.uint2single(util.single2uint(img_L))
+
+ util.imshow(util.single2uint(img_L), title='Noisy image with noise level {}'.format(noise_level_img)) if show_img else None
+
+ img_L = util.single2tensor4(img_L)
+ noise_level_map = torch.ones((1, 1, img_L.size(2), img_L.size(3)), dtype=torch.float).mul_(noise_level_model/255.)
+ img_L = torch.cat((img_L, noise_level_map), dim=1)
+ img_L = img_L.to(device)
+
+ # ------------------------------------
+ # (2) img_E
+ # ------------------------------------
+
+ if not x8:
+ img_E = model(img_L)
+ else:
+ img_E = utils_model.test_mode(model, img_L, mode=3)
+
+ img_E = util.tensor2uint(img_E)
+
+ if need_H:
+
+ # --------------------------------
+ # (3) img_H
+ # --------------------------------
+
+ img_H = util.imread_uint(H_paths[idx], n_channels=n_channels)
+ img_H = img_H.squeeze()
+
+ # --------------------------------
+ # PSNR and SSIM
+ # --------------------------------
+
+ psnr = util.calculate_psnr(img_E, img_H, border=border)
+ ssim = util.calculate_ssim(img_E, img_H, border=border)
+ test_results['psnr'].append(psnr)
+ test_results['ssim'].append(ssim)
+ logger.info('{:s} - PSNR: {:.2f} dB; SSIM: {:.4f}.'.format(img_name+ext, psnr, ssim))
+ util.imshow(np.concatenate([img_E, img_H], axis=1), title='Recovered / Ground-truth') if show_img else None
+
+ # ------------------------------------
+ # save results
+ # ------------------------------------
+
+ util.imsave(img_E, os.path.join(E_path, img_name+ext))
+
+ if need_H:
+ ave_psnr = sum(test_results['psnr']) / len(test_results['psnr'])
+ ave_ssim = sum(test_results['ssim']) / len(test_results['ssim'])
+ logger.info('Average PSNR/SSIM(RGB) - {} - PSNR: {:.2f} dB; SSIM: {:.4f}'.format(result_name, ave_psnr, ave_ssim))
+
+if __name__ == '__main__':
+
+ main()
diff --git a/KAIR/main_test_ffdnet.py b/KAIR/main_test_ffdnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..9407259b67fb2fdd6525f91151d7ec9d342b54da
--- /dev/null
+++ b/KAIR/main_test_ffdnet.py
@@ -0,0 +1,198 @@
+import os.path
+import logging
+
+import numpy as np
+from collections import OrderedDict
+
+import torch
+
+from utils import utils_logger
+from utils import utils_image as util
+
+
+'''
+Spyder (Python 3.6)
+PyTorch 1.1.0
+Windows 10 or Linux
+
+Kai Zhang (cskaizhang@gmail.com)
+github: https://github.com/cszn/KAIR
+ https://github.com/cszn/FFDNet
+
+@article{zhang2018ffdnet,
+ title={FFDNet: Toward a fast and flexible solution for CNN-based image denoising},
+ author={Zhang, Kai and Zuo, Wangmeng and Zhang, Lei},
+ journal={IEEE Transactions on Image Processing},
+ volume={27},
+ number={9},
+ pages={4608--4622},
+ year={2018},
+ publisher={IEEE}
+}
+
+% If you have any question, please feel free to contact with me.
+% Kai Zhang (e-mail: cskaizhang@gmail.com; github: https://github.com/cszn)
+
+by Kai Zhang (12/Dec./2019)
+'''
+
+"""
+# --------------------------------------------
+|--model_zoo # model_zoo
+ |--ffdnet_gray # model_name, for color images
+ |--ffdnet_color
+ |--ffdnet_color_clip # for clipped uint8 color images
+ |--ffdnet_gray_clip
+|--testset # testsets
+ |--set12 # testset_name
+ |--bsd68
+ |--cbsd68
+|--results # results
+ |--set12_ffdnet_gray # result_name = testset_name + '_' + model_name
+ |--set12_ffdnet_color
+ |--cbsd68_ffdnet_color_clip
+# --------------------------------------------
+"""
+
+
+def main():
+
+ # ----------------------------------------
+ # Preparation
+ # ----------------------------------------
+
+ noise_level_img = 15 # noise level for noisy image
+ noise_level_model = noise_level_img # noise level for model
+ model_name = 'ffdnet_gray' # 'ffdnet_gray' | 'ffdnet_color' | 'ffdnet_color_clip' | 'ffdnet_gray_clip'
+ testset_name = 'bsd68' # test set, 'bsd68' | 'cbsd68' | 'set12'
+ need_degradation = True # default: True
+ show_img = False # default: False
+
+
+
+
+ task_current = 'dn' # 'dn' for denoising | 'sr' for super-resolution
+ sf = 1 # unused for denoising
+ if 'color' in model_name:
+ n_channels = 3 # setting for color image
+ nc = 96 # setting for color image
+ nb = 12 # setting for color image
+ else:
+ n_channels = 1 # setting for grayscale image
+ nc = 64 # setting for grayscale image
+ nb = 15 # setting for grayscale image
+ if 'clip' in model_name:
+ use_clip = True # clip the intensities into range of [0, 1]
+ else:
+ use_clip = False
+ model_pool = 'model_zoo' # fixed
+ testsets = 'testsets' # fixed
+ results = 'results' # fixed
+ result_name = testset_name + '_' + model_name
+ border = sf if task_current == 'sr' else 0 # shave boader to calculate PSNR and SSIM
+ model_path = os.path.join(model_pool, model_name+'.pth')
+
+ # ----------------------------------------
+ # L_path, E_path, H_path
+ # ----------------------------------------
+
+ L_path = os.path.join(testsets, testset_name) # L_path, for Low-quality images
+ H_path = L_path # H_path, for High-quality images
+ E_path = os.path.join(results, result_name) # E_path, for Estimated images
+ util.mkdir(E_path)
+
+ if H_path == L_path:
+ need_degradation = True
+ logger_name = result_name
+ utils_logger.logger_info(logger_name, log_path=os.path.join(E_path, logger_name+'.log'))
+ logger = logging.getLogger(logger_name)
+
+ need_H = True if H_path is not None else False
+ device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
+
+ # ----------------------------------------
+ # load model
+ # ----------------------------------------
+
+ from models.network_ffdnet import FFDNet as net
+ model = net(in_nc=n_channels, out_nc=n_channels, nc=nc, nb=nb, act_mode='R')
+ model.load_state_dict(torch.load(model_path), strict=True)
+ model.eval()
+ for k, v in model.named_parameters():
+ v.requires_grad = False
+ model = model.to(device)
+ logger.info('Model path: {:s}'.format(model_path))
+
+ test_results = OrderedDict()
+ test_results['psnr'] = []
+ test_results['ssim'] = []
+
+ logger.info('model_name:{}, model sigma:{}, image sigma:{}'.format(model_name, noise_level_img, noise_level_model))
+ logger.info(L_path)
+ L_paths = util.get_image_paths(L_path)
+ H_paths = util.get_image_paths(H_path) if need_H else None
+
+ for idx, img in enumerate(L_paths):
+
+ # ------------------------------------
+ # (1) img_L
+ # ------------------------------------
+
+ img_name, ext = os.path.splitext(os.path.basename(img))
+ # logger.info('{:->4d}--> {:>10s}'.format(idx+1, img_name+ext))
+ img_L = util.imread_uint(img, n_channels=n_channels)
+ img_L = util.uint2single(img_L)
+
+ if need_degradation: # degradation process
+ np.random.seed(seed=0) # for reproducibility
+ img_L += np.random.normal(0, noise_level_img/255., img_L.shape)
+ if use_clip:
+ img_L = util.uint2single(util.single2uint(img_L))
+
+ util.imshow(util.single2uint(img_L), title='Noisy image with noise level {}'.format(noise_level_img)) if show_img else None
+
+ img_L = util.single2tensor4(img_L)
+ img_L = img_L.to(device)
+
+ sigma = torch.full((1,1,1,1), noise_level_model/255.).type_as(img_L)
+
+ # ------------------------------------
+ # (2) img_E
+ # ------------------------------------
+
+ img_E = model(img_L, sigma)
+ img_E = util.tensor2uint(img_E)
+
+ if need_H:
+
+ # --------------------------------
+ # (3) img_H
+ # --------------------------------
+ img_H = util.imread_uint(H_paths[idx], n_channels=n_channels)
+ img_H = img_H.squeeze()
+
+ # --------------------------------
+ # PSNR and SSIM
+ # --------------------------------
+
+ psnr = util.calculate_psnr(img_E, img_H, border=border)
+ ssim = util.calculate_ssim(img_E, img_H, border=border)
+ test_results['psnr'].append(psnr)
+ test_results['ssim'].append(ssim)
+ logger.info('{:s} - PSNR: {:.2f} dB; SSIM: {:.4f}.'.format(img_name+ext, psnr, ssim))
+ util.imshow(np.concatenate([img_E, img_H], axis=1), title='Recovered / Ground-truth') if show_img else None
+
+ # ------------------------------------
+ # save results
+ # ------------------------------------
+
+ util.imsave(img_E, os.path.join(E_path, img_name+ext))
+
+ if need_H:
+ ave_psnr = sum(test_results['psnr']) / len(test_results['psnr'])
+ ave_ssim = sum(test_results['ssim']) / len(test_results['ssim'])
+ logger.info('Average PSNR/SSIM(RGB) - {} - PSNR: {:.2f} dB; SSIM: {:.4f}'.format(result_name, ave_psnr, ave_ssim))
+
+if __name__ == '__main__':
+
+ main()
diff --git a/KAIR/main_test_imdn.py b/KAIR/main_test_imdn.py
new file mode 100644
index 0000000000000000000000000000000000000000..1c597a00b49920e6ecfd308bdc4614950492030a
--- /dev/null
+++ b/KAIR/main_test_imdn.py
@@ -0,0 +1,212 @@
+import os.path
+import logging
+import re
+
+import numpy as np
+from collections import OrderedDict
+
+import torch
+
+from utils import utils_logger
+from utils import utils_image as util
+from utils import utils_model
+
+
+'''
+Spyder (Python 3.6)
+PyTorch 1.1.0
+Windows 10 or Linux
+
+Kai Zhang (cskaizhang@gmail.com)
+github: https://github.com/cszn/KAIR
+
+If you have any question, please feel free to contact with me.
+Kai Zhang (e-mail: cskaizhang@gmail.com)
+(github: https://github.com/cszn/KAIR)
+
+by Kai Zhang (12/Dec./2019)
+'''
+
+"""
+# --------------------------------------------
+# simplified information multi-distillation
+# network (IMDN) for SR
+# --------------------------------------------
+@inproceedings{hui2019lightweight,
+ title={Lightweight Image Super-Resolution with Information Multi-distillation Network},
+ author={Hui, Zheng and Gao, Xinbo and Yang, Yunchu and Wang, Xiumei},
+ booktitle={Proceedings of the 27th ACM International Conference on Multimedia (ACM MM)},
+ pages={2024--2032},
+ year={2019}
+}
+@inproceedings{zhang2019aim,
+ title={AIM 2019 Challenge on Constrained Super-Resolution: Methods and Results},
+ author={Kai Zhang and Shuhang Gu and Radu Timofte and others},
+ booktitle={IEEE International Conference on Computer Vision Workshops},
+ year={2019}
+}
+# --------------------------------------------
+|--model_zoo # model_zoo
+ |--imdn_x4 # model_name, optimized for PSNR
+|--testset # testsets
+ |--set5 # testset_name
+ |--srbsd68
+|--results # results
+ |--set5_imdn_x4 # result_name = testset_name + '_' + model_name
+# --------------------------------------------
+"""
+
+
+def main():
+
+ # ----------------------------------------
+ # Preparation
+ # ----------------------------------------
+
+ model_name = 'imdn_x4' # 'imdn_x4'
+ testset_name = 'set5' # test set, 'set5' | 'srbsd68'
+ need_degradation = True # default: True
+ x8 = False # default: False, x8 to boost performance, default: False
+ sf = [int(s) for s in re.findall(r'\d+', model_name)][0] # scale factor
+ show_img = False # default: False
+
+
+
+
+ task_current = 'sr' # 'dn' for denoising | 'sr' for super-resolution
+ n_channels = 3 # fixed
+ model_pool = 'model_zoo' # fixed
+ testsets = 'testsets' # fixed
+ results = 'results' # fixed
+ noise_level_img = 0 # fixed: 0, noise level for LR image
+ result_name = testset_name + '_' + model_name
+ border = sf if task_current == 'sr' else 0 # shave boader to calculate PSNR and SSIM
+ model_path = os.path.join(model_pool, model_name+'.pth')
+
+ # ----------------------------------------
+ # L_path, E_path, H_path
+ # ----------------------------------------
+
+ L_path = os.path.join(testsets, testset_name) # L_path, for Low-quality images
+ H_path = L_path # H_path, for High-quality images
+ E_path = os.path.join(results, result_name) # E_path, for Estimated images
+ util.mkdir(E_path)
+
+ if H_path == L_path:
+ need_degradation = True
+ logger_name = result_name
+ utils_logger.logger_info(logger_name, log_path=os.path.join(E_path, logger_name+'.log'))
+ logger = logging.getLogger(logger_name)
+
+ need_H = True if H_path is not None else False
+ device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
+
+ # ----------------------------------------
+ # load model
+ # ----------------------------------------
+
+ from models.network_imdn import IMDN as net
+ model = net(in_nc=n_channels, out_nc=n_channels, nc=64, nb=8, upscale=4, act_mode='L', upsample_mode='pixelshuffle')
+
+ model.load_state_dict(torch.load(model_path), strict=True)
+ model.eval()
+ for k, v in model.named_parameters():
+ v.requires_grad = False
+ model = model.to(device)
+ logger.info('Model path: {:s}'.format(model_path))
+ number_parameters = sum(map(lambda x: x.numel(), model.parameters()))
+ logger.info('Params number: {}'.format(number_parameters))
+
+ test_results = OrderedDict()
+ test_results['psnr'] = []
+ test_results['ssim'] = []
+ test_results['psnr_y'] = []
+ test_results['ssim_y'] = []
+
+ logger.info('model_name:{}, image sigma:{}'.format(model_name, noise_level_img))
+ logger.info(L_path)
+ L_paths = util.get_image_paths(L_path)
+ H_paths = util.get_image_paths(H_path) if need_H else None
+
+ for idx, img in enumerate(L_paths):
+
+ # ------------------------------------
+ # (1) img_L
+ # ------------------------------------
+
+ img_name, ext = os.path.splitext(os.path.basename(img))
+ # logger.info('{:->4d}--> {:>10s}'.format(idx+1, img_name+ext))
+ img_L = util.imread_uint(img, n_channels=n_channels)
+ img_L = util.uint2single(img_L)
+
+ # degradation process, bicubic downsampling
+ if need_degradation:
+ img_L = util.modcrop(img_L, sf)
+ img_L = util.imresize_np(img_L, 1/sf)
+ # img_L = util.uint2single(util.single2uint(img_L))
+ # np.random.seed(seed=0) # for reproducibility
+ # img_L += np.random.normal(0, noise_level_img/255., img_L.shape)
+
+ util.imshow(util.single2uint(img_L), title='LR image with noise level {}'.format(noise_level_img)) if show_img else None
+
+ img_L = util.single2tensor4(img_L)
+ img_L = img_L.to(device)
+
+ # ------------------------------------
+ # (2) img_E
+ # ------------------------------------
+
+ if not x8:
+ img_E = model(img_L)
+ else:
+ img_E = utils_model.test_mode(model, img_L, mode=3, sf=sf)
+
+ img_E = util.tensor2uint(img_E)
+
+ if need_H:
+
+ # --------------------------------
+ # (3) img_H
+ # --------------------------------
+
+ img_H = util.imread_uint(H_paths[idx], n_channels=n_channels)
+ img_H = img_H.squeeze()
+ img_H = util.modcrop(img_H, sf)
+
+ # --------------------------------
+ # PSNR and SSIM
+ # --------------------------------
+
+ psnr = util.calculate_psnr(img_E, img_H, border=border)
+ ssim = util.calculate_ssim(img_E, img_H, border=border)
+ test_results['psnr'].append(psnr)
+ test_results['ssim'].append(ssim)
+ logger.info('{:s} - PSNR: {:.2f} dB; SSIM: {:.4f}.'.format(img_name+ext, psnr, ssim))
+ util.imshow(np.concatenate([img_E, img_H], axis=1), title='Recovered / Ground-truth') if show_img else None
+
+ if np.ndim(img_H) == 3: # RGB image
+ img_E_y = util.rgb2ycbcr(img_E, only_y=True)
+ img_H_y = util.rgb2ycbcr(img_H, only_y=True)
+ psnr_y = util.calculate_psnr(img_E_y, img_H_y, border=border)
+ ssim_y = util.calculate_ssim(img_E_y, img_H_y, border=border)
+ test_results['psnr_y'].append(psnr_y)
+ test_results['ssim_y'].append(ssim_y)
+
+ # ------------------------------------
+ # save results
+ # ------------------------------------
+
+ util.imsave(img_E, os.path.join(E_path, img_name+'.png'))
+
+ if need_H:
+ ave_psnr = sum(test_results['psnr']) / len(test_results['psnr'])
+ ave_ssim = sum(test_results['ssim']) / len(test_results['ssim'])
+ logger.info('Average PSNR/SSIM(RGB) - {} - x{} --PSNR: {:.2f} dB; SSIM: {:.4f}'.format(result_name, sf, ave_psnr, ave_ssim))
+ if np.ndim(img_H) == 3:
+ ave_psnr_y = sum(test_results['psnr_y']) / len(test_results['psnr_y'])
+ ave_ssim_y = sum(test_results['ssim_y']) / len(test_results['ssim_y'])
+ logger.info('Average PSNR/SSIM( Y ) - {} - x{} - PSNR: {:.2f} dB; SSIM: {:.4f}'.format(result_name, sf, ave_psnr_y, ave_ssim_y))
+
+if __name__ == '__main__':
+
+ main()
diff --git a/KAIR/main_test_ircnn_denoiser.py b/KAIR/main_test_ircnn_denoiser.py
new file mode 100644
index 0000000000000000000000000000000000000000..2cf4ebca373fe76cf40be18ee65c3004f369ef90
--- /dev/null
+++ b/KAIR/main_test_ircnn_denoiser.py
@@ -0,0 +1,183 @@
+import os.path
+import logging
+
+import numpy as np
+from datetime import datetime
+from collections import OrderedDict
+from scipy.io import loadmat
+
+import torch
+
+from utils import utils_logger
+from utils import utils_model
+from utils import utils_image as util
+
+
+'''
+Spyder (Python 3.6)
+PyTorch 1.1.0
+Windows 10 or Linux
+
+Kai Zhang (cskaizhang@gmail.com)
+github: https://github.com/cszn/KAIR
+ https://github.com/cszn/IRCNN
+
+@inproceedings{zhang2017learning,
+title={Learning deep CNN denoiser prior for image restoration},
+author={Zhang, Kai and Zuo, Wangmeng and Gu, Shuhang and Zhang, Lei},
+booktitle={IEEE conference on computer vision and pattern recognition},
+pages={3929--3938},
+year={2017}
+}
+
+% If you have any question, please feel free to contact with me.
+% Kai Zhang (e-mail: cskaizhang@gmail.com; github: https://github.com/cszn)
+
+by Kai Zhang (12/Dec./2019)
+'''
+
+"""
+# --------------------------------------------
+|--model_zoo # model_zoo
+ |--ircnn_gray # model_name
+ |--ircnn_color
+|--testset # testsets
+ |--set12 # testset_name
+ |--bsd68
+ |--cbsd68
+|--results # results
+ |--set12_ircnn_gray # result_name = testset_name + '_' + model_name
+ |--cbsd68_ircnn_color
+# --------------------------------------------
+"""
+
+
+def main():
+
+ # ----------------------------------------
+ # Preparation
+ # ----------------------------------------
+ noise_level_img = 50 # noise level for noisy image
+ model_name = 'ircnn_gray' # 'ircnn_gray' | 'ircnn_color'
+ testset_name = 'set12' # test set, 'bsd68' | 'set12'
+ need_degradation = True # default: True
+ x8 = False # default: False, x8 to boost performance
+ show_img = False # default: False
+ current_idx = min(24, np.int(np.ceil(noise_level_img/2)-1)) # current_idx+1 th denoiser
+
+
+ task_current = 'dn' # fixed, 'dn' for denoising | 'sr' for super-resolution
+ sf = 1 # unused for denoising
+ if 'color' in model_name:
+ n_channels = 3 # fixed, 1 for grayscale image, 3 for color image
+ else:
+ n_channels = 1 # fixed for grayscale image
+
+ model_pool = 'model_zoo' # fixed
+ testsets = 'testsets' # fixed
+ results = 'results' # fixed
+ result_name = testset_name + '_' + model_name # fixed
+ border = sf if task_current == 'sr' else 0 # shave boader to calculate PSNR and SSIM
+ model_path = os.path.join(model_pool, model_name+'.pth')
+
+ # ----------------------------------------
+ # L_path, E_path, H_path
+ # ----------------------------------------
+ L_path = os.path.join(testsets, testset_name) # L_path, for Low-quality images
+ H_path = L_path # H_path, for High-quality images
+ E_path = os.path.join(results, result_name) # E_path, for Estimated images
+ util.mkdir(E_path)
+
+ if H_path == L_path:
+ need_degradation = True
+ logger_name = result_name
+ utils_logger.logger_info(logger_name, log_path=os.path.join(E_path, logger_name+'.log'))
+ logger = logging.getLogger(logger_name)
+
+ need_H = True if H_path is not None else False
+ device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
+
+ # ----------------------------------------
+ # load model
+ # ----------------------------------------
+ model25 = torch.load(model_path)
+ from models.network_dncnn import IRCNN as net
+ model = net(in_nc=n_channels, out_nc=n_channels, nc=64)
+ model.load_state_dict(model25[str(current_idx)], strict=True)
+ model.eval()
+ for _, v in model.named_parameters():
+ v.requires_grad = False
+ model = model.to(device)
+ logger.info('Model path: {:s}'.format(model_path))
+ number_parameters = sum(map(lambda x: x.numel(), model.parameters()))
+ logger.info('Params number: {}'.format(number_parameters))
+
+ test_results = OrderedDict()
+ test_results['psnr'] = []
+ test_results['ssim'] = []
+
+ logger.info('model_name:{}, image sigma:{}'.format(model_name, noise_level_img))
+ logger.info(L_path)
+ L_paths = util.get_image_paths(L_path)
+ H_paths = util.get_image_paths(H_path) if need_H else None
+
+ for idx, img in enumerate(L_paths):
+
+ # ------------------------------------
+ # (1) img_L
+ # ------------------------------------
+ img_name, ext = os.path.splitext(os.path.basename(img))
+ # logger.info('{:->4d}--> {:>10s}'.format(idx+1, img_name+ext))
+ img_L = util.imread_uint(img, n_channels=n_channels)
+ img_L = util.uint2single(img_L)
+
+ if need_degradation: # degradation process
+ np.random.seed(seed=0) # for reproducibility
+ img_L += np.random.normal(0, noise_level_img/255., img_L.shape)
+
+ util.imshow(util.single2uint(img_L), title='Noisy image with noise level {}'.format(noise_level_img)) if show_img else None
+
+ img_L = util.single2tensor4(img_L)
+ img_L = img_L.to(device)
+
+ # ------------------------------------
+ # (2) img_E
+ # ------------------------------------
+ if not x8:
+ img_E = model(img_L)
+ else:
+ img_E = utils_model.test_mode(model, img_L, mode=3)
+
+ img_E = util.tensor2uint(img_E)
+
+ if need_H:
+
+ # --------------------------------
+ # (3) img_H
+ # --------------------------------
+ img_H = util.imread_uint(H_paths[idx], n_channels=n_channels)
+ img_H = img_H.squeeze()
+
+ # --------------------------------
+ # PSNR and SSIM
+ # --------------------------------
+ psnr = util.calculate_psnr(img_E, img_H, border=border)
+ ssim = util.calculate_ssim(img_E, img_H, border=border)
+ test_results['psnr'].append(psnr)
+ test_results['ssim'].append(ssim)
+ logger.info('{:s} - PSNR: {:.2f} dB; SSIM: {:.4f}.'.format(img_name+ext, psnr, ssim))
+ util.imshow(np.concatenate([img_E, img_H], axis=1), title='Recovered / Ground-truth') if show_img else None
+
+ # ------------------------------------
+ # save results
+ # ------------------------------------
+ util.imsave(img_E, os.path.join(E_path, img_name+ext))
+
+ if need_H:
+ ave_psnr = sum(test_results['psnr']) / len(test_results['psnr'])
+ ave_ssim = sum(test_results['ssim']) / len(test_results['ssim'])
+ logger.info('Average PSNR/SSIM(RGB) - {} - PSNR: {:.2f} dB; SSIM: {:.4f}'.format(result_name, ave_psnr, ave_ssim))
+
+if __name__ == '__main__':
+
+ main()
diff --git a/KAIR/main_test_msrresnet.py b/KAIR/main_test_msrresnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..207498bc68eeeb316abbae78e383b28b33a2fbdf
--- /dev/null
+++ b/KAIR/main_test_msrresnet.py
@@ -0,0 +1,213 @@
+import os.path
+import logging
+import re
+
+import numpy as np
+from collections import OrderedDict
+
+import torch
+
+from utils import utils_logger
+from utils import utils_image as util
+from utils import utils_model
+
+
+'''
+Spyder (Python 3.6)
+PyTorch 1.1.0
+Windows 10 or Linux
+
+Kai Zhang (cskaizhang@gmail.com)
+github: https://github.com/cszn/KAIR
+
+If you have any question, please feel free to contact with me.
+Kai Zhang (e-mail: cskaizhang@gmail.com)
+(github: https://github.com/cszn/KAIR)
+
+by Kai Zhang (12/Dec./2019)
+'''
+
+"""
+# --------------------------------------------
+testing demo for RRDB-ESRGAN
+https://github.com/xinntao/ESRGAN
+@inproceedings{wang2018esrgan,
+ title={Esrgan: Enhanced super-resolution generative adversarial networks},
+ author={Wang, Xintao and Yu, Ke and Wu, Shixiang and Gu, Jinjin and Liu, Yihao and Dong, Chao and Qiao, Yu and Change Loy, Chen},
+ booktitle={European Conference on Computer Vision (ECCV)},
+ pages={0--0},
+ year={2018}
+}
+@inproceedings{ledig2017photo,
+ title={Photo-realistic single image super-resolution using a generative adversarial network},
+ author={Ledig, Christian and Theis, Lucas and Husz{\'a}r, Ferenc and Caballero, Jose and Cunningham, Andrew and Acosta, Alejandro and Aitken, Andrew and Tejani, Alykhan and Totz, Johannes and Wang, Zehan and others},
+ booktitle={IEEE conference on computer vision and pattern recognition},
+ pages={4681--4690},
+ year={2017}
+}
+# --------------------------------------------
+|--model_zoo # model_zoo
+ |--msrresnet_x4_gan # model_name, optimized for perceptual quality
+ |--msrresnet_x4_psnr # model_name, optimized for PSNR
+|--testset # testsets
+ |--set5 # testset_name
+ |--srbsd68
+|--results # results
+ |--set5_msrresnet_x4_gan # result_name = testset_name + '_' + model_name
+ |--set5_msrresnet_x4_psnr
+# --------------------------------------------
+"""
+
+
+def main():
+
+ # ----------------------------------------
+ # Preparation
+ # ----------------------------------------
+
+ model_name = 'msrresnet_x4_psnr' # 'msrresnet_x4_gan' | 'msrresnet_x4_psnr'
+ testset_name = 'set5' # test set, 'set5' | 'srbsd68'
+ need_degradation = True # default: True
+ x8 = False # default: False, x8 to boost performance, default: False
+ sf = [int(s) for s in re.findall(r'\d+', model_name)][0] # scale factor
+ show_img = False # default: False
+
+
+
+
+ task_current = 'sr' # 'dn' for denoising | 'sr' for super-resolution
+ n_channels = 3 # fixed
+ model_pool = 'model_zoo' # fixed
+ testsets = 'testsets' # fixed
+ results = 'results' # fixed
+ noise_level_img = 0 # fixed: 0, noise level for LR image
+ result_name = testset_name + '_' + model_name
+ border = sf if task_current == 'sr' else 0 # shave boader to calculate PSNR and SSIM
+ model_path = os.path.join(model_pool, model_name+'.pth')
+
+ # ----------------------------------------
+ # L_path, E_path, H_path
+ # ----------------------------------------
+
+ L_path = os.path.join(testsets, testset_name) # L_path, for Low-quality images
+ H_path = L_path # H_path, for High-quality images
+ E_path = os.path.join(results, result_name) # E_path, for Estimated images
+ util.mkdir(E_path)
+
+ if H_path == L_path:
+ need_degradation = True
+ logger_name = result_name
+ utils_logger.logger_info(logger_name, log_path=os.path.join(E_path, logger_name+'.log'))
+ logger = logging.getLogger(logger_name)
+
+ need_H = True if H_path is not None else False
+ device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
+
+ # ----------------------------------------
+ # load model
+ # ----------------------------------------
+
+ from models.network_msrresnet import MSRResNet1 as net
+ model = net(in_nc=n_channels, out_nc=n_channels, nc=64, nb=16, upscale=4)
+ model.load_state_dict(torch.load(model_path), strict=True)
+ model.eval()
+ for k, v in model.named_parameters():
+ v.requires_grad = False
+ model = model.to(device)
+ logger.info('Model path: {:s}'.format(model_path))
+ number_parameters = sum(map(lambda x: x.numel(), model.parameters()))
+ logger.info('Params number: {}'.format(number_parameters))
+
+ test_results = OrderedDict()
+ test_results['psnr'] = []
+ test_results['ssim'] = []
+ test_results['psnr_y'] = []
+ test_results['ssim_y'] = []
+
+ logger.info('model_name:{}, image sigma:{}'.format(model_name, noise_level_img))
+ logger.info(L_path)
+ L_paths = util.get_image_paths(L_path)
+ H_paths = util.get_image_paths(H_path) if need_H else None
+
+ for idx, img in enumerate(L_paths):
+
+ # ------------------------------------
+ # (1) img_L
+ # ------------------------------------
+
+ img_name, ext = os.path.splitext(os.path.basename(img))
+ # logger.info('{:->4d}--> {:>10s}'.format(idx+1, img_name+ext))
+ img_L = util.imread_uint(img, n_channels=n_channels)
+ img_L = util.uint2single(img_L)
+
+ # degradation process, bicubic downsampling
+ if need_degradation:
+ img_L = util.modcrop(img_L, sf)
+ img_L = util.imresize_np(img_L, 1/sf)
+ # img_L = util.uint2single(util.single2uint(img_L))
+ # np.random.seed(seed=0) # for reproducibility
+ # img_L += np.random.normal(0, noise_level_img/255., img_L.shape)
+
+ util.imshow(util.single2uint(img_L), title='LR image with noise level {}'.format(noise_level_img)) if show_img else None
+
+ img_L = util.single2tensor4(img_L)
+ img_L = img_L.to(device)
+
+ # ------------------------------------
+ # (2) img_E
+ # ------------------------------------
+
+ if not x8:
+ img_E = model(img_L)
+ else:
+ img_E = utils_model.test_mode(model, img_L, mode=3, sf=sf)
+
+ img_E = util.tensor2uint(img_E)
+
+ if need_H:
+
+ # --------------------------------
+ # (3) img_H
+ # --------------------------------
+
+ img_H = util.imread_uint(H_paths[idx], n_channels=n_channels)
+ img_H = img_H.squeeze()
+ img_H = util.modcrop(img_H, sf)
+
+ # --------------------------------
+ # PSNR and SSIM
+ # --------------------------------
+
+ psnr = util.calculate_psnr(img_E, img_H, border=border)
+ ssim = util.calculate_ssim(img_E, img_H, border=border)
+ test_results['psnr'].append(psnr)
+ test_results['ssim'].append(ssim)
+ logger.info('{:s} - PSNR: {:.2f} dB; SSIM: {:.4f}.'.format(img_name+ext, psnr, ssim))
+ util.imshow(np.concatenate([img_E, img_H], axis=1), title='Recovered / Ground-truth') if show_img else None
+
+ if np.ndim(img_H) == 3: # RGB image
+ img_E_y = util.rgb2ycbcr(img_E, only_y=True)
+ img_H_y = util.rgb2ycbcr(img_H, only_y=True)
+ psnr_y = util.calculate_psnr(img_E_y, img_H_y, border=border)
+ ssim_y = util.calculate_ssim(img_E_y, img_H_y, border=border)
+ test_results['psnr_y'].append(psnr_y)
+ test_results['ssim_y'].append(ssim_y)
+
+ # ------------------------------------
+ # save results
+ # ------------------------------------
+
+ util.imsave(img_E, os.path.join(E_path, img_name+'.png'))
+
+ if need_H:
+ ave_psnr = sum(test_results['psnr']) / len(test_results['psnr'])
+ ave_ssim = sum(test_results['ssim']) / len(test_results['ssim'])
+ logger.info('Average PSNR/SSIM(RGB) - {} - x{} --PSNR: {:.2f} dB; SSIM: {:.4f}'.format(result_name, sf, ave_psnr, ave_ssim))
+ if np.ndim(img_H) == 3:
+ ave_psnr_y = sum(test_results['psnr_y']) / len(test_results['psnr_y'])
+ ave_ssim_y = sum(test_results['ssim_y']) / len(test_results['ssim_y'])
+ logger.info('Average PSNR/SSIM( Y ) - {} - x{} - PSNR: {:.2f} dB; SSIM: {:.4f}'.format(result_name, sf, ave_psnr_y, ave_ssim_y))
+
+if __name__ == '__main__':
+
+ main()
diff --git a/KAIR/main_test_rrdb.py b/KAIR/main_test_rrdb.py
new file mode 100644
index 0000000000000000000000000000000000000000..f1883c7c98c5e8e6bba1d3a90aac4201a9e213e3
--- /dev/null
+++ b/KAIR/main_test_rrdb.py
@@ -0,0 +1,205 @@
+import os.path
+import logging
+import re
+
+import numpy as np
+from collections import OrderedDict
+
+import torch
+
+from utils import utils_logger
+from utils import utils_image as util
+from utils import utils_model
+
+
+'''
+Spyder (Python 3.6)
+PyTorch 1.1.0
+Windows 10 or Linux
+
+Kai Zhang (cskaizhang@gmail.com)
+github: https://github.com/cszn/KAIR
+
+If you have any question, please feel free to contact with me.
+Kai Zhang (e-mail: cskaizhang@gmail.com)
+(github: https://github.com/cszn/KAIR)
+
+by Kai Zhang (12/Dec./2019)
+'''
+
+"""
+# --------------------------------------------
+testing demo for RRDB-ESRGAN
+https://github.com/xinntao/ESRGAN
+@inproceedings{wang2018esrgan,
+ title={Esrgan: Enhanced super-resolution generative adversarial networks},
+ author={Wang, Xintao and Yu, Ke and Wu, Shixiang and Gu, Jinjin and Liu, Yihao and Dong, Chao and Qiao, Yu and Change Loy, Chen},
+ booktitle={European Conference on Computer Vision (ECCV)},
+ pages={0--0},
+ year={2018}
+}
+# --------------------------------------------
+|--model_zoo # model_zoo
+ |--rrdb_x4_esrgan # model_name, optimized for perceptual quality
+ |--rrdb_x4_psnr # model_name, optimized for PSNR
+|--testset # testsets
+ |--set5 # testset_name
+ |--srbsd68
+|--results # results
+ |--set5_rrdb_x4_esrgan# result_name = testset_name + '_' + model_name
+ |--set5_rrdb_x4_psnr
+# --------------------------------------------
+"""
+
+
+def main():
+
+ # ----------------------------------------
+ # Preparation
+ # ----------------------------------------
+
+ model_name = 'rrdb_x4_esrgan' # 'rrdb_x4_esrgan' | 'rrdb_x4_psnr'
+ testset_name = 'set5' # test set, 'set5' | 'srbsd68'
+ need_degradation = True # default: True
+ x8 = False # default: False, x8 to boost performance
+ sf = [int(s) for s in re.findall(r'\d+', model_name)][0] # scale factor
+ show_img = False # default: False
+
+
+
+
+ task_current = 'sr' # 'dn' for denoising | 'sr' for super-resolution
+ n_channels = 3 # fixed
+ model_pool = 'model_zoo' # fixed
+ testsets = 'testsets' # fixed
+ results = 'results' # fixed
+ noise_level_img = 0 # fixed: 0, noise level for LR image
+ result_name = testset_name + '_' + model_name
+ border = sf if task_current == 'sr' else 0 # shave boader to calculate PSNR and SSIM
+ model_path = os.path.join(model_pool, model_name+'.pth')
+
+ # ----------------------------------------
+ # L_path, E_path, H_path
+ # ----------------------------------------
+
+ L_path = os.path.join(testsets, testset_name) # L_path, for Low-quality images
+ H_path = L_path # H_path, for High-quality images
+ E_path = os.path.join(results, result_name) # E_path, for Estimated images
+ util.mkdir(E_path)
+
+ if H_path == L_path:
+ need_degradation = True
+ logger_name = result_name
+ utils_logger.logger_info(logger_name, log_path=os.path.join(E_path, logger_name+'.log'))
+ logger = logging.getLogger(logger_name)
+
+ need_H = True if H_path is not None else False
+ device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
+
+ # ----------------------------------------
+ # load model
+ # ----------------------------------------
+
+ from models.network_rrdb import RRDB as net
+ model = net(in_nc=n_channels, out_nc=n_channels, nc=64, nb=23, gc=32, upscale=4, act_mode='L', upsample_mode='upconv')
+ model.load_state_dict(torch.load(model_path), strict=True) # strict=False
+ model.eval()
+ for k, v in model.named_parameters():
+ v.requires_grad = False
+ model = model.to(device)
+ logger.info('Model path: {:s}'.format(model_path))
+ number_parameters = sum(map(lambda x: x.numel(), model.parameters()))
+ logger.info('Params number: {}'.format(number_parameters))
+
+ test_results = OrderedDict()
+ test_results['psnr'] = []
+ test_results['ssim'] = []
+ test_results['psnr_y'] = []
+ test_results['ssim_y'] = []
+
+ logger.info('model_name:{}, image sigma:{}'.format(model_name, noise_level_img))
+ logger.info(L_path)
+ L_paths = util.get_image_paths(L_path)
+ H_paths = util.get_image_paths(H_path) if need_H else None
+
+ for idx, img in enumerate(L_paths):
+
+ # ------------------------------------
+ # (1) img_L
+ # ------------------------------------
+
+ img_name, ext = os.path.splitext(os.path.basename(img))
+ # logger.info('{:->4d}--> {:>10s}'.format(idx+1, img_name+ext))
+ img_L = util.imread_uint(img, n_channels=n_channels)
+ img_L = util.uint2single(img_L)
+
+ # degradation process, bicubic downsampling + Gaussian noise
+ if need_degradation:
+ img_L = util.modcrop(img_L, sf)
+ img_L = util.imresize_np(img_L, 1/sf)
+ # np.random.seed(seed=0) # for reproducibility
+ # img_L += np.random.normal(0, noise_level_img/255., img_L.shape)
+
+ util.imshow(util.single2uint(img_L), title='LR image with noise level {}'.format(noise_level_img)) if show_img else None
+
+ img_L = util.single2tensor4(img_L)
+ img_L = img_L.to(device)
+
+ # ------------------------------------
+ # (2) img_E
+ # ------------------------------------
+
+ if not x8:
+ img_E = model(img_L)
+ else:
+ img_E = utils_model.test_mode(model, img_L, mode=3, sf=sf)
+
+ img_E = util.tensor2uint(img_E)
+
+ if need_H:
+
+ # --------------------------------
+ # (3) img_H
+ # --------------------------------
+
+ img_H = util.imread_uint(H_paths[idx], n_channels=n_channels)
+ img_H = img_H.squeeze()
+ img_H = util.modcrop(img_H, sf)
+
+ # --------------------------------
+ # PSNR and SSIM
+ # --------------------------------
+
+ psnr = util.calculate_psnr(img_E, img_H, border=border)
+ ssim = util.calculate_ssim(img_E, img_H, border=border)
+ test_results['psnr'].append(psnr)
+ test_results['ssim'].append(ssim)
+ logger.info('{:s} - PSNR: {:.2f} dB; SSIM: {:.4f}.'.format(img_name+ext, psnr, ssim))
+ util.imshow(np.concatenate([img_E, img_H], axis=1), title='Recovered / Ground-truth') if show_img else None
+
+ if np.ndim(img_H) == 3: # RGB image
+ img_E_y = util.rgb2ycbcr(img_E, only_y=True)
+ img_H_y = util.rgb2ycbcr(img_H, only_y=True)
+ psnr_y = util.calculate_psnr(img_E_y, img_H_y, border=border)
+ ssim_y = util.calculate_ssim(img_E_y, img_H_y, border=border)
+ test_results['psnr_y'].append(psnr_y)
+ test_results['ssim_y'].append(ssim_y)
+
+ # ------------------------------------
+ # save results
+ # ------------------------------------
+
+ util.imsave(img_E, os.path.join(E_path, img_name+'.png'))
+
+ if need_H:
+ ave_psnr = sum(test_results['psnr']) / len(test_results['psnr'])
+ ave_ssim = sum(test_results['ssim']) / len(test_results['ssim'])
+ logger.info('Average PSNR/SSIM(RGB) - {} - x{} --PSNR: {:.2f} dB; SSIM: {:.4f}'.format(result_name, sf, ave_psnr, ave_ssim))
+ if np.ndim(img_H) == 3:
+ ave_psnr_y = sum(test_results['psnr_y']) / len(test_results['psnr_y'])
+ ave_ssim_y = sum(test_results['ssim_y']) / len(test_results['ssim_y'])
+ logger.info('Average PSNR/SSIM( Y ) - {} - x{} - PSNR: {:.2f} dB; SSIM: {:.4f}'.format(result_name, sf, ave_psnr_y, ave_ssim_y))
+
+if __name__ == '__main__':
+
+ main()
diff --git a/KAIR/main_test_srmd.py b/KAIR/main_test_srmd.py
new file mode 100644
index 0000000000000000000000000000000000000000..8a72ab5cdd4cd78a0894b54191e0aec726f738e7
--- /dev/null
+++ b/KAIR/main_test_srmd.py
@@ -0,0 +1,233 @@
+import os.path
+import logging
+import re
+
+import numpy as np
+from collections import OrderedDict
+from scipy.io import loadmat
+
+import torch
+
+from utils import utils_deblur
+from utils import utils_sisr as sr
+from utils import utils_logger
+from utils import utils_image as util
+from utils import utils_model
+
+
+'''
+Spyder (Python 3.6)
+PyTorch 1.1.0
+Windows 10 or Linux
+
+Kai Zhang (cskaizhang@gmail.com)
+github: https://github.com/cszn/KAIR
+ https://github.com/cszn/SRMD
+
+@inproceedings{zhang2018learning,
+ title={Learning a single convolutional super-resolution network for multiple degradations},
+ author={Zhang, Kai and Zuo, Wangmeng and Zhang, Lei},
+ booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
+ pages={3262--3271},
+ year={2018}
+}
+
+% If you have any question, please feel free to contact with me.
+% Kai Zhang (e-mail: cskaizhang@gmail.com; github: https://github.com/cszn)
+
+by Kai Zhang (12/Dec./2019)
+'''
+
+"""
+# --------------------------------------------
+|--model_zoo # model_zoo
+ |--srmdnf_x2 # model_name, for noise-free LR image SR
+ |--srmdnf_x3
+ |--srmdnf_x4
+ |--srmd_x2 # model_name, for noisy LR image
+ |--srmd_x3
+ |--srmd_x4
+|--testset # testsets
+ |--set5 # testset_name
+ |--srbsd68
+|--results # results
+ |--set5_srmdnf_x2 # result_name = testset_name + '_' + model_name
+ |--set5_srmdnf_x3
+ |--set5_srmdnf_x4
+ |--set5_srmd_x2
+ |--srbsd68_srmd_x2
+# --------------------------------------------
+"""
+
+
+def main():
+
+ # ----------------------------------------
+ # Preparation
+ # ----------------------------------------
+
+ noise_level_img = 0 # default: 0, noise level for LR image
+ noise_level_model = noise_level_img # noise level for model
+ model_name = 'srmdnf_x4' # 'srmd_x2' | 'srmd_x3' | 'srmd_x4' | 'srmdnf_x2' | 'srmdnf_x3' | 'srmdnf_x4'
+ testset_name = 'set5' # test set, 'set5' | 'srbsd68'
+ sf = [int(s) for s in re.findall(r'\d+', model_name)][0] # scale factor
+ x8 = False # default: False, x8 to boost performance
+ need_degradation = True # default: True, use degradation model to generate LR image
+ show_img = False # default: False
+
+
+
+
+ srmd_pca_path = os.path.join('kernels', 'srmd_pca_matlab.mat')
+ task_current = 'sr' # 'dn' for denoising | 'sr' for super-resolution
+ n_channels = 3 # fixed
+ in_nc = 18 if 'nf' in model_name else 19
+ nc = 128 # fixed, number of channels
+ nb = 12 # fixed, number of conv layers
+ model_pool = 'model_zoo' # fixed
+ testsets = 'testsets' # fixed
+ results = 'results' # fixed
+ result_name = testset_name + '_' + model_name
+ border = sf if task_current == 'sr' else 0 # shave boader to calculate PSNR and SSIM
+ model_path = os.path.join(model_pool, model_name+'.pth')
+
+ # ----------------------------------------
+ # L_path, E_path, H_path
+ # ----------------------------------------
+
+ L_path = os.path.join(testsets, testset_name) # L_path, for Low-quality images
+ H_path = L_path # H_path, for High-quality images
+ E_path = os.path.join(results, result_name) # E_path, for Estimated images
+ util.mkdir(E_path)
+
+ if H_path == L_path:
+ need_degradation = True
+ logger_name = result_name
+ utils_logger.logger_info(logger_name, log_path=os.path.join(E_path, logger_name+'.log'))
+ logger = logging.getLogger(logger_name)
+
+ need_H = True if H_path is not None else False
+ device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
+
+ # ----------------------------------------
+ # load model
+ # ----------------------------------------
+
+ from models.network_srmd import SRMD as net
+ model = net(in_nc=in_nc, out_nc=n_channels, nc=nc, nb=nb, upscale=sf, act_mode='R', upsample_mode='pixelshuffle')
+ model.load_state_dict(torch.load(model_path), strict=False)
+ model.eval()
+ for k, v in model.named_parameters():
+ v.requires_grad = False
+ model = model.to(device)
+ logger.info('Model path: {:s}'.format(model_path))
+ number_parameters = sum(map(lambda x: x.numel(), model.parameters()))
+ logger.info('Params number: {}'.format(number_parameters))
+
+ test_results = OrderedDict()
+ test_results['psnr'] = []
+ test_results['ssim'] = []
+ test_results['psnr_y'] = []
+ test_results['ssim_y'] = []
+
+ logger.info('model_name:{}, model sigma:{}, image sigma:{}'.format(model_name, noise_level_img, noise_level_model))
+ logger.info(L_path)
+ L_paths = util.get_image_paths(L_path)
+ H_paths = util.get_image_paths(H_path) if need_H else None
+
+ # ----------------------------------------
+ # kernel and PCA reduced feature
+ # ----------------------------------------
+
+ # kernel = sr.anisotropic_Gaussian(ksize=15, theta=np.pi, l1=4, l2=4)
+ kernel = utils_deblur.fspecial('gaussian', 15, 0.01) # Gaussian kernel, delta kernel 0.01
+
+ P = loadmat(srmd_pca_path)['P']
+ degradation_vector = np.dot(P, np.reshape(kernel, (-1), order="F"))
+ if 'nf' not in model_name: # noise-free SR
+ degradation_vector = np.append(degradation_vector, noise_level_model/255.)
+ degradation_vector = torch.from_numpy(degradation_vector).view(1, -1, 1, 1).float()
+
+ for idx, img in enumerate(L_paths):
+
+ # ------------------------------------
+ # (1) img_L
+ # ------------------------------------
+
+ img_name, ext = os.path.splitext(os.path.basename(img))
+ # logger.info('{:->4d}--> {:>10s}'.format(idx+1, img_name+ext))
+ img_L = util.imread_uint(img, n_channels=n_channels)
+ img_L = util.uint2single(img_L)
+
+ # degradation process, blur + bicubic downsampling + Gaussian noise
+ if need_degradation:
+ img_L = util.modcrop(img_L, sf)
+ img_L = sr.srmd_degradation(img_L, kernel, sf) # equivalent to bicubic degradation if kernel is a delta kernel
+ np.random.seed(seed=0) # for reproducibility
+ img_L += np.random.normal(0, noise_level_img/255., img_L.shape)
+
+ util.imshow(util.single2uint(img_L), title='LR image with noise level {}'.format(noise_level_img)) if show_img else None
+
+ img_L = util.single2tensor4(img_L)
+ degradation_map = degradation_vector.repeat(1, 1, img_L.size(-2), img_L.size(-1))
+ img_L = torch.cat((img_L, degradation_map), dim=1)
+ img_L = img_L.to(device)
+
+ # ------------------------------------
+ # (2) img_E
+ # ------------------------------------
+
+ if not x8:
+ img_E = model(img_L)
+ else:
+ img_E = utils_model.test_mode(model, img_L, mode=3, sf=sf)
+
+ img_E = util.tensor2uint(img_E)
+
+ if need_H:
+
+ # --------------------------------
+ # (3) img_H
+ # --------------------------------
+
+ img_H = util.imread_uint(H_paths[idx], n_channels=n_channels)
+ img_H = img_H.squeeze()
+ img_H = util.modcrop(img_H, sf)
+
+ # --------------------------------
+ # PSNR and SSIM
+ # --------------------------------
+
+ psnr = util.calculate_psnr(img_E, img_H, border=border)
+ ssim = util.calculate_ssim(img_E, img_H, border=border)
+ test_results['psnr'].append(psnr)
+ test_results['ssim'].append(ssim)
+ logger.info('{:s} - PSNR: {:.2f} dB; SSIM: {:.4f}.'.format(img_name+ext, psnr, ssim))
+ util.imshow(np.concatenate([img_E, img_H], axis=1), title='Recovered / Ground-truth') if show_img else None
+
+ if np.ndim(img_H) == 3: # RGB image
+ img_E_y = util.rgb2ycbcr(img_E, only_y=True)
+ img_H_y = util.rgb2ycbcr(img_H, only_y=True)
+ psnr_y = util.calculate_psnr(img_E_y, img_H_y, border=border)
+ ssim_y = util.calculate_ssim(img_E_y, img_H_y, border=border)
+ test_results['psnr_y'].append(psnr_y)
+ test_results['ssim_y'].append(ssim_y)
+
+ # ------------------------------------
+ # save results
+ # ------------------------------------
+
+ util.imsave(img_E, os.path.join(E_path, img_name+'.png'))
+
+ if need_H:
+ ave_psnr = sum(test_results['psnr']) / len(test_results['psnr'])
+ ave_ssim = sum(test_results['ssim']) / len(test_results['ssim'])
+ logger.info('Average PSNR/SSIM(RGB) - {} - x{} --PSNR: {:.2f} dB; SSIM: {:.4f}'.format(result_name, sf, ave_psnr, ave_ssim))
+ if np.ndim(img_H) == 3:
+ ave_psnr_y = sum(test_results['psnr_y']) / len(test_results['psnr_y'])
+ ave_ssim_y = sum(test_results['ssim_y']) / len(test_results['ssim_y'])
+ logger.info('Average PSNR/SSIM( Y ) - {} - x{} - PSNR: {:.2f} dB; SSIM: {:.4f}'.format(result_name, sf, ave_psnr_y, ave_ssim_y))
+
+if __name__ == '__main__':
+
+ main()
diff --git a/KAIR/main_test_swinir.py b/KAIR/main_test_swinir.py
new file mode 100644
index 0000000000000000000000000000000000000000..2e17e361e728bcf82c7755bb15e4d22009e19259
--- /dev/null
+++ b/KAIR/main_test_swinir.py
@@ -0,0 +1,306 @@
+import argparse
+import cv2
+import glob
+import numpy as np
+from collections import OrderedDict
+import os
+import torch
+import requests
+from pathlib import Path
+
+from models.network_swinir import SwinIR as net
+from utils import utils_image as util
+
+
+def main():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--task', type=str, default='color_dn', help='classical_sr, lightweight_sr, real_sr, '
+ 'gray_dn, color_dn, jpeg_car')
+ parser.add_argument('--scale', type=int, default=1, help='scale factor: 1, 2, 3, 4, 8') # 1 for dn and jpeg car
+ parser.add_argument('--noise', type=int, default=15, help='noise level: 15, 25, 50')
+ parser.add_argument('--jpeg', type=int, default=40, help='scale factor: 10, 20, 30, 40')
+ parser.add_argument('--training_patch_size', type=int, default=128, help='patch size used in training SwinIR. '
+ 'Just used to differentiate two different settings in Table 2 of the paper. '
+ 'Images are NOT tested patch by patch.')
+ parser.add_argument('--large_model', action='store_true', help='use large model, only provided for real image sr')
+ parser.add_argument('--model_path', type=str,
+ default='model_zoo/swinir/001_classicalSR_DIV2K_s48w8_SwinIR-M_x2.pth')
+ parser.add_argument('--folder_lq', type=str, default=None, help='input low-quality test image folder')
+ parser.add_argument('--folder_gt', type=str, default=None, help='input ground-truth test image folder')
+ parser.add_argument('--tile', type=int, default=None, help='Tile size, None for no tile during testing (testing as a whole)')
+ parser.add_argument('--tile_overlap', type=int, default=32, help='Overlapping of different tiles')
+ args = parser.parse_args()
+
+ device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
+ # set up model
+ if os.path.exists(args.model_path):
+ print(f'loading model from {args.model_path}')
+ else:
+ os.makedirs(os.path.dirname(args.model_path), exist_ok=True)
+ url = 'https://github.com/JingyunLiang/SwinIR/releases/download/v0.0/{}'.format(os.path.basename(args.model_path))
+ r = requests.get(url, allow_redirects=True)
+ print(f'downloading model {args.model_path}')
+ open(args.model_path, 'wb').write(r.content)
+
+ model = define_model(args)
+ model.eval()
+ model = model.to(device)
+
+ # setup folder and path
+ folder, save_dir, border, window_size = setup(args)
+ os.makedirs(save_dir, exist_ok=True)
+ test_results = OrderedDict()
+ test_results['psnr'] = []
+ test_results['ssim'] = []
+ test_results['psnr_y'] = []
+ test_results['ssim_y'] = []
+ test_results['psnr_b'] = []
+ psnr, ssim, psnr_y, ssim_y, psnr_b = 0, 0, 0, 0, 0
+
+ task = "real_sr"
+ img_gt = None
+ for idx, path in enumerate(sorted(glob.glob(os.path.join(folder, '*')))):
+ # read image
+ (imgname, imgext) = os.path.splitext(os.path.basename(path))
+
+ # out_imgname = Path(f'/home/cll/Desktop/WillemDafoe/swinIRx2_aligned/{imgname}_SwinIR.png')
+ # if out_imgname.exists():
+ # print("Skipping: ", str(out_imgname))
+ # continue
+
+ try:
+ img_lq, img_gt = get_image_pair(args, path, task) # image to HWC-BGR, float32
+ except AttributeError as e:
+ print(f"ValueError received: {e}")
+ continue
+ img_lq = np.transpose(img_lq if img_lq.shape[2] == 1 else img_lq[:, :, [2, 1, 0]], (2, 0, 1)) # HCW-BGR to CHW-RGB
+ img_lq = torch.from_numpy(img_lq).float().unsqueeze(0).to(device) # CHW-RGB to NCHW-RGB
+
+ # inference
+ with torch.no_grad():
+ # pad input image to be a multiple of window_size
+ _, _, h_old, w_old = img_lq.size()
+ h_pad = (h_old // window_size + 1) * window_size - h_old
+ w_pad = (w_old // window_size + 1) * window_size - w_old
+ img_lq = torch.cat([img_lq, torch.flip(img_lq, [2])], 2)[:, :, :h_old + h_pad, :]
+ img_lq = torch.cat([img_lq, torch.flip(img_lq, [3])], 3)[:, :, :, :w_old + w_pad]
+ output = test(img_lq, model, args, window_size)
+ output = output[..., :h_old * args.scale, :w_old * args.scale]
+
+ # save image
+ output = output.data.squeeze().float().cpu().clamp_(0, 1).numpy()
+ if output.ndim == 3:
+ output = np.transpose(output[[2, 1, 0], :, :], (1, 2, 0)) # CHW-RGB to HCW-BGR
+ output = (output * 255.0).round().astype(np.uint8) # float32 to uint8
+
+ print("SAVING: ", save_dir)
+ print("SAVING: ", imgname)
+ cv2.imwrite(f'{save_dir}/{imgname}_SwinIR.png', output)
+
+ # evaluate psnr/ssim/psnr_b
+ if img_gt is not None:
+ img_gt = (img_gt * 255.0).round().astype(np.uint8) # float32 to uint8
+ img_gt = img_gt[:h_old * args.scale, :w_old * args.scale, ...] # crop gt
+ img_gt = np.squeeze(img_gt)
+
+ psnr = util.calculate_psnr(output, img_gt, border=border)
+ ssim = util.calculate_ssim(output, img_gt, border=border)
+ test_results['psnr'].append(psnr)
+ test_results['ssim'].append(ssim)
+ if img_gt.ndim == 3: # RGB image
+ output_y = util.bgr2ycbcr(output.astype(np.float32) / 255.) * 255.
+ img_gt_y = util.bgr2ycbcr(img_gt.astype(np.float32) / 255.) * 255.
+ psnr_y = util.calculate_psnr(output_y, img_gt_y, border=border)
+ ssim_y = util.calculate_ssim(output_y, img_gt_y, border=border)
+ test_results['psnr_y'].append(psnr_y)
+ test_results['ssim_y'].append(ssim_y)
+ if args.task in ['jpeg_car']:
+ psnr_b = util.calculate_psnrb(output, img_gt, border=border)
+ test_results['psnr_b'].append(psnr_b)
+ print('Testing {:d} {:20s} - PSNR: {:.2f} dB; SSIM: {:.4f}; '
+ 'PSNR_Y: {:.2f} dB; SSIM_Y: {:.4f}; '
+ 'PSNR_B: {:.2f} dB.'.
+ format(idx, imgname, psnr, ssim, psnr_y, ssim_y, psnr_b))
+ else:
+ print('Testing {:d} {:20s}'.format(idx, imgname))
+
+ # summarize psnr/ssim
+ if img_gt is not None:
+ ave_psnr = sum(test_results['psnr']) / len(test_results['psnr'])
+ ave_ssim = sum(test_results['ssim']) / len(test_results['ssim'])
+ print('\n{} \n-- Average PSNR/SSIM(RGB): {:.2f} dB; {:.4f}'.format(save_dir, ave_psnr, ave_ssim))
+ if img_gt.ndim == 3:
+ ave_psnr_y = sum(test_results['psnr_y']) / len(test_results['psnr_y'])
+ ave_ssim_y = sum(test_results['ssim_y']) / len(test_results['ssim_y'])
+ print('-- Average PSNR_Y/SSIM_Y: {:.2f} dB; {:.4f}'.format(ave_psnr_y, ave_ssim_y))
+ if args.task in ['jpeg_car']:
+ ave_psnr_b = sum(test_results['psnr_b']) / len(test_results['psnr_b'])
+ print('-- Average PSNR_B: {:.2f} dB'.format(ave_psnr_b))
+
+
+def define_model(args):
+ # 001 classical image sr
+ if args.task == 'classical_sr':
+ model = net(upscale=args.scale, in_chans=3, img_size=args.training_patch_size, window_size=8,
+ img_range=1., depths=[6, 6, 6, 6, 6, 6], embed_dim=180, num_heads=[6, 6, 6, 6, 6, 6],
+ mlp_ratio=2, upsampler='pixelshuffle', resi_connection='1conv')
+ param_key_g = 'params'
+
+ # 002 lightweight image sr
+ # use 'pixelshuffledirect' to save parameters
+ elif args.task == 'lightweight_sr':
+ model = net(upscale=args.scale, in_chans=3, img_size=64, window_size=8,
+ img_range=1., depths=[6, 6, 6, 6], embed_dim=60, num_heads=[6, 6, 6, 6],
+ mlp_ratio=2, upsampler='pixelshuffledirect', resi_connection='1conv')
+ param_key_g = 'params'
+
+ # 003 real-world image sr
+ elif args.task == 'real_sr':
+ if not args.large_model:
+ # use 'nearest+conv' to avoid block artifacts
+ model = net(upscale=args.scale, in_chans=3, img_size=args.training_patch_size, window_size=8,
+ img_range=1., depths=[6, 6, 6, 6, 6, 6], embed_dim=180, num_heads=[6, 6, 6, 6, 6, 6],
+ mlp_ratio=2, upsampler='nearest+conv', resi_connection='3conv')
+ else:
+ # larger model size; use '3conv' to save parameters and memory; use ema for GAN training
+ model = net(upscale=4, in_chans=3, img_size=64, window_size=8,
+ img_range=1., depths=[6, 6, 6, 6, 6, 6, 6, 6, 6], embed_dim=240,
+ num_heads=[8, 8, 8, 8, 8, 8, 8, 8, 8],
+ mlp_ratio=2, upsampler='nearest+conv', resi_connection='3conv')
+ param_key_g = 'params_ema'
+
+ # 004 grayscale image denoising
+ elif args.task == 'gray_dn':
+ model = net(upscale=1, in_chans=1, img_size=128, window_size=8,
+ img_range=1., depths=[6, 6, 6, 6, 6, 6], embed_dim=180, num_heads=[6, 6, 6, 6, 6, 6],
+ mlp_ratio=2, upsampler='', resi_connection='1conv')
+ param_key_g = 'params'
+
+ # 005 color image denoising
+ elif args.task == 'color_dn':
+ model = net(upscale=1, in_chans=3, img_size=128, window_size=8,
+ img_range=1., depths=[6, 6, 6, 6, 6, 6], embed_dim=180, num_heads=[6, 6, 6, 6, 6, 6],
+ mlp_ratio=2, upsampler='', resi_connection='1conv')
+ param_key_g = 'params'
+
+ # 006 JPEG compression artifact reduction
+ # use window_size=7 because JPEG encoding uses 8x8; use img_range=255 because it's sligtly better than 1
+ elif args.task == 'jpeg_car':
+ model = net(upscale=1, in_chans=1, img_size=126, window_size=7,
+ img_range=255., depths=[6, 6, 6, 6, 6, 6], embed_dim=180, num_heads=[6, 6, 6, 6, 6, 6],
+ mlp_ratio=2, upsampler='', resi_connection='1conv')
+ param_key_g = 'params'
+
+ pretrained_model = torch.load(args.model_path)
+ model.load_state_dict(pretrained_model[param_key_g] if param_key_g in pretrained_model.keys() else pretrained_model, strict=True)
+
+ return model
+
+
+def setup(args):
+ # 001 classical image sr/ 002 lightweight image sr
+ if args.task in ['classical_sr', 'lightweight_sr']:
+ save_dir = f'results/swinir_{args.task}_x{args.scale}'
+ # folder = args.folder_gt
+ folder = args.folder_lq
+ border = args.scale
+ window_size = 8
+
+ # 003 real-world image sr
+ elif args.task in ['real_sr']:
+ save_dir = f'results/swinir_{args.task}_x{args.scale}'
+ if args.large_model:
+ save_dir += '_large'
+ folder = args.folder_lq
+ border = 0
+ window_size = 8
+
+ # 004 grayscale image denoising/ 005 color image denoising
+ elif args.task in ['gray_dn', 'color_dn']:
+ save_dir = f'results/swinir_{args.task}_noise{args.noise}'
+ folder = args.folder_gt
+ border = 0
+ window_size = 8
+
+ # 006 JPEG compression artifact reduction
+ elif args.task in ['jpeg_car']:
+ save_dir = f'results/swinir_{args.task}_jpeg{args.jpeg}'
+ folder = args.folder_gt
+ border = 0
+ window_size = 7
+
+ return folder, save_dir, border, window_size
+
+
+def get_image_pair(args, path, task):
+ (imgname, imgext) = os.path.splitext(os.path.basename(path))
+
+ # 001 classical image sr/ 002 lightweight image sr (load lq-gt image pairs)
+ if task in ['classical_sr', 'lightweight_sr']:
+ img_gt = cv2.imread(path, cv2.IMREAD_COLOR).astype(np.float32) / 255.
+ img_lq = cv2.imread(f'{args.folder_lq}/{imgname}x{args.scale}{imgext}', cv2.IMREAD_COLOR).astype(
+ np.float32) / 255.
+
+ # 003 real-world image sr (load lq image only)
+ elif task in ['real_sr']:
+ img_gt = None
+ img_lq = cv2.imread(path, cv2.IMREAD_COLOR).astype(np.float32) / 255.
+
+ # 004 grayscale image denoising (load gt image and generate lq image on-the-fly)
+ elif task in ['gray_dn']:
+ img_gt = cv2.imread(path, cv2.IMREAD_GRAYSCALE).astype(np.float32) / 255.
+ np.random.seed(seed=0)
+ img_lq = img_gt + np.random.normal(0, args.noise / 255., img_gt.shape)
+ img_gt = np.expand_dims(img_gt, axis=2)
+ img_lq = np.expand_dims(img_lq, axis=2)
+
+ # 005 color image denoising (load gt image and generate lq image on-the-fly)
+ elif task in ['color_dn']:
+ img_gt = cv2.imread(path, cv2.IMREAD_COLOR).astype(np.float32) / 255.
+ np.random.seed(seed=0)
+ img_lq = img_gt + np.random.normal(0, args.noise / 255., img_gt.shape)
+
+ # 006 JPEG compression artifact reduction (load gt image and generate lq image on-the-fly)
+ elif task in ['jpeg_car']:
+ img_gt = cv2.imread(path, 0)
+ result, encimg = cv2.imencode('.jpg', img_gt, [int(cv2.IMWRITE_JPEG_QUALITY), args.jpeg])
+ img_lq = cv2.imdecode(encimg, 0)
+ img_gt = np.expand_dims(img_gt, axis=2).astype(np.float32) / 255.
+ img_lq = np.expand_dims(img_lq, axis=2).astype(np.float32) / 255.
+
+ return img_lq, img_gt
+
+
+def test(img_lq, model, args, window_size):
+ if args.tile is None:
+ # test the image as a whole
+ output = model(img_lq)
+ else:
+ # test the image tile by tile
+ b, c, h, w = img_lq.size()
+ tile = min(args.tile, h, w)
+ assert tile % window_size == 0, "tile size should be a multiple of window_size"
+ tile_overlap = args.tile_overlap
+ sf = args.scale
+
+ print(tile)
+ stride = tile - tile_overlap
+ h_idx_list = list(range(0, h-tile, stride)) + [h-tile]
+ w_idx_list = list(range(0, w-tile, stride)) + [w-tile]
+ E = torch.zeros(b, c, h*sf, w*sf).type_as(img_lq)
+ W = torch.zeros_like(E)
+
+ for h_idx in h_idx_list:
+ for w_idx in w_idx_list:
+ in_patch = img_lq[..., h_idx:h_idx+tile, w_idx:w_idx+tile]
+ out_patch = model(in_patch)
+ out_patch_mask = torch.ones_like(out_patch)
+
+ E[..., h_idx*sf:(h_idx+tile)*sf, w_idx*sf:(w_idx+tile)*sf].add_(out_patch)
+ W[..., h_idx*sf:(h_idx+tile)*sf, w_idx*sf:(w_idx+tile)*sf].add_(out_patch_mask)
+ output = E.div_(W)
+
+ return output
+
+if __name__ == '__main__':
+ main()
diff --git a/KAIR/main_test_usrnet.py b/KAIR/main_test_usrnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..5b8e42adf62f4658d44c004008302af2cc7ddcb2
--- /dev/null
+++ b/KAIR/main_test_usrnet.py
@@ -0,0 +1,226 @@
+import os.path
+import cv2
+import logging
+import time
+import os
+
+import numpy as np
+from datetime import datetime
+from collections import OrderedDict
+from scipy.io import loadmat
+#import hdf5storage
+from scipy import ndimage
+from scipy.signal import convolve2d
+
+import torch
+
+from utils import utils_deblur
+from utils import utils_logger
+from utils import utils_sisr as sr
+from utils import utils_image as util
+from models.network_usrnet import USRNet as net
+
+
+'''
+Spyder (Python 3.6)
+PyTorch 1.4.0
+Windows 10 or Linux
+
+Kai Zhang (cskaizhang@gmail.com)
+github: https://github.com/cszn/USRNet
+ https://github.com/cszn/KAIR
+
+If you have any question, please feel free to contact with me.
+Kai Zhang (e-mail: cskaizhang@gmail.com)
+
+by Kai Zhang (12/March/2020)
+'''
+
+"""
+# --------------------------------------------
+testing code of USRNet for the Table 1 in the paper
+@inproceedings{zhang2020deep,
+ title={Deep unfolding network for image super-resolution},
+ author={Zhang, Kai and Van Gool, Luc and Timofte, Radu},
+ booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
+ pages={0--0},
+ year={2020}
+}
+# --------------------------------------------
+|--model_zoo # model_zoo
+ |--usrgan # model_name, optimized for perceptual quality
+ |--usrnet # model_name, optimized for PSNR
+ |--usrgan_tiny # model_name, tiny model optimized for perceptual quality
+ |--usrnet_tiny # model_name, tiny model optimized for PSNR
+|--testsets # testsets
+ |--set5 # testset_name
+ |--set14
+ |--urban100
+ |--bsd100
+ |--srbsd68 # already cropped
+|--results # results
+ |--srbsd68_usrnet # result_name = testset_name + '_' + model_name
+ |--srbsd68_usrgan
+ |--srbsd68_usrnet_tiny
+ |--srbsd68_usrgan_tiny
+# --------------------------------------------
+"""
+
+
+def main():
+
+ # ----------------------------------------
+ # Preparation
+ # ----------------------------------------
+ model_name = 'usrnet' # 'usrgan' | 'usrnet' | 'usrgan_tiny' | 'usrnet_tiny'
+ testset_name = 'set5' # test set, 'set5' | 'srbsd68'
+ test_sf = [4] if 'gan' in model_name else [2, 3, 4] # scale factor, from {1,2,3,4}
+
+ show_img = False # default: False
+ save_L = True # save LR image
+ save_E = True # save estimated image
+ save_LEH = False # save zoomed LR, E and H images
+
+ # ----------------------------------------
+ # load testing kernels
+ # ----------------------------------------
+ # kernels = hdf5storage.loadmat(os.path.join('kernels', 'kernels.mat'))['kernels']
+ kernels = loadmat(os.path.join('kernels', 'kernels_12.mat'))['kernels']
+
+ n_channels = 1 if 'gray' in model_name else 3 # 3 for color image, 1 for grayscale image
+ model_pool = 'model_zoo' # fixed
+ testsets = 'testsets' # fixed
+ results = 'results' # fixed
+ noise_level_img = 0 # fixed: 0, noise level for LR image
+ noise_level_model = noise_level_img # fixed, noise level of model, default 0
+ result_name = testset_name + '_' + model_name
+ model_path = os.path.join(model_pool, model_name+'.pth')
+
+ # ----------------------------------------
+ # L_path = H_path, E_path, logger
+ # ----------------------------------------
+ L_path = os.path.join(testsets, testset_name) # L_path and H_path, fixed, for Low-quality images
+ E_path = os.path.join(results, result_name) # E_path, fixed, for Estimated images
+ util.mkdir(E_path)
+
+ logger_name = result_name
+ utils_logger.logger_info(logger_name, log_path=os.path.join(E_path, logger_name+'.log'))
+ logger = logging.getLogger(logger_name)
+
+ device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
+
+ # ----------------------------------------
+ # load model
+ # ----------------------------------------
+ if 'tiny' in model_name:
+ model = net(n_iter=6, h_nc=32, in_nc=4, out_nc=3, nc=[16, 32, 64, 64],
+ nb=2, act_mode="R", downsample_mode='strideconv', upsample_mode="convtranspose")
+ else:
+ model = net(n_iter=8, h_nc=64, in_nc=4, out_nc=3, nc=[64, 128, 256, 512],
+ nb=2, act_mode="R", downsample_mode='strideconv', upsample_mode="convtranspose")
+
+ model.load_state_dict(torch.load(model_path), strict=True)
+ model.eval()
+ for key, v in model.named_parameters():
+ v.requires_grad = False
+ number_parameters = sum(map(lambda x: x.numel(), model.parameters()))
+ model = model.to(device)
+
+ logger.info('Model path: {:s}'.format(model_path))
+ logger.info('Params number: {}'.format(number_parameters))
+ logger.info('Model_name:{}, image sigma:{}'.format(model_name, noise_level_img))
+ logger.info(L_path)
+ L_paths = util.get_image_paths(L_path)
+
+ # --------------------------------
+ # read images
+ # --------------------------------
+ test_results_ave = OrderedDict()
+ test_results_ave['psnr_sf_k'] = []
+
+ for sf in test_sf:
+
+ for k_index in range(kernels.shape[1]):
+
+ test_results = OrderedDict()
+ test_results['psnr'] = []
+ kernel = kernels[0, k_index].astype(np.float64)
+
+ ## other kernels
+ # kernel = utils_deblur.blurkernel_synthesis(h=25) # motion kernel
+ # kernel = utils_deblur.fspecial('gaussian', 25, 1.6) # Gaussian kernel
+ # kernel = sr.shift_pixel(kernel, sf) # pixel shift; optional
+ # kernel /= np.sum(kernel)
+
+ util.surf(kernel) if show_img else None
+ idx = 0
+
+ for img in L_paths:
+
+ # --------------------------------
+ # (1) classical degradation, img_L
+ # --------------------------------
+ idx += 1
+ img_name, ext = os.path.splitext(os.path.basename(img))
+ img_H = util.imread_uint(img, n_channels=n_channels) # HR image, int8
+ img_H = util.modcrop(img_H, np.lcm(sf,8)) # modcrop
+
+ # generate degraded LR image
+ img_L = ndimage.filters.convolve(img_H, kernel[..., np.newaxis], mode='wrap') # blur
+ img_L = sr.downsample_np(img_L, sf, center=False) # downsample, standard s-fold downsampler
+ img_L = util.uint2single(img_L) # uint2single
+
+ np.random.seed(seed=0) # for reproducibility
+ img_L += np.random.normal(0, noise_level_img, img_L.shape) # add AWGN
+
+ util.imshow(util.single2uint(img_L)) if show_img else None
+
+ x = util.single2tensor4(img_L)
+ k = util.single2tensor4(kernel[..., np.newaxis])
+ sigma = torch.tensor(noise_level_model).float().view([1, 1, 1, 1])
+ [x, k, sigma] = [el.to(device) for el in [x, k, sigma]]
+
+ # --------------------------------
+ # (2) inference
+ # --------------------------------
+ x = model(x, k, sf, sigma)
+
+ # --------------------------------
+ # (3) img_E
+ # --------------------------------
+ img_E = util.tensor2uint(x)
+
+ if save_E:
+ util.imsave(img_E, os.path.join(E_path, img_name+'_x'+str(sf)+'_k'+str(k_index+1)+'_'+model_name+'.png'))
+
+
+ # --------------------------------
+ # (4) img_LEH
+ # --------------------------------
+ img_L = util.single2uint(img_L)
+ if save_LEH:
+ k_v = kernel/np.max(kernel)*1.2
+ k_v = util.single2uint(np.tile(k_v[..., np.newaxis], [1, 1, 3]))
+ k_v = cv2.resize(k_v, (3*k_v.shape[1], 3*k_v.shape[0]), interpolation=cv2.INTER_NEAREST)
+ img_I = cv2.resize(img_L, (sf*img_L.shape[1], sf*img_L.shape[0]), interpolation=cv2.INTER_NEAREST)
+ img_I[:k_v.shape[0], -k_v.shape[1]:, :] = k_v
+ img_I[:img_L.shape[0], :img_L.shape[1], :] = img_L
+ util.imshow(np.concatenate([img_I, img_E, img_H], axis=1), title='LR / Recovered / Ground-truth') if show_img else None
+ util.imsave(np.concatenate([img_I, img_E, img_H], axis=1), os.path.join(E_path, img_name+'_x'+str(sf)+'_k'+str(k_index+1)+'_LEH.png'))
+
+ if save_L:
+ util.imsave(img_L, os.path.join(E_path, img_name+'_x'+str(sf)+'_k'+str(k_index+1)+'_LR.png'))
+
+ psnr = util.calculate_psnr(img_E, img_H, border=sf**2) # change with your own border
+ test_results['psnr'].append(psnr)
+ logger.info('{:->4d}--> {:>10s} -- x{:>2d} --k{:>2d} PSNR: {:.2f}dB'.format(idx, img_name+ext, sf, k_index, psnr))
+
+ ave_psnr_k = sum(test_results['psnr']) / len(test_results['psnr'])
+ logger.info('------> Average PSNR(RGB) of ({}) scale factor: ({}), kernel: ({}) sigma: ({}): {:.2f} dB'.format(testset_name, sf, k_index+1, noise_level_model, ave_psnr_k))
+ test_results_ave['psnr_sf_k'].append(ave_psnr_k)
+ logger.info(test_results_ave['psnr_sf_k'])
+
+
+if __name__ == '__main__':
+
+ main()
diff --git a/KAIR/main_test_vrt.py b/KAIR/main_test_vrt.py
new file mode 100755
index 0000000000000000000000000000000000000000..4cf1d1eb211c732b870cfb318e632f4db6678909
--- /dev/null
+++ b/KAIR/main_test_vrt.py
@@ -0,0 +1,349 @@
+# Copyright (c) Facebook, Inc. and its affiliates.
+#
+# This source code is licensed under the BSD license found in the
+# LICENSE file in the root directory of this source tree.
+
+
+import argparse
+import cv2
+import glob
+import os
+import torch
+import requests
+import numpy as np
+from os import path as osp
+from collections import OrderedDict
+from torch.utils.data import DataLoader
+
+from models.network_vrt import VRT as net
+from utils import utils_image as util
+from data.dataset_video_test import VideoRecurrentTestDataset, VideoTestVimeo90KDataset, SingleVideoRecurrentTestDataset
+
+
+def main():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--task', type=str, default='001_VRT_videosr_bi_REDS_6frames', help='tasks: 001 to 008')
+ parser.add_argument('--sigma', type=int, default=0, help='noise level for denoising: 10, 20, 30, 40, 50')
+ parser.add_argument('--folder_lq', type=str, default='testsets/REDS4/sharp_bicubic',
+ help='input low-quality test video folder')
+ parser.add_argument('--folder_gt', type=str, default=None,
+ help='input ground-truth test video folder')
+ parser.add_argument('--tile', type=int, nargs='+', default=[40,128,128],
+ help='Tile size, [0,0,0] for no tile during testing (testing as a whole)')
+ parser.add_argument('--tile_overlap', type=int, nargs='+', default=[2,20,20],
+ help='Overlapping of different tiles')
+ args = parser.parse_args()
+
+ # define model
+ device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
+ model = prepare_model_dataset(args)
+ model.eval()
+ model = model.to(device)
+ if 'vimeo' in args.folder_lq.lower():
+ test_set = VideoTestVimeo90KDataset({'dataroot_gt':args.folder_gt, 'dataroot_lq':args.folder_lq,
+ 'meta_info_file': "data/meta_info/meta_info_Vimeo90K_test_GT.txt",
+ 'pad_sequence': True, 'num_frame': 7, 'cache_data': False})
+ elif args.folder_gt is not None:
+ test_set = VideoRecurrentTestDataset({'dataroot_gt':args.folder_gt, 'dataroot_lq':args.folder_lq,
+ 'sigma':args.sigma, 'num_frame':-1, 'cache_data': False})
+ else:
+ test_set = SingleVideoRecurrentTestDataset({'dataroot_gt':args.folder_gt, 'dataroot_lq':args.folder_lq,
+ 'sigma':args.sigma, 'num_frame':-1, 'cache_data': False})
+
+ test_loader = DataLoader(dataset=test_set, num_workers=8, batch_size=1, shuffle=False)
+
+ save_dir = f'results/{args.task}'
+ os.makedirs(save_dir, exist_ok=True)
+ test_results = OrderedDict()
+ test_results['psnr'] = []
+ test_results['ssim'] = []
+ test_results['psnr_y'] = []
+ test_results['ssim_y'] = []
+
+ assert len(test_loader) != 0, f'No dataset found at {args.folder_lq}'
+
+ for idx, batch in enumerate(test_loader):
+ lq = batch['L'].to(device)
+ folder = batch['folder']
+ gt = batch['H'] if 'H' in batch else None
+
+ # inference
+ with torch.no_grad():
+ output = test_video(lq, model, args)
+
+ if 'vimeo' in args.folder_lq.lower():
+ output = output[:, 3:4, :, :, :]
+ gt = gt.unsqueeze(0)
+ batch['lq_path'] = [['im4.png']]
+
+ test_results_folder = OrderedDict()
+ test_results_folder['psnr'] = []
+ test_results_folder['ssim'] = []
+ test_results_folder['psnr_y'] = []
+ test_results_folder['ssim_y'] = []
+
+ for i in range(output.shape[1]):
+ # save image
+ img = output[:, i, ...].data.squeeze().float().cpu().clamp_(0, 1).numpy()
+ if img.ndim == 3:
+ img = np.transpose(img[[2, 1, 0], :, :], (1, 2, 0)) # CHW-RGB to HCW-BGR
+ img = (img * 255.0).round().astype(np.uint8) # float32 to uint8
+ seq_ = osp.splitext(osp.basename(batch['lq_path'][i][0]))[0]
+ os.makedirs(f'{save_dir}/{folder[0]}', exist_ok=True)
+ cv2.imwrite(f'{save_dir}/{folder[0]}/{seq_}.png', img)
+
+ # evaluate psnr/ssim
+ if gt is not None:
+ img_gt = gt[:, i, ...].data.squeeze().float().cpu().clamp_(0, 1).numpy()
+ if img_gt.ndim == 3:
+ img_gt = np.transpose(img_gt[[2, 1, 0], :, :], (1, 2, 0)) # CHW-RGB to HCW-BGR
+ img_gt = (img_gt * 255.0).round().astype(np.uint8) # float32 to uint8
+ img_gt = np.squeeze(img_gt)
+
+ test_results_folder['psnr'].append(util.calculate_psnr(img, img_gt, border=0))
+ test_results_folder['ssim'].append(util.calculate_ssim(img, img_gt, border=0))
+ if img_gt.ndim == 3: # RGB image
+ img = util.bgr2ycbcr(img.astype(np.float32) / 255.) * 255.
+ img_gt = util.bgr2ycbcr(img_gt.astype(np.float32) / 255.) * 255.
+ test_results_folder['psnr_y'].append(util.calculate_psnr(img, img_gt, border=0))
+ test_results_folder['ssim_y'].append(util.calculate_ssim(img, img_gt, border=0))
+ else:
+ test_results_folder['psnr_y'] = test_results_folder['psnr']
+ test_results_folder['ssim_y'] = test_results_folder['ssim']
+
+ if gt is not None:
+ psnr = sum(test_results_folder['psnr']) / len(test_results_folder['psnr'])
+ ssim = sum(test_results_folder['ssim']) / len(test_results_folder['ssim'])
+ psnr_y = sum(test_results_folder['psnr_y']) / len(test_results_folder['psnr_y'])
+ ssim_y = sum(test_results_folder['ssim_y']) / len(test_results_folder['ssim_y'])
+ test_results['psnr'].append(psnr)
+ test_results['ssim'].append(ssim)
+ test_results['psnr_y'].append(psnr_y)
+ test_results['ssim_y'].append(ssim_y)
+ print('Testing {:20s} ({:2d}/{}) - PSNR: {:.2f} dB; SSIM: {:.4f}; PSNR_Y: {:.2f} dB; SSIM_Y: {:.4f}'.
+ format(folder[0], idx, len(test_loader), psnr, ssim, psnr_y, ssim_y))
+ else:
+ print('Testing {:20s} ({:2d}/{})'.format(folder[0], idx, len(test_loader)))
+
+ # summarize psnr/ssim
+ if gt is not None:
+ ave_psnr = sum(test_results['psnr']) / len(test_results['psnr'])
+ ave_ssim = sum(test_results['ssim']) / len(test_results['ssim'])
+ ave_psnr_y = sum(test_results['psnr_y']) / len(test_results['psnr_y'])
+ ave_ssim_y = sum(test_results['ssim_y']) / len(test_results['ssim_y'])
+ print('\n{} \n-- Average PSNR: {:.2f} dB; SSIM: {:.4f}; PSNR_Y: {:.2f} dB; SSIM_Y: {:.4f}'.
+ format(save_dir, ave_psnr, ave_ssim, ave_psnr_y, ave_ssim_y))
+
+
+def prepare_model_dataset(args):
+ ''' prepare model and dataset according to args.task. '''
+
+ # define model
+ if args.task == '001_VRT_videosr_bi_REDS_6frames':
+ model = net(upscale=4, img_size=[6,64,64], window_size=[6,8,8], depths=[8,8,8,8,8,8,8, 4,4,4,4, 4,4],
+ indep_reconsts=[11,12], embed_dims=[120,120,120,120,120,120,120, 180,180,180,180, 180,180],
+ num_heads=[6,6,6,6,6,6,6, 6,6,6,6, 6,6], pa_frames=2, deformable_groups=12)
+ datasets = ['REDS4']
+ args.scale = 4
+ args.window_size = [6,8,8]
+ args.nonblind_denoising = False
+
+ elif args.task == '002_VRT_videosr_bi_REDS_16frames':
+ model = net(upscale=4, img_size=[16,64,64], window_size=[8,8,8], depths=[8,8,8,8,8,8,8, 4,4,4,4, 4,4],
+ indep_reconsts=[11,12], embed_dims=[120,120,120,120,120,120,120, 180,180,180,180, 180,180],
+ num_heads=[6,6,6,6,6,6,6, 6,6,6,6, 6,6], pa_frames=6, deformable_groups=24)
+ datasets = ['REDS4']
+ args.scale = 4
+ args.window_size = [8,8,8]
+ args.nonblind_denoising = False
+
+ elif args.task in ['003_VRT_videosr_bi_Vimeo_7frames', '004_VRT_videosr_bd_Vimeo_7frames']:
+ model = net(upscale=4, img_size=[8,64,64], window_size=[8,8,8], depths=[8,8,8,8,8,8,8, 4,4,4,4, 4,4],
+ indep_reconsts=[11,12], embed_dims=[120,120,120,120,120,120,120, 180,180,180,180, 180,180],
+ num_heads=[6,6,6,6,6,6,6, 6,6,6,6, 6,6], pa_frames=4, deformable_groups=16)
+ datasets = ['Vid4'] # 'Vimeo'. Vimeo dataset is too large. Please refer to #training to download it.
+ args.scale = 4
+ args.window_size = [8,8,8]
+ args.nonblind_denoising = False
+
+ elif args.task in ['005_VRT_videodeblurring_DVD']:
+ model = net(upscale=1, img_size=[6,192,192], window_size=[6,8,8], depths=[8,8,8,8,8,8,8, 4,4, 4,4],
+ indep_reconsts=[9,10], embed_dims=[96,96,96,96,96,96,96, 120,120, 120,120],
+ num_heads=[6,6,6,6,6,6,6, 6,6, 6,6], pa_frames=2, deformable_groups=16)
+ datasets = ['DVD10']
+ args.scale = 1
+ args.window_size = [6,8,8]
+ args.nonblind_denoising = False
+
+ elif args.task in ['006_VRT_videodeblurring_GoPro']:
+ model = net(upscale=1, img_size=[6,192,192], window_size=[6,8,8], depths=[8,8,8,8,8,8,8, 4,4, 4,4],
+ indep_reconsts=[9,10], embed_dims=[96,96,96,96,96,96,96, 120,120, 120,120],
+ num_heads=[6,6,6,6,6,6,6, 6,6, 6,6], pa_frames=2, deformable_groups=16)
+ datasets = ['GoPro11-part1', 'GoPro11-part2']
+ args.scale = 1
+ args.window_size = [6,8,8]
+ args.nonblind_denoising = False
+
+ elif args.task in ['007_VRT_videodeblurring_REDS']:
+ model = net(upscale=1, img_size=[6,192,192], window_size=[6,8,8], depths=[8,8,8,8,8,8,8, 4,4, 4,4],
+ indep_reconsts=[9,10], embed_dims=[96,96,96,96,96,96,96, 120,120, 120,120],
+ num_heads=[6,6,6,6,6,6,6, 6,6, 6,6], pa_frames=2, deformable_groups=16)
+ datasets = ['REDS4']
+ args.scale = 1
+ args.window_size = [6,8,8]
+ args.nonblind_denoising = False
+
+ elif args.task == '008_VRT_videodenoising_DAVIS':
+ model = net(upscale=1, img_size=[6,192,192], window_size=[6,8,8], depths=[8,8,8,8,8,8,8, 4,4, 4,4],
+ indep_reconsts=[9,10], embed_dims=[96,96,96,96,96,96,96, 120,120, 120,120],
+ num_heads=[6,6,6,6,6,6,6, 6,6, 6,6], pa_frames=2, deformable_groups=16,
+ nonblind_denoising=True)
+ datasets = ['Set8', 'DAVIS-test']
+ args.scale = 1
+ args.window_size = [6,8,8]
+ args.nonblind_denoising = True
+
+ # download model
+ model_path = f'model_zoo/vrt/{args.task}.pth'
+ if os.path.exists(model_path):
+ print(f'loading model from ./{model_path}')
+ else:
+ os.makedirs(os.path.dirname(model_path), exist_ok=True)
+ url = 'https://github.com/JingyunLiang/VRT/releases/download/v0.0/{}'.format(os.path.basename(model_path))
+ r = requests.get(url, allow_redirects=True)
+ print(f'downloading model {model_path}')
+ open(model_path, 'wb').write(r.content)
+
+ pretrained_model = torch.load(model_path)
+ model.load_state_dict(pretrained_model['params'] if 'params' in pretrained_model.keys() else pretrained_model)
+
+ # download datasets
+ if os.path.exists(f'{args.folder_lq}'):
+ print(f'using dataset from {args.folder_lq}')
+ else:
+ if 'vimeo' in args.folder_lq.lower():
+ print(f'Vimeo dataset is not at {args.folder_lq}! Please refer to #training of Readme.md to download it.')
+ else:
+ os.makedirs('testsets', exist_ok=True)
+ for dataset in datasets:
+ url = f'https://github.com/JingyunLiang/VRT/releases/download/v0.0/testset_{dataset}.tar.gz'
+ r = requests.get(url, allow_redirects=True)
+ print(f'downloading testing dataset {dataset}')
+ open(f'testsets/{dataset}.tar.gz', 'wb').write(r.content)
+ os.system(f'tar -xvf testsets/{dataset}.tar.gz -C testsets')
+ os.system(f'rm testsets/{dataset}.tar.gz')
+
+ return model
+
+
+def test_video(lq, model, args):
+ '''test the video as a whole or as clips (divided temporally). '''
+
+ num_frame_testing = args.tile[0]
+ if num_frame_testing:
+ # test as multiple clips if out-of-memory
+ sf = args.scale
+ num_frame_overlapping = args.tile_overlap[0]
+ not_overlap_border = False
+ b, d, c, h, w = lq.size()
+ c = c - 1 if args.nonblind_denoising else c
+ stride = num_frame_testing - num_frame_overlapping
+ d_idx_list = list(range(0, d-num_frame_testing, stride)) + [max(0, d-num_frame_testing)]
+ E = torch.zeros(b, d, c, h*sf, w*sf)
+ W = torch.zeros(b, d, 1, 1, 1)
+
+ for d_idx in d_idx_list:
+ lq_clip = lq[:, d_idx:d_idx+num_frame_testing, ...]
+ print("LQ.size: ", lq.size())
+ out_clip = test_clip(lq_clip, model, args)
+ print("OUTPUT size: ", out_clip.size())
+ out_clip_mask = torch.ones((b, min(num_frame_testing, d), 1, 1, 1))
+
+ if not_overlap_border:
+ if d_idx < d_idx_list[-1]:
+ out_clip[:, -num_frame_overlapping//2:, ...] *= 0
+ out_clip_mask[:, -num_frame_overlapping//2:, ...] *= 0
+ if d_idx > d_idx_list[0]:
+ out_clip[:, :num_frame_overlapping//2, ...] *= 0
+ out_clip_mask[:, :num_frame_overlapping//2, ...] *= 0
+
+ E[:, d_idx:d_idx+num_frame_testing, ...].add_(out_clip)
+ W[:, d_idx:d_idx+num_frame_testing, ...].add_(out_clip_mask)
+ output = E.div_(W)
+ print("OUTPUT final size: ", output.size())
+ else:
+ # test as one clip (the whole video) if you have enough memory
+ window_size = args.window_size
+ d_old = lq.size(1)
+ d_pad = (window_size[0] - d_old % window_size[0]) % window_size[0]
+ lq = torch.cat([lq, torch.flip(lq[:, -d_pad:, ...], [1])], 1) if d_pad else lq
+ output = test_clip(lq, model, args)
+ output = output[:, :d_old, :, :, :]
+
+ return output
+
+
+def test_clip(lq, model, args):
+ ''' test the clip as a whole or as patches. '''
+
+ sf = args.scale
+ window_size = args.window_size
+ size_patch_testing = args.tile[1]
+ assert size_patch_testing % window_size[-1] == 0, 'testing patch size should be a multiple of window_size.'
+
+ if size_patch_testing:
+ # divide the clip to patches (spatially only, tested patch by patch)
+ overlap_size = args.tile_overlap[1]
+ not_overlap_border = True
+
+ # test patch by patch
+ b, d, c, h, w = lq.size()
+ c = c - 1 if args.nonblind_denoising else c
+ stride = size_patch_testing - overlap_size
+ h_idx_list = list(range(0, h-size_patch_testing, stride)) + [max(0, h-size_patch_testing)]
+ w_idx_list = list(range(0, w-size_patch_testing, stride)) + [max(0, w-size_patch_testing)]
+ E = torch.zeros(b, d, c, h*sf, w*sf)
+ W = torch.zeros_like(E)
+
+ for h_idx in h_idx_list:
+ for w_idx in w_idx_list:
+ in_patch = lq[..., h_idx:h_idx+size_patch_testing, w_idx:w_idx+size_patch_testing]
+ out_patch = model(in_patch).detach().cpu()
+
+ out_patch_mask = torch.ones_like(out_patch)
+
+ if not_overlap_border:
+ if h_idx < h_idx_list[-1]:
+ out_patch[..., -overlap_size//2:, :] *= 0
+ out_patch_mask[..., -overlap_size//2:, :] *= 0
+ if w_idx < w_idx_list[-1]:
+ out_patch[..., :, -overlap_size//2:] *= 0
+ out_patch_mask[..., :, -overlap_size//2:] *= 0
+ if h_idx > h_idx_list[0]:
+ out_patch[..., :overlap_size//2, :] *= 0
+ out_patch_mask[..., :overlap_size//2, :] *= 0
+ if w_idx > w_idx_list[0]:
+ out_patch[..., :, :overlap_size//2] *= 0
+ out_patch_mask[..., :, :overlap_size//2] *= 0
+
+ E[..., h_idx*sf:(h_idx+size_patch_testing)*sf, w_idx*sf:(w_idx+size_patch_testing)*sf].add_(out_patch)
+ W[..., h_idx*sf:(h_idx+size_patch_testing)*sf, w_idx*sf:(w_idx+size_patch_testing)*sf].add_(out_patch_mask)
+ output = E.div_(W)
+
+ else:
+ _, _, _, h_old, w_old = lq.size()
+ h_pad = (window_size[1] - h_old % window_size[1]) % window_size[1]
+ w_pad = (window_size[2] - w_old % window_size[2]) % window_size[2]
+
+ lq = torch.cat([lq, torch.flip(lq[:, :, :, -h_pad:, :], [3])], 3) if h_pad else lq
+ lq = torch.cat([lq, torch.flip(lq[:, :, :, :, -w_pad:], [4])], 4) if w_pad else lq
+
+ output = model(lq).detach().cpu()
+
+ output = output[:, :, :, :h_old*sf, :w_old*sf]
+
+ return output
+
+
+if __name__ == '__main__':
+ main()
diff --git a/KAIR/main_train_dncnn.py b/KAIR/main_train_dncnn.py
new file mode 100644
index 0000000000000000000000000000000000000000..7cf0c10c690d22d8091ce7ea5e9e6eacce8c132c
--- /dev/null
+++ b/KAIR/main_train_dncnn.py
@@ -0,0 +1,250 @@
+import os.path
+import math
+import argparse
+import time
+import random
+import numpy as np
+from collections import OrderedDict
+import logging
+import torch
+from torch.utils.data import DataLoader
+
+
+from utils import utils_logger
+from utils import utils_image as util
+from utils import utils_option as option
+
+from data.select_dataset import define_Dataset
+from models.select_model import define_Model
+
+
+'''
+# --------------------------------------------
+# training code for DnCNN
+# --------------------------------------------
+# Kai Zhang (cskaizhang@gmail.com)
+# github: https://github.com/cszn/KAIR
+# https://github.com/cszn/DnCNN
+#
+# Reference:
+@article{zhang2017beyond,
+ title={Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising},
+ author={Zhang, Kai and Zuo, Wangmeng and Chen, Yunjin and Meng, Deyu and Zhang, Lei},
+ journal={IEEE Transactions on Image Processing},
+ volume={26},
+ number={7},
+ pages={3142--3155},
+ year={2017},
+ publisher={IEEE}
+}
+# --------------------------------------------
+# https://github.com/xinntao/BasicSR
+# --------------------------------------------
+'''
+
+
+def main(json_path='options/train_dncnn.json'):
+
+ '''
+ # ----------------------------------------
+ # Step--1 (prepare opt)
+ # ----------------------------------------
+ '''
+
+ parser = argparse.ArgumentParser()
+ parser.add_argument('-opt', type=str, default=json_path, help='Path to option JSON file.')
+
+ opt = option.parse(parser.parse_args().opt, is_train=True)
+ util.mkdirs((path for key, path in opt['path'].items() if 'pretrained' not in key))
+
+ # ----------------------------------------
+ # update opt
+ # ----------------------------------------
+ # -->-->-->-->-->-->-->-->-->-->-->-->-->-
+ init_iter, init_path_G = option.find_last_checkpoint(opt['path']['models'], net_type='G')
+ opt['path']['pretrained_netG'] = init_path_G
+ current_step = init_iter
+
+ border = 0
+ # --<--<--<--<--<--<--<--<--<--<--<--<--<-
+
+ # ----------------------------------------
+ # save opt to a '../option.json' file
+ # ----------------------------------------
+ option.save(opt)
+
+ # ----------------------------------------
+ # return None for missing key
+ # ----------------------------------------
+ opt = option.dict_to_nonedict(opt)
+
+ # ----------------------------------------
+ # configure logger
+ # ----------------------------------------
+ logger_name = 'train'
+ utils_logger.logger_info(logger_name, os.path.join(opt['path']['log'], logger_name+'.log'))
+ logger = logging.getLogger(logger_name)
+ logger.info(option.dict2str(opt))
+
+ # ----------------------------------------
+ # seed
+ # ----------------------------------------
+ seed = opt['train']['manual_seed']
+ if seed is None:
+ seed = random.randint(1, 10000)
+ logger.info('Random seed: {}'.format(seed))
+ random.seed(seed)
+ np.random.seed(seed)
+ torch.manual_seed(seed)
+ torch.cuda.manual_seed_all(seed)
+
+ '''
+ # ----------------------------------------
+ # Step--2 (creat dataloader)
+ # ----------------------------------------
+ '''
+
+ # ----------------------------------------
+ # 1) create_dataset
+ # 2) creat_dataloader for train and test
+ # ----------------------------------------
+ dataset_type = opt['datasets']['train']['dataset_type']
+ for phase, dataset_opt in opt['datasets'].items():
+ if phase == 'train':
+ train_set = define_Dataset(dataset_opt)
+ train_size = int(math.ceil(len(train_set) / dataset_opt['dataloader_batch_size']))
+ logger.info('Number of train images: {:,d}, iters: {:,d}'.format(len(train_set), train_size))
+ train_loader = DataLoader(train_set,
+ batch_size=dataset_opt['dataloader_batch_size'],
+ shuffle=dataset_opt['dataloader_shuffle'],
+ num_workers=dataset_opt['dataloader_num_workers'],
+ drop_last=True,
+ pin_memory=True)
+ elif phase == 'test':
+ test_set = define_Dataset(dataset_opt)
+ test_loader = DataLoader(test_set, batch_size=1,
+ shuffle=False, num_workers=1,
+ drop_last=False, pin_memory=True)
+ else:
+ raise NotImplementedError("Phase [%s] is not recognized." % phase)
+
+ '''
+ # ----------------------------------------
+ # Step--3 (initialize model)
+ # ----------------------------------------
+ '''
+
+ model = define_Model(opt)
+
+ if opt['merge_bn'] and current_step > opt['merge_bn_startpoint']:
+ logger.info('^_^ -----merging bnorm----- ^_^')
+ model.merge_bnorm_test()
+
+ logger.info(model.info_network())
+ model.init_train()
+ logger.info(model.info_params())
+
+ '''
+ # ----------------------------------------
+ # Step--4 (main training)
+ # ----------------------------------------
+ '''
+
+ for epoch in range(1000000): # keep running
+ for i, train_data in enumerate(train_loader):
+
+ current_step += 1
+
+ if dataset_type == 'dnpatch' and current_step % 20000 == 0: # for 'train400'
+ train_loader.dataset.update_data()
+
+ # -------------------------------
+ # 1) update learning rate
+ # -------------------------------
+ model.update_learning_rate(current_step)
+
+ # -------------------------------
+ # 2) feed patch pairs
+ # -------------------------------
+ model.feed_data(train_data)
+
+ # -------------------------------
+ # 3) optimize parameters
+ # -------------------------------
+ model.optimize_parameters(current_step)
+
+ # -------------------------------
+ # merge bnorm
+ # -------------------------------
+ if opt['merge_bn'] and opt['merge_bn_startpoint'] == current_step:
+ logger.info('^_^ -----merging bnorm----- ^_^')
+ model.merge_bnorm_train()
+ model.print_network()
+
+ # -------------------------------
+ # 4) training information
+ # -------------------------------
+ if current_step % opt['train']['checkpoint_print'] == 0:
+ logs = model.current_log() # such as loss
+ message = ' '.format(epoch, current_step, model.current_learning_rate())
+ for k, v in logs.items(): # merge log information into message
+ message += '{:s}: {:.3e} '.format(k, v)
+ logger.info(message)
+
+ # -------------------------------
+ # 5) save model
+ # -------------------------------
+ if current_step % opt['train']['checkpoint_save'] == 0:
+ logger.info('Saving the model.')
+ model.save(current_step)
+
+ # -------------------------------
+ # 6) testing
+ # -------------------------------
+ if current_step % opt['train']['checkpoint_test'] == 0:
+
+ avg_psnr = 0.0
+ idx = 0
+
+ for test_data in test_loader:
+ idx += 1
+ image_name_ext = os.path.basename(test_data['L_path'][0])
+ img_name, ext = os.path.splitext(image_name_ext)
+
+ img_dir = os.path.join(opt['path']['images'], img_name)
+ util.mkdir(img_dir)
+
+ model.feed_data(test_data)
+ model.test()
+
+ visuals = model.current_visuals()
+ E_img = util.tensor2uint(visuals['E'])
+ H_img = util.tensor2uint(visuals['H'])
+
+ # -----------------------
+ # save estimated image E
+ # -----------------------
+ save_img_path = os.path.join(img_dir, '{:s}_{:d}.png'.format(img_name, current_step))
+ util.imsave(E_img, save_img_path)
+
+ # -----------------------
+ # calculate PSNR
+ # -----------------------
+ current_psnr = util.calculate_psnr(E_img, H_img, border=border)
+
+ logger.info('{:->4d}--> {:>10s} | {:<4.2f}dB'.format(idx, image_name_ext, current_psnr))
+
+ avg_psnr += current_psnr
+
+ avg_psnr = avg_psnr / idx
+
+ # testing log
+ logger.info('-->-->-->-->-->-->-->-->-->-->-->-->-
+ init_iter_G, init_path_G = option.find_last_checkpoint(opt['path']['models'], net_type='G')
+ opt['path']['pretrained_netG'] = init_path_G
+ init_iter_optimizerG, init_path_optimizerG = option.find_last_checkpoint(opt['path']['models'], net_type='optimizerG')
+ opt['path']['pretrained_optimizerG'] = init_path_optimizerG
+ current_step = max(init_iter_G, init_iter_optimizerG)
+
+ border = opt['scale']
+ # --<--<--<--<--<--<--<--<--<--<--<--<--<-
+
+ # ----------------------------------------
+ # save opt to a '../option.json' file
+ # ----------------------------------------
+ if opt['rank'] == 0:
+ option.save(opt)
+
+ # ----------------------------------------
+ # return None for missing key
+ # ----------------------------------------
+ opt = option.dict_to_nonedict(opt)
+
+ # ----------------------------------------
+ # configure logger
+ # ----------------------------------------
+ if opt['rank'] == 0:
+ logger_name = 'train'
+ utils_logger.logger_info(logger_name, os.path.join(opt['path']['log'], logger_name+'.log'))
+ logger = logging.getLogger(logger_name)
+ logger.info(option.dict2str(opt))
+
+ # ----------------------------------------
+ # seed
+ # ----------------------------------------
+ seed = opt['train']['manual_seed']
+ if seed is None:
+ seed = random.randint(1, 10000)
+ print('Random seed: {}'.format(seed))
+ random.seed(seed)
+ np.random.seed(seed)
+ torch.manual_seed(seed)
+ torch.cuda.manual_seed_all(seed)
+
+ '''
+ # ----------------------------------------
+ # Step--2 (creat dataloader)
+ # ----------------------------------------
+ '''
+
+ # ----------------------------------------
+ # 1) create_dataset
+ # 2) creat_dataloader for train and test
+ # ----------------------------------------
+ for phase, dataset_opt in opt['datasets'].items():
+ if phase == 'train':
+ train_set = define_Dataset(dataset_opt)
+ train_size = int(math.ceil(len(train_set) / dataset_opt['dataloader_batch_size']))
+ if opt['rank'] == 0:
+ logger.info('Number of train images: {:,d}, iters: {:,d}'.format(len(train_set), train_size))
+ if opt['dist']:
+ train_sampler = DistributedSampler(train_set, shuffle=dataset_opt['dataloader_shuffle'], drop_last=True, seed=seed)
+ train_loader = DataLoader(train_set,
+ batch_size=dataset_opt['dataloader_batch_size']//opt['num_gpu'],
+ shuffle=False,
+ num_workers=dataset_opt['dataloader_num_workers']//opt['num_gpu'],
+ drop_last=True,
+ pin_memory=True,
+ sampler=train_sampler)
+ else:
+ train_loader = DataLoader(train_set,
+ batch_size=dataset_opt['dataloader_batch_size'],
+ shuffle=dataset_opt['dataloader_shuffle'],
+ num_workers=dataset_opt['dataloader_num_workers'],
+ drop_last=True,
+ pin_memory=True)
+
+ elif phase == 'test':
+ test_set = define_Dataset(dataset_opt)
+ test_loader = DataLoader(test_set, batch_size=1,
+ shuffle=False, num_workers=1,
+ drop_last=False, pin_memory=True)
+ else:
+ raise NotImplementedError("Phase [%s] is not recognized." % phase)
+
+ '''
+ # ----------------------------------------
+ # Step--3 (initialize model)
+ # ----------------------------------------
+ '''
+
+ model = define_Model(opt)
+ model.init_train()
+ if opt['rank'] == 0:
+ logger.info(model.info_network())
+ logger.info(model.info_params())
+
+ '''
+ # ----------------------------------------
+ # Step--4 (main training)
+ # ----------------------------------------
+ '''
+
+ for epoch in range(1000000): # keep running
+ for i, train_data in enumerate(train_loader):
+
+ current_step += 1
+
+ # -------------------------------
+ # 1) update learning rate
+ # -------------------------------
+ model.update_learning_rate(current_step)
+
+ # -------------------------------
+ # 2) feed patch pairs
+ # -------------------------------
+ model.feed_data(train_data)
+
+ # -------------------------------
+ # 3) optimize parameters
+ # -------------------------------
+ model.optimize_parameters(current_step)
+
+ # -------------------------------
+ # 4) training information
+ # -------------------------------
+ if current_step % opt['train']['checkpoint_print'] == 0 and opt['rank'] == 0:
+ logs = model.current_log() # such as loss
+ message = ' '.format(epoch, current_step, model.current_learning_rate())
+ for k, v in logs.items(): # merge log information into message
+ message += '{:s}: {:.3e} '.format(k, v)
+ logger.info(message)
+
+ # -------------------------------
+ # 5) save model
+ # -------------------------------
+ if current_step % opt['train']['checkpoint_save'] == 0 and opt['rank'] == 0:
+ logger.info('Saving the model.')
+ model.save(current_step)
+
+ # -------------------------------
+ # 6) testing
+ # -------------------------------
+ if current_step % opt['train']['checkpoint_test'] == 0 and opt['rank'] == 0:
+
+ avg_psnr = 0.0
+ idx = 0
+
+ for test_data in test_loader:
+ idx += 1
+ image_name_ext = os.path.basename(test_data['L_path'][0])
+ img_name, ext = os.path.splitext(image_name_ext)
+
+ img_dir = os.path.join(opt['path']['images'], img_name)
+ util.mkdir(img_dir)
+
+ model.feed_data(test_data)
+ model.test()
+
+ visuals = model.current_visuals()
+ E_img = util.tensor2uint(visuals['E'])
+ H_img = util.tensor2uint(visuals['H'])
+
+ # -----------------------
+ # save estimated image E
+ # -----------------------
+ save_img_path = os.path.join(img_dir, '{:s}_{:d}.png'.format(img_name, current_step))
+ util.imsave(E_img, save_img_path)
+
+ # -----------------------
+ # calculate PSNR
+ # -----------------------
+ current_psnr = util.calculate_psnr(E_img, H_img, border=border)
+
+ logger.info('{:->4d}--> {:>10s} | {:<4.2f}dB'.format(idx, image_name_ext, current_psnr))
+
+ avg_psnr += current_psnr
+
+ avg_psnr = avg_psnr / idx
+
+ # testing log
+ logger.info('-->-->-->-->-->-->-->-->-->-->-->-->-
+ init_iter_G, init_path_G = option.find_last_checkpoint(opt['path']['models'], net_type='G')
+ init_iter_D, init_path_D = option.find_last_checkpoint(opt['path']['models'], net_type='D')
+ init_iter_E, init_path_E = option.find_last_checkpoint(opt['path']['models'], net_type='E')
+ opt['path']['pretrained_netG'] = init_path_G
+ opt['path']['pretrained_netD'] = init_path_D
+ opt['path']['pretrained_netE'] = init_path_E
+ init_iter_optimizerG, init_path_optimizerG = option.find_last_checkpoint(opt['path']['models'], net_type='optimizerG')
+ init_iter_optimizerD, init_path_optimizerD = option.find_last_checkpoint(opt['path']['models'], net_type='optimizerD')
+ opt['path']['pretrained_optimizerG'] = init_path_optimizerG
+ opt['path']['pretrained_optimizerD'] = init_path_optimizerD
+ current_step = max(init_iter_G, init_iter_D, init_iter_E, init_iter_optimizerG, init_iter_optimizerD)
+ current_step = 0
+
+ # opt['path']['pretrained_netG'] = ''
+ # current_step = 0
+ border = opt['scale']
+ # --<--<--<--<--<--<--<--<--<--<--<--<--<-
+
+ # ----------------------------------------
+ # save opt to a '../option.json' file
+ # ----------------------------------------
+ if opt['rank'] == 0:
+ option.save(opt)
+
+ # ----------------------------------------
+ # return None for missing key
+ # ----------------------------------------
+ opt = option.dict_to_nonedict(opt)
+
+ # ----------------------------------------
+ # configure logger
+ # ----------------------------------------
+ if opt['rank'] == 0:
+ logger_name = 'train'
+ utils_logger.logger_info(logger_name, os.path.join(opt['path']['log'], logger_name+'.log'))
+ logger = logging.getLogger(logger_name)
+ logger.info(option.dict2str(opt))
+
+ # ----------------------------------------
+ # seed
+ # ----------------------------------------
+ seed = opt['train']['manual_seed']
+ if seed is None:
+ seed = random.randint(1, 10000)
+ print('Random seed: {}'.format(seed))
+ random.seed(seed)
+ np.random.seed(seed)
+ torch.manual_seed(seed)
+ torch.cuda.manual_seed_all(seed)
+
+ '''
+ # ----------------------------------------
+ # Step--2 (creat dataloader)
+ # ----------------------------------------
+ '''
+
+ # ----------------------------------------
+ # 1) create_dataset
+ # 2) creat_dataloader for train and test
+ # ----------------------------------------
+ for phase, dataset_opt in opt['datasets'].items():
+ if phase == 'train':
+ train_set = define_Dataset(dataset_opt)
+ train_size = int(math.ceil(len(train_set) / dataset_opt['dataloader_batch_size']))
+ if opt['rank'] == 0:
+ logger.info('Number of train images: {:,d}, iters: {:,d}'.format(len(train_set), train_size))
+ if opt['dist']:
+ train_sampler = DistributedSampler(train_set, shuffle=dataset_opt['dataloader_shuffle'], drop_last=True, seed=seed)
+ train_loader = DataLoader(train_set,
+ batch_size=dataset_opt['dataloader_batch_size']//opt['num_gpu'],
+ shuffle=False,
+ num_workers=dataset_opt['dataloader_num_workers']//opt['num_gpu'],
+ drop_last=True,
+ pin_memory=True,
+ sampler=train_sampler)
+ else:
+ train_loader = DataLoader(train_set,
+ batch_size=dataset_opt['dataloader_batch_size'],
+ shuffle=dataset_opt['dataloader_shuffle'],
+ num_workers=dataset_opt['dataloader_num_workers'],
+ drop_last=True,
+ pin_memory=True)
+
+ elif phase == 'test':
+ test_set = define_Dataset(dataset_opt)
+ test_loader = DataLoader(test_set, batch_size=1,
+ shuffle=False, num_workers=1,
+ drop_last=False, pin_memory=True)
+ else:
+ raise NotImplementedError("Phase [%s] is not recognized." % phase)
+
+ '''
+ # ----------------------------------------
+ # Step--3 (initialize model)
+ # ----------------------------------------
+ '''
+
+ model = define_Model(opt)
+
+ model.init_train()
+ if opt['rank'] == 0:
+ logger.info(model.info_network())
+ logger.info(model.info_params())
+
+ '''
+ # ----------------------------------------
+ # Step--4 (main training)
+ # ----------------------------------------
+ '''
+
+ for epoch in range(1000000): # keep running
+ for i, train_data in enumerate(train_loader):
+
+ current_step += 1
+
+ # -------------------------------
+ # 1) update learning rate
+ # -------------------------------
+ model.update_learning_rate(current_step)
+
+ # -------------------------------
+ # 2) feed patch pairs
+ # -------------------------------
+ model.feed_data(train_data)
+
+ # -------------------------------
+ # 3) optimize parameters
+ # -------------------------------
+ model.optimize_parameters(current_step)
+
+ # -------------------------------
+ # 4) training information
+ # -------------------------------
+ if current_step % opt['train']['checkpoint_print'] == 0 and opt['rank'] == 0:
+ logs = model.current_log() # such as loss
+ message = ' '.format(epoch, current_step, model.current_learning_rate())
+ for k, v in logs.items(): # merge log information into message
+ message += '{:s}: {:.3e} '.format(k, v)
+ logger.info(message)
+
+ # -------------------------------
+ # 5) save model
+ # -------------------------------
+ if current_step % opt['train']['checkpoint_save'] == 0 and opt['rank'] == 0:
+ logger.info('Saving the model.')
+ model.save(current_step)
+
+ # -------------------------------
+ # 6) testing
+ # -------------------------------
+ if current_step % opt['train']['checkpoint_test'] == 0 and opt['rank'] == 0:
+
+ avg_psnr = 0.0
+ idx = 0
+
+ for test_data in test_loader:
+ idx += 1
+ image_name_ext = os.path.basename(test_data['L_path'][0])
+ img_name, ext = os.path.splitext(image_name_ext)
+
+ img_dir = os.path.join(opt['path']['images'], img_name)
+ util.mkdir(img_dir)
+
+ model.feed_data(test_data)
+ model.test()
+
+ visuals = model.current_visuals()
+ E_img = util.tensor2uint(visuals['E'])
+ H_img = util.tensor2uint(visuals['H'])
+
+ # -----------------------
+ # save estimated image E
+ # -----------------------
+ save_img_path = os.path.join(img_dir, '{:s}_{:d}.png'.format(img_name, current_step))
+ util.imsave(E_img, save_img_path)
+
+ # -----------------------
+ # calculate PSNR
+ # -----------------------
+ current_psnr = util.calculate_psnr(E_img, H_img, border=border)
+
+ logger.info('{:->4d}--> {:>10s} | {:<4.2f}dB'.format(idx, image_name_ext, current_psnr))
+
+ avg_psnr += current_psnr
+
+ avg_psnr = avg_psnr / idx
+
+ # testing log
+ logger.info('-->-->-->-->-->-->-->-->-->-->-->-->-
+ init_iter_G, init_path_G = option.find_last_checkpoint(opt['path']['models'], net_type='G')
+ init_iter_E, init_path_E = option.find_last_checkpoint(opt['path']['models'], net_type='E')
+ opt['path']['pretrained_netG'] = init_path_G
+ opt['path']['pretrained_netE'] = init_path_E
+ init_iter_optimizerG, init_path_optimizerG = option.find_last_checkpoint(opt['path']['models'], net_type='optimizerG')
+ opt['path']['pretrained_optimizerG'] = init_path_optimizerG
+ current_step = max(init_iter_G, init_iter_E, init_iter_optimizerG)
+
+ border = opt['scale']
+ # --<--<--<--<--<--<--<--<--<--<--<--<--<-
+
+ # ----------------------------------------
+ # save opt to a '../option.json' file
+ # ----------------------------------------
+ if opt['rank'] == 0:
+ option.save(opt)
+
+ # ----------------------------------------
+ # return None for missing key
+ # ----------------------------------------
+ opt = option.dict_to_nonedict(opt)
+
+ # ----------------------------------------
+ # configure logger
+ # ----------------------------------------
+ if opt['rank'] == 0:
+ logger_name = 'train'
+ utils_logger.logger_info(logger_name, os.path.join(opt['path']['log'], logger_name+'.log'))
+ logger = logging.getLogger(logger_name)
+ logger.info(option.dict2str(opt))
+
+ # ----------------------------------------
+ # seed
+ # ----------------------------------------
+ seed = opt['train']['manual_seed']
+ if seed is None:
+ seed = random.randint(1, 10000)
+ print('Random seed: {}'.format(seed))
+ random.seed(seed)
+ np.random.seed(seed)
+ torch.manual_seed(seed)
+ torch.cuda.manual_seed_all(seed)
+
+ '''
+ # ----------------------------------------
+ # Step--2 (creat dataloader)
+ # ----------------------------------------
+ '''
+
+ # ----------------------------------------
+ # 1) create_dataset
+ # 2) creat_dataloader for train and test
+ # ----------------------------------------
+ for phase, dataset_opt in opt['datasets'].items():
+ if phase == 'train':
+ train_set = define_Dataset(dataset_opt)
+ train_size = int(math.ceil(len(train_set) / dataset_opt['dataloader_batch_size']))
+ if opt['rank'] == 0:
+ logger.info('Number of train images: {:,d}, iters: {:,d}'.format(len(train_set), train_size))
+ if opt['dist']:
+ train_sampler = DistributedSampler(train_set, shuffle=dataset_opt['dataloader_shuffle'], drop_last=True, seed=seed)
+ train_loader = DataLoader(train_set,
+ batch_size=dataset_opt['dataloader_batch_size']//opt['num_gpu'],
+ shuffle=False,
+ num_workers=dataset_opt['dataloader_num_workers']//opt['num_gpu'],
+ drop_last=True,
+ pin_memory=True,
+ sampler=train_sampler)
+ else:
+ train_loader = DataLoader(train_set,
+ batch_size=dataset_opt['dataloader_batch_size'],
+ shuffle=dataset_opt['dataloader_shuffle'],
+ num_workers=dataset_opt['dataloader_num_workers'],
+ drop_last=True,
+ pin_memory=True)
+
+ elif phase == 'test':
+ test_set = define_Dataset(dataset_opt)
+ test_loader = DataLoader(test_set, batch_size=1,
+ shuffle=False, num_workers=1,
+ drop_last=False, pin_memory=True)
+ else:
+ raise NotImplementedError("Phase [%s] is not recognized." % phase)
+
+ '''
+ # ----------------------------------------
+ # Step--3 (initialize model)
+ # ----------------------------------------
+ '''
+
+ model = define_Model(opt)
+ model.init_train()
+ if opt['rank'] == 0:
+ logger.info(model.info_network())
+ logger.info(model.info_params())
+
+ '''
+ # ----------------------------------------
+ # Step--4 (main training)
+ # ----------------------------------------
+ '''
+
+ for epoch in range(1000000): # keep running
+ for i, train_data in enumerate(train_loader):
+
+ current_step += 1
+
+ # -------------------------------
+ # 1) update learning rate
+ # -------------------------------
+ model.update_learning_rate(current_step)
+
+ # -------------------------------
+ # 2) feed patch pairs
+ # -------------------------------
+ model.feed_data(train_data)
+
+ # -------------------------------
+ # 3) optimize parameters
+ # -------------------------------
+ model.optimize_parameters(current_step)
+
+ # -------------------------------
+ # 4) training information
+ # -------------------------------
+ if current_step % opt['train']['checkpoint_print'] == 0 and opt['rank'] == 0:
+ logs = model.current_log() # such as loss
+ message = ' '.format(epoch, current_step, model.current_learning_rate())
+ for k, v in logs.items(): # merge log information into message
+ message += '{:s}: {:.3e} '.format(k, v)
+ logger.info(message)
+
+ # -------------------------------
+ # 5) save model
+ # -------------------------------
+ if current_step % opt['train']['checkpoint_save'] == 0 and opt['rank'] == 0:
+ logger.info('Saving the model.')
+ model.save(current_step)
+
+ # -------------------------------
+ # 6) testing
+ # -------------------------------
+ if current_step % opt['train']['checkpoint_test'] == 0 and opt['rank'] == 0:
+
+ avg_psnr = 0.0
+ idx = 0
+
+ for test_data in test_loader:
+ idx += 1
+ image_name_ext = os.path.basename(test_data['L_path'][0])
+ img_name, ext = os.path.splitext(image_name_ext)
+
+ img_dir = os.path.join(opt['path']['images'], img_name)
+ util.mkdir(img_dir)
+
+ model.feed_data(test_data)
+ model.test()
+
+ visuals = model.current_visuals()
+ E_img = util.tensor2uint(visuals['E'])
+ H_img = util.tensor2uint(visuals['H'])
+
+ # -----------------------
+ # save estimated image E
+ # -----------------------
+ save_img_path = os.path.join(img_dir, '{:s}_{:d}.png'.format(img_name, current_step))
+ util.imsave(E_img, save_img_path)
+
+ # -----------------------
+ # calculate PSNR
+ # -----------------------
+ current_psnr = util.calculate_psnr(E_img, H_img, border=border)
+
+ logger.info('{:->4d}--> {:>10s} | {:<4.2f}dB'.format(idx, image_name_ext, current_psnr))
+
+ avg_psnr += current_psnr
+
+ avg_psnr = avg_psnr / idx
+
+ # testing log
+ logger.info('-->-->-->-->-->-->-->-->-->-->-->-->-
+ init_iter, init_path_G = option.find_last_checkpoint(opt['path']['models'], net_type='G')
+ opt['path']['pretrained_netG'] = init_path_G
+ current_step = init_iter
+
+ border = opt['scale']
+ # --<--<--<--<--<--<--<--<--<--<--<--<--<-
+
+ # ----------------------------------------
+ # save opt to a '../option.json' file
+ # ----------------------------------------
+ option.save(opt)
+
+ # ----------------------------------------
+ # return None for missing key
+ # ----------------------------------------
+ opt = option.dict_to_nonedict(opt)
+
+ # ----------------------------------------
+ # configure logger
+ # ----------------------------------------
+ logger_name = 'train'
+ utils_logger.logger_info(logger_name, os.path.join(opt['path']['log'], logger_name+'.log'))
+ logger = logging.getLogger(logger_name)
+ logger.info(option.dict2str(opt))
+
+
+ # ----------------------------------------
+ # seed
+ # ----------------------------------------
+ seed = opt['train']['manual_seed']
+ if seed is None:
+ seed = random.randint(1, 10000)
+ logger.info('Random seed: {}'.format(seed))
+ random.seed(seed)
+ np.random.seed(seed)
+ torch.manual_seed(seed)
+ torch.cuda.manual_seed_all(seed)
+
+ '''
+ # ----------------------------------------
+ # Step--2 (creat dataloader)
+ # ----------------------------------------
+ '''
+
+ # ----------------------------------------
+ # 1) create_dataset
+ # 2) creat_dataloader for train and test
+ # ----------------------------------------
+ for phase, dataset_opt in opt['datasets'].items():
+ if phase == 'train':
+ train_set = define_Dataset(dataset_opt)
+ train_size = int(math.ceil(len(train_set) / dataset_opt['dataloader_batch_size']))
+ logger.info('Number of train images: {:,d}, iters: {:,d}'.format(len(train_set), train_size))
+ train_loader = DataLoader(train_set,
+ batch_size=dataset_opt['dataloader_batch_size'],
+ shuffle=dataset_opt['dataloader_shuffle'],
+ num_workers=dataset_opt['dataloader_num_workers'],
+ drop_last=True,
+ pin_memory=True)
+ elif phase == 'test':
+ test_set = define_Dataset(dataset_opt)
+ test_loader = DataLoader(test_set, batch_size=1,
+ shuffle=False, num_workers=1,
+ drop_last=False, pin_memory=True)
+ else:
+ raise NotImplementedError("Phase [%s] is not recognized." % phase)
+
+ '''
+ # ----------------------------------------
+ # Step--3 (initialize model)
+ # ----------------------------------------
+ '''
+
+ model = define_Model(opt)
+
+ logger.info(model.info_network())
+ model.init_train()
+ logger.info(model.info_params())
+
+ '''
+ # ----------------------------------------
+ # Step--4 (main training)
+ # ----------------------------------------
+ '''
+
+ for epoch in range(1000000): # keep running
+ for i, train_data in enumerate(train_loader):
+
+ current_step += 1
+
+ # -------------------------------
+ # 1) update learning rate
+ # -------------------------------
+ model.update_learning_rate(current_step)
+
+ # -------------------------------
+ # 2) feed patch pairs
+ # -------------------------------
+ model.feed_data(train_data)
+
+ # -------------------------------
+ # 3) optimize parameters
+ # -------------------------------
+ model.optimize_parameters(current_step)
+
+ # -------------------------------
+ # 4) training information
+ # -------------------------------
+ if current_step % opt['train']['checkpoint_print'] == 0:
+ logs = model.current_log() # such as loss
+ message = ' '.format(epoch, current_step, model.current_learning_rate())
+ for k, v in logs.items(): # merge log information into message
+ message += '{:s}: {:.3e} '.format(k, v)
+ logger.info(message)
+
+ # -------------------------------
+ # 5) save model
+ # -------------------------------
+ if current_step % opt['train']['checkpoint_save'] == 0:
+ logger.info('Saving the model.')
+ model.save(current_step)
+
+ # -------------------------------
+ # 6) testing
+ # -------------------------------
+ if current_step % opt['train']['checkpoint_test'] == 0:
+
+ avg_psnr = 0.0
+ idx = 0
+
+ for test_data in test_loader:
+ idx += 1
+ image_name_ext = os.path.basename(test_data['L_path'][0])
+ img_name, ext = os.path.splitext(image_name_ext)
+
+ img_dir = os.path.join(opt['path']['images'], img_name)
+ util.mkdir(img_dir)
+
+ model.feed_data(test_data)
+ model.test()
+
+ visuals = model.current_visuals()
+ E_img = util.tensor2uint(visuals['E'])
+ H_img = util.tensor2uint(visuals['H'])
+
+ # -----------------------
+ # save estimated image E
+ # -----------------------
+ save_img_path = os.path.join(img_dir, '{:s}_{:d}.png'.format(img_name, current_step))
+ util.imsave(E_img, save_img_path)
+
+ # -----------------------
+ # calculate PSNR
+ # -----------------------
+ current_psnr = util.calculate_psnr(E_img, H_img, border=border)
+
+ logger.info('{:->4d}--> {:>10s} | {:<4.2f}dB'.format(idx, image_name_ext, current_psnr))
+
+ avg_psnr += current_psnr
+
+ avg_psnr = avg_psnr / idx
+
+ # testing log
+ logger.info('-->-->-->-->-->-->-->-->-->-->-->-->-
+ init_iter_G, init_path_G = option.find_last_checkpoint(opt['path']['models'], net_type='G',
+ pretrained_path=opt['path']['pretrained_netG'])
+ init_iter_E, init_path_E = option.find_last_checkpoint(opt['path']['models'], net_type='E',
+ pretrained_path=opt['path']['pretrained_netE'])
+ opt['path']['pretrained_netG'] = init_path_G
+ opt['path']['pretrained_netE'] = init_path_E
+ init_iter_optimizerG, init_path_optimizerG = option.find_last_checkpoint(opt['path']['models'],
+ net_type='optimizerG')
+ opt['path']['pretrained_optimizerG'] = init_path_optimizerG
+ current_step = max(init_iter_G, init_iter_E, init_iter_optimizerG)
+
+ # --<--<--<--<--<--<--<--<--<--<--<--<--<-
+
+ # ----------------------------------------
+ # save opt to a '../option.json' file
+ # ----------------------------------------
+ if opt['rank'] == 0:
+ option.save(opt)
+
+ # ----------------------------------------
+ # return None for missing key
+ # ----------------------------------------
+ opt = option.dict_to_nonedict(opt)
+
+ # ----------------------------------------
+ # configure logger
+ # ----------------------------------------
+ if opt['rank'] == 0:
+ logger_name = 'train'
+ utils_logger.logger_info(logger_name, os.path.join(opt['path']['log'], logger_name+'.log'))
+ logger = logging.getLogger(logger_name)
+ logger.info(option.dict2str(opt))
+
+ # ----------------------------------------
+ # seed
+ # ----------------------------------------
+ seed = opt['train']['manual_seed']
+ if seed is None:
+ seed = random.randint(1, 10000)
+ print('Random seed: {}'.format(seed))
+ random.seed(seed)
+ np.random.seed(seed)
+ torch.manual_seed(seed)
+ torch.cuda.manual_seed_all(seed)
+
+ '''
+ # ----------------------------------------
+ # Step--2 (creat dataloader)
+ # ----------------------------------------
+ '''
+
+ # ----------------------------------------
+ # 1) create_dataset
+ # 2) creat_dataloader for train and test
+ # ----------------------------------------
+ for phase, dataset_opt in opt['datasets'].items():
+ if phase == 'train':
+ train_set = define_Dataset(dataset_opt)
+ train_size = int(math.ceil(len(train_set) / dataset_opt['dataloader_batch_size']))
+ if opt['rank'] == 0:
+ logger.info('Number of train images: {:,d}, iters: {:,d}'.format(len(train_set), train_size))
+ if opt['dist']:
+ train_sampler = DistributedSampler(train_set, shuffle=dataset_opt['dataloader_shuffle'],
+ drop_last=True, seed=seed)
+ train_loader = DataLoader(train_set,
+ batch_size=dataset_opt['dataloader_batch_size']//opt['num_gpu'],
+ shuffle=False,
+ num_workers=dataset_opt['dataloader_num_workers']//opt['num_gpu'],
+ drop_last=True,
+ pin_memory=True,
+ sampler=train_sampler)
+ else:
+ train_loader = DataLoader(train_set,
+ batch_size=dataset_opt['dataloader_batch_size'],
+ shuffle=dataset_opt['dataloader_shuffle'],
+ num_workers=dataset_opt['dataloader_num_workers'],
+ drop_last=True,
+ pin_memory=True)
+
+ elif phase == 'test':
+ test_set = define_Dataset(dataset_opt)
+ test_loader = DataLoader(test_set, batch_size=1,
+ shuffle=False, num_workers=1,
+ drop_last=False, pin_memory=True)
+ else:
+ raise NotImplementedError("Phase [%s] is not recognized." % phase)
+
+ '''
+ # ----------------------------------------
+ # Step--3 (initialize model)
+ # ----------------------------------------
+ '''
+
+ model = define_Model(opt)
+ model.init_train()
+ if opt['rank'] == 0:
+ logger.info(model.info_network())
+ logger.info(model.info_params())
+
+ '''
+ # ----------------------------------------
+ # Step--4 (main training)
+ # ----------------------------------------
+ '''
+
+ for epoch in range(1000000): # keep running
+ for i, train_data in enumerate(train_loader):
+
+ current_step += 1
+
+ # -------------------------------
+ # 1) update learning rate
+ # -------------------------------
+ model.update_learning_rate(current_step)
+
+ # -------------------------------
+ # 2) feed patch pairs
+ # -------------------------------
+ model.feed_data(train_data)
+
+ # -------------------------------
+ # 3) optimize parameters
+ # -------------------------------
+ model.optimize_parameters(current_step)
+
+ # -------------------------------
+ # 4) training information
+ # -------------------------------
+ if current_step % opt['train']['checkpoint_print'] == 0 and opt['rank'] == 0:
+ logs = model.current_log() # such as loss
+ message = ' '.format(epoch, current_step,
+ model.current_learning_rate())
+ for k, v in logs.items(): # merge log information into message
+ message += '{:s}: {:.3e} '.format(k, v)
+ logger.info(message)
+
+ # -------------------------------
+ # 5) save model
+ # -------------------------------
+ if current_step % opt['train']['checkpoint_save'] == 0 and opt['rank'] == 0:
+ logger.info('Saving the model.')
+ model.save(current_step)
+
+ if opt['use_static_graph'] and (current_step == opt['train']['fix_iter'] - 1):
+ current_step += 1
+ model.update_learning_rate(current_step)
+ model.save(current_step)
+ current_step -= 1
+ logger.info('Saving models ahead of time when changing the computation graph with use_static_graph=True'
+ ' (we need it due to a bug with use_checkpoint=True in distributed training). The training '
+ 'will be terminated by PyTorch in the next iteration. Just resume training with the same '
+ '.json config file.')
+
+ # -------------------------------
+ # 6) testing
+ # -------------------------------
+ if current_step % opt['train']['checkpoint_test'] == 0 and opt['rank'] == 0:
+
+ test_results = OrderedDict()
+ test_results['psnr'] = []
+ test_results['ssim'] = []
+ test_results['psnr_y'] = []
+ test_results['ssim_y'] = []
+
+ for idx, test_data in enumerate(test_loader):
+ model.feed_data(test_data)
+ model.test()
+
+ visuals = model.current_visuals()
+ output = visuals['E']
+ gt = visuals['H'] if 'H' in visuals else None
+ folder = test_data['folder']
+
+ test_results_folder = OrderedDict()
+ test_results_folder['psnr'] = []
+ test_results_folder['ssim'] = []
+ test_results_folder['psnr_y'] = []
+ test_results_folder['ssim_y'] = []
+
+ for i in range(output.shape[0]):
+ # -----------------------
+ # save estimated image E
+ # -----------------------
+ img = output[i, ...].clamp_(0, 1).numpy()
+ if img.ndim == 3:
+ img = np.transpose(img[[2, 1, 0], :, :], (1, 2, 0)) # CHW-RGB to HCW-BGR
+ img = (img * 255.0).round().astype(np.uint8) # float32 to uint8
+ if opt['val']['save_img']:
+ save_dir = opt['path']['images']
+ util.mkdir(save_dir)
+ seq_ = os.path.basename(test_data['lq_path'][i][0]).split('.')[0]
+ os.makedirs(f'{save_dir}/{folder[0]}', exist_ok=True)
+ cv2.imwrite(f'{save_dir}/{folder[0]}/{seq_}_{current_step:d}.png', img)
+
+ # -----------------------
+ # calculate PSNR
+ # -----------------------
+ img_gt = gt[i, ...].clamp_(0, 1).numpy()
+ if img_gt.ndim == 3:
+ img_gt = np.transpose(img_gt[[2, 1, 0], :, :], (1, 2, 0)) # CHW-RGB to HCW-BGR
+ img_gt = (img_gt * 255.0).round().astype(np.uint8) # float32 to uint8
+ img_gt = np.squeeze(img_gt)
+
+ test_results_folder['psnr'].append(util.calculate_psnr(img, img_gt, border=0))
+ test_results_folder['ssim'].append(util.calculate_ssim(img, img_gt, border=0))
+ if img_gt.ndim == 3: # RGB image
+ img = util.bgr2ycbcr(img.astype(np.float32) / 255.) * 255.
+ img_gt = util.bgr2ycbcr(img_gt.astype(np.float32) / 255.) * 255.
+ test_results_folder['psnr_y'].append(util.calculate_psnr(img, img_gt, border=0))
+ test_results_folder['ssim_y'].append(util.calculate_ssim(img, img_gt, border=0))
+ else:
+ test_results_folder['psnr_y'] = test_results_folder['psnr']
+ test_results_folder['ssim_y'] = test_results_folder['ssim']
+
+ psnr = sum(test_results_folder['psnr']) / len(test_results_folder['psnr'])
+ ssim = sum(test_results_folder['ssim']) / len(test_results_folder['ssim'])
+ psnr_y = sum(test_results_folder['psnr_y']) / len(test_results_folder['psnr_y'])
+ ssim_y = sum(test_results_folder['ssim_y']) / len(test_results_folder['ssim_y'])
+
+ if gt is not None:
+ logger.info('Testing {:20s} ({:2d}/{}) - PSNR: {:.2f} dB; SSIM: {:.4f}; '
+ 'PSNR_Y: {:.2f} dB; SSIM_Y: {:.4f}'.
+ format(folder[0], idx, len(test_loader), psnr, ssim, psnr_y, ssim_y))
+ test_results['psnr'].append(psnr)
+ test_results['ssim'].append(ssim)
+ test_results['psnr_y'].append(psnr_y)
+ test_results['ssim_y'].append(ssim_y)
+ else:
+ logger.info('Testing {:20s} ({:2d}/{})'.format(folder[0], idx, len(test_loader)))
+
+ # summarize psnr/ssim
+ if gt is not None:
+ ave_psnr = sum(test_results['psnr']) / len(test_results['psnr'])
+ ave_ssim = sum(test_results['ssim']) / len(test_results['ssim'])
+ ave_psnr_y = sum(test_results['psnr_y']) / len(test_results['psnr_y'])
+ ave_ssim_y = sum(test_results['ssim_y']) / len(test_results['ssim_y'])
+ logger.info(' opt['train']['total_iter']:
+ logger.info('Finish training.')
+ model.save(current_step)
+ sys.exit()
+
+if __name__ == '__main__':
+ main()
diff --git a/KAIR/matlab/Cal_PSNRSSIM.m b/KAIR/matlab/Cal_PSNRSSIM.m
new file mode 100644
index 0000000000000000000000000000000000000000..bdc7b3997171a7977bb11ae03a014faff4f7ce50
--- /dev/null
+++ b/KAIR/matlab/Cal_PSNRSSIM.m
@@ -0,0 +1,221 @@
+function [psnr_cur, ssim_cur] = Cal_PSNRSSIM(A,B,row,col)
+
+
+[n,m,ch]=size(B);
+A = A(row+1:n-row,col+1:m-col,:);
+B = B(row+1:n-row,col+1:m-col,:);
+A=double(A); % Ground-truth
+B=double(B); %
+
+e=A(:)-B(:);
+mse=mean(e.^2);
+psnr_cur=10*log10(255^2/mse);
+
+if ch==1
+ [ssim_cur, ~] = ssim_index(A, B);
+else
+ ssim_cur = (ssim_index(A(:,:,1), B(:,:,1)) + ssim_index(A(:,:,2), B(:,:,2)) + ssim_index(A(:,:,3), B(:,:,3)))/3;
+end
+
+
+function [mssim, ssim_map] = ssim_index(img1, img2, K, window, L)
+
+%========================================================================
+%SSIM Index, Version 1.0
+%Copyright(c) 2003 Zhou Wang
+%All Rights Reserved.
+%
+%The author is with Howard Hughes Medical Institute, and Laboratory
+%for Computational Vision at Center for Neural Science and Courant
+%Institute of Mathematical Sciences, New York University.
+%
+%----------------------------------------------------------------------
+%Permission to use, copy, or modify this software and its documentation
+%for educational and research purposes only and without fee is hereby
+%granted, provided that this copyright notice and the original authors'
+%names appear on all copies and supporting documentation. This program
+%shall not be used, rewritten, or adapted as the basis of a commercial
+%software or hardware product without first obtaining permission of the
+%authors. The authors make no representations about the suitability of
+%this software for any purpose. It is provided "as is" without express
+%or implied warranty.
+%----------------------------------------------------------------------
+%
+%This is an implementation of the algorithm for calculating the
+%Structural SIMilarity (SSIM) index between two images. Please refer
+%to the following paper:
+%
+%Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, "Image
+%quality assessment: From error measurement to structural similarity"
+%IEEE Transactios on Image Processing, vol. 13, no. 1, Jan. 2004.
+%
+%Kindly report any suggestions or corrections to zhouwang@ieee.org
+%
+%----------------------------------------------------------------------
+%
+%Input : (1) img1: the first image being compared
+% (2) img2: the second image being compared
+% (3) K: constants in the SSIM index formula (see the above
+% reference). defualt value: K = [0.01 0.03]
+% (4) window: local window for statistics (see the above
+% reference). default widnow is Gaussian given by
+% window = fspecial('gaussian', 11, 1.5);
+% (5) L: dynamic range of the images. default: L = 255
+%
+%Output: (1) mssim: the mean SSIM index value between 2 images.
+% If one of the images being compared is regarded as
+% perfect quality, then mssim can be considered as the
+% quality measure of the other image.
+% If img1 = img2, then mssim = 1.
+% (2) ssim_map: the SSIM index map of the test image. The map
+% has a smaller size than the input images. The actual size:
+% size(img1) - size(window) + 1.
+%
+%Default Usage:
+% Given 2 test images img1 and img2, whose dynamic range is 0-255
+%
+% [mssim ssim_map] = ssim_index(img1, img2);
+%
+%Advanced Usage:
+% User defined parameters. For example
+%
+% K = [0.05 0.05];
+% window = ones(8);
+% L = 100;
+% [mssim ssim_map] = ssim_index(img1, img2, K, window, L);
+%
+%See the results:
+%
+% mssim %Gives the mssim value
+% imshow(max(0, ssim_map).^4) %Shows the SSIM index map
+%
+%========================================================================
+
+
+if (nargin < 2 || nargin > 5)
+ ssim_index = -Inf;
+ ssim_map = -Inf;
+ return;
+end
+
+if (size(img1) ~= size(img2))
+ ssim_index = -Inf;
+ ssim_map = -Inf;
+ return;
+end
+
+[M N] = size(img1);
+
+if (nargin == 2)
+ if ((M < 11) || (N < 11))
+ ssim_index = -Inf;
+ ssim_map = -Inf;
+ return
+ end
+ window = fspecial('gaussian', 11, 1.5); %
+ K(1) = 0.01; % default settings
+ K(2) = 0.03; %
+ L = 255; %
+end
+
+if (nargin == 3)
+ if ((M < 11) || (N < 11))
+ ssim_index = -Inf;
+ ssim_map = -Inf;
+ return
+ end
+ window = fspecial('gaussian', 11, 1.5);
+ L = 255;
+ if (length(K) == 2)
+ if (K(1) < 0 || K(2) < 0)
+ ssim_index = -Inf;
+ ssim_map = -Inf;
+ return;
+ end
+ else
+ ssim_index = -Inf;
+ ssim_map = -Inf;
+ return;
+ end
+end
+
+if (nargin == 4)
+ [H W] = size(window);
+ if ((H*W) < 4 || (H > M) || (W > N))
+ ssim_index = -Inf;
+ ssim_map = -Inf;
+ return
+ end
+ L = 255;
+ if (length(K) == 2)
+ if (K(1) < 0 || K(2) < 0)
+ ssim_index = -Inf;
+ ssim_map = -Inf;
+ return;
+ end
+ else
+ ssim_index = -Inf;
+ ssim_map = -Inf;
+ return;
+ end
+end
+
+if (nargin == 5)
+ [H W] = size(window);
+ if ((H*W) < 4 || (H > M) || (W > N))
+ ssim_index = -Inf;
+ ssim_map = -Inf;
+ return
+ end
+ if (length(K) == 2)
+ if (K(1) < 0 || K(2) < 0)
+ ssim_index = -Inf;
+ ssim_map = -Inf;
+ return;
+ end
+ else
+ ssim_index = -Inf;
+ ssim_map = -Inf;
+ return;
+ end
+end
+
+C1 = (K(1)*L)^2;
+C2 = (K(2)*L)^2;
+window = window/sum(sum(window));
+img1 = double(img1);
+img2 = double(img2);
+
+mu1 = filter2(window, img1, 'valid');
+mu2 = filter2(window, img2, 'valid');
+mu1_sq = mu1.*mu1;
+mu2_sq = mu2.*mu2;
+mu1_mu2 = mu1.*mu2;
+sigma1_sq = filter2(window, img1.*img1, 'valid') - mu1_sq;
+sigma2_sq = filter2(window, img2.*img2, 'valid') - mu2_sq;
+sigma12 = filter2(window, img1.*img2, 'valid') - mu1_mu2;
+
+if (C1 > 0 & C2 > 0)
+ ssim_map = ((2*mu1_mu2 + C1).*(2*sigma12 + C2))./((mu1_sq + mu2_sq + C1).*(sigma1_sq + sigma2_sq + C2));
+else
+ numerator1 = 2*mu1_mu2 + C1;
+ numerator2 = 2*sigma12 + C2;
+ denominator1 = mu1_sq + mu2_sq + C1;
+ denominator2 = sigma1_sq + sigma2_sq + C2;
+ ssim_map = ones(size(mu1));
+ index = (denominator1.*denominator2 > 0);
+ ssim_map(index) = (numerator1(index).*numerator2(index))./(denominator1(index).*denominator2(index));
+ index = (denominator1 ~= 0) & (denominator2 == 0);
+ ssim_map(index) = numerator1(index)./denominator1(index);
+end
+
+mssim = mean2(ssim_map);
+
+return
+
+
+
+
+
+
+
diff --git a/KAIR/matlab/README.md b/KAIR/matlab/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..d7c67173ef7f9379a991e74005d0083a8bc32a2a
--- /dev/null
+++ b/KAIR/matlab/README.md
@@ -0,0 +1,17 @@
+
+
+Run matlab file [main_denoising_gray.m](https://github.com/cszn/KAIR/blob/master/matlab/main_denoising_gray.m) for local zoom.
+
+```matlab
+upperleft_pixel = [172, 218];
+box = [35, 35];
+zoomfactor = 3;
+zoom_position = 'ur'; % 'ur' = 'upper-right'
+nline = 2;
+```
+
+
 +
+
+
+
diff --git a/KAIR/matlab/center_replace.m b/KAIR/matlab/center_replace.m
new file mode 100644
index 0000000000000000000000000000000000000000..0aebbdf745c7b89eb588493c40f87e27c07e3116
--- /dev/null
+++ b/KAIR/matlab/center_replace.m
@@ -0,0 +1,11 @@
+function [im] = center_replace(im,im2)
+
+[w,h,~] = size(im);
+
+[a,b,~] = size(im2);
+c1 = w-a-(w-a)/2;
+c2 = h-b-(h-b)/2;
+im(c1+1:c1+a,c2+1:c2+b,:) = im2;
+
+end
+
diff --git a/KAIR/matlab/denoising_gray/05_bm3d_2582.png b/KAIR/matlab/denoising_gray/05_bm3d_2582.png
new file mode 100644
index 0000000000000000000000000000000000000000..9e0ca721a3ccdd09af533ef4e66fbd019ada4c7e
Binary files /dev/null and b/KAIR/matlab/denoising_gray/05_bm3d_2582.png differ
diff --git a/KAIR/matlab/denoising_gray/05_dncnn_2683.png b/KAIR/matlab/denoising_gray/05_dncnn_2683.png
new file mode 100644
index 0000000000000000000000000000000000000000..52b19164c835e635132609404bedb14f87abfd9f
Binary files /dev/null and b/KAIR/matlab/denoising_gray/05_dncnn_2683.png differ
diff --git a/KAIR/matlab/denoising_gray/05_drunet_2731.png b/KAIR/matlab/denoising_gray/05_drunet_2731.png
new file mode 100644
index 0000000000000000000000000000000000000000..85996b7f9dc5687b32161b794253cc0331aada60
Binary files /dev/null and b/KAIR/matlab/denoising_gray/05_drunet_2731.png differ
diff --git a/KAIR/matlab/denoising_gray/05_ffdnet_2692.png b/KAIR/matlab/denoising_gray/05_ffdnet_2692.png
new file mode 100644
index 0000000000000000000000000000000000000000..c33f5b36efa9e4c776869da9347c8c6a4536ff8b
Binary files /dev/null and b/KAIR/matlab/denoising_gray/05_ffdnet_2692.png differ
diff --git a/KAIR/matlab/denoising_gray/05_noisy_1478.png b/KAIR/matlab/denoising_gray/05_noisy_1478.png
new file mode 100644
index 0000000000000000000000000000000000000000..92cd862dae729d07e6c8132a211b5b25a69e5587
Binary files /dev/null and b/KAIR/matlab/denoising_gray/05_noisy_1478.png differ
diff --git a/KAIR/matlab/denoising_gray_results/05_bm3d_2582.png b/KAIR/matlab/denoising_gray_results/05_bm3d_2582.png
new file mode 100644
index 0000000000000000000000000000000000000000..c3e07f67bffa3a1ac274be2c2fd633b41923b6e1
Binary files /dev/null and b/KAIR/matlab/denoising_gray_results/05_bm3d_2582.png differ
diff --git a/KAIR/matlab/denoising_gray_results/05_dncnn_2683.png b/KAIR/matlab/denoising_gray_results/05_dncnn_2683.png
new file mode 100644
index 0000000000000000000000000000000000000000..01138a03c40ac63981fa204ede2b2026c4b0e528
Binary files /dev/null and b/KAIR/matlab/denoising_gray_results/05_dncnn_2683.png differ
diff --git a/KAIR/matlab/denoising_gray_results/05_drunet_2731.png b/KAIR/matlab/denoising_gray_results/05_drunet_2731.png
new file mode 100644
index 0000000000000000000000000000000000000000..e8f0d9f49a56fb08abbeffb367fe50bfe2143f30
Binary files /dev/null and b/KAIR/matlab/denoising_gray_results/05_drunet_2731.png differ
diff --git a/KAIR/matlab/denoising_gray_results/05_ffdnet_2692.png b/KAIR/matlab/denoising_gray_results/05_ffdnet_2692.png
new file mode 100644
index 0000000000000000000000000000000000000000..0303f4cc1585288eec91cf14ae4e66212d93e4ee
Binary files /dev/null and b/KAIR/matlab/denoising_gray_results/05_ffdnet_2692.png differ
diff --git a/KAIR/matlab/denoising_gray_results/05_noisy_1478.png b/KAIR/matlab/denoising_gray_results/05_noisy_1478.png
new file mode 100644
index 0000000000000000000000000000000000000000..b6996fa51de2296a4d36791ea1422c441aa10c4a
Binary files /dev/null and b/KAIR/matlab/denoising_gray_results/05_noisy_1478.png differ
diff --git a/KAIR/matlab/main_denoising_color.m b/KAIR/matlab/main_denoising_color.m
new file mode 100644
index 0000000000000000000000000000000000000000..3940b026807bf8816f88fb9df71b1e706e19142e
--- /dev/null
+++ b/KAIR/matlab/main_denoising_color.m
@@ -0,0 +1,52 @@
+
+
+
+input_folder = 'denoising_color';
+output_folder = 'denoising_color_results';
+
+upperleft_pixel = [220, 5];
+box = [60, 60];
+zoomfactor = 3;
+zoom_position = 'lr';
+nline = 2;
+
+ext = {'*.jpg','*.png','*.bmp'};
+
+images = [];
+
+for i = 1:length(ext)
+
+ images = [images dir(fullfile(input_folder, ext{i}))];
+
+end
+
+if isdir(output_folder) == 0
+ mkdir(output_folder);
+end
+
+for i = 1:numel(images)
+
+ [~, name, exte] = fileparts(images(i).name);
+ I = imread( fullfile(input_folder,images(i).name));
+
+ % if i == 1
+ % imtool(double(I)/256)
+ % end
+
+ I = zoom_function(I, upperleft_pixel, box, zoomfactor, zoom_position,nline);
+
+ imwrite(I, fullfile(output_folder,images(i).name), 'Compression','none');
+
+ imshow(I)
+ title(name);
+
+ pause(1)
+
+end
+
+close;
+
+
+
+
+
diff --git a/KAIR/matlab/main_denoising_gray.m b/KAIR/matlab/main_denoising_gray.m
new file mode 100644
index 0000000000000000000000000000000000000000..c5498471cc6e42ae19e1174e3065ffe6953ebdf3
--- /dev/null
+++ b/KAIR/matlab/main_denoising_gray.m
@@ -0,0 +1,51 @@
+
+
+
+input_folder = 'denoising_gray';
+output_folder = 'denoising_gray_results';
+
+upperleft_pixel = [172, 218];
+box = [35, 35];
+zoomfactor = 3;
+zoom_position = 'ur';
+nline = 2;
+
+ext = {'*.jpg','*.png','*.bmp'};
+
+images = [];
+for i = 1:length(ext)
+ images = [images, dir(fullfile(input_folder, ext{i}))];
+end
+
+if isfolder(output_folder) == 0
+ mkdir(output_folder);
+end
+
+for i = 1:numel(images)
+
+ [~, name, exte] = fileparts(images(i).name);
+ I = imread( fullfile(input_folder,images(i).name));
+
+% if i == 1
+% imtool(double(I)/256)
+% end
+
+ I = zoom_function(I, upperleft_pixel, box, zoomfactor, zoom_position,nline);
+
+ imwrite(I, fullfile(output_folder,images(i).name), 'Compression','none');
+
+ imshow(I)
+ title(name);
+ pause(1)
+
+
+end
+
+
+
+
+
+
+
+
+
diff --git a/KAIR/matlab/modcrop.m b/KAIR/matlab/modcrop.m
new file mode 100644
index 0000000000000000000000000000000000000000..728c68810609913d8ae8475a0d7305a92a1f1fae
--- /dev/null
+++ b/KAIR/matlab/modcrop.m
@@ -0,0 +1,12 @@
+function imgs = modcrop(imgs, modulo)
+if size(imgs,3)==1
+ sz = size(imgs);
+ sz = sz - mod(sz, modulo);
+ imgs = imgs(1:sz(1), 1:sz(2));
+else
+ tmpsz = size(imgs);
+ sz = tmpsz(1:2);
+ sz = sz - mod(sz, modulo);
+ imgs = imgs(1:sz(1), 1:sz(2),:);
+end
+
diff --git a/KAIR/matlab/shave.m b/KAIR/matlab/shave.m
new file mode 100644
index 0000000000000000000000000000000000000000..2a931ffded4fcd1bc6d2fc990a1d8a14cc7efb31
--- /dev/null
+++ b/KAIR/matlab/shave.m
@@ -0,0 +1,3 @@
+function I = shave(I, border)
+I = I(1+border(1):end-border(1), ...
+ 1+border(2):end-border(2), :, :);
diff --git a/KAIR/matlab/zoom_function.m b/KAIR/matlab/zoom_function.m
new file mode 100644
index 0000000000000000000000000000000000000000..6771712c8097578febc1c7e018c195ce3dca1a74
--- /dev/null
+++ b/KAIR/matlab/zoom_function.m
@@ -0,0 +1,60 @@
+function [I]=zoom_function(I,upperleft_pixel,box,zoomfactor,zoom_position,nline)
+
+y = upperleft_pixel(1);
+x = upperleft_pixel(2);
+box1 = box(1);
+box2 = box(2); %4
+
+s_color = [0 255 0];
+l_color = [255 0 0];
+
+
+
+[~, ~, hw] = size( I );
+
+if hw == 1
+ I=repmat(I,[1,1,3]);
+end
+
+Imin = I(x:x+box1-1,y:y+box2-1,:);
+I(x-nline:x+box1-1+nline,y-nline:y+box2-1+nline,1) = s_color(1);
+I(x-nline:x+box1-1+nline,y-nline:y+box2-1+nline,2) = s_color(2);
+I(x-nline:x+box1-1+nline,y-nline:y+box2-1+nline,3) = s_color(3);
+I(x:x+box1-1,y:y+box2-1,:) = Imin;
+Imax = imresize(Imin,zoomfactor,'nearest');
+
+switch lower(zoom_position)
+ case {'uper_left','ul'}
+
+ I(1:2*nline+zoomfactor*box1,1:2*nline+zoomfactor*box2,1) = l_color(1);
+ I(1:2*nline+zoomfactor*box1,1:2*nline+zoomfactor*box2,2) = l_color(2);
+ I(1:2*nline+zoomfactor*box1,1:2*nline+zoomfactor*box2,3) = l_color(3);
+ I(1+nline:zoomfactor*box1+nline,1+nline:zoomfactor*box2+nline,:) = Imax;
+
+ case {'uper_right','ur'}
+
+ I(1:2*nline+zoomfactor*box1,end-2*nline-zoomfactor*box2+1:end,1) = l_color(1);
+ I(1:2*nline+zoomfactor*box1,end-2*nline-zoomfactor*box2+1:end,2) = l_color(2);
+ I(1:2*nline+zoomfactor*box1,end-2*nline-zoomfactor*box2+1:end,3) = l_color(3);
+ I(1+nline:zoomfactor*box1+nline,end-nline-zoomfactor*box2+1:end-nline,:) = Imax;
+
+ case {'lower_left','ll'}
+
+ I(end-2*nline-zoomfactor*box1+1:end,1:2*nline+zoomfactor*box2,1) = l_color(1);
+ I(end-2*nline-zoomfactor*box1+1:end,1:2*nline+zoomfactor*box2,2) = l_color(2);
+ I(end-2*nline-zoomfactor*box1+1:end,1:2*nline+zoomfactor*box2,3) = l_color(3);
+ I(end-nline-zoomfactor*box1+1:end-nline,1+nline:zoomfactor*box2+nline,:) = Imax;
+
+ case {'lower_right','lr'}
+
+ I(end-2*nline-zoomfactor*box1+1:end,end-2*nline-zoomfactor*box2+1:end,1) = l_color(1);
+ I(end-2*nline-zoomfactor*box1+1:end,end-2*nline-zoomfactor*box2+1:end,2) = l_color(2);
+ I(end-2*nline-zoomfactor*box1+1:end,end-2*nline-zoomfactor*box2+1:end,3) = l_color(3);
+ I(end-nline-zoomfactor*box1+1:end-nline,end-nline-zoomfactor*box2+1:end-nline,:) = Imax;
+
+
+
+end
+
+
+
diff --git a/KAIR/models/basicblock.py b/KAIR/models/basicblock.py
new file mode 100644
index 0000000000000000000000000000000000000000..12b8404bfdf570df859b6e57cc4cfb0e6aeb3068
--- /dev/null
+++ b/KAIR/models/basicblock.py
@@ -0,0 +1,591 @@
+from collections import OrderedDict
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+
+'''
+# --------------------------------------------
+# Advanced nn.Sequential
+# https://github.com/xinntao/BasicSR
+# --------------------------------------------
+'''
+
+
+def sequential(*args):
+ """Advanced nn.Sequential.
+
+ Args:
+ nn.Sequential, nn.Module
+
+ Returns:
+ nn.Sequential
+ """
+ if len(args) == 1:
+ if isinstance(args[0], OrderedDict):
+ raise NotImplementedError('sequential does not support OrderedDict input.')
+ return args[0] # No sequential is needed.
+ modules = []
+ for module in args:
+ if isinstance(module, nn.Sequential):
+ for submodule in module.children():
+ modules.append(submodule)
+ elif isinstance(module, nn.Module):
+ modules.append(module)
+ return nn.Sequential(*modules)
+
+
+'''
+# --------------------------------------------
+# Useful blocks
+# https://github.com/xinntao/BasicSR
+# --------------------------------
+# conv + normaliation + relu (conv)
+# (PixelUnShuffle)
+# (ConditionalBatchNorm2d)
+# concat (ConcatBlock)
+# sum (ShortcutBlock)
+# resblock (ResBlock)
+# Channel Attention (CA) Layer (CALayer)
+# Residual Channel Attention Block (RCABlock)
+# Residual Channel Attention Group (RCAGroup)
+# Residual Dense Block (ResidualDenseBlock_5C)
+# Residual in Residual Dense Block (RRDB)
+# --------------------------------------------
+'''
+
+
+# --------------------------------------------
+# return nn.Sequantial of (Conv + BN + ReLU)
+# --------------------------------------------
+def conv(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=True, mode='CBR', negative_slope=0.2):
+ L = []
+ for t in mode:
+ if t == 'C':
+ L.append(nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding, bias=bias))
+ elif t == 'T':
+ L.append(nn.ConvTranspose2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding, bias=bias))
+ elif t == 'B':
+ L.append(nn.BatchNorm2d(out_channels, momentum=0.9, eps=1e-04, affine=True))
+ elif t == 'I':
+ L.append(nn.InstanceNorm2d(out_channels, affine=True))
+ elif t == 'R':
+ L.append(nn.ReLU(inplace=True))
+ elif t == 'r':
+ L.append(nn.ReLU(inplace=False))
+ elif t == 'L':
+ L.append(nn.LeakyReLU(negative_slope=negative_slope, inplace=True))
+ elif t == 'l':
+ L.append(nn.LeakyReLU(negative_slope=negative_slope, inplace=False))
+ elif t == '2':
+ L.append(nn.PixelShuffle(upscale_factor=2))
+ elif t == '3':
+ L.append(nn.PixelShuffle(upscale_factor=3))
+ elif t == '4':
+ L.append(nn.PixelShuffle(upscale_factor=4))
+ elif t == 'U':
+ L.append(nn.Upsample(scale_factor=2, mode='nearest'))
+ elif t == 'u':
+ L.append(nn.Upsample(scale_factor=3, mode='nearest'))
+ elif t == 'v':
+ L.append(nn.Upsample(scale_factor=4, mode='nearest'))
+ elif t == 'M':
+ L.append(nn.MaxPool2d(kernel_size=kernel_size, stride=stride, padding=0))
+ elif t == 'A':
+ L.append(nn.AvgPool2d(kernel_size=kernel_size, stride=stride, padding=0))
+ else:
+ raise NotImplementedError('Undefined type: '.format(t))
+ return sequential(*L)
+
+
+# --------------------------------------------
+# inverse of pixel_shuffle
+# --------------------------------------------
+def pixel_unshuffle(input, upscale_factor):
+ r"""Rearranges elements in a Tensor of shape :math:`(C, rH, rW)` to a
+ tensor of shape :math:`(*, r^2C, H, W)`.
+
+ Authors:
+ Zhaoyi Yan, https://github.com/Zhaoyi-Yan
+ Kai Zhang, https://github.com/cszn/FFDNet
+
+ Date:
+ 01/Jan/2019
+ """
+ batch_size, channels, in_height, in_width = input.size()
+
+ out_height = in_height // upscale_factor
+ out_width = in_width // upscale_factor
+
+ input_view = input.contiguous().view(
+ batch_size, channels, out_height, upscale_factor,
+ out_width, upscale_factor)
+
+ channels *= upscale_factor ** 2
+ unshuffle_out = input_view.permute(0, 1, 3, 5, 2, 4).contiguous()
+ return unshuffle_out.view(batch_size, channels, out_height, out_width)
+
+
+class PixelUnShuffle(nn.Module):
+ r"""Rearranges elements in a Tensor of shape :math:`(C, rH, rW)` to a
+ tensor of shape :math:`(*, r^2C, H, W)`.
+
+ Authors:
+ Zhaoyi Yan, https://github.com/Zhaoyi-Yan
+ Kai Zhang, https://github.com/cszn/FFDNet
+
+ Date:
+ 01/Jan/2019
+ """
+
+ def __init__(self, upscale_factor):
+ super(PixelUnShuffle, self).__init__()
+ self.upscale_factor = upscale_factor
+
+ def forward(self, input):
+ return pixel_unshuffle(input, self.upscale_factor)
+
+ def extra_repr(self):
+ return 'upscale_factor={}'.format(self.upscale_factor)
+
+
+# --------------------------------------------
+# conditional batch norm
+# https://github.com/pytorch/pytorch/issues/8985#issuecomment-405080775
+# --------------------------------------------
+class ConditionalBatchNorm2d(nn.Module):
+ def __init__(self, num_features, num_classes):
+ super().__init__()
+ self.num_features = num_features
+ self.bn = nn.BatchNorm2d(num_features, affine=False)
+ self.embed = nn.Embedding(num_classes, num_features * 2)
+ self.embed.weight.data[:, :num_features].normal_(1, 0.02) # Initialise scale at N(1, 0.02)
+ self.embed.weight.data[:, num_features:].zero_() # Initialise bias at 0
+
+ def forward(self, x, y):
+ out = self.bn(x)
+ gamma, beta = self.embed(y).chunk(2, 1)
+ out = gamma.view(-1, self.num_features, 1, 1) * out + beta.view(-1, self.num_features, 1, 1)
+ return out
+
+
+# --------------------------------------------
+# Concat the output of a submodule to its input
+# --------------------------------------------
+class ConcatBlock(nn.Module):
+ def __init__(self, submodule):
+ super(ConcatBlock, self).__init__()
+ self.sub = submodule
+
+ def forward(self, x):
+ output = torch.cat((x, self.sub(x)), dim=1)
+ return output
+
+ def __repr__(self):
+ return self.sub.__repr__() + 'concat'
+
+
+# --------------------------------------------
+# sum the output of a submodule to its input
+# --------------------------------------------
+class ShortcutBlock(nn.Module):
+ def __init__(self, submodule):
+ super(ShortcutBlock, self).__init__()
+
+ self.sub = submodule
+
+ def forward(self, x):
+ output = x + self.sub(x)
+ return output
+
+ def __repr__(self):
+ tmpstr = 'Identity + \n|'
+ modstr = self.sub.__repr__().replace('\n', '\n|')
+ tmpstr = tmpstr + modstr
+ return tmpstr
+
+
+# --------------------------------------------
+# Res Block: x + conv(relu(conv(x)))
+# --------------------------------------------
+class ResBlock(nn.Module):
+ def __init__(self, in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=True, mode='CRC', negative_slope=0.2):
+ super(ResBlock, self).__init__()
+
+ assert in_channels == out_channels, 'Only support in_channels==out_channels.'
+ if mode[0] in ['R', 'L']:
+ mode = mode[0].lower() + mode[1:]
+
+ self.res = conv(in_channels, out_channels, kernel_size, stride, padding, bias, mode, negative_slope)
+
+ def forward(self, x):
+ res = self.res(x)
+ return x + res
+
+
+# --------------------------------------------
+# simplified information multi-distillation block (IMDB)
+# x + conv1(concat(split(relu(conv(x)))x3))
+# --------------------------------------------
+class IMDBlock(nn.Module):
+ """
+ @inproceedings{hui2019lightweight,
+ title={Lightweight Image Super-Resolution with Information Multi-distillation Network},
+ author={Hui, Zheng and Gao, Xinbo and Yang, Yunchu and Wang, Xiumei},
+ booktitle={Proceedings of the 27th ACM International Conference on Multimedia (ACM MM)},
+ pages={2024--2032},
+ year={2019}
+ }
+ @inproceedings{zhang2019aim,
+ title={AIM 2019 Challenge on Constrained Super-Resolution: Methods and Results},
+ author={Kai Zhang and Shuhang Gu and Radu Timofte and others},
+ booktitle={IEEE International Conference on Computer Vision Workshops},
+ year={2019}
+ }
+ """
+ def __init__(self, in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=True, mode='CL', d_rate=0.25, negative_slope=0.05):
+ super(IMDBlock, self).__init__()
+ self.d_nc = int(in_channels * d_rate)
+ self.r_nc = int(in_channels - self.d_nc)
+
+ assert mode[0] == 'C', 'convolutional layer first'
+
+ self.conv1 = conv(in_channels, in_channels, kernel_size, stride, padding, bias, mode, negative_slope)
+ self.conv2 = conv(self.r_nc, in_channels, kernel_size, stride, padding, bias, mode, negative_slope)
+ self.conv3 = conv(self.r_nc, in_channels, kernel_size, stride, padding, bias, mode, negative_slope)
+ self.conv4 = conv(self.r_nc, self.d_nc, kernel_size, stride, padding, bias, mode[0], negative_slope)
+ self.conv1x1 = conv(self.d_nc*4, out_channels, kernel_size=1, stride=1, padding=0, bias=bias, mode=mode[0], negative_slope=negative_slope)
+
+ def forward(self, x):
+ d1, r1 = torch.split(self.conv1(x), (self.d_nc, self.r_nc), dim=1)
+ d2, r2 = torch.split(self.conv2(r1), (self.d_nc, self.r_nc), dim=1)
+ d3, r3 = torch.split(self.conv3(r2), (self.d_nc, self.r_nc), dim=1)
+ d4 = self.conv4(r3)
+ res = self.conv1x1(torch.cat((d1, d2, d3, d4), dim=1))
+ return x + res
+
+
+# --------------------------------------------
+# Enhanced Spatial Attention (ESA)
+# --------------------------------------------
+class ESA(nn.Module):
+ def __init__(self, channel=64, reduction=4, bias=True):
+ super(ESA, self).__init__()
+ # -->conv3x3(conv21)-----------------------------------------------------------------------------------------+
+ # conv1x1(conv1)-->conv3x3-2(conv2)-->maxpool7-3-->conv3x3(conv3)(relu)-->conv3x3(conv4)(relu)-->conv3x3(conv5)-->bilinear--->conv1x1(conv6)-->sigmoid
+ self.r_nc = channel // reduction
+ self.conv1 = nn.Conv2d(channel, self.r_nc, kernel_size=1)
+ self.conv21 = nn.Conv2d(self.r_nc, self.r_nc, kernel_size=1)
+ self.conv2 = nn.Conv2d(self.r_nc, self.r_nc, kernel_size=3, stride=2, padding=0)
+ self.conv3 = nn.Conv2d(self.r_nc, self.r_nc, kernel_size=3, padding=1)
+ self.conv4 = nn.Conv2d(self.r_nc, self.r_nc, kernel_size=3, padding=1)
+ self.conv5 = nn.Conv2d(self.r_nc, self.r_nc, kernel_size=3, padding=1)
+ self.conv6 = nn.Conv2d(self.r_nc, channel, kernel_size=1)
+ self.sigmoid = nn.Sigmoid()
+ self.relu = nn.ReLU(inplace=True)
+
+ def forward(self, x):
+ x1 = self.conv1(x)
+ x2 = F.max_pool2d(self.conv2(x1), kernel_size=7, stride=3) # 1/6
+ x2 = self.relu(self.conv3(x2))
+ x2 = self.relu(self.conv4(x2))
+ x2 = F.interpolate(self.conv5(x2), (x.size(2), x.size(3)), mode='bilinear', align_corners=False)
+ x2 = self.conv6(x2 + self.conv21(x1))
+ return x.mul(self.sigmoid(x2))
+ # return x.mul_(self.sigmoid(x2))
+
+
+class CFRB(nn.Module):
+ def __init__(self, in_channels=50, out_channels=50, kernel_size=3, stride=1, padding=1, bias=True, mode='CL', d_rate=0.5, negative_slope=0.05):
+ super(CFRB, self).__init__()
+ self.d_nc = int(in_channels * d_rate)
+ self.r_nc = in_channels # int(in_channels - self.d_nc)
+
+ assert mode[0] == 'C', 'convolutional layer first'
+
+ self.conv1_d = conv(in_channels, self.d_nc, kernel_size=1, stride=1, padding=0, bias=bias, mode=mode[0])
+ self.conv1_r = conv(in_channels, self.r_nc, kernel_size, stride, padding, bias=bias, mode=mode[0])
+ self.conv2_d = conv(self.r_nc, self.d_nc, kernel_size=1, stride=1, padding=0, bias=bias, mode=mode[0])
+ self.conv2_r = conv(self.r_nc, self.r_nc, kernel_size, stride, padding, bias=bias, mode=mode[0])
+ self.conv3_d = conv(self.r_nc, self.d_nc, kernel_size=1, stride=1, padding=0, bias=bias, mode=mode[0])
+ self.conv3_r = conv(self.r_nc, self.r_nc, kernel_size, stride, padding, bias=bias, mode=mode[0])
+ self.conv4_d = conv(self.r_nc, self.d_nc, kernel_size, stride, padding, bias=bias, mode=mode[0])
+ self.conv1x1 = conv(self.d_nc*4, out_channels, kernel_size=1, stride=1, padding=0, bias=bias, mode=mode[0])
+ self.act = conv(mode=mode[-1], negative_slope=negative_slope)
+ self.esa = ESA(in_channels, reduction=4, bias=True)
+
+ def forward(self, x):
+ d1 = self.conv1_d(x)
+ x = self.act(self.conv1_r(x)+x)
+ d2 = self.conv2_d(x)
+ x = self.act(self.conv2_r(x)+x)
+ d3 = self.conv3_d(x)
+ x = self.act(self.conv3_r(x)+x)
+ x = self.conv4_d(x)
+ x = self.act(torch.cat([d1, d2, d3, x], dim=1))
+ x = self.esa(self.conv1x1(x))
+ return x
+
+
+# --------------------------------------------
+# Channel Attention (CA) Layer
+# --------------------------------------------
+class CALayer(nn.Module):
+ def __init__(self, channel=64, reduction=16):
+ super(CALayer, self).__init__()
+
+ self.avg_pool = nn.AdaptiveAvgPool2d(1)
+ self.conv_fc = nn.Sequential(
+ nn.Conv2d(channel, channel // reduction, 1, padding=0, bias=True),
+ nn.ReLU(inplace=True),
+ nn.Conv2d(channel // reduction, channel, 1, padding=0, bias=True),
+ nn.Sigmoid()
+ )
+
+ def forward(self, x):
+ y = self.avg_pool(x)
+ y = self.conv_fc(y)
+ return x * y
+
+
+# --------------------------------------------
+# Residual Channel Attention Block (RCAB)
+# --------------------------------------------
+class RCABlock(nn.Module):
+ def __init__(self, in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=True, mode='CRC', reduction=16, negative_slope=0.2):
+ super(RCABlock, self).__init__()
+ assert in_channels == out_channels, 'Only support in_channels==out_channels.'
+ if mode[0] in ['R','L']:
+ mode = mode[0].lower() + mode[1:]
+
+ self.res = conv(in_channels, out_channels, kernel_size, stride, padding, bias, mode, negative_slope)
+ self.ca = CALayer(out_channels, reduction)
+
+ def forward(self, x):
+ res = self.res(x)
+ res = self.ca(res)
+ return res + x
+
+
+# --------------------------------------------
+# Residual Channel Attention Group (RG)
+# --------------------------------------------
+class RCAGroup(nn.Module):
+ def __init__(self, in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=True, mode='CRC', reduction=16, nb=12, negative_slope=0.2):
+ super(RCAGroup, self).__init__()
+ assert in_channels == out_channels, 'Only support in_channels==out_channels.'
+ if mode[0] in ['R','L']:
+ mode = mode[0].lower() + mode[1:]
+
+ RG = [RCABlock(in_channels, out_channels, kernel_size, stride, padding, bias, mode, reduction, negative_slope) for _ in range(nb)]
+ RG.append(conv(out_channels, out_channels, mode='C'))
+ self.rg = nn.Sequential(*RG) # self.rg = ShortcutBlock(nn.Sequential(*RG))
+
+ def forward(self, x):
+ res = self.rg(x)
+ return res + x
+
+
+# --------------------------------------------
+# Residual Dense Block
+# style: 5 convs
+# --------------------------------------------
+class ResidualDenseBlock_5C(nn.Module):
+ def __init__(self, nc=64, gc=32, kernel_size=3, stride=1, padding=1, bias=True, mode='CR', negative_slope=0.2):
+ super(ResidualDenseBlock_5C, self).__init__()
+ # gc: growth channel
+ self.conv1 = conv(nc, gc, kernel_size, stride, padding, bias, mode, negative_slope)
+ self.conv2 = conv(nc+gc, gc, kernel_size, stride, padding, bias, mode, negative_slope)
+ self.conv3 = conv(nc+2*gc, gc, kernel_size, stride, padding, bias, mode, negative_slope)
+ self.conv4 = conv(nc+3*gc, gc, kernel_size, stride, padding, bias, mode, negative_slope)
+ self.conv5 = conv(nc+4*gc, nc, kernel_size, stride, padding, bias, mode[:-1], negative_slope)
+
+ def forward(self, x):
+ x1 = self.conv1(x)
+ x2 = self.conv2(torch.cat((x, x1), 1))
+ x3 = self.conv3(torch.cat((x, x1, x2), 1))
+ x4 = self.conv4(torch.cat((x, x1, x2, x3), 1))
+ x5 = self.conv5(torch.cat((x, x1, x2, x3, x4), 1))
+ return x5.mul_(0.2) + x
+
+
+# --------------------------------------------
+# Residual in Residual Dense Block
+# 3x5c
+# --------------------------------------------
+class RRDB(nn.Module):
+ def __init__(self, nc=64, gc=32, kernel_size=3, stride=1, padding=1, bias=True, mode='CR', negative_slope=0.2):
+ super(RRDB, self).__init__()
+
+ self.RDB1 = ResidualDenseBlock_5C(nc, gc, kernel_size, stride, padding, bias, mode, negative_slope)
+ self.RDB2 = ResidualDenseBlock_5C(nc, gc, kernel_size, stride, padding, bias, mode, negative_slope)
+ self.RDB3 = ResidualDenseBlock_5C(nc, gc, kernel_size, stride, padding, bias, mode, negative_slope)
+
+ def forward(self, x):
+ out = self.RDB1(x)
+ out = self.RDB2(out)
+ out = self.RDB3(out)
+ return out.mul_(0.2) + x
+
+
+"""
+# --------------------------------------------
+# Upsampler
+# Kai Zhang, https://github.com/cszn/KAIR
+# --------------------------------------------
+# upsample_pixelshuffle
+# upsample_upconv
+# upsample_convtranspose
+# --------------------------------------------
+"""
+
+
+# --------------------------------------------
+# conv + subp (+ relu)
+# --------------------------------------------
+def upsample_pixelshuffle(in_channels=64, out_channels=3, kernel_size=3, stride=1, padding=1, bias=True, mode='2R', negative_slope=0.2):
+ assert len(mode)<4 and mode[0] in ['2', '3', '4'], 'mode examples: 2, 2R, 2BR, 3, ..., 4BR.'
+ up1 = conv(in_channels, out_channels * (int(mode[0]) ** 2), kernel_size, stride, padding, bias, mode='C'+mode, negative_slope=negative_slope)
+ return up1
+
+
+# --------------------------------------------
+# nearest_upsample + conv (+ R)
+# --------------------------------------------
+def upsample_upconv(in_channels=64, out_channels=3, kernel_size=3, stride=1, padding=1, bias=True, mode='2R', negative_slope=0.2):
+ assert len(mode)<4 and mode[0] in ['2', '3', '4'], 'mode examples: 2, 2R, 2BR, 3, ..., 4BR'
+ if mode[0] == '2':
+ uc = 'UC'
+ elif mode[0] == '3':
+ uc = 'uC'
+ elif mode[0] == '4':
+ uc = 'vC'
+ mode = mode.replace(mode[0], uc)
+ up1 = conv(in_channels, out_channels, kernel_size, stride, padding, bias, mode=mode, negative_slope=negative_slope)
+ return up1
+
+
+# --------------------------------------------
+# convTranspose (+ relu)
+# --------------------------------------------
+def upsample_convtranspose(in_channels=64, out_channels=3, kernel_size=2, stride=2, padding=0, bias=True, mode='2R', negative_slope=0.2):
+ assert len(mode)<4 and mode[0] in ['2', '3', '4'], 'mode examples: 2, 2R, 2BR, 3, ..., 4BR.'
+ kernel_size = int(mode[0])
+ stride = int(mode[0])
+ mode = mode.replace(mode[0], 'T')
+ up1 = conv(in_channels, out_channels, kernel_size, stride, padding, bias, mode, negative_slope)
+ return up1
+
+
+'''
+# --------------------------------------------
+# Downsampler
+# Kai Zhang, https://github.com/cszn/KAIR
+# --------------------------------------------
+# downsample_strideconv
+# downsample_maxpool
+# downsample_avgpool
+# --------------------------------------------
+'''
+
+
+# --------------------------------------------
+# strideconv (+ relu)
+# --------------------------------------------
+def downsample_strideconv(in_channels=64, out_channels=64, kernel_size=2, stride=2, padding=0, bias=True, mode='2R', negative_slope=0.2):
+ assert len(mode)<4 and mode[0] in ['2', '3', '4'], 'mode examples: 2, 2R, 2BR, 3, ..., 4BR.'
+ kernel_size = int(mode[0])
+ stride = int(mode[0])
+ mode = mode.replace(mode[0], 'C')
+ down1 = conv(in_channels, out_channels, kernel_size, stride, padding, bias, mode, negative_slope)
+ return down1
+
+
+# --------------------------------------------
+# maxpooling + conv (+ relu)
+# --------------------------------------------
+def downsample_maxpool(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=0, bias=True, mode='2R', negative_slope=0.2):
+ assert len(mode)<4 and mode[0] in ['2', '3'], 'mode examples: 2, 2R, 2BR, 3, ..., 3BR.'
+ kernel_size_pool = int(mode[0])
+ stride_pool = int(mode[0])
+ mode = mode.replace(mode[0], 'MC')
+ pool = conv(kernel_size=kernel_size_pool, stride=stride_pool, mode=mode[0], negative_slope=negative_slope)
+ pool_tail = conv(in_channels, out_channels, kernel_size, stride, padding, bias, mode=mode[1:], negative_slope=negative_slope)
+ return sequential(pool, pool_tail)
+
+
+# --------------------------------------------
+# averagepooling + conv (+ relu)
+# --------------------------------------------
+def downsample_avgpool(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=True, mode='2R', negative_slope=0.2):
+ assert len(mode)<4 and mode[0] in ['2', '3'], 'mode examples: 2, 2R, 2BR, 3, ..., 3BR.'
+ kernel_size_pool = int(mode[0])
+ stride_pool = int(mode[0])
+ mode = mode.replace(mode[0], 'AC')
+ pool = conv(kernel_size=kernel_size_pool, stride=stride_pool, mode=mode[0], negative_slope=negative_slope)
+ pool_tail = conv(in_channels, out_channels, kernel_size, stride, padding, bias, mode=mode[1:], negative_slope=negative_slope)
+ return sequential(pool, pool_tail)
+
+
+'''
+# --------------------------------------------
+# NonLocalBlock2D:
+# embedded_gaussian
+# +W(softmax(thetaXphi)Xg)
+# --------------------------------------------
+'''
+
+
+# --------------------------------------------
+# non-local block with embedded_gaussian
+# https://github.com/AlexHex7/Non-local_pytorch
+# --------------------------------------------
+class NonLocalBlock2D(nn.Module):
+ def __init__(self, nc=64, kernel_size=1, stride=1, padding=0, bias=True, act_mode='B', downsample=False, downsample_mode='maxpool', negative_slope=0.2):
+
+ super(NonLocalBlock2D, self).__init__()
+
+ inter_nc = nc // 2
+ self.inter_nc = inter_nc
+ self.W = conv(inter_nc, nc, kernel_size, stride, padding, bias, mode='C'+act_mode)
+ self.theta = conv(nc, inter_nc, kernel_size, stride, padding, bias, mode='C')
+
+ if downsample:
+ if downsample_mode == 'avgpool':
+ downsample_block = downsample_avgpool
+ elif downsample_mode == 'maxpool':
+ downsample_block = downsample_maxpool
+ elif downsample_mode == 'strideconv':
+ downsample_block = downsample_strideconv
+ else:
+ raise NotImplementedError('downsample mode [{:s}] is not found'.format(downsample_mode))
+ self.phi = downsample_block(nc, inter_nc, kernel_size, stride, padding, bias, mode='2')
+ self.g = downsample_block(nc, inter_nc, kernel_size, stride, padding, bias, mode='2')
+ else:
+ self.phi = conv(nc, inter_nc, kernel_size, stride, padding, bias, mode='C')
+ self.g = conv(nc, inter_nc, kernel_size, stride, padding, bias, mode='C')
+
+ def forward(self, x):
+ '''
+ :param x: (b, c, t, h, w)
+ :return:
+ '''
+
+ batch_size = x.size(0)
+
+ g_x = self.g(x).view(batch_size, self.inter_nc, -1)
+ g_x = g_x.permute(0, 2, 1)
+
+ theta_x = self.theta(x).view(batch_size, self.inter_nc, -1)
+ theta_x = theta_x.permute(0, 2, 1)
+ phi_x = self.phi(x).view(batch_size, self.inter_nc, -1)
+ f = torch.matmul(theta_x, phi_x)
+ f_div_C = F.softmax(f, dim=-1)
+
+ y = torch.matmul(f_div_C, g_x)
+ y = y.permute(0, 2, 1).contiguous()
+ y = y.view(batch_size, self.inter_nc, *x.size()[2:])
+ W_y = self.W(y)
+ z = W_y + x
+
+ return z
diff --git a/KAIR/models/einstein.png b/KAIR/models/einstein.png
new file mode 100644
index 0000000000000000000000000000000000000000..da4ca098b6655f7e8106e2e28bfda00de40dcdcf
Binary files /dev/null and b/KAIR/models/einstein.png differ
diff --git a/KAIR/models/loss.py b/KAIR/models/loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..0a01d7d719f66f0947739caf223cad7ea0dbefca
--- /dev/null
+++ b/KAIR/models/loss.py
@@ -0,0 +1,287 @@
+import torch
+import torch.nn as nn
+import torchvision
+from torch.nn import functional as F
+from torch import autograd as autograd
+
+
+"""
+Sequential(
+ (0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): ReLU(inplace)
+ (2*): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): ReLU(inplace)
+ (4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
+ (5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (6): ReLU(inplace)
+ (7*): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (8): ReLU(inplace)
+ (9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
+ (10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (11): ReLU(inplace)
+ (12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (13): ReLU(inplace)
+ (14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (15): ReLU(inplace)
+ (16*): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (17): ReLU(inplace)
+ (18): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
+ (19): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (20): ReLU(inplace)
+ (21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (22): ReLU(inplace)
+ (23): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (24): ReLU(inplace)
+ (25*): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (26): ReLU(inplace)
+ (27): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
+ (28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (29): ReLU(inplace)
+ (30): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (31): ReLU(inplace)
+ (32): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (33): ReLU(inplace)
+ (34*): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (35): ReLU(inplace)
+ (36): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
+)
+"""
+
+
+# --------------------------------------------
+# Perceptual loss
+# --------------------------------------------
+class VGGFeatureExtractor(nn.Module):
+ def __init__(self, feature_layer=[2,7,16,25,34], use_input_norm=True, use_range_norm=False):
+ super(VGGFeatureExtractor, self).__init__()
+ '''
+ use_input_norm: If True, x: [0, 1] --> (x - mean) / std
+ use_range_norm: If True, x: [0, 1] --> x: [-1, 1]
+ '''
+ model = torchvision.models.vgg19(pretrained=True)
+ self.use_input_norm = use_input_norm
+ self.use_range_norm = use_range_norm
+ if self.use_input_norm:
+ mean = torch.Tensor([0.485, 0.456, 0.406]).view(1, 3, 1, 1)
+ std = torch.Tensor([0.229, 0.224, 0.225]).view(1, 3, 1, 1)
+ self.register_buffer('mean', mean)
+ self.register_buffer('std', std)
+ self.list_outputs = isinstance(feature_layer, list)
+ if self.list_outputs:
+ self.features = nn.Sequential()
+ feature_layer = [-1] + feature_layer
+ for i in range(len(feature_layer)-1):
+ self.features.add_module('child'+str(i), nn.Sequential(*list(model.features.children())[(feature_layer[i]+1):(feature_layer[i+1]+1)]))
+ else:
+ self.features = nn.Sequential(*list(model.features.children())[:(feature_layer + 1)])
+
+ print(self.features)
+
+ # No need to BP to variable
+ for k, v in self.features.named_parameters():
+ v.requires_grad = False
+
+ def forward(self, x):
+ if self.use_range_norm:
+ x = (x + 1.0) / 2.0
+ if self.use_input_norm:
+ x = (x - self.mean) / self.std
+ if self.list_outputs:
+ output = []
+ for child_model in self.features.children():
+ x = child_model(x)
+ output.append(x.clone())
+ return output
+ else:
+ return self.features(x)
+
+
+class PerceptualLoss(nn.Module):
+ """VGG Perceptual loss
+ """
+
+ def __init__(self, feature_layer=[2,7,16,25,34], weights=[0.1,0.1,1.0,1.0,1.0], lossfn_type='l1', use_input_norm=True, use_range_norm=False):
+ super(PerceptualLoss, self).__init__()
+ self.vgg = VGGFeatureExtractor(feature_layer=feature_layer, use_input_norm=use_input_norm, use_range_norm=use_range_norm)
+ self.lossfn_type = lossfn_type
+ self.weights = weights
+ if self.lossfn_type == 'l1':
+ self.lossfn = nn.L1Loss()
+ else:
+ self.lossfn = nn.MSELoss()
+ print(f'feature_layer: {feature_layer} with weights: {weights}')
+
+ def forward(self, x, gt):
+ """Forward function.
+ Args:
+ x (Tensor): Input tensor with shape (n, c, h, w).
+ gt (Tensor): Ground-truth tensor with shape (n, c, h, w).
+ Returns:
+ Tensor: Forward results.
+ """
+ x_vgg, gt_vgg = self.vgg(x), self.vgg(gt.detach())
+ loss = 0.0
+ if isinstance(x_vgg, list):
+ n = len(x_vgg)
+ for i in range(n):
+ loss += self.weights[i] * self.lossfn(x_vgg[i], gt_vgg[i])
+ else:
+ loss += self.lossfn(x_vgg, gt_vgg.detach())
+ return loss
+
+# --------------------------------------------
+# GAN loss: gan, ragan
+# --------------------------------------------
+class GANLoss(nn.Module):
+ def __init__(self, gan_type, real_label_val=1.0, fake_label_val=0.0):
+ super(GANLoss, self).__init__()
+ self.gan_type = gan_type.lower()
+ self.real_label_val = real_label_val
+ self.fake_label_val = fake_label_val
+
+ if self.gan_type == 'gan' or self.gan_type == 'ragan':
+ self.loss = nn.BCEWithLogitsLoss()
+ elif self.gan_type == 'lsgan':
+ self.loss = nn.MSELoss()
+ elif self.gan_type == 'wgan':
+ def wgan_loss(input, target):
+ # target is boolean
+ return -1 * input.mean() if target else input.mean()
+
+ self.loss = wgan_loss
+ elif self.gan_type == 'softplusgan':
+ def softplusgan_loss(input, target):
+ # target is boolean
+ return F.softplus(-input).mean() if target else F.softplus(input).mean()
+
+ self.loss = softplusgan_loss
+ else:
+ raise NotImplementedError('GAN type [{:s}] is not found'.format(self.gan_type))
+
+ def get_target_label(self, input, target_is_real):
+ if self.gan_type in ['wgan', 'softplusgan']:
+ return target_is_real
+ if target_is_real:
+ return torch.empty_like(input).fill_(self.real_label_val)
+ else:
+ return torch.empty_like(input).fill_(self.fake_label_val)
+
+ def forward(self, input, target_is_real):
+ target_label = self.get_target_label(input, target_is_real)
+ loss = self.loss(input, target_label)
+ return loss
+
+
+# --------------------------------------------
+# TV loss
+# --------------------------------------------
+class TVLoss(nn.Module):
+ def __init__(self, tv_loss_weight=1):
+ """
+ Total variation loss
+ https://github.com/jxgu1016/Total_Variation_Loss.pytorch
+ Args:
+ tv_loss_weight (int):
+ """
+ super(TVLoss, self).__init__()
+ self.tv_loss_weight = tv_loss_weight
+
+ def forward(self, x):
+ batch_size = x.size()[0]
+ h_x = x.size()[2]
+ w_x = x.size()[3]
+ count_h = self.tensor_size(x[:, :, 1:, :])
+ count_w = self.tensor_size(x[:, :, :, 1:])
+ h_tv = torch.pow((x[:, :, 1:, :] - x[:, :, :h_x - 1, :]), 2).sum()
+ w_tv = torch.pow((x[:, :, :, 1:] - x[:, :, :, :w_x - 1]), 2).sum()
+ return self.tv_loss_weight * 2 * (h_tv / count_h + w_tv / count_w) / batch_size
+
+ @staticmethod
+ def tensor_size(t):
+ return t.size()[1] * t.size()[2] * t.size()[3]
+
+
+# --------------------------------------------
+# Charbonnier loss
+# --------------------------------------------
+class CharbonnierLoss(nn.Module):
+ """Charbonnier Loss (L1)"""
+
+ def __init__(self, eps=1e-9):
+ super(CharbonnierLoss, self).__init__()
+ self.eps = eps
+
+ def forward(self, x, y):
+ diff = x - y
+ loss = torch.mean(torch.sqrt((diff * diff) + self.eps))
+ return loss
+
+
+
+def r1_penalty(real_pred, real_img):
+ """R1 regularization for discriminator. The core idea is to
+ penalize the gradient on real data alone: when the
+ generator distribution produces the true data distribution
+ and the discriminator is equal to 0 on the data manifold, the
+ gradient penalty ensures that the discriminator cannot create
+ a non-zero gradient orthogonal to the data manifold without
+ suffering a loss in the GAN game.
+ Ref:
+ Eq. 9 in Which training methods for GANs do actually converge.
+ """
+ grad_real = autograd.grad(
+ outputs=real_pred.sum(), inputs=real_img, create_graph=True)[0]
+ grad_penalty = grad_real.pow(2).view(grad_real.shape[0], -1).sum(1).mean()
+ return grad_penalty
+
+
+def g_path_regularize(fake_img, latents, mean_path_length, decay=0.01):
+ noise = torch.randn_like(fake_img) / math.sqrt(
+ fake_img.shape[2] * fake_img.shape[3])
+ grad = autograd.grad(
+ outputs=(fake_img * noise).sum(), inputs=latents, create_graph=True)[0]
+ path_lengths = torch.sqrt(grad.pow(2).sum(2).mean(1))
+
+ path_mean = mean_path_length + decay * (
+ path_lengths.mean() - mean_path_length)
+
+ path_penalty = (path_lengths - path_mean).pow(2).mean()
+
+ return path_penalty, path_lengths.detach().mean(), path_mean.detach()
+
+
+def gradient_penalty_loss(discriminator, real_data, fake_data, weight=None):
+ """Calculate gradient penalty for wgan-gp.
+ Args:
+ discriminator (nn.Module): Network for the discriminator.
+ real_data (Tensor): Real input data.
+ fake_data (Tensor): Fake input data.
+ weight (Tensor): Weight tensor. Default: None.
+ Returns:
+ Tensor: A tensor for gradient penalty.
+ """
+
+ batch_size = real_data.size(0)
+ alpha = real_data.new_tensor(torch.rand(batch_size, 1, 1, 1))
+
+ # interpolate between real_data and fake_data
+ interpolates = alpha * real_data + (1. - alpha) * fake_data
+ interpolates = autograd.Variable(interpolates, requires_grad=True)
+
+ disc_interpolates = discriminator(interpolates)
+ gradients = autograd.grad(
+ outputs=disc_interpolates,
+ inputs=interpolates,
+ grad_outputs=torch.ones_like(disc_interpolates),
+ create_graph=True,
+ retain_graph=True,
+ only_inputs=True)[0]
+
+ if weight is not None:
+ gradients = gradients * weight
+
+ gradients_penalty = ((gradients.norm(2, dim=1) - 1)**2).mean()
+ if weight is not None:
+ gradients_penalty /= torch.mean(weight)
+
+ return gradients_penalty
diff --git a/KAIR/models/loss_ssim.py b/KAIR/models/loss_ssim.py
new file mode 100644
index 0000000000000000000000000000000000000000..1120b5b99800129764b14a40138429f8077dc34f
--- /dev/null
+++ b/KAIR/models/loss_ssim.py
@@ -0,0 +1,115 @@
+import torch
+import torch.nn.functional as F
+from torch.autograd import Variable
+import numpy as np
+from math import exp
+
+"""
+# ============================================
+# SSIM loss
+# https://github.com/Po-Hsun-Su/pytorch-ssim
+# ============================================
+"""
+
+
+def gaussian(window_size, sigma):
+ gauss = torch.Tensor([exp(-(x - window_size//2)**2/float(2*sigma**2)) for x in range(window_size)])
+ return gauss/gauss.sum()
+
+
+def create_window(window_size, channel):
+ _1D_window = gaussian(window_size, 1.5).unsqueeze(1)
+ _2D_window = _1D_window.mm(_1D_window.t()).float().unsqueeze(0).unsqueeze(0)
+ window = Variable(_2D_window.expand(channel, 1, window_size, window_size).contiguous())
+ return window
+
+
+def _ssim(img1, img2, window, window_size, channel, size_average=True):
+ mu1 = F.conv2d(img1, window, padding=window_size//2, groups=channel)
+ mu2 = F.conv2d(img2, window, padding=window_size//2, groups=channel)
+
+ mu1_sq = mu1.pow(2)
+ mu2_sq = mu2.pow(2)
+ mu1_mu2 = mu1*mu2
+
+ sigma1_sq = F.conv2d(img1*img1, window, padding=window_size//2, groups=channel) - mu1_sq
+ sigma2_sq = F.conv2d(img2*img2, window, padding=window_size//2, groups=channel) - mu2_sq
+ sigma12 = F.conv2d(img1*img2, window, padding=window_size//2, groups=channel) - mu1_mu2
+
+ C1 = 0.01**2
+ C2 = 0.03**2
+
+ ssim_map = ((2*mu1_mu2 + C1)*(2*sigma12 + C2))/((mu1_sq + mu2_sq + C1)*(sigma1_sq + sigma2_sq + C2))
+ if size_average:
+ return ssim_map.mean()
+ else:
+ return ssim_map.mean(1).mean(1).mean(1)
+
+
+class SSIMLoss(torch.nn.Module):
+ def __init__(self, window_size=11, size_average=True):
+ super(SSIMLoss, self).__init__()
+ self.window_size = window_size
+ self.size_average = size_average
+ self.channel = 1
+ self.window = create_window(window_size, self.channel)
+
+ def forward(self, img1, img2):
+ (_, channel, _, _) = img1.size()
+ if channel == self.channel and self.window.data.type() == img1.data.type():
+ window = self.window
+ else:
+ window = create_window(self.window_size, channel)
+
+ if img1.is_cuda:
+ window = window.cuda(img1.get_device())
+ window = window.type_as(img1)
+
+ self.window = window
+ self.channel = channel
+
+ return _ssim(img1, img2, window, self.window_size, channel, self.size_average)
+
+
+def ssim(img1, img2, window_size=11, size_average=True):
+ (_, channel, _, _) = img1.size()
+ window = create_window(window_size, channel)
+
+ if img1.is_cuda:
+ window = window.cuda(img1.get_device())
+ window = window.type_as(img1)
+
+ return _ssim(img1, img2, window, window_size, channel, size_average)
+
+
+if __name__ == '__main__':
+ import cv2
+ from torch import optim
+ from skimage import io
+ npImg1 = cv2.imread("einstein.png")
+
+ img1 = torch.from_numpy(np.rollaxis(npImg1, 2)).float().unsqueeze(0)/255.0
+ img2 = torch.rand(img1.size())
+
+ if torch.cuda.is_available():
+ img1 = img1.cuda()
+ img2 = img2.cuda()
+
+ img1 = Variable(img1, requires_grad=False)
+ img2 = Variable(img2, requires_grad=True)
+
+ ssim_value = ssim(img1, img2).item()
+ print("Initial ssim:", ssim_value)
+
+ ssim_loss = SSIMLoss()
+ optimizer = optim.Adam([img2], lr=0.01)
+
+ while ssim_value < 0.99:
+ optimizer.zero_grad()
+ ssim_out = -ssim_loss(img1, img2)
+ ssim_value = -ssim_out.item()
+ print('{:<4.4f}'.format(ssim_value))
+ ssim_out.backward()
+ optimizer.step()
+ img = np.transpose(img2.detach().cpu().squeeze().float().numpy(), (1,2,0))
+ io.imshow(np.uint8(np.clip(img*255, 0, 255)))
diff --git a/KAIR/models/model_base.py b/KAIR/models/model_base.py
new file mode 100644
index 0000000000000000000000000000000000000000..0ae3bce9453fa21b8ce0e037b437ba738b67f76b
--- /dev/null
+++ b/KAIR/models/model_base.py
@@ -0,0 +1,220 @@
+import os
+import torch
+import torch.nn as nn
+from utils.utils_bnorm import merge_bn, tidy_sequential
+from torch.nn.parallel import DataParallel, DistributedDataParallel
+
+
+class ModelBase():
+ def __init__(self, opt):
+ self.opt = opt # opt
+ self.save_dir = opt['path']['models'] # save models
+ self.device = torch.device('cuda' if opt['gpu_ids'] is not None else 'cpu')
+ self.is_train = opt['is_train'] # training or not
+ self.schedulers = [] # schedulers
+
+ """
+ # ----------------------------------------
+ # Preparation before training with data
+ # Save model during training
+ # ----------------------------------------
+ """
+
+ def init_train(self):
+ pass
+
+ def load(self):
+ pass
+
+ def save(self, label):
+ pass
+
+ def define_loss(self):
+ pass
+
+ def define_optimizer(self):
+ pass
+
+ def define_scheduler(self):
+ pass
+
+ """
+ # ----------------------------------------
+ # Optimization during training with data
+ # Testing/evaluation
+ # ----------------------------------------
+ """
+
+ def feed_data(self, data):
+ pass
+
+ def optimize_parameters(self):
+ pass
+
+ def current_visuals(self):
+ pass
+
+ def current_losses(self):
+ pass
+
+ def update_learning_rate(self, n):
+ for scheduler in self.schedulers:
+ scheduler.step(n)
+
+ def current_learning_rate(self):
+ return self.schedulers[0].get_lr()[0]
+
+ def requires_grad(self, model, flag=True):
+ for p in model.parameters():
+ p.requires_grad = flag
+
+ """
+ # ----------------------------------------
+ # Information of net
+ # ----------------------------------------
+ """
+
+ def print_network(self):
+ pass
+
+ def info_network(self):
+ pass
+
+ def print_params(self):
+ pass
+
+ def info_params(self):
+ pass
+
+ def get_bare_model(self, network):
+ """Get bare model, especially under wrapping with
+ DistributedDataParallel or DataParallel.
+ """
+ if isinstance(network, (DataParallel, DistributedDataParallel)):
+ network = network.module
+ return network
+
+ def model_to_device(self, network):
+ """Model to device. It also warps models with DistributedDataParallel
+ or DataParallel.
+ Args:
+ network (nn.Module)
+ """
+ network = network.to(self.device)
+ if self.opt['dist']:
+ find_unused_parameters = self.opt.get('find_unused_parameters', True)
+ use_static_graph = self.opt.get('use_static_graph', False)
+ network = DistributedDataParallel(network, device_ids=[torch.cuda.current_device()], find_unused_parameters=find_unused_parameters)
+ if use_static_graph:
+ print('Using static graph. Make sure that "unused parameters" will not change during training loop.')
+ network._set_static_graph()
+ else:
+ network = DataParallel(network)
+ return network
+
+ # ----------------------------------------
+ # network name and number of parameters
+ # ----------------------------------------
+ def describe_network(self, network):
+ network = self.get_bare_model(network)
+ msg = '\n'
+ msg += 'Networks name: {}'.format(network.__class__.__name__) + '\n'
+ msg += 'Params number: {}'.format(sum(map(lambda x: x.numel(), network.parameters()))) + '\n'
+ msg += 'Net structure:\n{}'.format(str(network)) + '\n'
+ return msg
+
+ # ----------------------------------------
+ # parameters description
+ # ----------------------------------------
+ def describe_params(self, network):
+ network = self.get_bare_model(network)
+ msg = '\n'
+ msg += ' | {:^6s} | {:^6s} | {:^6s} | {:^6s} || {:<20s}'.format('mean', 'min', 'max', 'std', 'shape', 'param_name') + '\n'
+ for name, param in network.state_dict().items():
+ if not 'num_batches_tracked' in name:
+ v = param.data.clone().float()
+ msg += ' | {:>6.3f} | {:>6.3f} | {:>6.3f} | {:>6.3f} | {} || {:s}'.format(v.mean(), v.min(), v.max(), v.std(), v.shape, name) + '\n'
+ return msg
+
+ """
+ # ----------------------------------------
+ # Save prameters
+ # Load prameters
+ # ----------------------------------------
+ """
+
+ # ----------------------------------------
+ # save the state_dict of the network
+ # ----------------------------------------
+ def save_network(self, save_dir, network, network_label, iter_label):
+ save_filename = '{}_{}.pth'.format(iter_label, network_label)
+ save_path = os.path.join(save_dir, save_filename)
+ network = self.get_bare_model(network)
+ state_dict = network.state_dict()
+ for key, param in state_dict.items():
+ state_dict[key] = param.cpu()
+ torch.save(state_dict, save_path)
+
+ # ----------------------------------------
+ # load the state_dict of the network
+ # ----------------------------------------
+ def load_network(self, load_path, network, strict=True, param_key='params'):
+ network = self.get_bare_model(network)
+ if strict:
+ state_dict = torch.load(load_path)
+ if param_key in state_dict.keys():
+ state_dict = state_dict[param_key]
+ network.load_state_dict(state_dict, strict=strict)
+ else:
+ state_dict_old = torch.load(load_path)
+ if param_key in state_dict_old.keys():
+ state_dict_old = state_dict_old[param_key]
+ state_dict = network.state_dict()
+ for ((key_old, param_old),(key, param)) in zip(state_dict_old.items(), state_dict.items()):
+ state_dict[key] = param_old
+ network.load_state_dict(state_dict, strict=True)
+ del state_dict_old, state_dict
+
+ # ----------------------------------------
+ # save the state_dict of the optimizer
+ # ----------------------------------------
+ def save_optimizer(self, save_dir, optimizer, optimizer_label, iter_label):
+ save_filename = '{}_{}.pth'.format(iter_label, optimizer_label)
+ save_path = os.path.join(save_dir, save_filename)
+ torch.save(optimizer.state_dict(), save_path)
+
+ # ----------------------------------------
+ # load the state_dict of the optimizer
+ # ----------------------------------------
+ def load_optimizer(self, load_path, optimizer):
+ optimizer.load_state_dict(torch.load(load_path, map_location=lambda storage, loc: storage.cuda(torch.cuda.current_device())))
+
+ def update_E(self, decay=0.999):
+ netG = self.get_bare_model(self.netG)
+ netG_params = dict(netG.named_parameters())
+ netE_params = dict(self.netE.named_parameters())
+ for k in netG_params.keys():
+ netE_params[k].data.mul_(decay).add_(netG_params[k].data, alpha=1-decay)
+
+ """
+ # ----------------------------------------
+ # Merge Batch Normalization for training
+ # Merge Batch Normalization for testing
+ # ----------------------------------------
+ """
+
+ # ----------------------------------------
+ # merge bn during training
+ # ----------------------------------------
+ def merge_bnorm_train(self):
+ merge_bn(self.netG)
+ tidy_sequential(self.netG)
+ self.define_optimizer()
+ self.define_scheduler()
+
+ # ----------------------------------------
+ # merge bn before testing
+ # ----------------------------------------
+ def merge_bnorm_test(self):
+ merge_bn(self.netG)
+ tidy_sequential(self.netG)
diff --git a/KAIR/models/model_gan.py b/KAIR/models/model_gan.py
new file mode 100644
index 0000000000000000000000000000000000000000..1755d8dab0b36d601e5b9b99e3e524ef96aa7895
--- /dev/null
+++ b/KAIR/models/model_gan.py
@@ -0,0 +1,353 @@
+from collections import OrderedDict
+import torch
+import torch.nn as nn
+from torch.optim import lr_scheduler
+from torch.optim import Adam
+
+from models.select_network import define_G, define_D
+from models.model_base import ModelBase
+from models.loss import GANLoss, PerceptualLoss
+from models.loss_ssim import SSIMLoss
+
+
+class ModelGAN(ModelBase):
+ """Train with pixel-VGG-GAN loss"""
+ def __init__(self, opt):
+ super(ModelGAN, self).__init__(opt)
+ # ------------------------------------
+ # define network
+ # ------------------------------------
+ self.opt_train = self.opt['train'] # training option
+ self.netG = define_G(opt)
+ self.netG = self.model_to_device(self.netG)
+ if self.is_train:
+ self.netD = define_D(opt)
+ self.netD = self.model_to_device(self.netD)
+ if self.opt_train['E_decay'] > 0:
+ self.netE = define_G(opt).to(self.device).eval()
+
+ """
+ # ----------------------------------------
+ # Preparation before training with data
+ # Save model during training
+ # ----------------------------------------
+ """
+
+ # ----------------------------------------
+ # initialize training
+ # ----------------------------------------
+ def init_train(self):
+ self.load() # load model
+ self.netG.train() # set training mode,for BN
+ self.netD.train() # set training mode,for BN
+ self.define_loss() # define loss
+ self.define_optimizer() # define optimizer
+ self.load_optimizers() # load optimizer
+ self.define_scheduler() # define scheduler
+ self.log_dict = OrderedDict() # log
+
+ # ----------------------------------------
+ # load pre-trained G and D model
+ # ----------------------------------------
+ def load(self):
+ load_path_G = self.opt['path']['pretrained_netG']
+ if load_path_G is not None:
+ print('Loading model for G [{:s}] ...'.format(load_path_G))
+ self.load_network(load_path_G, self.netG, strict=self.opt_train['G_param_strict'])
+ load_path_E = self.opt['path']['pretrained_netE']
+ if self.opt_train['E_decay'] > 0:
+ if load_path_E is not None:
+ print('Loading model for E [{:s}] ...'.format(load_path_E))
+ self.load_network(load_path_E, self.netE, strict=self.opt_train['E_param_strict'])
+ else:
+ print('Copying model for E')
+ self.update_E(0)
+ self.netE.eval()
+
+ load_path_D = self.opt['path']['pretrained_netD']
+ if self.opt['is_train'] and load_path_D is not None:
+ print('Loading model for D [{:s}] ...'.format(load_path_D))
+ self.load_network(load_path_D, self.netD, strict=self.opt_train['D_param_strict'])
+
+ # ----------------------------------------
+ # load optimizerG and optimizerD
+ # ----------------------------------------
+ def load_optimizers(self):
+ load_path_optimizerG = self.opt['path']['pretrained_optimizerG']
+ if load_path_optimizerG is not None and self.opt_train['G_optimizer_reuse']:
+ print('Loading optimizerG [{:s}] ...'.format(load_path_optimizerG))
+ self.load_optimizer(load_path_optimizerG, self.G_optimizer)
+ load_path_optimizerD = self.opt['path']['pretrained_optimizerD']
+ if load_path_optimizerD is not None and self.opt_train['D_optimizer_reuse']:
+ print('Loading optimizerD [{:s}] ...'.format(load_path_optimizerD))
+ self.load_optimizer(load_path_optimizerD, self.D_optimizer)
+
+ # ----------------------------------------
+ # save model / optimizer(optional)
+ # ----------------------------------------
+ def save(self, iter_label):
+ self.save_network(self.save_dir, self.netG, 'G', iter_label)
+ self.save_network(self.save_dir, self.netD, 'D', iter_label)
+ if self.opt_train['E_decay'] > 0:
+ self.save_network(self.save_dir, self.netE, 'E', iter_label)
+ if self.opt_train['G_optimizer_reuse']:
+ self.save_optimizer(self.save_dir, self.G_optimizer, 'optimizerG', iter_label)
+ if self.opt_train['D_optimizer_reuse']:
+ self.save_optimizer(self.save_dir, self.D_optimizer, 'optimizerD', iter_label)
+
+ # ----------------------------------------
+ # define loss
+ # ----------------------------------------
+ def define_loss(self):
+ # ------------------------------------
+ # 1) G_loss
+ # ------------------------------------
+ if self.opt_train['G_lossfn_weight'] > 0:
+ G_lossfn_type = self.opt_train['G_lossfn_type']
+ if G_lossfn_type == 'l1':
+ self.G_lossfn = nn.L1Loss().to(self.device)
+ elif G_lossfn_type == 'l2':
+ self.G_lossfn = nn.MSELoss().to(self.device)
+ elif G_lossfn_type == 'l2sum':
+ self.G_lossfn = nn.MSELoss(reduction='sum').to(self.device)
+ elif G_lossfn_type == 'ssim':
+ self.G_lossfn = SSIMLoss().to(self.device)
+ else:
+ raise NotImplementedError('Loss type [{:s}] is not found.'.format(G_lossfn_type))
+ self.G_lossfn_weight = self.opt_train['G_lossfn_weight']
+ else:
+ print('Do not use pixel loss.')
+ self.G_lossfn = None
+
+ # ------------------------------------
+ # 2) F_loss
+ # ------------------------------------
+ if self.opt_train['F_lossfn_weight'] > 0:
+ F_feature_layer = self.opt_train['F_feature_layer']
+ F_weights = self.opt_train['F_weights']
+ F_lossfn_type = self.opt_train['F_lossfn_type']
+ F_use_input_norm = self.opt_train['F_use_input_norm']
+ F_use_range_norm = self.opt_train['F_use_range_norm']
+ if self.opt['dist']:
+ self.F_lossfn = PerceptualLoss(feature_layer=F_feature_layer, weights=F_weights, lossfn_type=F_lossfn_type, use_input_norm=F_use_input_norm, use_range_norm=F_use_range_norm).to(self.device)
+ else:
+ self.F_lossfn = PerceptualLoss(feature_layer=F_feature_layer, weights=F_weights, lossfn_type=F_lossfn_type, use_input_norm=F_use_input_norm, use_range_norm=F_use_range_norm)
+ self.F_lossfn.vgg = self.model_to_device(self.F_lossfn.vgg)
+ self.F_lossfn.lossfn = self.F_lossfn.lossfn.to(self.device)
+ self.F_lossfn_weight = self.opt_train['F_lossfn_weight']
+ else:
+ print('Do not use feature loss.')
+ self.F_lossfn = None
+
+ # ------------------------------------
+ # 3) D_loss
+ # ------------------------------------
+ self.D_lossfn = GANLoss(self.opt_train['gan_type'], 1.0, 0.0).to(self.device)
+ self.D_lossfn_weight = self.opt_train['D_lossfn_weight']
+
+ self.D_update_ratio = self.opt_train['D_update_ratio'] if self.opt_train['D_update_ratio'] else 1
+ self.D_init_iters = self.opt_train['D_init_iters'] if self.opt_train['D_init_iters'] else 0
+
+ # ----------------------------------------
+ # define optimizer, G and D
+ # ----------------------------------------
+ def define_optimizer(self):
+ G_optim_params = []
+ for k, v in self.netG.named_parameters():
+ if v.requires_grad:
+ G_optim_params.append(v)
+ else:
+ print('Params [{:s}] will not optimize.'.format(k))
+
+ self.G_optimizer = Adam(G_optim_params, lr=self.opt_train['G_optimizer_lr'], weight_decay=0)
+ self.D_optimizer = Adam(self.netD.parameters(), lr=self.opt_train['D_optimizer_lr'], weight_decay=0)
+
+ # ----------------------------------------
+ # define scheduler, only "MultiStepLR"
+ # ----------------------------------------
+ def define_scheduler(self):
+ self.schedulers.append(lr_scheduler.MultiStepLR(self.G_optimizer,
+ self.opt_train['G_scheduler_milestones'],
+ self.opt_train['G_scheduler_gamma']
+ ))
+ self.schedulers.append(lr_scheduler.MultiStepLR(self.D_optimizer,
+ self.opt_train['D_scheduler_milestones'],
+ self.opt_train['D_scheduler_gamma']
+ ))
+
+ """
+ # ----------------------------------------
+ # Optimization during training with data
+ # Testing/evaluation
+ # ----------------------------------------
+ """
+
+ # ----------------------------------------
+ # feed L/H data
+ # ----------------------------------------
+ def feed_data(self, data, need_H=True):
+ self.L = data['L'].to(self.device)
+ if need_H:
+ self.H = data['H'].to(self.device)
+
+ # ----------------------------------------
+ # feed L to netG and get E
+ # ----------------------------------------
+ def netG_forward(self):
+ self.E = self.netG(self.L)
+
+ # ----------------------------------------
+ # update parameters and get loss
+ # ----------------------------------------
+ def optimize_parameters(self, current_step):
+ # ------------------------------------
+ # optimize G
+ # ------------------------------------
+ for p in self.netD.parameters():
+ p.requires_grad = False
+
+ self.G_optimizer.zero_grad()
+ self.netG_forward()
+ loss_G_total = 0
+
+ if current_step % self.D_update_ratio == 0 and current_step > self.D_init_iters: # updata D first
+ if self.opt_train['G_lossfn_weight'] > 0:
+ G_loss = self.G_lossfn_weight * self.G_lossfn(self.E, self.H)
+ loss_G_total += G_loss # 1) pixel loss
+ if self.opt_train['F_lossfn_weight'] > 0:
+ F_loss = self.F_lossfn_weight * self.F_lossfn(self.E, self.H)
+ loss_G_total += F_loss # 2) VGG feature loss
+
+ if self.opt['train']['gan_type'] in ['gan', 'lsgan', 'wgan', 'softplusgan']:
+ pred_g_fake = self.netD(self.E)
+ D_loss = self.D_lossfn_weight * self.D_lossfn(pred_g_fake, True)
+ elif self.opt['train']['gan_type'] == 'ragan':
+ pred_d_real = self.netD(self.H).detach()
+ pred_g_fake = self.netD(self.E)
+ D_loss = self.D_lossfn_weight * (
+ self.D_lossfn(pred_d_real - torch.mean(pred_g_fake, 0, True), False) +
+ self.D_lossfn(pred_g_fake - torch.mean(pred_d_real, 0, True), True)) / 2
+ loss_G_total += D_loss # 3) GAN loss
+
+ loss_G_total.backward()
+ self.G_optimizer.step()
+
+ # ------------------------------------
+ # optimize D
+ # ------------------------------------
+ for p in self.netD.parameters():
+ p.requires_grad = True
+
+ self.D_optimizer.zero_grad()
+
+ # In order to avoid the error in distributed training:
+ # "Error detected in CudnnBatchNormBackward: RuntimeError: one of
+ # the variables needed for gradient computation has been modified by
+ # an inplace operation",
+ # we separate the backwards for real and fake, and also detach the
+ # tensor for calculating mean.
+ if self.opt_train['gan_type'] in ['gan', 'lsgan', 'wgan', 'softplusgan']:
+ # real
+ pred_d_real = self.netD(self.H) # 1) real data
+ l_d_real = self.D_lossfn(pred_d_real, True)
+ l_d_real.backward()
+ # fake
+ pred_d_fake = self.netD(self.E.detach().clone()) # 2) fake data, detach to avoid BP to G
+ l_d_fake = self.D_lossfn(pred_d_fake, False)
+ l_d_fake.backward()
+ elif self.opt_train['gan_type'] == 'ragan':
+ # real
+ pred_d_fake = self.netD(self.E).detach() # 1) fake data, detach to avoid BP to G
+ pred_d_real = self.netD(self.H) # 2) real data
+ l_d_real = 0.5 * self.D_lossfn(pred_d_real - torch.mean(pred_d_fake, 0, True), True)
+ l_d_real.backward()
+ # fake
+ pred_d_fake = self.netD(self.E.detach())
+ l_d_fake = 0.5 * self.D_lossfn(pred_d_fake - torch.mean(pred_d_real.detach(), 0, True), False)
+ l_d_fake.backward()
+
+ self.D_optimizer.step()
+
+ # ------------------------------------
+ # record log
+ # ------------------------------------
+ if current_step % self.D_update_ratio == 0 and current_step > self.D_init_iters:
+ if self.opt_train['G_lossfn_weight'] > 0:
+ self.log_dict['G_loss'] = G_loss.item()
+ if self.opt_train['F_lossfn_weight'] > 0:
+ self.log_dict['F_loss'] = F_loss.item()
+ self.log_dict['D_loss'] = D_loss.item()
+
+ #self.log_dict['l_d_real'] = l_d_real.item()
+ #self.log_dict['l_d_fake'] = l_d_fake.item()
+ self.log_dict['D_real'] = torch.mean(pred_d_real.detach())
+ self.log_dict['D_fake'] = torch.mean(pred_d_fake.detach())
+
+ if self.opt_train['E_decay'] > 0:
+ self.update_E(self.opt_train['E_decay'])
+
+ # ----------------------------------------
+ # test and inference
+ # ----------------------------------------
+ def test(self):
+ self.netG.eval()
+ with torch.no_grad():
+ self.netG_forward()
+ self.netG.train()
+
+ # ----------------------------------------
+ # get log_dict
+ # ----------------------------------------
+ def current_log(self):
+ return self.log_dict
+
+ # ----------------------------------------
+ # get L, E, H images
+ # ----------------------------------------
+ def current_visuals(self, need_H=True):
+ out_dict = OrderedDict()
+ out_dict['L'] = self.L.detach()[0].float().cpu()
+ out_dict['E'] = self.E.detach()[0].float().cpu()
+ if need_H:
+ out_dict['H'] = self.H.detach()[0].float().cpu()
+ return out_dict
+
+ """
+ # ----------------------------------------
+ # Information of netG, netD and netF
+ # ----------------------------------------
+ """
+
+ # ----------------------------------------
+ # print network
+ # ----------------------------------------
+ def print_network(self):
+ msg = self.describe_network(self.netG)
+ print(msg)
+ if self.is_train:
+ msg = self.describe_network(self.netD)
+ print(msg)
+
+ # ----------------------------------------
+ # print params
+ # ----------------------------------------
+ def print_params(self):
+ msg = self.describe_params(self.netG)
+ print(msg)
+
+ # ----------------------------------------
+ # network information
+ # ----------------------------------------
+ def info_network(self):
+ msg = self.describe_network(self.netG)
+ if self.is_train:
+ msg += self.describe_network(self.netD)
+ return msg
+
+ # ----------------------------------------
+ # params information
+ # ----------------------------------------
+ def info_params(self):
+ msg = self.describe_params(self.netG)
+ return msg
+
diff --git a/KAIR/models/model_plain.py b/KAIR/models/model_plain.py
new file mode 100644
index 0000000000000000000000000000000000000000..069569ce8669ceca20e23f4104f95604535434b1
--- /dev/null
+++ b/KAIR/models/model_plain.py
@@ -0,0 +1,273 @@
+from collections import OrderedDict
+import torch
+import torch.nn as nn
+from torch.optim import lr_scheduler
+from torch.optim import Adam
+
+from models.select_network import define_G
+from models.model_base import ModelBase
+from models.loss import CharbonnierLoss
+from models.loss_ssim import SSIMLoss
+
+from utils.utils_model import test_mode
+from utils.utils_regularizers import regularizer_orth, regularizer_clip
+
+
+class ModelPlain(ModelBase):
+ """Train with pixel loss"""
+ def __init__(self, opt):
+ super(ModelPlain, self).__init__(opt)
+ # ------------------------------------
+ # define network
+ # ------------------------------------
+ self.opt_train = self.opt['train'] # training option
+ self.netG = define_G(opt)
+ self.netG = self.model_to_device(self.netG)
+ if self.opt_train['E_decay'] > 0:
+ self.netE = define_G(opt).to(self.device).eval()
+
+ """
+ # ----------------------------------------
+ # Preparation before training with data
+ # Save model during training
+ # ----------------------------------------
+ """
+
+ # ----------------------------------------
+ # initialize training
+ # ----------------------------------------
+ def init_train(self):
+ self.load() # load model
+ self.netG.train() # set training mode,for BN
+ self.define_loss() # define loss
+ self.define_optimizer() # define optimizer
+ self.load_optimizers() # load optimizer
+ self.define_scheduler() # define scheduler
+ self.log_dict = OrderedDict() # log
+
+ # ----------------------------------------
+ # load pre-trained G model
+ # ----------------------------------------
+ def load(self):
+ load_path_G = self.opt['path']['pretrained_netG']
+ if load_path_G is not None:
+ print('Loading model for G [{:s}] ...'.format(load_path_G))
+ self.load_network(load_path_G, self.netG, strict=self.opt_train['G_param_strict'], param_key='params')
+ load_path_E = self.opt['path']['pretrained_netE']
+ if self.opt_train['E_decay'] > 0:
+ if load_path_E is not None:
+ print('Loading model for E [{:s}] ...'.format(load_path_E))
+ self.load_network(load_path_E, self.netE, strict=self.opt_train['E_param_strict'], param_key='params_ema')
+ else:
+ print('Copying model for E ...')
+ self.update_E(0)
+ self.netE.eval()
+
+ # ----------------------------------------
+ # load optimizer
+ # ----------------------------------------
+ def load_optimizers(self):
+ load_path_optimizerG = self.opt['path']['pretrained_optimizerG']
+ if load_path_optimizerG is not None and self.opt_train['G_optimizer_reuse']:
+ print('Loading optimizerG [{:s}] ...'.format(load_path_optimizerG))
+ self.load_optimizer(load_path_optimizerG, self.G_optimizer)
+
+ # ----------------------------------------
+ # save model / optimizer(optional)
+ # ----------------------------------------
+ def save(self, iter_label):
+ self.save_network(self.save_dir, self.netG, 'G', iter_label)
+ if self.opt_train['E_decay'] > 0:
+ self.save_network(self.save_dir, self.netE, 'E', iter_label)
+ if self.opt_train['G_optimizer_reuse']:
+ self.save_optimizer(self.save_dir, self.G_optimizer, 'optimizerG', iter_label)
+
+ # ----------------------------------------
+ # define loss
+ # ----------------------------------------
+ def define_loss(self):
+ G_lossfn_type = self.opt_train['G_lossfn_type']
+ if G_lossfn_type == 'l1':
+ self.G_lossfn = nn.L1Loss().to(self.device)
+ elif G_lossfn_type == 'l2':
+ self.G_lossfn = nn.MSELoss().to(self.device)
+ elif G_lossfn_type == 'l2sum':
+ self.G_lossfn = nn.MSELoss(reduction='sum').to(self.device)
+ elif G_lossfn_type == 'ssim':
+ self.G_lossfn = SSIMLoss().to(self.device)
+ elif G_lossfn_type == 'charbonnier':
+ self.G_lossfn = CharbonnierLoss(self.opt_train['G_charbonnier_eps']).to(self.device)
+ else:
+ raise NotImplementedError('Loss type [{:s}] is not found.'.format(G_lossfn_type))
+ self.G_lossfn_weight = self.opt_train['G_lossfn_weight']
+
+ # ----------------------------------------
+ # define optimizer
+ # ----------------------------------------
+ def define_optimizer(self):
+ G_optim_params = []
+ for k, v in self.netG.named_parameters():
+ if v.requires_grad:
+ G_optim_params.append(v)
+ else:
+ print('Params [{:s}] will not optimize.'.format(k))
+ if self.opt_train['G_optimizer_type'] == 'adam':
+ self.G_optimizer = Adam(G_optim_params, lr=self.opt_train['G_optimizer_lr'],
+ betas=self.opt_train['G_optimizer_betas'],
+ weight_decay=self.opt_train['G_optimizer_wd'])
+ else:
+ raise NotImplementedError
+
+ # ----------------------------------------
+ # define scheduler, only "MultiStepLR"
+ # ----------------------------------------
+ def define_scheduler(self):
+ if self.opt_train['G_scheduler_type'] == 'MultiStepLR':
+ self.schedulers.append(lr_scheduler.MultiStepLR(self.G_optimizer,
+ self.opt_train['G_scheduler_milestones'],
+ self.opt_train['G_scheduler_gamma']
+ ))
+ elif self.opt_train['G_scheduler_type'] == 'CosineAnnealingWarmRestarts':
+ self.schedulers.append(lr_scheduler.CosineAnnealingWarmRestarts(self.G_optimizer,
+ self.opt_train['G_scheduler_periods'],
+ self.opt_train['G_scheduler_restart_weights'],
+ self.opt_train['G_scheduler_eta_min']
+ ))
+ else:
+ raise NotImplementedError
+
+ """
+ # ----------------------------------------
+ # Optimization during training with data
+ # Testing/evaluation
+ # ----------------------------------------
+ """
+
+ # ----------------------------------------
+ # feed L/H data
+ # ----------------------------------------
+ def feed_data(self, data, need_H=True):
+ self.L = data['L'].to(self.device)
+ if need_H:
+ self.H = data['H'].to(self.device)
+
+ # ----------------------------------------
+ # feed L to netG
+ # ----------------------------------------
+ def netG_forward(self):
+ self.E = self.netG(self.L)
+
+ # ----------------------------------------
+ # update parameters and get loss
+ # ----------------------------------------
+ def optimize_parameters(self, current_step):
+ self.G_optimizer.zero_grad()
+ self.netG_forward()
+ G_loss = self.G_lossfn_weight * self.G_lossfn(self.E, self.H)
+ G_loss.backward()
+
+ # ------------------------------------
+ # clip_grad
+ # ------------------------------------
+ # `clip_grad_norm` helps prevent the exploding gradient problem.
+ G_optimizer_clipgrad = self.opt_train['G_optimizer_clipgrad'] if self.opt_train['G_optimizer_clipgrad'] else 0
+ if G_optimizer_clipgrad > 0:
+ torch.nn.utils.clip_grad_norm_(self.parameters(), max_norm=self.opt_train['G_optimizer_clipgrad'], norm_type=2)
+
+ self.G_optimizer.step()
+
+ # ------------------------------------
+ # regularizer
+ # ------------------------------------
+ G_regularizer_orthstep = self.opt_train['G_regularizer_orthstep'] if self.opt_train['G_regularizer_orthstep'] else 0
+ if G_regularizer_orthstep > 0 and current_step % G_regularizer_orthstep == 0 and current_step % self.opt['train']['checkpoint_save'] != 0:
+ self.netG.apply(regularizer_orth)
+ G_regularizer_clipstep = self.opt_train['G_regularizer_clipstep'] if self.opt_train['G_regularizer_clipstep'] else 0
+ if G_regularizer_clipstep > 0 and current_step % G_regularizer_clipstep == 0 and current_step % self.opt['train']['checkpoint_save'] != 0:
+ self.netG.apply(regularizer_clip)
+
+ # self.log_dict['G_loss'] = G_loss.item()/self.E.size()[0] # if `reduction='sum'`
+ self.log_dict['G_loss'] = G_loss.item()
+
+ if self.opt_train['E_decay'] > 0:
+ self.update_E(self.opt_train['E_decay'])
+
+ # ----------------------------------------
+ # test / inference
+ # ----------------------------------------
+ def test(self):
+ self.netG.eval()
+ with torch.no_grad():
+ self.netG_forward()
+ self.netG.train()
+
+ # ----------------------------------------
+ # test / inference x8
+ # ----------------------------------------
+ def testx8(self):
+ self.netG.eval()
+ with torch.no_grad():
+ self.E = test_mode(self.netG, self.L, mode=3, sf=self.opt['scale'], modulo=1)
+ self.netG.train()
+
+ # ----------------------------------------
+ # get log_dict
+ # ----------------------------------------
+ def current_log(self):
+ return self.log_dict
+
+ # ----------------------------------------
+ # get L, E, H image
+ # ----------------------------------------
+ def current_visuals(self, need_H=True):
+ out_dict = OrderedDict()
+ out_dict['L'] = self.L.detach()[0].float().cpu()
+ out_dict['E'] = self.E.detach()[0].float().cpu()
+ if need_H:
+ out_dict['H'] = self.H.detach()[0].float().cpu()
+ return out_dict
+
+ # ----------------------------------------
+ # get L, E, H batch images
+ # ----------------------------------------
+ def current_results(self, need_H=True):
+ out_dict = OrderedDict()
+ out_dict['L'] = self.L.detach().float().cpu()
+ out_dict['E'] = self.E.detach().float().cpu()
+ if need_H:
+ out_dict['H'] = self.H.detach().float().cpu()
+ return out_dict
+
+ """
+ # ----------------------------------------
+ # Information of netG
+ # ----------------------------------------
+ """
+
+ # ----------------------------------------
+ # print network
+ # ----------------------------------------
+ def print_network(self):
+ msg = self.describe_network(self.netG)
+ print(msg)
+
+ # ----------------------------------------
+ # print params
+ # ----------------------------------------
+ def print_params(self):
+ msg = self.describe_params(self.netG)
+ print(msg)
+
+ # ----------------------------------------
+ # network information
+ # ----------------------------------------
+ def info_network(self):
+ msg = self.describe_network(self.netG)
+ return msg
+
+ # ----------------------------------------
+ # params information
+ # ----------------------------------------
+ def info_params(self):
+ msg = self.describe_params(self.netG)
+ return msg
diff --git a/KAIR/models/model_plain2.py b/KAIR/models/model_plain2.py
new file mode 100644
index 0000000000000000000000000000000000000000..53d0c878c50f2e91a8008c143c17421101843e15
--- /dev/null
+++ b/KAIR/models/model_plain2.py
@@ -0,0 +1,20 @@
+from models.model_plain import ModelPlain
+
+class ModelPlain2(ModelPlain):
+ """Train with two inputs (L, C) and with pixel loss"""
+
+ # ----------------------------------------
+ # feed L/H data
+ # ----------------------------------------
+ def feed_data(self, data, need_H=True):
+ self.L = data['L'].to(self.device)
+ self.C = data['C'].to(self.device)
+ if need_H:
+ self.H = data['H'].to(self.device)
+
+ # ----------------------------------------
+ # feed (L, C) to netG and get E
+ # ----------------------------------------
+ def netG_forward(self):
+ self.E = self.netG(self.L, self.C)
+
diff --git a/KAIR/models/model_plain4.py b/KAIR/models/model_plain4.py
new file mode 100644
index 0000000000000000000000000000000000000000..8a534cf26a1d46660b0e1af8176f4a38a6058343
--- /dev/null
+++ b/KAIR/models/model_plain4.py
@@ -0,0 +1,23 @@
+from models.model_plain import ModelPlain
+import numpy as np
+
+
+class ModelPlain4(ModelPlain):
+ """Train with four inputs (L, k, sf, sigma) and with pixel loss for USRNet"""
+
+ # ----------------------------------------
+ # feed L/H data
+ # ----------------------------------------
+ def feed_data(self, data, need_H=True):
+ self.L = data['L'].to(self.device) # low-quality image
+ self.k = data['k'].to(self.device) # blur kernel
+ self.sf = np.int(data['sf'][0,...].squeeze().cpu().numpy()) # scale factor
+ self.sigma = data['sigma'].to(self.device) # noise level
+ if need_H:
+ self.H = data['H'].to(self.device) # H
+
+ # ----------------------------------------
+ # feed (L, C) to netG and get E
+ # ----------------------------------------
+ def netG_forward(self):
+ self.E = self.netG(self.L, self.k, self.sf, self.sigma)
diff --git a/KAIR/models/model_vrt.py b/KAIR/models/model_vrt.py
new file mode 100644
index 0000000000000000000000000000000000000000..3b91a7677672364994326ae68a93c7725962b007
--- /dev/null
+++ b/KAIR/models/model_vrt.py
@@ -0,0 +1,258 @@
+from collections import OrderedDict
+import torch
+import torch.nn as nn
+from torch.optim import lr_scheduler
+from torch.optim import Adam
+
+from models.select_network import define_G
+from models.model_plain import ModelPlain
+from models.loss import CharbonnierLoss
+from models.loss_ssim import SSIMLoss
+
+from utils.utils_model import test_mode
+from utils.utils_regularizers import regularizer_orth, regularizer_clip
+
+
+class ModelVRT(ModelPlain):
+ """Train video restoration with pixel loss"""
+ def __init__(self, opt):
+ super(ModelVRT, self).__init__(opt)
+ self.fix_iter = self.opt_train.get('fix_iter', 0)
+ self.fix_keys = self.opt_train.get('fix_keys', [])
+ self.fix_unflagged = True
+
+ # ----------------------------------------
+ # define optimizer
+ # ----------------------------------------
+ def define_optimizer(self):
+ self.fix_keys = self.opt_train.get('fix_keys', [])
+ if self.opt_train.get('fix_iter', 0) and len(self.fix_keys) > 0:
+ fix_lr_mul = self.opt_train['fix_lr_mul']
+ print(f'Multiple the learning rate for keys: {self.fix_keys} with {fix_lr_mul}.')
+ if fix_lr_mul == 1:
+ G_optim_params = self.netG.parameters()
+ else: # separate flow params and normal params for different lr
+ normal_params = []
+ flow_params = []
+ for name, param in self.netG.named_parameters():
+ if any([key in name for key in self.fix_keys]):
+ flow_params.append(param)
+ else:
+ normal_params.append(param)
+ G_optim_params = [
+ { # add normal params first
+ 'params': normal_params,
+ 'lr': self.opt_train['G_optimizer_lr']
+ },
+ {
+ 'params': flow_params,
+ 'lr': self.opt_train['G_optimizer_lr'] * fix_lr_mul
+ },
+ ]
+
+ if self.opt_train['G_optimizer_type'] == 'adam':
+ self.G_optimizer = Adam(G_optim_params, lr=self.opt_train['G_optimizer_lr'],
+ betas=self.opt_train['G_optimizer_betas'],
+ weight_decay=self.opt_train['G_optimizer_wd'])
+ else:
+ raise NotImplementedError
+ else:
+ super(ModelVRT, self).define_optimizer()
+
+ # ----------------------------------------
+ # update parameters and get loss
+ # ----------------------------------------
+ def optimize_parameters(self, current_step):
+ if self.fix_iter:
+ if self.fix_unflagged and current_step < self.fix_iter:
+ print(f'Fix keys: {self.fix_keys} for the first {self.fix_iter} iters.')
+ self.fix_unflagged = False
+ for name, param in self.netG.named_parameters():
+ if any([key in name for key in self.fix_keys]):
+ param.requires_grad_(False)
+ elif current_step == self.fix_iter:
+ print(f'Train all the parameters from {self.fix_iter} iters.')
+ self.netG.requires_grad_(True)
+
+ super(ModelVRT, self).optimize_parameters(current_step)
+
+ # ----------------------------------------
+ # test / inference
+ # ----------------------------------------
+ def test(self):
+ n = self.L.size(1)
+ self.netG.eval()
+
+ pad_seq = self.opt_train.get('pad_seq', False)
+ flip_seq = self.opt_train.get('flip_seq', False)
+ self.center_frame_only = self.opt_train.get('center_frame_only', False)
+
+ if pad_seq:
+ n = n + 1
+ self.L = torch.cat([self.L, self.L[:, -1:, :, :, :]], dim=1)
+
+ if flip_seq:
+ self.L = torch.cat([self.L, self.L.flip(1)], dim=1)
+
+ with torch.no_grad():
+ self.E = self._test_video(self.L)
+
+ if flip_seq:
+ output_1 = self.E[:, :n, :, :, :]
+ output_2 = self.E[:, n:, :, :, :].flip(1)
+ self.E = 0.5 * (output_1 + output_2)
+
+ if pad_seq:
+ n = n - 1
+ self.E = self.E[:, :n, :, :, :]
+
+ if self.center_frame_only:
+ self.E = self.E[:, n // 2, :, :, :]
+
+ self.netG.train()
+
+ def _test_video(self, lq):
+ '''test the video as a whole or as clips (divided temporally). '''
+
+ num_frame_testing = self.opt['val'].get('num_frame_testing', 0)
+
+ if num_frame_testing:
+ # test as multiple clips if out-of-memory
+ sf = self.opt['scale']
+ num_frame_overlapping = self.opt['val'].get('num_frame_overlapping', 2)
+ not_overlap_border = False
+ b, d, c, h, w = lq.size()
+ c = c - 1 if self.opt['netG'].get('nonblind_denoising', False) else c
+ stride = num_frame_testing - num_frame_overlapping
+ d_idx_list = list(range(0, d-num_frame_testing, stride)) + [max(0, d-num_frame_testing)]
+ E = torch.zeros(b, d, c, h*sf, w*sf)
+ W = torch.zeros(b, d, 1, 1, 1)
+
+ for d_idx in d_idx_list:
+ lq_clip = lq[:, d_idx:d_idx+num_frame_testing, ...]
+ out_clip = self._test_clip(lq_clip)
+ out_clip_mask = torch.ones((b, min(num_frame_testing, d), 1, 1, 1))
+
+ if not_overlap_border:
+ if d_idx < d_idx_list[-1]:
+ out_clip[:, -num_frame_overlapping//2:, ...] *= 0
+ out_clip_mask[:, -num_frame_overlapping//2:, ...] *= 0
+ if d_idx > d_idx_list[0]:
+ out_clip[:, :num_frame_overlapping//2, ...] *= 0
+ out_clip_mask[:, :num_frame_overlapping//2, ...] *= 0
+
+ E[:, d_idx:d_idx+num_frame_testing, ...].add_(out_clip)
+ W[:, d_idx:d_idx+num_frame_testing, ...].add_(out_clip_mask)
+ output = E.div_(W)
+ else:
+ # test as one clip (the whole video) if you have enough memory
+ window_size = self.opt['netG'].get('window_size', [6,8,8])
+ d_old = lq.size(1)
+ d_pad = (d_old// window_size[0]+1)*window_size[0] - d_old
+ lq = torch.cat([lq, torch.flip(lq[:, -d_pad:, ...], [1])], 1)
+ output = self._test_clip(lq)
+ output = output[:, :d_old, :, :, :]
+
+ return output
+
+ def _test_clip(self, lq):
+ ''' test the clip as a whole or as patches. '''
+
+ sf = self.opt['scale']
+ window_size = self.opt['netG'].get('window_size', [6,8,8])
+ size_patch_testing = self.opt['val'].get('size_patch_testing', 0)
+ assert size_patch_testing % window_size[-1] == 0, 'testing patch size should be a multiple of window_size.'
