
File size: 9,053 Bytes
ac3f344 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 |
{
"cells": [
{
"cell_type": "markdown",
"source": [
"***Florence-2 Models Image Captions : Image-to-Text***\n",
"\n",
"*notebook by : [prithivMLmods](https://huggingface.co/prithivMLmods)🤗 x ❤️*"
],
"metadata": {
"id": "0wlBVusvHBDY"
}
},
{
"cell_type": "markdown",
"source": [
"***Installing all necessary packages***"
],
"metadata": {
"id": "v_lhI9uSHcfX"
}
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "d9NXmBEN4-5z"
},
"outputs": [],
"source": [
"%%capture\n",
"!pip install transformers==4.48.0 timm\n",
"!pip install huggingface_hub hf_xet\n",
"#Hold tight, this will take around 3-5 minutes."
]
},
{
"cell_type": "markdown",
"source": [
"***Run app 💨***"
],
"metadata": {
"id": "exk2jXyoHdwv"
}
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"colab": {
"background_save": true
},
"id": "3Z7bnSM35Sfc"
},
"outputs": [],
"source": [
"import gradio as gr\n",
"import subprocess\n",
"import torch\n",
"from PIL import Image\n",
"from transformers import AutoProcessor, AutoModelForCausalLM\n",
"\n",
"#--------- Hold tight — installation takes only 2–3 minutes ---------#\n",
"# Attempt to install flash-attn\n",
"try:\n",
" subprocess.run('pip install flash-attn==1.0.9 --no-build-isolation', env={'FLASH_ATTENTION_SKIP_CUDA_BUILD': \"TRUE\"}, check=True, shell=True)\n",
"except subprocess.CalledProcessError as e:\n",
" print(f\"Error installing flash-attn: {e}\")\n",
" print(\"Continuing without flash-attn.\")\n",
"#--------- Hold tight — installation takes only 2–3 minutes ---------#\n",
"\n",
"# Determine the device to use\n",
"device = \"cuda\" if torch.cuda.is_available() else \"cpu\"\n",
"\n",
"# Load the base model and processor\n",
