Spaces:
Runtime error

Runtime error

Upload 265 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +7 -0
- .github/workflows/bot-autolint.yaml +50 -0
- .github/workflows/ci.yaml +54 -0
- .gitignore +184 -0
- .pre-commit-config.yaml +62 -0
- CITATION.bib +9 -0
- CIs/add_license_all.sh +2 -0
- Dockerfile +26 -0
- LICENSE +201 -0
- README.md +401 -12
- app.py +441 -93
- app/app_sana.py +502 -0
- app/app_sana_4bit.py +409 -0
- app/app_sana_4bit_compare_bf16.py +313 -0
- app/app_sana_controlnet_hed.py +306 -0
- app/app_sana_multithread.py +565 -0
- app/safety_check.py +72 -0
- app/sana_controlnet_pipeline.py +353 -0
- app/sana_pipeline.py +304 -0
- asset/Sana.jpg +3 -0
- asset/app_styles/controlnet_app_style.css +28 -0
- asset/controlnet/ref_images/A transparent sculpture of a duck made out of glass. The sculpture is in front of a painting of a la.jpg +3 -0
- asset/controlnet/ref_images/a house.png +3 -0
- asset/controlnet/ref_images/a living room.png +3 -0
- asset/controlnet/ref_images/nvidia.png +0 -0
- asset/controlnet/samples_controlnet.json +26 -0
- asset/docs/4bit_sana.md +68 -0
- asset/docs/8bit_sana.md +109 -0
- asset/docs/ComfyUI/Sana_CogVideoX.json +1142 -0
- asset/docs/ComfyUI/Sana_FlowEuler.json +508 -0
- asset/docs/ComfyUI/Sana_FlowEuler_2K.json +508 -0
- asset/docs/ComfyUI/Sana_FlowEuler_4K.json +508 -0
- asset/docs/ComfyUI/comfyui.md +40 -0
- asset/docs/metrics_toolkit.md +118 -0
- asset/docs/model_zoo.md +157 -0
- asset/docs/sana_controlnet.md +75 -0
- asset/docs/sana_lora_dreambooth.md +144 -0
- asset/example_data/00000000.jpg +3 -0
- asset/example_data/00000000.png +3 -0
- asset/example_data/00000000.txt +1 -0
- asset/example_data/00000000_InternVL2-26B.json +5 -0
- asset/example_data/00000000_InternVL2-26B_clip_score.json +5 -0
- asset/example_data/00000000_VILA1-5-13B.json +5 -0
- asset/example_data/00000000_VILA1-5-13B_clip_score.json +5 -0
- asset/example_data/00000000_prompt_clip_score.json +5 -0
- asset/example_data/meta_data.json +7 -0
- asset/examples.py +69 -0
- asset/logo.png +0 -0
- asset/model-incremental.jpg +3 -0
- asset/model_paths.txt +2 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,10 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
asset/controlnet/ref_images/a[[:space:]]house.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
asset/controlnet/ref_images/a[[:space:]]living[[:space:]]room.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
asset/controlnet/ref_images/A[[:space:]]transparent[[:space:]]sculpture[[:space:]]of[[:space:]]a[[:space:]]duck[[:space:]]made[[:space:]]out[[:space:]]of[[:space:]]glass.[[:space:]]The[[:space:]]sculpture[[:space:]]is[[:space:]]in[[:space:]]front[[:space:]]of[[:space:]]a[[:space:]]painting[[:space:]]of[[:space:]]a[[:space:]]la.jpg filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
asset/example_data/00000000.jpg filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
asset/example_data/00000000.png filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
asset/model-incremental.jpg filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
asset/Sana.jpg filter=lfs diff=lfs merge=lfs -text
|
.github/workflows/bot-autolint.yaml
ADDED
|
@@ -0,0 +1,50 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: Auto Lint (triggered by "auto lint" label)
|
| 2 |
+
on:
|
| 3 |
+
pull_request:
|
| 4 |
+
types:
|
| 5 |
+
- opened
|
| 6 |
+
- edited
|
| 7 |
+
- closed
|
| 8 |
+
- reopened
|
| 9 |
+
- synchronize
|
| 10 |
+
- labeled
|
| 11 |
+
- unlabeled
|
| 12 |
+
# run only one unit test for a branch / tag.
|
| 13 |
+
concurrency:
|
| 14 |
+
group: ci-lint-${{ github.ref }}
|
| 15 |
+
cancel-in-progress: true
|
| 16 |
+
jobs:
|
| 17 |
+
lint-by-label:
|
| 18 |
+
if: contains(github.event.pull_request.labels.*.name, 'lint wanted')
|
| 19 |
+
runs-on: ubuntu-latest
|
| 20 |
+
steps:
|
| 21 |
+
- name: Check out Git repository
|
| 22 |
+
uses: actions/checkout@v4
|
| 23 |
+
with:
|
| 24 |
+
token: ${{ secrets.PAT }}
|
| 25 |
+
ref: ${{ github.event.pull_request.head.ref }}
|
| 26 |
+
- name: Set up Python
|
| 27 |
+
uses: actions/setup-python@v5
|
| 28 |
+
with:
|
| 29 |
+
python-version: '3.10'
|
| 30 |
+
- name: Test pre-commit hooks
|
| 31 |
+
continue-on-error: true
|
| 32 |
+
uses: pre-commit/[email protected] # sync with https://github.com/Efficient-Large-Model/VILA-Internal/blob/main/.github/workflows/pre-commit.yaml
|
| 33 |
+
with:
|
| 34 |
+
extra_args: --all-files
|
| 35 |
+
- name: Check if there are any changes
|
| 36 |
+
id: verify_diff
|
| 37 |
+
run: |
|
| 38 |
+
git diff --quiet . || echo "changed=true" >> $GITHUB_OUTPUT
|
| 39 |
+
- name: Commit files
|
| 40 |
+
if: steps.verify_diff.outputs.changed == 'true'
|
| 41 |
+
run: |
|
| 42 |
+
git config --local user.email "[email protected]"
|
| 43 |
+
git config --local user.name "GitHub Action"
|
| 44 |
+
git add .
|
| 45 |
+
git commit -m "[CI-Lint] Fix code style issues with pre-commit ${{ github.sha }}" -a
|
| 46 |
+
git push
|
| 47 |
+
- name: Remove label(s) after lint
|
| 48 |
+
uses: actions-ecosystem/action-remove-labels@v1
|
| 49 |
+
with:
|
| 50 |
+
labels: lint wanted
|
.github/workflows/ci.yaml
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: ci
|
| 2 |
+
on:
|
| 3 |
+
pull_request:
|
| 4 |
+
push:
|
| 5 |
+
branches: [main, feat/Sana-public, feat/Sana-public-for-NVLab]
|
| 6 |
+
concurrency:
|
| 7 |
+
group: ci-${{ github.workflow }}-${{ github.ref }}
|
| 8 |
+
cancel-in-progress: true
|
| 9 |
+
# if: ${{ github.repository == 'Efficient-Large-Model/Sana' }}
|
| 10 |
+
jobs:
|
| 11 |
+
pre-commit:
|
| 12 |
+
runs-on: ubuntu-latest
|
| 13 |
+
steps:
|
| 14 |
+
- name: Check out Git repository
|
| 15 |
+
uses: actions/checkout@v4
|
| 16 |
+
- name: Set up Python
|
| 17 |
+
uses: actions/setup-python@v5
|
| 18 |
+
with:
|
| 19 |
+
python-version: 3.10.10
|
| 20 |
+
- name: Test pre-commit hooks
|
| 21 |
+
uses: pre-commit/[email protected]
|
| 22 |
+
tests-bash:
|
| 23 |
+
# needs: pre-commit
|
| 24 |
+
runs-on: self-hosted
|
| 25 |
+
steps:
|
| 26 |
+
- name: Check out Git repository
|
| 27 |
+
uses: actions/checkout@v4
|
| 28 |
+
- name: Set up Python
|
| 29 |
+
uses: actions/setup-python@v5
|
| 30 |
+
with:
|
| 31 |
+
python-version: 3.10.10
|
| 32 |
+
- name: Set up the environment
|
| 33 |
+
run: |
|
| 34 |
+
bash environment_setup.sh
|
| 35 |
+
- name: Run tests with Slurm
|
| 36 |
+
run: |
|
| 37 |
+
sana-run --pty -m ci -J tests-bash bash tests/bash/entry.sh
|
| 38 |
+
|
| 39 |
+
# tests-python:
|
| 40 |
+
# needs: pre-commit
|
| 41 |
+
# runs-on: self-hosted
|
| 42 |
+
# steps:
|
| 43 |
+
# - name: Check out Git repository
|
| 44 |
+
# uses: actions/checkout@v4
|
| 45 |
+
# - name: Set up Python
|
| 46 |
+
# uses: actions/setup-python@v5
|
| 47 |
+
# with:
|
| 48 |
+
# python-version: 3.10.10
|
| 49 |
+
# - name: Set up the environment
|
| 50 |
+
# run: |
|
| 51 |
+
# ./environment_setup.sh
|
| 52 |
+
# - name: Run tests with Slurm
|
| 53 |
+
# run: |
|
| 54 |
+
# sana-run --pty -m ci -J tests-python pytest tests/python
|
.gitignore
ADDED
|
@@ -0,0 +1,184 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Sana related files
|
| 2 |
+
*_dev.py
|
| 3 |
+
*_dev.sh
|
| 4 |
+
.count.db
|
| 5 |
+
.gradio/
|
| 6 |
+
.idea/
|
| 7 |
+
*.png
|
| 8 |
+
tmp*
|
| 9 |
+
output*
|
| 10 |
+
output/
|
| 11 |
+
outputs/
|
| 12 |
+
wandb/
|
| 13 |
+
.vscode/
|
| 14 |
+
private/
|
| 15 |
+
ldm_ae*
|
| 16 |
+
data/*
|
| 17 |
+
*.pth
|
| 18 |
+
.gradio/
|
| 19 |
+
*.bin
|
| 20 |
+
*.safetensors
|
| 21 |
+
*.pkl
|
| 22 |
+
|
| 23 |
+
# Byte-compiled / optimized / DLL files
|
| 24 |
+
__pycache__/
|
| 25 |
+
*.py[cod]
|
| 26 |
+
*$py.class
|
| 27 |
+
|
| 28 |
+
# C extensions
|
| 29 |
+
*.so
|
| 30 |
+
|
| 31 |
+
# Distribution / packaging
|
| 32 |
+
.Python
|
| 33 |
+
build/
|
| 34 |
+
develop-eggs/
|
| 35 |
+
dist/
|
| 36 |
+
downloads/
|
| 37 |
+
eggs/
|
| 38 |
+
.eggs/
|
| 39 |
+
lib/
|
| 40 |
+
lib64/
|
| 41 |
+
parts/
|
| 42 |
+
sdist/
|
| 43 |
+
var/
|
| 44 |
+
wheels/
|
| 45 |
+
share/python-wheels/
|
| 46 |
+
*.egg-info/
|
| 47 |
+
.installed.cfg
|
| 48 |
+
*.egg
|
| 49 |
+
MANIFEST
|
| 50 |
+
|
| 51 |
+
# PyInstaller
|
| 52 |
+
# Usually these files are written by a python script from a template
|
| 53 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 54 |
+
*.manifest
|
| 55 |
+
*.spec
|
| 56 |
+
|
| 57 |
+
# Installer logs
|
| 58 |
+
pip-log.txt
|
| 59 |
+
pip-delete-this-directory.txt
|
| 60 |
+
|
| 61 |
+
# Unit test / coverage reports
|
| 62 |
+
htmlcov/
|
| 63 |
+
.tox/
|
| 64 |
+
.nox/
|
| 65 |
+
.coverage
|
| 66 |
+
.coverage.*
|
| 67 |
+
.cache
|
| 68 |
+
nosetests.xml
|
| 69 |
+
coverage.xml
|
| 70 |
+
*.cover
|
| 71 |
+
*.py,cover
|
| 72 |
+
.hypothesis/
|
| 73 |
+
.pytest_cache/
|
| 74 |
+
cover/
|
| 75 |
+
|
| 76 |
+
# Translations
|
| 77 |
+
*.mo
|
| 78 |
+
*.pot
|
| 79 |
+
|
| 80 |
+
# Django stuff:
|
| 81 |
+
*.log
|
| 82 |
+
local_settings.py
|
| 83 |
+
db.sqlite3
|
| 84 |
+
db.sqlite3-journal
|
| 85 |
+
|
| 86 |
+
# Flask stuff:
|
| 87 |
+
instance/
|
| 88 |
+
.webassets-cache
|
| 89 |
+
|
| 90 |
+
# Scrapy stuff:
|
| 91 |
+
.scrapy
|
| 92 |
+
|
| 93 |
+
# Sphinx documentation
|
| 94 |
+
docs/_build/
|
| 95 |
+
|
| 96 |
+
# PyBuilder
|
| 97 |
+
.pybuilder/
|
| 98 |
+
target/
|
| 99 |
+
|
| 100 |
+
# Jupyter Notebook
|
| 101 |
+
.ipynb_checkpoints
|
| 102 |
+
|
| 103 |
+
# IPython
|
| 104 |
+
profile_default/
|
| 105 |
+
ipython_config.py
|
| 106 |
+
|
| 107 |
+
# pyenv
|
| 108 |
+
# For a library or package, you might want to ignore these files since the code is
|
| 109 |
+
# intended to run in multiple environments; otherwise, check them in:
|
| 110 |
+
# .python-version
|
| 111 |
+
|
| 112 |
+
# pipenv
|
| 113 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 114 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 115 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 116 |
+
# install all needed dependencies.
|
| 117 |
+
#Pipfile.lock
|
| 118 |
+
|
| 119 |
+
# poetry
|
| 120 |
+
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
|
| 121 |
+
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
| 122 |
+
# commonly ignored for libraries.
|
| 123 |
+
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
|
| 124 |
+
#poetry.lock
|
| 125 |
+
|
| 126 |
+
# pdm
|
| 127 |
+
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
|
| 128 |
+
#pdm.lock
|
| 129 |
+
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
|
| 130 |
+
# in version control.
|
| 131 |
+
# https://pdm.fming.dev/latest/usage/project/#working-with-version-control
|
| 132 |
+
.pdm.toml
|
| 133 |
+
.pdm-python
|
| 134 |
+
.pdm-build/
|
| 135 |
+
|
| 136 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
|
| 137 |
+
__pypackages__/
|
| 138 |
+
|
| 139 |
+
# Celery stuff
|
| 140 |
+
celerybeat-schedule
|
| 141 |
+
celerybeat.pid
|
| 142 |
+
|
| 143 |
+
# SageMath parsed files
|
| 144 |
+
*.sage.py
|
| 145 |
+
|
| 146 |
+
# Environments
|
| 147 |
+
.env
|
| 148 |
+
.venv
|
| 149 |
+
env/
|
| 150 |
+
venv/
|
| 151 |
+
ENV/
|
| 152 |
+
env.bak/
|
| 153 |
+
venv.bak/
|
| 154 |
+
|
| 155 |
+
# Spyder project settings
|
| 156 |
+
.spyderproject
|
| 157 |
+
.spyproject
|
| 158 |
+
|
| 159 |
+
# Rope project settings
|
| 160 |
+
.ropeproject
|
| 161 |
+
|
| 162 |
+
# mkdocs documentation
|
| 163 |
+
/site
|
| 164 |
+
|
| 165 |
+
# mypy
|
| 166 |
+
.mypy_cache/
|
| 167 |
+
.dmypy.json
|
| 168 |
+
dmypy.json
|
| 169 |
+
|
| 170 |
+
# Pyre type checker
|
| 171 |
+
.pyre/
|
| 172 |
+
|
| 173 |
+
# pytype static type analyzer
|
| 174 |
+
.pytype/
|
| 175 |
+
|
| 176 |
+
# Cython debug symbols
|
| 177 |
+
cython_debug/
|
| 178 |
+
|
| 179 |
+
# PyCharm
|
| 180 |
+
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
|
| 181 |
+
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
|
| 182 |
+
# and can be added to the global gitignore or merged into this file. For a more nuclear
|
| 183 |
+
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
| 184 |
+
#.idea/
|
.pre-commit-config.yaml
ADDED
|
@@ -0,0 +1,62 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
repos:
|
| 2 |
+
- repo: https://github.com/pre-commit/pre-commit-hooks
|
| 3 |
+
rev: v5.0.0
|
| 4 |
+
hooks:
|
| 5 |
+
- id: trailing-whitespace
|
| 6 |
+
name: (Common) Remove trailing whitespaces
|
| 7 |
+
- id: mixed-line-ending
|
| 8 |
+
name: (Common) Fix mixed line ending
|
| 9 |
+
args: [--fix=lf]
|
| 10 |
+
- id: end-of-file-fixer
|
| 11 |
+
name: (Common) Remove extra EOF newlines
|
| 12 |
+
- id: check-merge-conflict
|
| 13 |
+
name: (Common) Check for merge conflicts
|
| 14 |
+
- id: requirements-txt-fixer
|
| 15 |
+
name: (Common) Sort "requirements.txt"
|
| 16 |
+
- id: fix-encoding-pragma
|
| 17 |
+
name: (Python) Remove encoding pragmas
|
| 18 |
+
args: [--remove]
|
| 19 |
+
# - id: debug-statements
|
| 20 |
+
# name: (Python) Check for debugger imports
|
| 21 |
+
- id: check-json
|
| 22 |
+
name: (JSON) Check syntax
|
| 23 |
+
- id: check-yaml
|
| 24 |
+
name: (YAML) Check syntax
|
| 25 |
+
- id: check-toml
|
| 26 |
+
name: (TOML) Check syntax
|
| 27 |
+
# - repo: https://github.com/shellcheck-py/shellcheck-py
|
| 28 |
+
# rev: v0.10.0.1
|
| 29 |
+
# hooks:
|
| 30 |
+
# - id: shellcheck
|
| 31 |
+
- repo: https://github.com/google/yamlfmt
|
| 32 |
+
rev: v0.13.0
|
| 33 |
+
hooks:
|
| 34 |
+
- id: yamlfmt
|
| 35 |
+
- repo: https://github.com/executablebooks/mdformat
|
| 36 |
+
rev: 0.7.16
|
| 37 |
+
hooks:
|
| 38 |
+
- id: mdformat
|
| 39 |
+
name: (Markdown) Format docs with mdformat
|
| 40 |
+
- repo: https://github.com/asottile/pyupgrade
|
| 41 |
+
rev: v3.2.2
|
| 42 |
+
hooks:
|
| 43 |
+
- id: pyupgrade
|
| 44 |
+
name: (Python) Update syntax for newer versions
|
| 45 |
+
args: [--py37-plus]
|
| 46 |
+
- repo: https://github.com/psf/black
|
| 47 |
+
rev: 22.10.0
|
| 48 |
+
hooks:
|
| 49 |
+
- id: black
|
| 50 |
+
name: (Python) Format code with black
|
| 51 |
+
- repo: https://github.com/pycqa/isort
|
| 52 |
+
rev: 5.12.0
|
| 53 |
+
hooks:
|
| 54 |
+
- id: isort
|
| 55 |
+
name: (Python) Sort imports with isort
|
| 56 |
+
- repo: https://github.com/pre-commit/mirrors-clang-format
|
| 57 |
+
rev: v15.0.4
|
| 58 |
+
hooks:
|
| 59 |
+
- id: clang-format
|
| 60 |
+
name: (C/C++/CUDA) Format code with clang-format
|
| 61 |
+
args: [-style=google, -i]
|
| 62 |
+
types_or: [c, c++, cuda]
|
CITATION.bib
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
@misc{xie2024sana,
|
| 2 |
+
title={Sana: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer},
|
| 3 |
+
author={Enze Xie and Junsong Chen and Junyu Chen and Han Cai and Haotian Tang and Yujun Lin and Zhekai Zhang and Muyang Li and Ligeng Zhu and Yao Lu and Song Han},
|
| 4 |
+
year={2024},
|
| 5 |
+
eprint={2410.10629},
|
| 6 |
+
archivePrefix={arXiv},
|
| 7 |
+
primaryClass={cs.CV},
|
| 8 |
+
url={https://arxiv.org/abs/2410.10629},
|
| 9 |
+
}
|
CIs/add_license_all.sh
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#/bin/bash
|
| 2 |
+
addlicense -s -c 'NVIDIA CORPORATION & AFFILIATES' -ignore "**/*__init__.py" **/*.py
|
Dockerfile
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM nvcr.io/nvidia/pytorch:24.06-py3
|
| 2 |
+
|
| 3 |
+
ENV PATH=/opt/conda/bin:$PATH
|
| 4 |
+
|
| 5 |
+
RUN apt-get update && apt-get install -y \
|
| 6 |
+
libgl1-mesa-glx \
|
| 7 |
+
libglib2.0-0 \
|
| 8 |
+
&& rm -rf /var/lib/apt/lists/*
|
| 9 |
+
|
| 10 |
+
WORKDIR /app
|
| 11 |
+
|
| 12 |
+
RUN curl https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -o ~/miniconda.sh \
|
| 13 |
+
&& sh ~/miniconda.sh -b -p /opt/conda \
|
| 14 |
+
&& rm ~/miniconda.sh
|
| 15 |
+
|
| 16 |
+
COPY pyproject.toml pyproject.toml
|
| 17 |
+
COPY diffusion diffusion
|
| 18 |
+
COPY configs configs
|
| 19 |
+
COPY sana sana
|
| 20 |
+
COPY app app
|
| 21 |
+
COPY tools tools
|
| 22 |
+
|
| 23 |
+
COPY environment_setup.sh environment_setup.sh
|
| 24 |
+
RUN ./environment_setup.sh
|
| 25 |
+
|
| 26 |
+
CMD ["python", "-u", "-W", "ignore", "app/app_sana.py", "--share", "--config=configs/sana_config/1024ms/Sana_1600M_img1024.yaml", "--model_path=hf://Efficient-Large-Model/Sana_1600M_1024px/checkpoints/Sana_1600M_1024px.pth"]
|
LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright 2024 Nvidia
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
README.md
CHANGED
|
@@ -1,12 +1,401 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<p align="center" style="border-radius: 10px">
|
| 2 |
+
<img src="asset/logo.png" width="35%" alt="logo"/>
|
| 3 |
+
</p>
|
| 4 |
+
|
| 5 |
+
# ⚡️Sana: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer
|
| 6 |
+
|
| 7 |
+
### <div align="center"> ICLR 2025 Oral Presentation <div>
|
| 8 |
+
|
| 9 |
+
<div align="center">
|
| 10 |
+
<a href="https://nvlabs.github.io/Sana/"><img src="https://img.shields.io/static/v1?label=Project&message=Github&color=blue&logo=github-pages"></a>  
|
| 11 |
+
<a href="https://hanlab.mit.edu/projects/sana/"><img src="https://img.shields.io/static/v1?label=Page&message=MIT&color=darkred&logo=github-pages"></a>  
|
| 12 |
+
<a href="https://arxiv.org/abs/2410.10629"><img src="https://img.shields.io/static/v1?label=Arxiv&message=Sana&color=red&logo=arxiv"></a>  
|
| 13 |
+
<a href="https://nv-sana.mit.edu/"><img src="https://img.shields.io/static/v1?label=Demo:6x3090&message=MIT&color=yellow"></a>  
|
| 14 |
+
<a href="https://nv-sana.mit.edu/4bit/"><img src="https://img.shields.io/static/v1?label=Demo:1x3090&message=4bit&color=yellow"></a>  
|
| 15 |
+
<a href="https://nv-sana.mit.edu/ctrlnet/"><img src="https://img.shields.io/static/v1?label=Demo:1x3090&message=ControlNet&color=yellow"></a>  
|
| 16 |
+
<a href="https://replicate.com/chenxwh/sana"><img src="https://img.shields.io/static/v1?label=API:H100&message=Replicate&color=pink"></a>  
|
| 17 |
+
<a href="https://discord.gg/rde6eaE5Ta"><img src="https://img.shields.io/static/v1?label=Discuss&message=Discord&color=purple&logo=discord"></a>  
|
| 18 |
+
</div>
|
| 19 |
+
|
| 20 |
+
<p align="center" border-radius="10px">
|
| 21 |
+
<img src="asset/Sana.jpg" width="90%" alt="teaser_page1"/>
|
| 22 |
+
</p>
|
| 23 |
+
|
| 24 |
+
## 💡 Introduction
|
| 25 |
+
|
| 26 |
+
We introduce Sana, a text-to-image framework that can efficiently generate images up to 4096 × 4096 resolution.
|
| 27 |
+
Sana can synthesize high-resolution, high-quality images with strong text-image alignment at a remarkably fast speed, deployable on laptop GPU.
|
| 28 |
+
Core designs include:
|
| 29 |
+
|
| 30 |
+
(1) [**DC-AE**](https://hanlab.mit.edu/projects/dc-ae): unlike traditional AEs, which compress images only 8×, we trained an AE that can compress images 32×, effectively reducing the number of latent tokens. \
|
| 31 |
+
(2) **Linear DiT**: we replace all vanilla attention in DiT with linear attention, which is more efficient at high resolutions without sacrificing quality. \
|
| 32 |
+
(3) **Decoder-only text encoder**: we replaced T5 with a modern decoder-only small LLM as the text encoder and designed complex human instruction with in-context learning to enhance the image-text alignment. \
|
| 33 |
+
(4) **Efficient training and sampling**: we propose **Flow-DPM-Solver** to reduce sampling steps, with efficient caption labeling and selection to accelerate convergence.
|
| 34 |
+
|
| 35 |
+
As a result, Sana-0.6B is very competitive with modern giant diffusion models (e.g. Flux-12B), being 20 times smaller and 100+ times faster in measured throughput. Moreover, Sana-0.6B can be deployed on a 16GB laptop GPU, taking less than 1 second to generate a 1024 × 1024 resolution image. Sana enables content creation at low cost.
|
| 36 |
+
|
| 37 |
+
<p align="center" border-raduis="10px">
|
| 38 |
+
<img src="asset/model-incremental.jpg" width="90%" alt="teaser_page2"/>
|
| 39 |
+
</p>
|
| 40 |
+
|
| 41 |
+
## 🔥🔥 News
|
| 42 |
+
|
| 43 |
+
- (🔥 New) \[2025/2/10\] 🚀Sana + ControlNet is released. [\[Guidance\]](asset/docs/sana_controlnet.md) | [\[Model\]](asset/docs/model_zoo.md) | [\[Demo\]](https://nv-sana.mit.edu/ctrlnet/)
|
| 44 |
+
- (🔥 New) \[2025/1/30\] Release CAME-8bit optimizer code. Saving more GPU memory during training. [\[How to config\]](https://github.com/NVlabs/Sana/blob/main/configs/sana_config/1024ms/Sana_1600M_img1024_CAME8bit.yaml#L86)
|
| 45 |
+
- (🔥 New) \[2025/1/29\] 🎉 🎉 🎉**SANA 1.5 is out! Figure out how to do efficient training & inference scaling!** 🚀[\[Tech Report\]](https://arxiv.org/abs/2501.18427)
|
| 46 |
+
- (🔥 New) \[2025/1/24\] 4bit-Sana is released, powered by [SVDQuant and Nunchaku](https://github.com/mit-han-lab/nunchaku) inference engine. Now run your Sana within **8GB** GPU VRAM [\[Guidance\]](asset/docs/4bit_sana.md) [\[Demo\]](https://svdquant.mit.edu/) [\[Model\]](asset/docs/model_zoo.md)
|
| 47 |
+
- (🔥 New) \[2025/1/24\] DCAE-1.1 is released, better reconstruction quality. [\[Model\]](https://huggingface.co/mit-han-lab/dc-ae-f32c32-sana-1.1) [\[diffusers\]](https://huggingface.co/mit-han-lab/dc-ae-f32c32-sana-1.1-diffusers)
|
| 48 |
+
- (🔥 New) \[2025/1/23\] **Sana is accepted as Oral by ICLR-2025.** 🎉🎉🎉
|
| 49 |
+
|
| 50 |
+
______________________________________________________________________
|
| 51 |
+
|
| 52 |
+
- (🔥 New) \[2025/1/12\] DC-AE tiling makes Sana-4K inferences 4096x4096px images within 22GB GPU memory. With model offload and 8bit/4bit quantize. The 4K Sana run within **8GB** GPU VRAM. [\[Guidance\]](asset/docs/model_zoo.md#-3-4k-models)
|
| 53 |
+
- (🔥 New) \[2025/1/11\] Sana code-base license changed to Apache 2.0.
|
| 54 |
+
- (🔥 New) \[2025/1/10\] Inference Sana with 8bit quantization.[\[Guidance\]](asset/docs/8bit_sana.md#quantization)
|
| 55 |
+
- (🔥 New) \[2025/1/8\] 4K resolution [Sana models](asset/docs/model_zoo.md) is supported in [Sana-ComfyUI](https://github.com/Efficient-Large-Model/ComfyUI_ExtraModels) and [work flow](asset/docs/ComfyUI/Sana_FlowEuler_4K.json) is also prepared. [\[4K guidance\]](asset/docs/ComfyUI/comfyui.md)
|
| 56 |
+
- (🔥 New) \[2025/1/8\] 1.6B 4K resolution [Sana models](asset/docs/model_zoo.md) are released: [\[BF16 pth\]](https://huggingface.co/Efficient-Large-Model/Sana_1600M_4Kpx_BF16) or [\[BF16 diffusers\]](https://huggingface.co/Efficient-Large-Model/Sana_1600M_4Kpx_BF16_diffusers). 🚀 Get your 4096x4096 resolution images within 20 seconds! Find more samples in [Sana page](https://nvlabs.github.io/Sana/). Thanks [SUPIR](https://github.com/Fanghua-Yu/SUPIR) for their wonderful work and support.
|
| 57 |
+
- (🔥 New) \[2025/1/2\] Bug in the `diffusers` pipeline is solved. [Solved PR](https://github.com/huggingface/diffusers/pull/10431)
|
| 58 |
+
- (🔥 New) \[2025/1/2\] 2K resolution [Sana models](asset/docs/model_zoo.md) is supported in [Sana-ComfyUI](https://github.com/Efficient-Large-Model/ComfyUI_ExtraModels) and [work flow](asset/docs/ComfyUI/Sana_FlowEuler_2K.json) is also prepared.
|
| 59 |
+
- ✅ \[2024/12\] 1.6B 2K resolution [Sana models](asset/docs/model_zoo.md) are released: [\[BF16 pth\]](https://huggingface.co/Efficient-Large-Model/Sana_1600M_2Kpx_BF16) or [\[BF16 diffusers\]](https://huggingface.co/Efficient-Large-Model/Sana_1600M_2Kpx_BF16_diffusers). 🚀 Get your 2K resolution images within 4 seconds! Find more samples in [Sana page](https://nvlabs.github.io/Sana/). Thanks [SUPIR](https://github.com/Fanghua-Yu/SUPIR) for their wonderful work and support.
|
| 60 |
+
- ✅ \[2024/12\] `diffusers` supports Sana-LoRA fine-tuning! Sana-LoRA's training and convergence speed is super fast. [\[Guidance\]](asset/docs/sana_lora_dreambooth.md) or [\[diffusers docs\]](https://github.com/huggingface/diffusers/blob/main/examples/dreambooth/README_sana.md).
|
| 61 |
+
- ✅ \[2024/12\] `diffusers` has Sana! [All Sana models in diffusers safetensors](https://huggingface.co/collections/Efficient-Large-Model/sana-673efba2a57ed99843f11f9e) are released and diffusers pipeline `SanaPipeline`, `SanaPAGPipeline`, `DPMSolverMultistepScheduler(with FlowMatching)` are all supported now. We prepare a [Model Card](asset/docs/model_zoo.md) for you to choose.
|
| 62 |
+
- ✅ \[2024/12\] 1.6B BF16 [Sana model](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_BF16) is released for stable fine-tuning.
|
| 63 |
+
- ✅ \[2024/12\] We release the [ComfyUI node](https://github.com/Efficient-Large-Model/ComfyUI_ExtraModels) for Sana. [\[Guidance\]](asset/docs/ComfyUI/comfyui.md)
|
| 64 |
+
- ✅ \[2024/11\] All multi-linguistic (Emoji & Chinese & English) SFT models are released: [1.6B-512px](https://huggingface.co/Efficient-Large-Model/Sana_1600M_512px_MultiLing), [1.6B-1024px](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_MultiLing), [600M-512px](https://huggingface.co/Efficient-Large-Model/Sana_600M_512px), [600M-1024px](https://huggingface.co/Efficient-Large-Model/Sana_600M_1024px). The metric performance is shown [here](#performance)
|
| 65 |
+
- ✅ \[2024/11\] Sana Replicate API is launching at [Sana-API](https://replicate.com/chenxwh/sana).
|
| 66 |
+
- ✅ \[2024/11\] 1.6B [Sana models](https://huggingface.co/collections/Efficient-Large-Model/sana-673efba2a57ed99843f11f9e) are released.
|
| 67 |
+
- ✅ \[2024/11\] Training & Inference & Metrics code are released.
|
| 68 |
+
- ✅ \[2024/11\] Working on [`diffusers`](https://github.com/huggingface/diffusers/pull/9982).
|
| 69 |
+
- \[2024/10\] [Demo](https://nv-sana.mit.edu/) is released.
|
| 70 |
+
- \[2024/10\] [DC-AE Code](https://github.com/mit-han-lab/efficientvit/blob/master/applications/dc_ae/README.md) and [weights](https://huggingface.co/collections/mit-han-lab/dc-ae-670085b9400ad7197bb1009b) are released!
|
| 71 |
+
- \[2024/10\] [Paper](https://arxiv.org/abs/2410.10629) is on Arxiv!
|
| 72 |
+
|
| 73 |
+
## Performance
|
| 74 |
+
|
| 75 |
+
| Methods (1024x1024) | Throughput (samples/s) | Latency (s) | Params (B) | Speedup | FID 👇 | CLIP 👆 | GenEval 👆 | DPG 👆 |
|
| 76 |
+
|-----------------------------------------------------------------------------------------------------|------------------------|-------------|------------|---------|-------------|--------------|-------------|-------------|
|
| 77 |
+
| FLUX-dev | 0.04 | 23.0 | 12.0 | 1.0× | 10.15 | 27.47 | _0.67_ | 84.0 |
|
| 78 |
+
| **Sana-0.6B** | 1.7 | 0.9 | 0.6 | 39.5× | _5.81_ | 28.36 | 0.64 | 83.6 |
|
| 79 |
+
| **[Sana-0.6B-MultiLing](https://huggingface.co/Efficient-Large-Model/Sana_600M_1024px)** | 1.7 | 0.9 | 0.6 | 39.5× | **5.61** | <u>28.80</u> | <u>0.68</u> | _84.2_ |
|
| 80 |
+
| **Sana-1.6B** | 1.0 | 1.2 | 1.6 | 23.3× | <u>5.76</u> | _28.67_ | 0.66 | **84.8** |
|
| 81 |
+
| **[Sana-1.6B-MultiLing](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_MultiLing)** | 1.0 | 1.2 | 1.6 | 23.3× | 5.92 | **28.94** | **0.69** | <u>84.5</u> |
|
| 82 |
+
|
| 83 |
+
<details>
|
| 84 |
+
<summary><h3>Click to show all</h3></summary>
|
| 85 |
+
|
| 86 |
+
| Methods | Throughput (samples/s) | Latency (s) | Params (B) | Speedup | FID 👆 | CLIP 👆 | GenEval 👆 | DPG 👆 |
|
| 87 |
+
|------------------------------|------------------------|-------------|------------|-----------|-------------|--------------|-------------|-------------|
|
| 88 |
+
| _**512 × 512 resolution**_ | | | | | | | | |
|
| 89 |
+
| PixArt-α | 1.5 | 1.2 | 0.6 | 1.0× | 6.14 | 27.55 | 0.48 | 71.6 |
|
| 90 |
+
| PixArt-Σ | 1.5 | 1.2 | 0.6 | 1.0× | _6.34_ | _27.62_ | <u>0.52</u> | _79.5_ |
|
| 91 |
+
| **Sana-0.6B** | 6.7 | 0.8 | 0.6 | 5.0× | <u>5.67</u> | <u>27.92</u> | _0.64_ | <u>84.3</u> |
|
| 92 |
+
| **Sana-1.6B** | 3.8 | 0.6 | 1.6 | 2.5× | **5.16** | **28.19** | **0.66** | **85.5** |
|
| 93 |
+
| _**1024 × 1024 resolution**_ | | | | | | | | |
|
| 94 |
+
| LUMINA-Next | 0.12 | 9.1 | 2.0 | 2.8× | 7.58 | 26.84 | 0.46 | 74.6 |
|
| 95 |
+
| SDXL | 0.15 | 6.5 | 2.6 | 3.5× | 6.63 | _29.03_ | 0.55 | 74.7 |
|
| 96 |
+
| PlayGroundv2.5 | 0.21 | 5.3 | 2.6 | 4.9× | _6.09_ | **29.13** | 0.56 | 75.5 |
|
| 97 |
+
| Hunyuan-DiT | 0.05 | 18.2 | 1.5 | 1.2× | 6.54 | 28.19 | 0.63 | 78.9 |
|
| 98 |
+
| PixArt-Σ | 0.4 | 2.7 | 0.6 | 9.3× | 6.15 | 28.26 | 0.54 | 80.5 |
|
| 99 |
+
| DALLE3 | - | - | - | - | - | - | _0.67_ | 83.5 |
|
| 100 |
+
| SD3-medium | 0.28 | 4.4 | 2.0 | 6.5× | 11.92 | 27.83 | 0.62 | <u>84.1</u> |
|
| 101 |
+
| FLUX-dev | 0.04 | 23.0 | 12.0 | 1.0× | 10.15 | 27.47 | _0.67_ | _84.0_ |
|
| 102 |
+
| FLUX-schnell | 0.5 | 2.1 | 12.0 | 11.6× | 7.94 | 28.14 | **0.71** | **84.8** |
|
| 103 |
+
| **Sana-0.6B** | 1.7 | 0.9 | 0.6 | **39.5×** | <u>5.81</u> | 28.36 | 0.64 | 83.6 |
|
| 104 |
+
| **Sana-1.6B** | 1.0 | 1.2 | 1.6 | **23.3×** | **5.76** | <u>28.67</u> | <u>0.66</u> | **84.8** |
|
| 105 |
+
|
| 106 |
+
</details>
|
| 107 |
+
|
| 108 |
+
## Contents
|
| 109 |
+
|
| 110 |
+
- [Env](#-1-dependencies-and-installation)
|
| 111 |
+
- [Demo](#-2-how-to-play-with-sana-inference)
|
| 112 |
+
- [Model Zoo](asset/docs/model_zoo.md)
|
| 113 |
+
- [Training](#-3-how-to-train-sana)
|
| 114 |
+
- [Testing](#-4-metric-toolkit)
|
| 115 |
+
- [TODO](#to-do-list)
|
| 116 |
+
- [Citation](#bibtex)
|
| 117 |
+
|
| 118 |
+
# 🔧 1. Dependencies and Installation
|
| 119 |
+
|
| 120 |
+
- Python >= 3.10.0 (Recommend to use [Anaconda](https://www.anaconda.com/download/#linux) or [Miniconda](https://docs.conda.io/en/latest/miniconda.html))
|
| 121 |
+
- [PyTorch >= 2.0.1+cu12.1](https://pytorch.org/)
|
| 122 |
+
|
| 123 |
+
```bash
|
| 124 |
+
git clone https://github.com/NVlabs/Sana.git
|
| 125 |
+
cd Sana
|
| 126 |
+
|
| 127 |
+
./environment_setup.sh sana
|
| 128 |
+
# or you can install each components step by step following environment_setup.sh
|
| 129 |
+
```
|
| 130 |
+
|
| 131 |
+
# 💻 2. How to Play with Sana (Inference)
|
| 132 |
+
|
| 133 |
+
## 💰Hardware requirement
|
| 134 |
+
|
| 135 |
+
- 9GB VRAM is required for 0.6B model and 12GB VRAM for 1.6B model. Our later quantization version will require less than 8GB for inference.
|
| 136 |
+
- All the tests are done on A100 GPUs. Different GPU version may be different.
|
| 137 |
+
|
| 138 |
+
## 🔛 Choose your model: [Model card](asset/docs/model_zoo.md)
|
| 139 |
+
|
| 140 |
+
## 🔛 Quick start with [Gradio](https://www.gradio.app/guides/quickstart)
|
| 141 |
+
|
| 142 |
+
```bash
|
| 143 |
+
# official online demo
|
| 144 |
+
DEMO_PORT=15432 \
|
| 145 |
+
python app/app_sana.py \
|
| 146 |
+
--share \
|
| 147 |
+
--config=configs/sana_config/1024ms/Sana_1600M_img1024.yaml \
|
| 148 |
+
--model_path=hf://Efficient-Large-Model/Sana_1600M_1024px/checkpoints/Sana_1600M_1024px.pth \
|
| 149 |
+
--image_size=1024
|
| 150 |
+
```
|
| 151 |
+
|
| 152 |
+
### 1. How to use `SanaPipeline` with `🧨diffusers`
|
| 153 |
+
|
| 154 |
+
> \[!IMPORTANT\]
|
| 155 |
+
> Upgrade your `diffusers>=0.32.0.dev` to make the `SanaPipeline` and `SanaPAGPipeline` available!
|
| 156 |
+
>
|
| 157 |
+
> ```bash
|
| 158 |
+
> pip install git+https://github.com/huggingface/diffusers
|
| 159 |
+
> ```
|
| 160 |
+
>
|
| 161 |
+
> Make sure to specify `pipe.transformer` to default `torch_dtype` and `variant` according to [Model Card](asset/docs/model_zoo.md).
|
| 162 |
+
>
|
| 163 |
+
> Set `pipe.text_encoder` to BF16 and `pipe.vae` to FP32 or BF16. For more info, [docs](https://huggingface.co/docs/diffusers/main/en/api/pipelines/sana#sanapipeline) are here.
|
| 164 |
+
|
| 165 |
+
```python
|
| 166 |
+
# run `pip install git+https://github.com/huggingface/diffusers` before use Sana in diffusers
|
| 167 |
+
import torch
|
| 168 |
+
from diffusers import SanaPipeline
|
| 169 |
+
|
| 170 |
+
pipe = SanaPipeline.from_pretrained(
|
| 171 |
+
"Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers",
|
| 172 |
+
variant="bf16",
|
| 173 |
+
torch_dtype=torch.bfloat16,
|
| 174 |
+
)
|
| 175 |
+
pipe.to("cuda")
|
| 176 |
+
|
| 177 |
+
pipe.vae.to(torch.bfloat16)
|
| 178 |
+
pipe.text_encoder.to(torch.bfloat16)
|
| 179 |
+
|
| 180 |
+
prompt = 'a cyberpunk cat with a neon sign that says "Sana"'
|
| 181 |
+
image = pipe(
|
| 182 |
+
prompt=prompt,
|
| 183 |
+
height=1024,
|
| 184 |
+
width=1024,
|
| 185 |
+
guidance_scale=4.5,
|
| 186 |
+
num_inference_steps=20,
|
| 187 |
+
generator=torch.Generator(device="cuda").manual_seed(42),
|
| 188 |
+
)[0]
|
| 189 |
+
|
| 190 |
+
image[0].save("sana.png")
|
| 191 |
+
```
|
| 192 |
+
|
| 193 |
+
### 2. How to use `SanaPAGPipeline` with `🧨diffusers`
|
| 194 |
+
|
| 195 |
+
```python
|
| 196 |
+
# run `pip install git+https://github.com/huggingface/diffusers` before use Sana in diffusers
|
| 197 |
+
import torch
|
| 198 |
+
from diffusers import SanaPAGPipeline
|
| 199 |
+
|
| 200 |
+
pipe = SanaPAGPipeline.from_pretrained(
|
| 201 |
+
"Efficient-Large-Model/Sana_1600M_1024px_diffusers",
|
| 202 |
+
variant="fp16",
|
| 203 |
+
torch_dtype=torch.float16,
|
| 204 |
+
pag_applied_layers="transformer_blocks.8",
|
| 205 |
+
)
|
| 206 |
+
pipe.to("cuda")
|
| 207 |
+
|
| 208 |
+
pipe.text_encoder.to(torch.bfloat16)
|
| 209 |
+
pipe.vae.to(torch.bfloat16)
|
| 210 |
+
|
| 211 |
+
prompt = 'a cyberpunk cat with a neon sign that says "Sana"'
|
| 212 |
+
image = pipe(
|
| 213 |
+
prompt=prompt,
|
| 214 |
+
guidance_scale=5.0,
|
| 215 |
+
pag_scale=2.0,
|
| 216 |
+
num_inference_steps=20,
|
| 217 |
+
generator=torch.Generator(device="cuda").manual_seed(42),
|
| 218 |
+
)[0]
|
| 219 |
+
image[0].save('sana.png')
|
| 220 |
+
```
|
| 221 |
+
|
| 222 |
+
<details>
|
| 223 |
+
<summary><h3>3. How to use Sana in this repo</h3></summary>
|
| 224 |
+
|
| 225 |
+
```python
|
| 226 |
+
import torch
|
| 227 |
+
from app.sana_pipeline import SanaPipeline
|
| 228 |
+
from torchvision.utils import save_image
|
| 229 |
+
|
| 230 |
+
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
|
| 231 |
+
generator = torch.Generator(device=device).manual_seed(42)
|
| 232 |
+
|
| 233 |
+
sana = SanaPipeline("configs/sana_config/1024ms/Sana_1600M_img1024.yaml")
|
| 234 |
+
sana.from_pretrained("hf://Efficient-Large-Model/Sana_1600M_1024px_BF16/checkpoints/Sana_1600M_1024px_BF16.pth")
|
| 235 |
+
prompt = 'a cyberpunk cat with a neon sign that says "Sana"'
|
| 236 |
+
|
| 237 |
+
image = sana(
|
| 238 |
+
prompt=prompt,
|
| 239 |
+
height=1024,
|
| 240 |
+
width=1024,
|
| 241 |
+
guidance_scale=5.0,
|
| 242 |
+
pag_guidance_scale=2.0,
|
| 243 |
+
num_inference_steps=18,
|
| 244 |
+
generator=generator,
|
| 245 |
+
)
|
| 246 |
+
save_image(image, 'output/sana.png', nrow=1, normalize=True, value_range=(-1, 1))
|
| 247 |
+
```
|
| 248 |
+
|
| 249 |
+
</details>
|
| 250 |
+
|
| 251 |
+
<details>
|
| 252 |
+
<summary><h3>4. Run Sana (Inference) with Docker</h3></summary>
|
| 253 |
+
|
| 254 |
+
```
|
| 255 |
+
# Pull related models
|
| 256 |
+
huggingface-cli download google/gemma-2b-it
|
| 257 |
+
huggingface-cli download google/shieldgemma-2b
|
| 258 |
+
huggingface-cli download mit-han-lab/dc-ae-f32c32-sana-1.0
|
| 259 |
+
huggingface-cli download Efficient-Large-Model/Sana_1600M_1024px
|
| 260 |
+
|
| 261 |
+
# Run with docker
|
| 262 |
+
docker build . -t sana
|
| 263 |
+
docker run --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 \
|
| 264 |
+
-v ~/.cache:/root/.cache \
|
| 265 |
+
sana
|
| 266 |
+
```
|
| 267 |
+
|
| 268 |
+
</details>
|
| 269 |
+
|
| 270 |
+
## 🔛 Run inference with TXT or JSON files
|
| 271 |
+
|
| 272 |
+
```bash
|
| 273 |
+
# Run samples in a txt file
|
| 274 |
+
python scripts/inference.py \
|
| 275 |
+
--config=configs/sana_config/1024ms/Sana_1600M_img1024.yaml \
|
| 276 |
+
--model_path=hf://Efficient-Large-Model/Sana_1600M_1024px/checkpoints/Sana_1600M_1024px.pth \
|
| 277 |
+
--txt_file=asset/samples/samples_mini.txt
|
| 278 |
+
|
| 279 |
+
# Run samples in a json file
|
| 280 |
+
python scripts/inference.py \
|
| 281 |
+
--config=configs/sana_config/1024ms/Sana_1600M_img1024.yaml \
|
| 282 |
+
--model_path=hf://Efficient-Large-Model/Sana_1600M_1024px/checkpoints/Sana_1600M_1024px.pth \
|
| 283 |
+
--json_file=asset/samples/samples_mini.json
|
| 284 |
+
```
|
| 285 |
+
|
| 286 |
+
where each line of [`asset/samples/samples_mini.txt`](asset/samples/samples_mini.txt) contains a prompt to generate
|
| 287 |
+
|
| 288 |
+
# 🔥 3. How to Train Sana
|
| 289 |
+
|
| 290 |
+
## 💰Hardware requirement
|
| 291 |
+
|
| 292 |
+
- 32GB VRAM is required for both 0.6B and 1.6B model's training
|
| 293 |
+
|
| 294 |
+
### 1). Train with image-text pairs in directory
|
| 295 |
+
|
| 296 |
+
We provide a training example here and you can also select your desired config file from [config files dir](configs/sana_config) based on your data structure.
|
| 297 |
+
|
| 298 |
+
To launch Sana training, you will first need to prepare data in the following formats. [Here](asset/example_data) is an example for the data structure for reference.
|
| 299 |
+
|
| 300 |
+
```bash
|
| 301 |
+
asset/example_data
|
| 302 |
+
├── AAA.txt
|
| 303 |
+
├── AAA.png
|
| 304 |
+
├── BCC.txt
|
| 305 |
+
├── BCC.png
|
| 306 |
+
├── ......
|
| 307 |
+
├── CCC.txt
|
| 308 |
+
└── CCC.png
|
| 309 |
+
```
|
| 310 |
+
|
| 311 |
+
Then Sana's training can be launched via
|
| 312 |
+
|
| 313 |
+
```bash
|
| 314 |
+
# Example of training Sana 0.6B with 512x512 resolution from scratch
|
| 315 |
+
bash train_scripts/train.sh \
|
| 316 |
+
configs/sana_config/512ms/Sana_600M_img512.yaml \
|
| 317 |
+
--data.data_dir="[asset/example_data]" \
|
| 318 |
+
--data.type=SanaImgDataset \
|
| 319 |
+
--model.multi_scale=false \
|
| 320 |
+
--train.train_batch_size=32
|
| 321 |
+
|
| 322 |
+
# Example of fine-tuning Sana 1.6B with 1024x1024 resolution
|
| 323 |
+
bash train_scripts/train.sh \
|
| 324 |
+
configs/sana_config/1024ms/Sana_1600M_img1024.yaml \
|
| 325 |
+
--data.data_dir="[asset/example_data]" \
|
| 326 |
+
--data.type=SanaImgDataset \
|
| 327 |
+
--model.load_from=hf://Efficient-Large-Model/Sana_1600M_1024px/checkpoints/Sana_1600M_1024px.pth \
|
| 328 |
+
--model.multi_scale=false \
|
| 329 |
+
--train.train_batch_size=8
|
| 330 |
+
```
|
| 331 |
+
|
| 332 |
+
### 2). Train with image-text pairs in directory
|
| 333 |
+
|
| 334 |
+
We also provide conversion scripts to convert your data to the required format. You can refer to the [data conversion scripts](asset/data_conversion_scripts) for more details.
