Spaces:
Sleeping

Sleeping
Update README
Browse files- README.md +84 -55
- app.py +1 -1
- milestone3/appUI.png +0 -0
README.md
CHANGED
|
@@ -19,77 +19,106 @@ This milestone includes finetuning a language model in HuggingFace for sentiment
|
|
| 19 |
|
| 20 |
Link to app: https://huggingface.co/spaces/andyqin18/sentiment-analysis-app
|
| 21 |
|
| 22 |
-
|
| 23 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 24 |
|
| 25 |
-
|
|
|
|
|
|
|
| 26 |
|
| 27 |
-
|
|
|
|
|
|
|
| 28 |
|
| 29 |
-
Then we can go back to our Github Repo and create the following files.
|
| 30 |
-
In order for the space to run properly, there must be at least three files in the root directory:
|
| 31 |
-
[README.md](README.md), [app.py](app.py), and [requirements.txt](requirements.txt)
|
| 32 |
|
| 33 |
-
|
|
|
|
| 34 |
```
|
| 35 |
-
|
| 36 |
-
|
| 37 |
-
|
| 38 |
-
colorFrom: green
|
| 39 |
-
colorTo: purple
|
| 40 |
-
sdk: streamlit
|
| 41 |
-
sdk_version: 1.17.0
|
| 42 |
-
app_file: app.py
|
| 43 |
-
pinned: false
|
| 44 |
-
---
|
| 45 |
```
|
|
|
|
| 46 |
|
| 47 |
-
|
|
|
|
|
|
|
|
|
|
| 48 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 49 |
|
| 50 |
-
|
|
|
|
| 51 |
|
| 52 |
-
Then we go to settings of the Github Repo and create a secret token to access the new HuggingFace space.
|
| 53 |
|
| 54 |
-
|
| 55 |
-
|
|
|
|
| 56 |
|
| 57 |
-
|
|
|
|
|
|
|
|
|
|
| 58 |
|
| 59 |
```
|
| 60 |
-
|
| 61 |
-
|
| 62 |
-
|
| 63 |
-
|
| 64 |
-
|
| 65 |
-
|
| 66 |
-
|
| 67 |
-
|
| 68 |
-
|
| 69 |
-
|
| 70 |
-
|
| 71 |
-
|
| 72 |
-
|
| 73 |
-
|
| 74 |
-
|
| 75 |
-
|
| 76 |
-
|
| 77 |
-
|
| 78 |
-
|
| 79 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 80 |
```
|
| 81 |
-
The Repo is now connected and synced with HuggingFace space!
|
| 82 |
|
| 83 |
-
##
|
| 84 |
|
| 85 |
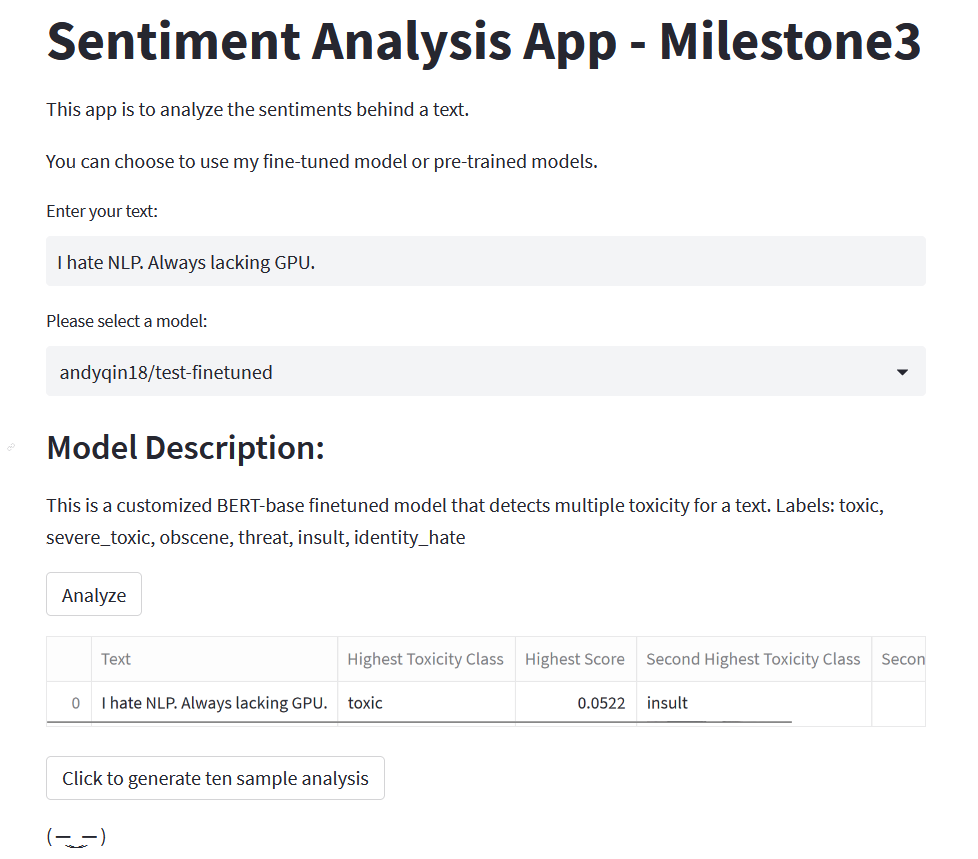
Modify [app.py](app.py) so that it takes in one text and generate an analysis using one of the provided models. Details are explained in comment lines. The app should look like this:
|
| 86 |
|
| 87 |
-
.
|
| 92 |
-
|
| 93 |
-
For creating the app, check this [video](https://www.youtube.com/watch?v=GSt00_-0ncQ)
|
| 94 |
-
|
| 95 |
-
The HuggingFace documentation is [here](https://huggingface.co/docs), and Streamlit APIs [here](https://docs.streamlit.io/library/api-reference).
|
|
|
|
| 19 |
|
| 20 |
Link to app: https://huggingface.co/spaces/andyqin18/sentiment-analysis-app
|
| 21 |
|
| 22 |
+
Here's the setup block:
|
| 23 |
+
```
|
| 24 |
+
import pandas as pd
|
| 25 |
+
import numpy as np
|
| 26 |
+
import torch
|
| 27 |
+
