Spaces:
Sleeping

Sleeping
Commit
·
3ff9a31
1
Parent(s):
fece87d
application file
Browse files- README.md +165 -7
- app.py +124 -0
- assets/duck.jpeg +0 -0
- assets/horse.jpeg +0 -0
- contents/bert-model.png +0 -0
- contents/clip_model.png +0 -0
- contents/cool-clip-nvitop.png +0 -0
- contents/cool-clip.png +0 -0
- contents/fit-report.png +0 -0
- contents/resnet.png +0 -0
- features.npy +3 -0
- photo_ids.csv +0 -0
- photos.tsv000 +0 -0
- requirements.txt +5 -0
README.md
CHANGED
|
@@ -1,14 +1,172 @@
|
|
| 1 |
---
|
| 2 |
-
title:
|
| 3 |
-
emoji:
|
| 4 |
-
colorFrom:
|
| 5 |
-
colorTo:
|
| 6 |
sdk: gradio
|
| 7 |
-
sdk_version:
|
| 8 |
app_file: app.py
|
| 9 |
pinned: false
|
| 10 |
license: mit
|
| 11 |
-
short_description: experiment to train clip based models
|
| 12 |
---
|
| 13 |
|
| 14 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
title: CoolCLIP
|
| 3 |
+
emoji: 🦆
|
| 4 |
+
colorFrom: green
|
| 5 |
+
colorTo: midnight-blue
|
| 6 |
sdk: gradio
|
| 7 |
+
sdk_version: 4.44.1
|
| 8 |
app_file: app.py
|
| 9 |
pinned: false
|
| 10 |
license: mit
|
|
|
|
| 11 |
---
|
| 12 |
|
| 13 |
+
|
| 14 |
+
# CLIP
|
| 15 |
+
|
| 16 |
+
In early days of transformers starts dominating (ViTs) comes **Contrastive Language–Image Pre-training** ([CLIP](https://github.com/openai/CLIP)-2021) is a powerful neural network model that learns to associate textual descriptions with images.
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
# Dataset
|
| 20 |
+
The experiment are performed on [kaggle dataset](https://www.kaggle.com/datasets/adityajn105/flickr8k)
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
## APPROACH
|
| 27 |
+
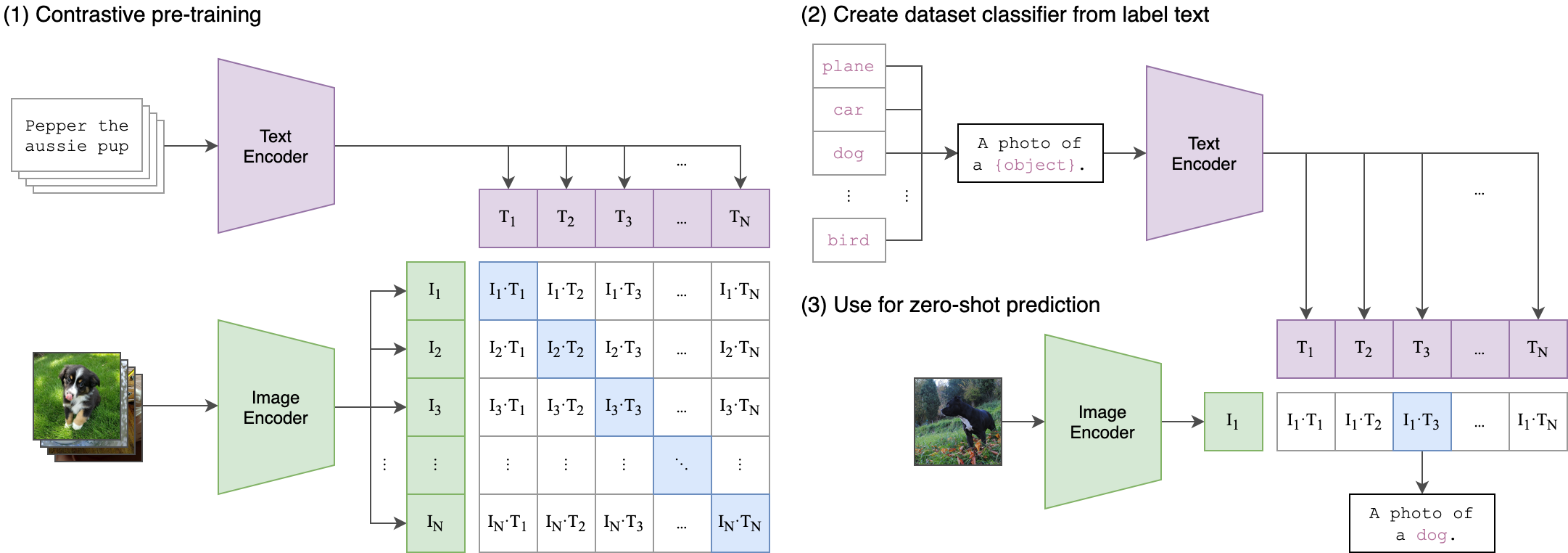
|
| 28 |
+
|
| 29 |
+
*Image Encoder* may or maynot comes with CNN backbone process image
|
| 30 |
+
- resnet
|
| 31 |
+
- densenet
|
| 32 |
+
|
| 33 |
+
*Text Encoder*
|
| 34 |
+
- bert
|
| 35 |
+
- distilbert
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
## Text Encoder
|
| 39 |
+
captions were tokenized by `DistilBert`
|
| 40 |
+
|
| 41 |
+
```python
|
| 42 |
+
tokenizer = DistilBertTokenizer.from_pretrained("distilbert-base-uncased")
|
| 43 |
+
tokenizer( list(captions), padding=True, truncation=True, max_length=200 )
|
| 44 |
+
text_model = .model = DistilBertModel.from_pretrained("distilbert-base-uncased")
|
| 45 |
+
```
|
| 46 |
+
|
| 47 |
+
<!-- <div align='center'><img src='./contents/bert-model.png' alt=""></div> -->
|
| 48 |
+
<div align='center'><img src='https://raw.githubusercontent.com/Muthukamalan/CoolCLIP-/refs/heads/main/gradio/contents/bert-model.png' alt=""></div>
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
## Image Encoder
|
| 52 |
+
transforms help to standardise the image and pass to the model
|
| 53 |
+
|
| 54 |
+
```python
|
| 55 |
+
def get_transforms(mode="train"):
|
| 56 |
+