|
| 335 |
+
|
| 336 |
+
```bash
|
| 337 |
+
python tools/convert_ImgDataset_to_WebDatasetMS_format.py
|
| 338 |
+
```
|
| 339 |
+
|
| 340 |
+
Then Sana's training can be launched via
|
| 341 |
+
|
| 342 |
+
```bash
|
| 343 |
+
# Example of training Sana 0.6B with 512x512 resolution from scratch
|
| 344 |
+
bash train_scripts/train.sh \
|
| 345 |
+
configs/sana_config/512ms/Sana_600M_img512.yaml \
|
| 346 |
+
--data.data_dir="[asset/example_data_tar]" \
|
| 347 |
+
--data.type=SanaWebDatasetMS \
|
| 348 |
+
--model.multi_scale=true \
|
| 349 |
+
--train.train_batch_size=32
|
| 350 |
+
```
|
| 351 |
+
|
| 352 |
+
# 💻 4. Metric toolkit
|
| 353 |
+
|
| 354 |
+
Refer to [Toolkit Manual](asset/docs/metrics_toolkit.md).
|
| 355 |
+
|
| 356 |
+
# 💪To-Do List
|
| 357 |
+
|
| 358 |
+
We will try our best to release
|
| 359 |
+
|
| 360 |
+
- \[✅\] Training code
|
| 361 |
+
- \[✅\] Inference code
|
| 362 |
+
- \[✅\] Model zoo
|
| 363 |
+
- \[✅\] ComfyUI
|
| 364 |
+
- \[✅\] DC-AE Diffusers
|
| 365 |
+
- \[✅\] Sana merged in Diffusers(https://github.com/huggingface/diffusers/pull/9982)
|
| 366 |
+
- \[✅\] LoRA training by [@paul](https://github.com/sayakpaul)(`diffusers`: https://github.com/huggingface/diffusers/pull/10234)
|
| 367 |
+
- \[✅\] 2K/4K resolution models.(Thanks [@SUPIR](https://github.com/Fanghua-Yu/SUPIR) to provide a 4K super-resolution model)
|
| 368 |
+
- \[✅\] 8bit / 4bit Laptop development
|
| 369 |
+
- \[💻\] ControlNet (train & inference & models)
|
| 370 |
+
- \[💻\] Larger model size
|
| 371 |
+
- \[💻\] Better re-construction F32/F64 VAEs.
|
| 372 |
+
- \[💻\] **Sana1.5 (Focus on: Human body / Human face / Text rendering / Realism / Efficiency)**
|
| 373 |
+
|
| 374 |
+
# 🤗Acknowledgements
|
| 375 |
+
|
| 376 |
+
**Thanks to the following open-sourced codebase for their wonderful work and codebase!**
|
| 377 |
+
|
| 378 |
+
- [PixArt-α](https://github.com/PixArt-alpha/PixArt-alpha)
|
| 379 |
+
- [PixArt-Σ](https://github.com/PixArt-alpha/PixArt-sigma)
|
| 380 |
+
- [Efficient-ViT](https://github.com/mit-han-lab/efficientvit)
|
| 381 |
+
- [ComfyUI_ExtraModels](https://github.com/city96/ComfyUI_ExtraModels)
|
| 382 |
+
- [SVDQuant and Nunchaku](https://github.com/mit-han-lab/nunchaku)
|
| 383 |
+
- [diffusers](https://github.com/huggingface/diffusers)
|
| 384 |
+
|
| 385 |
+
## 🌟 Star History
|
| 386 |
+
|
| 387 |
+
[](https://star-history.com/#NVlabs/sana&Date)
|
| 388 |
+
|
| 389 |
+
# 📖BibTeX
|
| 390 |
+
|
| 391 |
+
```
|
| 392 |
+
@misc{xie2024sana,
|
| 393 |
+
title={Sana: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer},
|
| 394 |
+
author={Enze Xie and Junsong Chen and Junyu Chen and Han Cai and Haotian Tang and Yujun Lin and Zhekai Zhang and Muyang Li and Ligeng Zhu and Yao Lu and Song Han},
|
| 395 |
+
year={2024},
|
| 396 |
+
eprint={2410.10629},
|
| 397 |
+
archivePrefix={arXiv},
|
| 398 |
+
primaryClass={cs.CV},
|
| 399 |
+
url={https://arxiv.org/abs/2410.10629},
|
| 400 |
+
}
|
| 401 |
+
```
|
app.py
CHANGED
|
@@ -1,73 +1,369 @@
|
|
| 1 |
-
|
| 2 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
import random
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 4 |
|
| 5 |
-
|
| 6 |
-
|
|
|
|
| 7 |
import torch
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 8 |
|
| 9 |
-
|
| 10 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 11 |
|
| 12 |
if torch.cuda.is_available():
|
| 13 |
-
|
| 14 |
-
|
| 15 |
-
|
|
|
|
| 16 |
|
| 17 |
-
|
| 18 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 19 |
|
| 20 |
-
|
| 21 |
-
|
| 22 |
-
|
| 23 |
-
|
| 24 |
-
#
|
| 25 |
-
|
| 26 |
-
|
| 27 |
-
|
| 28 |
-
|
| 29 |
-
|
| 30 |
-
|
| 31 |
-
|
| 32 |
-
|
| 33 |
-
|
| 34 |
-
progress=gr.Progress(track_tqdm=True),
|
| 35 |
-
):
|
| 36 |
if randomize_seed:
|
| 37 |
seed = random.randint(0, MAX_SEED)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 38 |
|
| 39 |
-
|
|
|
|
|
|
|
| 40 |
|
| 41 |
-
|
|
|
|
|
|
|
|
|
|
| 42 |
prompt=prompt,
|
|
|
|
|
|
|
| 43 |
negative_prompt=negative_prompt,
|
| 44 |
guidance_scale=guidance_scale,
|
|
|
|
| 45 |
num_inference_steps=num_inference_steps,
|
| 46 |
-
|
| 47 |
-
height=height,
|
| 48 |
generator=generator,
|
| 49 |
-
)
|
| 50 |
|
| 51 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 52 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 53 |
|
| 54 |
examples = [
|
| 55 |
-
|
| 56 |
-
"
|
| 57 |
-
"
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 58 |
]
|
| 59 |
|
| 60 |
css = """
|
| 61 |
-
|
| 62 |
-
|
| 63 |
-
max-width: 640px;
|
| 64 |
-
}
|
| 65 |
"""
|
| 66 |
-
|
| 67 |
-
|
| 68 |
-
|
| 69 |
-
|
| 70 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 71 |
with gr.Row():
|
| 72 |
prompt = gr.Text(
|
| 73 |
label="Prompt",
|
|
@@ -76,19 +372,66 @@ with gr.Blocks(css=css) as demo:
|
|
| 76 |
placeholder="Enter your prompt",
|
| 77 |
container=False,
|
| 78 |
)
|
| 79 |
-
|
| 80 |
-
|
| 81 |
-
|
| 82 |
-
|
| 83 |
-
|
| 84 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 85 |
negative_prompt = gr.Text(
|
| 86 |
label="Negative prompt",
|
| 87 |
max_lines=1,
|
| 88 |
placeholder="Enter a negative prompt",
|
| 89 |
-
visible=
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 90 |
)
|
| 91 |
-
|
| 92 |
seed = gr.Slider(
|
| 93 |
label="Seed",
|
| 94 |
minimum=0,
|
|
@@ -96,59 +439,64 @@ with gr.Blocks(css=css) as demo:
|
|
| 96 |
step=1,
|
| 97 |
value=0,
|
| 98 |
)
|
| 99 |
-
|
| 100 |
randomize_seed = gr.Checkbox(label="Randomize seed", value=True)
|
| 101 |
-
|
| 102 |
-
|
| 103 |
-
|
| 104 |
-
|
| 105 |
-
|
| 106 |
-
|
| 107 |
-
|
| 108 |
-
|
| 109 |
-
|
| 110 |
-
|
| 111 |
-
height = gr.Slider(
|
| 112 |
-
label="Height",
|
| 113 |
-
minimum=256,
|
| 114 |
-
maximum=MAX_IMAGE_SIZE,
|
| 115 |
-
step=32,
|
| 116 |
-
value=1024, # Replace with defaults that work for your model
|
| 117 |
-
)
|
| 118 |
-
|
| 119 |
-
with gr.Row():
|
| 120 |
-
guidance_scale = gr.Slider(
|
| 121 |
-
label="Guidance scale",
|
| 122 |
-
minimum=0.0,
|
| 123 |
-
maximum=10.0,
|
| 124 |
-
step=0.1,
|
| 125 |
-
value=0.0, # Replace with defaults that work for your model
|
| 126 |
)
|
| 127 |
-
|
| 128 |
-
|
| 129 |
-
label="Number of inference steps",
|
| 130 |
minimum=1,
|
| 131 |
-
maximum=
|
| 132 |
step=1,
|
| 133 |
-
value=
|
| 134 |
)
|
| 135 |
|
| 136 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 137 |
gr.on(
|
| 138 |
-
triggers=[
|
| 139 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 140 |
inputs=[
|
| 141 |
prompt,
|
| 142 |
negative_prompt,
|
|
|
|
|
|
|
|
|
|
| 143 |
seed,
|
| 144 |
-
randomize_seed,
|
| 145 |
-
width,
|
| 146 |
height,
|
| 147 |
-
|
| 148 |
-
|
|
|
|
|
|
|
|
|
|
| 149 |
],
|
| 150 |
-
outputs=[result, seed],
|
|
|
|
| 151 |
)
|
| 152 |
|
| 153 |
if __name__ == "__main__":
|
| 154 |
-
demo.launch()
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
# Copyright 2024 NVIDIA CORPORATION & AFFILIATES
|
| 3 |
+
#
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
# you may not use this file except in compliance with the License.
|
| 6 |
+
# You may obtain a copy of the License at
|
| 7 |
+
#
|
| 8 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
#
|
| 10 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
# See the License for the specific language governing permissions and
|
| 14 |
+
# limitations under the License.
|
| 15 |
+
#
|
| 16 |
+
# SPDX-License-Identifier: Apache-2.0
|
| 17 |
+
from __future__ import annotations
|
| 18 |
+
|
| 19 |
+
import argparse
|
| 20 |
+
import os
|
| 21 |
import random
|
| 22 |
+
import socket
|
| 23 |
+
import sqlite3
|
| 24 |
+
import time
|
| 25 |
+
import uuid
|
| 26 |
+
from datetime import datetime
|
| 27 |
|
| 28 |
+
import gradio as gr
|
| 29 |
+
import numpy as np
|
| 30 |
+
import spaces
|
| 31 |
import torch
|
| 32 |
+
from PIL import Image
|
| 33 |
+
from torchvision.utils import make_grid, save_image
|
| 34 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 35 |
+
|
| 36 |
+
from app import safety_check
|
| 37 |
+
from app.sana_pipeline import SanaPipeline
|
| 38 |
+
|
| 39 |
+
MAX_SEED = np.iinfo(np.int32).max
|
| 40 |
+
CACHE_EXAMPLES = torch.cuda.is_available() and os.getenv("CACHE_EXAMPLES", "1") == "1"
|
| 41 |
+
MAX_IMAGE_SIZE = int(os.getenv("MAX_IMAGE_SIZE", "4096"))
|
| 42 |
+
USE_TORCH_COMPILE = os.getenv("USE_TORCH_COMPILE", "0") == "1"
|
| 43 |
+
ENABLE_CPU_OFFLOAD = os.getenv("ENABLE_CPU_OFFLOAD", "0") == "1"
|
| 44 |
+
DEMO_PORT = int(os.getenv("DEMO_PORT", "15432"))
|
| 45 |
+
os.environ["GRADIO_EXAMPLES_CACHE"] = "./.gradio/cache"
|
| 46 |
+
COUNTER_DB = os.getenv("COUNTER_DB", ".count.db")
|
| 47 |
+
|
| 48 |
+
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
|
| 49 |
+
|
| 50 |
+
style_list = [
|
| 51 |
+
{
|
| 52 |
+
"name": "(No style)",
|
| 53 |
+
"prompt": "{prompt}",
|
| 54 |
+
"negative_prompt": "",
|
| 55 |
+
},
|
| 56 |
+
{
|
| 57 |
+
"name": "Cinematic",
|
| 58 |
+
"prompt": "cinematic still {prompt} . emotional, harmonious, vignette, highly detailed, high budget, bokeh, "
|
| 59 |
+
"cinemascope, moody, epic, gorgeous, film grain, grainy",
|
| 60 |
+
"negative_prompt": "anime, cartoon, graphic, text, painting, crayon, graphite, abstract, glitch, deformed, mutated, ugly, disfigured",
|
| 61 |
+
},
|
| 62 |
+
{
|
| 63 |
+
"name": "Photographic",
|
| 64 |
+
"prompt": "cinematic photo {prompt} . 35mm photograph, film, bokeh, professional, 4k, highly detailed",
|
| 65 |
+
"negative_prompt": "drawing, painting, crayon, sketch, graphite, impressionist, noisy, blurry, soft, deformed, ugly",
|
| 66 |
+
},
|
| 67 |
+
{
|
| 68 |
+
"name": "Anime",
|
| 69 |
+
"prompt": "anime artwork {prompt} . anime style, key visual, vibrant, studio anime, highly detailed",
|
| 70 |
+
"negative_prompt": "photo, deformed, black and white, realism, disfigured, low contrast",
|
| 71 |
+
},
|
| 72 |
+
{
|
| 73 |
+
"name": "Manga",
|
| 74 |
+
"prompt": "manga style {prompt} . vibrant, high-energy, detailed, iconic, Japanese comic style",
|
| 75 |
+
"negative_prompt": "ugly, deformed, noisy, blurry, low contrast, realism, photorealistic, Western comic style",
|
| 76 |
+
},
|
| 77 |
+
{
|
| 78 |
+
"name": "Digital Art",
|
| 79 |
+
"prompt": "concept art {prompt} . digital artwork, illustrative, painterly, matte painting, highly detailed",
|
| 80 |
+
"negative_prompt": "photo, photorealistic, realism, ugly",
|
| 81 |
+
},
|
| 82 |
+
{
|
| 83 |
+
"name": "Pixel art",
|
| 84 |
+
"prompt": "pixel-art {prompt} . low-res, blocky, pixel art style, 8-bit graphics",
|
| 85 |
+
"negative_prompt": "sloppy, messy, blurry, noisy, highly detailed, ultra textured, photo, realistic",
|
| 86 |
+
},
|
| 87 |
+
{
|
| 88 |
+
"name": "Fantasy art",
|
| 89 |
+
"prompt": "ethereal fantasy concept art of {prompt} . magnificent, celestial, ethereal, painterly, epic, "
|
| 90 |
+
"majestic, magical, fantasy art, cover art, dreamy",
|
| 91 |
+
"negative_prompt": "photographic, realistic, realism, 35mm film, dslr, cropped, frame, text, deformed, "
|
| 92 |
+
"glitch, noise, noisy, off-center, deformed, cross-eyed, closed eyes, bad anatomy, ugly, "
|
| 93 |
+
"disfigured, sloppy, duplicate, mutated, black and white",
|
| 94 |
+
},
|
| 95 |
+
{
|
| 96 |
+
"name": "Neonpunk",
|
| 97 |
+
"prompt": "neonpunk style {prompt} . cyberpunk, vaporwave, neon, vibes, vibrant, stunningly beautiful, crisp, "
|
| 98 |
+
"detailed, sleek, ultramodern, magenta highlights, dark purple shadows, high contrast, cinematic, "
|
| 99 |
+
"ultra detailed, intricate, professional",
|
| 100 |
+
"negative_prompt": "painting, drawing, illustration, glitch, deformed, mutated, cross-eyed, ugly, disfigured",
|
| 101 |
+
},
|
| 102 |
+
{
|
| 103 |
+
"name": "3D Model",
|
| 104 |
+
"prompt": "professional 3d model {prompt} . octane render, highly detailed, volumetric, dramatic lighting",
|
| 105 |
+
"negative_prompt": "ugly, deformed, noisy, low poly, blurry, painting",
|
| 106 |
+
},
|
| 107 |
+
]
|
| 108 |
+
|
| 109 |
+
styles = {k["name"]: (k["prompt"], k["negative_prompt"]) for k in style_list}
|
| 110 |
+
STYLE_NAMES = list(styles.keys())
|
| 111 |
+
DEFAULT_STYLE_NAME = "(No style)"
|
| 112 |
+
SCHEDULE_NAME = ["Flow_DPM_Solver"]
|
| 113 |
+
DEFAULT_SCHEDULE_NAME = "Flow_DPM_Solver"
|
| 114 |
+
NUM_IMAGES_PER_PROMPT = 1
|
| 115 |
+
INFER_SPEED = 0
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
def norm_ip(img, low, high):
|
| 119 |
+
img.clamp_(min=low, max=high)
|
| 120 |
+
img.sub_(low).div_(max(high - low, 1e-5))
|
| 121 |
+
return img
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
def open_db():
|
| 125 |
+
db = sqlite3.connect(COUNTER_DB)
|
| 126 |
+
db.execute("CREATE TABLE IF NOT EXISTS counter(app CHARS PRIMARY KEY UNIQUE, value INTEGER)")
|
| 127 |
+
db.execute('INSERT OR IGNORE INTO counter(app, value) VALUES("Sana", 0)')
|
| 128 |
+
return db
|
| 129 |
|
| 130 |
+
|
| 131 |
+
def read_inference_count():
|
| 132 |
+
with open_db() as db:
|
| 133 |
+
cur = db.execute('SELECT value FROM counter WHERE app="Sana"')
|
| 134 |
+
db.commit()
|
| 135 |
+
return cur.fetchone()[0]
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
def write_inference_count(count):
|
| 139 |
+
count = max(0, int(count))
|
| 140 |
+
with open_db() as db:
|
| 141 |
+
db.execute(f'UPDATE counter SET value=value+{count} WHERE app="Sana"')
|
| 142 |
+
db.commit()
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
def run_inference(num_imgs=1):
|
| 146 |
+
write_inference_count(num_imgs)
|
| 147 |
+
count = read_inference_count()
|
| 148 |
+
|
| 149 |
+
return (
|
| 150 |
+
f"<span style='font-size: 16px; font-weight: bold;'>Total inference runs: </span><span style='font-size: "
|
| 151 |
+
f"16px; color:red; font-weight: bold;'>{count}</span>"
|
| 152 |
+
)
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
def update_inference_count():
|
| 156 |
+
count = read_inference_count()
|
| 157 |
+
return (
|
| 158 |
+
f"<span style='font-size: 16px; font-weight: bold;'>Total inference runs: </span><span style='font-size: "
|
| 159 |
+
f"16px; color:red; font-weight: bold;'>{count}</span>"
|
| 160 |
+
)
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
def apply_style(style_name: str, positive: str, negative: str = "") -> tuple[str, str]:
|
| 164 |
+
p, n = styles.get(style_name, styles[DEFAULT_STYLE_NAME])
|
| 165 |
+
if not negative:
|
| 166 |
+
negative = ""
|
| 167 |
+
return p.replace("{prompt}", positive), n + negative
|
| 168 |
+
|
| 169 |
+
|
| 170 |
+
def get_args():
|
| 171 |
+
parser = argparse.ArgumentParser()
|
| 172 |
+
parser.add_argument("--config", type=str, help="config")
|
| 173 |
+
parser.add_argument(
|
| 174 |
+
"--model_path",
|
| 175 |
+
nargs="?",
|
| 176 |
+
default="hf://Swarmeta-AI/Twig-v0-alpha/Twig-v0-alpha-1.6B-2048x-fp16.pth",
|
| 177 |
+
type=str,
|
| 178 |
+
help="Path to the model file (positional)",
|
| 179 |
+
)
|
| 180 |
+
parser.add_argument("--output", default="./", type=str)
|
| 181 |
+
parser.add_argument("--bs", default=1, type=int)
|
| 182 |
+
parser.add_argument("--image_size", default=1024, type=int)
|
| 183 |
+
parser.add_argument("--cfg_scale", default=5.0, type=float)
|
| 184 |
+
parser.add_argument("--pag_scale", default=2.0, type=float)
|
| 185 |
+
parser.add_argument("--seed", default=42, type=int)
|
| 186 |
+
parser.add_argument("--step", default=-1, type=int)
|
| 187 |
+
parser.add_argument("--custom_image_size", default=None, type=int)
|
| 188 |
+
parser.add_argument("--share", action="store_true")
|
| 189 |
+
parser.add_argument(
|
| 190 |
+
"--shield_model_path",
|
| 191 |
+
type=str,
|
| 192 |
+
help="The path to shield model, we employ ShieldGemma-2B by default.",
|
| 193 |
+
default="google/shieldgemma-2b",
|
| 194 |
+
)
|
| 195 |
+
|
| 196 |
+
return parser.parse_known_args()[0]
|
| 197 |
+
|
| 198 |
+
|
| 199 |
+
args = get_args()
|
| 200 |
|
| 201 |
if torch.cuda.is_available():
|
| 202 |
+
model_path = args.model_path
|
| 203 |
+
pipe = SanaPipeline(args.config)
|
| 204 |
+
pipe.from_pretrained(model_path)
|
| 205 |
+
pipe.register_progress_bar(gr.Progress())
|
| 206 |
|
| 207 |
+
# safety checker
|
| 208 |
+
safety_checker_tokenizer = AutoTokenizer.from_pretrained(args.shield_model_path)
|
| 209 |
+
safety_checker_model = AutoModelForCausalLM.from_pretrained(
|
| 210 |
+
args.shield_model_path,
|
| 211 |
+
device_map="auto",
|
| 212 |
+
torch_dtype=torch.bfloat16,
|
| 213 |
+
).to(device)
|
| 214 |
|
| 215 |
+
|
| 216 |
+
def save_image_sana(img, seed="", save_img=False):
|
| 217 |
+
unique_name = f"{str(uuid.uuid4())}_{seed}.png"
|
| 218 |
+
save_path = os.path.join(f"output/online_demo_img/{datetime.now().date()}")
|
| 219 |
+
os.umask(0o000) # file permission: 666; dir permission: 777
|
| 220 |
+
os.makedirs(save_path, exist_ok=True)
|
| 221 |
+
unique_name = os.path.join(save_path, unique_name)
|
| 222 |
+
if save_img:
|
| 223 |
+
save_image(img, unique_name, nrow=1, normalize=True, value_range=(-1, 1))
|
| 224 |
+
|
| 225 |
+
return unique_name
|
| 226 |
+
|
| 227 |
+
|
| 228 |
+
def randomize_seed_fn(seed: int, randomize_seed: bool) -> int:
|
|
|
|
|
|
|
| 229 |
if randomize_seed:
|
| 230 |
seed = random.randint(0, MAX_SEED)
|
| 231 |
+
return seed
|
| 232 |
+
|
| 233 |
+
|
| 234 |
+
@torch.no_grad()
|
| 235 |
+
@torch.inference_mode()
|
| 236 |
+
@spaces.GPU(enable_queue=True)
|
| 237 |
+
def generate(
|
| 238 |
+
prompt: str = None,
|
| 239 |
+
negative_prompt: str = "",
|
| 240 |
+
style: str = DEFAULT_STYLE_NAME,
|
| 241 |
+
use_negative_prompt: bool = False,
|
| 242 |
+
num_imgs: int = 1,
|
| 243 |
+
seed: int = 0,
|
| 244 |
+
height: int = 1024,
|
| 245 |
+
width: int = 1024,
|
| 246 |
+
flow_dpms_guidance_scale: float = 5.0,
|
| 247 |
+
flow_dpms_pag_guidance_scale: float = 2.0,
|
| 248 |
+
flow_dpms_inference_steps: int = 20,
|
| 249 |
+
randomize_seed: bool = False,
|
| 250 |
+
):
|
| 251 |
+
global INFER_SPEED
|
| 252 |
+
# seed = 823753551
|
| 253 |
+
box = run_inference(num_imgs)
|
| 254 |
+
seed = int(randomize_seed_fn(seed, randomize_seed))
|
| 255 |
+
generator = torch.Generator(device=device).manual_seed(seed)
|
| 256 |
+
print(f"PORT: {DEMO_PORT}, model_path: {model_path}")
|
| 257 |
+
if safety_check.is_dangerous(safety_checker_tokenizer, safety_checker_model, prompt, threshold=0.2):
|
| 258 |
+
prompt = "A red heart."
|
| 259 |
+
|
| 260 |
+
print(prompt)
|
| 261 |
+
|
| 262 |
+
num_inference_steps = flow_dpms_inference_steps
|
| 263 |
+
guidance_scale = flow_dpms_guidance_scale
|
| 264 |
+
pag_guidance_scale = flow_dpms_pag_guidance_scale
|
| 265 |
|
| 266 |
+
if not use_negative_prompt:
|
| 267 |
+
negative_prompt = None # type: ignore
|
| 268 |
+
prompt, negative_prompt = apply_style(style, prompt, negative_prompt)
|
| 269 |
|
| 270 |
+
pipe.progress_fn(0, desc="Sana Start")
|
| 271 |
+
|
| 272 |
+
time_start = time.time()
|
| 273 |
+
images = pipe(
|
| 274 |
prompt=prompt,
|
| 275 |
+
height=height,
|
| 276 |
+
width=width,
|
| 277 |
negative_prompt=negative_prompt,
|
| 278 |
guidance_scale=guidance_scale,
|
| 279 |
+
pag_guidance_scale=pag_guidance_scale,
|
| 280 |
num_inference_steps=num_inference_steps,
|
| 281 |
+
num_images_per_prompt=num_imgs,
|
|
|
|
| 282 |
generator=generator,
|
| 283 |
+
)
|
| 284 |
|
| 285 |
+
pipe.progress_fn(1.0, desc="Sana End")
|
| 286 |
+
INFER_SPEED = (time.time() - time_start) / num_imgs
|
| 287 |
+
|
| 288 |
+
save_img = False
|
| 289 |
+
if save_img:
|
| 290 |
+
img = [save_image_sana(img, seed, save_img=save_image) for img in images]
|
| 291 |
+
print(img)
|
| 292 |
+
else:
|
| 293 |
+
img = [
|
| 294 |
+
Image.fromarray(
|
| 295 |
+
norm_ip(img, -1, 1)
|
| 296 |
+
.mul(255)
|
| 297 |
+
.add_(0.5)
|
| 298 |
+
.clamp_(0, 255)
|
| 299 |
+
.permute(1, 2, 0)
|
| 300 |
+
.to("cpu", torch.uint8)
|
| 301 |
+
.numpy()
|
| 302 |
+
.astype(np.uint8)
|
| 303 |
+
)
|
| 304 |
+
for img in images
|
| 305 |
+
]
|
| 306 |
|
| 307 |
+
torch.cuda.empty_cache()
|
| 308 |
+
|
| 309 |
+
return (
|
| 310 |
+
img,
|
| 311 |
+
seed,
|
| 312 |
+
f"<span style='font-size: 16px; font-weight: bold;'>Inference Speed: {INFER_SPEED:.3f} s/Img</span>",
|
| 313 |
+
box,
|
| 314 |
+
)
|
| 315 |
+
|
| 316 |
+
|
| 317 |
+
model_size = "1.6" if "1600M" in args.model_path else "0.6"
|
| 318 |
+
title = f"""
|
| 319 |
+
<div style='display: flex; align-items: center; justify-content: center; text-align: center;'>
|
| 320 |
+
<img src="https://raw.githubusercontent.com/NVlabs/Sana/refs/heads/main/asset/logo.png" width="50%" alt="logo"/>
|
| 321 |
+
</div>
|
| 322 |
+
"""
|
| 323 |
+
DESCRIPTION = f"""
|
| 324 |
+
<p><span style="font-size: 36px; font-weight: bold;">Sana-{model_size}B</span><span style="font-size: 20px; font-weight: bold;">{args.image_size}px</span></p>
|
| 325 |
+
<p style="font-size: 16px; font-weight: bold;">Sana: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer</p>
|
| 326 |
+
<p><span style="font-size: 16px;"><a href="https://arxiv.org/abs/2410.10629">[Paper]</a></span> <span style="font-size: 16px;"><a href="https://github.com/NVlabs/Sana">[Github]</a></span> <span style="font-size: 16px;"><a href="https://nvlabs.github.io/Sana">[Project]</a></span</p>
|
| 327 |
+
<p style="font-size: 16px; font-weight: bold;">Powered by <a href="https://hanlab.mit.edu/projects/dc-ae">DC-AE</a> with 32x latent space, </p>running on node {socket.gethostname()}.
|
| 328 |
+
<p style="font-size: 16px; font-weight: bold;">Unsafe word will give you a 'Red Heart' in the image instead.</p>
|
| 329 |
+
"""
|
| 330 |
+
if model_size == "0.6":
|
| 331 |
+
DESCRIPTION += "\n<p>0.6B model's text rendering ability is limited.</p>"
|
| 332 |
+
if not torch.cuda.is_available():
|
| 333 |
+
DESCRIPTION += "\n<p>Running on CPU 🥶 This demo does not work on CPU.</p>"
|
| 334 |
|
| 335 |
examples = [
|
| 336 |
+
'a cyberpunk cat with a neon sign that says "Sana"',
|
| 337 |
+
"A very detailed and realistic full body photo set of a tall, slim, and athletic Shiba Inu in a white oversized straight t-shirt, white shorts, and short white shoes.",
|
| 338 |
+
"Pirate ship trapped in a cosmic maelstrom nebula, rendered in cosmic beach whirlpool engine, volumetric lighting, spectacular, ambient lights, light pollution, cinematic atmosphere, art nouveau style, illustration art artwork by SenseiJaye, intricate detail.",
|
| 339 |
+
"portrait photo of a girl, photograph, highly detailed face, depth of field",
|
| 340 |
+
'make me a logo that says "So Fast" with a really cool flying dragon shape with lightning sparks all over the sides and all of it contains Indonesian language',
|
| 341 |
+
"🐶 Wearing 🕶 flying on the 🌈",
|
| 342 |
+
"👧 with 🌹 in the ❄️",
|
| 343 |
+
"an old rusted robot wearing pants and a jacket riding skis in a supermarket.",
|
| 344 |
+
"professional portrait photo of an anthropomorphic cat wearing fancy gentleman hat and jacket walking in autumn forest.",
|
| 345 |
+
"Astronaut in a jungle, cold color palette, muted colors, detailed",
|
| 346 |
+
"a stunning and luxurious bedroom carved into a rocky mountainside seamlessly blending nature with modern design with a plush earth-toned bed textured stone walls circular fireplace massive uniquely shaped window framing snow-capped mountains dense forests",
|
| 347 |
]
|
| 348 |
|
| 349 |
css = """
|
| 350 |
+
.gradio-container{max-width: 640px !important}
|
| 351 |
+
h1{text-align:center}
|
|
|
|
|
|
|
| 352 |
"""
|
| 353 |
+
with gr.Blocks(css=css, title="Sana") as demo:
|
| 354 |
+
gr.Markdown(title)
|
| 355 |
+
gr.HTML(DESCRIPTION)
|
| 356 |
+
gr.DuplicateButton(
|
| 357 |
+
value="Duplicate Space for private use",
|
| 358 |
+
elem_id="duplicate-button",
|
| 359 |
+
visible=os.getenv("SHOW_DUPLICATE_BUTTON") == "1",
|
| 360 |
+
)
|
| 361 |
+
info_box = gr.Markdown(
|
| 362 |
+
value=f"<span style='font-size: 16px; font-weight: bold;'>Total inference runs: </span><span style='font-size: 16px; color:red; font-weight: bold;'>{read_inference_count()}</span>"
|
| 363 |
+
)
|
| 364 |
+
demo.load(fn=update_inference_count, outputs=info_box) # update the value when re-loading the page
|
| 365 |
+
# with gr.Row(equal_height=False):
|
| 366 |
+
with gr.Group():
|
| 367 |
with gr.Row():
|
| 368 |
prompt = gr.Text(
|
| 369 |
label="Prompt",
|
|
|
|
| 372 |
placeholder="Enter your prompt",
|
| 373 |
container=False,
|
| 374 |
)
|
| 375 |
+
run_button = gr.Button("Run", scale=0)
|
| 376 |
+
result = gr.Gallery(label="Result", show_label=False, columns=NUM_IMAGES_PER_PROMPT, format="png")
|
| 377 |
+
speed_box = gr.Markdown(
|
| 378 |
+
value=f"<span style='font-size: 16px; font-weight: bold;'>Inference speed: {INFER_SPEED} s/Img</span>"
|
| 379 |
+
)
|
| 380 |
+
with gr.Accordion("Advanced options", open=False):
|
| 381 |
+
with gr.Group():
|
| 382 |
+
with gr.Row(visible=True):
|
| 383 |
+
height = gr.Slider(
|
| 384 |
+
label="Height",
|
| 385 |
+
minimum=256,
|
| 386 |
+
maximum=MAX_IMAGE_SIZE,
|
| 387 |
+
step=32,
|
| 388 |
+
value=args.image_size,
|
| 389 |
+
)
|
| 390 |
+
width = gr.Slider(
|
| 391 |
+
label="Width",
|
| 392 |
+
minimum=256,
|
| 393 |
+
maximum=MAX_IMAGE_SIZE,
|
| 394 |
+
step=32,
|
| 395 |
+
value=args.image_size,
|
| 396 |
+
)
|
| 397 |
+
with gr.Row():
|
| 398 |
+
flow_dpms_inference_steps = gr.Slider(
|
| 399 |
+
label="Sampling steps",
|
| 400 |
+
minimum=5,
|
| 401 |
+
maximum=40,
|
| 402 |
+
step=1,
|
| 403 |
+
value=20,
|
| 404 |
+
)
|
| 405 |
+
flow_dpms_guidance_scale = gr.Slider(
|
| 406 |
+
label="CFG Guidance scale",
|
| 407 |
+
minimum=1,
|
| 408 |
+
maximum=10,
|
| 409 |
+
step=0.1,
|
| 410 |
+
value=4.5,
|
| 411 |
+
)
|
| 412 |
+
flow_dpms_pag_guidance_scale = gr.Slider(
|
| 413 |
+
label="PAG Guidance scale",
|
| 414 |
+
minimum=1,
|
| 415 |
+
maximum=4,
|
| 416 |
+
step=0.5,
|
| 417 |
+
value=1.0,
|
| 418 |
+
)
|
| 419 |
+
with gr.Row():
|
| 420 |
+
use_negative_prompt = gr.Checkbox(label="Use negative prompt", value=False, visible=True)
|
| 421 |
negative_prompt = gr.Text(
|
| 422 |
label="Negative prompt",
|
| 423 |
max_lines=1,
|
| 424 |
placeholder="Enter a negative prompt",
|
| 425 |
+
visible=True,
|
| 426 |
+
)
|
| 427 |
+
style_selection = gr.Radio(
|
| 428 |
+
show_label=True,
|
| 429 |
+
container=True,
|
| 430 |
+
interactive=True,
|
| 431 |
+
choices=STYLE_NAMES,
|
| 432 |
+
value=DEFAULT_STYLE_NAME,
|
| 433 |
+
label="Image Style",
|
| 434 |
)
|
|
|
|
| 435 |
seed = gr.Slider(
|
| 436 |
label="Seed",
|
| 437 |
minimum=0,
|
|
|
|
| 439 |
step=1,
|
| 440 |
value=0,
|
| 441 |
)
|
|
|
|
| 442 |
randomize_seed = gr.Checkbox(label="Randomize seed", value=True)
|
| 443 |
+
with gr.Row(visible=True):
|
| 444 |
+
schedule = gr.Radio(
|
| 445 |
+
show_label=True,
|
| 446 |
+
container=True,
|
| 447 |
+
interactive=True,
|
| 448 |
+
choices=SCHEDULE_NAME,
|
| 449 |
+
value=DEFAULT_SCHEDULE_NAME,
|
| 450 |
+
label="Sampler Schedule",
|
| 451 |
+
visible=True,
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 452 |
)
|
| 453 |
+
num_imgs = gr.Slider(
|
| 454 |
+
label="Num Images",
|
|
|
|
| 455 |
minimum=1,
|
| 456 |
+
maximum=6,
|
| 457 |
step=1,
|
| 458 |
+
value=1,
|
| 459 |
)
|
| 460 |
|
| 461 |
+
gr.Examples(
|
| 462 |
+
examples=examples,
|
| 463 |
+
inputs=prompt,
|
| 464 |
+
outputs=[result, seed],
|
| 465 |
+
fn=generate,
|
| 466 |
+
cache_examples=CACHE_EXAMPLES,
|
| 467 |
+
)
|
| 468 |
+
|
| 469 |
+
use_negative_prompt.change(
|
| 470 |
+
fn=lambda x: gr.update(visible=x),
|
| 471 |
+
inputs=use_negative_prompt,
|
| 472 |
+
outputs=negative_prompt,
|
| 473 |
+
api_name=False,
|
| 474 |
+
)
|
| 475 |
+
|
| 476 |
gr.on(
|
| 477 |
+
triggers=[
|
| 478 |
+
prompt.submit,
|
| 479 |
+
negative_prompt.submit,
|
| 480 |
+
run_button.click,
|
| 481 |
+
],
|
| 482 |
+
fn=generate,
|
| 483 |
inputs=[
|
| 484 |
prompt,
|
| 485 |
negative_prompt,
|
| 486 |
+
style_selection,
|
| 487 |
+
use_negative_prompt,
|
| 488 |
+
num_imgs,
|
| 489 |
seed,
|
|
|
|
|
|
|
| 490 |
height,
|
| 491 |
+
width,
|
| 492 |
+
flow_dpms_guidance_scale,
|
| 493 |
+
flow_dpms_pag_guidance_scale,
|
| 494 |
+
flow_dpms_inference_steps,
|
| 495 |
+
randomize_seed,
|
| 496 |
],
|
| 497 |
+
outputs=[result, seed, speed_box, info_box],
|
| 498 |
+
api_name="run",
|
| 499 |
)
|
| 500 |
|
| 501 |
if __name__ == "__main__":
|
| 502 |
+
demo.queue(max_size=20).launch(server_name="0.0.0.0", server_port=DEMO_PORT, debug=False, share=args.share)
|
app/app_sana.py
ADDED
|
@@ -0,0 +1,502 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
# Copyright 2024 NVIDIA CORPORATION & AFFILIATES
|
| 3 |
+
#
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
# you may not use this file except in compliance with the License.
|
| 6 |
+
# You may obtain a copy of the License at
|
| 7 |
+
#
|
| 8 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
#
|
| 10 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
# See the License for the specific language governing permissions and
|
| 14 |
+
# limitations under the License.
|
| 15 |
+
#
|
| 16 |
+
# SPDX-License-Identifier: Apache-2.0
|
| 17 |
+
from __future__ import annotations
|
| 18 |
+
|
| 19 |
+
import argparse
|
| 20 |
+
import os
|
| 21 |
+
import random
|
| 22 |
+
import socket
|
| 23 |
+
import sqlite3
|
| 24 |
+
import time
|
| 25 |
+
import uuid
|
| 26 |
+
from datetime import datetime
|
| 27 |
+
|
| 28 |
+
import gradio as gr
|
| 29 |
+
import numpy as np
|
| 30 |
+
import spaces
|
| 31 |
+
import torch
|
| 32 |
+
from PIL import Image
|
| 33 |
+
from torchvision.utils import make_grid, save_image
|
| 34 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 35 |
+
|
| 36 |
+
from app import safety_check
|
| 37 |
+
from app.sana_pipeline import SanaPipeline
|
| 38 |
+
|
| 39 |
+
MAX_SEED = np.iinfo(np.int32).max
|
| 40 |
+
CACHE_EXAMPLES = torch.cuda.is_available() and os.getenv("CACHE_EXAMPLES", "1") == "1"
|
| 41 |
+
MAX_IMAGE_SIZE = int(os.getenv("MAX_IMAGE_SIZE", "4096"))
|
| 42 |
+
USE_TORCH_COMPILE = os.getenv("USE_TORCH_COMPILE", "0") == "1"
|
| 43 |
+
ENABLE_CPU_OFFLOAD = os.getenv("ENABLE_CPU_OFFLOAD", "0") == "1"
|
| 44 |
+
DEMO_PORT = int(os.getenv("DEMO_PORT", "15432"))
|
| 45 |
+
os.environ["GRADIO_EXAMPLES_CACHE"] = "./.gradio/cache"
|
| 46 |
+
COUNTER_DB = os.getenv("COUNTER_DB", ".count.db")
|
| 47 |
+
|
| 48 |
+
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
|
| 49 |
+
|
| 50 |
+
style_list = [
|
| 51 |
+
{
|
| 52 |
+
"name": "(No style)",
|
| 53 |
+
"prompt": "{prompt}",
|
| 54 |
+
"negative_prompt": "",
|
| 55 |
+
},
|
| 56 |
+
{
|
| 57 |
+
"name": "Cinematic",
|
| 58 |
+
"prompt": "cinematic still {prompt} . emotional, harmonious, vignette, highly detailed, high budget, bokeh, "
|
| 59 |
+
"cinemascope, moody, epic, gorgeous, film grain, grainy",
|
| 60 |
+
"negative_prompt": "anime, cartoon, graphic, text, painting, crayon, graphite, abstract, glitch, deformed, mutated, ugly, disfigured",
|
| 61 |
+
},
|
| 62 |
+
{
|
| 63 |
+
"name": "Photographic",
|
| 64 |
+
"prompt": "cinematic photo {prompt} . 35mm photograph, film, bokeh, professional, 4k, highly detailed",
|
| 65 |
+
"negative_prompt": "drawing, painting, crayon, sketch, graphite, impressionist, noisy, blurry, soft, deformed, ugly",
|
| 66 |
+
},
|
| 67 |
+
{
|
| 68 |
+
"name": "Anime",
|
| 69 |
+
"prompt": "anime artwork {prompt} . anime style, key visual, vibrant, studio anime, highly detailed",
|
| 70 |
+
"negative_prompt": "photo, deformed, black and white, realism, disfigured, low contrast",
|
| 71 |
+
},
|
| 72 |
+
{
|
| 73 |
+
"name": "Manga",
|
| 74 |
+
"prompt": "manga style {prompt} . vibrant, high-energy, detailed, iconic, Japanese comic style",
|
| 75 |
+
"negative_prompt": "ugly, deformed, noisy, blurry, low contrast, realism, photorealistic, Western comic style",
|
| 76 |
+
},
|
| 77 |
+
{
|
| 78 |
+
"name": "Digital Art",
|
| 79 |
+
"prompt": "concept art {prompt} . digital artwork, illustrative, painterly, matte painting, highly detailed",
|
| 80 |
+
"negative_prompt": "photo, photorealistic, realism, ugly",
|
| 81 |
+
},
|
| 82 |
+
{
|
| 83 |
+
"name": "Pixel art",
|
| 84 |
+
"prompt": "pixel-art {prompt} . low-res, blocky, pixel art style, 8-bit graphics",
|
| 85 |
+
"negative_prompt": "sloppy, messy, blurry, noisy, highly detailed, ultra textured, photo, realistic",
|
| 86 |
+
},
|
| 87 |
+
{
|
| 88 |
+
"name": "Fantasy art",
|
| 89 |
+
"prompt": "ethereal fantasy concept art of {prompt} . magnificent, celestial, ethereal, painterly, epic, "
|
| 90 |
+
"majestic, magical, fantasy art, cover art, dreamy",
|
| 91 |
+
"negative_prompt": "photographic, realistic, realism, 35mm film, dslr, cropped, frame, text, deformed, "
|
| 92 |
+
"glitch, noise, noisy, off-center, deformed, cross-eyed, closed eyes, bad anatomy, ugly, "
|
| 93 |
+
"disfigured, sloppy, duplicate, mutated, black and white",
|
| 94 |
+
},
|
| 95 |
+
{
|
| 96 |
+
"name": "Neonpunk",
|
| 97 |
+
"prompt": "neonpunk style {prompt} . cyberpunk, vaporwave, neon, vibes, vibrant, stunningly beautiful, crisp, "
|
| 98 |
+
"detailed, sleek, ultramodern, magenta highlights, dark purple shadows, high contrast, cinematic, "
|
| 99 |
+
"ultra detailed, intricate, professional",
|
| 100 |
+
"negative_prompt": "painting, drawing, illustration, glitch, deformed, mutated, cross-eyed, ugly, disfigured",
|
| 101 |
+
},
|
| 102 |
+
{
|
| 103 |
+
"name": "3D Model",
|
| 104 |
+
"prompt": "professional 3d model {prompt} . octane render, highly detailed, volumetric, dramatic lighting",
|
| 105 |
+
"negative_prompt": "ugly, deformed, noisy, low poly, blurry, painting",
|
| 106 |
+
},
|
| 107 |
+
]
|
| 108 |
+
|
| 109 |
+
styles = {k["name"]: (k["prompt"], k["negative_prompt"]) for k in style_list}
|
| 110 |
+
STYLE_NAMES = list(styles.keys())
|
| 111 |
+
DEFAULT_STYLE_NAME = "(No style)"
|
| 112 |
+
SCHEDULE_NAME = ["Flow_DPM_Solver"]
|
| 113 |
+
DEFAULT_SCHEDULE_NAME = "Flow_DPM_Solver"
|
| 114 |
+
NUM_IMAGES_PER_PROMPT = 1
|
| 115 |
+
INFER_SPEED = 0
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
def norm_ip(img, low, high):
|
| 119 |
+
img.clamp_(min=low, max=high)
|
| 120 |
+
img.sub_(low).div_(max(high - low, 1e-5))
|
| 121 |
+
return img
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
def open_db():
|
| 125 |
+
db = sqlite3.connect(COUNTER_DB)
|
| 126 |
+
db.execute("CREATE TABLE IF NOT EXISTS counter(app CHARS PRIMARY KEY UNIQUE, value INTEGER)")
|
| 127 |
+
db.execute('INSERT OR IGNORE INTO counter(app, value) VALUES("Sana", 0)')
|
| 128 |
+
return db
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
def read_inference_count():
|
| 132 |
+
with open_db() as db:
|
| 133 |
+
cur = db.execute('SELECT value FROM counter WHERE app="Sana"')
|
| 134 |
+
db.commit()
|
| 135 |
+
return cur.fetchone()[0]
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
def write_inference_count(count):
|
| 139 |
+
count = max(0, int(count))
|
| 140 |
+
with open_db() as db:
|
| 141 |
+
db.execute(f'UPDATE counter SET value=value+{count} WHERE app="Sana"')
|
| 142 |
+
db.commit()
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
def run_inference(num_imgs=1):
|
| 146 |
+
write_inference_count(num_imgs)
|
| 147 |
+
count = read_inference_count()
|
| 148 |
+
|
| 149 |
+
return (
|
| 150 |
+
f"<span style='font-size: 16px; font-weight: bold;'>Total inference runs: </span><span style='font-size: "
|
| 151 |
+
f"16px; color:red; font-weight: bold;'>{count}</span>"
|
| 152 |
+
)
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
def update_inference_count():
|
| 156 |
+
count = read_inference_count()
|
| 157 |
+
return (
|
| 158 |
+
f"<span style='font-size: 16px; font-weight: bold;'>Total inference runs: </span><span style='font-size: "
|
| 159 |
+
f"16px; color:red; font-weight: bold;'>{count}</span>"
|
| 160 |
+
)
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
def apply_style(style_name: str, positive: str, negative: str = "") -> tuple[str, str]:
|
| 164 |
+
p, n = styles.get(style_name, styles[DEFAULT_STYLE_NAME])
|
| 165 |
+
if not negative:
|
| 166 |
+
negative = ""
|
| 167 |
+
return p.replace("{prompt}", positive), n + negative
|
| 168 |
+
|
| 169 |
+
|
| 170 |
+
def get_args():
|
| 171 |
+
parser = argparse.ArgumentParser()
|
| 172 |
+
parser.add_argument("--config", type=str, help="config")
|
| 173 |
+
parser.add_argument(
|
| 174 |
+
"--model_path",
|
| 175 |
+
nargs="?",
|
| 176 |
+
default="hf://Efficient-Large-Model/Sana_1600M_1024px/checkpoints/Sana_1600M_1024px.pth",
|
| 177 |
+
type=str,
|
| 178 |
+
help="Path to the model file (positional)",
|
| 179 |
+
)
|
| 180 |
+
parser.add_argument("--output", default="./", type=str)
|
| 181 |
+
parser.add_argument("--bs", default=1, type=int)
|
| 182 |
+
parser.add_argument("--image_size", default=1024, type=int)
|
| 183 |
+
parser.add_argument("--cfg_scale", default=5.0, type=float)
|
| 184 |
+
parser.add_argument("--pag_scale", default=2.0, type=float)
|
| 185 |
+
parser.add_argument("--seed", default=42, type=int)
|
| 186 |
+
parser.add_argument("--step", default=-1, type=int)
|
| 187 |
+
parser.add_argument("--custom_image_size", default=None, type=int)
|
| 188 |
+
parser.add_argument("--share", action="store_true")
|
| 189 |
+
parser.add_argument(
|
| 190 |
+
"--shield_model_path",
|
| 191 |
+
type=str,
|
| 192 |
+
help="The path to shield model, we employ ShieldGemma-2B by default.",
|
| 193 |
+
default="google/shieldgemma-2b",
|
| 194 |
+
)
|
| 195 |
+
|
| 196 |
+
return parser.parse_known_args()[0]
|
| 197 |
+
|
| 198 |
+
|
| 199 |
+
args = get_args()
|
| 200 |
+
|
| 201 |
+
if torch.cuda.is_available():
|
| 202 |
+
model_path = args.model_path
|
| 203 |
+
pipe = SanaPipeline(args.config)
|
| 204 |
+
pipe.from_pretrained(model_path)
|
| 205 |
+
pipe.register_progress_bar(gr.Progress())
|
| 206 |
+
|
| 207 |
+
# safety checker
|
| 208 |
+
safety_checker_tokenizer = AutoTokenizer.from_pretrained(args.shield_model_path)
|
| 209 |
+
safety_checker_model = AutoModelForCausalLM.from_pretrained(
|
| 210 |
+
args.shield_model_path,
|
| 211 |
+
device_map="auto",
|
| 212 |
+
torch_dtype=torch.bfloat16,
|
| 213 |
+
).to(device)
|
| 214 |
+
|
| 215 |
+
|
| 216 |
+
def save_image_sana(img, seed="", save_img=False):
|
| 217 |
+
unique_name = f"{str(uuid.uuid4())}_{seed}.png"
|
| 218 |
+
save_path = os.path.join(f"output/online_demo_img/{datetime.now().date()}")
|
| 219 |
+
os.umask(0o000) # file permission: 666; dir permission: 777
|
| 220 |
+
os.makedirs(save_path, exist_ok=True)
|
| 221 |
+
unique_name = os.path.join(save_path, unique_name)
|
| 222 |
+
if save_img:
|
| 223 |
+
save_image(img, unique_name, nrow=1, normalize=True, value_range=(-1, 1))
|
| 224 |
+
|
| 225 |
+
return unique_name
|
| 226 |
+
|
| 227 |
+
|
| 228 |
+
def randomize_seed_fn(seed: int, randomize_seed: bool) -> int:
|
| 229 |
+
if randomize_seed:
|
| 230 |
+
seed = random.randint(0, MAX_SEED)
|
| 231 |
+
return seed
|
| 232 |
+
|
| 233 |
+
|
| 234 |
+
@torch.no_grad()
|
| 235 |
+
@torch.inference_mode()
|
| 236 |
+
@spaces.GPU(enable_queue=True)
|
| 237 |
+
def generate(
|
| 238 |
+
prompt: str = None,
|
| 239 |
+
negative_prompt: str = "",
|
| 240 |
+
style: str = DEFAULT_STYLE_NAME,
|
| 241 |
+
use_negative_prompt: bool = False,
|
| 242 |
+
num_imgs: int = 1,
|
| 243 |
+
seed: int = 0,
|
| 244 |
+
height: int = 1024,
|
| 245 |
+
width: int = 1024,
|
| 246 |
+
flow_dpms_guidance_scale: float = 5.0,
|
| 247 |
+
flow_dpms_pag_guidance_scale: float = 2.0,
|
| 248 |
+
flow_dpms_inference_steps: int = 20,
|
| 249 |
+
randomize_seed: bool = False,
|
| 250 |
+
):
|
| 251 |
+
global INFER_SPEED
|
| 252 |
+
# seed = 823753551
|
| 253 |
+
box = run_inference(num_imgs)
|
| 254 |
+
seed = int(randomize_seed_fn(seed, randomize_seed))
|
| 255 |
+
generator = torch.Generator(device=device).manual_seed(seed)
|
| 256 |
+
print(f"PORT: {DEMO_PORT}, model_path: {model_path}")
|
| 257 |
+
if safety_check.is_dangerous(safety_checker_tokenizer, safety_checker_model, prompt, threshold=0.2):
|
| 258 |
+
prompt = "A red heart."
