
Upload folder using huggingface_hub
Browse files- .gitattributes +13 -35
- .gitignore +421 -0
- .gradio/certificate.pem +31 -0
- LICENSE-CODE +21 -0
- LICENSE-MODEL +91 -0
- Makefile +99 -0
- README.md +745 -7
- demo/Janus_colab_demo.ipynb +0 -0
- demo/app.py +224 -0
- demo/app_janusflow.py +247 -0
- demo/app_januspro.py +245 -0
- demo/fastapi_app.py +178 -0
- demo/fastapi_client.py +78 -0
- generation_inference.py +116 -0
- images/badge.svg +1 -0
- images/doge.png +3 -0
- images/equation.png +0 -0
- images/logo.png +0 -0
- images/logo.svg +22 -0
- images/pie_chart.png +0 -0
- images/teaser.png +3 -0
- images/teaser_janusflow.png +3 -0
- images/teaser_januspro.png +0 -0
- images/ve.png +3 -0
- inference.py +67 -0
- interactivechat.py +150 -0
- janus/__init__.py +31 -0
- janus/janusflow/__init__.py +31 -0
- janus/janusflow/models/__init__.py +28 -0
- janus/janusflow/models/clip_encoder.py +122 -0
- janus/janusflow/models/image_processing_vlm.py +208 -0
- janus/janusflow/models/modeling_vlm.py +226 -0
- janus/janusflow/models/processing_vlm.py +455 -0
- janus/janusflow/models/siglip_vit.py +691 -0
- janus/janusflow/models/uvit.py +714 -0
- janus/models/__init__.py +28 -0
- janus/models/clip_encoder.py +122 -0
- janus/models/image_processing_vlm.py +208 -0
- janus/models/modeling_vlm.py +272 -0
- janus/models/processing_vlm.py +418 -0
- janus/models/projector.py +100 -0
- janus/models/siglip_vit.py +681 -0
- janus/models/vq_model.py +527 -0
- janus/utils/__init__.py +18 -0
- janus/utils/conversation.py +365 -0
- janus/utils/io.py +89 -0
- janus_pro_tech_report.pdf +3 -0
- januspro.txt +13 -0
- pyproject.toml +53 -0
- requirements.txt +19 -0
.gitattributes
CHANGED
|
@@ -1,35 +1,13 @@
|
|
| 1 |
-
|
| 2 |
-
*.
|
| 3 |
-
|
| 4 |
-
*.
|
| 5 |
-
*.
|
| 6 |
-
*.
|
| 7 |
-
*.
|
| 8 |
-
*.
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
|
| 14 |
-
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
-
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
-
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
-
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
-
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
-
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
-
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
-
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
-
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
-
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
-
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
-
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
-
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
-
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
-
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 29 |
-
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
-
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
-
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
-
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
-
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
-
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
-
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
| 1 |
+
* text eol=lf
|
| 2 |
+
*.ipynb linguist-detectable=false
|
| 3 |
+
|
| 4 |
+
*.png binary
|
| 5 |
+
*.jpg binary
|
| 6 |
+
*.jpeg binary
|
| 7 |
+
*.gif binary
|
| 8 |
+
*.pdf binary
|
| 9 |
+
images/doge.png filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
images/teaser.png filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
images/teaser_janusflow.png filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
images/ve.png filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
janus_pro_tech_report.pdf filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
.gitignore
ADDED
|
@@ -0,0 +1,421 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
##### Python.gitignore #####
|
| 2 |
+
# Byte-compiled / optimized / DLL files
|
| 3 |
+
**/__pycache__/
|
| 4 |
+
*.pyc
|
| 5 |
+
*.pyo
|
| 6 |
+
*.pyd
|
| 7 |
+
*.py[cod]
|
| 8 |
+
*$py.class
|
| 9 |
+
|
| 10 |
+
# C extensions
|
| 11 |
+
*.so
|
| 12 |
+
|
| 13 |
+
# Distribution / packaging
|
| 14 |
+
.Python
|
| 15 |
+
build/
|
| 16 |
+
develop-eggs/
|
| 17 |
+
dist/
|
| 18 |
+
downloads/
|
| 19 |
+
eggs/
|
| 20 |
+
.eggs/
|
| 21 |
+
lib/
|
| 22 |
+
lib64/
|
| 23 |
+
parts/
|
| 24 |
+
sdist/
|
| 25 |
+
var/
|
| 26 |
+
wheels/
|
| 27 |
+
wheelhouse/
|
| 28 |
+
share/python-wheels/
|
| 29 |
+
*.egg-info/
|
| 30 |
+
.installed.cfg
|
| 31 |
+
*.egg
|
| 32 |
+
MANIFEST
|
| 33 |
+
*.whl
|
| 34 |
+
|
| 35 |
+
# PyInstaller
|
| 36 |
+
# Usually these files are written by a python script from a template
|
| 37 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 38 |
+
*.manifest
|
| 39 |
+
*.spec
|
| 40 |
+
|
| 41 |
+
# Installer logs
|
| 42 |
+
pip-log.txt
|
| 43 |
+
pip-delete-this-directory.txt
|
| 44 |
+
|
| 45 |
+
# Unit test / coverage reports
|
| 46 |
+
htmlcov/
|
| 47 |
+
.tox/
|
| 48 |
+
.nox/
|
| 49 |
+
.coverage
|
| 50 |
+
.coverage.*
|
| 51 |
+
.cache
|
| 52 |
+
nosetests.xml
|
| 53 |
+
coverage.xml
|
| 54 |
+
*.cover
|
| 55 |
+
*.py,cover
|
| 56 |
+
.hypothesis/
|
| 57 |
+
.pytest_cache/
|
| 58 |
+
cover/
|
| 59 |
+
|
| 60 |
+
# Translations
|
| 61 |
+
*.mo
|
| 62 |
+
*.pot
|
| 63 |
+
|
| 64 |
+
# Django stuff:
|
| 65 |
+
*.log
|
| 66 |
+
local_settings.py
|
| 67 |
+
db.sqlite3
|
| 68 |
+
db.sqlite3-journal
|
| 69 |
+
|
| 70 |
+
# Flask stuff:
|
| 71 |
+
instance/
|
| 72 |
+
.webassets-cache
|
| 73 |
+
|
| 74 |
+
# Scrapy stuff:
|
| 75 |
+
.scrapy
|
| 76 |
+
|
| 77 |
+
# Sphinx documentation
|
| 78 |
+
docs/_build/
|
| 79 |
+
docs/source/_build/
|
| 80 |
+
_autosummary/
|
| 81 |
+
|
| 82 |
+
# PyBuilder
|
| 83 |
+
.pybuilder/
|
| 84 |
+
target/
|
| 85 |
+
|
| 86 |
+
# Jupyter Notebook
|
| 87 |
+
.ipynb_checkpoints
|
| 88 |
+
|
| 89 |
+
# IPython
|
| 90 |
+
profile_default/
|
| 91 |
+
ipython_config.py
|
| 92 |
+
|
| 93 |
+
# pyenv
|
| 94 |
+
# For a library or package, you might want to ignore these files since the code is
|
| 95 |
+
# intended to run in multiple environments; otherwise, check them in:
|
| 96 |
+
.python-version
|
| 97 |
+
|
| 98 |
+
# pipenv
|
| 99 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 100 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 101 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 102 |
+
# install all needed dependencies.
|
| 103 |
+
#Pipfile.lock
|
| 104 |
+
|
| 105 |
+
# poetry
|
| 106 |
+
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
|
| 107 |
+
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
| 108 |
+
# commonly ignored for libraries.
|
| 109 |
+
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
|
| 110 |
+
#poetry.lock
|
| 111 |
+
|
| 112 |
+
# pdm
|
| 113 |
+
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
|
| 114 |
+
#pdm.lock
|
| 115 |
+
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
|
| 116 |
+
# in version control.
|
| 117 |
+
# https://pdm.fming.dev/#use-with-ide
|
| 118 |
+
.pdm.toml
|
| 119 |
+
|
| 120 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
|
| 121 |
+
__pypackages__/
|
| 122 |
+
|
| 123 |
+
# Celery stuff
|
| 124 |
+
celerybeat-schedule
|
| 125 |
+
celerybeat.pid
|
| 126 |
+
|
| 127 |
+
# SageMath parsed files
|
| 128 |
+
*.sage.py
|
| 129 |
+
|
| 130 |
+
# Environments
|
| 131 |
+
.env
|
| 132 |
+
.venv
|
| 133 |
+
env/
|
| 134 |
+
venv/
|
| 135 |
+
ENV/
|
| 136 |
+
env.bak/
|
| 137 |
+
venv.bak/
|
| 138 |
+
|
| 139 |
+
# Spyder project settings
|
| 140 |
+
.spyderproject
|
| 141 |
+
.spyproject
|
| 142 |
+
|
| 143 |
+
# Rope project settings
|
| 144 |
+
.ropeproject
|
| 145 |
+
|
| 146 |
+
# mkdocs documentation
|
| 147 |
+
/site
|
| 148 |
+
|
| 149 |
+
# ruff
|
| 150 |
+
.ruff_cache/
|
| 151 |
+
|
| 152 |
+
# mypy
|
| 153 |
+
.mypy_cache/
|
| 154 |
+
.dmypy.json
|
| 155 |
+
dmypy.json
|
| 156 |
+
|
| 157 |
+
# Pyre type checker
|
| 158 |
+
.pyre/
|
| 159 |
+
|
| 160 |
+
# pytype static type analyzer
|
| 161 |
+
.pytype/
|
| 162 |
+
|
| 163 |
+
# Cython debug symbols
|
| 164 |
+
cython_debug/
|
| 165 |
+
|
| 166 |
+
# PyCharm
|
| 167 |
+
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
|
| 168 |
+
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
|
| 169 |
+
# and can be added to the global gitignore or merged into this file. For a more nuclear
|
| 170 |
+
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
| 171 |
+
.idea/
|
| 172 |
+
|
| 173 |
+
|
| 174 |
+
##### macOS.gitignore #####
|
| 175 |
+
# General
|
| 176 |
+
.DS_Store
|
| 177 |
+
.AppleDouble
|
| 178 |
+
.LSOverride
|
| 179 |
+
|
| 180 |
+
# Icon must end with two \r
|
| 181 |
+
Icon
|
| 182 |
+
|
| 183 |
+
# Thumbnails
|
| 184 |
+
._*
|
| 185 |
+
|
| 186 |
+
# Files that might appear in the root of a volume
|
| 187 |
+
.DocumentRevisions-V100
|
| 188 |
+
.fseventsd
|
| 189 |
+
.Spotlight-V100
|
| 190 |
+
.TemporaryItems
|
| 191 |
+
.Trashes
|
| 192 |
+
.VolumeIcon.icns
|
| 193 |
+
.com.apple.timemachine.donotpresent
|
| 194 |
+
|
| 195 |
+
# Directories potentially created on remote AFP share
|
| 196 |
+
.AppleDB
|
| 197 |
+
.AppleDesktop
|
| 198 |
+
Network Trash Folder
|
| 199 |
+
Temporary Items
|
| 200 |
+
.apdisk
|
| 201 |
+
|
| 202 |
+
|
| 203 |
+
##### Linux.gitignore #####
|
| 204 |
+
*~
|
| 205 |
+
|
| 206 |
+
# Temporary files which can be created if a process still has a handle open of a deleted file
|
| 207 |
+
.fuse_hidden*
|
| 208 |
+
|
| 209 |
+
# KDE directory preferences
|
| 210 |
+
.directory
|
| 211 |
+
|
| 212 |
+
# Linux trash folder which might appear on any partition or disk
|
| 213 |
+
.Trash-*
|
| 214 |
+
|
| 215 |
+
# .nfs files are created when an open file is removed but is still being accessed
|
| 216 |
+
.nfs*
|
| 217 |
+
|
| 218 |
+
|
| 219 |
+
##### Windows.gitignore #####
|
| 220 |
+
# Windows thumbnail cache files
|
| 221 |
+
Thumbs.db
|
| 222 |
+
Thumbs.db:encryptable
|
| 223 |
+
ehthumbs.db
|
| 224 |
+
ehthumbs_vista.db
|
| 225 |
+
|
| 226 |
+
# Dump file
|
| 227 |
+
*.stackdump
|
| 228 |
+
|
| 229 |
+
# Folder config file
|
| 230 |
+
[Dd]esktop.ini
|
| 231 |
+
|
| 232 |
+
# Recycle Bin used on file shares
|
| 233 |
+
$RECYCLE.BIN/
|
| 234 |
+
|
| 235 |
+
# Windows Installer files
|
| 236 |
+
*.cab
|
| 237 |
+
*.msi
|
| 238 |
+
*.msix
|
| 239 |
+
*.msm
|
| 240 |
+
*.msp
|
| 241 |
+
|
| 242 |
+
# Windows shortcuts
|
| 243 |
+
*.lnk
|
| 244 |
+
|
| 245 |
+
|
| 246 |
+
##### Archives.gitignore #####
|
| 247 |
+
# It's better to unpack these files and commit the raw source because
|
| 248 |
+
# git has its own built in compression methods.
|
| 249 |
+
*.7z
|
| 250 |
+
*.jar
|
| 251 |
+
*.rar
|
| 252 |
+
*.zip
|
| 253 |
+
*.gz
|
| 254 |
+
*.gzip
|
| 255 |
+
*.tgz
|
| 256 |
+
*.bzip
|
| 257 |
+
*.bzip2
|
| 258 |
+
*.bz2
|
| 259 |
+
*.xz
|
| 260 |
+
*.lzma
|
| 261 |
+
*.cab
|
| 262 |
+
*.xar
|
| 263 |
+
|
| 264 |
+
# Packing-only formats
|
| 265 |
+
*.iso
|
| 266 |
+
*.tar
|
| 267 |
+
|
| 268 |
+
# Package management formats
|
| 269 |
+
*.dmg
|
| 270 |
+
*.xpi
|
| 271 |
+
*.gem
|
| 272 |
+
*.egg
|
| 273 |
+
*.deb
|
| 274 |
+
*.rpm
|
| 275 |
+
*.msi
|
| 276 |
+
*.msm
|
| 277 |
+
*.msp
|
| 278 |
+
*.txz
|
| 279 |
+
|
| 280 |
+
|
| 281 |
+
##### Xcode.gitignore #####
|
| 282 |
+
# Xcode
|
| 283 |
+
#
|
| 284 |
+
# gitignore contributors: remember to update Global/Xcode.gitignore, Objective-C.gitignore & Swift.gitignore
|
| 285 |
+
|
| 286 |
+
## User settings
|
| 287 |
+
xcuserdata/
|
| 288 |
+
|
| 289 |
+
## Compatibility with Xcode 8 and earlier (ignoring not required starting Xcode 9)
|
| 290 |
+
*.xcscmblueprint
|
| 291 |
+
*.xccheckout
|
| 292 |
+
|
| 293 |
+
## Compatibility with Xcode 3 and earlier (ignoring not required starting Xcode 4)
|
| 294 |
+
build/
|
| 295 |
+
DerivedData/
|
| 296 |
+
*.moved-aside
|
| 297 |
+
*.pbxuser
|
| 298 |
+
!default.pbxuser
|
| 299 |
+
*.mode1v3
|
| 300 |
+
!default.mode1v3
|
| 301 |
+
*.mode2v3
|
| 302 |
+
!default.mode2v3
|
| 303 |
+
*.perspectivev3
|
| 304 |
+
!default.perspectivev3
|
| 305 |
+
|
| 306 |
+
## Gcc Patch
|
| 307 |
+
/*.gcno
|
| 308 |
+
|
| 309 |
+
|
| 310 |
+
##### JetBrains.gitignore #####
|
| 311 |
+
# Covers JetBrains IDEs: IntelliJ, RubyMine, PhpStorm, AppCode, PyCharm, CLion, Android Studio and WebStorm
|
| 312 |
+
# Reference: https://intellij-support.jetbrains.com/hc/en-us/articles/206544839
|
| 313 |
+
|
| 314 |
+
# User settings
|
| 315 |
+
.idea/*
|
| 316 |
+
|
| 317 |
+
# User-specific stuff
|
| 318 |
+
.idea/**/workspace.xml
|
| 319 |
+
.idea/**/tasks.xml
|
| 320 |
+
.idea/**/usage.statistics.xml
|
| 321 |
+
.idea/**/dictionaries
|
| 322 |
+
.idea/**/shelf
|
| 323 |
+
|
| 324 |
+
# Generated files
|
| 325 |
+
.idea/**/contentModel.xml
|
| 326 |
+
|
| 327 |
+
# Sensitive or high-churn files
|
| 328 |
+
.idea/**/dataSources/
|
| 329 |
+
.idea/**/dataSources.ids
|
| 330 |
+
.idea/**/dataSources.local.xml
|
| 331 |
+
.idea/**/sqlDataSources.xml
|
| 332 |
+
.idea/**/dynamic.xml
|
| 333 |
+
.idea/**/uiDesigner.xml
|
| 334 |
+
.idea/**/dbnavigator.xml
|
| 335 |
+
|
| 336 |
+
# Gradle
|
| 337 |
+
.idea/**/gradle.xml
|
| 338 |
+
.idea/**/libraries
|
| 339 |
+
|
| 340 |
+
# Gradle and Maven with auto-import
|
| 341 |
+
# When using Gradle or Maven with auto-import, you should exclude module files,
|
| 342 |
+
# since they will be recreated, and may cause churn. Uncomment if using
|
| 343 |
+
# auto-import.
|
| 344 |
+
# .idea/artifacts
|
| 345 |
+
# .idea/compiler.xml
|
| 346 |
+
# .idea/jarRepositories.xml
|
| 347 |
+
# .idea/modules.xml
|
| 348 |
+
# .idea/*.iml
|
| 349 |
+
# .idea/modules
|
| 350 |
+
# *.iml
|
| 351 |
+
# *.ipr
|
| 352 |
+
|
| 353 |
+
# CMake
|
| 354 |
+
cmake-build-*/
|
| 355 |
+
|
| 356 |
+
# Mongo Explorer plugin
|
| 357 |
+
.idea/**/mongoSettings.xml
|
| 358 |
+
|
| 359 |
+
# File-based project format
|
| 360 |
+
*.iws
|
| 361 |
+
|
| 362 |
+
# IntelliJ
|
| 363 |
+
out/
|
| 364 |
+
|
| 365 |
+
# mpeltonen/sbt-idea plugin
|
| 366 |
+
.idea_modules/
|
| 367 |
+
|
| 368 |
+
# JIRA plugin
|
| 369 |
+
atlassian-ide-plugin.xml
|
| 370 |
+
|
| 371 |
+
# Cursive Clojure plugin
|
| 372 |
+
.idea/replstate.xml
|
| 373 |
+
|
| 374 |
+
# Crashlytics plugin (for Android Studio and IntelliJ)
|
| 375 |
+
com_crashlytics_export_strings.xml
|
| 376 |
+
crashlytics.properties
|
| 377 |
+
crashlytics-build.properties
|
| 378 |
+
fabric.properties
|
| 379 |
+
|
| 380 |
+
# Editor-based Rest Client
|
| 381 |
+
.idea/httpRequests
|
| 382 |
+
|
| 383 |
+
# Android studio 3.1+ serialized cache file
|
| 384 |
+
.idea/caches/build_file_checksums.ser
|
| 385 |
+
|
| 386 |
+
|
| 387 |
+
##### VisualStudioCode.gitignore #####
|
| 388 |
+
.vscode/*
|
| 389 |
+
# !.vscode/settings.json
|
| 390 |
+
# !.vscode/tasks.json
|
| 391 |
+
# !.vscode/launch.json
|
| 392 |
+
!.vscode/extensions.json
|
| 393 |
+
*.code-workspace
|
| 394 |
+
|
| 395 |
+
# Local History for Visual Studio Code
|
| 396 |
+
.history/
|
| 397 |
+
|
| 398 |
+
|
| 399 |
+
##### Vim.gitignore #####
|
| 400 |
+
# Swap
|
| 401 |
+
.*.s[a-v][a-z]
|
| 402 |
+
!*.svg # comment out if you don't need vector files
|
| 403 |
+
.*.sw[a-p]
|
| 404 |
+
.s[a-rt-v][a-z]
|
| 405 |
+
.ss[a-gi-z]
|
| 406 |
+
.sw[a-p]
|
| 407 |
+
|
| 408 |
+
# Session
|
| 409 |
+
Session.vim
|
| 410 |
+
Sessionx.vim
|
| 411 |
+
|
| 412 |
+
# Temporary
|
| 413 |
+
.netrwhist
|
| 414 |
+
*~
|
| 415 |
+
# Auto-generated tag files
|
| 416 |
+
tags
|
| 417 |
+
# Persistent undo
|
| 418 |
+
[._]*.un~
|
| 419 |
+
.vscode
|
| 420 |
+
.github
|
| 421 |
+
generated_samples/
|
.gradio/certificate.pem
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
-----BEGIN CERTIFICATE-----
|
| 2 |
+
MIIFazCCA1OgAwIBAgIRAIIQz7DSQONZRGPgu2OCiwAwDQYJKoZIhvcNAQELBQAw
|
| 3 |
+
TzELMAkGA1UEBhMCVVMxKTAnBgNVBAoTIEludGVybmV0IFNlY3VyaXR5IFJlc2Vh
|
| 4 |
+
cmNoIEdyb3VwMRUwEwYDVQQDEwxJU1JHIFJvb3QgWDEwHhcNMTUwNjA0MTEwNDM4
|
| 5 |
+
WhcNMzUwNjA0MTEwNDM4WjBPMQswCQYDVQQGEwJVUzEpMCcGA1UEChMgSW50ZXJu
|
| 6 |
+
ZXQgU2VjdXJpdHkgUmVzZWFyY2ggR3JvdXAxFTATBgNVBAMTDElTUkcgUm9vdCBY
|
| 7 |
+
MTCCAiIwDQYJKoZIhvcNAQEBBQADggIPADCCAgoCggIBAK3oJHP0FDfzm54rVygc
|
| 8 |
+
h77ct984kIxuPOZXoHj3dcKi/vVqbvYATyjb3miGbESTtrFj/RQSa78f0uoxmyF+
|
| 9 |
+
0TM8ukj13Xnfs7j/EvEhmkvBioZxaUpmZmyPfjxwv60pIgbz5MDmgK7iS4+3mX6U
|
| 10 |
+
A5/TR5d8mUgjU+g4rk8Kb4Mu0UlXjIB0ttov0DiNewNwIRt18jA8+o+u3dpjq+sW
|
| 11 |
+
T8KOEUt+zwvo/7V3LvSye0rgTBIlDHCNAymg4VMk7BPZ7hm/ELNKjD+Jo2FR3qyH
|
| 12 |
+
B5T0Y3HsLuJvW5iB4YlcNHlsdu87kGJ55tukmi8mxdAQ4Q7e2RCOFvu396j3x+UC
|
| 13 |
+
B5iPNgiV5+I3lg02dZ77DnKxHZu8A/lJBdiB3QW0KtZB6awBdpUKD9jf1b0SHzUv
|
| 14 |
+
KBds0pjBqAlkd25HN7rOrFleaJ1/ctaJxQZBKT5ZPt0m9STJEadao0xAH0ahmbWn
|
| 15 |
+
OlFuhjuefXKnEgV4We0+UXgVCwOPjdAvBbI+e0ocS3MFEvzG6uBQE3xDk3SzynTn
|
| 16 |
+
jh8BCNAw1FtxNrQHusEwMFxIt4I7mKZ9YIqioymCzLq9gwQbooMDQaHWBfEbwrbw
|
| 17 |
+
qHyGO0aoSCqI3Haadr8faqU9GY/rOPNk3sgrDQoo//fb4hVC1CLQJ13hef4Y53CI
|
| 18 |
+
rU7m2Ys6xt0nUW7/vGT1M0NPAgMBAAGjQjBAMA4GA1UdDwEB/wQEAwIBBjAPBgNV
|
| 19 |
+
HRMBAf8EBTADAQH/MB0GA1UdDgQWBBR5tFnme7bl5AFzgAiIyBpY9umbbjANBgkq
|
| 20 |
+
hkiG9w0BAQsFAAOCAgEAVR9YqbyyqFDQDLHYGmkgJykIrGF1XIpu+ILlaS/V9lZL
|
| 21 |
+
ubhzEFnTIZd+50xx+7LSYK05qAvqFyFWhfFQDlnrzuBZ6brJFe+GnY+EgPbk6ZGQ
|
| 22 |
+
3BebYhtF8GaV0nxvwuo77x/Py9auJ/GpsMiu/X1+mvoiBOv/2X/qkSsisRcOj/KK
|
| 23 |
+
NFtY2PwByVS5uCbMiogziUwthDyC3+6WVwW6LLv3xLfHTjuCvjHIInNzktHCgKQ5
|
| 24 |
+
ORAzI4JMPJ+GslWYHb4phowim57iaztXOoJwTdwJx4nLCgdNbOhdjsnvzqvHu7Ur
|
| 25 |
+
TkXWStAmzOVyyghqpZXjFaH3pO3JLF+l+/+sKAIuvtd7u+Nxe5AW0wdeRlN8NwdC
|
| 26 |
+
jNPElpzVmbUq4JUagEiuTDkHzsxHpFKVK7q4+63SM1N95R1NbdWhscdCb+ZAJzVc
|
| 27 |
+
oyi3B43njTOQ5yOf+1CceWxG1bQVs5ZufpsMljq4Ui0/1lvh+wjChP4kqKOJ2qxq
|
| 28 |
+
4RgqsahDYVvTH9w7jXbyLeiNdd8XM2w9U/t7y0Ff/9yi0GE44Za4rF2LN9d11TPA
|
| 29 |
+
mRGunUHBcnWEvgJBQl9nJEiU0Zsnvgc/ubhPgXRR4Xq37Z0j4r7g1SgEEzwxA57d
|
| 30 |
+
emyPxgcYxn/eR44/KJ4EBs+lVDR3veyJm+kXQ99b21/+jh5Xos1AnX5iItreGCc=
|
| 31 |
+
-----END CERTIFICATE-----
|
LICENSE-CODE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2023 DeepSeek
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
LICENSE-MODEL
ADDED
|
@@ -0,0 +1,91 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
DEEPSEEK LICENSE AGREEMENT
|
| 2 |
+
|
| 3 |
+
Version 1.0, 23 October 2023
|
| 4 |
+
|
| 5 |
+
Copyright (c) 2023 DeepSeek
|
| 6 |
+
|
| 7 |
+
Section I: PREAMBLE
|
| 8 |
+
|
| 9 |
+
Large generative models are being widely adopted and used, and have the potential to transform the way individuals conceive and benefit from AI or ML technologies.
|
| 10 |
+
|
| 11 |
+
Notwithstanding the current and potential benefits that these artifacts can bring to society at large, there are also concerns about potential misuses of them, either due to their technical limitations or ethical considerations.
|
| 12 |
+
|
| 13 |
+
In short, this license strives for both the open and responsible downstream use of the accompanying model. When it comes to the open character, we took inspiration from open source permissive licenses regarding the grant of IP rights. Referring to the downstream responsible use, we added use-based restrictions not permitting the use of the model in very specific scenarios, in order for the licensor to be able to enforce the license in case potential misuses of the Model may occur. At the same time, we strive to promote open and responsible research on generative models for content generation.
|
| 14 |
+
|
| 15 |
+
Even though downstream derivative versions of the model could be released under different licensing terms, the latter will always have to include - at minimum - the same use-based restrictions as the ones in the original license (this license). We believe in the intersection between open and responsible AI development; thus, this agreement aims to strike a balance between both in order to enable responsible open-science in the field of AI.
|
| 16 |
+
|
| 17 |
+
This License governs the use of the model (and its derivatives) and is informed by the model card associated with the model.
|
| 18 |
+
|
| 19 |
+
NOW THEREFORE, You and DeepSeek agree as follows:
|
| 20 |
+
|
| 21 |
+
1. Definitions
|
| 22 |
+
"License" means the terms and conditions for use, reproduction, and Distribution as defined in this document.
|
| 23 |
+
"Data" means a collection of information and/or content extracted from the dataset used with the Model, including to train, pretrain, or otherwise evaluate the Model. The Data is not licensed under this License.
|
| 24 |
+
"Output" means the results of operating a Model as embodied in informational content resulting therefrom.
|
| 25 |
+
"Model" means any accompanying machine-learning based assemblies (including checkpoints), consisting of learnt weights, parameters (including optimizer states), corresponding to the model architecture as embodied in the Complementary Material, that have been trained or tuned, in whole or in part on the Data, using the Complementary Material.
|
| 26 |
+
"Derivatives of the Model" means all modifications to the Model, works based on the Model, or any other model which is created or initialized by transfer of patterns of the weights, parameters, activations or output of the Model, to the other model, in order to cause the other model to perform similarly to the Model, including - but not limited to - distillation methods entailing the use of intermediate data representations or methods based on the generation of synthetic data by the Model for training the other model.
|
| 27 |
+
"Complementary Material" means the accompanying source code and scripts used to define, run, load, benchmark or evaluate the Model, and used to prepare data for training or evaluation, if any. This includes any accompanying documentation, tutorials, examples, etc, if any.
|
| 28 |
+
"Distribution" means any transmission, reproduction, publication or other sharing of the Model or Derivatives of the Model to a third party, including providing the Model as a hosted service made available by electronic or other remote means - e.g. API-based or web access.
|
| 29 |
+
"DeepSeek" (or "we") means Beijing DeepSeek Artificial Intelligence Fundamental Technology Research Co., Ltd., Hangzhou DeepSeek Artificial Intelligence Fundamental Technology Research Co., Ltd. and/or any of their affiliates.
|
| 30 |
+
"You" (or "Your") means an individual or Legal Entity exercising permissions granted by this License and/or making use of the Model for whichever purpose and in any field of use, including usage of the Model in an end-use application - e.g. chatbot, translator, etc.
|
| 31 |
+
"Third Parties" means individuals or legal entities that are not under common control with DeepSeek or You.
|
| 32 |
+
|
| 33 |
+
Section II: INTELLECTUAL PROPERTY RIGHTS
|
| 34 |
+
|
| 35 |
+
Both copyright and patent grants apply to the Model, Derivatives of the Model and Complementary Material. The Model and Derivatives of the Model are subject to additional terms as described in Section III.
|
| 36 |
+
|
| 37 |
+
2. Grant of Copyright License. Subject to the terms and conditions of this License, DeepSeek hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable copyright license to reproduce, prepare, publicly display, publicly perform, sublicense, and distribute the Complementary Material, the Model, and Derivatives of the Model.
|
| 38 |
+
|
| 39 |
+
3. Grant of Patent License. Subject to the terms and conditions of this License and where and as applicable, DeepSeek hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable (except as stated in this paragraph) patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer the Model and the Complementary Material, where such license applies only to those patent claims licensable by DeepSeek that are necessarily infringed by its contribution(s). If You institute patent litigation against any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Model and/or Complementary Material constitutes direct or contributory patent infringement, then any patent licenses granted to You under this License for the Model and/or works shall terminate as of the date such litigation is asserted or filed.
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
Section III: CONDITIONS OF USAGE, DISTRIBUTION AND REDISTRIBUTION
|
| 43 |
+
|
| 44 |
+
4. Distribution and Redistribution. You may host for Third Party remote access purposes (e.g. software-as-a-service), reproduce and distribute copies of the Model or Derivatives of the Model thereof in any medium, with or without modifications, provided that You meet the following conditions:
|
| 45 |
+
a. Use-based restrictions as referenced in paragraph 5 MUST be included as an enforceable provision by You in any type of legal agreement (e.g. a license) governing the use and/or distribution of the Model or Derivatives of the Model, and You shall give notice to subsequent users You Distribute to, that the Model or Derivatives of the Model are subject to paragraph 5. This provision does not apply to the use of Complementary Material.
|
| 46 |
+
b. You must give any Third Party recipients of the Model or Derivatives of the Model a copy of this License;
|
| 47 |
+
c. You must cause any modified files to carry prominent notices stating that You changed the files;
|
| 48 |
+
d. You must retain all copyright, patent, trademark, and attribution notices excluding those notices that do not pertain to any part of the Model, Derivatives of the Model.
|
| 49 |
+
e. You may add Your own copyright statement to Your modifications and may provide additional or different license terms and conditions - respecting paragraph 4.a. – for use, reproduction, or Distribution of Your modifications, or for any such Derivatives of the Model as a whole, provided Your use, reproduction, and Distribution of the Model otherwise complies with the conditions stated in this License.
|
| 50 |
+
|
| 51 |
+
5. Use-based restrictions. The restrictions set forth in Attachment A are considered Use-based restrictions. Therefore You cannot use the Model and the Derivatives of the Model for the specified restricted uses. You may use the Model subject to this License, including only for lawful purposes and in accordance with the License. Use may include creating any content with, finetuning, updating, running, training, evaluating and/or reparametrizing the Model. You shall require all of Your users who use the Model or a Derivative of the Model to comply with the terms of this paragraph (paragraph 5).
|
| 52 |
+
|
| 53 |
+
6. The Output You Generate. Except as set forth herein, DeepSeek claims no rights in the Output You generate using the Model. You are accountable for the Output you generate and its subsequent uses. No use of the output can contravene any provision as stated in the License.
|
| 54 |
+
|
| 55 |
+
Section IV: OTHER PROVISIONS
|
| 56 |
+
|
| 57 |
+
7. Updates and Runtime Restrictions. To the maximum extent permitted by law, DeepSeek reserves the right to restrict (remotely or otherwise) usage of the Model in violation of this License.
|
| 58 |
+
|
| 59 |
+
8. Trademarks and related. Nothing in this License permits You to make use of DeepSeek’ trademarks, trade names, logos or to otherwise suggest endorsement or misrepresent the relationship between the parties; and any rights not expressly granted herein are reserved by DeepSeek.
|
| 60 |
+
|
| 61 |
+
9. Personal information, IP rights and related. This Model may contain personal information and works with IP rights. You commit to complying with applicable laws and regulations in the handling of personal information and the use of such works. Please note that DeepSeek's license granted to you to use the Model does not imply that you have obtained a legitimate basis for processing the related information or works. As an independent personal information processor and IP rights user, you need to ensure full compliance with relevant legal and regulatory requirements when handling personal information and works with IP rights that may be contained in the Model, and are willing to assume solely any risks and consequences that may arise from that.
|
| 62 |
+
|
| 63 |
+
10. Disclaimer of Warranty. Unless required by applicable law or agreed to in writing, DeepSeek provides the Model and the Complementary Material on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied, including, without limitation, any warranties or conditions of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE. You are solely responsible for determining the appropriateness of using or redistributing the Model, Derivatives of the Model, and the Complementary Material and assume any risks associated with Your exercise of permissions under this License.
|
| 64 |
+
|
| 65 |
+
11. Limitation of Liability. In no event and under no legal theory, whether in tort (including negligence), contract, or otherwise, unless required by applicable law (such as deliberate and grossly negligent acts) or agreed to in writing, shall DeepSeek be liable to You for damages, including any direct, indirect, special, incidental, or consequential damages of any character arising as a result of this License or out of the use or inability to use the Model and the Complementary Material (including but not limited to damages for loss of goodwill, work stoppage, computer failure or malfunction, or any and all other commercial damages or losses), even if DeepSeek has been advised of the possibility of such damages.
|
| 66 |
+
|
| 67 |
+
12. Accepting Warranty or Additional Liability. While redistributing the Model, Derivatives of the Model and the Complementary Material thereof, You may choose to offer, and charge a fee for, acceptance of support, warranty, indemnity, or other liability obligations and/or rights consistent with this License. However, in accepting such obligations, You may act only on Your own behalf and on Your sole responsibility, not on behalf of DeepSeek, and only if You agree to indemnify, defend, and hold DeepSeek harmless for any liability incurred by, or claims asserted against, DeepSeek by reason of your accepting any such warranty or additional liability.
|
| 68 |
+
|
| 69 |
+
13. If any provision of this License is held to be invalid, illegal or unenforceable, the remaining provisions shall be unaffected thereby and remain valid as if such provision had not been set forth herein.
|
| 70 |
+
|
| 71 |
+
14. Governing Law and Jurisdiction. This agreement will be governed and construed under PRC laws without regard to choice of law principles, and the UN Convention on Contracts for the International Sale of Goods does not apply to this agreement. The courts located in the domicile of Hangzhou DeepSeek Artificial Intelligence Fundamental Technology Research Co., Ltd. shall have exclusive jurisdiction of any dispute arising out of this agreement.
|
| 72 |
+
|
| 73 |
+
END OF TERMS AND CONDITIONS
|
| 74 |
+
|
| 75 |
+
Attachment A
|
| 76 |
+
|
| 77 |
+
Use Restrictions
|
| 78 |
+
|
| 79 |
+
You agree not to use the Model or Derivatives of the Model:
|
| 80 |
+
|
| 81 |
+
- In any way that violates any applicable national or international law or regulation or infringes upon the lawful rights and interests of any third party;
|
| 82 |
+
- For military use in any way;
|
| 83 |
+
- For the purpose of exploiting, harming or attempting to exploit or harm minors in any way;
|
| 84 |
+
- To generate or disseminate verifiably false information and/or content with the purpose of harming others;
|
| 85 |
+
- To generate or disseminate inappropriate content subject to applicable regulatory requirements;
|
| 86 |
+
- To generate or disseminate personal identifiable information without due authorization or for unreasonable use;
|
| 87 |
+
- To defame, disparage or otherwise harass others;
|
| 88 |
+
- For fully automated decision making that adversely impacts an individual’s legal rights or otherwise creates or modifies a binding, enforceable obligation;
|
| 89 |
+
- For any use intended to or which has the effect of discriminating against or harming individuals or groups based on online or offline social behavior or known or predicted personal or personality characteristics;
|
| 90 |
+
- To exploit any of the vulnerabilities of a specific group of persons based on their age, social, physical or mental characteristics, in order to materially distort the behavior of a person pertaining to that group in a manner that causes or is likely to cause that person or another person physical or psychological harm;
|
| 91 |
+
- For any use intended to or which has the effect of discriminating against individuals or groups based on legally protected characteristics or categories.
|
Makefile
ADDED
|
@@ -0,0 +1,99 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
print-% : ; @echo $* = $($*)
|
| 2 |
+
PROJECT_NAME = Janus
|
| 3 |
+
COPYRIGHT = "DeepSeek."
|
| 4 |
+
PROJECT_PATH = janus
|
| 5 |
+
SHELL = /bin/bash
|
| 6 |
+
SOURCE_FOLDERS = janus
|
| 7 |
+
PYTHON_FILES = $(shell find $(SOURCE_FOLDERS) -type f -name "*.py" -o -name "*.pyi") inference.py
|
| 8 |
+
COMMIT_HASH = $(shell git log -1 --format=%h)
|
| 9 |
+
PATH := $(HOME)/go/bin:$(PATH)
|
| 10 |
+
PYTHON ?= $(shell command -v python3 || command -v python)
|
| 11 |
+
PYTESTOPTS ?=
|
| 12 |
+
|
| 13 |
+
.PHONY: default
|
| 14 |
+
default: install
|
| 15 |
+
|
| 16 |
+
# Tools Installation
|
| 17 |
+
|
| 18 |
+
check_pip_install = $(PYTHON) -m pip show $(1) &>/dev/null || (cd && $(PYTHON) -m pip install $(1) --upgrade)
|
| 19 |
+
check_pip_install_extra = $(PYTHON) -m pip show $(1) &>/dev/null || (cd && $(PYTHON) -m pip install $(2) --upgrade)
|
| 20 |
+
|
| 21 |
+
pylint-install:
|
| 22 |
+
$(call check_pip_install_extra,pylint,pylint[spelling])
|
| 23 |
+
$(call check_pip_install,pyenchant)
|
| 24 |
+
|
| 25 |
+
flake8-install:
|
| 26 |
+
$(call check_pip_install,flake8)
|
| 27 |
+
$(call check_pip_install,flake8-bugbear)
|
| 28 |
+
$(call check_pip_install,flake8-comprehensions)
|
| 29 |
+
$(call check_pip_install,flake8-docstrings)
|
| 30 |
+
$(call check_pip_install,flake8-pyi)
|
| 31 |
+
$(call check_pip_install,flake8-simplify)
|
| 32 |
+
|
| 33 |
+
py-format-install:
|
| 34 |
+
$(call check_pip_install,isort)
|
| 35 |
+
$(call check_pip_install_extra,black,black[jupyter])
|
| 36 |
+
|
| 37 |
+
ruff-install:
|
| 38 |
+
$(call check_pip_install,ruff)
|
| 39 |
+
|
| 40 |
+
mypy-install:
|
| 41 |
+
$(call check_pip_install,mypy)
|
| 42 |
+
|
| 43 |
+
pre-commit-install:
|
| 44 |
+
$(call check_pip_install,pre-commit)
|
| 45 |
+
$(PYTHON) -m pre_commit install --install-hooks
|
| 46 |
+
|
| 47 |
+
go-install:
|
| 48 |
+
# requires go >= 1.16
|
| 49 |
+
command -v go || (sudo apt-get install -y golang && sudo ln -sf /usr/lib/go/bin/go /usr/bin/go)
|
| 50 |
+
|
| 51 |
+
addlicense-install: go-install
|
| 52 |
+
command -v addlicense || go install github.com/google/addlicense@latest
|
| 53 |
+
|
| 54 |
+
addlicense: addlicense-install
|
| 55 |
+
addlicense -c $(COPYRIGHT) -ignore tests/coverage.xml -l mit -y 2023-$(shell date +"%Y") -check $(SOURCE_FOLDERS)
|
| 56 |
+
|
| 57 |
+
# Python linters
|
| 58 |
+
|
| 59 |
+
pylint: pylint-install
|
| 60 |
+
$(PYTHON) -m pylint $(PROJECT_PATH)
|
| 61 |
+
|
| 62 |
+
flake8: flake8-install
|
| 63 |
+
$(PYTHON) -m flake8 --count --show-source --statistics
|
| 64 |
+
|
| 65 |
+
py-format: py-format-install
|
| 66 |
+
$(PYTHON) -m isort --project $(PROJECT_PATH) --check $(PYTHON_FILES) && \
|
| 67 |
+
$(PYTHON) -m black --check $(PYTHON_FILES)
|
| 68 |
+
|
| 69 |
+
black-format: py-format-install
|
| 70 |
+
$(PYTHON) -m black --check $(PYTHON_FILES)
|
| 71 |
+
|
| 72 |
+
ruff: ruff-install
|
| 73 |
+
$(PYTHON) -m ruff check .
|
| 74 |
+
|
| 75 |
+
ruff-fix: ruff-install
|
| 76 |
+
$(PYTHON) -m ruff check . --fix --exit-non-zero-on-fix
|
| 77 |
+
|
| 78 |
+
mypy: mypy-install
|
| 79 |
+
$(PYTHON) -m mypy $(PROJECT_PATH) --install-types --non-interactive
|
| 80 |
+
|
| 81 |
+
pre-commit: pre-commit-install
|
| 82 |
+
$(PYTHON) -m pre_commit run --all-files
|
| 83 |
+
|
| 84 |
+
# Utility functions
|
| 85 |
+
|
| 86 |
+
lint: ruff flake8 py-format mypy pylint addlicense
|
| 87 |
+
|
| 88 |
+
format: py-format-install ruff-install addlicense-install
|
| 89 |
+
$(PYTHON) -m isort --project $(PROJECT_PATH) $(PYTHON_FILES)
|
| 90 |
+
$(PYTHON) -m black $(PYTHON_FILES)
|
| 91 |
+
addlicense -c $(COPYRIGHT) -ignore tests/coverage.xml -l mit -y 2023-$(shell date +"%Y") $(SOURCE_FOLDERS) inference.py
|
| 92 |
+
|
| 93 |
+
clean-py:
|
| 94 |
+
find . -type f -name '*.py[co]' -delete
|
| 95 |
+
find . -depth -type d -name "__pycache__" -exec rm -r "{}" +
|
| 96 |
+
find . -depth -type d -name ".ruff_cache" -exec rm -r "{}" +
|
| 97 |
+
find . -depth -type d -name ".mypy_cache" -exec rm -r "{}" +
|
| 98 |
+
|
| 99 |
+
clean: clean-py
|
README.md
CHANGED
|
@@ -1,12 +1,750 @@
|
|
| 1 |
---
|
| 2 |
-
title:
|
| 3 |
-
|
| 4 |
-
colorFrom: purple
|
| 5 |
-
colorTo: yellow
|
| 6 |
sdk: gradio
|
| 7 |
sdk_version: 5.14.0
|
| 8 |
-
app_file: app.py
|
| 9 |
-
pinned: false
|
| 10 |
---
|
|
|
|
|
|
|
|
|
|
| 11 |
|
| 12 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
title: ningDSApp
|
| 3 |
+
app_file: demo/app_januspro.py
|
|
|
|
|
|
|
| 4 |
sdk: gradio
|
| 5 |
sdk_version: 5.14.0
|
|
|
|
|
|
|
| 6 |
---
|
| 7 |
+
<!-- markdownlint-disable first-line-h1 -->
|
| 8 |
+
<!-- markdownlint-disable html -->
|
| 9 |
+
<!-- markdownlint-disable no-duplicate-header -->
|
| 10 |
|
| 11 |
+
<div align="center">
|
| 12 |
+
<img src="images/logo.svg" width="60%" alt="DeepSeek LLM" />
|
| 13 |
+
</div>
|
| 14 |
+
<hr>
|
| 15 |
+
|
| 16 |
+
<div align="center">
|
| 17 |
+
<h1>🚀 Janus-Series: Unified Multimodal Understanding and Generation Models</h1>
|
| 18 |
+
|
| 19 |
+
</div>
|
| 20 |
+
|
| 21 |
+
<div align="center">
|
| 22 |
+
|
| 23 |
+
<a href="https://www.deepseek.com/" target="_blank">
|
| 24 |
+
<img alt="Homepage" src="images/badge.svg" />
|
| 25 |
+
</a>
|
| 26 |
+
</a>
|
| 27 |
+
<a href="https://huggingface.co/deepseek-ai" target="_blank">
|
| 28 |
+
<img alt="Hugging Face" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-DeepSeek%20AI-ffc107?color=ffc107&logoColor=white" />
|
| 29 |
+
</a>
|
| 30 |
+
|
| 31 |
+
</div>
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
<div align="center">
|
| 35 |
+
|
| 36 |
+
<!-- <a href="https://discord.gg/Tc7c45Zzu5" target="_blank">
|
| 37 |
+
<img alt="Discord" src="https://img.shields.io/badge/Discord-DeepSeek%20AI-7289da?logo=discord&logoColor=white&color=7289da" />
|
| 38 |
+
</a> -->
|
| 39 |
+
<!-- <a href="images/qr.jpeg" target="_blank">
|
| 40 |
+
<img alt="Wechat" src="https://img.shields.io/badge/WeChat-DeepSeek%20AI-brightgreen?logo=wechat&logoColor=white" />
|
| 41 |
+
</a> -->
|
| 42 |
+
<!-- <a href="https://twitter.com/deepseek_ai" target="_blank">
|
| 43 |
+
<img alt="Twitter Follow" src="https://img.shields.io/badge/Twitter-deepseek_ai-white?logo=x&logoColor=white" />
|
| 44 |
+
</a> -->
|
| 45 |
+
|
| 46 |
+
</div>
|
| 47 |
+
|
| 48 |
+
<div align="center">
|
| 49 |
+
|
| 50 |
+
<a href="LICENSE-CODE">
|
| 51 |
+
<img alt="Code License" src="https://img.shields.io/badge/Code_License-MIT-f5de53?&color=f5de53">
|
| 52 |
+
</a>
|
| 53 |
+
<a href="LICENSE-MODEL">
|
| 54 |
+
<img alt="Model License" src="https://img.shields.io/badge/Model_License-Model_Agreement-f5de53?&color=f5de53">
|
| 55 |
+
</a>
|
| 56 |
+
</div>
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
<p align="center">
|
| 60 |
+
<a href="#2-model-download"><b>📥 Model Download</b></a> |
|
| 61 |
+
<a href="#3-quick-start"><b>⚡ Quick Start</b></a> |
|
| 62 |
+
<a href="#4-license"><b>📜 License</b></a> |
|
| 63 |
+
<a href="#5-citation"><b>📖 Citation</b></a> <br>
|
| 64 |
+
<!-- 📄 Paper Link (<a href="https://arxiv.org/abs/2410.13848"><b>Janus</b></a>, <a href="https://arxiv.org/abs/2410.13848"><b>JanusFlow</b></a>) | -->
|
| 65 |
+
🤗 Online Demo (<a href="https://huggingface.co/spaces/deepseek-ai/Janus-Pro-7B"><b>Janus-Pro-7B</b></a>, <a href="https://huggingface.co/spaces/deepseek-ai/Janus-1.3B"><b>Janus</b></a>, <a href="https://huggingface.co/spaces/deepseek-ai/JanusFlow-1.3B"><b>JanusFlow</b></a>)
|
| 66 |
+
</p>
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
## News
|
| 70 |
+
|
| 71 |
+
**2025.01.27**: Janus-Pro is released, an advanced version of Janus, improving both multimodal understanding and visual generation significantly. See [paper](./janus_pro_tech_report.pdf)
|
| 72 |
+
|
| 73 |
+
**2024.11.13**: JanusFlow is released, a new unified model with rectified flow for image generation. See [paper](https://arxiv.org/abs/2411.07975), [demo](https://huggingface.co/spaces/deepseek-ai/JanusFlow-1.3B) and [usage](https://github.com/deepseek-ai/Janus?tab=readme-ov-file#janusflow).
|
| 74 |
+
|
| 75 |
+
**2024.10.23**: Evaluation code for reproducing the multimodal understanding results from the paper has been added to VLMEvalKit. Please refer to [this link]( https://github.com/open-compass/VLMEvalKit/pull/541).
|
| 76 |
+
|
| 77 |
+
**2024.10.20**: (1) Fix a bug in [tokenizer_config.json](https://huggingface.co/deepseek-ai/Janus-1.3B/blob/main/tokenizer_config.json). The previous version caused classifier-free guidance to not function properly, resulting in relatively poor visual generation quality. (2) Release Gradio demo ([online demo](https://huggingface.co/spaces/deepseek-ai/Janus-1.3B) and [local](#gradio-demo)).
