Spaces:
Build error

Build error
Commit
·
3dded80
1
Parent(s):
724e86c
Update app.py
Browse files
app.py
CHANGED
|
@@ -10,13 +10,18 @@ pragformer_reduction = transformers.AutoModel.from_pretrained("Pragformer/PragFo
|
|
| 10 |
|
| 11 |
|
| 12 |
#Event Listeners
|
|
|
|
|
|
|
|
|
|
| 13 |
tokenizer = transformers.AutoTokenizer.from_pretrained('NTUYG/DeepSCC-RoBERTa')
|
| 14 |
|
| 15 |
with open('c_data.json', 'r') as f:
|
| 16 |
data = json.load(f)
|
| 17 |
|
| 18 |
def fill_code(code_pth):
|
| 19 |
-
|
|
|
|
|
|
|
| 20 |
|
| 21 |
|
| 22 |
def predict(code_txt):
|
|
@@ -30,47 +35,47 @@ def predict(code_txt):
|
|
| 30 |
pred = pragformer(torch.tensor(tokenized['input_ids']), torch.tensor(tokenized['attention_mask']))
|
| 31 |
|
| 32 |
y_hat = torch.argmax(pred).item()
|
| 33 |
-
return
|
| 34 |
|
| 35 |
|
| 36 |
def is_private(code_txt):
|
| 37 |
-
|
| 38 |
-
|
| 39 |
|
| 40 |
-
|
| 41 |
-
|
| 42 |
-
|
| 43 |
-
|
| 44 |
-
|
| 45 |
-
|
| 46 |
-
|
| 47 |
-
|
| 48 |
|
| 49 |
-
|
| 50 |
-
|
| 51 |
-
|
| 52 |
-
|
| 53 |
-
|
| 54 |
|
| 55 |
|
| 56 |
def is_reduction(code_txt, label):
|
| 57 |
-
|
| 58 |
-
|
| 59 |
-
|
| 60 |
-
|
| 61 |
-
|
| 62 |
-
|
| 63 |
-
|
| 64 |
-
|
| 65 |
-
|
| 66 |
-
|
| 67 |
-
|
| 68 |
-
|
| 69 |
-
|
| 70 |
-
|
| 71 |
-
|
| 72 |
-
|
| 73 |
-
|
| 74 |
|
| 75 |
|
| 76 |
# Define GUI
|
|
@@ -88,12 +93,12 @@ with gr.Blocks() as pragformer_gui:
|
|
| 88 |
gr.Markdown("## Input")
|
| 89 |
with gr.Row():
|
| 90 |
with gr.Column():
|
| 91 |
-
drop = gr.Dropdown(list(data.keys()), label="
|
| 92 |
sample_btn = gr.Button("Sample")
|
| 93 |
|
| 94 |
-
pragma = gr.Textbox(label="
|
| 95 |
|
| 96 |
-
code_in = gr.Textbox(lines=5, label="Write some code and see if it should
|
| 97 |
submit_btn = gr.Button("Submit")
|
| 98 |
with gr.Column():
|
| 99 |
gr.Markdown("## Results")
|
|
@@ -113,6 +118,20 @@ with gr.Blocks() as pragformer_gui:
|
|
| 113 |
|
| 114 |
gr.Markdown(
|
| 115 |
"""
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 116 |
## Description
|
| 117 |
|
| 118 |
In past years, the world has switched to many-core and multi-core shared memory architectures.