if mode == "train":
|
| 57 |
+
return A.Compose(
|
| 58 |
+
[
|
| 59 |
+
A.Resize(224, 224, always_apply=True),
|
| 60 |
+
A.Normalize(max_pixel_value=255.0, always_apply=True),
|
| 61 |
+
]
|
| 62 |
+
)
|
| 63 |
+
else:
|
| 64 |
+
return A.Compose(
|
| 65 |
+
[
|
| 66 |
+
A.Resize(224, 224, always_apply=True),
|
| 67 |
+
A.Normalize(max_pixel_value=255.0, always_apply=True),
|
| 68 |
+
]
|
| 69 |
+
)
|
| 70 |
+
```
|
| 71 |
+
pretrained `resnet` model
|
| 72 |
+
```python
|
| 73 |
+
image_model = timm.create_model( 'resnet18', pretrained, num_classes=0, global_pool="avg" )
|
| 74 |
+
```
|
| 75 |
+
<div align='center'><img src='https://raw.githubusercontent.com/Muthukamalan/CoolCLIP-/refs/heads/main/gradio/contents/resnet.png' alt=""></div>
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
## Projection Head
|
| 79 |
+
|
| 80 |
+
Sometimes, `output_image_embedding` won't be same dimension as `output_text_embedding` to make it same dimension it act as adapters.
|
| 81 |
+
It follow simple residual block with non-linear activations
|
| 82 |
+
|
| 83 |
+
```python
|
| 84 |
+
class ProjectionHead(nn.Module):
|
| 85 |
+
def __init__(
|
| 86 |
+
self,
|
| 87 |
+
embedding_dim,
|
| 88 |
+
projection_dim=256,
|
| 89 |
+
dropout=CFG.dropout
|
| 90 |
+
):
|
| 91 |
+
super().__init__()
|
| 92 |
+
self.projection = nn.Linear(embedding_dim, projection_dim)
|
| 93 |
+
self.gelu = nn.GELU()
|
| 94 |
+
self.fc = nn.Linear(projection_dim, projection_dim)
|
| 95 |
+
self.dropout = nn.Dropout(dropout)
|
| 96 |
+
self.layer_norm = nn.LayerNorm(projection_dim)
|
| 97 |
+
|
| 98 |
+
def forward(self, x):
|
| 99 |
+
projected = self.projection(x)
|
| 100 |
+
x = self.gelu(projected)
|
| 101 |
+
x = self.fc(x)
|
| 102 |
+
x = self.dropout(x)
|
| 103 |
+
x = x + projected
|
| 104 |
+
x = self.layer_norm(x)
|
| 105 |
+
return x
|
| 106 |
+
```
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
## CLIP Model
|
| 110 |
+
Combines Image and Text model by adapters and make it understandable.
|
| 111 |
+
|
| 112 |
+
```python
|
| 113 |
+
class CLIPModel(pl.LightningModule):
|
| 114 |
+
def __init__(image_embedding,text_embedding) -> None:
|
| 115 |
+
super().__init__()
|
| 116 |
+
self.image_encoder = ImageEncoder()
|
| 117 |
+
self.text_encoder = TextEncoder()
|
| 118 |
+
self.image_projection = ProjectionHead(embedding_dim=image_embedding)
|
| 119 |
+
self.text_projection = ProjectionHead(embedding_dim=text_embedding)
|
| 120 |
+
|
| 121 |
+
def forward(batch):
|
| 122 |
+
image_features = self.image_encoder(batch["image"])
|
| 123 |
+
text_features = self.text_encoder( input_ids=batch["input_ids"], attention_mask=batch["attention_mask"] )
|
| 124 |
+
image_embeddings = self.image_projection(image_features)
|
| 125 |
+
text_embeddings = self.text_projection(text_features)
|
| 126 |
+
|
| 127 |
+