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
## 1. Introduction
|
| 81 |
+
|
| 82 |
+
<a href="./janus_pro_tech_report.pdf"><b>Janus-Pro: Unified Multimodal Understanding and
|
| 83 |
+
Generation with Data and Model Scaling</b></a>
|
| 84 |
+
|
| 85 |
+
**Janus-Pro** is an advanced version of the previous work Janus. Specifically, Janus-Pro incorporates (1) an optimized training strategy, (2) expanded training data, and (3) scaling to larger model size. With these improvements, Janus-Pro achieves significant advancements in both multimodal understanding and text-to-image instruction-following capabilities, while also enhancing the stability of text-to-image generation.
|
| 86 |
+
|
| 87 |
+
<div align="center">
|
| 88 |
+
<img alt="image" src="images/teaser_januspro.png" style="width:90%;">
|
| 89 |
+
</div>
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
<a href="https://arxiv.org/abs/2410.13848"><b>Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation</b></a>
|
| 93 |
+
|
| 94 |
+
**Janus** is a novel autoregressive framework that unifies multimodal understanding and generation. It addresses the limitations of previous approaches by decoupling visual encoding into separate pathways, while still utilizing a single, unified transformer architecture for processing. The decoupling not only alleviates the conflict between the visual encoder’s roles in understanding and generation, but also enhances the framework’s flexibility. Janus surpasses previous unified model and matches or exceeds the performance of task-specific models. The simplicity, high flexibility, and effectiveness of Janus make it a strong candidate for next-generation unified multimodal models.
|
| 95 |
+
|
| 96 |
+
<div align="center">
|
| 97 |
+
<img alt="image" src="images/teaser.png" style="width:90%;">
|
| 98 |
+
</div>
|
| 99 |
+
|
| 100 |
+
<a href="https://arxiv.org/abs/2411.07975"><b>JanusFlow: Harmonizing Autoregression and Rectified Flow for Unified Multimodal Understanding and Generation</b></a>
|
| 101 |
+
|
| 102 |
+
**JanusFlow** introduces a minimalist architecture that integrates autoregressive language models with rectified flow, a state-of-the-art method in generative modeling. Our key finding demonstrates that rectified flow can be straightforwardly trained within the large language model framework, eliminating the need for complex architectural modifications. Extensive experiments show that JanusFlow achieves comparable or superior performance to specialized models in their respective domains, while significantly outperforming existing unified approaches across standard benchmarks. This work represents a step toward more efficient and versatile vision-language models.
|
| 103 |
+
|
| 104 |
+
<div align="center">
|
| 105 |
+
<img alt="image" src="images/teaser_janusflow.png" style="width:90%;">
|
| 106 |
+
</div>
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
## 2. Model Download
|
| 110 |
+
|
| 111 |
+
We release Janus to the public to support a broader and more diverse range of research within both academic and commercial communities.
|
| 112 |
+
Please note that the use of this model is subject to the terms outlined in [License section](#5-license). Commercial usage is
|
| 113 |
+
permitted under these terms.
|
| 114 |
+
|
| 115 |
+
### Huggingface
|
| 116 |
+
|
| 117 |
+
| Model | Sequence Length | Download |
|
| 118 |
+
|-----------------------|-----------------|-----------------------------------------------------------------------------|
|
| 119 |
+
| Janus-1.3B | 4096 | [🤗 Hugging Face](https://huggingface.co/deepseek-ai/Janus-1.3B) |
|
| 120 |
+
| JanusFlow-1.3B | 4096 | [🤗 Hugging Face](https://huggingface.co/deepseek-ai/JanusFlow-1.3B) |
|
| 121 |
+
| Janus-Pro-1B | 4096 | [🤗 Hugging Face](https://huggingface.co/deepseek-ai/Janus-Pro-1B) |
|
| 122 |
+
| Janus-Pro-7B | 4096 | [🤗 Hugging Face](https://huggingface.co/deepseek-ai/Janus-Pro-7B) |
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
## 3. Quick Start
|
| 127 |
+
<details>
|
| 128 |
+
<summary><h3>Janus-Pro</h3></summary>
|
| 129 |
+
|
| 130 |
+
### Installation
|
| 131 |
+
|
| 132 |
+
On the basis of `Python >= 3.8` environment, install the necessary dependencies by running the following command:
|
| 133 |
+
|
| 134 |
+
```shell
|
| 135 |
+
pip install -e .
|
| 136 |
+
```
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
### Simple Inference Example
|
| 140 |
+
|
| 141 |
+
#### Multimodal Understanding
|
| 142 |
+
```python
|
| 143 |
+
|
| 144 |
+
import torch
|
| 145 |
+
from transformers import AutoModelForCausalLM
|
| 146 |
+
from janus.models import MultiModalityCausalLM, VLChatProcessor
|
| 147 |
+
from janus.utils.io import load_pil_images
|
| 148 |
+
|
| 149 |
+
# specify the path to the model
|
| 150 |
+
model_path = "deepseek-ai/Janus-Pro-7B"
|
| 151 |
+
vl_chat_processor: VLChatProcessor = VLChatProcessor.from_pretrained(model_path)
|
| 152 |
+
tokenizer = vl_chat_processor.tokenizer
|
| 153 |
+
|
| 154 |
+
vl_gpt: MultiModalityCausalLM = AutoModelForCausalLM.from_pretrained(
|
| 155 |
+
model_path, trust_remote_code=True
|
| 156 |
+
)
|
| 157 |
+
vl_gpt = vl_gpt.to(torch.bfloat16).cuda().eval()
|
| 158 |
+
|
| 159 |
+
conversation = [
|
| 160 |
+
{
|
| 161 |
+
"role": "<|User|>",
|
| 162 |
+
"content": f"<image_placeholder>\n{question}",
|
| 163 |
+
"images": [image],
|
| 164 |
+
},
|
| 165 |
+
{"role": "<|Assistant|>", "content": ""},
|
| 166 |
+
]
|
| 167 |
+
|
| 168 |
+
# load images and prepare for inputs
|
| 169 |
+
pil_images = load_pil_images(conversation)
|
| 170 |
+
prepare_inputs = vl_chat_processor(
|
| 171 |
+
conversations=conversation, images=pil_images, force_batchify=True
|
| 172 |
+
).to(vl_gpt.device)
|
| 173 |
+
|
| 174 |
+
# # run image encoder to get the image embeddings
|
| 175 |
+
inputs_embeds = vl_gpt.prepare_inputs_embeds(**prepare_inputs)
|
| 176 |
+
|
| 177 |
+
# # run the model to get the response
|
| 178 |
+
outputs = vl_gpt.language_model.generate(
|
| 179 |
+
inputs_embeds=inputs_embeds,
|
| 180 |
+
attention_mask=prepare_inputs.attention_mask,
|
| 181 |
+
pad_token_id=tokenizer.eos_token_id,
|
| 182 |
+
bos_token_id=tokenizer.bos_token_id,
|
| 183 |
+
eos_token_id=tokenizer.eos_token_id,
|
| 184 |
+
max_new_tokens=512,
|
| 185 |
+
do_sample=False,
|
| 186 |
+
use_cache=True,
|
| 187 |
+
)
|
| 188 |
+
|
| 189 |
+
answer = tokenizer.decode(outputs[0].cpu().tolist(), skip_special_tokens=True)
|
| 190 |
+
print(f"{prepare_inputs['sft_format'][0]}", answer)
|
| 191 |
+
|
| 192 |
+
```
|
| 193 |
+
|
| 194 |
+
#### Text-to-Image Generation
|
| 195 |
+
```python
|
| 196 |
+
import os
|
| 197 |
+
import PIL.Image
|
| 198 |
+
import torch
|
| 199 |
+
import numpy as np
|
| 200 |
+
from transformers import AutoModelForCausalLM
|
| 201 |
+
from janus.models import MultiModalityCausalLM, VLChatProcessor
|
| 202 |
+
|
| 203 |
+
|
| 204 |
+
# specify the path to the model
|
| 205 |
+
model_path = "deepseek-ai/Janus-Pro-7B"
|
| 206 |
+
vl_chat_processor: VLChatProcessor = VLChatProcessor.from_pretrained(model_path)
|
| 207 |
+
tokenizer = vl_chat_processor.tokenizer
|
| 208 |
+
|
| 209 |
+
vl_gpt: MultiModalityCausalLM = AutoModelForCausalLM.from_pretrained(
|
| 210 |
+
model_path, trust_remote_code=True
|
| 211 |
+
)
|
| 212 |
+
vl_gpt = vl_gpt.to(torch.bfloat16).cuda().eval()
|
| 213 |
+
|
| 214 |
+
conversation = [
|
| 215 |
+
{
|
| 216 |
+
"role": "<|User|>",
|
| 217 |
+
"content": "A stunning princess from kabul in red, white traditional clothing, blue eyes, brown hair",
|
| 218 |
+
},
|
| 219 |
+
{"role": "<|Assistant|>", "content": ""},
|
| 220 |
+
]
|
| 221 |
+
|
| 222 |
+
sft_format = vl_chat_processor.apply_sft_template_for_multi_turn_prompts(
|
| 223 |
+
conversations=conversation,
|
| 224 |
+
sft_format=vl_chat_processor.sft_format,
|
| 225 |
+
system_prompt="",
|
| 226 |
+
)
|
| 227 |
+
prompt = sft_format + vl_chat_processor.image_start_tag
|
| 228 |
+
|
| 229 |
+
|
| 230 |
+
@torch.inference_mode()
|
| 231 |
+
def generate(
|
| 232 |
+
mmgpt: MultiModalityCausalLM,
|
| 233 |
+
vl_chat_processor: VLChatProcessor,
|
| 234 |
+
prompt: str,
|
| 235 |
+
temperature: float = 1,
|
| 236 |
+
parallel_size: int = 16,
|
| 237 |
+
cfg_weight: float = 5,
|
| 238 |
+
image_token_num_per_image: int = 576,
|
| 239 |
+
img_size: int = 384,
|
| 240 |
+
patch_size: int = 16,
|
| 241 |
+
):
|
| 242 |
+
input_ids = vl_chat_processor.tokenizer.encode(prompt)
|
| 243 |
+
input_ids = torch.LongTensor(input_ids)
|
| 244 |
+
|
| 245 |
+
tokens = torch.zeros((parallel_size*2, len(input_ids)), dtype=torch.int).cuda()
|
| 246 |
+
for i in range(parallel_size*2):
|
| 247 |
+
tokens[i, :] = input_ids
|
| 248 |
+
if i % 2 != 0:
|
| 249 |
+
tokens[i, 1:-1] = vl_chat_processor.pad_id
|
| 250 |
+
|
| 251 |
+
inputs_embeds = mmgpt.language_model.get_input_embeddings()(tokens)
|
| 252 |
+
|
| 253 |
+
generated_tokens = torch.zeros((parallel_size, image_token_num_per_image), dtype=torch.int).cuda()
|
| 254 |
+
|
| 255 |
+
for i in range(image_token_num_per_image):
|
| 256 |
+
outputs = mmgpt.language_model.model(inputs_embeds=inputs_embeds, use_cache=True, past_key_values=outputs.past_key_values if i != 0 else None)
|
| 257 |
+
hidden_states = outputs.last_hidden_state
|
| 258 |
+
|
| 259 |
+
logits = mmgpt.gen_head(hidden_states[:, -1, :])
|
| 260 |
+
logit_cond = logits[0::2, :]
|
| 261 |
+
logit_uncond = logits[1::2, :]
|
| 262 |
+
|
| 263 |
+
logits = logit_uncond + cfg_weight * (logit_cond-logit_uncond)
|
| 264 |
+
probs = torch.softmax(logits / temperature, dim=-1)
|
| 265 |
+
|
| 266 |
+
next_token = torch.multinomial(probs, num_samples=1)
|
| 267 |
+
generated_tokens[:, i] = next_token.squeeze(dim=-1)
|
| 268 |
+
|
| 269 |
+
next_token = torch.cat([next_token.unsqueeze(dim=1), next_token.unsqueeze(dim=1)], dim=1).view(-1)
|
| 270 |
+
img_embeds = mmgpt.prepare_gen_img_embeds(next_token)
|
| 271 |
+
inputs_embeds = img_embeds.unsqueeze(dim=1)
|
| 272 |
+
|
| 273 |
+
|
| 274 |
+
dec = mmgpt.gen_vision_model.decode_code(generated_tokens.to(dtype=torch.int), shape=[parallel_size, 8, img_size//patch_size, img_size//patch_size])
|
| 275 |
+
dec = dec.to(torch.float32).cpu().numpy().transpose(0, 2, 3, 1)
|
| 276 |
+
|
| 277 |
+
dec = np.clip((dec + 1) / 2 * 255, 0, 255)
|
| 278 |
+
|
| 279 |
+
visual_img = np.zeros((parallel_size, img_size, img_size, 3), dtype=np.uint8)
|
| 280 |
+
visual_img[:, :, :] = dec
|
| 281 |
+
|
| 282 |
+
os.makedirs('generated_samples', exist_ok=True)
|
| 283 |
+
for i in range(parallel_size):
|
| 284 |
+
save_path = os.path.join('generated_samples', "img_{}.jpg".format(i))
|
| 285 |
+
PIL.Image.fromarray(visual_img[i]).save(save_path)
|
| 286 |
+
|
| 287 |
+
|
| 288 |
+
generate(
|
| 289 |
+
vl_gpt,
|
| 290 |
+
vl_chat_processor,
|
| 291 |
+
prompt,
|
| 292 |
+
)
|
| 293 |
+
```
|
| 294 |
+
|
| 295 |
+
### Gradio Demo
|
| 296 |
+
We have deployed online demo in [Huggingface](https://huggingface.co/spaces/deepseek-ai/Janus-Pro-7B).
|
| 297 |
+
|
| 298 |
+
|
| 299 |
+
For the local gradio demo, you can run with the following command:
|
| 300 |
+
|
| 301 |
+
```
|
| 302 |
+
pip install -e .[gradio]
|
| 303 |
+
|
| 304 |
+
python demo/app_januspro.py
|
| 305 |
+
```
|
| 306 |
+
|
| 307 |
+
Have Fun!
|
| 308 |
+
|
| 309 |
+
</details>
|
| 310 |
+
|
| 311 |
+
|
| 312 |
+
|
| 313 |
+
<details>
|
| 314 |
+
<summary><h3>Janus</h3></summary>
|
| 315 |
+
|
| 316 |
+
### Installation
|
| 317 |
+
|
| 318 |
+
On the basis of `Python >= 3.8` environment, install the necessary dependencies by running the following command:
|
| 319 |
+
|
| 320 |
+
```shell
|
| 321 |
+
pip install -e .
|
| 322 |
+
```
|
| 323 |
+
|
| 324 |
+
|
| 325 |
+
### Simple Inference Example
|
| 326 |
+
|
| 327 |
+
#### Multimodal Understanding
|
| 328 |
+
```python
|
| 329 |
+
|
| 330 |
+
import torch
|
| 331 |
+
from transformers import AutoModelForCausalLM
|
| 332 |
+
from janus.models import MultiModalityCausalLM, VLChatProcessor
|
| 333 |
+
from janus.utils.io import load_pil_images
|
| 334 |
+
|
| 335 |
+
# specify the path to the model
|
| 336 |
+
model_path = "deepseek-ai/Janus-1.3B"
|
| 337 |
+
vl_chat_processor: VLChatProcessor = VLChatProcessor.from_pretrained(model_path)
|
| 338 |
+
tokenizer = vl_chat_processor.tokenizer
|
| 339 |
+
|
| 340 |
+
vl_gpt: MultiModalityCausalLM = AutoModelForCausalLM.from_pretrained(
|
| 341 |
+
model_path, trust_remote_code=True
|
| 342 |
+
)
|
| 343 |
+
vl_gpt = vl_gpt.to(torch.bfloat16).cuda().eval()
|
| 344 |
+
|
| 345 |
+
conversation = [
|
| 346 |
+
{
|
| 347 |
+
"role": "User",
|
| 348 |
+
"content": "<image_placeholder>\nConvert the formula into latex code.",
|
| 349 |
+
"images": ["images/equation.png"],
|
| 350 |
+
},
|
| 351 |
+
{"role": "Assistant", "content": ""},
|
| 352 |
+
]
|
| 353 |
+
|
| 354 |
+
# load images and prepare for inputs
|
| 355 |
+
pil_images = load_pil_images(conversation)
|
| 356 |
+
prepare_inputs = vl_chat_processor(
|
| 357 |
+
conversations=conversation, images=pil_images, force_batchify=True
|
| 358 |
+
).to(vl_gpt.device)
|
| 359 |
+
|
| 360 |
+
# # run image encoder to get the image embeddings
|
| 361 |
+
inputs_embeds = vl_gpt.prepare_inputs_embeds(**prepare_inputs)
|
| 362 |
+
|
| 363 |
+
# # run the model to get the response
|
| 364 |
+
outputs = vl_gpt.language_model.generate(
|
| 365 |
+
inputs_embeds=inputs_embeds,
|
| 366 |
+
attention_mask=prepare_inputs.attention_mask,
|
| 367 |
+
pad_token_id=tokenizer.eos_token_id,
|
| 368 |
+
bos_token_id=tokenizer.bos_token_id,
|
| 369 |
+
eos_token_id=tokenizer.eos_token_id,
|
| 370 |
+
max_new_tokens=512,
|
| 371 |
+
do_sample=False,
|
| 372 |
+
use_cache=True,
|
| 373 |
+
)
|
| 374 |
+
|
| 375 |
+
answer = tokenizer.decode(outputs[0].cpu().tolist(), skip_special_tokens=True)
|
| 376 |
+
print(f"{prepare_inputs['sft_format'][0]}", answer)
|
| 377 |
+
|
| 378 |
+
```
|
| 379 |
+
|
| 380 |
+
#### Text-to-Image Generation
|
| 381 |
+
```python
|
| 382 |
+
import os
|
| 383 |
+
import PIL.Image
|
| 384 |
+
import torch
|
| 385 |
+
import numpy as np
|
| 386 |
+
from transformers import AutoModelForCausalLM
|
| 387 |
+
from janus.models import MultiModalityCausalLM, VLChatProcessor
|
| 388 |
+
|
| 389 |
+
|
| 390 |
+
# specify the path to the model
|
| 391 |
+
model_path = "deepseek-ai/Janus-1.3B"
|
| 392 |
+
vl_chat_processor: VLChatProcessor = VLChatProcessor.from_pretrained(model_path)
|
| 393 |
+
tokenizer = vl_chat_processor.tokenizer
|
| 394 |
+
|
| 395 |
+
vl_gpt: MultiModalityCausalLM = AutoModelForCausalLM.from_pretrained(
|
| 396 |
+
model_path, trust_remote_code=True
|
| 397 |
+
)
|
| 398 |
+
vl_gpt = vl_gpt.to(torch.bfloat16).cuda().eval()
|
| 399 |
+
|
| 400 |
+
conversation = [
|
| 401 |
+
{
|
| 402 |
+
"role": "User",
|
| 403 |
+
"content": "A stunning princess from kabul in red, white traditional clothing, blue eyes, brown hair",
|
| 404 |
+
},
|
| 405 |
+
{"role": "Assistant", "content": ""},
|
| 406 |
+
]
|
| 407 |
+
|
| 408 |
+
sft_format = vl_chat_processor.apply_sft_template_for_multi_turn_prompts(
|
| 409 |
+
conversations=conversation,
|
| 410 |
+
sft_format=vl_chat_processor.sft_format,
|
| 411 |
+
system_prompt="",
|
| 412 |
+
)
|
| 413 |
+
prompt = sft_format + vl_chat_processor.image_start_tag
|
| 414 |
+
|
| 415 |
+
|
| 416 |
+
@torch.inference_mode()
|
| 417 |
+
def generate(
|
| 418 |
+
mmgpt: MultiModalityCausalLM,
|
| 419 |
+
vl_chat_processor: VLChatProcessor,
|
| 420 |
+
prompt: str,
|
| 421 |
+
temperature: float = 1,
|
| 422 |
+
parallel_size: int = 16,
|
| 423 |
+
cfg_weight: float = 5,
|
| 424 |
+
image_token_num_per_image: int = 576,
|
| 425 |
+
img_size: int = 384,
|
| 426 |
+
patch_size: int = 16,
|
| 427 |
+
):
|
| 428 |
+
input_ids = vl_chat_processor.tokenizer.encode(prompt)
|
| 429 |
+
input_ids = torch.LongTensor(input_ids)
|
| 430 |
+
|
| 431 |
+
tokens = torch.zeros((parallel_size*2, len(input_ids)), dtype=torch.int).cuda()
|
| 432 |
+
for i in range(parallel_size*2):
|
| 433 |
+
tokens[i, :] = input_ids
|
| 434 |
+
if i % 2 != 0:
|
| 435 |
+
tokens[i, 1:-1] = vl_chat_processor.pad_id
|
| 436 |
+
|
| 437 |
+
inputs_embeds = mmgpt.language_model.get_input_embeddings()(tokens)
|
| 438 |
+
|
| 439 |
+
generated_tokens = torch.zeros((parallel_size, image_token_num_per_image), dtype=torch.int).cuda()
|
| 440 |
+
|
| 441 |
+
for i in range(image_token_num_per_image):
|
| 442 |
+
outputs = mmgpt.language_model.model(inputs_embeds=inputs_embeds, use_cache=True, past_key_values=outputs.past_key_values if i != 0 else None)
|
| 443 |
+
hidden_states = outputs.last_hidden_state
|
| 444 |
+
|
| 445 |
+
logits = mmgpt.gen_head(hidden_states[:, -1, :])
|
| 446 |
+
logit_cond = logits[0::2, :]
|
| 447 |
+
logit_uncond = logits[1::2, :]
|
| 448 |
+
|
| 449 |
+
logits = logit_uncond + cfg_weight * (logit_cond-logit_uncond)
|
| 450 |
+
probs = torch.softmax(logits / temperature, dim=-1)
|
| 451 |
+
|
| 452 |
+
next_token = torch.multinomial(probs, num_samples=1)
|
| 453 |
+
generated_tokens[:, i] = next_token.squeeze(dim=-1)
|
| 454 |
+
|
| 455 |
+
next_token = torch.cat([next_token.unsqueeze(dim=1), next_token.unsqueeze(dim=1)], dim=1).view(-1)
|
| 456 |
+
img_embeds = mmgpt.prepare_gen_img_embeds(next_token)
|
| 457 |
+
inputs_embeds = img_embeds.unsqueeze(dim=1)
|
| 458 |
+
|
| 459 |
+
|
| 460 |
+
dec = mmgpt.gen_vision_model.decode_code(generated_tokens.to(dtype=torch.int), shape=[parallel_size, 8, img_size//patch_size, img_size//patch_size])
|
| 461 |
+
dec = dec.to(torch.float32).cpu().numpy().transpose(0, 2, 3, 1)
|
| 462 |
+
|
| 463 |
+
dec = np.clip((dec + 1) / 2 * 255, 0, 255)
|
| 464 |
+
|
| 465 |
+
visual_img = np.zeros((parallel_size, img_size, img_size, 3), dtype=np.uint8)
|
| 466 |
+
visual_img[:, :, :] = dec
|
| 467 |
+
|
| 468 |
+
os.makedirs('generated_samples', exist_ok=True)
|
| 469 |
+
for i in range(parallel_size):
|
| 470 |
+
save_path = os.path.join('generated_samples', "img_{}.jpg".format(i))
|
| 471 |
+
PIL.Image.fromarray(visual_img[i]).save(save_path)
|
| 472 |
+
|
| 473 |
+
|
| 474 |
+
generate(
|
| 475 |
+
vl_gpt,
|
| 476 |
+
vl_chat_processor,
|
| 477 |
+
prompt,
|
| 478 |
+
)
|
| 479 |
+
```
|
| 480 |
+
|
| 481 |
+
### Gradio Demo
|
| 482 |
+
We have deployed online demo in [Huggingface](https://huggingface.co/spaces/deepseek-ai/Janus-1.3B).
|
| 483 |
+
|
| 484 |
+
|
| 485 |
+
For the local gradio demo, you can run with the following command:
|
| 486 |
+
|
| 487 |
+
```
|
| 488 |
+
pip install -e .[gradio]
|
| 489 |
+
|
| 490 |
+
python demo/app.py
|
| 491 |
+
```
|
| 492 |
+
|
| 493 |
+
Have Fun!
|
| 494 |
+
|
| 495 |
+
### FastAPI Demo
|
| 496 |
+
It's easy to run a FastAPI server to host an API server running the same functions as gradio.
|
| 497 |
+
|
| 498 |
+
To start FastAPI server, run the following command:
|
| 499 |
+
|
| 500 |
+
```
|
| 501 |
+
python demo/fastapi_app.py
|
| 502 |
+
```
|
| 503 |
+
|
| 504 |
+
To test the server, you can open another terminal and run:
|
| 505 |
+
|
| 506 |
+
```
|
| 507 |
+
python demo/fastapi_client.py
|
| 508 |
+
```
|
| 509 |
+
</details>
|
| 510 |
+
|
| 511 |
+
<details>
|
| 512 |
+
<summary><h3>JanusFlow</h3></summary>
|
| 513 |
+
|
| 514 |
+
### Installation
|
| 515 |
+
|
| 516 |
+
On the basis of `Python >= 3.8` environment, install the necessary dependencies by running the following command:
|
| 517 |
+
|
| 518 |
+
```shell
|
| 519 |
+
pip install -e .
|
| 520 |
+
pip install diffusers[torch]
|
| 521 |
+
```
|
| 522 |
+
|
| 523 |
+
### 🤗 Huggingface Online Demo
|
| 524 |
+
Check out the demo in [this link](https://huggingface.co/spaces/deepseek-ai/JanusFlow-1.3B).
|
| 525 |
+
|
| 526 |
+
### Simple Inference Example
|
| 527 |
+
|
| 528 |
+
#### Multimodal Understanding
|
| 529 |
+
```python
|
| 530 |
+
|
| 531 |
+
import torch
|
| 532 |
+
from janus.janusflow.models import MultiModalityCausalLM, VLChatProcessor
|
| 533 |
+
from janus.utils.io import load_pil_images
|
| 534 |
+
|
| 535 |
+
# specify the path to the model
|
| 536 |
+
model_path = "deepseek-ai/JanusFlow-1.3B"
|
| 537 |
+
vl_chat_processor: VLChatProcessor = VLChatProcessor.from_pretrained(model_path)
|
| 538 |
+
tokenizer = vl_chat_processor.tokenizer
|
| 539 |
+
|
| 540 |
+
vl_gpt = MultiModalityCausalLM.from_pretrained(
|
| 541 |
+
model_path, trust_remote_code=True
|
| 542 |
+
)
|
| 543 |
+
vl_gpt = vl_gpt.to(torch.bfloat16).cuda().eval()
|
| 544 |
+
|
| 545 |
+
conversation = [
|
| 546 |
+
{
|
| 547 |
+
"role": "User",
|
| 548 |
+
"content": "<image_placeholder>\nConvert the formula into latex code.",
|
| 549 |
+
"images": ["images/equation.png"],
|
| 550 |
+
},
|
| 551 |
+
{"role": "Assistant", "content": ""},
|
| 552 |
+
]
|
| 553 |
+
|
| 554 |
+
# load images and prepare for inputs
|
| 555 |
+
pil_images = load_pil_images(conversation)
|
| 556 |
+
prepare_inputs = vl_chat_processor(
|
| 557 |
+
conversations=conversation, images=pil_images, force_batchify=True
|
| 558 |
+
).to(vl_gpt.device)
|
| 559 |
+
|
| 560 |
+
# # run image encoder to get the image embeddings
|
| 561 |
+
inputs_embeds = vl_gpt.prepare_inputs_embeds(**prepare_inputs)
|
| 562 |
+
|
| 563 |
+
# # run the model to get the response
|
| 564 |
+
outputs = vl_gpt.language_model.generate(
|
| 565 |
+
inputs_embeds=inputs_embeds,
|
| 566 |
+
attention_mask=prepare_inputs.attention_mask,
|
| 567 |
+
pad_token_id=tokenizer.eos_token_id,
|
| 568 |
+
bos_token_id=tokenizer.bos_token_id,
|
| 569 |
+
eos_token_id=tokenizer.eos_token_id,
|
| 570 |
+
max_new_tokens=512,
|
| 571 |
+
do_sample=False,
|
| 572 |
+
use_cache=True,
|
| 573 |
+
)
|
| 574 |
+
|
| 575 |
+
answer = tokenizer.decode(outputs[0].cpu().tolist(), skip_special_tokens=True)
|
| 576 |
+
print(f"{prepare_inputs['sft_format'][0]}", answer)
|
| 577 |
+
|
| 578 |
+
```
|
| 579 |
+
|
| 580 |
+
#### Text-to-Image Generation
|
| 581 |
+
```python
|
| 582 |
+
import os
|
| 583 |
+
import PIL.Image
|
| 584 |
+
import torch
|
| 585 |
+
import numpy as np
|
| 586 |
+
from janus.janusflow.models import MultiModalityCausalLM, VLChatProcessor
|
| 587 |
+
import torchvision
|
| 588 |
+
|
| 589 |
+
|
| 590 |
+
# specify the path to the model
|
| 591 |
+
model_path = "deepseek-ai/JanusFlow-1.3B"
|
| 592 |
+
vl_chat_processor: VLChatProcessor = VLChatProcessor.from_pretrained(model_path)
|
| 593 |
+
tokenizer = vl_chat_processor.tokenizer
|
| 594 |
+
|
| 595 |
+
vl_gpt = MultiModalityCausalLM.from_pretrained(
|
| 596 |
+
model_path, trust_remote_code=True
|
| 597 |
+
)
|
| 598 |
+
vl_gpt = vl_gpt.to(torch.bfloat16).cuda().eval()
|
| 599 |
+
|
| 600 |
+
from diffusers.models import AutoencoderKL
|
| 601 |
+
# remember to use bfloat16 dtype, this vae doesn't work with fp16
|
| 602 |
+
vae = AutoencoderKL.from_pretrained("stabilityai/sdxl-vae")
|
| 603 |
+
vae = vae.to(torch.bfloat16).cuda().eval()
|
| 604 |
+
|
| 605 |
+
conversation = [
|
| 606 |
+
{
|
| 607 |
+
"role": "User",
|
| 608 |
+
"content": "A stunning princess from kabul in red, white traditional clothing, blue eyes, brown hair",
|
| 609 |
+
},
|
| 610 |
+
{"role": "Assistant", "content": ""},
|
| 611 |
+
]
|
| 612 |
+
|
| 613 |
+
sft_format = vl_chat_processor.apply_sft_template_for_multi_turn_prompts(
|
| 614 |
+
conversations=conversation,
|
| 615 |
+
sft_format=vl_chat_processor.sft_format,
|
| 616 |
+
system_prompt="",
|
| 617 |
+
)
|
| 618 |
+
prompt = sft_format + vl_chat_processor.image_gen_tag
|
| 619 |
+
|
| 620 |
+
|
| 621 |
+
@torch.inference_mode()
|
| 622 |
+
def generate(
|
| 623 |
+
mmgpt: MultiModalityCausalLM,
|
| 624 |
+
vl_chat_processor: VLChatProcessor,
|
| 625 |
+
prompt: str,
|
| 626 |
+
cfg_weight: float = 5.0,
|
| 627 |
+
num_inference_steps: int = 30,
|
| 628 |
+
batchsize: int = 5
|
| 629 |
+
):
|
| 630 |
+
input_ids = vl_chat_processor.tokenizer.encode(prompt)
|
| 631 |
+
input_ids = torch.LongTensor(input_ids)
|
| 632 |
+
|
| 633 |
+
tokens = torch.stack([input_ids] * 2 * batchsize).cuda()
|
| 634 |
+
tokens[batchsize:, 1:] = vl_chat_processor.pad_id
|
| 635 |
+
inputs_embeds = vl_gpt.language_model.get_input_embeddings()(tokens)
|
| 636 |
+
|
| 637 |
+
# we remove the last <bog> token and replace it with t_emb later
|
| 638 |
+
inputs_embeds = inputs_embeds[:, :-1, :]
|
| 639 |
+
|
| 640 |
+
# generate with rectified flow ode
|
| 641 |
+
# step 1: encode with vision_gen_enc
|
| 642 |
+
z = torch.randn((batchsize, 4, 48, 48), dtype=torch.bfloat16).cuda()
|
| 643 |
+
|
| 644 |
+
dt = 1.0 / num_inference_steps
|
| 645 |
+
dt = torch.zeros_like(z).cuda().to(torch.bfloat16) + dt
|
| 646 |
+
|
| 647 |
+
# step 2: run ode
|
| 648 |
+
attention_mask = torch.ones((2*batchsize, inputs_embeds.shape[1]+577)).to(vl_gpt.device)
|
| 649 |
+
attention_mask[batchsize:, 1:inputs_embeds.shape[1]] = 0
|
| 650 |
+
attention_mask = attention_mask.int()
|
| 651 |
+
for step in range(num_inference_steps):
|
| 652 |
+
# prepare inputs for the llm
|
| 653 |
+
z_input = torch.cat([z, z], dim=0) # for cfg
|
| 654 |
+
t = step / num_inference_steps * 1000.
|
| 655 |
+
t = torch.tensor([t] * z_input.shape[0]).to(dt)
|
| 656 |
+
z_enc = vl_gpt.vision_gen_enc_model(z_input, t)
|
| 657 |
+
z_emb, t_emb, hs = z_enc[0], z_enc[1], z_enc[2]
|
| 658 |
+
z_emb = z_emb.view(z_emb.shape[0], z_emb.shape[1], -1).permute(0, 2, 1)
|
| 659 |
+
z_emb = vl_gpt.vision_gen_enc_aligner(z_emb)
|
| 660 |
+
llm_emb = torch.cat([inputs_embeds, t_emb.unsqueeze(1), z_emb], dim=1)
|
| 661 |
+
|
| 662 |
+
# input to the llm
|
| 663 |
+
# we apply attention mask for CFG: 1 for tokens that are not masked, 0 for tokens that are masked.
|
| 664 |
+
if step == 0:
|
| 665 |
+
outputs = vl_gpt.language_model.model(inputs_embeds=llm_emb,
|
| 666 |
+
use_cache=True,
|
| 667 |
+
attention_mask=attention_mask,
|
| 668 |
+
past_key_values=None)
|
| 669 |
+
past_key_values = []
|
| 670 |
+
for kv_cache in past_key_values:
|
| 671 |
+
k, v = kv_cache[0], kv_cache[1]
|
| 672 |
+
past_key_values.append((k[:, :, :inputs_embeds.shape[1], :], v[:, :, :inputs_embeds.shape[1], :]))
|
| 673 |
+
past_key_values = tuple(past_key_values)
|
| 674 |
+
else:
|
| 675 |
+
outputs = vl_gpt.language_model.model(inputs_embeds=llm_emb,
|
| 676 |
+
use_cache=True,
|
| 677 |
+
attention_mask=attention_mask,
|
| 678 |
+
past_key_values=past_key_values)
|
| 679 |
+
hidden_states = outputs.last_hidden_state
|
| 680 |
+
|
| 681 |
+
# transform hidden_states back to v
|
| 682 |
+
hidden_states = vl_gpt.vision_gen_dec_aligner(vl_gpt.vision_gen_dec_aligner_norm(hidden_states[:, -576:, :]))
|
| 683 |
+
hidden_states = hidden_states.reshape(z_emb.shape[0], 24, 24, 768).permute(0, 3, 1, 2)
|
| 684 |
+
v = vl_gpt.vision_gen_dec_model(hidden_states, hs, t_emb)
|
| 685 |
+
v_cond, v_uncond = torch.chunk(v, 2)
|
| 686 |
+
v = cfg_weight * v_cond - (cfg_weight-1.) * v_uncond
|
| 687 |
+
z = z + dt * v
|
| 688 |
+
|
| 689 |
+
# step 3: decode with vision_gen_dec and sdxl vae
|
| 690 |
+
decoded_image = vae.decode(z / vae.config.scaling_factor).sample
|
| 691 |
+
|
| 692 |
+
os.makedirs('generated_samples', exist_ok=True)
|
| 693 |
+
save_path = os.path.join('generated_samples', "img.jpg")
|
| 694 |
+
torchvision.utils.save_image(decoded_image.clip_(-1.0, 1.0)*0.5+0.5, save_path)
|
| 695 |
+
|
| 696 |
+
generate(
|
| 697 |
+
vl_gpt,
|
| 698 |
+
vl_chat_processor,
|
| 699 |
+
prompt,
|
| 700 |
+
cfg_weight=2.0,
|
| 701 |
+
num_inference_steps=30,
|
| 702 |
+
batchsize=5
|
| 703 |
+
)
|
| 704 |
+
```
|
| 705 |
+
|
| 706 |
+
### Gradio Demo
|
| 707 |
+
For the local gradio demo, you can run with the following command:
|
| 708 |
+
|
| 709 |
+
```
|
| 710 |
+
pip install -e .[gradio]
|
| 711 |
+
|
| 712 |
+
python demo/app_janusflow.py
|
| 713 |
+
```
|
| 714 |
+
|
| 715 |
+
Have Fun!
|
| 716 |
+
|
| 717 |
+
</details>
|
| 718 |
+
|
| 719 |
+
## 4. License
|
| 720 |
+
|
| 721 |
+
This code repository is licensed under [the MIT License](https://github.com/deepseek-ai/DeepSeek-LLM/blob/HEAD/LICENSE-CODE). The use of Janus models is subject to [DeepSeek Model License](https://github.com/deepseek-ai/DeepSeek-LLM/blob/HEAD/LICENSE-MODEL).
|
| 722 |
+
|
| 723 |
+
## 5. Citation
|
| 724 |
+
|
| 725 |
+
```bibtex
|
| 726 |
+
@article{chen2025janus,
|
| 727 |
+
title={Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling},
|
| 728 |
+
author={Chen, Xiaokang and Wu, Zhiyu and Liu, Xingchao and Pan, Zizheng and Liu, Wen and Xie, Zhenda and Yu, Xingkai and Ruan, Chong},
|
| 729 |
+
journal={arXiv preprint arXiv:2501.17811},
|
| 730 |
+
year={2025}
|
| 731 |
+
}
|
| 732 |
+
|
| 733 |
+
@article{wu2024janus,
|
| 734 |
+
title={Janus: Decoupling visual encoding for unified multimodal understanding and generation},
|
| 735 |
+
author={Wu, Chengyue and Chen, Xiaokang and Wu, Zhiyu and Ma, Yiyang and Liu, Xingchao and Pan, Zizheng and Liu, Wen and Xie, Zhenda and Yu, Xingkai and Ruan, Chong and others},
|
| 736 |
+
journal={arXiv preprint arXiv:2410.13848},
|
| 737 |
+
year={2024}
|
| 738 |
+
}
|
| 739 |
+
|
| 740 |
+
@misc{ma2024janusflow,
|
| 741 |
+
title={JanusFlow: Harmonizing Autoregression and Rectified Flow for Unified Multimodal Understanding and Generation},
|
| 742 |
+
author={Yiyang Ma and Xingchao Liu and Xiaokang Chen and Wen Liu and Chengyue Wu and Zhiyu Wu and Zizheng Pan and Zhenda Xie and Haowei Zhang and Xingkai yu and Liang Zhao and Yisong Wang and Jiaying Liu and Chong Ruan},
|
| 743 |
+
journal={arXiv preprint arXiv:2411.07975},
|
| 744 |
+
year={2024}
|
| 745 |
+
}
|
| 746 |
+
```
|
| 747 |
+
|
| 748 |
+
## 6. Contact
|
| 749 |
+
|
| 750 |
+
If you have any questions, please raise an issue or contact us at [[email protected]](mailto:[email protected]).
|
demo/Janus_colab_demo.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
demo/app.py
ADDED
|
@@ -0,0 +1,224 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
import torch
|
| 3 |
+
from transformers import AutoConfig, AutoModelForCausalLM
|
| 4 |
+
from janus.models import MultiModalityCausalLM, VLChatProcessor
|
| 5 |
+
from PIL import Image
|
| 6 |
+
|
| 7 |
+
import numpy as np
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
# Load model and processor
|
| 11 |
+
model_path = "deepseek-ai/Janus-1.3B"
|
| 12 |
+
config = AutoConfig.from_pretrained(model_path)
|
| 13 |
+
language_config = config.language_config
|
| 14 |
+
language_config._attn_implementation = 'eager'
|
| 15 |
+
vl_gpt = AutoModelForCausalLM.from_pretrained(model_path,
|
| 16 |
+
language_config=language_config,
|
| 17 |
+
trust_remote_code=True)
|
| 18 |
+
vl_gpt = vl_gpt.to(torch.bfloat16).cuda()
|
| 19 |
+
|
| 20 |
+
vl_chat_processor = VLChatProcessor.from_pretrained(model_path)
|
| 21 |
+
tokenizer = vl_chat_processor.tokenizer
|
| 22 |
+
cuda_device = 'cuda' if torch.cuda.is_available() else 'cpu'
|
| 23 |
+
# Multimodal Understanding function
|
| 24 |
+
@torch.inference_mode()
|
| 25 |
+
# Multimodal Understanding function
|
| 26 |
+
def multimodal_understanding(image, question, seed, top_p, temperature):
|
| 27 |
+
# Clear CUDA cache before generating
|
| 28 |
+
torch.cuda.empty_cache()
|
| 29 |
+
|
| 30 |
+
# set seed
|
| 31 |
+
torch.manual_seed(seed)
|
| 32 |
+
np.random.seed(seed)
|
| 33 |
+
torch.cuda.manual_seed(seed)
|
| 34 |
+
|
| 35 |
+
conversation = [
|
| 36 |
+
{
|
| 37 |
+
"role": "User",
|
| 38 |
+
"content": f"<image_placeholder>\n{question}",
|
| 39 |
+
"images": [image],
|
| 40 |
+
},
|
| 41 |
+
{"role": "Assistant", "content": ""},
|
| 42 |
+
]
|
| 43 |
+
|
| 44 |
+
pil_images = [Image.fromarray(image)]
|
| 45 |
+
prepare_inputs = vl_chat_processor(
|
| 46 |
+
conversations=conversation, images=pil_images, force_batchify=True
|
| 47 |
+
).to(cuda_device, dtype=torch.bfloat16 if torch.cuda.is_available() else torch.float16)
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
inputs_embeds = vl_gpt.prepare_inputs_embeds(**prepare_inputs)
|
| 51 |
+
|
| 52 |
+
outputs = vl_gpt.language_model.generate(
|
| 53 |
+
inputs_embeds=inputs_embeds,
|
| 54 |
+
attention_mask=prepare_inputs.attention_mask,
|
| 55 |
+
pad_token_id=tokenizer.eos_token_id,
|
| 56 |
+
bos_token_id=tokenizer.bos_token_id,
|
| 57 |
+
eos_token_id=tokenizer.eos_token_id,
|
| 58 |
+
max_new_tokens=512,
|
| 59 |
+
do_sample=False if temperature == 0 else True,
|
| 60 |
+
use_cache=True,
|
| 61 |
+
temperature=temperature,
|
| 62 |
+
top_p=top_p,
|
| 63 |
+
)
|
| 64 |
+
|
| 65 |
+
answer = tokenizer.decode(outputs[0].cpu().tolist(), skip_special_tokens=True)
|
| 66 |
+
return answer
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
def generate(input_ids,
|
| 70 |
+
width,
|
| 71 |
+
height,
|
| 72 |
+
temperature: float = 1,
|
| 73 |
+
parallel_size: int = 5,
|
| 74 |
+
cfg_weight: float = 5,
|
| 75 |
+
image_token_num_per_image: int = 576,
|
| 76 |
+
patch_size: int = 16):
|
| 77 |
+
# Clear CUDA cache before generating
|
| 78 |
+
torch.cuda.empty_cache()
|
| 79 |
+
|
| 80 |
+
tokens = torch.zeros((parallel_size * 2, len(input_ids)), dtype=torch.int).to(cuda_device)
|
| 81 |
+
for i in range(parallel_size * 2):
|
| 82 |
+
tokens[i, :] = input_ids
|
| 83 |
+
if i % 2 != 0:
|
| 84 |
+
tokens[i, 1:-1] = vl_chat_processor.pad_id
|
| 85 |
+
inputs_embeds = vl_gpt.language_model.get_input_embeddings()(tokens)
|
| 86 |
+
generated_tokens = torch.zeros((parallel_size, image_token_num_per_image), dtype=torch.int).to(cuda_device)
|
| 87 |
+
|
| 88 |
+
pkv = None
|
| 89 |
+
for i in range(image_token_num_per_image):
|
| 90 |
+
outputs = vl_gpt.language_model.model(inputs_embeds=inputs_embeds,
|
| 91 |
+
use_cache=True,
|
| 92 |
+
past_key_values=pkv)
|
| 93 |
+
pkv = outputs.past_key_values
|
| 94 |
+
hidden_states = outputs.last_hidden_state
|
| 95 |
+
logits = vl_gpt.gen_head(hidden_states[:, -1, :])
|
| 96 |
+
logit_cond = logits[0::2, :]
|
| 97 |
+
logit_uncond = logits[1::2, :]
|
| 98 |
+
logits = logit_uncond + cfg_weight * (logit_cond - logit_uncond)
|
| 99 |
+
probs = torch.softmax(logits / temperature, dim=-1)
|
| 100 |
+
next_token = torch.multinomial(probs, num_samples=1)
|
| 101 |
+
generated_tokens[:, i] = next_token.squeeze(dim=-1)
|
| 102 |
+
next_token = torch.cat([next_token.unsqueeze(dim=1), next_token.unsqueeze(dim=1)], dim=1).view(-1)
|
| 103 |
+
img_embeds = vl_gpt.prepare_gen_img_embeds(next_token)
|
| 104 |
+
inputs_embeds = img_embeds.unsqueeze(dim=1)
|
| 105 |
+
patches = vl_gpt.gen_vision_model.decode_code(generated_tokens.to(dtype=torch.int),
|
| 106 |
+
shape=[parallel_size, 8, width // patch_size, height // patch_size])
|
| 107 |
+
|
| 108 |
+
return generated_tokens.to(dtype=torch.int), patches
|
| 109 |
+
|
| 110 |
+
def unpack(dec, width, height, parallel_size=5):
|
| 111 |
+
dec = dec.to(torch.float32).cpu().numpy().transpose(0, 2, 3, 1)
|
| 112 |
+
dec = np.clip((dec + 1) / 2 * 255, 0, 255)
|
| 113 |
+
|
| 114 |
+
visual_img = np.zeros((parallel_size, width, height, 3), dtype=np.uint8)
|
| 115 |
+
visual_img[:, :, :] = dec
|
| 116 |
+
|
| 117 |
+
return visual_img
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
@torch.inference_mode()
|
| 122 |
+
def generate_image(prompt,
|
| 123 |
+
seed=None,
|
| 124 |
+
guidance=5):
|
| 125 |
+
# Clear CUDA cache and avoid tracking gradients
|
| 126 |
+
torch.cuda.empty_cache()
|
| 127 |
+
# Set the seed for reproducible results
|
| 128 |
+
if seed is not None:
|
| 129 |
+
torch.manual_seed(seed)
|
| 130 |
+
torch.cuda.manual_seed(seed)
|
| 131 |
+
np.random.seed(seed)
|
| 132 |
+
width = 384
|
| 133 |
+
height = 384
|
| 134 |
+
parallel_size = 5
|
| 135 |
+
|
| 136 |
+
with torch.no_grad():
|
| 137 |
+
messages = [{'role': 'User', 'content': prompt},
|
| 138 |
+
{'role': 'Assistant', 'content': ''}]
|
| 139 |
+
text = vl_chat_processor.apply_sft_template_for_multi_turn_prompts(conversations=messages,
|
| 140 |
+
sft_format=vl_chat_processor.sft_format,
|
| 141 |
+
system_prompt='')
|
| 142 |
+
text = text + vl_chat_processor.image_start_tag
|
| 143 |
+
input_ids = torch.LongTensor(tokenizer.encode(text))
|
| 144 |
+
output, patches = generate(input_ids,
|
| 145 |
+
width // 16 * 16,
|
| 146 |
+
height // 16 * 16,
|
| 147 |
+
cfg_weight=guidance,
|
| 148 |
+
parallel_size=parallel_size)
|
| 149 |
+
images = unpack(patches,
|
| 150 |
+
width // 16 * 16,
|
| 151 |
+
height // 16 * 16)
|
| 152 |
+
|
| 153 |
+
return [Image.fromarray(images[i]).resize((1024, 1024), Image.LANCZOS) for i in range(parallel_size)]
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
# Gradio interface
|
| 158 |
+
with gr.Blocks() as demo:
|
| 159 |
+
gr.Markdown(value="# Multimodal Understanding")
|
| 160 |
+
# with gr.Row():
|
| 161 |
+
with gr.Row():
|
| 162 |
+
image_input = gr.Image()
|
| 163 |
+
with gr.Column():
|
| 164 |
+
question_input = gr.Textbox(label="Question")
|
| 165 |
+
und_seed_input = gr.Number(label="Seed", precision=0, value=42)
|
| 166 |
+
top_p = gr.Slider(minimum=0, maximum=1, value=0.95, step=0.05, label="top_p")
|
| 167 |
+
temperature = gr.Slider(minimum=0, maximum=1, value=0.1, step=0.05, label="temperature")
|
| 168 |
+
|
| 169 |
+
understanding_button = gr.Button("Chat")
|
| 170 |
+
understanding_output = gr.Textbox(label="Response")
|
| 171 |
+
|
| 172 |
+
examples_inpainting = gr.Examples(
|
| 173 |
+
label="Multimodal Understanding examples",
|
| 174 |
+
examples=[
|
| 175 |
+
[
|
| 176 |
+
"explain this meme",
|
| 177 |
+
"images/doge.png",
|
| 178 |
+
],
|
| 179 |
+
[
|
| 180 |
+
"Convert the formula into latex code.",
|
| 181 |
+
"images/equation.png",
|
| 182 |
+
],
|
| 183 |
+
],
|
| 184 |
+
inputs=[question_input, image_input],
|
| 185 |
+
)
|
| 186 |
+
|
| 187 |
+
|
| 188 |
+
gr.Markdown(value="# Text-to-Image Generation")
|
| 189 |
+
|
| 190 |
+
|
| 191 |
+
|
| 192 |
+
with gr.Row():
|
| 193 |
+
cfg_weight_input = gr.Slider(minimum=1, maximum=10, value=5, step=0.5, label="CFG Weight")
|
| 194 |
+
|
| 195 |
+
prompt_input = gr.Textbox(label="Prompt")
|
| 196 |
+
seed_input = gr.Number(label="Seed (Optional)", precision=0, value=12345)
|
| 197 |
+
|
| 198 |
+
generation_button = gr.Button("Generate Images")
|
| 199 |
+
|
| 200 |
+
image_output = gr.Gallery(label="Generated Images", columns=2, rows=2, height=300)
|
| 201 |
+
|
| 202 |
+
examples_t2i = gr.Examples(
|
| 203 |
+
label="Text to image generation examples. (Tips for designing prompts: Adding description like 'digital art' at the end of the prompt or writing the prompt in more detail can help produce better images!)",
|
| 204 |
+
examples=[
|
| 205 |
+
"Master shifu racoon wearing drip attire as a street gangster.",
|
| 206 |
+
"A cute and adorable baby fox with big brown eyes, autumn leaves in the background enchanting,immortal,fluffy, shiny mane,Petals,fairyism,unreal engine 5 and Octane Render,highly detailed, photorealistic, cinematic, natural colors.",
|
| 207 |
+
"The image features an intricately designed eye set against a circular backdrop adorned with ornate swirl patterns that evoke both realism and surrealism. At the center of attention is a strikingly vivid blue iris surrounded by delicate veins radiating outward from the pupil to create depth and intensity. The eyelashes are long and dark, casting subtle shadows on the skin around them which appears smooth yet slightly textured as if aged or weathered over time.\n\nAbove the eye, there's a stone-like structure resembling part of classical architecture, adding layers of mystery and timeless elegance to the composition. This architectural element contrasts sharply but harmoniously with the organic curves surrounding it. Below the eye lies another decorative motif reminiscent of baroque artistry, further enhancing the overall sense of eternity encapsulated within each meticulously crafted detail. \n\nOverall, the atmosphere exudes a mysterious aura intertwined seamlessly with elements suggesting timelessness, achieved through the juxtaposition of realistic textures and surreal artistic flourishes. Each component\u2014from the intricate designs framing the eye to the ancient-looking stone piece above\u2014contributes uniquely towards creating a visually captivating tableau imbued with enigmatic allure.",
|
| 208 |
+
],
|
| 209 |
+
inputs=prompt_input,
|
| 210 |
+
)
|
| 211 |
+
|
| 212 |
+
understanding_button.click(
|
| 213 |
+
multimodal_understanding,
|
| 214 |
+
inputs=[image_input, question_input, und_seed_input, top_p, temperature],
|
| 215 |
+
outputs=understanding_output
|
| 216 |
+
)
|
| 217 |
+
|
| 218 |
+
generation_button.click(
|
| 219 |
+
fn=generate_image,
|
| 220 |
+
inputs=[prompt_input, seed_input, cfg_weight_input],
|
| 221 |
+
outputs=image_output
|
| 222 |
+
)
|
| 223 |
+
|
| 224 |
+
demo.launch(share=True)
|
demo/app_janusflow.py
ADDED
|
@@ -0,0 +1,247 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
import torch
|
| 3 |
+
from janus.janusflow.models import MultiModalityCausalLM, VLChatProcessor
|
| 4 |
+
from PIL import Image
|
| 5 |
+
from diffusers.models import AutoencoderKL
|
| 6 |
+
import numpy as np
|
| 7 |
+
|
| 8 |
+
cuda_device = 'cuda' if torch.cuda.is_available() else 'cpu'
|
| 9 |
+
|
| 10 |
+
# Load model and processor
|
| 11 |
+
model_path = "deepseek-ai/JanusFlow-1.3B"
|
| 12 |
+
vl_chat_processor = VLChatProcessor.from_pretrained(model_path)
|
| 13 |
+
tokenizer = vl_chat_processor.tokenizer
|
| 14 |
+
|
| 15 |
+
vl_gpt = MultiModalityCausalLM.from_pretrained(model_path)
|
| 16 |
+
vl_gpt = vl_gpt.to(torch.bfloat16).to(cuda_device).eval()
|
| 17 |
+
|
| 18 |
+
# remember to use bfloat16 dtype, this vae doesn't work with fp16
|
| 19 |
+
vae = AutoencoderKL.from_pretrained("stabilityai/sdxl-vae")
|
| 20 |
+
vae = vae.to(torch.bfloat16).to(cuda_device).eval()
|
| 21 |
+
|
| 22 |
+
# Multimodal Understanding function
|
| 23 |
+
@torch.inference_mode()
|
| 24 |
+
# Multimodal Understanding function
|
| 25 |
+
def multimodal_understanding(image, question, seed, top_p, temperature):
|
| 26 |
+
# Clear CUDA cache before generating
|
| 27 |
+
torch.cuda.empty_cache()
|
| 28 |
+
|
| 29 |
+
# set seed
|
| 30 |
+
torch.manual_seed(seed)
|
| 31 |
+
np.random.seed(seed)
|
| 32 |
+
torch.cuda.manual_seed(seed)
|
| 33 |
+
|
| 34 |
+
conversation = [
|
| 35 |
+
{
|
| 36 |
+
"role": "User",
|
| 37 |
+
"content": f"<image_placeholder>\n{question}",
|
| 38 |
+
"images": [image],
|
| 39 |
+
},
|
| 40 |
+
{"role": "Assistant", "content": ""},
|
| 41 |
+
]
|
| 42 |
+
|
| 43 |
+
pil_images = [Image.fromarray(image)]
|
| 44 |
+
prepare_inputs = vl_chat_processor(
|
| 45 |
+
conversations=conversation, images=pil_images, force_batchify=True
|
| 46 |
+
).to(cuda_device, dtype=torch.bfloat16 if torch.cuda.is_available() else torch.float16)
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
inputs_embeds = vl_gpt.prepare_inputs_embeds(**prepare_inputs)
|
| 50 |
+
|
| 51 |
+
outputs = vl_gpt.language_model.generate(
|
| 52 |
+
inputs_embeds=inputs_embeds,
|
| 53 |
+
attention_mask=prepare_inputs.attention_mask,
|
| 54 |
+
pad_token_id=tokenizer.eos_token_id,
|
| 55 |
+
bos_token_id=tokenizer.bos_token_id,
|
| 56 |
+
eos_token_id=tokenizer.eos_token_id,
|
| 57 |
+
max_new_tokens=512,
|
| 58 |
+
do_sample=False if temperature == 0 else True,
|
| 59 |
+
use_cache=True,
|
| 60 |
+
temperature=temperature,
|
| 61 |
+
top_p=top_p,
|
| 62 |
+
)
|
| 63 |
+
|
| 64 |
+
answer = tokenizer.decode(outputs[0].cpu().tolist(), skip_special_tokens=True)
|
| 65 |
+
|
| 66 |
+
return answer
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
@torch.inference_mode()
|
| 70 |
+
def generate(
|
| 71 |
+
input_ids,
|
| 72 |
+
cfg_weight: float = 2.0,
|
| 73 |
+
num_inference_steps: int = 30
|
| 74 |
+
):
|
| 75 |
+
# we generate 5 images at a time, *2 for CFG
|
| 76 |
+
tokens = torch.stack([input_ids] * 10).cuda()
|
| 77 |
+
tokens[5:, 1:] = vl_chat_processor.pad_id
|
| 78 |
+
inputs_embeds = vl_gpt.language_model.get_input_embeddings()(tokens)
|
| 79 |
+
print(inputs_embeds.shape)
|
| 80 |
+
|
| 81 |
+
# we remove the last <bog> token and replace it with t_emb later
|
| 82 |
+
inputs_embeds = inputs_embeds[:, :-1, :]
|
| 83 |
+
|
| 84 |
+
# generate with rectified flow ode
|
| 85 |
+
# step 1: encode with vision_gen_enc
|
| 86 |
+
z = torch.randn((5, 4, 48, 48), dtype=torch.bfloat16).cuda()
|
| 87 |
+
|
| 88 |
+
dt = 1.0 / num_inference_steps
|
| 89 |
+
dt = torch.zeros_like(z).cuda().to(torch.bfloat16) + dt
|
| 90 |
+
|
| 91 |
+
# step 2: run ode
|
| 92 |
+
attention_mask = torch.ones((10, inputs_embeds.shape[1]+577)).to(vl_gpt.device)
|
| 93 |
+
attention_mask[5:, 1:inputs_embeds.shape[1]] = 0
|
| 94 |
+
attention_mask = attention_mask.int()
|
| 95 |
+
for step in range(num_inference_steps):
|
| 96 |
+
# prepare inputs for the llm
|
| 97 |
+
z_input = torch.cat([z, z], dim=0) # for cfg
|
| 98 |
+
t = step / num_inference_steps * 1000.
