

Commit
·
89b2a0b
1
Parent(s):
997a3f5
Update README
Browse files
README.md
CHANGED
|
@@ -20,7 +20,7 @@ It is trained on one million image-text pairs from the SSL4EO-S12-v1.1 dataset w
|
|
| 20 |
|
| 21 |
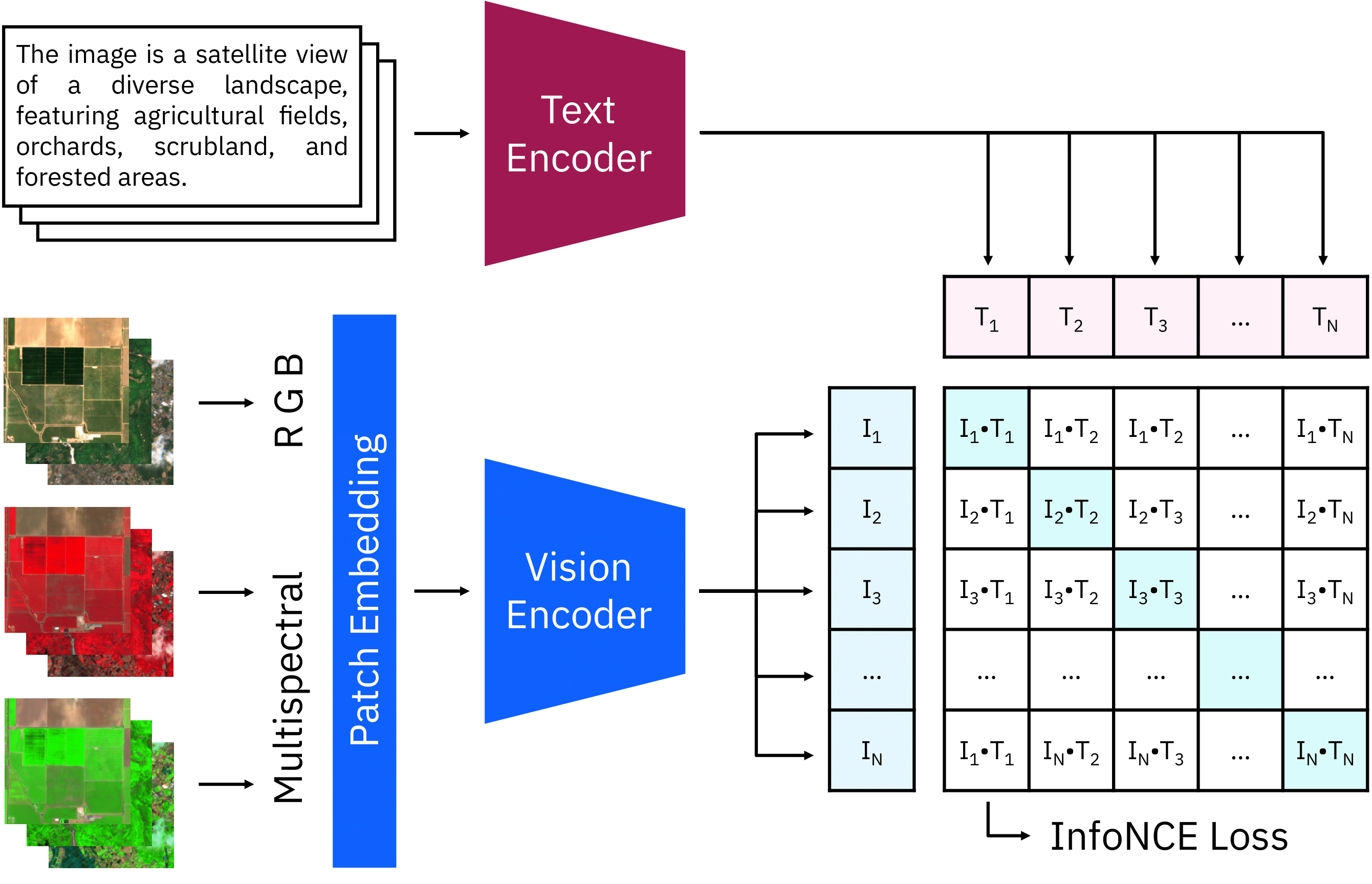
The CLIP model consists of two encoders for text and images. We extended the RGB patch embeddings to multispectral input and initialized the weights of the additional input channels with zeros. During the continual pre-training, the images and texts of each batch are encoded and combined. The loss increases the similarity of matching pairs while decreasing other combinations.
|
| 22 |
|
| 23 |
-