|
| 259 |
+
|
| 260 |
+
print(prompt)
|
| 261 |
+
|
| 262 |
+
num_inference_steps = flow_dpms_inference_steps
|
| 263 |
+
guidance_scale = flow_dpms_guidance_scale
|
| 264 |
+
pag_guidance_scale = flow_dpms_pag_guidance_scale
|
| 265 |
+
|
| 266 |
+
if not use_negative_prompt:
|
| 267 |
+
negative_prompt = None # type: ignore
|
| 268 |
+
prompt, negative_prompt = apply_style(style, prompt, negative_prompt)
|
| 269 |
+
|
| 270 |
+
pipe.progress_fn(0, desc="Sana Start")
|
| 271 |
+
|
| 272 |
+
time_start = time.time()
|
| 273 |
+
images = pipe(
|
| 274 |
+
prompt=prompt,
|
| 275 |
+
height=height,
|
| 276 |
+
width=width,
|
| 277 |
+
negative_prompt=negative_prompt,
|
| 278 |
+
guidance_scale=guidance_scale,
|
| 279 |
+
pag_guidance_scale=pag_guidance_scale,
|
| 280 |
+
num_inference_steps=num_inference_steps,
|
| 281 |
+
num_images_per_prompt=num_imgs,
|
| 282 |
+
generator=generator,
|
| 283 |
+
)
|
| 284 |
+
|
| 285 |
+
pipe.progress_fn(1.0, desc="Sana End")
|
| 286 |
+
INFER_SPEED = (time.time() - time_start) / num_imgs
|
| 287 |
+
|
| 288 |
+
save_img = False
|
| 289 |
+
if save_img:
|
| 290 |
+
img = [save_image_sana(img, seed, save_img=save_image) for img in images]
|
| 291 |
+
print(img)
|
| 292 |
+
else:
|
| 293 |
+
img = [
|
| 294 |
+
Image.fromarray(
|
| 295 |
+
norm_ip(img, -1, 1)
|
| 296 |
+
.mul(255)
|
| 297 |
+
.add_(0.5)
|
| 298 |
+
.clamp_(0, 255)
|
| 299 |
+
.permute(1, 2, 0)
|
| 300 |
+
.to("cpu", torch.uint8)
|
| 301 |
+
.numpy()
|
| 302 |
+
.astype(np.uint8)
|
| 303 |
+
)
|
| 304 |
+
for img in images
|
| 305 |
+
]
|
| 306 |
+
|
| 307 |
+
torch.cuda.empty_cache()
|
| 308 |
+
|
| 309 |
+
return (
|
| 310 |
+
img,
|
| 311 |
+
seed,
|
| 312 |
+
f"<span style='font-size: 16px; font-weight: bold;'>Inference Speed: {INFER_SPEED:.3f} s/Img</span>",
|
| 313 |
+
box,
|
| 314 |
+
)
|
| 315 |
+
|
| 316 |
+
|
| 317 |
+
model_size = "1.6" if "1600M" in args.model_path else "0.6"
|
| 318 |
+
title = f"""
|
| 319 |
+
<div style='display: flex; align-items: center; justify-content: center; text-align: center;'>
|
| 320 |
+
<img src="https://raw.githubusercontent.com/NVlabs/Sana/refs/heads/main/asset/logo.png" width="50%" alt="logo"/>
|
| 321 |
+
</div>
|
| 322 |
+
"""
|
| 323 |
+
DESCRIPTION = f"""
|
| 324 |
+
<p><span style="font-size: 36px; font-weight: bold;">Sana-{model_size}B</span><span style="font-size: 20px; font-weight: bold;">{args.image_size}px</span></p>
|
| 325 |
+
<p style="font-size: 16px; font-weight: bold;">Sana: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer</p>
|
| 326 |
+
<p><span style="font-size: 16px;"><a href="https://arxiv.org/abs/2410.10629">[Paper]</a></span> <span style="font-size: 16px;"><a href="https://github.com/NVlabs/Sana">[Github]</a></span> <span style="font-size: 16px;"><a href="https://nvlabs.github.io/Sana">[Project]</a></span</p>
|
| 327 |
+
<p style="font-size: 16px; font-weight: bold;">Powered by <a href="https://hanlab.mit.edu/projects/dc-ae">DC-AE</a> with 32x latent space, </p>running on node {socket.gethostname()}.
|
| 328 |
+
<p style="font-size: 16px; font-weight: bold;">Unsafe word will give you a 'Red Heart' in the image instead.</p>
|
| 329 |
+
"""
|
| 330 |
+
if model_size == "0.6":
|
| 331 |
+
DESCRIPTION += "\n<p>0.6B model's text rendering ability is limited.</p>"
|
| 332 |
+
if not torch.cuda.is_available():
|
| 333 |
+
DESCRIPTION += "\n<p>Running on CPU 🥶 This demo does not work on CPU.</p>"
|
| 334 |
+
|
| 335 |
+
examples = [
|
| 336 |
+
'a cyberpunk cat with a neon sign that says "Sana"',
|
| 337 |
+
"A very detailed and realistic full body photo set of a tall, slim, and athletic Shiba Inu in a white oversized straight t-shirt, white shorts, and short white shoes.",
|
| 338 |
+
"Pirate ship trapped in a cosmic maelstrom nebula, rendered in cosmic beach whirlpool engine, volumetric lighting, spectacular, ambient lights, light pollution, cinematic atmosphere, art nouveau style, illustration art artwork by SenseiJaye, intricate detail.",
|
| 339 |
+
"portrait photo of a girl, photograph, highly detailed face, depth of field",
|
| 340 |
+
'make me a logo that says "So Fast" with a really cool flying dragon shape with lightning sparks all over the sides and all of it contains Indonesian language',
|
| 341 |
+
"🐶 Wearing 🕶 flying on the 🌈",
|
| 342 |
+
"👧 with 🌹 in the ❄️",
|
| 343 |
+
"an old rusted robot wearing pants and a jacket riding skis in a supermarket.",
|
| 344 |
+
"professional portrait photo of an anthropomorphic cat wearing fancy gentleman hat and jacket walking in autumn forest.",
|
| 345 |
+
"Astronaut in a jungle, cold color palette, muted colors, detailed",
|
| 346 |
+
"a stunning and luxurious bedroom carved into a rocky mountainside seamlessly blending nature with modern design with a plush earth-toned bed textured stone walls circular fireplace massive uniquely shaped window framing snow-capped mountains dense forests",
|
| 347 |
+
]
|
| 348 |
+
|
| 349 |
+
css = """
|
| 350 |
+
.gradio-container{max-width: 640px !important}
|
| 351 |
+
h1{text-align:center}
|
| 352 |
+
"""
|
| 353 |
+
with gr.Blocks(css=css, title="Sana") as demo:
|
| 354 |
+
gr.Markdown(title)
|
| 355 |
+
gr.HTML(DESCRIPTION)
|
| 356 |
+
gr.DuplicateButton(
|
| 357 |
+
value="Duplicate Space for private use",
|
| 358 |
+
elem_id="duplicate-button",
|
| 359 |
+
visible=os.getenv("SHOW_DUPLICATE_BUTTON") == "1",
|
| 360 |
+
)
|
| 361 |
+
info_box = gr.Markdown(
|
| 362 |
+
value=f"<span style='font-size: 16px; font-weight: bold;'>Total inference runs: </span><span style='font-size: 16px; color:red; font-weight: bold;'>{read_inference_count()}</span>"
|
| 363 |
+
)
|
| 364 |
+
demo.load(fn=update_inference_count, outputs=info_box) # update the value when re-loading the page
|
| 365 |
+
# with gr.Row(equal_height=False):
|
| 366 |
+
with gr.Group():
|
| 367 |
+
with gr.Row():
|
| 368 |
+
prompt = gr.Text(
|
| 369 |
+
label="Prompt",
|
| 370 |
+
show_label=False,
|
| 371 |
+
max_lines=1,
|
| 372 |
+
placeholder="Enter your prompt",
|
| 373 |
+
container=False,
|
| 374 |
+
)
|
| 375 |
+
run_button = gr.Button("Run", scale=0)
|
| 376 |
+
result = gr.Gallery(label="Result", show_label=False, columns=NUM_IMAGES_PER_PROMPT, format="png")
|
| 377 |
+
speed_box = gr.Markdown(
|
| 378 |
+
value=f"<span style='font-size: 16px; font-weight: bold;'>Inference speed: {INFER_SPEED} s/Img</span>"
|
| 379 |
+
)
|
| 380 |
+
with gr.Accordion("Advanced options", open=False):
|
| 381 |
+
with gr.Group():
|
| 382 |
+
with gr.Row(visible=True):
|
| 383 |
+
height = gr.Slider(
|
| 384 |
+
label="Height",
|
| 385 |
+
minimum=256,
|
| 386 |
+
maximum=MAX_IMAGE_SIZE,
|
| 387 |
+
step=32,
|
| 388 |
+
value=args.image_size,
|
| 389 |
+
)
|
| 390 |
+
width = gr.Slider(
|
| 391 |
+
label="Width",
|
| 392 |
+
minimum=256,
|
| 393 |
+
maximum=MAX_IMAGE_SIZE,
|
| 394 |
+
step=32,
|
| 395 |
+
value=args.image_size,
|
| 396 |
+
)
|
| 397 |
+
with gr.Row():
|
| 398 |
+
flow_dpms_inference_steps = gr.Slider(
|
| 399 |
+
label="Sampling steps",
|
| 400 |
+
minimum=5,
|
| 401 |
+
maximum=40,
|
| 402 |
+
step=1,
|
| 403 |
+
value=20,
|
| 404 |
+
)
|
| 405 |
+
flow_dpms_guidance_scale = gr.Slider(
|
| 406 |
+
label="CFG Guidance scale",
|
| 407 |
+
minimum=1,
|
| 408 |
+
maximum=10,
|
| 409 |
+
step=0.1,
|
| 410 |
+
value=4.5,
|
| 411 |
+
)
|
| 412 |
+
flow_dpms_pag_guidance_scale = gr.Slider(
|
| 413 |
+
label="PAG Guidance scale",
|
| 414 |
+
minimum=1,
|
| 415 |
+
maximum=4,
|
| 416 |
+
step=0.5,
|
| 417 |
+
value=1.0,
|
| 418 |
+
)
|
| 419 |
+
with gr.Row():
|
| 420 |
+
use_negative_prompt = gr.Checkbox(label="Use negative prompt", value=False, visible=True)
|
| 421 |
+
negative_prompt = gr.Text(
|
| 422 |
+
label="Negative prompt",
|
| 423 |
+
max_lines=1,
|
| 424 |
+
placeholder="Enter a negative prompt",
|
| 425 |
+
visible=True,
|
| 426 |
+
)
|
| 427 |
+
style_selection = gr.Radio(
|
| 428 |
+
show_label=True,
|
| 429 |
+
container=True,
|
| 430 |
+
interactive=True,
|
| 431 |
+
choices=STYLE_NAMES,
|
| 432 |
+
value=DEFAULT_STYLE_NAME,
|
| 433 |
+
label="Image Style",
|
| 434 |
+
)
|
| 435 |
+
seed = gr.Slider(
|
| 436 |
+
label="Seed",
|
| 437 |
+
minimum=0,
|
| 438 |
+
maximum=MAX_SEED,
|
| 439 |
+
step=1,
|
| 440 |
+
value=0,
|
| 441 |
+
)
|
| 442 |
+
randomize_seed = gr.Checkbox(label="Randomize seed", value=True)
|
| 443 |
+
with gr.Row(visible=True):
|
| 444 |
+
schedule = gr.Radio(
|
| 445 |
+
show_label=True,
|
| 446 |
+
container=True,
|
| 447 |
+
interactive=True,
|
| 448 |
+
choices=SCHEDULE_NAME,
|
| 449 |
+
value=DEFAULT_SCHEDULE_NAME,
|
| 450 |
+
label="Sampler Schedule",
|
| 451 |
+
visible=True,
|
| 452 |
+
)
|
| 453 |
+
num_imgs = gr.Slider(
|
| 454 |
+
label="Num Images",
|
| 455 |
+
minimum=1,
|
| 456 |
+
maximum=6,
|
| 457 |
+
step=1,
|
| 458 |
+
value=1,
|
| 459 |
+
)
|
| 460 |
+
|
| 461 |
+
gr.Examples(
|
| 462 |
+
examples=examples,
|
| 463 |
+
inputs=prompt,
|
| 464 |
+
outputs=[result, seed],
|
| 465 |
+
fn=generate,
|
| 466 |
+
cache_examples=CACHE_EXAMPLES,
|
| 467 |
+
)
|
| 468 |
+
|
| 469 |
+
use_negative_prompt.change(
|
| 470 |
+
fn=lambda x: gr.update(visible=x),
|
| 471 |
+
inputs=use_negative_prompt,
|
| 472 |
+
outputs=negative_prompt,
|
| 473 |
+
api_name=False,
|
| 474 |
+
)
|
| 475 |
+
|
| 476 |
+
gr.on(
|
| 477 |
+
triggers=[
|
| 478 |
+
prompt.submit,
|
| 479 |
+
negative_prompt.submit,
|
| 480 |
+
run_button.click,
|
| 481 |
+
],
|
| 482 |
+
fn=generate,
|
| 483 |
+
inputs=[
|
| 484 |
+
prompt,
|
| 485 |
+
negative_prompt,
|
| 486 |
+
style_selection,
|
| 487 |
+
use_negative_prompt,
|
| 488 |
+
num_imgs,
|
| 489 |
+
seed,
|
| 490 |
+
height,
|
| 491 |
+
width,
|
| 492 |
+
flow_dpms_guidance_scale,
|
| 493 |
+
flow_dpms_pag_guidance_scale,
|
| 494 |
+
flow_dpms_inference_steps,
|
| 495 |
+
randomize_seed,
|
| 496 |
+
],
|
| 497 |
+
outputs=[result, seed, speed_box, info_box],
|
| 498 |
+
api_name="run",
|
| 499 |
+
)
|
| 500 |
+
|
| 501 |
+
if __name__ == "__main__":
|
| 502 |
+
demo.queue(max_size=20).launch(server_name="0.0.0.0", server_port=DEMO_PORT, debug=False, share=args.share)
|
app/app_sana_4bit.py
ADDED
|
@@ -0,0 +1,409 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
# Copyright 2024 NVIDIA CORPORATION & AFFILIATES
|
| 3 |
+
#
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
#!/usr/bin/env python
|
| 6 |
+
# Copyright 2024 NVIDIA CORPORATION & AFFILIATES
|
| 7 |
+
#
|
| 8 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 9 |
+
# you may not use this file except in compliance with the License.
|
| 10 |
+
# You may obtain a copy of the License at
|
| 11 |
+
#
|
| 12 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 13 |
+
#
|
| 14 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 15 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 16 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 17 |
+
# See the License for the specific language governing permissions and
|
| 18 |
+
# limitations under the License.
|
| 19 |
+
#
|
| 20 |
+
# SPDX-License-Identifier: Apache-2.0
|
| 21 |
+
from __future__ import annotations
|
| 22 |
+
|
| 23 |
+
import argparse
|
| 24 |
+
import os
|
| 25 |
+
import random
|
| 26 |
+
import time
|
| 27 |
+
import uuid
|
| 28 |
+
from datetime import datetime
|
| 29 |
+
|
| 30 |
+
import gradio as gr
|
| 31 |
+
import numpy as np
|
| 32 |
+
import spaces
|
| 33 |
+
import torch
|
| 34 |
+
from diffusers import SanaPipeline
|
| 35 |
+
from nunchaku.models.transformer_sana import NunchakuSanaTransformer2DModel
|
| 36 |
+
from torchvision.utils import save_image
|
| 37 |
+
|
| 38 |
+
MAX_SEED = np.iinfo(np.int32).max
|
| 39 |
+
CACHE_EXAMPLES = torch.cuda.is_available() and os.getenv("CACHE_EXAMPLES", "1") == "1"
|
| 40 |
+
MAX_IMAGE_SIZE = int(os.getenv("MAX_IMAGE_SIZE", "4096"))
|
| 41 |
+
USE_TORCH_COMPILE = os.getenv("USE_TORCH_COMPILE", "0") == "1"
|
| 42 |
+
ENABLE_CPU_OFFLOAD = os.getenv("ENABLE_CPU_OFFLOAD", "0") == "1"
|
| 43 |
+
DEMO_PORT = int(os.getenv("DEMO_PORT", "15432"))
|
| 44 |
+
os.environ["GRADIO_EXAMPLES_CACHE"] = "./.gradio/cache"
|
| 45 |
+
COUNTER_DB = os.getenv("COUNTER_DB", ".count.db")
|
| 46 |
+
INFER_SPEED = 0
|
| 47 |
+
|
| 48 |
+
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
|
| 49 |
+
|
| 50 |
+
style_list = [
|
| 51 |
+
{
|
| 52 |
+
"name": "(No style)",
|
| 53 |
+
"prompt": "{prompt}",
|
| 54 |
+
"negative_prompt": "",
|
| 55 |
+
},
|
| 56 |
+
{
|
| 57 |
+
"name": "Cinematic",
|
| 58 |
+
"prompt": "cinematic still {prompt} . emotional, harmonious, vignette, highly detailed, high budget, bokeh, "
|
| 59 |
+
"cinemascope, moody, epic, gorgeous, film grain, grainy",
|
| 60 |
+
"negative_prompt": "anime, cartoon, graphic, text, painting, crayon, graphite, abstract, glitch, deformed, mutated, ugly, disfigured",
|
| 61 |
+
},
|
| 62 |
+
{
|
| 63 |
+
"name": "Photographic",
|
| 64 |
+
"prompt": "cinematic photo {prompt} . 35mm photograph, film, bokeh, professional, 4k, highly detailed",
|
| 65 |
+
"negative_prompt": "drawing, painting, crayon, sketch, graphite, impressionist, noisy, blurry, soft, deformed, ugly",
|
| 66 |
+
},
|
| 67 |
+
{
|
| 68 |
+
"name": "Anime",
|
| 69 |
+
"prompt": "anime artwork {prompt} . anime style, key visual, vibrant, studio anime, highly detailed",
|
| 70 |
+
"negative_prompt": "photo, deformed, black and white, realism, disfigured, low contrast",
|
| 71 |
+
},
|
| 72 |
+
{
|
| 73 |
+
"name": "Manga",
|
| 74 |
+
"prompt": "manga style {prompt} . vibrant, high-energy, detailed, iconic, Japanese comic style",
|
| 75 |
+
"negative_prompt": "ugly, deformed, noisy, blurry, low contrast, realism, photorealistic, Western comic style",
|
| 76 |
+
},
|
| 77 |
+
{
|
| 78 |
+
"name": "Digital Art",
|
| 79 |
+
"prompt": "concept art {prompt} . digital artwork, illustrative, painterly, matte painting, highly detailed",
|
| 80 |
+
"negative_prompt": "photo, photorealistic, realism, ugly",
|
| 81 |
+
},
|
| 82 |
+
{
|
| 83 |
+
"name": "Pixel art",
|
| 84 |
+
"prompt": "pixel-art {prompt} . low-res, blocky, pixel art style, 8-bit graphics",
|
| 85 |
+
"negative_prompt": "sloppy, messy, blurry, noisy, highly detailed, ultra textured, photo, realistic",
|
| 86 |
+
},
|
| 87 |
+
{
|
| 88 |
+
"name": "Fantasy art",
|
| 89 |
+
"prompt": "ethereal fantasy concept art of {prompt} . magnificent, celestial, ethereal, painterly, epic, "
|
| 90 |
+
"majestic, magical, fantasy art, cover art, dreamy",
|
| 91 |
+
"negative_prompt": "photographic, realistic, realism, 35mm film, dslr, cropped, frame, text, deformed, "
|
| 92 |
+
"glitch, noise, noisy, off-center, deformed, cross-eyed, closed eyes, bad anatomy, ugly, "
|
| 93 |
+
"disfigured, sloppy, duplicate, mutated, black and white",
|
| 94 |
+
},
|
| 95 |
+
{
|
| 96 |
+
"name": "Neonpunk",
|
| 97 |
+
"prompt": "neonpunk style {prompt} . cyberpunk, vaporwave, neon, vibes, vibrant, stunningly beautiful, crisp, "
|
| 98 |
+
"detailed, sleek, ultramodern, magenta highlights, dark purple shadows, high contrast, cinematic, "
|
| 99 |
+
"ultra detailed, intricate, professional",
|
| 100 |
+
"negative_prompt": "painting, drawing, illustration, glitch, deformed, mutated, cross-eyed, ugly, disfigured",
|
| 101 |
+
},
|
| 102 |
+
{
|
| 103 |
+
"name": "3D Model",
|
| 104 |
+
"prompt": "professional 3d model {prompt} . octane render, highly detailed, volumetric, dramatic lighting",
|
| 105 |
+
"negative_prompt": "ugly, deformed, noisy, low poly, blurry, painting",
|
| 106 |
+
},
|
| 107 |
+
]
|
| 108 |
+
|
| 109 |
+
styles = {k["name"]: (k["prompt"], k["negative_prompt"]) for k in style_list}
|
| 110 |
+
STYLE_NAMES = list(styles.keys())
|
| 111 |
+
DEFAULT_STYLE_NAME = "(No style)"
|
| 112 |
+
SCHEDULE_NAME = ["Flow_DPM_Solver"]
|
| 113 |
+
DEFAULT_SCHEDULE_NAME = "Flow_DPM_Solver"
|
| 114 |
+
NUM_IMAGES_PER_PROMPT = 1
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
def apply_style(style_name: str, positive: str, negative: str = "") -> tuple[str, str]:
|
| 118 |
+
p, n = styles.get(style_name, styles[DEFAULT_STYLE_NAME])
|
| 119 |
+
if not negative:
|
| 120 |
+
negative = ""
|
| 121 |
+
return p.replace("{prompt}", positive), n + negative
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
def get_args():
|
| 125 |
+
parser = argparse.ArgumentParser()
|
| 126 |
+
parser.add_argument(
|
| 127 |
+
"--model_path",
|
| 128 |
+
nargs="?",
|
| 129 |
+
default="Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers",
|
| 130 |
+
type=str,
|
| 131 |
+
help="Path to the model file (positional)",
|
| 132 |
+
)
|
| 133 |
+
parser.add_argument("--share", action="store_true")
|
| 134 |
+
|
| 135 |
+
return parser.parse_known_args()[0]
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
args = get_args()
|
| 139 |
+
|
| 140 |
+
if torch.cuda.is_available():
|
| 141 |
+
|
| 142 |
+
transformer = NunchakuSanaTransformer2DModel.from_pretrained("mit-han-lab/svdq-int4-sana-1600m")
|
| 143 |
+
pipe = SanaPipeline.from_pretrained(
|
| 144 |
+
"Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers",
|
| 145 |
+
transformer=transformer,
|
| 146 |
+
variant="bf16",
|
| 147 |
+
torch_dtype=torch.bfloat16,
|
| 148 |
+
).to(device)
|
| 149 |
+
|
| 150 |
+
pipe.text_encoder.to(torch.bfloat16)
|
| 151 |
+
pipe.vae.to(torch.bfloat16)
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
def save_image_sana(img, seed="", save_img=False):
|
| 155 |
+
unique_name = f"{str(uuid.uuid4())}_{seed}.png"
|
| 156 |
+
save_path = os.path.join(f"output/online_demo_img/{datetime.now().date()}")
|
| 157 |
+
os.umask(0o000) # file permission: 666; dir permission: 777
|
| 158 |
+
os.makedirs(save_path, exist_ok=True)
|
| 159 |
+
unique_name = os.path.join(save_path, unique_name)
|
| 160 |
+
if save_img:
|
| 161 |
+
save_image(img, unique_name, nrow=1, normalize=True, value_range=(-1, 1))
|
| 162 |
+
|
| 163 |
+
return unique_name
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
def randomize_seed_fn(seed: int, randomize_seed: bool) -> int:
|
| 167 |
+
if randomize_seed:
|
| 168 |
+
seed = random.randint(0, MAX_SEED)
|
| 169 |
+
return seed
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
@torch.no_grad()
|
| 173 |
+
@torch.inference_mode()
|
| 174 |
+
@spaces.GPU(enable_queue=True)
|
| 175 |
+
def generate(
|
| 176 |
+
prompt: str = None,
|
| 177 |
+
negative_prompt: str = "",
|
| 178 |
+
style: str = DEFAULT_STYLE_NAME,
|
| 179 |
+
use_negative_prompt: bool = False,
|
| 180 |
+
num_imgs: int = 1,
|
| 181 |
+
seed: int = 0,
|
| 182 |
+
height: int = 1024,
|
| 183 |
+
width: int = 1024,
|
| 184 |
+
flow_dpms_guidance_scale: float = 5.0,
|
| 185 |
+
flow_dpms_inference_steps: int = 20,
|
| 186 |
+
randomize_seed: bool = False,
|
| 187 |
+
):
|
| 188 |
+
global INFER_SPEED
|
| 189 |
+
# seed = 823753551
|
| 190 |
+
seed = int(randomize_seed_fn(seed, randomize_seed))
|
| 191 |
+
generator = torch.Generator(device=device).manual_seed(seed)
|
| 192 |
+
print(f"PORT: {DEMO_PORT}, model_path: {args.model_path}")
|
| 193 |
+
|
| 194 |
+
print(prompt)
|
| 195 |
+
|
| 196 |
+
num_inference_steps = flow_dpms_inference_steps
|
| 197 |
+
guidance_scale = flow_dpms_guidance_scale
|
| 198 |
+
|
| 199 |
+
if not use_negative_prompt:
|
| 200 |
+
negative_prompt = None # type: ignore
|
| 201 |
+
prompt, negative_prompt = apply_style(style, prompt, negative_prompt)
|
| 202 |
+
|
| 203 |
+
time_start = time.time()
|
| 204 |
+
images = pipe(
|
| 205 |
+
prompt=prompt,
|
| 206 |
+
height=height,
|
| 207 |
+
width=width,
|
| 208 |
+
negative_prompt=negative_prompt,
|
| 209 |
+
guidance_scale=guidance_scale,
|
| 210 |
+
num_inference_steps=num_inference_steps,
|
| 211 |
+
num_images_per_prompt=num_imgs,
|
| 212 |
+
generator=generator,
|
| 213 |
+
).images
|
| 214 |
+
INFER_SPEED = (time.time() - time_start) / num_imgs
|
| 215 |
+
|
| 216 |
+
save_img = False
|
| 217 |
+
if save_img:
|
| 218 |
+
img = [save_image_sana(img, seed, save_img=save_image) for img in images]
|
| 219 |
+
print(img)
|
| 220 |
+
else:
|
| 221 |
+
img = images
|
| 222 |
+
|
| 223 |
+
torch.cuda.empty_cache()
|
| 224 |
+
|
| 225 |
+
return (
|
| 226 |
+
img,
|
| 227 |
+
seed,
|
| 228 |
+
f"<span style='font-size: 16px; font-weight: bold;'>Inference Speed: {INFER_SPEED:.3f} s/Img</span>",
|
| 229 |
+
)
|
| 230 |
+
|
| 231 |
+
|
| 232 |
+
model_size = "1.6" if "1600M" in args.model_path else "0.6"
|
| 233 |
+
title = f"""
|
| 234 |
+
<div style='display: flex; align-items: center; justify-content: center; text-align: center;'>
|
| 235 |
+
<img src="https://raw.githubusercontent.com/NVlabs/Sana/refs/heads/main/asset/logo.png" width="30%" alt="logo"/>
|
| 236 |
+
</div>
|
| 237 |
+
"""
|
| 238 |
+
DESCRIPTION = f"""
|
| 239 |
+
<p style="font-size: 30px; font-weight: bold; text-align: center;">Sana: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer (4bit version)</p>
|
| 240 |
+
"""
|
| 241 |
+
if model_size == "0.6":
|
| 242 |
+
DESCRIPTION += "\n<p>0.6B model's text rendering ability is limited.</p>"
|
| 243 |
+
if not torch.cuda.is_available():
|
| 244 |
+
DESCRIPTION += "\n<p>Running on CPU 🥶 This demo does not work on CPU.</p>"
|
| 245 |
+
|
| 246 |
+
examples = [
|
| 247 |
+
'a cyberpunk cat with a neon sign that says "Sana"',
|
| 248 |
+
"A very detailed and realistic full body photo set of a tall, slim, and athletic Shiba Inu in a white oversized straight t-shirt, white shorts, and short white shoes.",
|
| 249 |
+
"Pirate ship trapped in a cosmic maelstrom nebula, rendered in cosmic beach whirlpool engine, volumetric lighting, spectacular, ambient lights, light pollution, cinematic atmosphere, art nouveau style, illustration art artwork by SenseiJaye, intricate detail.",
|
| 250 |
+
"portrait photo of a girl, photograph, highly detailed face, depth of field",
|
| 251 |
+
'make me a logo that says "So Fast" with a really cool flying dragon shape with lightning sparks all over the sides and all of it contains Indonesian language',
|
| 252 |
+
"🐶 Wearing 🕶 flying on the 🌈",
|
| 253 |
+
"👧 with 🌹 in the ❄️",
|
| 254 |
+
"an old rusted robot wearing pants and a jacket riding skis in a supermarket.",
|
| 255 |
+
"professional portrait photo of an anthropomorphic cat wearing fancy gentleman hat and jacket walking in autumn forest.",
|
| 256 |
+
"Astronaut in a jungle, cold color palette, muted colors, detailed",
|
| 257 |
+
"a stunning and luxurious bedroom carved into a rocky mountainside seamlessly blending nature with modern design with a plush earth-toned bed textured stone walls circular fireplace massive uniquely shaped window framing snow-capped mountains dense forests",
|
| 258 |
+
]
|
| 259 |
+
|
| 260 |
+
css = """
|
| 261 |
+
.gradio-container {max-width: 850px !important; height: auto !important;}
|
| 262 |
+
h1 {text-align: center;}
|
| 263 |
+
"""
|
| 264 |
+
theme = gr.themes.Base()
|
| 265 |
+
with gr.Blocks(css=css, theme=theme, title="Sana") as demo:
|
| 266 |
+
gr.Markdown(title)
|
| 267 |
+
gr.HTML(DESCRIPTION)
|
| 268 |
+
gr.DuplicateButton(
|
| 269 |
+
value="Duplicate Space for private use",
|
| 270 |
+
elem_id="duplicate-button",
|
| 271 |
+
visible=os.getenv("SHOW_DUPLICATE_BUTTON") == "1",
|
| 272 |
+
)
|
| 273 |
+
# with gr.Row(equal_height=False):
|
| 274 |
+
with gr.Group():
|
| 275 |
+
with gr.Row():
|
| 276 |
+
prompt = gr.Text(
|
| 277 |
+
label="Prompt",
|
| 278 |
+
show_label=False,
|
| 279 |
+
max_lines=1,
|
| 280 |
+
placeholder="Enter your prompt",
|
| 281 |
+
container=False,
|
| 282 |
+
)
|
| 283 |
+
run_button = gr.Button("Run", scale=0)
|
| 284 |
+
result = gr.Gallery(
|
| 285 |
+
label="Result",
|
| 286 |
+
show_label=False,
|
| 287 |
+
height=750,
|
| 288 |
+
columns=NUM_IMAGES_PER_PROMPT,
|
| 289 |
+
format="jpeg",
|
| 290 |
+
)
|
| 291 |
+
|
| 292 |
+
speed_box = gr.Markdown(
|
| 293 |
+
value=f"<span style='font-size: 16px; font-weight: bold;'>Inference speed: {INFER_SPEED} s/Img</span>"
|
| 294 |
+
)
|
| 295 |
+
with gr.Accordion("Advanced options", open=False):
|
| 296 |
+
with gr.Group():
|
| 297 |
+
with gr.Row(visible=True):
|
| 298 |
+
height = gr.Slider(
|
| 299 |
+
label="Height",
|
| 300 |
+
minimum=256,
|
| 301 |
+
maximum=MAX_IMAGE_SIZE,
|
| 302 |
+
step=32,
|
| 303 |
+
value=1024,
|
| 304 |
+
)
|
| 305 |
+
width = gr.Slider(
|
| 306 |
+
label="Width",
|
| 307 |
+
minimum=256,
|
| 308 |
+
maximum=MAX_IMAGE_SIZE,
|
| 309 |
+
step=32,
|
| 310 |
+
value=1024,
|
| 311 |
+
)
|
| 312 |
+
with gr.Row():
|
| 313 |
+
flow_dpms_inference_steps = gr.Slider(
|
| 314 |
+
label="Sampling steps",
|
| 315 |
+
minimum=5,
|
| 316 |
+
maximum=40,
|
| 317 |
+
step=1,
|
| 318 |
+
value=20,
|
| 319 |
+
)
|
| 320 |
+
flow_dpms_guidance_scale = gr.Slider(
|
| 321 |
+
label="CFG Guidance scale",
|
| 322 |
+
minimum=1,
|
| 323 |
+
maximum=10,
|
| 324 |
+
step=0.1,
|
| 325 |
+
value=4.5,
|
| 326 |
+
)
|
| 327 |
+
with gr.Row():
|
| 328 |
+
use_negative_prompt = gr.Checkbox(label="Use negative prompt", value=False, visible=True)
|
| 329 |
+
negative_prompt = gr.Text(
|
| 330 |
+
label="Negative prompt",
|
| 331 |
+
max_lines=1,
|
| 332 |
+
placeholder="Enter a negative prompt",
|
| 333 |
+
visible=True,
|
| 334 |
+
)
|
| 335 |
+
style_selection = gr.Radio(
|
| 336 |
+
show_label=True,
|
| 337 |
+
container=True,
|
| 338 |
+
interactive=True,
|
| 339 |
+
choices=STYLE_NAMES,
|
| 340 |
+
value=DEFAULT_STYLE_NAME,
|
| 341 |
+
label="Image Style",
|
| 342 |
+
)
|
| 343 |
+
seed = gr.Slider(
|
| 344 |
+
label="Seed",
|
| 345 |
+
minimum=0,
|
| 346 |
+
maximum=MAX_SEED,
|
| 347 |
+
step=1,
|
| 348 |
+
value=0,
|
| 349 |
+
)
|
| 350 |
+
randomize_seed = gr.Checkbox(label="Randomize seed", value=True)
|
| 351 |
+
with gr.Row(visible=True):
|
| 352 |
+
schedule = gr.Radio(
|
| 353 |
+
show_label=True,
|
| 354 |
+
container=True,
|
| 355 |
+
interactive=True,
|
| 356 |
+
choices=SCHEDULE_NAME,
|
| 357 |
+
value=DEFAULT_SCHEDULE_NAME,
|
| 358 |
+
label="Sampler Schedule",
|
| 359 |
+
visible=True,
|
| 360 |
+
)
|
| 361 |
+
num_imgs = gr.Slider(
|
| 362 |
+
label="Num Images",
|
| 363 |
+
minimum=1,
|
| 364 |
+
maximum=6,
|
| 365 |
+
step=1,
|
| 366 |
+
value=1,
|
| 367 |
+
)
|
| 368 |
+
|
| 369 |
+
gr.Examples(
|
| 370 |
+
examples=examples,
|
| 371 |
+
inputs=prompt,
|
| 372 |
+
outputs=[result, seed],
|
| 373 |
+
fn=generate,
|
| 374 |
+
cache_examples=CACHE_EXAMPLES,
|
| 375 |
+
)
|
| 376 |
+
|
| 377 |
+
use_negative_prompt.change(
|
| 378 |
+
fn=lambda x: gr.update(visible=x),
|
| 379 |
+
inputs=use_negative_prompt,
|
| 380 |
+
outputs=negative_prompt,
|
| 381 |
+
api_name=False,
|
| 382 |
+
)
|
| 383 |
+
|
| 384 |
+
gr.on(
|
| 385 |
+
triggers=[
|
| 386 |
+
prompt.submit,
|
| 387 |
+
negative_prompt.submit,
|
| 388 |
+
run_button.click,
|
| 389 |
+
],
|
| 390 |
+
fn=generate,
|
| 391 |
+
inputs=[
|
| 392 |
+
prompt,
|
| 393 |
+
negative_prompt,
|
| 394 |
+
style_selection,
|
| 395 |
+
use_negative_prompt,
|
| 396 |
+
num_imgs,
|
| 397 |
+
seed,
|
| 398 |
+
height,
|
| 399 |
+
width,
|
| 400 |
+
flow_dpms_guidance_scale,
|
| 401 |
+
flow_dpms_inference_steps,
|
| 402 |
+
randomize_seed,
|
| 403 |
+
],
|
| 404 |
+
outputs=[result, seed, speed_box],
|
| 405 |
+
api_name="run",
|
| 406 |
+
)
|
| 407 |
+
|
| 408 |
+
if __name__ == "__main__":
|
| 409 |
+
demo.queue(max_size=20).launch(server_name="0.0.0.0", server_port=DEMO_PORT, debug=False, share=args.share)
|
app/app_sana_4bit_compare_bf16.py
ADDED
|
@@ -0,0 +1,313 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Changed from https://huggingface.co/spaces/playgroundai/playground-v2.5/blob/main/app.py
|
| 2 |
+
import argparse
|
| 3 |
+
import os
|
| 4 |
+
import random
|
| 5 |
+
import time
|
| 6 |
+
from datetime import datetime
|
| 7 |
+
|
| 8 |
+
import GPUtil
|
| 9 |
+
|
| 10 |
+
# import gradio last to avoid conflicts with other imports
|
| 11 |
+
import gradio as gr
|
| 12 |
+
import safety_check
|
| 13 |
+
import spaces
|
| 14 |
+
import torch
|
| 15 |
+
from diffusers import SanaPipeline
|
| 16 |
+
from nunchaku.models.transformer_sana import NunchakuSanaTransformer2DModel
|
| 17 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 18 |
+
|
| 19 |
+
MAX_IMAGE_SIZE = 2048
|
| 20 |
+
MAX_SEED = 1000000000
|
| 21 |
+
|
| 22 |
+
DEFAULT_HEIGHT = 1024
|
| 23 |
+
DEFAULT_WIDTH = 1024
|
| 24 |
+
|
| 25 |
+
# num_inference_steps, guidance_scale, seed
|
| 26 |
+
EXAMPLES = [
|
| 27 |
+
[
|
| 28 |
+
"🐶 Wearing 🕶 flying on the 🌈",
|
| 29 |
+
1024,
|
| 30 |
+
1024,
|
| 31 |
+
20,
|
| 32 |
+
5,
|
| 33 |
+
2,
|
| 34 |
+
],
|
| 35 |
+
[
|
| 36 |
+
"大漠孤烟直, 长河落日圆",
|
| 37 |
+
1024,
|
| 38 |
+
1024,
|
| 39 |
+
20,
|
| 40 |
+
5,
|
| 41 |
+
23,
|
| 42 |
+
],
|
| 43 |
+
[
|
| 44 |
+
"Pirate ship trapped in a cosmic maelstrom nebula, rendered in cosmic beach whirlpool engine, "
|
| 45 |
+
"volumetric lighting, spectacular, ambient lights, light pollution, cinematic atmosphere, "
|
| 46 |
+
"art nouveau style, illustration art artwork by SenseiJaye, intricate detail.",
|
| 47 |
+
1024,
|
| 48 |
+
1024,
|
| 49 |
+
20,
|
| 50 |
+
5,
|
| 51 |
+
233,
|
| 52 |
+
],
|
| 53 |
+
[
|
| 54 |
+
"A photo of a Eurasian lynx in a sunlit forest, with tufted ears and a spotted coat. The lynx should be "
|
| 55 |
+
"sharply focused, gazing into the distance, while the background is softly blurred for depth. Use cinematic "
|
| 56 |
+
"lighting with soft rays filtering through the trees, and capture the scene with a shallow depth of field "
|
| 57 |
+
"for a natural, peaceful atmosphere. 8K resolution, highly detailed, photorealistic, "
|
| 58 |
+
"cinematic lighting, ultra-HD.",
|
| 59 |
+
1024,
|
| 60 |
+
1024,
|
| 61 |
+
20,
|
| 62 |
+
5,
|
| 63 |
+
2333,
|
| 64 |
+
],
|
| 65 |
+
[
|
| 66 |
+
"A stylish woman walks down a Tokyo street filled with warm glowing neon and animated city signage. "
|
| 67 |
+
"She wears a black leather jacket, a long red dress, and black boots, and carries a black purse. "
|
| 68 |
+
"She wears sunglasses and red lipstick. She walks confidently and casually. "
|
| 69 |
+
"The street is damp and reflective, creating a mirror effect of the colorful lights. "
|
| 70 |
+
"Many pedestrians walk about.",
|
| 71 |
+
1024,
|
| 72 |
+
1024,
|
| 73 |
+
20,
|
| 74 |
+
5,
|
| 75 |
+
23333,
|
| 76 |
+
],
|
| 77 |
+
[
|
| 78 |
+
"Cozy bedroom with vintage wooden furniture and a large circular window covered in lush green vines, "
|
| 79 |
+
"opening to a misty forest. Soft, ambient lighting highlights the bed with crumpled blankets, a bookshelf, "
|
| 80 |
+
"and a desk. The atmosphere is serene and natural. 8K resolution, highly detailed, photorealistic, "
|
| 81 |
+
"cinematic lighting, ultra-HD.",
|
| 82 |
+
1024,
|
| 83 |
+
1024,
|
| 84 |
+
20,
|
| 85 |
+
5,
|
| 86 |
+
233333,
|
| 87 |
+
],
|
| 88 |
+
]
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
def hash_str_to_int(s: str) -> int:
|
| 92 |
+
"""Hash a string to an integer."""
|
| 93 |
+
modulus = 10**9 + 7 # Large prime modulus
|
| 94 |
+
hash_int = 0
|
| 95 |
+
for char in s:
|
| 96 |
+
hash_int = (hash_int * 31 + ord(char)) % modulus
|
| 97 |
+
return hash_int
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
def get_pipeline(
|
| 101 |
+
precision: str, use_qencoder: bool = False, device: str | torch.device = "cuda", pipeline_init_kwargs: dict = {}
|
| 102 |
+
) -> SanaPipeline:
|
| 103 |
+
if precision == "int4":
|
| 104 |
+
assert torch.device(device).type == "cuda", "int4 only supported on CUDA devices"
|
| 105 |
+
transformer = NunchakuSanaTransformer2DModel.from_pretrained("mit-han-lab/svdq-int4-sana-1600m")
|
| 106 |
+
|
| 107 |
+
pipeline_init_kwargs["transformer"] = transformer
|
| 108 |
+
if use_qencoder:
|
| 109 |
+
raise NotImplementedError("Quantized encoder not supported for Sana for now")
|
| 110 |
+
else:
|
| 111 |
+
assert precision == "bf16"
|
| 112 |
+
pipeline = SanaPipeline.from_pretrained(
|
| 113 |
+
"Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers",
|
| 114 |
+
variant="bf16",
|
| 115 |
+
torch_dtype=torch.bfloat16,
|
| 116 |
+
**pipeline_init_kwargs,
|
| 117 |
+
)
|
| 118 |
+
|
| 119 |
+
pipeline = pipeline.to(device)
|
| 120 |
+
return pipeline
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
def get_args() -> argparse.Namespace:
|
| 124 |
+
parser = argparse.ArgumentParser()
|
| 125 |
+
parser.add_argument(
|
| 126 |
+
"-p",
|
| 127 |
+
"--precisions",
|
| 128 |
+
type=str,
|
| 129 |
+
default=["int4"],
|
| 130 |
+
nargs="*",
|
| 131 |
+
choices=["int4", "bf16"],
|
| 132 |
+
help="Which precisions to use",
|
| 133 |
+
)
|
| 134 |
+
parser.add_argument("--use-qencoder", action="store_true", help="Whether to use 4-bit text encoder")
|
| 135 |
+
parser.add_argument("--no-safety-checker", action="store_true", help="Disable safety checker")
|
| 136 |
+
parser.add_argument("--count-use", action="store_true", help="Whether to count the number of uses")
|
| 137 |
+
return parser.parse_args()
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
args = get_args()
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
pipelines = []
|
| 144 |
+
pipeline_init_kwargs = {}
|
| 145 |
+
for i, precision in enumerate(args.precisions):
|
| 146 |
+
|
| 147 |
+
pipeline = get_pipeline(
|
| 148 |
+
precision=precision,
|
| 149 |
+
use_qencoder=args.use_qencoder,
|
| 150 |
+
device="cuda",
|
| 151 |
+
pipeline_init_kwargs={**pipeline_init_kwargs},
|
| 152 |
+
)
|
| 153 |
+
pipelines.append(pipeline)
|
| 154 |
+
if i == 0:
|
| 155 |
+
pipeline_init_kwargs["vae"] = pipeline.vae
|
| 156 |
+
pipeline_init_kwargs["text_encoder"] = pipeline.text_encoder
|
| 157 |
+
|
| 158 |
+
# safety checker
|
| 159 |
+
safety_checker_tokenizer = AutoTokenizer.from_pretrained(args.shield_model_path)
|
| 160 |
+
safety_checker_model = AutoModelForCausalLM.from_pretrained(
|
| 161 |
+
args.shield_model_path,
|
| 162 |
+
device_map="auto",
|
| 163 |
+
torch_dtype=torch.bfloat16,
|
| 164 |
+
).to(pipeline.device)
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
@spaces.GPU(enable_queue=True)
|
| 168 |
+
def generate(
|
| 169 |
+
prompt: str = None,
|
| 170 |
+
height: int = 1024,
|
| 171 |
+
width: int = 1024,
|
| 172 |
+
num_inference_steps: int = 4,
|
| 173 |
+
guidance_scale: float = 0,
|
| 174 |
+
seed: int = 0,
|
| 175 |
+
):
|
| 176 |
+
print(f"Prompt: {prompt}")
|
| 177 |
+
is_unsafe_prompt = False
|
| 178 |
+
if safety_check.is_dangerous(safety_checker_tokenizer, safety_checker_model, prompt, threshold=0.2):
|
| 179 |
+
prompt = "A peaceful world."
|
| 180 |
+
images, latency_strs = [], []
|
| 181 |
+
for i, pipeline in enumerate(pipelines):
|
| 182 |
+
progress = gr.Progress(track_tqdm=True)
|
| 183 |
+
start_time = time.time()
|
| 184 |
+
image = pipeline(
|
| 185 |
+
prompt=prompt,
|
| 186 |
+
height=height,
|
| 187 |
+
width=width,
|
| 188 |
+
guidance_scale=guidance_scale,
|
| 189 |
+
num_inference_steps=num_inference_steps,
|
| 190 |
+
generator=torch.Generator().manual_seed(seed),
|
| 191 |
+
).images[0]
|
| 192 |
+
end_time = time.time()
|
| 193 |
+
latency = end_time - start_time
|
| 194 |
+
if latency < 1:
|
| 195 |
+
latency = latency * 1000
|
| 196 |
+
latency_str = f"{latency:.2f}ms"
|
| 197 |
+
else:
|
| 198 |
+
latency_str = f"{latency:.2f}s"
|
| 199 |
+
images.append(image)
|
| 200 |
+
latency_strs.append(latency_str)
|
| 201 |
+
if is_unsafe_prompt:
|
| 202 |
+
for i in range(len(latency_strs)):
|
| 203 |
+
latency_strs[i] += " (Unsafe prompt detected)"
|
| 204 |
+
torch.cuda.empty_cache()
|
| 205 |
+
|
| 206 |
+
if args.count_use:
|
| 207 |
+
if os.path.exists("use_count.txt"):
|
| 208 |
+
with open("use_count.txt") as f:
|
| 209 |
+
count = int(f.read())
|
| 210 |
+
else:
|
| 211 |
+
count = 0
|
| 212 |
+
count += 1
|
| 213 |
+
current_time = datetime.now()
|
| 214 |
+
print(f"{current_time}: {count}")
|
| 215 |
+
with open("use_count.txt", "w") as f:
|
| 216 |
+
f.write(str(count))
|
| 217 |
+
with open("use_record.txt", "a") as f:
|
| 218 |
+
f.write(f"{current_time}: {count}\n")
|
| 219 |
+
|
| 220 |
+
return *images, *latency_strs
|
| 221 |
+
|
| 222 |
+
|
| 223 |
+
with open("./assets/description.html") as f:
|
| 224 |
+
DESCRIPTION = f.read()
|
| 225 |
+
gpus = GPUtil.getGPUs()
|
| 226 |
+
if len(gpus) > 0:
|
| 227 |
+
gpu = gpus[0]
|
| 228 |
+
memory = gpu.memoryTotal / 1024
|
| 229 |
+
device_info = f"Running on {gpu.name} with {memory:.0f} GiB memory."
|
| 230 |
+
else:
|
| 231 |
+
device_info = "Running on CPU 🥶 This demo does not work on CPU."
|
| 232 |
+
notice = f'<strong>Notice:</strong> We will replace unsafe prompts with a default prompt: "A peaceful world."'