"try:\n",
" vision_language_model_base = AutoModelForCausalLM.from_pretrained('microsoft/Florence-2-base', trust_remote_code=True).to(device).eval()\n",
" vision_language_processor_base = AutoProcessor.from_pretrained('microsoft/Florence-2-base', trust_remote_code=True)\n",
"except Exception as e:\n",
" print(f\"Error loading base model: {e}\")\n",
" vision_language_model_base = None\n",
" vision_language_processor_base = None\n",
"\n",
"# Load the large model and processor\n",
"try:\n",
" vision_language_model_large = AutoModelForCausalLM.from_pretrained('microsoft/Florence-2-large', trust_remote_code=True).to(device).eval()\n",
" vision_language_processor_large = AutoProcessor.from_pretrained('microsoft/Florence-2-large', trust_remote_code=True)\n",
"except Exception as e:\n",
" print(f\"Error loading large model: {e}\")\n",
" vision_language_model_large = None\n",
" vision_language_processor_large = None\n",
"\n",
"def describe_image(uploaded_image, model_choice):\n",
" \"\"\"\n",
" Generates a detailed description of the input image using the selected model.\n",
"\n",
" Args:\n",
" uploaded_image (PIL.Image.Image): The image to describe.\n",
" model_choice (str): The model to use, either \"Base\" or \"Large\".\n",
"\n",
" Returns:\n",
" str: A detailed textual description of the image or an error message.\n",
" \"\"\"\n",
" if uploaded_image is None:\n",
" return \"Please upload an image.\"\n",
"\n",
" if model_choice == \"Florence-2-base\":\n",
" if vision_language_model_base is None:\n",
" return \"Base model failed to load.\"\n",
" model = vision_language_model_base\n",
" processor = vision_language_processor_base\n",
" elif model_choice == \"Florence-2-large\":\n",
" if vision_language_model_large is None:\n",