|
| 99 |
+
t = torch.tensor([t] * z_input.shape[0]).to(dt)
|
| 100 |
+
z_enc = vl_gpt.vision_gen_enc_model(z_input, t)
|
| 101 |
+
z_emb, t_emb, hs = z_enc[0], z_enc[1], z_enc[2]
|
| 102 |
+
z_emb = z_emb.view(z_emb.shape[0], z_emb.shape[1], -1).permute(0, 2, 1)
|
| 103 |
+
z_emb = vl_gpt.vision_gen_enc_aligner(z_emb)
|
| 104 |
+
llm_emb = torch.cat([inputs_embeds, t_emb.unsqueeze(1), z_emb], dim=1)
|
| 105 |
+
|
| 106 |
+
# input to the llm
|
| 107 |
+
# we apply attention mask for CFG: 1 for tokens that are not masked, 0 for tokens that are masked.
|
| 108 |
+
if step == 0:
|
| 109 |
+
outputs = vl_gpt.language_model.model(inputs_embeds=llm_emb,
|
| 110 |
+
use_cache=True,
|
| 111 |
+
attention_mask=attention_mask,
|
| 112 |
+
past_key_values=None)
|
| 113 |
+
past_key_values = []
|
| 114 |
+
for kv_cache in past_key_values:
|
| 115 |
+
k, v = kv_cache[0], kv_cache[1]
|
| 116 |
+
past_key_values.append((k[:, :, :inputs_embeds.shape[1], :], v[:, :, :inputs_embeds.shape[1], :]))
|
| 117 |
+
past_key_values = tuple(past_key_values)
|
| 118 |
+
else:
|
| 119 |
+
outputs = vl_gpt.language_model.model(inputs_embeds=llm_emb,
|
| 120 |
+
use_cache=True,
|
| 121 |
+
attention_mask=attention_mask,
|
| 122 |
+
past_key_values=past_key_values)
|
| 123 |
+
hidden_states = outputs.last_hidden_state
|
| 124 |
+
|
| 125 |
+
# transform hidden_states back to v
|
| 126 |
+
hidden_states = vl_gpt.vision_gen_dec_aligner(vl_gpt.vision_gen_dec_aligner_norm(hidden_states[:, -576:, :]))
|
| 127 |
+
hidden_states = hidden_states.reshape(z_emb.shape[0], 24, 24, 768).permute(0, 3, 1, 2)
|
| 128 |
+
v = vl_gpt.vision_gen_dec_model(hidden_states, hs, t_emb)
|
| 129 |
+
v_cond, v_uncond = torch.chunk(v, 2)
|
| 130 |
+
v = cfg_weight * v_cond - (cfg_weight-1.) * v_uncond
|
| 131 |
+
z = z + dt * v
|
| 132 |
+
|
| 133 |
+
# step 3: decode with vision_gen_dec and sdxl vae
|
| 134 |
+
decoded_image = vae.decode(z / vae.config.scaling_factor).sample
|
| 135 |
+
|
| 136 |
+
images = decoded_image.float().clip_(-1., 1.).permute(0,2,3,1).cpu().numpy()
|
| 137 |
+
images = ((images+1) / 2. * 255).astype(np.uint8)
|
| 138 |
+
|
| 139 |
+
return images
|
| 140 |
+
|
| 141 |
+
def unpack(dec, width, height, parallel_size=5):
|
| 142 |
+
dec = dec.to(torch.float32).cpu().numpy().transpose(0, 2, 3, 1)
|
| 143 |
+
dec = np.clip((dec + 1) / 2 * 255, 0, 255)
|
| 144 |
+
|
| 145 |
+
visual_img = np.zeros((parallel_size, width, height, 3), dtype=np.uint8)
|
| 146 |
+
visual_img[:, :, :] = dec
|
| 147 |
+
|
| 148 |
+
return visual_img
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
@torch.inference_mode()
|
| 152 |
+
def generate_image(prompt,
|
| 153 |
+
seed=None,
|
| 154 |
+
guidance=5,
|
| 155 |
+
num_inference_steps=30):
|
| 156 |
+
# Clear CUDA cache and avoid tracking gradients
|
| 157 |
+
torch.cuda.empty_cache()
|
| 158 |
+
# Set the seed for reproducible results
|
| 159 |
+
if seed is not None:
|
| 160 |
+
torch.manual_seed(seed)
|
| 161 |
+
torch.cuda.manual_seed(seed)
|
| 162 |
+
np.random.seed(seed)
|
| 163 |
+
|
| 164 |
+
with torch.no_grad():
|
| 165 |
+
messages = [{'role': 'User', 'content': prompt},
|
| 166 |
+
{'role': 'Assistant', 'content': ''}]
|
| 167 |
+
text = vl_chat_processor.apply_sft_template_for_multi_turn_prompts(conversations=messages,
|
| 168 |
+
sft_format=vl_chat_processor.sft_format,
|
| 169 |
+
system_prompt='')
|
| 170 |
+
text = text + vl_chat_processor.image_start_tag
|
| 171 |
+
input_ids = torch.LongTensor(tokenizer.encode(text))
|
| 172 |
+
images = generate(input_ids,
|
| 173 |
+
cfg_weight=guidance,
|
| 174 |
+
num_inference_steps=num_inference_steps)
|
| 175 |
+
return [Image.fromarray(images[i]).resize((1024, 1024), Image.LANCZOS) for i in range(images.shape[0])]
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
|
| 179 |
+
# Gradio interface
|
| 180 |
+
with gr.Blocks() as demo:
|
| 181 |
+
gr.Markdown(value="# Multimodal Understanding")
|
| 182 |
+
# with gr.Row():
|
| 183 |
+
with gr.Row():
|
| 184 |
+
image_input = gr.Image()
|
| 185 |
+
with gr.Column():
|
| 186 |
+
question_input = gr.Textbox(label="Question")
|
| 187 |
+
und_seed_input = gr.Number(label="Seed", precision=0, value=42)
|
| 188 |
+
top_p = gr.Slider(minimum=0, maximum=1, value=0.95, step=0.05, label="top_p")
|
| 189 |
+
temperature = gr.Slider(minimum=0, maximum=1, value=0.1, step=0.05, label="temperature")
|
| 190 |
+
|
| 191 |
+
understanding_button = gr.Button("Chat")
|
| 192 |
+
understanding_output = gr.Textbox(label="Response")
|
| 193 |
+
|
| 194 |
+
examples_inpainting = gr.Examples(
|
| 195 |
+
label="Multimodal Understanding examples",
|
| 196 |
+
examples=[
|
| 197 |
+
[
|
| 198 |
+
"explain this meme",
|
| 199 |
+
"./images/doge.png",
|
| 200 |
+
],
|
| 201 |
+
[
|
| 202 |
+
"Convert the formula into latex code.",
|
| 203 |
+
"./images/equation.png",
|
| 204 |
+
],
|
| 205 |
+
],
|
| 206 |
+
inputs=[question_input, image_input],
|
| 207 |
+
)
|
| 208 |
+
|
| 209 |
+
|
| 210 |
+
gr.Markdown(value="# Text-to-Image Generation")
|
| 211 |
+
|
| 212 |
+
|
| 213 |
+
|
| 214 |
+
with gr.Row():
|
| 215 |
+
cfg_weight_input = gr.Slider(minimum=1, maximum=10, value=2, step=0.5, label="CFG Weight")
|
| 216 |
+
step_input = gr.Slider(minimum=1, maximum=50, value=30, step=1, label="Number of Inference Steps")
|
| 217 |
+
|
| 218 |
+
prompt_input = gr.Textbox(label="Prompt")
|
| 219 |
+
seed_input = gr.Number(label="Seed (Optional)", precision=0, value=12345)
|
| 220 |
+
|
| 221 |
+
generation_button = gr.Button("Generate Images")
|
| 222 |
+
|
| 223 |
+
image_output = gr.Gallery(label="Generated Images", columns=2, rows=2, height=300)
|
| 224 |
+
|
| 225 |
+
examples_t2i = gr.Examples(
|
| 226 |
+
label="Text to image generation examples.",
|
| 227 |
+
examples=[
|
| 228 |
+
"Master shifu racoon wearing drip attire as a street gangster.",
|
| 229 |
+
"A cute and adorable baby fox with big brown eyes, autumn leaves in the background enchanting,immortal,fluffy, shiny mane,Petals,fairyism,unreal engine 5 and Octane Render,highly detailed, photorealistic, cinematic, natural colors.",
|
| 230 |
+
"The image features an intricately designed eye set against a circular backdrop adorned with ornate swirl patterns that evoke both realism and surrealism. At the center of attention is a strikingly vivid blue iris surrounded by delicate veins radiating outward from the pupil to create depth and intensity. The eyelashes are long and dark, casting subtle shadows on the skin around them which appears smooth yet slightly textured as if aged or weathered over time.\n\nAbove the eye, there's a stone-like structure resembling part of classical architecture, adding layers of mystery and timeless elegance to the composition. This architectural element contrasts sharply but harmoniously with the organic curves surrounding it. Below the eye lies another decorative motif reminiscent of baroque artistry, further enhancing the overall sense of eternity encapsulated within each meticulously crafted detail. \n\nOverall, the atmosphere exudes a mysterious aura intertwined seamlessly with elements suggesting timelessness, achieved through the juxtaposition of realistic textures and surreal artistic flourishes. Each component\u2014from the intricate designs framing the eye to the ancient-looking stone piece above\u2014contributes uniquely towards creating a visually captivating tableau imbued with enigmatic allure.",
|
| 231 |
+
],
|
| 232 |
+
inputs=prompt_input,
|
| 233 |
+
)
|
| 234 |
+
|
| 235 |
+
understanding_button.click(
|
| 236 |
+
multimodal_understanding,
|
| 237 |
+
inputs=[image_input, question_input, und_seed_input, top_p, temperature],
|
| 238 |
+
outputs=understanding_output
|
| 239 |
+
)
|
| 240 |
+
|
| 241 |
+
generation_button.click(
|
| 242 |
+
fn=generate_image,
|
| 243 |
+
inputs=[prompt_input, seed_input, cfg_weight_input, step_input],
|
| 244 |
+
outputs=image_output
|
| 245 |
+
)
|
| 246 |
+
|
| 247 |
+
demo.launch(share=True)
|
demo/app_januspro.py
ADDED
|
@@ -0,0 +1,245 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
import torch
|
| 3 |
+
from transformers import AutoConfig, AutoModelForCausalLM
|
| 4 |
+
from janus.models import MultiModalityCausalLM, VLChatProcessor
|
| 5 |
+
from janus.utils.io import load_pil_images
|
| 6 |
+
from PIL import Image
|
| 7 |
+
|
| 8 |
+
import numpy as np
|
| 9 |
+
import os
|
| 10 |
+
import time
|
| 11 |
+
# import spaces # Import spaces for ZeroGPU compatibility
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
# Load model and processor
|
| 15 |
+
model_path = "deepseek-ai/Janus-Pro-7B"
|
| 16 |
+
config = AutoConfig.from_pretrained(model_path)
|
| 17 |
+
language_config = config.language_config
|
| 18 |
+
language_config._attn_implementation = 'eager'
|
| 19 |
+
vl_gpt = AutoModelForCausalLM.from_pretrained(model_path,
|
| 20 |
+
language_config=language_config,
|
| 21 |
+
trust_remote_code=True)
|
| 22 |
+
if torch.cuda.is_available():
|
| 23 |
+
vl_gpt = vl_gpt.to(torch.bfloat16).cuda()
|
| 24 |
+
else:
|
| 25 |
+
vl_gpt = vl_gpt.to(torch.float16)
|
| 26 |
+
|
| 27 |
+
vl_chat_processor = VLChatProcessor.from_pretrained(model_path)
|
| 28 |
+
tokenizer = vl_chat_processor.tokenizer
|
| 29 |
+
cuda_device = 'cuda' if torch.cuda.is_available() else 'cpu'
|
| 30 |
+
|
| 31 |
+
@torch.inference_mode()
|
| 32 |
+
# @spaces.GPU(duration=120)
|
| 33 |
+
# Multimodal Understanding function
|
| 34 |
+
def multimodal_understanding(image, question, seed, top_p, temperature):
|
| 35 |
+
# Clear CUDA cache before generating
|
| 36 |
+
torch.cuda.empty_cache()
|
| 37 |
+
|
| 38 |
+
# set seed
|
| 39 |
+
torch.manual_seed(seed)
|
| 40 |
+
np.random.seed(seed)
|
| 41 |
+
torch.cuda.manual_seed(seed)
|
| 42 |
+
|
| 43 |
+
conversation = [
|
| 44 |
+
{
|
| 45 |
+
"role": "<|User|>",
|
| 46 |
+
"content": f"<image_placeholder>\n{question}",
|
| 47 |
+
"images": [image],
|
| 48 |
+
},
|
| 49 |
+
{"role": "<|Assistant|>", "content": ""},
|
| 50 |
+
]
|
| 51 |
+
|
| 52 |
+
pil_images = [Image.fromarray(image)]
|
| 53 |
+
prepare_inputs = vl_chat_processor(
|
| 54 |
+
conversations=conversation, images=pil_images, force_batchify=True
|
| 55 |
+
).to(cuda_device, dtype=torch.bfloat16 if torch.cuda.is_available() else torch.float16)
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
inputs_embeds = vl_gpt.prepare_inputs_embeds(**prepare_inputs)
|
| 59 |
+
|
| 60 |
+
outputs = vl_gpt.language_model.generate(
|
| 61 |
+
inputs_embeds=inputs_embeds,
|
| 62 |
+
attention_mask=prepare_inputs.attention_mask,
|
| 63 |
+
pad_token_id=tokenizer.eos_token_id,
|
| 64 |
+
bos_token_id=tokenizer.bos_token_id,
|
| 65 |
+
eos_token_id=tokenizer.eos_token_id,
|
| 66 |
+
max_new_tokens=512,
|
| 67 |
+
do_sample=False if temperature == 0 else True,
|
| 68 |
+
use_cache=True,
|
| 69 |
+
temperature=temperature,
|
| 70 |
+
top_p=top_p,
|
| 71 |
+
)
|
| 72 |
+
|
| 73 |
+
answer = tokenizer.decode(outputs[0].cpu().tolist(), skip_special_tokens=True)
|
| 74 |
+
return answer
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
def generate(input_ids,
|
| 78 |
+
width,
|
| 79 |
+
height,
|
| 80 |
+
temperature: float = 1,
|
| 81 |
+
parallel_size: int = 5,
|
| 82 |
+
cfg_weight: float = 5,
|
| 83 |
+
image_token_num_per_image: int = 576,
|
| 84 |
+
patch_size: int = 16):
|
| 85 |
+
# Clear CUDA cache before generating
|
| 86 |
+
torch.cuda.empty_cache()
|
| 87 |
+
|
| 88 |
+
tokens = torch.zeros((parallel_size * 2, len(input_ids)), dtype=torch.int).to(cuda_device)
|
| 89 |
+
for i in range(parallel_size * 2):
|
| 90 |
+
tokens[i, :] = input_ids
|
| 91 |
+
if i % 2 != 0:
|
| 92 |
+
tokens[i, 1:-1] = vl_chat_processor.pad_id
|
| 93 |
+
inputs_embeds = vl_gpt.language_model.get_input_embeddings()(tokens)
|
| 94 |
+
generated_tokens = torch.zeros((parallel_size, image_token_num_per_image), dtype=torch.int).to(cuda_device)
|
| 95 |
+
|
| 96 |
+
pkv = None
|
| 97 |
+
for i in range(image_token_num_per_image):
|
| 98 |
+
with torch.no_grad():
|
| 99 |
+
outputs = vl_gpt.language_model.model(inputs_embeds=inputs_embeds,
|
| 100 |
+
use_cache=True,
|
| 101 |
+
past_key_values=pkv)
|
| 102 |
+
pkv = outputs.past_key_values
|
| 103 |
+
hidden_states = outputs.last_hidden_state
|
| 104 |
+
logits = vl_gpt.gen_head(hidden_states[:, -1, :])
|
| 105 |
+
logit_cond = logits[0::2, :]
|
| 106 |
+
logit_uncond = logits[1::2, :]
|
| 107 |
+
logits = logit_uncond + cfg_weight * (logit_cond - logit_uncond)
|
| 108 |
+
probs = torch.softmax(logits / temperature, dim=-1)
|
| 109 |
+
next_token = torch.multinomial(probs, num_samples=1)
|
| 110 |
+
generated_tokens[:, i] = next_token.squeeze(dim=-1)
|
| 111 |
+
next_token = torch.cat([next_token.unsqueeze(dim=1), next_token.unsqueeze(dim=1)], dim=1).view(-1)
|
| 112 |
+
|
| 113 |
+
img_embeds = vl_gpt.prepare_gen_img_embeds(next_token)
|
| 114 |
+
inputs_embeds = img_embeds.unsqueeze(dim=1)
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
patches = vl_gpt.gen_vision_model.decode_code(generated_tokens.to(dtype=torch.int),
|
| 119 |
+
shape=[parallel_size, 8, width // patch_size, height // patch_size])
|
| 120 |
+
|
| 121 |
+
return generated_tokens.to(dtype=torch.int), patches
|
| 122 |
+
|
| 123 |
+
def unpack(dec, width, height, parallel_size=5):
|
| 124 |
+
dec = dec.to(torch.float32).cpu().numpy().transpose(0, 2, 3, 1)
|
| 125 |
+
dec = np.clip((dec + 1) / 2 * 255, 0, 255)
|
| 126 |
+
|
| 127 |
+
visual_img = np.zeros((parallel_size, width, height, 3), dtype=np.uint8)
|
| 128 |
+
visual_img[:, :, :] = dec
|
| 129 |
+
|
| 130 |
+
return visual_img
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
@torch.inference_mode()
|
| 135 |
+
# @spaces.GPU(duration=120) # Specify a duration to avoid timeout
|
| 136 |
+
def generate_image(prompt,
|
| 137 |
+
seed=None,
|
| 138 |
+
guidance=5,
|
| 139 |
+
t2i_temperature=1.0):
|
| 140 |
+
# Clear CUDA cache and avoid tracking gradients
|
| 141 |
+
torch.cuda.empty_cache()
|
| 142 |
+
# Set the seed for reproducible results
|
| 143 |
+
if seed is not None:
|
| 144 |
+
torch.manual_seed(seed)
|
| 145 |
+
torch.cuda.manual_seed(seed)
|
| 146 |
+
np.random.seed(seed)
|
| 147 |
+
width = 384
|
| 148 |
+
height = 384
|
| 149 |
+
parallel_size = 5
|
| 150 |
+
|
| 151 |
+
with torch.no_grad():
|
| 152 |
+
messages = [{'role': '<|User|>', 'content': prompt},
|
| 153 |
+
{'role': '<|Assistant|>', 'content': ''}]
|
| 154 |
+
text = vl_chat_processor.apply_sft_template_for_multi_turn_prompts(conversations=messages,
|
| 155 |
+
sft_format=vl_chat_processor.sft_format,
|
| 156 |
+
system_prompt='')
|
| 157 |
+
text = text + vl_chat_processor.image_start_tag
|
| 158 |
+
|
| 159 |
+
input_ids = torch.LongTensor(tokenizer.encode(text))
|
| 160 |
+
output, patches = generate(input_ids,
|
| 161 |
+
width // 16 * 16,
|
| 162 |
+
height // 16 * 16,
|
| 163 |
+
cfg_weight=guidance,
|
| 164 |
+
parallel_size=parallel_size,
|
| 165 |
+
temperature=t2i_temperature)
|
| 166 |
+
images = unpack(patches,
|
| 167 |
+
width // 16 * 16,
|
| 168 |
+
height // 16 * 16,
|
| 169 |
+
parallel_size=parallel_size)
|
| 170 |
+
|
| 171 |
+
return [Image.fromarray(images[i]).resize((768, 768), Image.LANCZOS) for i in range(parallel_size)]
|
| 172 |
+
|
| 173 |
+
|
| 174 |
+
# Gradio interface
|
| 175 |
+
with gr.Blocks() as demo:
|
| 176 |
+
gr.Markdown(value="# Multimodal Understanding")
|
| 177 |
+
with gr.Row():
|
| 178 |
+
image_input = gr.Image()
|
| 179 |
+
with gr.Column():
|
| 180 |
+
question_input = gr.Textbox(label="Question")
|
| 181 |
+
und_seed_input = gr.Number(label="Seed", precision=0, value=42)
|
| 182 |
+
top_p = gr.Slider(minimum=0, maximum=1, value=0.95, step=0.05, label="top_p")
|
| 183 |
+
temperature = gr.Slider(minimum=0, maximum=1, value=0.1, step=0.05, label="temperature")
|
| 184 |
+
|
| 185 |
+
understanding_button = gr.Button("Chat")
|
| 186 |
+
understanding_output = gr.Textbox(label="Response")
|
| 187 |
+
|
| 188 |
+
examples_inpainting = gr.Examples(
|
| 189 |
+
label="Multimodal Understanding examples",
|
| 190 |
+
examples=[
|
| 191 |
+
[
|
| 192 |
+
"explain this meme",
|
| 193 |
+
"images/doge.png",
|
| 194 |
+
],
|
| 195 |
+
[
|
| 196 |
+
"Convert the formula into latex code.",
|
| 197 |
+
"images/equation.png",
|
| 198 |
+
],
|
| 199 |
+
],
|
| 200 |
+
inputs=[question_input, image_input],
|
| 201 |
+
)
|
| 202 |
+
|
| 203 |
+
|
| 204 |
+
gr.Markdown(value="# Text-to-Image Generation")
|
| 205 |
+
|
| 206 |
+
|
| 207 |
+
|
| 208 |
+
with gr.Row():
|
| 209 |
+
cfg_weight_input = gr.Slider(minimum=1, maximum=10, value=5, step=0.5, label="CFG Weight")
|
| 210 |
+
t2i_temperature = gr.Slider(minimum=0, maximum=1, value=1.0, step=0.05, label="temperature")
|
| 211 |
+
|
| 212 |
+
prompt_input = gr.Textbox(label="Prompt. (Prompt in more detail can help produce better images!)")
|
| 213 |
+
seed_input = gr.Number(label="Seed (Optional)", precision=0, value=12345)
|
| 214 |
+
|
| 215 |
+
generation_button = gr.Button("Generate Images")
|
| 216 |
+
|
| 217 |
+
image_output = gr.Gallery(label="Generated Images", columns=2, rows=2, height=300)
|
| 218 |
+
|
| 219 |
+
examples_t2i = gr.Examples(
|
| 220 |
+
label="Text to image generation examples.",
|
| 221 |
+
examples=[
|
| 222 |
+
"Master shifu racoon wearing drip attire as a street gangster.",
|
| 223 |
+
"The face of a beautiful girl",
|
| 224 |
+
"Astronaut in a jungle, cold color palette, muted colors, detailed, 8k",
|
| 225 |
+
"A glass of red wine on a reflective surface.",
|
| 226 |
+
"A cute and adorable baby fox with big brown eyes, autumn leaves in the background enchanting,immortal,fluffy, shiny mane,Petals,fairyism,unreal engine 5 and Octane Render,highly detailed, photorealistic, cinematic, natural colors.",
|
| 227 |
+
"The image features an intricately designed eye set against a circular backdrop adorned with ornate swirl patterns that evoke both realism and surrealism. At the center of attention is a strikingly vivid blue iris surrounded by delicate veins radiating outward from the pupil to create depth and intensity. The eyelashes are long and dark, casting subtle shadows on the skin around them which appears smooth yet slightly textured as if aged or weathered over time.\n\nAbove the eye, there's a stone-like structure resembling part of classical architecture, adding layers of mystery and timeless elegance to the composition. This architectural element contrasts sharply but harmoniously with the organic curves surrounding it. Below the eye lies another decorative motif reminiscent of baroque artistry, further enhancing the overall sense of eternity encapsulated within each meticulously crafted detail. \n\nOverall, the atmosphere exudes a mysterious aura intertwined seamlessly with elements suggesting timelessness, achieved through the juxtaposition of realistic textures and surreal artistic flourishes. Each component\u2014from the intricate designs framing the eye to the ancient-looking stone piece above\u2014contributes uniquely towards creating a visually captivating tableau imbued with enigmatic allure.",
|
| 228 |
+
],
|
| 229 |
+
inputs=prompt_input,
|
| 230 |
+
)
|
| 231 |
+
|
| 232 |
+
understanding_button.click(
|
| 233 |
+
multimodal_understanding,
|
| 234 |
+
inputs=[image_input, question_input, und_seed_input, top_p, temperature],
|
| 235 |
+
outputs=understanding_output
|
| 236 |
+
)
|
| 237 |
+
|
| 238 |
+
generation_button.click(
|
| 239 |
+
fn=generate_image,
|
| 240 |
+
inputs=[prompt_input, seed_input, cfg_weight_input, t2i_temperature],
|
| 241 |
+
outputs=image_output
|
| 242 |
+
)
|
| 243 |
+
|
| 244 |
+
demo.launch(share=True)
|
| 245 |
+
# demo.queue(concurrency_count=1, max_size=10).launch(server_name="0.0.0.0", server_port=37906, root_path="/path")
|
demo/fastapi_app.py
ADDED
|
@@ -0,0 +1,178 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from fastapi import FastAPI, File, Form, UploadFile, HTTPException
|
| 2 |
+
from fastapi.responses import JSONResponse, StreamingResponse
|
| 3 |
+
import torch
|
| 4 |
+
from transformers import AutoConfig, AutoModelForCausalLM
|
| 5 |
+
from janus.models import MultiModalityCausalLM, VLChatProcessor
|
| 6 |
+
from PIL import Image
|
| 7 |
+
import numpy as np
|
| 8 |
+
import io
|
| 9 |
+
|
| 10 |
+
app = FastAPI()
|
| 11 |
+
|
| 12 |
+
# Load model and processor
|
| 13 |
+
model_path = "deepseek-ai/Janus-1.3B"
|
| 14 |
+
config = AutoConfig.from_pretrained(model_path)
|
| 15 |
+
language_config = config.language_config
|
| 16 |
+
language_config._attn_implementation = 'eager'
|
| 17 |
+
vl_gpt = AutoModelForCausalLM.from_pretrained(model_path,
|
| 18 |
+
language_config=language_config,
|
| 19 |
+
trust_remote_code=True)
|
| 20 |
+
vl_gpt = vl_gpt.to(torch.bfloat16).cuda()
|
| 21 |
+
|
| 22 |
+
vl_chat_processor = VLChatProcessor.from_pretrained(model_path)
|
| 23 |
+
tokenizer = vl_chat_processor.tokenizer
|
| 24 |
+
cuda_device = 'cuda' if torch.cuda.is_available() else 'cpu'
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
@torch.inference_mode()
|
| 28 |
+
def multimodal_understanding(image_data, question, seed, top_p, temperature):
|
| 29 |
+
torch.cuda.empty_cache()
|
| 30 |
+
torch.manual_seed(seed)
|
| 31 |
+
np.random.seed(seed)
|
| 32 |
+
torch.cuda.manual_seed(seed)
|
| 33 |
+
|
| 34 |
+
conversation = [
|
| 35 |
+
{
|
| 36 |
+
"role": "User",
|
| 37 |
+
"content": f"<image_placeholder>\n{question}",
|
| 38 |
+
"images": [image_data],
|
| 39 |
+
},
|
| 40 |
+
{"role": "Assistant", "content": ""},
|
| 41 |
+
]
|
| 42 |
+
|
| 43 |
+
pil_images = [Image.open(io.BytesIO(image_data))]
|
| 44 |
+
prepare_inputs = vl_chat_processor(
|
| 45 |
+
conversations=conversation, images=pil_images, force_batchify=True
|
| 46 |
+
).to(cuda_device, dtype=torch.bfloat16 if torch.cuda.is_available() else torch.float16)
|
| 47 |
+
|
| 48 |
+
inputs_embeds = vl_gpt.prepare_inputs_embeds(**prepare_inputs)
|
| 49 |
+
outputs = vl_gpt.language_model.generate(
|
| 50 |
+
inputs_embeds=inputs_embeds,
|
| 51 |
+
attention_mask=prepare_inputs.attention_mask,
|
| 52 |
+
pad_token_id=tokenizer.eos_token_id,
|
| 53 |
+
bos_token_id=tokenizer.bos_token_id,
|
| 54 |
+
eos_token_id=tokenizer.eos_token_id,
|
| 55 |
+
max_new_tokens=512,
|
| 56 |
+
do_sample=False if temperature == 0 else True,
|
| 57 |
+
use_cache=True,
|
| 58 |
+
temperature=temperature,
|
| 59 |
+
top_p=top_p,
|
| 60 |
+
)
|
| 61 |
+
|
| 62 |
+
answer = tokenizer.decode(outputs[0].cpu().tolist(), skip_special_tokens=True)
|
| 63 |
+
return answer
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
@app.post("/understand_image_and_question/")
|
| 67 |
+
async def understand_image_and_question(
|
| 68 |
+
file: UploadFile = File(...),
|
| 69 |
+
question: str = Form(...),
|
| 70 |
+
seed: int = Form(42),
|
| 71 |
+
top_p: float = Form(0.95),
|
| 72 |
+
temperature: float = Form(0.1)
|
| 73 |
+
):
|
| 74 |
+
image_data = await file.read()
|
| 75 |
+
response = multimodal_understanding(image_data, question, seed, top_p, temperature)
|
| 76 |
+
return JSONResponse({"response": response})
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
def generate(input_ids,
|
| 80 |
+
width,
|
| 81 |
+
height,
|
| 82 |
+
temperature: float = 1,
|
| 83 |
+
parallel_size: int = 5,
|
| 84 |
+
cfg_weight: float = 5,
|
| 85 |
+
image_token_num_per_image: int = 576,
|
| 86 |
+
patch_size: int = 16):
|
| 87 |
+
torch.cuda.empty_cache()
|
| 88 |
+
tokens = torch.zeros((parallel_size * 2, len(input_ids)), dtype=torch.int).to(cuda_device)
|
| 89 |
+
for i in range(parallel_size * 2):
|
| 90 |
+
tokens[i, :] = input_ids
|
| 91 |
+
if i % 2 != 0:
|
| 92 |
+
tokens[i, 1:-1] = vl_chat_processor.pad_id
|
| 93 |
+
inputs_embeds = vl_gpt.language_model.get_input_embeddings()(tokens)
|
| 94 |
+
generated_tokens = torch.zeros((parallel_size, image_token_num_per_image), dtype=torch.int).to(cuda_device)
|
| 95 |
+
|
| 96 |
+
pkv = None
|
| 97 |
+
for i in range(image_token_num_per_image):
|
| 98 |
+
outputs = vl_gpt.language_model.model(inputs_embeds=inputs_embeds, use_cache=True, past_key_values=pkv)
|
| 99 |
+
pkv = outputs.past_key_values
|
| 100 |
+
hidden_states = outputs.last_hidden_state
|
| 101 |
+
logits = vl_gpt.gen_head(hidden_states[:, -1, :])
|
| 102 |
+
logit_cond = logits[0::2, :]
|
| 103 |
+
logit_uncond = logits[1::2, :]
|
| 104 |
+
logits = logit_uncond + cfg_weight * (logit_cond - logit_uncond)
|
| 105 |
+
probs = torch.softmax(logits / temperature, dim=-1)
|
| 106 |
+
next_token = torch.multinomial(probs, num_samples=1)
|
| 107 |
+
generated_tokens[:, i] = next_token.squeeze(dim=-1)
|
| 108 |
+
next_token = torch.cat([next_token.unsqueeze(dim=1), next_token.unsqueeze(dim=1)], dim=1).view(-1)
|
| 109 |
+
img_embeds = vl_gpt.prepare_gen_img_embeds(next_token)
|
| 110 |
+
inputs_embeds = img_embeds.unsqueeze(dim=1)
|
| 111 |
+
patches = vl_gpt.gen_vision_model.decode_code(
|
| 112 |
+
generated_tokens.to(dtype=torch.int),
|
| 113 |
+
shape=[parallel_size, 8, width // patch_size, height // patch_size]
|
| 114 |
+
)
|
| 115 |
+
|
| 116 |
+
return generated_tokens.to(dtype=torch.int), patches
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
def unpack(dec, width, height, parallel_size=5):
|
| 120 |
+
dec = dec.to(torch.float32).cpu().numpy().transpose(0, 2, 3, 1)
|
| 121 |
+
dec = np.clip((dec + 1) / 2 * 255, 0, 255)
|
| 122 |
+
|
| 123 |
+
visual_img = np.zeros((parallel_size, width, height, 3), dtype=np.uint8)
|
| 124 |
+
visual_img[:, :, :] = dec
|
| 125 |
+
|
| 126 |
+
return visual_img
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
@torch.inference_mode()
|
| 130 |
+
def generate_image(prompt, seed, guidance):
|
| 131 |
+
torch.cuda.empty_cache()
|
| 132 |
+
seed = seed if seed is not None else 12345
|
| 133 |
+
torch.manual_seed(seed)
|
| 134 |
+
torch.cuda.manual_seed(seed)
|
| 135 |
+
np.random.seed(seed)
|
| 136 |
+
width = 384
|
| 137 |
+
height = 384
|
| 138 |
+
parallel_size = 5
|
| 139 |
+
|
| 140 |
+
with torch.no_grad():
|
| 141 |
+
messages = [{'role': 'User', 'content': prompt}, {'role': 'Assistant', 'content': ''}]
|
| 142 |
+
text = vl_chat_processor.apply_sft_template_for_multi_turn_prompts(
|
| 143 |
+
conversations=messages,
|
| 144 |
+
sft_format=vl_chat_processor.sft_format,
|
| 145 |
+
system_prompt=''
|
| 146 |
+
)
|
| 147 |
+
text = text + vl_chat_processor.image_start_tag
|
| 148 |
+
input_ids = torch.LongTensor(tokenizer.encode(text))
|
| 149 |
+
_, patches = generate(input_ids, width // 16 * 16, height // 16 * 16, cfg_weight=guidance, parallel_size=parallel_size)
|
| 150 |
+
images = unpack(patches, width // 16 * 16, height // 16 * 16)
|
| 151 |
+
|
| 152 |
+
return [Image.fromarray(images[i]).resize((1024, 1024), Image.LANCZOS) for i in range(parallel_size)]
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
@app.post("/generate_images/")
|
| 156 |
+
async def generate_images(
|
| 157 |
+
prompt: str = Form(...),
|
| 158 |
+
seed: int = Form(None),
|
| 159 |
+
guidance: float = Form(5.0),
|
| 160 |
+
):
|
| 161 |
+
try:
|
| 162 |
+
images = generate_image(prompt, seed, guidance)
|
| 163 |
+
def image_stream():
|
| 164 |
+
for img in images:
|
| 165 |
+
buf = io.BytesIO()
|
| 166 |
+
img.save(buf, format='PNG')
|
| 167 |
+
buf.seek(0)
|
| 168 |
+
yield buf.read()
|
| 169 |
+
|
| 170 |
+
return StreamingResponse(image_stream(), media_type="multipart/related")
|
| 171 |
+
except Exception as e:
|
| 172 |
+
raise HTTPException(status_code=500, detail=f"Image generation failed: {str(e)}")
|
| 173 |
+
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
if __name__ == "__main__":
|
| 177 |
+
import uvicorn
|
| 178 |
+
uvicorn.run(app, host="0.0.0.0", port=8000)
|
demo/fastapi_client.py
ADDED
|
@@ -0,0 +1,78 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import requests
|
| 2 |
+
from PIL import Image
|
| 3 |
+
import io
|
| 4 |
+
# Endpoint URLs
|
| 5 |
+
understand_image_url = "http://localhost:8000/understand_image_and_question/"
|
| 6 |
+
generate_images_url = "http://localhost:8000/generate_images/"
|
| 7 |
+
|
| 8 |
+
# Use your image file path here
|
| 9 |
+
image_path = "images/equation.png"
|
| 10 |
+
|
| 11 |
+
# Function to call the image understanding endpoint
|
| 12 |
+
def understand_image_and_question(image_path, question, seed=42, top_p=0.95, temperature=0.1):
|
| 13 |
+
files = {'file': open(image_path, 'rb')}
|
| 14 |
+
data = {
|
| 15 |
+
'question': question,
|
| 16 |
+
'seed': seed,
|
| 17 |
+
'top_p': top_p,
|
| 18 |
+
'temperature': temperature
|
| 19 |
+
}
|
| 20 |
+
response = requests.post(understand_image_url, files=files, data=data)
|
| 21 |
+
response_data = response.json()
|
| 22 |
+
print("Image Understanding Response:", response_data['response'])
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
# Function to call the text-to-image generation endpoint
|
| 26 |
+
def generate_images(prompt, seed=None, guidance=5.0):
|
| 27 |
+
data = {
|
| 28 |
+
'prompt': prompt,
|
| 29 |
+
'seed': seed,
|
| 30 |
+
'guidance': guidance
|
| 31 |
+
}
|
| 32 |
+
response = requests.post(generate_images_url, data=data, stream=True)
|
| 33 |
+
|
| 34 |
+
if response.ok:
|
| 35 |
+
img_idx = 1
|
| 36 |
+
|
| 37 |
+
# We will create a new BytesIO for each image
|
| 38 |
+
buffers = {}
|
| 39 |
+
|
| 40 |
+
try:
|
| 41 |
+
for chunk in response.iter_content(chunk_size=1024):
|
| 42 |
+
if chunk:
|
| 43 |
+
# Use a boundary detection to determine new image start
|
| 44 |
+
if img_idx not in buffers:
|
| 45 |
+
buffers[img_idx] = io.BytesIO()
|
| 46 |
+
|
| 47 |
+
buffers[img_idx].write(chunk)
|
| 48 |
+
|
| 49 |
+
# Attempt to open the image
|
| 50 |
+
try:
|
| 51 |
+
buffer = buffers[img_idx]
|
| 52 |
+
buffer.seek(0)
|
| 53 |
+
image = Image.open(buffer)
|
| 54 |
+
img_path = f"generated_image_{img_idx}.png"
|
| 55 |
+
image.save(img_path)
|
| 56 |
+
print(f"Saved: {img_path}")
|
| 57 |
+
|
| 58 |
+
# Prepare the next image buffer
|
| 59 |
+
buffer.close()
|
| 60 |
+
img_idx += 1
|
| 61 |
+
|
| 62 |
+
except Exception as e:
|
| 63 |
+
# Continue loading data into the current buffer
|
| 64 |
+
continue
|
| 65 |
+
|
| 66 |
+
except Exception as e:
|
| 67 |
+
print("Error processing image:", e)
|
| 68 |
+
else:
|
| 69 |
+
print("Failed to generate images.")
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
# Example usage
|
| 73 |
+
if __name__ == "__main__":
|
| 74 |
+
# Call the image understanding API
|
| 75 |
+
understand_image_and_question(image_path, "What is this image about?")
|
| 76 |
+
|
| 77 |
+
# Call the image generation API
|
| 78 |
+
generate_images("A beautiful sunset over a mountain range, digital art.")
|
generation_inference.py
ADDED
|
@@ -0,0 +1,116 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2023-2024 DeepSeek.
|
| 2 |
+
#
|
| 3 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 4 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 5 |
+
# the Software without restriction, including without limitation the rights to
|
| 6 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
|
| 7 |
+
# the Software, and to permit persons to whom the Software is furnished to do so,
|
| 8 |
+
# subject to the following conditions:
|
| 9 |
+
#
|
| 10 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 11 |
+
# copies or substantial portions of the Software.
|
| 12 |
+
#
|
| 13 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 14 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
|
| 15 |
+
# FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
|
| 16 |
+
# COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
|
| 17 |
+
# IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
|
| 18 |
+
# CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
| 19 |
+
|
| 20 |
+
import torch
|
| 21 |
+
from transformers import AutoModelForCausalLM
|
| 22 |
+
|
| 23 |
+
from janus.models import MultiModalityCausalLM, VLChatProcessor
|
| 24 |
+
import numpy as np
|
| 25 |
+
import os
|
| 26 |
+
import PIL.Image
|
| 27 |
+
|
| 28 |
+
# specify the path to the model
|
| 29 |
+
model_path = "deepseek-ai/Janus-1.3B"
|
| 30 |
+
vl_chat_processor: VLChatProcessor = VLChatProcessor.from_pretrained(model_path)
|
| 31 |
+
tokenizer = vl_chat_processor.tokenizer
|
| 32 |
+
|
| 33 |
+
vl_gpt: MultiModalityCausalLM = AutoModelForCausalLM.from_pretrained(
|
| 34 |
+
model_path, trust_remote_code=True
|
| 35 |
+
)
|
| 36 |
+
vl_gpt = vl_gpt.to(torch.bfloat16).cuda().eval()
|
| 37 |
+
|
| 38 |
+
conversation = [
|
| 39 |
+
{
|
| 40 |
+
"role": "User",
|
| 41 |
+
"content": "A close-up high-contrast photo of Sydney Opera House sitting next to Eiffel tower, under a blue night sky of roiling energy, exploding yellow stars, and radiating swirls of blue.",
|
| 42 |
+
},
|
| 43 |
+
{"role": "Assistant", "content": ""},
|
| 44 |
+
]
|
| 45 |
+
|
| 46 |
+
sft_format = vl_chat_processor.apply_sft_template_for_multi_turn_prompts(
|
| 47 |
+
conversations=conversation,
|
| 48 |
+
sft_format=vl_chat_processor.sft_format,
|
| 49 |
+
system_prompt="",
|
| 50 |
+
)
|
| 51 |
+
prompt = sft_format + vl_chat_processor.image_start_tag
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
@torch.inference_mode()
|
| 55 |
+
def generate(
|
| 56 |
+
mmgpt: MultiModalityCausalLM,
|
| 57 |
+
vl_chat_processor: VLChatProcessor,
|
| 58 |
+
prompt: str,
|
| 59 |
+
temperature: float = 1,
|
| 60 |
+
parallel_size: int = 16,
|
| 61 |
+
cfg_weight: float = 5,
|
| 62 |
+
image_token_num_per_image: int = 576,
|
| 63 |
+
img_size: int = 384,
|
| 64 |
+
patch_size: int = 16,
|
| 65 |
+
):
|
| 66 |
+
input_ids = vl_chat_processor.tokenizer.encode(prompt)
|
| 67 |
+
input_ids = torch.LongTensor(input_ids)
|
| 68 |
+
|
| 69 |
+
tokens = torch.zeros((parallel_size*2, len(input_ids)), dtype=torch.int).cuda()
|
| 70 |
+
for i in range(parallel_size*2):
|
| 71 |
+
tokens[i, :] = input_ids
|
| 72 |
+
if i % 2 != 0:
|
| 73 |
+
tokens[i, 1:-1] = vl_chat_processor.pad_id
|
| 74 |
+
|
| 75 |
+
inputs_embeds = mmgpt.language_model.get_input_embeddings()(tokens)
|
| 76 |
+
|
| 77 |
+
generated_tokens = torch.zeros((parallel_size, image_token_num_per_image), dtype=torch.int).cuda()
|
| 78 |
+
|
| 79 |
+
for i in range(image_token_num_per_image):
|
| 80 |
+
outputs = mmgpt.language_model.model(inputs_embeds=inputs_embeds, use_cache=True, past_key_values=outputs.past_key_values if i != 0 else None)
|
| 81 |
+
hidden_states = outputs.last_hidden_state
|
| 82 |
+
|
| 83 |
+
logits = mmgpt.gen_head(hidden_states[:, -1, :])
|
| 84 |
+
logit_cond = logits[0::2, :]
|
| 85 |
+
logit_uncond = logits[1::2, :]
|
| 86 |
+
|
| 87 |
+
logits = logit_uncond + cfg_weight * (logit_cond-logit_uncond)
|
| 88 |
+
probs = torch.softmax(logits / temperature, dim=-1)
|
| 89 |
+
|
| 90 |
+
next_token = torch.multinomial(probs, num_samples=1)
|
| 91 |
+
generated_tokens[:, i] = next_token.squeeze(dim=-1)
|
| 92 |
+
|
| 93 |
+
next_token = torch.cat([next_token.unsqueeze(dim=1), next_token.unsqueeze(dim=1)], dim=1).view(-1)
|
| 94 |
+
img_embeds = mmgpt.prepare_gen_img_embeds(next_token)
|
| 95 |
+
inputs_embeds = img_embeds.unsqueeze(dim=1)
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
dec = mmgpt.gen_vision_model.decode_code(generated_tokens.to(dtype=torch.int), shape=[parallel_size, 8, img_size//patch_size, img_size//patch_size])
|
| 99 |
+
dec = dec.to(torch.float32).cpu().numpy().transpose(0, 2, 3, 1)
|
| 100 |
+
|
| 101 |
+
dec = np.clip((dec + 1) / 2 * 255, 0, 255)
|
| 102 |
+
|
| 103 |
+
visual_img = np.zeros((parallel_size, img_size, img_size, 3), dtype=np.uint8)
|
| 104 |
+
visual_img[:, :, :] = dec
|
| 105 |
+
|
| 106 |
+
os.makedirs('generated_samples', exist_ok=True)
|
| 107 |
+
for i in range(parallel_size):
|
| 108 |
+
save_path = os.path.join('generated_samples', "img_{}.jpg".format(i))
|
| 109 |
+
PIL.Image.fromarray(visual_img[i]).save(save_path)
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
generate(
|
| 113 |
+
vl_gpt,
|
| 114 |
+
vl_chat_processor,
|
| 115 |
+
prompt,
|
| 116 |
+
)
|
images/badge.svg
ADDED
|
|
images/doge.png
ADDED

|
Git LFS Details
|
images/equation.png
ADDED
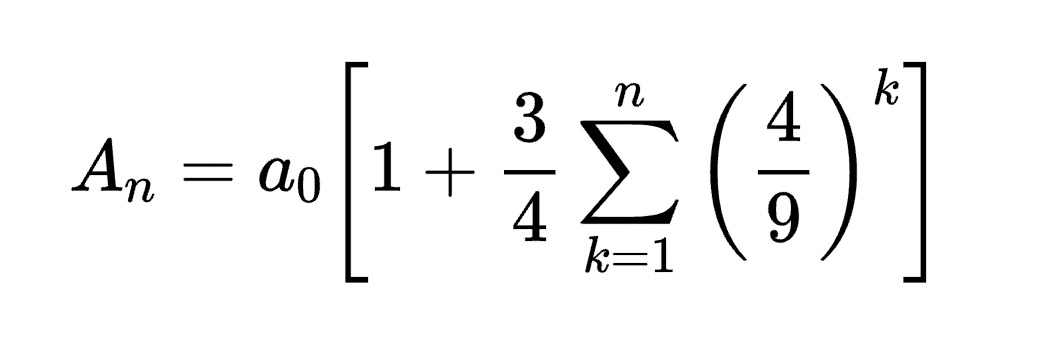
|
images/logo.png
ADDED
|
|
images/logo.svg
ADDED
|
|
images/pie_chart.png
ADDED
|
images/teaser.png
ADDED

|
Git LFS Details
|
images/teaser_janusflow.png
ADDED

|
Git LFS Details
|
images/teaser_januspro.png
ADDED
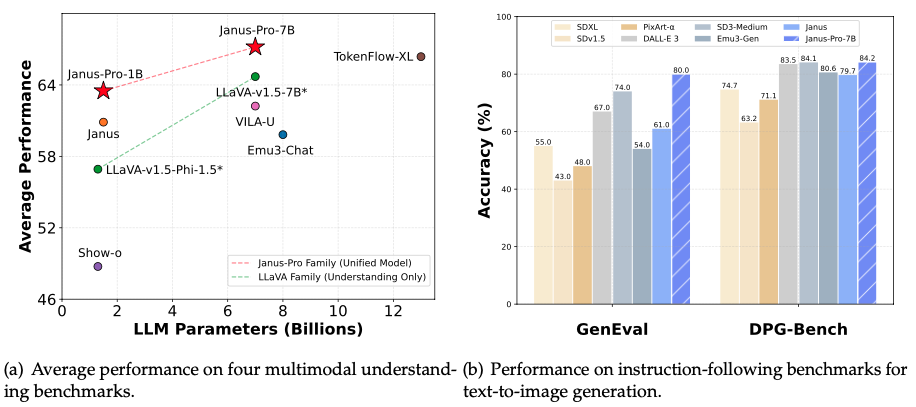
|
images/ve.png
ADDED

|
Git LFS Details
|
inference.py
ADDED
|
@@ -0,0 +1,67 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2023-2024 DeepSeek.
|
| 2 |
+
#
|
| 3 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 4 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 5 |
+
# the Software without restriction, including without limitation the rights to
|
| 6 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
|
| 7 |
+
# the Software, and to permit persons to whom the Software is furnished to do so,
|
| 8 |
+
# subject to the following conditions:
|
| 9 |
+
#
|
| 10 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 11 |
+
# copies or substantial portions of the Software.
|
| 12 |
+
#
|
| 13 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 14 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
|
| 15 |
+
# FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
|
| 16 |
+
# COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
|
| 17 |
+
# IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
|
| 18 |
+
# CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
| 19 |
+
|
| 20 |
+
import torch
|
| 21 |
+
from transformers import AutoModelForCausalLM
|
| 22 |
+
|
| 23 |
+
from janus.models import MultiModalityCausalLM, VLChatProcessor
|
| 24 |
+
from janus.utils.io import load_pil_images
|
| 25 |
+
|
| 26 |
+
# specify the path to the model
|
| 27 |
+
model_path = "deepseek-ai/Janus-1.3B"
|
| 28 |
+
vl_chat_processor: VLChatProcessor = VLChatProcessor.from_pretrained(model_path)
|
| 29 |
+
tokenizer = vl_chat_processor.tokenizer
|
| 30 |
+
|
| 31 |
+
vl_gpt: MultiModalityCausalLM = AutoModelForCausalLM.from_pretrained(
|
| 32 |
+
model_path, trust_remote_code=True
|
| 33 |
+
)
|
| 34 |
+
vl_gpt = vl_gpt.to(torch.bfloat16).cuda().eval()
|
| 35 |
+
|
| 36 |
+
conversation = [
|
| 37 |
+
{
|
| 38 |
+
"role": "User",
|
| 39 |
+
"content": "<image_placeholder>\nConvert the formula into latex code.",
|
| 40 |
+
"images": ["images/equation.png"],
|
| 41 |
+
},
|
| 42 |
+
{"role": "Assistant", "content": ""},
|
| 43 |
+
]
|
| 44 |
+
|
| 45 |
+
# load images and prepare for inputs
|
| 46 |
+
pil_images = load_pil_images(conversation)
|
| 47 |
+
prepare_inputs = vl_chat_processor(
|
| 48 |
+
conversations=conversation, images=pil_images, force_batchify=True
|
| 49 |
+
).to(vl_gpt.device)
|
| 50 |
+
|
| 51 |
+
# # run image encoder to get the image embeddings
|
| 52 |
+
inputs_embeds = vl_gpt.prepare_inputs_embeds(**prepare_inputs)
|
| 53 |
+
|
| 54 |
+
# # run the model to get the response
|
| 55 |
+
outputs = vl_gpt.language_model.generate(
|
| 56 |
+
inputs_embeds=inputs_embeds,
|
| 57 |
+
attention_mask=prepare_inputs.attention_mask,
|
| 58 |
+
pad_token_id=tokenizer.eos_token_id,
|
| 59 |
+
bos_token_id=tokenizer.bos_token_id,
|
| 60 |
+
eos_token_id=tokenizer.eos_token_id,
|
| 61 |
+
max_new_tokens=512,
|
| 62 |
+
do_sample=False,
|
| 63 |
+
use_cache=True,
|
| 64 |
+
)
|
| 65 |
+
|
| 66 |
+
answer = tokenizer.decode(outputs[0].cpu().tolist(), skip_special_tokens=True)
|
| 67 |
+
print(f"{prepare_inputs['sft_format'][0]}", answer)
|
interactivechat.py
ADDED
|
@@ -0,0 +1,150 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import PIL.Image
|
| 3 |
+
import torch
|
| 4 |
+
import numpy as np
|
| 5 |
+
from transformers import AutoModelForCausalLM
|
| 6 |
+
from janus.models import MultiModalityCausalLM, VLChatProcessor
|
| 7 |
+
import time
|
| 8 |
+
import re
|
| 9 |
+
|
| 10 |
+
# Specify the path to the model
|
| 11 |
+
model_path = "deepseek-ai/Janus-1.3B"
|
| 12 |
+
vl_chat_processor: VLChatProcessor = VLChatProcessor.from_pretrained(model_path)
|
| 13 |
+
tokenizer = vl_chat_processor.tokenizer
|
| 14 |
+
|
| 15 |
+
vl_gpt: MultiModalityCausalLM = AutoModelForCausalLM.from_pretrained(
|
| 16 |
+
model_path, trust_remote_code=True
|
| 17 |
+
)
|
| 18 |
+
vl_gpt = vl_gpt.to(torch.bfloat16).cuda().eval()
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def create_prompt(user_input: str) -> str:
|
| 22 |
+
conversation = [
|
| 23 |
+
{
|
| 24 |
+
"role": "User",
|
| 25 |
+
"content": user_input,
|
| 26 |
+
},
|
| 27 |
+
{"role": "Assistant", "content": ""},
|
| 28 |
+
]
|
| 29 |
+
|
| 30 |
+
sft_format = vl_chat_processor.apply_sft_template_for_multi_turn_prompts(
|
| 31 |
+
conversations=conversation,
|
| 32 |
+
sft_format=vl_chat_processor.sft_format,
|
| 33 |
+
system_prompt="",
|
| 34 |
+
)
|
| 35 |
+
prompt = sft_format + vl_chat_processor.image_start_tag
|
| 36 |
+
return prompt
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
@torch.inference_mode()
|
| 40 |
+
def generate(
|
| 41 |
+
mmgpt: MultiModalityCausalLM,
|
| 42 |
+
vl_chat_processor: VLChatProcessor,
|
| 43 |
+
prompt: str,
|
| 44 |
+
short_prompt: str,
|
| 45 |
+
parallel_size: int = 16,
|
| 46 |
+
temperature: float = 1,
|
| 47 |
+
cfg_weight: float = 5,
|
| 48 |
+
image_token_num_per_image: int = 576,
|
| 49 |
+
img_size: int = 384,
|
| 50 |
+
patch_size: int = 16,
|
| 51 |
+
):
|
| 52 |
+
input_ids = vl_chat_processor.tokenizer.encode(prompt)
|
| 53 |
+
input_ids = torch.LongTensor(input_ids)
|
| 54 |
+
|
| 55 |
+
tokens = torch.zeros((parallel_size * 2, len(input_ids)), dtype=torch.int).cuda()
|
| 56 |
+
for i in range(parallel_size * 2):
|
| 57 |
+
tokens[i, :] = input_ids
|
| 58 |
+
if i % 2 != 0:
|
| 59 |
+
tokens[i, 1:-1] = vl_chat_processor.pad_id
|
| 60 |
+
|
| 61 |
+
inputs_embeds = mmgpt.language_model.get_input_embeddings()(tokens)
|
| 62 |
+
|
| 63 |
+
generated_tokens = torch.zeros((parallel_size, image_token_num_per_image), dtype=torch.int).cuda()
|
| 64 |
+
outputs = None # Initialize outputs for use in the loop
|
| 65 |
+
|
| 66 |
+
for i in range(image_token_num_per_image):
|
| 67 |
+
outputs = mmgpt.language_model.model(
|
| 68 |
+
inputs_embeds=inputs_embeds,
|
| 69 |
+
use_cache=True,
|
| 70 |
+
past_key_values=outputs.past_key_values if i != 0 else None
|
| 71 |
+
)
|
| 72 |
+
hidden_states = outputs.last_hidden_state
|
| 73 |
+
|
| 74 |
+
logits = mmgpt.gen_head(hidden_states[:, -1, :])
|
| 75 |
+
logit_cond = logits[0::2, :]
|
| 76 |
+
logit_uncond = logits[1::2, :]
|
| 77 |
+
|
| 78 |
+
logits = logit_uncond + cfg_weight * (logit_cond - logit_uncond)
|
| 79 |
+
probs = torch.softmax(logits / temperature, dim=-1)
|
| 80 |
+
|
| 81 |
+
next_token = torch.multinomial(probs, num_samples=1)
|
| 82 |
+
generated_tokens[:, i] = next_token.squeeze(dim=-1)
|
| 83 |
+
|
| 84 |
+
next_token = torch.cat([next_token.unsqueeze(dim=1), next_token.unsqueeze(dim=1)], dim=1).view(-1)
|
| 85 |
+
img_embeds = mmgpt.prepare_gen_img_embeds(next_token)
|
| 86 |
+
inputs_embeds = img_embeds.unsqueeze(dim=1)
|
| 87 |
+
|
| 88 |
+
dec = mmgpt.gen_vision_model.decode_code(
|
| 89 |
+
generated_tokens.to(dtype=torch.int),
|
| 90 |
+
shape=[parallel_size, 8, img_size // patch_size, img_size // patch_size]
|
| 91 |
+
)
|
| 92 |
+
dec = dec.to(torch.float32).cpu().numpy().transpose(0, 2, 3, 1)
|
| 93 |
+
|
| 94 |
+
dec = np.clip((dec + 1) / 2 * 255, 0, 255)
|
| 95 |
+
|
| 96 |
+
visual_img = np.zeros((parallel_size, img_size, img_size, 3), dtype=np.uint8)
|
| 97 |
+
visual_img[:, :, :] = dec
|
| 98 |
+
|
| 99 |
+
os.makedirs('generated_samples', exist_ok=True)
|
| 100 |
+
|
| 101 |
+
# Create a timestamp
|
| 102 |
+
timestamp = time.strftime("%Y%m%d-%H%M%S")
|
| 103 |
+
|
| 104 |
+
# Sanitize the short_prompt to ensure it's safe for filenames
|
| 105 |
+
short_prompt = re.sub(r'\W+', '_', short_prompt)[:50]
|
| 106 |
+
|
| 107 |
+
# Save images with timestamp and part of the user prompt in the filename
|
| 108 |
+
for i in range(parallel_size):
|
| 109 |
+
save_path = os.path.join('generated_samples', f"img_{timestamp}_{short_prompt}_{i}.jpg")
|
| 110 |
+
PIL.Image.fromarray(visual_img[i]).save(save_path)
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
def interactive_image_generator():
|
| 114 |
+
print("Welcome to the interactive image generator!")