+
+ if size_patch_testing:
+ # divide the clip to patches (spatially only, tested patch by patch)
+ overlap_size = 20
+ not_overlap_border = True
+
+ # test patch by patch
+ b, d, c, h, w = lq.size()
+ c = c - 1 if self.opt['netG'].get('nonblind_denoising', False) else c
+ stride = size_patch_testing - overlap_size
+ h_idx_list = list(range(0, h-size_patch_testing, stride)) + [max(0, h-size_patch_testing)]
+ w_idx_list = list(range(0, w-size_patch_testing, stride)) + [max(0, w-size_patch_testing)]
+ E = torch.zeros(b, d, c, h*sf, w*sf)
+ W = torch.zeros_like(E)
+
+ for h_idx in h_idx_list:
+ for w_idx in w_idx_list:
+ in_patch = lq[..., h_idx:h_idx+size_patch_testing, w_idx:w_idx+size_patch_testing]
+ if hasattr(self, 'netE'):
+ out_patch = self.netE(in_patch).detach().cpu()
+ else:
+ out_patch = self.netG(in_patch).detach().cpu()
+
+ out_patch_mask = torch.ones_like(out_patch)
+
+ if not_overlap_border:
+ if h_idx < h_idx_list[-1]:
+ out_patch[..., -overlap_size//2:, :] *= 0
+ out_patch_mask[..., -overlap_size//2:, :] *= 0
+ if w_idx < w_idx_list[-1]:
+ out_patch[..., :, -overlap_size//2:] *= 0
+ out_patch_mask[..., :, -overlap_size//2:] *= 0
+ if h_idx > h_idx_list[0]:
+ out_patch[..., :overlap_size//2, :] *= 0
+ out_patch_mask[..., :overlap_size//2, :] *= 0
+ if w_idx > w_idx_list[0]:
+ out_patch[..., :, :overlap_size//2] *= 0
+ out_patch_mask[..., :, :overlap_size//2] *= 0
+
+ E[..., h_idx*sf:(h_idx+size_patch_testing)*sf, w_idx*sf:(w_idx+size_patch_testing)*sf].add_(out_patch)
+ W[..., h_idx*sf:(h_idx+size_patch_testing)*sf, w_idx*sf:(w_idx+size_patch_testing)*sf].add_(out_patch_mask)
+ output = E.div_(W)
+
+ else:
+ _, _, _, h_old, w_old = lq.size()
+ h_pad = (h_old// window_size[1]+1)*window_size[1] - h_old
+ w_pad = (w_old// window_size[2]+1)*window_size[2] - w_old
+
+ lq = torch.cat([lq, torch.flip(lq[:, :, :, -h_pad:, :], [3])], 3)
+ lq = torch.cat([lq, torch.flip(lq[:, :, :, :, -w_pad:], [4])], 4)
+
+ if hasattr(self, 'netE'):
+ output = self.netE(lq).detach().cpu()
+ else:
+ output = self.netG(lq).detach().cpu()
+
+ output = output[:, :, :, :h_old*sf, :w_old*sf]
+
+ return output
+
+ # ----------------------------------------
+ # load the state_dict of the network
+ # ----------------------------------------
+ def load_network(self, load_path, network, strict=True, param_key='params'):
+ network = self.get_bare_model(network)
+ state_dict = torch.load(load_path)
+ if param_key in state_dict.keys():
+ state_dict = state_dict[param_key]
+ self._print_different_keys_loading(network, state_dict, strict)
+ network.load_state_dict(state_dict, strict=strict)
+
+ def _print_different_keys_loading(self, crt_net, load_net, strict=True):
+ crt_net = self.get_bare_model(crt_net)
+ crt_net = crt_net.state_dict()
+ crt_net_keys = set(crt_net.keys())
+ load_net_keys = set(load_net.keys())
+
+ if crt_net_keys != load_net_keys:
+ print('Current net - loaded net:')
+ for v in sorted(list(crt_net_keys - load_net_keys)):
+ print(f' {v}')
+ print('Loaded net - current net:')
+ for v in sorted(list(load_net_keys - crt_net_keys)):
+ print(f' {v}')
+
+ # check the size for the same keys
+ if not strict:
+ common_keys = crt_net_keys & load_net_keys
+ for k in common_keys:
+ if crt_net[k].size() != load_net[k].size():
+ print(f'Size different, ignore [{k}]: crt_net: '
+ f'{crt_net[k].shape}; load_net: {load_net[k].shape}')
+ load_net[k + '.ignore'] = load_net.pop(k)
+
diff --git a/KAIR/models/network_discriminator.py b/KAIR/models/network_discriminator.py
new file mode 100644
index 0000000000000000000000000000000000000000..8542a36d7665fda79e9ca13024f93961d91db97d
--- /dev/null
+++ b/KAIR/models/network_discriminator.py
@@ -0,0 +1,338 @@
+import torch
+import torch.nn as nn
+from torch.nn import functional as F
+from torch.nn.utils import spectral_norm
+import models.basicblock as B
+import functools
+import numpy as np
+
+
+"""
+# --------------------------------------------
+# Discriminator_PatchGAN
+# Discriminator_UNet
+# --------------------------------------------
+"""
+
+
+# --------------------------------------------
+# PatchGAN discriminator
+# If n_layers = 3, then the receptive field is 70x70
+# --------------------------------------------
+class Discriminator_PatchGAN(nn.Module):
+ def __init__(self, input_nc=3, ndf=64, n_layers=3, norm_type='spectral'):
+ '''PatchGAN discriminator, receptive field = 70x70 if n_layers = 3
+ Args:
+ input_nc: number of input channels
+ ndf: base channel number
+ n_layers: number of conv layer with stride 2
+ norm_type: 'batch', 'instance', 'spectral', 'batchspectral', instancespectral'
+ Returns:
+ tensor: score
+ '''
+ super(Discriminator_PatchGAN, self).__init__()
+ self.n_layers = n_layers
+ norm_layer = self.get_norm_layer(norm_type=norm_type)
+
+ kw = 4
+ padw = int(np.ceil((kw - 1.0) / 2))
+ sequence = [[self.use_spectral_norm(nn.Conv2d(input_nc, ndf, kernel_size=kw, stride=2, padding=padw), norm_type), nn.LeakyReLU(0.2, True)]]
+
+ nf = ndf
+ for n in range(1, n_layers):
+ nf_prev = nf
+ nf = min(nf * 2, 512)
+ sequence += [[self.use_spectral_norm(nn.Conv2d(nf_prev, nf, kernel_size=kw, stride=2, padding=padw), norm_type),
+ norm_layer(nf),
+ nn.LeakyReLU(0.2, True)]]
+
+ nf_prev = nf
+ nf = min(nf * 2, 512)
+ sequence += [[self.use_spectral_norm(nn.Conv2d(nf_prev, nf, kernel_size=kw, stride=1, padding=padw), norm_type),
+ norm_layer(nf),
+ nn.LeakyReLU(0.2, True)]]
+
+ sequence += [[self.use_spectral_norm(nn.Conv2d(nf, 1, kernel_size=kw, stride=1, padding=padw), norm_type)]]
+
+ self.model = nn.Sequential()
+ for n in range(len(sequence)):
+ self.model.add_module('child' + str(n), nn.Sequential(*sequence[n]))
+
+ self.model.apply(self.weights_init)
+
+ def use_spectral_norm(self, module, norm_type='spectral'):
+ if 'spectral' in norm_type:
+ return spectral_norm(module)
+ return module
+
+ def get_norm_layer(self, norm_type='instance'):
+ if 'batch' in norm_type:
+ norm_layer = functools.partial(nn.BatchNorm2d, affine=True)
+ elif 'instance' in norm_type:
+ norm_layer = functools.partial(nn.InstanceNorm2d, affine=False)
+ else:
+ norm_layer = functools.partial(nn.Identity)
+ return norm_layer
+
+ def weights_init(self, m):
+ classname = m.__class__.__name__
+ if classname.find('Conv') != -1:
+ m.weight.data.normal_(0.0, 0.02)
+ elif classname.find('BatchNorm2d') != -1:
+ m.weight.data.normal_(1.0, 0.02)
+ m.bias.data.fill_(0)
+
+ def forward(self, x):
+ return self.model(x)
+
+
+class Discriminator_UNet(nn.Module):
+ """Defines a U-Net discriminator with spectral normalization (SN)"""
+
+ def __init__(self, input_nc=3, ndf=64):
+ super(Discriminator_UNet, self).__init__()
+ norm = spectral_norm
+
+ self.conv0 = nn.Conv2d(input_nc, ndf, kernel_size=3, stride=1, padding=1)
+
+ self.conv1 = norm(nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False))
+ self.conv2 = norm(nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False))
+ self.conv3 = norm(nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False))
+ # upsample
+ self.conv4 = norm(nn.Conv2d(ndf * 8, ndf * 4, 3, 1, 1, bias=False))
+ self.conv5 = norm(nn.Conv2d(ndf * 4, ndf * 2, 3, 1, 1, bias=False))
+ self.conv6 = norm(nn.Conv2d(ndf * 2, ndf, 3, 1, 1, bias=False))
+
+ # extra
+ self.conv7 = norm(nn.Conv2d(ndf, ndf, 3, 1, 1, bias=False))
+ self.conv8 = norm(nn.Conv2d(ndf, ndf, 3, 1, 1, bias=False))
+
+ self.conv9 = nn.Conv2d(ndf, 1, 3, 1, 1)
+ print('using the UNet discriminator')
+
+ def forward(self, x):
+ x0 = F.leaky_relu(self.conv0(x), negative_slope=0.2, inplace=True)
+ x1 = F.leaky_relu(self.conv1(x0), negative_slope=0.2, inplace=True)
+ x2 = F.leaky_relu(self.conv2(x1), negative_slope=0.2, inplace=True)
+ x3 = F.leaky_relu(self.conv3(x2), negative_slope=0.2, inplace=True)
+
+ # upsample
+ x3 = F.interpolate(x3, scale_factor=2, mode='bilinear', align_corners=False)
+ x4 = F.leaky_relu(self.conv4(x3), negative_slope=0.2, inplace=True)
+
+ x4 = x4 + x2
+ x4 = F.interpolate(x4, scale_factor=2, mode='bilinear', align_corners=False)
+ x5 = F.leaky_relu(self.conv5(x4), negative_slope=0.2, inplace=True)
+
+ x5 = x5 + x1
+ x5 = F.interpolate(x5, scale_factor=2, mode='bilinear', align_corners=False)
+ x6 = F.leaky_relu(self.conv6(x5), negative_slope=0.2, inplace=True)
+
+ x6 = x6 + x0
+
+ # extra
+ out = F.leaky_relu(self.conv7(x6), negative_slope=0.2, inplace=True)
+ out = F.leaky_relu(self.conv8(out), negative_slope=0.2, inplace=True)
+ out = self.conv9(out)
+
+ return out
+
+
+# --------------------------------------------
+# VGG style Discriminator with 96x96 input
+# --------------------------------------------
+class Discriminator_VGG_96(nn.Module):
+ def __init__(self, in_nc=3, base_nc=64, ac_type='BL'):
+ super(Discriminator_VGG_96, self).__init__()
+ # features
+ # hxw, c
+ # 96, 64
+ conv0 = B.conv(in_nc, base_nc, kernel_size=3, mode='C')
+ conv1 = B.conv(base_nc, base_nc, kernel_size=4, stride=2, mode='C'+ac_type)
+ # 48, 64
+ conv2 = B.conv(base_nc, base_nc*2, kernel_size=3, stride=1, mode='C'+ac_type)
+ conv3 = B.conv(base_nc*2, base_nc*2, kernel_size=4, stride=2, mode='C'+ac_type)
+ # 24, 128
+ conv4 = B.conv(base_nc*2, base_nc*4, kernel_size=3, stride=1, mode='C'+ac_type)
+ conv5 = B.conv(base_nc*4, base_nc*4, kernel_size=4, stride=2, mode='C'+ac_type)
+ # 12, 256
+ conv6 = B.conv(base_nc*4, base_nc*8, kernel_size=3, stride=1, mode='C'+ac_type)
+ conv7 = B.conv(base_nc*8, base_nc*8, kernel_size=4, stride=2, mode='C'+ac_type)
+ # 6, 512
+ conv8 = B.conv(base_nc*8, base_nc*8, kernel_size=3, stride=1, mode='C'+ac_type)
+ conv9 = B.conv(base_nc*8, base_nc*8, kernel_size=4, stride=2, mode='C'+ac_type)
+ # 3, 512
+ self.features = B.sequential(conv0, conv1, conv2, conv3, conv4,
+ conv5, conv6, conv7, conv8, conv9)
+
+ # classifier
+ self.classifier = nn.Sequential(
+ nn.Linear(512 * 3 * 3, 100), nn.LeakyReLU(0.2, True), nn.Linear(100, 1))
+
+ def forward(self, x):
+ x = self.features(x)
+ x = x.view(x.size(0), -1)
+ x = self.classifier(x)
+ return x
+
+
+# --------------------------------------------
+# VGG style Discriminator with 128x128 input
+# --------------------------------------------
+class Discriminator_VGG_128(nn.Module):
+ def __init__(self, in_nc=3, base_nc=64, ac_type='BL'):
+ super(Discriminator_VGG_128, self).__init__()
+ # features
+ # hxw, c
+ # 128, 64
+ conv0 = B.conv(in_nc, base_nc, kernel_size=3, mode='C')
+ conv1 = B.conv(base_nc, base_nc, kernel_size=4, stride=2, mode='C'+ac_type)
+ # 64, 64
+ conv2 = B.conv(base_nc, base_nc*2, kernel_size=3, stride=1, mode='C'+ac_type)
+ conv3 = B.conv(base_nc*2, base_nc*2, kernel_size=4, stride=2, mode='C'+ac_type)
+ # 32, 128
+ conv4 = B.conv(base_nc*2, base_nc*4, kernel_size=3, stride=1, mode='C'+ac_type)
+ conv5 = B.conv(base_nc*4, base_nc*4, kernel_size=4, stride=2, mode='C'+ac_type)
+ # 16, 256
+ conv6 = B.conv(base_nc*4, base_nc*8, kernel_size=3, stride=1, mode='C'+ac_type)
+ conv7 = B.conv(base_nc*8, base_nc*8, kernel_size=4, stride=2, mode='C'+ac_type)
+ # 8, 512
+ conv8 = B.conv(base_nc*8, base_nc*8, kernel_size=3, stride=1, mode='C'+ac_type)
+ conv9 = B.conv(base_nc*8, base_nc*8, kernel_size=4, stride=2, mode='C'+ac_type)
+ # 4, 512
+ self.features = B.sequential(conv0, conv1, conv2, conv3, conv4,
+ conv5, conv6, conv7, conv8, conv9)
+
+ # classifier
+ self.classifier = nn.Sequential(nn.Linear(512 * 4 * 4, 100),
+ nn.LeakyReLU(0.2, True),
+ nn.Linear(100, 1))
+
+ def forward(self, x):
+ x = self.features(x)
+ x = x.view(x.size(0), -1)
+ x = self.classifier(x)
+ return x
+
+
+# --------------------------------------------
+# VGG style Discriminator with 192x192 input
+# --------------------------------------------
+class Discriminator_VGG_192(nn.Module):
+ def __init__(self, in_nc=3, base_nc=64, ac_type='BL'):
+ super(Discriminator_VGG_192, self).__init__()
+ # features
+ # hxw, c
+ # 192, 64
+ conv0 = B.conv(in_nc, base_nc, kernel_size=3, mode='C')
+ conv1 = B.conv(base_nc, base_nc, kernel_size=4, stride=2, mode='C'+ac_type)
+ # 96, 64
+ conv2 = B.conv(base_nc, base_nc*2, kernel_size=3, stride=1, mode='C'+ac_type)
+ conv3 = B.conv(base_nc*2, base_nc*2, kernel_size=4, stride=2, mode='C'+ac_type)
+ # 48, 128
+ conv4 = B.conv(base_nc*2, base_nc*4, kernel_size=3, stride=1, mode='C'+ac_type)
+ conv5 = B.conv(base_nc*4, base_nc*4, kernel_size=4, stride=2, mode='C'+ac_type)
+ # 24, 256
+ conv6 = B.conv(base_nc*4, base_nc*8, kernel_size=3, stride=1, mode='C'+ac_type)
+ conv7 = B.conv(base_nc*8, base_nc*8, kernel_size=4, stride=2, mode='C'+ac_type)
+ # 12, 512
+ conv8 = B.conv(base_nc*8, base_nc*8, kernel_size=3, stride=1, mode='C'+ac_type)
+ conv9 = B.conv(base_nc*8, base_nc*8, kernel_size=4, stride=2, mode='C'+ac_type)
+ # 6, 512
+ conv10 = B.conv(base_nc*8, base_nc*8, kernel_size=3, stride=1, mode='C'+ac_type)
+ conv11 = B.conv(base_nc*8, base_nc*8, kernel_size=4, stride=2, mode='C'+ac_type)
+ # 3, 512
+ self.features = B.sequential(conv0, conv1, conv2, conv3, conv4, conv5,
+ conv6, conv7, conv8, conv9, conv10, conv11)
+
+ # classifier
+ self.classifier = nn.Sequential(nn.Linear(512 * 3 * 3, 100),
+ nn.LeakyReLU(0.2, True),
+ nn.Linear(100, 1))
+
+ def forward(self, x):
+ x = self.features(x)
+ x = x.view(x.size(0), -1)
+ x = self.classifier(x)
+ return x
+
+
+# --------------------------------------------
+# SN-VGG style Discriminator with 128x128 input
+# --------------------------------------------
+class Discriminator_VGG_128_SN(nn.Module):
+ def __init__(self):
+ super(Discriminator_VGG_128_SN, self).__init__()
+ # features
+ # hxw, c
+ # 128, 64
+ self.lrelu = nn.LeakyReLU(0.2, True)
+
+ self.conv0 = spectral_norm(nn.Conv2d(3, 64, 3, 1, 1))
+ self.conv1 = spectral_norm(nn.Conv2d(64, 64, 4, 2, 1))
+ # 64, 64
+ self.conv2 = spectral_norm(nn.Conv2d(64, 128, 3, 1, 1))
+ self.conv3 = spectral_norm(nn.Conv2d(128, 128, 4, 2, 1))
+ # 32, 128
+ self.conv4 = spectral_norm(nn.Conv2d(128, 256, 3, 1, 1))
+ self.conv5 = spectral_norm(nn.Conv2d(256, 256, 4, 2, 1))
+ # 16, 256
+ self.conv6 = spectral_norm(nn.Conv2d(256, 512, 3, 1, 1))
+ self.conv7 = spectral_norm(nn.Conv2d(512, 512, 4, 2, 1))
+ # 8, 512
+ self.conv8 = spectral_norm(nn.Conv2d(512, 512, 3, 1, 1))
+ self.conv9 = spectral_norm(nn.Conv2d(512, 512, 4, 2, 1))
+ # 4, 512
+
+ # classifier
+ self.linear0 = spectral_norm(nn.Linear(512 * 4 * 4, 100))
+ self.linear1 = spectral_norm(nn.Linear(100, 1))
+
+ def forward(self, x):
+ x = self.lrelu(self.conv0(x))
+ x = self.lrelu(self.conv1(x))
+ x = self.lrelu(self.conv2(x))
+ x = self.lrelu(self.conv3(x))
+ x = self.lrelu(self.conv4(x))
+ x = self.lrelu(self.conv5(x))
+ x = self.lrelu(self.conv6(x))
+ x = self.lrelu(self.conv7(x))
+ x = self.lrelu(self.conv8(x))
+ x = self.lrelu(self.conv9(x))
+ x = x.view(x.size(0), -1)
+ x = self.lrelu(self.linear0(x))
+ x = self.linear1(x)
+ return x
+
+
+if __name__ == '__main__':
+
+ x = torch.rand(1, 3, 96, 96)
+ net = Discriminator_VGG_96()
+ net.eval()
+ with torch.no_grad():
+ y = net(x)
+ print(y.size())
+
+ x = torch.rand(1, 3, 128, 128)
+ net = Discriminator_VGG_128()
+ net.eval()
+ with torch.no_grad():
+ y = net(x)
+ print(y.size())
+
+ x = torch.rand(1, 3, 192, 192)
+ net = Discriminator_VGG_192()
+ net.eval()
+ with torch.no_grad():
+ y = net(x)
+ print(y.size())
+
+ x = torch.rand(1, 3, 128, 128)
+ net = Discriminator_VGG_128_SN()
+ net.eval()
+ with torch.no_grad():
+ y = net(x)
+ print(y.size())
+
+ # run models/network_discriminator.py
diff --git a/KAIR/models/network_dncnn.py b/KAIR/models/network_dncnn.py
new file mode 100644
index 0000000000000000000000000000000000000000..7a3f20f65d5e76c5bc187563e21cb34d04a426e8
--- /dev/null
+++ b/KAIR/models/network_dncnn.py
@@ -0,0 +1,169 @@
+
+import torch.nn as nn
+import models.basicblock as B
+
+
+"""
+# --------------------------------------------
+# DnCNN (20 conv layers)
+# FDnCNN (20 conv layers)
+# IRCNN (7 conv layers)
+# --------------------------------------------
+# References:
+@article{zhang2017beyond,
+ title={Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising},
+ author={Zhang, Kai and Zuo, Wangmeng and Chen, Yunjin and Meng, Deyu and Zhang, Lei},
+ journal={IEEE Transactions on Image Processing},
+ volume={26},
+ number={7},
+ pages={3142--3155},
+ year={2017},
+ publisher={IEEE}
+}
+@article{zhang2018ffdnet,
+ title={FFDNet: Toward a fast and flexible solution for CNN-based image denoising},
+ author={Zhang, Kai and Zuo, Wangmeng and Zhang, Lei},
+ journal={IEEE Transactions on Image Processing},
+ volume={27},
+ number={9},
+ pages={4608--4622},
+ year={2018},
+ publisher={IEEE}
+}
+# --------------------------------------------
+"""
+
+
+# --------------------------------------------
+# DnCNN
+# --------------------------------------------
+class DnCNN(nn.Module):
+ def __init__(self, in_nc=1, out_nc=1, nc=64, nb=17, act_mode='BR'):
+ """
+ # ------------------------------------
+ in_nc: channel number of input
+ out_nc: channel number of output
+ nc: channel number
+ nb: total number of conv layers
+ act_mode: batch norm + activation function; 'BR' means BN+ReLU.
+ # ------------------------------------
+ Batch normalization and residual learning are
+ beneficial to Gaussian denoising (especially
+ for a single noise level).
+ The residual of a noisy image corrupted by additive white
+ Gaussian noise (AWGN) follows a constant
+ Gaussian distribution which stablizes batch
+ normalization during training.
+ # ------------------------------------
+ """
+ super(DnCNN, self).__init__()
+ assert 'R' in act_mode or 'L' in act_mode, 'Examples of activation function: R, L, BR, BL, IR, IL'
+ bias = True
+
+ m_head = B.conv(in_nc, nc, mode='C'+act_mode[-1], bias=bias)
+ m_body = [B.conv(nc, nc, mode='C'+act_mode, bias=bias) for _ in range(nb-2)]
+ m_tail = B.conv(nc, out_nc, mode='C', bias=bias)
+
+ self.model = B.sequential(m_head, *m_body, m_tail)
+
+ def forward(self, x):
+ n = self.model(x)
+ return x-n
+
+
+# --------------------------------------------
+# IRCNN denoiser
+# --------------------------------------------
+class IRCNN(nn.Module):
+ def __init__(self, in_nc=1, out_nc=1, nc=64):
+ """
+ # ------------------------------------
+ denoiser of IRCNN
+ in_nc: channel number of input
+ out_nc: channel number of output
+ nc: channel number
+ nb: total number of conv layers
+ act_mode: batch norm + activation function; 'BR' means BN+ReLU.
+ # ------------------------------------
+ Batch normalization and residual learning are
+ beneficial to Gaussian denoising (especially
+ for a single noise level).
+ The residual of a noisy image corrupted by additive white
+ Gaussian noise (AWGN) follows a constant
+ Gaussian distribution which stablizes batch
+ normalization during training.
+ # ------------------------------------
+ """
+ super(IRCNN, self).__init__()
+ L =[]
+ L.append(nn.Conv2d(in_channels=in_nc, out_channels=nc, kernel_size=3, stride=1, padding=1, dilation=1, bias=True))
+ L.append(nn.ReLU(inplace=True))
+ L.append(nn.Conv2d(in_channels=nc, out_channels=nc, kernel_size=3, stride=1, padding=2, dilation=2, bias=True))
+ L.append(nn.ReLU(inplace=True))
+ L.append(nn.Conv2d(in_channels=nc, out_channels=nc, kernel_size=3, stride=1, padding=3, dilation=3, bias=True))
+ L.append(nn.ReLU(inplace=True))
+ L.append(nn.Conv2d(in_channels=nc, out_channels=nc, kernel_size=3, stride=1, padding=4, dilation=4, bias=True))
+ L.append(nn.ReLU(inplace=True))
+ L.append(nn.Conv2d(in_channels=nc, out_channels=nc, kernel_size=3, stride=1, padding=3, dilation=3, bias=True))
+ L.append(nn.ReLU(inplace=True))
+ L.append(nn.Conv2d(in_channels=nc, out_channels=nc, kernel_size=3, stride=1, padding=2, dilation=2, bias=True))
+ L.append(nn.ReLU(inplace=True))
+ L.append(nn.Conv2d(in_channels=nc, out_channels=out_nc, kernel_size=3, stride=1, padding=1, dilation=1, bias=True))
+ self.model = B.sequential(*L)
+
+ def forward(self, x):
+ n = self.model(x)
+ return x-n
+
+
+# --------------------------------------------
+# FDnCNN
+# --------------------------------------------
+# Compared with DnCNN, FDnCNN has three modifications:
+# 1) add noise level map as input
+# 2) remove residual learning and BN
+# 3) train with L1 loss
+# may need more training time, but will not reduce the final PSNR too much.
+# --------------------------------------------
+class FDnCNN(nn.Module):
+ def __init__(self, in_nc=2, out_nc=1, nc=64, nb=20, act_mode='R'):
+ """
+ in_nc: channel number of input
+ out_nc: channel number of output
+ nc: channel number
+ nb: total number of conv layers
+ act_mode: batch norm + activation function; 'BR' means BN+ReLU.
+ """
+ super(FDnCNN, self).__init__()
+ assert 'R' in act_mode or 'L' in act_mode, 'Examples of activation function: R, L, BR, BL, IR, IL'
+ bias = True
+
+ m_head = B.conv(in_nc, nc, mode='C'+act_mode[-1], bias=bias)
+ m_body = [B.conv(nc, nc, mode='C'+act_mode, bias=bias) for _ in range(nb-2)]
+ m_tail = B.conv(nc, out_nc, mode='C', bias=bias)
+
+ self.model = B.sequential(m_head, *m_body, m_tail)
+
+ def forward(self, x):
+ x = self.model(x)
+ return x
+
+
+if __name__ == '__main__':
+ from utils import utils_model
+ import torch
+ model1 = DnCNN(in_nc=1, out_nc=1, nc=64, nb=20, act_mode='BR')
+ print(utils_model.describe_model(model1))
+
+ model2 = FDnCNN(in_nc=2, out_nc=1, nc=64, nb=20, act_mode='R')
+ print(utils_model.describe_model(model2))
+
+ x = torch.randn((1, 1, 240, 240))
+ x1 = model1(x)
+ print(x1.shape)
+
+ x = torch.randn((1, 2, 240, 240))
+ x2 = model2(x)
+ print(x2.shape)
+
+ # run models/network_dncnn.py
diff --git a/KAIR/models/network_dpsr.py b/KAIR/models/network_dpsr.py
new file mode 100644
index 0000000000000000000000000000000000000000..3099c27a88007cbf5fe026b75bc7d299d690e186
--- /dev/null
+++ b/KAIR/models/network_dpsr.py
@@ -0,0 +1,112 @@
+import math
+import torch.nn as nn
+import models.basicblock as B
+
+
+"""
+# --------------------------------------------
+# modified SRResNet
+# -- MSRResNet_prior (for DPSR)
+# --------------------------------------------
+References:
+@inproceedings{zhang2019deep,
+ title={Deep Plug-and-Play Super-Resolution for Arbitrary Blur Kernels},
+ author={Zhang, Kai and Zuo, Wangmeng and Zhang, Lei},
+ booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
+ pages={1671--1681},
+ year={2019}
+}
+@inproceedings{wang2018esrgan,
+ title={Esrgan: Enhanced super-resolution generative adversarial networks},
+ author={Wang, Xintao and Yu, Ke and Wu, Shixiang and Gu, Jinjin and Liu, Yihao and Dong, Chao and Qiao, Yu and Change Loy, Chen},
+ booktitle={European Conference on Computer Vision (ECCV)},
+ pages={0--0},
+ year={2018}
+}
+@inproceedings{ledig2017photo,
+ title={Photo-realistic single image super-resolution using a generative adversarial network},
+ author={Ledig, Christian and Theis, Lucas and Husz{\'a}r, Ferenc and Caballero, Jose and Cunningham, Andrew and Acosta, Alejandro and Aitken, Andrew and Tejani, Alykhan and Totz, Johannes and Wang, Zehan and others},
+ booktitle={IEEE conference on computer vision and pattern recognition},
+ pages={4681--4690},
+ year={2017}
+}
+# --------------------------------------------
+"""
+
+
+# --------------------------------------------
+# MSRResNet super-resolver prior for DPSR
+# https://github.com/cszn/DPSR
+# https://github.com/cszn/DPSR/blob/master/models/network_srresnet.py
+# --------------------------------------------
+class MSRResNet_prior(nn.Module):
+ def __init__(self, in_nc=4, out_nc=3, nc=96, nb=16, upscale=4, act_mode='R', upsample_mode='upconv'):
+ super(MSRResNet_prior, self).__init__()
+ n_upscale = int(math.log(upscale, 2))
+ if upscale == 3:
+ n_upscale = 1
+
+ m_head = B.conv(in_nc, nc, mode='C')
+
+ m_body = [B.ResBlock(nc, nc, mode='C'+act_mode+'C') for _ in range(nb)]
+ m_body.append(B.conv(nc, nc, mode='C'))
+
+ if upsample_mode == 'upconv':
+ upsample_block = B.upsample_upconv
+ elif upsample_mode == 'pixelshuffle':
+ upsample_block = B.upsample_pixelshuffle
+ elif upsample_mode == 'convtranspose':
+ upsample_block = B.upsample_convtranspose
+ else:
+ raise NotImplementedError('upsample mode [{:s}] is not found'.format(upsample_mode))
+ if upscale == 3:
+ m_uper = upsample_block(nc, nc, mode='3'+act_mode)
+ else:
+ m_uper = [upsample_block(nc, nc, mode='2'+act_mode) for _ in range(n_upscale)]
+
+ H_conv0 = B.conv(nc, nc, mode='C'+act_mode)
+ H_conv1 = B.conv(nc, out_nc, bias=False, mode='C')
+ m_tail = B.sequential(H_conv0, H_conv1)
+
+ self.model = B.sequential(m_head, B.ShortcutBlock(B.sequential(*m_body)), *m_uper, m_tail)
+
+ def forward(self, x):
+ x = self.model(x)
+ return x
+
+
+
+class SRResNet(nn.Module):
+ def __init__(self, in_nc=3, out_nc=3, nc=64, nb=16, upscale=4, act_mode='R', upsample_mode='upconv'):
+ super(SRResNet, self).__init__()
+ n_upscale = int(math.log(upscale, 2))
+ if upscale == 3:
+ n_upscale = 1
+
+ m_head = B.conv(in_nc, nc, mode='C')
+
+ m_body = [B.ResBlock(nc, nc, mode='C'+act_mode+'C') for _ in range(nb)]
+ m_body.append(B.conv(nc, nc, mode='C'))
+
+ if upsample_mode == 'upconv':
+ upsample_block = B.upsample_upconv
+ elif upsample_mode == 'pixelshuffle':
+ upsample_block = B.upsample_pixelshuffle
+ elif upsample_mode == 'convtranspose':
+ upsample_block = B.upsample_convtranspose
+ else:
+ raise NotImplementedError('upsample mode [{:s}] is not found'.format(upsample_mode))
+ if upscale == 3:
+ m_uper = upsample_block(nc, nc, mode='3'+act_mode)
+ else:
+ m_uper = [upsample_block(nc, nc, mode='2'+act_mode) for _ in range(n_upscale)]
+
+ H_conv0 = B.conv(nc, nc, mode='C'+act_mode)
+ H_conv1 = B.conv(nc, out_nc, bias=False, mode='C')
+ m_tail = B.sequential(H_conv0, H_conv1)
+
+ self.model = B.sequential(m_head, B.ShortcutBlock(B.sequential(*m_body)), *m_uper, m_tail)
+
+ def forward(self, x):
+ x = self.model(x)
+ return x
\ No newline at end of file
diff --git a/KAIR/models/network_faceenhancer.py b/KAIR/models/network_faceenhancer.py
new file mode 100644
index 0000000000000000000000000000000000000000..44df0eece0b219caef85e1c2a2c87f606332e273
--- /dev/null
+++ b/KAIR/models/network_faceenhancer.py
@@ -0,0 +1,687 @@
+'''
+@paper: GAN Prior Embedded Network for Blind Face Restoration in the Wild (CVPR2021)
+@author: yangxy (yangtao9009@gmail.com)
+# 2021-06-03, modified by Kai
+'''
+import sys
+op_path = 'models'
+if op_path not in sys.path:
+ sys.path.insert(0, op_path)
+from op import FusedLeakyReLU, fused_leaky_relu, upfirdn2d
+
+import math
+import random
+import numpy as np
+
+import torch
+from torch import nn
+from torch.nn import functional as F
+
+isconcat = True
+sss = 2 if isconcat else 1
+
+class PixelNorm(nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ def forward(self, input):
+ return input * torch.rsqrt(torch.mean(input ** 2, dim=1, keepdim=True) + 1e-8)
+
+
+def make_kernel(k):
+ k = torch.tensor(k, dtype=torch.float32)
+
+ if k.ndim == 1:
+ k = k[None, :] * k[:, None]
+
+ k /= k.sum()
+
+ return k
+
+
+class Upsample(nn.Module):
+ def __init__(self, kernel, factor=2):
+ super().__init__()
+
+ self.factor = factor
+ kernel = make_kernel(kernel) * (factor ** 2)
+ self.register_buffer('kernel', kernel)
+
+ p = kernel.shape[0] - factor
+
+ pad0 = (p + 1) // 2 + factor - 1
+ pad1 = p // 2
+
+ self.pad = (pad0, pad1)
+
+ def forward(self, input):
+ out = upfirdn2d(input, self.kernel, up=self.factor, down=1, pad=self.pad)
+
+ return out
+
+
+class Downsample(nn.Module):
+ def __init__(self, kernel, factor=2):
+ super().__init__()
+
+ self.factor = factor
+ kernel = make_kernel(kernel)
+ self.register_buffer('kernel', kernel)
+
+ p = kernel.shape[0] - factor
+
+ pad0 = (p + 1) // 2
+ pad1 = p // 2
+
+ self.pad = (pad0, pad1)
+
+ def forward(self, input):
+ out = upfirdn2d(input, self.kernel, up=1, down=self.factor, pad=self.pad)
+
+ return out
+
+
+class Blur(nn.Module):
+ def __init__(self, kernel, pad, upsample_factor=1):
+ super().__init__()
+
+ kernel = make_kernel(kernel)
+
+ if upsample_factor > 1:
+ kernel = kernel * (upsample_factor ** 2)
+
+ self.register_buffer('kernel', kernel)
+
+ self.pad = pad
+
+ def forward(self, input):
+ out = upfirdn2d(input, self.kernel, pad=self.pad)
+
+ return out
+
+
+class EqualConv2d(nn.Module):
+ def __init__(
+ self, in_channel, out_channel, kernel_size, stride=1, padding=0, bias=True
+ ):
+ super().__init__()
+
+ self.weight = nn.Parameter(
+ torch.randn(out_channel, in_channel, kernel_size, kernel_size)
+ )
+ self.scale = 1 / math.sqrt(in_channel * kernel_size ** 2)
+
+ self.stride = stride
+ self.padding = padding
+
+ if bias:
+ self.bias = nn.Parameter(torch.zeros(out_channel))
+
+ else:
+ self.bias = None
+
+ def forward(self, input):
+ out = F.conv2d(
+ input,
+ self.weight * self.scale,
+ bias=self.bias,
+ stride=self.stride,
+ padding=self.padding,
+ )
+
+ return out
+
+ def __repr__(self):
+ return (
+ f'{self.__class__.__name__}({self.weight.shape[1]}, {self.weight.shape[0]},'
+ f' {self.weight.shape[2]}, stride={self.stride}, padding={self.padding})'
+ )
+
+
+class EqualLinear(nn.Module):
+ def __init__(
+ self, in_dim, out_dim, bias=True, bias_init=0, lr_mul=1, activation=None
+ ):
+ super().__init__()
+
+ self.weight = nn.Parameter(torch.randn(out_dim, in_dim).div_(lr_mul))
+
+ if bias:
+ self.bias = nn.Parameter(torch.zeros(out_dim).fill_(bias_init))
+
+ else:
+ self.bias = None
+
+ self.activation = activation
+
+ self.scale = (1 / math.sqrt(in_dim)) * lr_mul
+ self.lr_mul = lr_mul
+
+ def forward(self, input):
+ if self.activation:
+ out = F.linear(input, self.weight * self.scale)
+ out = fused_leaky_relu(out, self.bias * self.lr_mul)
+
+ else:
+ out = F.linear(input, self.weight * self.scale, bias=self.bias * self.lr_mul)
+
+ return out
+
+ def __repr__(self):
+ return (
+ f'{self.__class__.__name__}({self.weight.shape[1]}, {self.weight.shape[0]})'
+ )
+
+
+class ScaledLeakyReLU(nn.Module):
+ def __init__(self, negative_slope=0.2):
+ super().__init__()
+
+ self.negative_slope = negative_slope
+
+ def forward(self, input):
+ out = F.leaky_relu(input, negative_slope=self.negative_slope)
+
+ return out * math.sqrt(2)
+
+
+class ModulatedConv2d(nn.Module):
+ def __init__(
+ self,
+ in_channel,
+ out_channel,
+ kernel_size,
+ style_dim,
+ demodulate=True,
+ upsample=False,
+ downsample=False,
+ blur_kernel=[1, 3, 3, 1],
+ ):
+ super().__init__()
+
+ self.eps = 1e-8
+ self.kernel_size = kernel_size
+ self.in_channel = in_channel
+ self.out_channel = out_channel
+ self.upsample = upsample
+ self.downsample = downsample
+
+ if upsample:
+ factor = 2
+ p = (len(blur_kernel) - factor) - (kernel_size - 1)
+ pad0 = (p + 1) // 2 + factor - 1
+ pad1 = p // 2 + 1
+
+ self.blur = Blur(blur_kernel, pad=(pad0, pad1), upsample_factor=factor)
+
+ if downsample:
+ factor = 2
+ p = (len(blur_kernel) - factor) + (kernel_size - 1)
+ pad0 = (p + 1) // 2
+ pad1 = p // 2
+
+ self.blur = Blur(blur_kernel, pad=(pad0, pad1))
+
+ fan_in = in_channel * kernel_size ** 2
+ self.scale = 1 / math.sqrt(fan_in)
+ self.padding = kernel_size // 2
+
+ self.weight = nn.Parameter(
+ torch.randn(1, out_channel, in_channel, kernel_size, kernel_size)
+ )
+
+ self.modulation = EqualLinear(style_dim, in_channel, bias_init=1)
+
+ self.demodulate = demodulate
+
+ def __repr__(self):
+ return (
+ f'{self.__class__.__name__}({self.in_channel}, {self.out_channel}, {self.kernel_size}, '
+ f'upsample={self.upsample}, downsample={self.downsample})'
+ )
+
+ def forward(self, input, style):
+ batch, in_channel, height, width = input.shape
+
+ style = self.modulation(style).view(batch, 1, in_channel, 1, 1)
+ weight = self.scale * self.weight * style
+
+ if self.demodulate:
+ demod = torch.rsqrt(weight.pow(2).sum([2, 3, 4]) + 1e-8)
+ weight = weight * demod.view(batch, self.out_channel, 1, 1, 1)
+
+ weight = weight.view(
+ batch * self.out_channel, in_channel, self.kernel_size, self.kernel_size
+ )
+
+ if self.upsample:
+ input = input.view(1, batch * in_channel, height, width)
+ weight = weight.view(
+ batch, self.out_channel, in_channel, self.kernel_size, self.kernel_size
+ )
+ weight = weight.transpose(1, 2).reshape(
+ batch * in_channel, self.out_channel, self.kernel_size, self.kernel_size
+ )
+ out = F.conv_transpose2d(input, weight, padding=0, stride=2, groups=batch)
+ _, _, height, width = out.shape
+ out = out.view(batch, self.out_channel, height, width)
+ out = self.blur(out)
+
+ elif self.downsample:
+ input = self.blur(input)
+ _, _, height, width = input.shape
+ input = input.view(1, batch * in_channel, height, width)
+ out = F.conv2d(input, weight, padding=0, stride=2, groups=batch)
+ _, _, height, width = out.shape
+ out = out.view(batch, self.out_channel, height, width)
+
+ else:
+ input = input.view(1, batch * in_channel, height, width)
+ out = F.conv2d(input, weight, padding=self.padding, groups=batch)
+ _, _, height, width = out.shape
+ out = out.view(batch, self.out_channel, height, width)
+
+ return out
+
+
+class NoiseInjection(nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ self.weight = nn.Parameter(torch.zeros(1))
+
+ def forward(self, image, noise=None):
+
+ if noise is not None:
+ #print(image.shape, noise.shape)
+ if isconcat: return torch.cat((image, self.weight * noise), dim=1) # concat
+ return image + self.weight * noise
+
+ if noise is None:
+ batch, _, height, width = image.shape
+ noise = image.new_empty(batch, 1, height, width).normal_()
+
+ return image + self.weight * noise
+ #return torch.cat((image, self.weight * noise), dim=1)
+
+
+class ConstantInput(nn.Module):
+ def __init__(self, channel, size=4):
+ super().__init__()
+
+ self.input = nn.Parameter(torch.randn(1, channel, size, size))
+
+ def forward(self, input):
+ batch = input.shape[0]
+ out = self.input.repeat(batch, 1, 1, 1)
+
+ return out
+
+
+class StyledConv(nn.Module):
+ def __init__(
+ self,
+ in_channel,
+ out_channel,
+ kernel_size,
+ style_dim,
+ upsample=False,
+ blur_kernel=[1, 3, 3, 1],
+ demodulate=True,
+ ):
+ super().__init__()
+
+ self.conv = ModulatedConv2d(
+ in_channel,
+ out_channel,
+ kernel_size,
+ style_dim,
+ upsample=upsample,
+ blur_kernel=blur_kernel,
+ demodulate=demodulate,
+ )
+
+ self.noise = NoiseInjection()
+ #self.bias = nn.Parameter(torch.zeros(1, out_channel, 1, 1))
+ #self.activate = ScaledLeakyReLU(0.2)
+ self.activate = FusedLeakyReLU(out_channel*sss)
+
+ def forward(self, input, style, noise=None):
+ out = self.conv(input, style)
+ out = self.noise(out, noise=noise)
+ # out = out + self.bias
+ out = self.activate(out)
+
+ return out
+
+
+class ToRGB(nn.Module):
+ def __init__(self, in_channel, style_dim, upsample=True, blur_kernel=[1, 3, 3, 1]):
+ super().__init__()
+
+ if upsample:
+ self.upsample = Upsample(blur_kernel)
+
+ self.conv = ModulatedConv2d(in_channel, 3, 1, style_dim, demodulate=False)
+ self.bias = nn.Parameter(torch.zeros(1, 3, 1, 1))
+
+ def forward(self, input, style, skip=None):
+ out = self.conv(input, style)
+ out = out + self.bias
+
+ if skip is not None:
+ skip = self.upsample(skip)
+
+ out = out + skip
+
+ return out
+
+class Generator(nn.Module):
+ def __init__(
+ self,
+ size,
+ style_dim,
+ n_mlp,
+ channel_multiplier=2,
+ blur_kernel=[1, 3, 3, 1],
+ lr_mlp=0.01,
+ ):
+ super().__init__()
+
+ self.size = size
+ self.n_mlp = n_mlp
+ self.style_dim = style_dim
+
+ layers = [PixelNorm()]
+
+ for i in range(n_mlp):
+ layers.append(
+ EqualLinear(
+ style_dim, style_dim, lr_mul=lr_mlp, activation='fused_lrelu'
+ )
+ )
+
+ self.style = nn.Sequential(*layers)
+
+ self.channels = {
+ 4: 512,
+ 8: 512,
+ 16: 512,
+ 32: 512,
+ 64: 256 * channel_multiplier,
+ 128: 128 * channel_multiplier,
+ 256: 64 * channel_multiplier,
+ 512: 32 * channel_multiplier,
+ 1024: 16 * channel_multiplier,
+ }
+
+ self.input = ConstantInput(self.channels[4])
+ self.conv1 = StyledConv(
+ self.channels[4], self.channels[4], 3, style_dim, blur_kernel=blur_kernel
+ )
+ self.to_rgb1 = ToRGB(self.channels[4]*sss, style_dim, upsample=False)
+
+ self.log_size = int(math.log(size, 2))
+
+ self.convs = nn.ModuleList()
+ self.upsamples = nn.ModuleList()
+ self.to_rgbs = nn.ModuleList()
+
+ in_channel = self.channels[4]
+
+ for i in range(3, self.log_size + 1):
+ out_channel = self.channels[2 ** i]
+
+ self.convs.append(
+ StyledConv(
+ in_channel*sss,
+ out_channel,
+ 3,
+ style_dim,
+ upsample=True,
+ blur_kernel=blur_kernel,
+ )
+ )
+
+ self.convs.append(
+ StyledConv(
+ out_channel*sss, out_channel, 3, style_dim, blur_kernel=blur_kernel
+ )
+ )
+
+ self.to_rgbs.append(ToRGB(out_channel*sss, style_dim))
+
+ in_channel = out_channel
+
+ self.n_latent = self.log_size * 2 - 2
+
+ def make_noise(self):
+ device = self.input.input.device
+
+ noises = [torch.randn(1, 1, 2 ** 2, 2 ** 2, device=device)]
+
+ for i in range(3, self.log_size + 1):
+ for _ in range(2):
+ noises.append(torch.randn(1, 1, 2 ** i, 2 ** i, device=device))
+
+ return noises
+
+ def mean_latent(self, n_latent):
+ latent_in = torch.randn(
+ n_latent, self.style_dim, device=self.input.input.device
+ )
+ latent = self.style(latent_in).mean(0, keepdim=True)
+
+ return latent
+
+ def get_latent(self, input):
+ return self.style(input)
+
+ def forward(
+ self,
+ styles,
+ return_latents=False,
+ inject_index=None,
+ truncation=1,
+ truncation_latent=None,
+ input_is_latent=False,
+ noise=None,
+ ):
+ if not input_is_latent:
+ styles = [self.style(s) for s in styles]
+
+ if noise is None:
+ '''
+ noise = [None] * (2 * (self.log_size - 2) + 1)
+ '''
+ noise = []
+ batch = styles[0].shape[0]
+ for i in range(self.n_mlp + 1):
+ size = 2 ** (i+2)
+ noise.append(torch.randn(batch, self.channels[size], size, size, device=styles[0].device))
+ #print(self.channels[size], size)
+
+ if truncation < 1:
+ style_t = []
+
+ for style in styles:
+ style_t.append(
+ truncation_latent + truncation * (style - truncation_latent)
+ )
+
+ styles = style_t
+
+ if len(styles) < 2:
+ inject_index = self.n_latent
+
+ latent = styles[0].unsqueeze(1).repeat(1, inject_index, 1)
+
+ else:
+ if inject_index is None:
+ inject_index = random.randint(1, self.n_latent - 1)
+
+ latent = styles[0].unsqueeze(1).repeat(1, inject_index, 1)
+ latent2 = styles[1].unsqueeze(1).repeat(1, self.n_latent - inject_index, 1)
+
+ latent = torch.cat([latent, latent2], 1)
+
+ out = self.input(latent)
+ out = self.conv1(out, latent[:, 0], noise=noise[0])
+
+ skip = self.to_rgb1(out, latent[:, 1])
+
+ i = 1
+ noise_i = 1
+
+ outs = []
+ for conv1, conv2, to_rgb in zip(
+ self.convs[::2], self.convs[1::2], self.to_rgbs
+ ):
+ #print(out.shape, noise[(noise_i)//2].shape, noise[(noise_i + 1)//2].shape)
+ out = conv1(out, latent[:, i], noise=noise[(noise_i + 1)//2]) ### 1 for 2
+ out = conv2(out, latent[:, i + 1], noise=noise[(noise_i + 2)//2]) ### 1 for 2
+ skip = to_rgb(out, latent[:, i + 2], skip)
+ #outs.append(skip.clone())
+
+ i += 2
+ noise_i += 2
+
+ image = skip
+
+ if return_latents:
+ return image, latent
+
+ else:
+ return image, None
+
+class ConvLayer(nn.Sequential):
+ def __init__(
+ self,
+ in_channel,
+ out_channel,
+ kernel_size,
+ downsample=False,
+ blur_kernel=[1, 3, 3, 1],
+ bias=True,
+ activate=True,
+ ):
+ layers = []
+
+ if downsample:
+ factor = 2
+ p = (len(blur_kernel) - factor) + (kernel_size - 1)
+ pad0 = (p + 1) // 2
+ pad1 = p // 2
+
+ layers.append(Blur(blur_kernel, pad=(pad0, pad1)))
+
+ stride = 2
+ self.padding = 0
+
+ else:
+ stride = 1
+ self.padding = kernel_size // 2
+
+ layers.append(
+ EqualConv2d(
+ in_channel,
+ out_channel,
+ kernel_size,
+ padding=self.padding,
+ stride=stride,
+ bias=bias and not activate,
+ )
+ )
+
+ if activate:
+ if bias:
+ layers.append(FusedLeakyReLU(out_channel))
+
+ else:
+ layers.append(ScaledLeakyReLU(0.2))
+
+ super().__init__(*layers)
+
+
+class ResBlock(nn.Module):
+ def __init__(self, in_channel, out_channel, blur_kernel=[1, 3, 3, 1]):
+ super().__init__()
+
+ self.conv1 = ConvLayer(in_channel, in_channel, 3)
+ self.conv2 = ConvLayer(in_channel, out_channel, 3, downsample=True)
+
+ self.skip = ConvLayer(
+ in_channel, out_channel, 1, downsample=True, activate=False, bias=False
+ )
+
+ def forward(self, input):
+ out = self.conv1(input)
+ out = self.conv2(out)
+
+ skip = self.skip(input)
+ out = (out + skip) / math.sqrt(2)
+
+ return out
+
+
+# -----------------------------
+# Main model
+# -----------------------------
+class FullGenerator(nn.Module):
+ def __init__(
+ self,
+ size,
+ style_dim,
+ n_mlp,
+ channel_multiplier=2,
+ blur_kernel=[1, 3, 3, 1],
+ lr_mlp=0.01,
+ ):
+ super().__init__()
+ channels = {
+ 4: 512,
+ 8: 512,
+ 16: 512,
+ 32: 512,
+ 64: 256 * channel_multiplier,
+ 128: 128 * channel_multiplier,
+ 256: 64 * channel_multiplier,
+ 512: 32 * channel_multiplier,
+ 1024: 16 * channel_multiplier,
+ }
+
+ self.log_size = int(math.log(size, 2))
+ self.generator = Generator(size, style_dim, n_mlp, channel_multiplier=channel_multiplier, blur_kernel=blur_kernel, lr_mlp=lr_mlp)
+
+ conv = [ConvLayer(3, channels[size], 1)]
+ self.ecd0 = nn.Sequential(*conv)
+ in_channel = channels[size]
+
+ self.names = ['ecd%d'%i for i in range(self.log_size-1)]
+ for i in range(self.log_size, 2, -1):
+ out_channel = channels[2 ** (i - 1)]
+ #conv = [ResBlock(in_channel, out_channel, blur_kernel)]
+ conv = [ConvLayer(in_channel, out_channel, 3, downsample=True)]
+ setattr(self, self.names[self.log_size-i+1], nn.Sequential(*conv))
+ in_channel = out_channel
+ self.final_linear = nn.Sequential(EqualLinear(channels[4] * 4 * 4, style_dim, activation='fused_lrelu'))
+
+ def forward(self,
+ inputs,
+ return_latents=False,
+ inject_index=None,
+ truncation=1,
+ truncation_latent=None,
+ input_is_latent=False,
+ ):
+ noise = []
+ for i in range(self.log_size-1):
+ ecd = getattr(self, self.names[i])
+ inputs = ecd(inputs)
+ noise.append(inputs)
+ #print(inputs.shape)
+ inputs = inputs.view(inputs.shape[0], -1)
+ outs = self.final_linear(inputs)
+ #print(outs.shape)
+ outs = self.generator([outs], return_latents, inject_index, truncation, truncation_latent, input_is_latent, noise=noise[::-1])
+ return outs
diff --git a/KAIR/models/network_feature.py b/KAIR/models/network_feature.py
new file mode 100644
index 0000000000000000000000000000000000000000..977f0b57558c7e385801597255033cc669ae7b65
--- /dev/null
+++ b/KAIR/models/network_feature.py
@@ -0,0 +1,46 @@
+import torch
+import torch.nn as nn
+import torchvision
+
+
+"""
+# --------------------------------------------
+# VGG Feature Extractor
+# --------------------------------------------
+"""
+
+# --------------------------------------------
+# VGG features
+# Assume input range is [0, 1]
+# --------------------------------------------
+class VGGFeatureExtractor(nn.Module):
+ def __init__(self,
+ feature_layer=34,
+ use_bn=False,
+ use_input_norm=True,
+ device=torch.device('cpu')):
+ super(VGGFeatureExtractor, self).__init__()
+ if use_bn:
+ model = torchvision.models.vgg19_bn(pretrained=True)
+ else:
+ model = torchvision.models.vgg19(pretrained=True)
+ self.use_input_norm = use_input_norm
+ if self.use_input_norm:
+ mean = torch.Tensor([0.485, 0.456, 0.406]).view(1, 3, 1, 1).to(device)
+ # [0.485-1, 0.456-1, 0.406-1] if input in range [-1,1]
+ std = torch.Tensor([0.229, 0.224, 0.225]).view(1, 3, 1, 1).to(device)
+ # [0.229*2, 0.224*2, 0.225*2] if input in range [-1,1]
+ self.register_buffer('mean', mean)
+ self.register_buffer('std', std)
+ self.features = nn.Sequential(*list(model.features.children())[:(feature_layer + 1)])
+ # No need to BP to variable
+ for k, v in self.features.named_parameters():
+ v.requires_grad = False
+
+ def forward(self, x):
+ if self.use_input_norm:
+ x = (x - self.mean) / self.std
+ output = self.features(x)
+ return output
+
+
diff --git a/KAIR/models/network_ffdnet.py b/KAIR/models/network_ffdnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..de2ce575cf309af05f1b5f30942e93a1fdf38e7d
--- /dev/null
+++ b/KAIR/models/network_ffdnet.py
@@ -0,0 +1,84 @@
+import numpy as np
+import torch.nn as nn
+import models.basicblock as B
+import torch
+
+"""
+# --------------------------------------------
+# FFDNet (15 or 12 conv layers)
+# --------------------------------------------
+Reference:
+@article{zhang2018ffdnet,
+ title={FFDNet: Toward a fast and flexible solution for CNN-based image denoising},
+ author={Zhang, Kai and Zuo, Wangmeng and Zhang, Lei},
+ journal={IEEE Transactions on Image Processing},
+ volume={27},
+ number={9},
+ pages={4608--4622},
+ year={2018},
+ publisher={IEEE}
+}
+"""
+
+
+# --------------------------------------------
+# FFDNet
+# --------------------------------------------
+class FFDNet(nn.Module):
+ def __init__(self, in_nc=1, out_nc=1, nc=64, nb=15, act_mode='R'):
+ """
+ # ------------------------------------
+ in_nc: channel number of input
+ out_nc: channel number of output
+ nc: channel number
+ nb: total number of conv layers
+ act_mode: batch norm + activation function; 'BR' means BN+ReLU.
+ # ------------------------------------
+ # ------------------------------------
+ """
+ super(FFDNet, self).__init__()
+ assert 'R' in act_mode or 'L' in act_mode, 'Examples of activation function: R, L, BR, BL, IR, IL'
+ bias = True
+ sf = 2
+
+ self.m_down = B.PixelUnShuffle(upscale_factor=sf)
+
+ m_head = B.conv(in_nc*sf*sf+1, nc, mode='C'+act_mode[-1], bias=bias)
+ m_body = [B.conv(nc, nc, mode='C'+act_mode, bias=bias) for _ in range(nb-2)]
+ m_tail = B.conv(nc, out_nc*sf*sf, mode='C', bias=bias)
+
+ self.model = B.sequential(m_head, *m_body, m_tail)
+
+ self.m_up = nn.PixelShuffle(upscale_factor=sf)
+
+ def forward(self, x, sigma):
+
+ h, w = x.size()[-2:]
+ paddingBottom = int(np.ceil(h/2)*2-h)
+ paddingRight = int(np.ceil(w/2)*2-w)
+ x = torch.nn.ReplicationPad2d((0, paddingRight, 0, paddingBottom))(x)
+
+ x = self.m_down(x)
+ # m = torch.ones(sigma.size()[0], sigma.size()[1], x.size()[-2], x.size()[-1]).type_as(x).mul(sigma)
+ m = sigma.repeat(1, 1, x.size()[-2], x.size()[-1])
+ x = torch.cat((x, m), 1)
+ x = self.model(x)
+ x = self.m_up(x)
+
+ x = x[..., :h, :w]
+ return x
+
+
+if __name__ == '__main__':
+ from utils import utils_model
+ model = FFDNet(in_nc=1, out_nc=1, nc=64, nb=15, act_mode='R')
+ print(utils_model.describe_model(model))
+
+ x = torch.randn((2,1,240,240))
+ sigma = torch.randn(2,1,1,1)
+ x = model(x, sigma)
+ print(x.shape)
+
+ # run models/network_ffdnet.py
+
+
diff --git a/KAIR/models/network_imdn.py b/KAIR/models/network_imdn.py
new file mode 100644
index 0000000000000000000000000000000000000000..faf7e6167f6a521f799735c6d135b0654364997a
--- /dev/null
+++ b/KAIR/models/network_imdn.py
@@ -0,0 +1,66 @@
+import math
+import torch.nn as nn
+import models.basicblock as B
+
+
+"""
+# --------------------------------------------
+# simplified information multi-distillation
+# network (IMDN) for SR
+# --------------------------------------------
+References:
+@inproceedings{hui2019lightweight,
+ title={Lightweight Image Super-Resolution with Information Multi-distillation Network},
+ author={Hui, Zheng and Gao, Xinbo and Yang, Yunchu and Wang, Xiumei},
+ booktitle={Proceedings of the 27th ACM International Conference on Multimedia (ACM MM)},
+ pages={2024--2032},
+ year={2019}
+}
+@inproceedings{zhang2019aim,
+ title={AIM 2019 Challenge on Constrained Super-Resolution: Methods and Results},
+ author={Kai Zhang and Shuhang Gu and Radu Timofte and others},
+ booktitle={IEEE International Conference on Computer Vision Workshops},
+ year={2019}
+}
+# --------------------------------------------
+"""
+
+
+# --------------------------------------------
+# modified version, https://github.com/Zheng222/IMDN
+# first place solution for AIM 2019 challenge
+# --------------------------------------------
+class IMDN(nn.Module):
+ def __init__(self, in_nc=3, out_nc=3, nc=64, nb=8, upscale=4, act_mode='L', upsample_mode='pixelshuffle', negative_slope=0.05):
+ """
+ in_nc: channel number of input
+ out_nc: channel number of output
+ nc: channel number
+ nb: number of residual blocks
+ upscale: up-scale factor
+ act_mode: activation function
+ upsample_mode: 'upconv' | 'pixelshuffle' | 'convtranspose'
+ """
+ super(IMDN, self).__init__()
+ assert 'R' in act_mode or 'L' in act_mode, 'Examples of activation function: R, L, BR, BL, IR, IL'
+
+ m_head = B.conv(in_nc, nc, mode='C')
+ m_body = [B.IMDBlock(nc, nc, mode='C'+act_mode, negative_slope=negative_slope) for _ in range(nb)]
+ m_body.append(B.conv(nc, nc, mode='C'))
+
+ if upsample_mode == 'upconv':
+ upsample_block = B.upsample_upconv
+ elif upsample_mode == 'pixelshuffle':
+ upsample_block = B.upsample_pixelshuffle
+ elif upsample_mode == 'convtranspose':
+ upsample_block = B.upsample_convtranspose
+ else:
+ raise NotImplementedError('upsample mode [{:s}] is not found'.format(upsample_mode))
+
+ m_uper = upsample_block(nc, out_nc, mode=str(upscale))
+
+ self.model = B.sequential(m_head, B.ShortcutBlock(B.sequential(*m_body)), *m_uper)
+
+ def forward(self, x):
+ x = self.model(x)
+ return x
diff --git a/KAIR/models/network_msrresnet.py b/KAIR/models/network_msrresnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..d5f7964b4dcf49b66d4c38eb90572b3474c32577
--- /dev/null
+++ b/KAIR/models/network_msrresnet.py
@@ -0,0 +1,182 @@
+import math
+import torch.nn as nn
+import models.basicblock as B
+import functools
+import torch.nn.functional as F
+import torch.nn.init as init
+
+
+"""
+# --------------------------------------------
+# modified SRResNet
+# -- MSRResNet0 (v0.0)
+# -- MSRResNet1 (v0.1)
+# --------------------------------------------
+References:
+@inproceedings{wang2018esrgan,
+ title={Esrgan: Enhanced super-resolution generative adversarial networks},
+ author={Wang, Xintao and Yu, Ke and Wu, Shixiang and Gu, Jinjin and Liu, Yihao and Dong, Chao and Qiao, Yu and Change Loy, Chen},
+ booktitle={European Concerence on Computer Vision (ECCV)},
+ pages={0--0},
+ year={2018}
+}
+@inproceedings{ledig2017photo,
+ title={Photo-realistic single image super-resolution using a generative adversarial network},
+ author={Ledig, Christian and Theis, Lucas and Husz{\'a}r, Ferenc and Caballero, Jose and Cunningham, Andrew and Acosta, Alejandro and Aitken, Andrew and Tejani, Alykhan and Totz, Johannes and Wang, Zehan and others},
+ booktitle={IEEE concerence on computer vision and pattern recognition},
+ pages={4681--4690},
+ year={2017}
+}
+# --------------------------------------------
+"""
+
+
+# --------------------------------------------
+# modified SRResNet v0.0
+# https://github.com/xinntao/ESRGAN
+# --------------------------------------------
+class MSRResNet0(nn.Module):
+ def __init__(self, in_nc=3, out_nc=3, nc=64, nb=16, upscale=4, act_mode='R', upsample_mode='upconv'):
+ """
+ in_nc: channel number of input
+ out_nc: channel number of output
+ nc: channel number
+ nb: number of residual blocks
+ upscale: up-scale factor
+ act_mode: activation function
+ upsample_mode: 'upconv' | 'pixelshuffle' | 'convtranspose'
+ """
+ super(MSRResNet0, self).__init__()
+ assert 'R' in act_mode or 'L' in act_mode, 'Examples of activation function: R, L, BR, BL, IR, IL'
+
+ n_upscale = int(math.log(upscale, 2))
+ if upscale == 3:
+ n_upscale = 1
+
+ m_head = B.conv(in_nc, nc, mode='C')
+
+ m_body = [B.ResBlock(nc, nc, mode='C'+act_mode+'C') for _ in range(nb)]
+ m_body.append(B.conv(nc, nc, mode='C'))
+
+ if upsample_mode == 'upconv':
+ upsample_block = B.upsample_upconv
+ elif upsample_mode == 'pixelshuffle':
+ upsample_block = B.upsample_pixelshuffle
+ elif upsample_mode == 'convtranspose':
+ upsample_block = B.upsample_convtranspose
+ else:
+ raise NotImplementedError('upsample mode [{:s}] is not found'.format(upsample_mode))
+ if upscale == 3:
+ m_uper = upsample_block(nc, nc, mode='3'+act_mode)
+ else:
+ m_uper = [upsample_block(nc, nc, mode='2'+act_mode) for _ in range(n_upscale)]
+
+ H_conv0 = B.conv(nc, nc, mode='C'+act_mode)
+ H_conv1 = B.conv(nc, out_nc, bias=False, mode='C')
+ m_tail = B.sequential(H_conv0, H_conv1)
+
+ self.model = B.sequential(m_head, B.ShortcutBlock(B.sequential(*m_body)), *m_uper, m_tail)
+
+ def forward(self, x):
+ x = self.model(x)
+ return x
+
+
+# --------------------------------------------
+# modified SRResNet v0.1
+# https://github.com/xinntao/ESRGAN
+# --------------------------------------------
+class MSRResNet1(nn.Module):
+ def __init__(self, in_nc=3, out_nc=3, nc=64, nb=16, upscale=4, act_mode='R', upsample_mode='upconv'):
+ super(MSRResNet1, self).__init__()
+ self.upscale = upscale
+
+ self.conv_first = nn.Conv2d(in_nc, nc, 3, 1, 1, bias=True)
+ basic_block = functools.partial(ResidualBlock_noBN, nc=nc)
+ self.recon_trunk = make_layer(basic_block, nb)
+
+ # upsampling
+ if self.upscale == 2:
+ self.upconv1 = nn.Conv2d(nc, nc * 4, 3, 1, 1, bias=True)
+ self.pixel_shuffle = nn.PixelShuffle(2)
+ elif self.upscale == 3:
+ self.upconv1 = nn.Conv2d(nc, nc * 9, 3, 1, 1, bias=True)
+ self.pixel_shuffle = nn.PixelShuffle(3)
+ elif self.upscale == 4:
+ self.upconv1 = nn.Conv2d(nc, nc * 4, 3, 1, 1, bias=True)
+ self.upconv2 = nn.Conv2d(nc, nc * 4, 3, 1, 1, bias=True)
+ self.pixel_shuffle = nn.PixelShuffle(2)
+
+ self.HRconv = nn.Conv2d(nc, nc, 3, 1, 1, bias=True)
+ self.conv_last = nn.Conv2d(nc, out_nc, 3, 1, 1, bias=True)
+
+ # activation function
+ self.lrelu = nn.LeakyReLU(negative_slope=0.1, inplace=True)
+
+ # initialization
+ initialize_weights([self.conv_first, self.upconv1, self.HRconv, self.conv_last], 0.1)
+ if self.upscale == 4:
+ initialize_weights(self.upconv2, 0.1)
+
+ def forward(self, x):
+ fea = self.lrelu(self.conv_first(x))
+ out = self.recon_trunk(fea)
+
+ if self.upscale == 4:
+ out = self.lrelu(self.pixel_shuffle(self.upconv1(out)))
+ out = self.lrelu(self.pixel_shuffle(self.upconv2(out)))
+ elif self.upscale == 3 or self.upscale == 2:
+ out = self.lrelu(self.pixel_shuffle(self.upconv1(out)))
+
+ out = self.conv_last(self.lrelu(self.HRconv(out)))
+ base = F.interpolate(x, scale_factor=self.upscale, mode='bilinear', align_corners=False)
+ out += base
+ return out
+
+
+def initialize_weights(net_l, scale=1):
+ if not isinstance(net_l, list):
+ net_l = [net_l]
+ for net in net_l:
+ for m in net.modules():
+ if isinstance(m, nn.Conv2d):
+ init.kaiming_normal_(m.weight, a=0, mode='fan_in')
+ m.weight.data *= scale # for residual block
+ if m.bias is not None:
+ m.bias.data.zero_()
+ elif isinstance(m, nn.Linear):
+ init.kaiming_normal_(m.weight, a=0, mode='fan_in')
+ m.weight.data *= scale
+ if m.bias is not None:
+ m.bias.data.zero_()
+ elif isinstance(m, nn.BatchNorm2d):
+ init.constant_(m.weight, 1)
+ init.constant_(m.bias.data, 0.0)
+
+
+def make_layer(block, n_layers):
+ layers = []
+ for _ in range(n_layers):
+ layers.append(block())
+ return nn.Sequential(*layers)
+
+
+class ResidualBlock_noBN(nn.Module):
+ '''Residual block w/o BN
+ ---Conv-ReLU-Conv-+-
+ |________________|
+ '''
+
+ def __init__(self, nc=64):
+ super(ResidualBlock_noBN, self).__init__()
+ self.conv1 = nn.Conv2d(nc, nc, 3, 1, 1, bias=True)
+ self.conv2 = nn.Conv2d(nc, nc, 3, 1, 1, bias=True)
+
+ # initialization
+ initialize_weights([self.conv1, self.conv2], 0.1)
+
+ def forward(self, x):
+ identity = x
+ out = F.relu(self.conv1(x), inplace=True)
+ out = self.conv2(out)
+ return identity + out
diff --git a/KAIR/models/network_rrdb.py b/KAIR/models/network_rrdb.py
new file mode 100644
index 0000000000000000000000000000000000000000..91ae94cc5ed857ffead176fc317d553edc97a507
--- /dev/null
+++ b/KAIR/models/network_rrdb.py
@@ -0,0 +1,54 @@
+import math
+import torch.nn as nn
+import models.basicblock as B
+
+
+"""
+# --------------------------------------------
+# SR network with Residual in Residual Dense Block (RRDB)
+# "ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks"
+# --------------------------------------------
+"""
+
+
+class RRDB(nn.Module):
+ """
+ gc: number of growth channels
+ nb: number of RRDB
+ """
+ def __init__(self, in_nc=3, out_nc=3, nc=64, nb=23, gc=32, upscale=4, act_mode='L', upsample_mode='upconv'):
+ super(RRDB, self).__init__()
+ assert 'R' in act_mode or 'L' in act_mode, 'Examples of activation function: R, L, BR, BL, IR, IL'
+
+ n_upscale = int(math.log(upscale, 2))
+ if upscale == 3:
+ n_upscale = 1
+
+ m_head = B.conv(in_nc, nc, mode='C')
+
+ m_body = [B.RRDB(nc, gc=32, mode='C'+act_mode) for _ in range(nb)]
+ m_body.append(B.conv(nc, nc, mode='C'))
+
+ if upsample_mode == 'upconv':
+ upsample_block = B.upsample_upconv
+ elif upsample_mode == 'pixelshuffle':
+ upsample_block = B.upsample_pixelshuffle
+ elif upsample_mode == 'convtranspose':
+ upsample_block = B.upsample_convtranspose
+ else:
+ raise NotImplementedError('upsample mode [{:s}] is not found'.format(upsample_mode))
+
+ if upscale == 3:
+ m_uper = upsample_block(nc, nc, mode='3'+act_mode)
+ else:
+ m_uper = [upsample_block(nc, nc, mode='2'+act_mode) for _ in range(n_upscale)]
+
+ H_conv0 = B.conv(nc, nc, mode='C'+act_mode)
+ H_conv1 = B.conv(nc, out_nc, mode='C')
+ m_tail = B.sequential(H_conv0, H_conv1)
+
+ self.model = B.sequential(m_head, B.ShortcutBlock(B.sequential(*m_body)), *m_uper, m_tail)
+
+ def forward(self, x):
+ x = self.model(x)
+ return x
diff --git a/KAIR/models/network_rrdbnet.py b/KAIR/models/network_rrdbnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..a35e5c017738eb40759245b6c6c80c1ba750db5e
--- /dev/null
+++ b/KAIR/models/network_rrdbnet.py
@@ -0,0 +1,103 @@
+import functools
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torch.nn.init as init
+
+
+def initialize_weights(net_l, scale=1):
+ if not isinstance(net_l, list):
+ net_l = [net_l]
+ for net in net_l:
+ for m in net.modules():
+ if isinstance(m, nn.Conv2d):
+ init.kaiming_normal_(m.weight, a=0, mode='fan_in')
+ m.weight.data *= scale # for residual block
+ if m.bias is not None:
+ m.bias.data.zero_()
+ elif isinstance(m, nn.Linear):
+ init.kaiming_normal_(m.weight, a=0, mode='fan_in')
+ m.weight.data *= scale
+ if m.bias is not None:
+ m.bias.data.zero_()
+ elif isinstance(m, nn.BatchNorm2d):
+ init.constant_(m.weight, 1)
+ init.constant_(m.bias.data, 0.0)
+
+
+def make_layer(block, n_layers):
+ layers = []
+ for _ in range(n_layers):
+ layers.append(block())
+ return nn.Sequential(*layers)
+
+
+class ResidualDenseBlock_5C(nn.Module):
+ def __init__(self, nf=64, gc=32, bias=True):
+ super(ResidualDenseBlock_5C, self).__init__()
+ # gc: growth channel, i.e. intermediate channels
+ self.conv1 = nn.Conv2d(nf, gc, 3, 1, 1, bias=bias)
+ self.conv2 = nn.Conv2d(nf + gc, gc, 3, 1, 1, bias=bias)
+ self.conv3 = nn.Conv2d(nf + 2 * gc, gc, 3, 1, 1, bias=bias)
+ self.conv4 = nn.Conv2d(nf + 3 * gc, gc, 3, 1, 1, bias=bias)
+ self.conv5 = nn.Conv2d(nf + 4 * gc, nf, 3, 1, 1, bias=bias)
+ self.lrelu = nn.LeakyReLU(negative_slope=0.2, inplace=True)
+
+ # initialization
+ initialize_weights([self.conv1, self.conv2, self.conv3, self.conv4, self.conv5], 0.1)
+
+ def forward(self, x):
+ x1 = self.lrelu(self.conv1(x))
+ x2 = self.lrelu(self.conv2(torch.cat((x, x1), 1)))
+ x3 = self.lrelu(self.conv3(torch.cat((x, x1, x2), 1)))
+ x4 = self.lrelu(self.conv4(torch.cat((x, x1, x2, x3), 1)))
+ x5 = self.conv5(torch.cat((x, x1, x2, x3, x4), 1))
+ return x5 * 0.2 + x
+
+
+class RRDB(nn.Module):
+ '''Residual in Residual Dense Block'''
+
+ def __init__(self, nf, gc=32):
+ super(RRDB, self).__init__()
+ self.RDB1 = ResidualDenseBlock_5C(nf, gc)
+ self.RDB2 = ResidualDenseBlock_5C(nf, gc)
+ self.RDB3 = ResidualDenseBlock_5C(nf, gc)
+
+ def forward(self, x):
+ out = self.RDB1(x)
+ out = self.RDB2(out)
+ out = self.RDB3(out)
+ return out * 0.2 + x
+
+
+class RRDBNet(nn.Module):
+ def __init__(self, in_nc=3, out_nc=3, nf=64, nb=23, gc=32, sf=4):
+ super(RRDBNet, self).__init__()
+ RRDB_block_f = functools.partial(RRDB, nf=nf, gc=gc)
+ self.sf = sf
+ print([in_nc, out_nc, nf, nb, gc, sf])
+
+ self.conv_first = nn.Conv2d(in_nc, nf, 3, 1, 1, bias=True)
+ self.RRDB_trunk = make_layer(RRDB_block_f, nb)
+ self.trunk_conv = nn.Conv2d(nf, nf, 3, 1, 1, bias=True)
+ #### upsampling
+ self.upconv1 = nn.Conv2d(nf, nf, 3, 1, 1, bias=True)
+ if self.sf==4:
+ self.upconv2 = nn.Conv2d(nf, nf, 3, 1, 1, bias=True)
+ self.HRconv = nn.Conv2d(nf, nf, 3, 1, 1, bias=True)
+ self.conv_last = nn.Conv2d(nf, out_nc, 3, 1, 1, bias=True)
+
+ self.lrelu = nn.LeakyReLU(negative_slope=0.2, inplace=True)
+
+ def forward(self, x):
+ fea = self.conv_first(x)
+ trunk = self.trunk_conv(self.RRDB_trunk(fea))
+ fea = fea + trunk
+
+ fea = self.lrelu(self.upconv1(F.interpolate(fea, scale_factor=2, mode='nearest')))
+ if self.sf == 4:
+ fea = self.lrelu(self.upconv2(F.interpolate(fea, scale_factor=2, mode='nearest')))
+ out = self.conv_last(self.lrelu(self.HRconv(fea)))
+
+ return out
diff --git a/KAIR/models/network_srmd.py b/KAIR/models/network_srmd.py
new file mode 100644
index 0000000000000000000000000000000000000000..4c414b236ac5986ff9ee3aea651d8ea433047ece
--- /dev/null
+++ b/KAIR/models/network_srmd.py
@@ -0,0 +1,81 @@
+
+import torch.nn as nn
+import models.basicblock as B
+import torch
+
+"""
+# --------------------------------------------
+# SRMD (15 conv layers)
+# --------------------------------------------
+Reference:
+@inproceedings{zhang2018learning,
+ title={Learning a single convolutional super-resolution network for multiple degradations},
+ author={Zhang, Kai and Zuo, Wangmeng and Zhang, Lei},
+ booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
+ pages={3262--3271},
+ year={2018}
+}
+http://openaccess.thecvf.com/content_cvpr_2018/papers/Zhang_Learning_a_Single_CVPR_2018_paper.pdf
+"""
+
+
+# --------------------------------------------
+# SRMD (SRMD, in_nc = 3+15+1 = 19)
+# SRMD (SRMDNF, in_nc = 3+15 = 18)
+# --------------------------------------------
+class SRMD(nn.Module):
+ def __init__(self, in_nc=19, out_nc=3, nc=128, nb=12, upscale=4, act_mode='R', upsample_mode='pixelshuffle'):
+ """
+ # ------------------------------------
+ in_nc: channel number of input, default: 3+15
+ out_nc: channel number of output
+ nc: channel number
+ nb: total number of conv layers
+ upscale: scale factor
+ act_mode: batch norm + activation function; 'BR' means BN+ReLU
+ upsample_mode: default 'pixelshuffle' = conv + pixelshuffle
+ # ------------------------------------
+ """
+ super(SRMD, self).__init__()
+ assert 'R' in act_mode or 'L' in act_mode, 'Examples of activation function: R, L, BR, BL, IR, IL'
+ bias = True
+
+ if upsample_mode == 'upconv':
+ upsample_block = B.upsample_upconv
+ elif upsample_mode == 'pixelshuffle':
+ upsample_block = B.upsample_pixelshuffle
+ elif upsample_mode == 'convtranspose':
+ upsample_block = B.upsample_convtranspose
+ else:
+ raise NotImplementedError('upsample mode [{:s}] is not found'.format(upsample_mode))
+
+ m_head = B.conv(in_nc, nc, mode='C'+act_mode[-1], bias=bias)
+ m_body = [B.conv(nc, nc, mode='C'+act_mode, bias=bias) for _ in range(nb-2)]
+ m_tail = upsample_block(nc, out_nc, mode=str(upscale), bias=bias)
+
+ self.model = B.sequential(m_head, *m_body, m_tail)
+
+# def forward(self, x, k_pca):
+# m = k_pca.repeat(1, 1, x.size()[-2], x.size()[-1])
+# x = torch.cat((x, m), 1)
+# x = self.body(x)
+
+ def forward(self, x):
+
+ x = self.model(x)
+
+ return x
+
+
+if __name__ == '__main__':
+ from utils import utils_model
+ model = SRMD(in_nc=18, out_nc=3, nc=64, nb=15, upscale=4, act_mode='R', upsample_mode='pixelshuffle')
+ print(utils_model.describe_model(model))
+
+ x = torch.randn((2, 3, 100, 100))
+ k_pca = torch.randn(2, 15, 1, 1)
+ x = model(x, k_pca)
+ print(x.shape)
+
+ # run models/network_srmd.py
+
diff --git a/KAIR/models/network_swinir.py b/KAIR/models/network_swinir.py
new file mode 100644
index 0000000000000000000000000000000000000000..0828a9a3f3355a6e677c35f25322b807af8c513d
--- /dev/null
+++ b/KAIR/models/network_swinir.py
@@ -0,0 +1,866 @@
+# -----------------------------------------------------------------------------------
+# SwinIR: Image Restoration Using Swin Transformer, https://arxiv.org/abs/2108.10257
+# Originally Written by Ze Liu, Modified by Jingyun Liang.
+# -----------------------------------------------------------------------------------
+
+import math
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torch.utils.checkpoint as checkpoint
+from timm.models.layers import DropPath, to_2tuple, trunc_normal_
+
+
+class Mlp(nn.Module):
+ def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
+ super().__init__()
+ out_features = out_features or in_features
+ hidden_features = hidden_features or in_features
+ self.fc1 = nn.Linear(in_features, hidden_features)
+ self.act = act_layer()
+ self.fc2 = nn.Linear(hidden_features, out_features)
+ self.drop = nn.Dropout(drop)
+
+ def forward(self, x):
+ x = self.fc1(x)
+ x = self.act(x)
+ x = self.drop(x)
+ x = self.fc2(x)
+ x = self.drop(x)
+ return x
+
+
+def window_partition(x, window_size):
+ """
+ Args:
+ x: (B, H, W, C)
+ window_size (int): window size
+
+ Returns:
+ windows: (num_windows*B, window_size, window_size, C)
+ """
+ B, H, W, C = x.shape
+ x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
+ windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
+ return windows
+
+
+def window_reverse(windows, window_size, H, W):
+ """
+ Args:
+ windows: (num_windows*B, window_size, window_size, C)
+ window_size (int): Window size
+ H (int): Height of image
+ W (int): Width of image
+
+ Returns:
+ x: (B, H, W, C)
+ """
+ B = int(windows.shape[0] / (H * W / window_size / window_size))
+ x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
+ x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
+ return x
+
+
+class WindowAttention(nn.Module):
+ r""" Window based multi-head self attention (W-MSA) module with relative position bias.
+ It supports both of shifted and non-shifted window.
+
+ Args:
+ dim (int): Number of input channels.
+ window_size (tuple[int]): The height and width of the window.
+ num_heads (int): Number of attention heads.
+ qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
+ qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
+ attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
+ proj_drop (float, optional): Dropout ratio of output. Default: 0.0
+ """
+
+ def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
+
+ super().__init__()
+ self.dim = dim
+ self.window_size = window_size # Wh, Ww
+ self.num_heads = num_heads
+ head_dim = dim // num_heads
+ self.scale = qk_scale or head_dim ** -0.5
+
+ # define a parameter table of relative position bias
+ self.relative_position_bias_table = nn.Parameter(
+ torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
+
+ # get pair-wise relative position index for each token inside the window
+ coords_h = torch.arange(self.window_size[0])
+ coords_w = torch.arange(self.window_size[1])
+ coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
+ coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
+ relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
+ relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
+ relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
+ relative_coords[:, :, 1] += self.window_size[1] - 1
+ relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
+ relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
+ self.register_buffer("relative_position_index", relative_position_index)
+
+ self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
+ self.attn_drop = nn.Dropout(attn_drop)
+ self.proj = nn.Linear(dim, dim)
+
+ self.proj_drop = nn.Dropout(proj_drop)
+
+ trunc_normal_(self.relative_position_bias_table, std=.02)
+ self.softmax = nn.Softmax(dim=-1)
+
+ def forward(self, x, mask=None):
+ """
+ Args:
+ x: input features with shape of (num_windows*B, N, C)
+ mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
+ """
+ B_, N, C = x.shape
+ qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
+ q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
+
+ q = q * self.scale
+ attn = (q @ k.transpose(-2, -1))
+
+ relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
+ self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
+ relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
+ attn = attn + relative_position_bias.unsqueeze(0)
+
+ if mask is not None:
+ nW = mask.shape[0]
+ attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
+ attn = attn.view(-1, self.num_heads, N, N)
+ attn = self.softmax(attn)
+ else:
+ attn = self.softmax(attn)
+
+ attn = self.attn_drop(attn)
+
+ x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
+ x = self.proj(x)
+ x = self.proj_drop(x)
+ return x
+
+ def extra_repr(self) -> str:
+ return f'dim={self.dim}, window_size={self.window_size}, num_heads={self.num_heads}'
+
+ def flops(self, N):
+ # calculate flops for 1 window with token length of N
+ flops = 0
+ # qkv = self.qkv(x)
+ flops += N * self.dim * 3 * self.dim
+ # attn = (q @ k.transpose(-2, -1))
+ flops += self.num_heads * N * (self.dim // self.num_heads) * N
+ # x = (attn @ v)
+ flops += self.num_heads * N * N * (self.dim // self.num_heads)
+ # x = self.proj(x)
+ flops += N * self.dim * self.dim
+ return flops
+
+
+class SwinTransformerBlock(nn.Module):
+ r""" Swin Transformer Block.
+
+ Args:
+ dim (int): Number of input channels.
+ input_resolution (tuple[int]): Input resulotion.
+ num_heads (int): Number of attention heads.
+ window_size (int): Window size.
+ shift_size (int): Shift size for SW-MSA.
+ mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
+ qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
+ qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
+ drop (float, optional): Dropout rate. Default: 0.0
+ attn_drop (float, optional): Attention dropout rate. Default: 0.0
+ drop_path (float, optional): Stochastic depth rate. Default: 0.0
+ act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
+ norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
+ """
+
+ def __init__(self, dim, input_resolution, num_heads, window_size=7, shift_size=0,
+ mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,
+ act_layer=nn.GELU, norm_layer=nn.LayerNorm):
+ super().__init__()
+ self.dim = dim
+ self.input_resolution = input_resolution
+ self.num_heads = num_heads
+ self.window_size = window_size
+ self.shift_size = shift_size
+ self.mlp_ratio = mlp_ratio
+ if min(self.input_resolution) <= self.window_size:
+ # if window size is larger than input resolution, we don't partition windows
+ self.shift_size = 0
+ self.window_size = min(self.input_resolution)
+ assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"
+
+ self.norm1 = norm_layer(dim)
+ self.attn = WindowAttention(
+ dim, window_size=to_2tuple(self.window_size), num_heads=num_heads,
+ qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
+
+ self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
+ self.norm2 = norm_layer(dim)
+ mlp_hidden_dim = int(dim * mlp_ratio)
+ self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
+
+ if self.shift_size > 0:
+ attn_mask = self.calculate_mask(self.input_resolution)
+ else:
+ attn_mask = None
+
+ self.register_buffer("attn_mask", attn_mask)
+
+ def calculate_mask(self, x_size):
+ # calculate attention mask for SW-MSA
+ H, W = x_size
+ img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
+ h_slices = (slice(0, -self.window_size),
+ slice(-self.window_size, -self.shift_size),
+ slice(-self.shift_size, None))
+ w_slices = (slice(0, -self.window_size),
+ slice(-self.window_size, -self.shift_size),
+ slice(-self.shift_size, None))
+ cnt = 0
+ for h in h_slices:
+ for w in w_slices:
+ img_mask[:, h, w, :] = cnt
+ cnt += 1
+
+ mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1
+ mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
+ attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
+ attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
+
+ return attn_mask
+
+ def forward(self, x, x_size):
+ H, W = x_size
+ B, L, C = x.shape
+ # assert L == H * W, "input feature has wrong size"
+
+ shortcut = x
+ x = self.norm1(x)
+ x = x.view(B, H, W, C)
+
+ # cyclic shift
+ if self.shift_size > 0:
+ shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
+ else:
+ shifted_x = x
+
+ # partition windows
+ x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C
+ x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C
+
+ # W-MSA/SW-MSA (to be compatible for testing on images whose shapes are the multiple of window size
+ if self.input_resolution == x_size:
+ attn_windows = self.attn(x_windows, mask=self.attn_mask) # nW*B, window_size*window_size, C
+ else:
+ attn_windows = self.attn(x_windows, mask=self.calculate_mask(x_size).to(x.device))
+
+ # merge windows
+ attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)
+ shifted_x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C
+
+ # reverse cyclic shift
+ if self.shift_size > 0:
+ x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
+ else:
+ x = shifted_x
+ x = x.view(B, H * W, C)
+
+ # FFN
+ x = shortcut + self.drop_path(x)
+ x = x + self.drop_path(self.mlp(self.norm2(x)))
+
+ return x
+
+ def extra_repr(self) -> str:
+ return f"dim={self.dim}, input_resolution={self.input_resolution}, num_heads={self.num_heads}, " \
+ f"window_size={self.window_size}, shift_size={self.shift_size}, mlp_ratio={self.mlp_ratio}"
+
+ def flops(self):
+ flops = 0
+ H, W = self.input_resolution
+ # norm1
+ flops += self.dim * H * W
+ # W-MSA/SW-MSA
+ nW = H * W / self.window_size / self.window_size
+ flops += nW * self.attn.flops(self.window_size * self.window_size)
+ # mlp
+ flops += 2 * H * W * self.dim * self.dim * self.mlp_ratio
+ # norm2
+ flops += self.dim * H * W
+ return flops
+
+
+class PatchMerging(nn.Module):
+ r""" Patch Merging Layer.
+
+ Args:
+ input_resolution (tuple[int]): Resolution of input feature.
+ dim (int): Number of input channels.
+ norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
+ """
+
+ def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
+ super().__init__()
+ self.input_resolution = input_resolution
+ self.dim = dim
+ self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
+ self.norm = norm_layer(4 * dim)
+
+ def forward(self, x):
+ """
+ x: B, H*W, C
+ """
+ H, W = self.input_resolution
+ B, L, C = x.shape
+ assert L == H * W, "input feature has wrong size"
+ assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
+
+ x = x.view(B, H, W, C)
+
+ x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
+ x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
+ x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
+ x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
+ x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
+ x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
+
+ x = self.norm(x)
+ x = self.reduction(x)
+
+ return x
+
+ def extra_repr(self) -> str:
+ return f"input_resolution={self.input_resolution}, dim={self.dim}"
+
+ def flops(self):
+ H, W = self.input_resolution
+ flops = H * W * self.dim
+ flops += (H // 2) * (W // 2) * 4 * self.dim * 2 * self.dim
+ return flops
+
+
+class BasicLayer(nn.Module):
+ """ A basic Swin Transformer layer for one stage.
+
+ Args:
+ dim (int): Number of input channels.
+ input_resolution (tuple[int]): Input resolution.
+ depth (int): Number of blocks.
+ num_heads (int): Number of attention heads.
+ window_size (int): Local window size.
+ mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
+ qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
+ qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
+ drop (float, optional): Dropout rate. Default: 0.0
+ attn_drop (float, optional): Attention dropout rate. Default: 0.0
+ drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
+ norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
+ downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
+ use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
+ """
+
+ def __init__(self, dim, input_resolution, depth, num_heads, window_size,
+ mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0.,
+ drop_path=0., norm_layer=nn.LayerNorm, downsample=None, use_checkpoint=False):
+
+ super().__init__()
+ self.dim = dim
+ self.input_resolution = input_resolution
+ self.depth = depth
+ self.use_checkpoint = use_checkpoint
+
+ # build blocks
+ self.blocks = nn.ModuleList([
+ SwinTransformerBlock(dim=dim, input_resolution=input_resolution,
+ num_heads=num_heads, window_size=window_size,
+ shift_size=0 if (i % 2 == 0) else window_size // 2,
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias, qk_scale=qk_scale,
+ drop=drop, attn_drop=attn_drop,
+ drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
+ norm_layer=norm_layer)
+ for i in range(depth)])
+
+ # patch merging layer
+ if downsample is not None:
+ self.downsample = downsample(input_resolution, dim=dim, norm_layer=norm_layer)
+ else:
+ self.downsample = None
+
+ def forward(self, x, x_size):
+ for blk in self.blocks:
+ if self.use_checkpoint:
+ x = checkpoint.checkpoint(blk, x, x_size)
+ else:
+ x = blk(x, x_size)
+ if self.downsample is not None:
+ x = self.downsample(x)
+ return x
+
+ def extra_repr(self) -> str:
+ return f"dim={self.dim}, input_resolution={self.input_resolution}, depth={self.depth}"
+
+ def flops(self):
+ flops = 0
+ for blk in self.blocks:
+ flops += blk.flops()
+ if self.downsample is not None:
+ flops += self.downsample.flops()
+ return flops
+
+
+class RSTB(nn.Module):
+ """Residual Swin Transformer Block (RSTB).
+
+ Args:
+ dim (int): Number of input channels.
+ input_resolution (tuple[int]): Input resolution.
+ depth (int): Number of blocks.
+ num_heads (int): Number of attention heads.
+ window_size (int): Local window size.
+ mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
+ qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
+ qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
+ drop (float, optional): Dropout rate. Default: 0.0
+ attn_drop (float, optional): Attention dropout rate. Default: 0.0
+ drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
+ norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
+ downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
+ use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
+ img_size: Input image size.
+ patch_size: Patch size.
+ resi_connection: The convolutional block before residual connection.
+ """
+
+ def __init__(self, dim, input_resolution, depth, num_heads, window_size,
+ mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0.,
+ drop_path=0., norm_layer=nn.LayerNorm, downsample=None, use_checkpoint=False,
+ img_size=224, patch_size=4, resi_connection='1conv'):
+ super(RSTB, self).__init__()
+
+ self.dim = dim
+ self.input_resolution = input_resolution
+
+ self.residual_group = BasicLayer(dim=dim,
+ input_resolution=input_resolution,
+ depth=depth,
+ num_heads=num_heads,
+ window_size=window_size,
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias, qk_scale=qk_scale,
+ drop=drop, attn_drop=attn_drop,
+ drop_path=drop_path,
+ norm_layer=norm_layer,
+ downsample=downsample,
+ use_checkpoint=use_checkpoint)
+
+ if resi_connection == '1conv':
+ self.conv = nn.Conv2d(dim, dim, 3, 1, 1)
+ elif resi_connection == '3conv':
+ # to save parameters and memory
+ self.conv = nn.Sequential(nn.Conv2d(dim, dim // 4, 3, 1, 1), nn.LeakyReLU(negative_slope=0.2, inplace=True),
+ nn.Conv2d(dim // 4, dim // 4, 1, 1, 0),
+ nn.LeakyReLU(negative_slope=0.2, inplace=True),
+ nn.Conv2d(dim // 4, dim, 3, 1, 1))
+
+ self.patch_embed = PatchEmbed(
+ img_size=img_size, patch_size=patch_size, in_chans=0, embed_dim=dim,
+ norm_layer=None)
+
+ self.patch_unembed = PatchUnEmbed(
+ img_size=img_size, patch_size=patch_size, in_chans=0, embed_dim=dim,
+ norm_layer=None)
+
+ def forward(self, x, x_size):
+ return self.patch_embed(self.conv(self.patch_unembed(self.residual_group(x, x_size), x_size))) + x
+
+ def flops(self):
+ flops = 0
+ flops += self.residual_group.flops()
+ H, W = self.input_resolution
+ flops += H * W * self.dim * self.dim * 9
+ flops += self.patch_embed.flops()
+ flops += self.patch_unembed.flops()
+
+ return flops
+
+
+class PatchEmbed(nn.Module):
+ r""" Image to Patch Embedding
+
+ Args:
+ img_size (int): Image size. Default: 224.
+ patch_size (int): Patch token size. Default: 4.
+ in_chans (int): Number of input image channels. Default: 3.
+ embed_dim (int): Number of linear projection output channels. Default: 96.
+ norm_layer (nn.Module, optional): Normalization layer. Default: None
+ """
+
+ def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
+ super().__init__()
+ img_size = to_2tuple(img_size)
+ patch_size = to_2tuple(patch_size)
+ patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
+ self.img_size = img_size
+ self.patch_size = patch_size
+ self.patches_resolution = patches_resolution
+ self.num_patches = patches_resolution[0] * patches_resolution[1]
+
+ self.in_chans = in_chans
+ self.embed_dim = embed_dim
+
+ if norm_layer is not None:
+ self.norm = norm_layer(embed_dim)
+ else:
+ self.norm = None
+
+ def forward(self, x):
+ x = x.flatten(2).transpose(1, 2) # B Ph*Pw C
+ if self.norm is not None:
+ x = self.norm(x)
+ return x
+
+ def flops(self):
+ flops = 0
+ H, W = self.img_size
+ if self.norm is not None:
+ flops += H * W * self.embed_dim
+ return flops
+
+
+class PatchUnEmbed(nn.Module):
+ r""" Image to Patch Unembedding
+
+ Args:
+ img_size (int): Image size. Default: 224.
+ patch_size (int): Patch token size. Default: 4.
+ in_chans (int): Number of input image channels. Default: 3.
+ embed_dim (int): Number of linear projection output channels. Default: 96.
+ norm_layer (nn.Module, optional): Normalization layer. Default: None
+ """
+
+ def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
+ super().__init__()
+ img_size = to_2tuple(img_size)
+ patch_size = to_2tuple(patch_size)
+ patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
+ self.img_size = img_size
+ self.patch_size = patch_size
+ self.patches_resolution = patches_resolution
+ self.num_patches = patches_resolution[0] * patches_resolution[1]
+
+ self.in_chans = in_chans
+ self.embed_dim = embed_dim
+
+ def forward(self, x, x_size):
+ B, HW, C = x.shape
+ x = x.transpose(1, 2).view(B, self.embed_dim, x_size[0], x_size[1]) # B Ph*Pw C
+ return x
+
+ def flops(self):
+ flops = 0
+ return flops
+
+
+class Upsample(nn.Sequential):
+ """Upsample module.
+
+ Args:
+ scale (int): Scale factor. Supported scales: 2^n and 3.
+ num_feat (int): Channel number of intermediate features.
+ """
+
+ def __init__(self, scale, num_feat):
+ m = []
+ if (scale & (scale - 1)) == 0: # scale = 2^n
+ for _ in range(int(math.log(scale, 2))):
+ m.append(nn.Conv2d(num_feat, 4 * num_feat, 3, 1, 1))
+ m.append(nn.PixelShuffle(2))
+ elif scale == 3:
+ m.append(nn.Conv2d(num_feat, 9 * num_feat, 3, 1, 1))
+ m.append(nn.PixelShuffle(3))
+ else:
+ raise ValueError(f'scale {scale} is not supported. ' 'Supported scales: 2^n and 3.')
+ super(Upsample, self).__init__(*m)
+
+
+class UpsampleOneStep(nn.Sequential):
+ """UpsampleOneStep module (the difference with Upsample is that it always only has 1conv + 1pixelshuffle)
+ Used in lightweight SR to save parameters.
+
+ Args:
+ scale (int): Scale factor. Supported scales: 2^n and 3.
+ num_feat (int): Channel number of intermediate features.
+
+ """
+
+ def __init__(self, scale, num_feat, num_out_ch, input_resolution=None):
+ self.num_feat = num_feat
+ self.input_resolution = input_resolution
+ m = []
+ m.append(nn.Conv2d(num_feat, (scale ** 2) * num_out_ch, 3, 1, 1))
+ m.append(nn.PixelShuffle(scale))
+ super(UpsampleOneStep, self).__init__(*m)
+
+ def flops(self):
+ H, W = self.input_resolution
+ flops = H * W * self.num_feat * 3 * 9
+ return flops
+
+
+class SwinIR(nn.Module):
+ r""" SwinIR
+ A PyTorch impl of : `SwinIR: Image Restoration Using Swin Transformer`, based on Swin Transformer.
+
+ Args:
+ img_size (int | tuple(int)): Input image size. Default 64
+ patch_size (int | tuple(int)): Patch size. Default: 1
+ in_chans (int): Number of input image channels. Default: 3
+ embed_dim (int): Patch embedding dimension. Default: 96
+ depths (tuple(int)): Depth of each Swin Transformer layer.
+ num_heads (tuple(int)): Number of attention heads in different layers.
+ window_size (int): Window size. Default: 7
+ mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4
+ qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True
+ qk_scale (float): Override default qk scale of head_dim ** -0.5 if set. Default: None
+ drop_rate (float): Dropout rate. Default: 0
+ attn_drop_rate (float): Attention dropout rate. Default: 0
+ drop_path_rate (float): Stochastic depth rate. Default: 0.1
+ norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.
+ ape (bool): If True, add absolute position embedding to the patch embedding. Default: False
+ patch_norm (bool): If True, add normalization after patch embedding. Default: True
+ use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False
+ upscale: Upscale factor. 2/3/4/8 for image SR, 1 for denoising and compress artifact reduction
+ img_range: Image range. 1. or 255.
+ upsampler: The reconstruction reconstruction module. 'pixelshuffle'/'pixelshuffledirect'/'nearest+conv'/None
+ resi_connection: The convolutional block before residual connection. '1conv'/'3conv'
+ """
+
+ def __init__(self, img_size=64, patch_size=1, in_chans=3,
+ embed_dim=96, depths=[6, 6, 6, 6], num_heads=[6, 6, 6, 6],
+ window_size=7, mlp_ratio=4., qkv_bias=True, qk_scale=None,
+ drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,
+ norm_layer=nn.LayerNorm, ape=False, patch_norm=True,
+ use_checkpoint=False, upscale=2, img_range=1., upsampler='', resi_connection='1conv',
+ **kwargs):
+ super(SwinIR, self).__init__()
+ num_in_ch = in_chans
+ num_out_ch = in_chans
+ num_feat = 64
+ self.img_range = img_range
+ if in_chans == 3:
+ rgb_mean = (0.4488, 0.4371, 0.4040)
+ self.mean = torch.Tensor(rgb_mean).view(1, 3, 1, 1)
+ else:
+ self.mean = torch.zeros(1, 1, 1, 1)
+ self.upscale = upscale
+ self.upsampler = upsampler
+ self.window_size = window_size
+
+ #####################################################################################################
+ ################################### 1, shallow feature extraction ###################################
+ self.conv_first = nn.Conv2d(num_in_ch, embed_dim, 3, 1, 1)
+
+ #####################################################################################################
+ ################################### 2, deep feature extraction ######################################
+ self.num_layers = len(depths)
+ self.embed_dim = embed_dim
+ self.ape = ape
+ self.patch_norm = patch_norm
+ self.num_features = embed_dim
+ self.mlp_ratio = mlp_ratio
+
+ # split image into non-overlapping patches
+ self.patch_embed = PatchEmbed(
+ img_size=img_size, patch_size=patch_size, in_chans=embed_dim, embed_dim=embed_dim,
+ norm_layer=norm_layer if self.patch_norm else None)
+ num_patches = self.patch_embed.num_patches
+ patches_resolution = self.patch_embed.patches_resolution
+ self.patches_resolution = patches_resolution
+
+ # merge non-overlapping patches into image
+ self.patch_unembed = PatchUnEmbed(
+ img_size=img_size, patch_size=patch_size, in_chans=embed_dim, embed_dim=embed_dim,
+ norm_layer=norm_layer if self.patch_norm else None)
+
+ # absolute position embedding
+ if self.ape:
+ self.absolute_pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dim))
+ trunc_normal_(self.absolute_pos_embed, std=.02)
+
+ self.pos_drop = nn.Dropout(p=drop_rate)
+
+ # stochastic depth
+ dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
+
+ # build Residual Swin Transformer blocks (RSTB)
+ self.layers = nn.ModuleList()
+ for i_layer in range(self.num_layers):
+ layer = RSTB(dim=embed_dim,
+ input_resolution=(patches_resolution[0],
+ patches_resolution[1]),
+ depth=depths[i_layer],
+ num_heads=num_heads[i_layer],
+ window_size=window_size,
+ mlp_ratio=self.mlp_ratio,
+ qkv_bias=qkv_bias, qk_scale=qk_scale,
+ drop=drop_rate, attn_drop=attn_drop_rate,
+ drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])], # no impact on SR results
+ norm_layer=norm_layer,
+ downsample=None,
+ use_checkpoint=use_checkpoint,
+ img_size=img_size,
+ patch_size=patch_size,
+ resi_connection=resi_connection
+
+ )
+ self.layers.append(layer)
+ self.norm = norm_layer(self.num_features)
+
+ # build the last conv layer in deep feature extraction
+ if resi_connection == '1conv':
+ self.conv_after_body = nn.Conv2d(embed_dim, embed_dim, 3, 1, 1)
+ elif resi_connection == '3conv':
+ # to save parameters and memory
+ self.conv_after_body = nn.Sequential(nn.Conv2d(embed_dim, embed_dim // 4, 3, 1, 1),
+ nn.LeakyReLU(negative_slope=0.2, inplace=True),
+ nn.Conv2d(embed_dim // 4, embed_dim // 4, 1, 1, 0),
+ nn.LeakyReLU(negative_slope=0.2, inplace=True),
+ nn.Conv2d(embed_dim // 4, embed_dim, 3, 1, 1))
+
+ #####################################################################################################
+ ################################ 3, high quality image reconstruction ################################
+ if self.upsampler == 'pixelshuffle':
+ # for classical SR
+ self.conv_before_upsample = nn.Sequential(nn.Conv2d(embed_dim, num_feat, 3, 1, 1),
+ nn.LeakyReLU(inplace=True))
+ self.upsample = Upsample(upscale, num_feat)
+ self.conv_last = nn.Conv2d(num_feat, num_out_ch, 3, 1, 1)
+ elif self.upsampler == 'pixelshuffledirect':
+ # for lightweight SR (to save parameters)
+ self.upsample = UpsampleOneStep(upscale, embed_dim, num_out_ch,
+ (patches_resolution[0], patches_resolution[1]))
+ elif self.upsampler == 'nearest+conv':
+ # for real-world SR (less artifacts)
+ # assert self.upscale == 4, 'only support x4 now.'
+ self.conv_before_upsample = nn.Sequential(nn.Conv2d(embed_dim, num_feat, 3, 1, 1),
+ nn.LeakyReLU(inplace=True))
+ self.conv_up1 = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
+ self.conv_up2 = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
+ self.conv_hr = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
+ self.conv_last = nn.Conv2d(num_feat, num_out_ch, 3, 1, 1)
+ self.lrelu = nn.LeakyReLU(negative_slope=0.2, inplace=True)
+ else:
+ # for image denoising and JPEG compression artifact reduction
+ self.conv_last = nn.Conv2d(embed_dim, num_out_ch, 3, 1, 1)
+
+ self.apply(self._init_weights)
+
+ def _init_weights(self, m):
+ if isinstance(m, nn.Linear):
+ trunc_normal_(m.weight, std=.02)
+ if isinstance(m, nn.Linear) and m.bias is not None:
+ nn.init.constant_(m.bias, 0)
+ elif isinstance(m, nn.LayerNorm):
+ nn.init.constant_(m.bias, 0)
+ nn.init.constant_(m.weight, 1.0)
+
+ @torch.jit.ignore
+ def no_weight_decay(self):
+ return {'absolute_pos_embed'}
+
+ @torch.jit.ignore
+ def no_weight_decay_keywords(self):
+ return {'relative_position_bias_table'}
+
+ def check_image_size(self, x):
+ _, _, h, w = x.size()
+ mod_pad_h = (self.window_size - h % self.window_size) % self.window_size
+ mod_pad_w = (self.window_size - w % self.window_size) % self.window_size
+ x = F.pad(x, (0, mod_pad_w, 0, mod_pad_h), 'reflect')
+ return x
+
+ def forward_features(self, x):
+ x_size = (x.shape[2], x.shape[3])
+ x = self.patch_embed(x)
+ if self.ape:
+ x = x + self.absolute_pos_embed
+ x = self.pos_drop(x)
+
+ for layer in self.layers:
+ x = layer(x, x_size)
+
+ x = self.norm(x) # B L C
+ x = self.patch_unembed(x, x_size)
+
+ return x
+
+ def forward(self, x):
+ H, W = x.shape[2:]
+ x = self.check_image_size(x)
+
+ self.mean = self.mean.type_as(x)
+ x = (x - self.mean) * self.img_range
+
+ if self.upsampler == 'pixelshuffle':
+ # for classical SR
+ x = self.conv_first(x)
+ x = self.conv_after_body(self.forward_features(x)) + x
+ x = self.conv_before_upsample(x)
+ x = self.conv_last(self.upsample(x))
+ elif self.upsampler == 'pixelshuffledirect':
+ # for lightweight SR
+ x = self.conv_first(x)
+ x = self.conv_after_body(self.forward_features(x)) + x
+ x = self.upsample(x)
+ elif self.upsampler == 'nearest+conv':
+ # for real-world SR
+ x = self.conv_first(x)
+ x = self.conv_after_body(self.forward_features(x)) + x
+ x = self.conv_before_upsample(x)
+ x = self.lrelu(self.conv_up1(torch.nn.functional.interpolate(x, scale_factor=2, mode='nearest')))
+ x = self.lrelu(self.conv_up2(x))
+ x = self.conv_last(self.lrelu(self.conv_hr(x)))
+ else:
+ # for image denoising and JPEG compression artifact reduction
+ x_first = self.conv_first(x)
+ res = self.conv_after_body(self.forward_features(x_first)) + x_first
+ x = x + self.conv_last(res)
+
+ x = x / self.img_range + self.mean
+
+ return x[:, :, :H*self.upscale, :W*self.upscale]
+
+ def flops(self):
+ flops = 0
+ H, W = self.patches_resolution
+ flops += H * W * 3 * self.embed_dim * 9
+ flops += self.patch_embed.flops()
+ for i, layer in enumerate(self.layers):
+ flops += layer.flops()
+ flops += H * W * 3 * self.embed_dim * self.embed_dim
+ flops += self.upsample.flops()
+ return flops
+
+
+if __name__ == '__main__':
+ upscale = 4
+ window_size = 8
+ height = (1024 // upscale // window_size + 1) * window_size
+ width = (720 // upscale // window_size + 1) * window_size
+ model = SwinIR(upscale=2, img_size=(height, width),
+ window_size=window_size, img_range=1., depths=[6, 6, 6, 6],
+ embed_dim=60, num_heads=[6, 6, 6, 6], mlp_ratio=2, upsampler='pixelshuffledirect')
+ print(model)
+ print(height, width, model.flops() / 1e9)
+
+ x = torch.randn((1, 3, height, width))
+ x = model(x)
+ print(x.shape)
diff --git a/KAIR/models/network_unet.py b/KAIR/models/network_unet.py
new file mode 100644
index 0000000000000000000000000000000000000000..fec5ca95e5bc2428ec05ddce92c80ea86ea43890
--- /dev/null
+++ b/KAIR/models/network_unet.py
@@ -0,0 +1,87 @@
+import torch
+import torch.nn as nn
+import models.basicblock as B
+import numpy as np
+
+'''
+# ====================
+# Residual U-Net
+# ====================
+citation:
+@article{zhang2020plug,
+title={Plug-and-Play Image Restoration with Deep Denoiser Prior},
+author={Zhang, Kai and Li, Yawei and Zuo, Wangmeng and Zhang, Lei and Van Gool, Luc and Timofte, Radu},
+journal={arXiv preprint},
+year={2020}
+}
+# ====================
+'''
+
+
+class UNetRes(nn.Module):
+ def __init__(self, in_nc=3, out_nc=3, nc=[64, 128, 256, 512], nb=4, act_mode='R', downsample_mode='strideconv', upsample_mode='convtranspose', bias=True):
+ super(UNetRes, self).__init__()
+
+ self.m_head = B.conv(in_nc, nc[0], bias=bias, mode='C')
+
+ # downsample
+ if downsample_mode == 'avgpool':
+ downsample_block = B.downsample_avgpool
+ elif downsample_mode == 'maxpool':
+ downsample_block = B.downsample_maxpool
+ elif downsample_mode == 'strideconv':
+ downsample_block = B.downsample_strideconv
+ else:
+ raise NotImplementedError('downsample mode [{:s}] is not found'.format(downsample_mode))
+
+ self.m_down1 = B.sequential(*[B.ResBlock(nc[0], nc[0], bias=bias, mode='C'+act_mode+'C') for _ in range(nb)], downsample_block(nc[0], nc[1], bias=bias, mode='2'))
+ self.m_down2 = B.sequential(*[B.ResBlock(nc[1], nc[1], bias=bias, mode='C'+act_mode+'C') for _ in range(nb)], downsample_block(nc[1], nc[2], bias=bias, mode='2'))
+ self.m_down3 = B.sequential(*[B.ResBlock(nc[2], nc[2], bias=bias, mode='C'+act_mode+'C') for _ in range(nb)], downsample_block(nc[2], nc[3], bias=bias, mode='2'))
+
+ self.m_body = B.sequential(*[B.ResBlock(nc[3], nc[3], bias=bias, mode='C'+act_mode+'C') for _ in range(nb)])
+
+ # upsample
+ if upsample_mode == 'upconv':
+ upsample_block = B.upsample_upconv
+ elif upsample_mode == 'pixelshuffle':
+ upsample_block = B.upsample_pixelshuffle
+ elif upsample_mode == 'convtranspose':
+ upsample_block = B.upsample_convtranspose
+ else:
+ raise NotImplementedError('upsample mode [{:s}] is not found'.format(upsample_mode))
+
+ self.m_up3 = B.sequential(upsample_block(nc[3], nc[2], bias=bias, mode='2'), *[B.ResBlock(nc[2], nc[2], bias=bias, mode='C'+act_mode+'C') for _ in range(nb)])
+ self.m_up2 = B.sequential(upsample_block(nc[2], nc[1], bias=bias, mode='2'), *[B.ResBlock(nc[1], nc[1], bias=bias, mode='C'+act_mode+'C') for _ in range(nb)])
+ self.m_up1 = B.sequential(upsample_block(nc[1], nc[0], bias=bias, mode='2'), *[B.ResBlock(nc[0], nc[0], bias=bias, mode='C'+act_mode+'C') for _ in range(nb)])
+
+ self.m_tail = B.conv(nc[0], out_nc, bias=bias, mode='C')
+
+ def forward(self, x0):
+# h, w = x.size()[-2:]
+# paddingBottom = int(np.ceil(h/8)*8-h)
+# paddingRight = int(np.ceil(w/8)*8-w)
+# x = nn.ReplicationPad2d((0, paddingRight, 0, paddingBottom))(x)
+
+ x1 = self.m_head(x0)
+ x2 = self.m_down1(x1)
+ x3 = self.m_down2(x2)
+ x4 = self.m_down3(x3)
+ x = self.m_body(x4)
+ x = self.m_up3(x+x4)
+ x = self.m_up2(x+x3)
+ x = self.m_up1(x+x2)
+ x = self.m_tail(x+x1)
+# x = x[..., :h, :w]
+
+ return x
+
+
+if __name__ == '__main__':
+ x = torch.rand(1,3,256,256)
+ net = UNetRes()
+ net.eval()
+ with torch.no_grad():
+ y = net(x)
+ print(y.size())
+
+# run models/network_unet.py
diff --git a/KAIR/models/network_usrnet.py b/KAIR/models/network_usrnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..cf7c7177998f155422062bca4a30bbe6f75d77fa
--- /dev/null
+++ b/KAIR/models/network_usrnet.py
@@ -0,0 +1,344 @@
+import torch
+import torch.nn as nn
+import models.basicblock as B
+import numpy as np
+from utils import utils_image as util
+
+
+"""
+# --------------------------------------------
+# Kai Zhang (cskaizhang@gmail.com)
+@inproceedings{zhang2020deep,
+ title={Deep unfolding network for image super-resolution},
+ author={Zhang, Kai and Van Gool, Luc and Timofte, Radu},
+ booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
+ pages={0--0},
+ year={2020}
+}
+# --------------------------------------------
+"""
+
+
+"""
+# --------------------------------------------
+# basic functions
+# --------------------------------------------
+"""
+
+
+def splits(a, sf):
+ '''split a into sfxsf distinct blocks
+
+ Args:
+ a: NxCxWxHx2
+ sf: split factor
+
+ Returns:
+ b: NxCx(W/sf)x(H/sf)x2x(sf^2)
+ '''
+ b = torch.stack(torch.chunk(a, sf, dim=2), dim=5)
+ b = torch.cat(torch.chunk(b, sf, dim=3), dim=5)
+ return b
+
+
+def c2c(x):
+ return torch.from_numpy(np.stack([np.float32(x.real), np.float32(x.imag)], axis=-1))
+
+
+def r2c(x):
+ # convert real to complex
+ return torch.stack([x, torch.zeros_like(x)], -1)
+
+
+def cdiv(x, y):
+ # complex division
+ a, b = x[..., 0], x[..., 1]
+ c, d = y[..., 0], y[..., 1]
+ cd2 = c**2 + d**2
+ return torch.stack([(a*c+b*d)/cd2, (b*c-a*d)/cd2], -1)
+
+
+def crdiv(x, y):
+ # complex/real division
+ a, b = x[..., 0], x[..., 1]
+ return torch.stack([a/y, b/y], -1)
+
+
+def csum(x, y):
+ # complex + real
+ return torch.stack([x[..., 0] + y, x[..., 1]], -1)
+
+
+def cabs(x):
+ # modulus of a complex number
+ return torch.pow(x[..., 0]**2+x[..., 1]**2, 0.5)
+
+
+def cabs2(x):
+ return x[..., 0]**2+x[..., 1]**2
+
+
+def cmul(t1, t2):
+ '''complex multiplication
+
+ Args:
+ t1: NxCxHxWx2, complex tensor
+ t2: NxCxHxWx2
+
+ Returns:
+ output: NxCxHxWx2
+ '''
+ real1, imag1 = t1[..., 0], t1[..., 1]
+ real2, imag2 = t2[..., 0], t2[..., 1]
+ return torch.stack([real1 * real2 - imag1 * imag2, real1 * imag2 + imag1 * real2], dim=-1)
+
+
+def cconj(t, inplace=False):
+ '''complex's conjugation
+
+ Args:
+ t: NxCxHxWx2
+
+ Returns:
+ output: NxCxHxWx2
+ '''
+ c = t.clone() if not inplace else t
+ c[..., 1] *= -1
+ return c
+
+
+def rfft(t):
+ # Real-to-complex Discrete Fourier Transform
+ return torch.rfft(t, 2, onesided=False)
+
+
+def irfft(t):
+ # Complex-to-real Inverse Discrete Fourier Transform
+ return torch.irfft(t, 2, onesided=False)
+
+
+def fft(t):
+ # Complex-to-complex Discrete Fourier Transform
+ return torch.fft(t, 2)
+
+
+def ifft(t):
+ # Complex-to-complex Inverse Discrete Fourier Transform
+ return torch.ifft(t, 2)
+
+
+def p2o(psf, shape):
+ '''
+ Convert point-spread function to optical transfer function.
+ otf = p2o(psf) computes the Fast Fourier Transform (FFT) of the
+ point-spread function (PSF) array and creates the optical transfer
+ function (OTF) array that is not influenced by the PSF off-centering.
+
+ Args:
+ psf: NxCxhxw
+ shape: [H, W]
+
+ Returns:
+ otf: NxCxHxWx2
+ '''
+ otf = torch.zeros(psf.shape[:-2] + shape).type_as(psf)
+ otf[...,:psf.shape[2],:psf.shape[3]].copy_(psf)
+ for axis, axis_size in enumerate(psf.shape[2:]):
+ otf = torch.roll(otf, -int(axis_size / 2), dims=axis+2)
+ otf = torch.rfft(otf, 2, onesided=False)
+ n_ops = torch.sum(torch.tensor(psf.shape).type_as(psf) * torch.log2(torch.tensor(psf.shape).type_as(psf)))
+ otf[..., 1][torch.abs(otf[..., 1]) < n_ops*2.22e-16] = torch.tensor(0).type_as(psf)
+ return otf
+
+
+def upsample(x, sf=3):
+ '''s-fold upsampler
+
+ Upsampling the spatial size by filling the new entries with zeros
+
+ x: tensor image, NxCxWxH
+ '''
+ st = 0
+ z = torch.zeros((x.shape[0], x.shape[1], x.shape[2]*sf, x.shape[3]*sf)).type_as(x)
+ z[..., st::sf, st::sf].copy_(x)
+ return z
+
+
+def downsample(x, sf=3):
+ '''s-fold downsampler
+
+ Keeping the upper-left pixel for each distinct sfxsf patch and discarding the others
+
+ x: tensor image, NxCxWxH
+ '''
+ st = 0
+ return x[..., st::sf, st::sf]
+
+
+def downsample_np(x, sf=3):
+ st = 0
+ return x[st::sf, st::sf, ...]
+
+
+"""
+# --------------------------------------------
+# (1) Prior module; ResUNet: act as a non-blind denoiser
+# x_k = P(z_k, beta_k)
+# --------------------------------------------
+"""
+
+
+class ResUNet(nn.Module):
+ def __init__(self, in_nc=4, out_nc=3, nc=[64, 128, 256, 512], nb=2, act_mode='R', downsample_mode='strideconv', upsample_mode='convtranspose'):
+ super(ResUNet, self).__init__()
+
+ self.m_head = B.conv(in_nc, nc[0], bias=False, mode='C')
+
+ # downsample
+ if downsample_mode == 'avgpool':
+ downsample_block = B.downsample_avgpool
+ elif downsample_mode == 'maxpool':
+ downsample_block = B.downsample_maxpool
+ elif downsample_mode == 'strideconv':
+ downsample_block = B.downsample_strideconv
+ else:
+ raise NotImplementedError('downsample mode [{:s}] is not found'.format(downsample_mode))
+
+ self.m_down1 = B.sequential(*[B.ResBlock(nc[0], nc[0], bias=False, mode='C'+act_mode+'C') for _ in range(nb)], downsample_block(nc[0], nc[1], bias=False, mode='2'))
+ self.m_down2 = B.sequential(*[B.ResBlock(nc[1], nc[1], bias=False, mode='C'+act_mode+'C') for _ in range(nb)], downsample_block(nc[1], nc[2], bias=False, mode='2'))
+ self.m_down3 = B.sequential(*[B.ResBlock(nc[2], nc[2], bias=False, mode='C'+act_mode+'C') for _ in range(nb)], downsample_block(nc[2], nc[3], bias=False, mode='2'))
+
+ self.m_body = B.sequential(*[B.ResBlock(nc[3], nc[3], bias=False, mode='C'+act_mode+'C') for _ in range(nb)])
+
+ # upsample
+ if upsample_mode == 'upconv':
+ upsample_block = B.upsample_upconv
+ elif upsample_mode == 'pixelshuffle':
+ upsample_block = B.upsample_pixelshuffle
+ elif upsample_mode == 'convtranspose':
+ upsample_block = B.upsample_convtranspose
+ else:
+ raise NotImplementedError('upsample mode [{:s}] is not found'.format(upsample_mode))
+
+ self.m_up3 = B.sequential(upsample_block(nc[3], nc[2], bias=False, mode='2'), *[B.ResBlock(nc[2], nc[2], bias=False, mode='C'+act_mode+'C') for _ in range(nb)])
+ self.m_up2 = B.sequential(upsample_block(nc[2], nc[1], bias=False, mode='2'), *[B.ResBlock(nc[1], nc[1], bias=False, mode='C'+act_mode+'C') for _ in range(nb)])
+ self.m_up1 = B.sequential(upsample_block(nc[1], nc[0], bias=False, mode='2'), *[B.ResBlock(nc[0], nc[0], bias=False, mode='C'+act_mode+'C') for _ in range(nb)])
+
+ self.m_tail = B.conv(nc[0], out_nc, bias=False, mode='C')
+
+ def forward(self, x):
+
+ h, w = x.size()[-2:]
+ paddingBottom = int(np.ceil(h/8)*8-h)
+ paddingRight = int(np.ceil(w/8)*8-w)
+ x = nn.ReplicationPad2d((0, paddingRight, 0, paddingBottom))(x)
+
+ x1 = self.m_head(x)
+ x2 = self.m_down1(x1)
+ x3 = self.m_down2(x2)
+ x4 = self.m_down3(x3)
+ x = self.m_body(x4)
+ x = self.m_up3(x+x4)
+ x = self.m_up2(x+x3)
+ x = self.m_up1(x+x2)
+ x = self.m_tail(x+x1)
+
+ x = x[..., :h, :w]
+
+ return x
+
+
+"""
+# --------------------------------------------
+# (2) Data module, closed-form solution
+# It is a trainable-parameter-free module ^_^
+# z_k = D(x_{k-1}, s, k, y, alpha_k)
+# some can be pre-calculated
+# --------------------------------------------
+"""
+
+
+class DataNet(nn.Module):
+ def __init__(self):
+ super(DataNet, self).__init__()
+
+ def forward(self, x, FB, FBC, F2B, FBFy, alpha, sf):
+ FR = FBFy + torch.rfft(alpha*x, 2, onesided=False)
+ x1 = cmul(FB, FR)
+ FBR = torch.mean(splits(x1, sf), dim=-1, keepdim=False)
+ invW = torch.mean(splits(F2B, sf), dim=-1, keepdim=False)
+ invWBR = cdiv(FBR, csum(invW, alpha))
+ FCBinvWBR = cmul(FBC, invWBR.repeat(1, 1, sf, sf, 1))
+ FX = (FR-FCBinvWBR)/alpha.unsqueeze(-1)
+ Xest = torch.irfft(FX, 2, onesided=False)
+
+ return Xest
+
+
+"""
+# --------------------------------------------
+# (3) Hyper-parameter module
+# --------------------------------------------
+"""
+
+
+class HyPaNet(nn.Module):
+ def __init__(self, in_nc=2, out_nc=8, channel=64):
+ super(HyPaNet, self).__init__()
+ self.mlp = nn.Sequential(
+ nn.Conv2d(in_nc, channel, 1, padding=0, bias=True),
+ nn.ReLU(inplace=True),
+ nn.Conv2d(channel, channel, 1, padding=0, bias=True),
+ nn.ReLU(inplace=True),
+ nn.Conv2d(channel, out_nc, 1, padding=0, bias=True),
+ nn.Softplus())
+
+ def forward(self, x):
+ x = self.mlp(x) + 1e-6
+ return x
+
+
+"""
+# --------------------------------------------
+# main USRNet
+# deep unfolding super-resolution network
+# --------------------------------------------
+"""
+
+
+class USRNet(nn.Module):
+ def __init__(self, n_iter=8, h_nc=64, in_nc=4, out_nc=3, nc=[64, 128, 256, 512], nb=2, act_mode='R', downsample_mode='strideconv', upsample_mode='convtranspose'):
+ super(USRNet, self).__init__()
+
+ self.d = DataNet()
+ self.p = ResUNet(in_nc=in_nc, out_nc=out_nc, nc=nc, nb=nb, act_mode=act_mode, downsample_mode=downsample_mode, upsample_mode=upsample_mode)
+ self.h = HyPaNet(in_nc=2, out_nc=n_iter*2, channel=h_nc)
+ self.n = n_iter
+
+ def forward(self, x, k, sf, sigma):
+ '''
+ x: tensor, NxCxWxH
+ k: tensor, Nx(1,3)xwxh
+ sf: integer, 1
+ sigma: tensor, Nx1x1x1
+ '''
+
+ # initialization & pre-calculation
+ w, h = x.shape[-2:]
+ FB = p2o(k, (w*sf, h*sf))
+ FBC = cconj(FB, inplace=False)
+ F2B = r2c(cabs2(FB))
+ STy = upsample(x, sf=sf)
+ FBFy = cmul(FBC, torch.rfft(STy, 2, onesided=False))
+ x = nn.functional.interpolate(x, scale_factor=sf, mode='nearest')
+
+ # hyper-parameter, alpha & beta
+ ab = self.h(torch.cat((sigma, torch.tensor(sf).type_as(sigma).expand_as(sigma)), dim=1))
+
+ # unfolding
+ for i in range(self.n):
+
+ x = self.d(x, FB, FBC, F2B, FBFy, ab[:, i:i+1, ...], sf)
+ x = self.p(torch.cat((x, ab[:, i+self.n:i+self.n+1, ...].repeat(1, 1, x.size(2), x.size(3))), dim=1))
+
+ return x
diff --git a/KAIR/models/network_usrnet_v1.py b/KAIR/models/network_usrnet_v1.py
new file mode 100644
index 0000000000000000000000000000000000000000..78b4d7726ab0f369df3a3e13bd6c7d1b38bba55e
--- /dev/null
+++ b/KAIR/models/network_usrnet_v1.py
@@ -0,0 +1,263 @@
+import torch
+import torch.nn as nn
+import models.basicblock as B
+import numpy as np
+from utils import utils_image as util
+import torch.fft
+
+
+# for pytorch version >= 1.8.1
+
+
+"""
+# --------------------------------------------
+# Kai Zhang (cskaizhang@gmail.com)
+@inproceedings{zhang2020deep,
+ title={Deep unfolding network for image super-resolution},
+ author={Zhang, Kai and Van Gool, Luc and Timofte, Radu},
+ booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
+ pages={0--0},
+ year={2020}
+}
+# --------------------------------------------
+"""
+
+
+"""
+# --------------------------------------------
+# basic functions
+# --------------------------------------------
+"""
+
+
+def splits(a, sf):
+ '''split a into sfxsf distinct blocks
+
+ Args:
+ a: NxCxWxH
+ sf: split factor
+
+ Returns:
+ b: NxCx(W/sf)x(H/sf)x(sf^2)
+ '''
+ b = torch.stack(torch.chunk(a, sf, dim=2), dim=4)
+ b = torch.cat(torch.chunk(b, sf, dim=3), dim=4)
+ return b
+
+
+def p2o(psf, shape):
+ '''
+ Convert point-spread function to optical transfer function.
+ otf = p2o(psf) computes the Fast Fourier Transform (FFT) of the
+ point-spread function (PSF) array and creates the optical transfer
+ function (OTF) array that is not influenced by the PSF off-centering.
+
+ Args:
+ psf: NxCxhxw
+ shape: [H, W]
+
+ Returns:
+ otf: NxCxHxWx2
+ '''
+ otf = torch.zeros(psf.shape[:-2] + shape).type_as(psf)
+ otf[...,:psf.shape[2],:psf.shape[3]].copy_(psf)
+ for axis, axis_size in enumerate(psf.shape[2:]):
+ otf = torch.roll(otf, -int(axis_size / 2), dims=axis+2)
+ otf = torch.fft.fftn(otf, dim=(-2,-1))
+ #n_ops = torch.sum(torch.tensor(psf.shape).type_as(psf) * torch.log2(torch.tensor(psf.shape).type_as(psf)))
+ #otf[..., 1][torch.abs(otf[..., 1]) < n_ops*2.22e-16] = torch.tensor(0).type_as(psf)
+ return otf
+
+
+def upsample(x, sf=3):
+ '''s-fold upsampler
+
+ Upsampling the spatial size by filling the new entries with zeros
+
+ x: tensor image, NxCxWxH
+ '''
+ st = 0
+ z = torch.zeros((x.shape[0], x.shape[1], x.shape[2]*sf, x.shape[3]*sf)).type_as(x)
+ z[..., st::sf, st::sf].copy_(x)
+ return z
+
+
+def downsample(x, sf=3):
+ '''s-fold downsampler
+
+ Keeping the upper-left pixel for each distinct sfxsf patch and discarding the others
+
+ x: tensor image, NxCxWxH
+ '''
+ st = 0
+ return x[..., st::sf, st::sf]
+
+
+def downsample_np(x, sf=3):
+ st = 0
+ return x[st::sf, st::sf, ...]
+
+
+"""
+# --------------------------------------------
+# (1) Prior module; ResUNet: act as a non-blind denoiser
+# x_k = P(z_k, beta_k)
+# --------------------------------------------
+"""
+
+
+class ResUNet(nn.Module):
+ def __init__(self, in_nc=4, out_nc=3, nc=[64, 128, 256, 512], nb=2, act_mode='R', downsample_mode='strideconv', upsample_mode='convtranspose'):
+ super(ResUNet, self).__init__()
+
+ self.m_head = B.conv(in_nc, nc[0], bias=False, mode='C')
+
+ # downsample
+ if downsample_mode == 'avgpool':
+ downsample_block = B.downsample_avgpool
+ elif downsample_mode == 'maxpool':
+ downsample_block = B.downsample_maxpool
+ elif downsample_mode == 'strideconv':
+ downsample_block = B.downsample_strideconv
+ else:
+ raise NotImplementedError('downsample mode [{:s}] is not found'.format(downsample_mode))
+
+ self.m_down1 = B.sequential(*[B.ResBlock(nc[0], nc[0], bias=False, mode='C'+act_mode+'C') for _ in range(nb)], downsample_block(nc[0], nc[1], bias=False, mode='2'))
+ self.m_down2 = B.sequential(*[B.ResBlock(nc[1], nc[1], bias=False, mode='C'+act_mode+'C') for _ in range(nb)], downsample_block(nc[1], nc[2], bias=False, mode='2'))
+ self.m_down3 = B.sequential(*[B.ResBlock(nc[2], nc[2], bias=False, mode='C'+act_mode+'C') for _ in range(nb)], downsample_block(nc[2], nc[3], bias=False, mode='2'))
+
+ self.m_body = B.sequential(*[B.ResBlock(nc[3], nc[3], bias=False, mode='C'+act_mode+'C') for _ in range(nb)])
+
+ # upsample
+ if upsample_mode == 'upconv':
+ upsample_block = B.upsample_upconv
+ elif upsample_mode == 'pixelshuffle':
+ upsample_block = B.upsample_pixelshuffle
+ elif upsample_mode == 'convtranspose':
+ upsample_block = B.upsample_convtranspose
+ else:
+ raise NotImplementedError('upsample mode [{:s}] is not found'.format(upsample_mode))
+
+ self.m_up3 = B.sequential(upsample_block(nc[3], nc[2], bias=False, mode='2'), *[B.ResBlock(nc[2], nc[2], bias=False, mode='C'+act_mode+'C') for _ in range(nb)])
+ self.m_up2 = B.sequential(upsample_block(nc[2], nc[1], bias=False, mode='2'), *[B.ResBlock(nc[1], nc[1], bias=False, mode='C'+act_mode+'C') for _ in range(nb)])
+ self.m_up1 = B.sequential(upsample_block(nc[1], nc[0], bias=False, mode='2'), *[B.ResBlock(nc[0], nc[0], bias=False, mode='C'+act_mode+'C') for _ in range(nb)])
+
+ self.m_tail = B.conv(nc[0], out_nc, bias=False, mode='C')
+
+ def forward(self, x):
+
+ h, w = x.size()[-2:]
+ paddingBottom = int(np.ceil(h/8)*8-h)
+ paddingRight = int(np.ceil(w/8)*8-w)
+ x = nn.ReplicationPad2d((0, paddingRight, 0, paddingBottom))(x)
+
+ x1 = self.m_head(x)
+ x2 = self.m_down1(x1)
+ x3 = self.m_down2(x2)
+ x4 = self.m_down3(x3)
+ x = self.m_body(x4)
+ x = self.m_up3(x+x4)
+ x = self.m_up2(x+x3)
+ x = self.m_up1(x+x2)
+ x = self.m_tail(x+x1)
+
+ x = x[..., :h, :w]
+
+ return x
+
+
+"""
+# --------------------------------------------
+# (2) Data module, closed-form solution
+# It is a trainable-parameter-free module ^_^
+# z_k = D(x_{k-1}, s, k, y, alpha_k)
+# some can be pre-calculated
+# --------------------------------------------
+"""
+
+
+class DataNet(nn.Module):
+ def __init__(self):
+ super(DataNet, self).__init__()
+
+ def forward(self, x, FB, FBC, F2B, FBFy, alpha, sf):
+
+ FR = FBFy + torch.fft.fftn(alpha*x, dim=(-2,-1))
+ x1 = FB.mul(FR)
+ FBR = torch.mean(splits(x1, sf), dim=-1, keepdim=False)
+ invW = torch.mean(splits(F2B, sf), dim=-1, keepdim=False)
+ invWBR = FBR.div(invW + alpha)
+ FCBinvWBR = FBC*invWBR.repeat(1, 1, sf, sf)
+ FX = (FR-FCBinvWBR)/alpha
+ Xest = torch.real(torch.fft.ifftn(FX, dim=(-2,-1)))
+
+ return Xest
+
+
+"""
+# --------------------------------------------
+# (3) Hyper-parameter module
+# --------------------------------------------
+"""
+
+
+class HyPaNet(nn.Module):
+ def __init__(self, in_nc=2, out_nc=8, channel=64):
+ super(HyPaNet, self).__init__()
+ self.mlp = nn.Sequential(
+ nn.Conv2d(in_nc, channel, 1, padding=0, bias=True),
+ nn.ReLU(inplace=True),
+ nn.Conv2d(channel, channel, 1, padding=0, bias=True),
+ nn.ReLU(inplace=True),
+ nn.Conv2d(channel, out_nc, 1, padding=0, bias=True),
+ nn.Softplus())
+
+ def forward(self, x):
+ x = self.mlp(x) + 1e-6
+ return x
+
+
+"""
+# --------------------------------------------
+# main USRNet
+# deep unfolding super-resolution network
+# --------------------------------------------
+"""
+
+
+class USRNet(nn.Module):
+ def __init__(self, n_iter=8, h_nc=64, in_nc=4, out_nc=3, nc=[64, 128, 256, 512], nb=2, act_mode='R', downsample_mode='strideconv', upsample_mode='convtranspose'):
+ super(USRNet, self).__init__()
+
+ self.d = DataNet()
+ self.p = ResUNet(in_nc=in_nc, out_nc=out_nc, nc=nc, nb=nb, act_mode=act_mode, downsample_mode=downsample_mode, upsample_mode=upsample_mode)
+ self.h = HyPaNet(in_nc=2, out_nc=n_iter*2, channel=h_nc)
+ self.n = n_iter
+
+ def forward(self, x, k, sf, sigma):
+ '''
+ x: tensor, NxCxWxH
+ k: tensor, Nx(1,3)xwxh
+ sf: integer, 1
+ sigma: tensor, Nx1x1x1
+ '''
+
+ # initialization & pre-calculation
+ w, h = x.shape[-2:]
+ FB = p2o(k, (w*sf, h*sf))
+ FBC = torch.conj(FB)
+ F2B = torch.pow(torch.abs(FB), 2)
+ STy = upsample(x, sf=sf)
+ FBFy = FBC*torch.fft.fftn(STy, dim=(-2,-1))
+ x = nn.functional.interpolate(x, scale_factor=sf, mode='nearest')
+
+ # hyper-parameter, alpha & beta
+ ab = self.h(torch.cat((sigma, torch.tensor(sf).type_as(sigma).expand_as(sigma)), dim=1))
+
+ # unfolding
+ for i in range(self.n):
+
+ x = self.d(x, FB, FBC, F2B, FBFy, ab[:, i:i+1, ...], sf)
+ x = self.p(torch.cat((x, ab[:, i+self.n:i+self.n+1, ...].repeat(1, 1, x.size(2), x.size(3))), dim=1))
+
+ return x
diff --git a/KAIR/models/network_vrt.py b/KAIR/models/network_vrt.py
new file mode 100755
index 0000000000000000000000000000000000000000..4419633b3c1f6ff1dfcc5786f4e5a3ca07cc10be
--- /dev/null
+++ b/KAIR/models/network_vrt.py
@@ -0,0 +1,1564 @@
+# Copyright (c) Facebook, Inc. and its affiliates.
+#
+# This source code is licensed under the BSD license found in the
+# LICENSE file in the root directory of this source tree.
+
+
+import os
+import warnings
+import math
+import torch
+import torch.nn as nn
+import torchvision
+import torch.nn.functional as F
+import torch.utils.checkpoint as checkpoint
+from distutils.version import LooseVersion
+from torch.nn.modules.utils import _pair, _single
+import numpy as np
+from functools import reduce, lru_cache
+from operator import mul
+from einops import rearrange
+from einops.layers.torch import Rearrange
+
+
+class ModulatedDeformConv(nn.Module):
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size,
+ stride=1,
+ padding=0,
+ dilation=1,
+ groups=1,
+ deformable_groups=1,
+ bias=True):
+ super(ModulatedDeformConv, self).__init__()
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.kernel_size = _pair(kernel_size)
+ self.stride = stride
+ self.padding = padding
+ self.dilation = dilation
+ self.groups = groups
+ self.deformable_groups = deformable_groups
+ self.with_bias = bias
+ # enable compatibility with nn.Conv2d
+ self.transposed = False
+ self.output_padding = _single(0)
+
+ self.weight = nn.Parameter(torch.Tensor(out_channels, in_channels // groups, *self.kernel_size))
+ if bias:
+ self.bias = nn.Parameter(torch.Tensor(out_channels))
+ else:
+ self.register_parameter('bias', None)
+ self.init_weights()
+
+ def init_weights(self):
+ n = self.in_channels
+ for k in self.kernel_size:
+ n *= k
+ stdv = 1. / math.sqrt(n)
+ self.weight.data.uniform_(-stdv, stdv)
+ if self.bias is not None:
+ self.bias.data.zero_()
+
+ # def forward(self, x, offset, mask):
+ # return modulated_deform_conv(x, offset, mask, self.weight, self.bias, self.stride, self.padding, self.dilation,
+ # self.groups, self.deformable_groups)
+
+
+class ModulatedDeformConvPack(ModulatedDeformConv):
+ """A ModulatedDeformable Conv Encapsulation that acts as normal Conv layers.
+
+ Args:
+ in_channels (int): Same as nn.Conv2d.
+ out_channels (int): Same as nn.Conv2d.
+ kernel_size (int or tuple[int]): Same as nn.Conv2d.
+ stride (int or tuple[int]): Same as nn.Conv2d.
+ padding (int or tuple[int]): Same as nn.Conv2d.
+ dilation (int or tuple[int]): Same as nn.Conv2d.
+ groups (int): Same as nn.Conv2d.
+ bias (bool or str): If specified as `auto`, it will be decided by the
+ norm_cfg. Bias will be set as True if norm_cfg is None, otherwise
+ False.
+ """
+
+ _version = 2
+
+ def __init__(self, *args, **kwargs):
+ super(ModulatedDeformConvPack, self).__init__(*args, **kwargs)
+
+ self.conv_offset = nn.Conv2d(
+ self.in_channels,
+ self.deformable_groups * 3 * self.kernel_size[0] * self.kernel_size[1],
+ kernel_size=self.kernel_size,
+ stride=_pair(self.stride),
+ padding=_pair(self.padding),
+ dilation=_pair(self.dilation),
+ bias=True)
+ self.init_weights()
+
+ def init_weights(self):
+ super(ModulatedDeformConvPack, self).init_weights()
+ if hasattr(self, 'conv_offset'):
+ self.conv_offset.weight.data.zero_()
+ self.conv_offset.bias.data.zero_()
+
+ # def forward(self, x):
+ # out = self.conv_offset(x)
+ # o1, o2, mask = torch.chunk(out, 3, dim=1)
+ # offset = torch.cat((o1, o2), dim=1)
+ # mask = torch.sigmoid(mask)
+ # return modulated_deform_conv(x, offset, mask, self.weight, self.bias, self.stride, self.padding, self.dilation,
+ # self.groups, self.deformable_groups)
+
+
+def _no_grad_trunc_normal_(tensor, mean, std, a, b):
+ # From: https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/layers/weight_init.py
+ # Cut & paste from PyTorch official master until it's in a few official releases - RW
+ # Method based on https://people.sc.fsu.edu/~jburkardt/presentations/truncated_normal.pdf
+ def norm_cdf(x):
+ # Computes standard normal cumulative distribution function
+ return (1. + math.erf(x / math.sqrt(2.))) / 2.
+
+ if (mean < a - 2 * std) or (mean > b + 2 * std):
+ warnings.warn(
+ 'mean is more than 2 std from [a, b] in nn.init.trunc_normal_. '
+ 'The distribution of values may be incorrect.',
+ stacklevel=2)
+
+ with torch.no_grad():
+ # Values are generated by using a truncated uniform distribution and
+ # then using the inverse CDF for the normal distribution.
+ # Get upper and lower cdf values
+ low = norm_cdf((a - mean) / std)
+ up = norm_cdf((b - mean) / std)
+
+ # Uniformly fill tensor with values from [low, up], then translate to
+ # [2l-1, 2u-1].
+ tensor.uniform_(2 * low - 1, 2 * up - 1)
+
+ # Use inverse cdf transform for normal distribution to get truncated
+ # standard normal
+ tensor.erfinv_()
+
+ # Transform to proper mean, std
+ tensor.mul_(std * math.sqrt(2.))
+ tensor.add_(mean)
+
+ # Clamp to ensure it's in the proper range
+ tensor.clamp_(min=a, max=b)
+ return tensor
+
+
+def trunc_normal_(tensor, mean=0., std=1., a=-2., b=2.):
+ r"""Fills the input Tensor with values drawn from a truncated
+ normal distribution.
+
+ From: https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/layers/weight_init.py
+
+ The values are effectively drawn from the
+ normal distribution :math:`\mathcal{N}(\text{mean}, \text{std}^2)`
+ with values outside :math:`[a, b]` redrawn until they are within
+ the bounds. The method used for generating the random values works
+ best when :math:`a \leq \text{mean} \leq b`.
+
+ Args:
+ tensor: an n-dimensional `torch.Tensor`
+ mean: the mean of the normal distribution
+ std: the standard deviation of the normal distribution
+ a: the minimum cutoff value
+ b: the maximum cutoff value
+
+ Examples:
+ >>> w = torch.empty(3, 5)
+ >>> nn.init.trunc_normal_(w)
+ """
+ return _no_grad_trunc_normal_(tensor, mean, std, a, b)
+
+
+def drop_path(x, drop_prob: float = 0., training: bool = False):
+ """Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
+ From: https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/layers/drop.py
+ """
+ if drop_prob == 0. or not training:
+ return x
+ keep_prob = 1 - drop_prob
+ shape = (x.shape[0], ) + (1, ) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
+ random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
+ random_tensor.floor_() # binarize
+ output = x.div(keep_prob) * random_tensor
+ return output
+
+
+class DropPath(nn.Module):
+ """Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
+ From: https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/layers/drop.py
+ """
+
+ def __init__(self, drop_prob=None):
+ super(DropPath, self).__init__()
+ self.drop_prob = drop_prob
+
+ def forward(self, x):
+ return drop_path(x, self.drop_prob, self.training)
+
+
+def flow_warp(x, flow, interp_mode='bilinear', padding_mode='zeros', align_corners=True, use_pad_mask=False):
+ """Warp an image or feature map with optical flow.
+
+ Args:
+ x (Tensor): Tensor with size (n, c, h, w).
+ flow (Tensor): Tensor with size (n, h, w, 2), normal value.
+ interp_mode (str): 'nearest' or 'bilinear' or 'nearest4'. Default: 'bilinear'.
+ padding_mode (str): 'zeros' or 'border' or 'reflection'.
+ Default: 'zeros'.
+ align_corners (bool): Before pytorch 1.3, the default value is
+ align_corners=True. After pytorch 1.3, the default value is
+ align_corners=False. Here, we use the True as default.
+ use_pad_mask (bool): only used for PWCNet, x is first padded with ones along the channel dimension.
+ The mask is generated according to the grid_sample results of the padded dimension.
+
+
+ Returns:
+ Tensor: Warped image or feature map.
+ """
+ # assert x.size()[-2:] == flow.size()[1:3] # temporaily turned off for image-wise shift
+ n, _, h, w = x.size()
+ # create mesh grid
+ # grid_y, grid_x = torch.meshgrid(torch.arange(0, h).type_as(x), torch.arange(0, w).type_as(x)) # an illegal memory access on TITAN RTX + PyTorch1.9.1
+ grid_y, grid_x = torch.meshgrid(torch.arange(0, h, dtype=x.dtype, device=x.device), torch.arange(0, w, dtype=x.dtype, device=x.device))
+ grid = torch.stack((grid_x, grid_y), 2).float() # W(x), H(y), 2
+ grid.requires_grad = False
+
+ vgrid = grid + flow
+
+ # if use_pad_mask: # for PWCNet
+ # x = F.pad(x, (0,0,0,0,0,1), mode='constant', value=1)
+
+ # scale grid to [-1,1]
+ if interp_mode == 'nearest4': # todo: bug, no gradient for flow model in this case!!! but the result is good
+ vgrid_x_floor = 2.0 * torch.floor(vgrid[:, :, :, 0]) / max(w - 1, 1) - 1.0
+ vgrid_x_ceil = 2.0 * torch.ceil(vgrid[:, :, :, 0]) / max(w - 1, 1) - 1.0
+ vgrid_y_floor = 2.0 * torch.floor(vgrid[:, :, :, 1]) / max(h - 1, 1) - 1.0
+ vgrid_y_ceil = 2.0 * torch.ceil(vgrid[:, :, :, 1]) / max(h - 1, 1) - 1.0
+
+ output00 = F.grid_sample(x, torch.stack((vgrid_x_floor, vgrid_y_floor), dim=3), mode='nearest', padding_mode=padding_mode, align_corners=align_corners)
+ output01 = F.grid_sample(x, torch.stack((vgrid_x_floor, vgrid_y_ceil), dim=3), mode='nearest', padding_mode=padding_mode, align_corners=align_corners)
+ output10 = F.grid_sample(x, torch.stack((vgrid_x_ceil, vgrid_y_floor), dim=3), mode='nearest', padding_mode=padding_mode, align_corners=align_corners)
+ output11 = F.grid_sample(x, torch.stack((vgrid_x_ceil, vgrid_y_ceil), dim=3), mode='nearest', padding_mode=padding_mode, align_corners=align_corners)
+
+ return torch.cat([output00, output01, output10, output11], 1)
+
+ else:
+ vgrid_x = 2.0 * vgrid[:, :, :, 0] / max(w - 1, 1) - 1.0
+ vgrid_y = 2.0 * vgrid[:, :, :, 1] / max(h - 1, 1) - 1.0
+ vgrid_scaled = torch.stack((vgrid_x, vgrid_y), dim=3)
+ output = F.grid_sample(x, vgrid_scaled, mode=interp_mode, padding_mode=padding_mode, align_corners=align_corners)
+
+ # if use_pad_mask: # for PWCNet
+ # output = _flow_warp_masking(output)
+
+ # TODO, what if align_corners=False
+ return output
+
+
+class DCNv2PackFlowGuided(ModulatedDeformConvPack):
+ """Flow-guided deformable alignment module.
+
+ Args:
+ in_channels (int): Same as nn.Conv2d.
+ out_channels (int): Same as nn.Conv2d.
+ kernel_size (int or tuple[int]): Same as nn.Conv2d.
+ stride (int or tuple[int]): Same as nn.Conv2d.
+ padding (int or tuple[int]): Same as nn.Conv2d.
+ dilation (int or tuple[int]): Same as nn.Conv2d.
+ groups (int): Same as nn.Conv2d.
+ bias (bool or str): If specified as `auto`, it will be decided by the
+ norm_cfg. Bias will be set as True if norm_cfg is None, otherwise
+ False.
+ max_residue_magnitude (int): The maximum magnitude of the offset residue. Default: 10.
+ pa_frames (int): The number of parallel warping frames. Default: 2.
+
+ Ref:
+ BasicVSR++: Improving Video Super-Resolution with Enhanced Propagation and Alignment.
+
+ """
+
+ def __init__(self, *args, **kwargs):
+ self.max_residue_magnitude = kwargs.pop('max_residue_magnitude', 10)
+ self.pa_frames = kwargs.pop('pa_frames', 2)
+
+ super(DCNv2PackFlowGuided, self).__init__(*args, **kwargs)
+
+ self.conv_offset = nn.Sequential(
+ nn.Conv2d((1+self.pa_frames//2) * self.in_channels + self.pa_frames, self.out_channels, 3, 1, 1),
+ nn.LeakyReLU(negative_slope=0.1, inplace=True),
+ nn.Conv2d(self.out_channels, self.out_channels, 3, 1, 1),
+ nn.LeakyReLU(negative_slope=0.1, inplace=True),
+ nn.Conv2d(self.out_channels, self.out_channels, 3, 1, 1),
+ nn.LeakyReLU(negative_slope=0.1, inplace=True),
+ nn.Conv2d(self.out_channels, 3 * 9 * self.deformable_groups, 3, 1, 1),
+ )
+
+ self.init_offset()
+
+ def init_offset(self):
+ super(ModulatedDeformConvPack, self).init_weights()
+ if hasattr(self, 'conv_offset'):
+ self.conv_offset[-1].weight.data.zero_()
+ self.conv_offset[-1].bias.data.zero_()
+
+ def forward(self, x, x_flow_warpeds, x_current, flows):
+ out = self.conv_offset(torch.cat(x_flow_warpeds + [x_current] + flows, dim=1))
+ o1, o2, mask = torch.chunk(out, 3, dim=1)
+
+ # offset
+ offset = self.max_residue_magnitude * torch.tanh(torch.cat((o1, o2), dim=1))
+ if self.pa_frames == 2:
+ offset = offset + flows[0].flip(1).repeat(1, offset.size(1)//2, 1, 1)
+ elif self.pa_frames == 4:
+ offset1, offset2 = torch.chunk(offset, 2, dim=1)
+ offset1 = offset1 + flows[0].flip(1).repeat(1, offset1.size(1) // 2, 1, 1)
+ offset2 = offset2 + flows[1].flip(1).repeat(1, offset2.size(1) // 2, 1, 1)
+ offset = torch.cat([offset1, offset2], dim=1)
+ elif self.pa_frames == 6:
+ offset = self.max_residue_magnitude * torch.tanh(torch.cat((o1, o2), dim=1))
+ offset1, offset2, offset3 = torch.chunk(offset, 3, dim=1)
+ offset1 = offset1 + flows[0].flip(1).repeat(1, offset1.size(1) // 2, 1, 1)
+ offset2 = offset2 + flows[1].flip(1).repeat(1, offset2.size(1) // 2, 1, 1)
+ offset3 = offset3 + flows[2].flip(1).repeat(1, offset3.size(1) // 2, 1, 1)
+ offset = torch.cat([offset1, offset2, offset3], dim=1)
+
+ # mask
+ mask = torch.sigmoid(mask)
+
+ return torchvision.ops.deform_conv2d(x, offset, self.weight, self.bias, self.stride, self.padding,
+ self.dilation, mask)
+
+
+class BasicModule(nn.Module):
+ """Basic Module for SpyNet.
+ """
+
+ def __init__(self):
+ super(BasicModule, self).__init__()
+
+ self.basic_module = nn.Sequential(
+ nn.Conv2d(in_channels=8, out_channels=32, kernel_size=7, stride=1, padding=3), nn.ReLU(inplace=False),
+ nn.Conv2d(in_channels=32, out_channels=64, kernel_size=7, stride=1, padding=3), nn.ReLU(inplace=False),
+ nn.Conv2d(in_channels=64, out_channels=32, kernel_size=7, stride=1, padding=3), nn.ReLU(inplace=False),
+ nn.Conv2d(in_channels=32, out_channels=16, kernel_size=7, stride=1, padding=3), nn.ReLU(inplace=False),
+ nn.Conv2d(in_channels=16, out_channels=2, kernel_size=7, stride=1, padding=3))
+
+ def forward(self, tensor_input):
+ return self.basic_module(tensor_input)
+
+
+class SpyNet(nn.Module):
+ """SpyNet architecture.
+
+ Args:
+ load_path (str): path for pretrained SpyNet. Default: None.
+ return_levels (list[int]): return flows of different levels. Default: [5].
+ """
+
+ def __init__(self, load_path=None, return_levels=[5]):
+ super(SpyNet, self).__init__()
+ self.return_levels = return_levels
+ self.basic_module = nn.ModuleList([BasicModule() for _ in range(6)])
+ if load_path:
+ if not os.path.exists(load_path):
+ import requests
+ url = 'https://github.com/JingyunLiang/VRT/releases/download/v0.0/spynet_sintel_final-3d2a1287.pth'
+ r = requests.get(url, allow_redirects=True)
+ print(f'downloading SpyNet pretrained model from {url}')
+ os.makedirs(os.path.dirname(load_path), exist_ok=True)
+ open(load_path, 'wb').write(r.content)
+
+ self.load_state_dict(torch.load(load_path, map_location=lambda storage, loc: storage)['params'])
+
+ self.register_buffer('mean', torch.Tensor([0.485, 0.456, 0.406]).view(1, 3, 1, 1))
+ self.register_buffer('std', torch.Tensor([0.229, 0.224, 0.225]).view(1, 3, 1, 1))
+
+ def preprocess(self, tensor_input):
+ tensor_output = (tensor_input - self.mean) / self.std
+ return tensor_output
+
+ def process(self, ref, supp, w, h, w_floor, h_floor):
+ flow_list = []
+
+ ref = [self.preprocess(ref)]
+ supp = [self.preprocess(supp)]
+
+ for level in range(5):
+ ref.insert(0, F.avg_pool2d(input=ref[0], kernel_size=2, stride=2, count_include_pad=False))
+ supp.insert(0, F.avg_pool2d(input=supp[0], kernel_size=2, stride=2, count_include_pad=False))
+
+ flow = ref[0].new_zeros(
+ [ref[0].size(0), 2,
+ int(math.floor(ref[0].size(2) / 2.0)),
+ int(math.floor(ref[0].size(3) / 2.0))])
+
+ for level in range(len(ref)):
+ upsampled_flow = F.interpolate(input=flow, scale_factor=2, mode='bilinear', align_corners=True) * 2.0
+
+ if upsampled_flow.size(2) != ref[level].size(2):
+ upsampled_flow = F.pad(input=upsampled_flow, pad=[0, 0, 0, 1], mode='replicate')
+ if upsampled_flow.size(3) != ref[level].size(3):
+ upsampled_flow = F.pad(input=upsampled_flow, pad=[0, 1, 0, 0], mode='replicate')
+
+ flow = self.basic_module[level](torch.cat([
+ ref[level],
+ flow_warp(
+ supp[level], upsampled_flow.permute(0, 2, 3, 1), interp_mode='bilinear', padding_mode='border'),
+ upsampled_flow
+ ], 1)) + upsampled_flow
+
+ if level in self.return_levels:
+ scale = 2**(5-level) # level=5 (scale=1), level=4 (scale=2), level=3 (scale=4), level=2 (scale=8)
+ flow_out = F.interpolate(input=flow, size=(h//scale, w//scale), mode='bilinear', align_corners=False)
+ flow_out[:, 0, :, :] *= float(w//scale) / float(w_floor//scale)
+ flow_out[:, 1, :, :] *= float(h//scale) / float(h_floor//scale)
+ flow_list.insert(0, flow_out)
+
+ return flow_list
+
+ def forward(self, ref, supp):
+ assert ref.size() == supp.size()
+
+ h, w = ref.size(2), ref.size(3)
+ w_floor = math.floor(math.ceil(w / 32.0) * 32.0)
+ h_floor = math.floor(math.ceil(h / 32.0) * 32.0)
+
+ ref = F.interpolate(input=ref, size=(h_floor, w_floor), mode='bilinear', align_corners=False)
+ supp = F.interpolate(input=supp, size=(h_floor, w_floor), mode='bilinear', align_corners=False)
+
+ flow_list = self.process(ref, supp, w, h, w_floor, h_floor)
+
+ return flow_list[0] if len(flow_list) == 1 else flow_list
+
+
+def window_partition(x, window_size):
+ """ Partition the input into windows. Attention will be conducted within the windows.
+
+ Args:
+ x: (B, D, H, W, C)
+ window_size (tuple[int]): window size
+
+ Returns:
+ windows: (B*num_windows, window_size*window_size, C)
+ """
+ B, D, H, W, C = x.shape
+ x = x.view(B, D // window_size[0], window_size[0], H // window_size[1], window_size[1], W // window_size[2],
+ window_size[2], C)
+ windows = x.permute(0, 1, 3, 5, 2, 4, 6, 7).contiguous().view(-1, reduce(mul, window_size), C)
+
+ return windows
+
+
+def window_reverse(windows, window_size, B, D, H, W):
+ """ Reverse windows back to the original input. Attention was conducted within the windows.
+
+ Args:
+ windows: (B*num_windows, window_size, window_size, C)
+ window_size (tuple[int]): Window size
+ H (int): Height of image
+ W (int): Width of image
+
+ Returns:
+ x: (B, D, H, W, C)
+ """
+ x = windows.view(B, D // window_size[0], H // window_size[1], W // window_size[2], window_size[0], window_size[1],
+ window_size[2], -1)
+ x = x.permute(0, 1, 4, 2, 5, 3, 6, 7).contiguous().view(B, D, H, W, -1)
+
+ return x
+
+
+def get_window_size(x_size, window_size, shift_size=None):
+ """ Get the window size and the shift size """
+
+ use_window_size = list(window_size)
+ if shift_size is not None:
+ use_shift_size = list(shift_size)
+ for i in range(len(x_size)):
+ if x_size[i] <= window_size[i]:
+ use_window_size[i] = x_size[i]
+ if shift_size is not None:
+ use_shift_size[i] = 0
+
+ if shift_size is None:
+ return tuple(use_window_size)
+ else:
+ return tuple(use_window_size), tuple(use_shift_size)
+
+
+@lru_cache()
+def compute_mask(D, H, W, window_size, shift_size, device):
+ """ Compute attnetion mask for input of size (D, H, W). @lru_cache caches each stage results. """
+
+ img_mask = torch.zeros((1, D, H, W, 1), device=device) # 1 Dp Hp Wp 1
+ cnt = 0
+ for d in slice(-window_size[0]), slice(-window_size[0], -shift_size[0]), slice(-shift_size[0], None):
+ for h in slice(-window_size[1]), slice(-window_size[1], -shift_size[1]), slice(-shift_size[1], None):
+ for w in slice(-window_size[2]), slice(-window_size[2], -shift_size[2]), slice(-shift_size[2], None):
+ img_mask[:, d, h, w, :] = cnt
+ cnt += 1
+ mask_windows = window_partition(img_mask, window_size) # nW, ws[0]*ws[1]*ws[2], 1
+ mask_windows = mask_windows.squeeze(-1) # nW, ws[0]*ws[1]*ws[2]
+ attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
+ attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
+
+ return attn_mask
+
+
+class Upsample(nn.Sequential):
+ """Upsample module for video SR.
+
+ Args:
+ scale (int): Scale factor. Supported scales: 2^n and 3.
+ num_feat (int): Channel number of intermediate features.
+ """
+
+ def __init__(self, scale, num_feat):
+ assert LooseVersion(torch.__version__) >= LooseVersion('1.8.1'), \
+ 'PyTorch version >= 1.8.1 to support 5D PixelShuffle.'
+
+ class Transpose_Dim12(nn.Module):
+ """ Transpose Dim1 and Dim2 of a tensor."""
+
+ def __init__(self):
+ super().__init__()
+
+ def forward(self, x):
+ return x.transpose(1, 2)
+
+ m = []
+ if (scale & (scale - 1)) == 0: # scale = 2^n
+ for _ in range(int(math.log(scale, 2))):
+ m.append(nn.Conv3d(num_feat, 4 * num_feat, kernel_size=(1, 3, 3), padding=(0, 1, 1)))
+ m.append(Transpose_Dim12())
+ m.append(nn.PixelShuffle(2))
+ m.append(Transpose_Dim12())
+ m.append(nn.LeakyReLU(negative_slope=0.1, inplace=True))
+ m.append(nn.Conv3d(num_feat, num_feat, kernel_size=(1, 3, 3), padding=(0, 1, 1)))
+ elif scale == 3:
+ m.append(nn.Conv3d(num_feat, 9 * num_feat, kernel_size=(1, 3, 3), padding=(0, 1, 1)))
+ m.append(Transpose_Dim12())
+ m.append(nn.PixelShuffle(3))
+ m.append(Transpose_Dim12())
+ m.append(nn.LeakyReLU(negative_slope=0.1, inplace=True))
+ m.append(nn.Conv3d(num_feat, num_feat, kernel_size=(1, 3, 3), padding=(0, 1, 1)))
+ else:
+ raise ValueError(f'scale {scale} is not supported. ' 'Supported scales: 2^n and 3.')
+ super(Upsample, self).__init__(*m)
+
+
+class Mlp_GEGLU(nn.Module):
+ """ Multilayer perceptron with gated linear unit (GEGLU). Ref. "GLU Variants Improve Transformer".
+
+ Args:
+ x: (B, D, H, W, C)
+
+ Returns:
+ x: (B, D, H, W, C)
+ """
+
+ def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
+ super().__init__()
+ out_features = out_features or in_features
+ hidden_features = hidden_features or in_features
+
+ self.fc11 = nn.Linear(in_features, hidden_features)
+ self.fc12 = nn.Linear(in_features, hidden_features)
+ self.act = act_layer()
+ self.fc2 = nn.Linear(hidden_features, out_features)
+ self.drop = nn.Dropout(drop)
+
+ def forward(self, x):
+ x = self.act(self.fc11(x)) * self.fc12(x)
+ x = self.drop(x)
+ x = self.fc2(x)
+
+ return x
+
+
+class WindowAttention(nn.Module):
+ """ Window based multi-head mutual attention and self attention.
+
+ Args:
+ dim (int): Number of input channels.
+ window_size (tuple[int]): The temporal length, height and width of the window.
+ num_heads (int): Number of attention heads.
+ qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
+ qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
+ mut_attn (bool): If True, add mutual attention to the module. Default: True
+ """
+
+ def __init__(self, dim, window_size, num_heads, qkv_bias=False, qk_scale=None, mut_attn=True):
+ super().__init__()
+ self.dim = dim
+ self.window_size = window_size
+ self.num_heads = num_heads
+ head_dim = dim // num_heads
+ self.scale = qk_scale or head_dim ** -0.5
+ self.mut_attn = mut_attn
+
+ # self attention with relative position bias
+ self.relative_position_bias_table = nn.Parameter(
+ torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1) * (2 * window_size[2] - 1),
+ num_heads)) # 2*Wd-1 * 2*Wh-1 * 2*Ww-1, nH
+ self.register_buffer("relative_position_index", self.get_position_index(window_size))
+ self.qkv_self = nn.Linear(dim, dim * 3, bias=qkv_bias)
+ self.proj = nn.Linear(dim, dim)
+
+ # mutual attention with sine position encoding
+ if self.mut_attn:
+ self.register_buffer("position_bias",
+ self.get_sine_position_encoding(window_size[1:], dim // 2, normalize=True))
+ self.qkv_mut = nn.Linear(dim, dim * 3, bias=qkv_bias)
+ self.proj = nn.Linear(2 * dim, dim)
+
+ self.softmax = nn.Softmax(dim=-1)
+ trunc_normal_(self.relative_position_bias_table, std=.02)
+
+ def forward(self, x, mask=None):
+ """ Forward function.
+
+ Args:
+ x: input features with shape of (num_windows*B, N, C)
+ mask: (0/-inf) mask with shape of (num_windows, N, N) or None
+ """
+
+ # self attention
+ B_, N, C = x.shape
+ qkv = self.qkv_self(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
+ q, k, v = qkv[0], qkv[1], qkv[2] # B_, nH, N, C
+ x_out = self.attention(q, k, v, mask, (B_, N, C), relative_position_encoding=True)
+
+ # mutual attention
+ if self.mut_attn:
+ qkv = self.qkv_mut(x + self.position_bias.repeat(1, 2, 1)).reshape(B_, N, 3, self.num_heads,
+ C // self.num_heads).permute(2, 0, 3, 1,
+ 4)
+ (q1, q2), (k1, k2), (v1, v2) = torch.chunk(qkv[0], 2, dim=2), torch.chunk(qkv[1], 2, dim=2), torch.chunk(
+ qkv[2], 2, dim=2) # B_, nH, N/2, C
+ x1_aligned = self.attention(q2, k1, v1, mask, (B_, N // 2, C), relative_position_encoding=False)
+ x2_aligned = self.attention(q1, k2, v2, mask, (B_, N // 2, C), relative_position_encoding=False)
+ x_out = torch.cat([torch.cat([x1_aligned, x2_aligned], 1), x_out], 2)
+
+ # projection
+ x = self.proj(x_out)
+
+ return x
+
+ def attention(self, q, k, v, mask, x_shape, relative_position_encoding=True):
+ B_, N, C = x_shape
+ attn = (q * self.scale) @ k.transpose(-2, -1)
+
+ if relative_position_encoding:
+ relative_position_bias = self.relative_position_bias_table[
+ self.relative_position_index[:N, :N].reshape(-1)].reshape(N, N, -1) # Wd*Wh*Ww, Wd*Wh*Ww,nH
+ attn = attn + relative_position_bias.permute(2, 0, 1).unsqueeze(0) # B_, nH, N, N
+
+ if mask is None:
+ attn = self.softmax(attn)
+ else:
+ nW = mask.shape[0]
+ attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask[:, :N, :N].unsqueeze(1).unsqueeze(0)
+ attn = attn.view(-1, self.num_heads, N, N)
+ attn = self.softmax(attn)
+
+ x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
+
+ return x
+
+ def get_position_index(self, window_size):
+ ''' Get pair-wise relative position index for each token inside the window. '''
+
+ coords_d = torch.arange(window_size[0])
+ coords_h = torch.arange(window_size[1])
+ coords_w = torch.arange(window_size[2])
+ coords = torch.stack(torch.meshgrid(coords_d, coords_h, coords_w)) # 3, Wd, Wh, Ww
+ coords_flatten = torch.flatten(coords, 1) # 3, Wd*Wh*Ww
+ relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 3, Wd*Wh*Ww, Wd*Wh*Ww
+ relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wd*Wh*Ww, Wd*Wh*Ww, 3
+ relative_coords[:, :, 0] += window_size[0] - 1 # shift to start from 0
+ relative_coords[:, :, 1] += window_size[1] - 1
+ relative_coords[:, :, 2] += window_size[2] - 1
+
+ relative_coords[:, :, 0] *= (2 * window_size[1] - 1) * (2 * window_size[2] - 1)
+ relative_coords[:, :, 1] *= (2 * window_size[2] - 1)
+ relative_position_index = relative_coords.sum(-1) # Wd*Wh*Ww, Wd*Wh*Ww
+
+ return relative_position_index
+
+ def get_sine_position_encoding(self, HW, num_pos_feats=64, temperature=10000, normalize=False, scale=None):
+ """ Get sine position encoding """
+
+ if scale is not None and normalize is False:
+ raise ValueError("normalize should be True if scale is passed")
+
+ if scale is None:
+ scale = 2 * math.pi
+
+ not_mask = torch.ones([1, HW[0], HW[1]])
+ y_embed = not_mask.cumsum(1, dtype=torch.float32)
+ x_embed = not_mask.cumsum(2, dtype=torch.float32)
+ if normalize:
+ eps = 1e-6
+ y_embed = y_embed / (y_embed[:, -1:, :] + eps) * scale
+ x_embed = x_embed / (x_embed[:, :, -1:] + eps) * scale
+
+ dim_t = torch.arange(num_pos_feats, dtype=torch.float32)
+ dim_t = temperature ** (2 * (dim_t // 2) / num_pos_feats)
+
+ # BxCxHxW
+ pos_x = x_embed[:, :, :, None] / dim_t
+ pos_y = y_embed[:, :, :, None] / dim_t
+ pos_x = torch.stack((pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()), dim=4).flatten(3)
+ pos_y = torch.stack((pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()), dim=4).flatten(3)
+ pos_embed = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)
+
+ return pos_embed.flatten(2).permute(0, 2, 1).contiguous()
+
+
+class TMSA(nn.Module):
+ """ Temporal Mutual Self Attention (TMSA).
+
+ Args:
+ dim (int): Number of input channels.
+ input_resolution (tuple[int]): Input resolution.
+ num_heads (int): Number of attention heads.
+ window_size (tuple[int]): Window size.
+ shift_size (tuple[int]): Shift size for mutual and self attention.
+ mut_attn (bool): If True, use mutual and self attention. Default: True.
+ mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
+ qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True.
+ qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
+ drop_path (float, optional): Stochastic depth rate. Default: 0.0.
+ act_layer (nn.Module, optional): Activation layer. Default: nn.GELU.
+ norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm.
+ use_checkpoint_attn (bool): If True, use torch.checkpoint for attention modules. Default: False.
+ use_checkpoint_ffn (bool): If True, use torch.checkpoint for feed-forward modules. Default: False.
+ """
+
+ def __init__(self,
+ dim,
+ input_resolution,
+ num_heads,
+ window_size=(6, 8, 8),
+ shift_size=(0, 0, 0),
+ mut_attn=True,
+ mlp_ratio=2.,
+ qkv_bias=True,
+ qk_scale=None,
+ drop_path=0.,
+ act_layer=nn.GELU,
+ norm_layer=nn.LayerNorm,
+ use_checkpoint_attn=False,
+ use_checkpoint_ffn=False
+ ):
+ super().__init__()
+ self.dim = dim
+ self.input_resolution = input_resolution
+ self.num_heads = num_heads
+ self.window_size = window_size
+ self.shift_size = shift_size
+ self.use_checkpoint_attn = use_checkpoint_attn
+ self.use_checkpoint_ffn = use_checkpoint_ffn
+
+ assert 0 <= self.shift_size[0] < self.window_size[0], "shift_size must in 0-window_size"
+ assert 0 <= self.shift_size[1] < self.window_size[1], "shift_size must in 0-window_size"
+ assert 0 <= self.shift_size[2] < self.window_size[2], "shift_size must in 0-window_size"
+
+ self.norm1 = norm_layer(dim)
+ self.attn = WindowAttention(dim, window_size=self.window_size, num_heads=num_heads, qkv_bias=qkv_bias,
+ qk_scale=qk_scale, mut_attn=mut_attn)
+ self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
+ self.norm2 = norm_layer(dim)
+ self.mlp = Mlp_GEGLU(in_features=dim, hidden_features=int(dim * mlp_ratio), act_layer=act_layer)
+
+ def forward_part1(self, x, mask_matrix):
+ B, D, H, W, C = x.shape
+ window_size, shift_size = get_window_size((D, H, W), self.window_size, self.shift_size)
+
+ x = self.norm1(x)
+
+ # pad feature maps to multiples of window size
+ pad_l = pad_t = pad_d0 = 0
+ pad_d1 = (window_size[0] - D % window_size[0]) % window_size[0]
+ pad_b = (window_size[1] - H % window_size[1]) % window_size[1]
+ pad_r = (window_size[2] - W % window_size[2]) % window_size[2]
+ x = F.pad(x, (0, 0, pad_l, pad_r, pad_t, pad_b, pad_d0, pad_d1), mode='constant')
+
+ _, Dp, Hp, Wp, _ = x.shape
+ # cyclic shift
+ if any(i > 0 for i in shift_size):
+ shifted_x = torch.roll(x, shifts=(-shift_size[0], -shift_size[1], -shift_size[2]), dims=(1, 2, 3))
+ attn_mask = mask_matrix
+ else:
+ shifted_x = x
+ attn_mask = None
+
+ # partition windows
+ x_windows = window_partition(shifted_x, window_size) # B*nW, Wd*Wh*Ww, C
+
+ # attention / shifted attention
+ attn_windows = self.attn(x_windows, mask=attn_mask) # B*nW, Wd*Wh*Ww, C
+
+ # merge windows
+ attn_windows = attn_windows.view(-1, *(window_size + (C,)))
+ shifted_x = window_reverse(attn_windows, window_size, B, Dp, Hp, Wp) # B D' H' W' C
+
+ # reverse cyclic shift
+ if any(i > 0 for i in shift_size):
+ x = torch.roll(shifted_x, shifts=(shift_size[0], shift_size[1], shift_size[2]), dims=(1, 2, 3))
+ else:
+ x = shifted_x
+
+ if pad_d1 > 0 or pad_r > 0 or pad_b > 0:
+ x = x[:, :D, :H, :W, :]
+
+ x = self.drop_path(x)
+
+ return x
+
+ def forward_part2(self, x):
+ return self.drop_path(self.mlp(self.norm2(x)))
+
+ def forward(self, x, mask_matrix):
+ """ Forward function.
+
+ Args:
+ x: Input feature, tensor size (B, D, H, W, C).
+ mask_matrix: Attention mask for cyclic shift.
+ """
+
+ # attention
+ if self.use_checkpoint_attn:
+ x = x + checkpoint.checkpoint(self.forward_part1, x, mask_matrix)
+ else:
+ x = x + self.forward_part1(x, mask_matrix)
+
+ # feed-forward
+ if self.use_checkpoint_ffn:
+ x = x + checkpoint.checkpoint(self.forward_part2, x)
+ else:
+ x = x + self.forward_part2(x)
+
+ return x
+
+
+class TMSAG(nn.Module):
+ """ Temporal Mutual Self Attention Group (TMSAG).
+
+ Args:
+ dim (int): Number of feature channels
+ input_resolution (tuple[int]): Input resolution.
+ depth (int): Depths of this stage.
+ num_heads (int): Number of attention head.
+ window_size (tuple[int]): Local window size. Default: (6,8,8).
+ shift_size (tuple[int]): Shift size for mutual and self attention. Default: None.
+ mut_attn (bool): If True, use mutual and self attention. Default: True.
+ mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 2.
+ qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
+ qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
+ drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
+ norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
+ use_checkpoint_attn (bool): If True, use torch.checkpoint for attention modules. Default: False.
+ use_checkpoint_ffn (bool): If True, use torch.checkpoint for feed-forward modules. Default: False.
+ """
+
+ def __init__(self,
+ dim,
+ input_resolution,
+ depth,
+ num_heads,
+ window_size=[6, 8, 8],
+ shift_size=None,
+ mut_attn=True,
+ mlp_ratio=2.,
+ qkv_bias=False,
+ qk_scale=None,
+ drop_path=0.,
+ norm_layer=nn.LayerNorm,
+ use_checkpoint_attn=False,
+ use_checkpoint_ffn=False
+ ):
+ super().__init__()
+ self.input_resolution = input_resolution
+ self.window_size = window_size
+ self.shift_size = list(i // 2 for i in window_size) if shift_size is None else shift_size
+
+ # build blocks
+ self.blocks = nn.ModuleList([
+ TMSA(
+ dim=dim,
+ input_resolution=input_resolution,
+ num_heads=num_heads,
+ window_size=window_size,
+ shift_size=[0, 0, 0] if i % 2 == 0 else self.shift_size,
+ mut_attn=mut_attn,
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
+ norm_layer=norm_layer,
+ use_checkpoint_attn=use_checkpoint_attn,
+ use_checkpoint_ffn=use_checkpoint_ffn
+ )
+ for i in range(depth)])
+
+ def forward(self, x):
+ """ Forward function.
+
+ Args:
+ x: Input feature, tensor size (B, C, D, H, W).
+ """
+ # calculate attention mask for attention
+ B, C, D, H, W = x.shape
+ window_size, shift_size = get_window_size((D, H, W), self.window_size, self.shift_size)
+ x = rearrange(x, 'b c d h w -> b d h w c')
+ Dp = int(np.ceil(D / window_size[0])) * window_size[0]
+ Hp = int(np.ceil(H / window_size[1])) * window_size[1]
+ Wp = int(np.ceil(W / window_size[2])) * window_size[2]
+ attn_mask = compute_mask(Dp, Hp, Wp, window_size, shift_size, x.device)
+
+ for blk in self.blocks:
+ x = blk(x, attn_mask)
+
+ x = x.view(B, D, H, W, -1)
+ x = rearrange(x, 'b d h w c -> b c d h w')
+
+ return x
+
+
+class RTMSA(nn.Module):
+ """ Residual Temporal Mutual Self Attention (RTMSA). Only used in stage 8.
+
+ Args:
+ dim (int): Number of input channels.
+ input_resolution (tuple[int]): Input resolution.
+ depth (int): Number of blocks.
+ num_heads (int): Number of attention heads.
+ window_size (int): Local window size.
+ mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
+ qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True.
+ qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
+ drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0.
+ norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm.
+ use_checkpoint_attn (bool): If True, use torch.checkpoint for attention modules. Default: False.
+ use_checkpoint_ffn (bool): If True, use torch.checkpoint for feed-forward modules. Default: False.
+ """
+
+ def __init__(self,
+ dim,
+ input_resolution,
+ depth,
+ num_heads,
+ window_size,
+ mlp_ratio=2.,
+ qkv_bias=True,
+ qk_scale=None,
+ drop_path=0.,
+ norm_layer=nn.LayerNorm,
+ use_checkpoint_attn=False,
+ use_checkpoint_ffn=None
+ ):
+ super(RTMSA, self).__init__()
+ self.dim = dim
+ self.input_resolution = input_resolution
+
+ self.residual_group = TMSAG(dim=dim,
+ input_resolution=input_resolution,
+ depth=depth,
+ num_heads=num_heads,
+ window_size=window_size,
+ mut_attn=False,
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias, qk_scale=qk_scale,
+ drop_path=drop_path,
+ norm_layer=norm_layer,
+ use_checkpoint_attn=use_checkpoint_attn,
+ use_checkpoint_ffn=use_checkpoint_ffn
+ )
+
+ self.linear = nn.Linear(dim, dim)
+
+ def forward(self, x):
+ return x + self.linear(self.residual_group(x).transpose(1, 4)).transpose(1, 4)
+
+
+class Stage(nn.Module):
+ """Residual Temporal Mutual Self Attention Group and Parallel Warping.
+
+ Args:
+ in_dim (int): Number of input channels.
+ dim (int): Number of channels.
+ input_resolution (tuple[int]): Input resolution.
+ depth (int): Number of blocks.
+ num_heads (int): Number of attention heads.
+ mul_attn_ratio (float): Ratio of mutual attention layers. Default: 0.75.
+ window_size (int): Local window size.
+ mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
+ qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
+ qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
+ drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
+ norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
+ pa_frames (float): Number of warpped frames. Default: 2.
+ deformable_groups (float): Number of deformable groups. Default: 16.
+ reshape (str): Downscale (down), upscale (up) or keep the size (none).
+ max_residue_magnitude (float): Maximum magnitude of the residual of optical flow.
+ use_checkpoint_attn (bool): If True, use torch.checkpoint for attention modules. Default: False.
+ use_checkpoint_ffn (bool): If True, use torch.checkpoint for feed-forward modules. Default: False.
+ """
+
+ def __init__(self,
+ in_dim,
+ dim,
+ input_resolution,
+ depth,
+ num_heads,
+ window_size,
+ mul_attn_ratio=0.75,
+ mlp_ratio=2.,
+ qkv_bias=True,
+ qk_scale=None,
+ drop_path=0.,
+ norm_layer=nn.LayerNorm,
+ pa_frames=2,
+ deformable_groups=16,
+ reshape=None,
+ max_residue_magnitude=10,
+ use_checkpoint_attn=False,
+ use_checkpoint_ffn=False
+ ):
+ super(Stage, self).__init__()
+ self.pa_frames = pa_frames
+
+ # reshape the tensor
+ if reshape == 'none':
+ self.reshape = nn.Sequential(Rearrange('n c d h w -> n d h w c'),
+ nn.LayerNorm(dim),
+ Rearrange('n d h w c -> n c d h w'))
+ elif reshape == 'down':
+ self.reshape = nn.Sequential(Rearrange('n c d (h neih) (w neiw) -> n d h w (neiw neih c)', neih=2, neiw=2),
+ nn.LayerNorm(4 * in_dim), nn.Linear(4 * in_dim, dim),
+ Rearrange('n d h w c -> n c d h w'))
+ elif reshape == 'up':
+ self.reshape = nn.Sequential(Rearrange('n (neiw neih c) d h w -> n d (h neih) (w neiw) c', neih=2, neiw=2),
+ nn.LayerNorm(in_dim // 4), nn.Linear(in_dim // 4, dim),
+ Rearrange('n d h w c -> n c d h w'))
+
+ # mutual and self attention
+ self.residual_group1 = TMSAG(dim=dim,
+ input_resolution=input_resolution,
+ depth=int(depth * mul_attn_ratio),
+ num_heads=num_heads,
+ window_size=(2, window_size[1], window_size[2]),
+ mut_attn=True,
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop_path=drop_path,
+ norm_layer=norm_layer,
+ use_checkpoint_attn=use_checkpoint_attn,
+ use_checkpoint_ffn=use_checkpoint_ffn
+ )
+ self.linear1 = nn.Linear(dim, dim)
+
+ # only self attention
+ self.residual_group2 = TMSAG(dim=dim,
+ input_resolution=input_resolution,
+ depth=depth - int(depth * mul_attn_ratio),
+ num_heads=num_heads,
+ window_size=window_size,
+ mut_attn=False,
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias, qk_scale=qk_scale,
+ drop_path=drop_path,
+ norm_layer=norm_layer,
+ use_checkpoint_attn=True,
+ use_checkpoint_ffn=use_checkpoint_ffn
+ )
+ self.linear2 = nn.Linear(dim, dim)
+
+ # parallel warping
+ self.pa_deform = DCNv2PackFlowGuided(dim, dim, 3, padding=1, deformable_groups=deformable_groups,
+ max_residue_magnitude=max_residue_magnitude, pa_frames=pa_frames)
+ self.pa_fuse = Mlp_GEGLU(dim * (1 + 2), dim * (1 + 2), dim)
+
+ def forward(self, x, flows_backward, flows_forward):
+ x = self.reshape(x)
+ x = self.linear1(self.residual_group1(x).transpose(1, 4)).transpose(1, 4) + x
+ x = self.linear2(self.residual_group2(x).transpose(1, 4)).transpose(1, 4) + x
+ x = x.transpose(1, 2)
+
+ x_backward, x_forward = getattr(self, f'get_aligned_feature_{self.pa_frames}frames')(x, flows_backward, flows_forward)
+ x = self.pa_fuse(torch.cat([x, x_backward, x_forward], 2).permute(0, 1, 3, 4, 2)).permute(0, 4, 1, 2, 3)
+
+ return x
+
+ def get_aligned_feature_2frames(self, x, flows_backward, flows_forward):
+ '''Parallel feature warping for 2 frames.'''
+
+ # backward
+ n = x.size(1)
+ x_backward = [torch.zeros_like(x[:, -1, ...])]
+ for i in range(n - 1, 0, -1):
+ x_i = x[:, i, ...]
+ flow = flows_backward[0][:, i - 1, ...]
+ x_i_warped = flow_warp(x_i, flow.permute(0, 2, 3, 1), 'bilinear') # frame i+1 aligned towards i
+ x_backward.insert(0, self.pa_deform(x_i, [x_i_warped], x[:, i - 1, ...], [flow]))
+
+ # forward
+ x_forward = [torch.zeros_like(x[:, 0, ...])]
+ for i in range(0, n - 1):
+ x_i = x[:, i, ...]
+ flow = flows_forward[0][:, i, ...]
+ x_i_warped = flow_warp(x_i, flow.permute(0, 2, 3, 1), 'bilinear') # frame i-1 aligned towards i
+ x_forward.append(self.pa_deform(x_i, [x_i_warped], x[:, i + 1, ...], [flow]))
+
+ return [torch.stack(x_backward, 1), torch.stack(x_forward, 1)]
+
+ def get_aligned_feature_4frames(self, x, flows_backward, flows_forward):
+ '''Parallel feature warping for 4 frames.'''
+
+ # backward
+ n = x.size(1)
+ x_backward = [torch.zeros_like(x[:, -1, ...])]
+ for i in range(n, 1, -1):
+ x_i = x[:, i - 1, ...]
+ flow1 = flows_backward[0][:, i - 2, ...]
+ if i == n:
+ x_ii = torch.zeros_like(x[:, n - 2, ...])
+ flow2 = torch.zeros_like(flows_backward[1][:, n - 3, ...])
+ else:
+ x_ii = x[:, i, ...]
+ flow2 = flows_backward[1][:, i - 2, ...]
+
+ x_i_warped = flow_warp(x_i, flow1.permute(0, 2, 3, 1), 'bilinear') # frame i+1 aligned towards i
+ x_ii_warped = flow_warp(x_ii, flow2.permute(0, 2, 3, 1), 'bilinear') # frame i+2 aligned towards i
+ x_backward.insert(0,
+ self.pa_deform(torch.cat([x_i, x_ii], 1), [x_i_warped, x_ii_warped], x[:, i - 2, ...], [flow1, flow2]))
+
+ # forward
+ x_forward = [torch.zeros_like(x[:, 0, ...])]
+ for i in range(-1, n - 2):
+ x_i = x[:, i + 1, ...]
+ flow1 = flows_forward[0][:, i + 1, ...]
+ if i == -1:
+ x_ii = torch.zeros_like(x[:, 1, ...])
+ flow2 = torch.zeros_like(flows_forward[1][:, 0, ...])
+ else:
+ x_ii = x[:, i, ...]
+ flow2 = flows_forward[1][:, i, ...]
+
+ x_i_warped = flow_warp(x_i, flow1.permute(0, 2, 3, 1), 'bilinear') # frame i-1 aligned towards i
+ x_ii_warped = flow_warp(x_ii, flow2.permute(0, 2, 3, 1), 'bilinear') # frame i-2 aligned towards i
+ x_forward.append(
+ self.pa_deform(torch.cat([x_i, x_ii], 1), [x_i_warped, x_ii_warped], x[:, i + 2, ...], [flow1, flow2]))
+
+ return [torch.stack(x_backward, 1), torch.stack(x_forward, 1)]
+
+ def get_aligned_feature_6frames(self, x, flows_backward, flows_forward):
+ '''Parallel feature warping for 6 frames.'''
+
+ # backward
+ n = x.size(1)
+ x_backward = [torch.zeros_like(x[:, -1, ...])]
+ for i in range(n + 1, 2, -1):
+ x_i = x[:, i - 2, ...]
+ flow1 = flows_backward[0][:, i - 3, ...]
+ if i == n + 1:
+ x_ii = torch.zeros_like(x[:, -1, ...])
+ flow2 = torch.zeros_like(flows_backward[1][:, -1, ...])
+ x_iii = torch.zeros_like(x[:, -1, ...])
+ flow3 = torch.zeros_like(flows_backward[2][:, -1, ...])
+ elif i == n:
+ x_ii = x[:, i - 1, ...]
+ flow2 = flows_backward[1][:, i - 3, ...]
+ x_iii = torch.zeros_like(x[:, -1, ...])
+ flow3 = torch.zeros_like(flows_backward[2][:, -1, ...])
+ else:
+ x_ii = x[:, i - 1, ...]
+ flow2 = flows_backward[1][:, i - 3, ...]
+ x_iii = x[:, i, ...]
+ flow3 = flows_backward[2][:, i - 3, ...]
+
+ x_i_warped = flow_warp(x_i, flow1.permute(0, 2, 3, 1), 'bilinear') # frame i+1 aligned towards i
+ x_ii_warped = flow_warp(x_ii, flow2.permute(0, 2, 3, 1), 'bilinear') # frame i+2 aligned towards i
+ x_iii_warped = flow_warp(x_iii, flow3.permute(0, 2, 3, 1), 'bilinear') # frame i+3 aligned towards i
+ x_backward.insert(0,
+ self.pa_deform(torch.cat([x_i, x_ii, x_iii], 1), [x_i_warped, x_ii_warped, x_iii_warped],
+ x[:, i - 3, ...], [flow1, flow2, flow3]))
+
+ # forward
+ x_forward = [torch.zeros_like(x[:, 0, ...])]
+ for i in range(0, n - 1):
+ x_i = x[:, i, ...]
+ flow1 = flows_forward[0][:, i, ...]
+ if i == 0:
+ x_ii = torch.zeros_like(x[:, 0, ...])
+ flow2 = torch.zeros_like(flows_forward[1][:, 0, ...])
+ x_iii = torch.zeros_like(x[:, 0, ...])
+ flow3 = torch.zeros_like(flows_forward[2][:, 0, ...])
+ elif i == 1:
+ x_ii = x[:, i - 1, ...]
+ flow2 = flows_forward[1][:, i - 1, ...]
+ x_iii = torch.zeros_like(x[:, 0, ...])
+ flow3 = torch.zeros_like(flows_forward[2][:, 0, ...])
+ else:
+ x_ii = x[:, i - 1, ...]
+ flow2 = flows_forward[1][:, i - 1, ...]
+ x_iii = x[:, i - 2, ...]
+ flow3 = flows_forward[2][:, i - 2, ...]
+
+ x_i_warped = flow_warp(x_i, flow1.permute(0, 2, 3, 1), 'bilinear') # frame i-1 aligned towards i
+ x_ii_warped = flow_warp(x_ii, flow2.permute(0, 2, 3, 1), 'bilinear') # frame i-2 aligned towards i
+ x_iii_warped = flow_warp(x_iii, flow3.permute(0, 2, 3, 1), 'bilinear') # frame i-3 aligned towards i
+ x_forward.append(self.pa_deform(torch.cat([x_i, x_ii, x_iii], 1), [x_i_warped, x_ii_warped, x_iii_warped],
+ x[:, i + 1, ...], [flow1, flow2, flow3]))
+
+ return [torch.stack(x_backward, 1), torch.stack(x_forward, 1)]
+
+
+class VRT(nn.Module):
+ """ Video Restoration Transformer (VRT).
+ A PyTorch impl of : `VRT: A Video Restoration Transformer` -
+ https://arxiv.org/pdf/2201.00000
+
+ Args:
+ upscale (int): Upscaling factor. Set as 1 for video deblurring, etc. Default: 4.
+ in_chans (int): Number of input image channels. Default: 3.
+ img_size (int | tuple(int)): Size of input image. Default: [6, 64, 64].
+ window_size (int | tuple(int)): Window size. Default: (6,8,8).
+ depths (list[int]): Depths of each Transformer stage.
+ indep_reconsts (list[int]): Layers that extract features of different frames independently.
+ embed_dims (list[int]): Number of linear projection output channels.
+ num_heads (list[int]): Number of attention head of each stage.
+ mul_attn_ratio (float): Ratio of mutual attention layers. Default: 0.75.
+ mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 2.
+ qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True.
+ qk_scale (float): Override default qk scale of head_dim ** -0.5 if set.
+ drop_path_rate (float): Stochastic depth rate. Default: 0.2.
+ norm_layer (obj): Normalization layer. Default: nn.LayerNorm.
+ spynet_path (str): Pretrained SpyNet model path.
+ pa_frames (float): Number of warpped frames. Default: 2.
+ deformable_groups (float): Number of deformable groups. Default: 16.
+ recal_all_flows (bool): If True, derive (t,t+2) and (t,t+3) flows from (t,t+1). Default: False.
+ nonblind_denoising (bool): If True, conduct experiments on non-blind denoising. Default: False.
+ use_checkpoint_attn (bool): If True, use torch.checkpoint for attention modules. Default: False.
+ use_checkpoint_ffn (bool): If True, use torch.checkpoint for feed-forward modules. Default: False.
+ no_checkpoint_attn_blocks (list[int]): Layers without torch.checkpoint for attention modules.
+ no_checkpoint_ffn_blocks (list[int]): Layers without torch.checkpoint for feed-forward modules.
+ """
+
+ def __init__(self,
+ upscale=4,
+ in_chans=3,
+ img_size=[6, 64, 64],
+ window_size=[6, 8, 8],
+ depths=[8, 8, 8, 8, 8, 8, 8, 4, 4, 4, 4, 4, 4],
+ indep_reconsts=[11, 12],
+ embed_dims=[120, 120, 120, 120, 120, 120, 120, 180, 180, 180, 180, 180, 180],
+ num_heads=[6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6],
+ mul_attn_ratio=0.75,
+ mlp_ratio=2.,
+ qkv_bias=True,
+ qk_scale=None,
+ drop_path_rate=0.2,
+ norm_layer=nn.LayerNorm,
+ spynet_path=None,
+ pa_frames=2,
+ deformable_groups=16,
+ recal_all_flows=False,
+ nonblind_denoising=False,
+ use_checkpoint_attn=False,
+ use_checkpoint_ffn=False,
+ no_checkpoint_attn_blocks=[],
+ no_checkpoint_ffn_blocks=[],
+ ):
+ super().__init__()
+ self.in_chans = in_chans
+ self.upscale = upscale
+ self.pa_frames = pa_frames
+ self.recal_all_flows = recal_all_flows
+ self.nonblind_denoising = nonblind_denoising
+
+ # conv_first
+ self.conv_first = nn.Conv3d(in_chans*(1+2*4)+1 if self.nonblind_denoising else in_chans*(1+2*4),
+ embed_dims[0], kernel_size=(1, 3, 3), padding=(0, 1, 1))
+
+ # main body
+ self.spynet = SpyNet(spynet_path, [2, 3, 4, 5])
+ dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
+ reshapes = ['none', 'down', 'down', 'down', 'up', 'up', 'up']
+ scales = [1, 2, 4, 8, 4, 2, 1]
+ use_checkpoint_attns = [False if i in no_checkpoint_attn_blocks else use_checkpoint_attn for i in
+ range(len(depths))]
+ use_checkpoint_ffns = [False if i in no_checkpoint_ffn_blocks else use_checkpoint_ffn for i in
+ range(len(depths))]
+
+ # stage 1- 7
+ for i in range(7):
+ setattr(self, f'stage{i + 1}',
+ Stage(
+ in_dim=embed_dims[i - 1],
+ dim=embed_dims[i],
+ input_resolution=(img_size[0], img_size[1] // scales[i], img_size[2] // scales[i]),
+ depth=depths[i],
+ num_heads=num_heads[i],
+ mul_attn_ratio=mul_attn_ratio,
+ window_size=window_size,
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop_path=dpr[sum(depths[:i]):sum(depths[:i + 1])],
+ norm_layer=norm_layer,
+ pa_frames=pa_frames,
+ deformable_groups=deformable_groups,
+ reshape=reshapes[i],
+ max_residue_magnitude=10 / scales[i],
+ use_checkpoint_attn=use_checkpoint_attns[i],
+ use_checkpoint_ffn=use_checkpoint_ffns[i],
+ )
+ )
+
+ # stage 8
+ self.stage8 = nn.ModuleList(
+ [nn.Sequential(
+ Rearrange('n c d h w -> n d h w c'),
+ nn.LayerNorm(embed_dims[6]),
+ nn.Linear(embed_dims[6], embed_dims[7]),
+ Rearrange('n d h w c -> n c d h w')
+ )]
+ )
+ for i in range(7, len(depths)):
+ self.stage8.append(
+ RTMSA(dim=embed_dims[i],
+ input_resolution=img_size,
+ depth=depths[i],
+ num_heads=num_heads[i],
+ window_size=[1, window_size[1], window_size[2]] if i in indep_reconsts else window_size,
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias, qk_scale=qk_scale,
+ drop_path=dpr[sum(depths[:i]):sum(depths[:i + 1])],
+ norm_layer=norm_layer,
+ use_checkpoint_attn=use_checkpoint_attns[i],
+ use_checkpoint_ffn=use_checkpoint_ffns[i]
+ )
+ )
+
+ self.norm = norm_layer(embed_dims[-1])
+ self.conv_after_body = nn.Linear(embed_dims[-1], embed_dims[0])
+
+ # reconstruction
+ num_feat = 64
+ if self.upscale == 1:
+ # for video deblurring, etc.
+ self.conv_last = nn.Conv3d(embed_dims[0], in_chans, kernel_size=(1, 3, 3), padding=(0, 1, 1))
+ else:
+ # for video sr
+ self.conv_before_upsample = nn.Sequential(
+ nn.Conv3d(embed_dims[0], num_feat, kernel_size=(1, 3, 3), padding=(0, 1, 1)),
+ nn.LeakyReLU(inplace=True))
+ self.upsample = Upsample(upscale, num_feat)
+ self.conv_last = nn.Conv3d(num_feat, in_chans, kernel_size=(1, 3, 3), padding=(0, 1, 1))
+
+ def forward(self, x):
+ # x: (N, D, C, H, W)
+
+ # obtain noise level map
+ if self.nonblind_denoising:
+ x, noise_level_map = x[:, :, :self.in_chans, :, :], x[:, :, self.in_chans:, :, :]
+
+ x_lq = x.clone()
+
+ # calculate flows
+ flows_backward, flows_forward = self.get_flows(x)
+
+ # warp input
+ x_backward, x_forward = self.get_aligned_image_2frames(x, flows_backward[0], flows_forward[0])
+ x = torch.cat([x, x_backward, x_forward], 2)
+
+ # concatenate noise level map
+ if self.nonblind_denoising:
+ x = torch.cat([x, noise_level_map], 2)
+
+ # main network
+ if self.upscale == 1:
+ # video deblurring, etc.
+ x = self.conv_first(x.transpose(1, 2))
+ x = x + self.conv_after_body(
+ self.forward_features(x, flows_backward, flows_forward).transpose(1, 4)).transpose(1, 4)
+ x = self.conv_last(x).transpose(1, 2)
+ return x + x_lq
+ else:
+ # video sr
+ x = self.conv_first(x.transpose(1, 2))
+ x = x + self.conv_after_body(
+ self.forward_features(x, flows_backward, flows_forward).transpose(1, 4)).transpose(1, 4)
+ x = self.conv_last(self.upsample(self.conv_before_upsample(x))).transpose(1, 2)
+ _, _, C, H, W = x.shape
+ return x + torch.nn.functional.interpolate(x_lq, size=(C, H, W), mode='trilinear', align_corners=False)
+
+ def get_flows(self, x):
+ ''' Get flows for 2 frames, 4 frames or 6 frames.'''
+
+ if self.pa_frames == 2:
+ flows_backward, flows_forward = self.get_flow_2frames(x)
+ elif self.pa_frames == 4:
+ flows_backward_2frames, flows_forward_2frames = self.get_flow_2frames(x)
+ flows_backward_4frames, flows_forward_4frames = self.get_flow_4frames(flows_forward_2frames, flows_backward_2frames)
+ flows_backward = flows_backward_2frames + flows_backward_4frames
+ flows_forward = flows_forward_2frames + flows_forward_4frames
+ elif self.pa_frames == 6:
+ flows_backward_2frames, flows_forward_2frames = self.get_flow_2frames(x)
+ flows_backward_4frames, flows_forward_4frames = self.get_flow_4frames(flows_forward_2frames, flows_backward_2frames)
+ flows_backward_6frames, flows_forward_6frames = self.get_flow_6frames(flows_forward_2frames, flows_backward_2frames, flows_forward_4frames, flows_backward_4frames)
+ flows_backward = flows_backward_2frames + flows_backward_4frames + flows_backward_6frames
+ flows_forward = flows_forward_2frames + flows_forward_4frames + flows_forward_6frames
+
+ return flows_backward, flows_forward
+
+ def get_flow_2frames(self, x):
+ '''Get flow between frames t and t+1 from x.'''
+
+ b, n, c, h, w = x.size()
+ x_1 = x[:, :-1, :, :, :].reshape(-1, c, h, w)
+ x_2 = x[:, 1:, :, :, :].reshape(-1, c, h, w)
+
+ # backward
+ flows_backward = self.spynet(x_1, x_2)
+ flows_backward = [flow.view(b, n-1, 2, h // (2 ** i), w // (2 ** i)) for flow, i in
+ zip(flows_backward, range(4))]
+
+ # forward
+ flows_forward = self.spynet(x_2, x_1)
+ flows_forward = [flow.view(b, n-1, 2, h // (2 ** i), w // (2 ** i)) for flow, i in
+ zip(flows_forward, range(4))]
+
+ return flows_backward, flows_forward
+
+ def get_flow_4frames(self, flows_forward, flows_backward):
+ '''Get flow between t and t+2 from (t,t+1) and (t+1,t+2).'''
+
+ # backward
+ d = flows_forward[0].shape[1]
+ flows_backward2 = []
+ for flows in flows_backward:
+ flow_list = []
+ for i in range(d - 1, 0, -1):
+ flow_n1 = flows[:, i - 1, :, :, :] # flow from i+1 to i
+ flow_n2 = flows[:, i, :, :, :] # flow from i+2 to i+1
+ flow_list.insert(0, flow_n1 + flow_warp(flow_n2, flow_n1.permute(0, 2, 3, 1))) # flow from i+2 to i
+ flows_backward2.append(torch.stack(flow_list, 1))
+
+ # forward
+ flows_forward2 = []
+ for flows in flows_forward:
+ flow_list = []
+ for i in range(1, d):
+ flow_n1 = flows[:, i, :, :, :] # flow from i-1 to i
+ flow_n2 = flows[:, i - 1, :, :, :] # flow from i-2 to i-1
+ flow_list.append(flow_n1 + flow_warp(flow_n2, flow_n1.permute(0, 2, 3, 1))) # flow from i-2 to i
+ flows_forward2.append(torch.stack(flow_list, 1))
+
+ return flows_backward2, flows_forward2
+
+ def get_flow_6frames(self, flows_forward, flows_backward, flows_forward2, flows_backward2):
+ '''Get flow between t and t+3 from (t,t+2) and (t+2,t+3).'''
+
+ # backward
+ d = flows_forward2[0].shape[1]
+ flows_backward3 = []
+ for flows, flows2 in zip(flows_backward, flows_backward2):
+ flow_list = []
+ for i in range(d - 1, 0, -1):
+ flow_n1 = flows2[:, i - 1, :, :, :] # flow from i+2 to i
+ flow_n2 = flows[:, i + 1, :, :, :] # flow from i+3 to i+2
+ flow_list.insert(0, flow_n1 + flow_warp(flow_n2, flow_n1.permute(0, 2, 3, 1))) # flow from i+3 to i
+ flows_backward3.append(torch.stack(flow_list, 1))
+
+ # forward
+ flows_forward3 = []
+ for flows, flows2 in zip(flows_forward, flows_forward2):
+ flow_list = []
+ for i in range(2, d + 1):
+ flow_n1 = flows2[:, i - 1, :, :, :] # flow from i-2 to i
+ flow_n2 = flows[:, i - 2, :, :, :] # flow from i-3 to i-2
+ flow_list.append(flow_n1 + flow_warp(flow_n2, flow_n1.permute(0, 2, 3, 1))) # flow from i-3 to i
+ flows_forward3.append(torch.stack(flow_list, 1))
+
+ return flows_backward3, flows_forward3
+
+ def get_aligned_image_2frames(self, x, flows_backward, flows_forward):
+ '''Parallel feature warping for 2 frames.'''
+
+ # backward
+ n = x.size(1)
+ x_backward = [torch.zeros_like(x[:, -1, ...]).repeat(1, 4, 1, 1)]
+ for i in range(n - 1, 0, -1):
+ x_i = x[:, i, ...]
+ flow = flows_backward[:, i - 1, ...]
+ x_backward.insert(0, flow_warp(x_i, flow.permute(0, 2, 3, 1), 'nearest4')) # frame i+1 aligned towards i
+
+ # forward
+ x_forward = [torch.zeros_like(x[:, 0, ...]).repeat(1, 4, 1, 1)]
+ for i in range(0, n - 1):
+ x_i = x[:, i, ...]
+ flow = flows_forward[:, i, ...]
+ x_forward.append(flow_warp(x_i, flow.permute(0, 2, 3, 1), 'nearest4')) # frame i-1 aligned towards i
+
+ return [torch.stack(x_backward, 1), torch.stack(x_forward, 1)]
+
+ def forward_features(self, x, flows_backward, flows_forward):
+ '''Main network for feature extraction.'''
+
+ x1 = self.stage1(x, flows_backward[0::4], flows_forward[0::4])
+ x2 = self.stage2(x1, flows_backward[1::4], flows_forward[1::4])
+ x3 = self.stage3(x2, flows_backward[2::4], flows_forward[2::4])
+ x4 = self.stage4(x3, flows_backward[3::4], flows_forward[3::4])
+ x = self.stage5(x4, flows_backward[2::4], flows_forward[2::4])
+ x = self.stage6(x + x3, flows_backward[1::4], flows_forward[1::4])
+ x = self.stage7(x + x2, flows_backward[0::4], flows_forward[0::4])
+ x = x + x1
+
+ for layer in self.stage8:
+ x = layer(x)
+
+ x = rearrange(x, 'n c d h w -> n d h w c')
+ x = self.norm(x)
+ x = rearrange(x, 'n d h w c -> n c d h w')
+
+ return x
+
+
+if __name__ == '__main__':
+ device = torch.device('cpu')
+ upscale = 4
+ window_size = 8
+ height = (256 // upscale // window_size) * window_size
+ width = (256 // upscale // window_size) * window_size
+
+ model = VRT(upscale=4,
+ img_size=[6, 64, 64],
+ window_size=[6, 8, 8],
+ depths=[8, 8, 8, 8, 8, 8, 8, 4, 4, 4, 4, 4, 4],
+ indep_reconsts=[11, 12],
+ embed_dims=[120, 120, 120, 120, 120, 120, 120, 180, 180, 180, 180, 180, 180],
+ num_heads=[6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6],
+ spynet_path=None,
+ pa_frames=2,
+ deformable_groups=12
+ ).to(device)
+ print(model)
+ print('{:>16s} : {:<.4f} [M]'.format('#Params', sum(map(lambda x: x.numel(), model.parameters())) / 10 ** 6))
+
+ x = torch.randn((2, 12, 3, height, width)).to(device)
+ x = model(x)
+ print(x.shape)
diff --git a/KAIR/models/op/__init__.py b/KAIR/models/op/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..d0918d92285955855be89f00096b888ee5597ce3
--- /dev/null
+++ b/KAIR/models/op/__init__.py
@@ -0,0 +1,2 @@
+from .fused_act import FusedLeakyReLU, fused_leaky_relu
+from .upfirdn2d import upfirdn2d
diff --git a/KAIR/models/op/fused_act.py b/KAIR/models/op/fused_act.py
new file mode 100644
index 0000000000000000000000000000000000000000..3a41592fd5329a4f5f6b4ce0b99da0a9baf54715
--- /dev/null
+++ b/KAIR/models/op/fused_act.py
@@ -0,0 +1,88 @@
+import os
+
+import torch
+from torch import nn
+from torch.autograd import Function
+from torch.utils.cpp_extension import load, _import_module_from_library
+
+
+module_path = os.path.dirname(__file__)
+fused = load(
+ 'fused',
+ sources=[
+ os.path.join(module_path, 'fused_bias_act.cpp'),
+ os.path.join(module_path, 'fused_bias_act_kernel.cu'),
+ ],
+)
+
+#fused = _import_module_from_library('fused', '/tmp/torch_extensions/fused', True)
+
+
+class FusedLeakyReLUFunctionBackward(Function):
+ @staticmethod
+ def forward(ctx, grad_output, out, negative_slope, scale):
+ ctx.save_for_backward(out)
+ ctx.negative_slope = negative_slope
+ ctx.scale = scale
+
+ empty = grad_output.new_empty(0)
+
+ grad_input = fused.fused_bias_act(
+ grad_output, empty, out, 3, 1, negative_slope, scale
+ )
+
+ dim = [0]
+
+ if grad_input.ndim > 2:
+ dim += list(range(2, grad_input.ndim))
+
+ grad_bias = grad_input.sum(dim).detach()
+
+ return grad_input, grad_bias
+
+ @staticmethod
+ def backward(ctx, gradgrad_input, gradgrad_bias):
+ out, = ctx.saved_tensors
+ gradgrad_out = fused.fused_bias_act(
+ gradgrad_input, gradgrad_bias, out, 3, 1, ctx.negative_slope, ctx.scale
+ )
+
+ return gradgrad_out, None, None, None
+
+
+class FusedLeakyReLUFunction(Function):
+ @staticmethod
+ def forward(ctx, input, bias, negative_slope, scale):
+ empty = input.new_empty(0)
+ out = fused.fused_bias_act(input, bias, empty, 3, 0, negative_slope, scale)
+ ctx.save_for_backward(out)
+ ctx.negative_slope = negative_slope
+ ctx.scale = scale
+
+ return out
+
+ @staticmethod
+ def backward(ctx, grad_output):
+ out, = ctx.saved_tensors
+
+ grad_input, grad_bias = FusedLeakyReLUFunctionBackward.apply(
+ grad_output, out, ctx.negative_slope, ctx.scale
+ )
+
+ return grad_input, grad_bias, None, None
+
+
+class FusedLeakyReLU(nn.Module):
+ def __init__(self, channel, negative_slope=0.2, scale=2 ** 0.5):
+ super().__init__()
+
+ self.bias = nn.Parameter(torch.zeros(channel))
+ self.negative_slope = negative_slope
+ self.scale = scale
+
+ def forward(self, input):
+ return fused_leaky_relu(input, self.bias, self.negative_slope, self.scale)
+
+
+def fused_leaky_relu(input, bias, negative_slope=0.2, scale=2 ** 0.5):
+ return FusedLeakyReLUFunction.apply(input, bias, negative_slope, scale)
diff --git a/KAIR/models/op/fused_bias_act.cpp b/KAIR/models/op/fused_bias_act.cpp
new file mode 100644
index 0000000000000000000000000000000000000000..a054318781a20596d8f516ef86745e5572aad0f7
--- /dev/null
+++ b/KAIR/models/op/fused_bias_act.cpp
@@ -0,0 +1,21 @@
+#include
+
+
+torch::Tensor fused_bias_act_op(const torch::Tensor& input, const torch::Tensor& bias, const torch::Tensor& refer,
+ int act, int grad, float alpha, float scale);
+
+#define CHECK_CUDA(x) TORCH_CHECK(x.type().is_cuda(), #x " must be a CUDA tensor")
+#define CHECK_CONTIGUOUS(x) TORCH_CHECK(x.is_contiguous(), #x " must be contiguous")
+#define CHECK_INPUT(x) CHECK_CUDA(x); CHECK_CONTIGUOUS(x)
+
+torch::Tensor fused_bias_act(const torch::Tensor& input, const torch::Tensor& bias, const torch::Tensor& refer,
+ int act, int grad, float alpha, float scale) {
+ CHECK_CUDA(input);
+ CHECK_CUDA(bias);
+
+ return fused_bias_act_op(input, bias, refer, act, grad, alpha, scale);
+}
+
+PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
+ m.def("fused_bias_act", &fused_bias_act, "fused bias act (CUDA)");
+}
\ No newline at end of file
diff --git a/KAIR/models/op/fused_bias_act_kernel.cu b/KAIR/models/op/fused_bias_act_kernel.cu
new file mode 100644
index 0000000000000000000000000000000000000000..8d2f03c73605faee6723d002ba5de88cb465a80e
--- /dev/null
+++ b/KAIR/models/op/fused_bias_act_kernel.cu
@@ -0,0 +1,99 @@
+// Copyright (c) 2019, NVIDIA Corporation. All rights reserved.
+//
+// This work is made available under the Nvidia Source Code License-NC.
+// To view a copy of this license, visit
+// https://nvlabs.github.io/stylegan2/license.html
+
+#include
+
+#include
+#include
+#include
+#include
+
+#include
+#include
+
+
+template
+static __global__ void fused_bias_act_kernel(scalar_t* out, const scalar_t* p_x, const scalar_t* p_b, const scalar_t* p_ref,
+ int act, int grad, scalar_t alpha, scalar_t scale, int loop_x, int size_x, int step_b, int size_b, int use_bias, int use_ref) {
+ int xi = blockIdx.x * loop_x * blockDim.x + threadIdx.x;
+
+ scalar_t zero = 0.0;
+
+ for (int loop_idx = 0; loop_idx < loop_x && xi < size_x; loop_idx++, xi += blockDim.x) {
+ scalar_t x = p_x[xi];
+
+ if (use_bias) {
+ x += p_b[(xi / step_b) % size_b];
+ }
+
+ scalar_t ref = use_ref ? p_ref[xi] : zero;
+
+ scalar_t y;
+
+ switch (act * 10 + grad) {
+ default:
+ case 10: y = x; break;
+ case 11: y = x; break;
+ case 12: y = 0.0; break;
+
+ case 30: y = (x > 0.0) ? x : x * alpha; break;
+ case 31: y = (ref > 0.0) ? x : x * alpha; break;
+ case 32: y = 0.0; break;
+ }
+
+ out[xi] = y * scale;
+ }
+}
+
+
+torch::Tensor fused_bias_act_op(const torch::Tensor& input, const torch::Tensor& bias, const torch::Tensor& refer,
+ int act, int grad, float alpha, float scale) {
+ int curDevice = -1;
+ cudaGetDevice(&curDevice);
+ cudaStream_t stream = at::cuda::getCurrentCUDAStream(curDevice);
+
+ auto x = input.contiguous();
+ auto b = bias.contiguous();
+ auto ref = refer.contiguous();
+
+ int use_bias = b.numel() ? 1 : 0;
+ int use_ref = ref.numel() ? 1 : 0;
+
+ int size_x = x.numel();
+ int size_b = b.numel();
+ int step_b = 1;
+
+ for (int i = 1 + 1; i < x.dim(); i++) {
+ step_b *= x.size(i);
+ }
+
+ int loop_x = 4;
+ int block_size = 4 * 32;
+ int grid_size = (size_x - 1) / (loop_x * block_size) + 1;
+
+ auto y = torch::empty_like(x);
+
+ AT_DISPATCH_FLOATING_TYPES_AND_HALF(x.scalar_type(), "fused_bias_act_kernel", [&] {
+ fused_bias_act_kernel<<>>(
+ y.data_ptr(),
+ x.data_ptr(),
+ b.data_ptr(),
+ ref.data_ptr(),
+ act,
+ grad,
+ alpha,
+ scale,
+ loop_x,
+ size_x,
+ step_b,
+ size_b,
+ use_bias,
+ use_ref
+ );
+ });
+
+ return y;
+}
\ No newline at end of file
diff --git a/KAIR/models/op/upfirdn2d.cpp b/KAIR/models/op/upfirdn2d.cpp
new file mode 100644
index 0000000000000000000000000000000000000000..b07aa2056864db83ff0aacbb1068e072ba9da4ad
--- /dev/null
+++ b/KAIR/models/op/upfirdn2d.cpp
@@ -0,0 +1,23 @@
+#include
+
+
+torch::Tensor upfirdn2d_op(const torch::Tensor& input, const torch::Tensor& kernel,
+ int up_x, int up_y, int down_x, int down_y,
+ int pad_x0, int pad_x1, int pad_y0, int pad_y1);
+
+#define CHECK_CUDA(x) TORCH_CHECK(x.type().is_cuda(), #x " must be a CUDA tensor")
+#define CHECK_CONTIGUOUS(x) TORCH_CHECK(x.is_contiguous(), #x " must be contiguous")
+#define CHECK_INPUT(x) CHECK_CUDA(x); CHECK_CONTIGUOUS(x)
+
+torch::Tensor upfirdn2d(const torch::Tensor& input, const torch::Tensor& kernel,
+ int up_x, int up_y, int down_x, int down_y,
+ int pad_x0, int pad_x1, int pad_y0, int pad_y1) {
+ CHECK_CUDA(input);
+ CHECK_CUDA(kernel);
+
+ return upfirdn2d_op(input, kernel, up_x, up_y, down_x, down_y, pad_x0, pad_x1, pad_y0, pad_y1);
+}
+
+PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
+ m.def("upfirdn2d", &upfirdn2d, "upfirdn2d (CUDA)");
+}
\ No newline at end of file
diff --git a/KAIR/models/op/upfirdn2d.py b/KAIR/models/op/upfirdn2d.py
new file mode 100644
index 0000000000000000000000000000000000000000..bd8dbca23f9951b345c36b278f68711ecbc3bdf8
--- /dev/null
+++ b/KAIR/models/op/upfirdn2d.py
@@ -0,0 +1,188 @@
+import os
+
+import torch
+from torch.autograd import Function
+from torch.utils.cpp_extension import load, _import_module_from_library
+
+
+module_path = os.path.dirname(__file__)
+upfirdn2d_op = load(
+ 'upfirdn2d',
+ sources=[
+ os.path.join(module_path, 'upfirdn2d.cpp'),
+ os.path.join(module_path, 'upfirdn2d_kernel.cu'),
+ ],
+)
+
+#upfirdn2d_op = _import_module_from_library('upfirdn2d', '/tmp/torch_extensions/upfirdn2d', True)
+
+class UpFirDn2dBackward(Function):
+ @staticmethod
+ def forward(
+ ctx, grad_output, kernel, grad_kernel, up, down, pad, g_pad, in_size, out_size
+ ):
+
+ up_x, up_y = up
+ down_x, down_y = down
+ g_pad_x0, g_pad_x1, g_pad_y0, g_pad_y1 = g_pad
+
+ grad_output = grad_output.reshape(-1, out_size[0], out_size[1], 1)
+
+ grad_input = upfirdn2d_op.upfirdn2d(
+ grad_output,
+ grad_kernel,
+ down_x,
+ down_y,
+ up_x,
+ up_y,
+ g_pad_x0,
+ g_pad_x1,
+ g_pad_y0,
+ g_pad_y1,
+ )
+ grad_input = grad_input.view(in_size[0], in_size[1], in_size[2], in_size[3])
+
+ ctx.save_for_backward(kernel)
+
+ pad_x0, pad_x1, pad_y0, pad_y1 = pad
+
+ ctx.up_x = up_x
+ ctx.up_y = up_y
+ ctx.down_x = down_x
+ ctx.down_y = down_y
+ ctx.pad_x0 = pad_x0
+ ctx.pad_x1 = pad_x1
+ ctx.pad_y0 = pad_y0
+ ctx.pad_y1 = pad_y1
+ ctx.in_size = in_size
+ ctx.out_size = out_size
+
+ return grad_input
+
+ @staticmethod
+ def backward(ctx, gradgrad_input):
+ kernel, = ctx.saved_tensors
+
+ gradgrad_input = gradgrad_input.reshape(-1, ctx.in_size[2], ctx.in_size[3], 1)
+
+ gradgrad_out = upfirdn2d_op.upfirdn2d(
+ gradgrad_input,
+ kernel,
+ ctx.up_x,
+ ctx.up_y,
+ ctx.down_x,
+ ctx.down_y,
+ ctx.pad_x0,
+ ctx.pad_x1,
+ ctx.pad_y0,
+ ctx.pad_y1,
+ )
+ # gradgrad_out = gradgrad_out.view(ctx.in_size[0], ctx.out_size[0], ctx.out_size[1], ctx.in_size[3])
+ gradgrad_out = gradgrad_out.view(
+ ctx.in_size[0], ctx.in_size[1], ctx.out_size[0], ctx.out_size[1]
+ )
+
+ return gradgrad_out, None, None, None, None, None, None, None, None
+
+
+class UpFirDn2d(Function):
+ @staticmethod
+ def forward(ctx, input, kernel, up, down, pad):
+ up_x, up_y = up
+ down_x, down_y = down
+ pad_x0, pad_x1, pad_y0, pad_y1 = pad
+
+ kernel_h, kernel_w = kernel.shape
+ batch, channel, in_h, in_w = input.shape
+ ctx.in_size = input.shape
+
+ input = input.reshape(-1, in_h, in_w, 1)
+
+ ctx.save_for_backward(kernel, torch.flip(kernel, [0, 1]))
+
+ out_h = (in_h * up_y + pad_y0 + pad_y1 - kernel_h) // down_y + 1
+ out_w = (in_w * up_x + pad_x0 + pad_x1 - kernel_w) // down_x + 1
+ ctx.out_size = (out_h, out_w)
+
+ ctx.up = (up_x, up_y)
+ ctx.down = (down_x, down_y)
+ ctx.pad = (pad_x0, pad_x1, pad_y0, pad_y1)
+
+ g_pad_x0 = kernel_w - pad_x0 - 1
+ g_pad_y0 = kernel_h - pad_y0 - 1
+ g_pad_x1 = in_w * up_x - out_w * down_x + pad_x0 - up_x + 1
+ g_pad_y1 = in_h * up_y - out_h * down_y + pad_y0 - up_y + 1
+
+ ctx.g_pad = (g_pad_x0, g_pad_x1, g_pad_y0, g_pad_y1)
+
+ out = upfirdn2d_op.upfirdn2d(
+ input, kernel, up_x, up_y, down_x, down_y, pad_x0, pad_x1, pad_y0, pad_y1
+ )
+ # out = out.view(major, out_h, out_w, minor)
+ out = out.view(-1, channel, out_h, out_w)
+
+ return out
+
+ @staticmethod
+ def backward(ctx, grad_output):
+ kernel, grad_kernel = ctx.saved_tensors
+
+ grad_input = UpFirDn2dBackward.apply(
+ grad_output,
+ kernel,
+ grad_kernel,
+ ctx.up,
+ ctx.down,
+ ctx.pad,
+ ctx.g_pad,
+ ctx.in_size,
+ ctx.out_size,
+ )
+
+ return grad_input, None, None, None, None
+
+
+def upfirdn2d(input, kernel, up=1, down=1, pad=(0, 0)):
+ out = UpFirDn2d.apply(
+ input, kernel, (up, up), (down, down), (pad[0], pad[1], pad[0], pad[1])
+ )
+
+ return out
+
+
+def upfirdn2d_native(
+ input, kernel, up_x, up_y, down_x, down_y, pad_x0, pad_x1, pad_y0, pad_y1
+):
+ _, in_h, in_w, minor = input.shape
+ kernel_h, kernel_w = kernel.shape
+
+ out = input.view(-1, in_h, 1, in_w, 1, minor)
+ out = F.pad(out, [0, 0, 0, up_x - 1, 0, 0, 0, up_y - 1])
+ out = out.view(-1, in_h * up_y, in_w * up_x, minor)
+
+ out = F.pad(
+ out, [0, 0, max(pad_x0, 0), max(pad_x1, 0), max(pad_y0, 0), max(pad_y1, 0)]
+ )
+ out = out[
+ :,
+ max(-pad_y0, 0) : out.shape[1] - max(-pad_y1, 0),
+ max(-pad_x0, 0) : out.shape[2] - max(-pad_x1, 0),
+ :,
+ ]
+
+ out = out.permute(0, 3, 1, 2)
+ out = out.reshape(
+ [-1, 1, in_h * up_y + pad_y0 + pad_y1, in_w * up_x + pad_x0 + pad_x1]
+ )
+ w = torch.flip(kernel, [0, 1]).view(1, 1, kernel_h, kernel_w)
+ out = F.conv2d(out, w)
+ out = out.reshape(
+ -1,
+ minor,
+ in_h * up_y + pad_y0 + pad_y1 - kernel_h + 1,
+ in_w * up_x + pad_x0 + pad_x1 - kernel_w + 1,
+ )
+ out = out.permute(0, 2, 3, 1)
+
+ return out[:, ::down_y, ::down_x, :]
+
diff --git a/KAIR/models/op/upfirdn2d_kernel.cu b/KAIR/models/op/upfirdn2d_kernel.cu
new file mode 100644
index 0000000000000000000000000000000000000000..871d4fe2fafb6c7863ea41656f8770f8a4a61b3a
--- /dev/null
+++ b/KAIR/models/op/upfirdn2d_kernel.cu
@@ -0,0 +1,272 @@
+// Copyright (c) 2019, NVIDIA Corporation. All rights reserved.
+//
+// This work is made available under the Nvidia Source Code License-NC.
+// To view a copy of this license, visit
+// https://nvlabs.github.io/stylegan2/license.html
+
+#include
+
+#include
+#include
+#include
+#include
+
+#include
+#include
+
+
+static __host__ __device__ __forceinline__ int floor_div(int a, int b) {
+ int c = a / b;
+
+ if (c * b > a) {
+ c--;
+ }
+
+ return c;
+}
+
+
+struct UpFirDn2DKernelParams {
+ int up_x;
+ int up_y;
+ int down_x;
+ int down_y;
+ int pad_x0;
+ int pad_x1;
+ int pad_y0;
+ int pad_y1;
+
+ int major_dim;
+ int in_h;
+ int in_w;
+ int minor_dim;
+ int kernel_h;
+ int kernel_w;
+ int out_h;
+ int out_w;
+ int loop_major;
+ int loop_x;
+};
+
+
+template
+__global__ void upfirdn2d_kernel(scalar_t* out, const scalar_t* input, const scalar_t* kernel, const UpFirDn2DKernelParams p) {
+ const int tile_in_h = ((tile_out_h - 1) * down_y + kernel_h - 1) / up_y + 1;
+ const int tile_in_w = ((tile_out_w - 1) * down_x + kernel_w - 1) / up_x + 1;
+
+ __shared__ volatile float sk[kernel_h][kernel_w];
+ __shared__ volatile float sx[tile_in_h][tile_in_w];
+
+ int minor_idx = blockIdx.x;
+ int tile_out_y = minor_idx / p.minor_dim;
+ minor_idx -= tile_out_y * p.minor_dim;
+ tile_out_y *= tile_out_h;
+ int tile_out_x_base = blockIdx.y * p.loop_x * tile_out_w;
+ int major_idx_base = blockIdx.z * p.loop_major;
+
+ if (tile_out_x_base >= p.out_w | tile_out_y >= p.out_h | major_idx_base >= p.major_dim) {
+ return;
+ }
+
+ for (int tap_idx = threadIdx.x; tap_idx < kernel_h * kernel_w; tap_idx += blockDim.x) {
+ int ky = tap_idx / kernel_w;
+ int kx = tap_idx - ky * kernel_w;
+ scalar_t v = 0.0;
+
+ if (kx < p.kernel_w & ky < p.kernel_h) {
+ v = kernel[(p.kernel_h - 1 - ky) * p.kernel_w + (p.kernel_w - 1 - kx)];
+ }
+
+ sk[ky][kx] = v;
+ }
+
+ for (int loop_major = 0, major_idx = major_idx_base; loop_major < p.loop_major & major_idx < p.major_dim; loop_major++, major_idx++) {
+ for (int loop_x = 0, tile_out_x = tile_out_x_base; loop_x < p.loop_x & tile_out_x < p.out_w; loop_x++, tile_out_x += tile_out_w) {
+ int tile_mid_x = tile_out_x * down_x + up_x - 1 - p.pad_x0;
+ int tile_mid_y = tile_out_y * down_y + up_y - 1 - p.pad_y0;
+ int tile_in_x = floor_div(tile_mid_x, up_x);
+ int tile_in_y = floor_div(tile_mid_y, up_y);
+
+ __syncthreads();
+
+ for (int in_idx = threadIdx.x; in_idx < tile_in_h * tile_in_w; in_idx += blockDim.x) {
+ int rel_in_y = in_idx / tile_in_w;
+ int rel_in_x = in_idx - rel_in_y * tile_in_w;
+ int in_x = rel_in_x + tile_in_x;
+ int in_y = rel_in_y + tile_in_y;
+
+ scalar_t v = 0.0;
+
+ if (in_x >= 0 & in_y >= 0 & in_x < p.in_w & in_y < p.in_h) {
+ v = input[((major_idx * p.in_h + in_y) * p.in_w + in_x) * p.minor_dim + minor_idx];
+ }
+
+ sx[rel_in_y][rel_in_x] = v;
+ }
+
+ __syncthreads();
+ for (int out_idx = threadIdx.x; out_idx < tile_out_h * tile_out_w; out_idx += blockDim.x) {
+ int rel_out_y = out_idx / tile_out_w;
+ int rel_out_x = out_idx - rel_out_y * tile_out_w;
+ int out_x = rel_out_x + tile_out_x;
+ int out_y = rel_out_y + tile_out_y;
+
+ int mid_x = tile_mid_x + rel_out_x * down_x;
+ int mid_y = tile_mid_y + rel_out_y * down_y;
+ int in_x = floor_div(mid_x, up_x);
+ int in_y = floor_div(mid_y, up_y);
+ int rel_in_x = in_x - tile_in_x;
+ int rel_in_y = in_y - tile_in_y;
+ int kernel_x = (in_x + 1) * up_x - mid_x - 1;
+ int kernel_y = (in_y + 1) * up_y - mid_y - 1;
+
+ scalar_t v = 0.0;
+
+ #pragma unroll
+ for (int y = 0; y < kernel_h / up_y; y++)
+ #pragma unroll
+ for (int x = 0; x < kernel_w / up_x; x++)
+ v += sx[rel_in_y + y][rel_in_x + x] * sk[kernel_y + y * up_y][kernel_x + x * up_x];
+
+ if (out_x < p.out_w & out_y < p.out_h) {
+ out[((major_idx * p.out_h + out_y) * p.out_w + out_x) * p.minor_dim + minor_idx] = v;
+ }
+ }
+ }
+ }
+}
+
+
+torch::Tensor upfirdn2d_op(const torch::Tensor& input, const torch::Tensor& kernel,
+ int up_x, int up_y, int down_x, int down_y,
+ int pad_x0, int pad_x1, int pad_y0, int pad_y1) {
+ int curDevice = -1;
+ cudaGetDevice(&curDevice);
+ cudaStream_t stream = at::cuda::getCurrentCUDAStream(curDevice);
+
+ UpFirDn2DKernelParams p;
+
+ auto x = input.contiguous();
+ auto k = kernel.contiguous();
+
+ p.major_dim = x.size(0);
+ p.in_h = x.size(1);
+ p.in_w = x.size(2);
+ p.minor_dim = x.size(3);
+ p.kernel_h = k.size(0);
+ p.kernel_w = k.size(1);
+ p.up_x = up_x;
+ p.up_y = up_y;
+ p.down_x = down_x;
+ p.down_y = down_y;
+ p.pad_x0 = pad_x0;
+ p.pad_x1 = pad_x1;
+ p.pad_y0 = pad_y0;
+ p.pad_y1 = pad_y1;
+
+ p.out_h = (p.in_h * p.up_y + p.pad_y0 + p.pad_y1 - p.kernel_h + p.down_y) / p.down_y;
+ p.out_w = (p.in_w * p.up_x + p.pad_x0 + p.pad_x1 - p.kernel_w + p.down_x) / p.down_x;
+
+ auto out = at::empty({p.major_dim, p.out_h, p.out_w, p.minor_dim}, x.options());
+
+ int mode = -1;
+
+ int tile_out_h;
+ int tile_out_w;
+
+ if (p.up_x == 1 && p.up_y == 1 && p.down_x == 1 && p.down_y == 1 && p.kernel_h <= 4 && p.kernel_w <= 4) {
+ mode = 1;
+ tile_out_h = 16;
+ tile_out_w = 64;
+ }
+
+ if (p.up_x == 1 && p.up_y == 1 && p.down_x == 1 && p.down_y == 1 && p.kernel_h <= 3 && p.kernel_w <= 3) {
+ mode = 2;
+ tile_out_h = 16;
+ tile_out_w = 64;
+ }
+
+ if (p.up_x == 2 && p.up_y == 2 && p.down_x == 1 && p.down_y == 1 && p.kernel_h <= 4 && p.kernel_w <= 4) {
+ mode = 3;
+ tile_out_h = 16;
+ tile_out_w = 64;
+ }
+
+ if (p.up_x == 2 && p.up_y == 2 && p.down_x == 1 && p.down_y == 1 && p.kernel_h <= 2 && p.kernel_w <= 2) {
+ mode = 4;
+ tile_out_h = 16;
+ tile_out_w = 64;
+ }
+
+ if (p.up_x == 1 && p.up_y == 1 && p.down_x == 2 && p.down_y == 2 && p.kernel_h <= 4 && p.kernel_w <= 4) {
+ mode = 5;
+ tile_out_h = 8;
+ tile_out_w = 32;
+ }
+
+ if (p.up_x == 1 && p.up_y == 1 && p.down_x == 2 && p.down_y == 2 && p.kernel_h <= 2 && p.kernel_w <= 2) {
+ mode = 6;
+ tile_out_h = 8;
+ tile_out_w = 32;
+ }
+
+ dim3 block_size;
+ dim3 grid_size;
+
+ if (tile_out_h > 0 && tile_out_w) {
+ p.loop_major = (p.major_dim - 1) / 16384 + 1;
+ p.loop_x = 1;
+ block_size = dim3(32 * 8, 1, 1);
+ grid_size = dim3(((p.out_h - 1) / tile_out_h + 1) * p.minor_dim,
+ (p.out_w - 1) / (p.loop_x * tile_out_w) + 1,
+ (p.major_dim - 1) / p.loop_major + 1);
+ }
+
+ AT_DISPATCH_FLOATING_TYPES_AND_HALF(x.scalar_type(), "upfirdn2d_cuda", [&] {
+ switch (mode) {
+ case 1:
+ upfirdn2d_kernel<<>>(
+ out.data_ptr(), x.data_ptr(), k.data_ptr(), p
+ );
+
+ break;
+
+ case 2:
+ upfirdn2d_kernel<<>>(
+ out.data_ptr(), x.data_ptr(), k.data_ptr(), p
+ );
+
+ break;
+
+ case 3:
+ upfirdn2d_kernel<<>>(
+ out.data_ptr(), x.data_ptr(), k.data_ptr(), p
+ );
+
+ break;
+
+ case 4:
+ upfirdn2d_kernel<<>>(
+ out.data_ptr(), x.data_ptr(), k.data_ptr(), p
+ );
+
+ break;
+
+ case 5:
+ upfirdn2d_kernel<<>>(
+ out.data_ptr(), x.data_ptr(), k.data_ptr(), p
+ );
+
+ break;
+
+ case 6:
+ upfirdn2d_kernel<<>>(
+ out.data_ptr(), x.data_ptr(), k.data_ptr(), p
+ );
+
+ break;
+ }
+ });
+
+ return out;
+}
\ No newline at end of file
diff --git a/KAIR/models/select_model.py b/KAIR/models/select_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..cd8af0f06d7dd919a73b473a5ccc3af810178151
--- /dev/null
+++ b/KAIR/models/select_model.py
@@ -0,0 +1,33 @@
+
+"""
+# --------------------------------------------
+# define training model
+# --------------------------------------------
+"""
+
+
+def define_Model(opt):
+ model = opt['model'] # one input: L
+
+ if model == 'plain':
+ from models.model_plain import ModelPlain as M
+
+ elif model == 'plain2': # two inputs: L, C
+ from models.model_plain2 import ModelPlain2 as M
+
+ elif model == 'plain4': # four inputs: L, k, sf, sigma
+ from models.model_plain4 import ModelPlain4 as M
+
+ elif model == 'gan': # one input: L
+ from models.model_gan import ModelGAN as M
+
+ elif model == 'vrt': # one video input L, for VRT
+ from models.model_vrt import ModelVRT as M
+
+ else:
+ raise NotImplementedError('Model [{:s}] is not defined.'.format(model))
+
+ m = M(opt)
+
+ print('Training model [{:s}] is created.'.format(m.__class__.__name__))
+ return m
diff --git a/KAIR/models/select_network.py b/KAIR/models/select_network.py
new file mode 100644
index 0000000000000000000000000000000000000000..c5f92d193018432849991d4c7382c0077013ef9b
--- /dev/null
+++ b/KAIR/models/select_network.py
@@ -0,0 +1,408 @@
+import functools
+import torch
+from torch.nn import init
+
+
+"""
+# --------------------------------------------
+# select the network of G, D and F
+# --------------------------------------------
+"""
+
+
+# --------------------------------------------
+# Generator, netG, G
+# --------------------------------------------
+def define_G(opt):
+ opt_net = opt['netG']
+ net_type = opt_net['net_type']
+
+
+ # ----------------------------------------
+ # denoising task
+ # ----------------------------------------
+
+ # ----------------------------------------
+ # DnCNN
+ # ----------------------------------------
+ if net_type == 'dncnn':
+ from models.network_dncnn import DnCNN as net
+ netG = net(in_nc=opt_net['in_nc'],
+ out_nc=opt_net['out_nc'],
+ nc=opt_net['nc'],
+ nb=opt_net['nb'], # total number of conv layers
+ act_mode=opt_net['act_mode'])
+
+ # ----------------------------------------
+ # Flexible DnCNN
+ # ----------------------------------------
+ elif net_type == 'fdncnn':
+ from models.network_dncnn import FDnCNN as net
+ netG = net(in_nc=opt_net['in_nc'],
+ out_nc=opt_net['out_nc'],
+ nc=opt_net['nc'],
+ nb=opt_net['nb'], # total number of conv layers
+ act_mode=opt_net['act_mode'])
+
+ # ----------------------------------------
+ # FFDNet
+ # ----------------------------------------
+ elif net_type == 'ffdnet':
+ from models.network_ffdnet import FFDNet as net
+ netG = net(in_nc=opt_net['in_nc'],
+ out_nc=opt_net['out_nc'],
+ nc=opt_net['nc'],
+ nb=opt_net['nb'],
+ act_mode=opt_net['act_mode'])
+
+ # ----------------------------------------
+ # others
+ # ----------------------------------------
+
+ # ----------------------------------------
+ # super-resolution task
+ # ----------------------------------------
+
+ # ----------------------------------------
+ # SRMD
+ # ----------------------------------------
+ elif net_type == 'srmd':
+ from models.network_srmd import SRMD as net
+ netG = net(in_nc=opt_net['in_nc'],
+ out_nc=opt_net['out_nc'],
+ nc=opt_net['nc'],
+ nb=opt_net['nb'],
+ upscale=opt_net['scale'],
+ act_mode=opt_net['act_mode'],
+ upsample_mode=opt_net['upsample_mode'])
+
+ # ----------------------------------------
+ # super-resolver prior of DPSR
+ # ----------------------------------------
+ elif net_type == 'dpsr':
+ from models.network_dpsr import MSRResNet_prior as net
+ netG = net(in_nc=opt_net['in_nc'],
+ out_nc=opt_net['out_nc'],
+ nc=opt_net['nc'],
+ nb=opt_net['nb'],
+ upscale=opt_net['scale'],
+ act_mode=opt_net['act_mode'],
+ upsample_mode=opt_net['upsample_mode'])
+
+ # ----------------------------------------
+ # modified SRResNet v0.0
+ # ----------------------------------------
+ elif net_type == 'msrresnet0':
+ from models.network_msrresnet import MSRResNet0 as net
+ netG = net(in_nc=opt_net['in_nc'],
+ out_nc=opt_net['out_nc'],
+ nc=opt_net['nc'],
+ nb=opt_net['nb'],
+ upscale=opt_net['scale'],
+ act_mode=opt_net['act_mode'],
+ upsample_mode=opt_net['upsample_mode'])
+
+ # ----------------------------------------
+ # modified SRResNet v0.1
+ # ----------------------------------------
+ elif net_type == 'msrresnet1':
+ from models.network_msrresnet import MSRResNet1 as net
+ netG = net(in_nc=opt_net['in_nc'],
+ out_nc=opt_net['out_nc'],
+ nc=opt_net['nc'],
+ nb=opt_net['nb'],
+ upscale=opt_net['scale'],
+ act_mode=opt_net['act_mode'],
+ upsample_mode=opt_net['upsample_mode'])
+
+ # ----------------------------------------
+ # RRDB
+ # ----------------------------------------
+ elif net_type == 'rrdb': # RRDB
+ from models.network_rrdb import RRDB as net
+ netG = net(in_nc=opt_net['in_nc'],
+ out_nc=opt_net['out_nc'],
+ nc=opt_net['nc'],
+ nb=opt_net['nb'],
+ gc=opt_net['gc'],
+ upscale=opt_net['scale'],
+ act_mode=opt_net['act_mode'],
+ upsample_mode=opt_net['upsample_mode'])
+
+ # ----------------------------------------
+ # RRDBNet
+ # ----------------------------------------
+ elif net_type == 'rrdbnet': # RRDBNet
+ from models.network_rrdbnet import RRDBNet as net
+ netG = net(in_nc=opt_net['in_nc'],
+ out_nc=opt_net['out_nc'],
+ nf=opt_net['nf'],
+ nb=opt_net['nb'],
+ gc=opt_net['gc'],
+ sf=opt_net['scale'])
+
+ # ----------------------------------------
+ # IMDB
+ # ----------------------------------------
+ elif net_type == 'imdn': # IMDB
+ from models.network_imdn import IMDN as net
+ netG = net(in_nc=opt_net['in_nc'],
+ out_nc=opt_net['out_nc'],
+ nc=opt_net['nc'],
+ nb=opt_net['nb'],
+ upscale=opt_net['scale'],
+ act_mode=opt_net['act_mode'],
+ upsample_mode=opt_net['upsample_mode'])
+
+ # ----------------------------------------
+ # USRNet
+ # ----------------------------------------
+ elif net_type == 'usrnet': # USRNet
+ from models.network_usrnet import USRNet as net
+ netG = net(n_iter=opt_net['n_iter'],
+ h_nc=opt_net['h_nc'],
+ in_nc=opt_net['in_nc'],
+ out_nc=opt_net['out_nc'],
+ nc=opt_net['nc'],
+ nb=opt_net['nb'],
+ act_mode=opt_net['act_mode'],
+ downsample_mode=opt_net['downsample_mode'],
+ upsample_mode=opt_net['upsample_mode']
+ )
+
+ # ----------------------------------------
+ # Deep Residual U-Net (drunet)
+ # ----------------------------------------
+ elif net_type == 'drunet':
+ from models.network_unet import UNetRes as net
+ netG = net(in_nc=opt_net['in_nc'],
+ out_nc=opt_net['out_nc'],
+ nc=opt_net['nc'],
+ nb=opt_net['nb'],
+ act_mode=opt_net['act_mode'],
+ downsample_mode=opt_net['downsample_mode'],
+ upsample_mode=opt_net['upsample_mode'],
+ bias=opt_net['bias'])
+
+ # ----------------------------------------
+ # SwinIR
+ # ----------------------------------------
+ elif net_type == 'swinir':
+ from models.network_swinir import SwinIR as net
+ netG = net(upscale=opt_net['upscale'],
+ in_chans=opt_net['in_chans'],
+ img_size=opt_net['img_size'],
+ window_size=opt_net['window_size'],
+ img_range=opt_net['img_range'],
+ depths=opt_net['depths'],
+ embed_dim=opt_net['embed_dim'],
+ num_heads=opt_net['num_heads'],
+ mlp_ratio=opt_net['mlp_ratio'],
+ upsampler=opt_net['upsampler'],
+ resi_connection=opt_net['resi_connection'])
+
+ # ----------------------------------------
+ # VRT
+ # ----------------------------------------
+ elif net_type == 'vrt':
+ from models.network_vrt import VRT as net
+ netG = net(upscale=opt_net['upscale'],
+ img_size=opt_net['img_size'],
+ window_size=opt_net['window_size'],
+ depths=opt_net['depths'],
+ indep_reconsts=opt_net['indep_reconsts'],
+ embed_dims=opt_net['embed_dims'],
+ num_heads=opt_net['num_heads'],
+ spynet_path=opt_net['spynet_path'],
+ pa_frames=opt_net['pa_frames'],
+ deformable_groups=opt_net['deformable_groups'],
+ nonblind_denoising=opt_net['nonblind_denoising'],
+ use_checkpoint_attn=opt_net['use_checkpoint_attn'],
+ use_checkpoint_ffn=opt_net['use_checkpoint_ffn'],
+ no_checkpoint_attn_blocks=opt_net['no_checkpoint_attn_blocks'],
+ no_checkpoint_ffn_blocks=opt_net['no_checkpoint_ffn_blocks'])
+
+ # ----------------------------------------
+ # others
+ # ----------------------------------------
+ # TODO
+
+ else:
+ raise NotImplementedError('netG [{:s}] is not found.'.format(net_type))
+
+ # ----------------------------------------
+ # initialize weights
+ # ----------------------------------------
+ if opt['is_train']:
+ init_weights(netG,
+ init_type=opt_net['init_type'],
+ init_bn_type=opt_net['init_bn_type'],
+ gain=opt_net['init_gain'])
+
+ return netG
+
+
+# --------------------------------------------
+# Discriminator, netD, D
+# --------------------------------------------
+def define_D(opt):
+ opt_net = opt['netD']
+ net_type = opt_net['net_type']
+
+ # ----------------------------------------
+ # discriminator_vgg_96
+ # ----------------------------------------
+ if net_type == 'discriminator_vgg_96':
+ from models.network_discriminator import Discriminator_VGG_96 as discriminator
+ netD = discriminator(in_nc=opt_net['in_nc'],
+ base_nc=opt_net['base_nc'],
+ ac_type=opt_net['act_mode'])
+
+ # ----------------------------------------
+ # discriminator_vgg_128
+ # ----------------------------------------
+ elif net_type == 'discriminator_vgg_128':
+ from models.network_discriminator import Discriminator_VGG_128 as discriminator
+ netD = discriminator(in_nc=opt_net['in_nc'],
+ base_nc=opt_net['base_nc'],
+ ac_type=opt_net['act_mode'])
+
+ # ----------------------------------------
+ # discriminator_vgg_192
+ # ----------------------------------------
+ elif net_type == 'discriminator_vgg_192':
+ from models.network_discriminator import Discriminator_VGG_192 as discriminator
+ netD = discriminator(in_nc=opt_net['in_nc'],
+ base_nc=opt_net['base_nc'],
+ ac_type=opt_net['act_mode'])
+
+ # ----------------------------------------
+ # discriminator_vgg_128_SN
+ # ----------------------------------------
+ elif net_type == 'discriminator_vgg_128_SN':
+ from models.network_discriminator import Discriminator_VGG_128_SN as discriminator
+ netD = discriminator()
+
+ elif net_type == 'discriminator_patchgan':
+ from models.network_discriminator import Discriminator_PatchGAN as discriminator
+ netD = discriminator(input_nc=opt_net['in_nc'],
+ ndf=opt_net['base_nc'],
+ n_layers=opt_net['n_layers'],
+ norm_type=opt_net['norm_type'])
+
+ elif net_type == 'discriminator_unet':
+ from models.network_discriminator import Discriminator_UNet as discriminator
+ netD = discriminator(input_nc=opt_net['in_nc'],
+ ndf=opt_net['base_nc'])
+
+ else:
+ raise NotImplementedError('netD [{:s}] is not found.'.format(net_type))
+
+ # ----------------------------------------
+ # initialize weights
+ # ----------------------------------------
+ init_weights(netD,
+ init_type=opt_net['init_type'],
+ init_bn_type=opt_net['init_bn_type'],
+ gain=opt_net['init_gain'])
+
+ return netD
+
+
+# --------------------------------------------
+# VGGfeature, netF, F
+# --------------------------------------------
+def define_F(opt, use_bn=False):
+ device = torch.device('cuda' if opt['gpu_ids'] else 'cpu')
+ from models.network_feature import VGGFeatureExtractor
+ # pytorch pretrained VGG19-54, before ReLU.
+ if use_bn:
+ feature_layer = 49
+ else:
+ feature_layer = 34
+ netF = VGGFeatureExtractor(feature_layer=feature_layer,
+ use_bn=use_bn,
+ use_input_norm=True,
+ device=device)
+ netF.eval() # No need to train, but need BP to input
+ return netF
+
+
+"""
+# --------------------------------------------
+# weights initialization
+# --------------------------------------------
+"""
+
+
+def init_weights(net, init_type='xavier_uniform', init_bn_type='uniform', gain=1):
+ """
+ # Kai Zhang, https://github.com/cszn/KAIR
+ #
+ # Args:
+ # init_type:
+ # default, none: pass init_weights
+ # normal; normal; xavier_normal; xavier_uniform;
+ # kaiming_normal; kaiming_uniform; orthogonal
+ # init_bn_type:
+ # uniform; constant
+ # gain:
+ # 0.2
+ """
+
+ def init_fn(m, init_type='xavier_uniform', init_bn_type='uniform', gain=1):
+ classname = m.__class__.__name__
+
+ if classname.find('Conv') != -1 or classname.find('Linear') != -1:
+
+ if init_type == 'normal':
+ init.normal_(m.weight.data, 0, 0.1)
+ m.weight.data.clamp_(-1, 1).mul_(gain)
+
+ elif init_type == 'uniform':
+ init.uniform_(m.weight.data, -0.2, 0.2)
+ m.weight.data.mul_(gain)
+
+ elif init_type == 'xavier_normal':
+ init.xavier_normal_(m.weight.data, gain=gain)
+ m.weight.data.clamp_(-1, 1)
+
+ elif init_type == 'xavier_uniform':
+ init.xavier_uniform_(m.weight.data, gain=gain)
+
+ elif init_type == 'kaiming_normal':
+ init.kaiming_normal_(m.weight.data, a=0, mode='fan_in', nonlinearity='relu')
+ m.weight.data.clamp_(-1, 1).mul_(gain)
+
+ elif init_type == 'kaiming_uniform':
+ init.kaiming_uniform_(m.weight.data, a=0, mode='fan_in', nonlinearity='relu')
+ m.weight.data.mul_(gain)
+
+ elif init_type == 'orthogonal':
+ init.orthogonal_(m.weight.data, gain=gain)
+
+ else:
+ raise NotImplementedError('Initialization method [{:s}] is not implemented'.format(init_type))
+
+ if m.bias is not None:
+ m.bias.data.zero_()
+
+ elif classname.find('BatchNorm2d') != -1:
+
+ if init_bn_type == 'uniform': # preferred
+ if m.affine:
+ init.uniform_(m.weight.data, 0.1, 1.0)
+ init.constant_(m.bias.data, 0.0)
+ elif init_bn_type == 'constant':
+ if m.affine:
+ init.constant_(m.weight.data, 1.0)
+ init.constant_(m.bias.data, 0.0)
+ else:
+ raise NotImplementedError('Initialization method [{:s}] is not implemented'.format(init_bn_type))
+
+ if init_type not in ['default', 'none']:
+ print('Initialization method [{:s} + {:s}], gain is [{:.2f}]'.format(init_type, init_bn_type, gain))
+ fn = functools.partial(init_fn, init_type=init_type, init_bn_type=init_bn_type, gain=gain)
+ net.apply(fn)
+ else:
+ print('Pass this initialization! Initialization was done during network definition!')
diff --git a/KAIR/options/swinir/train_swinir_car_jpeg.json b/KAIR/options/swinir/train_swinir_car_jpeg.json
new file mode 100644
index 0000000000000000000000000000000000000000..115c688ab863a7d9b69bc9883f7975567c048887
--- /dev/null
+++ b/KAIR/options/swinir/train_swinir_car_jpeg.json
@@ -0,0 +1,88 @@
+{
+ "task": "swinir_car_jpeg_40" // JPEG compression artifact reduction for quality factor 10/20/30/40. root/task/images-models-options
+ , "model": "plain" // "plain" | "plain2" if two inputs
+ , "gpu_ids": [0,1,2,3,4,5,6,7]
+ , "dist": true
+
+ , "is_color": false // color or grayscale
+
+ , "path": {
+ "root": "dejpeg" // "denoising" | "superresolution" | "dejpeg"
+ , "pretrained_netG": null // path of pretrained model. We fine-tune quality=10/20/30 models from quality=40 model, so that `G_optimizer_lr` and `G_scheduler_milestones` can be halved to save time.
+ , "pretrained_netE": null // path of pretrained model
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset" // just name
+ , "dataset_type": "jpeg" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch" | "jpeg"
+ , "dataroot_H": "trainsets/trainH"// path of H training dataset. DIV2K (800 training images) + Flickr2K (2650 images) + BSD500 (400 training&testing images) + WED(4744 images) in SwinIR
+ , "dataroot_L": null // path of L training dataset
+
+ , "H_size": 126 // patch_size
+ , "quality_factor": 40 // 10 | 20 | 30 | 40.
+ , "quality_factor_test": 40 //
+ , "is_color": false //
+
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 16
+ , "dataloader_batch_size": 8 // batch size 1 | 16 | 32 | 48 | 64 | 128. Total batch size =1x8=8 in SwinIR
+ }
+ , "test": {
+ "name": "test_dataset" // just name
+ , "dataset_type": "jpeg" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch" | "jpeg"
+ , "dataroot_H": "testsets/LIVE1" // path of H testing dataset
+ , "dataroot_L": null // path of L testing dataset
+
+ , "quality_factor": 40 // 10 | 20 | 30 | 40.
+ , "quality_factor_test": 40 //
+ , "is_color": false //
+
+ }
+ }
+
+ , "netG": {
+ "net_type": "swinir"
+ , "upscale": 1
+ , "in_chans": 1
+ , "img_size": 126
+ , "window_size": 7 // 7 works better than 8, maybe because jpeg encoding uses 8x8 patches
+ , "img_range": 255.0 // image_range=255.0 is slightly better
+ , "depths": [6, 6, 6, 6, 6, 6]
+ , "embed_dim": 180
+ , "num_heads": [6, 6, 6, 6, 6, 6]
+ , "mlp_ratio": 2
+ , "upsampler": null // "pixelshuffle" | "pixelshuffledirect" | "nearest+conv" | null
+ , "resi_connection": "1conv" // "1conv" | "3conv"
+
+ , "init_type": "default"
+ }
+
+ , "train": {
+ "G_lossfn_type": "charbonnier" // "l1" | "l2sum" | "l2" | "ssim" | "charbonnier" preferred
+ , "G_lossfn_weight": 1.0 // default
+ , "G_charbonnier_eps": 1e-9
+
+ , "E_decay": 0.999 // Exponential Moving Average for netG: set 0 to disable; default setting 0.999
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 2e-4 // learning rate
+ , "G_optimizer_wd": 0 // weight decay, default 0
+ , "G_optimizer_clipgrad": null // unused
+ , "G_optimizer_reuse": true //
+
+ , "G_scheduler_type": "MultiStepLR" // "MultiStepLR" is enough
+ , "G_scheduler_milestones": [800000, 1200000, 1400000, 1500000, 1600000]
+ , "G_scheduler_gamma": 0.5
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "G_param_strict": true
+ , "E_param_strict": true
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+}
diff --git a/KAIR/options/swinir/train_swinir_denoising_color.json b/KAIR/options/swinir/train_swinir_denoising_color.json
new file mode 100644
index 0000000000000000000000000000000000000000..465b67f58f5af2642641f09b5387f6faf41b788e
--- /dev/null
+++ b/KAIR/options/swinir/train_swinir_denoising_color.json
@@ -0,0 +1,86 @@
+{
+ "task": "swinir_denoising_color_15" // color Gaussian denoising for noise level 15/25/50. root/task/images-models-options
+ , "model": "plain" // "plain" | "plain2" if two inputs
+ , "gpu_ids": [0,1,2,3,4,5,6,7]
+ , "dist": true
+
+ , "n_channels": 3 // broadcast to "datasets", 1 for grayscale, 3 for color
+
+ , "path": {
+ "root": "denoising" // "denoising" | "superresolution" | "dejpeg"
+ , "pretrained_netG": null // path of pretrained model
+ , "pretrained_netE": null // path of pretrained model
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset" // just name
+ , "dataset_type": "dncnn" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch" | "jpeg"
+ , "dataroot_H": "trainsets/trainH"// path of H training dataset. DIV2K (800 training images) + Flickr2K (2650 images) + BSD500 (400 training&testing images) + WED(4744 images) in SwinIR
+ , "dataroot_L": null // path of L training dataset
+
+ , "H_size": 128 // patch_size
+ , "sigma": 15 // 15 | 25 | 50. We fine-tune sigma=25/50 models from sigma=15 model, so that `G_optimizer_lr` and `G_scheduler_milestones` can be halved to save time.