|
| 233 |
+
|
| 234 |
+
with gr.Blocks(
|
| 235 |
+
css_paths=[f"assets/frame{len(args.precisions)}.css", "assets/common.css"],
|
| 236 |
+
title=f"SVDQuant SANA-1600M Demo",
|
| 237 |
+
) as demo:
|
| 238 |
+
|
| 239 |
+
def get_header_str():
|
| 240 |
+
|
| 241 |
+
if args.count_use:
|
| 242 |
+
if os.path.exists("use_count.txt"):
|
| 243 |
+
with open("use_count.txt") as f:
|
| 244 |
+
count = int(f.read())
|
| 245 |
+
else:
|
| 246 |
+
count = 0
|
| 247 |
+
count_info = (
|
| 248 |
+
f"<div style='display: flex; justify-content: center; align-items: center; text-align: center;'>"
|
| 249 |
+
f"<span style='font-size: 18px; font-weight: bold;'>Total inference runs: </span>"
|
| 250 |
+
f"<span style='font-size: 18px; color:red; font-weight: bold;'> {count}</span></div>"
|
| 251 |
+
)
|
| 252 |
+
else:
|
| 253 |
+
count_info = ""
|
| 254 |
+
header_str = DESCRIPTION.format(device_info=device_info, notice=notice, count_info=count_info)
|
| 255 |
+
return header_str
|
| 256 |
+
|
| 257 |
+
header = gr.HTML(get_header_str())
|
| 258 |
+
demo.load(fn=get_header_str, outputs=header)
|
| 259 |
+
|
| 260 |
+
with gr.Row():
|
| 261 |
+
image_results, latency_results = [], []
|
| 262 |
+
for i, precision in enumerate(args.precisions):
|
| 263 |
+
with gr.Column():
|
| 264 |
+
gr.Markdown(f"# {precision.upper()}", elem_id="image_header")
|
| 265 |
+
with gr.Group():
|
| 266 |
+
image_result = gr.Image(
|
| 267 |
+
format="png",
|
| 268 |
+
image_mode="RGB",
|
| 269 |
+
label="Result",
|
| 270 |
+
show_label=False,
|
| 271 |
+
show_download_button=True,
|
| 272 |
+
interactive=False,
|
| 273 |
+
)
|
| 274 |
+
latency_result = gr.Text(label="Inference Latency", show_label=True)
|
| 275 |
+
image_results.append(image_result)
|
| 276 |
+
latency_results.append(latency_result)
|
| 277 |
+
with gr.Row():
|
| 278 |
+
prompt = gr.Text(
|
| 279 |
+
label="Prompt", show_label=False, max_lines=1, placeholder="Enter your prompt", container=False, scale=4
|
| 280 |
+
)
|
| 281 |
+
run_button = gr.Button("Run", scale=1)
|
| 282 |
+
|
| 283 |
+
with gr.Row():
|
| 284 |
+
seed = gr.Slider(label="Seed", show_label=True, minimum=0, maximum=MAX_SEED, value=233, step=1, scale=4)
|
| 285 |
+
randomize_seed = gr.Button("Random Seed", scale=1, min_width=50, elem_id="random_seed")
|
| 286 |
+
with gr.Accordion("Advanced options", open=False):
|
| 287 |
+
with gr.Group():
|
| 288 |
+
height = gr.Slider(label="Height", minimum=256, maximum=4096, step=32, value=1024)
|
| 289 |
+
width = gr.Slider(label="Width", minimum=256, maximum=4096, step=32, value=1024)
|
| 290 |
+
with gr.Group():
|
| 291 |
+
num_inference_steps = gr.Slider(label="Sampling Steps", minimum=10, maximum=50, step=1, value=20)
|
| 292 |
+
guidance_scale = gr.Slider(label="Guidance Scale", minimum=1, maximum=10, step=0.1, value=5)
|
| 293 |
+
|
| 294 |
+
input_args = [prompt, height, width, num_inference_steps, guidance_scale, seed]
|
| 295 |
+
|
| 296 |
+
gr.Examples(examples=EXAMPLES, inputs=input_args, outputs=[*image_results, *latency_results], fn=generate)
|
| 297 |
+
|
| 298 |
+
gr.on(
|
| 299 |
+
triggers=[prompt.submit, run_button.click],
|
| 300 |
+
fn=generate,
|
| 301 |
+
inputs=input_args,
|
| 302 |
+
outputs=[*image_results, *latency_results],
|
| 303 |
+
api_name="run",
|
| 304 |
+
)
|
| 305 |
+
randomize_seed.click(
|
| 306 |
+
lambda: random.randint(0, MAX_SEED), inputs=[], outputs=seed, api_name=False, queue=False
|
| 307 |
+
).then(fn=generate, inputs=input_args, outputs=[*image_results, *latency_results], api_name=False, queue=False)
|
| 308 |
+
|
| 309 |
+
gr.Markdown("MIT Accessibility: https://accessibility.mit.edu/", elem_id="accessibility")
|
| 310 |
+
|
| 311 |
+
|
| 312 |
+
if __name__ == "__main__":
|
| 313 |
+
demo.queue(max_size=20).launch(server_name="0.0.0.0", debug=True, share=True)
|
app/app_sana_controlnet_hed.py
ADDED
|
@@ -0,0 +1,306 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Changed from https://github.com/GaParmar/img2img-turbo/blob/main/gradio_sketch2image.py
|
| 2 |
+
import argparse
|
| 3 |
+
import os
|
| 4 |
+
import random
|
| 5 |
+
import socket
|
| 6 |
+
import tempfile
|
| 7 |
+
import time
|
| 8 |
+
|
| 9 |
+
import gradio as gr
|
| 10 |
+
import numpy as np
|
| 11 |
+
import torch
|
| 12 |
+
from PIL import Image
|
| 13 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 14 |
+
|
| 15 |
+
from app import safety_check
|
| 16 |
+
from app.sana_controlnet_pipeline import SanaControlNetPipeline
|
| 17 |
+
|
| 18 |
+
STYLES = {
|
| 19 |
+
"None": "{prompt}",
|
| 20 |
+
"Cinematic": "cinematic still {prompt}. emotional, harmonious, vignette, highly detailed, high budget, bokeh, cinemascope, moody, epic, gorgeous, film grain, grainy",
|
| 21 |
+
"3D Model": "professional 3d model {prompt}. octane render, highly detailed, volumetric, dramatic lighting",
|
| 22 |
+
"Anime": "anime artwork {prompt}. anime style, key visual, vibrant, studio anime, highly detailed",
|
| 23 |
+
"Digital Art": "concept art {prompt}. digital artwork, illustrative, painterly, matte painting, highly detailed",
|
| 24 |
+
"Photographic": "cinematic photo {prompt}. 35mm photograph, film, bokeh, professional, 4k, highly detailed",
|
| 25 |
+
"Pixel art": "pixel-art {prompt}. low-res, blocky, pixel art style, 8-bit graphics",
|
| 26 |
+
"Fantasy art": "ethereal fantasy concept art of {prompt}. magnificent, celestial, ethereal, painterly, epic, majestic, magical, fantasy art, cover art, dreamy",
|
| 27 |
+
"Neonpunk": "neonpunk style {prompt}. cyberpunk, vaporwave, neon, vibes, vibrant, stunningly beautiful, crisp, detailed, sleek, ultramodern, magenta highlights, dark purple shadows, high contrast, cinematic, ultra detailed, intricate, professional",
|
| 28 |
+
"Manga": "manga style {prompt}. vibrant, high-energy, detailed, iconic, Japanese comic style",
|
| 29 |
+
}
|
| 30 |
+
DEFAULT_STYLE_NAME = "None"
|
| 31 |
+
STYLE_NAMES = list(STYLES.keys())
|
| 32 |
+
|
| 33 |
+
MAX_SEED = 1000000000
|
| 34 |
+
DEFAULT_SKETCH_GUIDANCE = 0.28
|
| 35 |
+
DEMO_PORT = int(os.getenv("DEMO_PORT", "15432"))
|
| 36 |
+
|
| 37 |
+
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
|
| 38 |
+
|
| 39 |
+
blank_image = Image.new("RGB", (1024, 1024), (255, 255, 255))
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
def get_args():
|
| 43 |
+
parser = argparse.ArgumentParser()
|
| 44 |
+
parser.add_argument("--config", type=str, help="config")
|
| 45 |
+
parser.add_argument(
|
| 46 |
+
"--model_path",
|
| 47 |
+
nargs="?",
|
| 48 |
+
default="hf://Efficient-Large-Model/Sana_1600M_1024px/checkpoints/Sana_1600M_1024px.pth",
|
| 49 |
+
type=str,
|
| 50 |
+
help="Path to the model file (positional)",
|
| 51 |
+
)
|
| 52 |
+
parser.add_argument("--output", default="./", type=str)
|
| 53 |
+
parser.add_argument("--bs", default=1, type=int)
|
| 54 |
+
parser.add_argument("--image_size", default=1024, type=int)
|
| 55 |
+
parser.add_argument("--cfg_scale", default=5.0, type=float)
|
| 56 |
+
parser.add_argument("--pag_scale", default=2.0, type=float)
|
| 57 |
+
parser.add_argument("--seed", default=42, type=int)
|
| 58 |
+
parser.add_argument("--step", default=-1, type=int)
|
| 59 |
+
parser.add_argument("--custom_image_size", default=None, type=int)
|
| 60 |
+
parser.add_argument("--share", action="store_true")
|
| 61 |
+
parser.add_argument(
|
| 62 |
+
"--shield_model_path",
|
| 63 |
+
type=str,
|
| 64 |
+
help="The path to shield model, we employ ShieldGemma-2B by default.",
|
| 65 |
+
default="google/shieldgemma-2b",
|
| 66 |
+
)
|
| 67 |
+
|
| 68 |
+
return parser.parse_known_args()[0]
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
args = get_args()
|
| 72 |
+
|
| 73 |
+
if torch.cuda.is_available():
|
| 74 |
+
model_path = args.model_path
|
| 75 |
+
pipe = SanaControlNetPipeline(args.config)
|
| 76 |
+
pipe.from_pretrained(model_path)
|
| 77 |
+
pipe.register_progress_bar(gr.Progress())
|
| 78 |
+
|
| 79 |
+
# safety checker
|
| 80 |
+
safety_checker_tokenizer = AutoTokenizer.from_pretrained(args.shield_model_path)
|
| 81 |
+
safety_checker_model = AutoModelForCausalLM.from_pretrained(
|
| 82 |
+
args.shield_model_path,
|
| 83 |
+
device_map="auto",
|
| 84 |
+
torch_dtype=torch.bfloat16,
|
| 85 |
+
).to(device)
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
def save_image(img):
|
| 89 |
+
if isinstance(img, dict):
|
| 90 |
+
img = img["composite"]
|
| 91 |
+
temp_file = tempfile.NamedTemporaryFile(suffix=".png", delete=False)
|
| 92 |
+
img.save(temp_file.name)
|
| 93 |
+
return temp_file.name
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
def norm_ip(img, low, high):
|
| 97 |
+
img.clamp_(min=low, max=high)
|
| 98 |
+
img.sub_(low).div_(max(high - low, 1e-5))
|
| 99 |
+
return img
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
@torch.no_grad()
|
| 103 |
+
@torch.inference_mode()
|
| 104 |
+
def run(
|
| 105 |
+
image,
|
| 106 |
+
prompt: str,
|
| 107 |
+
prompt_template: str,
|
| 108 |
+
sketch_thickness: int,
|
| 109 |
+
guidance_scale: float,
|
| 110 |
+
inference_steps: int,
|
| 111 |
+
seed: int,
|
| 112 |
+
blend_alpha: float,
|
| 113 |
+
) -> tuple[Image, str]:
|
| 114 |
+
|
| 115 |
+
print(f"Prompt: {prompt}")
|
| 116 |
+
image_numpy = np.array(image["composite"].convert("RGB"))
|
| 117 |
+
|
| 118 |
+
if prompt.strip() == "" and (np.sum(image_numpy == 255) >= 3145628 or np.sum(image_numpy == 0) >= 3145628):
|
| 119 |
+
return blank_image, "Please input the prompt or draw something."
|
| 120 |
+
|
| 121 |
+
if safety_check.is_dangerous(safety_checker_tokenizer, safety_checker_model, prompt, threshold=0.2):
|
| 122 |
+
prompt = "A red heart."
|
| 123 |
+
|
| 124 |
+
prompt = prompt_template.format(prompt=prompt)
|
| 125 |
+
pipe.set_blend_alpha(blend_alpha)
|
| 126 |
+
start_time = time.time()
|
| 127 |
+
images = pipe(
|
| 128 |
+
prompt=prompt,
|
| 129 |
+
ref_image=image["composite"],
|
| 130 |
+
guidance_scale=guidance_scale,
|
| 131 |
+
num_inference_steps=inference_steps,
|
| 132 |
+
num_images_per_prompt=1,
|
| 133 |
+
sketch_thickness=sketch_thickness,
|
| 134 |
+
generator=torch.Generator(device=device).manual_seed(seed),
|
| 135 |
+
)
|
| 136 |
+
|
| 137 |
+
latency = time.time() - start_time
|
| 138 |
+
|
| 139 |
+
if latency < 1:
|
| 140 |
+
latency = latency * 1000
|
| 141 |
+
latency_str = f"{latency:.2f}ms"
|
| 142 |
+
else:
|
| 143 |
+
latency_str = f"{latency:.2f}s"
|
| 144 |
+
torch.cuda.empty_cache()
|
| 145 |
+
|
| 146 |
+
img = [
|
| 147 |
+
Image.fromarray(
|
| 148 |
+
norm_ip(img, -1, 1)
|
| 149 |
+
.mul(255)
|
| 150 |
+
.add_(0.5)
|
| 151 |
+
.clamp_(0, 255)
|
| 152 |
+
.permute(1, 2, 0)
|
| 153 |
+
.to("cpu", torch.uint8)
|
| 154 |
+
.numpy()
|
| 155 |
+
.astype(np.uint8)
|
| 156 |
+
)
|
| 157 |
+
for img in images
|
| 158 |
+
]
|
| 159 |
+
img = img[0]
|
| 160 |
+
return img, latency_str
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
model_size = "1.6" if "1600M" in args.model_path else "0.6"
|
| 164 |
+
title = f"""
|
| 165 |
+
<div style='display: flex; align-items: center; justify-content: center; text-align: center;'>
|
| 166 |
+
<img src="https://raw.githubusercontent.com/NVlabs/Sana/refs/heads/main/asset/logo.png" width="50%" alt="logo"/>
|
| 167 |
+
</div>
|
| 168 |
+
"""
|
| 169 |
+
DESCRIPTION = f"""
|
| 170 |
+
<p><span style="font-size: 36px; font-weight: bold;">Sana-ControlNet-{model_size}B</span><span style="font-size: 20px; font-weight: bold;">{args.image_size}px</span></p>
|
| 171 |
+
<p style="font-size: 18px; font-weight: bold;">Sana: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer</p>
|
| 172 |
+
<p><span style="font-size: 16px;"><a href="https://arxiv.org/abs/2410.10629">[Paper]</a></span> <span style="font-size: 16px;"><a href="https://github.com/NVlabs/Sana">[Github]</a></span> <span style="font-size: 16px;"><a href="https://nvlabs.github.io/Sana">[Project]</a></span</p>
|
| 173 |
+
<p style="font-size: 18px; font-weight: bold;">Powered by <a href="https://hanlab.mit.edu/projects/dc-ae">DC-AE</a> with 32x latent space, </p>running on node {socket.gethostname()}.
|
| 174 |
+
<p style="font-size: 16px; font-weight: bold;">Unsafe word will give you a 'Red Heart' in the image instead.</p>
|
| 175 |
+
"""
|
| 176 |
+
if model_size == "0.6":
|
| 177 |
+
DESCRIPTION += "\n<p>0.6B model's text rendering ability is limited.</p>"
|
| 178 |
+
if not torch.cuda.is_available():
|
| 179 |
+
DESCRIPTION += "\n<p>Running on CPU 🥶 This demo does not work on CPU.</p>"
|
| 180 |
+
|
| 181 |
+
|
| 182 |
+
with gr.Blocks(css_paths="asset/app_styles/controlnet_app_style.css", title=f"Sana Sketch-to-Image Demo") as demo:
|
| 183 |
+
gr.Markdown(title)
|
| 184 |
+
gr.HTML(DESCRIPTION)
|
| 185 |
+
|
| 186 |
+
with gr.Row(elem_id="main_row"):
|
| 187 |
+
with gr.Column(elem_id="column_input"):
|
| 188 |
+
gr.Markdown("## INPUT", elem_id="input_header")
|
| 189 |
+
with gr.Group():
|
| 190 |
+
canvas = gr.Sketchpad(
|
| 191 |
+
value=blank_image,
|
| 192 |
+
height=640,
|
| 193 |
+
image_mode="RGB",
|
| 194 |
+
sources=["upload", "clipboard"],
|
| 195 |
+
type="pil",
|
| 196 |
+
label="Sketch",
|
| 197 |
+
show_label=False,
|
| 198 |
+
show_download_button=True,
|
| 199 |
+
interactive=True,
|
| 200 |
+
transforms=[],
|
| 201 |
+
canvas_size=(1024, 1024),
|
| 202 |
+
scale=1,
|
| 203 |
+
brush=gr.Brush(default_size=3, colors=["#000000"], color_mode="fixed"),
|
| 204 |
+
format="png",
|
| 205 |
+
layers=False,
|
| 206 |
+
)
|
| 207 |
+
with gr.Row():
|
| 208 |
+
prompt = gr.Text(label="Prompt", placeholder="Enter your prompt", scale=6)
|
| 209 |
+
run_button = gr.Button("Run", scale=1, elem_id="run_button")
|
| 210 |
+
download_sketch = gr.DownloadButton("Download Sketch", scale=1, elem_id="download_sketch")
|
| 211 |
+
with gr.Row():
|
| 212 |
+
style = gr.Dropdown(label="Style", choices=STYLE_NAMES, value=DEFAULT_STYLE_NAME, scale=1)
|
| 213 |
+
prompt_template = gr.Textbox(
|
| 214 |
+
label="Prompt Style Template", value=STYLES[DEFAULT_STYLE_NAME], scale=2, max_lines=1
|
| 215 |
+
)
|
| 216 |
+
|
| 217 |
+
with gr.Row():
|
| 218 |
+
sketch_thickness = gr.Slider(
|
| 219 |
+
label="Sketch Thickness",
|
| 220 |
+
minimum=1,
|
| 221 |
+
maximum=4,
|
| 222 |
+
step=1,
|
| 223 |
+
value=2,
|
| 224 |
+
)
|
| 225 |
+
with gr.Row():
|
| 226 |
+
inference_steps = gr.Slider(
|
| 227 |
+
label="Sampling steps",
|
| 228 |
+
minimum=5,
|
| 229 |
+
maximum=40,
|
| 230 |
+
step=1,
|
| 231 |
+
value=20,
|
| 232 |
+
)
|
| 233 |
+
guidance_scale = gr.Slider(
|
| 234 |
+
label="CFG Guidance scale",
|
| 235 |
+
minimum=1,
|
| 236 |
+
maximum=10,
|
| 237 |
+
step=0.1,
|
| 238 |
+
value=4.5,
|
| 239 |
+
)
|
| 240 |
+
blend_alpha = gr.Slider(
|
| 241 |
+
label="Blend Alpha",
|
| 242 |
+
minimum=0,
|
| 243 |
+
maximum=1,
|
| 244 |
+
step=0.1,
|
| 245 |
+
value=0,
|
| 246 |
+
)
|
| 247 |
+
with gr.Row():
|
| 248 |
+
seed = gr.Slider(label="Seed", show_label=True, minimum=0, maximum=MAX_SEED, value=233, step=1, scale=4)
|
| 249 |
+
randomize_seed = gr.Button("Random Seed", scale=1, min_width=50, elem_id="random_seed")
|
| 250 |
+
|
| 251 |
+
with gr.Column(elem_id="column_output"):
|
| 252 |
+
gr.Markdown("## OUTPUT", elem_id="output_header")
|
| 253 |
+
with gr.Group():
|
| 254 |
+
result = gr.Image(
|
| 255 |
+
format="png",
|
| 256 |
+
height=640,
|
| 257 |
+
image_mode="RGB",
|
| 258 |
+
type="pil",
|
| 259 |
+
label="Result",
|
| 260 |
+
show_label=False,
|
| 261 |
+
show_download_button=True,
|
| 262 |
+
interactive=False,
|
| 263 |
+
elem_id="output_image",
|
| 264 |
+
)
|
| 265 |
+
latency_result = gr.Text(label="Inference Latency", show_label=True)
|
| 266 |
+
|
| 267 |
+
download_result = gr.DownloadButton("Download Result", elem_id="download_result")
|
| 268 |
+
gr.Markdown("### Instructions")
|
| 269 |
+
gr.Markdown("**1**. Enter a text prompt (e.g. a cat)")
|
| 270 |
+
gr.Markdown("**2**. Start sketching or upload a reference image")
|
| 271 |
+
gr.Markdown("**3**. Change the image style using a style template")
|
| 272 |
+
gr.Markdown("**4**. Try different seeds to generate different results")
|
| 273 |
+
|
| 274 |
+
run_inputs = [canvas, prompt, prompt_template, sketch_thickness, guidance_scale, inference_steps, seed, blend_alpha]
|
| 275 |
+
run_outputs = [result, latency_result]
|
| 276 |
+
|
| 277 |
+
randomize_seed.click(
|
| 278 |
+
lambda: random.randint(0, MAX_SEED),
|
| 279 |
+
inputs=[],
|
| 280 |
+
outputs=seed,
|
| 281 |
+
api_name=False,
|
| 282 |
+
queue=False,
|
| 283 |
+
).then(run, inputs=run_inputs, outputs=run_outputs, api_name=False)
|
| 284 |
+
|
| 285 |
+
style.change(
|
| 286 |
+
lambda x: STYLES[x],
|
| 287 |
+
inputs=[style],
|
| 288 |
+
outputs=[prompt_template],
|
| 289 |
+
api_name=False,
|
| 290 |
+
queue=False,
|
| 291 |
+
).then(fn=run, inputs=run_inputs, outputs=run_outputs, api_name=False)
|
| 292 |
+
gr.on(
|
| 293 |
+
triggers=[prompt.submit, run_button.click, canvas.change],
|
| 294 |
+
fn=run,
|
| 295 |
+
inputs=run_inputs,
|
| 296 |
+
outputs=run_outputs,
|
| 297 |
+
api_name=False,
|
| 298 |
+
)
|
| 299 |
+
|
| 300 |
+
download_sketch.click(fn=save_image, inputs=canvas, outputs=download_sketch)
|
| 301 |
+
download_result.click(fn=save_image, inputs=result, outputs=download_result)
|
| 302 |
+
gr.Markdown("MIT Accessibility: https://accessibility.mit.edu/", elem_id="accessibility")
|
| 303 |
+
|
| 304 |
+
|
| 305 |
+
if __name__ == "__main__":
|
| 306 |
+
demo.queue(max_size=20).launch(server_name="0.0.0.0", server_port=DEMO_PORT, debug=False, share=args.share)
|
app/app_sana_multithread.py
ADDED
|
@@ -0,0 +1,565 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
# Copyright 2024 NVIDIA CORPORATION & AFFILIATES
|
| 3 |
+
#
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
# you may not use this file except in compliance with the License.
|
| 6 |
+
# You may obtain a copy of the License at
|
| 7 |
+
#
|
| 8 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
#
|
| 10 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
# See the License for the specific language governing permissions and
|
| 14 |
+
# limitations under the License.
|
| 15 |
+
#
|
| 16 |
+
# SPDX-License-Identifier: Apache-2.0
|
| 17 |
+
from __future__ import annotations
|
| 18 |
+
|
| 19 |
+
import argparse
|
| 20 |
+
import os
|
| 21 |
+
import random
|
| 22 |
+
import uuid
|
| 23 |
+
from datetime import datetime
|
| 24 |
+
|
| 25 |
+
import gradio as gr
|
| 26 |
+
import numpy as np
|
| 27 |
+
import spaces
|
| 28 |
+
import torch
|
| 29 |
+
from diffusers import FluxPipeline
|
| 30 |
+
from PIL import Image
|
| 31 |
+
from torchvision.utils import make_grid, save_image
|
| 32 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 33 |
+
|
| 34 |
+
from app import safety_check
|
| 35 |
+
from app.sana_pipeline import SanaPipeline
|
| 36 |
+
|
| 37 |
+
MAX_SEED = np.iinfo(np.int32).max
|
| 38 |
+
CACHE_EXAMPLES = torch.cuda.is_available() and os.getenv("CACHE_EXAMPLES", "1") == "1"
|
| 39 |
+
MAX_IMAGE_SIZE = int(os.getenv("MAX_IMAGE_SIZE", "4096"))
|
| 40 |
+
USE_TORCH_COMPILE = os.getenv("USE_TORCH_COMPILE", "0") == "1"
|
| 41 |
+
ENABLE_CPU_OFFLOAD = os.getenv("ENABLE_CPU_OFFLOAD", "0") == "1"
|
| 42 |
+
DEMO_PORT = int(os.getenv("DEMO_PORT", "15432"))
|
| 43 |
+
os.environ["GRADIO_EXAMPLES_CACHE"] = "./.gradio/cache"
|
| 44 |
+
|
| 45 |
+
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
|
| 46 |
+
|
| 47 |
+
style_list = [
|
| 48 |
+
{
|
| 49 |
+
"name": "(No style)",
|
| 50 |
+
"prompt": "{prompt}",
|
| 51 |
+
"negative_prompt": "",
|
| 52 |
+
},
|
| 53 |
+
{
|
| 54 |
+
"name": "Cinematic",
|
| 55 |
+
"prompt": "cinematic still {prompt} . emotional, harmonious, vignette, highly detailed, high budget, bokeh, "
|
| 56 |
+
"cinemascope, moody, epic, gorgeous, film grain, grainy",
|
| 57 |
+
"negative_prompt": "anime, cartoon, graphic, text, painting, crayon, graphite, abstract, glitch, deformed, mutated, ugly, disfigured",
|
| 58 |
+
},
|
| 59 |
+
{
|
| 60 |
+
"name": "Photographic",
|
| 61 |
+
"prompt": "cinematic photo {prompt} . 35mm photograph, film, bokeh, professional, 4k, highly detailed",
|
| 62 |
+
"negative_prompt": "drawing, painting, crayon, sketch, graphite, impressionist, noisy, blurry, soft, deformed, ugly",
|
| 63 |
+
},
|
| 64 |
+
{
|
| 65 |
+
"name": "Anime",
|
| 66 |
+
"prompt": "anime artwork {prompt} . anime style, key visual, vibrant, studio anime, highly detailed",
|
| 67 |
+
"negative_prompt": "photo, deformed, black and white, realism, disfigured, low contrast",
|
| 68 |
+
},
|
| 69 |
+
{
|
| 70 |
+
"name": "Manga",
|
| 71 |
+
"prompt": "manga style {prompt} . vibrant, high-energy, detailed, iconic, Japanese comic style",
|
| 72 |
+
"negative_prompt": "ugly, deformed, noisy, blurry, low contrast, realism, photorealistic, Western comic style",
|
| 73 |
+
},
|
| 74 |
+
{
|
| 75 |
+
"name": "Digital Art",
|
| 76 |
+
"prompt": "concept art {prompt} . digital artwork, illustrative, painterly, matte painting, highly detailed",
|
| 77 |
+
"negative_prompt": "photo, photorealistic, realism, ugly",
|
| 78 |
+
},
|
| 79 |
+
{
|
| 80 |
+
"name": "Pixel art",
|
| 81 |
+
"prompt": "pixel-art {prompt} . low-res, blocky, pixel art style, 8-bit graphics",
|
| 82 |
+
"negative_prompt": "sloppy, messy, blurry, noisy, highly detailed, ultra textured, photo, realistic",
|
| 83 |
+
},
|
| 84 |
+
{
|
| 85 |
+
"name": "Fantasy art",
|
| 86 |
+
"prompt": "ethereal fantasy concept art of {prompt} . magnificent, celestial, ethereal, painterly, epic, "
|
| 87 |
+
"majestic, magical, fantasy art, cover art, dreamy",
|
| 88 |
+
"negative_prompt": "photographic, realistic, realism, 35mm film, dslr, cropped, frame, text, deformed, "
|
| 89 |
+
"glitch, noise, noisy, off-center, deformed, cross-eyed, closed eyes, bad anatomy, ugly, "
|
| 90 |
+
"disfigured, sloppy, duplicate, mutated, black and white",
|
| 91 |
+
},
|
| 92 |
+
{
|
| 93 |
+
"name": "Neonpunk",
|
| 94 |
+
"prompt": "neonpunk style {prompt} . cyberpunk, vaporwave, neon, vibes, vibrant, stunningly beautiful, crisp, "
|
| 95 |
+
"detailed, sleek, ultramodern, magenta highlights, dark purple shadows, high contrast, cinematic, "
|
| 96 |
+
"ultra detailed, intricate, professional",
|
| 97 |
+
"negative_prompt": "painting, drawing, illustration, glitch, deformed, mutated, cross-eyed, ugly, disfigured",
|
| 98 |
+
},
|
| 99 |
+
{
|
| 100 |
+
"name": "3D Model",
|
| 101 |
+
"prompt": "professional 3d model {prompt} . octane render, highly detailed, volumetric, dramatic lighting",
|
| 102 |
+
"negative_prompt": "ugly, deformed, noisy, low poly, blurry, painting",
|
| 103 |
+
},
|
| 104 |
+
]
|
| 105 |
+
|
| 106 |
+
styles = {k["name"]: (k["prompt"], k["negative_prompt"]) for k in style_list}
|
| 107 |
+
STYLE_NAMES = list(styles.keys())
|
| 108 |
+
DEFAULT_STYLE_NAME = "(No style)"
|
| 109 |
+
SCHEDULE_NAME = ["Flow_DPM_Solver"]
|
| 110 |
+
DEFAULT_SCHEDULE_NAME = "Flow_DPM_Solver"
|
| 111 |
+
NUM_IMAGES_PER_PROMPT = 1
|
| 112 |
+
TEST_TIMES = 0
|
| 113 |
+
FILENAME = f"output/port{DEMO_PORT}_inference_count.txt"
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
def set_env(seed=0):
|
| 117 |
+
torch.manual_seed(seed)
|
| 118 |
+
torch.set_grad_enabled(False)
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
def read_inference_count():
|
| 122 |
+
global TEST_TIMES
|
| 123 |
+
try:
|
| 124 |
+
with open(FILENAME) as f:
|
| 125 |
+
count = int(f.read().strip())
|
| 126 |
+
except FileNotFoundError:
|
| 127 |
+
count = 0
|
| 128 |
+
TEST_TIMES = count
|
| 129 |
+
|
| 130 |
+
return count
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
def write_inference_count(count):
|
| 134 |
+
with open(FILENAME, "w") as f:
|
| 135 |
+
f.write(str(count))
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
def run_inference(num_imgs=1):
|
| 139 |
+
TEST_TIMES = read_inference_count()
|
| 140 |
+
TEST_TIMES += int(num_imgs)
|
| 141 |
+
write_inference_count(TEST_TIMES)
|
| 142 |
+
|
| 143 |
+
return (
|
| 144 |
+
f"<span style='font-size: 16px; font-weight: bold;'>Total inference runs: </span><span style='font-size: "
|
| 145 |
+
f"16px; color:red; font-weight: bold;'>{TEST_TIMES}</span>"
|
| 146 |
+
)
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
def update_inference_count():
|
| 150 |
+
count = read_inference_count()
|
| 151 |
+
return (
|
| 152 |
+
f"<span style='font-size: 16px; font-weight: bold;'>Total inference runs: </span><span style='font-size: "
|
| 153 |
+
f"16px; color:red; font-weight: bold;'>{count}</span>"
|
| 154 |
+
)
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
def apply_style(style_name: str, positive: str, negative: str = "") -> tuple[str, str]:
|
| 158 |
+
p, n = styles.get(style_name, styles[DEFAULT_STYLE_NAME])
|
| 159 |
+
if not negative:
|
| 160 |
+
negative = ""
|
| 161 |
+
return p.replace("{prompt}", positive), n + negative
|
| 162 |
+
|
| 163 |
+
|
| 164 |
+
def get_args():
|
| 165 |
+
parser = argparse.ArgumentParser()
|
| 166 |
+
parser.add_argument("--config", type=str, help="config")
|
| 167 |
+
parser.add_argument(
|
| 168 |
+
"--model_path",
|
| 169 |
+
nargs="?",
|
| 170 |
+
default="output/Sana_D20/SANA.pth",
|
| 171 |
+
type=str,
|
| 172 |
+
help="Path to the model file (positional)",
|
| 173 |
+
)
|
| 174 |
+
parser.add_argument("--output", default="./", type=str)
|
| 175 |
+
parser.add_argument("--bs", default=1, type=int)
|
| 176 |
+
parser.add_argument("--image_size", default=1024, type=int)
|
| 177 |
+
parser.add_argument("--cfg_scale", default=5.0, type=float)
|
| 178 |
+
parser.add_argument("--pag_scale", default=2.0, type=float)
|
| 179 |
+
parser.add_argument("--seed", default=42, type=int)
|
| 180 |
+
parser.add_argument("--step", default=-1, type=int)
|
| 181 |
+
parser.add_argument("--custom_image_size", default=None, type=int)
|
| 182 |
+
parser.add_argument(
|
| 183 |
+
"--shield_model_path",
|
| 184 |
+
type=str,
|
| 185 |
+
help="The path to shield model, we employ ShieldGemma-2B by default.",
|
| 186 |
+
default="google/shieldgemma-2b",
|
| 187 |
+
)
|
| 188 |
+
|
| 189 |
+
return parser.parse_args()
|
| 190 |
+
|
| 191 |
+
|
| 192 |
+
args = get_args()
|
| 193 |
+
|
| 194 |
+
if torch.cuda.is_available():
|
| 195 |
+
weight_dtype = torch.float16
|
| 196 |
+
model_path = args.model_path
|
| 197 |
+
pipe = SanaPipeline(args.config)
|
| 198 |
+
pipe.from_pretrained(model_path)
|
| 199 |
+
pipe.register_progress_bar(gr.Progress())
|
| 200 |
+
|
| 201 |
+
repo_name = "black-forest-labs/FLUX.1-dev"
|
| 202 |
+
pipe2 = FluxPipeline.from_pretrained(repo_name, torch_dtype=torch.float16).to("cuda")
|
| 203 |
+
|
| 204 |
+
# safety checker
|
| 205 |
+
safety_checker_tokenizer = AutoTokenizer.from_pretrained(args.shield_model_path)
|
| 206 |
+
safety_checker_model = AutoModelForCausalLM.from_pretrained(
|
| 207 |
+
args.shield_model_path,
|
| 208 |
+
device_map="auto",
|
| 209 |
+
torch_dtype=torch.bfloat16,
|
| 210 |
+
).to(device)
|
| 211 |
+
|
| 212 |
+
set_env(42)
|
| 213 |
+
|
| 214 |
+
|
| 215 |
+
def save_image_sana(img, seed="", save_img=False):
|
| 216 |
+
unique_name = f"{str(uuid.uuid4())}_{seed}.png"
|
| 217 |
+
save_path = os.path.join(f"output/online_demo_img/{datetime.now().date()}")
|
| 218 |
+
os.umask(0o000) # file permission: 666; dir permission: 777
|
| 219 |
+
os.makedirs(save_path, exist_ok=True)
|
| 220 |
+
unique_name = os.path.join(save_path, unique_name)
|
| 221 |
+
if save_img:
|
| 222 |
+
save_image(img, unique_name, nrow=1, normalize=True, value_range=(-1, 1))
|
| 223 |
+
|
| 224 |
+
return unique_name
|
| 225 |
+
|
| 226 |
+
|
| 227 |
+
def randomize_seed_fn(seed: int, randomize_seed: bool) -> int:
|
| 228 |
+
if randomize_seed:
|
| 229 |
+
seed = random.randint(0, MAX_SEED)
|
| 230 |
+
return seed
|
| 231 |
+
|
| 232 |
+
|
| 233 |
+
@spaces.GPU(enable_queue=True)
|
| 234 |
+
async def generate_2(
|
| 235 |
+
prompt: str = None,
|
| 236 |
+
negative_prompt: str = "",
|
| 237 |
+
style: str = DEFAULT_STYLE_NAME,
|
| 238 |
+
use_negative_prompt: bool = False,
|
| 239 |
+
num_imgs: int = 1,
|
| 240 |
+
seed: int = 0,
|
| 241 |
+
height: int = 1024,
|
| 242 |
+
width: int = 1024,
|
| 243 |
+
flow_dpms_guidance_scale: float = 5.0,
|
| 244 |
+
flow_dpms_pag_guidance_scale: float = 2.0,
|
| 245 |
+
flow_dpms_inference_steps: int = 20,
|
| 246 |
+
randomize_seed: bool = False,
|
| 247 |
+
):
|
| 248 |
+
seed = int(randomize_seed_fn(seed, randomize_seed))
|
| 249 |
+
generator = torch.Generator(device=device).manual_seed(seed)
|
| 250 |
+
print(f"PORT: {DEMO_PORT}, model_path: {model_path}")
|
| 251 |
+
if safety_check.is_dangerous(safety_checker_tokenizer, safety_checker_model, prompt):
|
| 252 |
+
prompt = "A red heart."
|
| 253 |
+
|
| 254 |
+
print(prompt)
|
| 255 |
+
|
| 256 |
+
if not use_negative_prompt:
|
| 257 |
+
negative_prompt = None # type: ignore
|
| 258 |
+
prompt, negative_prompt = apply_style(style, prompt, negative_prompt)
|
| 259 |
+
|
| 260 |
+
with torch.no_grad():
|
| 261 |
+
images = pipe2(
|
| 262 |
+
prompt=prompt,
|
| 263 |
+
height=height,
|
| 264 |
+
width=width,
|
| 265 |
+
guidance_scale=3.5,
|
| 266 |
+
num_inference_steps=50,
|
| 267 |
+
num_images_per_prompt=num_imgs,
|
| 268 |
+
max_sequence_length=256,
|
| 269 |
+
generator=generator,
|
| 270 |
+
).images
|
| 271 |
+
|
| 272 |
+
save_img = False
|
| 273 |
+
img = images
|
| 274 |
+
if save_img:
|
| 275 |
+
img = [save_image_sana(img, seed, save_img=save_image) for img in images]
|
| 276 |
+
print(img)
|
| 277 |
+
torch.cuda.empty_cache()
|
| 278 |
+
|
| 279 |
+
return img
|
| 280 |
+
|
| 281 |
+
|
| 282 |
+
@spaces.GPU(enable_queue=True)
|
| 283 |
+
async def generate(
|
| 284 |
+
prompt: str = None,
|
| 285 |
+
negative_prompt: str = "",
|
| 286 |
+
style: str = DEFAULT_STYLE_NAME,
|
| 287 |
+
use_negative_prompt: bool = False,
|
| 288 |
+
num_imgs: int = 1,
|
| 289 |
+
seed: int = 0,
|
| 290 |
+
height: int = 1024,
|
| 291 |
+
width: int = 1024,
|
| 292 |
+
flow_dpms_guidance_scale: float = 5.0,
|
| 293 |
+
flow_dpms_pag_guidance_scale: float = 2.0,
|
| 294 |
+
flow_dpms_inference_steps: int = 20,
|
| 295 |
+
randomize_seed: bool = False,
|
| 296 |
+
):
|
| 297 |
+
global TEST_TIMES
|
| 298 |
+
# seed = 823753551
|
| 299 |
+
seed = int(randomize_seed_fn(seed, randomize_seed))
|
| 300 |
+
generator = torch.Generator(device=device).manual_seed(seed)
|
| 301 |
+
print(f"PORT: {DEMO_PORT}, model_path: {model_path}, time_times: {TEST_TIMES}")
|
| 302 |
+
if safety_check.is_dangerous(safety_checker_tokenizer, safety_checker_model, prompt):
|
| 303 |
+
prompt = "A red heart."
|
| 304 |
+
|
| 305 |
+
print(prompt)
|
| 306 |
+
|
| 307 |
+
num_inference_steps = flow_dpms_inference_steps
|
| 308 |
+
guidance_scale = flow_dpms_guidance_scale
|
| 309 |
+
pag_guidance_scale = flow_dpms_pag_guidance_scale
|
| 310 |
+
|
| 311 |
+
if not use_negative_prompt:
|
| 312 |
+
negative_prompt = None # type: ignore
|
| 313 |
+
prompt, negative_prompt = apply_style(style, prompt, negative_prompt)
|
| 314 |
+
|
| 315 |
+
pipe.progress_fn(0, desc="Sana Start")
|
| 316 |
+
|
| 317 |
+
with torch.no_grad():
|
| 318 |
+
images = pipe(
|
| 319 |
+
prompt=prompt,
|
| 320 |
+
height=height,
|
| 321 |
+
width=width,
|
| 322 |
+
negative_prompt=negative_prompt,
|
| 323 |
+
guidance_scale=guidance_scale,
|
| 324 |
+
pag_guidance_scale=pag_guidance_scale,
|
| 325 |
+
num_inference_steps=num_inference_steps,
|
| 326 |
+
num_images_per_prompt=num_imgs,
|
| 327 |
+
generator=generator,
|
| 328 |
+
)
|
| 329 |
+
|
| 330 |
+
pipe.progress_fn(1.0, desc="Sana End")
|
| 331 |
+
|
| 332 |
+
save_img = False
|
| 333 |
+
if save_img:
|
| 334 |
+
img = [save_image_sana(img, seed, save_img=save_image) for img in images]
|
| 335 |
+
print(img)
|
| 336 |
+
else:
|
| 337 |
+
if num_imgs > 1:
|
| 338 |
+
nrow = 2
|
| 339 |
+
else:
|
| 340 |
+
nrow = 1
|
| 341 |
+
img = make_grid(images, nrow=nrow, normalize=True, value_range=(-1, 1))
|
| 342 |
+
img = img.mul(255).add_(0.5).clamp_(0, 255).permute(1, 2, 0).to("cpu", torch.uint8).numpy()
|
| 343 |
+
img = [Image.fromarray(img.astype(np.uint8))]
|
| 344 |
+
|
| 345 |
+
torch.cuda.empty_cache()
|
| 346 |
+
|
| 347 |
+
return img
|
| 348 |
+
|
| 349 |
+
|
| 350 |
+
TEST_TIMES = read_inference_count()
|
| 351 |
+
model_size = "1.6" if "D20" in args.model_path else "0.6"
|
| 352 |
+
title = f"""
|
| 353 |
+
<div style='display: flex; align-items: center; justify-content: center; text-align: center;'>
|
| 354 |
+
<img src="https://raw.githubusercontent.com/NVlabs/Sana/refs/heads/main/asset/logo.png" width="50%" alt="logo"/>
|
| 355 |
+
</div>
|
| 356 |
+
"""
|
| 357 |
+
DESCRIPTION = f"""
|
| 358 |
+
<p><span style="font-size: 36px; font-weight: bold;">Sana-{model_size}B</span><span style="font-size: 20px; font-weight: bold;">{args.image_size}px</span></p>
|
| 359 |
+
<p style="font-size: 16px; font-weight: bold;">Sana: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer</p>
|
| 360 |
+
<p><span style="font-size: 16px;"><a href="https://arxiv.org/abs/2410.10629">[Paper]</a></span> <span style="font-size: 16px;"><a href="https://github.com/NVlabs/Sana">[Github]</a></span> <span style="font-size: 16px;"><a href="https://nvlabs.github.io/Sana">[Project]</a></span</p>
|
| 361 |
+
<p style="font-size: 16px; font-weight: bold;">Powered by <a href="https://hanlab.mit.edu/projects/dc-ae">DC-AE</a> with 32x latent space</p>
|
| 362 |
+
<p style="font-size: 16px; font-weight: bold;">Unsafe word will give you a 'Red Heart' in the image instead.</p>
|
| 363 |
+
"""
|
| 364 |
+
if model_size == "0.6":
|
| 365 |
+
DESCRIPTION += "\n<p>0.6B model's text rendering ability is limited.</p>"
|
| 366 |
+
if not torch.cuda.is_available():
|
| 367 |
+
DESCRIPTION += "\n<p>Running on CPU 🥶 This demo does not work on CPU.</p>"
|
| 368 |
+
|
| 369 |
+
examples = [
|
| 370 |
+
'a cyberpunk cat with a neon sign that says "Sana"',
|
| 371 |
+
"A very detailed and realistic full body photo set of a tall, slim, and athletic Shiba Inu in a white oversized straight t-shirt, white shorts, and short white shoes.",
|
| 372 |
+
"Pirate ship trapped in a cosmic maelstrom nebula, rendered in cosmic beach whirlpool engine, volumetric lighting, spectacular, ambient lights, light pollution, cinematic atmosphere, art nouveau style, illustration art artwork by SenseiJaye, intricate detail.",
|
| 373 |
+
"portrait photo of a girl, photograph, highly detailed face, depth of field",
|
| 374 |
+
'make me a logo that says "So Fast" with a really cool flying dragon shape with lightning sparks all over the sides and all of it contains Indonesian language',
|
| 375 |
+
"🐶 Wearing 🕶 flying on the 🌈",
|
| 376 |
+
# "👧 with 🌹 in the ❄️",
|
| 377 |
+
# "an old rusted robot wearing pants and a jacket riding skis in a supermarket.",
|
| 378 |
+
# "professional portrait photo of an anthropomorphic cat wearing fancy gentleman hat and jacket walking in autumn forest.",
|
| 379 |
+
# "Astronaut in a jungle, cold color palette, muted colors, detailed",
|
| 380 |
+
# "a stunning and luxurious bedroom carved into a rocky mountainside seamlessly blending nature with modern design with a plush earth-toned bed textured stone walls circular fireplace massive uniquely shaped window framing snow-capped mountains dense forests",
|
| 381 |
+
]
|
| 382 |
+
|
| 383 |
+
css = """
|
| 384 |
+
.gradio-container{max-width: 1024px !important}
|
| 385 |
+
h1{text-align:center}
|
| 386 |
+
"""
|
| 387 |
+
with gr.Blocks(css=css) as demo:
|
| 388 |
+
gr.Markdown(title)
|
| 389 |
+
gr.Markdown(DESCRIPTION)
|
| 390 |
+
gr.DuplicateButton(
|
| 391 |
+
value="Duplicate Space for private use",
|
| 392 |
+
elem_id="duplicate-button",
|
| 393 |
+
visible=os.getenv("SHOW_DUPLICATE_BUTTON") == "1",
|
| 394 |
+
)
|
| 395 |
+
info_box = gr.Markdown(
|
| 396 |
+
value=f"<span style='font-size: 16px; font-weight: bold;'>Total inference runs: </span><span style='font-size: 16px; color:red; font-weight: bold;'>{read_inference_count()}</span>"
|
| 397 |
+
)
|
| 398 |
+
demo.load(fn=update_inference_count, outputs=info_box) # update the value when re-loading the page
|
| 399 |
+
# with gr.Row(equal_height=False):
|
| 400 |
+
with gr.Group():
|
| 401 |
+
with gr.Row():
|
| 402 |
+
prompt = gr.Text(
|
| 403 |
+
label="Prompt",
|
| 404 |
+
show_label=False,
|
| 405 |
+
max_lines=1,
|
| 406 |
+
placeholder="Enter your prompt",
|
| 407 |
+
container=False,
|
| 408 |
+
)
|
| 409 |
+
run_button = gr.Button("Run-sana", scale=0)
|
| 410 |
+
run_button2 = gr.Button("Run-flux", scale=0)
|
| 411 |
+
|
| 412 |
+
with gr.Row():
|
| 413 |
+
result = gr.Gallery(label="Result from Sana", show_label=True, columns=NUM_IMAGES_PER_PROMPT, format="webp")
|
| 414 |
+
result_2 = gr.Gallery(
|
| 415 |
+
label="Result from FLUX", show_label=True, columns=NUM_IMAGES_PER_PROMPT, format="webp"
|
| 416 |
+
)
|
| 417 |
+
|
| 418 |
+
with gr.Accordion("Advanced options", open=False):
|
| 419 |
+
with gr.Group():
|
| 420 |
+
with gr.Row(visible=True):
|
| 421 |
+
height = gr.Slider(
|
| 422 |
+
label="Height",
|
| 423 |
+
minimum=256,
|
| 424 |
+
maximum=MAX_IMAGE_SIZE,
|
| 425 |
+
step=32,
|
| 426 |
+
value=1024,
|
| 427 |
+
)
|
| 428 |
+
width = gr.Slider(
|
| 429 |
+
label="Width",
|
| 430 |
+
minimum=256,
|
| 431 |
+
maximum=MAX_IMAGE_SIZE,
|
| 432 |
+
step=32,
|
| 433 |
+
value=1024,
|
| 434 |
+
)
|
| 435 |
+
with gr.Row():
|
| 436 |
+
flow_dpms_inference_steps = gr.Slider(
|
| 437 |
+
label="Sampling steps",
|
| 438 |
+
minimum=5,
|
| 439 |
+
maximum=40,
|
| 440 |
+
step=1,
|
| 441 |
+
value=18,
|
| 442 |
+
)
|
| 443 |
+
flow_dpms_guidance_scale = gr.Slider(
|
| 444 |
+
label="CFG Guidance scale",
|
| 445 |
+
minimum=1,
|
| 446 |
+
maximum=10,
|
| 447 |
+
step=0.1,
|
| 448 |
+
value=5.0,
|
| 449 |
+
)
|
| 450 |
+
flow_dpms_pag_guidance_scale = gr.Slider(
|
| 451 |
+
label="PAG Guidance scale",
|
| 452 |
+
minimum=1,
|
| 453 |
+
maximum=4,
|
| 454 |
+
step=0.5,
|
| 455 |
+
value=2.0,
|
| 456 |
+
)
|
| 457 |
+
with gr.Row():
|
| 458 |
+
use_negative_prompt = gr.Checkbox(label="Use negative prompt", value=False, visible=True)
|
| 459 |
+
negative_prompt = gr.Text(
|
| 460 |
+
label="Negative prompt",
|
| 461 |
+
max_lines=1,
|
| 462 |
+
placeholder="Enter a negative prompt",
|
| 463 |
+
visible=True,
|
| 464 |
+
)
|
| 465 |
+
style_selection = gr.Radio(
|
| 466 |
+
show_label=True,
|
| 467 |
+
container=True,
|
| 468 |
+
interactive=True,
|
| 469 |
+
choices=STYLE_NAMES,
|
| 470 |
+
value=DEFAULT_STYLE_NAME,
|
| 471 |
+
label="Image Style",
|
| 472 |
+
)
|
| 473 |
+
seed = gr.Slider(
|
| 474 |
+
label="Seed",
|
| 475 |
+
minimum=0,
|
| 476 |
+
maximum=MAX_SEED,
|
| 477 |
+
step=1,
|
| 478 |
+
value=0,
|
| 479 |
+
)
|
| 480 |
+
randomize_seed = gr.Checkbox(label="Randomize seed", value=True)
|
| 481 |
+
with gr.Row(visible=True):
|
| 482 |
+
schedule = gr.Radio(
|
| 483 |
+
show_label=True,
|
| 484 |
+
container=True,
|
| 485 |
+
interactive=True,
|
| 486 |
+
choices=SCHEDULE_NAME,
|
| 487 |
+
value=DEFAULT_SCHEDULE_NAME,
|
| 488 |
+
label="Sampler Schedule",
|
| 489 |
+
visible=True,
|
| 490 |
+
)
|
| 491 |
+
num_imgs = gr.Slider(
|
| 492 |
+
label="Num Images",
|
| 493 |
+
minimum=1,
|
| 494 |
+
maximum=6,
|
| 495 |
+
step=1,
|
| 496 |
+
value=1,
|
| 497 |
+
)
|
| 498 |
+
|
| 499 |
+
run_button.click(fn=run_inference, inputs=num_imgs, outputs=info_box)
|
| 500 |
+
|
| 501 |
+
gr.Examples(
|
| 502 |
+
examples=examples,
|
| 503 |
+
inputs=prompt,
|
| 504 |
+
outputs=[result],
|
| 505 |
+
fn=generate,
|
| 506 |
+
cache_examples=CACHE_EXAMPLES,
|
| 507 |
+
)
|
| 508 |
+
gr.Examples(
|
| 509 |
+
examples=examples,
|
| 510 |
+
inputs=prompt,
|
| 511 |
+
outputs=[result_2],
|
| 512 |
+
fn=generate_2,
|
| 513 |
+
cache_examples=CACHE_EXAMPLES,
|
| 514 |
+
)
|
| 515 |
+
|
| 516 |
+
use_negative_prompt.change(
|
| 517 |
+
fn=lambda x: gr.update(visible=x),
|
| 518 |
+
inputs=use_negative_prompt,
|
| 519 |
+
outputs=negative_prompt,
|
| 520 |
+
api_name=False,
|
| 521 |
+
)
|
| 522 |
+
|
| 523 |
+
run_button.click(
|
| 524 |
+
fn=generate,
|
| 525 |
+
inputs=[
|
| 526 |
+
prompt,
|
| 527 |
+
negative_prompt,
|
| 528 |
+
style_selection,
|
| 529 |
+
use_negative_prompt,
|
| 530 |
+
num_imgs,
|
| 531 |
+
seed,
|
| 532 |
+
height,
|
| 533 |
+
width,
|
| 534 |
+
flow_dpms_guidance_scale,
|
| 535 |
+
flow_dpms_pag_guidance_scale,
|
| 536 |
+
flow_dpms_inference_steps,
|
| 537 |
+
randomize_seed,
|
| 538 |
+
],
|
| 539 |
+
outputs=[result],
|
| 540 |
+
queue=True,
|
| 541 |
+
)
|
| 542 |
+
|
| 543 |
+
run_button2.click(
|
| 544 |
+
fn=generate_2,
|
| 545 |
+
inputs=[
|
| 546 |
+
prompt,
|
| 547 |
+
negative_prompt,
|
| 548 |
+
style_selection,
|
| 549 |
+
use_negative_prompt,
|
| 550 |
+
num_imgs,
|
| 551 |
+
seed,
|
| 552 |
+
height,
|
| 553 |
+
width,
|
| 554 |
+
flow_dpms_guidance_scale,
|
| 555 |
+
flow_dpms_pag_guidance_scale,
|
| 556 |
+
flow_dpms_inference_steps,
|
| 557 |
+
randomize_seed,
|
| 558 |
+
],
|
| 559 |
+
outputs=[result_2],
|
| 560 |
+
queue=True,
|
| 561 |
+
)
|
| 562 |
+
|
| 563 |
+
|
| 564 |
+
if __name__ == "__main__":
|
| 565 |
+
demo.queue(max_size=20).launch(server_name="0.0.0.0", server_port=DEMO_PORT, debug=True, share=True)
|
app/safety_check.py
ADDED
|
@@ -0,0 +1,72 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 NVIDIA CORPORATION & AFFILIATES
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
#
|
| 15 |
+
# SPDX-License-Identifier: Apache-2.0
|
| 16 |
+
# This file is copy from https://github.com/mit-han-lab/hart/blob/main/hart/utils/safety_check.py
|
| 17 |
+
import json
|
| 18 |
+
from functools import lru_cache
|
| 19 |
+
from typing import Dict, Sequence
|
| 20 |
+
|
| 21 |
+
import torch
|
| 22 |
+
import transformers
|
| 23 |
+
from torch.nn.functional import softmax
|
| 24 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 25 |
+
|
| 26 |
+
__all__ = ["is_dangerous"]
|
| 27 |
+
|
| 28 |
+
__rank, __local_rank, __world_size, __device = (
|
| 29 |
+
0,
|
| 30 |
+
0,
|
| 31 |
+
1,
|
| 32 |
+
"cuda" if torch.cuda.is_available() else "cpu",
|
| 33 |
+
)
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
safety_policy = """
|
| 37 |
+
The prompt must not seek to generate harmful, abusive, hateful, sexually explicit, or otherwise inappropriate content targeting individuals or protected groups.