" return \"Large model failed to load.\"\n",
" model = vision_language_model_large\n",
" processor = vision_language_processor_large\n",
" else:\n",
" return \"Invalid model choice.\"\n",
"\n",
" if not isinstance(uploaded_image, Image.Image):\n",
" uploaded_image = Image.fromarray(uploaded_image)\n",
"\n",
" inputs = processor(text=\"<MORE_DETAILED_CAPTION>\", images=uploaded_image, return_tensors=\"pt\").to(device)\n",
" with torch.no_grad():\n",
" generated_ids = model.generate(\n",
" input_ids=inputs[\"input_ids\"],\n",
" pixel_values=inputs[\"pixel_values\"],\n",
" max_new_tokens=1024,\n",
" early_stopping=False,\n",
" do_sample=False,\n",
" num_beams=3,\n",
" )\n",
" generated_text = processor.batch_decode(generated_ids, skip_special_tokens=False)[0]\n",
" processed_description = processor.post_process_generation(\n",
" generated_text,\n",
" task=\"<MORE_DETAILED_CAPTION>\",\n",
" image_size=(uploaded_image.width, uploaded_image.height)\n",
" )\n",
" image_description = processed_description[\"<MORE_DETAILED_CAPTION>\"]\n",
" print(\"\\nImage description generated!:\", image_description)\n",
" return image_description\n",
"\n",
"# Description for the interface\n",
"description = \"> Select the model to use for generating the image description. 'Base' is smaller and faster, while 'Large' is more accurate but slower.\"\n",
"if device == \"cpu\":\n",
" description += \" Note: Running on CPU, which may be slow for large models.\"\n",
"\n",
"css = \"\"\"\n",
".submit-btn {\n",
" background-color: #4682B4 !important;\n",
" color: white !important;\n",
"}\n",
".submit-btn:hover {\n",
" background-color: #87CEEB !important;\n",
"}\n",
"\"\"\"\n",
"\n",
"# Create the Gradio interface with Blocks\n",