|
| 24 |
|
| 25 |
## Evaluation
|
| 26 |
|
|
@@ -29,8 +29,7 @@ The following Figure compares our model with the OpenCLIP baselines and other EO
|
|
| 29 |
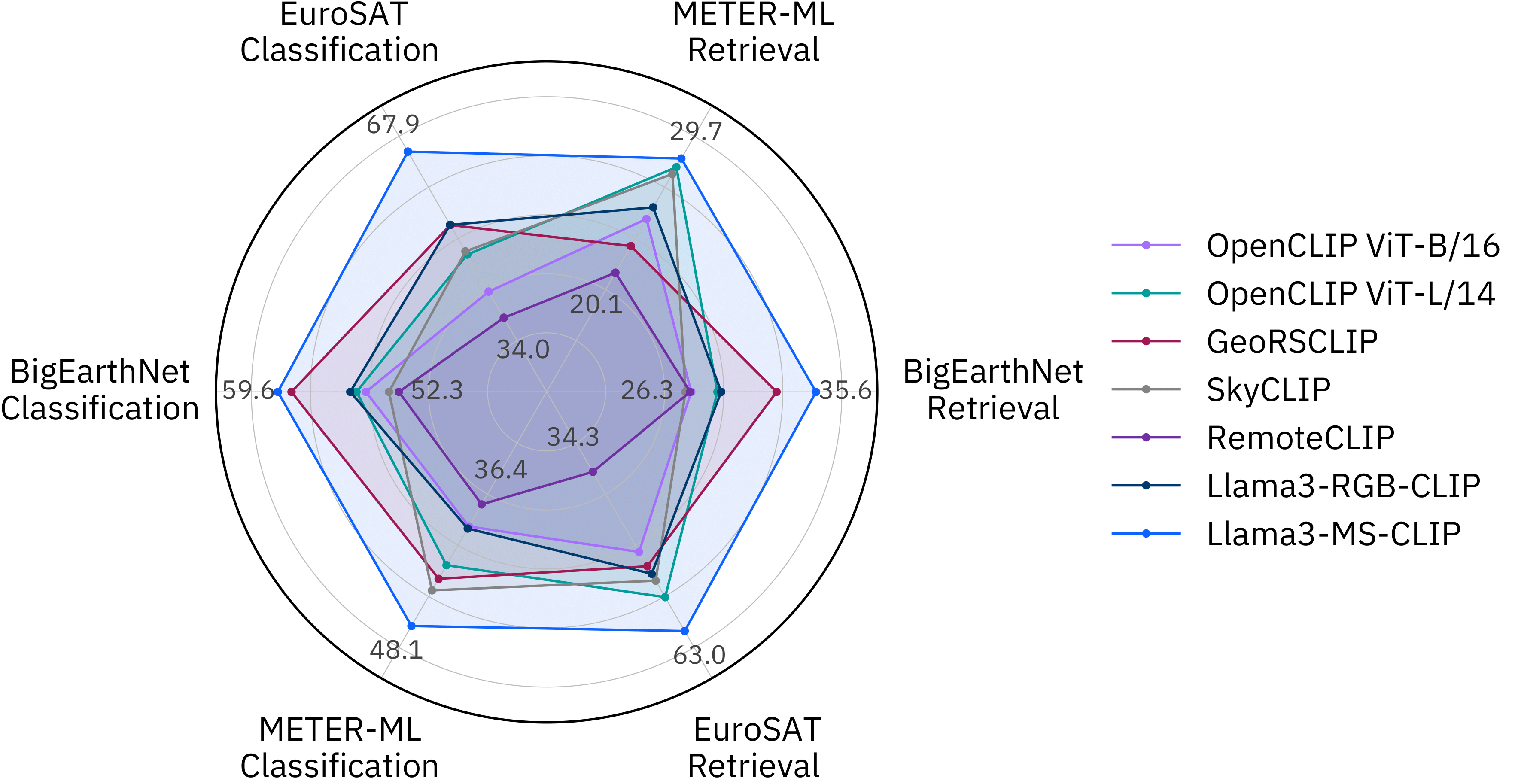
We applied a smoothed min-max scaling and annotated the lowest and highest scores.
|
| 30 |
Our multispectral CLIP model is outperforming other RGB-based models on most benchmarks.
|
| 31 |
|
| 32 |
-

|
| 33 |
-
|
| 34 |
|
| 35 |
## Usage
|
| 36 |
|
|
|
|
| 20 |
|
| 21 |
The CLIP model consists of two encoders for text and images. We extended the RGB patch embeddings to multispectral input and initialized the weights of the additional input channels with zeros. During the continual pre-training, the images and texts of each batch are encoded and combined. The loss increases the similarity of matching pairs while decreasing other combinations.
|
| 22 |
|
| 23 |
+
|
| 24 |
|
| 25 |
## Evaluation
|
| 26 |
|
|
|
|
| 29 |
We applied a smoothed min-max scaling and annotated the lowest and highest scores.
|
| 30 |
Our multispectral CLIP model is outperforming other RGB-based models on most benchmarks.
|
| 31 |
|
| 32 |
+
|
|
|
|
| 33 |
|
| 34 |
## Usage
|
| 35 |
|