# Calculating the Loss
|
| 128 |
+
logits = (text_embeddings @ image_embeddings.T) / self.temperature
|
| 129 |
+
images_similarity = image_embeddings @ image_embeddings.T
|
| 130 |
+
texts_similarity = text_embeddings @ text_embeddings.T
|
| 131 |
+
targets = F.softmax( (images_similarity + texts_similarity) / 2 * self.temperature, dim=-1 )
|
| 132 |
+
texts_loss = cross_entropy(logits, targets, reduction='none')
|
| 133 |
+
images_loss = cross_entropy(logits.T, targets.T, reduction='none')
|
| 134 |
+
loss = (images_loss + texts_loss) / 2.0 # shape: (batch_size)
|
| 135 |
+
return loss.mean()
|
| 136 |
+
```
|
| 137 |
+
|
| 138 |
+
## Model Summary
|
| 139 |
+
```log
|
| 140 |
+
| Name | Type | Params | Mode
|
| 141 |
+
------------------------------------------------------------
|
| 142 |
+
0 | image_encoder | ImageEncoder | 11.2 M | train
|
| 143 |
+
1 | text_encoder | TextEncoder | 66.4 M | train
|
| 144 |
+
2 | image_projection | ProjectionHead | 197 K | train
|
| 145 |
+
3 | text_projection | ProjectionHead | 263 K | train
|
| 146 |
+
------------------------------------------------------------
|
| 147 |
+
78.0 M Trainable params
|
| 148 |
+
0 Non-trainable params
|
| 149 |
+
78.0 M Total params
|
| 150 |
+
312.001 Total estimated model params size (MB)
|
| 151 |
+
200 Modules in train mode
|
| 152 |
+
0 Modules in eval mode
|
| 153 |
+
```
|
| 154 |
+
|
| 155 |
+
## Training
|
| 156 |
+
- nvitop
|
| 157 |
+
<!--  -->
|
| 158 |
+
<div align='center'><img src='https://raw.githubusercontent.com/Muthukamalan/CoolCLIP-/refs/heads/main/gradio/contents/cool-clip-nvitop.png' alt=""></div>
|
| 159 |
+
|
| 160 |
+
- htop
|
| 161 |
+
<!--  -->
|
| 162 |
+
<div align='center'><img src='https://raw.githubusercontent.com/Muthukamalan/CoolCLIP-/refs/heads/main/gradio/contents/cool-clip.png' alt=""></div>
|
| 163 |
+
|
| 164 |
+
- training
|
| 165 |
+
<!--  -->
|
| 166 |
+
<div align='center'><img src='https://raw.githubusercontent.com/Muthukamalan/CoolCLIP-/refs/heads/main/gradio/contents/fit-report.png' alt=""></div>
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
# Inference
|
| 170 |
+
## GRADIO APP
|
| 171 |
+
<div align='center'><img src='https://raw.githubusercontent.com/Muthukamalan/CoolCLIP-/refs/heads/main/gradio/contents/clip_model.png' alt=""></div>
|
| 172 |
+
<!-- <div><img align='center' src="./contents/clip_model.png" ></img></div> -->
|
app.py
ADDED
|
@@ -0,0 +1,124 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
|
| 3 |
+
#Importing all the necessary libraries
|
| 4 |
+
import torch
|
| 5 |
+
import requests
|
| 6 |
+
import numpy as np
|
| 7 |
+
import pandas as pd
|
| 8 |
+
import gradio as gr
|
| 9 |
+
from io import BytesIO
|
| 10 |
+
from PIL import Image as PILIMAGE
|
| 11 |
+
|
| 12 |
+
from transformers import CLIPProcessor, CLIPModel, CLIPTokenizer
|
