
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.71k
18.9k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 465
23.6k
| num_tokens_prompt
int64 556
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_20175 | rasdani/github-patches | git_diff | bridgecrewio__checkov-3750 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
CKV_AZURE_9 & CKV_AZURE_10 - Scan fails if protocol value is a wildcard
**Describe the issue**
CKV_AZURE_9 & CKV_AZURE_10
When scanning Bicep files the checks are looking for a protocol value of `tcp` and fail to catch when `*` is used.
**Examples**
The following bicep code fails to produce a finding for CKV_AZURE_9 & CKV_AZURE_10
```
resource nsg 'Microsoft.Network/networkSecurityGroups@2021-05-01' = {
name: nsgName
location: nsgLocation
properties: {
securityRules: [
{
name: 'badrule'
properties: {
access: 'Allow'
destinationAddressPrefix: '*'
destinationPortRange: '*'
direction: 'Inbound'
priority: 100
protocol: '*'
sourceAddressPrefix: '*'
sourcePortRange: '*'
}
}
]
}
}
```
While this works as expected:
```
resource nsg 'Microsoft.Network/networkSecurityGroups@2021-05-01' = {
name: nsgName
location: nsgLocation
properties: {
securityRules: [
{
name: 'badrule'
properties: {
access: 'Allow'
destinationAddressPrefix: '*'
destinationPortRange: '*'
direction: 'Inbound'
priority: 100
protocol: 'tcp'
sourceAddressPrefix: '*'
sourcePortRange: '*'
}
}
]
}
}
```
**Version (please complete the following information):**
- docker container 2.2.0
**Additional context**
A similar problem existed for Terraform that was previously fixed (see https://github.com/bridgecrewio/checkov/issues/601)
I believe the relevant lines is:
https://github.com/bridgecrewio/checkov/blob/master/checkov/arm/checks/resource/NSGRulePortAccessRestricted.py#LL48C4-L48C117
</issue>
<code>
[start of checkov/arm/checks/resource/NSGRulePortAccessRestricted.py]
1 import re
2 from typing import Union, Dict, Any
3
4 from checkov.common.models.enums import CheckResult, CheckCategories
5 from checkov.arm.base_resource_check import BaseResourceCheck
6
7 # https://docs.microsoft.com/en-us/azure/templates/microsoft.network/networksecuritygroups
8 # https://docs.microsoft.com/en-us/azure/templates/microsoft.network/networksecuritygroups/securityrules
9
10 INTERNET_ADDRESSES = ["*", "0.0.0.0", "<nw>/0", "/0", "internet", "any"] # nosec
11 PORT_RANGE = re.compile(r"\d+-\d+")
12
13
14 class NSGRulePortAccessRestricted(BaseResourceCheck):
15 def __init__(self, name: str, check_id: str, port: int) -> None:
16 supported_resources = (
17 "Microsoft.Network/networkSecurityGroups",
18 "Microsoft.Network/networkSecurityGroups/securityRules",
19 )
20 categories = (CheckCategories.NETWORKING,)
21 super().__init__(name=name, id=check_id, categories=categories, supported_resources=supported_resources)
22 self.port = port
23
24 def is_port_in_range(self, port_range: Union[int, str]) -> bool:
25 if re.match(PORT_RANGE, str(port_range)):
26 start, end = int(port_range.split("-")[0]), int(port_range.split("-")[1])
27 if start <= self.port <= end:
28 return True
29 if port_range in (str(self.port), "*"):
30 return True
31 return False
32
33 def scan_resource_conf(self, conf: Dict[str, Any]) -> CheckResult:
34 if "properties" in conf:
35 securityRules = []
36 if self.entity_type == "Microsoft.Network/networkSecurityGroups":
37 if "securityRules" in conf["properties"]:
38 securityRules.extend(conf["properties"]["securityRules"])
39 if self.entity_type == "Microsoft.Network/networkSecurityGroups/securityRules":
40 securityRules.append(conf)
41
42 for rule in securityRules:
43 portRanges = []
44 sourcePrefixes = []
45 if "properties" in rule:
46 if "access" in rule["properties"] and rule["properties"]["access"].lower() == "allow":
47 if "direction" in rule["properties"] and rule["properties"]["direction"].lower() == "inbound":
48 if "protocol" in rule["properties"] and rule["properties"]["protocol"].lower() == "tcp":
49 if "destinationPortRanges" in rule["properties"]:
50 portRanges.extend(rule["properties"]["destinationPortRanges"])
51 if "destinationPortRange" in rule["properties"]:
52 portRanges.append(rule["properties"]["destinationPortRange"])
53
54 if "sourceAddressPrefixes" in rule["properties"]:
55 sourcePrefixes.extend(rule["properties"]["sourceAddressPrefixes"])
56 if "sourceAddressPrefix" in rule["properties"]:
57 sourcePrefixes.append(rule["properties"]["sourceAddressPrefix"])
58
59 for portRange in portRanges:
60 if self.is_port_in_range(portRange):
61 for prefix in sourcePrefixes:
62 if prefix in INTERNET_ADDRESSES:
63 return CheckResult.FAILED
64
65 return CheckResult.PASSED
66
[end of checkov/arm/checks/resource/NSGRulePortAccessRestricted.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/checkov/arm/checks/resource/NSGRulePortAccessRestricted.py b/checkov/arm/checks/resource/NSGRulePortAccessRestricted.py
--- a/checkov/arm/checks/resource/NSGRulePortAccessRestricted.py
+++ b/checkov/arm/checks/resource/NSGRulePortAccessRestricted.py
@@ -45,7 +45,7 @@
if "properties" in rule:
if "access" in rule["properties"] and rule["properties"]["access"].lower() == "allow":
if "direction" in rule["properties"] and rule["properties"]["direction"].lower() == "inbound":
- if "protocol" in rule["properties"] and rule["properties"]["protocol"].lower() == "tcp":
+ if "protocol" in rule["properties"] and rule["properties"]["protocol"].lower() in ("tcp", "*"):
if "destinationPortRanges" in rule["properties"]:
portRanges.extend(rule["properties"]["destinationPortRanges"])
if "destinationPortRange" in rule["properties"]:
| {"golden_diff": "diff --git a/checkov/arm/checks/resource/NSGRulePortAccessRestricted.py b/checkov/arm/checks/resource/NSGRulePortAccessRestricted.py\n--- a/checkov/arm/checks/resource/NSGRulePortAccessRestricted.py\n+++ b/checkov/arm/checks/resource/NSGRulePortAccessRestricted.py\n@@ -45,7 +45,7 @@\n if \"properties\" in rule:\n if \"access\" in rule[\"properties\"] and rule[\"properties\"][\"access\"].lower() == \"allow\":\n if \"direction\" in rule[\"properties\"] and rule[\"properties\"][\"direction\"].lower() == \"inbound\":\n- if \"protocol\" in rule[\"properties\"] and rule[\"properties\"][\"protocol\"].lower() == \"tcp\":\n+ if \"protocol\" in rule[\"properties\"] and rule[\"properties\"][\"protocol\"].lower() in (\"tcp\", \"*\"):\n if \"destinationPortRanges\" in rule[\"properties\"]:\n portRanges.extend(rule[\"properties\"][\"destinationPortRanges\"])\n if \"destinationPortRange\" in rule[\"properties\"]:\n", "issue": "CKV_AZURE_9 & CKV_AZURE_10 - Scan fails if protocol value is a wildcard\n**Describe the issue**\r\nCKV_AZURE_9 & CKV_AZURE_10\r\n\r\nWhen scanning Bicep files the checks are looking for a protocol value of `tcp` and fail to catch when `*` is used.\r\n\r\n**Examples**\r\n\r\nThe following bicep code fails to produce a finding for CKV_AZURE_9 & CKV_AZURE_10\r\n```\r\nresource nsg 'Microsoft.Network/networkSecurityGroups@2021-05-01' = {\r\n name: nsgName\r\n location: nsgLocation\r\n properties: {\r\n securityRules: [\r\n {\r\n name: 'badrule'\r\n properties: {\r\n access: 'Allow'\r\n destinationAddressPrefix: '*'\r\n destinationPortRange: '*'\r\n direction: 'Inbound'\r\n priority: 100\r\n protocol: '*'\r\n sourceAddressPrefix: '*'\r\n sourcePortRange: '*'\r\n }\r\n }\r\n ]\r\n }\r\n}\r\n```\r\n\r\nWhile this works as expected:\r\n```\r\nresource nsg 'Microsoft.Network/networkSecurityGroups@2021-05-01' = {\r\n name: nsgName\r\n location: nsgLocation\r\n properties: {\r\n securityRules: [\r\n {\r\n name: 'badrule'\r\n properties: {\r\n access: 'Allow'\r\n destinationAddressPrefix: '*'\r\n destinationPortRange: '*'\r\n direction: 'Inbound'\r\n priority: 100\r\n protocol: 'tcp'\r\n sourceAddressPrefix: '*'\r\n sourcePortRange: '*'\r\n }\r\n }\r\n ]\r\n }\r\n}\r\n```\r\n\r\n**Version (please complete the following information):**\r\n - docker container 2.2.0\r\n\r\n**Additional context**\r\nA similar problem existed for Terraform that was previously fixed (see https://github.com/bridgecrewio/checkov/issues/601) \r\n\r\nI believe the relevant lines is: \r\nhttps://github.com/bridgecrewio/checkov/blob/master/checkov/arm/checks/resource/NSGRulePortAccessRestricted.py#LL48C4-L48C117\r\n\r\n\n", "before_files": [{"content": "import re\nfrom typing import Union, Dict, Any\n\nfrom checkov.common.models.enums import CheckResult, CheckCategories\nfrom checkov.arm.base_resource_check import BaseResourceCheck\n\n# https://docs.microsoft.com/en-us/azure/templates/microsoft.network/networksecuritygroups\n# https://docs.microsoft.com/en-us/azure/templates/microsoft.network/networksecuritygroups/securityrules\n\nINTERNET_ADDRESSES = [\"*\", \"0.0.0.0\", \"<nw>/0\", \"/0\", \"internet\", \"any\"] # nosec\nPORT_RANGE = re.compile(r\"\\d+-\\d+\")\n\n\nclass NSGRulePortAccessRestricted(BaseResourceCheck):\n def __init__(self, name: str, check_id: str, port: int) -> None:\n supported_resources = (\n \"Microsoft.Network/networkSecurityGroups\",\n \"Microsoft.Network/networkSecurityGroups/securityRules\",\n )\n categories = (CheckCategories.NETWORKING,)\n super().__init__(name=name, id=check_id, categories=categories, supported_resources=supported_resources)\n self.port = port\n\n def is_port_in_range(self, port_range: Union[int, str]) -> bool:\n if re.match(PORT_RANGE, str(port_range)):\n start, end = int(port_range.split(\"-\")[0]), int(port_range.split(\"-\")[1])\n if start <= self.port <= end:\n return True\n if port_range in (str(self.port), \"*\"):\n return True\n return False\n\n def scan_resource_conf(self, conf: Dict[str, Any]) -> CheckResult:\n if \"properties\" in conf:\n securityRules = []\n if self.entity_type == \"Microsoft.Network/networkSecurityGroups\":\n if \"securityRules\" in conf[\"properties\"]:\n securityRules.extend(conf[\"properties\"][\"securityRules\"])\n if self.entity_type == \"Microsoft.Network/networkSecurityGroups/securityRules\":\n securityRules.append(conf)\n\n for rule in securityRules:\n portRanges = []\n sourcePrefixes = []\n if \"properties\" in rule:\n if \"access\" in rule[\"properties\"] and rule[\"properties\"][\"access\"].lower() == \"allow\":\n if \"direction\" in rule[\"properties\"] and rule[\"properties\"][\"direction\"].lower() == \"inbound\":\n if \"protocol\" in rule[\"properties\"] and rule[\"properties\"][\"protocol\"].lower() == \"tcp\":\n if \"destinationPortRanges\" in rule[\"properties\"]:\n portRanges.extend(rule[\"properties\"][\"destinationPortRanges\"])\n if \"destinationPortRange\" in rule[\"properties\"]:\n portRanges.append(rule[\"properties\"][\"destinationPortRange\"])\n\n if \"sourceAddressPrefixes\" in rule[\"properties\"]:\n sourcePrefixes.extend(rule[\"properties\"][\"sourceAddressPrefixes\"])\n if \"sourceAddressPrefix\" in rule[\"properties\"]:\n sourcePrefixes.append(rule[\"properties\"][\"sourceAddressPrefix\"])\n\n for portRange in portRanges:\n if self.is_port_in_range(portRange):\n for prefix in sourcePrefixes:\n if prefix in INTERNET_ADDRESSES:\n return CheckResult.FAILED\n\n return CheckResult.PASSED\n", "path": "checkov/arm/checks/resource/NSGRulePortAccessRestricted.py"}]} | 1,801 | 221 |
gh_patches_debug_9237 | rasdani/github-patches | git_diff | mars-project__mars-1623 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[BUG] Setitem for DataFrame leads to a wrong dtypes
<!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Describe the bug**
Add columns for a DataFrame will lead to a wrong dtypes of input DataFrame.
**To Reproduce**
```python
In [1]: import mars.dataframe as md
In [2]: a = md.DataFrame({'a':[1,2,3]})
In [3]: a['new'] = 1
In [4]: a.op.inputs
Out[4]: [DataFrame <op=DataFrameDataSource, key=c212164d24d96ed634711c3b97f334cb>]
In [5]: a.op.inputs[0].dtypes
Out[5]:
a int64
new int64
dtype: object
```
**Expected behavior**
Input DataFrame's dtypes should have only one column.
</issue>
<code>
[start of mars/dataframe/indexing/setitem.py]
1 # Copyright 1999-2020 Alibaba Group Holding Ltd.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import numpy as np
16 import pandas as pd
17 from pandas.api.types import is_list_like
18
19 from ... import opcodes
20 from ...core import OutputType
21 from ...serialize import KeyField, AnyField
22 from ...tensor.core import TENSOR_TYPE
23 from ...tiles import TilesError
24 from ..core import SERIES_TYPE, DataFrame
25 from ..initializer import Series as asseries
26 from ..operands import DataFrameOperand, DataFrameOperandMixin
27 from ..utils import parse_index
28
29
30 class DataFrameSetitem(DataFrameOperand, DataFrameOperandMixin):
31 _op_type_ = opcodes.INDEXSETVALUE
32
33 _target = KeyField('target')
34 _indexes = AnyField('indexes')
35 _value = AnyField('value')
36
37 def __init__(self, target=None, indexes=None, value=None, output_types=None, **kw):
38 super().__init__(_target=target, _indexes=indexes,
39 _value=value, _output_types=output_types, **kw)
40 if self.output_types is None:
41 self.output_types = [OutputType.dataframe]
42
43 @property
44 def target(self):
45 return self._target
46
47 @property
48 def indexes(self):
49 return self._indexes
50
51 @property
52 def value(self):
53 return self._value
54
55 def _set_inputs(self, inputs):
56 super()._set_inputs(inputs)
57 self._target = self._inputs[0]
58 if len(inputs) > 1:
59 self._value = self._inputs[-1]
60
61 def __call__(self, target: DataFrame, value):
62 inputs = [target]
63 if np.isscalar(value):
64 value_dtype = np.array(value).dtype
65 else:
66 if isinstance(value, (pd.Series, SERIES_TYPE)):
67 value = asseries(value)
68 inputs.append(value)
69 value_dtype = value.dtype
70 elif is_list_like(value) or isinstance(value, TENSOR_TYPE):
71 value = asseries(value, index=target.index)
72 inputs.append(value)
73 value_dtype = value.dtype
74 else: # pragma: no cover
75 raise TypeError('Wrong value type, could be one of scalar, Series or tensor')
76
77 if value.index_value.key != target.index_value.key: # pragma: no cover
78 raise NotImplementedError('Does not support setting value '
79 'with different index for now')
80
81 index_value = target.index_value
82 dtypes = target.dtypes
83 dtypes.loc[self._indexes] = value_dtype
84 columns_value = parse_index(dtypes.index, store_data=True)
85 ret = self.new_dataframe(inputs, shape=(target.shape[0], len(dtypes)),
86 dtypes=dtypes, index_value=index_value,
87 columns_value=columns_value)
88 target.data = ret.data
89
90 @classmethod
91 def tile(cls, op):
92 out = op.outputs[0]
93 target = op.target
94 value = op.value
95 col = op.indexes
96 columns = target.columns_value.to_pandas()
97
98 if not np.isscalar(value):
99 # check if all chunk's index_value are identical
100 target_chunk_index_values = [c.index_value for c in target.chunks
101 if c.index[1] == 0]
102 value_chunk_index_values = [v.index_value for v in value.chunks]
103 is_identical = len(target_chunk_index_values) == len(target_chunk_index_values) and \
104 all(c.key == v.key for c, v in zip(target_chunk_index_values, value_chunk_index_values))
105 if not is_identical:
106 # do rechunk
107 if any(np.isnan(s) for s in target.nsplits[0]) or \
108 any(np.isnan(s) for s in value.nsplits[0]): # pragma: no cover
109 raise TilesError('target or value has unknown chunk shape')
110
111 value = value.rechunk({0: target.nsplits[0]})._inplace_tile()
112
113 out_chunks = []
114 nsplits = [list(ns) for ns in target.nsplits]
115 if col not in columns:
116 nsplits[1][-1] += 1
117 column_chunk_shape = target.chunk_shape[1]
118 # append to the last chunk on columns axis direction
119 for c in target.chunks:
120 if c.index[-1] != column_chunk_shape - 1:
121 # not effected, just output
122 out_chunks.append(c)
123 else:
124 chunk_op = op.copy().reset_key()
125 if np.isscalar(value):
126 chunk_inputs = [c]
127 else:
128 value_chunk = value.cix[c.index[0], ]
129 chunk_inputs = [c, value_chunk]
130
131 dtypes = c.dtypes
132 dtypes.loc[out.dtypes.index[-1]] = out.dtypes.iloc[-1]
133 chunk = chunk_op.new_chunk(chunk_inputs,
134 shape=(c.shape[0], c.shape[1] + 1),
135 dtypes=dtypes,
136 index_value=c.index_value,
137 columns_value=parse_index(dtypes.index, store_data=True),
138 index=c.index)
139 out_chunks.append(chunk)
140 else:
141 # replace exist column
142 for c in target.chunks:
143 if col in c.dtypes:
144 chunk_inputs = [c]
145 if not np.isscalar(value):
146 chunk_inputs.append(value.cix[c.index[0], ])
147 chunk_op = op.copy().reset_key()
148 chunk = chunk_op.new_chunk(chunk_inputs,
149 shape=c.shape,
150 dtypes=c.dtypes,
151 index_value=c.index_value,
152 columns_value=c.columns_value,
153 index=c.index)
154 out_chunks.append(chunk)
155 else:
156 out_chunks.append(c)
157
158 params = out.params
159 params['nsplits'] = tuple(tuple(ns) for ns in nsplits)
160 params['chunks'] = out_chunks
161 new_op = op.copy()
162 return new_op.new_tileables(op.inputs, kws=[params])
163
164 @classmethod
165 def execute(cls, ctx, op):
166 target = ctx[op.target.key].copy()
167 value = ctx[op.value.key] if not np.isscalar(op.value) else op.value
168 target[op.indexes] = value
169 ctx[op.outputs[0].key] = target
170
171
172 def dataframe_setitem(df, col, value):
173 op = DataFrameSetitem(target=df, indexes=col, value=value)
174 return op(df, value)
175
[end of mars/dataframe/indexing/setitem.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/mars/dataframe/indexing/setitem.py b/mars/dataframe/indexing/setitem.py
--- a/mars/dataframe/indexing/setitem.py
+++ b/mars/dataframe/indexing/setitem.py
@@ -79,7 +79,7 @@
'with different index for now')
index_value = target.index_value
- dtypes = target.dtypes
+ dtypes = target.dtypes.copy(deep=True)
dtypes.loc[self._indexes] = value_dtype
columns_value = parse_index(dtypes.index, store_data=True)
ret = self.new_dataframe(inputs, shape=(target.shape[0], len(dtypes)),
| {"golden_diff": "diff --git a/mars/dataframe/indexing/setitem.py b/mars/dataframe/indexing/setitem.py\n--- a/mars/dataframe/indexing/setitem.py\n+++ b/mars/dataframe/indexing/setitem.py\n@@ -79,7 +79,7 @@\n 'with different index for now')\n \n index_value = target.index_value\n- dtypes = target.dtypes\n+ dtypes = target.dtypes.copy(deep=True)\n dtypes.loc[self._indexes] = value_dtype\n columns_value = parse_index(dtypes.index, store_data=True)\n ret = self.new_dataframe(inputs, shape=(target.shape[0], len(dtypes)),\n", "issue": "[BUG] Setitem for DataFrame leads to a wrong dtypes\n<!--\r\nThank you for your contribution!\r\n\r\nPlease review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.\r\n-->\r\n\r\n**Describe the bug**\r\nAdd columns for a DataFrame will lead to a wrong dtypes of input DataFrame.\r\n\r\n**To Reproduce**\r\n```python\r\nIn [1]: import mars.dataframe as md \r\n\r\nIn [2]: a = md.DataFrame({'a':[1,2,3]}) \r\n\r\nIn [3]: a['new'] = 1 \r\n\r\nIn [4]: a.op.inputs \r\nOut[4]: [DataFrame <op=DataFrameDataSource, key=c212164d24d96ed634711c3b97f334cb>]\r\n\r\nIn [5]: a.op.inputs[0].dtypes \r\nOut[5]: \r\na int64\r\nnew int64\r\ndtype: object\r\n```\r\n**Expected behavior**\r\nInput DataFrame's dtypes should have only one column.\r\n\n", "before_files": [{"content": "# Copyright 1999-2020 Alibaba Group Holding Ltd.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport numpy as np\nimport pandas as pd\nfrom pandas.api.types import is_list_like\n\nfrom ... import opcodes\nfrom ...core import OutputType\nfrom ...serialize import KeyField, AnyField\nfrom ...tensor.core import TENSOR_TYPE\nfrom ...tiles import TilesError\nfrom ..core import SERIES_TYPE, DataFrame\nfrom ..initializer import Series as asseries\nfrom ..operands import DataFrameOperand, DataFrameOperandMixin\nfrom ..utils import parse_index\n\n\nclass DataFrameSetitem(DataFrameOperand, DataFrameOperandMixin):\n _op_type_ = opcodes.INDEXSETVALUE\n\n _target = KeyField('target')\n _indexes = AnyField('indexes')\n _value = AnyField('value')\n\n def __init__(self, target=None, indexes=None, value=None, output_types=None, **kw):\n super().__init__(_target=target, _indexes=indexes,\n _value=value, _output_types=output_types, **kw)\n if self.output_types is None:\n self.output_types = [OutputType.dataframe]\n\n @property\n def target(self):\n return self._target\n\n @property\n def indexes(self):\n return self._indexes\n\n @property\n def value(self):\n return self._value\n\n def _set_inputs(self, inputs):\n super()._set_inputs(inputs)\n self._target = self._inputs[0]\n if len(inputs) > 1:\n self._value = self._inputs[-1]\n\n def __call__(self, target: DataFrame, value):\n inputs = [target]\n if np.isscalar(value):\n value_dtype = np.array(value).dtype\n else:\n if isinstance(value, (pd.Series, SERIES_TYPE)):\n value = asseries(value)\n inputs.append(value)\n value_dtype = value.dtype\n elif is_list_like(value) or isinstance(value, TENSOR_TYPE):\n value = asseries(value, index=target.index)\n inputs.append(value)\n value_dtype = value.dtype\n else: # pragma: no cover\n raise TypeError('Wrong value type, could be one of scalar, Series or tensor')\n\n if value.index_value.key != target.index_value.key: # pragma: no cover\n raise NotImplementedError('Does not support setting value '\n 'with different index for now')\n\n index_value = target.index_value\n dtypes = target.dtypes\n dtypes.loc[self._indexes] = value_dtype\n columns_value = parse_index(dtypes.index, store_data=True)\n ret = self.new_dataframe(inputs, shape=(target.shape[0], len(dtypes)),\n dtypes=dtypes, index_value=index_value,\n columns_value=columns_value)\n target.data = ret.data\n\n @classmethod\n def tile(cls, op):\n out = op.outputs[0]\n target = op.target\n value = op.value\n col = op.indexes\n columns = target.columns_value.to_pandas()\n\n if not np.isscalar(value):\n # check if all chunk's index_value are identical\n target_chunk_index_values = [c.index_value for c in target.chunks\n if c.index[1] == 0]\n value_chunk_index_values = [v.index_value for v in value.chunks]\n is_identical = len(target_chunk_index_values) == len(target_chunk_index_values) and \\\n all(c.key == v.key for c, v in zip(target_chunk_index_values, value_chunk_index_values))\n if not is_identical:\n # do rechunk\n if any(np.isnan(s) for s in target.nsplits[0]) or \\\n any(np.isnan(s) for s in value.nsplits[0]): # pragma: no cover\n raise TilesError('target or value has unknown chunk shape')\n\n value = value.rechunk({0: target.nsplits[0]})._inplace_tile()\n\n out_chunks = []\n nsplits = [list(ns) for ns in target.nsplits]\n if col not in columns:\n nsplits[1][-1] += 1\n column_chunk_shape = target.chunk_shape[1]\n # append to the last chunk on columns axis direction\n for c in target.chunks:\n if c.index[-1] != column_chunk_shape - 1:\n # not effected, just output\n out_chunks.append(c)\n else:\n chunk_op = op.copy().reset_key()\n if np.isscalar(value):\n chunk_inputs = [c]\n else:\n value_chunk = value.cix[c.index[0], ]\n chunk_inputs = [c, value_chunk]\n\n dtypes = c.dtypes\n dtypes.loc[out.dtypes.index[-1]] = out.dtypes.iloc[-1]\n chunk = chunk_op.new_chunk(chunk_inputs,\n shape=(c.shape[0], c.shape[1] + 1),\n dtypes=dtypes,\n index_value=c.index_value,\n columns_value=parse_index(dtypes.index, store_data=True),\n index=c.index)\n out_chunks.append(chunk)\n else:\n # replace exist column\n for c in target.chunks:\n if col in c.dtypes:\n chunk_inputs = [c]\n if not np.isscalar(value):\n chunk_inputs.append(value.cix[c.index[0], ])\n chunk_op = op.copy().reset_key()\n chunk = chunk_op.new_chunk(chunk_inputs,\n shape=c.shape,\n dtypes=c.dtypes,\n index_value=c.index_value,\n columns_value=c.columns_value,\n index=c.index)\n out_chunks.append(chunk)\n else:\n out_chunks.append(c)\n\n params = out.params\n params['nsplits'] = tuple(tuple(ns) for ns in nsplits)\n params['chunks'] = out_chunks\n new_op = op.copy()\n return new_op.new_tileables(op.inputs, kws=[params])\n\n @classmethod\n def execute(cls, ctx, op):\n target = ctx[op.target.key].copy()\n value = ctx[op.value.key] if not np.isscalar(op.value) else op.value\n target[op.indexes] = value\n ctx[op.outputs[0].key] = target\n\n\ndef dataframe_setitem(df, col, value):\n op = DataFrameSetitem(target=df, indexes=col, value=value)\n return op(df, value)\n", "path": "mars/dataframe/indexing/setitem.py"}]} | 2,679 | 144 |
gh_patches_debug_29978 | rasdani/github-patches | git_diff | NVIDIA-Merlin__NVTabular-693 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[BUG] Horovod example scripts fail when user supplies batch size parameter
**Describe the bug**
Using the batch size parameter on the TF Horovod example causes a type error with a mismatch between str and int.
**Steps/Code to reproduce bug**
Run the TF Horovod example with the arguments `--b_size 1024`.
**Expected behavior**
The script should accept a user-provided batch size.
**Environment details (please complete the following information):**
- Environment location: Bare-metal
- Method of NVTabular install: conda
**Additional context**
I believe [this line](https://github.com/NVIDIA/NVTabular/blob/main/examples/horovod/tf_hvd_simple.py#L30) and the same line in the Torch example just need type coercions from str to int.
</issue>
<code>
[start of examples/horovod/tf_hvd_simple.py]
1 # External dependencies
2 import argparse
3 import glob
4 import os
5
6 import cupy
7
8 # we can control how much memory to give tensorflow with this environment variable
9 # IMPORTANT: make sure you do this before you initialize TF's runtime, otherwise
10 # TF will have claimed all free GPU memory
11 os.environ["TF_MEMORY_ALLOCATION"] = "0.3" # fraction of free memory
12 import horovod.tensorflow as hvd # noqa: E402
13 import tensorflow as tf # noqa: E402
14
15 import nvtabular as nvt # noqa: E402
16 from nvtabular.framework_utils.tensorflow import layers # noqa: E402
17 from nvtabular.loader.tensorflow import KerasSequenceLoader # noqa: E402
18
19 parser = argparse.ArgumentParser(description="Process some integers.")
20 parser.add_argument("--dir_in", default=None, help="Input directory")
21 parser.add_argument("--b_size", default=None, help="batch size")
22 parser.add_argument("--cats", default=None, help="categorical columns")
23 parser.add_argument("--cats_mh", default=None, help="categorical multihot columns")
24 parser.add_argument("--conts", default=None, help="continuous columns")
25 parser.add_argument("--labels", default=None, help="continuous columns")
26 args = parser.parse_args()
27
28
29 BASE_DIR = args.dir_in or "./data/"
30 BATCH_SIZE = args.b_size or 16384 # Batch Size
31 CATEGORICAL_COLUMNS = args.cats or ["movieId", "userId"] # Single-hot
32 CATEGORICAL_MH_COLUMNS = args.cats_mh or ["genres"] # Multi-hot
33 NUMERIC_COLUMNS = args.conts or []
34 TRAIN_PATHS = sorted(
35 glob.glob(os.path.join(BASE_DIR, "train/*.parquet"))
36 ) # Output from ETL-with-NVTabular
37 hvd.init()
38
39 # Seed with system randomness (or a static seed)
40 cupy.random.seed(None)
41
42
43 def seed_fn():
44 """
45 Generate consistent dataloader shuffle seeds across workers
46
47 Reseeds each worker's dataloader each epoch to get fresh a shuffle
48 that's consistent across workers.
49 """
50 min_int, max_int = tf.int32.limits
51 max_rand = max_int // hvd.size()
52
53 # Generate a seed fragment
54 seed_fragment = cupy.random.randint(0, max_rand).get()
55
56 # Aggregate seed fragments from all Horovod workers
57 seed_tensor = tf.constant(seed_fragment)
58 reduced_seed = hvd.allreduce(seed_tensor, name="shuffle_seed", op=hvd.mpi_ops.Sum) % max_rand
59
60 return reduced_seed
61
62
63 proc = nvt.Workflow.load(os.path.join(BASE_DIR, "workflow/"))
64 EMBEDDING_TABLE_SHAPES = nvt.ops.get_embedding_sizes(proc)
65
66 train_dataset_tf = KerasSequenceLoader(
67 TRAIN_PATHS, # you could also use a glob pattern
68 batch_size=BATCH_SIZE,
69 label_names=["rating"],
70 cat_names=CATEGORICAL_COLUMNS + CATEGORICAL_MH_COLUMNS,
71 cont_names=NUMERIC_COLUMNS,
72 engine="parquet",
73 shuffle=True,
74 seed_fn=seed_fn,
75 buffer_size=0.06, # how many batches to load at once
76 parts_per_chunk=1,
77 global_size=hvd.size(),
78 global_rank=hvd.rank(),
79 )
80 inputs = {} # tf.keras.Input placeholders for each feature to be used
81 emb_layers = [] # output of all embedding layers, which will be concatenated
82 for col in CATEGORICAL_COLUMNS:
83 inputs[col] = tf.keras.Input(name=col, dtype=tf.int32, shape=(1,))
84 # Note that we need two input tensors for multi-hot categorical features
85 for col in CATEGORICAL_MH_COLUMNS:
86 inputs[col + "__values"] = tf.keras.Input(name=f"{col}__values", dtype=tf.int64, shape=(1,))
87 inputs[col + "__nnzs"] = tf.keras.Input(name=f"{col}__nnzs", dtype=tf.int64, shape=(1,))
88 for col in CATEGORICAL_COLUMNS + CATEGORICAL_MH_COLUMNS:
89 emb_layers.append(
90 tf.feature_column.embedding_column(
91 tf.feature_column.categorical_column_with_identity(
92 col, EMBEDDING_TABLE_SHAPES[col][0] # Input dimension (vocab size)
93 ),
94 EMBEDDING_TABLE_SHAPES[col][1], # Embedding output dimension
95 )
96 )
97 emb_layer = layers.DenseFeatures(emb_layers)
98 x_emb_output = emb_layer(inputs)
99 x = tf.keras.layers.Dense(128, activation="relu")(x_emb_output)
100 x = tf.keras.layers.Dense(128, activation="relu")(x)
101 x = tf.keras.layers.Dense(128, activation="relu")(x)
102 x = tf.keras.layers.Dense(1, activation="sigmoid")(x)
103 model = tf.keras.Model(inputs=inputs, outputs=x)
104 loss = tf.losses.BinaryCrossentropy()
105 opt = tf.keras.optimizers.SGD(0.01 * hvd.size())
106 opt = hvd.DistributedOptimizer(opt)
107 checkpoint_dir = "./checkpoints"
108 checkpoint = tf.train.Checkpoint(model=model, optimizer=opt)
109
110
111 @tf.function(experimental_relax_shapes=True)
112 def training_step(examples, labels, first_batch):
113 with tf.GradientTape() as tape:
114 probs = model(examples, training=True)
115 loss_value = loss(labels, probs)
116 # Horovod: add Horovod Distributed GradientTape.
117 tape = hvd.DistributedGradientTape(tape, sparse_as_dense=True)
118 grads = tape.gradient(loss_value, model.trainable_variables)
119 opt.apply_gradients(zip(grads, model.trainable_variables))
120 # Horovod: broadcast initial variable states from rank 0 to all other processes.
121 # This is necessary to ensure consistent initialization of all workers when
122 # training is started with random weights or restored from a checkpoint.
123 #
124 # Note: broadcast should be done after the first gradient step to ensure optimizer
125 # initialization.
126 if first_batch:
127 hvd.broadcast_variables(model.variables, root_rank=0)
128 hvd.broadcast_variables(opt.variables(), root_rank=0)
129 return loss_value
130
131
132 # Horovod: adjust number of steps based on number of GPUs.
133 for batch, (examples, labels) in enumerate(train_dataset_tf):
134 loss_value = training_step(examples, labels, batch == 0)
135 if batch % 10 == 0 and hvd.local_rank() == 0:
136 print("Step #%d\tLoss: %.6f" % (batch, loss_value))
137 hvd.join()
138 # Horovod: save checkpoints only on worker 0 to prevent other workers from
139 # corrupting it.
140 if hvd.rank() == 0:
141 checkpoint.save(checkpoint_dir)
142
[end of examples/horovod/tf_hvd_simple.py]
[start of examples/horovod/torch-nvt-horovod.py]
1 import argparse
2 import glob
3 import os
4 from time import time
5
6 import cupy
7 import torch
8
9 import nvtabular as nvt
10 from nvtabular.framework_utils.torch.models import Model
11 from nvtabular.framework_utils.torch.utils import process_epoch
12 from nvtabular.loader.torch import DLDataLoader, TorchAsyncItr
13
14 # Horovod must be the last import to avoid conflicts
15 import horovod.torch as hvd # noqa: E402, isort:skip
16
17
18 parser = argparse.ArgumentParser(description="Train a multi-gpu model with Torch and Horovod")
19 parser.add_argument("--dir_in", default=None, help="Input directory")
20 parser.add_argument("--batch_size", default=None, help="Batch size")
21 parser.add_argument("--cats", default=None, help="Categorical columns")
22 parser.add_argument("--cats_mh", default=None, help="Categorical multihot columns")
23 parser.add_argument("--conts", default=None, help="Continuous columns")
24 parser.add_argument("--labels", default=None, help="Label columns")
25 parser.add_argument("--epochs", default=1, help="Training epochs")
26 args = parser.parse_args()
27
28 hvd.init()
29
30 gpu_to_use = hvd.local_rank()
31
32 if torch.cuda.is_available():
33 torch.cuda.set_device(gpu_to_use)
34
35
36 BASE_DIR = os.path.expanduser(args.dir_in or "./data/")
37 BATCH_SIZE = args.batch_size or 16384 # Batch Size
38 CATEGORICAL_COLUMNS = args.cats or ["movieId", "userId"] # Single-hot
39 CATEGORICAL_MH_COLUMNS = args.cats_mh or ["genres"] # Multi-hot
40 NUMERIC_COLUMNS = args.conts or []
41
42 # Output from ETL-with-NVTabular
43 TRAIN_PATHS = sorted(glob.glob(os.path.join(BASE_DIR, "train", "*.parquet")))
44
45 proc = nvt.Workflow.load(os.path.join(BASE_DIR, "workflow/"))
46
47 EMBEDDING_TABLE_SHAPES = nvt.ops.get_embedding_sizes(proc)
48
49
50 # TensorItrDataset returns a single batch of x_cat, x_cont, y.
51 def collate_fn(x):
52 return x
53
54
55 # Seed with system randomness (or a static seed)
56 cupy.random.seed(None)
57
58
59 def seed_fn():
60 """
61 Generate consistent dataloader shuffle seeds across workers
62
63 Reseeds each worker's dataloader each epoch to get fresh a shuffle
64 that's consistent across workers.
65 """
66
67 max_rand = torch.iinfo(torch.int).max // hvd.size()
68
69 # Generate a seed fragment
70 seed_fragment = cupy.random.randint(0, max_rand)
71
72 # Aggregate seed fragments from all Horovod workers
73 seed_tensor = torch.tensor(seed_fragment)
74 reduced_seed = hvd.allreduce(seed_tensor, name="shuffle_seed", op=hvd.mpi_ops.Sum) % max_rand
75
76 return reduced_seed
77
78
79 train_dataset = TorchAsyncItr(
80 nvt.Dataset(TRAIN_PATHS),
81 batch_size=BATCH_SIZE,
82 cats=CATEGORICAL_COLUMNS + CATEGORICAL_MH_COLUMNS,
83 conts=NUMERIC_COLUMNS,
84 labels=["rating"],
85 devices=[gpu_to_use],
86 global_size=hvd.size(),
87 global_rank=hvd.rank(),
88 shuffle=True,
89 seed_fn=seed_fn,
90 )
91 train_loader = DLDataLoader(
92 train_dataset, batch_size=None, collate_fn=collate_fn, pin_memory=False, num_workers=0
93 )
94
95
96 EMBEDDING_TABLE_SHAPES_TUPLE = (
97 {
98 CATEGORICAL_COLUMNS[0]: EMBEDDING_TABLE_SHAPES[CATEGORICAL_COLUMNS[0]],
99 CATEGORICAL_COLUMNS[1]: EMBEDDING_TABLE_SHAPES[CATEGORICAL_COLUMNS[1]],
100 },
101 {CATEGORICAL_MH_COLUMNS[0]: EMBEDDING_TABLE_SHAPES[CATEGORICAL_MH_COLUMNS[0]]},
102 )
103
104 model = Model(
105 embedding_table_shapes=EMBEDDING_TABLE_SHAPES_TUPLE,
106 num_continuous=0,
107 emb_dropout=0.0,
108 layer_hidden_dims=[128, 128, 128],
109 layer_dropout_rates=[0.0, 0.0, 0.0],
110 ).cuda()
111
112 lr_scaler = hvd.size()
113
114 optimizer = torch.optim.Adam(model.parameters(), lr=0.01 * lr_scaler)
115
116 hvd.broadcast_parameters(model.state_dict(), root_rank=0)
117 hvd.broadcast_optimizer_state(optimizer, root_rank=0)
118
119 optimizer = hvd.DistributedOptimizer(optimizer, named_parameters=model.named_parameters())
120
121 for epoch in range(args.epochs):
122 start = time()
123 print(f"Training epoch {epoch}")
124 train_loss, y_pred, y = process_epoch(train_loader, model, train=True, optimizer=optimizer)
125 hvd.join(gpu_to_use)
126 hvd.broadcast_parameters(model.state_dict(), root_rank=0)
127 print(f"Epoch {epoch:02d}. Train loss: {train_loss:.4f}.")
128 hvd.join(gpu_to_use)
129 t_final = time() - start
130 total_rows = train_dataset.num_rows_processed
131 print(
132 f"run_time: {t_final} - rows: {total_rows} - "
133 f"epochs: {epoch} - dl_thru: {total_rows / t_final}"
134 )
135
136
137 hvd.join(gpu_to_use)
138 if hvd.local_rank() == 0:
139 print("Training complete")
140
[end of examples/horovod/torch-nvt-horovod.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/examples/horovod/tf_hvd_simple.py b/examples/horovod/tf_hvd_simple.py
--- a/examples/horovod/tf_hvd_simple.py
+++ b/examples/horovod/tf_hvd_simple.py
@@ -18,7 +18,7 @@
parser = argparse.ArgumentParser(description="Process some integers.")
