VisualSimpleQA: A Benchmark for Decoupled Evaluation of Large Vision-Language Models in Fact-Seeking Question Answering
 WYLing
WYLing






Abstract
Large vision-language models (LVLMs) have demonstrated remarkable achievements, yet the generation of non-factual responses remains prevalent in fact-seeking question answering (QA). Current multimodal fact-seeking benchmarks primarily focus on comparing model outputs to ground truth answers, providing limited insights into the performance of modality-specific modules. To bridge this gap, we introduce VisualSimpleQA, a multimodal fact-seeking benchmark with two key features. First, it enables streamlined and decoupled evaluation of LVLMs in visual and linguistic modalities. Second, it incorporates well-defined difficulty criteria to guide human annotation and facilitates the extraction of a challenging subset, VisualSimpleQA-hard. Experiments on 15 LVLMs show that even state-of-the-art models such as GPT-4o achieve merely 60%+ correctness in multimodal fact-seeking QA on VisualSimpleQA and 30%+ on VisualSimpleQA-hard. Furthermore, the decoupled evaluation across these models highlights substantial opportunities for improvement in both visual and linguistic modules. The dataset is available at https://huggingface.co/datasets/WYLing/VisualSimpleQA.
Community
How to effectively evaluate the fact-seeking QA ability of Large Vision-Language Models (LVLMs)? Is the traditional end-to-end evaluation benchmark the optimal approach? How can we effectively annotate challenging multimodal fact-seeking QA benchmarks?
🤔 VisualSimpleQA provides a solution.
Effectively evaluating LVLMs in fact-seeking QA tasks is crucial for studying their reliability. Currently, mainstream evaluation benchmarks primarily adopt an end-to-end approach, directly comparing model-generated answers to multimodal questions with ground truth answers. However, LVLMs consist of multiple modality-specific modules, such as ViT for visual feature extraction and LLM for processing textual knowledge. Errors in model responses may stem from inaccurate visual recognition, insufficient textual knowledge, or a combination of both. Relying solely on end-to-end evaluation makes it difficult to pinpoint the weaknesses of specific modules, highlighting the need for a decoupled evaluation of fact-seeking capabilities.
To address this, we introduce VisualSimpleQA, a multimodal fact-seeking QA benchmark comprising 500 high-quality, human-annotated evaluation samples. Its key advantages include:
- A concise decoupled evaluation framework: Provides a simple and intuitive approach to assess the language and vision modules separately, helping identify weaknesses that require improvement.
- Clearly defined sample difficulty criteria: Unlike existing relevant benchmarks, VisualSimpleQA establishes a quantitative method for determining sample difficulty. Experiments validate the effectiveness of the criteria, aiding annotators in better controlling sample complexity and enhancing benchmark challenge levels.

This is an automated message from the Librarian Bot. I found the following papers similar to this paper.
The following papers were recommended by the Semantic Scholar API
- ChineseSimpleVQA --"See the World, Discover Knowledge": A Chinese Factuality Evaluation for Large Vision Language Models (2025)
- SimpleVQA: Multimodal Factuality Evaluation for Multimodal Large Language Models (2025)
- Visual-RAG: Benchmarking Text-to-Image Retrieval Augmented Generation for Visual Knowledge Intensive Queries (2025)
- MME-CoT: Benchmarking Chain-of-Thought in Large Multimodal Models for Reasoning Quality, Robustness, and Efficiency (2025)
- Chart-HQA: A Benchmark for Hypothetical Question Answering in Charts (2025)
- Fine-Grained Retrieval-Augmented Generation for Visual Question Answering (2025)
- MQADet: A Plug-and-Play Paradigm for Enhancing Open-Vocabulary Object Detection via Multimodal Question Answering (2025)
Please give a thumbs up to this comment if you found it helpful!
If you want recommendations for any Paper on Hugging Face checkout this Space
You can directly ask Librarian Bot for paper recommendations by tagging it in a comment:
@librarian-bot
recommend
Great!!!!
Chinese Translation:https://mp.weixin.qq.com/s/s0af6phzkjyxt2c61HAjVQ
🔥清华等推出VisualSimpleQA:解耦评估大型视觉语言模型事实准确性的基准测试
在人工智能快速发展的今天,大型视觉语言模型(LVLMs)已经成为AI领域的重要基石。然而,这些模型在回答事实性问题时常常会生成不准确的回应,这一问题限制了它们在实际应用中的广泛使用。
近日,来自清华大学、中关村实验室、人民大学和腾讯的研究团队共同推出了一个突破性的基准测试——VisualSimpleQA,旨在解决目前评估体系中存在的不足,提供更加精确和解耦的评估方法来测试大型视觉语言模型的事实准确性。
📊 为什么需要VisualSimpleQA?
目前的多模态事实性评估基准主要关注于比较模型输出与标准答案,但缺乏对模态特定模块的深入分析。而VisualSimpleQA的创新之处在于:
- 解耦评估:能够分别评估视觉模块和语言模块的性能
- 明确的难度标准:提出了量化样本难度的标准
- 高质量与多样性:所有样本由人类专家创建,覆盖广泛话题
- 减少评估偏差:40%的样本使用新收集的图像,避免使用可能被模型训练过的公共数据集
🧠 VisualSimpleQA如何工作?