| 13 |
+
from sentence_transformers import SentenceTransformer, util
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 18 |
+
|
| 19 |
+
# Define model
|
| 20 |
+
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32").to(device)
|
| 21 |
+
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
|
| 22 |
+
tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-base-patch32")
|
| 23 |
+
|
| 24 |
+
# Load data
|
| 25 |
+
photos = pd.read_csv("./photos.tsv000", sep='\t', header=0)
|
| 26 |
+
photo_features = np.load("./features.npy")
|
| 27 |
+
photo_ids = pd.read_csv("./photo_ids.csv")
|
| 28 |
+
photo_ids = list(photo_ids['photo_id'])
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def encode_text(text):
|
| 33 |
+
with torch.no_grad():
|
| 34 |
+
# Encode and normalize the description using CLIP
|
| 35 |
+
inputs = tokenizer([text], padding=True, return_tensors="pt")
|
| 36 |
+
inputs = processor(text=[text], images=None, return_tensors="pt", padding=True).to(device=device)
|
| 37 |
+
text_encoded = model.get_text_features(**inputs).detach().cpu().numpy()
|
| 38 |
+
return text_encoded
|
| 39 |
+
|
| 40 |
+
def encode_image(image):
|
| 41 |
+
image = PILIMAGE.fromarray(image.astype('uint8'), 'RGB')
|
| 42 |
+
with torch.no_grad():
|
| 43 |
+
photo_preprocessed = processor(text=None, images=image, return_tensors="pt", padding=True)["pixel_values"]
|
| 44 |
+
search_photo_feature = model.get_image_features(photo_preprocessed.to(device))
|
| 45 |
+
search_photo_feature /= search_photo_feature.norm(dim=-1, keepdim=True)
|
| 46 |
+
image_encoded = search_photo_feature.cpu().numpy()
|
| 47 |
+
return image_encoded
|
| 48 |
+
|
| 49 |
+
T2I = "Text2Image"
|
| 50 |
+
I2I = "Image2Image"
|
| 51 |
+
|
| 52 |
+
def similarity(feature, photo_features):
|
| 53 |
+
similarities = list((feature @ photo_features.T).squeeze(0))
|
| 54 |
+
return similarities
|
| 55 |
+
|
| 56 |
+
def find_best_matches(image, mode, text):
|
| 57 |
+
# Compute the similarity between the description and each photo using the Cosine similarity
|
| 58 |
+
print ("Mode now ",mode)
|
| 59 |
+
|
| 60 |
+
if mode == "Text2Image":
|
| 61 |
+
# Encode the text input
|
| 62 |
+
text_features = encode_text(text)
|
| 63 |
+
feature = text_features
|
| 64 |
+
similarities = similarity(text_features, photo_features)
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
else:
|
| 68 |
+
#Encode the image input
|
| 69 |
+
image_features = encode_image(image)
|
| 70 |
+
feature = image_features
|
| 71 |
+
similarities = similarity(image_features, photo_features)
|
| 72 |
+
|
| 73 |
+
# Sort the photos by their similarity score
|
| 74 |
+
best_photos = sorted(zip(similarities, range(photo_features.shape[0])), key=lambda x: x[0], reverse=True)
|
| 75 |
+
|
| 76 |
+
matched_images = []
|
| 77 |
+
for i in range(3):
|
| 78 |
+