|
| 115 |
+
|
| 116 |
+
# Ask for the number of images at the start of the session
|
| 117 |
+
while True:
|
| 118 |
+
num_images_input = input("How many images would you like to generate per prompt? (Enter a positive integer): ")
|
| 119 |
+
if num_images_input.isdigit() and int(num_images_input) > 0:
|
| 120 |
+
parallel_size = int(num_images_input)
|
| 121 |
+
break
|
| 122 |
+
else:
|
| 123 |
+
print("Invalid input. Please enter a positive integer.")
|
| 124 |
+
|
| 125 |
+
while True:
|
| 126 |
+
user_input = input("Please describe the image you'd like to generate (or type 'exit' to quit): ")
|
| 127 |
+
|
| 128 |
+
if user_input.lower() == 'exit':
|
| 129 |
+
print("Exiting the image generator. Goodbye!")
|
| 130 |
+
break
|
| 131 |
+
|
| 132 |
+
prompt = create_prompt(user_input)
|
| 133 |
+
|
| 134 |
+
# Create a sanitized version of user_input for the filename
|
| 135 |
+
short_prompt = re.sub(r'\W+', '_', user_input)[:50]
|
| 136 |
+
|
| 137 |
+
print(f"Generating {parallel_size} image(s) for: '{user_input}'")
|
| 138 |
+
generate(
|
| 139 |
+
mmgpt=vl_gpt,
|
| 140 |
+
vl_chat_processor=vl_chat_processor,
|
| 141 |
+
prompt=prompt,
|
| 142 |
+
short_prompt=short_prompt,
|
| 143 |
+
parallel_size=parallel_size # Pass the user-specified number of images
|
| 144 |
+
)
|
| 145 |
+
|
| 146 |
+
print("Image generation complete! Check the 'generated_samples' folder for the output.\n")
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
if __name__ == "__main__":
|
| 150 |
+
interactive_image_generator()
|
janus/__init__.py
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2023-2024 DeepSeek.
|
| 2 |
+
#
|
| 3 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 4 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 5 |
+
# the Software without restriction, including without limitation the rights to
|
| 6 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
|
| 7 |
+
# the Software, and to permit persons to whom the Software is furnished to do so,
|
| 8 |
+
# subject to the following conditions:
|
| 9 |
+
#
|
| 10 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 11 |
+
# copies or substantial portions of the Software.
|
| 12 |
+
#
|
| 13 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 14 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
|
| 15 |
+
# FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
|
| 16 |
+
# COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
|
| 17 |
+
# IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
|
| 18 |
+
# CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
# check if python version is above 3.10
|
| 22 |
+
import sys
|
| 23 |
+
|
| 24 |
+
if sys.version_info >= (3, 10):
|
| 25 |
+
print("Python version is above 3.10, patching the collections module.")
|
| 26 |
+
# Monkey patch collections
|
| 27 |
+
import collections
|
| 28 |
+
import collections.abc
|
| 29 |
+
|
| 30 |
+
for type_name in collections.abc.__all__:
|
| 31 |
+
setattr(collections, type_name, getattr(collections.abc, type_name))
|
janus/janusflow/__init__.py
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2023-2024 DeepSeek.
|
| 2 |
+
#
|
| 3 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 4 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 5 |
+
# the Software without restriction, including without limitation the rights to
|
| 6 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
|
| 7 |
+
# the Software, and to permit persons to whom the Software is furnished to do so,
|
| 8 |
+
# subject to the following conditions:
|
| 9 |
+
#
|
| 10 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 11 |
+
# copies or substantial portions of the Software.
|
| 12 |
+
#
|
| 13 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 14 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
|
| 15 |
+
# FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
|
| 16 |
+
# COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
|
| 17 |
+
# IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
|
| 18 |
+
# CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
# check if python version is above 3.10
|
| 22 |
+
import sys
|
| 23 |
+
|
| 24 |
+
if sys.version_info >= (3, 10):
|
| 25 |
+
print("Python version is above 3.10, patching the collections module.")
|
| 26 |
+
# Monkey patch collections
|
| 27 |
+
import collections
|
| 28 |
+
import collections.abc
|
| 29 |
+
|
| 30 |
+
for type_name in collections.abc.__all__:
|
| 31 |
+
setattr(collections, type_name, getattr(collections.abc, type_name))
|
janus/janusflow/models/__init__.py
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2023-2024 DeepSeek.
|
| 2 |
+
#
|
| 3 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 4 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 5 |
+
# the Software without restriction, including without limitation the rights to
|
| 6 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
|
| 7 |
+
# the Software, and to permit persons to whom the Software is furnished to do so,
|
| 8 |
+
# subject to the following conditions:
|
| 9 |
+
#
|
| 10 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 11 |
+
# copies or substantial portions of the Software.
|
| 12 |
+
#
|
| 13 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 14 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
|
| 15 |
+
# FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
|
| 16 |
+
# COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
|
| 17 |
+
# IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
|
| 18 |
+
# CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
| 19 |
+
|
| 20 |
+
from .image_processing_vlm import VLMImageProcessor
|
| 21 |
+
from .modeling_vlm import MultiModalityCausalLM
|
| 22 |
+
from .processing_vlm import VLChatProcessor
|
| 23 |
+
|
| 24 |
+
__all__ = [
|
| 25 |
+
"VLMImageProcessor",
|
| 26 |
+
"VLChatProcessor",
|
| 27 |
+
"MultiModalityCausalLM",
|
| 28 |
+
]
|
janus/janusflow/models/clip_encoder.py
ADDED
|
@@ -0,0 +1,122 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2023-2024 DeepSeek.
|
| 2 |
+
#
|
| 3 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 4 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 5 |
+
# the Software without restriction, including without limitation the rights to
|
| 6 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
|
| 7 |
+
# the Software, and to permit persons to whom the Software is furnished to do so,
|
| 8 |
+
# subject to the following conditions:
|
| 9 |
+
#
|
| 10 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 11 |
+
# copies or substantial portions of the Software.
|
| 12 |
+
#
|
| 13 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 14 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
|
| 15 |
+
# FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
|
| 16 |
+
# COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
|
| 17 |
+
# IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
|
| 18 |
+
# CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
| 19 |
+
|
| 20 |
+
from typing import Dict, List, Literal, Optional, Tuple, Union
|
| 21 |
+
|
| 22 |
+
import torch
|
| 23 |
+
import torch.nn as nn
|
| 24 |
+
import torchvision.transforms
|
| 25 |
+
from einops import rearrange
|
| 26 |
+
|
| 27 |
+
from janus.janusflow.models.siglip_vit import create_siglip_vit
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
class CLIPVisionTower(nn.Module):
|
| 31 |
+
def __init__(
|
| 32 |
+
self,
|
| 33 |
+
model_name: str = "siglip_large_patch16_384",
|
| 34 |
+
image_size: Union[Tuple[int, int], int] = 336,
|
| 35 |
+
select_feature: str = "patch",
|
| 36 |
+
select_layer: int = -2,
|
| 37 |
+
select_layers: list = None,
|
| 38 |
+
ckpt_path: str = "",
|
| 39 |
+
pixel_mean: Optional[List[float]] = None,
|
| 40 |
+
pixel_std: Optional[List[float]] = None,
|
| 41 |
+
**kwargs,
|
| 42 |
+
):
|
| 43 |
+
super().__init__()
|
| 44 |
+
|
| 45 |
+
self.model_name = model_name
|
| 46 |
+
self.select_feature = select_feature
|
| 47 |
+
self.select_layer = select_layer
|
| 48 |
+
self.select_layers = select_layers
|
| 49 |
+
|
| 50 |
+
vision_tower_params = {
|
| 51 |
+
"model_name": model_name,
|
| 52 |
+
"image_size": image_size,
|
| 53 |
+
"ckpt_path": ckpt_path,
|
| 54 |
+
"select_layer": select_layer,
|
| 55 |
+
}
|
| 56 |
+
vision_tower_params.update(kwargs)
|
| 57 |
+
self.vision_tower, self.forward_kwargs = self.build_vision_tower(
|
| 58 |
+
vision_tower_params
|
| 59 |
+
)
|
| 60 |
+
|
| 61 |
+
if pixel_mean is not None and pixel_std is not None:
|
| 62 |
+
image_norm = torchvision.transforms.Normalize(
|
| 63 |
+
mean=pixel_mean, std=pixel_std
|
| 64 |
+
)
|
| 65 |
+
else:
|
| 66 |
+
image_norm = None
|
| 67 |
+
|
| 68 |
+
self.image_norm = image_norm
|
| 69 |
+
|
| 70 |
+
def build_vision_tower(self, vision_tower_params):
|
| 71 |
+
if self.model_name.startswith("siglip"):
|
| 72 |
+
self.select_feature = "same"
|
| 73 |
+
vision_tower = create_siglip_vit(**vision_tower_params)
|
| 74 |
+
forward_kwargs = dict()
|
| 75 |
+
|
| 76 |
+
elif self.model_name.startswith("sam"):
|
| 77 |
+
vision_tower = create_sam_vit(**vision_tower_params)
|
| 78 |
+
forward_kwargs = dict()
|
| 79 |
+
|
| 80 |
+
else: # huggingface
|
| 81 |
+
from transformers import CLIPVisionModel
|
| 82 |
+
|
| 83 |
+
vision_tower = CLIPVisionModel.from_pretrained(**vision_tower_params)
|
| 84 |
+
forward_kwargs = dict(output_hidden_states=True)
|
| 85 |
+
|
| 86 |
+
return vision_tower, forward_kwargs
|
| 87 |
+
|
| 88 |
+
def feature_select(self, image_forward_outs):
|
| 89 |
+
if isinstance(image_forward_outs, torch.Tensor):
|
| 90 |
+
# the output has been the self.select_layer"s features
|
| 91 |
+
image_features = image_forward_outs
|
| 92 |
+
else:
|
| 93 |
+
image_features = image_forward_outs.hidden_states[self.select_layer]
|
| 94 |
+
|
| 95 |
+
if self.select_feature == "patch":
|
| 96 |
+
# if the output has cls_token
|
| 97 |
+
image_features = image_features[:, 1:]
|
| 98 |
+
elif self.select_feature == "cls_patch":
|
| 99 |
+
image_features = image_features
|
| 100 |
+
elif self.select_feature == "same":
|
| 101 |
+
image_features = image_features
|
| 102 |
+
|
| 103 |
+
else:
|
| 104 |
+
raise ValueError(f"Unexpected select feature: {self.select_feature}")
|
| 105 |
+
return image_features
|
| 106 |
+
|
| 107 |
+
def forward(self, images):
|
| 108 |
+
"""
|
| 109 |
+
|
| 110 |
+
Args:
|
| 111 |
+
images (torch.Tensor): [b, 3, H, W]
|
| 112 |
+
|
| 113 |
+
Returns:
|
| 114 |
+
image_features (torch.Tensor): [b, n_patch, d]
|
| 115 |
+
"""
|
| 116 |
+
|
| 117 |
+
if self.image_norm is not None:
|
| 118 |
+
images = self.image_norm(images)
|
| 119 |
+
|
| 120 |
+
image_forward_outs = self.vision_tower(images, **self.forward_kwargs)
|
| 121 |
+
image_features = self.feature_select(image_forward_outs)
|
| 122 |
+
return image_features
|
janus/janusflow/models/image_processing_vlm.py
ADDED
|
@@ -0,0 +1,208 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2023-2024 DeepSeek.
|
| 2 |
+
#
|
| 3 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 4 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 5 |
+
# the Software without restriction, including without limitation the rights to
|
| 6 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
|
| 7 |
+
# the Software, and to permit persons to whom the Software is furnished to do so,
|
| 8 |
+
# subject to the following conditions:
|
| 9 |
+
#
|
| 10 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 11 |
+
# copies or substantial portions of the Software.
|
| 12 |
+
#
|
| 13 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 14 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
|
| 15 |
+
# FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
|
| 16 |
+
# COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
|
| 17 |
+
# IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
|
| 18 |
+
# CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
| 19 |
+
|
| 20 |
+
from typing import List, Tuple, Union
|
| 21 |
+
|
| 22 |
+
import numpy as np
|
| 23 |
+
import torch
|
| 24 |
+
import torchvision
|
| 25 |
+
import torchvision.transforms.functional
|
| 26 |
+
from PIL import Image
|
| 27 |
+
from transformers import AutoImageProcessor, PretrainedConfig
|
| 28 |
+
from transformers.image_processing_utils import BaseImageProcessor, BatchFeature
|
| 29 |
+
from transformers.image_utils import to_numpy_array
|
| 30 |
+
from transformers.utils import logging
|
| 31 |
+
|
| 32 |
+
logger = logging.get_logger(__name__)
|
| 33 |
+
|
| 34 |
+
ImageType = Union[np.ndarray, torch.Tensor, Image.Image]
|
| 35 |
+
IMAGENET_MEAN = (0.48145466, 0.4578275, 0.40821073)
|
| 36 |
+
IMAGENET_STD = (0.26862954, 0.26130258, 0.27577711)
|
| 37 |
+
IMAGENET_INCEPTION_MEAN = (0.5, 0.5, 0.5)
|
| 38 |
+
IMAGENET_INCEPTION_STD = (0.5, 0.5, 0.5)
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def expand2square(pil_img, background_color):
|
| 42 |
+
width, height = pil_img.size
|
| 43 |
+
if width == height:
|
| 44 |
+
return pil_img
|
| 45 |
+
elif width > height:
|
| 46 |
+
result = Image.new(pil_img.mode, (width, width), background_color)
|
| 47 |
+
result.paste(pil_img, (0, (width - height) // 2))
|
| 48 |
+
return result
|
| 49 |
+
else:
|
| 50 |
+
result = Image.new(pil_img.mode, (height, height), background_color)
|
| 51 |
+
result.paste(pil_img, ((height - width) // 2, 0))
|
| 52 |
+
return result
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
class VLMImageProcessorConfig(PretrainedConfig):
|
| 56 |
+
model_type = "deepseek_vlm"
|
| 57 |
+
image_size: int
|
| 58 |
+
min_size: int
|
| 59 |
+
image_mean: Union[Tuple[float, float, float], List[float]]
|
| 60 |
+
image_std: Union[Tuple[float, float, float], List[float]]
|
| 61 |
+
rescale_factor: float
|
| 62 |
+
do_normalize: bool
|
| 63 |
+
|
| 64 |
+
def __init__(
|
| 65 |
+
self,
|
| 66 |
+
image_size: int,
|
| 67 |
+
min_size: int = 14,
|
| 68 |
+
image_mean: Union[Tuple[float, float, float], List[float]] = (
|
| 69 |
+
0.48145466,
|
| 70 |
+
0.4578275,
|
| 71 |
+
0.40821073,
|
| 72 |
+
),
|
| 73 |
+
image_std: Union[Tuple[float, float, float], List[float]] = (
|
| 74 |
+
0.26862954,
|
| 75 |
+
0.26130258,
|
| 76 |
+
0.27577711,
|
| 77 |
+
),
|
| 78 |
+
rescale_factor: float = 1.0 / 255.0,
|
| 79 |
+
do_normalize: bool = True,
|
| 80 |
+
**kwargs,
|
| 81 |
+
):
|
| 82 |
+
self.image_size = image_size
|
| 83 |
+
self.min_size = min_size
|
| 84 |
+
self.image_mean = image_mean
|
| 85 |
+
self.image_std = image_std
|
| 86 |
+
self.rescale_factor = rescale_factor
|
| 87 |
+
self.do_normalize = do_normalize
|
| 88 |
+
|
| 89 |
+
super().__init__(**kwargs)
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
class VLMImageProcessor(BaseImageProcessor):
|
| 93 |
+
model_input_names = ["pixel_values"]
|
| 94 |
+
|
| 95 |
+
def __init__(
|
| 96 |
+
self,
|
| 97 |
+
image_size: int,
|
| 98 |
+
min_size: int = 14,
|
| 99 |
+
image_mean: Union[Tuple[float, float, float], List[float]] = (
|
| 100 |
+
0.48145466,
|
| 101 |
+
0.4578275,
|
| 102 |
+
0.40821073,
|
| 103 |
+
),
|
| 104 |
+
image_std: Union[Tuple[float, float, float], List[float]] = (
|
| 105 |
+
0.26862954,
|
| 106 |
+
0.26130258,
|
| 107 |
+
0.27577711,
|
| 108 |
+
),
|
| 109 |
+
rescale_factor: float = 1.0 / 255.0,
|
| 110 |
+
do_normalize: bool = True,
|
| 111 |
+
**kwargs,
|
| 112 |
+
):
|
| 113 |
+
super().__init__(**kwargs)
|
| 114 |
+
|
| 115 |
+
self.image_size = image_size
|
| 116 |
+
self.rescale_factor = rescale_factor
|
| 117 |
+
self.image_mean = image_mean
|
| 118 |
+
self.image_std = image_std
|
| 119 |
+
self.min_size = min_size
|
| 120 |
+
self.do_normalize = do_normalize
|
| 121 |
+
|
| 122 |
+
if image_mean is None:
|
| 123 |
+
self.background_color = (127, 127, 127)
|
| 124 |
+
else:
|
| 125 |
+
self.background_color = tuple([int(x * 255) for x in image_mean])
|
| 126 |
+
|
| 127 |
+
def resize(self, pil_img: Image) -> np.ndarray:
|
| 128 |
+
"""
|
| 129 |
+
|
| 130 |
+
Args:
|
| 131 |
+
pil_img (PIL.Image): [H, W, 3] in PIL.Image in RGB
|
| 132 |
+
|
| 133 |
+
Returns:
|
| 134 |
+
x (np.ndarray): [3, self.image_size, self.image_size]
|
| 135 |
+
"""
|
| 136 |
+
|
| 137 |
+
width, height = pil_img.size
|
| 138 |
+
max_size = max(width, height)
|
| 139 |
+
|
| 140 |
+
size = [
|
| 141 |
+
max(int(height / max_size * self.image_size), self.min_size),
|
| 142 |
+
max(int(width / max_size * self.image_size), self.min_size),
|
| 143 |
+
]
|
| 144 |
+
|
| 145 |
+
if width <= 0 or height <= 0 or size[0] <= 0 or size[1] <= 0:
|
| 146 |
+
print(f"orig size = {pil_img.size}, new size = {size}")
|
| 147 |
+
raise ValueError("Invalid size!")
|
| 148 |
+
|
| 149 |
+
pil_img = torchvision.transforms.functional.resize(
|
| 150 |
+
pil_img,
|
| 151 |
+
size,
|
| 152 |
+
interpolation=torchvision.transforms.functional.InterpolationMode.BICUBIC,
|
| 153 |
+
antialias=True,
|
| 154 |
+
)
|
| 155 |
+
|
| 156 |
+
pil_img = expand2square(pil_img, self.background_color)
|
| 157 |
+
x = to_numpy_array(pil_img)
|
| 158 |
+
|
| 159 |
+
# [H, W, 3] -> [3, H, W]
|
| 160 |
+
x = np.transpose(x, (2, 0, 1))
|
| 161 |
+
|
| 162 |
+
return x
|
| 163 |
+
|
| 164 |
+
def preprocess(self, images, return_tensors: str = "pt", **kwargs) -> BatchFeature:
|
| 165 |
+
# resize and pad to [self.image_size, self.image_size]
|
| 166 |
+
# then convert from [H, W, 3] to [3, H, W]
|
| 167 |
+
images: List[np.ndarray] = [self.resize(image) for image in images]
|
| 168 |
+
|
| 169 |
+
# resacle from [0, 255] -> [0, 1]
|
| 170 |
+
images = [
|
| 171 |
+
self.rescale(
|
| 172 |
+
image=image,
|
| 173 |
+
scale=self.rescale_factor,
|
| 174 |
+
input_data_format="channels_first",
|
| 175 |
+
)
|
| 176 |
+
for image in images
|
| 177 |
+
]
|
| 178 |
+
|
| 179 |
+
# normalize
|
| 180 |
+
if self.do_normalize:
|
| 181 |
+
images = [
|
| 182 |
+
self.normalize(
|
| 183 |
+
image=image,
|
| 184 |
+
mean=self.image_mean,
|
| 185 |
+
std=self.image_std,
|
| 186 |
+
input_data_format="channels_first",
|
| 187 |
+
)
|
| 188 |
+
for image in images
|
| 189 |
+
]
|
| 190 |
+
|
| 191 |
+
data = {"pixel_values": images}
|
| 192 |
+
return BatchFeature(data=data, tensor_type=return_tensors)
|
| 193 |
+
|
| 194 |
+
@property
|
| 195 |
+
def default_shape(self):
|
| 196 |
+
return [3, self.image_size, self.image_size]
|
| 197 |
+
|
| 198 |
+
|
| 199 |
+
AutoImageProcessor.register(VLMImageProcessorConfig, VLMImageProcessor)
|
| 200 |
+
|
| 201 |
+
|
| 202 |
+
if __name__ == "__main__":
|
| 203 |
+
image_processor = VLMImageProcessor(
|
| 204 |
+
image_size=1024,
|
| 205 |
+
image_mean=IMAGENET_INCEPTION_MEAN,
|
| 206 |
+
image_std=IMAGENET_INCEPTION_STD,
|
| 207 |
+
do_normalize=True,
|
| 208 |
+
)
|
janus/janusflow/models/modeling_vlm.py
ADDED
|
@@ -0,0 +1,226 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2023-2024 DeepSeek.
|
| 2 |
+
#
|
| 3 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 4 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 5 |
+
# the Software without restriction, including without limitation the rights to
|
| 6 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
|
| 7 |
+
# the Software, and to permit persons to whom the Software is furnished to do so,
|
| 8 |
+
# subject to the following conditions:
|
| 9 |
+
#
|
| 10 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 11 |
+
# copies or substantial portions of the Software.
|
| 12 |
+
#
|
| 13 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 14 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
|
| 15 |
+
# FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
|
| 16 |
+
# COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
|
| 17 |
+
# IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
|
| 18 |
+
# CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
| 19 |
+
|
| 20 |
+
from attrdict import AttrDict
|
| 21 |
+
from einops import rearrange
|
| 22 |
+
import torch
|
| 23 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 24 |
+
from transformers import (
|
| 25 |
+
AutoConfig,
|
| 26 |
+
AutoModelForCausalLM,
|
| 27 |
+
PreTrainedModel,
|
| 28 |
+
LlamaConfig,
|
| 29 |
+
LlamaForCausalLM,
|
| 30 |
+
)
|
| 31 |
+
from transformers.models.llama.modeling_llama import LlamaRMSNorm
|
| 32 |
+
from janus.janusflow.models.clip_encoder import CLIPVisionTower
|
| 33 |
+
from janus.janusflow.models.uvit import ShallowUViTEncoder, ShallowUViTDecoder
|
| 34 |
+
import torch.nn as nn
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def model_name_to_cls(cls_name):
|
| 38 |
+
|
| 39 |
+
if "CLIPVisionTower" in cls_name:
|
| 40 |
+
cls = CLIPVisionTower
|
| 41 |
+
elif "ShallowUViTEncoder" in cls_name:
|
| 42 |
+
cls = ShallowUViTEncoder
|
| 43 |
+
elif "ShallowUViTDecoder" in cls_name:
|
| 44 |
+
cls = ShallowUViTDecoder
|
| 45 |
+
else:
|
| 46 |
+
raise ValueError(f"class_name {cls_name} is invalid.")
|
| 47 |
+
|
| 48 |
+
return cls
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
class VisionUnderstandEncoderConfig(PretrainedConfig):
|
| 52 |
+
model_type = "vision_und_enc"
|
| 53 |
+
cls: str = ""
|
| 54 |
+
params: AttrDict = {}
|
| 55 |
+
|
| 56 |
+
def __init__(self, **kwargs):
|
| 57 |
+
super().__init__(**kwargs)
|
| 58 |
+
|
| 59 |
+
self.cls = kwargs.get("cls", "")
|
| 60 |
+
if not isinstance(self.cls, str):
|
| 61 |
+
self.cls = self.cls.__name__
|
| 62 |
+
|
| 63 |
+
self.params = AttrDict(kwargs.get("params", {}))
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
class VisionGenerationEncoderConfig(PretrainedConfig):
|
| 67 |
+
model_type = "vision_gen_enc"
|
| 68 |
+
cls: str = ""
|
| 69 |
+
params: AttrDict = {}
|
| 70 |
+
|
| 71 |
+
def __init__(self, **kwargs):
|
| 72 |
+
super().__init__(**kwargs)
|
| 73 |
+
|
| 74 |
+
self.cls = kwargs.get("cls", "")
|
| 75 |
+
if not isinstance(self.cls, str):
|
| 76 |
+
self.cls = self.cls.__name__
|
| 77 |
+
|
| 78 |
+
self.params = AttrDict(kwargs.get("params", {}))
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
class VisionGenerationDecoderConfig(PretrainedConfig):
|
| 82 |
+
model_type = "vision_gen_dec"
|
| 83 |
+
cls: str = ""
|
| 84 |
+
params: AttrDict = {}
|
| 85 |
+
|
| 86 |
+
def __init__(self, **kwargs):
|
| 87 |
+
super().__init__(**kwargs)
|
| 88 |
+
|
| 89 |
+
self.cls = kwargs.get("cls", "")
|
| 90 |
+
if not isinstance(self.cls, str):
|
| 91 |
+
self.cls = self.cls.__name__
|
| 92 |
+
|
| 93 |
+
self.params = AttrDict(kwargs.get("params", {}))
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
class MultiModalityConfig(PretrainedConfig):
|
| 97 |
+
model_type = "multi_modality"
|
| 98 |
+
vision_und_enc_config: VisionUnderstandEncoderConfig
|
| 99 |
+
language_config: LlamaConfig
|
| 100 |
+
|
| 101 |
+
def __init__(self, **kwargs):
|
| 102 |
+
super().__init__(**kwargs)
|
| 103 |
+
vision_und_enc_config = kwargs.get("vision_und_enc_config", {})
|
| 104 |
+
self.vision_und_enc_config = VisionUnderstandEncoderConfig(
|
| 105 |
+
**vision_und_enc_config
|
| 106 |
+
)
|
| 107 |
+
|
| 108 |
+
vision_gen_enc_config = kwargs.get("vision_gen_enc_config", {})
|
| 109 |
+
self.vision_gen_enc_config = VisionGenerationEncoderConfig(
|
| 110 |
+
**vision_gen_enc_config
|
| 111 |
+
)
|
| 112 |
+
|
| 113 |
+
vision_gen_dec_config = kwargs.get("vision_gen_dec_config", {})
|
| 114 |
+
self.vision_gen_dec_config = VisionGenerationDecoderConfig(
|
| 115 |
+
**vision_gen_dec_config
|
| 116 |
+
)
|
| 117 |
+
|
| 118 |
+
language_config = kwargs.get("language_config", {})
|
| 119 |
+
if isinstance(language_config, LlamaConfig):
|
| 120 |
+
self.language_config = language_config
|
| 121 |
+
else:
|
| 122 |
+
self.language_config = LlamaConfig(**language_config)
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
class MultiModalityPreTrainedModel(PreTrainedModel):
|
| 126 |
+
config_class = MultiModalityConfig
|
| 127 |
+
base_model_prefix = "multi_modality"
|
| 128 |
+
_no_split_modules = []
|
| 129 |
+
_skip_keys_device_placement = "past_key_values"
|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
class MultiModalityCausalLM(MultiModalityPreTrainedModel):
|
| 133 |
+
|
| 134 |
+
def __init__(self, config: MultiModalityConfig):
|
| 135 |
+
super().__init__(config)
|
| 136 |
+
|
| 137 |
+
# vision understanding encoder
|
| 138 |
+
vision_und_enc_config = config.vision_und_enc_config
|
| 139 |
+
vision_und_enc_cls = model_name_to_cls(vision_und_enc_config.cls)
|
| 140 |
+
self.vision_und_enc_model = vision_und_enc_cls(**vision_und_enc_config.params)
|
| 141 |
+
|
| 142 |
+
# vision understanding aligner
|
| 143 |
+
self.vision_und_enc_aligner = nn.Linear(1024, 2048, bias=True)
|
| 144 |
+
|
| 145 |
+
# begin of understanding embedding
|
| 146 |
+
self.beg_of_und_embed = nn.Parameter(torch.zeros(1, 2048))
|
| 147 |
+
|
| 148 |
+
# vision generation encoder
|
| 149 |
+
vision_gen_enc_config = config.vision_gen_enc_config
|
| 150 |
+
vision_gen_enc_cls = model_name_to_cls(vision_gen_enc_config.cls)
|
| 151 |
+
self.vision_gen_enc_model = vision_gen_enc_cls(**vision_gen_enc_config.params)
|
| 152 |
+
|
| 153 |
+
# vision generation encoder aligner
|
| 154 |
+
self.vision_gen_enc_aligner = nn.Linear(768, 2048, bias=True)
|
| 155 |
+
|
| 156 |
+
# vision generation decoder
|
| 157 |
+
vision_gen_dec_config = config.vision_gen_dec_config
|
| 158 |
+
vision_gen_dec_cls = model_name_to_cls(vision_gen_dec_config.cls)
|
| 159 |
+
self.vision_gen_dec_model = vision_gen_dec_cls(**vision_gen_dec_config.params)
|
| 160 |
+
|
| 161 |
+
# language model
|
| 162 |
+
language_config = config.language_config
|
| 163 |
+
self.language_model = LlamaForCausalLM(language_config)
|
| 164 |
+
|
| 165 |
+
# vision generation decoder aligner
|
| 166 |
+
self.vision_gen_dec_aligner_norm = LlamaRMSNorm(
|
| 167 |
+
2048, eps=language_config.rms_norm_eps
|
| 168 |
+
)
|
| 169 |
+
self.vision_gen_dec_aligner = nn.Linear(2048, 768, bias=True)
|
| 170 |
+
|
| 171 |
+
def prepare_inputs_embeds(
|
| 172 |
+
self,
|
| 173 |
+
input_ids: torch.LongTensor,
|
| 174 |
+
pixel_values: torch.FloatTensor,
|
| 175 |
+
images_seq_mask: torch.LongTensor,
|
| 176 |
+
images_emb_mask: torch.LongTensor,
|
| 177 |
+
**kwargs,
|
| 178 |
+
):
|
| 179 |
+
"""
|
| 180 |
+
|
| 181 |
+
Args:
|
| 182 |
+
input_ids (torch.LongTensor): [b, T]
|
| 183 |
+
pixel_values (torch.FloatTensor): [b, n_images, 3, h, w]
|
| 184 |
+
images_seq_mask (torch.BoolTensor): [b, T]
|
| 185 |
+
images_emb_mask (torch.BoolTensor): [b, n_images, n_image_tokens]
|
| 186 |
+
|
| 187 |
+
assert torch.sum(images_seq_mask) == torch.sum(images_emb_mask)
|
| 188 |
+
|
| 189 |
+
Returns:
|
| 190 |
+
input_embeds (torch.Tensor): [b, T, D]
|
| 191 |
+
"""
|
| 192 |
+
|
| 193 |
+
bs, n = pixel_values.shape[0:2]
|
| 194 |
+
images = rearrange(pixel_values, "b n c h w -> (b n) c h w")
|
| 195 |
+
# [b x n, T2, D]
|
| 196 |
+
images_embeds = self.vision_und_enc_model(images)
|
| 197 |
+
images_embeds = self.vision_und_enc_aligner(images_embeds)
|
| 198 |
+
# print(images_embeds.shape, self.beg_of_und_embed.shape, images_seq_mask.shape, input_ids.shape)
|
| 199 |
+
beg_of_und_embed = self.beg_of_und_embed[0].detach().clone()
|
| 200 |
+
images_embeds = torch.cat(
|
| 201 |
+
[
|
| 202 |
+
beg_of_und_embed.view(1, 1, -1).repeat(images_embeds.shape[0], 1, 1),
|
| 203 |
+
images_embeds,
|
| 204 |
+
],
|
| 205 |
+
dim=1,
|
| 206 |
+
)
|
| 207 |
+
# [b x n, T2, D] -> [b, n x T2, D]
|
| 208 |
+
images_embeds = rearrange(images_embeds, "(b n) t d -> b (n t) d", b=bs, n=n)
|
| 209 |
+
# [b, n, T2] -> [b, n x T2]
|
| 210 |
+
images_emb_mask = rearrange(images_emb_mask, "b n t -> b (n t)")
|
| 211 |
+
|
| 212 |
+
# [b, T, D]
|
| 213 |
+
input_ids[input_ids < 0] = 0 # ignore the image embeddings
|
| 214 |
+
inputs_embeds = self.language_model.get_input_embeddings()(input_ids)
|
| 215 |
+
|
| 216 |
+
# replace with the image embeddings
|
| 217 |
+
inputs_embeds[images_seq_mask] = images_embeds[images_emb_mask]
|
| 218 |
+
|
| 219 |
+
return inputs_embeds
|
| 220 |
+
|
| 221 |
+
|
| 222 |
+
AutoConfig.register("vision_und_enc", VisionUnderstandEncoderConfig)
|
| 223 |
+
AutoConfig.register("vision_gen_enc", VisionGenerationEncoderConfig)
|
| 224 |
+
AutoConfig.register("vision_gen_dec", VisionGenerationDecoderConfig)
|
| 225 |
+
AutoConfig.register("multi_modality", MultiModalityConfig)
|
| 226 |
+
AutoModelForCausalLM.register(MultiModalityConfig, MultiModalityCausalLM)
|
janus/janusflow/models/processing_vlm.py
ADDED
|
@@ -0,0 +1,455 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2023-2024 DeepSeek.
|
| 2 |
+
#
|
| 3 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 4 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 5 |
+
# the Software without restriction, including without limitation the rights to
|
| 6 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
|
| 7 |
+
# the Software, and to permit persons to whom the Software is furnished to do so,
|
| 8 |
+
# subject to the following conditions:
|
| 9 |
+
#
|
| 10 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 11 |
+
# copies or substantial portions of the Software.
|
| 12 |
+
#
|
| 13 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 14 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
|
| 15 |
+
# FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
|
| 16 |
+
# COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
|
| 17 |
+
# IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
|
| 18 |
+
# CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
| 19 |
+
|
| 20 |
+
from dataclasses import dataclass
|
| 21 |
+
from typing import Dict, List
|
| 22 |
+
|
| 23 |
+
import torch
|
| 24 |
+
from PIL.Image import Image
|
| 25 |
+
from transformers import LlamaTokenizerFast
|
| 26 |
+
from transformers.processing_utils import ProcessorMixin
|
| 27 |
+
|
| 28 |
+
from janus.janusflow.models.image_processing_vlm import VLMImageProcessor
|
| 29 |
+
from janus.utils.conversation import get_conv_template
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
class DictOutput(object):
|
| 33 |
+
def keys(self):
|
| 34 |
+
return self.__dict__.keys()
|
| 35 |
+
|
| 36 |
+
def __getitem__(self, item):
|
| 37 |
+
return self.__dict__[item]
|
| 38 |
+
|
| 39 |
+
def __setitem__(self, key, value):
|
| 40 |
+
self.__dict__[key] = value
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
@dataclass
|
| 44 |
+
class VLChatProcessorOutput(DictOutput):
|
| 45 |
+
sft_format: str
|
| 46 |
+
input_ids: torch.Tensor
|
| 47 |
+
pixel_values: torch.Tensor
|
| 48 |
+
num_und_image_tokens: torch.IntTensor
|
| 49 |
+
|
| 50 |
+
def __len__(self):
|
| 51 |
+
return len(self.input_ids)
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
@dataclass
|
| 55 |
+
class BatchedVLChatProcessorOutput(DictOutput):
|
| 56 |
+
sft_format: List[str]
|
| 57 |
+
input_ids: torch.Tensor
|
| 58 |
+
pixel_values: torch.Tensor
|
| 59 |
+
attention_mask: torch.Tensor
|
| 60 |
+
images_seq_mask: torch.BoolTensor
|
| 61 |
+
images_emb_mask: torch.BoolTensor
|
| 62 |
+
|
| 63 |
+
def to(self, device, dtype=torch.bfloat16):
|
| 64 |
+
self.input_ids = self.input_ids.to(device)
|
| 65 |
+
self.attention_mask = self.attention_mask.to(device)
|
| 66 |
+
self.images_seq_mask = self.images_seq_mask.to(device)
|
| 67 |
+
self.images_emb_mask = self.images_emb_mask.to(device)
|
| 68 |
+
self.pixel_values = self.pixel_values.to(device=device, dtype=dtype)
|
| 69 |
+
return self
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
class VLChatProcessor(ProcessorMixin):
|
| 73 |
+
image_processor_class = "AutoImageProcessor"
|
| 74 |
+
tokenizer_class = ("LlamaTokenizer", "LlamaTokenizerFast")
|
| 75 |
+
|
| 76 |
+
attributes = ["image_processor", "tokenizer"]
|
| 77 |
+
|
| 78 |
+
system_prompt = (
|
| 79 |
+
"You are a helpful language and vision assistant. "
|
| 80 |
+
"You are able to understand the visual content that the user provides, "
|
| 81 |
+
"and assist the user with a variety of tasks using natural language."
|
| 82 |
+
)
|
| 83 |
+
|
| 84 |
+
def __init__(
|
| 85 |
+
self,
|
| 86 |
+
image_processor: VLMImageProcessor,
|
| 87 |
+
tokenizer: LlamaTokenizerFast,
|
| 88 |
+
image_tag: str = "<image_placeholder>",
|
| 89 |
+
image_start_tag: str = "<begin_of_image>",
|
| 90 |
+
image_end_tag: str = "<end_of_image>",
|
| 91 |
+
image_gen_tag: str = "<|begin▁of▁generation|>",
|
| 92 |
+
num_image_tokens: int = 576,
|
| 93 |
+
add_special_token: bool = False,
|
| 94 |
+
sft_format: str = "deepseek",
|
| 95 |
+
mask_prompt: bool = True,
|
| 96 |
+
ignore_id: int = -100,
|
| 97 |
+
**kwargs,
|
| 98 |
+
):
|
| 99 |
+
self.image_processor = image_processor
|
| 100 |
+
self.tokenizer = tokenizer
|
| 101 |
+
|
| 102 |
+
image_id = self.tokenizer.vocab.get(image_tag)
|
| 103 |
+
if image_id is None:
|
| 104 |
+
special_tokens = [image_tag]
|
| 105 |
+
special_tokens_dict = {"additional_special_tokens": special_tokens}
|
| 106 |
+
self.tokenizer.add_special_tokens(special_tokens_dict)
|
| 107 |
+
print(f"Add image tag = {image_tag} to the tokenizer")
|
| 108 |
+
|
| 109 |
+
image_gen_id = self.tokenizer.vocab.get(image_gen_tag)
|
| 110 |
+
if image_gen_id is None:
|
| 111 |
+
special_tokens = [image_gen_tag]
|
| 112 |
+
special_tokens_dict = {"additional_special_tokens": special_tokens}
|
| 113 |
+
self.tokenizer.add_special_tokens(special_tokens_dict)
|
| 114 |
+
print(f"Add generation tag = {image_gen_tag} to the tokenizer")
|
| 115 |
+
|
| 116 |
+
assert image_start_tag is not None and image_end_tag is not None
|
| 117 |
+
boi_id = self.tokenizer.vocab.get(image_start_tag)
|
| 118 |
+
eoi_id = self.tokenizer.vocab.get(image_end_tag)
|
| 119 |
+
if boi_id is None:
|
| 120 |
+
special_tokens = [image_start_tag]
|
| 121 |
+
special_tokens_dict = {"additional_special_tokens": special_tokens}
|
| 122 |
+
self.tokenizer.add_special_tokens(special_tokens_dict)
|
| 123 |
+
print(f"Add boi tag = {image_start_tag} to the tokenizer")
|
| 124 |
+
if eoi_id is None:
|
| 125 |
+
special_tokens = [image_end_tag]
|
| 126 |
+
special_tokens_dict = {"additional_special_tokens": special_tokens}
|
| 127 |
+
self.tokenizer.add_special_tokens(special_tokens_dict)
|
| 128 |
+
print(f"Add eoi tag = {image_end_tag} to the tokenizer")
|
| 129 |
+
|
| 130 |
+
self.image_tag = image_tag
|
| 131 |
+
self.image_gen_tag = image_gen_tag
|
| 132 |
+
self.image_start_tag = image_start_tag
|
| 133 |
+
self.image_end_tag = image_end_tag
|
| 134 |
+
|
| 135 |
+
self.num_image_tokens = num_image_tokens
|
| 136 |
+
self.add_special_token = add_special_token
|
| 137 |
+
self.sft_format = sft_format
|
| 138 |
+
self.mask_prompt = mask_prompt
|
| 139 |
+
self.ignore_id = ignore_id
|
| 140 |
+
self.tokenizer.pad_token_id = self.tokenizer.vocab.get("<|▁pad▁|>")
|
| 141 |
+
|
| 142 |
+
super().__init__(
|
| 143 |
+
image_processor,
|
| 144 |
+
tokenizer,
|
| 145 |
+
image_tag,
|
| 146 |
+
num_image_tokens,
|
| 147 |
+
add_special_token,
|
| 148 |
+
sft_format,
|
| 149 |
+
mask_prompt,
|
| 150 |
+
ignore_id,
|
| 151 |
+
**kwargs,
|
| 152 |
+
)
|
| 153 |
+
|
| 154 |
+
def new_chat_template(self):
|
| 155 |
+
conv = get_conv_template(self.sft_format)
|
| 156 |
+
conv.set_system_message(self.system_prompt)
|
| 157 |
+
return conv
|
| 158 |
+
|
| 159 |
+
def apply_sft_template_for_multi_turn_prompts(
|
| 160 |
+
self,
|
| 161 |
+
conversations: List[Dict[str, str]],
|
| 162 |
+
sft_format: str = "deepseek",
|
| 163 |
+
system_prompt: str = "",
|
| 164 |
+
):
|
| 165 |
+
"""
|
| 166 |
+
Applies the SFT template to conversation.
|
| 167 |
+
|
| 168 |
+
An example of conversation:
|
| 169 |
+
conversation = [
|
| 170 |
+
{
|
| 171 |
+
"role": "User",
|
| 172 |
+
"content": "<image_placeholder> is Figure 1.\n<image_placeholder> is Figure 2.\nWhich image is brighter?",
|
| 173 |
+
"images": [
|
| 174 |
+
"./multi-images/attribute_comparison_1.png",
|
| 175 |
+
"./multi-images/attribute_comparison_2.png"
|
| 176 |
+
]
|
| 177 |
+
},
|
| 178 |
+
{
|
| 179 |
+
"role": "Assistant",
|
| 180 |
+
"content": ""
|
| 181 |
+
}
|
| 182 |
+
]
|
| 183 |
+
|
| 184 |
+
Args:
|
| 185 |
+
conversations (List[Dict]): A conversation with a List of Dict[str, str] text.
|
| 186 |
+
sft_format (str, optional): The format of the SFT template to use. Defaults to "deepseek".
|
| 187 |
+
system_prompt (str, optional): The system prompt to use in the SFT template. Defaults to "".
|
| 188 |
+
|
| 189 |
+
Returns:
|
| 190 |
+
sft_prompt (str): The formatted text.
|
| 191 |
+
"""
|
| 192 |
+
|
| 193 |
+
conv = get_conv_template(sft_format)
|
| 194 |
+
conv.set_system_message(system_prompt)
|
| 195 |
+
for message in conversations:
|
| 196 |
+
conv.append_message(message["role"], message["content"].strip())
|
| 197 |
+
sft_prompt = conv.get_prompt().strip()
|
| 198 |
+
|
| 199 |
+
return sft_prompt
|
| 200 |
+
|
| 201 |
+
@property
|
| 202 |
+
def image_token(self):
|
| 203 |
+
return self.image_tag
|
| 204 |
+
|
| 205 |
+
@property
|
| 206 |
+
def image_id(self):
|
| 207 |
+
image_id = self.tokenizer.vocab.get(self.image_tag)
|
| 208 |
+
return image_id
|
| 209 |
+
|
| 210 |
+
@property
|
| 211 |
+
def image_start_id(self):
|
| 212 |
+
image_start_id = self.tokenizer.vocab.get(self.image_start_tag)
|
| 213 |
+
return image_start_id
|
| 214 |
+
|
| 215 |
+
@property
|
| 216 |
+
def image_end_id(self):
|
| 217 |
+
image_end_id = self.tokenizer.vocab.get(self.image_end_tag)
|
| 218 |
+
return image_end_id
|
| 219 |
+
|
| 220 |
+
@property
|
| 221 |
+
def image_start_token(self):
|
| 222 |
+
return self.image_start_tag
|
| 223 |
+
|
| 224 |
+
@property
|
| 225 |
+
def image_end_token(self):
|
| 226 |
+
return self.image_end_tag
|
| 227 |
+
|
| 228 |
+
@property
|
| 229 |
+
def pad_id(self):
|
| 230 |
+
pad_id = self.tokenizer.pad_token_id
|
| 231 |
+
if pad_id is None:
|
| 232 |
+
pad_id = self.tokenizer.eos_token_id
|
| 233 |
+
|
| 234 |
+
return pad_id
|
| 235 |
+
|
| 236 |
+
@property
|
| 237 |
+
def image_gen_id(self):
|
| 238 |
+
image_gen_id = self.tokenizer.vocab.get(self.image_gen_tag)
|
| 239 |
+
return image_gen_id
|
| 240 |
+
|
| 241 |
+
def add_image_token(
|
| 242 |
+
self,
|
| 243 |
+
image_indices: List[int],
|
| 244 |
+
input_ids: torch.LongTensor,
|
| 245 |
+
):
|
| 246 |
+
"""
|
| 247 |
+
|
| 248 |
+
Args:
|
| 249 |
+
image_indices (List[int]): [index_0, index_1, ..., index_j]
|
| 250 |
+
input_ids (torch.LongTensor): [N]
|
| 251 |
+
|
| 252 |
+
Returns:
|
| 253 |
+
input_ids (torch.LongTensor): [N + image tokens]
|
| 254 |
+
num_image_tokens (torch.IntTensor): [n_images]
|
| 255 |
+
"""
|
| 256 |
+
|
| 257 |
+
input_slices = []
|
| 258 |
+
|
| 259 |
+
start = 0
|
| 260 |
+
for index in image_indices:
|
| 261 |
+
if self.add_special_token:
|
| 262 |
+
end = index + 1
|
| 263 |
+
else:
|
| 264 |
+
end = index
|
| 265 |
+
|
| 266 |
+
# original text tokens
|
| 267 |
+
input_slices.append(input_ids[start:end])
|
| 268 |
+
|
| 269 |
+
# add boi, image tokens, eoi and set the mask as False
|
| 270 |
+
input_slices.append(self.image_start_id * torch.ones((1), dtype=torch.long))
|
| 271 |
+
input_slices.append(
|
| 272 |
+
self.image_id * torch.ones((self.num_image_tokens,), dtype=torch.long)
|
| 273 |
+
)
|
| 274 |
+
input_slices.append(self.image_end_id * torch.ones((1), dtype=torch.long))
|
| 275 |
+
start = index + 1
|
| 276 |
+
|
| 277 |
+
# the left part
|
| 278 |
+
input_slices.append(input_ids[start:])
|
| 279 |
+
|
| 280 |
+
# concat all slices
|
| 281 |
+
input_ids = torch.cat(input_slices, dim=0)
|
| 282 |
+
num_image_tokens = torch.IntTensor(
|
| 283 |
+
[self.num_image_tokens + 1] * len(image_indices)
|
| 284 |
+
)
|
| 285 |
+
# we add 1 to fit generation
|
| 286 |
+
|
| 287 |
+
return input_ids, num_image_tokens
|
| 288 |
+
|
| 289 |
+
def process_one(
|
| 290 |
+
self,
|
| 291 |
+
prompt: str = None,
|
| 292 |
+
conversations: List[Dict[str, str]] = None,
|
| 293 |
+
images: List[Image] = None,
|
| 294 |
+
**kwargs,
|
| 295 |
+
):
|
| 296 |
+
"""
|
| 297 |
+
|
| 298 |
+
Args:
|
| 299 |
+
prompt (str): the formatted prompt;
|
| 300 |
+
conversations (List[Dict]): conversations with a list of messages;
|
| 301 |
+
images (List[ImageType]): the list of images;
|
| 302 |
+
**kwargs:
|
| 303 |
+
|
| 304 |
+
Returns:
|
| 305 |
+
outputs (BaseProcessorOutput): the output of the processor,
|
| 306 |
+
- input_ids (torch.LongTensor): [N + image tokens]
|
| 307 |
+
- target_ids (torch.LongTensor): [N + image tokens]
|
| 308 |
+
- images (torch.FloatTensor): [n_images, 3, H, W]
|
| 309 |
+
- image_id (int): the id of the image token
|
| 310 |
+
- num_image_tokens (List[int]): the number of image tokens
|
| 311 |
+
"""
|
| 312 |
+
|
| 313 |
+
assert (
|
| 314 |
+
prompt is None or conversations is None
|
| 315 |
+
), "prompt and conversations cannot be used at the same time."
|
| 316 |
+
|
| 317 |
+
if prompt is None:
|
| 318 |
+
# apply sft format
|
| 319 |
+
sft_format = self.apply_sft_template_for_multi_turn_prompts(
|
| 320 |
+
conversations=conversations,
|
| 321 |
+
sft_format=self.sft_format,
|
| 322 |
+
system_prompt=self.system_prompt,
|
| 323 |
+
)
|
| 324 |
+
else:
|
| 325 |
+
sft_format = prompt
|
| 326 |
+
|
| 327 |
+
# tokenize
|
| 328 |
+
input_ids = self.tokenizer.encode(sft_format)
|
| 329 |
+
input_ids = torch.LongTensor(input_ids)
|
| 330 |
+
|
| 331 |
+
# add image tokens to the input_ids
|
| 332 |
+
image_token_mask: torch.BoolTensor = input_ids == self.image_id
|
| 333 |
+
image_indices = image_token_mask.nonzero()
|
| 334 |
+
|
| 335 |
+
input_ids, num_und_image_tokens = self.add_image_token(
|
| 336 |
+
image_indices=image_indices,
|
| 337 |
+
input_ids=input_ids,
|
| 338 |
+
)
|
| 339 |
+
|
| 340 |
+
# load images
|
| 341 |
+
images_outputs = self.image_processor(images, return_tensors="pt")
|
| 342 |
+
|
| 343 |
+
prepare = VLChatProcessorOutput(
|
| 344 |
+
sft_format=sft_format,
|
| 345 |
+
input_ids=input_ids,
|
| 346 |
+
pixel_values=images_outputs.pixel_values,
|
| 347 |
+
num_und_image_tokens=num_und_image_tokens,
|
| 348 |
+
)
|
| 349 |
+
|
| 350 |
+
return prepare
|
| 351 |
+
|
| 352 |
+
def __call__(
|
| 353 |
+
self,
|
| 354 |
+
*,
|
| 355 |
+
prompt: str = None,
|
| 356 |
+
conversations: List[Dict[str, str]] = None,
|
| 357 |
+
images: List[Image] = None,
|
| 358 |
+
force_batchify: bool = True,
|
| 359 |
+
**kwargs,
|
| 360 |
+
):
|
| 361 |
+
"""
|
| 362 |
+
|
| 363 |
+
Args:
|
| 364 |
+
prompt (str): the formatted prompt;
|
| 365 |
+
conversations (List[Dict]): conversations with a list of messages;
|
| 366 |
+
images (List[ImageType]): the list of images;
|
| 367 |
+
force_batchify (bool): force batchify the inputs;
|
| 368 |
+
**kwargs:
|
| 369 |
+
|
| 370 |
+
Returns:
|
| 371 |
+
outputs (BaseProcessorOutput): the output of the processor,
|
| 372 |
+
- input_ids (torch.LongTensor): [N + image tokens]
|
| 373 |
+
- images (torch.FloatTensor): [n_images, 3, H, W]
|
| 374 |
+
- image_id (int): the id of the image token
|
| 375 |
+
- num_image_tokens (List[int]): the number of image tokens
|
| 376 |
+
"""
|
| 377 |
+
|
| 378 |
+
prepare = self.process_one(
|
| 379 |
+
prompt=prompt, conversations=conversations, images=images
|
| 380 |
+
)
|
| 381 |
+
|
| 382 |
+
if force_batchify:
|
| 383 |
+
prepare = self.batchify([prepare])
|
| 384 |
+
|
| 385 |
+
return prepare
|
| 386 |
+
|
| 387 |
+
def batchify(
|
| 388 |
+
self, prepare_list: List[VLChatProcessorOutput]
|
| 389 |
+
) -> BatchedVLChatProcessorOutput:
|
| 390 |
+
"""
|
| 391 |
+
Preprocesses the inputs for multimodal inference.
|
| 392 |
+
|
| 393 |
+
Args:
|
| 394 |
+
prepare_list (List[VLChatProcessorOutput]): A list of VLChatProcessorOutput.
|
| 395 |
+
|
| 396 |
+
Returns:
|
| 397 |
+
BatchedVLChatProcessorOutput: A dictionary of the inputs to use for multimodal inference.
|
| 398 |
+
"""
|
| 399 |
+
|
| 400 |
+
batch_size = len(prepare_list)
|
| 401 |
+
sft_format = []
|
| 402 |
+
n_images = []
|
| 403 |
+
seq_lens = []
|
| 404 |
+
for prepare in prepare_list:
|
| 405 |
+
# we only fill the images for understanding tasks into the mask
|
| 406 |
+
n_images.append(len(prepare.num_und_image_tokens))
|
| 407 |
+
seq_lens.append(len(prepare))
|
| 408 |
+
|
| 409 |
+
input_token_max_len = max(seq_lens)
|
| 410 |
+
max_n_images = max(1, max(n_images))
|
| 411 |
+
|
| 412 |
+
batched_input_ids = torch.full(
|
| 413 |
+
(batch_size, input_token_max_len), self.pad_id
|
| 414 |
+
).long() # FIXME
|
| 415 |
+
batched_attention_mask = torch.zeros((batch_size, input_token_max_len)).long()
|
| 416 |
+
batched_pixel_values = torch.zeros(
|
| 417 |
+
(batch_size, max_n_images, *self.image_processor.default_shape)
|
| 418 |
+
).float()
|
| 419 |
+
batched_images_seq_mask = torch.zeros((batch_size, input_token_max_len)).bool()
|
| 420 |
+
batched_images_emb_mask = torch.zeros(
|
| 421 |
+
(
|
| 422 |
+
batch_size,
|
| 423 |
+
max_n_images,
|
| 424 |
+
self.num_image_tokens + 1,
|
| 425 |
+
) # add 1 to account for <image_beg>
|
| 426 |
+
).bool()
|
| 427 |
+
|
| 428 |
+
for i, prepare in enumerate(prepare_list):
|
| 429 |
+
input_ids = prepare.input_ids
|
| 430 |
+
seq_len = len(prepare)
|
| 431 |
+
n_image = len(prepare.num_und_image_tokens)
|
| 432 |
+
# left-padding
|
| 433 |
+
batched_attention_mask[i, -seq_len:] = 1
|
| 434 |
+
batched_input_ids[i, -seq_len:] = torch.LongTensor(input_ids)
|
| 435 |
+
batched_images_seq_mask[i, -seq_len:] = (input_ids == self.image_id) | (
|
| 436 |
+
input_ids == self.image_start_id
|
| 437 |
+
)
|
| 438 |
+
|
| 439 |
+
if n_image > 0:
|
| 440 |
+
batched_pixel_values[i, :n_image] = prepare.pixel_values
|
| 441 |
+
for j, n_image_tokens in enumerate(prepare.num_und_image_tokens):
|
| 442 |
+
batched_images_emb_mask[i, j, :n_image_tokens] = True
|
| 443 |
+
|
| 444 |
+
sft_format.append(prepare.sft_format)
|
| 445 |
+
|
| 446 |
+
batched_prepares = BatchedVLChatProcessorOutput(
|
| 447 |
+
input_ids=batched_input_ids,
|
| 448 |
+
attention_mask=batched_attention_mask,
|
| 449 |
+
pixel_values=batched_pixel_values,
|
| 450 |
+
images_seq_mask=batched_images_seq_mask,
|
| 451 |
+
images_emb_mask=batched_images_emb_mask,
|
| 452 |
+
sft_format=sft_format,
|
| 453 |
+
)
|
| 454 |
+
|
| 455 |
+
return batched_prepares
|
janus/janusflow/models/siglip_vit.py
ADDED
|
@@ -0,0 +1,691 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2023-2024 DeepSeek.