from sklearn.model_selection import train_test_split
|
| 28 |
+
from torch.utils.data import Dataset
|
| 29 |
+
from transformers import AutoTokenizer, AutoModelForSequenceClassification, TrainingArguments, Trainer
|
| 30 |
+
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
|
| 31 |
+
```
|
| 32 |
+
|
| 33 |
+
## 1. Prepare Data
|
| 34 |
+
First we extract comment strings and labels from `train.csv` and split them into training data and validation data with a percentage of 80% vs 20%. We also create 2 dictionaries that map labels to integers and back.
|
| 35 |
+
```
|
| 36 |
+
df = pd.read_csv("milestone3/comp/train.csv")
|
| 37 |
+
|
| 38 |
+
train_texts = df["comment_text"].values
|
| 39 |
+
labels = df.columns[2:]
|
| 40 |
+
id2label = {idx:label for idx, label in enumerate(labels)}
|
| 41 |
+
label2id = {label:idx for idx, label in enumerate(labels)}
|
| 42 |
+
train_labels = df[labels].values
|
| 43 |
+
|
| 44 |
|
| 45 |
+
# Randomly select 20000 samples within the data
|
| 46 |
+
np.random.seed(18)
|
| 47 |
+
small_train_texts = np.random.choice(train_texts, size=20000, replace=False)
|
| 48 |
|
| 49 |
+
np.random.seed(18)
|
| 50 |
+
small_train_labels_idx = np.random.choice(train_labels.shape[0], size=20000, replace=False)
|
| 51 |
+
small_train_labels = train_labels[small_train_labels_idx, :]
|
| 52 |
|
|
|
|
|
|
|
|
|
|
| 53 |
|
| 54 |
+
# Separate training data and validation data
|
| 55 |
+
train_texts, val_texts, train_labels, val_labels = train_test_split(small_train_texts, small_train_labels, test_size=.2)
|
| 56 |
```
|
| 57 |
+
|
| 58 |
+
## 2. Data Preprocessing
|
| 59 |
+
As models like BERT don't expect text as direct input, but rather `input_ids`, etc., we tokenize the text using the tokenizer. The `AutoTokenizer` will automatically load the appropriate tokenizer based on the checkpoint on the hub. We can now merge the labels and texts to datasets as a class we defined.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 60 |
```
|
| 61 |
+
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
|
| 62 |
|
| 63 |
+
class TextDataset(Dataset):
|
| 64 |
+
def __init__(self,texts,labels):
|
| 65 |
+
self.texts = texts
|
| 66 |
+
self.labels = labels
|
| 67 |
|
| 68 |
+
def __getitem__(self,idx):
|
| 69 |
+
encodings = tokenizer(self.texts[idx], truncation=True, padding="max_length")
|
| 70 |
+
item = {key: torch.tensor(val) for key, val in encodings.items()}
|
| 71 |
+
item['labels'] = torch.tensor(self.labels[idx],dtype=torch.float32)
|
| 72 |
+
del encodings
|
| 73 |
+
return item
|
| 74 |
|
| 75 |
+