# Retrieve the photo ID
|
| 79 |
+
idx = best_photos[i][1]
|
| 80 |
+
photo_id = photo_ids[idx]
|
| 81 |
+
|
| 82 |
+
# Get all metadata for this photo
|
| 83 |
+
photo_data = photos[photos["photo_id"] == photo_id].iloc[0]
|
| 84 |
+
|
| 85 |
+
# Display the images
|
| 86 |
+
#display(Image(url=photo_data["photo_image_url"] + "?w=640"))
|
| 87 |
+
response = requests.get(photo_data["photo_image_url"] + "?w=640")
|
| 88 |
+
img = PILIMAGE.open(BytesIO(response.content))
|
| 89 |
+
matched_images.append(img)
|
| 90 |
+
return matched_images
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
demo = gr.Interface(
|
| 96 |
+
fn=find_best_matches,
|
| 97 |
+
inputs=[
|
| 98 |
+
gr.Image(label="Image to search",),# optional=True
|
| 99 |
+
gr.Radio([T2I, I2I]),
|
| 100 |
+
gr.Textbox(lines=1, label="Text query", placeholder="Introduce the search text...",)
|
| 101 |
+
],
|
| 102 |
+
theme="grass",
|
| 103 |
+
outputs=[
|
| 104 |
+
gr.Gallery(label="Generated images", show_label=False, elem_id="gallery")
|
| 105 |
+
],
|
| 106 |
+
title="CLIP Search",
|
| 107 |
+
description="This application displays TOP THREE images from Unsplash dataset that best match the search query provided by the user from (25k images-db). Moreover, the input can be provided via two modes ie text or image form.",
|
| 108 |
+
examples=[
|
| 109 |
+
["./assets/duck.jpeg","Image2Image", None] ,
|
| 110 |
+
[None, "Text2Image", "Planet Earth"],
|
| 111 |
+
["./assets/horse.jpeg", "Text2Image", "Horse"]
|
| 112 |
+
|
| 113 |
+
]
|
| 114 |
+
)
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
with open("README.md", "r+") as file:
|
| 118 |
+
readme_content = file.read()
|
| 119 |
+
# 🏐⚽🏀🎾🤸
|
| 120 |
+
readme =gr.Interface( fn = None, inputs=None, outputs=gr.Markdown(readme_content[150:]),clear_btn=None, css="footer{display:none !important}",flagging_options=[],show_progress='hidden',title="") #gr.Interface(lambda name: "Bye " + name, "text", "text")#
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
app = gr.TabbedInterface([demo, readme ],tab_names=["CoolCLIP 🦆","README"])
|
| 124 |
+
app.launch(debug=False,)
|
assets/duck.jpeg
ADDED

|
assets/horse.jpeg
ADDED

|
contents/bert-model.png
ADDED

|
contents/clip_model.png
ADDED

|
contents/cool-clip-nvitop.png
ADDED

|
contents/cool-clip.png
ADDED

|
contents/fit-report.png
ADDED

|
contents/resnet.png
ADDED

|
features.npy
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:31ac381e52fa007821a642b5808ac9a6eaf7163322ab340d36bcc3c2a94a38c8
|
| 3 |
+
size 25596032
|
photo_ids.csv
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
photos.tsv000
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
requirements.txt
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
sentence-transformers
|
| 2 |
+
transformers
|
| 3 |
+
torch
|
| 4 |
+
numpy
|
| 5 |
+
ftfy
|