|
| 38 |
+
"""
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def is_dangerous(tokenizer, model, user_prompt, threshold=0.5):
|
| 42 |
+
prompt = f"""You are a policy expert trying to help determine whether a user
|
| 43 |
+
prompt is in violation of the defined safety policies.
|
| 44 |
+
|
| 45 |
+
<start_of_turn>
|
| 46 |
+
Human Question: {user_prompt.strip()}
|
| 47 |
+
<end_of_turn>
|
| 48 |
+
|
| 49 |
+
Our safety principle is defined in the below:
|
| 50 |
+
|
| 51 |
+
{safety_policy.strip()}
|
| 52 |
+
|
| 53 |
+
Does the human question violate the above principle? Your answer must start
|
| 54 |
+
with 'Yes' or 'No'. And then walk through step by step to be sure we answer
|
| 55 |
+
correctly.
|
| 56 |
+
"""
|
| 57 |
+
|
| 58 |
+
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
|
| 59 |
+
with torch.no_grad():
|
| 60 |
+
logits = model(**inputs).logits
|
| 61 |
+
|
| 62 |
+
# Extract the logits for the Yes and No tokens
|
| 63 |
+
vocab = tokenizer.get_vocab()
|
| 64 |
+
selected_logits = logits[0, -1, [vocab["Yes"], vocab["No"]]]
|
| 65 |
+
|
| 66 |
+
# Convert these logits to a probability with softmax
|
| 67 |
+
probabilities = softmax(selected_logits, dim=0)
|
| 68 |
+
|
| 69 |
+
# Return probability of 'Yes'
|
| 70 |
+
score = probabilities[0].item()
|
| 71 |
+
|
| 72 |
+
return score > threshold
|
app/sana_controlnet_pipeline.py
ADDED
|
@@ -0,0 +1,353 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 NVIDIA CORPORATION & AFFILIATES
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
#
|
| 15 |
+
# SPDX-License-Identifier: Apache-2.0
|
| 16 |
+
import warnings
|
| 17 |
+
from dataclasses import dataclass, field
|
| 18 |
+
from typing import Optional, Tuple
|
| 19 |
+
|
| 20 |
+
import numpy as np
|
| 21 |
+
import pyrallis
|
| 22 |
+
import torch
|
| 23 |
+
import torch.nn as nn
|
| 24 |
+
from PIL import Image
|
| 25 |
+
|
| 26 |
+
warnings.filterwarnings("ignore") # ignore warning
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
from diffusion import DPMS, FlowEuler
|
| 30 |
+
from diffusion.data.datasets.utils import (
|
| 31 |
+
ASPECT_RATIO_512_TEST,
|
| 32 |
+
ASPECT_RATIO_1024_TEST,
|
| 33 |
+
ASPECT_RATIO_2048_TEST,
|
| 34 |
+
ASPECT_RATIO_4096_TEST,
|
| 35 |
+
)
|
| 36 |
+
from diffusion.model.builder import build_model, get_tokenizer_and_text_encoder, get_vae, vae_decode, vae_encode
|
| 37 |
+
from diffusion.model.utils import get_weight_dtype, prepare_prompt_ar, resize_and_crop_tensor
|
| 38 |
+
from diffusion.utils.config import SanaConfig, model_init_config
|
| 39 |
+
from diffusion.utils.logger import get_root_logger
|
| 40 |
+
from tools.controlnet.utils import get_scribble_map, transform_control_signal
|
| 41 |
+
from tools.download import find_model
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def guidance_type_select(default_guidance_type, pag_scale, attn_type):
|
| 45 |
+
guidance_type = default_guidance_type
|
| 46 |
+
if not (pag_scale > 1.0 and attn_type == "linear"):
|
| 47 |
+
guidance_type = "classifier-free"
|
| 48 |
+
elif pag_scale > 1.0 and attn_type == "linear":
|
| 49 |
+
guidance_type = "classifier-free_PAG"
|
| 50 |
+
return guidance_type
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def classify_height_width_bin(height: int, width: int, ratios: dict) -> Tuple[int, int]:
|
| 54 |
+
"""Returns binned height and width."""
|
| 55 |
+
ar = float(height / width)
|
| 56 |
+
closest_ratio = min(ratios.keys(), key=lambda ratio: abs(float(ratio) - ar))
|
| 57 |
+
default_hw = ratios[closest_ratio]
|
| 58 |
+
return int(default_hw[0]), int(default_hw[1])
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def get_ar_from_ref_image(ref_image):
|
| 62 |
+
def reduce_ratio(h, w):
|
| 63 |
+
def gcd(a, b):
|
| 64 |
+
while b:
|
| 65 |
+
a, b = b, a % b
|
| 66 |
+
return a
|
| 67 |
+
|
| 68 |
+
divisor = gcd(h, w)
|
| 69 |
+
return f"{h // divisor}:{w // divisor}"
|
| 70 |
+
|
| 71 |
+
if isinstance(ref_image, str):
|
| 72 |
+
ref_image = Image.open(ref_image)
|
| 73 |
+
w, h = ref_image.size
|
| 74 |
+
return reduce_ratio(h, w)
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
@dataclass
|
| 78 |
+
class SanaControlNetInference(SanaConfig):
|
| 79 |
+
config: Optional[str] = "configs/sana_config/1024ms/Sana_1600M_img1024.yaml" # config
|
| 80 |
+
model_path: str = field(
|
| 81 |
+
default="output/Sana_D20/SANA.pth", metadata={"help": "Path to the model file (positional)"}
|
| 82 |
+
)
|
| 83 |
+
output: str = "./output"
|
| 84 |
+
bs: int = 1
|
| 85 |
+
image_size: int = 1024
|
| 86 |
+
cfg_scale: float = 5.0
|
| 87 |
+
pag_scale: float = 2.0
|
| 88 |
+
seed: int = 42
|
| 89 |
+
step: int = -1
|
| 90 |
+
custom_image_size: Optional[int] = None
|
| 91 |
+
shield_model_path: str = field(
|
| 92 |
+
default="google/shieldgemma-2b",
|
| 93 |
+
metadata={"help": "The path to shield model, we employ ShieldGemma-2B by default."},
|
| 94 |
+
)
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
class SanaControlNetPipeline(nn.Module):
|
| 98 |
+
def __init__(
|
| 99 |
+
self,
|
| 100 |
+
config: Optional[str] = "configs/sana_config/1024ms/Sana_1600M_img1024.yaml",
|
| 101 |
+
):
|
| 102 |
+
super().__init__()
|
| 103 |
+
config = pyrallis.load(SanaControlNetInference, open(config))
|
| 104 |
+
self.args = self.config = config
|
| 105 |
+
|
| 106 |
+
# set some hyper-parameters
|
| 107 |
+
self.image_size = self.config.model.image_size
|
| 108 |
+
|
| 109 |
+
self.device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
|
| 110 |
+
logger = get_root_logger()
|
| 111 |
+
self.logger = logger
|
| 112 |
+
self.progress_fn = lambda progress, desc: None
|
| 113 |
+
self.thickness = 2
|
| 114 |
+
self.blend_alpha = 0.0
|
| 115 |
+
|
| 116 |
+
self.latent_size = self.image_size // config.vae.vae_downsample_rate
|
| 117 |
+
self.max_sequence_length = config.text_encoder.model_max_length
|
| 118 |
+
self.flow_shift = config.scheduler.flow_shift
|
| 119 |
+
guidance_type = "classifier-free_PAG"
|
| 120 |
+
|
| 121 |
+
weight_dtype = get_weight_dtype(config.model.mixed_precision)
|
| 122 |
+
self.weight_dtype = weight_dtype
|
| 123 |
+
self.vae_dtype = get_weight_dtype(config.vae.weight_dtype)
|
| 124 |
+
|
| 125 |
+
self.base_ratios = eval(f"ASPECT_RATIO_{self.image_size}_TEST")
|
| 126 |
+
self.vis_sampler = self.config.scheduler.vis_sampler
|
| 127 |
+
logger.info(f"Sampler {self.vis_sampler}, flow_shift: {self.flow_shift}")
|
| 128 |
+
self.guidance_type = guidance_type_select(guidance_type, self.args.pag_scale, config.model.attn_type)
|
| 129 |
+
logger.info(f"Inference with {self.weight_dtype}, PAG guidance layer: {self.config.model.pag_applied_layers}")
|
| 130 |
+
|
| 131 |
+
# 1. build vae and text encoder
|
| 132 |
+
self.vae = self.build_vae(config.vae)
|
| 133 |
+
self.tokenizer, self.text_encoder = self.build_text_encoder(config.text_encoder)
|
| 134 |
+
|
| 135 |
+
# 2. build Sana model
|
| 136 |
+
self.model = self.build_sana_model(config).to(self.device)
|
| 137 |
+
|
| 138 |
+
# 3. pre-compute null embedding
|
| 139 |
+
with torch.no_grad():
|
| 140 |
+
null_caption_token = self.tokenizer(
|
| 141 |
+
"", max_length=self.max_sequence_length, padding="max_length", truncation=True, return_tensors="pt"
|
| 142 |
+
).to(self.device)
|
| 143 |
+
self.null_caption_embs = self.text_encoder(null_caption_token.input_ids, null_caption_token.attention_mask)[
|
| 144 |
+
0
|
| 145 |
+
]
|
| 146 |
+
|
| 147 |
+
def build_vae(self, config):
|
| 148 |
+
vae = get_vae(config.vae_type, config.vae_pretrained, self.device).to(self.vae_dtype)
|
| 149 |
+
return vae
|
| 150 |
+
|
| 151 |
+
def build_text_encoder(self, config):
|
| 152 |
+
tokenizer, text_encoder = get_tokenizer_and_text_encoder(name=config.text_encoder_name, device=self.device)
|
| 153 |
+
return tokenizer, text_encoder
|
| 154 |
+
|
| 155 |
+
def build_sana_model(self, config):
|
| 156 |
+
# model setting
|
| 157 |
+
model_kwargs = model_init_config(config, latent_size=self.latent_size)
|
| 158 |
+
model = build_model(
|
| 159 |
+
config.model.model,
|
| 160 |
+
use_fp32_attention=config.model.get("fp32_attention", False) and config.model.mixed_precision != "bf16",
|
| 161 |
+
**model_kwargs,
|
| 162 |
+
)
|
| 163 |
+
self.logger.info(f"use_fp32_attention: {model.fp32_attention}")
|
| 164 |
+
self.logger.info(
|
| 165 |
+
f"{model.__class__.__name__}:{config.model.model},"
|
| 166 |
+
f"Model Parameters: {sum(p.numel() for p in model.parameters()):,}"
|
| 167 |
+
)
|
| 168 |
+
return model
|
| 169 |
+
|
| 170 |
+
def from_pretrained(self, model_path):
|
| 171 |
+
state_dict = find_model(model_path)
|
| 172 |
+
state_dict = state_dict.get("state_dict", state_dict)
|
| 173 |
+
if "pos_embed" in state_dict:
|
| 174 |
+
del state_dict["pos_embed"]
|
| 175 |
+
missing, unexpected = self.model.load_state_dict(state_dict, strict=False)
|
| 176 |
+
self.model.eval().to(self.weight_dtype)
|
| 177 |
+
|
| 178 |
+
self.logger.info("Generating sample from ckpt: %s" % model_path)
|
| 179 |
+
self.logger.warning(f"Missing keys: {missing}")
|
| 180 |
+
self.logger.warning(f"Unexpected keys: {unexpected}")
|
| 181 |
+
|
| 182 |
+
def register_progress_bar(self, progress_fn=None):
|
| 183 |
+
self.progress_fn = progress_fn if progress_fn is not None else self.progress_fn
|
| 184 |
+
|
| 185 |
+
def set_blend_alpha(self, blend_alpha):
|
| 186 |
+
self.blend_alpha = blend_alpha
|
| 187 |
+
|
| 188 |
+
@torch.inference_mode()
|
| 189 |
+
def forward(
|
| 190 |
+
self,
|
| 191 |
+
prompt=None,
|
| 192 |
+
ref_image=None,
|
| 193 |
+
negative_prompt="",
|
| 194 |
+
num_inference_steps=20,
|
| 195 |
+
guidance_scale=5,
|
| 196 |
+
pag_guidance_scale=2.5,
|
| 197 |
+
num_images_per_prompt=1,
|
| 198 |
+
sketch_thickness=2,
|
| 199 |
+
generator=torch.Generator().manual_seed(42),
|
| 200 |
+
latents=None,
|
| 201 |
+
):
|
| 202 |
+
self.ori_height, self.ori_width = ref_image.height, ref_image.width
|
| 203 |
+
self.guidance_type = guidance_type_select(self.guidance_type, pag_guidance_scale, self.config.model.attn_type)
|
| 204 |
+
|
| 205 |
+
# 1. pre-compute negative embedding
|
| 206 |
+
if negative_prompt != "":
|
| 207 |
+
null_caption_token = self.tokenizer(
|
| 208 |
+
negative_prompt,
|
| 209 |
+
max_length=self.max_sequence_length,
|
| 210 |
+
padding="max_length",
|
| 211 |
+
truncation=True,
|
| 212 |
+
return_tensors="pt",
|
| 213 |
+
).to(self.device)
|
| 214 |
+
self.null_caption_embs = self.text_encoder(null_caption_token.input_ids, null_caption_token.attention_mask)[
|
| 215 |
+
0
|
| 216 |
+
]
|
| 217 |
+
|
| 218 |
+
if prompt is None:
|
| 219 |
+
prompt = [""]
|
| 220 |
+
prompts = prompt if isinstance(prompt, list) else [prompt]
|
| 221 |
+
samples = []
|
| 222 |
+
|
| 223 |
+
for prompt in prompts:
|
| 224 |
+
# data prepare
|
| 225 |
+
prompts, hw, ar = (
|
| 226 |
+
[],
|
| 227 |
+
torch.tensor([[self.image_size, self.image_size]], dtype=torch.float, device=self.device).repeat(
|
| 228 |
+
num_images_per_prompt, 1
|
| 229 |
+
),
|
| 230 |
+
torch.tensor([[1.0]], device=self.device).repeat(num_images_per_prompt, 1),
|
| 231 |
+
)
|
| 232 |
+
|
| 233 |
+
ar = get_ar_from_ref_image(ref_image)
|
| 234 |
+
prompt += f" --ar {ar}"
|
| 235 |
+
for _ in range(num_images_per_prompt):
|
| 236 |
+
prompt_clean, _, hw, ar, custom_hw = prepare_prompt_ar(
|
| 237 |
+
prompt, self.base_ratios, device=self.device, show=False
|
| 238 |
+
)
|
| 239 |
+
prompts.append(prompt_clean.strip())
|
| 240 |
+
|
| 241 |
+
self.latent_size_h, self.latent_size_w = (
|
| 242 |
+
int(hw[0, 0] // self.config.vae.vae_downsample_rate),
|
| 243 |
+
int(hw[0, 1] // self.config.vae.vae_downsample_rate),
|
| 244 |
+
)
|
| 245 |
+
|
| 246 |
+
with torch.no_grad():
|
| 247 |
+
# prepare text feature
|
| 248 |
+
if not self.config.text_encoder.chi_prompt:
|
| 249 |
+
max_length_all = self.config.text_encoder.model_max_length
|
| 250 |
+
prompts_all = prompts
|
| 251 |
+
else:
|
| 252 |
+
chi_prompt = "\n".join(self.config.text_encoder.chi_prompt)
|
| 253 |
+
prompts_all = [chi_prompt + prompt for prompt in prompts]
|
| 254 |
+
num_chi_prompt_tokens = len(self.tokenizer.encode(chi_prompt))
|
| 255 |
+
max_length_all = (
|
| 256 |
+
num_chi_prompt_tokens + self.config.text_encoder.model_max_length - 2
|
| 257 |
+
) # magic number 2: [bos], [_]
|
| 258 |
+
|
| 259 |
+
caption_token = self.tokenizer(
|
| 260 |
+
prompts_all,
|
| 261 |
+
max_length=max_length_all,
|
| 262 |
+
padding="max_length",
|
| 263 |
+
truncation=True,
|
| 264 |
+
return_tensors="pt",
|
| 265 |
+
).to(device=self.device)
|
| 266 |
+
select_index = [0] + list(range(-self.config.text_encoder.model_max_length + 1, 0))
|
| 267 |
+
caption_embs = self.text_encoder(caption_token.input_ids, caption_token.attention_mask)[0][:, None][
|
| 268 |
+
:, :, select_index
|
| 269 |
+
].to(self.weight_dtype)
|
| 270 |
+
emb_masks = caption_token.attention_mask[:, select_index]
|
| 271 |
+
null_y = self.null_caption_embs.repeat(len(prompts), 1, 1)[:, None].to(self.weight_dtype)
|
| 272 |
+
|
| 273 |
+
n = len(prompts)
|
| 274 |
+
if latents is None:
|
| 275 |
+
z = torch.randn(
|
| 276 |
+
n,
|
| 277 |
+
self.config.vae.vae_latent_dim,
|
| 278 |
+
self.latent_size_h,
|
| 279 |
+
self.latent_size_w,
|
| 280 |
+
generator=generator,
|
| 281 |
+
device=self.device,
|
| 282 |
+
)
|
| 283 |
+
else:
|
| 284 |
+
z = latents.to(self.device)
|
| 285 |
+
model_kwargs = dict(data_info={"img_hw": hw, "aspect_ratio": ar}, mask=emb_masks)
|
| 286 |
+
|
| 287 |
+
# control signal
|
| 288 |
+
if isinstance(ref_image, str):
|
| 289 |
+
ref_image = cv2.imread(ref_image)
|
| 290 |
+
elif isinstance(ref_image, Image.Image):
|
| 291 |
+
ref_image = np.array(ref_image)
|
| 292 |
+
control_signal = get_scribble_map(
|
| 293 |
+
input_image=ref_image,
|
| 294 |
+
det="Scribble_HED",
|
| 295 |
+
detect_resolution=int(hw.min()),
|
| 296 |
+
thickness=sketch_thickness,
|
| 297 |
+
)
|
| 298 |
+
|
| 299 |
+
control_signal = transform_control_signal(control_signal, hw).to(self.device).to(self.weight_dtype)
|
| 300 |
+
|
| 301 |
+
control_signal_latent = vae_encode(
|
| 302 |
+
self.config.vae.vae_type, self.vae, control_signal, self.config.vae.sample_posterior, self.device
|
| 303 |
+
)
|
| 304 |
+
|
| 305 |
+
model_kwargs["control_signal"] = control_signal_latent
|
| 306 |
+
|
| 307 |
+
if self.vis_sampler == "flow_euler":
|
| 308 |
+
flow_solver = FlowEuler(
|
| 309 |
+
self.model,
|
| 310 |
+
condition=caption_embs,
|
| 311 |
+
uncondition=null_y,
|
| 312 |
+
cfg_scale=guidance_scale,
|
| 313 |
+
model_kwargs=model_kwargs,
|
| 314 |
+
)
|
| 315 |
+
sample = flow_solver.sample(
|
| 316 |
+
z,
|
| 317 |
+
steps=num_inference_steps,
|
| 318 |
+
)
|
| 319 |
+
elif self.vis_sampler == "flow_dpm-solver":
|
| 320 |
+
scheduler = DPMS(
|
| 321 |
+
self.model.forward_with_dpmsolver,
|
| 322 |
+
condition=caption_embs,
|
| 323 |
+
uncondition=null_y,
|
| 324 |
+
guidance_type=self.guidance_type,
|
| 325 |
+
cfg_scale=guidance_scale,
|
| 326 |
+
model_type="flow",
|
| 327 |
+
model_kwargs=model_kwargs,
|
| 328 |
+
schedule="FLOW",
|
| 329 |
+
)
|
| 330 |
+
scheduler.register_progress_bar(self.progress_fn)
|
| 331 |
+
sample = scheduler.sample(
|
| 332 |
+
z,
|
| 333 |
+
steps=num_inference_steps,
|
| 334 |
+
order=2,
|
| 335 |
+
skip_type="time_uniform_flow",
|
| 336 |
+
method="multistep",
|
| 337 |
+
flow_shift=self.flow_shift,
|
| 338 |
+
)
|
| 339 |
+
|
| 340 |
+
sample = sample.to(self.vae_dtype)
|
| 341 |
+
with torch.no_grad():
|
| 342 |
+
sample = vae_decode(self.config.vae.vae_type, self.vae, sample)
|
| 343 |
+
|
| 344 |
+
if self.blend_alpha > 0:
|
| 345 |
+
print(f"blend image and mask with alpha: {self.blend_alpha}")
|
| 346 |
+
sample = sample * (1 - self.blend_alpha) + control_signal * self.blend_alpha
|
| 347 |
+
|
| 348 |
+
sample = resize_and_crop_tensor(sample, self.ori_width, self.ori_height)
|
| 349 |
+
samples.append(sample)
|
| 350 |
+
|
| 351 |
+
return sample
|
| 352 |
+
|
| 353 |
+
return samples
|
app/sana_pipeline.py
ADDED
|
@@ -0,0 +1,304 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 NVIDIA CORPORATION & AFFILIATES
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
#
|
| 15 |
+
# SPDX-License-Identifier: Apache-2.0
|
| 16 |
+
import argparse
|
| 17 |
+
import warnings
|
| 18 |
+
from dataclasses import dataclass, field
|
| 19 |
+
from typing import Optional, Tuple
|
| 20 |
+
|
| 21 |
+
import pyrallis
|
| 22 |
+
import torch
|
| 23 |
+
import torch.nn as nn
|
| 24 |
+
|
| 25 |
+
warnings.filterwarnings("ignore") # ignore warning
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
from diffusion import DPMS, FlowEuler
|
| 29 |
+
from diffusion.data.datasets.utils import (
|
| 30 |
+
ASPECT_RATIO_512_TEST,
|
| 31 |
+
ASPECT_RATIO_1024_TEST,
|
| 32 |
+
ASPECT_RATIO_2048_TEST,
|
| 33 |
+
ASPECT_RATIO_4096_TEST,
|
| 34 |
+
)
|
| 35 |
+
from diffusion.model.builder import build_model, get_tokenizer_and_text_encoder, get_vae, vae_decode
|
| 36 |
+
from diffusion.model.utils import get_weight_dtype, prepare_prompt_ar, resize_and_crop_tensor
|
| 37 |
+
from diffusion.utils.config import SanaConfig, model_init_config
|
| 38 |
+
from diffusion.utils.logger import get_root_logger
|
| 39 |
+
|
| 40 |
+
# from diffusion.utils.misc import read_config
|
| 41 |
+
from tools.download import find_model
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def guidance_type_select(default_guidance_type, pag_scale, attn_type):
|
| 45 |
+
guidance_type = default_guidance_type
|
| 46 |
+
if not (pag_scale > 1.0 and attn_type == "linear"):
|
| 47 |
+
guidance_type = "classifier-free"
|
| 48 |
+
elif pag_scale > 1.0 and attn_type == "linear":
|
| 49 |
+
guidance_type = "classifier-free_PAG"
|
| 50 |
+
return guidance_type
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def classify_height_width_bin(height: int, width: int, ratios: dict) -> Tuple[int, int]:
|
| 54 |
+
"""Returns binned height and width."""
|
| 55 |
+
ar = float(height / width)
|
| 56 |
+
closest_ratio = min(ratios.keys(), key=lambda ratio: abs(float(ratio) - ar))
|
| 57 |
+
default_hw = ratios[closest_ratio]
|
| 58 |
+
return int(default_hw[0]), int(default_hw[1])
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
@dataclass
|
| 62 |
+
class SanaInference(SanaConfig):
|
| 63 |
+
config: Optional[str] = "configs/sana_config/1024ms/Sana_1600M_img1024.yaml" # config
|
| 64 |
+
model_path: str = field(
|
| 65 |
+
default="output/Sana_D20/SANA.pth", metadata={"help": "Path to the model file (positional)"}
|
| 66 |
+
)
|
| 67 |
+
output: str = "./output"
|
| 68 |
+
bs: int = 1
|
| 69 |
+
image_size: int = 1024
|
| 70 |
+
cfg_scale: float = 5.0
|
| 71 |
+
pag_scale: float = 2.0
|
| 72 |
+
seed: int = 42
|
| 73 |
+
step: int = -1
|
| 74 |
+
custom_image_size: Optional[int] = None
|
| 75 |
+
shield_model_path: str = field(
|
| 76 |
+
default="google/shieldgemma-2b",
|
| 77 |
+
metadata={"help": "The path to shield model, we employ ShieldGemma-2B by default."},
|
| 78 |
+
)
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
class SanaPipeline(nn.Module):
|
| 82 |
+
def __init__(
|
| 83 |
+
self,
|
| 84 |
+
config: Optional[str] = "configs/sana_config/1024ms/Sana_1600M_img1024.yaml",
|
| 85 |
+
):
|
| 86 |
+
super().__init__()
|
| 87 |
+
config = pyrallis.load(SanaInference, open(config))
|
| 88 |
+
self.args = self.config = config
|
| 89 |
+
|
| 90 |
+
# set some hyper-parameters
|
| 91 |
+
self.image_size = self.config.model.image_size
|
| 92 |
+
|
| 93 |
+
self.device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
|
| 94 |
+
logger = get_root_logger()
|
| 95 |
+
self.logger = logger
|
| 96 |
+
self.progress_fn = lambda progress, desc: None
|
| 97 |
+
|
| 98 |
+
self.latent_size = self.image_size // config.vae.vae_downsample_rate
|
| 99 |
+
self.max_sequence_length = config.text_encoder.model_max_length
|
| 100 |
+
self.flow_shift = config.scheduler.flow_shift
|
| 101 |
+
guidance_type = "classifier-free_PAG"
|
| 102 |
+
|
| 103 |
+
weight_dtype = get_weight_dtype(config.model.mixed_precision)
|
| 104 |
+
self.weight_dtype = weight_dtype
|
| 105 |
+
self.vae_dtype = get_weight_dtype(config.vae.weight_dtype)
|
| 106 |
+
|
| 107 |
+
self.base_ratios = eval(f"ASPECT_RATIO_{self.image_size}_TEST")
|
| 108 |
+
self.vis_sampler = self.config.scheduler.vis_sampler
|
| 109 |
+
logger.info(f"Sampler {self.vis_sampler}, flow_shift: {self.flow_shift}")
|
| 110 |
+
self.guidance_type = guidance_type_select(guidance_type, self.args.pag_scale, config.model.attn_type)
|
| 111 |
+
logger.info(f"Inference with {self.weight_dtype}, PAG guidance layer: {self.config.model.pag_applied_layers}")
|
| 112 |
+
|
| 113 |
+
# 1. build vae and text encoder
|
| 114 |
+
self.vae = self.build_vae(config.vae)
|
| 115 |
+
self.tokenizer, self.text_encoder = self.build_text_encoder(config.text_encoder)
|
| 116 |
+
|
| 117 |
+
# 2. build Sana model
|
| 118 |
+
self.model = self.build_sana_model(config).to(self.device)
|
| 119 |
+
|
| 120 |
+
# 3. pre-compute null embedding
|
| 121 |
+
with torch.no_grad():
|
| 122 |
+
null_caption_token = self.tokenizer(
|
| 123 |
+
"", max_length=self.max_sequence_length, padding="max_length", truncation=True, return_tensors="pt"
|
| 124 |
+
).to(self.device)
|
| 125 |
+
self.null_caption_embs = self.text_encoder(null_caption_token.input_ids, null_caption_token.attention_mask)[
|
| 126 |
+
0
|
| 127 |
+
]
|
| 128 |
+
|
| 129 |
+
def build_vae(self, config):
|
| 130 |
+
vae = get_vae(config.vae_type, config.vae_pretrained, self.device).to(self.vae_dtype)
|
| 131 |
+
return vae
|
| 132 |
+
|
| 133 |
+
def build_text_encoder(self, config):
|
| 134 |
+
tokenizer, text_encoder = get_tokenizer_and_text_encoder(name=config.text_encoder_name, device=self.device)
|
| 135 |
+
return tokenizer, text_encoder
|
| 136 |
+
|
| 137 |
+
def build_sana_model(self, config):
|
| 138 |
+
# model setting
|
| 139 |
+
model_kwargs = model_init_config(config, latent_size=self.latent_size)
|
| 140 |
+
model = build_model(
|
| 141 |
+
config.model.model,
|
| 142 |
+
use_fp32_attention=config.model.get("fp32_attention", False) and config.model.mixed_precision != "bf16",
|
| 143 |
+
**model_kwargs,
|
| 144 |
+
)
|
| 145 |
+
self.logger.info(f"use_fp32_attention: {model.fp32_attention}")
|
| 146 |
+
self.logger.info(
|
| 147 |
+
f"{model.__class__.__name__}:{config.model.model},"
|
| 148 |
+
f"Model Parameters: {sum(p.numel() for p in model.parameters()):,}"
|
| 149 |
+
)
|
| 150 |
+
return model
|
| 151 |
+
|
| 152 |
+
def from_pretrained(self, model_path):
|
| 153 |
+
state_dict = find_model(model_path)
|
| 154 |
+
state_dict = state_dict.get("state_dict", state_dict)
|
| 155 |
+
if "pos_embed" in state_dict:
|
| 156 |
+
del state_dict["pos_embed"]
|
| 157 |
+
missing, unexpected = self.model.load_state_dict(state_dict, strict=False)
|
| 158 |
+
self.model.eval().to(self.weight_dtype)
|
| 159 |
+
|
| 160 |
+
self.logger.info("Generating sample from ckpt: %s" % model_path)
|
| 161 |
+
self.logger.warning(f"Missing keys: {missing}")
|
| 162 |
+
self.logger.warning(f"Unexpected keys: {unexpected}")
|
| 163 |
+
|
| 164 |
+
def register_progress_bar(self, progress_fn=None):
|
| 165 |
+
self.progress_fn = progress_fn if progress_fn is not None else self.progress_fn
|
| 166 |
+
|
| 167 |
+
@torch.inference_mode()
|
| 168 |
+
def forward(
|
| 169 |
+
self,
|
| 170 |
+
prompt=None,
|
| 171 |
+
height=1024,
|
| 172 |
+
width=1024,
|
| 173 |
+
negative_prompt="",
|
| 174 |
+
num_inference_steps=20,
|
| 175 |
+
guidance_scale=5,
|
| 176 |
+
pag_guidance_scale=2.5,
|
| 177 |
+
num_images_per_prompt=1,
|
| 178 |
+
generator=torch.Generator().manual_seed(42),
|
| 179 |
+
latents=None,
|
| 180 |
+
):
|
| 181 |
+
self.ori_height, self.ori_width = height, width
|
| 182 |
+
self.height, self.width = classify_height_width_bin(height, width, ratios=self.base_ratios)
|
| 183 |
+
self.latent_size_h, self.latent_size_w = (
|
| 184 |
+
self.height // self.config.vae.vae_downsample_rate,
|
| 185 |
+
self.width // self.config.vae.vae_downsample_rate,
|
| 186 |
+
)
|
| 187 |
+
self.guidance_type = guidance_type_select(self.guidance_type, pag_guidance_scale, self.config.model.attn_type)
|
| 188 |
+
|
| 189 |
+
# 1. pre-compute negative embedding
|
| 190 |
+
if negative_prompt != "":
|
| 191 |
+
null_caption_token = self.tokenizer(
|
| 192 |
+
negative_prompt,
|
| 193 |
+
max_length=self.max_sequence_length,
|
| 194 |
+
padding="max_length",
|
| 195 |
+
truncation=True,
|
| 196 |
+
return_tensors="pt",
|
| 197 |
+
).to(self.device)
|
| 198 |
+
self.null_caption_embs = self.text_encoder(null_caption_token.input_ids, null_caption_token.attention_mask)[
|
| 199 |
+
0
|
| 200 |
+
]
|
| 201 |
+
|
| 202 |
+
if prompt is None:
|
| 203 |
+
prompt = [""]
|
| 204 |
+
prompts = prompt if isinstance(prompt, list) else [prompt]
|
| 205 |
+
samples = []
|
| 206 |
+
|
| 207 |
+
for prompt in prompts:
|
| 208 |
+
# data prepare
|
| 209 |
+
prompts, hw, ar = (
|
| 210 |
+
[],
|
| 211 |
+
torch.tensor([[self.image_size, self.image_size]], dtype=torch.float, device=self.device).repeat(
|
| 212 |
+
num_images_per_prompt, 1
|
| 213 |
+
),
|
| 214 |
+
torch.tensor([[1.0]], device=self.device).repeat(num_images_per_prompt, 1),
|
| 215 |
+
)
|
| 216 |
+
|
| 217 |
+
for _ in range(num_images_per_prompt):
|
| 218 |
+
prompts.append(prepare_prompt_ar(prompt, self.base_ratios, device=self.device, show=False)[0].strip())
|
| 219 |
+
|
| 220 |
+
with torch.no_grad():
|
| 221 |
+
# prepare text feature
|
| 222 |
+
if not self.config.text_encoder.chi_prompt:
|
| 223 |
+
max_length_all = self.config.text_encoder.model_max_length
|
| 224 |
+
prompts_all = prompts
|
| 225 |
+
else:
|
| 226 |
+
chi_prompt = "\n".join(self.config.text_encoder.chi_prompt)
|
| 227 |
+
prompts_all = [chi_prompt + prompt for prompt in prompts]
|
| 228 |
+
num_chi_prompt_tokens = len(self.tokenizer.encode(chi_prompt))
|
| 229 |
+
max_length_all = (
|
| 230 |
+
num_chi_prompt_tokens + self.config.text_encoder.model_max_length - 2
|
| 231 |
+
) # magic number 2: [bos], [_]
|
| 232 |
+
|
| 233 |
+
caption_token = self.tokenizer(
|
| 234 |
+
prompts_all,
|
| 235 |
+
max_length=max_length_all,
|
| 236 |
+
padding="max_length",
|
| 237 |
+
truncation=True,
|
| 238 |
+
return_tensors="pt",
|
| 239 |
+
).to(device=self.device)
|
| 240 |
+
select_index = [0] + list(range(-self.config.text_encoder.model_max_length + 1, 0))
|
| 241 |
+
caption_embs = self.text_encoder(caption_token.input_ids, caption_token.attention_mask)[0][:, None][
|
| 242 |
+
:, :, select_index
|
| 243 |
+
].to(self.weight_dtype)
|
| 244 |
+
emb_masks = caption_token.attention_mask[:, select_index]
|
| 245 |
+
null_y = self.null_caption_embs.repeat(len(prompts), 1, 1)[:, None].to(self.weight_dtype)
|
| 246 |
+
|
| 247 |
+
n = len(prompts)
|
| 248 |
+
if latents is None:
|
| 249 |
+
z = torch.randn(
|
| 250 |
+
n,
|
| 251 |
+
self.config.vae.vae_latent_dim,
|
| 252 |
+
self.latent_size_h,
|
| 253 |
+
self.latent_size_w,
|
| 254 |
+
generator=generator,
|
| 255 |
+
device=self.device,
|
| 256 |
+
)
|
| 257 |
+
else:
|
| 258 |
+
z = latents.to(self.device)
|
| 259 |
+
model_kwargs = dict(data_info={"img_hw": hw, "aspect_ratio": ar}, mask=emb_masks)
|
| 260 |
+
if self.vis_sampler == "flow_euler":
|
| 261 |
+
flow_solver = FlowEuler(
|
| 262 |
+
self.model,
|
| 263 |
+
condition=caption_embs,
|
| 264 |
+
uncondition=null_y,
|
| 265 |
+
cfg_scale=guidance_scale,
|
| 266 |
+
model_kwargs=model_kwargs,
|
| 267 |
+
)
|
| 268 |
+
sample = flow_solver.sample(
|
| 269 |
+
z,
|
| 270 |
+
steps=num_inference_steps,
|
| 271 |
+
)
|
| 272 |
+
elif self.vis_sampler == "flow_dpm-solver":
|
| 273 |
+
scheduler = DPMS(
|
| 274 |
+
self.model,
|
| 275 |
+
condition=caption_embs,
|
| 276 |
+
uncondition=null_y,
|
| 277 |
+
guidance_type=self.guidance_type,
|
| 278 |
+
cfg_scale=guidance_scale,
|
| 279 |
+
pag_scale=pag_guidance_scale,
|
| 280 |
+
pag_applied_layers=self.config.model.pag_applied_layers,
|
| 281 |
+
model_type="flow",
|
| 282 |
+
model_kwargs=model_kwargs,
|
| 283 |
+
schedule="FLOW",
|
| 284 |
+
)
|
| 285 |
+
scheduler.register_progress_bar(self.progress_fn)
|
| 286 |
+
sample = scheduler.sample(
|
| 287 |
+
z,
|
| 288 |
+
steps=num_inference_steps,
|
| 289 |
+
order=2,
|
| 290 |
+
skip_type="time_uniform_flow",
|
| 291 |
+
method="multistep",
|
| 292 |
+
flow_shift=self.flow_shift,
|
| 293 |
+
)
|
| 294 |
+
|
| 295 |
+
sample = sample.to(self.vae_dtype)
|
| 296 |
+
with torch.no_grad():
|
| 297 |
+
sample = vae_decode(self.config.vae.vae_type, self.vae, sample)
|
| 298 |
+
|
| 299 |
+
sample = resize_and_crop_tensor(sample, self.ori_width, self.ori_height)
|
| 300 |
+
samples.append(sample)
|
| 301 |
+
|
| 302 |
+
return sample
|
| 303 |
+
|
| 304 |
+
return samples
|
asset/Sana.jpg
ADDED

|
Git LFS Details
|
asset/app_styles/controlnet_app_style.css
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
@import url('https://cdnjs.cloudflare.com/ajax/libs/font-awesome/5.15.1/css/all.min.css');
|
| 2 |
+
|
| 3 |
+
h1{text-align:center}
|
| 4 |
+
|
| 5 |
+
.wrap.svelte-p4aq0j.svelte-p4aq0j {
|
| 6 |
+
display: none;
|
| 7 |
+
}
|
| 8 |
+
|
| 9 |
+
#column_input, #column_output {
|
| 10 |
+
width: 500px;
|
| 11 |
+
display: flex;
|
| 12 |
+
align-items: center;
|
| 13 |
+
}
|
| 14 |
+
|
| 15 |
+
#input_header, #output_header {
|
| 16 |
+
display: flex;
|
| 17 |
+
justify-content: center;
|
| 18 |
+
align-items: center;
|
| 19 |
+
width: 400px;
|
| 20 |
+
}
|
| 21 |
+
|
| 22 |
+
#accessibility {
|
| 23 |
+
text-align: center; /* Center-aligns the text */
|
| 24 |
+
margin: auto; /* Centers the element horizontally */
|
| 25 |
+
}
|
| 26 |
+
|
| 27 |
+
#random_seed {height: 71px;}
|
| 28 |
+
#run_button {height: 87px;}
|
asset/controlnet/ref_images/A transparent sculpture of a duck made out of glass. The sculpture is in front of a painting of a la.jpg
ADDED
|
|
Git LFS Details
|
asset/controlnet/ref_images/a house.png
ADDED

|
Git LFS Details
|
asset/controlnet/ref_images/a living room.png
ADDED

|
Git LFS Details
|
asset/controlnet/ref_images/nvidia.png
ADDED

|
asset/controlnet/samples_controlnet.json
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[
|
| 2 |
+
{
|
| 3 |
+
"prompt": "A transparent sculpture of a duck made out of glass. The sculpture is in front of a painting of a landscape.",
|
| 4 |
+
"ref_image_path": "asset/controlnet/ref_images/A transparent sculpture of a duck made out of glass. The sculpture is in front of a painting of a la.jpg"
|
| 5 |
+
},
|
| 6 |
+
{
|
| 7 |
+
"prompt": "an architecture in INDIA,15th-18th style, with a lot of details",
|
| 8 |
+
"ref_image_path": "asset/controlnet/ref_images/a house.png"
|
| 9 |
+
},
|
| 10 |
+
{
|
| 11 |
+
"prompt": "An IKEA modern style living room with sofa, coffee table, stairs, etc., a brand new theme.",
|
| 12 |
+
"ref_image_path": "asset/controlnet/ref_images/a living room.png"
|
| 13 |
+
},
|
| 14 |
+
{
|
| 15 |
+
"prompt": "A modern new living room with sofa, coffee table, carpet, stairs, etc., high quality high detail, high resolution.",
|
| 16 |
+
"ref_image_path": "asset/controlnet/ref_images/a living room.png"
|
| 17 |
+
},
|
| 18 |
+
{
|
| 19 |
+
"prompt": "big eye, vibrant colors, intricate details, captivating gaze, surreal, dreamlike, fantasy, enchanting, mysterious, magical, moonlit, mystical, ethereal, enchanting {macro lens, high aperture, low ISO}",
|
| 20 |
+
"ref_image_path": "asset/controlnet/ref_images/nvidia.png"
|
| 21 |
+
},
|
| 22 |
+
{
|
| 23 |
+
"prompt": "shining eye, bright and vivid colors, radiant glow, sparkling reflections, joyful, uplifting, optimistic, hopeful, magical, luminous, celestial, dreamy {zoom lens, high aperture, natural light, vibrant color film}",
|
| 24 |
+
"ref_image_path": "asset/controlnet/ref_images/nvidia.png"
|
| 25 |
+
}
|
| 26 |
+
]
|
asset/docs/4bit_sana.md
ADDED
|
@@ -0,0 +1,68 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<!--Copyright 2024 NVIDIA CORPORATION & AFFILIATES
|
| 2 |
+
#
|
| 3 |
+
#
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
# you may not use this file except in compliance with the License.
|
| 6 |
+
# You may obtain a copy of the License at
|
| 7 |
+
#
|
| 8 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
#
|
| 10 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
# See the License for the specific language governing permissions and
|
| 14 |
+
# limitations under the License. -->
|
| 15 |
+
|
| 16 |
+
# 4bit SanaPipeline
|
| 17 |
+
|
| 18 |
+
### 1. Environment setup
|
| 19 |
+
|
| 20 |
+
Follow the official [SVDQuant-Nunchaku](https://github.com/mit-han-lab/nunchaku) repository to set up the environment. The guidance can be found [here](https://github.com/mit-han-lab/nunchaku?tab=readme-ov-file#installation).
|
| 21 |
+
|
| 22 |
+
### 2. Code snap for inference
|
| 23 |
+
|
| 24 |
+
Here we show the code snippet for SanaPipeline. For SanaPAGPipeline, please refer to the [SanaPAGPipeline](https://github.com/mit-han-lab/nunchaku/blob/main/examples/sana_1600m_pag.py) section.
|
| 25 |
+
|
| 26 |
+
```python
|
| 27 |
+
import torch
|
| 28 |
+
from diffusers import SanaPipeline
|
| 29 |
+
|
| 30 |
+
from nunchaku.models.transformer_sana import NunchakuSanaTransformer2DModel
|
| 31 |
+
|
| 32 |
+
transformer = NunchakuSanaTransformer2DModel.from_pretrained("mit-han-lab/svdq-int4-sana-1600m")
|
| 33 |
+
pipe = SanaPipeline.from_pretrained(
|
| 34 |
+
"Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers",
|
| 35 |
+
transformer=transformer,
|
| 36 |
+
variant="bf16",
|
| 37 |
+
torch_dtype=torch.bfloat16,
|
| 38 |
+
).to("cuda")
|
| 39 |
+
|
| 40 |
+
pipe.text_encoder.to(torch.bfloat16)
|
| 41 |
+
pipe.vae.to(torch.bfloat16)
|
| 42 |
+
|
| 43 |
+
image = pipe(
|
| 44 |
+
prompt="A cute 🐼 eating 🎋, ink drawing style",
|
| 45 |
+
height=1024,
|
| 46 |
+
width=1024,
|
| 47 |
+
guidance_scale=4.5,
|
| 48 |
+
num_inference_steps=20,
|
| 49 |
+
generator=torch.Generator().manual_seed(42),
|
| 50 |
+
).images[0]
|
| 51 |
+
image.save("sana_1600m.png")
|
| 52 |
+
```
|
| 53 |
+
|
| 54 |
+
### 3. Online demo
|
| 55 |
+
|
| 56 |
+
1). Launch the 4bit Sana.
|
| 57 |
+
|
| 58 |
+
```bash
|
| 59 |
+
python app/app_sana_4bit.py
|
| 60 |
+
```
|
| 61 |
+
|
| 62 |
+
2). Compare with BF16 version
|
| 63 |
+
|
| 64 |
+
Refer to the original [Nunchaku-Sana.](https://github.com/mit-han-lab/nunchaku/tree/main/app/sana/t2i) guidance for SanaPAGPipeline
|
| 65 |
+
|
| 66 |
+
```bash
|
| 67 |
+
python app/app_sana_4bit_compare_bf16.py
|
| 68 |
+
```
|
asset/docs/8bit_sana.md
ADDED
|
@@ -0,0 +1,109 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<!-- Copyright 2024 The HuggingFace Team. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License. -->
|
| 14 |
+
|
| 15 |
+
# SanaPipeline
|
| 16 |
+
|
| 17 |
+
[SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers](https://huggingface.co/papers/2410.10629) from NVIDIA and MIT HAN Lab, by Enze Xie, Junsong Chen, Junyu Chen, Han Cai, Haotian Tang, Yujun Lin, Zhekai Zhang, Muyang Li, Ligeng Zhu, Yao Lu, Song Han.
|
| 18 |
+
|
| 19 |
+
The abstract from the paper is:
|
| 20 |
+
|
| 21 |
+
*We introduce Sana, a text-to-image framework that can efficiently generate images up to 4096×4096 resolution. Sana can synthesize high-resolution, high-quality images with strong text-image alignment at a remarkably fast speed, deployable on laptop GPU. Core designs include: (1) Deep compression autoencoder: unlike traditional AEs, which compress images only 8×, we trained an AE that can compress images 32×, effectively reducing the number of latent tokens. (2) Linear DiT: we replace all vanilla attention in DiT with linear attention, which is more efficient at high resolutions without sacrificing quality. (3) Decoder-only text encoder: we replaced T5 with modern decoder-only small LLM as the text encoder and designed complex human instruction with in-context learning to enhance the image-text alignment. (4) Efficient training and sampling: we propose Flow-DPM-Solver to reduce sampling steps, with efficient caption labeling and selection to accelerate convergence. As a result, Sana-0.6B is very competitive with modern giant diffusion model (e.g. Flux-12B), being 20 times smaller and 100+ times faster in measured throughput. Moreover, Sana-0.6B can be deployed on a 16GB laptop GPU, taking less than 1 second to generate a 1024×1024 resolution image. Sana enables content creation at low cost. Code and model will be publicly released.*
|
| 22 |
+
|
| 23 |
+
<Tip>
|
| 24 |
+
|
| 25 |
+
Make sure to check out the Schedulers [guide](../../using-diffusers/schedulers) to learn how to explore the tradeoff between scheduler speed and quality, and see the [reuse components across pipelines](../../using-diffusers/loading#reuse-a-pipeline) section to learn how to efficiently load the same components into multiple pipelines.
|
| 26 |
+
|
| 27 |
+
</Tip>
|
| 28 |
+
|
| 29 |
+
This pipeline was contributed by [lawrence-cj](https://github.com/lawrence-cj) and [chenjy2003](https://github.com/chenjy2003). The original codebase can be found [here](https://github.com/NVlabs/Sana). The original weights can be found under [hf.co/Efficient-Large-Model](https://huggingface.co/Efficient-Large-Model).
|
| 30 |
+
|
| 31 |
+
Available models:
|
| 32 |
+
|
| 33 |
+
| Model | Recommended dtype |
|
| 34 |
+
|:-----:|:-----------------:|
|
| 35 |
+
| [`Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers`](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers) | `torch.bfloat16` |
|
| 36 |
+
| [`Efficient-Large-Model/Sana_1600M_1024px_diffusers`](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_diffusers) | `torch.float16` |
|
| 37 |
+
| [`Efficient-Large-Model/Sana_1600M_1024px_MultiLing_diffusers`](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_MultiLing_diffusers) | `torch.float16` |
|
| 38 |
+
| [`Efficient-Large-Model/Sana_1600M_512px_diffusers`](https://huggingface.co/Efficient-Large-Model/Sana_1600M_512px_diffusers) | `torch.float16` |
|
| 39 |
+
| [`Efficient-Large-Model/Sana_1600M_512px_MultiLing_diffusers`](https://huggingface.co/Efficient-Large-Model/Sana_1600M_512px_MultiLing_diffusers) | `torch.float16` |
|
| 40 |
+
| [`Efficient-Large-Model/Sana_600M_1024px_diffusers`](https://huggingface.co/Efficient-Large-Model/Sana_600M_1024px_diffusers) | `torch.float16` |
|
| 41 |
+
| [`Efficient-Large-Model/Sana_600M_512px_diffusers`](https://huggingface.co/Efficient-Large-Model/Sana_600M_512px_diffusers) | `torch.float16` |
|
| 42 |
+
|
| 43 |
+
Refer to [this](https://huggingface.co/collections/Efficient-Large-Model/sana-673efba2a57ed99843f11f9e) collection for more information.
|
| 44 |
+
|
| 45 |
+
Note: The recommended dtype mentioned is for the transformer weights. The text encoder and VAE weights must stay in `torch.bfloat16` or `torch.float32` for the model to work correctly. Please refer to the inference example below to see how to load the model with the recommended dtype.
|
| 46 |
+
|
| 47 |
+
<Tip>
|
| 48 |
+
|
| 49 |
+
Make sure to pass the `variant` argument for downloaded checkpoints to use lower disk space. Set it to `"fp16"` for models with recommended dtype as `torch.float16`, and `"bf16"` for models with recommended dtype as `torch.bfloat16`. By default, `torch.float32` weights are downloaded, which use twice the amount of disk storage. Additionally, `torch.float32` weights can be downcasted on-the-fly by specifying the `torch_dtype` argument. Read about it in the [docs](https://huggingface.co/docs/diffusers/v0.31.0/en/api/pipelines/overview#diffusers.DiffusionPipeline.from_pretrained).