|
| 2 |
+
#
|
| 3 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 4 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 5 |
+
# the Software without restriction, including without limitation the rights to
|
| 6 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
|
| 7 |
+
# the Software, and to permit persons to whom the Software is furnished to do so,
|
| 8 |
+
# subject to the following conditions:
|
| 9 |
+
#
|
| 10 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 11 |
+
# copies or substantial portions of the Software.
|
| 12 |
+
#
|
| 13 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 14 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
|
| 15 |
+
# FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
|
| 16 |
+
# COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
|
| 17 |
+
# IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
|
| 18 |
+
# CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
| 19 |
+
|
| 20 |
+
# https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/vision_transformer.py
|
| 21 |
+
import math
|
| 22 |
+
import warnings
|
| 23 |
+
from dataclasses import dataclass
|
| 24 |
+
from functools import partial
|
| 25 |
+
from typing import (
|
| 26 |
+
Callable,
|
| 27 |
+
Dict,
|
| 28 |
+
Final,
|
| 29 |
+
List,
|
| 30 |
+
Literal,
|
| 31 |
+
Optional,
|
| 32 |
+
Sequence,
|
| 33 |
+
Set,
|
| 34 |
+
Tuple,
|
| 35 |
+
Type,
|
| 36 |
+
Union,
|
| 37 |
+
)
|
| 38 |
+
|
| 39 |
+
import torch
|
| 40 |
+
import torch.nn as nn
|
| 41 |
+
import torch.nn.functional as F
|
| 42 |
+
from timm.layers import (
|
| 43 |
+
AttentionPoolLatent,
|
| 44 |
+
DropPath,
|
| 45 |
+
LayerType,
|
| 46 |
+
Mlp,
|
| 47 |
+
PatchDropout,
|
| 48 |
+
PatchEmbed,
|
| 49 |
+
resample_abs_pos_embed,
|
| 50 |
+
)
|
| 51 |
+
from timm.models._manipulate import checkpoint_seq, named_apply
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def _no_grad_trunc_normal_(tensor, mean, std, a, b):
|
| 55 |
+
# Cut & paste from PyTorch official master until it's in a few official releases - RW
|
| 56 |
+
# Method based on https://people.sc.fsu.edu/~jburkardt/presentations/truncated_normal.pdf
|
| 57 |
+
def norm_cdf(x):
|
| 58 |
+
# Computes standard normal cumulative distribution function
|
| 59 |
+
return (1.0 + math.erf(x / math.sqrt(2.0))) / 2.0
|
| 60 |
+
|
| 61 |
+
if (mean < a - 2 * std) or (mean > b + 2 * std):
|
| 62 |
+
warnings.warn(
|
| 63 |
+
"mean is more than 2 std from [a, b] in nn.init.trunc_normal_. "
|
| 64 |
+
"The distribution of values may be incorrect.",
|
| 65 |
+
stacklevel=2,
|
| 66 |
+
)
|
| 67 |
+
|
| 68 |
+
with torch.no_grad():
|
| 69 |
+
# Values are generated by using a truncated uniform distribution and
|
| 70 |
+
# then using the inverse CDF for the normal distribution.
|
| 71 |
+
# Get upper and lower cdf values
|
| 72 |
+
l = norm_cdf((a - mean) / std) # noqa: E741
|
| 73 |
+
u = norm_cdf((b - mean) / std)
|
| 74 |
+
|
| 75 |
+
# Uniformly fill tensor with values from [l, u], then translate to
|
| 76 |
+
# [2l-1, 2u-1].
|
| 77 |
+
tensor.uniform_(2 * l - 1, 2 * u - 1)
|
| 78 |
+
|
| 79 |
+
# Use inverse cdf transform for normal distribution to get truncated
|
| 80 |
+
# standard normal
|
| 81 |
+
tensor.erfinv_()
|
| 82 |
+
|
| 83 |
+
# Transform to proper mean, std
|
| 84 |
+
tensor.mul_(std * math.sqrt(2.0))
|
| 85 |
+
tensor.add_(mean)
|
| 86 |
+
|
| 87 |
+
# Clamp to ensure it's in the proper range
|
| 88 |
+
tensor.clamp_(min=a, max=b)
|
| 89 |
+
return tensor
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
def trunc_normal_(tensor, mean=0.0, std=1.0, a=-2.0, b=2.0):
|
| 93 |
+
# type: (torch.Tensor, float, float, float, float) -> torch.Tensor
|
| 94 |
+
r"""The original timm.models.layers.weight_init.trunc_normal_ can not handle bfloat16 yet, here we first
|
| 95 |
+
convert the tensor to float32, apply the trunc_normal_() in float32, and then convert it back to its original dtype.
|
| 96 |
+
Fills the input Tensor with values drawn from a truncated normal distribution. The values are effectively drawn
|
| 97 |
+
from the normal distribution :math:`\mathcal{N}(\text{mean}, \text{std}^2)`
|
| 98 |
+
with values outside :math:`[a, b]` redrawn until they are within
|
| 99 |
+
the bounds. The method used for generating the random values works
|
| 100 |
+
best when :math:`a \leq \text{mean} \leq b`.
|
| 101 |
+
Args:
|
| 102 |
+
tensor: an n-dimensional `torch.Tensor`
|
| 103 |
+
mean: the mean of the normal distribution
|
| 104 |
+
std: the standard deviation of the normal distribution
|
| 105 |
+
a: the minimum cutoff value
|
| 106 |
+
b: the maximum cutoff value
|
| 107 |
+
Examples:
|
| 108 |
+
>>> w = torch.empty(3, 5)
|
| 109 |
+
>>> nn.init.trunc_normal_(w)
|
| 110 |
+
"""
|
| 111 |
+
|
| 112 |
+
with torch.no_grad():
|
| 113 |
+
dtype = tensor.dtype
|
| 114 |
+
tensor_fp32 = tensor.float()
|
| 115 |
+
tensor_fp32 = _no_grad_trunc_normal_(tensor_fp32, mean, std, a, b)
|
| 116 |
+
tensor_dtype = tensor_fp32.to(dtype=dtype)
|
| 117 |
+
tensor.copy_(tensor_dtype)
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
def init_weights(self):
|
| 121 |
+
if self.pos_embed is not None:
|
| 122 |
+
trunc_normal_(self.pos_embed, std=self.pos_embed.shape[1] ** -0.5)
|
| 123 |
+
trunc_normal_(self.latent, std=self.latent_dim**-0.5)
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
def init_weights_vit_timm(module: nn.Module, name: str = "") -> None:
|
| 127 |
+
"""ViT weight initialization, original timm impl (for reproducibility)"""
|
| 128 |
+
if isinstance(module, nn.Linear):
|
| 129 |
+
trunc_normal_(module.weight, std=0.02)
|
| 130 |
+
if module.bias is not None:
|
| 131 |
+
nn.init.zeros_(module.bias)
|
| 132 |
+
elif hasattr(module, "init_weights"):
|
| 133 |
+
module.init_weights()
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
class Attention(nn.Module):
|
| 137 |
+
fused_attn: Final[bool]
|
| 138 |
+
|
| 139 |
+
def __init__(
|
| 140 |
+
self,
|
| 141 |
+
dim: int,
|
| 142 |
+
num_heads: int = 8,
|
| 143 |
+
qkv_bias: bool = False,
|
| 144 |
+
qk_norm: bool = False,
|
| 145 |
+
attn_drop: float = 0.0,
|
| 146 |
+
proj_drop: float = 0.0,
|
| 147 |
+
norm_layer: nn.Module = nn.LayerNorm,
|
| 148 |
+
) -> None:
|
| 149 |
+
super().__init__()
|
| 150 |
+
assert dim % num_heads == 0, "dim should be divisible by num_heads"
|
| 151 |
+
self.num_heads = num_heads
|
| 152 |
+
self.head_dim = dim // num_heads
|
| 153 |
+
self.scale = self.head_dim**-0.5
|
| 154 |
+
# self.fused_attn = use_fused_attn()
|
| 155 |
+
self.fused_attn = True
|
| 156 |
+
|
| 157 |
+
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
|
| 158 |
+
self.q_norm = norm_layer(self.head_dim) if qk_norm else nn.Identity()
|
| 159 |
+
self.k_norm = norm_layer(self.head_dim) if qk_norm else nn.Identity()
|
| 160 |
+
self.attn_drop = nn.Dropout(attn_drop)
|
| 161 |
+
self.proj = nn.Linear(dim, dim)
|
| 162 |
+
self.proj_drop = nn.Dropout(proj_drop) if proj_drop > 0.0 else nn.Identity()
|
| 163 |
+
|
| 164 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 165 |
+
B, N, C = x.shape
|
| 166 |
+
qkv = (
|
| 167 |
+
self.qkv(x)
|
| 168 |
+
.reshape(B, N, 3, self.num_heads, self.head_dim)
|
| 169 |
+
.permute(2, 0, 3, 1, 4)
|
| 170 |
+
)
|
| 171 |
+
q, k, v = qkv.unbind(0)
|
| 172 |
+
q, k = self.q_norm(q), self.k_norm(k)
|
| 173 |
+
|
| 174 |
+
if self.fused_attn:
|
| 175 |
+
x = F.scaled_dot_product_attention(
|
| 176 |
+
q,
|
| 177 |
+
k,
|
| 178 |
+
v,
|
| 179 |
+
dropout_p=self.attn_drop.p if self.training else 0.0,
|
| 180 |
+
)
|
| 181 |
+
else:
|
| 182 |
+
q = q * self.scale
|
| 183 |
+
attn = q @ k.transpose(-2, -1)
|
| 184 |
+
attn = attn.softmax(dim=-1)
|
| 185 |
+
attn = self.attn_drop(attn)
|
| 186 |
+
x = attn @ v
|
| 187 |
+
|
| 188 |
+
x = x.transpose(1, 2).reshape(B, N, C)
|
| 189 |
+
x = self.proj(x)
|
| 190 |
+
x = self.proj_drop(x)
|
| 191 |
+
return x
|
| 192 |
+
|
| 193 |
+
|
| 194 |
+
class LayerScale(nn.Module):
|
| 195 |
+
def __init__(
|
| 196 |
+
self,
|
| 197 |
+
dim: int,
|
| 198 |
+
init_values: float = 1e-5,
|
| 199 |
+
inplace: bool = False,
|
| 200 |
+
) -> None:
|
| 201 |
+
super().__init__()
|
| 202 |
+
self.inplace = inplace
|
| 203 |
+
self.gamma = nn.Parameter(init_values * torch.ones(dim))
|
| 204 |
+
|
| 205 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 206 |
+
return x.mul_(self.gamma) if self.inplace else x * self.gamma
|
| 207 |
+
|
| 208 |
+
|
| 209 |
+
class Block(nn.Module):
|
| 210 |
+
def __init__(
|
| 211 |
+
self,
|
| 212 |
+
dim: int,
|
| 213 |
+
num_heads: int,
|
| 214 |
+
mlp_ratio: float = 4.0,
|
| 215 |
+
qkv_bias: bool = False,
|
| 216 |
+
qk_norm: bool = False,
|
| 217 |
+
proj_drop: float = 0.0,
|
| 218 |
+
attn_drop: float = 0.0,
|
| 219 |
+
init_values: Optional[float] = None,
|
| 220 |
+
drop_path: float = 0.0,
|
| 221 |
+
act_layer: nn.Module = nn.GELU,
|
| 222 |
+
norm_layer: nn.Module = nn.LayerNorm,
|
| 223 |
+
mlp_layer: nn.Module = Mlp,
|
| 224 |
+
) -> None:
|
| 225 |
+
super().__init__()
|
| 226 |
+
self.norm1 = norm_layer(dim)
|
| 227 |
+
self.attn = Attention(
|
| 228 |
+
dim,
|
| 229 |
+
num_heads=num_heads,
|
| 230 |
+
qkv_bias=qkv_bias,
|
| 231 |
+
qk_norm=qk_norm,
|
| 232 |
+
attn_drop=attn_drop,
|
| 233 |
+
proj_drop=proj_drop,
|
| 234 |
+
norm_layer=norm_layer,
|
| 235 |
+
)
|
| 236 |
+
self.ls1 = (
|
| 237 |
+
LayerScale(dim, init_values=init_values) if init_values else nn.Identity()
|
| 238 |
+
)
|
| 239 |
+
self.drop_path1 = DropPath(drop_path) if drop_path > 0.0 else nn.Identity()
|
| 240 |
+
|
| 241 |
+
self.norm2 = norm_layer(dim)
|
| 242 |
+
self.mlp = mlp_layer(
|
| 243 |
+
in_features=dim,
|
| 244 |
+
hidden_features=int(dim * mlp_ratio),
|
| 245 |
+
act_layer=act_layer,
|
| 246 |
+
drop=proj_drop,
|
| 247 |
+
)
|
| 248 |
+
self.ls2 = (
|
| 249 |
+
LayerScale(dim, init_values=init_values) if init_values else nn.Identity()
|
| 250 |
+
)
|
| 251 |
+
self.drop_path2 = DropPath(drop_path) if drop_path > 0.0 else nn.Identity()
|
| 252 |
+
|
| 253 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 254 |
+
x = x + self.drop_path1(self.ls1(self.attn(self.norm1(x))))
|
| 255 |
+
x = x + self.drop_path2(self.ls2(self.mlp(self.norm2(x))))
|
| 256 |
+
return x
|
| 257 |
+
|
| 258 |
+
|
| 259 |
+
class VisionTransformer(nn.Module):
|
| 260 |
+
"""Vision Transformer
|
| 261 |
+
|
| 262 |
+
A PyTorch impl of : `An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale`
|
| 263 |
+
- https://arxiv.org/abs/2010.11929
|
| 264 |
+
"""
|
| 265 |
+
|
| 266 |
+
dynamic_img_size: Final[bool]
|
| 267 |
+
|
| 268 |
+
def __init__(
|
| 269 |
+
self,
|
| 270 |
+
img_size: Union[int, Tuple[int, int]] = 224,
|
| 271 |
+
patch_size: Union[int, Tuple[int, int]] = 16,
|
| 272 |
+
in_chans: int = 3,
|
| 273 |
+
num_classes: int = 1000,
|
| 274 |
+
global_pool: Literal["", "avg", "token", "map"] = "token",
|
| 275 |
+
embed_dim: int = 768,
|
| 276 |
+
depth: int = 12,
|
| 277 |
+
num_heads: int = 12,
|
| 278 |
+
mlp_ratio: float = 4.0,
|
| 279 |
+
qkv_bias: bool = True,
|
| 280 |
+
qk_norm: bool = False,
|
| 281 |
+
init_values: Optional[float] = None,
|
| 282 |
+
class_token: bool = True,
|
| 283 |
+
no_embed_class: bool = False,
|
| 284 |
+
reg_tokens: int = 0,
|
| 285 |
+
pre_norm: bool = False,
|
| 286 |
+
fc_norm: Optional[bool] = None,
|
| 287 |
+
dynamic_img_size: bool = False,
|
| 288 |
+
dynamic_img_pad: bool = False,
|
| 289 |
+
drop_rate: float = 0.0,
|
| 290 |
+
pos_drop_rate: float = 0.0,
|
| 291 |
+
patch_drop_rate: float = 0.0,
|
| 292 |
+
proj_drop_rate: float = 0.0,
|
| 293 |
+
attn_drop_rate: float = 0.0,
|
| 294 |
+
drop_path_rate: float = 0.0,
|
| 295 |
+
weight_init: Literal["skip", "jax", "jax_nlhb", "moco", ""] = "",
|
| 296 |
+
embed_layer: Callable = PatchEmbed,
|
| 297 |
+
norm_layer: Optional[LayerType] = None,
|
| 298 |
+
act_layer: Optional[LayerType] = None,
|
| 299 |
+
block_fn: Type[nn.Module] = Block,
|
| 300 |
+
mlp_layer: Type[nn.Module] = Mlp,
|
| 301 |
+
ignore_head: bool = False,
|
| 302 |
+
) -> None:
|
| 303 |
+
"""
|
| 304 |
+
Args:
|
| 305 |
+
img_size: Input image size.
|
| 306 |
+
patch_size: Patch size.
|
| 307 |
+
in_chans: Number of image input channels.
|
| 308 |
+
num_classes: Mumber of classes for classification head.
|
| 309 |
+
global_pool: Type of global pooling for final sequence (default: 'token').
|
| 310 |
+
embed_dim: Transformer embedding dimension.
|
| 311 |
+
depth: Depth of transformer.
|
| 312 |
+
num_heads: Number of attention heads.
|
| 313 |
+
mlp_ratio: Ratio of mlp hidden dim to embedding dim.
|
| 314 |
+
qkv_bias: Enable bias for qkv projections if True.
|
| 315 |
+
init_values: Layer-scale init values (layer-scale enabled if not None).
|
| 316 |
+
class_token: Use class token.
|
| 317 |
+
no_embed_class: Don't include position embeddings for class (or reg) tokens.
|
| 318 |
+
reg_tokens: Number of register tokens.
|
| 319 |
+
fc_norm: Pre head norm after pool (instead of before), if None, enabled when global_pool == 'avg'.
|
| 320 |
+
drop_rate: Head dropout rate.
|
| 321 |
+
pos_drop_rate: Position embedding dropout rate.
|
| 322 |
+
attn_drop_rate: Attention dropout rate.
|
| 323 |
+
drop_path_rate: Stochastic depth rate.
|
| 324 |
+
weight_init: Weight initialization scheme.
|
| 325 |
+
embed_layer: Patch embedding layer.
|
| 326 |
+
norm_layer: Normalization layer.
|
| 327 |
+
act_layer: MLP activation layer.
|
| 328 |
+
block_fn: Transformer block layer.
|
| 329 |
+
"""
|
| 330 |
+
super().__init__()
|
| 331 |
+
assert global_pool in ("", "avg", "token", "map")
|
| 332 |
+
assert class_token or global_pool != "token"
|
| 333 |
+
use_fc_norm = global_pool == "avg" if fc_norm is None else fc_norm
|
| 334 |
+
# norm_layer = get_norm_layer(norm_layer) or partial(nn.LayerNorm, eps=1e-6)
|
| 335 |
+
# act_layer = get_act_layer(act_layer) or nn.GELU
|
| 336 |
+
norm_layer = partial(nn.LayerNorm, eps=1e-6)
|
| 337 |
+
act_layer = nn.GELU
|
| 338 |
+
|
| 339 |
+
self.num_classes = num_classes
|
| 340 |
+
self.global_pool = global_pool
|
| 341 |
+
self.num_features = self.embed_dim = (
|
| 342 |
+
embed_dim # num_features for consistency with other models
|
| 343 |
+
)
|
| 344 |
+
self.num_prefix_tokens = 1 if class_token else 0
|
| 345 |
+
self.num_prefix_tokens += reg_tokens
|
| 346 |
+
self.num_reg_tokens = reg_tokens
|
| 347 |
+
self.has_class_token = class_token
|
| 348 |
+
self.no_embed_class = (
|
| 349 |
+
no_embed_class # don't embed prefix positions (includes reg)
|
| 350 |
+
)
|
| 351 |
+
self.dynamic_img_size = dynamic_img_size
|
| 352 |
+
self.grad_checkpointing = False
|
| 353 |
+
self.ignore_head = ignore_head
|
| 354 |
+
|
| 355 |
+
embed_args = {}
|
| 356 |
+
if dynamic_img_size:
|
| 357 |
+
# flatten deferred until after pos embed
|
| 358 |
+
embed_args.update(dict(strict_img_size=False, output_fmt="NHWC"))
|
| 359 |
+
self.patch_embed = embed_layer(
|
| 360 |
+
img_size=img_size,
|
| 361 |
+
patch_size=patch_size,
|
| 362 |
+
in_chans=in_chans,
|
| 363 |
+
embed_dim=embed_dim,
|
| 364 |
+
bias=not pre_norm, # disable bias if pre-norm is used (e.g. CLIP)
|
| 365 |
+
dynamic_img_pad=dynamic_img_pad,
|
| 366 |
+
**embed_args,
|
| 367 |
+
)
|
| 368 |
+
num_patches = self.patch_embed.num_patches
|
| 369 |
+
|
| 370 |
+
self.cls_token = (
|
| 371 |
+
nn.Parameter(torch.zeros(1, 1, embed_dim)) if class_token else None
|
| 372 |
+
)
|
| 373 |
+
self.reg_token = (
|
| 374 |
+
nn.Parameter(torch.zeros(1, reg_tokens, embed_dim)) if reg_tokens else None
|
| 375 |
+
)
|
| 376 |
+
embed_len = (
|
| 377 |
+
num_patches if no_embed_class else num_patches + self.num_prefix_tokens
|
| 378 |
+
)
|
| 379 |
+
self.pos_embed = nn.Parameter(torch.randn(1, embed_len, embed_dim) * 0.02)
|
| 380 |
+
self.pos_drop = nn.Dropout(p=pos_drop_rate)
|
| 381 |
+
if patch_drop_rate > 0:
|
| 382 |
+
self.patch_drop = PatchDropout(
|
| 383 |
+
patch_drop_rate,
|
| 384 |
+
num_prefix_tokens=self.num_prefix_tokens,
|
| 385 |
+
)
|
| 386 |
+
else:
|
| 387 |
+
self.patch_drop = nn.Identity()
|
| 388 |
+
self.norm_pre = norm_layer(embed_dim) if pre_norm else nn.Identity()
|
| 389 |
+
|
| 390 |
+
dpr = [
|
| 391 |
+
x.item() for x in torch.linspace(0, drop_path_rate, depth)
|
| 392 |
+
] # stochastic depth decay rule
|
| 393 |
+
self.blocks = nn.Sequential(
|
| 394 |
+
*[
|
| 395 |
+
block_fn(
|
| 396 |
+
dim=embed_dim,
|
| 397 |
+
num_heads=num_heads,
|
| 398 |
+
mlp_ratio=mlp_ratio,
|
| 399 |
+
qkv_bias=qkv_bias,
|
| 400 |
+
qk_norm=qk_norm,
|
| 401 |
+
init_values=init_values,
|
| 402 |
+
proj_drop=proj_drop_rate,
|
| 403 |
+
attn_drop=attn_drop_rate,
|
| 404 |
+
drop_path=dpr[i],
|
| 405 |
+
norm_layer=norm_layer,
|
| 406 |
+
act_layer=act_layer,
|
| 407 |
+
mlp_layer=mlp_layer,
|
| 408 |
+
)
|
| 409 |
+
for i in range(depth)
|
| 410 |
+
]
|
| 411 |
+
)
|
| 412 |
+
self.norm = norm_layer(embed_dim) if not use_fc_norm else nn.Identity()
|
| 413 |
+
|
| 414 |
+
# Classifier Head
|
| 415 |
+
if global_pool == "map":
|
| 416 |
+
AttentionPoolLatent.init_weights = init_weights
|
| 417 |
+
self.attn_pool = AttentionPoolLatent(
|
| 418 |
+
self.embed_dim,
|
| 419 |
+
num_heads=num_heads,
|
| 420 |
+
mlp_ratio=mlp_ratio,
|
| 421 |
+
norm_layer=norm_layer,
|
| 422 |
+
)
|
| 423 |
+
else:
|
| 424 |
+
self.attn_pool = None
|
| 425 |
+
self.fc_norm = norm_layer(embed_dim) if use_fc_norm else nn.Identity()
|
| 426 |
+
self.head_drop = nn.Dropout(drop_rate)
|
| 427 |
+
self.head = (
|
| 428 |
+
nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
|
| 429 |
+
)
|
| 430 |
+
|
| 431 |
+
if weight_init != "skip":
|
| 432 |
+
self.init_weights(weight_init)
|
| 433 |
+
|
| 434 |
+
def init_weights(self, mode: Literal["jax", "jax_nlhb", "moco", ""] = "") -> None:
|
| 435 |
+
assert mode in ("jax", "jax_nlhb", "moco", "")
|
| 436 |
+
# head_bias = -math.log(self.num_classes) if "nlhb" in mode else 0.0
|
| 437 |
+
trunc_normal_(self.pos_embed, std=0.02)
|
| 438 |
+
if self.cls_token is not None:
|
| 439 |
+
nn.init.normal_(self.cls_token, std=1e-6)
|
| 440 |
+
named_apply(init_weights_vit_timm, self)
|
| 441 |
+
|
| 442 |
+
@torch.jit.ignore
|
| 443 |
+
def no_weight_decay(self) -> Set:
|
| 444 |
+
return {"pos_embed", "cls_token", "dist_token"}
|
| 445 |
+
|
| 446 |
+
@torch.jit.ignore
|
| 447 |
+
def group_matcher(self, coarse: bool = False) -> Dict:
|
| 448 |
+
return dict(
|
| 449 |
+
stem=r"^cls_token|pos_embed|patch_embed", # stem and embed
|
| 450 |
+
blocks=[(r"^blocks\.(\d+)", None), (r"^norm", (99999,))],
|
| 451 |
+
)
|
| 452 |
+
|
| 453 |
+
@torch.jit.ignore
|
| 454 |
+
def set_grad_checkpointing(self, enable: bool = True) -> None:
|
| 455 |
+
self.grad_checkpointing = enable
|
| 456 |
+
|
| 457 |
+
@torch.jit.ignore
|
| 458 |
+
def get_classifier(self) -> nn.Module:
|
| 459 |
+
return self.head
|
| 460 |
+
|
| 461 |
+
def reset_classifier(self, num_classes: int, global_pool=None) -> None:
|
| 462 |
+
self.num_classes = num_classes
|
| 463 |
+
if global_pool is not None:
|
| 464 |
+
assert global_pool in ("", "avg", "token", "map")
|
| 465 |
+
if global_pool == "map" and self.attn_pool is None:
|
| 466 |
+
assert (
|
| 467 |
+
False
|
| 468 |
+
), "Cannot currently add attention pooling in reset_classifier()."
|
| 469 |
+
elif global_pool != "map " and self.attn_pool is not None:
|
| 470 |
+
self.attn_pool = None # remove attention pooling
|
| 471 |
+
self.global_pool = global_pool
|
| 472 |
+
self.head = (
|
| 473 |
+
nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
|
| 474 |
+
)
|
| 475 |
+
|
| 476 |
+
def _pos_embed(self, x: torch.Tensor) -> torch.Tensor:
|
| 477 |
+
if self.dynamic_img_size:
|
| 478 |
+
B, H, W, C = x.shape
|
| 479 |
+
pos_embed = resample_abs_pos_embed(
|
| 480 |
+
self.pos_embed,
|
| 481 |
+
(H, W),
|
| 482 |
+
num_prefix_tokens=0 if self.no_embed_class else self.num_prefix_tokens,
|
| 483 |
+
)
|
| 484 |
+
x = x.view(B, -1, C)
|
| 485 |
+
else:
|
| 486 |
+
pos_embed = self.pos_embed
|
| 487 |
+
|
| 488 |
+
to_cat = []
|
| 489 |
+
if self.cls_token is not None:
|
| 490 |
+
to_cat.append(self.cls_token.expand(x.shape[0], -1, -1))
|
| 491 |
+
if self.reg_token is not None:
|
| 492 |
+
to_cat.append(self.reg_token.expand(x.shape[0], -1, -1))
|
| 493 |
+
|
| 494 |
+
if self.no_embed_class:
|
| 495 |
+
# deit-3, updated JAX (big vision)
|
| 496 |
+
# position embedding does not overlap with class token, add then concat
|
| 497 |
+
x = x + pos_embed
|
| 498 |
+
if to_cat:
|
| 499 |
+
x = torch.cat(to_cat + [x], dim=1)
|
| 500 |
+
else:
|
| 501 |
+
# original timm, JAX, and deit vit impl
|
| 502 |
+
# pos_embed has entry for class token, concat then add
|
| 503 |
+
if to_cat:
|
| 504 |
+
x = torch.cat(to_cat + [x], dim=1)
|
| 505 |
+
x = x + pos_embed
|
| 506 |
+
|
| 507 |
+
return self.pos_drop(x)
|
| 508 |
+
|
| 509 |
+
def _intermediate_layers(
|
| 510 |
+
self,
|
| 511 |
+
x: torch.Tensor,
|
| 512 |
+
n: Union[int, Sequence] = 1,
|
| 513 |
+
) -> List[torch.Tensor]:
|
| 514 |
+
outputs, num_blocks = [], len(self.blocks)
|
| 515 |
+
take_indices = set(
|
| 516 |
+
range(num_blocks - n, num_blocks) if isinstance(n, int) else n
|
| 517 |
+
)
|
| 518 |
+
|
| 519 |
+
# forward pass
|
| 520 |
+
x = self.patch_embed(x)
|
| 521 |
+
x = self._pos_embed(x)
|
| 522 |
+
x = self.patch_drop(x)
|
| 523 |
+
x = self.norm_pre(x)
|
| 524 |
+
for i, blk in enumerate(self.blocks):
|
| 525 |
+
x = blk(x)
|
| 526 |
+
if i in take_indices:
|
| 527 |
+
outputs.append(x)
|
| 528 |
+
|
| 529 |
+
return outputs
|
| 530 |
+
|
| 531 |
+
def get_intermediate_layers(
|
| 532 |
+
self,
|
| 533 |
+
x: torch.Tensor,
|
| 534 |
+
n: Union[int, Sequence] = 1,
|
| 535 |
+
reshape: bool = False,
|
| 536 |
+
return_prefix_tokens: bool = False,
|
| 537 |
+
norm: bool = False,
|
| 538 |
+
) -> Tuple[Union[torch.Tensor, Tuple[torch.Tensor]]]:
|
| 539 |
+
"""Intermediate layer accessor (NOTE: This is a WIP experiment).
|
| 540 |
+
Inspired by DINO / DINOv2 interface
|
| 541 |
+
"""
|
| 542 |
+
# take last n blocks if n is an int, if in is a sequence, select by matching indices
|
| 543 |
+
outputs = self._intermediate_layers(x, n)
|
| 544 |
+
if norm:
|
| 545 |
+
outputs = [self.norm(out) for out in outputs]
|
| 546 |
+
prefix_tokens = [out[:, 0 : self.num_prefix_tokens] for out in outputs]
|
| 547 |
+
outputs = [out[:, self.num_prefix_tokens :] for out in outputs]
|
| 548 |
+
|
| 549 |
+
if reshape:
|
| 550 |
+
grid_size = self.patch_embed.grid_size
|
| 551 |
+
outputs = [
|
| 552 |
+
out.reshape(x.shape[0], grid_size[0], grid_size[1], -1)
|
| 553 |
+
.permute(0, 3, 1, 2)
|
| 554 |
+
.contiguous()
|
| 555 |
+
for out in outputs
|
| 556 |
+
]
|
| 557 |
+
|
| 558 |
+
if return_prefix_tokens:
|
| 559 |
+
return tuple(zip(outputs, prefix_tokens))
|
| 560 |
+
return tuple(outputs)
|
| 561 |
+
|
| 562 |
+
def forward_features(self, x: torch.Tensor) -> torch.Tensor:
|
| 563 |
+
x = self.patch_embed(x)
|
| 564 |
+
x = self._pos_embed(x)
|
| 565 |
+
x = self.patch_drop(x)
|
| 566 |
+
x = self.norm_pre(x)
|
| 567 |
+
if self.grad_checkpointing and not torch.jit.is_scripting():
|
| 568 |
+
x = checkpoint_seq(self.blocks, x)
|
| 569 |
+
else:
|
| 570 |
+
x = self.blocks(x)
|
| 571 |
+
x = self.norm(x)
|
| 572 |
+
return x
|
| 573 |
+
|
| 574 |
+
def forward_head(self, x: torch.Tensor, pre_logits: bool = False) -> torch.Tensor:
|
| 575 |
+
if self.attn_pool is not None:
|
| 576 |
+
x = self.attn_pool(x)
|
| 577 |
+
elif self.global_pool == "avg":
|
| 578 |
+
x = x[:, self.num_prefix_tokens :].mean(dim=1)
|
| 579 |
+
elif self.global_pool:
|
| 580 |
+
x = x[:, 0] # class token
|
| 581 |
+
x = self.fc_norm(x)
|
| 582 |
+
x = self.head_drop(x)
|
| 583 |
+
return x if pre_logits else self.head(x)
|
| 584 |
+
|
| 585 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 586 |
+
x = self.forward_features(x)
|
| 587 |
+
if not self.ignore_head:
|
| 588 |
+
x = self.forward_head(x)
|
| 589 |
+
return x
|
| 590 |
+
|
| 591 |
+
|
| 592 |
+
@dataclass
|
| 593 |
+
class SigLIPVisionCfg:
|
| 594 |
+
width: int = 1152
|
| 595 |
+
layers: Union[Tuple[int, int, int, int], int] = 27
|
| 596 |
+
heads: int = 16
|
| 597 |
+
patch_size: int = 14
|
| 598 |
+
image_size: Union[Tuple[int, int], int] = 336
|
| 599 |
+
global_pool: str = "map"
|
| 600 |
+
mlp_ratio: float = 3.7362
|
| 601 |
+
class_token: bool = False
|
| 602 |
+
num_classes: int = 0
|
| 603 |
+
use_checkpoint: bool = False
|
| 604 |
+
|
| 605 |
+
|
| 606 |
+
SigLIP_MODEL_CONFIG = {
|
| 607 |
+
"siglip_so400m_patch14_384": {
|
| 608 |
+
"image_size": 336,
|
| 609 |
+
"patch_size": 14,
|
| 610 |
+
"width": 1152,
|
| 611 |
+
"layers": 27,
|
| 612 |
+
"heads": 16,
|
| 613 |
+
"mlp_ratio": 3.7362,
|
| 614 |
+
"global_pool": "map",
|
| 615 |
+
"use_checkpoint": False,
|
| 616 |
+
},
|
| 617 |
+
"siglip_so400m_patch14_224": {
|
| 618 |
+
"image_size": 224,
|
| 619 |
+
"patch_size": 14,
|
| 620 |
+
"width": 1152,
|
| 621 |
+
"layers": 27,
|
| 622 |
+
"heads": 16,
|
| 623 |
+
"mlp_ratio": 3.7362,
|
| 624 |
+
"global_pool": "map",
|
| 625 |
+
"use_checkpoint": False,
|
| 626 |
+
},
|
| 627 |
+
"siglip_large_patch16_384": {
|
| 628 |
+
"image_size": 384,
|
| 629 |
+
"patch_size": 16,
|
| 630 |
+
"width": 1024,
|
| 631 |
+
"layers": 24,
|
| 632 |
+
"heads": 16,
|
| 633 |
+
"mlp_ratio": 4,
|
| 634 |
+
"global_pool": "map",
|
| 635 |
+
"use_checkpoint": False,
|
| 636 |
+
},
|
| 637 |
+
"siglip_large_patch16_256": {
|
| 638 |
+
"image_size": 256,
|
| 639 |
+
"patch_size": 16,
|
| 640 |
+
"width": 1024,
|
| 641 |
+
"layers": 24,
|
| 642 |
+
"heads": 16,
|
| 643 |
+
"mlp_ratio": 4,
|
| 644 |
+
"global_pool": "map",
|
| 645 |
+
"use_checkpoint": False,
|
| 646 |
+
},
|
| 647 |
+
}
|
| 648 |
+
|
| 649 |
+
|
| 650 |
+
def create_siglip_vit(
|
| 651 |
+
model_name: str = "siglip_so400m_patch14_384",
|
| 652 |
+
image_size: int = 384,
|
| 653 |
+
select_layer: int = -1,
|
| 654 |
+
ckpt_path: str = "",
|
| 655 |
+
**kwargs,
|
| 656 |
+
):
|
| 657 |
+
assert (
|
| 658 |
+
model_name in SigLIP_MODEL_CONFIG.keys()
|
| 659 |
+
), f"model name should be in {SigLIP_MODEL_CONFIG.keys()}"
|
| 660 |
+
|
| 661 |
+
vision_cfg = SigLIPVisionCfg(**SigLIP_MODEL_CONFIG[model_name])
|
| 662 |
+
|
| 663 |
+
if select_layer <= 0:
|
| 664 |
+
layers = min(vision_cfg.layers, vision_cfg.layers + select_layer + 1)
|
| 665 |
+
else:
|
| 666 |
+
layers = min(vision_cfg.layers, select_layer)
|
| 667 |
+
|
| 668 |
+
model = VisionTransformer(
|
| 669 |
+
img_size=image_size,
|
| 670 |
+
patch_size=vision_cfg.patch_size,
|
| 671 |
+
embed_dim=vision_cfg.width,
|
| 672 |
+
depth=layers,
|
| 673 |
+
num_heads=vision_cfg.heads,
|
| 674 |
+
mlp_ratio=vision_cfg.mlp_ratio,
|
| 675 |
+
class_token=vision_cfg.class_token,
|
| 676 |
+
global_pool=vision_cfg.global_pool,
|
| 677 |
+
ignore_head=kwargs.get("ignore_head", True),
|
| 678 |
+
weight_init=kwargs.get("weight_init", "skip"),
|
| 679 |
+
num_classes=0,
|
| 680 |
+
)
|
| 681 |
+
|
| 682 |
+
if ckpt_path:
|
| 683 |
+
state_dict = torch.load(ckpt_path, map_location="cpu")
|
| 684 |
+
|
| 685 |
+
incompatible_keys = model.load_state_dict(state_dict, strict=False)
|
| 686 |
+
print(
|
| 687 |
+
f"SigLIP-ViT restores from {ckpt_path},\n"
|
| 688 |
+
f"\tincompatible_keys:', {incompatible_keys}."
|
| 689 |
+
)
|
| 690 |
+
|
| 691 |
+
return model
|
janus/janusflow/models/uvit.py
ADDED
|
@@ -0,0 +1,714 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2023-2024 DeepSeek.
|
| 2 |
+
#
|
| 3 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 4 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 5 |
+
# the Software without restriction, including without limitation the rights to
|
| 6 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
|
| 7 |
+
# the Software, and to permit persons to whom the Software is furnished to do so,
|
| 8 |
+
# subject to the following conditions:
|
| 9 |
+
#
|
| 10 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 11 |
+
# copies or substantial portions of the Software.
|
| 12 |
+
#
|
| 13 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 14 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
|
| 15 |
+
# FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
|
| 16 |
+
# COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
|
| 17 |
+
# IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
|
| 18 |
+
# CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
| 19 |
+
|
| 20 |
+
# modified from: https://github.com/lucidrains/denoising-diffusion-pytorch/blob/main/denoising_diffusion_pytorch/simple_diffusion.py
|
| 21 |
+
import math
|
| 22 |
+
import torch
|
| 23 |
+
import torch.nn as nn
|
| 24 |
+
import torch.distributed as dist
|
| 25 |
+
import torch.nn.functional as F
|
| 26 |
+
from typing import Optional, Tuple, Union
|
| 27 |
+
|
| 28 |
+
import numpy as np
|
| 29 |
+
import torchvision
|
| 30 |
+
import torchvision.utils
|
| 31 |
+
from diffusers.models.embeddings import Timesteps, TimestepEmbedding
|
| 32 |
+
from transformers.models.llama.modeling_llama import LlamaRMSNorm as RMSNorm
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
class ImageHead(nn.Module):
|
| 36 |
+
|
| 37 |
+
def __init__(self, decoder_cfg, gpt_cfg, layer_id=None):
|
| 38 |
+
super().__init__()
|
| 39 |
+
self.layer_id = layer_id
|
| 40 |
+
cfg = (
|
| 41 |
+
AttrDict(
|
| 42 |
+
norm_type="layernorm",
|
| 43 |
+
is_exp_norm=False,
|
| 44 |
+
sequence_parallel=False,
|
| 45 |
+
use_userbuffer=False,
|
| 46 |
+
norm_eps=1e-5,
|
| 47 |
+
norm_bias=True,
|
| 48 |
+
gradient_accumulation_fusion=True,
|
| 49 |
+
use_fp32_head_weight=False,
|
| 50 |
+
)
|
| 51 |
+
+ gpt_cfg
|
| 52 |
+
)
|
| 53 |
+
group = PG.tensor_parallel_group()
|
| 54 |
+
assert cfg.norm_type in [
|
| 55 |
+
"layernorm",
|
| 56 |
+
"rmsnorm",
|
| 57 |
+
], f"Norm type:{cfg.norm_type} not supported"
|
| 58 |
+
if cfg.norm_type == "rmsnorm":
|
| 59 |
+
self.norm = DropoutAddRMSNorm(
|
| 60 |
+
cfg.n_embed,
|
| 61 |
+
prenorm=False,
|
| 62 |
+
eps=cfg.norm_eps,
|
| 63 |
+
is_exp_norm=cfg.is_exp_norm,
|
| 64 |
+
sequence_parallel=cfg.sequence_parallel,
|
| 65 |
+
)
|
| 66 |
+
else:
|
| 67 |
+
self.norm = DropoutAddLayerNorm(
|
| 68 |
+
cfg.n_embed,
|
| 69 |
+
prenorm=False,
|
| 70 |
+
eps=cfg.norm_eps,
|
| 71 |
+
is_exp_norm=cfg.is_exp_norm,
|
| 72 |
+
sequence_parallel=cfg.sequence_parallel,
|
| 73 |
+
bias=cfg.norm_bias,
|
| 74 |
+
)
|
| 75 |
+
|
| 76 |
+
multiple_of = 256
|
| 77 |
+
if decoder_cfg.in_channels % multiple_of != 0:
|
| 78 |
+
warnings.warn(
|
| 79 |
+
f"建议把 vocab_size 设置为 {multiple_of} 的倍数, 否则会影响矩阵乘法的性能"
|
| 80 |
+
)
|
| 81 |
+
|
| 82 |
+
dtype = default_dtype = torch.get_default_dtype()
|
| 83 |
+
if cfg.use_fp32_head_weight:
|
| 84 |
+
dtype = torch.float32
|
| 85 |
+
print(
|
| 86 |
+
"使用 fp32 head weight!!!! 与原来的 bf16 head weight 不兼容\n",
|
| 87 |
+
end="",
|
| 88 |
+
flush=True,
|
| 89 |
+
)
|
| 90 |
+
torch.set_default_dtype(dtype)
|
| 91 |
+
self.head = ColumnParallelLinear(
|
| 92 |
+
cfg.n_embed,
|
| 93 |
+
decoder_cfg.in_channels,
|
| 94 |
+
bias=True,
|
| 95 |
+
group=group,
|
| 96 |
+
sequence_parallel=cfg.sequence_parallel,
|
| 97 |
+
use_userbuffer=cfg.use_userbuffer,
|
| 98 |
+
gradient_accumulation_fusion=cfg.gradient_accumulation_fusion,
|
| 99 |
+
use_fp32_output=False,
|
| 100 |
+
)
|
| 101 |
+
torch.set_default_dtype(default_dtype)
|
| 102 |
+
|
| 103 |
+
self.use_fp32_head_weight = cfg.use_fp32_head_weight
|
| 104 |
+
|
| 105 |
+
def forward(
|
| 106 |
+
self, input_args, images_split_mask: Optional[torch.BoolTensor] = None, **kwargs
|
| 107 |
+
):
|
| 108 |
+
residual = None
|
| 109 |
+
if isinstance(input_args, tuple):
|
| 110 |
+
x, residual = input_args
|
| 111 |
+
else:
|
| 112 |
+
x = input_args
|
| 113 |
+
|
| 114 |
+
x = self.norm(x, residual)
|
| 115 |
+
|
| 116 |
+
if self.use_fp32_head_weight:
|
| 117 |
+
assert (
|
| 118 |
+
self.head.weight.dtype == torch.float32
|
| 119 |
+
), f"head.weight is {self.head.weight.dtype}"
|
| 120 |
+
x = x.float()
|
| 121 |
+
|
| 122 |
+
if images_split_mask is None:
|
| 123 |
+
logits = self.head(x)
|
| 124 |
+
else:
|
| 125 |
+
bs, n_images = images_split_mask.shape[:2]
|
| 126 |
+
n_embed = x.shape[-1]
|
| 127 |
+
|
| 128 |
+
images_embed = torch.masked_select(
|
| 129 |
+
x.unsqueeze(1), images_split_mask.unsqueeze(-1)
|
| 130 |
+
)
|
| 131 |
+
images_embed = images_embed.view((bs * n_images, -1, n_embed))
|
| 132 |
+
logits = self.head(images_embed)
|
| 133 |
+
|
| 134 |
+
return logits
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
class GlobalResponseNorm(nn.Module):
|
| 138 |
+
# Taken from https://github.com/facebookresearch/ConvNeXt-V2/blob/3608f67cc1dae164790c5d0aead7bf2d73d9719b/models/utils.py#L105
|
| 139 |
+
def __init__(self, dim):
|
| 140 |
+
super().__init__()
|
| 141 |
+
self.weight = nn.Parameter(torch.zeros(1, 1, 1, dim))
|
| 142 |
+
self.bias = nn.Parameter(torch.zeros(1, 1, 1, dim))
|
| 143 |
+
|
| 144 |
+
def forward(self, x):
|
| 145 |
+
gx = torch.norm(x, p=2, dim=(1, 2), keepdim=True)
|
| 146 |
+
nx = gx / (gx.mean(dim=-1, keepdim=True) + 1e-6)
|
| 147 |
+
|
| 148 |
+
return torch.addcmul(self.bias, (self.weight * nx + 1), x, value=1)
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
class Downsample2D(nn.Module):
|
| 152 |
+
"""A 2D downsampling layer with an optional convolution.
|
| 153 |
+
|
| 154 |
+
Parameters:
|
| 155 |
+
channels (`int`):
|
| 156 |
+
number of channels in the inputs and outputs.
|
| 157 |
+
use_conv (`bool`, default `False`):
|
| 158 |
+
option to use a convolution.
|
| 159 |
+
out_channels (`int`, optional):
|
| 160 |
+
number of output channels. Defaults to `channels`.
|
| 161 |
+
padding (`int`, default `1`):
|
| 162 |
+
padding for the convolution.
|
| 163 |
+
name (`str`, default `conv`):
|
| 164 |
+
name of the downsampling 2D layer.
|
| 165 |
+
"""
|
| 166 |
+
|
| 167 |
+
def __init__(
|
| 168 |
+
self,
|
| 169 |
+
channels: int,
|
| 170 |
+
use_conv: bool = False,
|
| 171 |
+
out_channels: Optional[int] = None,
|
| 172 |
+
padding: int = 1,
|
| 173 |
+
name: str = "conv",
|
| 174 |
+
kernel_size=3,
|
| 175 |
+
stride=2,
|
| 176 |
+
norm_type=None,
|
| 177 |
+
eps=None,
|
| 178 |
+
elementwise_affine=None,
|
| 179 |
+
bias=True,
|
| 180 |
+
):
|
| 181 |
+
super().__init__()
|
| 182 |
+
self.channels = channels
|
| 183 |
+
self.out_channels = out_channels or channels
|
| 184 |
+
self.use_conv = use_conv
|
| 185 |
+
self.padding = padding
|
| 186 |
+
self.name = name
|
| 187 |
+
|
| 188 |
+
if norm_type == "ln_norm":
|
| 189 |
+
self.norm = nn.LayerNorm(channels, eps, elementwise_affine)
|
| 190 |
+
elif norm_type == "rms_norm":
|
| 191 |
+
self.norm = RMSNorm(channels, eps)
|
| 192 |
+
elif norm_type is None:
|
| 193 |
+
self.norm = None
|
| 194 |
+
else:
|
| 195 |
+
raise ValueError(f"unknown norm_type: {norm_type}")
|
| 196 |
+
|
| 197 |
+
if use_conv:
|
| 198 |
+
conv = nn.Conv2d(
|
| 199 |
+
self.channels,
|
| 200 |
+
self.out_channels,
|
| 201 |
+
kernel_size=kernel_size,
|
| 202 |
+
stride=stride,
|
| 203 |
+
padding=padding,
|
| 204 |
+
bias=bias,
|
| 205 |
+
)
|
| 206 |
+
else:
|
| 207 |
+
assert self.channels == self.out_channels
|
| 208 |
+
conv = nn.AvgPool2d(kernel_size=stride, stride=stride)
|
| 209 |
+
|
| 210 |
+
# TODO(Suraj, Patrick) - clean up after weight dicts are correctly renamed
|
| 211 |
+
if name == "conv":
|
| 212 |
+
self.Conv2d_0 = conv
|
| 213 |
+
self.conv = conv
|
| 214 |
+
elif name == "Conv2d_0":
|
| 215 |
+
self.conv = conv
|
| 216 |
+
else:
|
| 217 |
+
self.conv = conv
|
| 218 |
+
|
| 219 |
+
def forward(self, hidden_states: torch.Tensor, *args, **kwargs) -> torch.Tensor:
|
| 220 |
+
|
| 221 |
+
assert hidden_states.shape[1] == self.channels
|
| 222 |
+
|
| 223 |
+
if self.norm is not None:
|
| 224 |
+
hidden_states = self.norm(hidden_states.permute(0, 2, 3, 1)).permute(
|
| 225 |
+
0, 3, 1, 2
|
| 226 |
+
)
|
| 227 |
+
|
| 228 |
+
if self.use_conv and self.padding == 0:
|
| 229 |
+
pad = (0, 1, 0, 1)
|
| 230 |
+
hidden_states = F.pad(hidden_states, pad, mode="constant", value=0)
|
| 231 |
+
|
| 232 |
+
assert hidden_states.shape[1] == self.channels
|
| 233 |
+
|
| 234 |
+
hidden_states = self.conv(hidden_states)
|
| 235 |
+
|
| 236 |
+
return hidden_states
|
| 237 |
+
|
| 238 |
+
|
| 239 |
+
class Upsample2D(nn.Module):
|
| 240 |
+
"""A 2D upsampling layer with an optional convolution.
|
| 241 |
+
|
| 242 |
+
Parameters:
|
| 243 |
+
channels (`int`):
|
| 244 |
+
number of channels in the inputs and outputs.
|
| 245 |
+
use_conv (`bool`, default `False`):
|
| 246 |
+
option to use a convolution.
|
| 247 |
+
use_conv_transpose (`bool`, default `False`):
|
| 248 |
+
option to use a convolution transpose.
|
| 249 |
+
out_channels (`int`, optional):
|
| 250 |
+
number of output channels. Defaults to `channels`.
|
| 251 |
+
name (`str`, default `conv`):
|
| 252 |
+
name of the upsampling 2D layer.
