# Hugging Face 🤗
## The Hugging Face Hub
In addition to the official [pre-trained models](https://www.sbert.net/docs/pretrained_models.html), you can find over 500 `sentence-transformer` models on the [Hugging Face Hub](http://hf.co/models?library=sentence-transformers&sort=downloads).
All models on the Hugging Face Hub come with the following:
1. An [automatically generated model card](https://huggingface.co/docs/hub/models-cards#what-are-model-cards) with a description, example code snippets, architecture overview, and more.
2. [Metadata tags](https://huggingface.co/docs/hub/models-cards#model-card-metadata) that help for discoverability and contain additional information such as a usage license.
3. An [interactive widget](https://huggingface.co/docs/hub/models-widgets) you can use to play with the model directly in the browser.
4. An [Inference API](https://huggingface.co/docs/hub/models-inference) that allows you to make inference requests.
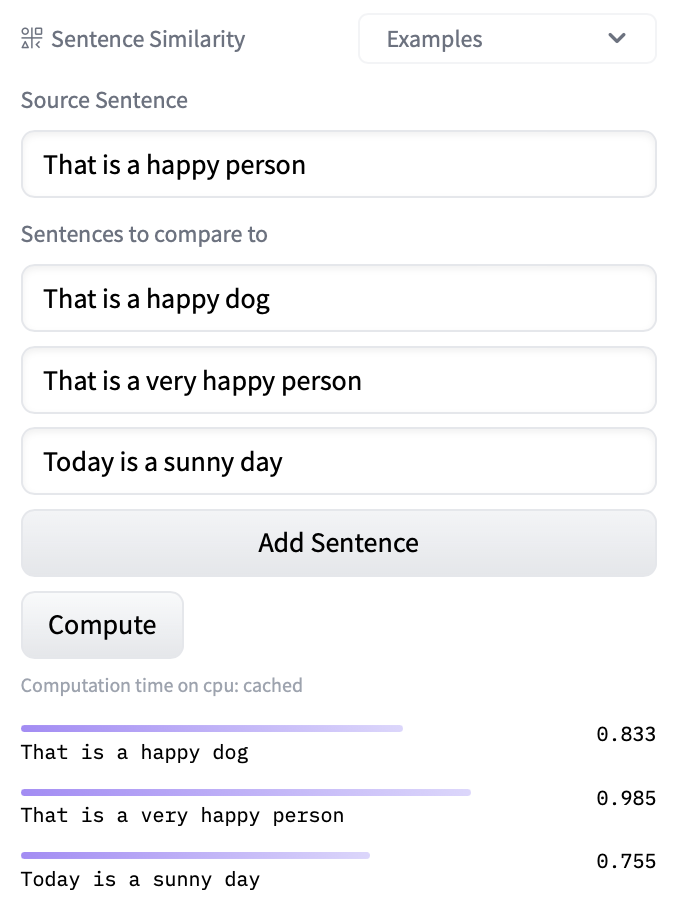 ## Using Hugging Face models
Any pre-trained models from the Hub can be loaded with a single line of code:
```py
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('model_name')
```
You can even click `Use in sentence-transformers` to get a code snippet that you can copy and paste!
## Using Hugging Face models
Any pre-trained models from the Hub can be loaded with a single line of code:
```py
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('model_name')
```
You can even click `Use in sentence-transformers` to get a code snippet that you can copy and paste!


Here is an example that loads the [multi-qa-MiniLM-L6-cos-v1 model](https://huggingface.co/sentence-transformers/multi-qa-MiniLM-L6-cos-v1) and uses it to encode sentences and then compute the distance between them for doing semantic search.
```py
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('multi-qa-MiniLM-L6-cos-v1')
query_embedding = model.encode('How big is London')
passage_embedding = model.encode(['London has 9,787,426 inhabitants at the 2011 census',
'London is known for its finacial district'])
print("Similarity:", util.dot_score(query_embedding, passage_embedding))
```
Here is another example, this time using the [clips/mfaq model](https://huggingface.co/clips/mfaq) for multilingual FAQ retrieval. After embedding the query and the answers, we perform a semantic search to find the most relevant answer.
```py
from sentence_transformers import SentenceTransformer, util
question = "How many models can I host on HuggingFace?"
answer_1 = "All plans come with unlimited private models and datasets."
answer_2 = "AutoNLP is an automatic way to train and deploy state-of-the-art NLP models, seamlessly integrated with the Hugging Face ecosystem."
answer_3 = "Based on how much training data and model variants are created, we send you a compute cost and payment link - as low as $10 per job."
model = SentenceTransformer('clips/mfaq')
query_embedding = model.encode(question)
corpus_embeddings = model.encode([answer_1, answer_2, answer_3])
print(util.semantic_search(query_embedding, corpus_embeddings))
```
## Sharing your models
Once you've installed the [Hub Client Library](https://huggingface.co/docs/huggingface_hub/quick-start), you can login through your terminal with your Hugging Face account.
```bash
pip install huggingface_hub
huggingface-cli login
```
Then, you can share your SentenceTransformers models by calling the [`save_to_hub` method](https://www.sbert.net/docs/package_reference/SentenceTransformer.html#sentence_transformers.SentenceTransformer.save_to_hub) from a trained model. By default, the model will be uploaded to your account, but you can upload to an [organization](https://huggingface.co/docs/hub/organizations) by passing setting an `organization` parameter. `save_to_hub` automatically generates a model card, an inference widget, example code snippets, and more.
```py
from sentence_transformers import SentenceTransformer
# Load or train a model
model.save_to_hub("my_new_model")
```
You can automatically add to the Hub's model card a list of datasets you used to train the model with the argument `train_datasets: Optional[List[str]] = None)`. See the "Datasets used to train" section in the [ITESM/sentece-embeddings-BETO](https://huggingface.co/ITESM/sentece-embeddings-BETO) model for an example of the final result.
```py
model.save_to_hub("my_new_model", train_datasets=["GEM/wiki_lingua", "code_search_net"])
```
## Sharing your embeddings
The Hugging Face Hub can also be used to store and share any embeddings you generate. You can export your embeddings to CSV, ZIP, Pickle, or any other format, and then upload them to the Hub as a [Dataset](https://huggingface.co/docs/hub/datasets-adding). Read the ["Getting Started With Embeddings" blog post](https://huggingface.co/blog/getting-started-with-embeddings#2-host-embeddings-for-free-on-the-hugging-face-hub) for more information.
## Additional resources
* [Hugging Face Hub docs](https://huggingface.co/docs/hub/index)
* Integration with Hub [announcement](https://huggingface.co/blog/sentence-transformers-in-the-hub).