
Update README.md
Browse files
README.md
CHANGED
|
@@ -1,19 +1,19 @@
|
|
| 1 |
---
|
| 2 |
library_name: transformers
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
license: mit
|
| 4 |
datasets:
|
| 5 |
-
- kodetr/stunting-qa-
|
| 6 |
language:
|
| 7 |
- id
|
| 8 |
metrics:
|
| 9 |
-
- bleu
|
| 10 |
-
- glue
|
| 11 |
- rouge
|
| 12 |
-
base_model:
|
| 13 |
-
- meta-llama/Llama-3.2-3B-Instruct
|
| 14 |
pipeline_tag: text-generation
|
| 15 |
-
|
| 16 |
-
- llama-
|
| 17 |
---
|
| 18 |
|
| 19 |
### Model Description
|
|
@@ -27,25 +27,69 @@ Konsultasi(Q&A) stunting pada anak
|
|
| 27 |
|
| 28 |
### Training
|
| 29 |
|
| 30 |
-

|
| 35 |
-
|
| 36 |
-
### Evaluation (GLUE)
|
| 37 |
-
|
| 38 |
-
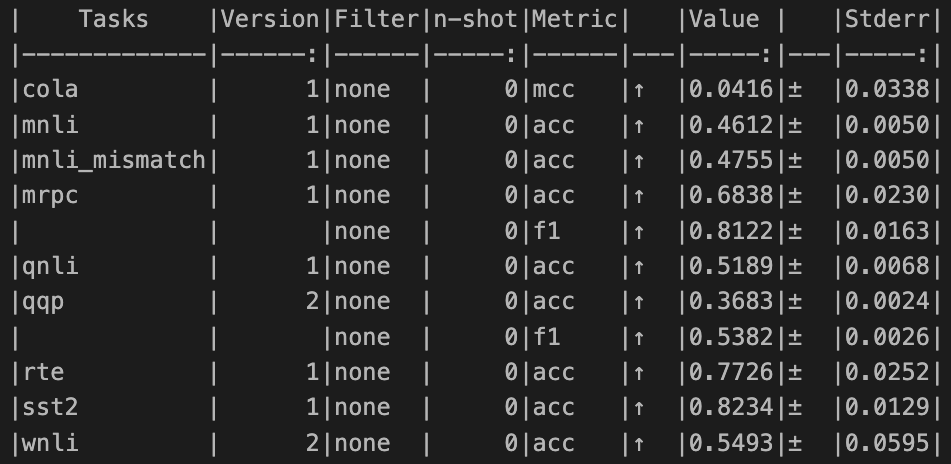
|
| 39 |
-
|
| 40 |
-
### Evaluation (ROUGE)
|
| 41 |
-
|
| 42 |
-
- **ROUGE Base Model:** {'rouge1': 0.32442426784015754, 'rouge2': 0.21091087320145585, 'rougeL': 0.2997913044723025, 'rougeLsum': 0.3028164031975752}
|
| 43 |
-
- **ROUGE Finetuned Model:** {'rouge1': 0.45885281015363844, 'rouge2': 0.33303682535111623, 'rougeL': 0.42486098123248783, 'rougeLsum': 0.43147191004805796}
|
| 44 |
-
|
| 45 |
-
### BERTSCORE
|
| 46 |
-
|
| 47 |
-
- **BERTScore Base Model - F1:** 0.7268
|
| 48 |
-
- **BERTScore Finetuned Model - F1:** 0.7687
|
| 49 |
|
| 50 |
### Use with transformers
|
| 51 |
|
|
@@ -55,7 +99,7 @@ Pastikan untuk memperbarui instalasi transformer Anda melalui pip install --upgr
|
|
| 55 |
import torch
|
| 56 |
from transformers import pipeline
|
| 57 |
|
| 58 |
-
model_id = "kodetr/stunting-qa-
|
| 59 |
pipe = pipeline(
|
| 60 |
"text-generation",
|
| 61 |
model=model_id,
|
|
|
|
| 1 |
---
|
| 2 |
library_name: transformers
|
| 3 |
+
tags:
|
| 4 |
+
- stunting
|
| 5 |
+
- kesehatan
|
| 6 |
+
- anak
|
| 7 |
license: mit
|
| 8 |
datasets:
|
| 9 |
+
- kodetr/stunting-qa-2025
|
| 10 |
language:
|
| 11 |
- id
|
| 12 |
metrics:
|
|
|
|
|
|
|
| 13 |
- rouge
|
|
|
|
|
|
|
| 14 |
pipeline_tag: text-generation
|
| 15 |
+
base_model:
|
| 16 |
+
- meta-llama/Llama-3.1-8B-Instruct
|
| 17 |
---
|
| 18 |
|
| 19 |
### Model Description
|
|
|
|
| 27 |
|
| 28 |
### Training
|
| 29 |
|
| 30 |
+

|
| 31 |
|
| 32 |
### Information Result Training
|