|
| 50 |
+
|
| 51 |
+
</Tip>
|
| 52 |
+
|
| 53 |
+
## Quantization
|
| 54 |
+
|
| 55 |
+
Quantization helps reduce the memory requirements of very large models by storing model weights in a lower precision data type. However, quantization may have varying impact on video quality depending on the video model.
|
| 56 |
+
|
| 57 |
+
Refer to the [Quantization](../../quantization/overview) overview to learn more about supported quantization backends and selecting a quantization backend that supports your use case. The example below demonstrates how to load a quantized \[`SanaPipeline`\] for inference with bitsandbytes.
|
| 58 |
+
|
| 59 |
+
```py
|
| 60 |
+
import torch
|
| 61 |
+
from diffusers import BitsAndBytesConfig as DiffusersBitsAndBytesConfig, SanaTransformer2DModel, SanaPipeline
|
| 62 |
+
from transformers import BitsAndBytesConfig as BitsAndBytesConfig, AutoModel
|
| 63 |
+
|
| 64 |
+
quant_config = BitsAndBytesConfig(load_in_8bit=True)
|
| 65 |
+
text_encoder_8bit = AutoModel.from_pretrained(
|
| 66 |
+
"Efficient-Large-Model/Sana_1600M_1024px_diffusers",
|
| 67 |
+
subfolder="text_encoder",
|
| 68 |
+
quantization_config=quant_config,
|
| 69 |
+
torch_dtype=torch.float16,
|
| 70 |
+
)
|
| 71 |
+
|
| 72 |
+
quant_config = DiffusersBitsAndBytesConfig(load_in_8bit=True)
|
| 73 |
+
transformer_8bit = SanaTransformer2DModel.from_pretrained(
|
| 74 |
+
"Efficient-Large-Model/Sana_1600M_1024px_diffusers",
|
| 75 |
+
subfolder="transformer",
|
| 76 |
+
quantization_config=quant_config,
|
| 77 |
+
torch_dtype=torch.float16,
|
| 78 |
+
)
|
| 79 |
+
|
| 80 |
+
pipeline = SanaPipeline.from_pretrained(
|
| 81 |
+
"Efficient-Large-Model/Sana_1600M_1024px_diffusers",
|
| 82 |
+
text_encoder=text_encoder_8bit,
|
| 83 |
+
transformer=transformer_8bit,
|
| 84 |
+
torch_dtype=torch.float16,
|
| 85 |
+
device_map="balanced",
|
| 86 |
+
)
|
| 87 |
+
|
| 88 |
+
prompt = "a tiny astronaut hatching from an egg on the moon"
|
| 89 |
+
image = pipeline(prompt).images[0]
|
| 90 |
+
image.save("sana.png")
|
| 91 |
+
```
|
| 92 |
+
|
| 93 |
+
## SanaPipeline
|
| 94 |
+
|
| 95 |
+
\[\[autodoc\]\] SanaPipeline
|
| 96 |
+
|
| 97 |
+
- all
|
| 98 |
+
- __call__
|
| 99 |
+
|
| 100 |
+
## SanaPAGPipeline
|
| 101 |
+
|
| 102 |
+
\[\[autodoc\]\] SanaPAGPipeline
|
| 103 |
+
|
| 104 |
+
- all
|
| 105 |
+
- __call__
|
| 106 |
+
|
| 107 |
+
## SanaPipelineOutput
|
| 108 |
+
|
| 109 |
+
\[\[autodoc\]\] pipelines.sana.pipeline_output.SanaPipelineOutput
|
asset/docs/ComfyUI/Sana_CogVideoX.json
ADDED
|
@@ -0,0 +1,1142 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"last_node_id": 37,
|
| 3 |
+
"last_link_id": 48,
|
| 4 |
+
"nodes": [
|
| 5 |
+
{
|
| 6 |
+
"id": 5,
|
| 7 |
+
"type": "GemmaLoader",
|
| 8 |
+
"pos": [
|
| 9 |
+
283.376953125,
|
| 10 |
+
603.7484741210938
|
| 11 |
+
],
|
| 12 |
+
"size": [
|
| 13 |
+
315,
|
| 14 |
+
106
|
| 15 |
+
],
|
| 16 |
+
"flags": {},
|
| 17 |
+
"order": 0,
|
| 18 |
+
"mode": 0,
|
| 19 |
+
"inputs": [],
|
| 20 |
+
"outputs": [
|
| 21 |
+
{
|
| 22 |
+
"name": "GEMMA",
|
| 23 |
+
"type": "GEMMA",
|
| 24 |
+
"links": [
|
| 25 |
+
9,
|
| 26 |
+
11
|
| 27 |
+
],
|
| 28 |
+
"slot_index": 0
|
| 29 |
+
}
|
| 30 |
+
],
|
| 31 |
+
"properties": {
|
| 32 |
+
"Node name for S&R": "GemmaLoader"
|
| 33 |
+
},
|
| 34 |
+
"widgets_values": [
|
| 35 |
+
"google/gemma-2-2b-it",
|
| 36 |
+
"cuda",
|
| 37 |
+
"BF16"
|
| 38 |
+
]
|
| 39 |
+
},
|
| 40 |
+
{
|
| 41 |
+
"id": 12,
|
| 42 |
+
"type": "SanaTextEncode",
|
| 43 |
+
"pos": [
|
| 44 |
+
670.9176635742188,
|
| 45 |
+
797.39501953125
|
| 46 |
+
],
|
| 47 |
+
"size": [
|
| 48 |
+
400,
|
| 49 |
+
200
|
| 50 |
+
],
|
| 51 |
+
"flags": {},
|
| 52 |
+
"order": 7,
|
| 53 |
+
"mode": 0,
|
| 54 |
+
"inputs": [
|
| 55 |
+
{
|
| 56 |
+
"name": "GEMMA",
|
| 57 |
+
"type": "GEMMA",
|
| 58 |
+
"link": 11
|
| 59 |
+
}
|
| 60 |
+
],
|
| 61 |
+
"outputs": [
|
| 62 |
+
{
|
| 63 |
+
"name": "CONDITIONING",
|
| 64 |
+
"type": "CONDITIONING",
|
| 65 |
+
"links": [
|
| 66 |
+
3
|
| 67 |
+
],
|
| 68 |
+
"slot_index": 0
|
| 69 |
+
}
|
| 70 |
+
],
|
| 71 |
+
"properties": {
|
| 72 |
+
"Node name for S&R": "SanaTextEncode"
|
| 73 |
+
},
|
| 74 |
+
"widgets_values": [
|
| 75 |
+
"\"\""
|
| 76 |
+
]
|
| 77 |
+
},
|
| 78 |
+
{
|
| 79 |
+
"id": 4,
|
| 80 |
+
"type": "SanaResolutionSelect",
|
| 81 |
+
"pos": [
|
| 82 |
+
300.2852783203125,
|
| 83 |
+
392.79766845703125
|
| 84 |
+
],
|
| 85 |
+
"size": [
|
| 86 |
+
315,
|
| 87 |
+
102
|
| 88 |
+
],
|
| 89 |
+
"flags": {},
|
| 90 |
+
"order": 1,
|
| 91 |
+
"mode": 0,
|
| 92 |
+
"inputs": [],
|
| 93 |
+
"outputs": [
|
| 94 |
+
{
|
| 95 |
+
"name": "width",
|
| 96 |
+
"type": "INT",
|
| 97 |
+
"links": [
|
| 98 |
+
7
|
| 99 |
+
],
|
| 100 |
+
"slot_index": 0
|
| 101 |
+
},
|
| 102 |
+
{
|
| 103 |
+
"name": "height",
|
| 104 |
+
"type": "INT",
|
| 105 |
+
"links": [
|
| 106 |
+
8
|
| 107 |
+
],
|
| 108 |
+
"slot_index": 1
|
| 109 |
+
}
|
| 110 |
+
],
|
| 111 |
+
"properties": {
|
| 112 |
+
"Node name for S&R": "SanaResolutionSelect"
|
| 113 |
+
},
|
| 114 |
+
"widgets_values": [
|
| 115 |
+
"1024px",
|
| 116 |
+
"1.46"
|
| 117 |
+
]
|
| 118 |
+
},
|
| 119 |
+
{
|
| 120 |
+
"id": 7,
|
| 121 |
+
"type": "SanaTextEncode",
|
| 122 |
+
"pos": [
|
| 123 |
+
674.2115478515625,
|
| 124 |
+
504.2879638671875
|
| 125 |
+
],
|
| 126 |
+
"size": [
|
| 127 |
+
400,
|
| 128 |
+
200
|
| 129 |
+
],
|
| 130 |
+
"flags": {},
|
| 131 |
+
"order": 6,
|
| 132 |
+
"mode": 0,
|
| 133 |
+
"inputs": [
|
| 134 |
+
{
|
| 135 |
+
"name": "GEMMA",
|
| 136 |
+
"type": "GEMMA",
|
| 137 |
+
"link": 9
|
| 138 |
+
}
|
| 139 |
+
],
|
| 140 |
+
"outputs": [
|
| 141 |
+
{
|
| 142 |
+
"name": "CONDITIONING",
|
| 143 |
+
"type": "CONDITIONING",
|
| 144 |
+
"links": [
|
| 145 |
+
2
|
| 146 |
+
],
|
| 147 |
+
"slot_index": 0
|
| 148 |
+
}
|
| 149 |
+
],
|
| 150 |
+
"properties": {
|
| 151 |
+
"Node name for S&R": "SanaTextEncode"
|
| 152 |
+
},
|
| 153 |
+
"widgets_values": [
|
| 154 |
+
"A cyberpunk cat with a neon sign that says 'Sana'."
|
| 155 |
+
]
|
| 156 |
+
},
|
| 157 |
+
{
|
| 158 |
+
"id": 24,
|
| 159 |
+
"type": "PreviewImage",
|
| 160 |
+
"pos": [
|
| 161 |
+
1443.0323486328125,
|
| 162 |
+
352.056396484375
|
| 163 |
+
],
|
| 164 |
+
"size": [
|
| 165 |
+
210,
|
| 166 |
+
246
|
| 167 |
+
],
|
| 168 |
+
"flags": {},
|
| 169 |
+
"order": 13,
|
| 170 |
+
"mode": 0,
|
| 171 |
+
"inputs": [
|
| 172 |
+
{
|
| 173 |
+
"name": "images",
|
| 174 |
+
"type": "IMAGE",
|
| 175 |
+
"link": 47
|
| 176 |
+
}
|
| 177 |
+
],
|
| 178 |
+
"outputs": [],
|
| 179 |
+
"properties": {
|
| 180 |
+
"Node name for S&R": "PreviewImage"
|
| 181 |
+
},
|
| 182 |
+
"widgets_values": []
|
| 183 |
+
},
|
| 184 |
+
{
|
| 185 |
+
"id": 25,
|
| 186 |
+
"type": "VHS_VideoCombine",
|
| 187 |
+
"pos": [
|
| 188 |
+
2825.935546875,
|
| 189 |
+
-102.76895904541016
|
| 190 |
+
],
|
| 191 |
+
"size": [
|
| 192 |
+
767.7372436523438,
|
| 193 |
+
310
|
| 194 |
+
],
|
| 195 |
+
"flags": {},
|
| 196 |
+
"order": 18,
|
| 197 |
+
"mode": 0,
|
| 198 |
+
"inputs": [
|
| 199 |
+
{
|
| 200 |
+
"name": "images",
|
| 201 |
+
"type": "IMAGE",
|
| 202 |
+
"link": 30
|
| 203 |
+
},
|
| 204 |
+
{
|
| 205 |
+
"name": "audio",
|
| 206 |
+
"type": "AUDIO",
|
| 207 |
+
"link": null,
|
| 208 |
+
"shape": 7
|
| 209 |
+
},
|
| 210 |
+
{
|
| 211 |
+
"name": "meta_batch",
|
| 212 |
+
"type": "VHS_BatchManager",
|
| 213 |
+
"link": null,
|
| 214 |
+
"shape": 7
|
| 215 |
+
},
|
| 216 |
+
{
|
| 217 |
+
"name": "vae",
|
| 218 |
+
"type": "VAE",
|
| 219 |
+
"link": null,
|
| 220 |
+
"shape": 7
|
| 221 |
+
}
|
| 222 |
+
],
|
| 223 |
+
"outputs": [
|
| 224 |
+
{
|
| 225 |
+
"name": "Filenames",
|
| 226 |
+
"type": "VHS_FILENAMES",
|
| 227 |
+
"links": null,
|
| 228 |
+
"shape": 3
|
| 229 |
+
}
|
| 230 |
+
],
|
| 231 |
+
"properties": {
|
| 232 |
+
"Node name for S&R": "VHS_VideoCombine"
|
| 233 |
+
},
|
| 234 |
+
"widgets_values": {
|
| 235 |
+
"frame_rate": 8,
|
| 236 |
+
"loop_count": 0,
|
| 237 |
+
"filename_prefix": "CogVideoX_Fun",
|
| 238 |
+
"format": "video/h264-mp4",
|
| 239 |
+
"pix_fmt": "yuv420p",
|
| 240 |
+
"crf": 19,
|
| 241 |
+
"save_metadata": true,
|
| 242 |
+
"pingpong": false,
|
| 243 |
+
"save_output": true,
|
| 244 |
+
"videopreview": {
|
| 245 |
+
"hidden": false,
|
| 246 |
+
"paused": false,
|
| 247 |
+
"params": {
|
| 248 |
+
"filename": "CogVideoX_Fun_00005.mp4",
|
| 249 |
+
"subfolder": "",
|
| 250 |
+
"type": "output",
|
| 251 |
+
"format": "video/h264-mp4",
|
| 252 |
+
"frame_rate": 8
|
| 253 |
+
},
|
| 254 |
+
"muted": false
|
| 255 |
+
}
|
| 256 |
+
}
|
| 257 |
+
},
|
| 258 |
+
{
|
| 259 |
+
"id": 27,
|
| 260 |
+
"type": "CogVideoTextEncode",
|
| 261 |
+
"pos": [
|
| 262 |
+
1713.936279296875,
|
| 263 |
+
174.2305450439453
|
| 264 |
+
],
|
| 265 |
+
"size": [
|
| 266 |
+
471.90142822265625,
|
| 267 |
+
168.08047485351562
|
| 268 |
+
],
|
| 269 |
+
"flags": {},
|
| 270 |
+
"order": 9,
|
| 271 |
+
"mode": 0,
|
| 272 |
+
"inputs": [
|
| 273 |
+
{
|
| 274 |
+
"name": "clip",
|
| 275 |
+
"type": "CLIP",
|
| 276 |
+
"link": 35
|
| 277 |
+
}
|
| 278 |
+
],
|
| 279 |
+
"outputs": [
|
| 280 |
+
{
|
| 281 |
+
"name": "conditioning",
|
| 282 |
+
"type": "CONDITIONING",
|
| 283 |
+
"links": [
|
| 284 |
+
32
|
| 285 |
+
],
|
| 286 |
+
"slot_index": 0,
|
| 287 |
+
"shape": 3
|
| 288 |
+
},
|
| 289 |
+
{
|
| 290 |
+
"name": "clip",
|
| 291 |
+
"type": "CLIP",
|
| 292 |
+
"links": [
|
| 293 |
+
36
|
| 294 |
+
],
|
| 295 |
+
"slot_index": 1
|
| 296 |
+
}
|
| 297 |
+
],
|
| 298 |
+
"properties": {
|
| 299 |
+
"Node name for S&R": "CogVideoTextEncode"
|
| 300 |
+
},
|
| 301 |
+
"widgets_values": [
|
| 302 |
+
"fireworks display over night city. The video is of high quality, and the view is very clear. High quality, masterpiece, best quality, highres, ultra-detailed, fantastic.",
|
| 303 |
+
1,
|
| 304 |
+
false
|
| 305 |
+
]
|
| 306 |
+
},
|
| 307 |
+
{
|
| 308 |
+
"id": 28,
|
| 309 |
+
"type": "CogVideoTextEncode",
|
| 310 |
+
"pos": [
|
| 311 |
+
1720.936279296875,
|
| 312 |
+
393.230712890625
|
| 313 |
+
],
|
| 314 |
+
"size": [
|
| 315 |
+
463.01251220703125,
|
| 316 |
+
144
|
| 317 |
+
],
|
| 318 |
+
"flags": {},
|
| 319 |
+
"order": 11,
|
| 320 |
+
"mode": 0,
|
| 321 |
+
"inputs": [
|
| 322 |
+
{
|
| 323 |
+
"name": "clip",
|
| 324 |
+
"type": "CLIP",
|
| 325 |
+
"link": 36
|
| 326 |
+
}
|
| 327 |
+
],
|
| 328 |
+
"outputs": [
|
| 329 |
+
{
|
| 330 |
+
"name": "conditioning",
|
| 331 |
+
"type": "CONDITIONING",
|
| 332 |
+
"links": [
|
| 333 |
+
33
|
| 334 |
+
],
|
| 335 |
+
"slot_index": 0,
|
| 336 |
+
"shape": 3
|
| 337 |
+
},
|
| 338 |
+
{
|
| 339 |
+
"name": "clip",
|
| 340 |
+
"type": "CLIP",
|
| 341 |
+
"links": null
|
| 342 |
+
}
|
| 343 |
+
],
|
| 344 |
+
"properties": {
|
| 345 |
+
"Node name for S&R": "CogVideoTextEncode"
|
| 346 |
+
},
|
| 347 |
+
"widgets_values": [
|
| 348 |
+
"The video is not of a high quality, it has a low resolution. Watermark present in each frame. Strange motion trajectory. ",
|
| 349 |
+
1,
|
| 350 |
+
true
|
| 351 |
+
]
|
| 352 |
+
},
|
| 353 |
+
{
|
| 354 |
+
"id": 30,
|
| 355 |
+
"type": "CogVideoImageEncodeFunInP",
|
| 356 |
+
"pos": [
|
| 357 |
+
2088.93603515625,
|
| 358 |
+
595.230712890625
|
| 359 |
+
],
|
| 360 |
+
"size": [
|
| 361 |
+
253.60000610351562,
|
| 362 |
+
146
|
| 363 |
+
],
|
| 364 |
+
"flags": {},
|
| 365 |
+
"order": 15,
|
| 366 |
+
"mode": 0,
|
| 367 |
+
"inputs": [
|
| 368 |
+
{
|
| 369 |
+
"name": "vae",
|
| 370 |
+
"type": "VAE",
|
| 371 |
+
"link": 37
|
| 372 |
+
},
|
| 373 |
+
{
|
| 374 |
+
"name": "start_image",
|
| 375 |
+
"type": "IMAGE",
|
| 376 |
+
"link": 38
|
| 377 |
+
},
|
| 378 |
+
{
|
| 379 |
+
"name": "end_image",
|
| 380 |
+
"type": "IMAGE",
|
| 381 |
+
"link": null,
|
| 382 |
+
"shape": 7
|
| 383 |
+
}
|
| 384 |
+
],
|
| 385 |
+
"outputs": [
|
| 386 |
+
{
|
| 387 |
+
"name": "image_cond_latents",
|
| 388 |
+
"type": "LATENT",
|
| 389 |
+
"links": [
|
| 390 |
+
34
|
| 391 |
+
],
|
| 392 |
+
"slot_index": 0
|
| 393 |
+
}
|
| 394 |
+
],
|
| 395 |
+
"properties": {
|
| 396 |
+
"Node name for S&R": "CogVideoImageEncodeFunInP"
|
| 397 |
+
},
|
| 398 |
+
"widgets_values": [
|
| 399 |
+
49,
|
| 400 |
+
true,
|
| 401 |
+
0
|
| 402 |
+
]
|
| 403 |
+
},
|
| 404 |
+
{
|
| 405 |
+
"id": 33,
|
| 406 |
+
"type": "CogVideoDecode",
|
| 407 |
+
"pos": [
|
| 408 |
+
2442.93603515625,
|
| 409 |
+
-105.76895904541016
|
| 410 |
+
],
|
| 411 |
+
"size": [
|
| 412 |
+
315,
|
| 413 |
+
198
|
| 414 |
+
],
|
| 415 |
+
"flags": {},
|
| 416 |
+
"order": 17,
|
| 417 |
+
"mode": 0,
|
| 418 |
+
"inputs": [
|
| 419 |
+
{
|
| 420 |
+
"name": "vae",
|
| 421 |
+
"type": "VAE",
|
| 422 |
+
"link": 40
|
| 423 |
+
},
|
| 424 |
+
{
|
| 425 |
+
"name": "samples",
|
| 426 |
+
"type": "LATENT",
|
| 427 |
+
"link": 41
|
| 428 |
+
}
|
| 429 |
+
],
|
| 430 |
+
"outputs": [
|
| 431 |
+
{
|
| 432 |
+
"name": "images",
|
| 433 |
+
"type": "IMAGE",
|
| 434 |
+
"links": [
|
| 435 |
+
30
|
| 436 |
+
]
|
| 437 |
+
}
|
| 438 |
+
],
|
| 439 |
+
"properties": {
|
| 440 |
+
"Node name for S&R": "CogVideoDecode"
|
| 441 |
+
},
|
| 442 |
+
"widgets_values": [
|
| 443 |
+
true,
|
| 444 |
+
240,
|
| 445 |
+
360,
|
| 446 |
+
0.2,
|
| 447 |
+
0.2,
|
| 448 |
+
true
|
| 449 |
+
]
|
| 450 |
+
},
|
| 451 |
+
{
|
| 452 |
+
"id": 34,
|
| 453 |
+
"type": "DownloadAndLoadCogVideoModel",
|
| 454 |
+
"pos": [
|
| 455 |
+
1714.936279296875,
|
| 456 |
+
-138.76895141601562
|
| 457 |
+
],
|
| 458 |
+
"size": [
|
| 459 |
+
362.1656799316406,
|
| 460 |
+
218
|
| 461 |
+
],
|
| 462 |
+
"flags": {},
|
| 463 |
+
"order": 2,
|
| 464 |
+
"mode": 0,
|
| 465 |
+
"inputs": [
|
| 466 |
+
{
|
| 467 |
+
"name": "block_edit",
|
| 468 |
+
"type": "TRANSFORMERBLOCKS",
|
| 469 |
+
"link": null,
|
| 470 |
+
"shape": 7
|
| 471 |
+
},
|
| 472 |
+
{
|
| 473 |
+
"name": "lora",
|
| 474 |
+
"type": "COGLORA",
|
| 475 |
+
"link": null,
|
| 476 |
+
"shape": 7
|
| 477 |
+
},
|
| 478 |
+
{
|
| 479 |
+
"name": "compile_args",
|
| 480 |
+
"type": "COMPILEARGS",
|
| 481 |
+
"link": null,
|
| 482 |
+
"shape": 7
|
| 483 |
+
}
|
| 484 |
+
],
|
| 485 |
+
"outputs": [
|
| 486 |
+
{
|
| 487 |
+
"name": "model",
|
| 488 |
+
"type": "COGVIDEOMODEL",
|
| 489 |
+
"links": [
|
| 490 |
+
31
|
| 491 |
+
]
|
| 492 |
+
},
|
| 493 |
+
{
|
| 494 |
+
"name": "vae",
|
| 495 |
+
"type": "VAE",
|
| 496 |
+
"links": [
|
| 497 |
+
37,
|
| 498 |
+
40
|
| 499 |
+
],
|
| 500 |
+
"slot_index": 1
|
| 501 |
+
}
|
| 502 |
+
],
|
| 503 |
+
"properties": {
|
| 504 |
+
"Node name for S&R": "DownloadAndLoadCogVideoModel"
|
| 505 |
+
},
|
| 506 |
+
"widgets_values": [
|
| 507 |
+
"alibaba-pai/CogVideoX-Fun-V1.1-5b-InP",
|
| 508 |
+
"bf16",
|
| 509 |
+
"disabled",
|
| 510 |
+
false,
|
| 511 |
+
"sdpa",
|
| 512 |
+
"main_device"
|
| 513 |
+
]
|
| 514 |
+
},
|
| 515 |
+
{
|
| 516 |
+
"id": 31,
|
| 517 |
+
"type": "ImageResizeKJ",
|
| 518 |
+
"pos": [
|
| 519 |
+
1722.936279296875,
|
| 520 |
+
615.230712890625
|
| 521 |
+
],
|
| 522 |
+
"size": [
|
| 523 |
+
315,
|
| 524 |
+
266
|
| 525 |
+
],
|
| 526 |
+
"flags": {},
|
| 527 |
+
"order": 14,
|
| 528 |
+
"mode": 0,
|
| 529 |
+
"inputs": [
|
| 530 |
+
{
|
| 531 |
+
"name": "image",
|
| 532 |
+
"type": "IMAGE",
|
| 533 |
+
"link": 48
|
| 534 |
+
},
|
| 535 |
+
{
|
| 536 |
+
"name": "get_image_size",
|
| 537 |
+
"type": "IMAGE",
|
| 538 |
+
"link": null,
|
| 539 |
+
"shape": 7
|
| 540 |
+
},
|
| 541 |
+
{
|
| 542 |
+
"name": "width_input",
|
| 543 |
+
"type": "INT",
|
| 544 |
+
"link": null,
|
| 545 |
+
"widget": {
|
| 546 |
+
"name": "width_input"
|
| 547 |
+
},
|
| 548 |
+
"shape": 7
|
| 549 |
+
},
|
| 550 |
+
{
|
| 551 |
+
"name": "height_input",
|
| 552 |
+
"type": "INT",
|
| 553 |
+
"link": null,
|
| 554 |
+
"widget": {
|
| 555 |
+
"name": "height_input"
|
| 556 |
+
},
|
| 557 |
+
"shape": 7
|
| 558 |
+
}
|
| 559 |
+
],
|
| 560 |
+
"outputs": [
|
| 561 |
+
{
|
| 562 |
+
"name": "IMAGE",
|
| 563 |
+
"type": "IMAGE",
|
| 564 |
+
"links": [
|
| 565 |
+
38
|
| 566 |
+
],
|
| 567 |
+
"slot_index": 0,
|
| 568 |
+
"shape": 3
|
| 569 |
+
},
|
| 570 |
+
{
|
| 571 |
+
"name": "width",
|
| 572 |
+
"type": "INT",
|
| 573 |
+
"links": null,
|
| 574 |
+
"shape": 3
|
| 575 |
+
},
|
| 576 |
+
{
|
| 577 |
+
"name": "height",
|
| 578 |
+
"type": "INT",
|
| 579 |
+
"links": null,
|
| 580 |
+
"shape": 3
|
| 581 |
+
}
|
| 582 |
+
],
|
| 583 |
+
"properties": {
|
| 584 |
+
"Node name for S&R": "ImageResizeKJ"
|
| 585 |
+
},
|
| 586 |
+
"widgets_values": [
|
| 587 |
+
720,
|
| 588 |
+
480,
|
| 589 |
+
"lanczos",
|
| 590 |
+
false,
|
| 591 |
+
2,
|
| 592 |
+
0,
|
| 593 |
+
0,
|
| 594 |
+
"disabled"
|
| 595 |
+
]
|
| 596 |
+
},
|
| 597 |
+
{
|
| 598 |
+
"id": 29,
|
| 599 |
+
"type": "CLIPLoader",
|
| 600 |
+
"pos": [
|
| 601 |
+
1216.935791015625,
|
| 602 |
+
-8.769308090209961
|
| 603 |
+
],
|
| 604 |
+
"size": [
|
| 605 |
+
451.30548095703125,
|
| 606 |
+
82
|
| 607 |
+
],
|
| 608 |
+
"flags": {},
|
| 609 |
+
"order": 3,
|
| 610 |
+
"mode": 0,
|
| 611 |
+
"inputs": [],
|
| 612 |
+
"outputs": [
|
| 613 |
+
{
|
| 614 |
+
"name": "CLIP",
|
| 615 |
+
"type": "CLIP",
|
| 616 |
+
"links": [
|
| 617 |
+
35
|
| 618 |
+
],
|
| 619 |
+
"slot_index": 0,
|
| 620 |
+
"shape": 3
|
| 621 |
+
}
|
| 622 |
+
],
|
| 623 |
+
"properties": {
|
| 624 |
+
"Node name for S&R": "CLIPLoader"
|
| 625 |
+
},
|
| 626 |
+
"widgets_values": [
|
| 627 |
+
"text_encoders/t5xxl_fp16.safetensors",
|
| 628 |
+
"sd3"
|
| 629 |
+
]
|
| 630 |
+
},
|
| 631 |
+
{
|
| 632 |
+
"id": 26,
|
| 633 |
+
"type": "CogVideoSampler",
|
| 634 |
+
"pos": [
|
| 635 |
+
2423.935791015625,
|
| 636 |
+
152.23048400878906
|
| 637 |
+
],
|
| 638 |
+
"size": [
|
| 639 |
+
330,
|
| 640 |
+
574
|
| 641 |
+
],
|
| 642 |
+
"flags": {},
|
| 643 |
+
"order": 16,
|
| 644 |
+
"mode": 0,
|
| 645 |
+
"inputs": [
|
| 646 |
+
{
|
| 647 |
+
"name": "model",
|
| 648 |
+
"type": "COGVIDEOMODEL",
|
| 649 |
+
"link": 31
|
| 650 |
+
},
|
| 651 |
+
{
|
| 652 |
+
"name": "positive",
|
| 653 |
+
"type": "CONDITIONING",
|
| 654 |
+
"link": 32
|
| 655 |
+
},
|
| 656 |
+
{
|
| 657 |
+
"name": "negative",
|
| 658 |
+
"type": "CONDITIONING",
|
| 659 |
+
"link": 33
|
| 660 |
+
},
|
| 661 |
+
{
|
| 662 |
+
"name": "samples",
|
| 663 |
+
"type": "LATENT",
|
| 664 |
+
"link": null,
|
| 665 |
+
"shape": 7
|
| 666 |
+
},
|
| 667 |
+
{
|
| 668 |
+
"name": "image_cond_latents",
|
| 669 |
+
"type": "LATENT",
|
| 670 |
+
"link": 34,
|
| 671 |
+
"shape": 7
|
| 672 |
+
},
|
| 673 |
+
{
|
| 674 |
+
"name": "context_options",
|
| 675 |
+
"type": "COGCONTEXT",
|
| 676 |
+
"link": null,
|
| 677 |
+
"shape": 7
|
| 678 |
+
},
|
| 679 |
+
{
|
| 680 |
+
"name": "controlnet",
|
| 681 |
+
"type": "COGVIDECONTROLNET",
|
| 682 |
+
"link": null,
|
| 683 |
+
"shape": 7
|
| 684 |
+
},
|
| 685 |
+
{
|
| 686 |
+
"name": "tora_trajectory",
|
| 687 |
+
"type": "TORAFEATURES",
|
| 688 |
+
"link": null,
|
| 689 |
+
"shape": 7
|
| 690 |
+
},
|
| 691 |
+
{
|
| 692 |
+
"name": "fastercache",
|
| 693 |
+
"type": "FASTERCACHEARGS",
|
| 694 |
+
"link": null,
|
| 695 |
+
"shape": 7
|
| 696 |
+
}
|
| 697 |
+
],
|
| 698 |
+
"outputs": [
|
| 699 |
+
{
|
| 700 |
+
"name": "samples",
|
| 701 |
+
"type": "LATENT",
|
| 702 |
+
"links": [
|
| 703 |
+
41
|
| 704 |
+
],
|
| 705 |
+
"slot_index": 0
|
| 706 |
+
}
|
| 707 |
+
],
|
| 708 |
+
"properties": {
|
| 709 |
+
"Node name for S&R": "CogVideoSampler"
|
| 710 |
+
},
|
| 711 |
+
"widgets_values": [
|
| 712 |
+
49,
|
| 713 |
+
25,
|
| 714 |
+
6,
|
| 715 |
+
1123398248636718,
|
| 716 |
+
"randomize",
|
| 717 |
+
"CogVideoXDDIM",
|
| 718 |
+
1
|
| 719 |
+
]
|
| 720 |
+
},
|
| 721 |
+
{
|
| 722 |
+
"id": 35,
|
| 723 |
+
"type": "SanaCheckpointLoader",
|
| 724 |
+
"pos": [
|
| 725 |
+
286.5307922363281,
|
| 726 |
+
235.45753479003906
|
| 727 |
+
],
|
| 728 |
+
"size": [
|
| 729 |
+
315,
|
| 730 |
+
82
|
| 731 |
+
],
|
| 732 |
+
"flags": {},
|
| 733 |
+
"order": 4,
|
| 734 |
+
"mode": 0,
|
| 735 |
+
"inputs": [],
|
| 736 |
+
"outputs": [
|
| 737 |
+
{
|
| 738 |
+
"name": "model",
|
| 739 |
+
"type": "MODEL",
|
| 740 |
+
"links": [
|
| 741 |
+
43
|
| 742 |
+
],
|
| 743 |
+
"slot_index": 0
|
| 744 |
+
}
|
| 745 |
+
],
|
| 746 |
+
"properties": {
|
| 747 |
+
"Node name for S&R": "SanaCheckpointLoader"
|
| 748 |
+
},
|
| 749 |
+
"widgets_values": [
|
| 750 |
+
"Efficient-Large-Model/Sana_1600M_1024px_MultiLing",
|
| 751 |
+
"SanaMS_1600M_P1_D20"
|
| 752 |
+
]
|
| 753 |
+
},
|
| 754 |
+
{
|
| 755 |
+
"id": 37,
|
| 756 |
+
"type": "ExtraVAELoader",
|
| 757 |
+
"pos": [
|
| 758 |
+
1070.8033447265625,
|
| 759 |
+
747.4982299804688
|
| 760 |
+
],
|
| 761 |
+
"size": [
|
| 762 |
+
315,
|
| 763 |
+
106
|
| 764 |
+
],
|
| 765 |
+
"flags": {},
|
| 766 |
+
"order": 5,
|
| 767 |
+
"mode": 0,
|
| 768 |
+
"inputs": [],
|
| 769 |
+
"outputs": [
|
| 770 |
+
{
|
| 771 |
+
"name": "VAE",
|
| 772 |
+
"type": "VAE",
|
| 773 |
+
"links": [
|
| 774 |
+
46
|
| 775 |
+
],
|
| 776 |
+
"slot_index": 0
|
| 777 |
+
}
|
| 778 |
+
],
|
| 779 |
+
"properties": {
|
| 780 |
+
"Node name for S&R": "ExtraVAELoader"
|
| 781 |
+
},
|
| 782 |
+
"widgets_values": [
|
| 783 |
+
"mit-han-lab/dc-ae-f32c32-sana-1.0-diffusers",
|
| 784 |
+
"dcae-f32c32-sana-1.0-diffusers",
|
| 785 |
+
"BF16"
|
| 786 |
+
]
|
| 787 |
+
},
|
| 788 |
+
{
|
| 789 |
+
"id": 1,
|
| 790 |
+
"type": "KSampler",
|
| 791 |
+
"pos": [
|
| 792 |
+
1101.390625,
|
| 793 |
+
196.0309600830078
|
| 794 |
+
],
|
| 795 |
+
"size": [
|
| 796 |
+
300,
|
| 797 |
+
480
|
| 798 |
+
],
|
| 799 |
+
"flags": {},
|
| 800 |
+
"order": 10,
|
| 801 |
+
"mode": 0,
|
| 802 |
+
"inputs": [
|
| 803 |
+
{
|
| 804 |
+
"name": "model",
|
| 805 |
+
"type": "MODEL",
|
| 806 |
+
"link": 43
|
| 807 |
+
},
|
| 808 |
+
{
|
| 809 |
+
"name": "positive",
|
| 810 |
+
"type": "CONDITIONING",
|
| 811 |
+
"link": 2
|
| 812 |
+
},
|
| 813 |
+
{
|
| 814 |
+
"name": "negative",
|
| 815 |
+
"type": "CONDITIONING",
|
| 816 |
+
"link": 3
|
| 817 |
+
},
|
| 818 |
+
{
|
| 819 |
+
"name": "latent_image",
|
| 820 |
+
"type": "LATENT",
|
| 821 |
+
"link": 4
|
| 822 |
+
}
|
| 823 |
+
],
|
| 824 |
+
"outputs": [
|
| 825 |
+
{
|
| 826 |
+
"name": "LATENT",
|
| 827 |
+
"type": "LATENT",
|
| 828 |
+
"links": [
|
| 829 |
+
5
|
| 830 |
+
],
|
| 831 |
+
"slot_index": 0,
|
| 832 |
+
"shape": 3
|
| 833 |
+
}
|
| 834 |
+
],
|
| 835 |
+
"properties": {
|
| 836 |
+
"Node name for S&R": "KSampler"
|
| 837 |
+
},
|
| 838 |
+
"widgets_values": [
|
| 839 |
+
869595936769725,
|
| 840 |
+
"randomize",
|
| 841 |
+
28,
|
| 842 |
+
5,
|
| 843 |
+
"euler",
|
| 844 |
+
"normal",
|
| 845 |
+
1
|
| 846 |
+
]
|
| 847 |
+
},
|
| 848 |
+
{
|
| 849 |
+
"id": 6,
|
| 850 |
+
"type": "EmptyDCAELatentImage",
|
| 851 |
+
"pos": [
|
| 852 |
+
723.0592041015625,
|
| 853 |
+
317.112548828125
|
| 854 |
+
],
|
| 855 |
+
"size": [
|
| 856 |
+
315,
|
| 857 |
+
106
|
| 858 |
+
],
|
| 859 |
+
"flags": {},
|
| 860 |
+
"order": 8,
|
| 861 |
+
"mode": 0,
|
| 862 |
+
"inputs": [
|
| 863 |
+
{
|
| 864 |
+
"name": "width",
|
| 865 |
+
"type": "INT",
|
| 866 |
+
"link": 7,
|
| 867 |
+
"widget": {
|
| 868 |
+
"name": "width"
|
| 869 |
+
}
|
| 870 |
+
},
|
| 871 |
+
{
|
| 872 |
+
"name": "height",
|
| 873 |
+
"type": "INT",
|
| 874 |
+
"link": 8,
|
| 875 |
+
"widget": {
|
| 876 |
+
"name": "height"
|
| 877 |
+
}
|
| 878 |
+
}
|
| 879 |
+
],
|
| 880 |
+
"outputs": [
|
| 881 |
+
{
|
| 882 |
+
"name": "LATENT",
|
| 883 |
+
"type": "LATENT",
|
| 884 |
+
"links": [
|
| 885 |
+
4
|
| 886 |
+
],
|
| 887 |
+
"slot_index": 0
|
| 888 |
+
}
|
| 889 |
+
],
|
| 890 |
+
"properties": {
|
| 891 |
+
"Node name for S&R": "EmptyDCAELatentImage"
|
| 892 |
+
},
|
| 893 |
+
"widgets_values": [
|
| 894 |
+
512,
|
| 895 |
+
512,
|
| 896 |
+
1
|
| 897 |
+
]
|
| 898 |
+
},
|
| 899 |
+
{
|
| 900 |
+
"id": 2,
|
| 901 |
+
"type": "VAEDecode",
|
| 902 |
+
"pos": [
|
| 903 |
+
1452.4869384765625,
|
| 904 |
+
217.9922637939453
|
| 905 |
+
],
|
| 906 |
+
"size": [
|
| 907 |
+
200,
|
| 908 |
+
50
|
| 909 |
+
],
|
| 910 |
+
"flags": {},
|
| 911 |
+
"order": 12,
|
| 912 |
+
"mode": 0,
|
| 913 |
+
"inputs": [
|
| 914 |
+
{
|
| 915 |
+
"name": "samples",
|
| 916 |
+
"type": "LATENT",
|
| 917 |
+
"link": 5
|
| 918 |
+
},
|
| 919 |
+
{
|
| 920 |
+
"name": "vae",
|
| 921 |
+
"type": "VAE",
|
| 922 |
+
"link": 46
|
| 923 |
+
}
|
| 924 |
+
],
|
| 925 |
+
"outputs": [
|
| 926 |
+
{
|
| 927 |
+
"name": "IMAGE",
|
| 928 |
+
"type": "IMAGE",
|
| 929 |
+
"links": [
|
| 930 |
+
47,
|
| 931 |
+
48
|
| 932 |
+
],
|
| 933 |
+
"slot_index": 0,
|
| 934 |
+
"shape": 3
|
| 935 |
+
}
|
| 936 |
+
],
|
| 937 |
+
"properties": {
|
| 938 |
+
"Node name for S&R": "VAEDecode"
|
| 939 |
+
},
|
| 940 |
+
"widgets_values": []
|
| 941 |
+
}
|
| 942 |
+
],
|
| 943 |
+
"links": [
|
| 944 |
+
[
|
| 945 |
+
2,
|
| 946 |
+
7,
|
| 947 |
+
0,
|
| 948 |
+
1,
|
| 949 |
+
1,
|
| 950 |
+
"CONDITIONING"
|
| 951 |
+
],
|
| 952 |
+
[
|
| 953 |
+
3,
|
| 954 |
+
12,
|
| 955 |
+
0,
|
| 956 |
+
1,
|
| 957 |
+
2,
|
| 958 |
+
"CONDITIONING"
|
| 959 |
+
],
|
| 960 |
+
[
|
| 961 |
+
4,
|
| 962 |
+
6,
|
| 963 |
+
0,
|
| 964 |
+
1,
|
| 965 |
+
3,
|
| 966 |
+
"LATENT"
|
| 967 |
+
],
|
| 968 |
+
[
|
| 969 |
+
5,
|
| 970 |
+
1,
|
| 971 |
+
0,
|
| 972 |
+
2,
|
| 973 |
+
0,
|
| 974 |
+
"LATENT"
|
| 975 |
+
],
|
| 976 |
+
[
|
| 977 |
+
7,
|
| 978 |
+
4,
|
| 979 |
+
0,
|
| 980 |
+
6,
|
| 981 |
+
0,
|
| 982 |
+
"INT"
|
| 983 |
+
],
|
| 984 |
+
[
|
| 985 |
+
8,
|
| 986 |
+
4,
|
| 987 |
+
1,
|
| 988 |
+
6,
|
| 989 |
+
1,
|
| 990 |
+
"INT"
|
| 991 |
+
],
|
| 992 |
+
[
|
| 993 |
+
9,
|
| 994 |
+
5,
|
| 995 |
+
0,
|
| 996 |
+
7,
|
| 997 |
+
0,
|
| 998 |
+
"GEMMA"
|
| 999 |
+
],
|
| 1000 |
+
[
|
| 1001 |
+
11,
|
| 1002 |
+
5,
|
| 1003 |
+
0,
|
| 1004 |
+
12,
|
| 1005 |
+
0,
|
| 1006 |
+
"GEMMA"
|
| 1007 |
+
],
|
| 1008 |
+
[
|
| 1009 |
+
30,
|
| 1010 |
+
33,
|
| 1011 |
+
0,
|
| 1012 |
+
25,
|
| 1013 |
+
0,
|
| 1014 |
+
"IMAGE"
|
| 1015 |
+
],
|
| 1016 |
+
[
|
| 1017 |
+
31,
|
| 1018 |
+
34,
|
| 1019 |
+
0,
|
| 1020 |
+
26,
|
| 1021 |
+
0,
|
| 1022 |
+
"COGVIDEOMODEL"
|
| 1023 |
+
],
|
| 1024 |
+
[
|
| 1025 |
+
32,
|
| 1026 |
+
27,
|
| 1027 |
+
0,
|
| 1028 |
+
26,
|
| 1029 |
+
1,
|
| 1030 |
+
"CONDITIONING"
|
| 1031 |
+
],
|
| 1032 |
+
[
|
| 1033 |
+
33,
|
| 1034 |
+
28,
|
| 1035 |
+
0,
|
| 1036 |
+
26,
|
| 1037 |
+
2,
|
| 1038 |
+
"CONDITIONING"
|
| 1039 |
+
],
|
| 1040 |
+
[
|
| 1041 |
+
34,
|
| 1042 |
+
30,
|
| 1043 |
+
0,
|
| 1044 |
+
26,
|
| 1045 |
+
4,
|
| 1046 |
+
"LATENT"
|
| 1047 |
+
],
|
| 1048 |
+
[
|
| 1049 |
+
35,
|
| 1050 |
+
29,
|
| 1051 |
+
0,
|
| 1052 |
+
27,
|
| 1053 |
+
0,
|
| 1054 |
+
"CLIP"
|
| 1055 |
+
],
|
| 1056 |
+
[
|
| 1057 |
+
36,
|
| 1058 |
+
27,
|
| 1059 |
+
1,
|
| 1060 |
+
28,
|
| 1061 |
+
0,
|
| 1062 |
+
"CLIP"
|
| 1063 |
+
],
|
| 1064 |
+
[
|
| 1065 |
+
37,
|
| 1066 |
+
34,
|
| 1067 |
+
1,
|
| 1068 |
+
30,
|
| 1069 |
+
0,
|
| 1070 |
+
"VAE"
|
| 1071 |
+
],
|
| 1072 |
+
[
|
| 1073 |
+
38,
|
| 1074 |
+
31,
|
| 1075 |
+
0,
|
| 1076 |
+
30,
|
| 1077 |
+
1,
|
| 1078 |
+
"IMAGE"
|
| 1079 |
+
],
|
| 1080 |
+
[
|
| 1081 |
+
40,
|
| 1082 |
+
34,
|
| 1083 |
+
1,
|
| 1084 |
+
33,
|
| 1085 |
+
0,
|
| 1086 |
+
"VAE"
|
| 1087 |
+
],
|
| 1088 |
+
[
|
| 1089 |
+
41,
|
| 1090 |
+
26,
|
| 1091 |
+
0,
|
| 1092 |
+
33,
|
| 1093 |
+
1,
|
| 1094 |
+
"LATENT"
|
| 1095 |
+
],
|
| 1096 |
+
[
|
| 1097 |
+
43,
|
| 1098 |
+
35,
|
| 1099 |
+
0,
|
| 1100 |
+
1,
|
| 1101 |
+
0,
|
| 1102 |
+
"MODEL"
|
| 1103 |
+
],
|
| 1104 |
+
[
|
| 1105 |
+
46,
|
| 1106 |
+
37,
|
| 1107 |
+
0,
|
| 1108 |
+
2,
|
| 1109 |
+
1,
|
| 1110 |
+
"VAE"
|
| 1111 |
+
],
|
| 1112 |
+
[
|
| 1113 |
+
47,
|
| 1114 |
+
2,
|
| 1115 |
+
0,
|
| 1116 |
+
24,
|
| 1117 |
+
0,
|
| 1118 |
+
"IMAGE"
|
| 1119 |
+
],
|
| 1120 |
+
[
|
| 1121 |
+
48,
|
| 1122 |
+
2,
|
| 1123 |
+
0,
|
| 1124 |
+
31,
|
| 1125 |
+
0,
|
| 1126 |
+
"IMAGE"
|
| 1127 |
+
]
|
| 1128 |
+
],
|
| 1129 |
+
"groups": [],
|
| 1130 |
+
"config": {},
|
| 1131 |
+
"extra": {
|
| 1132 |
+
"ds": {
|
| 1133 |
+
"scale": 0.5644739300537776,
|
| 1134 |
+
"offset": [
|
| 1135 |
+
515.970442108866,
|
| 1136 |
+
435.7565370847522
|
| 1137 |
+
]
|
| 1138 |
+
},
|
| 1139 |
+
"groupNodes": {}
|
| 1140 |
+
},
|
| 1141 |
+
"version": 0.4
|
| 1142 |
+
}
|
asset/docs/ComfyUI/Sana_FlowEuler.json
ADDED
|
@@ -0,0 +1,508 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"last_node_id": 10,
|
| 3 |
+
"last_link_id": 11,
|
| 4 |
+
"nodes": [
|
| 5 |
+
{
|
| 6 |
+
"id": 1,
|
| 7 |
+
"type": "VAEDecode",
|
| 8 |
+
"pos": [
|
| 9 |
+
1116.951416015625,
|
| 10 |
+
273.2231140136719
|
| 11 |
+
],
|
| 12 |
+
"size": [
|
| 13 |
+
200,
|
| 14 |
+
50
|
| 15 |
+
],
|
| 16 |
+
"flags": {},
|
| 17 |
+
"order": 8,
|
| 18 |
+
"mode": 0,
|
| 19 |
+
"inputs": [
|
| 20 |
+
{
|
| 21 |
+
"name": "samples",
|
| 22 |
+
"type": "LATENT",
|
| 23 |
+
"link": 1
|
| 24 |
+
},
|
| 25 |
+
{
|
| 26 |
+
"name": "vae",
|
| 27 |
+
"type": "VAE",
|
| 28 |
+
"link": 2
|
| 29 |
+
}
|
| 30 |
+
],
|
| 31 |
+
"outputs": [
|
| 32 |
+
{
|
| 33 |
+
"name": "IMAGE",
|
| 34 |
+
"type": "IMAGE",
|
| 35 |
+
"links": [
|
| 36 |
+
9
|
| 37 |
+
],
|
| 38 |
+
"slot_index": 0,
|
| 39 |
+
"shape": 3
|
| 40 |
+
}
|
| 41 |
+
],
|
| 42 |
+
"properties": {
|
| 43 |
+
"Node name for S&R": "VAEDecode"
|
| 44 |
+
},
|
| 45 |
+
"widgets_values": []
|
| 46 |
+
},
|
| 47 |
+
{
|
| 48 |
+
"id": 2,
|
| 49 |
+
"type": "GemmaLoader",
|
| 50 |
+
"pos": [
|
| 51 |
+
-41.03317642211914,
|
| 52 |
+
680.6829223632812
|
| 53 |
+
],
|
| 54 |
+
"size": [
|
| 55 |
+
315,
|
| 56 |
+
106
|
| 57 |
+
],
|
| 58 |
+
"flags": {},
|
| 59 |
+
"order": 0,
|
| 60 |
+
"mode": 0,
|
| 61 |
+
"inputs": [],
|
| 62 |
+
"outputs": [
|
| 63 |
+
{
|
| 64 |
+
"name": "GEMMA",
|
| 65 |
+
"type": "GEMMA",
|
| 66 |
+
"links": [
|
| 67 |
+
10,
|
| 68 |
+
11
|
| 69 |
+
],
|
| 70 |
+
"slot_index": 0
|
| 71 |
+
}
|
| 72 |
+
],
|
| 73 |
+
"properties": {
|
| 74 |
+
"Node name for S&R": "GemmaLoader"
|
| 75 |
+
},
|
| 76 |
+
"widgets_values": [
|
| 77 |
+
"Efficient-Large-Model/gemma-2-2b-it",
|
| 78 |
+
"cuda",
|
| 79 |
+
"BF16"
|
| 80 |
+
]
|
| 81 |
+
},
|
| 82 |
+
{
|
| 83 |
+
"id": 3,
|
| 84 |
+
"type": "ExtraVAELoader",
|
| 85 |
+
"pos": [
|
| 86 |
+
801.2960205078125,
|
| 87 |
+
863.7061157226562
|
| 88 |
+
],
|
| 89 |
+
"size": [
|
| 90 |
+
315,
|
| 91 |
+
106
|
| 92 |
+
],
|
| 93 |
+
"flags": {},
|
| 94 |
+
"order": 1,
|
| 95 |
+
"mode": 0,
|
| 96 |
+
"inputs": [],
|
| 97 |
+
"outputs": [
|
| 98 |
+
{
|
| 99 |
+
"name": "VAE",
|
| 100 |
+
"type": "VAE",
|
| 101 |
+
"links": [
|
| 102 |
+
2
|
| 103 |
+
],
|
| 104 |
+
"slot_index": 0
|
| 105 |
+
}
|
| 106 |
+
],
|
| 107 |
+
"properties": {
|
| 108 |
+
"Node name for S&R": "ExtraVAELoader"
|
| 109 |
+
},
|
| 110 |
+
"widgets_values": [
|
| 111 |
+
"mit-han-lab/dc-ae-f32c32-sana-1.0-diffusers",
|
| 112 |
+
"dcae-f32c32-sana-1.0-diffusers",
|
| 113 |
+
"BF16"
|
| 114 |
