
File size: 11,452 Bytes
2359bda |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 |
# Multilingual-Models
The issue with multilingual BERT (mBERT) as well as with XLM-RoBERTa is that those produce rather bad sentence representation out-of-the-box. Further, the vectors spaces between languages are not aligned, i.e., the sentences with the same content in different languages would be mapped to different locations in the vector space.
In my publication [Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation](https://arxiv.org/abs/2004.09813) I describe any easy approach to extend sentence embeddings to further languages.
Chien Vu also wrote a nice blog article on this technique: [A complete guide to transfer learning from English to other Languages using Sentence Embeddings BERT Models](https://towardsdatascience.com/a-complete-guide-to-transfer-learning-from-english-to-other-languages-using-sentence-embeddings-8c427f8804a9)
## Available Pre-trained Models
For a list of available models, see [Pretrained Models](https://www.sbert.net/docs/pretrained_models.html#multi-lingual-models).
## Usage
You can use the models in the following way:
```python
from sentence_transformers import SentenceTransformer
embedder = SentenceTransformer('model-name')
embeddings = embedder.encode(['Hello World', 'Hallo Welt', 'Hola mundo'])
print(embeddings)
```
## Performance
The performance was evaluated on the [Semantic Textual Similarity (STS) 2017 dataset](http://ixa2.si.ehu.es/stswiki/index.php/Main_Page). The task is to predict the semantic similarity (on a scale 0-5) of two given sentences. STS2017 has monolingual test data for English, Arabic, and Spanish, and cross-lingual test data for English-Arabic, -Spanish and -Turkish.
We extended the STS2017 and added cross-lingual test data for English-German, French-English, Italian-English, and Dutch-English ([STS2017-extended.zip](https://public.ukp.informatik.tu-darmstadt.de/reimers/sentence-transformers/datasets/STS2017-extended.zip)). The performance is measured using Spearman correlation between the predicted similarity score and the gold score.
<table class="docutils">
<tr>
<th>Model</th>
<th>AR-AR</th>
<th>AR-EN</th>
<th>ES-ES</th>
<th>ES-EN</th>
<th>EN-EN</th>
<th>TR-EN</th>
<th>EN-DE</th>
<th>FR-EN</th>
<th>IT-EN</th>
<th>NL-EN</th>
<th>Average</th>
</tr>
<tr>
<td>XLM-RoBERTa mean pooling </td>
<td align="center">25.7</td>
<td align="center">17.4</td>
<td align="center">51.8</td>
<td align="center">10.9</td>
<td align="center">50.7</td>
<td align="center">9.2</td>
<td align="center">21.3</td>
<td align="center">16.6</td>
<td align="center">22.9</td>
<td align="center">26.0</td>
<td align="center">25.2</td>
</tr>
<tr>
<td>mBERT mean pooling </td>
<td align="center">50.9</td>
<td align="center">16.7</td>
<td align="center">56.7</td>
<td align="center">21.5</td>
<td align="center">54.4</td>
<td align="center">16.0</td>
<td align="center">33.9</td>
<td align="center">33.0</td>
<td align="center">34.0</td>
<td align="center">35.6</td>
<td align="center">35.3</td>
</tr>
<tr>
<td>LASER</td>
<td align="center">68.9</td>
<td align="center">66.5</td>
<td align="center">79.7</td>
<td align="center">57.9</td>
<td align="center">77.6</td>
<td align="center">72.0</td>
<td align="center">64.2</td>
<td align="center">69.1</td>
<td align="center">70.8</td>
<td align="center">68.5</td>
<td align="center">69.5</td>
</tr>
<tr>
<td colspan="12"><b>Sentence Transformer Models</b></td>
</tr>
<tr>
<td>distiluse-base-multilingual-cased</td>
<td align="center">75.9</td>
<td align="center">77.6</td>
<td align="center">85.3</td>
<td align="center">78.7</td>
<td align="center">85.4</td>
<td align="center">75.5</td>
<td align="center">80.3</td>
<td align="center">80.2</td>
<td align="center">80.5</td>
<td align="center">81.7</td>
<td align="center">80.1</td>
</tr>
</table>
## Extend your own models
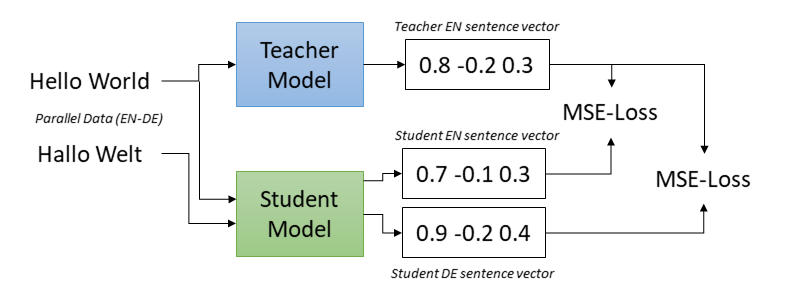
The idea is based on a fixed (monolingual) **teacher model**, that produces sentence embeddings with our desired properties in one language. The **student model** is supposed to mimic the teacher model, i.e., the same English sentence should be mapped to the same vector by the teacher and by the student model. In order that the student model works for further languages, we train the student model on parallel (translated) sentences. The translation of each sentence should also be mapped to the same vector as the original sentence.
In the above figure, the student model should map *Hello World* and the German translation *Hallo Welt* to the vector of *teacher_model('Hello World')*. We achieve this by training the student model using mean squared error (MSE) loss.
In our experiments we initiliazed the student model with the multilingual XLM-RoBERTa model.