| 33 |
+
```
|
| 34 |
+
***** train metrics *****
|
| 35 |
+
epoch = 2.9987
|
| 36 |
+
num_input_tokens_seen = 1900976
|
| 37 |
+
total_flos = 79944066GF
|
| 38 |
+
train_loss = 0.872
|
| 39 |
+
train_runtime = 1:06:36.18
|
| 40 |
+
train_samples_per_second = 5.737
|
| 41 |
+
train_steps_per_second = 0.358
|
| 42 |
+
```
|
| 43 |
+
|
| 44 |
+
### Evaluation
|
| 45 |
+
|
| 46 |
+
```
|
| 47 |
+
{
|
| 48 |
+
"predict_bleu-4": 46.238530502486256,
|
| 49 |
+
"predict_model_preparation_time": 0.0054,
|
| 50 |
+
"predict_rouge-1": 50.236485540434444,
|
| 51 |
+
"predict_rouge-2": 33.20428471604292,
|
| 52 |
+
"predict_rouge-l": 46.93391739073541,
|
| 53 |
+
"predict_runtime": 10532.8745,
|
| 54 |
+
"predict_samples_per_second": 0.726,
|
| 55 |
+
"predict_steps_per_second": 0.363
|
| 56 |
+
}
|
| 57 |
+
```
|
| 58 |
+
|
| 59 |
+
### Parameter
|
| 60 |
+
|
| 61 |
+
```
|
| 62 |
+
LlamaConfig {
|
| 63 |
+
"architectures": [
|
| 64 |
+
"LlamaForCausalLM"
|
| 65 |
+
],
|
| 66 |
+
"attention_bias": false,
|
| 67 |
+
"attention_dropout": 0.0,
|
| 68 |
+
"bos_token_id": 128000,
|
| 69 |
+
"eos_token_id": 128009,
|
| 70 |
+
"head_dim": 128,
|
| 71 |
+
"hidden_act": "silu",
|
| 72 |
+
"hidden_size": 4096,
|
| 73 |
+
"initializer_range": 0.02,
|
| 74 |
+
"intermediate_size": 14336,
|
| 75 |
+
"max_position_embeddings": 8192,
|
| 76 |
+
"mlp_bias": false,
|
| 77 |
+
"model_type": "llama",
|
| 78 |
+
"num_attention_heads": 32,
|
| 79 |
+
"num_hidden_layers": 32,
|
| 80 |
+
"num_key_value_heads": 8,
|
| 81 |
+
"pretraining_tp": 1,
|
| 82 |
+
"rms_norm_eps": 1e-05,
|
| 83 |
+
"rope_scaling": null,
|
| 84 |
+
"rope_theta": 500000.0,
|
| 85 |
+
"tie_word_embeddings": false,
|
| 86 |
+
"torch_dtype": "bfloat16",
|
| 87 |
+
"transformers_version": "4.51.3",
|
| 88 |
+
"use_cache": true,
|
| 89 |
+
"vocab_size": 128256
|
| 90 |
+
}
|
| 91 |
+
```
|
| 92 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 93 |
|
| 94 |
### Use with transformers
|
| 95 |
|
|
|
|
| 99 |
import torch
|
| 100 |
from transformers import pipeline
|
| 101 |
|
| 102 |
+
model_id = "kodetr/stunting-qa-v5"
|
| 103 |
pipe = pipeline(
|
| 104 |
"text-generation",
|
| 105 |
model=model_id,
|