|
| 253 |
+
"""
|
| 254 |
+
|
| 255 |
+
def __init__(
|
| 256 |
+
self,
|
| 257 |
+
channels: int,
|
| 258 |
+
use_conv: bool = False,
|
| 259 |
+
use_conv_transpose: bool = False,
|
| 260 |
+
out_channels: Optional[int] = None,
|
| 261 |
+
name: str = "conv",
|
| 262 |
+
kernel_size: Optional[int] = None,
|
| 263 |
+
padding=1,
|
| 264 |
+
stride=2,
|
| 265 |
+
norm_type=None,
|
| 266 |
+
eps=None,
|
| 267 |
+
elementwise_affine=None,
|
| 268 |
+
bias=True,
|
| 269 |
+
interpolate=True,
|
| 270 |
+
):
|
| 271 |
+
super().__init__()
|
| 272 |
+
self.channels = channels
|
| 273 |
+
self.out_channels = out_channels or channels
|
| 274 |
+
self.use_conv = use_conv
|
| 275 |
+
self.use_conv_transpose = use_conv_transpose
|
| 276 |
+
self.name = name
|
| 277 |
+
self.interpolate = interpolate
|
| 278 |
+
self.stride = stride
|
| 279 |
+
|
| 280 |
+
if norm_type == "ln_norm":
|
| 281 |
+
self.norm = nn.LayerNorm(channels, eps, elementwise_affine)
|
| 282 |
+
elif norm_type == "rms_norm":
|
| 283 |
+
self.norm = RMSNorm(channels, eps)
|
| 284 |
+
elif norm_type is None:
|
| 285 |
+
self.norm = None
|
| 286 |
+
else:
|
| 287 |
+
raise ValueError(f"unknown norm_type: {norm_type}")
|
| 288 |
+
|
| 289 |
+
conv = None
|
| 290 |
+
if use_conv_transpose:
|
| 291 |
+
if kernel_size is None:
|
| 292 |
+
kernel_size = 4
|
| 293 |
+
conv = nn.ConvTranspose2d(
|
| 294 |
+
channels,
|
| 295 |
+
self.out_channels,
|
| 296 |
+
kernel_size=kernel_size,
|
| 297 |
+
stride=stride,
|
| 298 |
+
padding=padding,
|
| 299 |
+
bias=bias,
|
| 300 |
+
)
|
| 301 |
+
elif use_conv:
|
| 302 |
+
if kernel_size is None:
|
| 303 |
+
kernel_size = 3
|
| 304 |
+
conv = nn.Conv2d(
|
| 305 |
+
self.channels,
|
| 306 |
+
self.out_channels,
|
| 307 |
+
kernel_size=kernel_size,
|
| 308 |
+
padding=padding,
|
| 309 |
+
bias=bias,
|
| 310 |
+
)
|
| 311 |
+
|
| 312 |
+
# TODO(Suraj, Patrick) - clean up after weight dicts are correctly renamed
|
| 313 |
+
if name == "conv":
|
| 314 |
+
self.conv = conv
|
| 315 |
+
else:
|
| 316 |
+
self.Conv2d_0 = conv
|
| 317 |
+
|
| 318 |
+
def forward(
|
| 319 |
+
self,
|
| 320 |
+
hidden_states: torch.Tensor,
|
| 321 |
+
output_size: Optional[int] = None,
|
| 322 |
+
*args,
|
| 323 |
+
**kwargs,
|
| 324 |
+
) -> torch.Tensor:
|
| 325 |
+
|
| 326 |
+
assert hidden_states.shape[1] == self.channels
|
| 327 |
+
|
| 328 |
+
if self.norm is not None:
|
| 329 |
+
hidden_states = self.norm(hidden_states.permute(0, 2, 3, 1)).permute(
|
| 330 |
+
0, 3, 1, 2
|
| 331 |
+
)
|
| 332 |
+
|
| 333 |
+
if self.use_conv_transpose:
|
| 334 |
+
return self.conv(hidden_states)
|
| 335 |
+
|
| 336 |
+
# Cast to float32 to as 'upsample_nearest2d_out_frame' op does not support bfloat16
|
| 337 |
+
# TODO(Suraj): Remove this cast once the issue is fixed in PyTorch
|
| 338 |
+
# https://github.com/pytorch/pytorch/issues/86679
|
| 339 |
+
dtype = hidden_states.dtype
|
| 340 |
+
if dtype == torch.bfloat16:
|
| 341 |
+
hidden_states = hidden_states.to(torch.float32)
|
| 342 |
+
|
| 343 |
+
# upsample_nearest_nhwc fails with large batch sizes. see https://github.com/huggingface/diffusers/issues/984
|
| 344 |
+
if hidden_states.shape[0] >= 64:
|
| 345 |
+
hidden_states = hidden_states.contiguous()
|
| 346 |
+
|
| 347 |
+
# if `output_size` is passed we force the interpolation output
|
| 348 |
+
# size and do not make use of `scale_factor=2`
|
| 349 |
+
if self.interpolate:
|
| 350 |
+
if output_size is None:
|
| 351 |
+
hidden_states = F.interpolate(
|
| 352 |
+
hidden_states, scale_factor=self.stride, mode="nearest"
|
| 353 |
+
)
|
| 354 |
+
else:
|
| 355 |
+
hidden_states = F.interpolate(
|
| 356 |
+
hidden_states, size=output_size, mode="nearest"
|
| 357 |
+
)
|
| 358 |
+
|
| 359 |
+
# If the input is bfloat16, we cast back to bfloat16
|
| 360 |
+
if dtype == torch.bfloat16:
|
| 361 |
+
hidden_states = hidden_states.to(dtype)
|
| 362 |
+
|
| 363 |
+
# TODO(Suraj, Patrick) - clean up after weight dicts are correctly renamed
|
| 364 |
+
if self.use_conv:
|
| 365 |
+
if self.name == "conv":
|
| 366 |
+
hidden_states = self.conv(hidden_states)
|
| 367 |
+
else:
|
| 368 |
+
hidden_states = self.Conv2d_0(hidden_states)
|
| 369 |
+
|
| 370 |
+
return hidden_states
|
| 371 |
+
|
| 372 |
+
|
| 373 |
+
class ConvNextBlock(nn.Module):
|
| 374 |
+
def __init__(
|
| 375 |
+
self,
|
| 376 |
+
channels,
|
| 377 |
+
norm_eps,
|
| 378 |
+
elementwise_affine,
|
| 379 |
+
use_bias,
|
| 380 |
+
hidden_dropout,
|
| 381 |
+
hidden_size,
|
| 382 |
+
res_ffn_factor: int = 4,
|
| 383 |
+
):
|
| 384 |
+
super().__init__()
|
| 385 |
+
self.depthwise = nn.Conv2d(
|
| 386 |
+
channels,
|
| 387 |
+
channels,
|
| 388 |
+
kernel_size=7,
|
| 389 |
+
padding=3,
|
| 390 |
+
groups=channels,
|
| 391 |
+
bias=use_bias,
|
| 392 |
+
)
|
| 393 |
+
self.norm = RMSNorm(channels, norm_eps)
|
| 394 |
+
self.channelwise_linear_1 = nn.Linear(
|
| 395 |
+
channels, int(channels * res_ffn_factor), bias=use_bias
|
| 396 |
+
)
|
| 397 |
+
self.channelwise_act = nn.GELU()
|
| 398 |
+
self.channelwise_norm = GlobalResponseNorm(int(channels * res_ffn_factor))
|
| 399 |
+
self.channelwise_linear_2 = nn.Linear(
|
| 400 |
+
int(channels * res_ffn_factor), channels, bias=use_bias
|
| 401 |
+
)
|
| 402 |
+
self.channelwise_dropout = nn.Dropout(hidden_dropout)
|
| 403 |
+
self.cond_embeds_mapper = nn.Linear(hidden_size, channels * 2, use_bias)
|
| 404 |
+
|
| 405 |
+
def forward(self, x, cond_embeds):
|
| 406 |
+
x_res = x
|
| 407 |
+
|
| 408 |
+
x = self.depthwise(x)
|
| 409 |
+
|
| 410 |
+
x = x.permute(0, 2, 3, 1)
|
| 411 |
+
x = self.norm(x)
|
| 412 |
+
x = self.channelwise_linear_1(x)
|
| 413 |
+
x = self.channelwise_act(x)
|
| 414 |
+
x = self.channelwise_norm(x)
|
| 415 |
+
x = self.channelwise_linear_2(x)
|
| 416 |
+
x = self.channelwise_dropout(x)
|
| 417 |
+
x = x.permute(0, 3, 1, 2)
|
| 418 |
+
|
| 419 |
+
x = x + x_res
|
| 420 |
+
|
| 421 |
+
scale, shift = self.cond_embeds_mapper(F.silu(cond_embeds)).chunk(2, dim=1)
|
| 422 |
+
# x = x * (1 + scale[:, :, None, None]) + shift[:, :, None, None]
|
| 423 |
+
x = torch.addcmul(
|
| 424 |
+
shift[:, :, None, None], x, (1 + scale)[:, :, None, None], value=1
|
| 425 |
+
)
|
| 426 |
+
|
| 427 |
+
return x
|
| 428 |
+
|
| 429 |
+
|
| 430 |
+
class Patchify(nn.Module):
|
| 431 |
+
def __init__(
|
| 432 |
+
self,
|
| 433 |
+
in_channels,
|
| 434 |
+
block_out_channels,
|
| 435 |
+
patch_size,
|
| 436 |
+
bias,
|
| 437 |
+
elementwise_affine,
|
| 438 |
+
eps,
|
| 439 |
+
kernel_size=None,
|
| 440 |
+
):
|
| 441 |
+
super().__init__()
|
| 442 |
+
if kernel_size is None:
|
| 443 |
+
kernel_size = patch_size
|
| 444 |
+
self.patch_conv = nn.Conv2d(
|
| 445 |
+
in_channels,
|
| 446 |
+
block_out_channels,
|
| 447 |
+
kernel_size=kernel_size,
|
| 448 |
+
stride=patch_size,
|
| 449 |
+
bias=bias,
|
| 450 |
+
)
|
| 451 |
+
self.norm = RMSNorm(block_out_channels, eps)
|
| 452 |
+
|
| 453 |
+
def forward(self, x):
|
| 454 |
+
embeddings = self.patch_conv(x)
|
| 455 |
+
embeddings = embeddings.permute(0, 2, 3, 1)
|
| 456 |
+
embeddings = self.norm(embeddings)
|
| 457 |
+
embeddings = embeddings.permute(0, 3, 1, 2)
|
| 458 |
+
return embeddings
|
| 459 |
+
|
| 460 |
+
|
| 461 |
+
class Unpatchify(nn.Module):
|
| 462 |
+
def __init__(
|
| 463 |
+
self, in_channels, out_channels, patch_size, bias, elementwise_affine, eps
|
| 464 |
+
):
|
| 465 |
+
super().__init__()
|
| 466 |
+
self.norm = RMSNorm(in_channels, eps)
|
| 467 |
+
self.unpatch_conv = nn.Conv2d(
|
| 468 |
+
in_channels,
|
| 469 |
+
out_channels * patch_size * patch_size,
|
| 470 |
+
kernel_size=1,
|
| 471 |
+
bias=bias,
|
| 472 |
+
)
|
| 473 |
+
self.pixel_shuffle = nn.PixelShuffle(patch_size)
|
| 474 |
+
self.patch_size = patch_size
|
| 475 |
+
|
| 476 |
+
def forward(self, x):
|
| 477 |
+
# [b, c, h, w]
|
| 478 |
+
x = x.permute(0, 2, 3, 1)
|
| 479 |
+
x = self.norm(x)
|
| 480 |
+
x = x.permute(0, 3, 1, 2)
|
| 481 |
+
x = self.unpatch_conv(x)
|
| 482 |
+
x = self.pixel_shuffle(x)
|
| 483 |
+
return x
|
| 484 |
+
|
| 485 |
+
|
| 486 |
+
class UVitBlock(nn.Module):
|
| 487 |
+
def __init__(
|
| 488 |
+
self,
|
| 489 |
+
channels,
|
| 490 |
+
out_channels,
|
| 491 |
+
num_res_blocks,
|
| 492 |
+
stride,
|
| 493 |
+
hidden_size,
|
| 494 |
+
hidden_dropout,
|
| 495 |
+
elementwise_affine,
|
| 496 |
+
norm_eps,
|
| 497 |
+
use_bias,
|
| 498 |
+
downsample: bool,
|
| 499 |
+
upsample: bool,
|
| 500 |
+
res_ffn_factor: int = 4,
|
| 501 |
+
seq_len=None,
|
| 502 |
+
concat_input=False,
|
| 503 |
+
original_input_channels=None,
|
| 504 |
+
use_zero=True,
|
| 505 |
+
norm_type="RMS",
|
| 506 |
+
):
|
| 507 |
+
super().__init__()
|
| 508 |
+
|
| 509 |
+
self.res_blocks = nn.ModuleList()
|
| 510 |
+
for i in range(num_res_blocks):
|
| 511 |
+
conv_block = ConvNextBlock(
|
| 512 |
+
channels,
|
| 513 |
+
norm_eps,
|
| 514 |
+
elementwise_affine,
|
| 515 |
+
use_bias,
|
| 516 |
+
hidden_dropout,
|
| 517 |
+
hidden_size,
|
| 518 |
+
res_ffn_factor=res_ffn_factor,
|
| 519 |
+
)
|
| 520 |
+
|
| 521 |
+
self.res_blocks.append(conv_block)
|
| 522 |
+
|
| 523 |
+
if downsample:
|
| 524 |
+
self.downsample = Downsample2D(
|
| 525 |
+
channels=channels,
|
| 526 |
+
out_channels=out_channels,
|
| 527 |
+
use_conv=True,
|
| 528 |
+
name="Conv2d_0",
|
| 529 |
+
kernel_size=3,
|
| 530 |
+
padding=1,
|
| 531 |
+
stride=stride,
|
| 532 |
+
norm_type="rms_norm",
|
| 533 |
+
eps=norm_eps,
|
| 534 |
+
elementwise_affine=elementwise_affine,
|
| 535 |
+
bias=use_bias,
|
| 536 |
+
)
|
| 537 |
+
else:
|
| 538 |
+
self.downsample = None
|
| 539 |
+
|
| 540 |
+
if upsample:
|
| 541 |
+
self.upsample = Upsample2D(
|
| 542 |
+
channels=channels,
|
| 543 |
+
out_channels=out_channels,
|
| 544 |
+
use_conv_transpose=False,
|
| 545 |
+
use_conv=True,
|
| 546 |
+
kernel_size=3,
|
| 547 |
+
padding=1,
|
| 548 |
+
stride=stride,
|
| 549 |
+
name="conv",
|
| 550 |
+
norm_type="rms_norm",
|
| 551 |
+
eps=norm_eps,
|
| 552 |
+
elementwise_affine=elementwise_affine,
|
| 553 |
+
bias=use_bias,
|
| 554 |
+
interpolate=True,
|
| 555 |
+
)
|
| 556 |
+
else:
|
| 557 |
+
self.upsample = None
|
| 558 |
+
|
| 559 |
+
def forward(self, x, emb, recompute=False):
|
| 560 |
+
for res_block in self.res_blocks:
|
| 561 |
+
x = res_block(x, emb)
|
| 562 |
+
|
| 563 |
+
if self.downsample is not None:
|
| 564 |
+
x = self.downsample(x)
|
| 565 |
+
|
| 566 |
+
if self.upsample is not None:
|
| 567 |
+
x = self.upsample(x)
|
| 568 |
+
|
| 569 |
+
return x
|
| 570 |
+
|
| 571 |
+
|
| 572 |
+
class ShallowUViTEncoder(nn.Module):
|
| 573 |
+
def __init__(
|
| 574 |
+
self,
|
| 575 |
+
input_channels=3,
|
| 576 |
+
stride=4,
|
| 577 |
+
kernel_size=7,
|
| 578 |
+
padding=None,
|
| 579 |
+
block_out_channels=(768,),
|
| 580 |
+
layers_in_middle=2,
|
| 581 |
+
hidden_size=2048,
|
| 582 |
+
elementwise_affine=True,
|
| 583 |
+
use_bias=True,
|
| 584 |
+
norm_eps=1e-6,
|
| 585 |
+
dropout=0.0,
|
| 586 |
+
use_mid_block=True,
|
| 587 |
+
**kwargs,
|
| 588 |
+
):
|
| 589 |
+
super().__init__()
|
| 590 |
+
|
| 591 |
+
self.time_proj = Timesteps(
|
| 592 |
+
block_out_channels[0], flip_sin_to_cos=True, downscale_freq_shift=0
|
| 593 |
+
)
|
| 594 |
+
self.time_embed = TimestepEmbedding(
|
| 595 |
+
block_out_channels[0], hidden_size, sample_proj_bias=use_bias
|
| 596 |
+
)
|
| 597 |
+
|
| 598 |
+
if padding is None:
|
| 599 |
+
padding = math.ceil(kernel_size - stride)
|
| 600 |
+
self.in_conv = nn.Conv2d(
|
| 601 |
+
in_channels=input_channels,
|
| 602 |
+
out_channels=block_out_channels[0],
|
| 603 |
+
kernel_size=kernel_size,
|
| 604 |
+
stride=stride,
|
| 605 |
+
padding=padding,
|
| 606 |
+
)
|
| 607 |
+
if use_mid_block:
|
| 608 |
+
self.mid_block = UVitBlock(
|
| 609 |
+
block_out_channels[-1],
|
| 610 |
+
block_out_channels[-1],
|
| 611 |
+
num_res_blocks=layers_in_middle,
|
| 612 |
+
hidden_size=hidden_size,
|
| 613 |
+
hidden_dropout=dropout,
|
| 614 |
+
elementwise_affine=elementwise_affine,
|
| 615 |
+
norm_eps=norm_eps,
|
| 616 |
+
use_bias=use_bias,
|
| 617 |
+
downsample=False,
|
| 618 |
+
upsample=False,
|
| 619 |
+
stride=1,
|
| 620 |
+
res_ffn_factor=4,
|
| 621 |
+
)
|
| 622 |
+
else:
|
| 623 |
+
self.mid_block = None
|
| 624 |
+
|
| 625 |
+
def get_num_extra_tensors(self):
|
| 626 |
+
return 2
|
| 627 |
+
|
| 628 |
+
def forward(self, x, timesteps):
|
| 629 |
+
|
| 630 |
+
bs = x.shape[0]
|
| 631 |
+
dtype = x.dtype
|
| 632 |
+
|
| 633 |
+
t_emb = self.time_proj(timesteps.flatten()).view(bs, -1).to(dtype)
|
| 634 |
+
t_emb = self.time_embed(t_emb)
|
| 635 |
+
x_emb = self.in_conv(x)
|
| 636 |
+
|
| 637 |
+
if self.mid_block is not None:
|
| 638 |
+
x_emb = self.mid_block(x_emb, t_emb)
|
| 639 |
+
|
| 640 |
+
hs = [x_emb]
|
| 641 |
+
return x_emb, t_emb, hs
|
| 642 |
+
|
| 643 |
+
|
| 644 |
+
class ShallowUViTDecoder(nn.Module):
|
| 645 |
+
def __init__(
|
| 646 |
+
self,
|
| 647 |
+
in_channels=768,
|
| 648 |
+
out_channels=3,
|
| 649 |
+
block_out_channels: Tuple[int] = (768,),
|
| 650 |
+
upsamples=2,
|
| 651 |
+
layers_in_middle=2,
|
| 652 |
+
hidden_size=2048,
|
| 653 |
+
elementwise_affine=True,
|
| 654 |
+
norm_eps=1e-6,
|
| 655 |
+
use_bias=True,
|
| 656 |
+
dropout=0.0,
|
| 657 |
+
use_mid_block=True,
|
| 658 |
+
**kwargs,
|
| 659 |
+
):
|
| 660 |
+
super().__init__()
|
| 661 |
+
if use_mid_block:
|
| 662 |
+
self.mid_block = UVitBlock(
|
| 663 |
+
in_channels + block_out_channels[-1],
|
| 664 |
+
block_out_channels[
|
| 665 |
+
-1
|
| 666 |
+
], # In fact, the parameter is not used because it has no effect when both downsample and upsample are set to false.
|
| 667 |
+
num_res_blocks=layers_in_middle,
|
| 668 |
+
hidden_size=hidden_size,
|
| 669 |
+
hidden_dropout=dropout,
|
| 670 |
+
elementwise_affine=elementwise_affine,
|
| 671 |
+
norm_eps=norm_eps,
|
| 672 |
+
use_bias=use_bias,
|
| 673 |
+
downsample=False,
|
| 674 |
+
upsample=False,
|
| 675 |
+
stride=1,
|
| 676 |
+
res_ffn_factor=4,
|
| 677 |
+
)
|
| 678 |
+
else:
|
| 679 |
+
self.mid_block = None
|
| 680 |
+
self.out_convs = nn.ModuleList()
|
| 681 |
+
for rank in range(upsamples):
|
| 682 |
+
if rank == upsamples - 1:
|
| 683 |
+
curr_out_channels = out_channels
|
| 684 |
+
else:
|
| 685 |
+
curr_out_channels = block_out_channels[-1]
|
| 686 |
+
if rank == 0:
|
| 687 |
+
curr_in_channels = block_out_channels[-1] + in_channels
|
| 688 |
+
else:
|
| 689 |
+
curr_in_channels = block_out_channels[-1]
|
| 690 |
+
self.out_convs.append(
|
| 691 |
+
Unpatchify(
|
| 692 |
+
curr_in_channels,
|
| 693 |
+
curr_out_channels,
|
| 694 |
+
patch_size=2,
|
| 695 |
+
bias=use_bias,
|
| 696 |
+
elementwise_affine=elementwise_affine,
|
| 697 |
+
eps=norm_eps,
|
| 698 |
+
)
|
| 699 |
+
)
|
| 700 |
+
self.input_norm = RMSNorm(in_channels, norm_eps)
|
| 701 |
+
|
| 702 |
+
def forward(self, x, hs, t_emb):
|
| 703 |
+
|
| 704 |
+
x = x.permute(0, 2, 3, 1)
|
| 705 |
+
x = self.input_norm(x)
|
| 706 |
+
x = x.permute(0, 3, 1, 2)
|
| 707 |
+
|
| 708 |
+
x = torch.cat([x, hs.pop()], dim=1)
|
| 709 |
+
if self.mid_block is not None:
|
| 710 |
+
x = self.mid_block(x, t_emb)
|
| 711 |
+
for out_conv in self.out_convs:
|
| 712 |
+
x = out_conv(x)
|
| 713 |
+
assert len(hs) == 0
|
| 714 |
+
return x
|
janus/models/__init__.py
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2023-2024 DeepSeek.
|
| 2 |
+
#
|
| 3 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 4 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 5 |
+
# the Software without restriction, including without limitation the rights to
|
| 6 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
|
| 7 |
+
# the Software, and to permit persons to whom the Software is furnished to do so,
|
| 8 |
+
# subject to the following conditions:
|
| 9 |
+
#
|
| 10 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 11 |
+
# copies or substantial portions of the Software.
|
| 12 |
+
#
|
| 13 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 14 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
|
| 15 |
+
# FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
|
| 16 |
+
# COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
|
| 17 |
+
# IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
|
| 18 |
+
# CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
| 19 |
+
|
| 20 |
+
from .image_processing_vlm import VLMImageProcessor
|
| 21 |
+
from .modeling_vlm import MultiModalityCausalLM
|
| 22 |
+
from .processing_vlm import VLChatProcessor
|
| 23 |
+
|
| 24 |
+
__all__ = [
|
| 25 |
+
"VLMImageProcessor",
|
| 26 |
+
"VLChatProcessor",
|
| 27 |
+
"MultiModalityCausalLM",
|
| 28 |
+
]
|
janus/models/clip_encoder.py
ADDED
|
@@ -0,0 +1,122 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2023-2024 DeepSeek.
|
| 2 |
+
#
|
| 3 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 4 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 5 |
+
# the Software without restriction, including without limitation the rights to
|
| 6 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
|
| 7 |
+
# the Software, and to permit persons to whom the Software is furnished to do so,
|
| 8 |
+
# subject to the following conditions:
|
| 9 |
+
#
|
| 10 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 11 |
+
# copies or substantial portions of the Software.
|
| 12 |
+
#
|
| 13 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 14 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
|
| 15 |
+
# FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
|
| 16 |
+
# COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
|
| 17 |
+
# IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
|
| 18 |
+
# CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
| 19 |
+
|
| 20 |
+
from typing import Dict, List, Literal, Optional, Tuple, Union
|
| 21 |
+
|
| 22 |
+
import torch
|
| 23 |
+
import torch.nn as nn
|
| 24 |
+
import torchvision.transforms
|
| 25 |
+
from einops import rearrange
|
| 26 |
+
|
| 27 |
+
from janus.models.siglip_vit import create_siglip_vit
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
class CLIPVisionTower(nn.Module):
|
| 31 |
+
def __init__(
|
| 32 |
+
self,
|
| 33 |
+
model_name: str = "siglip_large_patch16_384",
|
| 34 |
+
image_size: Union[Tuple[int, int], int] = 336,
|
| 35 |
+
select_feature: str = "patch",
|
| 36 |
+
select_layer: int = -2,
|
| 37 |
+
select_layers: list = None,
|
| 38 |
+
ckpt_path: str = "",
|
| 39 |
+
pixel_mean: Optional[List[float]] = None,
|
| 40 |
+
pixel_std: Optional[List[float]] = None,
|
| 41 |
+
**kwargs,
|
| 42 |
+
):
|
| 43 |
+
super().__init__()
|
| 44 |
+
|
| 45 |
+
self.model_name = model_name
|
| 46 |
+
self.select_feature = select_feature
|
| 47 |
+
self.select_layer = select_layer
|
| 48 |
+
self.select_layers = select_layers
|
| 49 |
+
|
| 50 |
+
vision_tower_params = {
|
| 51 |
+
"model_name": model_name,
|
| 52 |
+
"image_size": image_size,
|
| 53 |
+
"ckpt_path": ckpt_path,
|
| 54 |
+
"select_layer": select_layer,
|
| 55 |
+
}
|
| 56 |
+
vision_tower_params.update(kwargs)
|
| 57 |
+
self.vision_tower, self.forward_kwargs = self.build_vision_tower(
|
| 58 |
+
vision_tower_params
|
| 59 |
+
)
|
| 60 |
+
|
| 61 |
+
if pixel_mean is not None and pixel_std is not None:
|
| 62 |
+
image_norm = torchvision.transforms.Normalize(
|
| 63 |
+
mean=pixel_mean, std=pixel_std
|
| 64 |
+
)
|
| 65 |
+
else:
|
| 66 |
+
image_norm = None
|
| 67 |
+
|
| 68 |
+
self.image_norm = image_norm
|
| 69 |
+
|
| 70 |
+
def build_vision_tower(self, vision_tower_params):
|
| 71 |
+
if self.model_name.startswith("siglip"):
|
| 72 |
+
self.select_feature = "same"
|
| 73 |
+
vision_tower = create_siglip_vit(**vision_tower_params)
|
| 74 |
+
forward_kwargs = dict()
|
| 75 |
+
|
| 76 |
+
elif self.model_name.startswith("sam"):
|
| 77 |
+
vision_tower = create_sam_vit(**vision_tower_params)
|
| 78 |
+
forward_kwargs = dict()
|
| 79 |
+
|
| 80 |
+
else: # huggingface
|
| 81 |
+
from transformers import CLIPVisionModel
|
| 82 |
+
|
| 83 |
+
vision_tower = CLIPVisionModel.from_pretrained(**vision_tower_params)
|
| 84 |
+
forward_kwargs = dict(output_hidden_states=True)
|
| 85 |
+
|
| 86 |
+
return vision_tower, forward_kwargs
|
| 87 |
+
|
| 88 |
+
def feature_select(self, image_forward_outs):
|
| 89 |
+
if isinstance(image_forward_outs, torch.Tensor):
|
| 90 |
+
# the output has been the self.select_layer"s features
|
| 91 |
+
image_features = image_forward_outs
|
| 92 |
+
else:
|
| 93 |
+
image_features = image_forward_outs.hidden_states[self.select_layer]
|
| 94 |
+
|
| 95 |
+
if self.select_feature == "patch":
|
| 96 |
+
# if the output has cls_token
|
| 97 |
+
image_features = image_features[:, 1:]
|
| 98 |
+
elif self.select_feature == "cls_patch":
|
| 99 |
+
image_features = image_features
|
| 100 |
+
elif self.select_feature == "same":
|
| 101 |
+
image_features = image_features
|
| 102 |
+
|
| 103 |
+
else:
|
| 104 |
+
raise ValueError(f"Unexpected select feature: {self.select_feature}")
|
| 105 |
+
return image_features
|
| 106 |
+
|
| 107 |
+
def forward(self, images):
|
| 108 |
+
"""
|
| 109 |
+
|
| 110 |
+
Args:
|
| 111 |
+
images (torch.Tensor): [b, 3, H, W]
|
| 112 |
+
|
| 113 |
+
Returns:
|
| 114 |
+
image_features (torch.Tensor): [b, n_patch, d]
|
| 115 |
+
"""
|
| 116 |
+
|
| 117 |
+
if self.image_norm is not None:
|
| 118 |
+
images = self.image_norm(images)
|
| 119 |
+
|
| 120 |
+
image_forward_outs = self.vision_tower(images, **self.forward_kwargs)
|
| 121 |
+
image_features = self.feature_select(image_forward_outs)
|
| 122 |
+
return image_features
|
janus/models/image_processing_vlm.py
ADDED
|
@@ -0,0 +1,208 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2023-2024 DeepSeek.
|
| 2 |
+
#
|
| 3 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 4 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 5 |
+
# the Software without restriction, including without limitation the rights to
|
| 6 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
|
| 7 |
+
# the Software, and to permit persons to whom the Software is furnished to do so,
|
| 8 |
+
# subject to the following conditions:
|
| 9 |
+
#
|
| 10 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 11 |
+
# copies or substantial portions of the Software.
|
| 12 |
+
#
|
| 13 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 14 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
|
| 15 |
+
# FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
|
| 16 |
+
# COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
|
| 17 |
+
# IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
|
| 18 |
+
# CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
| 19 |
+
|
| 20 |
+
from typing import List, Tuple, Union
|
| 21 |
+
|
| 22 |
+
import numpy as np
|
| 23 |
+
import torch
|
| 24 |
+
import torchvision
|
| 25 |
+
import torchvision.transforms.functional
|
| 26 |
+
from PIL import Image
|
| 27 |
+
from transformers import AutoImageProcessor, PretrainedConfig
|
| 28 |
+
from transformers.image_processing_utils import BaseImageProcessor, BatchFeature
|
| 29 |
+
from transformers.image_utils import to_numpy_array
|
| 30 |
+
from transformers.utils import logging
|
| 31 |
+
|
| 32 |
+
logger = logging.get_logger(__name__)
|
| 33 |
+
|
| 34 |
+
ImageType = Union[np.ndarray, torch.Tensor, Image.Image]
|
| 35 |
+
IMAGENET_MEAN = (0.48145466, 0.4578275, 0.40821073)
|
| 36 |
+
IMAGENET_STD = (0.26862954, 0.26130258, 0.27577711)
|
| 37 |
+
IMAGENET_INCEPTION_MEAN = (0.5, 0.5, 0.5)
|
| 38 |
+
IMAGENET_INCEPTION_STD = (0.5, 0.5, 0.5)
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def expand2square(pil_img, background_color):
|
| 42 |
+
width, height = pil_img.size
|
| 43 |
+
if width == height:
|
| 44 |
+
return pil_img
|
| 45 |
+
elif width > height:
|
| 46 |
+
result = Image.new(pil_img.mode, (width, width), background_color)
|
| 47 |
+
result.paste(pil_img, (0, (width - height) // 2))
|
| 48 |
+
return result
|
| 49 |
+
else:
|
| 50 |
+
result = Image.new(pil_img.mode, (height, height), background_color)
|
| 51 |
+
result.paste(pil_img, ((height - width) // 2, 0))
|
| 52 |
+
return result
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
class VLMImageProcessorConfig(PretrainedConfig):
|
| 56 |
+
model_type = "deepseek_vlm"
|
| 57 |
+
image_size: int
|
| 58 |
+
min_size: int
|
| 59 |
+
image_mean: Union[Tuple[float, float, float], List[float]]
|
| 60 |
+
image_std: Union[Tuple[float, float, float], List[float]]
|
| 61 |
+
rescale_factor: float
|
| 62 |
+
do_normalize: bool
|
| 63 |
+
|
| 64 |
+
def __init__(
|
| 65 |
+
self,
|
| 66 |
+
image_size: int,
|
| 67 |
+
min_size: int = 14,
|
| 68 |
+
image_mean: Union[Tuple[float, float, float], List[float]] = (
|
| 69 |
+
0.48145466,
|
| 70 |
+
0.4578275,
|
| 71 |
+
0.40821073,
|
| 72 |
+
),
|
| 73 |
+
image_std: Union[Tuple[float, float, float], List[float]] = (
|
| 74 |
+
0.26862954,
|
| 75 |
+
0.26130258,
|
| 76 |
+
0.27577711,
|
| 77 |
+
),
|
| 78 |
+
rescale_factor: float = 1.0 / 255.0,
|
| 79 |
+
do_normalize: bool = True,
|
| 80 |
+
**kwargs,
|
| 81 |
+
):
|
| 82 |
+
self.image_size = image_size
|
| 83 |
+
self.min_size = min_size
|
| 84 |
+
self.image_mean = image_mean
|
| 85 |
+
self.image_std = image_std
|
| 86 |
+
self.rescale_factor = rescale_factor
|
| 87 |
+
self.do_normalize = do_normalize
|
| 88 |
+
|
| 89 |
+
super().__init__(**kwargs)
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
class VLMImageProcessor(BaseImageProcessor):
|
| 93 |
+
model_input_names = ["pixel_values"]
|
| 94 |
+
|
| 95 |
+
def __init__(
|
| 96 |
+
self,
|
| 97 |
+
image_size: int,
|
| 98 |
+
min_size: int = 14,
|
| 99 |
+
image_mean: Union[Tuple[float, float, float], List[float]] = (
|
| 100 |
+
0.48145466,
|
| 101 |
+
0.4578275,
|
| 102 |
+
0.40821073,
|
| 103 |
+
),
|
| 104 |
+
image_std: Union[Tuple[float, float, float], List[float]] = (
|
| 105 |
+
0.26862954,
|
| 106 |
+
0.26130258,
|
| 107 |
+
0.27577711,
|
| 108 |
+
),
|
| 109 |
+
rescale_factor: float = 1.0 / 255.0,
|
| 110 |
+
do_normalize: bool = True,
|
| 111 |
+
**kwargs,
|
| 112 |
+
):
|
| 113 |
+
super().__init__(**kwargs)
|
| 114 |
+
|
| 115 |
+
self.image_size = image_size
|
| 116 |
+
self.rescale_factor = rescale_factor
|
| 117 |
+
self.image_mean = image_mean
|
| 118 |
+
self.image_std = image_std
|
| 119 |
+
self.min_size = min_size
|
| 120 |
+
self.do_normalize = do_normalize
|
| 121 |
+
|
| 122 |
+
if image_mean is None:
|
| 123 |
+
self.background_color = (127, 127, 127)
|
| 124 |
+
else:
|
| 125 |
+
self.background_color = tuple([int(x * 255) for x in image_mean])
|
| 126 |
+
|
| 127 |
+
def resize(self, pil_img: Image) -> np.ndarray:
|
| 128 |
+
"""
|
| 129 |
+
|
| 130 |
+
Args:
|
| 131 |
+
pil_img (PIL.Image): [H, W, 3] in PIL.Image in RGB
|
| 132 |
+
|
| 133 |
+
Returns:
|
| 134 |
+
x (np.ndarray): [3, self.image_size, self.image_size]
|
| 135 |
+
"""
|
| 136 |
+
|
| 137 |
+
width, height = pil_img.size
|
| 138 |
+
max_size = max(width, height)
|
| 139 |
+
|
| 140 |
+
size = [
|
| 141 |
+
max(int(height / max_size * self.image_size), self.min_size),
|
| 142 |
+
max(int(width / max_size * self.image_size), self.min_size),
|
| 143 |
+
]
|
| 144 |
+
|
| 145 |
+
if width <= 0 or height <= 0 or size[0] <= 0 or size[1] <= 0:
|
| 146 |
+
print(f"orig size = {pil_img.size}, new size = {size}")
|
| 147 |
+
raise ValueError("Invalid size!")
|
| 148 |
+
|
| 149 |
+
pil_img = torchvision.transforms.functional.resize(
|
| 150 |
+
pil_img,
|
| 151 |
+
size,
|
| 152 |
+
interpolation=torchvision.transforms.functional.InterpolationMode.BICUBIC,
|
| 153 |
+
antialias=True,
|
| 154 |
+
)
|
| 155 |
+
|
| 156 |
+
pil_img = expand2square(pil_img, self.background_color)
|
| 157 |
+
x = to_numpy_array(pil_img)
|
| 158 |
+
|
| 159 |
+
# [H, W, 3] -> [3, H, W]
|
| 160 |
+
x = np.transpose(x, (2, 0, 1))
|
| 161 |
+
|
| 162 |
+
return x
|
| 163 |
+
|
| 164 |
+
def preprocess(self, images, return_tensors: str = "pt", **kwargs) -> BatchFeature:
|
| 165 |
+
# resize and pad to [self.image_size, self.image_size]
|
| 166 |
+
# then convert from [H, W, 3] to [3, H, W]
|
| 167 |
+
images: List[np.ndarray] = [self.resize(image) for image in images]
|
| 168 |
+
|
| 169 |
+
# resacle from [0, 255] -> [0, 1]
|
| 170 |
+
images = [
|
| 171 |
+
self.rescale(
|
| 172 |
+
image=image,
|
| 173 |
+
scale=self.rescale_factor,
|
| 174 |
+
input_data_format="channels_first",
|
| 175 |
+
)
|
| 176 |
+
for image in images
|
| 177 |
+
]
|
| 178 |
+
|
| 179 |
+
# normalize
|
| 180 |
+
if self.do_normalize:
|
| 181 |
+
images = [
|
| 182 |
+
self.normalize(
|
| 183 |
+
image=image,
|
| 184 |
+
mean=self.image_mean,
|
| 185 |
+
std=self.image_std,
|
| 186 |
+
input_data_format="channels_first",
|
| 187 |
+
)
|
| 188 |
+
for image in images
|
| 189 |
+
]
|
| 190 |
+
|
| 191 |
+
data = {"pixel_values": images}
|
| 192 |
+
return BatchFeature(data=data, tensor_type=return_tensors)
|
| 193 |
+
|
| 194 |
+
@property
|
| 195 |
+
def default_shape(self):
|
| 196 |
+
return [3, self.image_size, self.image_size]
|
| 197 |
+
|
| 198 |
+
|
| 199 |
+
AutoImageProcessor.register(VLMImageProcessorConfig, VLMImageProcessor)
|
| 200 |
+
|
| 201 |
+
|
| 202 |
+
if __name__ == "__main__":
|
| 203 |
+
image_processor = VLMImageProcessor(
|
| 204 |
+
image_size=1024,
|
| 205 |
+
image_mean=IMAGENET_INCEPTION_MEAN,
|
| 206 |
+
image_std=IMAGENET_INCEPTION_STD,
|
| 207 |
+
do_normalize=True,
|
| 208 |
+
)
|
janus/models/modeling_vlm.py
ADDED
|
@@ -0,0 +1,272 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2023-2024 DeepSeek.
|
| 2 |
+
#
|
| 3 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 4 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 5 |
+
# the Software without restriction, including without limitation the rights to
|
| 6 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
|
| 7 |
+
# the Software, and to permit persons to whom the Software is furnished to do so,
|
| 8 |
+
# subject to the following conditions:
|
| 9 |
+
#
|
| 10 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 11 |
+
# copies or substantial portions of the Software.
|
| 12 |
+
#
|
| 13 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 14 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
|
| 15 |
+
# FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
|
| 16 |
+
# COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
|
| 17 |
+
# IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
|
| 18 |
+
# CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
| 19 |
+
|
| 20 |
+
import torch
|
| 21 |
+
from attrdict import AttrDict
|
| 22 |
+
from einops import rearrange
|
| 23 |
+
from transformers import (
|
| 24 |
+
AutoConfig,
|
| 25 |
+
AutoModelForCausalLM,
|
| 26 |
+
LlamaConfig,
|
| 27 |
+
LlamaForCausalLM,
|
| 28 |
+
PreTrainedModel,
|
| 29 |
+
)
|
| 30 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 31 |
+
|
| 32 |
+
from janus.models.clip_encoder import CLIPVisionTower
|
| 33 |
+
from janus.models.projector import MlpProjector
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
class vision_head(torch.nn.Module):
|
| 37 |
+
def __init__(self, params):
|
| 38 |
+
super().__init__()
|
| 39 |
+
self.output_mlp_projector = torch.nn.Linear(
|
| 40 |
+
params.n_embed, params.image_token_embed
|
| 41 |
+
)
|
| 42 |
+
self.vision_activation = torch.nn.GELU()
|
| 43 |
+
self.vision_head = torch.nn.Linear(
|
| 44 |
+
params.image_token_embed, params.image_token_size
|
| 45 |
+
)
|
| 46 |
+
|
| 47 |
+
def forward(self, x):
|
| 48 |
+
x = self.output_mlp_projector(x)
|
| 49 |
+
x = self.vision_activation(x)
|
| 50 |
+
x = self.vision_head(x)
|
| 51 |
+
return x
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def model_name_to_cls(cls_name):
|
| 55 |
+
if "MlpProjector" in cls_name:
|
| 56 |
+
cls = MlpProjector
|
| 57 |
+
|
| 58 |
+
elif "CLIPVisionTower" in cls_name:
|
| 59 |
+
cls = CLIPVisionTower
|
| 60 |
+
|
| 61 |
+
elif "VQ" in cls_name:
|
| 62 |
+
from janus.models.vq_model import VQ_models
|
| 63 |
+
|
| 64 |
+
cls = VQ_models[cls_name]
|
| 65 |
+
elif "vision_head" in cls_name:
|
| 66 |
+
cls = vision_head
|
| 67 |
+
else:
|
| 68 |
+
raise ValueError(f"class_name {cls_name} is invalid.")
|
| 69 |
+
|
| 70 |
+
return cls
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
class VisionConfig(PretrainedConfig):
|
| 74 |
+
model_type = "vision"
|
| 75 |
+
cls: str = ""
|
| 76 |
+
params: AttrDict = {}
|
| 77 |
+
|
| 78 |
+
def __init__(self, **kwargs):
|
| 79 |
+
super().__init__(**kwargs)
|
| 80 |
+
|
| 81 |
+
self.cls = kwargs.get("cls", "")
|
| 82 |
+
if not isinstance(self.cls, str):
|
| 83 |
+
self.cls = self.cls.__name__
|
| 84 |
+
|
| 85 |
+
self.params = AttrDict(kwargs.get("params", {}))
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
class AlignerConfig(PretrainedConfig):
|
| 89 |
+
model_type = "aligner"
|
| 90 |
+
cls: str = ""
|
| 91 |
+
params: AttrDict = {}
|
| 92 |
+
|
| 93 |
+
def __init__(self, **kwargs):
|
| 94 |
+
super().__init__(**kwargs)
|
| 95 |
+
|
| 96 |
+
self.cls = kwargs.get("cls", "")
|
| 97 |
+
if not isinstance(self.cls, str):
|
| 98 |
+
self.cls = self.cls.__name__
|
| 99 |
+
|
| 100 |
+
self.params = AttrDict(kwargs.get("params", {}))
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
class GenVisionConfig(PretrainedConfig):
|
| 104 |
+
model_type = "gen_vision"
|
| 105 |
+
cls: str = ""
|
| 106 |
+
params: AttrDict = {}
|
| 107 |
+
|
| 108 |
+
def __init__(self, **kwargs):
|
| 109 |
+
super().__init__(**kwargs)
|
| 110 |
+
|
| 111 |
+
self.cls = kwargs.get("cls", "")
|
| 112 |
+
if not isinstance(self.cls, str):
|
| 113 |
+
self.cls = self.cls.__name__
|
| 114 |
+
|
| 115 |
+
self.params = AttrDict(kwargs.get("params", {}))
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
class GenAlignerConfig(PretrainedConfig):
|
| 119 |
+
model_type = "gen_aligner"
|
| 120 |
+
cls: str = ""
|
| 121 |
+
params: AttrDict = {}
|
| 122 |
+
|
| 123 |
+
def __init__(self, **kwargs):
|
| 124 |
+
super().__init__(**kwargs)
|
| 125 |
+
|
| 126 |
+
self.cls = kwargs.get("cls", "")
|
| 127 |
+
if not isinstance(self.cls, str):
|
| 128 |
+
self.cls = self.cls.__name__
|
| 129 |
+
|
| 130 |
+
self.params = AttrDict(kwargs.get("params", {}))
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
class GenHeadConfig(PretrainedConfig):
|
| 134 |
+
model_type = "gen_head"
|
| 135 |
+
cls: str = ""
|
| 136 |
+
params: AttrDict = {}
|
| 137 |
+
|
| 138 |
+
def __init__(self, **kwargs):
|
| 139 |
+
super().__init__(**kwargs)
|
| 140 |
+
|
| 141 |
+
self.cls = kwargs.get("cls", "")
|
| 142 |
+
if not isinstance(self.cls, str):
|
| 143 |
+
self.cls = self.cls.__name__
|
| 144 |
+
|
| 145 |
+
self.params = AttrDict(kwargs.get("params", {}))
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
class MultiModalityConfig(PretrainedConfig):
|
| 149 |
+
model_type = "multi_modality"
|
| 150 |
+
vision_config: VisionConfig
|
| 151 |
+
aligner_config: AlignerConfig
|
| 152 |
+
|
| 153 |
+
gen_vision_config: GenVisionConfig
|
| 154 |
+
gen_aligner_config: GenAlignerConfig
|
| 155 |
+
gen_head_config: GenHeadConfig
|
| 156 |
+
|
| 157 |
+
language_config: LlamaConfig
|
| 158 |
+
|
| 159 |
+
def __init__(self, **kwargs):
|
| 160 |
+
super().__init__(**kwargs)
|
| 161 |
+
vision_config = kwargs.get("vision_config", {})
|
| 162 |
+
self.vision_config = VisionConfig(**vision_config)
|
| 163 |
+
|
| 164 |
+
aligner_config = kwargs.get("aligner_config", {})
|
| 165 |
+
self.aligner_config = AlignerConfig(**aligner_config)
|
| 166 |
+
|
| 167 |
+
gen_vision_config = kwargs.get("gen_vision_config", {})
|
| 168 |
+
self.gen_vision_config = GenVisionConfig(**gen_vision_config)
|
| 169 |
+
|
| 170 |
+
gen_aligner_config = kwargs.get("gen_aligner_config", {})
|
| 171 |
+
self.gen_aligner_config = GenAlignerConfig(**gen_aligner_config)
|
| 172 |
+
|
| 173 |
+
gen_head_config = kwargs.get("gen_head_config", {})
|
| 174 |
+
self.gen_head_config = GenHeadConfig(**gen_head_config)
|
| 175 |
+
|
| 176 |
+
language_config = kwargs.get("language_config", {})
|
| 177 |
+
if isinstance(language_config, LlamaConfig):
|
| 178 |
+
self.language_config = language_config
|
| 179 |
+
else:
|
| 180 |
+
self.language_config = LlamaConfig(**language_config)
|
| 181 |
+
|
| 182 |
+
|
| 183 |
+
class MultiModalityPreTrainedModel(PreTrainedModel):
|
| 184 |
+
config_class = MultiModalityConfig
|
| 185 |
+
base_model_prefix = "multi_modality"
|
| 186 |
+
_no_split_modules = []
|
| 187 |
+
_skip_keys_device_placement = "past_key_values"
|
| 188 |
+
|
| 189 |
+
|
| 190 |
+
class MultiModalityCausalLM(MultiModalityPreTrainedModel):
|
| 191 |
+
def __init__(self, config: MultiModalityConfig):
|
| 192 |
+
super().__init__(config)
|
| 193 |
+
|
| 194 |
+
vision_config = config.vision_config
|
| 195 |
+
vision_cls = model_name_to_cls(vision_config.cls)
|
| 196 |
+
self.vision_model = vision_cls(**vision_config.params)
|
| 197 |
+
|
| 198 |
+
aligner_config = config.aligner_config
|
| 199 |
+
aligner_cls = model_name_to_cls(aligner_config.cls)
|
| 200 |
+
self.aligner = aligner_cls(aligner_config.params)
|
| 201 |
+
|
| 202 |
+
gen_vision_config = config.gen_vision_config
|
| 203 |
+
gen_vision_cls = model_name_to_cls(gen_vision_config.cls)
|
| 204 |
+
self.gen_vision_model = gen_vision_cls()
|
| 205 |
+
|
| 206 |
+
gen_aligner_config = config.gen_aligner_config
|
| 207 |
+
gen_aligner_cls = model_name_to_cls(gen_aligner_config.cls)
|
| 208 |
+
self.gen_aligner = gen_aligner_cls(gen_aligner_config.params)
|
| 209 |
+
|
| 210 |
+
gen_head_config = config.gen_head_config
|
| 211 |
+
gen_head_cls = model_name_to_cls(gen_head_config.cls)
|
| 212 |
+
self.gen_head = gen_head_cls(gen_head_config.params)
|
| 213 |
+
|
| 214 |
+
self.gen_embed = torch.nn.Embedding(
|
| 215 |
+
gen_vision_config.params.image_token_size, gen_vision_config.params.n_embed
|
| 216 |
+
)
|
| 217 |
+
|
| 218 |
+
language_config = config.language_config
|
| 219 |
+
self.language_model = LlamaForCausalLM(language_config)
|
| 220 |
+
|
| 221 |
+
def prepare_inputs_embeds(
|
| 222 |
+
self,
|
| 223 |
+
input_ids: torch.LongTensor,
|
| 224 |
+
pixel_values: torch.FloatTensor,
|
| 225 |
+
images_seq_mask: torch.LongTensor,
|
| 226 |
+
images_emb_mask: torch.LongTensor,
|
| 227 |
+
**kwargs,
|
| 228 |
+
):
|
| 229 |
+
"""
|
| 230 |
+
|
| 231 |
+
Args:
|
| 232 |
+
input_ids (torch.LongTensor): [b, T]
|
| 233 |
+
pixel_values (torch.FloatTensor): [b, n_images, 3, h, w]
|
| 234 |
+
images_seq_mask (torch.BoolTensor): [b, T]
|
| 235 |
+
images_emb_mask (torch.BoolTensor): [b, n_images, n_image_tokens]
|
| 236 |
+
|
| 237 |
+
assert torch.sum(images_seq_mask) == torch.sum(images_emb_mask)
|
| 238 |
+
|
| 239 |
+
Returns:
|
| 240 |
+
input_embeds (torch.Tensor): [b, T, D]
|
| 241 |
+
"""
|
| 242 |
+
|
| 243 |
+
bs, n = pixel_values.shape[0:2]
|
| 244 |
+
images = rearrange(pixel_values, "b n c h w -> (b n) c h w")
|
| 245 |
+
# [b x n, T2, D]
|
| 246 |
+
images_embeds = self.aligner(self.vision_model(images))
|
| 247 |
+
|
| 248 |
+
# [b x n, T2, D] -> [b, n x T2, D]
|
| 249 |
+
images_embeds = rearrange(images_embeds, "(b n) t d -> b (n t) d", b=bs, n=n)
|
| 250 |
+
# [b, n, T2] -> [b, n x T2]
|
| 251 |
+
images_emb_mask = rearrange(images_emb_mask, "b n t -> b (n t)")
|
| 252 |
+
|
| 253 |
+
# [b, T, D]
|
| 254 |
+
input_ids[input_ids < 0] = 0 # ignore the image embeddings
|
| 255 |
+
inputs_embeds = self.language_model.get_input_embeddings()(input_ids)
|
| 256 |
+
|
| 257 |
+
# replace with the image embeddings
|
| 258 |
+
inputs_embeds[images_seq_mask] = images_embeds[images_emb_mask]
|
| 259 |
+
|
| 260 |
+
return inputs_embeds
|
| 261 |
+
|
| 262 |
+
def prepare_gen_img_embeds(self, image_ids: torch.LongTensor):
|
| 263 |
+
return self.gen_aligner(self.gen_embed(image_ids))
|
| 264 |
+
|
| 265 |
+
|
| 266 |
+
AutoConfig.register("vision", VisionConfig)
|
| 267 |
+
AutoConfig.register("aligner", AlignerConfig)
|
| 268 |
+
AutoConfig.register("gen_vision", GenVisionConfig)
|
| 269 |
+
AutoConfig.register("gen_aligner", GenAlignerConfig)
|
| 270 |
+
AutoConfig.register("gen_head", GenHeadConfig)
|
| 271 |
+
AutoConfig.register("multi_modality", MultiModalityConfig)
|
| 272 |
+
AutoModelForCausalLM.register(MultiModalityConfig, MultiModalityCausalLM)
|
janus/models/processing_vlm.py
ADDED
|
@@ -0,0 +1,418 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2023-2024 DeepSeek.
|
| 2 |
+
#
|
| 3 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 4 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 5 |
+
# the Software without restriction, including without limitation the rights to
|
| 6 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
|
| 7 |
+
# the Software, and to permit persons to whom the Software is furnished to do so,
|
| 8 |
+
# subject to the following conditions:
|
| 9 |
+
#
|
| 10 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 11 |
+
# copies or substantial portions of the Software.
|
| 12 |
+
#
|
| 13 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 14 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
|
| 15 |
+
# FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
|
| 16 |
+
# COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
|
| 17 |
+
# IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
|
| 18 |
+
# CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
| 19 |
+
|
| 20 |
+
from dataclasses import dataclass
|
| 21 |
+
from typing import Dict, List
|
| 22 |
+
|
| 23 |
+
import torch
|
| 24 |
+
from PIL.Image import Image
|
| 25 |
+
from transformers import LlamaTokenizerFast
|
| 26 |
+
from transformers.processing_utils import ProcessorMixin
|
| 27 |
+
|
| 28 |
+
from janus.models.image_processing_vlm import VLMImageProcessor
|
| 29 |
+
from janus.utils.conversation import get_conv_template
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
class DictOutput(object):
|
| 33 |
+
def keys(self):
|
| 34 |
+
return self.__dict__.keys()
|
| 35 |
+
|
| 36 |
+
def __getitem__(self, item):
|
| 37 |
+
return self.__dict__[item]
|
| 38 |
+
|
| 39 |
+
def __setitem__(self, key, value):
|
| 40 |
+
self.__dict__[key] = value
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
@dataclass
|
| 44 |
+
class VLChatProcessorOutput(DictOutput):
|
| 45 |
+
sft_format: str
|
| 46 |
+
input_ids: torch.Tensor
|
| 47 |
+
pixel_values: torch.Tensor
|
| 48 |
+
num_image_tokens: torch.IntTensor
|
| 49 |
+
|
| 50 |
+
def __len__(self):
|
| 51 |
+
return len(self.input_ids)
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
@dataclass
|
| 55 |
+
class BatchedVLChatProcessorOutput(DictOutput):
|
| 56 |
+
sft_format: List[str]
|
| 57 |
+
input_ids: torch.Tensor
|
| 58 |
+
pixel_values: torch.Tensor
|
| 59 |
+
attention_mask: torch.Tensor
|
| 60 |
+
images_seq_mask: torch.BoolTensor
|
| 61 |
+
images_emb_mask: torch.BoolTensor
|
| 62 |
+
|
| 63 |
+
def to(self, device, dtype=torch.bfloat16):
|
| 64 |
+
self.input_ids = self.input_ids.to(device)
|
| 65 |
+
self.attention_mask = self.attention_mask.to(device)
|
| 66 |
+
self.images_seq_mask = self.images_seq_mask.to(device)
|
| 67 |
+
self.images_emb_mask = self.images_emb_mask.to(device)
|
| 68 |
+
self.pixel_values = self.pixel_values.to(device=device, dtype=dtype)
|
| 69 |
+
return self
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
class VLChatProcessor(ProcessorMixin):
|
| 73 |
+
image_processor_class = "AutoImageProcessor"
|
| 74 |
+
tokenizer_class = ("LlamaTokenizer", "LlamaTokenizerFast")
|
| 75 |
+
|
| 76 |
+
attributes = ["image_processor", "tokenizer"]
|
| 77 |
+
|
| 78 |
+
system_prompt = (
|
| 79 |
+
"You are a helpful language and vision assistant. "
|
| 80 |
+
"You are able to understand the visual content that the user provides, "
|
| 81 |
+
"and assist the user with a variety of tasks using natural language."
|
| 82 |
+
)
|
| 83 |
+
|
| 84 |
+
def __init__(
|
| 85 |
+
self,
|
| 86 |
+
image_processor: VLMImageProcessor,
|
| 87 |
+
tokenizer: LlamaTokenizerFast,
|
| 88 |
+
image_tag: str = "<image_placeholder>",
|
| 89 |
+
image_start_tag: str = "<begin_of_image>",
|
| 90 |
+
image_end_tag: str = "<end_of_image>",
|
| 91 |
+
pad_tag: str = "<|▁pad▁|>",
|
| 92 |
+
num_image_tokens: int = 576,
|
| 93 |
+
add_special_token: bool = False,
|
| 94 |
+
sft_format: str = "deepseek",
|
| 95 |
+
mask_prompt: bool = True,
|
| 96 |
+
ignore_id: int = -100,
|
| 97 |
+
**kwargs,
|
| 98 |
+
):
|
| 99 |
+
self.image_processor = image_processor
|
| 100 |
+
self.tokenizer = tokenizer
|
| 101 |
+
|
| 102 |
+
image_id = self.tokenizer.vocab.get(image_tag)
|
| 103 |
+
if image_id is None:
|
| 104 |
+
special_tokens = [image_tag]
|
| 105 |
+
special_tokens_dict = {"additional_special_tokens": special_tokens}
|
| 106 |
+
self.tokenizer.add_special_tokens(special_tokens_dict)
|
| 107 |
+
print(f"Add image tag = {image_tag} to the tokenizer")
|
| 108 |
+
|
| 109 |
+
self.image_tag = image_tag
|
| 110 |
+
self.image_start_tag = image_start_tag
|
| 111 |
+
self.image_end_tag = image_end_tag
|
| 112 |
+
self.pad_tag = pad_tag
|
| 113 |
+
|
| 114 |
+
self.num_image_tokens = num_image_tokens
|
| 115 |
+
self.add_special_token = add_special_token
|
| 116 |
+
self.sft_format = sft_format
|
| 117 |
+
self.mask_prompt = mask_prompt
|
| 118 |
+
self.ignore_id = ignore_id
|
| 119 |
+
|
| 120 |
+
super().__init__(
|
| 121 |
+
image_processor,
|
| 122 |
+
tokenizer,
|
| 123 |
+
image_tag,
|
| 124 |
+
num_image_tokens,
|
| 125 |
+
add_special_token,
|
| 126 |
+
sft_format,
|
| 127 |
+
mask_prompt,
|
| 128 |
+
ignore_id,
|
| 129 |
+
**kwargs,
|
| 130 |
+
)
|
| 131 |
+
|
| 132 |
+
def new_chat_template(self):
|
| 133 |
+
conv = get_conv_template(self.sft_format)
|
| 134 |
+
conv.set_system_message(self.system_prompt)
|
| 135 |
+
return conv
|
| 136 |
+
|
| 137 |
+
def apply_sft_template_for_multi_turn_prompts(
|
| 138 |
+
self,
|
| 139 |
+
conversations: List[Dict[str, str]],
|
| 140 |
+
sft_format: str = "deepseek",
|
| 141 |
+
system_prompt: str = "",
|
| 142 |
+
):
|
| 143 |
+
"""
|
| 144 |
+
Applies the SFT template to conversation.