+ , "sigma_test": 15 //
+
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 16
+ , "dataloader_batch_size": 8 // batch size 1 | 16 | 32 | 48 | 64 | 128. Total batch size =1x8=8 in SwinIR
+ }
+ , "test": {
+ "name": "test_dataset" // just name
+ , "dataset_type": "dncnn" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch" | "jpeg"
+ , "dataroot_H": "testsets/McMaster" // path of H testing dataset
+ , "dataroot_L": null // path of L testing dataset
+
+ , "sigma": 15 //
+ , "sigma_test": 15 //
+
+ }
+ }
+
+ , "netG": {
+ "net_type": "swinir"
+ , "upscale": 1
+ , "in_chans": 3
+ , "img_size": 128
+ , "window_size": 8
+ , "img_range": 1.0
+ , "depths": [6, 6, 6, 6, 6, 6]
+ , "embed_dim": 180
+ , "num_heads": [6, 6, 6, 6, 6, 6]
+ , "mlp_ratio": 2
+ , "upsampler": null // "pixelshuffle" | "pixelshuffledirect" | "nearest+conv" | null
+ , "resi_connection": "1conv" // "1conv" | "3conv"
+
+ , "init_type": "default"
+ }
+
+ , "train": {
+ "G_lossfn_type": "charbonnier" // "l1" | "l2sum" | "l2" | "ssim" | "charbonnier" preferred
+ , "G_lossfn_weight": 1.0 // default
+ , "G_charbonnier_eps": 1e-9
+
+ , "E_decay": 0.999 // Exponential Moving Average for netG: set 0 to disable; default setting 0.999
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 2e-4 // learning rate
+ , "G_optimizer_wd": 0 // weight decay, default 0
+ , "G_optimizer_clipgrad": null // unused
+ , "G_optimizer_reuse": true //
+
+ , "G_scheduler_type": "MultiStepLR" // "MultiStepLR" is enough
+ , "G_scheduler_milestones": [800000, 1200000, 1400000, 1500000, 1600000]
+ , "G_scheduler_gamma": 0.5
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "G_param_strict": true
+ , "E_param_strict": true
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+}
diff --git a/KAIR/options/swinir/train_swinir_denoising_gray.json b/KAIR/options/swinir/train_swinir_denoising_gray.json
new file mode 100644
index 0000000000000000000000000000000000000000..899a33384214d23612033f9d2842e4ff797c9a0d
--- /dev/null
+++ b/KAIR/options/swinir/train_swinir_denoising_gray.json
@@ -0,0 +1,86 @@
+{
+ "task": "swinir_denoising_gray_15" // grayscale Gaussian denoising for noise level 15/25/50. root/task/images-models-options
+ , "model": "plain" // "plain" | "plain2" if two inputs
+ , "gpu_ids": [0,1,2,3,4,5,6,7]
+ , "dist": true
+
+ , "n_channels": 1 // broadcast to "datasets", 1 for grayscale, 3 for color
+
+ , "path": {
+ "root": "denoising" // "denoising" | "superresolution" | "dejpeg"
+ , "pretrained_netG": null // path of pretrained model. We fine-tune sigma=25/50 models from sigma=15 model, so that `G_optimizer_lr` and `G_scheduler_milestones` can be halved to save time.
+ , "pretrained_netE": null // path of pretrained model
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset" // just name
+ , "dataset_type": "dncnn" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch" | "jpeg"
+ , "dataroot_H": "trainsets/trainH"// path of H training dataset. DIV2K (800 training images) + Flickr2K (2650 images) + BSD500 (400 training&testing images) + WED(4744 images) in SwinIR
+ , "dataroot_L": null // path of L training dataset
+
+ , "H_size": 128 // patch_size
+ , "sigma": 15 // 15 | 25 | 50.
+ , "sigma_test": 15 //
+
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 16
+ , "dataloader_batch_size": 8 // batch size 1 | 16 | 32 | 48 | 64 | 128. Total batch size =1x8=8 in SwinIR
+ }
+ , "test": {
+ "name": "test_dataset" // just name
+ , "dataset_type": "dncnn" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch" | "jpeg"
+ , "dataroot_H": "testsets/set12" // path of H testing dataset
+ , "dataroot_L": null // path of L testing dataset
+
+ , "sigma": 15 //
+ , "sigma_test": 15 //
+
+ }
+ }
+
+ , "netG": {
+ "net_type": "swinir"
+ , "upscale": 1
+ , "in_chans": 1
+ , "img_size": 128
+ , "window_size": 8
+ , "img_range": 1.0
+ , "depths": [6, 6, 6, 6, 6, 6]
+ , "embed_dim": 180
+ , "num_heads": [6, 6, 6, 6, 6, 6]
+ , "mlp_ratio": 2
+ , "upsampler": null // "pixelshuffle" | "pixelshuffledirect" | "nearest+conv" | null
+ , "resi_connection": "1conv" // "1conv" | "3conv"
+
+ , "init_type": "default"
+ }
+
+ , "train": {
+ "G_lossfn_type": "charbonnier" // "l1" | "l2sum" | "l2" | "ssim" | "charbonnier" preferred
+ , "G_lossfn_weight": 1.0 // default
+ , "G_charbonnier_eps": 1e-9
+
+ , "E_decay": 0.999 // Exponential Moving Average for netG: set 0 to disable; default setting 0.999
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 2e-4 // learning rate
+ , "G_optimizer_wd": 0 // weight decay, default 0
+ , "G_optimizer_clipgrad": null // unused
+ , "G_optimizer_reuse": true //
+
+ , "G_scheduler_type": "MultiStepLR" // "MultiStepLR" is enough
+ , "G_scheduler_milestones": [800000, 1200000, 1400000, 1500000, 1600000]
+ , "G_scheduler_gamma": 0.5
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "G_param_strict": true
+ , "E_param_strict": true
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+}
diff --git a/KAIR/options/swinir/train_swinir_sr_classical.json b/KAIR/options/swinir/train_swinir_sr_classical.json
new file mode 100644
index 0000000000000000000000000000000000000000..34736cbd3e826ab87c71b3f1000030222487d0ea
--- /dev/null
+++ b/KAIR/options/swinir/train_swinir_sr_classical.json
@@ -0,0 +1,81 @@
+{
+ "task": "swinir_sr_classical_patch48_x2" // classical image sr for x2/x3/x4/x8. root/task/images-models-options
+ , "model": "plain" // "plain" | "plain2" if two inputs
+ , "gpu_ids": [0,1,2,3,4,5,6,7]
+ , "dist": true
+
+ , "scale": 2 // 2 | 3 | 4 | 8
+ , "n_channels": 3 // broadcast to "datasets", 1 for grayscale, 3 for color
+
+ , "path": {
+ "root": "superresolution" // "denoising" | "superresolution" | "dejpeg"
+ , "pretrained_netG": null // path of pretrained model. We fine-tune X3/X4/X8 models from X2 model, so that `G_optimizer_lr` and `G_scheduler_milestones` can be halved to save time.
+ , "pretrained_netE": null // path of pretrained model
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset" // just name
+ , "dataset_type": "sr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch" | "jpeg"
+ , "dataroot_H": "/home/cll/datasets/REDS/train/train_sharp"// path of H training dataset. DIV2K (800 training images)
+ , "dataroot_L": null // path of L training dataset
+
+ , "H_size": 96 // 96/144|192/384 | 128/192/256/512. LR patch size is set to 48 or 64 when compared with RCAN or RRDB.
+
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 16
+ , "dataloader_batch_size": 32 // batch size 1 | 16 | 32 | 48 | 64 | 128. Total batch size =4x8=32 in SwinIR
+ }
+ , "test": {
+ "name": "test_dataset" // just name
+ , "dataset_type": "sr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch" | "jpeg"
+ , "dataroot_H": "/home/cll/datasets/REDS/val/val_sharp" // path of H testing dataset
+ , "dataroot_L": null // path of L testing dataset
+
+ }
+ }
+
+ , "netG": {
+ "net_type": "swinir"
+ , "upscale": 2 // 2 | 3 | 4 | 8
+ , "in_chans": 3
+ , "img_size": 48 // For fair comparison, LR patch size is set to 48 or 64 when compared with RCAN or RRDB.
+ , "window_size": 8
+ , "img_range": 1.0
+ , "depths": [6, 6, 6, 6, 6, 6]
+ , "embed_dim": 180
+ , "num_heads": [6, 6, 6, 6, 6, 6]
+ , "mlp_ratio": 2
+ , "upsampler": "pixelshuffle" // "pixelshuffle" | "pixelshuffledirect" | "nearest+conv" | null
+ , "resi_connection": "1conv" // "1conv" | "3conv"
+
+ , "init_type": "default"
+ }
+
+ , "train": {
+ "G_lossfn_type": "l1" // "l1" preferred | "l2sum" | "l2" | "ssim" | "charbonnier"
+ , "G_lossfn_weight": 1.0 // default
+
+ , "E_decay": 0.999 // Exponential Moving Average for netG: set 0 to disable; default setting 0.999
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 2e-4 // learning rate
+ , "G_optimizer_wd": 0 // weight decay, default 0
+ , "G_optimizer_clipgrad": null // unused
+ , "G_optimizer_reuse": true //
+
+ , "G_scheduler_type": "MultiStepLR" // "MultiStepLR" is enough
+ , "G_scheduler_milestones": [250000, 400000, 450000, 475000, 500000]
+ , "G_scheduler_gamma": 0.5
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "G_param_strict": true
+ , "E_param_strict": true
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+}
diff --git a/KAIR/options/swinir/train_swinir_sr_lightweight.json b/KAIR/options/swinir/train_swinir_sr_lightweight.json
new file mode 100644
index 0000000000000000000000000000000000000000..155e937fcbfd3a31588040fd390f1de4ec6feffd
--- /dev/null
+++ b/KAIR/options/swinir/train_swinir_sr_lightweight.json
@@ -0,0 +1,81 @@
+{
+ "task": "swinir_sr_lightweight_x2" // classical image sr for x2/x3/x4. root/task/images-models-options
+ , "model": "plain" // "plain" | "plain2" if two inputs
+ , "gpu_ids": [0,1,2,3,4,5,6,7]
+ , "dist": true
+
+ , "scale": 2 // 2 | 3 | 4
+ , "n_channels": 3 // broadcast to "datasets", 1 for grayscale, 3 for color
+
+ , "path": {
+ "root": "superresolution" // "denoising" | "superresolution" | "dejpeg"
+ , "pretrained_netG": null // path of pretrained model. We fine-tune X3/X4 models from X2 model, so that `G_optimizer_lr` and `G_scheduler_milestones` can be halved to save time.
+ , "pretrained_netE": null // path of pretrained model
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset" // just name
+ , "dataset_type": "sr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch" | "jpeg"
+ , "dataroot_H": "trainsets/trainH"// path of H training dataset. DIV2K (800 training images)
+ , "dataroot_L": "trainsets/trainL" // path of L training dataset
+
+ , "H_size": 128 // 128/192/256/512.
+
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 16
+ , "dataloader_batch_size": 64 // Total batch size =8x8=64 in SwinIR
+ }
+ , "test": {
+ "name": "test_dataset" // just name
+ , "dataset_type": "sr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch" | "jpeg"
+ , "dataroot_H": "testsets/Set5/HR" // path of H testing dataset
+ , "dataroot_L": "testsets/Set5/LR_bicubic/X2" // path of L testing dataset
+
+ }
+ }
+
+ , "netG": {
+ "net_type": "swinir"
+ , "upscale": 2 // 2 | 3 | 4
+ , "in_chans": 3
+ , "img_size": 64
+ , "window_size": 8
+ , "img_range": 1.0
+ , "depths": [6, 6, 6, 6]
+ , "embed_dim": 60
+ , "num_heads": [6, 6, 6, 6]
+ , "mlp_ratio": 2
+ , "upsampler": "pixelshuffledirect" // "pixelshuffle" | "pixelshuffledirect" | "nearest+conv" | null
+ , "resi_connection": "1conv" // "1conv" | "3conv"
+
+ , "init_type": "default"
+ }
+
+ , "train": {
+ "G_lossfn_type": "l1" // "l1" preferred | "l2sum" | "l2" | "ssim" | "charbonnier"
+ , "G_lossfn_weight": 1.0 // default
+
+ , "E_decay": 0.999 // Exponential Moving Average for netG: set 0 to disable; default setting 0.999
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 2e-4 // learning rate
+ , "G_optimizer_wd": 0 // weight decay, default 0
+ , "G_optimizer_clipgrad": null // unused
+ , "G_optimizer_reuse": true //
+
+ , "G_scheduler_type": "MultiStepLR" // "MultiStepLR" is enough
+ , "G_scheduler_milestones": [250000, 400000, 450000, 475000, 500000]
+ , "G_scheduler_gamma": 0.5
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "G_param_strict": true
+ , "E_param_strict": true
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+}
diff --git a/KAIR/options/swinir/train_swinir_sr_realworld_x2_gan.json b/KAIR/options/swinir/train_swinir_sr_realworld_x2_gan.json
new file mode 100644
index 0000000000000000000000000000000000000000..e20616c7a1b40b17015db063efe998f5113dffe1
--- /dev/null
+++ b/KAIR/options/swinir/train_swinir_sr_realworld_x2_gan.json
@@ -0,0 +1,121 @@
+{
+ "task": "swinir_sr_realworld_x2_gan" // real-world image sr. root/task/images|models|options
+ , "model": "plain" // "gan"
+ , "gpu_ids": [0, 1, 2, 3, 4, 5, 6, 7]
+
+ , "scale": 2 // broadcast to "datasets"
+ , "n_channels": 3 // broadcast to "datasets", 1 for grayscale, 3 for color
+
+ , "path": {
+ "root": "superresolution" // "denoising" | "superresolution" | "dejpeg"
+ , "pretrained_netG": "superresolution/swinir_sr_realworld_x2_gan/models/205000_G.pth" // path of pretrained model
+ , "pretrained_netD": null // "superresolution/swinir_sr_realworld_x2_gan/models/185000_D.pth" // path of pretrained model
+ , "pretrained_netE": "superresolution/swinir_sr_realworld_x2_gan/models/205000_E.pth" // path of pretrained model
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset" // just name
+ , "dataset_type": "blindsr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch" | "jpeg"
+ , "dataroot_H": "trainsets/trainH"// path of H training dataset. DIV2K (800 training images) + Flickr2K (2650 images) + + OST (10324 images)
+ , "dataroot_L": null // path of L training dataset
+
+ , "degradation_type": "bsrgan" // "bsrgan" | "bsrgan_plus"
+ , "H_size": 256 // patch_size 256 | 288 | 320
+ , "shuffle_prob": 0.1 //
+ , "lq_patchsize": 96
+ , "use_sharp": true
+
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 8
+ , "dataloader_batch_size": 16 // batch size 1 | 16 | 32 | 48 | 64 | 128. Total batch size =4x8=32 in SwinIR
+ }
+ , "test": {
+ "name": "test_dataset" // just name
+ , "dataset_type": "sr"
+
+ // , "degradation_type": "bsrgan" // "bsrgan" | "bsrgan_plus"
+ // , "H_size": 256 // patch_size 256 | 288 | 320
+ // , "shuffle_prob": 0.1 //
+ // , "lq_patchsize": 256
+ // , "use_sharp": false
+
+ , "dataroot_H": "/home/clindsey/testset_153/gt" // path of H testing dataset
+ , "dataroot_L": "/home/clindsey/testset_153/lq" // path of L testing dataset
+ }
+ }
+
+ , "netG": {
+ "net_type": "swinir"
+ , "upscale": 2
+ , "in_chans": 3
+ , "img_size": 96
+ , "window_size": 8
+ , "img_range": 1.0
+ , "depths": [6, 6, 6, 6, 6, 6]
+ , "embed_dim": 180
+ , "num_heads": [6, 6, 6, 6, 6, 6]
+ , "mlp_ratio": 2
+ , "upsampler": "nearest+conv" // "pixelshuffle" | "pixelshuffledirect" | "nearest+conv" | null
+ , "resi_connection": "3conv" // "1conv" | "3conv"
+
+ , "init_type": "default"
+ }
+
+ , "netD": {
+ "net_type": "discriminator_unet" // "discriminator_patchgan" | "discriminator_unet"
+ , "in_nc": 3
+ , "base_nc": 64
+ , "n_layers": 3 // only for "net_type":"discriminator_patchgan"
+ , "norm_type": "spectral" // only for "net_type":"discriminator_patchgan" | 'batch', 'instance', 'spectral', 'batchspectral', 'instancespectral'
+
+ , "init_type": "orthogonal" // "orthogonal" | "normal" | "uniform" | "xavier_normal" | "xavier_uniform" | "kaiming_normal" | "kaiming_uniform"
+ , "init_bn_type": "uniform" // "uniform" | "constant"
+ , "init_gain": 0.2
+ }
+
+ , "train": {
+ "G_lossfn_type": "l1" // "l1" | "l2" | "l2sum" | "l1c" | "ssim"
+ , "G_lossfn_weight": 5
+
+ , "F_lossfn_type": "l1" // "l1" | "l2"
+ , "F_lossfn_weight": 1
+ , "F_feature_layer": [2,7,16,25,34] // 25 | [2,7,16,25,34]
+ , "F_weights": [0.1,0.1,1.0,1.0,1.0] // 1.0 | [0.1,0.1,1.0,1.0,1.0]
+ , "F_use_input_norm": true
+ , "F_use_range_norm": false
+
+ , "gan_type": "gan" // "gan" | "ragan" | "lsgan" | "wgan" | "softplusgan"
+ , "D_lossfn_weight": 0.1
+
+ , "E_decay": 0.999 // Exponential Moving Average for netG: set 0 to disable; default setting 0.999
+
+ , "D_init_iters": 0
+
+ , "G_optimizer_type": "adam"
+ , "G_optimizer_lr": 1e-4 // learning rate
+ , "G_optimizer_wd": 0
+
+ , "D_optimizer_type": "adam"
+ , "D_optimizer_lr": 1e-4 // learning rate
+ , "D_optimizer_wd": 0
+
+ , "G_scheduler_type": "MultiStepLR"
+ , "G_scheduler_milestones": [400000, 500000, 600000, 800000, 900000]
+ , "G_scheduler_gamma": 0.5
+ , "G_optimizer_reuse": true
+
+ , "D_scheduler_type": "MultiStepLR"
+ , "D_scheduler_milestones": [400000, 500000, 600000, 800000, 900000]
+ , "D_scheduler_gamma": 0.5
+ , "D_optimizer_reuse": false
+
+ , "G_param_strict": true
+ , "D_param_strict": true
+ , "E_param_strict": true
+
+ , "checkpoint_test": 5000 // skip testing
+ , "checkpoint_save": 5000
+ , "checkpoint_print": 200
+ }
+}
diff --git a/KAIR/options/swinir/train_swinir_sr_realworld_x4_gan.json b/KAIR/options/swinir/train_swinir_sr_realworld_x4_gan.json
new file mode 100644
index 0000000000000000000000000000000000000000..20279ac9ab1d0c1bc3277451cdd439f6c4db37df
--- /dev/null
+++ b/KAIR/options/swinir/train_swinir_sr_realworld_x4_gan.json
@@ -0,0 +1,121 @@
+{
+ "task": "swinir_sr_realworld_x4_gan" // real-world image sr. root/task/images|models|options
+ , "model": "gan" // "gan"
+ , "gpu_ids": [0,1,2,3,4,5,6,7]
+
+ , "scale": 4 // broadcast to "datasets"
+ , "n_channels": 3 // broadcast to "datasets", 1 for grayscale, 3 for color
+
+ , "path": {
+ "root": "superresolution" // "denoising" | "superresolution" | "dejpeg"
+ , "pretrained_netG": null // path of pretrained model
+ , "pretrained_netD": null // path of pretrained model
+ , "pretrained_netE": null // path of pretrained model
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset" // just name
+ , "dataset_type": "blindsr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch" | "jpeg"
+ , "dataroot_H": "trainsets/trainH"// path of H training dataset. DIV2K (800 training images) + Flickr2K (2650 images) + + OST (10324 images)
+ , "dataroot_L": null // path of L training dataset
+
+ , "degradation_type": "bsrgan" // "bsrgan" | "bsrgan_plus"
+ , "H_size": 256 // patch_size 256 | 288 | 320
+ , "shuffle_prob": 0.1 //
+ , "lq_patchsize": 64
+ , "use_sharp": true
+
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 16
+ , "dataloader_batch_size": 32 // batch size 1 | 16 | 32 | 48 | 64 | 128. Total batch size =4x8=32 in SwinIR
+ }
+ , "test": {
+ "name": "test_dataset" // just name
+ , "dataset_type": "blindsr"
+
+ , "degradation_type": "bsrgan" // "bsrgan" | "bsrgan_plus"
+ , "H_size": 256 // patch_size 256 | 288 | 320
+ , "shuffle_prob": 0.1 //
+ , "lq_patchsize": 64
+ , "use_sharp": false
+
+ , "dataroot_H": "testsets/Set5/HR" // path of H testing dataset
+ , "dataroot_L": null // path of L testing dataset
+ }
+ }
+
+ , "netG": {
+ "net_type": "swinir"
+ , "upscale": 4
+ , "in_chans": 3
+ , "img_size": 64
+ , "window_size": 8
+ , "img_range": 1.0
+ , "depths": [6, 6, 6, 6, 6, 6]
+ , "embed_dim": 180
+ , "num_heads": [6, 6, 6, 6, 6, 6]
+ , "mlp_ratio": 2
+ , "upsampler": "nearest+conv" // "pixelshuffle" | "pixelshuffledirect" | "nearest+conv" | null
+ , "resi_connection": "1conv" // "1conv" | "3conv"
+
+ , "init_type": "default"
+ }
+
+ , "netD": {
+ "net_type": "discriminator_unet" // "discriminator_patchgan" | "discriminator_unet"
+ , "in_nc": 3
+ , "base_nc": 64
+ , "n_layers": 3 // only for "net_type":"discriminator_patchgan"
+ , "norm_type": "spectral" // only for "net_type":"discriminator_patchgan" | 'batch', 'instance', 'spectral', 'batchspectral', 'instancespectral'
+
+ , "init_type": "orthogonal" // "orthogonal" | "normal" | "uniform" | "xavier_normal" | "xavier_uniform" | "kaiming_normal" | "kaiming_uniform"
+ , "init_bn_type": "uniform" // "uniform" | "constant"
+ , "init_gain": 0.2
+ }
+
+ , "train": {
+ "G_lossfn_type": "l1" // "l1" | "l2" | "l2sum" | "l1c" | "ssim"
+ , "G_lossfn_weight": 1
+
+ , "F_lossfn_type": "l1" // "l1" | "l2"
+ , "F_lossfn_weight": 1
+ , "F_feature_layer": [2,7,16,25,34] // 25 | [2,7,16,25,34]
+ , "F_weights": [0.1,0.1,1.0,1.0,1.0] // 1.0 | [0.1,0.1,1.0,1.0,1.0]
+ , "F_use_input_norm": true
+ , "F_use_range_norm": false
+
+ , "gan_type": "gan" // "gan" | "ragan" | "lsgan" | "wgan" | "softplusgan"
+ , "D_lossfn_weight": 0.1
+
+ , "E_decay": 0.999 // Exponential Moving Average for netG: set 0 to disable; default setting 0.999
+
+ , "D_init_iters": 0
+
+ , "G_optimizer_type": "adam"
+ , "G_optimizer_lr": 1e-4 // learning rate
+ , "G_optimizer_wd": 0
+
+ , "D_optimizer_type": "adam"
+ , "D_optimizer_lr": 1e-4 // learning rate
+ , "D_optimizer_wd": 0
+
+ , "G_scheduler_type": "MultiStepLR"
+ , "G_scheduler_milestones": [400000, 500000, 550000, 575000, 600000]
+ , "G_scheduler_gamma": 0.5
+ , "G_optimizer_reuse": true
+
+ , "D_scheduler_type": "MultiStepLR"
+ , "D_scheduler_milestones": [400000, 500000, 550000, 575000, 600000]
+ , "D_scheduler_gamma": 0.5
+ , "D_optimizer_reuse": false
+
+ , "G_param_strict": true
+ , "D_param_strict": true
+ , "E_param_strict": true
+
+ , "checkpoint_test": 5000 // skip testing
+ , "checkpoint_save": 5000
+ , "checkpoint_print": 200
+ }
+}
diff --git a/KAIR/options/swinir/train_swinir_sr_realworld_x4_psnr.json b/KAIR/options/swinir/train_swinir_sr_realworld_x4_psnr.json
new file mode 100644
index 0000000000000000000000000000000000000000..2ddce9ec333e26cb86ef2057e35a5555823fb57e
--- /dev/null
+++ b/KAIR/options/swinir/train_swinir_sr_realworld_x4_psnr.json
@@ -0,0 +1,85 @@
+{
+ "task": "swinir_sr_realworld_x4_psnr" // real-world image sr. root/task/images-models-options
+ , "model": "plain" // "plain" | "plain2" if two inputs
+ , "gpu_ids": [0,1,2,3,4,5,6,7]
+ , "dist": true
+
+ , "scale": 4 // broadcast to "datasets"
+ , "n_channels": 3 // broadcast to "datasets", 1 for grayscale, 3 for color
+
+ , "path": {
+ "root": "superresolution" // "denoising" | "superresolution" | "dejpeg"
+ , "pretrained_netG": null // path of pretrained model
+ , "pretrained_netE": null // path of pretrained model
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset" // just name
+ , "dataset_type": "blindsr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch" | "jpeg"
+ , "dataroot_H": "trainsets/trainH"// path of H training dataset. DIV2K (800 training images) + Flickr2K (2650 images) + + OST (10324 images)
+ , "dataroot_L": null // path of L training dataset
+
+ , "degradation_type": "bsrgan" // "bsrgan" | "bsrgan_plus"
+ , "H_size": 256 // patch_size 256 | 288 | 320
+ , "shuffle_prob": 0.1 //
+ , "lq_patchsize": 64
+ , "use_sharp": true
+
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 16
+ , "dataloader_batch_size": 32 // batch size 1 | 16 | 32 | 48 | 64 | 128. Total batch size =4x8=32 in SwinIR
+ }
+ , "test": {
+ "name": "test_dataset" // just name
+ , "dataset_type": "sr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch" | "jpeg"
+ , "dataroot_H": "testsets/Set5/HR" // path of H testing dataset
+ , "dataroot_L": "testsets/Set5/LR_bicubic/X4" // path of L testing dataset
+
+ }
+ }
+
+ , "netG": {
+ "net_type": "swinir"
+ , "upscale": 4
+ , "in_chans": 3
+ , "img_size": 64
+ , "window_size": 8
+ , "img_range": 1.0
+ , "depths": [6, 6, 6, 6, 6, 6]
+ , "embed_dim": 180
+ , "num_heads": [6, 6, 6, 6, 6, 6]
+ , "mlp_ratio": 2
+ , "upsampler": "nearest+conv" // "pixelshuffle" | "pixelshuffledirect" | "nearest+conv" | null
+ , "resi_connection": "1conv" // "1conv" | "3conv"
+
+ , "init_type": "default"
+ }
+
+ , "train": {
+ "G_lossfn_type": "l1" // "l1" preferred | "l2sum" | "l2" | "ssim" | "charbonnier"
+ , "G_lossfn_weight": 1.0 // default
+
+ , "E_decay": 0.999 // Exponential Moving Average for netG: set 0 to disable; default setting 0.999
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 2e-4 // learning rate
+ , "G_optimizer_wd": 0 // weight decay, default 0
+ , "G_optimizer_clipgrad": null // unused
+ , "G_optimizer_reuse": true //
+
+ , "G_scheduler_type": "MultiStepLR" // "MultiStepLR" is enough
+ , "G_scheduler_milestones": [500000, 800000, 900000, 950000, 1000000]
+ , "G_scheduler_gamma": 0.5
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "G_param_strict": true
+ , "E_param_strict": true
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+}
diff --git a/KAIR/options/train_bsrgan_x4_gan.json b/KAIR/options/train_bsrgan_x4_gan.json
new file mode 100644
index 0000000000000000000000000000000000000000..65ac1d258150e152aea902a7e99e105b064a463d
--- /dev/null
+++ b/KAIR/options/train_bsrgan_x4_gan.json
@@ -0,0 +1,121 @@
+{
+ "task": "bsrgan_x4_gan" // root/task/images|models|options
+ , "model": "gan" // "gan"
+ , "gpu_ids": [0] // [0,1,2,3] for 4 GPUs
+
+ , "scale": 4 // broadcast to "netG" if SISR
+ , "n_channels": 3 // broadcast to "datasets", 1 for grayscale, 3 for color
+
+ , "path": {
+ "root": "superresolution" // "denoising" | "superresolution"
+ , "pretrained_netG": null // path of pretrained model
+ , "pretrained_netD": null // path of pretrained model
+ , "pretrained_netE": null // path of pretrained model
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset" // fixed
+ , "dataset_type": "blindsr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "trainsets/trainH"// path of H training dataset
+ , "dataroot_L": null // path of L training dataset
+
+ , "degradation_type": "bsrgan" // "bsrgan" | "bsrgan_plus"
+ , "H_size": 320 // patch_size 256 | 288 | 320
+ , "shuffle_prob": 0.1 //
+ , "lq_patchsize": 72
+ , "use_sharp": false
+
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 8 // 8 | 32 | 64
+ , "dataloader_batch_size": 4 // batch size 1 | 16 | 32 | 48 | 64 | 128
+ }
+ , "test": {
+ "name": "test_dataset" // fixed
+ , "dataset_type": "blindsr"
+
+ , "degradation_type": "bsrgan" // "bsrgan" | "bsrgan_plus"
+ , "H_size": 320 // patch_size 256 | 288 | 320
+ , "shuffle_prob": 0.1 //
+ , "lq_patchsize": 72
+ , "use_sharp": false
+
+ , "dataroot_H": "testsets/set5" // path of H testing dataset
+ , "dataroot_L": null // path of L testing dataset
+ }
+ }
+
+ , "netG": {
+ "net_type": "rrdbnet" // "dncnn" | "fdncnn" | "ffdnet" | "srmd" | "dpsr" | "srresnet0" | "srresnet1" | "rrdbnet"
+ , "in_nc": 3 // input channel number
+ , "out_nc": 3 // ouput channel number
+ , "nf": 64 // 96 for DPSR, 128 for SRMD, 64 for "dncnn"
+ , "nb": 23 // 12 for "srmd", 15 for "ffdnet", 20 for "dncnn", 16 for "srresnet" and "dpsr"
+ , "gc": 32 //
+ , "ng": 2 // unused
+ , "reduction" : 16 // unused
+ , "act_mode": "L" // "BR" for BN+ReLU | "R" for ReLU
+ , "bias": true
+
+ , "init_type": "orthogonal" // "orthogonal" | "normal" | "uniform" | "xavier_normal" | "xavier_uniform" | "kaiming_normal" | "kaiming_uniform"
+ , "init_bn_type": "uniform" // "uniform" | "constant"
+ , "init_gain": 0.2
+ }
+
+ , "netD": {
+ "net_type": "discriminator_unet" // "discriminator_patchgan" | "discriminator_unet"
+ , "in_nc": 3
+ , "base_nc": 64
+ , "n_layers": 3 // only for "net_type":"discriminator_patchgan"
+ , "norm_type": "spectral" // only for "net_type":"discriminator_patchgan" | 'batch', 'instance', 'spectral', 'batchspectral', 'instancespectral'
+
+ , "init_type": "orthogonal" // "orthogonal" | "normal" | "uniform" | "xavier_normal" | "xavier_uniform" | "kaiming_normal" | "kaiming_uniform"
+ , "init_bn_type": "uniform" // "uniform" | "constant"
+ , "init_gain": 0.2
+ }
+
+ , "train": {
+ "G_lossfn_type": "l1" // "l1" | "l2" | "l2sum" | "l1c" | "ssim"
+ , "G_lossfn_weight": 1
+
+ , "F_lossfn_type": "l1" // "l1" | "l2"
+ , "F_lossfn_weight": 1
+ , "F_feature_layer": [2,7,16,25,34] // 25 | [2,7,16,25,34]
+ , "F_weights": [0.1,0.1,1.0,1.0,1.0] // 1.0 | [0.1,0.1,1.0,1.0,1.0]
+ , "F_use_input_norm": true
+ , "F_use_range_norm": false
+
+ , "gan_type": "lsgan" // "gan" | "ragan" | "lsgan" | "wgan" | "softplusgan"
+ , "D_lossfn_weight": 1
+
+ , "E_decay": 0.999 // Exponential Moving Average for netG: set 0 to disable; default setting 0.999
+
+ , "D_init_iters": 0
+
+ , "G_optimizer_type": "adam"
+ , "G_optimizer_lr": 5e-5 // learning rate
+ , "G_optimizer_wd": 0
+
+ , "D_optimizer_type": "adam"
+ , "D_optimizer_lr": 5e-5 // learning rate
+ , "D_optimizer_wd": 0
+
+ , "G_scheduler_type": "MultiStepLR"
+ , "G_scheduler_milestones": [800000, 1600000]
+ , "G_scheduler_gamma": 0.5
+ , "G_optimizer_reuse": true
+
+ , "D_scheduler_type": "MultiStepLR"
+ , "D_scheduler_milestones": [800000, 1600000]
+ , "D_scheduler_gamma": 0.5
+ , "D_optimizer_reuse": false
+
+ , "G_param_strict": true
+ , "D_param_strict": true
+ , "E_param_strict": true
+
+ , "checkpoint_test": 50000000000 // skip testing
+ , "checkpoint_save": 5000
+ , "checkpoint_print": 200
+ }
+}
diff --git a/KAIR/options/train_bsrgan_x4_psnr.json b/KAIR/options/train_bsrgan_x4_psnr.json
new file mode 100644
index 0000000000000000000000000000000000000000..6a41f86b6511ff19bda5db0e472a13e298e01193
--- /dev/null
+++ b/KAIR/options/train_bsrgan_x4_psnr.json
@@ -0,0 +1,90 @@
+{
+ "task": "bsrgan_x4_psnr" // root/task/images|models|options
+ , "model": "plain" // "plain" | "plain2" if two inputs
+ , "gpu_ids": [0] // [0,1,2,3] for 4 GPUs
+ , "dist": true
+
+ , "scale": 4 // broadcast to "datasets"
+ , "n_channels": 3 // broadcast to "datasets", 1 for grayscale, 3 for color
+
+ , "path": {
+ "root": "superresolution" // "denoising" | "superresolution"
+ , "pretrained_netG": null // path of pretrained model
+ , "pretrained_netE": null // path of pretrained model
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset" // fixed
+ , "dataset_type": "blindsr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "trainsets/trainH"// path of H training dataset
+ , "dataroot_L": null // path of L training dataset
+
+ , "degradation_type": "bsrgan" // "bsrgan" | "bsrgan_plus"
+ , "H_size": 320 // patch_size 256 | 288 | 320
+ , "shuffle_prob": 0.1 //
+ , "lq_patchsize": 72
+ , "use_sharp": false
+
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 8 // 8 | 32 | 64
+ , "dataloader_batch_size": 4 // batch size for all GPUs, 1 | 16 | 32 | 48 | 64 | 128
+ }
+ , "test": {
+ "name": "test_dataset" // fixed
+ , "dataset_type": "blindsr"
+
+ , "degradation_type": "bsrgan" // "bsrgan" | "bsrgan_plus"
+ , "H_size": 320 // patch_size 256 | 288 | 320
+ , "shuffle_prob": 0.1 //
+ , "lq_patchsize": 72
+ , "use_sharp": false
+
+ , "dataroot_H": "testsets/set5" // path of H testing dataset
+ , "dataroot_L": null // path of L testing dataset
+ }
+ }
+
+ , "netG": {
+ "net_type": "rrdbnet" // "dncnn" | "fdncnn" | "ffdnet" | "srmd" | "dpsr" | "srresnet0" | "srresnet1" | "rrdbnet"
+ , "in_nc": 3 // input channel number
+ , "out_nc": 3 // ouput channel number
+ , "nf": 64 // 96 for DPSR, 128 for SRMD, 64 for "dncnn"
+ , "nb": 23 // 12 for "srmd", 15 for "ffdnet", 20 for "dncnn", 16 for "srresnet" and "dpsr"
+ , "gc": 32 //
+ , "ng": 2 // unused
+ , "reduction" : 16 // unused
+ , "act_mode": "L" // "BR" for BN+ReLU | "R" for ReLU
+ , "bias": true
+
+ , "init_type": "orthogonal" // "orthogonal" | "normal" | "uniform" | "xavier_normal" | "xavier_uniform" | "kaiming_normal" | "kaiming_uniform"
+ , "init_bn_type": "uniform" // "uniform" | "constant"
+ , "init_gain": 0.2
+ }
+
+ , "train": {
+ "G_lossfn_type": "l1" // "l1" preferred | "l2sum" | "l2" | "ssim"
+ , "G_lossfn_weight": 1.0 // default
+
+ , "E_decay": 0.999 // Exponential Moving Average for netG: set 0 to disable; default setting 0.999
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 1e-4 // learning rate
+ , "G_optimizer_clipgrad": null // unused
+ , "G_optimizer_reuse": true
+
+ , "G_scheduler_type": "MultiStepLR" // "MultiStepLR" is enough
+ , "G_scheduler_milestones": [200000, 400000, 600000, 800000, 1000000, 2000000]
+ , "G_scheduler_gamma": 0.5
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null //
+
+ , "G_param_strict": true
+ , "E_param_strict": true
+
+ , "checkpoint_test": 500000000 // skip testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+}
diff --git a/KAIR/options/train_dncnn.json b/KAIR/options/train_dncnn.json
new file mode 100644
index 0000000000000000000000000000000000000000..4bfc2d117b797f8f3c688205dad53f4fcad49ca6
--- /dev/null
+++ b/KAIR/options/train_dncnn.json
@@ -0,0 +1,81 @@
+{
+ "task": "dncnn25" // root/task/images-models-options
+ , "model": "plain" // "plain"
+ , "gpu_ids": [0]
+
+ , "scale": 1 // broadcast to "netG" if SISR
+ , "n_channels": 1 // broadcast to "datasets", 1 for grayscale, 3 for color
+
+ , "merge_bn": true // BN for DnCNN
+ , "merge_bn_startpoint": 400000 // merge BN after N iterations
+
+ , "path": {
+ "root": "denoising" // "denoising" | "superresolution"
+ , "pretrained_netG": null // path of pretrained model
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset" // just name
+ , "dataset_type": "dncnn" // "dncnn" | "dnpatch" for dncnn, | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "trainsets/trainH"// path of H training dataset
+ , "dataroot_L": null // path of L training dataset
+ , "H_size": 40 // patch size 40 | 64 | 96 | 128 | 192
+
+ , "sigma": 25 // 15, 25, 50 for DnCNN | [0, 75] for FFDNet and FDnCNN
+ , "sigma_test": 25 // 15, 25, 50 for DnCNN and ffdnet
+
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 8
+ , "dataloader_batch_size": 64 // batch size 1 | 16 | 32 | 48 | 64 | 128
+ }
+ , "test": {
+ "name": "test_dataset" // just name
+ , "dataset_type": "dncnn" // "dncnn" | "dnpatch" for dncnn, | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "testsets/bsd68" // path of H testing dataset
+ , "dataroot_L": null // path of L testing dataset
+
+ , "sigma": 25 // 15, 25, 50 for DnCNN | [0, 75] for FFDNet and FDnCNN
+ , "sigma_test": 25 // 15, 25, 50 for DnCNN and ffdnet
+
+ }
+ }
+
+ , "netG": {
+ "net_type": "dncnn" // "dncnn" | "fdncnn" | "ffdnet" | "srmd" | "dpsr" | "msrresnet0" | "msrresnet1" | "rrdb"
+ , "in_nc": 1 // input channel number
+ , "out_nc": 1 // ouput channel number
+ , "nc": 64 // 64 for "dncnn"
+ , "nb": 17 // 17 for "dncnn", 20 for dncnn3, 16 for "srresnet"
+ , "gc": 32 // unused
+ , "ng": 2 // unused
+ , "reduction" : 16 // unused
+ , "act_mode": "BR" // "BR" for BN+ReLU | "R" for ReLU
+ , "upsample_mode": "convtranspose" // "pixelshuffle" | "convtranspose" | "upconv"
+ , "downsample_mode": "strideconv" // "strideconv" | "avgpool" | "maxpool"
+
+ , "init_type": "orthogonal" // "orthogonal" | "normal" | "uniform" | "xavier_normal" | "xavier_uniform" | "kaiming_normal" | "kaiming_uniform"
+ , "init_bn_type": "uniform" // "uniform" | "constant"
+ , "init_gain": 0.2
+ }
+
+ , "train": {
+ "G_lossfn_type": "l1" // "l1" preferred | "l2sum" | "l2" | "ssim"
+ , "G_lossfn_weight": 1.0 // default
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 1e-4 // learning rate
+ , "G_optimizer_clipgrad": null // unused
+
+ , "G_scheduler_type": "MultiStepLR" // "MultiStepLR" is enough
+ , "G_scheduler_milestones": [200000, 400000, 600000, 800000, 1000000, 2000000]
+ , "G_scheduler_gamma": 0.5
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+}
diff --git a/KAIR/options/train_dpsr.json b/KAIR/options/train_dpsr.json
new file mode 100644
index 0000000000000000000000000000000000000000..563198e8049f3e30e524285e23c52ccc852aeba4
--- /dev/null
+++ b/KAIR/options/train_dpsr.json
@@ -0,0 +1,75 @@
+{
+ "task": "dpsr" // root/task/images-models-options
+ , "model": "plain" // "plain" | "plain2" if two inputs
+ , "gpu_ids": [0]
+
+ , "scale": 4 // broadcast to "netG" if SISR
+ , "n_channels": 3 // broadcast to "datasets", 1 for grayscale, 3 for color
+ , "sigma": [0, 50] // 15, 25, 50 for DnCNN | [0, 75] for FDnCNN and FFDNet
+ , "sigma_test": 0 // 15, 25, 50 for DnCNN, FDnCNN and FFDNet, 0 for SR
+
+ , "merge_bn": false // if no BN exists, set false
+ , "merge_bn_startpoint": 400000 // merge BN after N iterations
+
+ , "path": {
+ "root": "superresolution" // "denoising" | "superresolution"
+ , "pretrained_netG": null // path of pretrained model
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset" // just name
+ , "dataset_type": "dpsr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "trainsets/trainH"// path of H training dataset
+ , "dataroot_L": null // path of L training dataset
+ , "H_size": 96 // patch size 40 | 64 | 96 | 128 | 192
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 8
+ , "dataloader_batch_size": 32 // batch size 1 | 16 | 32 | 48 | 64 | 128
+ }
+ , "test": {
+ "name": "test_dataset" // just name
+ , "dataset_type": "dpsr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "testsets/set5" // path of H testing dataset
+ , "dataroot_L": null // path of L testing dataset
+ }
+ }
+
+ , "netG": {
+ "net_type": "dpsr" // "dncnn" | "fdncnn" | "ffdnet" | "srmd" | "dpsr" | "msrresnet0" | "msrresnet1" | "rrdb"
+ , "in_nc": 4 // input channel number
+ , "out_nc": 3 // ouput channel number
+ , "nc": 96 // 96 for DPSR, 128 for SRMD, 64 for "dncnn"
+ , "nb": 16 // 12 for "srmd", 15 for "ffdnet", 20 for "dncnn", 16 for "srresnet" and "dpsr"
+ , "gc": 32 // unused
+ , "ng": 2 // unused
+ , "reduction" : 16 // unused
+ , "act_mode": "R" // "BR" for BN+ReLU | "R" for ReLU
+ , "upsample_mode": "pixelshuffle" // "pixelshuffle" | "convtranspose" | "upconv"
+ , "downsample_mode": "strideconv" // "strideconv" | "avgpool" | "maxpool"
+
+ , "init_type": "orthogonal" // "orthogonal" | "normal" | "uniform" | "xavier_normal" | "xavier_uniform" | "kaiming_normal" | "kaiming_uniform"
+ , "init_bn_type": "uniform" // "uniform" | "constant"
+ , "init_gain": 0.2
+ }
+
+ , "train": {
+ "G_lossfn_type": "l1" // "l1" preferred | "l2sum" | "l2" | "ssim"
+ , "G_lossfn_weight": 1.0 // default
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 1e-4 // learning rate
+ , "G_optimizer_clipgrad": null // unused
+
+ , "G_scheduler_type": "MultiStepLR" // "MultiStepLR" is enough
+ , "G_scheduler_milestones": [200000, 400000, 600000, 800000, 1000000, 2000000]
+ , "G_scheduler_gamma": 0.5
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+}
diff --git a/KAIR/options/train_drunet.json b/KAIR/options/train_drunet.json
new file mode 100644
index 0000000000000000000000000000000000000000..12cfcadcc8752b8669f854c2a992d27c60eac79f
--- /dev/null
+++ b/KAIR/options/train_drunet.json
@@ -0,0 +1,72 @@
+{
+ "task": "drunet" // root/task/images-models-options
+ , "model": "plain" // "plain"
+ , "gpu_ids": [0]
+
+ , "scale": 1 // broadcast to "netG" if SISR
+ , "n_channels": 3 // broadcast to "datasets", 1 for grayscale, 3 for color
+ , "sigma": [0, 50] // 15, 25, 50 for DnCNN | [0, 75] for FFDNet and FDnCNN
+ , "sigma_test": 25 // 15, 25, 50 for DnCNN and ffdnet
+
+ , "path": {
+ "root": "denoising" // "denoising" | "superresolution"
+ , "pretrained_netG": null // path of pretrained model
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset" // just name
+ , "dataset_type": "fdncnn" // "dncnn" | "dnpatch" for dncnn, | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "trainsets/trainH"// path of H training dataset
+ , "dataroot_L": null // path of L training dataset
+ , "H_size": 128 // patch size 40 | 64 | 96 | 128 | 192
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 8
+ , "dataloader_batch_size": 64 // batch size 1 | 16 | 32 | 48 | 64 | 128
+ }
+ , "test": {
+ "name": "test_dataset" // just name
+ , "dataset_type": "fdncnn" // "dncnn" | "dnpatch" for dncnn, | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "testsets/set12" // path of H testing dataset
+ , "dataroot_L": null // path of L testing dataset
+ }
+ }
+
+ , "netG": {
+ "net_type": "drunet" // "dncnn" | "fdncnn" | "ffdnet" | "srmd" | "dpsr" | "srresnet0" | "srresnet1" | "rrdbnet"
+ , "in_nc": 4 // input channel number
+ , "out_nc": 3 // ouput channel number
+ , "nc": [64, 128, 256, 512] // 64 for "dncnn"
+ , "nb": 4 // 17 for "dncnn", 20 for dncnn3, 16 for "srresnet"
+ , "gc": 32 // unused
+ , "ng": 2 // unused
+ , "reduction": 16 // unused
+ , "act_mode": "R" // "BR" for BN+ReLU | "R" for ReLU
+ , "upsample_mode": "convtranspose" // "pixelshuffle" | "convtranspose" | "upconv"
+ , "downsample_mode": "strideconv" // "strideconv" | "avgpool" | "maxpool"
+ , "bias": false //
+ , "init_type": "orthogonal" // "orthogonal" | "normal" | "uniform" | "xavier_normal" | "xavier_uniform" | "kaiming_normal" | "kaiming_uniform"
+ , "init_bn_type": "uniform" // "uniform" | "constant"
+ , "init_gain": 0.2
+ }
+
+ , "train": {
+ "G_lossfn_type": "l1" // "l1" preferred | "l2sum" | "l2" | "ssim"
+ , "G_lossfn_weight": 1.0 // default
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 1e-4 // learning rate
+ , "G_optimizer_clipgrad": null // unused
+
+ , "G_scheduler_type": "MultiStepLR" // "MultiStepLR" is enough
+ , "G_scheduler_milestones": [100000,200000,300000,400000]
+ , "G_scheduler_gamma": 0.5
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+}
diff --git a/KAIR/options/train_fdncnn.json b/KAIR/options/train_fdncnn.json
new file mode 100644
index 0000000000000000000000000000000000000000..bbe2c0ec5268b8119df8fad3326f475577f7c7b0
--- /dev/null
+++ b/KAIR/options/train_fdncnn.json
@@ -0,0 +1,75 @@
+{
+ "task": "fdncnn" // root/task/images-models-options
+ , "model": "plain" // "plain"
+ , "gpu_ids": [0]
+
+ , "scale": 1 // broadcast to "netG" if SISR
+ , "n_channels": 1 // broadcast to "datasets", 1 for grayscale, 3 for color
+ , "sigma": [0, 75] // 15, 25, 50 for DnCNN | [0, 75] for FDnCNN and FFDNet
+ , "sigma_test": 25 // 15, 25, 50 for DnCNN, FDnCNN and FFDNet
+
+ , "merge_bn": false // if no BN exists, set false
+ , "merge_bn_startpoint": 400000 // merge BN after N iterations
+
+ , "path": {
+ "root": "denoising" // "denoising" | "superresolution"
+ , "pretrained_netG": null // path of pretrained model
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset" // just name
+ , "dataset_type": "fdncnn" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "trainsets/trainH"// path of H training dataset
+ , "dataroot_L": null // path of L training dataset
+ , "H_size": 48 // patch size 40 | 64 | 96 | 128 | 192
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 8
+ , "dataloader_batch_size": 64 // batch size 1 | 16 | 32 | 48 | 64 | 128
+ }
+ , "test": {
+ "name": "test_dataset" // just name
+ , "dataset_type": "fdncnn" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "testsets/bsd68" // path of H testing dataset
+ , "dataroot_L": null // path of L testing dataset
+ }
+ }
+
+ , "netG": {
+ "net_type": "fdncnn" // "dncnn" | "fdncnn" | "ffdnet" | "srmd" | "dpsr" | "msrresnet0" | "msrresnet1" | "rrdb"
+ , "in_nc": 2 // input channel number
+ , "out_nc": 1 // ouput channel number
+ , "nc": 64 // 64 for "dncnn"
+ , "nb": 20 // 20 for "dncnn", 16 for "srresnet"
+ , "gc": 32 // unused
+ , "ng": 2 // unused
+ , "reduction" : 16 // unused
+ , "act_mode": "R" // "BR" for BN+ReLU | "R" for ReLU
+ , "upsample_mode": "convtranspose" // "pixelshuffle" | "convtranspose" | "upconv"
+ , "downsample_mode": "strideconv" // "strideconv" | "avgpool" | "maxpool"
+
+ , "init_type": "orthogonal" // "orthogonal" | "normal" | "uniform" | "xavier_normal" | "xavier_uniform" | "kaiming_normal" | "kaiming_uniform"
+ , "init_bn_type": "uniform" // "uniform" | "constant"
+ , "init_gain": 0.2
+ }
+
+ , "train": {
+ "G_lossfn_type": "l1" // "l1" preferred | "l2sum" | "l2" | "ssim"
+ , "G_lossfn_weight": 1.0 // default
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 1e-4 // learning rate
+ , "G_optimizer_clipgrad": null // unused
+
+ , "G_scheduler_type": "MultiStepLR" // "MultiStepLR" is enough
+ , "G_scheduler_milestones": [200000, 400000, 600000, 800000, 1000000, 2000000]
+ , "G_scheduler_gamma": 0.5
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+}
diff --git a/KAIR/options/train_ffdnet.json b/KAIR/options/train_ffdnet.json
new file mode 100644
index 0000000000000000000000000000000000000000..8070e3763c304fec4d935b8fcfde9347d605561e
--- /dev/null
+++ b/KAIR/options/train_ffdnet.json
@@ -0,0 +1,75 @@
+{
+ "task": "ffdnet" // root/task/images-models-options
+ , "model": "plain2" // "plain"
+ , "gpu_ids": [0]
+
+ , "scale": 1 // broadcast to "netG" if SISR
+ , "n_channels": 1 // broadcast to "datasets", 1 for grayscale, 3 for color
+ , "sigma": [0, 75] // 15, 25, 50 for DnCNN | [0, 75] for FDnCNN and FFDNet
+ , "sigma_test": 25 // 15, 25, 50 for DnCNN, FDnCNN and FFDNet
+
+ , "merge_bn": false // if no BN exists, set false
+ , "merge_bn_startpoint": 400000 // merge BN after N iterations
+
+ , "path": {
+ "root": "denoising" // "denoising" | "superresolution"
+ , "pretrained_netG": null // path of pretrained model
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset" // just name
+ , "dataset_type": "ffdnet" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "trainsets/trainH"// path of H training dataset
+ , "dataroot_L": null // path of L training dataset
+ , "H_size": 64 // patch size 40 | 64 | 96 | 128 | 192
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 8
+ , "dataloader_batch_size": 64 // batch size 1 | 16 | 32 | 48 | 64 | 128
+ }
+ , "test": {
+ "name": "test_dataset" // just name
+ , "dataset_type": "ffdnet" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "testsets/bsd68" // path of H testing dataset
+ , "dataroot_L": null // path of L testing dataset
+ }
+ }
+
+ , "netG": {
+ "net_type": "ffdnet" // "dncnn" | "fdncnn" | "ffdnet" | "srmd" | "dpsr" | "msrresnet0" | "msrresnet1" | "rrdb"
+ , "in_nc": 1 // input channel number
+ , "out_nc": 1 // ouput channel number
+ , "nc": 64 // 64 for "dncnn"
+ , "nb": 15 // 15 for "ffdnet", 20 for "dncnn", 16 for "srresnet"
+ , "gc": 32 // unused
+ , "ng": 2 // unused
+ , "reduction" : 16 // unused
+ , "act_mode": "R" // "BR" for BN+ReLU | "R" for ReLU
+ , "upsample_mode": "convtranspose" // "pixelshuffle" | "convtranspose" | "upconv"
+ , "downsample_mode": "strideconv" // "strideconv" | "avgpool" | "maxpool"
+
+ , "init_type": "orthogonal" // "orthogonal" | "normal" | "uniform" | "xavier_normal" | "xavier_uniform" | "kaiming_normal" | "kaiming_uniform"
+ , "init_bn_type": "uniform" // "uniform" | "constant"
+ , "init_gain": 0.2
+ }
+
+ , "train": {
+ "G_lossfn_type": "l1" // "l1" preferred | "l2sum" | "l2" | "ssim"
+ , "G_lossfn_weight": 1.0 // default
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 1e-4 // learning rate
+ , "G_optimizer_clipgrad": null // unused
+
+ , "G_scheduler_type": "MultiStepLR" // "MultiStepLR" is enough
+ , "G_scheduler_milestones": [200000, 400000, 600000, 800000, 1000000, 2000000]
+ , "G_scheduler_gamma": 0.5
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+}
diff --git a/KAIR/options/train_imdn.json b/KAIR/options/train_imdn.json
new file mode 100644
index 0000000000000000000000000000000000000000..d32842dd8424b64740884b26cb016e788a4eb61e
--- /dev/null
+++ b/KAIR/options/train_imdn.json
@@ -0,0 +1,75 @@
+{
+ "task": "imdn" // root/task/images-models-options
+ , "model": "plain" // "plain" | "plain2" if two inputs
+ , "gpu_ids": [0]
+
+ , "scale": 4 // broadcast to "netG" if SISR
+ , "n_channels": 3 // broadcast to "datasets", 1 for grayscale, 3 for color
+ , "sigma": 0 // 15, 25, 50 for DnCNN | [0, 75] for FDnCNN and FFDNet
+ , "sigma_test": 0 // 15, 25, 50 for DnCNN, FDnCNN and FFDNet, 0 for SR
+
+ , "merge_bn": false // if no BN exists, set false
+ , "merge_bn_startpoint": 400000 // merge BN after N iterations
+
+ , "path": {
+ "root": "superresolution" // "denoising" | "superresolution"
+ , "pretrained_netG": null // path of pretrained model
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset" // just name
+ , "dataset_type": "sr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "trainsets/trainH"// path of H training dataset
+ , "dataroot_L": null // path of L training dataset
+ , "H_size": 96 // patch size 40 | 64 | 96 | 128 | 192
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 8
+ , "dataloader_batch_size": 64 // batch size 1 | 16 | 32 | 48 | 64 | 128
+ }
+ , "test": {
+ "name": "test_dataset" // just name
+ , "dataset_type": "sr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "testsets/set5" // path of H testing dataset
+ , "dataroot_L": null // path of L testing dataset
+ }
+ }
+
+ , "netG": {
+ "net_type": "imdn" // "dncnn" | "fdncnn" | "ffdnet" | "srmd" | "dpsr" | "msrresnet0" | "msrresnet1" | "rrdb"
+ , "in_nc": 3 // input channel number
+ , "out_nc": 3 // ouput channel number
+ , "nc": 64 // 96 for DPSR, 128 for SRMD, 64 for "dncnn"
+ , "nb": 8 // 12 for "srmd", 15 for "ffdnet", 20 for "dncnn", 16 for "srresnet" and "dpsr"
+ , "gc": 32 // unused
+ , "ng": 2 // unused
+ , "reduction" : 16 // unused
+ , "act_mode": "L" // "BR" for BN+ReLU | "R" for ReLU
+ , "upsample_mode": "pixelshuffle" // "pixelshuffle" | "convtranspose" | "upconv"
+ , "downsample_mode": "strideconv" // unused, "strideconv" | "avgpool" | "maxpool"
+
+ , "init_type": "orthogonal" // "orthogonal" | "normal" | "uniform" | "xavier_normal" | "xavier_uniform" | "kaiming_normal" | "kaiming_uniform"
+ , "init_bn_type": "uniform" // "uniform" | "constant"
+ , "init_gain": 0.2
+ }
+
+ , "train": {
+ "G_lossfn_type": "l1" // "l1" preferred | "l2sum" | "l2" | "ssim"
+ , "G_lossfn_weight": 1.0 // default
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 1e-4 // learning rate
+ , "G_optimizer_clipgrad": null // unused
+
+ , "G_scheduler_type": "MultiStepLR" // "MultiStepLR" is enough
+ , "G_scheduler_milestones": [200000, 400000, 600000, 800000, 1000000, 2000000]
+ , "G_scheduler_gamma": 0.5
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+}
diff --git a/KAIR/options/train_msrresnet_gan.json b/KAIR/options/train_msrresnet_gan.json
new file mode 100644
index 0000000000000000000000000000000000000000..64cb6582f6d0a7b6274ea36a1af612ca7bca77d8
--- /dev/null
+++ b/KAIR/options/train_msrresnet_gan.json
@@ -0,0 +1,115 @@
+{
+ "task": "msrresnet_gan" //
+ , "model": "gan" // "gan"
+ , "gpu_ids": [0]
+
+ , "scale": 4 // broadcast to "netG" if SISR
+ , "n_channels": 3 // broadcast to "datasets", 1 for grayscale, 3 for color
+ , "sigma": [0, 50] // 15, 25, 50 for DnCNN | [0, 75] for FDnCNN and FFDNet
+ , "sigma_test": 0 // 15, 25, 50 for DnCNN, FDnCNN and FFDNet, 0 for SR
+
+ , "merge_bn": false // if no BN exists, set false
+ , "merge_bn_startpoint": 400000 // merge BN after N iterations
+
+ , "path": {
+ "root": "superresolution" // "denoising" | "superresolution"
+ , "pretrained_netG": null // path of pretrained model
+ , "pretrained_netD": null // path of pretrained model
+ , "pretrained_netE": null // path of pretrained model
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset" // just name
+ , "dataset_type": "sr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "trainsets/trainH"// path of H training dataset
+ , "dataroot_L": null // path of L training dataset
+ , "H_size": 96 // patch size 40 | 64 | 96 | 128 | 192
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 8
+ , "dataloader_batch_size": 32 // batch size 1 | 16 | 32 | 48 | 64 | 128
+ }
+ , "test": {
+ "name": "test_dataset" // just name
+ , "dataset_type": "sr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "testsets/set5" // path of H testing dataset
+ , "dataroot_L": null // path of L testing dataset
+ }
+ }
+
+ , "netG": {
+ "net_type": "msrresnet0" // "dncnn" | "fdncnn" | "ffdnet" | "srmd" | "dpsr" | "msrresnet0" | "msrresnet1" | "rrdb"
+ , "in_nc": 3 // input channel number
+ , "out_nc": 3 // ouput channel number
+ , "nc": 64 // 96 for DPSR, 128 for SRMD, 64 for DnCNN and MSRResNet
+ , "nb": 16 // 12 for "srmd", 15 for "ffdnet", 20 for "dncnn", 16 for "srresnet" and "dpsr"
+ , "gc": 32 // unused
+ , "ng": 2 // unused
+ , "reduction" : 16 // unused
+ , "act_mode": "R" // "BR" for BN+ReLU | "R" for ReLU
+ , "upsample_mode": "upconv" // "pixelshuffle" | "convtranspose" | "upconv"
+ , "downsample_mode": "strideconv" // "strideconv" | "avgpool" | "maxpool"
+
+ , "init_type": "orthogonal" // "orthogonal" | "normal" | "uniform" | "xavier_normal" | "xavier_uniform" | "kaiming_normal" | "kaiming_uniform"
+ , "init_bn_type": "uniform" // "uniform" | "constant"
+ , "init_gain": 0.2
+ }
+
+ , "netD": {
+ "net_type": "discriminator_vgg_96" // "discriminator_patchgan" | "discriminator_unet" | "discriminator_vgg_192" | "discriminator_vgg_128" | "discriminator_vgg_96"
+ , "in_nc": 3
+ , "base_nc": 64
+ , "act_mode": "BL" // "BL" means BN+LeakyReLU
+ , "n_layers": 3 // only for "net_type":"discriminator_patchgan"
+ , "norm_type": 3 // only for "net_type":"discriminator_patchgan" | 'batch', 'instance', 'spectral', 'batchspectral', instancespectral'
+
+ , "init_type": "orthogonal" // "orthogonal" | "normal" | "uniform" | "xavier_normal" | "xavier_uniform" | "kaiming_normal" | "kaiming_uniform"
+ , "init_bn_type": "uniform" // "uniform" | "constant"
+ , "init_gain": 0.2
+ }
+
+ , "train": {
+ "G_lossfn_type": "l1" // "l1" | "l2" | "l2sum" | "l1c" | "ssim"
+ , "G_lossfn_weight": 1e-2
+
+ , "F_lossfn_type": "l1" // "l1" | "l2"
+ , "F_lossfn_weight": 1
+ , "F_feature_layer": 34 // 25 | [2,7,16,25,34]
+ , "F_weights": 1.0 // 1.0 | [0.1,0.1,1.0,1.0,1.0]
+ , "F_use_input_norm": true
+ , "F_use_range_norm": false
+
+ , "gan_type": "ragan" // "gan" | "ragan" | "lsgan" | "wgan" | "softplusgan"
+ , "D_lossfn_weight": 5e-3
+
+ , "E_decay": 0.999 // Exponential Moving Average for netG: set 0 to disable; default setting 0.999
+
+ , "D_init_iters": 0
+
+ , "G_optimizer_type": "adam"
+ , "G_optimizer_lr": 1e-5
+ , "G_optimizer_wd": 0
+
+ , "D_optimizer_type": "adam"
+ , "D_optimizer_lr": 1e-5
+ , "D_optimizer_wd": 0
+
+ , "G_scheduler_type": "MultiStepLR"
+ , "G_scheduler_milestones": [200000, 800000, 1200000, 2000000]
+ , "G_scheduler_gamma": 0.5
+ , "G_optimizer_reuse": false
+
+ , "D_scheduler_type": "MultiStepLR"
+ , "D_scheduler_milestones": [200000, 800000, 1200000, 2000000]
+ , "D_scheduler_gamma": 0.5
+ , "D_optimizer_reuse": false
+
+ , "G_param_strict": true
+ , "D_param_strict": true
+ , "E_param_strict": true
+
+ , "checkpoint_test": 5000
+ , "checkpoint_save": 5000
+ , "checkpoint_print": 200
+ }
+}
diff --git a/KAIR/options/train_msrresnet_psnr.json b/KAIR/options/train_msrresnet_psnr.json
new file mode 100644
index 0000000000000000000000000000000000000000..cfaaba9a1a121f04d55bc246e034fa55315cfcd5
--- /dev/null
+++ b/KAIR/options/train_msrresnet_psnr.json
@@ -0,0 +1,84 @@
+{
+ "task": "msrresnet_psnr" // root/task/images-models-options, pay attention to the difference between "msrresnet0" and "msrresnet1"
+ , "model": "plain" // "plain" | "plain2" if two inputs
+ , "gpu_ids": [0]
+ , "dist": true
+
+ , "scale": 4 // broadcast to "netG" if SISR
+ , "n_channels": 3 // broadcast to "datasets", 1 for grayscale, 3 for color
+ , "sigma": 0 // 15, 25, 50 for DnCNN | [0, 75] for FDnCNN and FFDNet
+ , "sigma_test": 0 // 15, 25, 50 for DnCNN, FDnCNN and FFDNet, 0 for SR
+
+ , "merge_bn": false // if no BN exists, set false
+ , "merge_bn_startpoint": 400000 // merge BN after N iterations
+
+ , "path": {
+ "root": "superresolution" // "denoising" | "superresolution"
+ , "pretrained_netG": null // path of pretrained model
+ , "pretrained_netE": null // path of pretrained model
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset" // just name
+ , "dataset_type": "sr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "trainsets/trainH"// path of H training dataset
+ , "dataroot_L": null // path of L training dataset
+ , "H_size": 96 // patch size 40 | 64 | 96 | 128 | 192
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 8
+ , "dataloader_batch_size": 32 // batch size 1 | 16 | 32 | 48 | 64 | 128
+ }
+ , "test": {
+ "name": "test_dataset" // just name
+ , "dataset_type": "sr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "testsets/set5" // path of H testing dataset
+ , "dataroot_L": null // path of L testing dataset
+ }
+ }
+
+ , "netG": {
+ "net_type": "msrresnet0" // "dncnn" | "fdncnn" | "ffdnet" | "srmd" | "dpsr" | "msrresnet0" | "msrresnet1" | "rrdb"
+ , "in_nc": 3 // input channel number
+ , "out_nc": 3 // ouput channel number
+ , "nc": 64 // 96 for DPSR, 128 for SRMD, 64 for "dncnn"
+ , "nb": 16 // 12 for "srmd", 15 for "ffdnet", 20 for "dncnn", 16 for "srresnet" and "dpsr"
+ , "gc": 32 // unused
+ , "ng": 2 // unused
+ , "reduction" : 16 // unused
+ , "act_mode": "R" // "BR" for BN+ReLU | "R" for ReLU
+ , "upsample_mode": "upconv" // "pixelshuffle" | "convtranspose" | "upconv"
+ , "downsample_mode": "strideconv" // "strideconv" | "avgpool" | "maxpool"
+
+ , "init_type": "orthogonal" // "orthogonal" | "normal" | "uniform" | "xavier_normal" | "xavier_uniform" | "kaiming_normal" | "kaiming_uniform"
+ , "init_bn_type": "uniform" // "uniform" | "constant"
+ , "init_gain": 0.2
+ }
+
+ , "train": {
+ "G_lossfn_type": "l1" // "l1" preferred | "l2sum" | "l2" | "ssim"
+ , "G_lossfn_weight": 1.0 // default
+
+ , "E_decay": 0.999 // Exponential Moving Average for netG: set 0 to disable; default setting 0.999
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 1e-4 // learning rate
+ , "G_optimizer_wd": 0 // weight decay, default 0
+ , "G_optimizer_clipgrad": null // unused
+ , "G_optimizer_reuse": false
+
+ , "G_scheduler_type": "MultiStepLR" // "MultiStepLR" is enough
+ , "G_scheduler_milestones": [200000, 400000, 600000, 800000, 1000000, 2000000]
+ , "G_scheduler_gamma": 0.5
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "G_param_strict": true
+ , "E_param_strict": true
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+}
diff --git a/KAIR/options/train_rrdb_psnr.json b/KAIR/options/train_rrdb_psnr.json
new file mode 100644
index 0000000000000000000000000000000000000000..9a0c28ecd83526992ffe96d6e6af7b53e6537921
--- /dev/null
+++ b/KAIR/options/train_rrdb_psnr.json
@@ -0,0 +1,75 @@
+{
+ "task": "rrdb" // root/task/images-models-options
+ , "model": "plain" // "plain" | "plain2" if two inputs
+ , "gpu_ids": [0]
+
+ , "scale": 4 // broadcast to "netG" if SISR
+ , "n_channels": 3 // broadcast to "datasets", 1 for grayscale, 3 for color
+ , "sigma": 0 // unused, 15, 25, 50 for DnCNN | [0, 75] for FDnCNN and FFDNet
+ , "sigma_test": 0 // unused, 15, 25, 50 for DnCNN, FDnCNN and FFDNet, 0 for SR
+
+ , "merge_bn": false // unused, if no BN exists, set false
+ , "merge_bn_startpoint": 400000 // unused, merge BN after N iterations
+
+ , "path": {
+ "root": "superresolution" // "denoising" | "superresolution"
+ , "pretrained_netG": null // path of pretrained model
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset" // just name
+ , "dataset_type": "sr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "trainsets/trainH"// path of H training dataset
+ , "dataroot_L": null // path of L training dataset
+ , "H_size": 96 // patch size 40 | 64 | 96 | 128 | 192
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 8
+ , "dataloader_batch_size": 16 // batch size 1 | 16 | 32 | 48 | 64 | 128
+ }
+ , "test": {
+ "name": "test_dataset" // just name
+ , "dataset_type": "sr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "testsets/set5" // path of H testing dataset
+ , "dataroot_L": null // path of L testing dataset
+ }
+ }
+
+ , "netG": {
+ "net_type": "rrdb" // "dncnn" | "fdncnn" | "ffdnet" | "srmd" | "dpsr" | "msrresnet0" | "msrresnet1" | "rrdb"
+ , "in_nc": 3 // input channel number
+ , "out_nc": 3 // ouput channel number
+ , "nc": 64 // 96 for "dpsr", 128 for "srmd", 64 for "dncnn" and "rrdb"
+ , "nb": 23 // 23 for "rrdb", 12 for "srmd", 15 for "ffdnet", 20 for "dncnn", 16 for "srresnet" and "dpsr"
+ , "gc": 32 // number of growth channels for "rrdb"
+ , "ng": 2 // unused
+ , "reduction" : 16 // unused
+ , "act_mode": "R" // "BR" for BN+ReLU | "R" for ReLU
+ , "upsample_mode": "upconv" // "pixelshuffle" | "convtranspose" | "upconv"
+ , "downsample_mode": "strideconv" // "strideconv" | "avgpool" | "maxpool"
+
+ , "init_type": "orthogonal" // "orthogonal" | "normal" | "uniform" | "xavier_normal" | "xavier_uniform" | "kaiming_normal" | "kaiming_uniform"
+ , "init_bn_type": "uniform" // "uniform" | "constant"
+ , "init_gain": 0.2
+ }
+
+ , "train": {
+ "G_lossfn_type": "l1" // "l1" preferred | "l2sum" | "l2" | "ssim"
+ , "G_lossfn_weight": 1.0 // default
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 1e-4 // learning rate
+ , "G_optimizer_clipgrad": null // unused
+
+ , "G_scheduler_type": "MultiStepLR" // "MultiStepLR" is enough
+ , "G_scheduler_milestones": [200000, 400000, 600000, 800000, 1000000, 2000000]
+ , "G_scheduler_gamma": 0.5
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+}
diff --git a/KAIR/options/train_srmd.json b/KAIR/options/train_srmd.json
new file mode 100644
index 0000000000000000000000000000000000000000..4f4fb035336716009ab3bd983fd88d63419b4c97
--- /dev/null
+++ b/KAIR/options/train_srmd.json
@@ -0,0 +1,75 @@
+{
+ "task": "srmd" // root/task/images-models-options
+ , "model": "plain" // "plain" | "plain2" if two inputs
+ , "gpu_ids": [0]
+
+ , "scale": 4 // broadcast to "netG" if SISR
+ , "n_channels": 3 // broadcast to "datasets", 1 for grayscale, 3 for color
+ , "sigma": [0, 50] // 15, 25, 50 for DnCNN | [0, 75] for FDnCNN and FFDNet
+ , "sigma_test": 0 // 15, 25, 50 for DnCNN, FDnCNN and FFDNet, 0 for SR
+
+ , "merge_bn": false // if no BN exists, set false
+ , "merge_bn_startpoint": 400000 // merge BN after N iterations
+
+ , "path": {
+ "root": "superresolution" // "denoising" | "superresolution"
+ , "pretrained_netG": null // path of pretrained model
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset" // just name
+ , "dataset_type": "srmd" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "trainsets/trainH"// path of H training dataset
+ , "dataroot_L": null // path of L training dataset
+ , "H_size": 96 // patch size 40 | 64 | 96 | 128 | 192
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 8
+ , "dataloader_batch_size": 64 // batch size 1 | 16 | 32 | 48 | 64 | 128
+ }
+ , "test": {
+ "name": "test_dataset" // just name
+ , "dataset_type": "srmd" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "testsets/set5" // path of H testing dataset
+ , "dataroot_L": null // path of L testing dataset
+ }
+ }
+
+ , "netG": {
+ "net_type": "srmd" // "dncnn" | "fdncnn" | "ffdnet" | "srmd" | "dpsr" | "msrresnet0" | "msrresnet1" | "rrdb"
+ , "in_nc": 19 // input channel number
+ , "out_nc": 3 // ouput channel number
+ , "nc": 128 // 128 for SRMD, 64 for "dncnn"
+ , "nb": 12 // 12 for "srmd", 15 for "ffdnet", 20 for "dncnn", 16 for "srresnet"
+ , "gc": 32 // unused
+ , "ng": 2 // unused
+ , "reduction" : 16 // unused
+ , "act_mode": "R" // "BR" for BN+ReLU | "R" for ReLU
+ , "upsample_mode": "pixelshuffle" // "pixelshuffle" | "convtranspose" | "upconv"
+ , "downsample_mode": "strideconv" // "strideconv" | "avgpool" | "maxpool"
+
+ , "init_type": "orthogonal" // "orthogonal" | "normal" | "uniform" | "xavier_normal" | "xavier_uniform" | "kaiming_normal" | "kaiming_uniform"
+ , "init_bn_type": "uniform" // "uniform" | "constant"
+ , "init_gain": 0.2
+ }
+
+ , "train": {
+ "G_lossfn_type": "l1" // "l1" preferred | "l2sum" | "l2" | "ssim"
+ , "G_lossfn_weight": 1.0 // default
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 1e-4 // learning rate
+ , "G_optimizer_clipgrad": null // unused
+
+ , "G_scheduler_type": "MultiStepLR" // "MultiStepLR" is enough
+ , "G_scheduler_milestones": [200000, 400000, 600000, 800000, 1000000, 2000000]
+ , "G_scheduler_gamma": 0.5
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+}
diff --git a/KAIR/options/train_usrnet.json b/KAIR/options/train_usrnet.json
new file mode 100644
index 0000000000000000000000000000000000000000..e620a06e93115c5ad02801ca7271eecbdd2e60dd
--- /dev/null
+++ b/KAIR/options/train_usrnet.json
@@ -0,0 +1,77 @@
+{
+ "task": "usrnet" //
+ , "model": "plain4" // "plain" | "gan"
+ , "gpu_ids": [0]
+ , "scale": 4
+ , "n_channels": 3 // 1 for grayscale image restoration, 3 for color image restoration
+ , "merge_bn": false
+ , "merge_bn_startpoint": 300000
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset"
+ , "dataset_type": "usrnet"
+ , "dataroot_H": "trainsets/trainH"
+ , "dataroot_L": null
+ , "H_size": 96 // 128 | 192
+ , "use_flip": true
+ , "use_rot": true
+ , "scales": [1, 2, 3, 4]
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 8
+ , "dataloader_batch_size": 48
+ }
+ , "test": {
+ "name": "test_dataset"
+ , "dataset_type": "usrnet"
+ , "dataroot_H": "testsets/set5"
+ , "dataroot_L": null
+ }
+ }
+
+ , "path": {
+ "root": "SR"
+ , "pretrained_netG": null
+ }
+
+ , "netG": {
+ "net_type": "usrnet" // "srresnet" | "rrdbnet" | "rcan" | "unet" | "unetplus" | "nonlocalunet"
+ , "n_iter": 6 // 8
+ , "h_nc": 32 // 64
+ , "in_nc": 4
+ , "out_nc": 3
+ , "nc": [16, 32, 64, 64] // [64, 128, 256, 512] for "unet"
+ , "nb": 2
+ , "gc": 32
+ , "ng": 2
+ , "reduction" : 16
+ , "act_mode": "R" // "BR" for BN+ReLU | "R" for ReLU
+ , "upsample_mode": "convtranspose" // "pixelshuffle" | "convtranspose" | "upconv"
+ , "downsample_mode": "strideconv" // "strideconv" | "avgpool" | "maxpool"
+
+ , "init_type": "orthogonal" // "orthogonal" | "normal" | "uniform" | "xavier_normal" | "xavier_uniform" | "kaiming_normal" | "kaiming_uniform"
+ , "init_bn_type": "uniform" // "uniform" | "constant"
+ , "init_gain": 0.2
+ }
+
+ , "train": {
+ "G_lossfn_type": "l1" // "l1" | "l2sum" | "l2" | "ssim"
+ , "G_lossfn_weight": 1.0
+
+ , "G_optimizer_type": "adam"
+ , "G_optimizer_lr": 1e-4
+ , "G_optimizer_wd": 0
+ , "G_optimizer_clipgrad": null
+
+ , "G_scheduler_type": "MultiStepLR"
+ , "G_scheduler_milestones": [100000, 200000, 300000, 400000]
+ , "G_scheduler_gamma": 0.5
+
+ , "G_regularizer_orthstep": null
+ , "G_regularizer_clipstep": null
+
+ , "checkpoint_test": 5000
+ , "checkpoint_save": 5000
+ , "checkpoint_print": 200
+ }
+}
diff --git a/KAIR/options/vrt/001_train_vrt_videosr_bi_reds_6frames.json b/KAIR/options/vrt/001_train_vrt_videosr_bi_reds_6frames.json
new file mode 100644
index 0000000000000000000000000000000000000000..07cb1be7a1d28ea7e936d33eeff6ce0c9e2d3dfa
--- /dev/null
+++ b/KAIR/options/vrt/001_train_vrt_videosr_bi_reds_6frames.json
@@ -0,0 +1,119 @@
+{
+ "task": "001_train_vrt_videosr_bi_reds_6frames"
+ , "model": "vrt"
+ , "gpu_ids": [0,1,2,3,4,5,6,7]
+ , "dist": true
+ , "find_unused_parameters": false
+ , "use_static_graph": true
+
+ ,"scale": 4
+ , "n_channels": 3
+
+ , "path": {
+ "root": "experiments"
+ , "pretrained_netG": "/home/cll/dev/KAIR/model_zoo/vrt/001_VRT_videosr_bi_REDS_6frames.pth"
+ , "pretrained_netE": null
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset"
+ , "dataset_type": "VideoRecurrentTrainDataset"
+ , "dataroot_gt": "/home/cll/datasets/REDS/train/train_sharp"
+ , "dataroot_lq": "/home/cll/datasets/REDS/train/train_sharp_bicubic/X4"
+ , "meta_info_file": "data/meta_info/meta_info_REDS_GT.txt"
+ , "filename_tmpl": "08d"
+ , "filename_ext": "png"
+ , "val_partition": "REDS4"
+ , "test_mode": false
+ , "io_backend": {"type": "disk"}
+ , "num_frame": 4
+ , "gt_size": 256
+ , "interval_list": [1]
+ , "random_reverse": false
+ , "use_hflip": true
+ , "use_rot": true
+
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 32
+ , "dataloader_batch_size": 8
+ }
+ , "test": {
+ "name": "test_dataset"
+ , "dataset_type": "VideoRecurrentTestDataset"
+ , "dataroot_gt": "/home/cll/Desktop/REDS4/GT"
+ , "dataroot_lq": "/home/cll/Desktop/REDS4/sharp_bicubic"
+ , "cache_data": true
+ , "io_backend": {"type": "disk"}
+ , "num_frame": -1
+ }
+ }
+
+ , "netG": {
+ "net_type": "vrt"
+ , "upscale": 4
+ , "img_size": [6,64,64]
+ , "window_size": [6,8,8]
+ , "depths": [8,8,8,8,8,8,8, 4,4,4,4, 4,4]
+ , "indep_reconsts": [11,12]
+ , "embed_dims": [120,120,120,120,120,120,120, 180,180,180,180, 180,180]
+ , "num_heads": [6,6,6,6,6,6,6, 6,6,6,6, 6,6]
+ , "spynet_path": "model_zoo/vrt/spynet_sintel_final-3d2a1287.pth" // automatical download
+ , "pa_frames": 2
+ , "deformable_groups": 12
+ , "nonblind_denoising": false
+
+ , "use_checkpoint_attn": false
+ , "use_checkpoint_ffn": false
+ , "no_checkpoint_attn_blocks": []
+ , "no_checkpoint_ffn_blocks": []
+
+ , "init_type": "default"
+ }
+
+
+ , "train": {
+ "G_lossfn_type": "charbonnier"
+ , "G_lossfn_weight": 1.0
+ , "G_charbonnier_eps": 1e-9
+
+ , "E_decay": 0 // Exponential Moving Average for netG: set 0 to disable; default setting 0.999
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 4e-4 // learning rate
+ , "G_optimizer_betas": [0.9,0.99]
+ , "G_optimizer_wd": 0 // weight decay, default 0
+ , "G_optimizer_clipgrad": null // unused
+ , "G_optimizer_reuse": true //
+
+ , "fix_iter": 20000
+ , "fix_lr_mul": 0.125
+ , "fix_keys": ["spynet", "deform"]
+
+ , "total_iter": 300000
+ , "G_scheduler_type": "CosineAnnealingWarmRestarts"
+ , "G_scheduler_periods": 300000
+ , "G_scheduler_eta_min": 1e-7
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "G_param_strict": true
+ , "E_param_strict": true
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+
+ , "val": {
+ "save_img": false
+ , "pad_seq": false
+ , "flip_seq": false
+ , "center_frame_only": false
+ , "num_frame_testing": 40
+ , "num_frame_overlapping": 2
+ , "size_patch_testing": 128
+ }
+
+}
diff --git a/KAIR/options/vrt/002_train_vrt_videosr_bi_reds_16frames.json b/KAIR/options/vrt/002_train_vrt_videosr_bi_reds_16frames.json
new file mode 100644
index 0000000000000000000000000000000000000000..b9176e52d723d52cfe2ee9c5b607d2a2e44ef9fa
--- /dev/null
+++ b/KAIR/options/vrt/002_train_vrt_videosr_bi_reds_16frames.json
@@ -0,0 +1,119 @@
+{
+ "task": "002_train_vrt_videosr_bi_reds_16frames"
+ , "model": "vrt"
+ , "gpu_ids": [0,1,2,3,4,5,6,7]
+ , "dist": true
+ , "find_unused_parameters": false
+ , "use_static_graph": true
+
+ ,"scale": 4
+ , "n_channels": 3
+
+ , "path": {
+ "root": "experiments"
+ , "pretrained_netG": null
+ , "pretrained_netE": null
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset"
+ , "dataset_type": "VideoRecurrentTrainDataset"
+ , "dataroot_gt": "trainsets/REDS/train_sharp_with_val.lmdb"
+ , "dataroot_lq": "trainsets/REDS/train_sharp_bicubic_with_val.lmdb"
+ , "meta_info_file": "data/meta_info/meta_info_REDS_GT.txt"
+ , "filename_tmpl": "08d"
+ , "filename_ext": "png"
+ , "val_partition": "REDS4"
+ , "test_mode": false
+ , "io_backend": {"type": "lmdb"}
+ , "num_frame": 6
+ , "gt_size": 256
+ , "interval_list": [1]
+ , "random_reverse": false
+ , "use_hflip": true
+ , "use_rot": true
+
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 32
+ , "dataloader_batch_size": 8
+ }
+ , "test": {
+ "name": "test_dataset"
+ , "dataset_type": "VideoRecurrentTestDataset"
+ , "dataroot_gt": "testsets/REDS4/GT"
+ , "dataroot_lq": "testsets/REDS4/sharp_bicubic"
+ , "cache_data": true
+ , "io_backend": {"type": "disk"}
+ , "num_frame": -1
+ }
+ }
+
+ , "netG": {
+ "net_type": "vrt"
+ , "upscale": 4
+ , "img_size": [16,64,64]
+ , "window_size": [8,8,8]
+ , "depths": [8,8,8,8,8,8,8, 4,4,4,4, 4,4]
+ , "indep_reconsts": [11,12]
+ , "embed_dims": [120,120,120,120,120,120,120, 180,180,180,180, 180,180]
+ , "num_heads": [6,6,6,6,6,6,6, 6,6,6,6, 6,6]
+ , "spynet_path": "model_zoo/vrt/spynet_sintel_final-3d2a1287.pth" // automatical download
+ , "pa_frames": 4
+ , "deformable_groups": 16
+ , "nonblind_denoising": false
+
+ , "use_checkpoint_attn": true
+ , "use_checkpoint_ffn": false
+ , "no_checkpoint_attn_blocks": [0,1,2,3,4,5]
+ , "no_checkpoint_ffn_blocks": []
+
+ , "init_type": "default"
+ }
+
+
+ , "train": {
+ "G_lossfn_type": "charbonnier"
+ , "G_lossfn_weight": 1.0
+ , "G_charbonnier_eps": 1e-9
+
+ , "E_decay": 0 // Exponential Moving Average for netG: set 0 to disable; default setting 0.999
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 4e-4 // learning rate
+ , "G_optimizer_betas": [0.9,0.99]
+ , "G_optimizer_wd": 0 // weight decay, default 0
+ , "G_optimizer_clipgrad": null // unused
+ , "G_optimizer_reuse": true //
+
+ , "fix_iter": 20000
+ , "fix_lr_mul": 0.125
+ , "fix_keys": ["spynet", "deform"]
+
+ , "total_iter": 300000
+ , "G_scheduler_type": "CosineAnnealingWarmRestarts"
+ , "G_scheduler_periods": 300000
+ , "G_scheduler_eta_min": 1e-7
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "G_param_strict": true
+ , "E_param_strict": true
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+
+ , "val": {
+ "save_img": false
+ , "pad_seq": false
+ , "flip_seq": false
+ , "center_frame_only": false
+ , "num_frame_testing": 40
+ , "num_frame_overlapping": 2
+ , "size_patch_testing": 128
+ }
+
+}
diff --git a/KAIR/options/vrt/003_train_vrt_videosr_bi_vimeo_7frames.json b/KAIR/options/vrt/003_train_vrt_videosr_bi_vimeo_7frames.json
new file mode 100644
index 0000000000000000000000000000000000000000..2f29ed7af577ca346b50c6e357a82c75e85ac711
--- /dev/null
+++ b/KAIR/options/vrt/003_train_vrt_videosr_bi_vimeo_7frames.json
@@ -0,0 +1,116 @@
+{
+ "task": "003_train_vrt_videosr_bi_vimeo_7frames"
+ , "model": "vrt"
+ , "gpu_ids": [0,1,2,3,4,5,6,7]
+ , "dist": true
+ , "find_unused_parameters": false
+ , "use_static_graph": true
+
+ ,"scale": 4
+ , "n_channels": 3
+
+ , "path": {
+ "root": "experiments"
+ , "pretrained_netG": "model_zoo/vrt/002_VRT_videosr_bi_REDS_16frames.pth"
+ , "pretrained_netE": null
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset"
+ , "dataset_type": "VideoRecurrentTrainVimeoDataset"
+ , "dataroot_gt": "trainsets/vimeo90k"
+ , "dataroot_lq": "trainsets/vimeo90k"
+ , "meta_info_file": "data/meta_info/meta_info_Vimeo90K_train_GT.txt"
+ , "io_backend": {"type": "disk"}
+ , "num_frame": -1
+ , "gt_size": 256
+ , "interval_list": [1]
+ , "random_reverse": true
+ , "use_hflip": true
+ , "use_rot": true
+ , "pad_sequence": true
+
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 32
+ , "dataloader_batch_size": 8
+ }
+ , "test": {
+ "name": "test_dataset"
+ , "dataset_type": "VideoRecurrentTestDataset"
+ , "dataroot_gt": "testsets/Vid4/GT"
+ , "dataroot_lq": "testsets/Vid4/BIx4"
+ , "cache_data": true
+ , "io_backend": {"type": "disk"}
+ , "num_frame": -1
+ }
+ }
+
+ , "netG": {
+ "net_type": "vrt"
+ , "upscale": 4
+ , "img_size": [8,64,64]
+ , "window_size": [8,8,8]
+ , "depths": [8,8,8,8,8,8,8, 4,4,4,4, 4,4]
+ , "indep_reconsts": [11,12]
+ , "embed_dims": [120,120,120,120,120,120,120, 180,180,180,180, 180,180]
+ , "num_heads": [6,6,6,6,6,6,6, 6,6,6,6, 6,6]
+ , "spynet_path": "model_zoo/vrt/spynet_sintel_final-3d2a1287.pth" // automatical download
+ , "pa_frames": 4
+ , "deformable_groups": 16
+ , "nonblind_denoising": false
+
+ , "use_checkpoint_attn": false
+ , "use_checkpoint_ffn": false
+ , "no_checkpoint_attn_blocks": []
+ , "no_checkpoint_ffn_blocks": []
+
+ , "init_type": "default"
+ }
+
+
+ , "train": {
+ "G_lossfn_type": "charbonnier"
+ , "G_lossfn_weight": 1.0
+ , "G_charbonnier_eps": 1e-9
+
+ , "E_decay": 0 // Exponential Moving Average for netG: set 0 to disable; default setting 0.999
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 4e-4 // learning rate
+ , "G_optimizer_betas": [0.9,0.99]
+ , "G_optimizer_wd": 0 // weight decay, default 0
+ , "G_optimizer_clipgrad": null // unused
+ , "G_optimizer_reuse": true //
+
+ , "fix_iter": 20000
+ , "fix_lr_mul": 0.125
+ , "fix_keys": ["spynet", "deform"]
+
+ , "total_iter": 300000
+ , "G_scheduler_type": "CosineAnnealingWarmRestarts"
+ , "G_scheduler_periods": 300000
+ , "G_scheduler_eta_min": 1e-7
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "G_param_strict": false
+ , "E_param_strict": false
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+
+ , "val": {
+ "save_img": false
+ , "pad_seq": false
+ , "flip_seq": false
+ , "center_frame_only": false
+ , "num_frame_testing": 32
+ , "num_frame_overlapping": 2
+ , "size_patch_testing": 128
+ }
+
+}
diff --git a/KAIR/options/vrt/004_train_vrt_videosr_bd_vimeo_7frames.json b/KAIR/options/vrt/004_train_vrt_videosr_bd_vimeo_7frames.json
new file mode 100644
index 0000000000000000000000000000000000000000..a4419982edbbf23aa8ab5e4c2cc4a211c2b70be5
--- /dev/null
+++ b/KAIR/options/vrt/004_train_vrt_videosr_bd_vimeo_7frames.json
@@ -0,0 +1,116 @@
+{
+ "task": "004_train_vrt_videosr_bd_vimeo_7frames"
+ , "model": "vrt"
+ , "gpu_ids": [0,1,2,3,4,5,6,7]
+ , "dist": true
+ , "find_unused_parameters": false
+ , "use_static_graph": true
+
+ ,"scale": 4
+ , "n_channels": 3
+
+ , "path": {
+ "root": "experiments"
+ , "pretrained_netG": "model_zoo/vrt/002_VRT_videosr_bi_REDS_16frames.pth"
+ , "pretrained_netE": null
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset"
+ , "dataset_type": "VideoRecurrentTrainVimeoDataset"
+ , "dataroot_gt": "trainsets/vimeo90k/vimeo90k_train_GT_all.lmdb"
+ , "dataroot_lq": "trainsets/vimeo90k/vimeo90k_train_BDLR7frames.lmdb"
+ , "meta_info_file": "data/meta_info/meta_info_Vimeo90K_train_GT.txt"
+ , "io_backend": {"type": "lmdb"}
+ , "num_frame": -1
+ , "gt_size": 256
+ , "interval_list": [1]
+ , "random_reverse": true
+ , "use_hflip": true
+ , "use_rot": true
+ , "pad_sequence": true
+
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 32
+ , "dataloader_batch_size": 8
+ }
+ , "test": {
+ "name": "test_dataset"
+ , "dataset_type": "VideoRecurrentTestDataset"
+ , "dataroot_gt": "testsets/Vid4/GT"
+ , "dataroot_lq": "testsets/Vid4/BDx4"
+ , "cache_data": true
+ , "io_backend": {"type": "disk"}
+ , "num_frame": -1
+ }
+ }
+
+ , "netG": {
+ "net_type": "vrt"
+ , "upscale": 4
+ , "img_size": [8,64,64]
+ , "window_size": [8,8,8]
+ , "depths": [8,8,8,8,8,8,8, 4,4,4,4, 4,4]
+ , "indep_reconsts": [11,12]
+ , "embed_dims": [120,120,120,120,120,120,120, 180,180,180,180, 180,180]
+ , "num_heads": [6,6,6,6,6,6,6, 6,6,6,6, 6,6]
+ , "spynet_path": "model_zoo/vrt/spynet_sintel_final-3d2a1287.pth" // automatical download
+ , "pa_frames": 4
+ , "deformable_groups": 16
+ , "nonblind_denoising": false
+
+ , "use_checkpoint_attn": false
+ , "use_checkpoint_ffn": false
+ , "no_checkpoint_attn_blocks": []
+ , "no_checkpoint_ffn_blocks": []
+
+ , "init_type": "default"
+ }
+
+
+ , "train": {
+ "G_lossfn_type": "charbonnier"
+ , "G_lossfn_weight": 1.0
+ , "G_charbonnier_eps": 1e-9
+
+ , "E_decay": 0 // Exponential Moving Average for netG: set 0 to disable; default setting 0.999
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 4e-4 // learning rate
+ , "G_optimizer_betas": [0.9,0.99]
+ , "G_optimizer_wd": 0 // weight decay, default 0
+ , "G_optimizer_clipgrad": null // unused
+ , "G_optimizer_reuse": true //
+
+ , "fix_iter": 20000
+ , "fix_lr_mul": 0.125
+ , "fix_keys": ["spynet", "deform"]
+
+ , "total_iter": 300000
+ , "G_scheduler_type": "CosineAnnealingWarmRestarts"
+ , "G_scheduler_periods": 300000
+ , "G_scheduler_eta_min": 1e-7
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "G_param_strict": false
+ , "E_param_strict": false
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+
+ , "val": {
+ "save_img": false
+ , "pad_seq": false
+ , "flip_seq": false
+ , "center_frame_only": false
+ , "num_frame_testing": 32
+ , "num_frame_overlapping": 2
+ , "size_patch_testing": 128
+ }
+
+}
diff --git a/KAIR/options/vrt/005_train_vrt_videodeblurring_dvd.json b/KAIR/options/vrt/005_train_vrt_videodeblurring_dvd.json
new file mode 100644
index 0000000000000000000000000000000000000000..d6864ee818fb915c24aa8c7ac3c038b3ccbc31d8
--- /dev/null
+++ b/KAIR/options/vrt/005_train_vrt_videodeblurring_dvd.json
@@ -0,0 +1,118 @@
+{
+ "task": "005_train_vrt_videodeblurring_dvd"
+ , "model": "vrt"
+ , "gpu_ids": [0,1,2,3,4,5,6,7]
+ , "dist": true
+ , "find_unused_parameters": false
+ , "use_static_graph": true
+
+ ,"scale": 1
+ , "n_channels": 3
+
+ , "path": {
+ "root": "experiments"
+ , "pretrained_netG": null
+ , "pretrained_netE": null
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset"
+ , "dataset_type": "VideoRecurrentTrainDataset"
+ , "dataroot_gt": "trainsets/DVD/train_GT.lmdb"
+ , "dataroot_lq": "trainsets/DVD/train_GT_blurred.lmdb"
+ , "meta_info_file": "data/meta_info/meta_info_DVD_train_GT.txt"
+ , "filename_tmpl": "05d"
+ , "filename_ext": "jpg"
+ , "test_mode": false
+ , "io_backend": {"type": "lmdb"}
+ , "num_frame": 6
+ , "gt_size": 192
+ , "interval_list": [1]
+ , "random_reverse": false
+ , "use_hflip": true
+ , "use_rot": true
+
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 32
+ , "dataloader_batch_size": 8
+ }
+ , "test": {
+ "name": "test_dataset"
+ , "dataset_type": "VideoRecurrentTestDataset"
+ , "dataroot_gt": "testsets/DVD10/test_GT"
+ , "dataroot_lq": "testsets/DVD10/test_GT_blurred"
+ , "cache_data": false
+ , "io_backend": {"type": "disk"}
+ , "num_frame": -1
+ }
+ }
+
+ , "netG": {
+ "net_type": "vrt"
+ , "upscale": 1
+ , "img_size": [6,192,192]
+ , "window_size": [6,8,8]
+ , "depths": [8,8,8,8,8,8,8, 4,4, 4,4]
+ , "indep_reconsts": [9,10]
+ , "embed_dims": [96,96,96,96,96,96,96, 120,120, 120,120]
+ , "num_heads": [6,6,6,6,6,6,6, 6,6, 6,6]
+ , "spynet_path": "model_zoo/vrt/spynet_sintel_final-3d2a1287.pth" // automatical download
+ , "pa_frames": 2
+ , "deformable_groups": 16
+ , "nonblind_denoising": false
+
+ , "use_checkpoint_attn": true
+ , "use_checkpoint_ffn": true
+ , "no_checkpoint_attn_blocks": [2,3,4]
+ , "no_checkpoint_ffn_blocks": [1,2,3,4,5,9]
+
+ , "init_type": "default"
+ }
+
+
+ , "train": {
+ "G_lossfn_type": "charbonnier"
+ , "G_lossfn_weight": 1.0
+ , "G_charbonnier_eps": 1e-9
+
+ , "E_decay": 0 // Exponential Moving Average for netG: set 0 to disable; default setting 0.999
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 4e-4 // learning rate
+ , "G_optimizer_betas": [0.9,0.99]
+ , "G_optimizer_wd": 0 // weight decay, default 0
+ , "G_optimizer_clipgrad": null // unused
+ , "G_optimizer_reuse": true //
+
+ , "fix_iter": 20000
+ , "fix_lr_mul": 0.125
+ , "fix_keys": ["spynet", "deform"]
+
+ , "total_iter": 300000
+ , "G_scheduler_type": "CosineAnnealingWarmRestarts"
+ , "G_scheduler_periods": 300000
+ , "G_scheduler_eta_min": 1e-7
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "G_param_strict": true
+ , "E_param_strict": true
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+
+ , "val": {
+ "save_img": false
+ , "pad_seq": false
+ , "flip_seq": false
+ , "center_frame_only": false
+ , "num_frame_testing": 12
+ , "num_frame_overlapping": 2
+ , "size_patch_testing": 256
+ }
+
+}
diff --git a/KAIR/options/vrt/006_train_vrt_videodeblurring_gopro.json b/KAIR/options/vrt/006_train_vrt_videodeblurring_gopro.json
new file mode 100644
index 0000000000000000000000000000000000000000..9caef49e94b806aae94d777013c87e52078afcf5
--- /dev/null
+++ b/KAIR/options/vrt/006_train_vrt_videodeblurring_gopro.json
@@ -0,0 +1,118 @@
+{
+ "task": "006_train_vrt_videodeblurring_gopro"
+ , "model": "vrt"
+ , "gpu_ids": [0,1,2,3,4,5,6,7]
+ , "dist": true
+ , "find_unused_parameters": false
+ , "use_static_graph": true
+
+ ,"scale": 1
+ , "n_channels": 3
+
+ , "path": {
+ "root": "experiments"
+ , "pretrained_netG": null
+ , "pretrained_netE": null
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset"
+ , "dataset_type": "VideoRecurrentTrainDataset"
+ , "dataroot_gt": "trainsets/GoPro/train_GT.lmdb"
+ , "dataroot_lq": "trainsets/GoPro/train_GT_blurred.lmdb"
+ , "meta_info_file": "data/meta_info/meta_info_GoPro_train_GT.txt"
+ , "filename_tmpl": "06d"
+ , "filename_ext": "png"
+ , "test_mode": false
+ , "io_backend": {"type": "lmdb"}
+ , "num_frame": 6
+ , "gt_size": 192
+ , "interval_list": [1]
+ , "random_reverse": false
+ , "use_hflip": true
+ , "use_rot": true
+
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 32
+ , "dataloader_batch_size": 8
+ }
+ , "test": {
+ "name": "test_dataset"
+ , "dataset_type": "VideoRecurrentTestDataset"
+ , "dataroot_gt": "testsets/GoPro11/test_GT"
+ , "dataroot_lq": "testsets/GoPro11/test_GT_blurred"
+ , "cache_data": false
+ , "io_backend": {"type": "disk"}
+ , "num_frame": -1
+ }
+ }
+
+ , "netG": {
+ "net_type": "vrt"
+ , "upscale": 1
+ , "img_size": [6,192,192]
+ , "window_size": [6,8,8]
+ , "depths": [8,8,8,8,8,8,8, 4,4, 4,4]
+ , "indep_reconsts": [9,10]
+ , "embed_dims": [96,96,96,96,96,96,96, 120,120, 120,120]
+ , "num_heads": [6,6,6,6,6,6,6, 6,6, 6,6]
+ , "spynet_path": "model_zoo/vrt/spynet_sintel_final-3d2a1287.pth" // automatical download
+ , "pa_frames": 2
+ , "deformable_groups": 16
+ , "nonblind_denoising": false
+
+ , "use_checkpoint_attn": true
+ , "use_checkpoint_ffn": true
+ , "no_checkpoint_attn_blocks": [2,3,4]
+ , "no_checkpoint_ffn_blocks": [1,2,3,4,5,9]
+
+ , "init_type": "default"
+ }
+
+
+ , "train": {
+ "G_lossfn_type": "charbonnier"
+ , "G_lossfn_weight": 1.0
+ , "G_charbonnier_eps": 1e-9
+
+ , "E_decay": 0 // Exponential Moving Average for netG: set 0 to disable; default setting 0.999
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 4e-4 // learning rate
+ , "G_optimizer_betas": [0.9,0.99]
+ , "G_optimizer_wd": 0 // weight decay, default 0
+ , "G_optimizer_clipgrad": null // unused
+ , "G_optimizer_reuse": true //
+
+ , "fix_iter": 20000
+ , "fix_lr_mul": 0.125
+ , "fix_keys": ["spynet", "deform"]
+
+ , "total_iter": 300000
+ , "G_scheduler_type": "CosineAnnealingWarmRestarts"
+ , "G_scheduler_periods": 300000
+ , "G_scheduler_eta_min": 1e-7
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "G_param_strict": true
+ , "E_param_strict": true
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+
+ , "val": {
+ "save_img": false
+ , "pad_seq": false
+ , "flip_seq": false
+ , "center_frame_only": false
+ , "num_frame_testing": 18
+ , "num_frame_overlapping": 2
+ , "size_patch_testing": 192
+ }
+
+}
diff --git a/KAIR/options/vrt/007_train_vrt_videodeblurring_reds.json b/KAIR/options/vrt/007_train_vrt_videodeblurring_reds.json
new file mode 100644
index 0000000000000000000000000000000000000000..dd95c4515b012fafebad88bd280f97e6c573b2f4
--- /dev/null
+++ b/KAIR/options/vrt/007_train_vrt_videodeblurring_reds.json
@@ -0,0 +1,118 @@
+{
+ "task": "007_train_vrt_videodeblurring_reds"
+ , "model": "vrt"
+ , "gpu_ids": [0,1,2,3,4,5,6,7]
+ , "dist": true
+ , "find_unused_parameters": false
+ , "use_static_graph": true
+
+ ,"scale": 1
+ , "n_channels": 3
+
+ , "path": {
+ "root": "experiments"
+ , "pretrained_netG": null
+ , "pretrained_netE": null
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset"
+ , "dataset_type": "VideoRecurrentTrainDataset"
+ , "dataroot_gt": "trainsets/REDS/train_sharp_with_val.lmdb"
+ , "dataroot_lq": "trainsets/REDS/train_blur_with_val.lmdb"
+ , "meta_info_file": "data/meta_info/meta_info_REDS_GT.txt"
+ , "filename_tmpl": "08d"
+ , "filename_ext": "png"
+ , "test_mode": false
+ , "io_backend": {"type": "lmdb"}
+ , "num_frame": 6
+ , "gt_size": 192
+ , "interval_list": [1]
+ , "random_reverse": false
+ , "use_hflip": true
+ , "use_rot": true
+
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 32
+ , "dataloader_batch_size": 8
+ }
+ , "test": {
+ "name": "test_dataset"
+ , "dataset_type": "VideoRecurrentTestDataset"
+ , "dataroot_gt": "testsets/REDS4/GT"
+ , "dataroot_lq": "testsets/REDS4/blur"
+ , "cache_data": false
+ , "io_backend": {"type": "disk"}
+ , "num_frame": -1
+ }
+ }
+
+ , "netG": {
+ "net_type": "vrt"
+ , "upscale": 1
+ , "img_size": [6,192,192]
+ , "window_size": [6,8,8]
+ , "depths": [8,8,8,8,8,8,8, 4,4, 4,4]
+ , "indep_reconsts": [9,10]
+ , "embed_dims": [96,96,96,96,96,96,96, 120,120, 120,120]
+ , "num_heads": [6,6,6,6,6,6,6, 6,6, 6,6]
+ , "spynet_path": "model_zoo/vrt/spynet_sintel_final-3d2a1287.pth" // automatical download
+ , "pa_frames": 2
+ , "deformable_groups": 16
+ , "nonblind_denoising": false
+
+ , "use_checkpoint_attn": true
+ , "use_checkpoint_ffn": true
+ , "no_checkpoint_attn_blocks": [2,3,4]
+ , "no_checkpoint_ffn_blocks": [1,2,3,4,5,9]
+
+ , "init_type": "default"
+ }
+
+
+ , "train": {
+ "G_lossfn_type": "charbonnier"
+ , "G_lossfn_weight": 1.0
+ , "G_charbonnier_eps": 1e-9
+
+ , "E_decay": 0 // Exponential Moving Average for netG: set 0 to disable; default setting 0.999
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 4e-4 // learning rate
+ , "G_optimizer_betas": [0.9,0.99]
+ , "G_optimizer_wd": 0 // weight decay, default 0
+ , "G_optimizer_clipgrad": null // unused
+ , "G_optimizer_reuse": true //
+
+ , "fix_iter": 20000
+ , "fix_lr_mul": 0.125
+ , "fix_keys": ["spynet", "deform"]
+
+ , "total_iter": 300000
+ , "G_scheduler_type": "CosineAnnealingWarmRestarts"
+ , "G_scheduler_periods": 300000
+ , "G_scheduler_eta_min": 1e-7
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "G_param_strict": true
+ , "E_param_strict": true
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+
+ , "val": {
+ "save_img": false
+ , "pad_seq": false
+ , "flip_seq": false
+ , "center_frame_only": false
+ , "num_frame_testing": 12
+ , "num_frame_overlapping": 2
+ , "size_patch_testing": 256
+ }
+
+}
diff --git a/KAIR/options/vrt/008_train_vrt_videodenoising_davis.json b/KAIR/options/vrt/008_train_vrt_videodenoising_davis.json
new file mode 100644
index 0000000000000000000000000000000000000000..93401c17a835f255aaff88810709178aeb78d35a
--- /dev/null
+++ b/KAIR/options/vrt/008_train_vrt_videodenoising_davis.json
@@ -0,0 +1,123 @@
+{
+ "task": "008_train_vrt_videodenoising_davis"
+ , "model": "vrt"
+ , "gpu_ids": [0,1,2,3,4,5,6,7]
+ , "dist": true
+ , "find_unused_parameters": false
+ , "use_static_graph": true
+
+ ,"scale": 1
+ , "n_channels": 3
+
+ , "path": {
+ "root": "experiments"
+ , "pretrained_netG": null
+ , "pretrained_netE": null
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset"
+ , "dataset_type": "VideoRecurrentTrainNonblindDenoisingDataset"
+ , "dataroot_gt": "trainsets/DAVIS/train_GT.lmdb"
+ , "dataroot_lq": "trainsets/DAVIS/train_GT.lmdb"
+ , "meta_info_file": "data/meta_info/meta_info_DAVIS_train_GT.txt"
+ , "filename_tmpl": "05d"
+ , "filename_ext": "jpg"
+ , "test_mode": false
+ , "io_backend": {"type": "lmdb"}
+ , "num_frame": 6
+ , "gt_size": 192
+ , "interval_list": [1]
+ , "random_reverse": false
+ , "use_hflip": true
+ , "use_rot": true
+
+ , "sigma_min": 0
+ , "sigma_max": 50
+
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 32
+ , "dataloader_batch_size": 8
+ }
+ , "test": {
+ "name": "test_dataset"
+ , "dataset_type": "VideoRecurrentTestDataset"
+ , "dataroot_gt": "testsets/Set8"
+ , "dataroot_lq": "testsets/Set8"
+ , "cache_data": true
+ , "io_backend": {"type": "disk"}
+ , "num_frame": -1
+
+ , "sigma": 30
+ }
+ }
+
+ , "netG": {
+ "net_type": "vrt"
+ , "upscale": 1
+ , "img_size": [6,192,192]
+ , "window_size": [6,8,8]
+ , "depths": [8,8,8,8,8,8,8, 4,4, 4,4]
+ , "indep_reconsts": [9,10]
+ , "embed_dims": [96,96,96,96,96,96,96, 120,120, 120,120]
+ , "num_heads": [6,6,6,6,6,6,6, 6,6, 6,6]
+ , "spynet_path": "model_zoo/vrt/spynet_sintel_final-3d2a1287.pth" // automatical download
+ , "pa_frames": 2
+ , "deformable_groups": 16
+ , "nonblind_denoising": true
+
+ , "use_checkpoint_attn": true
+ , "use_checkpoint_ffn": true
+ , "no_checkpoint_attn_blocks": [2,3,4]
+ , "no_checkpoint_ffn_blocks": [1,2,3,4,5,9]
+
+ , "init_type": "default"
+ }
+
+
+ , "train": {
+ "G_lossfn_type": "charbonnier"
+ , "G_lossfn_weight": 1.0
+ , "G_charbonnier_eps": 1e-9
+
+ , "E_decay": 0 // Exponential Moving Average for netG: set 0 to disable; default setting 0.999
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 4e-4 // learning rate
+ , "G_optimizer_betas": [0.9,0.99]
+ , "G_optimizer_wd": 0 // weight decay, default 0
+ , "G_optimizer_clipgrad": null // unused
+ , "G_optimizer_reuse": true //
+
+ , "fix_iter": 20000
+ , "fix_lr_mul": 0.125
+ , "fix_keys": ["spynet", "deform"]
+
+ , "total_iter": 300000
+ , "G_scheduler_type": "CosineAnnealingWarmRestarts"
+ , "G_scheduler_periods": 300000
+ , "G_scheduler_eta_min": 1e-7
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "G_param_strict": true
+ , "E_param_strict": true
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+
+ , "val": {
+ "save_img": false
+ , "pad_seq": false
+ , "flip_seq": false
+ , "center_frame_only": false
+ , "num_frame_testing": 12
+ , "num_frame_overlapping": 2
+ , "size_patch_testing": 256
+ }
+
+}
diff --git a/KAIR/outputs/2022-08-18/14-49-45/.hydra/config.yaml b/KAIR/outputs/2022-08-18/14-49-45/.hydra/config.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..84343d98c7d3995feb23624d60d91e51bef05e63
--- /dev/null
+++ b/KAIR/outputs/2022-08-18/14-49-45/.hydra/config.yaml
@@ -0,0 +1,98 @@
+arch:
+ _target_: arch.gcir.gcir_nano
+ pretrained: false
+ version: 1
+callbacks:
+ model_checkpoint:
+ _target_: callbacks.default.CustomModelCheckpoint
+ filename: '{epoch:03d}-{step:07d}'
+ every_n_train_steps: 1000
+ save_top_k: -1
+ save_last: true
+ dirpath: checkpoints
+ auto_insert_metric_name: false
+ verbose: true
+lmodule:
+ _target_: lmodule.sr_lmodule.SRLightningModule
+ hparams:
+ lpips_net: alex
+ l1_weight: 1
+ p_weight: 1
+ lr: ${lr}
+ betas: ${betas}
+ eps: ${eps}
+ weight_decay: ${weight_decay}
+ milestones: ${milestones}
+ gamma: ${gamma}
+datamodule:
+ _target_: datamodule.sr_datamodule.SRDataModule
+ train_dataset:
+ _target_: dataset.sr_dataset.BlindSRDataset
+ _convert_: partial
+ hq_data_dir: ${train_hq_data_dir}
+ sr_scale: ${sr_scale}
+ n_channels: 3
+ degradation_type: ${degradation_type}
+ shuffle_prob: 0.1
+ use_sharp: false
+ hq_patch_size: 256
+ lq_patch_size: 64
+ val_dataset:
+ _target_: dataset.sr_dataset.BlindSRDataset
+ _convert_: partial
+ hq_data_dir: ${val_data_dir}
+ sr_scale: ${sr_scale}
+ n_channels: 3
+ degradation_type: ${degradation_type}
+ shuffle_prob: 0.1
+ use_sharp: false
+ hq_patch_size: 256
+ lq_patch_size: 64
+ batch_size: ${batch_size}
+ num_workers: ${num_workers}
+ num_val_workers: 8
+ iterations_per_epoch: 1000
+ use_random_sampler: false
+trainer:
+ _target_: pytorch_lightning.Trainer
+ accelerator: gpu
+ strategy:
+ _target_: pytorch_lightning.plugins.training_type.ddp.DDPPlugin
+ find_unused_parameters: true
+ gpus: ${gpus}
+ precision: 32
+ max_steps: 100000
+ check_val_every_n_epoch: 10
+ replace_sampler_ddp: false
+ benchmark: true
+model: gcir_base
+name: gcir_base
+version: v1_SRscale2
+sr_scale: 2
+gpus:
+- 0
+- 1
+train_hq_data_dir: /home/cll/datasets/swinir_train
+val_data_dir: /home/cll/datasets/swinir_test
+epochs: 300
+warmup_epochs: 20
+cooldown_epochs: 10
+batch_size: 8
+num_workers: 8
+optimizer_name: adamw
+lr: 0.0001
+betas:
+- 0.9
+- 0.999
+eps: 1.0e-08
+weight_decay: 0.05
+milestones:
+- 50000
+- 100000
+- 150000
+- 200000
+- 300000
+gamma: 0.5
+degradation_type: bsrgan
+checkpoint_path: null
+use_channels_last: false
diff --git a/KAIR/outputs/2022-08-18/14-49-45/.hydra/hydra.yaml b/KAIR/outputs/2022-08-18/14-49-45/.hydra/hydra.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..2b015182fb7820195a3babe182d2d20ec3fc9abc
--- /dev/null
+++ b/KAIR/outputs/2022-08-18/14-49-45/.hydra/hydra.yaml
@@ -0,0 +1,161 @@
+hydra:
+ run:
+ dir: outputs/${now:%Y-%m-%d}/${now:%H-%M-%S}
+ sweep:
+ dir: multirun/${now:%Y-%m-%d}/${now:%H-%M-%S}
+ subdir: ${hydra.job.num}
+ launcher:
+ _target_: hydra._internal.core_plugins.basic_launcher.BasicLauncher
+ sweeper:
+ _target_: hydra._internal.core_plugins.basic_sweeper.BasicSweeper
+ max_batch_size: null
+ params: null
+ help:
+ app_name: ${hydra.job.name}
+ header: '${hydra.help.app_name} is powered by Hydra.
+
+ '
+ footer: 'Powered by Hydra (https://hydra.cc)
+
+ Use --hydra-help to view Hydra specific help
+
+ '
+ template: '${hydra.help.header}
+
+ == Configuration groups ==
+
+ Compose your configuration from those groups (group=option)
+
+
+ $APP_CONFIG_GROUPS
+
+
+ == Config ==
+
+ Override anything in the config (foo.bar=value)
+
+
+ $CONFIG
+
+
+ ${hydra.help.footer}
+
+ '
+ hydra_help:
+ template: 'Hydra (${hydra.runtime.version})
+
+ See https://hydra.cc for more info.
+
+
+ == Flags ==
+
+ $FLAGS_HELP
+
+
+ == Configuration groups ==
+
+ Compose your configuration from those groups (For example, append hydra/job_logging=disabled
+ to command line)
+
+
+ $HYDRA_CONFIG_GROUPS
+
+
+ Use ''--cfg hydra'' to Show the Hydra config.
+
+ '
+ hydra_help: ???
+ hydra_logging:
+ version: 1
+ formatters:
+ simple:
+ format: '[%(asctime)s][HYDRA] %(message)s'
+ handlers:
+ console:
+ class: logging.StreamHandler
+ formatter: simple
+ stream: ext://sys.stdout
+ root:
+ level: INFO
+ handlers:
+ - console
+ loggers:
+ logging_example:
+ level: DEBUG
+ disable_existing_loggers: false
+ job_logging:
+ version: 1
+ formatters:
+ simple:
+ format: '[%(asctime)s][%(name)s][%(levelname)s] - %(message)s'
+ handlers:
+ console:
+ class: logging.StreamHandler
+ formatter: simple
+ stream: ext://sys.stdout
+ file:
+ class: logging.FileHandler
+ formatter: simple
+ filename: ${hydra.runtime.output_dir}/${hydra.job.name}.log
+ root:
+ level: INFO
+ handlers:
+ - console
+ - file
+ disable_existing_loggers: false
+ env: {}
+ mode: RUN
+ searchpath: []
+ callbacks: {}
+ output_subdir: .hydra
+ overrides:
+ hydra:
+ - hydra.mode=RUN
+ task:
+ - experiment=gcir/gcir_base.yaml
+ job:
+ name: train
+ chdir: null
+ override_dirname: experiment=gcir/gcir_base.yaml
+ id: ???
+ num: ???
+ config_name: config.yaml
+ env_set: {}
+ env_copy: []
+ config:
+ override_dirname:
+ kv_sep: '='
+ item_sep: ','
+ exclude_keys: []
+ runtime:
+ version: 1.2.0
+ version_base: '1.1'
+ cwd: /home/cll/dev/superresolution/KAIR
+ config_sources:
+ - path: hydra.conf
+ schema: pkg
+ provider: hydra
+ - path: configs
+ schema: pkg
+ provider: main
+ - path: ''
+ schema: structured
+ provider: schema
+ output_dir: /home/cll/dev/superresolution/KAIR/outputs/2022-08-18/14-49-45
+ choices:
+ experiment: gcir/gcir_base.yaml
+ trainer: lightning_default
+ datamodule: sr_datamodule
+ lmodule: sr_lmodule
+ callbacks: default
+ arch: gcir_base
+ hydra/env: default
+ hydra/callbacks: null
+ hydra/job_logging: default
+ hydra/hydra_logging: default
+ hydra/hydra_help: default
+ hydra/help: default
+ hydra/sweeper: basic
+ hydra/launcher: basic
+ hydra/output: default
+ verbose: false
diff --git a/KAIR/outputs/2022-08-18/14-49-45/.hydra/overrides.yaml b/KAIR/outputs/2022-08-18/14-49-45/.hydra/overrides.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..d40f8c4da6957765d87f2b2d1f9fe5ce51da16a7
--- /dev/null
+++ b/KAIR/outputs/2022-08-18/14-49-45/.hydra/overrides.yaml
@@ -0,0 +1 @@
+- experiment=gcir/gcir_base.yaml
diff --git a/KAIR/outputs/2022-08-18/14-49-45/train.log b/KAIR/outputs/2022-08-18/14-49-45/train.log
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/KAIR/outputs/2022-08-18/14-50-30/.hydra/config.yaml b/KAIR/outputs/2022-08-18/14-50-30/.hydra/config.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..de067cb461cd8be8b72c06bb50a7dd4b966b1801
--- /dev/null
+++ b/KAIR/outputs/2022-08-18/14-50-30/.hydra/config.yaml
@@ -0,0 +1,98 @@
+arch:
+ _target_: arch.gcir.gcir_nano
+ pretrained: false
+ version: 1
+callbacks:
+ model_checkpoint:
+ _target_: callbacks.default.CustomModelCheckpoint
+ filename: '{epoch:03d}-{step:07d}'
+ every_n_train_steps: 1000
+ save_top_k: -1
+ save_last: true
+ dirpath: checkpoints
+ auto_insert_metric_name: false
+ verbose: true
+lmodule:
+ _target_: lmodule.sr_lmodule.SRLightningModule
+ params:
+ lpips_net: alex
+ l1_weight: 1
+ p_weight: 1
+ lr: ${lr}
+ betas: ${betas}
+ eps: ${eps}
+ weight_decay: ${weight_decay}
+ milestones: ${milestones}
+ gamma: ${gamma}
+datamodule:
+ _target_: datamodule.sr_datamodule.SRDataModule
+ train_dataset:
+ _target_: dataset.sr_dataset.BlindSRDataset
+ _convert_: partial
+ hq_data_dir: ${train_hq_data_dir}
+ sr_scale: ${sr_scale}
+ n_channels: 3
+ degradation_type: ${degradation_type}
+ shuffle_prob: 0.1
+ use_sharp: false
+ hq_patch_size: 256
+ lq_patch_size: 64
+ val_dataset:
+ _target_: dataset.sr_dataset.BlindSRDataset
+ _convert_: partial
+ hq_data_dir: ${val_data_dir}
+ sr_scale: ${sr_scale}
+ n_channels: 3
+ degradation_type: ${degradation_type}
+ shuffle_prob: 0.1
+ use_sharp: false
+ hq_patch_size: 256
+ lq_patch_size: 64
+ batch_size: ${batch_size}
+ num_workers: ${num_workers}
+ num_val_workers: 8
+ iterations_per_epoch: 1000
+ use_random_sampler: false
+trainer:
+ _target_: pytorch_lightning.Trainer
+ accelerator: gpu
+ strategy:
+ _target_: pytorch_lightning.plugins.training_type.ddp.DDPPlugin
+ find_unused_parameters: true
+ gpus: ${gpus}
+ precision: 32
+ max_steps: 100000
+ check_val_every_n_epoch: 10
+ replace_sampler_ddp: false
+ benchmark: true
+model: gcir_base
+name: gcir_base
+version: v1_SRscale2
+sr_scale: 2
+gpus:
+- 0
+- 1
+train_hq_data_dir: /home/cll/datasets/swinir_train
+val_data_dir: /home/cll/datasets/swinir_test
+epochs: 300
+warmup_epochs: 20
+cooldown_epochs: 10
+batch_size: 8
+num_workers: 8
+optimizer_name: adamw
+lr: 0.0001
+betas:
+- 0.9
+- 0.999
+eps: 1.0e-08
+weight_decay: 0.05
+milestones:
+- 50000
+- 100000
+- 150000
+- 200000
+- 300000
+gamma: 0.5
+degradation_type: bsrgan
+checkpoint_path: null
+use_channels_last: false
diff --git a/KAIR/outputs/2022-08-18/14-50-30/.hydra/hydra.yaml b/KAIR/outputs/2022-08-18/14-50-30/.hydra/hydra.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..def385afd51d9c4fe6df81a7d9132efc4c1e8119
--- /dev/null
+++ b/KAIR/outputs/2022-08-18/14-50-30/.hydra/hydra.yaml
@@ -0,0 +1,161 @@
+hydra:
+ run:
+ dir: outputs/${now:%Y-%m-%d}/${now:%H-%M-%S}
+ sweep:
+ dir: multirun/${now:%Y-%m-%d}/${now:%H-%M-%S}
+ subdir: ${hydra.job.num}
+ launcher:
+ _target_: hydra._internal.core_plugins.basic_launcher.BasicLauncher
+ sweeper:
+ _target_: hydra._internal.core_plugins.basic_sweeper.BasicSweeper
+ max_batch_size: null
+ params: null
+ help:
+ app_name: ${hydra.job.name}
+ header: '${hydra.help.app_name} is powered by Hydra.
+
+ '
+ footer: 'Powered by Hydra (https://hydra.cc)
+
+ Use --hydra-help to view Hydra specific help
+
+ '
+ template: '${hydra.help.header}
+
+ == Configuration groups ==
+
+ Compose your configuration from those groups (group=option)
+
+
+ $APP_CONFIG_GROUPS
+
+
+ == Config ==
+
+ Override anything in the config (foo.bar=value)
+
+
+ $CONFIG
+
+
+ ${hydra.help.footer}
+
+ '
+ hydra_help:
+ template: 'Hydra (${hydra.runtime.version})
+
+ See https://hydra.cc for more info.
+
+
+ == Flags ==
+
+ $FLAGS_HELP
+
+
+ == Configuration groups ==
+
+ Compose your configuration from those groups (For example, append hydra/job_logging=disabled
+ to command line)
+
+
+ $HYDRA_CONFIG_GROUPS
+
+
+ Use ''--cfg hydra'' to Show the Hydra config.
+
+ '
+ hydra_help: ???
+ hydra_logging:
+ version: 1
+ formatters:
+ simple:
+ format: '[%(asctime)s][HYDRA] %(message)s'
+ handlers:
+ console:
+ class: logging.StreamHandler
+ formatter: simple
+ stream: ext://sys.stdout
+ root:
+ level: INFO
+ handlers:
+ - console
+ loggers:
+ logging_example:
+ level: DEBUG
+ disable_existing_loggers: false
+ job_logging:
+ version: 1
+ formatters:
+ simple:
+ format: '[%(asctime)s][%(name)s][%(levelname)s] - %(message)s'
+ handlers:
+ console:
+ class: logging.StreamHandler
+ formatter: simple
+ stream: ext://sys.stdout
+ file:
+ class: logging.FileHandler
+ formatter: simple
+ filename: ${hydra.runtime.output_dir}/${hydra.job.name}.log
+ root:
+ level: INFO
+ handlers:
+ - console
+ - file
+ disable_existing_loggers: false
+ env: {}
+ mode: RUN
+ searchpath: []
+ callbacks: {}
+ output_subdir: .hydra
+ overrides:
+ hydra:
+ - hydra.mode=RUN
+ task:
+ - experiment=gcir/gcir_base.yaml
+ job:
+ name: train
+ chdir: null
+ override_dirname: experiment=gcir/gcir_base.yaml
+ id: ???
+ num: ???
+ config_name: config.yaml
+ env_set: {}
+ env_copy: []
+ config:
+ override_dirname:
+ kv_sep: '='
+ item_sep: ','
+ exclude_keys: []
+ runtime:
+ version: 1.2.0
+ version_base: '1.1'
+ cwd: /home/cll/dev/superresolution/KAIR
+ config_sources:
+ - path: hydra.conf
+ schema: pkg
+ provider: hydra
+ - path: configs
+ schema: pkg
+ provider: main
+ - path: ''
+ schema: structured
+ provider: schema
+ output_dir: /home/cll/dev/superresolution/KAIR/outputs/2022-08-18/14-50-30
+ choices:
+ experiment: gcir/gcir_base.yaml
+ trainer: lightning_default
+ datamodule: sr_datamodule
+ lmodule: sr_lmodule
+ callbacks: default
+ arch: gcir_base
+ hydra/env: default
+ hydra/callbacks: null
+ hydra/job_logging: default
+ hydra/hydra_logging: default
+ hydra/hydra_help: default
+ hydra/help: default
+ hydra/sweeper: basic
+ hydra/launcher: basic
+ hydra/output: default
+ verbose: false
diff --git a/KAIR/outputs/2022-08-18/14-50-30/.hydra/overrides.yaml b/KAIR/outputs/2022-08-18/14-50-30/.hydra/overrides.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..d40f8c4da6957765d87f2b2d1f9fe5ce51da16a7
--- /dev/null
+++ b/KAIR/outputs/2022-08-18/14-50-30/.hydra/overrides.yaml
@@ -0,0 +1 @@
+- experiment=gcir/gcir_base.yaml
diff --git a/KAIR/outputs/2022-08-18/14-50-30/train.log b/KAIR/outputs/2022-08-18/14-50-30/train.log
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/KAIR/outputs/2022-08-18/14-50-56/.hydra/config.yaml b/KAIR/outputs/2022-08-18/14-50-56/.hydra/config.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..de067cb461cd8be8b72c06bb50a7dd4b966b1801
--- /dev/null
+++ b/KAIR/outputs/2022-08-18/14-50-56/.hydra/config.yaml
@@ -0,0 +1,98 @@
+arch:
+ _target_: arch.gcir.gcir_nano
+ pretrained: false
+ version: 1
+callbacks:
+ model_checkpoint:
+ _target_: callbacks.default.CustomModelCheckpoint
+ filename: '{epoch:03d}-{step:07d}'
+ every_n_train_steps: 1000
+ save_top_k: -1
+ save_last: true
+ dirpath: checkpoints
+ auto_insert_metric_name: false
+ verbose: true
+lmodule:
+ _target_: lmodule.sr_lmodule.SRLightningModule
+ params:
+ lpips_net: alex
+ l1_weight: 1
+ p_weight: 1
+ lr: ${lr}
+ betas: ${betas}
+ eps: ${eps}
+ weight_decay: ${weight_decay}
+ milestones: ${milestones}
+ gamma: ${gamma}
+datamodule:
+ _target_: datamodule.sr_datamodule.SRDataModule
+ train_dataset:
+ _target_: dataset.sr_dataset.BlindSRDataset
+ _convert_: partial
+ hq_data_dir: ${train_hq_data_dir}
+ sr_scale: ${sr_scale}
+ n_channels: 3
+ degradation_type: ${degradation_type}
+ shuffle_prob: 0.1
+ use_sharp: false
+ hq_patch_size: 256
+ lq_patch_size: 64
+ val_dataset:
+ _target_: dataset.sr_dataset.BlindSRDataset
+ _convert_: partial
+ hq_data_dir: ${val_data_dir}
+ sr_scale: ${sr_scale}
+ n_channels: 3
+ degradation_type: ${degradation_type}
+ shuffle_prob: 0.1
+ use_sharp: false
+ hq_patch_size: 256
+ lq_patch_size: 64
+ batch_size: ${batch_size}
+ num_workers: ${num_workers}
+ num_val_workers: 8
+ iterations_per_epoch: 1000
+ use_random_sampler: false
+trainer:
+ _target_: pytorch_lightning.Trainer
+ accelerator: gpu
+ strategy:
+ _target_: pytorch_lightning.plugins.training_type.ddp.DDPPlugin
+ find_unused_parameters: true
+ gpus: ${gpus}
+ precision: 32
+ max_steps: 100000
+ check_val_every_n_epoch: 10
+ replace_sampler_ddp: false
+ benchmark: true
+model: gcir_base
+name: gcir_base
+version: v1_SRscale2
+sr_scale: 2
+gpus:
+- 0
+- 1
+train_hq_data_dir: /home/cll/datasets/swinir_train
+val_data_dir: /home/cll/datasets/swinir_test
+epochs: 300
+warmup_epochs: 20
+cooldown_epochs: 10
+batch_size: 8
+num_workers: 8
+optimizer_name: adamw
+lr: 0.0001
+betas:
+- 0.9
+- 0.999
+eps: 1.0e-08
+weight_decay: 0.05
+milestones:
+- 50000
+- 100000
+- 150000
+- 200000
+- 300000
+gamma: 0.5
+degradation_type: bsrgan
+checkpoint_path: null
+use_channels_last: false
diff --git a/KAIR/outputs/2022-08-18/14-50-56/.hydra/hydra.yaml b/KAIR/outputs/2022-08-18/14-50-56/.hydra/hydra.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..ef46fd59c06127631e4d48bde7413a82cd668bd4
--- /dev/null
+++ b/KAIR/outputs/2022-08-18/14-50-56/.hydra/hydra.yaml
@@ -0,0 +1,161 @@
+hydra:
+ run:
+ dir: outputs/${now:%Y-%m-%d}/${now:%H-%M-%S}
+ sweep:
+ dir: multirun/${now:%Y-%m-%d}/${now:%H-%M-%S}
+ subdir: ${hydra.job.num}
+ launcher:
+ _target_: hydra._internal.core_plugins.basic_launcher.BasicLauncher
+ sweeper:
+ _target_: hydra._internal.core_plugins.basic_sweeper.BasicSweeper
+ max_batch_size: null
+ params: null
+ help:
+ app_name: ${hydra.job.name}
+ header: '${hydra.help.app_name} is powered by Hydra.
+
+ '
+ footer: 'Powered by Hydra (https://hydra.cc)
+
+ Use --hydra-help to view Hydra specific help
+
+ '
+ template: '${hydra.help.header}
+
+ == Configuration groups ==
+
+ Compose your configuration from those groups (group=option)
+
+
+ $APP_CONFIG_GROUPS
+
+
+ == Config ==
+
+ Override anything in the config (foo.bar=value)
+
+
+ $CONFIG
+
+
+ ${hydra.help.footer}
+
+ '
+ hydra_help:
+ template: 'Hydra (${hydra.runtime.version})
+
+ See https://hydra.cc for more info.
+
+
+ == Flags ==
+
+ $FLAGS_HELP
+
+
+ == Configuration groups ==
+
+ Compose your configuration from those groups (For example, append hydra/job_logging=disabled
+ to command line)
+
+
+ $HYDRA_CONFIG_GROUPS
+
+
+ Use ''--cfg hydra'' to Show the Hydra config.
+
+ '
+ hydra_help: ???
+ hydra_logging:
+ version: 1
+ formatters:
+ simple:
+ format: '[%(asctime)s][HYDRA] %(message)s'
+ handlers:
+ console:
+ class: logging.StreamHandler
+ formatter: simple
+ stream: ext://sys.stdout
+ root:
+ level: INFO
+ handlers:
+ - console
+ loggers:
+ logging_example:
+ level: DEBUG
+ disable_existing_loggers: false
+ job_logging:
+ version: 1
+ formatters:
+ simple:
+ format: '[%(asctime)s][%(name)s][%(levelname)s] - %(message)s'
+ handlers:
+ console:
+ class: logging.StreamHandler
+ formatter: simple
+ stream: ext://sys.stdout
+ file:
+ class: logging.FileHandler
+ formatter: simple
+ filename: ${hydra.runtime.output_dir}/${hydra.job.name}.log
+ root:
+ level: INFO
+ handlers:
+ - console
+ - file
+ disable_existing_loggers: false
+ env: {}
+ mode: RUN
+ searchpath: []
+ callbacks: {}
+ output_subdir: .hydra
+ overrides:
+ hydra:
+ - hydra.mode=RUN
+ task:
+ - experiment=gcir/gcir_base.yaml
+ job:
+ name: train
+ chdir: null
+ override_dirname: experiment=gcir/gcir_base.yaml
+ id: ???
+ num: ???
+ config_name: config.yaml
+ env_set: {}
+ env_copy: []
+ config:
+ override_dirname:
+ kv_sep: '='
+ item_sep: ','
+ exclude_keys: []
+ runtime:
+ version: 1.2.0
+ version_base: '1.1'
+ cwd: /home/cll/dev/superresolution/KAIR
+ config_sources:
+ - path: hydra.conf
+ schema: pkg
+ provider: hydra
+ - path: configs
+ schema: pkg
+ provider: main
+ - path: ''
+ schema: structured
+ provider: schema
+ output_dir: /home/cll/dev/superresolution/KAIR/outputs/2022-08-18/14-50-56
+ choices:
+ experiment: gcir/gcir_base.yaml
+ trainer: lightning_default
+ datamodule: sr_datamodule
+ lmodule: sr_lmodule
+ callbacks: default
+ arch: gcir_base
+ hydra/env: default
+ hydra/callbacks: null
+ hydra/job_logging: default
+ hydra/hydra_logging: default
+ hydra/hydra_help: default
+ hydra/help: default
+ hydra/sweeper: basic
+ hydra/launcher: basic
+ hydra/output: default
+ verbose: false
diff --git a/KAIR/outputs/2022-08-18/14-50-56/.hydra/overrides.yaml b/KAIR/outputs/2022-08-18/14-50-56/.hydra/overrides.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..d40f8c4da6957765d87f2b2d1f9fe5ce51da16a7
--- /dev/null
+++ b/KAIR/outputs/2022-08-18/14-50-56/.hydra/overrides.yaml
@@ -0,0 +1 @@
+- experiment=gcir/gcir_base.yaml
diff --git a/KAIR/outputs/2022-08-18/14-50-56/train.log b/KAIR/outputs/2022-08-18/14-50-56/train.log
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/KAIR/requirement.txt b/KAIR/requirement.txt
new file mode 100644
index 0000000000000000000000000000000000000000..825a07be1a9002048a3f8b1b6c2c6a27a6929981
--- /dev/null
+++ b/KAIR/requirement.txt
@@ -0,0 +1,10 @@
+opencv-python
+scikit-image
+pillow
+torchvision
+hdf5storage
+ninja
+lmdb
+requests
+timm
+einops
\ No newline at end of file
diff --git a/KAIR/results/swinir_real_sr_x2/gradio_img_SwinIR.png b/KAIR/results/swinir_real_sr_x2/gradio_img_SwinIR.png
new file mode 100644
index 0000000000000000000000000000000000000000..5a2cb661fe5184430de6355ca79a5574e8acc315
Binary files /dev/null and b/KAIR/results/swinir_real_sr_x2/gradio_img_SwinIR.png differ
diff --git a/KAIR/results/swinir_real_sr_x4_large/gradio_img_SwinIR.png b/KAIR/results/swinir_real_sr_x4_large/gradio_img_SwinIR.png
new file mode 100644
index 0000000000000000000000000000000000000000..c3f3253561ce92a33eef91100835779f00fd3d01
Binary files /dev/null and b/KAIR/results/swinir_real_sr_x4_large/gradio_img_SwinIR.png differ
diff --git a/KAIR/retinaface/README.md b/KAIR/retinaface/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..263dd1f070a33c2e0b720c660e2e1575e13beb89
--- /dev/null
+++ b/KAIR/retinaface/README.md
@@ -0,0 +1 @@
+This code is useful when you use `main_test_face_enhancement.py`.
diff --git a/KAIR/retinaface/data_faces/FDDB/img_list.txt b/KAIR/retinaface/data_faces/FDDB/img_list.txt
new file mode 100644
index 0000000000000000000000000000000000000000..5cf3d3199ca5c9c5ef4a904f1b9c89b821a7978a
--- /dev/null
+++ b/KAIR/retinaface/data_faces/FDDB/img_list.txt
@@ -0,0 +1,2845 @@
+2002/08/11/big/img_591
+2002/08/26/big/img_265
+2002/07/19/big/img_423
+2002/08/24/big/img_490
+2002/08/31/big/img_17676
+2002/07/31/big/img_228
+2002/07/24/big/img_402
+2002/08/04/big/img_769
+2002/07/19/big/img_581
+2002/08/13/big/img_723
+2002/08/12/big/img_821
+2003/01/17/big/img_610
+2002/08/13/big/img_1116
+2002/08/28/big/img_19238
+2002/08/21/big/img_660
+2002/08/14/big/img_607
+2002/08/05/big/img_3708
+2002/08/19/big/img_511
+2002/08/07/big/img_1316
+2002/07/25/big/img_1047
+2002/07/23/big/img_474
+2002/07/27/big/img_970
+2002/09/02/big/img_15752
+2002/09/01/big/img_16378
+2002/09/01/big/img_16189
+2002/08/26/big/img_276
+2002/07/24/big/img_518
+2002/08/14/big/img_1027
+2002/08/24/big/img_733
+2002/08/15/big/img_249
+2003/01/15/big/img_1371
+2002/08/07/big/img_1348
+2003/01/01/big/img_331
+2002/08/23/big/img_536
+2002/07/30/big/img_224
+2002/08/10/big/img_763
+2002/08/21/big/img_293
+2002/08/15/big/img_1211
+2002/08/15/big/img_1194
+2003/01/15/big/img_390
+2002/08/06/big/img_2893
+2002/08/17/big/img_691
+2002/08/07/big/img_1695
+2002/08/16/big/img_829
+2002/07/25/big/img_201
+2002/08/23/big/img_36
+2003/01/15/big/img_763
+2003/01/15/big/img_637
+2002/08/22/big/img_592
+2002/07/25/big/img_817
+2003/01/15/big/img_1219
+2002/08/05/big/img_3508
+2002/08/15/big/img_1108
+2002/07/19/big/img_488
+2003/01/16/big/img_704
+2003/01/13/big/img_1087
+2002/08/10/big/img_670
+2002/07/24/big/img_104
+2002/08/27/big/img_19823
+2002/09/01/big/img_16229
+2003/01/13/big/img_846
+2002/08/04/big/img_412
+2002/07/22/big/img_554
+2002/08/12/big/img_331
+2002/08/02/big/img_533
+2002/08/12/big/img_259
+2002/08/18/big/img_328
+2003/01/14/big/img_630
+2002/08/05/big/img_3541
+2002/08/06/big/img_2390
+2002/08/20/big/img_150
+2002/08/02/big/img_1231
+2002/08/16/big/img_710
+2002/08/19/big/img_591
+2002/07/22/big/img_725
+2002/07/24/big/img_820
+2003/01/13/big/img_568
+2002/08/22/big/img_853
+2002/08/09/big/img_648
+2002/08/23/big/img_528
+2003/01/14/big/img_888
+2002/08/30/big/img_18201
+2002/08/13/big/img_965
+2003/01/14/big/img_660
+2002/07/19/big/img_517
+2003/01/14/big/img_406
+2002/08/30/big/img_18433
+2002/08/07/big/img_1630
+2002/08/06/big/img_2717
+2002/08/21/big/img_470
+2002/07/23/big/img_633
+2002/08/20/big/img_915
+2002/08/16/big/img_893
+2002/07/29/big/img_644
+2002/08/15/big/img_529
+2002/08/16/big/img_668
+2002/08/07/big/img_1871
+2002/07/25/big/img_192
+2002/07/31/big/img_961
+2002/08/19/big/img_738
+2002/07/31/big/img_382
+2002/08/19/big/img_298
+2003/01/17/big/img_608
+2002/08/21/big/img_514
+2002/07/23/big/img_183
+2003/01/17/big/img_536
+2002/07/24/big/img_478
+2002/08/06/big/img_2997
+2002/09/02/big/img_15380
+2002/08/07/big/img_1153
+2002/07/31/big/img_967
+2002/07/31/big/img_711
+2002/08/26/big/img_664
+2003/01/01/big/img_326
+2002/08/24/big/img_775
+2002/08/08/big/img_961
+2002/08/16/big/img_77
+2002/08/12/big/img_296
+2002/07/22/big/img_905
+2003/01/13/big/img_284
+2002/08/13/big/img_887
+2002/08/24/big/img_849
+2002/07/30/big/img_345
+2002/08/18/big/img_419
+2002/08/01/big/img_1347
+2002/08/05/big/img_3670
+2002/07/21/big/img_479
+2002/08/08/big/img_913
+2002/09/02/big/img_15828
+2002/08/30/big/img_18194
+2002/08/08/big/img_471
+2002/08/22/big/img_734
+2002/08/09/big/img_586
+2002/08/09/big/img_454
+2002/07/29/big/img_47
+2002/07/19/big/img_381
+2002/07/29/big/img_733
+2002/08/20/big/img_327
+2002/07/21/big/img_96
+2002/08/06/big/img_2680
+2002/07/25/big/img_919
+2002/07/21/big/img_158
+2002/07/22/big/img_801
+2002/07/22/big/img_567
+2002/07/24/big/img_804
+2002/07/24/big/img_690
+2003/01/15/big/img_576
+2002/08/14/big/img_335
+2003/01/13/big/img_390
+2002/08/11/big/img_258
+2002/07/23/big/img_917
+2002/08/15/big/img_525
+2003/01/15/big/img_505
+2002/07/30/big/img_886
+2003/01/16/big/img_640
+2003/01/14/big/img_642
+2003/01/17/big/img_844
+2002/08/04/big/img_571
+2002/08/29/big/img_18702
+2003/01/15/big/img_240
+2002/07/29/big/img_553
+2002/08/10/big/img_354
+2002/08/18/big/img_17
+2003/01/15/big/img_782
+2002/07/27/big/img_382
+2002/08/14/big/img_970
+2003/01/16/big/img_70
+2003/01/16/big/img_625
+2002/08/18/big/img_341
+2002/08/26/big/img_188
+2002/08/09/big/img_405
+2002/08/02/big/img_37
+2002/08/13/big/img_748
+2002/07/22/big/img_399
+2002/07/25/big/img_844
+2002/08/12/big/img_340
+2003/01/13/big/img_815
+2002/08/26/big/img_5
+2002/08/10/big/img_158
+2002/08/18/big/img_95
+2002/07/29/big/img_1297
+2003/01/13/big/img_508
+2002/09/01/big/img_16680
+2003/01/16/big/img_338
+2002/08/13/big/img_517
+2002/07/22/big/img_626
+2002/08/06/big/img_3024
+2002/07/26/big/img_499
+2003/01/13/big/img_387
+2002/08/31/big/img_18025
+2002/08/13/big/img_520
+2003/01/16/big/img_576
+2002/07/26/big/img_121
+2002/08/25/big/img_703
+2002/08/26/big/img_615
+2002/08/17/big/img_434
+2002/08/02/big/img_677
+2002/08/18/big/img_276
+2002/08/05/big/img_3672
+2002/07/26/big/img_700
+2002/07/31/big/img_277
+2003/01/14/big/img_220
+2002/08/23/big/img_232
+2002/08/31/big/img_17422
+2002/07/22/big/img_508
+2002/08/13/big/img_681
+2003/01/15/big/img_638
+2002/08/30/big/img_18408
+2003/01/14/big/img_533
+2003/01/17/big/img_12
+2002/08/28/big/img_19388
+2002/08/08/big/img_133
+2002/07/26/big/img_885
+2002/08/19/big/img_387
+2002/08/27/big/img_19976
+2002/08/26/big/img_118
+2002/08/28/big/img_19146
+2002/08/05/big/img_3259
+2002/08/15/big/img_536
+2002/07/22/big/img_279
+2002/07/22/big/img_9
+2002/08/13/big/img_301
+2002/08/15/big/img_974
+2002/08/06/big/img_2355
+2002/08/01/big/img_1526
+2002/08/03/big/img_417
+2002/08/04/big/img_407
+2002/08/15/big/img_1029
+2002/07/29/big/img_700
+2002/08/01/big/img_1463
+2002/08/31/big/img_17365
+2002/07/28/big/img_223
+2002/07/19/big/img_827
+2002/07/27/big/img_531
+2002/07/19/big/img_845
+2002/08/20/big/img_382
+2002/07/31/big/img_268
+2002/08/27/big/img_19705
+2002/08/02/big/img_830
+2002/08/23/big/img_250
+2002/07/20/big/img_777
+2002/08/21/big/img_879
+2002/08/26/big/img_20146
+2002/08/23/big/img_789
+2002/08/06/big/img_2683
+2002/08/25/big/img_576
+2002/08/09/big/img_498
+2002/08/08/big/img_384
+2002/08/26/big/img_592
+2002/07/29/big/img_1470
+2002/08/21/big/img_452
+2002/08/30/big/img_18395
+2002/08/15/big/img_215
+2002/07/21/big/img_643
+2002/07/22/big/img_209
+2003/01/17/big/img_346
+2002/08/25/big/img_658
+2002/08/21/big/img_221
+2002/08/14/big/img_60
+2003/01/17/big/img_885
+2003/01/16/big/img_482
+2002/08/19/big/img_593
+2002/08/08/big/img_233
+2002/07/30/big/img_458
+2002/07/23/big/img_384
+2003/01/15/big/img_670
+2003/01/15/big/img_267
+2002/08/26/big/img_540
+2002/07/29/big/img_552
+2002/07/30/big/img_997
+2003/01/17/big/img_377
+2002/08/21/big/img_265
+2002/08/09/big/img_561
+2002/07/31/big/img_945
+2002/09/02/big/img_15252
+2002/08/11/big/img_276
+2002/07/22/big/img_491
+2002/07/26/big/img_517
+2002/08/14/big/img_726
+2002/08/08/big/img_46
+2002/08/28/big/img_19458
+2002/08/06/big/img_2935
+2002/07/29/big/img_1392
+2002/08/13/big/img_776
+2002/08/24/big/img_616
+2002/08/14/big/img_1065
+2002/07/29/big/img_889
+2002/08/18/big/img_188
+2002/08/07/big/img_1453
+2002/08/02/big/img_760
+2002/07/28/big/img_416
+2002/08/07/big/img_1393
+2002/08/26/big/img_292
+2002/08/26/big/img_301
+2003/01/13/big/img_195
+2002/07/26/big/img_532
+2002/08/20/big/img_550
+2002/08/05/big/img_3658
+2002/08/26/big/img_738
+2002/09/02/big/img_15750
+2003/01/17/big/img_451
+2002/07/23/big/img_339
+2002/08/16/big/img_637
+2002/08/14/big/img_748
+2002/08/06/big/img_2739
+2002/07/25/big/img_482
+2002/08/19/big/img_191
+2002/08/26/big/img_537
+2003/01/15/big/img_716
+2003/01/15/big/img_767
+2002/08/02/big/img_452
+2002/08/08/big/img_1011
+2002/08/10/big/img_144
+2003/01/14/big/img_122
+2002/07/24/big/img_586
+2002/07/24/big/img_762
+2002/08/20/big/img_369
+2002/07/30/big/img_146
+2002/08/23/big/img_396
+2003/01/15/big/img_200
+2002/08/15/big/img_1183
+2003/01/14/big/img_698
+2002/08/09/big/img_792
+2002/08/06/big/img_2347
+2002/07/31/big/img_911
+2002/08/26/big/img_722
+2002/08/23/big/img_621
+2002/08/05/big/img_3790
+2003/01/13/big/img_633
+2002/08/09/big/img_224
+2002/07/24/big/img_454
+2002/07/21/big/img_202
+2002/08/02/big/img_630
+2002/08/30/big/img_18315
+2002/07/19/big/img_491
+2002/09/01/big/img_16456
+2002/08/09/big/img_242
+2002/07/25/big/img_595
+2002/07/22/big/img_522
+2002/08/01/big/img_1593
+2002/07/29/big/img_336
+2002/08/15/big/img_448
+2002/08/28/big/img_19281
+2002/07/29/big/img_342
+2002/08/12/big/img_78
+2003/01/14/big/img_525
+2002/07/28/big/img_147
+2002/08/11/big/img_353
+2002/08/22/big/img_513
+2002/08/04/big/img_721
+2002/08/17/big/img_247
+2003/01/14/big/img_891
+2002/08/20/big/img_853
+2002/07/19/big/img_414
+2002/08/01/big/img_1530
+2003/01/14/big/img_924
+2002/08/22/big/img_468
+2002/08/18/big/img_354
+2002/08/30/big/img_18193
+2002/08/23/big/img_492
+2002/08/15/big/img_871
+2002/08/12/big/img_494
+2002/08/06/big/img_2470
+2002/07/23/big/img_923
+2002/08/26/big/img_155
+2002/08/08/big/img_669
+2002/07/23/big/img_404
+2002/08/28/big/img_19421
+2002/08/29/big/img_18993
+2002/08/25/big/img_416
+2003/01/17/big/img_434
+2002/07/29/big/img_1370
+2002/07/28/big/img_483
+2002/08/11/big/img_50
+2002/08/10/big/img_404
+2002/09/02/big/img_15057
+2003/01/14/big/img_911
+2002/09/01/big/img_16697
+2003/01/16/big/img_665
+2002/09/01/big/img_16708
+2002/08/22/big/img_612
+2002/08/28/big/img_19471
+2002/08/02/big/img_198
+2003/01/16/big/img_527
+2002/08/22/big/img_209
+2002/08/30/big/img_18205
+2003/01/14/big/img_114
+2003/01/14/big/img_1028
+2003/01/16/big/img_894
+2003/01/14/big/img_837
+2002/07/30/big/img_9
+2002/08/06/big/img_2821
+2002/08/04/big/img_85
+2003/01/13/big/img_884
+2002/07/22/big/img_570
+2002/08/07/big/img_1773
+2002/07/26/big/img_208
+2003/01/17/big/img_946
+2002/07/19/big/img_930
+2003/01/01/big/img_698
+2003/01/17/big/img_612
+2002/07/19/big/img_372
+2002/07/30/big/img_721
+2003/01/14/big/img_649
+2002/08/19/big/img_4
+2002/07/25/big/img_1024
+2003/01/15/big/img_601
+2002/08/30/big/img_18470
+2002/07/22/big/img_29
+2002/08/07/big/img_1686
+2002/07/20/big/img_294
+2002/08/14/big/img_800
+2002/08/19/big/img_353
+2002/08/19/big/img_350
+2002/08/05/big/img_3392
+2002/08/09/big/img_622
+2003/01/15/big/img_236
+2002/08/11/big/img_643
+2002/08/05/big/img_3458
+2002/08/12/big/img_413
+2002/08/22/big/img_415
+2002/08/13/big/img_635
+2002/08/07/big/img_1198
+2002/08/04/big/img_873
+2002/08/12/big/img_407
+2003/01/15/big/img_346
+2002/08/02/big/img_275
+2002/08/17/big/img_997
+2002/08/21/big/img_958
+2002/08/20/big/img_579
+2002/07/29/big/img_142
+2003/01/14/big/img_1115
+2002/08/16/big/img_365
+2002/07/29/big/img_1414
+2002/08/17/big/img_489
+2002/08/13/big/img_1010
+2002/07/31/big/img_276
+2002/07/25/big/img_1000
+2002/08/23/big/img_524
+2002/08/28/big/img_19147
+2003/01/13/big/img_433
+2002/08/20/big/img_205
+2003/01/01/big/img_458
+2002/07/29/big/img_1449
+2003/01/16/big/img_696
+2002/08/28/big/img_19296
+2002/08/29/big/img_18688
+2002/08/21/big/img_767
+2002/08/20/big/img_532
+2002/08/26/big/img_187
+2002/07/26/big/img_183
+2002/07/27/big/img_890
+2003/01/13/big/img_576
+2002/07/30/big/img_15
+2002/07/31/big/img_889
+2002/08/31/big/img_17759
+2003/01/14/big/img_1114
+2002/07/19/big/img_445
+2002/08/03/big/img_593
+2002/07/24/big/img_750
+2002/07/30/big/img_133
+2002/08/25/big/img_671
+2002/07/20/big/img_351
+2002/08/31/big/img_17276
+2002/08/05/big/img_3231
+2002/09/02/big/img_15882
+2002/08/14/big/img_115
+2002/08/02/big/img_1148
+2002/07/25/big/img_936
+2002/07/31/big/img_639
+2002/08/04/big/img_427
+2002/08/22/big/img_843
+2003/01/17/big/img_17
+2003/01/13/big/img_690
+2002/08/13/big/img_472
+2002/08/09/big/img_425
+2002/08/05/big/img_3450
+2003/01/17/big/img_439
+2002/08/13/big/img_539
+2002/07/28/big/img_35
+2002/08/16/big/img_241
+2002/08/06/big/img_2898
+2003/01/16/big/img_429
+2002/08/05/big/img_3817
+2002/08/27/big/img_19919
+2002/07/19/big/img_422
+2002/08/15/big/img_560
+2002/07/23/big/img_750
+2002/07/30/big/img_353
+2002/08/05/big/img_43
+2002/08/23/big/img_305
+2002/08/01/big/img_2137
+2002/08/30/big/img_18097
+2002/08/01/big/img_1389
+2002/08/02/big/img_308
+2003/01/14/big/img_652
+2002/08/01/big/img_1798
+2003/01/14/big/img_732
+2003/01/16/big/img_294
+2002/08/26/big/img_213
+2002/07/24/big/img_842
+2003/01/13/big/img_630
+2003/01/13/big/img_634
+2002/08/06/big/img_2285
+2002/08/01/big/img_2162
+2002/08/30/big/img_18134
+2002/08/02/big/img_1045
+2002/08/01/big/img_2143
+2002/07/25/big/img_135
+2002/07/20/big/img_645
+2002/08/05/big/img_3666
+2002/08/14/big/img_523
+2002/08/04/big/img_425
+2003/01/14/big/img_137
+2003/01/01/big/img_176
+2002/08/15/big/img_505
+2002/08/24/big/img_386
+2002/08/05/big/img_3187
+2002/08/15/big/img_419
+2003/01/13/big/img_520
+2002/08/04/big/img_444
+2002/08/26/big/img_483
+2002/08/05/big/img_3449
+2002/08/30/big/img_18409
+2002/08/28/big/img_19455
+2002/08/27/big/img_20090
+2002/07/23/big/img_625
+2002/08/24/big/img_205
+2002/08/08/big/img_938
+2003/01/13/big/img_527
+2002/08/07/big/img_1712
+2002/07/24/big/img_801
+2002/08/09/big/img_579
+2003/01/14/big/img_41
+2003/01/15/big/img_1130
+2002/07/21/big/img_672
+2002/08/07/big/img_1590
+2003/01/01/big/img_532
+2002/08/02/big/img_529
+2002/08/05/big/img_3591
+2002/08/23/big/img_5
+2003/01/14/big/img_882
+2002/08/28/big/img_19234
+2002/07/24/big/img_398
+2003/01/14/big/img_592
+2002/08/22/big/img_548
+2002/08/12/big/img_761
+2003/01/16/big/img_497
+2002/08/18/big/img_133
+2002/08/08/big/img_874
+2002/07/19/big/img_247
+2002/08/15/big/img_170
+2002/08/27/big/img_19679
+2002/08/20/big/img_246
+2002/08/24/big/img_358
+2002/07/29/big/img_599
+2002/08/01/big/img_1555
+2002/07/30/big/img_491
+2002/07/30/big/img_371
+2003/01/16/big/img_682
+2002/07/25/big/img_619
+2003/01/15/big/img_587
+2002/08/02/big/img_1212
+2002/08/01/big/img_2152
+2002/07/25/big/img_668
+2003/01/16/big/img_574
+2002/08/28/big/img_19464
+2002/08/11/big/img_536
+2002/07/24/big/img_201
+2002/08/05/big/img_3488
+2002/07/25/big/img_887
+2002/07/22/big/img_789
+2002/07/30/big/img_432
+2002/08/16/big/img_166
+2002/09/01/big/img_16333
+2002/07/26/big/img_1010
+2002/07/21/big/img_793
+2002/07/22/big/img_720
+2002/07/31/big/img_337
+2002/07/27/big/img_185
+2002/08/23/big/img_440
+2002/07/31/big/img_801
+2002/07/25/big/img_478
+2003/01/14/big/img_171
+2002/08/07/big/img_1054
+2002/09/02/big/img_15659
+2002/07/29/big/img_1348
+2002/08/09/big/img_337
+2002/08/26/big/img_684
+2002/07/31/big/img_537
+2002/08/15/big/img_808
+2003/01/13/big/img_740
+2002/08/07/big/img_1667
+2002/08/03/big/img_404
+2002/08/06/big/img_2520
+2002/07/19/big/img_230
+2002/07/19/big/img_356
+2003/01/16/big/img_627
+2002/08/04/big/img_474
+2002/07/29/big/img_833
+2002/07/25/big/img_176
+2002/08/01/big/img_1684
+2002/08/21/big/img_643
+2002/08/27/big/img_19673
+2002/08/02/big/img_838
+2002/08/06/big/img_2378
+2003/01/15/big/img_48
+2002/07/30/big/img_470
+2002/08/15/big/img_963
+2002/08/24/big/img_444
+2002/08/16/big/img_662
+2002/08/15/big/img_1209
+2002/07/24/big/img_25
+2002/08/06/big/img_2740
+2002/07/29/big/img_996
+2002/08/31/big/img_18074
+2002/08/04/big/img_343
+2003/01/17/big/img_509
+2003/01/13/big/img_726
+2002/08/07/big/img_1466
+2002/07/26/big/img_307
+2002/08/10/big/img_598
+2002/08/13/big/img_890
+2002/08/14/big/img_997
+2002/07/19/big/img_392
+2002/08/02/big/img_475
+2002/08/29/big/img_19038
+2002/07/29/big/img_538
+2002/07/29/big/img_502
+2002/08/02/big/img_364
+2002/08/31/big/img_17353
+2002/08/08/big/img_539
+2002/08/01/big/img_1449
+2002/07/22/big/img_363
+2002/08/02/big/img_90
+2002/09/01/big/img_16867
+2002/08/05/big/img_3371
+2002/07/30/big/img_342
+2002/08/07/big/img_1363
+2002/08/22/big/img_790
+2003/01/15/big/img_404
+2002/08/05/big/img_3447
+2002/09/01/big/img_16167
+2003/01/13/big/img_840
+2002/08/22/big/img_1001
+2002/08/09/big/img_431
+2002/07/27/big/img_618
+2002/07/31/big/img_741
+2002/07/30/big/img_964
+2002/07/25/big/img_86
+2002/07/29/big/img_275
+2002/08/21/big/img_921
+2002/07/26/big/img_892
+2002/08/21/big/img_663
+2003/01/13/big/img_567
+2003/01/14/big/img_719
+2002/07/28/big/img_251
+2003/01/15/big/img_1123
+2002/07/29/big/img_260
+2002/08/24/big/img_337
+2002/08/01/big/img_1914
+2002/08/13/big/img_373
+2003/01/15/big/img_589
+2002/08/13/big/img_906
+2002/07/26/big/img_270
+2002/08/26/big/img_313
+2002/08/25/big/img_694
+2003/01/01/big/img_327
+2002/07/23/big/img_261
+2002/08/26/big/img_642
+2002/07/29/big/img_918
+2002/07/23/big/img_455
+2002/07/24/big/img_612
+2002/07/23/big/img_534
+2002/07/19/big/img_534
+2002/07/19/big/img_726
+2002/08/01/big/img_2146
+2002/08/02/big/img_543
+2003/01/16/big/img_777
+2002/07/30/big/img_484
+2002/08/13/big/img_1161
+2002/07/21/big/img_390
+2002/08/06/big/img_2288
+2002/08/21/big/img_677
+2002/08/13/big/img_747
+2002/08/15/big/img_1248
+2002/07/31/big/img_416
+2002/09/02/big/img_15259
+2002/08/16/big/img_781
+2002/08/24/big/img_754
+2002/07/24/big/img_803
+2002/08/20/big/img_609
+2002/08/28/big/img_19571
+2002/09/01/big/img_16140
+2002/08/26/big/img_769
+2002/07/20/big/img_588
+2002/08/02/big/img_898
+2002/07/21/big/img_466
+2002/08/14/big/img_1046
+2002/07/25/big/img_212
+2002/08/26/big/img_353
+2002/08/19/big/img_810
+2002/08/31/big/img_17824
+2002/08/12/big/img_631
+2002/07/19/big/img_828
+2002/07/24/big/img_130
+2002/08/25/big/img_580
+2002/07/31/big/img_699
+2002/07/23/big/img_808
+2002/07/31/big/img_377
+2003/01/16/big/img_570
+2002/09/01/big/img_16254
+2002/07/21/big/img_471
+2002/08/01/big/img_1548
+2002/08/18/big/img_252
+2002/08/19/big/img_576
+2002/08/20/big/img_464
+2002/07/27/big/img_735
+2002/08/21/big/img_589
+2003/01/15/big/img_1192
+2002/08/09/big/img_302
+2002/07/31/big/img_594
+2002/08/23/big/img_19
+2002/08/29/big/img_18819
+2002/08/19/big/img_293
+2002/07/30/big/img_331
+2002/08/23/big/img_607
+2002/07/30/big/img_363
+2002/08/16/big/img_766
+2003/01/13/big/img_481
+2002/08/06/big/img_2515
+2002/09/02/big/img_15913
+2002/09/02/big/img_15827
+2002/09/02/big/img_15053
+2002/08/07/big/img_1576
+2002/07/23/big/img_268
+2002/08/21/big/img_152
+2003/01/15/big/img_578
+2002/07/21/big/img_589
+2002/07/20/big/img_548
+2002/08/27/big/img_19693
+2002/08/31/big/img_17252
+2002/07/31/big/img_138
+2002/07/23/big/img_372
+2002/08/16/big/img_695
+2002/07/27/big/img_287
+2002/08/15/big/img_315
+2002/08/10/big/img_361
+2002/07/29/big/img_899
+2002/08/13/big/img_771
+2002/08/21/big/img_92
+2003/01/15/big/img_425
+2003/01/16/big/img_450
+2002/09/01/big/img_16942
+2002/08/02/big/img_51
+2002/09/02/big/img_15379
+2002/08/24/big/img_147
+2002/08/30/big/img_18122
+2002/07/26/big/img_950
+2002/08/07/big/img_1400
+2002/08/17/big/img_468
+2002/08/15/big/img_470
+2002/07/30/big/img_318
+2002/07/22/big/img_644
+2002/08/27/big/img_19732
+2002/07/23/big/img_601
+2002/08/26/big/img_398
+2002/08/21/big/img_428
+2002/08/06/big/img_2119
+2002/08/29/big/img_19103
+2003/01/14/big/img_933
+2002/08/11/big/img_674
+2002/08/28/big/img_19420
+2002/08/03/big/img_418
+2002/08/17/big/img_312
+2002/07/25/big/img_1044
+2003/01/17/big/img_671
+2002/08/30/big/img_18297
+2002/07/25/big/img_755
+2002/07/23/big/img_471
+2002/08/21/big/img_39
+2002/07/26/big/img_699
+2003/01/14/big/img_33
+2002/07/31/big/img_411
+2002/08/16/big/img_645
+2003/01/17/big/img_116
+2002/09/02/big/img_15903
+2002/08/20/big/img_120
+2002/08/22/big/img_176
+2002/07/29/big/img_1316
+2002/08/27/big/img_19914
+2002/07/22/big/img_719
+2002/08/28/big/img_19239
+2003/01/13/big/img_385
+2002/08/08/big/img_525
+2002/07/19/big/img_782
+2002/08/13/big/img_843
+2002/07/30/big/img_107
+2002/08/11/big/img_752
+2002/07/29/big/img_383
+2002/08/26/big/img_249
+2002/08/29/big/img_18860
+2002/07/30/big/img_70
+2002/07/26/big/img_194
+2002/08/15/big/img_530
+2002/08/08/big/img_816
+2002/07/31/big/img_286
+2003/01/13/big/img_294
+2002/07/31/big/img_251
+2002/07/24/big/img_13
+2002/08/31/big/img_17938
+2002/07/22/big/img_642
+2003/01/14/big/img_728
+2002/08/18/big/img_47
+2002/08/22/big/img_306
+2002/08/20/big/img_348
+2002/08/15/big/img_764
+2002/08/08/big/img_163
+2002/07/23/big/img_531
+2002/07/23/big/img_467
+2003/01/16/big/img_743
+2003/01/13/big/img_535
+2002/08/02/big/img_523
+2002/08/22/big/img_120
+2002/08/11/big/img_496
+2002/08/29/big/img_19075
+2002/08/08/big/img_465
+2002/08/09/big/img_790
+2002/08/19/big/img_588
+2002/08/23/big/img_407
+2003/01/17/big/img_435
+2002/08/24/big/img_398
+2002/08/27/big/img_19899
+2003/01/15/big/img_335
+2002/08/13/big/img_493
+2002/09/02/big/img_15460
+2002/07/31/big/img_470
+2002/08/05/big/img_3550
+2002/07/28/big/img_123
+2002/08/01/big/img_1498
+2002/08/04/big/img_504
+2003/01/17/big/img_427
+2002/08/27/big/img_19708
+2002/07/27/big/img_861
+2002/07/25/big/img_685
+2002/07/31/big/img_207
+2003/01/14/big/img_745
+2002/08/31/big/img_17756
+2002/08/24/big/img_288
+2002/08/18/big/img_181
+2002/08/10/big/img_520
+2002/08/25/big/img_705
+2002/08/23/big/img_226
+2002/08/04/big/img_727
+2002/07/24/big/img_625
+2002/08/28/big/img_19157
+2002/08/23/big/img_586
+2002/07/31/big/img_232
+2003/01/13/big/img_240
+2003/01/14/big/img_321
+2003/01/15/big/img_533
+2002/07/23/big/img_480
+2002/07/24/big/img_371
+2002/08/21/big/img_702
+2002/08/31/big/img_17075
+2002/09/02/big/img_15278
+2002/07/29/big/img_246
+2003/01/15/big/img_829
+2003/01/15/big/img_1213
+2003/01/16/big/img_441
+2002/08/14/big/img_921
+2002/07/23/big/img_425
+2002/08/15/big/img_296
+2002/07/19/big/img_135
+2002/07/26/big/img_402
+2003/01/17/big/img_88
+2002/08/20/big/img_872
+2002/08/13/big/img_1110
+2003/01/16/big/img_1040
+2002/07/23/big/img_9
+2002/08/13/big/img_700
+2002/08/16/big/img_371
+2002/08/27/big/img_19966
+2003/01/17/big/img_391
+2002/08/18/big/img_426
+2002/08/01/big/img_1618
+2002/07/21/big/img_754
+2003/01/14/big/img_1101
+2003/01/16/big/img_1022
+2002/07/22/big/img_275
+2002/08/24/big/img_86
+2002/08/17/big/img_582
+2003/01/15/big/img_765
+2003/01/17/big/img_449
+2002/07/28/big/img_265
+2003/01/13/big/img_552
+2002/07/28/big/img_115
+2003/01/16/big/img_56
+2002/08/02/big/img_1232
+2003/01/17/big/img_925
+2002/07/22/big/img_445
+2002/07/25/big/img_957
+2002/07/20/big/img_589
+2002/08/31/big/img_17107
+2002/07/29/big/img_483
+2002/08/14/big/img_1063
+2002/08/07/big/img_1545
+2002/08/14/big/img_680
+2002/09/01/big/img_16694
+2002/08/14/big/img_257
+2002/08/11/big/img_726
+2002/07/26/big/img_681
+2002/07/25/big/img_481
+2003/01/14/big/img_737
+2002/08/28/big/img_19480
+2003/01/16/big/img_362
+2002/08/27/big/img_19865
+2003/01/01/big/img_547
+2002/09/02/big/img_15074
+2002/08/01/big/img_1453
+2002/08/22/big/img_594
+2002/08/28/big/img_19263
+2002/08/13/big/img_478
+2002/07/29/big/img_1358
+2003/01/14/big/img_1022
+2002/08/16/big/img_450
+2002/08/02/big/img_159
+2002/07/26/big/img_781
+2003/01/13/big/img_601
+2002/08/20/big/img_407
+2002/08/15/big/img_468
+2002/08/31/big/img_17902
+2002/08/16/big/img_81
+2002/07/25/big/img_987
+2002/07/25/big/img_500
+2002/08/02/big/img_31
+2002/08/18/big/img_538
+2002/08/08/big/img_54
+2002/07/23/big/img_686
+2002/07/24/big/img_836
+2003/01/17/big/img_734
+2002/08/16/big/img_1055
+2003/01/16/big/img_521
+2002/07/25/big/img_612
+2002/08/22/big/img_778
+2002/08/03/big/img_251
+2002/08/12/big/img_436
+2002/08/23/big/img_705
+2002/07/28/big/img_243
+2002/07/25/big/img_1029
+2002/08/20/big/img_287
+2002/08/29/big/img_18739
+2002/08/05/big/img_3272
+2002/07/27/big/img_214
+2003/01/14/big/img_5
+2002/08/01/big/img_1380
+2002/08/29/big/img_19097
+2002/07/30/big/img_486
+2002/08/29/big/img_18707
+2002/08/10/big/img_559
+2002/08/15/big/img_365
+2002/08/09/big/img_525
+2002/08/10/big/img_689
+2002/07/25/big/img_502
+2002/08/03/big/img_667
+2002/08/10/big/img_855
+2002/08/10/big/img_706
+2002/08/18/big/img_603
+2003/01/16/big/img_1055
+2002/08/31/big/img_17890
+2002/08/15/big/img_761
+2003/01/15/big/img_489
+2002/08/26/big/img_351
+2002/08/01/big/img_1772
+2002/08/31/big/img_17729
+2002/07/25/big/img_609
+2003/01/13/big/img_539
+2002/07/27/big/img_686
+2002/07/31/big/img_311
+2002/08/22/big/img_799
+2003/01/16/big/img_936
+2002/08/31/big/img_17813
+2002/08/04/big/img_862
+2002/08/09/big/img_332
+2002/07/20/big/img_148
+2002/08/12/big/img_426
+2002/07/24/big/img_69
+2002/07/27/big/img_685
+2002/08/02/big/img_480
+2002/08/26/big/img_154
+2002/07/24/big/img_598
+2002/08/01/big/img_1881
+2002/08/20/big/img_667
+2003/01/14/big/img_495
+2002/07/21/big/img_744
+2002/07/30/big/img_150
+2002/07/23/big/img_924
+2002/08/08/big/img_272
+2002/07/23/big/img_310
+2002/07/25/big/img_1011
+2002/09/02/big/img_15725
+2002/07/19/big/img_814
+2002/08/20/big/img_936
+2002/07/25/big/img_85
+2002/08/24/big/img_662
+2002/08/09/big/img_495
+2003/01/15/big/img_196
+2002/08/16/big/img_707
+2002/08/28/big/img_19370
+2002/08/06/big/img_2366
+2002/08/06/big/img_3012
+2002/08/01/big/img_1452
+2002/07/31/big/img_742
+2002/07/27/big/img_914
+2003/01/13/big/img_290
+2002/07/31/big/img_288
+2002/08/02/big/img_171
+2002/08/22/big/img_191
+2002/07/27/big/img_1066
+2002/08/12/big/img_383
+2003/01/17/big/img_1018
+2002/08/01/big/img_1785
+2002/08/11/big/img_390
+2002/08/27/big/img_20037
+2002/08/12/big/img_38
+2003/01/15/big/img_103
+2002/08/26/big/img_31
+2002/08/18/big/img_660
+2002/07/22/big/img_694
+2002/08/15/big/img_24
+2002/07/27/big/img_1077
+2002/08/01/big/img_1943
+2002/07/22/big/img_292
+2002/09/01/big/img_16857
+2002/07/22/big/img_892
+2003/01/14/big/img_46
+2002/08/09/big/img_469
+2002/08/09/big/img_414
+2003/01/16/big/img_40
+2002/08/28/big/img_19231
+2002/07/27/big/img_978
+2002/07/23/big/img_475
+2002/07/25/big/img_92
+2002/08/09/big/img_799
+2002/07/25/big/img_491
+2002/08/03/big/img_654
+2003/01/15/big/img_687
+2002/08/11/big/img_478
+2002/08/07/big/img_1664
+2002/08/20/big/img_362
+2002/08/01/big/img_1298
+2003/01/13/big/img_500
+2002/08/06/big/img_2896
+2002/08/30/big/img_18529
+2002/08/16/big/img_1020
+2002/07/29/big/img_892
+2002/08/29/big/img_18726
+2002/07/21/big/img_453
+2002/08/17/big/img_437
+2002/07/19/big/img_665
+2002/07/22/big/img_440
+2002/07/19/big/img_582
+2002/07/21/big/img_233
+2003/01/01/big/img_82
+2002/07/25/big/img_341
+2002/07/29/big/img_864
+2002/08/02/big/img_276
+2002/08/29/big/img_18654
+2002/07/27/big/img_1024
+2002/08/19/big/img_373
+2003/01/15/big/img_241
+2002/07/25/big/img_84
+2002/08/13/big/img_834
+2002/08/10/big/img_511
+2002/08/01/big/img_1627
+2002/08/08/big/img_607
+2002/08/06/big/img_2083
+2002/08/01/big/img_1486
+2002/08/08/big/img_700
+2002/08/01/big/img_1954
+2002/08/21/big/img_54
+2002/07/30/big/img_847
+2002/08/28/big/img_19169
+2002/07/21/big/img_549
+2002/08/03/big/img_693
+2002/07/31/big/img_1002
+2003/01/14/big/img_1035
+2003/01/16/big/img_622
+2002/07/30/big/img_1201
+2002/08/10/big/img_444
+2002/07/31/big/img_374
+2002/08/21/big/img_301
+2002/08/13/big/img_1095
+2003/01/13/big/img_288
+2002/07/25/big/img_232
+2003/01/13/big/img_967
+2002/08/26/big/img_360
+2002/08/05/big/img_67
+2002/08/29/big/img_18969
+2002/07/28/big/img_16
+2002/08/16/big/img_515
+2002/07/20/big/img_708
+2002/08/18/big/img_178
+2003/01/15/big/img_509
+2002/07/25/big/img_430
+2002/08/21/big/img_738
+2002/08/16/big/img_886
+2002/09/02/big/img_15605
+2002/09/01/big/img_16242
+2002/08/24/big/img_711
+2002/07/25/big/img_90
+2002/08/09/big/img_491
+2002/07/30/big/img_534
+2003/01/13/big/img_474
+2002/08/25/big/img_510
+2002/08/15/big/img_555
+2002/08/02/big/img_775
+2002/07/23/big/img_975
+2002/08/19/big/img_229
+2003/01/17/big/img_860
+2003/01/02/big/img_10
+2002/07/23/big/img_542
+2002/08/06/big/img_2535
+2002/07/22/big/img_37
+2002/08/06/big/img_2342
+2002/08/25/big/img_515
+2002/08/25/big/img_336
+2002/08/18/big/img_837
+2002/08/21/big/img_616
+2003/01/17/big/img_24
+2002/07/26/big/img_936
+2002/08/14/big/img_896
+2002/07/29/big/img_465
+2002/07/31/big/img_543
+2002/08/01/big/img_1411
+2002/08/02/big/img_423
+2002/08/21/big/img_44
+2002/07/31/big/img_11
+2003/01/15/big/img_628
+2003/01/15/big/img_605
+2002/07/30/big/img_571
+2002/07/23/big/img_428
+2002/08/15/big/img_942
+2002/07/26/big/img_531
+2003/01/16/big/img_59
+2002/08/02/big/img_410
+2002/07/31/big/img_230
+2002/08/19/big/img_806
+2003/01/14/big/img_462
+2002/08/16/big/img_370
+2002/08/13/big/img_380
+2002/08/16/big/img_932
+2002/07/19/big/img_393
+2002/08/20/big/img_764
+2002/08/15/big/img_616
+2002/07/26/big/img_267
+2002/07/27/big/img_1069
+2002/08/14/big/img_1041
+2003/01/13/big/img_594
+2002/09/01/big/img_16845
+2002/08/09/big/img_229
+2003/01/16/big/img_639
+2002/08/19/big/img_398
+2002/08/18/big/img_978
+2002/08/24/big/img_296
+2002/07/29/big/img_415
+2002/07/30/big/img_923
+2002/08/18/big/img_575
+2002/08/22/big/img_182
+2002/07/25/big/img_806
+2002/07/22/big/img_49
+2002/07/29/big/img_989
+2003/01/17/big/img_789
+2003/01/15/big/img_503
+2002/09/01/big/img_16062
+2003/01/17/big/img_794
+2002/08/15/big/img_564
+2003/01/15/big/img_222
+2002/08/01/big/img_1656
+2003/01/13/big/img_432
+2002/07/19/big/img_426
+2002/08/17/big/img_244
+2002/08/13/big/img_805
+2002/09/02/big/img_15067
+2002/08/11/big/img_58
+2002/08/22/big/img_636
+2002/07/22/big/img_416
+2002/08/13/big/img_836
+2002/08/26/big/img_363
+2002/07/30/big/img_917
+2003/01/14/big/img_206
+2002/08/12/big/img_311
+2002/08/31/big/img_17623
+2002/07/29/big/img_661
+2003/01/13/big/img_417
+2002/08/02/big/img_463
+2002/08/02/big/img_669
+2002/08/26/big/img_670
+2002/08/02/big/img_375
+2002/07/19/big/img_209
+2002/08/08/big/img_115
+2002/08/21/big/img_399
+2002/08/20/big/img_911
+2002/08/07/big/img_1212
+2002/08/20/big/img_578
+2002/08/22/big/img_554
+2002/08/21/big/img_484
+2002/07/25/big/img_450
+2002/08/03/big/img_542
+2002/08/15/big/img_561
+2002/07/23/big/img_360
+2002/08/30/big/img_18137
+2002/07/25/big/img_250
+2002/08/03/big/img_647
+2002/08/20/big/img_375
+2002/08/14/big/img_387
+2002/09/01/big/img_16990
+2002/08/28/big/img_19341
+2003/01/15/big/img_239
+2002/08/20/big/img_528
+2002/08/12/big/img_130
+2002/09/02/big/img_15108
+2003/01/15/big/img_372
+2002/08/16/big/img_678
+2002/08/04/big/img_623
+2002/07/23/big/img_477
+2002/08/28/big/img_19590
+2003/01/17/big/img_978
+2002/09/01/big/img_16692
+2002/07/20/big/img_109
+2002/08/06/big/img_2660
+2003/01/14/big/img_464
+2002/08/09/big/img_618
+2002/07/22/big/img_722
+2002/08/25/big/img_419
+2002/08/03/big/img_314
+2002/08/25/big/img_40
+2002/07/27/big/img_430
+2002/08/10/big/img_569
+2002/08/23/big/img_398
+2002/07/23/big/img_893
+2002/08/16/big/img_261
+2002/08/06/big/img_2668
+2002/07/22/big/img_835
+2002/09/02/big/img_15093
+2003/01/16/big/img_65
+2002/08/21/big/img_448
+2003/01/14/big/img_351
+2003/01/17/big/img_133
+2002/07/28/big/img_493
+2003/01/15/big/img_640
+2002/09/01/big/img_16880
+2002/08/15/big/img_350
+2002/08/20/big/img_624
+2002/08/25/big/img_604
+2002/08/06/big/img_2200
+2002/08/23/big/img_290
+2002/08/13/big/img_1152
+2003/01/14/big/img_251
+2002/08/02/big/img_538
+2002/08/22/big/img_613
+2003/01/13/big/img_351
+2002/08/18/big/img_368
+2002/07/23/big/img_392
+2002/07/25/big/img_198
+2002/07/25/big/img_418
+2002/08/26/big/img_614
+2002/07/23/big/img_405
+2003/01/14/big/img_445
+2002/07/25/big/img_326
+2002/08/10/big/img_734
+2003/01/14/big/img_530
+2002/08/08/big/img_561
+2002/08/29/big/img_18990
+2002/08/10/big/img_576
+2002/07/29/big/img_1494
+2002/07/19/big/img_198
+2002/08/10/big/img_562
+2002/07/22/big/img_901
+2003/01/14/big/img_37
+2002/09/02/big/img_15629
+2003/01/14/big/img_58
+2002/08/01/big/img_1364
+2002/07/27/big/img_636
+2003/01/13/big/img_241
+2002/09/01/big/img_16988
+2003/01/13/big/img_560
+2002/08/09/big/img_533
+2002/07/31/big/img_249
+2003/01/17/big/img_1007
+2002/07/21/big/img_64
+2003/01/13/big/img_537
+2003/01/15/big/img_606
+2002/08/18/big/img_651
+2002/08/24/big/img_405
+2002/07/26/big/img_837
+2002/08/09/big/img_562
+2002/08/01/big/img_1983
+2002/08/03/big/img_514
+2002/07/29/big/img_314
+2002/08/12/big/img_493
+2003/01/14/big/img_121
+2003/01/14/big/img_479
+2002/08/04/big/img_410
+2002/07/22/big/img_607
+2003/01/17/big/img_417
+2002/07/20/big/img_547
+2002/08/13/big/img_396
+2002/08/31/big/img_17538
+2002/08/13/big/img_187
+2002/08/12/big/img_328
+2003/01/14/big/img_569
+2002/07/27/big/img_1081
+2002/08/14/big/img_504
+2002/08/23/big/img_785
+2002/07/26/big/img_339
+2002/08/07/big/img_1156
+2002/08/07/big/img_1456
+2002/08/23/big/img_378
+2002/08/27/big/img_19719
+2002/07/31/big/img_39
+2002/07/31/big/img_883
+2003/01/14/big/img_676
+2002/07/29/big/img_214
+2002/07/26/big/img_669
+2002/07/25/big/img_202
+2002/08/08/big/img_259
+2003/01/17/big/img_943
+2003/01/15/big/img_512
+2002/08/05/big/img_3295
+2002/08/27/big/img_19685
+2002/08/08/big/img_277
+2002/08/30/big/img_18154
+2002/07/22/big/img_663
+2002/08/29/big/img_18914
+2002/07/31/big/img_908
+2002/08/27/big/img_19926
+2003/01/13/big/img_791
+2003/01/15/big/img_827
+2002/08/18/big/img_878
+2002/08/14/big/img_670
+2002/07/20/big/img_182
+2002/08/15/big/img_291
+2002/08/06/big/img_2600
+2002/07/23/big/img_587
+2002/08/14/big/img_577
+2003/01/15/big/img_585
+2002/07/30/big/img_310
+2002/08/03/big/img_658
+2002/08/10/big/img_157
+2002/08/19/big/img_811
+2002/07/29/big/img_1318
+2002/08/04/big/img_104
+2002/07/30/big/img_332
+2002/07/24/big/img_789
+2002/07/29/big/img_516
+2002/07/23/big/img_843
+2002/08/01/big/img_1528
+2002/08/13/big/img_798
+2002/08/07/big/img_1729
+2002/08/28/big/img_19448
+2003/01/16/big/img_95
+2002/08/12/big/img_473
+2002/07/27/big/img_269
+2003/01/16/big/img_621
+2002/07/29/big/img_772
+2002/07/24/big/img_171
+2002/07/19/big/img_429
+2002/08/07/big/img_1933
+2002/08/27/big/img_19629
+2002/08/05/big/img_3688
+2002/08/07/big/img_1691
+2002/07/23/big/img_600
+2002/07/29/big/img_666
+2002/08/25/big/img_566
+2002/08/06/big/img_2659
+2002/08/29/big/img_18929
+2002/08/16/big/img_407
+2002/08/18/big/img_774
+2002/08/19/big/img_249
+2002/08/06/big/img_2427
+2002/08/29/big/img_18899
+2002/08/01/big/img_1818
+2002/07/31/big/img_108
+2002/07/29/big/img_500
+2002/08/11/big/img_115
+2002/07/19/big/img_521
+2002/08/02/big/img_1163
+2002/07/22/big/img_62
+2002/08/13/big/img_466
+2002/08/21/big/img_956
+2002/08/23/big/img_602
+2002/08/20/big/img_858
+2002/07/25/big/img_690
+2002/07/19/big/img_130
+2002/08/04/big/img_874
+2002/07/26/big/img_489
+2002/07/22/big/img_548
+2002/08/10/big/img_191
+2002/07/25/big/img_1051
+2002/08/18/big/img_473
+2002/08/12/big/img_755
+2002/08/18/big/img_413
+2002/08/08/big/img_1044
+2002/08/17/big/img_680
+2002/08/26/big/img_235
+2002/08/20/big/img_330
+2002/08/22/big/img_344
+2002/08/09/big/img_593
+2002/07/31/big/img_1006
+2002/08/14/big/img_337
+2002/08/16/big/img_728
+2002/07/24/big/img_834
+2002/08/04/big/img_552
+2002/09/02/big/img_15213
+2002/07/25/big/img_725
+2002/08/30/big/img_18290
+2003/01/01/big/img_475
+2002/07/27/big/img_1083
+2002/08/29/big/img_18955
+2002/08/31/big/img_17232
+2002/08/08/big/img_480
+2002/08/01/big/img_1311
+2002/07/30/big/img_745
+2002/08/03/big/img_649
+2002/08/12/big/img_193
+2002/07/29/big/img_228
+2002/07/25/big/img_836
+2002/08/20/big/img_400
+2002/07/30/big/img_507
+2002/09/02/big/img_15072
+2002/07/26/big/img_658
+2002/07/28/big/img_503
+2002/08/05/big/img_3814
+2002/08/24/big/img_745
+2003/01/13/big/img_817
+2002/08/08/big/img_579
+2002/07/22/big/img_251
+2003/01/13/big/img_689
+2002/07/25/big/img_407
+2002/08/13/big/img_1050
+2002/08/14/big/img_733
+2002/07/24/big/img_82
+2003/01/17/big/img_288
+2003/01/15/big/img_475
+2002/08/14/big/img_620
+2002/08/21/big/img_167
+2002/07/19/big/img_300
+2002/07/26/big/img_219
+2002/08/01/big/img_1468
+2002/07/23/big/img_260
+2002/08/09/big/img_555
+2002/07/19/big/img_160
+2002/08/02/big/img_1060
+2003/01/14/big/img_149
+2002/08/15/big/img_346
+2002/08/24/big/img_597
+2002/08/22/big/img_502
+2002/08/30/big/img_18228
+2002/07/21/big/img_766
+2003/01/15/big/img_841
+2002/07/24/big/img_516
+2002/08/02/big/img_265
+2002/08/15/big/img_1243
+2003/01/15/big/img_223
+2002/08/04/big/img_236
+2002/07/22/big/img_309
+2002/07/20/big/img_656
+2002/07/31/big/img_412
+2002/09/01/big/img_16462
+2003/01/16/big/img_431
+2002/07/22/big/img_793
+2002/08/15/big/img_877
+2002/07/26/big/img_282
+2002/07/25/big/img_529
+2002/08/24/big/img_613
+2003/01/17/big/img_700
+2002/08/06/big/img_2526
+2002/08/24/big/img_394
+2002/08/21/big/img_521
+2002/08/25/big/img_560
+2002/07/29/big/img_966
+2002/07/25/big/img_448
+2003/01/13/big/img_782
+2002/08/21/big/img_296
+2002/09/01/big/img_16755
+2002/08/05/big/img_3552
+2002/09/02/big/img_15823
+2003/01/14/big/img_193
+2002/07/21/big/img_159
+2002/08/02/big/img_564
+2002/08/16/big/img_300
+2002/07/19/big/img_269
+2002/08/13/big/img_676
+2002/07/28/big/img_57
+2002/08/05/big/img_3318
+2002/07/31/big/img_218
+2002/08/21/big/img_898
+2002/07/29/big/img_109
+2002/07/19/big/img_854
+2002/08/23/big/img_311
+2002/08/14/big/img_318
+2002/07/25/big/img_523
+2002/07/21/big/img_678
+2003/01/17/big/img_690
+2002/08/28/big/img_19503
+2002/08/18/big/img_251
+2002/08/22/big/img_672
+2002/08/20/big/img_663
+2002/08/02/big/img_148
+2002/09/02/big/img_15580
+2002/07/25/big/img_778
+2002/08/14/big/img_565
+2002/08/12/big/img_374
+2002/08/13/big/img_1018
+2002/08/20/big/img_474
+2002/08/25/big/img_33
+2002/08/02/big/img_1190
+2002/08/08/big/img_864
+2002/08/14/big/img_1071
+2002/08/30/big/img_18103
+2002/08/18/big/img_533
+2003/01/16/big/img_650
+2002/07/25/big/img_108
+2002/07/26/big/img_81
+2002/07/27/big/img_543
+2002/07/29/big/img_521
+2003/01/13/big/img_434
+2002/08/26/big/img_674
+2002/08/06/big/img_2932
+2002/08/07/big/img_1262
+2003/01/15/big/img_201
+2003/01/16/big/img_673
+2002/09/02/big/img_15988
+2002/07/29/big/img_1306
+2003/01/14/big/img_1072
+2002/08/30/big/img_18232
+2002/08/05/big/img_3711
+2002/07/23/big/img_775
+2002/08/01/big/img_16
+2003/01/16/big/img_630
+2002/08/22/big/img_695
+2002/08/14/big/img_51
+2002/08/14/big/img_782
+2002/08/24/big/img_742
+2003/01/14/big/img_512
+2003/01/15/big/img_1183
+2003/01/15/big/img_714
+2002/08/01/big/img_2078
+2002/07/31/big/img_682
+2002/09/02/big/img_15687
+2002/07/26/big/img_518
+2002/08/27/big/img_19676
+2002/09/02/big/img_15969
+2002/08/02/big/img_931
+2002/08/25/big/img_508
+2002/08/29/big/img_18616
+2002/07/22/big/img_839
+2002/07/28/big/img_313
+2003/01/14/big/img_155
+2002/08/02/big/img_1105
+2002/08/09/big/img_53
+2002/08/16/big/img_469
+2002/08/15/big/img_502
+2002/08/20/big/img_575
+2002/07/25/big/img_138
+2003/01/16/big/img_579
+2002/07/19/big/img_352
+2003/01/14/big/img_762
+2003/01/01/big/img_588
+2002/08/02/big/img_981
+2002/08/21/big/img_447
+2002/09/01/big/img_16151
+2003/01/14/big/img_769
+2002/08/23/big/img_461
+2002/08/17/big/img_240
+2002/09/02/big/img_15220
+2002/07/19/big/img_408
+2002/09/02/big/img_15496
+2002/07/29/big/img_758
+2002/08/28/big/img_19392
+2002/08/06/big/img_2723
+2002/08/31/big/img_17752
+2002/08/23/big/img_469
+2002/08/13/big/img_515
+2002/09/02/big/img_15551
+2002/08/03/big/img_462
+2002/07/24/big/img_613
+2002/07/22/big/img_61
+2002/08/08/big/img_171
+2002/08/21/big/img_177
+2003/01/14/big/img_105
+2002/08/02/big/img_1017
+2002/08/22/big/img_106
+2002/07/27/big/img_542
+2002/07/21/big/img_665
+2002/07/23/big/img_595
+2002/08/04/big/img_657
+2002/08/29/big/img_19002
+2003/01/15/big/img_550
+2002/08/14/big/img_662
+2002/07/20/big/img_425
+2002/08/30/big/img_18528
+2002/07/26/big/img_611
+2002/07/22/big/img_849
+2002/08/07/big/img_1655
+2002/08/21/big/img_638
+2003/01/17/big/img_732
+2003/01/01/big/img_496
+2002/08/18/big/img_713
+2002/08/08/big/img_109
+2002/07/27/big/img_1008
+2002/07/20/big/img_559
+2002/08/16/big/img_699
+2002/08/31/big/img_17702
+2002/07/31/big/img_1013
+2002/08/01/big/img_2027
+2002/08/02/big/img_1001
+2002/08/03/big/img_210
+2002/08/01/big/img_2087
+2003/01/14/big/img_199
+2002/07/29/big/img_48
+2002/07/19/big/img_727
+2002/08/09/big/img_249
+2002/08/04/big/img_632
+2002/08/22/big/img_620
+2003/01/01/big/img_457
+2002/08/05/big/img_3223
+2002/07/27/big/img_240
+2002/07/25/big/img_797
+2002/08/13/big/img_430
+2002/07/25/big/img_615
+2002/08/12/big/img_28
+2002/07/30/big/img_220
+2002/07/24/big/img_89
+2002/08/21/big/img_357
+2002/08/09/big/img_590
+2003/01/13/big/img_525
+2002/08/17/big/img_818
+2003/01/02/big/img_7
+2002/07/26/big/img_636
+2003/01/13/big/img_1122
+2002/07/23/big/img_810
+2002/08/20/big/img_888
+2002/07/27/big/img_3
+2002/08/15/big/img_451
+2002/09/02/big/img_15787
+2002/07/31/big/img_281
+2002/08/05/big/img_3274
+2002/08/07/big/img_1254
+2002/07/31/big/img_27
+2002/08/01/big/img_1366
+2002/07/30/big/img_182
+2002/08/27/big/img_19690
+2002/07/29/big/img_68
+2002/08/23/big/img_754
+2002/07/30/big/img_540
+2002/08/27/big/img_20063
+2002/08/14/big/img_471
+2002/08/02/big/img_615
+2002/07/30/big/img_186
+2002/08/25/big/img_150
+2002/07/27/big/img_626
+2002/07/20/big/img_225
+2003/01/15/big/img_1252
+2002/07/19/big/img_367
+2003/01/15/big/img_582
+2002/08/09/big/img_572
+2002/08/08/big/img_428
+2003/01/15/big/img_639
+2002/08/28/big/img_19245
+2002/07/24/big/img_321
+2002/08/02/big/img_662
+2002/08/08/big/img_1033
+2003/01/17/big/img_867
+2002/07/22/big/img_652
+2003/01/14/big/img_224
+2002/08/18/big/img_49
+2002/07/26/big/img_46
+2002/08/31/big/img_18021
+2002/07/25/big/img_151
+2002/08/23/big/img_540
+2002/08/25/big/img_693
+2002/07/23/big/img_340
+2002/07/28/big/img_117
+2002/09/02/big/img_15768
+2002/08/26/big/img_562
+2002/07/24/big/img_480
+2003/01/15/big/img_341
+2002/08/10/big/img_783
+2002/08/20/big/img_132
+2003/01/14/big/img_370
+2002/07/20/big/img_720
+2002/08/03/big/img_144
+2002/08/20/big/img_538
+2002/08/01/big/img_1745
+2002/08/11/big/img_683
+2002/08/03/big/img_328
+2002/08/10/big/img_793
+2002/08/14/big/img_689
+2002/08/02/big/img_162
+2003/01/17/big/img_411
+2002/07/31/big/img_361
+2002/08/15/big/img_289
+2002/08/08/big/img_254
+2002/08/15/big/img_996
+2002/08/20/big/img_785
+2002/07/24/big/img_511
+2002/08/06/big/img_2614
+2002/08/29/big/img_18733
+2002/08/17/big/img_78
+2002/07/30/big/img_378
+2002/08/31/big/img_17947
+2002/08/26/big/img_88
+2002/07/30/big/img_558
+2002/08/02/big/img_67
+2003/01/14/big/img_325
+2002/07/29/big/img_1357
+2002/07/19/big/img_391
+2002/07/30/big/img_307
+2003/01/13/big/img_219
+2002/07/24/big/img_807
+2002/08/23/big/img_543
+2002/08/29/big/img_18620
+2002/07/22/big/img_769
+2002/08/26/big/img_503
+2002/07/30/big/img_78
+2002/08/14/big/img_1036
+2002/08/09/big/img_58
+2002/07/24/big/img_616
+2002/08/02/big/img_464
+2002/07/26/big/img_576
+2002/07/22/big/img_273
+2003/01/16/big/img_470
+2002/07/29/big/img_329
+2002/07/30/big/img_1086
+2002/07/31/big/img_353
+2002/09/02/big/img_15275
+2003/01/17/big/img_555
+2002/08/26/big/img_212
+2002/08/01/big/img_1692
+2003/01/15/big/img_600
+2002/07/29/big/img_825
+2002/08/08/big/img_68
+2002/08/10/big/img_719
+2002/07/31/big/img_636
+2002/07/29/big/img_325
+2002/07/21/big/img_515
+2002/07/22/big/img_705
+2003/01/13/big/img_818
+2002/08/09/big/img_486
+2002/08/22/big/img_141
+2002/07/22/big/img_303
+2002/08/09/big/img_393
+2002/07/29/big/img_963
+2002/08/02/big/img_1215
+2002/08/19/big/img_674
+2002/08/12/big/img_690
+2002/08/21/big/img_637
+2002/08/21/big/img_841
+2002/08/24/big/img_71
+2002/07/25/big/img_596
+2002/07/24/big/img_864
+2002/08/18/big/img_293
+2003/01/14/big/img_657
+2002/08/15/big/img_411
+2002/08/16/big/img_348
+2002/08/05/big/img_3157
+2002/07/20/big/img_663
+2003/01/13/big/img_654
+2003/01/16/big/img_433
+2002/08/30/big/img_18200
+2002/08/12/big/img_226
+2003/01/16/big/img_491
+2002/08/08/big/img_666
+2002/07/19/big/img_576
+2003/01/15/big/img_776
+2003/01/16/big/img_899
+2002/07/19/big/img_397
+2002/08/14/big/img_44
+2003/01/15/big/img_762
+2002/08/02/big/img_982
+2002/09/02/big/img_15234
+2002/08/17/big/img_556
+2002/08/21/big/img_410
+2002/08/21/big/img_386
+2002/07/19/big/img_690
+2002/08/05/big/img_3052
+2002/08/14/big/img_219
+2002/08/16/big/img_273
+2003/01/15/big/img_752
+2002/08/08/big/img_184
+2002/07/31/big/img_743
+2002/08/23/big/img_338
+2003/01/14/big/img_1055
+2002/08/05/big/img_3405
+2003/01/15/big/img_17
+2002/08/03/big/img_141
+2002/08/14/big/img_549
+2002/07/27/big/img_1034
+2002/07/31/big/img_932
+2002/08/30/big/img_18487
+2002/09/02/big/img_15814
+2002/08/01/big/img_2086
+2002/09/01/big/img_16535
+2002/07/22/big/img_500
+2003/01/13/big/img_400
+2002/08/25/big/img_607
+2002/08/30/big/img_18384
+2003/01/14/big/img_951
+2002/08/13/big/img_1150
+2002/08/08/big/img_1022
+2002/08/10/big/img_428
+2002/08/28/big/img_19242
+2002/08/05/big/img_3098
+2002/07/23/big/img_400
+2002/08/26/big/img_365
+2002/07/20/big/img_318
+2002/08/13/big/img_740
+2003/01/16/big/img_37
+2002/08/26/big/img_274
+2002/08/02/big/img_205
+2002/08/21/big/img_695
+2002/08/06/big/img_2289
+2002/08/20/big/img_794
+2002/08/18/big/img_438
+2002/08/07/big/img_1380
+2002/08/02/big/img_737
+2002/08/07/big/img_1651
+2002/08/15/big/img_1238
+2002/08/01/big/img_1681
+2002/08/06/big/img_3017
+2002/07/23/big/img_706
+2002/07/31/big/img_392
+2002/08/09/big/img_539
+2002/07/29/big/img_835
+2002/08/26/big/img_723
+2002/08/28/big/img_19235
+2003/01/16/big/img_353
+2002/08/10/big/img_150
+2002/08/29/big/img_19025
+2002/08/21/big/img_310
+2002/08/10/big/img_823
+2002/07/26/big/img_981
+2002/08/11/big/img_288
+2002/08/19/big/img_534
+2002/08/21/big/img_300
+2002/07/31/big/img_49
+2002/07/30/big/img_469
+2002/08/28/big/img_19197
+2002/08/25/big/img_205
+2002/08/10/big/img_390
+2002/08/23/big/img_291
+2002/08/26/big/img_230
+2002/08/18/big/img_76
+2002/07/23/big/img_409
+2002/08/14/big/img_1053
+2003/01/14/big/img_291
+2002/08/10/big/img_503
+2002/08/27/big/img_19928
+2002/08/03/big/img_563
+2002/08/17/big/img_250
+2002/08/06/big/img_2381
+2002/08/17/big/img_948
+2002/08/06/big/img_2710
+2002/07/22/big/img_696
+2002/07/31/big/img_670
+2002/08/12/big/img_594
+2002/07/29/big/img_624
+2003/01/17/big/img_934
+2002/08/03/big/img_584
+2002/08/22/big/img_1003
+2002/08/05/big/img_3396
+2003/01/13/big/img_570
+2002/08/02/big/img_219
+2002/09/02/big/img_15774
+2002/08/16/big/img_818
+2002/08/23/big/img_402
+2003/01/14/big/img_552
+2002/07/29/big/img_71
+2002/08/05/big/img_3592
+2002/08/16/big/img_80
+2002/07/27/big/img_672
+2003/01/13/big/img_470
+2003/01/16/big/img_702
+2002/09/01/big/img_16130
+2002/08/08/big/img_240
+2002/09/01/big/img_16338
+2002/07/26/big/img_312
+2003/01/14/big/img_538
+2002/07/20/big/img_695
+2002/08/30/big/img_18098
+2002/08/25/big/img_259
+2002/08/16/big/img_1042
+2002/08/09/big/img_837
+2002/08/31/big/img_17760
+2002/07/31/big/img_14
+2002/08/09/big/img_361
+2003/01/16/big/img_107
+2002/08/14/big/img_124
+2002/07/19/big/img_463
+2003/01/15/big/img_275
+2002/07/25/big/img_1151
+2002/07/29/big/img_1501
+2002/08/27/big/img_19889
+2002/08/29/big/img_18603
+2003/01/17/big/img_601
+2002/08/25/big/img_355
+2002/08/08/big/img_297
+2002/08/20/big/img_290
+2002/07/31/big/img_195
+2003/01/01/big/img_336
+2002/08/18/big/img_369
+2002/07/25/big/img_621
+2002/08/11/big/img_508
+2003/01/14/big/img_458
+2003/01/15/big/img_795
+2002/08/12/big/img_498
+2002/08/01/big/img_1734
+2002/08/02/big/img_246
+2002/08/16/big/img_565
+2002/08/11/big/img_475
+2002/08/22/big/img_408
+2002/07/28/big/img_78
+2002/07/21/big/img_81
+2003/01/14/big/img_697
+2002/08/14/big/img_661
+2002/08/15/big/img_507
+2002/08/19/big/img_55
+2002/07/22/big/img_152
+2003/01/14/big/img_470
+2002/08/03/big/img_379
+2002/08/22/big/img_506
+2003/01/16/big/img_966
+2002/08/18/big/img_698
+2002/08/24/big/img_528
+2002/08/23/big/img_10
+2002/08/01/big/img_1655
+2002/08/22/big/img_953
+2002/07/19/big/img_630
+2002/07/22/big/img_889
+2002/08/16/big/img_351
+2003/01/16/big/img_83
+2002/07/19/big/img_805
+2002/08/14/big/img_704
+2002/07/19/big/img_389
+2002/08/31/big/img_17765
+2002/07/29/big/img_606
+2003/01/17/big/img_939
+2002/09/02/big/img_15081
+2002/08/21/big/img_181
+2002/07/29/big/img_1321
+2002/07/21/big/img_497
+2002/07/20/big/img_539
+2002/08/24/big/img_119
+2002/08/01/big/img_1281
+2002/07/26/big/img_207
+2002/07/26/big/img_432
+2002/07/27/big/img_1006
+2002/08/05/big/img_3087
+2002/08/14/big/img_252
+2002/08/14/big/img_798
+2002/07/24/big/img_538
+2002/09/02/big/img_15507
+2002/08/08/big/img_901
+2003/01/14/big/img_557
+2002/08/07/big/img_1819
+2002/08/04/big/img_470
+2002/08/01/big/img_1504
+2002/08/16/big/img_1070
+2002/08/16/big/img_372
+2002/08/23/big/img_416
+2002/08/30/big/img_18208
+2002/08/01/big/img_2043
+2002/07/22/big/img_385
+2002/08/22/big/img_466
+2002/08/21/big/img_869
+2002/08/28/big/img_19429
+2002/08/02/big/img_770
+2002/07/23/big/img_433
+2003/01/14/big/img_13
+2002/07/27/big/img_953
+2002/09/02/big/img_15728
+2002/08/01/big/img_1361
+2002/08/29/big/img_18897
+2002/08/26/big/img_534
+2002/08/11/big/img_121
+2002/08/26/big/img_20130
+2002/07/31/big/img_363
+2002/08/13/big/img_978
+2002/07/25/big/img_835
+2002/08/02/big/img_906
+2003/01/14/big/img_548
+2002/07/30/big/img_80
+2002/07/26/big/img_982
+2003/01/16/big/img_99
+2002/08/19/big/img_362
+2002/08/24/big/img_376
+2002/08/07/big/img_1264
+2002/07/27/big/img_938
+2003/01/17/big/img_535
+2002/07/26/big/img_457
+2002/08/08/big/img_848
+2003/01/15/big/img_859
+2003/01/15/big/img_622
+2002/07/30/big/img_403
+2002/07/29/big/img_217
+2002/07/26/big/img_891
+2002/07/24/big/img_70
+2002/08/25/big/img_619
+2002/08/05/big/img_3375
+2002/08/01/big/img_2160
+2002/08/06/big/img_2227
+2003/01/14/big/img_117
+2002/08/14/big/img_227
+2002/08/13/big/img_565
+2002/08/19/big/img_625
+2002/08/03/big/img_812
+2002/07/24/big/img_41
+2002/08/16/big/img_235
+2002/07/29/big/img_759
+2002/07/21/big/img_433
+2002/07/29/big/img_190
+2003/01/16/big/img_435
+2003/01/13/big/img_708
+2002/07/30/big/img_57
+2002/08/22/big/img_162
+2003/01/01/big/img_558
+2003/01/15/big/img_604
+2002/08/16/big/img_935
+2002/08/20/big/img_394
+2002/07/28/big/img_465
+2002/09/02/big/img_15534
+2002/08/16/big/img_87
+2002/07/22/big/img_469
+2002/08/12/big/img_245
+2003/01/13/big/img_236
+2002/08/06/big/img_2736
+2002/08/03/big/img_348
+2003/01/14/big/img_218
+2002/07/26/big/img_232
+2003/01/15/big/img_244
+2002/07/25/big/img_1121
+2002/08/01/big/img_1484
+2002/07/26/big/img_541
+2002/08/07/big/img_1244
+2002/07/31/big/img_3
+2002/08/30/big/img_18437
+2002/08/29/big/img_19094
+2002/08/01/big/img_1355
+2002/08/19/big/img_338
+2002/07/19/big/img_255
+2002/07/21/big/img_76
+2002/08/25/big/img_199
+2002/08/12/big/img_740
+2002/07/30/big/img_852
+2002/08/15/big/img_599
+2002/08/23/big/img_254
+2002/08/19/big/img_125
+2002/07/24/big/img_2
+2002/08/04/big/img_145
+2002/08/05/big/img_3137
+2002/07/28/big/img_463
+2003/01/14/big/img_801
+2002/07/23/big/img_366
+2002/08/26/big/img_600
+2002/08/26/big/img_649
+2002/09/02/big/img_15849
+2002/07/26/big/img_248
+2003/01/13/big/img_200
+2002/08/07/big/img_1794
+2002/08/31/big/img_17270
+2002/08/23/big/img_608
+2003/01/13/big/img_837
+2002/08/23/big/img_581
+2002/08/20/big/img_754
+2002/08/18/big/img_183
+2002/08/20/big/img_328
+2002/07/22/big/img_494
+2002/07/29/big/img_399
+2002/08/28/big/img_19284
+2002/08/08/big/img_566
+2002/07/25/big/img_376
+2002/07/23/big/img_138
+2002/07/25/big/img_435
+2002/08/17/big/img_685
+2002/07/19/big/img_90
+2002/07/20/big/img_716
+2002/08/31/big/img_17458
+2002/08/26/big/img_461
+2002/07/25/big/img_355
+2002/08/06/big/img_2152
+2002/07/27/big/img_932
+2002/07/23/big/img_232
+2002/08/08/big/img_1020
+2002/07/31/big/img_366
+2002/08/06/big/img_2667
+2002/08/21/big/img_465
+2002/08/15/big/img_305
+2002/08/02/big/img_247
+2002/07/28/big/img_46
+2002/08/27/big/img_19922
+2002/08/23/big/img_643
+2003/01/13/big/img_624
+2002/08/23/big/img_625
+2002/08/05/big/img_3787
+2003/01/13/big/img_627
+2002/09/01/big/img_16381
+2002/08/05/big/img_3668
+2002/07/21/big/img_535
+2002/08/27/big/img_19680
+2002/07/22/big/img_413
+2002/07/29/big/img_481
+2003/01/15/big/img_496
+2002/07/23/big/img_701
+2002/08/29/big/img_18670
+2002/07/28/big/img_319
+2003/01/14/big/img_517
+2002/07/26/big/img_256
+2003/01/16/big/img_593
+2002/07/30/big/img_956
+2002/07/30/big/img_667
+2002/07/25/big/img_100
+2002/08/11/big/img_570
+2002/07/26/big/img_745
+2002/08/04/big/img_834
+2002/08/25/big/img_521
+2002/08/01/big/img_2148
+2002/09/02/big/img_15183
+2002/08/22/big/img_514
+2002/08/23/big/img_477
+2002/07/23/big/img_336
+2002/07/26/big/img_481
+2002/08/20/big/img_409
+2002/07/23/big/img_918
+2002/08/09/big/img_474
+2002/08/02/big/img_929
+2002/08/31/big/img_17932
+2002/08/19/big/img_161
+2002/08/09/big/img_667
+2002/07/31/big/img_805
+2002/09/02/big/img_15678
+2002/08/31/big/img_17509
+2002/08/29/big/img_18998
+2002/07/23/big/img_301
+2002/08/07/big/img_1612
+2002/08/06/big/img_2472
+2002/07/23/big/img_466
+2002/08/27/big/img_19634
+2003/01/16/big/img_16
+2002/08/14/big/img_193
+2002/08/21/big/img_340
+2002/08/27/big/img_19799
+2002/08/01/big/img_1345
+2002/08/07/big/img_1448
+2002/08/11/big/img_324
+2003/01/16/big/img_754
+2002/08/13/big/img_418
+2003/01/16/big/img_544
+2002/08/19/big/img_135
+2002/08/10/big/img_455
+2002/08/10/big/img_693
+2002/08/31/big/img_17967
+2002/08/28/big/img_19229
+2002/08/04/big/img_811
+2002/09/01/big/img_16225
+2003/01/16/big/img_428
+2002/09/02/big/img_15295
+2002/07/26/big/img_108
+2002/07/21/big/img_477
+2002/08/07/big/img_1354
+2002/08/23/big/img_246
+2002/08/16/big/img_652
+2002/07/27/big/img_553
+2002/07/31/big/img_346
+2002/08/04/big/img_537
+2002/08/08/big/img_498
+2002/08/29/big/img_18956
+2003/01/13/big/img_922
+2002/08/31/big/img_17425
+2002/07/26/big/img_438
+2002/08/19/big/img_185
+2003/01/16/big/img_33
+2002/08/10/big/img_252
+2002/07/29/big/img_598
+2002/08/27/big/img_19820
+2002/08/06/big/img_2664
+2002/08/20/big/img_705
+2003/01/14/big/img_816
+2002/08/03/big/img_552
+2002/07/25/big/img_561
+2002/07/25/big/img_934
+2002/08/01/big/img_1893
+2003/01/14/big/img_746
+2003/01/16/big/img_519
+2002/08/03/big/img_681
+2002/07/24/big/img_808
+2002/08/14/big/img_803
+2002/08/25/big/img_155
+2002/07/30/big/img_1107
+2002/08/29/big/img_18882
+2003/01/15/big/img_598
+2002/08/19/big/img_122
+2002/07/30/big/img_428
+2002/07/24/big/img_684
+2002/08/22/big/img_192
+2002/08/22/big/img_543
+2002/08/07/big/img_1318
+2002/08/18/big/img_25
+2002/07/26/big/img_583
+2002/07/20/big/img_464
+2002/08/19/big/img_664
+2002/08/24/big/img_861
+2002/09/01/big/img_16136
+2002/08/22/big/img_400
+2002/08/12/big/img_445
+2003/01/14/big/img_174
+2002/08/27/big/img_19677
+2002/08/31/big/img_17214
+2002/08/30/big/img_18175
+2003/01/17/big/img_402
+2002/08/06/big/img_2396
+2002/08/18/big/img_448
+2002/08/21/big/img_165
+2002/08/31/big/img_17609
+2003/01/01/big/img_151
+2002/08/26/big/img_372
+2002/09/02/big/img_15994
+2002/07/26/big/img_660
+2002/09/02/big/img_15197
+2002/07/29/big/img_258
+2002/08/30/big/img_18525
+2003/01/13/big/img_368
+2002/07/29/big/img_1538
+2002/07/21/big/img_787
+2002/08/18/big/img_152
+2002/08/06/big/img_2379
+2003/01/17/big/img_864
+2002/08/27/big/img_19998
+2002/08/01/big/img_1634
+2002/07/25/big/img_414
+2002/08/22/big/img_627
+2002/08/07/big/img_1669
+2002/08/16/big/img_1052
+2002/08/31/big/img_17796
+2002/08/18/big/img_199
+2002/09/02/big/img_15147
+2002/08/09/big/img_460
+2002/08/14/big/img_581
+2002/08/30/big/img_18286
+2002/07/26/big/img_337
+2002/08/18/big/img_589
+2003/01/14/big/img_866
+2002/07/20/big/img_624
+2002/08/01/big/img_1801
+2002/07/24/big/img_683
+2002/08/09/big/img_725
+2003/01/14/big/img_34
+2002/07/30/big/img_144
+2002/07/30/big/img_706
+2002/08/08/big/img_394
+2002/08/19/big/img_619
+2002/08/06/big/img_2703
+2002/08/29/big/img_19034
+2002/07/24/big/img_67
+2002/08/27/big/img_19841
+2002/08/19/big/img_427
+2003/01/14/big/img_333
+2002/09/01/big/img_16406
+2002/07/19/big/img_882
+2002/08/17/big/img_238
+2003/01/14/big/img_739
+2002/07/22/big/img_151
+2002/08/21/big/img_743
+2002/07/25/big/img_1048
+2002/07/30/big/img_395
+2003/01/13/big/img_584
+2002/08/13/big/img_742
+2002/08/13/big/img_1168
+2003/01/14/big/img_147
+2002/07/26/big/img_803
+2002/08/05/big/img_3298
+2002/08/07/big/img_1451
+2002/08/16/big/img_424
+2002/07/29/big/img_1069
+2002/09/01/big/img_16735
+2002/07/21/big/img_637
+2003/01/14/big/img_585
+2002/08/02/big/img_358
+2003/01/13/big/img_358
+2002/08/14/big/img_198
+2002/08/17/big/img_935
+2002/08/04/big/img_42
+2002/08/30/big/img_18245
+2002/07/25/big/img_158
+2002/08/22/big/img_744
+2002/08/06/big/img_2291
+2002/08/05/big/img_3044
+2002/07/30/big/img_272
+2002/08/23/big/img_641
+2002/07/24/big/img_797
+2002/07/30/big/img_392
+2003/01/14/big/img_447
+2002/07/31/big/img_898
+2002/08/06/big/img_2812
+2002/08/13/big/img_564
+2002/07/22/big/img_43
+2002/07/26/big/img_634
+2002/07/19/big/img_843
+2002/08/26/big/img_58
+2002/07/21/big/img_375
+2002/08/25/big/img_729
+2002/07/19/big/img_561
+2003/01/15/big/img_884
+2002/07/25/big/img_891
+2002/08/09/big/img_558
+2002/08/26/big/img_587
+2002/08/13/big/img_1146
+2002/09/02/big/img_15153
+2002/07/26/big/img_316
+2002/08/01/big/img_1940
+2002/08/26/big/img_90
+2003/01/13/big/img_347
+2002/07/25/big/img_520
+2002/08/29/big/img_18718
+2002/08/28/big/img_19219
+2002/08/13/big/img_375
+2002/07/20/big/img_719
+2002/08/31/big/img_17431
+2002/07/28/big/img_192
+2002/08/26/big/img_259
+2002/08/18/big/img_484
+2002/07/29/big/img_580
+2002/07/26/big/img_84
+2002/08/02/big/img_302
+2002/08/31/big/img_17007
+2003/01/15/big/img_543
+2002/09/01/big/img_16488
+2002/08/22/big/img_798
+2002/07/30/big/img_383
+2002/08/04/big/img_668
+2002/08/13/big/img_156
+2002/08/07/big/img_1353
+2002/07/25/big/img_281
+2003/01/14/big/img_587
+2003/01/15/big/img_524
+2002/08/19/big/img_726
+2002/08/21/big/img_709
+2002/08/26/big/img_465
+2002/07/31/big/img_658
+2002/08/28/big/img_19148
+2002/07/23/big/img_423
+2002/08/16/big/img_758
+2002/08/22/big/img_523
+2002/08/16/big/img_591
+2002/08/23/big/img_845
+2002/07/26/big/img_678
+2002/08/09/big/img_806
+2002/08/06/big/img_2369
+2002/07/29/big/img_457
+2002/07/19/big/img_278
+2002/08/30/big/img_18107
+2002/07/26/big/img_444
+2002/08/20/big/img_278
+2002/08/26/big/img_92
+2002/08/26/big/img_257
+2002/07/25/big/img_266
+2002/08/05/big/img_3829
+2002/07/26/big/img_757
+2002/07/29/big/img_1536
+2002/08/09/big/img_472
+2003/01/17/big/img_480
+2002/08/28/big/img_19355
+2002/07/26/big/img_97
+2002/08/06/big/img_2503
+2002/07/19/big/img_254
+2002/08/01/big/img_1470
+2002/08/21/big/img_42
+2002/08/20/big/img_217
+2002/08/06/big/img_2459
+2002/07/19/big/img_552
+2002/08/13/big/img_717
+2002/08/12/big/img_586
+2002/08/20/big/img_411
+2003/01/13/big/img_768
+2002/08/07/big/img_1747
+2002/08/15/big/img_385
+2002/08/01/big/img_1648
+2002/08/15/big/img_311
+2002/08/21/big/img_95
+2002/08/09/big/img_108
+2002/08/21/big/img_398
+2002/08/17/big/img_340
+2002/08/14/big/img_474
+2002/08/13/big/img_294
+2002/08/24/big/img_840
+2002/08/09/big/img_808
+2002/08/23/big/img_491
+2002/07/28/big/img_33
+2003/01/13/big/img_664
+2002/08/02/big/img_261
+2002/08/09/big/img_591
+2002/07/26/big/img_309
+2003/01/14/big/img_372
+2002/08/19/big/img_581
+2002/08/19/big/img_168
+2002/08/26/big/img_422
+2002/07/24/big/img_106
+2002/08/01/big/img_1936
+2002/08/05/big/img_3764
+2002/08/21/big/img_266
+2002/08/31/big/img_17968
+2002/08/01/big/img_1941
+2002/08/15/big/img_550
+2002/08/14/big/img_13
+2002/07/30/big/img_171
+2003/01/13/big/img_490
+2002/07/25/big/img_427
+2002/07/19/big/img_770
+2002/08/12/big/img_759
+2003/01/15/big/img_1360
+2002/08/05/big/img_3692
+2003/01/16/big/img_30
+2002/07/25/big/img_1026
+2002/07/22/big/img_288
+2002/08/29/big/img_18801
+2002/07/24/big/img_793
+2002/08/13/big/img_178
+2002/08/06/big/img_2322
+2003/01/14/big/img_560
+2002/08/18/big/img_408
+2003/01/16/big/img_915
+2003/01/16/big/img_679
+2002/08/07/big/img_1552
+2002/08/29/big/img_19050
+2002/08/01/big/img_2172
+2002/07/31/big/img_30
+2002/07/30/big/img_1019
+2002/07/30/big/img_587
+2003/01/13/big/img_773
+2002/07/30/big/img_410
+2002/07/28/big/img_65
+2002/08/05/big/img_3138
+2002/07/23/big/img_541
+2002/08/22/big/img_963
+2002/07/27/big/img_657
+2002/07/30/big/img_1051
+2003/01/16/big/img_150
+2002/07/31/big/img_519
+2002/08/01/big/img_1961
+2002/08/05/big/img_3752
+2002/07/23/big/img_631
+2003/01/14/big/img_237
+2002/07/28/big/img_21
+2002/07/22/big/img_813
+2002/08/05/big/img_3563
+2003/01/17/big/img_620
+2002/07/19/big/img_523
+2002/07/30/big/img_904
+2002/08/29/big/img_18642
+2002/08/11/big/img_492
+2002/08/01/big/img_2130
+2002/07/25/big/img_618
+2002/08/17/big/img_305
+2003/01/16/big/img_520
+2002/07/26/big/img_495
+2002/08/17/big/img_164
+2002/08/03/big/img_440
+2002/07/24/big/img_441
+2002/08/06/big/img_2146
+2002/08/11/big/img_558
+2002/08/02/big/img_545
+2002/08/31/big/img_18090
+2003/01/01/big/img_136
+2002/07/25/big/img_1099
+2003/01/13/big/img_728
+2003/01/16/big/img_197
+2002/07/26/big/img_651
+2002/08/11/big/img_676
+2003/01/15/big/img_10
+2002/08/21/big/img_250
+2002/08/14/big/img_325
+2002/08/04/big/img_390
+2002/07/24/big/img_554
+2003/01/16/big/img_333
+2002/07/31/big/img_922
+2002/09/02/big/img_15586
+2003/01/16/big/img_184
+2002/07/22/big/img_766
+2002/07/21/big/img_608
+2002/08/07/big/img_1578
+2002/08/17/big/img_961
+2002/07/27/big/img_324
+2002/08/05/big/img_3765
+2002/08/23/big/img_462
+2003/01/16/big/img_382
+2002/08/27/big/img_19838
+2002/08/01/big/img_1505
+2002/08/21/big/img_662
+2002/08/14/big/img_605
+2002/08/19/big/img_816
+2002/07/29/big/img_136
+2002/08/20/big/img_719
+2002/08/06/big/img_2826
+2002/08/10/big/img_630
+2003/01/17/big/img_973
+2002/08/14/big/img_116
+2002/08/02/big/img_666
+2002/08/21/big/img_710
+2002/08/05/big/img_55
+2002/07/31/big/img_229
+2002/08/01/big/img_1549
+2002/07/23/big/img_432
+2002/07/21/big/img_430
+2002/08/21/big/img_549
+2002/08/08/big/img_985
+2002/07/20/big/img_610
+2002/07/23/big/img_978
+2002/08/23/big/img_219
+2002/07/25/big/img_175
+2003/01/15/big/img_230
+2002/08/23/big/img_385
+2002/07/31/big/img_879
+2002/08/12/big/img_495
+2002/08/22/big/img_499
+2002/08/30/big/img_18322
+2002/08/15/big/img_795
+2002/08/13/big/img_835
+2003/01/17/big/img_930
+2002/07/30/big/img_873
+2002/08/11/big/img_257
+2002/07/31/big/img_593
+2002/08/21/big/img_916
+2003/01/13/big/img_814
+2002/07/25/big/img_722
+2002/08/16/big/img_379
+2002/07/31/big/img_497
+2002/07/22/big/img_602
+2002/08/21/big/img_642
+2002/08/21/big/img_614
+2002/08/23/big/img_482
+2002/07/29/big/img_603
+2002/08/13/big/img_705
+2002/07/23/big/img_833
+2003/01/14/big/img_511
+2002/07/24/big/img_376
+2002/08/17/big/img_1030
+2002/08/05/big/img_3576
+2002/08/16/big/img_540
+2002/07/22/big/img_630
+2002/08/10/big/img_180
+2002/08/14/big/img_905
+2002/08/29/big/img_18777
+2002/08/22/big/img_693
+2003/01/16/big/img_933
+2002/08/20/big/img_555
+2002/08/15/big/img_549
+2003/01/14/big/img_830
+2003/01/16/big/img_64
+2002/08/27/big/img_19670
+2002/08/22/big/img_729
+2002/07/27/big/img_981
+2002/08/09/big/img_458
+2003/01/17/big/img_884
+2002/07/25/big/img_639
+2002/08/31/big/img_18008
+2002/08/22/big/img_249
+2002/08/17/big/img_971
+2002/08/04/big/img_308
+2002/07/28/big/img_362
+2002/08/12/big/img_142
+2002/08/26/big/img_61
+2002/08/14/big/img_422
+2002/07/19/big/img_607
+2003/01/15/big/img_717
+2002/08/01/big/img_1475
+2002/08/29/big/img_19061
+2003/01/01/big/img_346
+2002/07/20/big/img_315
+2003/01/15/big/img_756
+2002/08/15/big/img_879
+2002/08/08/big/img_615
+2003/01/13/big/img_431
+2002/08/05/big/img_3233
+2002/08/24/big/img_526
+2003/01/13/big/img_717
+2002/09/01/big/img_16408
+2002/07/22/big/img_217
+2002/07/31/big/img_960
+2002/08/21/big/img_610
+2002/08/05/big/img_3753
+2002/08/03/big/img_151
+2002/08/21/big/img_267
+2002/08/01/big/img_2175
+2002/08/04/big/img_556
+2002/08/21/big/img_527
+2002/09/02/big/img_15800
+2002/07/27/big/img_156
+2002/07/20/big/img_590
+2002/08/15/big/img_700
+2002/08/08/big/img_444
+2002/07/25/big/img_94
+2002/07/24/big/img_778
+2002/08/14/big/img_694
+2002/07/20/big/img_666
+2002/08/02/big/img_200
+2002/08/02/big/img_578
+2003/01/17/big/img_332
+2002/09/01/big/img_16352
+2002/08/27/big/img_19668
+2002/07/23/big/img_823
+2002/08/13/big/img_431
+2003/01/16/big/img_463
+2002/08/27/big/img_19711
+2002/08/23/big/img_154
+2002/07/31/big/img_360
+2002/08/23/big/img_555
+2002/08/10/big/img_561
+2003/01/14/big/img_550
+2002/08/07/big/img_1370
+2002/07/30/big/img_1184
+2002/08/01/big/img_1445
+2002/08/23/big/img_22
+2002/07/30/big/img_606
+2003/01/17/big/img_271
+2002/08/31/big/img_17316
+2002/08/16/big/img_973
+2002/07/26/big/img_77
+2002/07/20/big/img_788
+2002/08/06/big/img_2426
+2002/08/07/big/img_1498
+2002/08/16/big/img_358
+2002/08/06/big/img_2851
+2002/08/12/big/img_359
+2002/08/01/big/img_1521
+2002/08/02/big/img_709
+2002/08/20/big/img_935
+2002/08/12/big/img_188
+2002/08/24/big/img_411
+2002/08/22/big/img_680
+2002/08/06/big/img_2480
+2002/07/20/big/img_627
+2002/07/30/big/img_214
+2002/07/25/big/img_354
+2002/08/02/big/img_636
+2003/01/15/big/img_661
+2002/08/07/big/img_1327
+2002/08/01/big/img_2108
+2002/08/31/big/img_17919
+2002/08/29/big/img_18768
+2002/08/05/big/img_3840
+2002/07/26/big/img_242
+2003/01/14/big/img_451
+2002/08/20/big/img_923
+2002/08/27/big/img_19908
+2002/08/16/big/img_282
+2002/08/19/big/img_440
+2003/01/01/big/img_230
+2002/08/08/big/img_212
+2002/07/20/big/img_443
+2002/08/25/big/img_635
+2003/01/13/big/img_1169
+2002/07/26/big/img_998
+2002/08/15/big/img_995
+2002/08/06/big/img_3002
+2002/07/29/big/img_460
+2003/01/14/big/img_925
+2002/07/23/big/img_539
+2002/08/16/big/img_694
+2003/01/13/big/img_459
+2002/07/23/big/img_249
+2002/08/20/big/img_539
+2002/08/04/big/img_186
+2002/08/26/big/img_264
+2002/07/22/big/img_704
+2002/08/25/big/img_277
+2002/08/22/big/img_988
+2002/07/29/big/img_504
+2002/08/05/big/img_3600
+2002/08/30/big/img_18380
+2003/01/14/big/img_937
+2002/08/21/big/img_254
+2002/08/10/big/img_130
+2002/08/20/big/img_339
+2003/01/14/big/img_428
+2002/08/20/big/img_889
+2002/08/31/big/img_17637
+2002/07/26/big/img_644
+2002/09/01/big/img_16776
+2002/08/06/big/img_2239
+2002/08/06/big/img_2646
+2003/01/13/big/img_491
+2002/08/10/big/img_579
+2002/08/21/big/img_713
+2002/08/22/big/img_482
+2002/07/22/big/img_167
+2002/07/24/big/img_539
+2002/08/14/big/img_721
+2002/07/25/big/img_389
+2002/09/01/big/img_16591
+2002/08/13/big/img_543
+2003/01/14/big/img_432
+2002/08/09/big/img_287
+2002/07/26/big/img_126
+2002/08/23/big/img_412
+2002/08/15/big/img_1034
+2002/08/28/big/img_19485
+2002/07/31/big/img_236
+2002/07/30/big/img_523
+2002/07/19/big/img_141
+2003/01/17/big/img_957
+2002/08/04/big/img_81
+2002/07/25/big/img_206
+2002/08/15/big/img_716
+2002/08/13/big/img_403
+2002/08/15/big/img_685
+2002/07/26/big/img_884
+2002/07/19/big/img_499
+2002/07/23/big/img_772
+2002/07/27/big/img_752
+2003/01/14/big/img_493
+2002/08/25/big/img_664
+2002/07/31/big/img_334
+2002/08/26/big/img_678
+2002/09/01/big/img_16541
+2003/01/14/big/img_347
+2002/07/23/big/img_187
+2002/07/30/big/img_1163
+2002/08/05/big/img_35
+2002/08/22/big/img_944
+2002/08/07/big/img_1239
+2002/07/29/big/img_1215
+2002/08/03/big/img_312
+2002/08/05/big/img_3523
+2002/07/29/big/img_218
+2002/08/13/big/img_672
+2002/08/16/big/img_205
+2002/08/17/big/img_594
+2002/07/29/big/img_1411
+2002/07/30/big/img_942
+2003/01/16/big/img_312
+2002/08/08/big/img_312
+2002/07/25/big/img_15
+2002/08/09/big/img_839
+2002/08/01/big/img_2069
+2002/08/31/big/img_17512
+2002/08/01/big/img_3
+2002/07/31/big/img_320
+2003/01/15/big/img_1265
+2002/08/14/big/img_563
+2002/07/31/big/img_167
+2002/08/20/big/img_374
+2002/08/13/big/img_406
+2002/08/08/big/img_625
+2002/08/02/big/img_314
+2002/08/27/big/img_19964
+2002/09/01/big/img_16670
+2002/07/31/big/img_599
+2002/08/29/big/img_18906
+2002/07/24/big/img_373
+2002/07/26/big/img_513
+2002/09/02/big/img_15497
+2002/08/19/big/img_117
+2003/01/01/big/img_158
+2002/08/24/big/img_178
+2003/01/13/big/img_935
+2002/08/13/big/img_609
+2002/08/30/big/img_18341
+2002/08/25/big/img_674
+2003/01/13/big/img_209
+2002/08/13/big/img_258
+2002/08/05/big/img_3543
+2002/08/07/big/img_1970
+2002/08/06/big/img_3004
+2003/01/17/big/img_487
+2002/08/24/big/img_873
+2002/08/29/big/img_18730
+2002/08/09/big/img_375
+2003/01/16/big/img_751
+2002/08/02/big/img_603
+2002/08/19/big/img_325
+2002/09/01/big/img_16420
+2002/08/05/big/img_3633
+2002/08/21/big/img_516
+2002/07/19/big/img_501
+2002/07/26/big/img_688
+2002/07/24/big/img_256
+2002/07/25/big/img_438
+2002/07/31/big/img_1017
+2002/08/22/big/img_512
+2002/07/21/big/img_543
+2002/08/08/big/img_223
+2002/08/19/big/img_189
+2002/08/12/big/img_630
+2002/07/30/big/img_958
+2002/07/28/big/img_208
+2002/08/31/big/img_17691
+2002/07/22/big/img_542
+2002/07/19/big/img_741
+2002/07/19/big/img_158
+2002/08/15/big/img_399
+2002/08/01/big/img_2159
+2002/08/14/big/img_455
+2002/08/17/big/img_1011
+2002/08/26/big/img_744
+2002/08/12/big/img_624
+2003/01/17/big/img_821
+2002/08/16/big/img_980
+2002/07/28/big/img_281
+2002/07/25/big/img_171
+2002/08/03/big/img_116
+2002/07/22/big/img_467
+2002/07/31/big/img_750
+2002/07/26/big/img_435
+2002/07/19/big/img_822
+2002/08/13/big/img_626
+2002/08/11/big/img_344
+2002/08/02/big/img_473
+2002/09/01/big/img_16817
+2002/08/01/big/img_1275
+2002/08/28/big/img_19270
+2002/07/23/big/img_607
+2002/08/09/big/img_316
+2002/07/29/big/img_626
+2002/07/24/big/img_824
+2002/07/22/big/img_342
+2002/08/08/big/img_794
+2002/08/07/big/img_1209
+2002/07/19/big/img_18
+2002/08/25/big/img_634
+2002/07/24/big/img_730
+2003/01/17/big/img_356
+2002/07/23/big/img_305
+2002/07/30/big/img_453
+2003/01/13/big/img_972
+2002/08/06/big/img_2610
+2002/08/29/big/img_18920
+2002/07/31/big/img_123
+2002/07/26/big/img_979
+2002/08/24/big/img_635
+2002/08/05/big/img_3704
+2002/08/07/big/img_1358
+2002/07/22/big/img_306
+2002/08/13/big/img_619
+2002/08/02/big/img_366
diff --git a/KAIR/retinaface/data_faces/__init__.py b/KAIR/retinaface/data_faces/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..ea50ebaf88d64e75f4960bc99b14f138a343e575
--- /dev/null
+++ b/KAIR/retinaface/data_faces/__init__.py
@@ -0,0 +1,3 @@
+from .wider_face import WiderFaceDetection, detection_collate
+from .data_augment import *
+from .config import *
diff --git a/KAIR/retinaface/data_faces/config.py b/KAIR/retinaface/data_faces/config.py
new file mode 100644
index 0000000000000000000000000000000000000000..e57cdc530e3d78c4aa6310985c90c5ee125f8f01
--- /dev/null
+++ b/KAIR/retinaface/data_faces/config.py
@@ -0,0 +1,42 @@
+# config.py
+
+cfg_mnet = {
+ 'name': 'mobilenet0.25',
+ 'min_sizes': [[16, 32], [64, 128], [256, 512]],
+ 'steps': [8, 16, 32],
+ 'variance': [0.1, 0.2],
+ 'clip': False,
+ 'loc_weight': 2.0,
+ 'gpu_train': True,
+ 'batch_size': 32,
+ 'ngpu': 1,
+ 'epoch': 250,
+ 'decay1': 190,
+ 'decay2': 220,
+ 'image_size': 640,
+ 'pretrain': False,
+ 'return_layers': {'stage1': 1, 'stage2': 2, 'stage3': 3},
+ 'in_channel': 32,
+ 'out_channel': 64
+}
+
+cfg_re50 = {
+ 'name': 'Resnet50',
+ 'min_sizes': [[16, 32], [64, 128], [256, 512]],
+ 'steps': [8, 16, 32],
+ 'variance': [0.1, 0.2],
+ 'clip': False,
+ 'loc_weight': 2.0,
+ 'gpu_train': True,
+ 'batch_size': 24,
+ 'ngpu': 4,
+ 'epoch': 100,
+ 'decay1': 70,
+ 'decay2': 90,
+ 'image_size': 840,
+ 'pretrain': False,
+ 'return_layers': {'layer2': 1, 'layer3': 2, 'layer4': 3},
+ 'in_channel': 256,
+ 'out_channel': 256
+}
+
diff --git a/KAIR/retinaface/data_faces/data_augment.py b/KAIR/retinaface/data_faces/data_augment.py
new file mode 100644
index 0000000000000000000000000000000000000000..882dc2bfbf51972899ce563874dad91217bfe35f
--- /dev/null
+++ b/KAIR/retinaface/data_faces/data_augment.py
@@ -0,0 +1,237 @@
+import cv2
+import numpy as np
+import random
+from utils_faces.box_utils import matrix_iof
+
+
+def _crop(image, boxes, labels, landm, img_dim):
+ height, width, _ = image.shape
+ pad_image_flag = True
+
+ for _ in range(250):
+ """
+ if random.uniform(0, 1) <= 0.2:
+ scale = 1.0
+ else:
+ scale = random.uniform(0.3, 1.0)
+ """
+ PRE_SCALES = [0.3, 0.45, 0.6, 0.8, 1.0]
+ scale = random.choice(PRE_SCALES)
+ short_side = min(width, height)
+ w = int(scale * short_side)
+ h = w
+
+ if width == w:
+ l = 0
+ else:
+ l = random.randrange(width - w)
+ if height == h:
+ t = 0
+ else:
+ t = random.randrange(height - h)
+ roi = np.array((l, t, l + w, t + h))
+
+ value = matrix_iof(boxes, roi[np.newaxis])
+ flag = (value >= 1)
+ if not flag.any():
+ continue
+
+ centers = (boxes[:, :2] + boxes[:, 2:]) / 2
+ mask_a = np.logical_and(roi[:2] < centers, centers < roi[2:]).all(axis=1)
+ boxes_t = boxes[mask_a].copy()
+ labels_t = labels[mask_a].copy()
+ landms_t = landm[mask_a].copy()
+ landms_t = landms_t.reshape([-1, 5, 2])
+
+ if boxes_t.shape[0] == 0:
+ continue
+
+ image_t = image[roi[1]:roi[3], roi[0]:roi[2]]
+
+ boxes_t[:, :2] = np.maximum(boxes_t[:, :2], roi[:2])
+ boxes_t[:, :2] -= roi[:2]
+ boxes_t[:, 2:] = np.minimum(boxes_t[:, 2:], roi[2:])
+ boxes_t[:, 2:] -= roi[:2]
+
+ # landm
+ landms_t[:, :, :2] = landms_t[:, :, :2] - roi[:2]
+ landms_t[:, :, :2] = np.maximum(landms_t[:, :, :2], np.array([0, 0]))
+ landms_t[:, :, :2] = np.minimum(landms_t[:, :, :2], roi[2:] - roi[:2])
+ landms_t = landms_t.reshape([-1, 10])
+
+
+ # make sure that the cropped image contains at least one face > 16 pixel at training image scale
+ b_w_t = (boxes_t[:, 2] - boxes_t[:, 0] + 1) / w * img_dim
+ b_h_t = (boxes_t[:, 3] - boxes_t[:, 1] + 1) / h * img_dim
+ mask_b = np.minimum(b_w_t, b_h_t) > 0.0
+ boxes_t = boxes_t[mask_b]
+ labels_t = labels_t[mask_b]
+ landms_t = landms_t[mask_b]
+
+ if boxes_t.shape[0] == 0:
+ continue
+
+ pad_image_flag = False
+
+ return image_t, boxes_t, labels_t, landms_t, pad_image_flag
+ return image, boxes, labels, landm, pad_image_flag
+
+
+def _distort(image):
+
+ def _convert(image, alpha=1, beta=0):
+ tmp = image.astype(float) * alpha + beta
+ tmp[tmp < 0] = 0
+ tmp[tmp > 255] = 255
+ image[:] = tmp
+
+ image = image.copy()
+
+ if random.randrange(2):
+
+ #brightness distortion
+ if random.randrange(2):
+ _convert(image, beta=random.uniform(-32, 32))
+
+ #contrast distortion
+ if random.randrange(2):
+ _convert(image, alpha=random.uniform(0.5, 1.5))
+
+ image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
+
+ #saturation distortion
+ if random.randrange(2):
+ _convert(image[:, :, 1], alpha=random.uniform(0.5, 1.5))
+
+ #hue distortion
+ if random.randrange(2):
+ tmp = image[:, :, 0].astype(int) + random.randint(-18, 18)
+ tmp %= 180
+ image[:, :, 0] = tmp
+
+ image = cv2.cvtColor(image, cv2.COLOR_HSV2BGR)
+
+ else:
+
+ #brightness distortion
+ if random.randrange(2):
+ _convert(image, beta=random.uniform(-32, 32))
+
+ image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
+
+ #saturation distortion
+ if random.randrange(2):
+ _convert(image[:, :, 1], alpha=random.uniform(0.5, 1.5))
+
+ #hue distortion
+ if random.randrange(2):
+ tmp = image[:, :, 0].astype(int) + random.randint(-18, 18)
+ tmp %= 180
+ image[:, :, 0] = tmp
+
+ image = cv2.cvtColor(image, cv2.COLOR_HSV2BGR)
+
+ #contrast distortion
+ if random.randrange(2):
+ _convert(image, alpha=random.uniform(0.5, 1.5))
+
+ return image
+
+
+def _expand(image, boxes, fill, p):
+ if random.randrange(2):
+ return image, boxes
+
+ height, width, depth = image.shape
+
+ scale = random.uniform(1, p)
+ w = int(scale * width)
+ h = int(scale * height)
+
+ left = random.randint(0, w - width)
+ top = random.randint(0, h - height)
+
+ boxes_t = boxes.copy()
+ boxes_t[:, :2] += (left, top)
+ boxes_t[:, 2:] += (left, top)
+ expand_image = np.empty(
+ (h, w, depth),
+ dtype=image.dtype)
+ expand_image[:, :] = fill
+ expand_image[top:top + height, left:left + width] = image
+ image = expand_image
+
+ return image, boxes_t
+
+
+def _mirror(image, boxes, landms):
+ _, width, _ = image.shape
+ if random.randrange(2):
+ image = image[:, ::-1]
+ boxes = boxes.copy()
+ boxes[:, 0::2] = width - boxes[:, 2::-2]
+
+ # landm
+ landms = landms.copy()
+ landms = landms.reshape([-1, 5, 2])
+ landms[:, :, 0] = width - landms[:, :, 0]
+ tmp = landms[:, 1, :].copy()
+ landms[:, 1, :] = landms[:, 0, :]
+ landms[:, 0, :] = tmp
+ tmp1 = landms[:, 4, :].copy()
+ landms[:, 4, :] = landms[:, 3, :]
+ landms[:, 3, :] = tmp1
+ landms = landms.reshape([-1, 10])
+
+ return image, boxes, landms
+
+
+def _pad_to_square(image, rgb_mean, pad_image_flag):
+ if not pad_image_flag:
+ return image
+ height, width, _ = image.shape
+ long_side = max(width, height)
+ image_t = np.empty((long_side, long_side, 3), dtype=image.dtype)
+ image_t[:, :] = rgb_mean
+ image_t[0:0 + height, 0:0 + width] = image
+ return image_t
+
+
+def _resize_subtract_mean(image, insize, rgb_mean):
+ interp_methods = [cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_AREA, cv2.INTER_NEAREST, cv2.INTER_LANCZOS4]
+ interp_method = interp_methods[random.randrange(5)]
+ image = cv2.resize(image, (insize, insize), interpolation=interp_method)
+ image = image.astype(np.float32)
+ image -= rgb_mean
+ return image.transpose(2, 0, 1)
+
+
+class preproc(object):
+
+ def __init__(self, img_dim, rgb_means):
+ self.img_dim = img_dim
+ self.rgb_means = rgb_means
+
+ def __call__(self, image, targets):
+ assert targets.shape[0] > 0, "this image does not have gt"
+
+ boxes = targets[:, :4].copy()
+ labels = targets[:, -1].copy()
+ landm = targets[:, 4:-1].copy()
+
+ image_t, boxes_t, labels_t, landm_t, pad_image_flag = _crop(image, boxes, labels, landm, self.img_dim)
+ image_t = _distort(image_t)
+ image_t = _pad_to_square(image_t,self.rgb_means, pad_image_flag)
+ image_t, boxes_t, landm_t = _mirror(image_t, boxes_t, landm_t)
+ height, width, _ = image_t.shape
+ image_t = _resize_subtract_mean(image_t, self.img_dim, self.rgb_means)
+ boxes_t[:, 0::2] /= width
+ boxes_t[:, 1::2] /= height
+
+ landm_t[:, 0::2] /= width
+ landm_t[:, 1::2] /= height
+
+ labels_t = np.expand_dims(labels_t, 1)
+ targets_t = np.hstack((boxes_t, landm_t, labels_t))
+
+ return image_t, targets_t
diff --git a/KAIR/retinaface/data_faces/wider_face.py b/KAIR/retinaface/data_faces/wider_face.py
new file mode 100644
index 0000000000000000000000000000000000000000..22f56efdc221bd4162d22884669ba44a3d4de5cd
--- /dev/null
+++ b/KAIR/retinaface/data_faces/wider_face.py
@@ -0,0 +1,101 @@
+import os
+import os.path
+import sys
+import torch
+import torch.utils.data as data
+import cv2
+import numpy as np
+
+class WiderFaceDetection(data.Dataset):
+ def __init__(self, txt_path, preproc=None):
+ self.preproc = preproc
+ self.imgs_path = []
+ self.words = []
+ f = open(txt_path,'r')
+ lines = f.readlines()
+ isFirst = True
+ labels = []
+ for line in lines:
+ line = line.rstrip()
+ if line.startswith('#'):
+ if isFirst is True:
+ isFirst = False
+ else:
+ labels_copy = labels.copy()
+ self.words.append(labels_copy)
+ labels.clear()
+ path = line[2:]
+ path = txt_path.replace('label.txt','images/') + path
+ self.imgs_path.append(path)
+ else:
+ line = line.split(' ')
+ label = [float(x) for x in line]
+ labels.append(label)
+
+ self.words.append(labels)
+
+ def __len__(self):
+ return len(self.imgs_path)
+
+ def __getitem__(self, index):
+ img = cv2.imread(self.imgs_path[index])
+ height, width, _ = img.shape
+
+ labels = self.words[index]
+ annotations = np.zeros((0, 15))
+ if len(labels) == 0:
+ return annotations
+ for idx, label in enumerate(labels):
+ annotation = np.zeros((1, 15))
+ # bbox
+ annotation[0, 0] = label[0] # x1
+ annotation[0, 1] = label[1] # y1
+ annotation[0, 2] = label[0] + label[2] # x2
+ annotation[0, 3] = label[1] + label[3] # y2
+
+ # landmarks
+ annotation[0, 4] = label[4] # l0_x
+ annotation[0, 5] = label[5] # l0_y
+ annotation[0, 6] = label[7] # l1_x
+ annotation[0, 7] = label[8] # l1_y
+ annotation[0, 8] = label[10] # l2_x
+ annotation[0, 9] = label[11] # l2_y
+ annotation[0, 10] = label[13] # l3_x
+ annotation[0, 11] = label[14] # l3_y
+ annotation[0, 12] = label[16] # l4_x
+ annotation[0, 13] = label[17] # l4_y
+ if (annotation[0, 4]<0):
+ annotation[0, 14] = -1
+ else:
+ annotation[0, 14] = 1
+
+ annotations = np.append(annotations, annotation, axis=0)
+ target = np.array(annotations)
+ if self.preproc is not None:
+ img, target = self.preproc(img, target)
+
+ return torch.from_numpy(img), target
+
+def detection_collate(batch):
+ """Custom collate fn for dealing with batches of images that have a different
+ number of associated object annotations (bounding boxes).