parser.add_argument("--dir_in", default=None, help="Input directory")
-parser.add_argument("--b_size", default=None, help="batch size")
+parser.add_argument("--batch_size", default=None, help="batch size")
parser.add_argument("--cats", default=None, help="categorical columns")
parser.add_argument("--cats_mh", default=None, help="categorical multihot columns")
parser.add_argument("--conts", default=None, help="continuous columns")
@@ -27,7 +27,7 @@
BASE_DIR = args.dir_in or "./data/"
-BATCH_SIZE = args.b_size or 16384 # Batch Size
+BATCH_SIZE = int(args.batch_size) or 16384 # Batch Size
CATEGORICAL_COLUMNS = args.cats or ["movieId", "userId"] # Single-hot
CATEGORICAL_MH_COLUMNS = args.cats_mh or ["genres"] # Multi-hot
NUMERIC_COLUMNS = args.conts or []
diff --git a/examples/horovod/torch-nvt-horovod.py b/examples/horovod/torch-nvt-horovod.py
--- a/examples/horovod/torch-nvt-horovod.py
+++ b/examples/horovod/torch-nvt-horovod.py
@@ -34,7 +34,7 @@
BASE_DIR = os.path.expanduser(args.dir_in or "./data/")
-BATCH_SIZE = args.batch_size or 16384 # Batch Size
+BATCH_SIZE = int(args.batch_size) or 16384 # Batch Size
CATEGORICAL_COLUMNS = args.cats or ["movieId", "userId"] # Single-hot
CATEGORICAL_MH_COLUMNS = args.cats_mh or ["genres"] # Multi-hot
NUMERIC_COLUMNS = args.conts or []
| {"golden_diff": "diff --git a/examples/horovod/tf_hvd_simple.py b/examples/horovod/tf_hvd_simple.py\n--- a/examples/horovod/tf_hvd_simple.py\n+++ b/examples/horovod/tf_hvd_simple.py\n@@ -18,7 +18,7 @@\n \n parser = argparse.ArgumentParser(description=\"Process some integers.\")\n parser.add_argument(\"--dir_in\", default=None, help=\"Input directory\")\n-parser.add_argument(\"--b_size\", default=None, help=\"batch size\")\n+parser.add_argument(\"--batch_size\", default=None, help=\"batch size\")\n parser.add_argument(\"--cats\", default=None, help=\"categorical columns\")\n parser.add_argument(\"--cats_mh\", default=None, help=\"categorical multihot columns\")\n parser.add_argument(\"--conts\", default=None, help=\"continuous columns\")\n@@ -27,7 +27,7 @@\n \n \n BASE_DIR = args.dir_in or \"./data/\"\n-BATCH_SIZE = args.b_size or 16384 # Batch Size\n+BATCH_SIZE = int(args.batch_size) or 16384 # Batch Size\n CATEGORICAL_COLUMNS = args.cats or [\"movieId\", \"userId\"] # Single-hot\n CATEGORICAL_MH_COLUMNS = args.cats_mh or [\"genres\"] # Multi-hot\n NUMERIC_COLUMNS = args.conts or []\ndiff --git a/examples/horovod/torch-nvt-horovod.py b/examples/horovod/torch-nvt-horovod.py\n--- a/examples/horovod/torch-nvt-horovod.py\n+++ b/examples/horovod/torch-nvt-horovod.py\n@@ -34,7 +34,7 @@\n \n \n BASE_DIR = os.path.expanduser(args.dir_in or \"./data/\")\n-BATCH_SIZE = args.batch_size or 16384 # Batch Size\n+BATCH_SIZE = int(args.batch_size) or 16384 # Batch Size\n CATEGORICAL_COLUMNS = args.cats or [\"movieId\", \"userId\"] # Single-hot\n CATEGORICAL_MH_COLUMNS = args.cats_mh or [\"genres\"] # Multi-hot\n NUMERIC_COLUMNS = args.conts or []\n", "issue": "[BUG] Horovod example scripts fail when user supplies batch size parameter\n**Describe the bug**\r\nUsing the batch size parameter on the TF Horovod example causes a type error with a mismatch between str and int.\r\n\r\n**Steps/Code to reproduce bug**\r\nRun the TF Horovod example with the arguments `--b_size 1024`.\r\n\r\n**Expected behavior**\r\nThe script should accept a user-provided batch size.\r\n\r\n**Environment details (please complete the following information):**\r\n - Environment location: Bare-metal\r\n - Method of NVTabular install: conda\r\n \r\n**Additional context**\r\nI believe [this line](https://github.com/NVIDIA/NVTabular/blob/main/examples/horovod/tf_hvd_simple.py#L30) and the same line in the Torch example just need type coercions from str to int.\r\n\n", "before_files": [{"content": "# External dependencies\nimport argparse\nimport glob\nimport os\n\nimport cupy\n\n# we can control how much memory to give tensorflow with this environment variable\n# IMPORTANT: make sure you do this before you initialize TF's runtime, otherwise\n# TF will have claimed all free GPU memory\nos.environ[\"TF_MEMORY_ALLOCATION\"] = \"0.3\" # fraction of free memory\nimport horovod.tensorflow as hvd # noqa: E402\nimport tensorflow as tf # noqa: E402\n\nimport nvtabular as nvt # noqa: E402\nfrom nvtabular.framework_utils.tensorflow import layers # noqa: E402\nfrom nvtabular.loader.tensorflow import KerasSequenceLoader # noqa: E402\n\nparser = argparse.ArgumentParser(description=\"Process some integers.\")\nparser.add_argument(\"--dir_in\", default=None, help=\"Input directory\")\nparser.add_argument(\"--b_size\", default=None, help=\"batch size\")\nparser.add_argument(\"--cats\", default=None, help=\"categorical columns\")\nparser.add_argument(\"--cats_mh\", default=None, help=\"categorical multihot columns\")\nparser.add_argument(\"--conts\", default=None, help=\"continuous columns\")\nparser.add_argument(\"--labels\", default=None, help=\"continuous columns\")\nargs = parser.parse_args()\n\n\nBASE_DIR = args.dir_in or \"./data/\"\nBATCH_SIZE = args.b_size or 16384 # Batch Size\nCATEGORICAL_COLUMNS = args.cats or [\"movieId\", \"userId\"] # Single-hot\nCATEGORICAL_MH_COLUMNS = args.cats_mh or [\"genres\"] # Multi-hot\nNUMERIC_COLUMNS = args.conts or []\nTRAIN_PATHS = sorted(\n glob.glob(os.path.join(BASE_DIR, \"train/*.parquet\"))\n) # Output from ETL-with-NVTabular\nhvd.init()\n\n# Seed with system randomness (or a static seed)\ncupy.random.seed(None)\n\n\ndef seed_fn():\n \"\"\"\n Generate consistent dataloader shuffle seeds across workers\n\n Reseeds each worker's dataloader each epoch to get fresh a shuffle\n that's consistent across workers.\n \"\"\"\n min_int, max_int = tf.int32.limits\n max_rand = max_int // hvd.size()\n\n # Generate a seed fragment\n seed_fragment = cupy.random.randint(0, max_rand).get()\n\n # Aggregate seed fragments from all Horovod workers\n seed_tensor = tf.constant(seed_fragment)\n reduced_seed = hvd.allreduce(seed_tensor, name=\"shuffle_seed\", op=hvd.mpi_ops.Sum) % max_rand\n\n return reduced_seed\n\n\nproc = nvt.Workflow.load(os.path.join(BASE_DIR, \"workflow/\"))\nEMBEDDING_TABLE_SHAPES = nvt.ops.get_embedding_sizes(proc)\n\ntrain_dataset_tf = KerasSequenceLoader(\n TRAIN_PATHS, # you could also use a glob pattern\n batch_size=BATCH_SIZE,\n label_names=[\"rating\"],\n cat_names=CATEGORICAL_COLUMNS + CATEGORICAL_MH_COLUMNS,\n cont_names=NUMERIC_COLUMNS,\n engine=\"parquet\",\n shuffle=True,\n seed_fn=seed_fn,\n buffer_size=0.06, # how many batches to load at once\n parts_per_chunk=1,\n global_size=hvd.size(),\n global_rank=hvd.rank(),\n)\ninputs = {} # tf.keras.Input placeholders for each feature to be used\nemb_layers = [] # output of all embedding layers, which will be concatenated\nfor col in CATEGORICAL_COLUMNS:\n inputs[col] = tf.keras.Input(name=col, dtype=tf.int32, shape=(1,))\n# Note that we need two input tensors for multi-hot categorical features\nfor col in CATEGORICAL_MH_COLUMNS:\n inputs[col + \"__values\"] = tf.keras.Input(name=f\"{col}__values\", dtype=tf.int64, shape=(1,))\n inputs[col + \"__nnzs\"] = tf.keras.Input(name=f\"{col}__nnzs\", dtype=tf.int64, shape=(1,))\nfor col in CATEGORICAL_COLUMNS + CATEGORICAL_MH_COLUMNS:\n emb_layers.append(\n tf.feature_column.embedding_column(\n tf.feature_column.categorical_column_with_identity(\n col, EMBEDDING_TABLE_SHAPES[col][0] # Input dimension (vocab size)\n ),\n EMBEDDING_TABLE_SHAPES[col][1], # Embedding output dimension\n )\n )\nemb_layer = layers.DenseFeatures(emb_layers)\nx_emb_output = emb_layer(inputs)\nx = tf.keras.layers.Dense(128, activation=\"relu\")(x_emb_output)\nx = tf.keras.layers.Dense(128, activation=\"relu\")(x)\nx = tf.keras.layers.Dense(128, activation=\"relu\")(x)\nx = tf.keras.layers.Dense(1, activation=\"sigmoid\")(x)\nmodel = tf.keras.Model(inputs=inputs, outputs=x)\nloss = tf.losses.BinaryCrossentropy()\nopt = tf.keras.optimizers.SGD(0.01 * hvd.size())\nopt = hvd.DistributedOptimizer(opt)\ncheckpoint_dir = \"./checkpoints\"\ncheckpoint = tf.train.Checkpoint(model=model, optimizer=opt)\n\n\[email protected](experimental_relax_shapes=True)\ndef training_step(examples, labels, first_batch):\n with tf.GradientTape() as tape:\n probs = model(examples, training=True)\n loss_value = loss(labels, probs)\n # Horovod: add Horovod Distributed GradientTape.\n tape = hvd.DistributedGradientTape(tape, sparse_as_dense=True)\n grads = tape.gradient(loss_value, model.trainable_variables)\n opt.apply_gradients(zip(grads, model.trainable_variables))\n # Horovod: broadcast initial variable states from rank 0 to all other processes.\n # This is necessary to ensure consistent initialization of all workers when\n # training is started with random weights or restored from a checkpoint.\n #\n # Note: broadcast should be done after the first gradient step to ensure optimizer\n # initialization.\n if first_batch:\n hvd.broadcast_variables(model.variables, root_rank=0)\n hvd.broadcast_variables(opt.variables(), root_rank=0)\n return loss_value\n\n\n# Horovod: adjust number of steps based on number of GPUs.\nfor batch, (examples, labels) in enumerate(train_dataset_tf):\n loss_value = training_step(examples, labels, batch == 0)\n if batch % 10 == 0 and hvd.local_rank() == 0:\n print(\"Step #%d\\tLoss: %.6f\" % (batch, loss_value))\nhvd.join()\n# Horovod: save checkpoints only on worker 0 to prevent other workers from\n# corrupting it.\nif hvd.rank() == 0:\n checkpoint.save(checkpoint_dir)\n", "path": "examples/horovod/tf_hvd_simple.py"}, {"content": "import argparse\nimport glob\nimport os\nfrom time import time\n\nimport cupy\nimport torch\n\nimport nvtabular as nvt\nfrom nvtabular.framework_utils.torch.models import Model\nfrom nvtabular.framework_utils.torch.utils import process_epoch\nfrom nvtabular.loader.torch import DLDataLoader, TorchAsyncItr\n\n# Horovod must be the last import to avoid conflicts\nimport horovod.torch as hvd # noqa: E402, isort:skip\n\n\nparser = argparse.ArgumentParser(description=\"Train a multi-gpu model with Torch and Horovod\")\nparser.add_argument(\"--dir_in\", default=None, help=\"Input directory\")\nparser.add_argument(\"--batch_size\", default=None, help=\"Batch size\")\nparser.add_argument(\"--cats\", default=None, help=\"Categorical columns\")\nparser.add_argument(\"--cats_mh\", default=None, help=\"Categorical multihot columns\")\nparser.add_argument(\"--conts\", default=None, help=\"Continuous columns\")\nparser.add_argument(\"--labels\", default=None, help=\"Label columns\")\nparser.add_argument(\"--epochs\", default=1, help=\"Training epochs\")\nargs = parser.parse_args()\n\nhvd.init()\n\ngpu_to_use = hvd.local_rank()\n\nif torch.cuda.is_available():\n torch.cuda.set_device(gpu_to_use)\n\n\nBASE_DIR = os.path.expanduser(args.dir_in or \"./data/\")\nBATCH_SIZE = args.batch_size or 16384 # Batch Size\nCATEGORICAL_COLUMNS = args.cats or [\"movieId\", \"userId\"] # Single-hot\nCATEGORICAL_MH_COLUMNS = args.cats_mh or [\"genres\"] # Multi-hot\nNUMERIC_COLUMNS = args.conts or []\n\n# Output from ETL-with-NVTabular\nTRAIN_PATHS = sorted(glob.glob(os.path.join(BASE_DIR, \"train\", \"*.parquet\")))\n\nproc = nvt.Workflow.load(os.path.join(BASE_DIR, \"workflow/\"))\n\nEMBEDDING_TABLE_SHAPES = nvt.ops.get_embedding_sizes(proc)\n\n\n# TensorItrDataset returns a single batch of x_cat, x_cont, y.\ndef collate_fn(x):\n return x\n\n\n# Seed with system randomness (or a static seed)\ncupy.random.seed(None)\n\n\ndef seed_fn():\n \"\"\"\n Generate consistent dataloader shuffle seeds across workers\n\n Reseeds each worker's dataloader each epoch to get fresh a shuffle\n that's consistent across workers.\n \"\"\"\n\n max_rand = torch.iinfo(torch.int).max // hvd.size()\n\n # Generate a seed fragment\n seed_fragment = cupy.random.randint(0, max_rand)\n\n # Aggregate seed fragments from all Horovod workers\n seed_tensor = torch.tensor(seed_fragment)\n reduced_seed = hvd.allreduce(seed_tensor, name=\"shuffle_seed\", op=hvd.mpi_ops.Sum) % max_rand\n\n return reduced_seed\n\n\ntrain_dataset = TorchAsyncItr(\n nvt.Dataset(TRAIN_PATHS),\n batch_size=BATCH_SIZE,\n cats=CATEGORICAL_COLUMNS + CATEGORICAL_MH_COLUMNS,\n conts=NUMERIC_COLUMNS,\n labels=[\"rating\"],\n devices=[gpu_to_use],\n global_size=hvd.size(),\n global_rank=hvd.rank(),\n shuffle=True,\n seed_fn=seed_fn,\n)\ntrain_loader = DLDataLoader(\n train_dataset, batch_size=None, collate_fn=collate_fn, pin_memory=False, num_workers=0\n)\n\n\nEMBEDDING_TABLE_SHAPES_TUPLE = (\n {\n CATEGORICAL_COLUMNS[0]: EMBEDDING_TABLE_SHAPES[CATEGORICAL_COLUMNS[0]],\n CATEGORICAL_COLUMNS[1]: EMBEDDING_TABLE_SHAPES[CATEGORICAL_COLUMNS[1]],\n },\n {CATEGORICAL_MH_COLUMNS[0]: EMBEDDING_TABLE_SHAPES[CATEGORICAL_MH_COLUMNS[0]]},\n)\n\nmodel = Model(\n embedding_table_shapes=EMBEDDING_TABLE_SHAPES_TUPLE,\n num_continuous=0,\n emb_dropout=0.0,\n layer_hidden_dims=[128, 128, 128],\n layer_dropout_rates=[0.0, 0.0, 0.0],\n).cuda()\n\nlr_scaler = hvd.size()\n\noptimizer = torch.optim.Adam(model.parameters(), lr=0.01 * lr_scaler)\n\nhvd.broadcast_parameters(model.state_dict(), root_rank=0)\nhvd.broadcast_optimizer_state(optimizer, root_rank=0)\n\noptimizer = hvd.DistributedOptimizer(optimizer, named_parameters=model.named_parameters())\n\nfor epoch in range(args.epochs):\n start = time()\n print(f\"Training epoch {epoch}\")\n train_loss, y_pred, y = process_epoch(train_loader, model, train=True, optimizer=optimizer)\n hvd.join(gpu_to_use)\n hvd.broadcast_parameters(model.state_dict(), root_rank=0)\n print(f\"Epoch {epoch:02d}. Train loss: {train_loss:.4f}.\")\n hvd.join(gpu_to_use)\n t_final = time() - start\n total_rows = train_dataset.num_rows_processed\n print(\n f\"run_time: {t_final} - rows: {total_rows} - \"\n f\"epochs: {epoch} - dl_thru: {total_rows / t_final}\"\n )\n\n\nhvd.join(gpu_to_use)\nif hvd.local_rank() == 0:\n print(\"Training complete\")\n", "path": "examples/horovod/torch-nvt-horovod.py"}]} | 4,039 | 479 |
gh_patches_debug_8436 | rasdani/github-patches | git_diff | microsoft__playwright-python-959 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Bug]: `record_har_omit_content` does not work properly
### Playwright version
1.15.3
### Operating system
Linux
### What browsers are you seeing the problem on?
Chromium, Firefox, WebKit
### Other information
Repo to present bug:
https://github.com/qwark97/har_omit_content_bug
Bug occurs also outside the docker image
### What happened? / Describe the bug
Using `record_har_omit_content` as a `new_page` parameter can manipulate presence of the `text` filed inside `entry.response.content` object in `.har` file.
Not using this parameter (defaults to `False` https://playwright.dev/python/docs/api/class-browser#browser-new-page) allows to see `text` inside `.har` file. Using `record_har_omit_content=True` also works as expected - `text` is absent. Unfortunatelly, passing `record_har_omit_content=False` explicitely **does not** work as expected -> `.har` file **will not** contain `text` filed.
It also looks like passing anything except explicit `None` as a `record_har_omit_content` value (type doesn't matter) will cause with missing `text` filed
### Code snippet to reproduce your bug
_No response_
### Relevant log output
_No response_
</issue>
<code>
[start of playwright/_impl/_browser.py]
1 # Copyright (c) Microsoft Corporation.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import base64
16 import json
17 from pathlib import Path
18 from types import SimpleNamespace
19 from typing import TYPE_CHECKING, Dict, List, Union
20
21 from playwright._impl._api_structures import (
22 Geolocation,
23 HttpCredentials,
24 ProxySettings,
25 StorageState,
26 ViewportSize,
27 )
28 from playwright._impl._browser_context import BrowserContext
29 from playwright._impl._cdp_session import CDPSession
30 from playwright._impl._connection import ChannelOwner, from_channel
31 from playwright._impl._helper import (
32 ColorScheme,
33 ForcedColors,
34 ReducedMotion,
35 async_readfile,
36 is_safe_close_error,
37 locals_to_params,
38 )
39 from playwright._impl._network import serialize_headers
40 from playwright._impl._page import Page
41
42 if TYPE_CHECKING: # pragma: no cover
43 from playwright._impl._browser_type import BrowserType
44
45
46 class Browser(ChannelOwner):
47
48 Events = SimpleNamespace(
49 Disconnected="disconnected",
50 )
51
52 def __init__(
53 self, parent: "BrowserType", type: str, guid: str, initializer: Dict
54 ) -> None:
55 super().__init__(parent, type, guid, initializer)
56 self._browser_type = parent
57 self._is_connected = True
58 self._is_closed_or_closing = False
59 self._is_remote = False
60 self._is_connected_over_websocket = False
61
62 self._contexts: List[BrowserContext] = []
63 self._channel.on("close", lambda _: self._on_close())
64
65 def __repr__(self) -> str:
66 return f"<Browser type={self._browser_type} version={self.version}>"
67
68 def _on_close(self) -> None:
69 self._is_connected = False
70 self.emit(Browser.Events.Disconnected, self)
71 self._is_closed_or_closing = True
72
73 @property
74 def contexts(self) -> List[BrowserContext]:
75 return self._contexts.copy()
76
77 def is_connected(self) -> bool:
78 return self._is_connected
79
80 async def new_context(
81 self,
82 viewport: ViewportSize = None,
83 screen: ViewportSize = None,
84 noViewport: bool = None,
85 ignoreHTTPSErrors: bool = None,
86 javaScriptEnabled: bool = None,
87 bypassCSP: bool = None,
88 userAgent: str = None,
89 locale: str = None,
90 timezoneId: str = None,
91 geolocation: Geolocation = None,
92 permissions: List[str] = None,
93 extraHTTPHeaders: Dict[str, str] = None,
94 offline: bool = None,
95 httpCredentials: HttpCredentials = None,
96 deviceScaleFactor: float = None,
97 isMobile: bool = None,
98 hasTouch: bool = None,
99 colorScheme: ColorScheme = None,
100 reducedMotion: ReducedMotion = None,
101 forcedColors: ForcedColors = None,
102 acceptDownloads: bool = None,
103 defaultBrowserType: str = None,
104 proxy: ProxySettings = None,
105 recordHarPath: Union[Path, str] = None,
106 recordHarOmitContent: bool = None,
107 recordVideoDir: Union[Path, str] = None,
108 recordVideoSize: ViewportSize = None,
109 storageState: Union[StorageState, str, Path] = None,
110 baseURL: str = None,
111 strictSelectors: bool = None,
112 ) -> BrowserContext:
113 params = locals_to_params(locals())
114 await normalize_context_params(self._connection._is_sync, params)
115
116 channel = await self._channel.send("newContext", params)
117 context = from_channel(channel)
118 self._contexts.append(context)
119 context._browser = self
120 context._options = params
121 return context
122
123 async def new_page(
124 self,
125 viewport: ViewportSize = None,
126 screen: ViewportSize = None,
127 noViewport: bool = None,
128 ignoreHTTPSErrors: bool = None,
129 javaScriptEnabled: bool = None,
130 bypassCSP: bool = None,
131 userAgent: str = None,
132 locale: str = None,
133 timezoneId: str = None,
134 geolocation: Geolocation = None,
135 permissions: List[str] = None,
136 extraHTTPHeaders: Dict[str, str] = None,
137 offline: bool = None,
138 httpCredentials: HttpCredentials = None,
139 deviceScaleFactor: float = None,
140 isMobile: bool = None,
141 hasTouch: bool = None,
142 colorScheme: ColorScheme = None,
143 forcedColors: ForcedColors = None,
144 reducedMotion: ReducedMotion = None,
145 acceptDownloads: bool = None,
146 defaultBrowserType: str = None,
147 proxy: ProxySettings = None,
148 recordHarPath: Union[Path, str] = None,
149 recordHarOmitContent: bool = None,
150 recordVideoDir: Union[Path, str] = None,
151 recordVideoSize: ViewportSize = None,
152 storageState: Union[StorageState, str, Path] = None,
153 baseURL: str = None,
154 strictSelectors: bool = None,
155 ) -> Page:
156 params = locals_to_params(locals())
157 context = await self.new_context(**params)
158 page = await context.new_page()
159 page._owned_context = context
160 context._owner_page = page
161 return page
162
163 async def close(self) -> None:
164 if self._is_closed_or_closing:
165 return
166 self._is_closed_or_closing = True
167 try:
168 await self._channel.send("close")
169 except Exception as e:
170 if not is_safe_close_error(e):
171 raise e
172 if self._is_connected_over_websocket:
173 await self._connection.stop_async()
174
175 @property
176 def version(self) -> str:
177 return self._initializer["version"]
178
179 async def new_browser_cdp_session(self) -> CDPSession:
180 return from_channel(await self._channel.send("newBrowserCDPSession"))
181
182 async def start_tracing(
183 self,
184 page: Page = None,
185 path: Union[str, Path] = None,
186 screenshots: bool = None,
187 categories: List[str] = None,
188 ) -> None:
189 params = locals_to_params(locals())
190 if page:
191 params["page"] = page._channel
192 if path:
193 params["path"] = str(path)
194 await self._channel.send("startTracing", params)
195
196 async def stop_tracing(self) -> bytes:
197 encoded_binary = await self._channel.send("stopTracing")
198 return base64.b64decode(encoded_binary)
199
200
201 async def normalize_context_params(is_sync: bool, params: Dict) -> None:
202 params["sdkLanguage"] = "python" if is_sync else "python-async"
203 if params.get("noViewport"):
204 del params["noViewport"]
205 params["noDefaultViewport"] = True
206 if "defaultBrowserType" in params:
207 del params["defaultBrowserType"]
208 if "extraHTTPHeaders" in params:
209 params["extraHTTPHeaders"] = serialize_headers(params["extraHTTPHeaders"])
210 if "recordHarPath" in params:
211 params["recordHar"] = {"path": str(params["recordHarPath"])}
212 if "recordHarOmitContent" in params:
213 params["recordHar"]["omitContent"] = True
214 del params["recordHarOmitContent"]
215 del params["recordHarPath"]
216 if "recordVideoDir" in params:
217 params["recordVideo"] = {"dir": str(params["recordVideoDir"])}
218 if "recordVideoSize" in params:
219 params["recordVideo"]["size"] = params["recordVideoSize"]
220 del params["recordVideoSize"]
221 del params["recordVideoDir"]
222 if "storageState" in params:
223 storageState = params["storageState"]
224 if not isinstance(storageState, dict):
225 params["storageState"] = json.loads(
226 (await async_readfile(storageState)).decode()
227 )
228
[end of playwright/_impl/_browser.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/playwright/_impl/_browser.py b/playwright/_impl/_browser.py
--- a/playwright/_impl/_browser.py
+++ b/playwright/_impl/_browser.py
@@ -210,7 +210,7 @@
if "recordHarPath" in params:
params["recordHar"] = {"path": str(params["recordHarPath"])}
if "recordHarOmitContent" in params:
- params["recordHar"]["omitContent"] = True
+ params["recordHar"]["omitContent"] = params["recordHarOmitContent"]
del params["recordHarOmitContent"]
del params["recordHarPath"]
if "recordVideoDir" in params:
| {"golden_diff": "diff --git a/playwright/_impl/_browser.py b/playwright/_impl/_browser.py\n--- a/playwright/_impl/_browser.py\n+++ b/playwright/_impl/_browser.py\n@@ -210,7 +210,7 @@\n if \"recordHarPath\" in params:\n params[\"recordHar\"] = {\"path\": str(params[\"recordHarPath\"])}\n if \"recordHarOmitContent\" in params:\n- params[\"recordHar\"][\"omitContent\"] = True\n+ params[\"recordHar\"][\"omitContent\"] = params[\"recordHarOmitContent\"]\n del params[\"recordHarOmitContent\"]\n del params[\"recordHarPath\"]\n if \"recordVideoDir\" in params:\n", "issue": "[Bug]: `record_har_omit_content` does not work properly\n### Playwright version\r\n\r\n1.15.3\r\n\r\n### Operating system\r\n\r\nLinux\r\n\r\n### What browsers are you seeing the problem on?\r\n\r\nChromium, Firefox, WebKit\r\n\r\n### Other information\r\n\r\nRepo to present bug:\r\nhttps://github.com/qwark97/har_omit_content_bug\r\n\r\nBug occurs also outside the docker image\r\n\r\n### What happened? / Describe the bug\r\n\r\nUsing `record_har_omit_content` as a `new_page` parameter can manipulate presence of the `text` filed inside `entry.response.content` object in `.har` file.\r\n\r\nNot using this parameter (defaults to `False` https://playwright.dev/python/docs/api/class-browser#browser-new-page) allows to see `text` inside `.har` file. Using `record_har_omit_content=True` also works as expected - `text` is absent. Unfortunatelly, passing `record_har_omit_content=False` explicitely **does not** work as expected -> `.har` file **will not** contain `text` filed.\r\n\r\nIt also looks like passing anything except explicit `None` as a `record_har_omit_content` value (type doesn't matter) will cause with missing `text` filed\r\n\r\n### Code snippet to reproduce your bug\r\n\r\n_No response_\r\n\r\n### Relevant log output\r\n\r\n_No response_\n", "before_files": [{"content": "# Copyright (c) Microsoft Corporation.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport base64\nimport json\nfrom pathlib import Path\nfrom types import SimpleNamespace\nfrom typing import TYPE_CHECKING, Dict, List, Union\n\nfrom playwright._impl._api_structures import (\n Geolocation,\n HttpCredentials,\n ProxySettings,\n StorageState,\n ViewportSize,\n)\nfrom playwright._impl._browser_context import BrowserContext\nfrom playwright._impl._cdp_session import CDPSession\nfrom playwright._impl._connection import ChannelOwner, from_channel\nfrom playwright._impl._helper import (\n ColorScheme,\n ForcedColors,\n ReducedMotion,\n async_readfile,\n is_safe_close_error,\n locals_to_params,\n)\nfrom playwright._impl._network import serialize_headers\nfrom playwright._impl._page import Page\n\nif TYPE_CHECKING: # pragma: no cover\n from playwright._impl._browser_type import BrowserType\n\n\nclass Browser(ChannelOwner):\n\n Events = SimpleNamespace(\n Disconnected=\"disconnected\",\n )\n\n def __init__(\n self, parent: \"BrowserType\", type: str, guid: str, initializer: Dict\n ) -> None:\n super().__init__(parent, type, guid, initializer)\n self._browser_type = parent\n self._is_connected = True\n self._is_closed_or_closing = False\n self._is_remote = False\n self._is_connected_over_websocket = False\n\n self._contexts: List[BrowserContext] = []\n self._channel.on(\"close\", lambda _: self._on_close())\n\n def __repr__(self) -> str:\n return f\"<Browser type={self._browser_type} version={self.version}>\"\n\n def _on_close(self) -> None:\n self._is_connected = False\n self.emit(Browser.Events.Disconnected, self)\n self._is_closed_or_closing = True\n\n @property\n def contexts(self) -> List[BrowserContext]:\n return self._contexts.copy()\n\n def is_connected(self) -> bool:\n return self._is_connected\n\n async def new_context(\n self,\n viewport: ViewportSize = None,\n screen: ViewportSize = None,\n noViewport: bool = None,\n ignoreHTTPSErrors: bool = None,\n javaScriptEnabled: bool = None,\n bypassCSP: bool = None,\n userAgent: str = None,\n locale: str = None,\n timezoneId: str = None,\n geolocation: Geolocation = None,\n permissions: List[str] = None,\n extraHTTPHeaders: Dict[str, str] = None,\n offline: bool = None,\n httpCredentials: HttpCredentials = None,\n deviceScaleFactor: float = None,\n isMobile: bool = None,\n hasTouch: bool = None,\n colorScheme: ColorScheme = None,\n reducedMotion: ReducedMotion = None,\n forcedColors: ForcedColors = None,\n acceptDownloads: bool = None,\n defaultBrowserType: str = None,\n proxy: ProxySettings = None,\n recordHarPath: Union[Path, str] = None,\n recordHarOmitContent: bool = None,\n recordVideoDir: Union[Path, str] = None,\n recordVideoSize: ViewportSize = None,\n storageState: Union[StorageState, str, Path] = None,\n baseURL: str = None,\n strictSelectors: bool = None,\n ) -> BrowserContext:\n params = locals_to_params(locals())\n await normalize_context_params(self._connection._is_sync, params)\n\n channel = await self._channel.send(\"newContext\", params)\n context = from_channel(channel)\n self._contexts.append(context)\n context._browser = self\n context._options = params\n return context\n\n async def new_page(\n self,\n viewport: ViewportSize = None,\n screen: ViewportSize = None,\n noViewport: bool = None,\n ignoreHTTPSErrors: bool = None,\n javaScriptEnabled: bool = None,\n bypassCSP: bool = None,\n userAgent: str = None,\n locale: str = None,\n timezoneId: str = None,\n geolocation: Geolocation = None,\n permissions: List[str] = None,\n extraHTTPHeaders: Dict[str, str] = None,\n offline: bool = None,\n httpCredentials: HttpCredentials = None,\n deviceScaleFactor: float = None,\n isMobile: bool = None,\n hasTouch: bool = None,\n colorScheme: ColorScheme = None,\n forcedColors: ForcedColors = None,\n reducedMotion: ReducedMotion = None,\n acceptDownloads: bool = None,\n defaultBrowserType: str = None,\n proxy: ProxySettings = None,\n recordHarPath: Union[Path, str] = None,\n recordHarOmitContent: bool = None,\n recordVideoDir: Union[Path, str] = None,\n recordVideoSize: ViewportSize = None,\n storageState: Union[StorageState, str, Path] = None,\n baseURL: str = None,\n strictSelectors: bool = None,\n ) -> Page:\n params = locals_to_params(locals())\n context = await self.new_context(**params)\n page = await context.new_page()\n page._owned_context = context\n context._owner_page = page\n return page\n\n async def close(self) -> None:\n if self._is_closed_or_closing:\n return\n self._is_closed_or_closing = True\n try:\n await self._channel.send(\"close\")\n except Exception as e:\n if not is_safe_close_error(e):\n raise e\n if self._is_connected_over_websocket:\n await self._connection.stop_async()\n\n @property\n def version(self) -> str:\n return self._initializer[\"version\"]\n\n async def new_browser_cdp_session(self) -> CDPSession:\n return from_channel(await self._channel.send(\"newBrowserCDPSession\"))\n\n async def start_tracing(\n self,\n page: Page = None,\n path: Union[str, Path] = None,\n screenshots: bool = None,\n categories: List[str] = None,\n ) -> None:\n params = locals_to_params(locals())\n if page:\n params[\"page\"] = page._channel\n if path:\n params[\"path\"] = str(path)\n await self._channel.send(\"startTracing\", params)\n\n async def stop_tracing(self) -> bytes:\n encoded_binary = await self._channel.send(\"stopTracing\")\n return base64.b64decode(encoded_binary)\n\n\nasync def normalize_context_params(is_sync: bool, params: Dict) -> None:\n params[\"sdkLanguage\"] = \"python\" if is_sync else \"python-async\"\n if params.get(\"noViewport\"):\n del params[\"noViewport\"]\n params[\"noDefaultViewport\"] = True\n if \"defaultBrowserType\" in params:\n del params[\"defaultBrowserType\"]\n if \"extraHTTPHeaders\" in params:\n params[\"extraHTTPHeaders\"] = serialize_headers(params[\"extraHTTPHeaders\"])\n if \"recordHarPath\" in params:\n params[\"recordHar\"] = {\"path\": str(params[\"recordHarPath\"])}\n if \"recordHarOmitContent\" in params:\n params[\"recordHar\"][\"omitContent\"] = True\n del params[\"recordHarOmitContent\"]\n del params[\"recordHarPath\"]\n if \"recordVideoDir\" in params:\n params[\"recordVideo\"] = {\"dir\": str(params[\"recordVideoDir\"])}\n if \"recordVideoSize\" in params:\n params[\"recordVideo\"][\"size\"] = params[\"recordVideoSize\"]\n del params[\"recordVideoSize\"]\n del params[\"recordVideoDir\"]\n if \"storageState\" in params:\n storageState = params[\"storageState\"]\n if not isinstance(storageState, dict):\n params[\"storageState\"] = json.loads(\n (await async_readfile(storageState)).decode()\n )\n", "path": "playwright/_impl/_browser.py"}]} | 3,244 | 154 |
gh_patches_debug_5785 | rasdani/github-patches | git_diff | ivy-llc__ivy-17476 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
matrix_power
</issue>
<code>
[start of ivy/functional/frontends/paddle/tensor/linalg.py]
1 # global
2 import ivy
3 from ivy.func_wrapper import with_unsupported_dtypes, with_supported_dtypes
4 from ivy.functional.frontends.paddle import promote_types_of_paddle_inputs
5 from ivy.functional.frontends.paddle.func_wrapper import (
6 to_ivy_arrays_and_back,
7 )
8
9
10 @with_supported_dtypes(
11 {"2.4.2 and below": ("float32", "float64", "int32", "int64")}, "paddle"
12 )
13 @to_ivy_arrays_and_back
14 def cross(x, y, /, *, axis=9, name=None):
15 x, y = promote_types_of_paddle_inputs(x, y)
16 return ivy.cross(x, y, axis=axis)
17
18
19 # matmul
20 @with_unsupported_dtypes({"2.4.2 and below": ("float16", "bfloat16")}, "paddle")
21 @to_ivy_arrays_and_back
22 def matmul(x, y, transpose_x=False, transpose_y=False, name=None):
23 x, y = promote_types_of_paddle_inputs(x, y)
24 return ivy.matmul(x, y, transpose_a=transpose_x, transpose_b=transpose_y)
25
26
27 # norm
28 @with_supported_dtypes({"2.4.2 and below": ("float32", "float64")}, "paddle")
29 @to_ivy_arrays_and_back
30 def norm(x, p="fro", axis=None, keepdim=False, name=None):
31 if axis is None and p is not None:
32 if p == "fro":
33 p = 2
34 ret = ivy.vector_norm(x.flatten(), ord=p, axis=-1)
35 if keepdim:
36 ret = ret.reshape([1] * len(x.shape))
37 if len(ret.shape) == 0:
38 return ivy.array([ret])
39 return ret
40
41 if isinstance(axis, tuple):
42 axis = list(axis)
43 if isinstance(axis, list) and len(axis) == 1:
44 axis = axis[0]
45
46 if isinstance(axis, int):
47 if p == "fro":
48 p = 2
49 if p in [0, 1, 2, ivy.inf, -ivy.inf]:
50 ret = ivy.vector_norm(x, ord=p, axis=axis, keepdims=keepdim)
51 elif isinstance(p, (int, float)):
52 ret = ivy.pow(
53 ivy.sum(ivy.pow(ivy.abs(x), p), axis=axis, keepdims=keepdim),
54 float(1.0 / p),
55 )
56
57 elif isinstance(axis, list) and len(axis) == 2:
58 if p == 0:
59 raise ValueError
60 elif p == 1:
61 ret = ivy.sum(ivy.abs(x), axis=axis, keepdims=keepdim)
62 elif p == 2 or p == "fro":
63 ret = ivy.matrix_norm(x, ord="fro", axis=axis, keepdims=keepdim)
64 elif p == ivy.inf:
65 ret = ivy.max(ivy.abs(x), axis=axis, keepdims=keepdim)
66 elif p == -ivy.inf:
67 ret = ivy.min(ivy.abs(x), axis=axis, keepdims=keepdim)
68 elif isinstance(p, (int, float)) and p > 0:
69 ret = ivy.pow(
70 ivy.sum(ivy.pow(ivy.abs(x), p), axis=axis, keepdims=keepdim),
71 float(1.0 / p),
72 )
73 else:
74 raise ValueError
75
76 else:
77 raise ValueError
78
79 if len(ret.shape) == 0:
80 ret = ivy.array(
81 [ret]
82 ) # this is done so as to match shape of output from paddle
83 return ret
84
85
86 # eig
87 @to_ivy_arrays_and_back
88 def eig(x, name=None):
89 return ivy.eig(x)
90
91
92 # eigvals
93 @to_ivy_arrays_and_back
94 def eigvals(x, name=None):
95 return ivy.eigvals(x)
96
97
98 # eigvalsh
99 @to_ivy_arrays_and_back
100 def eigvalsh(x, UPLO="L", name=None):
101 return ivy.eigvalsh(x, UPLO=UPLO)
102
103
104 # eigh
105 @to_ivy_arrays_and_back
106 def eigh(x, UPLO="L", name=None):
107 return ivy.eigh(x, UPLO=UPLO)
108
109
110 # pinv
111 @with_unsupported_dtypes({"2.4.2 and below": ("float16", "bfloat16")}, "paddle")
112 @to_ivy_arrays_and_back
113 def pinv(x, rcond=1e-15, hermitian=False, name=None):
114 # TODO: Add hermitian functionality
115 return ivy.pinv(x, rtol=rcond)
116
117
118 # solve
119 @with_unsupported_dtypes({"2.4.2 and below": ("float16", "bfloat16")}, "paddle")
120 @to_ivy_arrays_and_back
121 def solve(x1, x2, name=None):
122 return ivy.solve(x1, x2)
123
124
125 # cholesky
126 @with_supported_dtypes({"2.4.2 and below": ("float32", "float64")}, "paddle")
127 @to_ivy_arrays_and_back
128 def cholesky(x, /, *, upper=False, name=None):
129 return ivy.cholesky(x, upper=upper)
130
131
132 # bmm
133 @with_unsupported_dtypes({"2.4.2 and below": ("float16", "bfloat16")}, "paddle")
134 @to_ivy_arrays_and_back
135 def bmm(x, y, transpose_x=False, transpose_y=False, name=None):
136 if len(ivy.shape(x)) != 3 or len(ivy.shape(y)) != 3:
137 raise RuntimeError("input must be 3D matrices")
138 x, y = promote_types_of_paddle_inputs(x, y)
139 return ivy.matmul(x, y, transpose_a=transpose_x, transpose_b=transpose_y)
140
141
142 # matrix_power
143 @with_unsupported_dtypes({"2.4.2 and below": ("float16", "bfloat16")}, "paddle")
144 @to_ivy_arrays_and_back
145 def matrix_power(x, n, name=None):
146 return ivy.matrix_power(x, n)
147
[end of ivy/functional/frontends/paddle/tensor/linalg.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/ivy/functional/frontends/paddle/tensor/linalg.py b/ivy/functional/frontends/paddle/tensor/linalg.py
--- a/ivy/functional/frontends/paddle/tensor/linalg.py
+++ b/ivy/functional/frontends/paddle/tensor/linalg.py
@@ -130,3 +130,10 @@
raise RuntimeError("input must be 3D matrices")
x, y = promote_types_of_paddle_inputs(x, y)
return ivy.matmul(x, y, transpose_a=transpose_x, transpose_b=transpose_y)
+
+
+# matrix_power
+@with_unsupported_dtypes({"2.4.2 and below": ("float16", "bfloat16")}, "paddle")
+@to_ivy_arrays_and_back
+def matrix_power(x, n, name=None):
+ return ivy.matrix_power(x, n)
| {"golden_diff": "diff --git a/ivy/functional/frontends/paddle/tensor/linalg.py b/ivy/functional/frontends/paddle/tensor/linalg.py\n--- a/ivy/functional/frontends/paddle/tensor/linalg.py\n+++ b/ivy/functional/frontends/paddle/tensor/linalg.py\n@@ -130,3 +130,10 @@\n raise RuntimeError(\"input must be 3D matrices\")\n x, y = promote_types_of_paddle_inputs(x, y)\n return ivy.matmul(x, y, transpose_a=transpose_x, transpose_b=transpose_y)\n+\n+\n+# matrix_power\n+@with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n+@to_ivy_arrays_and_back\n+def matrix_power(x, n, name=None):\n+ return ivy.matrix_power(x, n)\n", "issue": " matrix_power\n\n", "before_files": [{"content": "# global\nimport ivy\nfrom ivy.func_wrapper import with_unsupported_dtypes, with_supported_dtypes\nfrom ivy.functional.frontends.paddle import promote_types_of_paddle_inputs\nfrom ivy.functional.frontends.paddle.func_wrapper import (\n to_ivy_arrays_and_back,\n)\n\n\n@with_supported_dtypes(\n {\"2.4.2 and below\": (\"float32\", \"float64\", \"int32\", \"int64\")}, \"paddle\"\n)\n@to_ivy_arrays_and_back\ndef cross(x, y, /, *, axis=9, name=None):\n x, y = promote_types_of_paddle_inputs(x, y)\n return ivy.cross(x, y, axis=axis)\n\n\n# matmul\n@with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef matmul(x, y, transpose_x=False, transpose_y=False, name=None):\n x, y = promote_types_of_paddle_inputs(x, y)\n return ivy.matmul(x, y, transpose_a=transpose_x, transpose_b=transpose_y)\n\n\n# norm\n@with_supported_dtypes({\"2.4.2 and below\": (\"float32\", \"float64\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef norm(x, p=\"fro\", axis=None, keepdim=False, name=None):\n if axis is None and p is not None:\n if p == \"fro\":\n p = 2\n ret = ivy.vector_norm(x.flatten(), ord=p, axis=-1)\n if keepdim:\n ret = ret.reshape([1] * len(x.shape))\n if len(ret.shape) == 0:\n return ivy.array([ret])\n return ret\n\n if isinstance(axis, tuple):\n axis = list(axis)\n if isinstance(axis, list) and len(axis) == 1:\n axis = axis[0]\n\n if isinstance(axis, int):\n if p == \"fro\":\n p = 2\n if p in [0, 1, 2, ivy.inf, -ivy.inf]:\n ret = ivy.vector_norm(x, ord=p, axis=axis, keepdims=keepdim)\n elif isinstance(p, (int, float)):\n ret = ivy.pow(\n ivy.sum(ivy.pow(ivy.abs(x), p), axis=axis, keepdims=keepdim),\n float(1.0 / p),\n )\n\n elif isinstance(axis, list) and len(axis) == 2:\n if p == 0:\n raise ValueError\n elif p == 1:\n ret = ivy.sum(ivy.abs(x), axis=axis, keepdims=keepdim)\n elif p == 2 or p == \"fro\":\n ret = ivy.matrix_norm(x, ord=\"fro\", axis=axis, keepdims=keepdim)\n elif p == ivy.inf:\n ret = ivy.max(ivy.abs(x), axis=axis, keepdims=keepdim)\n elif p == -ivy.inf:\n ret = ivy.min(ivy.abs(x), axis=axis, keepdims=keepdim)\n elif isinstance(p, (int, float)) and p > 0:\n ret = ivy.pow(\n ivy.sum(ivy.pow(ivy.abs(x), p), axis=axis, keepdims=keepdim),\n float(1.0 / p),\n )\n else:\n raise ValueError\n\n else:\n raise ValueError\n\n if len(ret.shape) == 0:\n ret = ivy.array(\n [ret]\n ) # this is done so as to match shape of output from paddle\n return ret\n\n\n# eig\n@to_ivy_arrays_and_back\ndef eig(x, name=None):\n return ivy.eig(x)\n\n\n# eigvals\n@to_ivy_arrays_and_back\ndef eigvals(x, name=None):\n return ivy.eigvals(x)\n\n\n# eigvalsh\n@to_ivy_arrays_and_back\ndef eigvalsh(x, UPLO=\"L\", name=None):\n return ivy.eigvalsh(x, UPLO=UPLO)\n\n\n# eigh\n@to_ivy_arrays_and_back\ndef eigh(x, UPLO=\"L\", name=None):\n return ivy.eigh(x, UPLO=UPLO)\n\n\n# pinv\n@with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef pinv(x, rcond=1e-15, hermitian=False, name=None):\n # TODO: Add hermitian functionality\n return ivy.pinv(x, rtol=rcond)\n\n\n# solve\n@with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef solve(x1, x2, name=None):\n return ivy.solve(x1, x2)\n\n\n# cholesky\n@with_supported_dtypes({\"2.4.2 and below\": (\"float32\", \"float64\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef cholesky(x, /, *, upper=False, name=None):\n return ivy.cholesky(x, upper=upper)\n\n\n# bmm\n@with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef bmm(x, y, transpose_x=False, transpose_y=False, name=None):\n if len(ivy.shape(x)) != 3 or len(ivy.shape(y)) != 3:\n raise RuntimeError(\"input must be 3D matrices\")\n x, y = promote_types_of_paddle_inputs(x, y)\n return ivy.matmul(x, y, transpose_a=transpose_x, transpose_b=transpose_y)\n\n\n# matrix_power\n@with_unsupported_dtypes({\"2.4.2 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef matrix_power(x, n, name=None):\n return ivy.matrix_power(x, n)\n", "path": "ivy/functional/frontends/paddle/tensor/linalg.py"}]} | 2,277 | 196 |
gh_patches_debug_31652 | rasdani/github-patches | git_diff | mosaicml__composer-595 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Pin the pyright version
The environment variable `PYRIGHT_PYTHON_FORCE_VERSION` needs to be set when pyright is installed from pip. Ideally we can set this variable in the setup.py (e.g. `os.environ['PYRIGHT_PYTHON_FORCE_VERSION'] = '...'`); but if not, then it should be in the `.ci/Jenkinsfile`.
</issue>
<code>
[start of setup.py]
1 # Copyright 2021 MosaicML. All Rights Reserved.
