# Global Context Vision Transformer (GC ViT)
This model contains the official PyTorch implementation of **Global Context Vision Transformers** (ICML2023) \
\
[Global Context Vision
Transformers](https://arxiv.org/pdf/2206.09959.pdf) \
[Ali Hatamizadeh](https://research.nvidia.com/person/ali-hatamizadeh),
[Hongxu (Danny) Yin](https://scholar.princeton.edu/hongxu),
[Greg Heinrich](https://developer.nvidia.com/blog/author/gheinrich/),
[Jan Kautz](https://jankautz.com/),
and [Pavlo Molchanov](https://www.pmolchanov.com/).
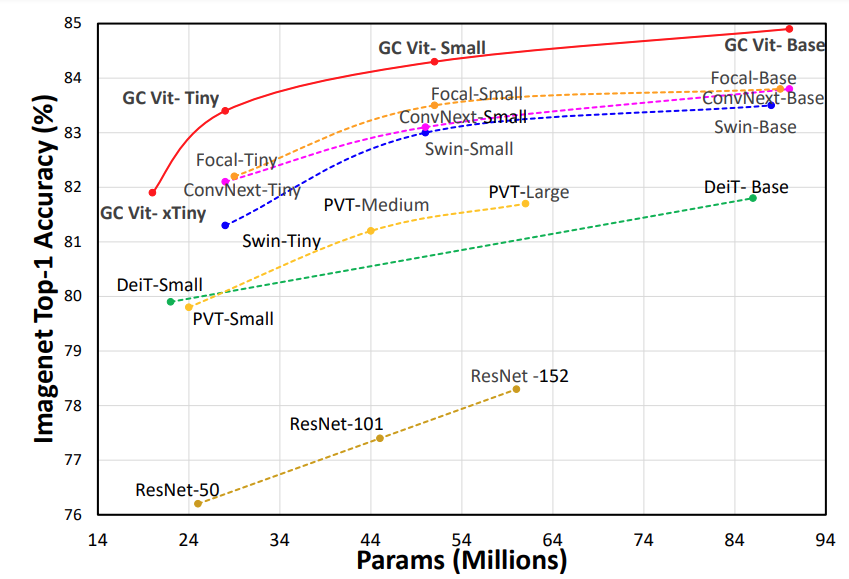
GC ViT achieves state-of-the-art results across image classification, object detection and semantic segmentation tasks. On ImageNet-1K dataset for classification, GC ViT variants with `51M`, `90M` and `201M` parameters achieve `84.3`, `85.9` and `85.7` Top-1 accuracy, respectively, surpassing comparably-sized prior art such as CNN-based ConvNeXt and ViT-based Swin Transformer.
The architecture of GC ViT is demonstrated in the following:

## Introduction
**GC ViT** leverages global context self-attention modules, joint with local self-attention, to effectively yet efficiently model both long and short-range spatial interactions, without the need for expensive
operations such as computing attention masks or shifting local windows.

## ImageNet Benchmarks
**ImageNet-1K Pretrained Models**
| Model Variant |
Acc@1 |
#Params(M) |
FLOPs(G) |
Download |
| GC ViT-XXT |
79.9 |
12 |
2.1 |
model |
| GC ViT-XT |
82.0 |
20 |
2.6 |
model |
| GC ViT-T |
83.5 |
28 |
4.7 |
model |
| GC ViT-T2 |
83.7 |
34 |
5.5 |
model |
| GC ViT-S |
84.3 |
51 |
8.5 |
model |
| GC ViT-S2 |
84.8 |
68 |
10.7 |
model |
| GC ViT-B |
85.0 |
90 |
14.8 |
model |
| GC ViT-L |
85.7 |
201 |
32.6 |
model |
**ImageNet-21K Pretrained Models**
| Model Variant |
Resolution |
Acc@1 |
#Params(M) |
FLOPs(G) |
Download |
| GC ViT-L |
224 x 224 |
86.6 |
201 |
32.6 |
model |
| GC ViT-L |
384 x 384 |
87.4 |
201 |
120.4 |
model |
## Citation
Please consider citing GC ViT paper if it is useful for your work:
```
@inproceedings{hatamizadeh2023global,
title={Global context vision transformers},
author={Hatamizadeh, Ali and Yin, Hongxu and Heinrich, Greg and Kautz, Jan and Molchanov, Pavlo},
booktitle={International Conference on Machine Learning},
pages={12633--12646},
year={2023},
organization={PMLR}
}
```
## Licenses
Copyright © 2023, NVIDIA Corporation. All rights reserved.
This work is made available under the Nvidia Source Code License-NC. Click [here](LICENSE) to view a copy of this license.
The pre-trained models are shared under [CC-BY-NC-SA-4.0](https://creativecommons.org/licenses/by-nc-sa/4.0/). If you remix, transform, or build upon the material, you must distribute your contributions under the same license as the original.
For license information regarding the timm, please refer to its [repository](https://github.com/rwightman/pytorch-image-models).
For license information regarding the ImageNet dataset, please refer to the ImageNet [official website](https://www.image-net.org/).