
explain
Browse files- app.py +22 -25
- requirements.txt +0 -2
- xgb/data.png +0 -0
- xgb/feature.png +0 -0
- xgb/record.png +0 -0
app.py
CHANGED
|
@@ -105,14 +105,6 @@ def like(issue):
|
|
| 105 |
'''
|
| 106 |
EXPLAINABLE AI
|
| 107 |
'''
|
| 108 |
-
import shap
|
| 109 |
-
df=pd.read_csv("xgb/re.csv")
|
| 110 |
-
df.columns=['id', 'date', 'age', 'dist_subway', 'dist_stores', 'lat', 'long', 'price']
|
| 111 |
-
data=df.loc[:,['age', 'dist_subway', 'dist_stores', 'lat', 'long', 'price']]
|
| 112 |
-
|
| 113 |
-
from sklearn.model_selection import train_test_split
|
| 114 |
-
X,y=data.iloc[:,:-1],data.iloc[:,-1]
|
| 115 |
-
X_train, X_test, y_train,y_test=train_test_split(X,y, test_size=0.1, random_state=42)
|
| 116 |
|
| 117 |
|
| 118 |
'''
|
|
@@ -228,25 +220,30 @@ With no need for jargon, SSDS delivers tangible value to our fintech operations.
|
|
| 228 |
""")
|
| 229 |
|
| 230 |
with gr.Tab("Explainable AI"):
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 231 |
|
|
|
|
| 232 |
|
| 233 |
-
file_name = 'xgb/xgb.model'
|
| 234 |
-
bst = pickle.load(open(file_name, "rb"))
|
| 235 |
-
explainer_xgb = shap.Explainer(bst) # , X100)
|
| 236 |
-
shap_values_xgb = explainer_xgb(X_test)
|
| 237 |
-
|
| 238 |
-
sample_ind = 20
|
| 239 |
-
shap.partial_dependence_plot(
|
| 240 |
-
"dist_subway",
|
| 241 |
-
bst.predict,
|
| 242 |
-
X_test,
|
| 243 |
-
model_expected_value=True,
|
| 244 |
-
feature_expected_value=True,
|
| 245 |
-
ice=False,
|
| 246 |
-
shap_values=shap_values_xgb[sample_ind: sample_ind + 1, :],
|
| 247 |
-
)
|
| 248 |
-
shap.force_plot(explainer_xgb.expected_value, shap_values_xgb[0].values, X_test.iloc[0], matplotlib=True)
|
| 249 |
-
shap.plots.beeswarm(shap_values_xgb)
|
| 250 |
|
| 251 |
with gr.Tab("Fine Tune LLM"):
|
| 252 |
in_like = gr.Textbox(placeholder="having credit card problem" , label="Issue",
|
|
|
|
| 105 |
'''
|
| 106 |
EXPLAINABLE AI
|
| 107 |
'''
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 108 |
|
| 109 |
|
| 110 |
'''
|
|
|
|
| 220 |
""")
|
| 221 |
|
| 222 |
with gr.Tab("Explainable AI"):
|
| 223 |
+
gr.Markdown("""
|
| 224 |
+
Explain by Dataset
|
| 225 |
+
=============
|
| 226 |
+

|
| 227 |
+
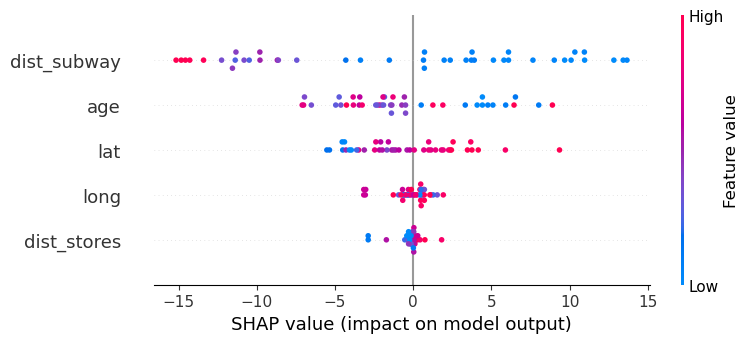
sorted feature from top(most import)
|
| 228 |
+
|
| 229 |
+
dist_subway when at low value(green) make big impact to price
|
| 230 |
+
|
| 231 |
+
Explain by Feature
|
| 232 |
+
=============
|
| 233 |
+

|
| 234 |
+
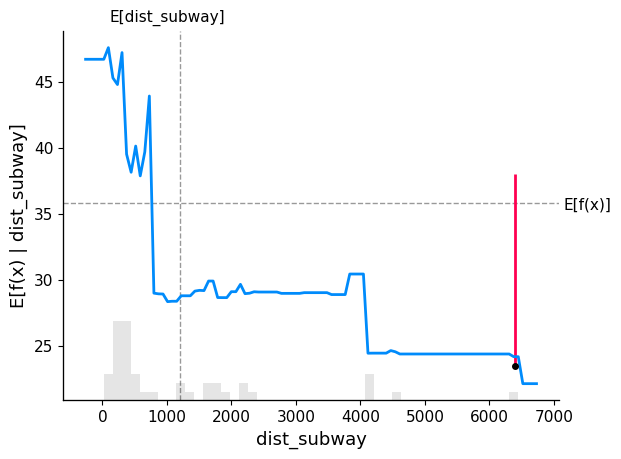
dist lower than 900 spike the price f(x)
|
| 235 |
+
|
| 236 |
+
also highlighted the shap value for record[20] at around 6500
|
| 237 |
+
|
| 238 |
+
Explain by Record
|
| 239 |
+
=============
|
| 240 |
+

|
| 241 |
+
the largest contribution to positive price is dist_subway
|
| 242 |
+
|
| 243 |
+
second contribution is age
|
| 244 |
|
| 245 |
+
""")
|
| 246 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 247 |
|
| 248 |
with gr.Tab("Fine Tune LLM"):
|
| 249 |
in_like = gr.Textbox(placeholder="having credit card problem" , label="Issue",
|
requirements.txt
CHANGED
|
@@ -5,5 +5,3 @@ pandas==2.1.3
|
|
| 5 |
#yfinance==0.2.31
|
| 6 |
#scikit-learn
|
| 7 |
plotly
|
| 8 |
-
shap
|
| 9 |
-
xgboost
|
|
|
|
| 5 |
#yfinance==0.2.31
|
| 6 |
#scikit-learn
|
| 7 |
plotly
|
|
|
|
|
|
xgb/data.png
ADDED
|
xgb/feature.png
ADDED
|
xgb/record.png
ADDED

|