"with gr.Blocks(theme=\"bethecloud/storj_theme\", css=css) as demo:\n",
" gr.Markdown(\"# **[Florence-2 Models Image Captions](https://huggingface.co/collections/prithivMLmods/multimodal-implementations-67c9982ea04b39f0608badb0)**\")\n",
" gr.Markdown(description)\n",
" with gr.Row():\n",
" # Left column: Input image and Generate button\n",
" with gr.Column():\n",
" image_input = gr.Image(label=\"Upload Image\", type=\"pil\")\n",
" generate_btn = gr.Button(\"Generate Caption\", elem_classes=\"submit-btn\")\n",
" # Right column: Model choice, output, and examples\n",
" with gr.Column():\n",
" model_choice = gr.Radio([\"Florence-2-base\", \"Florence-2-large\"], label=\"Model Choice\", value=\"Florence-2-base\")\n",
" with gr.Row():\n",
" output = gr.Textbox(label=\"Generated Caption\", lines=4, show_copy_button=True)\n",
" # Connect the button to the function\n",
" generate_btn.click(fn=describe_image, inputs=[image_input, model_choice], outputs=output)\n",
"\n",
"# Launch the interface\n",
"demo.launch(debug=True)"
]
},
{
"cell_type": "markdown",
"source": [
"## **Demo Inference Screenshots**\n",
"\n",
"| 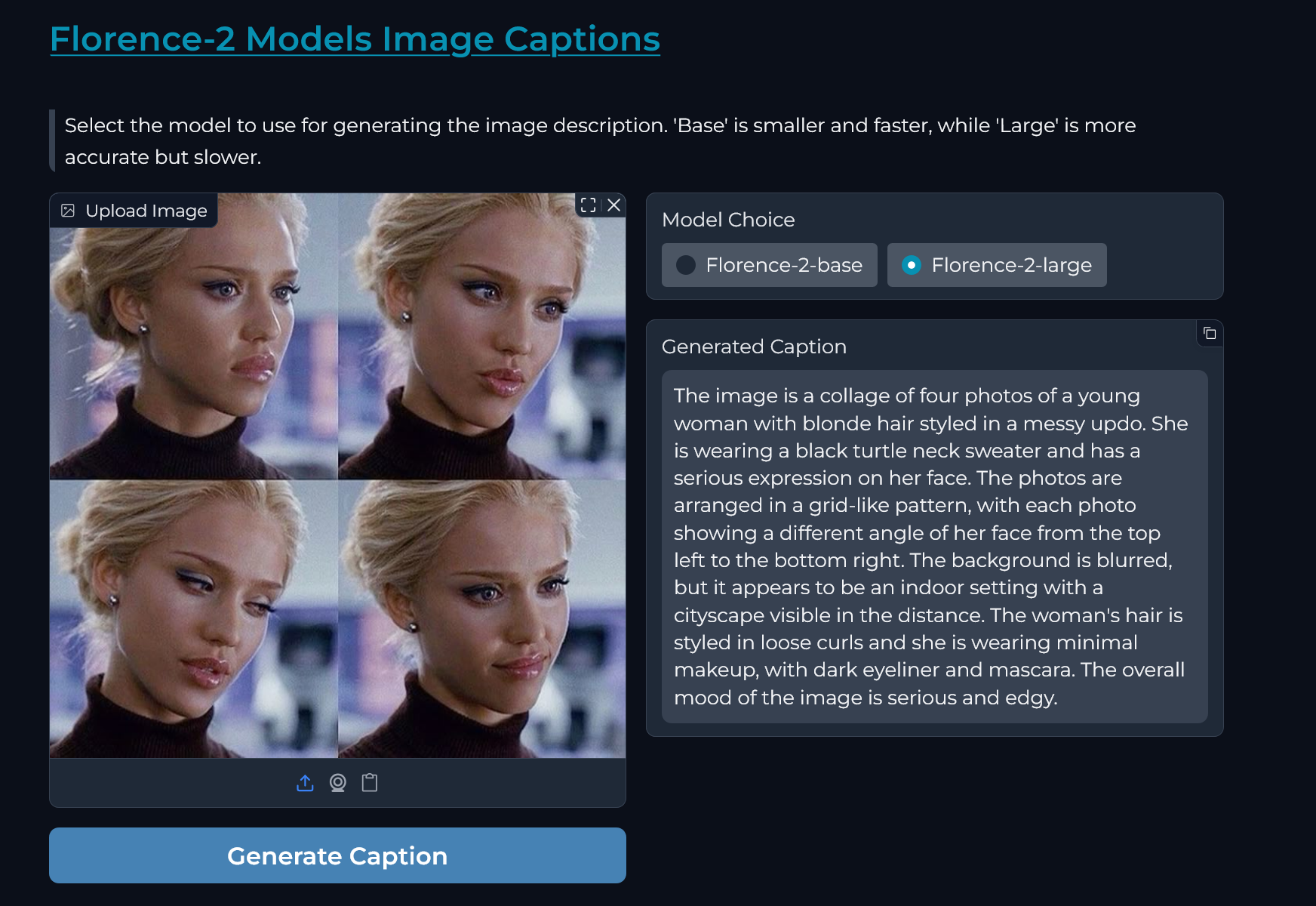 | 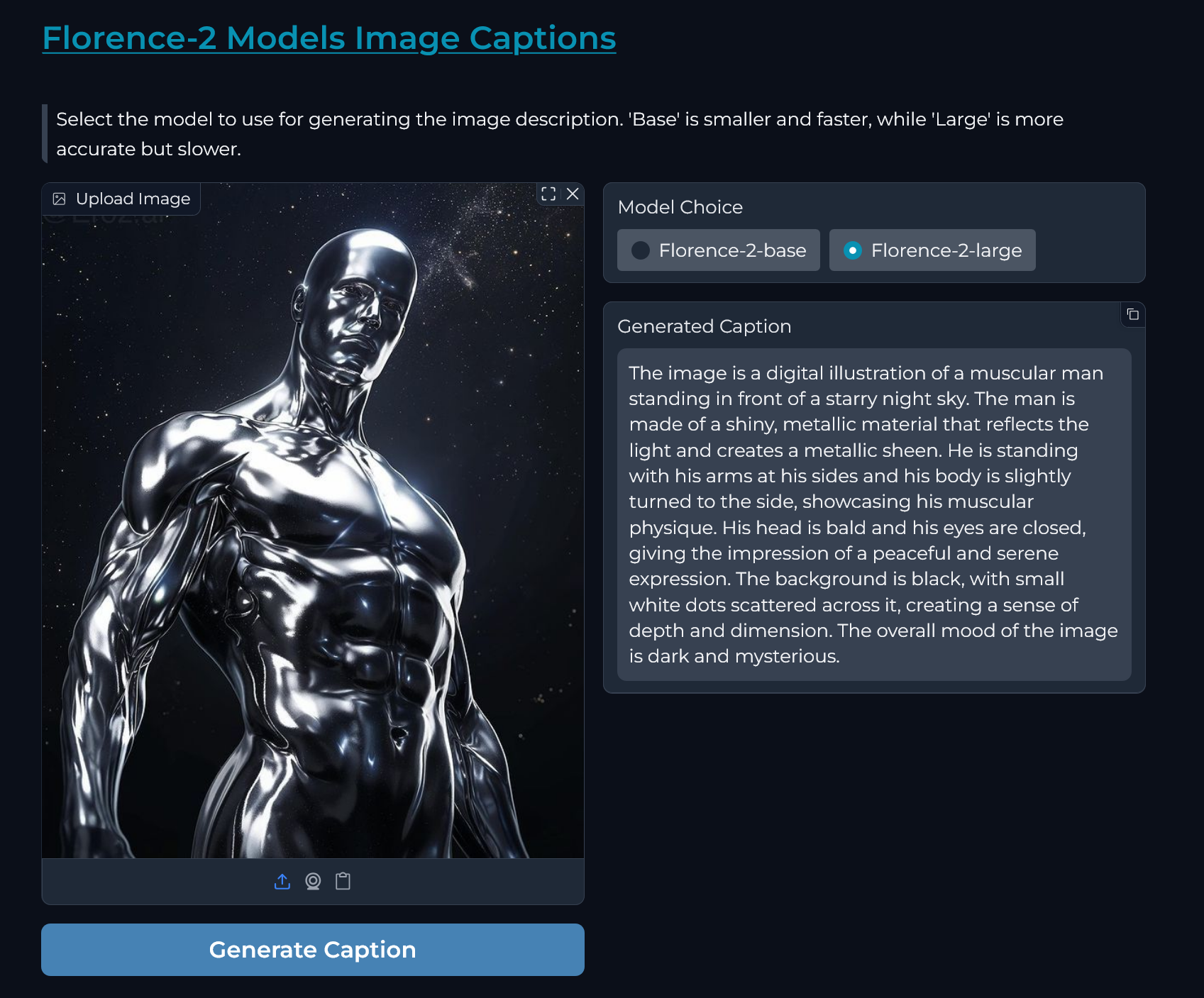 |\n",
"|:---------------------------------------------------------------------------------------------------------------------------------------:|:---------------------------------------------------------------------------------------------------------------------------------------:|\n"
],
"metadata": {
"id": "NFKGwtueGfcW"
}
}
],
"metadata": {
"accelerator": "GPU",
"colab": {
"gpuType": "T4",
"provenance": []
},
"kernelspec": {
"display_name": "Python 3",
"name": "python3"
},
"language_info": {
"name": "python"
}
},
"nbformat": 4,
"nbformat_minor": 0
} |