+
+ Arguments:
+ batch: (tuple) A tuple of tensor images and lists of annotations
+
+ Return:
+ A tuple containing:
+ 1) (tensor) batch of images stacked on their 0 dim
+ 2) (list of tensors) annotations for a given image are stacked on 0 dim
+ """
+ targets = []
+ imgs = []
+ for _, sample in enumerate(batch):
+ for _, tup in enumerate(sample):
+ if torch.is_tensor(tup):
+ imgs.append(tup)
+ elif isinstance(tup, type(np.empty(0))):
+ annos = torch.from_numpy(tup).float()
+ targets.append(annos)
+
+ return (torch.stack(imgs, 0), targets)
diff --git a/KAIR/retinaface/facemodels/__init__.py b/KAIR/retinaface/facemodels/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..8b137891791fe96927ad78e64b0aad7bded08bdc
--- /dev/null
+++ b/KAIR/retinaface/facemodels/__init__.py
@@ -0,0 +1 @@
+
diff --git a/KAIR/retinaface/facemodels/net.py b/KAIR/retinaface/facemodels/net.py
new file mode 100644
index 0000000000000000000000000000000000000000..beb6040b24258f8b96020c1c9fc2610819718017
--- /dev/null
+++ b/KAIR/retinaface/facemodels/net.py
@@ -0,0 +1,137 @@
+import time
+import torch
+import torch.nn as nn
+import torchvision.models._utils as _utils
+import torchvision.models as models
+import torch.nn.functional as F
+from torch.autograd import Variable
+
+def conv_bn(inp, oup, stride = 1, leaky = 0):
+ return nn.Sequential(
+ nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
+ nn.BatchNorm2d(oup),
+ nn.LeakyReLU(negative_slope=leaky, inplace=True)
+ )
+
+def conv_bn_no_relu(inp, oup, stride):
+ return nn.Sequential(
+ nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
+ nn.BatchNorm2d(oup),
+ )
+
+def conv_bn1X1(inp, oup, stride, leaky=0):
+ return nn.Sequential(
+ nn.Conv2d(inp, oup, 1, stride, padding=0, bias=False),
+ nn.BatchNorm2d(oup),
+ nn.LeakyReLU(negative_slope=leaky, inplace=True)
+ )
+
+def conv_dw(inp, oup, stride, leaky=0.1):
+ return nn.Sequential(
+ nn.Conv2d(inp, inp, 3, stride, 1, groups=inp, bias=False),
+ nn.BatchNorm2d(inp),
+ nn.LeakyReLU(negative_slope= leaky,inplace=True),
+
+ nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
+ nn.BatchNorm2d(oup),
+ nn.LeakyReLU(negative_slope= leaky,inplace=True),
+ )
+
+class SSH(nn.Module):
+ def __init__(self, in_channel, out_channel):
+ super(SSH, self).__init__()
+ assert out_channel % 4 == 0
+ leaky = 0
+ if (out_channel <= 64):
+ leaky = 0.1
+ self.conv3X3 = conv_bn_no_relu(in_channel, out_channel//2, stride=1)
+
+ self.conv5X5_1 = conv_bn(in_channel, out_channel//4, stride=1, leaky = leaky)
+ self.conv5X5_2 = conv_bn_no_relu(out_channel//4, out_channel//4, stride=1)
+
+ self.conv7X7_2 = conv_bn(out_channel//4, out_channel//4, stride=1, leaky = leaky)
+ self.conv7x7_3 = conv_bn_no_relu(out_channel//4, out_channel//4, stride=1)
+
+ def forward(self, input):
+ conv3X3 = self.conv3X3(input)
+
+ conv5X5_1 = self.conv5X5_1(input)
+ conv5X5 = self.conv5X5_2(conv5X5_1)
+
+ conv7X7_2 = self.conv7X7_2(conv5X5_1)
+ conv7X7 = self.conv7x7_3(conv7X7_2)
+
+ out = torch.cat([conv3X3, conv5X5, conv7X7], dim=1)
+ out = F.relu(out)
+ return out
+
+class FPN(nn.Module):
+ def __init__(self,in_channels_list,out_channels):
+ super(FPN,self).__init__()
+ leaky = 0
+ if (out_channels <= 64):
+ leaky = 0.1
+ self.output1 = conv_bn1X1(in_channels_list[0], out_channels, stride = 1, leaky = leaky)
+ self.output2 = conv_bn1X1(in_channels_list[1], out_channels, stride = 1, leaky = leaky)
+ self.output3 = conv_bn1X1(in_channels_list[2], out_channels, stride = 1, leaky = leaky)
+
+ self.merge1 = conv_bn(out_channels, out_channels, leaky = leaky)
+ self.merge2 = conv_bn(out_channels, out_channels, leaky = leaky)
+
+ def forward(self, input):
+ # names = list(input.keys())
+ input = list(input.values())
+
+ output1 = self.output1(input[0])
+ output2 = self.output2(input[1])
+ output3 = self.output3(input[2])
+
+ up3 = F.interpolate(output3, size=[output2.size(2), output2.size(3)], mode="nearest")
+ output2 = output2 + up3
+ output2 = self.merge2(output2)
+
+ up2 = F.interpolate(output2, size=[output1.size(2), output1.size(3)], mode="nearest")
+ output1 = output1 + up2
+ output1 = self.merge1(output1)
+
+ out = [output1, output2, output3]
+ return out
+
+
+
+class MobileNetV1(nn.Module):
+ def __init__(self):
+ super(MobileNetV1, self).__init__()
+ self.stage1 = nn.Sequential(
+ conv_bn(3, 8, 2, leaky = 0.1), # 3
+ conv_dw(8, 16, 1), # 7
+ conv_dw(16, 32, 2), # 11
+ conv_dw(32, 32, 1), # 19
+ conv_dw(32, 64, 2), # 27
+ conv_dw(64, 64, 1), # 43
+ )
+ self.stage2 = nn.Sequential(
+ conv_dw(64, 128, 2), # 43 + 16 = 59
+ conv_dw(128, 128, 1), # 59 + 32 = 91
+ conv_dw(128, 128, 1), # 91 + 32 = 123
+ conv_dw(128, 128, 1), # 123 + 32 = 155
+ conv_dw(128, 128, 1), # 155 + 32 = 187
+ conv_dw(128, 128, 1), # 187 + 32 = 219
+ )
+ self.stage3 = nn.Sequential(
+ conv_dw(128, 256, 2), # 219 +3 2 = 241
+ conv_dw(256, 256, 1), # 241 + 64 = 301
+ )
+ self.avg = nn.AdaptiveAvgPool2d((1,1))
+ self.fc = nn.Linear(256, 1000)
+
+ def forward(self, x):
+ x = self.stage1(x)
+ x = self.stage2(x)
+ x = self.stage3(x)
+ x = self.avg(x)
+ # x = self.model(x)
+ x = x.view(-1, 256)
+ x = self.fc(x)
+ return x
+
diff --git a/KAIR/retinaface/facemodels/retinaface.py b/KAIR/retinaface/facemodels/retinaface.py
new file mode 100644
index 0000000000000000000000000000000000000000..b7092a2bc2f35d06ce99d25473bce913ef3fd8e7
--- /dev/null
+++ b/KAIR/retinaface/facemodels/retinaface.py
@@ -0,0 +1,127 @@
+import torch
+import torch.nn as nn
+import torchvision.models.detection.backbone_utils as backbone_utils
+import torchvision.models._utils as _utils
+import torch.nn.functional as F
+from collections import OrderedDict
+
+from facemodels.net import MobileNetV1 as MobileNetV1
+from facemodels.net import FPN as FPN
+from facemodels.net import SSH as SSH
+
+
+
+class ClassHead(nn.Module):
+ def __init__(self,inchannels=512,num_anchors=3):
+ super(ClassHead,self).__init__()
+ self.num_anchors = num_anchors
+ self.conv1x1 = nn.Conv2d(inchannels,self.num_anchors*2,kernel_size=(1,1),stride=1,padding=0)
+
+ def forward(self,x):
+ out = self.conv1x1(x)
+ out = out.permute(0,2,3,1).contiguous()
+
+ return out.view(out.shape[0], -1, 2)
+
+class BboxHead(nn.Module):
+ def __init__(self,inchannels=512,num_anchors=3):
+ super(BboxHead,self).__init__()
+ self.conv1x1 = nn.Conv2d(inchannels,num_anchors*4,kernel_size=(1,1),stride=1,padding=0)
+
+ def forward(self,x):
+ out = self.conv1x1(x)
+ out = out.permute(0,2,3,1).contiguous()
+
+ return out.view(out.shape[0], -1, 4)
+
+class LandmarkHead(nn.Module):
+ def __init__(self,inchannels=512,num_anchors=3):
+ super(LandmarkHead,self).__init__()
+ self.conv1x1 = nn.Conv2d(inchannels,num_anchors*10,kernel_size=(1,1),stride=1,padding=0)
+
+ def forward(self,x):
+ out = self.conv1x1(x)
+ out = out.permute(0,2,3,1).contiguous()
+
+ return out.view(out.shape[0], -1, 10)
+
+class RetinaFace(nn.Module):
+ def __init__(self, cfg = None, phase = 'train'):
+ """
+ :param cfg: Network related settings.
+ :param phase: train or test.
+ """
+ super(RetinaFace,self).__init__()
+ self.phase = phase
+ backbone = None
+ if cfg['name'] == 'mobilenet0.25':
+ backbone = MobileNetV1()
+ if cfg['pretrain']:
+ checkpoint = torch.load("./weights/mobilenetV1X0.25_pretrain.tar", map_location=torch.device('cpu'))
+ from collections import OrderedDict
+ new_state_dict = OrderedDict()
+ for k, v in checkpoint['state_dict'].items():
+ name = k[7:] # remove module.
+ new_state_dict[name] = v
+ # load params
+ backbone.load_state_dict(new_state_dict)
+ elif cfg['name'] == 'Resnet50':
+ import torchvision.models as models
+ backbone = models.resnet50(pretrained=cfg['pretrain'])
+
+ self.body = _utils.IntermediateLayerGetter(backbone, cfg['return_layers'])
+ in_channels_stage2 = cfg['in_channel']
+ in_channels_list = [
+ in_channels_stage2 * 2,
+ in_channels_stage2 * 4,
+ in_channels_stage2 * 8,
+ ]
+ out_channels = cfg['out_channel']
+ self.fpn = FPN(in_channels_list,out_channels)
+ self.ssh1 = SSH(out_channels, out_channels)
+ self.ssh2 = SSH(out_channels, out_channels)
+ self.ssh3 = SSH(out_channels, out_channels)
+
+ self.ClassHead = self._make_class_head(fpn_num=3, inchannels=cfg['out_channel'])
+ self.BboxHead = self._make_bbox_head(fpn_num=3, inchannels=cfg['out_channel'])
+ self.LandmarkHead = self._make_landmark_head(fpn_num=3, inchannels=cfg['out_channel'])
+
+ def _make_class_head(self,fpn_num=3,inchannels=64,anchor_num=2):
+ classhead = nn.ModuleList()
+ for i in range(fpn_num):
+ classhead.append(ClassHead(inchannels,anchor_num))
+ return classhead
+
+ def _make_bbox_head(self,fpn_num=3,inchannels=64,anchor_num=2):
+ bboxhead = nn.ModuleList()
+ for i in range(fpn_num):
+ bboxhead.append(BboxHead(inchannels,anchor_num))
+ return bboxhead
+
+ def _make_landmark_head(self,fpn_num=3,inchannels=64,anchor_num=2):
+ landmarkhead = nn.ModuleList()
+ for i in range(fpn_num):
+ landmarkhead.append(LandmarkHead(inchannels,anchor_num))
+ return landmarkhead
+
+ def forward(self,inputs):
+ out = self.body(inputs)
+
+ # FPN
+ fpn = self.fpn(out)
+
+ # SSH
+ feature1 = self.ssh1(fpn[0])
+ feature2 = self.ssh2(fpn[1])
+ feature3 = self.ssh3(fpn[2])
+ features = [feature1, feature2, feature3]
+
+ bbox_regressions = torch.cat([self.BboxHead[i](feature) for i, feature in enumerate(features)], dim=1)
+ classifications = torch.cat([self.ClassHead[i](feature) for i, feature in enumerate(features)],dim=1)
+ ldm_regressions = torch.cat([self.LandmarkHead[i](feature) for i, feature in enumerate(features)], dim=1)
+
+ if self.phase == 'train':
+ output = (bbox_regressions, classifications, ldm_regressions)
+ else:
+ output = (bbox_regressions, F.softmax(classifications, dim=-1), ldm_regressions)
+ return output
\ No newline at end of file
diff --git a/KAIR/retinaface/layers/__init__.py b/KAIR/retinaface/layers/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..53a3f4b5160995d93bc7911e808b3045d74362c9
--- /dev/null
+++ b/KAIR/retinaface/layers/__init__.py
@@ -0,0 +1,2 @@
+from .functions import *
+from .modules import *
diff --git a/KAIR/retinaface/layers/functions/prior_box.py b/KAIR/retinaface/layers/functions/prior_box.py
new file mode 100644
index 0000000000000000000000000000000000000000..80c7f858371ed71f39ed609eb44b423d8693bf61
--- /dev/null
+++ b/KAIR/retinaface/layers/functions/prior_box.py
@@ -0,0 +1,34 @@
+import torch
+from itertools import product as product
+import numpy as np
+from math import ceil
+
+
+class PriorBox(object):
+ def __init__(self, cfg, image_size=None, phase='train'):
+ super(PriorBox, self).__init__()
+ self.min_sizes = cfg['min_sizes']
+ self.steps = cfg['steps']
+ self.clip = cfg['clip']
+ self.image_size = image_size
+ self.feature_maps = [[ceil(self.image_size[0]/step), ceil(self.image_size[1]/step)] for step in self.steps]
+ self.name = "s"
+
+ def forward(self):
+ anchors = []
+ for k, f in enumerate(self.feature_maps):
+ min_sizes = self.min_sizes[k]
+ for i, j in product(range(f[0]), range(f[1])):
+ for min_size in min_sizes:
+ s_kx = min_size / self.image_size[1]
+ s_ky = min_size / self.image_size[0]
+ dense_cx = [x * self.steps[k] / self.image_size[1] for x in [j + 0.5]]
+ dense_cy = [y * self.steps[k] / self.image_size[0] for y in [i + 0.5]]
+ for cy, cx in product(dense_cy, dense_cx):
+ anchors += [cx, cy, s_kx, s_ky]
+
+ # back to torch land
+ output = torch.Tensor(anchors).view(-1, 4)
+ if self.clip:
+ output.clamp_(max=1, min=0)
+ return output
diff --git a/KAIR/retinaface/layers/modules/__init__.py b/KAIR/retinaface/layers/modules/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..cf24bddbf283f233d0b93fc074a2bac2f5c044a9
--- /dev/null
+++ b/KAIR/retinaface/layers/modules/__init__.py
@@ -0,0 +1,3 @@
+from .multibox_loss import MultiBoxLoss
+
+__all__ = ['MultiBoxLoss']
diff --git a/KAIR/retinaface/layers/modules/multibox_loss.py b/KAIR/retinaface/layers/modules/multibox_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..75d2367be35e11a119810949f6ccce439984b978
--- /dev/null
+++ b/KAIR/retinaface/layers/modules/multibox_loss.py
@@ -0,0 +1,125 @@
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from torch.autograd import Variable
+from utils_faces.box_utils import match, log_sum_exp
+from data_faces import cfg_mnet
+GPU = cfg_mnet['gpu_train']
+
+class MultiBoxLoss(nn.Module):
+ """SSD Weighted Loss Function
+ Compute Targets:
+ 1) Produce Confidence Target Indices by matching ground truth boxes
+ with (default) 'priorboxes' that have jaccard index > threshold parameter
+ (default threshold: 0.5).
+ 2) Produce localization target by 'encoding' variance into offsets of ground
+ truth boxes and their matched 'priorboxes'.
+ 3) Hard negative mining to filter the excessive number of negative examples
+ that comes with using a large number of default bounding boxes.
+ (default negative:positive ratio 3:1)
+ Objective Loss:
+ L(x,c,l,g) = (Lconf(x, c) + αLloc(x,l,g)) / N
+ Where, Lconf is the CrossEntropy Loss and Lloc is the SmoothL1 Loss
+ weighted by α which is set to 1 by cross val.
+ Args:
+ c: class confidences,
+ l: predicted boxes,
+ g: ground truth boxes
+ N: number of matched default boxes
+ See: https://arxiv.org/pdf/1512.02325.pdf for more details.
+ """
+
+ def __init__(self, num_classes, overlap_thresh, prior_for_matching, bkg_label, neg_mining, neg_pos, neg_overlap, encode_target):
+ super(MultiBoxLoss, self).__init__()
+ self.num_classes = num_classes
+ self.threshold = overlap_thresh
+ self.background_label = bkg_label
+ self.encode_target = encode_target
+ self.use_prior_for_matching = prior_for_matching
+ self.do_neg_mining = neg_mining
+ self.negpos_ratio = neg_pos
+ self.neg_overlap = neg_overlap
+ self.variance = [0.1, 0.2]
+
+ def forward(self, predictions, priors, targets):
+ """Multibox Loss
+ Args:
+ predictions (tuple): A tuple containing loc preds, conf preds,
+ and prior boxes from SSD net.
+ conf shape: torch.size(batch_size,num_priors,num_classes)
+ loc shape: torch.size(batch_size,num_priors,4)
+ priors shape: torch.size(num_priors,4)
+
+ ground_truth (tensor): Ground truth boxes and labels for a batch,
+ shape: [batch_size,num_objs,5] (last idx is the label).
+ """
+
+ loc_data, conf_data, landm_data = predictions
+ priors = priors
+ num = loc_data.size(0)
+ num_priors = (priors.size(0))
+
+ # match priors (default boxes) and ground truth boxes
+ loc_t = torch.Tensor(num, num_priors, 4)
+ landm_t = torch.Tensor(num, num_priors, 10)
+ conf_t = torch.LongTensor(num, num_priors)
+ for idx in range(num):
+ truths = targets[idx][:, :4].data
+ labels = targets[idx][:, -1].data
+ landms = targets[idx][:, 4:14].data
+ defaults = priors.data
+ match(self.threshold, truths, defaults, self.variance, labels, landms, loc_t, conf_t, landm_t, idx)
+ if GPU:
+ loc_t = loc_t.cuda()
+ conf_t = conf_t.cuda()
+ landm_t = landm_t.cuda()
+
+ zeros = torch.tensor(0).cuda()
+ # landm Loss (Smooth L1)
+ # Shape: [batch,num_priors,10]
+ pos1 = conf_t > zeros
+ num_pos_landm = pos1.long().sum(1, keepdim=True)
+ N1 = max(num_pos_landm.data.sum().float(), 1)
+ pos_idx1 = pos1.unsqueeze(pos1.dim()).expand_as(landm_data)
+ landm_p = landm_data[pos_idx1].view(-1, 10)
+ landm_t = landm_t[pos_idx1].view(-1, 10)
+ loss_landm = F.smooth_l1_loss(landm_p, landm_t, reduction='sum')
+
+
+ pos = conf_t != zeros
+ conf_t[pos] = 1
+
+ # Localization Loss (Smooth L1)
+ # Shape: [batch,num_priors,4]
+ pos_idx = pos.unsqueeze(pos.dim()).expand_as(loc_data)
+ loc_p = loc_data[pos_idx].view(-1, 4)
+ loc_t = loc_t[pos_idx].view(-1, 4)
+ loss_l = F.smooth_l1_loss(loc_p, loc_t, reduction='sum')
+
+ # Compute max conf across batch for hard negative mining
+ batch_conf = conf_data.view(-1, self.num_classes)
+ loss_c = log_sum_exp(batch_conf) - batch_conf.gather(1, conf_t.view(-1, 1))
+
+ # Hard Negative Mining
+ loss_c[pos.view(-1, 1)] = 0 # filter out pos boxes for now
+ loss_c = loss_c.view(num, -1)
+ _, loss_idx = loss_c.sort(1, descending=True)
+ _, idx_rank = loss_idx.sort(1)
+ num_pos = pos.long().sum(1, keepdim=True)
+ num_neg = torch.clamp(self.negpos_ratio*num_pos, max=pos.size(1)-1)
+ neg = idx_rank < num_neg.expand_as(idx_rank)
+
+ # Confidence Loss Including Positive and Negative Examples
+ pos_idx = pos.unsqueeze(2).expand_as(conf_data)
+ neg_idx = neg.unsqueeze(2).expand_as(conf_data)
+ conf_p = conf_data[(pos_idx+neg_idx).gt(0)].view(-1,self.num_classes)
+ targets_weighted = conf_t[(pos+neg).gt(0)]
+ loss_c = F.cross_entropy(conf_p, targets_weighted, reduction='sum')
+
+ # Sum of losses: L(x,c,l,g) = (Lconf(x, c) + αLloc(x,l,g)) / N
+ N = max(num_pos.data.sum().float(), 1)
+ loss_l /= N
+ loss_c /= N
+ loss_landm /= N1
+
+ return loss_l, loss_c, loss_landm
diff --git a/KAIR/retinaface/retinaface_detection.py b/KAIR/retinaface/retinaface_detection.py
new file mode 100644
index 0000000000000000000000000000000000000000..24e9919bb3f9656cc2601f868a85276ad852c00f
--- /dev/null
+++ b/KAIR/retinaface/retinaface_detection.py
@@ -0,0 +1,124 @@
+'''
+@paper: GAN Prior Embedded Network for Blind Face Restoration in the Wild (CVPR2021)
+@author: yangxy (yangtao9009@gmail.com)
+'''
+
+
+import sys
+path_retinaface = 'retinaface'
+if path_retinaface not in sys.path:
+ sys.path.insert(0, path_retinaface)
+
+import os
+import torch
+import torch.backends.cudnn as cudnn
+import numpy as np
+from data_faces import cfg_re50
+from layers.functions.prior_box import PriorBox
+from utils_faces.nms.py_cpu_nms import py_cpu_nms
+import cv2
+from facemodels.retinaface import RetinaFace
+from utils_faces.box_utils import decode, decode_landm
+import time
+
+
+class RetinaFaceDetection(object):
+ def __init__(self, model_path):
+ torch.set_grad_enabled(False)
+ cudnn.benchmark = True
+ self.pretrained_path = model_path
+ self.device = torch.cuda.current_device()
+ self.cfg = cfg_re50
+ self.net = RetinaFace(cfg=self.cfg, phase='test')
+ self.load_model()
+ self.net = self.net.cuda()
+
+ def check_keys(self, pretrained_state_dict):
+ ckpt_keys = set(pretrained_state_dict.keys())
+ model_keys = set(self.net.state_dict().keys())
+ used_pretrained_keys = model_keys & ckpt_keys
+ unused_pretrained_keys = ckpt_keys - model_keys
+ missing_keys = model_keys - ckpt_keys
+ assert len(used_pretrained_keys) > 0, 'load NONE from pretrained checkpoint'
+ return True
+
+ def remove_prefix(self, state_dict, prefix):
+ ''' Old style model is stored with all names of parameters sharing common prefix 'module.' '''
+ f = lambda x: x.split(prefix, 1)[-1] if x.startswith(prefix) else x
+ return {f(key): value for key, value in state_dict.items()}
+
+ def load_model(self, load_to_cpu=False):
+ if load_to_cpu:
+ pretrained_dict = torch.load(self.pretrained_path, map_location=lambda storage, loc: storage)
+ else:
+ pretrained_dict = torch.load(self.pretrained_path, map_location=lambda storage, loc: storage.cuda())
+ if "state_dict" in pretrained_dict.keys():
+ pretrained_dict = self.remove_prefix(pretrained_dict['state_dict'], 'module.')
+ else:
+ pretrained_dict = self.remove_prefix(pretrained_dict, 'module.')
+ self.check_keys(pretrained_dict)
+ self.net.load_state_dict(pretrained_dict, strict=False)
+ self.net.eval()
+
+ def detect(self, img_raw, resize=1, confidence_threshold=0.9, nms_threshold=0.4, top_k=5000, keep_top_k=750, save_image=False):
+ img = np.float32(img_raw)
+
+ im_height, im_width = img.shape[:2]
+ scale = torch.Tensor([img.shape[1], img.shape[0], img.shape[1], img.shape[0]])
+ img -= (104, 117, 123)
+ img = img.transpose(2, 0, 1)
+ img = torch.from_numpy(img).unsqueeze(0)
+ img = img.cuda()
+ scale = scale.cuda()
+
+ loc, conf, landms = self.net(img) # forward pass
+
+ priorbox = PriorBox(self.cfg, image_size=(im_height, im_width))
+ priors = priorbox.forward()
+ priors = priors.cuda()
+ prior_data = priors.data
+ boxes = decode(loc.data.squeeze(0), prior_data, self.cfg['variance'])
+ boxes = boxes * scale / resize
+ boxes = boxes.cpu().numpy()
+ scores = conf.squeeze(0).data.cpu().numpy()[:, 1]
+ landms = decode_landm(landms.data.squeeze(0), prior_data, self.cfg['variance'])
+ scale1 = torch.Tensor([img.shape[3], img.shape[2], img.shape[3], img.shape[2],
+ img.shape[3], img.shape[2], img.shape[3], img.shape[2],
+ img.shape[3], img.shape[2]])
+ scale1 = scale1.cuda()
+ landms = landms * scale1 / resize
+ landms = landms.cpu().numpy()
+
+ # ignore low scores
+ inds = np.where(scores > confidence_threshold)[0]
+ boxes = boxes[inds]
+ landms = landms[inds]
+ scores = scores[inds]
+
+ # keep top-K before NMS
+ order = scores.argsort()[::-1][:top_k]
+ boxes = boxes[order]
+ landms = landms[order]
+ scores = scores[order]
+
+ # do NMS
+ dets = np.hstack((boxes, scores[:, np.newaxis])).astype(np.float32, copy=False)
+ keep = py_cpu_nms(dets, nms_threshold)
+ # keep = nms(dets, nms_threshold,force_cpu=args.cpu)
+ dets = dets[keep, :]
+ landms = landms[keep]
+
+ # keep top-K faster NMS
+ dets = dets[:keep_top_k, :]
+ landms = landms[:keep_top_k, :]
+
+ # sort faces(delete)
+ fscores = [det[4] for det in dets]
+ sorted_idx = sorted(range(len(fscores)), key=lambda k:fscores[k], reverse=False) # sort index
+ tmp = [landms[idx] for idx in sorted_idx]
+ landms = np.asarray(tmp)
+
+ landms = landms.reshape((-1, 5, 2))
+ landms = landms.transpose((0, 2, 1))
+ landms = landms.reshape(-1, 10, )
+ return dets, landms
diff --git a/KAIR/retinaface/utils_faces/__init__.py b/KAIR/retinaface/utils_faces/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..8b137891791fe96927ad78e64b0aad7bded08bdc
--- /dev/null
+++ b/KAIR/retinaface/utils_faces/__init__.py
@@ -0,0 +1 @@
+
diff --git a/KAIR/retinaface/utils_faces/box_utils.py b/KAIR/retinaface/utils_faces/box_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..c1d12bc612ae3ba3ea9d138bfc5997a2b15d8dd9
--- /dev/null
+++ b/KAIR/retinaface/utils_faces/box_utils.py
@@ -0,0 +1,330 @@
+import torch
+import numpy as np
+
+
+def point_form(boxes):
+ """ Convert prior_boxes to (xmin, ymin, xmax, ymax)
+ representation for comparison to point form ground truth data.
+ Args:
+ boxes: (tensor) center-size default boxes from priorbox layers.
+ Return:
+ boxes: (tensor) Converted xmin, ymin, xmax, ymax form of boxes.
+ """
+ return torch.cat((boxes[:, :2] - boxes[:, 2:]/2, # xmin, ymin
+ boxes[:, :2] + boxes[:, 2:]/2), 1) # xmax, ymax
+
+
+def center_size(boxes):
+ """ Convert prior_boxes to (cx, cy, w, h)
+ representation for comparison to center-size form ground truth data.
+ Args:
+ boxes: (tensor) point_form boxes
+ Return:
+ boxes: (tensor) Converted xmin, ymin, xmax, ymax form of boxes.
+ """
+ return torch.cat((boxes[:, 2:] + boxes[:, :2])/2, # cx, cy
+ boxes[:, 2:] - boxes[:, :2], 1) # w, h
+
+
+def intersect(box_a, box_b):
+ """ We resize both tensors to [A,B,2] without new malloc:
+ [A,2] -> [A,1,2] -> [A,B,2]
+ [B,2] -> [1,B,2] -> [A,B,2]
+ Then we compute the area of intersect between box_a and box_b.
+ Args:
+ box_a: (tensor) bounding boxes, Shape: [A,4].
+ box_b: (tensor) bounding boxes, Shape: [B,4].
+ Return:
+ (tensor) intersection area, Shape: [A,B].
+ """
+ A = box_a.size(0)
+ B = box_b.size(0)
+ max_xy = torch.min(box_a[:, 2:].unsqueeze(1).expand(A, B, 2),
+ box_b[:, 2:].unsqueeze(0).expand(A, B, 2))
+ min_xy = torch.max(box_a[:, :2].unsqueeze(1).expand(A, B, 2),
+ box_b[:, :2].unsqueeze(0).expand(A, B, 2))
+ inter = torch.clamp((max_xy - min_xy), min=0)
+ return inter[:, :, 0] * inter[:, :, 1]
+
+
+def jaccard(box_a, box_b):
+ """Compute the jaccard overlap of two sets of boxes. The jaccard overlap
+ is simply the intersection over union of two boxes. Here we operate on
+ ground truth boxes and default boxes.
+ E.g.:
+ A ∩ B / A ∪ B = A ∩ B / (area(A) + area(B) - A ∩ B)
+ Args:
+ box_a: (tensor) Ground truth bounding boxes, Shape: [num_objects,4]
+ box_b: (tensor) Prior boxes from priorbox layers, Shape: [num_priors,4]
+ Return:
+ jaccard overlap: (tensor) Shape: [box_a.size(0), box_b.size(0)]
+ """
+ inter = intersect(box_a, box_b)
+ area_a = ((box_a[:, 2]-box_a[:, 0]) *
+ (box_a[:, 3]-box_a[:, 1])).unsqueeze(1).expand_as(inter) # [A,B]
+ area_b = ((box_b[:, 2]-box_b[:, 0]) *
+ (box_b[:, 3]-box_b[:, 1])).unsqueeze(0).expand_as(inter) # [A,B]
+ union = area_a + area_b - inter
+ return inter / union # [A,B]
+
+
+def matrix_iou(a, b):
+ """
+ return iou of a and b, numpy version for data augenmentation
+ """
+ lt = np.maximum(a[:, np.newaxis, :2], b[:, :2])
+ rb = np.minimum(a[:, np.newaxis, 2:], b[:, 2:])
+
+ area_i = np.prod(rb - lt, axis=2) * (lt < rb).all(axis=2)
+ area_a = np.prod(a[:, 2:] - a[:, :2], axis=1)
+ area_b = np.prod(b[:, 2:] - b[:, :2], axis=1)
+ return area_i / (area_a[:, np.newaxis] + area_b - area_i)
+
+
+def matrix_iof(a, b):
+ """
+ return iof of a and b, numpy version for data augenmentation
+ """
+ lt = np.maximum(a[:, np.newaxis, :2], b[:, :2])
+ rb = np.minimum(a[:, np.newaxis, 2:], b[:, 2:])
+
+ area_i = np.prod(rb - lt, axis=2) * (lt < rb).all(axis=2)
+ area_a = np.prod(a[:, 2:] - a[:, :2], axis=1)
+ return area_i / np.maximum(area_a[:, np.newaxis], 1)
+
+
+def match(threshold, truths, priors, variances, labels, landms, loc_t, conf_t, landm_t, idx):
+ """Match each prior box with the ground truth box of the highest jaccard
+ overlap, encode the bounding boxes, then return the matched indices
+ corresponding to both confidence and location preds.
+ Args:
+ threshold: (float) The overlap threshold used when mathing boxes.
+ truths: (tensor) Ground truth boxes, Shape: [num_obj, 4].
+ priors: (tensor) Prior boxes from priorbox layers, Shape: [n_priors,4].
+ variances: (tensor) Variances corresponding to each prior coord,
+ Shape: [num_priors, 4].
+ labels: (tensor) All the class labels for the image, Shape: [num_obj].
+ landms: (tensor) Ground truth landms, Shape [num_obj, 10].
+ loc_t: (tensor) Tensor to be filled w/ endcoded location targets.
+ conf_t: (tensor) Tensor to be filled w/ matched indices for conf preds.
+ landm_t: (tensor) Tensor to be filled w/ endcoded landm targets.
+ idx: (int) current batch index
+ Return:
+ The matched indices corresponding to 1)location 2)confidence 3)landm preds.
+ """
+ # jaccard index
+ overlaps = jaccard(
+ truths,
+ point_form(priors)
+ )
+ # (Bipartite Matching)
+ # [1,num_objects] best prior for each ground truth
+ best_prior_overlap, best_prior_idx = overlaps.max(1, keepdim=True)
+
+ # ignore hard gt
+ valid_gt_idx = best_prior_overlap[:, 0] >= 0.2
+ best_prior_idx_filter = best_prior_idx[valid_gt_idx, :]
+ if best_prior_idx_filter.shape[0] <= 0:
+ loc_t[idx] = 0
+ conf_t[idx] = 0
+ return
+
+ # [1,num_priors] best ground truth for each prior
+ best_truth_overlap, best_truth_idx = overlaps.max(0, keepdim=True)
+ best_truth_idx.squeeze_(0)
+ best_truth_overlap.squeeze_(0)
+ best_prior_idx.squeeze_(1)
+ best_prior_idx_filter.squeeze_(1)
+ best_prior_overlap.squeeze_(1)
+ best_truth_overlap.index_fill_(0, best_prior_idx_filter, 2) # ensure best prior
+ # TODO refactor: index best_prior_idx with long tensor
+ # ensure every gt matches with its prior of max overlap
+ for j in range(best_prior_idx.size(0)): # 判别此anchor是预测哪一个boxes
+ best_truth_idx[best_prior_idx[j]] = j
+ matches = truths[best_truth_idx] # Shape: [num_priors,4] 此处为每一个anchor对应的bbox取出来
+ conf = labels[best_truth_idx] # Shape: [num_priors] 此处为每一个anchor对应的label取出来
+ conf[best_truth_overlap < threshold] = 0 # label as background overlap<0.35的全部作为负样本
+ loc = encode(matches, priors, variances)
+
+ matches_landm = landms[best_truth_idx]
+ landm = encode_landm(matches_landm, priors, variances)
+ loc_t[idx] = loc # [num_priors,4] encoded offsets to learn
+ conf_t[idx] = conf # [num_priors] top class label for each prior
+ landm_t[idx] = landm
+
+
+def encode(matched, priors, variances):
+ """Encode the variances from the priorbox layers into the ground truth boxes
+ we have matched (based on jaccard overlap) with the prior boxes.
+ Args:
+ matched: (tensor) Coords of ground truth for each prior in point-form
+ Shape: [num_priors, 4].
+ priors: (tensor) Prior boxes in center-offset form
+ Shape: [num_priors,4].
+ variances: (list[float]) Variances of priorboxes
+ Return:
+ encoded boxes (tensor), Shape: [num_priors, 4]
+ """
+
+ # dist b/t match center and prior's center
+ g_cxcy = (matched[:, :2] + matched[:, 2:])/2 - priors[:, :2]
+ # encode variance
+ g_cxcy /= (variances[0] * priors[:, 2:])
+ # match wh / prior wh
+ g_wh = (matched[:, 2:] - matched[:, :2]) / priors[:, 2:]
+ g_wh = torch.log(g_wh) / variances[1]
+ # return target for smooth_l1_loss
+ return torch.cat([g_cxcy, g_wh], 1) # [num_priors,4]
+
+def encode_landm(matched, priors, variances):
+ """Encode the variances from the priorbox layers into the ground truth boxes
+ we have matched (based on jaccard overlap) with the prior boxes.
+ Args:
+ matched: (tensor) Coords of ground truth for each prior in point-form
+ Shape: [num_priors, 10].
+ priors: (tensor) Prior boxes in center-offset form
+ Shape: [num_priors,4].
+ variances: (list[float]) Variances of priorboxes
+ Return:
+ encoded landm (tensor), Shape: [num_priors, 10]
+ """
+
+ # dist b/t match center and prior's center
+ matched = torch.reshape(matched, (matched.size(0), 5, 2))
+ priors_cx = priors[:, 0].unsqueeze(1).expand(matched.size(0), 5).unsqueeze(2)
+ priors_cy = priors[:, 1].unsqueeze(1).expand(matched.size(0), 5).unsqueeze(2)
+ priors_w = priors[:, 2].unsqueeze(1).expand(matched.size(0), 5).unsqueeze(2)
+ priors_h = priors[:, 3].unsqueeze(1).expand(matched.size(0), 5).unsqueeze(2)
+ priors = torch.cat([priors_cx, priors_cy, priors_w, priors_h], dim=2)
+ g_cxcy = matched[:, :, :2] - priors[:, :, :2]
+ # encode variance
+ g_cxcy /= (variances[0] * priors[:, :, 2:])
+ # g_cxcy /= priors[:, :, 2:]
+ g_cxcy = g_cxcy.reshape(g_cxcy.size(0), -1)
+ # return target for smooth_l1_loss
+ return g_cxcy
+
+
+# Adapted from https://github.com/Hakuyume/chainer-ssd
+def decode(loc, priors, variances):
+ """Decode locations from predictions using priors to undo
+ the encoding we did for offset regression at train time.
+ Args:
+ loc (tensor): location predictions for loc layers,
+ Shape: [num_priors,4]
+ priors (tensor): Prior boxes in center-offset form.
+ Shape: [num_priors,4].
+ variances: (list[float]) Variances of priorboxes
+ Return:
+ decoded bounding box predictions
+ """
+
+ boxes = torch.cat((
+ priors[:, :2] + loc[:, :2] * variances[0] * priors[:, 2:],
+ priors[:, 2:] * torch.exp(loc[:, 2:] * variances[1])), 1)
+ boxes[:, :2] -= boxes[:, 2:] / 2
+ boxes[:, 2:] += boxes[:, :2]
+ return boxes
+
+def decode_landm(pre, priors, variances):
+ """Decode landm from predictions using priors to undo
+ the encoding we did for offset regression at train time.
+ Args:
+ pre (tensor): landm predictions for loc layers,
+ Shape: [num_priors,10]
+ priors (tensor): Prior boxes in center-offset form.
+ Shape: [num_priors,4].
+ variances: (list[float]) Variances of priorboxes
+ Return:
+ decoded landm predictions
+ """
+ landms = torch.cat((priors[:, :2] + pre[:, :2] * variances[0] * priors[:, 2:],
+ priors[:, :2] + pre[:, 2:4] * variances[0] * priors[:, 2:],
+ priors[:, :2] + pre[:, 4:6] * variances[0] * priors[:, 2:],
+ priors[:, :2] + pre[:, 6:8] * variances[0] * priors[:, 2:],
+ priors[:, :2] + pre[:, 8:10] * variances[0] * priors[:, 2:],
+ ), dim=1)
+ return landms
+
+
+def log_sum_exp(x):
+ """Utility function for computing log_sum_exp while determining
+ This will be used to determine unaveraged confidence loss across
+ all examples in a batch.
+ Args:
+ x (Variable(tensor)): conf_preds from conf layers
+ """
+ x_max = x.data.max()
+ return torch.log(torch.sum(torch.exp(x-x_max), 1, keepdim=True)) + x_max
+
+
+# Original author: Francisco Massa:
+# https://github.com/fmassa/object-detection.torch
+# Ported to PyTorch by Max deGroot (02/01/2017)
+def nms(boxes, scores, overlap=0.5, top_k=200):
+ """Apply non-maximum suppression at test time to avoid detecting too many
+ overlapping bounding boxes for a given object.
+ Args:
+ boxes: (tensor) The location preds for the img, Shape: [num_priors,4].
+ scores: (tensor) The class predscores for the img, Shape:[num_priors].
+ overlap: (float) The overlap thresh for suppressing unnecessary boxes.
+ top_k: (int) The Maximum number of box preds to consider.
+ Return:
+ The indices of the kept boxes with respect to num_priors.
+ """
+
+ keep = torch.Tensor(scores.size(0)).fill_(0).long()
+ if boxes.numel() == 0:
+ return keep
+ x1 = boxes[:, 0]
+ y1 = boxes[:, 1]
+ x2 = boxes[:, 2]
+ y2 = boxes[:, 3]
+ area = torch.mul(x2 - x1, y2 - y1)
+ v, idx = scores.sort(0) # sort in ascending order
+ # I = I[v >= 0.01]
+ idx = idx[-top_k:] # indices of the top-k largest vals
+ xx1 = boxes.new()
+ yy1 = boxes.new()
+ xx2 = boxes.new()
+ yy2 = boxes.new()
+ w = boxes.new()
+ h = boxes.new()
+
+ # keep = torch.Tensor()
+ count = 0
+ while idx.numel() > 0:
+ i = idx[-1] # index of current largest val
+ # keep.append(i)
+ keep[count] = i
+ count += 1
+ if idx.size(0) == 1:
+ break
+ idx = idx[:-1] # remove kept element from view
+ # load bboxes of next highest vals
+ torch.index_select(x1, 0, idx, out=xx1)
+ torch.index_select(y1, 0, idx, out=yy1)
+ torch.index_select(x2, 0, idx, out=xx2)
+ torch.index_select(y2, 0, idx, out=yy2)
+ # store element-wise max with next highest score
+ xx1 = torch.clamp(xx1, min=x1[i])
+ yy1 = torch.clamp(yy1, min=y1[i])
+ xx2 = torch.clamp(xx2, max=x2[i])
+ yy2 = torch.clamp(yy2, max=y2[i])
+ w.resize_as_(xx2)
+ h.resize_as_(yy2)
+ w = xx2 - xx1
+ h = yy2 - yy1
+ # check sizes of xx1 and xx2.. after each iteration
+ w = torch.clamp(w, min=0.0)
+ h = torch.clamp(h, min=0.0)
+ inter = w*h
+ # IoU = i / (area(a) + area(b) - i)
+ rem_areas = torch.index_select(area, 0, idx) # load remaining areas)
+ union = (rem_areas - inter) + area[i]
+ IoU = inter/union # store result in iou
+ # keep only elements with an IoU <= overlap
+ idx = idx[IoU.le(overlap)]
+ return keep, count
+
+
diff --git a/KAIR/retinaface/utils_faces/nms/__init__.py b/KAIR/retinaface/utils_faces/nms/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..8b137891791fe96927ad78e64b0aad7bded08bdc
--- /dev/null
+++ b/KAIR/retinaface/utils_faces/nms/__init__.py
@@ -0,0 +1 @@
+
diff --git a/KAIR/retinaface/utils_faces/nms/py_cpu_nms.py b/KAIR/retinaface/utils_faces/nms/py_cpu_nms.py
new file mode 100644
index 0000000000000000000000000000000000000000..54e7b25fef72b518df6dcf8d6fb78b986796c6e3
--- /dev/null
+++ b/KAIR/retinaface/utils_faces/nms/py_cpu_nms.py
@@ -0,0 +1,38 @@
+# --------------------------------------------------------
+# Fast R-CNN
+# Copyright (c) 2015 Microsoft
+# Licensed under The MIT License [see LICENSE for details]
+# Written by Ross Girshick
+# --------------------------------------------------------
+
+import numpy as np
+
+def py_cpu_nms(dets, thresh):
+ """Pure Python NMS baseline."""
+ x1 = dets[:, 0]
+ y1 = dets[:, 1]
+ x2 = dets[:, 2]
+ y2 = dets[:, 3]
+ scores = dets[:, 4]
+
+ areas = (x2 - x1 + 1) * (y2 - y1 + 1)
+ order = scores.argsort()[::-1]
+
+ keep = []
+ while order.size > 0:
+ i = order[0]
+ keep.append(i)
+ xx1 = np.maximum(x1[i], x1[order[1:]])
+ yy1 = np.maximum(y1[i], y1[order[1:]])
+ xx2 = np.minimum(x2[i], x2[order[1:]])
+ yy2 = np.minimum(y2[i], y2[order[1:]])
+
+ w = np.maximum(0.0, xx2 - xx1 + 1)
+ h = np.maximum(0.0, yy2 - yy1 + 1)
+ inter = w * h
+ ovr = inter / (areas[i] + areas[order[1:]] - inter)
+
+ inds = np.where(ovr <= thresh)[0]
+ order = order[inds + 1]
+
+ return keep
diff --git a/KAIR/retinaface/utils_faces/timer.py b/KAIR/retinaface/utils_faces/timer.py
new file mode 100644
index 0000000000000000000000000000000000000000..e4b3b8098a5ad41f8d18d42b6b2fedb694aa5508
--- /dev/null
+++ b/KAIR/retinaface/utils_faces/timer.py
@@ -0,0 +1,40 @@
+# --------------------------------------------------------
+# Fast R-CNN
+# Copyright (c) 2015 Microsoft
+# Licensed under The MIT License [see LICENSE for details]
+# Written by Ross Girshick
+# --------------------------------------------------------
+
+import time
+
+
+class Timer(object):
+ """A simple timer."""
+ def __init__(self):
+ self.total_time = 0.
+ self.calls = 0
+ self.start_time = 0.
+ self.diff = 0.
+ self.average_time = 0.
+
+ def tic(self):
+ # using time.time instead of time.clock because time time.clock
+ # does not normalize for multithreading
+ self.start_time = time.time()
+
+ def toc(self, average=True):
+ self.diff = time.time() - self.start_time
+ self.total_time += self.diff
+ self.calls += 1
+ self.average_time = self.total_time / self.calls
+ if average:
+ return self.average_time
+ else:
+ return self.diff
+
+ def clear(self):
+ self.total_time = 0.
+ self.calls = 0
+ self.start_time = 0.
+ self.diff = 0.
+ self.average_time = 0.
diff --git a/KAIR/scripts/data_preparation/create_lmdb.py b/KAIR/scripts/data_preparation/create_lmdb.py
new file mode 100755
index 0000000000000000000000000000000000000000..8738b8134122aafd306b5e882c415f5036ce4d47
--- /dev/null
+++ b/KAIR/scripts/data_preparation/create_lmdb.py
@@ -0,0 +1,400 @@
+import argparse
+from os import path as osp
+
+from utils.utils_video import scandir
+from utils.utils_lmdb import make_lmdb_from_imgs
+
+
+def create_lmdb_for_div2k():
+ """Create lmdb files for DIV2K dataset.
+
+ Usage:
+ Before run this script, please run `extract_subimages.py`.
+ Typically, there are four folders to be processed for DIV2K dataset.
+ DIV2K_train_HR_sub
+ DIV2K_train_LR_bicubic/X2_sub
+ DIV2K_train_LR_bicubic/X3_sub
+ DIV2K_train_LR_bicubic/X4_sub
+ Remember to modify opt configurations according to your settings.
+ """
+ # HR images
+ folder_path = 'trainsets/DIV2K/DIV2K_train_HR_sub'
+ lmdb_path = 'trainsets/DIV2K/DIV2K_train_HR_sub.lmdb'
+ img_path_list, keys = prepare_keys_div2k(folder_path)
+ make_lmdb_from_imgs(folder_path, lmdb_path, img_path_list, keys)
+
+ # LRx2 images
+ folder_path = 'trainsets/DIV2K/DIV2K_train_LR_bicubic/X2_sub'
+ lmdb_path = 'trainsets/DIV2K/DIV2K_train_LR_bicubic_X2_sub.lmdb'
+ img_path_list, keys = prepare_keys_div2k(folder_path)
+ make_lmdb_from_imgs(folder_path, lmdb_path, img_path_list, keys)
+
+ # LRx3 images
+ folder_path = 'trainsets/DIV2K/DIV2K_train_LR_bicubic/X3_sub'
+ lmdb_path = 'trainsets/DIV2K/DIV2K_train_LR_bicubic_X3_sub.lmdb'
+ img_path_list, keys = prepare_keys_div2k(folder_path)
+ make_lmdb_from_imgs(folder_path, lmdb_path, img_path_list, keys)
+
+ # LRx4 images
+ folder_path = 'trainsets/DIV2K/DIV2K_train_LR_bicubic/X4_sub'
+ lmdb_path = 'trainsets/DIV2K/DIV2K_train_LR_bicubic_X4_sub.lmdb'
+ img_path_list, keys = prepare_keys_div2k(folder_path)
+ make_lmdb_from_imgs(folder_path, lmdb_path, img_path_list, keys)
+
+
+def prepare_keys_div2k(folder_path):
+ """Prepare image path list and keys for DIV2K dataset.
+
+ Args:
+ folder_path (str): Folder path.
+
+ Returns:
+ list[str]: Image path list.
+ list[str]: Key list.
+ """
+ print('Reading image path list ...')
+ img_path_list = sorted(list(scandir(folder_path, suffix='png', recursive=False)))
+ keys = [img_path.split('.png')[0] for img_path in sorted(img_path_list)]
+
+ return img_path_list, keys
+
+
+def create_lmdb_for_reds():
+ """Create lmdb files for REDS dataset.
+
+ Usage:
+ Before run this script, please run `regroup_reds_dataset.py`.
+ We take three folders for example:
+ train_sharp
+ train_sharp_bicubic
+ train_blur (for video deblurring)
+ Remember to modify opt configurations according to your settings.
+ """
+ # train_sharp
+ folder_path = 'trainsets/REDS/train_sharp'
+ lmdb_path = 'trainsets/REDS/train_sharp_with_val.lmdb'
+ img_path_list, keys = prepare_keys_reds(folder_path)
+ make_lmdb_from_imgs(folder_path, lmdb_path, img_path_list, keys, multiprocessing_read=True)
+
+ # train_sharp_bicubic
+ folder_path = 'trainsets/REDS/train_sharp_bicubic'
+ lmdb_path = 'trainsets/REDS/train_sharp_bicubic_with_val.lmdb'
+ img_path_list, keys = prepare_keys_reds(folder_path)
+ make_lmdb_from_imgs(folder_path, lmdb_path, img_path_list, keys, multiprocessing_read=True)
+
+ # train_blur (for video deblurring)
+ folder_path = 'trainsets/REDS_blur/train_blur'
+ lmdb_path = 'trainsets/REDS_blur/train_blur_with_val.lmdb'
+ img_path_list, keys = prepare_keys_reds(folder_path)
+ make_lmdb_from_imgs(folder_path, lmdb_path, img_path_list, keys, multiprocessing_read=True)
+
+ # train_blur_bicubic (for video deblurring-sr)
+ folder_path = 'trainsets/REDS_blur_bicubic/train_blur_bicubic'
+ lmdb_path = 'trainsets/REDS_blur_bicubic/train_blur_bicubic_with_val.lmdb'
+ img_path_list, keys = prepare_keys_reds(folder_path)
+ make_lmdb_from_imgs(folder_path, lmdb_path, img_path_list, keys, multiprocessing_read=True)
+
+
+def prepare_keys_reds(folder_path):
+ """Prepare image path list and keys for REDS dataset.
+
+ Args:
+ folder_path (str): Folder path.
+
+ Returns:
+ list[str]: Image path list.
+ list[str]: Key list.
+ """
+ print('Reading image path list ...')
+ img_path_list = sorted(list(scandir(folder_path, suffix='png', recursive=True)))
+ keys = [v.split('.png')[0] for v in img_path_list] # example: 000/00000000
+
+ return img_path_list, keys
+
+
+def create_lmdb_for_vimeo90k():
+ """Create lmdb files for Vimeo90K dataset.
+
+ Usage:
+ Remember to modify opt configurations according to your settings.
+ """
+ # GT
+ folder_path = 'trainsets/vimeo90k/vimeo_septuplet/sequences'
+ lmdb_path = 'trainsets/vimeo90k/vimeo90k_train_GT_only4th.lmdb'
+ train_list_path = 'trainsets/vimeo90k/vimeo_septuplet/sep_trainlist.txt'
+ img_path_list, keys = prepare_keys_vimeo90k(folder_path, train_list_path, 'gt')
+ make_lmdb_from_imgs(folder_path, lmdb_path, img_path_list, keys, multiprocessing_read=True)
+
+ # LQ
+ folder_path = 'trainsets/vimeo90k/vimeo_septuplet_matlabLRx4/sequences'
+ lmdb_path = 'trainsets/vimeo90k/vimeo90k_train_LR7frames.lmdb'
+ train_list_path = 'trainsets/vimeo90k/vimeo_septuplet/sep_trainlist.txt'
+ img_path_list, keys = prepare_keys_vimeo90k(folder_path, train_list_path, 'lq')
+ make_lmdb_from_imgs(folder_path, lmdb_path, img_path_list, keys, multiprocessing_read=True)
+
+
+def create_lmdb_for_vimeo90k_bd():
+ """Create lmdb files for Vimeo90K dataset (blur-downsampled lr only).
+
+ Usage:
+ Remember to modify opt configurations according to your settings.
+ """
+ # LQ (blur-downsampled, BD)
+ folder_path = 'trainsets/vimeo90k/vimeo_septuplet_BDLRx4/sequences'
+ lmdb_path = 'trainsets/vimeo90k/vimeo90k_train_BDLR7frames.lmdb'
+ train_list_path = 'trainsets/vimeo90k/vimeo_septuplet/sep_trainlist.txt'
+ img_path_list, keys = prepare_keys_vimeo90k(folder_path, train_list_path, 'lq')
+ make_lmdb_from_imgs(folder_path, lmdb_path, img_path_list, keys, multiprocessing_read=True)
+
+
+def prepare_keys_vimeo90k(folder_path, train_list_path, mode):
+ """Prepare image path list and keys for Vimeo90K dataset.
+
+ Args:
+ folder_path (str): Folder path.
+ train_list_path (str): Path to the official train list.
+ mode (str): One of 'gt' or 'lq'.
+
+ Returns:
+ list[str]: Image path list.
+ list[str]: Key list.
+ """
+ print('Reading image path list ...')
+ with open(train_list_path, 'r') as fin:
+ train_list = [line.strip() for line in fin]
+
+ img_path_list = []
+ keys = []
+ for line in train_list:
+ folder, sub_folder = line.split('/')
+ img_path_list.extend([osp.join(folder, sub_folder, f'im{j + 1}.png') for j in range(7)])
+ keys.extend([f'{folder}/{sub_folder}/im{j + 1}' for j in range(7)])
+
+ if mode == 'gt':
+ print('Only keep the 4th frame for the gt mode.')
+ img_path_list = [v for v in img_path_list if v.endswith('im4.png')]
+ keys = [v for v in keys if v.endswith('/im4')]
+
+ return img_path_list, keys
+
+
+def create_lmdb_for_dvd():
+ """Create lmdb files for DVD dataset.
+
+ Usage:
+ We take two folders for example:
+ GT
+ input
+ Remember to modify opt configurations according to your settings.
+ """
+ # train_sharp
+ folder_path = 'trainsets/DVD/train_GT'
+ lmdb_path = 'trainsets/DVD/train_GT.lmdb'
+ img_path_list, keys = prepare_keys_dvd(folder_path)
+ make_lmdb_from_imgs(folder_path, lmdb_path, img_path_list, keys, multiprocessing_read=True)
+
+ # train_sharp_bicubic
+ folder_path = 'trainsets/DVD/train_GT_blurred'
+ lmdb_path = 'trainsets/DVD/train_GT_blurred.lmdb'
+ img_path_list, keys = prepare_keys_dvd(folder_path)
+ make_lmdb_from_imgs(folder_path, lmdb_path, img_path_list, keys, multiprocessing_read=True)
+
+
+def prepare_keys_dvd(folder_path):
+ """Prepare image path list and keys for DVD dataset.
+
+ Args:
+ folder_path (str): Folder path.
+
+ Returns:
+ list[str]: Image path list.
+ list[str]: Key list.
+ """
+ print('Reading image path list ...')
+ img_path_list = sorted(list(scandir(folder_path, suffix='jpg', recursive=True)))
+ keys = [v.split('.jpg')[0] for v in img_path_list] # example: 000/00000000
+
+ return img_path_list, keys
+
+
+def create_lmdb_for_gopro():
+ """Create lmdb files for GoPro dataset.
+
+ Usage:
+ We take two folders for example:
+ GT
+ input
+ Remember to modify opt configurations according to your settings.
+ """
+ # train_sharp
+ folder_path = 'trainsets/GoPro/train_GT'
+ lmdb_path = 'trainsets/GoPro/train_GT.lmdb'
+ img_path_list, keys = prepare_keys_gopro(folder_path)
+ make_lmdb_from_imgs(folder_path, lmdb_path, img_path_list, keys, multiprocessing_read=True)
+
+ # train_sharp_bicubic
+ folder_path = 'trainsets/GoPro/train_GT_blurred'
+ lmdb_path = 'trainsets/GoPro/train_GT_blurred.lmdb'
+ img_path_list, keys = prepare_keys_gopro(folder_path)
+ make_lmdb_from_imgs(folder_path, lmdb_path, img_path_list, keys, multiprocessing_read=True)
+
+
+def prepare_keys_gopro(folder_path):
+ """Prepare image path list and keys for GoPro dataset.
+
+ Args:
+ folder_path (str): Folder path.
+
+ Returns:
+ list[str]: Image path list.
+ list[str]: Key list.
+ """
+ print('Reading image path list ...')
+ img_path_list = sorted(list(scandir(folder_path, suffix='png', recursive=True)))
+ keys = [v.split('.png')[0] for v in img_path_list] # example: 000/00000000
+
+ return img_path_list, keys
+
+
+def create_lmdb_for_davis():
+ """Create lmdb files for DAVIS dataset.
+
+ Usage:
+ We take one folders for example:
+ GT
+ Remember to modify opt configurations according to your settings.
+ """
+ # train_sharp
+ folder_path = 'trainsets/DAVIS/train_GT'
+ lmdb_path = 'trainsets/DAVIS/train_GT.lmdb'
+ img_path_list, keys = prepare_keys_davis(folder_path)
+ make_lmdb_from_imgs(folder_path, lmdb_path, img_path_list, keys, multiprocessing_read=True)
+
+
+def prepare_keys_davis(folder_path):
+ """Prepare image path list and keys for DAVIS dataset.
+
+ Args:
+ folder_path (str): Folder path.
+
+ Returns:
+ list[str]: Image path list.
+ list[str]: Key list.
+ """
+ print('Reading image path list ...')
+ img_path_list = sorted(list(scandir(folder_path, suffix='jpg', recursive=True)))
+ keys = [v.split('.jpg')[0] for v in img_path_list] # example: 000/00000000
+
+ return img_path_list, keys
+
+
+
+def create_lmdb_for_ldv():
+ """Create lmdb files for LDV dataset.
+
+ Usage:
+ We take two folders for example:
+ GT
+ input
+ Remember to modify opt configurations according to your settings.
+ """
+ # training_raw
+ folder_path = 'trainsets/LDV/training_raw'
+ lmdb_path = 'trainsets/LDV/training_raw.lmdb'
+ img_path_list, keys = prepare_keys_ldv(folder_path)
+ make_lmdb_from_imgs(folder_path, lmdb_path, img_path_list, keys, multiprocessing_read=True)
+
+ # training_fixed-QP
+ folder_path = 'trainsets/LDV/training_fixed-QP'
+ lmdb_path = 'trainsets/LDV/training_fixed-QP.lmdb'
+ img_path_list, keys = prepare_keys_ldv(folder_path)
+ make_lmdb_from_imgs(folder_path, lmdb_path, img_path_list, keys, multiprocessing_read=True)
+
+ # training_fixed-rate
+ folder_path = 'trainsets/LDV/training_fixed-rate'
+ lmdb_path = 'trainsets/LDV/training_fixed-rate.lmdb'
+ img_path_list, keys = prepare_keys_ldv(folder_path)
+ make_lmdb_from_imgs(folder_path, lmdb_path, img_path_list, keys, multiprocessing_read=True)
+
+
+def prepare_keys_ldv(folder_path):
+ """Prepare image path list and keys for LDV dataset.
+
+ Args:
+ folder_path (str): Folder path.
+
+ Returns:
+ list[str]: Image path list.
+ list[str]: Key list.
+ """
+ print('Reading image path list ...')
+ img_path_list = sorted(list(scandir(folder_path, suffix='png', recursive=True)))
+ keys = [v.split('.png')[0] for v in img_path_list] # example: 000/00000000
+
+ return img_path_list, keys
+
+
+def create_lmdb_for_reds_orig():
+ """Create lmdb files for REDS_orig dataset (120 fps).
+
+ Usage:
+ Before run this script, please run `regroup_reds_dataset.py`.
+ We take one folders for example:
+ train_orig
+ Remember to modify opt configurations according to your settings.
+ """
+ # train_sharp
+ folder_path = 'trainsets/REDS_orig/train_orig'
+ lmdb_path = 'trainsets/REDS_orig/train_orig_with_val.lmdb'
+ img_path_list, keys = prepare_keys_reds_orig(folder_path)
+ make_lmdb_from_imgs(folder_path, lmdb_path, img_path_list, keys, multiprocessing_read=True)
+
+
+def prepare_keys_reds_orig(folder_path):
+ """Prepare image path list and keys for REDS_orig dataset (120 fps).
+
+ Args:
+ folder_path (str): Folder path.
+
+ Returns:
+ list[str]: Image path list.
+ list[str]: Key list.
+ """
+ print('Reading image path list ...')
+ img_path_list = sorted(list(scandir(folder_path, suffix='png', recursive=True)))
+ keys = [v.split('.png')[0] for v in img_path_list] # example: 000/00000000
+
+ return img_path_list, keys
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+
+ parser.add_argument(
+ '--dataset',
+ type=str,
+ help=("Options: 'DIV2K', 'REDS', 'Vimeo90K', 'Vimeo90K_BD', 'DVD', 'GoPro',"
+ "'DAVIS', 'LDV', 'REDS_orig' "
+ 'You may need to modify the corresponding configurations in codes.'))
+ args = parser.parse_args()
+ dataset = args.dataset.lower()
+ if dataset == 'div2k':
+ create_lmdb_for_div2k()
+ elif dataset == 'reds':
+ create_lmdb_for_reds()
+ elif dataset == 'vimeo90k':
+ create_lmdb_for_vimeo90k()
+ elif dataset == 'vimeo90k_bd':
+ create_lmdb_for_vimeo90k_bd()
+ elif dataset == 'dvd':
+ create_lmdb_for_dvd()
+ elif dataset == 'gopro':
+ create_lmdb_for_gopro()
+ elif dataset == 'davis':
+ create_lmdb_for_davis()
+ elif dataset == 'ldv':
+ create_lmdb_for_ldv()
+ elif dataset == 'reds_orig':
+ create_lmdb_for_reds_orig()
+ else:
+ raise ValueError('Wrong dataset.')
diff --git a/KAIR/scripts/data_preparation/prepare_DAVIS.py b/KAIR/scripts/data_preparation/prepare_DAVIS.py
new file mode 100644
index 0000000000000000000000000000000000000000..b84fc6576b6ba3d15616114316c961acb46fc604
--- /dev/null
+++ b/KAIR/scripts/data_preparation/prepare_DAVIS.py
@@ -0,0 +1,33 @@
+import os
+import glob
+import shutil
+
+
+def generate_meta_info_txt(data_path, meta_info_path):
+ '''generate meta_info_DAVIS_GT.txt for DAVIS
+
+ :param data_path: dataset path.
+ :return: None
+ '''
+ f= open(meta_info_path, "w+")
+ file_list = sorted(glob.glob(os.path.join(data_path, 'train_GT/*')))
+ total_frames = 0
+ for path in file_list:
+ name = os.path.basename(path)
+ frames = sorted(glob.glob(os.path.join(path, '*')))
+ start_frame = os.path.basename(frames[0]).split('.')[0]
+
+ print(name, len(frames), start_frame)
+ total_frames += len(frames)
+
+ f.write(f"{name} {len(frames)} (480,854,3) {start_frame}\r\n")
+
+ assert total_frames == 6208, f'DAVIS training set should have 6208 images, but got {total_frames} images'
+
+if __name__ == '__main__':
+
+ dataset_path = 'trainsets/DAVIS'
+
+ generate_meta_info_txt(dataset_path, 'data/meta_info/meta_info_DAVIS_GT.txt')
+
+
diff --git a/KAIR/scripts/data_preparation/prepare_DVD.py b/KAIR/scripts/data_preparation/prepare_DVD.py
new file mode 100644
index 0000000000000000000000000000000000000000..51ed65e15521bd0ddc4d40e3793902a339fa4478
--- /dev/null
+++ b/KAIR/scripts/data_preparation/prepare_DVD.py
@@ -0,0 +1,59 @@
+import os
+import glob
+import shutil
+
+
+def rearrange_dir_structure(dataset_path):
+ '''move files to follow the directory structure as REDS
+
+ Original DVD dataset is organized as DVD/quantitative_datasets/720p_240fps_1/GT/00000.jpg.
+ We move files and organize them as DVD/train_GT_with_val/720p_240fps_1/00000.jpg (similar to REDS).
+
+ :param dataset_path: dataset path
+ :return: None
+ '''
+ os.makedirs(os.path.join(dataset_path, 'train_GT_with_val'), exist_ok=True)
+ os.makedirs(os.path.join(dataset_path, 'train_GT_blurred_with_val'), exist_ok=True)
+
+ file_list = sorted(glob.glob(os.path.join(dataset_path, '*')))
+ for path in file_list:
+ if 'train_GT_with_val' in path or 'train_GT_blurred_with_val' in path:
+ continue
+ name = os.path.basename(path)
+ print(name)
+
+ shutil.move(os.path.join(path, 'GT'), os.path.join(f'{dataset_path}/train_GT_with_val', name))
+ shutil.move(os.path.join(path, 'input'), os.path.join(f'{dataset_path}/train_GT_blurred_with_val', name))
+ shutil.rmtree(path)
+
+
+def generate_meta_info_txt(data_path, meta_info_path):
+ '''generate meta_info_DVD_GT.txt for DVD
+
+ :param data_path: dataset path.
+ :return: None
+ '''
+ f= open(meta_info_path, "w+")
+ file_list = sorted(glob.glob(os.path.join(data_path, 'train_GT_with_val/*')))
+ total_frames = 0
+ for path in file_list:
+ name = os.path.basename(path)
+ frames = sorted(glob.glob(os.path.join(path, '*')))
+ start_frame = os.path.basename(frames[0]).split('.')[0]
+
+ print(name, len(frames), start_frame)
+ total_frames += len(frames)
+
+ f.write(f"{name} {len(frames)} (720,1280,3) {start_frame}\r\n")
+
+ assert total_frames == 6708, f'DVD training+Validation set should have 6708 images, but got {total_frames} images'
+
+
+if __name__ == '__main__':
+
+ dataset_path = 'trainsets/DeepVideoDeblurring_Dataset/quantitative_datasets'
+
+ rearrange_dir_structure(dataset_path)
+ generate_meta_info_txt(dataset_path, 'data/meta_info/meta_info_DVD_GT.txt')
+
+
diff --git a/KAIR/scripts/data_preparation/prepare_GoPro_as_video.py b/KAIR/scripts/data_preparation/prepare_GoPro_as_video.py
new file mode 100644
index 0000000000000000000000000000000000000000..e28cad953617e0c8c239e79ccc15228cc337add7
--- /dev/null
+++ b/KAIR/scripts/data_preparation/prepare_GoPro_as_video.py
@@ -0,0 +1,58 @@
+import os
+import glob
+import shutil
+
+
+def rearrange_dir_structure(dataset_path, traintest='train'):
+ '''move files to follow the directory structure as REDS
+
+ Original GoPro dataset is organized as GoPro/train/GOPR0854_11_00-000022.png
+ We move files and organize them as GoPro/train_GT/GOPR0854_11_00/000022.jpg (similar to REDS).
+
+ :param dataset_path: dataset path
+ :return: None
+ '''
+ os.makedirs(os.path.join(dataset_path, f'{traintest}_GT'), exist_ok=True)
+ os.makedirs(os.path.join(dataset_path, f'{traintest}_GT_blurred'), exist_ok=True)
+
+ file_list = sorted(glob.glob(os.path.join(f'{dataset_path}/{traintest}', '*')))
+ for path in file_list:
+ name = os.path.basename(path)
+ print(name)
+
+ shutil.move(os.path.join(path, 'sharp'), os.path.join(f'{dataset_path}/{traintest}_GT', name))
+ shutil.move(os.path.join(path, 'blur'), os.path.join(f'{dataset_path}/{traintest}_GT_blurred', name))
+
+ shutil.rmtree(os.path.join(dataset_path, traintest))
+
+
+def generate_meta_info_txt(data_path, meta_info_path):
+ '''generate meta_info_GoPro_GT.txt for GoPro
+
+ :param data_path: dataset path.
+ :return: None
+ '''
+ f= open(meta_info_path, "w+")
+ file_list = sorted(glob.glob(os.path.join(data_path, 'train_GT/*')))
+ total_frames = 0
+ for path in file_list:
+ name = os.path.basename(path)
+ frames = sorted(glob.glob(os.path.join(path, '*')))
+ start_frame = os.path.basename(frames[0]).split('.')[0]
+
+ print(name, len(frames), start_frame)
+ total_frames += len(frames)
+
+ f.write(f"{name} {len(frames)} (720,1280,3) {start_frame}\r\n")
+
+ assert total_frames == 2103, f'GoPro training set should have 2103 images, but got {total_frames} images'
+
+if __name__ == '__main__':
+
+ dataset_path = 'trainsets/GoPro'
+
+ rearrange_dir_structure(dataset_path, 'train')
+ rearrange_dir_structure(dataset_path, 'test')
+ generate_meta_info_txt(dataset_path, 'data/meta_info/meta_info_GoPro_GT.txt')
+
+
diff --git a/KAIR/scripts/data_preparation/prepare_UDM10.py b/KAIR/scripts/data_preparation/prepare_UDM10.py
new file mode 100644
index 0000000000000000000000000000000000000000..6cc5d0ef3b9611136cc8c299bd59776eaf4bd207
--- /dev/null
+++ b/KAIR/scripts/data_preparation/prepare_UDM10.py
@@ -0,0 +1,36 @@
+import os
+import glob
+import shutil
+
+
+def rearrange_dir_structure(dataset_path):
+ '''move files to follow the directory structure as REDS
+
+ Original DVD dataset is organized as DVD/quantitative_datasets/720p_240fps_1/GT/00000.jpg.
+ We move files and organize them as DVD/train_GT_with_val/720p_240fps_1/00000.jpg (similar to REDS).
+
+ :param dataset_path: dataset path
+ :return: None
+ '''
+ os.makedirs(os.path.join(dataset_path, 'GT'), exist_ok=True)
+ os.makedirs(os.path.join(dataset_path, 'BDx4'), exist_ok=True)
+
+ file_list = sorted(glob.glob(os.path.join(dataset_path, '*')))
+ for path in file_list:
+ if 'GT' in path or 'BDx4' in path:
+ continue
+ name = os.path.basename(path)
+ print(name)
+
+ shutil.move(os.path.join(path, 'truth'), os.path.join(f'{dataset_path}/GT', name))
+ shutil.move(os.path.join(path, 'blur4'), os.path.join(f'{dataset_path}/BDx4', name))
+ shutil.rmtree(path)
+
+
+if __name__ == '__main__':
+
+ dataset_path = 'trainsets/UDM10'
+
+ rearrange_dir_structure(dataset_path)
+
+
diff --git a/KAIR/scripts/data_preparation/regroup_reds_dataset.py b/KAIR/scripts/data_preparation/regroup_reds_dataset.py
new file mode 100755
index 0000000000000000000000000000000000000000..b607982bc51acd1c16892f24cf209c4f62ee93c8
--- /dev/null
+++ b/KAIR/scripts/data_preparation/regroup_reds_dataset.py
@@ -0,0 +1,40 @@
+import glob
+import os
+
+
+def regroup_reds_dataset(train_path, val_path):
+ """Regroup original REDS datasets.
+
+ We merge train and validation data into one folder, and separate the
+ validation clips in reds_dataset.py.
+ There are 240 training clips (starting from 0 to 239),
+ so we name the validation clip index starting from 240 to 269 (total 30
+ validation clips).
+
+ Args:
+ train_path (str): Path to the train folder.
+ val_path (str): Path to the validation folder.
+ """
+ # move the validation data to the train folder
+ val_folders = glob.glob(os.path.join(val_path, '*'))
+ for folder in val_folders:
+ new_folder_idx = int(folder.split('/')[-1]) + 240
+ os.system(f'cp -r {folder} {os.path.join(train_path, str(new_folder_idx))}')
+
+
+if __name__ == '__main__':
+ # train_sharp
+ train_path = 'trainsets/REDS/train_sharp'
+ val_path = 'trainsets/REDS/val_sharp'
+ regroup_reds_dataset(train_path, val_path)
+
+ # train_sharp_bicubic
+ train_path = 'trainsets/REDS/train_sharp_bicubic/X4'
+ val_path = 'trainsets/REDS/val_sharp_bicubic/X4'
+ regroup_reds_dataset(train_path, val_path)
+
+ # train_blur (for video deblurring)
+ train_path = 'trainsets/REDS/train_blur'
+ val_path = 'trainsets/REDS/val_blur'
+ regroup_reds_dataset(train_path, val_path)
+
diff --git a/KAIR/scripts/matlab_scripts/evaluate_video_deblurring.m b/KAIR/scripts/matlab_scripts/evaluate_video_deblurring.m
new file mode 100644
index 0000000000000000000000000000000000000000..564415da187b41b36b02898d018527ac8b2cbbd7
--- /dev/null
+++ b/KAIR/scripts/matlab_scripts/evaluate_video_deblurring.m
@@ -0,0 +1,40 @@
+%% Based on codes from https://github.com/swz30/MPRNet/blob/main/Deblurring/evaluate_GOPRO_HIDE.m
+%% Evaluation by Matlab is often 0.01 better than Python for SSIM.
+%% Euler command: module load matlab/R2020a; cd scripts/matlab_scripts; matlab -nodisplay -nojvm -singleCompThread -r evaluate_video_deblurring
+
+
+close all;clear all;
+
+datasets = {'DVD', 'GoPro'};
+num_set = length(datasets);
+file_paths = {'results/005_VRT_videodeblurring_DVD/*/',
+ 'results/006_VRT_videodeblurring_GoPro/*/'};
+gt_paths = {'testsets/DVD10/test_GT/*/',
+ 'testsets/GoPro11/test_GT/*/'};
+
+for idx_set = 1:num_set
+ file_path = file_paths{idx_set};
+ gt_path = gt_paths{idx_set};
+ path_list = [dir(strcat(file_path,'*.jpg')); dir(strcat(file_path,'*.png'))];
+ gt_list = [dir(strcat(gt_path,'*.jpg')); dir(strcat(gt_path,'*.png'))];
+ img_num = length(path_list);
+ fprintf('For %s dataset, it has %d LQ images and %d GT images\n', datasets{idx_set}, length(path_list), length(gt_list));
+
+ total_psnr = 0;
+ total_ssim = 0;
+ if img_num > 0
+ for j = 1:img_num
+ input = imread(strcat(path_list(j).folder, '/', path_list(j).name));
+ gt = imread(strcat(gt_list(j).folder, '/', gt_list(j).name));
+ ssim_val = ssim(input, gt);
+ psnr_val = psnr(input, gt);
+ total_ssim = total_ssim + ssim_val;
+ total_psnr = total_psnr + psnr_val;
+ end
+ end
+ qm_psnr = total_psnr / img_num;
+ qm_ssim = total_ssim / img_num;
+
+ fprintf('For %s dataset PSNR: %f SSIM: %f\n', datasets{idx_set}, qm_psnr, qm_ssim);
+
+end
\ No newline at end of file
diff --git a/KAIR/scripts/matlab_scripts/generate_LR_UDM10_BD.m b/KAIR/scripts/matlab_scripts/generate_LR_UDM10_BD.m
new file mode 100755
index 0000000000000000000000000000000000000000..5ced0521c6a85cdc104a734f26558f841f067eab
--- /dev/null
+++ b/KAIR/scripts/matlab_scripts/generate_LR_UDM10_BD.m
@@ -0,0 +1,60 @@
+function generate_LR_UDM10()
+%% matlab code to genetate blur-downsampled (BD) for UDM10 dataset
+% Euler command: module load matlab/R2020a; cd scripts/matlab_scripts; matlab -nodisplay -nojvm -singleCompThread -r generate_LR_UDM10_BD
+
+up_scale = 4;
+mod_scale = 4;
+sigma = 1.6;
+idx = 0;
+filepaths = dir('/cluster/work/cvl/videosr/UDM10/GT/*/*.png');
+for i = 1 : length(filepaths)
+ [~,imname,ext] = fileparts(filepaths(i).name);
+ folder_path = filepaths(i).folder;
+ save_LR_folder = strrep(folder_path,'GT','BDx4');
+ if ~exist(save_LR_folder, 'dir')
+ mkdir(save_LR_folder);
+ end
+ if isempty(imname)
+ disp('Ignore . folder.');
+ elseif strcmp(imname, '.')
+ disp('Ignore .. folder.');
+ else
+ idx = idx + 1;
+ str_result = sprintf('%d\t%s.\n', idx, imname);
+ fprintf(str_result);
+ % read image
+ img = imread(fullfile(folder_path, [imname, ext]));
+ img = im2double(img);
+ % modcrop
+ img = modcrop(img, mod_scale);
+ % LR
+ im_LR = BD_degradation(img, up_scale, sigma);
+ if exist('save_LR_folder', 'var')
+ fprintf('\n %d, %s', idx, imname)
+ imwrite(im_LR, fullfile(save_LR_folder, [imname, '.png']));
+ end
+ end
+end
+end
+
+%% modcrop
+function img = modcrop(img, modulo)
+if size(img,3) == 1
+ sz = size(img);
+ sz = sz - mod(sz, modulo);
+ img = img(1:sz(1), 1:sz(2));
+else
+ tmpsz = size(img);
+ sz = tmpsz(1:2);
+ sz = sz - mod(sz, modulo);
+ img = img(1:sz(1), 1:sz(2),:);
+end
+end
+
+%% blur-downsampling degradation
+function img = BD_degradation(img, up_scale, sigma)
+kernelsize = ceil(sigma * 3) * 2 + 2;
+kernel = fspecial('gaussian', kernelsize, sigma);
+img = imfilter(img, kernel, 'replicate');
+img = img(up_scale/2:up_scale:end-up_scale/2, up_scale/2:up_scale:end-up_scale/2, :);
+end
\ No newline at end of file
diff --git a/KAIR/scripts/matlab_scripts/generate_LR_Vimeo90K.m b/KAIR/scripts/matlab_scripts/generate_LR_Vimeo90K.m
new file mode 100755
index 0000000000000000000000000000000000000000..acdd62e5227547c8e11dacf998a43c3719f60e99
--- /dev/null
+++ b/KAIR/scripts/matlab_scripts/generate_LR_Vimeo90K.m
@@ -0,0 +1,49 @@
+function generate_LR_Vimeo90K()
+%% matlab code to genetate bicubic-downsampled for Vimeo90K dataset
+
+up_scale = 4;
+mod_scale = 4;
+idx = 0;
+filepaths = dir('trainsets/vimeo90k/vimeo_septuplet/sequences/*/*/*.png');
+for i = 1 : length(filepaths)
+ [~,imname,ext] = fileparts(filepaths(i).name);
+ folder_path = filepaths(i).folder;
+ save_LR_folder = strrep(folder_path,'vimeo_septuplet','vimeo_septuplet_matlabLRx4');
+ if ~exist(save_LR_folder, 'dir')
+ mkdir(save_LR_folder);
+ end
+ if isempty(imname)
+ disp('Ignore . folder.');
+ elseif strcmp(imname, '.')
+ disp('Ignore .. folder.');
+ else
+ idx = idx + 1;
+ str_result = sprintf('%d\t%s.\n', idx, imname);
+ fprintf(str_result);
+ % read image
+ img = imread(fullfile(folder_path, [imname, ext]));
+ img = im2double(img);
+ % modcrop
+ img = modcrop(img, mod_scale);
+ % LR
+ im_LR = imresize(img, 1/up_scale, 'bicubic');
+ if exist('save_LR_folder', 'var')
+ imwrite(im_LR, fullfile(save_LR_folder, [imname, '.png']));
+ end
+ end
+end
+end
+
+%% modcrop
+function img = modcrop(img, modulo)
+if size(img,3) == 1
+ sz = size(img);
+ sz = sz - mod(sz, modulo);
+ img = img(1:sz(1), 1:sz(2));
+else
+ tmpsz = size(img);
+ sz = tmpsz(1:2);
+ sz = sz - mod(sz, modulo);
+ img = img(1:sz(1), 1:sz(2),:);
+end
+end
diff --git a/KAIR/scripts/matlab_scripts/generate_LR_Vimeo90K_BD.m b/KAIR/scripts/matlab_scripts/generate_LR_Vimeo90K_BD.m
new file mode 100755
index 0000000000000000000000000000000000000000..916134fa1509a6da15e12f4038aea455abfa4f3a
--- /dev/null
+++ b/KAIR/scripts/matlab_scripts/generate_LR_Vimeo90K_BD.m
@@ -0,0 +1,60 @@
+function generate_LR_Vimeo90K()
+%% matlab code to genetate blur-downsampled (BD) for Vimeo90K dataset
+% Euler module load matlab/R2020a; cd scripts/matlab_scripts; matlab -nodisplay -nojvm -singleCompThread -r generate_LR_Vimeo90K_BD
+
+up_scale = 4;
+mod_scale = 4;
+sigma = 1.6;
+idx = 0;
+filepaths = dir('/scratch/190250671.tmpdir/vimeo90k/vimeo_septuplet/sequences/*/*/*.png');
+for i = 1 : length(filepaths)
+ [~,imname,ext] = fileparts(filepaths(i).name);
+ folder_path = filepaths(i).folder;
+ save_LR_folder = strrep(folder_path,'vimeo_septuplet','vimeo_septuplet_BDLRx4');
+ if ~exist(save_LR_folder, 'dir')
+ mkdir(save_LR_folder);
+ end
+ if isempty(imname)
+ disp('Ignore . folder.');
+ elseif strcmp(imname, '.')
+ disp('Ignore .. folder.');
+ else
+ idx = idx + 1;
+ str_result = sprintf('%d\t%s.\n', idx, imname);
+ fprintf(str_result);
+ % read image
+ img = imread(fullfile(folder_path, [imname, ext]));
+ img = im2double(img);
+ % modcrop
+ img = modcrop(img, mod_scale);
+ % LR
+ im_LR = BD_degradation(img, up_scale, sigma);
+ if exist('save_LR_folder', 'var')
+ fprintf('\n %d, %s', idx, imname)
+ imwrite(im_LR, fullfile(save_LR_folder, [imname, '.png']));
+ end
+ end
+end
+end
+
+%% modcrop
+function img = modcrop(img, modulo)
+if size(img,3) == 1
+ sz = size(img);
+ sz = sz - mod(sz, modulo);
+ img = img(1:sz(1), 1:sz(2));
+else
+ tmpsz = size(img);
+ sz = tmpsz(1:2);
+ sz = sz - mod(sz, modulo);
+ img = img(1:sz(1), 1:sz(2),:);
+end
+end
+
+%% blur-downsampling degradation
+function img = BD_degradation(img, up_scale, sigma)
+kernelsize = ceil(sigma * 3) * 2 + 2;
+kernel = fspecial('gaussian', kernelsize, sigma);
+img = imfilter(img, kernel, 'replicate');
+img = img(up_scale/2:up_scale:end-up_scale/2, up_scale/2:up_scale:end-up_scale/2, :);
+end
\ No newline at end of file
diff --git a/KAIR/utils/utils_alignfaces.py b/KAIR/utils/utils_alignfaces.py
new file mode 100644
index 0000000000000000000000000000000000000000..fa74e8a2e8984f5075d0cbd06afd494c9661a015
--- /dev/null
+++ b/KAIR/utils/utils_alignfaces.py
@@ -0,0 +1,263 @@
+# -*- coding: utf-8 -*-
+"""
+Created on Mon Apr 24 15:43:29 2017
+@author: zhaoy
+"""
+import cv2
+import numpy as np
+from skimage import transform as trans
+
+# reference facial points, a list of coordinates (x,y)
+REFERENCE_FACIAL_POINTS = [
+ [30.29459953, 51.69630051],
+ [65.53179932, 51.50139999],
+ [48.02519989, 71.73660278],
+ [33.54930115, 92.3655014],
+ [62.72990036, 92.20410156]
+]
+
+DEFAULT_CROP_SIZE = (96, 112)
+
+
+def _umeyama(src, dst, estimate_scale=True, scale=1.0):
+ """Estimate N-D similarity transformation with or without scaling.
+ Parameters
+ ----------
+ src : (M, N) array
+ Source coordinates.
+ dst : (M, N) array
+ Destination coordinates.
+ estimate_scale : bool
+ Whether to estimate scaling factor.
+ Returns
+ -------
+ T : (N + 1, N + 1)
+ The homogeneous similarity transformation matrix. The matrix contains
+ NaN values only if the problem is not well-conditioned.
+ References
+ ----------
+ .. [1] "Least-squares estimation of transformation parameters between two
+ point patterns", Shinji Umeyama, PAMI 1991, :DOI:`10.1109/34.88573`
+ """
+
+ num = src.shape[0]
+ dim = src.shape[1]
+
+ # Compute mean of src and dst.
+ src_mean = src.mean(axis=0)
+ dst_mean = dst.mean(axis=0)
+
+ # Subtract mean from src and dst.
+ src_demean = src - src_mean
+ dst_demean = dst - dst_mean
+
+ # Eq. (38).
+ A = dst_demean.T @ src_demean / num
+
+ # Eq. (39).
+ d = np.ones((dim,), dtype=np.double)
+ if np.linalg.det(A) < 0:
+ d[dim - 1] = -1
+
+ T = np.eye(dim + 1, dtype=np.double)
+
+ U, S, V = np.linalg.svd(A)
+
+ # Eq. (40) and (43).
+ rank = np.linalg.matrix_rank(A)
+ if rank == 0:
+ return np.nan * T
+ elif rank == dim - 1:
+ if np.linalg.det(U) * np.linalg.det(V) > 0:
+ T[:dim, :dim] = U @ V
+ else:
+ s = d[dim - 1]
+ d[dim - 1] = -1
+ T[:dim, :dim] = U @ np.diag(d) @ V
+ d[dim - 1] = s
+ else:
+ T[:dim, :dim] = U @ np.diag(d) @ V
+
+ if estimate_scale:
+ # Eq. (41) and (42).
+ scale = 1.0 / src_demean.var(axis=0).sum() * (S @ d)
+ else:
+ scale = scale
+
+ T[:dim, dim] = dst_mean - scale * (T[:dim, :dim] @ src_mean.T)
+ T[:dim, :dim] *= scale
+
+ return T, scale
+
+
+class FaceWarpException(Exception):
+ def __str__(self):
+ return 'In File {}:{}'.format(
+ __file__, super.__str__(self))
+
+
+def get_reference_facial_points(output_size=None,
+ inner_padding_factor=0.0,
+ outer_padding=(0, 0),
+ default_square=False):
+ tmp_5pts = np.array(REFERENCE_FACIAL_POINTS)
+ tmp_crop_size = np.array(DEFAULT_CROP_SIZE)
+
+ # 0) make the inner region a square
+ if default_square:
+ size_diff = max(tmp_crop_size) - tmp_crop_size
+ tmp_5pts += size_diff / 2
+ tmp_crop_size += size_diff
+
+ if (output_size and
+ output_size[0] == tmp_crop_size[0] and
+ output_size[1] == tmp_crop_size[1]):
+ print('output_size == DEFAULT_CROP_SIZE {}: return default reference points'.format(tmp_crop_size))
+ return tmp_5pts
+
+ if (inner_padding_factor == 0 and
+ outer_padding == (0, 0)):
+ if output_size is None:
+ print('No paddings to do: return default reference points')
+ return tmp_5pts
+ else:
+ raise FaceWarpException(
+ 'No paddings to do, output_size must be None or {}'.format(tmp_crop_size))
+
+ # check output size
+ if not (0 <= inner_padding_factor <= 1.0):
+ raise FaceWarpException('Not (0 <= inner_padding_factor <= 1.0)')
+
+ if ((inner_padding_factor > 0 or outer_padding[0] > 0 or outer_padding[1] > 0)
+ and output_size is None):
+ output_size = tmp_crop_size * \
+ (1 + inner_padding_factor * 2).astype(np.int32)
+ output_size += np.array(outer_padding)
+ print(' deduced from paddings, output_size = ', output_size)
+
+ if not (outer_padding[0] < output_size[0]
+ and outer_padding[1] < output_size[1]):
+ raise FaceWarpException('Not (outer_padding[0] < output_size[0]'
+ 'and outer_padding[1] < output_size[1])')
+
+ # 1) pad the inner region according inner_padding_factor
+ # print('---> STEP1: pad the inner region according inner_padding_factor')
+ if inner_padding_factor > 0:
+ size_diff = tmp_crop_size * inner_padding_factor * 2
+ tmp_5pts += size_diff / 2
+ tmp_crop_size += np.round(size_diff).astype(np.int32)
+
+ # print(' crop_size = ', tmp_crop_size)
+ # print(' reference_5pts = ', tmp_5pts)
+
+ # 2) resize the padded inner region
+ # print('---> STEP2: resize the padded inner region')
+ size_bf_outer_pad = np.array(output_size) - np.array(outer_padding) * 2
+ # print(' crop_size = ', tmp_crop_size)
+ # print(' size_bf_outer_pad = ', size_bf_outer_pad)
+
+ if size_bf_outer_pad[0] * tmp_crop_size[1] != size_bf_outer_pad[1] * tmp_crop_size[0]:
+ raise FaceWarpException('Must have (output_size - outer_padding)'
+ '= some_scale * (crop_size * (1.0 + inner_padding_factor)')
+
+ scale_factor = size_bf_outer_pad[0].astype(np.float32) / tmp_crop_size[0]
+ # print(' resize scale_factor = ', scale_factor)
+ tmp_5pts = tmp_5pts * scale_factor
+ # size_diff = tmp_crop_size * (scale_factor - min(scale_factor))
+ # tmp_5pts = tmp_5pts + size_diff / 2
+ tmp_crop_size = size_bf_outer_pad
+ # print(' crop_size = ', tmp_crop_size)
+ # print(' reference_5pts = ', tmp_5pts)
+
+ # 3) add outer_padding to make output_size
+ reference_5point = tmp_5pts + np.array(outer_padding)
+ tmp_crop_size = output_size
+ # print('---> STEP3: add outer_padding to make output_size')
+ # print(' crop_size = ', tmp_crop_size)
+ # print(' reference_5pts = ', tmp_5pts)
+ #
+ # print('===> end get_reference_facial_points\n')
+
+ return reference_5point
+
+
+def get_affine_transform_matrix(src_pts, dst_pts):
+ tfm = np.float32([[1, 0, 0], [0, 1, 0]])
+ n_pts = src_pts.shape[0]
+ ones = np.ones((n_pts, 1), src_pts.dtype)
+ src_pts_ = np.hstack([src_pts, ones])
+ dst_pts_ = np.hstack([dst_pts, ones])
+
+ A, res, rank, s = np.linalg.lstsq(src_pts_, dst_pts_)
+
+ if rank == 3:
+ tfm = np.float32([
+ [A[0, 0], A[1, 0], A[2, 0]],
+ [A[0, 1], A[1, 1], A[2, 1]]
+ ])
+ elif rank == 2:
+ tfm = np.float32([
+ [A[0, 0], A[1, 0], 0],
+ [A[0, 1], A[1, 1], 0]
+ ])
+
+ return tfm
+
+
+def warp_and_crop_face(src_img,
+ facial_pts,
+ reference_pts=None,
+ crop_size=(96, 112),
+ align_type='smilarity'): #smilarity cv2_affine affine
+ if reference_pts is None:
+ if crop_size[0] == 96 and crop_size[1] == 112:
+ reference_pts = REFERENCE_FACIAL_POINTS
+ else:
+ default_square = False
+ inner_padding_factor = 0
+ outer_padding = (0, 0)
+ output_size = crop_size
+
+ reference_pts = get_reference_facial_points(output_size,
+ inner_padding_factor,
+ outer_padding,
+ default_square)
+
+ ref_pts = np.float32(reference_pts)
+ ref_pts_shp = ref_pts.shape
+ if max(ref_pts_shp) < 3 or min(ref_pts_shp) != 2:
+ raise FaceWarpException(
+ 'reference_pts.shape must be (K,2) or (2,K) and K>2')
+
+ if ref_pts_shp[0] == 2:
+ ref_pts = ref_pts.T
+
+ src_pts = np.float32(facial_pts)
+ src_pts_shp = src_pts.shape
+ if max(src_pts_shp) < 3 or min(src_pts_shp) != 2:
+ raise FaceWarpException(
+ 'facial_pts.shape must be (K,2) or (2,K) and K>2')
+
+ if src_pts_shp[0] == 2:
+ src_pts = src_pts.T
+
+ if src_pts.shape != ref_pts.shape:
+ raise FaceWarpException(
+ 'facial_pts and reference_pts must have the same shape')
+
+ if align_type is 'cv2_affine':
+ tfm = cv2.getAffineTransform(src_pts[0:3], ref_pts[0:3])
+ tfm_inv = cv2.getAffineTransform(ref_pts[0:3], src_pts[0:3])
+ elif align_type is 'affine':
+ tfm = get_affine_transform_matrix(src_pts, ref_pts)
+ tfm_inv = get_affine_transform_matrix(ref_pts, src_pts)
+ else:
+ params, scale = _umeyama(src_pts, ref_pts)
+ tfm = params[:2, :]
+
+ params, _ = _umeyama(ref_pts, src_pts, False, scale=1.0/scale)
+ tfm_inv = params[:2, :]
+
+ face_img = cv2.warpAffine(src_img, tfm, (crop_size[0], crop_size[1]), flags=3)
+
+ return face_img, tfm_inv
diff --git a/KAIR/utils/utils_blindsr.py b/KAIR/utils/utils_blindsr.py
new file mode 100644
index 0000000000000000000000000000000000000000..83b009c1cfaa5fe3d32fbbcd836b64991204f482
--- /dev/null
+++ b/KAIR/utils/utils_blindsr.py
@@ -0,0 +1,631 @@
+# -*- coding: utf-8 -*-
+import numpy as np
+import cv2
+import torch
+
+from utils import utils_image as util
+
+import random
+from scipy import ndimage
+import scipy
+import scipy.stats as ss
+from scipy.interpolate import interp2d
+from scipy.linalg import orth
+
+
+
+
+"""
+# --------------------------------------------
+# super-resolution
+# --------------------------------------------
+#
+# kai zhang (cskaizhang@gmail.com)
+# https://github.com/cszn
+# from 2019/03--2021/08
+# --------------------------------------------
+"""
+
+def modcrop_np(img, sf):
+ '''
+ args:
+ img: numpy image, wxh or wxhxc
+ sf: scale factor
+
+ return:
+ cropped image
+ '''
+ w, h = img.shape[:2]
+ im = np.copy(img)
+ return im[:w - w % sf, :h - h % sf, ...]
+
+
+"""
+# --------------------------------------------
+# anisotropic gaussian kernels
+# --------------------------------------------
+"""
+def analytic_kernel(k):
+ """calculate the x4 kernel from the x2 kernel (for proof see appendix in paper)"""
+ k_size = k.shape[0]
+ # calculate the big kernels size
+ big_k = np.zeros((3 * k_size - 2, 3 * k_size - 2))
+ # loop over the small kernel to fill the big one
+ for r in range(k_size):
+ for c in range(k_size):
+ big_k[2 * r:2 * r + k_size, 2 * c:2 * c + k_size] += k[r, c] * k
+ # crop the edges of the big kernel to ignore very small values and increase run time of sr
+ crop = k_size // 2
+ cropped_big_k = big_k[crop:-crop, crop:-crop]
+ # normalize to 1
+ return cropped_big_k / cropped_big_k.sum()
+
+
+def anisotropic_gaussian(ksize=15, theta=np.pi, l1=6, l2=6):
+ """ generate an anisotropic gaussian kernel
+ args:
+ ksize : e.g., 15, kernel size
+ theta : [0, pi], rotation angle range
+ l1 : [0.1,50], scaling of eigenvalues
+ l2 : [0.1,l1], scaling of eigenvalues
+ if l1 = l2, will get an isotropic gaussian kernel.
+
+ returns:
+ k : kernel
+ """
+
+ v = np.dot(np.array([[np.cos(theta), -np.sin(theta)], [np.sin(theta), np.cos(theta)]]), np.array([1., 0.]))
+ v = np.array([[v[0], v[1]], [v[1], -v[0]]])
+ d = np.array([[l1, 0], [0, l2]])
+ sigma = np.dot(np.dot(v, d), np.linalg.inv(v))
+ k = gm_blur_kernel(mean=[0, 0], cov=sigma, size=ksize)
+
+ return k
+
+
+def gm_blur_kernel(mean, cov, size=15):
+ center = size / 2.0 + 0.5
+ k = np.zeros([size, size])
+ for y in range(size):
+ for x in range(size):
+ cy = y - center + 1
+ cx = x - center + 1
+ k[y, x] = ss.multivariate_normal.pdf([cx, cy], mean=mean, cov=cov)
+
+ k = k / np.sum(k)
+ return k
+
+
+def shift_pixel(x, sf, upper_left=true):
+ """shift pixel for super-resolution with different scale factors
+ args:
+ x: wxhxc or wxh
+ sf: scale factor
+ upper_left: shift direction
+ """
+ h, w = x.shape[:2]
+ shift = (sf-1)*0.5
+ xv, yv = np.arange(0, w, 1.0), np.arange(0, h, 1.0)
+ if upper_left:
+ x1 = xv + shift
+ y1 = yv + shift
+ else:
+ x1 = xv - shift
+ y1 = yv - shift
+
+ x1 = np.clip(x1, 0, w-1)
+ y1 = np.clip(y1, 0, h-1)
+
+ if x.ndim == 2:
+ x = interp2d(xv, yv, x)(x1, y1)
+ if x.ndim == 3:
+ for i in range(x.shape[-1]):
+ x[:, :, i] = interp2d(xv, yv, x[:, :, i])(x1, y1)
+
+ return x
+
+
+def blur(x, k):
+ '''
+ x: image, nxcxhxw
+ k: kernel, nx1xhxw
+ '''
+ n, c = x.shape[:2]
+ p1, p2 = (k.shape[-2]-1)//2, (k.shape[-1]-1)//2
+ x = torch.nn.functional.pad(x, pad=(p1, p2, p1, p2), mode='replicate')
+ k = k.repeat(1,c,1,1)
+ k = k.view(-1, 1, k.shape[2], k.shape[3])
+ x = x.view(1, -1, x.shape[2], x.shape[3])
+ x = torch.nn.functional.conv2d(x, k, bias=none, stride=1, padding=0, groups=n*c)
+ x = x.view(n, c, x.shape[2], x.shape[3])
+
+ return x
+
+
+
+def gen_kernel(k_size=np.array([15, 15]), scale_factor=np.array([4, 4]), min_var=0.6, max_var=10., noise_level=0):
+ """"
+ # modified version of https://github.com/assafshocher/blindsr_dataset_generator
+ # kai zhang
+ # min_var = 0.175 * sf # variance of the gaussian kernel will be sampled between min_var and max_var
+ # max_var = 2.5 * sf
+ """
+ # set random eigen-vals (lambdas) and angle (theta) for cov matrix
+ lambda_1 = min_var + np.random.rand() * (max_var - min_var)
+ lambda_2 = min_var + np.random.rand() * (max_var - min_var)
+ theta = np.random.rand() * np.pi # random theta
+ noise = -noise_level + np.random.rand(*k_size) * noise_level * 2
+
+ # set cov matrix using lambdas and theta
+ lambda = np.diag([lambda_1, lambda_2])
+ q = np.array([[np.cos(theta), -np.sin(theta)],
+ [np.sin(theta), np.cos(theta)]])
+ sigma = q @ lambda @ q.t
+ inv_sigma = np.linalg.inv(sigma)[none, none, :, :]
+
+ # set expectation position (shifting kernel for aligned image)
+ mu = k_size // 2 - 0.5*(scale_factor - 1) # - 0.5 * (scale_factor - k_size % 2)
+ mu = mu[none, none, :, none]
+
+ # create meshgrid for gaussian
+ [x,y] = np.meshgrid(range(k_size[0]), range(k_size[1]))
+ z = np.stack([x, y], 2)[:, :, :, none]
+
+ # calcualte gaussian for every pixel of the kernel
+ zz = z-mu
+ zz_t = zz.transpose(0,1,3,2)
+ raw_kernel = np.exp(-0.5 * np.squeeze(zz_t @ inv_sigma @ zz)) * (1 + noise)
+
+ # shift the kernel so it will be centered
+ #raw_kernel_centered = kernel_shift(raw_kernel, scale_factor)
+
+ # normalize the kernel and return
+ #kernel = raw_kernel_centered / np.sum(raw_kernel_centered)
+ kernel = raw_kernel / np.sum(raw_kernel)
+ return kernel
+
+
+def fspecial_gaussian(hsize, sigma):
+ hsize = [hsize, hsize]
+ siz = [(hsize[0]-1.0)/2.0, (hsize[1]-1.0)/2.0]
+ std = sigma
+ [x, y] = np.meshgrid(np.arange(-siz[1], siz[1]+1), np.arange(-siz[0], siz[0]+1))
+ arg = -(x*x + y*y)/(2*std*std)
+ h = np.exp(arg)
+ h[h < scipy.finfo(float).eps * h.max()] = 0
+ sumh = h.sum()
+ if sumh != 0:
+ h = h/sumh
+ return h
+
+
+def fspecial_laplacian(alpha):
+ alpha = max([0, min([alpha,1])])
+ h1 = alpha/(alpha+1)
+ h2 = (1-alpha)/(alpha+1)
+ h = [[h1, h2, h1], [h2, -4/(alpha+1), h2], [h1, h2, h1]]
+ h = np.array(h)
+ return h
+
+
+def fspecial(filter_type, *args, **kwargs):
+ '''
+ python code from:
+ https://github.com/ronaldosena/imagens-medicas-2/blob/40171a6c259edec7827a6693a93955de2bd39e76/aulas/aula_2_-_uniform_filter/matlab_fspecial.py
+ '''
+ if filter_type == 'gaussian':
+ return fspecial_gaussian(*args, **kwargs)
+ if filter_type == 'laplacian':
+ return fspecial_laplacian(*args, **kwargs)
+
+"""
+# --------------------------------------------
+# degradation models
+# --------------------------------------------
+"""
+
+
+def bicubic_degradation(x, sf=3):
+ '''
+ args:
+ x: hxwxc image, [0, 1]
+ sf: down-scale factor
+
+ return:
+ bicubicly downsampled lr image
+ '''
+ x = util.imresize_np(x, scale=1/sf)
+ return x
+
+
+def srmd_degradation(x, k, sf=3):
+ ''' blur + bicubic downsampling
+
+ args:
+ x: hxwxc image, [0, 1]
+ k: hxw, double
+ sf: down-scale factor
+
+ return:
+ downsampled lr image
+
+ reference:
+ @inproceedings{zhang2018learning,
+ title={learning a single convolutional super-resolution network for multiple degradations},
+ author={zhang, kai and zuo, wangmeng and zhang, lei},
+ booktitle={ieee conference on computer vision and pattern recognition},
+ pages={3262--3271},
+ year={2018}
+ }
+ '''
+ x = ndimage.filters.convolve(x, np.expand_dims(k, axis=2), mode='wrap') # 'nearest' | 'mirror'
+ x = bicubic_degradation(x, sf=sf)
+ return x
+
+
+def dpsr_degradation(x, k, sf=3):
+
+ ''' bicubic downsampling + blur
+
+ args:
+ x: hxwxc image, [0, 1]
+ k: hxw, double
+ sf: down-scale factor
+
+ return:
+ downsampled lr image
+
+ reference:
+ @inproceedings{zhang2019deep,
+ title={deep plug-and-play super-resolution for arbitrary blur kernels},
+ author={zhang, kai and zuo, wangmeng and zhang, lei},
+ booktitle={ieee conference on computer vision and pattern recognition},
+ pages={1671--1681},
+ year={2019}
+ }
+ '''
+ x = bicubic_degradation(x, sf=sf)
+ x = ndimage.filters.convolve(x, np.expand_dims(k, axis=2), mode='wrap')
+ return x
+
+
+def classical_degradation(x, k, sf=3):
+ ''' blur + downsampling
+
+ args:
+ x: hxwxc image, [0, 1]/[0, 255]
+ k: hxw, double
+ sf: down-scale factor
+
+ return:
+ downsampled lr image
+ '''
+ x = ndimage.filters.convolve(x, np.expand_dims(k, axis=2), mode='wrap')
+ #x = filters.correlate(x, np.expand_dims(np.flip(k), axis=2))
+ st = 0
+ return x[st::sf, st::sf, ...]
+
+
+def add_sharpening(img, weight=0.5, radius=50, threshold=10):
+ """usm sharpening. borrowed from real-esrgan
+ input image: i; blurry image: b.
+ 1. k = i + weight * (i - b)
+ 2. mask = 1 if abs(i - b) > threshold, else: 0
+ 3. blur mask:
+ 4. out = mask * k + (1 - mask) * i
+ args:
+ img (numpy array): input image, hwc, bgr; float32, [0, 1].
+ weight (float): sharp weight. default: 1.
+ radius (float): kernel size of gaussian blur. default: 50.
+ threshold (int):
+ """
+ if radius % 2 == 0:
+ radius += 1
+ blur = cv2.gaussianblur(img, (radius, radius), 0)
+ residual = img - blur
+ mask = np.abs(residual) * 255 > threshold
+ mask = mask.astype('float32')
+ soft_mask = cv2.gaussianblur(mask, (radius, radius), 0)
+
+ k = img + weight * residual
+ k = np.clip(k, 0, 1)
+ return soft_mask * k + (1 - soft_mask) * img
+
+
+def add_blur(img, sf=4):
+ wd2 = 4.0 + sf
+ wd = 2.0 + 0.2*sf
+ if random.random() < 0.5:
+ l1 = wd2*random.random()
+ l2 = wd2*random.random()
+ k = anisotropic_gaussian(ksize=2*random.randint(2,11)+3, theta=random.random()*np.pi, l1=l1, l2=l2)
+ else:
+ k = fspecial('gaussian', 2*random.randint(2,11)+3, wd*random.random())
+ img = ndimage.filters.convolve(img, np.expand_dims(k, axis=2), mode='mirror')
+
+ return img
+
+
+def add_resize(img, sf=4):
+ rnum = np.random.rand()
+ if rnum > 0.8: # up
+ sf1 = random.uniform(1, 2)
+ elif rnum < 0.7: # down
+ sf1 = random.uniform(0.5/sf, 1)
+ else:
+ sf1 = 1.0
+ img = cv2.resize(img, (int(sf1*img.shape[1]), int(sf1*img.shape[0])), interpolation=random.choice([1, 2, 3]))
+ img = np.clip(img, 0.0, 1.0)
+
+ return img
+
+
+def add_gaussian_noise(img, noise_level1=2, noise_level2=25):
+ noise_level = random.randint(noise_level1, noise_level2)
+ rnum = np.random.rand()
+ if rnum > 0.6: # add color gaussian noise
+ img += np.random.normal(0, noise_level/255.0, img.shape).astype(np.float32)
+ elif rnum < 0.4: # add grayscale gaussian noise
+ img += np.random.normal(0, noise_level/255.0, (*img.shape[:2], 1)).astype(np.float32)
+ else: # add noise
+ l = noise_level2/255.
+ d = np.diag(np.random.rand(3))
+ u = orth(np.random.rand(3,3))
+ conv = np.dot(np.dot(np.transpose(u), d), u)
+ img += np.random.multivariate_normal([0,0,0], np.abs(l**2*conv), img.shape[:2]).astype(np.float32)
+ img = np.clip(img, 0.0, 1.0)
+ return img
+
+
+def add_speckle_noise(img, noise_level1=2, noise_level2=25):
+ noise_level = random.randint(noise_level1, noise_level2)
+ img = np.clip(img, 0.0, 1.0)
+ rnum = random.random()
+ if rnum > 0.6:
+ img += img*np.random.normal(0, noise_level/255.0, img.shape).astype(np.float32)
+ elif rnum < 0.4:
+ img += img*np.random.normal(0, noise_level/255.0, (*img.shape[:2], 1)).astype(np.float32)
+ else:
+ l = noise_level2/255.
+ d = np.diag(np.random.rand(3))
+ u = orth(np.random.rand(3,3))
+ conv = np.dot(np.dot(np.transpose(u), d), u)
+ img += img*np.random.multivariate_normal([0,0,0], np.abs(l**2*conv), img.shape[:2]).astype(np.float32)
+ img = np.clip(img, 0.0, 1.0)
+ return img
+
+
+def add_poisson_noise(img):
+ img = np.clip((img * 255.0).round(), 0, 255) / 255.
+ vals = 10**(2*random.random()+2.0) # [2, 4]
+ if random.random() < 0.5:
+ img = np.random.poisson(img * vals).astype(np.float32) / vals
+ else:
+ img_gray = np.dot(img[...,:3], [0.299, 0.587, 0.114])
+ img_gray = np.clip((img_gray * 255.0).round(), 0, 255) / 255.
+ noise_gray = np.random.poisson(img_gray * vals).astype(np.float32) / vals - img_gray
+ img += noise_gray[:, :, np.newaxis]
+ img = np.clip(img, 0.0, 1.0)
+ return img
+
+
+def add_jpeg_noise(img):
+ quality_factor = random.randint(30, 95)
+ img = cv2.cvtcolor(util.single2uint(img), cv2.color_rgb2bgr)
+ result, encimg = cv2.imencode('.jpg', img, [int(cv2.imwrite_jpeg_quality), quality_factor])
+ img = cv2.imdecode(encimg, 1)
+ img = cv2.cvtcolor(util.uint2single(img), cv2.color_bgr2rgb)
+ return img
+
+
+def random_crop(lq, hq, sf=4, lq_patchsize=64):
+ h, w = lq.shape[:2]
+ rnd_h = random.randint(0, h-lq_patchsize)
+ rnd_w = random.randint(0, w-lq_patchsize)
+ lq = lq[rnd_h:rnd_h + lq_patchsize, rnd_w:rnd_w + lq_patchsize, :]
+
+ rnd_h_h, rnd_w_h = int(rnd_h * sf), int(rnd_w * sf)
+ hq = hq[rnd_h_h:rnd_h_h + lq_patchsize*sf, rnd_w_h:rnd_w_h + lq_patchsize*sf, :]
+ return lq, hq
+
+
+def degradation_bsrgan(img, sf=4, lq_patchsize=72, isp_model=none):
+ """
+ this is the degradation model of bsrgan from the paper
+ "designing a practical degradation model for deep blind image super-resolution"
+ ----------
+ img: hxwxc, [0, 1], its size should be large than (lq_patchsizexsf)x(lq_patchsizexsf)
+ sf: scale factor
+ isp_model: camera isp model
+
+ returns
+ -------
+ img: low-quality patch, size: lq_patchsizexlq_patchsizexc, range: [0, 1]
+ hq: corresponding high-quality patch, size: (lq_patchsizexsf)x(lq_patchsizexsf)xc, range: [0, 1]
+ """
+ isp_prob, jpeg_prob, scale2_prob = 0.25, 0.9, 0.25
+ sf_ori = sf
+
+ h1, w1 = img.shape[:2]
+ img = img.copy()[:w1 - w1 % sf, :h1 - h1 % sf, ...] # mod crop
+ h, w = img.shape[:2]
+
+ if h < lq_patchsize*sf or w < lq_patchsize*sf:
+ raise valueerror(f'img size ({h1}x{w1}) is too small!')
+
+ hq = img.copy()
+
+ if sf == 4 and random.random() < scale2_prob: # downsample1
+ if np.random.rand() < 0.5:
+ img = cv2.resize(img, (int(1/2*img.shape[1]), int(1/2*img.shape[0])), interpolation=random.choice([1,2,3]))
+ else:
+ img = util.imresize_np(img, 1/2, true)
+ img = np.clip(img, 0.0, 1.0)
+ sf = 2
+
+ shuffle_order = random.sample(range(7), 7)
+ idx1, idx2 = shuffle_order.index(2), shuffle_order.index(3)
+ if idx1 > idx2: # keep downsample3 last
+ shuffle_order[idx1], shuffle_order[idx2] = shuffle_order[idx2], shuffle_order[idx1]
+
+ for i in shuffle_order:
+
+ if i == 0:
+ img = add_blur(img, sf=sf)
+
+ elif i == 1:
+ img = add_blur(img, sf=sf)
+
+ elif i == 2:
+ a, b = img.shape[1], img.shape[0]
+ # downsample2
+ if random.random() < 0.75:
+ sf1 = random.uniform(1,2*sf)
+ img = cv2.resize(img, (int(1/sf1*img.shape[1]), int(1/sf1*img.shape[0])), interpolation=random.choice([1,2,3]))
+ else:
+ k = fspecial('gaussian', 25, random.uniform(0.1, 0.6*sf))
+ k_shifted = shift_pixel(k, sf)
+ k_shifted = k_shifted/k_shifted.sum() # blur with shifted kernel
+ img = ndimage.filters.convolve(img, np.expand_dims(k_shifted, axis=2), mode='mirror')
+ img = img[0::sf, 0::sf, ...] # nearest downsampling
+ img = np.clip(img, 0.0, 1.0)
+
+ elif i == 3:
+ # downsample3
+ img = cv2.resize(img, (int(1/sf*a), int(1/sf*b)), interpolation=random.choice([1,2,3]))
+ img = np.clip(img, 0.0, 1.0)
+
+ elif i == 4:
+ # add gaussian noise
+ img = add_gaussian_noise(img, noise_level1=2, noise_level2=25)
+
+ elif i == 5:
+ # add jpeg noise
+ if random.random() < jpeg_prob:
+ img = add_jpeg_noise(img)
+
+ elif i == 6:
+ # add processed camera sensor noise
+ if random.random() < isp_prob and isp_model is not none:
+ with torch.no_grad():
+ img, hq = isp_model.forward(img.copy(), hq)
+
+ # add final jpeg compression noise
+ img = add_jpeg_noise(img)
+
+ # random crop
+ img, hq = random_crop(img, hq, sf_ori, lq_patchsize)
+
+ return img, hq
+
+
+
+
+def degradation_bsrgan_plus(img, sf=4, shuffle_prob=0.5, use_sharp=false, lq_patchsize=64, isp_model=none):
+ """
+ this is an extended degradation model by combining
+ the degradation models of bsrgan and real-esrgan
+ ----------
+ img: hxwxc, [0, 1], its size should be large than (lq_patchsizexsf)x(lq_patchsizexsf)
+ sf: scale factor
+ use_shuffle: the degradation shuffle
+ use_sharp: sharpening the img
+
+ returns
+ -------
+ img: low-quality patch, size: lq_patchsizexlq_patchsizexc, range: [0, 1]
+ hq: corresponding high-quality patch, size: (lq_patchsizexsf)x(lq_patchsizexsf)xc, range: [0, 1]
+ """
+
+ h1, w1 = img.shape[:2]
+ img = img.copy()[:w1 - w1 % sf, :h1 - h1 % sf, ...] # mod crop
+ h, w = img.shape[:2]
+
+ if h < lq_patchsize*sf or w < lq_patchsize*sf:
+ raise valueerror(f'img size ({h1}x{w1}) is too small!')
+
+ if use_sharp:
+ img = add_sharpening(img)
+ hq = img.copy()
+
+ if random.random() < shuffle_prob:
+ shuffle_order = random.sample(range(13), 13)
+ else:
+ shuffle_order = list(range(13))
+ # local shuffle for noise, jpeg is always the last one
+ shuffle_order[2:6] = random.sample(shuffle_order[2:6], len(range(2, 6)))
+ shuffle_order[9:13] = random.sample(shuffle_order[9:13], len(range(9, 13)))
+
+ poisson_prob, speckle_prob, isp_prob = 0.1, 0.1, 0.1
+
+ for i in shuffle_order:
+ if i == 0:
+ img = add_blur(img, sf=sf)
+ elif i == 1:
+ img = add_resize(img, sf=sf)
+ elif i == 2:
+ img = add_gaussian_noise(img, noise_level1=2, noise_level2=25)
+ elif i == 3:
+ if random.random() < poisson_prob:
+ img = add_poisson_noise(img)
+ elif i == 4:
+ if random.random() < speckle_prob:
+ img = add_speckle_noise(img)
+ elif i == 5:
+ if random.random() < isp_prob and isp_model is not none:
+ with torch.no_grad():
+ img, hq = isp_model.forward(img.copy(), hq)
+ elif i == 6:
+ img = add_jpeg_noise(img)
+ elif i == 7:
+ img = add_blur(img, sf=sf)
+ elif i == 8:
+ img = add_resize(img, sf=sf)
+ elif i == 9:
+ img = add_gaussian_noise(img, noise_level1=2, noise_level2=25)
+ elif i == 10:
+ if random.random() < poisson_prob:
+ img = add_poisson_noise(img)
+ elif i == 11:
+ if random.random() < speckle_prob:
+ img = add_speckle_noise(img)
+ elif i == 12:
+ if random.random() < isp_prob and isp_model is not none:
+ with torch.no_grad():
+ img, hq = isp_model.forward(img.copy(), hq)
+ else:
+ print('check the shuffle!')
+
+ # resize to desired size
+ img = cv2.resize(img, (int(1/sf*hq.shape[1]), int(1/sf*hq.shape[0])), interpolation=random.choice([1, 2, 3]))
+
+ # add final jpeg compression noise
+ img = add_jpeg_noise(img)
+
+ # random crop
+ img, hq = random_crop(img, hq, sf, lq_patchsize)
+
+ return img, hq
+
+
+
+if __name__ == '__main__':
+ img = util.imread_uint('utils/test.png', 3)
+ img = util.uint2single(img)
+ sf = 4
+
+ for i in range(20):
+ img_lq, img_hq = degradation_bsrgan(img, sf=sf, lq_patchsize=72)
+ print(i)
+ lq_nearest = cv2.resize(util.single2uint(img_lq), (int(sf*img_lq.shape[1]), int(sf*img_lq.shape[0])), interpolation=0)
+ img_concat = np.concatenate([lq_nearest, util.single2uint(img_hq)], axis=1)
+ util.imsave(img_concat, str(i)+'.png')
+
+# for i in range(10):
+# img_lq, img_hq = degradation_bsrgan_plus(img, sf=sf, shuffle_prob=0.1, use_sharp=true, lq_patchsize=64)
+# print(i)
+# lq_nearest = cv2.resize(util.single2uint(img_lq), (int(sf*img_lq.shape[1]), int(sf*img_lq.shape[0])), interpolation=0)
+# img_concat = np.concatenate([lq_nearest, util.single2uint(img_hq)], axis=1)
+# util.imsave(img_concat, str(i)+'.png')
+
+# run utils/utils_blindsr.py
diff --git a/KAIR/utils/utils_bnorm.py b/KAIR/utils/utils_bnorm.py
new file mode 100644
index 0000000000000000000000000000000000000000..9bd346e05b66efd074f81f1961068e2de45ac5da
--- /dev/null
+++ b/KAIR/utils/utils_bnorm.py
@@ -0,0 +1,91 @@
+import torch
+import torch.nn as nn
+
+
+"""
+# --------------------------------------------
+# Batch Normalization
+# --------------------------------------------
+
+# Kai Zhang (cskaizhang@gmail.com)
+# https://github.com/cszn
+# 01/Jan/2019
+# --------------------------------------------
+"""
+
+
+# --------------------------------------------
+# remove/delete specified layer
+# --------------------------------------------
+def deleteLayer(model, layer_type=nn.BatchNorm2d):
+ ''' Kai Zhang, 11/Jan/2019.
+ '''
+ for k, m in list(model.named_children()):
+ if isinstance(m, layer_type):
+ del model._modules[k]
+ deleteLayer(m, layer_type)
+
+
+# --------------------------------------------
+# merge bn, "conv+bn" --> "conv"
+# --------------------------------------------
+def merge_bn(model):
+ ''' Kai Zhang, 11/Jan/2019.
+ merge all 'Conv+BN' (or 'TConv+BN') into 'Conv' (or 'TConv')
+ based on https://github.com/pytorch/pytorch/pull/901
+ '''
+ prev_m = None
+ for k, m in list(model.named_children()):
+ if (isinstance(m, nn.BatchNorm2d) or isinstance(m, nn.BatchNorm1d)) and (isinstance(prev_m, nn.Conv2d) or isinstance(prev_m, nn.Linear) or isinstance(prev_m, nn.ConvTranspose2d)):
+
+ w = prev_m.weight.data
+
+ if prev_m.bias is None:
+ zeros = torch.Tensor(prev_m.out_channels).zero_().type(w.type())
+ prev_m.bias = nn.Parameter(zeros)
+ b = prev_m.bias.data
+
+ invstd = m.running_var.clone().add_(m.eps).pow_(-0.5)
+ if isinstance(prev_m, nn.ConvTranspose2d):
+ w.mul_(invstd.view(1, w.size(1), 1, 1).expand_as(w))
+ else:
+ w.mul_(invstd.view(w.size(0), 1, 1, 1).expand_as(w))
+ b.add_(-m.running_mean).mul_(invstd)
+ if m.affine:
+ if isinstance(prev_m, nn.ConvTranspose2d):
+ w.mul_(m.weight.data.view(1, w.size(1), 1, 1).expand_as(w))
+ else:
+ w.mul_(m.weight.data.view(w.size(0), 1, 1, 1).expand_as(w))
+ b.mul_(m.weight.data).add_(m.bias.data)
+
+ del model._modules[k]
+ prev_m = m
+ merge_bn(m)
+
+
+# --------------------------------------------
+# add bn, "conv" --> "conv+bn"
+# --------------------------------------------
+def add_bn(model):
+ ''' Kai Zhang, 11/Jan/2019.
+ '''
+ for k, m in list(model.named_children()):
+ if (isinstance(m, nn.Conv2d) or isinstance(m, nn.Linear) or isinstance(m, nn.ConvTranspose2d)):
+ b = nn.BatchNorm2d(m.out_channels, momentum=0.1, affine=True)
+ b.weight.data.fill_(1)
+ new_m = nn.Sequential(model._modules[k], b)
+ model._modules[k] = new_m
+ add_bn(m)
+
+
+# --------------------------------------------
+# tidy model after removing bn
+# --------------------------------------------
+def tidy_sequential(model):
+ ''' Kai Zhang, 11/Jan/2019.
+ '''
+ for k, m in list(model.named_children()):
+ if isinstance(m, nn.Sequential):
+ if m.__len__() == 1:
+ model._modules[k] = m.__getitem__(0)
+ tidy_sequential(m)
diff --git a/KAIR/utils/utils_deblur.py b/KAIR/utils/utils_deblur.py
new file mode 100644
index 0000000000000000000000000000000000000000..c5457b9c1df3bd7bbe8758cf8be5824273b8db29
--- /dev/null
+++ b/KAIR/utils/utils_deblur.py
@@ -0,0 +1,655 @@
+# -*- coding: utf-8 -*-
+import numpy as np
+import scipy
+from scipy import fftpack
+import torch
+
+from math import cos, sin
+from numpy import zeros, ones, prod, array, pi, log, min, mod, arange, sum, mgrid, exp, pad, round
+from numpy.random import randn, rand
+from scipy.signal import convolve2d
+import cv2
+import random
+# import utils_image as util
+
+'''
+modified by Kai Zhang (github: https://github.com/cszn)
+03/03/2019
+'''
+
+
+def get_uperleft_denominator(img, kernel):
+ '''
+ img: HxWxC
+ kernel: hxw
+ denominator: HxWx1
+ upperleft: HxWxC
+ '''
+ V = psf2otf(kernel, img.shape[:2])
+ denominator = np.expand_dims(np.abs(V)**2, axis=2)
+ upperleft = np.expand_dims(np.conj(V), axis=2) * np.fft.fft2(img, axes=[0, 1])
+ return upperleft, denominator
+
+
+def get_uperleft_denominator_pytorch(img, kernel):
+ '''
+ img: NxCxHxW
+ kernel: Nx1xhxw
+ denominator: Nx1xHxW
+ upperleft: NxCxHxWx2
+ '''
+ V = p2o(kernel, img.shape[-2:]) # Nx1xHxWx2
+ denominator = V[..., 0]**2+V[..., 1]**2 # Nx1xHxW
+ upperleft = cmul(cconj(V), rfft(img)) # Nx1xHxWx2 * NxCxHxWx2
+ return upperleft, denominator
+
+
+def c2c(x):
+ return torch.from_numpy(np.stack([np.float32(x.real), np.float32(x.imag)], axis=-1))
+
+
+def r2c(x):
+ return torch.stack([x, torch.zeros_like(x)], -1)
+
+
+def cdiv(x, y):
+ a, b = x[..., 0], x[..., 1]
+ c, d = y[..., 0], y[..., 1]
+ cd2 = c**2 + d**2
+ return torch.stack([(a*c+b*d)/cd2, (b*c-a*d)/cd2], -1)
+
+
+def cabs(x):
+ return torch.pow(x[..., 0]**2+x[..., 1]**2, 0.5)
+
+
+def cmul(t1, t2):
+ '''
+ complex multiplication
+ t1: NxCxHxWx2
+ output: NxCxHxWx2
+ '''
+ real1, imag1 = t1[..., 0], t1[..., 1]
+ real2, imag2 = t2[..., 0], t2[..., 1]
+ return torch.stack([real1 * real2 - imag1 * imag2, real1 * imag2 + imag1 * real2], dim=-1)
+
+
+def cconj(t, inplace=False):
+ '''
+ # complex's conjugation
+ t: NxCxHxWx2
+ output: NxCxHxWx2
+ '''
+ c = t.clone() if not inplace else t
+ c[..., 1] *= -1
+ return c
+
+
+def rfft(t):
+ return torch.rfft(t, 2, onesided=False)
+
+
+def irfft(t):
+ return torch.irfft(t, 2, onesided=False)
+
+
+def fft(t):
+ return torch.fft(t, 2)
+
+
+def ifft(t):
+ return torch.ifft(t, 2)
+
+
+def p2o(psf, shape):
+ '''
+ # psf: NxCxhxw
+ # shape: [H,W]
+ # otf: NxCxHxWx2
+ '''
+ otf = torch.zeros(psf.shape[:-2] + shape).type_as(psf)
+ otf[...,:psf.shape[2],:psf.shape[3]].copy_(psf)
+ for axis, axis_size in enumerate(psf.shape[2:]):
+ otf = torch.roll(otf, -int(axis_size / 2), dims=axis+2)
+ otf = torch.rfft(otf, 2, onesided=False)
+ n_ops = torch.sum(torch.tensor(psf.shape).type_as(psf) * torch.log2(torch.tensor(psf.shape).type_as(psf)))
+ otf[...,1][torch.abs(otf[...,1])= abs(y)] = abs(x)[abs(x) >= abs(y)]
+ maxxy[abs(y) >= abs(x)] = abs(y)[abs(y) >= abs(x)]
+ minxy = np.zeros(x.shape)
+ minxy[abs(x) <= abs(y)] = abs(x)[abs(x) <= abs(y)]
+ minxy[abs(y) <= abs(x)] = abs(y)[abs(y) <= abs(x)]
+ m1 = (rad**2 < (maxxy+0.5)**2 + (minxy-0.5)**2)*(minxy-0.5) +\
+ (rad**2 >= (maxxy+0.5)**2 + (minxy-0.5)**2)*\
+ np.sqrt((rad**2 + 0j) - (maxxy + 0.5)**2)
+ m2 = (rad**2 > (maxxy-0.5)**2 + (minxy+0.5)**2)*(minxy+0.5) +\
+ (rad**2 <= (maxxy-0.5)**2 + (minxy+0.5)**2)*\
+ np.sqrt((rad**2 + 0j) - (maxxy - 0.5)**2)
+ h = None
+ return h
+
+
+def fspecial_gaussian(hsize, sigma):
+ hsize = [hsize, hsize]
+ siz = [(hsize[0]-1.0)/2.0, (hsize[1]-1.0)/2.0]
+ std = sigma
+ [x, y] = np.meshgrid(np.arange(-siz[1], siz[1]+1), np.arange(-siz[0], siz[0]+1))
+ arg = -(x*x + y*y)/(2*std*std)
+ h = np.exp(arg)
+ h[h < scipy.finfo(float).eps * h.max()] = 0
+ sumh = h.sum()
+ if sumh != 0:
+ h = h/sumh
+ return h
+
+
+def fspecial_laplacian(alpha):
+ alpha = max([0, min([alpha,1])])
+ h1 = alpha/(alpha+1)
+ h2 = (1-alpha)/(alpha+1)
+ h = [[h1, h2, h1], [h2, -4/(alpha+1), h2], [h1, h2, h1]]
+ h = np.array(h)
+ return h
+
+
+def fspecial_log(hsize, sigma):
+ raise(NotImplemented)
+
+
+def fspecial_motion(motion_len, theta):
+ raise(NotImplemented)
+
+
+def fspecial_prewitt():
+ return np.array([[1, 1, 1], [0, 0, 0], [-1, -1, -1]])
+
+
+def fspecial_sobel():
+ return np.array([[1, 2, 1], [0, 0, 0], [-1, -2, -1]])
+
+
+def fspecial(filter_type, *args, **kwargs):
+ '''
+ python code from:
+ https://github.com/ronaldosena/imagens-medicas-2/blob/40171a6c259edec7827a6693a93955de2bd39e76/Aulas/aula_2_-_uniform_filter/matlab_fspecial.py
+ '''
+ if filter_type == 'average':
+ return fspecial_average(*args, **kwargs)
+ if filter_type == 'disk':
+ return fspecial_disk(*args, **kwargs)
+ if filter_type == 'gaussian':
+ return fspecial_gaussian(*args, **kwargs)
+ if filter_type == 'laplacian':
+ return fspecial_laplacian(*args, **kwargs)
+ if filter_type == 'log':
+ return fspecial_log(*args, **kwargs)
+ if filter_type == 'motion':
+ return fspecial_motion(*args, **kwargs)
+ if filter_type == 'prewitt':
+ return fspecial_prewitt(*args, **kwargs)
+ if filter_type == 'sobel':
+ return fspecial_sobel(*args, **kwargs)
+
+
+def fspecial_gauss(size, sigma):
+ x, y = mgrid[-size // 2 + 1 : size // 2 + 1, -size // 2 + 1 : size // 2 + 1]
+ g = exp(-((x ** 2 + y ** 2) / (2.0 * sigma ** 2)))
+ return g / g.sum()
+
+
+def blurkernel_synthesis(h=37, w=None):
+ # https://github.com/tkkcc/prior/blob/879a0b6c117c810776d8cc6b63720bf29f7d0cc4/util/gen_kernel.py
+ w = h if w is None else w
+ kdims = [h, w]
+ x = randomTrajectory(250)
+ k = None
+ while k is None:
+ k = kernelFromTrajectory(x)
+
+ # center pad to kdims
+ pad_width = ((kdims[0] - k.shape[0]) // 2, (kdims[1] - k.shape[1]) // 2)
+ pad_width = [(pad_width[0],), (pad_width[1],)]
+
+ if pad_width[0][0]<0 or pad_width[1][0]<0:
+ k = k[0:h, 0:h]
+ else:
+ k = pad(k, pad_width, "constant")
+ x1,x2 = k.shape
+ if np.random.randint(0, 4) == 1:
+ k = cv2.resize(k, (random.randint(x1, 5*x1), random.randint(x2, 5*x2)), interpolation=cv2.INTER_LINEAR)
+ y1, y2 = k.shape
+ k = k[(y1-x1)//2: (y1-x1)//2+x1, (y2-x2)//2: (y2-x2)//2+x2]
+
+ if sum(k)<0.1:
+ k = fspecial_gaussian(h, 0.1+6*np.random.rand(1))
+ k = k / sum(k)
+ # import matplotlib.pyplot as plt
+ # plt.imshow(k, interpolation="nearest", cmap="gray")
+ # plt.show()
+ return k
+
+
+def kernelFromTrajectory(x):
+ h = 5 - log(rand()) / 0.15
+ h = round(min([h, 27])).astype(int)
+ h = h + 1 - h % 2
+ w = h
+ k = zeros((h, w))
+
+ xmin = min(x[0])
+ xmax = max(x[0])
+ ymin = min(x[1])
+ ymax = max(x[1])
+ xthr = arange(xmin, xmax, (xmax - xmin) / w)
+ ythr = arange(ymin, ymax, (ymax - ymin) / h)
+
+ for i in range(1, xthr.size):
+ for j in range(1, ythr.size):
+ idx = (
+ (x[0, :] >= xthr[i - 1])
+ & (x[0, :] < xthr[i])
+ & (x[1, :] >= ythr[j - 1])
+ & (x[1, :] < ythr[j])
+ )
+ k[i - 1, j - 1] = sum(idx)
+ if sum(k) == 0:
+ return
+ k = k / sum(k)
+ k = convolve2d(k, fspecial_gauss(3, 1), "same")
+ k = k / sum(k)
+ return k
+
+
+def randomTrajectory(T):
+ x = zeros((3, T))
+ v = randn(3, T)
+ r = zeros((3, T))
+ trv = 1 / 1
+ trr = 2 * pi / T
+ for t in range(1, T):
+ F_rot = randn(3) / (t + 1) + r[:, t - 1]
+ F_trans = randn(3) / (t + 1)
+ r[:, t] = r[:, t - 1] + trr * F_rot
+ v[:, t] = v[:, t - 1] + trv * F_trans
+ st = v[:, t]
+ st = rot3D(st, r[:, t])
+ x[:, t] = x[:, t - 1] + st
+ return x
+
+
+def rot3D(x, r):
+ Rx = array([[1, 0, 0], [0, cos(r[0]), -sin(r[0])], [0, sin(r[0]), cos(r[0])]])
+ Ry = array([[cos(r[1]), 0, sin(r[1])], [0, 1, 0], [-sin(r[1]), 0, cos(r[1])]])
+ Rz = array([[cos(r[2]), -sin(r[2]), 0], [sin(r[2]), cos(r[2]), 0], [0, 0, 1]])
+ R = Rz @ Ry @ Rx
+ x = R @ x
+ return x
+
+
+if __name__ == '__main__':
+ a = opt_fft_size([111])
+ print(a)
+
+ print(fspecial('gaussian', 5, 1))
+
+ print(p2o(torch.zeros(1,1,4,4).float(),(14,14)).shape)
+
+ k = blurkernel_synthesis(11)
+ import matplotlib.pyplot as plt
+ plt.imshow(k, interpolation="nearest", cmap="gray")
+ plt.show()
diff --git a/KAIR/utils/utils_dist.py b/KAIR/utils/utils_dist.py
new file mode 100644
index 0000000000000000000000000000000000000000..7729e3af0b8fc3f48bb050b5eb31eaf971488d1e
--- /dev/null
+++ b/KAIR/utils/utils_dist.py
@@ -0,0 +1,201 @@
+# Modified from https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/dist_utils.py # noqa: E501
+import functools
+import os
+import subprocess
+import torch
+import torch.distributed as dist
+import torch.multiprocessing as mp
+
+
+# ----------------------------------
+# init
+# ----------------------------------
+def init_dist(launcher, backend='nccl', **kwargs):
+ if mp.get_start_method(allow_none=True) is None:
+ mp.set_start_method('spawn')
+ if launcher == 'pytorch':
+ _init_dist_pytorch(backend, **kwargs)
+ elif launcher == 'slurm':
+ _init_dist_slurm(backend, **kwargs)
+ else:
+ raise ValueError(f'Invalid launcher type: {launcher}')
+
+
+def _init_dist_pytorch(backend, **kwargs):
+ rank = int(os.environ['RANK'])
+ num_gpus = torch.cuda.device_count()
+ torch.cuda.set_device(rank % num_gpus)
+ dist.init_process_group(backend=backend, **kwargs)
+
+
+def _init_dist_slurm(backend, port=None):
+ """Initialize slurm distributed training environment.
+ If argument ``port`` is not specified, then the master port will be system
+ environment variable ``MASTER_PORT``. If ``MASTER_PORT`` is not in system
+ environment variable, then a default port ``29500`` will be used.
+ Args:
+ backend (str): Backend of torch.distributed.
+ port (int, optional): Master port. Defaults to None.
+ """
+ proc_id = int(os.environ['SLURM_PROCID'])
+ ntasks = int(os.environ['SLURM_NTASKS'])
+ node_list = os.environ['SLURM_NODELIST']
+ num_gpus = torch.cuda.device_count()
+ torch.cuda.set_device(proc_id % num_gpus)
+ addr = subprocess.getoutput(
+ f'scontrol show hostname {node_list} | head -n1')
+ # specify master port
+ if port is not None:
+ os.environ['MASTER_PORT'] = str(port)
+ elif 'MASTER_PORT' in os.environ:
+ pass # use MASTER_PORT in the environment variable
+ else:
+ # 29500 is torch.distributed default port
+ os.environ['MASTER_PORT'] = '29500'
+ os.environ['MASTER_ADDR'] = addr
+ os.environ['WORLD_SIZE'] = str(ntasks)
+ os.environ['LOCAL_RANK'] = str(proc_id % num_gpus)
+ os.environ['RANK'] = str(proc_id)
+ dist.init_process_group(backend=backend)
+
+
+
+# ----------------------------------
+# get rank and world_size
+# ----------------------------------
+def get_dist_info():
+ if dist.is_available():
+ initialized = dist.is_initialized()
+ else:
+ initialized = False
+ if initialized:
+ rank = dist.get_rank()
+ world_size = dist.get_world_size()
+ else:
+ rank = 0
+ world_size = 1
+ return rank, world_size
+
+
+def get_rank():
+ if not dist.is_available():
+ return 0
+
+ if not dist.is_initialized():
+ return 0
+
+ return dist.get_rank()
+
+
+def get_world_size():
+ if not dist.is_available():
+ return 1
+
+ if not dist.is_initialized():
+ return 1
+
+ return dist.get_world_size()
+
+
+def master_only(func):
+
+ @functools.wraps(func)
+ def wrapper(*args, **kwargs):
+ rank, _ = get_dist_info()
+ if rank == 0:
+ return func(*args, **kwargs)
+
+ return wrapper
+
+
+
+
+
+
+# ----------------------------------
+# operation across ranks
+# ----------------------------------
+def reduce_sum(tensor):
+ if not dist.is_available():
+ return tensor
+
+ if not dist.is_initialized():
+ return tensor
+
+ tensor = tensor.clone()
+ dist.all_reduce(tensor, op=dist.ReduceOp.SUM)
+
+ return tensor
+
+
+def gather_grad(params):
+ world_size = get_world_size()
+
+ if world_size == 1:
+ return
+
+ for param in params:
+ if param.grad is not None:
+ dist.all_reduce(param.grad.data, op=dist.ReduceOp.SUM)
+ param.grad.data.div_(world_size)
+
+
+def all_gather(data):
+ world_size = get_world_size()
+
+ if world_size == 1:
+ return [data]
+
+ buffer = pickle.dumps(data)
+ storage = torch.ByteStorage.from_buffer(buffer)
+ tensor = torch.ByteTensor(storage).to('cuda')
+
+ local_size = torch.IntTensor([tensor.numel()]).to('cuda')
+ size_list = [torch.IntTensor([0]).to('cuda') for _ in range(world_size)]
+ dist.all_gather(size_list, local_size)
+ size_list = [int(size.item()) for size in size_list]
+ max_size = max(size_list)
+
+ tensor_list = []
+ for _ in size_list:
+ tensor_list.append(torch.ByteTensor(size=(max_size,)).to('cuda'))
+
+ if local_size != max_size:
+ padding = torch.ByteTensor(size=(max_size - local_size,)).to('cuda')
+ tensor = torch.cat((tensor, padding), 0)
+
+ dist.all_gather(tensor_list, tensor)
+
+ data_list = []
+
+ for size, tensor in zip(size_list, tensor_list):
+ buffer = tensor.cpu().numpy().tobytes()[:size]
+ data_list.append(pickle.loads(buffer))
+
+ return data_list
+
+
+def reduce_loss_dict(loss_dict):
+ world_size = get_world_size()
+
+ if world_size < 2:
+ return loss_dict
+
+ with torch.no_grad():
+ keys = []
+ losses = []
+
+ for k in sorted(loss_dict.keys()):
+ keys.append(k)
+ losses.append(loss_dict[k])
+
+ losses = torch.stack(losses, 0)
+ dist.reduce(losses, dst=0)
+
+ if dist.get_rank() == 0:
+ losses /= world_size
+
+ reduced_losses = {k: v for k, v in zip(keys, losses)}
+
+ return reduced_losses
+
diff --git a/KAIR/utils/utils_googledownload.py b/KAIR/utils/utils_googledownload.py
new file mode 100644
index 0000000000000000000000000000000000000000..f4acaf78d7cc60bec569cae2f02f2ec049407615
--- /dev/null
+++ b/KAIR/utils/utils_googledownload.py
@@ -0,0 +1,93 @@
+import math
+import requests
+from tqdm import tqdm
+
+
+'''
+borrowed from
+https://github.com/xinntao/BasicSR/blob/28883e15eedc3381d23235ff3cf7c454c4be87e6/basicsr/utils/download_util.py
+'''
+
+
+def sizeof_fmt(size, suffix='B'):
+ """Get human readable file size.
+ Args:
+ size (int): File size.
+ suffix (str): Suffix. Default: 'B'.
+ Return:
+ str: Formated file siz.
+ """
+ for unit in ['', 'K', 'M', 'G', 'T', 'P', 'E', 'Z']:
+ if abs(size) < 1024.0:
+ return f'{size:3.1f} {unit}{suffix}'
+ size /= 1024.0
+ return f'{size:3.1f} Y{suffix}'
+
+
+def download_file_from_google_drive(file_id, save_path):
+ """Download files from google drive.
+ Ref:
+ https://stackoverflow.com/questions/25010369/wget-curl-large-file-from-google-drive # noqa E501
+ Args:
+ file_id (str): File id.
+ save_path (str): Save path.
+ """
+
+ session = requests.Session()
+ URL = 'https://docs.google.com/uc?export=download'
+ params = {'id': file_id}
+
+ response = session.get(URL, params=params, stream=True)
+ token = get_confirm_token(response)
+ if token:
+ params['confirm'] = token
+ response = session.get(URL, params=params, stream=True)
+
+ # get file size
+ response_file_size = session.get(
+ URL, params=params, stream=True, headers={'Range': 'bytes=0-2'})
+ if 'Content-Range' in response_file_size.headers:
+ file_size = int(
+ response_file_size.headers['Content-Range'].split('/')[1])
+ else:
+ file_size = None
+
+ save_response_content(response, save_path, file_size)
+
+
+def get_confirm_token(response):
+ for key, value in response.cookies.items():
+ if key.startswith('download_warning'):
+ return value
+ return None
+
+
+def save_response_content(response,
+ destination,
+ file_size=None,
+ chunk_size=32768):
+ if file_size is not None:
+ pbar = tqdm(total=math.ceil(file_size / chunk_size), unit='chunk')
+
+ readable_file_size = sizeof_fmt(file_size)
+ else:
+ pbar = None
+
+ with open(destination, 'wb') as f:
+ downloaded_size = 0
+ for chunk in response.iter_content(chunk_size):
+ downloaded_size += chunk_size
+ if pbar is not None:
+ pbar.update(1)
+ pbar.set_description(f'Download {sizeof_fmt(downloaded_size)} '
+ f'/ {readable_file_size}')
+ if chunk: # filter out keep-alive new chunks
+ f.write(chunk)
+ if pbar is not None:
+ pbar.close()
+
+
+if __name__ == "__main__":
+ file_id = '1WNULM1e8gRNvsngVscsQ8tpaOqJ4mYtv'
+ save_path = 'BSRGAN.pth'
+ download_file_from_google_drive(file_id, save_path)
diff --git a/KAIR/utils/utils_image.py b/KAIR/utils/utils_image.py
new file mode 100644
index 0000000000000000000000000000000000000000..0e513a8bc1594c9ce2ba47ce3fe3b497269b7f16
--- /dev/null
+++ b/KAIR/utils/utils_image.py
@@ -0,0 +1,1016 @@
+import os
+import math
+import random
+import numpy as np
+import torch
+import cv2
+from torchvision.utils import make_grid
+from datetime import datetime
+# import torchvision.transforms as transforms
+import matplotlib.pyplot as plt
+from mpl_toolkits.mplot3d import Axes3D
+os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
+
+
+'''
+# --------------------------------------------
+# Kai Zhang (github: https://github.com/cszn)
+# 03/Mar/2019
+# --------------------------------------------
+# https://github.com/twhui/SRGAN-pyTorch
+# https://github.com/xinntao/BasicSR
+# --------------------------------------------
+'''
+
+
+IMG_EXTENSIONS = ['.jpg', '.JPG', '.jpeg', '.JPEG', '.png', '.PNG', '.ppm', '.PPM', '.bmp', '.BMP', '.tif']
+
+
+def is_image_file(filename):
+ return any(filename.endswith(extension) for extension in IMG_EXTENSIONS)
+
+
+def get_timestamp():
+ return datetime.now().strftime('%y%m%d-%H%M%S')
+
+
+def imshow(x, title=None, cbar=False, figsize=None):
+ plt.figure(figsize=figsize)
+ plt.imshow(np.squeeze(x), interpolation='nearest', cmap='gray')
+ if title:
+ plt.title(title)
+ if cbar:
+ plt.colorbar()
+ plt.show()
+
+
+def surf(Z, cmap='rainbow', figsize=None):
+ plt.figure(figsize=figsize)
+ ax3 = plt.axes(projection='3d')
+
+ w, h = Z.shape[:2]
+ xx = np.arange(0,w,1)
+ yy = np.arange(0,h,1)
+ X, Y = np.meshgrid(xx, yy)
+ ax3.plot_surface(X,Y,Z,cmap=cmap)
+ #ax3.contour(X,Y,Z, zdim='z',offset=-2,cmap=cmap)
+ plt.show()
+
+
+'''
+# --------------------------------------------
+# get image pathes
+# --------------------------------------------
+'''
+
+
+def get_image_paths(dataroot):
+ paths = None # return None if dataroot is None
+ if isinstance(dataroot, str):
+ paths = sorted(_get_paths_from_images(dataroot))
+ elif isinstance(dataroot, list):
+ paths = []
+ for i in dataroot:
+ paths += sorted(_get_paths_from_images(i))
+ return paths
+
+
+def _get_paths_from_images(path):
+ assert os.path.isdir(path), '{:s} is not a valid directory'.format(path)
+ images = []
+ for dirpath, _, fnames in sorted(os.walk(path)):
+ for fname in sorted(fnames):
+ if is_image_file(fname):
+ img_path = os.path.join(dirpath, fname)
+ images.append(img_path)
+ assert images, '{:s} has no valid image file'.format(path)
+ return images
+
+
+'''
+# --------------------------------------------
+# split large images into small images
+# --------------------------------------------
+'''
+
+
+def patches_from_image(img, p_size=512, p_overlap=64, p_max=800):
+ w, h = img.shape[:2]
+ patches = []
+ if w > p_max and h > p_max:
+ w1 = list(np.arange(0, w-p_size, p_size-p_overlap, dtype=np.int))
+ h1 = list(np.arange(0, h-p_size, p_size-p_overlap, dtype=np.int))
+ w1.append(w-p_size)
+ h1.append(h-p_size)
+ # print(w1)
+ # print(h1)
+ for i in w1:
+ for j in h1:
+ patches.append(img[i:i+p_size, j:j+p_size,:])
+ else:
+ patches.append(img)
+
+ return patches
+
+
+def imssave(imgs, img_path):
+ """
+ imgs: list, N images of size WxHxC
+ """
+ img_name, ext = os.path.splitext(os.path.basename(img_path))
+ for i, img in enumerate(imgs):
+ if img.ndim == 3:
+ img = img[:, :, [2, 1, 0]]
+ new_path = os.path.join(os.path.dirname(img_path), img_name+str('_{:04d}'.format(i))+'.png')
+ cv2.imwrite(new_path, img)
+
+
+def split_imageset(original_dataroot, taget_dataroot, n_channels=3, p_size=512, p_overlap=96, p_max=800):
+ """
+ split the large images from original_dataroot into small overlapped images with size (p_size)x(p_size),
+ and save them into taget_dataroot; only the images with larger size than (p_max)x(p_max)
+ will be splitted.
+
+ Args:
+ original_dataroot:
+ taget_dataroot:
+ p_size: size of small images
+ p_overlap: patch size in training is a good choice
+ p_max: images with smaller size than (p_max)x(p_max) keep unchanged.
+ """
+ paths = get_image_paths(original_dataroot)
+ for img_path in paths:
+ # img_name, ext = os.path.splitext(os.path.basename(img_path))
+ img = imread_uint(img_path, n_channels=n_channels)
+ patches = patches_from_image(img, p_size, p_overlap, p_max)
+ imssave(patches, os.path.join(taget_dataroot, os.path.basename(img_path)))
+ #if original_dataroot == taget_dataroot:
+ #del img_path
+
+'''
+# --------------------------------------------
+# makedir
+# --------------------------------------------
+'''
+
+
+def mkdir(path):
+ if not os.path.exists(path):
+ os.makedirs(path)
+
+
+def mkdirs(paths):
+ if isinstance(paths, str):
+ mkdir(paths)
+ else:
+ for path in paths:
+ mkdir(path)
+
+
+def mkdir_and_rename(path):
+ if os.path.exists(path):
+ new_name = path + '_archived_' + get_timestamp()
+ print('Path already exists. Rename it to [{:s}]'.format(new_name))
+ os.rename(path, new_name)
+ os.makedirs(path)
+
+
+'''
+# --------------------------------------------
+# read image from path
+# opencv is fast, but read BGR numpy image
+# --------------------------------------------
+'''
+
+
+# --------------------------------------------
+# get uint8 image of size HxWxn_channles (RGB)
+# --------------------------------------------
+def imread_uint(path, n_channels=3):
+ # input: path
+ # output: HxWx3(RGB or GGG), or HxWx1 (G)
+ if n_channels == 1:
+ img = cv2.imread(path, 0) # cv2.IMREAD_GRAYSCALE
+ img = np.expand_dims(img, axis=2) # HxWx1
+ elif n_channels == 3:
+ img = cv2.imread(path, cv2.IMREAD_UNCHANGED) # BGR or G
+ if img.ndim == 2:
+ img = cv2.cvtColor(img, cv2.COLOR_GRAY2RGB) # GGG
+ else:
+ img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # RGB
+ return img
+
+
+# --------------------------------------------
+# matlab's imwrite
+# --------------------------------------------
+def imsave(img, img_path):
+ img = np.squeeze(img)
+ if img.ndim == 3:
+ img = img[:, :, [2, 1, 0]]
+ cv2.imwrite(img_path, img)
+
+def imwrite(img, img_path):
+ img = np.squeeze(img)
+ if img.ndim == 3:
+ img = img[:, :, [2, 1, 0]]
+ cv2.imwrite(img_path, img)
+
+
+
+# --------------------------------------------
+# get single image of size HxWxn_channles (BGR)
+# --------------------------------------------
+def read_img(path):
+ # read image by cv2
+ # return: Numpy float32, HWC, BGR, [0,1]
+ img = cv2.imread(path, cv2.IMREAD_UNCHANGED) # cv2.IMREAD_GRAYSCALE
+ img = img.astype(np.float32) / 255.
+ if img.ndim == 2:
+ img = np.expand_dims(img, axis=2)
+ # some images have 4 channels
+ if img.shape[2] > 3:
+ img = img[:, :, :3]
+ return img
+
+
+'''
+# --------------------------------------------
+# image format conversion
+# --------------------------------------------
+# numpy(single) <---> numpy(uint)
+# numpy(single) <---> tensor
+# numpy(uint) <---> tensor
+# --------------------------------------------
+'''
+
+
+# --------------------------------------------
+# numpy(single) [0, 1] <---> numpy(uint)
+# --------------------------------------------
+
+
+def uint2single(img):
+
+ return np.float32(img/255.)
+
+
+def single2uint(img):
+
+ return np.uint8((img.clip(0, 1)*255.).round())
+
+
+def uint162single(img):
+
+ return np.float32(img/65535.)
+
+
+def single2uint16(img):
+
+ return np.uint16((img.clip(0, 1)*65535.).round())
+
+
+# --------------------------------------------
+# numpy(uint) (HxWxC or HxW) <---> tensor
+# --------------------------------------------
+
+
+# convert uint to 4-dimensional torch tensor
+def uint2tensor4(img):
+ if img.ndim == 2:
+ img = np.expand_dims(img, axis=2)
+ return torch.from_numpy(np.ascontiguousarray(img)).permute(2, 0, 1).float().div(255.).unsqueeze(0)
+
+
+# convert uint to 3-dimensional torch tensor
+def uint2tensor3(img):
+ if img.ndim == 2:
+ img = np.expand_dims(img, axis=2)
+ return torch.from_numpy(np.ascontiguousarray(img)).permute(2, 0, 1).float().div(255.)
+
+
+# convert 2/3/4-dimensional torch tensor to uint
+def tensor2uint(img):
+ img = img.data.squeeze().float().clamp_(0, 1).cpu().numpy()
+ if img.ndim == 3:
+ img = np.transpose(img, (1, 2, 0))
+ return np.uint8((img*255.0).round())
+
+
+# --------------------------------------------
+# numpy(single) (HxWxC) <---> tensor
+# --------------------------------------------
+
+
+# convert single (HxWxC) to 3-dimensional torch tensor
+def single2tensor3(img):
+ return torch.from_numpy(np.ascontiguousarray(img)).permute(2, 0, 1).float()
+
+
+# convert single (HxWxC) to 4-dimensional torch tensor
+def single2tensor4(img):
+ return torch.from_numpy(np.ascontiguousarray(img)).permute(2, 0, 1).float().unsqueeze(0)
+
+
+# convert torch tensor to single
+def tensor2single(img):
+ img = img.data.squeeze().float().cpu().numpy()
+ if img.ndim == 3:
+ img = np.transpose(img, (1, 2, 0))
+
+ return img
+
+# convert torch tensor to single
+def tensor2single3(img):
+ img = img.data.squeeze().float().cpu().numpy()
+ if img.ndim == 3:
+ img = np.transpose(img, (1, 2, 0))
+ elif img.ndim == 2:
+ img = np.expand_dims(img, axis=2)
+ return img
+
+
+def single2tensor5(img):
+ return torch.from_numpy(np.ascontiguousarray(img)).permute(2, 0, 1, 3).float().unsqueeze(0)
+
+
+def single32tensor5(img):
+ return torch.from_numpy(np.ascontiguousarray(img)).float().unsqueeze(0).unsqueeze(0)
+
+
+def single42tensor4(img):
+ return torch.from_numpy(np.ascontiguousarray(img)).permute(2, 0, 1, 3).float()
+
+
+# from skimage.io import imread, imsave
+def tensor2img(tensor, out_type=np.uint8, min_max=(0, 1)):
+ '''
+ Converts a torch Tensor into an image Numpy array of BGR channel order
+ Input: 4D(B,(3/1),H,W), 3D(C,H,W), or 2D(H,W), any range, RGB channel order
+ Output: 3D(H,W,C) or 2D(H,W), [0,255], np.uint8 (default)
+ '''
+ tensor = tensor.squeeze().float().cpu().clamp_(*min_max) # squeeze first, then clamp
+ tensor = (tensor - min_max[0]) / (min_max[1] - min_max[0]) # to range [0,1]
+ n_dim = tensor.dim()
+ if n_dim == 4:
+ n_img = len(tensor)
+ img_np = make_grid(tensor, nrow=int(math.sqrt(n_img)), normalize=False).numpy()
+ img_np = np.transpose(img_np[[2, 1, 0], :, :], (1, 2, 0)) # HWC, BGR
+ elif n_dim == 3:
+ img_np = tensor.numpy()
+ img_np = np.transpose(img_np[[2, 1, 0], :, :], (1, 2, 0)) # HWC, BGR
+ elif n_dim == 2:
+ img_np = tensor.numpy()
+ else:
+ raise TypeError(
+ 'Only support 4D, 3D and 2D tensor. But received with dimension: {:d}'.format(n_dim))
+ if out_type == np.uint8:
+ img_np = (img_np * 255.0).round()
+ # Important. Unlike matlab, numpy.uint8() WILL NOT round by default.
+ return img_np.astype(out_type)
+
+
+'''
+# --------------------------------------------
+# Augmentation, flipe and/or rotate
+# --------------------------------------------
+# The following two are enough.
+# (1) augmet_img: numpy image of WxHxC or WxH
+# (2) augment_img_tensor4: tensor image 1xCxWxH
+# --------------------------------------------
+'''
+
+
+def augment_img(img, mode=0):
+ '''Kai Zhang (github: https://github.com/cszn)
+ '''
+ if mode == 0:
+ return img
+ elif mode == 1:
+ return np.flipud(np.rot90(img))
+ elif mode == 2:
+ return np.flipud(img)
+ elif mode == 3:
+ return np.rot90(img, k=3)
+ elif mode == 4:
+ return np.flipud(np.rot90(img, k=2))
+ elif mode == 5:
+ return np.rot90(img)
+ elif mode == 6:
+ return np.rot90(img, k=2)
+ elif mode == 7:
+ return np.flipud(np.rot90(img, k=3))
+
+
+def augment_img_tensor4(img, mode=0):
+ '''Kai Zhang (github: https://github.com/cszn)
+ '''
+ if mode == 0:
+ return img
+ elif mode == 1:
+ return img.rot90(1, [2, 3]).flip([2])
+ elif mode == 2:
+ return img.flip([2])
+ elif mode == 3:
+ return img.rot90(3, [2, 3])
+ elif mode == 4:
+ return img.rot90(2, [2, 3]).flip([2])
+ elif mode == 5:
+ return img.rot90(1, [2, 3])
+ elif mode == 6:
+ return img.rot90(2, [2, 3])
+ elif mode == 7:
+ return img.rot90(3, [2, 3]).flip([2])
+
+
+def augment_img_tensor(img, mode=0):
+ '''Kai Zhang (github: https://github.com/cszn)
+ '''
+ img_size = img.size()
+ img_np = img.data.cpu().numpy()
+ if len(img_size) == 3:
+ img_np = np.transpose(img_np, (1, 2, 0))
+ elif len(img_size) == 4:
+ img_np = np.transpose(img_np, (2, 3, 1, 0))
+ img_np = augment_img(img_np, mode=mode)
+ img_tensor = torch.from_numpy(np.ascontiguousarray(img_np))
+ if len(img_size) == 3:
+ img_tensor = img_tensor.permute(2, 0, 1)
+ elif len(img_size) == 4:
+ img_tensor = img_tensor.permute(3, 2, 0, 1)
+
+ return img_tensor.type_as(img)
+
+
+def augment_img_np3(img, mode=0):
+ if mode == 0:
+ return img
+ elif mode == 1:
+ return img.transpose(1, 0, 2)
+ elif mode == 2:
+ return img[::-1, :, :]
+ elif mode == 3:
+ img = img[::-1, :, :]
+ img = img.transpose(1, 0, 2)
+ return img
+ elif mode == 4:
+ return img[:, ::-1, :]
+ elif mode == 5:
+ img = img[:, ::-1, :]
+ img = img.transpose(1, 0, 2)
+ return img
+ elif mode == 6:
+ img = img[:, ::-1, :]
+ img = img[::-1, :, :]
+ return img
+ elif mode == 7:
+ img = img[:, ::-1, :]
+ img = img[::-1, :, :]
+ img = img.transpose(1, 0, 2)
+ return img
+
+
+def augment_imgs(img_list, hflip=True, rot=True):
+ # horizontal flip OR rotate
+ hflip = hflip and random.random() < 0.5
+ vflip = rot and random.random() < 0.5
+ rot90 = rot and random.random() < 0.5
+
+ def _augment(img):
+ if hflip:
+ img = img[:, ::-1, :]
+ if vflip:
+ img = img[::-1, :, :]
+ if rot90:
+ img = img.transpose(1, 0, 2)
+ return img
+
+ return [_augment(img) for img in img_list]
+
+
+'''
+# --------------------------------------------
+# modcrop and shave
+# --------------------------------------------
+'''
+
+
+def modcrop(img_in, scale):
+ # img_in: Numpy, HWC or HW
+ img = np.copy(img_in)
+ if img.ndim == 2:
+ H, W = img.shape
+ H_r, W_r = H % scale, W % scale
+ img = img[:H - H_r, :W - W_r]
+ elif img.ndim == 3:
+ H, W, C = img.shape
+ H_r, W_r = H % scale, W % scale
+ img = img[:H - H_r, :W - W_r, :]
+ else:
+ raise ValueError('Wrong img ndim: [{:d}].'.format(img.ndim))
+ return img
+
+
+def shave(img_in, border=0):
+ # img_in: Numpy, HWC or HW
+ img = np.copy(img_in)
+ h, w = img.shape[:2]
+ img = img[border:h-border, border:w-border]
+ return img
+
+
+'''
+# --------------------------------------------
+# image processing process on numpy image
+# channel_convert(in_c, tar_type, img_list):
+# rgb2ycbcr(img, only_y=True):
+# bgr2ycbcr(img, only_y=True):
+# ycbcr2rgb(img):
+# --------------------------------------------
+'''
+
+
+def rgb2ycbcr(img, only_y=True):
+ '''same as matlab rgb2ycbcr
+ only_y: only return Y channel
+ Input:
+ uint8, [0, 255]
+ float, [0, 1]
+ '''
+ in_img_type = img.dtype
+ img.astype(np.float32)
+ if in_img_type != np.uint8:
+ img *= 255.
+ # convert
+ if only_y:
+ rlt = np.dot(img, [65.481, 128.553, 24.966]) / 255.0 + 16.0
+ else:
+ rlt = np.matmul(img, [[65.481, -37.797, 112.0], [128.553, -74.203, -93.786],
+ [24.966, 112.0, -18.214]]) / 255.0 + [16, 128, 128]
+ if in_img_type == np.uint8:
+ rlt = rlt.round()
+ else:
+ rlt /= 255.
+ return rlt.astype(in_img_type)
+
+
+def ycbcr2rgb(img):
+ '''same as matlab ycbcr2rgb
+ Input:
+ uint8, [0, 255]
+ float, [0, 1]
+ '''
+ in_img_type = img.dtype
+ img.astype(np.float32)
+ if in_img_type != np.uint8:
+ img *= 255.
+ # convert
+ rlt = np.matmul(img, [[0.00456621, 0.00456621, 0.00456621], [0, -0.00153632, 0.00791071],
+ [0.00625893, -0.00318811, 0]]) * 255.0 + [-222.921, 135.576, -276.836]
+ rlt = np.clip(rlt, 0, 255)
+ if in_img_type == np.uint8:
+ rlt = rlt.round()
+ else:
+ rlt /= 255.
+ return rlt.astype(in_img_type)
+
+
+def bgr2ycbcr(img, only_y=True):
+ '''bgr version of rgb2ycbcr
+ only_y: only return Y channel
+ Input:
+ uint8, [0, 255]
+ float, [0, 1]
+ '''
+ in_img_type = img.dtype
+ img.astype(np.float32)
+ if in_img_type != np.uint8:
+ img *= 255.
+ # convert
+ if only_y:
+ rlt = np.dot(img, [24.966, 128.553, 65.481]) / 255.0 + 16.0
+ else:
+ rlt = np.matmul(img, [[24.966, 112.0, -18.214], [128.553, -74.203, -93.786],
+ [65.481, -37.797, 112.0]]) / 255.0 + [16, 128, 128]
+ if in_img_type == np.uint8:
+ rlt = rlt.round()
+ else:
+ rlt /= 255.
+ return rlt.astype(in_img_type)
+
+
+def channel_convert(in_c, tar_type, img_list):
+ # conversion among BGR, gray and y
+ if in_c == 3 and tar_type == 'gray': # BGR to gray
+ gray_list = [cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) for img in img_list]
+ return [np.expand_dims(img, axis=2) for img in gray_list]
+ elif in_c == 3 and tar_type == 'y': # BGR to y
+ y_list = [bgr2ycbcr(img, only_y=True) for img in img_list]
+ return [np.expand_dims(img, axis=2) for img in y_list]
+ elif in_c == 1 and tar_type == 'RGB': # gray/y to BGR
+ return [cv2.cvtColor(img, cv2.COLOR_GRAY2BGR) for img in img_list]
+ else:
+ return img_list
+
+
+'''
+# --------------------------------------------
+# metric, PSNR, SSIM and PSNRB
+# --------------------------------------------
+'''
+
+
+# --------------------------------------------
+# PSNR
+# --------------------------------------------
+def calculate_psnr(img1, img2, border=0):
+ # img1 and img2 have range [0, 255]
+ #img1 = img1.squeeze()
+ #img2 = img2.squeeze()
+ if not img1.shape == img2.shape:
+ raise ValueError('Input images must have the same dimensions.')
+ h, w = img1.shape[:2]
+ img1 = img1[border:h-border, border:w-border]
+ img2 = img2[border:h-border, border:w-border]
+
+ img1 = img1.astype(np.float64)
+ img2 = img2.astype(np.float64)
+ mse = np.mean((img1 - img2)**2)
+ if mse == 0:
+ return float('inf')
+ return 20 * math.log10(255.0 / math.sqrt(mse))
+
+
+# --------------------------------------------
+# SSIM
+# --------------------------------------------
+def calculate_ssim(img1, img2, border=0):
+ '''calculate SSIM
+ the same outputs as MATLAB's
+ img1, img2: [0, 255]
+ '''
+ #img1 = img1.squeeze()
+ #img2 = img2.squeeze()
+ if not img1.shape == img2.shape:
+ raise ValueError('Input images must have the same dimensions.')
+ h, w = img1.shape[:2]
+ img1 = img1[border:h-border, border:w-border]
+ img2 = img2[border:h-border, border:w-border]
+
+ if img1.ndim == 2:
+ return ssim(img1, img2)
+ elif img1.ndim == 3:
+ if img1.shape[2] == 3:
+ ssims = []
+ for i in range(3):
+ ssims.append(ssim(img1[:,:,i], img2[:,:,i]))
+ return np.array(ssims).mean()
+ elif img1.shape[2] == 1:
+ return ssim(np.squeeze(img1), np.squeeze(img2))
+ else:
+ raise ValueError('Wrong input image dimensions.')
+
+
+def ssim(img1, img2):
+ C1 = (0.01 * 255)**2
+ C2 = (0.03 * 255)**2
+
+ img1 = img1.astype(np.float64)
+ img2 = img2.astype(np.float64)
+ kernel = cv2.getGaussianKernel(11, 1.5)
+ window = np.outer(kernel, kernel.transpose())
+
+ mu1 = cv2.filter2D(img1, -1, window)[5:-5, 5:-5] # valid
+ mu2 = cv2.filter2D(img2, -1, window)[5:-5, 5:-5]
+ mu1_sq = mu1**2
+ mu2_sq = mu2**2
+ mu1_mu2 = mu1 * mu2
+ sigma1_sq = cv2.filter2D(img1**2, -1, window)[5:-5, 5:-5] - mu1_sq
+ sigma2_sq = cv2.filter2D(img2**2, -1, window)[5:-5, 5:-5] - mu2_sq
+ sigma12 = cv2.filter2D(img1 * img2, -1, window)[5:-5, 5:-5] - mu1_mu2
+
+ ssim_map = ((2 * mu1_mu2 + C1) * (2 * sigma12 + C2)) / ((mu1_sq + mu2_sq + C1) *
+ (sigma1_sq + sigma2_sq + C2))
+ return ssim_map.mean()
+
+
+def _blocking_effect_factor(im):
+ block_size = 8
+
+ block_horizontal_positions = torch.arange(7, im.shape[3] - 1, 8)
+ block_vertical_positions = torch.arange(7, im.shape[2] - 1, 8)
+
+ horizontal_block_difference = (
+ (im[:, :, :, block_horizontal_positions] - im[:, :, :, block_horizontal_positions + 1]) ** 2).sum(
+ 3).sum(2).sum(1)
+ vertical_block_difference = (
+ (im[:, :, block_vertical_positions, :] - im[:, :, block_vertical_positions + 1, :]) ** 2).sum(3).sum(
+ 2).sum(1)
+
+ nonblock_horizontal_positions = np.setdiff1d(torch.arange(0, im.shape[3] - 1), block_horizontal_positions)
+ nonblock_vertical_positions = np.setdiff1d(torch.arange(0, im.shape[2] - 1), block_vertical_positions)
+
+ horizontal_nonblock_difference = (
+ (im[:, :, :, nonblock_horizontal_positions] - im[:, :, :, nonblock_horizontal_positions + 1]) ** 2).sum(
+ 3).sum(2).sum(1)
+ vertical_nonblock_difference = (
+ (im[:, :, nonblock_vertical_positions, :] - im[:, :, nonblock_vertical_positions + 1, :]) ** 2).sum(
+ 3).sum(2).sum(1)
+
+ n_boundary_horiz = im.shape[2] * (im.shape[3] // block_size - 1)
+ n_boundary_vert = im.shape[3] * (im.shape[2] // block_size - 1)
+ boundary_difference = (horizontal_block_difference + vertical_block_difference) / (
+ n_boundary_horiz + n_boundary_vert)
+
+ n_nonboundary_horiz = im.shape[2] * (im.shape[3] - 1) - n_boundary_horiz
+ n_nonboundary_vert = im.shape[3] * (im.shape[2] - 1) - n_boundary_vert
+ nonboundary_difference = (horizontal_nonblock_difference + vertical_nonblock_difference) / (
+ n_nonboundary_horiz + n_nonboundary_vert)
+
+ scaler = np.log2(block_size) / np.log2(min([im.shape[2], im.shape[3]]))
+ bef = scaler * (boundary_difference - nonboundary_difference)
+
+ bef[boundary_difference <= nonboundary_difference] = 0
+ return bef
+
+
+def calculate_psnrb(img1, img2, border=0):
+ """Calculate PSNR-B (Peak Signal-to-Noise Ratio).
+ Ref: Quality assessment of deblocked images, for JPEG image deblocking evaluation
+ # https://gitlab.com/Queuecumber/quantization-guided-ac/-/blob/master/metrics/psnrb.py
+ Args:
+ img1 (ndarray): Images with range [0, 255].
+ img2 (ndarray): Images with range [0, 255].
+ border (int): Cropped pixels in each edge of an image. These
+ pixels are not involved in the PSNR calculation.
+ test_y_channel (bool): Test on Y channel of YCbCr. Default: False.
+ Returns:
+ float: psnr result.
+ """
+
+ if not img1.shape == img2.shape:
+ raise ValueError('Input images must have the same dimensions.')
+
+ if img1.ndim == 2:
+ img1, img2 = np.expand_dims(img1, 2), np.expand_dims(img2, 2)
+
+ h, w = img1.shape[:2]
+ img1 = img1[border:h-border, border:w-border]
+ img2 = img2[border:h-border, border:w-border]
+
+ img1 = img1.astype(np.float64)
+ img2 = img2.astype(np.float64)
+
+ # follow https://gitlab.com/Queuecumber/quantization-guided-ac/-/blob/master/metrics/psnrb.py
+ img1 = torch.from_numpy(img1).permute(2, 0, 1).unsqueeze(0) / 255.
+ img2 = torch.from_numpy(img2).permute(2, 0, 1).unsqueeze(0) / 255.
+
+ total = 0
+ for c in range(img1.shape[1]):
+ mse = torch.nn.functional.mse_loss(img1[:, c:c + 1, :, :], img2[:, c:c + 1, :, :], reduction='none')
+ bef = _blocking_effect_factor(img1[:, c:c + 1, :, :])
+
+ mse = mse.view(mse.shape[0], -1).mean(1)
+ total += 10 * torch.log10(1 / (mse + bef))
+
+ return float(total) / img1.shape[1]
+
+'''
+# --------------------------------------------
+# matlab's bicubic imresize (numpy and torch) [0, 1]
+# --------------------------------------------
+'''
+
+
+# matlab 'imresize' function, now only support 'bicubic'
+def cubic(x):
+ absx = torch.abs(x)
+ absx2 = absx**2
+ absx3 = absx**3
+ return (1.5*absx3 - 2.5*absx2 + 1) * ((absx <= 1).type_as(absx)) + \
+ (-0.5*absx3 + 2.5*absx2 - 4*absx + 2) * (((absx > 1)*(absx <= 2)).type_as(absx))
+
+
+def calculate_weights_indices(in_length, out_length, scale, kernel, kernel_width, antialiasing):
+ if (scale < 1) and (antialiasing):
+ # Use a modified kernel to simultaneously interpolate and antialias- larger kernel width
+ kernel_width = kernel_width / scale
+
+ # Output-space coordinates
+ x = torch.linspace(1, out_length, out_length)
+
+ # Input-space coordinates. Calculate the inverse mapping such that 0.5
+ # in output space maps to 0.5 in input space, and 0.5+scale in output
+ # space maps to 1.5 in input space.
+ u = x / scale + 0.5 * (1 - 1 / scale)
+
+ # What is the left-most pixel that can be involved in the computation?
+ left = torch.floor(u - kernel_width / 2)
+
+ # What is the maximum number of pixels that can be involved in the
+ # computation? Note: it's OK to use an extra pixel here; if the
+ # corresponding weights are all zero, it will be eliminated at the end
+ # of this function.
+ P = math.ceil(kernel_width) + 2
+
+ # The indices of the input pixels involved in computing the k-th output
+ # pixel are in row k of the indices matrix.
+ indices = left.view(out_length, 1).expand(out_length, P) + torch.linspace(0, P - 1, P).view(
+ 1, P).expand(out_length, P)
+
+ # The weights used to compute the k-th output pixel are in row k of the
+ # weights matrix.
+ distance_to_center = u.view(out_length, 1).expand(out_length, P) - indices
+ # apply cubic kernel
+ if (scale < 1) and (antialiasing):
+ weights = scale * cubic(distance_to_center * scale)
+ else:
+ weights = cubic(distance_to_center)
+ # Normalize the weights matrix so that each row sums to 1.
+ weights_sum = torch.sum(weights, 1).view(out_length, 1)
+ weights = weights / weights_sum.expand(out_length, P)
+
+ # If a column in weights is all zero, get rid of it. only consider the first and last column.
+ weights_zero_tmp = torch.sum((weights == 0), 0)
+ if not math.isclose(weights_zero_tmp[0], 0, rel_tol=1e-6):
+ indices = indices.narrow(1, 1, P - 2)
+ weights = weights.narrow(1, 1, P - 2)
+ if not math.isclose(weights_zero_tmp[-1], 0, rel_tol=1e-6):
+ indices = indices.narrow(1, 0, P - 2)
+ weights = weights.narrow(1, 0, P - 2)
+ weights = weights.contiguous()
+ indices = indices.contiguous()
+ sym_len_s = -indices.min() + 1
+ sym_len_e = indices.max() - in_length
+ indices = indices + sym_len_s - 1
+ return weights, indices, int(sym_len_s), int(sym_len_e)
+
+
+# --------------------------------------------
+# imresize for tensor image [0, 1]
+# --------------------------------------------
+def imresize(img, scale, antialiasing=True):
+ # Now the scale should be the same for H and W
+ # input: img: pytorch tensor, CHW or HW [0,1]
+ # output: CHW or HW [0,1] w/o round
+ need_squeeze = True if img.dim() == 2 else False
+ if need_squeeze:
+ img.unsqueeze_(0)
+ in_C, in_H, in_W = img.size()
+ out_C, out_H, out_W = in_C, math.ceil(in_H * scale), math.ceil(in_W * scale)
+ kernel_width = 4
+ kernel = 'cubic'
+
+ # Return the desired dimension order for performing the resize. The
+ # strategy is to perform the resize first along the dimension with the
+ # smallest scale factor.
+ # Now we do not support this.
+
+ # get weights and indices
+ weights_H, indices_H, sym_len_Hs, sym_len_He = calculate_weights_indices(
+ in_H, out_H, scale, kernel, kernel_width, antialiasing)
+ weights_W, indices_W, sym_len_Ws, sym_len_We = calculate_weights_indices(
+ in_W, out_W, scale, kernel, kernel_width, antialiasing)
+ # process H dimension
+ # symmetric copying
+ img_aug = torch.FloatTensor(in_C, in_H + sym_len_Hs + sym_len_He, in_W)
+ img_aug.narrow(1, sym_len_Hs, in_H).copy_(img)
+
+ sym_patch = img[:, :sym_len_Hs, :]
+ inv_idx = torch.arange(sym_patch.size(1) - 1, -1, -1).long()
+ sym_patch_inv = sym_patch.index_select(1, inv_idx)
+ img_aug.narrow(1, 0, sym_len_Hs).copy_(sym_patch_inv)
+
+ sym_patch = img[:, -sym_len_He:, :]
+ inv_idx = torch.arange(sym_patch.size(1) - 1, -1, -1).long()
+ sym_patch_inv = sym_patch.index_select(1, inv_idx)
+ img_aug.narrow(1, sym_len_Hs + in_H, sym_len_He).copy_(sym_patch_inv)
+
+ out_1 = torch.FloatTensor(in_C, out_H, in_W)
+ kernel_width = weights_H.size(1)
+ for i in range(out_H):
+ idx = int(indices_H[i][0])
+ for j in range(out_C):
+ out_1[j, i, :] = img_aug[j, idx:idx + kernel_width, :].transpose(0, 1).mv(weights_H[i])
+
+ # process W dimension
+ # symmetric copying
+ out_1_aug = torch.FloatTensor(in_C, out_H, in_W + sym_len_Ws + sym_len_We)
+ out_1_aug.narrow(2, sym_len_Ws, in_W).copy_(out_1)
+
+ sym_patch = out_1[:, :, :sym_len_Ws]
+ inv_idx = torch.arange(sym_patch.size(2) - 1, -1, -1).long()
+ sym_patch_inv = sym_patch.index_select(2, inv_idx)
+ out_1_aug.narrow(2, 0, sym_len_Ws).copy_(sym_patch_inv)
+
+ sym_patch = out_1[:, :, -sym_len_We:]
+ inv_idx = torch.arange(sym_patch.size(2) - 1, -1, -1).long()
+ sym_patch_inv = sym_patch.index_select(2, inv_idx)
+ out_1_aug.narrow(2, sym_len_Ws + in_W, sym_len_We).copy_(sym_patch_inv)
+
+ out_2 = torch.FloatTensor(in_C, out_H, out_W)
+ kernel_width = weights_W.size(1)
+ for i in range(out_W):
+ idx = int(indices_W[i][0])
+ for j in range(out_C):
+ out_2[j, :, i] = out_1_aug[j, :, idx:idx + kernel_width].mv(weights_W[i])
+ if need_squeeze:
+ out_2.squeeze_()
+ return out_2
+
+
+# --------------------------------------------
+# imresize for numpy image [0, 1]
+# --------------------------------------------
+def imresize_np(img, scale, antialiasing=True):
+ # Now the scale should be the same for H and W
+ # input: img: Numpy, HWC or HW [0,1]
+ # output: HWC or HW [0,1] w/o round
+ img = torch.from_numpy(img)
+ need_squeeze = True if img.dim() == 2 else False
+ if need_squeeze:
+ img.unsqueeze_(2)
+
+ in_H, in_W, in_C = img.size()
+ out_C, out_H, out_W = in_C, math.ceil(in_H * scale), math.ceil(in_W * scale)
+ kernel_width = 4
+ kernel = 'cubic'
+
+ # Return the desired dimension order for performing the resize. The
+ # strategy is to perform the resize first along the dimension with the
+ # smallest scale factor.
+ # Now we do not support this.
+
+ # get weights and indices
+ weights_H, indices_H, sym_len_Hs, sym_len_He = calculate_weights_indices(
+ in_H, out_H, scale, kernel, kernel_width, antialiasing)
+ weights_W, indices_W, sym_len_Ws, sym_len_We = calculate_weights_indices(
+ in_W, out_W, scale, kernel, kernel_width, antialiasing)
+ # process H dimension
+ # symmetric copying
+ img_aug = torch.FloatTensor(in_H + sym_len_Hs + sym_len_He, in_W, in_C)
+ img_aug.narrow(0, sym_len_Hs, in_H).copy_(img)
+
+ sym_patch = img[:sym_len_Hs, :, :]
+ inv_idx = torch.arange(sym_patch.size(0) - 1, -1, -1).long()
+ sym_patch_inv = sym_patch.index_select(0, inv_idx)
+ img_aug.narrow(0, 0, sym_len_Hs).copy_(sym_patch_inv)
+
+ sym_patch = img[-sym_len_He:, :, :]
+ inv_idx = torch.arange(sym_patch.size(0) - 1, -1, -1).long()
+ sym_patch_inv = sym_patch.index_select(0, inv_idx)
+ img_aug.narrow(0, sym_len_Hs + in_H, sym_len_He).copy_(sym_patch_inv)
+
+ out_1 = torch.FloatTensor(out_H, in_W, in_C)
+ kernel_width = weights_H.size(1)
+ for i in range(out_H):
+ idx = int(indices_H[i][0])
+ for j in range(out_C):
+ out_1[i, :, j] = img_aug[idx:idx + kernel_width, :, j].transpose(0, 1).mv(weights_H[i])
+
+ # process W dimension
+ # symmetric copying
+ out_1_aug = torch.FloatTensor(out_H, in_W + sym_len_Ws + sym_len_We, in_C)
+ out_1_aug.narrow(1, sym_len_Ws, in_W).copy_(out_1)
+
+ sym_patch = out_1[:, :sym_len_Ws, :]
+ inv_idx = torch.arange(sym_patch.size(1) - 1, -1, -1).long()
+ sym_patch_inv = sym_patch.index_select(1, inv_idx)
+ out_1_aug.narrow(1, 0, sym_len_Ws).copy_(sym_patch_inv)
+
+ sym_patch = out_1[:, -sym_len_We:, :]
+ inv_idx = torch.arange(sym_patch.size(1) - 1, -1, -1).long()
+ sym_patch_inv = sym_patch.index_select(1, inv_idx)
+ out_1_aug.narrow(1, sym_len_Ws + in_W, sym_len_We).copy_(sym_patch_inv)
+
+ out_2 = torch.FloatTensor(out_H, out_W, in_C)
+ kernel_width = weights_W.size(1)
+ for i in range(out_W):
+ idx = int(indices_W[i][0])
+ for j in range(out_C):
+ out_2[:, i, j] = out_1_aug[:, idx:idx + kernel_width, j].mv(weights_W[i])
+ if need_squeeze:
+ out_2.squeeze_()
+
+ return out_2.numpy()
+
+
+if __name__ == '__main__':
+ img = imread_uint('test.bmp', 3)
+# img = uint2single(img)
+# img_bicubic = imresize_np(img, 1/4)
+# imshow(single2uint(img_bicubic))
+#
+# img_tensor = single2tensor4(img)
+# for i in range(8):
+# imshow(np.concatenate((augment_img(img, i), tensor2single(augment_img_tensor4(img_tensor, i))), 1))
+
+# patches = patches_from_image(img, p_size=128, p_overlap=0, p_max=200)
+# imssave(patches,'a.png')
+
+
+
+
+
+
+
diff --git a/KAIR/utils/utils_lmdb.py b/KAIR/utils/utils_lmdb.py
new file mode 100755
index 0000000000000000000000000000000000000000..75192c346bb9c0b96f8b09635ed548bd6e797d89
--- /dev/null
+++ b/KAIR/utils/utils_lmdb.py
@@ -0,0 +1,205 @@
+import cv2
+import lmdb
+import sys
+from multiprocessing import Pool
+from os import path as osp
+from tqdm import tqdm
+
+
+def make_lmdb_from_imgs(data_path,
+ lmdb_path,
+ img_path_list,
+ keys,
+ batch=5000,
+ compress_level=1,
+ multiprocessing_read=False,
+ n_thread=40,
+ map_size=None):
+ """Make lmdb from images.
+
+ Contents of lmdb. The file structure is:
+ example.lmdb
+ ├── data.mdb
+ ├── lock.mdb
+ ├── meta_info.txt
+
+ The data.mdb and lock.mdb are standard lmdb files and you can refer to
+ https://lmdb.readthedocs.io/en/release/ for more details.
+
+ The meta_info.txt is a specified txt file to record the meta information
+ of our datasets. It will be automatically created when preparing
+ datasets by our provided dataset tools.
+ Each line in the txt file records 1)image name (with extension),
+ 2)image shape, and 3)compression level, separated by a white space.
+
+ For example, the meta information could be:
+ `000_00000000.png (720,1280,3) 1`, which means:
+ 1) image name (with extension): 000_00000000.png;
+ 2) image shape: (720,1280,3);
+ 3) compression level: 1
+
+ We use the image name without extension as the lmdb key.
+
+ If `multiprocessing_read` is True, it will read all the images to memory
+ using multiprocessing. Thus, your server needs to have enough memory.
+
+ Args:
+ data_path (str): Data path for reading images.
+ lmdb_path (str): Lmdb save path.
+ img_path_list (str): Image path list.
+ keys (str): Used for lmdb keys.
+ batch (int): After processing batch images, lmdb commits.
+ Default: 5000.
+ compress_level (int): Compress level when encoding images. Default: 1.
+ multiprocessing_read (bool): Whether use multiprocessing to read all
+ the images to memory. Default: False.
+ n_thread (int): For multiprocessing.
+ map_size (int | None): Map size for lmdb env. If None, use the
+ estimated size from images. Default: None
+ """
+
+ assert len(img_path_list) == len(keys), ('img_path_list and keys should have the same length, '
+ f'but got {len(img_path_list)} and {len(keys)}')
+ print(f'Create lmdb for {data_path}, save to {lmdb_path}...')
+ print(f'Totoal images: {len(img_path_list)}')
+ if not lmdb_path.endswith('.lmdb'):
+ raise ValueError("lmdb_path must end with '.lmdb'.")
+ if osp.exists(lmdb_path):
+ print(f'Folder {lmdb_path} already exists. Exit.')
+ sys.exit(1)
+
+ if multiprocessing_read:
+ # read all the images to memory (multiprocessing)
+ dataset = {} # use dict to keep the order for multiprocessing
+ shapes = {}
+ print(f'Read images with multiprocessing, #thread: {n_thread} ...')
+ pbar = tqdm(total=len(img_path_list), unit='image')
+
+ def callback(arg):
+ """get the image data and update pbar."""
+ key, dataset[key], shapes[key] = arg
+ pbar.update(1)
+ pbar.set_description(f'Read {key}')
+
+ pool = Pool(n_thread)
+ for path, key in zip(img_path_list, keys):
+ pool.apply_async(read_img_worker, args=(osp.join(data_path, path), key, compress_level), callback=callback)
+ pool.close()
+ pool.join()
+ pbar.close()
+ print(f'Finish reading {len(img_path_list)} images.')
+
+ # create lmdb environment
+ if map_size is None:
+ # obtain data size for one image
+ img = cv2.imread(osp.join(data_path, img_path_list[0]), cv2.IMREAD_UNCHANGED)
+ _, img_byte = cv2.imencode('.png', img, [cv2.IMWRITE_PNG_COMPRESSION, compress_level])
+ data_size_per_img = img_byte.nbytes
+ print('Data size per image is: ', data_size_per_img)
+ data_size = data_size_per_img * len(img_path_list)
+ map_size = data_size * 10
+
+ env = lmdb.open(lmdb_path, map_size=map_size)
+
+ # write data to lmdb
+ pbar = tqdm(total=len(img_path_list), unit='chunk')
+ txn = env.begin(write=True)
+ txt_file = open(osp.join(lmdb_path, 'meta_info.txt'), 'w')
+ for idx, (path, key) in enumerate(zip(img_path_list, keys)):
+ pbar.update(1)
+ pbar.set_description(f'Write {key}')
+ key_byte = key.encode('ascii')
+ if multiprocessing_read:
+ img_byte = dataset[key]
+ h, w, c = shapes[key]
+ else:
+ _, img_byte, img_shape = read_img_worker(osp.join(data_path, path), key, compress_level)
+ h, w, c = img_shape
+
+ txn.put(key_byte, img_byte)
+ # write meta information
+ txt_file.write(f'{key}.png ({h},{w},{c}) {compress_level}\n')
+ if idx % batch == 0:
+ txn.commit()
+ txn = env.begin(write=True)
+ pbar.close()
+ txn.commit()
+ env.close()
+ txt_file.close()
+ print('\nFinish writing lmdb.')
+
+
+def read_img_worker(path, key, compress_level):
+ """Read image worker.
+
+ Args:
+ path (str): Image path.
+ key (str): Image key.
+ compress_level (int): Compress level when encoding images.
+
+ Returns:
+ str: Image key.
+ byte: Image byte.
+ tuple[int]: Image shape.
+ """
+
+ img = cv2.imread(path, cv2.IMREAD_UNCHANGED)
+ # deal with `libpng error: Read Error`
+ if img is None:
+ print(f'To deal with `libpng error: Read Error`, use PIL to load {path}')
+ from PIL import Image
+ import numpy as np
+ img = Image.open(path)
+ img = np.asanyarray(img)
+ img = img[:, :, [2, 1, 0]]
+
+ if img.ndim == 2:
+ h, w = img.shape
+ c = 1
+ else:
+ h, w, c = img.shape
+ _, img_byte = cv2.imencode('.png', img, [cv2.IMWRITE_PNG_COMPRESSION, compress_level])
+ return (key, img_byte, (h, w, c))
+
+
+class LmdbMaker():
+ """LMDB Maker.
+
+ Args:
+ lmdb_path (str): Lmdb save path.
+ map_size (int): Map size for lmdb env. Default: 1024 ** 4, 1TB.
+ batch (int): After processing batch images, lmdb commits.
+ Default: 5000.
+ compress_level (int): Compress level when encoding images. Default: 1.
+ """
+
+ def __init__(self, lmdb_path, map_size=1024**4, batch=5000, compress_level=1):
+ if not lmdb_path.endswith('.lmdb'):
+ raise ValueError("lmdb_path must end with '.lmdb'.")
+ if osp.exists(lmdb_path):
+ print(f'Folder {lmdb_path} already exists. Exit.')
+ sys.exit(1)
+
+ self.lmdb_path = lmdb_path
+ self.batch = batch
+ self.compress_level = compress_level
+ self.env = lmdb.open(lmdb_path, map_size=map_size)
+ self.txn = self.env.begin(write=True)
+ self.txt_file = open(osp.join(lmdb_path, 'meta_info.txt'), 'w')
+ self.counter = 0
+
+ def put(self, img_byte, key, img_shape):
+ self.counter += 1
+ key_byte = key.encode('ascii')
+ self.txn.put(key_byte, img_byte)
+ # write meta information
+ h, w, c = img_shape
+ self.txt_file.write(f'{key}.png ({h},{w},{c}) {self.compress_level}\n')
+ if self.counter % self.batch == 0:
+ self.txn.commit()
+ self.txn = self.env.begin(write=True)
+
+ def close(self):
+ self.txn.commit()
+ self.env.close()
+ self.txt_file.close()
diff --git a/KAIR/utils/utils_logger.py b/KAIR/utils/utils_logger.py
new file mode 100644
index 0000000000000000000000000000000000000000..3067190e1b09b244814e0ccc4496b18f06e22b54
--- /dev/null
+++ b/KAIR/utils/utils_logger.py
@@ -0,0 +1,66 @@
+import sys
+import datetime
+import logging
+
+
+'''
+# --------------------------------------------
+# Kai Zhang (github: https://github.com/cszn)
+# 03/Mar/2019
+# --------------------------------------------
+# https://github.com/xinntao/BasicSR
+# --------------------------------------------
+'''
+
+
+def log(*args, **kwargs):
+ print(datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S:"), *args, **kwargs)
+
+
+'''
+# --------------------------------------------
+# logger
+# --------------------------------------------
+'''
+
+
+def logger_info(logger_name, log_path='default_logger.log'):
+ ''' set up logger
+ modified by Kai Zhang (github: https://github.com/cszn)
+ '''
+ log = logging.getLogger(logger_name)
+ if log.hasHandlers():
+ print('LogHandlers exist!')
+ else:
+ print('LogHandlers setup!')
+ level = logging.INFO
+ formatter = logging.Formatter('%(asctime)s.%(msecs)03d : %(message)s', datefmt='%y-%m-%d %H:%M:%S')
+ fh = logging.FileHandler(log_path, mode='a')
+ fh.setFormatter(formatter)
+ log.setLevel(level)
+ log.addHandler(fh)
+ # print(len(log.handlers))
+
+ sh = logging.StreamHandler()
+ sh.setFormatter(formatter)
+ log.addHandler(sh)
+
+
+'''
+# --------------------------------------------
+# print to file and std_out simultaneously
+# --------------------------------------------
+'''
+
+
+class logger_print(object):
+ def __init__(self, log_path="default.log"):
+ self.terminal = sys.stdout
+ self.log = open(log_path, 'a')
+
+ def write(self, message):
+ self.terminal.write(message)
+ self.log.write(message) # write the message
+
+ def flush(self):
+ pass
diff --git a/KAIR/utils/utils_mat.py b/KAIR/utils/utils_mat.py
new file mode 100644
index 0000000000000000000000000000000000000000..cd25d500c0eae77a3b815b8e956205b737ee43d4
--- /dev/null
+++ b/KAIR/utils/utils_mat.py
@@ -0,0 +1,88 @@
+import os
+import json
+import scipy.io as spio
+import pandas as pd
+
+
+def loadmat(filename):
+ '''
+ this function should be called instead of direct spio.loadmat
+ as it cures the problem of not properly recovering python dictionaries
+ from mat files. It calls the function check keys to cure all entries
+ which are still mat-objects
+ '''
+ data = spio.loadmat(filename, struct_as_record=False, squeeze_me=True)
+ return dict_to_nonedict(_check_keys(data))
+
+def _check_keys(dict):
+ '''
+ checks if entries in dictionary are mat-objects. If yes
+ todict is called to change them to nested dictionaries
+ '''
+ for key in dict:
+ if isinstance(dict[key], spio.matlab.mio5_params.mat_struct):
+ dict[key] = _todict(dict[key])
+ return dict
+
+def _todict(matobj):
+ '''
+ A recursive function which constructs from matobjects nested dictionaries
+ '''
+ dict = {}
+ for strg in matobj._fieldnames:
+ elem = matobj.__dict__[strg]
+ if isinstance(elem, spio.matlab.mio5_params.mat_struct):
+ dict[strg] = _todict(elem)
+ else:
+ dict[strg] = elem
+ return dict
+
+
+def dict_to_nonedict(opt):
+ if isinstance(opt, dict):
+ new_opt = dict()
+ for key, sub_opt in opt.items():
+ new_opt[key] = dict_to_nonedict(sub_opt)
+ return NoneDict(**new_opt)
+ elif isinstance(opt, list):
+ return [dict_to_nonedict(sub_opt) for sub_opt in opt]
+ else:
+ return opt
+
+
+class NoneDict(dict):
+ def __missing__(self, key):
+ return None
+
+
+def mat2json(mat_path=None, filepath = None):
+ """
+ Converts .mat file to .json and writes new file
+ Parameters
+ ----------
+ mat_path: Str
+ path/filename .mat存放路径
+ filepath: Str
+ 如果需要保存成json, 添加这一路径. 否则不保存
+ Returns
+ 返回转化的字典
+ -------
+ None
+ Examples
+ --------
+ >>> mat2json(blah blah)
+ """
+
+ matlabFile = loadmat(mat_path)
+ #pop all those dumb fields that don't let you jsonize file
+ matlabFile.pop('__header__')
+ matlabFile.pop('__version__')
+ matlabFile.pop('__globals__')
+ #jsonize the file - orientation is 'index'
+ matlabFile = pd.Series(matlabFile).to_json()
+
+ if filepath:
+ json_path = os.path.splitext(os.path.split(mat_path)[1])[0] + '.json'
+ with open(json_path, 'w') as f:
+ f.write(matlabFile)
+ return matlabFile
\ No newline at end of file
diff --git a/KAIR/utils/utils_matconvnet.py b/KAIR/utils/utils_matconvnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..37d5929692e8eadf5ec57d1616626a0611492ee2
--- /dev/null
+++ b/KAIR/utils/utils_matconvnet.py
@@ -0,0 +1,197 @@
+# -*- coding: utf-8 -*-
+import numpy as np
+import torch
+from collections import OrderedDict
+
+# import scipy.io as io
+import hdf5storage
+
+"""
+# --------------------------------------------
+# Convert matconvnet SimpleNN model into pytorch model
+# --------------------------------------------
+# Kai Zhang (cskaizhang@gmail.com)
+# https://github.com/cszn
+# 28/Nov/2019
+# --------------------------------------------
+"""
+
+
+def weights2tensor(x, squeeze=False, in_features=None, out_features=None):
+ """Modified version of https://github.com/albanie/pytorch-mcn
+ Adjust memory layout and load weights as torch tensor
+ Args:
+ x (ndaray): a numpy array, corresponding to a set of network weights
+ stored in column major order
+ squeeze (bool) [False]: whether to squeeze the tensor (i.e. remove
+ singletons from the trailing dimensions. So after converting to
+ pytorch layout (C_out, C_in, H, W), if the shape is (A, B, 1, 1)
+ it will be reshaped to a matrix with shape (A,B).
+ in_features (int :: None): used to reshape weights for a linear block.
+ out_features (int :: None): used to reshape weights for a linear block.
+ Returns:
+ torch.tensor: a permuted sets of weights, matching the pytorch layout
+ convention
+ """
+ if x.ndim == 4:
+ x = x.transpose((3, 2, 0, 1))
+# for FFDNet, pixel-shuffle layer
+# if x.shape[1]==13:
+# x=x[:,[0,2,1,3, 4,6,5,7, 8,10,9,11, 12],:,:]
+# if x.shape[0]==12:
+# x=x[[0,2,1,3, 4,6,5,7, 8,10,9,11],:,:,:]
+# if x.shape[1]==5:
+# x=x[:,[0,2,1,3, 4],:,:]
+# if x.shape[0]==4:
+# x=x[[0,2,1,3],:,:,:]
+## for SRMD, pixel-shuffle layer
+# if x.shape[0]==12:
+# x=x[[0,2,1,3, 4,6,5,7, 8,10,9,11],:,:,:]
+# if x.shape[0]==27:
+# x=x[[0,3,6,1,4,7,2,5,8, 0+9,3+9,6+9,1+9,4+9,7+9,2+9,5+9,8+9, 0+18,3+18,6+18,1+18,4+18,7+18,2+18,5+18,8+18],:,:,:]
+# if x.shape[0]==48:
+# x=x[[0,4,8,12,1,5,9,13,2,6,10,14,3,7,11,15, 0+16,4+16,8+16,12+16,1+16,5+16,9+16,13+16,2+16,6+16,10+16,14+16,3+16,7+16,11+16,15+16, 0+32,4+32,8+32,12+32,1+32,5+32,9+32,13+32,2+32,6+32,10+32,14+32,3+32,7+32,11+32,15+32],:,:,:]
+
+ elif x.ndim == 3: # add by Kai
+ x = x[:,:,:,None]
+ x = x.transpose((3, 2, 0, 1))
+ elif x.ndim == 2:
+ if x.shape[1] == 1:
+ x = x.flatten()
+ if squeeze:
+ if in_features and out_features:
+ x = x.reshape((out_features, in_features))
+ x = np.squeeze(x)
+ return torch.from_numpy(np.ascontiguousarray(x))
+
+
+def save_model(network, save_path):
+ state_dict = network.state_dict()
+ for key, param in state_dict.items():
+ state_dict[key] = param.cpu()
+ torch.save(state_dict, save_path)
+
+
+if __name__ == '__main__':
+
+
+# from utils import utils_logger
+# import logging
+# utils_logger.logger_info('a', 'a.log')
+# logger = logging.getLogger('a')
+#
+ # mcn = hdf5storage.loadmat('/model_zoo/matfile/FFDNet_Clip_gray.mat')
+ mcn = hdf5storage.loadmat('models/modelcolor.mat')
+
+
+ #logger.info(mcn['CNNdenoiser'][0][0][0][1][0][0][0][0])
+
+ mat_net = OrderedDict()
+ for idx in range(25):
+ mat_net[str(idx)] = OrderedDict()
+ count = -1
+
+ print(idx)
+ for i in range(13):
+
+ if mcn['CNNdenoiser'][0][idx][0][i][0][0][0][0] == 'conv':
+
+ count += 1
+ w = mcn['CNNdenoiser'][0][idx][0][i][0][1][0][0]
+ # print(w.shape)
+ w = weights2tensor(w)
+ # print(w.shape)
+
+ b = mcn['CNNdenoiser'][0][idx][0][i][0][1][0][1]
+ b = weights2tensor(b)
+ print(b.shape)
+
+ mat_net[str(idx)]['model.{:d}.weight'.format(count*2)] = w
+ mat_net[str(idx)]['model.{:d}.bias'.format(count*2)] = b
+
+ torch.save(mat_net, 'model_zoo/modelcolor.pth')
+
+
+
+# from models.network_dncnn import IRCNN as net
+# network = net(in_nc=3, out_nc=3, nc=64)
+# state_dict = network.state_dict()
+#
+# #show_kv(state_dict)
+#
+# for i in range(len(mcn['net'][0][0][0])):
+# print(mcn['net'][0][0][0][i][0][0][0][0])
+#
+# count = -1
+# mat_net = OrderedDict()
+# for i in range(len(mcn['net'][0][0][0])):
+# if mcn['net'][0][0][0][i][0][0][0][0] == 'conv':
+#
+# count += 1
+# w = mcn['net'][0][0][0][i][0][1][0][0]
+# print(w.shape)
+# w = weights2tensor(w)
+# print(w.shape)
+#
+# b = mcn['net'][0][0][0][i][0][1][0][1]
+# b = weights2tensor(b)
+# print(b.shape)
+#
+# mat_net['model.{:d}.weight'.format(count*2)] = w
+# mat_net['model.{:d}.bias'.format(count*2)] = b
+#
+# torch.save(mat_net, 'E:/pytorch/KAIR_ongoing/model_zoo/ffdnet_gray_clip.pth')
+#
+#
+#
+# crt_net = torch.load('E:/pytorch/KAIR_ongoing/model_zoo/imdn_x4.pth')
+# def show_kv(net):
+# for k, v in net.items():
+# print(k)
+#
+# show_kv(crt_net)
+
+
+# from models.network_dncnn import DnCNN as net
+# network = net(in_nc=2, out_nc=1, nc=64, nb=20, act_mode='R')
+
+# from models.network_srmd import SRMD as net
+# #network = net(in_nc=1, out_nc=1, nc=64, nb=15, act_mode='R')
+# network = net(in_nc=19, out_nc=3, nc=128, nb=12, upscale=4, act_mode='R', upsample_mode='pixelshuffle')
+#
+# from models.network_rrdb import RRDB as net
+# network = net(in_nc=3, out_nc=3, nc=64, nb=23, gc=32, upscale=4, act_mode='L', upsample_mode='upconv')
+#
+# state_dict = network.state_dict()
+# for key, param in state_dict.items():
+# print(key)
+# from models.network_imdn import IMDN as net
+# network = net(in_nc=3, out_nc=3, nc=64, nb=8, upscale=4, act_mode='L', upsample_mode='pixelshuffle')
+# state_dict = network.state_dict()
+# mat_net = OrderedDict()
+# for ((key, param),(key2, param2)) in zip(state_dict.items(), crt_net.items()):
+# mat_net[key] = param2
+# torch.save(mat_net, 'model_zoo/imdn_x4_1.pth')
+#
+
+# net_old = torch.load('net_old.pth')
+# def show_kv(net):
+# for k, v in net.items():
+# print(k)
+#
+# show_kv(net_old)
+# from models.network_dpsr import MSRResNet_prior as net
+# model = net(in_nc=4, out_nc=3, nc=96, nb=16, upscale=4, act_mode='R', upsample_mode='pixelshuffle')
+# state_dict = network.state_dict()
+# net_new = OrderedDict()
+# for ((key, param),(key_old, param_old)) in zip(state_dict.items(), net_old.items()):
+# net_new[key] = param_old
+# torch.save(net_new, 'net_new.pth')
+
+
+ # print(key)
+ # print(param.size())
+
+
+
+ # run utils/utils_matconvnet.py
diff --git a/KAIR/utils/utils_model.py b/KAIR/utils/utils_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..94ced53c0e34bd0938e5e55ed22b1cf214885477
--- /dev/null
+++ b/KAIR/utils/utils_model.py
@@ -0,0 +1,330 @@
+# -*- coding: utf-8 -*-
+import numpy as np
+import torch
+from utils import utils_image as util
+import re
+import glob
+import os
+
+
+'''
+# --------------------------------------------
+# Model
+# --------------------------------------------
+# Kai Zhang (github: https://github.com/cszn)
+# 03/Mar/2019
+# --------------------------------------------
+'''
+
+
+def find_last_checkpoint(save_dir, net_type='G', pretrained_path=None):
+ """
+ # ---------------------------------------
+ # Kai Zhang (github: https://github.com/cszn)
+ # 03/Mar/2019
+ # ---------------------------------------
+ Args:
+ save_dir: model folder
+ net_type: 'G' or 'D' or 'optimizerG' or 'optimizerD'
+ pretrained_path: pretrained model path. If save_dir does not have any model, load from pretrained_path
+
+ Return:
+ init_iter: iteration number
+ init_path: model path
+ # ---------------------------------------
+ """
+
+ file_list = glob.glob(os.path.join(save_dir, '*_{}.pth'.format(net_type)))
+ if file_list:
+ iter_exist = []
+ for file_ in file_list:
+ iter_current = re.findall(r"(\d+)_{}.pth".format(net_type), file_)
+ iter_exist.append(int(iter_current[0]))
+ init_iter = max(iter_exist)
+ init_path = os.path.join(save_dir, '{}_{}.pth'.format(init_iter, net_type))
+ else:
+ init_iter = 0
+ init_path = pretrained_path
+ return init_iter, init_path
+
+
+def test_mode(model, L, mode=0, refield=32, min_size=256, sf=1, modulo=1):
+ '''
+ # ---------------------------------------
+ # Kai Zhang (github: https://github.com/cszn)
+ # 03/Mar/2019
+ # ---------------------------------------
+ Args:
+ model: trained model
+ L: input Low-quality image
+ mode:
+ (0) normal: test(model, L)
+ (1) pad: test_pad(model, L, modulo=16)
+ (2) split: test_split(model, L, refield=32, min_size=256, sf=1, modulo=1)
+ (3) x8: test_x8(model, L, modulo=1) ^_^
+ (4) split and x8: test_split_x8(model, L, refield=32, min_size=256, sf=1, modulo=1)
+ refield: effective receptive filed of the network, 32 is enough
+ useful when split, i.e., mode=2, 4
+ min_size: min_sizeXmin_size image, e.g., 256X256 image
+ useful when split, i.e., mode=2, 4
+ sf: scale factor for super-resolution, otherwise 1
+ modulo: 1 if split
+ useful when pad, i.e., mode=1
+
+ Returns:
+ E: estimated image
+ # ---------------------------------------
+ '''
+ if mode == 0:
+ E = test(model, L)
+ elif mode == 1:
+ E = test_pad(model, L, modulo, sf)
+ elif mode == 2:
+ E = test_split(model, L, refield, min_size, sf, modulo)
+ elif mode == 3:
+ E = test_x8(model, L, modulo, sf)
+ elif mode == 4:
+ E = test_split_x8(model, L, refield, min_size, sf, modulo)
+ return E
+
+
+'''
+# --------------------------------------------
+# normal (0)
+# --------------------------------------------
+'''
+
+
+def test(model, L):
+ E = model(L)
+ return E
+
+
+'''
+# --------------------------------------------
+# pad (1)
+# --------------------------------------------
+'''
+
+
+def test_pad(model, L, modulo=16, sf=1):
+ h, w = L.size()[-2:]
+ paddingBottom = int(np.ceil(h/modulo)*modulo-h)
+ paddingRight = int(np.ceil(w/modulo)*modulo-w)
+ L = torch.nn.ReplicationPad2d((0, paddingRight, 0, paddingBottom))(L)
+ E = model(L)
+ E = E[..., :h*sf, :w*sf]
+ return E
+
+
+'''
+# --------------------------------------------
+# split (function)
+# --------------------------------------------
+'''
+
+
+def test_split_fn(model, L, refield=32, min_size=256, sf=1, modulo=1):
+ """
+ Args:
+ model: trained model
+ L: input Low-quality image
+ refield: effective receptive filed of the network, 32 is enough
+ min_size: min_sizeXmin_size image, e.g., 256X256 image
+ sf: scale factor for super-resolution, otherwise 1
+ modulo: 1 if split
+
+ Returns:
+ E: estimated result
+ """
+ h, w = L.size()[-2:]
+ if h*w <= min_size**2:
+ L = torch.nn.ReplicationPad2d((0, int(np.ceil(w/modulo)*modulo-w), 0, int(np.ceil(h/modulo)*modulo-h)))(L)
+ E = model(L)
+ E = E[..., :h*sf, :w*sf]
+ else:
+ top = slice(0, (h//2//refield+1)*refield)
+ bottom = slice(h - (h//2//refield+1)*refield, h)
+ left = slice(0, (w//2//refield+1)*refield)
+ right = slice(w - (w//2//refield+1)*refield, w)
+ Ls = [L[..., top, left], L[..., top, right], L[..., bottom, left], L[..., bottom, right]]
+
+ if h * w <= 4*(min_size**2):
+ Es = [model(Ls[i]) for i in range(4)]
+ else:
+ Es = [test_split_fn(model, Ls[i], refield=refield, min_size=min_size, sf=sf, modulo=modulo) for i in range(4)]
+
+ b, c = Es[0].size()[:2]
+ E = torch.zeros(b, c, sf * h, sf * w).type_as(L)
+
+ E[..., :h//2*sf, :w//2*sf] = Es[0][..., :h//2*sf, :w//2*sf]
+ E[..., :h//2*sf, w//2*sf:w*sf] = Es[1][..., :h//2*sf, (-w + w//2)*sf:]
+ E[..., h//2*sf:h*sf, :w//2*sf] = Es[2][..., (-h + h//2)*sf:, :w//2*sf]
+ E[..., h//2*sf:h*sf, w//2*sf:w*sf] = Es[3][..., (-h + h//2)*sf:, (-w + w//2)*sf:]
+ return E
+
+
+'''
+# --------------------------------------------
+# split (2)
+# --------------------------------------------
+'''
+
+
+def test_split(model, L, refield=32, min_size=256, sf=1, modulo=1):
+ E = test_split_fn(model, L, refield=refield, min_size=min_size, sf=sf, modulo=modulo)
+ return E
+
+
+'''
+# --------------------------------------------
+# x8 (3)
+# --------------------------------------------
+'''
+
+
+def test_x8(model, L, modulo=1, sf=1):
+ E_list = [test_pad(model, util.augment_img_tensor4(L, mode=i), modulo=modulo, sf=sf) for i in range(8)]
+ for i in range(len(E_list)):
+ if i == 3 or i == 5:
+ E_list[i] = util.augment_img_tensor4(E_list[i], mode=8 - i)
+ else:
+ E_list[i] = util.augment_img_tensor4(E_list[i], mode=i)
+ output_cat = torch.stack(E_list, dim=0)
+ E = output_cat.mean(dim=0, keepdim=False)
+ return E
+
+
+'''
+# --------------------------------------------
+# split and x8 (4)
+# --------------------------------------------
+'''
+
+
+def test_split_x8(model, L, refield=32, min_size=256, sf=1, modulo=1):
+ E_list = [test_split_fn(model, util.augment_img_tensor4(L, mode=i), refield=refield, min_size=min_size, sf=sf, modulo=modulo) for i in range(8)]
+ for k, i in enumerate(range(len(E_list))):
+ if i==3 or i==5:
+ E_list[k] = util.augment_img_tensor4(E_list[k], mode=8-i)
+ else:
+ E_list[k] = util.augment_img_tensor4(E_list[k], mode=i)
+ output_cat = torch.stack(E_list, dim=0)
+ E = output_cat.mean(dim=0, keepdim=False)
+ return E
+
+
+'''
+# ^_^-^_^-^_^-^_^-^_^-^_^-^_^-^_^-^_^-^_^-^_^-
+# _^_^-^_^-^_^-^_^-^_^-^_^-^_^-^_^-^_^-^_^-^_^
+# ^_^-^_^-^_^-^_^-^_^-^_^-^_^-^_^-^_^-^_^-^_^-
+'''
+
+
+'''
+# --------------------------------------------
+# print
+# --------------------------------------------
+'''
+
+
+# --------------------------------------------
+# print model
+# --------------------------------------------
+def print_model(model):
+ msg = describe_model(model)
+ print(msg)
+
+
+# --------------------------------------------
+# print params
+# --------------------------------------------
+def print_params(model):
+ msg = describe_params(model)
+ print(msg)
+
+
+'''
+# --------------------------------------------
+# information
+# --------------------------------------------
+'''
+
+
+# --------------------------------------------
+# model inforation
+# --------------------------------------------
+def info_model(model):
+ msg = describe_model(model)
+ return msg
+
+
+# --------------------------------------------
+# params inforation
+# --------------------------------------------
+def info_params(model):
+ msg = describe_params(model)
+ return msg
+
+
+'''
+# --------------------------------------------
+# description
+# --------------------------------------------
+'''
+
+
+# --------------------------------------------
+# model name and total number of parameters
+# --------------------------------------------
+def describe_model(model):
+ if isinstance(model, torch.nn.DataParallel):
+ model = model.module
+ msg = '\n'
+ msg += 'models name: {}'.format(model.__class__.__name__) + '\n'
+ msg += 'Params number: {}'.format(sum(map(lambda x: x.numel(), model.parameters()))) + '\n'
+ msg += 'Net structure:\n{}'.format(str(model)) + '\n'
+ return msg
+
+
+# --------------------------------------------
+# parameters description
+# --------------------------------------------
+def describe_params(model):
+ if isinstance(model, torch.nn.DataParallel):
+ model = model.module
+ msg = '\n'
+ msg += ' | {:^6s} | {:^6s} | {:^6s} | {:^6s} || {:<20s}'.format('mean', 'min', 'max', 'std', 'shape', 'param_name') + '\n'
+ for name, param in model.state_dict().items():
+ if not 'num_batches_tracked' in name:
+ v = param.data.clone().float()
+ msg += ' | {:>6.3f} | {:>6.3f} | {:>6.3f} | {:>6.3f} | {} || {:s}'.format(v.mean(), v.min(), v.max(), v.std(), v.shape, name) + '\n'
+ return msg
+
+
+if __name__ == '__main__':
+
+ class Net(torch.nn.Module):
+ def __init__(self, in_channels=3, out_channels=3):
+ super(Net, self).__init__()
+ self.conv = torch.nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=3, padding=1)
+
+ def forward(self, x):
+ x = self.conv(x)
+ return x
+
+ start = torch.cuda.Event(enable_timing=True)
+ end = torch.cuda.Event(enable_timing=True)
+
+ model = Net()
+ model = model.eval()
+ print_model(model)
+ print_params(model)
+ x = torch.randn((2,3,401,401))
+ torch.cuda.empty_cache()
+ with torch.no_grad():
+ for mode in range(5):
+ y = test_mode(model, x, mode, refield=32, min_size=256, sf=1, modulo=1)
+ print(y.shape)
+
+ # run utils/utils_model.py
diff --git a/KAIR/utils/utils_modelsummary.py b/KAIR/utils/utils_modelsummary.py
new file mode 100644
index 0000000000000000000000000000000000000000..5e040e31d8ddffbb8b7b2e2dc4ddf0b9cdca6a23
--- /dev/null
+++ b/KAIR/utils/utils_modelsummary.py
@@ -0,0 +1,485 @@
+import torch.nn as nn
+import torch
+import numpy as np
+
+'''
+---- 1) FLOPs: floating point operations
+---- 2) #Activations: the number of elements of all ‘Conv2d’ outputs
+---- 3) #Conv2d: the number of ‘Conv2d’ layers
+# --------------------------------------------
+# Kai Zhang (github: https://github.com/cszn)
+# 21/July/2020
+# --------------------------------------------
+# Reference
+https://github.com/sovrasov/flops-counter.pytorch.git
+
+# If you use this code, please consider the following citation:
+
+@inproceedings{zhang2020aim, %
+ title={AIM 2020 Challenge on Efficient Super-Resolution: Methods and Results},
+ author={Kai Zhang and Martin Danelljan and Yawei Li and Radu Timofte and others},
+ booktitle={European Conference on Computer Vision Workshops},
+ year={2020}
+}
+# --------------------------------------------
+'''
+
+def get_model_flops(model, input_res, print_per_layer_stat=True,
+ input_constructor=None):
+ assert type(input_res) is tuple, 'Please provide the size of the input image.'
+ assert len(input_res) >= 3, 'Input image should have 3 dimensions.'
+ flops_model = add_flops_counting_methods(model)
+ flops_model.eval().start_flops_count()
+ if input_constructor:
+ input = input_constructor(input_res)
+ _ = flops_model(**input)
+ else:
+ device = list(flops_model.parameters())[-1].device
+ batch = torch.FloatTensor(1, *input_res).to(device)
+ _ = flops_model(batch)
+
+ if print_per_layer_stat:
+ print_model_with_flops(flops_model)
+ flops_count = flops_model.compute_average_flops_cost()
+ flops_model.stop_flops_count()
+
+ return flops_count
+
+def get_model_activation(model, input_res, input_constructor=None):
+ assert type(input_res) is tuple, 'Please provide the size of the input image.'
+ assert len(input_res) >= 3, 'Input image should have 3 dimensions.'
+ activation_model = add_activation_counting_methods(model)
+ activation_model.eval().start_activation_count()
+ if input_constructor:
+ input = input_constructor(input_res)
+ _ = activation_model(**input)
+ else:
+ device = list(activation_model.parameters())[-1].device
+ batch = torch.FloatTensor(1, *input_res).to(device)
+ _ = activation_model(batch)
+
+ activation_count, num_conv = activation_model.compute_average_activation_cost()
+ activation_model.stop_activation_count()
+
+ return activation_count, num_conv
+
+
+def get_model_complexity_info(model, input_res, print_per_layer_stat=True, as_strings=True,
+ input_constructor=None):
+ assert type(input_res) is tuple
+ assert len(input_res) >= 3
+ flops_model = add_flops_counting_methods(model)
+ flops_model.eval().start_flops_count()
+ if input_constructor:
+ input = input_constructor(input_res)
+ _ = flops_model(**input)
+ else:
+ batch = torch.FloatTensor(1, *input_res)
+ _ = flops_model(batch)
+
+ if print_per_layer_stat:
+ print_model_with_flops(flops_model)
+ flops_count = flops_model.compute_average_flops_cost()
+ params_count = get_model_parameters_number(flops_model)
+ flops_model.stop_flops_count()
+
+ if as_strings:
+ return flops_to_string(flops_count), params_to_string(params_count)
+
+ return flops_count, params_count
+
+
+def flops_to_string(flops, units='GMac', precision=2):
+ if units is None:
+ if flops // 10**9 > 0:
+ return str(round(flops / 10.**9, precision)) + ' GMac'
+ elif flops // 10**6 > 0:
+ return str(round(flops / 10.**6, precision)) + ' MMac'
+ elif flops // 10**3 > 0:
+ return str(round(flops / 10.**3, precision)) + ' KMac'
+ else:
+ return str(flops) + ' Mac'
+ else:
+ if units == 'GMac':
+ return str(round(flops / 10.**9, precision)) + ' ' + units
+ elif units == 'MMac':
+ return str(round(flops / 10.**6, precision)) + ' ' + units
+ elif units == 'KMac':
+ return str(round(flops / 10.**3, precision)) + ' ' + units
+ else:
+ return str(flops) + ' Mac'
+
+
+def params_to_string(params_num):
+ if params_num // 10 ** 6 > 0:
+ return str(round(params_num / 10 ** 6, 2)) + ' M'
+ elif params_num // 10 ** 3:
+ return str(round(params_num / 10 ** 3, 2)) + ' k'
+ else:
+ return str(params_num)
+
+
+def print_model_with_flops(model, units='GMac', precision=3):
+ total_flops = model.compute_average_flops_cost()
+
+ def accumulate_flops(self):
+ if is_supported_instance(self):
+ return self.__flops__ / model.__batch_counter__
+ else:
+ sum = 0
+ for m in self.children():
+ sum += m.accumulate_flops()
+ return sum
+
+ def flops_repr(self):
+ accumulated_flops_cost = self.accumulate_flops()
+ return ', '.join([flops_to_string(accumulated_flops_cost, units=units, precision=precision),
+ '{:.3%} MACs'.format(accumulated_flops_cost / total_flops),
+ self.original_extra_repr()])
+
+ def add_extra_repr(m):
+ m.accumulate_flops = accumulate_flops.__get__(m)
+ flops_extra_repr = flops_repr.__get__(m)
+ if m.extra_repr != flops_extra_repr:
+ m.original_extra_repr = m.extra_repr
+ m.extra_repr = flops_extra_repr
+ assert m.extra_repr != m.original_extra_repr
+
+ def del_extra_repr(m):
+ if hasattr(m, 'original_extra_repr'):
+ m.extra_repr = m.original_extra_repr
+ del m.original_extra_repr
+ if hasattr(m, 'accumulate_flops'):
+ del m.accumulate_flops
+
+ model.apply(add_extra_repr)
+ print(model)
+ model.apply(del_extra_repr)
+
+
+def get_model_parameters_number(model):
+ params_num = sum(p.numel() for p in model.parameters() if p.requires_grad)
+ return params_num
+
+
+def add_flops_counting_methods(net_main_module):
+ # adding additional methods to the existing module object,
+ # this is done this way so that each function has access to self object
+ # embed()
+ net_main_module.start_flops_count = start_flops_count.__get__(net_main_module)
+ net_main_module.stop_flops_count = stop_flops_count.__get__(net_main_module)
+ net_main_module.reset_flops_count = reset_flops_count.__get__(net_main_module)
+ net_main_module.compute_average_flops_cost = compute_average_flops_cost.__get__(net_main_module)
+
+ net_main_module.reset_flops_count()
+ return net_main_module
+
+
+def compute_average_flops_cost(self):
+ """
+ A method that will be available after add_flops_counting_methods() is called
+ on a desired net object.
+
+ Returns current mean flops consumption per image.
+
+ """
+
+ flops_sum = 0
+ for module in self.modules():
+ if is_supported_instance(module):
+ flops_sum += module.__flops__
+
+ return flops_sum
+
+
+def start_flops_count(self):
+ """
+ A method that will be available after add_flops_counting_methods() is called
+ on a desired net object.
+
+ Activates the computation of mean flops consumption per image.
+ Call it before you run the network.
+
+ """
+ self.apply(add_flops_counter_hook_function)
+
+
+def stop_flops_count(self):
+ """
+ A method that will be available after add_flops_counting_methods() is called
+ on a desired net object.
+
+ Stops computing the mean flops consumption per image.
+ Call whenever you want to pause the computation.
+
+ """
+ self.apply(remove_flops_counter_hook_function)
+
+
+def reset_flops_count(self):
+ """
+ A method that will be available after add_flops_counting_methods() is called
+ on a desired net object.
+
+ Resets statistics computed so far.
+
+ """
+ self.apply(add_flops_counter_variable_or_reset)
+
+
+def add_flops_counter_hook_function(module):
+ if is_supported_instance(module):
+ if hasattr(module, '__flops_handle__'):
+ return
+
+ if isinstance(module, (nn.Conv2d, nn.Conv3d, nn.ConvTranspose2d)):
+ handle = module.register_forward_hook(conv_flops_counter_hook)
+ elif isinstance(module, (nn.ReLU, nn.PReLU, nn.ELU, nn.LeakyReLU, nn.ReLU6)):
+ handle = module.register_forward_hook(relu_flops_counter_hook)
+ elif isinstance(module, nn.Linear):
+ handle = module.register_forward_hook(linear_flops_counter_hook)
+ elif isinstance(module, (nn.BatchNorm2d)):
+ handle = module.register_forward_hook(bn_flops_counter_hook)
+ else:
+ handle = module.register_forward_hook(empty_flops_counter_hook)
+ module.__flops_handle__ = handle
+
+
+def remove_flops_counter_hook_function(module):
+ if is_supported_instance(module):
+ if hasattr(module, '__flops_handle__'):
+ module.__flops_handle__.remove()
+ del module.__flops_handle__
+
+
+def add_flops_counter_variable_or_reset(module):
+ if is_supported_instance(module):
+ module.__flops__ = 0
+
+
+# ---- Internal functions
+def is_supported_instance(module):
+ if isinstance(module,
+ (
+ nn.Conv2d, nn.ConvTranspose2d,
+ nn.BatchNorm2d,
+ nn.Linear,
+ nn.ReLU, nn.PReLU, nn.ELU, nn.LeakyReLU, nn.ReLU6,
+ )):
+ return True
+
+ return False
+
+
+def conv_flops_counter_hook(conv_module, input, output):
+ # Can have multiple inputs, getting the first one
+ # input = input[0]
+
+ batch_size = output.shape[0]
+ output_dims = list(output.shape[2:])
+
+ kernel_dims = list(conv_module.kernel_size)
+ in_channels = conv_module.in_channels
+ out_channels = conv_module.out_channels
+ groups = conv_module.groups
+
+ filters_per_channel = out_channels // groups
+ conv_per_position_flops = np.prod(kernel_dims) * in_channels * filters_per_channel
+
+ active_elements_count = batch_size * np.prod(output_dims)
+ overall_conv_flops = int(conv_per_position_flops) * int(active_elements_count)
+
+ # overall_flops = overall_conv_flops
+
+ conv_module.__flops__ += int(overall_conv_flops)
+ # conv_module.__output_dims__ = output_dims
+
+
+def relu_flops_counter_hook(module, input, output):
+ active_elements_count = output.numel()
+ module.__flops__ += int(active_elements_count)
+ # print(module.__flops__, id(module))
+ # print(module)
+
+
+def linear_flops_counter_hook(module, input, output):
+ input = input[0]
+ if len(input.shape) == 1:
+ batch_size = 1
+ module.__flops__ += int(batch_size * input.shape[0] * output.shape[0])
+ else:
+ batch_size = input.shape[0]
+ module.__flops__ += int(batch_size * input.shape[1] * output.shape[1])
+
+
+def bn_flops_counter_hook(module, input, output):
+ # input = input[0]
+ # TODO: need to check here
+ # batch_flops = np.prod(input.shape)
+ # if module.affine:
+ # batch_flops *= 2
+ # module.__flops__ += int(batch_flops)
+ batch = output.shape[0]
+ output_dims = output.shape[2:]
+ channels = module.num_features
+ batch_flops = batch * channels * np.prod(output_dims)
+ if module.affine:
+ batch_flops *= 2
+ module.__flops__ += int(batch_flops)
+
+
+# ---- Count the number of convolutional layers and the activation
+def add_activation_counting_methods(net_main_module):
+ # adding additional methods to the existing module object,
+ # this is done this way so that each function has access to self object
+ # embed()
+ net_main_module.start_activation_count = start_activation_count.__get__(net_main_module)
+ net_main_module.stop_activation_count = stop_activation_count.__get__(net_main_module)
+ net_main_module.reset_activation_count = reset_activation_count.__get__(net_main_module)
+ net_main_module.compute_average_activation_cost = compute_average_activation_cost.__get__(net_main_module)
+
+ net_main_module.reset_activation_count()
+ return net_main_module
+
+
+def compute_average_activation_cost(self):
+ """
+ A method that will be available after add_activation_counting_methods() is called
+ on a desired net object.
+
+ Returns current mean activation consumption per image.
+
+ """
+
+ activation_sum = 0
+ num_conv = 0
+ for module in self.modules():
+ if is_supported_instance_for_activation(module):
+ activation_sum += module.__activation__
+ num_conv += module.__num_conv__
+ return activation_sum, num_conv
+
+
+def start_activation_count(self):
+ """
+ A method that will be available after add_activation_counting_methods() is called
+ on a desired net object.
+
+ Activates the computation of mean activation consumption per image.
+ Call it before you run the network.
+
+ """
+ self.apply(add_activation_counter_hook_function)
+
+
+def stop_activation_count(self):
+ """
+ A method that will be available after add_activation_counting_methods() is called
+ on a desired net object.
+
+ Stops computing the mean activation consumption per image.
+ Call whenever you want to pause the computation.
+
+ """
+ self.apply(remove_activation_counter_hook_function)
+
+
+def reset_activation_count(self):
+ """
+ A method that will be available after add_activation_counting_methods() is called
+ on a desired net object.
+
+ Resets statistics computed so far.
+
+ """
+ self.apply(add_activation_counter_variable_or_reset)
+
+
+def add_activation_counter_hook_function(module):
+ if is_supported_instance_for_activation(module):
+ if hasattr(module, '__activation_handle__'):
+ return
+
+ if isinstance(module, (nn.Conv2d, nn.ConvTranspose2d)):
+ handle = module.register_forward_hook(conv_activation_counter_hook)
+ module.__activation_handle__ = handle
+
+
+def remove_activation_counter_hook_function(module):
+ if is_supported_instance_for_activation(module):
+ if hasattr(module, '__activation_handle__'):
+ module.__activation_handle__.remove()
+ del module.__activation_handle__
+
+
+def add_activation_counter_variable_or_reset(module):
+ if is_supported_instance_for_activation(module):
+ module.__activation__ = 0
+ module.__num_conv__ = 0
+
+
+def is_supported_instance_for_activation(module):
+ if isinstance(module,
+ (
+ nn.Conv2d, nn.ConvTranspose2d,
+ )):
+ return True
+
+ return False
+
+def conv_activation_counter_hook(module, input, output):
+ """
+ Calculate the activations in the convolutional operation.
+ Reference: Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár, Designing Network Design Spaces.
+ :param module:
+ :param input:
+ :param output:
+ :return:
+ """
+ module.__activation__ += output.numel()
+ module.__num_conv__ += 1
+
+
+def empty_flops_counter_hook(module, input, output):
+ module.__flops__ += 0
+
+
+def upsample_flops_counter_hook(module, input, output):
+ output_size = output[0]
+ batch_size = output_size.shape[0]
+ output_elements_count = batch_size
+ for val in output_size.shape[1:]:
+ output_elements_count *= val
+ module.__flops__ += int(output_elements_count)
+
+
+def pool_flops_counter_hook(module, input, output):
+ input = input[0]
+ module.__flops__ += int(np.prod(input.shape))
+
+
+def dconv_flops_counter_hook(dconv_module, input, output):
+ input = input[0]
+
+ batch_size = input.shape[0]
+ output_dims = list(output.shape[2:])
+
+ m_channels, in_channels, kernel_dim1, _, = dconv_module.weight.shape
+ out_channels, _, kernel_dim2, _, = dconv_module.projection.shape
+ # groups = dconv_module.groups
+
+ # filters_per_channel = out_channels // groups
+ conv_per_position_flops1 = kernel_dim1 ** 2 * in_channels * m_channels
+ conv_per_position_flops2 = kernel_dim2 ** 2 * out_channels * m_channels
+ active_elements_count = batch_size * np.prod(output_dims)
+
+ overall_conv_flops = (conv_per_position_flops1 + conv_per_position_flops2) * active_elements_count
+ overall_flops = overall_conv_flops
+
+ dconv_module.__flops__ += int(overall_flops)
+ # dconv_module.__output_dims__ = output_dims
+
+
+
+
+
diff --git a/KAIR/utils/utils_option.py b/KAIR/utils/utils_option.py
new file mode 100644
index 0000000000000000000000000000000000000000..cf096210e2d8ea553b06a91ac5cdaa21127d837c
--- /dev/null
+++ b/KAIR/utils/utils_option.py
@@ -0,0 +1,255 @@
+import os
+from collections import OrderedDict
+from datetime import datetime
+import json
+import re
+import glob
+
+
+'''
+# --------------------------------------------
+# Kai Zhang (github: https://github.com/cszn)
+# 03/Mar/2019
+# --------------------------------------------
+# https://github.com/xinntao/BasicSR
+# --------------------------------------------
+'''
+
+
+def get_timestamp():
+ return datetime.now().strftime('_%y%m%d_%H%M%S')
+
+
+def parse(opt_path, is_train=True):
+
+ # ----------------------------------------
+ # remove comments starting with '//'
+ # ----------------------------------------
+ json_str = ''
+ with open(opt_path, 'r') as f:
+ for line in f:
+ line = line.split('//')[0] + '\n'
+ json_str += line
+
+ # ----------------------------------------
+ # initialize opt
+ # ----------------------------------------
+ opt = json.loads(json_str, object_pairs_hook=OrderedDict)
+
+ opt['opt_path'] = opt_path
+ opt['is_train'] = is_train
+
+ # ----------------------------------------
+ # set default
+ # ----------------------------------------
+ if 'merge_bn' not in opt:
+ opt['merge_bn'] = False
+ opt['merge_bn_startpoint'] = -1
+
+ if 'scale' not in opt:
+ opt['scale'] = 1
+
+ # ----------------------------------------
+ # datasets
+ # ----------------------------------------
+ for phase, dataset in opt['datasets'].items():
+ phase = phase.split('_')[0]
+ dataset['phase'] = phase
+ dataset['scale'] = opt['scale'] # broadcast
+ dataset['n_channels'] = opt['n_channels'] # broadcast
+ if 'dataroot_H' in dataset and dataset['dataroot_H'] is not None:
+ dataset['dataroot_H'] = os.path.expanduser(dataset['dataroot_H'])
+ if 'dataroot_L' in dataset and dataset['dataroot_L'] is not None:
+ dataset['dataroot_L'] = os.path.expanduser(dataset['dataroot_L'])
+
+ # ----------------------------------------
+ # path
+ # ----------------------------------------
+ for key, path in opt['path'].items():
+ if path and key in opt['path']:
+ opt['path'][key] = os.path.expanduser(path)
+
+ path_task = os.path.join(opt['path']['root'], opt['task'])
+ opt['path']['task'] = path_task
+ opt['path']['log'] = path_task
+ opt['path']['options'] = os.path.join(path_task, 'options')
+
+ if is_train:
+ opt['path']['models'] = os.path.join(path_task, 'models')
+ opt['path']['images'] = os.path.join(path_task, 'images')
+ else: # test
+ opt['path']['images'] = os.path.join(path_task, 'test_images')
+
+ # ----------------------------------------
+ # network
+ # ----------------------------------------
+ opt['netG']['scale'] = opt['scale'] if 'scale' in opt else 1
+
+ # ----------------------------------------
+ # GPU devices
+ # ----------------------------------------
+ gpu_list = ','.join(str(x) for x in opt['gpu_ids'])
+ os.environ['CUDA_VISIBLE_DEVICES'] = gpu_list
+ print('export CUDA_VISIBLE_DEVICES=' + gpu_list)
+
+ # ----------------------------------------
+ # default setting for distributeddataparallel
+ # ----------------------------------------
+ if 'find_unused_parameters' not in opt:
+ opt['find_unused_parameters'] = True
+ if 'use_static_graph' not in opt:
+ opt['use_static_graph'] = False
+ if 'dist' not in opt:
+ opt['dist'] = False
+ opt['num_gpu'] = len(opt['gpu_ids'])
+ print('number of GPUs is: ' + str(opt['num_gpu']))
+
+ # ----------------------------------------
+ # default setting for perceptual loss
+ # ----------------------------------------
+ if 'F_feature_layer' not in opt['train']:
+ opt['train']['F_feature_layer'] = 34 # 25; [2,7,16,25,34]
+ if 'F_weights' not in opt['train']:
+ opt['train']['F_weights'] = 1.0 # 1.0; [0.1,0.1,1.0,1.0,1.0]
+ if 'F_lossfn_type' not in opt['train']:
+ opt['train']['F_lossfn_type'] = 'l1'
+ if 'F_use_input_norm' not in opt['train']:
+ opt['train']['F_use_input_norm'] = True
+ if 'F_use_range_norm' not in opt['train']:
+ opt['train']['F_use_range_norm'] = False
+
+ # ----------------------------------------
+ # default setting for optimizer
+ # ----------------------------------------
+ if 'G_optimizer_type' not in opt['train']:
+ opt['train']['G_optimizer_type'] = "adam"
+ if 'G_optimizer_betas' not in opt['train']:
+ opt['train']['G_optimizer_betas'] = [0.9,0.999]
+ if 'G_scheduler_restart_weights' not in opt['train']:
+ opt['train']['G_scheduler_restart_weights'] = 1
+ if 'G_optimizer_wd' not in opt['train']:
+ opt['train']['G_optimizer_wd'] = 0
+ if 'G_optimizer_reuse' not in opt['train']:
+ opt['train']['G_optimizer_reuse'] = False
+ if 'netD' in opt and 'D_optimizer_reuse' not in opt['train']:
+ opt['train']['D_optimizer_reuse'] = False
+
+ # ----------------------------------------
+ # default setting of strict for model loading
+ # ----------------------------------------
+ if 'G_param_strict' not in opt['train']:
+ opt['train']['G_param_strict'] = True
+ if 'netD' in opt and 'D_param_strict' not in opt['path']:
+ opt['train']['D_param_strict'] = True
+ if 'E_param_strict' not in opt['path']:
+ opt['train']['E_param_strict'] = True
+
+ # ----------------------------------------
+ # Exponential Moving Average
+ # ----------------------------------------
+ if 'E_decay' not in opt['train']:
+ opt['train']['E_decay'] = 0
+
+ # ----------------------------------------
+ # default setting for discriminator
+ # ----------------------------------------
+ if 'netD' in opt:
+ if 'net_type' not in opt['netD']:
+ opt['netD']['net_type'] = 'discriminator_patchgan' # discriminator_unet
+ if 'in_nc' not in opt['netD']:
+ opt['netD']['in_nc'] = 3
+ if 'base_nc' not in opt['netD']:
+ opt['netD']['base_nc'] = 64
+ if 'n_layers' not in opt['netD']:
+ opt['netD']['n_layers'] = 3
+ if 'norm_type' not in opt['netD']:
+ opt['netD']['norm_type'] = 'spectral'
+
+
+ return opt
+
+
+def find_last_checkpoint(save_dir, net_type='G', pretrained_path=None):
+ """
+ Args:
+ save_dir: model folder
+ net_type: 'G' or 'D' or 'optimizerG' or 'optimizerD'
+ pretrained_path: pretrained model path. If save_dir does not have any model, load from pretrained_path
+
+ Return:
+ init_iter: iteration number
+ init_path: model path
+ """
+ file_list = glob.glob(os.path.join(save_dir, '*_{}.pth'.format(net_type)))
+ if file_list:
+ iter_exist = []
+ for file_ in file_list:
+ iter_current = re.findall(r"(\d+)_{}.pth".format(net_type), file_)
+ iter_exist.append(int(iter_current[0]))
+ init_iter = max(iter_exist)
+ init_path = os.path.join(save_dir, '{}_{}.pth'.format(init_iter, net_type))
+ else:
+ init_iter = 0
+ init_path = pretrained_path
+ return init_iter, init_path
+
+
+'''
+# --------------------------------------------
+# convert the opt into json file
+# --------------------------------------------
+'''
+
+
+def save(opt):
+ opt_path = opt['opt_path']
+ opt_path_copy = opt['path']['options']
+ dirname, filename_ext = os.path.split(opt_path)
+ filename, ext = os.path.splitext(filename_ext)
+ dump_path = os.path.join(opt_path_copy, filename+get_timestamp()+ext)
+ with open(dump_path, 'w') as dump_file:
+ json.dump(opt, dump_file, indent=2)
+
+
+'''
+# --------------------------------------------
+# dict to string for logger
+# --------------------------------------------
+'''
+
+
+def dict2str(opt, indent_l=1):
+ msg = ''
+ for k, v in opt.items():
+ if isinstance(v, dict):
+ msg += ' ' * (indent_l * 2) + k + ':[\n'
+ msg += dict2str(v, indent_l + 1)
+ msg += ' ' * (indent_l * 2) + ']\n'
+ else:
+ msg += ' ' * (indent_l * 2) + k + ': ' + str(v) + '\n'
+ return msg
+
+
+'''
+# --------------------------------------------
+# convert OrderedDict to NoneDict,
+# return None for missing key
+# --------------------------------------------
+'''
+
+
+def dict_to_nonedict(opt):
+ if isinstance(opt, dict):
+ new_opt = dict()
+ for key, sub_opt in opt.items():
+ new_opt[key] = dict_to_nonedict(sub_opt)
+ return NoneDict(**new_opt)
+ elif isinstance(opt, list):
+ return [dict_to_nonedict(sub_opt) for sub_opt in opt]
+ else:
+ return opt
+
+
+class NoneDict(dict):
+ def __missing__(self, key):
+ return None
diff --git a/KAIR/utils/utils_params.py b/KAIR/utils/utils_params.py
new file mode 100644
index 0000000000000000000000000000000000000000..def1cb79e11472b9b8ebbaae4bd83e7216af2ccb
--- /dev/null
+++ b/KAIR/utils/utils_params.py
@@ -0,0 +1,135 @@
+import torch
+
+import torchvision
+
+from models import basicblock as B
+
+def show_kv(net):
+ for k, v in net.items():
+ print(k)
+
+# should run train debug mode first to get an initial model
+#crt_net = torch.load('../../experiments/debug_SRResNet_bicx4_in3nf64nb16/models/8_G.pth')
+#
+#for k, v in crt_net.items():
+# print(k)
+#for k, v in crt_net.items():
+# if k in pretrained_net:
+# crt_net[k] = pretrained_net[k]
+# print('replace ... ', k)
+
+# x2 -> x4
+#crt_net['model.5.weight'] = pretrained_net['model.2.weight']
+#crt_net['model.5.bias'] = pretrained_net['model.2.bias']
+#crt_net['model.8.weight'] = pretrained_net['model.5.weight']
+#crt_net['model.8.bias'] = pretrained_net['model.5.bias']
+#crt_net['model.10.weight'] = pretrained_net['model.7.weight']
+#crt_net['model.10.bias'] = pretrained_net['model.7.bias']
+#torch.save(crt_net, '../pretrained_tmp.pth')
+
+# x2 -> x3
+'''
+in_filter = pretrained_net['model.2.weight'] # 256, 64, 3, 3
+new_filter = torch.Tensor(576, 64, 3, 3)
+new_filter[0:256, :, :, :] = in_filter
+new_filter[256:512, :, :, :] = in_filter
+new_filter[512:, :, :, :] = in_filter[0:576-512, :, :, :]
+crt_net['model.2.weight'] = new_filter
+
+in_bias = pretrained_net['model.2.bias'] # 256, 64, 3, 3
+new_bias = torch.Tensor(576)
+new_bias[0:256] = in_bias
+new_bias[256:512] = in_bias
+new_bias[512:] = in_bias[0:576 - 512]
+crt_net['model.2.bias'] = new_bias
+
+torch.save(crt_net, '../pretrained_tmp.pth')
+'''
+
+# x2 -> x8
+'''
+crt_net['model.5.weight'] = pretrained_net['model.2.weight']
+crt_net['model.5.bias'] = pretrained_net['model.2.bias']
+crt_net['model.8.weight'] = pretrained_net['model.2.weight']
+crt_net['model.8.bias'] = pretrained_net['model.2.bias']
+crt_net['model.11.weight'] = pretrained_net['model.5.weight']
+crt_net['model.11.bias'] = pretrained_net['model.5.bias']
+crt_net['model.13.weight'] = pretrained_net['model.7.weight']
+crt_net['model.13.bias'] = pretrained_net['model.7.bias']
+torch.save(crt_net, '../pretrained_tmp.pth')
+'''
+
+# x3/4/8 RGB -> Y
+
+def rgb2gray_net(net, only_input=True):
+
+ if only_input:
+ in_filter = net['0.weight']
+ in_new_filter = in_filter[:,0,:,:]*0.2989 + in_filter[:,1,:,:]*0.587 + in_filter[:,2,:,:]*0.114
+ in_new_filter.unsqueeze_(1)
+ net['0.weight'] = in_new_filter
+
+# out_filter = pretrained_net['model.13.weight']
+# out_new_filter = out_filter[0, :, :, :] * 0.2989 + out_filter[1, :, :, :] * 0.587 + \
+# out_filter[2, :, :, :] * 0.114
+# out_new_filter.unsqueeze_(0)
+# crt_net['model.13.weight'] = out_new_filter
+# out_bias = pretrained_net['model.13.bias']
+# out_new_bias = out_bias[0] * 0.2989 + out_bias[1] * 0.587 + out_bias[2] * 0.114
+# out_new_bias = torch.Tensor(1).fill_(out_new_bias)
+# crt_net['model.13.bias'] = out_new_bias
+
+# torch.save(crt_net, '../pretrained_tmp.pth')
+
+ return net
+
+
+
+if __name__ == '__main__':
+
+ net = torchvision.models.vgg19(pretrained=True)
+ for k,v in net.features.named_parameters():
+ if k=='0.weight':
+ in_new_filter = v[:,0,:,:]*0.2989 + v[:,1,:,:]*0.587 + v[:,2,:,:]*0.114
+ in_new_filter.unsqueeze_(1)
+ v = in_new_filter
+ print(v.shape)
+ print(v[0,0,0,0])
+ if k=='0.bias':
+ in_new_bias = v
+ print(v[0])
+
+ print(net.features[0])
+
+ net.features[0] = B.conv(1, 64, mode='C')
+
+ print(net.features[0])
+ net.features[0].weight.data=in_new_filter
+ net.features[0].bias.data=in_new_bias
+
+ for k,v in net.features.named_parameters():
+ if k=='0.weight':
+ print(v[0,0,0,0])
+ if k=='0.bias':
+ print(v[0])
+
+ # transfer parameters of old model to new one
+ model_old = torch.load(model_path)
+ state_dict = model.state_dict()
+ for ((key, param),(key2, param2)) in zip(model_old.items(), state_dict.items()):
+ state_dict[key2] = param
+ print([key, key2])
+ # print([param.size(), param2.size()])
+ torch.save(state_dict, 'model_new.pth')
+
+
+ # rgb2gray_net(net)
+
+
+
+
+
+
+
+
+
diff --git a/KAIR/utils/utils_receptivefield.py b/KAIR/utils/utils_receptivefield.py
new file mode 100644
index 0000000000000000000000000000000000000000..394456390644ba9edc406b810f67d09b0e2ff114
--- /dev/null
+++ b/KAIR/utils/utils_receptivefield.py
@@ -0,0 +1,62 @@
+# -*- coding: utf-8 -*-
+
+# online calculation: https://fomoro.com/research/article/receptive-field-calculator#
+
+# [filter size, stride, padding]
+#Assume the two dimensions are the same
+#Each kernel requires the following parameters:
+# - k_i: kernel size
+# - s_i: stride
+# - p_i: padding (if padding is uneven, right padding will higher than left padding; "SAME" option in tensorflow)
+#
+#Each layer i requires the following parameters to be fully represented:
+# - n_i: number of feature (data layer has n_1 = imagesize )
+# - j_i: distance (projected to image pixel distance) between center of two adjacent features
+# - r_i: receptive field of a feature in layer i
+# - start_i: position of the first feature's receptive field in layer i (idx start from 0, negative means the center fall into padding)
+
+import math
+
+def outFromIn(conv, layerIn):
+ n_in = layerIn[0]
+ j_in = layerIn[1]
+ r_in = layerIn[2]
+ start_in = layerIn[3]
+ k = conv[0]
+ s = conv[1]
+ p = conv[2]
+
+ n_out = math.floor((n_in - k + 2*p)/s) + 1
+ actualP = (n_out-1)*s - n_in + k
+ pR = math.ceil(actualP/2)
+ pL = math.floor(actualP/2)
+
+ j_out = j_in * s
+ r_out = r_in + (k - 1)*j_in
+ start_out = start_in + ((k-1)/2 - pL)*j_in
+ return n_out, j_out, r_out, start_out
+
+def printLayer(layer, layer_name):
+ print(layer_name + ":")
+ print(" n features: %s jump: %s receptive size: %s start: %s " % (layer[0], layer[1], layer[2], layer[3]))
+
+
+
+layerInfos = []
+if __name__ == '__main__':
+
+ convnet = [[3,1,1],[3,1,1],[3,1,1],[4,2,1],[2,2,0],[3,1,1]]
+ layer_names = ['conv1','conv2','conv3','conv4','conv5','conv6','conv7','conv8','conv9','conv10','conv11','conv12']
+ imsize = 128
+
+ print ("-------Net summary------")
+ currentLayer = [imsize, 1, 1, 0.5]
+ printLayer(currentLayer, "input image")
+ for i in range(len(convnet)):
+ currentLayer = outFromIn(convnet[i], currentLayer)
+ layerInfos.append(currentLayer)
+ printLayer(currentLayer, layer_names[i])
+
+
+# run utils/utils_receptivefield.py
+
\ No newline at end of file
diff --git a/KAIR/utils/utils_regularizers.py b/KAIR/utils/utils_regularizers.py
new file mode 100644
index 0000000000000000000000000000000000000000..17e7c8524b716f36e10b41d72fee2e375af69454
--- /dev/null
+++ b/KAIR/utils/utils_regularizers.py
@@ -0,0 +1,104 @@
+import torch
+import torch.nn as nn
+
+
+'''
+# --------------------------------------------
+# Kai Zhang (github: https://github.com/cszn)
+# 03/Mar/2019
+# --------------------------------------------
+'''
+
+
+# --------------------------------------------
+# SVD Orthogonal Regularization
+# --------------------------------------------
+def regularizer_orth(m):
+ """
+ # ----------------------------------------
+ # SVD Orthogonal Regularization
+ # ----------------------------------------
+ # Applies regularization to the training by performing the
+ # orthogonalization technique described in the paper
+ # This function is to be called by the torch.nn.Module.apply() method,
+ # which applies svd_orthogonalization() to every layer of the model.
+ # usage: net.apply(regularizer_orth)
+ # ----------------------------------------
+ """
+ classname = m.__class__.__name__
+ if classname.find('Conv') != -1:
+ w = m.weight.data.clone()
+ c_out, c_in, f1, f2 = w.size()
+ # dtype = m.weight.data.type()
+ w = w.permute(2, 3, 1, 0).contiguous().view(f1*f2*c_in, c_out)
+ # self.netG.apply(svd_orthogonalization)
+ u, s, v = torch.svd(w)
+ s[s > 1.5] = s[s > 1.5] - 1e-4
+ s[s < 0.5] = s[s < 0.5] + 1e-4
+ w = torch.mm(torch.mm(u, torch.diag(s)), v.t())
+ m.weight.data = w.view(f1, f2, c_in, c_out).permute(3, 2, 0, 1) # .type(dtype)
+ else:
+ pass
+
+
+# --------------------------------------------
+# SVD Orthogonal Regularization
+# --------------------------------------------
+def regularizer_orth2(m):
+ """
+ # ----------------------------------------
+ # Applies regularization to the training by performing the
+ # orthogonalization technique described in the paper
+ # This function is to be called by the torch.nn.Module.apply() method,
+ # which applies svd_orthogonalization() to every layer of the model.