2
3 import os
4 import site
5 import sys
6 import textwrap
7
8 import setuptools
9 from setuptools import setup
10 from setuptools.command.develop import develop as develop_orig
11
12 _IS_ROOT = os.getuid() == 0
13 _IS_USER = "--user" in sys.argv[1:]
14 _IS_VIRTUALENV = "VIRTUAL_ENV" in os.environ
15
16
17 # From https://stackoverflow.com/questions/51292333/how-to-tell-from-setup-py-if-the-module-is-being-installed-in-editable-mode
18 class develop(develop_orig):
19
20 def run(self):
21 if _IS_ROOT and (not _IS_VIRTUALENV) and (not _IS_USER):
22 raise RuntimeError(
23 textwrap.dedent("""\
24 When installing in editable mode as root outside of a virtual environment,
25 please specify `--user`. Editable installs as the root user outside of a virtual environment
26 do not work without the `--user` flag. Please instead run something like: `pip install --user -e .`"""
27 ))
28 super().run()
29
30
31 # From https://github.com/pypa/pip/issues/7953#issuecomment-645133255
32 site.ENABLE_USER_SITE = _IS_USER
33
34
35 def package_files(directory: str):
36 # from https://stackoverflow.com/a/36693250
37 paths = []
38 for (path, _, filenames) in os.walk(directory):
39 for filename in filenames:
40 paths.append(os.path.join('..', path, filename))
41 return paths
42
43
44 with open("README.md", "r", encoding="utf-8") as fh:
45 long_description = fh.read()
46
47 install_requires = [
48 "pyyaml>=5.4.1",
49 "tqdm>=4.62.3",
50 "torchmetrics>=0.6.0",
51 "torch_optimizer==0.1.0",
52 "torchvision>=0.9.0",
53 "torch>=1.9",
54 "yahp>=0.0.14",
55 "requests>=2.26.0",
56 "numpy==1.21.5",
57 "apache-libcloud>=3.3.1",
58 "psutil>=5.8.0",
59 ]
60 extra_deps = {}
61
62 extra_deps['base'] = []
63
64 extra_deps['dev'] = [
65 # Imports for docs builds and running tests
66 "custom_inherit==2.3.2",
67 'junitparser>=2.1.1',
68 'coverage[toml]>=6.1.1',
69 'fasteners>=0.16.3', # run_directory_uploader tests require fasteners
70 'pytest>=7.0.0',
71 'toml>=0.10.2',
72 'yapf>=0.32.0',
73 'isort>=5.9.3',
74 'ipython>=7.29.0',
75 'ipykernel>=6.5.0',
76 'jupyter>=1.0.0',
77 'yamllint>=1.26.2',
78 'pytest-timeout>=1.4.2',
79 'pyright==1.1.224.post1',
80 'recommonmark>=0.7.1',
81 'sphinx>=4.2.0',
82 'sphinx_copybutton>=0.4.0',
83 'sphinx_markdown_tables>=0.0.15',
84 'sphinx-argparse>=0.3.1',
85 'sphinxcontrib.katex>=0.8.6',
86 'sphinxext.opengraph>=0.4.2',
87 'sphinxemoji>=0.2.0',
88 'furo>=2022.1.2',
89 'sphinx-copybutton>=0.4.0',
90 'testbook>=0.4.2',
91 'myst-parser==0.16.1',
92 'pylint>=2.12.2',
93 'docformatter>=1.4',
94 'sphinx_panels>=0.6.0',
95 ]
96
97 extra_deps["deepspeed"] = [
98 'deepspeed>=0.5.5',
99 ]
100
101 extra_deps["wandb"] = [
102 'wandb>=0.12.2',
103 ]
104
105 extra_deps["unet"] = [
106 'monai>=0.7.0',
107 'scikit-learn>=1.0.1',
108 ]
109
110 extra_deps["timm"] = [
111 'timm>=0.5.4',
112 ]
113
114 extra_deps["nlp"] = [
115 'transformers>=4.11',
116 'datasets>=1.14',
117 ]
118
119 extra_deps['all'] = set(dep for deps in extra_deps.values() for dep in deps)
120
121 setup(name="mosaicml",
122 version="0.3.1",
123 author="MosaicML",
124 author_email="[email protected]",
125 description="composing methods for ML training efficiency",
126 long_description=long_description,
127 long_description_content_type="text/markdown",
128 url="https://github.com/mosaicml/composer",
129 include_package_data=True,
130 package_data={
131 "composer": ['py.typed'],
132 "": package_files('composer/yamls'),
133 "": package_files('composer/algorithms')
134 },
135 packages=setuptools.find_packages(exclude=["tests*"]),
136 classifiers=[
137 "Programming Language :: Python :: 3",
138 "Programming Language :: Python :: 3.7",
139 "Programming Language :: Python :: 3.8",
140 "Programming Language :: Python :: 3.9",
141 ],
142 install_requires=install_requires,
143 entry_points={
144 'console_scripts': ['composer = composer.cli.launcher:main',],
145 },
146 extras_require=extra_deps,
147 dependency_links=['https://developer.download.nvidia.com/compute/redist'],
148 python_requires='>=3.7',
149 ext_package="composer",
150 cmdclass={'develop': develop})
151
152 # only visible if user installs with verbose -v flag
153 # Printing to stdout as not to interfere with setup.py CLI flags (e.g. --version)
154 print("*" * 20, file=sys.stderr)
155 print(textwrap.dedent("""\
156 NOTE: For best performance, we recommend installing Pillow-SIMD
157 for accelerated image processing operations. To install:
158 \t pip uninstall pillow && pip install pillow-simd"""),
159 file=sys.stderr)
160 print("*" * 20, file=sys.stderr)
161
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -66,10 +66,10 @@
"custom_inherit==2.3.2",
'junitparser>=2.1.1',
'coverage[toml]>=6.1.1',
- 'fasteners>=0.16.3', # run_directory_uploader tests require fasteners
+ 'fasteners==0.17.3', # run_directory_uploader tests require fasteners
'pytest>=7.0.0',
- 'toml>=0.10.2',
- 'yapf>=0.32.0',
+ 'toml==0.10.2',
+ 'yapf==0.32.0',
'isort>=5.9.3',
'ipython>=7.29.0',
'ipykernel>=6.5.0',
@@ -77,38 +77,38 @@
'yamllint>=1.26.2',
'pytest-timeout>=1.4.2',
'pyright==1.1.224.post1',
- 'recommonmark>=0.7.1',
+ 'recommonmark==0.7.1',
'sphinx>=4.2.0',
- 'sphinx_copybutton>=0.4.0',
- 'sphinx_markdown_tables>=0.0.15',
- 'sphinx-argparse>=0.3.1',
- 'sphinxcontrib.katex>=0.8.6',
- 'sphinxext.opengraph>=0.4.2',
- 'sphinxemoji>=0.2.0',
+ 'sphinx_copybutton==0.5.0',
+ 'sphinx_markdown_tables==0.0.15',
+ 'sphinx-argparse==0.3.1',
+ 'sphinxcontrib.katex==0.8.6',
+ 'sphinxext.opengraph==0.6.1',
+ 'sphinxemoji==0.2.0',
'furo>=2022.1.2',
- 'sphinx-copybutton>=0.4.0',
- 'testbook>=0.4.2',
+ 'sphinx-copybutton==0.5.0',
+ 'testbook==0.4.2',
'myst-parser==0.16.1',
'pylint>=2.12.2',
'docformatter>=1.4',
- 'sphinx_panels>=0.6.0',
+ 'sphinx_panels==0.6.0',
]
extra_deps["deepspeed"] = [
- 'deepspeed>=0.5.5',
+ 'deepspeed==0.5.10',
]
extra_deps["wandb"] = [
- 'wandb>=0.12.2',
+ 'wandb==0.12.10',
]
extra_deps["unet"] = [
- 'monai>=0.7.0',
+ 'monai==0.8.1',
'scikit-learn>=1.0.1',
]
extra_deps["timm"] = [
- 'timm>=0.5.4',
+ 'timm==0.5.4',
]
extra_deps["nlp"] = [
| {"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -66,10 +66,10 @@\n \"custom_inherit==2.3.2\",\n 'junitparser>=2.1.1',\n 'coverage[toml]>=6.1.1',\n- 'fasteners>=0.16.3', # run_directory_uploader tests require fasteners\n+ 'fasteners==0.17.3', # run_directory_uploader tests require fasteners\n 'pytest>=7.0.0',\n- 'toml>=0.10.2',\n- 'yapf>=0.32.0',\n+ 'toml==0.10.2',\n+ 'yapf==0.32.0',\n 'isort>=5.9.3',\n 'ipython>=7.29.0',\n 'ipykernel>=6.5.0',\n@@ -77,38 +77,38 @@\n 'yamllint>=1.26.2',\n 'pytest-timeout>=1.4.2',\n 'pyright==1.1.224.post1',\n- 'recommonmark>=0.7.1',\n+ 'recommonmark==0.7.1',\n 'sphinx>=4.2.0',\n- 'sphinx_copybutton>=0.4.0',\n- 'sphinx_markdown_tables>=0.0.15',\n- 'sphinx-argparse>=0.3.1',\n- 'sphinxcontrib.katex>=0.8.6',\n- 'sphinxext.opengraph>=0.4.2',\n- 'sphinxemoji>=0.2.0',\n+ 'sphinx_copybutton==0.5.0',\n+ 'sphinx_markdown_tables==0.0.15',\n+ 'sphinx-argparse==0.3.1',\n+ 'sphinxcontrib.katex==0.8.6',\n+ 'sphinxext.opengraph==0.6.1',\n+ 'sphinxemoji==0.2.0',\n 'furo>=2022.1.2',\n- 'sphinx-copybutton>=0.4.0',\n- 'testbook>=0.4.2',\n+ 'sphinx-copybutton==0.5.0',\n+ 'testbook==0.4.2',\n 'myst-parser==0.16.1',\n 'pylint>=2.12.2',\n 'docformatter>=1.4',\n- 'sphinx_panels>=0.6.0',\n+ 'sphinx_panels==0.6.0',\n ]\n \n extra_deps[\"deepspeed\"] = [\n- 'deepspeed>=0.5.5',\n+ 'deepspeed==0.5.10',\n ]\n \n extra_deps[\"wandb\"] = [\n- 'wandb>=0.12.2',\n+ 'wandb==0.12.10',\n ]\n \n extra_deps[\"unet\"] = [\n- 'monai>=0.7.0',\n+ 'monai==0.8.1',\n 'scikit-learn>=1.0.1',\n ]\n \n extra_deps[\"timm\"] = [\n- 'timm>=0.5.4',\n+ 'timm==0.5.4',\n ]\n \n extra_deps[\"nlp\"] = [\n", "issue": "Pin the pyright version\nThe environment variable `PYRIGHT_PYTHON_FORCE_VERSION` needs to be set when pyright is installed from pip. Ideally we can set this variable in the setup.py (e.g. `os.environ['PYRIGHT_PYTHON_FORCE_VERSION'] = '...'`); but if not, then it should be in the `.ci/Jenkinsfile`.\n", "before_files": [{"content": "# Copyright 2021 MosaicML. All Rights Reserved.\n\nimport os\nimport site\nimport sys\nimport textwrap\n\nimport setuptools\nfrom setuptools import setup\nfrom setuptools.command.develop import develop as develop_orig\n\n_IS_ROOT = os.getuid() == 0\n_IS_USER = \"--user\" in sys.argv[1:]\n_IS_VIRTUALENV = \"VIRTUAL_ENV\" in os.environ\n\n\n# From https://stackoverflow.com/questions/51292333/how-to-tell-from-setup-py-if-the-module-is-being-installed-in-editable-mode\nclass develop(develop_orig):\n\n def run(self):\n if _IS_ROOT and (not _IS_VIRTUALENV) and (not _IS_USER):\n raise RuntimeError(\n textwrap.dedent(\"\"\"\\\n When installing in editable mode as root outside of a virtual environment,\n please specify `--user`. Editable installs as the root user outside of a virtual environment\n do not work without the `--user` flag. Please instead run something like: `pip install --user -e .`\"\"\"\n ))\n super().run()\n\n\n# From https://github.com/pypa/pip/issues/7953#issuecomment-645133255\nsite.ENABLE_USER_SITE = _IS_USER\n\n\ndef package_files(directory: str):\n # from https://stackoverflow.com/a/36693250\n paths = []\n for (path, _, filenames) in os.walk(directory):\n for filename in filenames:\n paths.append(os.path.join('..', path, filename))\n return paths\n\n\nwith open(\"README.md\", \"r\", encoding=\"utf-8\") as fh:\n long_description = fh.read()\n\ninstall_requires = [\n \"pyyaml>=5.4.1\",\n \"tqdm>=4.62.3\",\n \"torchmetrics>=0.6.0\",\n \"torch_optimizer==0.1.0\",\n \"torchvision>=0.9.0\",\n \"torch>=1.9\",\n \"yahp>=0.0.14\",\n \"requests>=2.26.0\",\n \"numpy==1.21.5\",\n \"apache-libcloud>=3.3.1\",\n \"psutil>=5.8.0\",\n]\nextra_deps = {}\n\nextra_deps['base'] = []\n\nextra_deps['dev'] = [\n # Imports for docs builds and running tests\n \"custom_inherit==2.3.2\",\n 'junitparser>=2.1.1',\n 'coverage[toml]>=6.1.1',\n 'fasteners>=0.16.3', # run_directory_uploader tests require fasteners\n 'pytest>=7.0.0',\n 'toml>=0.10.2',\n 'yapf>=0.32.0',\n 'isort>=5.9.3',\n 'ipython>=7.29.0',\n 'ipykernel>=6.5.0',\n 'jupyter>=1.0.0',\n 'yamllint>=1.26.2',\n 'pytest-timeout>=1.4.2',\n 'pyright==1.1.224.post1',\n 'recommonmark>=0.7.1',\n 'sphinx>=4.2.0',\n 'sphinx_copybutton>=0.4.0',\n 'sphinx_markdown_tables>=0.0.15',\n 'sphinx-argparse>=0.3.1',\n 'sphinxcontrib.katex>=0.8.6',\n 'sphinxext.opengraph>=0.4.2',\n 'sphinxemoji>=0.2.0',\n 'furo>=2022.1.2',\n 'sphinx-copybutton>=0.4.0',\n 'testbook>=0.4.2',\n 'myst-parser==0.16.1',\n 'pylint>=2.12.2',\n 'docformatter>=1.4',\n 'sphinx_panels>=0.6.0',\n]\n\nextra_deps[\"deepspeed\"] = [\n 'deepspeed>=0.5.5',\n]\n\nextra_deps[\"wandb\"] = [\n 'wandb>=0.12.2',\n]\n\nextra_deps[\"unet\"] = [\n 'monai>=0.7.0',\n 'scikit-learn>=1.0.1',\n]\n\nextra_deps[\"timm\"] = [\n 'timm>=0.5.4',\n]\n\nextra_deps[\"nlp\"] = [\n 'transformers>=4.11',\n 'datasets>=1.14',\n]\n\nextra_deps['all'] = set(dep for deps in extra_deps.values() for dep in deps)\n\nsetup(name=\"mosaicml\",\n version=\"0.3.1\",\n author=\"MosaicML\",\n author_email=\"[email protected]\",\n description=\"composing methods for ML training efficiency\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n url=\"https://github.com/mosaicml/composer\",\n include_package_data=True,\n package_data={\n \"composer\": ['py.typed'],\n \"\": package_files('composer/yamls'),\n \"\": package_files('composer/algorithms')\n },\n packages=setuptools.find_packages(exclude=[\"tests*\"]),\n classifiers=[\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n ],\n install_requires=install_requires,\n entry_points={\n 'console_scripts': ['composer = composer.cli.launcher:main',],\n },\n extras_require=extra_deps,\n dependency_links=['https://developer.download.nvidia.com/compute/redist'],\n python_requires='>=3.7',\n ext_package=\"composer\",\n cmdclass={'develop': develop})\n\n# only visible if user installs with verbose -v flag\n# Printing to stdout as not to interfere with setup.py CLI flags (e.g. --version)\nprint(\"*\" * 20, file=sys.stderr)\nprint(textwrap.dedent(\"\"\"\\\n NOTE: For best performance, we recommend installing Pillow-SIMD\n for accelerated image processing operations. To install:\n \\t pip uninstall pillow && pip install pillow-simd\"\"\"),\n file=sys.stderr)\nprint(\"*\" * 20, file=sys.stderr)\n", "path": "setup.py"}]} | 2,406 | 781 |
gh_patches_debug_43875 | rasdani/github-patches | git_diff | certbot__certbot-1875 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Webroot breaks for non-root due to chown
Hi,
Today I'm trying out letsencrypt and stumbled upon that using webroot breaks when not using root due to a chown on line 72 of letsencrypt/plugins/webroot.py:
```
49 def prepare(self): # pylint: disable=missing-docstring
50 path_map = self.conf("map")
51
52 if not path_map:
53 raise errors.PluginError("--{0} must be set".format(
54 self.option_name("path")))
55 for name, path in path_map.items():
56 if not os.path.isdir(path):
57 raise errors.PluginError(path + " does not exist or is not a directory")
58 self.full_roots[name] = os.path.join(path, challenges.HTTP01.URI_ROOT_PATH)
59
60 logger.debug("Creating root challenges validation dir at %s",
61 self.full_roots[name])
62 try:
63 os.makedirs(self.full_roots[name])
64 # Set permissions as parent directory (GH #1389)
65 # We don't use the parameters in makedirs because it
66 # may not always work
67 # https://stackoverflow.com/questions/5231901/permission-problems-when-creating-a-dir-with-os-makedirs-python
68 stat_path = os.stat(path)
69 filemode = stat.S_IMODE(stat_path.st_mode)
70 os.chmod(self.full_roots[name], filemode)
71 # Set owner and group, too
72 os.chown(self.full_roots[name], stat_path.st_uid,
73 stat_path.st_gid)
74
75 except OSError as exception:
76 if exception.errno != errno.EEXIST:
77 raise errors.PluginError(
78 "Couldn't create root for {0} http-01 "
79 "challenge responses: {1}", name, exception)
```
It tries to set the ownership of the directory to the owner of the parent. So currently to bypass this issue either the webroot must be chown'd to the letsencrypt user, or the script needs to be run as root. Neither of which are satisfactory solutions. Is chown at all neccesary when letsencrypt is not run as root?
</issue>
<code>
[start of letsencrypt/plugins/webroot.py]
1 """Webroot plugin."""
2 import errno
3 import logging
4 import os
5 import stat
6
7 import zope.interface
8
9 from acme import challenges
10
11 from letsencrypt import errors
12 from letsencrypt import interfaces
13 from letsencrypt.plugins import common
14
15
16 logger = logging.getLogger(__name__)
17
18
19 class Authenticator(common.Plugin):
20 """Webroot Authenticator."""
21 zope.interface.implements(interfaces.IAuthenticator)
22 zope.interface.classProvides(interfaces.IPluginFactory)
23
24 description = "Webroot Authenticator"
25
26 MORE_INFO = """\
27 Authenticator plugin that performs http-01 challenge by saving
28 necessary validation resources to appropriate paths on the file
29 system. It expects that there is some other HTTP server configured
30 to serve all files under specified web root ({0})."""
31
32 def more_info(self): # pylint: disable=missing-docstring,no-self-use
33 return self.MORE_INFO.format(self.conf("path"))
34
35 @classmethod
36 def add_parser_arguments(cls, add):
37 # --webroot-path and --webroot-map are added in cli.py because they
38 # are parsed in conjunction with --domains
39 pass
40
41 def get_chall_pref(self, domain): # pragma: no cover
42 # pylint: disable=missing-docstring,no-self-use,unused-argument
43 return [challenges.HTTP01]
44
45 def __init__(self, *args, **kwargs):
46 super(Authenticator, self).__init__(*args, **kwargs)
47 self.full_roots = {}
48
49 def prepare(self): # pylint: disable=missing-docstring
50 path_map = self.conf("map")
51
52 if not path_map:
53 raise errors.PluginError("--{0} must be set".format(
54 self.option_name("path")))
55 for name, path in path_map.items():
56 if not os.path.isdir(path):
57 raise errors.PluginError(path + " does not exist or is not a directory")
58 self.full_roots[name] = os.path.join(path, challenges.HTTP01.URI_ROOT_PATH)
59
60 logger.debug("Creating root challenges validation dir at %s",
61 self.full_roots[name])
62 try:
63 os.makedirs(self.full_roots[name])
64 # Set permissions as parent directory (GH #1389)
65 # We don't use the parameters in makedirs because it
66 # may not always work
67 # https://stackoverflow.com/questions/5231901/permission-problems-when-creating-a-dir-with-os-makedirs-python
68 stat_path = os.stat(path)
69 filemode = stat.S_IMODE(stat_path.st_mode)
70 os.chmod(self.full_roots[name], filemode)
71 # Set owner and group, too
72 os.chown(self.full_roots[name], stat_path.st_uid,
73 stat_path.st_gid)
74
75 except OSError as exception:
76 if exception.errno != errno.EEXIST:
77 raise errors.PluginError(
78 "Couldn't create root for {0} http-01 "
79 "challenge responses: {1}", name, exception)
80
81 def perform(self, achalls): # pylint: disable=missing-docstring
82 assert self.full_roots, "Webroot plugin appears to be missing webroot map"
83 return [self._perform_single(achall) for achall in achalls]
84
85 def _path_for_achall(self, achall):
86 try:
87 path = self.full_roots[achall.domain]
88 except IndexError:
89 raise errors.PluginError("Missing --webroot-path for domain: {1}"
90 .format(achall.domain))
91 if not os.path.exists(path):
92 raise errors.PluginError("Mysteriously missing path {0} for domain: {1}"
93 .format(path, achall.domain))
94 return os.path.join(path, achall.chall.encode("token"))
95
96 def _perform_single(self, achall):
97 response, validation = achall.response_and_validation()
98 path = self._path_for_achall(achall)
99 logger.debug("Attempting to save validation to %s", path)
100 with open(path, "w") as validation_file:
101 validation_file.write(validation.encode())
102
103 # Set permissions as parent directory (GH #1389)
104 parent_path = self.full_roots[achall.domain]
105 stat_parent_path = os.stat(parent_path)
106 filemode = stat.S_IMODE(stat_parent_path.st_mode)
107 # Remove execution bit (not needed for this file)
108 os.chmod(path, filemode & ~stat.S_IEXEC)
109 os.chown(path, stat_parent_path.st_uid, stat_parent_path.st_gid)
110
111 return response
112
113 def cleanup(self, achalls): # pylint: disable=missing-docstring
114 for achall in achalls:
115 path = self._path_for_achall(achall)
116 logger.debug("Removing %s", path)
117 os.remove(path)
118
[end of letsencrypt/plugins/webroot.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/letsencrypt/plugins/webroot.py b/letsencrypt/plugins/webroot.py
--- a/letsencrypt/plugins/webroot.py
+++ b/letsencrypt/plugins/webroot.py
@@ -2,7 +2,6 @@
import errno
import logging
import os
-import stat
import zope.interface
@@ -59,24 +58,38 @@
logger.debug("Creating root challenges validation dir at %s",
self.full_roots[name])
+
+ # Change the permissions to be writable (GH #1389)
+ # Umask is used instead of chmod to ensure the client can also
+ # run as non-root (GH #1795)
+ old_umask = os.umask(0o022)
+
try:
- os.makedirs(self.full_roots[name])
- # Set permissions as parent directory (GH #1389)
- # We don't use the parameters in makedirs because it
- # may not always work
+ # This is coupled with the "umask" call above because
+ # os.makedirs's "mode" parameter may not always work:
# https://stackoverflow.com/questions/5231901/permission-problems-when-creating-a-dir-with-os-makedirs-python
- stat_path = os.stat(path)
- filemode = stat.S_IMODE(stat_path.st_mode)
- os.chmod(self.full_roots[name], filemode)
- # Set owner and group, too
- os.chown(self.full_roots[name], stat_path.st_uid,
- stat_path.st_gid)
+ os.makedirs(self.full_roots[name], 0o0755)
+
+ # Set owner as parent directory if possible
+ try:
+ stat_path = os.stat(path)
+ os.chown(self.full_roots[name], stat_path.st_uid,
+ stat_path.st_gid)
+ except OSError as exception:
+ if exception.errno == errno.EACCES:
+ logger.debug("Insufficient permissions to change owner and uid - ignoring")
+ else:
+ raise errors.PluginError(
+ "Couldn't create root for {0} http-01 "
+ "challenge responses: {1}", name, exception)
except OSError as exception:
if exception.errno != errno.EEXIST:
raise errors.PluginError(
"Couldn't create root for {0} http-01 "
"challenge responses: {1}", name, exception)
+ finally:
+ os.umask(old_umask)
def perform(self, achalls): # pylint: disable=missing-docstring
assert self.full_roots, "Webroot plugin appears to be missing webroot map"
@@ -87,26 +100,26 @@
path = self.full_roots[achall.domain]
except IndexError:
raise errors.PluginError("Missing --webroot-path for domain: {1}"
- .format(achall.domain))
+ .format(achall.domain))
if not os.path.exists(path):
raise errors.PluginError("Mysteriously missing path {0} for domain: {1}"
- .format(path, achall.domain))
+ .format(path, achall.domain))
return os.path.join(path, achall.chall.encode("token"))
def _perform_single(self, achall):
response, validation = achall.response_and_validation()
+
path = self._path_for_achall(achall)
logger.debug("Attempting to save validation to %s", path)
- with open(path, "w") as validation_file:
- validation_file.write(validation.encode())
-
- # Set permissions as parent directory (GH #1389)
- parent_path = self.full_roots[achall.domain]
- stat_parent_path = os.stat(parent_path)
- filemode = stat.S_IMODE(stat_parent_path.st_mode)
- # Remove execution bit (not needed for this file)
- os.chmod(path, filemode & ~stat.S_IEXEC)
- os.chown(path, stat_parent_path.st_uid, stat_parent_path.st_gid)
+
+ # Change permissions to be world-readable, owner-writable (GH #1795)
+ old_umask = os.umask(0o022)
+
+ try:
+ with open(path, "w") as validation_file:
+ validation_file.write(validation.encode())
+ finally:
+ os.umask(old_umask)
return response
| {"golden_diff": "diff --git a/letsencrypt/plugins/webroot.py b/letsencrypt/plugins/webroot.py\n--- a/letsencrypt/plugins/webroot.py\n+++ b/letsencrypt/plugins/webroot.py\n@@ -2,7 +2,6 @@\n import errno\n import logging\n import os\n-import stat\n \n import zope.interface\n \n@@ -59,24 +58,38 @@\n \n logger.debug(\"Creating root challenges validation dir at %s\",\n self.full_roots[name])\n+\n+ # Change the permissions to be writable (GH #1389)\n+ # Umask is used instead of chmod to ensure the client can also\n+ # run as non-root (GH #1795)\n+ old_umask = os.umask(0o022)\n+\n try:\n- os.makedirs(self.full_roots[name])\n- # Set permissions as parent directory (GH #1389)\n- # We don't use the parameters in makedirs because it\n- # may not always work\n+ # This is coupled with the \"umask\" call above because\n+ # os.makedirs's \"mode\" parameter may not always work:\n # https://stackoverflow.com/questions/5231901/permission-problems-when-creating-a-dir-with-os-makedirs-python\n- stat_path = os.stat(path)\n- filemode = stat.S_IMODE(stat_path.st_mode)\n- os.chmod(self.full_roots[name], filemode)\n- # Set owner and group, too\n- os.chown(self.full_roots[name], stat_path.st_uid,\n- stat_path.st_gid)\n+ os.makedirs(self.full_roots[name], 0o0755)\n+\n+ # Set owner as parent directory if possible\n+ try:\n+ stat_path = os.stat(path)\n+ os.chown(self.full_roots[name], stat_path.st_uid,\n+ stat_path.st_gid)\n+ except OSError as exception:\n+ if exception.errno == errno.EACCES:\n+ logger.debug(\"Insufficient permissions to change owner and uid - ignoring\")\n+ else:\n+ raise errors.PluginError(\n+ \"Couldn't create root for {0} http-01 \"\n+ \"challenge responses: {1}\", name, exception)\n \n except OSError as exception:\n if exception.errno != errno.EEXIST:\n raise errors.PluginError(\n \"Couldn't create root for {0} http-01 \"\n \"challenge responses: {1}\", name, exception)\n+ finally:\n+ os.umask(old_umask)\n \n def perform(self, achalls): # pylint: disable=missing-docstring\n assert self.full_roots, \"Webroot plugin appears to be missing webroot map\"\n@@ -87,26 +100,26 @@\n path = self.full_roots[achall.domain]\n except IndexError:\n raise errors.PluginError(\"Missing --webroot-path for domain: {1}\"\n- .format(achall.domain))\n+ .format(achall.domain))\n if not os.path.exists(path):\n raise errors.PluginError(\"Mysteriously missing path {0} for domain: {1}\"\n- .format(path, achall.domain))\n+ .format(path, achall.domain))\n return os.path.join(path, achall.chall.encode(\"token\"))\n \n def _perform_single(self, achall):\n response, validation = achall.response_and_validation()\n+\n path = self._path_for_achall(achall)\n logger.debug(\"Attempting to save validation to %s\", path)\n- with open(path, \"w\") as validation_file:\n- validation_file.write(validation.encode())\n-\n- # Set permissions as parent directory (GH #1389)\n- parent_path = self.full_roots[achall.domain]\n- stat_parent_path = os.stat(parent_path)\n- filemode = stat.S_IMODE(stat_parent_path.st_mode)\n- # Remove execution bit (not needed for this file)\n- os.chmod(path, filemode & ~stat.S_IEXEC)\n- os.chown(path, stat_parent_path.st_uid, stat_parent_path.st_gid)\n+\n+ # Change permissions to be world-readable, owner-writable (GH #1795)\n+ old_umask = os.umask(0o022)\n+\n+ try:\n+ with open(path, \"w\") as validation_file:\n+ validation_file.write(validation.encode())\n+ finally:\n+ os.umask(old_umask)\n \n return response\n", "issue": "Webroot breaks for non-root due to chown\nHi,\n\nToday I'm trying out letsencrypt and stumbled upon that using webroot breaks when not using root due to a chown on line 72 of letsencrypt/plugins/webroot.py:\n\n```\n 49 def prepare(self): # pylint: disable=missing-docstring\n 50 path_map = self.conf(\"map\")\n 51\n 52 if not path_map:\n 53 raise errors.PluginError(\"--{0} must be set\".format(\n 54 self.option_name(\"path\")))\n 55 for name, path in path_map.items():\n 56 if not os.path.isdir(path):\n 57 raise errors.PluginError(path + \" does not exist or is not a directory\")\n 58 self.full_roots[name] = os.path.join(path, challenges.HTTP01.URI_ROOT_PATH)\n 59\n 60 logger.debug(\"Creating root challenges validation dir at %s\",\n 61 self.full_roots[name])\n 62 try:\n 63 os.makedirs(self.full_roots[name])\n 64 # Set permissions as parent directory (GH #1389)\n 65 # We don't use the parameters in makedirs because it\n 66 # may not always work\n 67 # https://stackoverflow.com/questions/5231901/permission-problems-when-creating-a-dir-with-os-makedirs-python\n 68 stat_path = os.stat(path)\n 69 filemode = stat.S_IMODE(stat_path.st_mode)\n 70 os.chmod(self.full_roots[name], filemode)\n 71 # Set owner and group, too\n 72 os.chown(self.full_roots[name], stat_path.st_uid,\n 73 stat_path.st_gid)\n 74\n 75 except OSError as exception:\n 76 if exception.errno != errno.EEXIST:\n 77 raise errors.PluginError(\n 78 \"Couldn't create root for {0} http-01 \"\n 79 \"challenge responses: {1}\", name, exception)\n```\n\nIt tries to set the ownership of the directory to the owner of the parent. So currently to bypass this issue either the webroot must be chown'd to the letsencrypt user, or the script needs to be run as root. Neither of which are satisfactory solutions. Is chown at all neccesary when letsencrypt is not run as root?\n\n", "before_files": [{"content": "\"\"\"Webroot plugin.\"\"\"\nimport errno\nimport logging\nimport os\nimport stat\n\nimport zope.interface\n\nfrom acme import challenges\n\nfrom letsencrypt import errors\nfrom letsencrypt import interfaces\nfrom letsencrypt.plugins import common\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass Authenticator(common.Plugin):\n \"\"\"Webroot Authenticator.\"\"\"\n zope.interface.implements(interfaces.IAuthenticator)\n zope.interface.classProvides(interfaces.IPluginFactory)\n\n description = \"Webroot Authenticator\"\n\n MORE_INFO = \"\"\"\\\nAuthenticator plugin that performs http-01 challenge by saving\nnecessary validation resources to appropriate paths on the file\nsystem. It expects that there is some other HTTP server configured\nto serve all files under specified web root ({0}).\"\"\"\n\n def more_info(self): # pylint: disable=missing-docstring,no-self-use\n return self.MORE_INFO.format(self.conf(\"path\"))\n\n @classmethod\n def add_parser_arguments(cls, add):\n # --webroot-path and --webroot-map are added in cli.py because they\n # are parsed in conjunction with --domains\n pass\n\n def get_chall_pref(self, domain): # pragma: no cover\n # pylint: disable=missing-docstring,no-self-use,unused-argument\n return [challenges.HTTP01]\n\n def __init__(self, *args, **kwargs):\n super(Authenticator, self).__init__(*args, **kwargs)\n self.full_roots = {}\n\n def prepare(self): # pylint: disable=missing-docstring\n path_map = self.conf(\"map\")\n\n if not path_map:\n raise errors.PluginError(\"--{0} must be set\".format(\n self.option_name(\"path\")))\n for name, path in path_map.items():\n if not os.path.isdir(path):\n raise errors.PluginError(path + \" does not exist or is not a directory\")\n self.full_roots[name] = os.path.join(path, challenges.HTTP01.URI_ROOT_PATH)\n\n logger.debug(\"Creating root challenges validation dir at %s\",\n self.full_roots[name])\n try:\n os.makedirs(self.full_roots[name])\n # Set permissions as parent directory (GH #1389)\n # We don't use the parameters in makedirs because it\n # may not always work\n # https://stackoverflow.com/questions/5231901/permission-problems-when-creating-a-dir-with-os-makedirs-python\n stat_path = os.stat(path)\n filemode = stat.S_IMODE(stat_path.st_mode)\n os.chmod(self.full_roots[name], filemode)\n # Set owner and group, too\n os.chown(self.full_roots[name], stat_path.st_uid,\n stat_path.st_gid)\n\n except OSError as exception:\n if exception.errno != errno.EEXIST:\n raise errors.PluginError(\n \"Couldn't create root for {0} http-01 \"\n \"challenge responses: {1}\", name, exception)\n\n def perform(self, achalls): # pylint: disable=missing-docstring\n assert self.full_roots, \"Webroot plugin appears to be missing webroot map\"\n return [self._perform_single(achall) for achall in achalls]\n\n def _path_for_achall(self, achall):\n try:\n path = self.full_roots[achall.domain]\n except IndexError:\n raise errors.PluginError(\"Missing --webroot-path for domain: {1}\"\n .format(achall.domain))\n if not os.path.exists(path):\n raise errors.PluginError(\"Mysteriously missing path {0} for domain: {1}\"\n .format(path, achall.domain))\n return os.path.join(path, achall.chall.encode(\"token\"))\n\n def _perform_single(self, achall):\n response, validation = achall.response_and_validation()\n path = self._path_for_achall(achall)\n logger.debug(\"Attempting to save validation to %s\", path)\n with open(path, \"w\") as validation_file:\n validation_file.write(validation.encode())\n\n # Set permissions as parent directory (GH #1389)\n parent_path = self.full_roots[achall.domain]\n stat_parent_path = os.stat(parent_path)\n filemode = stat.S_IMODE(stat_parent_path.st_mode)\n # Remove execution bit (not needed for this file)\n os.chmod(path, filemode & ~stat.S_IEXEC)\n os.chown(path, stat_parent_path.st_uid, stat_parent_path.st_gid)\n\n return response\n\n def cleanup(self, achalls): # pylint: disable=missing-docstring\n for achall in achalls:\n path = self._path_for_achall(achall)\n logger.debug(\"Removing %s\", path)\n os.remove(path)\n", "path": "letsencrypt/plugins/webroot.py"}]} | 2,363 | 983 |
gh_patches_debug_51715 | rasdani/github-patches | git_diff | paperless-ngx__paperless-ngx-1358 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[BUG] Error starting gunicorn when IPv6 is disabled on host
### Description
Paperless fails to launch in at least certain scenarios when IPv6 is disabled on the host. This was working before a change from listening on `0.0.0.0` to listening on `::`.
### Steps to reproduce
Add the following to `/etc/sysctl.conf`:
```
net.ipv6.conf.all.disable_ipv6=1
net.ipv6.conf.default.disable_ipv6=1
net.ipv6.conf.lo.disable_ipv6=1
```
Set `GRUB_CMDLINE_LINUX_DEFAULT="ipv6.disable=1"` in `/etc/default/grub`, and `update-grub`.
Reboot and run paperless-ngx
### Webserver logs
```bash
Paperless-ngx docker container starting...
Mapping UID and GID for paperless:paperless to 1000:65538
usermod: no changes
Creating directory /tmp/paperless
Adjusting permissions of paperless files. This may take a while.
Waiting for PostgreSQL to start...
Waiting for Redis: redis://paperless-redis.paperless.svc:6379
Connected to Redis broker: redis://paperless-redis.paperless.svc:6379
Apply database migrations...
Operations to perform:
Apply all migrations: admin, auth, authtoken, contenttypes, django_q, documents, paperless_mail, sessions
Running migrations:
No migrations to apply.
Executing /usr/local/bin/paperless_cmd.sh
2022-08-04 14:20:24,984 INFO Set uid to user 0 succeeded
2022-08-04 14:20:24,985 INFO supervisord started with pid 49
2022-08-04 14:20:25,988 INFO spawned: 'consumer' with pid 50
2022-08-04 14:20:25,990 INFO spawned: 'gunicorn' with pid 51
2022-08-04 14:20:25,992 INFO spawned: 'scheduler' with pid 52
[2022-08-04 10:20:26 -0400] [51] [INFO] Starting gunicorn 20.1.0
[2022-08-04 10:20:35 -0400] [72] [ERROR] Retrying in 1 second.
[2022-08-04 10:20:36 -0400] [72] [ERROR] Retrying in 1 second.
[2022-08-04 10:20:37 -0400] [72] [ERROR] Can't connect to ('::', 8000)
2022-08-04 14:20:37,727 INFO exited: gunicorn (exit status 1; not expected)
2022-08-04 14:20:38,730 INFO spawned: 'gunicorn' with pid 74
[2022-08-04 10:20:39 -0400] [74] [INFO] Starting gunicorn 20.1.0
[2022-08-04 10:20:39 -0400] [74] [ERROR] Retrying in 1 second.
2022-08-04 14:20:40,017 INFO success: gunicorn entered RUNNING state, process has stayed up for > than 1 seconds (startsecs)
[2022-08-04 10:20:40 -0400] [74] [ERROR] Retrying in 1 second.
[2022-08-04 10:20:41 -0400] [74] [ERROR] Retrying in 1 second.
[2022-08-04 10:20:42 -0400] [74] [ERROR] Retrying in 1 second.
[2022-08-04 10:20:43 -0400] [74] [ERROR] Retrying in 1 second.
[2022-08-04 10:20:44 -0400] [74] [ERROR] Can't connect to ('::', 8000)
2022-08-04 14:20:44,069 INFO exited: gunicorn (exit status 1; not expected)
```
### Paperless-ngx version
1.8.0
### Host OS
Ubuntu 22.04 x64, Microk8s 1.22
### Installation method
Docker - official image
### Browser
_No response_
### Configuration changes
_No response_
### Other
This seems to be a regression from https://github.com/paperless-ngx/paperless-ngx/pull/924. Changing the listen IP back to 0.0.0.0 in gunicorn.conf.py causing it to bind correctly again
</issue>
<code>
[start of gunicorn.conf.py]
1 import os
2
3 bind = f'[::]:{os.getenv("PAPERLESS_PORT", 8000)}'
4 workers = int(os.getenv("PAPERLESS_WEBSERVER_WORKERS", 1))
5 worker_class = "paperless.workers.ConfigurableWorker"
6 timeout = 120
7
8
9 def pre_fork(server, worker):
10 pass
11
12
13 def pre_exec(server):
14 server.log.info("Forked child, re-executing.")
15
16
17 def when_ready(server):
18 server.log.info("Server is ready. Spawning workers")
19
20
21 def worker_int(worker):
22 worker.log.info("worker received INT or QUIT signal")
23
24 ## get traceback info
25 import threading, sys, traceback
26
27 id2name = {th.ident: th.name for th in threading.enumerate()}
28 code = []
29 for threadId, stack in sys._current_frames().items():
30 code.append("\n# Thread: %s(%d)" % (id2name.get(threadId, ""), threadId))
31 for filename, lineno, name, line in traceback.extract_stack(stack):
32 code.append('File: "%s", line %d, in %s' % (filename, lineno, name))
33 if line:
34 code.append(" %s" % (line.strip()))
35 worker.log.debug("\n".join(code))
36
37
38 def worker_abort(worker):
39 worker.log.info("worker received SIGABRT signal")
40
[end of gunicorn.conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/gunicorn.conf.py b/gunicorn.conf.py
--- a/gunicorn.conf.py
+++ b/gunicorn.conf.py
@@ -1,6 +1,6 @@
import os
-bind = f'[::]:{os.getenv("PAPERLESS_PORT", 8000)}'
+bind = f'{os.getenv("PAPERLESS_BIND_ADDR", "[::]")}:{os.getenv("PAPERLESS_PORT", 8000)}'
workers = int(os.getenv("PAPERLESS_WEBSERVER_WORKERS", 1))
worker_class = "paperless.workers.ConfigurableWorker"
timeout = 120
| {"golden_diff": "diff --git a/gunicorn.conf.py b/gunicorn.conf.py\n--- a/gunicorn.conf.py\n+++ b/gunicorn.conf.py\n@@ -1,6 +1,6 @@\n import os\n \n-bind = f'[::]:{os.getenv(\"PAPERLESS_PORT\", 8000)}'\n+bind = f'{os.getenv(\"PAPERLESS_BIND_ADDR\", \"[::]\")}:{os.getenv(\"PAPERLESS_PORT\", 8000)}'\n workers = int(os.getenv(\"PAPERLESS_WEBSERVER_WORKERS\", 1))\n worker_class = \"paperless.workers.ConfigurableWorker\"\n timeout = 120\n", "issue": "[BUG] Error starting gunicorn when IPv6 is disabled on host\n### Description\n\nPaperless fails to launch in at least certain scenarios when IPv6 is disabled on the host. This was working before a change from listening on `0.0.0.0` to listening on `::`.\n\n### Steps to reproduce\n\nAdd the following to `/etc/sysctl.conf`:\r\n\r\n```\r\nnet.ipv6.conf.all.disable_ipv6=1\r\nnet.ipv6.conf.default.disable_ipv6=1\r\nnet.ipv6.conf.lo.disable_ipv6=1\r\n```\r\n\r\nSet `GRUB_CMDLINE_LINUX_DEFAULT=\"ipv6.disable=1\"` in `/etc/default/grub`, and `update-grub`.\r\n\r\nReboot and run paperless-ngx\n\n### Webserver logs\n\n```bash\nPaperless-ngx docker container starting...\r\nMapping UID and GID for paperless:paperless to 1000:65538\r\nusermod: no changes\r\nCreating directory /tmp/paperless\r\nAdjusting permissions of paperless files. This may take a while.\r\nWaiting for PostgreSQL to start...\r\nWaiting for Redis: redis://paperless-redis.paperless.svc:6379\r\nConnected to Redis broker: redis://paperless-redis.paperless.svc:6379\r\nApply database migrations...\r\nOperations to perform:\r\n Apply all migrations: admin, auth, authtoken, contenttypes, django_q, documents, paperless_mail, sessions\r\nRunning migrations:\r\n No migrations to apply.\r\nExecuting /usr/local/bin/paperless_cmd.sh\r\n2022-08-04 14:20:24,984 INFO Set uid to user 0 succeeded\r\n2022-08-04 14:20:24,985 INFO supervisord started with pid 49\r\n2022-08-04 14:20:25,988 INFO spawned: 'consumer' with pid 50\r\n2022-08-04 14:20:25,990 INFO spawned: 'gunicorn' with pid 51\r\n2022-08-04 14:20:25,992 INFO spawned: 'scheduler' with pid 52\r\n[2022-08-04 10:20:26 -0400] [51] [INFO] Starting gunicorn 20.1.0\r\n[2022-08-04 10:20:35 -0400] [72] [ERROR] Retrying in 1 second.\r\n[2022-08-04 10:20:36 -0400] [72] [ERROR] Retrying in 1 second.\r\n[2022-08-04 10:20:37 -0400] [72] [ERROR] Can't connect to ('::', 8000)\r\n2022-08-04 14:20:37,727 INFO exited: gunicorn (exit status 1; not expected)\r\n2022-08-04 14:20:38,730 INFO spawned: 'gunicorn' with pid 74\r\n[2022-08-04 10:20:39 -0400] [74] [INFO] Starting gunicorn 20.1.0\r\n[2022-08-04 10:20:39 -0400] [74] [ERROR] Retrying in 1 second.\r\n2022-08-04 14:20:40,017 INFO success: gunicorn entered RUNNING state, process has stayed up for > than 1 seconds (startsecs)\r\n[2022-08-04 10:20:40 -0400] [74] [ERROR] Retrying in 1 second.\r\n[2022-08-04 10:20:41 -0400] [74] [ERROR] Retrying in 1 second.\r\n[2022-08-04 10:20:42 -0400] [74] [ERROR] Retrying in 1 second.\r\n[2022-08-04 10:20:43 -0400] [74] [ERROR] Retrying in 1 second.\r\n[2022-08-04 10:20:44 -0400] [74] [ERROR] Can't connect to ('::', 8000)\r\n2022-08-04 14:20:44,069 INFO exited: gunicorn (exit status 1; not expected)\n```\n\n\n### Paperless-ngx version\n\n1.8.0\n\n### Host OS\n\nUbuntu 22.04 x64, Microk8s 1.22\n\n### Installation method\n\nDocker - official image\n\n### Browser\n\n_No response_\n\n### Configuration changes\n\n_No response_\n\n### Other\n\nThis seems to be a regression from https://github.com/paperless-ngx/paperless-ngx/pull/924. Changing the listen IP back to 0.0.0.0 in gunicorn.conf.py causing it to bind correctly again\n", "before_files": [{"content": "import os\n\nbind = f'[::]:{os.getenv(\"PAPERLESS_PORT\", 8000)}'\nworkers = int(os.getenv(\"PAPERLESS_WEBSERVER_WORKERS\", 1))\nworker_class = \"paperless.workers.ConfigurableWorker\"\ntimeout = 120\n\n\ndef pre_fork(server, worker):\n pass\n\n\ndef pre_exec(server):\n server.log.info(\"Forked child, re-executing.\")\n\n\ndef when_ready(server):\n server.log.info(\"Server is ready. Spawning workers\")\n\n\ndef worker_int(worker):\n worker.log.info(\"worker received INT or QUIT signal\")\n\n ## get traceback info\n import threading, sys, traceback\n\n id2name = {th.ident: th.name for th in threading.enumerate()}\n code = []\n for threadId, stack in sys._current_frames().items():\n code.append(\"\\n# Thread: %s(%d)\" % (id2name.get(threadId, \"\"), threadId))\n for filename, lineno, name, line in traceback.extract_stack(stack):\n code.append('File: \"%s\", line %d, in %s' % (filename, lineno, name))\n if line:\n code.append(\" %s\" % (line.strip()))\n worker.log.debug(\"\\n\".join(code))\n\n\ndef worker_abort(worker):\n worker.log.info(\"worker received SIGABRT signal\")\n", "path": "gunicorn.conf.py"}]} | 2,135 | 133 |
gh_patches_debug_15632 | rasdani/github-patches | git_diff | getredash__redash-3362 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Clickhouse: password is optional but we try to access it anyway
For Clickhouse type data sources, we don't require a password. But the code does require it by trying to directly access the value in the options dictionary, instead of using `get`:
https://github.com/getredash/redash/blob/823e4ccdd6fcfee5d0df0d919d87af3100876549/redash/query_runner/clickhouse.py#L77
</issue>
<code>
[start of redash/query_runner/clickhouse.py]
1 import logging
2 import re
3
4 import requests
5
6 from redash.query_runner import *
7 from redash.utils import json_dumps, json_loads
8
9 logger = logging.getLogger(__name__)
10
11
12 class ClickHouse(BaseSQLQueryRunner):
13 noop_query = "SELECT 1"
14
15 @classmethod
16 def configuration_schema(cls):
17 return {
18 "type": "object",
19 "properties": {
20 "url": {
21 "type": "string",
22 "default": "http://127.0.0.1:8123"
23 },
24 "user": {
25 "type": "string",
26 "default": "default"
27 },
28 "password": {
29 "type": "string"
30 },
31 "dbname": {
32 "type": "string",
33 "title": "Database Name"
34 },
35 "timeout": {
36 "type": "number",
37 "title": "Request Timeout",
38 "default": 30
39 }
40 },
41 "required": ["dbname"],
42 "secret": ["password"]
43 }
44
45 @classmethod
46 def type(cls):
47 return "clickhouse"
48
49 def _get_tables(self, schema):
50 query = "SELECT database, table, name FROM system.columns WHERE database NOT IN ('system')"
51
52 results, error = self.run_query(query, None)
53
54 if error is not None:
55 raise Exception("Failed getting schema.")