|
| 145 |
+
|
| 146 |
+
An example of conversation:
|
| 147 |
+
conversation = [
|
| 148 |
+
{
|
| 149 |
+
"role": "User",
|
| 150 |
+
"content": "<image_placeholder> is Figure 1.\n<image_placeholder> is Figure 2.\nWhich image is brighter?",
|
| 151 |
+
"images": [
|
| 152 |
+
"./multi-images/attribute_comparison_1.png",
|
| 153 |
+
"./multi-images/attribute_comparison_2.png"
|
| 154 |
+
]
|
| 155 |
+
},
|
| 156 |
+
{
|
| 157 |
+
"role": "Assistant",
|
| 158 |
+
"content": ""
|
| 159 |
+
}
|
| 160 |
+
]
|
| 161 |
+
|
| 162 |
+
Args:
|
| 163 |
+
conversations (List[Dict]): A conversation with a List of Dict[str, str] text.
|
| 164 |
+
sft_format (str, optional): The format of the SFT template to use. Defaults to "deepseek".
|
| 165 |
+
system_prompt (str, optional): The system prompt to use in the SFT template. Defaults to "".
|
| 166 |
+
|
| 167 |
+
Returns:
|
| 168 |
+
sft_prompt (str): The formatted text.
|
| 169 |
+
"""
|
| 170 |
+
|
| 171 |
+
conv = get_conv_template(sft_format)
|
| 172 |
+
conv.set_system_message(system_prompt)
|
| 173 |
+
for message in conversations:
|
| 174 |
+
conv.append_message(message["role"], message["content"].strip())
|
| 175 |
+
sft_prompt = conv.get_prompt().strip()
|
| 176 |
+
|
| 177 |
+
return sft_prompt
|
| 178 |
+
|
| 179 |
+
@property
|
| 180 |
+
def image_token(self):
|
| 181 |
+
return self.image_tag
|
| 182 |
+
|
| 183 |
+
@property
|
| 184 |
+
def image_id(self):
|
| 185 |
+
image_id = self.tokenizer.vocab.get(self.image_tag)
|
| 186 |
+
return image_id
|
| 187 |
+
|
| 188 |
+
@property
|
| 189 |
+
def image_start_id(self):
|
| 190 |
+
image_start_id = self.tokenizer.vocab.get(self.image_start_tag)
|
| 191 |
+
return image_start_id
|
| 192 |
+
|
| 193 |
+
@property
|
| 194 |
+
def image_end_id(self):
|
| 195 |
+
image_end_id = self.tokenizer.vocab.get(self.image_end_tag)
|
| 196 |
+
return image_end_id
|
| 197 |
+
|
| 198 |
+
@property
|
| 199 |
+
def image_start_token(self):
|
| 200 |
+
return self.image_start_tag
|
| 201 |
+
|
| 202 |
+
@property
|
| 203 |
+
def image_end_token(self):
|
| 204 |
+
return self.image_end_tag
|
| 205 |
+
|
| 206 |
+
@property
|
| 207 |
+
def pad_id(self):
|
| 208 |
+
pad_id = self.tokenizer.vocab.get(self.pad_tag)
|
| 209 |
+
# pad_id = self.tokenizer.pad_token_id
|
| 210 |
+
# if pad_id is None:
|
| 211 |
+
# pad_id = self.tokenizer.eos_token_id
|
| 212 |
+
|
| 213 |
+
return pad_id
|
| 214 |
+
|
| 215 |
+
def add_image_token(
|
| 216 |
+
self,
|
| 217 |
+
image_indices: List[int],
|
| 218 |
+
input_ids: torch.LongTensor,
|
| 219 |
+
):
|
| 220 |
+
"""
|
| 221 |
+
|
| 222 |
+
Args:
|
| 223 |
+
image_indices (List[int]): [index_0, index_1, ..., index_j]
|
| 224 |
+
input_ids (torch.LongTensor): [N]
|
| 225 |
+
|
| 226 |
+
Returns:
|
| 227 |
+
input_ids (torch.LongTensor): [N + image tokens]
|
| 228 |
+
num_image_tokens (torch.IntTensor): [n_images]
|
| 229 |
+
"""
|
| 230 |
+
|
| 231 |
+
input_slices = []
|
| 232 |
+
|
| 233 |
+
start = 0
|
| 234 |
+
for index in image_indices:
|
| 235 |
+
if self.add_special_token:
|
| 236 |
+
end = index + 1
|
| 237 |
+
else:
|
| 238 |
+
end = index
|
| 239 |
+
|
| 240 |
+
# original text tokens
|
| 241 |
+
input_slices.append(input_ids[start:end])
|
| 242 |
+
|
| 243 |
+
# add boi, image tokens, eoi and set the mask as False
|
| 244 |
+
input_slices.append(self.image_start_id * torch.ones((1), dtype=torch.long))
|
| 245 |
+
input_slices.append(
|
| 246 |
+
self.image_id * torch.ones((self.num_image_tokens,), dtype=torch.long)
|
| 247 |
+
)
|
| 248 |
+
input_slices.append(self.image_end_id * torch.ones((1), dtype=torch.long))
|
| 249 |
+
start = index + 1
|
| 250 |
+
|
| 251 |
+
# the left part
|
| 252 |
+
input_slices.append(input_ids[start:])
|
| 253 |
+
|
| 254 |
+
# concat all slices
|
| 255 |
+
input_ids = torch.cat(input_slices, dim=0)
|
| 256 |
+
num_image_tokens = torch.IntTensor([self.num_image_tokens] * len(image_indices))
|
| 257 |
+
|
| 258 |
+
return input_ids, num_image_tokens
|
| 259 |
+
|
| 260 |
+
def process_one(
|
| 261 |
+
self,
|
| 262 |
+
prompt: str = None,
|
| 263 |
+
conversations: List[Dict[str, str]] = None,
|
| 264 |
+
images: List[Image] = None,
|
| 265 |
+
**kwargs,
|
| 266 |
+
):
|
| 267 |
+
"""
|
| 268 |
+
|
| 269 |
+
Args:
|
| 270 |
+
prompt (str): the formatted prompt;
|
| 271 |
+
conversations (List[Dict]): conversations with a list of messages;
|
| 272 |
+
images (List[ImageType]): the list of images;
|
| 273 |
+
**kwargs:
|
| 274 |
+
|
| 275 |
+
Returns:
|
| 276 |
+
outputs (BaseProcessorOutput): the output of the processor,
|
| 277 |
+
- input_ids (torch.LongTensor): [N + image tokens]
|
| 278 |
+
- target_ids (torch.LongTensor): [N + image tokens]
|
| 279 |
+
- images (torch.FloatTensor): [n_images, 3, H, W]
|
| 280 |
+
- image_id (int): the id of the image token
|
| 281 |
+
- num_image_tokens (List[int]): the number of image tokens
|
| 282 |
+
"""
|
| 283 |
+
|
| 284 |
+
assert (
|
| 285 |
+
prompt is None or conversations is None
|
| 286 |
+
), "prompt and conversations cannot be used at the same time."
|
| 287 |
+
|
| 288 |
+
if prompt is None:
|
| 289 |
+
# apply sft format
|
| 290 |
+
sft_format = self.apply_sft_template_for_multi_turn_prompts(
|
| 291 |
+
conversations=conversations,
|
| 292 |
+
sft_format=self.sft_format,
|
| 293 |
+
system_prompt=self.system_prompt,
|
| 294 |
+
)
|
| 295 |
+
else:
|
| 296 |
+
sft_format = prompt
|
| 297 |
+
|
| 298 |
+
# tokenize
|
| 299 |
+
input_ids = self.tokenizer.encode(sft_format)
|
| 300 |
+
input_ids = torch.LongTensor(input_ids)
|
| 301 |
+
|
| 302 |
+
# add image tokens to the input_ids
|
| 303 |
+
image_token_mask: torch.BoolTensor = input_ids == self.image_id
|
| 304 |
+
image_indices = image_token_mask.nonzero()
|
| 305 |
+
input_ids, num_image_tokens = self.add_image_token(
|
| 306 |
+
image_indices=image_indices,
|
| 307 |
+
input_ids=input_ids,
|
| 308 |
+
)
|
| 309 |
+
|
| 310 |
+
# load images
|
| 311 |
+
images_outputs = self.image_processor(images, return_tensors="pt")
|
| 312 |
+
|
| 313 |
+
prepare = VLChatProcessorOutput(
|
| 314 |
+
sft_format=sft_format,
|
| 315 |
+
input_ids=input_ids,
|
| 316 |
+
pixel_values=images_outputs.pixel_values,
|
| 317 |
+
num_image_tokens=num_image_tokens,
|
| 318 |
+
)
|
| 319 |
+
|
| 320 |
+
return prepare
|
| 321 |
+
|
| 322 |
+
def __call__(
|
| 323 |
+
self,
|
| 324 |
+
*,
|
| 325 |
+
prompt: str = None,
|
| 326 |
+
conversations: List[Dict[str, str]] = None,
|
| 327 |
+
images: List[Image] = None,
|
| 328 |
+
force_batchify: bool = True,
|
| 329 |
+
**kwargs,
|
| 330 |
+
):
|
| 331 |
+
"""
|
| 332 |
+
|
| 333 |
+
Args:
|
| 334 |
+
prompt (str): the formatted prompt;
|
| 335 |
+
conversations (List[Dict]): conversations with a list of messages;
|
| 336 |
+
images (List[ImageType]): the list of images;
|
| 337 |
+
force_batchify (bool): force batchify the inputs;
|
| 338 |
+
**kwargs:
|
| 339 |
+
|
| 340 |
+
Returns:
|
| 341 |
+
outputs (BaseProcessorOutput): the output of the processor,
|
| 342 |
+
- input_ids (torch.LongTensor): [N + image tokens]
|
| 343 |
+
- images (torch.FloatTensor): [n_images, 3, H, W]
|
| 344 |
+
- image_id (int): the id of the image token
|
| 345 |
+
- num_image_tokens (List[int]): the number of image tokens
|
| 346 |
+
"""
|
| 347 |
+
|
| 348 |
+
prepare = self.process_one(
|
| 349 |
+
prompt=prompt, conversations=conversations, images=images
|
| 350 |
+
)
|
| 351 |
+
|
| 352 |
+
if force_batchify:
|
| 353 |
+
prepare = self.batchify([prepare])
|
| 354 |
+
|
| 355 |
+
return prepare
|
| 356 |
+
|
| 357 |
+
def batchify(
|
| 358 |
+
self, prepare_list: List[VLChatProcessorOutput]
|
| 359 |
+
) -> BatchedVLChatProcessorOutput:
|
| 360 |
+
"""
|
| 361 |
+
Preprocesses the inputs for multimodal inference.
|
| 362 |
+
|
| 363 |
+
Args:
|
| 364 |
+
prepare_list (List[VLChatProcessorOutput]): A list of VLChatProcessorOutput.
|
| 365 |
+
|
| 366 |
+
Returns:
|
| 367 |
+
BatchedVLChatProcessorOutput: A dictionary of the inputs to use for multimodal inference.
|
| 368 |
+
"""
|
| 369 |
+
|
| 370 |
+
batch_size = len(prepare_list)
|
| 371 |
+
sft_format = []
|
| 372 |
+
n_images = []
|
| 373 |
+
seq_lens = []
|
| 374 |
+
for prepare in prepare_list:
|
| 375 |
+
n_images.append(len(prepare.num_image_tokens))
|
| 376 |
+
seq_lens.append(len(prepare))
|
| 377 |
+
|
| 378 |
+
input_token_max_len = max(seq_lens)
|
| 379 |
+
max_n_images = max(1, max(n_images))
|
| 380 |
+
|
| 381 |
+
batched_input_ids = torch.full(
|
| 382 |
+
(batch_size, input_token_max_len), self.pad_id
|
| 383 |
+
).long() # FIXME
|
| 384 |
+
batched_attention_mask = torch.zeros((batch_size, input_token_max_len)).long()
|
| 385 |
+
batched_pixel_values = torch.zeros(
|
| 386 |
+
(batch_size, max_n_images, *self.image_processor.default_shape)
|
| 387 |
+
).float()
|
| 388 |
+
batched_images_seq_mask = torch.zeros((batch_size, input_token_max_len)).bool()
|
| 389 |
+
batched_images_emb_mask = torch.zeros(
|
| 390 |
+
(batch_size, max_n_images, self.num_image_tokens)
|
| 391 |
+
).bool()
|
| 392 |
+
|
| 393 |
+
for i, prepare in enumerate(prepare_list):
|
| 394 |
+
input_ids = prepare.input_ids
|
| 395 |
+
seq_len = len(prepare)
|
| 396 |
+
n_image = len(prepare.num_image_tokens)
|
| 397 |
+
# left-padding
|
| 398 |
+
batched_attention_mask[i, -seq_len:] = 1
|
| 399 |
+
batched_input_ids[i, -seq_len:] = torch.LongTensor(input_ids)
|
| 400 |
+
batched_images_seq_mask[i, -seq_len:] = input_ids == self.image_id
|
| 401 |
+
|
| 402 |
+
if n_image > 0:
|
| 403 |
+
batched_pixel_values[i, :n_image] = prepare.pixel_values
|
| 404 |
+
for j, n_image_tokens in enumerate(prepare.num_image_tokens):
|
| 405 |
+
batched_images_emb_mask[i, j, :n_image_tokens] = True
|
| 406 |
+
|
| 407 |
+
sft_format.append(prepare.sft_format)
|
| 408 |
+
|
| 409 |
+
batched_prepares = BatchedVLChatProcessorOutput(
|
| 410 |
+
input_ids=batched_input_ids,
|
| 411 |
+
attention_mask=batched_attention_mask,
|
| 412 |
+
pixel_values=batched_pixel_values,
|
| 413 |
+
images_seq_mask=batched_images_seq_mask,
|
| 414 |
+
images_emb_mask=batched_images_emb_mask,
|
| 415 |
+
sft_format=sft_format,
|
| 416 |
+
)
|
| 417 |
+
|
| 418 |
+
return batched_prepares
|
janus/models/projector.py
ADDED
|
@@ -0,0 +1,100 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2023-2024 DeepSeek.
|
| 2 |
+
#
|
| 3 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 4 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 5 |
+
# the Software without restriction, including without limitation the rights to
|
| 6 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
|
| 7 |
+
# the Software, and to permit persons to whom the Software is furnished to do so,
|
| 8 |
+
# subject to the following conditions:
|
| 9 |
+
#
|
| 10 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 11 |
+
# copies or substantial portions of the Software.
|
| 12 |
+
#
|
| 13 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 14 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
|
| 15 |
+
# FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
|
| 16 |
+
# COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
|
| 17 |
+
# IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
|
| 18 |
+
# CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
| 19 |
+
|
| 20 |
+
from typing import Tuple, Union
|
| 21 |
+
|
| 22 |
+
import torch
|
| 23 |
+
import torch.nn as nn
|
| 24 |
+
from attrdict import AttrDict
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
class MlpProjector(nn.Module):
|
| 28 |
+
def __init__(self, cfg):
|
| 29 |
+
super().__init__()
|
| 30 |
+
|
| 31 |
+
self.cfg = cfg
|
| 32 |
+
|
| 33 |
+
if cfg.projector_type == "identity":
|
| 34 |
+
modules = nn.Identity()
|
| 35 |
+
|
| 36 |
+
elif cfg.projector_type == "linear":
|
| 37 |
+
modules = nn.Linear(cfg.input_dim, cfg.n_embed)
|
| 38 |
+
|
| 39 |
+
elif cfg.projector_type == "mlp_gelu":
|
| 40 |
+
mlp_depth = cfg.get("depth", 1)
|
| 41 |
+
modules = [nn.Linear(cfg.input_dim, cfg.n_embed)]
|
| 42 |
+
for _ in range(1, mlp_depth):
|
| 43 |
+
modules.append(nn.GELU())
|
| 44 |
+
modules.append(nn.Linear(cfg.n_embed, cfg.n_embed))
|
| 45 |
+
modules = nn.Sequential(*modules)
|
| 46 |
+
|
| 47 |
+
elif cfg.projector_type == "low_high_hybrid_split_mlp_gelu":
|
| 48 |
+
mlp_depth = cfg.get("depth", 1)
|
| 49 |
+
self.high_up_proj = nn.Linear(cfg.input_dim, cfg.n_embed // 2)
|
| 50 |
+
self.low_up_proj = nn.Linear(cfg.input_dim, cfg.n_embed // 2)
|
| 51 |
+
|
| 52 |
+
modules = []
|
| 53 |
+
for _ in range(1, mlp_depth):
|
| 54 |
+
modules.append(nn.GELU())
|
| 55 |
+
modules.append(nn.Linear(cfg.n_embed, cfg.n_embed))
|
| 56 |
+
modules = nn.Sequential(*modules)
|
| 57 |
+
|
| 58 |
+
else:
|
| 59 |
+
raise ValueError(f"Unknown projector type: {cfg.projector_type}")
|
| 60 |
+
|
| 61 |
+
self.layers = modules
|
| 62 |
+
|
| 63 |
+
def forward(
|
| 64 |
+
self, x_or_tuple: Union[Tuple[torch.Tensor, torch.Tensor], torch.Tensor]
|
| 65 |
+
):
|
| 66 |
+
"""
|
| 67 |
+
|
| 68 |
+
Args:
|
| 69 |
+
x_or_tuple (Union[Tuple[torch.Tensor, torch.Tensor], torch.Tensor]: if it is a tuple of torch.Tensor,
|
| 70 |
+
then it comes from the hybrid vision encoder, and x = high_res_x, low_res_x);
|
| 71 |
+
otherwise it is the feature from the single vision encoder.
|
| 72 |
+
|
| 73 |
+
Returns:
|
| 74 |
+
x (torch.Tensor): [b, s, c]
|
| 75 |
+
"""
|
| 76 |
+
|
| 77 |
+
if isinstance(x_or_tuple, tuple):
|
| 78 |
+
# self.cfg.projector_type == "low_high_hybrid_split_mlp_gelu":
|
| 79 |
+
high_x, low_x = x_or_tuple
|
| 80 |
+
high_x = self.high_up_proj(high_x)
|
| 81 |
+
low_x = self.low_up_proj(low_x)
|
| 82 |
+
x = torch.concat([high_x, low_x], dim=-1)
|
| 83 |
+
else:
|
| 84 |
+
x = x_or_tuple
|
| 85 |
+
|
| 86 |
+
return self.layers(x)
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
if __name__ == "__main__":
|
| 90 |
+
cfg = AttrDict(
|
| 91 |
+
input_dim=1024,
|
| 92 |
+
n_embed=2048,
|
| 93 |
+
depth=2,
|
| 94 |
+
projector_type="low_high_hybrid_split_mlp_gelu",
|
| 95 |
+
)
|
| 96 |
+
inputs = (torch.rand(4, 576, 1024), torch.rand(4, 576, 1024))
|
| 97 |
+
|
| 98 |
+
m = MlpProjector(cfg)
|
| 99 |
+
out = m(inputs)
|
| 100 |
+
print(out.shape)
|
janus/models/siglip_vit.py
ADDED
|
@@ -0,0 +1,681 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2023-2024 DeepSeek.
|
| 2 |
+
#
|
| 3 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 4 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 5 |
+
# the Software without restriction, including without limitation the rights to
|
| 6 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
|
| 7 |
+
# the Software, and to permit persons to whom the Software is furnished to do so,
|
| 8 |
+
# subject to the following conditions:
|
| 9 |
+
#
|
| 10 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 11 |
+
# copies or substantial portions of the Software.
|
| 12 |
+
#
|
| 13 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 14 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
|
| 15 |
+
# FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
|
| 16 |
+
# COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
|
| 17 |
+
# IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
|
| 18 |
+
# CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
| 19 |
+
|
| 20 |
+
# https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/vision_transformer.py
|
| 21 |
+
import math
|
| 22 |
+
import warnings
|
| 23 |
+
from dataclasses import dataclass
|
| 24 |
+
from functools import partial
|
| 25 |
+
from typing import (
|
| 26 |
+
Callable,
|
| 27 |
+
Dict,
|
| 28 |
+
Final,
|
| 29 |
+
List,
|
| 30 |
+
Literal,
|
| 31 |
+
Optional,
|
| 32 |
+
Sequence,
|
| 33 |
+
Set,
|
| 34 |
+
Tuple,
|
| 35 |
+
Type,
|
| 36 |
+
Union,
|
| 37 |
+
)
|
| 38 |
+
|
| 39 |
+
import torch
|
| 40 |
+
import torch.nn as nn
|
| 41 |
+
import torch.nn.functional as F
|
| 42 |
+
from timm.layers import (
|
| 43 |
+
AttentionPoolLatent,
|
| 44 |
+
DropPath,
|
| 45 |
+
LayerType,
|
| 46 |
+
Mlp,
|
| 47 |
+
PatchDropout,
|
| 48 |
+
PatchEmbed,
|
| 49 |
+
resample_abs_pos_embed,
|
| 50 |
+
)
|
| 51 |
+
from timm.models._manipulate import checkpoint_seq, named_apply
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def _no_grad_trunc_normal_(tensor, mean, std, a, b):
|
| 55 |
+
# Cut & paste from PyTorch official master until it's in a few official releases - RW
|
| 56 |
+
# Method based on https://people.sc.fsu.edu/~jburkardt/presentations/truncated_normal.pdf
|
| 57 |
+
def norm_cdf(x):
|
| 58 |
+
# Computes standard normal cumulative distribution function
|
| 59 |
+
return (1.0 + math.erf(x / math.sqrt(2.0))) / 2.0
|
| 60 |
+
|
| 61 |
+
if (mean < a - 2 * std) or (mean > b + 2 * std):
|
| 62 |
+
warnings.warn(
|
| 63 |
+
"mean is more than 2 std from [a, b] in nn.init.trunc_normal_. "
|
| 64 |
+
"The distribution of values may be incorrect.",
|
| 65 |
+
stacklevel=2,
|
| 66 |
+
)
|
| 67 |
+
|
| 68 |
+
with torch.no_grad():
|
| 69 |
+
# Values are generated by using a truncated uniform distribution and
|
| 70 |
+
# then using the inverse CDF for the normal distribution.
|
| 71 |
+
# Get upper and lower cdf values
|
| 72 |
+
l = norm_cdf((a - mean) / std) # noqa: E741
|
| 73 |
+
u = norm_cdf((b - mean) / std)
|
| 74 |
+
|
| 75 |
+
# Uniformly fill tensor with values from [l, u], then translate to
|
| 76 |
+
# [2l-1, 2u-1].
|
| 77 |
+
tensor.uniform_(2 * l - 1, 2 * u - 1)
|
| 78 |
+
|
| 79 |
+
# Use inverse cdf transform for normal distribution to get truncated
|
| 80 |
+
# standard normal
|
| 81 |
+
tensor.erfinv_()
|
| 82 |
+
|
| 83 |
+
# Transform to proper mean, std
|
| 84 |
+
tensor.mul_(std * math.sqrt(2.0))
|
| 85 |
+
tensor.add_(mean)
|
| 86 |
+
|
| 87 |
+
# Clamp to ensure it's in the proper range
|
| 88 |
+
tensor.clamp_(min=a, max=b)
|
| 89 |
+
return tensor
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
def trunc_normal_(tensor, mean=0.0, std=1.0, a=-2.0, b=2.0):
|
| 93 |
+
# type: (torch.Tensor, float, float, float, float) -> torch.Tensor
|
| 94 |
+
r"""The original timm.models.layers.weight_init.trunc_normal_ can not handle bfloat16 yet, here we first
|
| 95 |
+
convert the tensor to float32, apply the trunc_normal_() in float32, and then convert it back to its original dtype.
|
| 96 |
+
Fills the input Tensor with values drawn from a truncated normal distribution. The values are effectively drawn
|
| 97 |
+
from the normal distribution :math:`\mathcal{N}(\text{mean}, \text{std}^2)`
|
| 98 |
+
with values outside :math:`[a, b]` redrawn until they are within
|
| 99 |
+
the bounds. The method used for generating the random values works
|
| 100 |
+
best when :math:`a \leq \text{mean} \leq b`.
|
| 101 |
+
Args:
|
| 102 |
+
tensor: an n-dimensional `torch.Tensor`
|
| 103 |
+
mean: the mean of the normal distribution
|
| 104 |
+
std: the standard deviation of the normal distribution
|
| 105 |
+
a: the minimum cutoff value
|
| 106 |
+
b: the maximum cutoff value
|
| 107 |
+
Examples:
|
| 108 |
+
>>> w = torch.empty(3, 5)
|
| 109 |
+
>>> nn.init.trunc_normal_(w)
|
| 110 |
+
"""
|
| 111 |
+
|
| 112 |
+
with torch.no_grad():
|
| 113 |
+
dtype = tensor.dtype
|
| 114 |
+
tensor_fp32 = tensor.float()
|
| 115 |
+
tensor_fp32 = _no_grad_trunc_normal_(tensor_fp32, mean, std, a, b)
|
| 116 |
+
tensor_dtype = tensor_fp32.to(dtype=dtype)
|
| 117 |
+
tensor.copy_(tensor_dtype)
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
def init_weights(self):
|
| 121 |
+
if self.pos_embed is not None:
|
| 122 |
+
trunc_normal_(self.pos_embed, std=self.pos_embed.shape[1] ** -0.5)
|
| 123 |
+
trunc_normal_(self.latent, std=self.latent_dim**-0.5)
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
def init_weights_vit_timm(module: nn.Module, name: str = "") -> None:
|
| 127 |
+
"""ViT weight initialization, original timm impl (for reproducibility)"""
|
| 128 |
+
if isinstance(module, nn.Linear):
|
| 129 |
+
trunc_normal_(module.weight, std=0.02)
|
| 130 |
+
if module.bias is not None:
|
| 131 |
+
nn.init.zeros_(module.bias)
|
| 132 |
+
elif hasattr(module, "init_weights"):
|
| 133 |
+
module.init_weights()
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
class Attention(nn.Module):
|
| 137 |
+
fused_attn: Final[bool]
|
| 138 |
+
|
| 139 |
+
def __init__(
|
| 140 |
+
self,
|
| 141 |
+
dim: int,
|
| 142 |
+
num_heads: int = 8,
|
| 143 |
+
qkv_bias: bool = False,
|
| 144 |
+
qk_norm: bool = False,
|
| 145 |
+
attn_drop: float = 0.0,
|
| 146 |
+
proj_drop: float = 0.0,
|
| 147 |
+
norm_layer: nn.Module = nn.LayerNorm,
|
| 148 |
+
) -> None:
|
| 149 |
+
super().__init__()
|
| 150 |
+
assert dim % num_heads == 0, "dim should be divisible by num_heads"
|
| 151 |
+
self.num_heads = num_heads
|
| 152 |
+
self.head_dim = dim // num_heads
|
| 153 |
+
self.scale = self.head_dim**-0.5
|
| 154 |
+
# self.fused_attn = use_fused_attn()
|
| 155 |
+
self.fused_attn = True
|
| 156 |
+
|
| 157 |
+
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
|
| 158 |
+
self.q_norm = norm_layer(self.head_dim) if qk_norm else nn.Identity()
|
| 159 |
+
self.k_norm = norm_layer(self.head_dim) if qk_norm else nn.Identity()
|
| 160 |
+
self.attn_drop = nn.Dropout(attn_drop)
|
| 161 |
+
self.proj = nn.Linear(dim, dim)
|
| 162 |
+
self.proj_drop = nn.Dropout(proj_drop) if proj_drop > 0.0 else nn.Identity()
|
| 163 |
+
|
| 164 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 165 |
+
B, N, C = x.shape
|
| 166 |
+
qkv = (
|
| 167 |
+
self.qkv(x)
|
| 168 |
+
.reshape(B, N, 3, self.num_heads, self.head_dim)
|
| 169 |
+
.permute(2, 0, 3, 1, 4)
|
| 170 |
+
)
|
| 171 |
+
q, k, v = qkv.unbind(0)
|
| 172 |
+
q, k = self.q_norm(q), self.k_norm(k)
|
| 173 |
+
|
| 174 |
+
if self.fused_attn:
|
| 175 |
+
x = F.scaled_dot_product_attention(
|
| 176 |
+
q,
|
| 177 |
+
k,
|
| 178 |
+
v,
|
| 179 |
+
dropout_p=self.attn_drop.p if self.training else 0.0,
|
| 180 |
+
)
|
| 181 |
+
else:
|
| 182 |
+
q = q * self.scale
|
| 183 |
+
attn = q @ k.transpose(-2, -1)
|
| 184 |
+
attn = attn.softmax(dim=-1)
|
| 185 |
+
attn = self.attn_drop(attn)
|
| 186 |
+
x = attn @ v
|
| 187 |
+
|
| 188 |
+
x = x.transpose(1, 2).reshape(B, N, C)
|
| 189 |
+
x = self.proj(x)
|
| 190 |
+
x = self.proj_drop(x)
|
| 191 |
+
return x
|
| 192 |
+
|
| 193 |
+
|
| 194 |
+
class LayerScale(nn.Module):
|
| 195 |
+
def __init__(
|
| 196 |
+
self,
|
| 197 |
+
dim: int,
|
| 198 |
+
init_values: float = 1e-5,
|
| 199 |
+
inplace: bool = False,
|
| 200 |
+
) -> None:
|
| 201 |
+
super().__init__()
|
| 202 |
+
self.inplace = inplace
|
| 203 |
+
self.gamma = nn.Parameter(init_values * torch.ones(dim))
|
| 204 |
+
|
| 205 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 206 |
+
return x.mul_(self.gamma) if self.inplace else x * self.gamma
|
| 207 |
+
|
| 208 |
+
|
| 209 |
+
class Block(nn.Module):
|
| 210 |
+
def __init__(
|
| 211 |
+
self,
|
| 212 |
+
dim: int,
|
| 213 |
+
num_heads: int,
|
| 214 |
+
mlp_ratio: float = 4.0,
|
| 215 |
+
qkv_bias: bool = False,
|
| 216 |
+
qk_norm: bool = False,
|
| 217 |
+
proj_drop: float = 0.0,
|
| 218 |
+
attn_drop: float = 0.0,
|
| 219 |
+
init_values: Optional[float] = None,
|
| 220 |
+
drop_path: float = 0.0,
|
| 221 |
+
act_layer: nn.Module = nn.GELU,
|
| 222 |
+
norm_layer: nn.Module = nn.LayerNorm,
|
| 223 |
+
mlp_layer: nn.Module = Mlp,
|
| 224 |
+
) -> None:
|
| 225 |
+
super().__init__()
|
| 226 |
+
self.norm1 = norm_layer(dim)
|
| 227 |
+
self.attn = Attention(
|
| 228 |
+
dim,
|
| 229 |
+
num_heads=num_heads,
|
| 230 |
+
qkv_bias=qkv_bias,
|
| 231 |
+
qk_norm=qk_norm,
|
| 232 |
+
attn_drop=attn_drop,
|
| 233 |
+
proj_drop=proj_drop,
|
| 234 |
+
norm_layer=norm_layer,
|
| 235 |
+
)
|
| 236 |
+
self.ls1 = (
|
| 237 |
+
LayerScale(dim, init_values=init_values) if init_values else nn.Identity()
|
| 238 |
+
)
|
| 239 |
+
self.drop_path1 = DropPath(drop_path) if drop_path > 0.0 else nn.Identity()
|
| 240 |
+
|
| 241 |
+
self.norm2 = norm_layer(dim)
|
| 242 |
+
self.mlp = mlp_layer(
|
| 243 |
+
in_features=dim,
|
| 244 |
+
hidden_features=int(dim * mlp_ratio),
|
| 245 |
+
act_layer=act_layer,
|
| 246 |
+
drop=proj_drop,
|
| 247 |
+
)
|
| 248 |
+
self.ls2 = (
|
| 249 |
+
LayerScale(dim, init_values=init_values) if init_values else nn.Identity()
|
| 250 |
+
)
|
| 251 |
+
self.drop_path2 = DropPath(drop_path) if drop_path > 0.0 else nn.Identity()
|
| 252 |
+
|
| 253 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 254 |
+
x = x + self.drop_path1(self.ls1(self.attn(self.norm1(x))))
|
| 255 |
+
x = x + self.drop_path2(self.ls2(self.mlp(self.norm2(x))))
|
| 256 |
+
return x
|
| 257 |
+
|
| 258 |
+
|
| 259 |
+
class VisionTransformer(nn.Module):
|
| 260 |
+
"""Vision Transformer
|
| 261 |
+
|
| 262 |
+
A PyTorch impl of : `An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale`
|
| 263 |
+
- https://arxiv.org/abs/2010.11929
|
| 264 |
+
"""
|
| 265 |
+
|
| 266 |
+
dynamic_img_size: Final[bool]
|
| 267 |
+
|
| 268 |
+
def __init__(
|
| 269 |
+
self,
|
| 270 |
+
img_size: Union[int, Tuple[int, int]] = 224,
|
| 271 |
+
patch_size: Union[int, Tuple[int, int]] = 16,
|
| 272 |
+
in_chans: int = 3,
|
| 273 |
+
num_classes: int = 1000,
|
| 274 |
+
global_pool: Literal["", "avg", "token", "map"] = "token",
|
| 275 |
+
embed_dim: int = 768,
|
| 276 |
+
depth: int = 12,
|
| 277 |
+
num_heads: int = 12,
|
| 278 |
+
mlp_ratio: float = 4.0,
|
| 279 |
+
qkv_bias: bool = True,
|
| 280 |
+
qk_norm: bool = False,
|
| 281 |
+
init_values: Optional[float] = None,
|
| 282 |
+
class_token: bool = True,
|
| 283 |
+
no_embed_class: bool = False,
|
| 284 |
+
reg_tokens: int = 0,
|
| 285 |
+
pre_norm: bool = False,
|
| 286 |
+
fc_norm: Optional[bool] = None,
|
| 287 |
+
dynamic_img_size: bool = False,
|
| 288 |
+
dynamic_img_pad: bool = False,
|
| 289 |
+
drop_rate: float = 0.0,
|
| 290 |
+
pos_drop_rate: float = 0.0,
|
| 291 |
+
patch_drop_rate: float = 0.0,
|
| 292 |
+
proj_drop_rate: float = 0.0,
|
| 293 |
+
attn_drop_rate: float = 0.0,
|
| 294 |
+
drop_path_rate: float = 0.0,
|
| 295 |
+
weight_init: Literal["skip", "jax", "jax_nlhb", "moco", ""] = "",
|
| 296 |
+
embed_layer: Callable = PatchEmbed,
|
| 297 |
+
norm_layer: Optional[LayerType] = None,
|
| 298 |
+
act_layer: Optional[LayerType] = None,
|
| 299 |
+
block_fn: Type[nn.Module] = Block,
|
| 300 |
+
mlp_layer: Type[nn.Module] = Mlp,
|
| 301 |
+
ignore_head: bool = False,
|
| 302 |
+
) -> None:
|
| 303 |
+
"""
|
| 304 |
+
Args:
|
| 305 |
+
img_size: Input image size.
|
| 306 |
+
patch_size: Patch size.
|
| 307 |
+
in_chans: Number of image input channels.
|
| 308 |
+
num_classes: Mumber of classes for classification head.
|
| 309 |
+
global_pool: Type of global pooling for final sequence (default: 'token').
|
| 310 |
+
embed_dim: Transformer embedding dimension.
|
| 311 |
+
depth: Depth of transformer.
|
| 312 |
+
num_heads: Number of attention heads.
|
| 313 |
+
mlp_ratio: Ratio of mlp hidden dim to embedding dim.
|
| 314 |
+
qkv_bias: Enable bias for qkv projections if True.
|
| 315 |
+
init_values: Layer-scale init values (layer-scale enabled if not None).
|
| 316 |
+
class_token: Use class token.
|
| 317 |
+
no_embed_class: Don't include position embeddings for class (or reg) tokens.
|
| 318 |
+
reg_tokens: Number of register tokens.
|
| 319 |
+
fc_norm: Pre head norm after pool (instead of before), if None, enabled when global_pool == 'avg'.
|
| 320 |
+
drop_rate: Head dropout rate.
|
| 321 |
+
pos_drop_rate: Position embedding dropout rate.
|
| 322 |
+
attn_drop_rate: Attention dropout rate.
|
| 323 |
+
drop_path_rate: Stochastic depth rate.
|
| 324 |
+
weight_init: Weight initialization scheme.
|
| 325 |
+
embed_layer: Patch embedding layer.
|
| 326 |
+
norm_layer: Normalization layer.
|
| 327 |
+
act_layer: MLP activation layer.
|
| 328 |
+
block_fn: Transformer block layer.
|
| 329 |
+
"""
|
| 330 |
+
super().__init__()
|
| 331 |
+
assert global_pool in ("", "avg", "token", "map")
|
| 332 |
+
assert class_token or global_pool != "token"
|
| 333 |
+
use_fc_norm = global_pool == "avg" if fc_norm is None else fc_norm
|
| 334 |
+
# norm_layer = get_norm_layer(norm_layer) or partial(nn.LayerNorm, eps=1e-6)
|
| 335 |
+
# act_layer = get_act_layer(act_layer) or nn.GELU
|
| 336 |
+
norm_layer = partial(nn.LayerNorm, eps=1e-6)
|
| 337 |
+
act_layer = nn.GELU
|
| 338 |
+
|
| 339 |
+
self.num_classes = num_classes
|
| 340 |
+
self.global_pool = global_pool
|
| 341 |
+
self.num_features = self.embed_dim = (
|
| 342 |
+
embed_dim # num_features for consistency with other models
|
| 343 |
+
)
|
| 344 |
+
self.num_prefix_tokens = 1 if class_token else 0
|
| 345 |
+
self.num_prefix_tokens += reg_tokens
|
| 346 |
+
self.num_reg_tokens = reg_tokens
|
| 347 |
+
self.has_class_token = class_token
|
| 348 |
+
self.no_embed_class = (
|
| 349 |
+
no_embed_class # don't embed prefix positions (includes reg)
|
| 350 |
+
)
|
| 351 |
+
self.dynamic_img_size = dynamic_img_size
|
| 352 |
+
self.grad_checkpointing = False
|
| 353 |
+
self.ignore_head = ignore_head
|
| 354 |
+
|
| 355 |
+
embed_args = {}
|
| 356 |
+
if dynamic_img_size:
|
| 357 |
+
# flatten deferred until after pos embed
|
| 358 |
+
embed_args.update(dict(strict_img_size=False, output_fmt="NHWC"))
|
| 359 |
+
self.patch_embed = embed_layer(
|
| 360 |
+
img_size=img_size,
|
| 361 |
+
patch_size=patch_size,
|
| 362 |
+
in_chans=in_chans,
|
| 363 |
+
embed_dim=embed_dim,
|
| 364 |
+
bias=not pre_norm, # disable bias if pre-norm is used (e.g. CLIP)
|
| 365 |
+
dynamic_img_pad=dynamic_img_pad,
|
| 366 |
+
**embed_args,
|
| 367 |
+
)
|
| 368 |
+
num_patches = self.patch_embed.num_patches
|
| 369 |
+
|
| 370 |
+
self.cls_token = (
|
| 371 |
+
nn.Parameter(torch.zeros(1, 1, embed_dim)) if class_token else None
|
| 372 |
+
)
|
| 373 |
+
self.reg_token = (
|
| 374 |
+
nn.Parameter(torch.zeros(1, reg_tokens, embed_dim)) if reg_tokens else None
|
| 375 |
+
)
|
| 376 |
+
embed_len = (
|
| 377 |
+
num_patches if no_embed_class else num_patches + self.num_prefix_tokens
|
| 378 |
+
)
|
| 379 |
+
self.pos_embed = nn.Parameter(torch.randn(1, embed_len, embed_dim) * 0.02)
|
| 380 |
+
self.pos_drop = nn.Dropout(p=pos_drop_rate)
|
| 381 |
+
if patch_drop_rate > 0:
|
| 382 |
+
self.patch_drop = PatchDropout(
|
| 383 |
+
patch_drop_rate,
|
| 384 |
+
num_prefix_tokens=self.num_prefix_tokens,
|
| 385 |
+
)
|
| 386 |
+
else:
|
| 387 |
+
self.patch_drop = nn.Identity()
|
| 388 |
+
self.norm_pre = norm_layer(embed_dim) if pre_norm else nn.Identity()
|
| 389 |
+
|
| 390 |
+
dpr = [
|
| 391 |
+
x.item() for x in torch.linspace(0, drop_path_rate, depth)
|
| 392 |
+
] # stochastic depth decay rule
|
| 393 |
+
self.blocks = nn.Sequential(
|
| 394 |
+
*[
|
| 395 |
+
block_fn(
|
| 396 |
+
dim=embed_dim,
|
| 397 |
+
num_heads=num_heads,
|
| 398 |
+
mlp_ratio=mlp_ratio,
|
| 399 |
+
qkv_bias=qkv_bias,
|
| 400 |
+
qk_norm=qk_norm,
|
| 401 |
+
init_values=init_values,
|
| 402 |
+
proj_drop=proj_drop_rate,
|
| 403 |
+
attn_drop=attn_drop_rate,
|
| 404 |
+
drop_path=dpr[i],
|
| 405 |
+
norm_layer=norm_layer,
|
| 406 |
+
act_layer=act_layer,
|
| 407 |
+
mlp_layer=mlp_layer,
|
| 408 |
+
)
|
| 409 |
+
for i in range(depth)
|
| 410 |
+
]
|
| 411 |
+
)
|
| 412 |
+
self.norm = norm_layer(embed_dim) if not use_fc_norm else nn.Identity()
|
| 413 |
+
|
| 414 |
+
# Classifier Head
|
| 415 |
+
if global_pool == "map":
|
| 416 |
+
AttentionPoolLatent.init_weights = init_weights
|
| 417 |
+
self.attn_pool = AttentionPoolLatent(
|
| 418 |
+
self.embed_dim,
|
| 419 |
+
num_heads=num_heads,
|
| 420 |
+
mlp_ratio=mlp_ratio,
|
| 421 |
+
norm_layer=norm_layer,
|
| 422 |
+
)
|
| 423 |
+
else:
|
| 424 |
+
self.attn_pool = None
|
| 425 |
+
self.fc_norm = norm_layer(embed_dim) if use_fc_norm else nn.Identity()
|
| 426 |
+
self.head_drop = nn.Dropout(drop_rate)
|
| 427 |
+
self.head = (
|
| 428 |
+
nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
|
| 429 |
+
)
|
| 430 |
+
|
| 431 |
+
if weight_init != "skip":
|
| 432 |
+
self.init_weights(weight_init)
|
| 433 |
+
|
| 434 |
+
def init_weights(self, mode: Literal["jax", "jax_nlhb", "moco", ""] = "") -> None:
|
| 435 |
+
assert mode in ("jax", "jax_nlhb", "moco", "")
|
| 436 |
+
# head_bias = -math.log(self.num_classes) if "nlhb" in mode else 0.0
|
| 437 |
+
trunc_normal_(self.pos_embed, std=0.02)
|
| 438 |
+
if self.cls_token is not None:
|
| 439 |
+
nn.init.normal_(self.cls_token, std=1e-6)
|
| 440 |
+
named_apply(init_weights_vit_timm, self)
|
| 441 |
+
|
| 442 |
+
@torch.jit.ignore
|
| 443 |
+
def no_weight_decay(self) -> Set:
|
| 444 |
+
return {"pos_embed", "cls_token", "dist_token"}
|
| 445 |
+
|
| 446 |
+
@torch.jit.ignore
|
| 447 |
+
def group_matcher(self, coarse: bool = False) -> Dict:
|
| 448 |
+
return dict(
|
| 449 |
+
stem=r"^cls_token|pos_embed|patch_embed", # stem and embed
|
| 450 |
+
blocks=[(r"^blocks\.(\d+)", None), (r"^norm", (99999,))],
|
| 451 |
+
)
|
| 452 |
+
|
| 453 |
+
@torch.jit.ignore
|
| 454 |
+
def set_grad_checkpointing(self, enable: bool = True) -> None:
|
| 455 |
+
self.grad_checkpointing = enable
|
| 456 |
+
|
| 457 |
+
@torch.jit.ignore
|
| 458 |
+
def get_classifier(self) -> nn.Module:
|
| 459 |
+
return self.head
|
| 460 |
+
|
| 461 |
+
def reset_classifier(self, num_classes: int, global_pool=None) -> None:
|
| 462 |
+
self.num_classes = num_classes
|
| 463 |
+
if global_pool is not None:
|
| 464 |
+
assert global_pool in ("", "avg", "token", "map")
|
| 465 |
+
if global_pool == "map" and self.attn_pool is None:
|
| 466 |
+
assert (
|
| 467 |
+
False
|
| 468 |
+
), "Cannot currently add attention pooling in reset_classifier()."
|
| 469 |
+
elif global_pool != "map " and self.attn_pool is not None:
|
| 470 |
+
self.attn_pool = None # remove attention pooling
|
| 471 |
+
self.global_pool = global_pool
|
| 472 |
+
self.head = (
|
| 473 |
+
nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
|
| 474 |
+
)
|
| 475 |
+
|
| 476 |
+
def _pos_embed(self, x: torch.Tensor) -> torch.Tensor:
|
| 477 |
+
if self.dynamic_img_size:
|
| 478 |
+
B, H, W, C = x.shape
|
| 479 |
+
pos_embed = resample_abs_pos_embed(
|
| 480 |
+
self.pos_embed,
|
| 481 |
+
(H, W),
|
| 482 |
+
num_prefix_tokens=0 if self.no_embed_class else self.num_prefix_tokens,
|
| 483 |
+
)
|
| 484 |
+
x = x.view(B, -1, C)
|
| 485 |
+
else:
|
| 486 |
+
pos_embed = self.pos_embed
|
| 487 |
+
|
| 488 |
+
to_cat = []
|
| 489 |
+
if self.cls_token is not None:
|
| 490 |
+
to_cat.append(self.cls_token.expand(x.shape[0], -1, -1))
|
| 491 |
+
if self.reg_token is not None:
|
| 492 |
+
to_cat.append(self.reg_token.expand(x.shape[0], -1, -1))
|
| 493 |
+
|
| 494 |
+
if self.no_embed_class:
|
| 495 |
+
# deit-3, updated JAX (big vision)
|
| 496 |
+
# position embedding does not overlap with class token, add then concat
|
| 497 |
+
x = x + pos_embed
|
| 498 |
+
if to_cat:
|
| 499 |
+
x = torch.cat(to_cat + [x], dim=1)
|
| 500 |
+
else:
|
| 501 |
+
# original timm, JAX, and deit vit impl
|
| 502 |
+
# pos_embed has entry for class token, concat then add
|
| 503 |
+
if to_cat:
|
| 504 |
+
x = torch.cat(to_cat + [x], dim=1)
|
| 505 |
+
x = x + pos_embed
|
| 506 |
+
|
| 507 |
+
return self.pos_drop(x)
|
| 508 |
+
|
| 509 |
+
def _intermediate_layers(
|
| 510 |
+
self,
|
| 511 |
+
x: torch.Tensor,
|
| 512 |
+
n: Union[int, Sequence] = 1,
|
| 513 |
+
) -> List[torch.Tensor]:
|
| 514 |
+
outputs, num_blocks = [], len(self.blocks)
|
| 515 |
+
take_indices = set(
|
| 516 |
+
range(num_blocks - n, num_blocks) if isinstance(n, int) else n
|
| 517 |
+
)
|
| 518 |
+
|
| 519 |
+
# forward pass
|
| 520 |
+
x = self.patch_embed(x)
|
| 521 |
+
x = self._pos_embed(x)
|
| 522 |
+
x = self.patch_drop(x)
|
| 523 |
+
x = self.norm_pre(x)
|
| 524 |
+
for i, blk in enumerate(self.blocks):
|
| 525 |
+
x = blk(x)
|
| 526 |
+
if i in take_indices:
|
| 527 |
+
outputs.append(x)
|
| 528 |
+
|
| 529 |
+
return outputs
|
| 530 |
+
|
| 531 |
+
def get_intermediate_layers(
|
| 532 |
+
self,
|
| 533 |
+
x: torch.Tensor,
|
| 534 |
+
n: Union[int, Sequence] = 1,
|
| 535 |
+
reshape: bool = False,
|
| 536 |
+
return_prefix_tokens: bool = False,
|
| 537 |
+
norm: bool = False,
|
| 538 |
+
) -> Tuple[Union[torch.Tensor, Tuple[torch.Tensor]]]:
|
| 539 |
+
"""Intermediate layer accessor (NOTE: This is a WIP experiment).
|
| 540 |
+
Inspired by DINO / DINOv2 interface
|
| 541 |
+
"""
|
| 542 |
+
# take last n blocks if n is an int, if in is a sequence, select by matching indices
|
| 543 |
+
outputs = self._intermediate_layers(x, n)
|
| 544 |
+
if norm:
|
| 545 |
+
outputs = [self.norm(out) for out in outputs]
|
| 546 |
+
prefix_tokens = [out[:, 0 : self.num_prefix_tokens] for out in outputs]
|
| 547 |
+
outputs = [out[:, self.num_prefix_tokens :] for out in outputs]
|
| 548 |
+
|
| 549 |
+
if reshape:
|
| 550 |
+
grid_size = self.patch_embed.grid_size
|
| 551 |
+
outputs = [
|
| 552 |
+
out.reshape(x.shape[0], grid_size[0], grid_size[1], -1)
|
| 553 |
+
.permute(0, 3, 1, 2)
|
| 554 |
+
.contiguous()
|
| 555 |
+
for out in outputs
|
| 556 |
+
]
|
| 557 |
+
|
| 558 |
+
if return_prefix_tokens:
|
| 559 |
+
return tuple(zip(outputs, prefix_tokens))
|
| 560 |
+
return tuple(outputs)
|
| 561 |
+
|
| 562 |
+
def forward_features(self, x: torch.Tensor) -> torch.Tensor:
|
| 563 |
+
x = self.patch_embed(x)
|
| 564 |
+
x = self._pos_embed(x)
|
| 565 |
+
x = self.patch_drop(x)
|
| 566 |
+
x = self.norm_pre(x)
|
| 567 |
+
if self.grad_checkpointing and not torch.jit.is_scripting():
|
| 568 |
+
x = checkpoint_seq(self.blocks, x)
|
| 569 |
+
else:
|
| 570 |
+
x = self.blocks(x)
|
| 571 |
+
x = self.norm(x)
|
| 572 |
+
return x
|
| 573 |
+
|
| 574 |
+
def forward_head(self, x: torch.Tensor, pre_logits: bool = False) -> torch.Tensor:
|
| 575 |
+
if self.attn_pool is not None:
|
| 576 |
+
x = self.attn_pool(x)
|
| 577 |
+
elif self.global_pool == "avg":
|
| 578 |
+
x = x[:, self.num_prefix_tokens :].mean(dim=1)
|
| 579 |
+
elif self.global_pool:
|
| 580 |
+
x = x[:, 0] # class token
|
| 581 |
+
x = self.fc_norm(x)
|
| 582 |
+
x = self.head_drop(x)
|
| 583 |
+
return x if pre_logits else self.head(x)
|
| 584 |
+
|
| 585 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 586 |
+
x = self.forward_features(x)
|
| 587 |
+
if not self.ignore_head:
|
| 588 |
+
x = self.forward_head(x)
|
| 589 |
+
return x
|
| 590 |
+
|
| 591 |
+
|
| 592 |
+
@dataclass
|
| 593 |
+
class SigLIPVisionCfg:
|
| 594 |
+
width: int = 1152
|
| 595 |
+
layers: Union[Tuple[int, int, int, int], int] = 27
|
| 596 |
+
heads: int = 16
|
| 597 |
+
patch_size: int = 14
|
| 598 |
+
image_size: Union[Tuple[int, int], int] = 336
|
| 599 |
+
global_pool: str = "map"
|
| 600 |
+
mlp_ratio: float = 3.7362
|
| 601 |
+
class_token: bool = False
|
| 602 |
+
num_classes: int = 0
|
| 603 |
+
use_checkpoint: bool = False
|
| 604 |
+
|
| 605 |
+
|
| 606 |
+
SigLIP_MODEL_CONFIG = {
|
| 607 |
+
"siglip_so400m_patch14_384": {
|
| 608 |
+
"image_size": 336,
|
| 609 |
+
"patch_size": 14,
|
| 610 |
+
"width": 1152,
|
| 611 |
+
"layers": 27,
|
| 612 |
+
"heads": 16,
|
| 613 |
+
"mlp_ratio": 3.7362,
|
| 614 |
+
"global_pool": "map",
|
| 615 |
+
"use_checkpoint": False,
|
| 616 |
+
},
|
| 617 |
+
"siglip_so400m_patch14_224": {
|
| 618 |
+
"image_size": 224,
|
| 619 |
+
"patch_size": 14,
|
| 620 |
+
"width": 1152,
|
| 621 |
+
"layers": 27,
|
| 622 |
+
"heads": 16,
|
| 623 |
+
"mlp_ratio": 3.7362,
|
| 624 |
+
"global_pool": "map",
|
| 625 |
+
"use_checkpoint": False,
|
| 626 |
+
},
|
| 627 |
+
"siglip_large_patch16_384": {
|
| 628 |
+
"image_size": 384,
|
| 629 |
+
"patch_size": 16,
|
| 630 |
+
"width": 1024,
|
| 631 |
+
"layers": 24,
|
| 632 |
+
"heads": 16,
|
| 633 |
+
"mlp_ratio": 4,
|
| 634 |
+
"global_pool": "map",
|
| 635 |
+
"use_checkpoint": False,
|
| 636 |
+
},
|
| 637 |
+
}
|
| 638 |
+
|
| 639 |
+
|
| 640 |
+
def create_siglip_vit(
|
| 641 |
+
model_name: str = "siglip_so400m_patch14_384",
|
| 642 |
+
image_size: int = 384,
|
| 643 |
+
select_layer: int = -1,
|
| 644 |
+
ckpt_path: str = "",
|
| 645 |
+
**kwargs,
|
| 646 |
+
):
|
| 647 |
+
assert (
|
| 648 |
+
model_name in SigLIP_MODEL_CONFIG.keys()
|
| 649 |
+
), f"model name should be in {SigLIP_MODEL_CONFIG.keys()}"
|
| 650 |
+
|
| 651 |
+
vision_cfg = SigLIPVisionCfg(**SigLIP_MODEL_CONFIG[model_name])
|
| 652 |
+
|
| 653 |
+
if select_layer <= 0:
|
| 654 |
+
layers = min(vision_cfg.layers, vision_cfg.layers + select_layer + 1)
|
| 655 |
+
else:
|
| 656 |
+
layers = min(vision_cfg.layers, select_layer)
|
| 657 |
+
|
| 658 |
+
model = VisionTransformer(
|
| 659 |
+
img_size=image_size,
|
| 660 |
+
patch_size=vision_cfg.patch_size,
|
| 661 |
+
embed_dim=vision_cfg.width,
|
| 662 |
+
depth=layers,
|
| 663 |
+
num_heads=vision_cfg.heads,
|
| 664 |
+
mlp_ratio=vision_cfg.mlp_ratio,
|
| 665 |
+
class_token=vision_cfg.class_token,
|
| 666 |
+
global_pool=vision_cfg.global_pool,
|
| 667 |
+
ignore_head=kwargs.get("ignore_head", True),
|
| 668 |
+
weight_init=kwargs.get("weight_init", "skip"),
|
| 669 |
+
num_classes=0,
|
| 670 |
+
)
|
| 671 |
+
|
| 672 |
+
if ckpt_path:
|
| 673 |
+
state_dict = torch.load(ckpt_path, map_location="cpu")
|
| 674 |
+
|
| 675 |
+
incompatible_keys = model.load_state_dict(state_dict, strict=False)
|
| 676 |
+
print(
|
| 677 |
+
f"SigLIP-ViT restores from {ckpt_path},\n"
|
| 678 |
+
f"\tincompatible_keys:', {incompatible_keys}."
|
| 679 |
+
)
|
| 680 |
+
|
| 681 |
+
return model
|
janus/models/vq_model.py
ADDED
|
@@ -0,0 +1,527 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2023-2024 DeepSeek.