+ # usage: net.apply(regularizer_orth2)
+ # ----------------------------------------
+ """
+ classname = m.__class__.__name__
+ if classname.find('Conv') != -1:
+ w = m.weight.data.clone()
+ c_out, c_in, f1, f2 = w.size()
+ # dtype = m.weight.data.type()
+ w = w.permute(2, 3, 1, 0).contiguous().view(f1*f2*c_in, c_out)
+ u, s, v = torch.svd(w)
+ s_mean = s.mean()
+ s[s > 1.5*s_mean] = s[s > 1.5*s_mean] - 1e-4
+ s[s < 0.5*s_mean] = s[s < 0.5*s_mean] + 1e-4
+ w = torch.mm(torch.mm(u, torch.diag(s)), v.t())
+ m.weight.data = w.view(f1, f2, c_in, c_out).permute(3, 2, 0, 1) # .type(dtype)
+ else:
+ pass
+
+
+
+def regularizer_clip(m):
+ """
+ # ----------------------------------------
+ # usage: net.apply(regularizer_clip)
+ # ----------------------------------------
+ """
+ eps = 1e-4
+ c_min = -1.5
+ c_max = 1.5
+
+ classname = m.__class__.__name__
+ if classname.find('Conv') != -1 or classname.find('Linear') != -1:
+ w = m.weight.data.clone()
+ w[w > c_max] -= eps
+ w[w < c_min] += eps
+ m.weight.data = w
+
+ if m.bias is not None:
+ b = m.bias.data.clone()
+ b[b > c_max] -= eps
+ b[b < c_min] += eps
+ m.bias.data = b
+
+# elif classname.find('BatchNorm2d') != -1:
+#
+# rv = m.running_var.data.clone()
+# rm = m.running_mean.data.clone()
+#
+# if m.affine:
+# m.weight.data
+# m.bias.data
diff --git a/KAIR/utils/utils_sisr.py b/KAIR/utils/utils_sisr.py
new file mode 100644
index 0000000000000000000000000000000000000000..fde7881526c5544ed09657872b044af5fa99b3a9
--- /dev/null
+++ b/KAIR/utils/utils_sisr.py
@@ -0,0 +1,848 @@
+# -*- coding: utf-8 -*-
+from utils import utils_image as util
+import random
+
+import scipy
+import scipy.stats as ss
+import scipy.io as io
+from scipy import ndimage
+from scipy.interpolate import interp2d
+
+import numpy as np
+import torch
+
+
+"""
+# --------------------------------------------
+# Super-Resolution
+# --------------------------------------------
+#
+# Kai Zhang (cskaizhang@gmail.com)
+# https://github.com/cszn
+# modified by Kai Zhang (github: https://github.com/cszn)
+# 03/03/2020
+# --------------------------------------------
+"""
+
+
+"""
+# --------------------------------------------
+# anisotropic Gaussian kernels
+# --------------------------------------------
+"""
+
+
+def anisotropic_Gaussian(ksize=15, theta=np.pi, l1=6, l2=6):
+ """ generate an anisotropic Gaussian kernel
+ Args:
+ ksize : e.g., 15, kernel size
+ theta : [0, pi], rotation angle range
+ l1 : [0.1,50], scaling of eigenvalues
+ l2 : [0.1,l1], scaling of eigenvalues
+ If l1 = l2, will get an isotropic Gaussian kernel.
+ Returns:
+ k : kernel
+ """
+
+ v = np.dot(np.array([[np.cos(theta), -np.sin(theta)], [np.sin(theta), np.cos(theta)]]), np.array([1., 0.]))
+ V = np.array([[v[0], v[1]], [v[1], -v[0]]])
+ D = np.array([[l1, 0], [0, l2]])
+ Sigma = np.dot(np.dot(V, D), np.linalg.inv(V))
+ k = gm_blur_kernel(mean=[0, 0], cov=Sigma, size=ksize)
+
+ return k
+
+
+def gm_blur_kernel(mean, cov, size=15):
+ center = size / 2.0 + 0.5
+ k = np.zeros([size, size])
+ for y in range(size):
+ for x in range(size):
+ cy = y - center + 1
+ cx = x - center + 1
+ k[y, x] = ss.multivariate_normal.pdf([cx, cy], mean=mean, cov=cov)
+
+ k = k / np.sum(k)
+ return k
+
+
+"""
+# --------------------------------------------
+# calculate PCA projection matrix
+# --------------------------------------------
+"""
+
+
+def get_pca_matrix(x, dim_pca=15):
+ """
+ Args:
+ x: 225x10000 matrix
+ dim_pca: 15
+ Returns:
+ pca_matrix: 15x225
+ """
+ C = np.dot(x, x.T)
+ w, v = scipy.linalg.eigh(C)
+ pca_matrix = v[:, -dim_pca:].T
+
+ return pca_matrix
+
+
+def show_pca(x):
+ """
+ x: PCA projection matrix, e.g., 15x225
+ """
+ for i in range(x.shape[0]):
+ xc = np.reshape(x[i, :], (int(np.sqrt(x.shape[1])), -1), order="F")
+ util.surf(xc)
+
+
+def cal_pca_matrix(path='PCA_matrix.mat', ksize=15, l_max=12.0, dim_pca=15, num_samples=500):
+ kernels = np.zeros([ksize*ksize, num_samples], dtype=np.float32)
+ for i in range(num_samples):
+
+ theta = np.pi*np.random.rand(1)
+ l1 = 0.1+l_max*np.random.rand(1)
+ l2 = 0.1+(l1-0.1)*np.random.rand(1)
+
+ k = anisotropic_Gaussian(ksize=ksize, theta=theta[0], l1=l1[0], l2=l2[0])
+
+ # util.imshow(k)
+
+ kernels[:, i] = np.reshape(k, (-1), order="F") # k.flatten(order='F')
+
+ # io.savemat('k.mat', {'k': kernels})
+
+ pca_matrix = get_pca_matrix(kernels, dim_pca=dim_pca)
+
+ io.savemat(path, {'p': pca_matrix})
+
+ return pca_matrix
+
+
+"""
+# --------------------------------------------
+# shifted anisotropic Gaussian kernels
+# --------------------------------------------
+"""
+
+
+def shifted_anisotropic_Gaussian(k_size=np.array([15, 15]), scale_factor=np.array([4, 4]), min_var=0.6, max_var=10., noise_level=0):
+ """"
+ # modified version of https://github.com/assafshocher/BlindSR_dataset_generator
+ # Kai Zhang
+ # min_var = 0.175 * sf # variance of the gaussian kernel will be sampled between min_var and max_var
+ # max_var = 2.5 * sf
+ """
+ # Set random eigen-vals (lambdas) and angle (theta) for COV matrix
+ lambda_1 = min_var + np.random.rand() * (max_var - min_var)
+ lambda_2 = min_var + np.random.rand() * (max_var - min_var)
+ theta = np.random.rand() * np.pi # random theta
+ noise = -noise_level + np.random.rand(*k_size) * noise_level * 2
+
+ # Set COV matrix using Lambdas and Theta
+ LAMBDA = np.diag([lambda_1, lambda_2])
+ Q = np.array([[np.cos(theta), -np.sin(theta)],
+ [np.sin(theta), np.cos(theta)]])
+ SIGMA = Q @ LAMBDA @ Q.T
+ INV_SIGMA = np.linalg.inv(SIGMA)[None, None, :, :]
+
+ # Set expectation position (shifting kernel for aligned image)
+ MU = k_size // 2 - 0.5*(scale_factor - 1) # - 0.5 * (scale_factor - k_size % 2)
+ MU = MU[None, None, :, None]
+
+ # Create meshgrid for Gaussian
+ [X,Y] = np.meshgrid(range(k_size[0]), range(k_size[1]))
+ Z = np.stack([X, Y], 2)[:, :, :, None]
+
+ # Calcualte Gaussian for every pixel of the kernel
+ ZZ = Z-MU
+ ZZ_t = ZZ.transpose(0,1,3,2)
+ raw_kernel = np.exp(-0.5 * np.squeeze(ZZ_t @ INV_SIGMA @ ZZ)) * (1 + noise)
+
+ # shift the kernel so it will be centered
+ #raw_kernel_centered = kernel_shift(raw_kernel, scale_factor)
+
+ # Normalize the kernel and return
+ #kernel = raw_kernel_centered / np.sum(raw_kernel_centered)
+ kernel = raw_kernel / np.sum(raw_kernel)
+ return kernel
+
+
+def gen_kernel(k_size=np.array([25, 25]), scale_factor=np.array([4, 4]), min_var=0.6, max_var=12., noise_level=0):
+ """"
+ # modified version of https://github.com/assafshocher/BlindSR_dataset_generator
+ # Kai Zhang
+ # min_var = 0.175 * sf # variance of the gaussian kernel will be sampled between min_var and max_var
+ # max_var = 2.5 * sf
+ """
+ sf = random.choice([1, 2, 3, 4])
+ scale_factor = np.array([sf, sf])
+ # Set random eigen-vals (lambdas) and angle (theta) for COV matrix
+ lambda_1 = min_var + np.random.rand() * (max_var - min_var)
+ lambda_2 = min_var + np.random.rand() * (max_var - min_var)
+ theta = np.random.rand() * np.pi # random theta
+ noise = 0#-noise_level + np.random.rand(*k_size) * noise_level * 2
+
+ # Set COV matrix using Lambdas and Theta
+ LAMBDA = np.diag([lambda_1, lambda_2])
+ Q = np.array([[np.cos(theta), -np.sin(theta)],
+ [np.sin(theta), np.cos(theta)]])
+ SIGMA = Q @ LAMBDA @ Q.T
+ INV_SIGMA = np.linalg.inv(SIGMA)[None, None, :, :]
+
+ # Set expectation position (shifting kernel for aligned image)
+ MU = k_size // 2 - 0.5*(scale_factor - 1) # - 0.5 * (scale_factor - k_size % 2)
+ MU = MU[None, None, :, None]
+
+ # Create meshgrid for Gaussian
+ [X,Y] = np.meshgrid(range(k_size[0]), range(k_size[1]))
+ Z = np.stack([X, Y], 2)[:, :, :, None]
+
+ # Calcualte Gaussian for every pixel of the kernel
+ ZZ = Z-MU
+ ZZ_t = ZZ.transpose(0,1,3,2)
+ raw_kernel = np.exp(-0.5 * np.squeeze(ZZ_t @ INV_SIGMA @ ZZ)) * (1 + noise)
+
+ # shift the kernel so it will be centered
+ #raw_kernel_centered = kernel_shift(raw_kernel, scale_factor)
+
+ # Normalize the kernel and return
+ #kernel = raw_kernel_centered / np.sum(raw_kernel_centered)
+ kernel = raw_kernel / np.sum(raw_kernel)
+ return kernel
+
+
+"""
+# --------------------------------------------
+# degradation models
+# --------------------------------------------
+"""
+
+
+def bicubic_degradation(x, sf=3):
+ '''
+ Args:
+ x: HxWxC image, [0, 1]
+ sf: down-scale factor
+ Return:
+ bicubicly downsampled LR image
+ '''
+ x = util.imresize_np(x, scale=1/sf)
+ return x
+
+
+def srmd_degradation(x, k, sf=3):
+ ''' blur + bicubic downsampling
+ Args:
+ x: HxWxC image, [0, 1]
+ k: hxw, double
+ sf: down-scale factor
+ Return:
+ downsampled LR image
+ Reference:
+ @inproceedings{zhang2018learning,
+ title={Learning a single convolutional super-resolution network for multiple degradations},
+ author={Zhang, Kai and Zuo, Wangmeng and Zhang, Lei},
+ booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
+ pages={3262--3271},
+ year={2018}
+ }
+ '''
+ x = ndimage.filters.convolve(x, np.expand_dims(k, axis=2), mode='wrap') # 'nearest' | 'mirror'
+ x = bicubic_degradation(x, sf=sf)
+ return x
+
+
+def dpsr_degradation(x, k, sf=3):
+
+ ''' bicubic downsampling + blur
+ Args:
+ x: HxWxC image, [0, 1]
+ k: hxw, double
+ sf: down-scale factor
+ Return:
+ downsampled LR image
+ Reference:
+ @inproceedings{zhang2019deep,
+ title={Deep Plug-and-Play Super-Resolution for Arbitrary Blur Kernels},
+ author={Zhang, Kai and Zuo, Wangmeng and Zhang, Lei},
+ booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
+ pages={1671--1681},
+ year={2019}
+ }
+ '''
+ x = bicubic_degradation(x, sf=sf)
+ x = ndimage.filters.convolve(x, np.expand_dims(k, axis=2), mode='wrap')
+ return x
+
+
+def classical_degradation(x, k, sf=3):
+ ''' blur + downsampling
+
+ Args:
+ x: HxWxC image, [0, 1]/[0, 255]
+ k: hxw, double
+ sf: down-scale factor
+
+ Return:
+ downsampled LR image
+ '''
+ x = ndimage.filters.convolve(x, np.expand_dims(k, axis=2), mode='wrap')
+ #x = filters.correlate(x, np.expand_dims(np.flip(k), axis=2))
+ st = 0
+ return x[st::sf, st::sf, ...]
+
+
+def modcrop_np(img, sf):
+ '''
+ Args:
+ img: numpy image, WxH or WxHxC
+ sf: scale factor
+ Return:
+ cropped image
+ '''
+ w, h = img.shape[:2]
+ im = np.copy(img)
+ return im[:w - w % sf, :h - h % sf, ...]
+
+
+'''
+# =================
+# Numpy
+# =================
+'''
+
+
+def shift_pixel(x, sf, upper_left=True):
+ """shift pixel for super-resolution with different scale factors
+ Args:
+ x: WxHxC or WxH, image or kernel
+ sf: scale factor
+ upper_left: shift direction
+ """
+ h, w = x.shape[:2]
+ shift = (sf-1)*0.5
+ xv, yv = np.arange(0, w, 1.0), np.arange(0, h, 1.0)
+ if upper_left:
+ x1 = xv + shift
+ y1 = yv + shift
+ else:
+ x1 = xv - shift
+ y1 = yv - shift
+
+ x1 = np.clip(x1, 0, w-1)
+ y1 = np.clip(y1, 0, h-1)
+
+ if x.ndim == 2:
+ x = interp2d(xv, yv, x)(x1, y1)
+ if x.ndim == 3:
+ for i in range(x.shape[-1]):
+ x[:, :, i] = interp2d(xv, yv, x[:, :, i])(x1, y1)
+
+ return x
+
+
+'''
+# =================
+# pytorch
+# =================
+'''
+
+
+def splits(a, sf):
+ '''
+ a: tensor NxCxWxHx2
+ sf: scale factor
+ out: tensor NxCx(W/sf)x(H/sf)x2x(sf^2)
+ '''
+ b = torch.stack(torch.chunk(a, sf, dim=2), dim=5)
+ b = torch.cat(torch.chunk(b, sf, dim=3), dim=5)
+ return b
+
+
+def c2c(x):
+ return torch.from_numpy(np.stack([np.float32(x.real), np.float32(x.imag)], axis=-1))
+
+
+def r2c(x):
+ return torch.stack([x, torch.zeros_like(x)], -1)
+
+
+def cdiv(x, y):
+ a, b = x[..., 0], x[..., 1]
+ c, d = y[..., 0], y[..., 1]
+ cd2 = c**2 + d**2
+ return torch.stack([(a*c+b*d)/cd2, (b*c-a*d)/cd2], -1)
+
+
+def csum(x, y):
+ return torch.stack([x[..., 0] + y, x[..., 1]], -1)
+
+
+def cabs(x):
+ return torch.pow(x[..., 0]**2+x[..., 1]**2, 0.5)
+
+
+def cmul(t1, t2):
+ '''
+ complex multiplication
+ t1: NxCxHxWx2
+ output: NxCxHxWx2
+ '''
+ real1, imag1 = t1[..., 0], t1[..., 1]
+ real2, imag2 = t2[..., 0], t2[..., 1]
+ return torch.stack([real1 * real2 - imag1 * imag2, real1 * imag2 + imag1 * real2], dim=-1)
+
+
+def cconj(t, inplace=False):
+ '''
+ # complex's conjugation
+ t: NxCxHxWx2
+ output: NxCxHxWx2
+ '''
+ c = t.clone() if not inplace else t
+ c[..., 1] *= -1
+ return c
+
+
+def rfft(t):
+ return torch.rfft(t, 2, onesided=False)
+
+
+def irfft(t):
+ return torch.irfft(t, 2, onesided=False)
+
+
+def fft(t):
+ return torch.fft(t, 2)
+
+
+def ifft(t):
+ return torch.ifft(t, 2)
+
+
+def p2o(psf, shape):
+ '''
+ Args:
+ psf: NxCxhxw
+ shape: [H,W]
+
+ Returns:
+ otf: NxCxHxWx2
+ '''
+ otf = torch.zeros(psf.shape[:-2] + shape).type_as(psf)
+ otf[...,:psf.shape[2],:psf.shape[3]].copy_(psf)
+ for axis, axis_size in enumerate(psf.shape[2:]):
+ otf = torch.roll(otf, -int(axis_size / 2), dims=axis+2)
+ otf = torch.rfft(otf, 2, onesided=False)
+ n_ops = torch.sum(torch.tensor(psf.shape).type_as(psf) * torch.log2(torch.tensor(psf.shape).type_as(psf)))
+ otf[...,1][torch.abs(otf[...,1]) x[N, 1, W + 2 pad, H + 2 pad] (pariodic padding)
+ '''
+ x = torch.cat([x, x[:, :, 0:pad, :]], dim=2)
+ x = torch.cat([x, x[:, :, :, 0:pad]], dim=3)
+ x = torch.cat([x[:, :, -2 * pad:-pad, :], x], dim=2)
+ x = torch.cat([x[:, :, :, -2 * pad:-pad], x], dim=3)
+ return x
+
+
+def pad_circular(input, padding):
+ # type: (Tensor, List[int]) -> Tensor
+ """
+ Arguments
+ :param input: tensor of shape :math:`(N, C_{\text{in}}, H, [W, D]))`
+ :param padding: (tuple): m-elem tuple where m is the degree of convolution
+ Returns
+ :return: tensor of shape :math:`(N, C_{\text{in}}, [D + 2 * padding[0],
+ H + 2 * padding[1]], W + 2 * padding[2]))`
+ """
+ offset = 3
+ for dimension in range(input.dim() - offset + 1):
+ input = dim_pad_circular(input, padding[dimension], dimension + offset)
+ return input
+
+
+def dim_pad_circular(input, padding, dimension):
+ # type: (Tensor, int, int) -> Tensor
+ input = torch.cat([input, input[[slice(None)] * (dimension - 1) +
+ [slice(0, padding)]]], dim=dimension - 1)
+ input = torch.cat([input[[slice(None)] * (dimension - 1) +
+ [slice(-2 * padding, -padding)]], input], dim=dimension - 1)
+ return input
+
+
+def imfilter(x, k):
+ '''
+ x: image, NxcxHxW
+ k: kernel, cx1xhxw
+ '''
+ x = pad_circular(x, padding=((k.shape[-2]-1)//2, (k.shape[-1]-1)//2))
+ x = torch.nn.functional.conv2d(x, k, groups=x.shape[1])
+ return x
+
+
+def G(x, k, sf=3, center=False):
+ '''
+ x: image, NxcxHxW
+ k: kernel, cx1xhxw
+ sf: scale factor
+ center: the first one or the moddle one
+
+ Matlab function:
+ tmp = imfilter(x,h,'circular');
+ y = downsample2(tmp,K);
+ '''
+ x = downsample(imfilter(x, k), sf=sf, center=center)
+ return x
+
+
+def Gt(x, k, sf=3, center=False):
+ '''
+ x: image, NxcxHxW
+ k: kernel, cx1xhxw
+ sf: scale factor
+ center: the first one or the moddle one
+
+ Matlab function:
+ tmp = upsample2(x,K);
+ y = imfilter(tmp,h,'circular');
+ '''
+ x = imfilter(upsample(x, sf=sf, center=center), k)
+ return x
+
+
+def interpolation_down(x, sf, center=False):
+ mask = torch.zeros_like(x)
+ if center:
+ start = torch.tensor((sf-1)//2)
+ mask[..., start::sf, start::sf] = torch.tensor(1).type_as(x)
+ LR = x[..., start::sf, start::sf]
+ else:
+ mask[..., ::sf, ::sf] = torch.tensor(1).type_as(x)
+ LR = x[..., ::sf, ::sf]
+ y = x.mul(mask)
+
+ return LR, y, mask
+
+
+'''
+# =================
+Numpy
+# =================
+'''
+
+
+def blockproc(im, blocksize, fun):
+ xblocks = np.split(im, range(blocksize[0], im.shape[0], blocksize[0]), axis=0)
+ xblocks_proc = []
+ for xb in xblocks:
+ yblocks = np.split(xb, range(blocksize[1], im.shape[1], blocksize[1]), axis=1)
+ yblocks_proc = []
+ for yb in yblocks:
+ yb_proc = fun(yb)
+ yblocks_proc.append(yb_proc)
+ xblocks_proc.append(np.concatenate(yblocks_proc, axis=1))
+
+ proc = np.concatenate(xblocks_proc, axis=0)
+
+ return proc
+
+
+def fun_reshape(a):
+ return np.reshape(a, (-1,1,a.shape[-1]), order='F')
+
+
+def fun_mul(a, b):
+ return a*b
+
+
+def BlockMM(nr, nc, Nb, m, x1):
+ '''
+ myfun = @(block_struct) reshape(block_struct.data,m,1);
+ x1 = blockproc(x1,[nr nc],myfun);
+ x1 = reshape(x1,m,Nb);
+ x1 = sum(x1,2);
+ x = reshape(x1,nr,nc);
+ '''
+ fun = fun_reshape
+ x1 = blockproc(x1, blocksize=(nr, nc), fun=fun)
+ x1 = np.reshape(x1, (m, Nb, x1.shape[-1]), order='F')
+ x1 = np.sum(x1, 1)
+ x = np.reshape(x1, (nr, nc, x1.shape[-1]), order='F')
+ return x
+
+
+def INVLS(FB, FBC, F2B, FR, tau, Nb, nr, nc, m):
+ '''
+ x1 = FB.*FR;
+ FBR = BlockMM(nr,nc,Nb,m,x1);
+ invW = BlockMM(nr,nc,Nb,m,F2B);
+ invWBR = FBR./(invW + tau*Nb);
+ fun = @(block_struct) block_struct.data.*invWBR;
+ FCBinvWBR = blockproc(FBC,[nr,nc],fun);
+ FX = (FR-FCBinvWBR)/tau;
+ Xest = real(ifft2(FX));
+ '''
+ x1 = FB*FR
+ FBR = BlockMM(nr, nc, Nb, m, x1)
+ invW = BlockMM(nr, nc, Nb, m, F2B)
+ invWBR = FBR/(invW + tau*Nb)
+ FCBinvWBR = blockproc(FBC, [nr, nc], lambda im: fun_mul(im, invWBR))
+ FX = (FR-FCBinvWBR)/tau
+ Xest = np.real(np.fft.ifft2(FX, axes=(0, 1)))
+ return Xest
+
+
+def psf2otf(psf, shape=None):
+ """
+ Convert point-spread function to optical transfer function.
+ Compute the Fast Fourier Transform (FFT) of the point-spread
+ function (PSF) array and creates the optical transfer function (OTF)
+ array that is not influenced by the PSF off-centering.
+ By default, the OTF array is the same size as the PSF array.
+ To ensure that the OTF is not altered due to PSF off-centering, PSF2OTF
+ post-pads the PSF array (down or to the right) with zeros to match
+ dimensions specified in OUTSIZE, then circularly shifts the values of
+ the PSF array up (or to the left) until the central pixel reaches (1,1)
+ position.
+ Parameters
+ ----------
+ psf : `numpy.ndarray`
+ PSF array
+ shape : int
+ Output shape of the OTF array
+ Returns
+ -------
+ otf : `numpy.ndarray`
+ OTF array
+ Notes
+ -----
+ Adapted from MATLAB psf2otf function
+ """
+ if type(shape) == type(None):
+ shape = psf.shape
+ shape = np.array(shape)
+ if np.all(psf == 0):
+ # return np.zeros_like(psf)
+ return np.zeros(shape)
+ if len(psf.shape) == 1:
+ psf = psf.reshape((1, psf.shape[0]))
+ inshape = psf.shape
+ psf = zero_pad(psf, shape, position='corner')
+ for axis, axis_size in enumerate(inshape):
+ psf = np.roll(psf, -int(axis_size / 2), axis=axis)
+ # Compute the OTF
+ otf = np.fft.fft2(psf, axes=(0, 1))
+ # Estimate the rough number of operations involved in the FFT
+ # and discard the PSF imaginary part if within roundoff error
+ # roundoff error = machine epsilon = sys.float_info.epsilon
+ # or np.finfo().eps
+ n_ops = np.sum(psf.size * np.log2(psf.shape))
+ otf = np.real_if_close(otf, tol=n_ops)
+ return otf
+
+
+def zero_pad(image, shape, position='corner'):
+ """
+ Extends image to a certain size with zeros
+ Parameters
+ ----------
+ image: real 2d `numpy.ndarray`
+ Input image
+ shape: tuple of int
+ Desired output shape of the image
+ position : str, optional
+ The position of the input image in the output one:
+ * 'corner'
+ top-left corner (default)
+ * 'center'
+ centered
+ Returns
+ -------
+ padded_img: real `numpy.ndarray`
+ The zero-padded image
+ """
+ shape = np.asarray(shape, dtype=int)
+ imshape = np.asarray(image.shape, dtype=int)
+ if np.alltrue(imshape == shape):
+ return image
+ if np.any(shape <= 0):
+ raise ValueError("ZERO_PAD: null or negative shape given")
+ dshape = shape - imshape
+ if np.any(dshape < 0):
+ raise ValueError("ZERO_PAD: target size smaller than source one")
+ pad_img = np.zeros(shape, dtype=image.dtype)
+ idx, idy = np.indices(imshape)
+ if position == 'center':
+ if np.any(dshape % 2 != 0):
+ raise ValueError("ZERO_PAD: source and target shapes "
+ "have different parity.")
+ offx, offy = dshape // 2
+ else:
+ offx, offy = (0, 0)
+ pad_img[idx + offx, idy + offy] = image
+ return pad_img
+
+
+def upsample_np(x, sf=3, center=False):
+ st = (sf-1)//2 if center else 0
+ z = np.zeros((x.shape[0]*sf, x.shape[1]*sf, x.shape[2]))
+ z[st::sf, st::sf, ...] = x
+ return z
+
+
+def downsample_np(x, sf=3, center=False):
+ st = (sf-1)//2 if center else 0
+ return x[st::sf, st::sf, ...]
+
+
+def imfilter_np(x, k):
+ '''
+ x: image, NxcxHxW
+ k: kernel, cx1xhxw
+ '''
+ x = ndimage.filters.convolve(x, np.expand_dims(k, axis=2), mode='wrap')
+ return x
+
+
+def G_np(x, k, sf=3, center=False):
+ '''
+ x: image, NxcxHxW
+ k: kernel, cx1xhxw
+
+ Matlab function:
+ tmp = imfilter(x,h,'circular');
+ y = downsample2(tmp,K);
+ '''
+ x = downsample_np(imfilter_np(x, k), sf=sf, center=center)
+ return x
+
+
+def Gt_np(x, k, sf=3, center=False):
+ '''
+ x: image, NxcxHxW
+ k: kernel, cx1xhxw
+
+ Matlab function:
+ tmp = upsample2(x,K);
+ y = imfilter(tmp,h,'circular');
+ '''
+ x = imfilter_np(upsample_np(x, sf=sf, center=center), k)
+ return x
+
+
+if __name__ == '__main__':
+ img = util.imread_uint('test.bmp', 3)
+
+ img = util.uint2single(img)
+ k = anisotropic_Gaussian(ksize=15, theta=np.pi, l1=6, l2=6)
+ util.imshow(k*10)
+
+
+ for sf in [2, 3, 4]:
+
+ # modcrop
+ img = modcrop_np(img, sf=sf)
+
+ # 1) bicubic degradation
+ img_b = bicubic_degradation(img, sf=sf)
+ print(img_b.shape)
+
+ # 2) srmd degradation
+ img_s = srmd_degradation(img, k, sf=sf)
+ print(img_s.shape)
+
+ # 3) dpsr degradation
+ img_d = dpsr_degradation(img, k, sf=sf)
+ print(img_d.shape)
+
+ # 4) classical degradation
+ img_d = classical_degradation(img, k, sf=sf)
+ print(img_d.shape)
+
+ k = anisotropic_Gaussian(ksize=7, theta=0.25*np.pi, l1=0.01, l2=0.01)
+ #print(k)
+# util.imshow(k*10)
+
+ k = shifted_anisotropic_Gaussian(k_size=np.array([15, 15]), scale_factor=np.array([4, 4]), min_var=0.8, max_var=10.8, noise_level=0.0)
+# util.imshow(k*10)
+
+
+ # PCA
+# pca_matrix = cal_pca_matrix(ksize=15, l_max=10.0, dim_pca=15, num_samples=12500)
+# print(pca_matrix.shape)
+# show_pca(pca_matrix)
+ # run utils/utils_sisr.py
+ # run utils_sisr.py
+
+
+
+
+
+
+
diff --git a/KAIR/utils/utils_video.py b/KAIR/utils/utils_video.py
new file mode 100644
index 0000000000000000000000000000000000000000..596dd4203098cf7b36f3d8499ccbf299623381ae
--- /dev/null
+++ b/KAIR/utils/utils_video.py
@@ -0,0 +1,493 @@
+import os
+import cv2
+import numpy as np
+import torch
+import random
+from os import path as osp
+from torch.nn import functional as F
+from abc import ABCMeta, abstractmethod
+
+
+def scandir(dir_path, suffix=None, recursive=False, full_path=False):
+ """Scan a directory to find the interested files.
+
+ Args:
+ dir_path (str): Path of the directory.
+ suffix (str | tuple(str), optional): File suffix that we are
+ interested in. Default: None.
+ recursive (bool, optional): If set to True, recursively scan the
+ directory. Default: False.
+ full_path (bool, optional): If set to True, include the dir_path.
+ Default: False.
+
+ Returns:
+ A generator for all the interested files with relative paths.
+ """
+
+ if (suffix is not None) and not isinstance(suffix, (str, tuple)):
+ raise TypeError('"suffix" must be a string or tuple of strings')
+
+ root = dir_path
+
+ def _scandir(dir_path, suffix, recursive):
+ for entry in os.scandir(dir_path):
+ if not entry.name.startswith('.') and entry.is_file():
+ if full_path:
+ return_path = entry.path
+ else:
+ return_path = osp.relpath(entry.path, root)
+
+ if suffix is None:
+ yield return_path
+ elif return_path.endswith(suffix):
+ yield return_path
+ else:
+ if recursive:
+ yield from _scandir(entry.path, suffix=suffix, recursive=recursive)
+ else:
+ continue
+
+ return _scandir(dir_path, suffix=suffix, recursive=recursive)
+
+
+def read_img_seq(path, require_mod_crop=False, scale=1, return_imgname=False):
+ """Read a sequence of images from a given folder path.
+
+ Args:
+ path (list[str] | str): List of image paths or image folder path.
+ require_mod_crop (bool): Require mod crop for each image.
+ Default: False.
+ scale (int): Scale factor for mod_crop. Default: 1.
+ return_imgname(bool): Whether return image names. Default False.
+
+ Returns:
+ Tensor: size (t, c, h, w), RGB, [0, 1].
+ list[str]: Returned image name list.
+ """
+ if isinstance(path, list):
+ img_paths = path
+ else:
+ img_paths = sorted(list(scandir(path, full_path=True)))
+ imgs = [cv2.imread(v).astype(np.float32) / 255. for v in img_paths]
+
+ if require_mod_crop:
+ imgs = [mod_crop(img, scale) for img in imgs]
+ imgs = img2tensor(imgs, bgr2rgb=True, float32=True)
+ imgs = torch.stack(imgs, dim=0)
+
+ if return_imgname:
+ imgnames = [osp.splitext(osp.basename(path))[0] for path in img_paths]
+ return imgs, imgnames
+ else:
+ return imgs
+
+
+def img2tensor(imgs, bgr2rgb=True, float32=True):
+ """Numpy array to tensor.
+
+ Args:
+ imgs (list[ndarray] | ndarray): Input images.
+ bgr2rgb (bool): Whether to change bgr to rgb.
+ float32 (bool): Whether to change to float32.
+
+ Returns:
+ list[tensor] | tensor: Tensor images. If returned results only have
+ one element, just return tensor.
+ """
+
+ def _totensor(img, bgr2rgb, float32):
+ if img.shape[2] == 3 and bgr2rgb:
+ if img.dtype == 'float64':
+ img = img.astype('float32')
+ img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
+ img = torch.from_numpy(img.transpose(2, 0, 1))
+ if float32:
+ img = img.float()
+ return img
+
+ if isinstance(imgs, list):
+ return [_totensor(img, bgr2rgb, float32) for img in imgs]
+ else:
+ return _totensor(imgs, bgr2rgb, float32)
+
+
+def tensor2img(tensor, rgb2bgr=True, out_type=np.uint8, min_max=(0, 1)):
+ """Convert torch Tensors into image numpy arrays.
+
+ After clamping to [min, max], values will be normalized to [0, 1].
+
+ Args:
+ tensor (Tensor or list[Tensor]): Accept shapes:
+ 1) 4D mini-batch Tensor of shape (B x 3/1 x H x W);
+ 2) 3D Tensor of shape (3/1 x H x W);
+ 3) 2D Tensor of shape (H x W).
+ Tensor channel should be in RGB order.
+ rgb2bgr (bool): Whether to change rgb to bgr.
+ out_type (numpy type): output types. If ``np.uint8``, transform outputs
+ to uint8 type with range [0, 255]; otherwise, float type with
+ range [0, 1]. Default: ``np.uint8``.
+ min_max (tuple[int]): min and max values for clamp.
+
+ Returns:
+ (Tensor or list): 3D ndarray of shape (H x W x C) OR 2D ndarray of
+ shape (H x W). The channel order is BGR.
+ """
+ if not (torch.is_tensor(tensor) or (isinstance(tensor, list) and all(torch.is_tensor(t) for t in tensor))):
+ raise TypeError(f'tensor or list of tensors expected, got {type(tensor)}')
+
+ if torch.is_tensor(tensor):
+ tensor = [tensor]
+ result = []
+ for _tensor in tensor:
+ _tensor = _tensor.squeeze(0).float().detach().cpu().clamp_(*min_max)
+ _tensor = (_tensor - min_max[0]) / (min_max[1] - min_max[0])
+
+ n_dim = _tensor.dim()
+ if n_dim == 4:
+ img_np = make_grid(_tensor, nrow=int(math.sqrt(_tensor.size(0))), normalize=False).numpy()
+ img_np = img_np.transpose(1, 2, 0)
+ if rgb2bgr:
+ img_np = cv2.cvtColor(img_np, cv2.COLOR_RGB2BGR)
+ elif n_dim == 3:
+ img_np = _tensor.numpy()
+ img_np = img_np.transpose(1, 2, 0)
+ if img_np.shape[2] == 1: # gray image
+ img_np = np.squeeze(img_np, axis=2)
+ else:
+ if rgb2bgr:
+ img_np = cv2.cvtColor(img_np, cv2.COLOR_RGB2BGR)
+ elif n_dim == 2:
+ img_np = _tensor.numpy()
+ else:
+ raise TypeError(f'Only support 4D, 3D or 2D tensor. But received with dimension: {n_dim}')
+ if out_type == np.uint8:
+ # Unlike MATLAB, numpy.unit8() WILL NOT round by default.
+ img_np = (img_np * 255.0).round()
+ img_np = img_np.astype(out_type)
+ result.append(img_np)
+ if len(result) == 1:
+ result = result[0]
+ return result
+
+
+def augment(imgs, hflip=True, rotation=True, flows=None, return_status=False):
+ """Augment: horizontal flips OR rotate (0, 90, 180, 270 degrees).
+
+ We use vertical flip and transpose for rotation implementation.
+ All the images in the list use the same augmentation.
+
+ Args:
+ imgs (list[ndarray] | ndarray): Images to be augmented. If the input
+ is an ndarray, it will be transformed to a list.
+ hflip (bool): Horizontal flip. Default: True.
+ rotation (bool): Ratotation. Default: True.
+ flows (list[ndarray]: Flows to be augmented. If the input is an
+ ndarray, it will be transformed to a list.
+ Dimension is (h, w, 2). Default: None.
+ return_status (bool): Return the status of flip and rotation.
+ Default: False.
+
+ Returns:
+ list[ndarray] | ndarray: Augmented images and flows. If returned
+ results only have one element, just return ndarray.
+
+ """
+ hflip = hflip and random.random() < 0.5
+ vflip = rotation and random.random() < 0.5
+ rot90 = rotation and random.random() < 0.5
+
+ def _augment(img):
+ if hflip: # horizontal
+ cv2.flip(img, 1, img)
+ if vflip: # vertical
+ cv2.flip(img, 0, img)
+ if rot90:
+ img = img.transpose(1, 0, 2)
+ return img
+
+ def _augment_flow(flow):
+ if hflip: # horizontal
+ cv2.flip(flow, 1, flow)
+ flow[:, :, 0] *= -1
+ if vflip: # vertical
+ cv2.flip(flow, 0, flow)
+ flow[:, :, 1] *= -1
+ if rot90:
+ flow = flow.transpose(1, 0, 2)
+ flow = flow[:, :, [1, 0]]
+ return flow
+
+ if not isinstance(imgs, list):
+ imgs = [imgs]
+ imgs = [_augment(img) for img in imgs]
+ if len(imgs) == 1:
+ imgs = imgs[0]
+
+ if flows is not None:
+ if not isinstance(flows, list):
+ flows = [flows]
+ flows = [_augment_flow(flow) for flow in flows]
+ if len(flows) == 1:
+ flows = flows[0]
+ return imgs, flows
+ else:
+ if return_status:
+ return imgs, (hflip, vflip, rot90)
+ else:
+ return imgs
+
+
+def paired_random_crop(img_gts, img_lqs, gt_patch_size, scale, gt_path=None):
+ """Paired random crop. Support Numpy array and Tensor inputs.
+
+ It crops lists of lq and gt images with corresponding locations.
+
+ Args:
+ img_gts (list[ndarray] | ndarray | list[Tensor] | Tensor): GT images. Note that all images
+ should have the same shape. If the input is an ndarray, it will
+ be transformed to a list containing itself.
+ img_lqs (list[ndarray] | ndarray): LQ images. Note that all images
+ should have the same shape. If the input is an ndarray, it will
+ be transformed to a list containing itself.
+ gt_patch_size (int): GT patch size.
+ scale (int): Scale factor.
+ gt_path (str): Path to ground-truth. Default: None.
+
+ Returns:
+ list[ndarray] | ndarray: GT images and LQ images. If returned results
+ only have one element, just return ndarray.
+ """
+
+ if not isinstance(img_gts, list):
+ img_gts = [img_gts]
+ if not isinstance(img_lqs, list):
+ img_lqs = [img_lqs]
+
+ # determine input type: Numpy array or Tensor
+ input_type = 'Tensor' if torch.is_tensor(img_gts[0]) else 'Numpy'
+
+ if input_type == 'Tensor':
+ h_lq, w_lq = img_lqs[0].size()[-2:]
+ h_gt, w_gt = img_gts[0].size()[-2:]
+ else:
+ h_lq, w_lq = img_lqs[0].shape[0:2]
+ h_gt, w_gt = img_gts[0].shape[0:2]
+ lq_patch_size = gt_patch_size // scale
+
+ if h_gt != h_lq * scale or w_gt != w_lq * scale:
+ raise ValueError(f'Scale mismatches. GT ({h_gt}, {w_gt}) is not {scale}x ',
+ f'multiplication of LQ ({h_lq}, {w_lq}).')
+ if h_lq < lq_patch_size or w_lq < lq_patch_size:
+ raise ValueError(f'LQ ({h_lq}, {w_lq}) is smaller than patch size '
+ f'({lq_patch_size}, {lq_patch_size}). '
+ f'Please remove {gt_path}.')
+
+ # randomly choose top and left coordinates for lq patch
+ top = random.randint(0, h_lq - lq_patch_size)
+ left = random.randint(0, w_lq - lq_patch_size)
+
+ # crop lq patch
+ if input_type == 'Tensor':
+ img_lqs = [v[:, :, top:top + lq_patch_size, left:left + lq_patch_size] for v in img_lqs]
+ else:
+ img_lqs = [v[top:top + lq_patch_size, left:left + lq_patch_size, ...] for v in img_lqs]
+
+ # crop corresponding gt patch
+ top_gt, left_gt = int(top * scale), int(left * scale)
+ if input_type == 'Tensor':
+ img_gts = [v[:, :, top_gt:top_gt + gt_patch_size, left_gt:left_gt + gt_patch_size] for v in img_gts]
+ else:
+ img_gts = [v[top_gt:top_gt + gt_patch_size, left_gt:left_gt + gt_patch_size, ...] for v in img_gts]
+ if len(img_gts) == 1:
+ img_gts = img_gts[0]
+ if len(img_lqs) == 1:
+ img_lqs = img_lqs[0]
+ return img_gts, img_lqs
+
+
+# Modified from https://github.com/open-mmlab/mmcv/blob/master/mmcv/fileio/file_client.py # noqa: E501
+class BaseStorageBackend(metaclass=ABCMeta):
+ """Abstract class of storage backends.
+
+ All backends need to implement two apis: ``get()`` and ``get_text()``.
+ ``get()`` reads the file as a byte stream and ``get_text()`` reads the file
+ as texts.
+ """
+
+ @abstractmethod
+ def get(self, filepath):
+ pass
+
+ @abstractmethod
+ def get_text(self, filepath):
+ pass
+
+
+class MemcachedBackend(BaseStorageBackend):
+ """Memcached storage backend.
+
+ Attributes:
+ server_list_cfg (str): Config file for memcached server list.
+ client_cfg (str): Config file for memcached client.
+ sys_path (str | None): Additional path to be appended to `sys.path`.
+ Default: None.
+ """
+
+ def __init__(self, server_list_cfg, client_cfg, sys_path=None):
+ if sys_path is not None:
+ import sys
+ sys.path.append(sys_path)
+ try:
+ import mc
+ except ImportError:
+ raise ImportError('Please install memcached to enable MemcachedBackend.')
+
+ self.server_list_cfg = server_list_cfg
+ self.client_cfg = client_cfg
+ self._client = mc.MemcachedClient.GetInstance(self.server_list_cfg, self.client_cfg)
+ # mc.pyvector servers as a point which points to a memory cache
+ self._mc_buffer = mc.pyvector()
+
+ def get(self, filepath):
+ filepath = str(filepath)
+ import mc
+ self._client.Get(filepath, self._mc_buffer)
+ value_buf = mc.ConvertBuffer(self._mc_buffer)
+ return value_buf
+
+ def get_text(self, filepath):
+ raise NotImplementedError
+
+
+class HardDiskBackend(BaseStorageBackend):
+ """Raw hard disks storage backend."""
+
+ def get(self, filepath):
+ filepath = str(filepath)
+ with open(filepath, 'rb') as f:
+ value_buf = f.read()
+ return value_buf
+
+ def get_text(self, filepath):
+ filepath = str(filepath)
+ with open(filepath, 'r') as f:
+ value_buf = f.read()
+ return value_buf
+
+
+class LmdbBackend(BaseStorageBackend):
+ """Lmdb storage backend.
+
+ Args:
+ db_paths (str | list[str]): Lmdb database paths.
+ client_keys (str | list[str]): Lmdb client keys. Default: 'default'.
+ readonly (bool, optional): Lmdb environment parameter. If True,
+ disallow any write operations. Default: True.
+ lock (bool, optional): Lmdb environment parameter. If False, when
+ concurrent access occurs, do not lock the database. Default: False.
+ readahead (bool, optional): Lmdb environment parameter. If False,
+ disable the OS filesystem readahead mechanism, which may improve
+ random read performance when a database is larger than RAM.
+ Default: False.
+
+ Attributes:
+ db_paths (list): Lmdb database path.
+ _client (list): A list of several lmdb envs.
+ """
+
+ def __init__(self, db_paths, client_keys='default', readonly=True, lock=False, readahead=False, **kwargs):
+ try:
+ import lmdb
+ except ImportError:
+ raise ImportError('Please install lmdb to enable LmdbBackend.')
+
+ if isinstance(client_keys, str):
+ client_keys = [client_keys]
+
+ if isinstance(db_paths, list):
+ self.db_paths = [str(v) for v in db_paths]
+ elif isinstance(db_paths, str):
+ self.db_paths = [str(db_paths)]
+ assert len(client_keys) == len(self.db_paths), ('client_keys and db_paths should have the same length, '
+ f'but received {len(client_keys)} and {len(self.db_paths)}.')
+
+ self._client = {}
+ for client, path in zip(client_keys, self.db_paths):
+ self._client[client] = lmdb.open(path, readonly=readonly, lock=lock, readahead=readahead, **kwargs)
+
+ def get(self, filepath, client_key):
+ """Get values according to the filepath from one lmdb named client_key.
+
+ Args:
+ filepath (str | obj:`Path`): Here, filepath is the lmdb key.
+ client_key (str): Used for distinguishing different lmdb envs.
+ """
+ filepath = str(filepath)
+ assert client_key in self._client, (f'client_key {client_key} is not ' 'in lmdb clients.')
+ client = self._client[client_key]
+ with client.begin(write=False) as txn:
+ value_buf = txn.get(filepath.encode('ascii'))
+ return value_buf
+
+ def get_text(self, filepath):
+ raise NotImplementedError
+
+
+class FileClient(object):
+ """A general file client to access files in different backend.
+
+ The client loads a file or text in a specified backend from its path
+ and return it as a binary file. it can also register other backend
+ accessor with a given name and backend class.
+
+ Attributes:
+ backend (str): The storage backend type. Options are "disk",
+ "memcached" and "lmdb".
+ client (:obj:`BaseStorageBackend`): The backend object.
+ """
+
+ _backends = {
+ 'disk': HardDiskBackend,
+ 'memcached': MemcachedBackend,
+ 'lmdb': LmdbBackend,
+ }
+
+ def __init__(self, backend='disk', **kwargs):
+ if backend not in self._backends:
+ raise ValueError(f'Backend {backend} is not supported. Currently supported ones'
+ f' are {list(self._backends.keys())}')
+ self.backend = backend
+ self.client = self._backends[backend](**kwargs)
+
+ def get(self, filepath, client_key='default'):
+ # client_key is used only for lmdb, where different fileclients have
+ # different lmdb environments.
+ if self.backend == 'lmdb':
+ return self.client.get(filepath, client_key)
+ else:
+ return self.client.get(filepath)
+
+ def get_text(self, filepath):
+ return self.client.get_text(filepath)
+
+
+def imfrombytes(content, flag='color', float32=False):
+ """Read an image from bytes.
+
+ Args:
+ content (bytes): Image bytes got from files or other streams.
+ flag (str): Flags specifying the color type of a loaded image,
+ candidates are `color`, `grayscale` and `unchanged`.
+ float32 (bool): Whether to change to float32., If True, will also norm
+ to [0, 1]. Default: False.
+
+ Returns:
+ ndarray: Loaded image array.
+ """
+ img_np = np.frombuffer(content, np.uint8)
+ imread_flags = {'color': cv2.IMREAD_COLOR, 'grayscale': cv2.IMREAD_GRAYSCALE, 'unchanged': cv2.IMREAD_UNCHANGED}
+ img = cv2.imdecode(img_np, imread_flags[flag])
+ if float32:
+ img = img.astype(np.float32) / 255.
+ return img
+
diff --git a/KAIR/utils/utils_videoio.py b/KAIR/utils/utils_videoio.py
new file mode 100644
index 0000000000000000000000000000000000000000..5be8c7f06802d5aaa7155a1cdcb27d2838a0882c
--- /dev/null
+++ b/KAIR/utils/utils_videoio.py
@@ -0,0 +1,555 @@
+import os
+import cv2
+import numpy as np
+import torch
+import random
+from os import path as osp
+from torchvision.utils import make_grid
+import sys
+from pathlib import Path
+import six
+from collections import OrderedDict
+import math
+import glob
+import av
+import io
+from cv2 import (CAP_PROP_FOURCC, CAP_PROP_FPS, CAP_PROP_FRAME_COUNT,
+ CAP_PROP_FRAME_HEIGHT, CAP_PROP_FRAME_WIDTH,
+ CAP_PROP_POS_FRAMES, VideoWriter_fourcc)
+
+if sys.version_info <= (3, 3):
+ FileNotFoundError = IOError
+else:
+ FileNotFoundError = FileNotFoundError
+
+
+def is_str(x):
+ """Whether the input is an string instance."""
+ return isinstance(x, six.string_types)
+
+
+def is_filepath(x):
+ return is_str(x) or isinstance(x, Path)
+
+
+def fopen(filepath, *args, **kwargs):
+ if is_str(filepath):
+ return open(filepath, *args, **kwargs)
+ elif isinstance(filepath, Path):
+ return filepath.open(*args, **kwargs)
+ raise ValueError('`filepath` should be a string or a Path')
+
+
+def check_file_exist(filename, msg_tmpl='file "{}" does not exist'):
+ if not osp.isfile(filename):
+ raise FileNotFoundError(msg_tmpl.format(filename))
+
+
+def mkdir_or_exist(dir_name, mode=0o777):
+ if dir_name == '':
+ return
+ dir_name = osp.expanduser(dir_name)
+ os.makedirs(dir_name, mode=mode, exist_ok=True)
+
+
+def symlink(src, dst, overwrite=True, **kwargs):
+ if os.path.lexists(dst) and overwrite:
+ os.remove(dst)
+ os.symlink(src, dst, **kwargs)
+
+
+def scandir(dir_path, suffix=None, recursive=False, case_sensitive=True):
+ """Scan a directory to find the interested files.
+ Args:
+ dir_path (str | :obj:`Path`): Path of the directory.
+ suffix (str | tuple(str), optional): File suffix that we are
+ interested in. Default: None.
+ recursive (bool, optional): If set to True, recursively scan the
+ directory. Default: False.
+ case_sensitive (bool, optional) : If set to False, ignore the case of
+ suffix. Default: True.
+ Returns:
+ A generator for all the interested files with relative paths.
+ """
+ if isinstance(dir_path, (str, Path)):
+ dir_path = str(dir_path)
+ else:
+ raise TypeError('"dir_path" must be a string or Path object')
+
+ if (suffix is not None) and not isinstance(suffix, (str, tuple)):
+ raise TypeError('"suffix" must be a string or tuple of strings')
+
+ if suffix is not None and not case_sensitive:
+ suffix = suffix.lower() if isinstance(suffix, str) else tuple(
+ item.lower() for item in suffix)
+
+ root = dir_path
+
+ def _scandir(dir_path, suffix, recursive, case_sensitive):
+ for entry in os.scandir(dir_path):
+ if not entry.name.startswith('.') and entry.is_file():
+ rel_path = osp.relpath(entry.path, root)
+ _rel_path = rel_path if case_sensitive else rel_path.lower()
+ if suffix is None or _rel_path.endswith(suffix):
+ yield rel_path
+ elif recursive and os.path.isdir(entry.path):
+ # scan recursively if entry.path is a directory
+ yield from _scandir(entry.path, suffix, recursive,
+ case_sensitive)
+
+ return _scandir(dir_path, suffix, recursive, case_sensitive)
+
+
+class Cache:
+
+ def __init__(self, capacity):
+ self._cache = OrderedDict()
+ self._capacity = int(capacity)
+ if capacity <= 0:
+ raise ValueError('capacity must be a positive integer')
+
+ @property
+ def capacity(self):
+ return self._capacity
+
+ @property
+ def size(self):
+ return len(self._cache)
+
+ def put(self, key, val):
+ if key in self._cache:
+ return
+ if len(self._cache) >= self.capacity:
+ self._cache.popitem(last=False)
+ self._cache[key] = val
+
+ def get(self, key, default=None):
+ val = self._cache[key] if key in self._cache else default
+ return val
+
+
+class VideoReader:
+ """Video class with similar usage to a list object.
+
+ This video warpper class provides convenient apis to access frames.
+ There exists an issue of OpenCV's VideoCapture class that jumping to a
+ certain frame may be inaccurate. It is fixed in this class by checking
+ the position after jumping each time.
+ Cache is used when decoding videos. So if the same frame is visited for
+ the second time, there is no need to decode again if it is stored in the
+ cache.
+
+ """
+
+ def __init__(self, filename, cache_capacity=10):
+ # Check whether the video path is a url
+ if not filename.startswith(('https://', 'http://')):
+ check_file_exist(filename, 'Video file not found: ' + filename)
+ self._vcap = cv2.VideoCapture(filename)
+ assert cache_capacity > 0
+ self._cache = Cache(cache_capacity)
+ self._position = 0
+ # get basic info
+ self._width = int(self._vcap.get(CAP_PROP_FRAME_WIDTH))
+ self._height = int(self._vcap.get(CAP_PROP_FRAME_HEIGHT))
+ self._fps = self._vcap.get(CAP_PROP_FPS)
+ self._frame_cnt = int(self._vcap.get(CAP_PROP_FRAME_COUNT))
+ self._fourcc = self._vcap.get(CAP_PROP_FOURCC)
+
+ @property
+ def vcap(self):
+ """:obj:`cv2.VideoCapture`: The raw VideoCapture object."""
+ return self._vcap
+
+ @property
+ def opened(self):
+ """bool: Indicate whether the video is opened."""
+ return self._vcap.isOpened()
+
+ @property
+ def width(self):
+ """int: Width of video frames."""
+ return self._width
+
+ @property
+ def height(self):
+ """int: Height of video frames."""
+ return self._height
+
+ @property
+ def resolution(self):
+ """tuple: Video resolution (width, height)."""
+ return (self._width, self._height)
+
+ @property
+ def fps(self):
+ """float: FPS of the video."""
+ return self._fps
+
+ @property
+ def frame_cnt(self):
+ """int: Total frames of the video."""
+ return self._frame_cnt
+
+ @property
+ def fourcc(self):
+ """str: "Four character code" of the video."""
+ return self._fourcc
+
+ @property
+ def position(self):
+ """int: Current cursor position, indicating frame decoded."""
+ return self._position
+
+ def _get_real_position(self):
+ return int(round(self._vcap.get(CAP_PROP_POS_FRAMES)))
+
+ def _set_real_position(self, frame_id):
+ self._vcap.set(CAP_PROP_POS_FRAMES, frame_id)
+ pos = self._get_real_position()
+ for _ in range(frame_id - pos):
+ self._vcap.read()
+ self._position = frame_id
+
+ def read(self):
+ """Read the next frame.
+
+ If the next frame have been decoded before and in the cache, then
+ return it directly, otherwise decode, cache and return it.
+
+ Returns:
+ ndarray or None: Return the frame if successful, otherwise None.
+ """
+ # pos = self._position
+ if self._cache:
+ img = self._cache.get(self._position)
+ if img is not None:
+ ret = True
+ else:
+ if self._position != self._get_real_position():
+ self._set_real_position(self._position)
+ ret, img = self._vcap.read()
+ if ret:
+ self._cache.put(self._position, img)
+ else:
+ ret, img = self._vcap.read()
+ if ret:
+ self._position += 1
+ return img
+
+ def get_frame(self, frame_id):
+ """Get frame by index.
+
+ Args:
+ frame_id (int): Index of the expected frame, 0-based.
+
+ Returns:
+ ndarray or None: Return the frame if successful, otherwise None.
+ """
+ if frame_id < 0 or frame_id >= self._frame_cnt:
+ raise IndexError(
+ f'"frame_id" must be between 0 and {self._frame_cnt - 1}')
+ if frame_id == self._position:
+ return self.read()
+ if self._cache:
+ img = self._cache.get(frame_id)
+ if img is not None:
+ self._position = frame_id + 1
+ return img
+ self._set_real_position(frame_id)
+ ret, img = self._vcap.read()
+ if ret:
+ if self._cache:
+ self._cache.put(self._position, img)
+ self._position += 1
+ return img
+
+ def current_frame(self):
+ """Get the current frame (frame that is just visited).
+
+ Returns:
+ ndarray or None: If the video is fresh, return None, otherwise
+ return the frame.
+ """
+ if self._position == 0:
+ return None
+ return self._cache.get(self._position - 1)
+
+ def cvt2frames(self,
+ frame_dir,
+ file_start=0,
+ filename_tmpl='{:06d}.jpg',
+ start=0,
+ max_num=0,
+ show_progress=False):
+ """Convert a video to frame images.
+
+ Args:
+ frame_dir (str): Output directory to store all the frame images.
+ file_start (int): Filenames will start from the specified number.
+ filename_tmpl (str): Filename template with the index as the
+ placeholder.
+ start (int): The starting frame index.
+ max_num (int): Maximum number of frames to be written.
+ show_progress (bool): Whether to show a progress bar.
+ """
+ mkdir_or_exist(frame_dir)
+ if max_num == 0:
+ task_num = self.frame_cnt - start
+ else:
+ task_num = min(self.frame_cnt - start, max_num)
+ if task_num <= 0:
+ raise ValueError('start must be less than total frame number')
+ if start > 0:
+ self._set_real_position(start)
+
+ def write_frame(file_idx):
+ img = self.read()
+ if img is None:
+ return
+ filename = osp.join(frame_dir, filename_tmpl.format(file_idx))
+ cv2.imwrite(filename, img)
+
+ if show_progress:
+ pass
+ #track_progress(write_frame, range(file_start,file_start + task_num))
+ else:
+ for i in range(task_num):
+ write_frame(file_start + i)
+
+ def __len__(self):
+ return self.frame_cnt
+
+ def __getitem__(self, index):
+ if isinstance(index, slice):
+ return [
+ self.get_frame(i)
+ for i in range(*index.indices(self.frame_cnt))
+ ]
+ # support negative indexing
+ if index < 0:
+ index += self.frame_cnt
+ if index < 0:
+ raise IndexError('index out of range')
+ return self.get_frame(index)
+
+ def __iter__(self):
+ self._set_real_position(0)
+ return self
+
+ def __next__(self):
+ img = self.read()
+ if img is not None:
+ return img
+ else:
+ raise StopIteration
+
+ next = __next__
+
+ def __enter__(self):
+ return self
+
+ def __exit__(self, exc_type, exc_value, traceback):
+ self._vcap.release()
+
+
+def frames2video(frame_dir,
+ video_file,
+ fps=30,
+ fourcc='XVID',
+ filename_tmpl='{:06d}.jpg',
+ start=0,
+ end=0,
+ show_progress=False):
+ """Read the frame images from a directory and join them as a video.
+
+ Args:
+ frame_dir (str): The directory containing video frames.
+ video_file (str): Output filename.
+ fps (float): FPS of the output video.
+ fourcc (str): Fourcc of the output video, this should be compatible
+ with the output file type.
+ filename_tmpl (str): Filename template with the index as the variable.
+ start (int): Starting frame index.
+ end (int): Ending frame index.
+ show_progress (bool): Whether to show a progress bar.
+ """
+ if end == 0:
+ ext = filename_tmpl.split('.')[-1]
+ end = len([name for name in scandir(frame_dir, ext)])
+ first_file = osp.join(frame_dir, filename_tmpl.format(start))
+ check_file_exist(first_file, 'The start frame not found: ' + first_file)
+ img = cv2.imread(first_file)
+ height, width = img.shape[:2]
+ resolution = (width, height)
+ vwriter = cv2.VideoWriter(video_file, VideoWriter_fourcc(*fourcc), fps,
+ resolution)
+
+ def write_frame(file_idx):
+ filename = osp.join(frame_dir, filename_tmpl.format(file_idx))
+ img = cv2.imread(filename)
+ vwriter.write(img)
+
+ if show_progress:
+ pass
+ # track_progress(write_frame, range(start, end))
+ else:
+ for i in range(start, end):
+ write_frame(i)
+ vwriter.release()
+
+
+def video2images(video_path, output_dir):
+ vidcap = cv2.VideoCapture(video_path)
+ in_fps = vidcap.get(cv2.CAP_PROP_FPS)
+ print('video fps:', in_fps)
+ if not os.path.isdir(output_dir):
+ os.makedirs(output_dir)
+ loaded, frame = vidcap.read()
+ total_frames = int(vidcap.get(cv2.CAP_PROP_FRAME_COUNT))
+ print(f'number of total frames is: {total_frames:06}')
+ for i_frame in range(total_frames):
+ if i_frame % 100 == 0:
+ print(f'{i_frame:06} / {total_frames:06}')
+ frame_name = os.path.join(output_dir, f'{i_frame:06}' + '.png')
+ cv2.imwrite(frame_name, frame)
+ loaded, frame = vidcap.read()
+
+
+def images2video(image_dir, video_path, fps=24, image_ext='png'):
+ '''
+ #codec = cv2.VideoWriter_fourcc(*'XVID')
+ #codec = cv2.VideoWriter_fourcc('A','V','C','1')
+ #codec = cv2.VideoWriter_fourcc('Y','U','V','1')
+ #codec = cv2.VideoWriter_fourcc('P','I','M','1')
+ #codec = cv2.VideoWriter_fourcc('M','J','P','G')
+ codec = cv2.VideoWriter_fourcc('M','P','4','2')
+ #codec = cv2.VideoWriter_fourcc('D','I','V','3')
+ #codec = cv2.VideoWriter_fourcc('D','I','V','X')
+ #codec = cv2.VideoWriter_fourcc('U','2','6','3')
+ #codec = cv2.VideoWriter_fourcc('I','2','6','3')
+ #codec = cv2.VideoWriter_fourcc('F','L','V','1')
+ #codec = cv2.VideoWriter_fourcc('H','2','6','4')
+ #codec = cv2.VideoWriter_fourcc('A','Y','U','V')
+ #codec = cv2.VideoWriter_fourcc('I','U','Y','V')
+ 编码器常用的几种:
+ cv2.VideoWriter_fourcc("I", "4", "2", "0")
+ 压缩的yuv颜色编码器,4:2:0色彩度子采样 兼容性好,产生很大的视频 avi
+ cv2.VideoWriter_fourcc("P", I", "M", "1")
+ 采用mpeg-1编码,文件为avi
+ cv2.VideoWriter_fourcc("X", "V", "T", "D")
+ 采用mpeg-4编码,得到视频大小平均 拓展名avi
+ cv2.VideoWriter_fourcc("T", "H", "E", "O")
+ Ogg Vorbis, 拓展名为ogv
+ cv2.VideoWriter_fourcc("F", "L", "V", "1")
+ FLASH视频,拓展名为.flv
+ '''
+ image_files = sorted(glob.glob(os.path.join(image_dir, '*.{}'.format(image_ext))))
+ print(len(image_files))
+ height, width, _ = cv2.imread(image_files[0]).shape
+ out_fourcc = cv2.VideoWriter_fourcc('M', 'J', 'P', 'G') # cv2.VideoWriter_fourcc(*'MP4V')
+ out_video = cv2.VideoWriter(video_path, out_fourcc, fps, (width, height))
+
+ for image_file in image_files:
+ img = cv2.imread(image_file)
+ img = cv2.resize(img, (width, height), interpolation=3)
+ out_video.write(img)
+ out_video.release()
+
+
+def add_video_compression(imgs):
+ codec_type = ['libx264', 'h264', 'mpeg4']
+ codec_prob = [1 / 3., 1 / 3., 1 / 3.]
+ codec = random.choices(codec_type, codec_prob)[0]
+ # codec = 'mpeg4'
+ bitrate = [1e4, 1e5]
+ bitrate = np.random.randint(bitrate[0], bitrate[1] + 1)
+
+ buf = io.BytesIO()
+ with av.open(buf, 'w', 'mp4') as container:
+ stream = container.add_stream(codec, rate=1)
+ stream.height = imgs[0].shape[0]
+ stream.width = imgs[0].shape[1]
+ stream.pix_fmt = 'yuv420p'
+ stream.bit_rate = bitrate
+
+ for img in imgs:
+ img = np.uint8((img.clip(0, 1)*255.).round())
+ frame = av.VideoFrame.from_ndarray(img, format='rgb24')
+ frame.pict_type = 'NONE'
+ # pdb.set_trace()
+ for packet in stream.encode(frame):
+ container.mux(packet)
+
+ # Flush stream
+ for packet in stream.encode():
+ container.mux(packet)
+
+ outputs = []
+ with av.open(buf, 'r', 'mp4') as container:
+ if container.streams.video:
+ for frame in container.decode(**{'video': 0}):
+ outputs.append(
+ frame.to_rgb().to_ndarray().astype(np.float32) / 255.)
+
+ #outputs = np.stack(outputs, axis=0)
+ return outputs
+
+
+if __name__ == '__main__':
+
+ # -----------------------------------
+ # test VideoReader(filename, cache_capacity=10)
+ # -----------------------------------
+# video_reader = VideoReader('utils/test.mp4')
+# from utils import utils_image as util
+# inputs = []
+# for frame in video_reader:
+# print(frame.dtype)
+# util.imshow(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
+# #util.imshow(np.flip(frame, axis=2))
+
+ # -----------------------------------
+ # test video2images(video_path, output_dir)
+ # -----------------------------------
+# video2images('utils/test.mp4', 'frames')
+
+ # -----------------------------------
+ # test images2video(image_dir, video_path, fps=24, image_ext='png')
+ # -----------------------------------
+# images2video('frames', 'video_02.mp4', fps=30, image_ext='png')
+
+
+ # -----------------------------------
+ # test frames2video(frame_dir, video_file, fps=30, fourcc='XVID', filename_tmpl='{:06d}.png')
+ # -----------------------------------
+# frames2video('frames', 'video_01.mp4', filename_tmpl='{:06d}.png')
+
+
+ # -----------------------------------
+ # test add_video_compression(imgs)
+ # -----------------------------------
+# imgs = []
+# image_ext = 'png'
+# frames = 'frames'
+# from utils import utils_image as util
+# image_files = sorted(glob.glob(os.path.join(frames, '*.{}'.format(image_ext))))
+# for i, image_file in enumerate(image_files):
+# if i < 7:
+# img = util.imread_uint(image_file, 3)
+# img = util.uint2single(img)
+# imgs.append(img)
+#
+# results = add_video_compression(imgs)
+# for i, img in enumerate(results):
+# util.imshow(util.single2uint(img))
+# util.imsave(util.single2uint(img),f'{i:05}.png')
+
+ # run utils/utils_video.py
+
+
+
+
+
+
+
diff --git a/README.md b/README.md
index 65d6fce5d9695bf89c13b4c04233a45209844b78..00acef7785b5d6792d14ebacb82be1913b42e501 100644
--- a/README.md
+++ b/README.md
@@ -1,13 +1,12 @@
---
-title: LambdaSuperRes
-emoji: 🌖
-colorFrom: pink
-colorTo: pink
+title: Swinir Private Test
+emoji: 🐠
+colorFrom: purple
+colorTo: red
sdk: gradio
sdk_version: 3.2
app_file: app.py
pinned: false
-license: mit
---
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/app.py b/app.py
new file mode 100644
index 0000000000000000000000000000000000000000..9a8be4f3d2aa336bd1c5f04931a96af5595030a0
--- /dev/null
+++ b/app.py
@@ -0,0 +1,148 @@
+import datetime
+import hashlib
+import numpy as np
+import os
+import subprocess
+from pathlib import Path
+from typing import Any, Dict
+
+import cv2
+import gradio as gr
+from joblib import Parallel, delayed
+from numpy.typing import NDArray
+from PIL import Image
+
+
+def _run_in_subprocess(command: str, wd: str) -> Any:
+ p = subprocess.Popen(command, shell=True, cwd=wd)
+ (output, err) = p.communicate()
+ p_status = p.wait()
+ print("Status of subprocess: ", p_status)
+ return p_status
+
+
+SWIN_IR_WD = "KAIR"
+SWINIR_CKPT_DIR: str = Path("KAIR/model_zoo/")
+MODEL_NAME_TO_PATH: Dict[str, Path] = {
+ "LambdaSwinIR_v0.1": Path(str(SWINIR_CKPT_DIR) + "/805000_G.pth"),
+}
+SWINIR_NAME_TO_PATCH_SIZE: Dict[str, int] = {
+ "LambdaSwinIR_v0.1": 96,
+}
+SWINIR_NAME_TO_SCALE: Dict[str, int] = {
+ "LambdaSwinIR_v0.1": 2,
+}
+SWINIR_NAME_TO_LARGE_MODEL: Dict[str, bool] = {
+ "LambdaSwinIR_v0.1": False,
+}
+
+def _run_swin_ir(
+ image: NDArray,
+ model_path: Path,
+ patch_size: int,
+ scale: int,
+ is_large_model: bool,
+):
+ print("model_path: ", str(model_path))
+ m = hashlib.sha256()
+ now_time = datetime.datetime.utcnow()
+ m.update(bytes(str(model_path), encoding='utf-8') +
+ bytes(now_time.strftime("%Y-%m-%d %H:%M:%S.%f"), encoding='utf-8'))
+ random_id = m.hexdigest()[0:20]
+
+ cwd = os.getcwd()
+
+ input_root = Path(cwd + "/sr_interactive_tmp")
+ input_root.mkdir(parents=True, exist_ok=True)
+ Image.fromarray(image).save(str(input_root) + "/gradio_img.png")
+ command = f"python main_test_swinir.py --scale {scale} " + \
+ f"--folder_lq {input_root} --task real_sr " + \
+ f"--model_path {cwd}/{model_path} --training_patch_size {patch_size}"
+ if is_large_model:
+ command += " --large_model"
+ print("COMMAND: ", command)
+ status = _run_in_subprocess(command, wd=cwd + "/" + SWIN_IR_WD)
+ print("STATUS: ", status)
+
+ if scale == 2:
+ str_scale = "2"
+ if scale == 4:
+ str_scale = "4_large"
+ output_img = Image.open(f"{cwd}/KAIR/results/swinir_real_sr_x{str_scale}/gradio_img_SwinIR.png")
+ output_root = Path("./sr_interactive_tmp_output")
+ output_root.mkdir(parents=True, exist_ok=True)
+
+ output_img.save(str(output_root) + "/SwinIR_" + random_id + ".png")
+ print("SAVING: SwinIR_" + random_id + ".png")
+ result = np.array(output_img)
+ return result
+
+
+def _bilinear_upsample(image: NDArray):
+ result = cv2.resize(
+ image,
+ dsize=(image.shape[1] * 2, image.shape[0] * 2),
+ interpolation=cv2.INTER_LANCZOS4
+ )
+ return result
+
+
+def _decide_sr_algo(model_name: str, image: NDArray):
+ # if "SwinIR" in model_name:
+ # result = _run_swin_ir(image,
+ # model_path=MODEL_NAME_TO_PATH[model_name],
+ # patch_size=SWINIR_NAME_TO_PATCH_SIZE[model_name],
+ # scale=SWINIR_NAME_TO_SCALE[model_name],
+ # is_large_model=("SwinIR-L" in model_name))
+ # else:
+ # result = _bilinear_upsample(image)
+
+ # elif algo == SR_OPTIONS[1]:
+ # result = _run_maxine(image, mode="SR")
+ # elif algo == SR_OPTIONS[2]:
+ # result = _run_maxine(image, mode="UPSCALE")
+ # return result
+ result = _run_swin_ir(image,
+ model_path=MODEL_NAME_TO_PATH[model_name],
+ patch_size=SWINIR_NAME_TO_PATCH_SIZE[model_name],
+ scale=SWINIR_NAME_TO_SCALE[model_name],
+ is_large_model=SWINIR_NAME_TO_LARGE_MODEL[model_name])
+ return result
+
+
+def _super_resolve(model_name: str, input_img):
+ # futures = []
+ # with ThreadPoolExecutor(max_workers=4) as executor:
+ # for model_name in model_names:
+ # futures.append(executor.submit(_decide_sr_algo, model_name, input_img))
+
+ # return [f.result() for f in futures]
+ # return Parallel(n_jobs=2, prefer="threads")(
+ # delayed(_decide_sr_algo)(model_name, input_img)
+ # for model_name in model_names
+ # )
+ return _decide_sr_algo(model_name, input_img)
+
+def _gradio_handler(sr_option: str, input_img: NDArray):
+ return _super_resolve(sr_option, input_img)
+
+
+gr.close_all()
+SR_OPTIONS = ["LambdaSwinIR_v0.1"]
+examples = [
+ ["LambdaSwinIR_v0.1", "examples/oldphoto6.png"],
+ ["LambdaSwinIR_v0.1", "examples/Lincoln.png"],
+ ["LambdaSwinIR_v0.1", "examples/OST_009.png"],
+ ["LambdaSwinIR_v0.1", "examples/00003.png"],
+ ["LambdaSwinIR_v0.1", "examples/00000067_cropped.png"],
+]
+ui = gr.Interface(fn=_gradio_handler,
+ inputs=[
+ gr.Radio(SR_OPTIONS),
+ gr.Image(image_mode="RGB")
+ ],
+ outputs=["image"],
+ live=False,
+ examples=examples,
+ cache_examples=True)
+ui.launch(enable_queue=True)
diff --git a/examples/00000067_cropped.png b/examples/00000067_cropped.png
new file mode 100644
index 0000000000000000000000000000000000000000..66bab29f3f9a3a1ce0fb869eae7e6e9702644782
Binary files /dev/null and b/examples/00000067_cropped.png differ
diff --git a/examples/00003.png b/examples/00003.png
new file mode 100644
index 0000000000000000000000000000000000000000..00cad23adf5d658caf03a0a2874f0c89d96c5ddc
Binary files /dev/null and b/examples/00003.png differ
diff --git a/examples/Lincoln.png b/examples/Lincoln.png
new file mode 100644
index 0000000000000000000000000000000000000000..de6cc486200ac14e4c6e7bb5f0de8127865385ca
Binary files /dev/null and b/examples/Lincoln.png differ
diff --git a/examples/OST_009.png b/examples/OST_009.png
new file mode 100644
index 0000000000000000000000000000000000000000..10bbc831acb7065827a14eb7e0538312a8d6f3e2
Binary files /dev/null and b/examples/OST_009.png differ
diff --git a/examples/oldphoto6.png b/examples/oldphoto6.png
new file mode 100644
index 0000000000000000000000000000000000000000..8d0b76d9f5a97531b0e648b84a4c0050f4a4cdf5
Binary files /dev/null and b/examples/oldphoto6.png differ
diff --git a/requirements.txt b/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..9f0640ceefd5a7d6f19ca7fcd189c9eb9bf05878
--- /dev/null
+++ b/requirements.txt
@@ -0,0 +1,13 @@
+opencv-python
+scikit-image
+pillow
+torchvision
+hdf5storage
+ninja
+lmdb
+requests
+timm
+einops
+matplotlib
+gradio
+joblib
+
+
+
+
diff --git a/KAIR/matlab/center_replace.m b/KAIR/matlab/center_replace.m
new file mode 100644
index 0000000000000000000000000000000000000000..0aebbdf745c7b89eb588493c40f87e27c07e3116
--- /dev/null
+++ b/KAIR/matlab/center_replace.m
@@ -0,0 +1,11 @@
+function [im] = center_replace(im,im2)
+
+[w,h,~] = size(im);
+
+[a,b,~] = size(im2);
+c1 = w-a-(w-a)/2;
+c2 = h-b-(h-b)/2;
+im(c1+1:c1+a,c2+1:c2+b,:) = im2;
+
+end
+
diff --git a/KAIR/matlab/denoising_gray/05_bm3d_2582.png b/KAIR/matlab/denoising_gray/05_bm3d_2582.png
new file mode 100644
index 0000000000000000000000000000000000000000..9e0ca721a3ccdd09af533ef4e66fbd019ada4c7e
Binary files /dev/null and b/KAIR/matlab/denoising_gray/05_bm3d_2582.png differ
diff --git a/KAIR/matlab/denoising_gray/05_dncnn_2683.png b/KAIR/matlab/denoising_gray/05_dncnn_2683.png
new file mode 100644
index 0000000000000000000000000000000000000000..52b19164c835e635132609404bedb14f87abfd9f
Binary files /dev/null and b/KAIR/matlab/denoising_gray/05_dncnn_2683.png differ
diff --git a/KAIR/matlab/denoising_gray/05_drunet_2731.png b/KAIR/matlab/denoising_gray/05_drunet_2731.png
new file mode 100644
index 0000000000000000000000000000000000000000..85996b7f9dc5687b32161b794253cc0331aada60
Binary files /dev/null and b/KAIR/matlab/denoising_gray/05_drunet_2731.png differ
diff --git a/KAIR/matlab/denoising_gray/05_ffdnet_2692.png b/KAIR/matlab/denoising_gray/05_ffdnet_2692.png
new file mode 100644
index 0000000000000000000000000000000000000000..c33f5b36efa9e4c776869da9347c8c6a4536ff8b
Binary files /dev/null and b/KAIR/matlab/denoising_gray/05_ffdnet_2692.png differ
diff --git a/KAIR/matlab/denoising_gray/05_noisy_1478.png b/KAIR/matlab/denoising_gray/05_noisy_1478.png
new file mode 100644
index 0000000000000000000000000000000000000000..92cd862dae729d07e6c8132a211b5b25a69e5587
Binary files /dev/null and b/KAIR/matlab/denoising_gray/05_noisy_1478.png differ
diff --git a/KAIR/matlab/denoising_gray_results/05_bm3d_2582.png b/KAIR/matlab/denoising_gray_results/05_bm3d_2582.png
new file mode 100644
index 0000000000000000000000000000000000000000..c3e07f67bffa3a1ac274be2c2fd633b41923b6e1
Binary files /dev/null and b/KAIR/matlab/denoising_gray_results/05_bm3d_2582.png differ
diff --git a/KAIR/matlab/denoising_gray_results/05_dncnn_2683.png b/KAIR/matlab/denoising_gray_results/05_dncnn_2683.png
new file mode 100644
index 0000000000000000000000000000000000000000..01138a03c40ac63981fa204ede2b2026c4b0e528
Binary files /dev/null and b/KAIR/matlab/denoising_gray_results/05_dncnn_2683.png differ
diff --git a/KAIR/matlab/denoising_gray_results/05_drunet_2731.png b/KAIR/matlab/denoising_gray_results/05_drunet_2731.png
new file mode 100644
index 0000000000000000000000000000000000000000..e8f0d9f49a56fb08abbeffb367fe50bfe2143f30
Binary files /dev/null and b/KAIR/matlab/denoising_gray_results/05_drunet_2731.png differ
diff --git a/KAIR/matlab/denoising_gray_results/05_ffdnet_2692.png b/KAIR/matlab/denoising_gray_results/05_ffdnet_2692.png
new file mode 100644
index 0000000000000000000000000000000000000000..0303f4cc1585288eec91cf14ae4e66212d93e4ee
Binary files /dev/null and b/KAIR/matlab/denoising_gray_results/05_ffdnet_2692.png differ
diff --git a/KAIR/matlab/denoising_gray_results/05_noisy_1478.png b/KAIR/matlab/denoising_gray_results/05_noisy_1478.png
new file mode 100644
index 0000000000000000000000000000000000000000..b6996fa51de2296a4d36791ea1422c441aa10c4a
Binary files /dev/null and b/KAIR/matlab/denoising_gray_results/05_noisy_1478.png differ
diff --git a/KAIR/matlab/main_denoising_color.m b/KAIR/matlab/main_denoising_color.m
new file mode 100644
index 0000000000000000000000000000000000000000..3940b026807bf8816f88fb9df71b1e706e19142e
--- /dev/null
+++ b/KAIR/matlab/main_denoising_color.m
@@ -0,0 +1,52 @@
+
+
+
+input_folder = 'denoising_color';
+output_folder = 'denoising_color_results';
+
+upperleft_pixel = [220, 5];
+box = [60, 60];
+zoomfactor = 3;
+zoom_position = 'lr';
+nline = 2;
+
+ext = {'*.jpg','*.png','*.bmp'};
+
+images = [];
+
+for i = 1:length(ext)
+
+ images = [images dir(fullfile(input_folder, ext{i}))];
+
+end
+
+if isdir(output_folder) == 0
+ mkdir(output_folder);
+end
+
+for i = 1:numel(images)
+
+ [~, name, exte] = fileparts(images(i).name);
+ I = imread( fullfile(input_folder,images(i).name));
+
+ % if i == 1
+ % imtool(double(I)/256)
+ % end
+
+ I = zoom_function(I, upperleft_pixel, box, zoomfactor, zoom_position,nline);
+
+ imwrite(I, fullfile(output_folder,images(i).name), 'Compression','none');
+
+ imshow(I)
+ title(name);
+
+ pause(1)
+
+end
+
+close;
+
+
+
+
+
diff --git a/KAIR/matlab/main_denoising_gray.m b/KAIR/matlab/main_denoising_gray.m
new file mode 100644
index 0000000000000000000000000000000000000000..c5498471cc6e42ae19e1174e3065ffe6953ebdf3
--- /dev/null
+++ b/KAIR/matlab/main_denoising_gray.m
@@ -0,0 +1,51 @@
+
+
+
+input_folder = 'denoising_gray';
+output_folder = 'denoising_gray_results';
+
+upperleft_pixel = [172, 218];
+box = [35, 35];
+zoomfactor = 3;
+zoom_position = 'ur';
+nline = 2;
+
+ext = {'*.jpg','*.png','*.bmp'};
+
+images = [];
+for i = 1:length(ext)
+ images = [images, dir(fullfile(input_folder, ext{i}))];
+end
+
+if isfolder(output_folder) == 0
+ mkdir(output_folder);
+end
+
+for i = 1:numel(images)
+
+ [~, name, exte] = fileparts(images(i).name);
+ I = imread( fullfile(input_folder,images(i).name));
+
+% if i == 1
+% imtool(double(I)/256)
+% end
+
+ I = zoom_function(I, upperleft_pixel, box, zoomfactor, zoom_position,nline);
+
+ imwrite(I, fullfile(output_folder,images(i).name), 'Compression','none');
+
+ imshow(I)
+ title(name);
+ pause(1)
+
+
+end
+
+
+
+
+
+
+
+
+
diff --git a/KAIR/matlab/modcrop.m b/KAIR/matlab/modcrop.m
new file mode 100644
index 0000000000000000000000000000000000000000..728c68810609913d8ae8475a0d7305a92a1f1fae
--- /dev/null
+++ b/KAIR/matlab/modcrop.m
@@ -0,0 +1,12 @@
+function imgs = modcrop(imgs, modulo)
+if size(imgs,3)==1
+ sz = size(imgs);
+ sz = sz - mod(sz, modulo);
+ imgs = imgs(1:sz(1), 1:sz(2));
+else
+ tmpsz = size(imgs);
+ sz = tmpsz(1:2);
+ sz = sz - mod(sz, modulo);
+ imgs = imgs(1:sz(1), 1:sz(2),:);
+end
+
diff --git a/KAIR/matlab/shave.m b/KAIR/matlab/shave.m
new file mode 100644
index 0000000000000000000000000000000000000000..2a931ffded4fcd1bc6d2fc990a1d8a14cc7efb31
--- /dev/null
+++ b/KAIR/matlab/shave.m
@@ -0,0 +1,3 @@
+function I = shave(I, border)
+I = I(1+border(1):end-border(1), ...
+ 1+border(2):end-border(2), :, :);
diff --git a/KAIR/matlab/zoom_function.m b/KAIR/matlab/zoom_function.m
new file mode 100644
index 0000000000000000000000000000000000000000..6771712c8097578febc1c7e018c195ce3dca1a74
--- /dev/null
+++ b/KAIR/matlab/zoom_function.m
@@ -0,0 +1,60 @@
+function [I]=zoom_function(I,upperleft_pixel,box,zoomfactor,zoom_position,nline)
+
+y = upperleft_pixel(1);
+x = upperleft_pixel(2);
+box1 = box(1);
+box2 = box(2); %4
+
+s_color = [0 255 0];
+l_color = [255 0 0];
+
+
+
+[~, ~, hw] = size( I );
+
+if hw == 1
+ I=repmat(I,[1,1,3]);
+end
+
+Imin = I(x:x+box1-1,y:y+box2-1,:);
+I(x-nline:x+box1-1+nline,y-nline:y+box2-1+nline,1) = s_color(1);
+I(x-nline:x+box1-1+nline,y-nline:y+box2-1+nline,2) = s_color(2);
+I(x-nline:x+box1-1+nline,y-nline:y+box2-1+nline,3) = s_color(3);
+I(x:x+box1-1,y:y+box2-1,:) = Imin;
+Imax = imresize(Imin,zoomfactor,'nearest');
+
+switch lower(zoom_position)
+ case {'uper_left','ul'}
+
+ I(1:2*nline+zoomfactor*box1,1:2*nline+zoomfactor*box2,1) = l_color(1);
+ I(1:2*nline+zoomfactor*box1,1:2*nline+zoomfactor*box2,2) = l_color(2);
+ I(1:2*nline+zoomfactor*box1,1:2*nline+zoomfactor*box2,3) = l_color(3);
+ I(1+nline:zoomfactor*box1+nline,1+nline:zoomfactor*box2+nline,:) = Imax;
+
+ case {'uper_right','ur'}
+
+ I(1:2*nline+zoomfactor*box1,end-2*nline-zoomfactor*box2+1:end,1) = l_color(1);
+ I(1:2*nline+zoomfactor*box1,end-2*nline-zoomfactor*box2+1:end,2) = l_color(2);
+ I(1:2*nline+zoomfactor*box1,end-2*nline-zoomfactor*box2+1:end,3) = l_color(3);
+ I(1+nline:zoomfactor*box1+nline,end-nline-zoomfactor*box2+1:end-nline,:) = Imax;
+
+ case {'lower_left','ll'}
+
+ I(end-2*nline-zoomfactor*box1+1:end,1:2*nline+zoomfactor*box2,1) = l_color(1);
+ I(end-2*nline-zoomfactor*box1+1:end,1:2*nline+zoomfactor*box2,2) = l_color(2);
+ I(end-2*nline-zoomfactor*box1+1:end,1:2*nline+zoomfactor*box2,3) = l_color(3);
+ I(end-nline-zoomfactor*box1+1:end-nline,1+nline:zoomfactor*box2+nline,:) = Imax;
+
+ case {'lower_right','lr'}
+
+ I(end-2*nline-zoomfactor*box1+1:end,end-2*nline-zoomfactor*box2+1:end,1) = l_color(1);
+ I(end-2*nline-zoomfactor*box1+1:end,end-2*nline-zoomfactor*box2+1:end,2) = l_color(2);
+ I(end-2*nline-zoomfactor*box1+1:end,end-2*nline-zoomfactor*box2+1:end,3) = l_color(3);
+ I(end-nline-zoomfactor*box1+1:end-nline,end-nline-zoomfactor*box2+1:end-nline,:) = Imax;
+
+
+
+end
+
+
+
diff --git a/KAIR/models/basicblock.py b/KAIR/models/basicblock.py
new file mode 100644
index 0000000000000000000000000000000000000000..12b8404bfdf570df859b6e57cc4cfb0e6aeb3068
--- /dev/null
+++ b/KAIR/models/basicblock.py
@@ -0,0 +1,591 @@
+from collections import OrderedDict
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+
+'''
+# --------------------------------------------
+# Advanced nn.Sequential
+# https://github.com/xinntao/BasicSR
+# --------------------------------------------
+'''
+
+
+def sequential(*args):
+ """Advanced nn.Sequential.
+
+ Args:
+ nn.Sequential, nn.Module
+
+ Returns:
+ nn.Sequential
+ """
+ if len(args) == 1:
+ if isinstance(args[0], OrderedDict):
+ raise NotImplementedError('sequential does not support OrderedDict input.')
+ return args[0] # No sequential is needed.
+ modules = []
+ for module in args:
+ if isinstance(module, nn.Sequential):
+ for submodule in module.children():
+ modules.append(submodule)
+ elif isinstance(module, nn.Module):
+ modules.append(module)
+ return nn.Sequential(*modules)
+
+
+'''
+# --------------------------------------------
+# Useful blocks
+# https://github.com/xinntao/BasicSR
+# --------------------------------
+# conv + normaliation + relu (conv)
+# (PixelUnShuffle)
+# (ConditionalBatchNorm2d)
+# concat (ConcatBlock)
+# sum (ShortcutBlock)
+# resblock (ResBlock)
+# Channel Attention (CA) Layer (CALayer)
+# Residual Channel Attention Block (RCABlock)
+# Residual Channel Attention Group (RCAGroup)
+# Residual Dense Block (ResidualDenseBlock_5C)
+# Residual in Residual Dense Block (RRDB)
+# --------------------------------------------
+'''
+
+
+# --------------------------------------------
+# return nn.Sequantial of (Conv + BN + ReLU)
+# --------------------------------------------
+def conv(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=True, mode='CBR', negative_slope=0.2):
+ L = []
+ for t in mode:
+ if t == 'C':
+ L.append(nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding, bias=bias))
+ elif t == 'T':
+ L.append(nn.ConvTranspose2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=padding, bias=bias))
+ elif t == 'B':
+ L.append(nn.BatchNorm2d(out_channels, momentum=0.9, eps=1e-04, affine=True))
+ elif t == 'I':
+ L.append(nn.InstanceNorm2d(out_channels, affine=True))
+ elif t == 'R':
+ L.append(nn.ReLU(inplace=True))
+ elif t == 'r':
+ L.append(nn.ReLU(inplace=False))
+ elif t == 'L':
+ L.append(nn.LeakyReLU(negative_slope=negative_slope, inplace=True))
+ elif t == 'l':
+ L.append(nn.LeakyReLU(negative_slope=negative_slope, inplace=False))
+ elif t == '2':
+ L.append(nn.PixelShuffle(upscale_factor=2))
+ elif t == '3':
+ L.append(nn.PixelShuffle(upscale_factor=3))
+ elif t == '4':
+ L.append(nn.PixelShuffle(upscale_factor=4))
+ elif t == 'U':
+ L.append(nn.Upsample(scale_factor=2, mode='nearest'))
+ elif t == 'u':
+ L.append(nn.Upsample(scale_factor=3, mode='nearest'))
+ elif t == 'v':
+ L.append(nn.Upsample(scale_factor=4, mode='nearest'))
+ elif t == 'M':
+ L.append(nn.MaxPool2d(kernel_size=kernel_size, stride=stride, padding=0))
+ elif t == 'A':
+ L.append(nn.AvgPool2d(kernel_size=kernel_size, stride=stride, padding=0))
+ else:
+ raise NotImplementedError('Undefined type: '.format(t))
+ return sequential(*L)
+
+
+# --------------------------------------------
+# inverse of pixel_shuffle
+# --------------------------------------------
+def pixel_unshuffle(input, upscale_factor):
+ r"""Rearranges elements in a Tensor of shape :math:`(C, rH, rW)` to a
+ tensor of shape :math:`(*, r^2C, H, W)`.
+
+ Authors:
+ Zhaoyi Yan, https://github.com/Zhaoyi-Yan
+ Kai Zhang, https://github.com/cszn/FFDNet
+
+ Date:
+ 01/Jan/2019
+ """
+ batch_size, channels, in_height, in_width = input.size()
+
+ out_height = in_height // upscale_factor
+ out_width = in_width // upscale_factor
+
+ input_view = input.contiguous().view(
+ batch_size, channels, out_height, upscale_factor,
+ out_width, upscale_factor)
+
+ channels *= upscale_factor ** 2
+ unshuffle_out = input_view.permute(0, 1, 3, 5, 2, 4).contiguous()
+ return unshuffle_out.view(batch_size, channels, out_height, out_width)
+
+
+class PixelUnShuffle(nn.Module):
+ r"""Rearranges elements in a Tensor of shape :math:`(C, rH, rW)` to a
+ tensor of shape :math:`(*, r^2C, H, W)`.
+
+ Authors:
+ Zhaoyi Yan, https://github.com/Zhaoyi-Yan
+ Kai Zhang, https://github.com/cszn/FFDNet
+
+ Date:
+ 01/Jan/2019
+ """
+
+ def __init__(self, upscale_factor):
+ super(PixelUnShuffle, self).__init__()
+ self.upscale_factor = upscale_factor
+
+ def forward(self, input):
+ return pixel_unshuffle(input, self.upscale_factor)
+
+ def extra_repr(self):
+ return 'upscale_factor={}'.format(self.upscale_factor)
+
+
+# --------------------------------------------
+# conditional batch norm
+# https://github.com/pytorch/pytorch/issues/8985#issuecomment-405080775
+# --------------------------------------------
+class ConditionalBatchNorm2d(nn.Module):
+ def __init__(self, num_features, num_classes):
+ super().__init__()
+ self.num_features = num_features
+ self.bn = nn.BatchNorm2d(num_features, affine=False)
+ self.embed = nn.Embedding(num_classes, num_features * 2)
+ self.embed.weight.data[:, :num_features].normal_(1, 0.02) # Initialise scale at N(1, 0.02)
+ self.embed.weight.data[:, num_features:].zero_() # Initialise bias at 0
+
+ def forward(self, x, y):
+ out = self.bn(x)
+ gamma, beta = self.embed(y).chunk(2, 1)
+ out = gamma.view(-1, self.num_features, 1, 1) * out + beta.view(-1, self.num_features, 1, 1)
+ return out
+
+
+# --------------------------------------------
+# Concat the output of a submodule to its input
+# --------------------------------------------
+class ConcatBlock(nn.Module):
+ def __init__(self, submodule):
+ super(ConcatBlock, self).__init__()
+ self.sub = submodule
+
+ def forward(self, x):
+ output = torch.cat((x, self.sub(x)), dim=1)
+ return output
+
+ def __repr__(self):
+ return self.sub.__repr__() + 'concat'
+
+
+# --------------------------------------------
+# sum the output of a submodule to its input
+# --------------------------------------------
+class ShortcutBlock(nn.Module):
+ def __init__(self, submodule):
+ super(ShortcutBlock, self).__init__()
+
+ self.sub = submodule
+
+ def forward(self, x):
+ output = x + self.sub(x)
+ return output
+
+ def __repr__(self):
+ tmpstr = 'Identity + \n|'
+ modstr = self.sub.__repr__().replace('\n', '\n|')
+ tmpstr = tmpstr + modstr
+ return tmpstr
+
+
+# --------------------------------------------
+# Res Block: x + conv(relu(conv(x)))
+# --------------------------------------------
+class ResBlock(nn.Module):
+ def __init__(self, in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=True, mode='CRC', negative_slope=0.2):
+ super(ResBlock, self).__init__()
+
+ assert in_channels == out_channels, 'Only support in_channels==out_channels.'
+ if mode[0] in ['R', 'L']:
+ mode = mode[0].lower() + mode[1:]
+
+ self.res = conv(in_channels, out_channels, kernel_size, stride, padding, bias, mode, negative_slope)
+
+ def forward(self, x):
+ res = self.res(x)
+ return x + res
+
+
+# --------------------------------------------
+# simplified information multi-distillation block (IMDB)
+# x + conv1(concat(split(relu(conv(x)))x3))
+# --------------------------------------------
+class IMDBlock(nn.Module):
+ """
+ @inproceedings{hui2019lightweight,
+ title={Lightweight Image Super-Resolution with Information Multi-distillation Network},
+ author={Hui, Zheng and Gao, Xinbo and Yang, Yunchu and Wang, Xiumei},
+ booktitle={Proceedings of the 27th ACM International Conference on Multimedia (ACM MM)},
+ pages={2024--2032},
+ year={2019}
+ }
+ @inproceedings{zhang2019aim,
+ title={AIM 2019 Challenge on Constrained Super-Resolution: Methods and Results},
+ author={Kai Zhang and Shuhang Gu and Radu Timofte and others},
+ booktitle={IEEE International Conference on Computer Vision Workshops},
+ year={2019}
+ }
+ """
+ def __init__(self, in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=True, mode='CL', d_rate=0.25, negative_slope=0.05):
+ super(IMDBlock, self).__init__()
+ self.d_nc = int(in_channels * d_rate)
+ self.r_nc = int(in_channels - self.d_nc)
+
+ assert mode[0] == 'C', 'convolutional layer first'
+
+ self.conv1 = conv(in_channels, in_channels, kernel_size, stride, padding, bias, mode, negative_slope)
+ self.conv2 = conv(self.r_nc, in_channels, kernel_size, stride, padding, bias, mode, negative_slope)
+ self.conv3 = conv(self.r_nc, in_channels, kernel_size, stride, padding, bias, mode, negative_slope)
+ self.conv4 = conv(self.r_nc, self.d_nc, kernel_size, stride, padding, bias, mode[0], negative_slope)
+ self.conv1x1 = conv(self.d_nc*4, out_channels, kernel_size=1, stride=1, padding=0, bias=bias, mode=mode[0], negative_slope=negative_slope)
+
+ def forward(self, x):
+ d1, r1 = torch.split(self.conv1(x), (self.d_nc, self.r_nc), dim=1)
+ d2, r2 = torch.split(self.conv2(r1), (self.d_nc, self.r_nc), dim=1)
+ d3, r3 = torch.split(self.conv3(r2), (self.d_nc, self.r_nc), dim=1)
+ d4 = self.conv4(r3)
+ res = self.conv1x1(torch.cat((d1, d2, d3, d4), dim=1))
+ return x + res
+
+
+# --------------------------------------------
+# Enhanced Spatial Attention (ESA)
+# --------------------------------------------
+class ESA(nn.Module):
+ def __init__(self, channel=64, reduction=4, bias=True):
+ super(ESA, self).__init__()
+ # -->conv3x3(conv21)-----------------------------------------------------------------------------------------+
+ # conv1x1(conv1)-->conv3x3-2(conv2)-->maxpool7-3-->conv3x3(conv3)(relu)-->conv3x3(conv4)(relu)-->conv3x3(conv5)-->bilinear--->conv1x1(conv6)-->sigmoid
+ self.r_nc = channel // reduction
+ self.conv1 = nn.Conv2d(channel, self.r_nc, kernel_size=1)
+ self.conv21 = nn.Conv2d(self.r_nc, self.r_nc, kernel_size=1)
+ self.conv2 = nn.Conv2d(self.r_nc, self.r_nc, kernel_size=3, stride=2, padding=0)
+ self.conv3 = nn.Conv2d(self.r_nc, self.r_nc, kernel_size=3, padding=1)
+ self.conv4 = nn.Conv2d(self.r_nc, self.r_nc, kernel_size=3, padding=1)
+ self.conv5 = nn.Conv2d(self.r_nc, self.r_nc, kernel_size=3, padding=1)
+ self.conv6 = nn.Conv2d(self.r_nc, channel, kernel_size=1)
+ self.sigmoid = nn.Sigmoid()
+ self.relu = nn.ReLU(inplace=True)
+
+ def forward(self, x):
+ x1 = self.conv1(x)
+ x2 = F.max_pool2d(self.conv2(x1), kernel_size=7, stride=3) # 1/6
+ x2 = self.relu(self.conv3(x2))
+ x2 = self.relu(self.conv4(x2))
+ x2 = F.interpolate(self.conv5(x2), (x.size(2), x.size(3)), mode='bilinear', align_corners=False)
+ x2 = self.conv6(x2 + self.conv21(x1))
+ return x.mul(self.sigmoid(x2))
+ # return x.mul_(self.sigmoid(x2))
+
+
+class CFRB(nn.Module):
+ def __init__(self, in_channels=50, out_channels=50, kernel_size=3, stride=1, padding=1, bias=True, mode='CL', d_rate=0.5, negative_slope=0.05):
+ super(CFRB, self).__init__()
+ self.d_nc = int(in_channels * d_rate)
+ self.r_nc = in_channels # int(in_channels - self.d_nc)
+
+ assert mode[0] == 'C', 'convolutional layer first'
+
+ self.conv1_d = conv(in_channels, self.d_nc, kernel_size=1, stride=1, padding=0, bias=bias, mode=mode[0])
+ self.conv1_r = conv(in_channels, self.r_nc, kernel_size, stride, padding, bias=bias, mode=mode[0])
+ self.conv2_d = conv(self.r_nc, self.d_nc, kernel_size=1, stride=1, padding=0, bias=bias, mode=mode[0])
+ self.conv2_r = conv(self.r_nc, self.r_nc, kernel_size, stride, padding, bias=bias, mode=mode[0])
+ self.conv3_d = conv(self.r_nc, self.d_nc, kernel_size=1, stride=1, padding=0, bias=bias, mode=mode[0])
+ self.conv3_r = conv(self.r_nc, self.r_nc, kernel_size, stride, padding, bias=bias, mode=mode[0])
+ self.conv4_d = conv(self.r_nc, self.d_nc, kernel_size, stride, padding, bias=bias, mode=mode[0])
+ self.conv1x1 = conv(self.d_nc*4, out_channels, kernel_size=1, stride=1, padding=0, bias=bias, mode=mode[0])
+ self.act = conv(mode=mode[-1], negative_slope=negative_slope)
+ self.esa = ESA(in_channels, reduction=4, bias=True)
+
+ def forward(self, x):
+ d1 = self.conv1_d(x)
+ x = self.act(self.conv1_r(x)+x)
+ d2 = self.conv2_d(x)
+ x = self.act(self.conv2_r(x)+x)
+ d3 = self.conv3_d(x)
+ x = self.act(self.conv3_r(x)+x)
+ x = self.conv4_d(x)
+ x = self.act(torch.cat([d1, d2, d3, x], dim=1))
+ x = self.esa(self.conv1x1(x))
+ return x
+
+
+# --------------------------------------------
+# Channel Attention (CA) Layer
+# --------------------------------------------
+class CALayer(nn.Module):
+ def __init__(self, channel=64, reduction=16):
+ super(CALayer, self).__init__()
+
+ self.avg_pool = nn.AdaptiveAvgPool2d(1)
+ self.conv_fc = nn.Sequential(
+ nn.Conv2d(channel, channel // reduction, 1, padding=0, bias=True),
+ nn.ReLU(inplace=True),
+ nn.Conv2d(channel // reduction, channel, 1, padding=0, bias=True),
+ nn.Sigmoid()
+ )
+
+ def forward(self, x):
+ y = self.avg_pool(x)
+ y = self.conv_fc(y)
+ return x * y
+
+
+# --------------------------------------------
+# Residual Channel Attention Block (RCAB)
+# --------------------------------------------
+class RCABlock(nn.Module):
+ def __init__(self, in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=True, mode='CRC', reduction=16, negative_slope=0.2):
+ super(RCABlock, self).__init__()
+ assert in_channels == out_channels, 'Only support in_channels==out_channels.'
+ if mode[0] in ['R','L']:
+ mode = mode[0].lower() + mode[1:]
+
+ self.res = conv(in_channels, out_channels, kernel_size, stride, padding, bias, mode, negative_slope)
+ self.ca = CALayer(out_channels, reduction)
+
+ def forward(self, x):
+ res = self.res(x)
+ res = self.ca(res)
+ return res + x
+
+
+# --------------------------------------------
+# Residual Channel Attention Group (RG)
+# --------------------------------------------
+class RCAGroup(nn.Module):
+ def __init__(self, in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=True, mode='CRC', reduction=16, nb=12, negative_slope=0.2):
+ super(RCAGroup, self).__init__()
+ assert in_channels == out_channels, 'Only support in_channels==out_channels.'
+ if mode[0] in ['R','L']:
+ mode = mode[0].lower() + mode[1:]
+
+ RG = [RCABlock(in_channels, out_channels, kernel_size, stride, padding, bias, mode, reduction, negative_slope) for _ in range(nb)]
+ RG.append(conv(out_channels, out_channels, mode='C'))
+ self.rg = nn.Sequential(*RG) # self.rg = ShortcutBlock(nn.Sequential(*RG))
+
+ def forward(self, x):
+ res = self.rg(x)
+ return res + x
+
+
+# --------------------------------------------
+# Residual Dense Block
+# style: 5 convs
+# --------------------------------------------
+class ResidualDenseBlock_5C(nn.Module):
+ def __init__(self, nc=64, gc=32, kernel_size=3, stride=1, padding=1, bias=True, mode='CR', negative_slope=0.2):
+ super(ResidualDenseBlock_5C, self).__init__()
+ # gc: growth channel
+ self.conv1 = conv(nc, gc, kernel_size, stride, padding, bias, mode, negative_slope)
+ self.conv2 = conv(nc+gc, gc, kernel_size, stride, padding, bias, mode, negative_slope)
+ self.conv3 = conv(nc+2*gc, gc, kernel_size, stride, padding, bias, mode, negative_slope)
+ self.conv4 = conv(nc+3*gc, gc, kernel_size, stride, padding, bias, mode, negative_slope)
+ self.conv5 = conv(nc+4*gc, nc, kernel_size, stride, padding, bias, mode[:-1], negative_slope)
+
+ def forward(self, x):
+ x1 = self.conv1(x)
+ x2 = self.conv2(torch.cat((x, x1), 1))
+ x3 = self.conv3(torch.cat((x, x1, x2), 1))
+ x4 = self.conv4(torch.cat((x, x1, x2, x3), 1))
+ x5 = self.conv5(torch.cat((x, x1, x2, x3, x4), 1))
+ return x5.mul_(0.2) + x
+
+
+# --------------------------------------------
+# Residual in Residual Dense Block
+# 3x5c
+# --------------------------------------------
+class RRDB(nn.Module):
+ def __init__(self, nc=64, gc=32, kernel_size=3, stride=1, padding=1, bias=True, mode='CR', negative_slope=0.2):
+ super(RRDB, self).__init__()
+
+ self.RDB1 = ResidualDenseBlock_5C(nc, gc, kernel_size, stride, padding, bias, mode, negative_slope)
+ self.RDB2 = ResidualDenseBlock_5C(nc, gc, kernel_size, stride, padding, bias, mode, negative_slope)
+ self.RDB3 = ResidualDenseBlock_5C(nc, gc, kernel_size, stride, padding, bias, mode, negative_slope)
+
+ def forward(self, x):
+ out = self.RDB1(x)
+ out = self.RDB2(out)
+ out = self.RDB3(out)
+ return out.mul_(0.2) + x
+
+
+"""
+# --------------------------------------------
+# Upsampler
+# Kai Zhang, https://github.com/cszn/KAIR
+# --------------------------------------------
+# upsample_pixelshuffle
+# upsample_upconv
+# upsample_convtranspose
+# --------------------------------------------
+"""
+
+
+# --------------------------------------------
+# conv + subp (+ relu)
+# --------------------------------------------
+def upsample_pixelshuffle(in_channels=64, out_channels=3, kernel_size=3, stride=1, padding=1, bias=True, mode='2R', negative_slope=0.2):
+ assert len(mode)<4 and mode[0] in ['2', '3', '4'], 'mode examples: 2, 2R, 2BR, 3, ..., 4BR.'
+ up1 = conv(in_channels, out_channels * (int(mode[0]) ** 2), kernel_size, stride, padding, bias, mode='C'+mode, negative_slope=negative_slope)
+ return up1
+
+
+# --------------------------------------------
+# nearest_upsample + conv (+ R)
+# --------------------------------------------
+def upsample_upconv(in_channels=64, out_channels=3, kernel_size=3, stride=1, padding=1, bias=True, mode='2R', negative_slope=0.2):
+ assert len(mode)<4 and mode[0] in ['2', '3', '4'], 'mode examples: 2, 2R, 2BR, 3, ..., 4BR'
+ if mode[0] == '2':
+ uc = 'UC'
+ elif mode[0] == '3':
+ uc = 'uC'
+ elif mode[0] == '4':
+ uc = 'vC'
+ mode = mode.replace(mode[0], uc)
+ up1 = conv(in_channels, out_channels, kernel_size, stride, padding, bias, mode=mode, negative_slope=negative_slope)
+ return up1
+
+
+# --------------------------------------------
+# convTranspose (+ relu)
+# --------------------------------------------
+def upsample_convtranspose(in_channels=64, out_channels=3, kernel_size=2, stride=2, padding=0, bias=True, mode='2R', negative_slope=0.2):
+ assert len(mode)<4 and mode[0] in ['2', '3', '4'], 'mode examples: 2, 2R, 2BR, 3, ..., 4BR.'
+ kernel_size = int(mode[0])
+ stride = int(mode[0])
+ mode = mode.replace(mode[0], 'T')
+ up1 = conv(in_channels, out_channels, kernel_size, stride, padding, bias, mode, negative_slope)
+ return up1
+
+
+'''
+# --------------------------------------------
+# Downsampler
+# Kai Zhang, https://github.com/cszn/KAIR
+# --------------------------------------------
+# downsample_strideconv
+# downsample_maxpool
+# downsample_avgpool
+# --------------------------------------------
+'''
+
+
+# --------------------------------------------
+# strideconv (+ relu)
+# --------------------------------------------
+def downsample_strideconv(in_channels=64, out_channels=64, kernel_size=2, stride=2, padding=0, bias=True, mode='2R', negative_slope=0.2):
+ assert len(mode)<4 and mode[0] in ['2', '3', '4'], 'mode examples: 2, 2R, 2BR, 3, ..., 4BR.'
+ kernel_size = int(mode[0])
+ stride = int(mode[0])
+ mode = mode.replace(mode[0], 'C')
+ down1 = conv(in_channels, out_channels, kernel_size, stride, padding, bias, mode, negative_slope)
+ return down1
+
+
+# --------------------------------------------
+# maxpooling + conv (+ relu)
+# --------------------------------------------
+def downsample_maxpool(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=0, bias=True, mode='2R', negative_slope=0.2):
+ assert len(mode)<4 and mode[0] in ['2', '3'], 'mode examples: 2, 2R, 2BR, 3, ..., 3BR.'
+ kernel_size_pool = int(mode[0])
+ stride_pool = int(mode[0])
+ mode = mode.replace(mode[0], 'MC')
+ pool = conv(kernel_size=kernel_size_pool, stride=stride_pool, mode=mode[0], negative_slope=negative_slope)
+ pool_tail = conv(in_channels, out_channels, kernel_size, stride, padding, bias, mode=mode[1:], negative_slope=negative_slope)
+ return sequential(pool, pool_tail)
+
+
+# --------------------------------------------
+# averagepooling + conv (+ relu)
+# --------------------------------------------
+def downsample_avgpool(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=True, mode='2R', negative_slope=0.2):
+ assert len(mode)<4 and mode[0] in ['2', '3'], 'mode examples: 2, 2R, 2BR, 3, ..., 3BR.'
+ kernel_size_pool = int(mode[0])
+ stride_pool = int(mode[0])
+ mode = mode.replace(mode[0], 'AC')
+ pool = conv(kernel_size=kernel_size_pool, stride=stride_pool, mode=mode[0], negative_slope=negative_slope)
+ pool_tail = conv(in_channels, out_channels, kernel_size, stride, padding, bias, mode=mode[1:], negative_slope=negative_slope)
+ return sequential(pool, pool_tail)
+
+
+'''
+# --------------------------------------------
+# NonLocalBlock2D:
+# embedded_gaussian
+# +W(softmax(thetaXphi)Xg)
+# --------------------------------------------
+'''
+
+
+# --------------------------------------------
+# non-local block with embedded_gaussian
+# https://github.com/AlexHex7/Non-local_pytorch
+# --------------------------------------------
+class NonLocalBlock2D(nn.Module):
+ def __init__(self, nc=64, kernel_size=1, stride=1, padding=0, bias=True, act_mode='B', downsample=False, downsample_mode='maxpool', negative_slope=0.2):
+
+ super(NonLocalBlock2D, self).__init__()
+
+ inter_nc = nc // 2
+ self.inter_nc = inter_nc
+ self.W = conv(inter_nc, nc, kernel_size, stride, padding, bias, mode='C'+act_mode)
+ self.theta = conv(nc, inter_nc, kernel_size, stride, padding, bias, mode='C')
+
+ if downsample:
+ if downsample_mode == 'avgpool':
+ downsample_block = downsample_avgpool
+ elif downsample_mode == 'maxpool':
+ downsample_block = downsample_maxpool
+ elif downsample_mode == 'strideconv':
+ downsample_block = downsample_strideconv
+ else:
+ raise NotImplementedError('downsample mode [{:s}] is not found'.format(downsample_mode))
+ self.phi = downsample_block(nc, inter_nc, kernel_size, stride, padding, bias, mode='2')
+ self.g = downsample_block(nc, inter_nc, kernel_size, stride, padding, bias, mode='2')
+ else:
+ self.phi = conv(nc, inter_nc, kernel_size, stride, padding, bias, mode='C')
+ self.g = conv(nc, inter_nc, kernel_size, stride, padding, bias, mode='C')
+
+ def forward(self, x):
+ '''
+ :param x: (b, c, t, h, w)
+ :return:
+ '''
+
+ batch_size = x.size(0)
+
+ g_x = self.g(x).view(batch_size, self.inter_nc, -1)
+ g_x = g_x.permute(0, 2, 1)
+
+ theta_x = self.theta(x).view(batch_size, self.inter_nc, -1)
+ theta_x = theta_x.permute(0, 2, 1)
+ phi_x = self.phi(x).view(batch_size, self.inter_nc, -1)
+ f = torch.matmul(theta_x, phi_x)
+ f_div_C = F.softmax(f, dim=-1)
+
+ y = torch.matmul(f_div_C, g_x)
+ y = y.permute(0, 2, 1).contiguous()
+ y = y.view(batch_size, self.inter_nc, *x.size()[2:])
+ W_y = self.W(y)
+ z = W_y + x
+
+ return z
diff --git a/KAIR/models/einstein.png b/KAIR/models/einstein.png
new file mode 100644
index 0000000000000000000000000000000000000000..da4ca098b6655f7e8106e2e28bfda00de40dcdcf
Binary files /dev/null and b/KAIR/models/einstein.png differ
diff --git a/KAIR/models/loss.py b/KAIR/models/loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..0a01d7d719f66f0947739caf223cad7ea0dbefca
--- /dev/null
+++ b/KAIR/models/loss.py
@@ -0,0 +1,287 @@
+import torch
+import torch.nn as nn
+import torchvision
+from torch.nn import functional as F
+from torch import autograd as autograd
+
+
+"""
+Sequential(
+ (0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (1): ReLU(inplace)
+ (2*): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (3): ReLU(inplace)
+ (4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
+ (5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (6): ReLU(inplace)
+ (7*): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (8): ReLU(inplace)
+ (9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
+ (10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (11): ReLU(inplace)
+ (12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (13): ReLU(inplace)
+ (14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (15): ReLU(inplace)
+ (16*): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (17): ReLU(inplace)
+ (18): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
+ (19): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (20): ReLU(inplace)
+ (21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (22): ReLU(inplace)
+ (23): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (24): ReLU(inplace)
+ (25*): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (26): ReLU(inplace)
+ (27): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
+ (28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (29): ReLU(inplace)
+ (30): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (31): ReLU(inplace)
+ (32): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (33): ReLU(inplace)
+ (34*): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+ (35): ReLU(inplace)
+ (36): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
+)
+"""
+
+
+# --------------------------------------------
+# Perceptual loss
+# --------------------------------------------
+class VGGFeatureExtractor(nn.Module):
+ def __init__(self, feature_layer=[2,7,16,25,34], use_input_norm=True, use_range_norm=False):
+ super(VGGFeatureExtractor, self).__init__()
+ '''
+ use_input_norm: If True, x: [0, 1] --> (x - mean) / std
+ use_range_norm: If True, x: [0, 1] --> x: [-1, 1]
+ '''
+ model = torchvision.models.vgg19(pretrained=True)
+ self.use_input_norm = use_input_norm
+ self.use_range_norm = use_range_norm
+ if self.use_input_norm:
+ mean = torch.Tensor([0.485, 0.456, 0.406]).view(1, 3, 1, 1)
+ std = torch.Tensor([0.229, 0.224, 0.225]).view(1, 3, 1, 1)
+ self.register_buffer('mean', mean)
+ self.register_buffer('std', std)
+ self.list_outputs = isinstance(feature_layer, list)
+ if self.list_outputs:
+ self.features = nn.Sequential()
+ feature_layer = [-1] + feature_layer
+ for i in range(len(feature_layer)-1):
+ self.features.add_module('child'+str(i), nn.Sequential(*list(model.features.children())[(feature_layer[i]+1):(feature_layer[i+1]+1)]))
+ else:
+ self.features = nn.Sequential(*list(model.features.children())[:(feature_layer + 1)])
+
+ print(self.features)
+
+ # No need to BP to variable
+ for k, v in self.features.named_parameters():
+ v.requires_grad = False
+
+ def forward(self, x):
+ if self.use_range_norm:
+ x = (x + 1.0) / 2.0
+ if self.use_input_norm:
+ x = (x - self.mean) / self.std
+ if self.list_outputs:
+ output = []
+ for child_model in self.features.children():
+ x = child_model(x)
+ output.append(x.clone())
+ return output
+ else:
+ return self.features(x)
+
+
+class PerceptualLoss(nn.Module):
+ """VGG Perceptual loss
+ """
+
+ def __init__(self, feature_layer=[2,7,16,25,34], weights=[0.1,0.1,1.0,1.0,1.0], lossfn_type='l1', use_input_norm=True, use_range_norm=False):
+ super(PerceptualLoss, self).__init__()
+ self.vgg = VGGFeatureExtractor(feature_layer=feature_layer, use_input_norm=use_input_norm, use_range_norm=use_range_norm)
+ self.lossfn_type = lossfn_type
+ self.weights = weights
+ if self.lossfn_type == 'l1':
+ self.lossfn = nn.L1Loss()
+ else:
+ self.lossfn = nn.MSELoss()
+ print(f'feature_layer: {feature_layer} with weights: {weights}')
+
+ def forward(self, x, gt):
+ """Forward function.
+ Args:
+ x (Tensor): Input tensor with shape (n, c, h, w).
+ gt (Tensor): Ground-truth tensor with shape (n, c, h, w).
+ Returns:
+ Tensor: Forward results.
+ """
+ x_vgg, gt_vgg = self.vgg(x), self.vgg(gt.detach())
+ loss = 0.0
+ if isinstance(x_vgg, list):
+ n = len(x_vgg)
+ for i in range(n):
+ loss += self.weights[i] * self.lossfn(x_vgg[i], gt_vgg[i])
+ else:
+ loss += self.lossfn(x_vgg, gt_vgg.detach())
+ return loss
+
+# --------------------------------------------
+# GAN loss: gan, ragan
+# --------------------------------------------
+class GANLoss(nn.Module):
+ def __init__(self, gan_type, real_label_val=1.0, fake_label_val=0.0):
+ super(GANLoss, self).__init__()
+ self.gan_type = gan_type.lower()
+ self.real_label_val = real_label_val
+ self.fake_label_val = fake_label_val
+
+ if self.gan_type == 'gan' or self.gan_type == 'ragan':
+ self.loss = nn.BCEWithLogitsLoss()
+ elif self.gan_type == 'lsgan':
+ self.loss = nn.MSELoss()
+ elif self.gan_type == 'wgan':
+ def wgan_loss(input, target):
+ # target is boolean
+ return -1 * input.mean() if target else input.mean()
+
+ self.loss = wgan_loss
+ elif self.gan_type == 'softplusgan':
+ def softplusgan_loss(input, target):
+ # target is boolean
+ return F.softplus(-input).mean() if target else F.softplus(input).mean()
+
+ self.loss = softplusgan_loss
+ else:
+ raise NotImplementedError('GAN type [{:s}] is not found'.format(self.gan_type))
+
+ def get_target_label(self, input, target_is_real):
+ if self.gan_type in ['wgan', 'softplusgan']:
+ return target_is_real
+ if target_is_real:
+ return torch.empty_like(input).fill_(self.real_label_val)
+ else:
+ return torch.empty_like(input).fill_(self.fake_label_val)
+
+ def forward(self, input, target_is_real):
+ target_label = self.get_target_label(input, target_is_real)
+ loss = self.loss(input, target_label)
+ return loss
+
+
+# --------------------------------------------
+# TV loss
+# --------------------------------------------
+class TVLoss(nn.Module):
+ def __init__(self, tv_loss_weight=1):
+ """
+ Total variation loss
+ https://github.com/jxgu1016/Total_Variation_Loss.pytorch
+ Args:
+ tv_loss_weight (int):
+ """
+ super(TVLoss, self).__init__()
+ self.tv_loss_weight = tv_loss_weight
+
+ def forward(self, x):
+ batch_size = x.size()[0]
+ h_x = x.size()[2]
+ w_x = x.size()[3]
+ count_h = self.tensor_size(x[:, :, 1:, :])
+ count_w = self.tensor_size(x[:, :, :, 1:])
+ h_tv = torch.pow((x[:, :, 1:, :] - x[:, :, :h_x - 1, :]), 2).sum()
+ w_tv = torch.pow((x[:, :, :, 1:] - x[:, :, :, :w_x - 1]), 2).sum()
+ return self.tv_loss_weight * 2 * (h_tv / count_h + w_tv / count_w) / batch_size
+
+ @staticmethod
+ def tensor_size(t):
+ return t.size()[1] * t.size()[2] * t.size()[3]
+
+
+# --------------------------------------------
+# Charbonnier loss
+# --------------------------------------------
+class CharbonnierLoss(nn.Module):
+ """Charbonnier Loss (L1)"""
+
+ def __init__(self, eps=1e-9):
+ super(CharbonnierLoss, self).__init__()
+ self.eps = eps
+
+ def forward(self, x, y):
+ diff = x - y
+ loss = torch.mean(torch.sqrt((diff * diff) + self.eps))
+ return loss
+
+
+
+def r1_penalty(real_pred, real_img):
+ """R1 regularization for discriminator. The core idea is to
+ penalize the gradient on real data alone: when the
+ generator distribution produces the true data distribution
+ and the discriminator is equal to 0 on the data manifold, the
+ gradient penalty ensures that the discriminator cannot create
+ a non-zero gradient orthogonal to the data manifold without
+ suffering a loss in the GAN game.
+ Ref:
+ Eq. 9 in Which training methods for GANs do actually converge.
+ """
+ grad_real = autograd.grad(
+ outputs=real_pred.sum(), inputs=real_img, create_graph=True)[0]
+ grad_penalty = grad_real.pow(2).view(grad_real.shape[0], -1).sum(1).mean()
+ return grad_penalty
+
+
+def g_path_regularize(fake_img, latents, mean_path_length, decay=0.01):
+ noise = torch.randn_like(fake_img) / math.sqrt(
+ fake_img.shape[2] * fake_img.shape[3])
+ grad = autograd.grad(
+ outputs=(fake_img * noise).sum(), inputs=latents, create_graph=True)[0]
+ path_lengths = torch.sqrt(grad.pow(2).sum(2).mean(1))
+
+ path_mean = mean_path_length + decay * (
+ path_lengths.mean() - mean_path_length)
+
+ path_penalty = (path_lengths - path_mean).pow(2).mean()
+
+ return path_penalty, path_lengths.detach().mean(), path_mean.detach()
+
+
+def gradient_penalty_loss(discriminator, real_data, fake_data, weight=None):
+ """Calculate gradient penalty for wgan-gp.
+ Args:
+ discriminator (nn.Module): Network for the discriminator.
+ real_data (Tensor): Real input data.
+ fake_data (Tensor): Fake input data.
+ weight (Tensor): Weight tensor. Default: None.
+ Returns:
+ Tensor: A tensor for gradient penalty.
+ """
+
+ batch_size = real_data.size(0)
+ alpha = real_data.new_tensor(torch.rand(batch_size, 1, 1, 1))
+
+ # interpolate between real_data and fake_data
+ interpolates = alpha * real_data + (1. - alpha) * fake_data
+ interpolates = autograd.Variable(interpolates, requires_grad=True)
+
+ disc_interpolates = discriminator(interpolates)
+ gradients = autograd.grad(
+ outputs=disc_interpolates,
+ inputs=interpolates,
+ grad_outputs=torch.ones_like(disc_interpolates),
+ create_graph=True,
+ retain_graph=True,
+ only_inputs=True)[0]
+
+ if weight is not None:
+ gradients = gradients * weight
+
+ gradients_penalty = ((gradients.norm(2, dim=1) - 1)**2).mean()
+ if weight is not None:
+ gradients_penalty /= torch.mean(weight)
+
+ return gradients_penalty
diff --git a/KAIR/models/loss_ssim.py b/KAIR/models/loss_ssim.py
new file mode 100644
index 0000000000000000000000000000000000000000..1120b5b99800129764b14a40138429f8077dc34f
--- /dev/null
+++ b/KAIR/models/loss_ssim.py
@@ -0,0 +1,115 @@
+import torch
+import torch.nn.functional as F
+from torch.autograd import Variable
+import numpy as np
+from math import exp
+
+"""
+# ============================================
+# SSIM loss
+# https://github.com/Po-Hsun-Su/pytorch-ssim
+# ============================================
+"""
+
+
+def gaussian(window_size, sigma):
+ gauss = torch.Tensor([exp(-(x - window_size//2)**2/float(2*sigma**2)) for x in range(window_size)])
+ return gauss/gauss.sum()
+
+
+def create_window(window_size, channel):
+ _1D_window = gaussian(window_size, 1.5).unsqueeze(1)
+ _2D_window = _1D_window.mm(_1D_window.t()).float().unsqueeze(0).unsqueeze(0)
+ window = Variable(_2D_window.expand(channel, 1, window_size, window_size).contiguous())
+ return window
+
+
+def _ssim(img1, img2, window, window_size, channel, size_average=True):
+ mu1 = F.conv2d(img1, window, padding=window_size//2, groups=channel)
+ mu2 = F.conv2d(img2, window, padding=window_size//2, groups=channel)
+
+ mu1_sq = mu1.pow(2)
+ mu2_sq = mu2.pow(2)
+ mu1_mu2 = mu1*mu2
+
+ sigma1_sq = F.conv2d(img1*img1, window, padding=window_size//2, groups=channel) - mu1_sq
+ sigma2_sq = F.conv2d(img2*img2, window, padding=window_size//2, groups=channel) - mu2_sq
+ sigma12 = F.conv2d(img1*img2, window, padding=window_size//2, groups=channel) - mu1_mu2
+
+ C1 = 0.01**2
+ C2 = 0.03**2
+
+ ssim_map = ((2*mu1_mu2 + C1)*(2*sigma12 + C2))/((mu1_sq + mu2_sq + C1)*(sigma1_sq + sigma2_sq + C2))
+ if size_average:
+ return ssim_map.mean()
+ else:
+ return ssim_map.mean(1).mean(1).mean(1)
+
+
+class SSIMLoss(torch.nn.Module):
+ def __init__(self, window_size=11, size_average=True):
+ super(SSIMLoss, self).__init__()
+ self.window_size = window_size
+ self.size_average = size_average
+ self.channel = 1
+ self.window = create_window(window_size, self.channel)
+
+ def forward(self, img1, img2):
+ (_, channel, _, _) = img1.size()
+ if channel == self.channel and self.window.data.type() == img1.data.type():
+ window = self.window
+ else:
+ window = create_window(self.window_size, channel)
+
+ if img1.is_cuda:
+ window = window.cuda(img1.get_device())
+ window = window.type_as(img1)
+
+ self.window = window
+ self.channel = channel
+
+ return _ssim(img1, img2, window, self.window_size, channel, self.size_average)
+
+
+def ssim(img1, img2, window_size=11, size_average=True):
+ (_, channel, _, _) = img1.size()
+ window = create_window(window_size, channel)
+
+ if img1.is_cuda:
+ window = window.cuda(img1.get_device())
+ window = window.type_as(img1)
+
+ return _ssim(img1, img2, window, window_size, channel, size_average)
+
+
+if __name__ == '__main__':
+ import cv2
+ from torch import optim
+ from skimage import io
+ npImg1 = cv2.imread("einstein.png")
+
+ img1 = torch.from_numpy(np.rollaxis(npImg1, 2)).float().unsqueeze(0)/255.0
+ img2 = torch.rand(img1.size())
+
+ if torch.cuda.is_available():
+ img1 = img1.cuda()
+ img2 = img2.cuda()
+
+ img1 = Variable(img1, requires_grad=False)
+ img2 = Variable(img2, requires_grad=True)
+
+ ssim_value = ssim(img1, img2).item()
+ print("Initial ssim:", ssim_value)
+
+ ssim_loss = SSIMLoss()
+ optimizer = optim.Adam([img2], lr=0.01)
+
+ while ssim_value < 0.99:
+ optimizer.zero_grad()
+ ssim_out = -ssim_loss(img1, img2)
+ ssim_value = -ssim_out.item()
+ print('{:<4.4f}'.format(ssim_value))
+ ssim_out.backward()
+ optimizer.step()
+ img = np.transpose(img2.detach().cpu().squeeze().float().numpy(), (1,2,0))
+ io.imshow(np.uint8(np.clip(img*255, 0, 255)))
diff --git a/KAIR/models/model_base.py b/KAIR/models/model_base.py
new file mode 100644
index 0000000000000000000000000000000000000000..0ae3bce9453fa21b8ce0e037b437ba738b67f76b
--- /dev/null
+++ b/KAIR/models/model_base.py
@@ -0,0 +1,220 @@
+import os
+import torch
+import torch.nn as nn
+from utils.utils_bnorm import merge_bn, tidy_sequential
+from torch.nn.parallel import DataParallel, DistributedDataParallel
+
+
+class ModelBase():
+ def __init__(self, opt):
+ self.opt = opt # opt
+ self.save_dir = opt['path']['models'] # save models
+ self.device = torch.device('cuda' if opt['gpu_ids'] is not None else 'cpu')
+ self.is_train = opt['is_train'] # training or not
+ self.schedulers = [] # schedulers
+
+ """
+ # ----------------------------------------
+ # Preparation before training with data
+ # Save model during training
+ # ----------------------------------------
+ """
+
+ def init_train(self):
+ pass
+
+ def load(self):
+ pass
+
+ def save(self, label):
+ pass
+
+ def define_loss(self):
+ pass
+
+ def define_optimizer(self):
+ pass
+
+ def define_scheduler(self):
+ pass
+
+ """
+ # ----------------------------------------
+ # Optimization during training with data
+ # Testing/evaluation
+ # ----------------------------------------
+ """
+
+ def feed_data(self, data):
+ pass
+
+ def optimize_parameters(self):
+ pass
+
+ def current_visuals(self):
+ pass
+
+ def current_losses(self):
+ pass
+
+ def update_learning_rate(self, n):
+ for scheduler in self.schedulers:
+ scheduler.step(n)
+
+ def current_learning_rate(self):
+ return self.schedulers[0].get_lr()[0]
+
+ def requires_grad(self, model, flag=True):
+ for p in model.parameters():
+ p.requires_grad = flag
+
+ """
+ # ----------------------------------------
+ # Information of net
+ # ----------------------------------------
+ """
+
+ def print_network(self):
+ pass
+
+ def info_network(self):
+ pass
+
+ def print_params(self):
+ pass
+
+ def info_params(self):
+ pass
+
+ def get_bare_model(self, network):
+ """Get bare model, especially under wrapping with
+ DistributedDataParallel or DataParallel.
+ """
+ if isinstance(network, (DataParallel, DistributedDataParallel)):
+ network = network.module
+ return network
+
+ def model_to_device(self, network):
+ """Model to device. It also warps models with DistributedDataParallel
+ or DataParallel.
+ Args:
+ network (nn.Module)
+ """
+ network = network.to(self.device)
+ if self.opt['dist']:
+ find_unused_parameters = self.opt.get('find_unused_parameters', True)
+ use_static_graph = self.opt.get('use_static_graph', False)
+ network = DistributedDataParallel(network, device_ids=[torch.cuda.current_device()], find_unused_parameters=find_unused_parameters)
+ if use_static_graph:
+ print('Using static graph. Make sure that "unused parameters" will not change during training loop.')
+ network._set_static_graph()
+ else:
+ network = DataParallel(network)
+ return network
+
+ # ----------------------------------------
+ # network name and number of parameters
+ # ----------------------------------------
+ def describe_network(self, network):
+ network = self.get_bare_model(network)
+ msg = '\n'
+ msg += 'Networks name: {}'.format(network.__class__.__name__) + '\n'
+ msg += 'Params number: {}'.format(sum(map(lambda x: x.numel(), network.parameters()))) + '\n'
+ msg += 'Net structure:\n{}'.format(str(network)) + '\n'
+ return msg
+
+ # ----------------------------------------
+ # parameters description
+ # ----------------------------------------
+ def describe_params(self, network):
+ network = self.get_bare_model(network)
+ msg = '\n'
+ msg += ' | {:^6s} | {:^6s} | {:^6s} | {:^6s} || {:<20s}'.format('mean', 'min', 'max', 'std', 'shape', 'param_name') + '\n'
+ for name, param in network.state_dict().items():
+ if not 'num_batches_tracked' in name:
+ v = param.data.clone().float()
+ msg += ' | {:>6.3f} | {:>6.3f} | {:>6.3f} | {:>6.3f} | {} || {:s}'.format(v.mean(), v.min(), v.max(), v.std(), v.shape, name) + '\n'
+ return msg
+
+ """
+ # ----------------------------------------
+ # Save prameters
+ # Load prameters
+ # ----------------------------------------
+ """
+
+ # ----------------------------------------
+ # save the state_dict of the network
+ # ----------------------------------------
+ def save_network(self, save_dir, network, network_label, iter_label):
+ save_filename = '{}_{}.pth'.format(iter_label, network_label)
+ save_path = os.path.join(save_dir, save_filename)
+ network = self.get_bare_model(network)
+ state_dict = network.state_dict()
+ for key, param in state_dict.items():
+ state_dict[key] = param.cpu()
+ torch.save(state_dict, save_path)
+
+ # ----------------------------------------
+ # load the state_dict of the network
+ # ----------------------------------------
+ def load_network(self, load_path, network, strict=True, param_key='params'):
+ network = self.get_bare_model(network)
+ if strict:
+ state_dict = torch.load(load_path)
+ if param_key in state_dict.keys():
+ state_dict = state_dict[param_key]
+ network.load_state_dict(state_dict, strict=strict)
+ else:
+ state_dict_old = torch.load(load_path)
+ if param_key in state_dict_old.keys():
+ state_dict_old = state_dict_old[param_key]
+ state_dict = network.state_dict()
+ for ((key_old, param_old),(key, param)) in zip(state_dict_old.items(), state_dict.items()):
+ state_dict[key] = param_old
+ network.load_state_dict(state_dict, strict=True)
+ del state_dict_old, state_dict
+
+ # ----------------------------------------
+ # save the state_dict of the optimizer
+ # ----------------------------------------
+ def save_optimizer(self, save_dir, optimizer, optimizer_label, iter_label):
+ save_filename = '{}_{}.pth'.format(iter_label, optimizer_label)
+ save_path = os.path.join(save_dir, save_filename)
+ torch.save(optimizer.state_dict(), save_path)
+
+ # ----------------------------------------
+ # load the state_dict of the optimizer
+ # ----------------------------------------
+ def load_optimizer(self, load_path, optimizer):
+ optimizer.load_state_dict(torch.load(load_path, map_location=lambda storage, loc: storage.cuda(torch.cuda.current_device())))
+
+ def update_E(self, decay=0.999):
+ netG = self.get_bare_model(self.netG)
+ netG_params = dict(netG.named_parameters())
+ netE_params = dict(self.netE.named_parameters())
+ for k in netG_params.keys():
+ netE_params[k].data.mul_(decay).add_(netG_params[k].data, alpha=1-decay)
+
+ """
+ # ----------------------------------------
+ # Merge Batch Normalization for training
+ # Merge Batch Normalization for testing
+ # ----------------------------------------
+ """
+
+ # ----------------------------------------
+ # merge bn during training
+ # ----------------------------------------
+ def merge_bnorm_train(self):
+ merge_bn(self.netG)
+ tidy_sequential(self.netG)
+ self.define_optimizer()
+ self.define_scheduler()
+
+ # ----------------------------------------
+ # merge bn before testing
+ # ----------------------------------------
+ def merge_bnorm_test(self):
+ merge_bn(self.netG)
+ tidy_sequential(self.netG)
diff --git a/KAIR/models/model_gan.py b/KAIR/models/model_gan.py
new file mode 100644
index 0000000000000000000000000000000000000000..1755d8dab0b36d601e5b9b99e3e524ef96aa7895
--- /dev/null
+++ b/KAIR/models/model_gan.py
@@ -0,0 +1,353 @@
+from collections import OrderedDict
+import torch
+import torch.nn as nn
+from torch.optim import lr_scheduler
+from torch.optim import Adam
+
+from models.select_network import define_G, define_D
+from models.model_base import ModelBase
+from models.loss import GANLoss, PerceptualLoss
+from models.loss_ssim import SSIMLoss
+
+
+class ModelGAN(ModelBase):
+ """Train with pixel-VGG-GAN loss"""
+ def __init__(self, opt):
+ super(ModelGAN, self).__init__(opt)
+ # ------------------------------------
+ # define network
+ # ------------------------------------
+ self.opt_train = self.opt['train'] # training option
+ self.netG = define_G(opt)
+ self.netG = self.model_to_device(self.netG)
+ if self.is_train:
+ self.netD = define_D(opt)
+ self.netD = self.model_to_device(self.netD)
+ if self.opt_train['E_decay'] > 0:
+ self.netE = define_G(opt).to(self.device).eval()
+
+ """
+ # ----------------------------------------
+ # Preparation before training with data
+ # Save model during training
+ # ----------------------------------------
+ """
+
+ # ----------------------------------------
+ # initialize training
+ # ----------------------------------------
+ def init_train(self):
+ self.load() # load model
+ self.netG.train() # set training mode,for BN
+ self.netD.train() # set training mode,for BN
+ self.define_loss() # define loss
+ self.define_optimizer() # define optimizer
+ self.load_optimizers() # load optimizer
+ self.define_scheduler() # define scheduler
+ self.log_dict = OrderedDict() # log
+
+ # ----------------------------------------
+ # load pre-trained G and D model
+ # ----------------------------------------
+ def load(self):
+ load_path_G = self.opt['path']['pretrained_netG']
+ if load_path_G is not None:
+ print('Loading model for G [{:s}] ...'.format(load_path_G))
+ self.load_network(load_path_G, self.netG, strict=self.opt_train['G_param_strict'])
+ load_path_E = self.opt['path']['pretrained_netE']
+ if self.opt_train['E_decay'] > 0:
+ if load_path_E is not None:
+ print('Loading model for E [{:s}] ...'.format(load_path_E))
+ self.load_network(load_path_E, self.netE, strict=self.opt_train['E_param_strict'])
+ else:
+ print('Copying model for E')
+ self.update_E(0)
+ self.netE.eval()
+
+ load_path_D = self.opt['path']['pretrained_netD']
+ if self.opt['is_train'] and load_path_D is not None:
+ print('Loading model for D [{:s}] ...'.format(load_path_D))
+ self.load_network(load_path_D, self.netD, strict=self.opt_train['D_param_strict'])
+
+ # ----------------------------------------
+ # load optimizerG and optimizerD
+ # ----------------------------------------
+ def load_optimizers(self):
+ load_path_optimizerG = self.opt['path']['pretrained_optimizerG']
+ if load_path_optimizerG is not None and self.opt_train['G_optimizer_reuse']:
+ print('Loading optimizerG [{:s}] ...'.format(load_path_optimizerG))
+ self.load_optimizer(load_path_optimizerG, self.G_optimizer)
+ load_path_optimizerD = self.opt['path']['pretrained_optimizerD']
+ if load_path_optimizerD is not None and self.opt_train['D_optimizer_reuse']:
+ print('Loading optimizerD [{:s}] ...'.format(load_path_optimizerD))
+ self.load_optimizer(load_path_optimizerD, self.D_optimizer)
+
+ # ----------------------------------------
+ # save model / optimizer(optional)
+ # ----------------------------------------
+ def save(self, iter_label):
+ self.save_network(self.save_dir, self.netG, 'G', iter_label)
+ self.save_network(self.save_dir, self.netD, 'D', iter_label)
+ if self.opt_train['E_decay'] > 0:
+ self.save_network(self.save_dir, self.netE, 'E', iter_label)
+ if self.opt_train['G_optimizer_reuse']:
+ self.save_optimizer(self.save_dir, self.G_optimizer, 'optimizerG', iter_label)
+ if self.opt_train['D_optimizer_reuse']:
+ self.save_optimizer(self.save_dir, self.D_optimizer, 'optimizerD', iter_label)
+
+ # ----------------------------------------
+ # define loss
+ # ----------------------------------------
+ def define_loss(self):
+ # ------------------------------------
+ # 1) G_loss
+ # ------------------------------------
+ if self.opt_train['G_lossfn_weight'] > 0:
+ G_lossfn_type = self.opt_train['G_lossfn_type']
+ if G_lossfn_type == 'l1':
+ self.G_lossfn = nn.L1Loss().to(self.device)
+ elif G_lossfn_type == 'l2':
+ self.G_lossfn = nn.MSELoss().to(self.device)
+ elif G_lossfn_type == 'l2sum':
+ self.G_lossfn = nn.MSELoss(reduction='sum').to(self.device)
+ elif G_lossfn_type == 'ssim':
+ self.G_lossfn = SSIMLoss().to(self.device)
+ else:
+ raise NotImplementedError('Loss type [{:s}] is not found.'.format(G_lossfn_type))
+ self.G_lossfn_weight = self.opt_train['G_lossfn_weight']
+ else:
+ print('Do not use pixel loss.')
+ self.G_lossfn = None
+
+ # ------------------------------------
+ # 2) F_loss
+ # ------------------------------------
+ if self.opt_train['F_lossfn_weight'] > 0:
+ F_feature_layer = self.opt_train['F_feature_layer']
+ F_weights = self.opt_train['F_weights']
+ F_lossfn_type = self.opt_train['F_lossfn_type']
+ F_use_input_norm = self.opt_train['F_use_input_norm']
+ F_use_range_norm = self.opt_train['F_use_range_norm']
+ if self.opt['dist']:
+ self.F_lossfn = PerceptualLoss(feature_layer=F_feature_layer, weights=F_weights, lossfn_type=F_lossfn_type, use_input_norm=F_use_input_norm, use_range_norm=F_use_range_norm).to(self.device)
+ else:
+ self.F_lossfn = PerceptualLoss(feature_layer=F_feature_layer, weights=F_weights, lossfn_type=F_lossfn_type, use_input_norm=F_use_input_norm, use_range_norm=F_use_range_norm)
+ self.F_lossfn.vgg = self.model_to_device(self.F_lossfn.vgg)
+ self.F_lossfn.lossfn = self.F_lossfn.lossfn.to(self.device)
+ self.F_lossfn_weight = self.opt_train['F_lossfn_weight']
+ else:
+ print('Do not use feature loss.')
+ self.F_lossfn = None
+
+ # ------------------------------------
+ # 3) D_loss
+ # ------------------------------------
+ self.D_lossfn = GANLoss(self.opt_train['gan_type'], 1.0, 0.0).to(self.device)
+ self.D_lossfn_weight = self.opt_train['D_lossfn_weight']
+
+ self.D_update_ratio = self.opt_train['D_update_ratio'] if self.opt_train['D_update_ratio'] else 1
+ self.D_init_iters = self.opt_train['D_init_iters'] if self.opt_train['D_init_iters'] else 0
+
+ # ----------------------------------------
+ # define optimizer, G and D
+ # ----------------------------------------
+ def define_optimizer(self):
+ G_optim_params = []
+ for k, v in self.netG.named_parameters():
+ if v.requires_grad:
+ G_optim_params.append(v)
+ else:
+ print('Params [{:s}] will not optimize.'.format(k))
+
+ self.G_optimizer = Adam(G_optim_params, lr=self.opt_train['G_optimizer_lr'], weight_decay=0)
+ self.D_optimizer = Adam(self.netD.parameters(), lr=self.opt_train['D_optimizer_lr'], weight_decay=0)
+
+ # ----------------------------------------
+ # define scheduler, only "MultiStepLR"
+ # ----------------------------------------
+ def define_scheduler(self):
+ self.schedulers.append(lr_scheduler.MultiStepLR(self.G_optimizer,
+ self.opt_train['G_scheduler_milestones'],
+ self.opt_train['G_scheduler_gamma']
+ ))
+ self.schedulers.append(lr_scheduler.MultiStepLR(self.D_optimizer,
+ self.opt_train['D_scheduler_milestones'],
+ self.opt_train['D_scheduler_gamma']
+ ))
+
+ """
+ # ----------------------------------------
+ # Optimization during training with data
+ # Testing/evaluation
+ # ----------------------------------------
+ """
+
+ # ----------------------------------------
+ # feed L/H data
+ # ----------------------------------------
+ def feed_data(self, data, need_H=True):
+ self.L = data['L'].to(self.device)
+ if need_H:
+ self.H = data['H'].to(self.device)
+
+ # ----------------------------------------
+ # feed L to netG and get E
+ # ----------------------------------------
+ def netG_forward(self):
+ self.E = self.netG(self.L)
+
+ # ----------------------------------------
+ # update parameters and get loss
+ # ----------------------------------------
+ def optimize_parameters(self, current_step):
+ # ------------------------------------
+ # optimize G
+ # ------------------------------------
+ for p in self.netD.parameters():
+ p.requires_grad = False
+
+ self.G_optimizer.zero_grad()
+ self.netG_forward()
+ loss_G_total = 0
+
+ if current_step % self.D_update_ratio == 0 and current_step > self.D_init_iters: # updata D first
+ if self.opt_train['G_lossfn_weight'] > 0:
+ G_loss = self.G_lossfn_weight * self.G_lossfn(self.E, self.H)
+ loss_G_total += G_loss # 1) pixel loss
+ if self.opt_train['F_lossfn_weight'] > 0:
+ F_loss = self.F_lossfn_weight * self.F_lossfn(self.E, self.H)
+ loss_G_total += F_loss # 2) VGG feature loss
+
+ if self.opt['train']['gan_type'] in ['gan', 'lsgan', 'wgan', 'softplusgan']:
+ pred_g_fake = self.netD(self.E)
+ D_loss = self.D_lossfn_weight * self.D_lossfn(pred_g_fake, True)
+ elif self.opt['train']['gan_type'] == 'ragan':
+ pred_d_real = self.netD(self.H).detach()
+ pred_g_fake = self.netD(self.E)
+ D_loss = self.D_lossfn_weight * (
+ self.D_lossfn(pred_d_real - torch.mean(pred_g_fake, 0, True), False) +
+ self.D_lossfn(pred_g_fake - torch.mean(pred_d_real, 0, True), True)) / 2
+ loss_G_total += D_loss # 3) GAN loss
+
+ loss_G_total.backward()
+ self.G_optimizer.step()
+
+ # ------------------------------------
+ # optimize D
+ # ------------------------------------
+ for p in self.netD.parameters():
+ p.requires_grad = True
+
+ self.D_optimizer.zero_grad()
+
+ # In order to avoid the error in distributed training:
+ # "Error detected in CudnnBatchNormBackward: RuntimeError: one of
+ # the variables needed for gradient computation has been modified by
+ # an inplace operation",
+ # we separate the backwards for real and fake, and also detach the
+ # tensor for calculating mean.
+ if self.opt_train['gan_type'] in ['gan', 'lsgan', 'wgan', 'softplusgan']:
+ # real
+ pred_d_real = self.netD(self.H) # 1) real data
+ l_d_real = self.D_lossfn(pred_d_real, True)
+ l_d_real.backward()
+ # fake
+ pred_d_fake = self.netD(self.E.detach().clone()) # 2) fake data, detach to avoid BP to G
+ l_d_fake = self.D_lossfn(pred_d_fake, False)
+ l_d_fake.backward()
+ elif self.opt_train['gan_type'] == 'ragan':
+ # real
+ pred_d_fake = self.netD(self.E).detach() # 1) fake data, detach to avoid BP to G
+ pred_d_real = self.netD(self.H) # 2) real data
+ l_d_real = 0.5 * self.D_lossfn(pred_d_real - torch.mean(pred_d_fake, 0, True), True)
+ l_d_real.backward()
+ # fake
+ pred_d_fake = self.netD(self.E.detach())
+ l_d_fake = 0.5 * self.D_lossfn(pred_d_fake - torch.mean(pred_d_real.detach(), 0, True), False)
+ l_d_fake.backward()
+
+ self.D_optimizer.step()
+
+ # ------------------------------------
+ # record log
+ # ------------------------------------
+ if current_step % self.D_update_ratio == 0 and current_step > self.D_init_iters:
+ if self.opt_train['G_lossfn_weight'] > 0:
+ self.log_dict['G_loss'] = G_loss.item()
+ if self.opt_train['F_lossfn_weight'] > 0:
+ self.log_dict['F_loss'] = F_loss.item()
+ self.log_dict['D_loss'] = D_loss.item()
+
+ #self.log_dict['l_d_real'] = l_d_real.item()
+ #self.log_dict['l_d_fake'] = l_d_fake.item()
+ self.log_dict['D_real'] = torch.mean(pred_d_real.detach())
+ self.log_dict['D_fake'] = torch.mean(pred_d_fake.detach())
+
+ if self.opt_train['E_decay'] > 0:
+ self.update_E(self.opt_train['E_decay'])
+
+ # ----------------------------------------
+ # test and inference
+ # ----------------------------------------
+ def test(self):
+ self.netG.eval()
+ with torch.no_grad():
+ self.netG_forward()
+ self.netG.train()
+
+ # ----------------------------------------
+ # get log_dict
+ # ----------------------------------------
+ def current_log(self):
+ return self.log_dict
+
+ # ----------------------------------------
+ # get L, E, H images
+ # ----------------------------------------
+ def current_visuals(self, need_H=True):
+ out_dict = OrderedDict()
+ out_dict['L'] = self.L.detach()[0].float().cpu()
+ out_dict['E'] = self.E.detach()[0].float().cpu()
+ if need_H:
+ out_dict['H'] = self.H.detach()[0].float().cpu()
+ return out_dict
+
+ """
+ # ----------------------------------------
+ # Information of netG, netD and netF
+ # ----------------------------------------
+ """
+
+ # ----------------------------------------
+ # print network
+ # ----------------------------------------
+ def print_network(self):
+ msg = self.describe_network(self.netG)
+ print(msg)
+ if self.is_train:
+ msg = self.describe_network(self.netD)
+ print(msg)
+
+ # ----------------------------------------
+ # print params
+ # ----------------------------------------
+ def print_params(self):
+ msg = self.describe_params(self.netG)
+ print(msg)
+
+ # ----------------------------------------
+ # network information
+ # ----------------------------------------
+ def info_network(self):
+ msg = self.describe_network(self.netG)
+ if self.is_train:
+ msg += self.describe_network(self.netD)
+ return msg
+
+ # ----------------------------------------
+ # params information
+ # ----------------------------------------
+ def info_params(self):
+ msg = self.describe_params(self.netG)
+ return msg
+
diff --git a/KAIR/models/model_plain.py b/KAIR/models/model_plain.py
new file mode 100644
index 0000000000000000000000000000000000000000..069569ce8669ceca20e23f4104f95604535434b1
--- /dev/null
+++ b/KAIR/models/model_plain.py
@@ -0,0 +1,273 @@
+from collections import OrderedDict
+import torch
+import torch.nn as nn
+from torch.optim import lr_scheduler
+from torch.optim import Adam
+
+from models.select_network import define_G
+from models.model_base import ModelBase
+from models.loss import CharbonnierLoss
+from models.loss_ssim import SSIMLoss
+
+from utils.utils_model import test_mode
+from utils.utils_regularizers import regularizer_orth, regularizer_clip
+
+
+class ModelPlain(ModelBase):
+ """Train with pixel loss"""
+ def __init__(self, opt):
+ super(ModelPlain, self).__init__(opt)
+ # ------------------------------------
+ # define network
+ # ------------------------------------
+ self.opt_train = self.opt['train'] # training option
+ self.netG = define_G(opt)
+ self.netG = self.model_to_device(self.netG)
+ if self.opt_train['E_decay'] > 0:
+ self.netE = define_G(opt).to(self.device).eval()
+
+ """
+ # ----------------------------------------
+ # Preparation before training with data
+ # Save model during training
+ # ----------------------------------------
+ """
+
+ # ----------------------------------------
+ # initialize training
+ # ----------------------------------------
+ def init_train(self):
+ self.load() # load model
+ self.netG.train() # set training mode,for BN
+ self.define_loss() # define loss
+ self.define_optimizer() # define optimizer
+ self.load_optimizers() # load optimizer
+ self.define_scheduler() # define scheduler
+ self.log_dict = OrderedDict() # log
+
+ # ----------------------------------------
+ # load pre-trained G model
+ # ----------------------------------------
+ def load(self):
+ load_path_G = self.opt['path']['pretrained_netG']
+ if load_path_G is not None:
+ print('Loading model for G [{:s}] ...'.format(load_path_G))
+ self.load_network(load_path_G, self.netG, strict=self.opt_train['G_param_strict'], param_key='params')
+ load_path_E = self.opt['path']['pretrained_netE']
+ if self.opt_train['E_decay'] > 0:
+ if load_path_E is not None:
+ print('Loading model for E [{:s}] ...'.format(load_path_E))
+ self.load_network(load_path_E, self.netE, strict=self.opt_train['E_param_strict'], param_key='params_ema')
+ else:
+ print('Copying model for E ...')
+ self.update_E(0)
+ self.netE.eval()
+
+ # ----------------------------------------
+ # load optimizer
+ # ----------------------------------------
+ def load_optimizers(self):
+ load_path_optimizerG = self.opt['path']['pretrained_optimizerG']
+ if load_path_optimizerG is not None and self.opt_train['G_optimizer_reuse']:
+ print('Loading optimizerG [{:s}] ...'.format(load_path_optimizerG))
+ self.load_optimizer(load_path_optimizerG, self.G_optimizer)
+
+ # ----------------------------------------
+ # save model / optimizer(optional)
+ # ----------------------------------------
+ def save(self, iter_label):
+ self.save_network(self.save_dir, self.netG, 'G', iter_label)
+ if self.opt_train['E_decay'] > 0:
+ self.save_network(self.save_dir, self.netE, 'E', iter_label)
+ if self.opt_train['G_optimizer_reuse']:
+ self.save_optimizer(self.save_dir, self.G_optimizer, 'optimizerG', iter_label)
+
+ # ----------------------------------------
+ # define loss
+ # ----------------------------------------
+ def define_loss(self):
+ G_lossfn_type = self.opt_train['G_lossfn_type']
+ if G_lossfn_type == 'l1':
+ self.G_lossfn = nn.L1Loss().to(self.device)
+ elif G_lossfn_type == 'l2':
+ self.G_lossfn = nn.MSELoss().to(self.device)
+ elif G_lossfn_type == 'l2sum':
+ self.G_lossfn = nn.MSELoss(reduction='sum').to(self.device)
+ elif G_lossfn_type == 'ssim':
+ self.G_lossfn = SSIMLoss().to(self.device)
+ elif G_lossfn_type == 'charbonnier':
+ self.G_lossfn = CharbonnierLoss(self.opt_train['G_charbonnier_eps']).to(self.device)
+ else:
+ raise NotImplementedError('Loss type [{:s}] is not found.'.format(G_lossfn_type))
+ self.G_lossfn_weight = self.opt_train['G_lossfn_weight']
+
+ # ----------------------------------------
+ # define optimizer
+ # ----------------------------------------
+ def define_optimizer(self):
+ G_optim_params = []
+ for k, v in self.netG.named_parameters():
+ if v.requires_grad:
+ G_optim_params.append(v)
+ else:
+ print('Params [{:s}] will not optimize.'.format(k))
+ if self.opt_train['G_optimizer_type'] == 'adam':
+ self.G_optimizer = Adam(G_optim_params, lr=self.opt_train['G_optimizer_lr'],
+ betas=self.opt_train['G_optimizer_betas'],
+ weight_decay=self.opt_train['G_optimizer_wd'])
+ else:
+ raise NotImplementedError
+
+ # ----------------------------------------
+ # define scheduler, only "MultiStepLR"
+ # ----------------------------------------
+ def define_scheduler(self):
+ if self.opt_train['G_scheduler_type'] == 'MultiStepLR':
+ self.schedulers.append(lr_scheduler.MultiStepLR(self.G_optimizer,
+ self.opt_train['G_scheduler_milestones'],
+ self.opt_train['G_scheduler_gamma']
+ ))
+ elif self.opt_train['G_scheduler_type'] == 'CosineAnnealingWarmRestarts':
+ self.schedulers.append(lr_scheduler.CosineAnnealingWarmRestarts(self.G_optimizer,
+ self.opt_train['G_scheduler_periods'],
+ self.opt_train['G_scheduler_restart_weights'],
+ self.opt_train['G_scheduler_eta_min']
+ ))
+ else:
+ raise NotImplementedError
+
+ """
+ # ----------------------------------------
+ # Optimization during training with data
+ # Testing/evaluation
+ # ----------------------------------------
+ """
+
+ # ----------------------------------------
+ # feed L/H data
+ # ----------------------------------------
+ def feed_data(self, data, need_H=True):
+ self.L = data['L'].to(self.device)
+ if need_H:
+ self.H = data['H'].to(self.device)
+
+ # ----------------------------------------
+ # feed L to netG
+ # ----------------------------------------
+ def netG_forward(self):
+ self.E = self.netG(self.L)
+
+ # ----------------------------------------
+ # update parameters and get loss
+ # ----------------------------------------
+ def optimize_parameters(self, current_step):
+ self.G_optimizer.zero_grad()
+ self.netG_forward()
+ G_loss = self.G_lossfn_weight * self.G_lossfn(self.E, self.H)
+ G_loss.backward()
+
+ # ------------------------------------
+ # clip_grad
+ # ------------------------------------
+ # `clip_grad_norm` helps prevent the exploding gradient problem.
+ G_optimizer_clipgrad = self.opt_train['G_optimizer_clipgrad'] if self.opt_train['G_optimizer_clipgrad'] else 0
+ if G_optimizer_clipgrad > 0:
+ torch.nn.utils.clip_grad_norm_(self.parameters(), max_norm=self.opt_train['G_optimizer_clipgrad'], norm_type=2)
+
+ self.G_optimizer.step()
+
+ # ------------------------------------
+ # regularizer
+ # ------------------------------------
+ G_regularizer_orthstep = self.opt_train['G_regularizer_orthstep'] if self.opt_train['G_regularizer_orthstep'] else 0
+ if G_regularizer_orthstep > 0 and current_step % G_regularizer_orthstep == 0 and current_step % self.opt['train']['checkpoint_save'] != 0:
+ self.netG.apply(regularizer_orth)
+ G_regularizer_clipstep = self.opt_train['G_regularizer_clipstep'] if self.opt_train['G_regularizer_clipstep'] else 0
+ if G_regularizer_clipstep > 0 and current_step % G_regularizer_clipstep == 0 and current_step % self.opt['train']['checkpoint_save'] != 0:
+ self.netG.apply(regularizer_clip)
+
+ # self.log_dict['G_loss'] = G_loss.item()/self.E.size()[0] # if `reduction='sum'`
+ self.log_dict['G_loss'] = G_loss.item()
+
+ if self.opt_train['E_decay'] > 0:
+ self.update_E(self.opt_train['E_decay'])
+
+ # ----------------------------------------
+ # test / inference
+ # ----------------------------------------
+ def test(self):
+ self.netG.eval()
+ with torch.no_grad():
+ self.netG_forward()
+ self.netG.train()
+
+ # ----------------------------------------
+ # test / inference x8
+ # ----------------------------------------
+ def testx8(self):
+ self.netG.eval()
+ with torch.no_grad():
+ self.E = test_mode(self.netG, self.L, mode=3, sf=self.opt['scale'], modulo=1)
+ self.netG.train()
+
+ # ----------------------------------------
+ # get log_dict
+ # ----------------------------------------
+ def current_log(self):
+ return self.log_dict
+
+ # ----------------------------------------
+ # get L, E, H image
+ # ----------------------------------------
+ def current_visuals(self, need_H=True):
+ out_dict = OrderedDict()
+ out_dict['L'] = self.L.detach()[0].float().cpu()
+ out_dict['E'] = self.E.detach()[0].float().cpu()
+ if need_H:
+ out_dict['H'] = self.H.detach()[0].float().cpu()
+ return out_dict
+
+ # ----------------------------------------
+ # get L, E, H batch images
+ # ----------------------------------------
+ def current_results(self, need_H=True):
+ out_dict = OrderedDict()
+ out_dict['L'] = self.L.detach().float().cpu()
+ out_dict['E'] = self.E.detach().float().cpu()
+ if need_H:
+ out_dict['H'] = self.H.detach().float().cpu()
+ return out_dict
+
+ """
+ # ----------------------------------------
+ # Information of netG
+ # ----------------------------------------
+ """
+
+ # ----------------------------------------
+ # print network
+ # ----------------------------------------
+ def print_network(self):
+ msg = self.describe_network(self.netG)
+ print(msg)
+
+ # ----------------------------------------
+ # print params
+ # ----------------------------------------
+ def print_params(self):
+ msg = self.describe_params(self.netG)
+ print(msg)
+
+ # ----------------------------------------
+ # network information
+ # ----------------------------------------
+ def info_network(self):
+ msg = self.describe_network(self.netG)
+ return msg
+
+ # ----------------------------------------
+ # params information
+ # ----------------------------------------
+ def info_params(self):
+ msg = self.describe_params(self.netG)
+ return msg
diff --git a/KAIR/models/model_plain2.py b/KAIR/models/model_plain2.py
new file mode 100644
index 0000000000000000000000000000000000000000..53d0c878c50f2e91a8008c143c17421101843e15
--- /dev/null
+++ b/KAIR/models/model_plain2.py
@@ -0,0 +1,20 @@
+from models.model_plain import ModelPlain
+
+class ModelPlain2(ModelPlain):
+ """Train with two inputs (L, C) and with pixel loss"""
+
+ # ----------------------------------------
+ # feed L/H data
+ # ----------------------------------------
+ def feed_data(self, data, need_H=True):
+ self.L = data['L'].to(self.device)
+ self.C = data['C'].to(self.device)
+ if need_H:
+ self.H = data['H'].to(self.device)
+
+ # ----------------------------------------
+ # feed (L, C) to netG and get E
+ # ----------------------------------------
+ def netG_forward(self):
+ self.E = self.netG(self.L, self.C)
+
diff --git a/KAIR/models/model_plain4.py b/KAIR/models/model_plain4.py
new file mode 100644
index 0000000000000000000000000000000000000000..8a534cf26a1d46660b0e1af8176f4a38a6058343
--- /dev/null
+++ b/KAIR/models/model_plain4.py
@@ -0,0 +1,23 @@
+from models.model_plain import ModelPlain
+import numpy as np
+
+
+class ModelPlain4(ModelPlain):
+ """Train with four inputs (L, k, sf, sigma) and with pixel loss for USRNet"""
+
+ # ----------------------------------------
+ # feed L/H data
+ # ----------------------------------------
+ def feed_data(self, data, need_H=True):
+ self.L = data['L'].to(self.device) # low-quality image
+ self.k = data['k'].to(self.device) # blur kernel
+ self.sf = np.int(data['sf'][0,...].squeeze().cpu().numpy()) # scale factor
+ self.sigma = data['sigma'].to(self.device) # noise level
+ if need_H:
+ self.H = data['H'].to(self.device) # H
+
+ # ----------------------------------------
+ # feed (L, C) to netG and get E
+ # ----------------------------------------
+ def netG_forward(self):
+ self.E = self.netG(self.L, self.k, self.sf, self.sigma)
diff --git a/KAIR/models/model_vrt.py b/KAIR/models/model_vrt.py
new file mode 100644
index 0000000000000000000000000000000000000000..3b91a7677672364994326ae68a93c7725962b007
--- /dev/null
+++ b/KAIR/models/model_vrt.py
@@ -0,0 +1,258 @@
+from collections import OrderedDict
+import torch
+import torch.nn as nn
+from torch.optim import lr_scheduler
+from torch.optim import Adam
+
+from models.select_network import define_G
+from models.model_plain import ModelPlain
+from models.loss import CharbonnierLoss
+from models.loss_ssim import SSIMLoss
+
+from utils.utils_model import test_mode
+from utils.utils_regularizers import regularizer_orth, regularizer_clip
+
+
+class ModelVRT(ModelPlain):
+ """Train video restoration with pixel loss"""
+ def __init__(self, opt):
+ super(ModelVRT, self).__init__(opt)
+ self.fix_iter = self.opt_train.get('fix_iter', 0)
+ self.fix_keys = self.opt_train.get('fix_keys', [])
+ self.fix_unflagged = True
+
+ # ----------------------------------------
+ # define optimizer
+ # ----------------------------------------
+ def define_optimizer(self):
+ self.fix_keys = self.opt_train.get('fix_keys', [])
+ if self.opt_train.get('fix_iter', 0) and len(self.fix_keys) > 0:
+ fix_lr_mul = self.opt_train['fix_lr_mul']
+ print(f'Multiple the learning rate for keys: {self.fix_keys} with {fix_lr_mul}.')
+ if fix_lr_mul == 1:
+ G_optim_params = self.netG.parameters()
+ else: # separate flow params and normal params for different lr
+ normal_params = []
+ flow_params = []
+ for name, param in self.netG.named_parameters():
+ if any([key in name for key in self.fix_keys]):
+ flow_params.append(param)
+ else:
+ normal_params.append(param)
+ G_optim_params = [
+ { # add normal params first
+ 'params': normal_params,
+ 'lr': self.opt_train['G_optimizer_lr']
+ },
+ {
+ 'params': flow_params,
+ 'lr': self.opt_train['G_optimizer_lr'] * fix_lr_mul
+ },
+ ]
+
+ if self.opt_train['G_optimizer_type'] == 'adam':
+ self.G_optimizer = Adam(G_optim_params, lr=self.opt_train['G_optimizer_lr'],
+ betas=self.opt_train['G_optimizer_betas'],
+ weight_decay=self.opt_train['G_optimizer_wd'])
+ else:
+ raise NotImplementedError
+ else:
+ super(ModelVRT, self).define_optimizer()
+
+ # ----------------------------------------
+ # update parameters and get loss
+ # ----------------------------------------
+ def optimize_parameters(self, current_step):
+ if self.fix_iter:
+ if self.fix_unflagged and current_step < self.fix_iter:
+ print(f'Fix keys: {self.fix_keys} for the first {self.fix_iter} iters.')
+ self.fix_unflagged = False
+ for name, param in self.netG.named_parameters():
+ if any([key in name for key in self.fix_keys]):
+ param.requires_grad_(False)
+ elif current_step == self.fix_iter:
+ print(f'Train all the parameters from {self.fix_iter} iters.')
+ self.netG.requires_grad_(True)
+
+ super(ModelVRT, self).optimize_parameters(current_step)
+
+ # ----------------------------------------
+ # test / inference
+ # ----------------------------------------
+ def test(self):
+ n = self.L.size(1)
+ self.netG.eval()
+
+ pad_seq = self.opt_train.get('pad_seq', False)
+ flip_seq = self.opt_train.get('flip_seq', False)
+ self.center_frame_only = self.opt_train.get('center_frame_only', False)
+
+ if pad_seq:
+ n = n + 1
+ self.L = torch.cat([self.L, self.L[:, -1:, :, :, :]], dim=1)
+
+ if flip_seq:
+ self.L = torch.cat([self.L, self.L.flip(1)], dim=1)
+
+ with torch.no_grad():
+ self.E = self._test_video(self.L)
+
+ if flip_seq:
+ output_1 = self.E[:, :n, :, :, :]
+ output_2 = self.E[:, n:, :, :, :].flip(1)
+ self.E = 0.5 * (output_1 + output_2)
+
+ if pad_seq:
+ n = n - 1
+ self.E = self.E[:, :n, :, :, :]
+
+ if self.center_frame_only:
+ self.E = self.E[:, n // 2, :, :, :]
+
+ self.netG.train()
+
+ def _test_video(self, lq):
+ '''test the video as a whole or as clips (divided temporally). '''
+
+ num_frame_testing = self.opt['val'].get('num_frame_testing', 0)
+
+ if num_frame_testing:
+ # test as multiple clips if out-of-memory
+ sf = self.opt['scale']
+ num_frame_overlapping = self.opt['val'].get('num_frame_overlapping', 2)
+ not_overlap_border = False
+ b, d, c, h, w = lq.size()
+ c = c - 1 if self.opt['netG'].get('nonblind_denoising', False) else c
+ stride = num_frame_testing - num_frame_overlapping
+ d_idx_list = list(range(0, d-num_frame_testing, stride)) + [max(0, d-num_frame_testing)]
+ E = torch.zeros(b, d, c, h*sf, w*sf)
+ W = torch.zeros(b, d, 1, 1, 1)
+
+ for d_idx in d_idx_list:
+ lq_clip = lq[:, d_idx:d_idx+num_frame_testing, ...]
+ out_clip = self._test_clip(lq_clip)
+ out_clip_mask = torch.ones((b, min(num_frame_testing, d), 1, 1, 1))
+
+ if not_overlap_border:
+ if d_idx < d_idx_list[-1]:
+ out_clip[:, -num_frame_overlapping//2:, ...] *= 0
+ out_clip_mask[:, -num_frame_overlapping//2:, ...] *= 0
+ if d_idx > d_idx_list[0]:
+ out_clip[:, :num_frame_overlapping//2, ...] *= 0
+ out_clip_mask[:, :num_frame_overlapping//2, ...] *= 0
+
+ E[:, d_idx:d_idx+num_frame_testing, ...].add_(out_clip)
+ W[:, d_idx:d_idx+num_frame_testing, ...].add_(out_clip_mask)
+ output = E.div_(W)
+ else:
+ # test as one clip (the whole video) if you have enough memory
+ window_size = self.opt['netG'].get('window_size', [6,8,8])
+ d_old = lq.size(1)
+ d_pad = (d_old// window_size[0]+1)*window_size[0] - d_old
+ lq = torch.cat([lq, torch.flip(lq[:, -d_pad:, ...], [1])], 1)
+ output = self._test_clip(lq)
+ output = output[:, :d_old, :, :, :]
+
+ return output
+
+ def _test_clip(self, lq):
+ ''' test the clip as a whole or as patches. '''
+
+ sf = self.opt['scale']
+ window_size = self.opt['netG'].get('window_size', [6,8,8])
+ size_patch_testing = self.opt['val'].get('size_patch_testing', 0)
+ assert size_patch_testing % window_size[-1] == 0, 'testing patch size should be a multiple of window_size.'
+
+ if size_patch_testing:
+ # divide the clip to patches (spatially only, tested patch by patch)
+ overlap_size = 20
+ not_overlap_border = True
+
+ # test patch by patch
+ b, d, c, h, w = lq.size()
+ c = c - 1 if self.opt['netG'].get('nonblind_denoising', False) else c
+ stride = size_patch_testing - overlap_size
+ h_idx_list = list(range(0, h-size_patch_testing, stride)) + [max(0, h-size_patch_testing)]
+ w_idx_list = list(range(0, w-size_patch_testing, stride)) + [max(0, w-size_patch_testing)]
+ E = torch.zeros(b, d, c, h*sf, w*sf)
+ W = torch.zeros_like(E)
+
+ for h_idx in h_idx_list:
+ for w_idx in w_idx_list:
+ in_patch = lq[..., h_idx:h_idx+size_patch_testing, w_idx:w_idx+size_patch_testing]
+ if hasattr(self, 'netE'):
+ out_patch = self.netE(in_patch).detach().cpu()
+ else:
+ out_patch = self.netG(in_patch).detach().cpu()
+
+ out_patch_mask = torch.ones_like(out_patch)
+
+ if not_overlap_border:
+ if h_idx < h_idx_list[-1]:
+ out_patch[..., -overlap_size//2:, :] *= 0
+ out_patch_mask[..., -overlap_size//2:, :] *= 0
+ if w_idx < w_idx_list[-1]:
+ out_patch[..., :, -overlap_size//2:] *= 0
+ out_patch_mask[..., :, -overlap_size//2:] *= 0
+ if h_idx > h_idx_list[0]:
+ out_patch[..., :overlap_size//2, :] *= 0
+ out_patch_mask[..., :overlap_size//2, :] *= 0
+ if w_idx > w_idx_list[0]:
+ out_patch[..., :, :overlap_size//2] *= 0
+ out_patch_mask[..., :, :overlap_size//2] *= 0
+
+ E[..., h_idx*sf:(h_idx+size_patch_testing)*sf, w_idx*sf:(w_idx+size_patch_testing)*sf].add_(out_patch)
+ W[..., h_idx*sf:(h_idx+size_patch_testing)*sf, w_idx*sf:(w_idx+size_patch_testing)*sf].add_(out_patch_mask)
+ output = E.div_(W)
+
+ else:
+ _, _, _, h_old, w_old = lq.size()
+ h_pad = (h_old// window_size[1]+1)*window_size[1] - h_old
+ w_pad = (w_old// window_size[2]+1)*window_size[2] - w_old
+
+ lq = torch.cat([lq, torch.flip(lq[:, :, :, -h_pad:, :], [3])], 3)
+ lq = torch.cat([lq, torch.flip(lq[:, :, :, :, -w_pad:], [4])], 4)
+
+ if hasattr(self, 'netE'):
+ output = self.netE(lq).detach().cpu()
+ else:
+ output = self.netG(lq).detach().cpu()
+
+ output = output[:, :, :, :h_old*sf, :w_old*sf]
+
+ return output
+
+ # ----------------------------------------
+ # load the state_dict of the network
+ # ----------------------------------------
+ def load_network(self, load_path, network, strict=True, param_key='params'):
+ network = self.get_bare_model(network)
+ state_dict = torch.load(load_path)
+ if param_key in state_dict.keys():
+ state_dict = state_dict[param_key]
+ self._print_different_keys_loading(network, state_dict, strict)
+ network.load_state_dict(state_dict, strict=strict)
+
+ def _print_different_keys_loading(self, crt_net, load_net, strict=True):
+ crt_net = self.get_bare_model(crt_net)
+ crt_net = crt_net.state_dict()
+ crt_net_keys = set(crt_net.keys())
+ load_net_keys = set(load_net.keys())
+
+ if crt_net_keys != load_net_keys:
+ print('Current net - loaded net:')
+ for v in sorted(list(crt_net_keys - load_net_keys)):
+ print(f' {v}')
+ print('Loaded net - current net:')
+ for v in sorted(list(load_net_keys - crt_net_keys)):
+ print(f' {v}')
+
+ # check the size for the same keys
+ if not strict:
+ common_keys = crt_net_keys & load_net_keys
+ for k in common_keys:
+ if crt_net[k].size() != load_net[k].size():
+ print(f'Size different, ignore [{k}]: crt_net: '
+ f'{crt_net[k].shape}; load_net: {load_net[k].shape}')
+ load_net[k + '.ignore'] = load_net.pop(k)
+
diff --git a/KAIR/models/network_discriminator.py b/KAIR/models/network_discriminator.py
new file mode 100644
index 0000000000000000000000000000000000000000..8542a36d7665fda79e9ca13024f93961d91db97d
--- /dev/null
+++ b/KAIR/models/network_discriminator.py
@@ -0,0 +1,338 @@
+import torch
+import torch.nn as nn
+from torch.nn import functional as F
+from torch.nn.utils import spectral_norm
+import models.basicblock as B
+import functools
+import numpy as np
+
+
+"""
+# --------------------------------------------
+# Discriminator_PatchGAN
+# Discriminator_UNet
+# --------------------------------------------
+"""
+
+
+# --------------------------------------------
+# PatchGAN discriminator
+# If n_layers = 3, then the receptive field is 70x70
+# --------------------------------------------
+class Discriminator_PatchGAN(nn.Module):
+ def __init__(self, input_nc=3, ndf=64, n_layers=3, norm_type='spectral'):
+ '''PatchGAN discriminator, receptive field = 70x70 if n_layers = 3
+ Args:
+ input_nc: number of input channels
+ ndf: base channel number
+ n_layers: number of conv layer with stride 2
+ norm_type: 'batch', 'instance', 'spectral', 'batchspectral', instancespectral'
+ Returns:
+ tensor: score
+ '''
+ super(Discriminator_PatchGAN, self).__init__()
+ self.n_layers = n_layers
+ norm_layer = self.get_norm_layer(norm_type=norm_type)
+
+ kw = 4
+ padw = int(np.ceil((kw - 1.0) / 2))
+ sequence = [[self.use_spectral_norm(nn.Conv2d(input_nc, ndf, kernel_size=kw, stride=2, padding=padw), norm_type), nn.LeakyReLU(0.2, True)]]
+
+ nf = ndf
+ for n in range(1, n_layers):
+ nf_prev = nf
+ nf = min(nf * 2, 512)
+ sequence += [[self.use_spectral_norm(nn.Conv2d(nf_prev, nf, kernel_size=kw, stride=2, padding=padw), norm_type),
+ norm_layer(nf),
+ nn.LeakyReLU(0.2, True)]]
+
+ nf_prev = nf
+ nf = min(nf * 2, 512)
+ sequence += [[self.use_spectral_norm(nn.Conv2d(nf_prev, nf, kernel_size=kw, stride=1, padding=padw), norm_type),
+ norm_layer(nf),
+ nn.LeakyReLU(0.2, True)]]
+
+ sequence += [[self.use_spectral_norm(nn.Conv2d(nf, 1, kernel_size=kw, stride=1, padding=padw), norm_type)]]
+
+ self.model = nn.Sequential()
+ for n in range(len(sequence)):
+ self.model.add_module('child' + str(n), nn.Sequential(*sequence[n]))
+
+ self.model.apply(self.weights_init)
+
+ def use_spectral_norm(self, module, norm_type='spectral'):
+ if 'spectral' in norm_type:
+ return spectral_norm(module)
+ return module
+
+ def get_norm_layer(self, norm_type='instance'):
+ if 'batch' in norm_type:
+ norm_layer = functools.partial(nn.BatchNorm2d, affine=True)
+ elif 'instance' in norm_type:
+ norm_layer = functools.partial(nn.InstanceNorm2d, affine=False)
+ else:
+ norm_layer = functools.partial(nn.Identity)
+ return norm_layer
+
+ def weights_init(self, m):
+ classname = m.__class__.__name__
+ if classname.find('Conv') != -1:
+ m.weight.data.normal_(0.0, 0.02)
+ elif classname.find('BatchNorm2d') != -1:
+ m.weight.data.normal_(1.0, 0.02)
+ m.bias.data.fill_(0)
+
+ def forward(self, x):
+ return self.model(x)
+
+
+class Discriminator_UNet(nn.Module):
+ """Defines a U-Net discriminator with spectral normalization (SN)"""
+
+ def __init__(self, input_nc=3, ndf=64):
+ super(Discriminator_UNet, self).__init__()
+ norm = spectral_norm
+
+ self.conv0 = nn.Conv2d(input_nc, ndf, kernel_size=3, stride=1, padding=1)
+
+ self.conv1 = norm(nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False))
+ self.conv2 = norm(nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False))
+ self.conv3 = norm(nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False))
+ # upsample
+ self.conv4 = norm(nn.Conv2d(ndf * 8, ndf * 4, 3, 1, 1, bias=False))
+ self.conv5 = norm(nn.Conv2d(ndf * 4, ndf * 2, 3, 1, 1, bias=False))
+ self.conv6 = norm(nn.Conv2d(ndf * 2, ndf, 3, 1, 1, bias=False))
+
+ # extra
+ self.conv7 = norm(nn.Conv2d(ndf, ndf, 3, 1, 1, bias=False))
+ self.conv8 = norm(nn.Conv2d(ndf, ndf, 3, 1, 1, bias=False))
+
+ self.conv9 = nn.Conv2d(ndf, 1, 3, 1, 1)
+ print('using the UNet discriminator')
+
+ def forward(self, x):
+ x0 = F.leaky_relu(self.conv0(x), negative_slope=0.2, inplace=True)
+ x1 = F.leaky_relu(self.conv1(x0), negative_slope=0.2, inplace=True)
+ x2 = F.leaky_relu(self.conv2(x1), negative_slope=0.2, inplace=True)
+ x3 = F.leaky_relu(self.conv3(x2), negative_slope=0.2, inplace=True)
+
+ # upsample
+ x3 = F.interpolate(x3, scale_factor=2, mode='bilinear', align_corners=False)
+ x4 = F.leaky_relu(self.conv4(x3), negative_slope=0.2, inplace=True)
+
+ x4 = x4 + x2
+ x4 = F.interpolate(x4, scale_factor=2, mode='bilinear', align_corners=False)
+ x5 = F.leaky_relu(self.conv5(x4), negative_slope=0.2, inplace=True)
+
+ x5 = x5 + x1
+ x5 = F.interpolate(x5, scale_factor=2, mode='bilinear', align_corners=False)
+ x6 = F.leaky_relu(self.conv6(x5), negative_slope=0.2, inplace=True)
+
+ x6 = x6 + x0
+
+ # extra
+ out = F.leaky_relu(self.conv7(x6), negative_slope=0.2, inplace=True)
+ out = F.leaky_relu(self.conv8(out), negative_slope=0.2, inplace=True)
+ out = self.conv9(out)
+
+ return out
+
+
+# --------------------------------------------
+# VGG style Discriminator with 96x96 input
+# --------------------------------------------
+class Discriminator_VGG_96(nn.Module):
+ def __init__(self, in_nc=3, base_nc=64, ac_type='BL'):
+ super(Discriminator_VGG_96, self).__init__()
+ # features
+ # hxw, c
+ # 96, 64
+ conv0 = B.conv(in_nc, base_nc, kernel_size=3, mode='C')
+ conv1 = B.conv(base_nc, base_nc, kernel_size=4, stride=2, mode='C'+ac_type)
+ # 48, 64
+ conv2 = B.conv(base_nc, base_nc*2, kernel_size=3, stride=1, mode='C'+ac_type)
+ conv3 = B.conv(base_nc*2, base_nc*2, kernel_size=4, stride=2, mode='C'+ac_type)
+ # 24, 128
+ conv4 = B.conv(base_nc*2, base_nc*4, kernel_size=3, stride=1, mode='C'+ac_type)
+ conv5 = B.conv(base_nc*4, base_nc*4, kernel_size=4, stride=2, mode='C'+ac_type)
+ # 12, 256
+ conv6 = B.conv(base_nc*4, base_nc*8, kernel_size=3, stride=1, mode='C'+ac_type)
+ conv7 = B.conv(base_nc*8, base_nc*8, kernel_size=4, stride=2, mode='C'+ac_type)
+ # 6, 512
+ conv8 = B.conv(base_nc*8, base_nc*8, kernel_size=3, stride=1, mode='C'+ac_type)
+ conv9 = B.conv(base_nc*8, base_nc*8, kernel_size=4, stride=2, mode='C'+ac_type)
+ # 3, 512
+ self.features = B.sequential(conv0, conv1, conv2, conv3, conv4,
+ conv5, conv6, conv7, conv8, conv9)
+
+ # classifier
+ self.classifier = nn.Sequential(
+ nn.Linear(512 * 3 * 3, 100), nn.LeakyReLU(0.2, True), nn.Linear(100, 1))
+
+ def forward(self, x):
+ x = self.features(x)
+ x = x.view(x.size(0), -1)
+ x = self.classifier(x)
+ return x
+
+
+# --------------------------------------------
+# VGG style Discriminator with 128x128 input
+# --------------------------------------------
+class Discriminator_VGG_128(nn.Module):
+ def __init__(self, in_nc=3, base_nc=64, ac_type='BL'):
+ super(Discriminator_VGG_128, self).__init__()
+ # features
+ # hxw, c
+ # 128, 64
+ conv0 = B.conv(in_nc, base_nc, kernel_size=3, mode='C')
+ conv1 = B.conv(base_nc, base_nc, kernel_size=4, stride=2, mode='C'+ac_type)
+ # 64, 64
+ conv2 = B.conv(base_nc, base_nc*2, kernel_size=3, stride=1, mode='C'+ac_type)
+ conv3 = B.conv(base_nc*2, base_nc*2, kernel_size=4, stride=2, mode='C'+ac_type)
+ # 32, 128
+ conv4 = B.conv(base_nc*2, base_nc*4, kernel_size=3, stride=1, mode='C'+ac_type)
+ conv5 = B.conv(base_nc*4, base_nc*4, kernel_size=4, stride=2, mode='C'+ac_type)
+ # 16, 256
+ conv6 = B.conv(base_nc*4, base_nc*8, kernel_size=3, stride=1, mode='C'+ac_type)
+ conv7 = B.conv(base_nc*8, base_nc*8, kernel_size=4, stride=2, mode='C'+ac_type)
+ # 8, 512
+ conv8 = B.conv(base_nc*8, base_nc*8, kernel_size=3, stride=1, mode='C'+ac_type)
+ conv9 = B.conv(base_nc*8, base_nc*8, kernel_size=4, stride=2, mode='C'+ac_type)
+ # 4, 512
+ self.features = B.sequential(conv0, conv1, conv2, conv3, conv4,
+ conv5, conv6, conv7, conv8, conv9)
+
+ # classifier
+ self.classifier = nn.Sequential(nn.Linear(512 * 4 * 4, 100),
+ nn.LeakyReLU(0.2, True),
+ nn.Linear(100, 1))
+
+ def forward(self, x):
+ x = self.features(x)
+ x = x.view(x.size(0), -1)
+ x = self.classifier(x)
+ return x
+
+
+# --------------------------------------------
+# VGG style Discriminator with 192x192 input
+# --------------------------------------------
+class Discriminator_VGG_192(nn.Module):
+ def __init__(self, in_nc=3, base_nc=64, ac_type='BL'):
+ super(Discriminator_VGG_192, self).__init__()
+ # features
+ # hxw, c
+ # 192, 64
+ conv0 = B.conv(in_nc, base_nc, kernel_size=3, mode='C')
+ conv1 = B.conv(base_nc, base_nc, kernel_size=4, stride=2, mode='C'+ac_type)
+ # 96, 64
+ conv2 = B.conv(base_nc, base_nc*2, kernel_size=3, stride=1, mode='C'+ac_type)
+ conv3 = B.conv(base_nc*2, base_nc*2, kernel_size=4, stride=2, mode='C'+ac_type)
+ # 48, 128
+ conv4 = B.conv(base_nc*2, base_nc*4, kernel_size=3, stride=1, mode='C'+ac_type)
+ conv5 = B.conv(base_nc*4, base_nc*4, kernel_size=4, stride=2, mode='C'+ac_type)
+ # 24, 256
+ conv6 = B.conv(base_nc*4, base_nc*8, kernel_size=3, stride=1, mode='C'+ac_type)
+ conv7 = B.conv(base_nc*8, base_nc*8, kernel_size=4, stride=2, mode='C'+ac_type)
+ # 12, 512
+ conv8 = B.conv(base_nc*8, base_nc*8, kernel_size=3, stride=1, mode='C'+ac_type)
+ conv9 = B.conv(base_nc*8, base_nc*8, kernel_size=4, stride=2, mode='C'+ac_type)
+ # 6, 512
+ conv10 = B.conv(base_nc*8, base_nc*8, kernel_size=3, stride=1, mode='C'+ac_type)
+ conv11 = B.conv(base_nc*8, base_nc*8, kernel_size=4, stride=2, mode='C'+ac_type)
+ # 3, 512
+ self.features = B.sequential(conv0, conv1, conv2, conv3, conv4, conv5,
+ conv6, conv7, conv8, conv9, conv10, conv11)
+
+ # classifier
+ self.classifier = nn.Sequential(nn.Linear(512 * 3 * 3, 100),
+ nn.LeakyReLU(0.2, True),
+ nn.Linear(100, 1))
+
+ def forward(self, x):
+ x = self.features(x)
+ x = x.view(x.size(0), -1)
+ x = self.classifier(x)
+ return x
+
+
+# --------------------------------------------
+# SN-VGG style Discriminator with 128x128 input
+# --------------------------------------------
+class Discriminator_VGG_128_SN(nn.Module):
+ def __init__(self):
+ super(Discriminator_VGG_128_SN, self).__init__()
+ # features
+ # hxw, c
+ # 128, 64
+ self.lrelu = nn.LeakyReLU(0.2, True)
+
+ self.conv0 = spectral_norm(nn.Conv2d(3, 64, 3, 1, 1))
+ self.conv1 = spectral_norm(nn.Conv2d(64, 64, 4, 2, 1))
+ # 64, 64
+ self.conv2 = spectral_norm(nn.Conv2d(64, 128, 3, 1, 1))
+ self.conv3 = spectral_norm(nn.Conv2d(128, 128, 4, 2, 1))
+ # 32, 128
+ self.conv4 = spectral_norm(nn.Conv2d(128, 256, 3, 1, 1))
+ self.conv5 = spectral_norm(nn.Conv2d(256, 256, 4, 2, 1))
+ # 16, 256
+ self.conv6 = spectral_norm(nn.Conv2d(256, 512, 3, 1, 1))
+ self.conv7 = spectral_norm(nn.Conv2d(512, 512, 4, 2, 1))
+ # 8, 512
+ self.conv8 = spectral_norm(nn.Conv2d(512, 512, 3, 1, 1))
+ self.conv9 = spectral_norm(nn.Conv2d(512, 512, 4, 2, 1))
+ # 4, 512
+
+ # classifier
+ self.linear0 = spectral_norm(nn.Linear(512 * 4 * 4, 100))
+ self.linear1 = spectral_norm(nn.Linear(100, 1))
+
+ def forward(self, x):
+ x = self.lrelu(self.conv0(x))
+ x = self.lrelu(self.conv1(x))
+ x = self.lrelu(self.conv2(x))
+ x = self.lrelu(self.conv3(x))
+ x = self.lrelu(self.conv4(x))
+ x = self.lrelu(self.conv5(x))
+ x = self.lrelu(self.conv6(x))
+ x = self.lrelu(self.conv7(x))
+ x = self.lrelu(self.conv8(x))
+ x = self.lrelu(self.conv9(x))
+ x = x.view(x.size(0), -1)
+ x = self.lrelu(self.linear0(x))
+ x = self.linear1(x)
+ return x
+
+
+if __name__ == '__main__':
+
+ x = torch.rand(1, 3, 96, 96)
+ net = Discriminator_VGG_96()
+ net.eval()
+ with torch.no_grad():
+ y = net(x)
+ print(y.size())
+
+ x = torch.rand(1, 3, 128, 128)
+ net = Discriminator_VGG_128()
+ net.eval()
+ with torch.no_grad():
+ y = net(x)
+ print(y.size())
+
+ x = torch.rand(1, 3, 192, 192)
+ net = Discriminator_VGG_192()
+ net.eval()
+ with torch.no_grad():
+ y = net(x)
+ print(y.size())
+
+ x = torch.rand(1, 3, 128, 128)
+ net = Discriminator_VGG_128_SN()
+ net.eval()
+ with torch.no_grad():
+ y = net(x)
+ print(y.size())
+
+ # run models/network_discriminator.py
diff --git a/KAIR/models/network_dncnn.py b/KAIR/models/network_dncnn.py
new file mode 100644
index 0000000000000000000000000000000000000000..7a3f20f65d5e76c5bc187563e21cb34d04a426e8
--- /dev/null
+++ b/KAIR/models/network_dncnn.py
@@ -0,0 +1,169 @@
+
+import torch.nn as nn
+import models.basicblock as B
+
+
+"""
+# --------------------------------------------
+# DnCNN (20 conv layers)
+# FDnCNN (20 conv layers)
+# IRCNN (7 conv layers)
+# --------------------------------------------
+# References:
+@article{zhang2017beyond,
+ title={Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising},
+ author={Zhang, Kai and Zuo, Wangmeng and Chen, Yunjin and Meng, Deyu and Zhang, Lei},
+ journal={IEEE Transactions on Image Processing},
+ volume={26},
+ number={7},
+ pages={3142--3155},
+ year={2017},
+ publisher={IEEE}
+}
+@article{zhang2018ffdnet,
+ title={FFDNet: Toward a fast and flexible solution for CNN-based image denoising},
+ author={Zhang, Kai and Zuo, Wangmeng and Zhang, Lei},
+ journal={IEEE Transactions on Image Processing},
+ volume={27},
+ number={9},
+ pages={4608--4622},
+ year={2018},
+ publisher={IEEE}
+}
+# --------------------------------------------
+"""
+
+
+# --------------------------------------------
+# DnCNN
+# --------------------------------------------
+class DnCNN(nn.Module):
+ def __init__(self, in_nc=1, out_nc=1, nc=64, nb=17, act_mode='BR'):
+ """
+ # ------------------------------------
+ in_nc: channel number of input
+ out_nc: channel number of output
+ nc: channel number
+ nb: total number of conv layers
+ act_mode: batch norm + activation function; 'BR' means BN+ReLU.
+ # ------------------------------------
+ Batch normalization and residual learning are
+ beneficial to Gaussian denoising (especially
+ for a single noise level).
+ The residual of a noisy image corrupted by additive white
+ Gaussian noise (AWGN) follows a constant
+ Gaussian distribution which stablizes batch
+ normalization during training.
+ # ------------------------------------
+ """
+ super(DnCNN, self).__init__()
+ assert 'R' in act_mode or 'L' in act_mode, 'Examples of activation function: R, L, BR, BL, IR, IL'
+ bias = True
+
+ m_head = B.conv(in_nc, nc, mode='C'+act_mode[-1], bias=bias)
+ m_body = [B.conv(nc, nc, mode='C'+act_mode, bias=bias) for _ in range(nb-2)]
+ m_tail = B.conv(nc, out_nc, mode='C', bias=bias)
+
+ self.model = B.sequential(m_head, *m_body, m_tail)
+
+ def forward(self, x):
+ n = self.model(x)
+ return x-n
+
+
+# --------------------------------------------
+# IRCNN denoiser
+# --------------------------------------------
+class IRCNN(nn.Module):
+ def __init__(self, in_nc=1, out_nc=1, nc=64):
+ """
+ # ------------------------------------
+ denoiser of IRCNN
+ in_nc: channel number of input
+ out_nc: channel number of output
+ nc: channel number
+ nb: total number of conv layers
+ act_mode: batch norm + activation function; 'BR' means BN+ReLU.
+ # ------------------------------------
+ Batch normalization and residual learning are
+ beneficial to Gaussian denoising (especially
+ for a single noise level).
+ The residual of a noisy image corrupted by additive white
+ Gaussian noise (AWGN) follows a constant
+ Gaussian distribution which stablizes batch
+ normalization during training.
+ # ------------------------------------
+ """
+ super(IRCNN, self).__init__()
+ L =[]
+ L.append(nn.Conv2d(in_channels=in_nc, out_channels=nc, kernel_size=3, stride=1, padding=1, dilation=1, bias=True))
+ L.append(nn.ReLU(inplace=True))
+ L.append(nn.Conv2d(in_channels=nc, out_channels=nc, kernel_size=3, stride=1, padding=2, dilation=2, bias=True))
+ L.append(nn.ReLU(inplace=True))
+ L.append(nn.Conv2d(in_channels=nc, out_channels=nc, kernel_size=3, stride=1, padding=3, dilation=3, bias=True))
+ L.append(nn.ReLU(inplace=True))
+ L.append(nn.Conv2d(in_channels=nc, out_channels=nc, kernel_size=3, stride=1, padding=4, dilation=4, bias=True))
+ L.append(nn.ReLU(inplace=True))
+ L.append(nn.Conv2d(in_channels=nc, out_channels=nc, kernel_size=3, stride=1, padding=3, dilation=3, bias=True))
+ L.append(nn.ReLU(inplace=True))
+ L.append(nn.Conv2d(in_channels=nc, out_channels=nc, kernel_size=3, stride=1, padding=2, dilation=2, bias=True))
+ L.append(nn.ReLU(inplace=True))
+ L.append(nn.Conv2d(in_channels=nc, out_channels=out_nc, kernel_size=3, stride=1, padding=1, dilation=1, bias=True))
+ self.model = B.sequential(*L)
+
+ def forward(self, x):
+ n = self.model(x)
+ return x-n
+
+
+# --------------------------------------------
+# FDnCNN
+# --------------------------------------------
+# Compared with DnCNN, FDnCNN has three modifications:
+# 1) add noise level map as input
+# 2) remove residual learning and BN
+# 3) train with L1 loss
+# may need more training time, but will not reduce the final PSNR too much.
+# --------------------------------------------
+class FDnCNN(nn.Module):
+ def __init__(self, in_nc=2, out_nc=1, nc=64, nb=20, act_mode='R'):
+ """
+ in_nc: channel number of input
+ out_nc: channel number of output
+ nc: channel number
+ nb: total number of conv layers
+ act_mode: batch norm + activation function; 'BR' means BN+ReLU.
+ """
+ super(FDnCNN, self).__init__()
+ assert 'R' in act_mode or 'L' in act_mode, 'Examples of activation function: R, L, BR, BL, IR, IL'
+ bias = True
+
+ m_head = B.conv(in_nc, nc, mode='C'+act_mode[-1], bias=bias)
+ m_body = [B.conv(nc, nc, mode='C'+act_mode, bias=bias) for _ in range(nb-2)]
+ m_tail = B.conv(nc, out_nc, mode='C', bias=bias)
+
+ self.model = B.sequential(m_head, *m_body, m_tail)
+
+ def forward(self, x):
+ x = self.model(x)
+ return x
+
+
+if __name__ == '__main__':
+ from utils import utils_model
+ import torch
+ model1 = DnCNN(in_nc=1, out_nc=1, nc=64, nb=20, act_mode='BR')
+ print(utils_model.describe_model(model1))
+
+ model2 = FDnCNN(in_nc=2, out_nc=1, nc=64, nb=20, act_mode='R')
+ print(utils_model.describe_model(model2))
+
+ x = torch.randn((1, 1, 240, 240))
+ x1 = model1(x)
+ print(x1.shape)
+
+ x = torch.randn((1, 2, 240, 240))
+ x2 = model2(x)
+ print(x2.shape)
+
+ # run models/network_dncnn.py
diff --git a/KAIR/models/network_dpsr.py b/KAIR/models/network_dpsr.py
new file mode 100644
index 0000000000000000000000000000000000000000..3099c27a88007cbf5fe026b75bc7d299d690e186
--- /dev/null
+++ b/KAIR/models/network_dpsr.py
@@ -0,0 +1,112 @@
+import math
+import torch.nn as nn
+import models.basicblock as B
+
+
+"""
+# --------------------------------------------
+# modified SRResNet
+# -- MSRResNet_prior (for DPSR)
+# --------------------------------------------
+References:
+@inproceedings{zhang2019deep,
+ title={Deep Plug-and-Play Super-Resolution for Arbitrary Blur Kernels},
+ author={Zhang, Kai and Zuo, Wangmeng and Zhang, Lei},
+ booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
+ pages={1671--1681},
+ year={2019}
+}
+@inproceedings{wang2018esrgan,
+ title={Esrgan: Enhanced super-resolution generative adversarial networks},
+ author={Wang, Xintao and Yu, Ke and Wu, Shixiang and Gu, Jinjin and Liu, Yihao and Dong, Chao and Qiao, Yu and Change Loy, Chen},
+ booktitle={European Conference on Computer Vision (ECCV)},
+ pages={0--0},
+ year={2018}
+}
+@inproceedings{ledig2017photo,
+ title={Photo-realistic single image super-resolution using a generative adversarial network},
+ author={Ledig, Christian and Theis, Lucas and Husz{\'a}r, Ferenc and Caballero, Jose and Cunningham, Andrew and Acosta, Alejandro and Aitken, Andrew and Tejani, Alykhan and Totz, Johannes and Wang, Zehan and others},
+ booktitle={IEEE conference on computer vision and pattern recognition},
+ pages={4681--4690},
+ year={2017}
+}
+# --------------------------------------------
+"""
+
+
+# --------------------------------------------
+# MSRResNet super-resolver prior for DPSR
+# https://github.com/cszn/DPSR
+# https://github.com/cszn/DPSR/blob/master/models/network_srresnet.py
+# --------------------------------------------
+class MSRResNet_prior(nn.Module):
+ def __init__(self, in_nc=4, out_nc=3, nc=96, nb=16, upscale=4, act_mode='R', upsample_mode='upconv'):
+ super(MSRResNet_prior, self).__init__()
+ n_upscale = int(math.log(upscale, 2))
+ if upscale == 3:
+ n_upscale = 1
+
+ m_head = B.conv(in_nc, nc, mode='C')
+
+ m_body = [B.ResBlock(nc, nc, mode='C'+act_mode+'C') for _ in range(nb)]
+ m_body.append(B.conv(nc, nc, mode='C'))
+
+ if upsample_mode == 'upconv':
+ upsample_block = B.upsample_upconv
+ elif upsample_mode == 'pixelshuffle':
+ upsample_block = B.upsample_pixelshuffle
+ elif upsample_mode == 'convtranspose':
+ upsample_block = B.upsample_convtranspose
+ else:
+ raise NotImplementedError('upsample mode [{:s}] is not found'.format(upsample_mode))
+ if upscale == 3:
+ m_uper = upsample_block(nc, nc, mode='3'+act_mode)
+ else:
+ m_uper = [upsample_block(nc, nc, mode='2'+act_mode) for _ in range(n_upscale)]
+
+ H_conv0 = B.conv(nc, nc, mode='C'+act_mode)
+ H_conv1 = B.conv(nc, out_nc, bias=False, mode='C')
+ m_tail = B.sequential(H_conv0, H_conv1)
+
+ self.model = B.sequential(m_head, B.ShortcutBlock(B.sequential(*m_body)), *m_uper, m_tail)
+
+ def forward(self, x):
+ x = self.model(x)
+ return x
+
+
+
+class SRResNet(nn.Module):
+ def __init__(self, in_nc=3, out_nc=3, nc=64, nb=16, upscale=4, act_mode='R', upsample_mode='upconv'):
+ super(SRResNet, self).__init__()
+ n_upscale = int(math.log(upscale, 2))
+ if upscale == 3:
+ n_upscale = 1
+
+ m_head = B.conv(in_nc, nc, mode='C')
+
+ m_body = [B.ResBlock(nc, nc, mode='C'+act_mode+'C') for _ in range(nb)]
+ m_body.append(B.conv(nc, nc, mode='C'))
+
+ if upsample_mode == 'upconv':
+ upsample_block = B.upsample_upconv
+ elif upsample_mode == 'pixelshuffle':
+ upsample_block = B.upsample_pixelshuffle
+ elif upsample_mode == 'convtranspose':
+ upsample_block = B.upsample_convtranspose
+ else:
+ raise NotImplementedError('upsample mode [{:s}] is not found'.format(upsample_mode))
+ if upscale == 3:
+ m_uper = upsample_block(nc, nc, mode='3'+act_mode)
+ else:
+ m_uper = [upsample_block(nc, nc, mode='2'+act_mode) for _ in range(n_upscale)]
+
+ H_conv0 = B.conv(nc, nc, mode='C'+act_mode)
+ H_conv1 = B.conv(nc, out_nc, bias=False, mode='C')
+ m_tail = B.sequential(H_conv0, H_conv1)
+
+ self.model = B.sequential(m_head, B.ShortcutBlock(B.sequential(*m_body)), *m_uper, m_tail)
+
+ def forward(self, x):
+ x = self.model(x)
+ return x
\ No newline at end of file
diff --git a/KAIR/models/network_faceenhancer.py b/KAIR/models/network_faceenhancer.py
new file mode 100644
index 0000000000000000000000000000000000000000..44df0eece0b219caef85e1c2a2c87f606332e273
--- /dev/null
+++ b/KAIR/models/network_faceenhancer.py
@@ -0,0 +1,687 @@
+'''
+@paper: GAN Prior Embedded Network for Blind Face Restoration in the Wild (CVPR2021)
+@author: yangxy (yangtao9009@gmail.com)
+# 2021-06-03, modified by Kai
+'''
+import sys
+op_path = 'models'
+if op_path not in sys.path:
+ sys.path.insert(0, op_path)
+from op import FusedLeakyReLU, fused_leaky_relu, upfirdn2d
+
+import math
+import random
+import numpy as np
+
+import torch
+from torch import nn
+from torch.nn import functional as F
+
+isconcat = True
+sss = 2 if isconcat else 1
+
+class PixelNorm(nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ def forward(self, input):
+ return input * torch.rsqrt(torch.mean(input ** 2, dim=1, keepdim=True) + 1e-8)
+
+
+def make_kernel(k):
+ k = torch.tensor(k, dtype=torch.float32)
+
+ if k.ndim == 1:
+ k = k[None, :] * k[:, None]
+
+ k /= k.sum()
+
+ return k
+
+
+class Upsample(nn.Module):
+ def __init__(self, kernel, factor=2):
+ super().__init__()
+
+ self.factor = factor
+ kernel = make_kernel(kernel) * (factor ** 2)
+ self.register_buffer('kernel', kernel)
+
+ p = kernel.shape[0] - factor
+
+ pad0 = (p + 1) // 2 + factor - 1
+ pad1 = p // 2
+
+ self.pad = (pad0, pad1)
+
+ def forward(self, input):
+ out = upfirdn2d(input, self.kernel, up=self.factor, down=1, pad=self.pad)
+
+ return out
+
+
+class Downsample(nn.Module):
+ def __init__(self, kernel, factor=2):
+ super().__init__()
+
+ self.factor = factor
+ kernel = make_kernel(kernel)
+ self.register_buffer('kernel', kernel)
+
+ p = kernel.shape[0] - factor
+
+ pad0 = (p + 1) // 2
+ pad1 = p // 2
+
+ self.pad = (pad0, pad1)
+
+ def forward(self, input):
+ out = upfirdn2d(input, self.kernel, up=1, down=self.factor, pad=self.pad)
+
+ return out
+
+
+class Blur(nn.Module):
+ def __init__(self, kernel, pad, upsample_factor=1):
+ super().__init__()
+
+ kernel = make_kernel(kernel)
+
+ if upsample_factor > 1:
+ kernel = kernel * (upsample_factor ** 2)
+
+ self.register_buffer('kernel', kernel)
+
+ self.pad = pad
+
+ def forward(self, input):
+ out = upfirdn2d(input, self.kernel, pad=self.pad)
+
+ return out
+
+
+class EqualConv2d(nn.Module):
+ def __init__(
+ self, in_channel, out_channel, kernel_size, stride=1, padding=0, bias=True
+ ):
+ super().__init__()
+
+ self.weight = nn.Parameter(
+ torch.randn(out_channel, in_channel, kernel_size, kernel_size)
+ )
+ self.scale = 1 / math.sqrt(in_channel * kernel_size ** 2)
+
+ self.stride = stride
+ self.padding = padding
+
+ if bias:
+ self.bias = nn.Parameter(torch.zeros(out_channel))
+
+ else:
+ self.bias = None
+
+ def forward(self, input):
+ out = F.conv2d(
+ input,
+ self.weight * self.scale,
+ bias=self.bias,
+ stride=self.stride,
+ padding=self.padding,
+ )
+
+ return out
+
+ def __repr__(self):
+ return (
+ f'{self.__class__.__name__}({self.weight.shape[1]}, {self.weight.shape[0]},'
+ f' {self.weight.shape[2]}, stride={self.stride}, padding={self.padding})'
+ )
+
+
+class EqualLinear(nn.Module):
+ def __init__(
+ self, in_dim, out_dim, bias=True, bias_init=0, lr_mul=1, activation=None
+ ):
+ super().__init__()
+
+ self.weight = nn.Parameter(torch.randn(out_dim, in_dim).div_(lr_mul))
+
+ if bias:
+ self.bias = nn.Parameter(torch.zeros(out_dim).fill_(bias_init))
+
+ else:
+ self.bias = None
+
+ self.activation = activation
+
+ self.scale = (1 / math.sqrt(in_dim)) * lr_mul
+ self.lr_mul = lr_mul
+
+ def forward(self, input):
+ if self.activation:
+ out = F.linear(input, self.weight * self.scale)
+ out = fused_leaky_relu(out, self.bias * self.lr_mul)
+
+ else:
+ out = F.linear(input, self.weight * self.scale, bias=self.bias * self.lr_mul)
+
+ return out
+
+ def __repr__(self):
+ return (
+ f'{self.__class__.__name__}({self.weight.shape[1]}, {self.weight.shape[0]})'
+ )
+
+
+class ScaledLeakyReLU(nn.Module):
+ def __init__(self, negative_slope=0.2):
+ super().__init__()
+
+ self.negative_slope = negative_slope
+
+ def forward(self, input):
+ out = F.leaky_relu(input, negative_slope=self.negative_slope)
+
+ return out * math.sqrt(2)
+
+
+class ModulatedConv2d(nn.Module):
+ def __init__(
+ self,
+ in_channel,
+ out_channel,
+ kernel_size,
+ style_dim,
+ demodulate=True,
+ upsample=False,
+ downsample=False,
+ blur_kernel=[1, 3, 3, 1],
+ ):
+ super().__init__()
+
+ self.eps = 1e-8
+ self.kernel_size = kernel_size
+ self.in_channel = in_channel
+ self.out_channel = out_channel
+ self.upsample = upsample
+ self.downsample = downsample
+
+ if upsample:
+ factor = 2
+ p = (len(blur_kernel) - factor) - (kernel_size - 1)
+ pad0 = (p + 1) // 2 + factor - 1
+ pad1 = p // 2 + 1
+
+ self.blur = Blur(blur_kernel, pad=(pad0, pad1), upsample_factor=factor)
+
+ if downsample:
+ factor = 2
+ p = (len(blur_kernel) - factor) + (kernel_size - 1)
+ pad0 = (p + 1) // 2
+ pad1 = p // 2
+
+ self.blur = Blur(blur_kernel, pad=(pad0, pad1))
+
+ fan_in = in_channel * kernel_size ** 2
+ self.scale = 1 / math.sqrt(fan_in)
+ self.padding = kernel_size // 2
+
+ self.weight = nn.Parameter(
+ torch.randn(1, out_channel, in_channel, kernel_size, kernel_size)
+ )
+
+ self.modulation = EqualLinear(style_dim, in_channel, bias_init=1)
+
+ self.demodulate = demodulate
+
+ def __repr__(self):
+ return (
+ f'{self.__class__.__name__}({self.in_channel}, {self.out_channel}, {self.kernel_size}, '
+ f'upsample={self.upsample}, downsample={self.downsample})'
+ )
+
+ def forward(self, input, style):
+ batch, in_channel, height, width = input.shape
+
+ style = self.modulation(style).view(batch, 1, in_channel, 1, 1)
+ weight = self.scale * self.weight * style
+
+ if self.demodulate:
+ demod = torch.rsqrt(weight.pow(2).sum([2, 3, 4]) + 1e-8)
+ weight = weight * demod.view(batch, self.out_channel, 1, 1, 1)
+
+ weight = weight.view(
+ batch * self.out_channel, in_channel, self.kernel_size, self.kernel_size
+ )
+
+ if self.upsample:
+ input = input.view(1, batch * in_channel, height, width)
+ weight = weight.view(
+ batch, self.out_channel, in_channel, self.kernel_size, self.kernel_size
+ )
+ weight = weight.transpose(1, 2).reshape(
+ batch * in_channel, self.out_channel, self.kernel_size, self.kernel_size
+ )
+ out = F.conv_transpose2d(input, weight, padding=0, stride=2, groups=batch)
+ _, _, height, width = out.shape
+ out = out.view(batch, self.out_channel, height, width)
+ out = self.blur(out)
+
+ elif self.downsample:
+ input = self.blur(input)
+ _, _, height, width = input.shape
+ input = input.view(1, batch * in_channel, height, width)
+ out = F.conv2d(input, weight, padding=0, stride=2, groups=batch)
+ _, _, height, width = out.shape
+ out = out.view(batch, self.out_channel, height, width)
+
+ else:
+ input = input.view(1, batch * in_channel, height, width)
+ out = F.conv2d(input, weight, padding=self.padding, groups=batch)
+ _, _, height, width = out.shape
+ out = out.view(batch, self.out_channel, height, width)
+
+ return out
+
+
+class NoiseInjection(nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ self.weight = nn.Parameter(torch.zeros(1))
+
+ def forward(self, image, noise=None):
+
+ if noise is not None:
+ #print(image.shape, noise.shape)
+ if isconcat: return torch.cat((image, self.weight * noise), dim=1) # concat
+ return image + self.weight * noise
+
+ if noise is None:
+ batch, _, height, width = image.shape
+ noise = image.new_empty(batch, 1, height, width).normal_()
+
+ return image + self.weight * noise
+ #return torch.cat((image, self.weight * noise), dim=1)
+
+
+class ConstantInput(nn.Module):
+ def __init__(self, channel, size=4):
+ super().__init__()
+
+ self.input = nn.Parameter(torch.randn(1, channel, size, size))
+
+ def forward(self, input):
+ batch = input.shape[0]
+ out = self.input.repeat(batch, 1, 1, 1)
+
+ return out
+
+
+class StyledConv(nn.Module):
+ def __init__(
+ self,
+ in_channel,
+ out_channel,
+ kernel_size,
+ style_dim,
+ upsample=False,
+ blur_kernel=[1, 3, 3, 1],
+ demodulate=True,
+ ):
+ super().__init__()
+
+ self.conv = ModulatedConv2d(
+ in_channel,
+ out_channel,
+ kernel_size,
+ style_dim,
+ upsample=upsample,
+ blur_kernel=blur_kernel,
+ demodulate=demodulate,
+ )
+
+ self.noise = NoiseInjection()
+ #self.bias = nn.Parameter(torch.zeros(1, out_channel, 1, 1))
+ #self.activate = ScaledLeakyReLU(0.2)
+ self.activate = FusedLeakyReLU(out_channel*sss)
+
+ def forward(self, input, style, noise=None):
+ out = self.conv(input, style)
+ out = self.noise(out, noise=noise)
+ # out = out + self.bias
+ out = self.activate(out)
+
+ return out
+
+
+class ToRGB(nn.Module):
+ def __init__(self, in_channel, style_dim, upsample=True, blur_kernel=[1, 3, 3, 1]):
+ super().__init__()
+
+ if upsample:
+ self.upsample = Upsample(blur_kernel)
+
+ self.conv = ModulatedConv2d(in_channel, 3, 1, style_dim, demodulate=False)
+ self.bias = nn.Parameter(torch.zeros(1, 3, 1, 1))
+
+ def forward(self, input, style, skip=None):
+ out = self.conv(input, style)
+ out = out + self.bias
+
+ if skip is not None:
+ skip = self.upsample(skip)
+
+ out = out + skip
+
+ return out
+
+class Generator(nn.Module):
+ def __init__(
+ self,
+ size,
+ style_dim,
+ n_mlp,
+ channel_multiplier=2,
+ blur_kernel=[1, 3, 3, 1],
+ lr_mlp=0.01,
+ ):
+ super().__init__()
+
+ self.size = size
+ self.n_mlp = n_mlp
+ self.style_dim = style_dim
+
+ layers = [PixelNorm()]
+
+ for i in range(n_mlp):
+ layers.append(
+ EqualLinear(
+ style_dim, style_dim, lr_mul=lr_mlp, activation='fused_lrelu'
+ )
+ )
+
+ self.style = nn.Sequential(*layers)
+
+ self.channels = {
+ 4: 512,
+ 8: 512,
+ 16: 512,
+ 32: 512,
+ 64: 256 * channel_multiplier,
+ 128: 128 * channel_multiplier,
+ 256: 64 * channel_multiplier,
+ 512: 32 * channel_multiplier,
+ 1024: 16 * channel_multiplier,
+ }
+
+ self.input = ConstantInput(self.channels[4])
+ self.conv1 = StyledConv(
+ self.channels[4], self.channels[4], 3, style_dim, blur_kernel=blur_kernel
+ )
+ self.to_rgb1 = ToRGB(self.channels[4]*sss, style_dim, upsample=False)
+
+ self.log_size = int(math.log(size, 2))
+
+ self.convs = nn.ModuleList()
+ self.upsamples = nn.ModuleList()
+ self.to_rgbs = nn.ModuleList()
+
+ in_channel = self.channels[4]
+
+ for i in range(3, self.log_size + 1):
+ out_channel = self.channels[2 ** i]
+
+ self.convs.append(
+ StyledConv(
+ in_channel*sss,
+ out_channel,
+ 3,
+ style_dim,
+ upsample=True,
+ blur_kernel=blur_kernel,
+ )
+ )
+
+ self.convs.append(
+ StyledConv(
+ out_channel*sss, out_channel, 3, style_dim, blur_kernel=blur_kernel
+ )
+ )
+
+ self.to_rgbs.append(ToRGB(out_channel*sss, style_dim))
+
+ in_channel = out_channel
+
+ self.n_latent = self.log_size * 2 - 2
+
+ def make_noise(self):
+ device = self.input.input.device
+
+ noises = [torch.randn(1, 1, 2 ** 2, 2 ** 2, device=device)]
+
+ for i in range(3, self.log_size + 1):
+ for _ in range(2):
+ noises.append(torch.randn(1, 1, 2 ** i, 2 ** i, device=device))
+
+ return noises
+
+ def mean_latent(self, n_latent):
+ latent_in = torch.randn(
+ n_latent, self.style_dim, device=self.input.input.device
+ )
+ latent = self.style(latent_in).mean(0, keepdim=True)
+
+ return latent
+
+ def get_latent(self, input):
+ return self.style(input)
+
+ def forward(
+ self,
+ styles,
+ return_latents=False,
+ inject_index=None,
+ truncation=1,
+ truncation_latent=None,
+ input_is_latent=False,
+ noise=None,
+ ):
+ if not input_is_latent:
+ styles = [self.style(s) for s in styles]
+
+ if noise is None:
+ '''
+ noise = [None] * (2 * (self.log_size - 2) + 1)
+ '''
+ noise = []
+ batch = styles[0].shape[0]
+ for i in range(self.n_mlp + 1):
+ size = 2 ** (i+2)
+ noise.append(torch.randn(batch, self.channels[size], size, size, device=styles[0].device))
+ #print(self.channels[size], size)
+
+ if truncation < 1:
+ style_t = []
+
+ for style in styles:
+ style_t.append(
+ truncation_latent + truncation * (style - truncation_latent)
+ )
+
+ styles = style_t
+
+ if len(styles) < 2:
+ inject_index = self.n_latent
+
+ latent = styles[0].unsqueeze(1).repeat(1, inject_index, 1)
+
+ else:
+ if inject_index is None:
+ inject_index = random.randint(1, self.n_latent - 1)
+
+ latent = styles[0].unsqueeze(1).repeat(1, inject_index, 1)
+ latent2 = styles[1].unsqueeze(1).repeat(1, self.n_latent - inject_index, 1)
+
+ latent = torch.cat([latent, latent2], 1)
+
+ out = self.input(latent)
+ out = self.conv1(out, latent[:, 0], noise=noise[0])
+
+ skip = self.to_rgb1(out, latent[:, 1])
+
+ i = 1
+ noise_i = 1
+
+ outs = []
+ for conv1, conv2, to_rgb in zip(
+ self.convs[::2], self.convs[1::2], self.to_rgbs
+ ):
+ #print(out.shape, noise[(noise_i)//2].shape, noise[(noise_i + 1)//2].shape)
+ out = conv1(out, latent[:, i], noise=noise[(noise_i + 1)//2]) ### 1 for 2
+ out = conv2(out, latent[:, i + 1], noise=noise[(noise_i + 2)//2]) ### 1 for 2
+ skip = to_rgb(out, latent[:, i + 2], skip)
+ #outs.append(skip.clone())
+
+ i += 2
+ noise_i += 2
+
+ image = skip
+
+ if return_latents:
+ return image, latent
+
+ else:
+ return image, None
+
+class ConvLayer(nn.Sequential):
+ def __init__(
+ self,
+ in_channel,
+ out_channel,
+ kernel_size,
+ downsample=False,
+ blur_kernel=[1, 3, 3, 1],
+ bias=True,
+ activate=True,
+ ):
+ layers = []
+
+ if downsample:
+ factor = 2
+ p = (len(blur_kernel) - factor) + (kernel_size - 1)
+ pad0 = (p + 1) // 2
+ pad1 = p // 2
+
+ layers.append(Blur(blur_kernel, pad=(pad0, pad1)))
+
+ stride = 2
+ self.padding = 0
+
+ else:
+ stride = 1
+ self.padding = kernel_size // 2
+
+ layers.append(
+ EqualConv2d(
+ in_channel,
+ out_channel,
+ kernel_size,
+ padding=self.padding,
+ stride=stride,
+ bias=bias and not activate,
+ )
+ )
+
+ if activate:
+ if bias:
+ layers.append(FusedLeakyReLU(out_channel))
+
+ else:
+ layers.append(ScaledLeakyReLU(0.2))
+
+ super().__init__(*layers)
+
+
+class ResBlock(nn.Module):
+ def __init__(self, in_channel, out_channel, blur_kernel=[1, 3, 3, 1]):
+ super().__init__()
+
+ self.conv1 = ConvLayer(in_channel, in_channel, 3)
+ self.conv2 = ConvLayer(in_channel, out_channel, 3, downsample=True)
+
+ self.skip = ConvLayer(
+ in_channel, out_channel, 1, downsample=True, activate=False, bias=False
+ )
+
+ def forward(self, input):
+ out = self.conv1(input)
+ out = self.conv2(out)
+
+ skip = self.skip(input)
+ out = (out + skip) / math.sqrt(2)
+
+ return out
+
+
+# -----------------------------
+# Main model
+# -----------------------------
+class FullGenerator(nn.Module):
+ def __init__(
+ self,
+ size,
+ style_dim,
+ n_mlp,
+ channel_multiplier=2,
+ blur_kernel=[1, 3, 3, 1],
+ lr_mlp=0.01,
+ ):
+ super().__init__()
+ channels = {
+ 4: 512,
+ 8: 512,
+ 16: 512,
+ 32: 512,
+ 64: 256 * channel_multiplier,
+ 128: 128 * channel_multiplier,
+ 256: 64 * channel_multiplier,
+ 512: 32 * channel_multiplier,
+ 1024: 16 * channel_multiplier,
+ }
+
+ self.log_size = int(math.log(size, 2))
+ self.generator = Generator(size, style_dim, n_mlp, channel_multiplier=channel_multiplier, blur_kernel=blur_kernel, lr_mlp=lr_mlp)
+
+ conv = [ConvLayer(3, channels[size], 1)]
+ self.ecd0 = nn.Sequential(*conv)
+ in_channel = channels[size]
+
+ self.names = ['ecd%d'%i for i in range(self.log_size-1)]
+ for i in range(self.log_size, 2, -1):
+ out_channel = channels[2 ** (i - 1)]
+ #conv = [ResBlock(in_channel, out_channel, blur_kernel)]
+ conv = [ConvLayer(in_channel, out_channel, 3, downsample=True)]
+ setattr(self, self.names[self.log_size-i+1], nn.Sequential(*conv))
+ in_channel = out_channel
+ self.final_linear = nn.Sequential(EqualLinear(channels[4] * 4 * 4, style_dim, activation='fused_lrelu'))
+
+ def forward(self,
+ inputs,
+ return_latents=False,
+ inject_index=None,
+ truncation=1,
+ truncation_latent=None,
+ input_is_latent=False,
+ ):
+ noise = []
+ for i in range(self.log_size-1):
+ ecd = getattr(self, self.names[i])
+ inputs = ecd(inputs)
+ noise.append(inputs)
+ #print(inputs.shape)
+ inputs = inputs.view(inputs.shape[0], -1)
+ outs = self.final_linear(inputs)
+ #print(outs.shape)
+ outs = self.generator([outs], return_latents, inject_index, truncation, truncation_latent, input_is_latent, noise=noise[::-1])
+ return outs
diff --git a/KAIR/models/network_feature.py b/KAIR/models/network_feature.py
new file mode 100644
index 0000000000000000000000000000000000000000..977f0b57558c7e385801597255033cc669ae7b65
--- /dev/null
+++ b/KAIR/models/network_feature.py
@@ -0,0 +1,46 @@
+import torch
+import torch.nn as nn
+import torchvision
+
+
+"""
+# --------------------------------------------
+# VGG Feature Extractor
+# --------------------------------------------
+"""
+
+# --------------------------------------------
+# VGG features
+# Assume input range is [0, 1]
+# --------------------------------------------
+class VGGFeatureExtractor(nn.Module):
+ def __init__(self,
+ feature_layer=34,
+ use_bn=False,
+ use_input_norm=True,
+ device=torch.device('cpu')):
+ super(VGGFeatureExtractor, self).__init__()
+ if use_bn:
+ model = torchvision.models.vgg19_bn(pretrained=True)
+ else:
+ model = torchvision.models.vgg19(pretrained=True)
+ self.use_input_norm = use_input_norm
+ if self.use_input_norm:
+ mean = torch.Tensor([0.485, 0.456, 0.406]).view(1, 3, 1, 1).to(device)
+ # [0.485-1, 0.456-1, 0.406-1] if input in range [-1,1]
+ std = torch.Tensor([0.229, 0.224, 0.225]).view(1, 3, 1, 1).to(device)
+ # [0.229*2, 0.224*2, 0.225*2] if input in range [-1,1]
+ self.register_buffer('mean', mean)
+ self.register_buffer('std', std)
+ self.features = nn.Sequential(*list(model.features.children())[:(feature_layer + 1)])
+ # No need to BP to variable
+ for k, v in self.features.named_parameters():
+ v.requires_grad = False
+
+ def forward(self, x):
+ if self.use_input_norm:
+ x = (x - self.mean) / self.std
+ output = self.features(x)
+ return output
+
+
diff --git a/KAIR/models/network_ffdnet.py b/KAIR/models/network_ffdnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..de2ce575cf309af05f1b5f30942e93a1fdf38e7d
--- /dev/null
+++ b/KAIR/models/network_ffdnet.py
@@ -0,0 +1,84 @@
+import numpy as np
+import torch.nn as nn
+import models.basicblock as B
+import torch
+
+"""
+# --------------------------------------------
+# FFDNet (15 or 12 conv layers)
+# --------------------------------------------
+Reference:
+@article{zhang2018ffdnet,
+ title={FFDNet: Toward a fast and flexible solution for CNN-based image denoising},
+ author={Zhang, Kai and Zuo, Wangmeng and Zhang, Lei},
+ journal={IEEE Transactions on Image Processing},
+ volume={27},
+ number={9},
+ pages={4608--4622},
+ year={2018},
+ publisher={IEEE}
+}
+"""
+
+
+# --------------------------------------------
+# FFDNet
+# --------------------------------------------
+class FFDNet(nn.Module):
+ def __init__(self, in_nc=1, out_nc=1, nc=64, nb=15, act_mode='R'):
+ """
+ # ------------------------------------
+ in_nc: channel number of input
+ out_nc: channel number of output
+ nc: channel number
+ nb: total number of conv layers
+ act_mode: batch norm + activation function; 'BR' means BN+ReLU.
+ # ------------------------------------
+ # ------------------------------------
+ """
+ super(FFDNet, self).__init__()
+ assert 'R' in act_mode or 'L' in act_mode, 'Examples of activation function: R, L, BR, BL, IR, IL'
+ bias = True
+ sf = 2
+
+ self.m_down = B.PixelUnShuffle(upscale_factor=sf)
+
+ m_head = B.conv(in_nc*sf*sf+1, nc, mode='C'+act_mode[-1], bias=bias)
+ m_body = [B.conv(nc, nc, mode='C'+act_mode, bias=bias) for _ in range(nb-2)]
+ m_tail = B.conv(nc, out_nc*sf*sf, mode='C', bias=bias)
+
+ self.model = B.sequential(m_head, *m_body, m_tail)
+
+ self.m_up = nn.PixelShuffle(upscale_factor=sf)
+
+ def forward(self, x, sigma):
+
+ h, w = x.size()[-2:]
+ paddingBottom = int(np.ceil(h/2)*2-h)
+ paddingRight = int(np.ceil(w/2)*2-w)
+ x = torch.nn.ReplicationPad2d((0, paddingRight, 0, paddingBottom))(x)
+
+ x = self.m_down(x)
+ # m = torch.ones(sigma.size()[0], sigma.size()[1], x.size()[-2], x.size()[-1]).type_as(x).mul(sigma)
+ m = sigma.repeat(1, 1, x.size()[-2], x.size()[-1])
+ x = torch.cat((x, m), 1)
+ x = self.model(x)
+ x = self.m_up(x)
+
+ x = x[..., :h, :w]
+ return x
+
+
+if __name__ == '__main__':
+ from utils import utils_model
+ model = FFDNet(in_nc=1, out_nc=1, nc=64, nb=15, act_mode='R')
+ print(utils_model.describe_model(model))
+
+ x = torch.randn((2,1,240,240))
+ sigma = torch.randn(2,1,1,1)
+ x = model(x, sigma)
+ print(x.shape)
+
+ # run models/network_ffdnet.py
+
+
diff --git a/KAIR/models/network_imdn.py b/KAIR/models/network_imdn.py
new file mode 100644
index 0000000000000000000000000000000000000000..faf7e6167f6a521f799735c6d135b0654364997a
--- /dev/null
+++ b/KAIR/models/network_imdn.py
@@ -0,0 +1,66 @@
+import math
+import torch.nn as nn
+import models.basicblock as B
+
+
+"""
+# --------------------------------------------
+# simplified information multi-distillation
+# network (IMDN) for SR
+# --------------------------------------------
+References:
+@inproceedings{hui2019lightweight,
+ title={Lightweight Image Super-Resolution with Information Multi-distillation Network},
+ author={Hui, Zheng and Gao, Xinbo and Yang, Yunchu and Wang, Xiumei},
+ booktitle={Proceedings of the 27th ACM International Conference on Multimedia (ACM MM)},
+ pages={2024--2032},
+ year={2019}
+}
+@inproceedings{zhang2019aim,
+ title={AIM 2019 Challenge on Constrained Super-Resolution: Methods and Results},
+ author={Kai Zhang and Shuhang Gu and Radu Timofte and others},
+ booktitle={IEEE International Conference on Computer Vision Workshops},
+ year={2019}
+}
+# --------------------------------------------
+"""
+
+
+# --------------------------------------------
+# modified version, https://github.com/Zheng222/IMDN
+# first place solution for AIM 2019 challenge
+# --------------------------------------------
+class IMDN(nn.Module):
+ def __init__(self, in_nc=3, out_nc=3, nc=64, nb=8, upscale=4, act_mode='L', upsample_mode='pixelshuffle', negative_slope=0.05):
+ """
+ in_nc: channel number of input
+ out_nc: channel number of output
+ nc: channel number
+ nb: number of residual blocks
+ upscale: up-scale factor
+ act_mode: activation function
+ upsample_mode: 'upconv' | 'pixelshuffle' | 'convtranspose'
+ """
+ super(IMDN, self).__init__()
+ assert 'R' in act_mode or 'L' in act_mode, 'Examples of activation function: R, L, BR, BL, IR, IL'
+
+ m_head = B.conv(in_nc, nc, mode='C')
+ m_body = [B.IMDBlock(nc, nc, mode='C'+act_mode, negative_slope=negative_slope) for _ in range(nb)]
+ m_body.append(B.conv(nc, nc, mode='C'))
+
+ if upsample_mode == 'upconv':
+ upsample_block = B.upsample_upconv
+ elif upsample_mode == 'pixelshuffle':
+ upsample_block = B.upsample_pixelshuffle
+ elif upsample_mode == 'convtranspose':
+ upsample_block = B.upsample_convtranspose
+ else:
+ raise NotImplementedError('upsample mode [{:s}] is not found'.format(upsample_mode))
+
+ m_uper = upsample_block(nc, out_nc, mode=str(upscale))
+
+ self.model = B.sequential(m_head, B.ShortcutBlock(B.sequential(*m_body)), *m_uper)
+
+ def forward(self, x):
+ x = self.model(x)
+ return x
diff --git a/KAIR/models/network_msrresnet.py b/KAIR/models/network_msrresnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..d5f7964b4dcf49b66d4c38eb90572b3474c32577
--- /dev/null
+++ b/KAIR/models/network_msrresnet.py
@@ -0,0 +1,182 @@
+import math
+import torch.nn as nn
+import models.basicblock as B
+import functools
+import torch.nn.functional as F
+import torch.nn.init as init
+
+
+"""
+# --------------------------------------------
+# modified SRResNet
+# -- MSRResNet0 (v0.0)
+# -- MSRResNet1 (v0.1)
+# --------------------------------------------
+References:
+@inproceedings{wang2018esrgan,
+ title={Esrgan: Enhanced super-resolution generative adversarial networks},
+ author={Wang, Xintao and Yu, Ke and Wu, Shixiang and Gu, Jinjin and Liu, Yihao and Dong, Chao and Qiao, Yu and Change Loy, Chen},
+ booktitle={European Concerence on Computer Vision (ECCV)},
+ pages={0--0},
+ year={2018}
+}
+@inproceedings{ledig2017photo,
+ title={Photo-realistic single image super-resolution using a generative adversarial network},
+ author={Ledig, Christian and Theis, Lucas and Husz{\'a}r, Ferenc and Caballero, Jose and Cunningham, Andrew and Acosta, Alejandro and Aitken, Andrew and Tejani, Alykhan and Totz, Johannes and Wang, Zehan and others},
+ booktitle={IEEE concerence on computer vision and pattern recognition},
+ pages={4681--4690},
+ year={2017}
+}
+# --------------------------------------------
+"""
+
+
+# --------------------------------------------
+# modified SRResNet v0.0
+# https://github.com/xinntao/ESRGAN
+# --------------------------------------------
+class MSRResNet0(nn.Module):
+ def __init__(self, in_nc=3, out_nc=3, nc=64, nb=16, upscale=4, act_mode='R', upsample_mode='upconv'):
+ """
+ in_nc: channel number of input
+ out_nc: channel number of output
+ nc: channel number
+ nb: number of residual blocks
+ upscale: up-scale factor
+ act_mode: activation function
+ upsample_mode: 'upconv' | 'pixelshuffle' | 'convtranspose'
+ """
+ super(MSRResNet0, self).__init__()
+ assert 'R' in act_mode or 'L' in act_mode, 'Examples of activation function: R, L, BR, BL, IR, IL'
+
+ n_upscale = int(math.log(upscale, 2))
+ if upscale == 3:
+ n_upscale = 1
+
+ m_head = B.conv(in_nc, nc, mode='C')
+
+ m_body = [B.ResBlock(nc, nc, mode='C'+act_mode+'C') for _ in range(nb)]
+ m_body.append(B.conv(nc, nc, mode='C'))
+
+ if upsample_mode == 'upconv':
+ upsample_block = B.upsample_upconv
+ elif upsample_mode == 'pixelshuffle':
+ upsample_block = B.upsample_pixelshuffle
+ elif upsample_mode == 'convtranspose':
+ upsample_block = B.upsample_convtranspose
+ else:
+ raise NotImplementedError('upsample mode [{:s}] is not found'.format(upsample_mode))
+ if upscale == 3:
+ m_uper = upsample_block(nc, nc, mode='3'+act_mode)
+ else:
+ m_uper = [upsample_block(nc, nc, mode='2'+act_mode) for _ in range(n_upscale)]
+
+ H_conv0 = B.conv(nc, nc, mode='C'+act_mode)
+ H_conv1 = B.conv(nc, out_nc, bias=False, mode='C')
+ m_tail = B.sequential(H_conv0, H_conv1)
+
+ self.model = B.sequential(m_head, B.ShortcutBlock(B.sequential(*m_body)), *m_uper, m_tail)
+
+ def forward(self, x):
+ x = self.model(x)
+ return x
+
+
+# --------------------------------------------
+# modified SRResNet v0.1
+# https://github.com/xinntao/ESRGAN
+# --------------------------------------------
+class MSRResNet1(nn.Module):
+ def __init__(self, in_nc=3, out_nc=3, nc=64, nb=16, upscale=4, act_mode='R', upsample_mode='upconv'):
+ super(MSRResNet1, self).__init__()
+ self.upscale = upscale
+
+ self.conv_first = nn.Conv2d(in_nc, nc, 3, 1, 1, bias=True)
+ basic_block = functools.partial(ResidualBlock_noBN, nc=nc)
+ self.recon_trunk = make_layer(basic_block, nb)
+
+ # upsampling
+ if self.upscale == 2:
+ self.upconv1 = nn.Conv2d(nc, nc * 4, 3, 1, 1, bias=True)
+ self.pixel_shuffle = nn.PixelShuffle(2)
+ elif self.upscale == 3:
+ self.upconv1 = nn.Conv2d(nc, nc * 9, 3, 1, 1, bias=True)
+ self.pixel_shuffle = nn.PixelShuffle(3)
+ elif self.upscale == 4:
+ self.upconv1 = nn.Conv2d(nc, nc * 4, 3, 1, 1, bias=True)
+ self.upconv2 = nn.Conv2d(nc, nc * 4, 3, 1, 1, bias=True)
+ self.pixel_shuffle = nn.PixelShuffle(2)
+
+ self.HRconv = nn.Conv2d(nc, nc, 3, 1, 1, bias=True)
+ self.conv_last = nn.Conv2d(nc, out_nc, 3, 1, 1, bias=True)
+
+ # activation function
+ self.lrelu = nn.LeakyReLU(negative_slope=0.1, inplace=True)
+
+ # initialization
+ initialize_weights([self.conv_first, self.upconv1, self.HRconv, self.conv_last], 0.1)
+ if self.upscale == 4:
+ initialize_weights(self.upconv2, 0.1)
+
+ def forward(self, x):
+ fea = self.lrelu(self.conv_first(x))
+ out = self.recon_trunk(fea)
+
+ if self.upscale == 4:
+ out = self.lrelu(self.pixel_shuffle(self.upconv1(out)))
+ out = self.lrelu(self.pixel_shuffle(self.upconv2(out)))
+ elif self.upscale == 3 or self.upscale == 2:
+ out = self.lrelu(self.pixel_shuffle(self.upconv1(out)))
+
+ out = self.conv_last(self.lrelu(self.HRconv(out)))
+ base = F.interpolate(x, scale_factor=self.upscale, mode='bilinear', align_corners=False)
+ out += base
+ return out
+
+
+def initialize_weights(net_l, scale=1):
+ if not isinstance(net_l, list):
+ net_l = [net_l]
+ for net in net_l:
+ for m in net.modules():
+ if isinstance(m, nn.Conv2d):
+ init.kaiming_normal_(m.weight, a=0, mode='fan_in')
+ m.weight.data *= scale # for residual block
+ if m.bias is not None:
+ m.bias.data.zero_()
+ elif isinstance(m, nn.Linear):
+ init.kaiming_normal_(m.weight, a=0, mode='fan_in')
+ m.weight.data *= scale
+ if m.bias is not None:
+ m.bias.data.zero_()
+ elif isinstance(m, nn.BatchNorm2d):
+ init.constant_(m.weight, 1)
+ init.constant_(m.bias.data, 0.0)
+
+
+def make_layer(block, n_layers):
+ layers = []
+ for _ in range(n_layers):
+ layers.append(block())
+ return nn.Sequential(*layers)
+
+
+class ResidualBlock_noBN(nn.Module):
+ '''Residual block w/o BN
+ ---Conv-ReLU-Conv-+-
+ |________________|
+ '''
+
+ def __init__(self, nc=64):
+ super(ResidualBlock_noBN, self).__init__()
+ self.conv1 = nn.Conv2d(nc, nc, 3, 1, 1, bias=True)
+ self.conv2 = nn.Conv2d(nc, nc, 3, 1, 1, bias=True)
+
+ # initialization
+ initialize_weights([self.conv1, self.conv2], 0.1)
+
+ def forward(self, x):
+ identity = x
+ out = F.relu(self.conv1(x), inplace=True)
+ out = self.conv2(out)
+ return identity + out
diff --git a/KAIR/models/network_rrdb.py b/KAIR/models/network_rrdb.py
new file mode 100644
index 0000000000000000000000000000000000000000..91ae94cc5ed857ffead176fc317d553edc97a507
--- /dev/null
+++ b/KAIR/models/network_rrdb.py
@@ -0,0 +1,54 @@
+import math
+import torch.nn as nn
+import models.basicblock as B
+
+
+"""
+# --------------------------------------------
+# SR network with Residual in Residual Dense Block (RRDB)
+# "ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks"
+# --------------------------------------------
+"""
+
+
+class RRDB(nn.Module):
+ """
+ gc: number of growth channels
+ nb: number of RRDB
+ """
+ def __init__(self, in_nc=3, out_nc=3, nc=64, nb=23, gc=32, upscale=4, act_mode='L', upsample_mode='upconv'):
+ super(RRDB, self).__init__()
+ assert 'R' in act_mode or 'L' in act_mode, 'Examples of activation function: R, L, BR, BL, IR, IL'
+
+ n_upscale = int(math.log(upscale, 2))
+ if upscale == 3:
+ n_upscale = 1
+
+ m_head = B.conv(in_nc, nc, mode='C')
+
+ m_body = [B.RRDB(nc, gc=32, mode='C'+act_mode) for _ in range(nb)]
+ m_body.append(B.conv(nc, nc, mode='C'))
+
+ if upsample_mode == 'upconv':
+ upsample_block = B.upsample_upconv
+ elif upsample_mode == 'pixelshuffle':
+ upsample_block = B.upsample_pixelshuffle
+ elif upsample_mode == 'convtranspose':
+ upsample_block = B.upsample_convtranspose
+ else:
+ raise NotImplementedError('upsample mode [{:s}] is not found'.format(upsample_mode))
+
+ if upscale == 3:
+ m_uper = upsample_block(nc, nc, mode='3'+act_mode)
+ else:
+ m_uper = [upsample_block(nc, nc, mode='2'+act_mode) for _ in range(n_upscale)]
+
+ H_conv0 = B.conv(nc, nc, mode='C'+act_mode)
+ H_conv1 = B.conv(nc, out_nc, mode='C')
+ m_tail = B.sequential(H_conv0, H_conv1)
+
+ self.model = B.sequential(m_head, B.ShortcutBlock(B.sequential(*m_body)), *m_uper, m_tail)
+
+ def forward(self, x):
+ x = self.model(x)
+ return x
diff --git a/KAIR/models/network_rrdbnet.py b/KAIR/models/network_rrdbnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..a35e5c017738eb40759245b6c6c80c1ba750db5e
--- /dev/null
+++ b/KAIR/models/network_rrdbnet.py
@@ -0,0 +1,103 @@
+import functools
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torch.nn.init as init
+
+
+def initialize_weights(net_l, scale=1):
+ if not isinstance(net_l, list):
+ net_l = [net_l]
+ for net in net_l:
+ for m in net.modules():
+ if isinstance(m, nn.Conv2d):
+ init.kaiming_normal_(m.weight, a=0, mode='fan_in')
+ m.weight.data *= scale # for residual block
+ if m.bias is not None:
+ m.bias.data.zero_()
+ elif isinstance(m, nn.Linear):
+ init.kaiming_normal_(m.weight, a=0, mode='fan_in')
+ m.weight.data *= scale
+ if m.bias is not None:
+ m.bias.data.zero_()
+ elif isinstance(m, nn.BatchNorm2d):
+ init.constant_(m.weight, 1)
+ init.constant_(m.bias.data, 0.0)
+
+
+def make_layer(block, n_layers):
+ layers = []
+ for _ in range(n_layers):
+ layers.append(block())
+ return nn.Sequential(*layers)
+
+
+class ResidualDenseBlock_5C(nn.Module):
+ def __init__(self, nf=64, gc=32, bias=True):
+ super(ResidualDenseBlock_5C, self).__init__()
+ # gc: growth channel, i.e. intermediate channels
+ self.conv1 = nn.Conv2d(nf, gc, 3, 1, 1, bias=bias)
+ self.conv2 = nn.Conv2d(nf + gc, gc, 3, 1, 1, bias=bias)
+ self.conv3 = nn.Conv2d(nf + 2 * gc, gc, 3, 1, 1, bias=bias)
+ self.conv4 = nn.Conv2d(nf + 3 * gc, gc, 3, 1, 1, bias=bias)
+ self.conv5 = nn.Conv2d(nf + 4 * gc, nf, 3, 1, 1, bias=bias)
+ self.lrelu = nn.LeakyReLU(negative_slope=0.2, inplace=True)
+
+ # initialization
+ initialize_weights([self.conv1, self.conv2, self.conv3, self.conv4, self.conv5], 0.1)
+
+ def forward(self, x):
+ x1 = self.lrelu(self.conv1(x))
+ x2 = self.lrelu(self.conv2(torch.cat((x, x1), 1)))
+ x3 = self.lrelu(self.conv3(torch.cat((x, x1, x2), 1)))
+ x4 = self.lrelu(self.conv4(torch.cat((x, x1, x2, x3), 1)))
+ x5 = self.conv5(torch.cat((x, x1, x2, x3, x4), 1))
+ return x5 * 0.2 + x
+
+
+class RRDB(nn.Module):
+ '''Residual in Residual Dense Block'''
+
+ def __init__(self, nf, gc=32):
+ super(RRDB, self).__init__()
+ self.RDB1 = ResidualDenseBlock_5C(nf, gc)
+ self.RDB2 = ResidualDenseBlock_5C(nf, gc)
+ self.RDB3 = ResidualDenseBlock_5C(nf, gc)
+
+ def forward(self, x):
+ out = self.RDB1(x)
+ out = self.RDB2(out)
+ out = self.RDB3(out)
+ return out * 0.2 + x
+
+
+class RRDBNet(nn.Module):
+ def __init__(self, in_nc=3, out_nc=3, nf=64, nb=23, gc=32, sf=4):
+ super(RRDBNet, self).__init__()
+ RRDB_block_f = functools.partial(RRDB, nf=nf, gc=gc)
+ self.sf = sf
+ print([in_nc, out_nc, nf, nb, gc, sf])
+
+ self.conv_first = nn.Conv2d(in_nc, nf, 3, 1, 1, bias=True)
+ self.RRDB_trunk = make_layer(RRDB_block_f, nb)
+ self.trunk_conv = nn.Conv2d(nf, nf, 3, 1, 1, bias=True)
+ #### upsampling
+ self.upconv1 = nn.Conv2d(nf, nf, 3, 1, 1, bias=True)
+ if self.sf==4:
+ self.upconv2 = nn.Conv2d(nf, nf, 3, 1, 1, bias=True)
+ self.HRconv = nn.Conv2d(nf, nf, 3, 1, 1, bias=True)
+ self.conv_last = nn.Conv2d(nf, out_nc, 3, 1, 1, bias=True)
+
+ self.lrelu = nn.LeakyReLU(negative_slope=0.2, inplace=True)
+
+ def forward(self, x):
+ fea = self.conv_first(x)
+ trunk = self.trunk_conv(self.RRDB_trunk(fea))
+ fea = fea + trunk
+
+ fea = self.lrelu(self.upconv1(F.interpolate(fea, scale_factor=2, mode='nearest')))
+ if self.sf == 4:
+ fea = self.lrelu(self.upconv2(F.interpolate(fea, scale_factor=2, mode='nearest')))
+ out = self.conv_last(self.lrelu(self.HRconv(fea)))
+
+ return out
diff --git a/KAIR/models/network_srmd.py b/KAIR/models/network_srmd.py
new file mode 100644
index 0000000000000000000000000000000000000000..4c414b236ac5986ff9ee3aea651d8ea433047ece
--- /dev/null
+++ b/KAIR/models/network_srmd.py
@@ -0,0 +1,81 @@
+
+import torch.nn as nn
+import models.basicblock as B
+import torch
+
+"""
+# --------------------------------------------
+# SRMD (15 conv layers)
+# --------------------------------------------
+Reference:
+@inproceedings{zhang2018learning,
+ title={Learning a single convolutional super-resolution network for multiple degradations},
+ author={Zhang, Kai and Zuo, Wangmeng and Zhang, Lei},
+ booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
+ pages={3262--3271},
+ year={2018}
+}
+http://openaccess.thecvf.com/content_cvpr_2018/papers/Zhang_Learning_a_Single_CVPR_2018_paper.pdf
+"""
+
+
+# --------------------------------------------
+# SRMD (SRMD, in_nc = 3+15+1 = 19)
+# SRMD (SRMDNF, in_nc = 3+15 = 18)
+# --------------------------------------------
+class SRMD(nn.Module):
+ def __init__(self, in_nc=19, out_nc=3, nc=128, nb=12, upscale=4, act_mode='R', upsample_mode='pixelshuffle'):
+ """
+ # ------------------------------------
+ in_nc: channel number of input, default: 3+15
+ out_nc: channel number of output
+ nc: channel number
+ nb: total number of conv layers
+ upscale: scale factor
+ act_mode: batch norm + activation function; 'BR' means BN+ReLU
+ upsample_mode: default 'pixelshuffle' = conv + pixelshuffle
+ # ------------------------------------
+ """
+ super(SRMD, self).__init__()
+ assert 'R' in act_mode or 'L' in act_mode, 'Examples of activation function: R, L, BR, BL, IR, IL'
+ bias = True
+
+ if upsample_mode == 'upconv':
+ upsample_block = B.upsample_upconv
+ elif upsample_mode == 'pixelshuffle':
+ upsample_block = B.upsample_pixelshuffle
+ elif upsample_mode == 'convtranspose':
+ upsample_block = B.upsample_convtranspose
+ else:
+ raise NotImplementedError('upsample mode [{:s}] is not found'.format(upsample_mode))
+
+ m_head = B.conv(in_nc, nc, mode='C'+act_mode[-1], bias=bias)
+ m_body = [B.conv(nc, nc, mode='C'+act_mode, bias=bias) for _ in range(nb-2)]
+ m_tail = upsample_block(nc, out_nc, mode=str(upscale), bias=bias)
+
+ self.model = B.sequential(m_head, *m_body, m_tail)
+
+# def forward(self, x, k_pca):
+# m = k_pca.repeat(1, 1, x.size()[-2], x.size()[-1])
+# x = torch.cat((x, m), 1)
+# x = self.body(x)
+
+ def forward(self, x):
+
+ x = self.model(x)
+
+ return x
+
+
+if __name__ == '__main__':
+ from utils import utils_model
+ model = SRMD(in_nc=18, out_nc=3, nc=64, nb=15, upscale=4, act_mode='R', upsample_mode='pixelshuffle')
+ print(utils_model.describe_model(model))
+
+ x = torch.randn((2, 3, 100, 100))
+ k_pca = torch.randn(2, 15, 1, 1)
+ x = model(x, k_pca)
+ print(x.shape)
+
+ # run models/network_srmd.py
+
diff --git a/KAIR/models/network_swinir.py b/KAIR/models/network_swinir.py
new file mode 100644
index 0000000000000000000000000000000000000000..0828a9a3f3355a6e677c35f25322b807af8c513d
--- /dev/null
+++ b/KAIR/models/network_swinir.py
@@ -0,0 +1,866 @@
+# -----------------------------------------------------------------------------------
+# SwinIR: Image Restoration Using Swin Transformer, https://arxiv.org/abs/2108.10257
+# Originally Written by Ze Liu, Modified by Jingyun Liang.
+# -----------------------------------------------------------------------------------
+
+import math
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torch.utils.checkpoint as checkpoint
+from timm.models.layers import DropPath, to_2tuple, trunc_normal_
+
+
+class Mlp(nn.Module):
+ def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
+ super().__init__()
+ out_features = out_features or in_features
+ hidden_features = hidden_features or in_features
+ self.fc1 = nn.Linear(in_features, hidden_features)
+ self.act = act_layer()
+ self.fc2 = nn.Linear(hidden_features, out_features)
+ self.drop = nn.Dropout(drop)
+
+ def forward(self, x):
+ x = self.fc1(x)
+ x = self.act(x)
+ x = self.drop(x)
+ x = self.fc2(x)
+ x = self.drop(x)
+ return x
+
+
+def window_partition(x, window_size):
+ """
+ Args:
+ x: (B, H, W, C)
+ window_size (int): window size
+
+ Returns:
+ windows: (num_windows*B, window_size, window_size, C)
+ """
+ B, H, W, C = x.shape
+ x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
+ windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
+ return windows
+
+
+def window_reverse(windows, window_size, H, W):
+ """
+ Args:
+ windows: (num_windows*B, window_size, window_size, C)
+ window_size (int): Window size
+ H (int): Height of image
+ W (int): Width of image
+
+ Returns:
+ x: (B, H, W, C)
+ """
+ B = int(windows.shape[0] / (H * W / window_size / window_size))
+ x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
+ x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
+ return x
+
+
+class WindowAttention(nn.Module):
+ r""" Window based multi-head self attention (W-MSA) module with relative position bias.
+ It supports both of shifted and non-shifted window.
+
+ Args:
+ dim (int): Number of input channels.
+ window_size (tuple[int]): The height and width of the window.