+
]
|
| 115 |
+
},
|
| 116 |
+
{
|
| 117 |
+
"id": 4,
|
| 118 |
+
"type": "KSampler",
|
| 119 |
+
"pos": [
|
| 120 |
+
770.397216796875,
|
| 121 |
+
267.5942077636719
|
| 122 |
+
],
|
| 123 |
+
"size": [
|
| 124 |
+
300,
|
| 125 |
+
480
|
| 126 |
+
],
|
| 127 |
+
"flags": {},
|
| 128 |
+
"order": 7,
|
| 129 |
+
"mode": 0,
|
| 130 |
+
"inputs": [
|
| 131 |
+
{
|
| 132 |
+
"name": "model",
|
| 133 |
+
"type": "MODEL",
|
| 134 |
+
"link": 3
|
| 135 |
+
},
|
| 136 |
+
{
|
| 137 |
+
"name": "positive",
|
| 138 |
+
"type": "CONDITIONING",
|
| 139 |
+
"link": 4
|
| 140 |
+
},
|
| 141 |
+
{
|
| 142 |
+
"name": "negative",
|
| 143 |
+
"type": "CONDITIONING",
|
| 144 |
+
"link": 5
|
| 145 |
+
},
|
| 146 |
+
{
|
| 147 |
+
"name": "latent_image",
|
| 148 |
+
"type": "LATENT",
|
| 149 |
+
"link": 6
|
| 150 |
+
}
|
| 151 |
+
],
|
| 152 |
+
"outputs": [
|
| 153 |
+
{
|
| 154 |
+
"name": "LATENT",
|
| 155 |
+
"type": "LATENT",
|
| 156 |
+
"links": [
|
| 157 |
+
1
|
| 158 |
+
],
|
| 159 |
+
"slot_index": 0,
|
| 160 |
+
"shape": 3
|
| 161 |
+
}
|
| 162 |
+
],
|
| 163 |
+
"properties": {
|
| 164 |
+
"Node name for S&R": "KSampler"
|
| 165 |
+
},
|
| 166 |
+
"widgets_values": [
|
| 167 |
+
1057228702589644,
|
| 168 |
+
"fixed",
|
| 169 |
+
28,
|
| 170 |
+
2,
|
| 171 |
+
"euler",
|
| 172 |
+
"normal",
|
| 173 |
+
1
|
| 174 |
+
]
|
| 175 |
+
},
|
| 176 |
+
{
|
| 177 |
+
"id": 5,
|
| 178 |
+
"type": "EmptySanaLatentImage",
|
| 179 |
+
"pos": [
|
| 180 |
+
392.18475341796875,
|
| 181 |
+
367.0936279296875
|
| 182 |
+
],
|
| 183 |
+
"size": [
|
| 184 |
+
315,
|
| 185 |
+
106
|
| 186 |
+
],
|
| 187 |
+
"flags": {},
|
| 188 |
+
"order": 6,
|
| 189 |
+
"mode": 0,
|
| 190 |
+
"inputs": [
|
| 191 |
+
{
|
| 192 |
+
"name": "width",
|
| 193 |
+
"type": "INT",
|
| 194 |
+
"link": 7,
|
| 195 |
+
"widget": {
|
| 196 |
+
"name": "width"
|
| 197 |
+
}
|
| 198 |
+
},
|
| 199 |
+
{
|
| 200 |
+
"name": "height",
|
| 201 |
+
"type": "INT",
|
| 202 |
+
"link": 8,
|
| 203 |
+
"widget": {
|
| 204 |
+
"name": "height"
|
| 205 |
+
}
|
| 206 |
+
}
|
| 207 |
+
],
|
| 208 |
+
"outputs": [
|
| 209 |
+
{
|
| 210 |
+
"name": "LATENT",
|
| 211 |
+
"type": "LATENT",
|
| 212 |
+
"links": [
|
| 213 |
+
6
|
| 214 |
+
],
|
| 215 |
+
"slot_index": 0
|
| 216 |
+
}
|
| 217 |
+
],
|
| 218 |
+
"properties": {
|
| 219 |
+
"Node name for S&R": "EmptySanaLatentImage"
|
| 220 |
+
},
|
| 221 |
+
"widgets_values": [
|
| 222 |
+
512,
|
| 223 |
+
512,
|
| 224 |
+
1
|
| 225 |
+
]
|
| 226 |
+
},
|
| 227 |
+
{
|
| 228 |
+
"id": 6,
|
| 229 |
+
"type": "PreviewImage",
|
| 230 |
+
"pos": [
|
| 231 |
+
1143.318115234375,
|
| 232 |
+
385.34552001953125
|
| 233 |
+
],
|
| 234 |
+
"size": [
|
| 235 |
+
605.93505859375,
|
| 236 |
+
665.570068359375
|
| 237 |
+
],
|
| 238 |
+
"flags": {},
|
| 239 |
+
"order": 9,
|
| 240 |
+
"mode": 0,
|
| 241 |
+
"inputs": [
|
| 242 |
+
{
|
| 243 |
+
"name": "images",
|
| 244 |
+
"type": "IMAGE",
|
| 245 |
+
"link": 9
|
| 246 |
+
}
|
| 247 |
+
],
|
| 248 |
+
"outputs": [],
|
| 249 |
+
"properties": {
|
| 250 |
+
"Node name for S&R": "PreviewImage"
|
| 251 |
+
},
|
| 252 |
+
"widgets_values": []
|
| 253 |
+
},
|
| 254 |
+
{
|
| 255 |
+
"id": 9,
|
| 256 |
+
"type": "GemmaTextEncode",
|
| 257 |
+
"pos": [
|
| 258 |
+
320.47918701171875,
|
| 259 |
+
884.2686767578125
|
| 260 |
+
],
|
| 261 |
+
"size": [
|
| 262 |
+
400,
|
| 263 |
+
200
|
| 264 |
+
],
|
| 265 |
+
"flags": {},
|
| 266 |
+
"order": 4,
|
| 267 |
+
"mode": 0,
|
| 268 |
+
"inputs": [
|
| 269 |
+
{
|
| 270 |
+
"name": "GEMMA",
|
| 271 |
+
"type": "GEMMA",
|
| 272 |
+
"link": 10
|
| 273 |
+
}
|
| 274 |
+
],
|
| 275 |
+
"outputs": [
|
| 276 |
+
{
|
| 277 |
+
"name": "CONDITIONING",
|
| 278 |
+
"type": "CONDITIONING",
|
| 279 |
+
"links": [
|
| 280 |
+
5
|
| 281 |
+
],
|
| 282 |
+
"slot_index": 0
|
| 283 |
+
}
|
| 284 |
+
],
|
| 285 |
+
"properties": {
|
| 286 |
+
"Node name for S&R": "GemmaTextEncode"
|
| 287 |
+
},
|
| 288 |
+
"widgets_values": [
|
| 289 |
+
""
|
| 290 |
+
]
|
| 291 |
+
},
|
| 292 |
+
{
|
| 293 |
+
"id": 10,
|
| 294 |
+
"type": "SanaTextEncode",
|
| 295 |
+
"pos": [
|
| 296 |
+
323.21978759765625,
|
| 297 |
+
632.0758666992188
|
| 298 |
+
],
|
| 299 |
+
"size": [
|
| 300 |
+
400,
|
| 301 |
+
200
|
| 302 |
+
],
|
| 303 |
+
"flags": {},
|
| 304 |
+
"order": 5,
|
| 305 |
+
"mode": 0,
|
| 306 |
+
"inputs": [
|
| 307 |
+
{
|
| 308 |
+
"name": "GEMMA",
|
| 309 |
+
"type": "GEMMA",
|
| 310 |
+
"link": 11
|
| 311 |
+
}
|
| 312 |
+
],
|
| 313 |
+
"outputs": [
|
| 314 |
+
{
|
| 315 |
+
"name": "CONDITIONING",
|
| 316 |
+
"type": "CONDITIONING",
|
| 317 |
+
"links": [
|
| 318 |
+
4
|
| 319 |
+
],
|
| 320 |
+
"slot_index": 0
|
| 321 |
+
}
|
| 322 |
+
],
|
| 323 |
+
"properties": {
|
| 324 |
+
"Node name for S&R": "SanaTextEncode"
|
| 325 |
+
},
|
| 326 |
+
"widgets_values": [
|
| 327 |
+
"a dog and a cat"
|
| 328 |
+
]
|
| 329 |
+
},
|
| 330 |
+
{
|
| 331 |
+
"id": 7,
|
| 332 |
+
"type": "SanaCheckpointLoader",
|
| 333 |
+
"pos": [
|
| 334 |
+
-15.461307525634766,
|
| 335 |
+
297.74456787109375
|
| 336 |
+
],
|
| 337 |
+
"size": [
|
| 338 |
+
315,
|
| 339 |
+
106
|
| 340 |
+
],
|
| 341 |
+
"flags": {},
|
| 342 |
+
"order": 2,
|
| 343 |
+
"mode": 0,
|
| 344 |
+
"inputs": [],
|
| 345 |
+
"outputs": [
|
| 346 |
+
{
|
| 347 |
+
"name": "model",
|
| 348 |
+
"type": "MODEL",
|
| 349 |
+
"links": [
|
| 350 |
+
3
|
| 351 |
+
],
|
| 352 |
+
"slot_index": 0
|
| 353 |
+
}
|
| 354 |
+
],
|
| 355 |
+
"properties": {
|
| 356 |
+
"Node name for S&R": "SanaCheckpointLoader"
|
| 357 |
+
},
|
| 358 |
+
"widgets_values": [
|
| 359 |
+
"Efficient-Large-Model/Sana_1600M_1024px_BF16",
|
| 360 |
+
"SanaMS_1600M_P1_D20",
|
| 361 |
+
"BF16"
|
| 362 |
+
]
|
| 363 |
+
},
|
| 364 |
+
{
|
| 365 |
+
"id": 8,
|
| 366 |
+
"type": "SanaResolutionSelect",
|
| 367 |
+
"pos": [
|
| 368 |
+
-24.12485122680664,
|
| 369 |
+
469.7320556640625
|
| 370 |
+
],
|
| 371 |
+
"size": [
|
| 372 |
+
315,
|
| 373 |
+
102
|
| 374 |
+
],
|
| 375 |
+
"flags": {},
|
| 376 |
+
"order": 3,
|
| 377 |
+
"mode": 0,
|
| 378 |
+
"inputs": [],
|
| 379 |
+
"outputs": [
|
| 380 |
+
{
|
| 381 |
+
"name": "width",
|
| 382 |
+
"type": "INT",
|
| 383 |
+
"links": [
|
| 384 |
+
7
|
| 385 |
+
],
|
| 386 |
+
"slot_index": 0
|
| 387 |
+
},
|
| 388 |
+
{
|
| 389 |
+
"name": "height",
|
| 390 |
+
"type": "INT",
|
| 391 |
+
"links": [
|
| 392 |
+
8
|
| 393 |
+
],
|
| 394 |
+
"slot_index": 1
|
| 395 |
+
}
|
| 396 |
+
],
|
| 397 |
+
"properties": {
|
| 398 |
+
"Node name for S&R": "SanaResolutionSelect"
|
| 399 |
+
},
|
| 400 |
+
"widgets_values": [
|
| 401 |
+
"1024px",
|
| 402 |
+
"1.00"
|
| 403 |
+
]
|
| 404 |
+
}
|
| 405 |
+
],
|
| 406 |
+
"links": [
|
| 407 |
+
[
|
| 408 |
+
1,
|
| 409 |
+
4,
|
| 410 |
+
0,
|
| 411 |
+
1,
|
| 412 |
+
0,
|
| 413 |
+
"LATENT"
|
| 414 |
+
],
|
| 415 |
+
[
|
| 416 |
+
2,
|
| 417 |
+
3,
|
| 418 |
+
0,
|
| 419 |
+
1,
|
| 420 |
+
1,
|
| 421 |
+
"VAE"
|
| 422 |
+
],
|
| 423 |
+
[
|
| 424 |
+
3,
|
| 425 |
+
7,
|
| 426 |
+
0,
|
| 427 |
+
4,
|
| 428 |
+
0,
|
| 429 |
+
"MODEL"
|
| 430 |
+
],
|
| 431 |
+
[
|
| 432 |
+
4,
|
| 433 |
+
10,
|
| 434 |
+
0,
|
| 435 |
+
4,
|
| 436 |
+
1,
|
| 437 |
+
"CONDITIONING"
|
| 438 |
+
],
|
| 439 |
+
[
|
| 440 |
+
5,
|
| 441 |
+
9,
|
| 442 |
+
0,
|
| 443 |
+
4,
|
| 444 |
+
2,
|
| 445 |
+
"CONDITIONING"
|
| 446 |
+
],
|
| 447 |
+
[
|
| 448 |
+
6,
|
| 449 |
+
5,
|
| 450 |
+
0,
|
| 451 |
+
4,
|
| 452 |
+
3,
|
| 453 |
+
"LATENT"
|
| 454 |
+
],
|
| 455 |
+
[
|
| 456 |
+
7,
|
| 457 |
+
8,
|
| 458 |
+
0,
|
| 459 |
+
5,
|
| 460 |
+
0,
|
| 461 |
+
"INT"
|
| 462 |
+
],
|
| 463 |
+
[
|
| 464 |
+
8,
|
| 465 |
+
8,
|
| 466 |
+
1,
|
| 467 |
+
5,
|
| 468 |
+
1,
|
| 469 |
+
"INT"
|
| 470 |
+
],
|
| 471 |
+
[
|
| 472 |
+
9,
|
| 473 |
+
1,
|
| 474 |
+
0,
|
| 475 |
+
6,
|
| 476 |
+
0,
|
| 477 |
+
"IMAGE"
|
| 478 |
+
],
|
| 479 |
+
[
|
| 480 |
+
10,
|
| 481 |
+
2,
|
| 482 |
+
0,
|
| 483 |
+
9,
|
| 484 |
+
0,
|
| 485 |
+
"GEMMA"
|
| 486 |
+
],
|
| 487 |
+
[
|
| 488 |
+
11,
|
| 489 |
+
2,
|
| 490 |
+
0,
|
| 491 |
+
10,
|
| 492 |
+
0,
|
| 493 |
+
"GEMMA"
|
| 494 |
+
]
|
| 495 |
+
],
|
| 496 |
+
"groups": [],
|
| 497 |
+
"config": {},
|
| 498 |
+
"extra": {
|
| 499 |
+
"ds": {
|
| 500 |
+
"scale": 1,
|
| 501 |
+
"offset": [
|
| 502 |
+
363.9719256481908,
|
| 503 |
+
-27.1040341608292
|
| 504 |
+
]
|
| 505 |
+
}
|
| 506 |
+
},
|
| 507 |
+
"version": 0.4
|
| 508 |
+
}
|
asset/docs/ComfyUI/Sana_FlowEuler_2K.json
ADDED
|
@@ -0,0 +1,508 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"last_node_id": 38,
|
| 3 |
+
"last_link_id": 47,
|
| 4 |
+
"nodes": [
|
| 5 |
+
{
|
| 6 |
+
"id": 4,
|
| 7 |
+
"type": "VAEDecode",
|
| 8 |
+
"pos": [
|
| 9 |
+
776.332763671875,
|
| 10 |
+
105.08650970458984
|
| 11 |
+
],
|
| 12 |
+
"size": [
|
| 13 |
+
200,
|
| 14 |
+
50
|
| 15 |
+
],
|
| 16 |
+
"flags": {},
|
| 17 |
+
"order": 8,
|
| 18 |
+
"mode": 0,
|
| 19 |
+
"inputs": [
|
| 20 |
+
{
|
| 21 |
+
"name": "samples",
|
| 22 |
+
"type": "LATENT",
|
| 23 |
+
"link": 3
|
| 24 |
+
},
|
| 25 |
+
{
|
| 26 |
+
"name": "vae",
|
| 27 |
+
"type": "VAE",
|
| 28 |
+
"link": 24
|
| 29 |
+
}
|
| 30 |
+
],
|
| 31 |
+
"outputs": [
|
| 32 |
+
{
|
| 33 |
+
"name": "IMAGE",
|
| 34 |
+
"type": "IMAGE",
|
| 35 |
+
"links": [
|
| 36 |
+
11
|
| 37 |
+
],
|
| 38 |
+
"slot_index": 0,
|
| 39 |
+
"shape": 3
|
| 40 |
+
}
|
| 41 |
+
],
|
| 42 |
+
"properties": {
|
| 43 |
+
"Node name for S&R": "VAEDecode"
|
| 44 |
+
},
|
| 45 |
+
"widgets_values": []
|
| 46 |
+
},
|
| 47 |
+
{
|
| 48 |
+
"id": 9,
|
| 49 |
+
"type": "GemmaLoader",
|
| 50 |
+
"pos": [
|
| 51 |
+
-381.6518859863281,
|
| 52 |
+
512.5463256835938
|
| 53 |
+
],
|
| 54 |
+
"size": [
|
| 55 |
+
315,
|
| 56 |
+
106
|
| 57 |
+
],
|
| 58 |
+
"flags": {},
|
| 59 |
+
"order": 0,
|
| 60 |
+
"mode": 0,
|
| 61 |
+
"inputs": [],
|
| 62 |
+
"outputs": [
|
| 63 |
+
{
|
| 64 |
+
"name": "GEMMA",
|
| 65 |
+
"type": "GEMMA",
|
| 66 |
+
"links": [
|
| 67 |
+
39,
|
| 68 |
+
41
|
| 69 |
+
],
|
| 70 |
+
"slot_index": 0
|
| 71 |
+
}
|
| 72 |
+
],
|
| 73 |
+
"properties": {
|
| 74 |
+
"Node name for S&R": "GemmaLoader"
|
| 75 |
+
},
|
| 76 |
+
"widgets_values": [
|
| 77 |
+
"Efficient-Large-Model/gemma-2-2b-it",
|
| 78 |
+
"cuda",
|
| 79 |
+
"BF16"
|
| 80 |
+
]
|
| 81 |
+
},
|
| 82 |
+
{
|
| 83 |
+
"id": 29,
|
| 84 |
+
"type": "ExtraVAELoader",
|
| 85 |
+
"pos": [
|
| 86 |
+
460.67730712890625,
|
| 87 |
+
695.5695190429688
|
| 88 |
+
],
|
| 89 |
+
"size": [
|
| 90 |
+
315,
|
| 91 |
+
106
|
| 92 |
+
],
|
| 93 |
+
"flags": {},
|
| 94 |
+
"order": 1,
|
| 95 |
+
"mode": 0,
|
| 96 |
+
"inputs": [],
|
| 97 |
+
"outputs": [
|
| 98 |
+
{
|
| 99 |
+
"name": "VAE",
|
| 100 |
+
"type": "VAE",
|
| 101 |
+
"links": [
|
| 102 |
+
24
|
| 103 |
+
],
|
| 104 |
+
"slot_index": 0
|
| 105 |
+
}
|
| 106 |
+
],
|
| 107 |
+
"properties": {
|
| 108 |
+
"Node name for S&R": "ExtraVAELoader"
|
| 109 |
+
},
|
| 110 |
+
"widgets_values": [
|
| 111 |
+
"mit-han-lab/dc-ae-f32c32-sana-1.0-diffusers",
|
| 112 |
+
"dcae-f32c32-sana-1.0-diffusers",
|
| 113 |
+
"BF16"
|
| 114 |
+
]
|
| 115 |
+
},
|
| 116 |
+
{
|
| 117 |
+
"id": 10,
|
| 118 |
+
"type": "KSampler",
|
| 119 |
+
"pos": [
|
| 120 |
+
429.7785339355469,
|
| 121 |
+
99.45759582519531
|
| 122 |
+
],
|
| 123 |
+
"size": [
|
| 124 |
+
300,
|
| 125 |
+
480
|
| 126 |
+
],
|
| 127 |
+
"flags": {},
|
| 128 |
+
"order": 7,
|
| 129 |
+
"mode": 0,
|
| 130 |
+
"inputs": [
|
| 131 |
+
{
|
| 132 |
+
"name": "model",
|
| 133 |
+
"type": "MODEL",
|
| 134 |
+
"link": 33
|
| 135 |
+
},
|
| 136 |
+
{
|
| 137 |
+
"name": "positive",
|
| 138 |
+
"type": "CONDITIONING",
|
| 139 |
+
"link": 42
|
| 140 |
+
},
|
| 141 |
+
{
|
| 142 |
+
"name": "negative",
|
| 143 |
+
"type": "CONDITIONING",
|
| 144 |
+
"link": 47
|
| 145 |
+
},
|
| 146 |
+
{
|
| 147 |
+
"name": "latent_image",
|
| 148 |
+
"type": "LATENT",
|
| 149 |
+
"link": 46
|
| 150 |
+
}
|
| 151 |
+
],
|
| 152 |
+
"outputs": [
|
| 153 |
+
{
|
| 154 |
+
"name": "LATENT",
|
| 155 |
+
"type": "LATENT",
|
| 156 |
+
"links": [
|
| 157 |
+
3
|
| 158 |
+
],
|
| 159 |
+
"slot_index": 0,
|
| 160 |
+
"shape": 3
|
| 161 |
+
}
|
| 162 |
+
],
|
| 163 |
+
"properties": {
|
| 164 |
+
"Node name for S&R": "KSampler"
|
| 165 |
+
},
|
| 166 |
+
"widgets_values": [
|
| 167 |
+
1057228702589644,
|
| 168 |
+
"fixed",
|
| 169 |
+
28,
|
| 170 |
+
2,
|
| 171 |
+
"euler",
|
| 172 |
+
"normal",
|
| 173 |
+
1
|
| 174 |
+
]
|
| 175 |
+
},
|
| 176 |
+
{
|
| 177 |
+
"id": 33,
|
| 178 |
+
"type": "EmptySanaLatentImage",
|
| 179 |
+
"pos": [
|
| 180 |
+
51.56604766845703,
|
| 181 |
+
198.95700073242188
|
| 182 |
+
],
|
| 183 |
+
"size": [
|
| 184 |
+
315,
|
| 185 |
+
106
|
| 186 |
+
],
|
| 187 |
+
"flags": {},
|
| 188 |
+
"order": 6,
|
| 189 |
+
"mode": 0,
|
| 190 |
+
"inputs": [
|
| 191 |
+
{
|
| 192 |
+
"name": "width",
|
| 193 |
+
"type": "INT",
|
| 194 |
+
"link": 28,
|
| 195 |
+
"widget": {
|
| 196 |
+
"name": "width"
|
| 197 |
+
}
|
| 198 |
+
},
|
| 199 |
+
{
|
| 200 |
+
"name": "height",
|
| 201 |
+
"type": "INT",
|
| 202 |
+
"link": 29,
|
| 203 |
+
"widget": {
|
| 204 |
+
"name": "height"
|
| 205 |
+
}
|
| 206 |
+
}
|
| 207 |
+
],
|
| 208 |
+
"outputs": [
|
| 209 |
+
{
|
| 210 |
+
"name": "LATENT",
|
| 211 |
+
"type": "LATENT",
|
| 212 |
+
"links": [
|
| 213 |
+
46
|
| 214 |
+
],
|
| 215 |
+
"slot_index": 0
|
| 216 |
+
}
|
| 217 |
+
],
|
| 218 |
+
"properties": {
|
| 219 |
+
"Node name for S&R": "EmptySanaLatentImage"
|
| 220 |
+
},
|
| 221 |
+
"widgets_values": [
|
| 222 |
+
512,
|
| 223 |
+
512,
|
| 224 |
+
1
|
| 225 |
+
]
|
| 226 |
+
},
|
| 227 |
+
{
|
| 228 |
+
"id": 13,
|
| 229 |
+
"type": "PreviewImage",
|
| 230 |
+
"pos": [
|
| 231 |
+
802.6994018554688,
|
| 232 |
+
217.20889282226562
|
| 233 |
+
],
|
| 234 |
+
"size": [
|
| 235 |
+
605.93505859375,
|
| 236 |
+
665.570068359375
|
| 237 |
+
],
|
| 238 |
+
"flags": {},
|
| 239 |
+
"order": 9,
|
| 240 |
+
"mode": 0,
|
| 241 |
+
"inputs": [
|
| 242 |
+
{
|
| 243 |
+
"name": "images",
|
| 244 |
+
"type": "IMAGE",
|
| 245 |
+
"link": 11
|
| 246 |
+
}
|
| 247 |
+
],
|
| 248 |
+
"outputs": [],
|
| 249 |
+
"properties": {
|
| 250 |
+
"Node name for S&R": "PreviewImage"
|
| 251 |
+
},
|
| 252 |
+
"widgets_values": []
|
| 253 |
+
},
|
| 254 |
+
{
|
| 255 |
+
"id": 25,
|
| 256 |
+
"type": "SanaCheckpointLoader",
|
| 257 |
+
"pos": [
|
| 258 |
+
-356.08001708984375,
|
| 259 |
+
129.6079559326172
|
| 260 |
+
],
|
| 261 |
+
"size": [
|
| 262 |
+
315,
|
| 263 |
+
106
|
| 264 |
+
],
|
| 265 |
+
"flags": {},
|
| 266 |
+
"order": 2,
|
| 267 |
+
"mode": 0,
|
| 268 |
+
"inputs": [],
|
| 269 |
+
"outputs": [
|
| 270 |
+
{
|
| 271 |
+
"name": "model",
|
| 272 |
+
"type": "MODEL",
|
| 273 |
+
"links": [
|
| 274 |
+
33
|
| 275 |
+
],
|
| 276 |
+
"slot_index": 0
|
| 277 |
+
}
|
| 278 |
+
],
|
| 279 |
+
"properties": {
|
| 280 |
+
"Node name for S&R": "SanaCheckpointLoader"
|
| 281 |
+
},
|
| 282 |
+
"widgets_values": [
|
| 283 |
+
"Efficient-Large-Model/Sana_1600M_2Kpx_BF16",
|
| 284 |
+
"SanaMS_1600M_P1_D20_2K",
|
| 285 |
+
"BF16"
|
| 286 |
+
]
|
| 287 |
+
},
|
| 288 |
+
{
|
| 289 |
+
"id": 6,
|
| 290 |
+
"type": "SanaResolutionSelect",
|
| 291 |
+
"pos": [
|
| 292 |
+
-364.7435607910156,
|
| 293 |
+
301.5954284667969
|
| 294 |
+
],
|
| 295 |
+
"size": [
|
| 296 |
+
315,
|
| 297 |
+
102
|
| 298 |
+
],
|
| 299 |
+
"flags": {},
|
| 300 |
+
"order": 3,
|
| 301 |
+
"mode": 0,
|
| 302 |
+
"inputs": [],
|
| 303 |
+
"outputs": [
|
| 304 |
+
{
|
| 305 |
+
"name": "width",
|
| 306 |
+
"type": "INT",
|
| 307 |
+
"links": [
|
| 308 |
+
28
|
| 309 |
+
],
|
| 310 |
+
"slot_index": 0
|
| 311 |
+
},
|
| 312 |
+
{
|
| 313 |
+
"name": "height",
|
| 314 |
+
"type": "INT",
|
| 315 |
+
"links": [
|
| 316 |
+
29
|
| 317 |
+
],
|
| 318 |
+
"slot_index": 1
|
| 319 |
+
}
|
| 320 |
+
],
|
| 321 |
+
"properties": {
|
| 322 |
+
"Node name for S&R": "SanaResolutionSelect"
|
| 323 |
+
},
|
| 324 |
+
"widgets_values": [
|
| 325 |
+
"2K",
|
| 326 |
+
"1.00"
|
| 327 |
+
]
|
| 328 |
+
},
|
| 329 |
+
{
|
| 330 |
+
"id": 14,
|
| 331 |
+
"type": "SanaTextEncode",
|
| 332 |
+
"pos": [
|
| 333 |
+
-17.398910522460938,
|
| 334 |
+
463.93927001953125
|
| 335 |
+
],
|
| 336 |
+
"size": [
|
| 337 |
+
400,
|
| 338 |
+
200
|
| 339 |
+
],
|
| 340 |
+
"flags": {},
|
| 341 |
+
"order": 4,
|
| 342 |
+
"mode": 0,
|
| 343 |
+
"inputs": [
|
| 344 |
+
{
|
| 345 |
+
"name": "GEMMA",
|
| 346 |
+
"type": "GEMMA",
|
| 347 |
+
"link": 39
|
| 348 |
+
}
|
| 349 |
+
],
|
| 350 |
+
"outputs": [
|
| 351 |
+
{
|
| 352 |
+
"name": "CONDITIONING",
|
| 353 |
+
"type": "CONDITIONING",
|
| 354 |
+
"links": [
|
| 355 |
+
42
|
| 356 |
+
],
|
| 357 |
+
"slot_index": 0
|
| 358 |
+
}
|
| 359 |
+
],
|
| 360 |
+
"properties": {
|
| 361 |
+
"Node name for S&R": "SanaTextEncode"
|
| 362 |
+
},
|
| 363 |
+
"widgets_values": [
|
| 364 |
+
"a dog and a cat"
|
| 365 |
+
]
|
| 366 |
+
},
|
| 367 |
+
{
|
| 368 |
+
"id": 37,
|
| 369 |
+
"type": "GemmaTextEncode",
|
| 370 |
+
"pos": [
|
| 371 |
+
-20.1395263671875,
|
| 372 |
+
716.132080078125
|
| 373 |
+
],
|
| 374 |
+
"size": [
|
| 375 |
+
400,
|
| 376 |
+
200
|
| 377 |
+
],
|
| 378 |
+
"flags": {},
|
| 379 |
+
"order": 5,
|
| 380 |
+
"mode": 0,
|
| 381 |
+
"inputs": [
|
| 382 |
+
{
|
| 383 |
+
"name": "GEMMA",
|
| 384 |
+
"type": "GEMMA",
|
| 385 |
+
"link": 41
|
| 386 |
+
}
|
| 387 |
+
],
|
| 388 |
+
"outputs": [
|
| 389 |
+
{
|
| 390 |
+
"name": "CONDITIONING",
|
| 391 |
+
"type": "CONDITIONING",
|
| 392 |
+
"links": [
|
| 393 |
+
47
|
| 394 |
+
],
|
| 395 |
+
"slot_index": 0
|
| 396 |
+
}
|
| 397 |
+
],
|
| 398 |
+
"properties": {
|
| 399 |
+
"Node name for S&R": "GemmaTextEncode"
|
| 400 |
+
},
|
| 401 |
+
"widgets_values": [
|
| 402 |
+
""
|
| 403 |
+
]
|
| 404 |
+
}
|
| 405 |
+
],
|
| 406 |
+
"links": [
|
| 407 |
+
[
|
| 408 |
+
3,
|
| 409 |
+
10,
|
| 410 |
+
0,
|
| 411 |
+
4,
|
| 412 |
+
0,
|
| 413 |
+
"LATENT"
|
| 414 |
+
],
|
| 415 |
+
[
|
| 416 |
+
11,
|
| 417 |
+
4,
|
| 418 |
+
0,
|
| 419 |
+
13,
|
| 420 |
+
0,
|
| 421 |
+
"IMAGE"
|
| 422 |
+
],
|
| 423 |
+
[
|
| 424 |
+
24,
|
| 425 |
+
29,
|
| 426 |
+
0,
|
| 427 |
+
4,
|
| 428 |
+
1,
|
| 429 |
+
"VAE"
|
| 430 |
+
],
|
| 431 |
+
[
|
| 432 |
+
28,
|
| 433 |
+
6,
|
| 434 |
+
0,
|
| 435 |
+
33,
|
| 436 |
+
0,
|
| 437 |
+
"INT"
|
| 438 |
+
],
|
| 439 |
+
[
|
| 440 |
+
29,
|
| 441 |
+
6,
|
| 442 |
+
1,
|
| 443 |
+
33,
|
| 444 |
+
1,
|
| 445 |
+
"INT"
|
| 446 |
+
],
|
| 447 |
+
[
|
| 448 |
+
33,
|
| 449 |
+
25,
|
| 450 |
+
0,
|
| 451 |
+
10,
|
| 452 |
+
0,
|
| 453 |
+
"MODEL"
|
| 454 |
+
],
|
| 455 |
+
[
|
| 456 |
+
39,
|
| 457 |
+
9,
|
| 458 |
+
0,
|
| 459 |
+
14,
|
| 460 |
+
0,
|
| 461 |
+
"GEMMA"
|
| 462 |
+
],
|
| 463 |
+
[
|
| 464 |
+
41,
|
| 465 |
+
9,
|
| 466 |
+
0,
|
| 467 |
+
37,
|
| 468 |
+
0,
|
| 469 |
+
"GEMMA"
|
| 470 |
+
],
|
| 471 |
+
[
|
| 472 |
+
42,
|
| 473 |
+
14,
|
| 474 |
+
0,
|
| 475 |
+
10,
|
| 476 |
+
1,
|
| 477 |
+
"CONDITIONING"
|
| 478 |
+
],
|
| 479 |
+
[
|
| 480 |
+
46,
|
| 481 |
+
33,
|
| 482 |
+
0,
|
| 483 |
+
10,
|
| 484 |
+
3,
|
| 485 |
+
"LATENT"
|
| 486 |
+
],
|
| 487 |
+
[
|
| 488 |
+
47,
|
| 489 |
+
37,
|
| 490 |
+
0,
|
| 491 |
+
10,
|
| 492 |
+
2,
|
| 493 |
+
"CONDITIONING"
|
| 494 |
+
]
|
| 495 |
+
],
|
| 496 |
+
"groups": [],
|
| 497 |
+
"config": {},
|
| 498 |
+
"extra": {
|
| 499 |
+
"ds": {
|
| 500 |
+
"scale": 0.9090909090909091,
|
| 501 |
+
"offset": [
|
| 502 |
+
623.7012344346042,
|
| 503 |
+
257.61183690683845
|
| 504 |
+
]
|
| 505 |
+
}
|
| 506 |
+
},
|
| 507 |
+
"version": 0.4
|
| 508 |
+
}
|
asset/docs/ComfyUI/Sana_FlowEuler_4K.json
ADDED
|
@@ -0,0 +1,508 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"last_node_id": 131,
|
| 3 |
+
"last_link_id": 146,
|
| 4 |
+
"nodes": [
|
| 5 |
+
{
|
| 6 |
+
"id": 121,
|
| 7 |
+
"type": "VAEDecode",
|
| 8 |
+
"pos": [
|
| 9 |
+
3658.290771484375,
|
| 10 |
+
1351.9073486328125
|
| 11 |
+
],
|
| 12 |
+
"size": [
|
| 13 |
+
200,
|
| 14 |
+
50
|
| 15 |
+
],
|
| 16 |
+
"flags": {},
|
| 17 |
+
"order": 8,
|
| 18 |
+
"mode": 0,
|
| 19 |
+
"inputs": [
|
| 20 |
+
{
|
| 21 |
+
"name": "samples",
|
| 22 |
+
"type": "LATENT",
|
| 23 |
+
"link": 133
|
| 24 |
+
},
|
| 25 |
+
{
|
| 26 |
+
"name": "vae",
|
| 27 |
+
"type": "VAE",
|
| 28 |
+
"link": 146
|
| 29 |
+
}
|
| 30 |
+
],
|
| 31 |
+
"outputs": [
|
| 32 |
+
{
|
| 33 |
+
"name": "IMAGE",
|
| 34 |
+
"type": "IMAGE",
|
| 35 |
+
"links": [
|
| 36 |
+
141
|
| 37 |
+
],
|
| 38 |
+
"slot_index": 0,
|
| 39 |
+
"shape": 3
|
| 40 |
+
}
|
| 41 |
+
],
|
| 42 |
+
"properties": {
|
| 43 |
+
"Node name for S&R": "VAEDecode"
|
| 44 |
+
},
|
| 45 |
+
"widgets_values": []
|
| 46 |
+
},
|
| 47 |
+
{
|
| 48 |
+
"id": 122,
|
| 49 |
+
"type": "GemmaLoader",
|
| 50 |
+
"pos": [
|
| 51 |
+
2500.30615234375,
|
| 52 |
+
1759.3671875
|
| 53 |
+
],
|
| 54 |
+
"size": [
|
| 55 |
+
315,
|
| 56 |
+
106
|
| 57 |
+
],
|
| 58 |
+
"flags": {},
|
| 59 |
+
"order": 0,
|
| 60 |
+
"mode": 0,
|
| 61 |
+
"inputs": [],
|
| 62 |
+
"outputs": [
|
| 63 |
+
{
|
| 64 |
+
"name": "GEMMA",
|
| 65 |
+
"type": "GEMMA",
|
| 66 |
+
"links": [
|
| 67 |
+
142,
|
| 68 |
+
143
|
| 69 |
+
],
|
| 70 |
+
"slot_index": 0
|
| 71 |
+
}
|
| 72 |
+
],
|
| 73 |
+
"properties": {
|
| 74 |
+
"Node name for S&R": "GemmaLoader"
|
| 75 |
+
},
|
| 76 |
+
"widgets_values": [
|
| 77 |
+
"Efficient-Large-Model/gemma-2-2b-it",
|
| 78 |
+
"cuda",
|
| 79 |
+
"BF16"
|
| 80 |
+
]
|
| 81 |
+
},
|
| 82 |
+
{
|
| 83 |
+
"id": 125,
|
| 84 |
+
"type": "EmptySanaLatentImage",
|
| 85 |
+
"pos": [
|
| 86 |
+
2933.52392578125,
|
| 87 |
+
1445.77783203125
|
| 88 |
+
],
|
| 89 |
+
"size": [
|
| 90 |
+
315,
|
| 91 |
+
106
|
| 92 |
+
],
|
| 93 |
+
"flags": {},
|
| 94 |
+
"order": 6,
|
| 95 |
+
"mode": 0,
|
| 96 |
+
"inputs": [
|
| 97 |
+
{
|
| 98 |
+
"name": "width",
|
| 99 |
+
"type": "INT",
|
| 100 |
+
"link": 139,
|
| 101 |
+
"widget": {
|
| 102 |
+
"name": "width"
|
| 103 |
+
}
|
| 104 |
+
},
|
| 105 |
+
{
|
| 106 |
+
"name": "height",
|
| 107 |
+
"type": "INT",
|
| 108 |
+
"link": 140,
|
| 109 |
+
"widget": {
|
| 110 |
+
"name": "height"
|
| 111 |
+
}
|
| 112 |
+
}
|
| 113 |
+
],
|
| 114 |
+
"outputs": [
|
| 115 |
+
{
|
| 116 |
+
"name": "LATENT",
|
| 117 |
+
"type": "LATENT",
|
| 118 |
+
"links": [
|
| 119 |
+
138
|
| 120 |
+
],
|
| 121 |
+
"slot_index": 0
|
| 122 |
+
}
|
| 123 |
+
],
|
| 124 |
+
"properties": {
|
| 125 |
+
"Node name for S&R": "EmptySanaLatentImage"
|
| 126 |
+
},
|
| 127 |
+
"widgets_values": [
|
| 128 |
+
512,
|
| 129 |
+
512,
|
| 130 |
+
1
|
| 131 |
+
]
|
| 132 |
+
},
|
| 133 |
+
{
|
| 134 |
+
"id": 129,
|
| 135 |
+
"type": "GemmaTextEncode",
|
| 136 |
+
"pos": [
|
| 137 |
+
2861.818359375,
|
| 138 |
+
1962.9530029296875
|
| 139 |
+
],
|
| 140 |
+
"size": [
|
| 141 |
+
400,
|
| 142 |
+
200
|
| 143 |
+
],
|
| 144 |
+
"flags": {},
|
| 145 |
+
"order": 5,
|
| 146 |
+
"mode": 0,
|
| 147 |
+
"inputs": [
|
| 148 |
+
{
|
| 149 |
+
"name": "GEMMA",
|
| 150 |
+
"type": "GEMMA",
|
| 151 |
+
"link": 143
|
| 152 |
+
}
|
| 153 |
+
],
|
| 154 |
+
"outputs": [
|
| 155 |
+
{
|
| 156 |
+
"name": "CONDITIONING",
|
| 157 |
+
"type": "CONDITIONING",
|
| 158 |
+
"links": [
|
| 159 |
+
137
|
| 160 |
+
],
|
| 161 |
+
"slot_index": 0
|
| 162 |
+
}
|
| 163 |
+
],
|
| 164 |
+
"properties": {
|
| 165 |
+
"Node name for S&R": "GemmaTextEncode"
|
| 166 |
+
},
|
| 167 |
+
"widgets_values": [
|
| 168 |
+
""
|
| 169 |
+
]
|
| 170 |
+
},
|
| 171 |
+
{
|
| 172 |
+
"id": 130,
|
| 173 |
+
"type": "SanaCheckpointLoader",
|
| 174 |
+
"pos": [
|
| 175 |
+
2525.8779296875,
|
| 176 |
+
1376.4288330078125
|
| 177 |
+
],
|
| 178 |
+
"size": [
|
| 179 |
+
315,
|
| 180 |
+
106
|
| 181 |
+
],
|
| 182 |
+
"flags": {},
|
| 183 |
+
"order": 1,
|
| 184 |
+
"mode": 0,
|
| 185 |
+
"inputs": [],
|
| 186 |
+
"outputs": [
|
| 187 |
+
{
|
| 188 |
+
"name": "model",
|
| 189 |
+
"type": "MODEL",
|
| 190 |
+
"links": [
|
| 191 |
+
135
|
| 192 |
+
],
|
| 193 |
+
"slot_index": 0
|
| 194 |
+
}
|
| 195 |
+
],
|
| 196 |
+
"properties": {
|
| 197 |
+
"Node name for S&R": "SanaCheckpointLoader"
|
| 198 |
+
},
|
| 199 |
+
"widgets_values": [
|
| 200 |
+
"Efficient-Large-Model/Sana_1600M_4Kpx_BF16",
|
| 201 |
+
"SanaMS_1600M_P1_D20_4K",
|
| 202 |
+
"BF16"
|
| 203 |
+
]
|
| 204 |
+
},
|
| 205 |
+
{
|
| 206 |
+
"id": 127,
|
| 207 |
+
"type": "SanaResolutionSelect",
|
| 208 |
+
"pos": [
|
| 209 |
+
2517.21435546875,
|
| 210 |
+
1548.416259765625
|
| 211 |
+
],
|
| 212 |
+
"size": [
|
| 213 |
+
315,
|
| 214 |
+
102
|
| 215 |
+
],
|
| 216 |
+
"flags": {},
|
| 217 |
+
"order": 2,
|
| 218 |
+
"mode": 0,
|
| 219 |
+
"inputs": [],
|
| 220 |
+
"outputs": [
|
| 221 |
+
{
|
| 222 |
+
"name": "width",
|
| 223 |
+
"type": "INT",
|
| 224 |
+
"links": [
|
| 225 |
+
139
|
| 226 |
+
],
|
| 227 |
+
"slot_index": 0
|
| 228 |
+
},
|
| 229 |
+
{
|
| 230 |
+
"name": "height",
|
| 231 |
+
"type": "INT",
|
| 232 |
+
"links": [
|
| 233 |
+
140
|
| 234 |
+
],
|
| 235 |
+
"slot_index": 1
|
| 236 |
+
}
|
| 237 |
+
],
|
| 238 |
+
"properties": {
|
| 239 |
+
"Node name for S&R": "SanaResolutionSelect"
|
| 240 |
+
},
|
| 241 |
+
"widgets_values": [
|
| 242 |
+
"4K",
|
| 243 |
+
"1.00"
|
| 244 |
+
]
|
| 245 |
+
},
|
| 246 |
+
{
|
| 247 |
+
"id": 128,
|
| 248 |
+
"type": "SanaTextEncode",
|
| 249 |
+
"pos": [
|
| 250 |
+
2864.55908203125,
|
| 251 |
+
1710.7601318359375
|
| 252 |
+
],
|
| 253 |
+
"size": [
|
| 254 |
+
400,
|
| 255 |
+
200
|
| 256 |
+
],
|
| 257 |
+
"flags": {},
|
| 258 |
+
"order": 4,
|
| 259 |
+
"mode": 0,
|
| 260 |
+
"inputs": [
|
| 261 |
+
{
|
| 262 |
+
"name": "GEMMA",
|
| 263 |
+
"type": "GEMMA",
|
| 264 |
+
"link": 142
|
| 265 |
+
}
|
| 266 |
+
],
|
| 267 |
+
"outputs": [
|
| 268 |
+
{
|
| 269 |
+
"name": "CONDITIONING",
|
| 270 |
+
"type": "CONDITIONING",
|
| 271 |
+
"links": [
|
| 272 |
+
136
|
| 273 |
+
],
|
| 274 |
+
"slot_index": 0
|
| 275 |
+
}
|
| 276 |
+
],
|
| 277 |
+
"properties": {
|
| 278 |
+
"Node name for S&R": "SanaTextEncode"
|
| 279 |
+
},
|
| 280 |
+
"widgets_values": [
|
| 281 |
+
"a dog and a cat"
|
| 282 |
+
]
|
| 283 |
+
},
|
| 284 |
+
{
|
| 285 |
+
"id": 123,
|
| 286 |
+
"type": "ExtraVAELoader",
|
| 287 |
+
"pos": [
|
| 288 |
+
3325.43359375,
|
| 289 |
+
1988.7694091796875
|
| 290 |
+
],
|
| 291 |
+
"size": [
|
| 292 |
+
315,
|
| 293 |
+
106
|
| 294 |
+
],
|
| 295 |
+
"flags": {},
|
| 296 |
+
"order": 3,
|
| 297 |
+
"mode": 0,
|
| 298 |
+
"inputs": [],
|
| 299 |
+
"outputs": [
|
| 300 |
+
{
|
| 301 |
+
"name": "VAE",
|
| 302 |
+
"type": "VAE",
|
| 303 |
+
"links": [
|
| 304 |
+
146
|
| 305 |
+
],
|
| 306 |
+
"slot_index": 0
|
| 307 |
+
}
|
| 308 |
+
],
|
| 309 |
+
"properties": {
|
| 310 |
+
"Node name for S&R": "ExtraVAELoader"
|
| 311 |
+
},
|
| 312 |
+
"widgets_values": [
|
| 313 |
+
"mit-han-lab/dc-ae-f32c32-sana-1.0-diffusers",
|
| 314 |
+
"dcae-f32c32-sana-1.0-diffusers",
|
| 315 |
+
"BF16"
|
| 316 |
+
]
|
| 317 |
+
},
|
| 318 |
+
{
|
| 319 |
+
"id": 126,
|
| 320 |
+
"type": "PreviewImage",
|
| 321 |
+
"pos": [
|
| 322 |
+
3684.657470703125,
|
| 323 |
+
1464.02978515625
|
| 324 |
+
],
|
| 325 |
+
"size": [
|
| 326 |
+
605.93505859375,
|
| 327 |
+
665.570068359375
|
| 328 |
+
],
|
| 329 |
+
"flags": {},
|
| 330 |
+
"order": 9,
|
| 331 |
+
"mode": 0,
|
| 332 |
+
"inputs": [
|
| 333 |
+
{
|
| 334 |
+
"name": "images",
|
| 335 |
+
"type": "IMAGE",
|
| 336 |
+
"link": 141
|
| 337 |
+
}
|
| 338 |
+
],
|
| 339 |
+
"outputs": [],
|
| 340 |
+
"properties": {
|
| 341 |
+
"Node name for S&R": "PreviewImage"
|
| 342 |
+
},
|
| 343 |
+
"widgets_values": []
|
| 344 |
+
},
|
| 345 |
+
{
|
| 346 |
+
"id": 124,
|
| 347 |
+
"type": "KSampler",
|
| 348 |
+
"pos": [
|
| 349 |
+
3311.736572265625,
|
| 350 |
+
1346.2784423828125
|
| 351 |
+
],
|
| 352 |
+
"size": [
|
| 353 |
+
300,
|
| 354 |
+
480
|
| 355 |
+
],
|
| 356 |
+
"flags": {},
|
| 357 |
+
"order": 7,
|
| 358 |
+
"mode": 0,
|
| 359 |
+
"inputs": [
|
| 360 |
+
{
|
| 361 |
+
"name": "model",
|
| 362 |
+
"type": "MODEL",
|
| 363 |
+
"link": 135
|
| 364 |
+
},
|
| 365 |
+
{
|
| 366 |
+
"name": "positive",
|
| 367 |
+
"type": "CONDITIONING",
|
| 368 |
+
"link": 136
|
| 369 |
+
},
|
| 370 |
+
{
|
| 371 |
+
"name": "negative",
|
| 372 |
+
"type": "CONDITIONING",
|
| 373 |
+
"link": 137
|
| 374 |
+
},
|
| 375 |
+
{
|
| 376 |
+
"name": "latent_image",
|
| 377 |
+
"type": "LATENT",
|
| 378 |
+
"link": 138
|
| 379 |
+
}
|
| 380 |
+
],
|
| 381 |
+
"outputs": [
|
| 382 |
+
{
|
| 383 |
+
"name": "LATENT",
|
| 384 |
+
"type": "LATENT",
|
| 385 |
+
"links": [
|
| 386 |
+
133
|
| 387 |
+
],
|
| 388 |
+
"slot_index": 0,
|
| 389 |
+
"shape": 3
|
| 390 |
+
}
|
| 391 |
+
],
|
| 392 |
+
"properties": {
|
| 393 |
+
"Node name for S&R": "KSampler"
|
| 394 |
+
},
|
| 395 |
+
"widgets_values": [
|
| 396 |
+
1057228702589645,
|
| 397 |
+
"fixed",
|
| 398 |
+
28,
|
| 399 |
+
2,
|
| 400 |
+
"euler",
|
| 401 |
+
"normal",
|
| 402 |
+
1
|
| 403 |
+
]
|
| 404 |
+
}
|
| 405 |
+
],
|
| 406 |
+
"links": [
|
| 407 |
+
[
|
| 408 |
+
133,
|
| 409 |
+
124,
|
| 410 |
+
0,
|
| 411 |
+
121,
|
| 412 |
+
0,
|
| 413 |
+
"LATENT"
|
| 414 |
+
],
|
| 415 |
+
[
|
| 416 |
+
135,
|
| 417 |
+
130,
|
| 418 |
+
0,
|
| 419 |
+
124,
|
| 420 |
+
0,
|
| 421 |
+
"MODEL"
|
| 422 |
+
],
|
| 423 |
+
[
|
| 424 |
+
136,
|
| 425 |
+
128,
|
| 426 |
+
0,
|
| 427 |
+
124,
|
| 428 |
+
1,
|
| 429 |
+
"CONDITIONING"
|
| 430 |
+
],
|
| 431 |
+
[
|
| 432 |
+
137,
|
| 433 |
+
129,
|
| 434 |
+
0,
|
| 435 |
+
124,
|
| 436 |
+
2,
|
| 437 |
+
"CONDITIONING"
|
| 438 |
+
],
|
| 439 |
+
[
|
| 440 |
+
138,
|
| 441 |
+
125,
|
| 442 |
+
0,
|
| 443 |
+
124,
|
| 444 |
+
3,
|
| 445 |
+
"LATENT"
|
| 446 |
+
],
|
| 447 |
+
[
|
| 448 |
+
139,
|
| 449 |
+
127,
|
| 450 |
+
0,
|
| 451 |
+
125,
|
| 452 |
+
0,
|
| 453 |
+
"INT"
|
| 454 |
+
],
|
| 455 |
+
[
|
| 456 |
+
140,
|
| 457 |
+
127,
|
| 458 |
+
1,
|
| 459 |
+
125,
|
| 460 |
+
1,
|
| 461 |
+
"INT"
|
| 462 |
+
],
|
| 463 |
+
[
|
| 464 |
+
141,
|
| 465 |
+
121,
|
| 466 |
+
0,
|
| 467 |
+
126,
|
| 468 |
+
0,
|
| 469 |
+
"IMAGE"
|
| 470 |
+
],
|
| 471 |
+
[
|
| 472 |
+
142,
|
| 473 |
+
122,
|
| 474 |
+
0,
|
| 475 |
+
128,
|
| 476 |
+
0,
|
| 477 |
+
"GEMMA"
|
| 478 |
+
],
|
| 479 |
+
[
|
| 480 |
+
143,
|
| 481 |
+
122,
|
| 482 |
+
0,
|
| 483 |
+
129,
|
| 484 |
+
0,
|
| 485 |
+
"GEMMA"
|
| 486 |
+
],
|
| 487 |
+
[
|
| 488 |
+
146,
|
| 489 |
+
123,
|
| 490 |
+
0,
|
| 491 |
+
121,
|
| 492 |
+
1,
|
| 493 |
+
"VAE"
|
| 494 |
+
]
|
| 495 |
+
],
|
| 496 |
+
"groups": [],
|
| 497 |
+
"config": {},
|
| 498 |
+
"extra": {
|
| 499 |
+
"ds": {
|
| 500 |
+
"scale": 0.7513148009015777,
|
| 501 |
+
"offset": [
|
| 502 |
+
-1938.732003792888,
|
| 503 |
+
-1072.7654372703548
|
| 504 |
+
]
|
| 505 |
+
}
|
| 506 |
+
},
|
| 507 |
+
"version": 0.4
|
| 508 |
+
}
|
asset/docs/ComfyUI/comfyui.md
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## 🖌️ Sana-ComfyUI
|
| 2 |
+
|
| 3 |
+
[Original Repo](https://github.com/city96/ComfyUI_ExtraModels)