56
57 results = json_loads(results)
58
59 for row in results['rows']:
60 table_name = '{}.{}'.format(row['database'], row['table'])
61
62 if table_name not in schema:
63 schema[table_name] = {'name': table_name, 'columns': []}
64
65 schema[table_name]['columns'].append(row['name'])
66
67 return schema.values()
68
69 def _send_query(self, data, stream=False):
70 r = requests.post(
71 self.configuration['url'],
72 data=data.encode("utf-8"),
73 stream=stream,
74 timeout=self.configuration.get('timeout', 30),
75 params={
76 'user': self.configuration['user'],
77 'password': self.configuration['password'],
78 'database': self.configuration['dbname']
79 }
80 )
81 if r.status_code != 200:
82 raise Exception(r.text)
83 # logging.warning(r.json())
84 return r.json()
85
86 @staticmethod
87 def _define_column_type(column):
88 c = column.lower()
89 f = re.search(r'^nullable\((.*)\)$', c)
90 if f is not None:
91 c = f.group(1)
92 if c.startswith('int') or c.startswith('uint'):
93 return TYPE_INTEGER
94 elif c.startswith('float'):
95 return TYPE_FLOAT
96 elif c == 'datetime':
97 return TYPE_DATETIME
98 elif c == 'date':
99 return TYPE_DATE
100 else:
101 return TYPE_STRING
102
103 def _clickhouse_query(self, query):
104 query += '\nFORMAT JSON'
105 result = self._send_query(query)
106 columns = []
107 columns_int64 = [] # db converts value to string if its type equals UInt64
108 columns_totals = {}
109
110 for r in result['meta']:
111 column_name = r['name']
112 column_type = self._define_column_type(r['type'])
113
114 if r['type'] in ('Int64', 'UInt64', 'Nullable(Int64)', 'Nullable(UInt64)'):
115 columns_int64.append(column_name)
116 else:
117 columns_totals[column_name] = 'Total' if column_type == TYPE_STRING else None
118
119 columns.append({'name': column_name, 'friendly_name': column_name, 'type': column_type})
120
121 rows = result['data']
122 for row in rows:
123 for column in columns_int64:
124 try:
125 row[column] = int(row[column])
126 except TypeError:
127 row[column] = None
128
129 if 'totals' in result:
130 totals = result['totals']
131 for column, value in columns_totals.iteritems():
132 totals[column] = value
133 rows.append(totals)
134
135 return {'columns': columns, 'rows': rows}
136
137 def run_query(self, query, user):
138 logger.debug("Clickhouse is about to execute query: %s", query)
139 if query == "":
140 json_data = None
141 error = "Query is empty"
142 return json_data, error
143 try:
144 q = self._clickhouse_query(query)
145 data = json_dumps(q)
146 error = None
147 except Exception as e:
148 data = None
149 logging.exception(e)
150 error = unicode(e)
151 return data, error
152
153 register(ClickHouse)
154
[end of redash/query_runner/clickhouse.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/redash/query_runner/clickhouse.py b/redash/query_runner/clickhouse.py
--- a/redash/query_runner/clickhouse.py
+++ b/redash/query_runner/clickhouse.py
@@ -68,13 +68,13 @@
def _send_query(self, data, stream=False):
r = requests.post(
- self.configuration['url'],
+ self.configuration.get('url', "http://127.0.0.1:8123"),
data=data.encode("utf-8"),
stream=stream,
timeout=self.configuration.get('timeout', 30),
params={
- 'user': self.configuration['user'],
- 'password': self.configuration['password'],
+ 'user': self.configuration.get('user', "default"),
+ 'password': self.configuration.get('password', ""),
'database': self.configuration['dbname']
}
)
| {"golden_diff": "diff --git a/redash/query_runner/clickhouse.py b/redash/query_runner/clickhouse.py\n--- a/redash/query_runner/clickhouse.py\n+++ b/redash/query_runner/clickhouse.py\n@@ -68,13 +68,13 @@\n \n def _send_query(self, data, stream=False):\n r = requests.post(\n- self.configuration['url'],\n+ self.configuration.get('url', \"http://127.0.0.1:8123\"),\n data=data.encode(\"utf-8\"),\n stream=stream,\n timeout=self.configuration.get('timeout', 30),\n params={\n- 'user': self.configuration['user'],\n- 'password': self.configuration['password'],\n+ 'user': self.configuration.get('user', \"default\"),\n+ 'password': self.configuration.get('password', \"\"),\n 'database': self.configuration['dbname']\n }\n )\n", "issue": "Clickhouse: password is optional but we try to access it anyway\nFor Clickhouse type data sources, we don't require a password. But the code does require it by trying to directly access the value in the options dictionary, instead of using `get`:\r\n\r\nhttps://github.com/getredash/redash/blob/823e4ccdd6fcfee5d0df0d919d87af3100876549/redash/query_runner/clickhouse.py#L77\n", "before_files": [{"content": "import logging\nimport re\n\nimport requests\n\nfrom redash.query_runner import *\nfrom redash.utils import json_dumps, json_loads\n\nlogger = logging.getLogger(__name__)\n\n\nclass ClickHouse(BaseSQLQueryRunner):\n noop_query = \"SELECT 1\"\n\n @classmethod\n def configuration_schema(cls):\n return {\n \"type\": \"object\",\n \"properties\": {\n \"url\": {\n \"type\": \"string\",\n \"default\": \"http://127.0.0.1:8123\"\n },\n \"user\": {\n \"type\": \"string\",\n \"default\": \"default\"\n },\n \"password\": {\n \"type\": \"string\"\n },\n \"dbname\": {\n \"type\": \"string\",\n \"title\": \"Database Name\"\n },\n \"timeout\": {\n \"type\": \"number\",\n \"title\": \"Request Timeout\",\n \"default\": 30\n }\n },\n \"required\": [\"dbname\"],\n \"secret\": [\"password\"]\n }\n\n @classmethod\n def type(cls):\n return \"clickhouse\"\n\n def _get_tables(self, schema):\n query = \"SELECT database, table, name FROM system.columns WHERE database NOT IN ('system')\"\n\n results, error = self.run_query(query, None)\n\n if error is not None:\n raise Exception(\"Failed getting schema.\")\n\n results = json_loads(results)\n\n for row in results['rows']:\n table_name = '{}.{}'.format(row['database'], row['table'])\n\n if table_name not in schema:\n schema[table_name] = {'name': table_name, 'columns': []}\n\n schema[table_name]['columns'].append(row['name'])\n\n return schema.values()\n\n def _send_query(self, data, stream=False):\n r = requests.post(\n self.configuration['url'],\n data=data.encode(\"utf-8\"),\n stream=stream,\n timeout=self.configuration.get('timeout', 30),\n params={\n 'user': self.configuration['user'],\n 'password': self.configuration['password'],\n 'database': self.configuration['dbname']\n }\n )\n if r.status_code != 200:\n raise Exception(r.text)\n # logging.warning(r.json())\n return r.json()\n\n @staticmethod\n def _define_column_type(column):\n c = column.lower()\n f = re.search(r'^nullable\\((.*)\\)$', c)\n if f is not None:\n c = f.group(1)\n if c.startswith('int') or c.startswith('uint'):\n return TYPE_INTEGER\n elif c.startswith('float'):\n return TYPE_FLOAT\n elif c == 'datetime':\n return TYPE_DATETIME\n elif c == 'date':\n return TYPE_DATE\n else:\n return TYPE_STRING\n\n def _clickhouse_query(self, query):\n query += '\\nFORMAT JSON'\n result = self._send_query(query)\n columns = []\n columns_int64 = [] # db converts value to string if its type equals UInt64\n columns_totals = {}\n\n for r in result['meta']:\n column_name = r['name']\n column_type = self._define_column_type(r['type'])\n\n if r['type'] in ('Int64', 'UInt64', 'Nullable(Int64)', 'Nullable(UInt64)'):\n columns_int64.append(column_name)\n else:\n columns_totals[column_name] = 'Total' if column_type == TYPE_STRING else None\n\n columns.append({'name': column_name, 'friendly_name': column_name, 'type': column_type})\n\n rows = result['data']\n for row in rows:\n for column in columns_int64:\n try:\n row[column] = int(row[column])\n except TypeError:\n row[column] = None\n\n if 'totals' in result:\n totals = result['totals']\n for column, value in columns_totals.iteritems():\n totals[column] = value\n rows.append(totals)\n\n return {'columns': columns, 'rows': rows}\n\n def run_query(self, query, user):\n logger.debug(\"Clickhouse is about to execute query: %s\", query)\n if query == \"\":\n json_data = None\n error = \"Query is empty\"\n return json_data, error\n try:\n q = self._clickhouse_query(query)\n data = json_dumps(q)\n error = None\n except Exception as e:\n data = None\n logging.exception(e)\n error = unicode(e)\n return data, error\n\nregister(ClickHouse)\n", "path": "redash/query_runner/clickhouse.py"}]} | 1,999 | 200 |
gh_patches_debug_6611 | rasdani/github-patches | git_diff | obspy__obspy-3183 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Baer picker failing with fi_prep_cif_var error
**Description of the Problem**
I recently installed obspy on a new python install. Everything appeared to be working until I ran the tests for a package that made a call to the obspy.signal.trigger.pk_baer, which gives the following error:
```
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Input In [5], in <module>
----> 1 p_pick, phase_info = pk_baer(trace.data, df, 20, 60, 7.0, 12.0, 100, 100)
File ~/Gits/obspy/obspy/signal/trigger.py:406, in pk_baer(reltrc, samp_int, tdownmax, tupevent, thr1, thr2, preset_len, p_dur, return_cf)
402 # index in pk_mbaer.c starts with 1, 0 index is lost, length must be
403 # one shorter
404 args = (len(reltrc) - 1, C.byref(pptime), pfm, samp_int,
405 tdownmax, tupevent, thr1, thr2, preset_len, p_dur, cf_p)
--> 406 errcode = clibsignal.ppick(reltrc, *args)
407 if errcode != 0:
408 raise MemoryError("Error in function ppick of mk_mbaer.c")
RuntimeError: ffi_prep_cif_var failed
```
It seems fairly likely to me that one of the libraries I have installed introduced a problem in this environment compared to my old environment. I'm just not sure how to begin figuring out the issue. I tried it in my old environment just to be sure and it works fine.
**Steps to Reproduce**
Running the tests yields the following failures:
FAILED obspy/signal/tests/test_trigger.py::TriggerTestCase::test_pk_baer
FAILED obspy/signal/tests/test_trigger.py::TriggerTestCase::test_pk_baer_cf
in addition to a third, unrelated error in TauPy
Additionally, going through the trigger/picker tutorial will also reproduce the problem (this is probably what the test code is doing, anyways):
```
from obspy.core import read
from obspy.signal.trigger import pk_baer
trace = read("https://examples.obspy.org/ev0_6.a01.gse2")[0]
df = trace.stats.sampling_rate
p_pick, phase_info = pk_baer(trace.data, df,20, 60, 7.0, 12.0, 100, 100)
```
**Versions**
ObsPy: 1.2.2.post0+547.g221c7ef4a9.obspy.master (I tried both this and 1.2.2 as downloaded from conda-forge)
Python: 3.8.12
OS: Ubuntu 16
**Obspy Installation**
I tried installing obspy in two different ways and got the same result both ways: `conda install -c conda-forge obspy` (technically I used mamba, but that shouldn't matter) and from the latest master (`pip install -e {path_to_source}').
**Old Environment**
Obspy: 1.2.2 (installed from conda)
Python: 3.8.8
OS: Ubuntu 16
Thank you,
Shawn
</issue>
<code>
[start of obspy/signal/headers.py]
1 # -*- coding: utf-8 -*-
2 """
3 Defines the libsignal and evalresp structures and blockettes.
4 """
5 import ctypes as C # NOQA
6
7 import numpy as np
8
9 from obspy.core.util.libnames import _load_cdll
10
11
12 # Import shared libsignal
13 clibsignal = _load_cdll("signal")
14 # Import shared libevresp
15 clibevresp = _load_cdll("evresp")
16
17 clibsignal.calcSteer.argtypes = [
18 C.c_int, C.c_int, C.c_int, C.c_int, C.c_int, C.c_float,
19 np.ctypeslib.ndpointer(dtype=np.float32, ndim=3,
20 flags='C_CONTIGUOUS'),
21 np.ctypeslib.ndpointer(dtype=np.complex128, ndim=4,
22 flags='C_CONTIGUOUS'),
23 ]
24 clibsignal.calcSteer.restype = C.c_void_p
25
26 clibsignal.generalizedBeamformer.argtypes = [
27 np.ctypeslib.ndpointer(dtype=np.float64, ndim=2,
28 flags='C_CONTIGUOUS'),
29 np.ctypeslib.ndpointer(dtype=np.float64, ndim=2,
30 flags='C_CONTIGUOUS'),
31 np.ctypeslib.ndpointer(dtype=np.complex128, ndim=4,
32 flags='C_CONTIGUOUS'),
33 np.ctypeslib.ndpointer(dtype=np.complex128, ndim=3,
34 flags='C_CONTIGUOUS'),
35 C.c_int, C.c_int, C.c_int, C.c_int, C.c_int,
36 C.c_double,
37 C.c_int,
38 ]
39 clibsignal.generalizedBeamformer.restype = C.c_int
40
41 clibsignal.X_corr.argtypes = [
42 np.ctypeslib.ndpointer(dtype=np.float32, ndim=1,
43 flags='C_CONTIGUOUS'),
44 np.ctypeslib.ndpointer(dtype=np.float32, ndim=1,
45 flags='C_CONTIGUOUS'),
46 np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,
47 flags='C_CONTIGUOUS'),
48 C.c_int, C.c_int, C.c_int,
49 C.POINTER(C.c_int), C.POINTER(C.c_double)]
50 clibsignal.X_corr.restype = C.c_int
51
52 clibsignal.recstalta.argtypes = [
53 np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,
54 flags='C_CONTIGUOUS'),
55 np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,
56 flags='C_CONTIGUOUS'),
57 C.c_int, C.c_int, C.c_int]
58 clibsignal.recstalta.restype = C.c_void_p
59
60 clibsignal.ppick.argtypes = [
61 np.ctypeslib.ndpointer(dtype=np.float32, ndim=1,
62 flags='C_CONTIGUOUS'),
63 C.c_int, C.POINTER(C.c_int), C.c_char_p, C.c_float, C.c_int, C.c_int,
64 C.c_float, C.c_float, C.c_int, C.c_int]
65 clibsignal.ppick.restype = C.c_int
66
67 clibsignal.ar_picker.argtypes = [
68 np.ctypeslib.ndpointer(dtype=np.float32, ndim=1,
69 flags='C_CONTIGUOUS'),
70 np.ctypeslib.ndpointer(dtype=np.float32, ndim=1,
71 flags='C_CONTIGUOUS'),
72 np.ctypeslib.ndpointer(dtype=np.float32, ndim=1,
73 flags='C_CONTIGUOUS'),
74 C.c_int, C.c_float, C.c_float, C.c_float, C.c_float, C.c_float,
75 C.c_float, C.c_float, C.c_int, C.c_int, C.POINTER(C.c_float),
76 C.POINTER(C.c_float), C.c_double, C.c_double, C.c_int]
77 clibsignal.ar_picker.restypes = C.c_int
78
79 clibsignal.utl_geo_km.argtypes = [C.c_double, C.c_double, C.c_double,
80 C.POINTER(C.c_double),
81 C.POINTER(C.c_double)]
82 clibsignal.utl_geo_km.restype = C.c_void_p
83
84 head_stalta_t = np.dtype([
85 ('N', np.uint32),
86 ('nsta', np.uint32),
87 ('nlta', np.uint32),
88 ], align=True)
89
90 clibsignal.stalta.argtypes = [
91 np.ctypeslib.ndpointer(dtype=head_stalta_t, ndim=1,
92 flags='C_CONTIGUOUS'),
93 np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,
94 flags='C_CONTIGUOUS'),
95 np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,
96 flags='C_CONTIGUOUS'),
97 ]
98 clibsignal.stalta.restype = C.c_int
99
100 clibsignal.hermite_interpolation.argtypes = [
101 np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,
102 flags='C_CONTIGUOUS'),
103 np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,
104 flags='C_CONTIGUOUS'),
105 np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,
106 flags='C_CONTIGUOUS'),
107 np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,
108 flags='C_CONTIGUOUS'),
109 C.c_int, C.c_int, C.c_double, C.c_double]
110 clibsignal.hermite_interpolation.restype = C.c_void_p
111
112 clibsignal.lanczos_resample.argtypes = [
113 # y_in
114 np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,
115 flags='C_CONTIGUOUS'),
116 # y_out
117 np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,
118 flags='C_CONTIGUOUS'),
119 # dt
120 C.c_double,
121 # offset
122 C.c_double,
123 # len_in
124 C.c_int,
125 # len_out,
126 C.c_int,
127 # a,
128 C.c_int,
129 # window
130 C.c_int]
131 clibsignal.lanczos_resample.restype = None
132
133 clibsignal.calculate_kernel.argtypes = [
134 # double *x
135 np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,
136 flags='C_CONTIGUOUS'),
137 # double *y
138 np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,
139 flags='C_CONTIGUOUS'),
140 # int len
141 C.c_int,
142 # int a,
143 C.c_int,
144 # int return_type,
145 C.c_int,
146 # enum lanczos_window_type window
147 C.c_int]
148 clibsignal.calculate_kernel.restype = None
149
150 clibsignal.aic_simple.argtypes = [
151 # double *aic, output
152 np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,
153 flags='C_CONTIGUOUS'),
154 # double *arr, input
155 np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,
156 flags='C_CONTIGUOUS'),
157 # arr size
158 C.c_uint32]
159 clibsignal.recstalta.restype = C.c_void_p
160
161 STALEN = 64
162 NETLEN = 64
163 CHALEN = 64
164 LOCIDLEN = 64
165
166
167 class C_COMPLEX(C.Structure): # noqa
168 _fields_ = [("real", C.c_double),
169 ("imag", C.c_double)]
170
171
172 class RESPONSE(C.Structure):
173 pass
174
175
176 RESPONSE._fields_ = [("station", C.c_char * STALEN),
177 ("network", C.c_char * NETLEN),
178 ("locid", C.c_char * LOCIDLEN),
179 ("channel", C.c_char * CHALEN),
180 ("rvec", C.POINTER(C_COMPLEX)),
181 ("nfreqs", C.c_int),
182 ("freqs", C.POINTER(C.c_double)),
183 ("next", C.POINTER(RESPONSE))]
184
185 clibevresp.evresp.argtypes = [
186 C.c_char_p,
187 C.c_char_p,
188 C.c_char_p,
189 C.c_char_p,
190 C.c_char_p,
191 C.c_char_p,
192 C.c_char_p,
193 np.ctypeslib.ndpointer(dtype=np.float64,
194 ndim=1,
195 flags='C_CONTIGUOUS'),
196 C.c_int,
197 C.c_char_p,
198 C.c_char_p,
199 C.c_int,
200 C.c_int,
201 C.c_int,
202 C.c_int]
203 clibevresp.evresp.restype = C.POINTER(RESPONSE)
204
205 clibevresp.free_response.argtypes = [C.POINTER(RESPONSE)]
206 clibevresp.free_response.restype = C.c_void_p
207
[end of obspy/signal/headers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/obspy/signal/headers.py b/obspy/signal/headers.py
--- a/obspy/signal/headers.py
+++ b/obspy/signal/headers.py
@@ -61,7 +61,7 @@
np.ctypeslib.ndpointer(dtype=np.float32, ndim=1,
flags='C_CONTIGUOUS'),
C.c_int, C.POINTER(C.c_int), C.c_char_p, C.c_float, C.c_int, C.c_int,
- C.c_float, C.c_float, C.c_int, C.c_int]
+ C.c_float, C.c_float, C.c_int, C.c_int, C.POINTER(C.c_float)]
clibsignal.ppick.restype = C.c_int
clibsignal.ar_picker.argtypes = [
| {"golden_diff": "diff --git a/obspy/signal/headers.py b/obspy/signal/headers.py\n--- a/obspy/signal/headers.py\n+++ b/obspy/signal/headers.py\n@@ -61,7 +61,7 @@\n np.ctypeslib.ndpointer(dtype=np.float32, ndim=1,\n flags='C_CONTIGUOUS'),\n C.c_int, C.POINTER(C.c_int), C.c_char_p, C.c_float, C.c_int, C.c_int,\n- C.c_float, C.c_float, C.c_int, C.c_int]\n+ C.c_float, C.c_float, C.c_int, C.c_int, C.POINTER(C.c_float)]\n clibsignal.ppick.restype = C.c_int\n \n clibsignal.ar_picker.argtypes = [\n", "issue": "Baer picker failing with fi_prep_cif_var error\n**Description of the Problem**\r\n\r\nI recently installed obspy on a new python install. Everything appeared to be working until I ran the tests for a package that made a call to the obspy.signal.trigger.pk_baer, which gives the following error:\r\n\r\n```\r\n---------------------------------------------------------------------------\r\nRuntimeError Traceback (most recent call last)\r\nInput In [5], in <module>\r\n----> 1 p_pick, phase_info = pk_baer(trace.data, df, 20, 60, 7.0, 12.0, 100, 100)\r\n\r\nFile ~/Gits/obspy/obspy/signal/trigger.py:406, in pk_baer(reltrc, samp_int, tdownmax, tupevent, thr1, thr2, preset_len, p_dur, return_cf)\r\n 402 # index in pk_mbaer.c starts with 1, 0 index is lost, length must be\r\n 403 # one shorter\r\n 404 args = (len(reltrc) - 1, C.byref(pptime), pfm, samp_int,\r\n 405 tdownmax, tupevent, thr1, thr2, preset_len, p_dur, cf_p)\r\n--> 406 errcode = clibsignal.ppick(reltrc, *args)\r\n 407 if errcode != 0:\r\n 408 raise MemoryError(\"Error in function ppick of mk_mbaer.c\")\r\n\r\nRuntimeError: ffi_prep_cif_var failed\r\n```\r\n\r\nIt seems fairly likely to me that one of the libraries I have installed introduced a problem in this environment compared to my old environment. I'm just not sure how to begin figuring out the issue. I tried it in my old environment just to be sure and it works fine.\r\n\r\n**Steps to Reproduce**\r\nRunning the tests yields the following failures:\r\nFAILED obspy/signal/tests/test_trigger.py::TriggerTestCase::test_pk_baer\r\nFAILED obspy/signal/tests/test_trigger.py::TriggerTestCase::test_pk_baer_cf\r\nin addition to a third, unrelated error in TauPy\r\n\r\nAdditionally, going through the trigger/picker tutorial will also reproduce the problem (this is probably what the test code is doing, anyways):\r\n```\r\nfrom obspy.core import read\r\nfrom obspy.signal.trigger import pk_baer\r\ntrace = read(\"https://examples.obspy.org/ev0_6.a01.gse2\")[0]\r\ndf = trace.stats.sampling_rate\r\np_pick, phase_info = pk_baer(trace.data, df,20, 60, 7.0, 12.0, 100, 100)\r\n```\r\n\r\n**Versions**\r\nObsPy: 1.2.2.post0+547.g221c7ef4a9.obspy.master (I tried both this and 1.2.2 as downloaded from conda-forge)\r\nPython: 3.8.12\r\nOS: Ubuntu 16\r\n\r\n**Obspy Installation**\r\nI tried installing obspy in two different ways and got the same result both ways: `conda install -c conda-forge obspy` (technically I used mamba, but that shouldn't matter) and from the latest master (`pip install -e {path_to_source}').\r\n\r\n**Old Environment**\r\nObspy: 1.2.2 (installed from conda)\r\nPython: 3.8.8\r\nOS: Ubuntu 16\r\n\r\nThank you,\r\nShawn\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\nDefines the libsignal and evalresp structures and blockettes.\n\"\"\"\nimport ctypes as C # NOQA\n\nimport numpy as np\n\nfrom obspy.core.util.libnames import _load_cdll\n\n\n# Import shared libsignal\nclibsignal = _load_cdll(\"signal\")\n# Import shared libevresp\nclibevresp = _load_cdll(\"evresp\")\n\nclibsignal.calcSteer.argtypes = [\n C.c_int, C.c_int, C.c_int, C.c_int, C.c_int, C.c_float,\n np.ctypeslib.ndpointer(dtype=np.float32, ndim=3,\n flags='C_CONTIGUOUS'),\n np.ctypeslib.ndpointer(dtype=np.complex128, ndim=4,\n flags='C_CONTIGUOUS'),\n]\nclibsignal.calcSteer.restype = C.c_void_p\n\nclibsignal.generalizedBeamformer.argtypes = [\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=2,\n flags='C_CONTIGUOUS'),\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=2,\n flags='C_CONTIGUOUS'),\n np.ctypeslib.ndpointer(dtype=np.complex128, ndim=4,\n flags='C_CONTIGUOUS'),\n np.ctypeslib.ndpointer(dtype=np.complex128, ndim=3,\n flags='C_CONTIGUOUS'),\n C.c_int, C.c_int, C.c_int, C.c_int, C.c_int,\n C.c_double,\n C.c_int,\n]\nclibsignal.generalizedBeamformer.restype = C.c_int\n\nclibsignal.X_corr.argtypes = [\n np.ctypeslib.ndpointer(dtype=np.float32, ndim=1,\n flags='C_CONTIGUOUS'),\n np.ctypeslib.ndpointer(dtype=np.float32, ndim=1,\n flags='C_CONTIGUOUS'),\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags='C_CONTIGUOUS'),\n C.c_int, C.c_int, C.c_int,\n C.POINTER(C.c_int), C.POINTER(C.c_double)]\nclibsignal.X_corr.restype = C.c_int\n\nclibsignal.recstalta.argtypes = [\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags='C_CONTIGUOUS'),\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags='C_CONTIGUOUS'),\n C.c_int, C.c_int, C.c_int]\nclibsignal.recstalta.restype = C.c_void_p\n\nclibsignal.ppick.argtypes = [\n np.ctypeslib.ndpointer(dtype=np.float32, ndim=1,\n flags='C_CONTIGUOUS'),\n C.c_int, C.POINTER(C.c_int), C.c_char_p, C.c_float, C.c_int, C.c_int,\n C.c_float, C.c_float, C.c_int, C.c_int]\nclibsignal.ppick.restype = C.c_int\n\nclibsignal.ar_picker.argtypes = [\n np.ctypeslib.ndpointer(dtype=np.float32, ndim=1,\n flags='C_CONTIGUOUS'),\n np.ctypeslib.ndpointer(dtype=np.float32, ndim=1,\n flags='C_CONTIGUOUS'),\n np.ctypeslib.ndpointer(dtype=np.float32, ndim=1,\n flags='C_CONTIGUOUS'),\n C.c_int, C.c_float, C.c_float, C.c_float, C.c_float, C.c_float,\n C.c_float, C.c_float, C.c_int, C.c_int, C.POINTER(C.c_float),\n C.POINTER(C.c_float), C.c_double, C.c_double, C.c_int]\nclibsignal.ar_picker.restypes = C.c_int\n\nclibsignal.utl_geo_km.argtypes = [C.c_double, C.c_double, C.c_double,\n C.POINTER(C.c_double),\n C.POINTER(C.c_double)]\nclibsignal.utl_geo_km.restype = C.c_void_p\n\nhead_stalta_t = np.dtype([\n ('N', np.uint32),\n ('nsta', np.uint32),\n ('nlta', np.uint32),\n], align=True)\n\nclibsignal.stalta.argtypes = [\n np.ctypeslib.ndpointer(dtype=head_stalta_t, ndim=1,\n flags='C_CONTIGUOUS'),\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags='C_CONTIGUOUS'),\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags='C_CONTIGUOUS'),\n]\nclibsignal.stalta.restype = C.c_int\n\nclibsignal.hermite_interpolation.argtypes = [\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags='C_CONTIGUOUS'),\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags='C_CONTIGUOUS'),\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags='C_CONTIGUOUS'),\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags='C_CONTIGUOUS'),\n C.c_int, C.c_int, C.c_double, C.c_double]\nclibsignal.hermite_interpolation.restype = C.c_void_p\n\nclibsignal.lanczos_resample.argtypes = [\n # y_in\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags='C_CONTIGUOUS'),\n # y_out\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags='C_CONTIGUOUS'),\n # dt\n C.c_double,\n # offset\n C.c_double,\n # len_in\n C.c_int,\n # len_out,\n C.c_int,\n # a,\n C.c_int,\n # window\n C.c_int]\nclibsignal.lanczos_resample.restype = None\n\nclibsignal.calculate_kernel.argtypes = [\n # double *x\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags='C_CONTIGUOUS'),\n # double *y\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags='C_CONTIGUOUS'),\n # int len\n C.c_int,\n # int a,\n C.c_int,\n # int return_type,\n C.c_int,\n # enum lanczos_window_type window\n C.c_int]\nclibsignal.calculate_kernel.restype = None\n\nclibsignal.aic_simple.argtypes = [\n # double *aic, output\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags='C_CONTIGUOUS'),\n # double *arr, input\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags='C_CONTIGUOUS'),\n # arr size\n C.c_uint32]\nclibsignal.recstalta.restype = C.c_void_p\n\nSTALEN = 64\nNETLEN = 64\nCHALEN = 64\nLOCIDLEN = 64\n\n\nclass C_COMPLEX(C.Structure): # noqa\n _fields_ = [(\"real\", C.c_double),\n (\"imag\", C.c_double)]\n\n\nclass RESPONSE(C.Structure):\n pass\n\n\nRESPONSE._fields_ = [(\"station\", C.c_char * STALEN),\n (\"network\", C.c_char * NETLEN),\n (\"locid\", C.c_char * LOCIDLEN),\n (\"channel\", C.c_char * CHALEN),\n (\"rvec\", C.POINTER(C_COMPLEX)),\n (\"nfreqs\", C.c_int),\n (\"freqs\", C.POINTER(C.c_double)),\n (\"next\", C.POINTER(RESPONSE))]\n\nclibevresp.evresp.argtypes = [\n C.c_char_p,\n C.c_char_p,\n C.c_char_p,\n C.c_char_p,\n C.c_char_p,\n C.c_char_p,\n C.c_char_p,\n np.ctypeslib.ndpointer(dtype=np.float64,\n ndim=1,\n flags='C_CONTIGUOUS'),\n C.c_int,\n C.c_char_p,\n C.c_char_p,\n C.c_int,\n C.c_int,\n C.c_int,\n C.c_int]\nclibevresp.evresp.restype = C.POINTER(RESPONSE)\n\nclibevresp.free_response.argtypes = [C.POINTER(RESPONSE)]\nclibevresp.free_response.restype = C.c_void_p\n", "path": "obspy/signal/headers.py"}]} | 3,759 | 176 |
gh_patches_debug_13711 | rasdani/github-patches | git_diff | modin-project__modin-1146 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Update pandas version to 1.0.3
</issue>
<code>
[start of setup.py]
1 from setuptools import setup, find_packages
2 import versioneer
3
4 with open("README.md", "r") as fh:
5 long_description = fh.read()
6
7 dask_deps = ["dask>=2.1.0", "distributed>=2.3.2"]
8 ray_deps = ["ray==0.8.0"]
9
10 setup(
11 name="modin",
12 version=versioneer.get_version(),
13 cmdclass=versioneer.get_cmdclass(),
14 description="Modin: Make your pandas code run faster by changing one line of code.",
15 packages=find_packages(),
16 url="https://github.com/modin-project/modin",
17 long_description=long_description,
18 long_description_content_type="text/markdown",
19 install_requires=["pandas==1.0.1", "packaging"],
20 extras_require={
21 # can be installed by pip install modin[dask]
22 "dask": dask_deps,
23 "ray": ray_deps,
24 "all": dask_deps + ray_deps,
25 },
26 python_requires=">=3.5",
27 )
28
[end of setup.py]
[start of modin/pandas/__init__.py]
1 import pandas
2
3 __pandas_version__ = "1.0.1"
4
5 if pandas.__version__ != __pandas_version__:
6 import warnings
7
8 warnings.warn(
9 "The pandas version installed does not match the required pandas version in "
10 "Modin. This may cause undesired side effects!".format(__pandas_version__)
11 )
12
13 from pandas import (
14 eval,
15 unique,
16 value_counts,
17 cut,
18 to_numeric,
19 factorize,
20 test,
21 qcut,
22 date_range,
23 period_range,
24 Index,
25 MultiIndex,
26 CategoricalIndex,
27 bdate_range,
28 DatetimeIndex,
29 Timedelta,
30 Timestamp,
31 to_timedelta,
32 set_eng_float_format,
33 options,
34 set_option,
35 NaT,
36 PeriodIndex,
37 Categorical,
38 Interval,
39 UInt8Dtype,
40 UInt16Dtype,
41 UInt32Dtype,
42 UInt64Dtype,
43 SparseDtype,
44 Int8Dtype,
45 Int16Dtype,
46 Int32Dtype,
47 Int64Dtype,
48 StringDtype,
49 BooleanDtype,
50 CategoricalDtype,
51 DatetimeTZDtype,
52 IntervalDtype,
53 PeriodDtype,
54 RangeIndex,
55 Int64Index,
56 UInt64Index,
57 Float64Index,
58 TimedeltaIndex,
59 IntervalIndex,
60 IndexSlice,
61 Grouper,
62 array,
63 Period,
64 show_versions,
65 DateOffset,
66 timedelta_range,
67 infer_freq,
68 interval_range,
69 ExcelWriter,
70 datetime,
71 NamedAgg,
72 NA,
73 )
74 import threading
75 import os
76 import types
77 import sys
78 import multiprocessing
79
80 from .. import __version__
81 from .concat import concat
82 from .dataframe import DataFrame
83 from .datetimes import to_datetime
84 from .io import (
85 read_csv,
86 read_parquet,
87 read_json,
88 read_html,
89 read_clipboard,
90 read_excel,
91 read_hdf,
92 read_feather,
93 read_stata,
94 read_sas,
95 read_pickle,
96 read_sql,
97 read_gbq,
98 read_table,
99 read_fwf,
100 read_sql_table,
101 read_sql_query,
102 read_spss,
103 ExcelFile,
104 to_pickle,
105 HDFStore,
106 json_normalize,
107 read_orc,
108 )
109 from .reshape import get_dummies, melt, crosstab, lreshape, wide_to_long
110 from .series import Series
111 from .general import (
112 isna,
113 isnull,
114 merge,
115 merge_asof,
116 merge_ordered,
117 pivot_table,
118 notnull,
119 notna,
120 pivot,
121 )
122 from .plotting import Plotting as plotting
123 from .. import __execution_engine__ as execution_engine
124
125 # Set this so that Pandas doesn't try to multithread by itself
126 os.environ["OMP_NUM_THREADS"] = "1"
127 num_cpus = 1
128
129
130 def initialize_ray():
131 import ray
132
133 """Initializes ray based on environment variables and internal defaults."""
134 if threading.current_thread().name == "MainThread":
135 import secrets
136
137 plasma_directory = None
138 num_cpus = os.environ.get("MODIN_CPUS", None) or multiprocessing.cpu_count()
139 cluster = os.environ.get("MODIN_RAY_CLUSTER", None)
140 redis_address = os.environ.get("MODIN_REDIS_ADDRESS", None)
141 redis_password = secrets.token_hex(16)
142 if cluster == "True" and redis_address is not None:
143 # We only start ray in a cluster setting for the head node.
144 ray.init(
145 num_cpus=int(num_cpus),
146 include_webui=False,
147 ignore_reinit_error=True,
148 redis_address=redis_address,
149 redis_password=redis_password,
150 logging_level=100,
151 )
152 elif cluster is None:
153 object_store_memory = os.environ.get("MODIN_MEMORY", None)
154 if os.environ.get("MODIN_OUT_OF_CORE", "False").title() == "True":
155 from tempfile import gettempdir
156
157 plasma_directory = gettempdir()
158 # We may have already set the memory from the environment variable, we don't
159 # want to overwrite that value if we have.
160 if object_store_memory is None:
161 # Round down to the nearest Gigabyte.
162 mem_bytes = ray.utils.get_system_memory() // 10 ** 9 * 10 ** 9
163 # Default to 8x memory for out of core
164 object_store_memory = 8 * mem_bytes
165 # In case anything failed above, we can still improve the memory for Modin.
166 if object_store_memory is None:
167 # Round down to the nearest Gigabyte.
168 object_store_memory = int(
169 0.6 * ray.utils.get_system_memory() // 10 ** 9 * 10 ** 9
170 )
171 # If the memory pool is smaller than 2GB, just use the default in ray.
172 if object_store_memory == 0:
173 object_store_memory = None
174 else:
175 object_store_memory = int(object_store_memory)
176 ray.init(
177 num_cpus=int(num_cpus),
178 include_webui=False,
179 ignore_reinit_error=True,
180 plasma_directory=plasma_directory,
181 object_store_memory=object_store_memory,
182 redis_address=redis_address,
183 redis_password=redis_password,
184 logging_level=100,
185 memory=object_store_memory,
186 )
187 # Register custom serializer for method objects to avoid warning message.
188 # We serialize `MethodType` objects when we use AxisPartition operations.
189 ray.register_custom_serializer(types.MethodType, use_pickle=True)
190
191 # Register a fix import function to run on all_workers including the driver.
192 # This is a hack solution to fix #647, #746
193 def move_stdlib_ahead_of_site_packages(*args):
194 site_packages_path = None
195 site_packages_path_index = -1
196 for i, path in enumerate(sys.path):
197 if sys.exec_prefix in path and path.endswith("site-packages"):
198 site_packages_path = path
199 site_packages_path_index = i
200 # break on first found
201 break
202
203 if site_packages_path is not None:
204 # stdlib packages layout as follows:
205 # - python3.x
206 # - typing.py
207 # - site-packages/
208 # - pandas
209 # So extracting the dirname of the site_packages can point us
210 # to the directory containing standard libraries.
211 sys.path.insert(
212 site_packages_path_index, os.path.dirname(site_packages_path)
213 )
214
215 move_stdlib_ahead_of_site_packages()
216 ray.worker.global_worker.run_function_on_all_workers(
217 move_stdlib_ahead_of_site_packages
218 )
219
220
221 if execution_engine == "Ray":
222 import ray
223
224 initialize_ray()
225 num_cpus = ray.cluster_resources()["CPU"]
226 elif execution_engine == "Dask": # pragma: no cover
227 from distributed.client import get_client
228 import warnings
229
230 if threading.current_thread().name == "MainThread":
231 warnings.warn("The Dask Engine for Modin is experimental.")
232 try:
233 client = get_client()
234 except ValueError:
235 from distributed import Client
236
237 num_cpus = os.environ.get("MODIN_CPUS", None) or multiprocessing.cpu_count()
238 client = Client(n_workers=int(num_cpus))
239 elif execution_engine != "Python":
240 raise ImportError("Unrecognized execution engine: {}.".format(execution_engine))
241
242 DEFAULT_NPARTITIONS = max(4, int(num_cpus))
243
244 __all__ = [
245 "DataFrame",
246 "Series",
247 "read_csv",
248 "read_parquet",
249 "read_json",
250 "read_html",
251 "read_clipboard",
252 "read_excel",
253 "read_hdf",
254 "read_feather",
255 "read_stata",
256 "read_sas",
257 "read_pickle",
258 "read_sql",
259 "read_gbq",
260 "read_table",
261 "read_spss",
262 "read_orc",
263 "json_normalize",
264 "concat",
265 "eval",
266 "unique",
267 "value_counts",
268 "cut",
269 "to_numeric",
270 "factorize",
271 "test",
272 "qcut",
273 "to_datetime",
274 "get_dummies",
275 "isna",
276 "isnull",
277 "merge",
278 "pivot_table",
279 "date_range",
280 "Index",
281 "MultiIndex",
282 "Series",
283 "bdate_range",
284 "period_range",
285 "DatetimeIndex",
286 "to_timedelta",
287 "set_eng_float_format",
288 "options",
289 "set_option",
290 "CategoricalIndex",
291 "Timedelta",
292 "Timestamp",
293 "NaT",
294 "PeriodIndex",
295 "Categorical",
296 "__version__",
297 "melt",
298 "crosstab",
299 "plotting",
300 "Interval",
301 "UInt8Dtype",
302 "UInt16Dtype",
303 "UInt32Dtype",
304 "UInt64Dtype",
305 "SparseDtype",
306 "Int8Dtype",
307 "Int16Dtype",
308 "Int32Dtype",
309 "Int64Dtype",
310 "CategoricalDtype",
311 "DatetimeTZDtype",
312 "IntervalDtype",
313 "PeriodDtype",
314 "BooleanDtype",
315 "StringDtype",
316 "NA",
317 "RangeIndex",
318 "Int64Index",
319 "UInt64Index",
320 "Float64Index",
321 "TimedeltaIndex",
322 "IntervalIndex",
323 "IndexSlice",
324 "Grouper",
325 "array",
326 "Period",
327 "show_versions",
328 "DateOffset",
329 "timedelta_range",
330 "infer_freq",
331 "interval_range",
332 "ExcelWriter",
333 "read_fwf",
334 "read_sql_table",
335 "read_sql_query",
336 "ExcelFile",
337 "to_pickle",
338 "HDFStore",
339 "lreshape",
340 "wide_to_long",
341 "merge_asof",
342 "merge_ordered",
343 "notnull",
344 "notna",
345 "pivot",
346 "datetime",
347 "NamedAgg",
348 "DEFAULT_NPARTITIONS",
349 ]
350
351 del pandas
352
[end of modin/pandas/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/modin/pandas/__init__.py b/modin/pandas/__init__.py
--- a/modin/pandas/__init__.py
+++ b/modin/pandas/__init__.py
@@ -1,6 +1,6 @@
import pandas
-__pandas_version__ = "1.0.1"
+__pandas_version__ = "1.0.3"
if pandas.__version__ != __pandas_version__:
import warnings
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -16,7 +16,7 @@
url="https://github.com/modin-project/modin",
long_description=long_description,
long_description_content_type="text/markdown",
- install_requires=["pandas==1.0.1", "packaging"],
+ install_requires=["pandas==1.0.3", "packaging"],
extras_require={
# can be installed by pip install modin[dask]
"dask": dask_deps,
| {"golden_diff": "diff --git a/modin/pandas/__init__.py b/modin/pandas/__init__.py\n--- a/modin/pandas/__init__.py\n+++ b/modin/pandas/__init__.py\n@@ -1,6 +1,6 @@\n import pandas\n \n-__pandas_version__ = \"1.0.1\"\n+__pandas_version__ = \"1.0.3\"\n \n if pandas.__version__ != __pandas_version__:\n import warnings\ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -16,7 +16,7 @@\n url=\"https://github.com/modin-project/modin\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n- install_requires=[\"pandas==1.0.1\", \"packaging\"],\n+ install_requires=[\"pandas==1.0.3\", \"packaging\"],\n extras_require={\n # can be installed by pip install modin[dask]\n \"dask\": dask_deps,\n", "issue": "Update pandas version to 1.0.3\n\n", "before_files": [{"content": "from setuptools import setup, find_packages\nimport versioneer\n\nwith open(\"README.md\", \"r\") as fh:\n long_description = fh.read()\n\ndask_deps = [\"dask>=2.1.0\", \"distributed>=2.3.2\"]\nray_deps = [\"ray==0.8.0\"]\n\nsetup(\n name=\"modin\",\n version=versioneer.get_version(),\n cmdclass=versioneer.get_cmdclass(),\n description=\"Modin: Make your pandas code run faster by changing one line of code.\",\n packages=find_packages(),\n url=\"https://github.com/modin-project/modin\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n install_requires=[\"pandas==1.0.1\", \"packaging\"],\n extras_require={\n # can be installed by pip install modin[dask]\n \"dask\": dask_deps,\n \"ray\": ray_deps,\n \"all\": dask_deps + ray_deps,\n },\n python_requires=\">=3.5\",\n)\n", "path": "setup.py"}, {"content": "import pandas\n\n__pandas_version__ = \"1.0.1\"\n\nif pandas.__version__ != __pandas_version__:\n import warnings\n\n warnings.warn(\n \"The pandas version installed does not match the required pandas version in \"\n \"Modin. This may cause undesired side effects!\".format(__pandas_version__)\n )\n\nfrom pandas import (\n eval,\n unique,\n value_counts,\n cut,\n to_numeric,\n factorize,\n test,\n qcut,\n date_range,\n period_range,\n Index,\n MultiIndex,\n CategoricalIndex,\n bdate_range,\n DatetimeIndex,\n Timedelta,\n Timestamp,\n to_timedelta,\n set_eng_float_format,\n options,\n set_option,\n NaT,\n PeriodIndex,\n Categorical,\n Interval,\n UInt8Dtype,\n UInt16Dtype,\n UInt32Dtype,\n UInt64Dtype,\n SparseDtype,\n Int8Dtype,\n Int16Dtype,\n Int32Dtype,\n Int64Dtype,\n StringDtype,\n BooleanDtype,\n CategoricalDtype,\n DatetimeTZDtype,\n IntervalDtype,\n PeriodDtype,\n RangeIndex,\n Int64Index,\n UInt64Index,\n Float64Index,\n TimedeltaIndex,\n IntervalIndex,\n IndexSlice,\n Grouper,\n array,\n Period,\n show_versions,\n DateOffset,\n timedelta_range,\n infer_freq,\n interval_range,\n ExcelWriter,\n datetime,\n NamedAgg,\n NA,\n)\nimport threading\nimport os\nimport types\nimport sys\nimport multiprocessing\n\nfrom .. import __version__\nfrom .concat import concat\nfrom .dataframe import DataFrame\nfrom .datetimes import to_datetime\nfrom .io import (\n read_csv,\n read_parquet,\n read_json,\n read_html,\n read_clipboard,\n read_excel,\n read_hdf,\n read_feather,\n read_stata,\n read_sas,\n read_pickle,\n read_sql,\n read_gbq,\n read_table,\n read_fwf,\n read_sql_table,\n read_sql_query,\n read_spss,\n ExcelFile,\n to_pickle,\n HDFStore,\n json_normalize,\n read_orc,\n)\nfrom .reshape import get_dummies, melt, crosstab, lreshape, wide_to_long\nfrom .series import Series\nfrom .general import (\n isna,\n isnull,\n merge,\n merge_asof,\n merge_ordered,\n pivot_table,\n notnull,\n notna,\n pivot,\n)\nfrom .plotting import Plotting as plotting\nfrom .. import __execution_engine__ as execution_engine\n\n# Set this so that Pandas doesn't try to multithread by itself\nos.environ[\"OMP_NUM_THREADS\"] = \"1\"\nnum_cpus = 1\n\n\ndef initialize_ray():\n import ray\n\n \"\"\"Initializes ray based on environment variables and internal defaults.\"\"\"\n if threading.current_thread().name == \"MainThread\":\n import secrets\n\n plasma_directory = None\n num_cpus = os.environ.get(\"MODIN_CPUS\", None) or multiprocessing.cpu_count()\n cluster = os.environ.get(\"MODIN_RAY_CLUSTER\", None)\n redis_address = os.environ.get(\"MODIN_REDIS_ADDRESS\", None)\n redis_password = secrets.token_hex(16)\n if cluster == \"True\" and redis_address is not None:\n # We only start ray in a cluster setting for the head node.\n ray.init(\n num_cpus=int(num_cpus),\n include_webui=False,\n ignore_reinit_error=True,\n redis_address=redis_address,\n redis_password=redis_password,\n logging_level=100,\n )\n elif cluster is None:\n object_store_memory = os.environ.get(\"MODIN_MEMORY\", None)\n if os.environ.get(\"MODIN_OUT_OF_CORE\", \"False\").title() == \"True\":\n from tempfile import gettempdir\n\n plasma_directory = gettempdir()\n # We may have already set the memory from the environment variable, we don't\n # want to overwrite that value if we have.\n if object_store_memory is None:\n # Round down to the nearest Gigabyte.\n mem_bytes = ray.utils.get_system_memory() // 10 ** 9 * 10 ** 9\n # Default to 8x memory for out of core\n object_store_memory = 8 * mem_bytes\n # In case anything failed above, we can still improve the memory for Modin.\n if object_store_memory is None:\n # Round down to the nearest Gigabyte.\n object_store_memory = int(\n 0.6 * ray.utils.get_system_memory() // 10 ** 9 * 10 ** 9\n )\n # If the memory pool is smaller than 2GB, just use the default in ray.\n if object_store_memory == 0:\n object_store_memory = None\n else:\n object_store_memory = int(object_store_memory)\n ray.init(\n num_cpus=int(num_cpus),\n include_webui=False,\n ignore_reinit_error=True,\n plasma_directory=plasma_directory,\n object_store_memory=object_store_memory,\n redis_address=redis_address,\n redis_password=redis_password,\n logging_level=100,\n memory=object_store_memory,\n )\n # Register custom serializer for method objects to avoid warning message.\n # We serialize `MethodType` objects when we use AxisPartition operations.\n ray.register_custom_serializer(types.MethodType, use_pickle=True)\n\n # Register a fix import function to run on all_workers including the driver.\n # This is a hack solution to fix #647, #746\n def move_stdlib_ahead_of_site_packages(*args):\n site_packages_path = None\n site_packages_path_index = -1\n for i, path in enumerate(sys.path):\n if sys.exec_prefix in path and path.endswith(\"site-packages\"):\n site_packages_path = path\n site_packages_path_index = i\n # break on first found\n break\n\n if site_packages_path is not None:\n # stdlib packages layout as follows:\n # - python3.x\n # - typing.py\n # - site-packages/\n # - pandas\n # So extracting the dirname of the site_packages can point us\n # to the directory containing standard libraries.\n sys.path.insert(\n site_packages_path_index, os.path.dirname(site_packages_path)\n )\n\n move_stdlib_ahead_of_site_packages()\n ray.worker.global_worker.run_function_on_all_workers(\n move_stdlib_ahead_of_site_packages\n )\n\n\nif execution_engine == \"Ray\":\n import ray\n\n initialize_ray()\n num_cpus = ray.cluster_resources()[\"CPU\"]\nelif execution_engine == \"Dask\": # pragma: no cover\n from distributed.client import get_client\n import warnings\n\n if threading.current_thread().name == \"MainThread\":\n warnings.warn(\"The Dask Engine for Modin is experimental.\")\n try:\n client = get_client()\n except ValueError:\n from distributed import Client\n\n num_cpus = os.environ.get(\"MODIN_CPUS\", None) or multiprocessing.cpu_count()\n client = Client(n_workers=int(num_cpus))\nelif execution_engine != \"Python\":\n raise ImportError(\"Unrecognized execution engine: {}.\".format(execution_engine))\n\nDEFAULT_NPARTITIONS = max(4, int(num_cpus))\n\n__all__ = [\n \"DataFrame\",\n \"Series\",\n \"read_csv\",\n \"read_parquet\",\n \"read_json\",\n \"read_html\",\n \"read_clipboard\",\n \"read_excel\",\n \"read_hdf\",\n \"read_feather\",\n \"read_stata\",\n \"read_sas\",\n \"read_pickle\",\n \"read_sql\",\n \"read_gbq\",\n \"read_table\",\n \"read_spss\",\n \"read_orc\",\n \"json_normalize\",\n \"concat\",\n \"eval\",\n \"unique\",\n \"value_counts\",\n \"cut\",\n \"to_numeric\",\n \"factorize\",\n \"test\",\n \"qcut\",\n \"to_datetime\",\n \"get_dummies\",\n \"isna\",\n \"isnull\",\n \"merge\",\n \"pivot_table\",\n \"date_range\",\n \"Index\",\n \"MultiIndex\",\n \"Series\",\n \"bdate_range\",\n \"period_range\",\n \"DatetimeIndex\",\n \"to_timedelta\",\n \"set_eng_float_format\",\n \"options\",\n \"set_option\",\n \"CategoricalIndex\",\n \"Timedelta\",\n \"Timestamp\",\n \"NaT\",\n \"PeriodIndex\",\n \"Categorical\",\n \"__version__\",\n \"melt\",\n \"crosstab\",\n \"plotting\",\n \"Interval\",\n \"UInt8Dtype\",\n \"UInt16Dtype\",\n \"UInt32Dtype\",\n \"UInt64Dtype\",\n \"SparseDtype\",\n \"Int8Dtype\",\n \"Int16Dtype\",\n \"Int32Dtype\",\n \"Int64Dtype\",\n \"CategoricalDtype\",\n \"DatetimeTZDtype\",\n \"IntervalDtype\",\n \"PeriodDtype\",\n \"BooleanDtype\",\n \"StringDtype\",\n \"NA\",\n \"RangeIndex\",\n \"Int64Index\",\n \"UInt64Index\",\n \"Float64Index\",\n \"TimedeltaIndex\",\n \"IntervalIndex\",\n \"IndexSlice\",\n \"Grouper\",\n \"array\",\n \"Period\",\n \"show_versions\",\n \"DateOffset\",\n \"timedelta_range\",\n \"infer_freq\",\n \"interval_range\",\n \"ExcelWriter\",\n \"read_fwf\",\n \"read_sql_table\",\n \"read_sql_query\",\n \"ExcelFile\",\n \"to_pickle\",\n \"HDFStore\",\n \"lreshape\",\n \"wide_to_long\",\n \"merge_asof\",\n \"merge_ordered\",\n \"notnull\",\n \"notna\",\n \"pivot\",\n \"datetime\",\n \"NamedAgg\",\n \"DEFAULT_NPARTITIONS\",\n]\n\ndel pandas\n", "path": "modin/pandas/__init__.py"}]} | 3,967 | 226 |
gh_patches_debug_17760 | rasdani/github-patches | git_diff | joke2k__faker-105 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Default locale to language if no territory given.