+ num_heads (int): Number of attention heads.
+ qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
+ qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
+ attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
+ proj_drop (float, optional): Dropout ratio of output. Default: 0.0
+ """
+
+ def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
+
+ super().__init__()
+ self.dim = dim
+ self.window_size = window_size # Wh, Ww
+ self.num_heads = num_heads
+ head_dim = dim // num_heads
+ self.scale = qk_scale or head_dim ** -0.5
+
+ # define a parameter table of relative position bias
+ self.relative_position_bias_table = nn.Parameter(
+ torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
+
+ # get pair-wise relative position index for each token inside the window
+ coords_h = torch.arange(self.window_size[0])
+ coords_w = torch.arange(self.window_size[1])
+ coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
+ coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
+ relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
+ relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
+ relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
+ relative_coords[:, :, 1] += self.window_size[1] - 1
+ relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
+ relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
+ self.register_buffer("relative_position_index", relative_position_index)
+
+ self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
+ self.attn_drop = nn.Dropout(attn_drop)
+ self.proj = nn.Linear(dim, dim)
+
+ self.proj_drop = nn.Dropout(proj_drop)
+
+ trunc_normal_(self.relative_position_bias_table, std=.02)
+ self.softmax = nn.Softmax(dim=-1)
+
+ def forward(self, x, mask=None):
+ """
+ Args:
+ x: input features with shape of (num_windows*B, N, C)
+ mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
+ """
+ B_, N, C = x.shape
+ qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
+ q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
+
+ q = q * self.scale
+ attn = (q @ k.transpose(-2, -1))
+
+ relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
+ self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
+ relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
+ attn = attn + relative_position_bias.unsqueeze(0)
+
+ if mask is not None:
+ nW = mask.shape[0]
+ attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
+ attn = attn.view(-1, self.num_heads, N, N)
+ attn = self.softmax(attn)
+ else:
+ attn = self.softmax(attn)
+
+ attn = self.attn_drop(attn)
+
+ x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
+ x = self.proj(x)
+ x = self.proj_drop(x)
+ return x
+
+ def extra_repr(self) -> str:
+ return f'dim={self.dim}, window_size={self.window_size}, num_heads={self.num_heads}'
+
+ def flops(self, N):
+ # calculate flops for 1 window with token length of N
+ flops = 0
+ # qkv = self.qkv(x)
+ flops += N * self.dim * 3 * self.dim
+ # attn = (q @ k.transpose(-2, -1))
+ flops += self.num_heads * N * (self.dim // self.num_heads) * N
+ # x = (attn @ v)
+ flops += self.num_heads * N * N * (self.dim // self.num_heads)
+ # x = self.proj(x)
+ flops += N * self.dim * self.dim
+ return flops
+
+
+class SwinTransformerBlock(nn.Module):
+ r""" Swin Transformer Block.
+
+ Args:
+ dim (int): Number of input channels.
+ input_resolution (tuple[int]): Input resulotion.
+ num_heads (int): Number of attention heads.
+ window_size (int): Window size.
+ shift_size (int): Shift size for SW-MSA.
+ mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
+ qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
+ qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
+ drop (float, optional): Dropout rate. Default: 0.0
+ attn_drop (float, optional): Attention dropout rate. Default: 0.0
+ drop_path (float, optional): Stochastic depth rate. Default: 0.0
+ act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
+ norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
+ """
+
+ def __init__(self, dim, input_resolution, num_heads, window_size=7, shift_size=0,
+ mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,
+ act_layer=nn.GELU, norm_layer=nn.LayerNorm):
+ super().__init__()
+ self.dim = dim
+ self.input_resolution = input_resolution
+ self.num_heads = num_heads
+ self.window_size = window_size
+ self.shift_size = shift_size
+ self.mlp_ratio = mlp_ratio
+ if min(self.input_resolution) <= self.window_size:
+ # if window size is larger than input resolution, we don't partition windows
+ self.shift_size = 0
+ self.window_size = min(self.input_resolution)
+ assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"
+
+ self.norm1 = norm_layer(dim)
+ self.attn = WindowAttention(
+ dim, window_size=to_2tuple(self.window_size), num_heads=num_heads,
+ qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
+
+ self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
+ self.norm2 = norm_layer(dim)
+ mlp_hidden_dim = int(dim * mlp_ratio)
+ self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
+
+ if self.shift_size > 0:
+ attn_mask = self.calculate_mask(self.input_resolution)
+ else:
+ attn_mask = None
+
+ self.register_buffer("attn_mask", attn_mask)
+
+ def calculate_mask(self, x_size):
+ # calculate attention mask for SW-MSA
+ H, W = x_size
+ img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
+ h_slices = (slice(0, -self.window_size),
+ slice(-self.window_size, -self.shift_size),
+ slice(-self.shift_size, None))
+ w_slices = (slice(0, -self.window_size),
+ slice(-self.window_size, -self.shift_size),
+ slice(-self.shift_size, None))
+ cnt = 0
+ for h in h_slices:
+ for w in w_slices:
+ img_mask[:, h, w, :] = cnt
+ cnt += 1
+
+ mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1
+ mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
+ attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
+ attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
+
+ return attn_mask
+
+ def forward(self, x, x_size):
+ H, W = x_size
+ B, L, C = x.shape
+ # assert L == H * W, "input feature has wrong size"
+
+ shortcut = x
+ x = self.norm1(x)
+ x = x.view(B, H, W, C)
+
+ # cyclic shift
+ if self.shift_size > 0:
+ shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
+ else:
+ shifted_x = x
+
+ # partition windows
+ x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C
+ x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C
+
+ # W-MSA/SW-MSA (to be compatible for testing on images whose shapes are the multiple of window size
+ if self.input_resolution == x_size:
+ attn_windows = self.attn(x_windows, mask=self.attn_mask) # nW*B, window_size*window_size, C
+ else:
+ attn_windows = self.attn(x_windows, mask=self.calculate_mask(x_size).to(x.device))
+
+ # merge windows
+ attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)
+ shifted_x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C
+
+ # reverse cyclic shift
+ if self.shift_size > 0:
+ x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
+ else:
+ x = shifted_x
+ x = x.view(B, H * W, C)
+
+ # FFN
+ x = shortcut + self.drop_path(x)
+ x = x + self.drop_path(self.mlp(self.norm2(x)))
+
+ return x
+
+ def extra_repr(self) -> str:
+ return f"dim={self.dim}, input_resolution={self.input_resolution}, num_heads={self.num_heads}, " \
+ f"window_size={self.window_size}, shift_size={self.shift_size}, mlp_ratio={self.mlp_ratio}"
+
+ def flops(self):
+ flops = 0
+ H, W = self.input_resolution
+ # norm1
+ flops += self.dim * H * W
+ # W-MSA/SW-MSA
+ nW = H * W / self.window_size / self.window_size
+ flops += nW * self.attn.flops(self.window_size * self.window_size)
+ # mlp
+ flops += 2 * H * W * self.dim * self.dim * self.mlp_ratio
+ # norm2
+ flops += self.dim * H * W
+ return flops
+
+
+class PatchMerging(nn.Module):
+ r""" Patch Merging Layer.
+
+ Args:
+ input_resolution (tuple[int]): Resolution of input feature.
+ dim (int): Number of input channels.
+ norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
+ """
+
+ def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
+ super().__init__()
+ self.input_resolution = input_resolution
+ self.dim = dim
+ self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
+ self.norm = norm_layer(4 * dim)
+
+ def forward(self, x):
+ """
+ x: B, H*W, C
+ """
+ H, W = self.input_resolution
+ B, L, C = x.shape
+ assert L == H * W, "input feature has wrong size"
+ assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
+
+ x = x.view(B, H, W, C)
+
+ x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
+ x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
+ x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
+ x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
+ x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
+ x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
+
+ x = self.norm(x)
+ x = self.reduction(x)
+
+ return x
+
+ def extra_repr(self) -> str:
+ return f"input_resolution={self.input_resolution}, dim={self.dim}"
+
+ def flops(self):
+ H, W = self.input_resolution
+ flops = H * W * self.dim
+ flops += (H // 2) * (W // 2) * 4 * self.dim * 2 * self.dim
+ return flops
+
+
+class BasicLayer(nn.Module):
+ """ A basic Swin Transformer layer for one stage.
+
+ Args:
+ dim (int): Number of input channels.
+ input_resolution (tuple[int]): Input resolution.
+ depth (int): Number of blocks.
+ num_heads (int): Number of attention heads.
+ window_size (int): Local window size.
+ mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
+ qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
+ qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
+ drop (float, optional): Dropout rate. Default: 0.0
+ attn_drop (float, optional): Attention dropout rate. Default: 0.0
+ drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
+ norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
+ downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
+ use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
+ """
+
+ def __init__(self, dim, input_resolution, depth, num_heads, window_size,
+ mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0.,
+ drop_path=0., norm_layer=nn.LayerNorm, downsample=None, use_checkpoint=False):
+
+ super().__init__()
+ self.dim = dim
+ self.input_resolution = input_resolution
+ self.depth = depth
+ self.use_checkpoint = use_checkpoint
+
+ # build blocks
+ self.blocks = nn.ModuleList([
+ SwinTransformerBlock(dim=dim, input_resolution=input_resolution,
+ num_heads=num_heads, window_size=window_size,
+ shift_size=0 if (i % 2 == 0) else window_size // 2,
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias, qk_scale=qk_scale,
+ drop=drop, attn_drop=attn_drop,
+ drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
+ norm_layer=norm_layer)
+ for i in range(depth)])
+
+ # patch merging layer
+ if downsample is not None:
+ self.downsample = downsample(input_resolution, dim=dim, norm_layer=norm_layer)
+ else:
+ self.downsample = None
+
+ def forward(self, x, x_size):
+ for blk in self.blocks:
+ if self.use_checkpoint:
+ x = checkpoint.checkpoint(blk, x, x_size)
+ else:
+ x = blk(x, x_size)
+ if self.downsample is not None:
+ x = self.downsample(x)
+ return x
+
+ def extra_repr(self) -> str:
+ return f"dim={self.dim}, input_resolution={self.input_resolution}, depth={self.depth}"
+
+ def flops(self):
+ flops = 0
+ for blk in self.blocks:
+ flops += blk.flops()
+ if self.downsample is not None:
+ flops += self.downsample.flops()
+ return flops
+
+
+class RSTB(nn.Module):
+ """Residual Swin Transformer Block (RSTB).
+
+ Args:
+ dim (int): Number of input channels.
+ input_resolution (tuple[int]): Input resolution.
+ depth (int): Number of blocks.
+ num_heads (int): Number of attention heads.
+ window_size (int): Local window size.
+ mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
+ qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
+ qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
+ drop (float, optional): Dropout rate. Default: 0.0
+ attn_drop (float, optional): Attention dropout rate. Default: 0.0
+ drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
+ norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
+ downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
+ use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
+ img_size: Input image size.
+ patch_size: Patch size.
+ resi_connection: The convolutional block before residual connection.
+ """
+
+ def __init__(self, dim, input_resolution, depth, num_heads, window_size,
+ mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0.,
+ drop_path=0., norm_layer=nn.LayerNorm, downsample=None, use_checkpoint=False,
+ img_size=224, patch_size=4, resi_connection='1conv'):
+ super(RSTB, self).__init__()
+
+ self.dim = dim
+ self.input_resolution = input_resolution
+
+ self.residual_group = BasicLayer(dim=dim,
+ input_resolution=input_resolution,
+ depth=depth,
+ num_heads=num_heads,
+ window_size=window_size,
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias, qk_scale=qk_scale,
+ drop=drop, attn_drop=attn_drop,
+ drop_path=drop_path,
+ norm_layer=norm_layer,
+ downsample=downsample,
+ use_checkpoint=use_checkpoint)
+
+ if resi_connection == '1conv':
+ self.conv = nn.Conv2d(dim, dim, 3, 1, 1)
+ elif resi_connection == '3conv':
+ # to save parameters and memory
+ self.conv = nn.Sequential(nn.Conv2d(dim, dim // 4, 3, 1, 1), nn.LeakyReLU(negative_slope=0.2, inplace=True),
+ nn.Conv2d(dim // 4, dim // 4, 1, 1, 0),
+ nn.LeakyReLU(negative_slope=0.2, inplace=True),
+ nn.Conv2d(dim // 4, dim, 3, 1, 1))
+
+ self.patch_embed = PatchEmbed(
+ img_size=img_size, patch_size=patch_size, in_chans=0, embed_dim=dim,
+ norm_layer=None)
+
+ self.patch_unembed = PatchUnEmbed(
+ img_size=img_size, patch_size=patch_size, in_chans=0, embed_dim=dim,
+ norm_layer=None)
+
+ def forward(self, x, x_size):
+ return self.patch_embed(self.conv(self.patch_unembed(self.residual_group(x, x_size), x_size))) + x
+
+ def flops(self):
+ flops = 0
+ flops += self.residual_group.flops()
+ H, W = self.input_resolution
+ flops += H * W * self.dim * self.dim * 9
+ flops += self.patch_embed.flops()
+ flops += self.patch_unembed.flops()
+
+ return flops
+
+
+class PatchEmbed(nn.Module):
+ r""" Image to Patch Embedding
+
+ Args:
+ img_size (int): Image size. Default: 224.
+ patch_size (int): Patch token size. Default: 4.
+ in_chans (int): Number of input image channels. Default: 3.
+ embed_dim (int): Number of linear projection output channels. Default: 96.
+ norm_layer (nn.Module, optional): Normalization layer. Default: None
+ """
+
+ def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
+ super().__init__()
+ img_size = to_2tuple(img_size)
+ patch_size = to_2tuple(patch_size)
+ patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
+ self.img_size = img_size
+ self.patch_size = patch_size
+ self.patches_resolution = patches_resolution
+ self.num_patches = patches_resolution[0] * patches_resolution[1]
+
+ self.in_chans = in_chans
+ self.embed_dim = embed_dim
+
+ if norm_layer is not None:
+ self.norm = norm_layer(embed_dim)
+ else:
+ self.norm = None
+
+ def forward(self, x):
+ x = x.flatten(2).transpose(1, 2) # B Ph*Pw C
+ if self.norm is not None:
+ x = self.norm(x)
+ return x
+
+ def flops(self):
+ flops = 0
+ H, W = self.img_size
+ if self.norm is not None:
+ flops += H * W * self.embed_dim
+ return flops
+
+
+class PatchUnEmbed(nn.Module):
+ r""" Image to Patch Unembedding
+
+ Args:
+ img_size (int): Image size. Default: 224.
+ patch_size (int): Patch token size. Default: 4.
+ in_chans (int): Number of input image channels. Default: 3.
+ embed_dim (int): Number of linear projection output channels. Default: 96.
+ norm_layer (nn.Module, optional): Normalization layer. Default: None
+ """
+
+ def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
+ super().__init__()
+ img_size = to_2tuple(img_size)
+ patch_size = to_2tuple(patch_size)
+ patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
+ self.img_size = img_size
+ self.patch_size = patch_size
+ self.patches_resolution = patches_resolution
+ self.num_patches = patches_resolution[0] * patches_resolution[1]
+
+ self.in_chans = in_chans
+ self.embed_dim = embed_dim
+
+ def forward(self, x, x_size):
+ B, HW, C = x.shape
+ x = x.transpose(1, 2).view(B, self.embed_dim, x_size[0], x_size[1]) # B Ph*Pw C
+ return x
+
+ def flops(self):
+ flops = 0
+ return flops
+
+
+class Upsample(nn.Sequential):
+ """Upsample module.
+
+ Args:
+ scale (int): Scale factor. Supported scales: 2^n and 3.
+ num_feat (int): Channel number of intermediate features.
+ """
+
+ def __init__(self, scale, num_feat):
+ m = []
+ if (scale & (scale - 1)) == 0: # scale = 2^n
+ for _ in range(int(math.log(scale, 2))):
+ m.append(nn.Conv2d(num_feat, 4 * num_feat, 3, 1, 1))
+ m.append(nn.PixelShuffle(2))
+ elif scale == 3:
+ m.append(nn.Conv2d(num_feat, 9 * num_feat, 3, 1, 1))
+ m.append(nn.PixelShuffle(3))
+ else:
+ raise ValueError(f'scale {scale} is not supported. ' 'Supported scales: 2^n and 3.')
+ super(Upsample, self).__init__(*m)
+
+
+class UpsampleOneStep(nn.Sequential):
+ """UpsampleOneStep module (the difference with Upsample is that it always only has 1conv + 1pixelshuffle)
+ Used in lightweight SR to save parameters.
+
+ Args:
+ scale (int): Scale factor. Supported scales: 2^n and 3.
+ num_feat (int): Channel number of intermediate features.
+
+ """
+
+ def __init__(self, scale, num_feat, num_out_ch, input_resolution=None):
+ self.num_feat = num_feat
+ self.input_resolution = input_resolution
+ m = []
+ m.append(nn.Conv2d(num_feat, (scale ** 2) * num_out_ch, 3, 1, 1))
+ m.append(nn.PixelShuffle(scale))
+ super(UpsampleOneStep, self).__init__(*m)
+
+ def flops(self):
+ H, W = self.input_resolution
+ flops = H * W * self.num_feat * 3 * 9
+ return flops
+
+
+class SwinIR(nn.Module):
+ r""" SwinIR
+ A PyTorch impl of : `SwinIR: Image Restoration Using Swin Transformer`, based on Swin Transformer.
+
+ Args:
+ img_size (int | tuple(int)): Input image size. Default 64
+ patch_size (int | tuple(int)): Patch size. Default: 1
+ in_chans (int): Number of input image channels. Default: 3
+ embed_dim (int): Patch embedding dimension. Default: 96
+ depths (tuple(int)): Depth of each Swin Transformer layer.
+ num_heads (tuple(int)): Number of attention heads in different layers.
+ window_size (int): Window size. Default: 7
+ mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4
+ qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True
+ qk_scale (float): Override default qk scale of head_dim ** -0.5 if set. Default: None
+ drop_rate (float): Dropout rate. Default: 0
+ attn_drop_rate (float): Attention dropout rate. Default: 0
+ drop_path_rate (float): Stochastic depth rate. Default: 0.1
+ norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.
+ ape (bool): If True, add absolute position embedding to the patch embedding. Default: False
+ patch_norm (bool): If True, add normalization after patch embedding. Default: True
+ use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False
+ upscale: Upscale factor. 2/3/4/8 for image SR, 1 for denoising and compress artifact reduction
+ img_range: Image range. 1. or 255.
+ upsampler: The reconstruction reconstruction module. 'pixelshuffle'/'pixelshuffledirect'/'nearest+conv'/None
+ resi_connection: The convolutional block before residual connection. '1conv'/'3conv'
+ """
+
+ def __init__(self, img_size=64, patch_size=1, in_chans=3,
+ embed_dim=96, depths=[6, 6, 6, 6], num_heads=[6, 6, 6, 6],
+ window_size=7, mlp_ratio=4., qkv_bias=True, qk_scale=None,
+ drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,
+ norm_layer=nn.LayerNorm, ape=False, patch_norm=True,
+ use_checkpoint=False, upscale=2, img_range=1., upsampler='', resi_connection='1conv',
+ **kwargs):
+ super(SwinIR, self).__init__()
+ num_in_ch = in_chans
+ num_out_ch = in_chans
+ num_feat = 64
+ self.img_range = img_range
+ if in_chans == 3:
+ rgb_mean = (0.4488, 0.4371, 0.4040)
+ self.mean = torch.Tensor(rgb_mean).view(1, 3, 1, 1)
+ else:
+ self.mean = torch.zeros(1, 1, 1, 1)
+ self.upscale = upscale
+ self.upsampler = upsampler
+ self.window_size = window_size
+
+ #####################################################################################################
+ ################################### 1, shallow feature extraction ###################################
+ self.conv_first = nn.Conv2d(num_in_ch, embed_dim, 3, 1, 1)
+
+ #####################################################################################################
+ ################################### 2, deep feature extraction ######################################
+ self.num_layers = len(depths)
+ self.embed_dim = embed_dim
+ self.ape = ape
+ self.patch_norm = patch_norm
+ self.num_features = embed_dim
+ self.mlp_ratio = mlp_ratio
+
+ # split image into non-overlapping patches
+ self.patch_embed = PatchEmbed(
+ img_size=img_size, patch_size=patch_size, in_chans=embed_dim, embed_dim=embed_dim,
+ norm_layer=norm_layer if self.patch_norm else None)
+ num_patches = self.patch_embed.num_patches
+ patches_resolution = self.patch_embed.patches_resolution
+ self.patches_resolution = patches_resolution
+
+ # merge non-overlapping patches into image
+ self.patch_unembed = PatchUnEmbed(
+ img_size=img_size, patch_size=patch_size, in_chans=embed_dim, embed_dim=embed_dim,
+ norm_layer=norm_layer if self.patch_norm else None)
+
+ # absolute position embedding
+ if self.ape:
+ self.absolute_pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dim))
+ trunc_normal_(self.absolute_pos_embed, std=.02)
+
+ self.pos_drop = nn.Dropout(p=drop_rate)
+
+ # stochastic depth
+ dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
+
+ # build Residual Swin Transformer blocks (RSTB)
+ self.layers = nn.ModuleList()
+ for i_layer in range(self.num_layers):
+ layer = RSTB(dim=embed_dim,
+ input_resolution=(patches_resolution[0],
+ patches_resolution[1]),
+ depth=depths[i_layer],
+ num_heads=num_heads[i_layer],
+ window_size=window_size,
+ mlp_ratio=self.mlp_ratio,
+ qkv_bias=qkv_bias, qk_scale=qk_scale,
+ drop=drop_rate, attn_drop=attn_drop_rate,
+ drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])], # no impact on SR results
+ norm_layer=norm_layer,
+ downsample=None,
+ use_checkpoint=use_checkpoint,
+ img_size=img_size,
+ patch_size=patch_size,
+ resi_connection=resi_connection
+
+ )
+ self.layers.append(layer)
+ self.norm = norm_layer(self.num_features)
+
+ # build the last conv layer in deep feature extraction
+ if resi_connection == '1conv':
+ self.conv_after_body = nn.Conv2d(embed_dim, embed_dim, 3, 1, 1)
+ elif resi_connection == '3conv':
+ # to save parameters and memory
+ self.conv_after_body = nn.Sequential(nn.Conv2d(embed_dim, embed_dim // 4, 3, 1, 1),
+ nn.LeakyReLU(negative_slope=0.2, inplace=True),
+ nn.Conv2d(embed_dim // 4, embed_dim // 4, 1, 1, 0),
+ nn.LeakyReLU(negative_slope=0.2, inplace=True),
+ nn.Conv2d(embed_dim // 4, embed_dim, 3, 1, 1))
+
+ #####################################################################################################
+ ################################ 3, high quality image reconstruction ################################
+ if self.upsampler == 'pixelshuffle':
+ # for classical SR
+ self.conv_before_upsample = nn.Sequential(nn.Conv2d(embed_dim, num_feat, 3, 1, 1),
+ nn.LeakyReLU(inplace=True))
+ self.upsample = Upsample(upscale, num_feat)
+ self.conv_last = nn.Conv2d(num_feat, num_out_ch, 3, 1, 1)
+ elif self.upsampler == 'pixelshuffledirect':
+ # for lightweight SR (to save parameters)
+ self.upsample = UpsampleOneStep(upscale, embed_dim, num_out_ch,
+ (patches_resolution[0], patches_resolution[1]))
+ elif self.upsampler == 'nearest+conv':
+ # for real-world SR (less artifacts)
+ # assert self.upscale == 4, 'only support x4 now.'
+ self.conv_before_upsample = nn.Sequential(nn.Conv2d(embed_dim, num_feat, 3, 1, 1),
+ nn.LeakyReLU(inplace=True))
+ self.conv_up1 = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
+ self.conv_up2 = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
+ self.conv_hr = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
+ self.conv_last = nn.Conv2d(num_feat, num_out_ch, 3, 1, 1)
+ self.lrelu = nn.LeakyReLU(negative_slope=0.2, inplace=True)
+ else:
+ # for image denoising and JPEG compression artifact reduction
+ self.conv_last = nn.Conv2d(embed_dim, num_out_ch, 3, 1, 1)
+
+ self.apply(self._init_weights)
+
+ def _init_weights(self, m):
+ if isinstance(m, nn.Linear):
+ trunc_normal_(m.weight, std=.02)
+ if isinstance(m, nn.Linear) and m.bias is not None:
+ nn.init.constant_(m.bias, 0)
+ elif isinstance(m, nn.LayerNorm):
+ nn.init.constant_(m.bias, 0)
+ nn.init.constant_(m.weight, 1.0)
+
+ @torch.jit.ignore
+ def no_weight_decay(self):
+ return {'absolute_pos_embed'}
+
+ @torch.jit.ignore
+ def no_weight_decay_keywords(self):
+ return {'relative_position_bias_table'}
+
+ def check_image_size(self, x):
+ _, _, h, w = x.size()
+ mod_pad_h = (self.window_size - h % self.window_size) % self.window_size
+ mod_pad_w = (self.window_size - w % self.window_size) % self.window_size
+ x = F.pad(x, (0, mod_pad_w, 0, mod_pad_h), 'reflect')
+ return x
+
+ def forward_features(self, x):
+ x_size = (x.shape[2], x.shape[3])
+ x = self.patch_embed(x)
+ if self.ape:
+ x = x + self.absolute_pos_embed
+ x = self.pos_drop(x)
+
+ for layer in self.layers:
+ x = layer(x, x_size)
+
+ x = self.norm(x) # B L C
+ x = self.patch_unembed(x, x_size)
+
+ return x
+
+ def forward(self, x):
+ H, W = x.shape[2:]
+ x = self.check_image_size(x)
+
+ self.mean = self.mean.type_as(x)
+ x = (x - self.mean) * self.img_range
+
+ if self.upsampler == 'pixelshuffle':
+ # for classical SR
+ x = self.conv_first(x)
+ x = self.conv_after_body(self.forward_features(x)) + x
+ x = self.conv_before_upsample(x)
+ x = self.conv_last(self.upsample(x))
+ elif self.upsampler == 'pixelshuffledirect':
+ # for lightweight SR
+ x = self.conv_first(x)
+ x = self.conv_after_body(self.forward_features(x)) + x
+ x = self.upsample(x)
+ elif self.upsampler == 'nearest+conv':
+ # for real-world SR
+ x = self.conv_first(x)
+ x = self.conv_after_body(self.forward_features(x)) + x
+ x = self.conv_before_upsample(x)
+ x = self.lrelu(self.conv_up1(torch.nn.functional.interpolate(x, scale_factor=2, mode='nearest')))
+ x = self.lrelu(self.conv_up2(x))
+ x = self.conv_last(self.lrelu(self.conv_hr(x)))
+ else:
+ # for image denoising and JPEG compression artifact reduction
+ x_first = self.conv_first(x)
+ res = self.conv_after_body(self.forward_features(x_first)) + x_first
+ x = x + self.conv_last(res)
+
+ x = x / self.img_range + self.mean
+
+ return x[:, :, :H*self.upscale, :W*self.upscale]
+
+ def flops(self):
+ flops = 0
+ H, W = self.patches_resolution
+ flops += H * W * 3 * self.embed_dim * 9
+ flops += self.patch_embed.flops()
+ for i, layer in enumerate(self.layers):
+ flops += layer.flops()
+ flops += H * W * 3 * self.embed_dim * self.embed_dim
+ flops += self.upsample.flops()
+ return flops
+
+
+if __name__ == '__main__':
+ upscale = 4
+ window_size = 8
+ height = (1024 // upscale // window_size + 1) * window_size
+ width = (720 // upscale // window_size + 1) * window_size
+ model = SwinIR(upscale=2, img_size=(height, width),
+ window_size=window_size, img_range=1., depths=[6, 6, 6, 6],
+ embed_dim=60, num_heads=[6, 6, 6, 6], mlp_ratio=2, upsampler='pixelshuffledirect')
+ print(model)
+ print(height, width, model.flops() / 1e9)
+
+ x = torch.randn((1, 3, height, width))
+ x = model(x)
+ print(x.shape)
diff --git a/KAIR/models/network_unet.py b/KAIR/models/network_unet.py
new file mode 100644
index 0000000000000000000000000000000000000000..fec5ca95e5bc2428ec05ddce92c80ea86ea43890
--- /dev/null
+++ b/KAIR/models/network_unet.py
@@ -0,0 +1,87 @@
+import torch
+import torch.nn as nn
+import models.basicblock as B
+import numpy as np
+
+'''
+# ====================
+# Residual U-Net
+# ====================
+citation:
+@article{zhang2020plug,
+title={Plug-and-Play Image Restoration with Deep Denoiser Prior},
+author={Zhang, Kai and Li, Yawei and Zuo, Wangmeng and Zhang, Lei and Van Gool, Luc and Timofte, Radu},
+journal={arXiv preprint},
+year={2020}
+}
+# ====================
+'''
+
+
+class UNetRes(nn.Module):
+ def __init__(self, in_nc=3, out_nc=3, nc=[64, 128, 256, 512], nb=4, act_mode='R', downsample_mode='strideconv', upsample_mode='convtranspose', bias=True):
+ super(UNetRes, self).__init__()
+
+ self.m_head = B.conv(in_nc, nc[0], bias=bias, mode='C')
+
+ # downsample
+ if downsample_mode == 'avgpool':
+ downsample_block = B.downsample_avgpool
+ elif downsample_mode == 'maxpool':
+ downsample_block = B.downsample_maxpool
+ elif downsample_mode == 'strideconv':
+ downsample_block = B.downsample_strideconv
+ else:
+ raise NotImplementedError('downsample mode [{:s}] is not found'.format(downsample_mode))
+
+ self.m_down1 = B.sequential(*[B.ResBlock(nc[0], nc[0], bias=bias, mode='C'+act_mode+'C') for _ in range(nb)], downsample_block(nc[0], nc[1], bias=bias, mode='2'))
+ self.m_down2 = B.sequential(*[B.ResBlock(nc[1], nc[1], bias=bias, mode='C'+act_mode+'C') for _ in range(nb)], downsample_block(nc[1], nc[2], bias=bias, mode='2'))
+ self.m_down3 = B.sequential(*[B.ResBlock(nc[2], nc[2], bias=bias, mode='C'+act_mode+'C') for _ in range(nb)], downsample_block(nc[2], nc[3], bias=bias, mode='2'))
+
+ self.m_body = B.sequential(*[B.ResBlock(nc[3], nc[3], bias=bias, mode='C'+act_mode+'C') for _ in range(nb)])
+
+ # upsample
+ if upsample_mode == 'upconv':
+ upsample_block = B.upsample_upconv
+ elif upsample_mode == 'pixelshuffle':
+ upsample_block = B.upsample_pixelshuffle
+ elif upsample_mode == 'convtranspose':
+ upsample_block = B.upsample_convtranspose
+ else:
+ raise NotImplementedError('upsample mode [{:s}] is not found'.format(upsample_mode))
+
+ self.m_up3 = B.sequential(upsample_block(nc[3], nc[2], bias=bias, mode='2'), *[B.ResBlock(nc[2], nc[2], bias=bias, mode='C'+act_mode+'C') for _ in range(nb)])
+ self.m_up2 = B.sequential(upsample_block(nc[2], nc[1], bias=bias, mode='2'), *[B.ResBlock(nc[1], nc[1], bias=bias, mode='C'+act_mode+'C') for _ in range(nb)])
+ self.m_up1 = B.sequential(upsample_block(nc[1], nc[0], bias=bias, mode='2'), *[B.ResBlock(nc[0], nc[0], bias=bias, mode='C'+act_mode+'C') for _ in range(nb)])
+
+ self.m_tail = B.conv(nc[0], out_nc, bias=bias, mode='C')
+
+ def forward(self, x0):
+# h, w = x.size()[-2:]
+# paddingBottom = int(np.ceil(h/8)*8-h)
+# paddingRight = int(np.ceil(w/8)*8-w)
+# x = nn.ReplicationPad2d((0, paddingRight, 0, paddingBottom))(x)
+
+ x1 = self.m_head(x0)
+ x2 = self.m_down1(x1)
+ x3 = self.m_down2(x2)
+ x4 = self.m_down3(x3)
+ x = self.m_body(x4)
+ x = self.m_up3(x+x4)
+ x = self.m_up2(x+x3)
+ x = self.m_up1(x+x2)
+ x = self.m_tail(x+x1)
+# x = x[..., :h, :w]
+
+ return x
+
+
+if __name__ == '__main__':
+ x = torch.rand(1,3,256,256)
+ net = UNetRes()
+ net.eval()
+ with torch.no_grad():
+ y = net(x)
+ print(y.size())
+
+# run models/network_unet.py
diff --git a/KAIR/models/network_usrnet.py b/KAIR/models/network_usrnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..cf7c7177998f155422062bca4a30bbe6f75d77fa
--- /dev/null
+++ b/KAIR/models/network_usrnet.py
@@ -0,0 +1,344 @@
+import torch
+import torch.nn as nn
+import models.basicblock as B
+import numpy as np
+from utils import utils_image as util
+
+
+"""
+# --------------------------------------------
+# Kai Zhang (cskaizhang@gmail.com)
+@inproceedings{zhang2020deep,
+ title={Deep unfolding network for image super-resolution},
+ author={Zhang, Kai and Van Gool, Luc and Timofte, Radu},
+ booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
+ pages={0--0},
+ year={2020}
+}
+# --------------------------------------------
+"""
+
+
+"""
+# --------------------------------------------
+# basic functions
+# --------------------------------------------
+"""
+
+
+def splits(a, sf):
+ '''split a into sfxsf distinct blocks
+
+ Args:
+ a: NxCxWxHx2
+ sf: split factor
+
+ Returns:
+ b: NxCx(W/sf)x(H/sf)x2x(sf^2)
+ '''
+ b = torch.stack(torch.chunk(a, sf, dim=2), dim=5)
+ b = torch.cat(torch.chunk(b, sf, dim=3), dim=5)
+ return b
+
+
+def c2c(x):
+ return torch.from_numpy(np.stack([np.float32(x.real), np.float32(x.imag)], axis=-1))
+
+
+def r2c(x):
+ # convert real to complex
+ return torch.stack([x, torch.zeros_like(x)], -1)
+
+
+def cdiv(x, y):
+ # complex division
+ a, b = x[..., 0], x[..., 1]
+ c, d = y[..., 0], y[..., 1]
+ cd2 = c**2 + d**2
+ return torch.stack([(a*c+b*d)/cd2, (b*c-a*d)/cd2], -1)
+
+
+def crdiv(x, y):
+ # complex/real division
+ a, b = x[..., 0], x[..., 1]
+ return torch.stack([a/y, b/y], -1)
+
+
+def csum(x, y):
+ # complex + real
+ return torch.stack([x[..., 0] + y, x[..., 1]], -1)
+
+
+def cabs(x):
+ # modulus of a complex number
+ return torch.pow(x[..., 0]**2+x[..., 1]**2, 0.5)
+
+
+def cabs2(x):
+ return x[..., 0]**2+x[..., 1]**2
+
+
+def cmul(t1, t2):
+ '''complex multiplication
+
+ Args:
+ t1: NxCxHxWx2, complex tensor
+ t2: NxCxHxWx2
+
+ Returns:
+ output: NxCxHxWx2
+ '''
+ real1, imag1 = t1[..., 0], t1[..., 1]
+ real2, imag2 = t2[..., 0], t2[..., 1]
+ return torch.stack([real1 * real2 - imag1 * imag2, real1 * imag2 + imag1 * real2], dim=-1)
+
+
+def cconj(t, inplace=False):
+ '''complex's conjugation
+
+ Args:
+ t: NxCxHxWx2
+
+ Returns:
+ output: NxCxHxWx2
+ '''
+ c = t.clone() if not inplace else t
+ c[..., 1] *= -1
+ return c
+
+
+def rfft(t):
+ # Real-to-complex Discrete Fourier Transform
+ return torch.rfft(t, 2, onesided=False)
+
+
+def irfft(t):
+ # Complex-to-real Inverse Discrete Fourier Transform
+ return torch.irfft(t, 2, onesided=False)
+
+
+def fft(t):
+ # Complex-to-complex Discrete Fourier Transform
+ return torch.fft(t, 2)
+
+
+def ifft(t):
+ # Complex-to-complex Inverse Discrete Fourier Transform
+ return torch.ifft(t, 2)
+
+
+def p2o(psf, shape):
+ '''
+ Convert point-spread function to optical transfer function.
+ otf = p2o(psf) computes the Fast Fourier Transform (FFT) of the
+ point-spread function (PSF) array and creates the optical transfer
+ function (OTF) array that is not influenced by the PSF off-centering.
+
+ Args:
+ psf: NxCxhxw
+ shape: [H, W]
+
+ Returns:
+ otf: NxCxHxWx2
+ '''
+ otf = torch.zeros(psf.shape[:-2] + shape).type_as(psf)
+ otf[...,:psf.shape[2],:psf.shape[3]].copy_(psf)
+ for axis, axis_size in enumerate(psf.shape[2:]):
+ otf = torch.roll(otf, -int(axis_size / 2), dims=axis+2)
+ otf = torch.rfft(otf, 2, onesided=False)
+ n_ops = torch.sum(torch.tensor(psf.shape).type_as(psf) * torch.log2(torch.tensor(psf.shape).type_as(psf)))
+ otf[..., 1][torch.abs(otf[..., 1]) < n_ops*2.22e-16] = torch.tensor(0).type_as(psf)
+ return otf
+
+
+def upsample(x, sf=3):
+ '''s-fold upsampler
+
+ Upsampling the spatial size by filling the new entries with zeros
+
+ x: tensor image, NxCxWxH
+ '''
+ st = 0
+ z = torch.zeros((x.shape[0], x.shape[1], x.shape[2]*sf, x.shape[3]*sf)).type_as(x)
+ z[..., st::sf, st::sf].copy_(x)
+ return z
+
+
+def downsample(x, sf=3):
+ '''s-fold downsampler
+
+ Keeping the upper-left pixel for each distinct sfxsf patch and discarding the others
+
+ x: tensor image, NxCxWxH
+ '''
+ st = 0
+ return x[..., st::sf, st::sf]
+
+
+def downsample_np(x, sf=3):
+ st = 0
+ return x[st::sf, st::sf, ...]
+
+
+"""
+# --------------------------------------------
+# (1) Prior module; ResUNet: act as a non-blind denoiser
+# x_k = P(z_k, beta_k)
+# --------------------------------------------
+"""
+
+
+class ResUNet(nn.Module):
+ def __init__(self, in_nc=4, out_nc=3, nc=[64, 128, 256, 512], nb=2, act_mode='R', downsample_mode='strideconv', upsample_mode='convtranspose'):
+ super(ResUNet, self).__init__()
+
+ self.m_head = B.conv(in_nc, nc[0], bias=False, mode='C')
+
+ # downsample
+ if downsample_mode == 'avgpool':
+ downsample_block = B.downsample_avgpool
+ elif downsample_mode == 'maxpool':
+ downsample_block = B.downsample_maxpool
+ elif downsample_mode == 'strideconv':
+ downsample_block = B.downsample_strideconv
+ else:
+ raise NotImplementedError('downsample mode [{:s}] is not found'.format(downsample_mode))
+
+ self.m_down1 = B.sequential(*[B.ResBlock(nc[0], nc[0], bias=False, mode='C'+act_mode+'C') for _ in range(nb)], downsample_block(nc[0], nc[1], bias=False, mode='2'))
+ self.m_down2 = B.sequential(*[B.ResBlock(nc[1], nc[1], bias=False, mode='C'+act_mode+'C') for _ in range(nb)], downsample_block(nc[1], nc[2], bias=False, mode='2'))
+ self.m_down3 = B.sequential(*[B.ResBlock(nc[2], nc[2], bias=False, mode='C'+act_mode+'C') for _ in range(nb)], downsample_block(nc[2], nc[3], bias=False, mode='2'))
+
+ self.m_body = B.sequential(*[B.ResBlock(nc[3], nc[3], bias=False, mode='C'+act_mode+'C') for _ in range(nb)])
+
+ # upsample
+ if upsample_mode == 'upconv':
+ upsample_block = B.upsample_upconv
+ elif upsample_mode == 'pixelshuffle':
+ upsample_block = B.upsample_pixelshuffle
+ elif upsample_mode == 'convtranspose':
+ upsample_block = B.upsample_convtranspose
+ else:
+ raise NotImplementedError('upsample mode [{:s}] is not found'.format(upsample_mode))
+
+ self.m_up3 = B.sequential(upsample_block(nc[3], nc[2], bias=False, mode='2'), *[B.ResBlock(nc[2], nc[2], bias=False, mode='C'+act_mode+'C') for _ in range(nb)])
+ self.m_up2 = B.sequential(upsample_block(nc[2], nc[1], bias=False, mode='2'), *[B.ResBlock(nc[1], nc[1], bias=False, mode='C'+act_mode+'C') for _ in range(nb)])
+ self.m_up1 = B.sequential(upsample_block(nc[1], nc[0], bias=False, mode='2'), *[B.ResBlock(nc[0], nc[0], bias=False, mode='C'+act_mode+'C') for _ in range(nb)])
+
+ self.m_tail = B.conv(nc[0], out_nc, bias=False, mode='C')
+
+ def forward(self, x):
+
+ h, w = x.size()[-2:]
+ paddingBottom = int(np.ceil(h/8)*8-h)
+ paddingRight = int(np.ceil(w/8)*8-w)
+ x = nn.ReplicationPad2d((0, paddingRight, 0, paddingBottom))(x)
+
+ x1 = self.m_head(x)
+ x2 = self.m_down1(x1)
+ x3 = self.m_down2(x2)
+ x4 = self.m_down3(x3)
+ x = self.m_body(x4)
+ x = self.m_up3(x+x4)
+ x = self.m_up2(x+x3)
+ x = self.m_up1(x+x2)
+ x = self.m_tail(x+x1)
+
+ x = x[..., :h, :w]
+
+ return x
+
+
+"""
+# --------------------------------------------
+# (2) Data module, closed-form solution
+# It is a trainable-parameter-free module ^_^
+# z_k = D(x_{k-1}, s, k, y, alpha_k)
+# some can be pre-calculated
+# --------------------------------------------
+"""
+
+
+class DataNet(nn.Module):
+ def __init__(self):
+ super(DataNet, self).__init__()
+
+ def forward(self, x, FB, FBC, F2B, FBFy, alpha, sf):
+ FR = FBFy + torch.rfft(alpha*x, 2, onesided=False)
+ x1 = cmul(FB, FR)
+ FBR = torch.mean(splits(x1, sf), dim=-1, keepdim=False)
+ invW = torch.mean(splits(F2B, sf), dim=-1, keepdim=False)
+ invWBR = cdiv(FBR, csum(invW, alpha))
+ FCBinvWBR = cmul(FBC, invWBR.repeat(1, 1, sf, sf, 1))
+ FX = (FR-FCBinvWBR)/alpha.unsqueeze(-1)
+ Xest = torch.irfft(FX, 2, onesided=False)
+
+ return Xest
+
+
+"""
+# --------------------------------------------
+# (3) Hyper-parameter module
+# --------------------------------------------
+"""
+
+
+class HyPaNet(nn.Module):
+ def __init__(self, in_nc=2, out_nc=8, channel=64):
+ super(HyPaNet, self).__init__()
+ self.mlp = nn.Sequential(
+ nn.Conv2d(in_nc, channel, 1, padding=0, bias=True),
+ nn.ReLU(inplace=True),
+ nn.Conv2d(channel, channel, 1, padding=0, bias=True),
+ nn.ReLU(inplace=True),
+ nn.Conv2d(channel, out_nc, 1, padding=0, bias=True),
+ nn.Softplus())
+
+ def forward(self, x):
+ x = self.mlp(x) + 1e-6
+ return x
+
+
+"""
+# --------------------------------------------
+# main USRNet
+# deep unfolding super-resolution network
+# --------------------------------------------
+"""
+
+
+class USRNet(nn.Module):
+ def __init__(self, n_iter=8, h_nc=64, in_nc=4, out_nc=3, nc=[64, 128, 256, 512], nb=2, act_mode='R', downsample_mode='strideconv', upsample_mode='convtranspose'):
+ super(USRNet, self).__init__()
+
+ self.d = DataNet()
+ self.p = ResUNet(in_nc=in_nc, out_nc=out_nc, nc=nc, nb=nb, act_mode=act_mode, downsample_mode=downsample_mode, upsample_mode=upsample_mode)
+ self.h = HyPaNet(in_nc=2, out_nc=n_iter*2, channel=h_nc)
+ self.n = n_iter
+
+ def forward(self, x, k, sf, sigma):
+ '''
+ x: tensor, NxCxWxH
+ k: tensor, Nx(1,3)xwxh
+ sf: integer, 1
+ sigma: tensor, Nx1x1x1
+ '''
+
+ # initialization & pre-calculation
+ w, h = x.shape[-2:]
+ FB = p2o(k, (w*sf, h*sf))
+ FBC = cconj(FB, inplace=False)
+ F2B = r2c(cabs2(FB))
+ STy = upsample(x, sf=sf)
+ FBFy = cmul(FBC, torch.rfft(STy, 2, onesided=False))
+ x = nn.functional.interpolate(x, scale_factor=sf, mode='nearest')
+
+ # hyper-parameter, alpha & beta
+ ab = self.h(torch.cat((sigma, torch.tensor(sf).type_as(sigma).expand_as(sigma)), dim=1))
+
+ # unfolding
+ for i in range(self.n):
+
+ x = self.d(x, FB, FBC, F2B, FBFy, ab[:, i:i+1, ...], sf)
+ x = self.p(torch.cat((x, ab[:, i+self.n:i+self.n+1, ...].repeat(1, 1, x.size(2), x.size(3))), dim=1))
+
+ return x
diff --git a/KAIR/models/network_usrnet_v1.py b/KAIR/models/network_usrnet_v1.py
new file mode 100644
index 0000000000000000000000000000000000000000..78b4d7726ab0f369df3a3e13bd6c7d1b38bba55e
--- /dev/null
+++ b/KAIR/models/network_usrnet_v1.py
@@ -0,0 +1,263 @@
+import torch
+import torch.nn as nn
+import models.basicblock as B
+import numpy as np
+from utils import utils_image as util
+import torch.fft
+
+
+# for pytorch version >= 1.8.1
+
+
+"""
+# --------------------------------------------
+# Kai Zhang (cskaizhang@gmail.com)
+@inproceedings{zhang2020deep,
+ title={Deep unfolding network for image super-resolution},
+ author={Zhang, Kai and Van Gool, Luc and Timofte, Radu},
+ booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
+ pages={0--0},
+ year={2020}
+}
+# --------------------------------------------
+"""
+
+
+"""
+# --------------------------------------------
+# basic functions
+# --------------------------------------------
+"""
+
+
+def splits(a, sf):
+ '''split a into sfxsf distinct blocks
+
+ Args:
+ a: NxCxWxH
+ sf: split factor
+
+ Returns:
+ b: NxCx(W/sf)x(H/sf)x(sf^2)
+ '''
+ b = torch.stack(torch.chunk(a, sf, dim=2), dim=4)
+ b = torch.cat(torch.chunk(b, sf, dim=3), dim=4)
+ return b
+
+
+def p2o(psf, shape):
+ '''
+ Convert point-spread function to optical transfer function.
+ otf = p2o(psf) computes the Fast Fourier Transform (FFT) of the
+ point-spread function (PSF) array and creates the optical transfer
+ function (OTF) array that is not influenced by the PSF off-centering.
+
+ Args:
+ psf: NxCxhxw
+ shape: [H, W]
+
+ Returns:
+ otf: NxCxHxWx2
+ '''
+ otf = torch.zeros(psf.shape[:-2] + shape).type_as(psf)
+ otf[...,:psf.shape[2],:psf.shape[3]].copy_(psf)
+ for axis, axis_size in enumerate(psf.shape[2:]):
+ otf = torch.roll(otf, -int(axis_size / 2), dims=axis+2)
+ otf = torch.fft.fftn(otf, dim=(-2,-1))
+ #n_ops = torch.sum(torch.tensor(psf.shape).type_as(psf) * torch.log2(torch.tensor(psf.shape).type_as(psf)))
+ #otf[..., 1][torch.abs(otf[..., 1]) < n_ops*2.22e-16] = torch.tensor(0).type_as(psf)
+ return otf
+
+
+def upsample(x, sf=3):
+ '''s-fold upsampler
+
+ Upsampling the spatial size by filling the new entries with zeros
+
+ x: tensor image, NxCxWxH
+ '''
+ st = 0
+ z = torch.zeros((x.shape[0], x.shape[1], x.shape[2]*sf, x.shape[3]*sf)).type_as(x)
+ z[..., st::sf, st::sf].copy_(x)
+ return z
+
+
+def downsample(x, sf=3):
+ '''s-fold downsampler
+
+ Keeping the upper-left pixel for each distinct sfxsf patch and discarding the others
+
+ x: tensor image, NxCxWxH
+ '''
+ st = 0
+ return x[..., st::sf, st::sf]
+
+
+def downsample_np(x, sf=3):
+ st = 0
+ return x[st::sf, st::sf, ...]
+
+
+"""
+# --------------------------------------------
+# (1) Prior module; ResUNet: act as a non-blind denoiser
+# x_k = P(z_k, beta_k)
+# --------------------------------------------
+"""
+
+
+class ResUNet(nn.Module):
+ def __init__(self, in_nc=4, out_nc=3, nc=[64, 128, 256, 512], nb=2, act_mode='R', downsample_mode='strideconv', upsample_mode='convtranspose'):
+ super(ResUNet, self).__init__()
+
+ self.m_head = B.conv(in_nc, nc[0], bias=False, mode='C')
+
+ # downsample
+ if downsample_mode == 'avgpool':
+ downsample_block = B.downsample_avgpool
+ elif downsample_mode == 'maxpool':
+ downsample_block = B.downsample_maxpool
+ elif downsample_mode == 'strideconv':
+ downsample_block = B.downsample_strideconv
+ else:
+ raise NotImplementedError('downsample mode [{:s}] is not found'.format(downsample_mode))
+
+ self.m_down1 = B.sequential(*[B.ResBlock(nc[0], nc[0], bias=False, mode='C'+act_mode+'C') for _ in range(nb)], downsample_block(nc[0], nc[1], bias=False, mode='2'))
+ self.m_down2 = B.sequential(*[B.ResBlock(nc[1], nc[1], bias=False, mode='C'+act_mode+'C') for _ in range(nb)], downsample_block(nc[1], nc[2], bias=False, mode='2'))
+ self.m_down3 = B.sequential(*[B.ResBlock(nc[2], nc[2], bias=False, mode='C'+act_mode+'C') for _ in range(nb)], downsample_block(nc[2], nc[3], bias=False, mode='2'))
+
+ self.m_body = B.sequential(*[B.ResBlock(nc[3], nc[3], bias=False, mode='C'+act_mode+'C') for _ in range(nb)])
+
+ # upsample
+ if upsample_mode == 'upconv':
+ upsample_block = B.upsample_upconv
+ elif upsample_mode == 'pixelshuffle':
+ upsample_block = B.upsample_pixelshuffle
+ elif upsample_mode == 'convtranspose':
+ upsample_block = B.upsample_convtranspose
+ else:
+ raise NotImplementedError('upsample mode [{:s}] is not found'.format(upsample_mode))
+
+ self.m_up3 = B.sequential(upsample_block(nc[3], nc[2], bias=False, mode='2'), *[B.ResBlock(nc[2], nc[2], bias=False, mode='C'+act_mode+'C') for _ in range(nb)])
+ self.m_up2 = B.sequential(upsample_block(nc[2], nc[1], bias=False, mode='2'), *[B.ResBlock(nc[1], nc[1], bias=False, mode='C'+act_mode+'C') for _ in range(nb)])
+ self.m_up1 = B.sequential(upsample_block(nc[1], nc[0], bias=False, mode='2'), *[B.ResBlock(nc[0], nc[0], bias=False, mode='C'+act_mode+'C') for _ in range(nb)])
+
+ self.m_tail = B.conv(nc[0], out_nc, bias=False, mode='C')
+
+ def forward(self, x):
+
+ h, w = x.size()[-2:]
+ paddingBottom = int(np.ceil(h/8)*8-h)
+ paddingRight = int(np.ceil(w/8)*8-w)
+ x = nn.ReplicationPad2d((0, paddingRight, 0, paddingBottom))(x)
+
+ x1 = self.m_head(x)
+ x2 = self.m_down1(x1)
+ x3 = self.m_down2(x2)
+ x4 = self.m_down3(x3)
+ x = self.m_body(x4)
+ x = self.m_up3(x+x4)
+ x = self.m_up2(x+x3)
+ x = self.m_up1(x+x2)
+ x = self.m_tail(x+x1)
+
+ x = x[..., :h, :w]
+
+ return x
+
+
+"""
+# --------------------------------------------
+# (2) Data module, closed-form solution
+# It is a trainable-parameter-free module ^_^
+# z_k = D(x_{k-1}, s, k, y, alpha_k)
+# some can be pre-calculated
+# --------------------------------------------
+"""
+
+
+class DataNet(nn.Module):
+ def __init__(self):
+ super(DataNet, self).__init__()
+
+ def forward(self, x, FB, FBC, F2B, FBFy, alpha, sf):
+
+ FR = FBFy + torch.fft.fftn(alpha*x, dim=(-2,-1))
+ x1 = FB.mul(FR)
+ FBR = torch.mean(splits(x1, sf), dim=-1, keepdim=False)
+ invW = torch.mean(splits(F2B, sf), dim=-1, keepdim=False)
+ invWBR = FBR.div(invW + alpha)
+ FCBinvWBR = FBC*invWBR.repeat(1, 1, sf, sf)
+ FX = (FR-FCBinvWBR)/alpha
+ Xest = torch.real(torch.fft.ifftn(FX, dim=(-2,-1)))
+
+ return Xest
+
+
+"""
+# --------------------------------------------
+# (3) Hyper-parameter module
+# --------------------------------------------
+"""
+
+
+class HyPaNet(nn.Module):
+ def __init__(self, in_nc=2, out_nc=8, channel=64):
+ super(HyPaNet, self).__init__()
+ self.mlp = nn.Sequential(
+ nn.Conv2d(in_nc, channel, 1, padding=0, bias=True),
+ nn.ReLU(inplace=True),
+ nn.Conv2d(channel, channel, 1, padding=0, bias=True),
+ nn.ReLU(inplace=True),
+ nn.Conv2d(channel, out_nc, 1, padding=0, bias=True),
+ nn.Softplus())
+
+ def forward(self, x):
+ x = self.mlp(x) + 1e-6
+ return x
+
+
+"""
+# --------------------------------------------
+# main USRNet
+# deep unfolding super-resolution network
+# --------------------------------------------
+"""
+
+
+class USRNet(nn.Module):
+ def __init__(self, n_iter=8, h_nc=64, in_nc=4, out_nc=3, nc=[64, 128, 256, 512], nb=2, act_mode='R', downsample_mode='strideconv', upsample_mode='convtranspose'):
+ super(USRNet, self).__init__()
+
+ self.d = DataNet()
+ self.p = ResUNet(in_nc=in_nc, out_nc=out_nc, nc=nc, nb=nb, act_mode=act_mode, downsample_mode=downsample_mode, upsample_mode=upsample_mode)
+ self.h = HyPaNet(in_nc=2, out_nc=n_iter*2, channel=h_nc)
+ self.n = n_iter
+
+ def forward(self, x, k, sf, sigma):
+ '''
+ x: tensor, NxCxWxH
+ k: tensor, Nx(1,3)xwxh
+ sf: integer, 1
+ sigma: tensor, Nx1x1x1
+ '''
+
+ # initialization & pre-calculation
+ w, h = x.shape[-2:]
+ FB = p2o(k, (w*sf, h*sf))
+ FBC = torch.conj(FB)
+ F2B = torch.pow(torch.abs(FB), 2)
+ STy = upsample(x, sf=sf)
+ FBFy = FBC*torch.fft.fftn(STy, dim=(-2,-1))
+ x = nn.functional.interpolate(x, scale_factor=sf, mode='nearest')
+
+ # hyper-parameter, alpha & beta
+ ab = self.h(torch.cat((sigma, torch.tensor(sf).type_as(sigma).expand_as(sigma)), dim=1))
+
+ # unfolding
+ for i in range(self.n):
+
+ x = self.d(x, FB, FBC, F2B, FBFy, ab[:, i:i+1, ...], sf)
+ x = self.p(torch.cat((x, ab[:, i+self.n:i+self.n+1, ...].repeat(1, 1, x.size(2), x.size(3))), dim=1))
+
+ return x
diff --git a/KAIR/models/network_vrt.py b/KAIR/models/network_vrt.py
new file mode 100755
index 0000000000000000000000000000000000000000..4419633b3c1f6ff1dfcc5786f4e5a3ca07cc10be
--- /dev/null
+++ b/KAIR/models/network_vrt.py
@@ -0,0 +1,1564 @@
+# Copyright (c) Facebook, Inc. and its affiliates.
+#
+# This source code is licensed under the BSD license found in the
+# LICENSE file in the root directory of this source tree.
+
+
+import os
+import warnings
+import math
+import torch
+import torch.nn as nn
+import torchvision
+import torch.nn.functional as F
+import torch.utils.checkpoint as checkpoint
+from distutils.version import LooseVersion
+from torch.nn.modules.utils import _pair, _single
+import numpy as np
+from functools import reduce, lru_cache
+from operator import mul
+from einops import rearrange
+from einops.layers.torch import Rearrange
+
+
+class ModulatedDeformConv(nn.Module):
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size,
+ stride=1,
+ padding=0,
+ dilation=1,
+ groups=1,
+ deformable_groups=1,
+ bias=True):
+ super(ModulatedDeformConv, self).__init__()
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.kernel_size = _pair(kernel_size)
+ self.stride = stride
+ self.padding = padding
+ self.dilation = dilation
+ self.groups = groups
+ self.deformable_groups = deformable_groups
+ self.with_bias = bias
+ # enable compatibility with nn.Conv2d
+ self.transposed = False
+ self.output_padding = _single(0)
+
+ self.weight = nn.Parameter(torch.Tensor(out_channels, in_channels // groups, *self.kernel_size))
+ if bias:
+ self.bias = nn.Parameter(torch.Tensor(out_channels))
+ else:
+ self.register_parameter('bias', None)
+ self.init_weights()
+
+ def init_weights(self):
+ n = self.in_channels
+ for k in self.kernel_size:
+ n *= k
+ stdv = 1. / math.sqrt(n)
+ self.weight.data.uniform_(-stdv, stdv)
+ if self.bias is not None:
+ self.bias.data.zero_()
+
+ # def forward(self, x, offset, mask):
+ # return modulated_deform_conv(x, offset, mask, self.weight, self.bias, self.stride, self.padding, self.dilation,
+ # self.groups, self.deformable_groups)
+
+
+class ModulatedDeformConvPack(ModulatedDeformConv):
+ """A ModulatedDeformable Conv Encapsulation that acts as normal Conv layers.
+
+ Args:
+ in_channels (int): Same as nn.Conv2d.
+ out_channels (int): Same as nn.Conv2d.
+ kernel_size (int or tuple[int]): Same as nn.Conv2d.
+ stride (int or tuple[int]): Same as nn.Conv2d.
+ padding (int or tuple[int]): Same as nn.Conv2d.
+ dilation (int or tuple[int]): Same as nn.Conv2d.
+ groups (int): Same as nn.Conv2d.
+ bias (bool or str): If specified as `auto`, it will be decided by the
+ norm_cfg. Bias will be set as True if norm_cfg is None, otherwise
+ False.
+ """
+
+ _version = 2
+
+ def __init__(self, *args, **kwargs):
+ super(ModulatedDeformConvPack, self).__init__(*args, **kwargs)
+
+ self.conv_offset = nn.Conv2d(
+ self.in_channels,
+ self.deformable_groups * 3 * self.kernel_size[0] * self.kernel_size[1],
+ kernel_size=self.kernel_size,
+ stride=_pair(self.stride),
+ padding=_pair(self.padding),
+ dilation=_pair(self.dilation),
+ bias=True)
+ self.init_weights()
+
+ def init_weights(self):
+ super(ModulatedDeformConvPack, self).init_weights()
+ if hasattr(self, 'conv_offset'):
+ self.conv_offset.weight.data.zero_()
+ self.conv_offset.bias.data.zero_()
+
+ # def forward(self, x):
+ # out = self.conv_offset(x)
+ # o1, o2, mask = torch.chunk(out, 3, dim=1)
+ # offset = torch.cat((o1, o2), dim=1)
+ # mask = torch.sigmoid(mask)
+ # return modulated_deform_conv(x, offset, mask, self.weight, self.bias, self.stride, self.padding, self.dilation,
+ # self.groups, self.deformable_groups)
+
+
+def _no_grad_trunc_normal_(tensor, mean, std, a, b):
+ # From: https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/layers/weight_init.py
+ # Cut & paste from PyTorch official master until it's in a few official releases - RW
+ # Method based on https://people.sc.fsu.edu/~jburkardt/presentations/truncated_normal.pdf
+ def norm_cdf(x):
+ # Computes standard normal cumulative distribution function
+ return (1. + math.erf(x / math.sqrt(2.))) / 2.
+
+ if (mean < a - 2 * std) or (mean > b + 2 * std):
+ warnings.warn(
+ 'mean is more than 2 std from [a, b] in nn.init.trunc_normal_. '
+ 'The distribution of values may be incorrect.',
+ stacklevel=2)
+
+ with torch.no_grad():
+ # Values are generated by using a truncated uniform distribution and
+ # then using the inverse CDF for the normal distribution.
+ # Get upper and lower cdf values
+ low = norm_cdf((a - mean) / std)
+ up = norm_cdf((b - mean) / std)
+
+ # Uniformly fill tensor with values from [low, up], then translate to
+ # [2l-1, 2u-1].
+ tensor.uniform_(2 * low - 1, 2 * up - 1)
+
+ # Use inverse cdf transform for normal distribution to get truncated
+ # standard normal
+ tensor.erfinv_()
+
+ # Transform to proper mean, std
+ tensor.mul_(std * math.sqrt(2.))
+ tensor.add_(mean)
+
+ # Clamp to ensure it's in the proper range
+ tensor.clamp_(min=a, max=b)
+ return tensor
+
+
+def trunc_normal_(tensor, mean=0., std=1., a=-2., b=2.):
+ r"""Fills the input Tensor with values drawn from a truncated
+ normal distribution.
+
+ From: https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/layers/weight_init.py
+
+ The values are effectively drawn from the
+ normal distribution :math:`\mathcal{N}(\text{mean}, \text{std}^2)`
+ with values outside :math:`[a, b]` redrawn until they are within
+ the bounds. The method used for generating the random values works
+ best when :math:`a \leq \text{mean} \leq b`.
+
+ Args:
+ tensor: an n-dimensional `torch.Tensor`
+ mean: the mean of the normal distribution
+ std: the standard deviation of the normal distribution
+ a: the minimum cutoff value
+ b: the maximum cutoff value
+
+ Examples:
+ >>> w = torch.empty(3, 5)
+ >>> nn.init.trunc_normal_(w)
+ """
+ return _no_grad_trunc_normal_(tensor, mean, std, a, b)
+
+
+def drop_path(x, drop_prob: float = 0., training: bool = False):
+ """Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
+ From: https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/layers/drop.py
+ """
+ if drop_prob == 0. or not training:
+ return x
+ keep_prob = 1 - drop_prob
+ shape = (x.shape[0], ) + (1, ) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
+ random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
+ random_tensor.floor_() # binarize
+ output = x.div(keep_prob) * random_tensor
+ return output
+
+
+class DropPath(nn.Module):
+ """Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
+ From: https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/layers/drop.py
+ """
+
+ def __init__(self, drop_prob=None):
+ super(DropPath, self).__init__()
+ self.drop_prob = drop_prob
+
+ def forward(self, x):
+ return drop_path(x, self.drop_prob, self.training)
+
+
+def flow_warp(x, flow, interp_mode='bilinear', padding_mode='zeros', align_corners=True, use_pad_mask=False):
+ """Warp an image or feature map with optical flow.
+
+ Args:
+ x (Tensor): Tensor with size (n, c, h, w).
+ flow (Tensor): Tensor with size (n, h, w, 2), normal value.
+ interp_mode (str): 'nearest' or 'bilinear' or 'nearest4'. Default: 'bilinear'.
+ padding_mode (str): 'zeros' or 'border' or 'reflection'.
+ Default: 'zeros'.
+ align_corners (bool): Before pytorch 1.3, the default value is
+ align_corners=True. After pytorch 1.3, the default value is
+ align_corners=False. Here, we use the True as default.
+ use_pad_mask (bool): only used for PWCNet, x is first padded with ones along the channel dimension.
+ The mask is generated according to the grid_sample results of the padded dimension.
+
+
+ Returns:
+ Tensor: Warped image or feature map.
+ """
+ # assert x.size()[-2:] == flow.size()[1:3] # temporaily turned off for image-wise shift
+ n, _, h, w = x.size()
+ # create mesh grid
+ # grid_y, grid_x = torch.meshgrid(torch.arange(0, h).type_as(x), torch.arange(0, w).type_as(x)) # an illegal memory access on TITAN RTX + PyTorch1.9.1
+ grid_y, grid_x = torch.meshgrid(torch.arange(0, h, dtype=x.dtype, device=x.device), torch.arange(0, w, dtype=x.dtype, device=x.device))
+ grid = torch.stack((grid_x, grid_y), 2).float() # W(x), H(y), 2
+ grid.requires_grad = False
+
+ vgrid = grid + flow
+
+ # if use_pad_mask: # for PWCNet
+ # x = F.pad(x, (0,0,0,0,0,1), mode='constant', value=1)
+
+ # scale grid to [-1,1]
+ if interp_mode == 'nearest4': # todo: bug, no gradient for flow model in this case!!! but the result is good
+ vgrid_x_floor = 2.0 * torch.floor(vgrid[:, :, :, 0]) / max(w - 1, 1) - 1.0
+ vgrid_x_ceil = 2.0 * torch.ceil(vgrid[:, :, :, 0]) / max(w - 1, 1) - 1.0
+ vgrid_y_floor = 2.0 * torch.floor(vgrid[:, :, :, 1]) / max(h - 1, 1) - 1.0
+ vgrid_y_ceil = 2.0 * torch.ceil(vgrid[:, :, :, 1]) / max(h - 1, 1) - 1.0
+
+ output00 = F.grid_sample(x, torch.stack((vgrid_x_floor, vgrid_y_floor), dim=3), mode='nearest', padding_mode=padding_mode, align_corners=align_corners)
+ output01 = F.grid_sample(x, torch.stack((vgrid_x_floor, vgrid_y_ceil), dim=3), mode='nearest', padding_mode=padding_mode, align_corners=align_corners)
+ output10 = F.grid_sample(x, torch.stack((vgrid_x_ceil, vgrid_y_floor), dim=3), mode='nearest', padding_mode=padding_mode, align_corners=align_corners)
+ output11 = F.grid_sample(x, torch.stack((vgrid_x_ceil, vgrid_y_ceil), dim=3), mode='nearest', padding_mode=padding_mode, align_corners=align_corners)
+
+ return torch.cat([output00, output01, output10, output11], 1)
+
+ else:
+ vgrid_x = 2.0 * vgrid[:, :, :, 0] / max(w - 1, 1) - 1.0
+ vgrid_y = 2.0 * vgrid[:, :, :, 1] / max(h - 1, 1) - 1.0
+ vgrid_scaled = torch.stack((vgrid_x, vgrid_y), dim=3)
+ output = F.grid_sample(x, vgrid_scaled, mode=interp_mode, padding_mode=padding_mode, align_corners=align_corners)
+
+ # if use_pad_mask: # for PWCNet
+ # output = _flow_warp_masking(output)
+
+ # TODO, what if align_corners=False
+ return output
+
+
+class DCNv2PackFlowGuided(ModulatedDeformConvPack):
+ """Flow-guided deformable alignment module.
+
+ Args:
+ in_channels (int): Same as nn.Conv2d.
+ out_channels (int): Same as nn.Conv2d.
+ kernel_size (int or tuple[int]): Same as nn.Conv2d.
+ stride (int or tuple[int]): Same as nn.Conv2d.
+ padding (int or tuple[int]): Same as nn.Conv2d.
+ dilation (int or tuple[int]): Same as nn.Conv2d.
+ groups (int): Same as nn.Conv2d.
+ bias (bool or str): If specified as `auto`, it will be decided by the
+ norm_cfg. Bias will be set as True if norm_cfg is None, otherwise
+ False.
+ max_residue_magnitude (int): The maximum magnitude of the offset residue. Default: 10.
+ pa_frames (int): The number of parallel warping frames. Default: 2.
+
+ Ref:
+ BasicVSR++: Improving Video Super-Resolution with Enhanced Propagation and Alignment.
+
+ """
+
+ def __init__(self, *args, **kwargs):
+ self.max_residue_magnitude = kwargs.pop('max_residue_magnitude', 10)
+ self.pa_frames = kwargs.pop('pa_frames', 2)
+
+ super(DCNv2PackFlowGuided, self).__init__(*args, **kwargs)
+
+ self.conv_offset = nn.Sequential(
+ nn.Conv2d((1+self.pa_frames//2) * self.in_channels + self.pa_frames, self.out_channels, 3, 1, 1),
+ nn.LeakyReLU(negative_slope=0.1, inplace=True),
+ nn.Conv2d(self.out_channels, self.out_channels, 3, 1, 1),
+ nn.LeakyReLU(negative_slope=0.1, inplace=True),
+ nn.Conv2d(self.out_channels, self.out_channels, 3, 1, 1),
+ nn.LeakyReLU(negative_slope=0.1, inplace=True),
+ nn.Conv2d(self.out_channels, 3 * 9 * self.deformable_groups, 3, 1, 1),
+ )
+
+ self.init_offset()
+
+ def init_offset(self):
+ super(ModulatedDeformConvPack, self).init_weights()
+ if hasattr(self, 'conv_offset'):
+ self.conv_offset[-1].weight.data.zero_()
+ self.conv_offset[-1].bias.data.zero_()
+
+ def forward(self, x, x_flow_warpeds, x_current, flows):
+ out = self.conv_offset(torch.cat(x_flow_warpeds + [x_current] + flows, dim=1))
+ o1, o2, mask = torch.chunk(out, 3, dim=1)
+
+ # offset
+ offset = self.max_residue_magnitude * torch.tanh(torch.cat((o1, o2), dim=1))
+ if self.pa_frames == 2:
+ offset = offset + flows[0].flip(1).repeat(1, offset.size(1)//2, 1, 1)
+ elif self.pa_frames == 4:
+ offset1, offset2 = torch.chunk(offset, 2, dim=1)
+ offset1 = offset1 + flows[0].flip(1).repeat(1, offset1.size(1) // 2, 1, 1)
+ offset2 = offset2 + flows[1].flip(1).repeat(1, offset2.size(1) // 2, 1, 1)
+ offset = torch.cat([offset1, offset2], dim=1)
+ elif self.pa_frames == 6:
+ offset = self.max_residue_magnitude * torch.tanh(torch.cat((o1, o2), dim=1))
+ offset1, offset2, offset3 = torch.chunk(offset, 3, dim=1)
+ offset1 = offset1 + flows[0].flip(1).repeat(1, offset1.size(1) // 2, 1, 1)
+ offset2 = offset2 + flows[1].flip(1).repeat(1, offset2.size(1) // 2, 1, 1)
+ offset3 = offset3 + flows[2].flip(1).repeat(1, offset3.size(1) // 2, 1, 1)
+ offset = torch.cat([offset1, offset2, offset3], dim=1)
+
+ # mask
+ mask = torch.sigmoid(mask)
+
+ return torchvision.ops.deform_conv2d(x, offset, self.weight, self.bias, self.stride, self.padding,
+ self.dilation, mask)
+
+
+class BasicModule(nn.Module):
+ """Basic Module for SpyNet.
+ """
+
+ def __init__(self):
+ super(BasicModule, self).__init__()
+
+ self.basic_module = nn.Sequential(
+ nn.Conv2d(in_channels=8, out_channels=32, kernel_size=7, stride=1, padding=3), nn.ReLU(inplace=False),
+ nn.Conv2d(in_channels=32, out_channels=64, kernel_size=7, stride=1, padding=3), nn.ReLU(inplace=False),
+ nn.Conv2d(in_channels=64, out_channels=32, kernel_size=7, stride=1, padding=3), nn.ReLU(inplace=False),
+ nn.Conv2d(in_channels=32, out_channels=16, kernel_size=7, stride=1, padding=3), nn.ReLU(inplace=False),
+ nn.Conv2d(in_channels=16, out_channels=2, kernel_size=7, stride=1, padding=3))
+
+ def forward(self, tensor_input):
+ return self.basic_module(tensor_input)
+
+
+class SpyNet(nn.Module):
+ """SpyNet architecture.
+
+ Args:
+ load_path (str): path for pretrained SpyNet. Default: None.
+ return_levels (list[int]): return flows of different levels. Default: [5].
+ """
+
+ def __init__(self, load_path=None, return_levels=[5]):
+ super(SpyNet, self).__init__()
+ self.return_levels = return_levels
+ self.basic_module = nn.ModuleList([BasicModule() for _ in range(6)])
+ if load_path:
+ if not os.path.exists(load_path):
+ import requests
+ url = 'https://github.com/JingyunLiang/VRT/releases/download/v0.0/spynet_sintel_final-3d2a1287.pth'
+ r = requests.get(url, allow_redirects=True)
+ print(f'downloading SpyNet pretrained model from {url}')
+ os.makedirs(os.path.dirname(load_path), exist_ok=True)
+ open(load_path, 'wb').write(r.content)
+
+ self.load_state_dict(torch.load(load_path, map_location=lambda storage, loc: storage)['params'])
+
+ self.register_buffer('mean', torch.Tensor([0.485, 0.456, 0.406]).view(1, 3, 1, 1))
+ self.register_buffer('std', torch.Tensor([0.229, 0.224, 0.225]).view(1, 3, 1, 1))
+
+ def preprocess(self, tensor_input):
+ tensor_output = (tensor_input - self.mean) / self.std
+ return tensor_output
+
+ def process(self, ref, supp, w, h, w_floor, h_floor):
+ flow_list = []
+
+ ref = [self.preprocess(ref)]
+ supp = [self.preprocess(supp)]
+
+ for level in range(5):
+ ref.insert(0, F.avg_pool2d(input=ref[0], kernel_size=2, stride=2, count_include_pad=False))
+ supp.insert(0, F.avg_pool2d(input=supp[0], kernel_size=2, stride=2, count_include_pad=False))
+
+ flow = ref[0].new_zeros(
+ [ref[0].size(0), 2,
+ int(math.floor(ref[0].size(2) / 2.0)),
+ int(math.floor(ref[0].size(3) / 2.0))])
+
+ for level in range(len(ref)):
+ upsampled_flow = F.interpolate(input=flow, scale_factor=2, mode='bilinear', align_corners=True) * 2.0
+
+ if upsampled_flow.size(2) != ref[level].size(2):
+ upsampled_flow = F.pad(input=upsampled_flow, pad=[0, 0, 0, 1], mode='replicate')
+ if upsampled_flow.size(3) != ref[level].size(3):
+ upsampled_flow = F.pad(input=upsampled_flow, pad=[0, 1, 0, 0], mode='replicate')
+
+ flow = self.basic_module[level](torch.cat([
+ ref[level],
+ flow_warp(
+ supp[level], upsampled_flow.permute(0, 2, 3, 1), interp_mode='bilinear', padding_mode='border'),
+ upsampled_flow
+ ], 1)) + upsampled_flow
+
+ if level in self.return_levels:
+ scale = 2**(5-level) # level=5 (scale=1), level=4 (scale=2), level=3 (scale=4), level=2 (scale=8)
+ flow_out = F.interpolate(input=flow, size=(h//scale, w//scale), mode='bilinear', align_corners=False)
+ flow_out[:, 0, :, :] *= float(w//scale) / float(w_floor//scale)
+ flow_out[:, 1, :, :] *= float(h//scale) / float(h_floor//scale)
+ flow_list.insert(0, flow_out)
+
+ return flow_list
+
+ def forward(self, ref, supp):
+ assert ref.size() == supp.size()
+
+ h, w = ref.size(2), ref.size(3)
+ w_floor = math.floor(math.ceil(w / 32.0) * 32.0)
+ h_floor = math.floor(math.ceil(h / 32.0) * 32.0)
+
+ ref = F.interpolate(input=ref, size=(h_floor, w_floor), mode='bilinear', align_corners=False)
+ supp = F.interpolate(input=supp, size=(h_floor, w_floor), mode='bilinear', align_corners=False)
+
+ flow_list = self.process(ref, supp, w, h, w_floor, h_floor)
+
+ return flow_list[0] if len(flow_list) == 1 else flow_list
+
+
+def window_partition(x, window_size):
+ """ Partition the input into windows. Attention will be conducted within the windows.
+
+ Args:
+ x: (B, D, H, W, C)
+ window_size (tuple[int]): window size
+
+ Returns:
+ windows: (B*num_windows, window_size*window_size, C)
+ """
+ B, D, H, W, C = x.shape
+ x = x.view(B, D // window_size[0], window_size[0], H // window_size[1], window_size[1], W // window_size[2],
+ window_size[2], C)
+ windows = x.permute(0, 1, 3, 5, 2, 4, 6, 7).contiguous().view(-1, reduce(mul, window_size), C)
+
+ return windows
+
+
+def window_reverse(windows, window_size, B, D, H, W):
+ """ Reverse windows back to the original input. Attention was conducted within the windows.
+
+ Args:
+ windows: (B*num_windows, window_size, window_size, C)
+ window_size (tuple[int]): Window size
+ H (int): Height of image
+ W (int): Width of image
+
+ Returns:
+ x: (B, D, H, W, C)
+ """
+ x = windows.view(B, D // window_size[0], H // window_size[1], W // window_size[2], window_size[0], window_size[1],
+ window_size[2], -1)
+ x = x.permute(0, 1, 4, 2, 5, 3, 6, 7).contiguous().view(B, D, H, W, -1)
+
+ return x
+
+
+def get_window_size(x_size, window_size, shift_size=None):
+ """ Get the window size and the shift size """
+
+ use_window_size = list(window_size)
+ if shift_size is not None:
+ use_shift_size = list(shift_size)
+ for i in range(len(x_size)):
+ if x_size[i] <= window_size[i]:
+ use_window_size[i] = x_size[i]
+ if shift_size is not None:
+ use_shift_size[i] = 0
+
+ if shift_size is None:
+ return tuple(use_window_size)
+ else:
+ return tuple(use_window_size), tuple(use_shift_size)
+
+
+@lru_cache()
+def compute_mask(D, H, W, window_size, shift_size, device):
+ """ Compute attnetion mask for input of size (D, H, W). @lru_cache caches each stage results. """
+
+ img_mask = torch.zeros((1, D, H, W, 1), device=device) # 1 Dp Hp Wp 1
+ cnt = 0
+ for d in slice(-window_size[0]), slice(-window_size[0], -shift_size[0]), slice(-shift_size[0], None):
+ for h in slice(-window_size[1]), slice(-window_size[1], -shift_size[1]), slice(-shift_size[1], None):
+ for w in slice(-window_size[2]), slice(-window_size[2], -shift_size[2]), slice(-shift_size[2], None):
+ img_mask[:, d, h, w, :] = cnt
+ cnt += 1
+ mask_windows = window_partition(img_mask, window_size) # nW, ws[0]*ws[1]*ws[2], 1
+ mask_windows = mask_windows.squeeze(-1) # nW, ws[0]*ws[1]*ws[2]
+ attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
+ attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
+
+ return attn_mask
+
+
+class Upsample(nn.Sequential):
+ """Upsample module for video SR.
+
+ Args:
+ scale (int): Scale factor. Supported scales: 2^n and 3.
+ num_feat (int): Channel number of intermediate features.
+ """
+
+ def __init__(self, scale, num_feat):
+ assert LooseVersion(torch.__version__) >= LooseVersion('1.8.1'), \
+ 'PyTorch version >= 1.8.1 to support 5D PixelShuffle.'
+
+ class Transpose_Dim12(nn.Module):
+ """ Transpose Dim1 and Dim2 of a tensor."""
+
+ def __init__(self):
+ super().__init__()
+
+ def forward(self, x):
+ return x.transpose(1, 2)
+
+ m = []
+ if (scale & (scale - 1)) == 0: # scale = 2^n
+ for _ in range(int(math.log(scale, 2))):
+ m.append(nn.Conv3d(num_feat, 4 * num_feat, kernel_size=(1, 3, 3), padding=(0, 1, 1)))
+ m.append(Transpose_Dim12())
+ m.append(nn.PixelShuffle(2))
+ m.append(Transpose_Dim12())
+ m.append(nn.LeakyReLU(negative_slope=0.1, inplace=True))
+ m.append(nn.Conv3d(num_feat, num_feat, kernel_size=(1, 3, 3), padding=(0, 1, 1)))
+ elif scale == 3:
+ m.append(nn.Conv3d(num_feat, 9 * num_feat, kernel_size=(1, 3, 3), padding=(0, 1, 1)))
+ m.append(Transpose_Dim12())
+ m.append(nn.PixelShuffle(3))
+ m.append(Transpose_Dim12())
+ m.append(nn.LeakyReLU(negative_slope=0.1, inplace=True))
+ m.append(nn.Conv3d(num_feat, num_feat, kernel_size=(1, 3, 3), padding=(0, 1, 1)))
+ else:
+ raise ValueError(f'scale {scale} is not supported. ' 'Supported scales: 2^n and 3.')
+ super(Upsample, self).__init__(*m)
+
+
+class Mlp_GEGLU(nn.Module):
+ """ Multilayer perceptron with gated linear unit (GEGLU). Ref. "GLU Variants Improve Transformer".
+
+ Args:
+ x: (B, D, H, W, C)
+
+ Returns:
+ x: (B, D, H, W, C)
+ """
+
+ def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
+ super().__init__()
+ out_features = out_features or in_features
+ hidden_features = hidden_features or in_features
+
+ self.fc11 = nn.Linear(in_features, hidden_features)
+ self.fc12 = nn.Linear(in_features, hidden_features)
+ self.act = act_layer()
+ self.fc2 = nn.Linear(hidden_features, out_features)
+ self.drop = nn.Dropout(drop)
+
+ def forward(self, x):
+ x = self.act(self.fc11(x)) * self.fc12(x)
+ x = self.drop(x)
+ x = self.fc2(x)
+
+ return x
+
+
+class WindowAttention(nn.Module):
+ """ Window based multi-head mutual attention and self attention.
+
+ Args:
+ dim (int): Number of input channels.
+ window_size (tuple[int]): The temporal length, height and width of the window.
+ num_heads (int): Number of attention heads.
+ qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
+ qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
+ mut_attn (bool): If True, add mutual attention to the module. Default: True
+ """
+
+ def __init__(self, dim, window_size, num_heads, qkv_bias=False, qk_scale=None, mut_attn=True):
+ super().__init__()
+ self.dim = dim
+ self.window_size = window_size
+ self.num_heads = num_heads
+ head_dim = dim // num_heads
+ self.scale = qk_scale or head_dim ** -0.5
+ self.mut_attn = mut_attn
+
+ # self attention with relative position bias
+ self.relative_position_bias_table = nn.Parameter(
+ torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1) * (2 * window_size[2] - 1),
+ num_heads)) # 2*Wd-1 * 2*Wh-1 * 2*Ww-1, nH
+ self.register_buffer("relative_position_index", self.get_position_index(window_size))
+ self.qkv_self = nn.Linear(dim, dim * 3, bias=qkv_bias)
+ self.proj = nn.Linear(dim, dim)
+
+ # mutual attention with sine position encoding
+ if self.mut_attn:
+ self.register_buffer("position_bias",
+ self.get_sine_position_encoding(window_size[1:], dim // 2, normalize=True))
+ self.qkv_mut = nn.Linear(dim, dim * 3, bias=qkv_bias)
+ self.proj = nn.Linear(2 * dim, dim)
+
+ self.softmax = nn.Softmax(dim=-1)
+ trunc_normal_(self.relative_position_bias_table, std=.02)
+
+ def forward(self, x, mask=None):
+ """ Forward function.
+
+ Args:
+ x: input features with shape of (num_windows*B, N, C)
+ mask: (0/-inf) mask with shape of (num_windows, N, N) or None
+ """
+
+ # self attention
+ B_, N, C = x.shape
+ qkv = self.qkv_self(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
+ q, k, v = qkv[0], qkv[1], qkv[2] # B_, nH, N, C
+ x_out = self.attention(q, k, v, mask, (B_, N, C), relative_position_encoding=True)
+
+ # mutual attention
+ if self.mut_attn:
+ qkv = self.qkv_mut(x + self.position_bias.repeat(1, 2, 1)).reshape(B_, N, 3, self.num_heads,
+ C // self.num_heads).permute(2, 0, 3, 1,
+ 4)
+ (q1, q2), (k1, k2), (v1, v2) = torch.chunk(qkv[0], 2, dim=2), torch.chunk(qkv[1], 2, dim=2), torch.chunk(
+ qkv[2], 2, dim=2) # B_, nH, N/2, C
+ x1_aligned = self.attention(q2, k1, v1, mask, (B_, N // 2, C), relative_position_encoding=False)
+ x2_aligned = self.attention(q1, k2, v2, mask, (B_, N // 2, C), relative_position_encoding=False)
+ x_out = torch.cat([torch.cat([x1_aligned, x2_aligned], 1), x_out], 2)
+
+ # projection
+ x = self.proj(x_out)
+
+ return x
+
+ def attention(self, q, k, v, mask, x_shape, relative_position_encoding=True):
+ B_, N, C = x_shape
+ attn = (q * self.scale) @ k.transpose(-2, -1)
+
+ if relative_position_encoding:
+ relative_position_bias = self.relative_position_bias_table[
+ self.relative_position_index[:N, :N].reshape(-1)].reshape(N, N, -1) # Wd*Wh*Ww, Wd*Wh*Ww,nH
+ attn = attn + relative_position_bias.permute(2, 0, 1).unsqueeze(0) # B_, nH, N, N
+
+ if mask is None:
+ attn = self.softmax(attn)
+ else:
+ nW = mask.shape[0]
+ attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask[:, :N, :N].unsqueeze(1).unsqueeze(0)
+ attn = attn.view(-1, self.num_heads, N, N)
+ attn = self.softmax(attn)
+
+ x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
+
+ return x
+
+ def get_position_index(self, window_size):
+ ''' Get pair-wise relative position index for each token inside the window. '''
+
+ coords_d = torch.arange(window_size[0])
+ coords_h = torch.arange(window_size[1])
+ coords_w = torch.arange(window_size[2])
+ coords = torch.stack(torch.meshgrid(coords_d, coords_h, coords_w)) # 3, Wd, Wh, Ww
+ coords_flatten = torch.flatten(coords, 1) # 3, Wd*Wh*Ww
+ relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 3, Wd*Wh*Ww, Wd*Wh*Ww
+ relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wd*Wh*Ww, Wd*Wh*Ww, 3
+ relative_coords[:, :, 0] += window_size[0] - 1 # shift to start from 0
+ relative_coords[:, :, 1] += window_size[1] - 1
+ relative_coords[:, :, 2] += window_size[2] - 1
+
+ relative_coords[:, :, 0] *= (2 * window_size[1] - 1) * (2 * window_size[2] - 1)
+ relative_coords[:, :, 1] *= (2 * window_size[2] - 1)
+ relative_position_index = relative_coords.sum(-1) # Wd*Wh*Ww, Wd*Wh*Ww
+
+ return relative_position_index
+
+ def get_sine_position_encoding(self, HW, num_pos_feats=64, temperature=10000, normalize=False, scale=None):
+ """ Get sine position encoding """
+
+ if scale is not None and normalize is False:
+ raise ValueError("normalize should be True if scale is passed")
+
+ if scale is None:
+ scale = 2 * math.pi
+
+ not_mask = torch.ones([1, HW[0], HW[1]])
+ y_embed = not_mask.cumsum(1, dtype=torch.float32)
+ x_embed = not_mask.cumsum(2, dtype=torch.float32)
+ if normalize:
+ eps = 1e-6
+ y_embed = y_embed / (y_embed[:, -1:, :] + eps) * scale
+ x_embed = x_embed / (x_embed[:, :, -1:] + eps) * scale
+
+ dim_t = torch.arange(num_pos_feats, dtype=torch.float32)
+ dim_t = temperature ** (2 * (dim_t // 2) / num_pos_feats)
+
+ # BxCxHxW
+ pos_x = x_embed[:, :, :, None] / dim_t
+ pos_y = y_embed[:, :, :, None] / dim_t
+ pos_x = torch.stack((pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()), dim=4).flatten(3)
+ pos_y = torch.stack((pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()), dim=4).flatten(3)
+ pos_embed = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)
+
+ return pos_embed.flatten(2).permute(0, 2, 1).contiguous()
+
+
+class TMSA(nn.Module):
+ """ Temporal Mutual Self Attention (TMSA).
+
+ Args:
+ dim (int): Number of input channels.
+ input_resolution (tuple[int]): Input resolution.
+ num_heads (int): Number of attention heads.
+ window_size (tuple[int]): Window size.
+ shift_size (tuple[int]): Shift size for mutual and self attention.
+ mut_attn (bool): If True, use mutual and self attention. Default: True.
+ mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
+ qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True.
+ qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
+ drop_path (float, optional): Stochastic depth rate. Default: 0.0.
+ act_layer (nn.Module, optional): Activation layer. Default: nn.GELU.
+ norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm.
+ use_checkpoint_attn (bool): If True, use torch.checkpoint for attention modules. Default: False.
+ use_checkpoint_ffn (bool): If True, use torch.checkpoint for feed-forward modules. Default: False.
+ """
+
+ def __init__(self,
+ dim,
+ input_resolution,
+ num_heads,
+ window_size=(6, 8, 8),
+ shift_size=(0, 0, 0),
+ mut_attn=True,
+ mlp_ratio=2.,
+ qkv_bias=True,
+ qk_scale=None,
+ drop_path=0.,
+ act_layer=nn.GELU,
+ norm_layer=nn.LayerNorm,
+ use_checkpoint_attn=False,
+ use_checkpoint_ffn=False
+ ):
+ super().__init__()
+ self.dim = dim
+ self.input_resolution = input_resolution
+ self.num_heads = num_heads
+ self.window_size = window_size
+ self.shift_size = shift_size
+ self.use_checkpoint_attn = use_checkpoint_attn
+ self.use_checkpoint_ffn = use_checkpoint_ffn
+
+ assert 0 <= self.shift_size[0] < self.window_size[0], "shift_size must in 0-window_size"
+ assert 0 <= self.shift_size[1] < self.window_size[1], "shift_size must in 0-window_size"
+ assert 0 <= self.shift_size[2] < self.window_size[2], "shift_size must in 0-window_size"
+
+ self.norm1 = norm_layer(dim)
+ self.attn = WindowAttention(dim, window_size=self.window_size, num_heads=num_heads, qkv_bias=qkv_bias,
+ qk_scale=qk_scale, mut_attn=mut_attn)
+ self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
+ self.norm2 = norm_layer(dim)
+ self.mlp = Mlp_GEGLU(in_features=dim, hidden_features=int(dim * mlp_ratio), act_layer=act_layer)
+
+ def forward_part1(self, x, mask_matrix):
+ B, D, H, W, C = x.shape
+ window_size, shift_size = get_window_size((D, H, W), self.window_size, self.shift_size)
+
+ x = self.norm1(x)
+
+ # pad feature maps to multiples of window size
+ pad_l = pad_t = pad_d0 = 0
+ pad_d1 = (window_size[0] - D % window_size[0]) % window_size[0]
+ pad_b = (window_size[1] - H % window_size[1]) % window_size[1]
+ pad_r = (window_size[2] - W % window_size[2]) % window_size[2]
+ x = F.pad(x, (0, 0, pad_l, pad_r, pad_t, pad_b, pad_d0, pad_d1), mode='constant')
+
+ _, Dp, Hp, Wp, _ = x.shape
+ # cyclic shift
+ if any(i > 0 for i in shift_size):
+ shifted_x = torch.roll(x, shifts=(-shift_size[0], -shift_size[1], -shift_size[2]), dims=(1, 2, 3))
+ attn_mask = mask_matrix
+ else:
+ shifted_x = x
+ attn_mask = None
+
+ # partition windows
+ x_windows = window_partition(shifted_x, window_size) # B*nW, Wd*Wh*Ww, C
+
+ # attention / shifted attention
+ attn_windows = self.attn(x_windows, mask=attn_mask) # B*nW, Wd*Wh*Ww, C
+
+ # merge windows
+ attn_windows = attn_windows.view(-1, *(window_size + (C,)))
+ shifted_x = window_reverse(attn_windows, window_size, B, Dp, Hp, Wp) # B D' H' W' C
+
+ # reverse cyclic shift
+ if any(i > 0 for i in shift_size):
+ x = torch.roll(shifted_x, shifts=(shift_size[0], shift_size[1], shift_size[2]), dims=(1, 2, 3))
+ else:
+ x = shifted_x
+
+ if pad_d1 > 0 or pad_r > 0 or pad_b > 0:
+ x = x[:, :D, :H, :W, :]
+
+ x = self.drop_path(x)
+
+ return x
+
+ def forward_part2(self, x):
+ return self.drop_path(self.mlp(self.norm2(x)))
+
+ def forward(self, x, mask_matrix):
+ """ Forward function.
+
+ Args:
+ x: Input feature, tensor size (B, D, H, W, C).
+ mask_matrix: Attention mask for cyclic shift.
+ """
+
+ # attention
+ if self.use_checkpoint_attn:
+ x = x + checkpoint.checkpoint(self.forward_part1, x, mask_matrix)
+ else:
+ x = x + self.forward_part1(x, mask_matrix)
+
+ # feed-forward
+ if self.use_checkpoint_ffn:
+ x = x + checkpoint.checkpoint(self.forward_part2, x)
+ else:
+ x = x + self.forward_part2(x)
+
+ return x
+
+
+class TMSAG(nn.Module):
+ """ Temporal Mutual Self Attention Group (TMSAG).
+
+ Args:
+ dim (int): Number of feature channels
+ input_resolution (tuple[int]): Input resolution.
+ depth (int): Depths of this stage.
+ num_heads (int): Number of attention head.
+ window_size (tuple[int]): Local window size. Default: (6,8,8).
+ shift_size (tuple[int]): Shift size for mutual and self attention. Default: None.
+ mut_attn (bool): If True, use mutual and self attention. Default: True.
+ mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 2.
+ qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
+ qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
+ drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
+ norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
+ use_checkpoint_attn (bool): If True, use torch.checkpoint for attention modules. Default: False.
+ use_checkpoint_ffn (bool): If True, use torch.checkpoint for feed-forward modules. Default: False.
+ """
+
+ def __init__(self,
+ dim,
+ input_resolution,
+ depth,
+ num_heads,
+ window_size=[6, 8, 8],
+ shift_size=None,
+ mut_attn=True,
+ mlp_ratio=2.,
+ qkv_bias=False,
+ qk_scale=None,
+ drop_path=0.,
+ norm_layer=nn.LayerNorm,
+ use_checkpoint_attn=False,
+ use_checkpoint_ffn=False
+ ):
+ super().__init__()
+ self.input_resolution = input_resolution
+ self.window_size = window_size
+ self.shift_size = list(i // 2 for i in window_size) if shift_size is None else shift_size
+
+ # build blocks
+ self.blocks = nn.ModuleList([
+ TMSA(
+ dim=dim,
+ input_resolution=input_resolution,
+ num_heads=num_heads,
+ window_size=window_size,
+ shift_size=[0, 0, 0] if i % 2 == 0 else self.shift_size,
+ mut_attn=mut_attn,
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
+ norm_layer=norm_layer,
+ use_checkpoint_attn=use_checkpoint_attn,
+ use_checkpoint_ffn=use_checkpoint_ffn
+ )
+ for i in range(depth)])
+
+ def forward(self, x):
+ """ Forward function.
+
+ Args:
+ x: Input feature, tensor size (B, C, D, H, W).
+ """
+ # calculate attention mask for attention
+ B, C, D, H, W = x.shape
+ window_size, shift_size = get_window_size((D, H, W), self.window_size, self.shift_size)
+ x = rearrange(x, 'b c d h w -> b d h w c')
+ Dp = int(np.ceil(D / window_size[0])) * window_size[0]
+ Hp = int(np.ceil(H / window_size[1])) * window_size[1]
+ Wp = int(np.ceil(W / window_size[2])) * window_size[2]
+ attn_mask = compute_mask(Dp, Hp, Wp, window_size, shift_size, x.device)
+
+ for blk in self.blocks:
+ x = blk(x, attn_mask)
+
+ x = x.view(B, D, H, W, -1)
+ x = rearrange(x, 'b d h w c -> b c d h w')
+
+ return x
+
+
+class RTMSA(nn.Module):
+ """ Residual Temporal Mutual Self Attention (RTMSA). Only used in stage 8.
+
+ Args:
+ dim (int): Number of input channels.
+ input_resolution (tuple[int]): Input resolution.
+ depth (int): Number of blocks.
+ num_heads (int): Number of attention heads.
+ window_size (int): Local window size.
+ mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
+ qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True.
+ qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
+ drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0.
+ norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm.
+ use_checkpoint_attn (bool): If True, use torch.checkpoint for attention modules. Default: False.
+ use_checkpoint_ffn (bool): If True, use torch.checkpoint for feed-forward modules. Default: False.
+ """
+
+ def __init__(self,
+ dim,
+ input_resolution,
+ depth,
+ num_heads,
+ window_size,
+ mlp_ratio=2.,
+ qkv_bias=True,
+ qk_scale=None,
+ drop_path=0.,
+ norm_layer=nn.LayerNorm,
+ use_checkpoint_attn=False,
+ use_checkpoint_ffn=None
+ ):
+ super(RTMSA, self).__init__()
+ self.dim = dim
+ self.input_resolution = input_resolution
+
+ self.residual_group = TMSAG(dim=dim,
+ input_resolution=input_resolution,
+ depth=depth,
+ num_heads=num_heads,
+ window_size=window_size,
+ mut_attn=False,
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias, qk_scale=qk_scale,
+ drop_path=drop_path,
+ norm_layer=norm_layer,
+ use_checkpoint_attn=use_checkpoint_attn,
+ use_checkpoint_ffn=use_checkpoint_ffn
+ )
+
+ self.linear = nn.Linear(dim, dim)
+
+ def forward(self, x):
+ return x + self.linear(self.residual_group(x).transpose(1, 4)).transpose(1, 4)
+
+
+class Stage(nn.Module):
+ """Residual Temporal Mutual Self Attention Group and Parallel Warping.
+
+ Args:
+ in_dim (int): Number of input channels.
+ dim (int): Number of channels.
+ input_resolution (tuple[int]): Input resolution.
+ depth (int): Number of blocks.
+ num_heads (int): Number of attention heads.
+ mul_attn_ratio (float): Ratio of mutual attention layers. Default: 0.75.
+ window_size (int): Local window size.
+ mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
+ qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
+ qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
+ drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
+ norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
+ pa_frames (float): Number of warpped frames. Default: 2.
+ deformable_groups (float): Number of deformable groups. Default: 16.
+ reshape (str): Downscale (down), upscale (up) or keep the size (none).
+ max_residue_magnitude (float): Maximum magnitude of the residual of optical flow.
+ use_checkpoint_attn (bool): If True, use torch.checkpoint for attention modules. Default: False.
+ use_checkpoint_ffn (bool): If True, use torch.checkpoint for feed-forward modules. Default: False.
+ """
+
+ def __init__(self,
+ in_dim,
+ dim,
+ input_resolution,
+ depth,
+ num_heads,
+ window_size,
+ mul_attn_ratio=0.75,
+ mlp_ratio=2.,
+ qkv_bias=True,
+ qk_scale=None,
+ drop_path=0.,
+ norm_layer=nn.LayerNorm,
+ pa_frames=2,
+ deformable_groups=16,
+ reshape=None,
+ max_residue_magnitude=10,
+ use_checkpoint_attn=False,
+ use_checkpoint_ffn=False
+ ):
+ super(Stage, self).__init__()
+ self.pa_frames = pa_frames
+
+ # reshape the tensor
+ if reshape == 'none':
+ self.reshape = nn.Sequential(Rearrange('n c d h w -> n d h w c'),
+ nn.LayerNorm(dim),
+ Rearrange('n d h w c -> n c d h w'))
+ elif reshape == 'down':
+ self.reshape = nn.Sequential(Rearrange('n c d (h neih) (w neiw) -> n d h w (neiw neih c)', neih=2, neiw=2),
+ nn.LayerNorm(4 * in_dim), nn.Linear(4 * in_dim, dim),
+ Rearrange('n d h w c -> n c d h w'))
+ elif reshape == 'up':
+ self.reshape = nn.Sequential(Rearrange('n (neiw neih c) d h w -> n d (h neih) (w neiw) c', neih=2, neiw=2),
+ nn.LayerNorm(in_dim // 4), nn.Linear(in_dim // 4, dim),
+ Rearrange('n d h w c -> n c d h w'))
+
+ # mutual and self attention
+ self.residual_group1 = TMSAG(dim=dim,
+ input_resolution=input_resolution,
+ depth=int(depth * mul_attn_ratio),
+ num_heads=num_heads,
+ window_size=(2, window_size[1], window_size[2]),
+ mut_attn=True,
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop_path=drop_path,
+ norm_layer=norm_layer,
+ use_checkpoint_attn=use_checkpoint_attn,
+ use_checkpoint_ffn=use_checkpoint_ffn
+ )
+ self.linear1 = nn.Linear(dim, dim)
+
+ # only self attention
+ self.residual_group2 = TMSAG(dim=dim,
+ input_resolution=input_resolution,
+ depth=depth - int(depth * mul_attn_ratio),
+ num_heads=num_heads,
+ window_size=window_size,
+ mut_attn=False,
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias, qk_scale=qk_scale,
+ drop_path=drop_path,
+ norm_layer=norm_layer,
+ use_checkpoint_attn=True,
+ use_checkpoint_ffn=use_checkpoint_ffn
+ )
+ self.linear2 = nn.Linear(dim, dim)
+
+ # parallel warping
+ self.pa_deform = DCNv2PackFlowGuided(dim, dim, 3, padding=1, deformable_groups=deformable_groups,
+ max_residue_magnitude=max_residue_magnitude, pa_frames=pa_frames)
+ self.pa_fuse = Mlp_GEGLU(dim * (1 + 2), dim * (1 + 2), dim)
+
+ def forward(self, x, flows_backward, flows_forward):
+ x = self.reshape(x)
+ x = self.linear1(self.residual_group1(x).transpose(1, 4)).transpose(1, 4) + x
+ x = self.linear2(self.residual_group2(x).transpose(1, 4)).transpose(1, 4) + x
+ x = x.transpose(1, 2)
+
+ x_backward, x_forward = getattr(self, f'get_aligned_feature_{self.pa_frames}frames')(x, flows_backward, flows_forward)
+ x = self.pa_fuse(torch.cat([x, x_backward, x_forward], 2).permute(0, 1, 3, 4, 2)).permute(0, 4, 1, 2, 3)
+
+ return x
+
+ def get_aligned_feature_2frames(self, x, flows_backward, flows_forward):
+ '''Parallel feature warping for 2 frames.'''
+
+ # backward
+ n = x.size(1)
+ x_backward = [torch.zeros_like(x[:, -1, ...])]
+ for i in range(n - 1, 0, -1):
+ x_i = x[:, i, ...]
+ flow = flows_backward[0][:, i - 1, ...]
+ x_i_warped = flow_warp(x_i, flow.permute(0, 2, 3, 1), 'bilinear') # frame i+1 aligned towards i
+ x_backward.insert(0, self.pa_deform(x_i, [x_i_warped], x[:, i - 1, ...], [flow]))
+
+ # forward
+ x_forward = [torch.zeros_like(x[:, 0, ...])]
+ for i in range(0, n - 1):
+ x_i = x[:, i, ...]
+ flow = flows_forward[0][:, i, ...]
+ x_i_warped = flow_warp(x_i, flow.permute(0, 2, 3, 1), 'bilinear') # frame i-1 aligned towards i
+ x_forward.append(self.pa_deform(x_i, [x_i_warped], x[:, i + 1, ...], [flow]))
+
+ return [torch.stack(x_backward, 1), torch.stack(x_forward, 1)]
+
+ def get_aligned_feature_4frames(self, x, flows_backward, flows_forward):
+ '''Parallel feature warping for 4 frames.'''
+
+ # backward
+ n = x.size(1)
+ x_backward = [torch.zeros_like(x[:, -1, ...])]
+ for i in range(n, 1, -1):
+ x_i = x[:, i - 1, ...]
+ flow1 = flows_backward[0][:, i - 2, ...]
+ if i == n:
+ x_ii = torch.zeros_like(x[:, n - 2, ...])
+ flow2 = torch.zeros_like(flows_backward[1][:, n - 3, ...])
+ else:
+ x_ii = x[:, i, ...]
+ flow2 = flows_backward[1][:, i - 2, ...]
+
+ x_i_warped = flow_warp(x_i, flow1.permute(0, 2, 3, 1), 'bilinear') # frame i+1 aligned towards i
+ x_ii_warped = flow_warp(x_ii, flow2.permute(0, 2, 3, 1), 'bilinear') # frame i+2 aligned towards i
+ x_backward.insert(0,
+ self.pa_deform(torch.cat([x_i, x_ii], 1), [x_i_warped, x_ii_warped], x[:, i - 2, ...], [flow1, flow2]))
+
+ # forward
+ x_forward = [torch.zeros_like(x[:, 0, ...])]
+ for i in range(-1, n - 2):
+ x_i = x[:, i + 1, ...]
+ flow1 = flows_forward[0][:, i + 1, ...]
+ if i == -1:
+ x_ii = torch.zeros_like(x[:, 1, ...])
+ flow2 = torch.zeros_like(flows_forward[1][:, 0, ...])
+ else:
+ x_ii = x[:, i, ...]
+ flow2 = flows_forward[1][:, i, ...]
+
+ x_i_warped = flow_warp(x_i, flow1.permute(0, 2, 3, 1), 'bilinear') # frame i-1 aligned towards i
+ x_ii_warped = flow_warp(x_ii, flow2.permute(0, 2, 3, 1), 'bilinear') # frame i-2 aligned towards i
+ x_forward.append(
+ self.pa_deform(torch.cat([x_i, x_ii], 1), [x_i_warped, x_ii_warped], x[:, i + 2, ...], [flow1, flow2]))
+
+ return [torch.stack(x_backward, 1), torch.stack(x_forward, 1)]
+
+ def get_aligned_feature_6frames(self, x, flows_backward, flows_forward):
+ '''Parallel feature warping for 6 frames.'''
+
+ # backward
+ n = x.size(1)
+ x_backward = [torch.zeros_like(x[:, -1, ...])]
+ for i in range(n + 1, 2, -1):
+ x_i = x[:, i - 2, ...]
+ flow1 = flows_backward[0][:, i - 3, ...]
+ if i == n + 1:
+ x_ii = torch.zeros_like(x[:, -1, ...])
+ flow2 = torch.zeros_like(flows_backward[1][:, -1, ...])
+ x_iii = torch.zeros_like(x[:, -1, ...])
+ flow3 = torch.zeros_like(flows_backward[2][:, -1, ...])
+ elif i == n:
+ x_ii = x[:, i - 1, ...]
+ flow2 = flows_backward[1][:, i - 3, ...]
+ x_iii = torch.zeros_like(x[:, -1, ...])
+ flow3 = torch.zeros_like(flows_backward[2][:, -1, ...])
+ else:
+ x_ii = x[:, i - 1, ...]
+ flow2 = flows_backward[1][:, i - 3, ...]
+ x_iii = x[:, i, ...]
+ flow3 = flows_backward[2][:, i - 3, ...]
+
+ x_i_warped = flow_warp(x_i, flow1.permute(0, 2, 3, 1), 'bilinear') # frame i+1 aligned towards i
+ x_ii_warped = flow_warp(x_ii, flow2.permute(0, 2, 3, 1), 'bilinear') # frame i+2 aligned towards i
+ x_iii_warped = flow_warp(x_iii, flow3.permute(0, 2, 3, 1), 'bilinear') # frame i+3 aligned towards i
+ x_backward.insert(0,
+ self.pa_deform(torch.cat([x_i, x_ii, x_iii], 1), [x_i_warped, x_ii_warped, x_iii_warped],
+ x[:, i - 3, ...], [flow1, flow2, flow3]))
+
+ # forward
+ x_forward = [torch.zeros_like(x[:, 0, ...])]
+ for i in range(0, n - 1):
+ x_i = x[:, i, ...]
+ flow1 = flows_forward[0][:, i, ...]
+ if i == 0:
+ x_ii = torch.zeros_like(x[:, 0, ...])
+ flow2 = torch.zeros_like(flows_forward[1][:, 0, ...])
+ x_iii = torch.zeros_like(x[:, 0, ...])
+ flow3 = torch.zeros_like(flows_forward[2][:, 0, ...])
+ elif i == 1:
+ x_ii = x[:, i - 1, ...]
+ flow2 = flows_forward[1][:, i - 1, ...]
+ x_iii = torch.zeros_like(x[:, 0, ...])
+ flow3 = torch.zeros_like(flows_forward[2][:, 0, ...])
+ else:
+ x_ii = x[:, i - 1, ...]
+ flow2 = flows_forward[1][:, i - 1, ...]
+ x_iii = x[:, i - 2, ...]
+ flow3 = flows_forward[2][:, i - 2, ...]
+
+ x_i_warped = flow_warp(x_i, flow1.permute(0, 2, 3, 1), 'bilinear') # frame i-1 aligned towards i
+ x_ii_warped = flow_warp(x_ii, flow2.permute(0, 2, 3, 1), 'bilinear') # frame i-2 aligned towards i
+ x_iii_warped = flow_warp(x_iii, flow3.permute(0, 2, 3, 1), 'bilinear') # frame i-3 aligned towards i
+ x_forward.append(self.pa_deform(torch.cat([x_i, x_ii, x_iii], 1), [x_i_warped, x_ii_warped, x_iii_warped],
+ x[:, i + 1, ...], [flow1, flow2, flow3]))
+
+ return [torch.stack(x_backward, 1), torch.stack(x_forward, 1)]
+
+
+class VRT(nn.Module):
+ """ Video Restoration Transformer (VRT).
+ A PyTorch impl of : `VRT: A Video Restoration Transformer` -
+ https://arxiv.org/pdf/2201.00000
+
+ Args:
+ upscale (int): Upscaling factor. Set as 1 for video deblurring, etc. Default: 4.
+ in_chans (int): Number of input image channels. Default: 3.
+ img_size (int | tuple(int)): Size of input image. Default: [6, 64, 64].
+ window_size (int | tuple(int)): Window size. Default: (6,8,8).
+ depths (list[int]): Depths of each Transformer stage.
+ indep_reconsts (list[int]): Layers that extract features of different frames independently.
+ embed_dims (list[int]): Number of linear projection output channels.
+ num_heads (list[int]): Number of attention head of each stage.
+ mul_attn_ratio (float): Ratio of mutual attention layers. Default: 0.75.
+ mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 2.
+ qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True.
+ qk_scale (float): Override default qk scale of head_dim ** -0.5 if set.
+ drop_path_rate (float): Stochastic depth rate. Default: 0.2.
+ norm_layer (obj): Normalization layer. Default: nn.LayerNorm.
+ spynet_path (str): Pretrained SpyNet model path.
+ pa_frames (float): Number of warpped frames. Default: 2.
+ deformable_groups (float): Number of deformable groups. Default: 16.
+ recal_all_flows (bool): If True, derive (t,t+2) and (t,t+3) flows from (t,t+1). Default: False.
+ nonblind_denoising (bool): If True, conduct experiments on non-blind denoising. Default: False.
+ use_checkpoint_attn (bool): If True, use torch.checkpoint for attention modules. Default: False.
+ use_checkpoint_ffn (bool): If True, use torch.checkpoint for feed-forward modules. Default: False.
+ no_checkpoint_attn_blocks (list[int]): Layers without torch.checkpoint for attention modules.
+ no_checkpoint_ffn_blocks (list[int]): Layers without torch.checkpoint for feed-forward modules.
+ """
+
+ def __init__(self,
+ upscale=4,
+ in_chans=3,
+ img_size=[6, 64, 64],
+ window_size=[6, 8, 8],
+ depths=[8, 8, 8, 8, 8, 8, 8, 4, 4, 4, 4, 4, 4],
+ indep_reconsts=[11, 12],
+ embed_dims=[120, 120, 120, 120, 120, 120, 120, 180, 180, 180, 180, 180, 180],
+ num_heads=[6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6],
+ mul_attn_ratio=0.75,
+ mlp_ratio=2.,
+ qkv_bias=True,
+ qk_scale=None,
+ drop_path_rate=0.2,
+ norm_layer=nn.LayerNorm,
+ spynet_path=None,
+ pa_frames=2,
+ deformable_groups=16,
+ recal_all_flows=False,
+ nonblind_denoising=False,
+ use_checkpoint_attn=False,
+ use_checkpoint_ffn=False,
+ no_checkpoint_attn_blocks=[],
+ no_checkpoint_ffn_blocks=[],
+ ):
+ super().__init__()
+ self.in_chans = in_chans
+ self.upscale = upscale
+ self.pa_frames = pa_frames
+ self.recal_all_flows = recal_all_flows
+ self.nonblind_denoising = nonblind_denoising
+
+ # conv_first
+ self.conv_first = nn.Conv3d(in_chans*(1+2*4)+1 if self.nonblind_denoising else in_chans*(1+2*4),
+ embed_dims[0], kernel_size=(1, 3, 3), padding=(0, 1, 1))
+
+ # main body
+ self.spynet = SpyNet(spynet_path, [2, 3, 4, 5])
+ dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
+ reshapes = ['none', 'down', 'down', 'down', 'up', 'up', 'up']
+ scales = [1, 2, 4, 8, 4, 2, 1]
+ use_checkpoint_attns = [False if i in no_checkpoint_attn_blocks else use_checkpoint_attn for i in
+ range(len(depths))]
+ use_checkpoint_ffns = [False if i in no_checkpoint_ffn_blocks else use_checkpoint_ffn for i in
+ range(len(depths))]
+
+ # stage 1- 7
+ for i in range(7):
+ setattr(self, f'stage{i + 1}',
+ Stage(
+ in_dim=embed_dims[i - 1],
+ dim=embed_dims[i],
+ input_resolution=(img_size[0], img_size[1] // scales[i], img_size[2] // scales[i]),
+ depth=depths[i],
+ num_heads=num_heads[i],
+ mul_attn_ratio=mul_attn_ratio,
+ window_size=window_size,
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop_path=dpr[sum(depths[:i]):sum(depths[:i + 1])],
+ norm_layer=norm_layer,
+ pa_frames=pa_frames,
+ deformable_groups=deformable_groups,
+ reshape=reshapes[i],
+ max_residue_magnitude=10 / scales[i],
+ use_checkpoint_attn=use_checkpoint_attns[i],
+ use_checkpoint_ffn=use_checkpoint_ffns[i],
+ )
+ )
+
+ # stage 8
+ self.stage8 = nn.ModuleList(
+ [nn.Sequential(
+ Rearrange('n c d h w -> n d h w c'),
+ nn.LayerNorm(embed_dims[6]),
+ nn.Linear(embed_dims[6], embed_dims[7]),
+ Rearrange('n d h w c -> n c d h w')
+ )]
+ )
+ for i in range(7, len(depths)):
+ self.stage8.append(
+ RTMSA(dim=embed_dims[i],
+ input_resolution=img_size,
+ depth=depths[i],
+ num_heads=num_heads[i],
+ window_size=[1, window_size[1], window_size[2]] if i in indep_reconsts else window_size,
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias, qk_scale=qk_scale,
+ drop_path=dpr[sum(depths[:i]):sum(depths[:i + 1])],
+ norm_layer=norm_layer,
+ use_checkpoint_attn=use_checkpoint_attns[i],
+ use_checkpoint_ffn=use_checkpoint_ffns[i]
+ )
+ )
+
+ self.norm = norm_layer(embed_dims[-1])
+ self.conv_after_body = nn.Linear(embed_dims[-1], embed_dims[0])
+
+ # reconstruction
+ num_feat = 64
+ if self.upscale == 1:
+ # for video deblurring, etc.
+ self.conv_last = nn.Conv3d(embed_dims[0], in_chans, kernel_size=(1, 3, 3), padding=(0, 1, 1))
+ else:
+ # for video sr
+ self.conv_before_upsample = nn.Sequential(
+ nn.Conv3d(embed_dims[0], num_feat, kernel_size=(1, 3, 3), padding=(0, 1, 1)),
+ nn.LeakyReLU(inplace=True))
+ self.upsample = Upsample(upscale, num_feat)
+ self.conv_last = nn.Conv3d(num_feat, in_chans, kernel_size=(1, 3, 3), padding=(0, 1, 1))
+
+ def forward(self, x):
+ # x: (N, D, C, H, W)
+
+ # obtain noise level map
+ if self.nonblind_denoising:
+ x, noise_level_map = x[:, :, :self.in_chans, :, :], x[:, :, self.in_chans:, :, :]
+
+ x_lq = x.clone()
+
+ # calculate flows
+ flows_backward, flows_forward = self.get_flows(x)
+
+ # warp input
+ x_backward, x_forward = self.get_aligned_image_2frames(x, flows_backward[0], flows_forward[0])
+ x = torch.cat([x, x_backward, x_forward], 2)
+
+ # concatenate noise level map
+ if self.nonblind_denoising:
+ x = torch.cat([x, noise_level_map], 2)
+
+ # main network
+ if self.upscale == 1:
+ # video deblurring, etc.
+ x = self.conv_first(x.transpose(1, 2))
+ x = x + self.conv_after_body(
+ self.forward_features(x, flows_backward, flows_forward).transpose(1, 4)).transpose(1, 4)
+ x = self.conv_last(x).transpose(1, 2)
+ return x + x_lq
+ else:
+ # video sr
+ x = self.conv_first(x.transpose(1, 2))
+ x = x + self.conv_after_body(
+ self.forward_features(x, flows_backward, flows_forward).transpose(1, 4)).transpose(1, 4)
+ x = self.conv_last(self.upsample(self.conv_before_upsample(x))).transpose(1, 2)
+ _, _, C, H, W = x.shape
+ return x + torch.nn.functional.interpolate(x_lq, size=(C, H, W), mode='trilinear', align_corners=False)
+
+ def get_flows(self, x):
+ ''' Get flows for 2 frames, 4 frames or 6 frames.'''
+
+ if self.pa_frames == 2:
+ flows_backward, flows_forward = self.get_flow_2frames(x)
+ elif self.pa_frames == 4:
+ flows_backward_2frames, flows_forward_2frames = self.get_flow_2frames(x)
+ flows_backward_4frames, flows_forward_4frames = self.get_flow_4frames(flows_forward_2frames, flows_backward_2frames)
+ flows_backward = flows_backward_2frames + flows_backward_4frames
+ flows_forward = flows_forward_2frames + flows_forward_4frames
+ elif self.pa_frames == 6:
+ flows_backward_2frames, flows_forward_2frames = self.get_flow_2frames(x)
+ flows_backward_4frames, flows_forward_4frames = self.get_flow_4frames(flows_forward_2frames, flows_backward_2frames)
+ flows_backward_6frames, flows_forward_6frames = self.get_flow_6frames(flows_forward_2frames, flows_backward_2frames, flows_forward_4frames, flows_backward_4frames)
+ flows_backward = flows_backward_2frames + flows_backward_4frames + flows_backward_6frames
+ flows_forward = flows_forward_2frames + flows_forward_4frames + flows_forward_6frames
+
+ return flows_backward, flows_forward
+
+ def get_flow_2frames(self, x):
+ '''Get flow between frames t and t+1 from x.'''
+
+ b, n, c, h, w = x.size()
+ x_1 = x[:, :-1, :, :, :].reshape(-1, c, h, w)
+ x_2 = x[:, 1:, :, :, :].reshape(-1, c, h, w)
+
+ # backward
+ flows_backward = self.spynet(x_1, x_2)
+ flows_backward = [flow.view(b, n-1, 2, h // (2 ** i), w // (2 ** i)) for flow, i in
+ zip(flows_backward, range(4))]
+
+ # forward
+ flows_forward = self.spynet(x_2, x_1)
+ flows_forward = [flow.view(b, n-1, 2, h // (2 ** i), w // (2 ** i)) for flow, i in
+ zip(flows_forward, range(4))]
+
+ return flows_backward, flows_forward
+
+ def get_flow_4frames(self, flows_forward, flows_backward):
+ '''Get flow between t and t+2 from (t,t+1) and (t+1,t+2).'''
+
+ # backward
+ d = flows_forward[0].shape[1]
+ flows_backward2 = []
+ for flows in flows_backward:
+ flow_list = []
+ for i in range(d - 1, 0, -1):
+ flow_n1 = flows[:, i - 1, :, :, :] # flow from i+1 to i
+ flow_n2 = flows[:, i, :, :, :] # flow from i+2 to i+1
+ flow_list.insert(0, flow_n1 + flow_warp(flow_n2, flow_n1.permute(0, 2, 3, 1))) # flow from i+2 to i
+ flows_backward2.append(torch.stack(flow_list, 1))
+
+ # forward
+ flows_forward2 = []
+ for flows in flows_forward:
+ flow_list = []
+ for i in range(1, d):
+ flow_n1 = flows[:, i, :, :, :] # flow from i-1 to i
+ flow_n2 = flows[:, i - 1, :, :, :] # flow from i-2 to i-1
+ flow_list.append(flow_n1 + flow_warp(flow_n2, flow_n1.permute(0, 2, 3, 1))) # flow from i-2 to i
+ flows_forward2.append(torch.stack(flow_list, 1))
+
+ return flows_backward2, flows_forward2
+
+ def get_flow_6frames(self, flows_forward, flows_backward, flows_forward2, flows_backward2):
+ '''Get flow between t and t+3 from (t,t+2) and (t+2,t+3).'''
+
+ # backward
+ d = flows_forward2[0].shape[1]
+ flows_backward3 = []
+ for flows, flows2 in zip(flows_backward, flows_backward2):
+ flow_list = []
+ for i in range(d - 1, 0, -1):
+ flow_n1 = flows2[:, i - 1, :, :, :] # flow from i+2 to i
+ flow_n2 = flows[:, i + 1, :, :, :] # flow from i+3 to i+2
+ flow_list.insert(0, flow_n1 + flow_warp(flow_n2, flow_n1.permute(0, 2, 3, 1))) # flow from i+3 to i
+ flows_backward3.append(torch.stack(flow_list, 1))
+
+ # forward
+ flows_forward3 = []
+ for flows, flows2 in zip(flows_forward, flows_forward2):
+ flow_list = []
+ for i in range(2, d + 1):
+ flow_n1 = flows2[:, i - 1, :, :, :] # flow from i-2 to i
+ flow_n2 = flows[:, i - 2, :, :, :] # flow from i-3 to i-2
+ flow_list.append(flow_n1 + flow_warp(flow_n2, flow_n1.permute(0, 2, 3, 1))) # flow from i-3 to i
+ flows_forward3.append(torch.stack(flow_list, 1))
+
+ return flows_backward3, flows_forward3
+
+ def get_aligned_image_2frames(self, x, flows_backward, flows_forward):
+ '''Parallel feature warping for 2 frames.'''
+
+ # backward
+ n = x.size(1)
+ x_backward = [torch.zeros_like(x[:, -1, ...]).repeat(1, 4, 1, 1)]
+ for i in range(n - 1, 0, -1):
+ x_i = x[:, i, ...]
+ flow = flows_backward[:, i - 1, ...]
+ x_backward.insert(0, flow_warp(x_i, flow.permute(0, 2, 3, 1), 'nearest4')) # frame i+1 aligned towards i
+
+ # forward
+ x_forward = [torch.zeros_like(x[:, 0, ...]).repeat(1, 4, 1, 1)]
+ for i in range(0, n - 1):
+ x_i = x[:, i, ...]
+ flow = flows_forward[:, i, ...]
+ x_forward.append(flow_warp(x_i, flow.permute(0, 2, 3, 1), 'nearest4')) # frame i-1 aligned towards i
+
+ return [torch.stack(x_backward, 1), torch.stack(x_forward, 1)]
+
+ def forward_features(self, x, flows_backward, flows_forward):
+ '''Main network for feature extraction.'''
+
+ x1 = self.stage1(x, flows_backward[0::4], flows_forward[0::4])
+ x2 = self.stage2(x1, flows_backward[1::4], flows_forward[1::4])
+ x3 = self.stage3(x2, flows_backward[2::4], flows_forward[2::4])
+ x4 = self.stage4(x3, flows_backward[3::4], flows_forward[3::4])
+ x = self.stage5(x4, flows_backward[2::4], flows_forward[2::4])
+ x = self.stage6(x + x3, flows_backward[1::4], flows_forward[1::4])
+ x = self.stage7(x + x2, flows_backward[0::4], flows_forward[0::4])
+ x = x + x1
+
+ for layer in self.stage8:
+ x = layer(x)
+
+ x = rearrange(x, 'n c d h w -> n d h w c')
+ x = self.norm(x)
+ x = rearrange(x, 'n d h w c -> n c d h w')
+
+ return x
+
+
+if __name__ == '__main__':
+ device = torch.device('cpu')
+ upscale = 4
+ window_size = 8
+ height = (256 // upscale // window_size) * window_size
+ width = (256 // upscale // window_size) * window_size
+
+ model = VRT(upscale=4,
+ img_size=[6, 64, 64],
+ window_size=[6, 8, 8],
+ depths=[8, 8, 8, 8, 8, 8, 8, 4, 4, 4, 4, 4, 4],
+ indep_reconsts=[11, 12],
+ embed_dims=[120, 120, 120, 120, 120, 120, 120, 180, 180, 180, 180, 180, 180],
+ num_heads=[6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6],
+ spynet_path=None,
+ pa_frames=2,
+ deformable_groups=12
+ ).to(device)
+ print(model)
+ print('{:>16s} : {:<.4f} [M]'.format('#Params', sum(map(lambda x: x.numel(), model.parameters())) / 10 ** 6))
+
+ x = torch.randn((2, 12, 3, height, width)).to(device)
+ x = model(x)
+ print(x.shape)
diff --git a/KAIR/models/op/__init__.py b/KAIR/models/op/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..d0918d92285955855be89f00096b888ee5597ce3
--- /dev/null
+++ b/KAIR/models/op/__init__.py
@@ -0,0 +1,2 @@
+from .fused_act import FusedLeakyReLU, fused_leaky_relu
+from .upfirdn2d import upfirdn2d
diff --git a/KAIR/models/op/fused_act.py b/KAIR/models/op/fused_act.py
new file mode 100644
index 0000000000000000000000000000000000000000..3a41592fd5329a4f5f6b4ce0b99da0a9baf54715
--- /dev/null
+++ b/KAIR/models/op/fused_act.py
@@ -0,0 +1,88 @@
+import os
+
+import torch
+from torch import nn
+from torch.autograd import Function
+from torch.utils.cpp_extension import load, _import_module_from_library
+
+
+module_path = os.path.dirname(__file__)
+fused = load(
+ 'fused',
+ sources=[
+ os.path.join(module_path, 'fused_bias_act.cpp'),
+ os.path.join(module_path, 'fused_bias_act_kernel.cu'),
+ ],
+)
+
+#fused = _import_module_from_library('fused', '/tmp/torch_extensions/fused', True)
+
+
+class FusedLeakyReLUFunctionBackward(Function):
+ @staticmethod
+ def forward(ctx, grad_output, out, negative_slope, scale):
+ ctx.save_for_backward(out)
+ ctx.negative_slope = negative_slope
+ ctx.scale = scale
+
+ empty = grad_output.new_empty(0)
+
+ grad_input = fused.fused_bias_act(
+ grad_output, empty, out, 3, 1, negative_slope, scale
+ )
+
+ dim = [0]
+
+ if grad_input.ndim > 2:
+ dim += list(range(2, grad_input.ndim))
+
+ grad_bias = grad_input.sum(dim).detach()
+
+ return grad_input, grad_bias
+
+ @staticmethod
+ def backward(ctx, gradgrad_input, gradgrad_bias):
+ out, = ctx.saved_tensors
+ gradgrad_out = fused.fused_bias_act(
+ gradgrad_input, gradgrad_bias, out, 3, 1, ctx.negative_slope, ctx.scale
+ )
+
+ return gradgrad_out, None, None, None
+
+
+class FusedLeakyReLUFunction(Function):
+ @staticmethod
+ def forward(ctx, input, bias, negative_slope, scale):
+ empty = input.new_empty(0)
+ out = fused.fused_bias_act(input, bias, empty, 3, 0, negative_slope, scale)
+ ctx.save_for_backward(out)
+ ctx.negative_slope = negative_slope
+ ctx.scale = scale
+
+ return out
+
+ @staticmethod
+ def backward(ctx, grad_output):
+ out, = ctx.saved_tensors
+
+ grad_input, grad_bias = FusedLeakyReLUFunctionBackward.apply(
+ grad_output, out, ctx.negative_slope, ctx.scale
+ )
+
+ return grad_input, grad_bias, None, None
+
+
+class FusedLeakyReLU(nn.Module):
+ def __init__(self, channel, negative_slope=0.2, scale=2 ** 0.5):
+ super().__init__()
+
+ self.bias = nn.Parameter(torch.zeros(channel))
+ self.negative_slope = negative_slope
+ self.scale = scale
+
+ def forward(self, input):
+ return fused_leaky_relu(input, self.bias, self.negative_slope, self.scale)
+
+
+def fused_leaky_relu(input, bias, negative_slope=0.2, scale=2 ** 0.5):
+ return FusedLeakyReLUFunction.apply(input, bias, negative_slope, scale)
diff --git a/KAIR/models/op/fused_bias_act.cpp b/KAIR/models/op/fused_bias_act.cpp
new file mode 100644
index 0000000000000000000000000000000000000000..a054318781a20596d8f516ef86745e5572aad0f7
--- /dev/null
+++ b/KAIR/models/op/fused_bias_act.cpp
@@ -0,0 +1,21 @@
+#include
+
+
+torch::Tensor fused_bias_act_op(const torch::Tensor& input, const torch::Tensor& bias, const torch::Tensor& refer,
+ int act, int grad, float alpha, float scale);
+
+#define CHECK_CUDA(x) TORCH_CHECK(x.type().is_cuda(), #x " must be a CUDA tensor")
+#define CHECK_CONTIGUOUS(x) TORCH_CHECK(x.is_contiguous(), #x " must be contiguous")
+#define CHECK_INPUT(x) CHECK_CUDA(x); CHECK_CONTIGUOUS(x)
+
+torch::Tensor fused_bias_act(const torch::Tensor& input, const torch::Tensor& bias, const torch::Tensor& refer,
+ int act, int grad, float alpha, float scale) {
+ CHECK_CUDA(input);
+ CHECK_CUDA(bias);
+
+ return fused_bias_act_op(input, bias, refer, act, grad, alpha, scale);
+}
+
+PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
+ m.def("fused_bias_act", &fused_bias_act, "fused bias act (CUDA)");
+}
\ No newline at end of file
diff --git a/KAIR/models/op/fused_bias_act_kernel.cu b/KAIR/models/op/fused_bias_act_kernel.cu
new file mode 100644
index 0000000000000000000000000000000000000000..8d2f03c73605faee6723d002ba5de88cb465a80e
--- /dev/null
+++ b/KAIR/models/op/fused_bias_act_kernel.cu
@@ -0,0 +1,99 @@
+// Copyright (c) 2019, NVIDIA Corporation. All rights reserved.
+//
+// This work is made available under the Nvidia Source Code License-NC.
+// To view a copy of this license, visit
+// https://nvlabs.github.io/stylegan2/license.html
+
+#include
+
+#include
+#include
+#include
+#include
+
+#include
+#include
+
+
+template
+static __global__ void fused_bias_act_kernel(scalar_t* out, const scalar_t* p_x, const scalar_t* p_b, const scalar_t* p_ref,
+ int act, int grad, scalar_t alpha, scalar_t scale, int loop_x, int size_x, int step_b, int size_b, int use_bias, int use_ref) {
+ int xi = blockIdx.x * loop_x * blockDim.x + threadIdx.x;
+
+ scalar_t zero = 0.0;
+
+ for (int loop_idx = 0; loop_idx < loop_x && xi < size_x; loop_idx++, xi += blockDim.x) {
+ scalar_t x = p_x[xi];
+
+ if (use_bias) {
+ x += p_b[(xi / step_b) % size_b];
+ }
+
+ scalar_t ref = use_ref ? p_ref[xi] : zero;
+
+ scalar_t y;
+
+ switch (act * 10 + grad) {
+ default:
+ case 10: y = x; break;
+ case 11: y = x; break;
+ case 12: y = 0.0; break;
+
+ case 30: y = (x > 0.0) ? x : x * alpha; break;
+ case 31: y = (ref > 0.0) ? x : x * alpha; break;
+ case 32: y = 0.0; break;
+ }
+
+ out[xi] = y * scale;
+ }
+}
+
+
+torch::Tensor fused_bias_act_op(const torch::Tensor& input, const torch::Tensor& bias, const torch::Tensor& refer,
+ int act, int grad, float alpha, float scale) {
+ int curDevice = -1;
+ cudaGetDevice(&curDevice);
+ cudaStream_t stream = at::cuda::getCurrentCUDAStream(curDevice);
+
+ auto x = input.contiguous();
+ auto b = bias.contiguous();
+ auto ref = refer.contiguous();
+
+ int use_bias = b.numel() ? 1 : 0;
+ int use_ref = ref.numel() ? 1 : 0;
+
+ int size_x = x.numel();
+ int size_b = b.numel();
+ int step_b = 1;
+
+ for (int i = 1 + 1; i < x.dim(); i++) {
+ step_b *= x.size(i);
+ }
+
+ int loop_x = 4;
+ int block_size = 4 * 32;
+ int grid_size = (size_x - 1) / (loop_x * block_size) + 1;
+
+ auto y = torch::empty_like(x);
+
+ AT_DISPATCH_FLOATING_TYPES_AND_HALF(x.scalar_type(), "fused_bias_act_kernel", [&] {
+ fused_bias_act_kernel<<>>(
+ y.data_ptr(),
+ x.data_ptr(),
+ b.data_ptr(),
+ ref.data_ptr(),
+ act,
+ grad,
+ alpha,
+ scale,
+ loop_x,
+ size_x,
+ step_b,
+ size_b,
+ use_bias,
+ use_ref
+ );
+ });
+
+ return y;
+}
\ No newline at end of file
diff --git a/KAIR/models/op/upfirdn2d.cpp b/KAIR/models/op/upfirdn2d.cpp
new file mode 100644
index 0000000000000000000000000000000000000000..b07aa2056864db83ff0aacbb1068e072ba9da4ad
--- /dev/null
+++ b/KAIR/models/op/upfirdn2d.cpp
@@ -0,0 +1,23 @@
+#include
+
+
+torch::Tensor upfirdn2d_op(const torch::Tensor& input, const torch::Tensor& kernel,
+ int up_x, int up_y, int down_x, int down_y,
+ int pad_x0, int pad_x1, int pad_y0, int pad_y1);
+
+#define CHECK_CUDA(x) TORCH_CHECK(x.type().is_cuda(), #x " must be a CUDA tensor")
+#define CHECK_CONTIGUOUS(x) TORCH_CHECK(x.is_contiguous(), #x " must be contiguous")
+#define CHECK_INPUT(x) CHECK_CUDA(x); CHECK_CONTIGUOUS(x)
+
+torch::Tensor upfirdn2d(const torch::Tensor& input, const torch::Tensor& kernel,
+ int up_x, int up_y, int down_x, int down_y,
+ int pad_x0, int pad_x1, int pad_y0, int pad_y1) {
+ CHECK_CUDA(input);
+ CHECK_CUDA(kernel);
+
+ return upfirdn2d_op(input, kernel, up_x, up_y, down_x, down_y, pad_x0, pad_x1, pad_y0, pad_y1);
+}
+
+PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
+ m.def("upfirdn2d", &upfirdn2d, "upfirdn2d (CUDA)");
+}
\ No newline at end of file
diff --git a/KAIR/models/op/upfirdn2d.py b/KAIR/models/op/upfirdn2d.py
new file mode 100644
index 0000000000000000000000000000000000000000..bd8dbca23f9951b345c36b278f68711ecbc3bdf8
--- /dev/null
+++ b/KAIR/models/op/upfirdn2d.py
@@ -0,0 +1,188 @@
+import os
+
+import torch
+from torch.autograd import Function
+from torch.utils.cpp_extension import load, _import_module_from_library
+
+
+module_path = os.path.dirname(__file__)
+upfirdn2d_op = load(
+ 'upfirdn2d',
+ sources=[
+ os.path.join(module_path, 'upfirdn2d.cpp'),
+ os.path.join(module_path, 'upfirdn2d_kernel.cu'),
+ ],
+)
+
+#upfirdn2d_op = _import_module_from_library('upfirdn2d', '/tmp/torch_extensions/upfirdn2d', True)
+
+class UpFirDn2dBackward(Function):
+ @staticmethod
+ def forward(
+ ctx, grad_output, kernel, grad_kernel, up, down, pad, g_pad, in_size, out_size
+ ):
+
+ up_x, up_y = up
+ down_x, down_y = down
+ g_pad_x0, g_pad_x1, g_pad_y0, g_pad_y1 = g_pad
+
+ grad_output = grad_output.reshape(-1, out_size[0], out_size[1], 1)
+
+ grad_input = upfirdn2d_op.upfirdn2d(
+ grad_output,
+ grad_kernel,
+ down_x,
+ down_y,
+ up_x,
+ up_y,
+ g_pad_x0,
+ g_pad_x1,
+ g_pad_y0,
+ g_pad_y1,
+ )
+ grad_input = grad_input.view(in_size[0], in_size[1], in_size[2], in_size[3])
+
+ ctx.save_for_backward(kernel)
+
+ pad_x0, pad_x1, pad_y0, pad_y1 = pad
+
+ ctx.up_x = up_x
+ ctx.up_y = up_y
+ ctx.down_x = down_x
+ ctx.down_y = down_y
+ ctx.pad_x0 = pad_x0
+ ctx.pad_x1 = pad_x1
+ ctx.pad_y0 = pad_y0
+ ctx.pad_y1 = pad_y1
+ ctx.in_size = in_size
+ ctx.out_size = out_size
+
+ return grad_input
+
+ @staticmethod
+ def backward(ctx, gradgrad_input):
+ kernel, = ctx.saved_tensors
+
+ gradgrad_input = gradgrad_input.reshape(-1, ctx.in_size[2], ctx.in_size[3], 1)
+
+ gradgrad_out = upfirdn2d_op.upfirdn2d(
+ gradgrad_input,
+ kernel,
+ ctx.up_x,
+ ctx.up_y,
+ ctx.down_x,
+ ctx.down_y,
+ ctx.pad_x0,
+ ctx.pad_x1,
+ ctx.pad_y0,
+ ctx.pad_y1,
+ )
+ # gradgrad_out = gradgrad_out.view(ctx.in_size[0], ctx.out_size[0], ctx.out_size[1], ctx.in_size[3])
+ gradgrad_out = gradgrad_out.view(
+ ctx.in_size[0], ctx.in_size[1], ctx.out_size[0], ctx.out_size[1]
+ )
+
+ return gradgrad_out, None, None, None, None, None, None, None, None
+
+
+class UpFirDn2d(Function):
+ @staticmethod
+ def forward(ctx, input, kernel, up, down, pad):
+ up_x, up_y = up
+ down_x, down_y = down
+ pad_x0, pad_x1, pad_y0, pad_y1 = pad
+
+ kernel_h, kernel_w = kernel.shape
+ batch, channel, in_h, in_w = input.shape
+ ctx.in_size = input.shape
+
+ input = input.reshape(-1, in_h, in_w, 1)
+
+ ctx.save_for_backward(kernel, torch.flip(kernel, [0, 1]))
+
+ out_h = (in_h * up_y + pad_y0 + pad_y1 - kernel_h) // down_y + 1
+ out_w = (in_w * up_x + pad_x0 + pad_x1 - kernel_w) // down_x + 1
+ ctx.out_size = (out_h, out_w)
+
+ ctx.up = (up_x, up_y)
+ ctx.down = (down_x, down_y)
+ ctx.pad = (pad_x0, pad_x1, pad_y0, pad_y1)
+
+ g_pad_x0 = kernel_w - pad_x0 - 1
+ g_pad_y0 = kernel_h - pad_y0 - 1
+ g_pad_x1 = in_w * up_x - out_w * down_x + pad_x0 - up_x + 1
+ g_pad_y1 = in_h * up_y - out_h * down_y + pad_y0 - up_y + 1
+
+ ctx.g_pad = (g_pad_x0, g_pad_x1, g_pad_y0, g_pad_y1)
+
+ out = upfirdn2d_op.upfirdn2d(
+ input, kernel, up_x, up_y, down_x, down_y, pad_x0, pad_x1, pad_y0, pad_y1
+ )
+ # out = out.view(major, out_h, out_w, minor)
+ out = out.view(-1, channel, out_h, out_w)
+
+ return out
+
+ @staticmethod
+ def backward(ctx, grad_output):
+ kernel, grad_kernel = ctx.saved_tensors
+
+ grad_input = UpFirDn2dBackward.apply(
+ grad_output,
+ kernel,
+ grad_kernel,
+ ctx.up,
+ ctx.down,
+ ctx.pad,
+ ctx.g_pad,
+ ctx.in_size,
+ ctx.out_size,
+ )
+
+ return grad_input, None, None, None, None
+
+
+def upfirdn2d(input, kernel, up=1, down=1, pad=(0, 0)):
+ out = UpFirDn2d.apply(
+ input, kernel, (up, up), (down, down), (pad[0], pad[1], pad[0], pad[1])
+ )
+
+ return out
+
+
+def upfirdn2d_native(
+ input, kernel, up_x, up_y, down_x, down_y, pad_x0, pad_x1, pad_y0, pad_y1
+):
+ _, in_h, in_w, minor = input.shape
+ kernel_h, kernel_w = kernel.shape
+
+ out = input.view(-1, in_h, 1, in_w, 1, minor)
+ out = F.pad(out, [0, 0, 0, up_x - 1, 0, 0, 0, up_y - 1])
+ out = out.view(-1, in_h * up_y, in_w * up_x, minor)
+
+ out = F.pad(
+ out, [0, 0, max(pad_x0, 0), max(pad_x1, 0), max(pad_y0, 0), max(pad_y1, 0)]
+ )
+ out = out[
+ :,
+ max(-pad_y0, 0) : out.shape[1] - max(-pad_y1, 0),
+ max(-pad_x0, 0) : out.shape[2] - max(-pad_x1, 0),
+ :,
+ ]
+
+ out = out.permute(0, 3, 1, 2)
+ out = out.reshape(
+ [-1, 1, in_h * up_y + pad_y0 + pad_y1, in_w * up_x + pad_x0 + pad_x1]
+ )
+ w = torch.flip(kernel, [0, 1]).view(1, 1, kernel_h, kernel_w)
+ out = F.conv2d(out, w)
+ out = out.reshape(
+ -1,
+ minor,
+ in_h * up_y + pad_y0 + pad_y1 - kernel_h + 1,
+ in_w * up_x + pad_x0 + pad_x1 - kernel_w + 1,
+ )
+ out = out.permute(0, 2, 3, 1)
+
+ return out[:, ::down_y, ::down_x, :]
+
diff --git a/KAIR/models/op/upfirdn2d_kernel.cu b/KAIR/models/op/upfirdn2d_kernel.cu
new file mode 100644
index 0000000000000000000000000000000000000000..871d4fe2fafb6c7863ea41656f8770f8a4a61b3a
--- /dev/null
+++ b/KAIR/models/op/upfirdn2d_kernel.cu
@@ -0,0 +1,272 @@
+// Copyright (c) 2019, NVIDIA Corporation. All rights reserved.
+//
+// This work is made available under the Nvidia Source Code License-NC.
+// To view a copy of this license, visit
+// https://nvlabs.github.io/stylegan2/license.html
+
+#include
+
+#include
+#include
+#include
+#include
+
+#include
+#include
+
+
+static __host__ __device__ __forceinline__ int floor_div(int a, int b) {
+ int c = a / b;
+
+ if (c * b > a) {
+ c--;
+ }
+
+ return c;
+}
+
+
+struct UpFirDn2DKernelParams {
+ int up_x;
+ int up_y;
+ int down_x;
+ int down_y;
+ int pad_x0;
+ int pad_x1;
+ int pad_y0;
+ int pad_y1;
+
+ int major_dim;
+ int in_h;
+ int in_w;
+ int minor_dim;
+ int kernel_h;
+ int kernel_w;
+ int out_h;
+ int out_w;
+ int loop_major;
+ int loop_x;
+};
+
+
+template
+__global__ void upfirdn2d_kernel(scalar_t* out, const scalar_t* input, const scalar_t* kernel, const UpFirDn2DKernelParams p) {
+ const int tile_in_h = ((tile_out_h - 1) * down_y + kernel_h - 1) / up_y + 1;
+ const int tile_in_w = ((tile_out_w - 1) * down_x + kernel_w - 1) / up_x + 1;
+
+ __shared__ volatile float sk[kernel_h][kernel_w];
+ __shared__ volatile float sx[tile_in_h][tile_in_w];
+
+ int minor_idx = blockIdx.x;
+ int tile_out_y = minor_idx / p.minor_dim;
+ minor_idx -= tile_out_y * p.minor_dim;
+ tile_out_y *= tile_out_h;
+ int tile_out_x_base = blockIdx.y * p.loop_x * tile_out_w;
+ int major_idx_base = blockIdx.z * p.loop_major;
+
+ if (tile_out_x_base >= p.out_w | tile_out_y >= p.out_h | major_idx_base >= p.major_dim) {
+ return;
+ }
+
+ for (int tap_idx = threadIdx.x; tap_idx < kernel_h * kernel_w; tap_idx += blockDim.x) {
+ int ky = tap_idx / kernel_w;
+ int kx = tap_idx - ky * kernel_w;
+ scalar_t v = 0.0;
+
+ if (kx < p.kernel_w & ky < p.kernel_h) {
+ v = kernel[(p.kernel_h - 1 - ky) * p.kernel_w + (p.kernel_w - 1 - kx)];
+ }
+
+ sk[ky][kx] = v;
+ }
+
+ for (int loop_major = 0, major_idx = major_idx_base; loop_major < p.loop_major & major_idx < p.major_dim; loop_major++, major_idx++) {
+ for (int loop_x = 0, tile_out_x = tile_out_x_base; loop_x < p.loop_x & tile_out_x < p.out_w; loop_x++, tile_out_x += tile_out_w) {
+ int tile_mid_x = tile_out_x * down_x + up_x - 1 - p.pad_x0;
+ int tile_mid_y = tile_out_y * down_y + up_y - 1 - p.pad_y0;
+ int tile_in_x = floor_div(tile_mid_x, up_x);
+ int tile_in_y = floor_div(tile_mid_y, up_y);
+
+ __syncthreads();
+
+ for (int in_idx = threadIdx.x; in_idx < tile_in_h * tile_in_w; in_idx += blockDim.x) {
+ int rel_in_y = in_idx / tile_in_w;
+ int rel_in_x = in_idx - rel_in_y * tile_in_w;
+ int in_x = rel_in_x + tile_in_x;
+ int in_y = rel_in_y + tile_in_y;
+
+ scalar_t v = 0.0;
+
+ if (in_x >= 0 & in_y >= 0 & in_x < p.in_w & in_y < p.in_h) {
+ v = input[((major_idx * p.in_h + in_y) * p.in_w + in_x) * p.minor_dim + minor_idx];
+ }
+
+ sx[rel_in_y][rel_in_x] = v;
+ }
+
+ __syncthreads();
+ for (int out_idx = threadIdx.x; out_idx < tile_out_h * tile_out_w; out_idx += blockDim.x) {
+ int rel_out_y = out_idx / tile_out_w;
+ int rel_out_x = out_idx - rel_out_y * tile_out_w;
+ int out_x = rel_out_x + tile_out_x;
+ int out_y = rel_out_y + tile_out_y;
+
+ int mid_x = tile_mid_x + rel_out_x * down_x;
+ int mid_y = tile_mid_y + rel_out_y * down_y;
+ int in_x = floor_div(mid_x, up_x);
+ int in_y = floor_div(mid_y, up_y);
+ int rel_in_x = in_x - tile_in_x;
+ int rel_in_y = in_y - tile_in_y;
+ int kernel_x = (in_x + 1) * up_x - mid_x - 1;
+ int kernel_y = (in_y + 1) * up_y - mid_y - 1;
+
+ scalar_t v = 0.0;
+
+ #pragma unroll
+ for (int y = 0; y < kernel_h / up_y; y++)
+ #pragma unroll
+ for (int x = 0; x < kernel_w / up_x; x++)
+ v += sx[rel_in_y + y][rel_in_x + x] * sk[kernel_y + y * up_y][kernel_x + x * up_x];
+
+ if (out_x < p.out_w & out_y < p.out_h) {
+ out[((major_idx * p.out_h + out_y) * p.out_w + out_x) * p.minor_dim + minor_idx] = v;
+ }
+ }
+ }
+ }
+}
+
+
+torch::Tensor upfirdn2d_op(const torch::Tensor& input, const torch::Tensor& kernel,
+ int up_x, int up_y, int down_x, int down_y,
+ int pad_x0, int pad_x1, int pad_y0, int pad_y1) {
+ int curDevice = -1;
+ cudaGetDevice(&curDevice);
+ cudaStream_t stream = at::cuda::getCurrentCUDAStream(curDevice);
+
+ UpFirDn2DKernelParams p;
+
+ auto x = input.contiguous();
+ auto k = kernel.contiguous();
+
+ p.major_dim = x.size(0);
+ p.in_h = x.size(1);
+ p.in_w = x.size(2);
+ p.minor_dim = x.size(3);
+ p.kernel_h = k.size(0);
+ p.kernel_w = k.size(1);
+ p.up_x = up_x;
+ p.up_y = up_y;
+ p.down_x = down_x;
+ p.down_y = down_y;
+ p.pad_x0 = pad_x0;
+ p.pad_x1 = pad_x1;
+ p.pad_y0 = pad_y0;
+ p.pad_y1 = pad_y1;
+
+ p.out_h = (p.in_h * p.up_y + p.pad_y0 + p.pad_y1 - p.kernel_h + p.down_y) / p.down_y;
+ p.out_w = (p.in_w * p.up_x + p.pad_x0 + p.pad_x1 - p.kernel_w + p.down_x) / p.down_x;
+
+ auto out = at::empty({p.major_dim, p.out_h, p.out_w, p.minor_dim}, x.options());
+
+ int mode = -1;
+
+ int tile_out_h;
+ int tile_out_w;
+
+ if (p.up_x == 1 && p.up_y == 1 && p.down_x == 1 && p.down_y == 1 && p.kernel_h <= 4 && p.kernel_w <= 4) {
+ mode = 1;
+ tile_out_h = 16;
+ tile_out_w = 64;
+ }
+
+ if (p.up_x == 1 && p.up_y == 1 && p.down_x == 1 && p.down_y == 1 && p.kernel_h <= 3 && p.kernel_w <= 3) {
+ mode = 2;
+ tile_out_h = 16;
+ tile_out_w = 64;
+ }
+
+ if (p.up_x == 2 && p.up_y == 2 && p.down_x == 1 && p.down_y == 1 && p.kernel_h <= 4 && p.kernel_w <= 4) {
+ mode = 3;
+ tile_out_h = 16;
+ tile_out_w = 64;
+ }
+
+ if (p.up_x == 2 && p.up_y == 2 && p.down_x == 1 && p.down_y == 1 && p.kernel_h <= 2 && p.kernel_w <= 2) {
+ mode = 4;
+ tile_out_h = 16;
+ tile_out_w = 64;
+ }
+
+ if (p.up_x == 1 && p.up_y == 1 && p.down_x == 2 && p.down_y == 2 && p.kernel_h <= 4 && p.kernel_w <= 4) {
+ mode = 5;
+ tile_out_h = 8;
+ tile_out_w = 32;
+ }
+
+ if (p.up_x == 1 && p.up_y == 1 && p.down_x == 2 && p.down_y == 2 && p.kernel_h <= 2 && p.kernel_w <= 2) {
+ mode = 6;
+ tile_out_h = 8;
+ tile_out_w = 32;
+ }
+
+ dim3 block_size;
+ dim3 grid_size;
+
+ if (tile_out_h > 0 && tile_out_w) {
+ p.loop_major = (p.major_dim - 1) / 16384 + 1;
+ p.loop_x = 1;
+ block_size = dim3(32 * 8, 1, 1);
+ grid_size = dim3(((p.out_h - 1) / tile_out_h + 1) * p.minor_dim,
+ (p.out_w - 1) / (p.loop_x * tile_out_w) + 1,
+ (p.major_dim - 1) / p.loop_major + 1);
+ }
+
+ AT_DISPATCH_FLOATING_TYPES_AND_HALF(x.scalar_type(), "upfirdn2d_cuda", [&] {
+ switch (mode) {
+ case 1:
+ upfirdn2d_kernel<<>>(
+ out.data_ptr(), x.data_ptr(), k.data_ptr(), p
+ );
+
+ break;
+
+ case 2:
+ upfirdn2d_kernel<<>>(
+ out.data_ptr(), x.data_ptr(), k.data_ptr(), p
+ );
+
+ break;
+
+ case 3:
+ upfirdn2d_kernel<<>>(
+ out.data_ptr(), x.data_ptr(), k.data_ptr(), p
+ );
+
+ break;
+
+ case 4:
+ upfirdn2d_kernel<<>>(
+ out.data_ptr(), x.data_ptr(), k.data_ptr(), p
+ );
+
+ break;
+
+ case 5:
+ upfirdn2d_kernel<<>>(
+ out.data_ptr(), x.data_ptr(), k.data_ptr(), p
+ );
+
+ break;
+
+ case 6:
+ upfirdn2d_kernel<<>>(
+ out.data_ptr(), x.data_ptr(), k.data_ptr(), p
+ );
+
+ break;
+ }
+ });
+
+ return out;
+}
\ No newline at end of file
diff --git a/KAIR/models/select_model.py b/KAIR/models/select_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..cd8af0f06d7dd919a73b473a5ccc3af810178151
--- /dev/null
+++ b/KAIR/models/select_model.py
@@ -0,0 +1,33 @@
+
+"""
+# --------------------------------------------
+# define training model
+# --------------------------------------------
+"""
+
+
+def define_Model(opt):
+ model = opt['model'] # one input: L
+
+ if model == 'plain':
+ from models.model_plain import ModelPlain as M
+
+ elif model == 'plain2': # two inputs: L, C
+ from models.model_plain2 import ModelPlain2 as M
+
+ elif model == 'plain4': # four inputs: L, k, sf, sigma
+ from models.model_plain4 import ModelPlain4 as M
+
+ elif model == 'gan': # one input: L
+ from models.model_gan import ModelGAN as M
+
+ elif model == 'vrt': # one video input L, for VRT
+ from models.model_vrt import ModelVRT as M
+
+ else:
+ raise NotImplementedError('Model [{:s}] is not defined.'.format(model))
+
+ m = M(opt)
+
+ print('Training model [{:s}] is created.'.format(m.__class__.__name__))
+ return m
diff --git a/KAIR/models/select_network.py b/KAIR/models/select_network.py
new file mode 100644
index 0000000000000000000000000000000000000000..c5f92d193018432849991d4c7382c0077013ef9b
--- /dev/null
+++ b/KAIR/models/select_network.py
@@ -0,0 +1,408 @@
+import functools
+import torch
+from torch.nn import init
+
+
+"""
+# --------------------------------------------
+# select the network of G, D and F
+# --------------------------------------------
+"""
+
+
+# --------------------------------------------
+# Generator, netG, G
+# --------------------------------------------
+def define_G(opt):
+ opt_net = opt['netG']
+ net_type = opt_net['net_type']
+
+
+ # ----------------------------------------
+ # denoising task
+ # ----------------------------------------
+
+ # ----------------------------------------
+ # DnCNN
+ # ----------------------------------------
+ if net_type == 'dncnn':
+ from models.network_dncnn import DnCNN as net
+ netG = net(in_nc=opt_net['in_nc'],
+ out_nc=opt_net['out_nc'],
+ nc=opt_net['nc'],
+ nb=opt_net['nb'], # total number of conv layers
+ act_mode=opt_net['act_mode'])
+
+ # ----------------------------------------
+ # Flexible DnCNN
+ # ----------------------------------------
+ elif net_type == 'fdncnn':
+ from models.network_dncnn import FDnCNN as net
+ netG = net(in_nc=opt_net['in_nc'],
+ out_nc=opt_net['out_nc'],
+ nc=opt_net['nc'],
+ nb=opt_net['nb'], # total number of conv layers
+ act_mode=opt_net['act_mode'])
+
+ # ----------------------------------------
+ # FFDNet
+ # ----------------------------------------
+ elif net_type == 'ffdnet':
+ from models.network_ffdnet import FFDNet as net
+ netG = net(in_nc=opt_net['in_nc'],
+ out_nc=opt_net['out_nc'],
+ nc=opt_net['nc'],
+ nb=opt_net['nb'],
+ act_mode=opt_net['act_mode'])
+
+ # ----------------------------------------
+ # others
+ # ----------------------------------------
+
+ # ----------------------------------------
+ # super-resolution task
+ # ----------------------------------------
+
+ # ----------------------------------------
+ # SRMD
+ # ----------------------------------------
+ elif net_type == 'srmd':
+ from models.network_srmd import SRMD as net
+ netG = net(in_nc=opt_net['in_nc'],
+ out_nc=opt_net['out_nc'],
+ nc=opt_net['nc'],
+ nb=opt_net['nb'],
+ upscale=opt_net['scale'],
+ act_mode=opt_net['act_mode'],
+ upsample_mode=opt_net['upsample_mode'])
+
+ # ----------------------------------------
+ # super-resolver prior of DPSR
+ # ----------------------------------------
+ elif net_type == 'dpsr':
+ from models.network_dpsr import MSRResNet_prior as net
+ netG = net(in_nc=opt_net['in_nc'],
+ out_nc=opt_net['out_nc'],
+ nc=opt_net['nc'],
+ nb=opt_net['nb'],
+ upscale=opt_net['scale'],
+ act_mode=opt_net['act_mode'],
+ upsample_mode=opt_net['upsample_mode'])
+
+ # ----------------------------------------
+ # modified SRResNet v0.0
+ # ----------------------------------------
+ elif net_type == 'msrresnet0':
+ from models.network_msrresnet import MSRResNet0 as net
+ netG = net(in_nc=opt_net['in_nc'],
+ out_nc=opt_net['out_nc'],
+ nc=opt_net['nc'],
+ nb=opt_net['nb'],
+ upscale=opt_net['scale'],
+ act_mode=opt_net['act_mode'],
+ upsample_mode=opt_net['upsample_mode'])
+
+ # ----------------------------------------
+ # modified SRResNet v0.1
+ # ----------------------------------------
+ elif net_type == 'msrresnet1':
+ from models.network_msrresnet import MSRResNet1 as net
+ netG = net(in_nc=opt_net['in_nc'],
+ out_nc=opt_net['out_nc'],
+ nc=opt_net['nc'],
+ nb=opt_net['nb'],
+ upscale=opt_net['scale'],
+ act_mode=opt_net['act_mode'],
+ upsample_mode=opt_net['upsample_mode'])
+
+ # ----------------------------------------
+ # RRDB
+ # ----------------------------------------
+ elif net_type == 'rrdb': # RRDB
+ from models.network_rrdb import RRDB as net
+ netG = net(in_nc=opt_net['in_nc'],
+ out_nc=opt_net['out_nc'],
+ nc=opt_net['nc'],
+ nb=opt_net['nb'],
+ gc=opt_net['gc'],
+ upscale=opt_net['scale'],
+ act_mode=opt_net['act_mode'],
+ upsample_mode=opt_net['upsample_mode'])
+
+ # ----------------------------------------
+ # RRDBNet
+ # ----------------------------------------
+ elif net_type == 'rrdbnet': # RRDBNet
+ from models.network_rrdbnet import RRDBNet as net
+ netG = net(in_nc=opt_net['in_nc'],
+ out_nc=opt_net['out_nc'],
+ nf=opt_net['nf'],
+ nb=opt_net['nb'],
+ gc=opt_net['gc'],
+ sf=opt_net['scale'])
+
+ # ----------------------------------------
+ # IMDB
+ # ----------------------------------------
+ elif net_type == 'imdn': # IMDB
+ from models.network_imdn import IMDN as net
+ netG = net(in_nc=opt_net['in_nc'],
+ out_nc=opt_net['out_nc'],
+ nc=opt_net['nc'],
+ nb=opt_net['nb'],
+ upscale=opt_net['scale'],
+ act_mode=opt_net['act_mode'],
+ upsample_mode=opt_net['upsample_mode'])
+
+ # ----------------------------------------
+ # USRNet
+ # ----------------------------------------
+ elif net_type == 'usrnet': # USRNet
+ from models.network_usrnet import USRNet as net
+ netG = net(n_iter=opt_net['n_iter'],
+ h_nc=opt_net['h_nc'],
+ in_nc=opt_net['in_nc'],
+ out_nc=opt_net['out_nc'],
+ nc=opt_net['nc'],
+ nb=opt_net['nb'],
+ act_mode=opt_net['act_mode'],
+ downsample_mode=opt_net['downsample_mode'],
+ upsample_mode=opt_net['upsample_mode']
+ )
+
+ # ----------------------------------------
+ # Deep Residual U-Net (drunet)
+ # ----------------------------------------
+ elif net_type == 'drunet':
+ from models.network_unet import UNetRes as net
+ netG = net(in_nc=opt_net['in_nc'],
+ out_nc=opt_net['out_nc'],
+ nc=opt_net['nc'],
+ nb=opt_net['nb'],
+ act_mode=opt_net['act_mode'],
+ downsample_mode=opt_net['downsample_mode'],
+ upsample_mode=opt_net['upsample_mode'],
+ bias=opt_net['bias'])
+
+ # ----------------------------------------
+ # SwinIR
+ # ----------------------------------------
+ elif net_type == 'swinir':
+ from models.network_swinir import SwinIR as net
+ netG = net(upscale=opt_net['upscale'],
+ in_chans=opt_net['in_chans'],
+ img_size=opt_net['img_size'],
+ window_size=opt_net['window_size'],
+ img_range=opt_net['img_range'],
+ depths=opt_net['depths'],
+ embed_dim=opt_net['embed_dim'],
+ num_heads=opt_net['num_heads'],
+ mlp_ratio=opt_net['mlp_ratio'],
+ upsampler=opt_net['upsampler'],
+ resi_connection=opt_net['resi_connection'])
+
+ # ----------------------------------------
+ # VRT
+ # ----------------------------------------
+ elif net_type == 'vrt':
+ from models.network_vrt import VRT as net
+ netG = net(upscale=opt_net['upscale'],
+ img_size=opt_net['img_size'],
+ window_size=opt_net['window_size'],
+ depths=opt_net['depths'],
+ indep_reconsts=opt_net['indep_reconsts'],
+ embed_dims=opt_net['embed_dims'],
+ num_heads=opt_net['num_heads'],
+ spynet_path=opt_net['spynet_path'],
+ pa_frames=opt_net['pa_frames'],
+ deformable_groups=opt_net['deformable_groups'],
+ nonblind_denoising=opt_net['nonblind_denoising'],
+ use_checkpoint_attn=opt_net['use_checkpoint_attn'],
+ use_checkpoint_ffn=opt_net['use_checkpoint_ffn'],
+ no_checkpoint_attn_blocks=opt_net['no_checkpoint_attn_blocks'],
+ no_checkpoint_ffn_blocks=opt_net['no_checkpoint_ffn_blocks'])
+
+ # ----------------------------------------
+ # others
+ # ----------------------------------------
+ # TODO
+
+ else:
+ raise NotImplementedError('netG [{:s}] is not found.'.format(net_type))
+
+ # ----------------------------------------
+ # initialize weights
+ # ----------------------------------------
+ if opt['is_train']:
+ init_weights(netG,
+ init_type=opt_net['init_type'],
+ init_bn_type=opt_net['init_bn_type'],
+ gain=opt_net['init_gain'])
+
+ return netG
+
+
+# --------------------------------------------
+# Discriminator, netD, D
+# --------------------------------------------
+def define_D(opt):
+ opt_net = opt['netD']
+ net_type = opt_net['net_type']
+
+ # ----------------------------------------
+ # discriminator_vgg_96
+ # ----------------------------------------
+ if net_type == 'discriminator_vgg_96':
+ from models.network_discriminator import Discriminator_VGG_96 as discriminator
+ netD = discriminator(in_nc=opt_net['in_nc'],
+ base_nc=opt_net['base_nc'],
+ ac_type=opt_net['act_mode'])
+
+ # ----------------------------------------
+ # discriminator_vgg_128
+ # ----------------------------------------
+ elif net_type == 'discriminator_vgg_128':
+ from models.network_discriminator import Discriminator_VGG_128 as discriminator
+ netD = discriminator(in_nc=opt_net['in_nc'],
+ base_nc=opt_net['base_nc'],
+ ac_type=opt_net['act_mode'])
+
+ # ----------------------------------------
+ # discriminator_vgg_192
+ # ----------------------------------------
+ elif net_type == 'discriminator_vgg_192':
+ from models.network_discriminator import Discriminator_VGG_192 as discriminator
+ netD = discriminator(in_nc=opt_net['in_nc'],
+ base_nc=opt_net['base_nc'],
+ ac_type=opt_net['act_mode'])
+
+ # ----------------------------------------
+ # discriminator_vgg_128_SN
+ # ----------------------------------------
+ elif net_type == 'discriminator_vgg_128_SN':
+ from models.network_discriminator import Discriminator_VGG_128_SN as discriminator
+ netD = discriminator()
+
+ elif net_type == 'discriminator_patchgan':
+ from models.network_discriminator import Discriminator_PatchGAN as discriminator
+ netD = discriminator(input_nc=opt_net['in_nc'],
+ ndf=opt_net['base_nc'],
+ n_layers=opt_net['n_layers'],
+ norm_type=opt_net['norm_type'])
+
+ elif net_type == 'discriminator_unet':
+ from models.network_discriminator import Discriminator_UNet as discriminator
+ netD = discriminator(input_nc=opt_net['in_nc'],
+ ndf=opt_net['base_nc'])
+
+ else:
+ raise NotImplementedError('netD [{:s}] is not found.'.format(net_type))
+
+ # ----------------------------------------
+ # initialize weights
+ # ----------------------------------------
+ init_weights(netD,
+ init_type=opt_net['init_type'],
+ init_bn_type=opt_net['init_bn_type'],
+ gain=opt_net['init_gain'])
+
+ return netD
+
+
+# --------------------------------------------
+# VGGfeature, netF, F
+# --------------------------------------------
+def define_F(opt, use_bn=False):
+ device = torch.device('cuda' if opt['gpu_ids'] else 'cpu')
+ from models.network_feature import VGGFeatureExtractor
+ # pytorch pretrained VGG19-54, before ReLU.
+ if use_bn:
+ feature_layer = 49
+ else:
+ feature_layer = 34
+ netF = VGGFeatureExtractor(feature_layer=feature_layer,
+ use_bn=use_bn,
+ use_input_norm=True,
+ device=device)
+ netF.eval() # No need to train, but need BP to input
+ return netF
+
+
+"""
+# --------------------------------------------
+# weights initialization
+# --------------------------------------------
+"""
+
+
+def init_weights(net, init_type='xavier_uniform', init_bn_type='uniform', gain=1):
+ """
+ # Kai Zhang, https://github.com/cszn/KAIR
+ #
+ # Args:
+ # init_type:
+ # default, none: pass init_weights
+ # normal; normal; xavier_normal; xavier_uniform;
+ # kaiming_normal; kaiming_uniform; orthogonal
+ # init_bn_type:
+ # uniform; constant
+ # gain:
+ # 0.2
+ """
+
+ def init_fn(m, init_type='xavier_uniform', init_bn_type='uniform', gain=1):
+ classname = m.__class__.__name__
+
+ if classname.find('Conv') != -1 or classname.find('Linear') != -1:
+
+ if init_type == 'normal':
+ init.normal_(m.weight.data, 0, 0.1)
+ m.weight.data.clamp_(-1, 1).mul_(gain)
+
+ elif init_type == 'uniform':
+ init.uniform_(m.weight.data, -0.2, 0.2)
+ m.weight.data.mul_(gain)
+
+ elif init_type == 'xavier_normal':
+ init.xavier_normal_(m.weight.data, gain=gain)
+ m.weight.data.clamp_(-1, 1)
+
+ elif init_type == 'xavier_uniform':
+ init.xavier_uniform_(m.weight.data, gain=gain)
+
+ elif init_type == 'kaiming_normal':
+ init.kaiming_normal_(m.weight.data, a=0, mode='fan_in', nonlinearity='relu')
+ m.weight.data.clamp_(-1, 1).mul_(gain)
+
+ elif init_type == 'kaiming_uniform':
+ init.kaiming_uniform_(m.weight.data, a=0, mode='fan_in', nonlinearity='relu')
+ m.weight.data.mul_(gain)
+
+ elif init_type == 'orthogonal':
+ init.orthogonal_(m.weight.data, gain=gain)
+
+ else:
+ raise NotImplementedError('Initialization method [{:s}] is not implemented'.format(init_type))
+
+ if m.bias is not None:
+ m.bias.data.zero_()
+
+ elif classname.find('BatchNorm2d') != -1:
+
+ if init_bn_type == 'uniform': # preferred
+ if m.affine:
+ init.uniform_(m.weight.data, 0.1, 1.0)
+ init.constant_(m.bias.data, 0.0)
+ elif init_bn_type == 'constant':
+ if m.affine:
+ init.constant_(m.weight.data, 1.0)
+ init.constant_(m.bias.data, 0.0)
+ else:
+ raise NotImplementedError('Initialization method [{:s}] is not implemented'.format(init_bn_type))
+
+ if init_type not in ['default', 'none']:
+ print('Initialization method [{:s} + {:s}], gain is [{:.2f}]'.format(init_type, init_bn_type, gain))
+ fn = functools.partial(init_fn, init_type=init_type, init_bn_type=init_bn_type, gain=gain)
+ net.apply(fn)
+ else:
+ print('Pass this initialization! Initialization was done during network definition!')
diff --git a/KAIR/options/swinir/train_swinir_car_jpeg.json b/KAIR/options/swinir/train_swinir_car_jpeg.json
new file mode 100644
index 0000000000000000000000000000000000000000..115c688ab863a7d9b69bc9883f7975567c048887
--- /dev/null
+++ b/KAIR/options/swinir/train_swinir_car_jpeg.json
@@ -0,0 +1,88 @@
+{
+ "task": "swinir_car_jpeg_40" // JPEG compression artifact reduction for quality factor 10/20/30/40. root/task/images-models-options
+ , "model": "plain" // "plain" | "plain2" if two inputs
+ , "gpu_ids": [0,1,2,3,4,5,6,7]
+ , "dist": true
+
+ , "is_color": false // color or grayscale
+
+ , "path": {
+ "root": "dejpeg" // "denoising" | "superresolution" | "dejpeg"
+ , "pretrained_netG": null // path of pretrained model. We fine-tune quality=10/20/30 models from quality=40 model, so that `G_optimizer_lr` and `G_scheduler_milestones` can be halved to save time.
+ , "pretrained_netE": null // path of pretrained model
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset" // just name
+ , "dataset_type": "jpeg" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch" | "jpeg"
+ , "dataroot_H": "trainsets/trainH"// path of H training dataset. DIV2K (800 training images) + Flickr2K (2650 images) + BSD500 (400 training&testing images) + WED(4744 images) in SwinIR
+ , "dataroot_L": null // path of L training dataset
+
+ , "H_size": 126 // patch_size
+ , "quality_factor": 40 // 10 | 20 | 30 | 40.
+ , "quality_factor_test": 40 //
+ , "is_color": false //
+
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 16
+ , "dataloader_batch_size": 8 // batch size 1 | 16 | 32 | 48 | 64 | 128. Total batch size =1x8=8 in SwinIR
+ }
+ , "test": {
+ "name": "test_dataset" // just name
+ , "dataset_type": "jpeg" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch" | "jpeg"
+ , "dataroot_H": "testsets/LIVE1" // path of H testing dataset
+ , "dataroot_L": null // path of L testing dataset
+
+ , "quality_factor": 40 // 10 | 20 | 30 | 40.
+ , "quality_factor_test": 40 //
+ , "is_color": false //
+
+ }
+ }
+
+ , "netG": {
+ "net_type": "swinir"
+ , "upscale": 1
+ , "in_chans": 1
+ , "img_size": 126
+ , "window_size": 7 // 7 works better than 8, maybe because jpeg encoding uses 8x8 patches
+ , "img_range": 255.0 // image_range=255.0 is slightly better
+ , "depths": [6, 6, 6, 6, 6, 6]
+ , "embed_dim": 180
+ , "num_heads": [6, 6, 6, 6, 6, 6]
+ , "mlp_ratio": 2
+ , "upsampler": null // "pixelshuffle" | "pixelshuffledirect" | "nearest+conv" | null
+ , "resi_connection": "1conv" // "1conv" | "3conv"
+
+ , "init_type": "default"
+ }
+
+ , "train": {
+ "G_lossfn_type": "charbonnier" // "l1" | "l2sum" | "l2" | "ssim" | "charbonnier" preferred
+ , "G_lossfn_weight": 1.0 // default
+ , "G_charbonnier_eps": 1e-9
+
+ , "E_decay": 0.999 // Exponential Moving Average for netG: set 0 to disable; default setting 0.999
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 2e-4 // learning rate
+ , "G_optimizer_wd": 0 // weight decay, default 0
+ , "G_optimizer_clipgrad": null // unused
+ , "G_optimizer_reuse": true //
+
+ , "G_scheduler_type": "MultiStepLR" // "MultiStepLR" is enough
+ , "G_scheduler_milestones": [800000, 1200000, 1400000, 1500000, 1600000]
+ , "G_scheduler_gamma": 0.5
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "G_param_strict": true
+ , "E_param_strict": true
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+}
diff --git a/KAIR/options/swinir/train_swinir_denoising_color.json b/KAIR/options/swinir/train_swinir_denoising_color.json
new file mode 100644
index 0000000000000000000000000000000000000000..465b67f58f5af2642641f09b5387f6faf41b788e
--- /dev/null
+++ b/KAIR/options/swinir/train_swinir_denoising_color.json
@@ -0,0 +1,86 @@
+{
+ "task": "swinir_denoising_color_15" // color Gaussian denoising for noise level 15/25/50. root/task/images-models-options
+ , "model": "plain" // "plain" | "plain2" if two inputs
+ , "gpu_ids": [0,1,2,3,4,5,6,7]
+ , "dist": true
+
+ , "n_channels": 3 // broadcast to "datasets", 1 for grayscale, 3 for color
+
+ , "path": {
+ "root": "denoising" // "denoising" | "superresolution" | "dejpeg"
+ , "pretrained_netG": null // path of pretrained model
+ , "pretrained_netE": null // path of pretrained model
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset" // just name
+ , "dataset_type": "dncnn" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch" | "jpeg"
+ , "dataroot_H": "trainsets/trainH"// path of H training dataset. DIV2K (800 training images) + Flickr2K (2650 images) + BSD500 (400 training&testing images) + WED(4744 images) in SwinIR
+ , "dataroot_L": null // path of L training dataset
+
+ , "H_size": 128 // patch_size
+ , "sigma": 15 // 15 | 25 | 50. We fine-tune sigma=25/50 models from sigma=15 model, so that `G_optimizer_lr` and `G_scheduler_milestones` can be halved to save time.
+ , "sigma_test": 15 //
+
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 16
+ , "dataloader_batch_size": 8 // batch size 1 | 16 | 32 | 48 | 64 | 128. Total batch size =1x8=8 in SwinIR
+ }
+ , "test": {
+ "name": "test_dataset" // just name
+ , "dataset_type": "dncnn" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch" | "jpeg"
+ , "dataroot_H": "testsets/McMaster" // path of H testing dataset
+ , "dataroot_L": null // path of L testing dataset
+
+ , "sigma": 15 //
+ , "sigma_test": 15 //
+
+ }
+ }
+
+ , "netG": {
+ "net_type": "swinir"
+ , "upscale": 1
+ , "in_chans": 3
+ , "img_size": 128
+ , "window_size": 8
+ , "img_range": 1.0
+ , "depths": [6, 6, 6, 6, 6, 6]
+ , "embed_dim": 180
+ , "num_heads": [6, 6, 6, 6, 6, 6]
+ , "mlp_ratio": 2
+ , "upsampler": null // "pixelshuffle" | "pixelshuffledirect" | "nearest+conv" | null
+ , "resi_connection": "1conv" // "1conv" | "3conv"
+
+ , "init_type": "default"
+ }
+
+ , "train": {
+ "G_lossfn_type": "charbonnier" // "l1" | "l2sum" | "l2" | "ssim" | "charbonnier" preferred
+ , "G_lossfn_weight": 1.0 // default
+ , "G_charbonnier_eps": 1e-9
+
+ , "E_decay": 0.999 // Exponential Moving Average for netG: set 0 to disable; default setting 0.999
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 2e-4 // learning rate
+ , "G_optimizer_wd": 0 // weight decay, default 0
+ , "G_optimizer_clipgrad": null // unused
+ , "G_optimizer_reuse": true //
+
+ , "G_scheduler_type": "MultiStepLR" // "MultiStepLR" is enough
+ , "G_scheduler_milestones": [800000, 1200000, 1400000, 1500000, 1600000]
+ , "G_scheduler_gamma": 0.5
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "G_param_strict": true
+ , "E_param_strict": true
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+}
diff --git a/KAIR/options/swinir/train_swinir_denoising_gray.json b/KAIR/options/swinir/train_swinir_denoising_gray.json
new file mode 100644
index 0000000000000000000000000000000000000000..899a33384214d23612033f9d2842e4ff797c9a0d
--- /dev/null
+++ b/KAIR/options/swinir/train_swinir_denoising_gray.json
@@ -0,0 +1,86 @@
+{
+ "task": "swinir_denoising_gray_15" // grayscale Gaussian denoising for noise level 15/25/50. root/task/images-models-options
+ , "model": "plain" // "plain" | "plain2" if two inputs
+ , "gpu_ids": [0,1,2,3,4,5,6,7]
+ , "dist": true
+
+ , "n_channels": 1 // broadcast to "datasets", 1 for grayscale, 3 for color
+
+ , "path": {
+ "root": "denoising" // "denoising" | "superresolution" | "dejpeg"
+ , "pretrained_netG": null // path of pretrained model. We fine-tune sigma=25/50 models from sigma=15 model, so that `G_optimizer_lr` and `G_scheduler_milestones` can be halved to save time.
+ , "pretrained_netE": null // path of pretrained model
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset" // just name
+ , "dataset_type": "dncnn" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch" | "jpeg"
+ , "dataroot_H": "trainsets/trainH"// path of H training dataset. DIV2K (800 training images) + Flickr2K (2650 images) + BSD500 (400 training&testing images) + WED(4744 images) in SwinIR
+ , "dataroot_L": null // path of L training dataset
+
+ , "H_size": 128 // patch_size
+ , "sigma": 15 // 15 | 25 | 50.
+ , "sigma_test": 15 //
+
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 16
+ , "dataloader_batch_size": 8 // batch size 1 | 16 | 32 | 48 | 64 | 128. Total batch size =1x8=8 in SwinIR
+ }
+ , "test": {
+ "name": "test_dataset" // just name
+ , "dataset_type": "dncnn" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch" | "jpeg"
+ , "dataroot_H": "testsets/set12" // path of H testing dataset
+ , "dataroot_L": null // path of L testing dataset
+
+ , "sigma": 15 //
+ , "sigma_test": 15 //
+
+ }
+ }
+
+ , "netG": {
+ "net_type": "swinir"
+ , "upscale": 1
+ , "in_chans": 1
+ , "img_size": 128
+ , "window_size": 8
+ , "img_range": 1.0
+ , "depths": [6, 6, 6, 6, 6, 6]
+ , "embed_dim": 180
+ , "num_heads": [6, 6, 6, 6, 6, 6]
+ , "mlp_ratio": 2
+ , "upsampler": null // "pixelshuffle" | "pixelshuffledirect" | "nearest+conv" | null
+ , "resi_connection": "1conv" // "1conv" | "3conv"
+
+ , "init_type": "default"
+ }
+
+ , "train": {
+ "G_lossfn_type": "charbonnier" // "l1" | "l2sum" | "l2" | "ssim" | "charbonnier" preferred
+ , "G_lossfn_weight": 1.0 // default
+ , "G_charbonnier_eps": 1e-9
+
+ , "E_decay": 0.999 // Exponential Moving Average for netG: set 0 to disable; default setting 0.999
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 2e-4 // learning rate
+ , "G_optimizer_wd": 0 // weight decay, default 0
+ , "G_optimizer_clipgrad": null // unused
+ , "G_optimizer_reuse": true //
+
+ , "G_scheduler_type": "MultiStepLR" // "MultiStepLR" is enough
+ , "G_scheduler_milestones": [800000, 1200000, 1400000, 1500000, 1600000]
+ , "G_scheduler_gamma": 0.5
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "G_param_strict": true
+ , "E_param_strict": true
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+}
diff --git a/KAIR/options/swinir/train_swinir_sr_classical.json b/KAIR/options/swinir/train_swinir_sr_classical.json
new file mode 100644
index 0000000000000000000000000000000000000000..34736cbd3e826ab87c71b3f1000030222487d0ea
--- /dev/null
+++ b/KAIR/options/swinir/train_swinir_sr_classical.json
@@ -0,0 +1,81 @@
+{
+ "task": "swinir_sr_classical_patch48_x2" // classical image sr for x2/x3/x4/x8. root/task/images-models-options
+ , "model": "plain" // "plain" | "plain2" if two inputs
+ , "gpu_ids": [0,1,2,3,4,5,6,7]
+ , "dist": true
+
+ , "scale": 2 // 2 | 3 | 4 | 8
+ , "n_channels": 3 // broadcast to "datasets", 1 for grayscale, 3 for color
+
+ , "path": {
+ "root": "superresolution" // "denoising" | "superresolution" | "dejpeg"
+ , "pretrained_netG": null // path of pretrained model. We fine-tune X3/X4/X8 models from X2 model, so that `G_optimizer_lr` and `G_scheduler_milestones` can be halved to save time.
+ , "pretrained_netE": null // path of pretrained model
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset" // just name
+ , "dataset_type": "sr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch" | "jpeg"
+ , "dataroot_H": "/home/cll/datasets/REDS/train/train_sharp"// path of H training dataset. DIV2K (800 training images)
+ , "dataroot_L": null // path of L training dataset
+
+ , "H_size": 96 // 96/144|192/384 | 128/192/256/512. LR patch size is set to 48 or 64 when compared with RCAN or RRDB.
+
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 16
+ , "dataloader_batch_size": 32 // batch size 1 | 16 | 32 | 48 | 64 | 128. Total batch size =4x8=32 in SwinIR
+ }
+ , "test": {
+ "name": "test_dataset" // just name
+ , "dataset_type": "sr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch" | "jpeg"
+ , "dataroot_H": "/home/cll/datasets/REDS/val/val_sharp" // path of H testing dataset
+ , "dataroot_L": null // path of L testing dataset
+
+ }
+ }
+
+ , "netG": {
+ "net_type": "swinir"
+ , "upscale": 2 // 2 | 3 | 4 | 8
+ , "in_chans": 3
+ , "img_size": 48 // For fair comparison, LR patch size is set to 48 or 64 when compared with RCAN or RRDB.
+ , "window_size": 8
+ , "img_range": 1.0
+ , "depths": [6, 6, 6, 6, 6, 6]
+ , "embed_dim": 180
+ , "num_heads": [6, 6, 6, 6, 6, 6]
+ , "mlp_ratio": 2
+ , "upsampler": "pixelshuffle" // "pixelshuffle" | "pixelshuffledirect" | "nearest+conv" | null
+ , "resi_connection": "1conv" // "1conv" | "3conv"
+
+ , "init_type": "default"
+ }
+
+ , "train": {
+ "G_lossfn_type": "l1" // "l1" preferred | "l2sum" | "l2" | "ssim" | "charbonnier"
+ , "G_lossfn_weight": 1.0 // default
+
+ , "E_decay": 0.999 // Exponential Moving Average for netG: set 0 to disable; default setting 0.999
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 2e-4 // learning rate
+ , "G_optimizer_wd": 0 // weight decay, default 0
+ , "G_optimizer_clipgrad": null // unused
+ , "G_optimizer_reuse": true //
+
+ , "G_scheduler_type": "MultiStepLR" // "MultiStepLR" is enough
+ , "G_scheduler_milestones": [250000, 400000, 450000, 475000, 500000]
+ , "G_scheduler_gamma": 0.5
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "G_param_strict": true
+ , "E_param_strict": true
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+}
diff --git a/KAIR/options/swinir/train_swinir_sr_lightweight.json b/KAIR/options/swinir/train_swinir_sr_lightweight.json
new file mode 100644
index 0000000000000000000000000000000000000000..155e937fcbfd3a31588040fd390f1de4ec6feffd
--- /dev/null
+++ b/KAIR/options/swinir/train_swinir_sr_lightweight.json
@@ -0,0 +1,81 @@
+{
+ "task": "swinir_sr_lightweight_x2" // classical image sr for x2/x3/x4. root/task/images-models-options
+ , "model": "plain" // "plain" | "plain2" if two inputs
+ , "gpu_ids": [0,1,2,3,4,5,6,7]
+ , "dist": true
+
+ , "scale": 2 // 2 | 3 | 4
+ , "n_channels": 3 // broadcast to "datasets", 1 for grayscale, 3 for color
+
+ , "path": {
+ "root": "superresolution" // "denoising" | "superresolution" | "dejpeg"
+ , "pretrained_netG": null // path of pretrained model. We fine-tune X3/X4 models from X2 model, so that `G_optimizer_lr` and `G_scheduler_milestones` can be halved to save time.
+ , "pretrained_netE": null // path of pretrained model
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset" // just name
+ , "dataset_type": "sr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch" | "jpeg"
+ , "dataroot_H": "trainsets/trainH"// path of H training dataset. DIV2K (800 training images)
+ , "dataroot_L": "trainsets/trainL" // path of L training dataset
+
+ , "H_size": 128 // 128/192/256/512.
+
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 16
+ , "dataloader_batch_size": 64 // Total batch size =8x8=64 in SwinIR
+ }
+ , "test": {
+ "name": "test_dataset" // just name
+ , "dataset_type": "sr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch" | "jpeg"
+ , "dataroot_H": "testsets/Set5/HR" // path of H testing dataset
+ , "dataroot_L": "testsets/Set5/LR_bicubic/X2" // path of L testing dataset
+
+ }
+ }
+
+ , "netG": {
+ "net_type": "swinir"
+ , "upscale": 2 // 2 | 3 | 4
+ , "in_chans": 3
+ , "img_size": 64
+ , "window_size": 8
+ , "img_range": 1.0
+ , "depths": [6, 6, 6, 6]
+ , "embed_dim": 60
+ , "num_heads": [6, 6, 6, 6]
+ , "mlp_ratio": 2
+ , "upsampler": "pixelshuffledirect" // "pixelshuffle" | "pixelshuffledirect" | "nearest+conv" | null
+ , "resi_connection": "1conv" // "1conv" | "3conv"
+
+ , "init_type": "default"
+ }
+
+ , "train": {
+ "G_lossfn_type": "l1" // "l1" preferred | "l2sum" | "l2" | "ssim" | "charbonnier"
+ , "G_lossfn_weight": 1.0 // default
+
+ , "E_decay": 0.999 // Exponential Moving Average for netG: set 0 to disable; default setting 0.999
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 2e-4 // learning rate
+ , "G_optimizer_wd": 0 // weight decay, default 0
+ , "G_optimizer_clipgrad": null // unused
+ , "G_optimizer_reuse": true //
+
+ , "G_scheduler_type": "MultiStepLR" // "MultiStepLR" is enough
+ , "G_scheduler_milestones": [250000, 400000, 450000, 475000, 500000]
+ , "G_scheduler_gamma": 0.5
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "G_param_strict": true
+ , "E_param_strict": true
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+}
diff --git a/KAIR/options/swinir/train_swinir_sr_realworld_x2_gan.json b/KAIR/options/swinir/train_swinir_sr_realworld_x2_gan.json
new file mode 100644
index 0000000000000000000000000000000000000000..e20616c7a1b40b17015db063efe998f5113dffe1
--- /dev/null
+++ b/KAIR/options/swinir/train_swinir_sr_realworld_x2_gan.json
@@ -0,0 +1,121 @@
+{
+ "task": "swinir_sr_realworld_x2_gan" // real-world image sr. root/task/images|models|options
+ , "model": "plain" // "gan"
+ , "gpu_ids": [0, 1, 2, 3, 4, 5, 6, 7]
+
+ , "scale": 2 // broadcast to "datasets"
+ , "n_channels": 3 // broadcast to "datasets", 1 for grayscale, 3 for color
+
+ , "path": {
+ "root": "superresolution" // "denoising" | "superresolution" | "dejpeg"
+ , "pretrained_netG": "superresolution/swinir_sr_realworld_x2_gan/models/205000_G.pth" // path of pretrained model
+ , "pretrained_netD": null // "superresolution/swinir_sr_realworld_x2_gan/models/185000_D.pth" // path of pretrained model
+ , "pretrained_netE": "superresolution/swinir_sr_realworld_x2_gan/models/205000_E.pth" // path of pretrained model
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset" // just name
+ , "dataset_type": "blindsr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch" | "jpeg"
+ , "dataroot_H": "trainsets/trainH"// path of H training dataset. DIV2K (800 training images) + Flickr2K (2650 images) + + OST (10324 images)
+ , "dataroot_L": null // path of L training dataset
+
+ , "degradation_type": "bsrgan" // "bsrgan" | "bsrgan_plus"
+ , "H_size": 256 // patch_size 256 | 288 | 320
+ , "shuffle_prob": 0.1 //
+ , "lq_patchsize": 96
+ , "use_sharp": true
+
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 8
+ , "dataloader_batch_size": 16 // batch size 1 | 16 | 32 | 48 | 64 | 128. Total batch size =4x8=32 in SwinIR
+ }
+ , "test": {
+ "name": "test_dataset" // just name
+ , "dataset_type": "sr"
+
+ // , "degradation_type": "bsrgan" // "bsrgan" | "bsrgan_plus"
+ // , "H_size": 256 // patch_size 256 | 288 | 320
+ // , "shuffle_prob": 0.1 //
+ // , "lq_patchsize": 256
+ // , "use_sharp": false
+
+ , "dataroot_H": "/home/clindsey/testset_153/gt" // path of H testing dataset
+ , "dataroot_L": "/home/clindsey/testset_153/lq" // path of L testing dataset
+ }
+ }
+
+ , "netG": {
+ "net_type": "swinir"
+ , "upscale": 2
+ , "in_chans": 3
+ , "img_size": 96
+ , "window_size": 8
+ , "img_range": 1.0
+ , "depths": [6, 6, 6, 6, 6, 6]
+ , "embed_dim": 180
+ , "num_heads": [6, 6, 6, 6, 6, 6]
+ , "mlp_ratio": 2
+ , "upsampler": "nearest+conv" // "pixelshuffle" | "pixelshuffledirect" | "nearest+conv" | null
+ , "resi_connection": "3conv" // "1conv" | "3conv"
+
+ , "init_type": "default"
+ }
+
+ , "netD": {
+ "net_type": "discriminator_unet" // "discriminator_patchgan" | "discriminator_unet"
+ , "in_nc": 3
+ , "base_nc": 64
+ , "n_layers": 3 // only for "net_type":"discriminator_patchgan"
+ , "norm_type": "spectral" // only for "net_type":"discriminator_patchgan" | 'batch', 'instance', 'spectral', 'batchspectral', 'instancespectral'
+
+ , "init_type": "orthogonal" // "orthogonal" | "normal" | "uniform" | "xavier_normal" | "xavier_uniform" | "kaiming_normal" | "kaiming_uniform"
+ , "init_bn_type": "uniform" // "uniform" | "constant"
+ , "init_gain": 0.2
+ }
+
+ , "train": {
+ "G_lossfn_type": "l1" // "l1" | "l2" | "l2sum" | "l1c" | "ssim"
+ , "G_lossfn_weight": 5
+
+ , "F_lossfn_type": "l1" // "l1" | "l2"
+ , "F_lossfn_weight": 1
+ , "F_feature_layer": [2,7,16,25,34] // 25 | [2,7,16,25,34]
+ , "F_weights": [0.1,0.1,1.0,1.0,1.0] // 1.0 | [0.1,0.1,1.0,1.0,1.0]
+ , "F_use_input_norm": true
+ , "F_use_range_norm": false
+
+ , "gan_type": "gan" // "gan" | "ragan" | "lsgan" | "wgan" | "softplusgan"
+ , "D_lossfn_weight": 0.1
+
+ , "E_decay": 0.999 // Exponential Moving Average for netG: set 0 to disable; default setting 0.999
+
+ , "D_init_iters": 0
+
+ , "G_optimizer_type": "adam"
+ , "G_optimizer_lr": 1e-4 // learning rate
+ , "G_optimizer_wd": 0
+
+ , "D_optimizer_type": "adam"
+ , "D_optimizer_lr": 1e-4 // learning rate
+ , "D_optimizer_wd": 0
+
+ , "G_scheduler_type": "MultiStepLR"
+ , "G_scheduler_milestones": [400000, 500000, 600000, 800000, 900000]
+ , "G_scheduler_gamma": 0.5
+ , "G_optimizer_reuse": true
+
+ , "D_scheduler_type": "MultiStepLR"
+ , "D_scheduler_milestones": [400000, 500000, 600000, 800000, 900000]
+ , "D_scheduler_gamma": 0.5
+ , "D_optimizer_reuse": false
+
+ , "G_param_strict": true
+ , "D_param_strict": true
+ , "E_param_strict": true
+
+ , "checkpoint_test": 5000 // skip testing
+ , "checkpoint_save": 5000
+ , "checkpoint_print": 200
+ }
+}
diff --git a/KAIR/options/swinir/train_swinir_sr_realworld_x4_gan.json b/KAIR/options/swinir/train_swinir_sr_realworld_x4_gan.json
new file mode 100644
index 0000000000000000000000000000000000000000..20279ac9ab1d0c1bc3277451cdd439f6c4db37df
--- /dev/null
+++ b/KAIR/options/swinir/train_swinir_sr_realworld_x4_gan.json
@@ -0,0 +1,121 @@
+{
+ "task": "swinir_sr_realworld_x4_gan" // real-world image sr. root/task/images|models|options
+ , "model": "gan" // "gan"
+ , "gpu_ids": [0,1,2,3,4,5,6,7]
+
+ , "scale": 4 // broadcast to "datasets"
+ , "n_channels": 3 // broadcast to "datasets", 1 for grayscale, 3 for color
+
+ , "path": {
+ "root": "superresolution" // "denoising" | "superresolution" | "dejpeg"
+ , "pretrained_netG": null // path of pretrained model
+ , "pretrained_netD": null // path of pretrained model
+ , "pretrained_netE": null // path of pretrained model
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset" // just name
+ , "dataset_type": "blindsr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch" | "jpeg"
+ , "dataroot_H": "trainsets/trainH"// path of H training dataset. DIV2K (800 training images) + Flickr2K (2650 images) + + OST (10324 images)
+ , "dataroot_L": null // path of L training dataset
+
+ , "degradation_type": "bsrgan" // "bsrgan" | "bsrgan_plus"
+ , "H_size": 256 // patch_size 256 | 288 | 320
+ , "shuffle_prob": 0.1 //
+ , "lq_patchsize": 64
+ , "use_sharp": true
+
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 16
+ , "dataloader_batch_size": 32 // batch size 1 | 16 | 32 | 48 | 64 | 128. Total batch size =4x8=32 in SwinIR
+ }
+ , "test": {
+ "name": "test_dataset" // just name
+ , "dataset_type": "blindsr"
+
+ , "degradation_type": "bsrgan" // "bsrgan" | "bsrgan_plus"
+ , "H_size": 256 // patch_size 256 | 288 | 320
+ , "shuffle_prob": 0.1 //
+ , "lq_patchsize": 64
+ , "use_sharp": false
+
+ , "dataroot_H": "testsets/Set5/HR" // path of H testing dataset
+ , "dataroot_L": null // path of L testing dataset
+ }
+ }
+
+ , "netG": {
+ "net_type": "swinir"
+ , "upscale": 4
+ , "in_chans": 3
+ , "img_size": 64
+ , "window_size": 8
+ , "img_range": 1.0
+ , "depths": [6, 6, 6, 6, 6, 6]
+ , "embed_dim": 180
+ , "num_heads": [6, 6, 6, 6, 6, 6]
+ , "mlp_ratio": 2
+ , "upsampler": "nearest+conv" // "pixelshuffle" | "pixelshuffledirect" | "nearest+conv" | null
+ , "resi_connection": "1conv" // "1conv" | "3conv"
+
+ , "init_type": "default"
+ }
+
+ , "netD": {
+ "net_type": "discriminator_unet" // "discriminator_patchgan" | "discriminator_unet"
+ , "in_nc": 3
+ , "base_nc": 64
+ , "n_layers": 3 // only for "net_type":"discriminator_patchgan"
+ , "norm_type": "spectral" // only for "net_type":"discriminator_patchgan" | 'batch', 'instance', 'spectral', 'batchspectral', 'instancespectral'
+
+ , "init_type": "orthogonal" // "orthogonal" | "normal" | "uniform" | "xavier_normal" | "xavier_uniform" | "kaiming_normal" | "kaiming_uniform"
+ , "init_bn_type": "uniform" // "uniform" | "constant"
+ , "init_gain": 0.2
+ }
+
+ , "train": {
+ "G_lossfn_type": "l1" // "l1" | "l2" | "l2sum" | "l1c" | "ssim"
+ , "G_lossfn_weight": 1
+
+ , "F_lossfn_type": "l1" // "l1" | "l2"
+ , "F_lossfn_weight": 1
+ , "F_feature_layer": [2,7,16,25,34] // 25 | [2,7,16,25,34]
+ , "F_weights": [0.1,0.1,1.0,1.0,1.0] // 1.0 | [0.1,0.1,1.0,1.0,1.0]
+ , "F_use_input_norm": true
+ , "F_use_range_norm": false
+
+ , "gan_type": "gan" // "gan" | "ragan" | "lsgan" | "wgan" | "softplusgan"
+ , "D_lossfn_weight": 0.1
+
+ , "E_decay": 0.999 // Exponential Moving Average for netG: set 0 to disable; default setting 0.999
+
+ , "D_init_iters": 0
+
+ , "G_optimizer_type": "adam"
+ , "G_optimizer_lr": 1e-4 // learning rate
+ , "G_optimizer_wd": 0
+
+ , "D_optimizer_type": "adam"
+ , "D_optimizer_lr": 1e-4 // learning rate
+ , "D_optimizer_wd": 0
+
+ , "G_scheduler_type": "MultiStepLR"
+ , "G_scheduler_milestones": [400000, 500000, 550000, 575000, 600000]
+ , "G_scheduler_gamma": 0.5
+ , "G_optimizer_reuse": true
+
+ , "D_scheduler_type": "MultiStepLR"
+ , "D_scheduler_milestones": [400000, 500000, 550000, 575000, 600000]
+ , "D_scheduler_gamma": 0.5
+ , "D_optimizer_reuse": false
+
+ , "G_param_strict": true
+ , "D_param_strict": true
+ , "E_param_strict": true
+
+ , "checkpoint_test": 5000 // skip testing
+ , "checkpoint_save": 5000
+ , "checkpoint_print": 200
+ }
+}
diff --git a/KAIR/options/swinir/train_swinir_sr_realworld_x4_psnr.json b/KAIR/options/swinir/train_swinir_sr_realworld_x4_psnr.json
new file mode 100644
index 0000000000000000000000000000000000000000..2ddce9ec333e26cb86ef2057e35a5555823fb57e
--- /dev/null
+++ b/KAIR/options/swinir/train_swinir_sr_realworld_x4_psnr.json
@@ -0,0 +1,85 @@
+{
+ "task": "swinir_sr_realworld_x4_psnr" // real-world image sr. root/task/images-models-options
+ , "model": "plain" // "plain" | "plain2" if two inputs
+ , "gpu_ids": [0,1,2,3,4,5,6,7]
+ , "dist": true
+
+ , "scale": 4 // broadcast to "datasets"
+ , "n_channels": 3 // broadcast to "datasets", 1 for grayscale, 3 for color
+
+ , "path": {
+ "root": "superresolution" // "denoising" | "superresolution" | "dejpeg"
+ , "pretrained_netG": null // path of pretrained model
+ , "pretrained_netE": null // path of pretrained model
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset" // just name
+ , "dataset_type": "blindsr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch" | "jpeg"
+ , "dataroot_H": "trainsets/trainH"// path of H training dataset. DIV2K (800 training images) + Flickr2K (2650 images) + + OST (10324 images)
+ , "dataroot_L": null // path of L training dataset
+
+ , "degradation_type": "bsrgan" // "bsrgan" | "bsrgan_plus"
+ , "H_size": 256 // patch_size 256 | 288 | 320
+ , "shuffle_prob": 0.1 //
+ , "lq_patchsize": 64
+ , "use_sharp": true
+
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 16
+ , "dataloader_batch_size": 32 // batch size 1 | 16 | 32 | 48 | 64 | 128. Total batch size =4x8=32 in SwinIR
+ }
+ , "test": {
+ "name": "test_dataset" // just name
+ , "dataset_type": "sr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch" | "jpeg"
+ , "dataroot_H": "testsets/Set5/HR" // path of H testing dataset
+ , "dataroot_L": "testsets/Set5/LR_bicubic/X4" // path of L testing dataset
+
+ }
+ }
+
+ , "netG": {
+ "net_type": "swinir"
+ , "upscale": 4
+ , "in_chans": 3
+ , "img_size": 64
+ , "window_size": 8
+ , "img_range": 1.0
+ , "depths": [6, 6, 6, 6, 6, 6]
+ , "embed_dim": 180
+ , "num_heads": [6, 6, 6, 6, 6, 6]
+ , "mlp_ratio": 2
+ , "upsampler": "nearest+conv" // "pixelshuffle" | "pixelshuffledirect" | "nearest+conv" | null
+ , "resi_connection": "1conv" // "1conv" | "3conv"
+
+ , "init_type": "default"
+ }
+
+ , "train": {
+ "G_lossfn_type": "l1" // "l1" preferred | "l2sum" | "l2" | "ssim" | "charbonnier"
+ , "G_lossfn_weight": 1.0 // default
+
+ , "E_decay": 0.999 // Exponential Moving Average for netG: set 0 to disable; default setting 0.999
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 2e-4 // learning rate
+ , "G_optimizer_wd": 0 // weight decay, default 0
+ , "G_optimizer_clipgrad": null // unused
+ , "G_optimizer_reuse": true //
+
+ , "G_scheduler_type": "MultiStepLR" // "MultiStepLR" is enough
+ , "G_scheduler_milestones": [500000, 800000, 900000, 950000, 1000000]
+ , "G_scheduler_gamma": 0.5
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "G_param_strict": true
+ , "E_param_strict": true
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+}
diff --git a/KAIR/options/train_bsrgan_x4_gan.json b/KAIR/options/train_bsrgan_x4_gan.json
new file mode 100644
index 0000000000000000000000000000000000000000..65ac1d258150e152aea902a7e99e105b064a463d
--- /dev/null
+++ b/KAIR/options/train_bsrgan_x4_gan.json
@@ -0,0 +1,121 @@
+{
+ "task": "bsrgan_x4_gan" // root/task/images|models|options
+ , "model": "gan" // "gan"
+ , "gpu_ids": [0] // [0,1,2,3] for 4 GPUs
+
+ , "scale": 4 // broadcast to "netG" if SISR
+ , "n_channels": 3 // broadcast to "datasets", 1 for grayscale, 3 for color
+
+ , "path": {
+ "root": "superresolution" // "denoising" | "superresolution"
+ , "pretrained_netG": null // path of pretrained model
+ , "pretrained_netD": null // path of pretrained model
+ , "pretrained_netE": null // path of pretrained model
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset" // fixed
+ , "dataset_type": "blindsr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "trainsets/trainH"// path of H training dataset
+ , "dataroot_L": null // path of L training dataset
+
+ , "degradation_type": "bsrgan" // "bsrgan" | "bsrgan_plus"
+ , "H_size": 320 // patch_size 256 | 288 | 320
+ , "shuffle_prob": 0.1 //
+ , "lq_patchsize": 72
+ , "use_sharp": false
+
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 8 // 8 | 32 | 64
+ , "dataloader_batch_size": 4 // batch size 1 | 16 | 32 | 48 | 64 | 128
+ }
+ , "test": {
+ "name": "test_dataset" // fixed
+ , "dataset_type": "blindsr"
+
+ , "degradation_type": "bsrgan" // "bsrgan" | "bsrgan_plus"
+ , "H_size": 320 // patch_size 256 | 288 | 320
+ , "shuffle_prob": 0.1 //
+ , "lq_patchsize": 72
+ , "use_sharp": false
+
+ , "dataroot_H": "testsets/set5" // path of H testing dataset
+ , "dataroot_L": null // path of L testing dataset
+ }
+ }
+
+ , "netG": {
+ "net_type": "rrdbnet" // "dncnn" | "fdncnn" | "ffdnet" | "srmd" | "dpsr" | "srresnet0" | "srresnet1" | "rrdbnet"
+ , "in_nc": 3 // input channel number
+ , "out_nc": 3 // ouput channel number
+ , "nf": 64 // 96 for DPSR, 128 for SRMD, 64 for "dncnn"
+ , "nb": 23 // 12 for "srmd", 15 for "ffdnet", 20 for "dncnn", 16 for "srresnet" and "dpsr"
+ , "gc": 32 //
+ , "ng": 2 // unused
+ , "reduction" : 16 // unused
+ , "act_mode": "L" // "BR" for BN+ReLU | "R" for ReLU
+ , "bias": true
+
+ , "init_type": "orthogonal" // "orthogonal" | "normal" | "uniform" | "xavier_normal" | "xavier_uniform" | "kaiming_normal" | "kaiming_uniform"
+ , "init_bn_type": "uniform" // "uniform" | "constant"
+ , "init_gain": 0.2
+ }
+
+ , "netD": {
+ "net_type": "discriminator_unet" // "discriminator_patchgan" | "discriminator_unet"
+ , "in_nc": 3
+ , "base_nc": 64
+ , "n_layers": 3 // only for "net_type":"discriminator_patchgan"
+ , "norm_type": "spectral" // only for "net_type":"discriminator_patchgan" | 'batch', 'instance', 'spectral', 'batchspectral', 'instancespectral'
+
+ , "init_type": "orthogonal" // "orthogonal" | "normal" | "uniform" | "xavier_normal" | "xavier_uniform" | "kaiming_normal" | "kaiming_uniform"
+ , "init_bn_type": "uniform" // "uniform" | "constant"
+ , "init_gain": 0.2
+ }
+
+ , "train": {
+ "G_lossfn_type": "l1" // "l1" | "l2" | "l2sum" | "l1c" | "ssim"
+ , "G_lossfn_weight": 1
+
+ , "F_lossfn_type": "l1" // "l1" | "l2"
+ , "F_lossfn_weight": 1
+ , "F_feature_layer": [2,7,16,25,34] // 25 | [2,7,16,25,34]
+ , "F_weights": [0.1,0.1,1.0,1.0,1.0] // 1.0 | [0.1,0.1,1.0,1.0,1.0]
+ , "F_use_input_norm": true
+ , "F_use_range_norm": false
+
+ , "gan_type": "lsgan" // "gan" | "ragan" | "lsgan" | "wgan" | "softplusgan"
+ , "D_lossfn_weight": 1
+
+ , "E_decay": 0.999 // Exponential Moving Average for netG: set 0 to disable; default setting 0.999
+
+ , "D_init_iters": 0
+
+ , "G_optimizer_type": "adam"
+ , "G_optimizer_lr": 5e-5 // learning rate
+ , "G_optimizer_wd": 0
+
+ , "D_optimizer_type": "adam"
+ , "D_optimizer_lr": 5e-5 // learning rate
+ , "D_optimizer_wd": 0
+
+ , "G_scheduler_type": "MultiStepLR"
+ , "G_scheduler_milestones": [800000, 1600000]
+ , "G_scheduler_gamma": 0.5
+ , "G_optimizer_reuse": true
+
+ , "D_scheduler_type": "MultiStepLR"
+ , "D_scheduler_milestones": [800000, 1600000]
+ , "D_scheduler_gamma": 0.5
+ , "D_optimizer_reuse": false
+
+ , "G_param_strict": true
+ , "D_param_strict": true
+ , "E_param_strict": true
+
+ , "checkpoint_test": 50000000000 // skip testing
+ , "checkpoint_save": 5000
+ , "checkpoint_print": 200
+ }
+}
diff --git a/KAIR/options/train_bsrgan_x4_psnr.json b/KAIR/options/train_bsrgan_x4_psnr.json
new file mode 100644
index 0000000000000000000000000000000000000000..6a41f86b6511ff19bda5db0e472a13e298e01193
--- /dev/null
+++ b/KAIR/options/train_bsrgan_x4_psnr.json
@@ -0,0 +1,90 @@
+{
+ "task": "bsrgan_x4_psnr" // root/task/images|models|options
+ , "model": "plain" // "plain" | "plain2" if two inputs
+ , "gpu_ids": [0] // [0,1,2,3] for 4 GPUs
+ , "dist": true
+
+ , "scale": 4 // broadcast to "datasets"
+ , "n_channels": 3 // broadcast to "datasets", 1 for grayscale, 3 for color
+
+ , "path": {
+ "root": "superresolution" // "denoising" | "superresolution"
+ , "pretrained_netG": null // path of pretrained model
+ , "pretrained_netE": null // path of pretrained model
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset" // fixed
+ , "dataset_type": "blindsr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "trainsets/trainH"// path of H training dataset
+ , "dataroot_L": null // path of L training dataset
+
+ , "degradation_type": "bsrgan" // "bsrgan" | "bsrgan_plus"
+ , "H_size": 320 // patch_size 256 | 288 | 320
+ , "shuffle_prob": 0.1 //
+ , "lq_patchsize": 72
+ , "use_sharp": false
+
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 8 // 8 | 32 | 64
+ , "dataloader_batch_size": 4 // batch size for all GPUs, 1 | 16 | 32 | 48 | 64 | 128
+ }
+ , "test": {
+ "name": "test_dataset" // fixed
+ , "dataset_type": "blindsr"
+
+ , "degradation_type": "bsrgan" // "bsrgan" | "bsrgan_plus"
+ , "H_size": 320 // patch_size 256 | 288 | 320
+ , "shuffle_prob": 0.1 //
+ , "lq_patchsize": 72
+ , "use_sharp": false
+
+ , "dataroot_H": "testsets/set5" // path of H testing dataset
+ , "dataroot_L": null // path of L testing dataset
+ }
+ }
+
+ , "netG": {
+ "net_type": "rrdbnet" // "dncnn" | "fdncnn" | "ffdnet" | "srmd" | "dpsr" | "srresnet0" | "srresnet1" | "rrdbnet"
+ , "in_nc": 3 // input channel number
+ , "out_nc": 3 // ouput channel number
+ , "nf": 64 // 96 for DPSR, 128 for SRMD, 64 for "dncnn"
+ , "nb": 23 // 12 for "srmd", 15 for "ffdnet", 20 for "dncnn", 16 for "srresnet" and "dpsr"
+ , "gc": 32 //
+ , "ng": 2 // unused
+ , "reduction" : 16 // unused
+ , "act_mode": "L" // "BR" for BN+ReLU | "R" for ReLU
+ , "bias": true
+
+ , "init_type": "orthogonal" // "orthogonal" | "normal" | "uniform" | "xavier_normal" | "xavier_uniform" | "kaiming_normal" | "kaiming_uniform"
+ , "init_bn_type": "uniform" // "uniform" | "constant"
+ , "init_gain": 0.2
+ }
+
+ , "train": {
+ "G_lossfn_type": "l1" // "l1" preferred | "l2sum" | "l2" | "ssim"
+ , "G_lossfn_weight": 1.0 // default
+
+ , "E_decay": 0.999 // Exponential Moving Average for netG: set 0 to disable; default setting 0.999
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 1e-4 // learning rate
+ , "G_optimizer_clipgrad": null // unused
+ , "G_optimizer_reuse": true
+
+ , "G_scheduler_type": "MultiStepLR" // "MultiStepLR" is enough
+ , "G_scheduler_milestones": [200000, 400000, 600000, 800000, 1000000, 2000000]
+ , "G_scheduler_gamma": 0.5
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null //
+
+ , "G_param_strict": true
+ , "E_param_strict": true
+
+ , "checkpoint_test": 500000000 // skip testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+}
diff --git a/KAIR/options/train_dncnn.json b/KAIR/options/train_dncnn.json
new file mode 100644
index 0000000000000000000000000000000000000000..4bfc2d117b797f8f3c688205dad53f4fcad49ca6
--- /dev/null
+++ b/KAIR/options/train_dncnn.json
@@ -0,0 +1,81 @@
+{
+ "task": "dncnn25" // root/task/images-models-options
+ , "model": "plain" // "plain"
+ , "gpu_ids": [0]
+
+ , "scale": 1 // broadcast to "netG" if SISR
+ , "n_channels": 1 // broadcast to "datasets", 1 for grayscale, 3 for color
+
+ , "merge_bn": true // BN for DnCNN
+ , "merge_bn_startpoint": 400000 // merge BN after N iterations
+
+ , "path": {
+ "root": "denoising" // "denoising" | "superresolution"
+ , "pretrained_netG": null // path of pretrained model
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset" // just name
+ , "dataset_type": "dncnn" // "dncnn" | "dnpatch" for dncnn, | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "trainsets/trainH"// path of H training dataset
+ , "dataroot_L": null // path of L training dataset
+ , "H_size": 40 // patch size 40 | 64 | 96 | 128 | 192
+
+ , "sigma": 25 // 15, 25, 50 for DnCNN | [0, 75] for FFDNet and FDnCNN
+ , "sigma_test": 25 // 15, 25, 50 for DnCNN and ffdnet
+
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 8
+ , "dataloader_batch_size": 64 // batch size 1 | 16 | 32 | 48 | 64 | 128
+ }
+ , "test": {
+ "name": "test_dataset" // just name
+ , "dataset_type": "dncnn" // "dncnn" | "dnpatch" for dncnn, | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "testsets/bsd68" // path of H testing dataset
+ , "dataroot_L": null // path of L testing dataset
+
+ , "sigma": 25 // 15, 25, 50 for DnCNN | [0, 75] for FFDNet and FDnCNN
+ , "sigma_test": 25 // 15, 25, 50 for DnCNN and ffdnet
+
+ }
+ }
+
+ , "netG": {
+ "net_type": "dncnn" // "dncnn" | "fdncnn" | "ffdnet" | "srmd" | "dpsr" | "msrresnet0" | "msrresnet1" | "rrdb"
+ , "in_nc": 1 // input channel number
+ , "out_nc": 1 // ouput channel number
+ , "nc": 64 // 64 for "dncnn"
+ , "nb": 17 // 17 for "dncnn", 20 for dncnn3, 16 for "srresnet"
+ , "gc": 32 // unused
+ , "ng": 2 // unused
+ , "reduction" : 16 // unused
+ , "act_mode": "BR" // "BR" for BN+ReLU | "R" for ReLU
+ , "upsample_mode": "convtranspose" // "pixelshuffle" | "convtranspose" | "upconv"
+ , "downsample_mode": "strideconv" // "strideconv" | "avgpool" | "maxpool"
+
+ , "init_type": "orthogonal" // "orthogonal" | "normal" | "uniform" | "xavier_normal" | "xavier_uniform" | "kaiming_normal" | "kaiming_uniform"
+ , "init_bn_type": "uniform" // "uniform" | "constant"
+ , "init_gain": 0.2
+ }
+
+ , "train": {
+ "G_lossfn_type": "l1" // "l1" preferred | "l2sum" | "l2" | "ssim"
+ , "G_lossfn_weight": 1.0 // default
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 1e-4 // learning rate
+ , "G_optimizer_clipgrad": null // unused
+
+ , "G_scheduler_type": "MultiStepLR" // "MultiStepLR" is enough
+ , "G_scheduler_milestones": [200000, 400000, 600000, 800000, 1000000, 2000000]
+ , "G_scheduler_gamma": 0.5
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+}
diff --git a/KAIR/options/train_dpsr.json b/KAIR/options/train_dpsr.json
new file mode 100644
index 0000000000000000000000000000000000000000..563198e8049f3e30e524285e23c52ccc852aeba4
--- /dev/null
+++ b/KAIR/options/train_dpsr.json
@@ -0,0 +1,75 @@
+{
+ "task": "dpsr" // root/task/images-models-options
+ , "model": "plain" // "plain" | "plain2" if two inputs
+ , "gpu_ids": [0]
+
+ , "scale": 4 // broadcast to "netG" if SISR
+ , "n_channels": 3 // broadcast to "datasets", 1 for grayscale, 3 for color
+ , "sigma": [0, 50] // 15, 25, 50 for DnCNN | [0, 75] for FDnCNN and FFDNet
+ , "sigma_test": 0 // 15, 25, 50 for DnCNN, FDnCNN and FFDNet, 0 for SR
+
+ , "merge_bn": false // if no BN exists, set false
+ , "merge_bn_startpoint": 400000 // merge BN after N iterations
+
+ , "path": {
+ "root": "superresolution" // "denoising" | "superresolution"
+ , "pretrained_netG": null // path of pretrained model
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset" // just name
+ , "dataset_type": "dpsr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "trainsets/trainH"// path of H training dataset
+ , "dataroot_L": null // path of L training dataset
+ , "H_size": 96 // patch size 40 | 64 | 96 | 128 | 192
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 8
+ , "dataloader_batch_size": 32 // batch size 1 | 16 | 32 | 48 | 64 | 128
+ }
+ , "test": {
+ "name": "test_dataset" // just name
+ , "dataset_type": "dpsr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "testsets/set5" // path of H testing dataset
+ , "dataroot_L": null // path of L testing dataset
+ }
+ }
+
+ , "netG": {
+ "net_type": "dpsr" // "dncnn" | "fdncnn" | "ffdnet" | "srmd" | "dpsr" | "msrresnet0" | "msrresnet1" | "rrdb"
+ , "in_nc": 4 // input channel number
+ , "out_nc": 3 // ouput channel number
+ , "nc": 96 // 96 for DPSR, 128 for SRMD, 64 for "dncnn"
+ , "nb": 16 // 12 for "srmd", 15 for "ffdnet", 20 for "dncnn", 16 for "srresnet" and "dpsr"
+ , "gc": 32 // unused
+ , "ng": 2 // unused
+ , "reduction" : 16 // unused
+ , "act_mode": "R" // "BR" for BN+ReLU | "R" for ReLU
+ , "upsample_mode": "pixelshuffle" // "pixelshuffle" | "convtranspose" | "upconv"
+ , "downsample_mode": "strideconv" // "strideconv" | "avgpool" | "maxpool"
+
+ , "init_type": "orthogonal" // "orthogonal" | "normal" | "uniform" | "xavier_normal" | "xavier_uniform" | "kaiming_normal" | "kaiming_uniform"
+ , "init_bn_type": "uniform" // "uniform" | "constant"
+ , "init_gain": 0.2
+ }
+
+ , "train": {
+ "G_lossfn_type": "l1" // "l1" preferred | "l2sum" | "l2" | "ssim"
+ , "G_lossfn_weight": 1.0 // default
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 1e-4 // learning rate
+ , "G_optimizer_clipgrad": null // unused
+
+ , "G_scheduler_type": "MultiStepLR" // "MultiStepLR" is enough
+ , "G_scheduler_milestones": [200000, 400000, 600000, 800000, 1000000, 2000000]
+ , "G_scheduler_gamma": 0.5
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+}
diff --git a/KAIR/options/train_drunet.json b/KAIR/options/train_drunet.json
new file mode 100644
index 0000000000000000000000000000000000000000..12cfcadcc8752b8669f854c2a992d27c60eac79f
--- /dev/null
+++ b/KAIR/options/train_drunet.json
@@ -0,0 +1,72 @@
+{
+ "task": "drunet" // root/task/images-models-options
+ , "model": "plain" // "plain"
+ , "gpu_ids": [0]
+
+ , "scale": 1 // broadcast to "netG" if SISR
+ , "n_channels": 3 // broadcast to "datasets", 1 for grayscale, 3 for color
+ , "sigma": [0, 50] // 15, 25, 50 for DnCNN | [0, 75] for FFDNet and FDnCNN
+ , "sigma_test": 25 // 15, 25, 50 for DnCNN and ffdnet
+
+ , "path": {
+ "root": "denoising" // "denoising" | "superresolution"
+ , "pretrained_netG": null // path of pretrained model
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset" // just name
+ , "dataset_type": "fdncnn" // "dncnn" | "dnpatch" for dncnn, | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "trainsets/trainH"// path of H training dataset
+ , "dataroot_L": null // path of L training dataset
+ , "H_size": 128 // patch size 40 | 64 | 96 | 128 | 192
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 8
+ , "dataloader_batch_size": 64 // batch size 1 | 16 | 32 | 48 | 64 | 128
+ }
+ , "test": {
+ "name": "test_dataset" // just name
+ , "dataset_type": "fdncnn" // "dncnn" | "dnpatch" for dncnn, | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "testsets/set12" // path of H testing dataset
+ , "dataroot_L": null // path of L testing dataset
+ }
+ }
+
+ , "netG": {
+ "net_type": "drunet" // "dncnn" | "fdncnn" | "ffdnet" | "srmd" | "dpsr" | "srresnet0" | "srresnet1" | "rrdbnet"
+ , "in_nc": 4 // input channel number
+ , "out_nc": 3 // ouput channel number
+ , "nc": [64, 128, 256, 512] // 64 for "dncnn"
+ , "nb": 4 // 17 for "dncnn", 20 for dncnn3, 16 for "srresnet"
+ , "gc": 32 // unused
+ , "ng": 2 // unused
+ , "reduction": 16 // unused
+ , "act_mode": "R" // "BR" for BN+ReLU | "R" for ReLU
+ , "upsample_mode": "convtranspose" // "pixelshuffle" | "convtranspose" | "upconv"
+ , "downsample_mode": "strideconv" // "strideconv" | "avgpool" | "maxpool"
+ , "bias": false //
+ , "init_type": "orthogonal" // "orthogonal" | "normal" | "uniform" | "xavier_normal" | "xavier_uniform" | "kaiming_normal" | "kaiming_uniform"
+ , "init_bn_type": "uniform" // "uniform" | "constant"
+ , "init_gain": 0.2
+ }
+
+ , "train": {
+ "G_lossfn_type": "l1" // "l1" preferred | "l2sum" | "l2" | "ssim"
+ , "G_lossfn_weight": 1.0 // default
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 1e-4 // learning rate
+ , "G_optimizer_clipgrad": null // unused
+
+ , "G_scheduler_type": "MultiStepLR" // "MultiStepLR" is enough
+ , "G_scheduler_milestones": [100000,200000,300000,400000]
+ , "G_scheduler_gamma": 0.5
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+}
diff --git a/KAIR/options/train_fdncnn.json b/KAIR/options/train_fdncnn.json
new file mode 100644
index 0000000000000000000000000000000000000000..bbe2c0ec5268b8119df8fad3326f475577f7c7b0
--- /dev/null
+++ b/KAIR/options/train_fdncnn.json
@@ -0,0 +1,75 @@
+{
+ "task": "fdncnn" // root/task/images-models-options
+ , "model": "plain" // "plain"
+ , "gpu_ids": [0]
+
+ , "scale": 1 // broadcast to "netG" if SISR
+ , "n_channels": 1 // broadcast to "datasets", 1 for grayscale, 3 for color
+ , "sigma": [0, 75] // 15, 25, 50 for DnCNN | [0, 75] for FDnCNN and FFDNet
+ , "sigma_test": 25 // 15, 25, 50 for DnCNN, FDnCNN and FFDNet
+
+ , "merge_bn": false // if no BN exists, set false
+ , "merge_bn_startpoint": 400000 // merge BN after N iterations
+
+ , "path": {
+ "root": "denoising" // "denoising" | "superresolution"
+ , "pretrained_netG": null // path of pretrained model
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset" // just name
+ , "dataset_type": "fdncnn" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "trainsets/trainH"// path of H training dataset
+ , "dataroot_L": null // path of L training dataset
+ , "H_size": 48 // patch size 40 | 64 | 96 | 128 | 192
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 8
+ , "dataloader_batch_size": 64 // batch size 1 | 16 | 32 | 48 | 64 | 128
+ }
+ , "test": {
+ "name": "test_dataset" // just name
+ , "dataset_type": "fdncnn" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "testsets/bsd68" // path of H testing dataset
+ , "dataroot_L": null // path of L testing dataset
+ }
+ }
+
+ , "netG": {
+ "net_type": "fdncnn" // "dncnn" | "fdncnn" | "ffdnet" | "srmd" | "dpsr" | "msrresnet0" | "msrresnet1" | "rrdb"
+ , "in_nc": 2 // input channel number
+ , "out_nc": 1 // ouput channel number
+ , "nc": 64 // 64 for "dncnn"
+ , "nb": 20 // 20 for "dncnn", 16 for "srresnet"
+ , "gc": 32 // unused
+ , "ng": 2 // unused
+ , "reduction" : 16 // unused
+ , "act_mode": "R" // "BR" for BN+ReLU | "R" for ReLU
+ , "upsample_mode": "convtranspose" // "pixelshuffle" | "convtranspose" | "upconv"
+ , "downsample_mode": "strideconv" // "strideconv" | "avgpool" | "maxpool"
+
+ , "init_type": "orthogonal" // "orthogonal" | "normal" | "uniform" | "xavier_normal" | "xavier_uniform" | "kaiming_normal" | "kaiming_uniform"
+ , "init_bn_type": "uniform" // "uniform" | "constant"
+ , "init_gain": 0.2
+ }
+
+ , "train": {
+ "G_lossfn_type": "l1" // "l1" preferred | "l2sum" | "l2" | "ssim"
+ , "G_lossfn_weight": 1.0 // default
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 1e-4 // learning rate
+ , "G_optimizer_clipgrad": null // unused
+
+ , "G_scheduler_type": "MultiStepLR" // "MultiStepLR" is enough
+ , "G_scheduler_milestones": [200000, 400000, 600000, 800000, 1000000, 2000000]
+ , "G_scheduler_gamma": 0.5
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+}
diff --git a/KAIR/options/train_ffdnet.json b/KAIR/options/train_ffdnet.json
new file mode 100644
index 0000000000000000000000000000000000000000..8070e3763c304fec4d935b8fcfde9347d605561e
--- /dev/null
+++ b/KAIR/options/train_ffdnet.json
@@ -0,0 +1,75 @@
+{
+ "task": "ffdnet" // root/task/images-models-options
+ , "model": "plain2" // "plain"
+ , "gpu_ids": [0]
+
+ , "scale": 1 // broadcast to "netG" if SISR
+ , "n_channels": 1 // broadcast to "datasets", 1 for grayscale, 3 for color
+ , "sigma": [0, 75] // 15, 25, 50 for DnCNN | [0, 75] for FDnCNN and FFDNet
+ , "sigma_test": 25 // 15, 25, 50 for DnCNN, FDnCNN and FFDNet
+
+ , "merge_bn": false // if no BN exists, set false
+ , "merge_bn_startpoint": 400000 // merge BN after N iterations
+
+ , "path": {
+ "root": "denoising" // "denoising" | "superresolution"
+ , "pretrained_netG": null // path of pretrained model
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset" // just name
+ , "dataset_type": "ffdnet" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "trainsets/trainH"// path of H training dataset
+ , "dataroot_L": null // path of L training dataset
+ , "H_size": 64 // patch size 40 | 64 | 96 | 128 | 192
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 8
+ , "dataloader_batch_size": 64 // batch size 1 | 16 | 32 | 48 | 64 | 128
+ }
+ , "test": {
+ "name": "test_dataset" // just name
+ , "dataset_type": "ffdnet" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "testsets/bsd68" // path of H testing dataset
+ , "dataroot_L": null // path of L testing dataset
+ }
+ }
+
+ , "netG": {
+ "net_type": "ffdnet" // "dncnn" | "fdncnn" | "ffdnet" | "srmd" | "dpsr" | "msrresnet0" | "msrresnet1" | "rrdb"
+ , "in_nc": 1 // input channel number
+ , "out_nc": 1 // ouput channel number
+ , "nc": 64 // 64 for "dncnn"
+ , "nb": 15 // 15 for "ffdnet", 20 for "dncnn", 16 for "srresnet"
+ , "gc": 32 // unused
+ , "ng": 2 // unused
+ , "reduction" : 16 // unused
+ , "act_mode": "R" // "BR" for BN+ReLU | "R" for ReLU
+ , "upsample_mode": "convtranspose" // "pixelshuffle" | "convtranspose" | "upconv"
+ , "downsample_mode": "strideconv" // "strideconv" | "avgpool" | "maxpool"
+
+ , "init_type": "orthogonal" // "orthogonal" | "normal" | "uniform" | "xavier_normal" | "xavier_uniform" | "kaiming_normal" | "kaiming_uniform"
+ , "init_bn_type": "uniform" // "uniform" | "constant"
+ , "init_gain": 0.2
+ }
+
+ , "train": {
+ "G_lossfn_type": "l1" // "l1" preferred | "l2sum" | "l2" | "ssim"
+ , "G_lossfn_weight": 1.0 // default
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 1e-4 // learning rate
+ , "G_optimizer_clipgrad": null // unused
+
+ , "G_scheduler_type": "MultiStepLR" // "MultiStepLR" is enough
+ , "G_scheduler_milestones": [200000, 400000, 600000, 800000, 1000000, 2000000]
+ , "G_scheduler_gamma": 0.5
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+}
diff --git a/KAIR/options/train_imdn.json b/KAIR/options/train_imdn.json
new file mode 100644
index 0000000000000000000000000000000000000000..d32842dd8424b64740884b26cb016e788a4eb61e
--- /dev/null
+++ b/KAIR/options/train_imdn.json
@@ -0,0 +1,75 @@
+{
+ "task": "imdn" // root/task/images-models-options
+ , "model": "plain" // "plain" | "plain2" if two inputs
+ , "gpu_ids": [0]
+
+ , "scale": 4 // broadcast to "netG" if SISR
+ , "n_channels": 3 // broadcast to "datasets", 1 for grayscale, 3 for color
+ , "sigma": 0 // 15, 25, 50 for DnCNN | [0, 75] for FDnCNN and FFDNet
+ , "sigma_test": 0 // 15, 25, 50 for DnCNN, FDnCNN and FFDNet, 0 for SR
+
+ , "merge_bn": false // if no BN exists, set false
+ , "merge_bn_startpoint": 400000 // merge BN after N iterations
+
+ , "path": {
+ "root": "superresolution" // "denoising" | "superresolution"
+ , "pretrained_netG": null // path of pretrained model
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset" // just name
+ , "dataset_type": "sr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "trainsets/trainH"// path of H training dataset
+ , "dataroot_L": null // path of L training dataset
+ , "H_size": 96 // patch size 40 | 64 | 96 | 128 | 192
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 8
+ , "dataloader_batch_size": 64 // batch size 1 | 16 | 32 | 48 | 64 | 128
+ }
+ , "test": {
+ "name": "test_dataset" // just name
+ , "dataset_type": "sr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "testsets/set5" // path of H testing dataset
+ , "dataroot_L": null // path of L testing dataset
+ }
+ }
+
+ , "netG": {
+ "net_type": "imdn" // "dncnn" | "fdncnn" | "ffdnet" | "srmd" | "dpsr" | "msrresnet0" | "msrresnet1" | "rrdb"
+ , "in_nc": 3 // input channel number
+ , "out_nc": 3 // ouput channel number
+ , "nc": 64 // 96 for DPSR, 128 for SRMD, 64 for "dncnn"
+ , "nb": 8 // 12 for "srmd", 15 for "ffdnet", 20 for "dncnn", 16 for "srresnet" and "dpsr"
+ , "gc": 32 // unused
+ , "ng": 2 // unused
+ , "reduction" : 16 // unused
+ , "act_mode": "L" // "BR" for BN+ReLU | "R" for ReLU
+ , "upsample_mode": "pixelshuffle" // "pixelshuffle" | "convtranspose" | "upconv"
+ , "downsample_mode": "strideconv" // unused, "strideconv" | "avgpool" | "maxpool"
+
+ , "init_type": "orthogonal" // "orthogonal" | "normal" | "uniform" | "xavier_normal" | "xavier_uniform" | "kaiming_normal" | "kaiming_uniform"
+ , "init_bn_type": "uniform" // "uniform" | "constant"
+ , "init_gain": 0.2
+ }
+
+ , "train": {
+ "G_lossfn_type": "l1" // "l1" preferred | "l2sum" | "l2" | "ssim"
+ , "G_lossfn_weight": 1.0 // default
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 1e-4 // learning rate
+ , "G_optimizer_clipgrad": null // unused
+
+ , "G_scheduler_type": "MultiStepLR" // "MultiStepLR" is enough
+ , "G_scheduler_milestones": [200000, 400000, 600000, 800000, 1000000, 2000000]
+ , "G_scheduler_gamma": 0.5
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+}
diff --git a/KAIR/options/train_msrresnet_gan.json b/KAIR/options/train_msrresnet_gan.json
new file mode 100644
index 0000000000000000000000000000000000000000..64cb6582f6d0a7b6274ea36a1af612ca7bca77d8
--- /dev/null
+++ b/KAIR/options/train_msrresnet_gan.json
@@ -0,0 +1,115 @@
+{
+ "task": "msrresnet_gan" //
+ , "model": "gan" // "gan"
+ , "gpu_ids": [0]
+
+ , "scale": 4 // broadcast to "netG" if SISR
+ , "n_channels": 3 // broadcast to "datasets", 1 for grayscale, 3 for color
+ , "sigma": [0, 50] // 15, 25, 50 for DnCNN | [0, 75] for FDnCNN and FFDNet
+ , "sigma_test": 0 // 15, 25, 50 for DnCNN, FDnCNN and FFDNet, 0 for SR
+
+ , "merge_bn": false // if no BN exists, set false
+ , "merge_bn_startpoint": 400000 // merge BN after N iterations
+
+ , "path": {
+ "root": "superresolution" // "denoising" | "superresolution"
+ , "pretrained_netG": null // path of pretrained model
+ , "pretrained_netD": null // path of pretrained model
+ , "pretrained_netE": null // path of pretrained model
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset" // just name
+ , "dataset_type": "sr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "trainsets/trainH"// path of H training dataset
+ , "dataroot_L": null // path of L training dataset
+ , "H_size": 96 // patch size 40 | 64 | 96 | 128 | 192
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 8
+ , "dataloader_batch_size": 32 // batch size 1 | 16 | 32 | 48 | 64 | 128
+ }
+ , "test": {
+ "name": "test_dataset" // just name
+ , "dataset_type": "sr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "testsets/set5" // path of H testing dataset
+ , "dataroot_L": null // path of L testing dataset
+ }
+ }
+
+ , "netG": {
+ "net_type": "msrresnet0" // "dncnn" | "fdncnn" | "ffdnet" | "srmd" | "dpsr" | "msrresnet0" | "msrresnet1" | "rrdb"
+ , "in_nc": 3 // input channel number
+ , "out_nc": 3 // ouput channel number
+ , "nc": 64 // 96 for DPSR, 128 for SRMD, 64 for DnCNN and MSRResNet
+ , "nb": 16 // 12 for "srmd", 15 for "ffdnet", 20 for "dncnn", 16 for "srresnet" and "dpsr"
+ , "gc": 32 // unused
+ , "ng": 2 // unused
+ , "reduction" : 16 // unused
+ , "act_mode": "R" // "BR" for BN+ReLU | "R" for ReLU
+ , "upsample_mode": "upconv" // "pixelshuffle" | "convtranspose" | "upconv"
+ , "downsample_mode": "strideconv" // "strideconv" | "avgpool" | "maxpool"
+
+ , "init_type": "orthogonal" // "orthogonal" | "normal" | "uniform" | "xavier_normal" | "xavier_uniform" | "kaiming_normal" | "kaiming_uniform"
+ , "init_bn_type": "uniform" // "uniform" | "constant"
+ , "init_gain": 0.2
+ }
+
+ , "netD": {
+ "net_type": "discriminator_vgg_96" // "discriminator_patchgan" | "discriminator_unet" | "discriminator_vgg_192" | "discriminator_vgg_128" | "discriminator_vgg_96"
+ , "in_nc": 3
+ , "base_nc": 64
+ , "act_mode": "BL" // "BL" means BN+LeakyReLU
+ , "n_layers": 3 // only for "net_type":"discriminator_patchgan"
+ , "norm_type": 3 // only for "net_type":"discriminator_patchgan" | 'batch', 'instance', 'spectral', 'batchspectral', instancespectral'
+
+ , "init_type": "orthogonal" // "orthogonal" | "normal" | "uniform" | "xavier_normal" | "xavier_uniform" | "kaiming_normal" | "kaiming_uniform"
+ , "init_bn_type": "uniform" // "uniform" | "constant"
+ , "init_gain": 0.2
+ }
+
+ , "train": {
+ "G_lossfn_type": "l1" // "l1" | "l2" | "l2sum" | "l1c" | "ssim"
+ , "G_lossfn_weight": 1e-2
+
+ , "F_lossfn_type": "l1" // "l1" | "l2"
+ , "F_lossfn_weight": 1
+ , "F_feature_layer": 34 // 25 | [2,7,16,25,34]
+ , "F_weights": 1.0 // 1.0 | [0.1,0.1,1.0,1.0,1.0]
+ , "F_use_input_norm": true
+ , "F_use_range_norm": false
+
+ , "gan_type": "ragan" // "gan" | "ragan" | "lsgan" | "wgan" | "softplusgan"
+ , "D_lossfn_weight": 5e-3
+
+ , "E_decay": 0.999 // Exponential Moving Average for netG: set 0 to disable; default setting 0.999
+
+ , "D_init_iters": 0
+
+ , "G_optimizer_type": "adam"
+ , "G_optimizer_lr": 1e-5
+ , "G_optimizer_wd": 0
+
+ , "D_optimizer_type": "adam"
+ , "D_optimizer_lr": 1e-5
+ , "D_optimizer_wd": 0
+
+ , "G_scheduler_type": "MultiStepLR"
+ , "G_scheduler_milestones": [200000, 800000, 1200000, 2000000]
+ , "G_scheduler_gamma": 0.5
+ , "G_optimizer_reuse": false
+
+ , "D_scheduler_type": "MultiStepLR"
+ , "D_scheduler_milestones": [200000, 800000, 1200000, 2000000]
+ , "D_scheduler_gamma": 0.5
+ , "D_optimizer_reuse": false
+
+ , "G_param_strict": true
+ , "D_param_strict": true
+ , "E_param_strict": true
+
+ , "checkpoint_test": 5000
+ , "checkpoint_save": 5000
+ , "checkpoint_print": 200
+ }
+}
diff --git a/KAIR/options/train_msrresnet_psnr.json b/KAIR/options/train_msrresnet_psnr.json
new file mode 100644
index 0000000000000000000000000000000000000000..cfaaba9a1a121f04d55bc246e034fa55315cfcd5
--- /dev/null
+++ b/KAIR/options/train_msrresnet_psnr.json
@@ -0,0 +1,84 @@
+{
+ "task": "msrresnet_psnr" // root/task/images-models-options, pay attention to the difference between "msrresnet0" and "msrresnet1"
+ , "model": "plain" // "plain" | "plain2" if two inputs
+ , "gpu_ids": [0]
+ , "dist": true
+
+ , "scale": 4 // broadcast to "netG" if SISR
+ , "n_channels": 3 // broadcast to "datasets", 1 for grayscale, 3 for color
+ , "sigma": 0 // 15, 25, 50 for DnCNN | [0, 75] for FDnCNN and FFDNet
+ , "sigma_test": 0 // 15, 25, 50 for DnCNN, FDnCNN and FFDNet, 0 for SR
+
+ , "merge_bn": false // if no BN exists, set false
+ , "merge_bn_startpoint": 400000 // merge BN after N iterations
+
+ , "path": {
+ "root": "superresolution" // "denoising" | "superresolution"
+ , "pretrained_netG": null // path of pretrained model
+ , "pretrained_netE": null // path of pretrained model
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset" // just name
+ , "dataset_type": "sr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "trainsets/trainH"// path of H training dataset
+ , "dataroot_L": null // path of L training dataset
+ , "H_size": 96 // patch size 40 | 64 | 96 | 128 | 192
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 8
+ , "dataloader_batch_size": 32 // batch size 1 | 16 | 32 | 48 | 64 | 128
+ }
+ , "test": {
+ "name": "test_dataset" // just name
+ , "dataset_type": "sr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "testsets/set5" // path of H testing dataset
+ , "dataroot_L": null // path of L testing dataset
+ }
+ }
+
+ , "netG": {
+ "net_type": "msrresnet0" // "dncnn" | "fdncnn" | "ffdnet" | "srmd" | "dpsr" | "msrresnet0" | "msrresnet1" | "rrdb"
+ , "in_nc": 3 // input channel number
+ , "out_nc": 3 // ouput channel number
+ , "nc": 64 // 96 for DPSR, 128 for SRMD, 64 for "dncnn"
+ , "nb": 16 // 12 for "srmd", 15 for "ffdnet", 20 for "dncnn", 16 for "srresnet" and "dpsr"
+ , "gc": 32 // unused
+ , "ng": 2 // unused
+ , "reduction" : 16 // unused
+ , "act_mode": "R" // "BR" for BN+ReLU | "R" for ReLU
+ , "upsample_mode": "upconv" // "pixelshuffle" | "convtranspose" | "upconv"
+ , "downsample_mode": "strideconv" // "strideconv" | "avgpool" | "maxpool"
+
+ , "init_type": "orthogonal" // "orthogonal" | "normal" | "uniform" | "xavier_normal" | "xavier_uniform" | "kaiming_normal" | "kaiming_uniform"
+ , "init_bn_type": "uniform" // "uniform" | "constant"
+ , "init_gain": 0.2
+ }
+
+ , "train": {
+ "G_lossfn_type": "l1" // "l1" preferred | "l2sum" | "l2" | "ssim"
+ , "G_lossfn_weight": 1.0 // default
+
+ , "E_decay": 0.999 // Exponential Moving Average for netG: set 0 to disable; default setting 0.999
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 1e-4 // learning rate
+ , "G_optimizer_wd": 0 // weight decay, default 0
+ , "G_optimizer_clipgrad": null // unused
+ , "G_optimizer_reuse": false
+
+ , "G_scheduler_type": "MultiStepLR" // "MultiStepLR" is enough
+ , "G_scheduler_milestones": [200000, 400000, 600000, 800000, 1000000, 2000000]
+ , "G_scheduler_gamma": 0.5
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "G_param_strict": true
+ , "E_param_strict": true
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+}
diff --git a/KAIR/options/train_rrdb_psnr.json b/KAIR/options/train_rrdb_psnr.json
new file mode 100644
index 0000000000000000000000000000000000000000..9a0c28ecd83526992ffe96d6e6af7b53e6537921
--- /dev/null
+++ b/KAIR/options/train_rrdb_psnr.json
@@ -0,0 +1,75 @@
+{
+ "task": "rrdb" // root/task/images-models-options
+ , "model": "plain" // "plain" | "plain2" if two inputs
+ , "gpu_ids": [0]
+
+ , "scale": 4 // broadcast to "netG" if SISR
+ , "n_channels": 3 // broadcast to "datasets", 1 for grayscale, 3 for color
+ , "sigma": 0 // unused, 15, 25, 50 for DnCNN | [0, 75] for FDnCNN and FFDNet
+ , "sigma_test": 0 // unused, 15, 25, 50 for DnCNN, FDnCNN and FFDNet, 0 for SR
+
+ , "merge_bn": false // unused, if no BN exists, set false
+ , "merge_bn_startpoint": 400000 // unused, merge BN after N iterations
+
+ , "path": {
+ "root": "superresolution" // "denoising" | "superresolution"
+ , "pretrained_netG": null // path of pretrained model
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset" // just name
+ , "dataset_type": "sr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "trainsets/trainH"// path of H training dataset
+ , "dataroot_L": null // path of L training dataset
+ , "H_size": 96 // patch size 40 | 64 | 96 | 128 | 192
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 8
+ , "dataloader_batch_size": 16 // batch size 1 | 16 | 32 | 48 | 64 | 128
+ }
+ , "test": {
+ "name": "test_dataset" // just name
+ , "dataset_type": "sr" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "testsets/set5" // path of H testing dataset
+ , "dataroot_L": null // path of L testing dataset
+ }
+ }
+
+ , "netG": {
+ "net_type": "rrdb" // "dncnn" | "fdncnn" | "ffdnet" | "srmd" | "dpsr" | "msrresnet0" | "msrresnet1" | "rrdb"
+ , "in_nc": 3 // input channel number
+ , "out_nc": 3 // ouput channel number
+ , "nc": 64 // 96 for "dpsr", 128 for "srmd", 64 for "dncnn" and "rrdb"
+ , "nb": 23 // 23 for "rrdb", 12 for "srmd", 15 for "ffdnet", 20 for "dncnn", 16 for "srresnet" and "dpsr"
+ , "gc": 32 // number of growth channels for "rrdb"
+ , "ng": 2 // unused
+ , "reduction" : 16 // unused
+ , "act_mode": "R" // "BR" for BN+ReLU | "R" for ReLU
+ , "upsample_mode": "upconv" // "pixelshuffle" | "convtranspose" | "upconv"
+ , "downsample_mode": "strideconv" // "strideconv" | "avgpool" | "maxpool"
+
+ , "init_type": "orthogonal" // "orthogonal" | "normal" | "uniform" | "xavier_normal" | "xavier_uniform" | "kaiming_normal" | "kaiming_uniform"
+ , "init_bn_type": "uniform" // "uniform" | "constant"
+ , "init_gain": 0.2
+ }
+
+ , "train": {
+ "G_lossfn_type": "l1" // "l1" preferred | "l2sum" | "l2" | "ssim"
+ , "G_lossfn_weight": 1.0 // default
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 1e-4 // learning rate
+ , "G_optimizer_clipgrad": null // unused
+
+ , "G_scheduler_type": "MultiStepLR" // "MultiStepLR" is enough
+ , "G_scheduler_milestones": [200000, 400000, 600000, 800000, 1000000, 2000000]
+ , "G_scheduler_gamma": 0.5
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+}
diff --git a/KAIR/options/train_srmd.json b/KAIR/options/train_srmd.json
new file mode 100644
index 0000000000000000000000000000000000000000..4f4fb035336716009ab3bd983fd88d63419b4c97
--- /dev/null
+++ b/KAIR/options/train_srmd.json
@@ -0,0 +1,75 @@
+{
+ "task": "srmd" // root/task/images-models-options
+ , "model": "plain" // "plain" | "plain2" if two inputs
+ , "gpu_ids": [0]
+
+ , "scale": 4 // broadcast to "netG" if SISR
+ , "n_channels": 3 // broadcast to "datasets", 1 for grayscale, 3 for color
+ , "sigma": [0, 50] // 15, 25, 50 for DnCNN | [0, 75] for FDnCNN and FFDNet
+ , "sigma_test": 0 // 15, 25, 50 for DnCNN, FDnCNN and FFDNet, 0 for SR
+
+ , "merge_bn": false // if no BN exists, set false
+ , "merge_bn_startpoint": 400000 // merge BN after N iterations
+
+ , "path": {
+ "root": "superresolution" // "denoising" | "superresolution"
+ , "pretrained_netG": null // path of pretrained model
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset" // just name
+ , "dataset_type": "srmd" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "trainsets/trainH"// path of H training dataset
+ , "dataroot_L": null // path of L training dataset
+ , "H_size": 96 // patch size 40 | 64 | 96 | 128 | 192
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 8
+ , "dataloader_batch_size": 64 // batch size 1 | 16 | 32 | 48 | 64 | 128
+ }
+ , "test": {
+ "name": "test_dataset" // just name
+ , "dataset_type": "srmd" // "dncnn" | "dnpatch" | "fdncnn" | "ffdnet" | "sr" | "srmd" | "dpsr" | "plain" | "plainpatch"
+ , "dataroot_H": "testsets/set5" // path of H testing dataset
+ , "dataroot_L": null // path of L testing dataset
+ }
+ }
+
+ , "netG": {
+ "net_type": "srmd" // "dncnn" | "fdncnn" | "ffdnet" | "srmd" | "dpsr" | "msrresnet0" | "msrresnet1" | "rrdb"
+ , "in_nc": 19 // input channel number
+ , "out_nc": 3 // ouput channel number
+ , "nc": 128 // 128 for SRMD, 64 for "dncnn"
+ , "nb": 12 // 12 for "srmd", 15 for "ffdnet", 20 for "dncnn", 16 for "srresnet"
+ , "gc": 32 // unused
+ , "ng": 2 // unused
+ , "reduction" : 16 // unused
+ , "act_mode": "R" // "BR" for BN+ReLU | "R" for ReLU
+ , "upsample_mode": "pixelshuffle" // "pixelshuffle" | "convtranspose" | "upconv"
+ , "downsample_mode": "strideconv" // "strideconv" | "avgpool" | "maxpool"
+
+ , "init_type": "orthogonal" // "orthogonal" | "normal" | "uniform" | "xavier_normal" | "xavier_uniform" | "kaiming_normal" | "kaiming_uniform"
+ , "init_bn_type": "uniform" // "uniform" | "constant"
+ , "init_gain": 0.2
+ }
+
+ , "train": {
+ "G_lossfn_type": "l1" // "l1" preferred | "l2sum" | "l2" | "ssim"
+ , "G_lossfn_weight": 1.0 // default
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 1e-4 // learning rate
+ , "G_optimizer_clipgrad": null // unused
+
+ , "G_scheduler_type": "MultiStepLR" // "MultiStepLR" is enough
+ , "G_scheduler_milestones": [200000, 400000, 600000, 800000, 1000000, 2000000]
+ , "G_scheduler_gamma": 0.5
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+}
diff --git a/KAIR/options/train_usrnet.json b/KAIR/options/train_usrnet.json
new file mode 100644
index 0000000000000000000000000000000000000000..e620a06e93115c5ad02801ca7271eecbdd2e60dd
--- /dev/null
+++ b/KAIR/options/train_usrnet.json
@@ -0,0 +1,77 @@
+{
+ "task": "usrnet" //
+ , "model": "plain4" // "plain" | "gan"
+ , "gpu_ids": [0]
+ , "scale": 4
+ , "n_channels": 3 // 1 for grayscale image restoration, 3 for color image restoration
+ , "merge_bn": false
+ , "merge_bn_startpoint": 300000
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset"
+ , "dataset_type": "usrnet"
+ , "dataroot_H": "trainsets/trainH"
+ , "dataroot_L": null
+ , "H_size": 96 // 128 | 192
+ , "use_flip": true
+ , "use_rot": true
+ , "scales": [1, 2, 3, 4]
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 8
+ , "dataloader_batch_size": 48
+ }
+ , "test": {
+ "name": "test_dataset"
+ , "dataset_type": "usrnet"
+ , "dataroot_H": "testsets/set5"
+ , "dataroot_L": null
+ }
+ }
+
+ , "path": {
+ "root": "SR"
+ , "pretrained_netG": null
+ }
+
+ , "netG": {
+ "net_type": "usrnet" // "srresnet" | "rrdbnet" | "rcan" | "unet" | "unetplus" | "nonlocalunet"
+ , "n_iter": 6 // 8
+ , "h_nc": 32 // 64
+ , "in_nc": 4
+ , "out_nc": 3
+ , "nc": [16, 32, 64, 64] // [64, 128, 256, 512] for "unet"
+ , "nb": 2
+ , "gc": 32
+ , "ng": 2
+ , "reduction" : 16
+ , "act_mode": "R" // "BR" for BN+ReLU | "R" for ReLU
+ , "upsample_mode": "convtranspose" // "pixelshuffle" | "convtranspose" | "upconv"
+ , "downsample_mode": "strideconv" // "strideconv" | "avgpool" | "maxpool"
+
+ , "init_type": "orthogonal" // "orthogonal" | "normal" | "uniform" | "xavier_normal" | "xavier_uniform" | "kaiming_normal" | "kaiming_uniform"
+ , "init_bn_type": "uniform" // "uniform" | "constant"
+ , "init_gain": 0.2
+ }
+
+ , "train": {
+ "G_lossfn_type": "l1" // "l1" | "l2sum" | "l2" | "ssim"
+ , "G_lossfn_weight": 1.0
+
+ , "G_optimizer_type": "adam"
+ , "G_optimizer_lr": 1e-4
+ , "G_optimizer_wd": 0
+ , "G_optimizer_clipgrad": null
+
+ , "G_scheduler_type": "MultiStepLR"
+ , "G_scheduler_milestones": [100000, 200000, 300000, 400000]
+ , "G_scheduler_gamma": 0.5
+
+ , "G_regularizer_orthstep": null
+ , "G_regularizer_clipstep": null
+
+ , "checkpoint_test": 5000
+ , "checkpoint_save": 5000
+ , "checkpoint_print": 200
+ }
+}
diff --git a/KAIR/options/vrt/001_train_vrt_videosr_bi_reds_6frames.json b/KAIR/options/vrt/001_train_vrt_videosr_bi_reds_6frames.json
new file mode 100644
index 0000000000000000000000000000000000000000..07cb1be7a1d28ea7e936d33eeff6ce0c9e2d3dfa
--- /dev/null
+++ b/KAIR/options/vrt/001_train_vrt_videosr_bi_reds_6frames.json
@@ -0,0 +1,119 @@
+{
+ "task": "001_train_vrt_videosr_bi_reds_6frames"
+ , "model": "vrt"
+ , "gpu_ids": [0,1,2,3,4,5,6,7]
+ , "dist": true
+ , "find_unused_parameters": false
+ , "use_static_graph": true
+
+ ,"scale": 4
+ , "n_channels": 3
+
+ , "path": {
+ "root": "experiments"
+ , "pretrained_netG": "/home/cll/dev/KAIR/model_zoo/vrt/001_VRT_videosr_bi_REDS_6frames.pth"
+ , "pretrained_netE": null
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset"
+ , "dataset_type": "VideoRecurrentTrainDataset"
+ , "dataroot_gt": "/home/cll/datasets/REDS/train/train_sharp"
+ , "dataroot_lq": "/home/cll/datasets/REDS/train/train_sharp_bicubic/X4"
+ , "meta_info_file": "data/meta_info/meta_info_REDS_GT.txt"
+ , "filename_tmpl": "08d"
+ , "filename_ext": "png"
+ , "val_partition": "REDS4"
+ , "test_mode": false
+ , "io_backend": {"type": "disk"}
+ , "num_frame": 4
+ , "gt_size": 256
+ , "interval_list": [1]
+ , "random_reverse": false
+ , "use_hflip": true
+ , "use_rot": true
+
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 32
+ , "dataloader_batch_size": 8
+ }
+ , "test": {
+ "name": "test_dataset"
+ , "dataset_type": "VideoRecurrentTestDataset"
+ , "dataroot_gt": "/home/cll/Desktop/REDS4/GT"
+ , "dataroot_lq": "/home/cll/Desktop/REDS4/sharp_bicubic"
+ , "cache_data": true
+ , "io_backend": {"type": "disk"}
+ , "num_frame": -1
+ }
+ }
+
+ , "netG": {
+ "net_type": "vrt"
+ , "upscale": 4
+ , "img_size": [6,64,64]
+ , "window_size": [6,8,8]
+ , "depths": [8,8,8,8,8,8,8, 4,4,4,4, 4,4]
+ , "indep_reconsts": [11,12]
+ , "embed_dims": [120,120,120,120,120,120,120, 180,180,180,180, 180,180]
+ , "num_heads": [6,6,6,6,6,6,6, 6,6,6,6, 6,6]
+ , "spynet_path": "model_zoo/vrt/spynet_sintel_final-3d2a1287.pth" // automatical download
+ , "pa_frames": 2
+ , "deformable_groups": 12
+ , "nonblind_denoising": false
+
+ , "use_checkpoint_attn": false
+ , "use_checkpoint_ffn": false
+ , "no_checkpoint_attn_blocks": []
+ , "no_checkpoint_ffn_blocks": []
+
+ , "init_type": "default"
+ }
+
+
+ , "train": {
+ "G_lossfn_type": "charbonnier"
+ , "G_lossfn_weight": 1.0
+ , "G_charbonnier_eps": 1e-9
+
+ , "E_decay": 0 // Exponential Moving Average for netG: set 0 to disable; default setting 0.999
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 4e-4 // learning rate
+ , "G_optimizer_betas": [0.9,0.99]
+ , "G_optimizer_wd": 0 // weight decay, default 0
+ , "G_optimizer_clipgrad": null // unused
+ , "G_optimizer_reuse": true //
+
+ , "fix_iter": 20000
+ , "fix_lr_mul": 0.125
+ , "fix_keys": ["spynet", "deform"]
+
+ , "total_iter": 300000
+ , "G_scheduler_type": "CosineAnnealingWarmRestarts"
+ , "G_scheduler_periods": 300000
+ , "G_scheduler_eta_min": 1e-7
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "G_param_strict": true
+ , "E_param_strict": true
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+
+ , "val": {
+ "save_img": false
+ , "pad_seq": false
+ , "flip_seq": false
+ , "center_frame_only": false
+ , "num_frame_testing": 40
+ , "num_frame_overlapping": 2
+ , "size_patch_testing": 128
+ }
+
+}
diff --git a/KAIR/options/vrt/002_train_vrt_videosr_bi_reds_16frames.json b/KAIR/options/vrt/002_train_vrt_videosr_bi_reds_16frames.json
new file mode 100644
index 0000000000000000000000000000000000000000..b9176e52d723d52cfe2ee9c5b607d2a2e44ef9fa
--- /dev/null
+++ b/KAIR/options/vrt/002_train_vrt_videosr_bi_reds_16frames.json
@@ -0,0 +1,119 @@
+{
+ "task": "002_train_vrt_videosr_bi_reds_16frames"
+ , "model": "vrt"
+ , "gpu_ids": [0,1,2,3,4,5,6,7]
+ , "dist": true
+ , "find_unused_parameters": false
+ , "use_static_graph": true
+
+ ,"scale": 4
+ , "n_channels": 3
+
+ , "path": {
+ "root": "experiments"
+ , "pretrained_netG": null
+ , "pretrained_netE": null
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset"
+ , "dataset_type": "VideoRecurrentTrainDataset"
+ , "dataroot_gt": "trainsets/REDS/train_sharp_with_val.lmdb"
+ , "dataroot_lq": "trainsets/REDS/train_sharp_bicubic_with_val.lmdb"
+ , "meta_info_file": "data/meta_info/meta_info_REDS_GT.txt"
+ , "filename_tmpl": "08d"
+ , "filename_ext": "png"
+ , "val_partition": "REDS4"
+ , "test_mode": false
+ , "io_backend": {"type": "lmdb"}
+ , "num_frame": 6
+ , "gt_size": 256
+ , "interval_list": [1]
+ , "random_reverse": false
+ , "use_hflip": true
+ , "use_rot": true
+
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 32
+ , "dataloader_batch_size": 8
+ }
+ , "test": {
+ "name": "test_dataset"
+ , "dataset_type": "VideoRecurrentTestDataset"
+ , "dataroot_gt": "testsets/REDS4/GT"
+ , "dataroot_lq": "testsets/REDS4/sharp_bicubic"
+ , "cache_data": true
+ , "io_backend": {"type": "disk"}
+ , "num_frame": -1
+ }
+ }
+
+ , "netG": {
+ "net_type": "vrt"
+ , "upscale": 4
+ , "img_size": [16,64,64]
+ , "window_size": [8,8,8]
+ , "depths": [8,8,8,8,8,8,8, 4,4,4,4, 4,4]
+ , "indep_reconsts": [11,12]
+ , "embed_dims": [120,120,120,120,120,120,120, 180,180,180,180, 180,180]
+ , "num_heads": [6,6,6,6,6,6,6, 6,6,6,6, 6,6]
+ , "spynet_path": "model_zoo/vrt/spynet_sintel_final-3d2a1287.pth" // automatical download
+ , "pa_frames": 4
+ , "deformable_groups": 16
+ , "nonblind_denoising": false
+
+ , "use_checkpoint_attn": true
+ , "use_checkpoint_ffn": false
+ , "no_checkpoint_attn_blocks": [0,1,2,3,4,5]
+ , "no_checkpoint_ffn_blocks": []
+
+ , "init_type": "default"
+ }
+
+
+ , "train": {
+ "G_lossfn_type": "charbonnier"
+ , "G_lossfn_weight": 1.0
+ , "G_charbonnier_eps": 1e-9
+
+ , "E_decay": 0 // Exponential Moving Average for netG: set 0 to disable; default setting 0.999
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 4e-4 // learning rate
+ , "G_optimizer_betas": [0.9,0.99]
+ , "G_optimizer_wd": 0 // weight decay, default 0
+ , "G_optimizer_clipgrad": null // unused
+ , "G_optimizer_reuse": true //
+
+ , "fix_iter": 20000
+ , "fix_lr_mul": 0.125
+ , "fix_keys": ["spynet", "deform"]
+
+ , "total_iter": 300000
+ , "G_scheduler_type": "CosineAnnealingWarmRestarts"
+ , "G_scheduler_periods": 300000
+ , "G_scheduler_eta_min": 1e-7
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "G_param_strict": true
+ , "E_param_strict": true
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+
+ , "val": {
+ "save_img": false
+ , "pad_seq": false
+ , "flip_seq": false
+ , "center_frame_only": false
+ , "num_frame_testing": 40
+ , "num_frame_overlapping": 2
+ , "size_patch_testing": 128
+ }
+
+}
diff --git a/KAIR/options/vrt/003_train_vrt_videosr_bi_vimeo_7frames.json b/KAIR/options/vrt/003_train_vrt_videosr_bi_vimeo_7frames.json
new file mode 100644
index 0000000000000000000000000000000000000000..2f29ed7af577ca346b50c6e357a82c75e85ac711
--- /dev/null
+++ b/KAIR/options/vrt/003_train_vrt_videosr_bi_vimeo_7frames.json
@@ -0,0 +1,116 @@
+{
+ "task": "003_train_vrt_videosr_bi_vimeo_7frames"
+ , "model": "vrt"
+ , "gpu_ids": [0,1,2,3,4,5,6,7]
+ , "dist": true
+ , "find_unused_parameters": false
+ , "use_static_graph": true
+
+ ,"scale": 4
+ , "n_channels": 3
+
+ , "path": {
+ "root": "experiments"
+ , "pretrained_netG": "model_zoo/vrt/002_VRT_videosr_bi_REDS_16frames.pth"
+ , "pretrained_netE": null
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset"
+ , "dataset_type": "VideoRecurrentTrainVimeoDataset"
+ , "dataroot_gt": "trainsets/vimeo90k"
+ , "dataroot_lq": "trainsets/vimeo90k"
+ , "meta_info_file": "data/meta_info/meta_info_Vimeo90K_train_GT.txt"
+ , "io_backend": {"type": "disk"}
+ , "num_frame": -1
+ , "gt_size": 256
+ , "interval_list": [1]
+ , "random_reverse": true
+ , "use_hflip": true
+ , "use_rot": true
+ , "pad_sequence": true
+
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 32
+ , "dataloader_batch_size": 8
+ }
+ , "test": {
+ "name": "test_dataset"
+ , "dataset_type": "VideoRecurrentTestDataset"
+ , "dataroot_gt": "testsets/Vid4/GT"
+ , "dataroot_lq": "testsets/Vid4/BIx4"
+ , "cache_data": true
+ , "io_backend": {"type": "disk"}
+ , "num_frame": -1
+ }
+ }
+
+ , "netG": {
+ "net_type": "vrt"
+ , "upscale": 4
+ , "img_size": [8,64,64]
+ , "window_size": [8,8,8]
+ , "depths": [8,8,8,8,8,8,8, 4,4,4,4, 4,4]
+ , "indep_reconsts": [11,12]
+ , "embed_dims": [120,120,120,120,120,120,120, 180,180,180,180, 180,180]
+ , "num_heads": [6,6,6,6,6,6,6, 6,6,6,6, 6,6]
+ , "spynet_path": "model_zoo/vrt/spynet_sintel_final-3d2a1287.pth" // automatical download
+ , "pa_frames": 4
+ , "deformable_groups": 16
+ , "nonblind_denoising": false
+
+ , "use_checkpoint_attn": false
+ , "use_checkpoint_ffn": false
+ , "no_checkpoint_attn_blocks": []
+ , "no_checkpoint_ffn_blocks": []
+
+ , "init_type": "default"
+ }
+
+
+ , "train": {
+ "G_lossfn_type": "charbonnier"
+ , "G_lossfn_weight": 1.0
+ , "G_charbonnier_eps": 1e-9
+
+ , "E_decay": 0 // Exponential Moving Average for netG: set 0 to disable; default setting 0.999
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 4e-4 // learning rate
+ , "G_optimizer_betas": [0.9,0.99]
+ , "G_optimizer_wd": 0 // weight decay, default 0
+ , "G_optimizer_clipgrad": null // unused
+ , "G_optimizer_reuse": true //
+
+ , "fix_iter": 20000
+ , "fix_lr_mul": 0.125
+ , "fix_keys": ["spynet", "deform"]
+
+ , "total_iter": 300000
+ , "G_scheduler_type": "CosineAnnealingWarmRestarts"
+ , "G_scheduler_periods": 300000
+ , "G_scheduler_eta_min": 1e-7
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "G_param_strict": false
+ , "E_param_strict": false
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+
+ , "val": {
+ "save_img": false
+ , "pad_seq": false
+ , "flip_seq": false
+ , "center_frame_only": false
+ , "num_frame_testing": 32
+ , "num_frame_overlapping": 2
+ , "size_patch_testing": 128
+ }
+
+}
diff --git a/KAIR/options/vrt/004_train_vrt_videosr_bd_vimeo_7frames.json b/KAIR/options/vrt/004_train_vrt_videosr_bd_vimeo_7frames.json
new file mode 100644
index 0000000000000000000000000000000000000000..a4419982edbbf23aa8ab5e4c2cc4a211c2b70be5
--- /dev/null
+++ b/KAIR/options/vrt/004_train_vrt_videosr_bd_vimeo_7frames.json
@@ -0,0 +1,116 @@
+{
+ "task": "004_train_vrt_videosr_bd_vimeo_7frames"
+ , "model": "vrt"
+ , "gpu_ids": [0,1,2,3,4,5,6,7]
+ , "dist": true
+ , "find_unused_parameters": false
+ , "use_static_graph": true
+
+ ,"scale": 4
+ , "n_channels": 3
+
+ , "path": {
+ "root": "experiments"
+ , "pretrained_netG": "model_zoo/vrt/002_VRT_videosr_bi_REDS_16frames.pth"
+ , "pretrained_netE": null
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset"
+ , "dataset_type": "VideoRecurrentTrainVimeoDataset"
+ , "dataroot_gt": "trainsets/vimeo90k/vimeo90k_train_GT_all.lmdb"
+ , "dataroot_lq": "trainsets/vimeo90k/vimeo90k_train_BDLR7frames.lmdb"
+ , "meta_info_file": "data/meta_info/meta_info_Vimeo90K_train_GT.txt"
+ , "io_backend": {"type": "lmdb"}
+ , "num_frame": -1
+ , "gt_size": 256
+ , "interval_list": [1]
+ , "random_reverse": true
+ , "use_hflip": true
+ , "use_rot": true
+ , "pad_sequence": true
+
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 32
+ , "dataloader_batch_size": 8
+ }
+ , "test": {
+ "name": "test_dataset"
+ , "dataset_type": "VideoRecurrentTestDataset"
+ , "dataroot_gt": "testsets/Vid4/GT"
+ , "dataroot_lq": "testsets/Vid4/BDx4"
+ , "cache_data": true
+ , "io_backend": {"type": "disk"}
+ , "num_frame": -1
+ }
+ }
+
+ , "netG": {
+ "net_type": "vrt"
+ , "upscale": 4
+ , "img_size": [8,64,64]
+ , "window_size": [8,8,8]
+ , "depths": [8,8,8,8,8,8,8, 4,4,4,4, 4,4]
+ , "indep_reconsts": [11,12]
+ , "embed_dims": [120,120,120,120,120,120,120, 180,180,180,180, 180,180]
+ , "num_heads": [6,6,6,6,6,6,6, 6,6,6,6, 6,6]
+ , "spynet_path": "model_zoo/vrt/spynet_sintel_final-3d2a1287.pth" // automatical download
+ , "pa_frames": 4
+ , "deformable_groups": 16
+ , "nonblind_denoising": false
+
+ , "use_checkpoint_attn": false
+ , "use_checkpoint_ffn": false
+ , "no_checkpoint_attn_blocks": []
+ , "no_checkpoint_ffn_blocks": []
+
+ , "init_type": "default"
+ }
+
+
+ , "train": {
+ "G_lossfn_type": "charbonnier"
+ , "G_lossfn_weight": 1.0
+ , "G_charbonnier_eps": 1e-9
+
+ , "E_decay": 0 // Exponential Moving Average for netG: set 0 to disable; default setting 0.999
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 4e-4 // learning rate
+ , "G_optimizer_betas": [0.9,0.99]
+ , "G_optimizer_wd": 0 // weight decay, default 0
+ , "G_optimizer_clipgrad": null // unused
+ , "G_optimizer_reuse": true //
+
+ , "fix_iter": 20000
+ , "fix_lr_mul": 0.125
+ , "fix_keys": ["spynet", "deform"]
+
+ , "total_iter": 300000
+ , "G_scheduler_type": "CosineAnnealingWarmRestarts"
+ , "G_scheduler_periods": 300000
+ , "G_scheduler_eta_min": 1e-7
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "G_param_strict": false
+ , "E_param_strict": false
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+
+ , "val": {
+ "save_img": false
+ , "pad_seq": false
+ , "flip_seq": false
+ , "center_frame_only": false
+ , "num_frame_testing": 32
+ , "num_frame_overlapping": 2
+ , "size_patch_testing": 128
+ }
+
+}
diff --git a/KAIR/options/vrt/005_train_vrt_videodeblurring_dvd.json b/KAIR/options/vrt/005_train_vrt_videodeblurring_dvd.json
new file mode 100644
index 0000000000000000000000000000000000000000..d6864ee818fb915c24aa8c7ac3c038b3ccbc31d8
--- /dev/null
+++ b/KAIR/options/vrt/005_train_vrt_videodeblurring_dvd.json
@@ -0,0 +1,118 @@
+{
+ "task": "005_train_vrt_videodeblurring_dvd"
+ , "model": "vrt"
+ , "gpu_ids": [0,1,2,3,4,5,6,7]
+ , "dist": true
+ , "find_unused_parameters": false
+ , "use_static_graph": true
+
+ ,"scale": 1
+ , "n_channels": 3
+
+ , "path": {
+ "root": "experiments"
+ , "pretrained_netG": null
+ , "pretrained_netE": null
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset"
+ , "dataset_type": "VideoRecurrentTrainDataset"
+ , "dataroot_gt": "trainsets/DVD/train_GT.lmdb"
+ , "dataroot_lq": "trainsets/DVD/train_GT_blurred.lmdb"
+ , "meta_info_file": "data/meta_info/meta_info_DVD_train_GT.txt"
+ , "filename_tmpl": "05d"
+ , "filename_ext": "jpg"
+ , "test_mode": false
+ , "io_backend": {"type": "lmdb"}
+ , "num_frame": 6
+ , "gt_size": 192
+ , "interval_list": [1]
+ , "random_reverse": false
+ , "use_hflip": true
+ , "use_rot": true
+
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 32
+ , "dataloader_batch_size": 8
+ }
+ , "test": {
+ "name": "test_dataset"
+ , "dataset_type": "VideoRecurrentTestDataset"
+ , "dataroot_gt": "testsets/DVD10/test_GT"
+ , "dataroot_lq": "testsets/DVD10/test_GT_blurred"
+ , "cache_data": false
+ , "io_backend": {"type": "disk"}
+ , "num_frame": -1
+ }
+ }
+
+ , "netG": {
+ "net_type": "vrt"
+ , "upscale": 1
+ , "img_size": [6,192,192]
+ , "window_size": [6,8,8]
+ , "depths": [8,8,8,8,8,8,8, 4,4, 4,4]
+ , "indep_reconsts": [9,10]
+ , "embed_dims": [96,96,96,96,96,96,96, 120,120, 120,120]
+ , "num_heads": [6,6,6,6,6,6,6, 6,6, 6,6]
+ , "spynet_path": "model_zoo/vrt/spynet_sintel_final-3d2a1287.pth" // automatical download
+ , "pa_frames": 2
+ , "deformable_groups": 16
+ , "nonblind_denoising": false
+
+ , "use_checkpoint_attn": true
+ , "use_checkpoint_ffn": true
+ , "no_checkpoint_attn_blocks": [2,3,4]
+ , "no_checkpoint_ffn_blocks": [1,2,3,4,5,9]
+
+ , "init_type": "default"
+ }
+
+
+ , "train": {
+ "G_lossfn_type": "charbonnier"
+ , "G_lossfn_weight": 1.0
+ , "G_charbonnier_eps": 1e-9
+
+ , "E_decay": 0 // Exponential Moving Average for netG: set 0 to disable; default setting 0.999
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 4e-4 // learning rate
+ , "G_optimizer_betas": [0.9,0.99]
+ , "G_optimizer_wd": 0 // weight decay, default 0
+ , "G_optimizer_clipgrad": null // unused
+ , "G_optimizer_reuse": true //
+
+ , "fix_iter": 20000
+ , "fix_lr_mul": 0.125
+ , "fix_keys": ["spynet", "deform"]
+
+ , "total_iter": 300000
+ , "G_scheduler_type": "CosineAnnealingWarmRestarts"
+ , "G_scheduler_periods": 300000
+ , "G_scheduler_eta_min": 1e-7
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "G_param_strict": true
+ , "E_param_strict": true
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+
+ , "val": {
+ "save_img": false
+ , "pad_seq": false
+ , "flip_seq": false
+ , "center_frame_only": false
+ , "num_frame_testing": 12
+ , "num_frame_overlapping": 2
+ , "size_patch_testing": 256
+ }
+
+}
diff --git a/KAIR/options/vrt/006_train_vrt_videodeblurring_gopro.json b/KAIR/options/vrt/006_train_vrt_videodeblurring_gopro.json
new file mode 100644
index 0000000000000000000000000000000000000000..9caef49e94b806aae94d777013c87e52078afcf5
--- /dev/null
+++ b/KAIR/options/vrt/006_train_vrt_videodeblurring_gopro.json
@@ -0,0 +1,118 @@
+{
+ "task": "006_train_vrt_videodeblurring_gopro"
+ , "model": "vrt"
+ , "gpu_ids": [0,1,2,3,4,5,6,7]
+ , "dist": true
+ , "find_unused_parameters": false
+ , "use_static_graph": true
+
+ ,"scale": 1
+ , "n_channels": 3
+
+ , "path": {
+ "root": "experiments"
+ , "pretrained_netG": null
+ , "pretrained_netE": null
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset"
+ , "dataset_type": "VideoRecurrentTrainDataset"
+ , "dataroot_gt": "trainsets/GoPro/train_GT.lmdb"
+ , "dataroot_lq": "trainsets/GoPro/train_GT_blurred.lmdb"
+ , "meta_info_file": "data/meta_info/meta_info_GoPro_train_GT.txt"
+ , "filename_tmpl": "06d"
+ , "filename_ext": "png"
+ , "test_mode": false
+ , "io_backend": {"type": "lmdb"}
+ , "num_frame": 6
+ , "gt_size": 192
+ , "interval_list": [1]
+ , "random_reverse": false
+ , "use_hflip": true
+ , "use_rot": true
+
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 32
+ , "dataloader_batch_size": 8
+ }
+ , "test": {
+ "name": "test_dataset"
+ , "dataset_type": "VideoRecurrentTestDataset"
+ , "dataroot_gt": "testsets/GoPro11/test_GT"
+ , "dataroot_lq": "testsets/GoPro11/test_GT_blurred"
+ , "cache_data": false
+ , "io_backend": {"type": "disk"}
+ , "num_frame": -1
+ }
+ }
+
+ , "netG": {
+ "net_type": "vrt"
+ , "upscale": 1
+ , "img_size": [6,192,192]
+ , "window_size": [6,8,8]
+ , "depths": [8,8,8,8,8,8,8, 4,4, 4,4]
+ , "indep_reconsts": [9,10]
+ , "embed_dims": [96,96,96,96,96,96,96, 120,120, 120,120]
+ , "num_heads": [6,6,6,6,6,6,6, 6,6, 6,6]
+ , "spynet_path": "model_zoo/vrt/spynet_sintel_final-3d2a1287.pth" // automatical download
+ , "pa_frames": 2
+ , "deformable_groups": 16
+ , "nonblind_denoising": false
+
+ , "use_checkpoint_attn": true
+ , "use_checkpoint_ffn": true
+ , "no_checkpoint_attn_blocks": [2,3,4]
+ , "no_checkpoint_ffn_blocks": [1,2,3,4,5,9]
+
+ , "init_type": "default"
+ }
+
+
+ , "train": {
+ "G_lossfn_type": "charbonnier"
+ , "G_lossfn_weight": 1.0
+ , "G_charbonnier_eps": 1e-9
+
+ , "E_decay": 0 // Exponential Moving Average for netG: set 0 to disable; default setting 0.999
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 4e-4 // learning rate
+ , "G_optimizer_betas": [0.9,0.99]
+ , "G_optimizer_wd": 0 // weight decay, default 0
+ , "G_optimizer_clipgrad": null // unused
+ , "G_optimizer_reuse": true //
+
+ , "fix_iter": 20000
+ , "fix_lr_mul": 0.125
+ , "fix_keys": ["spynet", "deform"]
+
+ , "total_iter": 300000
+ , "G_scheduler_type": "CosineAnnealingWarmRestarts"
+ , "G_scheduler_periods": 300000
+ , "G_scheduler_eta_min": 1e-7
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "G_param_strict": true
+ , "E_param_strict": true
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+
+ , "val": {
+ "save_img": false
+ , "pad_seq": false
+ , "flip_seq": false
+ , "center_frame_only": false
+ , "num_frame_testing": 18
+ , "num_frame_overlapping": 2
+ , "size_patch_testing": 192
+ }
+
+}
diff --git a/KAIR/options/vrt/007_train_vrt_videodeblurring_reds.json b/KAIR/options/vrt/007_train_vrt_videodeblurring_reds.json
new file mode 100644
index 0000000000000000000000000000000000000000..dd95c4515b012fafebad88bd280f97e6c573b2f4
--- /dev/null
+++ b/KAIR/options/vrt/007_train_vrt_videodeblurring_reds.json
@@ -0,0 +1,118 @@
+{
+ "task": "007_train_vrt_videodeblurring_reds"
+ , "model": "vrt"
+ , "gpu_ids": [0,1,2,3,4,5,6,7]
+ , "dist": true
+ , "find_unused_parameters": false
+ , "use_static_graph": true
+
+ ,"scale": 1
+ , "n_channels": 3
+
+ , "path": {
+ "root": "experiments"
+ , "pretrained_netG": null
+ , "pretrained_netE": null
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset"
+ , "dataset_type": "VideoRecurrentTrainDataset"
+ , "dataroot_gt": "trainsets/REDS/train_sharp_with_val.lmdb"
+ , "dataroot_lq": "trainsets/REDS/train_blur_with_val.lmdb"
+ , "meta_info_file": "data/meta_info/meta_info_REDS_GT.txt"
+ , "filename_tmpl": "08d"
+ , "filename_ext": "png"
+ , "test_mode": false
+ , "io_backend": {"type": "lmdb"}
+ , "num_frame": 6
+ , "gt_size": 192
+ , "interval_list": [1]
+ , "random_reverse": false
+ , "use_hflip": true
+ , "use_rot": true
+
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 32
+ , "dataloader_batch_size": 8
+ }
+ , "test": {
+ "name": "test_dataset"
+ , "dataset_type": "VideoRecurrentTestDataset"
+ , "dataroot_gt": "testsets/REDS4/GT"
+ , "dataroot_lq": "testsets/REDS4/blur"
+ , "cache_data": false
+ , "io_backend": {"type": "disk"}
+ , "num_frame": -1
+ }
+ }
+
+ , "netG": {
+ "net_type": "vrt"
+ , "upscale": 1
+ , "img_size": [6,192,192]
+ , "window_size": [6,8,8]
+ , "depths": [8,8,8,8,8,8,8, 4,4, 4,4]
+ , "indep_reconsts": [9,10]
+ , "embed_dims": [96,96,96,96,96,96,96, 120,120, 120,120]
+ , "num_heads": [6,6,6,6,6,6,6, 6,6, 6,6]
+ , "spynet_path": "model_zoo/vrt/spynet_sintel_final-3d2a1287.pth" // automatical download
+ , "pa_frames": 2
+ , "deformable_groups": 16
+ , "nonblind_denoising": false
+
+ , "use_checkpoint_attn": true
+ , "use_checkpoint_ffn": true
+ , "no_checkpoint_attn_blocks": [2,3,4]
+ , "no_checkpoint_ffn_blocks": [1,2,3,4,5,9]
+
+ , "init_type": "default"
+ }
+
+
+ , "train": {
+ "G_lossfn_type": "charbonnier"
+ , "G_lossfn_weight": 1.0
+ , "G_charbonnier_eps": 1e-9
+
+ , "E_decay": 0 // Exponential Moving Average for netG: set 0 to disable; default setting 0.999
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 4e-4 // learning rate
+ , "G_optimizer_betas": [0.9,0.99]
+ , "G_optimizer_wd": 0 // weight decay, default 0
+ , "G_optimizer_clipgrad": null // unused
+ , "G_optimizer_reuse": true //
+
+ , "fix_iter": 20000
+ , "fix_lr_mul": 0.125
+ , "fix_keys": ["spynet", "deform"]
+
+ , "total_iter": 300000
+ , "G_scheduler_type": "CosineAnnealingWarmRestarts"
+ , "G_scheduler_periods": 300000
+ , "G_scheduler_eta_min": 1e-7
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "G_param_strict": true
+ , "E_param_strict": true
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+
+ , "val": {
+ "save_img": false
+ , "pad_seq": false
+ , "flip_seq": false
+ , "center_frame_only": false
+ , "num_frame_testing": 12
+ , "num_frame_overlapping": 2
+ , "size_patch_testing": 256
+ }
+
+}
diff --git a/KAIR/options/vrt/008_train_vrt_videodenoising_davis.json b/KAIR/options/vrt/008_train_vrt_videodenoising_davis.json
new file mode 100644
index 0000000000000000000000000000000000000000..93401c17a835f255aaff88810709178aeb78d35a
--- /dev/null
+++ b/KAIR/options/vrt/008_train_vrt_videodenoising_davis.json
@@ -0,0 +1,123 @@
+{
+ "task": "008_train_vrt_videodenoising_davis"
+ , "model": "vrt"
+ , "gpu_ids": [0,1,2,3,4,5,6,7]
+ , "dist": true
+ , "find_unused_parameters": false
+ , "use_static_graph": true
+
+ ,"scale": 1
+ , "n_channels": 3
+
+ , "path": {
+ "root": "experiments"
+ , "pretrained_netG": null
+ , "pretrained_netE": null
+ }
+
+ , "datasets": {
+ "train": {
+ "name": "train_dataset"
+ , "dataset_type": "VideoRecurrentTrainNonblindDenoisingDataset"
+ , "dataroot_gt": "trainsets/DAVIS/train_GT.lmdb"
+ , "dataroot_lq": "trainsets/DAVIS/train_GT.lmdb"
+ , "meta_info_file": "data/meta_info/meta_info_DAVIS_train_GT.txt"
+ , "filename_tmpl": "05d"
+ , "filename_ext": "jpg"
+ , "test_mode": false
+ , "io_backend": {"type": "lmdb"}
+ , "num_frame": 6
+ , "gt_size": 192
+ , "interval_list": [1]
+ , "random_reverse": false
+ , "use_hflip": true
+ , "use_rot": true
+
+ , "sigma_min": 0
+ , "sigma_max": 50
+
+ , "dataloader_shuffle": true
+ , "dataloader_num_workers": 32
+ , "dataloader_batch_size": 8
+ }
+ , "test": {
+ "name": "test_dataset"
+ , "dataset_type": "VideoRecurrentTestDataset"
+ , "dataroot_gt": "testsets/Set8"
+ , "dataroot_lq": "testsets/Set8"
+ , "cache_data": true
+ , "io_backend": {"type": "disk"}
+ , "num_frame": -1
+
+ , "sigma": 30
+ }
+ }
+
+ , "netG": {
+ "net_type": "vrt"
+ , "upscale": 1
+ , "img_size": [6,192,192]
+ , "window_size": [6,8,8]
+ , "depths": [8,8,8,8,8,8,8, 4,4, 4,4]
+ , "indep_reconsts": [9,10]
+ , "embed_dims": [96,96,96,96,96,96,96, 120,120, 120,120]
+ , "num_heads": [6,6,6,6,6,6,6, 6,6, 6,6]
+ , "spynet_path": "model_zoo/vrt/spynet_sintel_final-3d2a1287.pth" // automatical download
+ , "pa_frames": 2
+ , "deformable_groups": 16
+ , "nonblind_denoising": true
+
+ , "use_checkpoint_attn": true
+ , "use_checkpoint_ffn": true
+ , "no_checkpoint_attn_blocks": [2,3,4]
+ , "no_checkpoint_ffn_blocks": [1,2,3,4,5,9]
+
+ , "init_type": "default"
+ }
+
+
+ , "train": {
+ "G_lossfn_type": "charbonnier"
+ , "G_lossfn_weight": 1.0
+ , "G_charbonnier_eps": 1e-9
+
+ , "E_decay": 0 // Exponential Moving Average for netG: set 0 to disable; default setting 0.999
+
+ , "G_optimizer_type": "adam" // fixed, adam is enough
+ , "G_optimizer_lr": 4e-4 // learning rate
+ , "G_optimizer_betas": [0.9,0.99]
+ , "G_optimizer_wd": 0 // weight decay, default 0
+ , "G_optimizer_clipgrad": null // unused
+ , "G_optimizer_reuse": true //
+
+ , "fix_iter": 20000
+ , "fix_lr_mul": 0.125
+ , "fix_keys": ["spynet", "deform"]
+
+ , "total_iter": 300000
+ , "G_scheduler_type": "CosineAnnealingWarmRestarts"
+ , "G_scheduler_periods": 300000
+ , "G_scheduler_eta_min": 1e-7
+
+ , "G_regularizer_orthstep": null // unused
+ , "G_regularizer_clipstep": null // unused
+
+ , "G_param_strict": true
+ , "E_param_strict": true
+
+ , "checkpoint_test": 5000 // for testing
+ , "checkpoint_save": 5000 // for saving model
+ , "checkpoint_print": 200 // for print
+ }
+
+ , "val": {
+ "save_img": false
+ , "pad_seq": false
+ , "flip_seq": false
+ , "center_frame_only": false
+ , "num_frame_testing": 12
+ , "num_frame_overlapping": 2
+ , "size_patch_testing": 256
+ }
+
+}
diff --git a/KAIR/outputs/2022-08-18/14-49-45/.hydra/config.yaml b/KAIR/outputs/2022-08-18/14-49-45/.hydra/config.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..84343d98c7d3995feb23624d60d91e51bef05e63
--- /dev/null
+++ b/KAIR/outputs/2022-08-18/14-49-45/.hydra/config.yaml
@@ -0,0 +1,98 @@
+arch:
+ _target_: arch.gcir.gcir_nano
+ pretrained: false
+ version: 1
+callbacks:
+ model_checkpoint:
+ _target_: callbacks.default.CustomModelCheckpoint
+ filename: '{epoch:03d}-{step:07d}'
+ every_n_train_steps: 1000
+ save_top_k: -1
+ save_last: true
+ dirpath: checkpoints
+ auto_insert_metric_name: false
+ verbose: true
+lmodule:
+ _target_: lmodule.sr_lmodule.SRLightningModule
+ hparams:
+ lpips_net: alex
+ l1_weight: 1
+ p_weight: 1
+ lr: ${lr}
+ betas: ${betas}
+ eps: ${eps}
+ weight_decay: ${weight_decay}
+ milestones: ${milestones}
+ gamma: ${gamma}
+datamodule:
+ _target_: datamodule.sr_datamodule.SRDataModule
+ train_dataset:
+ _target_: dataset.sr_dataset.BlindSRDataset
+ _convert_: partial
+ hq_data_dir: ${train_hq_data_dir}
+ sr_scale: ${sr_scale}
+ n_channels: 3
+ degradation_type: ${degradation_type}
+ shuffle_prob: 0.1
+ use_sharp: false
+ hq_patch_size: 256
+ lq_patch_size: 64
+ val_dataset:
+ _target_: dataset.sr_dataset.BlindSRDataset
+ _convert_: partial
+ hq_data_dir: ${val_data_dir}
+ sr_scale: ${sr_scale}
+ n_channels: 3
+ degradation_type: ${degradation_type}
+ shuffle_prob: 0.1
+ use_sharp: false
+ hq_patch_size: 256
+ lq_patch_size: 64
+ batch_size: ${batch_size}
+ num_workers: ${num_workers}
+ num_val_workers: 8
+ iterations_per_epoch: 1000
+ use_random_sampler: false
+trainer:
+ _target_: pytorch_lightning.Trainer
+ accelerator: gpu
+ strategy:
+ _target_: pytorch_lightning.plugins.training_type.ddp.DDPPlugin
+ find_unused_parameters: true
+ gpus: ${gpus}
+ precision: 32
+ max_steps: 100000
+ check_val_every_n_epoch: 10
+ replace_sampler_ddp: false
+ benchmark: true
+model: gcir_base
+name: gcir_base
+version: v1_SRscale2
+sr_scale: 2
+gpus:
+- 0
+- 1
+train_hq_data_dir: /home/cll/datasets/swinir_train
+val_data_dir: /home/cll/datasets/swinir_test
+epochs: 300
+warmup_epochs: 20
+cooldown_epochs: 10
+batch_size: 8
+num_workers: 8
+optimizer_name: adamw
+lr: 0.0001
+betas:
+- 0.9
+- 0.999
+eps: 1.0e-08
+weight_decay: 0.05
+milestones:
+- 50000
+- 100000
+- 150000
+- 200000
+- 300000
+gamma: 0.5
+degradation_type: bsrgan
+checkpoint_path: null
+use_channels_last: false
diff --git a/KAIR/outputs/2022-08-18/14-49-45/.hydra/hydra.yaml b/KAIR/outputs/2022-08-18/14-49-45/.hydra/hydra.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..2b015182fb7820195a3babe182d2d20ec3fc9abc
--- /dev/null
+++ b/KAIR/outputs/2022-08-18/14-49-45/.hydra/hydra.yaml
@@ -0,0 +1,161 @@
+hydra:
+ run:
+ dir: outputs/${now:%Y-%m-%d}/${now:%H-%M-%S}
+ sweep:
+ dir: multirun/${now:%Y-%m-%d}/${now:%H-%M-%S}
+ subdir: ${hydra.job.num}
+ launcher:
+ _target_: hydra._internal.core_plugins.basic_launcher.BasicLauncher
+ sweeper:
+ _target_: hydra._internal.core_plugins.basic_sweeper.BasicSweeper
+ max_batch_size: null
+ params: null
+ help:
+ app_name: ${hydra.job.name}
+ header: '${hydra.help.app_name} is powered by Hydra.