|
|
@@ -132,16 +151,12 @@ with gr.Blocks() as pragformer_gui:
|
|
| 132 |
|
| 133 |
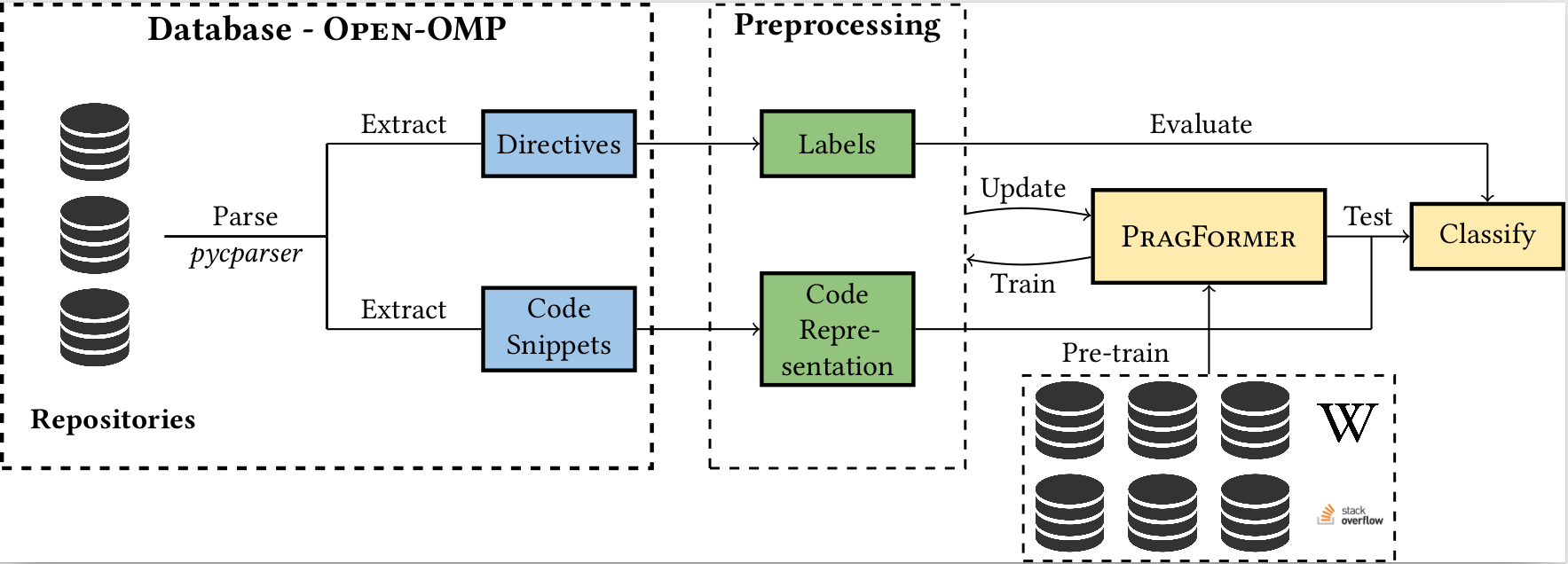
|
| 134 |
|
|
|
|
| 135 |
|
| 136 |
-
## How it Works?
|
| 137 |
-
|
| 138 |
-
To use the PragFormer tool, you will need to input a C language for-loop. You can either write your own code or use the samples
|
| 139 |
-
provided in the dropdown menu, which have been gathered from GitHub. Once you submit the code, the PragFormer model will analyze
|
| 140 |
-
it and predict whether the for-loop should be parallelized using OpenMP. If the PragFormer model determines that parallelization
|
| 141 |
-
is necessary, two additional models will be used to determine if ***private*** or ***reduction*** clauses are needed.
|
| 142 |
""")
|
| 143 |
|
| 144 |
|
|
|
|
| 145 |
|
| 146 |
pragformer_gui.launch()
|
| 147 |
|
|
|
|
| 10 |
|
| 11 |
|
| 12 |
#Event Listeners
|
| 13 |
+
with_omp_str = 'Should contain a parallel work-sharing loop construct'
|
| 14 |
+
without_omp_str = 'Should not contain a parallel work-sharing loop construct'
|
| 15 |
+
|
| 16 |
tokenizer = transformers.AutoTokenizer.from_pretrained('NTUYG/DeepSCC-RoBERTa')
|
| 17 |
|
| 18 |
with open('c_data.json', 'r') as f:
|
| 19 |
data = json.load(f)
|
| 20 |
|
| 21 |
def fill_code(code_pth):
|
| 22 |
+
pragma = data[code_pth]['pragma']
|
| 23 |
+
code = data[code_pth]['code']
|
| 24 |
+
return 'None' if len(pragma)==0 else pragma, code
|
| 25 |
|
| 26 |
|
| 27 |
def predict(code_txt):
|
|
|
|
| 35 |
pred = pragformer(torch.tensor(tokenized['input_ids']), torch.tensor(tokenized['attention_mask']))
|
| 36 |
|
| 37 |
y_hat = torch.argmax(pred).item()
|
| 38 |
+
return with_omp_str if y_hat==1 else without_omp_str, torch.nn.Softmax(dim=1)(pred).squeeze()[y_hat].item()
|
| 39 |
|
| 40 |
|
| 41 |
def is_private(code_txt):
|
| 42 |
+
if predict(code_txt)[0] == without_omp_str:
|
| 43 |
+
return gr.update(visible=False)
|
| 44 |
|
| 45 |
+
code = code_txt.lstrip().rstrip()
|
| 46 |
+
tokenized = tokenizer.batch_encode_plus(
|
| 47 |
+
[code],
|
| 48 |
+
max_length = 150,
|
| 49 |
+
pad_to_max_length = True,
|
| 50 |
+
truncation = True
|
| 51 |
+
)
|
| 52 |
+
pred = pragformer_private(torch.tensor(tokenized['input_ids']), torch.tensor(tokenized['attention_mask']))
|
| 53 |
|
| 54 |
+
y_hat = torch.argmax(pred).item()
|
| 55 |
+
# if y_hat == 0:
|
| 56 |
+
# return gr.update(visible=False)
|
| 57 |
+
# else:
|
| 58 |
+
return gr.update(value=f"{'should not contain private' if y_hat==0 else 'should contain private'} with confidence: {torch.nn.Softmax(dim=1)(pred).squeeze()[y_hat].item()}", visible=True)
|
| 59 |
|
| 60 |
|
| 61 |
def is_reduction(code_txt, label):
|
| 62 |
+
if predict(code_txt)[0] == without_omp_str:
|
| 63 |
+
return gr.update(visible=False)
|
| 64 |
+
|
| 65 |
+
code = code_txt.lstrip().rstrip()