It would be great that if faker was initialized with only a locale and no territory, that it would use a sensible default.
For example I currently have to do the following if using something such as "en" instead of "en_US".
``` py
from faker import Factory
from faker import AVAILABLE_LOCALES
locale = 'en'
if locale not in AVAILABLE_LOCALES:
locale = next(l for l in AVAILABLE_LOCALES if l.startswith(locale))
factory = Factory.create(locale)
```
This happens when using dynamic mock data in local development where django sets the locale to "en" because we do not define territories.
</issue>
<code>
[start of faker/factory.py]
1 from __future__ import unicode_literals
2 from __future__ import absolute_import
3 import sys
4 from faker import DEFAULT_LOCALE, DEFAULT_PROVIDERS, AVAILABLE_LOCALES
5 from faker import Generator
6 from faker import providers as providers_mod
7
8
9 class Factory(object):
10
11 @classmethod
12 def create(cls, locale=None, providers=None, generator=None, **config):
13
14 # fix locale to package name
15 locale = locale.replace('-', '_') if locale else DEFAULT_LOCALE
16 if '_' in locale:
17 locale = locale[:2] + locale[2:].upper()
18 if locale not in AVAILABLE_LOCALES:
19 raise AttributeError('Invalid configuration for faker locale "{0}"'.format(locale))
20
21 providers = providers or DEFAULT_PROVIDERS
22
23 faker = generator or Generator(**config)
24 faker.add_provider(providers_mod.BaseProvider)
25 for provider_name in providers:
26
27 provider_class, lang_found = cls._get_provider_class(provider_name, locale)
28 provider = provider_class(faker)
29 provider.__provider__ = provider_name
30 provider.__lang__ = lang_found
31 faker.add_provider(provider)
32
33 return faker
34
35 @classmethod
36 def _get_provider_class(cls, provider, locale=''):
37
38 provider_class = cls._find_provider_class(provider, locale)
39
40 if provider_class:
41 return provider_class, locale
42
43 if locale and locale != DEFAULT_LOCALE:
44 # fallback to default locale
45 provider_class = cls._find_provider_class(provider, DEFAULT_LOCALE)
46 if provider_class:
47 return provider_class, DEFAULT_LOCALE
48
49 # fallback to no locale
50 provider_class = cls._find_provider_class(provider)
51 if provider_class:
52 return provider_class, None
53
54 raise ValueError('Unable to find provider "{0}" with locale "{1}"'.format(provider, locale))
55
56 @classmethod
57 def _find_provider_class(cls, provider, locale=''):
58
59 path = "{providers}{lang}.{provider}".format(
60 providers=providers_mod.__package__ or providers_mod.__name__,
61 lang='.' + locale if locale else '',
62 provider=provider
63 )
64
65 try:
66 __import__(path)
67 except ImportError:
68 return None
69
70 return sys.modules[path].Provider
71
[end of faker/factory.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/faker/factory.py b/faker/factory.py
--- a/faker/factory.py
+++ b/faker/factory.py
@@ -1,5 +1,6 @@
from __future__ import unicode_literals
from __future__ import absolute_import
+import locale as pylocale
import sys
from faker import DEFAULT_LOCALE, DEFAULT_PROVIDERS, AVAILABLE_LOCALES
from faker import Generator
@@ -13,8 +14,7 @@
# fix locale to package name
locale = locale.replace('-', '_') if locale else DEFAULT_LOCALE
- if '_' in locale:
- locale = locale[:2] + locale[2:].upper()
+ locale = pylocale.normalize(locale).split('.')[0]
if locale not in AVAILABLE_LOCALES:
raise AttributeError('Invalid configuration for faker locale "{0}"'.format(locale))
| {"golden_diff": "diff --git a/faker/factory.py b/faker/factory.py\n--- a/faker/factory.py\n+++ b/faker/factory.py\n@@ -1,5 +1,6 @@\n from __future__ import unicode_literals\n from __future__ import absolute_import\n+import locale as pylocale\n import sys\n from faker import DEFAULT_LOCALE, DEFAULT_PROVIDERS, AVAILABLE_LOCALES\n from faker import Generator\n@@ -13,8 +14,7 @@\n \n # fix locale to package name\n locale = locale.replace('-', '_') if locale else DEFAULT_LOCALE\n- if '_' in locale:\n- locale = locale[:2] + locale[2:].upper()\n+ locale = pylocale.normalize(locale).split('.')[0]\n if locale not in AVAILABLE_LOCALES:\n raise AttributeError('Invalid configuration for faker locale \"{0}\"'.format(locale))\n", "issue": "Default locale to language if no territory given.\nIt would be great that if faker was initialized with only a locale and no territory, that it would use a sensible default.\n\nFor example I currently have to do the following if using something such as \"en\" instead of \"en_US\". \n\n``` py\nfrom faker import Factory\nfrom faker import AVAILABLE_LOCALES\n\nlocale = 'en'\nif locale not in AVAILABLE_LOCALES:\n locale = next(l for l in AVAILABLE_LOCALES if l.startswith(locale))\n\nfactory = Factory.create(locale)\n```\n\nThis happens when using dynamic mock data in local development where django sets the locale to \"en\" because we do not define territories.\n\n", "before_files": [{"content": "from __future__ import unicode_literals\nfrom __future__ import absolute_import\nimport sys\nfrom faker import DEFAULT_LOCALE, DEFAULT_PROVIDERS, AVAILABLE_LOCALES\nfrom faker import Generator\nfrom faker import providers as providers_mod\n\n\nclass Factory(object):\n\n @classmethod\n def create(cls, locale=None, providers=None, generator=None, **config):\n\n # fix locale to package name\n locale = locale.replace('-', '_') if locale else DEFAULT_LOCALE\n if '_' in locale:\n locale = locale[:2] + locale[2:].upper()\n if locale not in AVAILABLE_LOCALES:\n raise AttributeError('Invalid configuration for faker locale \"{0}\"'.format(locale))\n\n providers = providers or DEFAULT_PROVIDERS\n\n faker = generator or Generator(**config)\n faker.add_provider(providers_mod.BaseProvider)\n for provider_name in providers:\n\n provider_class, lang_found = cls._get_provider_class(provider_name, locale)\n provider = provider_class(faker)\n provider.__provider__ = provider_name\n provider.__lang__ = lang_found\n faker.add_provider(provider)\n\n return faker\n\n @classmethod\n def _get_provider_class(cls, provider, locale=''):\n\n provider_class = cls._find_provider_class(provider, locale)\n\n if provider_class:\n return provider_class, locale\n\n if locale and locale != DEFAULT_LOCALE:\n # fallback to default locale\n provider_class = cls._find_provider_class(provider, DEFAULT_LOCALE)\n if provider_class:\n return provider_class, DEFAULT_LOCALE\n\n # fallback to no locale\n provider_class = cls._find_provider_class(provider)\n if provider_class:\n return provider_class, None\n\n raise ValueError('Unable to find provider \"{0}\" with locale \"{1}\"'.format(provider, locale))\n\n @classmethod\n def _find_provider_class(cls, provider, locale=''):\n\n path = \"{providers}{lang}.{provider}\".format(\n providers=providers_mod.__package__ or providers_mod.__name__,\n lang='.' + locale if locale else '',\n provider=provider\n )\n\n try:\n __import__(path)\n except ImportError:\n return None\n\n return sys.modules[path].Provider\n", "path": "faker/factory.py"}]} | 1,277 | 186 |
gh_patches_debug_20593 | rasdani/github-patches | git_diff | pyload__pyload-1385 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Feature Request: [UploadedNet] Detect Maintenance Mode
Please update the UploadedNet plugin so it detects uploaded maintenance mode.
Adding a timer to re-check indefinitely every 5 minutes or so might be necessary.
Else all links in the queue are skipped as offline and have to be restarted manually.
Here is the html code if Uploaded is in maintenance
http://paste2.org/OaBy4vZ6
EDiT: A check for the head title "uploaded.net - Maintenance - Wartungsarbeiten" should suffice, I guess..
</issue>
<code>
[start of module/plugins/hoster/UploadedTo.py]
1 # -*- coding: utf-8 -*-
2
3 import re
4 import time
5
6 from module.network.RequestFactory import getURL
7 from module.plugins.internal.CaptchaService import ReCaptcha
8 from module.plugins.internal.SimpleHoster import SimpleHoster, create_getInfo
9
10
11 class UploadedTo(SimpleHoster):
12 __name__ = "UploadedTo"
13 __type__ = "hoster"
14 __version__ = "0.86"
15
16 __pattern__ = r'https?://(?:www\.)?(uploaded\.(to|net)|ul\.to)(/file/|/?\?id=|.*?&id=|/)(?P<ID>\w+)'
17 __config__ = [("use_premium", "bool", "Use premium account if available", True)]
18
19 __description__ = """Uploaded.net hoster plugin"""
20 __license__ = "GPLv3"
21 __authors__ = [("Walter Purcaro", "[email protected]")]
22
23
24 DISPOSITION = False
25
26 API_KEY = "lhF2IeeprweDfu9ccWlxXVVypA5nA3EL"
27
28 URL_REPLACEMENTS = [(__pattern__ + ".*", r'http://uploaded.net/file/\g<ID>')]
29
30 LINK_PREMIUM_PATTERN = r'<div class="tfree".*\s*<form method="post" action="(.+?)"'
31
32 WAIT_PATTERN = r'Current waiting period: <span>(\d+)'
33 DL_LIMIT_ERROR = r'You have reached the max. number of possible free downloads for this hour'
34
35
36 @classmethod
37 def apiInfo(cls, url="", get={}, post={}):
38 info = super(UploadedTo, cls).apiInfo(url)
39
40 for _i in xrange(5):
41 html = getURL("http://uploaded.net/api/filemultiple",
42 get={"apikey": cls.API_KEY, 'id_0': re.match(cls.__pattern__, url).group('ID')},
43 decode=True)
44
45 if html != "can't find request":
46 api = html.split(",", 4)
47 if api[0] == "online":
48 info.update({'name': api[4].strip(), 'size': api[2], 'status': 2})
49 else:
50 info['status'] = 1
51 break
52 else:
53 time.sleep(3)
54
55 return info
56
57
58 def setup(self):
59 self.multiDL = self.resumeDownload = self.premium
60 self.chunkLimit = 1 # critical problems with more chunks
61
62
63 def checkErrors(self):
64 if 'var free_enabled = false;' in self.html:
65 self.logError(_("Free-download capacities exhausted"))
66 self.retry(24, 5 * 60)
67
68 elif "limit-size" in self.html:
69 self.fail(_("File too big for free download"))
70
71 elif "limit-slot" in self.html: # Temporary restriction so just wait a bit
72 self.wait(30 * 60, True)
73 self.retry()
74
75 elif "limit-parallel" in self.html:
76 self.fail(_("Cannot download in parallel"))
77
78 elif "limit-dl" in self.html or self.DL_LIMIT_ERROR in self.html: # limit-dl
79 self.wait(3 * 60 * 60, True)
80 self.retry()
81
82 elif '"err":"captcha"' in self.html:
83 self.invalidCaptcha()
84
85 else:
86 m = re.search(self.WAIT_PATTERN, self.html)
87 if m:
88 self.wait(m.group(1))
89
90
91 def handleFree(self, pyfile):
92 self.load("http://uploaded.net/language/en", just_header=True)
93
94 self.html = self.load("http://uploaded.net/js/download.js", decode=True)
95
96 recaptcha = ReCaptcha(self)
97 response, challenge = recaptcha.challenge()
98
99 self.html = self.load("http://uploaded.net/io/ticket/captcha/%s" % self.info['pattern']['ID'],
100 post={'recaptcha_challenge_field': challenge,
101 'recaptcha_response_field' : response})
102
103 if "type:'download'" in self.html:
104 self.correctCaptcha()
105 try:
106 self.link = re.search("url:'(.+?)'", self.html).group(1)
107
108 except Exception:
109 pass
110
111 self.checkErrors()
112
113
114 def checkFile(self, rules={}):
115 if self.checkDownload({'limit-dl': self.DL_LIMIT_ERROR}):
116 self.wait(3 * 60 * 60, True)
117 self.retry()
118
119 return super(UploadedTo, self).checkFile(rules)
120
121
122 getInfo = create_getInfo(UploadedTo)
123
[end of module/plugins/hoster/UploadedTo.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/module/plugins/hoster/UploadedTo.py b/module/plugins/hoster/UploadedTo.py
--- a/module/plugins/hoster/UploadedTo.py
+++ b/module/plugins/hoster/UploadedTo.py
@@ -11,7 +11,7 @@
class UploadedTo(SimpleHoster):
__name__ = "UploadedTo"
__type__ = "hoster"
- __version__ = "0.86"
+ __version__ = "0.87"
__pattern__ = r'https?://(?:www\.)?(uploaded\.(to|net)|ul\.to)(/file/|/?\?id=|.*?&id=|/)(?P<ID>\w+)'
__config__ = [("use_premium", "bool", "Use premium account if available", True)]
@@ -27,6 +27,8 @@
URL_REPLACEMENTS = [(__pattern__ + ".*", r'http://uploaded.net/file/\g<ID>')]
+ TEMP_OFFLINE_PATTERN = r'<title>uploaded\.net - Maintenance - Wartungsarbeiten</title>'
+
LINK_PREMIUM_PATTERN = r'<div class="tfree".*\s*<form method="post" action="(.+?)"'
WAIT_PATTERN = r'Current waiting period: <span>(\d+)'
| {"golden_diff": "diff --git a/module/plugins/hoster/UploadedTo.py b/module/plugins/hoster/UploadedTo.py\n--- a/module/plugins/hoster/UploadedTo.py\n+++ b/module/plugins/hoster/UploadedTo.py\n@@ -11,7 +11,7 @@\n class UploadedTo(SimpleHoster):\n __name__ = \"UploadedTo\"\n __type__ = \"hoster\"\n- __version__ = \"0.86\"\n+ __version__ = \"0.87\"\n \n __pattern__ = r'https?://(?:www\\.)?(uploaded\\.(to|net)|ul\\.to)(/file/|/?\\?id=|.*?&id=|/)(?P<ID>\\w+)'\n __config__ = [(\"use_premium\", \"bool\", \"Use premium account if available\", True)]\n@@ -27,6 +27,8 @@\n \n URL_REPLACEMENTS = [(__pattern__ + \".*\", r'http://uploaded.net/file/\\g<ID>')]\n \n+ TEMP_OFFLINE_PATTERN = r'<title>uploaded\\.net - Maintenance - Wartungsarbeiten</title>'\n+\n LINK_PREMIUM_PATTERN = r'<div class=\"tfree\".*\\s*<form method=\"post\" action=\"(.+?)\"'\n \n WAIT_PATTERN = r'Current waiting period: <span>(\\d+)'\n", "issue": "Feature Request: [UploadedNet] Detect Maintenance Mode\nPlease update the UploadedNet plugin so it detects uploaded maintenance mode.\n\nAdding a timer to re-check indefinitely every 5 minutes or so might be necessary.\n\nElse all links in the queue are skipped as offline and have to be restarted manually.\n\nHere is the html code if Uploaded is in maintenance\n\nhttp://paste2.org/OaBy4vZ6\n\nEDiT: A check for the head title \"uploaded.net - Maintenance - Wartungsarbeiten\" should suffice, I guess..\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\nimport re\nimport time\n\nfrom module.network.RequestFactory import getURL\nfrom module.plugins.internal.CaptchaService import ReCaptcha\nfrom module.plugins.internal.SimpleHoster import SimpleHoster, create_getInfo\n\n\nclass UploadedTo(SimpleHoster):\n __name__ = \"UploadedTo\"\n __type__ = \"hoster\"\n __version__ = \"0.86\"\n\n __pattern__ = r'https?://(?:www\\.)?(uploaded\\.(to|net)|ul\\.to)(/file/|/?\\?id=|.*?&id=|/)(?P<ID>\\w+)'\n __config__ = [(\"use_premium\", \"bool\", \"Use premium account if available\", True)]\n\n __description__ = \"\"\"Uploaded.net hoster plugin\"\"\"\n __license__ = \"GPLv3\"\n __authors__ = [(\"Walter Purcaro\", \"[email protected]\")]\n\n\n DISPOSITION = False\n\n API_KEY = \"lhF2IeeprweDfu9ccWlxXVVypA5nA3EL\"\n\n URL_REPLACEMENTS = [(__pattern__ + \".*\", r'http://uploaded.net/file/\\g<ID>')]\n\n LINK_PREMIUM_PATTERN = r'<div class=\"tfree\".*\\s*<form method=\"post\" action=\"(.+?)\"'\n\n WAIT_PATTERN = r'Current waiting period: <span>(\\d+)'\n DL_LIMIT_ERROR = r'You have reached the max. number of possible free downloads for this hour'\n\n\n @classmethod\n def apiInfo(cls, url=\"\", get={}, post={}):\n info = super(UploadedTo, cls).apiInfo(url)\n\n for _i in xrange(5):\n html = getURL(\"http://uploaded.net/api/filemultiple\",\n get={\"apikey\": cls.API_KEY, 'id_0': re.match(cls.__pattern__, url).group('ID')},\n decode=True)\n\n if html != \"can't find request\":\n api = html.split(\",\", 4)\n if api[0] == \"online\":\n info.update({'name': api[4].strip(), 'size': api[2], 'status': 2})\n else:\n info['status'] = 1\n break\n else:\n time.sleep(3)\n\n return info\n\n\n def setup(self):\n self.multiDL = self.resumeDownload = self.premium\n self.chunkLimit = 1 # critical problems with more chunks\n\n\n def checkErrors(self):\n if 'var free_enabled = false;' in self.html:\n self.logError(_(\"Free-download capacities exhausted\"))\n self.retry(24, 5 * 60)\n\n elif \"limit-size\" in self.html:\n self.fail(_(\"File too big for free download\"))\n\n elif \"limit-slot\" in self.html: # Temporary restriction so just wait a bit\n self.wait(30 * 60, True)\n self.retry()\n\n elif \"limit-parallel\" in self.html:\n self.fail(_(\"Cannot download in parallel\"))\n\n elif \"limit-dl\" in self.html or self.DL_LIMIT_ERROR in self.html: # limit-dl\n self.wait(3 * 60 * 60, True)\n self.retry()\n\n elif '\"err\":\"captcha\"' in self.html:\n self.invalidCaptcha()\n\n else:\n m = re.search(self.WAIT_PATTERN, self.html)\n if m:\n self.wait(m.group(1))\n\n\n def handleFree(self, pyfile):\n self.load(\"http://uploaded.net/language/en\", just_header=True)\n\n self.html = self.load(\"http://uploaded.net/js/download.js\", decode=True)\n\n recaptcha = ReCaptcha(self)\n response, challenge = recaptcha.challenge()\n\n self.html = self.load(\"http://uploaded.net/io/ticket/captcha/%s\" % self.info['pattern']['ID'],\n post={'recaptcha_challenge_field': challenge,\n 'recaptcha_response_field' : response})\n\n if \"type:'download'\" in self.html:\n self.correctCaptcha()\n try:\n self.link = re.search(\"url:'(.+?)'\", self.html).group(1)\n\n except Exception:\n pass\n\n self.checkErrors()\n\n\n def checkFile(self, rules={}):\n if self.checkDownload({'limit-dl': self.DL_LIMIT_ERROR}):\n self.wait(3 * 60 * 60, True)\n self.retry()\n\n return super(UploadedTo, self).checkFile(rules)\n\n\ngetInfo = create_getInfo(UploadedTo)\n", "path": "module/plugins/hoster/UploadedTo.py"}]} | 1,930 | 298 |
gh_patches_debug_9143 | rasdani/github-patches | git_diff | google-deepmind__dm-haiku-168 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Examples are distributed as part of the package
Hi,
I think the examples are folder are currently packaged as part of the package on PyPI. This means that installing haiku will also install the examples as the package `examples`. Should these be excluded from the distribution?
JAX also has examples in their repo, but those are excluded from packaging in
https://github.com/google/jax/blob/main/setup.py#L33
</issue>
<code>
[start of setup.py]
1 # Copyright 2019 DeepMind Technologies Limited. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 # ==============================================================================
15 """Setup for pip package."""
16
17 from setuptools import find_namespace_packages
18 from setuptools import setup
19
20
21 def _get_version():
22 with open('haiku/__init__.py') as fp:
23 for line in fp:
24 if line.startswith('__version__'):
25 g = {}
26 exec(line, g) # pylint: disable=exec-used
27 return g['__version__']
28 raise ValueError('`__version__` not defined in `haiku/__init__.py`')
29
30
31 def _parse_requirements(requirements_txt_path):
32 with open(requirements_txt_path) as fp:
33 return fp.read().splitlines()
34
35
36 _VERSION = _get_version()
37
38 EXTRA_PACKAGES = {
39 'jax': ['jax>=0.1.71'],
40 'jaxlib': ['jaxlib>=0.1.49'],
41 }
42
43 setup(
44 name='dm-haiku',
45 version=_VERSION,
46 url='https://github.com/deepmind/dm-haiku',
47 license='Apache 2.0',
48 author='DeepMind',
49 description='Haiku is a library for building neural networks in JAX.',
50 long_description=open('README.md').read(),
51 long_description_content_type='text/markdown',
52 author_email='[email protected]',
53 # Contained modules and scripts.
54 packages=find_namespace_packages(exclude=['*_test.py']),
55 install_requires=_parse_requirements('requirements.txt'),
56 extras_require=EXTRA_PACKAGES,
57 tests_require=_parse_requirements('requirements-test.txt'),
58 requires_python='>=3.7',
59 include_package_data=True,
60 zip_safe=False,
61 # PyPI package information.
62 classifiers=[
63 'Development Status :: 4 - Beta',
64 'Intended Audience :: Developers',
65 'Intended Audience :: Education',
66 'Intended Audience :: Science/Research',
67 'License :: OSI Approved :: Apache Software License',
68 'Programming Language :: Python :: 3',
69 'Programming Language :: Python :: 3.7',
70 'Programming Language :: Python :: 3.8',
71 'Topic :: Scientific/Engineering :: Mathematics',
72 'Topic :: Software Development :: Libraries :: Python Modules',
73 'Topic :: Software Development :: Libraries',
74 ],
75 )
76
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -51,7 +51,7 @@
long_description_content_type='text/markdown',
author_email='[email protected]',
# Contained modules and scripts.
- packages=find_namespace_packages(exclude=['*_test.py']),
+ packages=find_namespace_packages(exclude=['*_test.py', 'examples']),
install_requires=_parse_requirements('requirements.txt'),
extras_require=EXTRA_PACKAGES,
tests_require=_parse_requirements('requirements-test.txt'),
| {"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -51,7 +51,7 @@\n long_description_content_type='text/markdown',\n author_email='[email protected]',\n # Contained modules and scripts.\n- packages=find_namespace_packages(exclude=['*_test.py']),\n+ packages=find_namespace_packages(exclude=['*_test.py', 'examples']),\n install_requires=_parse_requirements('requirements.txt'),\n extras_require=EXTRA_PACKAGES,\n tests_require=_parse_requirements('requirements-test.txt'),\n", "issue": "Examples are distributed as part of the package\nHi, \r\n\r\nI think the examples are folder are currently packaged as part of the package on PyPI. This means that installing haiku will also install the examples as the package `examples`. Should these be excluded from the distribution?\r\n\r\nJAX also has examples in their repo, but those are excluded from packaging in \r\n\r\nhttps://github.com/google/jax/blob/main/setup.py#L33\r\n\r\n\n", "before_files": [{"content": "# Copyright 2019 DeepMind Technologies Limited. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\"\"\"Setup for pip package.\"\"\"\n\nfrom setuptools import find_namespace_packages\nfrom setuptools import setup\n\n\ndef _get_version():\n with open('haiku/__init__.py') as fp:\n for line in fp:\n if line.startswith('__version__'):\n g = {}\n exec(line, g) # pylint: disable=exec-used\n return g['__version__']\n raise ValueError('`__version__` not defined in `haiku/__init__.py`')\n\n\ndef _parse_requirements(requirements_txt_path):\n with open(requirements_txt_path) as fp:\n return fp.read().splitlines()\n\n\n_VERSION = _get_version()\n\nEXTRA_PACKAGES = {\n 'jax': ['jax>=0.1.71'],\n 'jaxlib': ['jaxlib>=0.1.49'],\n}\n\nsetup(\n name='dm-haiku',\n version=_VERSION,\n url='https://github.com/deepmind/dm-haiku',\n license='Apache 2.0',\n author='DeepMind',\n description='Haiku is a library for building neural networks in JAX.',\n long_description=open('README.md').read(),\n long_description_content_type='text/markdown',\n author_email='[email protected]',\n # Contained modules and scripts.\n packages=find_namespace_packages(exclude=['*_test.py']),\n install_requires=_parse_requirements('requirements.txt'),\n extras_require=EXTRA_PACKAGES,\n tests_require=_parse_requirements('requirements-test.txt'),\n requires_python='>=3.7',\n include_package_data=True,\n zip_safe=False,\n # PyPI package information.\n classifiers=[\n 'Development Status :: 4 - Beta',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Education',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: Apache Software License',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Topic :: Scientific/Engineering :: Mathematics',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n 'Topic :: Software Development :: Libraries',\n ],\n)\n", "path": "setup.py"}]} | 1,369 | 121 |
gh_patches_debug_2119 | rasdani/github-patches | git_diff | qtile__qtile-1578 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
qtile error to load
</issue>
<code>
[start of libqtile/scripts/qtile.py]
1 # Copyright (c) 2008, Aldo Cortesi. All rights reserved.
2 # Copyright (c) 2011, Florian Mounier
3 #
4 # Permission is hereby granted, free of charge, to any person obtaining a copy
5 # of this software and associated documentation files (the "Software"), to deal
6 # in the Software without restriction, including without limitation the rights
7 # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
8 # copies of the Software, and to permit persons to whom the Software is
9 # furnished to do so, subject to the following conditions:
10 #
11 # The above copyright notice and this permission notice shall be included in
12 # all copies or substantial portions of the Software.
13 #
14 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
15 # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
16 # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
17 # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
18 # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
19 # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
20 # SOFTWARE.
21
22 # Set the locale before any widgets or anything are imported, so any widget
23 # whose defaults depend on a reasonable locale sees something reasonable.
24 import locale
25 import logging
26 from os import path, getenv, makedirs
27
28 from libqtile.log_utils import init_log, logger
29 from libqtile import confreader
30 from libqtile.backend.x11 import xcore
31
32 locale.setlocale(locale.LC_ALL, locale.getdefaultlocale()) # type: ignore
33
34 try:
35 import pkg_resources
36 VERSION = pkg_resources.require("qtile")[0].version
37 except (pkg_resources.DistributionNotFound, ImportError):
38 VERSION = 'dev'
39
40
41 def rename_process():
42 """
43 Try to rename the qtile process if py-setproctitle is installed:
44
45 http://code.google.com/p/py-setproctitle/
46
47 Will fail silently if it's not installed. Setting the title lets you do
48 stuff like "killall qtile".
49 """
50 try:
51 import setproctitle
52 setproctitle.setproctitle("qtile")
53 except ImportError:
54 pass
55
56
57 def make_qtile():
58 from argparse import ArgumentParser
59 parser = ArgumentParser(
60 description='A full-featured, pure-Python tiling window manager.',
61 prog='qtile',
62 )
63 parser.add_argument(
64 '--version',
65 action='version',
66 version=VERSION,
67 )
68 parser.add_argument(
69 "-c", "--config",
70 action="store",
71 default=path.expanduser(path.join(
72 getenv('XDG_CONFIG_HOME', '~/.config'), 'qtile', 'config.py')),
73 dest="configfile",
74 help='Use the specified configuration file',
75 )
76 parser.add_argument(
77 "-s", "--socket",
78 action="store",
79 default=None,
80 dest="socket",
81 help='Path of the Qtile IPC socket.'
82 )
83 parser.add_argument(
84 "-n", "--no-spawn",
85 action="store_true",
86 default=False,
87 dest="no_spawn",
88 help='Avoid spawning apps. (Used for restart)'
89 )
90 parser.add_argument(
91 '-l', '--log-level',
92 default='WARNING',
93 dest='log_level',
94 choices=('DEBUG', 'INFO', 'WARNING', 'ERROR', 'CRITICAL'),
95 help='Set qtile log level'
96 )
97 parser.add_argument(
98 '--with-state',
99 default=None,
100 dest='state',
101 help='Pickled QtileState object (typically used only internally)',
102 )
103 options = parser.parse_args()
104 log_level = getattr(logging, options.log_level)
105 init_log(log_level=log_level)
106
107 kore = xcore.XCore()
108 try:
109 if not path.isfile(options.configfile):
110 try:
111 makedirs(path.dirname(options.configfile), exist_ok=True)
112 from shutil import copyfile
113 default_config_path = path.join(path.dirname(__file__),
114 "..",
115 "resources",
116 "default_config.py")
117 copyfile(default_config_path, options.configfile)
118 logger.info('Copied default_config.py to %s', options.configfile)
119 except Exception as e:
120 logger.exception('Failed to copy default_config.py to %s: (%s)',
121 options.configfile, e)
122
123 config = confreader.Config.from_file(kore, options.configfile)
124 except Exception as e:
125 logger.exception('Error while reading config file (%s)', e)
126 config = confreader.Config()
127 from libqtile.widget import TextBox
128 widgets = config.screens[0].bottom.widgets
129 widgets.insert(0, TextBox('Config Err!'))
130
131 # XXX: the import is here because we need to call init_log
132 # before start importing stuff
133 from libqtile.core import session_manager
134 return session_manager.SessionManager(
135 kore,
136 config,
137 fname=options.socket,
138 no_spawn=options.no_spawn,
139 state=options.state,
140 )
141
142
143 def main():
144 rename_process()
145 q = make_qtile()
146 try:
147 q.loop()
148 except Exception:
149 logger.exception('Qtile crashed')
150 logger.info('Exiting...')
151
[end of libqtile/scripts/qtile.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/libqtile/scripts/qtile.py b/libqtile/scripts/qtile.py
--- a/libqtile/scripts/qtile.py
+++ b/libqtile/scripts/qtile.py
@@ -29,7 +29,11 @@
from libqtile import confreader
from libqtile.backend.x11 import xcore
-locale.setlocale(locale.LC_ALL, locale.getdefaultlocale()) # type: ignore
+try:
+ locale.setlocale(locale.LC_ALL, locale.getdefaultlocale()) # type: ignore
+except locale.Error:
+ pass
+
try:
import pkg_resources
| {"golden_diff": "diff --git a/libqtile/scripts/qtile.py b/libqtile/scripts/qtile.py\n--- a/libqtile/scripts/qtile.py\n+++ b/libqtile/scripts/qtile.py\n@@ -29,7 +29,11 @@\n from libqtile import confreader\n from libqtile.backend.x11 import xcore\n \n-locale.setlocale(locale.LC_ALL, locale.getdefaultlocale()) # type: ignore\n+try:\n+ locale.setlocale(locale.LC_ALL, locale.getdefaultlocale()) # type: ignore\n+except locale.Error:\n+ pass\n+\n \n try:\n import pkg_resources\n", "issue": "qtile error to load\n\n", "before_files": [{"content": "# Copyright (c) 2008, Aldo Cortesi. All rights reserved.\n# Copyright (c) 2011, Florian Mounier\n#\n# Permission is hereby granted, free of charge, to any person obtaining a copy\n# of this software and associated documentation files (the \"Software\"), to deal\n# in the Software without restriction, including without limitation the rights\n# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell\n# copies of the Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\n# SOFTWARE.\n\n# Set the locale before any widgets or anything are imported, so any widget\n# whose defaults depend on a reasonable locale sees something reasonable.\nimport locale\nimport logging\nfrom os import path, getenv, makedirs\n\nfrom libqtile.log_utils import init_log, logger\nfrom libqtile import confreader\nfrom libqtile.backend.x11 import xcore\n\nlocale.setlocale(locale.LC_ALL, locale.getdefaultlocale()) # type: ignore\n\ntry:\n import pkg_resources\n VERSION = pkg_resources.require(\"qtile\")[0].version\nexcept (pkg_resources.DistributionNotFound, ImportError):\n VERSION = 'dev'\n\n\ndef rename_process():\n \"\"\"\n Try to rename the qtile process if py-setproctitle is installed:\n\n http://code.google.com/p/py-setproctitle/\n\n Will fail silently if it's not installed. Setting the title lets you do\n stuff like \"killall qtile\".\n \"\"\"\n try:\n import setproctitle\n setproctitle.setproctitle(\"qtile\")\n except ImportError:\n pass\n\n\ndef make_qtile():\n from argparse import ArgumentParser\n parser = ArgumentParser(\n description='A full-featured, pure-Python tiling window manager.',\n prog='qtile',\n )\n parser.add_argument(\n '--version',\n action='version',\n version=VERSION,\n )\n parser.add_argument(\n \"-c\", \"--config\",\n action=\"store\",\n default=path.expanduser(path.join(\n getenv('XDG_CONFIG_HOME', '~/.config'), 'qtile', 'config.py')),\n dest=\"configfile\",\n help='Use the specified configuration file',\n )\n parser.add_argument(\n \"-s\", \"--socket\",\n action=\"store\",\n default=None,\n dest=\"socket\",\n help='Path of the Qtile IPC socket.'\n )\n parser.add_argument(\n \"-n\", \"--no-spawn\",\n action=\"store_true\",\n default=False,\n dest=\"no_spawn\",\n help='Avoid spawning apps. (Used for restart)'\n )\n parser.add_argument(\n '-l', '--log-level',\n default='WARNING',\n dest='log_level',\n choices=('DEBUG', 'INFO', 'WARNING', 'ERROR', 'CRITICAL'),\n help='Set qtile log level'\n )\n parser.add_argument(\n '--with-state',\n default=None,\n dest='state',\n help='Pickled QtileState object (typically used only internally)',\n )\n options = parser.parse_args()\n log_level = getattr(logging, options.log_level)\n init_log(log_level=log_level)\n\n kore = xcore.XCore()\n try:\n if not path.isfile(options.configfile):\n try:\n makedirs(path.dirname(options.configfile), exist_ok=True)\n from shutil import copyfile\n default_config_path = path.join(path.dirname(__file__),\n \"..\",\n \"resources\",\n \"default_config.py\")\n copyfile(default_config_path, options.configfile)\n logger.info('Copied default_config.py to %s', options.configfile)\n except Exception as e:\n logger.exception('Failed to copy default_config.py to %s: (%s)',\n options.configfile, e)\n\n config = confreader.Config.from_file(kore, options.configfile)\n except Exception as e:\n logger.exception('Error while reading config file (%s)', e)\n config = confreader.Config()\n from libqtile.widget import TextBox\n widgets = config.screens[0].bottom.widgets\n widgets.insert(0, TextBox('Config Err!'))\n\n # XXX: the import is here because we need to call init_log\n # before start importing stuff\n from libqtile.core import session_manager\n return session_manager.SessionManager(\n kore,\n config,\n fname=options.socket,\n no_spawn=options.no_spawn,\n state=options.state,\n )\n\n\ndef main():\n rename_process()\n q = make_qtile()\n try:\n q.loop()\n except Exception:\n logger.exception('Qtile crashed')\n logger.info('Exiting...')\n", "path": "libqtile/scripts/qtile.py"}]} | 2,018 | 135 |
gh_patches_debug_9071 | rasdani/github-patches | git_diff | wagtail__wagtail-4341 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Please set up the Wagtail logo to appear as the favicon in readthedocs.
When I have multiple readthedocs tabs open side-by-side, I can't tell which tab is for which set of documentation. [Here is an example of a site that has done this](http://linuxmint-installation-guide.readthedocs.io/en/latest/).
</issue>
<code>
[start of docs/conf.py]
1 # -*- coding: utf-8 -*-
2 #
3 # Wagtail documentation build configuration file, created by
4 # sphinx-quickstart on Tue Jan 14 17:38:55 2014.
5 #
6 # This file is execfile()d with the current directory set to its
7 # containing dir.
8 #
9 # Note that not all possible configuration values are present in this
10 # autogenerated file.
11 #
12 # All configuration values have a default; values that are commented out
13 # serve to show the default.
14
15 import sys
16 import os
17
18
19 # on_rtd is whether we are on readthedocs.org, this line of code grabbed from docs.readthedocs.org
20 on_rtd = os.environ.get('READTHEDOCS', None) == 'True'
21
22 if not on_rtd: # only import and set the theme if we're building docs locally
23 import sphinx_rtd_theme
24 html_theme = 'sphinx_rtd_theme'
25 html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]
26
27 # If extensions (or modules to document with autodoc) are in another directory,
28 # add these directories to sys.path here. If the directory is relative to the
29 # documentation root, use os.path.abspath to make it absolute, like shown here.
30 sys.path.insert(0, os.path.abspath('..'))
31
32 # Autodoc may need to import some models modules which require django settings
33 # be configured
34 os.environ['DJANGO_SETTINGS_MODULE'] = 'wagtail.tests.settings'
35 import django
36 django.setup()
37
38 # Use SQLite3 database engine so it doesn't attempt to use psycopg2 on RTD
39 os.environ['DATABASE_ENGINE'] = 'django.db.backends.sqlite3'
40
41
42 # -- General configuration ------------------------------------------------
43
44 # If your documentation needs a minimal Sphinx version, state it here.
45 #needs_sphinx = '1.0'
46
47 # Add any Sphinx extension module names here, as strings. They can be
48 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
49 # ones.
50 extensions = [
51 'sphinx.ext.autodoc',
52 ]
53
54 if not on_rtd:
55 extensions.append('sphinxcontrib.spelling')
56
57 # Add any paths that contain templates here, relative to this directory.
58 templates_path = ['_templates']
59
60 # The suffix of source filenames.
61 source_suffix = '.rst'
62
63 # The encoding of source files.
64 #source_encoding = 'utf-8-sig'
65
66 # The master toctree document.
67 master_doc = 'index'
68
69 # General information about the project.
70 project = u'Wagtail'
71 copyright = u'2015, Torchbox'
72
73 # The version info for the project you're documenting, acts as replacement for
74 # |version| and |release|, also used in various other places throughout the
75 # built documents.
76
77 # Get Wagtail version
78 from wagtail import __version__, VERSION
79
80 # The short X.Y version.
81 version = '{}.{}'.format(VERSION[0], VERSION[1])
82 # The full version, including alpha/beta/rc tags.
83 release = __version__
84
85 # The language for content autogenerated by Sphinx. Refer to documentation
86 # for a list of supported languages.
87 #language = None
88
89 # There are two options for replacing |today|: either, you set today to some
90 # non-false value, then it is used:
91 #today = ''
92 # Else, today_fmt is used as the format for a strftime call.
93 #today_fmt = '%B %d, %Y'
94
95 # List of patterns, relative to source directory, that match files and
96 # directories to ignore when looking for source files.
97 exclude_patterns = ['_build']
98
99 # The reST default role (used for this markup: `text`) to use for all
100 # documents.
101 #default_role = None
102
103 # If true, '()' will be appended to :func: etc. cross-reference text.
104 #add_function_parentheses = True
105
106 # If true, the current module name will be prepended to all description
107 # unit titles (such as .. function::).
108 #add_module_names = True
109
110 # If true, sectionauthor and moduleauthor directives will be shown in the
111 # output. They are ignored by default.
112 #show_authors = False
113
114 # The name of the Pygments (syntax highlighting) style to use.
115 pygments_style = 'sphinx'
116
117 # A list of ignored prefixes for module index sorting.
118 #modindex_common_prefix = []
119
120 # If true, keep warnings as "system message" paragraphs in the built documents.
121 #keep_warnings = False
122
123
124 # splhinxcontrib.spelling settings
125
126 spelling_lang = 'en_GB'
127 spelling_word_list_filename='spelling_wordlist.txt'
128
129
130 # -- Options for HTML output ----------------------------------------------
131
132
133 # Theme options are theme-specific and customize the look and feel of a theme
134 # further. For a list of options available for each theme, see the
135 # documentation.
136 #html_theme_options = {}
137
138
139
140 # The name for this set of Sphinx documents. If None, it defaults to
141 # "<project> v<release> documentation".
142 #html_title = None
143
144 # A shorter title for the navigation bar. Default is the same as html_title.
145 #html_short_title = None
146
147 # The name of an image file (relative to this directory) to place at the top
148 # of the sidebar.
149 html_logo = 'logo.png'
150
151 # The name of an image file (within the static path) to use as favicon of the
152 # docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32
153 # pixels large.
154 #html_favicon = None
155
156 # Add any paths that contain custom static files (such as style sheets) here,
157 # relative to this directory. They are copied after the builtin static files,
158 # so a file named "default.css" will overwrite the builtin "default.css".
159 html_static_path = ['_static']
160
161 # Add any extra paths that contain custom files (such as robots.txt or
162 # .htaccess) here, relative to this directory. These files are copied
163 # directly to the root of the documentation.
164 #html_extra_path = []
165
166 # If not '', a 'Last updated on:' timestamp is inserted at every page bottom,
167 # using the given strftime format.
168 #html_last_updated_fmt = '%b %d, %Y'
169
170 # If true, SmartyPants will be used to convert quotes and dashes to
171 # typographically correct entities.
172 #html_use_smartypants = True
173
174 # Custom sidebar templates, maps document names to template names.
175 #html_sidebars = {}
176
177 # Additional templates that should be rendered to pages, maps page names to
178 # template names.
179 #html_additional_pages = {}
180
181 # If false, no module index is generated.
182 #html_domain_indices = True
183
184 # If false, no index is generated.
185 #html_use_index = True
186
187 # If true, the index is split into individual pages for each letter.
188 #html_split_index = False
189
190 # If true, links to the reST sources are added to the pages.
191 #html_show_sourcelink = True
192
193 # If true, "Created using Sphinx" is shown in the HTML footer. Default is True.
194 #html_show_sphinx = True
195
196 # If true, "(C) Copyright ..." is shown in the HTML footer. Default is True.
197 #html_show_copyright = True
198
199 # If true, an OpenSearch description file will be output, and all pages will
200 # contain a <link> tag referring to it. The value of this option must be the
201 # base URL from which the finished HTML is served.
202 #html_use_opensearch = ''
203
204 # This is the file name suffix for HTML files (e.g. ".xhtml").
205 #html_file_suffix = None
206
207 # Output file base name for HTML help builder.
208 htmlhelp_basename = 'Wagtaildoc'
209
210
211 # -- Options for LaTeX output ---------------------------------------------
212
213 latex_elements = {
214 # The paper size ('letterpaper' or 'a4paper').
215 #'papersize': 'letterpaper',
216
217 # The font size ('10pt', '11pt' or '12pt').
218 #'pointsize': '10pt',
219
220 # Additional stuff for the LaTeX preamble.
221 #'preamble': '',
222 }
223
224 # Grouping the document tree into LaTeX files. List of tuples
225 # (source start file, target name, title,
226 # author, documentclass [howto, manual, or own class]).
227 latex_documents = [
228 ('index', 'Wagtail.tex', u'Wagtail Documentation',
229 u'Torchbox', 'manual'),
230 ]
231
232 # The name of an image file (relative to this directory) to place at the top of
233 # the title page.
234 #latex_logo = None
235
236 # For "manual" documents, if this is true, then toplevel headings are parts,
237 # not chapters.
238 #latex_use_parts = False
239
240 # If true, show page references after internal links.
241 #latex_show_pagerefs = False
242
243 # If true, show URL addresses after external links.
244 #latex_show_urls = False
245
246 # Documents to append as an appendix to all manuals.
247 #latex_appendices = []
248
249 # If false, no module index is generated.
250 #latex_domain_indices = True
251
252
253 # -- Options for manual page output ---------------------------------------
254
255 # One entry per manual page. List of tuples
256 # (source start file, name, description, authors, manual section).
257 man_pages = [
258 ('index', 'wagtail', u'Wagtail Documentation',
259 [u'Torchbox'], 1)
260 ]
261
262 # If true, show URL addresses after external links.
263 #man_show_urls = False
264
265
266 # -- Options for Texinfo output -------------------------------------------
267
268 # Grouping the document tree into Texinfo files. List of tuples
269 # (source start file, target name, title, author,
270 # dir menu entry, description, category)
271 texinfo_documents = [
272 ('index', 'Wagtail', u'Wagtail Documentation',
273 u'Torchbox', 'Wagtail', 'One line description of project.',
274 'Miscellaneous'),
275 ]
276
277 # Documents to append as an appendix to all manuals.
278 #texinfo_appendices = []
279
280 # If false, no module index is generated.
281 #texinfo_domain_indices = True
282
283 # How to display URL addresses: 'footnote', 'no', or 'inline'.
284 #texinfo_show_urls = 'footnote'
285
286 # If true, do not generate a @detailmenu in the "Top" node's menu.