def __len__(self):
|
| 76 |
+
return len(self.labels)
|
| 77 |
|
|
|
|
| 78 |
|
| 79 |
+
train_dataset = TextDataset(train_texts, train_labels)
|
| 80 |
+
val_dataset = TextDataset(val_texts, val_labels)
|
| 81 |
+
```
|
| 82 |
|
| 83 |
+
## 3. Train the model using Trainer
|
| 84 |
+
We define a model that includes a pre-trained base and also set the problem to `multi_label_classification`. Then we train the model using `Trainer`, which requires `TrainingArguments` beforehand that specify training hyperparameters, where we can set learning rate, batch sizes and `push_to_hub=True`.
|
| 85 |
+
|
| 86 |
+
After verifying Token with HuggingFace, the model is now pushed to the hub.
|
| 87 |
|
| 88 |
```
|
| 89 |
+
model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased",
|
| 90 |
+
problem_type="multi_label_classification",
|
| 91 |
+
num_labels=len(labels),
|
| 92 |
+
id2label=id2label,
|
| 93 |
+
label2id=label2id)
|
| 94 |
+
model.to(device)
|
| 95 |
+
|
| 96 |
+
training_args = TrainingArguments(
|
| 97 |
+
output_dir="finetuned-bert-uncased",
|
| 98 |
+
evaluation_strategy = "epoch",
|
| 99 |
+
save_strategy = "epoch",
|
| 100 |
+
learning_rate=2e-5,
|
| 101 |
+
per_device_train_batch_size=16,
|
| 102 |
+
per_device_eval_batch_size=16,
|
| 103 |
+
num_train_epochs=5,
|
| 104 |
+
load_best_model_at_end=True,
|
| 105 |
+
push_to_hub=True
|
| 106 |
+
)
|
| 107 |
+
|
| 108 |
+
trainer = Trainer(
|
| 109 |
+
model=model,
|
| 110 |
+
args=training_args,
|
| 111 |
+
train_dataset=train_dataset,
|
| 112 |
+
eval_dataset=val_dataset,
|
| 113 |
+
tokenizer=tokenizer
|
| 114 |
+
)
|
| 115 |
+
|
| 116 |
+
trainer.train()
|
| 117 |
+
trainer.push_to_hub()
|
| 118 |
```
|
|
|
|
| 119 |
|
| 120 |
+
## 4. Update the app
|
| 121 |
|
| 122 |
Modify [app.py](app.py) so that it takes in one text and generate an analysis using one of the provided models. Details are explained in comment lines. The app should look like this:
|
| 123 |
|
| 124 |
+

|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
app.py
CHANGED
|
@@ -34,7 +34,7 @@ model_descrip = {
|
|
| 34 |
Labels: POS; NEU; NEG"
|
| 35 |
}
|
| 36 |
|
| 37 |
-
user_input = st.text_input("Enter your text:", value="
|
| 38 |
user_model = st.selectbox("Please select a model:", model_descrip)
|
| 39 |
|
| 40 |
|
|
|
|
| 34 |
Labels: POS; NEU; NEG"
|
| 35 |
}
|
| 36 |
|
| 37 |
+
user_input = st.text_input("Enter your text:", value="I hate NLP. Always lacking GPU.")
|
| 38 |
user_model = st.selectbox("Please select a model:", model_descrip)
|
| 39 |
|
| 40 |
|
milestone3/appUI.png
ADDED
|