|
| 66 |
+
tokenized = tokenizer.batch_encode_plus(
|
| 67 |
+
[code],
|
| 68 |
+
max_length = 150,
|
| 69 |
+
pad_to_max_length = True,
|
| 70 |
+
truncation = True
|
| 71 |
+
)
|
| 72 |
+
pred = pragformer_reduction(torch.tensor(tokenized['input_ids']), torch.tensor(tokenized['attention_mask']))
|
| 73 |
+
|
| 74 |
+
y_hat = torch.argmax(pred).item()
|
| 75 |
+
# if y_hat == 0:
|
| 76 |
+
# return gr.update(visible=False)
|
| 77 |
+
# else:
|
| 78 |
+
return gr.update(value=f"{'should not contain reduction' if y_hat==0 else 'should contain reduction'} with confidence: {torch.nn.Softmax(dim=1)(pred).squeeze()[y_hat].item()}", visible=True)
|
| 79 |
|
| 80 |
|
| 81 |
# Define GUI
|
|
|
|
| 93 |
gr.Markdown("## Input")
|
| 94 |
with gr.Row():
|
| 95 |
with gr.Column():
|
| 96 |
+
drop = gr.Dropdown(list(data.keys()), label="Mix of parallel and not-parallel code snippets", value="Minyoung-Kim1110/OpenMP/Excercise/atomic/0")
|
| 97 |
sample_btn = gr.Button("Sample")
|
| 98 |
|
| 99 |
+
pragma = gr.Textbox(label="Original Parallelization Classification (if any)")
|
| 100 |
|
| 101 |
+
code_in = gr.Textbox(lines=5, label="Write some code and see if it should contain a parallel work-sharing loop construct")
|
| 102 |
submit_btn = gr.Button("Submit")
|
| 103 |
with gr.Column():
|
| 104 |
gr.Markdown("## Results")
|
|
|
|
| 118 |
|
| 119 |
gr.Markdown(
|
| 120 |
"""
|
| 121 |
+
|
| 122 |
+
## How it Works?
|
| 123 |
+
|
| 124 |
+
To use the PragFormer tool, you will need to input a C language for-loop. You can either write your own code or use the samples
|
| 125 |
+
provided in the dropdown menu, which have been gathered from GitHub. Once you submit the code, the PragFormer model will analyze
|
| 126 |
+
it and predict whether the for-loop should be parallelized using OpenMP. If the PragFormer model determines that parallelization
|
| 127 |
+
is necessary, two additional models will be used to determine if adding specific data-sharing attributes, such as ***private*** or ***reduction*** clauses, is needed.
|
| 128 |
+
|
| 129 |
+
***private***- Specifies that each thread should have its own instance of a variable.
|
| 130 |
+
|
| 131 |
+
***reduction***- Specifies that one or more variables that are private to each thread are the subject of a reduction operation at
|
| 132 |
+
the end of the parallel region.
|
| 133 |
+
|
| 134 |
+
|
| 135 |
## Description
|
| 136 |
|
| 137 |
In past years, the world has switched to many-core and multi-core shared memory architectures.
|
|
|
|
| 151 |
|
| 152 |

|
| 153 |
|
| 154 |
+
Link to [PragFormer](https://arxiv.org/abs/2204.12835) Paper
|
| 155 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 156 |
""")
|
| 157 |
|
| 158 |
|
| 159 |
+
pragformer_gui.launch()
|
| 160 |
|
| 161 |
pragformer_gui.launch()
|
| 162 |
|