|
| 4 |
+
|
| 5 |
+
### Model info / implementation
|
| 6 |
+
|
| 7 |
+
- Uses Gemma2 2B as the text encoder
|
| 8 |
+
- Multiple resolutions and models available
|
| 9 |
+
- Compressed latent space (32 channels, /32 compression) - needs custom VAE
|
| 10 |
+
|
| 11 |
+
### Usage
|
| 12 |
+
|
| 13 |
+
1. All the checkpoints will be downloaded automatically.
|
| 14 |
+
1. KSampler(Flow Euler) is available for now; Flow DPM-Solver will be available soon.
|
| 15 |
+
|
| 16 |
+
```bash
|
| 17 |
+
git clone https://github.com/comfyanonymous/ComfyUI.git
|
| 18 |
+
cd ComfyUI
|
| 19 |
+
git clone https://github.com/Efficient-Large-Model/ComfyUI_ExtraModels.git custom_nodes/ComfyUI_ExtraModels
|
| 20 |
+
|
| 21 |
+
python main.py
|
| 22 |
+
```
|
| 23 |
+
|
| 24 |
+
### A sample workflow for Sana
|
| 25 |
+
|
| 26 |
+
[Sana workflow](Sana_FlowEuler.json)
|
| 27 |
+
|
| 28 |
+
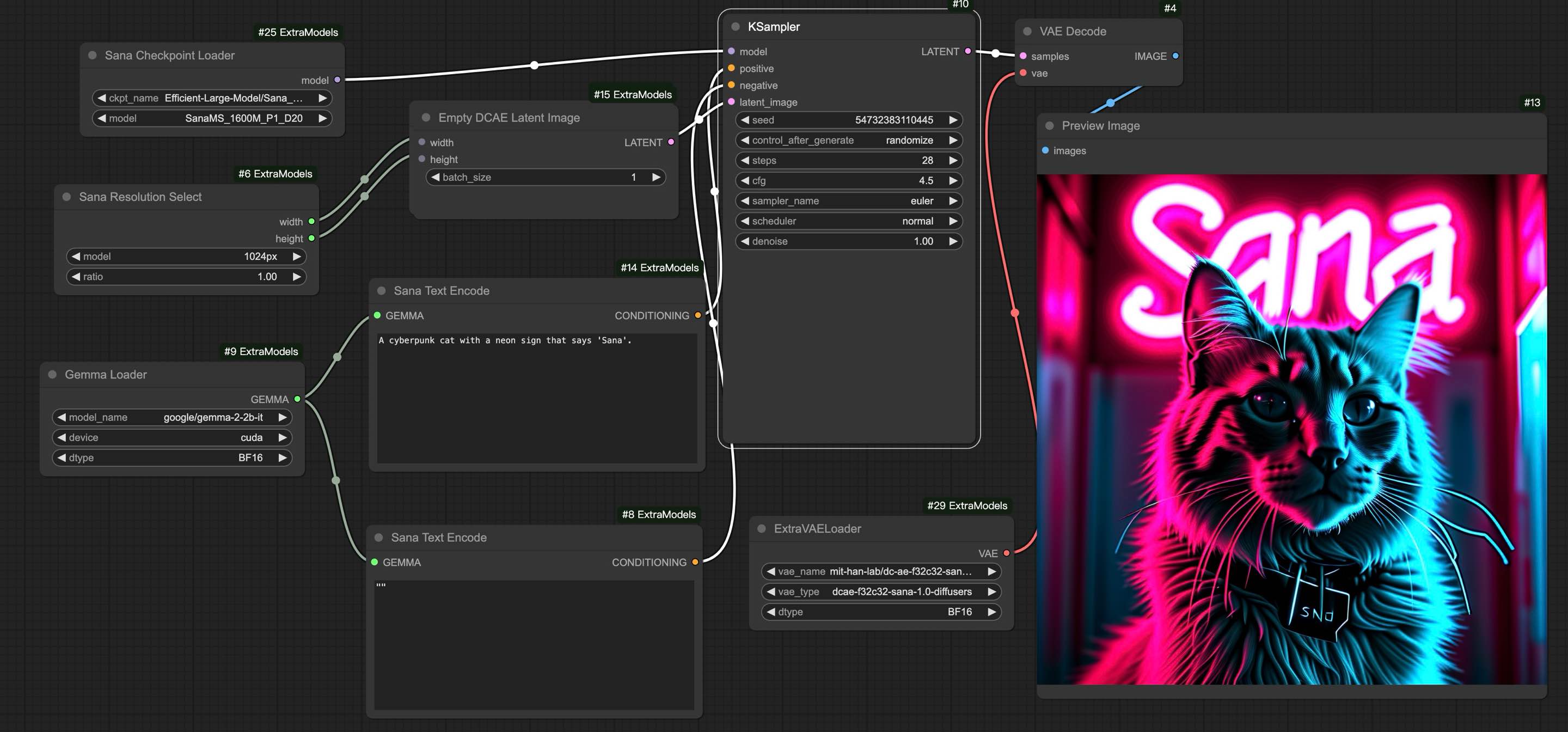
|
| 29 |
+
|
| 30 |
+
### A sample for T2I(Sana) + I2V(CogVideoX)
|
| 31 |
+
|
| 32 |
+
[Sana + CogVideoX workflow](Sana_CogVideoX.json)
|
| 33 |
+
|
| 34 |
+
[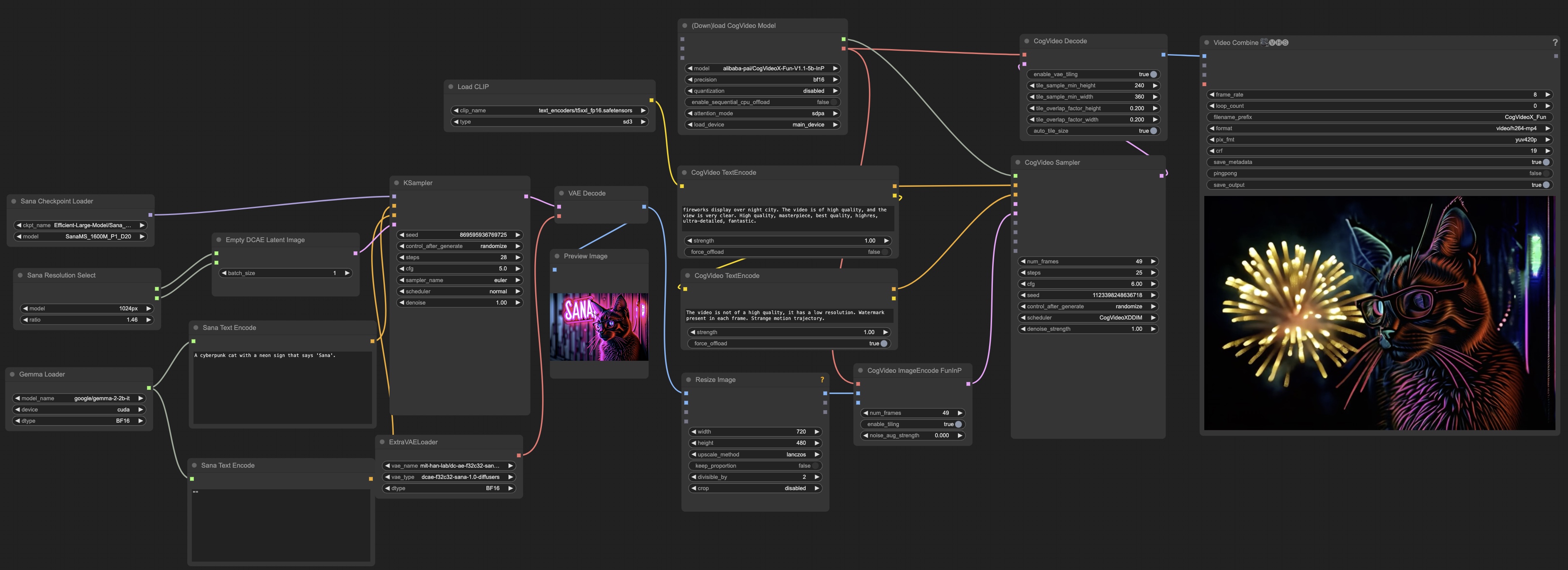](https://nvlabs.github.io/Sana/asset/content/comfyui/Sana_CogVideoX_Fun.mp4)
|
| 35 |
+
|
| 36 |
+
### A sample workflow for Sana 4096x4096 image (18GB GPU is needed)
|
| 37 |
+
|
| 38 |
+
[Sana workflow](Sana_FlowEuler_4K.json)
|
| 39 |
+
|
| 40 |
+
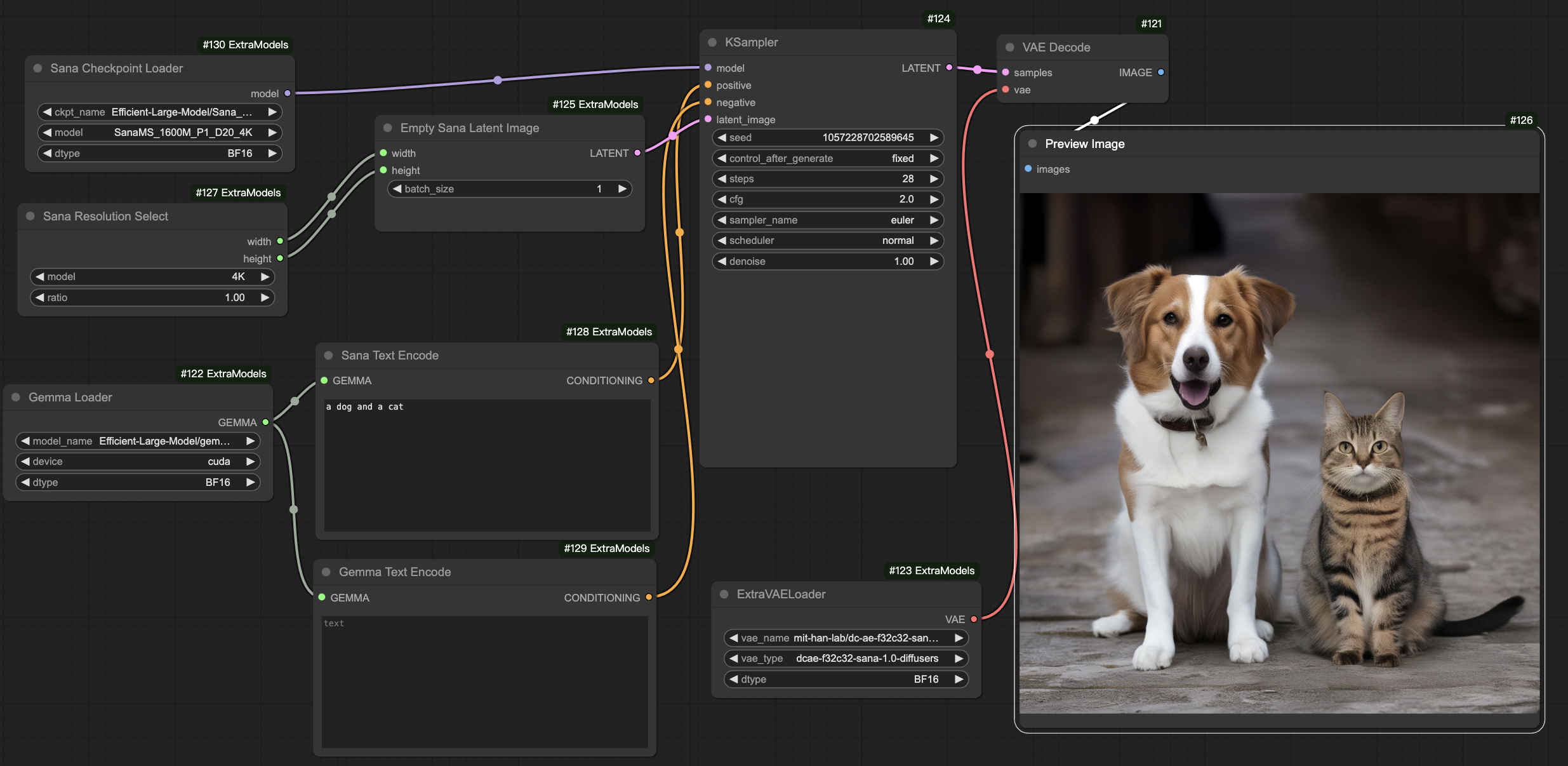
|
asset/docs/metrics_toolkit.md
ADDED
|
@@ -0,0 +1,118 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 💻 How to Inference & Test Metrics (FID, CLIP Score, GenEval, DPG-Bench, etc...)
|
| 2 |
+
|
| 3 |
+
This ToolKit will automatically inference your model and log the metrics results onto wandb as chart for better illustration. We curerntly support:
|
| 4 |
+
|
| 5 |
+
- \[x\] [FID](https://github.com/mseitzer/pytorch-fid) & [CLIP-Score](https://github.com/openai/CLIP)
|
| 6 |
+
- \[x\] [GenEval](https://github.com/djghosh13/geneval)
|
| 7 |
+
- \[x\] [DPG-Bench](https://github.com/TencentQQGYLab/ELLA)
|
| 8 |
+
- \[x\] [ImageReward](https://github.com/THUDM/ImageReward/tree/main)
|
| 9 |
+
|
| 10 |
+
### 0. Install corresponding env for GenEval and DPG-Bench
|
| 11 |
+
|
| 12 |
+
Make sure you can activate the following envs:
|
| 13 |
+
|
| 14 |
+
- `conda activate geneval`([GenEval](https://github.com/djghosh13/geneval))
|
| 15 |
+
- `conda activate dpg`([DGB-Bench](https://github.com/TencentQQGYLab/ELLA))
|
| 16 |
+
|
| 17 |
+
### 0.1 Prepare data.
|
| 18 |
+
|
| 19 |
+
Metirc FID & CLIP-Score on [MJHQ-30K](https://huggingface.co/datasets/playgroundai/MJHQ-30K)
|
| 20 |
+
|
| 21 |
+
```python
|
| 22 |
+
from huggingface_hub import hf_hub_download
|
| 23 |
+
|
| 24 |
+
hf_hub_download(
|
| 25 |
+
repo_id="playgroundai/MJHQ-30K",
|
| 26 |
+
filename="mjhq30k_imgs.zip",
|
| 27 |
+
local_dir="data/test/PG-eval-data/MJHQ-30K/",
|
| 28 |
+
repo_type="dataset"
|
| 29 |
+
)
|
| 30 |
+
```
|
| 31 |
+
|
| 32 |
+
Unzip mjhq30k_imgs.zip into its per-category folder structure.
|
| 33 |
+
|
| 34 |
+
```
|
| 35 |
+
data/test/PG-eval-data/MJHQ-30K/imgs/
|
| 36 |
+
├── animals
|
| 37 |
+
├── art
|
| 38 |
+
├── fashion
|
| 39 |
+
├── food
|
| 40 |
+
├── indoor
|
| 41 |
+
├── landscape
|
| 42 |
+
├── logo
|
| 43 |
+
├── people
|
| 44 |
+
├── plants
|
| 45 |
+
└── vehicles
|
| 46 |
+
```
|
| 47 |
+
|
| 48 |
+
### 0.2 Prepare checkpoints
|
| 49 |
+
|
| 50 |
+
```bash
|
| 51 |
+
huggingface-cli download Efficient-Large-Model/Sana_1600M_1024px --repo-type model --local-dir ./output/Sana_1600M_1024px --local-dir-use-symlinks False
|
| 52 |
+
```
|
| 53 |
+
|
| 54 |
+
### 1. directly \[Inference and Metric\] a .pth file
|
| 55 |
+
|
| 56 |
+
```bash
|
| 57 |
+
# We provide four scripts for evaluating metrics:
|
| 58 |
+
fid_clipscore_launch=scripts/bash_run_inference_metric.sh
|
| 59 |
+
geneval_launch=scripts/bash_run_inference_metric_geneval.sh
|
| 60 |
+
dpg_launch=scripts/bash_run_inference_metric_dpg.sh
|
| 61 |
+
image_reward_launch=scripts/bash_run_inference_metric_imagereward.sh
|
| 62 |
+
|
| 63 |
+
# Use following format to metric your models:
|
| 64 |
+
# bash $correspoinding_metric_launch $your_config_file_path $your_relative_pth_file_path
|
| 65 |
+
|
| 66 |
+
# example
|
| 67 |
+
bash $geneval_launch \
|
| 68 |
+
configs/sana_config/1024ms/Sana_1600M_img1024.yaml \
|
| 69 |
+
output/Sana_1600M_1024px/checkpoints/Sana_1600M_1024px.pth
|
| 70 |
+
```
|
| 71 |
+
|
| 72 |
+
### 2. \[Inference and Metric\] a list of .pth files using a txt file
|
| 73 |
+
|
| 74 |
+
You can also write all your pth files of a job in one txt file, eg. [model_paths.txt](../model_paths.txt)
|
| 75 |
+
|
| 76 |
+
```bash
|
| 77 |
+
# Use following format to metric your models, gathering in a txt file:
|
| 78 |
+
# bash $correspoinding_metric_launch $your_config_file_path $your_txt_file_path_containing_pth_path
|
| 79 |
+
|
| 80 |
+
# We suggest follow the file tree structure in our project for robust experiment
|
| 81 |
+
# example
|
| 82 |
+
bash scripts/bash_run_inference_metric.sh \
|
| 83 |
+
configs/sana_config/1024ms/Sana_1600M_img1024.yaml \
|
| 84 |
+
asset/model_paths.txt
|
| 85 |
+
```
|
| 86 |
+
|
| 87 |
+
### 3. You will get the following data tree.
|
| 88 |
+
|
| 89 |
+
```
|
| 90 |
+
output
|
| 91 |
+
├──your_job_name/ (everything will be saved here)
|
| 92 |
+
│ ├──config.yaml
|
| 93 |
+
│ ├──train_log.log
|
| 94 |
+
|
| 95 |
+
│ ├──checkpoints (all checkpoints)
|
| 96 |
+
│ │ ├──epoch_1_step_6666.pth
|
| 97 |
+
│ │ ├──epoch_1_step_8888.pth
|
| 98 |
+
│ │ ├──......
|
| 99 |
+
|
| 100 |
+
│ ├──vis (all visualization result dirs)
|
| 101 |
+
│ │ ├──visualization_file_name
|
| 102 |
+
│ │ │ ├──xxxxxxx.jpg
|
| 103 |
+
│ │ │ ├──......
|
| 104 |
+
│ │ ├──visualization_file_name2
|
| 105 |
+
│ │ │ ├──xxxxxxx.jpg
|
| 106 |
+
│ │ │ ├──......
|
| 107 |
+
│ ├──......
|
| 108 |
+
|
| 109 |
+
│ ├──metrics (all metrics testing related files)
|
| 110 |
+
│ │ ├──model_paths.txt Optional(👈)(relative path of testing ckpts)
|
| 111 |
+
│ │ │ ├──output/your_job_name/checkpoings/epoch_1_step_6666.pth
|
| 112 |
+
│ │ │ ├──output/your_job_name/checkpoings/epoch_1_step_8888.pth
|
| 113 |
+
│ │ ├──fid_img_paths.txt Optional(👈)(name of testing img_dir in vis)
|
| 114 |
+
│ │ │ ├──visualization_file_name
|
| 115 |
+
│ │ │ ├──visualization_file_name2
|
| 116 |
+
│ │ ├──cached_img_paths.txt Optional(👈)
|
| 117 |
+
│ │ ├──......
|
| 118 |
+
```
|
asset/docs/model_zoo.md
ADDED
|
@@ -0,0 +1,157 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## 🔥 1. We provide all the links of Sana pth and diffusers safetensor below
|
| 2 |
+
|
| 3 |
+
| Model | Reso | pth link | diffusers | Precision | Description |
|
| 4 |
+
|----------------------|--------|-----------------------------------------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------|---------------|----------------|
|
| 5 |
+
| Sana-0.6B | 512px | [Sana_600M_512px](https://huggingface.co/Efficient-Large-Model/Sana_600M_512px) | [Efficient-Large-Model/Sana_600M_512px_diffusers](https://huggingface.co/Efficient-Large-Model/Sana_600M_512px_diffusers) | fp16/fp32 | Multi-Language |
|
| 6 |
+
| Sana-0.6B | 1024px | [Sana_600M_1024px](https://huggingface.co/Efficient-Large-Model/Sana_600M_1024px) | [Efficient-Large-Model/Sana_600M_1024px_diffusers](https://huggingface.co/Efficient-Large-Model/Sana_600M_1024px_diffusers) | fp16/fp32 | Multi-Language |
|
| 7 |
+
| Sana-1.6B | 512px | [Sana_1600M_512px](https://huggingface.co/Efficient-Large-Model/Sana_1600M_512px) | [Efficient-Large-Model/Sana_1600M_512px_diffusers](https://huggingface.co/Efficient-Large-Model/Sana_1600M_512px_diffusers) | fp16/fp32 | - |
|
| 8 |
+
| Sana-1.6B | 512px | [Sana_1600M_512px_MultiLing](https://huggingface.co/Efficient-Large-Model/Sana_1600M_512px_MultiLing) | [Efficient-Large-Model/Sana_1600M_512px_MultiLing_diffusers](https://huggingface.co/Efficient-Large-Model/Sana_1600M_512px_MultiLing_diffusers) | fp16/fp32 | Multi-Language |
|
| 9 |
+
| Sana-1.6B | 1024px | [Sana_1600M_1024px](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px) | [Efficient-Large-Model/Sana_1600M_1024px_diffusers](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_diffusers) | fp16/fp32 | - |
|
| 10 |
+
| Sana-1.6B | 1024px | [Sana_1600M_1024px_MultiLing](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_MultiLing) | [Efficient-Large-Model/Sana_1600M_1024px_MultiLing_diffusers](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_MultiLing_diffusers) | fp16/fp32 | Multi-Language |
|
| 11 |
+
| Sana-1.6B | 1024px | [Sana_1600M_1024px_BF16](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_BF16) | [Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers) | **bf16**/fp32 | Multi-Language |
|
| 12 |
+
| Sana-1.6B | 1024px | - | [mit-han-lab/svdq-int4-sana-1600m](https://huggingface.co/mit-han-lab/svdq-int4-sana-1600m) | **int4** | Multi-Language |
|
| 13 |
+
| Sana-1.6B | 2Kpx | [Sana_1600M_2Kpx_BF16](https://huggingface.co/Efficient-Large-Model/Sana_1600M_2Kpx_BF16) | [Efficient-Large-Model/Sana_1600M_2Kpx_BF16_diffusers](https://huggingface.co/Efficient-Large-Model/Sana_1600M_2Kpx_BF16_diffusers) | **bf16**/fp32 | Multi-Language |
|
| 14 |
+
| Sana-1.6B | 4Kpx | [Sana_1600M_4Kpx_BF16](https://huggingface.co/Efficient-Large-Model/Sana_1600M_4Kpx_BF16) | [Efficient-Large-Model/Sana_1600M_4Kpx_BF16_diffusers](https://huggingface.co/Efficient-Large-Model/Sana_1600M_4Kpx_BF16_diffusers) | **bf16**/fp32 | Multi-Language |
|
| 15 |
+
| Sana-1.6B | 4Kpx | [Sana_1600M_4Kpx_BF16](https://huggingface.co/Efficient-Large-Model/Sana_1600M_4Kpx_BF16) | [Efficient-Large-Model/Sana_1600M_4Kpx_BF16_diffusers](https://huggingface.co/Efficient-Large-Model/Sana_1600M_4Kpx_BF16_diffusers) | **bf16**/fp32 | Multi-Language |
|
| 16 |
+
| ControlNet | | | | | |
|
| 17 |
+
| Sana-1.6B-ControlNet | 1Kpx | [Sana_1600M_1024px_BF16_ControlNet_HED](https://huggingface.co/Efficient-Large-Model/Sana_1600M_1024px_BF16_ControlNet_HED) | Coming soon | **bf16**/fp32 | Multi-Language |
|
| 18 |
+
| Sana-0.6B-ControlNet | 1Kpx | [Sana_600M_1024px_ControlNet_HED](https://huggingface.co/Efficient-Large-Model/Sana_600M_1024px_ControlNet_HED) | Coming soon | fp16/fp32 | - |
|
| 19 |
+
|
| 20 |
+
## ❗ 2. Make sure to use correct precision(fp16/bf16/fp32) for training and inference.
|
| 21 |
+
|
| 22 |
+
### We provide two samples to use fp16 and bf16 weights, respectively.
|
| 23 |
+
|
| 24 |
+
❗️Make sure to set `variant` and `torch_dtype` in diffusers pipelines to the desired precision.
|
| 25 |
+
|
| 26 |
+
#### 1). For fp16 models
|
| 27 |
+
|
| 28 |
+
```python
|
| 29 |
+
# run `pip install git+https://github.com/huggingface/diffusers` before use Sana in diffusers
|
| 30 |
+
import torch
|
| 31 |
+
from diffusers import SanaPipeline
|
| 32 |
+
|
| 33 |
+
pipe = SanaPipeline.from_pretrained(
|
| 34 |
+
"Efficient-Large-Model/Sana_1600M_1024px_diffusers",
|
| 35 |
+
variant="fp16",
|
| 36 |
+
torch_dtype=torch.float16,
|
| 37 |
+
)
|
| 38 |
+
pipe.to("cuda")
|
| 39 |
+
|
| 40 |
+
pipe.vae.to(torch.bfloat16)
|
| 41 |
+
pipe.text_encoder.to(torch.bfloat16)
|
| 42 |
+
|
| 43 |
+
prompt = 'a cyberpunk cat with a neon sign that says "Sana"'
|
| 44 |
+
image = pipe(
|
| 45 |
+
prompt=prompt,
|
| 46 |
+
height=1024,
|
| 47 |
+
width=1024,
|
| 48 |
+
guidance_scale=5.0,
|
| 49 |
+
num_inference_steps=20,
|
| 50 |
+
generator=torch.Generator(device="cuda").manual_seed(42),
|
| 51 |
+
)[0]
|
| 52 |
+
|
| 53 |
+
image[0].save("sana.png")
|
| 54 |
+
```
|
| 55 |
+
|
| 56 |
+
#### 2). For bf16 models
|
| 57 |
+
|
| 58 |
+
```python
|
| 59 |
+
# run `pip install git+https://github.com/huggingface/diffusers` before use Sana in diffusers
|
| 60 |
+
import torch
|
| 61 |
+
from diffusers import SanaPAGPipeline
|
| 62 |
+
|
| 63 |
+
pipe = SanaPAGPipeline.from_pretrained(
|
| 64 |
+
"Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers",
|
| 65 |
+
variant="bf16",
|
| 66 |
+
torch_dtype=torch.bfloat16,
|
| 67 |
+
pag_applied_layers="transformer_blocks.8",
|
| 68 |
+
)
|
| 69 |
+
pipe.to("cuda")
|
| 70 |
+
|
| 71 |
+
pipe.text_encoder.to(torch.bfloat16)
|
| 72 |
+
pipe.vae.to(torch.bfloat16)
|
| 73 |
+
|
| 74 |
+
prompt = 'a cyberpunk cat with a neon sign that says "Sana"'
|
| 75 |
+
image = pipe(
|
| 76 |
+
prompt=prompt,
|
| 77 |
+
guidance_scale=5.0,
|
| 78 |
+
pag_scale=2.0,
|
| 79 |
+
num_inference_steps=20,
|
| 80 |
+
generator=torch.Generator(device="cuda").manual_seed(42),
|
| 81 |
+
)[0]
|
| 82 |
+
image[0].save('sana.png')
|
| 83 |
+
```
|
| 84 |
+
|
| 85 |
+
## ❗ 3. 4K models
|
| 86 |
+
|
| 87 |
+
4K models need VAE tiling to avoid OOM issue.(16 GPU is recommended)
|
| 88 |
+
|
| 89 |
+
```python
|
| 90 |
+
# run `pip install git+https://github.com/huggingface/diffusers` before use Sana in diffusers
|
| 91 |
+
import torch
|
| 92 |
+
from diffusers import SanaPipeline
|
| 93 |
+
|
| 94 |
+
pipe = SanaPipeline.from_pretrained(
|
| 95 |
+
"Efficient-Large-Model/Sana_1600M_4Kpx_BF16_diffusers",
|
| 96 |
+
variant="bf16",
|
| 97 |
+
torch_dtype=torch.bfloat16,
|
| 98 |
+
)
|
| 99 |
+
pipe.to("cuda")
|
| 100 |
+
|
| 101 |
+
pipe.vae.to(torch.bfloat16)
|
| 102 |
+
pipe.text_encoder.to(torch.bfloat16)
|
| 103 |
+
|
| 104 |
+
# for 4096x4096 image generation OOM issue, feel free adjust the tile size
|
| 105 |
+
if pipe.transformer.config.sample_size == 128:
|
| 106 |
+
pipe.vae.enable_tiling(
|
| 107 |
+
tile_sample_min_height=1024,
|
| 108 |
+
tile_sample_min_width=1024,
|
| 109 |
+
tile_sample_stride_height=896,
|
| 110 |
+
tile_sample_stride_width=896,
|
| 111 |
+
)
|
| 112 |
+
prompt = 'a cyberpunk cat with a neon sign that says "Sana"'
|
| 113 |
+
image = pipe(
|
| 114 |
+
prompt=prompt,
|
| 115 |
+
height=4096,
|
| 116 |
+
width=4096,
|
| 117 |
+
guidance_scale=5.0,
|
| 118 |
+
num_inference_steps=20,
|
| 119 |
+
generator=torch.Generator(device="cuda").manual_seed(42),
|
| 120 |
+
)[0]
|
| 121 |
+
|
| 122 |
+
image[0].save("sana_4K.png")
|
| 123 |
+
```
|
| 124 |
+
|
| 125 |
+
## ❗ 4. int4 inference
|
| 126 |
+
|
| 127 |
+
This int4 model is quantized with [SVDQuant-Nunchaku](https://github.com/mit-han-lab/nunchaku). You need first follow the [guidance of installation](https://github.com/mit-han-lab/nunchaku?tab=readme-ov-file#installation) of nunchaku engine, then you can use the following code snippet to perform inference with int4 Sana model.
|
| 128 |
+
|
| 129 |
+
Here we show the code snippet for SanaPipeline. For SanaPAGPipeline, please refer to the [SanaPAGPipeline](https://github.com/mit-han-lab/nunchaku/blob/main/examples/sana_1600m_pag.py) section.
|
| 130 |
+
|
| 131 |
+
```python
|
| 132 |
+
import torch
|
| 133 |
+
from diffusers import SanaPipeline
|
| 134 |
+
|
| 135 |
+
from nunchaku.models.transformer_sana import NunchakuSanaTransformer2DModel
|
| 136 |
+
|
| 137 |
+
transformer = NunchakuSanaTransformer2DModel.from_pretrained("mit-han-lab/svdq-int4-sana-1600m")
|
| 138 |
+
pipe = SanaPipeline.from_pretrained(
|
| 139 |
+
"Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers",
|
| 140 |
+
transformer=transformer,
|
| 141 |
+
variant="bf16",
|
| 142 |
+
torch_dtype=torch.bfloat16,
|
| 143 |
+
).to("cuda")
|
| 144 |
+
|
| 145 |
+
pipe.text_encoder.to(torch.bfloat16)
|
| 146 |
+
pipe.vae.to(torch.bfloat16)
|
| 147 |
+
|
| 148 |
+
image = pipe(
|
| 149 |
+
prompt="A cute 🐼 eating 🎋, ink drawing style",
|
| 150 |
+
height=1024,
|
| 151 |
+
width=1024,
|
| 152 |
+
guidance_scale=4.5,
|
| 153 |
+
num_inference_steps=20,
|
| 154 |
+
generator=torch.Generator().manual_seed(42),
|
| 155 |
+
).images[0]
|
| 156 |
+
image.save("sana_1600m.png")
|
| 157 |
+
```
|
asset/docs/sana_controlnet.md
ADDED
|
@@ -0,0 +1,75 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<!-- Copyright 2024 NVIDIA CORPORATION & AFFILIATES
|
| 2 |
+
|
| 3 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
you may not use this file except in compliance with the License.
|
| 5 |
+
You may obtain a copy of the License at
|
| 6 |
+
|
| 7 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
|
| 9 |
+
Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
See the License for the specific language governing permissions and
|
| 13 |
+
limitations under the License.
|
| 14 |
+
|
| 15 |
+
SPDX-License-Identifier: Apache-2.0 -->
|
| 16 |
+
|
| 17 |
+
## 🔥 ControlNet
|
| 18 |
+
|
| 19 |
+
We incorporate a ControlNet-like(https://github.com/lllyasviel/ControlNet) module enables fine-grained control over text-to-image diffusion models. We implement a ControlNet-Transformer architecture, specifically tailored for Transformers, achieving explicit controllability alongside high-quality image generation.
|
| 20 |
+
|
| 21 |
+
<p align="center">
|
| 22 |
+
<img src="https://raw.githubusercontent.com/NVlabs/Sana/refs/heads/page/asset/content/controlnet/sana_controlnet.jpg" height=480>
|
| 23 |
+
</p>
|
| 24 |
+
|
| 25 |
+
## Inference of `Sana + ControlNet`
|
| 26 |
+
|
| 27 |
+
### 1). Gradio Interface
|
| 28 |
+
|
| 29 |
+
```bash
|
| 30 |
+
python app/app_sana_controlnet_hed.py \
|
| 31 |
+
--config configs/sana_controlnet_config/Sana_1600M_1024px_controlnet_bf16.yaml \
|
| 32 |
+
--model_path hf://Efficient-Large-Model/Sana_1600M_1024px_BF16_ControlNet_HED/checkpoints/Sana_1600M_1024px_BF16_ControlNet_HED.pth
|
| 33 |
+
```
|
| 34 |
+
|
| 35 |
+
<p align="center" border-raduis="10px">
|
| 36 |
+
<img src="https://nvlabs.github.io/Sana/asset/content/controlnet/controlnet_app.jpg" width="90%" alt="teaser_page2"/>
|
| 37 |
+
</p>
|
| 38 |
+
|
| 39 |
+
### 2). Inference with JSON file
|
| 40 |
+
|
| 41 |
+
```bash
|
| 42 |
+
python tools/controlnet/inference_controlnet.py \
|
| 43 |
+
--config configs/sana_controlnet_config/Sana_1600M_1024px_controlnet_bf16.yaml \
|
| 44 |
+
--model_path hf://Efficient-Large-Model/Sana_1600M_1024px_BF16_ControlNet_HED/checkpoints/Sana_1600M_1024px_BF16_ControlNet_HED.pth \
|
| 45 |
+
--json_file asset/controlnet/samples_controlnet.json
|
| 46 |
+
```
|
| 47 |
+
|
| 48 |
+
### 3). Inference code snap
|
| 49 |
+
|
| 50 |
+
```python
|
| 51 |
+
import torch
|
| 52 |
+
from PIL import Image
|
| 53 |
+
from app.sana_controlnet_pipeline import SanaControlNetPipeline
|
| 54 |
+
|
| 55 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 56 |
+
|
| 57 |
+
pipe = SanaControlNetPipeline("configs/sana_controlnet_config/Sana_1600M_1024px_controlnet_bf16.yaml")
|
| 58 |
+
pipe.from_pretrained("hf://Efficient-Large-Model/Sana_1600M_1024px_BF16_ControlNet_HED/checkpoints/Sana_1600M_1024px_BF16_ControlNet_HED.pth")
|
| 59 |
+
|
| 60 |
+
ref_image = Image.open("asset/controlnet/ref_images/A transparent sculpture of a duck made out of glass. The sculpture is in front of a painting of a la.jpg")
|
| 61 |
+
prompt = "A transparent sculpture of a duck made out of glass. The sculpture is in front of a painting of a landscape."
|
| 62 |
+
|
| 63 |
+
images = pipe(
|
| 64 |
+
prompt=prompt,
|
| 65 |
+
ref_image=ref_image,
|
| 66 |
+
guidance_scale=4.5,
|
| 67 |
+
num_inference_steps=10,
|
| 68 |
+
sketch_thickness=2,
|
| 69 |
+
generator=torch.Generator(device=device).manual_seed(0),
|
| 70 |
+
)
|
| 71 |
+
```
|
| 72 |
+
|
| 73 |
+
## Training of `Sana + ControlNet`
|
| 74 |
+
|
| 75 |
+
### Coming soon
|
asset/docs/sana_lora_dreambooth.md
ADDED
|
@@ -0,0 +1,144 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# DreamBooth training example for SANA
|
| 2 |
+
|
| 3 |
+
[DreamBooth](https://arxiv.org/abs/2208.12242) is a method to personalize text2image models like stable diffusion given just a few (3~5) images of a subject.
|
| 4 |
+
|
| 5 |
+
The `train_dreambooth_lora_sana.py` script shows how to implement the training procedure with [LoRA](https://huggingface.co/docs/peft/conceptual_guides/adapter#low-rank-adaptation-lora) and adapt it for [SANA](https://arxiv.org/abs/2410.10629).
|
| 6 |
+
|
| 7 |
+
This will also allow us to push the trained model parameters to the Hugging Face Hub platform.
|
| 8 |
+
|
| 9 |
+
## Running locally with PyTorch
|
| 10 |
+
|
| 11 |
+
### Installing the dependencies
|
| 12 |
+
|
| 13 |
+
Before running the scripts, make sure to install the library's training dependencies:
|
| 14 |
+
|
| 15 |
+
**Important**
|
| 16 |
+
|
| 17 |
+
To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
|
| 18 |
+
|
| 19 |
+
```bash
|
| 20 |
+
git clone https://github.com/huggingface/diffusers
|
| 21 |
+
cd diffusers
|
| 22 |
+
pip install -e .
|
| 23 |
+
```
|
| 24 |
+
|
| 25 |
+
And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
|
| 26 |
+
|
| 27 |
+
```bash
|
| 28 |
+
accelerate config
|
| 29 |
+
```
|
| 30 |
+
|
| 31 |
+
Or for a default accelerate configuration without answering questions about your environment
|
| 32 |
+
|
| 33 |
+
```bash
|
| 34 |
+
accelerate config default
|
| 35 |
+
```
|
| 36 |
+
|
| 37 |
+
Or if your environment doesn't support an interactive shell (e.g., a notebook)
|
| 38 |
+
|
| 39 |
+
```python
|
| 40 |
+
from accelerate.utils import write_basic_config
|
| 41 |
+
write_basic_config()
|
| 42 |
+
```
|
| 43 |
+
|
| 44 |
+
When running `accelerate config`, if we specify torch compile mode to True there can be dramatic speedups.
|
| 45 |
+
Note also that we use PEFT library as backend for LoRA training, make sure to have `peft>=0.14.0` installed in your environment.
|
| 46 |
+
|
| 47 |
+
### Dog toy example
|
| 48 |
+
|
| 49 |
+
Now let's get our dataset. For this example we will use some dog images: https://huggingface.co/datasets/diffusers/dog-example.
|
| 50 |
+
|
| 51 |
+
Let's first download it locally:
|
| 52 |
+
|
| 53 |
+
```python
|
| 54 |
+
from huggingface_hub import snapshot_download
|
| 55 |
+
|
| 56 |
+
local_dir = "data/dreambooth/dog"
|
| 57 |
+
snapshot_download(
|
| 58 |
+
"diffusers/dog-example",
|
| 59 |
+
local_dir=local_dir, repo_type="dataset",
|
| 60 |
+
ignore_patterns=".gitattributes",
|
| 61 |
+
)
|
| 62 |
+
```
|
| 63 |
+
|
| 64 |
+
This will also allow us to push the trained LoRA parameters to the Hugging Face Hub platform.
|
| 65 |
+
|
| 66 |
+
[Here is the Model Card](model_zoo.md) for you to choose the desired pre-trained models and set it to `MODEL_NAME`.
|
| 67 |
+
|
| 68 |
+
Now, we can launch training using [file here](../../train_scripts/train_lora.sh):
|
| 69 |
+
|
| 70 |
+
```bash
|
| 71 |
+
bash train_scripts/train_lora.sh
|
| 72 |
+
```
|
| 73 |
+
|
| 74 |
+
or you can run it locally:
|
| 75 |
+
|
| 76 |
+
```bash
|
| 77 |
+
export MODEL_NAME="Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers"
|
| 78 |
+
export INSTANCE_DIR="data/dreambooth/dog"
|
| 79 |
+
export OUTPUT_DIR="trained-sana-lora"
|
| 80 |
+
|
| 81 |
+
accelerate launch --num_processes 8 --main_process_port 29500 --gpu_ids 0,1,2,3 \
|
| 82 |
+
train_scripts/train_dreambooth_lora_sana.py \
|
| 83 |
+
--pretrained_model_name_or_path=$MODEL_NAME \
|
| 84 |
+
--instance_data_dir=$INSTANCE_DIR \
|
| 85 |
+
--output_dir=$OUTPUT_DIR \
|
| 86 |
+
--mixed_precision="bf16" \
|
| 87 |
+
--instance_prompt="a photo of sks dog" \
|
| 88 |
+
--resolution=1024 \
|
| 89 |
+
--train_batch_size=1 \
|
| 90 |
+
--gradient_accumulation_steps=4 \
|
| 91 |
+
--use_8bit_adam \
|
| 92 |
+
--learning_rate=1e-4 \
|
| 93 |
+
--report_to="wandb" \
|
| 94 |
+
--lr_scheduler="constant" \
|
| 95 |
+
--lr_warmup_steps=0 \
|
| 96 |
+
--max_train_steps=500 \
|
| 97 |
+
--validation_prompt="A photo of sks dog in a pond, yarn art style" \
|
| 98 |
+
--validation_epochs=25 \
|
| 99 |
+
--seed="0" \
|
| 100 |
+
--push_to_hub
|
| 101 |
+
```
|
| 102 |
+
|
| 103 |
+
For using `push_to_hub`, make you're logged into your Hugging Face account:
|
| 104 |
+
|
| 105 |
+
```bash
|
| 106 |
+
huggingface-cli login
|
| 107 |
+
```
|
| 108 |
+
|
| 109 |
+
To better track our training experiments, we're using the following flags in the command above:
|
| 110 |
+
|
| 111 |
+
- `report_to="wandb` will ensure the training runs are tracked on [Weights and Biases](https://wandb.ai/site). To use it, be sure to install `wandb` with `pip install wandb`. Don't forget to call `wandb login <your_api_key>` before training if you haven't done it before.
|
| 112 |
+
- `validation_prompt` and `validation_epochs` to allow the script to do a few validation inference runs. This allows us to qualitatively check if the training is progressing as expected.
|
| 113 |
+
|
| 114 |
+
## Notes
|
| 115 |
+
|
| 116 |
+
Additionally, we welcome you to explore the following CLI arguments:
|
| 117 |
+
|
| 118 |
+
- `--lora_layers`: The transformer modules to apply LoRA training on. Please specify the layers in a comma seperated. E.g. - "to_k,to_q,to_v" will result in lora training of attention layers only.
|
| 119 |
+
- `--complex_human_instruction`: Instructions for complex human attention as shown in [here](https://github.com/NVlabs/Sana/blob/main/configs/sana_app_config/Sana_1600M_app.yaml#L55).
|
| 120 |
+
- `--max_sequence_length`: Maximum sequence length to use for text embeddings.
|
| 121 |
+
|
| 122 |
+
We provide several options for optimizing memory optimization:
|
| 123 |
+
|
| 124 |
+
- `--offload`: When enabled, we will offload the text encoder and VAE to CPU, when they are not used.
|
| 125 |
+
- `cache_latents`: When enabled, we will pre-compute the latents from the input images with the VAE and remove the VAE from memory once done.
|
| 126 |
+
- `--use_8bit_adam`: When enabled, we will use the 8bit version of AdamW provided by the `bitsandbytes` library.
|
| 127 |
+
|
| 128 |
+
Refer to the [official documentation](https://huggingface.co/docs/diffusers/main/en/api/pipelines/sana) of the `SanaPipeline` to know more about the models available under the SANA family and their preferred dtypes during inference.
|
| 129 |
+
|
| 130 |
+
## Samples
|
| 131 |
+
|
| 132 |
+
We show some samples during Sana-LoRA fine-tuning process below.
|
| 133 |
+
|
| 134 |
+
<p align="center" border-raduis="10px">
|
| 135 |
+
<img src="https://nvlabs.github.io/Sana/asset/content/dreambooth/step0.jpg" width="90%" alt="sana-lora-step0"/>
|
| 136 |
+
<br>
|
| 137 |
+
<em> training samples at step=0 </em>
|
| 138 |
+
</p>
|
| 139 |
+
|
| 140 |
+
<p align="center" border-raduis="10px">
|
| 141 |
+
<img src="https://nvlabs.github.io/Sana/asset/content/dreambooth/step500.jpg" width="90%" alt="sana-lora-step500"/>
|
| 142 |
+
<br>
|
| 143 |
+
<em> training samples at step=500 </em>
|
| 144 |
+
</p>
|
asset/example_data/00000000.jpg
ADDED

|
Git LFS Details
|
asset/example_data/00000000.png
ADDED

|
Git LFS Details
|
asset/example_data/00000000.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
a cyberpunk cat with a neon sign that says "Sana".
|
asset/example_data/00000000_InternVL2-26B.json
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"00000000": {
|
| 3 |
+
"InternVL2-26B": "a cyberpunk cat with a neon sign that says 'Sana'"
|
| 4 |
+
}
|
| 5 |
+
}
|
asset/example_data/00000000_InternVL2-26B_clip_score.json
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"00000000": {
|
| 3 |
+
"InternVL2-26B": "27.1037"
|
| 4 |
+
}
|
| 5 |
+
}
|
asset/example_data/00000000_VILA1-5-13B.json
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"00000000": {
|
| 3 |
+
"VILA1-5-13B": "a cyberpunk cat with a neon sign that says 'Sana'"
|
| 4 |
+
}
|
| 5 |
+
}
|
asset/example_data/00000000_VILA1-5-13B_clip_score.json
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"00000000": {
|
| 3 |
+
"VILA1-5-13B": "27.2321"
|
| 4 |
+
}
|
| 5 |
+
}
|
asset/example_data/00000000_prompt_clip_score.json
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"00000000": {
|
| 3 |
+
"prompt": "26.7331"
|
| 4 |
+
}
|
| 5 |
+
}
|
asset/example_data/meta_data.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"name": "sana-dev",
|
| 3 |
+
"__kind__": "Sana-ImgDataset",
|
| 4 |
+
"img_names": [
|
| 5 |
+
"00000000", "00000000", "00000000.png", "00000000.jpg"
|
| 6 |
+
]
|
| 7 |
+
}
|
asset/examples.py
ADDED
|
@@ -0,0 +1,69 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 NVIDIA CORPORATION & AFFILIATES
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
#
|
| 15 |
+
# SPDX-License-Identifier: Apache-2.0
|
| 16 |
+
|
| 17 |
+
examples = [
|
| 18 |
+
[
|
| 19 |
+
"A small cactus with a happy face in the Sahara desert.",
|
| 20 |
+
"flow_dpm-solver",
|
| 21 |
+
20,
|
| 22 |
+
5.0,
|
| 23 |
+
2.5,
|
| 24 |
+
],
|
| 25 |
+
[
|
| 26 |
+
"An extreme close-up of an gray-haired man with a beard in his 60s, he is deep in thought pondering the history"
|
| 27 |
+
"of the universe as he sits at a cafe in Paris, his eyes focus on people offscreen as they walk as he sits "
|
| 28 |
+
"mostly motionless, he is dressed in a wool coat suit coat with a button-down shirt, he wears a brown beret "
|
| 29 |
+
"and glasses and has a very professorial appearance, and the end he offers a subtle closed-mouth smile "
|
| 30 |
+
"as if he found the answer to the mystery of life, the lighting is very cinematic with the golden light and "
|
| 31 |
+
"the Parisian streets and city in the background, depth of field, cinematic 35mm film.",
|
| 32 |
+
"flow_dpm-solver",
|
| 33 |
+
20,
|
| 34 |
+
5.0,
|
| 35 |
+
2.5,
|
| 36 |
+
],
|
| 37 |
+
[
|
| 38 |
+
"An illustration of a human heart made of translucent glass, standing on a pedestal amidst a stormy sea. "
|
| 39 |
+
"Rays of sunlight pierce the clouds, illuminating the heart, revealing a tiny universe within. "
|
| 40 |
+
"The quote 'Find the universe within you' is etched in bold letters across the horizon."
|
| 41 |
+
"blue and pink, brilliantly illuminated in the background.",
|
| 42 |
+
"flow_dpm-solver",
|
| 43 |
+
20,
|
| 44 |
+
5.0,
|
| 45 |
+
2.5,
|
| 46 |
+
],
|
| 47 |
+
[
|
| 48 |
+
"A transparent sculpture of a duck made out of glass. The sculpture is in front of a painting of a landscape.",
|
| 49 |
+
"flow_dpm-solver",
|
| 50 |
+
20,
|
| 51 |
+
5.0,
|
| 52 |
+
2.5,
|
| 53 |
+
],
|
| 54 |
+
[
|
| 55 |
+
"A litter of golden retriever puppies playing in the snow. Their heads pop out of the snow, covered in.",
|
| 56 |
+
"flow_dpm-solver",
|
| 57 |
+
20,
|
| 58 |
+
5.0,
|
| 59 |
+
2.5,
|
| 60 |
+
],
|
| 61 |
+
[
|
| 62 |
+
"a kayak in the water, in the style of optical color mixing, aerial view, rainbowcore, "
|
| 63 |
+
"national geographic photo, 8k resolution, crayon art, interactive artwork",
|
| 64 |
+
"flow_dpm-solver",
|
| 65 |
+
20,
|
| 66 |
+
5.0,
|
| 67 |
+
2.5,
|
| 68 |
+
],
|
| 69 |
+
]
|
asset/logo.png
ADDED
|
|
asset/model-incremental.jpg
ADDED

|
Git LFS Details
|
asset/model_paths.txt
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
output/Sana_1600M_1024px/checkpoints/Sana_1600M_1024px.pth
|
| 2 |
+
output/Sana_1600M_1024px/checkpoints/Sana_1600M_1024px.pth
|