287 #texinfo_no_detailmenu = False
288
289
290 def setup(app):
291 app.add_stylesheet('css/custom.css')
292
[end of docs/conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -151,7 +151,7 @@
# The name of an image file (within the static path) to use as favicon of the
# docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32
# pixels large.
-#html_favicon = None
+html_favicon = 'favicon.ico'
# Add any paths that contain custom static files (such as style sheets) here,
# relative to this directory. They are copied after the builtin static files,
| {"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -151,7 +151,7 @@\n # The name of an image file (within the static path) to use as favicon of the\n # docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32\n # pixels large.\n-#html_favicon = None\n+html_favicon = 'favicon.ico'\n \n # Add any paths that contain custom static files (such as style sheets) here,\n # relative to this directory. They are copied after the builtin static files,\n", "issue": "Please set up the Wagtail logo to appear as the favicon in readthedocs.\nWhen I have multiple readthedocs tabs open side-by-side, I can't tell which tab is for which set of documentation. [Here is an example of a site that has done this](http://linuxmint-installation-guide.readthedocs.io/en/latest/).\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Wagtail documentation build configuration file, created by\n# sphinx-quickstart on Tue Jan 14 17:38:55 2014.\n#\n# This file is execfile()d with the current directory set to its\n# containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\nimport sys\nimport os\n\n\n# on_rtd is whether we are on readthedocs.org, this line of code grabbed from docs.readthedocs.org\non_rtd = os.environ.get('READTHEDOCS', None) == 'True'\n\nif not on_rtd: # only import and set the theme if we're building docs locally\n import sphinx_rtd_theme\n html_theme = 'sphinx_rtd_theme'\n html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\nsys.path.insert(0, os.path.abspath('..'))\n\n# Autodoc may need to import some models modules which require django settings\n# be configured\nos.environ['DJANGO_SETTINGS_MODULE'] = 'wagtail.tests.settings'\nimport django\ndjango.setup()\n\n# Use SQLite3 database engine so it doesn't attempt to use psycopg2 on RTD\nos.environ['DATABASE_ENGINE'] = 'django.db.backends.sqlite3'\n\n\n# -- General configuration ------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n 'sphinx.ext.autodoc',\n]\n\nif not on_rtd:\n extensions.append('sphinxcontrib.spelling')\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# The suffix of source filenames.\nsource_suffix = '.rst'\n\n# The encoding of source files.\n#source_encoding = 'utf-8-sig'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# General information about the project.\nproject = u'Wagtail'\ncopyright = u'2015, Torchbox'\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n\n# Get Wagtail version\nfrom wagtail import __version__, VERSION\n\n# The short X.Y version.\nversion = '{}.{}'.format(VERSION[0], VERSION[1])\n# The full version, including alpha/beta/rc tags.\nrelease = __version__\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#language = None\n\n# There are two options for replacing |today|: either, you set today to some\n# non-false value, then it is used:\n#today = ''\n# Else, today_fmt is used as the format for a strftime call.\n#today_fmt = '%B %d, %Y'\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\nexclude_patterns = ['_build']\n\n# The reST default role (used for this markup: `text`) to use for all\n# documents.\n#default_role = None\n\n# If true, '()' will be appended to :func: etc. cross-reference text.\n#add_function_parentheses = True\n\n# If true, the current module name will be prepended to all description\n# unit titles (such as .. function::).\n#add_module_names = True\n\n# If true, sectionauthor and moduleauthor directives will be shown in the\n# output. They are ignored by default.\n#show_authors = False\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# A list of ignored prefixes for module index sorting.\n#modindex_common_prefix = []\n\n# If true, keep warnings as \"system message\" paragraphs in the built documents.\n#keep_warnings = False\n\n\n# splhinxcontrib.spelling settings\n\nspelling_lang = 'en_GB'\nspelling_word_list_filename='spelling_wordlist.txt'\n\n\n# -- Options for HTML output ----------------------------------------------\n\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n#html_theme_options = {}\n\n\n\n# The name for this set of Sphinx documents. If None, it defaults to\n# \"<project> v<release> documentation\".\n#html_title = None\n\n# A shorter title for the navigation bar. Default is the same as html_title.\n#html_short_title = None\n\n# The name of an image file (relative to this directory) to place at the top\n# of the sidebar.\nhtml_logo = 'logo.png'\n\n# The name of an image file (within the static path) to use as favicon of the\n# docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32\n# pixels large.\n#html_favicon = None\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = ['_static']\n\n# Add any extra paths that contain custom files (such as robots.txt or\n# .htaccess) here, relative to this directory. These files are copied\n# directly to the root of the documentation.\n#html_extra_path = []\n\n# If not '', a 'Last updated on:' timestamp is inserted at every page bottom,\n# using the given strftime format.\n#html_last_updated_fmt = '%b %d, %Y'\n\n# If true, SmartyPants will be used to convert quotes and dashes to\n# typographically correct entities.\n#html_use_smartypants = True\n\n# Custom sidebar templates, maps document names to template names.\n#html_sidebars = {}\n\n# Additional templates that should be rendered to pages, maps page names to\n# template names.\n#html_additional_pages = {}\n\n# If false, no module index is generated.\n#html_domain_indices = True\n\n# If false, no index is generated.\n#html_use_index = True\n\n# If true, the index is split into individual pages for each letter.\n#html_split_index = False\n\n# If true, links to the reST sources are added to the pages.\n#html_show_sourcelink = True\n\n# If true, \"Created using Sphinx\" is shown in the HTML footer. Default is True.\n#html_show_sphinx = True\n\n# If true, \"(C) Copyright ...\" is shown in the HTML footer. Default is True.\n#html_show_copyright = True\n\n# If true, an OpenSearch description file will be output, and all pages will\n# contain a <link> tag referring to it. The value of this option must be the\n# base URL from which the finished HTML is served.\n#html_use_opensearch = ''\n\n# This is the file name suffix for HTML files (e.g. \".xhtml\").\n#html_file_suffix = None\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'Wagtaildoc'\n\n\n# -- Options for LaTeX output ---------------------------------------------\n\nlatex_elements = {\n# The paper size ('letterpaper' or 'a4paper').\n#'papersize': 'letterpaper',\n\n# The font size ('10pt', '11pt' or '12pt').\n#'pointsize': '10pt',\n\n# Additional stuff for the LaTeX preamble.\n#'preamble': '',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n ('index', 'Wagtail.tex', u'Wagtail Documentation',\n u'Torchbox', 'manual'),\n]\n\n# The name of an image file (relative to this directory) to place at the top of\n# the title page.\n#latex_logo = None\n\n# For \"manual\" documents, if this is true, then toplevel headings are parts,\n# not chapters.\n#latex_use_parts = False\n\n# If true, show page references after internal links.\n#latex_show_pagerefs = False\n\n# If true, show URL addresses after external links.\n#latex_show_urls = False\n\n# Documents to append as an appendix to all manuals.\n#latex_appendices = []\n\n# If false, no module index is generated.\n#latex_domain_indices = True\n\n\n# -- Options for manual page output ---------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n ('index', 'wagtail', u'Wagtail Documentation',\n [u'Torchbox'], 1)\n]\n\n# If true, show URL addresses after external links.\n#man_show_urls = False\n\n\n# -- Options for Texinfo output -------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n ('index', 'Wagtail', u'Wagtail Documentation',\n u'Torchbox', 'Wagtail', 'One line description of project.',\n 'Miscellaneous'),\n]\n\n# Documents to append as an appendix to all manuals.\n#texinfo_appendices = []\n\n# If false, no module index is generated.\n#texinfo_domain_indices = True\n\n# How to display URL addresses: 'footnote', 'no', or 'inline'.\n#texinfo_show_urls = 'footnote'\n\n# If true, do not generate a @detailmenu in the \"Top\" node's menu.\n#texinfo_no_detailmenu = False\n\n\ndef setup(app):\n app.add_stylesheet('css/custom.css')\n", "path": "docs/conf.py"}]} | 3,646 | 142 |
gh_patches_debug_20420 | rasdani/github-patches | git_diff | dynaconf__dynaconf-877 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[bug] Dynaconf doesn't load configuration file if cwd doesn't exist
**Describe the bug**
When the current workdir directory has been removed, dynaconf refuses to load configuration files.
**To Reproduce**
Steps to reproduce the behavior:
1. Having the following folder structure
<!-- Describe or use the command `$ tree -v` and paste below -->
<details>
<summary> Project structure </summary>
```bash
# /tmp/dyn.yaml
# /home/user/bug_dynaconf/
# app.py
# script.sh
```
</details>
2. Having the following config files:
<!-- Please adjust if you are using different files and formats! -->
<details>
<summary> Config files </summary>
**/tmp/dyn.yaml**
```yaml
offset: 24
```
</details>
3. Having the following app code:
<details>
<summary> Code </summary>
**app.py**
```python
from dynaconf import Dynaconf
settings = Dynaconf(
settings_files=["/tmp/dyn.yaml"]
)
print(settings.offset)
settings.validators.validate()
print(type(settings.offset))
```
</details>
4. Executing under the following environment
<details>
<summary> Execution </summary>
**script.sh**
```bash
#!/bin/bash -x
python3 -m venv venv
source venv/bin/activate
pip install dynaconf==3.1.12
PARENT=$(realpath .)
mkdir nonexistent_dir
cd nonexistent_dir
rm -r ../nonexistent_dir
python $PARENT/app.py
```
</details>
**Expected behavior**
the `app.py` should have printed the type of `offset`, which is an `int`
**Actual behavior**
~~~Python
Traceback (most recent call last):
File "/home/mtarral/debug_dynaconf/app.py", line 7, in <module>
print(settings.offset)
File "/home/mtarral/debug_dynaconf/venv/lib/python3.8/site-packages/dynaconf/base.py", line 138, in __getattr__
value = getattr(self._wrapped, name)
File "/home/mtarral/debug_dynaconf/venv/lib/python3.8/site-packages/dynaconf/base.py", line 300, in __getattribute__
return super().__getattribute__(name)
AttributeError: 'Settings' object has no attribute 'OFFSET'
~~~
**Environment (please complete the following information):**
- OS: ubuntu 20.04
- Dynaconf Version 3.1.12
**Additional context**
Following https://github.com/dynaconf/dynaconf/issues/853, I tried to repro with 3.1.12, and found this issue now.
Thanks for dynaconf !
[bug] Dynaconf doesn't load configuration file if cwd doesn't exist
**Describe the bug**
When the current workdir directory has been removed, dynaconf refuses to load configuration files.
**To Reproduce**
Steps to reproduce the behavior:
1. Having the following folder structure
<!-- Describe or use the command `$ tree -v` and paste below -->
<details>
<summary> Project structure </summary>
```bash
# /tmp/dyn.yaml
# /home/user/bug_dynaconf/
# app.py
# script.sh
```
</details>
2. Having the following config files:
<!-- Please adjust if you are using different files and formats! -->
<details>
<summary> Config files </summary>
**/tmp/dyn.yaml**
```yaml
offset: 24
```
</details>
3. Having the following app code:
<details>
<summary> Code </summary>
**app.py**
```python
from dynaconf import Dynaconf
settings = Dynaconf(
settings_files=["/tmp/dyn.yaml"]
)
print(settings.offset)
settings.validators.validate()
print(type(settings.offset))
```
</details>
4. Executing under the following environment
<details>
<summary> Execution </summary>
**script.sh**
```bash
#!/bin/bash -x
python3 -m venv venv
source venv/bin/activate
pip install dynaconf==3.1.12
PARENT=$(realpath .)
mkdir nonexistent_dir
cd nonexistent_dir
rm -r ../nonexistent_dir
python $PARENT/app.py
```
</details>
**Expected behavior**
the `app.py` should have printed the type of `offset`, which is an `int`
**Actual behavior**
~~~Python
Traceback (most recent call last):
File "/home/mtarral/debug_dynaconf/app.py", line 7, in <module>
print(settings.offset)
File "/home/mtarral/debug_dynaconf/venv/lib/python3.8/site-packages/dynaconf/base.py", line 138, in __getattr__
value = getattr(self._wrapped, name)
File "/home/mtarral/debug_dynaconf/venv/lib/python3.8/site-packages/dynaconf/base.py", line 300, in __getattribute__
return super().__getattribute__(name)
AttributeError: 'Settings' object has no attribute 'OFFSET'
~~~
**Environment (please complete the following information):**
- OS: ubuntu 20.04
- Dynaconf Version 3.1.12
**Additional context**
Following https://github.com/dynaconf/dynaconf/issues/853, I tried to repro with 3.1.12, and found this issue now.
Thanks for dynaconf !
</issue>
<code>
[start of dynaconf/utils/files.py]
1 from __future__ import annotations
2
3 import inspect
4 import io
5 import os
6
7 from dynaconf.utils import deduplicate
8
9
10 def _walk_to_root(path, break_at=None):
11 """
12 Directories starting from the given directory up to the root or break_at
13 """
14 if not os.path.exists(path): # pragma: no cover
15 raise OSError("Starting path not found")
16
17 if os.path.isfile(path): # pragma: no cover
18 path = os.path.dirname(path)
19
20 last_dir = None
21 current_dir = os.path.abspath(path)
22 paths = []
23 while last_dir != current_dir:
24 paths.append(current_dir)
25 paths.append(os.path.join(current_dir, "config"))
26 if break_at and current_dir == os.path.abspath(break_at): # noqa
27 break
28 parent_dir = os.path.abspath(os.path.join(current_dir, os.path.pardir))
29 last_dir, current_dir = current_dir, parent_dir
30 return paths
31
32
33 SEARCHTREE = []
34
35
36 def find_file(filename=".env", project_root=None, skip_files=None, **kwargs):
37 """Search in increasingly higher folders for the given file
38 Returns path to the file if found, or an empty string otherwise.
39
40 This function will build a `search_tree` based on:
41
42 - Project_root if specified
43 - Invoked script location and its parents until root
44 - Current working directory
45
46 For each path in the `search_tree` it will also look for an
47 additional `./config` folder.
48 """
49 search_tree = []
50 try:
51 work_dir = os.getcwd()
52 except FileNotFoundError:
53 return ""
54 skip_files = skip_files or []
55
56 # If filename is an absolute path and exists, just return it
57 # if the absolute path does not exist, return empty string so
58 # that it can be joined and avoid IoError
59 if os.path.isabs(filename):
60 return filename if os.path.exists(filename) else ""
61
62 if project_root is not None:
63 search_tree.extend(_walk_to_root(project_root, break_at=work_dir))
64
65 script_dir = os.path.dirname(os.path.abspath(inspect.stack()[-1].filename))
66
67 # Path to invoked script and recursively to root with its ./config dirs
68 search_tree.extend(_walk_to_root(script_dir))
69
70 # Path to where Python interpreter was invoked and recursively to root
71 search_tree.extend(_walk_to_root(work_dir))
72
73 # Don't look the same place twice
74 search_tree = deduplicate(search_tree)
75
76 global SEARCHTREE
77 SEARCHTREE[:] = search_tree
78
79 for dirname in search_tree:
80 check_path = os.path.join(dirname, filename)
81 if check_path in skip_files:
82 continue
83 if os.path.exists(check_path):
84 return check_path # First found will return
85
86 # return empty string if not found so it can still be joined in os.path
87 return ""
88
89
90 def read_file(path, **kwargs):
91 content = ""
92 with open(path, **kwargs) as open_file:
93 content = open_file.read().strip()
94 return content
95
96
97 def get_local_filename(filename):
98 """Takes a filename like `settings.toml` and returns `settings.local.toml`
99
100 Arguments:
101 filename {str} -- The filename or complete path
102
103 Returns:
104 [str] -- The same name or path with `.local.` added.
105 """
106 name, _, extension = os.path.basename(str(filename)).rpartition(
107 os.path.extsep
108 )
109
110 return os.path.join(
111 os.path.dirname(str(filename)), f"{name}.local.{extension}"
112 )
113
[end of dynaconf/utils/files.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/dynaconf/utils/files.py b/dynaconf/utils/files.py
--- a/dynaconf/utils/files.py
+++ b/dynaconf/utils/files.py
@@ -46,6 +46,12 @@
For each path in the `search_tree` it will also look for an
additional `./config` folder.
"""
+ # If filename is an absolute path and exists, just return it
+ # if the absolute path does not exist, return empty string so
+ # that it can be joined and avoid IoError
+ if os.path.isabs(filename):
+ return filename if os.path.exists(filename) else ""
+
search_tree = []
try:
work_dir = os.getcwd()
@@ -53,12 +59,6 @@
return ""
skip_files = skip_files or []
- # If filename is an absolute path and exists, just return it
- # if the absolute path does not exist, return empty string so
- # that it can be joined and avoid IoError
- if os.path.isabs(filename):
- return filename if os.path.exists(filename) else ""
-
if project_root is not None:
search_tree.extend(_walk_to_root(project_root, break_at=work_dir))
| {"golden_diff": "diff --git a/dynaconf/utils/files.py b/dynaconf/utils/files.py\n--- a/dynaconf/utils/files.py\n+++ b/dynaconf/utils/files.py\n@@ -46,6 +46,12 @@\n For each path in the `search_tree` it will also look for an\n additional `./config` folder.\n \"\"\"\n+ # If filename is an absolute path and exists, just return it\n+ # if the absolute path does not exist, return empty string so\n+ # that it can be joined and avoid IoError\n+ if os.path.isabs(filename):\n+ return filename if os.path.exists(filename) else \"\"\n+\n search_tree = []\n try:\n work_dir = os.getcwd()\n@@ -53,12 +59,6 @@\n return \"\"\n skip_files = skip_files or []\n \n- # If filename is an absolute path and exists, just return it\n- # if the absolute path does not exist, return empty string so\n- # that it can be joined and avoid IoError\n- if os.path.isabs(filename):\n- return filename if os.path.exists(filename) else \"\"\n-\n if project_root is not None:\n search_tree.extend(_walk_to_root(project_root, break_at=work_dir))\n", "issue": "[bug] Dynaconf doesn't load configuration file if cwd doesn't exist\n**Describe the bug**\r\nWhen the current workdir directory has been removed, dynaconf refuses to load configuration files.\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n\r\n1. Having the following folder structure\r\n\r\n<!-- Describe or use the command `$ tree -v` and paste below -->\r\n\r\n<details>\r\n<summary> Project structure </summary>\r\n\r\n```bash\r\n\r\n# /tmp/dyn.yaml\r\n# /home/user/bug_dynaconf/\r\n# app.py\r\n# script.sh\r\n```\r\n</details>\r\n\r\n\r\n2. Having the following config files:\r\n\r\n<!-- Please adjust if you are using different files and formats! -->\r\n\r\n<details>\r\n<summary> Config files </summary>\r\n\r\n**/tmp/dyn.yaml**\r\n```yaml\r\noffset: 24\r\n```\r\n</details>\r\n\r\n3. Having the following app code:\r\n\r\n<details>\r\n<summary> Code </summary>\r\n\r\n**app.py**\r\n```python\r\n\r\nfrom dynaconf import Dynaconf\r\n\r\nsettings = Dynaconf(\r\n settings_files=[\"/tmp/dyn.yaml\"]\r\n)\r\n\r\nprint(settings.offset)\r\n\r\nsettings.validators.validate()\r\n\r\nprint(type(settings.offset))\r\n\r\n```\r\n\r\n</details>\r\n\r\n4. Executing under the following environment\r\n\r\n<details>\r\n<summary> Execution </summary>\r\n\r\n**script.sh**\r\n```bash\r\n#!/bin/bash -x\r\n\r\npython3 -m venv venv\r\nsource venv/bin/activate\r\npip install dynaconf==3.1.12\r\nPARENT=$(realpath .)\r\nmkdir nonexistent_dir\r\ncd nonexistent_dir\r\nrm -r ../nonexistent_dir\r\npython $PARENT/app.py\r\n```\r\n\r\n</details>\r\n\r\n**Expected behavior**\r\nthe `app.py` should have printed the type of `offset`, which is an `int`\r\n\r\n**Actual behavior**\r\n~~~Python\r\nTraceback (most recent call last):\r\n File \"/home/mtarral/debug_dynaconf/app.py\", line 7, in <module>\r\n print(settings.offset)\r\n File \"/home/mtarral/debug_dynaconf/venv/lib/python3.8/site-packages/dynaconf/base.py\", line 138, in __getattr__\r\n value = getattr(self._wrapped, name)\r\n File \"/home/mtarral/debug_dynaconf/venv/lib/python3.8/site-packages/dynaconf/base.py\", line 300, in __getattribute__\r\n return super().__getattribute__(name)\r\nAttributeError: 'Settings' object has no attribute 'OFFSET'\r\n~~~\r\n\r\n**Environment (please complete the following information):**\r\n - OS: ubuntu 20.04\r\n - Dynaconf Version 3.1.12\r\n\r\n**Additional context**\r\nFollowing https://github.com/dynaconf/dynaconf/issues/853, I tried to repro with 3.1.12, and found this issue now.\r\n\r\nThanks for dynaconf !\r\n\n[bug] Dynaconf doesn't load configuration file if cwd doesn't exist\n**Describe the bug**\r\nWhen the current workdir directory has been removed, dynaconf refuses to load configuration files.\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n\r\n1. Having the following folder structure\r\n\r\n<!-- Describe or use the command `$ tree -v` and paste below -->\r\n\r\n<details>\r\n<summary> Project structure </summary>\r\n\r\n```bash\r\n\r\n# /tmp/dyn.yaml\r\n# /home/user/bug_dynaconf/\r\n# app.py\r\n# script.sh\r\n```\r\n</details>\r\n\r\n\r\n2. Having the following config files:\r\n\r\n<!-- Please adjust if you are using different files and formats! -->\r\n\r\n<details>\r\n<summary> Config files </summary>\r\n\r\n**/tmp/dyn.yaml**\r\n```yaml\r\noffset: 24\r\n```\r\n</details>\r\n\r\n3. Having the following app code:\r\n\r\n<details>\r\n<summary> Code </summary>\r\n\r\n**app.py**\r\n```python\r\n\r\nfrom dynaconf import Dynaconf\r\n\r\nsettings = Dynaconf(\r\n settings_files=[\"/tmp/dyn.yaml\"]\r\n)\r\n\r\nprint(settings.offset)\r\n\r\nsettings.validators.validate()\r\n\r\nprint(type(settings.offset))\r\n\r\n```\r\n\r\n</details>\r\n\r\n4. Executing under the following environment\r\n\r\n<details>\r\n<summary> Execution </summary>\r\n\r\n**script.sh**\r\n```bash\r\n#!/bin/bash -x\r\n\r\npython3 -m venv venv\r\nsource venv/bin/activate\r\npip install dynaconf==3.1.12\r\nPARENT=$(realpath .)\r\nmkdir nonexistent_dir\r\ncd nonexistent_dir\r\nrm -r ../nonexistent_dir\r\npython $PARENT/app.py\r\n```\r\n\r\n</details>\r\n\r\n**Expected behavior**\r\nthe `app.py` should have printed the type of `offset`, which is an `int`\r\n\r\n**Actual behavior**\r\n~~~Python\r\nTraceback (most recent call last):\r\n File \"/home/mtarral/debug_dynaconf/app.py\", line 7, in <module>\r\n print(settings.offset)\r\n File \"/home/mtarral/debug_dynaconf/venv/lib/python3.8/site-packages/dynaconf/base.py\", line 138, in __getattr__\r\n value = getattr(self._wrapped, name)\r\n File \"/home/mtarral/debug_dynaconf/venv/lib/python3.8/site-packages/dynaconf/base.py\", line 300, in __getattribute__\r\n return super().__getattribute__(name)\r\nAttributeError: 'Settings' object has no attribute 'OFFSET'\r\n~~~\r\n\r\n**Environment (please complete the following information):**\r\n - OS: ubuntu 20.04\r\n - Dynaconf Version 3.1.12\r\n\r\n**Additional context**\r\nFollowing https://github.com/dynaconf/dynaconf/issues/853, I tried to repro with 3.1.12, and found this issue now.\r\n\r\nThanks for dynaconf !\r\n\n", "before_files": [{"content": "from __future__ import annotations\n\nimport inspect\nimport io\nimport os\n\nfrom dynaconf.utils import deduplicate\n\n\ndef _walk_to_root(path, break_at=None):\n \"\"\"\n Directories starting from the given directory up to the root or break_at\n \"\"\"\n if not os.path.exists(path): # pragma: no cover\n raise OSError(\"Starting path not found\")\n\n if os.path.isfile(path): # pragma: no cover\n path = os.path.dirname(path)\n\n last_dir = None\n current_dir = os.path.abspath(path)\n paths = []\n while last_dir != current_dir:\n paths.append(current_dir)\n paths.append(os.path.join(current_dir, \"config\"))\n if break_at and current_dir == os.path.abspath(break_at): # noqa\n break\n parent_dir = os.path.abspath(os.path.join(current_dir, os.path.pardir))\n last_dir, current_dir = current_dir, parent_dir\n return paths\n\n\nSEARCHTREE = []\n\n\ndef find_file(filename=\".env\", project_root=None, skip_files=None, **kwargs):\n \"\"\"Search in increasingly higher folders for the given file\n Returns path to the file if found, or an empty string otherwise.\n\n This function will build a `search_tree` based on:\n\n - Project_root if specified\n - Invoked script location and its parents until root\n - Current working directory\n\n For each path in the `search_tree` it will also look for an\n additional `./config` folder.\n \"\"\"\n search_tree = []\n try:\n work_dir = os.getcwd()\n except FileNotFoundError:\n return \"\"\n skip_files = skip_files or []\n\n # If filename is an absolute path and exists, just return it\n # if the absolute path does not exist, return empty string so\n # that it can be joined and avoid IoError\n if os.path.isabs(filename):\n return filename if os.path.exists(filename) else \"\"\n\n if project_root is not None:\n search_tree.extend(_walk_to_root(project_root, break_at=work_dir))\n\n script_dir = os.path.dirname(os.path.abspath(inspect.stack()[-1].filename))\n\n # Path to invoked script and recursively to root with its ./config dirs\n search_tree.extend(_walk_to_root(script_dir))\n\n # Path to where Python interpreter was invoked and recursively to root\n search_tree.extend(_walk_to_root(work_dir))\n\n # Don't look the same place twice\n search_tree = deduplicate(search_tree)\n\n global SEARCHTREE\n SEARCHTREE[:] = search_tree\n\n for dirname in search_tree:\n check_path = os.path.join(dirname, filename)\n if check_path in skip_files:\n continue\n if os.path.exists(check_path):\n return check_path # First found will return\n\n # return empty string if not found so it can still be joined in os.path\n return \"\"\n\n\ndef read_file(path, **kwargs):\n content = \"\"\n with open(path, **kwargs) as open_file:\n content = open_file.read().strip()\n return content\n\n\ndef get_local_filename(filename):\n \"\"\"Takes a filename like `settings.toml` and returns `settings.local.toml`\n\n Arguments:\n filename {str} -- The filename or complete path\n\n Returns:\n [str] -- The same name or path with `.local.` added.\n \"\"\"\n name, _, extension = os.path.basename(str(filename)).rpartition(\n os.path.extsep\n )\n\n return os.path.join(\n os.path.dirname(str(filename)), f\"{name}.local.{extension}\"\n )\n", "path": "dynaconf/utils/files.py"}]} | 2,752 | 275 |
gh_patches_debug_12875 | rasdani/github-patches | git_diff | ray-project__ray-7114 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Turn off OMP_NUM_THREADS warnings?
Can we just turn off the warnings on each ray.init? We can't force everyone to set the environment variable.
https://github.com/ray-project/ray/blob/3f99be8dad5e0e1abfaede1f25753a0af74f1648/python/ray/__init__.py#L16-L21
</issue>
<code>
[start of python/ray/__init__.py]
1 import os
2 import logging
3 from os.path import dirname
4 import sys
5
6 logger = logging.getLogger(__name__)
7
8 # MUST add pickle5 to the import path because it will be imported by some
9 # raylet modules.
10
11 if "pickle5" in sys.modules:
12 raise ImportError("Ray must be imported before pickle5 because Ray "
13 "requires a specific version of pickle5 (which is "
14 "packaged along with Ray).")
15
16 if "OMP_NUM_THREADS" not in os.environ:
17 logger.warning("[ray] Forcing OMP_NUM_THREADS=1 to avoid performance "
18 "degradation with many workers (issue #6998). You can "
19 "override this by explicitly setting OMP_NUM_THREADS.")
20 os.environ["OMP_NUM_THREADS"] = "1"
21
22 # Add the directory containing pickle5 to the Python path so that we find the
23 # pickle5 version packaged with ray and not a pre-existing pickle5.
24 pickle5_path = os.path.join(
25 os.path.abspath(os.path.dirname(__file__)), "pickle5_files")
26 sys.path.insert(0, pickle5_path)
27
28 # Importing psutil & setproctitle. Must be before ray._raylet is initialized.
29 thirdparty_files = os.path.join(
30 os.path.abspath(os.path.dirname(__file__)), "thirdparty_files")
31 sys.path.insert(0, thirdparty_files)
32
33 # Expose ray ABI symbols which may be dependent by other shared
34 # libraries such as _streaming.so. See BUILD.bazel:_raylet
35 so_path = os.path.join(dirname(__file__), "_raylet.so")
36 if os.path.exists(so_path):
37 import ctypes
38 from ctypes import CDLL
39 CDLL(so_path, ctypes.RTLD_GLOBAL)
40
41 # MUST import ray._raylet before pyarrow to initialize some global variables.
42 # It seems the library related to memory allocation in pyarrow will destroy the
43 # initialization of grpc if we import pyarrow at first.
44 # NOTE(JoeyJiang): See https://github.com/ray-project/ray/issues/5219 for more
45 # details.
46 import ray._raylet # noqa: E402
47
48 if "pyarrow" in sys.modules:
49 raise ImportError("Ray must be imported before pyarrow because Ray "
50 "requires a specific version of pyarrow (which is "
51 "packaged along with Ray).")
52
53 # Add the directory containing pyarrow to the Python path so that we find the
54 # pyarrow version packaged with ray and not a pre-existing pyarrow.
55 pyarrow_path = os.path.join(
56 os.path.abspath(os.path.dirname(__file__)), "pyarrow_files")
57 sys.path.insert(0, pyarrow_path)
58
59 # See https://github.com/ray-project/ray/issues/131.
60 helpful_message = """
61
62 If you are using Anaconda, try fixing this problem by running:
63
64 conda install libgcc
65 """
66
67 try:
68 import pyarrow # noqa: F401
69
70 # pyarrow is not imported inside of _raylet because of the issue described
71 # above. In order for Cython to compile _raylet, pyarrow is set to None
72 # in _raylet instead, so we give _raylet a real reference to it here.
73 # We first do the attribute checks here so that building the documentation
74 # succeeds without fully installing ray..
75 # TODO(edoakes): Fix this.
76 if hasattr(ray, "_raylet") and hasattr(ray._raylet, "pyarrow"):
77 ray._raylet.pyarrow = pyarrow
78 except ImportError as e:
79 if ((hasattr(e, "msg") and isinstance(e.msg, str)
80 and ("libstdc++" in e.msg or "CXX" in e.msg))):
81 # This code path should be taken with Python 3.
82 e.msg += helpful_message
83 elif (hasattr(e, "message") and isinstance(e.message, str)
84 and ("libstdc++" in e.message or "CXX" in e.message)):
85 # This code path should be taken with Python 2.
86 condition = (hasattr(e, "args") and isinstance(e.args, tuple)
87 and len(e.args) == 1 and isinstance(e.args[0], str))
88 if condition:
89 e.args = (e.args[0] + helpful_message, )
90 else:
91 if not hasattr(e, "args"):
92 e.args = ()
93 elif not isinstance(e.args, tuple):
94 e.args = (e.args, )
95 e.args += (helpful_message, )
96 raise
97
98 from ray._raylet import (
99 ActorCheckpointID,
100 ActorClassID,
101 ActorID,
102 ClientID,
103 Config as _Config,
104 JobID,
105 WorkerID,
106 FunctionID,
107 ObjectID,
108 TaskID,
109 UniqueID,
110 Language,
111 ) # noqa: E402
112
113 _config = _Config()
114
115 from ray.profiling import profile # noqa: E402
116 from ray.state import (jobs, nodes, actors, tasks, objects, timeline,
117 object_transfer_timeline, cluster_resources,
118 available_resources, errors) # noqa: E402
119 from ray.worker import (
120 LOCAL_MODE,
121 SCRIPT_MODE,
122 WORKER_MODE,
123 connect,
124 disconnect,
125 get,
126 get_gpu_ids,
127 get_resource_ids,
128 get_webui_url,
129 init,
130 is_initialized,
131 put,
132 register_custom_serializer,
133 remote,
134 shutdown,
135 show_in_webui,
136 wait,
137 ) # noqa: E402
138 import ray.internal # noqa: E402
139 import ray.projects # noqa: E402
140 # We import ray.actor because some code is run in actor.py which initializes
141 # some functions in the worker.
142 import ray.actor # noqa: F401
143 from ray.actor import method # noqa: E402
144 from ray.runtime_context import _get_runtime_context # noqa: E402
145 from ray.cross_language import java_function, java_actor_class # noqa: E402
146
147 # Ray version string.
148 __version__ = "0.9.0.dev0"
149
150 __all__ = [
151 "jobs",
152 "nodes",
153 "actors",
154 "tasks",
155 "objects",
156 "timeline",
157 "object_transfer_timeline",
158 "cluster_resources",
159 "available_resources",
160 "errors",
161 "LOCAL_MODE",
162 "PYTHON_MODE",
163 "SCRIPT_MODE",
164 "WORKER_MODE",
165 "__version__",
166 "_config",
167 "_get_runtime_context",
168 "actor",
169 "connect",
170 "disconnect",
171 "get",
172 "get_gpu_ids",
173 "get_resource_ids",
174 "get_webui_url",
175 "init",
176 "internal",
177 "is_initialized",
178 "method",
179 "profile",
180 "projects",
181 "put",
182 "register_custom_serializer",
183 "remote",
184 "shutdown",
185 "show_in_webui",
186 "wait",
187 "Language",
188 "java_function",
189 "java_actor_class",
190 ]
191
192 # ID types
193 __all__ += [
194 "ActorCheckpointID",
195 "ActorClassID",
196 "ActorID",
197 "ClientID",
198 "JobID",
199 "WorkerID",
200 "FunctionID",
201 "ObjectID",
202 "TaskID",
203 "UniqueID",
204 ]
205
206 import ctypes # noqa: E402
207 # Windows only
208 if hasattr(ctypes, "windll"):
209 # Makes sure that all child processes die when we die. Also makes sure that
210 # fatal crashes result in process termination rather than an error dialog
211 # (the latter is annoying since we have a lot of processes). This is done
212 # by associating all child processes with a "job" object that imposes this
213 # behavior.
214 (lambda kernel32: (lambda job: (lambda n: kernel32.SetInformationJobObject(job, 9, "\0" * 17 + chr(0x8 | 0x4 | 0x20) + "\0" * (n - 18), n))(0x90 if ctypes.sizeof(ctypes.c_void_p) > ctypes.sizeof(ctypes.c_int) else 0x70) and kernel32.AssignProcessToJobObject(job, ctypes.c_void_p(kernel32.GetCurrentProcess())))(ctypes.c_void_p(kernel32.CreateJobObjectW(None, None))) if kernel32 is not None else None)(ctypes.windll.kernel32) # noqa: E501
215
[end of python/ray/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/python/ray/__init__.py b/python/ray/__init__.py
--- a/python/ray/__init__.py
+++ b/python/ray/__init__.py
@@ -14,9 +14,9 @@
"packaged along with Ray).")
if "OMP_NUM_THREADS" not in os.environ:
- logger.warning("[ray] Forcing OMP_NUM_THREADS=1 to avoid performance "
- "degradation with many workers (issue #6998). You can "
- "override this by explicitly setting OMP_NUM_THREADS.")
+ logger.debug("[ray] Forcing OMP_NUM_THREADS=1 to avoid performance "
+ "degradation with many workers (issue #6998). You can "
+ "override this by explicitly setting OMP_NUM_THREADS.")
os.environ["OMP_NUM_THREADS"] = "1"
# Add the directory containing pickle5 to the Python path so that we find the
| {"golden_diff": "diff --git a/python/ray/__init__.py b/python/ray/__init__.py\n--- a/python/ray/__init__.py\n+++ b/python/ray/__init__.py\n@@ -14,9 +14,9 @@\n \"packaged along with Ray).\")\n \n if \"OMP_NUM_THREADS\" not in os.environ:\n- logger.warning(\"[ray] Forcing OMP_NUM_THREADS=1 to avoid performance \"\n- \"degradation with many workers (issue #6998). You can \"\n- \"override this by explicitly setting OMP_NUM_THREADS.\")\n+ logger.debug(\"[ray] Forcing OMP_NUM_THREADS=1 to avoid performance \"\n+ \"degradation with many workers (issue #6998). You can \"\n+ \"override this by explicitly setting OMP_NUM_THREADS.\")\n os.environ[\"OMP_NUM_THREADS\"] = \"1\"\n \n # Add the directory containing pickle5 to the Python path so that we find the\n", "issue": "Turn off OMP_NUM_THREADS warnings? \nCan we just turn off the warnings on each ray.init? We can't force everyone to set the environment variable. \r\n\r\nhttps://github.com/ray-project/ray/blob/3f99be8dad5e0e1abfaede1f25753a0af74f1648/python/ray/__init__.py#L16-L21\n", "before_files": [{"content": "import os\nimport logging\nfrom os.path import dirname\nimport sys\n\nlogger = logging.getLogger(__name__)\n\n# MUST add pickle5 to the import path because it will be imported by some\n# raylet modules.\n\nif \"pickle5\" in sys.modules:\n raise ImportError(\"Ray must be imported before pickle5 because Ray \"\n \"requires a specific version of pickle5 (which is \"\n \"packaged along with Ray).\")\n\nif \"OMP_NUM_THREADS\" not in os.environ:\n logger.warning(\"[ray] Forcing OMP_NUM_THREADS=1 to avoid performance \"\n \"degradation with many workers (issue #6998). You can \"\n \"override this by explicitly setting OMP_NUM_THREADS.\")\n os.environ[\"OMP_NUM_THREADS\"] = \"1\"\n\n# Add the directory containing pickle5 to the Python path so that we find the\n# pickle5 version packaged with ray and not a pre-existing pickle5.\npickle5_path = os.path.join(\n os.path.abspath(os.path.dirname(__file__)), \"pickle5_files\")\nsys.path.insert(0, pickle5_path)\n\n# Importing psutil & setproctitle. Must be before ray._raylet is initialized.\nthirdparty_files = os.path.join(\n os.path.abspath(os.path.dirname(__file__)), \"thirdparty_files\")\nsys.path.insert(0, thirdparty_files)\n\n# Expose ray ABI symbols which may be dependent by other shared\n# libraries such as _streaming.so. See BUILD.bazel:_raylet\nso_path = os.path.join(dirname(__file__), \"_raylet.so\")\nif os.path.exists(so_path):\n import ctypes\n from ctypes import CDLL\n CDLL(so_path, ctypes.RTLD_GLOBAL)\n\n# MUST import ray._raylet before pyarrow to initialize some global variables.\n# It seems the library related to memory allocation in pyarrow will destroy the\n# initialization of grpc if we import pyarrow at first.\n# NOTE(JoeyJiang): See https://github.com/ray-project/ray/issues/5219 for more\n# details.\nimport ray._raylet # noqa: E402\n\nif \"pyarrow\" in sys.modules:\n raise ImportError(\"Ray must be imported before pyarrow because Ray \"\n \"requires a specific version of pyarrow (which is \"\n \"packaged along with Ray).\")\n\n# Add the directory containing pyarrow to the Python path so that we find the\n# pyarrow version packaged with ray and not a pre-existing pyarrow.\npyarrow_path = os.path.join(\n os.path.abspath(os.path.dirname(__file__)), \"pyarrow_files\")\nsys.path.insert(0, pyarrow_path)\n\n# See https://github.com/ray-project/ray/issues/131.\nhelpful_message = \"\"\"\n\nIf you are using Anaconda, try fixing this problem by running:\n\n conda install libgcc\n\"\"\"\n\ntry:\n import pyarrow # noqa: F401\n\n # pyarrow is not imported inside of _raylet because of the issue described\n # above. In order for Cython to compile _raylet, pyarrow is set to None\n # in _raylet instead, so we give _raylet a real reference to it here.\n # We first do the attribute checks here so that building the documentation\n # succeeds without fully installing ray..\n # TODO(edoakes): Fix this.\n if hasattr(ray, \"_raylet\") and hasattr(ray._raylet, \"pyarrow\"):\n ray._raylet.pyarrow = pyarrow\nexcept ImportError as e:\n if ((hasattr(e, \"msg\") and isinstance(e.msg, str)\n and (\"libstdc++\" in e.msg or \"CXX\" in e.msg))):\n # This code path should be taken with Python 3.\n e.msg += helpful_message\n elif (hasattr(e, \"message\") and isinstance(e.message, str)\n and (\"libstdc++\" in e.message or \"CXX\" in e.message)):\n # This code path should be taken with Python 2.\n condition = (hasattr(e, \"args\") and isinstance(e.args, tuple)\n and len(e.args) == 1 and isinstance(e.args[0], str))\n if condition:\n e.args = (e.args[0] + helpful_message, )\n else:\n if not hasattr(e, \"args\"):\n e.args = ()\n elif not isinstance(e.args, tuple):\n e.args = (e.args, )\n e.args += (helpful_message, )\n raise\n\nfrom ray._raylet import (\n ActorCheckpointID,\n ActorClassID,\n ActorID,\n ClientID,\n Config as _Config,\n JobID,\n WorkerID,\n FunctionID,\n ObjectID,\n TaskID,\n UniqueID,\n Language,\n) # noqa: E402\n\n_config = _Config()\n\nfrom ray.profiling import profile # noqa: E402\nfrom ray.state import (jobs, nodes, actors, tasks, objects, timeline,\n object_transfer_timeline, cluster_resources,\n available_resources, errors) # noqa: E402\nfrom ray.worker import (\n LOCAL_MODE,\n SCRIPT_MODE,\n WORKER_MODE,\n connect,\n disconnect,\n get,\n get_gpu_ids,\n get_resource_ids,\n get_webui_url,\n init,\n is_initialized,\n put,\n register_custom_serializer,\n remote,\n shutdown,\n show_in_webui,\n wait,\n) # noqa: E402\nimport ray.internal # noqa: E402\nimport ray.projects # noqa: E402\n# We import ray.actor because some code is run in actor.py which initializes\n# some functions in the worker.\nimport ray.actor # noqa: F401\nfrom ray.actor import method # noqa: E402\nfrom ray.runtime_context import _get_runtime_context # noqa: E402\nfrom ray.cross_language import java_function, java_actor_class # noqa: E402\n\n# Ray version string.\n__version__ = \"0.9.0.dev0\"\n\n__all__ = [\n \"jobs\",\n \"nodes\",\n \"actors\",\n \"tasks\",\n \"objects\",\n \"timeline\",\n \"object_transfer_timeline\",\n \"cluster_resources\",\n \"available_resources\",\n \"errors\",\n \"LOCAL_MODE\",\n \"PYTHON_MODE\",\n \"SCRIPT_MODE\",\n \"WORKER_MODE\",\n \"__version__\",\n \"_config\",\n \"_get_runtime_context\",\n \"actor\",\n \"connect\",\n \"disconnect\",\n \"get\",\n \"get_gpu_ids\",\n \"get_resource_ids\",\n \"get_webui_url\",\n \"init\",\n \"internal\",\n \"is_initialized\",\n \"method\",\n \"profile\",\n \"projects\",\n \"put\",\n \"register_custom_serializer\",\n \"remote\",\n \"shutdown\",\n \"show_in_webui\",\n \"wait\",\n \"Language\",\n \"java_function\",\n \"java_actor_class\",\n]\n\n# ID types\n__all__ += [\n \"ActorCheckpointID\",\n \"ActorClassID\",\n \"ActorID\",\n \"ClientID\",\n \"JobID\",\n \"WorkerID\",\n \"FunctionID\",\n \"ObjectID\",\n \"TaskID\",\n \"UniqueID\",\n]\n\nimport ctypes # noqa: E402\n# Windows only\nif hasattr(ctypes, \"windll\"):\n # Makes sure that all child processes die when we die. Also makes sure that\n # fatal crashes result in process termination rather than an error dialog\n # (the latter is annoying since we have a lot of processes). This is done\n # by associating all child processes with a \"job\" object that imposes this\n # behavior.\n (lambda kernel32: (lambda job: (lambda n: kernel32.SetInformationJobObject(job, 9, \"\\0\" * 17 + chr(0x8 | 0x4 | 0x20) + \"\\0\" * (n - 18), n))(0x90 if ctypes.sizeof(ctypes.c_void_p) > ctypes.sizeof(ctypes.c_int) else 0x70) and kernel32.AssignProcessToJobObject(job, ctypes.c_void_p(kernel32.GetCurrentProcess())))(ctypes.c_void_p(kernel32.CreateJobObjectW(None, None))) if kernel32 is not None else None)(ctypes.windll.kernel32) # noqa: E501\n", "path": "python/ray/__init__.py"}]} | 2,993 | 205 |
gh_patches_debug_9754 | rasdani/github-patches | git_diff | graspologic-org__graspologic-968 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[BUG] mug2vec assumes undirected graphs but doesn't check for this
## Expected Behavior
Should run on a set of directed graphs
## Actual Behavior
Breaks on this line
https://github.com/microsoft/graspologic/blob/2125f27bc3f2739f4f2c784d5b700417df63c5d7/graspologic/embed/mug2vec.py#L141
since `omni_embedding` is a tuple
</issue>
<code>
[start of graspologic/embed/mug2vec.py]
1 # Copyright (c) Microsoft Corporation and contributors.
2 # Licensed under the MIT License.
3
4 from typing import Any, Optional
5
6 import numpy as np
7 from sklearn.base import BaseEstimator
8 from typing_extensions import Literal
9
10 from graspologic.types import List
11
12 from ..types import GraphRepresentation
13 from ..utils import pass_to_ranks
14 from .mds import ClassicalMDS
15 from .omni import OmnibusEmbed
16
17
18 class mug2vec(BaseEstimator):
19 r"""
20 Multigraphs-2-vectors (mug2vec).
21
22 mug2vec is a sequence of three algorithms that learns a feature vector for each
23 input graph.
24
25 Steps:
26
27 1. Pass to ranks - ranks all edge weights from smallest to largest valued edges
28 then normalize by a constant.
29
30 2. Omnibus embedding - jointly learns a low dimensional matrix representation for
31 all graphs under the random dot product model (RDPG).
32
33 3. Classical MDS (cMDS) - learns a feature vector for each graph by computing
34 Euclidean distance between each pair of graph embeddings from omnibus embedding,
35 followed by an eigen decomposition.
36
37 Parameters
38 ----------
39 pass_to_ranks: {'simple-nonzero' (default), 'simple-all', 'zero-boost'} string, or None
40
41 - 'simple-nonzero'
42 assigns ranks to all non-zero edges, settling ties using
43 the average. Ranks are then scaled by
44 :math:`\frac{rank(\text{non-zero edges})}{\text{total non-zero edges} + 1}`
45 - 'simple-all'
46 assigns ranks to all non-zero edges, settling ties using
47 the average. Ranks are then scaled by
48 :math:`\frac{rank(\text{non-zero edges})}{n^2 + 1}`
49 where n is the number of nodes
50 - 'zero-boost'
51 preserves the edge weight for all 0s, but ranks the other
52 edges as if the ranks of all 0 edges has been assigned. If there are
53 10 0-valued edges, the lowest non-zero edge gets weight 11 / (number
54 of possible edges). Ties settled by the average of the weight that those
55 edges would have received. Number of possible edges is determined
56 by the type of graph (loopless or looped, directed or undirected).
57 - None
58 No pass to ranks applied.
59
60 omnibus_components, cmds_components : int or None, default = None
61 Desired dimensionality of output data. If "full",
62 ``n_components`` must be ``<= min(X.shape)``. Otherwise, ``n_components`` must be
63 ``< min(X.shape)``. If None, then optimal dimensions will be chosen by
64 :func:`~graspologic.embed.select_dimension` using ``n_elbows`` argument.
65
66 omnibus_n_elbows, cmds_n_elbows: int, optional, default: 2
67 If ``n_components`` is None, then compute the optimal embedding dimension using
68 :func:`~graspologic.embed.select_dimension`. Otherwise, ignored.
69
70 svd_seed : int or None (default ``None``)
71 Allows you to seed the randomized svd solver used in the Omnibus embedding
72 for deterministic, albeit pseudo-randomized behavior.
73
74 Attributes
75 ----------
76 omnibus_n_components_ : int
77 Equals the parameter ``n_components``. If input ``n_components`` was None,
78 then equals the optimal embedding dimension.
79
80 cmds_n_components_ : int
81 Equals the parameter ``n_components``. If input ``n_components`` was None,
82 then equals the optimal embedding dimension.
83
84 embeddings_ : array, shape (n_components, n_features)
85 Embeddings from the pipeline. Each graph is a point in ``n_features``
86 dimensions.