+
+ '
+ footer: 'Powered by Hydra (https://hydra.cc)
+
+ Use --hydra-help to view Hydra specific help
+
+ '
+ template: '${hydra.help.header}
+
+ == Configuration groups ==
+
+ Compose your configuration from those groups (group=option)
+
+
+ $APP_CONFIG_GROUPS
+
+
+ == Config ==
+
+ Override anything in the config (foo.bar=value)
+
+
+ $CONFIG
+
+
+ ${hydra.help.footer}
+
+ '
+ hydra_help:
+ template: 'Hydra (${hydra.runtime.version})
+
+ See https://hydra.cc for more info.
+
+
+ == Flags ==
+
+ $FLAGS_HELP
+
+
+ == Configuration groups ==
+
+ Compose your configuration from those groups (For example, append hydra/job_logging=disabled
+ to command line)
+
+
+ $HYDRA_CONFIG_GROUPS
+
+
+ Use ''--cfg hydra'' to Show the Hydra config.
+
+ '
+ hydra_help: ???
+ hydra_logging:
+ version: 1
+ formatters:
+ simple:
+ format: '[%(asctime)s][HYDRA] %(message)s'
+ handlers:
+ console:
+ class: logging.StreamHandler
+ formatter: simple
+ stream: ext://sys.stdout
+ root:
+ level: INFO
+ handlers:
+ - console
+ loggers:
+ logging_example:
+ level: DEBUG
+ disable_existing_loggers: false
+ job_logging:
+ version: 1
+ formatters:
+ simple:
+ format: '[%(asctime)s][%(name)s][%(levelname)s] - %(message)s'
+ handlers:
+ console:
+ class: logging.StreamHandler
+ formatter: simple
+ stream: ext://sys.stdout
+ file:
+ class: logging.FileHandler
+ formatter: simple
+ filename: ${hydra.runtime.output_dir}/${hydra.job.name}.log
+ root:
+ level: INFO
+ handlers:
+ - console
+ - file
+ disable_existing_loggers: false
+ env: {}
+ mode: RUN
+ searchpath: []
+ callbacks: {}
+ output_subdir: .hydra
+ overrides:
+ hydra:
+ - hydra.mode=RUN
+ task:
+ - experiment=gcir/gcir_base.yaml
+ job:
+ name: train
+ chdir: null
+ override_dirname: experiment=gcir/gcir_base.yaml
+ id: ???
+ num: ???
+ config_name: config.yaml
+ env_set: {}
+ env_copy: []
+ config:
+ override_dirname:
+ kv_sep: '='
+ item_sep: ','
+ exclude_keys: []
+ runtime:
+ version: 1.2.0
+ version_base: '1.1'
+ cwd: /home/cll/dev/superresolution/KAIR
+ config_sources:
+ - path: hydra.conf
+ schema: pkg
+ provider: hydra
+ - path: configs
+ schema: pkg
+ provider: main
+ - path: ''
+ schema: structured
+ provider: schema
+ output_dir: /home/cll/dev/superresolution/KAIR/outputs/2022-08-18/14-49-45
+ choices:
+ experiment: gcir/gcir_base.yaml
+ trainer: lightning_default
+ datamodule: sr_datamodule
+ lmodule: sr_lmodule
+ callbacks: default
+ arch: gcir_base
+ hydra/env: default
+ hydra/callbacks: null
+ hydra/job_logging: default
+ hydra/hydra_logging: default
+ hydra/hydra_help: default
+ hydra/help: default
+ hydra/sweeper: basic
+ hydra/launcher: basic
+ hydra/output: default
+ verbose: false
diff --git a/KAIR/outputs/2022-08-18/14-49-45/.hydra/overrides.yaml b/KAIR/outputs/2022-08-18/14-49-45/.hydra/overrides.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..d40f8c4da6957765d87f2b2d1f9fe5ce51da16a7
--- /dev/null
+++ b/KAIR/outputs/2022-08-18/14-49-45/.hydra/overrides.yaml
@@ -0,0 +1 @@
+- experiment=gcir/gcir_base.yaml
diff --git a/KAIR/outputs/2022-08-18/14-49-45/train.log b/KAIR/outputs/2022-08-18/14-49-45/train.log
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/KAIR/outputs/2022-08-18/14-50-30/.hydra/config.yaml b/KAIR/outputs/2022-08-18/14-50-30/.hydra/config.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..de067cb461cd8be8b72c06bb50a7dd4b966b1801
--- /dev/null
+++ b/KAIR/outputs/2022-08-18/14-50-30/.hydra/config.yaml
@@ -0,0 +1,98 @@
+arch:
+ _target_: arch.gcir.gcir_nano
+ pretrained: false
+ version: 1
+callbacks:
+ model_checkpoint:
+ _target_: callbacks.default.CustomModelCheckpoint
+ filename: '{epoch:03d}-{step:07d}'
+ every_n_train_steps: 1000
+ save_top_k: -1
+ save_last: true
+ dirpath: checkpoints
+ auto_insert_metric_name: false
+ verbose: true
+lmodule:
+ _target_: lmodule.sr_lmodule.SRLightningModule
+ params:
+ lpips_net: alex
+ l1_weight: 1
+ p_weight: 1
+ lr: ${lr}
+ betas: ${betas}
+ eps: ${eps}
+ weight_decay: ${weight_decay}
+ milestones: ${milestones}
+ gamma: ${gamma}
+datamodule:
+ _target_: datamodule.sr_datamodule.SRDataModule
+ train_dataset:
+ _target_: dataset.sr_dataset.BlindSRDataset
+ _convert_: partial
+ hq_data_dir: ${train_hq_data_dir}
+ sr_scale: ${sr_scale}
+ n_channels: 3
+ degradation_type: ${degradation_type}
+ shuffle_prob: 0.1
+ use_sharp: false
+ hq_patch_size: 256
+ lq_patch_size: 64
+ val_dataset:
+ _target_: dataset.sr_dataset.BlindSRDataset
+ _convert_: partial
+ hq_data_dir: ${val_data_dir}
+ sr_scale: ${sr_scale}
+ n_channels: 3
+ degradation_type: ${degradation_type}
+ shuffle_prob: 0.1
+ use_sharp: false
+ hq_patch_size: 256
+ lq_patch_size: 64
+ batch_size: ${batch_size}
+ num_workers: ${num_workers}
+ num_val_workers: 8
+ iterations_per_epoch: 1000
+ use_random_sampler: false
+trainer:
+ _target_: pytorch_lightning.Trainer
+ accelerator: gpu
+ strategy:
+ _target_: pytorch_lightning.plugins.training_type.ddp.DDPPlugin
+ find_unused_parameters: true
+ gpus: ${gpus}
+ precision: 32
+ max_steps: 100000
+ check_val_every_n_epoch: 10
+ replace_sampler_ddp: false
+ benchmark: true
+model: gcir_base
+name: gcir_base
+version: v1_SRscale2
+sr_scale: 2
+gpus:
+- 0
+- 1
+train_hq_data_dir: /home/cll/datasets/swinir_train
+val_data_dir: /home/cll/datasets/swinir_test
+epochs: 300
+warmup_epochs: 20
+cooldown_epochs: 10
+batch_size: 8
+num_workers: 8
+optimizer_name: adamw
+lr: 0.0001
+betas:
+- 0.9
+- 0.999
+eps: 1.0e-08
+weight_decay: 0.05
+milestones:
+- 50000
+- 100000
+- 150000
+- 200000
+- 300000
+gamma: 0.5
+degradation_type: bsrgan
+checkpoint_path: null
+use_channels_last: false
diff --git a/KAIR/outputs/2022-08-18/14-50-30/.hydra/hydra.yaml b/KAIR/outputs/2022-08-18/14-50-30/.hydra/hydra.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..def385afd51d9c4fe6df81a7d9132efc4c1e8119
--- /dev/null
+++ b/KAIR/outputs/2022-08-18/14-50-30/.hydra/hydra.yaml
@@ -0,0 +1,161 @@
+hydra:
+ run:
+ dir: outputs/${now:%Y-%m-%d}/${now:%H-%M-%S}
+ sweep:
+ dir: multirun/${now:%Y-%m-%d}/${now:%H-%M-%S}
+ subdir: ${hydra.job.num}
+ launcher:
+ _target_: hydra._internal.core_plugins.basic_launcher.BasicLauncher
+ sweeper:
+ _target_: hydra._internal.core_plugins.basic_sweeper.BasicSweeper
+ max_batch_size: null
+ params: null
+ help:
+ app_name: ${hydra.job.name}
+ header: '${hydra.help.app_name} is powered by Hydra.
+
+ '
+ footer: 'Powered by Hydra (https://hydra.cc)
+
+ Use --hydra-help to view Hydra specific help
+
+ '
+ template: '${hydra.help.header}
+
+ == Configuration groups ==
+
+ Compose your configuration from those groups (group=option)
+
+
+ $APP_CONFIG_GROUPS
+
+
+ == Config ==
+
+ Override anything in the config (foo.bar=value)
+
+
+ $CONFIG
+
+
+ ${hydra.help.footer}
+
+ '
+ hydra_help:
+ template: 'Hydra (${hydra.runtime.version})
+
+ See https://hydra.cc for more info.
+
+
+ == Flags ==
+
+ $FLAGS_HELP
+
+
+ == Configuration groups ==
+
+ Compose your configuration from those groups (For example, append hydra/job_logging=disabled
+ to command line)
+
+
+ $HYDRA_CONFIG_GROUPS
+
+
+ Use ''--cfg hydra'' to Show the Hydra config.
+
+ '
+ hydra_help: ???
+ hydra_logging:
+ version: 1
+ formatters:
+ simple:
+ format: '[%(asctime)s][HYDRA] %(message)s'
+ handlers:
+ console:
+ class: logging.StreamHandler
+ formatter: simple
+ stream: ext://sys.stdout
+ root:
+ level: INFO
+ handlers:
+ - console
+ loggers:
+ logging_example:
+ level: DEBUG
+ disable_existing_loggers: false
+ job_logging:
+ version: 1
+ formatters:
+ simple:
+ format: '[%(asctime)s][%(name)s][%(levelname)s] - %(message)s'
+ handlers:
+ console:
+ class: logging.StreamHandler
+ formatter: simple
+ stream: ext://sys.stdout
+ file:
+ class: logging.FileHandler
+ formatter: simple
+ filename: ${hydra.runtime.output_dir}/${hydra.job.name}.log
+ root:
+ level: INFO
+ handlers:
+ - console
+ - file
+ disable_existing_loggers: false
+ env: {}
+ mode: RUN
+ searchpath: []
+ callbacks: {}
+ output_subdir: .hydra
+ overrides:
+ hydra:
+ - hydra.mode=RUN
+ task:
+ - experiment=gcir/gcir_base.yaml
+ job:
+ name: train
+ chdir: null
+ override_dirname: experiment=gcir/gcir_base.yaml
+ id: ???
+ num: ???
+ config_name: config.yaml
+ env_set: {}
+ env_copy: []
+ config:
+ override_dirname:
+ kv_sep: '='
+ item_sep: ','
+ exclude_keys: []
+ runtime:
+ version: 1.2.0
+ version_base: '1.1'
+ cwd: /home/cll/dev/superresolution/KAIR
+ config_sources:
+ - path: hydra.conf
+ schema: pkg
+ provider: hydra
+ - path: configs
+ schema: pkg
+ provider: main
+ - path: ''
+ schema: structured
+ provider: schema
+ output_dir: /home/cll/dev/superresolution/KAIR/outputs/2022-08-18/14-50-30
+ choices:
+ experiment: gcir/gcir_base.yaml
+ trainer: lightning_default
+ datamodule: sr_datamodule
+ lmodule: sr_lmodule
+ callbacks: default
+ arch: gcir_base
+ hydra/env: default
+ hydra/callbacks: null
+ hydra/job_logging: default
+ hydra/hydra_logging: default
+ hydra/hydra_help: default
+ hydra/help: default
+ hydra/sweeper: basic
+ hydra/launcher: basic
+ hydra/output: default
+ verbose: false
diff --git a/KAIR/outputs/2022-08-18/14-50-30/.hydra/overrides.yaml b/KAIR/outputs/2022-08-18/14-50-30/.hydra/overrides.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..d40f8c4da6957765d87f2b2d1f9fe5ce51da16a7
--- /dev/null
+++ b/KAIR/outputs/2022-08-18/14-50-30/.hydra/overrides.yaml
@@ -0,0 +1 @@
+- experiment=gcir/gcir_base.yaml
diff --git a/KAIR/outputs/2022-08-18/14-50-30/train.log b/KAIR/outputs/2022-08-18/14-50-30/train.log
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/KAIR/outputs/2022-08-18/14-50-56/.hydra/config.yaml b/KAIR/outputs/2022-08-18/14-50-56/.hydra/config.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..de067cb461cd8be8b72c06bb50a7dd4b966b1801
--- /dev/null
+++ b/KAIR/outputs/2022-08-18/14-50-56/.hydra/config.yaml
@@ -0,0 +1,98 @@
+arch:
+ _target_: arch.gcir.gcir_nano
+ pretrained: false
+ version: 1
+callbacks:
+ model_checkpoint:
+ _target_: callbacks.default.CustomModelCheckpoint
+ filename: '{epoch:03d}-{step:07d}'
+ every_n_train_steps: 1000
+ save_top_k: -1
+ save_last: true
+ dirpath: checkpoints
+ auto_insert_metric_name: false
+ verbose: true
+lmodule:
+ _target_: lmodule.sr_lmodule.SRLightningModule
+ params:
+ lpips_net: alex
+ l1_weight: 1
+ p_weight: 1
+ lr: ${lr}
+ betas: ${betas}
+ eps: ${eps}
+ weight_decay: ${weight_decay}
+ milestones: ${milestones}
+ gamma: ${gamma}
+datamodule:
+ _target_: datamodule.sr_datamodule.SRDataModule
+ train_dataset:
+ _target_: dataset.sr_dataset.BlindSRDataset
+ _convert_: partial
+ hq_data_dir: ${train_hq_data_dir}
+ sr_scale: ${sr_scale}
+ n_channels: 3
+ degradation_type: ${degradation_type}
+ shuffle_prob: 0.1
+ use_sharp: false
+ hq_patch_size: 256
+ lq_patch_size: 64
+ val_dataset:
+ _target_: dataset.sr_dataset.BlindSRDataset
+ _convert_: partial
+ hq_data_dir: ${val_data_dir}
+ sr_scale: ${sr_scale}
+ n_channels: 3
+ degradation_type: ${degradation_type}
+ shuffle_prob: 0.1
+ use_sharp: false
+ hq_patch_size: 256
+ lq_patch_size: 64
+ batch_size: ${batch_size}
+ num_workers: ${num_workers}
+ num_val_workers: 8
+ iterations_per_epoch: 1000
+ use_random_sampler: false
+trainer:
+ _target_: pytorch_lightning.Trainer
+ accelerator: gpu
+ strategy:
+ _target_: pytorch_lightning.plugins.training_type.ddp.DDPPlugin
+ find_unused_parameters: true
+ gpus: ${gpus}
+ precision: 32
+ max_steps: 100000
+ check_val_every_n_epoch: 10
+ replace_sampler_ddp: false
+ benchmark: true
+model: gcir_base
+name: gcir_base
+version: v1_SRscale2
+sr_scale: 2
+gpus:
+- 0
+- 1
+train_hq_data_dir: /home/cll/datasets/swinir_train
+val_data_dir: /home/cll/datasets/swinir_test
+epochs: 300
+warmup_epochs: 20
+cooldown_epochs: 10
+batch_size: 8
+num_workers: 8
+optimizer_name: adamw
+lr: 0.0001
+betas:
+- 0.9
+- 0.999
+eps: 1.0e-08
+weight_decay: 0.05
+milestones:
+- 50000
+- 100000
+- 150000
+- 200000
+- 300000
+gamma: 0.5
+degradation_type: bsrgan
+checkpoint_path: null
+use_channels_last: false
diff --git a/KAIR/outputs/2022-08-18/14-50-56/.hydra/hydra.yaml b/KAIR/outputs/2022-08-18/14-50-56/.hydra/hydra.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..ef46fd59c06127631e4d48bde7413a82cd668bd4
--- /dev/null
+++ b/KAIR/outputs/2022-08-18/14-50-56/.hydra/hydra.yaml
@@ -0,0 +1,161 @@
+hydra:
+ run:
+ dir: outputs/${now:%Y-%m-%d}/${now:%H-%M-%S}
+ sweep:
+ dir: multirun/${now:%Y-%m-%d}/${now:%H-%M-%S}
+ subdir: ${hydra.job.num}
+ launcher:
+ _target_: hydra._internal.core_plugins.basic_launcher.BasicLauncher
+ sweeper:
+ _target_: hydra._internal.core_plugins.basic_sweeper.BasicSweeper
+ max_batch_size: null
+ params: null
+ help:
+ app_name: ${hydra.job.name}
+ header: '${hydra.help.app_name} is powered by Hydra.
+
+ '
+ footer: 'Powered by Hydra (https://hydra.cc)
+
+ Use --hydra-help to view Hydra specific help
+
+ '
+ template: '${hydra.help.header}
+
+ == Configuration groups ==
+
+ Compose your configuration from those groups (group=option)
+
+
+ $APP_CONFIG_GROUPS
+
+
+ == Config ==
+
+ Override anything in the config (foo.bar=value)
+
+
+ $CONFIG
+
+
+ ${hydra.help.footer}
+
+ '
+ hydra_help:
+ template: 'Hydra (${hydra.runtime.version})
+
+ See https://hydra.cc for more info.
+
+
+ == Flags ==
+
+ $FLAGS_HELP
+
+
+ == Configuration groups ==
+
+ Compose your configuration from those groups (For example, append hydra/job_logging=disabled
+ to command line)
+
+
+ $HYDRA_CONFIG_GROUPS
+
+
+ Use ''--cfg hydra'' to Show the Hydra config.
+
+ '
+ hydra_help: ???
+ hydra_logging:
+ version: 1
+ formatters:
+ simple:
+ format: '[%(asctime)s][HYDRA] %(message)s'
+ handlers:
+ console:
+ class: logging.StreamHandler
+ formatter: simple
+ stream: ext://sys.stdout
+ root:
+ level: INFO
+ handlers:
+ - console
+ loggers:
+ logging_example:
+ level: DEBUG
+ disable_existing_loggers: false
+ job_logging:
+ version: 1
+ formatters:
+ simple:
+ format: '[%(asctime)s][%(name)s][%(levelname)s] - %(message)s'
+ handlers:
+ console:
+ class: logging.StreamHandler
+ formatter: simple
+ stream: ext://sys.stdout
+ file:
+ class: logging.FileHandler
+ formatter: simple
+ filename: ${hydra.runtime.output_dir}/${hydra.job.name}.log
+ root:
+ level: INFO
+ handlers:
+ - console
+ - file
+ disable_existing_loggers: false
+ env: {}
+ mode: RUN
+ searchpath: []
+ callbacks: {}
+ output_subdir: .hydra
+ overrides:
+ hydra:
+ - hydra.mode=RUN
+ task:
+ - experiment=gcir/gcir_base.yaml
+ job:
+ name: train
+ chdir: null
+ override_dirname: experiment=gcir/gcir_base.yaml
+ id: ???
+ num: ???
+ config_name: config.yaml
+ env_set: {}
+ env_copy: []
+ config:
+ override_dirname:
+ kv_sep: '='
+ item_sep: ','
+ exclude_keys: []
+ runtime:
+ version: 1.2.0
+ version_base: '1.1'
+ cwd: /home/cll/dev/superresolution/KAIR
+ config_sources:
+ - path: hydra.conf
+ schema: pkg
+ provider: hydra
+ - path: configs
+ schema: pkg
+ provider: main
+ - path: ''
+ schema: structured
+ provider: schema
+ output_dir: /home/cll/dev/superresolution/KAIR/outputs/2022-08-18/14-50-56
+ choices:
+ experiment: gcir/gcir_base.yaml
+ trainer: lightning_default
+ datamodule: sr_datamodule
+ lmodule: sr_lmodule
+ callbacks: default
+ arch: gcir_base
+ hydra/env: default
+ hydra/callbacks: null
+ hydra/job_logging: default
+ hydra/hydra_logging: default
+ hydra/hydra_help: default
+ hydra/help: default
+ hydra/sweeper: basic
+ hydra/launcher: basic
+ hydra/output: default
+ verbose: false
diff --git a/KAIR/outputs/2022-08-18/14-50-56/.hydra/overrides.yaml b/KAIR/outputs/2022-08-18/14-50-56/.hydra/overrides.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..d40f8c4da6957765d87f2b2d1f9fe5ce51da16a7
--- /dev/null
+++ b/KAIR/outputs/2022-08-18/14-50-56/.hydra/overrides.yaml
@@ -0,0 +1 @@
+- experiment=gcir/gcir_base.yaml
diff --git a/KAIR/outputs/2022-08-18/14-50-56/train.log b/KAIR/outputs/2022-08-18/14-50-56/train.log
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/KAIR/requirement.txt b/KAIR/requirement.txt
new file mode 100644
index 0000000000000000000000000000000000000000..825a07be1a9002048a3f8b1b6c2c6a27a6929981
--- /dev/null
+++ b/KAIR/requirement.txt
@@ -0,0 +1,10 @@
+opencv-python
+scikit-image
+pillow
+torchvision
+hdf5storage
+ninja
+lmdb
+requests
+timm
+einops
\ No newline at end of file
diff --git a/KAIR/results/swinir_real_sr_x2/gradio_img_SwinIR.png b/KAIR/results/swinir_real_sr_x2/gradio_img_SwinIR.png
new file mode 100644
index 0000000000000000000000000000000000000000..5a2cb661fe5184430de6355ca79a5574e8acc315
Binary files /dev/null and b/KAIR/results/swinir_real_sr_x2/gradio_img_SwinIR.png differ
diff --git a/KAIR/results/swinir_real_sr_x4_large/gradio_img_SwinIR.png b/KAIR/results/swinir_real_sr_x4_large/gradio_img_SwinIR.png
new file mode 100644
index 0000000000000000000000000000000000000000..c3f3253561ce92a33eef91100835779f00fd3d01
Binary files /dev/null and b/KAIR/results/swinir_real_sr_x4_large/gradio_img_SwinIR.png differ
diff --git a/KAIR/retinaface/README.md b/KAIR/retinaface/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..263dd1f070a33c2e0b720c660e2e1575e13beb89
--- /dev/null
+++ b/KAIR/retinaface/README.md
@@ -0,0 +1 @@
+This code is useful when you use `main_test_face_enhancement.py`.
diff --git a/KAIR/retinaface/data_faces/FDDB/img_list.txt b/KAIR/retinaface/data_faces/FDDB/img_list.txt
new file mode 100644
index 0000000000000000000000000000000000000000..5cf3d3199ca5c9c5ef4a904f1b9c89b821a7978a
--- /dev/null
+++ b/KAIR/retinaface/data_faces/FDDB/img_list.txt
@@ -0,0 +1,2845 @@
+2002/08/11/big/img_591
+2002/08/26/big/img_265
+2002/07/19/big/img_423
+2002/08/24/big/img_490
+2002/08/31/big/img_17676
+2002/07/31/big/img_228
+2002/07/24/big/img_402
+2002/08/04/big/img_769
+2002/07/19/big/img_581
+2002/08/13/big/img_723
+2002/08/12/big/img_821
+2003/01/17/big/img_610
+2002/08/13/big/img_1116
+2002/08/28/big/img_19238
+2002/08/21/big/img_660
+2002/08/14/big/img_607
+2002/08/05/big/img_3708
+2002/08/19/big/img_511
+2002/08/07/big/img_1316
+2002/07/25/big/img_1047
+2002/07/23/big/img_474
+2002/07/27/big/img_970
+2002/09/02/big/img_15752
+2002/09/01/big/img_16378
+2002/09/01/big/img_16189
+2002/08/26/big/img_276
+2002/07/24/big/img_518
+2002/08/14/big/img_1027
+2002/08/24/big/img_733
+2002/08/15/big/img_249
+2003/01/15/big/img_1371
+2002/08/07/big/img_1348
+2003/01/01/big/img_331
+2002/08/23/big/img_536
+2002/07/30/big/img_224
+2002/08/10/big/img_763
+2002/08/21/big/img_293
+2002/08/15/big/img_1211
+2002/08/15/big/img_1194
+2003/01/15/big/img_390
+2002/08/06/big/img_2893
+2002/08/17/big/img_691
+2002/08/07/big/img_1695
+2002/08/16/big/img_829
+2002/07/25/big/img_201
+2002/08/23/big/img_36
+2003/01/15/big/img_763
+2003/01/15/big/img_637
+2002/08/22/big/img_592
+2002/07/25/big/img_817
+2003/01/15/big/img_1219
+2002/08/05/big/img_3508
+2002/08/15/big/img_1108
+2002/07/19/big/img_488
+2003/01/16/big/img_704
+2003/01/13/big/img_1087
+2002/08/10/big/img_670
+2002/07/24/big/img_104
+2002/08/27/big/img_19823
+2002/09/01/big/img_16229
+2003/01/13/big/img_846
+2002/08/04/big/img_412
+2002/07/22/big/img_554
+2002/08/12/big/img_331
+2002/08/02/big/img_533
+2002/08/12/big/img_259
+2002/08/18/big/img_328
+2003/01/14/big/img_630
+2002/08/05/big/img_3541
+2002/08/06/big/img_2390
+2002/08/20/big/img_150
+2002/08/02/big/img_1231
+2002/08/16/big/img_710
+2002/08/19/big/img_591
+2002/07/22/big/img_725
+2002/07/24/big/img_820
+2003/01/13/big/img_568
+2002/08/22/big/img_853
+2002/08/09/big/img_648
+2002/08/23/big/img_528
+2003/01/14/big/img_888
+2002/08/30/big/img_18201
+2002/08/13/big/img_965
+2003/01/14/big/img_660
+2002/07/19/big/img_517
+2003/01/14/big/img_406
+2002/08/30/big/img_18433
+2002/08/07/big/img_1630
+2002/08/06/big/img_2717
+2002/08/21/big/img_470
+2002/07/23/big/img_633
+2002/08/20/big/img_915
+2002/08/16/big/img_893
+2002/07/29/big/img_644
+2002/08/15/big/img_529
+2002/08/16/big/img_668
+2002/08/07/big/img_1871
+2002/07/25/big/img_192
+2002/07/31/big/img_961
+2002/08/19/big/img_738
+2002/07/31/big/img_382
+2002/08/19/big/img_298
+2003/01/17/big/img_608
+2002/08/21/big/img_514
+2002/07/23/big/img_183
+2003/01/17/big/img_536
+2002/07/24/big/img_478
+2002/08/06/big/img_2997
+2002/09/02/big/img_15380
+2002/08/07/big/img_1153
+2002/07/31/big/img_967
+2002/07/31/big/img_711
+2002/08/26/big/img_664
+2003/01/01/big/img_326
+2002/08/24/big/img_775
+2002/08/08/big/img_961
+2002/08/16/big/img_77
+2002/08/12/big/img_296
+2002/07/22/big/img_905
+2003/01/13/big/img_284
+2002/08/13/big/img_887
+2002/08/24/big/img_849
+2002/07/30/big/img_345
+2002/08/18/big/img_419
+2002/08/01/big/img_1347
+2002/08/05/big/img_3670
+2002/07/21/big/img_479
+2002/08/08/big/img_913
+2002/09/02/big/img_15828
+2002/08/30/big/img_18194
+2002/08/08/big/img_471
+2002/08/22/big/img_734
+2002/08/09/big/img_586
+2002/08/09/big/img_454
+2002/07/29/big/img_47
+2002/07/19/big/img_381
+2002/07/29/big/img_733
+2002/08/20/big/img_327
+2002/07/21/big/img_96
+2002/08/06/big/img_2680
+2002/07/25/big/img_919
+2002/07/21/big/img_158
+2002/07/22/big/img_801
+2002/07/22/big/img_567
+2002/07/24/big/img_804
+2002/07/24/big/img_690
+2003/01/15/big/img_576
+2002/08/14/big/img_335
+2003/01/13/big/img_390
+2002/08/11/big/img_258
+2002/07/23/big/img_917
+2002/08/15/big/img_525
+2003/01/15/big/img_505
+2002/07/30/big/img_886
+2003/01/16/big/img_640
+2003/01/14/big/img_642
+2003/01/17/big/img_844
+2002/08/04/big/img_571
+2002/08/29/big/img_18702
+2003/01/15/big/img_240
+2002/07/29/big/img_553
+2002/08/10/big/img_354
+2002/08/18/big/img_17
+2003/01/15/big/img_782
+2002/07/27/big/img_382
+2002/08/14/big/img_970
+2003/01/16/big/img_70
+2003/01/16/big/img_625
+2002/08/18/big/img_341
+2002/08/26/big/img_188
+2002/08/09/big/img_405
+2002/08/02/big/img_37
+2002/08/13/big/img_748
+2002/07/22/big/img_399
+2002/07/25/big/img_844
+2002/08/12/big/img_340
+2003/01/13/big/img_815
+2002/08/26/big/img_5
+2002/08/10/big/img_158
+2002/08/18/big/img_95
+2002/07/29/big/img_1297
+2003/01/13/big/img_508
+2002/09/01/big/img_16680
+2003/01/16/big/img_338
+2002/08/13/big/img_517
+2002/07/22/big/img_626
+2002/08/06/big/img_3024
+2002/07/26/big/img_499
+2003/01/13/big/img_387
+2002/08/31/big/img_18025
+2002/08/13/big/img_520
+2003/01/16/big/img_576
+2002/07/26/big/img_121
+2002/08/25/big/img_703
+2002/08/26/big/img_615
+2002/08/17/big/img_434
+2002/08/02/big/img_677
+2002/08/18/big/img_276
+2002/08/05/big/img_3672
+2002/07/26/big/img_700
+2002/07/31/big/img_277
+2003/01/14/big/img_220
+2002/08/23/big/img_232
+2002/08/31/big/img_17422
+2002/07/22/big/img_508
+2002/08/13/big/img_681
+2003/01/15/big/img_638
+2002/08/30/big/img_18408
+2003/01/14/big/img_533
+2003/01/17/big/img_12
+2002/08/28/big/img_19388
+2002/08/08/big/img_133
+2002/07/26/big/img_885
+2002/08/19/big/img_387
+2002/08/27/big/img_19976
+2002/08/26/big/img_118
+2002/08/28/big/img_19146
+2002/08/05/big/img_3259
+2002/08/15/big/img_536
+2002/07/22/big/img_279
+2002/07/22/big/img_9
+2002/08/13/big/img_301
+2002/08/15/big/img_974
+2002/08/06/big/img_2355
+2002/08/01/big/img_1526
+2002/08/03/big/img_417
+2002/08/04/big/img_407
+2002/08/15/big/img_1029
+2002/07/29/big/img_700
+2002/08/01/big/img_1463
+2002/08/31/big/img_17365
+2002/07/28/big/img_223
+2002/07/19/big/img_827
+2002/07/27/big/img_531
+2002/07/19/big/img_845
+2002/08/20/big/img_382
+2002/07/31/big/img_268
+2002/08/27/big/img_19705
+2002/08/02/big/img_830
+2002/08/23/big/img_250
+2002/07/20/big/img_777
+2002/08/21/big/img_879
+2002/08/26/big/img_20146
+2002/08/23/big/img_789
+2002/08/06/big/img_2683
+2002/08/25/big/img_576
+2002/08/09/big/img_498
+2002/08/08/big/img_384
+2002/08/26/big/img_592
+2002/07/29/big/img_1470
+2002/08/21/big/img_452
+2002/08/30/big/img_18395
+2002/08/15/big/img_215
+2002/07/21/big/img_643
+2002/07/22/big/img_209
+2003/01/17/big/img_346
+2002/08/25/big/img_658
+2002/08/21/big/img_221
+2002/08/14/big/img_60
+2003/01/17/big/img_885
+2003/01/16/big/img_482
+2002/08/19/big/img_593
+2002/08/08/big/img_233
+2002/07/30/big/img_458
+2002/07/23/big/img_384
+2003/01/15/big/img_670
+2003/01/15/big/img_267
+2002/08/26/big/img_540
+2002/07/29/big/img_552
+2002/07/30/big/img_997
+2003/01/17/big/img_377
+2002/08/21/big/img_265
+2002/08/09/big/img_561
+2002/07/31/big/img_945
+2002/09/02/big/img_15252
+2002/08/11/big/img_276
+2002/07/22/big/img_491
+2002/07/26/big/img_517
+2002/08/14/big/img_726
+2002/08/08/big/img_46
+2002/08/28/big/img_19458
+2002/08/06/big/img_2935
+2002/07/29/big/img_1392
+2002/08/13/big/img_776
+2002/08/24/big/img_616
+2002/08/14/big/img_1065
+2002/07/29/big/img_889
+2002/08/18/big/img_188
+2002/08/07/big/img_1453
+2002/08/02/big/img_760
+2002/07/28/big/img_416
+2002/08/07/big/img_1393
+2002/08/26/big/img_292
+2002/08/26/big/img_301
+2003/01/13/big/img_195
+2002/07/26/big/img_532
+2002/08/20/big/img_550
+2002/08/05/big/img_3658
+2002/08/26/big/img_738
+2002/09/02/big/img_15750
+2003/01/17/big/img_451
+2002/07/23/big/img_339
+2002/08/16/big/img_637
+2002/08/14/big/img_748
+2002/08/06/big/img_2739
+2002/07/25/big/img_482
+2002/08/19/big/img_191
+2002/08/26/big/img_537
+2003/01/15/big/img_716
+2003/01/15/big/img_767
+2002/08/02/big/img_452
+2002/08/08/big/img_1011
+2002/08/10/big/img_144
+2003/01/14/big/img_122
+2002/07/24/big/img_586
+2002/07/24/big/img_762
+2002/08/20/big/img_369
+2002/07/30/big/img_146
+2002/08/23/big/img_396
+2003/01/15/big/img_200
+2002/08/15/big/img_1183
+2003/01/14/big/img_698
+2002/08/09/big/img_792
+2002/08/06/big/img_2347
+2002/07/31/big/img_911
+2002/08/26/big/img_722
+2002/08/23/big/img_621
+2002/08/05/big/img_3790
+2003/01/13/big/img_633
+2002/08/09/big/img_224
+2002/07/24/big/img_454
+2002/07/21/big/img_202
+2002/08/02/big/img_630
+2002/08/30/big/img_18315
+2002/07/19/big/img_491
+2002/09/01/big/img_16456
+2002/08/09/big/img_242
+2002/07/25/big/img_595
+2002/07/22/big/img_522
+2002/08/01/big/img_1593
+2002/07/29/big/img_336
+2002/08/15/big/img_448
+2002/08/28/big/img_19281
+2002/07/29/big/img_342
+2002/08/12/big/img_78
+2003/01/14/big/img_525
+2002/07/28/big/img_147
+2002/08/11/big/img_353
+2002/08/22/big/img_513
+2002/08/04/big/img_721
+2002/08/17/big/img_247
+2003/01/14/big/img_891
+2002/08/20/big/img_853
+2002/07/19/big/img_414
+2002/08/01/big/img_1530
+2003/01/14/big/img_924
+2002/08/22/big/img_468
+2002/08/18/big/img_354
+2002/08/30/big/img_18193
+2002/08/23/big/img_492
+2002/08/15/big/img_871
+2002/08/12/big/img_494
+2002/08/06/big/img_2470
+2002/07/23/big/img_923
+2002/08/26/big/img_155
+2002/08/08/big/img_669
+2002/07/23/big/img_404
+2002/08/28/big/img_19421
+2002/08/29/big/img_18993
+2002/08/25/big/img_416
+2003/01/17/big/img_434
+2002/07/29/big/img_1370
+2002/07/28/big/img_483
+2002/08/11/big/img_50
+2002/08/10/big/img_404
+2002/09/02/big/img_15057
+2003/01/14/big/img_911
+2002/09/01/big/img_16697
+2003/01/16/big/img_665
+2002/09/01/big/img_16708
+2002/08/22/big/img_612
+2002/08/28/big/img_19471
+2002/08/02/big/img_198
+2003/01/16/big/img_527
+2002/08/22/big/img_209
+2002/08/30/big/img_18205
+2003/01/14/big/img_114
+2003/01/14/big/img_1028
+2003/01/16/big/img_894
+2003/01/14/big/img_837
+2002/07/30/big/img_9
+2002/08/06/big/img_2821
+2002/08/04/big/img_85
+2003/01/13/big/img_884
+2002/07/22/big/img_570
+2002/08/07/big/img_1773
+2002/07/26/big/img_208
+2003/01/17/big/img_946
+2002/07/19/big/img_930
+2003/01/01/big/img_698
+2003/01/17/big/img_612
+2002/07/19/big/img_372
+2002/07/30/big/img_721
+2003/01/14/big/img_649
+2002/08/19/big/img_4
+2002/07/25/big/img_1024
+2003/01/15/big/img_601
+2002/08/30/big/img_18470
+2002/07/22/big/img_29
+2002/08/07/big/img_1686
+2002/07/20/big/img_294
+2002/08/14/big/img_800
+2002/08/19/big/img_353
+2002/08/19/big/img_350
+2002/08/05/big/img_3392
+2002/08/09/big/img_622
+2003/01/15/big/img_236
+2002/08/11/big/img_643
+2002/08/05/big/img_3458
+2002/08/12/big/img_413
+2002/08/22/big/img_415
+2002/08/13/big/img_635
+2002/08/07/big/img_1198
+2002/08/04/big/img_873
+2002/08/12/big/img_407
+2003/01/15/big/img_346
+2002/08/02/big/img_275
+2002/08/17/big/img_997
+2002/08/21/big/img_958
+2002/08/20/big/img_579
+2002/07/29/big/img_142
+2003/01/14/big/img_1115
+2002/08/16/big/img_365
+2002/07/29/big/img_1414
+2002/08/17/big/img_489
+2002/08/13/big/img_1010
+2002/07/31/big/img_276
+2002/07/25/big/img_1000
+2002/08/23/big/img_524
+2002/08/28/big/img_19147
+2003/01/13/big/img_433
+2002/08/20/big/img_205
+2003/01/01/big/img_458
+2002/07/29/big/img_1449
+2003/01/16/big/img_696
+2002/08/28/big/img_19296
+2002/08/29/big/img_18688
+2002/08/21/big/img_767
+2002/08/20/big/img_532
+2002/08/26/big/img_187
+2002/07/26/big/img_183
+2002/07/27/big/img_890
+2003/01/13/big/img_576
+2002/07/30/big/img_15
+2002/07/31/big/img_889
+2002/08/31/big/img_17759
+2003/01/14/big/img_1114
+2002/07/19/big/img_445
+2002/08/03/big/img_593
+2002/07/24/big/img_750
+2002/07/30/big/img_133
+2002/08/25/big/img_671
+2002/07/20/big/img_351
+2002/08/31/big/img_17276
+2002/08/05/big/img_3231
+2002/09/02/big/img_15882
+2002/08/14/big/img_115
+2002/08/02/big/img_1148
+2002/07/25/big/img_936
+2002/07/31/big/img_639
+2002/08/04/big/img_427
+2002/08/22/big/img_843
+2003/01/17/big/img_17
+2003/01/13/big/img_690
+2002/08/13/big/img_472
+2002/08/09/big/img_425
+2002/08/05/big/img_3450
+2003/01/17/big/img_439
+2002/08/13/big/img_539
+2002/07/28/big/img_35
+2002/08/16/big/img_241
+2002/08/06/big/img_2898
+2003/01/16/big/img_429
+2002/08/05/big/img_3817
+2002/08/27/big/img_19919
+2002/07/19/big/img_422
+2002/08/15/big/img_560
+2002/07/23/big/img_750
+2002/07/30/big/img_353
+2002/08/05/big/img_43
+2002/08/23/big/img_305
+2002/08/01/big/img_2137
+2002/08/30/big/img_18097
+2002/08/01/big/img_1389
+2002/08/02/big/img_308
+2003/01/14/big/img_652
+2002/08/01/big/img_1798
+2003/01/14/big/img_732
+2003/01/16/big/img_294
+2002/08/26/big/img_213
+2002/07/24/big/img_842
+2003/01/13/big/img_630
+2003/01/13/big/img_634
+2002/08/06/big/img_2285
+2002/08/01/big/img_2162
+2002/08/30/big/img_18134
+2002/08/02/big/img_1045
+2002/08/01/big/img_2143
+2002/07/25/big/img_135
+2002/07/20/big/img_645
+2002/08/05/big/img_3666
+2002/08/14/big/img_523
+2002/08/04/big/img_425
+2003/01/14/big/img_137
+2003/01/01/big/img_176
+2002/08/15/big/img_505
+2002/08/24/big/img_386
+2002/08/05/big/img_3187
+2002/08/15/big/img_419
+2003/01/13/big/img_520
+2002/08/04/big/img_444
+2002/08/26/big/img_483
+2002/08/05/big/img_3449
+2002/08/30/big/img_18409
+2002/08/28/big/img_19455
+2002/08/27/big/img_20090
+2002/07/23/big/img_625
+2002/08/24/big/img_205
+2002/08/08/big/img_938
+2003/01/13/big/img_527
+2002/08/07/big/img_1712
+2002/07/24/big/img_801
+2002/08/09/big/img_579
+2003/01/14/big/img_41
+2003/01/15/big/img_1130
+2002/07/21/big/img_672
+2002/08/07/big/img_1590
+2003/01/01/big/img_532
+2002/08/02/big/img_529
+2002/08/05/big/img_3591
+2002/08/23/big/img_5
+2003/01/14/big/img_882
+2002/08/28/big/img_19234
+2002/07/24/big/img_398
+2003/01/14/big/img_592
+2002/08/22/big/img_548
+2002/08/12/big/img_761
+2003/01/16/big/img_497
+2002/08/18/big/img_133
+2002/08/08/big/img_874
+2002/07/19/big/img_247
+2002/08/15/big/img_170
+2002/08/27/big/img_19679
+2002/08/20/big/img_246
+2002/08/24/big/img_358
+2002/07/29/big/img_599
+2002/08/01/big/img_1555
+2002/07/30/big/img_491
+2002/07/30/big/img_371
+2003/01/16/big/img_682
+2002/07/25/big/img_619
+2003/01/15/big/img_587
+2002/08/02/big/img_1212
+2002/08/01/big/img_2152
+2002/07/25/big/img_668
+2003/01/16/big/img_574
+2002/08/28/big/img_19464
+2002/08/11/big/img_536
+2002/07/24/big/img_201
+2002/08/05/big/img_3488
+2002/07/25/big/img_887
+2002/07/22/big/img_789
+2002/07/30/big/img_432
+2002/08/16/big/img_166
+2002/09/01/big/img_16333
+2002/07/26/big/img_1010
+2002/07/21/big/img_793
+2002/07/22/big/img_720
+2002/07/31/big/img_337
+2002/07/27/big/img_185
+2002/08/23/big/img_440
+2002/07/31/big/img_801
+2002/07/25/big/img_478
+2003/01/14/big/img_171
+2002/08/07/big/img_1054
+2002/09/02/big/img_15659
+2002/07/29/big/img_1348
+2002/08/09/big/img_337
+2002/08/26/big/img_684
+2002/07/31/big/img_537
+2002/08/15/big/img_808
+2003/01/13/big/img_740
+2002/08/07/big/img_1667
+2002/08/03/big/img_404
+2002/08/06/big/img_2520
+2002/07/19/big/img_230
+2002/07/19/big/img_356
+2003/01/16/big/img_627
+2002/08/04/big/img_474
+2002/07/29/big/img_833
+2002/07/25/big/img_176
+2002/08/01/big/img_1684
+2002/08/21/big/img_643
+2002/08/27/big/img_19673
+2002/08/02/big/img_838
+2002/08/06/big/img_2378
+2003/01/15/big/img_48
+2002/07/30/big/img_470
+2002/08/15/big/img_963
+2002/08/24/big/img_444
+2002/08/16/big/img_662
+2002/08/15/big/img_1209
+2002/07/24/big/img_25
+2002/08/06/big/img_2740
+2002/07/29/big/img_996
+2002/08/31/big/img_18074
+2002/08/04/big/img_343
+2003/01/17/big/img_509
+2003/01/13/big/img_726
+2002/08/07/big/img_1466
+2002/07/26/big/img_307
+2002/08/10/big/img_598
+2002/08/13/big/img_890
+2002/08/14/big/img_997
+2002/07/19/big/img_392
+2002/08/02/big/img_475
+2002/08/29/big/img_19038
+2002/07/29/big/img_538
+2002/07/29/big/img_502
+2002/08/02/big/img_364
+2002/08/31/big/img_17353
+2002/08/08/big/img_539
+2002/08/01/big/img_1449
+2002/07/22/big/img_363
+2002/08/02/big/img_90
+2002/09/01/big/img_16867
+2002/08/05/big/img_3371
+2002/07/30/big/img_342
+2002/08/07/big/img_1363
+2002/08/22/big/img_790
+2003/01/15/big/img_404
+2002/08/05/big/img_3447
+2002/09/01/big/img_16167
+2003/01/13/big/img_840
+2002/08/22/big/img_1001
+2002/08/09/big/img_431
+2002/07/27/big/img_618
+2002/07/31/big/img_741
+2002/07/30/big/img_964
+2002/07/25/big/img_86
+2002/07/29/big/img_275
+2002/08/21/big/img_921
+2002/07/26/big/img_892
+2002/08/21/big/img_663
+2003/01/13/big/img_567
+2003/01/14/big/img_719
+2002/07/28/big/img_251
+2003/01/15/big/img_1123
+2002/07/29/big/img_260
+2002/08/24/big/img_337
+2002/08/01/big/img_1914
+2002/08/13/big/img_373
+2003/01/15/big/img_589
+2002/08/13/big/img_906
+2002/07/26/big/img_270
+2002/08/26/big/img_313
+2002/08/25/big/img_694
+2003/01/01/big/img_327
+2002/07/23/big/img_261
+2002/08/26/big/img_642
+2002/07/29/big/img_918
+2002/07/23/big/img_455
+2002/07/24/big/img_612
+2002/07/23/big/img_534
+2002/07/19/big/img_534
+2002/07/19/big/img_726
+2002/08/01/big/img_2146
+2002/08/02/big/img_543
+2003/01/16/big/img_777
+2002/07/30/big/img_484
+2002/08/13/big/img_1161
+2002/07/21/big/img_390
+2002/08/06/big/img_2288
+2002/08/21/big/img_677
+2002/08/13/big/img_747
+2002/08/15/big/img_1248
+2002/07/31/big/img_416
+2002/09/02/big/img_15259
+2002/08/16/big/img_781
+2002/08/24/big/img_754
+2002/07/24/big/img_803
+2002/08/20/big/img_609
+2002/08/28/big/img_19571
+2002/09/01/big/img_16140
+2002/08/26/big/img_769
+2002/07/20/big/img_588
+2002/08/02/big/img_898
+2002/07/21/big/img_466
+2002/08/14/big/img_1046
+2002/07/25/big/img_212
+2002/08/26/big/img_353
+2002/08/19/big/img_810
+2002/08/31/big/img_17824
+2002/08/12/big/img_631
+2002/07/19/big/img_828
+2002/07/24/big/img_130
+2002/08/25/big/img_580
+2002/07/31/big/img_699
+2002/07/23/big/img_808
+2002/07/31/big/img_377
+2003/01/16/big/img_570
+2002/09/01/big/img_16254
+2002/07/21/big/img_471
+2002/08/01/big/img_1548
+2002/08/18/big/img_252
+2002/08/19/big/img_576
+2002/08/20/big/img_464
+2002/07/27/big/img_735
+2002/08/21/big/img_589
+2003/01/15/big/img_1192
+2002/08/09/big/img_302
+2002/07/31/big/img_594
+2002/08/23/big/img_19
+2002/08/29/big/img_18819
+2002/08/19/big/img_293
+2002/07/30/big/img_331
+2002/08/23/big/img_607
+2002/07/30/big/img_363
+2002/08/16/big/img_766
+2003/01/13/big/img_481
+2002/08/06/big/img_2515
+2002/09/02/big/img_15913
+2002/09/02/big/img_15827
+2002/09/02/big/img_15053
+2002/08/07/big/img_1576
+2002/07/23/big/img_268
+2002/08/21/big/img_152
+2003/01/15/big/img_578
+2002/07/21/big/img_589
+2002/07/20/big/img_548
+2002/08/27/big/img_19693
+2002/08/31/big/img_17252
+2002/07/31/big/img_138
+2002/07/23/big/img_372
+2002/08/16/big/img_695
+2002/07/27/big/img_287
+2002/08/15/big/img_315
+2002/08/10/big/img_361
+2002/07/29/big/img_899
+2002/08/13/big/img_771
+2002/08/21/big/img_92
+2003/01/15/big/img_425
+2003/01/16/big/img_450
+2002/09/01/big/img_16942
+2002/08/02/big/img_51
+2002/09/02/big/img_15379
+2002/08/24/big/img_147
+2002/08/30/big/img_18122
+2002/07/26/big/img_950
+2002/08/07/big/img_1400
+2002/08/17/big/img_468
+2002/08/15/big/img_470
+2002/07/30/big/img_318
+2002/07/22/big/img_644
+2002/08/27/big/img_19732
+2002/07/23/big/img_601
+2002/08/26/big/img_398
+2002/08/21/big/img_428
+2002/08/06/big/img_2119
+2002/08/29/big/img_19103
+2003/01/14/big/img_933
+2002/08/11/big/img_674
+2002/08/28/big/img_19420
+2002/08/03/big/img_418
+2002/08/17/big/img_312
+2002/07/25/big/img_1044
+2003/01/17/big/img_671
+2002/08/30/big/img_18297
+2002/07/25/big/img_755
+2002/07/23/big/img_471
+2002/08/21/big/img_39
+2002/07/26/big/img_699
+2003/01/14/big/img_33
+2002/07/31/big/img_411
+2002/08/16/big/img_645
+2003/01/17/big/img_116
+2002/09/02/big/img_15903
+2002/08/20/big/img_120
+2002/08/22/big/img_176
+2002/07/29/big/img_1316
+2002/08/27/big/img_19914
+2002/07/22/big/img_719
+2002/08/28/big/img_19239
+2003/01/13/big/img_385
+2002/08/08/big/img_525
+2002/07/19/big/img_782
+2002/08/13/big/img_843
+2002/07/30/big/img_107
+2002/08/11/big/img_752
+2002/07/29/big/img_383
+2002/08/26/big/img_249
+2002/08/29/big/img_18860
+2002/07/30/big/img_70
+2002/07/26/big/img_194
+2002/08/15/big/img_530
+2002/08/08/big/img_816
+2002/07/31/big/img_286
+2003/01/13/big/img_294
+2002/07/31/big/img_251
+2002/07/24/big/img_13
+2002/08/31/big/img_17938
+2002/07/22/big/img_642
+2003/01/14/big/img_728
+2002/08/18/big/img_47
+2002/08/22/big/img_306
+2002/08/20/big/img_348
+2002/08/15/big/img_764
+2002/08/08/big/img_163
+2002/07/23/big/img_531
+2002/07/23/big/img_467
+2003/01/16/big/img_743
+2003/01/13/big/img_535
+2002/08/02/big/img_523
+2002/08/22/big/img_120
+2002/08/11/big/img_496
+2002/08/29/big/img_19075
+2002/08/08/big/img_465
+2002/08/09/big/img_790
+2002/08/19/big/img_588
+2002/08/23/big/img_407
+2003/01/17/big/img_435
+2002/08/24/big/img_398
+2002/08/27/big/img_19899
+2003/01/15/big/img_335
+2002/08/13/big/img_493
+2002/09/02/big/img_15460
+2002/07/31/big/img_470
+2002/08/05/big/img_3550
+2002/07/28/big/img_123
+2002/08/01/big/img_1498
+2002/08/04/big/img_504
+2003/01/17/big/img_427
+2002/08/27/big/img_19708
+2002/07/27/big/img_861
+2002/07/25/big/img_685
+2002/07/31/big/img_207
+2003/01/14/big/img_745
+2002/08/31/big/img_17756
+2002/08/24/big/img_288
+2002/08/18/big/img_181
+2002/08/10/big/img_520
+2002/08/25/big/img_705
+2002/08/23/big/img_226
+2002/08/04/big/img_727
+2002/07/24/big/img_625
+2002/08/28/big/img_19157
+2002/08/23/big/img_586
+2002/07/31/big/img_232
+2003/01/13/big/img_240
+2003/01/14/big/img_321
+2003/01/15/big/img_533
+2002/07/23/big/img_480
+2002/07/24/big/img_371
+2002/08/21/big/img_702
+2002/08/31/big/img_17075
+2002/09/02/big/img_15278
+2002/07/29/big/img_246
+2003/01/15/big/img_829
+2003/01/15/big/img_1213
+2003/01/16/big/img_441
+2002/08/14/big/img_921
+2002/07/23/big/img_425
+2002/08/15/big/img_296
+2002/07/19/big/img_135
+2002/07/26/big/img_402
+2003/01/17/big/img_88
+2002/08/20/big/img_872
+2002/08/13/big/img_1110
+2003/01/16/big/img_1040
+2002/07/23/big/img_9
+2002/08/13/big/img_700
+2002/08/16/big/img_371
+2002/08/27/big/img_19966
+2003/01/17/big/img_391
+2002/08/18/big/img_426
+2002/08/01/big/img_1618
+2002/07/21/big/img_754
+2003/01/14/big/img_1101
+2003/01/16/big/img_1022
+2002/07/22/big/img_275
+2002/08/24/big/img_86
+2002/08/17/big/img_582
+2003/01/15/big/img_765
+2003/01/17/big/img_449
+2002/07/28/big/img_265
+2003/01/13/big/img_552
+2002/07/28/big/img_115
+2003/01/16/big/img_56
+2002/08/02/big/img_1232
+2003/01/17/big/img_925
+2002/07/22/big/img_445
+2002/07/25/big/img_957
+2002/07/20/big/img_589
+2002/08/31/big/img_17107
+2002/07/29/big/img_483
+2002/08/14/big/img_1063
+2002/08/07/big/img_1545
+2002/08/14/big/img_680
+2002/09/01/big/img_16694
+2002/08/14/big/img_257
+2002/08/11/big/img_726
+2002/07/26/big/img_681
+2002/07/25/big/img_481
+2003/01/14/big/img_737
+2002/08/28/big/img_19480
+2003/01/16/big/img_362
+2002/08/27/big/img_19865
+2003/01/01/big/img_547
+2002/09/02/big/img_15074
+2002/08/01/big/img_1453
+2002/08/22/big/img_594
+2002/08/28/big/img_19263
+2002/08/13/big/img_478
+2002/07/29/big/img_1358
+2003/01/14/big/img_1022
+2002/08/16/big/img_450
+2002/08/02/big/img_159
+2002/07/26/big/img_781
+2003/01/13/big/img_601
+2002/08/20/big/img_407
+2002/08/15/big/img_468
+2002/08/31/big/img_17902
+2002/08/16/big/img_81
+2002/07/25/big/img_987
+2002/07/25/big/img_500
+2002/08/02/big/img_31
+2002/08/18/big/img_538
+2002/08/08/big/img_54
+2002/07/23/big/img_686
+2002/07/24/big/img_836
+2003/01/17/big/img_734
+2002/08/16/big/img_1055
+2003/01/16/big/img_521
+2002/07/25/big/img_612
+2002/08/22/big/img_778
+2002/08/03/big/img_251
+2002/08/12/big/img_436
+2002/08/23/big/img_705
+2002/07/28/big/img_243
+2002/07/25/big/img_1029
+2002/08/20/big/img_287
+2002/08/29/big/img_18739
+2002/08/05/big/img_3272
+2002/07/27/big/img_214
+2003/01/14/big/img_5
+2002/08/01/big/img_1380
+2002/08/29/big/img_19097
+2002/07/30/big/img_486
+2002/08/29/big/img_18707
+2002/08/10/big/img_559
+2002/08/15/big/img_365
+2002/08/09/big/img_525
+2002/08/10/big/img_689
+2002/07/25/big/img_502
+2002/08/03/big/img_667
+2002/08/10/big/img_855
+2002/08/10/big/img_706
+2002/08/18/big/img_603
+2003/01/16/big/img_1055
+2002/08/31/big/img_17890
+2002/08/15/big/img_761
+2003/01/15/big/img_489
+2002/08/26/big/img_351
+2002/08/01/big/img_1772
+2002/08/31/big/img_17729
+2002/07/25/big/img_609
+2003/01/13/big/img_539
+2002/07/27/big/img_686
+2002/07/31/big/img_311
+2002/08/22/big/img_799
+2003/01/16/big/img_936
+2002/08/31/big/img_17813
+2002/08/04/big/img_862
+2002/08/09/big/img_332
+2002/07/20/big/img_148
+2002/08/12/big/img_426
+2002/07/24/big/img_69
+2002/07/27/big/img_685
+2002/08/02/big/img_480
+2002/08/26/big/img_154
+2002/07/24/big/img_598
+2002/08/01/big/img_1881
+2002/08/20/big/img_667
+2003/01/14/big/img_495
+2002/07/21/big/img_744
+2002/07/30/big/img_150
+2002/07/23/big/img_924
+2002/08/08/big/img_272
+2002/07/23/big/img_310
+2002/07/25/big/img_1011
+2002/09/02/big/img_15725
+2002/07/19/big/img_814
+2002/08/20/big/img_936
+2002/07/25/big/img_85
+2002/08/24/big/img_662
+2002/08/09/big/img_495
+2003/01/15/big/img_196
+2002/08/16/big/img_707
+2002/08/28/big/img_19370
+2002/08/06/big/img_2366
+2002/08/06/big/img_3012
+2002/08/01/big/img_1452
+2002/07/31/big/img_742
+2002/07/27/big/img_914
+2003/01/13/big/img_290
+2002/07/31/big/img_288
+2002/08/02/big/img_171
+2002/08/22/big/img_191
+2002/07/27/big/img_1066
+2002/08/12/big/img_383
+2003/01/17/big/img_1018
+2002/08/01/big/img_1785
+2002/08/11/big/img_390
+2002/08/27/big/img_20037
+2002/08/12/big/img_38
+2003/01/15/big/img_103
+2002/08/26/big/img_31
+2002/08/18/big/img_660
+2002/07/22/big/img_694
+2002/08/15/big/img_24
+2002/07/27/big/img_1077
+2002/08/01/big/img_1943
+2002/07/22/big/img_292
+2002/09/01/big/img_16857
+2002/07/22/big/img_892
+2003/01/14/big/img_46
+2002/08/09/big/img_469
+2002/08/09/big/img_414
+2003/01/16/big/img_40
+2002/08/28/big/img_19231
+2002/07/27/big/img_978
+2002/07/23/big/img_475
+2002/07/25/big/img_92
+2002/08/09/big/img_799
+2002/07/25/big/img_491
+2002/08/03/big/img_654
+2003/01/15/big/img_687
+2002/08/11/big/img_478
+2002/08/07/big/img_1664
+2002/08/20/big/img_362
+2002/08/01/big/img_1298
+2003/01/13/big/img_500
+2002/08/06/big/img_2896
+2002/08/30/big/img_18529
+2002/08/16/big/img_1020
+2002/07/29/big/img_892
+2002/08/29/big/img_18726
+2002/07/21/big/img_453
+2002/08/17/big/img_437
+2002/07/19/big/img_665
+2002/07/22/big/img_440
+2002/07/19/big/img_582
+2002/07/21/big/img_233
+2003/01/01/big/img_82
+2002/07/25/big/img_341
+2002/07/29/big/img_864
+2002/08/02/big/img_276
+2002/08/29/big/img_18654
+2002/07/27/big/img_1024
+2002/08/19/big/img_373
+2003/01/15/big/img_241
+2002/07/25/big/img_84
+2002/08/13/big/img_834
+2002/08/10/big/img_511
+2002/08/01/big/img_1627
+2002/08/08/big/img_607
+2002/08/06/big/img_2083
+2002/08/01/big/img_1486
+2002/08/08/big/img_700
+2002/08/01/big/img_1954
+2002/08/21/big/img_54
+2002/07/30/big/img_847
+2002/08/28/big/img_19169
+2002/07/21/big/img_549
+2002/08/03/big/img_693
+2002/07/31/big/img_1002
+2003/01/14/big/img_1035
+2003/01/16/big/img_622
+2002/07/30/big/img_1201
+2002/08/10/big/img_444
+2002/07/31/big/img_374
+2002/08/21/big/img_301
+2002/08/13/big/img_1095
+2003/01/13/big/img_288
+2002/07/25/big/img_232
+2003/01/13/big/img_967
+2002/08/26/big/img_360
+2002/08/05/big/img_67
+2002/08/29/big/img_18969
+2002/07/28/big/img_16
+2002/08/16/big/img_515
+2002/07/20/big/img_708
+2002/08/18/big/img_178
+2003/01/15/big/img_509
+2002/07/25/big/img_430
+2002/08/21/big/img_738
+2002/08/16/big/img_886
+2002/09/02/big/img_15605
+2002/09/01/big/img_16242
+2002/08/24/big/img_711
+2002/07/25/big/img_90
+2002/08/09/big/img_491
+2002/07/30/big/img_534
+2003/01/13/big/img_474
+2002/08/25/big/img_510
+2002/08/15/big/img_555
+2002/08/02/big/img_775
+2002/07/23/big/img_975
+2002/08/19/big/img_229
+2003/01/17/big/img_860
+2003/01/02/big/img_10
+2002/07/23/big/img_542
+2002/08/06/big/img_2535
+2002/07/22/big/img_37
+2002/08/06/big/img_2342
+2002/08/25/big/img_515
+2002/08/25/big/img_336
+2002/08/18/big/img_837
+2002/08/21/big/img_616
+2003/01/17/big/img_24
+2002/07/26/big/img_936
+2002/08/14/big/img_896
+2002/07/29/big/img_465
+2002/07/31/big/img_543
+2002/08/01/big/img_1411
+2002/08/02/big/img_423
+2002/08/21/big/img_44
+2002/07/31/big/img_11
+2003/01/15/big/img_628
+2003/01/15/big/img_605
+2002/07/30/big/img_571
+2002/07/23/big/img_428
+2002/08/15/big/img_942
+2002/07/26/big/img_531
+2003/01/16/big/img_59
+2002/08/02/big/img_410
+2002/07/31/big/img_230
+2002/08/19/big/img_806
+2003/01/14/big/img_462
+2002/08/16/big/img_370
+2002/08/13/big/img_380
+2002/08/16/big/img_932
+2002/07/19/big/img_393
+2002/08/20/big/img_764
+2002/08/15/big/img_616
+2002/07/26/big/img_267
+2002/07/27/big/img_1069
+2002/08/14/big/img_1041
+2003/01/13/big/img_594
+2002/09/01/big/img_16845
+2002/08/09/big/img_229
+2003/01/16/big/img_639
+2002/08/19/big/img_398
+2002/08/18/big/img_978
+2002/08/24/big/img_296
+2002/07/29/big/img_415
+2002/07/30/big/img_923
+2002/08/18/big/img_575
+2002/08/22/big/img_182
+2002/07/25/big/img_806
+2002/07/22/big/img_49
+2002/07/29/big/img_989
+2003/01/17/big/img_789
+2003/01/15/big/img_503
+2002/09/01/big/img_16062
+2003/01/17/big/img_794
+2002/08/15/big/img_564
+2003/01/15/big/img_222
+2002/08/01/big/img_1656
+2003/01/13/big/img_432
+2002/07/19/big/img_426
+2002/08/17/big/img_244
+2002/08/13/big/img_805
+2002/09/02/big/img_15067
+2002/08/11/big/img_58
+2002/08/22/big/img_636
+2002/07/22/big/img_416
+2002/08/13/big/img_836
+2002/08/26/big/img_363
+2002/07/30/big/img_917
+2003/01/14/big/img_206
+2002/08/12/big/img_311
+2002/08/31/big/img_17623
+2002/07/29/big/img_661
+2003/01/13/big/img_417
+2002/08/02/big/img_463
+2002/08/02/big/img_669
+2002/08/26/big/img_670
+2002/08/02/big/img_375
+2002/07/19/big/img_209
+2002/08/08/big/img_115
+2002/08/21/big/img_399
+2002/08/20/big/img_911
+2002/08/07/big/img_1212
+2002/08/20/big/img_578
+2002/08/22/big/img_554
+2002/08/21/big/img_484
+2002/07/25/big/img_450
+2002/08/03/big/img_542
+2002/08/15/big/img_561
+2002/07/23/big/img_360
+2002/08/30/big/img_18137
+2002/07/25/big/img_250
+2002/08/03/big/img_647
+2002/08/20/big/img_375
+2002/08/14/big/img_387
+2002/09/01/big/img_16990
+2002/08/28/big/img_19341
+2003/01/15/big/img_239
+2002/08/20/big/img_528
+2002/08/12/big/img_130
+2002/09/02/big/img_15108
+2003/01/15/big/img_372
+2002/08/16/big/img_678
+2002/08/04/big/img_623
+2002/07/23/big/img_477
+2002/08/28/big/img_19590
+2003/01/17/big/img_978
+2002/09/01/big/img_16692
+2002/07/20/big/img_109
+2002/08/06/big/img_2660
+2003/01/14/big/img_464
+2002/08/09/big/img_618
+2002/07/22/big/img_722
+2002/08/25/big/img_419
+2002/08/03/big/img_314
+2002/08/25/big/img_40
+2002/07/27/big/img_430
+2002/08/10/big/img_569
+2002/08/23/big/img_398
+2002/07/23/big/img_893
+2002/08/16/big/img_261
+2002/08/06/big/img_2668
+2002/07/22/big/img_835
+2002/09/02/big/img_15093
+2003/01/16/big/img_65
+2002/08/21/big/img_448
+2003/01/14/big/img_351
+2003/01/17/big/img_133
+2002/07/28/big/img_493
+2003/01/15/big/img_640
+2002/09/01/big/img_16880
+2002/08/15/big/img_350
+2002/08/20/big/img_624
+2002/08/25/big/img_604
+2002/08/06/big/img_2200
+2002/08/23/big/img_290
+2002/08/13/big/img_1152
+2003/01/14/big/img_251
+2002/08/02/big/img_538
+2002/08/22/big/img_613
+2003/01/13/big/img_351
+2002/08/18/big/img_368
+2002/07/23/big/img_392
+2002/07/25/big/img_198
+2002/07/25/big/img_418
+2002/08/26/big/img_614
+2002/07/23/big/img_405
+2003/01/14/big/img_445
+2002/07/25/big/img_326
+2002/08/10/big/img_734
+2003/01/14/big/img_530
+2002/08/08/big/img_561
+2002/08/29/big/img_18990
+2002/08/10/big/img_576
+2002/07/29/big/img_1494
+2002/07/19/big/img_198
+2002/08/10/big/img_562
+2002/07/22/big/img_901
+2003/01/14/big/img_37
+2002/09/02/big/img_15629
+2003/01/14/big/img_58
+2002/08/01/big/img_1364
+2002/07/27/big/img_636
+2003/01/13/big/img_241
+2002/09/01/big/img_16988
+2003/01/13/big/img_560
+2002/08/09/big/img_533
+2002/07/31/big/img_249
+2003/01/17/big/img_1007
+2002/07/21/big/img_64
+2003/01/13/big/img_537
+2003/01/15/big/img_606
+2002/08/18/big/img_651
+2002/08/24/big/img_405
+2002/07/26/big/img_837
+2002/08/09/big/img_562
+2002/08/01/big/img_1983
+2002/08/03/big/img_514
+2002/07/29/big/img_314
+2002/08/12/big/img_493
+2003/01/14/big/img_121
+2003/01/14/big/img_479
+2002/08/04/big/img_410
+2002/07/22/big/img_607
+2003/01/17/big/img_417
+2002/07/20/big/img_547
+2002/08/13/big/img_396
+2002/08/31/big/img_17538
+2002/08/13/big/img_187
+2002/08/12/big/img_328
+2003/01/14/big/img_569
+2002/07/27/big/img_1081
+2002/08/14/big/img_504
+2002/08/23/big/img_785
+2002/07/26/big/img_339
+2002/08/07/big/img_1156
+2002/08/07/big/img_1456
+2002/08/23/big/img_378
+2002/08/27/big/img_19719
+2002/07/31/big/img_39
+2002/07/31/big/img_883
+2003/01/14/big/img_676
+2002/07/29/big/img_214
+2002/07/26/big/img_669
+2002/07/25/big/img_202
+2002/08/08/big/img_259
+2003/01/17/big/img_943
+2003/01/15/big/img_512
+2002/08/05/big/img_3295
+2002/08/27/big/img_19685
+2002/08/08/big/img_277
+2002/08/30/big/img_18154
+2002/07/22/big/img_663
+2002/08/29/big/img_18914
+2002/07/31/big/img_908
+2002/08/27/big/img_19926
+2003/01/13/big/img_791
+2003/01/15/big/img_827
+2002/08/18/big/img_878
+2002/08/14/big/img_670
+2002/07/20/big/img_182
+2002/08/15/big/img_291
+2002/08/06/big/img_2600
+2002/07/23/big/img_587
+2002/08/14/big/img_577
+2003/01/15/big/img_585
+2002/07/30/big/img_310
+2002/08/03/big/img_658
+2002/08/10/big/img_157
+2002/08/19/big/img_811
+2002/07/29/big/img_1318
+2002/08/04/big/img_104
+2002/07/30/big/img_332
+2002/07/24/big/img_789
+2002/07/29/big/img_516
+2002/07/23/big/img_843
+2002/08/01/big/img_1528
+2002/08/13/big/img_798
+2002/08/07/big/img_1729
+2002/08/28/big/img_19448
+2003/01/16/big/img_95
+2002/08/12/big/img_473
+2002/07/27/big/img_269
+2003/01/16/big/img_621
+2002/07/29/big/img_772
+2002/07/24/big/img_171
+2002/07/19/big/img_429
+2002/08/07/big/img_1933
+2002/08/27/big/img_19629
+2002/08/05/big/img_3688
+2002/08/07/big/img_1691
+2002/07/23/big/img_600
+2002/07/29/big/img_666
+2002/08/25/big/img_566
+2002/08/06/big/img_2659
+2002/08/29/big/img_18929
+2002/08/16/big/img_407
+2002/08/18/big/img_774
+2002/08/19/big/img_249
+2002/08/06/big/img_2427
+2002/08/29/big/img_18899
+2002/08/01/big/img_1818
+2002/07/31/big/img_108
+2002/07/29/big/img_500
+2002/08/11/big/img_115
+2002/07/19/big/img_521
+2002/08/02/big/img_1163
+2002/07/22/big/img_62
+2002/08/13/big/img_466
+2002/08/21/big/img_956
+2002/08/23/big/img_602
+2002/08/20/big/img_858
+2002/07/25/big/img_690
+2002/07/19/big/img_130
+2002/08/04/big/img_874
+2002/07/26/big/img_489
+2002/07/22/big/img_548
+2002/08/10/big/img_191
+2002/07/25/big/img_1051
+2002/08/18/big/img_473
+2002/08/12/big/img_755
+2002/08/18/big/img_413
+2002/08/08/big/img_1044
+2002/08/17/big/img_680
+2002/08/26/big/img_235
+2002/08/20/big/img_330
+2002/08/22/big/img_344
+2002/08/09/big/img_593
+2002/07/31/big/img_1006
+2002/08/14/big/img_337
+2002/08/16/big/img_728
+2002/07/24/big/img_834
+2002/08/04/big/img_552
+2002/09/02/big/img_15213
+2002/07/25/big/img_725
+2002/08/30/big/img_18290
+2003/01/01/big/img_475
+2002/07/27/big/img_1083
+2002/08/29/big/img_18955
+2002/08/31/big/img_17232
+2002/08/08/big/img_480
+2002/08/01/big/img_1311
+2002/07/30/big/img_745
+2002/08/03/big/img_649
+2002/08/12/big/img_193
+2002/07/29/big/img_228
+2002/07/25/big/img_836
+2002/08/20/big/img_400
+2002/07/30/big/img_507
+2002/09/02/big/img_15072
+2002/07/26/big/img_658
+2002/07/28/big/img_503
+2002/08/05/big/img_3814
+2002/08/24/big/img_745
+2003/01/13/big/img_817
+2002/08/08/big/img_579
+2002/07/22/big/img_251
+2003/01/13/big/img_689
+2002/07/25/big/img_407
+2002/08/13/big/img_1050
+2002/08/14/big/img_733
+2002/07/24/big/img_82
+2003/01/17/big/img_288
+2003/01/15/big/img_475
+2002/08/14/big/img_620
+2002/08/21/big/img_167
+2002/07/19/big/img_300
+2002/07/26/big/img_219
+2002/08/01/big/img_1468
+2002/07/23/big/img_260
+2002/08/09/big/img_555
+2002/07/19/big/img_160
+2002/08/02/big/img_1060
+2003/01/14/big/img_149
+2002/08/15/big/img_346
+2002/08/24/big/img_597
+2002/08/22/big/img_502
+2002/08/30/big/img_18228
+2002/07/21/big/img_766
+2003/01/15/big/img_841
+2002/07/24/big/img_516
+2002/08/02/big/img_265
+2002/08/15/big/img_1243
+2003/01/15/big/img_223
+2002/08/04/big/img_236
+2002/07/22/big/img_309
+2002/07/20/big/img_656
+2002/07/31/big/img_412
+2002/09/01/big/img_16462
+2003/01/16/big/img_431
+2002/07/22/big/img_793
+2002/08/15/big/img_877
+2002/07/26/big/img_282
+2002/07/25/big/img_529
+2002/08/24/big/img_613
+2003/01/17/big/img_700
+2002/08/06/big/img_2526
+2002/08/24/big/img_394
+2002/08/21/big/img_521
+2002/08/25/big/img_560
+2002/07/29/big/img_966
+2002/07/25/big/img_448
+2003/01/13/big/img_782
+2002/08/21/big/img_296
+2002/09/01/big/img_16755
+2002/08/05/big/img_3552
+2002/09/02/big/img_15823
+2003/01/14/big/img_193
+2002/07/21/big/img_159
+2002/08/02/big/img_564
+2002/08/16/big/img_300
+2002/07/19/big/img_269
+2002/08/13/big/img_676
+2002/07/28/big/img_57
+2002/08/05/big/img_3318
+2002/07/31/big/img_218
+2002/08/21/big/img_898
+2002/07/29/big/img_109
+2002/07/19/big/img_854
+2002/08/23/big/img_311
+2002/08/14/big/img_318
+2002/07/25/big/img_523
+2002/07/21/big/img_678
+2003/01/17/big/img_690
+2002/08/28/big/img_19503
+2002/08/18/big/img_251
+2002/08/22/big/img_672
+2002/08/20/big/img_663
+2002/08/02/big/img_148
+2002/09/02/big/img_15580
+2002/07/25/big/img_778
+2002/08/14/big/img_565
+2002/08/12/big/img_374
+2002/08/13/big/img_1018
+2002/08/20/big/img_474
+2002/08/25/big/img_33
+2002/08/02/big/img_1190
+2002/08/08/big/img_864
+2002/08/14/big/img_1071
+2002/08/30/big/img_18103
+2002/08/18/big/img_533
+2003/01/16/big/img_650
+2002/07/25/big/img_108
+2002/07/26/big/img_81
+2002/07/27/big/img_543
+2002/07/29/big/img_521
+2003/01/13/big/img_434
+2002/08/26/big/img_674
+2002/08/06/big/img_2932
+2002/08/07/big/img_1262
+2003/01/15/big/img_201
+2003/01/16/big/img_673
+2002/09/02/big/img_15988
+2002/07/29/big/img_1306
+2003/01/14/big/img_1072
+2002/08/30/big/img_18232
+2002/08/05/big/img_3711
+2002/07/23/big/img_775
+2002/08/01/big/img_16
+2003/01/16/big/img_630
+2002/08/22/big/img_695
+2002/08/14/big/img_51
+2002/08/14/big/img_782
+2002/08/24/big/img_742
+2003/01/14/big/img_512
+2003/01/15/big/img_1183
+2003/01/15/big/img_714
+2002/08/01/big/img_2078
+2002/07/31/big/img_682
+2002/09/02/big/img_15687
+2002/07/26/big/img_518
+2002/08/27/big/img_19676
+2002/09/02/big/img_15969
+2002/08/02/big/img_931
+2002/08/25/big/img_508
+2002/08/29/big/img_18616
+2002/07/22/big/img_839
+2002/07/28/big/img_313
+2003/01/14/big/img_155
+2002/08/02/big/img_1105
+2002/08/09/big/img_53
+2002/08/16/big/img_469
+2002/08/15/big/img_502
+2002/08/20/big/img_575
+2002/07/25/big/img_138
+2003/01/16/big/img_579
+2002/07/19/big/img_352
+2003/01/14/big/img_762
+2003/01/01/big/img_588
+2002/08/02/big/img_981
+2002/08/21/big/img_447
+2002/09/01/big/img_16151
+2003/01/14/big/img_769
+2002/08/23/big/img_461
+2002/08/17/big/img_240
+2002/09/02/big/img_15220
+2002/07/19/big/img_408
+2002/09/02/big/img_15496
+2002/07/29/big/img_758
+2002/08/28/big/img_19392
+2002/08/06/big/img_2723
+2002/08/31/big/img_17752
+2002/08/23/big/img_469
+2002/08/13/big/img_515
+2002/09/02/big/img_15551
+2002/08/03/big/img_462
+2002/07/24/big/img_613
+2002/07/22/big/img_61
+2002/08/08/big/img_171
+2002/08/21/big/img_177
+2003/01/14/big/img_105
+2002/08/02/big/img_1017
+2002/08/22/big/img_106
+2002/07/27/big/img_542
+2002/07/21/big/img_665
+2002/07/23/big/img_595
+2002/08/04/big/img_657
+2002/08/29/big/img_19002
+2003/01/15/big/img_550
+2002/08/14/big/img_662
+2002/07/20/big/img_425
+2002/08/30/big/img_18528
+2002/07/26/big/img_611
+2002/07/22/big/img_849
+2002/08/07/big/img_1655
+2002/08/21/big/img_638
+2003/01/17/big/img_732
+2003/01/01/big/img_496
+2002/08/18/big/img_713
+2002/08/08/big/img_109
+2002/07/27/big/img_1008
+2002/07/20/big/img_559
+2002/08/16/big/img_699
+2002/08/31/big/img_17702
+2002/07/31/big/img_1013
+2002/08/01/big/img_2027
+2002/08/02/big/img_1001
+2002/08/03/big/img_210
+2002/08/01/big/img_2087
+2003/01/14/big/img_199
+2002/07/29/big/img_48
+2002/07/19/big/img_727
+2002/08/09/big/img_249
+2002/08/04/big/img_632
+2002/08/22/big/img_620
+2003/01/01/big/img_457
+2002/08/05/big/img_3223
+2002/07/27/big/img_240
+2002/07/25/big/img_797
+2002/08/13/big/img_430
+2002/07/25/big/img_615
+2002/08/12/big/img_28
+2002/07/30/big/img_220
+2002/07/24/big/img_89
+2002/08/21/big/img_357
+2002/08/09/big/img_590
+2003/01/13/big/img_525
+2002/08/17/big/img_818
+2003/01/02/big/img_7
+2002/07/26/big/img_636
+2003/01/13/big/img_1122
+2002/07/23/big/img_810
+2002/08/20/big/img_888
+2002/07/27/big/img_3
+2002/08/15/big/img_451
+2002/09/02/big/img_15787
+2002/07/31/big/img_281
+2002/08/05/big/img_3274
+2002/08/07/big/img_1254
+2002/07/31/big/img_27
+2002/08/01/big/img_1366
+2002/07/30/big/img_182
+2002/08/27/big/img_19690
+2002/07/29/big/img_68
+2002/08/23/big/img_754
+2002/07/30/big/img_540
+2002/08/27/big/img_20063
+2002/08/14/big/img_471
+2002/08/02/big/img_615
+2002/07/30/big/img_186
+2002/08/25/big/img_150
+2002/07/27/big/img_626
+2002/07/20/big/img_225
+2003/01/15/big/img_1252
+2002/07/19/big/img_367
+2003/01/15/big/img_582
+2002/08/09/big/img_572
+2002/08/08/big/img_428
+2003/01/15/big/img_639
+2002/08/28/big/img_19245
+2002/07/24/big/img_321
+2002/08/02/big/img_662
+2002/08/08/big/img_1033
+2003/01/17/big/img_867
+2002/07/22/big/img_652
+2003/01/14/big/img_224
+2002/08/18/big/img_49
+2002/07/26/big/img_46
+2002/08/31/big/img_18021
+2002/07/25/big/img_151
+2002/08/23/big/img_540
+2002/08/25/big/img_693
+2002/07/23/big/img_340
+2002/07/28/big/img_117
+2002/09/02/big/img_15768
+2002/08/26/big/img_562
+2002/07/24/big/img_480
+2003/01/15/big/img_341
+2002/08/10/big/img_783
+2002/08/20/big/img_132
+2003/01/14/big/img_370
+2002/07/20/big/img_720
+2002/08/03/big/img_144
+2002/08/20/big/img_538
+2002/08/01/big/img_1745
+2002/08/11/big/img_683
+2002/08/03/big/img_328
+2002/08/10/big/img_793
+2002/08/14/big/img_689
+2002/08/02/big/img_162
+2003/01/17/big/img_411
+2002/07/31/big/img_361
+2002/08/15/big/img_289
+2002/08/08/big/img_254
+2002/08/15/big/img_996
+2002/08/20/big/img_785
+2002/07/24/big/img_511
+2002/08/06/big/img_2614
+2002/08/29/big/img_18733
+2002/08/17/big/img_78
+2002/07/30/big/img_378
+2002/08/31/big/img_17947
+2002/08/26/big/img_88
+2002/07/30/big/img_558
+2002/08/02/big/img_67
+2003/01/14/big/img_325
+2002/07/29/big/img_1357
+2002/07/19/big/img_391
+2002/07/30/big/img_307
+2003/01/13/big/img_219
+2002/07/24/big/img_807
+2002/08/23/big/img_543
+2002/08/29/big/img_18620
+2002/07/22/big/img_769
+2002/08/26/big/img_503
+2002/07/30/big/img_78
+2002/08/14/big/img_1036
+2002/08/09/big/img_58
+2002/07/24/big/img_616
+2002/08/02/big/img_464
+2002/07/26/big/img_576
+2002/07/22/big/img_273
+2003/01/16/big/img_470
+2002/07/29/big/img_329
+2002/07/30/big/img_1086
+2002/07/31/big/img_353
+2002/09/02/big/img_15275
+2003/01/17/big/img_555
+2002/08/26/big/img_212
+2002/08/01/big/img_1692
+2003/01/15/big/img_600
+2002/07/29/big/img_825
+2002/08/08/big/img_68
+2002/08/10/big/img_719
+2002/07/31/big/img_636
+2002/07/29/big/img_325
+2002/07/21/big/img_515
+2002/07/22/big/img_705
+2003/01/13/big/img_818
+2002/08/09/big/img_486
+2002/08/22/big/img_141
+2002/07/22/big/img_303
+2002/08/09/big/img_393
+2002/07/29/big/img_963
+2002/08/02/big/img_1215
+2002/08/19/big/img_674
+2002/08/12/big/img_690
+2002/08/21/big/img_637
+2002/08/21/big/img_841
+2002/08/24/big/img_71
+2002/07/25/big/img_596
+2002/07/24/big/img_864
+2002/08/18/big/img_293
+2003/01/14/big/img_657
+2002/08/15/big/img_411
+2002/08/16/big/img_348
+2002/08/05/big/img_3157
+2002/07/20/big/img_663
+2003/01/13/big/img_654
+2003/01/16/big/img_433
+2002/08/30/big/img_18200
+2002/08/12/big/img_226
+2003/01/16/big/img_491
+2002/08/08/big/img_666
+2002/07/19/big/img_576
+2003/01/15/big/img_776
+2003/01/16/big/img_899
+2002/07/19/big/img_397
+2002/08/14/big/img_44
+2003/01/15/big/img_762
+2002/08/02/big/img_982
+2002/09/02/big/img_15234
+2002/08/17/big/img_556
+2002/08/21/big/img_410
+2002/08/21/big/img_386
+2002/07/19/big/img_690
+2002/08/05/big/img_3052
+2002/08/14/big/img_219
+2002/08/16/big/img_273
+2003/01/15/big/img_752
+2002/08/08/big/img_184
+2002/07/31/big/img_743
+2002/08/23/big/img_338
+2003/01/14/big/img_1055
+2002/08/05/big/img_3405
+2003/01/15/big/img_17
+2002/08/03/big/img_141
+2002/08/14/big/img_549
+2002/07/27/big/img_1034
+2002/07/31/big/img_932
+2002/08/30/big/img_18487
+2002/09/02/big/img_15814
+2002/08/01/big/img_2086
+2002/09/01/big/img_16535
+2002/07/22/big/img_500
+2003/01/13/big/img_400
+2002/08/25/big/img_607
+2002/08/30/big/img_18384
+2003/01/14/big/img_951
+2002/08/13/big/img_1150
+2002/08/08/big/img_1022
+2002/08/10/big/img_428
+2002/08/28/big/img_19242
+2002/08/05/big/img_3098
+2002/07/23/big/img_400
+2002/08/26/big/img_365
+2002/07/20/big/img_318
+2002/08/13/big/img_740
+2003/01/16/big/img_37
+2002/08/26/big/img_274
+2002/08/02/big/img_205
+2002/08/21/big/img_695
+2002/08/06/big/img_2289
+2002/08/20/big/img_794
+2002/08/18/big/img_438
+2002/08/07/big/img_1380
+2002/08/02/big/img_737
+2002/08/07/big/img_1651
+2002/08/15/big/img_1238
+2002/08/01/big/img_1681
+2002/08/06/big/img_3017
+2002/07/23/big/img_706
+2002/07/31/big/img_392
+2002/08/09/big/img_539
+2002/07/29/big/img_835
+2002/08/26/big/img_723
+2002/08/28/big/img_19235
+2003/01/16/big/img_353
+2002/08/10/big/img_150
+2002/08/29/big/img_19025
+2002/08/21/big/img_310
+2002/08/10/big/img_823
+2002/07/26/big/img_981
+2002/08/11/big/img_288
+2002/08/19/big/img_534
+2002/08/21/big/img_300
+2002/07/31/big/img_49
+2002/07/30/big/img_469
+2002/08/28/big/img_19197
+2002/08/25/big/img_205
+2002/08/10/big/img_390
+2002/08/23/big/img_291
+2002/08/26/big/img_230
+2002/08/18/big/img_76
+2002/07/23/big/img_409
+2002/08/14/big/img_1053
+2003/01/14/big/img_291
+2002/08/10/big/img_503
+2002/08/27/big/img_19928
+2002/08/03/big/img_563
+2002/08/17/big/img_250
+2002/08/06/big/img_2381
+2002/08/17/big/img_948
+2002/08/06/big/img_2710
+2002/07/22/big/img_696
+2002/07/31/big/img_670
+2002/08/12/big/img_594
+2002/07/29/big/img_624
+2003/01/17/big/img_934
+2002/08/03/big/img_584
+2002/08/22/big/img_1003
+2002/08/05/big/img_3396
+2003/01/13/big/img_570
+2002/08/02/big/img_219
+2002/09/02/big/img_15774
+2002/08/16/big/img_818
+2002/08/23/big/img_402
+2003/01/14/big/img_552
+2002/07/29/big/img_71
+2002/08/05/big/img_3592
+2002/08/16/big/img_80
+2002/07/27/big/img_672
+2003/01/13/big/img_470
+2003/01/16/big/img_702
+2002/09/01/big/img_16130
+2002/08/08/big/img_240
+2002/09/01/big/img_16338
+2002/07/26/big/img_312
+2003/01/14/big/img_538
+2002/07/20/big/img_695
+2002/08/30/big/img_18098
+2002/08/25/big/img_259
+2002/08/16/big/img_1042
+2002/08/09/big/img_837
+2002/08/31/big/img_17760
+2002/07/31/big/img_14
+2002/08/09/big/img_361
+2003/01/16/big/img_107
+2002/08/14/big/img_124
+2002/07/19/big/img_463
+2003/01/15/big/img_275
+2002/07/25/big/img_1151
+2002/07/29/big/img_1501
+2002/08/27/big/img_19889
+2002/08/29/big/img_18603
+2003/01/17/big/img_601
+2002/08/25/big/img_355
+2002/08/08/big/img_297
+2002/08/20/big/img_290
+2002/07/31/big/img_195
+2003/01/01/big/img_336
+2002/08/18/big/img_369
+2002/07/25/big/img_621
+2002/08/11/big/img_508
+2003/01/14/big/img_458
+2003/01/15/big/img_795
+2002/08/12/big/img_498
+2002/08/01/big/img_1734
+2002/08/02/big/img_246
+2002/08/16/big/img_565
+2002/08/11/big/img_475
+2002/08/22/big/img_408
+2002/07/28/big/img_78
+2002/07/21/big/img_81
+2003/01/14/big/img_697
+2002/08/14/big/img_661
+2002/08/15/big/img_507
+2002/08/19/big/img_55
+2002/07/22/big/img_152
+2003/01/14/big/img_470
+2002/08/03/big/img_379
+2002/08/22/big/img_506
+2003/01/16/big/img_966
+2002/08/18/big/img_698
+2002/08/24/big/img_528
+2002/08/23/big/img_10
+2002/08/01/big/img_1655
+2002/08/22/big/img_953
+2002/07/19/big/img_630
+2002/07/22/big/img_889
+2002/08/16/big/img_351
+2003/01/16/big/img_83
+2002/07/19/big/img_805
+2002/08/14/big/img_704
+2002/07/19/big/img_389
+2002/08/31/big/img_17765
+2002/07/29/big/img_606
+2003/01/17/big/img_939
+2002/09/02/big/img_15081
+2002/08/21/big/img_181
+2002/07/29/big/img_1321
+2002/07/21/big/img_497
+2002/07/20/big/img_539
+2002/08/24/big/img_119
+2002/08/01/big/img_1281
+2002/07/26/big/img_207
+2002/07/26/big/img_432
+2002/07/27/big/img_1006
+2002/08/05/big/img_3087
+2002/08/14/big/img_252
+2002/08/14/big/img_798
+2002/07/24/big/img_538
+2002/09/02/big/img_15507
+2002/08/08/big/img_901
+2003/01/14/big/img_557
+2002/08/07/big/img_1819
+2002/08/04/big/img_470
+2002/08/01/big/img_1504
+2002/08/16/big/img_1070
+2002/08/16/big/img_372
+2002/08/23/big/img_416
+2002/08/30/big/img_18208
+2002/08/01/big/img_2043
+2002/07/22/big/img_385
+2002/08/22/big/img_466
+2002/08/21/big/img_869
+2002/08/28/big/img_19429
+2002/08/02/big/img_770
+2002/07/23/big/img_433
+2003/01/14/big/img_13
+2002/07/27/big/img_953
+2002/09/02/big/img_15728
+2002/08/01/big/img_1361
+2002/08/29/big/img_18897
+2002/08/26/big/img_534
+2002/08/11/big/img_121
+2002/08/26/big/img_20130
+2002/07/31/big/img_363
+2002/08/13/big/img_978
+2002/07/25/big/img_835
+2002/08/02/big/img_906
+2003/01/14/big/img_548
+2002/07/30/big/img_80
+2002/07/26/big/img_982
+2003/01/16/big/img_99
+2002/08/19/big/img_362
+2002/08/24/big/img_376
+2002/08/07/big/img_1264
+2002/07/27/big/img_938
+2003/01/17/big/img_535
+2002/07/26/big/img_457
+2002/08/08/big/img_848
+2003/01/15/big/img_859
+2003/01/15/big/img_622
+2002/07/30/big/img_403
+2002/07/29/big/img_217
+2002/07/26/big/img_891
+2002/07/24/big/img_70
+2002/08/25/big/img_619
+2002/08/05/big/img_3375
+2002/08/01/big/img_2160
+2002/08/06/big/img_2227
+2003/01/14/big/img_117
+2002/08/14/big/img_227
+2002/08/13/big/img_565
+2002/08/19/big/img_625
+2002/08/03/big/img_812
+2002/07/24/big/img_41
+2002/08/16/big/img_235
+2002/07/29/big/img_759
+2002/07/21/big/img_433
+2002/07/29/big/img_190
+2003/01/16/big/img_435
+2003/01/13/big/img_708
+2002/07/30/big/img_57
+2002/08/22/big/img_162
+2003/01/01/big/img_558
+2003/01/15/big/img_604
+2002/08/16/big/img_935
+2002/08/20/big/img_394
+2002/07/28/big/img_465
+2002/09/02/big/img_15534
+2002/08/16/big/img_87
+2002/07/22/big/img_469
+2002/08/12/big/img_245
+2003/01/13/big/img_236
+2002/08/06/big/img_2736
+2002/08/03/big/img_348
+2003/01/14/big/img_218
+2002/07/26/big/img_232
+2003/01/15/big/img_244
+2002/07/25/big/img_1121
+2002/08/01/big/img_1484
+2002/07/26/big/img_541
+2002/08/07/big/img_1244
+2002/07/31/big/img_3
+2002/08/30/big/img_18437
+2002/08/29/big/img_19094
+2002/08/01/big/img_1355
+2002/08/19/big/img_338
+2002/07/19/big/img_255
+2002/07/21/big/img_76
+2002/08/25/big/img_199
+2002/08/12/big/img_740
+2002/07/30/big/img_852
+2002/08/15/big/img_599
+2002/08/23/big/img_254
+2002/08/19/big/img_125
+2002/07/24/big/img_2
+2002/08/04/big/img_145
+2002/08/05/big/img_3137
+2002/07/28/big/img_463
+2003/01/14/big/img_801
+2002/07/23/big/img_366
+2002/08/26/big/img_600
+2002/08/26/big/img_649
+2002/09/02/big/img_15849
+2002/07/26/big/img_248
+2003/01/13/big/img_200
+2002/08/07/big/img_1794
+2002/08/31/big/img_17270
+2002/08/23/big/img_608
+2003/01/13/big/img_837
+2002/08/23/big/img_581
+2002/08/20/big/img_754
+2002/08/18/big/img_183
+2002/08/20/big/img_328
+2002/07/22/big/img_494
+2002/07/29/big/img_399
+2002/08/28/big/img_19284
+2002/08/08/big/img_566
+2002/07/25/big/img_376
+2002/07/23/big/img_138
+2002/07/25/big/img_435
+2002/08/17/big/img_685
+2002/07/19/big/img_90
+2002/07/20/big/img_716
+2002/08/31/big/img_17458
+2002/08/26/big/img_461
+2002/07/25/big/img_355
+2002/08/06/big/img_2152
+2002/07/27/big/img_932
+2002/07/23/big/img_232
+2002/08/08/big/img_1020
+2002/07/31/big/img_366
+2002/08/06/big/img_2667
+2002/08/21/big/img_465
+2002/08/15/big/img_305
+2002/08/02/big/img_247
+2002/07/28/big/img_46
+2002/08/27/big/img_19922
+2002/08/23/big/img_643
+2003/01/13/big/img_624
+2002/08/23/big/img_625
+2002/08/05/big/img_3787
+2003/01/13/big/img_627
+2002/09/01/big/img_16381
+2002/08/05/big/img_3668
+2002/07/21/big/img_535
+2002/08/27/big/img_19680
+2002/07/22/big/img_413
+2002/07/29/big/img_481
+2003/01/15/big/img_496
+2002/07/23/big/img_701
+2002/08/29/big/img_18670
+2002/07/28/big/img_319
+2003/01/14/big/img_517
+2002/07/26/big/img_256
+2003/01/16/big/img_593
+2002/07/30/big/img_956
+2002/07/30/big/img_667
+2002/07/25/big/img_100
+2002/08/11/big/img_570
+2002/07/26/big/img_745
+2002/08/04/big/img_834
+2002/08/25/big/img_521
+2002/08/01/big/img_2148
+2002/09/02/big/img_15183
+2002/08/22/big/img_514
+2002/08/23/big/img_477
+2002/07/23/big/img_336
+2002/07/26/big/img_481
+2002/08/20/big/img_409
+2002/07/23/big/img_918
+2002/08/09/big/img_474
+2002/08/02/big/img_929
+2002/08/31/big/img_17932
+2002/08/19/big/img_161
+2002/08/09/big/img_667
+2002/07/31/big/img_805
+2002/09/02/big/img_15678
+2002/08/31/big/img_17509
+2002/08/29/big/img_18998
+2002/07/23/big/img_301
+2002/08/07/big/img_1612
+2002/08/06/big/img_2472
+2002/07/23/big/img_466
+2002/08/27/big/img_19634
+2003/01/16/big/img_16
+2002/08/14/big/img_193
+2002/08/21/big/img_340
+2002/08/27/big/img_19799
+2002/08/01/big/img_1345
+2002/08/07/big/img_1448
+2002/08/11/big/img_324
+2003/01/16/big/img_754
+2002/08/13/big/img_418
+2003/01/16/big/img_544
+2002/08/19/big/img_135
+2002/08/10/big/img_455
+2002/08/10/big/img_693
+2002/08/31/big/img_17967
+2002/08/28/big/img_19229
+2002/08/04/big/img_811
+2002/09/01/big/img_16225
+2003/01/16/big/img_428
+2002/09/02/big/img_15295
+2002/07/26/big/img_108
+2002/07/21/big/img_477
+2002/08/07/big/img_1354
+2002/08/23/big/img_246
+2002/08/16/big/img_652
+2002/07/27/big/img_553
+2002/07/31/big/img_346
+2002/08/04/big/img_537
+2002/08/08/big/img_498
+2002/08/29/big/img_18956
+2003/01/13/big/img_922
+2002/08/31/big/img_17425
+2002/07/26/big/img_438
+2002/08/19/big/img_185
+2003/01/16/big/img_33
+2002/08/10/big/img_252
+2002/07/29/big/img_598
+2002/08/27/big/img_19820
+2002/08/06/big/img_2664
+2002/08/20/big/img_705
+2003/01/14/big/img_816
+2002/08/03/big/img_552
+2002/07/25/big/img_561
+2002/07/25/big/img_934
+2002/08/01/big/img_1893
+2003/01/14/big/img_746
+2003/01/16/big/img_519
+2002/08/03/big/img_681
+2002/07/24/big/img_808
+2002/08/14/big/img_803
+2002/08/25/big/img_155
+2002/07/30/big/img_1107
+2002/08/29/big/img_18882
+2003/01/15/big/img_598
+2002/08/19/big/img_122
+2002/07/30/big/img_428
+2002/07/24/big/img_684
+2002/08/22/big/img_192
+2002/08/22/big/img_543
+2002/08/07/big/img_1318
+2002/08/18/big/img_25
+2002/07/26/big/img_583
+2002/07/20/big/img_464
+2002/08/19/big/img_664
+2002/08/24/big/img_861
+2002/09/01/big/img_16136
+2002/08/22/big/img_400
+2002/08/12/big/img_445
+2003/01/14/big/img_174
+2002/08/27/big/img_19677
+2002/08/31/big/img_17214
+2002/08/30/big/img_18175
+2003/01/17/big/img_402
+2002/08/06/big/img_2396
+2002/08/18/big/img_448
+2002/08/21/big/img_165
+2002/08/31/big/img_17609
+2003/01/01/big/img_151
+2002/08/26/big/img_372
+2002/09/02/big/img_15994
+2002/07/26/big/img_660
+2002/09/02/big/img_15197
+2002/07/29/big/img_258
+2002/08/30/big/img_18525
+2003/01/13/big/img_368
+2002/07/29/big/img_1538
+2002/07/21/big/img_787
+2002/08/18/big/img_152
+2002/08/06/big/img_2379
+2003/01/17/big/img_864
+2002/08/27/big/img_19998
+2002/08/01/big/img_1634
+2002/07/25/big/img_414
+2002/08/22/big/img_627
+2002/08/07/big/img_1669
+2002/08/16/big/img_1052
+2002/08/31/big/img_17796
+2002/08/18/big/img_199
+2002/09/02/big/img_15147
+2002/08/09/big/img_460
+2002/08/14/big/img_581
+2002/08/30/big/img_18286
+2002/07/26/big/img_337
+2002/08/18/big/img_589
+2003/01/14/big/img_866
+2002/07/20/big/img_624
+2002/08/01/big/img_1801
+2002/07/24/big/img_683
+2002/08/09/big/img_725
+2003/01/14/big/img_34
+2002/07/30/big/img_144
+2002/07/30/big/img_706
+2002/08/08/big/img_394
+2002/08/19/big/img_619
+2002/08/06/big/img_2703
+2002/08/29/big/img_19034
+2002/07/24/big/img_67
+2002/08/27/big/img_19841
+2002/08/19/big/img_427
+2003/01/14/big/img_333
+2002/09/01/big/img_16406
+2002/07/19/big/img_882
+2002/08/17/big/img_238
+2003/01/14/big/img_739
+2002/07/22/big/img_151
+2002/08/21/big/img_743
+2002/07/25/big/img_1048
+2002/07/30/big/img_395
+2003/01/13/big/img_584
+2002/08/13/big/img_742
+2002/08/13/big/img_1168
+2003/01/14/big/img_147
+2002/07/26/big/img_803
+2002/08/05/big/img_3298
+2002/08/07/big/img_1451
+2002/08/16/big/img_424
+2002/07/29/big/img_1069
+2002/09/01/big/img_16735
+2002/07/21/big/img_637
+2003/01/14/big/img_585
+2002/08/02/big/img_358
+2003/01/13/big/img_358
+2002/08/14/big/img_198
+2002/08/17/big/img_935
+2002/08/04/big/img_42
+2002/08/30/big/img_18245
+2002/07/25/big/img_158
+2002/08/22/big/img_744
+2002/08/06/big/img_2291
+2002/08/05/big/img_3044
+2002/07/30/big/img_272
+2002/08/23/big/img_641
+2002/07/24/big/img_797
+2002/07/30/big/img_392
+2003/01/14/big/img_447
+2002/07/31/big/img_898
+2002/08/06/big/img_2812
+2002/08/13/big/img_564
+2002/07/22/big/img_43
+2002/07/26/big/img_634
+2002/07/19/big/img_843
+2002/08/26/big/img_58
+2002/07/21/big/img_375
+2002/08/25/big/img_729
+2002/07/19/big/img_561
+2003/01/15/big/img_884
+2002/07/25/big/img_891
+2002/08/09/big/img_558
+2002/08/26/big/img_587
+2002/08/13/big/img_1146
+2002/09/02/big/img_15153
+2002/07/26/big/img_316
+2002/08/01/big/img_1940
+2002/08/26/big/img_90
+2003/01/13/big/img_347
+2002/07/25/big/img_520
+2002/08/29/big/img_18718
+2002/08/28/big/img_19219
+2002/08/13/big/img_375
+2002/07/20/big/img_719
+2002/08/31/big/img_17431
+2002/07/28/big/img_192
+2002/08/26/big/img_259
+2002/08/18/big/img_484
+2002/07/29/big/img_580
+2002/07/26/big/img_84
+2002/08/02/big/img_302
+2002/08/31/big/img_17007
+2003/01/15/big/img_543
+2002/09/01/big/img_16488
+2002/08/22/big/img_798
+2002/07/30/big/img_383
+2002/08/04/big/img_668
+2002/08/13/big/img_156
+2002/08/07/big/img_1353
+2002/07/25/big/img_281
+2003/01/14/big/img_587
+2003/01/15/big/img_524
+2002/08/19/big/img_726
+2002/08/21/big/img_709
+2002/08/26/big/img_465
+2002/07/31/big/img_658
+2002/08/28/big/img_19148
+2002/07/23/big/img_423
+2002/08/16/big/img_758
+2002/08/22/big/img_523
+2002/08/16/big/img_591
+2002/08/23/big/img_845
+2002/07/26/big/img_678
+2002/08/09/big/img_806
+2002/08/06/big/img_2369
+2002/07/29/big/img_457
+2002/07/19/big/img_278
+2002/08/30/big/img_18107
+2002/07/26/big/img_444
+2002/08/20/big/img_278
+2002/08/26/big/img_92
+2002/08/26/big/img_257
+2002/07/25/big/img_266
+2002/08/05/big/img_3829
+2002/07/26/big/img_757
+2002/07/29/big/img_1536
+2002/08/09/big/img_472
+2003/01/17/big/img_480
+2002/08/28/big/img_19355
+2002/07/26/big/img_97
+2002/08/06/big/img_2503
+2002/07/19/big/img_254
+2002/08/01/big/img_1470
+2002/08/21/big/img_42
+2002/08/20/big/img_217
+2002/08/06/big/img_2459
+2002/07/19/big/img_552
+2002/08/13/big/img_717
+2002/08/12/big/img_586
+2002/08/20/big/img_411
+2003/01/13/big/img_768
+2002/08/07/big/img_1747
+2002/08/15/big/img_385
+2002/08/01/big/img_1648
+2002/08/15/big/img_311
+2002/08/21/big/img_95
+2002/08/09/big/img_108
+2002/08/21/big/img_398
+2002/08/17/big/img_340
+2002/08/14/big/img_474
+2002/08/13/big/img_294
+2002/08/24/big/img_840
+2002/08/09/big/img_808
+2002/08/23/big/img_491
+2002/07/28/big/img_33
+2003/01/13/big/img_664
+2002/08/02/big/img_261
+2002/08/09/big/img_591
+2002/07/26/big/img_309
+2003/01/14/big/img_372
+2002/08/19/big/img_581
+2002/08/19/big/img_168
+2002/08/26/big/img_422
+2002/07/24/big/img_106
+2002/08/01/big/img_1936
+2002/08/05/big/img_3764
+2002/08/21/big/img_266
+2002/08/31/big/img_17968
+2002/08/01/big/img_1941
+2002/08/15/big/img_550
+2002/08/14/big/img_13
+2002/07/30/big/img_171
+2003/01/13/big/img_490
+2002/07/25/big/img_427
+2002/07/19/big/img_770
+2002/08/12/big/img_759
+2003/01/15/big/img_1360
+2002/08/05/big/img_3692
+2003/01/16/big/img_30
+2002/07/25/big/img_1026
+2002/07/22/big/img_288
+2002/08/29/big/img_18801
+2002/07/24/big/img_793
+2002/08/13/big/img_178
+2002/08/06/big/img_2322
+2003/01/14/big/img_560
+2002/08/18/big/img_408
+2003/01/16/big/img_915
+2003/01/16/big/img_679
+2002/08/07/big/img_1552
+2002/08/29/big/img_19050
+2002/08/01/big/img_2172
+2002/07/31/big/img_30
+2002/07/30/big/img_1019
+2002/07/30/big/img_587
+2003/01/13/big/img_773
+2002/07/30/big/img_410
+2002/07/28/big/img_65
+2002/08/05/big/img_3138
+2002/07/23/big/img_541
+2002/08/22/big/img_963
+2002/07/27/big/img_657
+2002/07/30/big/img_1051
+2003/01/16/big/img_150
+2002/07/31/big/img_519
+2002/08/01/big/img_1961
+2002/08/05/big/img_3752
+2002/07/23/big/img_631
+2003/01/14/big/img_237
+2002/07/28/big/img_21
+2002/07/22/big/img_813
+2002/08/05/big/img_3563
+2003/01/17/big/img_620
+2002/07/19/big/img_523
+2002/07/30/big/img_904
+2002/08/29/big/img_18642
+2002/08/11/big/img_492
+2002/08/01/big/img_2130
+2002/07/25/big/img_618
+2002/08/17/big/img_305
+2003/01/16/big/img_520
+2002/07/26/big/img_495
+2002/08/17/big/img_164
+2002/08/03/big/img_440
+2002/07/24/big/img_441
+2002/08/06/big/img_2146
+2002/08/11/big/img_558
+2002/08/02/big/img_545
+2002/08/31/big/img_18090
+2003/01/01/big/img_136
+2002/07/25/big/img_1099
+2003/01/13/big/img_728
+2003/01/16/big/img_197
+2002/07/26/big/img_651
+2002/08/11/big/img_676
+2003/01/15/big/img_10
+2002/08/21/big/img_250
+2002/08/14/big/img_325
+2002/08/04/big/img_390
+2002/07/24/big/img_554
+2003/01/16/big/img_333
+2002/07/31/big/img_922
+2002/09/02/big/img_15586
+2003/01/16/big/img_184
+2002/07/22/big/img_766
+2002/07/21/big/img_608
+2002/08/07/big/img_1578
+2002/08/17/big/img_961
+2002/07/27/big/img_324
+2002/08/05/big/img_3765
+2002/08/23/big/img_462
+2003/01/16/big/img_382
+2002/08/27/big/img_19838
+2002/08/01/big/img_1505
+2002/08/21/big/img_662
+2002/08/14/big/img_605
+2002/08/19/big/img_816
+2002/07/29/big/img_136
+2002/08/20/big/img_719
+2002/08/06/big/img_2826
+2002/08/10/big/img_630
+2003/01/17/big/img_973
+2002/08/14/big/img_116
+2002/08/02/big/img_666
+2002/08/21/big/img_710
+2002/08/05/big/img_55
+2002/07/31/big/img_229
+2002/08/01/big/img_1549
+2002/07/23/big/img_432
+2002/07/21/big/img_430
+2002/08/21/big/img_549
+2002/08/08/big/img_985
+2002/07/20/big/img_610
+2002/07/23/big/img_978
+2002/08/23/big/img_219
+2002/07/25/big/img_175
+2003/01/15/big/img_230
+2002/08/23/big/img_385
+2002/07/31/big/img_879
+2002/08/12/big/img_495
+2002/08/22/big/img_499
+2002/08/30/big/img_18322
+2002/08/15/big/img_795
+2002/08/13/big/img_835
+2003/01/17/big/img_930
+2002/07/30/big/img_873
+2002/08/11/big/img_257
+2002/07/31/big/img_593
+2002/08/21/big/img_916
+2003/01/13/big/img_814
+2002/07/25/big/img_722
+2002/08/16/big/img_379
+2002/07/31/big/img_497
+2002/07/22/big/img_602
+2002/08/21/big/img_642
+2002/08/21/big/img_614
+2002/08/23/big/img_482
+2002/07/29/big/img_603
+2002/08/13/big/img_705
+2002/07/23/big/img_833
+2003/01/14/big/img_511
+2002/07/24/big/img_376
+2002/08/17/big/img_1030
+2002/08/05/big/img_3576
+2002/08/16/big/img_540
+2002/07/22/big/img_630
+2002/08/10/big/img_180
+2002/08/14/big/img_905
+2002/08/29/big/img_18777
+2002/08/22/big/img_693
+2003/01/16/big/img_933
+2002/08/20/big/img_555
+2002/08/15/big/img_549
+2003/01/14/big/img_830
+2003/01/16/big/img_64
+2002/08/27/big/img_19670
+2002/08/22/big/img_729
+2002/07/27/big/img_981
+2002/08/09/big/img_458
+2003/01/17/big/img_884
+2002/07/25/big/img_639
+2002/08/31/big/img_18008
+2002/08/22/big/img_249
+2002/08/17/big/img_971
+2002/08/04/big/img_308
+2002/07/28/big/img_362
+2002/08/12/big/img_142
+2002/08/26/big/img_61
+2002/08/14/big/img_422
+2002/07/19/big/img_607
+2003/01/15/big/img_717
+2002/08/01/big/img_1475
+2002/08/29/big/img_19061
+2003/01/01/big/img_346
+2002/07/20/big/img_315
+2003/01/15/big/img_756
+2002/08/15/big/img_879
+2002/08/08/big/img_615
+2003/01/13/big/img_431
+2002/08/05/big/img_3233
+2002/08/24/big/img_526
+2003/01/13/big/img_717
+2002/09/01/big/img_16408
+2002/07/22/big/img_217
+2002/07/31/big/img_960
+2002/08/21/big/img_610
+2002/08/05/big/img_3753
+2002/08/03/big/img_151
+2002/08/21/big/img_267
+2002/08/01/big/img_2175
+2002/08/04/big/img_556
+2002/08/21/big/img_527
+2002/09/02/big/img_15800
+2002/07/27/big/img_156
+2002/07/20/big/img_590
+2002/08/15/big/img_700
+2002/08/08/big/img_444
+2002/07/25/big/img_94
+2002/07/24/big/img_778
+2002/08/14/big/img_694
+2002/07/20/big/img_666
+2002/08/02/big/img_200
+2002/08/02/big/img_578
+2003/01/17/big/img_332
+2002/09/01/big/img_16352
+2002/08/27/big/img_19668
+2002/07/23/big/img_823
+2002/08/13/big/img_431
+2003/01/16/big/img_463
+2002/08/27/big/img_19711
+2002/08/23/big/img_154
+2002/07/31/big/img_360
+2002/08/23/big/img_555
+2002/08/10/big/img_561
+2003/01/14/big/img_550
+2002/08/07/big/img_1370
+2002/07/30/big/img_1184
+2002/08/01/big/img_1445
+2002/08/23/big/img_22
+2002/07/30/big/img_606
+2003/01/17/big/img_271
+2002/08/31/big/img_17316
+2002/08/16/big/img_973
+2002/07/26/big/img_77
+2002/07/20/big/img_788
+2002/08/06/big/img_2426
+2002/08/07/big/img_1498
+2002/08/16/big/img_358
+2002/08/06/big/img_2851
+2002/08/12/big/img_359
+2002/08/01/big/img_1521
+2002/08/02/big/img_709
+2002/08/20/big/img_935
+2002/08/12/big/img_188
+2002/08/24/big/img_411
+2002/08/22/big/img_680
+2002/08/06/big/img_2480
+2002/07/20/big/img_627
+2002/07/30/big/img_214
+2002/07/25/big/img_354
+2002/08/02/big/img_636
+2003/01/15/big/img_661
+2002/08/07/big/img_1327
+2002/08/01/big/img_2108
+2002/08/31/big/img_17919
+2002/08/29/big/img_18768
+2002/08/05/big/img_3840
+2002/07/26/big/img_242
+2003/01/14/big/img_451
+2002/08/20/big/img_923
+2002/08/27/big/img_19908
+2002/08/16/big/img_282
+2002/08/19/big/img_440
+2003/01/01/big/img_230
+2002/08/08/big/img_212
+2002/07/20/big/img_443
+2002/08/25/big/img_635
+2003/01/13/big/img_1169
+2002/07/26/big/img_998
+2002/08/15/big/img_995
+2002/08/06/big/img_3002
+2002/07/29/big/img_460
+2003/01/14/big/img_925
+2002/07/23/big/img_539
+2002/08/16/big/img_694
+2003/01/13/big/img_459
+2002/07/23/big/img_249
+2002/08/20/big/img_539
+2002/08/04/big/img_186
+2002/08/26/big/img_264
+2002/07/22/big/img_704
+2002/08/25/big/img_277
+2002/08/22/big/img_988
+2002/07/29/big/img_504
+2002/08/05/big/img_3600
+2002/08/30/big/img_18380
+2003/01/14/big/img_937
+2002/08/21/big/img_254
+2002/08/10/big/img_130
+2002/08/20/big/img_339
+2003/01/14/big/img_428
+2002/08/20/big/img_889
+2002/08/31/big/img_17637
+2002/07/26/big/img_644
+2002/09/01/big/img_16776
+2002/08/06/big/img_2239
+2002/08/06/big/img_2646
+2003/01/13/big/img_491
+2002/08/10/big/img_579
+2002/08/21/big/img_713
+2002/08/22/big/img_482
+2002/07/22/big/img_167
+2002/07/24/big/img_539
+2002/08/14/big/img_721
+2002/07/25/big/img_389
+2002/09/01/big/img_16591
+2002/08/13/big/img_543
+2003/01/14/big/img_432
+2002/08/09/big/img_287
+2002/07/26/big/img_126
+2002/08/23/big/img_412
+2002/08/15/big/img_1034
+2002/08/28/big/img_19485
+2002/07/31/big/img_236
+2002/07/30/big/img_523
+2002/07/19/big/img_141
+2003/01/17/big/img_957
+2002/08/04/big/img_81
+2002/07/25/big/img_206
+2002/08/15/big/img_716
+2002/08/13/big/img_403
+2002/08/15/big/img_685
+2002/07/26/big/img_884
+2002/07/19/big/img_499
+2002/07/23/big/img_772
+2002/07/27/big/img_752
+2003/01/14/big/img_493
+2002/08/25/big/img_664
+2002/07/31/big/img_334
+2002/08/26/big/img_678
+2002/09/01/big/img_16541
+2003/01/14/big/img_347
+2002/07/23/big/img_187
+2002/07/30/big/img_1163
+2002/08/05/big/img_35
+2002/08/22/big/img_944
+2002/08/07/big/img_1239
+2002/07/29/big/img_1215
+2002/08/03/big/img_312
+2002/08/05/big/img_3523
+2002/07/29/big/img_218
+2002/08/13/big/img_672
+2002/08/16/big/img_205
+2002/08/17/big/img_594
+2002/07/29/big/img_1411
+2002/07/30/big/img_942
+2003/01/16/big/img_312
+2002/08/08/big/img_312
+2002/07/25/big/img_15
+2002/08/09/big/img_839
+2002/08/01/big/img_2069
+2002/08/31/big/img_17512
+2002/08/01/big/img_3
+2002/07/31/big/img_320
+2003/01/15/big/img_1265
+2002/08/14/big/img_563
+2002/07/31/big/img_167
+2002/08/20/big/img_374
+2002/08/13/big/img_406
+2002/08/08/big/img_625
+2002/08/02/big/img_314
+2002/08/27/big/img_19964
+2002/09/01/big/img_16670
+2002/07/31/big/img_599
+2002/08/29/big/img_18906
+2002/07/24/big/img_373
+2002/07/26/big/img_513
+2002/09/02/big/img_15497
+2002/08/19/big/img_117
+2003/01/01/big/img_158
+2002/08/24/big/img_178
+2003/01/13/big/img_935
+2002/08/13/big/img_609
+2002/08/30/big/img_18341
+2002/08/25/big/img_674
+2003/01/13/big/img_209
+2002/08/13/big/img_258
+2002/08/05/big/img_3543
+2002/08/07/big/img_1970
+2002/08/06/big/img_3004
+2003/01/17/big/img_487
+2002/08/24/big/img_873
+2002/08/29/big/img_18730
+2002/08/09/big/img_375
+2003/01/16/big/img_751
+2002/08/02/big/img_603
+2002/08/19/big/img_325
+2002/09/01/big/img_16420
+2002/08/05/big/img_3633
+2002/08/21/big/img_516
+2002/07/19/big/img_501
+2002/07/26/big/img_688
+2002/07/24/big/img_256
+2002/07/25/big/img_438
+2002/07/31/big/img_1017
+2002/08/22/big/img_512
+2002/07/21/big/img_543
+2002/08/08/big/img_223
+2002/08/19/big/img_189
+2002/08/12/big/img_630
+2002/07/30/big/img_958
+2002/07/28/big/img_208
+2002/08/31/big/img_17691
+2002/07/22/big/img_542
+2002/07/19/big/img_741
+2002/07/19/big/img_158
+2002/08/15/big/img_399
+2002/08/01/big/img_2159
+2002/08/14/big/img_455
+2002/08/17/big/img_1011
+2002/08/26/big/img_744
+2002/08/12/big/img_624
+2003/01/17/big/img_821
+2002/08/16/big/img_980
+2002/07/28/big/img_281
+2002/07/25/big/img_171
+2002/08/03/big/img_116
+2002/07/22/big/img_467
+2002/07/31/big/img_750
+2002/07/26/big/img_435
+2002/07/19/big/img_822
+2002/08/13/big/img_626
+2002/08/11/big/img_344
+2002/08/02/big/img_473
+2002/09/01/big/img_16817
+2002/08/01/big/img_1275
+2002/08/28/big/img_19270
+2002/07/23/big/img_607
+2002/08/09/big/img_316
+2002/07/29/big/img_626
+2002/07/24/big/img_824
+2002/07/22/big/img_342
+2002/08/08/big/img_794
+2002/08/07/big/img_1209
+2002/07/19/big/img_18
+2002/08/25/big/img_634
+2002/07/24/big/img_730
+2003/01/17/big/img_356
+2002/07/23/big/img_305
+2002/07/30/big/img_453
+2003/01/13/big/img_972
+2002/08/06/big/img_2610
+2002/08/29/big/img_18920
+2002/07/31/big/img_123
+2002/07/26/big/img_979
+2002/08/24/big/img_635
+2002/08/05/big/img_3704
+2002/08/07/big/img_1358
+2002/07/22/big/img_306
+2002/08/13/big/img_619
+2002/08/02/big/img_366
diff --git a/KAIR/retinaface/data_faces/__init__.py b/KAIR/retinaface/data_faces/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..ea50ebaf88d64e75f4960bc99b14f138a343e575
--- /dev/null
+++ b/KAIR/retinaface/data_faces/__init__.py
@@ -0,0 +1,3 @@
+from .wider_face import WiderFaceDetection, detection_collate
+from .data_augment import *
+from .config import *
diff --git a/KAIR/retinaface/data_faces/config.py b/KAIR/retinaface/data_faces/config.py
new file mode 100644
index 0000000000000000000000000000000000000000..e57cdc530e3d78c4aa6310985c90c5ee125f8f01
--- /dev/null
+++ b/KAIR/retinaface/data_faces/config.py
@@ -0,0 +1,42 @@
+# config.py
+
+cfg_mnet = {
+ 'name': 'mobilenet0.25',
+ 'min_sizes': [[16, 32], [64, 128], [256, 512]],
+ 'steps': [8, 16, 32],
+ 'variance': [0.1, 0.2],
+ 'clip': False,
+ 'loc_weight': 2.0,
+ 'gpu_train': True,
+ 'batch_size': 32,
+ 'ngpu': 1,
+ 'epoch': 250,
+ 'decay1': 190,
+ 'decay2': 220,
+ 'image_size': 640,
+ 'pretrain': False,
+ 'return_layers': {'stage1': 1, 'stage2': 2, 'stage3': 3},
+ 'in_channel': 32,
+ 'out_channel': 64
+}
+
+cfg_re50 = {
+ 'name': 'Resnet50',
+ 'min_sizes': [[16, 32], [64, 128], [256, 512]],
+ 'steps': [8, 16, 32],
+ 'variance': [0.1, 0.2],
+ 'clip': False,
+ 'loc_weight': 2.0,
+ 'gpu_train': True,
+ 'batch_size': 24,
+ 'ngpu': 4,
+ 'epoch': 100,
+ 'decay1': 70,
+ 'decay2': 90,
+ 'image_size': 840,
+ 'pretrain': False,
+ 'return_layers': {'layer2': 1, 'layer3': 2, 'layer4': 3},
+ 'in_channel': 256,
+ 'out_channel': 256
+}
+
diff --git a/KAIR/retinaface/data_faces/data_augment.py b/KAIR/retinaface/data_faces/data_augment.py
new file mode 100644
index 0000000000000000000000000000000000000000..882dc2bfbf51972899ce563874dad91217bfe35f
--- /dev/null
+++ b/KAIR/retinaface/data_faces/data_augment.py
@@ -0,0 +1,237 @@
+import cv2
+import numpy as np
+import random
+from utils_faces.box_utils import matrix_iof
+
+
+def _crop(image, boxes, labels, landm, img_dim):
+ height, width, _ = image.shape
+ pad_image_flag = True
+
+ for _ in range(250):
+ """
+ if random.uniform(0, 1) <= 0.2:
+ scale = 1.0
+ else:
+ scale = random.uniform(0.3, 1.0)
+ """
+ PRE_SCALES = [0.3, 0.45, 0.6, 0.8, 1.0]
+ scale = random.choice(PRE_SCALES)
+ short_side = min(width, height)
+ w = int(scale * short_side)
+ h = w
+
+ if width == w:
+ l = 0
+ else:
+ l = random.randrange(width - w)
+ if height == h:
+ t = 0
+ else:
+ t = random.randrange(height - h)
+ roi = np.array((l, t, l + w, t + h))
+
+ value = matrix_iof(boxes, roi[np.newaxis])
+ flag = (value >= 1)
+ if not flag.any():
+ continue
+
+ centers = (boxes[:, :2] + boxes[:, 2:]) / 2
+ mask_a = np.logical_and(roi[:2] < centers, centers < roi[2:]).all(axis=1)
+ boxes_t = boxes[mask_a].copy()
+ labels_t = labels[mask_a].copy()
+ landms_t = landm[mask_a].copy()
+ landms_t = landms_t.reshape([-1, 5, 2])
+
+ if boxes_t.shape[0] == 0:
+ continue
+
+ image_t = image[roi[1]:roi[3], roi[0]:roi[2]]
+
+ boxes_t[:, :2] = np.maximum(boxes_t[:, :2], roi[:2])
+ boxes_t[:, :2] -= roi[:2]
+ boxes_t[:, 2:] = np.minimum(boxes_t[:, 2:], roi[2:])
+ boxes_t[:, 2:] -= roi[:2]
+
+ # landm
+ landms_t[:, :, :2] = landms_t[:, :, :2] - roi[:2]
+ landms_t[:, :, :2] = np.maximum(landms_t[:, :, :2], np.array([0, 0]))
+ landms_t[:, :, :2] = np.minimum(landms_t[:, :, :2], roi[2:] - roi[:2])
+ landms_t = landms_t.reshape([-1, 10])
+
+
+ # make sure that the cropped image contains at least one face > 16 pixel at training image scale
+ b_w_t = (boxes_t[:, 2] - boxes_t[:, 0] + 1) / w * img_dim
+ b_h_t = (boxes_t[:, 3] - boxes_t[:, 1] + 1) / h * img_dim
+ mask_b = np.minimum(b_w_t, b_h_t) > 0.0
+ boxes_t = boxes_t[mask_b]
+ labels_t = labels_t[mask_b]
+ landms_t = landms_t[mask_b]
+
+ if boxes_t.shape[0] == 0:
+ continue
+
+ pad_image_flag = False
+
+ return image_t, boxes_t, labels_t, landms_t, pad_image_flag
+ return image, boxes, labels, landm, pad_image_flag
+
+
+def _distort(image):
+
+ def _convert(image, alpha=1, beta=0):
+ tmp = image.astype(float) * alpha + beta
+ tmp[tmp < 0] = 0
+ tmp[tmp > 255] = 255
+ image[:] = tmp
+
+ image = image.copy()
+
+ if random.randrange(2):
+
+ #brightness distortion
+ if random.randrange(2):
+ _convert(image, beta=random.uniform(-32, 32))
+
+ #contrast distortion
+ if random.randrange(2):
+ _convert(image, alpha=random.uniform(0.5, 1.5))
+
+ image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
+
+ #saturation distortion
+ if random.randrange(2):
+ _convert(image[:, :, 1], alpha=random.uniform(0.5, 1.5))
+
+ #hue distortion
+ if random.randrange(2):
+ tmp = image[:, :, 0].astype(int) + random.randint(-18, 18)
+ tmp %= 180
+ image[:, :, 0] = tmp
+
+ image = cv2.cvtColor(image, cv2.COLOR_HSV2BGR)
+
+ else:
+
+ #brightness distortion
+ if random.randrange(2):
+ _convert(image, beta=random.uniform(-32, 32))
+
+ image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
+
+ #saturation distortion
+ if random.randrange(2):
+ _convert(image[:, :, 1], alpha=random.uniform(0.5, 1.5))
+
+ #hue distortion
+ if random.randrange(2):
+ tmp = image[:, :, 0].astype(int) + random.randint(-18, 18)
+ tmp %= 180
+ image[:, :, 0] = tmp
+
+ image = cv2.cvtColor(image, cv2.COLOR_HSV2BGR)
+
+ #contrast distortion
+ if random.randrange(2):
+ _convert(image, alpha=random.uniform(0.5, 1.5))
+
+ return image
+
+
+def _expand(image, boxes, fill, p):
+ if random.randrange(2):
+ return image, boxes
+
+ height, width, depth = image.shape
+
+ scale = random.uniform(1, p)
+ w = int(scale * width)
+ h = int(scale * height)
+
+ left = random.randint(0, w - width)
+ top = random.randint(0, h - height)
+
+ boxes_t = boxes.copy()
+ boxes_t[:, :2] += (left, top)
+ boxes_t[:, 2:] += (left, top)
+ expand_image = np.empty(
+ (h, w, depth),
+ dtype=image.dtype)
+ expand_image[:, :] = fill
+ expand_image[top:top + height, left:left + width] = image
+ image = expand_image
+
+ return image, boxes_t
+
+
+def _mirror(image, boxes, landms):
+ _, width, _ = image.shape
+ if random.randrange(2):
+ image = image[:, ::-1]
+ boxes = boxes.copy()
+ boxes[:, 0::2] = width - boxes[:, 2::-2]
+
+ # landm
+ landms = landms.copy()
+ landms = landms.reshape([-1, 5, 2])
+ landms[:, :, 0] = width - landms[:, :, 0]
+ tmp = landms[:, 1, :].copy()
+ landms[:, 1, :] = landms[:, 0, :]
+ landms[:, 0, :] = tmp
+ tmp1 = landms[:, 4, :].copy()
+ landms[:, 4, :] = landms[:, 3, :]
+ landms[:, 3, :] = tmp1
+ landms = landms.reshape([-1, 10])
+
+ return image, boxes, landms
+
+
+def _pad_to_square(image, rgb_mean, pad_image_flag):
+ if not pad_image_flag:
+ return image
+ height, width, _ = image.shape
+ long_side = max(width, height)
+ image_t = np.empty((long_side, long_side, 3), dtype=image.dtype)
+ image_t[:, :] = rgb_mean
+ image_t[0:0 + height, 0:0 + width] = image
+ return image_t
+
+
+def _resize_subtract_mean(image, insize, rgb_mean):
+ interp_methods = [cv2.INTER_LINEAR, cv2.INTER_CUBIC, cv2.INTER_AREA, cv2.INTER_NEAREST, cv2.INTER_LANCZOS4]
+ interp_method = interp_methods[random.randrange(5)]
+ image = cv2.resize(image, (insize, insize), interpolation=interp_method)
+ image = image.astype(np.float32)
+ image -= rgb_mean
+ return image.transpose(2, 0, 1)
+
+
+class preproc(object):
+
+ def __init__(self, img_dim, rgb_means):
+ self.img_dim = img_dim
+ self.rgb_means = rgb_means
+
+ def __call__(self, image, targets):
+ assert targets.shape[0] > 0, "this image does not have gt"
+
+ boxes = targets[:, :4].copy()
+ labels = targets[:, -1].copy()
+ landm = targets[:, 4:-1].copy()
+
+ image_t, boxes_t, labels_t, landm_t, pad_image_flag = _crop(image, boxes, labels, landm, self.img_dim)
+ image_t = _distort(image_t)
+ image_t = _pad_to_square(image_t,self.rgb_means, pad_image_flag)
+ image_t, boxes_t, landm_t = _mirror(image_t, boxes_t, landm_t)
+ height, width, _ = image_t.shape
+ image_t = _resize_subtract_mean(image_t, self.img_dim, self.rgb_means)
+ boxes_t[:, 0::2] /= width
+ boxes_t[:, 1::2] /= height
+
+ landm_t[:, 0::2] /= width
+ landm_t[:, 1::2] /= height
+
+ labels_t = np.expand_dims(labels_t, 1)
+ targets_t = np.hstack((boxes_t, landm_t, labels_t))
+
+ return image_t, targets_t
diff --git a/KAIR/retinaface/data_faces/wider_face.py b/KAIR/retinaface/data_faces/wider_face.py
new file mode 100644
index 0000000000000000000000000000000000000000..22f56efdc221bd4162d22884669ba44a3d4de5cd
--- /dev/null
+++ b/KAIR/retinaface/data_faces/wider_face.py
@@ -0,0 +1,101 @@
+import os
+import os.path
+import sys
+import torch
+import torch.utils.data as data
+import cv2
+import numpy as np
+
+class WiderFaceDetection(data.Dataset):
+ def __init__(self, txt_path, preproc=None):
+ self.preproc = preproc
+ self.imgs_path = []
+ self.words = []
+ f = open(txt_path,'r')
+ lines = f.readlines()
+ isFirst = True
+ labels = []
+ for line in lines:
+ line = line.rstrip()
+ if line.startswith('#'):
+ if isFirst is True:
+ isFirst = False
+ else:
+ labels_copy = labels.copy()
+ self.words.append(labels_copy)
+ labels.clear()
+ path = line[2:]
+ path = txt_path.replace('label.txt','images/') + path
+ self.imgs_path.append(path)
+ else:
+ line = line.split(' ')
+ label = [float(x) for x in line]
+ labels.append(label)
+
+ self.words.append(labels)
+
+ def __len__(self):
+ return len(self.imgs_path)
+
+ def __getitem__(self, index):
+ img = cv2.imread(self.imgs_path[index])
+ height, width, _ = img.shape
+
+ labels = self.words[index]
+ annotations = np.zeros((0, 15))
+ if len(labels) == 0:
+ return annotations
+ for idx, label in enumerate(labels):
+ annotation = np.zeros((1, 15))
+ # bbox
+ annotation[0, 0] = label[0] # x1
+ annotation[0, 1] = label[1] # y1
+ annotation[0, 2] = label[0] + label[2] # x2
+ annotation[0, 3] = label[1] + label[3] # y2
+
+ # landmarks
+ annotation[0, 4] = label[4] # l0_x
+ annotation[0, 5] = label[5] # l0_y
+ annotation[0, 6] = label[7] # l1_x
+ annotation[0, 7] = label[8] # l1_y
+ annotation[0, 8] = label[10] # l2_x
+ annotation[0, 9] = label[11] # l2_y
+ annotation[0, 10] = label[13] # l3_x
+ annotation[0, 11] = label[14] # l3_y
+ annotation[0, 12] = label[16] # l4_x
+ annotation[0, 13] = label[17] # l4_y
+ if (annotation[0, 4]<0):
+ annotation[0, 14] = -1
+ else:
+ annotation[0, 14] = 1
+
+ annotations = np.append(annotations, annotation, axis=0)
+ target = np.array(annotations)
+ if self.preproc is not None:
+ img, target = self.preproc(img, target)
+
+ return torch.from_numpy(img), target
+
+def detection_collate(batch):
+ """Custom collate fn for dealing with batches of images that have a different
+ number of associated object annotations (bounding boxes).
+
+ Arguments:
+ batch: (tuple) A tuple of tensor images and lists of annotations
+
+ Return:
+ A tuple containing:
+ 1) (tensor) batch of images stacked on their 0 dim
+ 2) (list of tensors) annotations for a given image are stacked on 0 dim
+ """
+ targets = []
+ imgs = []
+ for _, sample in enumerate(batch):
+ for _, tup in enumerate(sample):
+ if torch.is_tensor(tup):
+ imgs.append(tup)
+ elif isinstance(tup, type(np.empty(0))):
+ annos = torch.from_numpy(tup).float()
+ targets.append(annos)
+
+ return (torch.stack(imgs, 0), targets)
diff --git a/KAIR/retinaface/facemodels/__init__.py b/KAIR/retinaface/facemodels/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..8b137891791fe96927ad78e64b0aad7bded08bdc
--- /dev/null
+++ b/KAIR/retinaface/facemodels/__init__.py
@@ -0,0 +1 @@
+
diff --git a/KAIR/retinaface/facemodels/net.py b/KAIR/retinaface/facemodels/net.py
new file mode 100644
index 0000000000000000000000000000000000000000..beb6040b24258f8b96020c1c9fc2610819718017
--- /dev/null
+++ b/KAIR/retinaface/facemodels/net.py
@@ -0,0 +1,137 @@
+import time
+import torch
+import torch.nn as nn
+import torchvision.models._utils as _utils
+import torchvision.models as models
+import torch.nn.functional as F
+from torch.autograd import Variable
+
+def conv_bn(inp, oup, stride = 1, leaky = 0):
+ return nn.Sequential(
+ nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
+ nn.BatchNorm2d(oup),
+ nn.LeakyReLU(negative_slope=leaky, inplace=True)
+ )
+
+def conv_bn_no_relu(inp, oup, stride):
+ return nn.Sequential(
+ nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
+ nn.BatchNorm2d(oup),
+ )
+
+def conv_bn1X1(inp, oup, stride, leaky=0):
+ return nn.Sequential(
+ nn.Conv2d(inp, oup, 1, stride, padding=0, bias=False),
+ nn.BatchNorm2d(oup),
+ nn.LeakyReLU(negative_slope=leaky, inplace=True)
+ )
+
+def conv_dw(inp, oup, stride, leaky=0.1):
+ return nn.Sequential(
+ nn.Conv2d(inp, inp, 3, stride, 1, groups=inp, bias=False),
+ nn.BatchNorm2d(inp),
+ nn.LeakyReLU(negative_slope= leaky,inplace=True),
+
+ nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
+ nn.BatchNorm2d(oup),
+ nn.LeakyReLU(negative_slope= leaky,inplace=True),
+ )
+
+class SSH(nn.Module):
+ def __init__(self, in_channel, out_channel):
+ super(SSH, self).__init__()
+ assert out_channel % 4 == 0
+ leaky = 0
+ if (out_channel <= 64):
+ leaky = 0.1
+ self.conv3X3 = conv_bn_no_relu(in_channel, out_channel//2, stride=1)
+
+ self.conv5X5_1 = conv_bn(in_channel, out_channel//4, stride=1, leaky = leaky)
+ self.conv5X5_2 = conv_bn_no_relu(out_channel//4, out_channel//4, stride=1)
+
+ self.conv7X7_2 = conv_bn(out_channel//4, out_channel//4, stride=1, leaky = leaky)
+ self.conv7x7_3 = conv_bn_no_relu(out_channel//4, out_channel//4, stride=1)
+
+ def forward(self, input):
+ conv3X3 = self.conv3X3(input)
+
+ conv5X5_1 = self.conv5X5_1(input)
+ conv5X5 = self.conv5X5_2(conv5X5_1)
+
+ conv7X7_2 = self.conv7X7_2(conv5X5_1)
+ conv7X7 = self.conv7x7_3(conv7X7_2)
+
+ out = torch.cat([conv3X3, conv5X5, conv7X7], dim=1)
+ out = F.relu(out)
+ return out
+
+class FPN(nn.Module):
+ def __init__(self,in_channels_list,out_channels):
+ super(FPN,self).__init__()
+ leaky = 0
+ if (out_channels <= 64):
+ leaky = 0.1
+ self.output1 = conv_bn1X1(in_channels_list[0], out_channels, stride = 1, leaky = leaky)
+ self.output2 = conv_bn1X1(in_channels_list[1], out_channels, stride = 1, leaky = leaky)
+ self.output3 = conv_bn1X1(in_channels_list[2], out_channels, stride = 1, leaky = leaky)
+
+ self.merge1 = conv_bn(out_channels, out_channels, leaky = leaky)
+ self.merge2 = conv_bn(out_channels, out_channels, leaky = leaky)
+
+ def forward(self, input):
+ # names = list(input.keys())
+ input = list(input.values())
+
+ output1 = self.output1(input[0])
+ output2 = self.output2(input[1])
+ output3 = self.output3(input[2])
+
+ up3 = F.interpolate(output3, size=[output2.size(2), output2.size(3)], mode="nearest")
+ output2 = output2 + up3
+ output2 = self.merge2(output2)
+
+ up2 = F.interpolate(output2, size=[output1.size(2), output1.size(3)], mode="nearest")
+ output1 = output1 + up2
+ output1 = self.merge1(output1)
+
+ out = [output1, output2, output3]
+ return out
+
+
+
+class MobileNetV1(nn.Module):
+ def __init__(self):
+ super(MobileNetV1, self).__init__()
+ self.stage1 = nn.Sequential(
+ conv_bn(3, 8, 2, leaky = 0.1), # 3
+ conv_dw(8, 16, 1), # 7
+ conv_dw(16, 32, 2), # 11
+ conv_dw(32, 32, 1), # 19
+ conv_dw(32, 64, 2), # 27
+ conv_dw(64, 64, 1), # 43
+ )
+ self.stage2 = nn.Sequential(
+ conv_dw(64, 128, 2), # 43 + 16 = 59
+ conv_dw(128, 128, 1), # 59 + 32 = 91
+ conv_dw(128, 128, 1), # 91 + 32 = 123
+ conv_dw(128, 128, 1), # 123 + 32 = 155
+ conv_dw(128, 128, 1), # 155 + 32 = 187
+ conv_dw(128, 128, 1), # 187 + 32 = 219
+ )
+ self.stage3 = nn.Sequential(
+ conv_dw(128, 256, 2), # 219 +3 2 = 241
+ conv_dw(256, 256, 1), # 241 + 64 = 301
+ )
+ self.avg = nn.AdaptiveAvgPool2d((1,1))
+ self.fc = nn.Linear(256, 1000)
+
+ def forward(self, x):
+ x = self.stage1(x)
+ x = self.stage2(x)
+ x = self.stage3(x)
+ x = self.avg(x)
+ # x = self.model(x)
+ x = x.view(-1, 256)
+ x = self.fc(x)
+ return x
+
diff --git a/KAIR/retinaface/facemodels/retinaface.py b/KAIR/retinaface/facemodels/retinaface.py
new file mode 100644
index 0000000000000000000000000000000000000000..b7092a2bc2f35d06ce99d25473bce913ef3fd8e7
--- /dev/null
+++ b/KAIR/retinaface/facemodels/retinaface.py
@@ -0,0 +1,127 @@
+import torch
+import torch.nn as nn
+import torchvision.models.detection.backbone_utils as backbone_utils
+import torchvision.models._utils as _utils
+import torch.nn.functional as F
+from collections import OrderedDict
+
+from facemodels.net import MobileNetV1 as MobileNetV1
+from facemodels.net import FPN as FPN
+from facemodels.net import SSH as SSH
+
+
+
+class ClassHead(nn.Module):
+ def __init__(self,inchannels=512,num_anchors=3):
+ super(ClassHead,self).__init__()
+ self.num_anchors = num_anchors
+ self.conv1x1 = nn.Conv2d(inchannels,self.num_anchors*2,kernel_size=(1,1),stride=1,padding=0)
+
+ def forward(self,x):
+ out = self.conv1x1(x)
+ out = out.permute(0,2,3,1).contiguous()
+
+ return out.view(out.shape[0], -1, 2)
+
+class BboxHead(nn.Module):
+ def __init__(self,inchannels=512,num_anchors=3):
+ super(BboxHead,self).__init__()
+ self.conv1x1 = nn.Conv2d(inchannels,num_anchors*4,kernel_size=(1,1),stride=1,padding=0)
+
+ def forward(self,x):
+ out = self.conv1x1(x)
+ out = out.permute(0,2,3,1).contiguous()
+
+ return out.view(out.shape[0], -1, 4)
+
+class LandmarkHead(nn.Module):
+ def __init__(self,inchannels=512,num_anchors=3):
+ super(LandmarkHead,self).__init__()
+ self.conv1x1 = nn.Conv2d(inchannels,num_anchors*10,kernel_size=(1,1),stride=1,padding=0)
+
+ def forward(self,x):
+ out = self.conv1x1(x)
+ out = out.permute(0,2,3,1).contiguous()
+
+ return out.view(out.shape[0], -1, 10)
+
+class RetinaFace(nn.Module):
+ def __init__(self, cfg = None, phase = 'train'):
+ """
+ :param cfg: Network related settings.
+ :param phase: train or test.
+ """
+ super(RetinaFace,self).__init__()
+ self.phase = phase
+ backbone = None
+ if cfg['name'] == 'mobilenet0.25':
+ backbone = MobileNetV1()
+ if cfg['pretrain']:
+ checkpoint = torch.load("./weights/mobilenetV1X0.25_pretrain.tar", map_location=torch.device('cpu'))
+ from collections import OrderedDict
+ new_state_dict = OrderedDict()
+ for k, v in checkpoint['state_dict'].items():
+ name = k[7:] # remove module.
+ new_state_dict[name] = v
+ # load params
+ backbone.load_state_dict(new_state_dict)
+ elif cfg['name'] == 'Resnet50':
+ import torchvision.models as models
+ backbone = models.resnet50(pretrained=cfg['pretrain'])
+
+ self.body = _utils.IntermediateLayerGetter(backbone, cfg['return_layers'])
+ in_channels_stage2 = cfg['in_channel']
+ in_channels_list = [
+ in_channels_stage2 * 2,
+ in_channels_stage2 * 4,
+ in_channels_stage2 * 8,
+ ]
+ out_channels = cfg['out_channel']
+ self.fpn = FPN(in_channels_list,out_channels)
+ self.ssh1 = SSH(out_channels, out_channels)
+ self.ssh2 = SSH(out_channels, out_channels)
+ self.ssh3 = SSH(out_channels, out_channels)
+
+ self.ClassHead = self._make_class_head(fpn_num=3, inchannels=cfg['out_channel'])
+ self.BboxHead = self._make_bbox_head(fpn_num=3, inchannels=cfg['out_channel'])
+ self.LandmarkHead = self._make_landmark_head(fpn_num=3, inchannels=cfg['out_channel'])
+
+ def _make_class_head(self,fpn_num=3,inchannels=64,anchor_num=2):
+ classhead = nn.ModuleList()
+ for i in range(fpn_num):
+ classhead.append(ClassHead(inchannels,anchor_num))
+ return classhead
+
+ def _make_bbox_head(self,fpn_num=3,inchannels=64,anchor_num=2):
+ bboxhead = nn.ModuleList()
+ for i in range(fpn_num):
+ bboxhead.append(BboxHead(inchannels,anchor_num))
+ return bboxhead
+
+ def _make_landmark_head(self,fpn_num=3,inchannels=64,anchor_num=2):
+ landmarkhead = nn.ModuleList()
+ for i in range(fpn_num):
+ landmarkhead.append(LandmarkHead(inchannels,anchor_num))
+ return landmarkhead
+
+ def forward(self,inputs):
+ out = self.body(inputs)
+
+ # FPN
+ fpn = self.fpn(out)
+
+ # SSH
+ feature1 = self.ssh1(fpn[0])
+ feature2 = self.ssh2(fpn[1])
+ feature3 = self.ssh3(fpn[2])
+ features = [feature1, feature2, feature3]
+
+ bbox_regressions = torch.cat([self.BboxHead[i](feature) for i, feature in enumerate(features)], dim=1)
+ classifications = torch.cat([self.ClassHead[i](feature) for i, feature in enumerate(features)],dim=1)
+ ldm_regressions = torch.cat([self.LandmarkHead[i](feature) for i, feature in enumerate(features)], dim=1)
+
+ if self.phase == 'train':
+ output = (bbox_regressions, classifications, ldm_regressions)
+ else:
+ output = (bbox_regressions, F.softmax(classifications, dim=-1), ldm_regressions)
+ return output
\ No newline at end of file
diff --git a/KAIR/retinaface/layers/__init__.py b/KAIR/retinaface/layers/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..53a3f4b5160995d93bc7911e808b3045d74362c9
--- /dev/null
+++ b/KAIR/retinaface/layers/__init__.py
@@ -0,0 +1,2 @@
+from .functions import *
+from .modules import *
diff --git a/KAIR/retinaface/layers/functions/prior_box.py b/KAIR/retinaface/layers/functions/prior_box.py
new file mode 100644
index 0000000000000000000000000000000000000000..80c7f858371ed71f39ed609eb44b423d8693bf61
--- /dev/null
+++ b/KAIR/retinaface/layers/functions/prior_box.py
@@ -0,0 +1,34 @@
+import torch
+from itertools import product as product
+import numpy as np
+from math import ceil
+
+
+class PriorBox(object):
+ def __init__(self, cfg, image_size=None, phase='train'):
+ super(PriorBox, self).__init__()
+ self.min_sizes = cfg['min_sizes']
+ self.steps = cfg['steps']
+ self.clip = cfg['clip']
+ self.image_size = image_size
+ self.feature_maps = [[ceil(self.image_size[0]/step), ceil(self.image_size[1]/step)] for step in self.steps]
+ self.name = "s"
+
+ def forward(self):
+ anchors = []
+ for k, f in enumerate(self.feature_maps):
+ min_sizes = self.min_sizes[k]
+ for i, j in product(range(f[0]), range(f[1])):
+ for min_size in min_sizes:
+ s_kx = min_size / self.image_size[1]
+ s_ky = min_size / self.image_size[0]
+ dense_cx = [x * self.steps[k] / self.image_size[1] for x in [j + 0.5]]
+ dense_cy = [y * self.steps[k] / self.image_size[0] for y in [i + 0.5]]
+ for cy, cx in product(dense_cy, dense_cx):
+ anchors += [cx, cy, s_kx, s_ky]
+
+ # back to torch land
+ output = torch.Tensor(anchors).view(-1, 4)
+ if self.clip:
+ output.clamp_(max=1, min=0)
+ return output
diff --git a/KAIR/retinaface/layers/modules/__init__.py b/KAIR/retinaface/layers/modules/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..cf24bddbf283f233d0b93fc074a2bac2f5c044a9
--- /dev/null
+++ b/KAIR/retinaface/layers/modules/__init__.py
@@ -0,0 +1,3 @@
+from .multibox_loss import MultiBoxLoss
+
+__all__ = ['MultiBoxLoss']
diff --git a/KAIR/retinaface/layers/modules/multibox_loss.py b/KAIR/retinaface/layers/modules/multibox_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..75d2367be35e11a119810949f6ccce439984b978
--- /dev/null
+++ b/KAIR/retinaface/layers/modules/multibox_loss.py
@@ -0,0 +1,125 @@
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from torch.autograd import Variable
+from utils_faces.box_utils import match, log_sum_exp
+from data_faces import cfg_mnet
+GPU = cfg_mnet['gpu_train']
+
+class MultiBoxLoss(nn.Module):
+ """SSD Weighted Loss Function
+ Compute Targets:
+ 1) Produce Confidence Target Indices by matching ground truth boxes
+ with (default) 'priorboxes' that have jaccard index > threshold parameter
+ (default threshold: 0.5).
+ 2) Produce localization target by 'encoding' variance into offsets of ground
+ truth boxes and their matched 'priorboxes'.
+ 3) Hard negative mining to filter the excessive number of negative examples
+ that comes with using a large number of default bounding boxes.
+ (default negative:positive ratio 3:1)
+ Objective Loss:
+ L(x,c,l,g) = (Lconf(x, c) + αLloc(x,l,g)) / N
+ Where, Lconf is the CrossEntropy Loss and Lloc is the SmoothL1 Loss
+ weighted by α which is set to 1 by cross val.
+ Args:
+ c: class confidences,
+ l: predicted boxes,
+ g: ground truth boxes
+ N: number of matched default boxes
+ See: https://arxiv.org/pdf/1512.02325.pdf for more details.
+ """
+
+ def __init__(self, num_classes, overlap_thresh, prior_for_matching, bkg_label, neg_mining, neg_pos, neg_overlap, encode_target):
+ super(MultiBoxLoss, self).__init__()
+ self.num_classes = num_classes
+ self.threshold = overlap_thresh
+ self.background_label = bkg_label
+ self.encode_target = encode_target
+ self.use_prior_for_matching = prior_for_matching
+ self.do_neg_mining = neg_mining
+ self.negpos_ratio = neg_pos
+ self.neg_overlap = neg_overlap
+ self.variance = [0.1, 0.2]
+
+ def forward(self, predictions, priors, targets):
+ """Multibox Loss
+ Args:
+ predictions (tuple): A tuple containing loc preds, conf preds,
+ and prior boxes from SSD net.
+ conf shape: torch.size(batch_size,num_priors,num_classes)
+ loc shape: torch.size(batch_size,num_priors,4)
+ priors shape: torch.size(num_priors,4)
+
+ ground_truth (tensor): Ground truth boxes and labels for a batch,
+ shape: [batch_size,num_objs,5] (last idx is the label).
+ """
+
+ loc_data, conf_data, landm_data = predictions
+ priors = priors
+ num = loc_data.size(0)
+ num_priors = (priors.size(0))
+
+ # match priors (default boxes) and ground truth boxes
+ loc_t = torch.Tensor(num, num_priors, 4)
+ landm_t = torch.Tensor(num, num_priors, 10)
+ conf_t = torch.LongTensor(num, num_priors)
+ for idx in range(num):
+ truths = targets[idx][:, :4].data
+ labels = targets[idx][:, -1].data
+ landms = targets[idx][:, 4:14].data
+ defaults = priors.data
+ match(self.threshold, truths, defaults, self.variance, labels, landms, loc_t, conf_t, landm_t, idx)
+ if GPU:
+ loc_t = loc_t.cuda()
+ conf_t = conf_t.cuda()
+ landm_t = landm_t.cuda()
+
+ zeros = torch.tensor(0).cuda()
+ # landm Loss (Smooth L1)
+ # Shape: [batch,num_priors,10]
+ pos1 = conf_t > zeros
+ num_pos_landm = pos1.long().sum(1, keepdim=True)
+ N1 = max(num_pos_landm.data.sum().float(), 1)
+ pos_idx1 = pos1.unsqueeze(pos1.dim()).expand_as(landm_data)
+ landm_p = landm_data[pos_idx1].view(-1, 10)
+ landm_t = landm_t[pos_idx1].view(-1, 10)
+ loss_landm = F.smooth_l1_loss(landm_p, landm_t, reduction='sum')
+
+
+ pos = conf_t != zeros
+ conf_t[pos] = 1
+
+ # Localization Loss (Smooth L1)
+ # Shape: [batch,num_priors,4]
+ pos_idx = pos.unsqueeze(pos.dim()).expand_as(loc_data)
+ loc_p = loc_data[pos_idx].view(-1, 4)
+ loc_t = loc_t[pos_idx].view(-1, 4)
+ loss_l = F.smooth_l1_loss(loc_p, loc_t, reduction='sum')
+
+ # Compute max conf across batch for hard negative mining
+ batch_conf = conf_data.view(-1, self.num_classes)
+ loss_c = log_sum_exp(batch_conf) - batch_conf.gather(1, conf_t.view(-1, 1))
+
+ # Hard Negative Mining
+ loss_c[pos.view(-1, 1)] = 0 # filter out pos boxes for now
+ loss_c = loss_c.view(num, -1)
+ _, loss_idx = loss_c.sort(1, descending=True)
+ _, idx_rank = loss_idx.sort(1)
+ num_pos = pos.long().sum(1, keepdim=True)
+ num_neg = torch.clamp(self.negpos_ratio*num_pos, max=pos.size(1)-1)
+ neg = idx_rank < num_neg.expand_as(idx_rank)
+
+ # Confidence Loss Including Positive and Negative Examples
+ pos_idx = pos.unsqueeze(2).expand_as(conf_data)
+ neg_idx = neg.unsqueeze(2).expand_as(conf_data)
+ conf_p = conf_data[(pos_idx+neg_idx).gt(0)].view(-1,self.num_classes)
+ targets_weighted = conf_t[(pos+neg).gt(0)]
+ loss_c = F.cross_entropy(conf_p, targets_weighted, reduction='sum')
+
+ # Sum of losses: L(x,c,l,g) = (Lconf(x, c) + αLloc(x,l,g)) / N
+ N = max(num_pos.data.sum().float(), 1)
+ loss_l /= N
+ loss_c /= N
+ loss_landm /= N1
+
+ return loss_l, loss_c, loss_landm
diff --git a/KAIR/retinaface/retinaface_detection.py b/KAIR/retinaface/retinaface_detection.py
new file mode 100644
index 0000000000000000000000000000000000000000..24e9919bb3f9656cc2601f868a85276ad852c00f
--- /dev/null
+++ b/KAIR/retinaface/retinaface_detection.py
@@ -0,0 +1,124 @@
+'''
+@paper: GAN Prior Embedded Network for Blind Face Restoration in the Wild (CVPR2021)
+@author: yangxy (yangtao9009@gmail.com)
+'''
+
+
+import sys
+path_retinaface = 'retinaface'
+if path_retinaface not in sys.path:
+ sys.path.insert(0, path_retinaface)
+
+import os
+import torch
+import torch.backends.cudnn as cudnn
+import numpy as np
+from data_faces import cfg_re50
+from layers.functions.prior_box import PriorBox
+from utils_faces.nms.py_cpu_nms import py_cpu_nms
+import cv2
+from facemodels.retinaface import RetinaFace
+from utils_faces.box_utils import decode, decode_landm
+import time
+
+
+class RetinaFaceDetection(object):
+ def __init__(self, model_path):
+ torch.set_grad_enabled(False)
+ cudnn.benchmark = True
+ self.pretrained_path = model_path
+ self.device = torch.cuda.current_device()
+ self.cfg = cfg_re50
+ self.net = RetinaFace(cfg=self.cfg, phase='test')
+ self.load_model()
+ self.net = self.net.cuda()
+
+ def check_keys(self, pretrained_state_dict):
+ ckpt_keys = set(pretrained_state_dict.keys())
+ model_keys = set(self.net.state_dict().keys())
+ used_pretrained_keys = model_keys & ckpt_keys
+ unused_pretrained_keys = ckpt_keys - model_keys
+ missing_keys = model_keys - ckpt_keys
+ assert len(used_pretrained_keys) > 0, 'load NONE from pretrained checkpoint'
+ return True
+
+ def remove_prefix(self, state_dict, prefix):
+ ''' Old style model is stored with all names of parameters sharing common prefix 'module.' '''
+ f = lambda x: x.split(prefix, 1)[-1] if x.startswith(prefix) else x
+ return {f(key): value for key, value in state_dict.items()}
+
+ def load_model(self, load_to_cpu=False):
+ if load_to_cpu:
+ pretrained_dict = torch.load(self.pretrained_path, map_location=lambda storage, loc: storage)
+ else:
+ pretrained_dict = torch.load(self.pretrained_path, map_location=lambda storage, loc: storage.cuda())
+ if "state_dict" in pretrained_dict.keys():
+ pretrained_dict = self.remove_prefix(pretrained_dict['state_dict'], 'module.')
+ else:
+ pretrained_dict = self.remove_prefix(pretrained_dict, 'module.')
+ self.check_keys(pretrained_dict)
+ self.net.load_state_dict(pretrained_dict, strict=False)
+ self.net.eval()
+
+ def detect(self, img_raw, resize=1, confidence_threshold=0.9, nms_threshold=0.4, top_k=5000, keep_top_k=750, save_image=False):
+ img = np.float32(img_raw)
+
+ im_height, im_width = img.shape[:2]
+ scale = torch.Tensor([img.shape[1], img.shape[0], img.shape[1], img.shape[0]])
+ img -= (104, 117, 123)
+ img = img.transpose(2, 0, 1)
+ img = torch.from_numpy(img).unsqueeze(0)
+ img = img.cuda()
+ scale = scale.cuda()
+
+ loc, conf, landms = self.net(img) # forward pass
+
+ priorbox = PriorBox(self.cfg, image_size=(im_height, im_width))
+ priors = priorbox.forward()
+ priors = priors.cuda()
+ prior_data = priors.data
+ boxes = decode(loc.data.squeeze(0), prior_data, self.cfg['variance'])
+ boxes = boxes * scale / resize
+ boxes = boxes.cpu().numpy()
+ scores = conf.squeeze(0).data.cpu().numpy()[:, 1]
+ landms = decode_landm(landms.data.squeeze(0), prior_data, self.cfg['variance'])
+ scale1 = torch.Tensor([img.shape[3], img.shape[2], img.shape[3], img.shape[2],
+ img.shape[3], img.shape[2], img.shape[3], img.shape[2],
+ img.shape[3], img.shape[2]])
+ scale1 = scale1.cuda()
+ landms = landms * scale1 / resize
+ landms = landms.cpu().numpy()
+
+ # ignore low scores
+ inds = np.where(scores > confidence_threshold)[0]
+ boxes = boxes[inds]
+ landms = landms[inds]
+ scores = scores[inds]
+
+ # keep top-K before NMS
+ order = scores.argsort()[::-1][:top_k]
+ boxes = boxes[order]
+ landms = landms[order]
+ scores = scores[order]
+
+ # do NMS
+ dets = np.hstack((boxes, scores[:, np.newaxis])).astype(np.float32, copy=False)
+ keep = py_cpu_nms(dets, nms_threshold)
+ # keep = nms(dets, nms_threshold,force_cpu=args.cpu)
+ dets = dets[keep, :]
+ landms = landms[keep]
+
+ # keep top-K faster NMS
+ dets = dets[:keep_top_k, :]
+ landms = landms[:keep_top_k, :]
+
+ # sort faces(delete)
+ fscores = [det[4] for det in dets]
+ sorted_idx = sorted(range(len(fscores)), key=lambda k:fscores[k], reverse=False) # sort index
+ tmp = [landms[idx] for idx in sorted_idx]
+ landms = np.asarray(tmp)
+
+ landms = landms.reshape((-1, 5, 2))
+ landms = landms.transpose((0, 2, 1))
+ landms = landms.reshape(-1, 10, )
+ return dets, landms
diff --git a/KAIR/retinaface/utils_faces/__init__.py b/KAIR/retinaface/utils_faces/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..8b137891791fe96927ad78e64b0aad7bded08bdc
--- /dev/null
+++ b/KAIR/retinaface/utils_faces/__init__.py
@@ -0,0 +1 @@
+
diff --git a/KAIR/retinaface/utils_faces/box_utils.py b/KAIR/retinaface/utils_faces/box_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..c1d12bc612ae3ba3ea9d138bfc5997a2b15d8dd9
--- /dev/null
+++ b/KAIR/retinaface/utils_faces/box_utils.py
@@ -0,0 +1,330 @@
+import torch
+import numpy as np
+
+
+def point_form(boxes):
+ """ Convert prior_boxes to (xmin, ymin, xmax, ymax)
+ representation for comparison to point form ground truth data.
+ Args:
+ boxes: (tensor) center-size default boxes from priorbox layers.
+ Return:
+ boxes: (tensor) Converted xmin, ymin, xmax, ymax form of boxes.
+ """
+ return torch.cat((boxes[:, :2] - boxes[:, 2:]/2, # xmin, ymin
+ boxes[:, :2] + boxes[:, 2:]/2), 1) # xmax, ymax
+
+
+def center_size(boxes):
+ """ Convert prior_boxes to (cx, cy, w, h)
+ representation for comparison to center-size form ground truth data.
+ Args:
+ boxes: (tensor) point_form boxes
+ Return:
+ boxes: (tensor) Converted xmin, ymin, xmax, ymax form of boxes.
+ """
+ return torch.cat((boxes[:, 2:] + boxes[:, :2])/2, # cx, cy
+ boxes[:, 2:] - boxes[:, :2], 1) # w, h
+
+
+def intersect(box_a, box_b):
+ """ We resize both tensors to [A,B,2] without new malloc:
+ [A,2] -> [A,1,2] -> [A,B,2]
+ [B,2] -> [1,B,2] -> [A,B,2]
+ Then we compute the area of intersect between box_a and box_b.
+ Args:
+ box_a: (tensor) bounding boxes, Shape: [A,4].
+ box_b: (tensor) bounding boxes, Shape: [B,4].
+ Return:
+ (tensor) intersection area, Shape: [A,B].
+ """
+ A = box_a.size(0)
+ B = box_b.size(0)
+ max_xy = torch.min(box_a[:, 2:].unsqueeze(1).expand(A, B, 2),
+ box_b[:, 2:].unsqueeze(0).expand(A, B, 2))
+ min_xy = torch.max(box_a[:, :2].unsqueeze(1).expand(A, B, 2),
+ box_b[:, :2].unsqueeze(0).expand(A, B, 2))
+ inter = torch.clamp((max_xy - min_xy), min=0)
+ return inter[:, :, 0] * inter[:, :, 1]
+
+
+def jaccard(box_a, box_b):
+ """Compute the jaccard overlap of two sets of boxes. The jaccard overlap
+ is simply the intersection over union of two boxes. Here we operate on
+ ground truth boxes and default boxes.
+ E.g.:
+ A ∩ B / A ∪ B = A ∩ B / (area(A) + area(B) - A ∩ B)
+ Args:
+ box_a: (tensor) Ground truth bounding boxes, Shape: [num_objects,4]
+ box_b: (tensor) Prior boxes from priorbox layers, Shape: [num_priors,4]
+ Return:
+ jaccard overlap: (tensor) Shape: [box_a.size(0), box_b.size(0)]
+ """
+ inter = intersect(box_a, box_b)
+ area_a = ((box_a[:, 2]-box_a[:, 0]) *
+ (box_a[:, 3]-box_a[:, 1])).unsqueeze(1).expand_as(inter) # [A,B]
+ area_b = ((box_b[:, 2]-box_b[:, 0]) *
+ (box_b[:, 3]-box_b[:, 1])).unsqueeze(0).expand_as(inter) # [A,B]
+ union = area_a + area_b - inter
+ return inter / union # [A,B]
+
+
+def matrix_iou(a, b):
+ """
+ return iou of a and b, numpy version for data augenmentation
+ """
+ lt = np.maximum(a[:, np.newaxis, :2], b[:, :2])
+ rb = np.minimum(a[:, np.newaxis, 2:], b[:, 2:])
+
+ area_i = np.prod(rb - lt, axis=2) * (lt < rb).all(axis=2)
+ area_a = np.prod(a[:, 2:] - a[:, :2], axis=1)
+ area_b = np.prod(b[:, 2:] - b[:, :2], axis=1)
+ return area_i / (area_a[:, np.newaxis] + area_b - area_i)
+
+
+def matrix_iof(a, b):
+ """
+ return iof of a and b, numpy version for data augenmentation
+ """
+ lt = np.maximum(a[:, np.newaxis, :2], b[:, :2])
+ rb = np.minimum(a[:, np.newaxis, 2:], b[:, 2:])
+
+ area_i = np.prod(rb - lt, axis=2) * (lt < rb).all(axis=2)
+ area_a = np.prod(a[:, 2:] - a[:, :2], axis=1)
+ return area_i / np.maximum(area_a[:, np.newaxis], 1)
+
+
+def match(threshold, truths, priors, variances, labels, landms, loc_t, conf_t, landm_t, idx):
+ """Match each prior box with the ground truth box of the highest jaccard
+ overlap, encode the bounding boxes, then return the matched indices
+ corresponding to both confidence and location preds.
+ Args:
+ threshold: (float) The overlap threshold used when mathing boxes.
+ truths: (tensor) Ground truth boxes, Shape: [num_obj, 4].
+ priors: (tensor) Prior boxes from priorbox layers, Shape: [n_priors,4].
+ variances: (tensor) Variances corresponding to each prior coord,
+ Shape: [num_priors, 4].
+ labels: (tensor) All the class labels for the image, Shape: [num_obj].
+ landms: (tensor) Ground truth landms, Shape [num_obj, 10].
+ loc_t: (tensor) Tensor to be filled w/ endcoded location targets.
+ conf_t: (tensor) Tensor to be filled w/ matched indices for conf preds.
+ landm_t: (tensor) Tensor to be filled w/ endcoded landm targets.
+ idx: (int) current batch index
+ Return:
+ The matched indices corresponding to 1)location 2)confidence 3)landm preds.
+ """
+ # jaccard index
+ overlaps = jaccard(
+ truths,
+ point_form(priors)
+ )
+ # (Bipartite Matching)
+ # [1,num_objects] best prior for each ground truth
+ best_prior_overlap, best_prior_idx = overlaps.max(1, keepdim=True)
+
+ # ignore hard gt
+ valid_gt_idx = best_prior_overlap[:, 0] >= 0.2
+ best_prior_idx_filter = best_prior_idx[valid_gt_idx, :]
+ if best_prior_idx_filter.shape[0] <= 0:
+ loc_t[idx] = 0
+ conf_t[idx] = 0
+ return
+
+ # [1,num_priors] best ground truth for each prior
+ best_truth_overlap, best_truth_idx = overlaps.max(0, keepdim=True)
+ best_truth_idx.squeeze_(0)
+ best_truth_overlap.squeeze_(0)
+ best_prior_idx.squeeze_(1)
+ best_prior_idx_filter.squeeze_(1)
+ best_prior_overlap.squeeze_(1)
+ best_truth_overlap.index_fill_(0, best_prior_idx_filter, 2) # ensure best prior
+ # TODO refactor: index best_prior_idx with long tensor
+ # ensure every gt matches with its prior of max overlap
+ for j in range(best_prior_idx.size(0)): # 判别此anchor是预测哪一个boxes
+ best_truth_idx[best_prior_idx[j]] = j
+ matches = truths[best_truth_idx] # Shape: [num_priors,4] 此处为每一个anchor对应的bbox取出来
+ conf = labels[best_truth_idx] # Shape: [num_priors] 此处为每一个anchor对应的label取出来
+ conf[best_truth_overlap < threshold] = 0 # label as background overlap<0.35的全部作为负样本
+ loc = encode(matches, priors, variances)
+
+ matches_landm = landms[best_truth_idx]
+ landm = encode_landm(matches_landm, priors, variances)
+ loc_t[idx] = loc # [num_priors,4] encoded offsets to learn
+ conf_t[idx] = conf # [num_priors] top class label for each prior
+ landm_t[idx] = landm
+
+
+def encode(matched, priors, variances):
+ """Encode the variances from the priorbox layers into the ground truth boxes
+ we have matched (based on jaccard overlap) with the prior boxes.
+ Args:
+ matched: (tensor) Coords of ground truth for each prior in point-form
+ Shape: [num_priors, 4].
+ priors: (tensor) Prior boxes in center-offset form
+ Shape: [num_priors,4].
+ variances: (list[float]) Variances of priorboxes
+ Return:
+ encoded boxes (tensor), Shape: [num_priors, 4]
+ """
+
+ # dist b/t match center and prior's center
+ g_cxcy = (matched[:, :2] + matched[:, 2:])/2 - priors[:, :2]
+ # encode variance
+ g_cxcy /= (variances[0] * priors[:, 2:])
+ # match wh / prior wh
+ g_wh = (matched[:, 2:] - matched[:, :2]) / priors[:, 2:]
+ g_wh = torch.log(g_wh) / variances[1]
+ # return target for smooth_l1_loss
+ return torch.cat([g_cxcy, g_wh], 1) # [num_priors,4]
+
+def encode_landm(matched, priors, variances):
+ """Encode the variances from the priorbox layers into the ground truth boxes
+ we have matched (based on jaccard overlap) with the prior boxes.
+ Args:
+ matched: (tensor) Coords of ground truth for each prior in point-form
+ Shape: [num_priors, 10].
+ priors: (tensor) Prior boxes in center-offset form
+ Shape: [num_priors,4].
+ variances: (list[float]) Variances of priorboxes
+ Return:
+ encoded landm (tensor), Shape: [num_priors, 10]
+ """
+
+ # dist b/t match center and prior's center
+ matched = torch.reshape(matched, (matched.size(0), 5, 2))
+ priors_cx = priors[:, 0].unsqueeze(1).expand(matched.size(0), 5).unsqueeze(2)
+ priors_cy = priors[:, 1].unsqueeze(1).expand(matched.size(0), 5).unsqueeze(2)
+ priors_w = priors[:, 2].unsqueeze(1).expand(matched.size(0), 5).unsqueeze(2)
+ priors_h = priors[:, 3].unsqueeze(1).expand(matched.size(0), 5).unsqueeze(2)
+ priors = torch.cat([priors_cx, priors_cy, priors_w, priors_h], dim=2)
+ g_cxcy = matched[:, :, :2] - priors[:, :, :2]
+ # encode variance
+ g_cxcy /= (variances[0] * priors[:, :, 2:])
+ # g_cxcy /= priors[:, :, 2:]
+ g_cxcy = g_cxcy.reshape(g_cxcy.size(0), -1)
+ # return target for smooth_l1_loss
+ return g_cxcy
+
+
+# Adapted from https://github.com/Hakuyume/chainer-ssd
+def decode(loc, priors, variances):
+ """Decode locations from predictions using priors to undo
+ the encoding we did for offset regression at train time.
+ Args:
+ loc (tensor): location predictions for loc layers,
+ Shape: [num_priors,4]
+ priors (tensor): Prior boxes in center-offset form.
+ Shape: [num_priors,4].
+ variances: (list[float]) Variances of priorboxes
+ Return:
+ decoded bounding box predictions
+ """
+
+ boxes = torch.cat((
+ priors[:, :2] + loc[:, :2] * variances[0] * priors[:, 2:],
+ priors[:, 2:] * torch.exp(loc[:, 2:] * variances[1])), 1)
+ boxes[:, :2] -= boxes[:, 2:] / 2
+ boxes[:, 2:] += boxes[:, :2]
+ return boxes
+
+def decode_landm(pre, priors, variances):
+ """Decode landm from predictions using priors to undo
+ the encoding we did for offset regression at train time.
+ Args:
+ pre (tensor): landm predictions for loc layers,
+ Shape: [num_priors,10]
+ priors (tensor): Prior boxes in center-offset form.
+ Shape: [num_priors,4].
+ variances: (list[float]) Variances of priorboxes
+ Return:
+ decoded landm predictions
+ """
+ landms = torch.cat((priors[:, :2] + pre[:, :2] * variances[0] * priors[:, 2:],
+ priors[:, :2] + pre[:, 2:4] * variances[0] * priors[:, 2:],
+ priors[:, :2] + pre[:, 4:6] * variances[0] * priors[:, 2:],
+ priors[:, :2] + pre[:, 6:8] * variances[0] * priors[:, 2:],
+ priors[:, :2] + pre[:, 8:10] * variances[0] * priors[:, 2:],
+ ), dim=1)
+ return landms
+
+
+def log_sum_exp(x):
+ """Utility function for computing log_sum_exp while determining
+ This will be used to determine unaveraged confidence loss across
+ all examples in a batch.
+ Args:
+ x (Variable(tensor)): conf_preds from conf layers
+ """
+ x_max = x.data.max()
+ return torch.log(torch.sum(torch.exp(x-x_max), 1, keepdim=True)) + x_max
+
+
+# Original author: Francisco Massa:
+# https://github.com/fmassa/object-detection.torch
+# Ported to PyTorch by Max deGroot (02/01/2017)
+def nms(boxes, scores, overlap=0.5, top_k=200):
+ """Apply non-maximum suppression at test time to avoid detecting too many
+ overlapping bounding boxes for a given object.
+ Args:
+ boxes: (tensor) The location preds for the img, Shape: [num_priors,4].
+ scores: (tensor) The class predscores for the img, Shape:[num_priors].
+ overlap: (float) The overlap thresh for suppressing unnecessary boxes.
+ top_k: (int) The Maximum number of box preds to consider.
+ Return:
+ The indices of the kept boxes with respect to num_priors.
+ """
+
+ keep = torch.Tensor(scores.size(0)).fill_(0).long()
+ if boxes.numel() == 0:
+ return keep
+ x1 = boxes[:, 0]
+ y1 = boxes[:, 1]
+ x2 = boxes[:, 2]
+ y2 = boxes[:, 3]
+ area = torch.mul(x2 - x1, y2 - y1)
+ v, idx = scores.sort(0) # sort in ascending order
+ # I = I[v >= 0.01]
+ idx = idx[-top_k:] # indices of the top-k largest vals
+ xx1 = boxes.new()
+ yy1 = boxes.new()
+ xx2 = boxes.new()
+ yy2 = boxes.new()
+ w = boxes.new()
+ h = boxes.new()
+
+ # keep = torch.Tensor()
+ count = 0
+ while idx.numel() > 0:
+ i = idx[-1] # index of current largest val
+ # keep.append(i)
+ keep[count] = i
+ count += 1
+ if idx.size(0) == 1:
+ break
+ idx = idx[:-1] # remove kept element from view
+ # load bboxes of next highest vals
+ torch.index_select(x1, 0, idx, out=xx1)
+ torch.index_select(y1, 0, idx, out=yy1)
+ torch.index_select(x2, 0, idx, out=xx2)
+ torch.index_select(y2, 0, idx, out=yy2)
+ # store element-wise max with next highest score
+ xx1 = torch.clamp(xx1, min=x1[i])
+ yy1 = torch.clamp(yy1, min=y1[i])
+ xx2 = torch.clamp(xx2, max=x2[i])
+ yy2 = torch.clamp(yy2, max=y2[i])
+ w.resize_as_(xx2)
+ h.resize_as_(yy2)
+ w = xx2 - xx1
+ h = yy2 - yy1
+ # check sizes of xx1 and xx2.. after each iteration
+ w = torch.clamp(w, min=0.0)
+ h = torch.clamp(h, min=0.0)
+ inter = w*h
+ # IoU = i / (area(a) + area(b) - i)
+ rem_areas = torch.index_select(area, 0, idx) # load remaining areas)
+ union = (rem_areas - inter) + area[i]
+ IoU = inter/union # store result in iou
+ # keep only elements with an IoU <= overlap
+ idx = idx[IoU.le(overlap)]
+ return keep, count
+
+
diff --git a/KAIR/retinaface/utils_faces/nms/__init__.py b/KAIR/retinaface/utils_faces/nms/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..8b137891791fe96927ad78e64b0aad7bded08bdc
--- /dev/null
+++ b/KAIR/retinaface/utils_faces/nms/__init__.py
@@ -0,0 +1 @@
+
diff --git a/KAIR/retinaface/utils_faces/nms/py_cpu_nms.py b/KAIR/retinaface/utils_faces/nms/py_cpu_nms.py
new file mode 100644
index 0000000000000000000000000000000000000000..54e7b25fef72b518df6dcf8d6fb78b986796c6e3
--- /dev/null
+++ b/KAIR/retinaface/utils_faces/nms/py_cpu_nms.py
@@ -0,0 +1,38 @@
+# --------------------------------------------------------
+# Fast R-CNN
+# Copyright (c) 2015 Microsoft
+# Licensed under The MIT License [see LICENSE for details]
+# Written by Ross Girshick
+# --------------------------------------------------------
+
+import numpy as np
+
+def py_cpu_nms(dets, thresh):
+ """Pure Python NMS baseline."""
+ x1 = dets[:, 0]
+ y1 = dets[:, 1]
+ x2 = dets[:, 2]
+ y2 = dets[:, 3]
+ scores = dets[:, 4]
+
+ areas = (x2 - x1 + 1) * (y2 - y1 + 1)
+ order = scores.argsort()[::-1]
+
+ keep = []
+ while order.size > 0:
+ i = order[0]
+ keep.append(i)
+ xx1 = np.maximum(x1[i], x1[order[1:]])
+ yy1 = np.maximum(y1[i], y1[order[1:]])
+ xx2 = np.minimum(x2[i], x2[order[1:]])
+ yy2 = np.minimum(y2[i], y2[order[1:]])
+
+ w = np.maximum(0.0, xx2 - xx1 + 1)
+ h = np.maximum(0.0, yy2 - yy1 + 1)
+ inter = w * h
+ ovr = inter / (areas[i] + areas[order[1:]] - inter)
+
+ inds = np.where(ovr <= thresh)[0]
+ order = order[inds + 1]
+
+ return keep
diff --git a/KAIR/retinaface/utils_faces/timer.py b/KAIR/retinaface/utils_faces/timer.py
new file mode 100644
index 0000000000000000000000000000000000000000..e4b3b8098a5ad41f8d18d42b6b2fedb694aa5508
--- /dev/null
+++ b/KAIR/retinaface/utils_faces/timer.py
@@ -0,0 +1,40 @@
+# --------------------------------------------------------
+# Fast R-CNN
+# Copyright (c) 2015 Microsoft
+# Licensed under The MIT License [see LICENSE for details]
+# Written by Ross Girshick
+# --------------------------------------------------------
+
+import time
+
+
+class Timer(object):
+ """A simple timer."""
+ def __init__(self):
+ self.total_time = 0.
+ self.calls = 0
+ self.start_time = 0.
+ self.diff = 0.
+ self.average_time = 0.
+
+ def tic(self):
+ # using time.time instead of time.clock because time time.clock
+ # does not normalize for multithreading
+ self.start_time = time.time()
+
+ def toc(self, average=True):
+ self.diff = time.time() - self.start_time
+ self.total_time += self.diff
+ self.calls += 1
+ self.average_time = self.total_time / self.calls
+ if average:
+ return self.average_time
+ else:
+ return self.diff
+
+ def clear(self):
+ self.total_time = 0.
+ self.calls = 0
+ self.start_time = 0.
+ self.diff = 0.
+ self.average_time = 0.
diff --git a/KAIR/scripts/data_preparation/create_lmdb.py b/KAIR/scripts/data_preparation/create_lmdb.py
new file mode 100755
index 0000000000000000000000000000000000000000..8738b8134122aafd306b5e882c415f5036ce4d47
--- /dev/null
+++ b/KAIR/scripts/data_preparation/create_lmdb.py
@@ -0,0 +1,400 @@
+import argparse
+from os import path as osp
+
+from utils.utils_video import scandir
+from utils.utils_lmdb import make_lmdb_from_imgs
+
+
+def create_lmdb_for_div2k():
+ """Create lmdb files for DIV2K dataset.
+
+ Usage:
+ Before run this script, please run `extract_subimages.py`.
+ Typically, there are four folders to be processed for DIV2K dataset.
+ DIV2K_train_HR_sub
+ DIV2K_train_LR_bicubic/X2_sub
+ DIV2K_train_LR_bicubic/X3_sub
+ DIV2K_train_LR_bicubic/X4_sub
+ Remember to modify opt configurations according to your settings.
+ """
+ # HR images
+ folder_path = 'trainsets/DIV2K/DIV2K_train_HR_sub'
+ lmdb_path = 'trainsets/DIV2K/DIV2K_train_HR_sub.lmdb'
+ img_path_list, keys = prepare_keys_div2k(folder_path)
+ make_lmdb_from_imgs(folder_path, lmdb_path, img_path_list, keys)
+
+ # LRx2 images
+ folder_path = 'trainsets/DIV2K/DIV2K_train_LR_bicubic/X2_sub'
+ lmdb_path = 'trainsets/DIV2K/DIV2K_train_LR_bicubic_X2_sub.lmdb'
+ img_path_list, keys = prepare_keys_div2k(folder_path)
+ make_lmdb_from_imgs(folder_path, lmdb_path, img_path_list, keys)
+
+ # LRx3 images
+ folder_path = 'trainsets/DIV2K/DIV2K_train_LR_bicubic/X3_sub'
+ lmdb_path = 'trainsets/DIV2K/DIV2K_train_LR_bicubic_X3_sub.lmdb'
+ img_path_list, keys = prepare_keys_div2k(folder_path)
+ make_lmdb_from_imgs(folder_path, lmdb_path, img_path_list, keys)
+
+ # LRx4 images
+ folder_path = 'trainsets/DIV2K/DIV2K_train_LR_bicubic/X4_sub'
+ lmdb_path = 'trainsets/DIV2K/DIV2K_train_LR_bicubic_X4_sub.lmdb'
+ img_path_list, keys = prepare_keys_div2k(folder_path)
+ make_lmdb_from_imgs(folder_path, lmdb_path, img_path_list, keys)
+
+
+def prepare_keys_div2k(folder_path):
+ """Prepare image path list and keys for DIV2K dataset.
+
+ Args:
+ folder_path (str): Folder path.
+
+ Returns:
+ list[str]: Image path list.
+ list[str]: Key list.
+ """
+ print('Reading image path list ...')
+ img_path_list = sorted(list(scandir(folder_path, suffix='png', recursive=False)))
+ keys = [img_path.split('.png')[0] for img_path in sorted(img_path_list)]
+
+ return img_path_list, keys
+
+
+def create_lmdb_for_reds():
+ """Create lmdb files for REDS dataset.
+
+ Usage:
+ Before run this script, please run `regroup_reds_dataset.py`.
+ We take three folders for example:
+ train_sharp
+ train_sharp_bicubic
+ train_blur (for video deblurring)
+ Remember to modify opt configurations according to your settings.
+ """
+ # train_sharp
+ folder_path = 'trainsets/REDS/train_sharp'
+ lmdb_path = 'trainsets/REDS/train_sharp_with_val.lmdb'
+ img_path_list, keys = prepare_keys_reds(folder_path)
+ make_lmdb_from_imgs(folder_path, lmdb_path, img_path_list, keys, multiprocessing_read=True)
+
+ # train_sharp_bicubic
+ folder_path = 'trainsets/REDS/train_sharp_bicubic'
+ lmdb_path = 'trainsets/REDS/train_sharp_bicubic_with_val.lmdb'
+ img_path_list, keys = prepare_keys_reds(folder_path)
+ make_lmdb_from_imgs(folder_path, lmdb_path, img_path_list, keys, multiprocessing_read=True)
+
+ # train_blur (for video deblurring)
+ folder_path = 'trainsets/REDS_blur/train_blur'
+ lmdb_path = 'trainsets/REDS_blur/train_blur_with_val.lmdb'
+ img_path_list, keys = prepare_keys_reds(folder_path)
+ make_lmdb_from_imgs(folder_path, lmdb_path, img_path_list, keys, multiprocessing_read=True)
+
+ # train_blur_bicubic (for video deblurring-sr)
+ folder_path = 'trainsets/REDS_blur_bicubic/train_blur_bicubic'
+ lmdb_path = 'trainsets/REDS_blur_bicubic/train_blur_bicubic_with_val.lmdb'
+ img_path_list, keys = prepare_keys_reds(folder_path)
+ make_lmdb_from_imgs(folder_path, lmdb_path, img_path_list, keys, multiprocessing_read=True)
+
+
+def prepare_keys_reds(folder_path):
+ """Prepare image path list and keys for REDS dataset.
+
+ Args:
+ folder_path (str): Folder path.
+
+ Returns:
+ list[str]: Image path list.
+ list[str]: Key list.
+ """
+ print('Reading image path list ...')
+ img_path_list = sorted(list(scandir(folder_path, suffix='png', recursive=True)))
+ keys = [v.split('.png')[0] for v in img_path_list] # example: 000/00000000
+
+ return img_path_list, keys
+
+
+def create_lmdb_for_vimeo90k():
+ """Create lmdb files for Vimeo90K dataset.
+
+ Usage:
+ Remember to modify opt configurations according to your settings.
+ """
+ # GT
+ folder_path = 'trainsets/vimeo90k/vimeo_septuplet/sequences'
+ lmdb_path = 'trainsets/vimeo90k/vimeo90k_train_GT_only4th.lmdb'
+ train_list_path = 'trainsets/vimeo90k/vimeo_septuplet/sep_trainlist.txt'
+ img_path_list, keys = prepare_keys_vimeo90k(folder_path, train_list_path, 'gt')
+ make_lmdb_from_imgs(folder_path, lmdb_path, img_path_list, keys, multiprocessing_read=True)
+
+ # LQ
+ folder_path = 'trainsets/vimeo90k/vimeo_septuplet_matlabLRx4/sequences'
+ lmdb_path = 'trainsets/vimeo90k/vimeo90k_train_LR7frames.lmdb'
+ train_list_path = 'trainsets/vimeo90k/vimeo_septuplet/sep_trainlist.txt'
+ img_path_list, keys = prepare_keys_vimeo90k(folder_path, train_list_path, 'lq')
+ make_lmdb_from_imgs(folder_path, lmdb_path, img_path_list, keys, multiprocessing_read=True)
+
+
+def create_lmdb_for_vimeo90k_bd():
+ """Create lmdb files for Vimeo90K dataset (blur-downsampled lr only).
+
+ Usage:
+ Remember to modify opt configurations according to your settings.
+ """
+ # LQ (blur-downsampled, BD)
+ folder_path = 'trainsets/vimeo90k/vimeo_septuplet_BDLRx4/sequences'
+ lmdb_path = 'trainsets/vimeo90k/vimeo90k_train_BDLR7frames.lmdb'
+ train_list_path = 'trainsets/vimeo90k/vimeo_septuplet/sep_trainlist.txt'
+ img_path_list, keys = prepare_keys_vimeo90k(folder_path, train_list_path, 'lq')
+ make_lmdb_from_imgs(folder_path, lmdb_path, img_path_list, keys, multiprocessing_read=True)
+
+
+def prepare_keys_vimeo90k(folder_path, train_list_path, mode):
+ """Prepare image path list and keys for Vimeo90K dataset.
+
+ Args:
+ folder_path (str): Folder path.
+ train_list_path (str): Path to the official train list.
+ mode (str): One of 'gt' or 'lq'.
+
+ Returns:
+ list[str]: Image path list.
+ list[str]: Key list.
+ """
+ print('Reading image path list ...')
+ with open(train_list_path, 'r') as fin:
+ train_list = [line.strip() for line in fin]
+
+ img_path_list = []
+ keys = []
+ for line in train_list:
+ folder, sub_folder = line.split('/')
+ img_path_list.extend([osp.join(folder, sub_folder, f'im{j + 1}.png') for j in range(7)])
+ keys.extend([f'{folder}/{sub_folder}/im{j + 1}' for j in range(7)])
+
+ if mode == 'gt':
+ print('Only keep the 4th frame for the gt mode.')
+ img_path_list = [v for v in img_path_list if v.endswith('im4.png')]
+ keys = [v for v in keys if v.endswith('/im4')]
+
+ return img_path_list, keys
+
+
+def create_lmdb_for_dvd():
+ """Create lmdb files for DVD dataset.
+
+ Usage:
+ We take two folders for example:
+ GT
+ input
+ Remember to modify opt configurations according to your settings.
+ """
+ # train_sharp
+ folder_path = 'trainsets/DVD/train_GT'
+ lmdb_path = 'trainsets/DVD/train_GT.lmdb'
+ img_path_list, keys = prepare_keys_dvd(folder_path)
+ make_lmdb_from_imgs(folder_path, lmdb_path, img_path_list, keys, multiprocessing_read=True)
+
+ # train_sharp_bicubic
+ folder_path = 'trainsets/DVD/train_GT_blurred'
+ lmdb_path = 'trainsets/DVD/train_GT_blurred.lmdb'
+ img_path_list, keys = prepare_keys_dvd(folder_path)
+ make_lmdb_from_imgs(folder_path, lmdb_path, img_path_list, keys, multiprocessing_read=True)
+
+
+def prepare_keys_dvd(folder_path):
+ """Prepare image path list and keys for DVD dataset.
+
+ Args:
+ folder_path (str): Folder path.
+
+ Returns:
+ list[str]: Image path list.
+ list[str]: Key list.
+ """
+ print('Reading image path list ...')
+ img_path_list = sorted(list(scandir(folder_path, suffix='jpg', recursive=True)))
+ keys = [v.split('.jpg')[0] for v in img_path_list] # example: 000/00000000
+
+ return img_path_list, keys
+
+
+def create_lmdb_for_gopro():
+ """Create lmdb files for GoPro dataset.
+
+ Usage:
+ We take two folders for example:
+ GT
+ input
+ Remember to modify opt configurations according to your settings.
+ """
+ # train_sharp
+ folder_path = 'trainsets/GoPro/train_GT'
+ lmdb_path = 'trainsets/GoPro/train_GT.lmdb'
+ img_path_list, keys = prepare_keys_gopro(folder_path)
+ make_lmdb_from_imgs(folder_path, lmdb_path, img_path_list, keys, multiprocessing_read=True)
+
+ # train_sharp_bicubic
+ folder_path = 'trainsets/GoPro/train_GT_blurred'
+ lmdb_path = 'trainsets/GoPro/train_GT_blurred.lmdb'
+ img_path_list, keys = prepare_keys_gopro(folder_path)
+ make_lmdb_from_imgs(folder_path, lmdb_path, img_path_list, keys, multiprocessing_read=True)
+
+
+def prepare_keys_gopro(folder_path):
+ """Prepare image path list and keys for GoPro dataset.
+
+ Args:
+ folder_path (str): Folder path.
+
+ Returns:
+ list[str]: Image path list.
+ list[str]: Key list.
+ """
+ print('Reading image path list ...')
+ img_path_list = sorted(list(scandir(folder_path, suffix='png', recursive=True)))
+ keys = [v.split('.png')[0] for v in img_path_list] # example: 000/00000000
+
+ return img_path_list, keys
+
+
+def create_lmdb_for_davis():
+ """Create lmdb files for DAVIS dataset.
+
+ Usage:
+ We take one folders for example:
+ GT
+ Remember to modify opt configurations according to your settings.
+ """
+ # train_sharp
+ folder_path = 'trainsets/DAVIS/train_GT'
+ lmdb_path = 'trainsets/DAVIS/train_GT.lmdb'
+ img_path_list, keys = prepare_keys_davis(folder_path)
+ make_lmdb_from_imgs(folder_path, lmdb_path, img_path_list, keys, multiprocessing_read=True)
+
+
+def prepare_keys_davis(folder_path):
+ """Prepare image path list and keys for DAVIS dataset.
+
+ Args:
+ folder_path (str): Folder path.
+
+ Returns:
+ list[str]: Image path list.
+ list[str]: Key list.
+ """
+ print('Reading image path list ...')
+ img_path_list = sorted(list(scandir(folder_path, suffix='jpg', recursive=True)))
+ keys = [v.split('.jpg')[0] for v in img_path_list] # example: 000/00000000
+
+ return img_path_list, keys
+
+
+
+def create_lmdb_for_ldv():
+ """Create lmdb files for LDV dataset.
+
+ Usage:
+ We take two folders for example:
+ GT
+ input
+ Remember to modify opt configurations according to your settings.
+ """
+ # training_raw
+ folder_path = 'trainsets/LDV/training_raw'
+ lmdb_path = 'trainsets/LDV/training_raw.lmdb'
+ img_path_list, keys = prepare_keys_ldv(folder_path)
+ make_lmdb_from_imgs(folder_path, lmdb_path, img_path_list, keys, multiprocessing_read=True)
+
+ # training_fixed-QP
+ folder_path = 'trainsets/LDV/training_fixed-QP'
+ lmdb_path = 'trainsets/LDV/training_fixed-QP.lmdb'
+ img_path_list, keys = prepare_keys_ldv(folder_path)
+ make_lmdb_from_imgs(folder_path, lmdb_path, img_path_list, keys, multiprocessing_read=True)
+
+ # training_fixed-rate
+ folder_path = 'trainsets/LDV/training_fixed-rate'
+ lmdb_path = 'trainsets/LDV/training_fixed-rate.lmdb'
+ img_path_list, keys = prepare_keys_ldv(folder_path)
+ make_lmdb_from_imgs(folder_path, lmdb_path, img_path_list, keys, multiprocessing_read=True)
+
+
+def prepare_keys_ldv(folder_path):
+ """Prepare image path list and keys for LDV dataset.
+
+ Args:
+ folder_path (str): Folder path.
+
+ Returns:
+ list[str]: Image path list.
+ list[str]: Key list.
+ """
+ print('Reading image path list ...')
+ img_path_list = sorted(list(scandir(folder_path, suffix='png', recursive=True)))
+ keys = [v.split('.png')[0] for v in img_path_list] # example: 000/00000000
+
+ return img_path_list, keys
+
+
+def create_lmdb_for_reds_orig():
+ """Create lmdb files for REDS_orig dataset (120 fps).
+
+ Usage:
+ Before run this script, please run `regroup_reds_dataset.py`.
+ We take one folders for example:
+ train_orig
+ Remember to modify opt configurations according to your settings.
+ """
+ # train_sharp
+ folder_path = 'trainsets/REDS_orig/train_orig'
+ lmdb_path = 'trainsets/REDS_orig/train_orig_with_val.lmdb'
+ img_path_list, keys = prepare_keys_reds_orig(folder_path)
+ make_lmdb_from_imgs(folder_path, lmdb_path, img_path_list, keys, multiprocessing_read=True)
+
+
+def prepare_keys_reds_orig(folder_path):
+ """Prepare image path list and keys for REDS_orig dataset (120 fps).
+
+ Args:
+ folder_path (str): Folder path.
+
+ Returns:
+ list[str]: Image path list.
+ list[str]: Key list.
+ """
+ print('Reading image path list ...')
+ img_path_list = sorted(list(scandir(folder_path, suffix='png', recursive=True)))
+ keys = [v.split('.png')[0] for v in img_path_list] # example: 000/00000000
+
+ return img_path_list, keys
+
+
+if __name__ == '__main__':
+ parser = argparse.ArgumentParser()
+
+ parser.add_argument(
+ '--dataset',
+ type=str,
+ help=("Options: 'DIV2K', 'REDS', 'Vimeo90K', 'Vimeo90K_BD', 'DVD', 'GoPro',"
+ "'DAVIS', 'LDV', 'REDS_orig' "
+ 'You may need to modify the corresponding configurations in codes.'))
+ args = parser.parse_args()
+ dataset = args.dataset.lower()
+ if dataset == 'div2k':
+ create_lmdb_for_div2k()
+ elif dataset == 'reds':
+ create_lmdb_for_reds()
+ elif dataset == 'vimeo90k':
+ create_lmdb_for_vimeo90k()
+ elif dataset == 'vimeo90k_bd':
+ create_lmdb_for_vimeo90k_bd()
+ elif dataset == 'dvd':
+ create_lmdb_for_dvd()
+ elif dataset == 'gopro':
+ create_lmdb_for_gopro()
+ elif dataset == 'davis':
+ create_lmdb_for_davis()
+ elif dataset == 'ldv':
+ create_lmdb_for_ldv()
+ elif dataset == 'reds_orig':
+ create_lmdb_for_reds_orig()
+ else:
+ raise ValueError('Wrong dataset.')
diff --git a/KAIR/scripts/data_preparation/prepare_DAVIS.py b/KAIR/scripts/data_preparation/prepare_DAVIS.py
new file mode 100644
index 0000000000000000000000000000000000000000..b84fc6576b6ba3d15616114316c961acb46fc604
--- /dev/null
+++ b/KAIR/scripts/data_preparation/prepare_DAVIS.py
@@ -0,0 +1,33 @@
+import os
+import glob
+import shutil
+
+
+def generate_meta_info_txt(data_path, meta_info_path):
+ '''generate meta_info_DAVIS_GT.txt for DAVIS
+
+ :param data_path: dataset path.
+ :return: None
+ '''
+ f= open(meta_info_path, "w+")
+ file_list = sorted(glob.glob(os.path.join(data_path, 'train_GT/*')))
+ total_frames = 0
+ for path in file_list:
+ name = os.path.basename(path)
+ frames = sorted(glob.glob(os.path.join(path, '*')))
+ start_frame = os.path.basename(frames[0]).split('.')[0]
+
+ print(name, len(frames), start_frame)
+ total_frames += len(frames)
+
+ f.write(f"{name} {len(frames)} (480,854,3) {start_frame}\r\n")
+
+ assert total_frames == 6208, f'DAVIS training set should have 6208 images, but got {total_frames} images'
+
+if __name__ == '__main__':
+
+ dataset_path = 'trainsets/DAVIS'
+
+ generate_meta_info_txt(dataset_path, 'data/meta_info/meta_info_DAVIS_GT.txt')
+
+
diff --git a/KAIR/scripts/data_preparation/prepare_DVD.py b/KAIR/scripts/data_preparation/prepare_DVD.py
new file mode 100644
index 0000000000000000000000000000000000000000..51ed65e15521bd0ddc4d40e3793902a339fa4478
--- /dev/null
+++ b/KAIR/scripts/data_preparation/prepare_DVD.py
@@ -0,0 +1,59 @@
+import os
+import glob
+import shutil
+
+
+def rearrange_dir_structure(dataset_path):
+ '''move files to follow the directory structure as REDS
+
+ Original DVD dataset is organized as DVD/quantitative_datasets/720p_240fps_1/GT/00000.jpg.
+ We move files and organize them as DVD/train_GT_with_val/720p_240fps_1/00000.jpg (similar to REDS).
+
+ :param dataset_path: dataset path
+ :return: None
+ '''
+ os.makedirs(os.path.join(dataset_path, 'train_GT_with_val'), exist_ok=True)
+ os.makedirs(os.path.join(dataset_path, 'train_GT_blurred_with_val'), exist_ok=True)
+
+ file_list = sorted(glob.glob(os.path.join(dataset_path, '*')))
+ for path in file_list:
+ if 'train_GT_with_val' in path or 'train_GT_blurred_with_val' in path:
+ continue
+ name = os.path.basename(path)
+ print(name)
+
+ shutil.move(os.path.join(path, 'GT'), os.path.join(f'{dataset_path}/train_GT_with_val', name))
+ shutil.move(os.path.join(path, 'input'), os.path.join(f'{dataset_path}/train_GT_blurred_with_val', name))
+ shutil.rmtree(path)
+
+
+def generate_meta_info_txt(data_path, meta_info_path):
+ '''generate meta_info_DVD_GT.txt for DVD
+
+ :param data_path: dataset path.
+ :return: None
+ '''
+ f= open(meta_info_path, "w+")
+ file_list = sorted(glob.glob(os.path.join(data_path, 'train_GT_with_val/*')))
+ total_frames = 0
+ for path in file_list:
+ name = os.path.basename(path)
+ frames = sorted(glob.glob(os.path.join(path, '*')))
+ start_frame = os.path.basename(frames[0]).split('.')[0]
+
+ print(name, len(frames), start_frame)
+ total_frames += len(frames)
+
+ f.write(f"{name} {len(frames)} (720,1280,3) {start_frame}\r\n")
+
+ assert total_frames == 6708, f'DVD training+Validation set should have 6708 images, but got {total_frames} images'
+
+
+if __name__ == '__main__':
+
+ dataset_path = 'trainsets/DeepVideoDeblurring_Dataset/quantitative_datasets'
+
+ rearrange_dir_structure(dataset_path)
+ generate_meta_info_txt(dataset_path, 'data/meta_info/meta_info_DVD_GT.txt')
+
+
diff --git a/KAIR/scripts/data_preparation/prepare_GoPro_as_video.py b/KAIR/scripts/data_preparation/prepare_GoPro_as_video.py
new file mode 100644
index 0000000000000000000000000000000000000000..e28cad953617e0c8c239e79ccc15228cc337add7
--- /dev/null
+++ b/KAIR/scripts/data_preparation/prepare_GoPro_as_video.py
@@ -0,0 +1,58 @@
+import os
+import glob
+import shutil
+
+
+def rearrange_dir_structure(dataset_path, traintest='train'):
+ '''move files to follow the directory structure as REDS
+
+ Original GoPro dataset is organized as GoPro/train/GOPR0854_11_00-000022.png
+ We move files and organize them as GoPro/train_GT/GOPR0854_11_00/000022.jpg (similar to REDS).
+
+ :param dataset_path: dataset path
+ :return: None
+ '''
+ os.makedirs(os.path.join(dataset_path, f'{traintest}_GT'), exist_ok=True)
+ os.makedirs(os.path.join(dataset_path, f'{traintest}_GT_blurred'), exist_ok=True)
+
+ file_list = sorted(glob.glob(os.path.join(f'{dataset_path}/{traintest}', '*')))
+ for path in file_list:
+ name = os.path.basename(path)
+ print(name)
+
+ shutil.move(os.path.join(path, 'sharp'), os.path.join(f'{dataset_path}/{traintest}_GT', name))
+ shutil.move(os.path.join(path, 'blur'), os.path.join(f'{dataset_path}/{traintest}_GT_blurred', name))
+
+ shutil.rmtree(os.path.join(dataset_path, traintest))
+
+
+def generate_meta_info_txt(data_path, meta_info_path):
+ '''generate meta_info_GoPro_GT.txt for GoPro
+
+ :param data_path: dataset path.
+ :return: None
+ '''
+ f= open(meta_info_path, "w+")
+ file_list = sorted(glob.glob(os.path.join(data_path, 'train_GT/*')))
+ total_frames = 0
+ for path in file_list:
+ name = os.path.basename(path)
+ frames = sorted(glob.glob(os.path.join(path, '*')))
+ start_frame = os.path.basename(frames[0]).split('.')[0]
+
+ print(name, len(frames), start_frame)
+ total_frames += len(frames)
+
+ f.write(f"{name} {len(frames)} (720,1280,3) {start_frame}\r\n")
+
+ assert total_frames == 2103, f'GoPro training set should have 2103 images, but got {total_frames} images'
+
+if __name__ == '__main__':
+
+ dataset_path = 'trainsets/GoPro'
+
+ rearrange_dir_structure(dataset_path, 'train')
+ rearrange_dir_structure(dataset_path, 'test')
+ generate_meta_info_txt(dataset_path, 'data/meta_info/meta_info_GoPro_GT.txt')
+
+
diff --git a/KAIR/scripts/data_preparation/prepare_UDM10.py b/KAIR/scripts/data_preparation/prepare_UDM10.py
new file mode 100644
index 0000000000000000000000000000000000000000..6cc5d0ef3b9611136cc8c299bd59776eaf4bd207
--- /dev/null
+++ b/KAIR/scripts/data_preparation/prepare_UDM10.py
@@ -0,0 +1,36 @@
+import os
+import glob
+import shutil
+
+
+def rearrange_dir_structure(dataset_path):
+ '''move files to follow the directory structure as REDS
+
+ Original DVD dataset is organized as DVD/quantitative_datasets/720p_240fps_1/GT/00000.jpg.
+ We move files and organize them as DVD/train_GT_with_val/720p_240fps_1/00000.jpg (similar to REDS).
+
+ :param dataset_path: dataset path
+ :return: None
+ '''
+ os.makedirs(os.path.join(dataset_path, 'GT'), exist_ok=True)
+ os.makedirs(os.path.join(dataset_path, 'BDx4'), exist_ok=True)
+
+ file_list = sorted(glob.glob(os.path.join(dataset_path, '*')))
+ for path in file_list:
+ if 'GT' in path or 'BDx4' in path:
+ continue
+ name = os.path.basename(path)
+ print(name)
+
+ shutil.move(os.path.join(path, 'truth'), os.path.join(f'{dataset_path}/GT', name))
+ shutil.move(os.path.join(path, 'blur4'), os.path.join(f'{dataset_path}/BDx4', name))
+ shutil.rmtree(path)
+
+
+if __name__ == '__main__':
+
+ dataset_path = 'trainsets/UDM10'
+
+ rearrange_dir_structure(dataset_path)
+
+
diff --git a/KAIR/scripts/data_preparation/regroup_reds_dataset.py b/KAIR/scripts/data_preparation/regroup_reds_dataset.py
new file mode 100755
index 0000000000000000000000000000000000000000..b607982bc51acd1c16892f24cf209c4f62ee93c8
--- /dev/null
+++ b/KAIR/scripts/data_preparation/regroup_reds_dataset.py
@@ -0,0 +1,40 @@
+import glob
+import os
+
+
+def regroup_reds_dataset(train_path, val_path):
+ """Regroup original REDS datasets.
+
+ We merge train and validation data into one folder, and separate the
+ validation clips in reds_dataset.py.
+ There are 240 training clips (starting from 0 to 239),
+ so we name the validation clip index starting from 240 to 269 (total 30
+ validation clips).
+
+ Args:
+ train_path (str): Path to the train folder.
+ val_path (str): Path to the validation folder.
+ """
+ # move the validation data to the train folder
+ val_folders = glob.glob(os.path.join(val_path, '*'))
+ for folder in val_folders:
+ new_folder_idx = int(folder.split('/')[-1]) + 240
+ os.system(f'cp -r {folder} {os.path.join(train_path, str(new_folder_idx))}')
+
+
+if __name__ == '__main__':
+ # train_sharp
+ train_path = 'trainsets/REDS/train_sharp'
+ val_path = 'trainsets/REDS/val_sharp'
+ regroup_reds_dataset(train_path, val_path)
+
+ # train_sharp_bicubic
+ train_path = 'trainsets/REDS/train_sharp_bicubic/X4'
+ val_path = 'trainsets/REDS/val_sharp_bicubic/X4'
+ regroup_reds_dataset(train_path, val_path)
+
+ # train_blur (for video deblurring)
+ train_path = 'trainsets/REDS/train_blur'
+ val_path = 'trainsets/REDS/val_blur'
+ regroup_reds_dataset(train_path, val_path)
+
diff --git a/KAIR/scripts/matlab_scripts/evaluate_video_deblurring.m b/KAIR/scripts/matlab_scripts/evaluate_video_deblurring.m
new file mode 100644
index 0000000000000000000000000000000000000000..564415da187b41b36b02898d018527ac8b2cbbd7
--- /dev/null
+++ b/KAIR/scripts/matlab_scripts/evaluate_video_deblurring.m
@@ -0,0 +1,40 @@
+%% Based on codes from https://github.com/swz30/MPRNet/blob/main/Deblurring/evaluate_GOPRO_HIDE.m
+%% Evaluation by Matlab is often 0.01 better than Python for SSIM.