|
| 2 |
+
#
|
| 3 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 4 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 5 |
+
# the Software without restriction, including without limitation the rights to
|
| 6 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
|
| 7 |
+
# the Software, and to permit persons to whom the Software is furnished to do so,
|
| 8 |
+
# subject to the following conditions:
|
| 9 |
+
#
|
| 10 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 11 |
+
# copies or substantial portions of the Software.
|
| 12 |
+
#
|
| 13 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 14 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
|
| 15 |
+
# FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
|
| 16 |
+
# COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
|
| 17 |
+
# IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
|
| 18 |
+
# CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
from dataclasses import dataclass, field
|
| 22 |
+
from typing import List
|
| 23 |
+
|
| 24 |
+
import torch
|
| 25 |
+
import torch.nn as nn
|
| 26 |
+
import torch.nn.functional as F
|
| 27 |
+
|
| 28 |
+
from functools import partial
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
@dataclass
|
| 32 |
+
class ModelArgs:
|
| 33 |
+
codebook_size: int = 16384
|
| 34 |
+
codebook_embed_dim: int = 8
|
| 35 |
+
codebook_l2_norm: bool = True
|
| 36 |
+
codebook_show_usage: bool = True
|
| 37 |
+
commit_loss_beta: float = 0.25
|
| 38 |
+
entropy_loss_ratio: float = 0.0
|
| 39 |
+
|
| 40 |
+
encoder_ch_mult: List[int] = field(default_factory=lambda: [1, 1, 2, 2, 4])
|
| 41 |
+
decoder_ch_mult: List[int] = field(default_factory=lambda: [1, 1, 2, 2, 4])
|
| 42 |
+
z_channels: int = 256
|
| 43 |
+
dropout_p: float = 0.0
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
class Encoder(nn.Module):
|
| 47 |
+
def __init__(
|
| 48 |
+
self,
|
| 49 |
+
in_channels=3,
|
| 50 |
+
ch=128,
|
| 51 |
+
ch_mult=(1, 1, 2, 2, 4),
|
| 52 |
+
num_res_blocks=2,
|
| 53 |
+
norm_type="group",
|
| 54 |
+
dropout=0.0,
|
| 55 |
+
resamp_with_conv=True,
|
| 56 |
+
z_channels=256,
|
| 57 |
+
):
|
| 58 |
+
super().__init__()
|
| 59 |
+
self.num_resolutions = len(ch_mult)
|
| 60 |
+
self.num_res_blocks = num_res_blocks
|
| 61 |
+
self.conv_in = nn.Conv2d(in_channels, ch, kernel_size=3, stride=1, padding=1)
|
| 62 |
+
|
| 63 |
+
# downsampling
|
| 64 |
+
in_ch_mult = (1,) + tuple(ch_mult)
|
| 65 |
+
self.conv_blocks = nn.ModuleList()
|
| 66 |
+
for i_level in range(self.num_resolutions):
|
| 67 |
+
conv_block = nn.Module()
|
| 68 |
+
# res & attn
|
| 69 |
+
res_block = nn.ModuleList()
|
| 70 |
+
attn_block = nn.ModuleList()
|
| 71 |
+
block_in = ch * in_ch_mult[i_level]
|
| 72 |
+
block_out = ch * ch_mult[i_level]
|
| 73 |
+
for _ in range(self.num_res_blocks):
|
| 74 |
+
res_block.append(
|
| 75 |
+
ResnetBlock(
|
| 76 |
+
block_in, block_out, dropout=dropout, norm_type=norm_type
|
| 77 |
+
)
|
| 78 |
+
)
|
| 79 |
+
block_in = block_out
|
| 80 |
+
if i_level == self.num_resolutions - 1:
|
| 81 |
+
attn_block.append(AttnBlock(block_in, norm_type))
|
| 82 |
+
conv_block.res = res_block
|
| 83 |
+
conv_block.attn = attn_block
|
| 84 |
+
# downsample
|
| 85 |
+
if i_level != self.num_resolutions - 1:
|
| 86 |
+
conv_block.downsample = Downsample(block_in, resamp_with_conv)
|
| 87 |
+
self.conv_blocks.append(conv_block)
|
| 88 |
+
|
| 89 |
+
# middle
|
| 90 |
+
self.mid = nn.ModuleList()
|
| 91 |
+
self.mid.append(
|
| 92 |
+
ResnetBlock(block_in, block_in, dropout=dropout, norm_type=norm_type)
|
| 93 |
+
)
|
| 94 |
+
self.mid.append(AttnBlock(block_in, norm_type=norm_type))
|
| 95 |
+
self.mid.append(
|
| 96 |
+
ResnetBlock(block_in, block_in, dropout=dropout, norm_type=norm_type)
|
| 97 |
+
)
|
| 98 |
+
|
| 99 |
+
# end
|
| 100 |
+
self.norm_out = Normalize(block_in, norm_type)
|
| 101 |
+
self.conv_out = nn.Conv2d(
|
| 102 |
+
block_in, z_channels, kernel_size=3, stride=1, padding=1
|
| 103 |
+
)
|
| 104 |
+
|
| 105 |
+
def forward(self, x):
|
| 106 |
+
h = self.conv_in(x)
|
| 107 |
+
# downsampling
|
| 108 |
+
for i_level, block in enumerate(self.conv_blocks):
|
| 109 |
+
for i_block in range(self.num_res_blocks):
|
| 110 |
+
h = block.res[i_block](h)
|
| 111 |
+
if len(block.attn) > 0:
|
| 112 |
+
h = block.attn[i_block](h)
|
| 113 |
+
if i_level != self.num_resolutions - 1:
|
| 114 |
+
h = block.downsample(h)
|
| 115 |
+
|
| 116 |
+
# middle
|
| 117 |
+
for mid_block in self.mid:
|
| 118 |
+
h = mid_block(h)
|
| 119 |
+
|
| 120 |
+
# end
|
| 121 |
+
h = self.norm_out(h)
|
| 122 |
+
h = nonlinearity(h)
|
| 123 |
+
h = self.conv_out(h)
|
| 124 |
+
return h
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
class Decoder(nn.Module):
|
| 128 |
+
def __init__(
|
| 129 |
+
self,
|
| 130 |
+
z_channels=256,
|
| 131 |
+
ch=128,
|
| 132 |
+
ch_mult=(1, 1, 2, 2, 4),
|
| 133 |
+
num_res_blocks=2,
|
| 134 |
+
norm_type="group",
|
| 135 |
+
dropout=0.0,
|
| 136 |
+
resamp_with_conv=True,
|
| 137 |
+
out_channels=3,
|
| 138 |
+
):
|
| 139 |
+
super().__init__()
|
| 140 |
+
self.num_resolutions = len(ch_mult)
|
| 141 |
+
self.num_res_blocks = num_res_blocks
|
| 142 |
+
|
| 143 |
+
block_in = ch * ch_mult[self.num_resolutions - 1]
|
| 144 |
+
# z to block_in
|
| 145 |
+
self.conv_in = nn.Conv2d(
|
| 146 |
+
z_channels, block_in, kernel_size=3, stride=1, padding=1
|
| 147 |
+
)
|
| 148 |
+
|
| 149 |
+
# middle
|
| 150 |
+
self.mid = nn.ModuleList()
|
| 151 |
+
self.mid.append(
|
| 152 |
+
ResnetBlock(block_in, block_in, dropout=dropout, norm_type=norm_type)
|
| 153 |
+
)
|
| 154 |
+
self.mid.append(AttnBlock(block_in, norm_type=norm_type))
|
| 155 |
+
self.mid.append(
|
| 156 |
+
ResnetBlock(block_in, block_in, dropout=dropout, norm_type=norm_type)
|
| 157 |
+
)
|
| 158 |
+
|
| 159 |
+
# upsampling
|
| 160 |
+
self.conv_blocks = nn.ModuleList()
|
| 161 |
+
for i_level in reversed(range(self.num_resolutions)):
|
| 162 |
+
conv_block = nn.Module()
|
| 163 |
+
# res & attn
|
| 164 |
+
res_block = nn.ModuleList()
|
| 165 |
+
attn_block = nn.ModuleList()
|
| 166 |
+
block_out = ch * ch_mult[i_level]
|
| 167 |
+
for _ in range(self.num_res_blocks + 1):
|
| 168 |
+
res_block.append(
|
| 169 |
+
ResnetBlock(
|
| 170 |
+
block_in, block_out, dropout=dropout, norm_type=norm_type
|
| 171 |
+
)
|
| 172 |
+
)
|
| 173 |
+
block_in = block_out
|
| 174 |
+
if i_level == self.num_resolutions - 1:
|
| 175 |
+
attn_block.append(AttnBlock(block_in, norm_type))
|
| 176 |
+
conv_block.res = res_block
|
| 177 |
+
conv_block.attn = attn_block
|
| 178 |
+
# downsample
|
| 179 |
+
if i_level != 0:
|
| 180 |
+
conv_block.upsample = Upsample(block_in, resamp_with_conv)
|
| 181 |
+
self.conv_blocks.append(conv_block)
|
| 182 |
+
|
| 183 |
+
# end
|
| 184 |
+
self.norm_out = Normalize(block_in, norm_type)
|
| 185 |
+
self.conv_out = nn.Conv2d(
|
| 186 |
+
block_in, out_channels, kernel_size=3, stride=1, padding=1
|
| 187 |
+
)
|
| 188 |
+
|
| 189 |
+
@property
|
| 190 |
+
def last_layer(self):
|
| 191 |
+
return self.conv_out.weight
|
| 192 |
+
|
| 193 |
+
def forward(self, z):
|
| 194 |
+
# z to block_in
|
| 195 |
+
h = self.conv_in(z)
|
| 196 |
+
|
| 197 |
+
# middle
|
| 198 |
+
for mid_block in self.mid:
|
| 199 |
+
h = mid_block(h)
|
| 200 |
+
|
| 201 |
+
# upsampling
|
| 202 |
+
for i_level, block in enumerate(self.conv_blocks):
|
| 203 |
+
for i_block in range(self.num_res_blocks + 1):
|
| 204 |
+
h = block.res[i_block](h)
|
| 205 |
+
if len(block.attn) > 0:
|
| 206 |
+
h = block.attn[i_block](h)
|
| 207 |
+
if i_level != self.num_resolutions - 1:
|
| 208 |
+
h = block.upsample(h)
|
| 209 |
+
|
| 210 |
+
# end
|
| 211 |
+
h = self.norm_out(h)
|
| 212 |
+
h = nonlinearity(h)
|
| 213 |
+
h = self.conv_out(h)
|
| 214 |
+
return h
|
| 215 |
+
|
| 216 |
+
|
| 217 |
+
class VectorQuantizer(nn.Module):
|
| 218 |
+
def __init__(self, n_e, e_dim, beta, entropy_loss_ratio, l2_norm, show_usage):
|
| 219 |
+
super().__init__()
|
| 220 |
+
self.n_e = n_e
|
| 221 |
+
self.e_dim = e_dim
|
| 222 |
+
self.beta = beta
|
| 223 |
+
self.entropy_loss_ratio = entropy_loss_ratio
|
| 224 |
+
self.l2_norm = l2_norm
|
| 225 |
+
self.show_usage = show_usage
|
| 226 |
+
|
| 227 |
+
self.embedding = nn.Embedding(self.n_e, self.e_dim)
|
| 228 |
+
self.embedding.weight.data.uniform_(-1.0 / self.n_e, 1.0 / self.n_e)
|
| 229 |
+
if self.l2_norm:
|
| 230 |
+
self.embedding.weight.data = F.normalize(
|
| 231 |
+
self.embedding.weight.data, p=2, dim=-1
|
| 232 |
+
)
|
| 233 |
+
if self.show_usage:
|
| 234 |
+
self.register_buffer("codebook_used", nn.Parameter(torch.zeros(65536)))
|
| 235 |
+
|
| 236 |
+
def forward(self, z):
|
| 237 |
+
# reshape z -> (batch, height, width, channel) and flatten
|
| 238 |
+
z = torch.einsum("b c h w -> b h w c", z).contiguous()
|
| 239 |
+
z_flattened = z.view(-1, self.e_dim)
|
| 240 |
+
# distances from z to embeddings e_j (z - e)^2 = z^2 + e^2 - 2 e * z
|
| 241 |
+
|
| 242 |
+
if self.l2_norm:
|
| 243 |
+
z = F.normalize(z, p=2, dim=-1)
|
| 244 |
+
z_flattened = F.normalize(z_flattened, p=2, dim=-1)
|
| 245 |
+
embedding = F.normalize(self.embedding.weight, p=2, dim=-1)
|
| 246 |
+
else:
|
| 247 |
+
embedding = self.embedding.weight
|
| 248 |
+
|
| 249 |
+
d = (
|
| 250 |
+
torch.sum(z_flattened**2, dim=1, keepdim=True)
|
| 251 |
+
+ torch.sum(embedding**2, dim=1)
|
| 252 |
+
- 2
|
| 253 |
+
* torch.einsum(
|
| 254 |
+
"bd,dn->bn", z_flattened, torch.einsum("n d -> d n", embedding)
|
| 255 |
+
)
|
| 256 |
+
)
|
| 257 |
+
|
| 258 |
+
min_encoding_indices = torch.argmin(d, dim=1)
|
| 259 |
+
z_q = embedding[min_encoding_indices].view(z.shape)
|
| 260 |
+
perplexity = None
|
| 261 |
+
min_encodings = None
|
| 262 |
+
vq_loss = None
|
| 263 |
+
commit_loss = None
|
| 264 |
+
entropy_loss = None
|
| 265 |
+
|
| 266 |
+
# compute loss for embedding
|
| 267 |
+
if self.training:
|
| 268 |
+
vq_loss = torch.mean((z_q - z.detach()) ** 2)
|
| 269 |
+
commit_loss = self.beta * torch.mean((z_q.detach() - z) ** 2)
|
| 270 |
+
entropy_loss = self.entropy_loss_ratio * compute_entropy_loss(-d)
|
| 271 |
+
|
| 272 |
+
# preserve gradients
|
| 273 |
+
z_q = z + (z_q - z).detach()
|
| 274 |
+
|
| 275 |
+
# reshape back to match original input shape
|
| 276 |
+
z_q = torch.einsum("b h w c -> b c h w", z_q)
|
| 277 |
+
|
| 278 |
+
return (
|
| 279 |
+
z_q,
|
| 280 |
+
(vq_loss, commit_loss, entropy_loss),
|
| 281 |
+
(perplexity, min_encodings, min_encoding_indices),
|
| 282 |
+
)
|
| 283 |
+
|
| 284 |
+
def get_codebook_entry(self, indices, shape=None, channel_first=True):
|
| 285 |
+
# shape = (batch, channel, height, width) if channel_first else (batch, height, width, channel)
|
| 286 |
+
if self.l2_norm:
|
| 287 |
+
embedding = F.normalize(self.embedding.weight, p=2, dim=-1)
|
| 288 |
+
else:
|
| 289 |
+
embedding = self.embedding.weight
|
| 290 |
+
z_q = embedding[indices] # (b*h*w, c)
|
| 291 |
+
|
| 292 |
+
if shape is not None:
|
| 293 |
+
if channel_first:
|
| 294 |
+
z_q = z_q.reshape(shape[0], shape[2], shape[3], shape[1])
|
| 295 |
+
# reshape back to match original input shape
|
| 296 |
+
z_q = z_q.permute(0, 3, 1, 2).contiguous()
|
| 297 |
+
else:
|
| 298 |
+
z_q = z_q.view(shape)
|
| 299 |
+
return z_q
|
| 300 |
+
|
| 301 |
+
|
| 302 |
+
class ResnetBlock(nn.Module):
|
| 303 |
+
def __init__(
|
| 304 |
+
self,
|
| 305 |
+
in_channels,
|
| 306 |
+
out_channels=None,
|
| 307 |
+
conv_shortcut=False,
|
| 308 |
+
dropout=0.0,
|
| 309 |
+
norm_type="group",
|
| 310 |
+
):
|
| 311 |
+
super().__init__()
|
| 312 |
+
self.in_channels = in_channels
|
| 313 |
+
out_channels = in_channels if out_channels is None else out_channels
|
| 314 |
+
self.out_channels = out_channels
|
| 315 |
+
self.use_conv_shortcut = conv_shortcut
|
| 316 |
+
|
| 317 |
+
self.norm1 = Normalize(in_channels, norm_type)
|
| 318 |
+
self.conv1 = nn.Conv2d(
|
| 319 |
+
in_channels, out_channels, kernel_size=3, stride=1, padding=1
|
| 320 |
+
)
|
| 321 |
+
self.norm2 = Normalize(out_channels, norm_type)
|
| 322 |
+
self.dropout = nn.Dropout(dropout)
|
| 323 |
+
self.conv2 = nn.Conv2d(
|
| 324 |
+
out_channels, out_channels, kernel_size=3, stride=1, padding=1
|
| 325 |
+
)
|
| 326 |
+
|
| 327 |
+
if self.in_channels != self.out_channels:
|
| 328 |
+
if self.use_conv_shortcut:
|
| 329 |
+
self.conv_shortcut = nn.Conv2d(
|
| 330 |
+
in_channels, out_channels, kernel_size=3, stride=1, padding=1
|
| 331 |
+
)
|
| 332 |
+
else:
|
| 333 |
+
self.nin_shortcut = nn.Conv2d(
|
| 334 |
+
in_channels, out_channels, kernel_size=1, stride=1, padding=0
|
| 335 |
+
)
|
| 336 |
+
|
| 337 |
+
def forward(self, x):
|
| 338 |
+
h = x
|
| 339 |
+
h = self.norm1(h)
|
| 340 |
+
h = nonlinearity(h)
|
| 341 |
+
h = self.conv1(h)
|
| 342 |
+
h = self.norm2(h)
|
| 343 |
+
h = nonlinearity(h)
|
| 344 |
+
h = self.dropout(h)
|
| 345 |
+
h = self.conv2(h)
|
| 346 |
+
|
| 347 |
+
if self.in_channels != self.out_channels:
|
| 348 |
+
if self.use_conv_shortcut:
|
| 349 |
+
x = self.conv_shortcut(x)
|
| 350 |
+
else:
|
| 351 |
+
x = self.nin_shortcut(x)
|
| 352 |
+
return x + h
|
| 353 |
+
|
| 354 |
+
|
| 355 |
+
class AttnBlock(nn.Module):
|
| 356 |
+
def __init__(self, in_channels, norm_type="group"):
|
| 357 |
+
super().__init__()
|
| 358 |
+
self.norm = Normalize(in_channels, norm_type)
|
| 359 |
+
self.q = nn.Conv2d(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
|
| 360 |
+
self.k = nn.Conv2d(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
|
| 361 |
+
self.v = nn.Conv2d(in_channels, in_channels, kernel_size=1, stride=1, padding=0)
|
| 362 |
+
self.proj_out = nn.Conv2d(
|
| 363 |
+
in_channels, in_channels, kernel_size=1, stride=1, padding=0
|
| 364 |
+
)
|
| 365 |
+
|
| 366 |
+
def forward(self, x):
|
| 367 |
+
h_ = x
|
| 368 |
+
h_ = self.norm(h_)
|
| 369 |
+
q = self.q(h_)
|
| 370 |
+
k = self.k(h_)
|
| 371 |
+
v = self.v(h_)
|
| 372 |
+
|
| 373 |
+
# compute attention
|
| 374 |
+
b, c, h, w = q.shape
|
| 375 |
+
q = q.reshape(b, c, h * w)
|
| 376 |
+
q = q.permute(0, 2, 1) # b,hw,c
|
| 377 |
+
k = k.reshape(b, c, h * w) # b,c,hw
|
| 378 |
+
w_ = torch.bmm(q, k) # b,hw,hw w[b,i,j]=sum_c q[b,i,c]k[b,c,j]
|
| 379 |
+
w_ = w_ * (int(c) ** (-0.5))
|
| 380 |
+
w_ = F.softmax(w_, dim=2)
|
| 381 |
+
|
| 382 |
+
# attend to values
|
| 383 |
+
v = v.reshape(b, c, h * w)
|
| 384 |
+
w_ = w_.permute(0, 2, 1) # b,hw,hw (first hw of k, second of q)
|
| 385 |
+
h_ = torch.bmm(v, w_) # b, c,hw (hw of q) h_[b,c,j] = sum_i v[b,c,i] w_[b,i,j]
|
| 386 |
+
h_ = h_.reshape(b, c, h, w)
|
| 387 |
+
|
| 388 |
+
h_ = self.proj_out(h_)
|
| 389 |
+
|
| 390 |
+
return x + h_
|
| 391 |
+
|
| 392 |
+
|
| 393 |
+
def nonlinearity(x):
|
| 394 |
+
# swish
|
| 395 |
+
return x * torch.sigmoid(x)
|
| 396 |
+
|
| 397 |
+
|
| 398 |
+
def Normalize(in_channels, norm_type="group"):
|
| 399 |
+
assert norm_type in ["group", "batch"]
|
| 400 |
+
if norm_type == "group":
|
| 401 |
+
return nn.GroupNorm(
|
| 402 |
+
num_groups=32, num_channels=in_channels, eps=1e-6, affine=True
|
| 403 |
+
)
|
| 404 |
+
elif norm_type == "batch":
|
| 405 |
+
return nn.SyncBatchNorm(in_channels)
|
| 406 |
+
|
| 407 |
+
|
| 408 |
+
class Upsample(nn.Module):
|
| 409 |
+
def __init__(self, in_channels, with_conv):
|
| 410 |
+
super().__init__()
|
| 411 |
+
self.with_conv = with_conv
|
| 412 |
+
if self.with_conv:
|
| 413 |
+
self.conv = nn.Conv2d(
|
| 414 |
+
in_channels, in_channels, kernel_size=3, stride=1, padding=1
|
| 415 |
+
)
|
| 416 |
+
|
| 417 |
+
def forward(self, x):
|
| 418 |
+
if x.dtype != torch.float32:
|
| 419 |
+
x = F.interpolate(x.to(torch.float), scale_factor=2.0, mode="nearest").to(
|
| 420 |
+
torch.bfloat16
|
| 421 |
+
)
|
| 422 |
+
else:
|
| 423 |
+
x = F.interpolate(x, scale_factor=2.0, mode="nearest")
|
| 424 |
+
|
| 425 |
+
if self.with_conv:
|
| 426 |
+
x = self.conv(x)
|
| 427 |
+
return x
|
| 428 |
+
|
| 429 |
+
|
| 430 |
+
class Downsample(nn.Module):
|
| 431 |
+
def __init__(self, in_channels, with_conv):
|
| 432 |
+
super().__init__()
|
| 433 |
+
self.with_conv = with_conv
|
| 434 |
+
if self.with_conv:
|
| 435 |
+
# no asymmetric padding in torch conv, must do it ourselves
|
| 436 |
+
self.conv = nn.Conv2d(
|
| 437 |
+
in_channels, in_channels, kernel_size=3, stride=2, padding=0
|
| 438 |
+
)
|
| 439 |
+
|
| 440 |
+
def forward(self, x):
|
| 441 |
+
if self.with_conv:
|
| 442 |
+
pad = (0, 1, 0, 1)
|
| 443 |
+
x = F.pad(x, pad, mode="constant", value=0)
|
| 444 |
+
x = self.conv(x)
|
| 445 |
+
else:
|
| 446 |
+
x = F.avg_pool2d(x, kernel_size=2, stride=2)
|
| 447 |
+
return x
|
| 448 |
+
|
| 449 |
+
|
| 450 |
+
def compute_entropy_loss(affinity, loss_type="softmax", temperature=0.01):
|
| 451 |
+
flat_affinity = affinity.reshape(-1, affinity.shape[-1])
|
| 452 |
+
flat_affinity /= temperature
|
| 453 |
+
probs = F.softmax(flat_affinity, dim=-1)
|
| 454 |
+
log_probs = F.log_softmax(flat_affinity + 1e-5, dim=-1)
|
| 455 |
+
if loss_type == "softmax":
|
| 456 |
+
target_probs = probs
|
| 457 |
+
else:
|
| 458 |
+
raise ValueError("Entropy loss {} not supported".format(loss_type))
|
| 459 |
+
avg_probs = torch.mean(target_probs, dim=0)
|
| 460 |
+
avg_entropy = -torch.sum(avg_probs * torch.log(avg_probs + 1e-5))
|
| 461 |
+
sample_entropy = -torch.mean(torch.sum(target_probs * log_probs, dim=-1))
|
| 462 |
+
loss = sample_entropy - avg_entropy
|
| 463 |
+
return loss
|
| 464 |
+
|
| 465 |
+
|
| 466 |
+
class VQModel(nn.Module):
|
| 467 |
+
def __init__(self, config: ModelArgs):
|
| 468 |
+
super().__init__()
|
| 469 |
+
self.config = config
|
| 470 |
+
self.encoder = Encoder(
|
| 471 |
+
ch_mult=config.encoder_ch_mult,
|
| 472 |
+
z_channels=config.z_channels,
|
| 473 |
+
dropout=config.dropout_p,
|
| 474 |
+
)
|
| 475 |
+
self.decoder = Decoder(
|
| 476 |
+
ch_mult=config.decoder_ch_mult,
|
| 477 |
+
z_channels=config.z_channels,
|
| 478 |
+
dropout=config.dropout_p,
|
| 479 |
+
)
|
| 480 |
+
|
| 481 |
+
self.quantize = VectorQuantizer(
|
| 482 |
+
config.codebook_size,
|
| 483 |
+
config.codebook_embed_dim,
|
| 484 |
+
config.commit_loss_beta,
|
| 485 |
+
config.entropy_loss_ratio,
|
| 486 |
+
config.codebook_l2_norm,
|
| 487 |
+
config.codebook_show_usage,
|
| 488 |
+
)
|
| 489 |
+
self.quant_conv = nn.Conv2d(config.z_channels, config.codebook_embed_dim, 1)
|
| 490 |
+
self.post_quant_conv = nn.Conv2d(
|
| 491 |
+
config.codebook_embed_dim, config.z_channels, 1
|
| 492 |
+
)
|
| 493 |
+
|
| 494 |
+
def encode(self, x):
|
| 495 |
+
h = self.encoder(x)
|
| 496 |
+
h = self.quant_conv(h)
|
| 497 |
+
quant, emb_loss, info = self.quantize(h)
|
| 498 |
+
return quant, emb_loss, info
|
| 499 |
+
|
| 500 |
+
def decode(self, quant):
|
| 501 |
+
quant = self.post_quant_conv(quant)
|
| 502 |
+
dec = self.decoder(quant)
|
| 503 |
+
return dec
|
| 504 |
+
|
| 505 |
+
def decode_code(self, code_b, shape=None, channel_first=True):
|
| 506 |
+
quant_b = self.quantize.get_codebook_entry(code_b, shape, channel_first)
|
| 507 |
+
dec = self.decode(quant_b)
|
| 508 |
+
return dec
|
| 509 |
+
|
| 510 |
+
def forward(self, input):
|
| 511 |
+
quant, diff, _ = self.encode(input)
|
| 512 |
+
dec = self.decode(quant)
|
| 513 |
+
return dec, diff
|
| 514 |
+
|
| 515 |
+
|
| 516 |
+
#################################################################################
|
| 517 |
+
# VQ Model Configs #
|
| 518 |
+
#################################################################################
|
| 519 |
+
def VQ_16(**kwargs):
|
| 520 |
+
return VQModel(
|
| 521 |
+
ModelArgs(
|
| 522 |
+
encoder_ch_mult=[1, 1, 2, 2, 4], decoder_ch_mult=[1, 1, 2, 2, 4], **kwargs
|
| 523 |
+
)
|
| 524 |
+
)
|
| 525 |
+
|
| 526 |
+
|
| 527 |
+
VQ_models = {"VQ-16": VQ_16}
|
janus/utils/__init__.py
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2023-2024 DeepSeek.
|
| 2 |
+
#
|
| 3 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 4 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 5 |
+
# the Software without restriction, including without limitation the rights to
|
| 6 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
|
| 7 |
+
# the Software, and to permit persons to whom the Software is furnished to do so,
|
| 8 |
+
# subject to the following conditions:
|
| 9 |
+
#
|
| 10 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 11 |
+
# copies or substantial portions of the Software.
|
| 12 |
+
#
|
| 13 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 14 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
|
| 15 |
+
# FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
|
| 16 |
+
# COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
|
| 17 |
+
# IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
|
| 18 |
+
# CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
janus/utils/conversation.py
ADDED
|
@@ -0,0 +1,365 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2023-2024 DeepSeek.
|
| 2 |
+
#
|
| 3 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 4 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 5 |
+
# the Software without restriction, including without limitation the rights to
|
| 6 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
|
| 7 |
+
# the Software, and to permit persons to whom the Software is furnished to do so,
|
| 8 |
+
# subject to the following conditions:
|
| 9 |
+
#
|
| 10 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 11 |
+
# copies or substantial portions of the Software.
|
| 12 |
+
#
|
| 13 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 14 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
|
| 15 |
+
# FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
|
| 16 |
+
# COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
|
| 17 |
+
# IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
|
| 18 |
+
# CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
| 19 |
+
|
| 20 |
+
"""
|
| 21 |
+
From https://github.com/lm-sys/FastChat/blob/main/fastchat/conversation.py
|
| 22 |
+
"""
|
| 23 |
+
|
| 24 |
+
import dataclasses
|
| 25 |
+
from enum import IntEnum, auto
|
| 26 |
+
from typing import Dict, List
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
class SeparatorStyle(IntEnum):
|
| 30 |
+
"""Separator styles."""
|
| 31 |
+
|
| 32 |
+
ADD_COLON_SINGLE = auto()
|
| 33 |
+
ADD_COLON_TWO = auto()
|
| 34 |
+
ADD_COLON_SPACE_SINGLE = auto()
|
| 35 |
+
NO_COLON_SINGLE = auto()
|
| 36 |
+
NO_COLON_TWO = auto()
|
| 37 |
+
ADD_NEW_LINE_SINGLE = auto()
|
| 38 |
+
LLAMA2 = auto()
|
| 39 |
+
CHATGLM = auto()
|
| 40 |
+
CHATML = auto()
|
| 41 |
+
CHATINTERN = auto()
|
| 42 |
+
DOLLY = auto()
|
| 43 |
+
RWKV = auto()
|
| 44 |
+
PHOENIX = auto()
|
| 45 |
+
ROBIN = auto()
|
| 46 |
+
DeepSeek = auto()
|
| 47 |
+
PLAIN = auto()
|
| 48 |
+
ALIGNMENT = auto()
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
@dataclasses.dataclass
|
| 52 |
+
class Conversation:
|
| 53 |
+
"""A class that manages prompt templates and keeps all conversation history."""
|
| 54 |
+
|
| 55 |
+
# The name of this template
|
| 56 |
+
name: str
|
| 57 |
+
# The template of the system prompt
|
| 58 |
+
system_template: str = "{system_message}"
|
| 59 |
+
# The system message
|
| 60 |
+
system_message: str = ""
|
| 61 |
+
# The names of two roles
|
| 62 |
+
roles: List[str] = (("USER", "ASSISTANT"),)
|
| 63 |
+
# All messages. Each item is (role, message).
|
| 64 |
+
messages: List[List[str]] = ()
|
| 65 |
+
# The number of few shot examples
|
| 66 |
+
offset: int = 0
|
| 67 |
+
# The separator style and configurations
|
| 68 |
+
sep_style: SeparatorStyle = SeparatorStyle.ADD_COLON_SINGLE
|
| 69 |
+
sep: str = "\n"
|
| 70 |
+
sep2: str = None
|
| 71 |
+
# Stop criteria (the default one is EOS token)
|
| 72 |
+
stop_str: str = None
|
| 73 |
+
# Stops generation if meeting any token in this list
|
| 74 |
+
stop_token_ids: List[int] = None
|
| 75 |
+
|
| 76 |
+
def get_prompt(self) -> str:
|
| 77 |
+
"""Get the prompt for generation."""
|
| 78 |
+
system_prompt = self.system_template.format(system_message=self.system_message)
|
| 79 |
+
|
| 80 |
+
if self.sep_style == SeparatorStyle.DeepSeek:
|
| 81 |
+
seps = [self.sep, self.sep2]
|
| 82 |
+
if system_prompt == "" or system_prompt is None:
|
| 83 |
+
ret = ""
|
| 84 |
+
else:
|
| 85 |
+
ret = system_prompt + seps[0]
|
| 86 |
+
for i, (role, message) in enumerate(self.messages):
|
| 87 |
+
if message:
|
| 88 |
+
ret += role + ": " + message + seps[i % 2]
|
| 89 |
+
else:
|
| 90 |
+
ret += role + ":"
|
| 91 |
+
return ret
|
| 92 |
+
elif self.sep_style == SeparatorStyle.LLAMA2:
|
| 93 |
+
seps = [self.sep, self.sep2]
|
| 94 |
+
if self.system_message:
|
| 95 |
+
ret = system_prompt
|
| 96 |
+
else:
|
| 97 |
+
ret = "[INST] "
|
| 98 |
+
for i, (role, message) in enumerate(self.messages):
|
| 99 |
+
tag = self.roles[i % 2]
|
| 100 |
+
if message:
|
| 101 |
+
if type(message) is tuple: # multimodal message
|
| 102 |
+
message, _ = message
|
| 103 |
+
if i == 0:
|
| 104 |
+
ret += message + " "
|
| 105 |
+
else:
|
| 106 |
+
ret += tag + " " + message + seps[i % 2]
|
| 107 |
+
else:
|
| 108 |
+
ret += tag
|
| 109 |
+
return ret
|
| 110 |
+
elif self.sep_style == SeparatorStyle.PLAIN:
|
| 111 |
+
seps = [self.sep, self.sep2]
|
| 112 |
+
ret = ""
|
| 113 |
+
for i, (role, message) in enumerate(self.messages):
|
| 114 |
+
if message:
|
| 115 |
+
if type(message) is tuple:
|
| 116 |
+
message, _, _ = message
|
| 117 |
+
if i % 2 == 0:
|
| 118 |
+
ret += message + seps[i % 2]
|
| 119 |
+
else:
|
| 120 |
+
ret += message + seps[i % 2]
|
| 121 |
+
else:
|
| 122 |
+
ret += ""
|
| 123 |
+
return ret
|
| 124 |
+
elif self.sep_style == SeparatorStyle.ALIGNMENT:
|
| 125 |
+
seps = [self.sep, self.sep2]
|
| 126 |
+
ret = ""
|
| 127 |
+
for i, (role, message) in enumerate(self.messages):
|
| 128 |
+
if message:
|
| 129 |
+
if type(message) is tuple:
|
| 130 |
+
message, _, _ = message
|
| 131 |
+
if i % 2 == 0:
|
| 132 |
+
ret += "<image>\n" + seps[i % 2]
|
| 133 |
+
else:
|
| 134 |
+
ret += message + seps[i % 2]
|
| 135 |
+
else:
|
| 136 |
+
ret += ""
|
| 137 |
+
return ret
|
| 138 |
+
else:
|
| 139 |
+
raise ValueError(f"Invalid style: {self.sep_style}")
|
| 140 |
+
|
| 141 |
+
def get_prompt_for_current_round(self, content=None):
|
| 142 |
+
"""Get current round formatted question prompt during sft training"""
|
| 143 |
+
if self.sep_style == SeparatorStyle.PLAIN:
|
| 144 |
+
formatted_question = "<image>\n"
|
| 145 |
+
elif self.sep_style == SeparatorStyle.DeepSeek:
|
| 146 |
+
formatted_question = (
|
| 147 |
+
f"{self.roles[0]}: " + content.strip() + self.sep + f"{self.roles[1]}:"
|
| 148 |
+
)
|
| 149 |
+
else:
|
| 150 |
+
raise ValueError(f"Unsupported sep_style: {self.sep_style}")
|
| 151 |
+
return formatted_question
|
| 152 |
+
|
| 153 |
+
def set_system_message(self, system_message: str):
|
| 154 |
+
"""Set the system message."""
|
| 155 |
+
self.system_message = system_message
|
| 156 |
+
|
| 157 |
+
def append_message(self, role: str, message: str):
|
| 158 |
+
"""Append a new message."""
|
| 159 |
+
self.messages.append([role, message])
|
| 160 |
+
|
| 161 |
+
def reset_message(self):
|
| 162 |
+
"""Reset a new message."""
|
| 163 |
+
self.messages = []
|
| 164 |
+
|
| 165 |
+
def update_last_message(self, message: str):
|
| 166 |
+
"""Update the last output.
|
| 167 |
+
|
| 168 |
+
The last message is typically set to be None when constructing the prompt,
|
| 169 |
+
so we need to update it in-place after getting the response from a model.
|
| 170 |
+
"""
|
| 171 |
+
self.messages[-1][1] = message
|
| 172 |
+
|
| 173 |
+
def to_gradio_chatbot(self):
|
| 174 |
+
"""Convert the conversation to gradio chatbot format."""
|
| 175 |
+
ret = []
|
| 176 |
+
for i, (role, msg) in enumerate(self.messages[self.offset :]):
|
| 177 |
+
if i % 2 == 0:
|
| 178 |
+
ret.append([msg, None])
|
| 179 |
+
else:
|
| 180 |
+
ret[-1][-1] = msg
|
| 181 |
+
return ret
|
| 182 |
+
|
| 183 |
+
def to_openai_api_messages(self):
|
| 184 |
+
"""Convert the conversation to OpenAI chat completion format."""
|
| 185 |
+
system_prompt = self.system_template.format(system_message=self.system_message)
|
| 186 |
+
ret = [{"role": "system", "content": system_prompt}]
|
| 187 |
+
|
| 188 |
+
for i, (_, msg) in enumerate(self.messages[self.offset :]):
|
| 189 |
+
if i % 2 == 0:
|
| 190 |
+
ret.append({"role": "user", "content": msg})
|
| 191 |
+
else:
|
| 192 |
+
if msg is not None:
|
| 193 |
+
ret.append({"role": "assistant", "content": msg})
|
| 194 |
+
return ret
|
| 195 |
+
|
| 196 |
+
def copy(self):
|
| 197 |
+
return Conversation(
|
| 198 |
+
name=self.name,
|
| 199 |
+
system_template=self.system_template,
|
| 200 |
+
system_message=self.system_message,
|
| 201 |
+
roles=self.roles,
|
| 202 |
+
messages=[[x, y] for x, y in self.messages],
|
| 203 |
+
offset=self.offset,
|
| 204 |
+
sep_style=self.sep_style,
|
| 205 |
+
sep=self.sep,
|
| 206 |
+
sep2=self.sep2,
|
| 207 |
+
stop_str=self.stop_str,
|
| 208 |
+
stop_token_ids=self.stop_token_ids,
|
| 209 |
+
)
|
| 210 |
+
|
| 211 |
+
def dict(self):
|
| 212 |
+
return {
|
| 213 |
+
"template_name": self.name,
|
| 214 |
+
"system_message": self.system_message,
|
| 215 |
+
"roles": self.roles,
|
| 216 |
+
"messages": self.messages,
|
| 217 |
+
"offset": self.offset,
|
| 218 |
+
}
|
| 219 |
+
|
| 220 |
+
|
| 221 |
+
# A global registry for all conversation templates
|
| 222 |
+
conv_templates: Dict[str, Conversation] = {}
|
| 223 |
+
|
| 224 |
+
|
| 225 |
+
def register_conv_template(template: Conversation, override: bool = False):
|
| 226 |
+
"""Register a new conversation template."""
|
| 227 |
+
if not override:
|
| 228 |
+
assert (
|
| 229 |
+
template.name not in conv_templates
|
| 230 |
+
), f"{template.name} has been registered."
|
| 231 |
+
|
| 232 |
+
conv_templates[template.name] = template
|
| 233 |
+
|
| 234 |
+
|
| 235 |
+
def get_conv_template(name: str) -> Conversation:
|
| 236 |
+
"""Get a conversation template."""
|
| 237 |
+
return conv_templates[name].copy()
|
| 238 |
+
|
| 239 |
+
|
| 240 |
+
# llava_llama2 template
|
| 241 |
+
register_conv_template(
|
| 242 |
+
Conversation(
|
| 243 |
+
name="llava_llama2",
|
| 244 |
+
system_message="You are a helpful language and vision assistant. "
|
| 245 |
+
"You are able to understand the visual content that the user provides, "
|
| 246 |
+
"and assist the user with a variety of tasks using natural language.",
|
| 247 |
+
system_template="[INST] <<SYS>>\n{system_message}\n<</SYS>>\n\n",
|
| 248 |
+
roles=("[INST]", "[/INST]"),
|
| 249 |
+
messages=(),
|
| 250 |
+
offset=0,
|
| 251 |
+
sep_style=SeparatorStyle.LLAMA2,
|
| 252 |
+
sep=" ",
|
| 253 |
+
sep2=" </s><s>",
|
| 254 |
+
stop_token_ids=[2],
|
| 255 |
+
)
|
| 256 |
+
)
|
| 257 |
+
|
| 258 |
+
# llama2 template
|
| 259 |
+
# reference: https://github.com/facebookresearch/llama/blob/cfc3fc8c1968d390eb830e65c63865e980873a06/llama/generation.py#L212
|
| 260 |
+
register_conv_template(
|
| 261 |
+
Conversation(
|
| 262 |
+
name="llama-2",
|
| 263 |
+
system_template="[INST] <<SYS>>\n{system_message}\n<</SYS>>\n\n",
|
| 264 |
+
roles=("[INST]", "[/INST]"),
|
| 265 |
+
messages=(),
|
| 266 |
+
offset=0,
|
| 267 |
+
sep_style=SeparatorStyle.LLAMA2,
|
| 268 |
+
sep=" ",
|
| 269 |
+
sep2=" </s><s>",
|
| 270 |
+
stop_token_ids=[2],
|
| 271 |
+
)
|
| 272 |
+
)
|
| 273 |
+
|
| 274 |
+
|
| 275 |
+
# deepseek template
|
| 276 |
+
register_conv_template(
|
| 277 |
+
Conversation(
|
| 278 |
+
name="deepseek_old",
|
| 279 |
+
system_template="{system_message}",
|
| 280 |
+
# system_message="You are a helpful assistant. Please answer truthfully and write out your "
|
| 281 |
+
# "thinking step by step to be sure you get the right answer.",
|
| 282 |
+
system_message="",
|
| 283 |
+
roles=("User", "Assistant"),
|
| 284 |
+
messages=(),
|
| 285 |
+
offset=0,
|
| 286 |
+
sep_style=SeparatorStyle.DeepSeek,
|
| 287 |
+
sep="\n\n",
|
| 288 |
+
sep2="<|end▁of▁sentence|>",
|
| 289 |
+
stop_token_ids=[100001],
|
| 290 |
+
stop_str=["User:", "<|end▁of▁sentence|>"],
|
| 291 |
+
)
|
| 292 |
+
)
|
| 293 |
+
register_conv_template(
|
| 294 |
+
Conversation(
|
| 295 |
+
name="deepseek",
|
| 296 |
+
system_template="{system_message}",
|
| 297 |
+
# system_message="You are a helpful assistant. Please answer truthfully and write out your "
|
| 298 |
+
# "thinking step by step to be sure you get the right answer.",
|
| 299 |
+
system_message="",
|
| 300 |
+
roles=("<|User|>", "<|Assistant|>"),
|
| 301 |
+
messages=(),
|
| 302 |
+
offset=0,
|
| 303 |
+
sep_style=SeparatorStyle.DeepSeek,
|
| 304 |
+
sep="\n\n",
|
| 305 |
+
sep2="<|end▁of▁sentence|>",
|
| 306 |
+
stop_token_ids=[100001],
|
| 307 |
+
stop_str=["<|User|>", "<|end▁of▁sentence|>"]
|
| 308 |
+
)
|
| 309 |
+
)
|
| 310 |
+
|
| 311 |
+
register_conv_template(
|
| 312 |
+
Conversation(
|
| 313 |
+
name="plain",
|
| 314 |
+
system_template="",
|
| 315 |
+
system_message="",
|
| 316 |
+
roles=("", ""),
|
| 317 |
+
messages=(),
|
| 318 |
+
offset=0,
|
| 319 |
+
sep_style=SeparatorStyle.PLAIN,
|
| 320 |
+
sep="",
|
| 321 |
+
sep2="",
|
| 322 |
+
stop_token_ids=[2],
|
| 323 |
+
stop_str=["</s>"],
|
| 324 |
+
)
|
| 325 |
+
)
|
| 326 |
+
|
| 327 |
+
|
| 328 |
+
register_conv_template(
|
| 329 |
+
Conversation(
|
| 330 |
+
name="alignment",
|
| 331 |
+
system_template="",
|
| 332 |
+
system_message="",
|
| 333 |
+
roles=("", ""),
|
| 334 |
+
messages=(),
|
| 335 |
+
offset=0,
|
| 336 |
+
sep_style=SeparatorStyle.ALIGNMENT,
|
| 337 |
+
sep="",
|
| 338 |
+
sep2="",
|
| 339 |
+
stop_token_ids=[2],
|
| 340 |
+
stop_str=["</s>"],
|
| 341 |
+
)
|
| 342 |
+
)
|
| 343 |
+
|
| 344 |
+
|
| 345 |
+
if __name__ == "__main__":
|
| 346 |
+
# print("Llama-2 template:")
|
| 347 |
+
# conv = get_conv_template("llama-2")
|
| 348 |
+
# conv.set_system_message("You are a helpful, respectful and honest assistant.")
|
| 349 |
+
# conv.append_message(conv.roles[0], "Hello!")
|
| 350 |
+
# conv.append_message(conv.roles[1], "Hi!")
|
| 351 |
+
# conv.append_message(conv.roles[0], "How are you?")
|
| 352 |
+
# conv.append_message(conv.roles[1], None)
|
| 353 |
+
# print(conv.get_prompt())
|
| 354 |
+
|
| 355 |
+
# print("\n")
|
| 356 |
+
|
| 357 |
+
print("deepseek template:")
|
| 358 |
+
conv = get_conv_template("deepseek")
|
| 359 |
+
conv.append_message(conv.roles[0], "Hello!")
|
| 360 |
+
conv.append_message(conv.roles[1], "Hi! This is Tony.")
|
| 361 |
+
conv.append_message(conv.roles[0], "Who are you?")
|
| 362 |
+
conv.append_message(conv.roles[1], "I am a helpful assistant.")
|
| 363 |
+
conv.append_message(conv.roles[0], "How are you?")
|
| 364 |
+
conv.append_message(conv.roles[1], None)
|
| 365 |
+
print(conv.get_prompt())
|
janus/utils/io.py
ADDED
|
@@ -0,0 +1,89 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2023-2024 DeepSeek.
|
| 2 |
+
#
|
| 3 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy of
|
| 4 |
+
# this software and associated documentation files (the "Software"), to deal in
|
| 5 |
+
# the Software without restriction, including without limitation the rights to
|
| 6 |
+
# use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
|
| 7 |
+
# the Software, and to permit persons to whom the Software is furnished to do so,
|
| 8 |
+
# subject to the following conditions:
|
| 9 |
+
#
|
| 10 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 11 |
+
# copies or substantial portions of the Software.
|
| 12 |
+
#
|
| 13 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 14 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
|
| 15 |
+
# FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
|
| 16 |
+
# COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
|
| 17 |
+
# IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
|
| 18 |
+
# CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
| 19 |
+
|
| 20 |
+
import json
|
| 21 |
+
from typing import Dict, List
|
| 22 |
+
|
| 23 |
+
import PIL.Image
|
| 24 |
+
import torch
|
| 25 |
+
import base64
|
| 26 |
+
import io
|
| 27 |
+
from transformers import AutoModelForCausalLM
|
| 28 |
+
|
| 29 |
+
from janus.models import MultiModalityCausalLM, VLChatProcessor
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def load_pretrained_model(model_path: str):
|
| 33 |
+
vl_chat_processor: VLChatProcessor = VLChatProcessor.from_pretrained(model_path)
|
| 34 |
+
tokenizer = vl_chat_processor.tokenizer
|
| 35 |
+
|
| 36 |
+
vl_gpt: MultiModalityCausalLM = AutoModelForCausalLM.from_pretrained(
|
| 37 |
+
model_path, trust_remote_code=True
|
| 38 |
+
)
|
| 39 |
+
vl_gpt = vl_gpt.to(torch.bfloat16).cuda().eval()
|
| 40 |
+
|
| 41 |
+
return tokenizer, vl_chat_processor, vl_gpt
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def load_pil_images(conversations: List[Dict[str, str]]) -> List[PIL.Image.Image]:
|
| 45 |
+
"""
|
| 46 |
+
|
| 47 |
+
Support file path or base64 images.
|
| 48 |
+
|
| 49 |
+
Args:
|
| 50 |
+
conversations (List[Dict[str, str]]): the conversations with a list of messages. An example is :
|
| 51 |
+
[
|
| 52 |
+
{
|
| 53 |
+
"role": "User",
|
| 54 |
+
"content": "<image_placeholder>\nExtract all information from this image and convert them into markdown format.",
|
| 55 |
+
"images": ["./examples/table_datasets.png"]
|
| 56 |
+
},
|
| 57 |
+
{"role": "Assistant", "content": ""},
|
| 58 |
+
]
|
| 59 |
+
|
| 60 |
+
Returns:
|
| 61 |
+
pil_images (List[PIL.Image.Image]): the list of PIL images.
|
| 62 |
+
|
| 63 |
+
"""
|
| 64 |
+
|
| 65 |
+
pil_images = []
|
| 66 |
+
|
| 67 |
+
for message in conversations:
|
| 68 |
+
if "images" not in message:
|
| 69 |
+
continue
|
| 70 |
+
|
| 71 |
+
for image_data in message["images"]:
|
| 72 |
+
if image_data.startswith("data:image"):
|
| 73 |
+
# Image data is in base64 format
|
| 74 |
+
_, image_data = image_data.split(",", 1)
|
| 75 |
+
image_bytes = base64.b64decode(image_data)
|
| 76 |
+
pil_img = PIL.Image.open(io.BytesIO(image_bytes))
|
| 77 |
+
else:
|
| 78 |
+
# Image data is a file path
|
| 79 |
+
pil_img = PIL.Image.open(image_data)
|
| 80 |
+
pil_img = pil_img.convert("RGB")
|
| 81 |
+
pil_images.append(pil_img)
|
| 82 |
+
|
| 83 |
+
return pil_images
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
def load_json(filepath):
|
| 87 |
+
with open(filepath, "r") as f:
|
| 88 |
+
data = json.load(f)
|
| 89 |
+
return data
|
janus_pro_tech_report.pdf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5aebe38af5e16ee20eff453e43ea5d810eba667281a6d12e2078f704fe260b46
|
| 3 |
+
size 2846268
|
januspro.txt
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
(januspro) C:\Users\sunri\Janus>python demo/app_januspro.py
|
| 2 |
+
Python version is above 3.10, patching the collections module.
|
| 3 |
+
C:\Users\sunri\anaconda3\envs\januspro\lib\site-packages\transformers\models\auto\image_processing_auto.py:590: FutureWarning: The image_processor_class argument is deprecated and will be removed in v4.42. Please use `slow_image_processor_class`, or `fast_image_processor_class` instead
|
| 4 |
+
warnings.warn(
|
| 5 |
+
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:26<00:00, 13.30s/it]
|
| 6 |
+
Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.48, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`.
|
| 7 |
+
You are using the default legacy behaviour of the <class 'transformers.models.llama.tokenization_llama_fast.LlamaTokenizerFast'>. This is expected, and simply means that the `legacy` (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set `legacy=False`. This should only be set if you understand what it means, and thoroughly read the reason why this was added as explained in https://github.com/huggingface/transformers/pull/24565 - if you loaded a llama tokenizer from a GGUF file you can ignore this message.
|
| 8 |
+
Some kwargs in processor config are unused and will not have any effect: sft_format, add_special_token, mask_prompt, num_image_tokens, ignore_id, image_tag.
|
| 9 |
+
信息: 用提供的模式无法找到文件。
|
| 10 |
+
* Running on local URL: http://127.0.0.1:7860
|
| 11 |
+
* Running on public URL: https://c2811768e57640e1bd.gradio.live
|
| 12 |
+
|
| 13 |
+
This share link expires in 72 hours. For free permanent hosting and GPU upgrades, run `gradio deploy` from the terminal in the working directory to deploy to Hugging Face Spaces (https://huggingface.co/spaces)
|
pyproject.toml
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[build-system]
|
| 2 |
+
requires = ["setuptools>=40.6.0", "wheel"]
|
| 3 |
+
build-backend = "setuptools.build_meta"
|
| 4 |
+
|
| 5 |
+
[project]
|
| 6 |
+
name = "janus"
|
| 7 |
+
version = "1.0.0"
|
| 8 |
+
description = "Janus"
|
| 9 |
+
authors = [{name = "DeepSeek-AI"}]
|
| 10 |
+
license = {file = "LICENSE-CODE"}
|
| 11 |
+
urls = {homepage = "https://github.com/deepseek-ai/Janus"}
|
| 12 |
+
readme = "README.md"
|
| 13 |
+
requires-python = ">=3.8"
|
| 14 |
+
dependencies = [
|
| 15 |
+
"torch>=2.0.1",
|
| 16 |
+
"transformers>=4.38.2",
|
| 17 |
+
"timm>=0.9.16",
|
| 18 |
+
"accelerate",
|
| 19 |
+
"sentencepiece",
|
| 20 |
+
"attrdict",
|
| 21 |
+
"einops",
|
| 22 |
+
]
|
| 23 |
+
|
| 24 |
+
[project.optional-dependencies]
|
| 25 |
+
gradio = [
|
| 26 |
+
"gradio==3.48.0",
|
| 27 |
+
"gradio-client==0.6.1",
|
| 28 |
+
"mdtex2html==1.3.0",
|
| 29 |
+
"pypinyin==0.50.0",
|
| 30 |
+
"tiktoken==0.5.2",
|
| 31 |
+
"tqdm==4.64.0",
|
| 32 |
+
"colorama==0.4.5",
|
| 33 |
+
"Pygments==2.12.0",
|
| 34 |
+
"markdown==3.4.1",
|
| 35 |
+
"SentencePiece==0.1.96"
|
| 36 |
+
]
|
| 37 |
+
lint = [
|
| 38 |
+
"isort",
|
| 39 |
+
"black[jupyter] >= 22.6.0",
|
| 40 |
+
"pylint[spelling] >= 2.15.0",
|
| 41 |
+
"flake8",
|
| 42 |
+
"flake8-bugbear",
|
| 43 |
+
"flake8-comprehensions",
|
| 44 |
+
"flake8-docstrings",
|
| 45 |
+
"flake8-pyi",
|
| 46 |
+
"flake8-simplify",
|
| 47 |
+
"ruff",
|
| 48 |
+
"pyenchant",
|
| 49 |
+
"pre-commit",
|
| 50 |
+
]
|
| 51 |
+
|
| 52 |
+
[tool.setuptools]
|
| 53 |
+
packages = {find = {exclude = ["images"]}}
|
requirements.txt
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
torch==2.0.1
|
| 2 |
+
transformers>=4.38.2
|
| 3 |
+
timm>=0.9.16
|
| 4 |
+
accelerate
|
| 5 |
+
sentencepiece
|
| 6 |
+
attrdict
|
| 7 |
+
einops
|
| 8 |
+
|
| 9 |
+
# for gradio demo
|
| 10 |
+
gradio==3.48.0
|
| 11 |
+
gradio-client==0.6.1
|
| 12 |
+
mdtex2html==1.3.0
|
| 13 |
+
pypinyin==0.50.0
|
| 14 |
+
tiktoken==0.5.2
|
| 15 |
+
tqdm==4.64.0
|
| 16 |
+
colorama==0.4.5
|
| 17 |
+
Pygments==2.12.0
|
| 18 |
+
markdown==3.4.1
|
| 19 |
+
SentencePiece==0.1.96
|