## Training
For a **fully automatic code example**, see [make_multilingual.py](make_multilingual.py).
This scripts downloads the [TED2020 corpus](https://github.com/UKPLab/sentence-transformers/blob/master/docs/datasets/TED2020.md?), a corpus with transcripts and translations from TED and TEDx talks. It than extends a monolingual model to several languages (en, de, es, it, fr, ar, tr). TED2020 contains parallel data for more than 100 languages, hence, you can simple change the script and train a multilingual model in your favorite languages.
## Data Format
As training data we require parallel sentences, i.e., sentences translated in various languages. As data format, we use a tab-separated .tsv file. In the first column, you have your source sentence, for example, an English sentence. In the following columns, you have the translations of this source sentence. If you have multiple translations per source sentence, you can put them in the same line or in different lines.
```
Source_sentence Target_lang1 Target_lang2 Target_lang3
Source_sentence Target_lang1 Target_lang2
```
An example file could look like this (EN DE ES):
```
Hello World Hallo Welt Hola Mundo
Sentences are separated with a tab character. Die Sätze sind per Tab getrennt. Las oraciones se separan con un carácter de tabulación.
```
The order of the translations are not important, it is only important that the first column contains a sentence in a language that is understood by the teacher model.
## Loading Training Datasets
You can load such a training file using the *ParallelSentencesDataset* class:
```python
from sentence_transformers.datasets import ParallelSentencesDataset
train_data = ParallelSentencesDataset(student_model=student_model, teacher_model=teacher_model)
train_data.load_data('path/to/tab/separated/train-en-de.tsv')
train_data.load_data('path/to/tab/separated/train-en-es.tsv.gz')
train_data.load_data('path/to/tab/separated/train-en-fr.tsv.gz')
train_dataloader = DataLoader(train_data, shuffle=True, batch_size=train_batch_size)
train_loss = losses.MSELoss(model=student_model)
```
You load a file with the *load_data()* method. You can load multiple files by calling load_data multiple times. You can also regular files or .gz-compressed files.
Per default, all datasets are weighted equally. In the above example a (source, translation)-pair will be sampled equally from all three datasets. If you pass a `weight` parameter (integer), you can weight some datasets higher or lower.
## Sources for Training Data
A great website for a vast number of parallel (translated) datasets is [OPUS](http://opus.nlpl.eu/). There, you find parallel datasets for more than 400 languages.
The [examples/training/multilingual](https://github.com/UKPLab/sentence-transformers/blob/master/examples/training/multilingual/) folder contains some scripts that downloads parallel training data and brings it into the right format:
- [get_parallel_data_opus.py](get_parallel_data_opus.py): This script downloads data from the [OPUS](http://opus.nlpl.eu/) website.
- [get_parallel_data_tatoeba.py](get_parallel_data_tatoeba.py): This script downloads data from the [Tatoeba](https://tatoeba.org/) website, a website for language learners with example sentences for more than many languages.
- [get_parallel_data_ted2020.py](get_parallel_data_ted2020.py): This script downloads data the [TED2020 corpus](https://github.com/UKPLab/sentence-transformers/blob/master/docs/datasets/TED2020.md), which contains transcripts and translations of more than 4,000 TED and TEDx talks in 100+ languages.
## Evaluation
Training can be evaluated in different ways. For an example how to use these evaluation methods, see [make_multilingual.py](make_multilingual.py).
### MSE Evaluation
You can measure the mean squared error (MSE) between the student embeddings and teacher embeddings. This can be achieved with the ``
```python
# src_sentences and trg_sentences are lists of translated sentences, such that trg_sentences[i] is the translation of src_sentences[i]
dev_mse = evaluation.MSEEvaluator(src_sentences, trg_sentences, teacher_model=teacher_model)
```
This evaluator computes the teacher embeddings for the `src_sentences`, for example, for English. During training, the student model is used to compute embeddings for the `trg_sentences`, for example, for Spanish. The distance between teacher and student embeddings is measures. Lower scores indicate a better performance.
### Translation Accuracy
You can also measure the translation accuracy. Given a list with source sentences, for example, 1000 English sentences. And a list with matching target (translated) sentences, for example, 1000 Spanish sentences.
For each sentence pair, we check if their embeddings are the closest using cosine similarity. I.e., for each `src_sentences[i]` we check if `trg_sentences[i]` has the highest similarity out of all target sentences. If this is the case, we have a hit, otherwise an error. This evaluator reports accuracy (higher = better).
```python
# src_sentences and trg_sentences are lists of translated sentences, such that trg_sentences[i] is the translation of src_sentences[i]
dev_trans_acc = evaluation.TranslationEvaluator(src_sentences, trg_sentences, name=os.path.basename(dev_file),batch_size=inference_batch_size)
```
### Multi-Lingual Semantic Textual Similarity
You can also measure the semantic textual similarity (STS) between sentence pairs in different languages:
```python
sts_evaluator = evaluation.EmbeddingSimilarityEvaluatorFromList(sentences1, sentences2, scores)
```
Where `sentences1` and `sentences2` are lists of sentences and score is numeric value indicating the sematic similarity between `sentences1[i]` and `sentences2[i]`.
## Citation
If you use the code for multilingual models, feel free to cite our publication [Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation](https://arxiv.org/abs/2004.09813):
```
@article{reimers-2020-multilingual-sentence-bert,
title = "Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation",
author = "Reimers, Nils and Gurevych, Iryna",
journal= "arXiv preprint arXiv:2004.09813",
month = "04",
year = "2020",
url = "http://arxiv.org/abs/2004.09813",
}
```
|