87
88 See also
89 --------
90 graspologic.utils.pass_to_ranks
91 graspologic.embed.OmnibusEmbed
92 graspologic.embed.ClassicalMDS
93 graspologic.embed.select_dimension
94 """
95
96 def __init__(
97 self,
98 pass_to_ranks: Literal[
99 "simple-nonzero", "simple-all", "zero-boost"
100 ] = "simple-nonzero",
101 omnibus_components: Optional[int] = None,
102 omnibus_n_elbows: int = 2,
103 cmds_components: Optional[int] = None,
104 cmds_n_elbows: int = 2,
105 svd_seed: Optional[int] = None,
106 ) -> None:
107 self.pass_to_ranks = pass_to_ranks
108 self.omnibus_components = omnibus_components
109 self.omnibus_n_elbows = omnibus_n_elbows
110 self.cmds_components = cmds_components
111 self.cmds_n_elbows = cmds_n_elbows
112 self.svd_seed = svd_seed
113
114 def _check_inputs(self) -> None:
115 variables = self.get_params()
116 variables.pop("pass_to_ranks")
117
118 for name, val in variables.items():
119 if val is not None:
120 if not isinstance(val, int):
121 msg = "{} must be an int or None.".format(name)
122 raise ValueError(msg)
123 elif val <= 0:
124 msg = "{} must be > 0.".format(name)
125 raise ValueError(msg)
126
127 def fit(
128 self, graphs: List[GraphRepresentation], y: Optional[Any] = None
129 ) -> "mug2vec":
130 """
131 Computes a vector for each graph.
132
133 Parameters
134 ----------
135 graphs : list of nx.Graph or ndarray, or ndarray
136 If list of nx.Graph, each Graph must contain same number of nodes.
137 If list of ndarray, each array must have shape (n_vertices, n_vertices).
138 If ndarray, then array must have shape (n_graphs, n_vertices, n_vertices).
139
140 y : Ignored
141
142 Returns
143 -------
144 self : returns an instance of self.
145 """
146 # Check these prior to PTR just in case
147 self._check_inputs()
148
149 if self.pass_to_ranks is not None:
150 graphs = [pass_to_ranks(g, self.pass_to_ranks) for g in graphs]
151
152 omni = OmnibusEmbed(
153 n_components=self.omnibus_components,
154 n_elbows=self.omnibus_n_elbows,
155 svd_seed=self.svd_seed,
156 )
157 omnibus_embedding = omni.fit_transform(graphs)
158
159 self.omnibus_n_components_ = omnibus_embedding.shape[-1]
160
161 cmds = ClassicalMDS(
162 n_components=self.cmds_components,
163 n_elbows=self.cmds_n_elbows,
164 svd_seed=self.svd_seed,
165 )
166 self.embeddings_: np.ndarray = cmds.fit_transform(omnibus_embedding)
167 self.cmds_components_ = self.embeddings_.shape[-1]
168
169 return self
170
171 def fit_transform(
172 self, graphs: List[GraphRepresentation], y: Optional[Any] = None
173 ) -> np.ndarray:
174 """
175 Computes a vector for each graph.
176
177 Parameters
178 ----------
179 graphs : list of nx.Graph or ndarray, or ndarray
180 If list of nx.Graph, each Graph must contain same number of nodes.
181 If list of ndarray, each array must have shape (n_vertices, n_vertices).
182 If ndarray, then array must have shape (n_graphs, n_vertices, n_vertices).
183
184 y : Ignored
185
186 Returns
187 -------
188 embeddings : embeddings generated by fit.
189 """
190 self.fit(graphs)
191
192 return self.embeddings_
193
[end of graspologic/embed/mug2vec.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/graspologic/embed/mug2vec.py b/graspologic/embed/mug2vec.py
--- a/graspologic/embed/mug2vec.py
+++ b/graspologic/embed/mug2vec.py
@@ -153,10 +153,11 @@
n_components=self.omnibus_components,
n_elbows=self.omnibus_n_elbows,
svd_seed=self.svd_seed,
+ concat=True,
)
omnibus_embedding = omni.fit_transform(graphs)
- self.omnibus_n_components_ = omnibus_embedding.shape[-1]
+ self.omnibus_n_components_ = len(omni.singular_values_)
cmds = ClassicalMDS(
n_components=self.cmds_components,
| {"golden_diff": "diff --git a/graspologic/embed/mug2vec.py b/graspologic/embed/mug2vec.py\n--- a/graspologic/embed/mug2vec.py\n+++ b/graspologic/embed/mug2vec.py\n@@ -153,10 +153,11 @@\n n_components=self.omnibus_components,\n n_elbows=self.omnibus_n_elbows,\n svd_seed=self.svd_seed,\n+ concat=True,\n )\n omnibus_embedding = omni.fit_transform(graphs)\n \n- self.omnibus_n_components_ = omnibus_embedding.shape[-1]\n+ self.omnibus_n_components_ = len(omni.singular_values_)\n \n cmds = ClassicalMDS(\n n_components=self.cmds_components,\n", "issue": "[BUG] mug2vec assumes undirected graphs but doesn't check for this\n## Expected Behavior\r\nShould run on a set of directed graphs\r\n\r\n## Actual Behavior\r\nBreaks on this line \r\nhttps://github.com/microsoft/graspologic/blob/2125f27bc3f2739f4f2c784d5b700417df63c5d7/graspologic/embed/mug2vec.py#L141\r\nsince `omni_embedding` is a tuple \r\n\n", "before_files": [{"content": "# Copyright (c) Microsoft Corporation and contributors.\n# Licensed under the MIT License.\n\nfrom typing import Any, Optional\n\nimport numpy as np\nfrom sklearn.base import BaseEstimator\nfrom typing_extensions import Literal\n\nfrom graspologic.types import List\n\nfrom ..types import GraphRepresentation\nfrom ..utils import pass_to_ranks\nfrom .mds import ClassicalMDS\nfrom .omni import OmnibusEmbed\n\n\nclass mug2vec(BaseEstimator):\n r\"\"\"\n Multigraphs-2-vectors (mug2vec).\n\n mug2vec is a sequence of three algorithms that learns a feature vector for each\n input graph.\n\n Steps:\n\n 1. Pass to ranks - ranks all edge weights from smallest to largest valued edges\n then normalize by a constant.\n\n 2. Omnibus embedding - jointly learns a low dimensional matrix representation for\n all graphs under the random dot product model (RDPG).\n\n 3. Classical MDS (cMDS) - learns a feature vector for each graph by computing\n Euclidean distance between each pair of graph embeddings from omnibus embedding,\n followed by an eigen decomposition.\n\n Parameters\n ----------\n pass_to_ranks: {'simple-nonzero' (default), 'simple-all', 'zero-boost'} string, or None\n\n - 'simple-nonzero'\n assigns ranks to all non-zero edges, settling ties using\n the average. Ranks are then scaled by\n :math:`\\frac{rank(\\text{non-zero edges})}{\\text{total non-zero edges} + 1}`\n - 'simple-all'\n assigns ranks to all non-zero edges, settling ties using\n the average. Ranks are then scaled by\n :math:`\\frac{rank(\\text{non-zero edges})}{n^2 + 1}`\n where n is the number of nodes\n - 'zero-boost'\n preserves the edge weight for all 0s, but ranks the other\n edges as if the ranks of all 0 edges has been assigned. If there are\n 10 0-valued edges, the lowest non-zero edge gets weight 11 / (number\n of possible edges). Ties settled by the average of the weight that those\n edges would have received. Number of possible edges is determined\n by the type of graph (loopless or looped, directed or undirected).\n - None\n No pass to ranks applied.\n\n omnibus_components, cmds_components : int or None, default = None\n Desired dimensionality of output data. If \"full\",\n ``n_components`` must be ``<= min(X.shape)``. Otherwise, ``n_components`` must be\n ``< min(X.shape)``. If None, then optimal dimensions will be chosen by\n :func:`~graspologic.embed.select_dimension` using ``n_elbows`` argument.\n\n omnibus_n_elbows, cmds_n_elbows: int, optional, default: 2\n If ``n_components`` is None, then compute the optimal embedding dimension using\n :func:`~graspologic.embed.select_dimension`. Otherwise, ignored.\n\n svd_seed : int or None (default ``None``)\n Allows you to seed the randomized svd solver used in the Omnibus embedding\n for deterministic, albeit pseudo-randomized behavior.\n\n Attributes\n ----------\n omnibus_n_components_ : int\n Equals the parameter ``n_components``. If input ``n_components`` was None,\n then equals the optimal embedding dimension.\n\n cmds_n_components_ : int\n Equals the parameter ``n_components``. If input ``n_components`` was None,\n then equals the optimal embedding dimension.\n\n embeddings_ : array, shape (n_components, n_features)\n Embeddings from the pipeline. Each graph is a point in ``n_features``\n dimensions.\n\n See also\n --------\n graspologic.utils.pass_to_ranks\n graspologic.embed.OmnibusEmbed\n graspologic.embed.ClassicalMDS\n graspologic.embed.select_dimension\n \"\"\"\n\n def __init__(\n self,\n pass_to_ranks: Literal[\n \"simple-nonzero\", \"simple-all\", \"zero-boost\"\n ] = \"simple-nonzero\",\n omnibus_components: Optional[int] = None,\n omnibus_n_elbows: int = 2,\n cmds_components: Optional[int] = None,\n cmds_n_elbows: int = 2,\n svd_seed: Optional[int] = None,\n ) -> None:\n self.pass_to_ranks = pass_to_ranks\n self.omnibus_components = omnibus_components\n self.omnibus_n_elbows = omnibus_n_elbows\n self.cmds_components = cmds_components\n self.cmds_n_elbows = cmds_n_elbows\n self.svd_seed = svd_seed\n\n def _check_inputs(self) -> None:\n variables = self.get_params()\n variables.pop(\"pass_to_ranks\")\n\n for name, val in variables.items():\n if val is not None:\n if not isinstance(val, int):\n msg = \"{} must be an int or None.\".format(name)\n raise ValueError(msg)\n elif val <= 0:\n msg = \"{} must be > 0.\".format(name)\n raise ValueError(msg)\n\n def fit(\n self, graphs: List[GraphRepresentation], y: Optional[Any] = None\n ) -> \"mug2vec\":\n \"\"\"\n Computes a vector for each graph.\n\n Parameters\n ----------\n graphs : list of nx.Graph or ndarray, or ndarray\n If list of nx.Graph, each Graph must contain same number of nodes.\n If list of ndarray, each array must have shape (n_vertices, n_vertices).\n If ndarray, then array must have shape (n_graphs, n_vertices, n_vertices).\n\n y : Ignored\n\n Returns\n -------\n self : returns an instance of self.\n \"\"\"\n # Check these prior to PTR just in case\n self._check_inputs()\n\n if self.pass_to_ranks is not None:\n graphs = [pass_to_ranks(g, self.pass_to_ranks) for g in graphs]\n\n omni = OmnibusEmbed(\n n_components=self.omnibus_components,\n n_elbows=self.omnibus_n_elbows,\n svd_seed=self.svd_seed,\n )\n omnibus_embedding = omni.fit_transform(graphs)\n\n self.omnibus_n_components_ = omnibus_embedding.shape[-1]\n\n cmds = ClassicalMDS(\n n_components=self.cmds_components,\n n_elbows=self.cmds_n_elbows,\n svd_seed=self.svd_seed,\n )\n self.embeddings_: np.ndarray = cmds.fit_transform(omnibus_embedding)\n self.cmds_components_ = self.embeddings_.shape[-1]\n\n return self\n\n def fit_transform(\n self, graphs: List[GraphRepresentation], y: Optional[Any] = None\n ) -> np.ndarray:\n \"\"\"\n Computes a vector for each graph.\n\n Parameters\n ----------\n graphs : list of nx.Graph or ndarray, or ndarray\n If list of nx.Graph, each Graph must contain same number of nodes.\n If list of ndarray, each array must have shape (n_vertices, n_vertices).\n If ndarray, then array must have shape (n_graphs, n_vertices, n_vertices).\n\n y : Ignored\n\n Returns\n -------\n embeddings : embeddings generated by fit.\n \"\"\"\n self.fit(graphs)\n\n return self.embeddings_\n", "path": "graspologic/embed/mug2vec.py"}]} | 2,747 | 165 |
gh_patches_debug_4210 | rasdani/github-patches | git_diff | huggingface__transformers-8049 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
BlenderbotSmallTokenizer throws tuple index out of range error for stopword
Using transformers==3.4.0
Script used:
```
from transformers import BlenderbotSmallTokenizer, BlenderbotForConditionalGeneration
mname = 'facebook/blenderbot-90M'
tokenizer = BlenderbotSmallTokenizer.from_pretrained(mname)
sentence = "."
tokenizer(sentence)['input_ids']
```
This throws `IndexError: tuple index out of range`
</issue>
<code>
[start of src/transformers/tokenization_blenderbot.py]
1 #!/usr/bin/env python3
2 # coding=utf-8
3 # Copyright (c) Facebook, Inc. and its affiliates.
4 #
5 # This source code is licensed under the MIT license found in the;
6 # you may not use this file except in compliance with the License.
7 # You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing, software
12 # distributed under the License is distributed on an "AS IS" BASIS,
13 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 # See the License for the specific language governing permissions and
15 # limitations under the License.
16 # LICENSE file in the root directory of this source tree.
17 """"BlenderbotTokenizer and BlenderbotSmallTokenizer"""
18 import json
19 import os
20 from typing import Dict, List, Optional, Tuple
21
22 import regex as re
23
24 from .tokenization_roberta import RobertaTokenizer
25 from .tokenization_utils import PreTrainedTokenizer
26 from .utils import logging
27
28
29 logger = logging.get_logger(__name__)
30
31
32 VOCAB_FILES_NAMES = {
33 "vocab_file": "vocab.json",
34 "merges_file": "merges.txt",
35 # "tokenizer_config_file": "tokenizer_config.json",
36 }
37 CKPT_3B = "facebook/blenderbot-3B"
38
39
40 class BlenderbotTokenizer(RobertaTokenizer):
41 r"""
42 Construct a Blenderbot tokenizer.
43
44 :class:`~transformers.Blenderbot` is nearly identical to :class:`~transformers.RobertaTokenizer` and runs
45 end-to-end tokenization: punctuation splitting and wordpiece. The only difference is that it doesnt add BOS
46 token to the beginning of sequences.
47
48 Refer to superclass :class:`~transformers.RobertaTokenizer` for usage examples and documentation concerning
49 parameters.
50 """
51 vocab_files_names = {
52 "vocab_file": "vocab.json",
53 "merges_file": "merges.txt",
54 "tokenizer_config_file": "tokenizer_config.json",
55 }
56 pretrained_vocab_files_map = {
57 "vocab_file": {CKPT_3B: "https://cdn.huggingface.co/facebook/blenderbot-3B/vocab.json"},
58 "merges_file": {CKPT_3B: "https://cdn.huggingface.co/facebook/blenderbot-3B/merges.txt"},
59 "tokenizer_config_file": {CKPT_3B: "https://cdn.huggingface.co/facebook/blenderbot-3B/tokenizer_config.json"},
60 }
61 max_model_input_sizes = {"facebook/blenderbot-3B": 128}
62
63 def build_inputs_with_special_tokens(self, token_ids_0: List[int], token_ids_1: List[int] = None):
64 """
65 Build model inputs from a sequence or a pair of sequence for sequence classification tasks
66 by concatenating and adding special tokens.
67 A Blenderbot sequence has the following format:
68
69 - single sequence: `` X </s>``
70
71 Args:
72 token_ids_0 (:obj:`List[int]`):
73 List of IDs to which the special tokens will be added
74 token_ids_1 (:obj:`List[int]`, `optional`):
75 Will be ignored
76
77 Returns:
78 :obj:`List[int]`: list of `input IDs <../glossary.html#input-ids>`__ with the appropriate special tokens.
79 """
80 return token_ids_0 + [self.eos_token_id]
81
82
83 def get_pairs(word):
84 """Return set of symbol pairs in a word.
85
86 Word is represented as tuple of symbols (symbols being variable-length strings).
87 """
88 pairs = set()
89 prev_char = word[0]
90 for char in word[1:]:
91 pairs.add((prev_char, char))
92 prev_char = char
93
94 pairs = set(pairs)
95 return pairs
96
97
98 class BlenderbotSmallTokenizer(PreTrainedTokenizer):
99 """
100 Constructs a Blenderbot-90M tokenizer based on BPE (Byte-Pair-Encoding)
101
102 This tokenizer inherits from :class:`~transformers.PreTrainedTokenizer` which contains most of the main methods. Users
103 should refer to the superclass for more information regarding methods.
104
105 Args:
106 vocab_file (:obj:`str`):
107 File containing the vocabulary.
108 merges_file (:obj:`str`):
109 Path to the merges file.
110 bos_token (:obj:`str`, `optional`, defaults to :obj:`"__start__"`):
111 The beginning of sentence token.
112 eos_token (:obj:`str`, `optional`, defaults to :obj:`"__end__"`):
113 The end of sentence token.
114 unk_token (:obj:`str`, `optional`, defaults to :obj:`"__unk__"`):
115 The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this token instead.
116 pad_token (:obj:`str`, `optional`, defaults to :obj:`"__pad__"`):
117 The token used for padding, for example when batching sequences of different lengths.
118 **kwargs
119 Additional keyword arguments passed along to :class:`~transformers.PreTrainedTokenizer`
120 """
121
122 vocab_files_names = {"vocab_file": "vocab.json", "merges_file": "merges.txt"}
123 pretrained_vocab_files_map = {
124 "vocab_file": {"facebook/blenderbot-90M": "https://cdn.huggingface.co/facebook/blenderbot-90M/vocab.json"},
125 "merges_file": {"facebook/blenderbot-90M": "https://cdn.huggingface.co/facebook/blenderbot-90M/merges.txt"},
126 }
127 max_model_input_sizes = {"facebook/blenderbot-90M": 512}
128
129 def __init__(
130 self,
131 vocab_file,
132 merges_file,
133 bos_token="__start__",
134 eos_token="__end__",
135 unk_token="__unk__",
136 pad_token="__null",
137 **kwargs
138 ):
139 super().__init__(unk_token=unk_token, bos_token=bos_token, eos_token=eos_token, pad_token=pad_token, **kwargs)
140
141 with open(vocab_file, encoding="utf-8") as vocab_handle:
142 self.encoder = json.load(vocab_handle)
143 self.decoder = {v: k for k, v in self.encoder.items()}
144 with open(merges_file, encoding="utf-8") as merges_handle:
145 merges = merges_handle.read().split("\n")[1:-1]
146 merges = [tuple(merge.split()) for merge in merges]
147 self.bpe_ranks = dict(zip(merges, range(len(merges))))
148 self.cache = {}
149
150 @property
151 def vocab_size(self) -> int:
152 return len(self.encoder)
153
154 def get_vocab(self) -> Dict:
155 return dict(self.encoder, **self.added_tokens_encoder)
156
157 def bpe(self, token: str) -> str:
158 if token in self.cache:
159 return self.cache[token]
160 token = re.sub("([.,!?()])", r" \1", token)
161 token = re.sub("(')", r" \1 ", token)
162 token = re.sub("\s{2,}", " ", token)
163 if "\n" in token:
164 token = token.replace("\n", " __newln__")
165
166 tokens = token.split(" ")
167 words = []
168 for token in tokens:
169 token = token.lower()
170 word = tuple(token)
171 word = tuple(list(word[:-1]) + [word[-1] + "</w>"])
172 pairs = get_pairs(word)
173
174 if not pairs:
175 words.append(token)
176 continue
177
178 while True:
179 bigram = min(pairs, key=lambda pair: self.bpe_ranks.get(pair, float("inf")))
180 if bigram not in self.bpe_ranks:
181 break
182 first, second = bigram
183 new_word = []
184 i = 0
185
186 while i < len(word):
187 try:
188 j = word.index(first, i)
189 new_word.extend(word[i:j])
190 i = j
191 except ValueError:
192 new_word.extend(word[i:])
193 break
194
195 if word[i] == first and i < len(word) - 1 and word[i + 1] == second:
196 new_word.append(first + second)
197 i += 2
198 else:
199 new_word.append(word[i])
200 i += 1
201 new_word = tuple(new_word)
202 word = new_word
203 if len(word) == 1:
204 break
205 else:
206 pairs = get_pairs(word)
207 word = "@@ ".join(word)
208 word = word[:-4]
209
210 self.cache[token] = word
211 words.append(word)
212 return " ".join(words)
213
214 def _tokenize(self, text: str) -> List[str]:
215 """ Split a string into tokens using BPE."""
216 split_tokens = []
217
218 words = re.findall(r"\S+\n?", text)
219
220 for token in words:
221 split_tokens.extend([t for t in self.bpe(token).split(" ")])
222 return split_tokens
223
224 def _convert_token_to_id(self, token: str) -> int:
225 """ Converts a token to an id using the vocab. """
226 token = token.lower()
227 return self.encoder.get(token, self.encoder.get(self.unk_token))
228
229 def _convert_id_to_token(self, index: int) -> str:
230 """Converts an index (integer) in a token (str) using the vocab."""
231 return self.decoder.get(index, self.unk_token)
232
233 def convert_tokens_to_string(self, tokens: List[str]) -> str:
234 """ Converts a sequence of tokens in a single string. """
235 out_string = " ".join(tokens).replace("@@ ", "").strip()
236 return out_string
237
238 def save_vocabulary(self, save_directory: str, filename_prefix: Optional[str] = None) -> Tuple[str]:
239 if not os.path.isdir(save_directory):
240 logger.error("Vocabulary path ({}) should be a directory".format(save_directory))
241 return
242 vocab_file = os.path.join(
243 save_directory, (filename_prefix + "-" if filename_prefix else "") + VOCAB_FILES_NAMES["vocab_file"]
244 )
245 merge_file = os.path.join(
246 save_directory, (filename_prefix + "-" if filename_prefix else "") + VOCAB_FILES_NAMES["merges_file"]
247 )
248
249 with open(vocab_file, "w", encoding="utf-8") as f:
250 f.write(json.dumps(self.encoder, ensure_ascii=False))
251
252 index = 0
253 with open(merge_file, "w", encoding="utf-8") as writer:
254 writer.write("#version: 0.2\n")
255 for bpe_tokens, token_index in sorted(self.bpe_ranks.items(), key=lambda kv: kv[1]):
256 if index != token_index:
257 logger.warning(
258 "Saving vocabulary to {}: BPE merge indices are not consecutive."
259 " Please check that the tokenizer is not corrupted!".format(merge_file)
260 )
261 index = token_index
262 writer.write(" ".join(bpe_tokens) + "\n")
263 index += 1
264
265 return vocab_file, merge_file
266
[end of src/transformers/tokenization_blenderbot.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/src/transformers/tokenization_blenderbot.py b/src/transformers/tokenization_blenderbot.py
--- a/src/transformers/tokenization_blenderbot.py
+++ b/src/transformers/tokenization_blenderbot.py
@@ -166,6 +166,9 @@
tokens = token.split(" ")
words = []
for token in tokens:
+ if not len(token):
+ continue
+
token = token.lower()
word = tuple(token)
word = tuple(list(word[:-1]) + [word[-1] + "</w>"])
| {"golden_diff": "diff --git a/src/transformers/tokenization_blenderbot.py b/src/transformers/tokenization_blenderbot.py\n--- a/src/transformers/tokenization_blenderbot.py\n+++ b/src/transformers/tokenization_blenderbot.py\n@@ -166,6 +166,9 @@\n tokens = token.split(\" \")\n words = []\n for token in tokens:\n+ if not len(token):\n+ continue\n+\n token = token.lower()\n word = tuple(token)\n word = tuple(list(word[:-1]) + [word[-1] + \"</w>\"])\n", "issue": "BlenderbotSmallTokenizer throws tuple index out of range error for stopword\nUsing transformers==3.4.0\r\n\r\nScript used:\r\n```\r\n\r\nfrom transformers import BlenderbotSmallTokenizer, BlenderbotForConditionalGeneration\r\nmname = 'facebook/blenderbot-90M'\r\ntokenizer = BlenderbotSmallTokenizer.from_pretrained(mname)\r\n\r\nsentence = \".\"\r\ntokenizer(sentence)['input_ids']\r\n```\r\n\r\nThis throws `IndexError: tuple index out of range`\n", "before_files": [{"content": "#!/usr/bin/env python3\n# coding=utf-8\n# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the;\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# LICENSE file in the root directory of this source tree.\n\"\"\"\"BlenderbotTokenizer and BlenderbotSmallTokenizer\"\"\"\nimport json\nimport os\nfrom typing import Dict, List, Optional, Tuple\n\nimport regex as re\n\nfrom .tokenization_roberta import RobertaTokenizer\nfrom .tokenization_utils import PreTrainedTokenizer\nfrom .utils import logging\n\n\nlogger = logging.get_logger(__name__)\n\n\nVOCAB_FILES_NAMES = {\n \"vocab_file\": \"vocab.json\",\n \"merges_file\": \"merges.txt\",\n # \"tokenizer_config_file\": \"tokenizer_config.json\",\n}\nCKPT_3B = \"facebook/blenderbot-3B\"\n\n\nclass BlenderbotTokenizer(RobertaTokenizer):\n r\"\"\"\n Construct a Blenderbot tokenizer.\n\n :class:`~transformers.Blenderbot` is nearly identical to :class:`~transformers.RobertaTokenizer` and runs\n end-to-end tokenization: punctuation splitting and wordpiece. The only difference is that it doesnt add BOS\n token to the beginning of sequences.\n\n Refer to superclass :class:`~transformers.RobertaTokenizer` for usage examples and documentation concerning\n parameters.\n \"\"\"\n vocab_files_names = {\n \"vocab_file\": \"vocab.json\",\n \"merges_file\": \"merges.txt\",\n \"tokenizer_config_file\": \"tokenizer_config.json\",\n }\n pretrained_vocab_files_map = {\n \"vocab_file\": {CKPT_3B: \"https://cdn.huggingface.co/facebook/blenderbot-3B/vocab.json\"},\n \"merges_file\": {CKPT_3B: \"https://cdn.huggingface.co/facebook/blenderbot-3B/merges.txt\"},\n \"tokenizer_config_file\": {CKPT_3B: \"https://cdn.huggingface.co/facebook/blenderbot-3B/tokenizer_config.json\"},\n }\n max_model_input_sizes = {\"facebook/blenderbot-3B\": 128}\n\n def build_inputs_with_special_tokens(self, token_ids_0: List[int], token_ids_1: List[int] = None):\n \"\"\"\n Build model inputs from a sequence or a pair of sequence for sequence classification tasks\n by concatenating and adding special tokens.\n A Blenderbot sequence has the following format:\n\n - single sequence: `` X </s>``\n\n Args:\n token_ids_0 (:obj:`List[int]`):\n List of IDs to which the special tokens will be added\n token_ids_1 (:obj:`List[int]`, `optional`):\n Will be ignored\n\n Returns:\n :obj:`List[int]`: list of `input IDs <../glossary.html#input-ids>`__ with the appropriate special tokens.\n \"\"\"\n return token_ids_0 + [self.eos_token_id]\n\n\ndef get_pairs(word):\n \"\"\"Return set of symbol pairs in a word.\n\n Word is represented as tuple of symbols (symbols being variable-length strings).\n \"\"\"\n pairs = set()\n prev_char = word[0]\n for char in word[1:]:\n pairs.add((prev_char, char))\n prev_char = char\n\n pairs = set(pairs)\n return pairs\n\n\nclass BlenderbotSmallTokenizer(PreTrainedTokenizer):\n \"\"\"\n Constructs a Blenderbot-90M tokenizer based on BPE (Byte-Pair-Encoding)\n\n This tokenizer inherits from :class:`~transformers.PreTrainedTokenizer` which contains most of the main methods. Users\n should refer to the superclass for more information regarding methods.\n\n Args:\n vocab_file (:obj:`str`):\n File containing the vocabulary.\n merges_file (:obj:`str`):\n Path to the merges file.\n bos_token (:obj:`str`, `optional`, defaults to :obj:`\"__start__\"`):\n The beginning of sentence token.\n eos_token (:obj:`str`, `optional`, defaults to :obj:`\"__end__\"`):\n The end of sentence token.\n unk_token (:obj:`str`, `optional`, defaults to :obj:`\"__unk__\"`):\n The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this token instead.\n pad_token (:obj:`str`, `optional`, defaults to :obj:`\"__pad__\"`):\n The token used for padding, for example when batching sequences of different lengths.\n **kwargs\n Additional keyword arguments passed along to :class:`~transformers.PreTrainedTokenizer`\n \"\"\"\n\n vocab_files_names = {\"vocab_file\": \"vocab.json\", \"merges_file\": \"merges.txt\"}\n pretrained_vocab_files_map = {\n \"vocab_file\": {\"facebook/blenderbot-90M\": \"https://cdn.huggingface.co/facebook/blenderbot-90M/vocab.json\"},\n \"merges_file\": {\"facebook/blenderbot-90M\": \"https://cdn.huggingface.co/facebook/blenderbot-90M/merges.txt\"},\n }\n max_model_input_sizes = {\"facebook/blenderbot-90M\": 512}\n\n def __init__(\n self,\n vocab_file,\n merges_file,\n bos_token=\"__start__\",\n eos_token=\"__end__\",\n unk_token=\"__unk__\",\n pad_token=\"__null\",\n **kwargs\n ):\n super().__init__(unk_token=unk_token, bos_token=bos_token, eos_token=eos_token, pad_token=pad_token, **kwargs)\n\n with open(vocab_file, encoding=\"utf-8\") as vocab_handle:\n self.encoder = json.load(vocab_handle)\n self.decoder = {v: k for k, v in self.encoder.items()}\n with open(merges_file, encoding=\"utf-8\") as merges_handle:\n merges = merges_handle.read().split(\"\\n\")[1:-1]\n merges = [tuple(merge.split()) for merge in merges]\n self.bpe_ranks = dict(zip(merges, range(len(merges))))\n self.cache = {}\n\n @property\n def vocab_size(self) -> int:\n return len(self.encoder)\n\n def get_vocab(self) -> Dict:\n return dict(self.encoder, **self.added_tokens_encoder)\n\n def bpe(self, token: str) -> str:\n if token in self.cache:\n return self.cache[token]\n token = re.sub(\"([.,!?()])\", r\" \\1\", token)\n token = re.sub(\"(')\", r\" \\1 \", token)\n token = re.sub(\"\\s{2,}\", \" \", token)\n if \"\\n\" in token:\n token = token.replace(\"\\n\", \" __newln__\")\n\n tokens = token.split(\" \")\n words = []\n for token in tokens:\n token = token.lower()\n word = tuple(token)\n word = tuple(list(word[:-1]) + [word[-1] + \"</w>\"])\n pairs = get_pairs(word)\n\n if not pairs:\n words.append(token)\n continue\n\n while True:\n bigram = min(pairs, key=lambda pair: self.bpe_ranks.get(pair, float(\"inf\")))\n if bigram not in self.bpe_ranks:\n break\n first, second = bigram\n new_word = []\n i = 0\n\n while i < len(word):\n try:\n j = word.index(first, i)\n new_word.extend(word[i:j])\n i = j\n except ValueError:\n new_word.extend(word[i:])\n break\n\n if word[i] == first and i < len(word) - 1 and word[i + 1] == second:\n new_word.append(first + second)\n i += 2\n else:\n new_word.append(word[i])\n i += 1\n new_word = tuple(new_word)\n word = new_word\n if len(word) == 1:\n break\n else:\n pairs = get_pairs(word)\n word = \"@@ \".join(word)\n word = word[:-4]\n\n self.cache[token] = word\n words.append(word)\n return \" \".join(words)\n\n def _tokenize(self, text: str) -> List[str]:\n \"\"\" Split a string into tokens using BPE.\"\"\"\n split_tokens = []\n\n words = re.findall(r\"\\S+\\n?\", text)\n\n for token in words:\n split_tokens.extend([t for t in self.bpe(token).split(\" \")])\n return split_tokens\n\n def _convert_token_to_id(self, token: str) -> int:\n \"\"\" Converts a token to an id using the vocab. \"\"\"\n token = token.lower()\n return self.encoder.get(token, self.encoder.get(self.unk_token))\n\n def _convert_id_to_token(self, index: int) -> str:\n \"\"\"Converts an index (integer) in a token (str) using the vocab.\"\"\"\n return self.decoder.get(index, self.unk_token)\n\n def convert_tokens_to_string(self, tokens: List[str]) -> str:\n \"\"\" Converts a sequence of tokens in a single string. \"\"\"\n out_string = \" \".join(tokens).replace(\"@@ \", \"\").strip()\n return out_string\n\n def save_vocabulary(self, save_directory: str, filename_prefix: Optional[str] = None) -> Tuple[str]:\n if not os.path.isdir(save_directory):\n logger.error(\"Vocabulary path ({}) should be a directory\".format(save_directory))\n return\n vocab_file = os.path.join(\n save_directory, (filename_prefix + \"-\" if filename_prefix else \"\") + VOCAB_FILES_NAMES[\"vocab_file\"]\n )\n merge_file = os.path.join(\n save_directory, (filename_prefix + \"-\" if filename_prefix else \"\") + VOCAB_FILES_NAMES[\"merges_file\"]\n )\n\n with open(vocab_file, \"w\", encoding=\"utf-8\") as f:\n f.write(json.dumps(self.encoder, ensure_ascii=False))\n\n index = 0\n with open(merge_file, \"w\", encoding=\"utf-8\") as writer:\n writer.write(\"#version: 0.2\\n\")\n for bpe_tokens, token_index in sorted(self.bpe_ranks.items(), key=lambda kv: kv[1]):\n if index != token_index:\n logger.warning(\n \"Saving vocabulary to {}: BPE merge indices are not consecutive.\"\n \" Please check that the tokenizer is not corrupted!\".format(merge_file)\n )\n index = token_index\n writer.write(\" \".join(bpe_tokens) + \"\\n\")\n index += 1\n\n return vocab_file, merge_file\n", "path": "src/transformers/tokenization_blenderbot.py"}]} | 3,730 | 127 |
gh_patches_debug_27520 | rasdani/github-patches | git_diff | open-telemetry__opentelemetry-python-contrib-378 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
OT Trace propagator fails with exception when no headers are present
**Describe your environment**
Latest version (main branch) of both opentelemetry-python and opentelemetry-python-contrib
**Steps to reproduce**
```python
from opentelemetry.propagators.ot_trace import OTTracePropagator
from opentelemetry.propagators.textmap import DictGetter
getter = DictGetter()
carrier = {}
propagator = OTTracePropagator()
propagator.extract(getter, carrier)
```
results in:
```
Traceback (most recent call last):
File "repro.py", line 8, in <module>
propagator.extract(getter, {})
File "(...)/opentelemetry-python-contrib/propagator/opentelemetry-propagator-ot-trace/src/opentelemetry/propagators/ot_trace/__init__.py", line 76, in extract
and _valid_extract_traceid.fullmatch(traceid) is not None
TypeError: expected string or bytes-like object
```
**What is the expected behavior?**
Propagator extraction returns an unmodified context due to lack of relevant headers in the carrier.
> If a value can not be parsed from the carrier, for a cross-cutting concern, the implementation MUST NOT throw an exception and MUST NOT store a new value in the Context, in order to preserve any previously existing valid value.
_from [OTel specification](https://github.com/open-telemetry/opentelemetry-specification/blob/main/specification/context/api-propagators.md#extract)_
**What is the actual behavior?**
Propagator extraction fails with an exception when no headers are present in the carrier.
**Additional context**
N/A
</issue>
<code>
[start of propagator/opentelemetry-propagator-ot-trace/src/opentelemetry/propagators/ot_trace/__init__.py]
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from re import compile as re_compile
16 from typing import Iterable, Optional
17
18 from opentelemetry.baggage import get_all, set_baggage
19 from opentelemetry.context import Context
20 from opentelemetry.propagators.textmap import (
21 Getter,
22 Setter,
23 TextMapPropagator,
24 TextMapPropagatorT,
25 )
26 from opentelemetry.trace import (
27 INVALID_SPAN_ID,
28 INVALID_TRACE_ID,
29 NonRecordingSpan,
30 SpanContext,
31 TraceFlags,
32 get_current_span,
33 set_span_in_context,
34 )
35
36 OT_TRACE_ID_HEADER = "ot-tracer-traceid"
37 OT_SPAN_ID_HEADER = "ot-tracer-spanid"
38 OT_SAMPLED_HEADER = "ot-tracer-sampled"
39 OT_BAGGAGE_PREFIX = "ot-baggage-"
40
41 _valid_header_name = re_compile(r"[\w_^`!#$%&'*+.|~]+")
42 _valid_header_value = re_compile(r"[\t\x20-\x7e\x80-\xff]+")
43 _valid_extract_traceid = re_compile(r"[0-9a-f]{1,32}")
44 _valid_extract_spanid = re_compile(r"[0-9a-f]{1,16}")
45
46
47 class OTTracePropagator(TextMapPropagator):
48 """Propagator for the OTTrace HTTP header format"""
49
50 def extract(
51 self,
52 getter: Getter[TextMapPropagatorT],
53 carrier: TextMapPropagatorT,
54 context: Optional[Context] = None,
55 ) -> Context:
56
57 traceid = _extract_first_element(
58 getter.get(carrier, OT_TRACE_ID_HEADER)
59 )
60
61 spanid = _extract_first_element(getter.get(carrier, OT_SPAN_ID_HEADER))
62
63 sampled = _extract_first_element(
64 getter.get(carrier, OT_SAMPLED_HEADER)
65 )
66
67 if sampled == "true":
68 traceflags = TraceFlags.SAMPLED
69 else:
70 traceflags = TraceFlags.DEFAULT
71
72 if (
73 traceid != INVALID_TRACE_ID
74 and _valid_extract_traceid.fullmatch(traceid) is not None
75 and spanid != INVALID_SPAN_ID
76 and _valid_extract_spanid.fullmatch(spanid) is not None
77 ):
78 context = set_span_in_context(
79 NonRecordingSpan(
80 SpanContext(
81 trace_id=int(traceid, 16),
82 span_id=int(spanid, 16),
83 is_remote=True,
84 trace_flags=traceflags,
85 )
86 ),
87 context,
88 )
89
90 baggage = get_all(context) or {}
91
92 for key in getter.keys(carrier):
93
94 if not key.startswith(OT_BAGGAGE_PREFIX):
95 continue
96
97 baggage[
98 key[len(OT_BAGGAGE_PREFIX) :]
99 ] = _extract_first_element(getter.get(carrier, key))
100
101 for key, value in baggage.items():
102 context = set_baggage(key, value, context)
103
104 return context
105
106 def inject(
107 self,
108 set_in_carrier: Setter[TextMapPropagatorT],
109 carrier: TextMapPropagatorT,
110 context: Optional[Context] = None,
111 ) -> None:
112
113 span_context = get_current_span(context).get_span_context()
114
115 if span_context.trace_id == INVALID_TRACE_ID:
116 return
117
118 set_in_carrier(
119 carrier, OT_TRACE_ID_HEADER, hex(span_context.trace_id)[2:][-16:]
120 )
121 set_in_carrier(
122 carrier, OT_SPAN_ID_HEADER, hex(span_context.span_id)[2:][-16:],
123 )
124
125 if span_context.trace_flags == TraceFlags.SAMPLED:
126 traceflags = "true"
127 else:
128 traceflags = "false"
129
130 set_in_carrier(carrier, OT_SAMPLED_HEADER, traceflags)
131
132 baggage = get_all(context)
133
134 if not baggage:
135 return
136
137 for header_name, header_value in baggage.items():
138
139 if (
140 _valid_header_name.fullmatch(header_name) is None
141 or _valid_header_value.fullmatch(header_value) is None
142 ):
143 continue
144
145 set_in_carrier(
146 carrier,
147 "".join([OT_BAGGAGE_PREFIX, header_name]),
148 header_value,
149 )
150
151 @property
152 def fields(self):
153 """Returns a set with the fields set in `inject`.
154
155 See
156 `opentelemetry.propagators.textmap.TextMapPropagator.fields`
157 """
158 return {
159 OT_TRACE_ID_HEADER,
160 OT_SPAN_ID_HEADER,
161 OT_SAMPLED_HEADER,
162 }
163
164
165 def _extract_first_element(
166 items: Iterable[TextMapPropagatorT],
167 ) -> Optional[TextMapPropagatorT]:
168 if items is None:
169 return None
170 return next(iter(items), None)
171
[end of propagator/opentelemetry-propagator-ot-trace/src/opentelemetry/propagators/ot_trace/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/propagator/opentelemetry-propagator-ot-trace/src/opentelemetry/propagators/ot_trace/__init__.py b/propagator/opentelemetry-propagator-ot-trace/src/opentelemetry/propagators/ot_trace/__init__.py
--- a/propagator/opentelemetry-propagator-ot-trace/src/opentelemetry/propagators/ot_trace/__init__.py
+++ b/propagator/opentelemetry-propagator-ot-trace/src/opentelemetry/propagators/ot_trace/__init__.py
@@ -13,7 +13,7 @@
# limitations under the License.
from re import compile as re_compile
-from typing import Iterable, Optional
+from typing import Any, Iterable, Optional
from opentelemetry.baggage import get_all, set_baggage
from opentelemetry.context import Context
@@ -55,10 +55,12 @@
) -> Context:
traceid = _extract_first_element(
- getter.get(carrier, OT_TRACE_ID_HEADER)
+ getter.get(carrier, OT_TRACE_ID_HEADER), INVALID_TRACE_ID
)
- spanid = _extract_first_element(getter.get(carrier, OT_SPAN_ID_HEADER))
+ spanid = _extract_first_element(
+ getter.get(carrier, OT_SPAN_ID_HEADER), INVALID_SPAN_ID
+ )
sampled = _extract_first_element(
getter.get(carrier, OT_SAMPLED_HEADER)
@@ -163,8 +165,8 @@
def _extract_first_element(
- items: Iterable[TextMapPropagatorT],
+ items: Iterable[TextMapPropagatorT], default: Any = None,
) -> Optional[TextMapPropagatorT]:
if items is None:
- return None
+ return default
return next(iter(items), None)
| {"golden_diff": "diff --git a/propagator/opentelemetry-propagator-ot-trace/src/opentelemetry/propagators/ot_trace/__init__.py b/propagator/opentelemetry-propagator-ot-trace/src/opentelemetry/propagators/ot_trace/__init__.py\n--- a/propagator/opentelemetry-propagator-ot-trace/src/opentelemetry/propagators/ot_trace/__init__.py\n+++ b/propagator/opentelemetry-propagator-ot-trace/src/opentelemetry/propagators/ot_trace/__init__.py\n@@ -13,7 +13,7 @@\n # limitations under the License.\n \n from re import compile as re_compile\n-from typing import Iterable, Optional\n+from typing import Any, Iterable, Optional\n \n from opentelemetry.baggage import get_all, set_baggage\n from opentelemetry.context import Context\n@@ -55,10 +55,12 @@\n ) -> Context:\n \n traceid = _extract_first_element(\n- getter.get(carrier, OT_TRACE_ID_HEADER)\n+ getter.get(carrier, OT_TRACE_ID_HEADER), INVALID_TRACE_ID\n )\n \n- spanid = _extract_first_element(getter.get(carrier, OT_SPAN_ID_HEADER))\n+ spanid = _extract_first_element(\n+ getter.get(carrier, OT_SPAN_ID_HEADER), INVALID_SPAN_ID\n+ )\n \n sampled = _extract_first_element(\n getter.get(carrier, OT_SAMPLED_HEADER)\n@@ -163,8 +165,8 @@\n \n \n def _extract_first_element(\n- items: Iterable[TextMapPropagatorT],\n+ items: Iterable[TextMapPropagatorT], default: Any = None,\n ) -> Optional[TextMapPropagatorT]:\n if items is None:\n- return None\n+ return default\n return next(iter(items), None)\n", "issue": "OT Trace propagator fails with exception when no headers are present\n**Describe your environment**\r\nLatest version (main branch) of both opentelemetry-python and opentelemetry-python-contrib\r\n\r\n**Steps to reproduce**\r\n```python\r\nfrom opentelemetry.propagators.ot_trace import OTTracePropagator\r\nfrom opentelemetry.propagators.textmap import DictGetter\r\n\r\ngetter = DictGetter()\r\ncarrier = {}\r\n\r\npropagator = OTTracePropagator()\r\npropagator.extract(getter, carrier)\r\n```\r\nresults in:\r\n```\r\nTraceback (most recent call last):\r\n File \"repro.py\", line 8, in <module>\r\n propagator.extract(getter, {})\r\n File \"(...)/opentelemetry-python-contrib/propagator/opentelemetry-propagator-ot-trace/src/opentelemetry/propagators/ot_trace/__init__.py\", line 76, in extract\r\n and _valid_extract_traceid.fullmatch(traceid) is not None\r\nTypeError: expected string or bytes-like object\r\n```\r\n**What is the expected behavior?**\r\nPropagator extraction returns an unmodified context due to lack of relevant headers in the carrier.\r\n> If a value can not be parsed from the carrier, for a cross-cutting concern, the implementation MUST NOT throw an exception and MUST NOT store a new value in the Context, in order to preserve any previously existing valid value.\r\n\r\n_from [OTel specification](https://github.com/open-telemetry/opentelemetry-specification/blob/main/specification/context/api-propagators.md#extract)_\r\n\r\n**What is the actual behavior?**\r\nPropagator extraction fails with an exception when no headers are present in the carrier.\r\n\r\n**Additional context**\r\nN/A\r\n\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom re import compile as re_compile\nfrom typing import Iterable, Optional\n\nfrom opentelemetry.baggage import get_all, set_baggage\nfrom opentelemetry.context import Context\nfrom opentelemetry.propagators.textmap import (\n Getter,\n Setter,\n TextMapPropagator,\n TextMapPropagatorT,\n)\nfrom opentelemetry.trace import (\n INVALID_SPAN_ID,\n INVALID_TRACE_ID,\n NonRecordingSpan,\n SpanContext,\n TraceFlags,\n get_current_span,\n set_span_in_context,\n)\n\nOT_TRACE_ID_HEADER = \"ot-tracer-traceid\"\nOT_SPAN_ID_HEADER = \"ot-tracer-spanid\"\nOT_SAMPLED_HEADER = \"ot-tracer-sampled\"\nOT_BAGGAGE_PREFIX = \"ot-baggage-\"\n\n_valid_header_name = re_compile(r\"[\\w_^`!#$%&'*+.|~]+\")\n_valid_header_value = re_compile(r\"[\\t\\x20-\\x7e\\x80-\\xff]+\")\n_valid_extract_traceid = re_compile(r\"[0-9a-f]{1,32}\")\n_valid_extract_spanid = re_compile(r\"[0-9a-f]{1,16}\")\n\n\nclass OTTracePropagator(TextMapPropagator):\n \"\"\"Propagator for the OTTrace HTTP header format\"\"\"\n\n def extract(\n self,\n getter: Getter[TextMapPropagatorT],\n carrier: TextMapPropagatorT,\n context: Optional[Context] = None,\n ) -> Context:\n\n traceid = _extract_first_element(\n getter.get(carrier, OT_TRACE_ID_HEADER)\n )\n\n spanid = _extract_first_element(getter.get(carrier, OT_SPAN_ID_HEADER))\n\n sampled = _extract_first_element(\n getter.get(carrier, OT_SAMPLED_HEADER)\n )\n\n if sampled == \"true\":\n traceflags = TraceFlags.SAMPLED\n else:\n traceflags = TraceFlags.DEFAULT\n\n if (\n traceid != INVALID_TRACE_ID\n and _valid_extract_traceid.fullmatch(traceid) is not None\n and spanid != INVALID_SPAN_ID\n and _valid_extract_spanid.fullmatch(spanid) is not None\n ):\n context = set_span_in_context(\n NonRecordingSpan(\n SpanContext(\n trace_id=int(traceid, 16),\n span_id=int(spanid, 16),\n is_remote=True,\n trace_flags=traceflags,\n )\n ),\n context,\n )\n\n baggage = get_all(context) or {}\n\n for key in getter.keys(carrier):\n\n if not key.startswith(OT_BAGGAGE_PREFIX):\n continue\n\n baggage[\n key[len(OT_BAGGAGE_PREFIX) :]\n ] = _extract_first_element(getter.get(carrier, key))\n\n for key, value in baggage.items():\n context = set_baggage(key, value, context)\n\n return context\n\n def inject(\n self,\n set_in_carrier: Setter[TextMapPropagatorT],\n carrier: TextMapPropagatorT,\n context: Optional[Context] = None,\n ) -> None:\n\n span_context = get_current_span(context).get_span_context()\n\n if span_context.trace_id == INVALID_TRACE_ID:\n return\n\n set_in_carrier(\n carrier, OT_TRACE_ID_HEADER, hex(span_context.trace_id)[2:][-16:]\n )\n set_in_carrier(\n carrier, OT_SPAN_ID_HEADER, hex(span_context.span_id)[2:][-16:],\n )\n\n if span_context.trace_flags == TraceFlags.SAMPLED:\n traceflags = \"true\"\n else:\n traceflags = \"false\"\n\n set_in_carrier(carrier, OT_SAMPLED_HEADER, traceflags)\n\n baggage = get_all(context)\n\n if not baggage:\n return\n\n for header_name, header_value in baggage.items():\n\n if (\n _valid_header_name.fullmatch(header_name) is None\n or _valid_header_value.fullmatch(header_value) is None\n ):\n continue\n\n set_in_carrier(\n carrier,\n \"\".join([OT_BAGGAGE_PREFIX, header_name]),\n header_value,\n )\n\n @property\n def fields(self):\n \"\"\"Returns a set with the fields set in `inject`.\n\n See\n `opentelemetry.propagators.textmap.TextMapPropagator.fields`\n \"\"\"\n return {\n OT_TRACE_ID_HEADER,\n OT_SPAN_ID_HEADER,\n OT_SAMPLED_HEADER,\n }\n\n\ndef _extract_first_element(\n items: Iterable[TextMapPropagatorT],\n) -> Optional[TextMapPropagatorT]:\n if items is None:\n return None\n return next(iter(items), None)\n", "path": "propagator/opentelemetry-propagator-ot-trace/src/opentelemetry/propagators/ot_trace/__init__.py"}]} | 2,502 | 415 |
gh_patches_debug_21177 | rasdani/github-patches | git_diff | Flexget__Flexget-2474 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Unhandled error in plugin argenteam
<!---
Before opening an issue, verify:
- Is this a feature request? Post it on https://feathub.com/Flexget/Flexget
- Did you recently upgrade? Look at the Change Log and Upgrade Actions to make sure that you don't need to make any changes to your config https://flexget.com/ChangeLog https://flexget.com/UpgradeActions
- Are you running FlexGet as a daemon? Stop it completely and then start it again https://flexget.com/CLI/daemon
- Did you search to see if the issue already exists? https://github.com/Flexget/Flexget/issues
- Did you fill out the issue template as completely as possible?