图1:VisualSimpleQA示例。 红框突出显示了兴趣区域(ROI)。每个样本都有多个属性和标签,这些属性和标签可以根据研究团队提出的难度标准来衡量其整体难度分数。
VisualSimpleQA的每个样本包含三个关键组成部分:
- 多模态事实性问题(需要图像理解)
- 改写后的纯文本问题(不依赖视觉输入)
- 回答问题所需的基本原理(理由)
这种设计使得研究人员可以:
- 通过纯文本问题评估模型的语言模块能力
- 通过比较多模态问题与纯文本问题的性能差异来评估模型的视觉模块能力
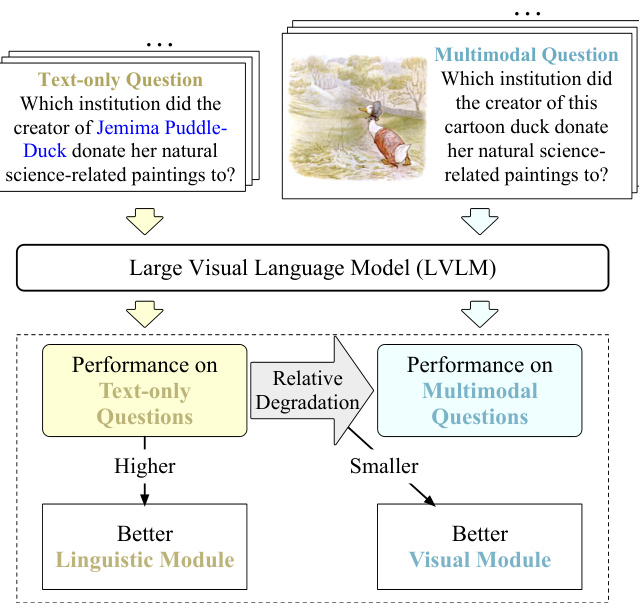
图2:解耦评估过程。 该图展示了如何分别评估模型的语言能力和视觉能力,并通过相对性能下降来量化视觉模块的表现。
📏 难度评估标准
VisualSimpleQA引入了一系列难度标准,从视觉识别和知识识别两个维度来衡量样本的难度:
视觉维度:
- 分辨率:图像像素数量
- 兴趣区域比例:ROI相对于原始图像的大小
- 理由粒度:所需提取的信息是粗粒度还是细粒度
- 图像中文本的存在或缺失:图像中是否含有辅助识别的文本
知识维度:
- 知识普及度:回答问题所需的知识在训练语料库中的流行程度
基于这些标准,研究团队从500个样本中挑选出了129个具有特别挑战性的样本,形成了VisualSimpleQA-hard子集。
🚀 实验结果令人震惊!
研究团队对15个前沿的开源和闭源大型视觉语言模型进行了评估,包括GPT-4o、Claude-3.5-Sonnet、Gemini 2.0等。
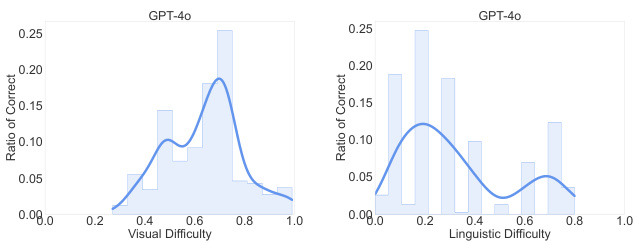
图3:GPT-4o在不同难度级别下的正确回答率。 左图基于GPT-4o正确回答纯文本问题和多模态问题的样本,右图基于GPT-4o正确回答纯文本问题的样本。
实验结果显示:
- 即使是最先进的模型如GPT-4o在VisualSimpleQA上的多模态问题正确率也仅达到**60%+,而在VisualSimpleQA-hard上更是仅有30%+**的正确率。
- 当前前沿LVLM在困难的视觉识别任务上仍需显著改进,特别是开源模型在从纯文本QA过渡到多模态QA时表现出较大的性能下降。
- 闭源前沿LVLM明显优于当前开源LVLM。例如,GPT-4o在纯文本QA的正确率上超过表现最好的开源模型Qwen2.5-VL-72B-Instruct 10.3%,在多模态QA上超过15.2%。
- 较大的模型明显优于较小的模型,在多模态和纯文本QA任务上都表现更好。
📚 样本多样性
VisualSimpleQA涵盖了广泛的主题类别,包括研究与教育、品牌与企业、影视娱乐、艺术、地理、体育、游戏、历史和政治等。
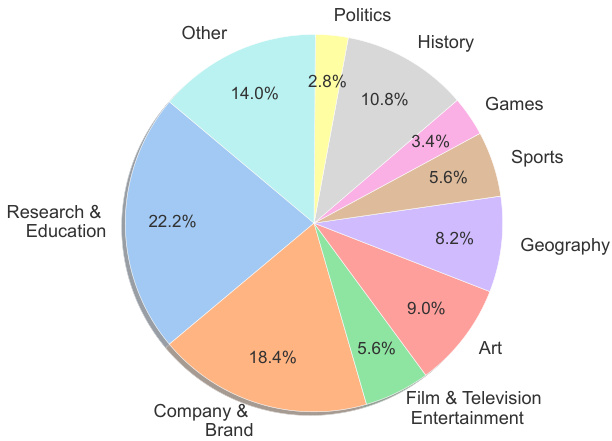
图4:VisualSimpleQA中的主题分布。 图表展示了测试集中不同主题类别的分布情况,覆盖了从教育到娱乐的多个领域。
💡 结论与启示
VisualSimpleQA为评估大型视觉语言模型的事实准确性提供了一个更为细致和解耦的框架。实验结果表明,即使是当前最先进的模型在事实性问答方面仍有巨大的提升空间,特别是在处理复杂视觉识别任务和长尾知识方面。
这一基准测试的推出,不仅有助于我们更好地理解当前LVLM的能力边界,也为未来的模型改进提供了明确的方向。对于研究人员和开发者来说,这是一个宝贵的工具,可以帮助他们更精确地定位模型中需要改进的模块,从而推动整个领域的进步。
Models citing this paper 0
No model linking this paper
Datasets citing this paper 1
Spaces citing this paper 0
No Space linking this paper