+%% Euler command: module load matlab/R2020a; cd scripts/matlab_scripts; matlab -nodisplay -nojvm -singleCompThread -r evaluate_video_deblurring
+
+
+close all;clear all;
+
+datasets = {'DVD', 'GoPro'};
+num_set = length(datasets);
+file_paths = {'results/005_VRT_videodeblurring_DVD/*/',
+ 'results/006_VRT_videodeblurring_GoPro/*/'};
+gt_paths = {'testsets/DVD10/test_GT/*/',
+ 'testsets/GoPro11/test_GT/*/'};
+
+for idx_set = 1:num_set
+ file_path = file_paths{idx_set};
+ gt_path = gt_paths{idx_set};
+ path_list = [dir(strcat(file_path,'*.jpg')); dir(strcat(file_path,'*.png'))];
+ gt_list = [dir(strcat(gt_path,'*.jpg')); dir(strcat(gt_path,'*.png'))];
+ img_num = length(path_list);
+ fprintf('For %s dataset, it has %d LQ images and %d GT images\n', datasets{idx_set}, length(path_list), length(gt_list));
+
+ total_psnr = 0;
+ total_ssim = 0;
+ if img_num > 0
+ for j = 1:img_num
+ input = imread(strcat(path_list(j).folder, '/', path_list(j).name));
+ gt = imread(strcat(gt_list(j).folder, '/', gt_list(j).name));
+ ssim_val = ssim(input, gt);
+ psnr_val = psnr(input, gt);
+ total_ssim = total_ssim + ssim_val;
+ total_psnr = total_psnr + psnr_val;
+ end
+ end
+ qm_psnr = total_psnr / img_num;
+ qm_ssim = total_ssim / img_num;
+
+ fprintf('For %s dataset PSNR: %f SSIM: %f\n', datasets{idx_set}, qm_psnr, qm_ssim);
+
+end
\ No newline at end of file
diff --git a/KAIR/scripts/matlab_scripts/generate_LR_UDM10_BD.m b/KAIR/scripts/matlab_scripts/generate_LR_UDM10_BD.m
new file mode 100755
index 0000000000000000000000000000000000000000..5ced0521c6a85cdc104a734f26558f841f067eab
--- /dev/null
+++ b/KAIR/scripts/matlab_scripts/generate_LR_UDM10_BD.m
@@ -0,0 +1,60 @@
+function generate_LR_UDM10()
+%% matlab code to genetate blur-downsampled (BD) for UDM10 dataset
+% Euler command: module load matlab/R2020a; cd scripts/matlab_scripts; matlab -nodisplay -nojvm -singleCompThread -r generate_LR_UDM10_BD
+
+up_scale = 4;
+mod_scale = 4;
+sigma = 1.6;
+idx = 0;
+filepaths = dir('/cluster/work/cvl/videosr/UDM10/GT/*/*.png');
+for i = 1 : length(filepaths)
+ [~,imname,ext] = fileparts(filepaths(i).name);
+ folder_path = filepaths(i).folder;
+ save_LR_folder = strrep(folder_path,'GT','BDx4');
+ if ~exist(save_LR_folder, 'dir')
+ mkdir(save_LR_folder);
+ end
+ if isempty(imname)
+ disp('Ignore . folder.');
+ elseif strcmp(imname, '.')
+ disp('Ignore .. folder.');
+ else
+ idx = idx + 1;
+ str_result = sprintf('%d\t%s.\n', idx, imname);
+ fprintf(str_result);
+ % read image
+ img = imread(fullfile(folder_path, [imname, ext]));
+ img = im2double(img);
+ % modcrop
+ img = modcrop(img, mod_scale);
+ % LR
+ im_LR = BD_degradation(img, up_scale, sigma);
+ if exist('save_LR_folder', 'var')
+ fprintf('\n %d, %s', idx, imname)
+ imwrite(im_LR, fullfile(save_LR_folder, [imname, '.png']));
+ end
+ end
+end
+end
+
+%% modcrop
+function img = modcrop(img, modulo)
+if size(img,3) == 1
+ sz = size(img);
+ sz = sz - mod(sz, modulo);
+ img = img(1:sz(1), 1:sz(2));
+else
+ tmpsz = size(img);
+ sz = tmpsz(1:2);
+ sz = sz - mod(sz, modulo);
+ img = img(1:sz(1), 1:sz(2),:);
+end
+end
+
+%% blur-downsampling degradation
+function img = BD_degradation(img, up_scale, sigma)
+kernelsize = ceil(sigma * 3) * 2 + 2;
+kernel = fspecial('gaussian', kernelsize, sigma);
+img = imfilter(img, kernel, 'replicate');
+img = img(up_scale/2:up_scale:end-up_scale/2, up_scale/2:up_scale:end-up_scale/2, :);
+end
\ No newline at end of file
diff --git a/KAIR/scripts/matlab_scripts/generate_LR_Vimeo90K.m b/KAIR/scripts/matlab_scripts/generate_LR_Vimeo90K.m
new file mode 100755
index 0000000000000000000000000000000000000000..acdd62e5227547c8e11dacf998a43c3719f60e99
--- /dev/null
+++ b/KAIR/scripts/matlab_scripts/generate_LR_Vimeo90K.m
@@ -0,0 +1,49 @@
+function generate_LR_Vimeo90K()
+%% matlab code to genetate bicubic-downsampled for Vimeo90K dataset
+
+up_scale = 4;
+mod_scale = 4;
+idx = 0;
+filepaths = dir('trainsets/vimeo90k/vimeo_septuplet/sequences/*/*/*.png');
+for i = 1 : length(filepaths)
+ [~,imname,ext] = fileparts(filepaths(i).name);
+ folder_path = filepaths(i).folder;
+ save_LR_folder = strrep(folder_path,'vimeo_septuplet','vimeo_septuplet_matlabLRx4');
+ if ~exist(save_LR_folder, 'dir')
+ mkdir(save_LR_folder);
+ end
+ if isempty(imname)
+ disp('Ignore . folder.');
+ elseif strcmp(imname, '.')
+ disp('Ignore .. folder.');
+ else
+ idx = idx + 1;
+ str_result = sprintf('%d\t%s.\n', idx, imname);
+ fprintf(str_result);
+ % read image
+ img = imread(fullfile(folder_path, [imname, ext]));
+ img = im2double(img);
+ % modcrop
+ img = modcrop(img, mod_scale);
+ % LR
+ im_LR = imresize(img, 1/up_scale, 'bicubic');
+ if exist('save_LR_folder', 'var')
+ imwrite(im_LR, fullfile(save_LR_folder, [imname, '.png']));
+ end
+ end
+end
+end
+
+%% modcrop
+function img = modcrop(img, modulo)
+if size(img,3) == 1
+ sz = size(img);
+ sz = sz - mod(sz, modulo);
+ img = img(1:sz(1), 1:sz(2));
+else
+ tmpsz = size(img);
+ sz = tmpsz(1:2);
+ sz = sz - mod(sz, modulo);
+ img = img(1:sz(1), 1:sz(2),:);
+end
+end
diff --git a/KAIR/scripts/matlab_scripts/generate_LR_Vimeo90K_BD.m b/KAIR/scripts/matlab_scripts/generate_LR_Vimeo90K_BD.m
new file mode 100755
index 0000000000000000000000000000000000000000..916134fa1509a6da15e12f4038aea455abfa4f3a
--- /dev/null
+++ b/KAIR/scripts/matlab_scripts/generate_LR_Vimeo90K_BD.m
@@ -0,0 +1,60 @@
+function generate_LR_Vimeo90K()
+%% matlab code to genetate blur-downsampled (BD) for Vimeo90K dataset
+% Euler module load matlab/R2020a; cd scripts/matlab_scripts; matlab -nodisplay -nojvm -singleCompThread -r generate_LR_Vimeo90K_BD
+
+up_scale = 4;
+mod_scale = 4;
+sigma = 1.6;
+idx = 0;
+filepaths = dir('/scratch/190250671.tmpdir/vimeo90k/vimeo_septuplet/sequences/*/*/*.png');
+for i = 1 : length(filepaths)
+ [~,imname,ext] = fileparts(filepaths(i).name);
+ folder_path = filepaths(i).folder;
+ save_LR_folder = strrep(folder_path,'vimeo_septuplet','vimeo_septuplet_BDLRx4');
+ if ~exist(save_LR_folder, 'dir')
+ mkdir(save_LR_folder);
+ end
+ if isempty(imname)
+ disp('Ignore . folder.');
+ elseif strcmp(imname, '.')
+ disp('Ignore .. folder.');
+ else
+ idx = idx + 1;
+ str_result = sprintf('%d\t%s.\n', idx, imname);
+ fprintf(str_result);
+ % read image
+ img = imread(fullfile(folder_path, [imname, ext]));
+ img = im2double(img);
+ % modcrop
+ img = modcrop(img, mod_scale);
+ % LR
+ im_LR = BD_degradation(img, up_scale, sigma);
+ if exist('save_LR_folder', 'var')
+ fprintf('\n %d, %s', idx, imname)
+ imwrite(im_LR, fullfile(save_LR_folder, [imname, '.png']));
+ end
+ end
+end
+end
+
+%% modcrop
+function img = modcrop(img, modulo)
+if size(img,3) == 1
+ sz = size(img);
+ sz = sz - mod(sz, modulo);
+ img = img(1:sz(1), 1:sz(2));
+else
+ tmpsz = size(img);
+ sz = tmpsz(1:2);
+ sz = sz - mod(sz, modulo);
+ img = img(1:sz(1), 1:sz(2),:);
+end
+end
+
+%% blur-downsampling degradation
+function img = BD_degradation(img, up_scale, sigma)
+kernelsize = ceil(sigma * 3) * 2 + 2;
+kernel = fspecial('gaussian', kernelsize, sigma);
+img = imfilter(img, kernel, 'replicate');
+img = img(up_scale/2:up_scale:end-up_scale/2, up_scale/2:up_scale:end-up_scale/2, :);
+end
\ No newline at end of file
diff --git a/KAIR/utils/utils_alignfaces.py b/KAIR/utils/utils_alignfaces.py
new file mode 100644
index 0000000000000000000000000000000000000000..fa74e8a2e8984f5075d0cbd06afd494c9661a015
--- /dev/null
+++ b/KAIR/utils/utils_alignfaces.py
@@ -0,0 +1,263 @@
+# -*- coding: utf-8 -*-
+"""
+Created on Mon Apr 24 15:43:29 2017
+@author: zhaoy
+"""
+import cv2
+import numpy as np
+from skimage import transform as trans
+
+# reference facial points, a list of coordinates (x,y)
+REFERENCE_FACIAL_POINTS = [
+ [30.29459953, 51.69630051],
+ [65.53179932, 51.50139999],
+ [48.02519989, 71.73660278],
+ [33.54930115, 92.3655014],
+ [62.72990036, 92.20410156]
+]
+
+DEFAULT_CROP_SIZE = (96, 112)
+
+
+def _umeyama(src, dst, estimate_scale=True, scale=1.0):
+ """Estimate N-D similarity transformation with or without scaling.
+ Parameters
+ ----------
+ src : (M, N) array
+ Source coordinates.
+ dst : (M, N) array
+ Destination coordinates.
+ estimate_scale : bool
+ Whether to estimate scaling factor.
+ Returns
+ -------
+ T : (N + 1, N + 1)
+ The homogeneous similarity transformation matrix. The matrix contains
+ NaN values only if the problem is not well-conditioned.
+ References
+ ----------
+ .. [1] "Least-squares estimation of transformation parameters between two
+ point patterns", Shinji Umeyama, PAMI 1991, :DOI:`10.1109/34.88573`
+ """
+
+ num = src.shape[0]
+ dim = src.shape[1]
+
+ # Compute mean of src and dst.
+ src_mean = src.mean(axis=0)
+ dst_mean = dst.mean(axis=0)
+
+ # Subtract mean from src and dst.
+ src_demean = src - src_mean
+ dst_demean = dst - dst_mean
+
+ # Eq. (38).
+ A = dst_demean.T @ src_demean / num
+
+ # Eq. (39).
+ d = np.ones((dim,), dtype=np.double)
+ if np.linalg.det(A) < 0:
+ d[dim - 1] = -1
+
+ T = np.eye(dim + 1, dtype=np.double)
+
+ U, S, V = np.linalg.svd(A)
+
+ # Eq. (40) and (43).
+ rank = np.linalg.matrix_rank(A)
+ if rank == 0:
+ return np.nan * T
+ elif rank == dim - 1:
+ if np.linalg.det(U) * np.linalg.det(V) > 0:
+ T[:dim, :dim] = U @ V
+ else:
+ s = d[dim - 1]
+ d[dim - 1] = -1
+ T[:dim, :dim] = U @ np.diag(d) @ V
+ d[dim - 1] = s
+ else:
+ T[:dim, :dim] = U @ np.diag(d) @ V
+
+ if estimate_scale:
+ # Eq. (41) and (42).
+ scale = 1.0 / src_demean.var(axis=0).sum() * (S @ d)
+ else:
+ scale = scale
+
+ T[:dim, dim] = dst_mean - scale * (T[:dim, :dim] @ src_mean.T)
+ T[:dim, :dim] *= scale
+
+ return T, scale
+
+
+class FaceWarpException(Exception):
+ def __str__(self):
+ return 'In File {}:{}'.format(
+ __file__, super.__str__(self))
+
+
+def get_reference_facial_points(output_size=None,
+ inner_padding_factor=0.0,
+ outer_padding=(0, 0),
+ default_square=False):
+ tmp_5pts = np.array(REFERENCE_FACIAL_POINTS)
+ tmp_crop_size = np.array(DEFAULT_CROP_SIZE)
+
+ # 0) make the inner region a square
+ if default_square:
+ size_diff = max(tmp_crop_size) - tmp_crop_size
+ tmp_5pts += size_diff / 2
+ tmp_crop_size += size_diff
+
+ if (output_size and
+ output_size[0] == tmp_crop_size[0] and
+ output_size[1] == tmp_crop_size[1]):
+ print('output_size == DEFAULT_CROP_SIZE {}: return default reference points'.format(tmp_crop_size))
+ return tmp_5pts
+
+ if (inner_padding_factor == 0 and
+ outer_padding == (0, 0)):
+ if output_size is None:
+ print('No paddings to do: return default reference points')
+ return tmp_5pts
+ else:
+ raise FaceWarpException(
+ 'No paddings to do, output_size must be None or {}'.format(tmp_crop_size))
+
+ # check output size
+ if not (0 <= inner_padding_factor <= 1.0):
+ raise FaceWarpException('Not (0 <= inner_padding_factor <= 1.0)')
+
+ if ((inner_padding_factor > 0 or outer_padding[0] > 0 or outer_padding[1] > 0)
+ and output_size is None):
+ output_size = tmp_crop_size * \
+ (1 + inner_padding_factor * 2).astype(np.int32)
+ output_size += np.array(outer_padding)
+ print(' deduced from paddings, output_size = ', output_size)
+
+ if not (outer_padding[0] < output_size[0]
+ and outer_padding[1] < output_size[1]):
+ raise FaceWarpException('Not (outer_padding[0] < output_size[0]'
+ 'and outer_padding[1] < output_size[1])')
+
+ # 1) pad the inner region according inner_padding_factor
+ # print('---> STEP1: pad the inner region according inner_padding_factor')
+ if inner_padding_factor > 0:
+ size_diff = tmp_crop_size * inner_padding_factor * 2
+ tmp_5pts += size_diff / 2
+ tmp_crop_size += np.round(size_diff).astype(np.int32)
+
+ # print(' crop_size = ', tmp_crop_size)
+ # print(' reference_5pts = ', tmp_5pts)
+
+ # 2) resize the padded inner region
+ # print('---> STEP2: resize the padded inner region')
+ size_bf_outer_pad = np.array(output_size) - np.array(outer_padding) * 2
+ # print(' crop_size = ', tmp_crop_size)
+ # print(' size_bf_outer_pad = ', size_bf_outer_pad)
+
+ if size_bf_outer_pad[0] * tmp_crop_size[1] != size_bf_outer_pad[1] * tmp_crop_size[0]:
+ raise FaceWarpException('Must have (output_size - outer_padding)'
+ '= some_scale * (crop_size * (1.0 + inner_padding_factor)')
+
+ scale_factor = size_bf_outer_pad[0].astype(np.float32) / tmp_crop_size[0]
+ # print(' resize scale_factor = ', scale_factor)
+ tmp_5pts = tmp_5pts * scale_factor
+ # size_diff = tmp_crop_size * (scale_factor - min(scale_factor))
+ # tmp_5pts = tmp_5pts + size_diff / 2
+ tmp_crop_size = size_bf_outer_pad
+ # print(' crop_size = ', tmp_crop_size)
+ # print(' reference_5pts = ', tmp_5pts)
+
+ # 3) add outer_padding to make output_size
+ reference_5point = tmp_5pts + np.array(outer_padding)
+ tmp_crop_size = output_size
+ # print('---> STEP3: add outer_padding to make output_size')
+ # print(' crop_size = ', tmp_crop_size)
+ # print(' reference_5pts = ', tmp_5pts)
+ #
+ # print('===> end get_reference_facial_points\n')
+
+ return reference_5point
+
+
+def get_affine_transform_matrix(src_pts, dst_pts):
+ tfm = np.float32([[1, 0, 0], [0, 1, 0]])
+ n_pts = src_pts.shape[0]
+ ones = np.ones((n_pts, 1), src_pts.dtype)
+ src_pts_ = np.hstack([src_pts, ones])
+ dst_pts_ = np.hstack([dst_pts, ones])
+
+ A, res, rank, s = np.linalg.lstsq(src_pts_, dst_pts_)
+
+ if rank == 3:
+ tfm = np.float32([
+ [A[0, 0], A[1, 0], A[2, 0]],
+ [A[0, 1], A[1, 1], A[2, 1]]
+ ])
+ elif rank == 2:
+ tfm = np.float32([
+ [A[0, 0], A[1, 0], 0],
+ [A[0, 1], A[1, 1], 0]
+ ])
+
+ return tfm
+
+
+def warp_and_crop_face(src_img,
+ facial_pts,
+ reference_pts=None,
+ crop_size=(96, 112),
+ align_type='smilarity'): #smilarity cv2_affine affine
+ if reference_pts is None:
+ if crop_size[0] == 96 and crop_size[1] == 112:
+ reference_pts = REFERENCE_FACIAL_POINTS
+ else:
+ default_square = False
+ inner_padding_factor = 0
+ outer_padding = (0, 0)
+ output_size = crop_size
+
+ reference_pts = get_reference_facial_points(output_size,
+ inner_padding_factor,
+ outer_padding,
+ default_square)
+
+ ref_pts = np.float32(reference_pts)
+ ref_pts_shp = ref_pts.shape
+ if max(ref_pts_shp) < 3 or min(ref_pts_shp) != 2:
+ raise FaceWarpException(
+ 'reference_pts.shape must be (K,2) or (2,K) and K>2')
+
+ if ref_pts_shp[0] == 2:
+ ref_pts = ref_pts.T
+
+ src_pts = np.float32(facial_pts)
+ src_pts_shp = src_pts.shape
+ if max(src_pts_shp) < 3 or min(src_pts_shp) != 2:
+ raise FaceWarpException(
+ 'facial_pts.shape must be (K,2) or (2,K) and K>2')
+
+ if src_pts_shp[0] == 2:
+ src_pts = src_pts.T
+
+ if src_pts.shape != ref_pts.shape:
+ raise FaceWarpException(
+ 'facial_pts and reference_pts must have the same shape')
+
+ if align_type is 'cv2_affine':
+ tfm = cv2.getAffineTransform(src_pts[0:3], ref_pts[0:3])
+ tfm_inv = cv2.getAffineTransform(ref_pts[0:3], src_pts[0:3])
+ elif align_type is 'affine':
+ tfm = get_affine_transform_matrix(src_pts, ref_pts)
+ tfm_inv = get_affine_transform_matrix(ref_pts, src_pts)
+ else:
+ params, scale = _umeyama(src_pts, ref_pts)
+ tfm = params[:2, :]
+
+ params, _ = _umeyama(ref_pts, src_pts, False, scale=1.0/scale)
+ tfm_inv = params[:2, :]
+
+ face_img = cv2.warpAffine(src_img, tfm, (crop_size[0], crop_size[1]), flags=3)
+
+ return face_img, tfm_inv
diff --git a/KAIR/utils/utils_blindsr.py b/KAIR/utils/utils_blindsr.py
new file mode 100644
index 0000000000000000000000000000000000000000..83b009c1cfaa5fe3d32fbbcd836b64991204f482
--- /dev/null
+++ b/KAIR/utils/utils_blindsr.py
@@ -0,0 +1,631 @@
+# -*- coding: utf-8 -*-
+import numpy as np
+import cv2
+import torch
+
+from utils import utils_image as util
+
+import random
+from scipy import ndimage
+import scipy
+import scipy.stats as ss
+from scipy.interpolate import interp2d
+from scipy.linalg import orth
+
+
+
+
+"""
+# --------------------------------------------
+# super-resolution
+# --------------------------------------------
+#
+# kai zhang (cskaizhang@gmail.com)
+# https://github.com/cszn
+# from 2019/03--2021/08
+# --------------------------------------------
+"""
+
+def modcrop_np(img, sf):
+ '''
+ args:
+ img: numpy image, wxh or wxhxc
+ sf: scale factor
+
+ return:
+ cropped image
+ '''
+ w, h = img.shape[:2]
+ im = np.copy(img)
+ return im[:w - w % sf, :h - h % sf, ...]
+
+
+"""
+# --------------------------------------------
+# anisotropic gaussian kernels
+# --------------------------------------------
+"""
+def analytic_kernel(k):
+ """calculate the x4 kernel from the x2 kernel (for proof see appendix in paper)"""
+ k_size = k.shape[0]
+ # calculate the big kernels size
+ big_k = np.zeros((3 * k_size - 2, 3 * k_size - 2))
+ # loop over the small kernel to fill the big one
+ for r in range(k_size):
+ for c in range(k_size):
+ big_k[2 * r:2 * r + k_size, 2 * c:2 * c + k_size] += k[r, c] * k
+ # crop the edges of the big kernel to ignore very small values and increase run time of sr
+ crop = k_size // 2
+ cropped_big_k = big_k[crop:-crop, crop:-crop]
+ # normalize to 1
+ return cropped_big_k / cropped_big_k.sum()
+
+
+def anisotropic_gaussian(ksize=15, theta=np.pi, l1=6, l2=6):
+ """ generate an anisotropic gaussian kernel
+ args:
+ ksize : e.g., 15, kernel size
+ theta : [0, pi], rotation angle range
+ l1 : [0.1,50], scaling of eigenvalues
+ l2 : [0.1,l1], scaling of eigenvalues
+ if l1 = l2, will get an isotropic gaussian kernel.
+
+ returns:
+ k : kernel
+ """
+
+ v = np.dot(np.array([[np.cos(theta), -np.sin(theta)], [np.sin(theta), np.cos(theta)]]), np.array([1., 0.]))
+ v = np.array([[v[0], v[1]], [v[1], -v[0]]])
+ d = np.array([[l1, 0], [0, l2]])
+ sigma = np.dot(np.dot(v, d), np.linalg.inv(v))
+ k = gm_blur_kernel(mean=[0, 0], cov=sigma, size=ksize)
+
+ return k
+
+
+def gm_blur_kernel(mean, cov, size=15):
+ center = size / 2.0 + 0.5
+ k = np.zeros([size, size])
+ for y in range(size):
+ for x in range(size):
+ cy = y - center + 1
+ cx = x - center + 1
+ k[y, x] = ss.multivariate_normal.pdf([cx, cy], mean=mean, cov=cov)
+
+ k = k / np.sum(k)
+ return k
+
+
+def shift_pixel(x, sf, upper_left=true):
+ """shift pixel for super-resolution with different scale factors
+ args:
+ x: wxhxc or wxh
+ sf: scale factor
+ upper_left: shift direction
+ """
+ h, w = x.shape[:2]
+ shift = (sf-1)*0.5
+ xv, yv = np.arange(0, w, 1.0), np.arange(0, h, 1.0)
+ if upper_left:
+ x1 = xv + shift
+ y1 = yv + shift
+ else:
+ x1 = xv - shift
+ y1 = yv - shift
+
+ x1 = np.clip(x1, 0, w-1)
+ y1 = np.clip(y1, 0, h-1)
+
+ if x.ndim == 2:
+ x = interp2d(xv, yv, x)(x1, y1)
+ if x.ndim == 3:
+ for i in range(x.shape[-1]):
+ x[:, :, i] = interp2d(xv, yv, x[:, :, i])(x1, y1)
+
+ return x
+
+
+def blur(x, k):
+ '''
+ x: image, nxcxhxw
+ k: kernel, nx1xhxw
+ '''
+ n, c = x.shape[:2]
+ p1, p2 = (k.shape[-2]-1)//2, (k.shape[-1]-1)//2
+ x = torch.nn.functional.pad(x, pad=(p1, p2, p1, p2), mode='replicate')
+ k = k.repeat(1,c,1,1)
+ k = k.view(-1, 1, k.shape[2], k.shape[3])
+ x = x.view(1, -1, x.shape[2], x.shape[3])
+ x = torch.nn.functional.conv2d(x, k, bias=none, stride=1, padding=0, groups=n*c)
+ x = x.view(n, c, x.shape[2], x.shape[3])
+
+ return x
+
+
+
+def gen_kernel(k_size=np.array([15, 15]), scale_factor=np.array([4, 4]), min_var=0.6, max_var=10., noise_level=0):
+ """"
+ # modified version of https://github.com/assafshocher/blindsr_dataset_generator
+ # kai zhang
+ # min_var = 0.175 * sf # variance of the gaussian kernel will be sampled between min_var and max_var
+ # max_var = 2.5 * sf
+ """
+ # set random eigen-vals (lambdas) and angle (theta) for cov matrix
+ lambda_1 = min_var + np.random.rand() * (max_var - min_var)
+ lambda_2 = min_var + np.random.rand() * (max_var - min_var)
+ theta = np.random.rand() * np.pi # random theta
+ noise = -noise_level + np.random.rand(*k_size) * noise_level * 2
+
+ # set cov matrix using lambdas and theta
+ lambda = np.diag([lambda_1, lambda_2])
+ q = np.array([[np.cos(theta), -np.sin(theta)],
+ [np.sin(theta), np.cos(theta)]])
+ sigma = q @ lambda @ q.t
+ inv_sigma = np.linalg.inv(sigma)[none, none, :, :]
+
+ # set expectation position (shifting kernel for aligned image)
+ mu = k_size // 2 - 0.5*(scale_factor - 1) # - 0.5 * (scale_factor - k_size % 2)
+ mu = mu[none, none, :, none]
+
+ # create meshgrid for gaussian
+ [x,y] = np.meshgrid(range(k_size[0]), range(k_size[1]))
+ z = np.stack([x, y], 2)[:, :, :, none]
+
+ # calcualte gaussian for every pixel of the kernel
+ zz = z-mu
+ zz_t = zz.transpose(0,1,3,2)
+ raw_kernel = np.exp(-0.5 * np.squeeze(zz_t @ inv_sigma @ zz)) * (1 + noise)
+
+ # shift the kernel so it will be centered
+ #raw_kernel_centered = kernel_shift(raw_kernel, scale_factor)
+
+ # normalize the kernel and return
+ #kernel = raw_kernel_centered / np.sum(raw_kernel_centered)
+ kernel = raw_kernel / np.sum(raw_kernel)
+ return kernel
+
+
+def fspecial_gaussian(hsize, sigma):
+ hsize = [hsize, hsize]
+ siz = [(hsize[0]-1.0)/2.0, (hsize[1]-1.0)/2.0]
+ std = sigma
+ [x, y] = np.meshgrid(np.arange(-siz[1], siz[1]+1), np.arange(-siz[0], siz[0]+1))
+ arg = -(x*x + y*y)/(2*std*std)
+ h = np.exp(arg)
+ h[h < scipy.finfo(float).eps * h.max()] = 0
+ sumh = h.sum()
+ if sumh != 0:
+ h = h/sumh
+ return h
+
+
+def fspecial_laplacian(alpha):
+ alpha = max([0, min([alpha,1])])
+ h1 = alpha/(alpha+1)
+ h2 = (1-alpha)/(alpha+1)
+ h = [[h1, h2, h1], [h2, -4/(alpha+1), h2], [h1, h2, h1]]
+ h = np.array(h)
+ return h
+
+
+def fspecial(filter_type, *args, **kwargs):
+ '''
+ python code from:
+ https://github.com/ronaldosena/imagens-medicas-2/blob/40171a6c259edec7827a6693a93955de2bd39e76/aulas/aula_2_-_uniform_filter/matlab_fspecial.py
+ '''
+ if filter_type == 'gaussian':
+ return fspecial_gaussian(*args, **kwargs)
+ if filter_type == 'laplacian':
+ return fspecial_laplacian(*args, **kwargs)
+
+"""
+# --------------------------------------------
+# degradation models
+# --------------------------------------------
+"""
+
+
+def bicubic_degradation(x, sf=3):
+ '''
+ args:
+ x: hxwxc image, [0, 1]
+ sf: down-scale factor
+
+ return:
+ bicubicly downsampled lr image
+ '''
+ x = util.imresize_np(x, scale=1/sf)
+ return x
+
+
+def srmd_degradation(x, k, sf=3):
+ ''' blur + bicubic downsampling
+
+ args:
+ x: hxwxc image, [0, 1]
+ k: hxw, double
+ sf: down-scale factor
+
+ return:
+ downsampled lr image
+
+ reference:
+ @inproceedings{zhang2018learning,
+ title={learning a single convolutional super-resolution network for multiple degradations},
+ author={zhang, kai and zuo, wangmeng and zhang, lei},
+ booktitle={ieee conference on computer vision and pattern recognition},
+ pages={3262--3271},
+ year={2018}
+ }
+ '''
+ x = ndimage.filters.convolve(x, np.expand_dims(k, axis=2), mode='wrap') # 'nearest' | 'mirror'
+ x = bicubic_degradation(x, sf=sf)
+ return x
+
+
+def dpsr_degradation(x, k, sf=3):
+
+ ''' bicubic downsampling + blur
+
+ args:
+ x: hxwxc image, [0, 1]
+ k: hxw, double
+ sf: down-scale factor
+
+ return:
+ downsampled lr image
+
+ reference:
+ @inproceedings{zhang2019deep,
+ title={deep plug-and-play super-resolution for arbitrary blur kernels},
+ author={zhang, kai and zuo, wangmeng and zhang, lei},
+ booktitle={ieee conference on computer vision and pattern recognition},
+ pages={1671--1681},
+ year={2019}
+ }
+ '''
+ x = bicubic_degradation(x, sf=sf)
+ x = ndimage.filters.convolve(x, np.expand_dims(k, axis=2), mode='wrap')
+ return x
+
+
+def classical_degradation(x, k, sf=3):
+ ''' blur + downsampling
+
+ args:
+ x: hxwxc image, [0, 1]/[0, 255]
+ k: hxw, double
+ sf: down-scale factor
+
+ return:
+ downsampled lr image
+ '''
+ x = ndimage.filters.convolve(x, np.expand_dims(k, axis=2), mode='wrap')
+ #x = filters.correlate(x, np.expand_dims(np.flip(k), axis=2))
+ st = 0
+ return x[st::sf, st::sf, ...]
+
+
+def add_sharpening(img, weight=0.5, radius=50, threshold=10):
+ """usm sharpening. borrowed from real-esrgan
+ input image: i; blurry image: b.
+ 1. k = i + weight * (i - b)
+ 2. mask = 1 if abs(i - b) > threshold, else: 0
+ 3. blur mask:
+ 4. out = mask * k + (1 - mask) * i
+ args:
+ img (numpy array): input image, hwc, bgr; float32, [0, 1].
+ weight (float): sharp weight. default: 1.
+ radius (float): kernel size of gaussian blur. default: 50.
+ threshold (int):
+ """
+ if radius % 2 == 0:
+ radius += 1
+ blur = cv2.gaussianblur(img, (radius, radius), 0)
+ residual = img - blur
+ mask = np.abs(residual) * 255 > threshold
+ mask = mask.astype('float32')
+ soft_mask = cv2.gaussianblur(mask, (radius, radius), 0)
+
+ k = img + weight * residual
+ k = np.clip(k, 0, 1)
+ return soft_mask * k + (1 - soft_mask) * img
+
+
+def add_blur(img, sf=4):
+ wd2 = 4.0 + sf
+ wd = 2.0 + 0.2*sf
+ if random.random() < 0.5:
+ l1 = wd2*random.random()
+ l2 = wd2*random.random()
+ k = anisotropic_gaussian(ksize=2*random.randint(2,11)+3, theta=random.random()*np.pi, l1=l1, l2=l2)
+ else:
+ k = fspecial('gaussian', 2*random.randint(2,11)+3, wd*random.random())
+ img = ndimage.filters.convolve(img, np.expand_dims(k, axis=2), mode='mirror')
+
+ return img
+
+
+def add_resize(img, sf=4):
+ rnum = np.random.rand()
+ if rnum > 0.8: # up
+ sf1 = random.uniform(1, 2)
+ elif rnum < 0.7: # down
+ sf1 = random.uniform(0.5/sf, 1)
+ else:
+ sf1 = 1.0
+ img = cv2.resize(img, (int(sf1*img.shape[1]), int(sf1*img.shape[0])), interpolation=random.choice([1, 2, 3]))
+ img = np.clip(img, 0.0, 1.0)
+
+ return img
+
+
+def add_gaussian_noise(img, noise_level1=2, noise_level2=25):
+ noise_level = random.randint(noise_level1, noise_level2)
+ rnum = np.random.rand()
+ if rnum > 0.6: # add color gaussian noise
+ img += np.random.normal(0, noise_level/255.0, img.shape).astype(np.float32)
+ elif rnum < 0.4: # add grayscale gaussian noise
+ img += np.random.normal(0, noise_level/255.0, (*img.shape[:2], 1)).astype(np.float32)
+ else: # add noise
+ l = noise_level2/255.
+ d = np.diag(np.random.rand(3))
+ u = orth(np.random.rand(3,3))
+ conv = np.dot(np.dot(np.transpose(u), d), u)
+ img += np.random.multivariate_normal([0,0,0], np.abs(l**2*conv), img.shape[:2]).astype(np.float32)
+ img = np.clip(img, 0.0, 1.0)
+ return img
+
+
+def add_speckle_noise(img, noise_level1=2, noise_level2=25):
+ noise_level = random.randint(noise_level1, noise_level2)
+ img = np.clip(img, 0.0, 1.0)
+ rnum = random.random()
+ if rnum > 0.6:
+ img += img*np.random.normal(0, noise_level/255.0, img.shape).astype(np.float32)
+ elif rnum < 0.4:
+ img += img*np.random.normal(0, noise_level/255.0, (*img.shape[:2], 1)).astype(np.float32)
+ else:
+ l = noise_level2/255.
+ d = np.diag(np.random.rand(3))
+ u = orth(np.random.rand(3,3))
+ conv = np.dot(np.dot(np.transpose(u), d), u)
+ img += img*np.random.multivariate_normal([0,0,0], np.abs(l**2*conv), img.shape[:2]).astype(np.float32)
+ img = np.clip(img, 0.0, 1.0)
+ return img
+
+
+def add_poisson_noise(img):
+ img = np.clip((img * 255.0).round(), 0, 255) / 255.
+ vals = 10**(2*random.random()+2.0) # [2, 4]
+ if random.random() < 0.5:
+ img = np.random.poisson(img * vals).astype(np.float32) / vals
+ else:
+ img_gray = np.dot(img[...,:3], [0.299, 0.587, 0.114])
+ img_gray = np.clip((img_gray * 255.0).round(), 0, 255) / 255.
+ noise_gray = np.random.poisson(img_gray * vals).astype(np.float32) / vals - img_gray
+ img += noise_gray[:, :, np.newaxis]
+ img = np.clip(img, 0.0, 1.0)
+ return img
+
+
+def add_jpeg_noise(img):
+ quality_factor = random.randint(30, 95)
+ img = cv2.cvtcolor(util.single2uint(img), cv2.color_rgb2bgr)
+ result, encimg = cv2.imencode('.jpg', img, [int(cv2.imwrite_jpeg_quality), quality_factor])
+ img = cv2.imdecode(encimg, 1)
+ img = cv2.cvtcolor(util.uint2single(img), cv2.color_bgr2rgb)
+ return img
+
+
+def random_crop(lq, hq, sf=4, lq_patchsize=64):
+ h, w = lq.shape[:2]
+ rnd_h = random.randint(0, h-lq_patchsize)
+ rnd_w = random.randint(0, w-lq_patchsize)
+ lq = lq[rnd_h:rnd_h + lq_patchsize, rnd_w:rnd_w + lq_patchsize, :]
+
+ rnd_h_h, rnd_w_h = int(rnd_h * sf), int(rnd_w * sf)
+ hq = hq[rnd_h_h:rnd_h_h + lq_patchsize*sf, rnd_w_h:rnd_w_h + lq_patchsize*sf, :]
+ return lq, hq
+
+
+def degradation_bsrgan(img, sf=4, lq_patchsize=72, isp_model=none):
+ """
+ this is the degradation model of bsrgan from the paper
+ "designing a practical degradation model for deep blind image super-resolution"
+ ----------
+ img: hxwxc, [0, 1], its size should be large than (lq_patchsizexsf)x(lq_patchsizexsf)
+ sf: scale factor
+ isp_model: camera isp model
+
+ returns
+ -------
+ img: low-quality patch, size: lq_patchsizexlq_patchsizexc, range: [0, 1]
+ hq: corresponding high-quality patch, size: (lq_patchsizexsf)x(lq_patchsizexsf)xc, range: [0, 1]
+ """
+ isp_prob, jpeg_prob, scale2_prob = 0.25, 0.9, 0.25
+ sf_ori = sf
+
+ h1, w1 = img.shape[:2]
+ img = img.copy()[:w1 - w1 % sf, :h1 - h1 % sf, ...] # mod crop
+ h, w = img.shape[:2]
+
+ if h < lq_patchsize*sf or w < lq_patchsize*sf:
+ raise valueerror(f'img size ({h1}x{w1}) is too small!')
+
+ hq = img.copy()
+
+ if sf == 4 and random.random() < scale2_prob: # downsample1
+ if np.random.rand() < 0.5:
+ img = cv2.resize(img, (int(1/2*img.shape[1]), int(1/2*img.shape[0])), interpolation=random.choice([1,2,3]))
+ else:
+ img = util.imresize_np(img, 1/2, true)
+ img = np.clip(img, 0.0, 1.0)
+ sf = 2
+
+ shuffle_order = random.sample(range(7), 7)
+ idx1, idx2 = shuffle_order.index(2), shuffle_order.index(3)
+ if idx1 > idx2: # keep downsample3 last
+ shuffle_order[idx1], shuffle_order[idx2] = shuffle_order[idx2], shuffle_order[idx1]
+
+ for i in shuffle_order:
+
+ if i == 0:
+ img = add_blur(img, sf=sf)
+
+ elif i == 1:
+ img = add_blur(img, sf=sf)
+
+ elif i == 2:
+ a, b = img.shape[1], img.shape[0]
+ # downsample2
+ if random.random() < 0.75:
+ sf1 = random.uniform(1,2*sf)
+ img = cv2.resize(img, (int(1/sf1*img.shape[1]), int(1/sf1*img.shape[0])), interpolation=random.choice([1,2,3]))
+ else:
+ k = fspecial('gaussian', 25, random.uniform(0.1, 0.6*sf))
+ k_shifted = shift_pixel(k, sf)
+ k_shifted = k_shifted/k_shifted.sum() # blur with shifted kernel
+ img = ndimage.filters.convolve(img, np.expand_dims(k_shifted, axis=2), mode='mirror')
+ img = img[0::sf, 0::sf, ...] # nearest downsampling
+ img = np.clip(img, 0.0, 1.0)
+
+ elif i == 3:
+ # downsample3
+ img = cv2.resize(img, (int(1/sf*a), int(1/sf*b)), interpolation=random.choice([1,2,3]))
+ img = np.clip(img, 0.0, 1.0)
+
+ elif i == 4:
+ # add gaussian noise
+ img = add_gaussian_noise(img, noise_level1=2, noise_level2=25)
+
+ elif i == 5:
+ # add jpeg noise
+ if random.random() < jpeg_prob:
+ img = add_jpeg_noise(img)
+
+ elif i == 6:
+ # add processed camera sensor noise
+ if random.random() < isp_prob and isp_model is not none:
+ with torch.no_grad():
+ img, hq = isp_model.forward(img.copy(), hq)
+
+ # add final jpeg compression noise
+ img = add_jpeg_noise(img)
+
+ # random crop
+ img, hq = random_crop(img, hq, sf_ori, lq_patchsize)
+
+ return img, hq
+
+
+
+
+def degradation_bsrgan_plus(img, sf=4, shuffle_prob=0.5, use_sharp=false, lq_patchsize=64, isp_model=none):
+ """
+ this is an extended degradation model by combining
+ the degradation models of bsrgan and real-esrgan
+ ----------
+ img: hxwxc, [0, 1], its size should be large than (lq_patchsizexsf)x(lq_patchsizexsf)
+ sf: scale factor
+ use_shuffle: the degradation shuffle
+ use_sharp: sharpening the img
+
+ returns
+ -------
+ img: low-quality patch, size: lq_patchsizexlq_patchsizexc, range: [0, 1]
+ hq: corresponding high-quality patch, size: (lq_patchsizexsf)x(lq_patchsizexsf)xc, range: [0, 1]
+ """
+
+ h1, w1 = img.shape[:2]
+ img = img.copy()[:w1 - w1 % sf, :h1 - h1 % sf, ...] # mod crop
+ h, w = img.shape[:2]
+
+ if h < lq_patchsize*sf or w < lq_patchsize*sf:
+ raise valueerror(f'img size ({h1}x{w1}) is too small!')
+
+ if use_sharp:
+ img = add_sharpening(img)
+ hq = img.copy()
+
+ if random.random() < shuffle_prob:
+ shuffle_order = random.sample(range(13), 13)
+ else:
+ shuffle_order = list(range(13))
+ # local shuffle for noise, jpeg is always the last one
+ shuffle_order[2:6] = random.sample(shuffle_order[2:6], len(range(2, 6)))
+ shuffle_order[9:13] = random.sample(shuffle_order[9:13], len(range(9, 13)))
+
+ poisson_prob, speckle_prob, isp_prob = 0.1, 0.1, 0.1
+
+ for i in shuffle_order:
+ if i == 0:
+ img = add_blur(img, sf=sf)
+ elif i == 1:
+ img = add_resize(img, sf=sf)
+ elif i == 2:
+ img = add_gaussian_noise(img, noise_level1=2, noise_level2=25)
+ elif i == 3:
+ if random.random() < poisson_prob:
+ img = add_poisson_noise(img)
+ elif i == 4:
+ if random.random() < speckle_prob:
+ img = add_speckle_noise(img)
+ elif i == 5:
+ if random.random() < isp_prob and isp_model is not none:
+ with torch.no_grad():
+ img, hq = isp_model.forward(img.copy(), hq)
+ elif i == 6:
+ img = add_jpeg_noise(img)
+ elif i == 7:
+ img = add_blur(img, sf=sf)
+ elif i == 8:
+ img = add_resize(img, sf=sf)
+ elif i == 9:
+ img = add_gaussian_noise(img, noise_level1=2, noise_level2=25)
+ elif i == 10:
+ if random.random() < poisson_prob:
+ img = add_poisson_noise(img)
+ elif i == 11:
+ if random.random() < speckle_prob:
+ img = add_speckle_noise(img)
+ elif i == 12:
+ if random.random() < isp_prob and isp_model is not none:
+ with torch.no_grad():
+ img, hq = isp_model.forward(img.copy(), hq)
+ else:
+ print('check the shuffle!')
+
+ # resize to desired size
+ img = cv2.resize(img, (int(1/sf*hq.shape[1]), int(1/sf*hq.shape[0])), interpolation=random.choice([1, 2, 3]))
+
+ # add final jpeg compression noise
+ img = add_jpeg_noise(img)
+
+ # random crop
+ img, hq = random_crop(img, hq, sf, lq_patchsize)
+
+ return img, hq
+
+
+
+if __name__ == '__main__':
+ img = util.imread_uint('utils/test.png', 3)
+ img = util.uint2single(img)
+ sf = 4
+
+ for i in range(20):
+ img_lq, img_hq = degradation_bsrgan(img, sf=sf, lq_patchsize=72)
+ print(i)
+ lq_nearest = cv2.resize(util.single2uint(img_lq), (int(sf*img_lq.shape[1]), int(sf*img_lq.shape[0])), interpolation=0)
+ img_concat = np.concatenate([lq_nearest, util.single2uint(img_hq)], axis=1)
+ util.imsave(img_concat, str(i)+'.png')
+
+# for i in range(10):
+# img_lq, img_hq = degradation_bsrgan_plus(img, sf=sf, shuffle_prob=0.1, use_sharp=true, lq_patchsize=64)
+# print(i)
+# lq_nearest = cv2.resize(util.single2uint(img_lq), (int(sf*img_lq.shape[1]), int(sf*img_lq.shape[0])), interpolation=0)
+# img_concat = np.concatenate([lq_nearest, util.single2uint(img_hq)], axis=1)
+# util.imsave(img_concat, str(i)+'.png')
+
+# run utils/utils_blindsr.py
diff --git a/KAIR/utils/utils_bnorm.py b/KAIR/utils/utils_bnorm.py
new file mode 100644
index 0000000000000000000000000000000000000000..9bd346e05b66efd074f81f1961068e2de45ac5da
--- /dev/null
+++ b/KAIR/utils/utils_bnorm.py
@@ -0,0 +1,91 @@
+import torch
+import torch.nn as nn
+
+
+"""
+# --------------------------------------------
+# Batch Normalization
+# --------------------------------------------
+
+# Kai Zhang (cskaizhang@gmail.com)
+# https://github.com/cszn
+# 01/Jan/2019
+# --------------------------------------------
+"""
+
+
+# --------------------------------------------
+# remove/delete specified layer
+# --------------------------------------------
+def deleteLayer(model, layer_type=nn.BatchNorm2d):
+ ''' Kai Zhang, 11/Jan/2019.
+ '''
+ for k, m in list(model.named_children()):
+ if isinstance(m, layer_type):
+ del model._modules[k]
+ deleteLayer(m, layer_type)
+
+
+# --------------------------------------------
+# merge bn, "conv+bn" --> "conv"
+# --------------------------------------------
+def merge_bn(model):
+ ''' Kai Zhang, 11/Jan/2019.
+ merge all 'Conv+BN' (or 'TConv+BN') into 'Conv' (or 'TConv')
+ based on https://github.com/pytorch/pytorch/pull/901
+ '''
+ prev_m = None
+ for k, m in list(model.named_children()):
+ if (isinstance(m, nn.BatchNorm2d) or isinstance(m, nn.BatchNorm1d)) and (isinstance(prev_m, nn.Conv2d) or isinstance(prev_m, nn.Linear) or isinstance(prev_m, nn.ConvTranspose2d)):
+
+ w = prev_m.weight.data
+
+ if prev_m.bias is None:
+ zeros = torch.Tensor(prev_m.out_channels).zero_().type(w.type())
+ prev_m.bias = nn.Parameter(zeros)
+ b = prev_m.bias.data
+
+ invstd = m.running_var.clone().add_(m.eps).pow_(-0.5)
+ if isinstance(prev_m, nn.ConvTranspose2d):
+ w.mul_(invstd.view(1, w.size(1), 1, 1).expand_as(w))
+ else:
+ w.mul_(invstd.view(w.size(0), 1, 1, 1).expand_as(w))
+ b.add_(-m.running_mean).mul_(invstd)
+ if m.affine:
+ if isinstance(prev_m, nn.ConvTranspose2d):
+ w.mul_(m.weight.data.view(1, w.size(1), 1, 1).expand_as(w))
+ else:
+ w.mul_(m.weight.data.view(w.size(0), 1, 1, 1).expand_as(w))
+ b.mul_(m.weight.data).add_(m.bias.data)
+
+ del model._modules[k]
+ prev_m = m
+ merge_bn(m)
+
+
+# --------------------------------------------
+# add bn, "conv" --> "conv+bn"
+# --------------------------------------------
+def add_bn(model):
+ ''' Kai Zhang, 11/Jan/2019.
+ '''
+ for k, m in list(model.named_children()):
+ if (isinstance(m, nn.Conv2d) or isinstance(m, nn.Linear) or isinstance(m, nn.ConvTranspose2d)):
+ b = nn.BatchNorm2d(m.out_channels, momentum=0.1, affine=True)
+ b.weight.data.fill_(1)
+ new_m = nn.Sequential(model._modules[k], b)
+ model._modules[k] = new_m
+ add_bn(m)
+
+
+# --------------------------------------------
+# tidy model after removing bn
+# --------------------------------------------
+def tidy_sequential(model):
+ ''' Kai Zhang, 11/Jan/2019.
+ '''
+ for k, m in list(model.named_children()):
+ if isinstance(m, nn.Sequential):
+ if m.__len__() == 1:
+ model._modules[k] = m.__getitem__(0)
+ tidy_sequential(m)
diff --git a/KAIR/utils/utils_deblur.py b/KAIR/utils/utils_deblur.py
new file mode 100644
index 0000000000000000000000000000000000000000..c5457b9c1df3bd7bbe8758cf8be5824273b8db29
--- /dev/null
+++ b/KAIR/utils/utils_deblur.py
@@ -0,0 +1,655 @@
+# -*- coding: utf-8 -*-
+import numpy as np
+import scipy
+from scipy import fftpack
+import torch
+
+from math import cos, sin
+from numpy import zeros, ones, prod, array, pi, log, min, mod, arange, sum, mgrid, exp, pad, round
+from numpy.random import randn, rand
+from scipy.signal import convolve2d
+import cv2
+import random
+# import utils_image as util
+
+'''
+modified by Kai Zhang (github: https://github.com/cszn)
+03/03/2019
+'''
+
+
+def get_uperleft_denominator(img, kernel):
+ '''
+ img: HxWxC
+ kernel: hxw
+ denominator: HxWx1
+ upperleft: HxWxC
+ '''
+ V = psf2otf(kernel, img.shape[:2])
+ denominator = np.expand_dims(np.abs(V)**2, axis=2)
+ upperleft = np.expand_dims(np.conj(V), axis=2) * np.fft.fft2(img, axes=[0, 1])
+ return upperleft, denominator
+
+
+def get_uperleft_denominator_pytorch(img, kernel):
+ '''
+ img: NxCxHxW
+ kernel: Nx1xhxw
+ denominator: Nx1xHxW
+ upperleft: NxCxHxWx2
+ '''
+ V = p2o(kernel, img.shape[-2:]) # Nx1xHxWx2
+ denominator = V[..., 0]**2+V[..., 1]**2 # Nx1xHxW
+ upperleft = cmul(cconj(V), rfft(img)) # Nx1xHxWx2 * NxCxHxWx2
+ return upperleft, denominator
+
+
+def c2c(x):
+ return torch.from_numpy(np.stack([np.float32(x.real), np.float32(x.imag)], axis=-1))
+
+
+def r2c(x):
+ return torch.stack([x, torch.zeros_like(x)], -1)
+
+
+def cdiv(x, y):
+ a, b = x[..., 0], x[..., 1]
+ c, d = y[..., 0], y[..., 1]
+ cd2 = c**2 + d**2
+ return torch.stack([(a*c+b*d)/cd2, (b*c-a*d)/cd2], -1)
+
+
+def cabs(x):
+ return torch.pow(x[..., 0]**2+x[..., 1]**2, 0.5)
+
+
+def cmul(t1, t2):
+ '''
+ complex multiplication
+ t1: NxCxHxWx2
+ output: NxCxHxWx2
+ '''
+ real1, imag1 = t1[..., 0], t1[..., 1]
+ real2, imag2 = t2[..., 0], t2[..., 1]
+ return torch.stack([real1 * real2 - imag1 * imag2, real1 * imag2 + imag1 * real2], dim=-1)
+
+
+def cconj(t, inplace=False):
+ '''
+ # complex's conjugation
+ t: NxCxHxWx2
+ output: NxCxHxWx2
+ '''
+ c = t.clone() if not inplace else t
+ c[..., 1] *= -1
+ return c
+
+
+def rfft(t):
+ return torch.rfft(t, 2, onesided=False)
+
+
+def irfft(t):
+ return torch.irfft(t, 2, onesided=False)
+
+
+def fft(t):
+ return torch.fft(t, 2)
+
+
+def ifft(t):
+ return torch.ifft(t, 2)
+
+
+def p2o(psf, shape):
+ '''
+ # psf: NxCxhxw
+ # shape: [H,W]
+ # otf: NxCxHxWx2
+ '''
+ otf = torch.zeros(psf.shape[:-2] + shape).type_as(psf)
+ otf[...,:psf.shape[2],:psf.shape[3]].copy_(psf)
+ for axis, axis_size in enumerate(psf.shape[2:]):
+ otf = torch.roll(otf, -int(axis_size / 2), dims=axis+2)
+ otf = torch.rfft(otf, 2, onesided=False)
+ n_ops = torch.sum(torch.tensor(psf.shape).type_as(psf) * torch.log2(torch.tensor(psf.shape).type_as(psf)))
+ otf[...,1][torch.abs(otf[...,1])= abs(y)] = abs(x)[abs(x) >= abs(y)]
+ maxxy[abs(y) >= abs(x)] = abs(y)[abs(y) >= abs(x)]
+ minxy = np.zeros(x.shape)
+ minxy[abs(x) <= abs(y)] = abs(x)[abs(x) <= abs(y)]
+ minxy[abs(y) <= abs(x)] = abs(y)[abs(y) <= abs(x)]
+ m1 = (rad**2 < (maxxy+0.5)**2 + (minxy-0.5)**2)*(minxy-0.5) +\
+ (rad**2 >= (maxxy+0.5)**2 + (minxy-0.5)**2)*\
+ np.sqrt((rad**2 + 0j) - (maxxy + 0.5)**2)
+ m2 = (rad**2 > (maxxy-0.5)**2 + (minxy+0.5)**2)*(minxy+0.5) +\
+ (rad**2 <= (maxxy-0.5)**2 + (minxy+0.5)**2)*\
+ np.sqrt((rad**2 + 0j) - (maxxy - 0.5)**2)
+ h = None
+ return h
+
+
+def fspecial_gaussian(hsize, sigma):
+ hsize = [hsize, hsize]
+ siz = [(hsize[0]-1.0)/2.0, (hsize[1]-1.0)/2.0]
+ std = sigma
+ [x, y] = np.meshgrid(np.arange(-siz[1], siz[1]+1), np.arange(-siz[0], siz[0]+1))
+ arg = -(x*x + y*y)/(2*std*std)
+ h = np.exp(arg)
+ h[h < scipy.finfo(float).eps * h.max()] = 0
+ sumh = h.sum()
+ if sumh != 0:
+ h = h/sumh
+ return h
+
+
+def fspecial_laplacian(alpha):
+ alpha = max([0, min([alpha,1])])
+ h1 = alpha/(alpha+1)
+ h2 = (1-alpha)/(alpha+1)
+ h = [[h1, h2, h1], [h2, -4/(alpha+1), h2], [h1, h2, h1]]
+ h = np.array(h)
+ return h
+
+
+def fspecial_log(hsize, sigma):
+ raise(NotImplemented)
+
+
+def fspecial_motion(motion_len, theta):
+ raise(NotImplemented)
+
+
+def fspecial_prewitt():
+ return np.array([[1, 1, 1], [0, 0, 0], [-1, -1, -1]])
+
+
+def fspecial_sobel():
+ return np.array([[1, 2, 1], [0, 0, 0], [-1, -2, -1]])
+
+
+def fspecial(filter_type, *args, **kwargs):
+ '''
+ python code from:
+ https://github.com/ronaldosena/imagens-medicas-2/blob/40171a6c259edec7827a6693a93955de2bd39e76/Aulas/aula_2_-_uniform_filter/matlab_fspecial.py
+ '''
+ if filter_type == 'average':
+ return fspecial_average(*args, **kwargs)
+ if filter_type == 'disk':
+ return fspecial_disk(*args, **kwargs)
+ if filter_type == 'gaussian':
+ return fspecial_gaussian(*args, **kwargs)
+ if filter_type == 'laplacian':
+ return fspecial_laplacian(*args, **kwargs)
+ if filter_type == 'log':
+ return fspecial_log(*args, **kwargs)
+ if filter_type == 'motion':
+ return fspecial_motion(*args, **kwargs)
+ if filter_type == 'prewitt':
+ return fspecial_prewitt(*args, **kwargs)
+ if filter_type == 'sobel':
+ return fspecial_sobel(*args, **kwargs)
+
+
+def fspecial_gauss(size, sigma):
+ x, y = mgrid[-size // 2 + 1 : size // 2 + 1, -size // 2 + 1 : size // 2 + 1]
+ g = exp(-((x ** 2 + y ** 2) / (2.0 * sigma ** 2)))
+ return g / g.sum()
+
+
+def blurkernel_synthesis(h=37, w=None):
+ # https://github.com/tkkcc/prior/blob/879a0b6c117c810776d8cc6b63720bf29f7d0cc4/util/gen_kernel.py
+ w = h if w is None else w
+ kdims = [h, w]
+ x = randomTrajectory(250)
+ k = None
+ while k is None:
+ k = kernelFromTrajectory(x)
+
+ # center pad to kdims
+ pad_width = ((kdims[0] - k.shape[0]) // 2, (kdims[1] - k.shape[1]) // 2)
+ pad_width = [(pad_width[0],), (pad_width[1],)]
+
+ if pad_width[0][0]<0 or pad_width[1][0]<0:
+ k = k[0:h, 0:h]
+ else:
+ k = pad(k, pad_width, "constant")
+ x1,x2 = k.shape
+ if np.random.randint(0, 4) == 1:
+ k = cv2.resize(k, (random.randint(x1, 5*x1), random.randint(x2, 5*x2)), interpolation=cv2.INTER_LINEAR)
+ y1, y2 = k.shape
+ k = k[(y1-x1)//2: (y1-x1)//2+x1, (y2-x2)//2: (y2-x2)//2+x2]
+
+ if sum(k)<0.1:
+ k = fspecial_gaussian(h, 0.1+6*np.random.rand(1))
+ k = k / sum(k)
+ # import matplotlib.pyplot as plt
+ # plt.imshow(k, interpolation="nearest", cmap="gray")
+ # plt.show()
+ return k
+
+
+def kernelFromTrajectory(x):
+ h = 5 - log(rand()) / 0.15
+ h = round(min([h, 27])).astype(int)
+ h = h + 1 - h % 2
+ w = h
+ k = zeros((h, w))
+
+ xmin = min(x[0])
+ xmax = max(x[0])
+ ymin = min(x[1])
+ ymax = max(x[1])
+ xthr = arange(xmin, xmax, (xmax - xmin) / w)
+ ythr = arange(ymin, ymax, (ymax - ymin) / h)
+
+ for i in range(1, xthr.size):
+ for j in range(1, ythr.size):
+ idx = (
+ (x[0, :] >= xthr[i - 1])
+ & (x[0, :] < xthr[i])
+ & (x[1, :] >= ythr[j - 1])
+ & (x[1, :] < ythr[j])
+ )
+ k[i - 1, j - 1] = sum(idx)
+ if sum(k) == 0:
+ return
+ k = k / sum(k)
+ k = convolve2d(k, fspecial_gauss(3, 1), "same")
+ k = k / sum(k)
+ return k
+
+
+def randomTrajectory(T):
+ x = zeros((3, T))
+ v = randn(3, T)
+ r = zeros((3, T))
+ trv = 1 / 1
+ trr = 2 * pi / T
+ for t in range(1, T):
+ F_rot = randn(3) / (t + 1) + r[:, t - 1]
+ F_trans = randn(3) / (t + 1)
+ r[:, t] = r[:, t - 1] + trr * F_rot
+ v[:, t] = v[:, t - 1] + trv * F_trans
+ st = v[:, t]
+ st = rot3D(st, r[:, t])
+ x[:, t] = x[:, t - 1] + st
+ return x
+
+
+def rot3D(x, r):
+ Rx = array([[1, 0, 0], [0, cos(r[0]), -sin(r[0])], [0, sin(r[0]), cos(r[0])]])
+ Ry = array([[cos(r[1]), 0, sin(r[1])], [0, 1, 0], [-sin(r[1]), 0, cos(r[1])]])
+ Rz = array([[cos(r[2]), -sin(r[2]), 0], [sin(r[2]), cos(r[2]), 0], [0, 0, 1]])
+ R = Rz @ Ry @ Rx
+ x = R @ x
+ return x
+
+
+if __name__ == '__main__':
+ a = opt_fft_size([111])
+ print(a)
+
+ print(fspecial('gaussian', 5, 1))
+
+ print(p2o(torch.zeros(1,1,4,4).float(),(14,14)).shape)
+
+ k = blurkernel_synthesis(11)
+ import matplotlib.pyplot as plt
+ plt.imshow(k, interpolation="nearest", cmap="gray")
+ plt.show()
diff --git a/KAIR/utils/utils_dist.py b/KAIR/utils/utils_dist.py
new file mode 100644
index 0000000000000000000000000000000000000000..7729e3af0b8fc3f48bb050b5eb31eaf971488d1e
--- /dev/null
+++ b/KAIR/utils/utils_dist.py
@@ -0,0 +1,201 @@
+# Modified from https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/dist_utils.py # noqa: E501
+import functools
+import os
+import subprocess
+import torch
+import torch.distributed as dist
+import torch.multiprocessing as mp
+
+
+# ----------------------------------
+# init
+# ----------------------------------
+def init_dist(launcher, backend='nccl', **kwargs):
+ if mp.get_start_method(allow_none=True) is None:
+ mp.set_start_method('spawn')
+ if launcher == 'pytorch':
+ _init_dist_pytorch(backend, **kwargs)
+ elif launcher == 'slurm':
+ _init_dist_slurm(backend, **kwargs)
+ else:
+ raise ValueError(f'Invalid launcher type: {launcher}')
+
+
+def _init_dist_pytorch(backend, **kwargs):
+ rank = int(os.environ['RANK'])
+ num_gpus = torch.cuda.device_count()
+ torch.cuda.set_device(rank % num_gpus)
+ dist.init_process_group(backend=backend, **kwargs)
+
+
+def _init_dist_slurm(backend, port=None):
+ """Initialize slurm distributed training environment.
+ If argument ``port`` is not specified, then the master port will be system
+ environment variable ``MASTER_PORT``. If ``MASTER_PORT`` is not in system
+ environment variable, then a default port ``29500`` will be used.
+ Args:
+ backend (str): Backend of torch.distributed.
+ port (int, optional): Master port. Defaults to None.
+ """
+ proc_id = int(os.environ['SLURM_PROCID'])
+ ntasks = int(os.environ['SLURM_NTASKS'])
+ node_list = os.environ['SLURM_NODELIST']
+ num_gpus = torch.cuda.device_count()
+ torch.cuda.set_device(proc_id % num_gpus)
+ addr = subprocess.getoutput(
+ f'scontrol show hostname {node_list} | head -n1')
+ # specify master port
+ if port is not None:
+ os.environ['MASTER_PORT'] = str(port)
+ elif 'MASTER_PORT' in os.environ:
+ pass # use MASTER_PORT in the environment variable
+ else:
+ # 29500 is torch.distributed default port
+ os.environ['MASTER_PORT'] = '29500'
+ os.environ['MASTER_ADDR'] = addr
+ os.environ['WORLD_SIZE'] = str(ntasks)
+ os.environ['LOCAL_RANK'] = str(proc_id % num_gpus)
+ os.environ['RANK'] = str(proc_id)
+ dist.init_process_group(backend=backend)
+
+
+
+# ----------------------------------
+# get rank and world_size
+# ----------------------------------
+def get_dist_info():
+ if dist.is_available():
+ initialized = dist.is_initialized()
+ else:
+ initialized = False
+ if initialized:
+ rank = dist.get_rank()
+ world_size = dist.get_world_size()
+ else:
+ rank = 0
+ world_size = 1
+ return rank, world_size
+
+
+def get_rank():
+ if not dist.is_available():
+ return 0
+
+ if not dist.is_initialized():
+ return 0
+
+ return dist.get_rank()
+
+
+def get_world_size():
+ if not dist.is_available():
+ return 1
+
+ if not dist.is_initialized():
+ return 1
+
+ return dist.get_world_size()
+
+
+def master_only(func):
+
+ @functools.wraps(func)
+ def wrapper(*args, **kwargs):
+ rank, _ = get_dist_info()
+ if rank == 0:
+ return func(*args, **kwargs)
+
+ return wrapper
+
+
+
+
+
+
+# ----------------------------------
+# operation across ranks
+# ----------------------------------
+def reduce_sum(tensor):
+ if not dist.is_available():
+ return tensor
+
+ if not dist.is_initialized():
+ return tensor
+
+ tensor = tensor.clone()
+ dist.all_reduce(tensor, op=dist.ReduceOp.SUM)
+
+ return tensor
+
+
+def gather_grad(params):
+ world_size = get_world_size()
+
+ if world_size == 1:
+ return
+
+ for param in params:
+ if param.grad is not None:
+ dist.all_reduce(param.grad.data, op=dist.ReduceOp.SUM)
+ param.grad.data.div_(world_size)
+
+
+def all_gather(data):
+ world_size = get_world_size()
+
+ if world_size == 1:
+ return [data]
+
+ buffer = pickle.dumps(data)
+ storage = torch.ByteStorage.from_buffer(buffer)
+ tensor = torch.ByteTensor(storage).to('cuda')
+
+ local_size = torch.IntTensor([tensor.numel()]).to('cuda')
+ size_list = [torch.IntTensor([0]).to('cuda') for _ in range(world_size)]
+ dist.all_gather(size_list, local_size)
+ size_list = [int(size.item()) for size in size_list]
+ max_size = max(size_list)
+
+ tensor_list = []
+ for _ in size_list:
+ tensor_list.append(torch.ByteTensor(size=(max_size,)).to('cuda'))
+
+ if local_size != max_size:
+ padding = torch.ByteTensor(size=(max_size - local_size,)).to('cuda')
+ tensor = torch.cat((tensor, padding), 0)
+
+ dist.all_gather(tensor_list, tensor)
+
+ data_list = []
+
+ for size, tensor in zip(size_list, tensor_list):
+ buffer = tensor.cpu().numpy().tobytes()[:size]
+ data_list.append(pickle.loads(buffer))
+
+ return data_list
+
+
+def reduce_loss_dict(loss_dict):
+ world_size = get_world_size()
+
+ if world_size < 2:
+ return loss_dict
+
+ with torch.no_grad():
+ keys = []
+ losses = []
+
+ for k in sorted(loss_dict.keys()):
+ keys.append(k)
+ losses.append(loss_dict[k])
+
+ losses = torch.stack(losses, 0)
+ dist.reduce(losses, dst=0)
+
+ if dist.get_rank() == 0:
+ losses /= world_size
+
+ reduced_losses = {k: v for k, v in zip(keys, losses)}
+
+ return reduced_losses
+
diff --git a/KAIR/utils/utils_googledownload.py b/KAIR/utils/utils_googledownload.py
new file mode 100644
index 0000000000000000000000000000000000000000..f4acaf78d7cc60bec569cae2f02f2ec049407615
--- /dev/null
+++ b/KAIR/utils/utils_googledownload.py
@@ -0,0 +1,93 @@
+import math
+import requests
+from tqdm import tqdm
+
+
+'''
+borrowed from
+https://github.com/xinntao/BasicSR/blob/28883e15eedc3381d23235ff3cf7c454c4be87e6/basicsr/utils/download_util.py
+'''
+
+
+def sizeof_fmt(size, suffix='B'):
+ """Get human readable file size.
+ Args:
+ size (int): File size.
+ suffix (str): Suffix. Default: 'B'.
+ Return:
+ str: Formated file siz.
+ """
+ for unit in ['', 'K', 'M', 'G', 'T', 'P', 'E', 'Z']:
+ if abs(size) < 1024.0:
+ return f'{size:3.1f} {unit}{suffix}'
+ size /= 1024.0
+ return f'{size:3.1f} Y{suffix}'
+
+
+def download_file_from_google_drive(file_id, save_path):
+ """Download files from google drive.
+ Ref:
+ https://stackoverflow.com/questions/25010369/wget-curl-large-file-from-google-drive # noqa E501
+ Args:
+ file_id (str): File id.
+ save_path (str): Save path.
+ """
+
+ session = requests.Session()
+ URL = 'https://docs.google.com/uc?export=download'
+ params = {'id': file_id}
+
+ response = session.get(URL, params=params, stream=True)
+ token = get_confirm_token(response)
+ if token:
+ params['confirm'] = token
+ response = session.get(URL, params=params, stream=True)
+
+ # get file size
+ response_file_size = session.get(
+ URL, params=params, stream=True, headers={'Range': 'bytes=0-2'})
+ if 'Content-Range' in response_file_size.headers:
+ file_size = int(
+ response_file_size.headers['Content-Range'].split('/')[1])
+ else:
+ file_size = None
+
+ save_response_content(response, save_path, file_size)
+
+
+def get_confirm_token(response):
+ for key, value in response.cookies.items():
+ if key.startswith('download_warning'):
+ return value
+ return None
+
+
+def save_response_content(response,
+ destination,
+ file_size=None,
+ chunk_size=32768):
+ if file_size is not None:
+ pbar = tqdm(total=math.ceil(file_size / chunk_size), unit='chunk')
+
+ readable_file_size = sizeof_fmt(file_size)
+ else:
+ pbar = None
+
+ with open(destination, 'wb') as f:
+ downloaded_size = 0
+ for chunk in response.iter_content(chunk_size):
+ downloaded_size += chunk_size
+ if pbar is not None:
+ pbar.update(1)
+ pbar.set_description(f'Download {sizeof_fmt(downloaded_size)} '
+ f'/ {readable_file_size}')
+ if chunk: # filter out keep-alive new chunks
+ f.write(chunk)
+ if pbar is not None:
+ pbar.close()
+
+
+if __name__ == "__main__":
+ file_id = '1WNULM1e8gRNvsngVscsQ8tpaOqJ4mYtv'
+ save_path = 'BSRGAN.pth'
+ download_file_from_google_drive(file_id, save_path)
diff --git a/KAIR/utils/utils_image.py b/KAIR/utils/utils_image.py
new file mode 100644
index 0000000000000000000000000000000000000000..0e513a8bc1594c9ce2ba47ce3fe3b497269b7f16
--- /dev/null
+++ b/KAIR/utils/utils_image.py
@@ -0,0 +1,1016 @@
+import os
+import math
+import random
+import numpy as np
+import torch
+import cv2
+from torchvision.utils import make_grid
+from datetime import datetime
+# import torchvision.transforms as transforms
+import matplotlib.pyplot as plt
+from mpl_toolkits.mplot3d import Axes3D
+os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
+
+
+'''
+# --------------------------------------------
+# Kai Zhang (github: https://github.com/cszn)
+# 03/Mar/2019
+# --------------------------------------------
+# https://github.com/twhui/SRGAN-pyTorch
+# https://github.com/xinntao/BasicSR
+# --------------------------------------------
+'''
+
+
+IMG_EXTENSIONS = ['.jpg', '.JPG', '.jpeg', '.JPEG', '.png', '.PNG', '.ppm', '.PPM', '.bmp', '.BMP', '.tif']
+
+
+def is_image_file(filename):
+ return any(filename.endswith(extension) for extension in IMG_EXTENSIONS)
+
+
+def get_timestamp():
+ return datetime.now().strftime('%y%m%d-%H%M%S')
+
+
+def imshow(x, title=None, cbar=False, figsize=None):
+ plt.figure(figsize=figsize)
+ plt.imshow(np.squeeze(x), interpolation='nearest', cmap='gray')
+ if title:
+ plt.title(title)
+ if cbar:
+ plt.colorbar()
+ plt.show()
+
+
+def surf(Z, cmap='rainbow', figsize=None):
+ plt.figure(figsize=figsize)
+ ax3 = plt.axes(projection='3d')
+
+ w, h = Z.shape[:2]
+ xx = np.arange(0,w,1)
+ yy = np.arange(0,h,1)
+ X, Y = np.meshgrid(xx, yy)
+ ax3.plot_surface(X,Y,Z,cmap=cmap)
+ #ax3.contour(X,Y,Z, zdim='z',offset=-2,cmap=cmap)
+ plt.show()
+
+
+'''
+# --------------------------------------------
+# get image pathes
+# --------------------------------------------
+'''
+
+
+def get_image_paths(dataroot):
+ paths = None # return None if dataroot is None
+ if isinstance(dataroot, str):
+ paths = sorted(_get_paths_from_images(dataroot))
+ elif isinstance(dataroot, list):
+ paths = []
+ for i in dataroot:
+ paths += sorted(_get_paths_from_images(i))
+ return paths
+
+
+def _get_paths_from_images(path):
+ assert os.path.isdir(path), '{:s} is not a valid directory'.format(path)
+ images = []
+ for dirpath, _, fnames in sorted(os.walk(path)):
+ for fname in sorted(fnames):
+ if is_image_file(fname):
+ img_path = os.path.join(dirpath, fname)
+ images.append(img_path)
+ assert images, '{:s} has no valid image file'.format(path)
+ return images
+
+
+'''
+# --------------------------------------------
+# split large images into small images
+# --------------------------------------------
+'''
+
+
+def patches_from_image(img, p_size=512, p_overlap=64, p_max=800):
+ w, h = img.shape[:2]
+ patches = []
+ if w > p_max and h > p_max:
+ w1 = list(np.arange(0, w-p_size, p_size-p_overlap, dtype=np.int))
+ h1 = list(np.arange(0, h-p_size, p_size-p_overlap, dtype=np.int))
+ w1.append(w-p_size)
+ h1.append(h-p_size)
+ # print(w1)
+ # print(h1)
+ for i in w1:
+ for j in h1:
+ patches.append(img[i:i+p_size, j:j+p_size,:])
+ else:
+ patches.append(img)
+
+ return patches
+
+
+def imssave(imgs, img_path):
+ """
+ imgs: list, N images of size WxHxC
+ """
+ img_name, ext = os.path.splitext(os.path.basename(img_path))
+ for i, img in enumerate(imgs):
+ if img.ndim == 3:
+ img = img[:, :, [2, 1, 0]]
+ new_path = os.path.join(os.path.dirname(img_path), img_name+str('_{:04d}'.format(i))+'.png')
+ cv2.imwrite(new_path, img)
+
+
+def split_imageset(original_dataroot, taget_dataroot, n_channels=3, p_size=512, p_overlap=96, p_max=800):
+ """
+ split the large images from original_dataroot into small overlapped images with size (p_size)x(p_size),
+ and save them into taget_dataroot; only the images with larger size than (p_max)x(p_max)
+ will be splitted.
+
+ Args:
+ original_dataroot:
+ taget_dataroot:
+ p_size: size of small images
+ p_overlap: patch size in training is a good choice
+ p_max: images with smaller size than (p_max)x(p_max) keep unchanged.
+ """
+ paths = get_image_paths(original_dataroot)
+ for img_path in paths:
+ # img_name, ext = os.path.splitext(os.path.basename(img_path))
+ img = imread_uint(img_path, n_channels=n_channels)
+ patches = patches_from_image(img, p_size, p_overlap, p_max)
+ imssave(patches, os.path.join(taget_dataroot, os.path.basename(img_path)))
+ #if original_dataroot == taget_dataroot:
+ #del img_path
+
+'''
+# --------------------------------------------
+# makedir
+# --------------------------------------------
+'''
+
+
+def mkdir(path):
+ if not os.path.exists(path):
+ os.makedirs(path)
+
+
+def mkdirs(paths):
+ if isinstance(paths, str):
+ mkdir(paths)
+ else:
+ for path in paths:
+ mkdir(path)
+
+
+def mkdir_and_rename(path):
+ if os.path.exists(path):
+ new_name = path + '_archived_' + get_timestamp()
+ print('Path already exists. Rename it to [{:s}]'.format(new_name))
+ os.rename(path, new_name)
+ os.makedirs(path)
+
+
+'''
+# --------------------------------------------
+# read image from path
+# opencv is fast, but read BGR numpy image
+# --------------------------------------------
+'''
+
+
+# --------------------------------------------
+# get uint8 image of size HxWxn_channles (RGB)
+# --------------------------------------------
+def imread_uint(path, n_channels=3):
+ # input: path
+ # output: HxWx3(RGB or GGG), or HxWx1 (G)
+ if n_channels == 1:
+ img = cv2.imread(path, 0) # cv2.IMREAD_GRAYSCALE
+ img = np.expand_dims(img, axis=2) # HxWx1
+ elif n_channels == 3:
+ img = cv2.imread(path, cv2.IMREAD_UNCHANGED) # BGR or G
+ if img.ndim == 2:
+ img = cv2.cvtColor(img, cv2.COLOR_GRAY2RGB) # GGG
+ else:
+ img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # RGB
+ return img
+
+
+# --------------------------------------------
+# matlab's imwrite
+# --------------------------------------------
+def imsave(img, img_path):
+ img = np.squeeze(img)
+ if img.ndim == 3:
+ img = img[:, :, [2, 1, 0]]
+ cv2.imwrite(img_path, img)
+
+def imwrite(img, img_path):
+ img = np.squeeze(img)
+ if img.ndim == 3:
+ img = img[:, :, [2, 1, 0]]
+ cv2.imwrite(img_path, img)
+
+
+
+# --------------------------------------------
+# get single image of size HxWxn_channles (BGR)
+# --------------------------------------------
+def read_img(path):
+ # read image by cv2
+ # return: Numpy float32, HWC, BGR, [0,1]
+ img = cv2.imread(path, cv2.IMREAD_UNCHANGED) # cv2.IMREAD_GRAYSCALE
+ img = img.astype(np.float32) / 255.
+ if img.ndim == 2:
+ img = np.expand_dims(img, axis=2)
+ # some images have 4 channels
+ if img.shape[2] > 3:
+ img = img[:, :, :3]
+ return img
+
+
+'''
+# --------------------------------------------
+# image format conversion
+# --------------------------------------------
+# numpy(single) <---> numpy(uint)
+# numpy(single) <---> tensor
+# numpy(uint) <---> tensor
+# --------------------------------------------
+'''
+
+
+# --------------------------------------------
+# numpy(single) [0, 1] <---> numpy(uint)
+# --------------------------------------------
+
+
+def uint2single(img):
+
+ return np.float32(img/255.)
+
+
+def single2uint(img):
+
+ return np.uint8((img.clip(0, 1)*255.).round())
+
+
+def uint162single(img):
+
+ return np.float32(img/65535.)
+
+
+def single2uint16(img):
+
+ return np.uint16((img.clip(0, 1)*65535.).round())
+
+
+# --------------------------------------------
+# numpy(uint) (HxWxC or HxW) <---> tensor
+# --------------------------------------------
+
+
+# convert uint to 4-dimensional torch tensor
+def uint2tensor4(img):
+ if img.ndim == 2:
+ img = np.expand_dims(img, axis=2)
+ return torch.from_numpy(np.ascontiguousarray(img)).permute(2, 0, 1).float().div(255.).unsqueeze(0)
+
+
+# convert uint to 3-dimensional torch tensor
+def uint2tensor3(img):
+ if img.ndim == 2:
+ img = np.expand_dims(img, axis=2)
+ return torch.from_numpy(np.ascontiguousarray(img)).permute(2, 0, 1).float().div(255.)
+
+
+# convert 2/3/4-dimensional torch tensor to uint
+def tensor2uint(img):
+ img = img.data.squeeze().float().clamp_(0, 1).cpu().numpy()
+ if img.ndim == 3:
+ img = np.transpose(img, (1, 2, 0))
+ return np.uint8((img*255.0).round())
+
+
+# --------------------------------------------
+# numpy(single) (HxWxC) <---> tensor
+# --------------------------------------------
+
+
+# convert single (HxWxC) to 3-dimensional torch tensor
+def single2tensor3(img):
+ return torch.from_numpy(np.ascontiguousarray(img)).permute(2, 0, 1).float()
+
+
+# convert single (HxWxC) to 4-dimensional torch tensor
+def single2tensor4(img):
+ return torch.from_numpy(np.ascontiguousarray(img)).permute(2, 0, 1).float().unsqueeze(0)
+
+
+# convert torch tensor to single
+def tensor2single(img):
+ img = img.data.squeeze().float().cpu().numpy()
+ if img.ndim == 3:
+ img = np.transpose(img, (1, 2, 0))
+
+ return img
+
+# convert torch tensor to single
+def tensor2single3(img):
+ img = img.data.squeeze().float().cpu().numpy()
+ if img.ndim == 3:
+ img = np.transpose(img, (1, 2, 0))
+ elif img.ndim == 2:
+ img = np.expand_dims(img, axis=2)
+ return img
+
+
+def single2tensor5(img):
+ return torch.from_numpy(np.ascontiguousarray(img)).permute(2, 0, 1, 3).float().unsqueeze(0)
+
+
+def single32tensor5(img):
+ return torch.from_numpy(np.ascontiguousarray(img)).float().unsqueeze(0).unsqueeze(0)
+
+
+def single42tensor4(img):
+ return torch.from_numpy(np.ascontiguousarray(img)).permute(2, 0, 1, 3).float()
+
+
+# from skimage.io import imread, imsave
+def tensor2img(tensor, out_type=np.uint8, min_max=(0, 1)):
+ '''
+ Converts a torch Tensor into an image Numpy array of BGR channel order
+ Input: 4D(B,(3/1),H,W), 3D(C,H,W), or 2D(H,W), any range, RGB channel order
+ Output: 3D(H,W,C) or 2D(H,W), [0,255], np.uint8 (default)
+ '''
+ tensor = tensor.squeeze().float().cpu().clamp_(*min_max) # squeeze first, then clamp
+ tensor = (tensor - min_max[0]) / (min_max[1] - min_max[0]) # to range [0,1]
+ n_dim = tensor.dim()
+ if n_dim == 4:
+ n_img = len(tensor)
+ img_np = make_grid(tensor, nrow=int(math.sqrt(n_img)), normalize=False).numpy()
+ img_np = np.transpose(img_np[[2, 1, 0], :, :], (1, 2, 0)) # HWC, BGR
+ elif n_dim == 3:
+ img_np = tensor.numpy()
+ img_np = np.transpose(img_np[[2, 1, 0], :, :], (1, 2, 0)) # HWC, BGR
+ elif n_dim == 2:
+ img_np = tensor.numpy()
+ else:
+ raise TypeError(
+ 'Only support 4D, 3D and 2D tensor. But received with dimension: {:d}'.format(n_dim))
+ if out_type == np.uint8:
+ img_np = (img_np * 255.0).round()
+ # Important. Unlike matlab, numpy.uint8() WILL NOT round by default.
+ return img_np.astype(out_type)
+
+
+'''
+# --------------------------------------------
+# Augmentation, flipe and/or rotate
+# --------------------------------------------
+# The following two are enough.
+# (1) augmet_img: numpy image of WxHxC or WxH
+# (2) augment_img_tensor4: tensor image 1xCxWxH
+# --------------------------------------------
+'''
+
+
+def augment_img(img, mode=0):
+ '''Kai Zhang (github: https://github.com/cszn)
+ '''
+ if mode == 0:
+ return img
+ elif mode == 1:
+ return np.flipud(np.rot90(img))
+ elif mode == 2:
+ return np.flipud(img)
+ elif mode == 3:
+ return np.rot90(img, k=3)
+ elif mode == 4:
+ return np.flipud(np.rot90(img, k=2))
+ elif mode == 5:
+ return np.rot90(img)
+ elif mode == 6:
+ return np.rot90(img, k=2)
+ elif mode == 7:
+ return np.flipud(np.rot90(img, k=3))
+
+
+def augment_img_tensor4(img, mode=0):
+ '''Kai Zhang (github: https://github.com/cszn)
+ '''
+ if mode == 0:
+ return img
+ elif mode == 1:
+ return img.rot90(1, [2, 3]).flip([2])
+ elif mode == 2:
+ return img.flip([2])
+ elif mode == 3:
+ return img.rot90(3, [2, 3])
+ elif mode == 4:
+ return img.rot90(2, [2, 3]).flip([2])
+ elif mode == 5:
+ return img.rot90(1, [2, 3])
+ elif mode == 6:
+ return img.rot90(2, [2, 3])
+ elif mode == 7:
+ return img.rot90(3, [2, 3]).flip([2])
+
+
+def augment_img_tensor(img, mode=0):
+ '''Kai Zhang (github: https://github.com/cszn)
+ '''
+ img_size = img.size()
+ img_np = img.data.cpu().numpy()
+ if len(img_size) == 3:
+ img_np = np.transpose(img_np, (1, 2, 0))
+ elif len(img_size) == 4:
+ img_np = np.transpose(img_np, (2, 3, 1, 0))
+ img_np = augment_img(img_np, mode=mode)
+ img_tensor = torch.from_numpy(np.ascontiguousarray(img_np))
+ if len(img_size) == 3:
+ img_tensor = img_tensor.permute(2, 0, 1)
+ elif len(img_size) == 4:
+ img_tensor = img_tensor.permute(3, 2, 0, 1)
+
+ return img_tensor.type_as(img)
+
+
+def augment_img_np3(img, mode=0):
+ if mode == 0:
+ return img
+ elif mode == 1:
+ return img.transpose(1, 0, 2)
+ elif mode == 2:
+ return img[::-1, :, :]
+ elif mode == 3:
+ img = img[::-1, :, :]
+ img = img.transpose(1, 0, 2)
+ return img
+ elif mode == 4:
+ return img[:, ::-1, :]
+ elif mode == 5:
+ img = img[:, ::-1, :]
+ img = img.transpose(1, 0, 2)
+ return img
+ elif mode == 6:
+ img = img[:, ::-1, :]
+ img = img[::-1, :, :]
+ return img
+ elif mode == 7:
+ img = img[:, ::-1, :]
+ img = img[::-1, :, :]
+ img = img.transpose(1, 0, 2)
+ return img
+
+
+def augment_imgs(img_list, hflip=True, rot=True):
+ # horizontal flip OR rotate
+ hflip = hflip and random.random() < 0.5
+ vflip = rot and random.random() < 0.5
+ rot90 = rot and random.random() < 0.5
+
+ def _augment(img):
+ if hflip:
+ img = img[:, ::-1, :]
+ if vflip:
+ img = img[::-1, :, :]
+ if rot90:
+ img = img.transpose(1, 0, 2)
+ return img
+
+ return [_augment(img) for img in img_list]
+
+
+'''
+# --------------------------------------------
+# modcrop and shave
+# --------------------------------------------
+'''
+
+
+def modcrop(img_in, scale):
+ # img_in: Numpy, HWC or HW
+ img = np.copy(img_in)
+ if img.ndim == 2:
+ H, W = img.shape
+ H_r, W_r = H % scale, W % scale
+ img = img[:H - H_r, :W - W_r]
+ elif img.ndim == 3:
+ H, W, C = img.shape
+ H_r, W_r = H % scale, W % scale
+ img = img[:H - H_r, :W - W_r, :]
+ else:
+ raise ValueError('Wrong img ndim: [{:d}].'.format(img.ndim))
+ return img
+
+
+def shave(img_in, border=0):
+ # img_in: Numpy, HWC or HW
+ img = np.copy(img_in)
+ h, w = img.shape[:2]
+ img = img[border:h-border, border:w-border]
+ return img
+
+
+'''
+# --------------------------------------------
+# image processing process on numpy image
+# channel_convert(in_c, tar_type, img_list):
+# rgb2ycbcr(img, only_y=True):
+# bgr2ycbcr(img, only_y=True):
+# ycbcr2rgb(img):
+# --------------------------------------------
+'''
+
+
+def rgb2ycbcr(img, only_y=True):
+ '''same as matlab rgb2ycbcr
+ only_y: only return Y channel
+ Input:
+ uint8, [0, 255]
+ float, [0, 1]
+ '''
+ in_img_type = img.dtype
+ img.astype(np.float32)
+ if in_img_type != np.uint8:
+ img *= 255.
+ # convert
+ if only_y:
+ rlt = np.dot(img, [65.481, 128.553, 24.966]) / 255.0 + 16.0
+ else:
+ rlt = np.matmul(img, [[65.481, -37.797, 112.0], [128.553, -74.203, -93.786],
+ [24.966, 112.0, -18.214]]) / 255.0 + [16, 128, 128]
+ if in_img_type == np.uint8:
+ rlt = rlt.round()
+ else:
+ rlt /= 255.
+ return rlt.astype(in_img_type)
+
+
+def ycbcr2rgb(img):
+ '''same as matlab ycbcr2rgb
+ Input:
+ uint8, [0, 255]
+ float, [0, 1]
+ '''
+ in_img_type = img.dtype
+ img.astype(np.float32)
+ if in_img_type != np.uint8:
+ img *= 255.
+ # convert
+ rlt = np.matmul(img, [[0.00456621, 0.00456621, 0.00456621], [0, -0.00153632, 0.00791071],
+ [0.00625893, -0.00318811, 0]]) * 255.0 + [-222.921, 135.576, -276.836]
+ rlt = np.clip(rlt, 0, 255)
+ if in_img_type == np.uint8:
+ rlt = rlt.round()
+ else:
+ rlt /= 255.
+ return rlt.astype(in_img_type)
+
+
+def bgr2ycbcr(img, only_y=True):
+ '''bgr version of rgb2ycbcr
+ only_y: only return Y channel
+ Input:
+ uint8, [0, 255]
+ float, [0, 1]
+ '''
+ in_img_type = img.dtype
+ img.astype(np.float32)
+ if in_img_type != np.uint8:
+ img *= 255.
+ # convert
+ if only_y:
+ rlt = np.dot(img, [24.966, 128.553, 65.481]) / 255.0 + 16.0
+ else:
+ rlt = np.matmul(img, [[24.966, 112.0, -18.214], [128.553, -74.203, -93.786],
+ [65.481, -37.797, 112.0]]) / 255.0 + [16, 128, 128]
+ if in_img_type == np.uint8:
+ rlt = rlt.round()
+ else:
+ rlt /= 255.
+ return rlt.astype(in_img_type)
+
+
+def channel_convert(in_c, tar_type, img_list):
+ # conversion among BGR, gray and y
+ if in_c == 3 and tar_type == 'gray': # BGR to gray
+ gray_list = [cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) for img in img_list]
+ return [np.expand_dims(img, axis=2) for img in gray_list]
+ elif in_c == 3 and tar_type == 'y': # BGR to y
+ y_list = [bgr2ycbcr(img, only_y=True) for img in img_list]
+ return [np.expand_dims(img, axis=2) for img in y_list]
+ elif in_c == 1 and tar_type == 'RGB': # gray/y to BGR
+ return [cv2.cvtColor(img, cv2.COLOR_GRAY2BGR) for img in img_list]
+ else:
+ return img_list
+
+
+'''
+# --------------------------------------------
+# metric, PSNR, SSIM and PSNRB
+# --------------------------------------------
+'''
+
+
+# --------------------------------------------
+# PSNR
+# --------------------------------------------
+def calculate_psnr(img1, img2, border=0):
+ # img1 and img2 have range [0, 255]
+ #img1 = img1.squeeze()
+ #img2 = img2.squeeze()
+ if not img1.shape == img2.shape:
+ raise ValueError('Input images must have the same dimensions.')
+ h, w = img1.shape[:2]
+ img1 = img1[border:h-border, border:w-border]
+ img2 = img2[border:h-border, border:w-border]
+
+ img1 = img1.astype(np.float64)
+ img2 = img2.astype(np.float64)
+ mse = np.mean((img1 - img2)**2)
+ if mse == 0:
+ return float('inf')
+ return 20 * math.log10(255.0 / math.sqrt(mse))
+
+
+# --------------------------------------------
+# SSIM
+# --------------------------------------------
+def calculate_ssim(img1, img2, border=0):
+ '''calculate SSIM
+ the same outputs as MATLAB's
+ img1, img2: [0, 255]
+ '''
+ #img1 = img1.squeeze()
+ #img2 = img2.squeeze()
+ if not img1.shape == img2.shape:
+ raise ValueError('Input images must have the same dimensions.')
+ h, w = img1.shape[:2]
+ img1 = img1[border:h-border, border:w-border]
+ img2 = img2[border:h-border, border:w-border]
+
+ if img1.ndim == 2:
+ return ssim(img1, img2)
+ elif img1.ndim == 3:
+ if img1.shape[2] == 3:
+ ssims = []
+ for i in range(3):
+ ssims.append(ssim(img1[:,:,i], img2[:,:,i]))
+ return np.array(ssims).mean()
+ elif img1.shape[2] == 1:
+ return ssim(np.squeeze(img1), np.squeeze(img2))
+ else:
+ raise ValueError('Wrong input image dimensions.')
+
+
+def ssim(img1, img2):
+ C1 = (0.01 * 255)**2
+ C2 = (0.03 * 255)**2
+
+ img1 = img1.astype(np.float64)
+ img2 = img2.astype(np.float64)
+ kernel = cv2.getGaussianKernel(11, 1.5)
+ window = np.outer(kernel, kernel.transpose())
+
+ mu1 = cv2.filter2D(img1, -1, window)[5:-5, 5:-5] # valid
+ mu2 = cv2.filter2D(img2, -1, window)[5:-5, 5:-5]
+ mu1_sq = mu1**2
+ mu2_sq = mu2**2
+ mu1_mu2 = mu1 * mu2
+ sigma1_sq = cv2.filter2D(img1**2, -1, window)[5:-5, 5:-5] - mu1_sq
+ sigma2_sq = cv2.filter2D(img2**2, -1, window)[5:-5, 5:-5] - mu2_sq
+ sigma12 = cv2.filter2D(img1 * img2, -1, window)[5:-5, 5:-5] - mu1_mu2
+
+ ssim_map = ((2 * mu1_mu2 + C1) * (2 * sigma12 + C2)) / ((mu1_sq + mu2_sq + C1) *
+ (sigma1_sq + sigma2_sq + C2))
+ return ssim_map.mean()
+
+
+def _blocking_effect_factor(im):
+ block_size = 8
+
+ block_horizontal_positions = torch.arange(7, im.shape[3] - 1, 8)
+ block_vertical_positions = torch.arange(7, im.shape[2] - 1, 8)
+
+ horizontal_block_difference = (
+ (im[:, :, :, block_horizontal_positions] - im[:, :, :, block_horizontal_positions + 1]) ** 2).sum(
+ 3).sum(2).sum(1)
+ vertical_block_difference = (
+ (im[:, :, block_vertical_positions, :] - im[:, :, block_vertical_positions + 1, :]) ** 2).sum(3).sum(
+ 2).sum(1)
+
+ nonblock_horizontal_positions = np.setdiff1d(torch.arange(0, im.shape[3] - 1), block_horizontal_positions)
+ nonblock_vertical_positions = np.setdiff1d(torch.arange(0, im.shape[2] - 1), block_vertical_positions)
+
+ horizontal_nonblock_difference = (
+ (im[:, :, :, nonblock_horizontal_positions] - im[:, :, :, nonblock_horizontal_positions + 1]) ** 2).sum(
+ 3).sum(2).sum(1)
+ vertical_nonblock_difference = (
+ (im[:, :, nonblock_vertical_positions, :] - im[:, :, nonblock_vertical_positions + 1, :]) ** 2).sum(
+ 3).sum(2).sum(1)
+
+ n_boundary_horiz = im.shape[2] * (im.shape[3] // block_size - 1)
+ n_boundary_vert = im.shape[3] * (im.shape[2] // block_size - 1)
+ boundary_difference = (horizontal_block_difference + vertical_block_difference) / (
+ n_boundary_horiz + n_boundary_vert)
+
+ n_nonboundary_horiz = im.shape[2] * (im.shape[3] - 1) - n_boundary_horiz
+ n_nonboundary_vert = im.shape[3] * (im.shape[2] - 1) - n_boundary_vert
+ nonboundary_difference = (horizontal_nonblock_difference + vertical_nonblock_difference) / (
+ n_nonboundary_horiz + n_nonboundary_vert)
+
+ scaler = np.log2(block_size) / np.log2(min([im.shape[2], im.shape[3]]))
+ bef = scaler * (boundary_difference - nonboundary_difference)
+
+ bef[boundary_difference <= nonboundary_difference] = 0
+ return bef
+
+
+def calculate_psnrb(img1, img2, border=0):
+ """Calculate PSNR-B (Peak Signal-to-Noise Ratio).
+ Ref: Quality assessment of deblocked images, for JPEG image deblocking evaluation
+ # https://gitlab.com/Queuecumber/quantization-guided-ac/-/blob/master/metrics/psnrb.py
+ Args:
+ img1 (ndarray): Images with range [0, 255].
+ img2 (ndarray): Images with range [0, 255].
+ border (int): Cropped pixels in each edge of an image. These
+ pixels are not involved in the PSNR calculation.
+ test_y_channel (bool): Test on Y channel of YCbCr. Default: False.
+ Returns:
+ float: psnr result.
+ """
+
+ if not img1.shape == img2.shape:
+ raise ValueError('Input images must have the same dimensions.')
+
+ if img1.ndim == 2:
+ img1, img2 = np.expand_dims(img1, 2), np.expand_dims(img2, 2)
+
+ h, w = img1.shape[:2]
+ img1 = img1[border:h-border, border:w-border]
+ img2 = img2[border:h-border, border:w-border]
+
+ img1 = img1.astype(np.float64)
+ img2 = img2.astype(np.float64)
+
+ # follow https://gitlab.com/Queuecumber/quantization-guided-ac/-/blob/master/metrics/psnrb.py
+ img1 = torch.from_numpy(img1).permute(2, 0, 1).unsqueeze(0) / 255.
+ img2 = torch.from_numpy(img2).permute(2, 0, 1).unsqueeze(0) / 255.
+
+ total = 0
+ for c in range(img1.shape[1]):
+ mse = torch.nn.functional.mse_loss(img1[:, c:c + 1, :, :], img2[:, c:c + 1, :, :], reduction='none')
+ bef = _blocking_effect_factor(img1[:, c:c + 1, :, :])
+
+ mse = mse.view(mse.shape[0], -1).mean(1)
+ total += 10 * torch.log10(1 / (mse + bef))
+
+ return float(total) / img1.shape[1]
+
+'''
+# --------------------------------------------
+# matlab's bicubic imresize (numpy and torch) [0, 1]
+# --------------------------------------------
+'''
+
+
+# matlab 'imresize' function, now only support 'bicubic'
+def cubic(x):
+ absx = torch.abs(x)
+ absx2 = absx**2
+ absx3 = absx**3
+ return (1.5*absx3 - 2.5*absx2 + 1) * ((absx <= 1).type_as(absx)) + \
+ (-0.5*absx3 + 2.5*absx2 - 4*absx + 2) * (((absx > 1)*(absx <= 2)).type_as(absx))
+
+
+def calculate_weights_indices(in_length, out_length, scale, kernel, kernel_width, antialiasing):
+ if (scale < 1) and (antialiasing):
+ # Use a modified kernel to simultaneously interpolate and antialias- larger kernel width
+ kernel_width = kernel_width / scale
+
+ # Output-space coordinates
+ x = torch.linspace(1, out_length, out_length)
+
+ # Input-space coordinates. Calculate the inverse mapping such that 0.5
+ # in output space maps to 0.5 in input space, and 0.5+scale in output
+ # space maps to 1.5 in input space.
+ u = x / scale + 0.5 * (1 - 1 / scale)
+
+ # What is the left-most pixel that can be involved in the computation?
+ left = torch.floor(u - kernel_width / 2)
+
+ # What is the maximum number of pixels that can be involved in the
+ # computation? Note: it's OK to use an extra pixel here; if the
+ # corresponding weights are all zero, it will be eliminated at the end
+ # of this function.
+ P = math.ceil(kernel_width) + 2
+
+ # The indices of the input pixels involved in computing the k-th output
+ # pixel are in row k of the indices matrix.
+ indices = left.view(out_length, 1).expand(out_length, P) + torch.linspace(0, P - 1, P).view(
+ 1, P).expand(out_length, P)
+
+ # The weights used to compute the k-th output pixel are in row k of the
+ # weights matrix.
+ distance_to_center = u.view(out_length, 1).expand(out_length, P) - indices
+ # apply cubic kernel
+ if (scale < 1) and (antialiasing):
+ weights = scale * cubic(distance_to_center * scale)
+ else:
+ weights = cubic(distance_to_center)
+ # Normalize the weights matrix so that each row sums to 1.
+ weights_sum = torch.sum(weights, 1).view(out_length, 1)
+ weights = weights / weights_sum.expand(out_length, P)
+
+ # If a column in weights is all zero, get rid of it. only consider the first and last column.
+ weights_zero_tmp = torch.sum((weights == 0), 0)
+ if not math.isclose(weights_zero_tmp[0], 0, rel_tol=1e-6):
+ indices = indices.narrow(1, 1, P - 2)
+ weights = weights.narrow(1, 1, P - 2)
+ if not math.isclose(weights_zero_tmp[-1], 0, rel_tol=1e-6):
+ indices = indices.narrow(1, 0, P - 2)
+ weights = weights.narrow(1, 0, P - 2)
+ weights = weights.contiguous()
+ indices = indices.contiguous()
+ sym_len_s = -indices.min() + 1
+ sym_len_e = indices.max() - in_length
+ indices = indices + sym_len_s - 1
+ return weights, indices, int(sym_len_s), int(sym_len_e)
+
+
+# --------------------------------------------
+# imresize for tensor image [0, 1]
+# --------------------------------------------
+def imresize(img, scale, antialiasing=True):
+ # Now the scale should be the same for H and W
+ # input: img: pytorch tensor, CHW or HW [0,1]
+ # output: CHW or HW [0,1] w/o round
+ need_squeeze = True if img.dim() == 2 else False
+ if need_squeeze:
+ img.unsqueeze_(0)
+ in_C, in_H, in_W = img.size()
+ out_C, out_H, out_W = in_C, math.ceil(in_H * scale), math.ceil(in_W * scale)
+ kernel_width = 4
+ kernel = 'cubic'
+
+ # Return the desired dimension order for performing the resize. The
+ # strategy is to perform the resize first along the dimension with the
+ # smallest scale factor.
+ # Now we do not support this.
+
+ # get weights and indices
+ weights_H, indices_H, sym_len_Hs, sym_len_He = calculate_weights_indices(
+ in_H, out_H, scale, kernel, kernel_width, antialiasing)
+ weights_W, indices_W, sym_len_Ws, sym_len_We = calculate_weights_indices(
+ in_W, out_W, scale, kernel, kernel_width, antialiasing)
+ # process H dimension
+ # symmetric copying
+ img_aug = torch.FloatTensor(in_C, in_H + sym_len_Hs + sym_len_He, in_W)
+ img_aug.narrow(1, sym_len_Hs, in_H).copy_(img)
+
+ sym_patch = img[:, :sym_len_Hs, :]
+ inv_idx = torch.arange(sym_patch.size(1) - 1, -1, -1).long()
+ sym_patch_inv = sym_patch.index_select(1, inv_idx)
+ img_aug.narrow(1, 0, sym_len_Hs).copy_(sym_patch_inv)
+
+ sym_patch = img[:, -sym_len_He:, :]
+ inv_idx = torch.arange(sym_patch.size(1) - 1, -1, -1).long()
+ sym_patch_inv = sym_patch.index_select(1, inv_idx)
+ img_aug.narrow(1, sym_len_Hs + in_H, sym_len_He).copy_(sym_patch_inv)
+
+ out_1 = torch.FloatTensor(in_C, out_H, in_W)
+ kernel_width = weights_H.size(1)
+ for i in range(out_H):
+ idx = int(indices_H[i][0])
+ for j in range(out_C):
+ out_1[j, i, :] = img_aug[j, idx:idx + kernel_width, :].transpose(0, 1).mv(weights_H[i])
+
+ # process W dimension
+ # symmetric copying
+ out_1_aug = torch.FloatTensor(in_C, out_H, in_W + sym_len_Ws + sym_len_We)
+ out_1_aug.narrow(2, sym_len_Ws, in_W).copy_(out_1)
+
+ sym_patch = out_1[:, :, :sym_len_Ws]
+ inv_idx = torch.arange(sym_patch.size(2) - 1, -1, -1).long()
+ sym_patch_inv = sym_patch.index_select(2, inv_idx)
+ out_1_aug.narrow(2, 0, sym_len_Ws).copy_(sym_patch_inv)
+
+ sym_patch = out_1[:, :, -sym_len_We:]
+ inv_idx = torch.arange(sym_patch.size(2) - 1, -1, -1).long()
+ sym_patch_inv = sym_patch.index_select(2, inv_idx)
+ out_1_aug.narrow(2, sym_len_Ws + in_W, sym_len_We).copy_(sym_patch_inv)
+
+ out_2 = torch.FloatTensor(in_C, out_H, out_W)
+ kernel_width = weights_W.size(1)
+ for i in range(out_W):
+ idx = int(indices_W[i][0])
+ for j in range(out_C):
+ out_2[j, :, i] = out_1_aug[j, :, idx:idx + kernel_width].mv(weights_W[i])
+ if need_squeeze:
+ out_2.squeeze_()
+ return out_2
+
+
+# --------------------------------------------
+# imresize for numpy image [0, 1]
+# --------------------------------------------
+def imresize_np(img, scale, antialiasing=True):
+ # Now the scale should be the same for H and W
+ # input: img: Numpy, HWC or HW [0,1]
+ # output: HWC or HW [0,1] w/o round
+ img = torch.from_numpy(img)
+ need_squeeze = True if img.dim() == 2 else False
+ if need_squeeze:
+ img.unsqueeze_(2)
+
+ in_H, in_W, in_C = img.size()
+ out_C, out_H, out_W = in_C, math.ceil(in_H * scale), math.ceil(in_W * scale)
+ kernel_width = 4
+ kernel = 'cubic'
+
+ # Return the desired dimension order for performing the resize. The
+ # strategy is to perform the resize first along the dimension with the
+ # smallest scale factor.
+ # Now we do not support this.
+
+ # get weights and indices
+ weights_H, indices_H, sym_len_Hs, sym_len_He = calculate_weights_indices(
+ in_H, out_H, scale, kernel, kernel_width, antialiasing)
+ weights_W, indices_W, sym_len_Ws, sym_len_We = calculate_weights_indices(
+ in_W, out_W, scale, kernel, kernel_width, antialiasing)
+ # process H dimension
+ # symmetric copying
+ img_aug = torch.FloatTensor(in_H + sym_len_Hs + sym_len_He, in_W, in_C)
+ img_aug.narrow(0, sym_len_Hs, in_H).copy_(img)
+
+ sym_patch = img[:sym_len_Hs, :, :]
+ inv_idx = torch.arange(sym_patch.size(0) - 1, -1, -1).long()
+ sym_patch_inv = sym_patch.index_select(0, inv_idx)
+ img_aug.narrow(0, 0, sym_len_Hs).copy_(sym_patch_inv)
+
+ sym_patch = img[-sym_len_He:, :, :]
+ inv_idx = torch.arange(sym_patch.size(0) - 1, -1, -1).long()
+ sym_patch_inv = sym_patch.index_select(0, inv_idx)
+ img_aug.narrow(0, sym_len_Hs + in_H, sym_len_He).copy_(sym_patch_inv)
+
+ out_1 = torch.FloatTensor(out_H, in_W, in_C)
+ kernel_width = weights_H.size(1)
+ for i in range(out_H):
+ idx = int(indices_H[i][0])
+ for j in range(out_C):
+ out_1[i, :, j] = img_aug[idx:idx + kernel_width, :, j].transpose(0, 1).mv(weights_H[i])
+
+ # process W dimension
+ # symmetric copying
+ out_1_aug = torch.FloatTensor(out_H, in_W + sym_len_Ws + sym_len_We, in_C)
+ out_1_aug.narrow(1, sym_len_Ws, in_W).copy_(out_1)
+
+ sym_patch = out_1[:, :sym_len_Ws, :]
+ inv_idx = torch.arange(sym_patch.size(1) - 1, -1, -1).long()
+ sym_patch_inv = sym_patch.index_select(1, inv_idx)
+ out_1_aug.narrow(1, 0, sym_len_Ws).copy_(sym_patch_inv)
+
+ sym_patch = out_1[:, -sym_len_We:, :]
+ inv_idx = torch.arange(sym_patch.size(1) - 1, -1, -1).long()
+ sym_patch_inv = sym_patch.index_select(1, inv_idx)
+ out_1_aug.narrow(1, sym_len_Ws + in_W, sym_len_We).copy_(sym_patch_inv)
+
+ out_2 = torch.FloatTensor(out_H, out_W, in_C)
+ kernel_width = weights_W.size(1)
+ for i in range(out_W):
+ idx = int(indices_W[i][0])
+ for j in range(out_C):
+ out_2[:, i, j] = out_1_aug[:, idx:idx + kernel_width, j].mv(weights_W[i])
+ if need_squeeze:
+ out_2.squeeze_()
+
+ return out_2.numpy()
+
+
+if __name__ == '__main__':
+ img = imread_uint('test.bmp', 3)
+# img = uint2single(img)
+# img_bicubic = imresize_np(img, 1/4)
+# imshow(single2uint(img_bicubic))
+#
+# img_tensor = single2tensor4(img)
+# for i in range(8):
+# imshow(np.concatenate((augment_img(img, i), tensor2single(augment_img_tensor4(img_tensor, i))), 1))
+
+# patches = patches_from_image(img, p_size=128, p_overlap=0, p_max=200)
+# imssave(patches,'a.png')
+
+
+
+
+
+
+
diff --git a/KAIR/utils/utils_lmdb.py b/KAIR/utils/utils_lmdb.py
new file mode 100755
index 0000000000000000000000000000000000000000..75192c346bb9c0b96f8b09635ed548bd6e797d89
--- /dev/null
+++ b/KAIR/utils/utils_lmdb.py
@@ -0,0 +1,205 @@
+import cv2
+import lmdb
+import sys
+from multiprocessing import Pool
+from os import path as osp
+from tqdm import tqdm
+
+
+def make_lmdb_from_imgs(data_path,
+ lmdb_path,
+ img_path_list,
+ keys,
+ batch=5000,
+ compress_level=1,
+ multiprocessing_read=False,
+ n_thread=40,
+ map_size=None):
+ """Make lmdb from images.
+
+ Contents of lmdb. The file structure is:
+ example.lmdb
+ ├── data.mdb
+ ├── lock.mdb
+ ├── meta_info.txt
+
+ The data.mdb and lock.mdb are standard lmdb files and you can refer to
+ https://lmdb.readthedocs.io/en/release/ for more details.
+
+ The meta_info.txt is a specified txt file to record the meta information
+ of our datasets. It will be automatically created when preparing
+ datasets by our provided dataset tools.
+ Each line in the txt file records 1)image name (with extension),
+ 2)image shape, and 3)compression level, separated by a white space.
+
+ For example, the meta information could be:
+ `000_00000000.png (720,1280,3) 1`, which means:
+ 1) image name (with extension): 000_00000000.png;
+ 2) image shape: (720,1280,3);
+ 3) compression level: 1
+
+ We use the image name without extension as the lmdb key.
+
+ If `multiprocessing_read` is True, it will read all the images to memory
+ using multiprocessing. Thus, your server needs to have enough memory.
+
+ Args:
+ data_path (str): Data path for reading images.
+ lmdb_path (str): Lmdb save path.
+ img_path_list (str): Image path list.
+ keys (str): Used for lmdb keys.
+ batch (int): After processing batch images, lmdb commits.
+ Default: 5000.
+ compress_level (int): Compress level when encoding images. Default: 1.
+ multiprocessing_read (bool): Whether use multiprocessing to read all
+ the images to memory. Default: False.
+ n_thread (int): For multiprocessing.
+ map_size (int | None): Map size for lmdb env. If None, use the
+ estimated size from images. Default: None
+ """
+
+ assert len(img_path_list) == len(keys), ('img_path_list and keys should have the same length, '
+ f'but got {len(img_path_list)} and {len(keys)}')
+ print(f'Create lmdb for {data_path}, save to {lmdb_path}...')
+ print(f'Totoal images: {len(img_path_list)}')
+ if not lmdb_path.endswith('.lmdb'):
+ raise ValueError("lmdb_path must end with '.lmdb'.")
+ if osp.exists(lmdb_path):
+ print(f'Folder {lmdb_path} already exists. Exit.')
+ sys.exit(1)
+
+ if multiprocessing_read:
+ # read all the images to memory (multiprocessing)
+ dataset = {} # use dict to keep the order for multiprocessing
+ shapes = {}
+ print(f'Read images with multiprocessing, #thread: {n_thread} ...')
+ pbar = tqdm(total=len(img_path_list), unit='image')
+
+ def callback(arg):
+ """get the image data and update pbar."""
+ key, dataset[key], shapes[key] = arg
+ pbar.update(1)
+ pbar.set_description(f'Read {key}')
+
+ pool = Pool(n_thread)
+ for path, key in zip(img_path_list, keys):
+ pool.apply_async(read_img_worker, args=(osp.join(data_path, path), key, compress_level), callback=callback)
+ pool.close()
+ pool.join()
+ pbar.close()
+ print(f'Finish reading {len(img_path_list)} images.')
+
+ # create lmdb environment
+ if map_size is None:
+ # obtain data size for one image
+ img = cv2.imread(osp.join(data_path, img_path_list[0]), cv2.IMREAD_UNCHANGED)
+ _, img_byte = cv2.imencode('.png', img, [cv2.IMWRITE_PNG_COMPRESSION, compress_level])
+ data_size_per_img = img_byte.nbytes
+ print('Data size per image is: ', data_size_per_img)
+ data_size = data_size_per_img * len(img_path_list)
+ map_size = data_size * 10
+
+ env = lmdb.open(lmdb_path, map_size=map_size)
+
+ # write data to lmdb
+ pbar = tqdm(total=len(img_path_list), unit='chunk')
+ txn = env.begin(write=True)
+ txt_file = open(osp.join(lmdb_path, 'meta_info.txt'), 'w')
+ for idx, (path, key) in enumerate(zip(img_path_list, keys)):
+ pbar.update(1)
+ pbar.set_description(f'Write {key}')
+ key_byte = key.encode('ascii')
+ if multiprocessing_read:
+ img_byte = dataset[key]
+ h, w, c = shapes[key]
+ else:
+ _, img_byte, img_shape = read_img_worker(osp.join(data_path, path), key, compress_level)
+ h, w, c = img_shape
+
+ txn.put(key_byte, img_byte)
+ # write meta information
+ txt_file.write(f'{key}.png ({h},{w},{c}) {compress_level}\n')
+ if idx % batch == 0:
+ txn.commit()
+ txn = env.begin(write=True)
+ pbar.close()
+ txn.commit()
+ env.close()
+ txt_file.close()
+ print('\nFinish writing lmdb.')
+
+
+def read_img_worker(path, key, compress_level):
+ """Read image worker.
+
+ Args:
+ path (str): Image path.
+ key (str): Image key.
+ compress_level (int): Compress level when encoding images.
+
+ Returns:
+ str: Image key.
+ byte: Image byte.
+ tuple[int]: Image shape.
+ """
+
+ img = cv2.imread(path, cv2.IMREAD_UNCHANGED)
+ # deal with `libpng error: Read Error`
+ if img is None:
+ print(f'To deal with `libpng error: Read Error`, use PIL to load {path}')
+ from PIL import Image
+ import numpy as np
+ img = Image.open(path)
+ img = np.asanyarray(img)
+ img = img[:, :, [2, 1, 0]]
+
+ if img.ndim == 2:
+ h, w = img.shape
+ c = 1
+ else:
+ h, w, c = img.shape
+ _, img_byte = cv2.imencode('.png', img, [cv2.IMWRITE_PNG_COMPRESSION, compress_level])
+ return (key, img_byte, (h, w, c))
+
+
+class LmdbMaker():
+ """LMDB Maker.
+
+ Args:
+ lmdb_path (str): Lmdb save path.
+ map_size (int): Map size for lmdb env. Default: 1024 ** 4, 1TB.
+ batch (int): After processing batch images, lmdb commits.
+ Default: 5000.
+ compress_level (int): Compress level when encoding images. Default: 1.
+ """
+
+ def __init__(self, lmdb_path, map_size=1024**4, batch=5000, compress_level=1):
+ if not lmdb_path.endswith('.lmdb'):
+ raise ValueError("lmdb_path must end with '.lmdb'.")
+ if osp.exists(lmdb_path):
+ print(f'Folder {lmdb_path} already exists. Exit.')
+ sys.exit(1)
+
+ self.lmdb_path = lmdb_path
+ self.batch = batch
+ self.compress_level = compress_level
+ self.env = lmdb.open(lmdb_path, map_size=map_size)
+ self.txn = self.env.begin(write=True)
+ self.txt_file = open(osp.join(lmdb_path, 'meta_info.txt'), 'w')
+ self.counter = 0
+
+ def put(self, img_byte, key, img_shape):
+ self.counter += 1
+ key_byte = key.encode('ascii')
+ self.txn.put(key_byte, img_byte)
+ # write meta information
+ h, w, c = img_shape
+ self.txt_file.write(f'{key}.png ({h},{w},{c}) {self.compress_level}\n')
+ if self.counter % self.batch == 0:
+ self.txn.commit()
+ self.txn = self.env.begin(write=True)
+
+ def close(self):
+ self.txn.commit()
+ self.env.close()
+ self.txt_file.close()
diff --git a/KAIR/utils/utils_logger.py b/KAIR/utils/utils_logger.py
new file mode 100644
index 0000000000000000000000000000000000000000..3067190e1b09b244814e0ccc4496b18f06e22b54
--- /dev/null
+++ b/KAIR/utils/utils_logger.py
@@ -0,0 +1,66 @@
+import sys
+import datetime
+import logging
+
+
+'''
+# --------------------------------------------
+# Kai Zhang (github: https://github.com/cszn)
+# 03/Mar/2019
+# --------------------------------------------
+# https://github.com/xinntao/BasicSR
+# --------------------------------------------
+'''
+
+
+def log(*args, **kwargs):
+ print(datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S:"), *args, **kwargs)
+
+
+'''
+# --------------------------------------------
+# logger
+# --------------------------------------------
+'''
+
+
+def logger_info(logger_name, log_path='default_logger.log'):
+ ''' set up logger
+ modified by Kai Zhang (github: https://github.com/cszn)
+ '''
+ log = logging.getLogger(logger_name)
+ if log.hasHandlers():
+ print('LogHandlers exist!')
+ else:
+ print('LogHandlers setup!')
+ level = logging.INFO
+ formatter = logging.Formatter('%(asctime)s.%(msecs)03d : %(message)s', datefmt='%y-%m-%d %H:%M:%S')
+ fh = logging.FileHandler(log_path, mode='a')
+ fh.setFormatter(formatter)
+ log.setLevel(level)
+ log.addHandler(fh)
+ # print(len(log.handlers))
+
+ sh = logging.StreamHandler()
+ sh.setFormatter(formatter)
+ log.addHandler(sh)
+
+
+'''
+# --------------------------------------------
+# print to file and std_out simultaneously
+# --------------------------------------------
+'''
+
+
+class logger_print(object):
+ def __init__(self, log_path="default.log"):
+ self.terminal = sys.stdout
+ self.log = open(log_path, 'a')
+
+ def write(self, message):
+ self.terminal.write(message)
+ self.log.write(message) # write the message
+
+ def flush(self):
+ pass
diff --git a/KAIR/utils/utils_mat.py b/KAIR/utils/utils_mat.py
new file mode 100644
index 0000000000000000000000000000000000000000..cd25d500c0eae77a3b815b8e956205b737ee43d4
--- /dev/null
+++ b/KAIR/utils/utils_mat.py
@@ -0,0 +1,88 @@
+import os
+import json
+import scipy.io as spio
+import pandas as pd
+
+
+def loadmat(filename):
+ '''
+ this function should be called instead of direct spio.loadmat
+ as it cures the problem of not properly recovering python dictionaries
+ from mat files. It calls the function check keys to cure all entries
+ which are still mat-objects
+ '''
+ data = spio.loadmat(filename, struct_as_record=False, squeeze_me=True)
+ return dict_to_nonedict(_check_keys(data))
+
+def _check_keys(dict):
+ '''
+ checks if entries in dictionary are mat-objects. If yes
+ todict is called to change them to nested dictionaries
+ '''
+ for key in dict:
+ if isinstance(dict[key], spio.matlab.mio5_params.mat_struct):
+ dict[key] = _todict(dict[key])
+ return dict
+
+def _todict(matobj):
+ '''
+ A recursive function which constructs from matobjects nested dictionaries
+ '''
+ dict = {}
+ for strg in matobj._fieldnames:
+ elem = matobj.__dict__[strg]
+ if isinstance(elem, spio.matlab.mio5_params.mat_struct):
+ dict[strg] = _todict(elem)
+ else:
+ dict[strg] = elem
+ return dict
+
+
+def dict_to_nonedict(opt):
+ if isinstance(opt, dict):
+ new_opt = dict()
+ for key, sub_opt in opt.items():
+ new_opt[key] = dict_to_nonedict(sub_opt)
+ return NoneDict(**new_opt)
+ elif isinstance(opt, list):
+ return [dict_to_nonedict(sub_opt) for sub_opt in opt]
+ else:
+ return opt
+
+
+class NoneDict(dict):
+ def __missing__(self, key):
+ return None
+
+
+def mat2json(mat_path=None, filepath = None):
+ """
+ Converts .mat file to .json and writes new file
+ Parameters
+ ----------
+ mat_path: Str
+ path/filename .mat存放路径
+ filepath: Str
+ 如果需要保存成json, 添加这一路径. 否则不保存
+ Returns
+ 返回转化的字典
+ -------
+ None
+ Examples
+ --------
+ >>> mat2json(blah blah)
+ """
+
+ matlabFile = loadmat(mat_path)
+ #pop all those dumb fields that don't let you jsonize file
+ matlabFile.pop('__header__')
+ matlabFile.pop('__version__')
+ matlabFile.pop('__globals__')
+ #jsonize the file - orientation is 'index'
+ matlabFile = pd.Series(matlabFile).to_json()
+
+ if filepath:
+ json_path = os.path.splitext(os.path.split(mat_path)[1])[0] + '.json'
+ with open(json_path, 'w') as f:
+ f.write(matlabFile)
+ return matlabFile
\ No newline at end of file
diff --git a/KAIR/utils/utils_matconvnet.py b/KAIR/utils/utils_matconvnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..37d5929692e8eadf5ec57d1616626a0611492ee2
--- /dev/null
+++ b/KAIR/utils/utils_matconvnet.py
@@ -0,0 +1,197 @@
+# -*- coding: utf-8 -*-
+import numpy as np
+import torch
+from collections import OrderedDict
+
+# import scipy.io as io
+import hdf5storage
+
+"""
+# --------------------------------------------
+# Convert matconvnet SimpleNN model into pytorch model
+# --------------------------------------------
+# Kai Zhang (cskaizhang@gmail.com)
+# https://github.com/cszn
+# 28/Nov/2019
+# --------------------------------------------
+"""
+
+
+def weights2tensor(x, squeeze=False, in_features=None, out_features=None):
+ """Modified version of https://github.com/albanie/pytorch-mcn
+ Adjust memory layout and load weights as torch tensor
+ Args:
+ x (ndaray): a numpy array, corresponding to a set of network weights
+ stored in column major order
+ squeeze (bool) [False]: whether to squeeze the tensor (i.e. remove
+ singletons from the trailing dimensions. So after converting to
+ pytorch layout (C_out, C_in, H, W), if the shape is (A, B, 1, 1)
+ it will be reshaped to a matrix with shape (A,B).
+ in_features (int :: None): used to reshape weights for a linear block.
+ out_features (int :: None): used to reshape weights for a linear block.
+ Returns:
+ torch.tensor: a permuted sets of weights, matching the pytorch layout
+ convention
+ """
+ if x.ndim == 4:
+ x = x.transpose((3, 2, 0, 1))
+# for FFDNet, pixel-shuffle layer
+# if x.shape[1]==13:
+# x=x[:,[0,2,1,3, 4,6,5,7, 8,10,9,11, 12],:,:]
+# if x.shape[0]==12:
+# x=x[[0,2,1,3, 4,6,5,7, 8,10,9,11],:,:,:]
+# if x.shape[1]==5:
+# x=x[:,[0,2,1,3, 4],:,:]
+# if x.shape[0]==4:
+# x=x[[0,2,1,3],:,:,:]
+## for SRMD, pixel-shuffle layer
+# if x.shape[0]==12:
+# x=x[[0,2,1,3, 4,6,5,7, 8,10,9,11],:,:,:]
+# if x.shape[0]==27:
+# x=x[[0,3,6,1,4,7,2,5,8, 0+9,3+9,6+9,1+9,4+9,7+9,2+9,5+9,8+9, 0+18,3+18,6+18,1+18,4+18,7+18,2+18,5+18,8+18],:,:,:]
+# if x.shape[0]==48:
+# x=x[[0,4,8,12,1,5,9,13,2,6,10,14,3,7,11,15, 0+16,4+16,8+16,12+16,1+16,5+16,9+16,13+16,2+16,6+16,10+16,14+16,3+16,7+16,11+16,15+16, 0+32,4+32,8+32,12+32,1+32,5+32,9+32,13+32,2+32,6+32,10+32,14+32,3+32,7+32,11+32,15+32],:,:,:]
+
+ elif x.ndim == 3: # add by Kai
+ x = x[:,:,:,None]
+ x = x.transpose((3, 2, 0, 1))
+ elif x.ndim == 2:
+ if x.shape[1] == 1:
+ x = x.flatten()
+ if squeeze:
+ if in_features and out_features:
+ x = x.reshape((out_features, in_features))
+ x = np.squeeze(x)
+ return torch.from_numpy(np.ascontiguousarray(x))
+
+
+def save_model(network, save_path):
+ state_dict = network.state_dict()
+ for key, param in state_dict.items():
+ state_dict[key] = param.cpu()
+ torch.save(state_dict, save_path)
+
+
+if __name__ == '__main__':
+
+
+# from utils import utils_logger
+# import logging
+# utils_logger.logger_info('a', 'a.log')
+# logger = logging.getLogger('a')
+#
+ # mcn = hdf5storage.loadmat('/model_zoo/matfile/FFDNet_Clip_gray.mat')
+ mcn = hdf5storage.loadmat('models/modelcolor.mat')
+
+
+ #logger.info(mcn['CNNdenoiser'][0][0][0][1][0][0][0][0])
+
+ mat_net = OrderedDict()
+ for idx in range(25):
+ mat_net[str(idx)] = OrderedDict()
+ count = -1
+
+ print(idx)
+ for i in range(13):
+
+ if mcn['CNNdenoiser'][0][idx][0][i][0][0][0][0] == 'conv':
+
+ count += 1
+ w = mcn['CNNdenoiser'][0][idx][0][i][0][1][0][0]
+ # print(w.shape)
+ w = weights2tensor(w)
+ # print(w.shape)
+
+ b = mcn['CNNdenoiser'][0][idx][0][i][0][1][0][1]
+ b = weights2tensor(b)
+ print(b.shape)
+
+ mat_net[str(idx)]['model.{:d}.weight'.format(count*2)] = w
+ mat_net[str(idx)]['model.{:d}.bias'.format(count*2)] = b
+
+ torch.save(mat_net, 'model_zoo/modelcolor.pth')
+
+
+
+# from models.network_dncnn import IRCNN as net
+# network = net(in_nc=3, out_nc=3, nc=64)
+# state_dict = network.state_dict()
+#
+# #show_kv(state_dict)
+#
+# for i in range(len(mcn['net'][0][0][0])):
+# print(mcn['net'][0][0][0][i][0][0][0][0])
+#
+# count = -1
+# mat_net = OrderedDict()
+# for i in range(len(mcn['net'][0][0][0])):
+# if mcn['net'][0][0][0][i][0][0][0][0] == 'conv':
+#
+# count += 1
+# w = mcn['net'][0][0][0][i][0][1][0][0]
+# print(w.shape)
+# w = weights2tensor(w)
+# print(w.shape)
+#
+# b = mcn['net'][0][0][0][i][0][1][0][1]
+# b = weights2tensor(b)
+# print(b.shape)
+#
+# mat_net['model.{:d}.weight'.format(count*2)] = w
+# mat_net['model.{:d}.bias'.format(count*2)] = b
+#
+# torch.save(mat_net, 'E:/pytorch/KAIR_ongoing/model_zoo/ffdnet_gray_clip.pth')
+#
+#
+#
+# crt_net = torch.load('E:/pytorch/KAIR_ongoing/model_zoo/imdn_x4.pth')
+# def show_kv(net):
+# for k, v in net.items():
+# print(k)
+#
+# show_kv(crt_net)
+
+
+# from models.network_dncnn import DnCNN as net
+# network = net(in_nc=2, out_nc=1, nc=64, nb=20, act_mode='R')
+
+# from models.network_srmd import SRMD as net
+# #network = net(in_nc=1, out_nc=1, nc=64, nb=15, act_mode='R')
+# network = net(in_nc=19, out_nc=3, nc=128, nb=12, upscale=4, act_mode='R', upsample_mode='pixelshuffle')
+#
+# from models.network_rrdb import RRDB as net
+# network = net(in_nc=3, out_nc=3, nc=64, nb=23, gc=32, upscale=4, act_mode='L', upsample_mode='upconv')
+#
+# state_dict = network.state_dict()
+# for key, param in state_dict.items():
+# print(key)
+# from models.network_imdn import IMDN as net
+# network = net(in_nc=3, out_nc=3, nc=64, nb=8, upscale=4, act_mode='L', upsample_mode='pixelshuffle')
+# state_dict = network.state_dict()
+# mat_net = OrderedDict()
+# for ((key, param),(key2, param2)) in zip(state_dict.items(), crt_net.items()):
+# mat_net[key] = param2
+# torch.save(mat_net, 'model_zoo/imdn_x4_1.pth')
+#
+
+# net_old = torch.load('net_old.pth')
+# def show_kv(net):
+# for k, v in net.items():
+# print(k)
+#
+# show_kv(net_old)
+# from models.network_dpsr import MSRResNet_prior as net
+# model = net(in_nc=4, out_nc=3, nc=96, nb=16, upscale=4, act_mode='R', upsample_mode='pixelshuffle')
+# state_dict = network.state_dict()
+# net_new = OrderedDict()
+# for ((key, param),(key_old, param_old)) in zip(state_dict.items(), net_old.items()):
+# net_new[key] = param_old
+# torch.save(net_new, 'net_new.pth')
+
+
+ # print(key)
+ # print(param.size())
+
+
+
+ # run utils/utils_matconvnet.py
diff --git a/KAIR/utils/utils_model.py b/KAIR/utils/utils_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..94ced53c0e34bd0938e5e55ed22b1cf214885477
--- /dev/null
+++ b/KAIR/utils/utils_model.py
@@ -0,0 +1,330 @@
+# -*- coding: utf-8 -*-
+import numpy as np
+import torch
+from utils import utils_image as util
+import re
+import glob
+import os
+
+
+'''
+# --------------------------------------------
+# Model
+# --------------------------------------------
+# Kai Zhang (github: https://github.com/cszn)
+# 03/Mar/2019
+# --------------------------------------------
+'''
+
+
+def find_last_checkpoint(save_dir, net_type='G', pretrained_path=None):
+ """
+ # ---------------------------------------
+ # Kai Zhang (github: https://github.com/cszn)
+ # 03/Mar/2019
+ # ---------------------------------------
+ Args:
+ save_dir: model folder
+ net_type: 'G' or 'D' or 'optimizerG' or 'optimizerD'
+ pretrained_path: pretrained model path. If save_dir does not have any model, load from pretrained_path
+
+ Return:
+ init_iter: iteration number
+ init_path: model path
+ # ---------------------------------------
+ """
+
+ file_list = glob.glob(os.path.join(save_dir, '*_{}.pth'.format(net_type)))
+ if file_list:
+ iter_exist = []
+ for file_ in file_list:
+ iter_current = re.findall(r"(\d+)_{}.pth".format(net_type), file_)
+ iter_exist.append(int(iter_current[0]))
+ init_iter = max(iter_exist)
+ init_path = os.path.join(save_dir, '{}_{}.pth'.format(init_iter, net_type))
+ else:
+ init_iter = 0
+ init_path = pretrained_path
+ return init_iter, init_path
+
+
+def test_mode(model, L, mode=0, refield=32, min_size=256, sf=1, modulo=1):
+ '''
+ # ---------------------------------------
+ # Kai Zhang (github: https://github.com/cszn)
+ # 03/Mar/2019
+ # ---------------------------------------
+ Args:
+ model: trained model
+ L: input Low-quality image
+ mode:
+ (0) normal: test(model, L)
+ (1) pad: test_pad(model, L, modulo=16)
+ (2) split: test_split(model, L, refield=32, min_size=256, sf=1, modulo=1)
+ (3) x8: test_x8(model, L, modulo=1) ^_^
+ (4) split and x8: test_split_x8(model, L, refield=32, min_size=256, sf=1, modulo=1)
+ refield: effective receptive filed of the network, 32 is enough
+ useful when split, i.e., mode=2, 4
+ min_size: min_sizeXmin_size image, e.g., 256X256 image
+ useful when split, i.e., mode=2, 4
+ sf: scale factor for super-resolution, otherwise 1
+ modulo: 1 if split
+ useful when pad, i.e., mode=1
+
+ Returns:
+ E: estimated image
+ # ---------------------------------------
+ '''
+ if mode == 0:
+ E = test(model, L)
+ elif mode == 1:
+ E = test_pad(model, L, modulo, sf)
+ elif mode == 2:
+ E = test_split(model, L, refield, min_size, sf, modulo)
+ elif mode == 3:
+ E = test_x8(model, L, modulo, sf)
+ elif mode == 4:
+ E = test_split_x8(model, L, refield, min_size, sf, modulo)
+ return E
+
+
+'''
+# --------------------------------------------
+# normal (0)
+# --------------------------------------------
+'''
+
+
+def test(model, L):
+ E = model(L)
+ return E
+
+
+'''
+# --------------------------------------------
+# pad (1)
+# --------------------------------------------
+'''
+
+
+def test_pad(model, L, modulo=16, sf=1):
+ h, w = L.size()[-2:]
+ paddingBottom = int(np.ceil(h/modulo)*modulo-h)
+ paddingRight = int(np.ceil(w/modulo)*modulo-w)
+ L = torch.nn.ReplicationPad2d((0, paddingRight, 0, paddingBottom))(L)
+ E = model(L)
+ E = E[..., :h*sf, :w*sf]
+ return E
+
+
+'''
+# --------------------------------------------
+# split (function)
+# --------------------------------------------
+'''
+
+
+def test_split_fn(model, L, refield=32, min_size=256, sf=1, modulo=1):
+ """
+ Args:
+ model: trained model
+ L: input Low-quality image
+ refield: effective receptive filed of the network, 32 is enough
+ min_size: min_sizeXmin_size image, e.g., 256X256 image
+ sf: scale factor for super-resolution, otherwise 1
+ modulo: 1 if split
+
+ Returns:
+ E: estimated result
+ """
+ h, w = L.size()[-2:]
+ if h*w <= min_size**2:
+ L = torch.nn.ReplicationPad2d((0, int(np.ceil(w/modulo)*modulo-w), 0, int(np.ceil(h/modulo)*modulo-h)))(L)
+ E = model(L)
+ E = E[..., :h*sf, :w*sf]
+ else:
+ top = slice(0, (h//2//refield+1)*refield)
+ bottom = slice(h - (h//2//refield+1)*refield, h)
+ left = slice(0, (w//2//refield+1)*refield)
+ right = slice(w - (w//2//refield+1)*refield, w)
+ Ls = [L[..., top, left], L[..., top, right], L[..., bottom, left], L[..., bottom, right]]
+
+ if h * w <= 4*(min_size**2):
+ Es = [model(Ls[i]) for i in range(4)]
+ else:
+ Es = [test_split_fn(model, Ls[i], refield=refield, min_size=min_size, sf=sf, modulo=modulo) for i in range(4)]
+
+ b, c = Es[0].size()[:2]
+ E = torch.zeros(b, c, sf * h, sf * w).type_as(L)
+
+ E[..., :h//2*sf, :w//2*sf] = Es[0][..., :h//2*sf, :w//2*sf]
+ E[..., :h//2*sf, w//2*sf:w*sf] = Es[1][..., :h//2*sf, (-w + w//2)*sf:]
+ E[..., h//2*sf:h*sf, :w//2*sf] = Es[2][..., (-h + h//2)*sf:, :w//2*sf]
+ E[..., h//2*sf:h*sf, w//2*sf:w*sf] = Es[3][..., (-h + h//2)*sf:, (-w + w//2)*sf:]
+ return E
+
+
+'''
+# --------------------------------------------
+# split (2)
+# --------------------------------------------
+'''
+
+
+def test_split(model, L, refield=32, min_size=256, sf=1, modulo=1):
+ E = test_split_fn(model, L, refield=refield, min_size=min_size, sf=sf, modulo=modulo)
+ return E
+
+
+'''
+# --------------------------------------------
+# x8 (3)
+# --------------------------------------------
+'''
+
+
+def test_x8(model, L, modulo=1, sf=1):
+ E_list = [test_pad(model, util.augment_img_tensor4(L, mode=i), modulo=modulo, sf=sf) for i in range(8)]
+ for i in range(len(E_list)):
+ if i == 3 or i == 5:
+ E_list[i] = util.augment_img_tensor4(E_list[i], mode=8 - i)
+ else:
+ E_list[i] = util.augment_img_tensor4(E_list[i], mode=i)
+ output_cat = torch.stack(E_list, dim=0)
+ E = output_cat.mean(dim=0, keepdim=False)
+ return E
+
+
+'''
+# --------------------------------------------
+# split and x8 (4)
+# --------------------------------------------
+'''
+
+
+def test_split_x8(model, L, refield=32, min_size=256, sf=1, modulo=1):
+ E_list = [test_split_fn(model, util.augment_img_tensor4(L, mode=i), refield=refield, min_size=min_size, sf=sf, modulo=modulo) for i in range(8)]
+ for k, i in enumerate(range(len(E_list))):
+ if i==3 or i==5:
+ E_list[k] = util.augment_img_tensor4(E_list[k], mode=8-i)
+ else:
+ E_list[k] = util.augment_img_tensor4(E_list[k], mode=i)
+ output_cat = torch.stack(E_list, dim=0)
+ E = output_cat.mean(dim=0, keepdim=False)
+ return E
+
+
+'''
+# ^_^-^_^-^_^-^_^-^_^-^_^-^_^-^_^-^_^-^_^-^_^-
+# _^_^-^_^-^_^-^_^-^_^-^_^-^_^-^_^-^_^-^_^-^_^
+# ^_^-^_^-^_^-^_^-^_^-^_^-^_^-^_^-^_^-^_^-^_^-
+'''
+
+
+'''
+# --------------------------------------------
+# print
+# --------------------------------------------
+'''
+
+
+# --------------------------------------------
+# print model
+# --------------------------------------------
+def print_model(model):
+ msg = describe_model(model)
+ print(msg)
+
+
+# --------------------------------------------
+# print params
+# --------------------------------------------
+def print_params(model):
+ msg = describe_params(model)
+ print(msg)
+
+
+'''
+# --------------------------------------------
+# information
+# --------------------------------------------
+'''
+
+
+# --------------------------------------------
+# model inforation
+# --------------------------------------------
+def info_model(model):
+ msg = describe_model(model)
+ return msg
+
+
+# --------------------------------------------
+# params inforation
+# --------------------------------------------
+def info_params(model):
+ msg = describe_params(model)
+ return msg
+
+
+'''
+# --------------------------------------------
+# description
+# --------------------------------------------
+'''
+
+
+# --------------------------------------------
+# model name and total number of parameters
+# --------------------------------------------
+def describe_model(model):
+ if isinstance(model, torch.nn.DataParallel):
+ model = model.module
+ msg = '\n'
+ msg += 'models name: {}'.format(model.__class__.__name__) + '\n'
+ msg += 'Params number: {}'.format(sum(map(lambda x: x.numel(), model.parameters()))) + '\n'
+ msg += 'Net structure:\n{}'.format(str(model)) + '\n'
+ return msg
+
+
+# --------------------------------------------
+# parameters description
+# --------------------------------------------
+def describe_params(model):
+ if isinstance(model, torch.nn.DataParallel):
+ model = model.module
+ msg = '\n'
+ msg += ' | {:^6s} | {:^6s} | {:^6s} | {:^6s} || {:<20s}'.format('mean', 'min', 'max', 'std', 'shape', 'param_name') + '\n'
+ for name, param in model.state_dict().items():
+ if not 'num_batches_tracked' in name:
+ v = param.data.clone().float()
+ msg += ' | {:>6.3f} | {:>6.3f} | {:>6.3f} | {:>6.3f} | {} || {:s}'.format(v.mean(), v.min(), v.max(), v.std(), v.shape, name) + '\n'
+ return msg
+
+
+if __name__ == '__main__':
+
+ class Net(torch.nn.Module):
+ def __init__(self, in_channels=3, out_channels=3):
+ super(Net, self).__init__()
+ self.conv = torch.nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=3, padding=1)
+
+ def forward(self, x):
+ x = self.conv(x)
+ return x
+
+ start = torch.cuda.Event(enable_timing=True)
+ end = torch.cuda.Event(enable_timing=True)
+
+ model = Net()
+ model = model.eval()
+ print_model(model)
+ print_params(model)
+ x = torch.randn((2,3,401,401))
+ torch.cuda.empty_cache()
+ with torch.no_grad():
+ for mode in range(5):
+ y = test_mode(model, x, mode, refield=32, min_size=256, sf=1, modulo=1)
+ print(y.shape)
+
+ # run utils/utils_model.py
diff --git a/KAIR/utils/utils_modelsummary.py b/KAIR/utils/utils_modelsummary.py
new file mode 100644
index 0000000000000000000000000000000000000000..5e040e31d8ddffbb8b7b2e2dc4ddf0b9cdca6a23
--- /dev/null
+++ b/KAIR/utils/utils_modelsummary.py
@@ -0,0 +1,485 @@
+import torch.nn as nn
+import torch
+import numpy as np
+
+'''
+---- 1) FLOPs: floating point operations
+---- 2) #Activations: the number of elements of all ‘Conv2d’ outputs
+---- 3) #Conv2d: the number of ‘Conv2d’ layers
+# --------------------------------------------
+# Kai Zhang (github: https://github.com/cszn)
+# 21/July/2020
+# --------------------------------------------
+# Reference
+https://github.com/sovrasov/flops-counter.pytorch.git
+
+# If you use this code, please consider the following citation:
+
+@inproceedings{zhang2020aim, %
+ title={AIM 2020 Challenge on Efficient Super-Resolution: Methods and Results},
+ author={Kai Zhang and Martin Danelljan and Yawei Li and Radu Timofte and others},
+ booktitle={European Conference on Computer Vision Workshops},
+ year={2020}
+}
+# --------------------------------------------
+'''
+
+def get_model_flops(model, input_res, print_per_layer_stat=True,
+ input_constructor=None):
+ assert type(input_res) is tuple, 'Please provide the size of the input image.'
+ assert len(input_res) >= 3, 'Input image should have 3 dimensions.'
+ flops_model = add_flops_counting_methods(model)
+ flops_model.eval().start_flops_count()
+ if input_constructor:
+ input = input_constructor(input_res)
+ _ = flops_model(**input)
+ else:
+ device = list(flops_model.parameters())[-1].device
+ batch = torch.FloatTensor(1, *input_res).to(device)
+ _ = flops_model(batch)
+
+ if print_per_layer_stat:
+ print_model_with_flops(flops_model)
+ flops_count = flops_model.compute_average_flops_cost()
+ flops_model.stop_flops_count()
+
+ return flops_count
+
+def get_model_activation(model, input_res, input_constructor=None):
+ assert type(input_res) is tuple, 'Please provide the size of the input image.'
+ assert len(input_res) >= 3, 'Input image should have 3 dimensions.'
+ activation_model = add_activation_counting_methods(model)
+ activation_model.eval().start_activation_count()
+ if input_constructor:
+ input = input_constructor(input_res)
+ _ = activation_model(**input)
+ else:
+ device = list(activation_model.parameters())[-1].device
+ batch = torch.FloatTensor(1, *input_res).to(device)
+ _ = activation_model(batch)
+
+ activation_count, num_conv = activation_model.compute_average_activation_cost()
+ activation_model.stop_activation_count()
+
+ return activation_count, num_conv
+
+
+def get_model_complexity_info(model, input_res, print_per_layer_stat=True, as_strings=True,
+ input_constructor=None):
+ assert type(input_res) is tuple
+ assert len(input_res) >= 3
+ flops_model = add_flops_counting_methods(model)
+ flops_model.eval().start_flops_count()
+ if input_constructor:
+ input = input_constructor(input_res)
+ _ = flops_model(**input)
+ else:
+ batch = torch.FloatTensor(1, *input_res)
+ _ = flops_model(batch)
+
+ if print_per_layer_stat:
+ print_model_with_flops(flops_model)
+ flops_count = flops_model.compute_average_flops_cost()
+ params_count = get_model_parameters_number(flops_model)
+ flops_model.stop_flops_count()
+
+ if as_strings:
+ return flops_to_string(flops_count), params_to_string(params_count)
+
+ return flops_count, params_count
+
+
+def flops_to_string(flops, units='GMac', precision=2):
+ if units is None:
+ if flops // 10**9 > 0:
+ return str(round(flops / 10.**9, precision)) + ' GMac'
+ elif flops // 10**6 > 0:
+ return str(round(flops / 10.**6, precision)) + ' MMac'
+ elif flops // 10**3 > 0:
+ return str(round(flops / 10.**3, precision)) + ' KMac'
+ else:
+ return str(flops) + ' Mac'
+ else:
+ if units == 'GMac':
+ return str(round(flops / 10.**9, precision)) + ' ' + units
+ elif units == 'MMac':
+ return str(round(flops / 10.**6, precision)) + ' ' + units
+ elif units == 'KMac':
+ return str(round(flops / 10.**3, precision)) + ' ' + units
+ else:
+ return str(flops) + ' Mac'
+
+
+def params_to_string(params_num):
+ if params_num // 10 ** 6 > 0:
+ return str(round(params_num / 10 ** 6, 2)) + ' M'
+ elif params_num // 10 ** 3:
+ return str(round(params_num / 10 ** 3, 2)) + ' k'
+ else:
+ return str(params_num)
+
+
+def print_model_with_flops(model, units='GMac', precision=3):
+ total_flops = model.compute_average_flops_cost()
+
+ def accumulate_flops(self):
+ if is_supported_instance(self):
+ return self.__flops__ / model.__batch_counter__
+ else:
+ sum = 0
+ for m in self.children():
+ sum += m.accumulate_flops()
+ return sum
+
+ def flops_repr(self):
+ accumulated_flops_cost = self.accumulate_flops()
+ return ', '.join([flops_to_string(accumulated_flops_cost, units=units, precision=precision),
+ '{:.3%} MACs'.format(accumulated_flops_cost / total_flops),
+ self.original_extra_repr()])
+
+ def add_extra_repr(m):
+ m.accumulate_flops = accumulate_flops.__get__(m)
+ flops_extra_repr = flops_repr.__get__(m)
+ if m.extra_repr != flops_extra_repr:
+ m.original_extra_repr = m.extra_repr
+ m.extra_repr = flops_extra_repr
+ assert m.extra_repr != m.original_extra_repr
+
+ def del_extra_repr(m):
+ if hasattr(m, 'original_extra_repr'):
+ m.extra_repr = m.original_extra_repr
+ del m.original_extra_repr
+ if hasattr(m, 'accumulate_flops'):
+ del m.accumulate_flops
+
+ model.apply(add_extra_repr)
+ print(model)
+ model.apply(del_extra_repr)
+
+
+def get_model_parameters_number(model):
+ params_num = sum(p.numel() for p in model.parameters() if p.requires_grad)
+ return params_num
+
+
+def add_flops_counting_methods(net_main_module):
+ # adding additional methods to the existing module object,
+ # this is done this way so that each function has access to self object
+ # embed()
+ net_main_module.start_flops_count = start_flops_count.__get__(net_main_module)
+ net_main_module.stop_flops_count = stop_flops_count.__get__(net_main_module)
+ net_main_module.reset_flops_count = reset_flops_count.__get__(net_main_module)
+ net_main_module.compute_average_flops_cost = compute_average_flops_cost.__get__(net_main_module)
+
+ net_main_module.reset_flops_count()
+ return net_main_module
+
+
+def compute_average_flops_cost(self):
+ """
+ A method that will be available after add_flops_counting_methods() is called
+ on a desired net object.
+
+ Returns current mean flops consumption per image.
+
+ """
+
+ flops_sum = 0
+ for module in self.modules():
+ if is_supported_instance(module):
+ flops_sum += module.__flops__
+
+ return flops_sum
+
+
+def start_flops_count(self):
+ """
+ A method that will be available after add_flops_counting_methods() is called
+ on a desired net object.
+
+ Activates the computation of mean flops consumption per image.
+ Call it before you run the network.
+
+ """
+ self.apply(add_flops_counter_hook_function)
+
+
+def stop_flops_count(self):
+ """
+ A method that will be available after add_flops_counting_methods() is called
+ on a desired net object.
+
+ Stops computing the mean flops consumption per image.
+ Call whenever you want to pause the computation.
+
+ """
+ self.apply(remove_flops_counter_hook_function)
+
+
+def reset_flops_count(self):
+ """
+ A method that will be available after add_flops_counting_methods() is called
+ on a desired net object.
+
+ Resets statistics computed so far.
+
+ """
+ self.apply(add_flops_counter_variable_or_reset)
+
+
+def add_flops_counter_hook_function(module):
+ if is_supported_instance(module):
+ if hasattr(module, '__flops_handle__'):
+ return
+
+ if isinstance(module, (nn.Conv2d, nn.Conv3d, nn.ConvTranspose2d)):
+ handle = module.register_forward_hook(conv_flops_counter_hook)
+ elif isinstance(module, (nn.ReLU, nn.PReLU, nn.ELU, nn.LeakyReLU, nn.ReLU6)):
+ handle = module.register_forward_hook(relu_flops_counter_hook)
+ elif isinstance(module, nn.Linear):
+ handle = module.register_forward_hook(linear_flops_counter_hook)
+ elif isinstance(module, (nn.BatchNorm2d)):
+ handle = module.register_forward_hook(bn_flops_counter_hook)
+ else:
+ handle = module.register_forward_hook(empty_flops_counter_hook)
+ module.__flops_handle__ = handle
+
+
+def remove_flops_counter_hook_function(module):
+ if is_supported_instance(module):
+ if hasattr(module, '__flops_handle__'):
+ module.__flops_handle__.remove()
+ del module.__flops_handle__
+
+
+def add_flops_counter_variable_or_reset(module):
+ if is_supported_instance(module):
+ module.__flops__ = 0
+
+
+# ---- Internal functions
+def is_supported_instance(module):
+ if isinstance(module,
+ (
+ nn.Conv2d, nn.ConvTranspose2d,
+ nn.BatchNorm2d,
+ nn.Linear,
+ nn.ReLU, nn.PReLU, nn.ELU, nn.LeakyReLU, nn.ReLU6,
+ )):
+ return True
+
+ return False
+
+
+def conv_flops_counter_hook(conv_module, input, output):
+ # Can have multiple inputs, getting the first one
+ # input = input[0]
+
+ batch_size = output.shape[0]
+ output_dims = list(output.shape[2:])
+
+ kernel_dims = list(conv_module.kernel_size)
+ in_channels = conv_module.in_channels
+ out_channels = conv_module.out_channels
+ groups = conv_module.groups
+
+ filters_per_channel = out_channels // groups
+ conv_per_position_flops = np.prod(kernel_dims) * in_channels * filters_per_channel
+
+ active_elements_count = batch_size * np.prod(output_dims)
+ overall_conv_flops = int(conv_per_position_flops) * int(active_elements_count)
+
+ # overall_flops = overall_conv_flops
+
+ conv_module.__flops__ += int(overall_conv_flops)
+ # conv_module.__output_dims__ = output_dims
+
+
+def relu_flops_counter_hook(module, input, output):
+ active_elements_count = output.numel()
+ module.__flops__ += int(active_elements_count)
+ # print(module.__flops__, id(module))
+ # print(module)
+
+
+def linear_flops_counter_hook(module, input, output):
+ input = input[0]
+ if len(input.shape) == 1:
+ batch_size = 1
+ module.__flops__ += int(batch_size * input.shape[0] * output.shape[0])
+ else:
+ batch_size = input.shape[0]
+ module.__flops__ += int(batch_size * input.shape[1] * output.shape[1])
+
+
+def bn_flops_counter_hook(module, input, output):
+ # input = input[0]
+ # TODO: need to check here
+ # batch_flops = np.prod(input.shape)
+ # if module.affine:
+ # batch_flops *= 2
+ # module.__flops__ += int(batch_flops)
+ batch = output.shape[0]
+ output_dims = output.shape[2:]
+ channels = module.num_features
+ batch_flops = batch * channels * np.prod(output_dims)
+ if module.affine:
+ batch_flops *= 2
+ module.__flops__ += int(batch_flops)
+
+
+# ---- Count the number of convolutional layers and the activation
+def add_activation_counting_methods(net_main_module):
+ # adding additional methods to the existing module object,
+ # this is done this way so that each function has access to self object
+ # embed()
+ net_main_module.start_activation_count = start_activation_count.__get__(net_main_module)
+ net_main_module.stop_activation_count = stop_activation_count.__get__(net_main_module)
+ net_main_module.reset_activation_count = reset_activation_count.__get__(net_main_module)
+ net_main_module.compute_average_activation_cost = compute_average_activation_cost.__get__(net_main_module)
+
+ net_main_module.reset_activation_count()
+ return net_main_module
+
+
+def compute_average_activation_cost(self):
+ """
+ A method that will be available after add_activation_counting_methods() is called
+ on a desired net object.
+
+ Returns current mean activation consumption per image.
+
+ """
+
+ activation_sum = 0
+ num_conv = 0
+ for module in self.modules():
+ if is_supported_instance_for_activation(module):
+ activation_sum += module.__activation__
+ num_conv += module.__num_conv__
+ return activation_sum, num_conv
+
+
+def start_activation_count(self):
+ """
+ A method that will be available after add_activation_counting_methods() is called
+ on a desired net object.
+
+ Activates the computation of mean activation consumption per image.
+ Call it before you run the network.
+
+ """
+ self.apply(add_activation_counter_hook_function)
+
+
+def stop_activation_count(self):
+ """
+ A method that will be available after add_activation_counting_methods() is called
+ on a desired net object.
+
+ Stops computing the mean activation consumption per image.
+ Call whenever you want to pause the computation.
+
+ """
+ self.apply(remove_activation_counter_hook_function)
+
+
+def reset_activation_count(self):
+ """
+ A method that will be available after add_activation_counting_methods() is called
+ on a desired net object.
+
+ Resets statistics computed so far.
+
+ """
+ self.apply(add_activation_counter_variable_or_reset)
+
+
+def add_activation_counter_hook_function(module):
+ if is_supported_instance_for_activation(module):
+ if hasattr(module, '__activation_handle__'):
+ return
+
+ if isinstance(module, (nn.Conv2d, nn.ConvTranspose2d)):
+ handle = module.register_forward_hook(conv_activation_counter_hook)
+ module.__activation_handle__ = handle
+
+
+def remove_activation_counter_hook_function(module):
+ if is_supported_instance_for_activation(module):
+ if hasattr(module, '__activation_handle__'):
+ module.__activation_handle__.remove()
+ del module.__activation_handle__
+
+
+def add_activation_counter_variable_or_reset(module):
+ if is_supported_instance_for_activation(module):
+ module.__activation__ = 0
+ module.__num_conv__ = 0
+
+
+def is_supported_instance_for_activation(module):
+ if isinstance(module,
+ (
+ nn.Conv2d, nn.ConvTranspose2d,
+ )):
+ return True
+
+ return False
+
+def conv_activation_counter_hook(module, input, output):
+ """
+ Calculate the activations in the convolutional operation.
+ Reference: Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick, Kaiming He, Piotr Dollár, Designing Network Design Spaces.
+ :param module:
+ :param input:
+ :param output:
+ :return:
+ """
+ module.__activation__ += output.numel()
+ module.__num_conv__ += 1
+
+
+def empty_flops_counter_hook(module, input, output):
+ module.__flops__ += 0
+
+
+def upsample_flops_counter_hook(module, input, output):
+ output_size = output[0]
+ batch_size = output_size.shape[0]
+ output_elements_count = batch_size
+ for val in output_size.shape[1:]:
+ output_elements_count *= val
+ module.__flops__ += int(output_elements_count)
+
+
+def pool_flops_counter_hook(module, input, output):
+ input = input[0]
+ module.__flops__ += int(np.prod(input.shape))
+
+
+def dconv_flops_counter_hook(dconv_module, input, output):
+ input = input[0]
+
+ batch_size = input.shape[0]
+ output_dims = list(output.shape[2:])
+
+ m_channels, in_channels, kernel_dim1, _, = dconv_module.weight.shape
+ out_channels, _, kernel_dim2, _, = dconv_module.projection.shape
+ # groups = dconv_module.groups
+
+ # filters_per_channel = out_channels // groups
+ conv_per_position_flops1 = kernel_dim1 ** 2 * in_channels * m_channels
+ conv_per_position_flops2 = kernel_dim2 ** 2 * out_channels * m_channels
+ active_elements_count = batch_size * np.prod(output_dims)
+
+ overall_conv_flops = (conv_per_position_flops1 + conv_per_position_flops2) * active_elements_count
+ overall_flops = overall_conv_flops
+
+ dconv_module.__flops__ += int(overall_flops)
+ # dconv_module.__output_dims__ = output_dims
+
+
+
+
+
diff --git a/KAIR/utils/utils_option.py b/KAIR/utils/utils_option.py
new file mode 100644
index 0000000000000000000000000000000000000000..cf096210e2d8ea553b06a91ac5cdaa21127d837c
--- /dev/null
+++ b/KAIR/utils/utils_option.py
@@ -0,0 +1,255 @@
+import os
+from collections import OrderedDict
+from datetime import datetime
+import json
+import re
+import glob
+
+
+'''
+# --------------------------------------------
+# Kai Zhang (github: https://github.com/cszn)
+# 03/Mar/2019
+# --------------------------------------------
+# https://github.com/xinntao/BasicSR
+# --------------------------------------------
+'''
+
+
+def get_timestamp():
+ return datetime.now().strftime('_%y%m%d_%H%M%S')
+
+
+def parse(opt_path, is_train=True):
+
+ # ----------------------------------------
+ # remove comments starting with '//'
+ # ----------------------------------------
+ json_str = ''
+ with open(opt_path, 'r') as f:
+ for line in f:
+ line = line.split('//')[0] + '\n'
+ json_str += line
+
+ # ----------------------------------------
+ # initialize opt
+ # ----------------------------------------
+ opt = json.loads(json_str, object_pairs_hook=OrderedDict)
+
+ opt['opt_path'] = opt_path
+ opt['is_train'] = is_train
+
+ # ----------------------------------------
+ # set default
+ # ----------------------------------------
+ if 'merge_bn' not in opt:
+ opt['merge_bn'] = False
+ opt['merge_bn_startpoint'] = -1
+
+ if 'scale' not in opt:
+ opt['scale'] = 1
+
+ # ----------------------------------------
+ # datasets
+ # ----------------------------------------
+ for phase, dataset in opt['datasets'].items():
+ phase = phase.split('_')[0]
+ dataset['phase'] = phase
+ dataset['scale'] = opt['scale'] # broadcast
+ dataset['n_channels'] = opt['n_channels'] # broadcast
+ if 'dataroot_H' in dataset and dataset['dataroot_H'] is not None:
+ dataset['dataroot_H'] = os.path.expanduser(dataset['dataroot_H'])
+ if 'dataroot_L' in dataset and dataset['dataroot_L'] is not None:
+ dataset['dataroot_L'] = os.path.expanduser(dataset['dataroot_L'])
+
+ # ----------------------------------------
+ # path
+ # ----------------------------------------
+ for key, path in opt['path'].items():
+ if path and key in opt['path']:
+ opt['path'][key] = os.path.expanduser(path)
+
+ path_task = os.path.join(opt['path']['root'], opt['task'])
+ opt['path']['task'] = path_task
+ opt['path']['log'] = path_task
+ opt['path']['options'] = os.path.join(path_task, 'options')
+
+ if is_train:
+ opt['path']['models'] = os.path.join(path_task, 'models')
+ opt['path']['images'] = os.path.join(path_task, 'images')
+ else: # test
+ opt['path']['images'] = os.path.join(path_task, 'test_images')
+
+ # ----------------------------------------
+ # network
+ # ----------------------------------------
+ opt['netG']['scale'] = opt['scale'] if 'scale' in opt else 1
+
+ # ----------------------------------------
+ # GPU devices
+ # ----------------------------------------
+ gpu_list = ','.join(str(x) for x in opt['gpu_ids'])
+ os.environ['CUDA_VISIBLE_DEVICES'] = gpu_list
+ print('export CUDA_VISIBLE_DEVICES=' + gpu_list)
+
+ # ----------------------------------------
+ # default setting for distributeddataparallel
+ # ----------------------------------------
+ if 'find_unused_parameters' not in opt:
+ opt['find_unused_parameters'] = True
+ if 'use_static_graph' not in opt:
+ opt['use_static_graph'] = False
+ if 'dist' not in opt:
+ opt['dist'] = False
+ opt['num_gpu'] = len(opt['gpu_ids'])
+ print('number of GPUs is: ' + str(opt['num_gpu']))
+
+ # ----------------------------------------
+ # default setting for perceptual loss
+ # ----------------------------------------
+ if 'F_feature_layer' not in opt['train']:
+ opt['train']['F_feature_layer'] = 34 # 25; [2,7,16,25,34]
+ if 'F_weights' not in opt['train']:
+ opt['train']['F_weights'] = 1.0 # 1.0; [0.1,0.1,1.0,1.0,1.0]
+ if 'F_lossfn_type' not in opt['train']:
+ opt['train']['F_lossfn_type'] = 'l1'
+ if 'F_use_input_norm' not in opt['train']:
+ opt['train']['F_use_input_norm'] = True
+ if 'F_use_range_norm' not in opt['train']:
+ opt['train']['F_use_range_norm'] = False
+
+ # ----------------------------------------
+ # default setting for optimizer
+ # ----------------------------------------
+ if 'G_optimizer_type' not in opt['train']:
+ opt['train']['G_optimizer_type'] = "adam"
+ if 'G_optimizer_betas' not in opt['train']:
+ opt['train']['G_optimizer_betas'] = [0.9,0.999]
+ if 'G_scheduler_restart_weights' not in opt['train']:
+ opt['train']['G_scheduler_restart_weights'] = 1
+ if 'G_optimizer_wd' not in opt['train']:
+ opt['train']['G_optimizer_wd'] = 0
+ if 'G_optimizer_reuse' not in opt['train']:
+ opt['train']['G_optimizer_reuse'] = False
+ if 'netD' in opt and 'D_optimizer_reuse' not in opt['train']:
+ opt['train']['D_optimizer_reuse'] = False
+
+ # ----------------------------------------
+ # default setting of strict for model loading
+ # ----------------------------------------
+ if 'G_param_strict' not in opt['train']:
+ opt['train']['G_param_strict'] = True
+ if 'netD' in opt and 'D_param_strict' not in opt['path']:
+ opt['train']['D_param_strict'] = True
+ if 'E_param_strict' not in opt['path']:
+ opt['train']['E_param_strict'] = True
+
+ # ----------------------------------------
+ # Exponential Moving Average
+ # ----------------------------------------
+ if 'E_decay' not in opt['train']:
+ opt['train']['E_decay'] = 0
+
+ # ----------------------------------------
+ # default setting for discriminator
+ # ----------------------------------------
+ if 'netD' in opt:
+ if 'net_type' not in opt['netD']:
+ opt['netD']['net_type'] = 'discriminator_patchgan' # discriminator_unet
+ if 'in_nc' not in opt['netD']:
+ opt['netD']['in_nc'] = 3
+ if 'base_nc' not in opt['netD']:
+ opt['netD']['base_nc'] = 64
+ if 'n_layers' not in opt['netD']:
+ opt['netD']['n_layers'] = 3
+ if 'norm_type' not in opt['netD']:
+ opt['netD']['norm_type'] = 'spectral'
+
+
+ return opt
+
+
+def find_last_checkpoint(save_dir, net_type='G', pretrained_path=None):
+ """
+ Args:
+ save_dir: model folder
+ net_type: 'G' or 'D' or 'optimizerG' or 'optimizerD'
+ pretrained_path: pretrained model path. If save_dir does not have any model, load from pretrained_path
+
+ Return:
+ init_iter: iteration number
+ init_path: model path
+ """
+ file_list = glob.glob(os.path.join(save_dir, '*_{}.pth'.format(net_type)))
+ if file_list:
+ iter_exist = []
+ for file_ in file_list:
+ iter_current = re.findall(r"(\d+)_{}.pth".format(net_type), file_)
+ iter_exist.append(int(iter_current[0]))
+ init_iter = max(iter_exist)
+ init_path = os.path.join(save_dir, '{}_{}.pth'.format(init_iter, net_type))
+ else:
+ init_iter = 0
+ init_path = pretrained_path
+ return init_iter, init_path
+
+
+'''
+# --------------------------------------------
+# convert the opt into json file
+# --------------------------------------------
+'''
+
+
+def save(opt):
+ opt_path = opt['opt_path']
+ opt_path_copy = opt['path']['options']
+ dirname, filename_ext = os.path.split(opt_path)
+ filename, ext = os.path.splitext(filename_ext)
+ dump_path = os.path.join(opt_path_copy, filename+get_timestamp()+ext)
+ with open(dump_path, 'w') as dump_file:
+ json.dump(opt, dump_file, indent=2)
+
+
+'''
+# --------------------------------------------
+# dict to string for logger
+# --------------------------------------------
+'''
+
+
+def dict2str(opt, indent_l=1):
+ msg = ''
+ for k, v in opt.items():
+ if isinstance(v, dict):
+ msg += ' ' * (indent_l * 2) + k + ':[\n'
+ msg += dict2str(v, indent_l + 1)
+ msg += ' ' * (indent_l * 2) + ']\n'
+ else:
+ msg += ' ' * (indent_l * 2) + k + ': ' + str(v) + '\n'
+ return msg
+
+
+'''
+# --------------------------------------------
+# convert OrderedDict to NoneDict,
+# return None for missing key
+# --------------------------------------------
+'''
+
+
+def dict_to_nonedict(opt):
+ if isinstance(opt, dict):
+ new_opt = dict()
+ for key, sub_opt in opt.items():
+ new_opt[key] = dict_to_nonedict(sub_opt)
+ return NoneDict(**new_opt)
+ elif isinstance(opt, list):
+ return [dict_to_nonedict(sub_opt) for sub_opt in opt]
+ else:
+ return opt
+
+
+class NoneDict(dict):
+ def __missing__(self, key):
+ return None
diff --git a/KAIR/utils/utils_params.py b/KAIR/utils/utils_params.py
new file mode 100644
index 0000000000000000000000000000000000000000..def1cb79e11472b9b8ebbaae4bd83e7216af2ccb
--- /dev/null
+++ b/KAIR/utils/utils_params.py
@@ -0,0 +1,135 @@
+import torch
+
+import torchvision
+
+from models import basicblock as B
+
+def show_kv(net):
+ for k, v in net.items():
+ print(k)
+
+# should run train debug mode first to get an initial model
+#crt_net = torch.load('../../experiments/debug_SRResNet_bicx4_in3nf64nb16/models/8_G.pth')
+#
+#for k, v in crt_net.items():
+# print(k)
+#for k, v in crt_net.items():
+# if k in pretrained_net:
+# crt_net[k] = pretrained_net[k]
+# print('replace ... ', k)
+
+# x2 -> x4
+#crt_net['model.5.weight'] = pretrained_net['model.2.weight']
+#crt_net['model.5.bias'] = pretrained_net['model.2.bias']
+#crt_net['model.8.weight'] = pretrained_net['model.5.weight']
+#crt_net['model.8.bias'] = pretrained_net['model.5.bias']
+#crt_net['model.10.weight'] = pretrained_net['model.7.weight']
+#crt_net['model.10.bias'] = pretrained_net['model.7.bias']
+#torch.save(crt_net, '../pretrained_tmp.pth')
+
+# x2 -> x3
+'''
+in_filter = pretrained_net['model.2.weight'] # 256, 64, 3, 3
+new_filter = torch.Tensor(576, 64, 3, 3)
+new_filter[0:256, :, :, :] = in_filter
+new_filter[256:512, :, :, :] = in_filter
+new_filter[512:, :, :, :] = in_filter[0:576-512, :, :, :]
+crt_net['model.2.weight'] = new_filter
+
+in_bias = pretrained_net['model.2.bias'] # 256, 64, 3, 3
+new_bias = torch.Tensor(576)
+new_bias[0:256] = in_bias
+new_bias[256:512] = in_bias
+new_bias[512:] = in_bias[0:576 - 512]
+crt_net['model.2.bias'] = new_bias
+
+torch.save(crt_net, '../pretrained_tmp.pth')
+'''
+
+# x2 -> x8
+'''
+crt_net['model.5.weight'] = pretrained_net['model.2.weight']
+crt_net['model.5.bias'] = pretrained_net['model.2.bias']
+crt_net['model.8.weight'] = pretrained_net['model.2.weight']
+crt_net['model.8.bias'] = pretrained_net['model.2.bias']
+crt_net['model.11.weight'] = pretrained_net['model.5.weight']
+crt_net['model.11.bias'] = pretrained_net['model.5.bias']
+crt_net['model.13.weight'] = pretrained_net['model.7.weight']
+crt_net['model.13.bias'] = pretrained_net['model.7.bias']
+torch.save(crt_net, '../pretrained_tmp.pth')
+'''
+
+# x3/4/8 RGB -> Y
+
+def rgb2gray_net(net, only_input=True):
+
+ if only_input:
+ in_filter = net['0.weight']
+ in_new_filter = in_filter[:,0,:,:]*0.2989 + in_filter[:,1,:,:]*0.587 + in_filter[:,2,:,:]*0.114
+ in_new_filter.unsqueeze_(1)
+ net['0.weight'] = in_new_filter
+
+# out_filter = pretrained_net['model.13.weight']
+# out_new_filter = out_filter[0, :, :, :] * 0.2989 + out_filter[1, :, :, :] * 0.587 + \
+# out_filter[2, :, :, :] * 0.114
+# out_new_filter.unsqueeze_(0)
+# crt_net['model.13.weight'] = out_new_filter
+# out_bias = pretrained_net['model.13.bias']
+# out_new_bias = out_bias[0] * 0.2989 + out_bias[1] * 0.587 + out_bias[2] * 0.114
+# out_new_bias = torch.Tensor(1).fill_(out_new_bias)
+# crt_net['model.13.bias'] = out_new_bias
+
+# torch.save(crt_net, '../pretrained_tmp.pth')
+
+ return net
+
+
+
+if __name__ == '__main__':
+
+ net = torchvision.models.vgg19(pretrained=True)
+ for k,v in net.features.named_parameters():
+ if k=='0.weight':
+ in_new_filter = v[:,0,:,:]*0.2989 + v[:,1,:,:]*0.587 + v[:,2,:,:]*0.114
+ in_new_filter.unsqueeze_(1)
+ v = in_new_filter
+ print(v.shape)
+ print(v[0,0,0,0])
+ if k=='0.bias':
+ in_new_bias = v
+ print(v[0])
+
+ print(net.features[0])
+
+ net.features[0] = B.conv(1, 64, mode='C')
+
+ print(net.features[0])
+ net.features[0].weight.data=in_new_filter
+ net.features[0].bias.data=in_new_bias
+
+ for k,v in net.features.named_parameters():
+ if k=='0.weight':
+ print(v[0,0,0,0])
+ if k=='0.bias':
+ print(v[0])
+
+ # transfer parameters of old model to new one
+ model_old = torch.load(model_path)
+ state_dict = model.state_dict()
+ for ((key, param),(key2, param2)) in zip(model_old.items(), state_dict.items()):
+ state_dict[key2] = param
+ print([key, key2])
+ # print([param.size(), param2.size()])
+ torch.save(state_dict, 'model_new.pth')
+
+
+ # rgb2gray_net(net)
+
+
+
+
+
+
+
+
+
diff --git a/KAIR/utils/utils_receptivefield.py b/KAIR/utils/utils_receptivefield.py
new file mode 100644
index 0000000000000000000000000000000000000000..394456390644ba9edc406b810f67d09b0e2ff114
--- /dev/null
+++ b/KAIR/utils/utils_receptivefield.py
@@ -0,0 +1,62 @@
+# -*- coding: utf-8 -*-
+
+# online calculation: https://fomoro.com/research/article/receptive-field-calculator#
+
+# [filter size, stride, padding]
+#Assume the two dimensions are the same
+#Each kernel requires the following parameters:
+# - k_i: kernel size
+# - s_i: stride
+# - p_i: padding (if padding is uneven, right padding will higher than left padding; "SAME" option in tensorflow)
+#
+#Each layer i requires the following parameters to be fully represented:
+# - n_i: number of feature (data layer has n_1 = imagesize )
+# - j_i: distance (projected to image pixel distance) between center of two adjacent features
+# - r_i: receptive field of a feature in layer i
+# - start_i: position of the first feature's receptive field in layer i (idx start from 0, negative means the center fall into padding)
+
+import math
+
+def outFromIn(conv, layerIn):
+ n_in = layerIn[0]
+ j_in = layerIn[1]
+ r_in = layerIn[2]
+ start_in = layerIn[3]
+ k = conv[0]
+ s = conv[1]
+ p = conv[2]
+
+ n_out = math.floor((n_in - k + 2*p)/s) + 1
+ actualP = (n_out-1)*s - n_in + k
+ pR = math.ceil(actualP/2)
+ pL = math.floor(actualP/2)
+
+ j_out = j_in * s
+ r_out = r_in + (k - 1)*j_in
+ start_out = start_in + ((k-1)/2 - pL)*j_in
+ return n_out, j_out, r_out, start_out
+
+def printLayer(layer, layer_name):
+ print(layer_name + ":")
+ print(" n features: %s jump: %s receptive size: %s start: %s " % (layer[0], layer[1], layer[2], layer[3]))
+
+
+
+layerInfos = []
+if __name__ == '__main__':
+
+ convnet = [[3,1,1],[3,1,1],[3,1,1],[4,2,1],[2,2,0],[3,1,1]]
+ layer_names = ['conv1','conv2','conv3','conv4','conv5','conv6','conv7','conv8','conv9','conv10','conv11','conv12']
+ imsize = 128
+
+ print ("-------Net summary------")
+ currentLayer = [imsize, 1, 1, 0.5]
+ printLayer(currentLayer, "input image")
+ for i in range(len(convnet)):
+ currentLayer = outFromIn(convnet[i], currentLayer)
+ layerInfos.append(currentLayer)
+ printLayer(currentLayer, layer_names[i])
+
+
+# run utils/utils_receptivefield.py
+
\ No newline at end of file
diff --git a/KAIR/utils/utils_regularizers.py b/KAIR/utils/utils_regularizers.py
new file mode 100644
index 0000000000000000000000000000000000000000..17e7c8524b716f36e10b41d72fee2e375af69454
--- /dev/null
+++ b/KAIR/utils/utils_regularizers.py
@@ -0,0 +1,104 @@
+import torch
+import torch.nn as nn
+
+
+'''
+# --------------------------------------------
+# Kai Zhang (github: https://github.com/cszn)
+# 03/Mar/2019
+# --------------------------------------------
+'''
+
+
+# --------------------------------------------
+# SVD Orthogonal Regularization
+# --------------------------------------------
+def regularizer_orth(m):
+ """
+ # ----------------------------------------
+ # SVD Orthogonal Regularization
+ # ----------------------------------------
+ # Applies regularization to the training by performing the
+ # orthogonalization technique described in the paper
+ # This function is to be called by the torch.nn.Module.apply() method,
+ # which applies svd_orthogonalization() to every layer of the model.
+ # usage: net.apply(regularizer_orth)
+ # ----------------------------------------
+ """
+ classname = m.__class__.__name__
+ if classname.find('Conv') != -1:
+ w = m.weight.data.clone()
+ c_out, c_in, f1, f2 = w.size()
+ # dtype = m.weight.data.type()
+ w = w.permute(2, 3, 1, 0).contiguous().view(f1*f2*c_in, c_out)
+ # self.netG.apply(svd_orthogonalization)
+ u, s, v = torch.svd(w)
+ s[s > 1.5] = s[s > 1.5] - 1e-4
+ s[s < 0.5] = s[s < 0.5] + 1e-4
+ w = torch.mm(torch.mm(u, torch.diag(s)), v.t())
+ m.weight.data = w.view(f1, f2, c_in, c_out).permute(3, 2, 0, 1) # .type(dtype)
+ else:
+ pass
+
+
+# --------------------------------------------
+# SVD Orthogonal Regularization
+# --------------------------------------------
+def regularizer_orth2(m):
+ """
+ # ----------------------------------------
+ # Applies regularization to the training by performing the
+ # orthogonalization technique described in the paper
+ # This function is to be called by the torch.nn.Module.apply() method,
+ # which applies svd_orthogonalization() to every layer of the model.
+ # usage: net.apply(regularizer_orth2)
+ # ----------------------------------------
+ """
+ classname = m.__class__.__name__
+ if classname.find('Conv') != -1:
+ w = m.weight.data.clone()
+ c_out, c_in, f1, f2 = w.size()
+ # dtype = m.weight.data.type()
+ w = w.permute(2, 3, 1, 0).contiguous().view(f1*f2*c_in, c_out)
+ u, s, v = torch.svd(w)
+ s_mean = s.mean()
+ s[s > 1.5*s_mean] = s[s > 1.5*s_mean] - 1e-4
+ s[s < 0.5*s_mean] = s[s < 0.5*s_mean] + 1e-4
+ w = torch.mm(torch.mm(u, torch.diag(s)), v.t())
+ m.weight.data = w.view(f1, f2, c_in, c_out).permute(3, 2, 0, 1) # .type(dtype)
+ else:
+ pass
+
+
+
+def regularizer_clip(m):
+ """
+ # ----------------------------------------
+ # usage: net.apply(regularizer_clip)
+ # ----------------------------------------
+ """
+ eps = 1e-4
+ c_min = -1.5
+ c_max = 1.5
+
+ classname = m.__class__.__name__
+ if classname.find('Conv') != -1 or classname.find('Linear') != -1:
+ w = m.weight.data.clone()
+ w[w > c_max] -= eps
+ w[w < c_min] += eps
+ m.weight.data = w
+
+ if m.bias is not None:
+ b = m.bias.data.clone()
+ b[b > c_max] -= eps
+ b[b < c_min] += eps
+ m.bias.data = b
+
+# elif classname.find('BatchNorm2d') != -1:
+#
+# rv = m.running_var.data.clone()
+# rm = m.running_mean.data.clone()
+#
+# if m.affine:
+# m.weight.data
+# m.bias.data
diff --git a/KAIR/utils/utils_sisr.py b/KAIR/utils/utils_sisr.py
new file mode 100644
index 0000000000000000000000000000000000000000..fde7881526c5544ed09657872b044af5fa99b3a9
--- /dev/null
+++ b/KAIR/utils/utils_sisr.py
@@ -0,0 +1,848 @@
+# -*- coding: utf-8 -*-
+from utils import utils_image as util
+import random
+
+import scipy
+import scipy.stats as ss
+import scipy.io as io
+from scipy import ndimage
+from scipy.interpolate import interp2d
+
+import numpy as np
+import torch
+
+
+"""
+# --------------------------------------------
+# Super-Resolution
+# --------------------------------------------
+#
+# Kai Zhang (cskaizhang@gmail.com)
+# https://github.com/cszn
+# modified by Kai Zhang (github: https://github.com/cszn)
+# 03/03/2020
+# --------------------------------------------
+"""
+
+
+"""
+# --------------------------------------------
+# anisotropic Gaussian kernels
+# --------------------------------------------
+"""
+
+
+def anisotropic_Gaussian(ksize=15, theta=np.pi, l1=6, l2=6):
+ """ generate an anisotropic Gaussian kernel
+ Args:
+ ksize : e.g., 15, kernel size
+ theta : [0, pi], rotation angle range
+ l1 : [0.1,50], scaling of eigenvalues
+ l2 : [0.1,l1], scaling of eigenvalues
+ If l1 = l2, will get an isotropic Gaussian kernel.
+ Returns:
+ k : kernel
+ """
+
+ v = np.dot(np.array([[np.cos(theta), -np.sin(theta)], [np.sin(theta), np.cos(theta)]]), np.array([1., 0.]))
+ V = np.array([[v[0], v[1]], [v[1], -v[0]]])
+ D = np.array([[l1, 0], [0, l2]])
+ Sigma = np.dot(np.dot(V, D), np.linalg.inv(V))
+ k = gm_blur_kernel(mean=[0, 0], cov=Sigma, size=ksize)
+
+ return k
+
+
+def gm_blur_kernel(mean, cov, size=15):
+ center = size / 2.0 + 0.5
+ k = np.zeros([size, size])
+ for y in range(size):
+ for x in range(size):
+ cy = y - center + 1
+ cx = x - center + 1
+ k[y, x] = ss.multivariate_normal.pdf([cx, cy], mean=mean, cov=cov)
+
+ k = k / np.sum(k)
+ return k
+
+
+"""
+# --------------------------------------------
+# calculate PCA projection matrix
+# --------------------------------------------
+"""
+
+
+def get_pca_matrix(x, dim_pca=15):
+ """
+ Args:
+ x: 225x10000 matrix
+ dim_pca: 15
+ Returns:
+ pca_matrix: 15x225
+ """
+ C = np.dot(x, x.T)
+ w, v = scipy.linalg.eigh(C)
+ pca_matrix = v[:, -dim_pca:].T
+
+ return pca_matrix
+
+
+def show_pca(x):
+ """
+ x: PCA projection matrix, e.g., 15x225
+ """
+ for i in range(x.shape[0]):
+ xc = np.reshape(x[i, :], (int(np.sqrt(x.shape[1])), -1), order="F")
+ util.surf(xc)
+
+
+def cal_pca_matrix(path='PCA_matrix.mat', ksize=15, l_max=12.0, dim_pca=15, num_samples=500):
+ kernels = np.zeros([ksize*ksize, num_samples], dtype=np.float32)
+ for i in range(num_samples):
+
+ theta = np.pi*np.random.rand(1)
+ l1 = 0.1+l_max*np.random.rand(1)
+ l2 = 0.1+(l1-0.1)*np.random.rand(1)
+
+ k = anisotropic_Gaussian(ksize=ksize, theta=theta[0], l1=l1[0], l2=l2[0])
+
+ # util.imshow(k)
+
+ kernels[:, i] = np.reshape(k, (-1), order="F") # k.flatten(order='F')
+
+ # io.savemat('k.mat', {'k': kernels})
+
+ pca_matrix = get_pca_matrix(kernels, dim_pca=dim_pca)
+
+ io.savemat(path, {'p': pca_matrix})
+
+ return pca_matrix
+
+
+"""
+# --------------------------------------------
+# shifted anisotropic Gaussian kernels
+# --------------------------------------------
+"""
+
+
+def shifted_anisotropic_Gaussian(k_size=np.array([15, 15]), scale_factor=np.array([4, 4]), min_var=0.6, max_var=10., noise_level=0):
+ """"
+ # modified version of https://github.com/assafshocher/BlindSR_dataset_generator
+ # Kai Zhang
+ # min_var = 0.175 * sf # variance of the gaussian kernel will be sampled between min_var and max_var
+ # max_var = 2.5 * sf
+ """
+ # Set random eigen-vals (lambdas) and angle (theta) for COV matrix
+ lambda_1 = min_var + np.random.rand() * (max_var - min_var)
+ lambda_2 = min_var + np.random.rand() * (max_var - min_var)
+ theta = np.random.rand() * np.pi # random theta
+ noise = -noise_level + np.random.rand(*k_size) * noise_level * 2
+
+ # Set COV matrix using Lambdas and Theta
+ LAMBDA = np.diag([lambda_1, lambda_2])
+ Q = np.array([[np.cos(theta), -np.sin(theta)],
+ [np.sin(theta), np.cos(theta)]])
+ SIGMA = Q @ LAMBDA @ Q.T
+ INV_SIGMA = np.linalg.inv(SIGMA)[None, None, :, :]
+
+ # Set expectation position (shifting kernel for aligned image)
+ MU = k_size // 2 - 0.5*(scale_factor - 1) # - 0.5 * (scale_factor - k_size % 2)
+ MU = MU[None, None, :, None]
+
+ # Create meshgrid for Gaussian
+ [X,Y] = np.meshgrid(range(k_size[0]), range(k_size[1]))
+ Z = np.stack([X, Y], 2)[:, :, :, None]
+
+ # Calcualte Gaussian for every pixel of the kernel
+ ZZ = Z-MU
+ ZZ_t = ZZ.transpose(0,1,3,2)
+ raw_kernel = np.exp(-0.5 * np.squeeze(ZZ_t @ INV_SIGMA @ ZZ)) * (1 + noise)
+
+ # shift the kernel so it will be centered
+ #raw_kernel_centered = kernel_shift(raw_kernel, scale_factor)
+
+ # Normalize the kernel and return
+ #kernel = raw_kernel_centered / np.sum(raw_kernel_centered)
+ kernel = raw_kernel / np.sum(raw_kernel)
+ return kernel
+
+
+def gen_kernel(k_size=np.array([25, 25]), scale_factor=np.array([4, 4]), min_var=0.6, max_var=12., noise_level=0):
+ """"
+ # modified version of https://github.com/assafshocher/BlindSR_dataset_generator
+ # Kai Zhang
+ # min_var = 0.175 * sf # variance of the gaussian kernel will be sampled between min_var and max_var
+ # max_var = 2.5 * sf
+ """
+ sf = random.choice([1, 2, 3, 4])
+ scale_factor = np.array([sf, sf])
+ # Set random eigen-vals (lambdas) and angle (theta) for COV matrix
+ lambda_1 = min_var + np.random.rand() * (max_var - min_var)
+ lambda_2 = min_var + np.random.rand() * (max_var - min_var)
+ theta = np.random.rand() * np.pi # random theta
+ noise = 0#-noise_level + np.random.rand(*k_size) * noise_level * 2
+
+ # Set COV matrix using Lambdas and Theta
+ LAMBDA = np.diag([lambda_1, lambda_2])
+ Q = np.array([[np.cos(theta), -np.sin(theta)],
+ [np.sin(theta), np.cos(theta)]])
+ SIGMA = Q @ LAMBDA @ Q.T
+ INV_SIGMA = np.linalg.inv(SIGMA)[None, None, :, :]
+
+ # Set expectation position (shifting kernel for aligned image)
+ MU = k_size // 2 - 0.5*(scale_factor - 1) # - 0.5 * (scale_factor - k_size % 2)
+ MU = MU[None, None, :, None]
+
+ # Create meshgrid for Gaussian
+ [X,Y] = np.meshgrid(range(k_size[0]), range(k_size[1]))
+ Z = np.stack([X, Y], 2)[:, :, :, None]
+
+ # Calcualte Gaussian for every pixel of the kernel
+ ZZ = Z-MU
+ ZZ_t = ZZ.transpose(0,1,3,2)
+ raw_kernel = np.exp(-0.5 * np.squeeze(ZZ_t @ INV_SIGMA @ ZZ)) * (1 + noise)
+
+ # shift the kernel so it will be centered
+ #raw_kernel_centered = kernel_shift(raw_kernel, scale_factor)
+
+ # Normalize the kernel and return
+ #kernel = raw_kernel_centered / np.sum(raw_kernel_centered)
+ kernel = raw_kernel / np.sum(raw_kernel)
+ return kernel
+
+
+"""
+# --------------------------------------------
+# degradation models
+# --------------------------------------------
+"""
+
+
+def bicubic_degradation(x, sf=3):
+ '''
+ Args:
+ x: HxWxC image, [0, 1]
+ sf: down-scale factor
+ Return:
+ bicubicly downsampled LR image
+ '''
+ x = util.imresize_np(x, scale=1/sf)
+ return x
+
+
+def srmd_degradation(x, k, sf=3):
+ ''' blur + bicubic downsampling
+ Args:
+ x: HxWxC image, [0, 1]
+ k: hxw, double
+ sf: down-scale factor
+ Return:
+ downsampled LR image
+ Reference:
+ @inproceedings{zhang2018learning,
+ title={Learning a single convolutional super-resolution network for multiple degradations},
+ author={Zhang, Kai and Zuo, Wangmeng and Zhang, Lei},
+ booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
+ pages={3262--3271},
+ year={2018}
+ }
+ '''
+ x = ndimage.filters.convolve(x, np.expand_dims(k, axis=2), mode='wrap') # 'nearest' | 'mirror'
+ x = bicubic_degradation(x, sf=sf)
+ return x
+
+
+def dpsr_degradation(x, k, sf=3):
+
+ ''' bicubic downsampling + blur
+ Args:
+ x: HxWxC image, [0, 1]
+ k: hxw, double
+ sf: down-scale factor
+ Return:
+ downsampled LR image
+ Reference:
+ @inproceedings{zhang2019deep,
+ title={Deep Plug-and-Play Super-Resolution for Arbitrary Blur Kernels},
+ author={Zhang, Kai and Zuo, Wangmeng and Zhang, Lei},
+ booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
+ pages={1671--1681},
+ year={2019}
+ }
+ '''
+ x = bicubic_degradation(x, sf=sf)
+ x = ndimage.filters.convolve(x, np.expand_dims(k, axis=2), mode='wrap')
+ return x
+
+
+def classical_degradation(x, k, sf=3):
+ ''' blur + downsampling
+
+ Args:
+ x: HxWxC image, [0, 1]/[0, 255]
+ k: hxw, double
+ sf: down-scale factor
+
+ Return:
+ downsampled LR image
+ '''
+ x = ndimage.filters.convolve(x, np.expand_dims(k, axis=2), mode='wrap')
+ #x = filters.correlate(x, np.expand_dims(np.flip(k), axis=2))
+ st = 0
+ return x[st::sf, st::sf, ...]
+
+
+def modcrop_np(img, sf):
+ '''
+ Args:
+ img: numpy image, WxH or WxHxC
+ sf: scale factor
+ Return:
+ cropped image
+ '''
+ w, h = img.shape[:2]
+ im = np.copy(img)
+ return im[:w - w % sf, :h - h % sf, ...]
+
+
+'''
+# =================
+# Numpy
+# =================
+'''
+
+
+def shift_pixel(x, sf, upper_left=True):
+ """shift pixel for super-resolution with different scale factors
+ Args:
+ x: WxHxC or WxH, image or kernel
+ sf: scale factor
+ upper_left: shift direction
+ """
+ h, w = x.shape[:2]
+ shift = (sf-1)*0.5
+ xv, yv = np.arange(0, w, 1.0), np.arange(0, h, 1.0)
+ if upper_left:
+ x1 = xv + shift
+ y1 = yv + shift
+ else:
+ x1 = xv - shift
+ y1 = yv - shift
+
+ x1 = np.clip(x1, 0, w-1)
+ y1 = np.clip(y1, 0, h-1)
+
+ if x.ndim == 2:
+ x = interp2d(xv, yv, x)(x1, y1)
+ if x.ndim == 3:
+ for i in range(x.shape[-1]):
+ x[:, :, i] = interp2d(xv, yv, x[:, :, i])(x1, y1)
+
+ return x
+
+
+'''
+# =================
+# pytorch
+# =================
+'''
+
+
+def splits(a, sf):
+ '''
+ a: tensor NxCxWxHx2
+ sf: scale factor
+ out: tensor NxCx(W/sf)x(H/sf)x2x(sf^2)
+ '''
+ b = torch.stack(torch.chunk(a, sf, dim=2), dim=5)
+ b = torch.cat(torch.chunk(b, sf, dim=3), dim=5)
+ return b
+
+
+def c2c(x):
+ return torch.from_numpy(np.stack([np.float32(x.real), np.float32(x.imag)], axis=-1))
+
+
+def r2c(x):
+ return torch.stack([x, torch.zeros_like(x)], -1)
+
+
+def cdiv(x, y):
+ a, b = x[..., 0], x[..., 1]
+ c, d = y[..., 0], y[..., 1]
+ cd2 = c**2 + d**2
+ return torch.stack([(a*c+b*d)/cd2, (b*c-a*d)/cd2], -1)
+
+
+def csum(x, y):
+ return torch.stack([x[..., 0] + y, x[..., 1]], -1)
+
+
+def cabs(x):
+ return torch.pow(x[..., 0]**2+x[..., 1]**2, 0.5)
+
+
+def cmul(t1, t2):
+ '''
+ complex multiplication
+ t1: NxCxHxWx2
+ output: NxCxHxWx2
+ '''
+ real1, imag1 = t1[..., 0], t1[..., 1]
+ real2, imag2 = t2[..., 0], t2[..., 1]
+ return torch.stack([real1 * real2 - imag1 * imag2, real1 * imag2 + imag1 * real2], dim=-1)
+
+
+def cconj(t, inplace=False):
+ '''
+ # complex's conjugation
+ t: NxCxHxWx2
+ output: NxCxHxWx2
+ '''
+ c = t.clone() if not inplace else t
+ c[..., 1] *= -1
+ return c
+
+
+def rfft(t):
+ return torch.rfft(t, 2, onesided=False)
+
+
+def irfft(t):
+ return torch.irfft(t, 2, onesided=False)
+
+
+def fft(t):
+ return torch.fft(t, 2)
+
+
+def ifft(t):
+ return torch.ifft(t, 2)
+
+
+def p2o(psf, shape):
+ '''
+ Args:
+ psf: NxCxhxw
+ shape: [H,W]
+
+ Returns:
+ otf: NxCxHxWx2
+ '''
+ otf = torch.zeros(psf.shape[:-2] + shape).type_as(psf)
+ otf[...,:psf.shape[2],:psf.shape[3]].copy_(psf)
+ for axis, axis_size in enumerate(psf.shape[2:]):
+ otf = torch.roll(otf, -int(axis_size / 2), dims=axis+2)
+ otf = torch.rfft(otf, 2, onesided=False)
+ n_ops = torch.sum(torch.tensor(psf.shape).type_as(psf) * torch.log2(torch.tensor(psf.shape).type_as(psf)))
+ otf[...,1][torch.abs(otf[...,1]) x[N, 1, W + 2 pad, H + 2 pad] (pariodic padding)
+ '''
+ x = torch.cat([x, x[:, :, 0:pad, :]], dim=2)
+ x = torch.cat([x, x[:, :, :, 0:pad]], dim=3)
+ x = torch.cat([x[:, :, -2 * pad:-pad, :], x], dim=2)
+ x = torch.cat([x[:, :, :, -2 * pad:-pad], x], dim=3)
+ return x
+
+
+def pad_circular(input, padding):
+ # type: (Tensor, List[int]) -> Tensor
+ """
+ Arguments
+ :param input: tensor of shape :math:`(N, C_{\text{in}}, H, [W, D]))`
+ :param padding: (tuple): m-elem tuple where m is the degree of convolution
+ Returns
+ :return: tensor of shape :math:`(N, C_{\text{in}}, [D + 2 * padding[0],
+ H + 2 * padding[1]], W + 2 * padding[2]))`
+ """
+ offset = 3
+ for dimension in range(input.dim() - offset + 1):
+ input = dim_pad_circular(input, padding[dimension], dimension + offset)
+ return input
+
+
+def dim_pad_circular(input, padding, dimension):
+ # type: (Tensor, int, int) -> Tensor
+ input = torch.cat([input, input[[slice(None)] * (dimension - 1) +
+ [slice(0, padding)]]], dim=dimension - 1)
+ input = torch.cat([input[[slice(None)] * (dimension - 1) +
+ [slice(-2 * padding, -padding)]], input], dim=dimension - 1)
+ return input
+
+
+def imfilter(x, k):
+ '''
+ x: image, NxcxHxW
+ k: kernel, cx1xhxw
+ '''
+ x = pad_circular(x, padding=((k.shape[-2]-1)//2, (k.shape[-1]-1)//2))
+ x = torch.nn.functional.conv2d(x, k, groups=x.shape[1])
+ return x
+
+
+def G(x, k, sf=3, center=False):
+ '''
+ x: image, NxcxHxW
+ k: kernel, cx1xhxw
+ sf: scale factor
+ center: the first one or the moddle one
+
+ Matlab function:
+ tmp = imfilter(x,h,'circular');
+ y = downsample2(tmp,K);
+ '''
+ x = downsample(imfilter(x, k), sf=sf, center=center)
+ return x
+
+
+def Gt(x, k, sf=3, center=False):
+ '''
+ x: image, NxcxHxW
+ k: kernel, cx1xhxw
+ sf: scale factor
+ center: the first one or the moddle one
+
+ Matlab function:
+ tmp = upsample2(x,K);
+ y = imfilter(tmp,h,'circular');
+ '''
+ x = imfilter(upsample(x, sf=sf, center=center), k)
+ return x
+
+
+def interpolation_down(x, sf, center=False):
+ mask = torch.zeros_like(x)
+ if center:
+ start = torch.tensor((sf-1)//2)
+ mask[..., start::sf, start::sf] = torch.tensor(1).type_as(x)
+ LR = x[..., start::sf, start::sf]
+ else:
+ mask[..., ::sf, ::sf] = torch.tensor(1).type_as(x)
+ LR = x[..., ::sf, ::sf]
+ y = x.mul(mask)
+
+ return LR, y, mask
+
+
+'''
+# =================
+Numpy
+# =================
+'''
+
+
+def blockproc(im, blocksize, fun):
+ xblocks = np.split(im, range(blocksize[0], im.shape[0], blocksize[0]), axis=0)
+ xblocks_proc = []
+ for xb in xblocks:
+ yblocks = np.split(xb, range(blocksize[1], im.shape[1], blocksize[1]), axis=1)
+ yblocks_proc = []
+ for yb in yblocks:
+ yb_proc = fun(yb)
+ yblocks_proc.append(yb_proc)
+ xblocks_proc.append(np.concatenate(yblocks_proc, axis=1))
+
+ proc = np.concatenate(xblocks_proc, axis=0)
+
+ return proc
+
+
+def fun_reshape(a):
+ return np.reshape(a, (-1,1,a.shape[-1]), order='F')
+
+
+def fun_mul(a, b):
+ return a*b
+
+
+def BlockMM(nr, nc, Nb, m, x1):
+ '''
+ myfun = @(block_struct) reshape(block_struct.data,m,1);
+ x1 = blockproc(x1,[nr nc],myfun);
+ x1 = reshape(x1,m,Nb);
+ x1 = sum(x1,2);
+ x = reshape(x1,nr,nc);
+ '''
+ fun = fun_reshape
+ x1 = blockproc(x1, blocksize=(nr, nc), fun=fun)
+ x1 = np.reshape(x1, (m, Nb, x1.shape[-1]), order='F')
+ x1 = np.sum(x1, 1)
+ x = np.reshape(x1, (nr, nc, x1.shape[-1]), order='F')
+ return x
+
+
+def INVLS(FB, FBC, F2B, FR, tau, Nb, nr, nc, m):
+ '''
+ x1 = FB.*FR;
+ FBR = BlockMM(nr,nc,Nb,m,x1);
+ invW = BlockMM(nr,nc,Nb,m,F2B);
+ invWBR = FBR./(invW + tau*Nb);
+ fun = @(block_struct) block_struct.data.*invWBR;
+ FCBinvWBR = blockproc(FBC,[nr,nc],fun);
+ FX = (FR-FCBinvWBR)/tau;
+ Xest = real(ifft2(FX));
+ '''
+ x1 = FB*FR
+ FBR = BlockMM(nr, nc, Nb, m, x1)
+ invW = BlockMM(nr, nc, Nb, m, F2B)
+ invWBR = FBR/(invW + tau*Nb)
+ FCBinvWBR = blockproc(FBC, [nr, nc], lambda im: fun_mul(im, invWBR))
+ FX = (FR-FCBinvWBR)/tau
+ Xest = np.real(np.fft.ifft2(FX, axes=(0, 1)))
+ return Xest
+
+
+def psf2otf(psf, shape=None):
+ """
+ Convert point-spread function to optical transfer function.
+ Compute the Fast Fourier Transform (FFT) of the point-spread
+ function (PSF) array and creates the optical transfer function (OTF)
+ array that is not influenced by the PSF off-centering.
+ By default, the OTF array is the same size as the PSF array.
+ To ensure that the OTF is not altered due to PSF off-centering, PSF2OTF
+ post-pads the PSF array (down or to the right) with zeros to match
+ dimensions specified in OUTSIZE, then circularly shifts the values of
+ the PSF array up (or to the left) until the central pixel reaches (1,1)
+ position.
+ Parameters
+ ----------
+ psf : `numpy.ndarray`
+ PSF array
+ shape : int
+ Output shape of the OTF array
+ Returns
+ -------
+ otf : `numpy.ndarray`
+ OTF array
+ Notes
+ -----
+ Adapted from MATLAB psf2otf function
+ """
+ if type(shape) == type(None):
+ shape = psf.shape
+ shape = np.array(shape)
+ if np.all(psf == 0):
+ # return np.zeros_like(psf)
+ return np.zeros(shape)
+ if len(psf.shape) == 1:
+ psf = psf.reshape((1, psf.shape[0]))
+ inshape = psf.shape
+ psf = zero_pad(psf, shape, position='corner')
+ for axis, axis_size in enumerate(inshape):
+ psf = np.roll(psf, -int(axis_size / 2), axis=axis)
+ # Compute the OTF
+ otf = np.fft.fft2(psf, axes=(0, 1))
+ # Estimate the rough number of operations involved in the FFT
+ # and discard the PSF imaginary part if within roundoff error
+ # roundoff error = machine epsilon = sys.float_info.epsilon
+ # or np.finfo().eps
+ n_ops = np.sum(psf.size * np.log2(psf.shape))
+ otf = np.real_if_close(otf, tol=n_ops)
+ return otf
+
+
+def zero_pad(image, shape, position='corner'):
+ """
+ Extends image to a certain size with zeros
+ Parameters
+ ----------
+ image: real 2d `numpy.ndarray`
+ Input image
+ shape: tuple of int
+ Desired output shape of the image
+ position : str, optional
+ The position of the input image in the output one:
+ * 'corner'
+ top-left corner (default)
+ * 'center'
+ centered
+ Returns
+ -------
+ padded_img: real `numpy.ndarray`
+ The zero-padded image
+ """
+ shape = np.asarray(shape, dtype=int)
+ imshape = np.asarray(image.shape, dtype=int)
+ if np.alltrue(imshape == shape):
+ return image
+ if np.any(shape <= 0):
+ raise ValueError("ZERO_PAD: null or negative shape given")
+ dshape = shape - imshape
+ if np.any(dshape < 0):
+ raise ValueError("ZERO_PAD: target size smaller than source one")
+ pad_img = np.zeros(shape, dtype=image.dtype)
+ idx, idy = np.indices(imshape)
+ if position == 'center':
+ if np.any(dshape % 2 != 0):
+ raise ValueError("ZERO_PAD: source and target shapes "
+ "have different parity.")
+ offx, offy = dshape // 2
+ else:
+ offx, offy = (0, 0)
+ pad_img[idx + offx, idy + offy] = image
+ return pad_img
+
+
+def upsample_np(x, sf=3, center=False):
+ st = (sf-1)//2 if center else 0
+ z = np.zeros((x.shape[0]*sf, x.shape[1]*sf, x.shape[2]))
+ z[st::sf, st::sf, ...] = x
+ return z
+
+
+def downsample_np(x, sf=3, center=False):
+ st = (sf-1)//2 if center else 0
+ return x[st::sf, st::sf, ...]
+
+
+def imfilter_np(x, k):
+ '''
+ x: image, NxcxHxW
+ k: kernel, cx1xhxw
+ '''
+ x = ndimage.filters.convolve(x, np.expand_dims(k, axis=2), mode='wrap')
+ return x
+
+
+def G_np(x, k, sf=3, center=False):
+ '''
+ x: image, NxcxHxW
+ k: kernel, cx1xhxw
+
+ Matlab function:
+ tmp = imfilter(x,h,'circular');
+ y = downsample2(tmp,K);
+ '''
+ x = downsample_np(imfilter_np(x, k), sf=sf, center=center)
+ return x
+
+
+def Gt_np(x, k, sf=3, center=False):
+ '''
+ x: image, NxcxHxW
+ k: kernel, cx1xhxw
+
+ Matlab function:
+ tmp = upsample2(x,K);
+ y = imfilter(tmp,h,'circular');
+ '''
+ x = imfilter_np(upsample_np(x, sf=sf, center=center), k)
+ return x
+
+
+if __name__ == '__main__':
+ img = util.imread_uint('test.bmp', 3)
+
+ img = util.uint2single(img)
+ k = anisotropic_Gaussian(ksize=15, theta=np.pi, l1=6, l2=6)
+ util.imshow(k*10)
+
+
+ for sf in [2, 3, 4]:
+
+ # modcrop
+ img = modcrop_np(img, sf=sf)
+
+ # 1) bicubic degradation
+ img_b = bicubic_degradation(img, sf=sf)
+ print(img_b.shape)
+
+ # 2) srmd degradation
+ img_s = srmd_degradation(img, k, sf=sf)
+ print(img_s.shape)
+
+ # 3) dpsr degradation
+ img_d = dpsr_degradation(img, k, sf=sf)
+ print(img_d.shape)
+
+ # 4) classical degradation
+ img_d = classical_degradation(img, k, sf=sf)
+ print(img_d.shape)
+
+ k = anisotropic_Gaussian(ksize=7, theta=0.25*np.pi, l1=0.01, l2=0.01)
+ #print(k)
+# util.imshow(k*10)
+
+ k = shifted_anisotropic_Gaussian(k_size=np.array([15, 15]), scale_factor=np.array([4, 4]), min_var=0.8, max_var=10.8, noise_level=0.0)
+# util.imshow(k*10)
+
+
+ # PCA
+# pca_matrix = cal_pca_matrix(ksize=15, l_max=10.0, dim_pca=15, num_samples=12500)
+# print(pca_matrix.shape)
+# show_pca(pca_matrix)
+ # run utils/utils_sisr.py
+ # run utils_sisr.py
+
+
+
+
+
+
+
diff --git a/KAIR/utils/utils_video.py b/KAIR/utils/utils_video.py
new file mode 100644
index 0000000000000000000000000000000000000000..596dd4203098cf7b36f3d8499ccbf299623381ae
--- /dev/null
+++ b/KAIR/utils/utils_video.py
@@ -0,0 +1,493 @@
+import os
+import cv2
+import numpy as np
+import torch
+import random
+from os import path as osp
+from torch.nn import functional as F
+from abc import ABCMeta, abstractmethod
+
+
+def scandir(dir_path, suffix=None, recursive=False, full_path=False):
+ """Scan a directory to find the interested files.
+
+ Args:
+ dir_path (str): Path of the directory.
+ suffix (str | tuple(str), optional): File suffix that we are
+ interested in. Default: None.
+ recursive (bool, optional): If set to True, recursively scan the
+ directory. Default: False.
+ full_path (bool, optional): If set to True, include the dir_path.
+ Default: False.
+
+ Returns:
+ A generator for all the interested files with relative paths.
+ """
+
+ if (suffix is not None) and not isinstance(suffix, (str, tuple)):
+ raise TypeError('"suffix" must be a string or tuple of strings')
+
+ root = dir_path
+
+ def _scandir(dir_path, suffix, recursive):
+ for entry in os.scandir(dir_path):
+ if not entry.name.startswith('.') and entry.is_file():
+ if full_path:
+ return_path = entry.path
+ else:
+ return_path = osp.relpath(entry.path, root)
+
+ if suffix is None:
+ yield return_path
+ elif return_path.endswith(suffix):
+ yield return_path
+ else:
+ if recursive:
+ yield from _scandir(entry.path, suffix=suffix, recursive=recursive)
+ else:
+ continue
+
+ return _scandir(dir_path, suffix=suffix, recursive=recursive)
+
+
+def read_img_seq(path, require_mod_crop=False, scale=1, return_imgname=False):
+ """Read a sequence of images from a given folder path.
+
+ Args:
+ path (list[str] | str): List of image paths or image folder path.
+ require_mod_crop (bool): Require mod crop for each image.
+ Default: False.
+ scale (int): Scale factor for mod_crop. Default: 1.
+ return_imgname(bool): Whether return image names. Default False.
+
+ Returns:
+ Tensor: size (t, c, h, w), RGB, [0, 1].
+ list[str]: Returned image name list.
+ """
+ if isinstance(path, list):
+ img_paths = path
+ else:
+ img_paths = sorted(list(scandir(path, full_path=True)))
+ imgs = [cv2.imread(v).astype(np.float32) / 255. for v in img_paths]
+
+ if require_mod_crop:
+ imgs = [mod_crop(img, scale) for img in imgs]
+ imgs = img2tensor(imgs, bgr2rgb=True, float32=True)
+ imgs = torch.stack(imgs, dim=0)
+
+ if return_imgname:
+ imgnames = [osp.splitext(osp.basename(path))[0] for path in img_paths]
+ return imgs, imgnames
+ else:
+ return imgs
+
+
+def img2tensor(imgs, bgr2rgb=True, float32=True):
+ """Numpy array to tensor.
+
+ Args:
+ imgs (list[ndarray] | ndarray): Input images.
+ bgr2rgb (bool): Whether to change bgr to rgb.
+ float32 (bool): Whether to change to float32.
+
+ Returns:
+ list[tensor] | tensor: Tensor images. If returned results only have
+ one element, just return tensor.
+ """
+
+ def _totensor(img, bgr2rgb, float32):
+ if img.shape[2] == 3 and bgr2rgb:
+ if img.dtype == 'float64':
+ img = img.astype('float32')
+ img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
+ img = torch.from_numpy(img.transpose(2, 0, 1))
+ if float32:
+ img = img.float()
+ return img
+
+ if isinstance(imgs, list):
+ return [_totensor(img, bgr2rgb, float32) for img in imgs]
+ else:
+ return _totensor(imgs, bgr2rgb, float32)
+
+
+def tensor2img(tensor, rgb2bgr=True, out_type=np.uint8, min_max=(0, 1)):
+ """Convert torch Tensors into image numpy arrays.
+
+ After clamping to [min, max], values will be normalized to [0, 1].
+
+ Args:
+ tensor (Tensor or list[Tensor]): Accept shapes:
+ 1) 4D mini-batch Tensor of shape (B x 3/1 x H x W);
+ 2) 3D Tensor of shape (3/1 x H x W);
+ 3) 2D Tensor of shape (H x W).
+ Tensor channel should be in RGB order.
+ rgb2bgr (bool): Whether to change rgb to bgr.
+ out_type (numpy type): output types. If ``np.uint8``, transform outputs
+ to uint8 type with range [0, 255]; otherwise, float type with
+ range [0, 1]. Default: ``np.uint8``.
+ min_max (tuple[int]): min and max values for clamp.
+
+ Returns:
+ (Tensor or list): 3D ndarray of shape (H x W x C) OR 2D ndarray of
+ shape (H x W). The channel order is BGR.
+ """
+ if not (torch.is_tensor(tensor) or (isinstance(tensor, list) and all(torch.is_tensor(t) for t in tensor))):
+ raise TypeError(f'tensor or list of tensors expected, got {type(tensor)}')
+
+ if torch.is_tensor(tensor):
+ tensor = [tensor]
+ result = []
+ for _tensor in tensor:
+ _tensor = _tensor.squeeze(0).float().detach().cpu().clamp_(*min_max)
+ _tensor = (_tensor - min_max[0]) / (min_max[1] - min_max[0])
+
+ n_dim = _tensor.dim()
+ if n_dim == 4:
+ img_np = make_grid(_tensor, nrow=int(math.sqrt(_tensor.size(0))), normalize=False).numpy()
+ img_np = img_np.transpose(1, 2, 0)
+ if rgb2bgr:
+ img_np = cv2.cvtColor(img_np, cv2.COLOR_RGB2BGR)
+ elif n_dim == 3:
+ img_np = _tensor.numpy()
+ img_np = img_np.transpose(1, 2, 0)
+ if img_np.shape[2] == 1: # gray image
+ img_np = np.squeeze(img_np, axis=2)
+ else:
+ if rgb2bgr:
+ img_np = cv2.cvtColor(img_np, cv2.COLOR_RGB2BGR)
+ elif n_dim == 2:
+ img_np = _tensor.numpy()
+ else:
+ raise TypeError(f'Only support 4D, 3D or 2D tensor. But received with dimension: {n_dim}')
+ if out_type == np.uint8:
+ # Unlike MATLAB, numpy.unit8() WILL NOT round by default.
+ img_np = (img_np * 255.0).round()
+ img_np = img_np.astype(out_type)
+ result.append(img_np)
+ if len(result) == 1:
+ result = result[0]
+ return result
+
+
+def augment(imgs, hflip=True, rotation=True, flows=None, return_status=False):
+ """Augment: horizontal flips OR rotate (0, 90, 180, 270 degrees).
+
+ We use vertical flip and transpose for rotation implementation.
+ All the images in the list use the same augmentation.
+
+ Args:
+ imgs (list[ndarray] | ndarray): Images to be augmented. If the input
+ is an ndarray, it will be transformed to a list.
+ hflip (bool): Horizontal flip. Default: True.
+ rotation (bool): Ratotation. Default: True.
+ flows (list[ndarray]: Flows to be augmented. If the input is an
+ ndarray, it will be transformed to a list.
+ Dimension is (h, w, 2). Default: None.
+ return_status (bool): Return the status of flip and rotation.
+ Default: False.
+
+ Returns:
+ list[ndarray] | ndarray: Augmented images and flows. If returned
+ results only have one element, just return ndarray.
+
+ """
+ hflip = hflip and random.random() < 0.5
+ vflip = rotation and random.random() < 0.5
+ rot90 = rotation and random.random() < 0.5
+
+ def _augment(img):
+ if hflip: # horizontal
+ cv2.flip(img, 1, img)
+ if vflip: # vertical
+ cv2.flip(img, 0, img)
+ if rot90:
+ img = img.transpose(1, 0, 2)
+ return img
+
+ def _augment_flow(flow):
+ if hflip: # horizontal
+ cv2.flip(flow, 1, flow)
+ flow[:, :, 0] *= -1
+ if vflip: # vertical
+ cv2.flip(flow, 0, flow)
+ flow[:, :, 1] *= -1
+ if rot90:
+ flow = flow.transpose(1, 0, 2)
+ flow = flow[:, :, [1, 0]]
+ return flow
+
+ if not isinstance(imgs, list):
+ imgs = [imgs]
+ imgs = [_augment(img) for img in imgs]
+ if len(imgs) == 1:
+ imgs = imgs[0]
+
+ if flows is not None:
+ if not isinstance(flows, list):
+ flows = [flows]
+ flows = [_augment_flow(flow) for flow in flows]
+ if len(flows) == 1:
+ flows = flows[0]
+ return imgs, flows
+ else:
+ if return_status:
+ return imgs, (hflip, vflip, rot90)
+ else:
+ return imgs
+
+
+def paired_random_crop(img_gts, img_lqs, gt_patch_size, scale, gt_path=None):
+ """Paired random crop. Support Numpy array and Tensor inputs.
+
+ It crops lists of lq and gt images with corresponding locations.
+
+ Args:
+ img_gts (list[ndarray] | ndarray | list[Tensor] | Tensor): GT images. Note that all images
+ should have the same shape. If the input is an ndarray, it will
+ be transformed to a list containing itself.
+ img_lqs (list[ndarray] | ndarray): LQ images. Note that all images
+ should have the same shape. If the input is an ndarray, it will
+ be transformed to a list containing itself.
+ gt_patch_size (int): GT patch size.
+ scale (int): Scale factor.
+ gt_path (str): Path to ground-truth. Default: None.
+
+ Returns:
+ list[ndarray] | ndarray: GT images and LQ images. If returned results
+ only have one element, just return ndarray.
+ """
+
+ if not isinstance(img_gts, list):
+ img_gts = [img_gts]
+ if not isinstance(img_lqs, list):
+ img_lqs = [img_lqs]
+
+ # determine input type: Numpy array or Tensor
+ input_type = 'Tensor' if torch.is_tensor(img_gts[0]) else 'Numpy'
+
+ if input_type == 'Tensor':
+ h_lq, w_lq = img_lqs[0].size()[-2:]
+ h_gt, w_gt = img_gts[0].size()[-2:]
+ else:
+ h_lq, w_lq = img_lqs[0].shape[0:2]
+ h_gt, w_gt = img_gts[0].shape[0:2]
+ lq_patch_size = gt_patch_size // scale
+
+ if h_gt != h_lq * scale or w_gt != w_lq * scale:
+ raise ValueError(f'Scale mismatches. GT ({h_gt}, {w_gt}) is not {scale}x ',
+ f'multiplication of LQ ({h_lq}, {w_lq}).')
+ if h_lq < lq_patch_size or w_lq < lq_patch_size:
+ raise ValueError(f'LQ ({h_lq}, {w_lq}) is smaller than patch size '
+ f'({lq_patch_size}, {lq_patch_size}). '
+ f'Please remove {gt_path}.')
+
+ # randomly choose top and left coordinates for lq patch
+ top = random.randint(0, h_lq - lq_patch_size)
+ left = random.randint(0, w_lq - lq_patch_size)
+
+ # crop lq patch
+ if input_type == 'Tensor':
+ img_lqs = [v[:, :, top:top + lq_patch_size, left:left + lq_patch_size] for v in img_lqs]
+ else:
+ img_lqs = [v[top:top + lq_patch_size, left:left + lq_patch_size, ...] for v in img_lqs]
+
+ # crop corresponding gt patch
+ top_gt, left_gt = int(top * scale), int(left * scale)
+ if input_type == 'Tensor':
+ img_gts = [v[:, :, top_gt:top_gt + gt_patch_size, left_gt:left_gt + gt_patch_size] for v in img_gts]
+ else:
+ img_gts = [v[top_gt:top_gt + gt_patch_size, left_gt:left_gt + gt_patch_size, ...] for v in img_gts]
+ if len(img_gts) == 1:
+ img_gts = img_gts[0]
+ if len(img_lqs) == 1:
+ img_lqs = img_lqs[0]
+ return img_gts, img_lqs
+
+
+# Modified from https://github.com/open-mmlab/mmcv/blob/master/mmcv/fileio/file_client.py # noqa: E501
+class BaseStorageBackend(metaclass=ABCMeta):
+ """Abstract class of storage backends.
+
+ All backends need to implement two apis: ``get()`` and ``get_text()``.
+ ``get()`` reads the file as a byte stream and ``get_text()`` reads the file
+ as texts.
+ """
+
+ @abstractmethod
+ def get(self, filepath):
+ pass
+
+ @abstractmethod
+ def get_text(self, filepath):
+ pass
+
+
+class MemcachedBackend(BaseStorageBackend):
+ """Memcached storage backend.
+
+ Attributes:
+ server_list_cfg (str): Config file for memcached server list.
+ client_cfg (str): Config file for memcached client.
+ sys_path (str | None): Additional path to be appended to `sys.path`.
+ Default: None.
+ """
+
+ def __init__(self, server_list_cfg, client_cfg, sys_path=None):
+ if sys_path is not None:
+ import sys
+ sys.path.append(sys_path)
+ try:
+ import mc
+ except ImportError:
+ raise ImportError('Please install memcached to enable MemcachedBackend.')
+
+ self.server_list_cfg = server_list_cfg
+ self.client_cfg = client_cfg
+ self._client = mc.MemcachedClient.GetInstance(self.server_list_cfg, self.client_cfg)
+ # mc.pyvector servers as a point which points to a memory cache
+ self._mc_buffer = mc.pyvector()
+
+ def get(self, filepath):
+ filepath = str(filepath)
+ import mc
+ self._client.Get(filepath, self._mc_buffer)
+ value_buf = mc.ConvertBuffer(self._mc_buffer)
+ return value_buf
+
+ def get_text(self, filepath):
+ raise NotImplementedError
+
+
+class HardDiskBackend(BaseStorageBackend):
+ """Raw hard disks storage backend."""
+
+ def get(self, filepath):
+ filepath = str(filepath)
+ with open(filepath, 'rb') as f:
+ value_buf = f.read()
+ return value_buf
+
+ def get_text(self, filepath):
+ filepath = str(filepath)
+ with open(filepath, 'r') as f:
+ value_buf = f.read()
+ return value_buf
+
+
+class LmdbBackend(BaseStorageBackend):
+ """Lmdb storage backend.
+
+ Args:
+ db_paths (str | list[str]): Lmdb database paths.
+ client_keys (str | list[str]): Lmdb client keys. Default: 'default'.
+ readonly (bool, optional): Lmdb environment parameter. If True,
+ disallow any write operations. Default: True.
+ lock (bool, optional): Lmdb environment parameter. If False, when
+ concurrent access occurs, do not lock the database. Default: False.
+ readahead (bool, optional): Lmdb environment parameter. If False,
+ disable the OS filesystem readahead mechanism, which may improve
+ random read performance when a database is larger than RAM.
+ Default: False.
+
+ Attributes:
+ db_paths (list): Lmdb database path.
+ _client (list): A list of several lmdb envs.
+ """
+
+ def __init__(self, db_paths, client_keys='default', readonly=True, lock=False, readahead=False, **kwargs):
+ try:
+ import lmdb
+ except ImportError:
+ raise ImportError('Please install lmdb to enable LmdbBackend.')
+
+ if isinstance(client_keys, str):
+ client_keys = [client_keys]
+
+ if isinstance(db_paths, list):
+ self.db_paths = [str(v) for v in db_paths]
+ elif isinstance(db_paths, str):
+ self.db_paths = [str(db_paths)]
+ assert len(client_keys) == len(self.db_paths), ('client_keys and db_paths should have the same length, '
+ f'but received {len(client_keys)} and {len(self.db_paths)}.')
+
+ self._client = {}
+ for client, path in zip(client_keys, self.db_paths):
+ self._client[client] = lmdb.open(path, readonly=readonly, lock=lock, readahead=readahead, **kwargs)
+
+ def get(self, filepath, client_key):
+ """Get values according to the filepath from one lmdb named client_key.
+
+ Args:
+ filepath (str | obj:`Path`): Here, filepath is the lmdb key.
+ client_key (str): Used for distinguishing different lmdb envs.
+ """
+ filepath = str(filepath)
+ assert client_key in self._client, (f'client_key {client_key} is not ' 'in lmdb clients.')
+ client = self._client[client_key]
+ with client.begin(write=False) as txn:
+ value_buf = txn.get(filepath.encode('ascii'))
+ return value_buf
+
+ def get_text(self, filepath):
+ raise NotImplementedError
+
+
+class FileClient(object):
+ """A general file client to access files in different backend.
+
+ The client loads a file or text in a specified backend from its path
+ and return it as a binary file. it can also register other backend
+ accessor with a given name and backend class.
+
+ Attributes:
+ backend (str): The storage backend type. Options are "disk",
+ "memcached" and "lmdb".
+ client (:obj:`BaseStorageBackend`): The backend object.
+ """
+
+ _backends = {
+ 'disk': HardDiskBackend,
+ 'memcached': MemcachedBackend,
+ 'lmdb': LmdbBackend,
+ }
+
+ def __init__(self, backend='disk', **kwargs):
+ if backend not in self._backends:
+ raise ValueError(f'Backend {backend} is not supported. Currently supported ones'
+ f' are {list(self._backends.keys())}')
+ self.backend = backend
+ self.client = self._backends[backend](**kwargs)
+
+ def get(self, filepath, client_key='default'):
+ # client_key is used only for lmdb, where different fileclients have
+ # different lmdb environments.
+ if self.backend == 'lmdb':
+ return self.client.get(filepath, client_key)
+ else:
+ return self.client.get(filepath)
+
+ def get_text(self, filepath):
+ return self.client.get_text(filepath)
+
+
+def imfrombytes(content, flag='color', float32=False):
+ """Read an image from bytes.
+
+ Args:
+ content (bytes): Image bytes got from files or other streams.
+ flag (str): Flags specifying the color type of a loaded image,
+ candidates are `color`, `grayscale` and `unchanged`.
+ float32 (bool): Whether to change to float32., If True, will also norm
+ to [0, 1]. Default: False.
+
+ Returns:
+ ndarray: Loaded image array.
+ """
+ img_np = np.frombuffer(content, np.uint8)
+ imread_flags = {'color': cv2.IMREAD_COLOR, 'grayscale': cv2.IMREAD_GRAYSCALE, 'unchanged': cv2.IMREAD_UNCHANGED}
+ img = cv2.imdecode(img_np, imread_flags[flag])
+ if float32:
+ img = img.astype(np.float32) / 255.
+ return img
+
diff --git a/KAIR/utils/utils_videoio.py b/KAIR/utils/utils_videoio.py
new file mode 100644
index 0000000000000000000000000000000000000000..5be8c7f06802d5aaa7155a1cdcb27d2838a0882c
--- /dev/null
+++ b/KAIR/utils/utils_videoio.py
@@ -0,0 +1,555 @@
+import os
+import cv2
+import numpy as np
+import torch
+import random
+from os import path as osp
+from torchvision.utils import make_grid
+import sys
+from pathlib import Path
+import six
+from collections import OrderedDict
+import math
+import glob
+import av
+import io
+from cv2 import (CAP_PROP_FOURCC, CAP_PROP_FPS, CAP_PROP_FRAME_COUNT,
+ CAP_PROP_FRAME_HEIGHT, CAP_PROP_FRAME_WIDTH,
+ CAP_PROP_POS_FRAMES, VideoWriter_fourcc)
+
+if sys.version_info <= (3, 3):
+ FileNotFoundError = IOError
+else:
+ FileNotFoundError = FileNotFoundError
+
+
+def is_str(x):
+ """Whether the input is an string instance."""
+ return isinstance(x, six.string_types)
+
+
+def is_filepath(x):
+ return is_str(x) or isinstance(x, Path)
+
+
+def fopen(filepath, *args, **kwargs):
+ if is_str(filepath):
+ return open(filepath, *args, **kwargs)
+ elif isinstance(filepath, Path):
+ return filepath.open(*args, **kwargs)
+ raise ValueError('`filepath` should be a string or a Path')
+
+
+def check_file_exist(filename, msg_tmpl='file "{}" does not exist'):
+ if not osp.isfile(filename):
+ raise FileNotFoundError(msg_tmpl.format(filename))
+
+
+def mkdir_or_exist(dir_name, mode=0o777):
+ if dir_name == '':
+ return
+ dir_name = osp.expanduser(dir_name)
+ os.makedirs(dir_name, mode=mode, exist_ok=True)
+
+
+def symlink(src, dst, overwrite=True, **kwargs):
+ if os.path.lexists(dst) and overwrite:
+ os.remove(dst)
+ os.symlink(src, dst, **kwargs)
+
+
+def scandir(dir_path, suffix=None, recursive=False, case_sensitive=True):
+ """Scan a directory to find the interested files.
+ Args:
+ dir_path (str | :obj:`Path`): Path of the directory.
+ suffix (str | tuple(str), optional): File suffix that we are
+ interested in. Default: None.
+ recursive (bool, optional): If set to True, recursively scan the
+ directory. Default: False.
+ case_sensitive (bool, optional) : If set to False, ignore the case of
+ suffix. Default: True.
+ Returns:
+ A generator for all the interested files with relative paths.
+ """
+ if isinstance(dir_path, (str, Path)):
+ dir_path = str(dir_path)
+ else:
+ raise TypeError('"dir_path" must be a string or Path object')
+
+ if (suffix is not None) and not isinstance(suffix, (str, tuple)):
+ raise TypeError('"suffix" must be a string or tuple of strings')
+
+ if suffix is not None and not case_sensitive:
+ suffix = suffix.lower() if isinstance(suffix, str) else tuple(
+ item.lower() for item in suffix)
+
+ root = dir_path
+
+ def _scandir(dir_path, suffix, recursive, case_sensitive):
+ for entry in os.scandir(dir_path):
+ if not entry.name.startswith('.') and entry.is_file():
+ rel_path = osp.relpath(entry.path, root)
+ _rel_path = rel_path if case_sensitive else rel_path.lower()
+ if suffix is None or _rel_path.endswith(suffix):
+ yield rel_path
+ elif recursive and os.path.isdir(entry.path):
+ # scan recursively if entry.path is a directory
+ yield from _scandir(entry.path, suffix, recursive,
+ case_sensitive)
+
+ return _scandir(dir_path, suffix, recursive, case_sensitive)
+
+
+class Cache:
+
+ def __init__(self, capacity):
+ self._cache = OrderedDict()
+ self._capacity = int(capacity)
+ if capacity <= 0:
+ raise ValueError('capacity must be a positive integer')
+
+ @property
+ def capacity(self):
+ return self._capacity
+
+ @property
+ def size(self):
+ return len(self._cache)
+
+ def put(self, key, val):
+ if key in self._cache:
+ return
+ if len(self._cache) >= self.capacity:
+ self._cache.popitem(last=False)
+ self._cache[key] = val
+
+ def get(self, key, default=None):
+ val = self._cache[key] if key in self._cache else default
+ return val
+
+
+class VideoReader:
+ """Video class with similar usage to a list object.
+
+ This video warpper class provides convenient apis to access frames.
+ There exists an issue of OpenCV's VideoCapture class that jumping to a
+ certain frame may be inaccurate. It is fixed in this class by checking
+ the position after jumping each time.
+ Cache is used when decoding videos. So if the same frame is visited for
+ the second time, there is no need to decode again if it is stored in the
+ cache.
+
+ """
+
+ def __init__(self, filename, cache_capacity=10):
+ # Check whether the video path is a url
+ if not filename.startswith(('https://', 'http://')):
+ check_file_exist(filename, 'Video file not found: ' + filename)
+ self._vcap = cv2.VideoCapture(filename)
+ assert cache_capacity > 0
+ self._cache = Cache(cache_capacity)
+ self._position = 0
+ # get basic info
+ self._width = int(self._vcap.get(CAP_PROP_FRAME_WIDTH))
+ self._height = int(self._vcap.get(CAP_PROP_FRAME_HEIGHT))
+ self._fps = self._vcap.get(CAP_PROP_FPS)
+ self._frame_cnt = int(self._vcap.get(CAP_PROP_FRAME_COUNT))
+ self._fourcc = self._vcap.get(CAP_PROP_FOURCC)
+
+ @property
+ def vcap(self):
+ """:obj:`cv2.VideoCapture`: The raw VideoCapture object."""
+ return self._vcap
+
+ @property
+ def opened(self):
+ """bool: Indicate whether the video is opened."""
+ return self._vcap.isOpened()
+
+ @property
+ def width(self):
+ """int: Width of video frames."""
+ return self._width
+
+ @property
+ def height(self):
+ """int: Height of video frames."""
+ return self._height
+
+ @property
+ def resolution(self):
+ """tuple: Video resolution (width, height)."""
+ return (self._width, self._height)
+
+ @property
+ def fps(self):
+ """float: FPS of the video."""
+ return self._fps
+
+ @property
+ def frame_cnt(self):
+ """int: Total frames of the video."""
+ return self._frame_cnt
+
+ @property
+ def fourcc(self):
+ """str: "Four character code" of the video."""
+ return self._fourcc
+
+ @property
+ def position(self):
+ """int: Current cursor position, indicating frame decoded."""
+ return self._position
+
+ def _get_real_position(self):
+ return int(round(self._vcap.get(CAP_PROP_POS_FRAMES)))
+
+ def _set_real_position(self, frame_id):
+ self._vcap.set(CAP_PROP_POS_FRAMES, frame_id)
+ pos = self._get_real_position()
+ for _ in range(frame_id - pos):
+ self._vcap.read()
+ self._position = frame_id
+
+ def read(self):
+ """Read the next frame.
+
+ If the next frame have been decoded before and in the cache, then
+ return it directly, otherwise decode, cache and return it.
+
+ Returns:
+ ndarray or None: Return the frame if successful, otherwise None.
+ """
+ # pos = self._position
+ if self._cache:
+ img = self._cache.get(self._position)
+ if img is not None:
+ ret = True
+ else:
+ if self._position != self._get_real_position():
+ self._set_real_position(self._position)
+ ret, img = self._vcap.read()
+ if ret:
+ self._cache.put(self._position, img)
+ else:
+ ret, img = self._vcap.read()
+ if ret:
+ self._position += 1
+ return img
+
+ def get_frame(self, frame_id):
+ """Get frame by index.
+
+ Args:
+ frame_id (int): Index of the expected frame, 0-based.
+
+ Returns:
+ ndarray or None: Return the frame if successful, otherwise None.
+ """
+ if frame_id < 0 or frame_id >= self._frame_cnt:
+ raise IndexError(
+ f'"frame_id" must be between 0 and {self._frame_cnt - 1}')
+ if frame_id == self._position:
+ return self.read()
+ if self._cache:
+ img = self._cache.get(frame_id)
+ if img is not None:
+ self._position = frame_id + 1
+ return img
+ self._set_real_position(frame_id)
+ ret, img = self._vcap.read()
+ if ret:
+ if self._cache:
+ self._cache.put(self._position, img)
+ self._position += 1
+ return img
+
+ def current_frame(self):
+ """Get the current frame (frame that is just visited).
+
+ Returns:
+ ndarray or None: If the video is fresh, return None, otherwise
+ return the frame.
+ """
+ if self._position == 0:
+ return None
+ return self._cache.get(self._position - 1)
+
+ def cvt2frames(self,
+ frame_dir,
+ file_start=0,
+ filename_tmpl='{:06d}.jpg',
+ start=0,
+ max_num=0,
+ show_progress=False):
+ """Convert a video to frame images.
+
+ Args:
+ frame_dir (str): Output directory to store all the frame images.
+ file_start (int): Filenames will start from the specified number.
+ filename_tmpl (str): Filename template with the index as the
+ placeholder.
+ start (int): The starting frame index.
+ max_num (int): Maximum number of frames to be written.
+ show_progress (bool): Whether to show a progress bar.
+ """
+ mkdir_or_exist(frame_dir)
+ if max_num == 0:
+ task_num = self.frame_cnt - start
+ else:
+ task_num = min(self.frame_cnt - start, max_num)
+ if task_num <= 0:
+ raise ValueError('start must be less than total frame number')
+ if start > 0:
+ self._set_real_position(start)
+
+ def write_frame(file_idx):
+ img = self.read()
+ if img is None:
+ return
+ filename = osp.join(frame_dir, filename_tmpl.format(file_idx))
+ cv2.imwrite(filename, img)
+
+ if show_progress:
+ pass
+ #track_progress(write_frame, range(file_start,file_start + task_num))
+ else:
+ for i in range(task_num):
+ write_frame(file_start + i)
+
+ def __len__(self):
+ return self.frame_cnt
+
+ def __getitem__(self, index):
+ if isinstance(index, slice):
+ return [
+ self.get_frame(i)
+ for i in range(*index.indices(self.frame_cnt))
+ ]
+ # support negative indexing
+ if index < 0:
+ index += self.frame_cnt
+ if index < 0:
+ raise IndexError('index out of range')
+ return self.get_frame(index)
+
+ def __iter__(self):
+ self._set_real_position(0)
+ return self
+
+ def __next__(self):
+ img = self.read()
+ if img is not None:
+ return img
+ else:
+ raise StopIteration
+
+ next = __next__
+
+ def __enter__(self):
+ return self
+
+ def __exit__(self, exc_type, exc_value, traceback):
+ self._vcap.release()
+
+
+def frames2video(frame_dir,
+ video_file,
+ fps=30,
+ fourcc='XVID',
+ filename_tmpl='{:06d}.jpg',
+ start=0,
+ end=0,
+ show_progress=False):
+ """Read the frame images from a directory and join them as a video.
+
+ Args:
+ frame_dir (str): The directory containing video frames.
+ video_file (str): Output filename.
+ fps (float): FPS of the output video.
+ fourcc (str): Fourcc of the output video, this should be compatible
+ with the output file type.
+ filename_tmpl (str): Filename template with the index as the variable.
+ start (int): Starting frame index.
+ end (int): Ending frame index.
+ show_progress (bool): Whether to show a progress bar.
+ """
+ if end == 0:
+ ext = filename_tmpl.split('.')[-1]
+ end = len([name for name in scandir(frame_dir, ext)])
+ first_file = osp.join(frame_dir, filename_tmpl.format(start))
+ check_file_exist(first_file, 'The start frame not found: ' + first_file)
+ img = cv2.imread(first_file)
+ height, width = img.shape[:2]
+ resolution = (width, height)
+ vwriter = cv2.VideoWriter(video_file, VideoWriter_fourcc(*fourcc), fps,
+ resolution)
+
+ def write_frame(file_idx):
+ filename = osp.join(frame_dir, filename_tmpl.format(file_idx))
+ img = cv2.imread(filename)
+ vwriter.write(img)
+
+ if show_progress:
+ pass
+ # track_progress(write_frame, range(start, end))
+ else:
+ for i in range(start, end):
+ write_frame(i)
+ vwriter.release()
+
+
+def video2images(video_path, output_dir):
+ vidcap = cv2.VideoCapture(video_path)
+ in_fps = vidcap.get(cv2.CAP_PROP_FPS)
+ print('video fps:', in_fps)
+ if not os.path.isdir(output_dir):
+ os.makedirs(output_dir)
+ loaded, frame = vidcap.read()
+ total_frames = int(vidcap.get(cv2.CAP_PROP_FRAME_COUNT))
+ print(f'number of total frames is: {total_frames:06}')
+ for i_frame in range(total_frames):
+ if i_frame % 100 == 0:
+ print(f'{i_frame:06} / {total_frames:06}')
+ frame_name = os.path.join(output_dir, f'{i_frame:06}' + '.png')
+ cv2.imwrite(frame_name, frame)
+ loaded, frame = vidcap.read()
+
+
+def images2video(image_dir, video_path, fps=24, image_ext='png'):
+ '''
+ #codec = cv2.VideoWriter_fourcc(*'XVID')
+ #codec = cv2.VideoWriter_fourcc('A','V','C','1')
+ #codec = cv2.VideoWriter_fourcc('Y','U','V','1')
+ #codec = cv2.VideoWriter_fourcc('P','I','M','1')
+ #codec = cv2.VideoWriter_fourcc('M','J','P','G')
+ codec = cv2.VideoWriter_fourcc('M','P','4','2')
+ #codec = cv2.VideoWriter_fourcc('D','I','V','3')
+ #codec = cv2.VideoWriter_fourcc('D','I','V','X')
+ #codec = cv2.VideoWriter_fourcc('U','2','6','3')
+ #codec = cv2.VideoWriter_fourcc('I','2','6','3')
+ #codec = cv2.VideoWriter_fourcc('F','L','V','1')
+ #codec = cv2.VideoWriter_fourcc('H','2','6','4')
+ #codec = cv2.VideoWriter_fourcc('A','Y','U','V')
+ #codec = cv2.VideoWriter_fourcc('I','U','Y','V')
+ 编码器常用的几种:
+ cv2.VideoWriter_fourcc("I", "4", "2", "0")
+ 压缩的yuv颜色编码器,4:2:0色彩度子采样 兼容性好,产生很大的视频 avi
+ cv2.VideoWriter_fourcc("P", I", "M", "1")
+ 采用mpeg-1编码,文件为avi
+ cv2.VideoWriter_fourcc("X", "V", "T", "D")
+ 采用mpeg-4编码,得到视频大小平均 拓展名avi
+ cv2.VideoWriter_fourcc("T", "H", "E", "O")
+ Ogg Vorbis, 拓展名为ogv
+ cv2.VideoWriter_fourcc("F", "L", "V", "1")
+ FLASH视频,拓展名为.flv
+ '''
+ image_files = sorted(glob.glob(os.path.join(image_dir, '*.{}'.format(image_ext))))
+ print(len(image_files))
+ height, width, _ = cv2.imread(image_files[0]).shape
+ out_fourcc = cv2.VideoWriter_fourcc('M', 'J', 'P', 'G') # cv2.VideoWriter_fourcc(*'MP4V')
+ out_video = cv2.VideoWriter(video_path, out_fourcc, fps, (width, height))
+
+ for image_file in image_files:
+ img = cv2.imread(image_file)
+ img = cv2.resize(img, (width, height), interpolation=3)
+ out_video.write(img)
+ out_video.release()
+
+
+def add_video_compression(imgs):
+ codec_type = ['libx264', 'h264', 'mpeg4']
+ codec_prob = [1 / 3., 1 / 3., 1 / 3.]
+ codec = random.choices(codec_type, codec_prob)[0]
+ # codec = 'mpeg4'
+ bitrate = [1e4, 1e5]
+ bitrate = np.random.randint(bitrate[0], bitrate[1] + 1)
+
+ buf = io.BytesIO()
+ with av.open(buf, 'w', 'mp4') as container:
+ stream = container.add_stream(codec, rate=1)
+ stream.height = imgs[0].shape[0]
+ stream.width = imgs[0].shape[1]
+ stream.pix_fmt = 'yuv420p'
+ stream.bit_rate = bitrate
+
+ for img in imgs:
+ img = np.uint8((img.clip(0, 1)*255.).round())
+ frame = av.VideoFrame.from_ndarray(img, format='rgb24')
+ frame.pict_type = 'NONE'
+ # pdb.set_trace()
+ for packet in stream.encode(frame):
+ container.mux(packet)
+
+ # Flush stream
+ for packet in stream.encode():
+ container.mux(packet)
+
+ outputs = []
+ with av.open(buf, 'r', 'mp4') as container:
+ if container.streams.video:
+ for frame in container.decode(**{'video': 0}):
+ outputs.append(
+ frame.to_rgb().to_ndarray().astype(np.float32) / 255.)
+
+ #outputs = np.stack(outputs, axis=0)
+ return outputs
+
+
+if __name__ == '__main__':
+
+ # -----------------------------------
+ # test VideoReader(filename, cache_capacity=10)
+ # -----------------------------------
+# video_reader = VideoReader('utils/test.mp4')
+# from utils import utils_image as util
+# inputs = []
+# for frame in video_reader:
+# print(frame.dtype)
+# util.imshow(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
+# #util.imshow(np.flip(frame, axis=2))
+
+ # -----------------------------------
+ # test video2images(video_path, output_dir)
+ # -----------------------------------
+# video2images('utils/test.mp4', 'frames')
+
+ # -----------------------------------
+ # test images2video(image_dir, video_path, fps=24, image_ext='png')
+ # -----------------------------------
+# images2video('frames', 'video_02.mp4', fps=30, image_ext='png')
+
+
+ # -----------------------------------
+ # test frames2video(frame_dir, video_file, fps=30, fourcc='XVID', filename_tmpl='{:06d}.png')
+ # -----------------------------------
+# frames2video('frames', 'video_01.mp4', filename_tmpl='{:06d}.png')
+
+
+ # -----------------------------------
+ # test add_video_compression(imgs)
+ # -----------------------------------
+# imgs = []
+# image_ext = 'png'
+# frames = 'frames'
+# from utils import utils_image as util
+# image_files = sorted(glob.glob(os.path.join(frames, '*.{}'.format(image_ext))))
+# for i, image_file in enumerate(image_files):
+# if i < 7:
+# img = util.imread_uint(image_file, 3)
+# img = util.uint2single(img)
+# imgs.append(img)
+#
+# results = add_video_compression(imgs)
+# for i, img in enumerate(results):
+# util.imshow(util.single2uint(img))
+# util.imsave(util.single2uint(img),f'{i:05}.png')
+
+ # run utils/utils_video.py
+
+
+
+
+
+
+
diff --git a/README.md b/README.md
index 65d6fce5d9695bf89c13b4c04233a45209844b78..00acef7785b5d6792d14ebacb82be1913b42e501 100644
--- a/README.md
+++ b/README.md
@@ -1,13 +1,12 @@
---
-title: LambdaSuperRes
-emoji: 🌖
-colorFrom: pink
-colorTo: pink
+title: Swinir Private Test
+emoji: 🐠
+colorFrom: purple
+colorTo: red
sdk: gradio
sdk_version: 3.2
app_file: app.py
pinned: false
-license: mit
---
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/app.py b/app.py
new file mode 100644
index 0000000000000000000000000000000000000000..9a8be4f3d2aa336bd1c5f04931a96af5595030a0
--- /dev/null
+++ b/app.py
@@ -0,0 +1,148 @@
+import datetime
+import hashlib
+import numpy as np
+import os
+import subprocess
+from pathlib import Path
+from typing import Any, Dict
+
+import cv2
+import gradio as gr
+from joblib import Parallel, delayed
+from numpy.typing import NDArray
+from PIL import Image
+
+
+def _run_in_subprocess(command: str, wd: str) -> Any:
+ p = subprocess.Popen(command, shell=True, cwd=wd)
+ (output, err) = p.communicate()
+ p_status = p.wait()
+ print("Status of subprocess: ", p_status)
+ return p_status
+
+
+SWIN_IR_WD = "KAIR"
+SWINIR_CKPT_DIR: str = Path("KAIR/model_zoo/")
+MODEL_NAME_TO_PATH: Dict[str, Path] = {
+ "LambdaSwinIR_v0.1": Path(str(SWINIR_CKPT_DIR) + "/805000_G.pth"),
+}
+SWINIR_NAME_TO_PATCH_SIZE: Dict[str, int] = {
+ "LambdaSwinIR_v0.1": 96,
+}
+SWINIR_NAME_TO_SCALE: Dict[str, int] = {
+ "LambdaSwinIR_v0.1": 2,
+}
+SWINIR_NAME_TO_LARGE_MODEL: Dict[str, bool] = {
+ "LambdaSwinIR_v0.1": False,
+}
+
+def _run_swin_ir(
+ image: NDArray,
+ model_path: Path,
+ patch_size: int,
+ scale: int,
+ is_large_model: bool,
+):
+ print("model_path: ", str(model_path))
+ m = hashlib.sha256()
+ now_time = datetime.datetime.utcnow()
+ m.update(bytes(str(model_path), encoding='utf-8') +
+ bytes(now_time.strftime("%Y-%m-%d %H:%M:%S.%f"), encoding='utf-8'))
+ random_id = m.hexdigest()[0:20]
+
+ cwd = os.getcwd()
+
+ input_root = Path(cwd + "/sr_interactive_tmp")
+ input_root.mkdir(parents=True, exist_ok=True)
+ Image.fromarray(image).save(str(input_root) + "/gradio_img.png")
+ command = f"python main_test_swinir.py --scale {scale} " + \
+ f"--folder_lq {input_root} --task real_sr " + \
+ f"--model_path {cwd}/{model_path} --training_patch_size {patch_size}"
+ if is_large_model:
+ command += " --large_model"
+ print("COMMAND: ", command)
+ status = _run_in_subprocess(command, wd=cwd + "/" + SWIN_IR_WD)
+ print("STATUS: ", status)
+
+ if scale == 2:
+ str_scale = "2"
+ if scale == 4:
+ str_scale = "4_large"
+ output_img = Image.open(f"{cwd}/KAIR/results/swinir_real_sr_x{str_scale}/gradio_img_SwinIR.png")
+ output_root = Path("./sr_interactive_tmp_output")
+ output_root.mkdir(parents=True, exist_ok=True)
+
+ output_img.save(str(output_root) + "/SwinIR_" + random_id + ".png")
+ print("SAVING: SwinIR_" + random_id + ".png")
+ result = np.array(output_img)
+ return result
+
+
+def _bilinear_upsample(image: NDArray):
+ result = cv2.resize(
+ image,
+ dsize=(image.shape[1] * 2, image.shape[0] * 2),
+ interpolation=cv2.INTER_LANCZOS4
+ )
+ return result
+
+
+def _decide_sr_algo(model_name: str, image: NDArray):
+ # if "SwinIR" in model_name:
+ # result = _run_swin_ir(image,
+ # model_path=MODEL_NAME_TO_PATH[model_name],
+ # patch_size=SWINIR_NAME_TO_PATCH_SIZE[model_name],
+ # scale=SWINIR_NAME_TO_SCALE[model_name],
+ # is_large_model=("SwinIR-L" in model_name))
+ # else:
+ # result = _bilinear_upsample(image)
+
+ # elif algo == SR_OPTIONS[1]:
+ # result = _run_maxine(image, mode="SR")
+ # elif algo == SR_OPTIONS[2]:
+ # result = _run_maxine(image, mode="UPSCALE")
+ # return result
+ result = _run_swin_ir(image,
+ model_path=MODEL_NAME_TO_PATH[model_name],
+ patch_size=SWINIR_NAME_TO_PATCH_SIZE[model_name],
+ scale=SWINIR_NAME_TO_SCALE[model_name],
+ is_large_model=SWINIR_NAME_TO_LARGE_MODEL[model_name])
+ return result
+
+
+def _super_resolve(model_name: str, input_img):
+ # futures = []
+ # with ThreadPoolExecutor(max_workers=4) as executor:
+ # for model_name in model_names:
+ # futures.append(executor.submit(_decide_sr_algo, model_name, input_img))
+
+ # return [f.result() for f in futures]
+ # return Parallel(n_jobs=2, prefer="threads")(
+ # delayed(_decide_sr_algo)(model_name, input_img)
+ # for model_name in model_names
+ # )
+ return _decide_sr_algo(model_name, input_img)
+
+def _gradio_handler(sr_option: str, input_img: NDArray):
+ return _super_resolve(sr_option, input_img)
+
+
+gr.close_all()
+SR_OPTIONS = ["LambdaSwinIR_v0.1"]
+examples = [
+ ["LambdaSwinIR_v0.1", "examples/oldphoto6.png"],
+ ["LambdaSwinIR_v0.1", "examples/Lincoln.png"],
+ ["LambdaSwinIR_v0.1", "examples/OST_009.png"],
+ ["LambdaSwinIR_v0.1", "examples/00003.png"],
+ ["LambdaSwinIR_v0.1", "examples/00000067_cropped.png"],
+]
+ui = gr.Interface(fn=_gradio_handler,
+ inputs=[
+ gr.Radio(SR_OPTIONS),
+ gr.Image(image_mode="RGB")
+ ],
+ outputs=["image"],
+ live=False,
+ examples=examples,
+ cache_examples=True)
+ui.launch(enable_queue=True)
diff --git a/examples/00000067_cropped.png b/examples/00000067_cropped.png
new file mode 100644
index 0000000000000000000000000000000000000000..66bab29f3f9a3a1ce0fb869eae7e6e9702644782
Binary files /dev/null and b/examples/00000067_cropped.png differ
diff --git a/examples/00003.png b/examples/00003.png
new file mode 100644
index 0000000000000000000000000000000000000000..00cad23adf5d658caf03a0a2874f0c89d96c5ddc
Binary files /dev/null and b/examples/00003.png differ
diff --git a/examples/Lincoln.png b/examples/Lincoln.png
new file mode 100644
index 0000000000000000000000000000000000000000..de6cc486200ac14e4c6e7bb5f0de8127865385ca
Binary files /dev/null and b/examples/Lincoln.png differ
diff --git a/examples/OST_009.png b/examples/OST_009.png
new file mode 100644
index 0000000000000000000000000000000000000000..10bbc831acb7065827a14eb7e0538312a8d6f3e2
Binary files /dev/null and b/examples/OST_009.png differ
diff --git a/examples/oldphoto6.png b/examples/oldphoto6.png
new file mode 100644
index 0000000000000000000000000000000000000000..8d0b76d9f5a97531b0e648b84a4c0050f4a4cdf5
Binary files /dev/null and b/examples/oldphoto6.png differ
diff --git a/requirements.txt b/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..9f0640ceefd5a7d6f19ca7fcd189c9eb9bf05878
--- /dev/null
+++ b/requirements.txt
@@ -0,0 +1,13 @@
+opencv-python
+scikit-image
+pillow
+torchvision
+hdf5storage
+ninja
+lmdb
+requests
+timm
+einops
+matplotlib
+gradio
+joblib