The issue template is here because it helps to ensure you submitted all the necessary information the first time, and allows us to more quickly review issues. Please fill it out correctly and do not ignore it, no matter how irrelevant you think it may be. Thanks in advance for your help with this!
--->
### Expected behavior:
<!---
Get list of shows from Trakt and download needed shows,
--->
### Actual behavior:
It gets the list of shows from Trakt and starts searching for each show using the plug-ins. It then crashes.
### Steps to reproduce:
- Step 1: It happens every time it runs.
#### Config:
```
variables: secrets.yml
templates:
tv:
configure_series:
settings:
quality: 720p+
identified_by: ep
from:
trakt_list:
account: "{? trakt.account ?}"
list: "{? trakt.series ?}"
type: shows
reject:
regexp:
reject:
- \b(s|d)ub(s|bed|lado|titulado)?\b
- \bhc\b
- \bdual\b
- \b3d\b
- \bfre(nch)?\b
- \bita(lian)?\b
- \bspa(nish)?\b
- \bger(man)?\b
- \bcastellano\b
- \brus(sian)?\b
- \btamil\b
- \bhindi\b
- \bh265\b
- \bx265\b
content_filter:
reject:
- '*.rar'
- '*.zip'
- '*.exe'
place_torrent:
utorrent:
url: "{? utorrent.url ?}"
username: "{? utorrent.user ?}"
password: "{? utorrent.pass ?}"
path: "{? utorrent.path ?}"
pushbullet:
notify:
entries:
title: "[flexget] Downloading"
message: "{{title}}"
via:
- pushbullet:
api_key: "{? pushbullet.api ?}"
tasks:
follow show from ep:
seen: local
trakt_list:
account: "{? trakt.account ?}"
list: "{? trakt.series ?}"
type: episodes
accept_all: yes
set_series_begin: yes
list_remove:
- trakt_list:
account: "{? trakt.account ?}"
list: "{? trakt.series ?}"
type: episodes
list_add:
- trakt_list:
account: "{? trakt.account ?}"
list: "{? trakt.series ?}"
type: shows
get shows:
template:
- tv
- reject
- place_torrent
- pushbullet
discover:
what:
- next_series_episodes:
from_start: yes
from:
- piratebay:
category: highres tv
- limetorrents:
category: tv
- rarbg:
category: [1, 18, 41, 49]
- argenteam:
force_subtitles: no
```
#### Log:
<details>
<summary>(click to expand)</summary>
Debug Log - https://pastebin.com/bTr4qX6a
```
2019-03-16 05:40 VERBOSE trakt_list get shows Retrieving `shows` list `720p_list`
2019-03-16 05:40 VERBOSE discover get shows Discovering 26 titles ...
2019-03-16 05:40 INFO discover get shows Ignoring interval because of --discover-now
2019-03-16 05:40 INFO task get shows Plugin next_series_episodes has requested task to be ran again after execution has completed. Reason: Look for next season
2019-03-16 05:40 VERBOSE discover get shows The Big Bang Theory (2007) S12E18 hasn't been released yet (Expected: 2019-04-04 00:00:00)
2019-03-16 05:40 VERBOSE discover get shows Modern Family (2009) S10E18 hasn't been released yet (Expected: 2019-03-20 00:00:00)
2019-03-16 05:40 VERBOSE discover get shows Game of Thrones (2011) S08E01 hasn't been released yet (Expected: 2019-04-14 00:00:00)
2019-03-16 05:40 VERBOSE discover get shows The Goldbergs (2013) S06E19 hasn't been released yet (Expected: 2019-03-20 00:00:00)
2019-03-16 05:40 VERBOSE discover get shows Schooled (2019) S01E09 hasn't been released yet (Expected: 2019-03-20 00:00:00)
2019-03-16 05:41 VERBOSE discover get shows Searching for `Shameless (2011) S04E04` with plugin `piratebay` (1 of 10)
2019-03-16 05:41 VERBOSE discover get shows Searching for `Shameless (2011) S04E04` with plugin `limetorrents` (1 of 10)
2019-03-16 05:41 VERBOSE discover get shows Searching for `Shameless (2011) S04E04` with plugin `rarbg` (1 of 10)
2019-03-16 05:41 VERBOSE discover get shows Searching for `Shameless (2011) S04E04` with plugin `argenteam` (1 of 10)
2019-03-16 05:41 CRITICAL task get shows BUG: Unhandled error in plugin discover: list index out of range
2019-03-16 05:41 CRITICAL manager get shows An unexpected crash has occurred. Writing crash report to C:\Users\Amishman\flexget\crash_report.2019.03.16.054135803000.log. Please verify you are running the latest version of flexget by using "flexget -V" from CLI or by using version_checker plugin at http://flexget.com/wiki/Plugins/version_checker. You are currently using version 2.20.12
2019-03-16 05:41 WARNING task get shows Aborting task (plugin: discover)
```
</details>
### Additional information:
- FlexGet version: 2.20.12
- Python version: 2.7.13
- Installation method: pip
- Using daemon (yes/no): no
- OS and version: Windows 7 Pro
- Link to crash log:
[crash_report.2019.03.16.054135803000.log](https://github.com/Flexget/Flexget/files/2973746/crash_report.2019.03.16.054135803000.log)
<!---
In config and debug/crash logs, remember to redact any personal or sensitive information such as passwords, API keys, private URLs and so on.
Please verify that the following data is present before submitting your issue:
- Link to a paste service or paste above the relevant config (preferably full config, including templates if present). Please make sure the paste does not expire, if possible.
- Link to a paste service or paste above debug-level logs of the relevant task/s (use `flexget -L debug execute --tasks <Task_name>`).
- FlexGet version (use `flexget -V` to get it).
- Full Python version, for example `2.7.11` (use `python -V` to get it). Note that FlexGet is not supported for use with Python v3.0, 3.1, 3.2 or 3.6.
- Installation method (pip, git install, etc).
- Whether or not you're running FlexGet as a daemon.
- OS and version.
- Attach crash log if one was generated, in addition to the debug-level log. It can be found in the directory with your config file.
--->
</issue>
<code>
[start of flexget/components/sites/sites/argenteam.py]
1 from __future__ import unicode_literals, division, absolute_import
2 from builtins import * # noqa pylint: disable=unused-import, redefined-builtin
3
4 import logging
5
6 from requests import RequestException
7
8 from flexget import plugin
9 from flexget.entry import Entry
10 from flexget.event import event
11 from flexget.components.sites.utils import normalize_scene
12
13 log = logging.getLogger('argenteam')
14
15
16 class SearchArgenteam(object):
17 """ Argenteam
18 Search plugin which gives results from www.argenteam.net, latin american (Argentina) web.
19
20 Configuration:
21 - force_subtitles: [yes/no] #Force download release with subtitles made by aRGENTeaM. Default is yes
22
23 Example
24 argenteam:
25 force_subtitles: yes
26 """
27
28 schema = {
29 'type': 'object',
30 'properties': {'force_subtitles': {'type': 'boolean', 'default': True}},
31 "additionalProperties": False,
32 }
33
34 base_url = 'http://www.argenteam.net/api/v1/'
35
36 @plugin.internet(log)
37 def search(self, task, entry, config):
38 """
39 Search for releases
40 """
41
42 entries = set()
43
44 for search_string in entry.get('search_strings', [entry['title']]):
45
46 try:
47 params = {'q': normalize_scene(search_string)}
48 resp = task.requests.get(self.base_url + 'search', params=params)
49 log.debug('Requesting: %s', resp.url)
50 response = resp.json()
51 except RequestException as e:
52 log.error('Argenteam request failed: %s', e)
53 return
54
55 if not response:
56 log.debug('Empty response from Argenteam')
57 continue
58
59 if not response.get('total'):
60 log.debug('No results found for %s', search_string)
61 continue
62
63 results = response.get('results')
64 if results[0]['type'] == 'tvshow':
65 log.error('Argenteam type tvshow not supported yet.')
66 continue
67
68 url = '{}{}?id={}'.format(self.base_url, results[0]['type'], results[0]['id'])
69 try:
70 resp = task.requests.get(url)
71 log.debug('Requesting releases for: %s', url)
72 response = resp.json()
73 except RequestException as e:
74 log.error('Argenteam request failed: %s', e)
75 return
76
77 for release in response['releases']:
78 for torrent in release['torrents']:
79 if (
80 config.get('force_subtitles')
81 and release['subtitles']
82 or not config.get('force_subtitles')
83 ):
84 e = Entry()
85
86 e['title'] = ' '.join(
87 (
88 search_string,
89 release['source'],
90 release['codec'],
91 release['team'],
92 release['tags'],
93 )
94 )
95 e['url'] = torrent['uri']
96
97 # Save aRGENTeaM subtitle URL for this release
98 if 'subtitles' in release:
99 e['argenteam_subtitle'] = release['subtitles'][0]['uri']
100 log.debug('Argenteam subtitle found: %s', e['argenteam_subtitle'])
101
102 if 'tvdb' in response:
103 e['tvdb_id'] = response['tvdb']
104 if 'info' in response and 'imdb' in response['info']:
105 e['imdb_id'] = response['info']['imdb']
106
107 entries.add(e)
108
109 return entries
110
111
112 @event('plugin.register')
113 def register_plugin():
114 plugin.register(SearchArgenteam, 'argenteam', interfaces=['search'], api_ver=2)
115
[end of flexget/components/sites/sites/argenteam.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/flexget/components/sites/sites/argenteam.py b/flexget/components/sites/sites/argenteam.py
--- a/flexget/components/sites/sites/argenteam.py
+++ b/flexget/components/sites/sites/argenteam.py
@@ -74,6 +74,7 @@
log.error('Argenteam request failed: %s', e)
return
+ log.debug('%s releases found.', len(response['releases']))
for release in response['releases']:
for torrent in release['torrents']:
if (
@@ -95,7 +96,7 @@
e['url'] = torrent['uri']
# Save aRGENTeaM subtitle URL for this release
- if 'subtitles' in release:
+ if 'subtitles' in release and len(release['subtitles']) > 0:
e['argenteam_subtitle'] = release['subtitles'][0]['uri']
log.debug('Argenteam subtitle found: %s', e['argenteam_subtitle'])
| {"golden_diff": "diff --git a/flexget/components/sites/sites/argenteam.py b/flexget/components/sites/sites/argenteam.py\n--- a/flexget/components/sites/sites/argenteam.py\n+++ b/flexget/components/sites/sites/argenteam.py\n@@ -74,6 +74,7 @@\n log.error('Argenteam request failed: %s', e)\n return\n \n+ log.debug('%s releases found.', len(response['releases']))\n for release in response['releases']:\n for torrent in release['torrents']:\n if (\n@@ -95,7 +96,7 @@\n e['url'] = torrent['uri']\n \n # Save aRGENTeaM subtitle URL for this release\n- if 'subtitles' in release:\n+ if 'subtitles' in release and len(release['subtitles']) > 0:\n e['argenteam_subtitle'] = release['subtitles'][0]['uri']\n log.debug('Argenteam subtitle found: %s', e['argenteam_subtitle'])\n", "issue": "Unhandled error in plugin argenteam\n<!---\r\nBefore opening an issue, verify:\r\n\r\n- Is this a feature request? Post it on https://feathub.com/Flexget/Flexget\r\n- Did you recently upgrade? Look at the Change Log and Upgrade Actions to make sure that you don't need to make any changes to your config https://flexget.com/ChangeLog https://flexget.com/UpgradeActions\r\n- Are you running FlexGet as a daemon? Stop it completely and then start it again https://flexget.com/CLI/daemon\r\n- Did you search to see if the issue already exists? https://github.com/Flexget/Flexget/issues\r\n- Did you fill out the issue template as completely as possible?\r\n\r\nThe issue template is here because it helps to ensure you submitted all the necessary information the first time, and allows us to more quickly review issues. Please fill it out correctly and do not ignore it, no matter how irrelevant you think it may be. Thanks in advance for your help with this!\r\n--->\r\n### Expected behavior:\r\n<!---\r\nGet list of shows from Trakt and download needed shows,\r\n--->\r\n\r\n### Actual behavior:\r\nIt gets the list of shows from Trakt and starts searching for each show using the plug-ins. It then crashes.\r\n### Steps to reproduce:\r\n- Step 1: It happens every time it runs.\r\n\r\n#### Config:\r\n```\r\nvariables: secrets.yml\r\n\r\ntemplates:\r\n\r\n\r\n tv:\r\n configure_series:\r\n settings:\r\n quality: 720p+\r\n identified_by: ep\r\n from:\r\n trakt_list:\r\n account: \"{? trakt.account ?}\"\r\n list: \"{? trakt.series ?}\"\r\n type: shows\r\n\r\n\r\n\r\n reject:\r\n regexp:\r\n reject:\r\n - \\b(s|d)ub(s|bed|lado|titulado)?\\b\r\n - \\bhc\\b\r\n - \\bdual\\b\r\n - \\b3d\\b\r\n - \\bfre(nch)?\\b\r\n - \\bita(lian)?\\b\r\n - \\bspa(nish)?\\b\r\n - \\bger(man)?\\b\r\n - \\bcastellano\\b\r\n - \\brus(sian)?\\b\r\n - \\btamil\\b\r\n - \\bhindi\\b\r\n - \\bh265\\b\r\n - \\bx265\\b\r\n content_filter:\r\n reject:\r\n - '*.rar'\r\n - '*.zip'\r\n - '*.exe'\r\n\r\n\r\n\r\n place_torrent:\r\n utorrent:\r\n url: \"{? utorrent.url ?}\"\r\n username: \"{? utorrent.user ?}\"\r\n password: \"{? utorrent.pass ?}\"\r\n path: \"{? utorrent.path ?}\"\r\n\r\n\r\n\r\n pushbullet:\r\n notify:\r\n entries:\r\n title: \"[flexget] Downloading\"\r\n message: \"{{title}}\"\r\n via:\r\n - pushbullet:\r\n api_key: \"{? pushbullet.api ?}\"\r\n\r\n\r\n\r\n\r\n\r\ntasks:\r\n\r\n\r\n follow show from ep:\r\n seen: local\r\n trakt_list:\r\n account: \"{? trakt.account ?}\"\r\n list: \"{? trakt.series ?}\"\r\n type: episodes\r\n accept_all: yes\r\n set_series_begin: yes\r\n list_remove:\r\n - trakt_list:\r\n account: \"{? trakt.account ?}\"\r\n list: \"{? trakt.series ?}\"\r\n type: episodes\r\n list_add:\r\n - trakt_list:\r\n account: \"{? trakt.account ?}\"\r\n list: \"{? trakt.series ?}\"\r\n type: shows\r\n\r\n\r\n\r\n get shows:\r\n template:\r\n - tv\r\n - reject\r\n - place_torrent\r\n - pushbullet\r\n discover:\r\n what:\r\n - next_series_episodes:\r\n from_start: yes\r\n from:\r\n - piratebay:\r\n category: highres tv\r\n - limetorrents:\r\n category: tv\r\n - rarbg:\r\n category: [1, 18, 41, 49]\r\n - argenteam:\r\n force_subtitles: no\r\n```\r\n \r\n#### Log:\r\n<details>\r\n <summary>(click to expand)</summary>\r\n\r\n\r\nDebug Log - https://pastebin.com/bTr4qX6a\r\n```\r\n2019-03-16 05:40 VERBOSE trakt_list get shows Retrieving `shows` list `720p_list`\r\n2019-03-16 05:40 VERBOSE discover get shows Discovering 26 titles ...\r\n2019-03-16 05:40 INFO discover get shows Ignoring interval because of --discover-now\r\n2019-03-16 05:40 INFO task get shows Plugin next_series_episodes has requested task to be ran again after execution has completed. Reason: Look for next season\r\n2019-03-16 05:40 VERBOSE discover get shows The Big Bang Theory (2007) S12E18 hasn't been released yet (Expected: 2019-04-04 00:00:00)\r\n2019-03-16 05:40 VERBOSE discover get shows Modern Family (2009) S10E18 hasn't been released yet (Expected: 2019-03-20 00:00:00)\r\n2019-03-16 05:40 VERBOSE discover get shows Game of Thrones (2011) S08E01 hasn't been released yet (Expected: 2019-04-14 00:00:00)\r\n2019-03-16 05:40 VERBOSE discover get shows The Goldbergs (2013) S06E19 hasn't been released yet (Expected: 2019-03-20 00:00:00)\r\n2019-03-16 05:40 VERBOSE discover get shows Schooled (2019) S01E09 hasn't been released yet (Expected: 2019-03-20 00:00:00)\r\n2019-03-16 05:41 VERBOSE discover get shows Searching for `Shameless (2011) S04E04` with plugin `piratebay` (1 of 10)\r\n2019-03-16 05:41 VERBOSE discover get shows Searching for `Shameless (2011) S04E04` with plugin `limetorrents` (1 of 10)\r\n2019-03-16 05:41 VERBOSE discover get shows Searching for `Shameless (2011) S04E04` with plugin `rarbg` (1 of 10)\r\n2019-03-16 05:41 VERBOSE discover get shows Searching for `Shameless (2011) S04E04` with plugin `argenteam` (1 of 10)\r\n2019-03-16 05:41 CRITICAL task get shows BUG: Unhandled error in plugin discover: list index out of range\r\n2019-03-16 05:41 CRITICAL manager get shows An unexpected crash has occurred. Writing crash report to C:\\Users\\Amishman\\flexget\\crash_report.2019.03.16.054135803000.log. Please verify you are running the latest version of flexget by using \"flexget -V\" from CLI or by using version_checker plugin at http://flexget.com/wiki/Plugins/version_checker. You are currently using version 2.20.12\r\n2019-03-16 05:41 WARNING task get shows Aborting task (plugin: discover)\r\n```\r\n</details>\r\n\r\n### Additional information:\r\n\r\n- FlexGet version: 2.20.12\r\n- Python version: 2.7.13\r\n- Installation method: pip\r\n- Using daemon (yes/no): no\r\n- OS and version: Windows 7 Pro\r\n- Link to crash log:\r\n[crash_report.2019.03.16.054135803000.log](https://github.com/Flexget/Flexget/files/2973746/crash_report.2019.03.16.054135803000.log)\r\n\r\n\r\n<!---\r\nIn config and debug/crash logs, remember to redact any personal or sensitive information such as passwords, API keys, private URLs and so on.\r\n\r\nPlease verify that the following data is present before submitting your issue:\r\n\r\n- Link to a paste service or paste above the relevant config (preferably full config, including templates if present). Please make sure the paste does not expire, if possible.\r\n- Link to a paste service or paste above debug-level logs of the relevant task/s (use `flexget -L debug execute --tasks <Task_name>`).\r\n- FlexGet version (use `flexget -V` to get it).\r\n- Full Python version, for example `2.7.11` (use `python -V` to get it). Note that FlexGet is not supported for use with Python v3.0, 3.1, 3.2 or 3.6.\r\n- Installation method (pip, git install, etc).\r\n- Whether or not you're running FlexGet as a daemon.\r\n- OS and version.\r\n- Attach crash log if one was generated, in addition to the debug-level log. It can be found in the directory with your config file.\r\n--->\r\n\n", "before_files": [{"content": "from __future__ import unicode_literals, division, absolute_import\nfrom builtins import * # noqa pylint: disable=unused-import, redefined-builtin\n\nimport logging\n\nfrom requests import RequestException\n\nfrom flexget import plugin\nfrom flexget.entry import Entry\nfrom flexget.event import event\nfrom flexget.components.sites.utils import normalize_scene\n\nlog = logging.getLogger('argenteam')\n\n\nclass SearchArgenteam(object):\n \"\"\" Argenteam\n Search plugin which gives results from www.argenteam.net, latin american (Argentina) web.\n\n Configuration:\n - force_subtitles: [yes/no] #Force download release with subtitles made by aRGENTeaM. Default is yes\n\n Example\n argenteam:\n force_subtitles: yes\n \"\"\"\n\n schema = {\n 'type': 'object',\n 'properties': {'force_subtitles': {'type': 'boolean', 'default': True}},\n \"additionalProperties\": False,\n }\n\n base_url = 'http://www.argenteam.net/api/v1/'\n\n @plugin.internet(log)\n def search(self, task, entry, config):\n \"\"\"\n Search for releases\n \"\"\"\n\n entries = set()\n\n for search_string in entry.get('search_strings', [entry['title']]):\n\n try:\n params = {'q': normalize_scene(search_string)}\n resp = task.requests.get(self.base_url + 'search', params=params)\n log.debug('Requesting: %s', resp.url)\n response = resp.json()\n except RequestException as e:\n log.error('Argenteam request failed: %s', e)\n return\n\n if not response:\n log.debug('Empty response from Argenteam')\n continue\n\n if not response.get('total'):\n log.debug('No results found for %s', search_string)\n continue\n\n results = response.get('results')\n if results[0]['type'] == 'tvshow':\n log.error('Argenteam type tvshow not supported yet.')\n continue\n\n url = '{}{}?id={}'.format(self.base_url, results[0]['type'], results[0]['id'])\n try:\n resp = task.requests.get(url)\n log.debug('Requesting releases for: %s', url)\n response = resp.json()\n except RequestException as e:\n log.error('Argenteam request failed: %s', e)\n return\n\n for release in response['releases']:\n for torrent in release['torrents']:\n if (\n config.get('force_subtitles')\n and release['subtitles']\n or not config.get('force_subtitles')\n ):\n e = Entry()\n\n e['title'] = ' '.join(\n (\n search_string,\n release['source'],\n release['codec'],\n release['team'],\n release['tags'],\n )\n )\n e['url'] = torrent['uri']\n\n # Save aRGENTeaM subtitle URL for this release\n if 'subtitles' in release:\n e['argenteam_subtitle'] = release['subtitles'][0]['uri']\n log.debug('Argenteam subtitle found: %s', e['argenteam_subtitle'])\n\n if 'tvdb' in response:\n e['tvdb_id'] = response['tvdb']\n if 'info' in response and 'imdb' in response['info']:\n e['imdb_id'] = response['info']['imdb']\n\n entries.add(e)\n\n return entries\n\n\n@event('plugin.register')\ndef register_plugin():\n plugin.register(SearchArgenteam, 'argenteam', interfaces=['search'], api_ver=2)\n", "path": "flexget/components/sites/sites/argenteam.py"}]} | 3,773 | 228 |
gh_patches_debug_3650 | rasdani/github-patches | git_diff | internetarchive__openlibrary-7836 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Members of `/usergroup/read-only` can edit covers
<!-- What problem are we solving? What does the experience look like today? What are the symptoms? -->
Members of the `read-only` usergroup are still able to upload cover images and URLs via the manage covers modal.
### Evidence / Screenshot (if possible)
### Relevant url?
<!-- `https://openlibrary.org/...` -->
### Steps to Reproduce
<!-- What steps caused you to find the bug? -->
While logged-in as a member of the read-only group:
1. Go to any book page
2. Attempt to add a new cover via the manage covers modal
<!-- What actually happened after these steps? What did you expect to happen? -->
* Actual: The cover is updated.
* Expected: The update fails gracefully.
### Details
- **Logged in (Y/N)?**Y
- **Browser type/version?**Any
- **Operating system?**Any
- **Environment (prod/dev/local)?** prod
<!-- If not sure, put prod -->
### Proposal & Constraints
<!-- What is the proposed solution / implementation? Is there a precedent of this approach succeeding elsewhere? -->
Check for membership in the read-only group before persisting the new cover. If submitter is a member, do not store the image.
### Related files
<!-- Files related to this issue; this is super useful for new contributors who might want to help! If you're not sure, leave this blank; a maintainer will add them. -->
POST handler for manage cover form: https://github.com/internetarchive/openlibrary/blob/master/openlibrary/plugins/upstream/covers.py#L34-L53
### Stakeholders
<!-- @ tag stakeholders of this bug -->
@seabelis
</issue>
<code>
[start of openlibrary/plugins/upstream/covers.py]
1 """Handle book cover/author photo upload.
2 """
3 from logging import getLogger
4
5 import requests
6 import web
7 from io import BytesIO
8
9 from infogami.utils import delegate
10 from infogami.utils.view import safeint
11 from openlibrary import accounts
12 from openlibrary.plugins.upstream.models import Image
13 from openlibrary.plugins.upstream.utils import (
14 get_coverstore_url,
15 get_coverstore_public_url,
16 render_template,
17 )
18
19 logger = getLogger("openlibrary.plugins.upstream.covers")
20
21
22 def setup():
23 pass
24
25
26 class add_cover(delegate.page):
27 path = r"(/books/OL\d+M)/add-cover"
28 cover_category = "b"
29
30 def GET(self, key):
31 book = web.ctx.site.get(key)
32 return render_template('covers/add', book)
33
34 def POST(self, key):
35 book = web.ctx.site.get(key)
36 if not book:
37 raise web.notfound("")
38
39 i = web.input(file={}, url="")
40
41 # remove references to field storage objects
42 web.ctx.pop("_fieldstorage", None)
43
44 data = self.upload(key, i)
45
46 if coverid := data.get('id'):
47 if isinstance(i.url, bytes):
48 i.url = i.url.decode("utf-8")
49 self.save(book, coverid, url=i.url)
50 cover = Image(web.ctx.site, "b", coverid)
51 return render_template("covers/saved", cover)
52 else:
53 return render_template("covers/add", book, {'url': i.url}, data)
54
55 def upload(self, key, i):
56 """Uploads a cover to coverstore and returns the response."""
57 olid = key.split("/")[-1]
58
59 if i.file is not None and hasattr(i.file, 'value'):
60 data = i.file.value
61 else:
62 data = None
63
64 if i.url and i.url.strip() == "https://":
65 i.url = ""
66
67 user = accounts.get_current_user()
68 params = {
69 "author": user and user.key,
70 "source_url": i.url,
71 "olid": olid,
72 "ip": web.ctx.ip,
73 }
74
75 upload_url = f'{get_coverstore_url()}/{self.cover_category}/upload2'
76
77 if upload_url.startswith("//"):
78 upload_url = "http:" + upload_url
79
80 try:
81 files = {'data': BytesIO(data)}
82 response = requests.post(upload_url, data=params, files=files)
83 return web.storage(response.json())
84 except requests.HTTPError as e:
85 logger.exception("Covers upload failed")
86 return web.storage({'error': str(e)})
87
88 def save(self, book, coverid, url=None):
89 book.covers = [coverid] + [cover.id for cover in book.get_covers()]
90 book._save(
91 f'{get_coverstore_public_url()}/b/id/{coverid}-S.jpg',
92 action="add-cover",
93 data={"url": url},
94 )
95
96
97 class add_work_cover(add_cover):
98 path = r"(/works/OL\d+W)/add-cover"
99 cover_category = "w"
100
101 def upload(self, key, i):
102 if "coverid" in i and safeint(i.coverid):
103 return web.storage(id=int(i.coverid))
104 else:
105 return add_cover.upload(self, key, i)
106
107
108 class add_photo(add_cover):
109 path = r"(/authors/OL\d+A)/add-photo"
110 cover_category = "a"
111
112 def save(self, author, photoid, url=None):
113 author.photos = [photoid] + [photo.id for photo in author.get_photos()]
114 author._save("Added new photo", action="add-photo", data={"url": url})
115
116
117 class manage_covers(delegate.page):
118 path = r"(/books/OL\d+M)/manage-covers"
119
120 def GET(self, key):
121 book = web.ctx.site.get(key)
122 if not book:
123 raise web.notfound()
124 return render_template("covers/manage", key, self.get_images(book))
125
126 def get_images(self, book):
127 return book.get_covers()
128
129 def get_image(self, book):
130 return book.get_cover()
131
132 def save_images(self, book, covers):
133 book.covers = covers
134 book._save('Update covers')
135
136 def POST(self, key):
137 book = web.ctx.site.get(key)
138 if not book:
139 raise web.notfound()
140
141 images = web.input(image=[]).image
142 if '-' in images:
143 images = [int(id) for id in images[: images.index('-')]]
144 self.save_images(book, images)
145 return render_template("covers/saved", self.get_image(book), showinfo=False)
146 else:
147 # ERROR
148 pass
149
150
151 class manage_work_covers(manage_covers):
152 path = r"(/works/OL\d+W)/manage-covers"
153
154
155 class manage_photos(manage_covers):
156 path = r"(/authors/OL\d+A)/manage-photos"
157
158 def get_images(self, author):
159 return author.get_photos()
160
161 def get_image(self, author):
162 return author.get_photo()
163
164 def save_images(self, author, photos):
165 author.photos = photos
166 author._save('Update photos')
167
[end of openlibrary/plugins/upstream/covers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/openlibrary/plugins/upstream/covers.py b/openlibrary/plugins/upstream/covers.py
--- a/openlibrary/plugins/upstream/covers.py
+++ b/openlibrary/plugins/upstream/covers.py
@@ -36,6 +36,10 @@
if not book:
raise web.notfound("")
+ user = accounts.get_current_user()
+ if user and user.is_read_only():
+ raise web.forbidden(message="Patron not permitted to upload images")
+
i = web.input(file={}, url="")
# remove references to field storage objects
| {"golden_diff": "diff --git a/openlibrary/plugins/upstream/covers.py b/openlibrary/plugins/upstream/covers.py\n--- a/openlibrary/plugins/upstream/covers.py\n+++ b/openlibrary/plugins/upstream/covers.py\n@@ -36,6 +36,10 @@\n if not book:\n raise web.notfound(\"\")\n \n+ user = accounts.get_current_user()\n+ if user and user.is_read_only():\n+ raise web.forbidden(message=\"Patron not permitted to upload images\")\n+\n i = web.input(file={}, url=\"\")\n \n # remove references to field storage objects\n", "issue": "Members of `/usergroup/read-only` can edit covers\n<!-- What problem are we solving? What does the experience look like today? What are the symptoms? -->\r\nMembers of the `read-only` usergroup are still able to upload cover images and URLs via the manage covers modal.\r\n\r\n### Evidence / Screenshot (if possible)\r\n\r\n### Relevant url?\r\n<!-- `https://openlibrary.org/...` -->\r\n\r\n### Steps to Reproduce\r\n<!-- What steps caused you to find the bug? -->\r\nWhile logged-in as a member of the read-only group:\r\n1. Go to any book page\r\n2. Attempt to add a new cover via the manage covers modal\r\n\r\n<!-- What actually happened after these steps? What did you expect to happen? -->\r\n* Actual: The cover is updated.\r\n* Expected: The update fails gracefully.\r\n\r\n### Details\r\n\r\n- **Logged in (Y/N)?**Y\r\n- **Browser type/version?**Any\r\n- **Operating system?**Any\r\n- **Environment (prod/dev/local)?** prod\r\n<!-- If not sure, put prod -->\r\n\r\n### Proposal & Constraints\r\n<!-- What is the proposed solution / implementation? Is there a precedent of this approach succeeding elsewhere? -->\r\nCheck for membership in the read-only group before persisting the new cover. If submitter is a member, do not store the image.\r\n\r\n### Related files\r\n<!-- Files related to this issue; this is super useful for new contributors who might want to help! If you're not sure, leave this blank; a maintainer will add them. -->\r\nPOST handler for manage cover form: https://github.com/internetarchive/openlibrary/blob/master/openlibrary/plugins/upstream/covers.py#L34-L53\r\n\r\n\r\n### Stakeholders\r\n<!-- @ tag stakeholders of this bug -->\r\n@seabelis \n", "before_files": [{"content": "\"\"\"Handle book cover/author photo upload.\n\"\"\"\nfrom logging import getLogger\n\nimport requests\nimport web\nfrom io import BytesIO\n\nfrom infogami.utils import delegate\nfrom infogami.utils.view import safeint\nfrom openlibrary import accounts\nfrom openlibrary.plugins.upstream.models import Image\nfrom openlibrary.plugins.upstream.utils import (\n get_coverstore_url,\n get_coverstore_public_url,\n render_template,\n)\n\nlogger = getLogger(\"openlibrary.plugins.upstream.covers\")\n\n\ndef setup():\n pass\n\n\nclass add_cover(delegate.page):\n path = r\"(/books/OL\\d+M)/add-cover\"\n cover_category = \"b\"\n\n def GET(self, key):\n book = web.ctx.site.get(key)\n return render_template('covers/add', book)\n\n def POST(self, key):\n book = web.ctx.site.get(key)\n if not book:\n raise web.notfound(\"\")\n\n i = web.input(file={}, url=\"\")\n\n # remove references to field storage objects\n web.ctx.pop(\"_fieldstorage\", None)\n\n data = self.upload(key, i)\n\n if coverid := data.get('id'):\n if isinstance(i.url, bytes):\n i.url = i.url.decode(\"utf-8\")\n self.save(book, coverid, url=i.url)\n cover = Image(web.ctx.site, \"b\", coverid)\n return render_template(\"covers/saved\", cover)\n else:\n return render_template(\"covers/add\", book, {'url': i.url}, data)\n\n def upload(self, key, i):\n \"\"\"Uploads a cover to coverstore and returns the response.\"\"\"\n olid = key.split(\"/\")[-1]\n\n if i.file is not None and hasattr(i.file, 'value'):\n data = i.file.value\n else:\n data = None\n\n if i.url and i.url.strip() == \"https://\":\n i.url = \"\"\n\n user = accounts.get_current_user()\n params = {\n \"author\": user and user.key,\n \"source_url\": i.url,\n \"olid\": olid,\n \"ip\": web.ctx.ip,\n }\n\n upload_url = f'{get_coverstore_url()}/{self.cover_category}/upload2'\n\n if upload_url.startswith(\"//\"):\n upload_url = \"http:\" + upload_url\n\n try:\n files = {'data': BytesIO(data)}\n response = requests.post(upload_url, data=params, files=files)\n return web.storage(response.json())\n except requests.HTTPError as e:\n logger.exception(\"Covers upload failed\")\n return web.storage({'error': str(e)})\n\n def save(self, book, coverid, url=None):\n book.covers = [coverid] + [cover.id for cover in book.get_covers()]\n book._save(\n f'{get_coverstore_public_url()}/b/id/{coverid}-S.jpg',\n action=\"add-cover\",\n data={\"url\": url},\n )\n\n\nclass add_work_cover(add_cover):\n path = r\"(/works/OL\\d+W)/add-cover\"\n cover_category = \"w\"\n\n def upload(self, key, i):\n if \"coverid\" in i and safeint(i.coverid):\n return web.storage(id=int(i.coverid))\n else:\n return add_cover.upload(self, key, i)\n\n\nclass add_photo(add_cover):\n path = r\"(/authors/OL\\d+A)/add-photo\"\n cover_category = \"a\"\n\n def save(self, author, photoid, url=None):\n author.photos = [photoid] + [photo.id for photo in author.get_photos()]\n author._save(\"Added new photo\", action=\"add-photo\", data={\"url\": url})\n\n\nclass manage_covers(delegate.page):\n path = r\"(/books/OL\\d+M)/manage-covers\"\n\n def GET(self, key):\n book = web.ctx.site.get(key)\n if not book:\n raise web.notfound()\n return render_template(\"covers/manage\", key, self.get_images(book))\n\n def get_images(self, book):\n return book.get_covers()\n\n def get_image(self, book):\n return book.get_cover()\n\n def save_images(self, book, covers):\n book.covers = covers\n book._save('Update covers')\n\n def POST(self, key):\n book = web.ctx.site.get(key)\n if not book:\n raise web.notfound()\n\n images = web.input(image=[]).image\n if '-' in images:\n images = [int(id) for id in images[: images.index('-')]]\n self.save_images(book, images)\n return render_template(\"covers/saved\", self.get_image(book), showinfo=False)\n else:\n # ERROR\n pass\n\n\nclass manage_work_covers(manage_covers):\n path = r\"(/works/OL\\d+W)/manage-covers\"\n\n\nclass manage_photos(manage_covers):\n path = r\"(/authors/OL\\d+A)/manage-photos\"\n\n def get_images(self, author):\n return author.get_photos()\n\n def get_image(self, author):\n return author.get_photo()\n\n def save_images(self, author, photos):\n author.photos = photos\n author._save('Update photos')\n", "path": "openlibrary/plugins/upstream/covers.py"}]} | 2,425 | 124 |
gh_patches_debug_11280 | rasdani/github-patches | git_diff | scverse__scanpy-1856 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Increase visibility of ecosystem page
As discussed at last meeting
- [ ] Document process for adding entries (note this on top of ecosystem page)
- [ ] Link from external
- [ ] Clarify goals/ differences b/w ecosystem and external
</issue>
<code>
[start of scanpy/external/__init__.py]
1 from . import tl
2 from . import pl
3 from . import pp
4 from . import exporting
5
6 import sys
7 from .. import _utils
8
9 _utils.annotate_doc_types(sys.modules[__name__], 'scanpy')
10 del sys, _utils
11
12
13 __doc__ = """\
14 External API
15 ============
16
17
18 Import Scanpy's wrappers to external tools as::
19
20 import scanpy.external as sce
21
22 If you'd like to see your tool included here, please open a `pull request <https://github.com/theislab/scanpy>`_!
23
24 Preprocessing: PP
25 ------------------
26
27 Data integration
28 ~~~~~~~~~~~~~~~~
29
30 .. autosummary::
31 :toctree: .
32
33 pp.bbknn
34 pp.harmony_integrate
35 pp.mnn_correct
36 pp.scanorama_integrate
37
38
39 Sample demultiplexing, Doublet detection
40 ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
41
42 .. autosummary::
43 :toctree: .
44
45 pp.scrublet
46 pp.scrublet_simulate_doublets
47 pl.scrublet_score_distribution
48 pp.hashsolo
49
50 Imputation
51 ~~~~~~~~~~
52
53 Note that the fundamental limitations of imputation are still under `debate
54 <https://github.com/theislab/scanpy/issues/189>`__.
55
56 .. autosummary::
57 :toctree: .
58
59 pp.dca
60 pp.magic
61
62
63 Tools: TL
64 ----------
65
66 Embeddings
67 ~~~~~~~~~~
68
69 .. autosummary::
70 :toctree: .
71
72 tl.phate
73 tl.palantir
74 tl.trimap
75 tl.sam
76
77 Clustering and trajectory inference
78 ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
79
80 .. autosummary::
81 :toctree: .
82
83 tl.phenograph
84 tl.harmony_timeseries
85 tl.wishbone
86 tl.palantir
87 tl.palantir_results
88
89 Gene scores, Cell cycle
90 ~~~~~~~~~~~~~~~~~~~~~~~
91
92 .. autosummary::
93 :toctree: .
94
95 tl.sandbag
96 tl.cyclone
97
98
99 Plotting: PL
100 ------------
101
102 .. autosummary::
103 :toctree: .
104
105 pl.phate
106 pl.trimap
107 pl.sam
108 pl.wishbone_marker_trajectory
109
110 Exporting
111 ---------
112
113 .. autosummary::
114 :toctree: .
115
116 exporting.spring_project
117 exporting.cellbrowser
118 """
119
[end of scanpy/external/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/scanpy/external/__init__.py b/scanpy/external/__init__.py
--- a/scanpy/external/__init__.py
+++ b/scanpy/external/__init__.py
@@ -14,12 +14,15 @@
External API
============
+.. note::
+ More tools that integrate well with scanpy and anndata can be found on the :doc:`ecosystem page <../ecosystem>`.
Import Scanpy's wrappers to external tools as::
import scanpy.external as sce
-If you'd like to see your tool included here, please open a `pull request <https://github.com/theislab/scanpy>`_!
+If you'd like to include a tool here, consider making a pull request (:doc:`instructions <../dev/external-tools>`).
+If the tool already uses `scanpy` or `anndata`, it may fit better in the :doc:`ecosystem page <../ecosystem>`.
Preprocessing: PP
------------------
| {"golden_diff": "diff --git a/scanpy/external/__init__.py b/scanpy/external/__init__.py\n--- a/scanpy/external/__init__.py\n+++ b/scanpy/external/__init__.py\n@@ -14,12 +14,15 @@\n External API\n ============\n \n+.. note::\n+ More tools that integrate well with scanpy and anndata can be found on the :doc:`ecosystem page <../ecosystem>`.\n \n Import Scanpy's wrappers to external tools as::\n \n import scanpy.external as sce\n \n-If you'd like to see your tool included here, please open a `pull request <https://github.com/theislab/scanpy>`_!\n+If you'd like to include a tool here, consider making a pull request (:doc:`instructions <../dev/external-tools>`).\n+If the tool already uses `scanpy` or `anndata`, it may fit better in the :doc:`ecosystem page <../ecosystem>`.\n \n Preprocessing: PP\n ------------------\n", "issue": "Increase visibility of ecosystem page\nAs discussed at last meeting\r\n\r\n- [ ] Document process for adding entries (note this on top of ecosystem page)\r\n- [ ] Link from external\r\n- [ ] Clarify goals/ differences b/w ecosystem and external\n", "before_files": [{"content": "from . import tl\nfrom . import pl\nfrom . import pp\nfrom . import exporting\n\nimport sys\nfrom .. import _utils\n\n_utils.annotate_doc_types(sys.modules[__name__], 'scanpy')\ndel sys, _utils\n\n\n__doc__ = \"\"\"\\\nExternal API\n============\n\n\nImport Scanpy's wrappers to external tools as::\n\n import scanpy.external as sce\n\nIf you'd like to see your tool included here, please open a `pull request <https://github.com/theislab/scanpy>`_!\n\nPreprocessing: PP\n------------------\n\nData integration\n~~~~~~~~~~~~~~~~\n\n.. autosummary::\n :toctree: .\n\n pp.bbknn\n pp.harmony_integrate\n pp.mnn_correct\n pp.scanorama_integrate\n\n\nSample demultiplexing, Doublet detection\n~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~\n\n.. autosummary::\n :toctree: .\n\n pp.scrublet\n pp.scrublet_simulate_doublets\n pl.scrublet_score_distribution\n pp.hashsolo\n\nImputation\n~~~~~~~~~~\n\nNote that the fundamental limitations of imputation are still under `debate\n<https://github.com/theislab/scanpy/issues/189>`__.\n\n.. autosummary::\n :toctree: .\n\n pp.dca\n pp.magic\n\n\nTools: TL\n----------\n\nEmbeddings\n~~~~~~~~~~\n\n.. autosummary::\n :toctree: .\n\n tl.phate\n tl.palantir\n tl.trimap\n tl.sam\n\nClustering and trajectory inference\n~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~\n\n.. autosummary::\n :toctree: .\n\n tl.phenograph\n tl.harmony_timeseries\n tl.wishbone\n tl.palantir\n tl.palantir_results\n\nGene scores, Cell cycle\n~~~~~~~~~~~~~~~~~~~~~~~\n\n.. autosummary::\n :toctree: .\n\n tl.sandbag\n tl.cyclone\n\n\nPlotting: PL\n------------\n\n.. autosummary::\n :toctree: .\n\n pl.phate\n pl.trimap\n pl.sam\n pl.wishbone_marker_trajectory\n\nExporting\n---------\n\n.. autosummary::\n :toctree: .\n\n exporting.spring_project\n exporting.cellbrowser\n\"\"\"\n", "path": "scanpy/external/__init__.py"}]} | 1,366 | 227 |
gh_patches_debug_37868 | rasdani/github-patches | git_diff | privacyidea__privacyidea-1524 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Change yubico POST request to GET request
See: https://community.privacyidea.org/t/yubico-auth-not-working-since-a-few-hours-quickfix/977/3
We need to change the POST request to the yubicloud to a GET request.
*bummer*
</issue>
<code>
[start of privacyidea/lib/tokens/yubicotoken.py]
1 # -*- coding: utf-8 -*-
2 #
3 # privacyIDEA is a fork of LinOTP
4 # May 08, 2014 Cornelius Kölbel
5 # License: AGPLv3
6 # contact: http://www.privacyidea.org
7 #
8 # 2017-11-24 Cornelius Kölbel <[email protected]>
9 # Generate the nonce on an HSM
10 # 2016-04-04 Cornelius Kölbel <[email protected]>
11 # Use central yubico_api_signature function
12 # 2015-01-28 Rewrite during flask migration
13 # Change to use requests module
14 # Cornelius Kölbel <[email protected]>
15 #
16 #
17 # Copyright (C) 2010 - 2014 LSE Leading Security Experts GmbH
18 # License: LSE
19 # contact: http://www.linotp.org
20 # http://www.lsexperts.de
21 # [email protected]
22 #
23 # This code is free software; you can redistribute it and/or
24 # modify it under the terms of the GNU AFFERO GENERAL PUBLIC LICENSE
25 # License as published by the Free Software Foundation; either
26 # version 3 of the License, or any later version.
27 #
28 # This code is distributed in the hope that it will be useful,
29 # but WITHOUT ANY WARRANTY; without even the implied warranty of
30 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
31 # GNU AFFERO GENERAL PUBLIC LICENSE for more details.
32 #
33 # You should have received a copy of the GNU Affero General Public
34 # License along with this program. If not, see <http://www.gnu.org/licenses/>.
35 #
36 __doc__ = """
37 This is the implementation of the yubico token type.
38 Authentication requests are forwarded to the Yubico Cloud service YubiCloud.
39
40 The code is tested in tests/test_lib_tokens_yubico
41 """
42 import logging
43 from privacyidea.lib.decorators import check_token_locked
44 import traceback
45 import requests
46 from privacyidea.api.lib.utils import getParam
47 from privacyidea.lib.crypto import geturandom
48 from privacyidea.lib.config import get_from_config
49 from privacyidea.lib.log import log_with
50 from privacyidea.lib.tokenclass import TokenClass, TOKENKIND
51 from privacyidea.lib.tokens.yubikeytoken import (yubico_check_api_signature,
52 yubico_api_signature)
53 import os
54 import binascii
55 from privacyidea.lib import _
56
57 YUBICO_LEN_ID = 12
58 YUBICO_LEN_OTP = 44
59 YUBICO_URL = "https://api.yubico.com/wsapi/2.0/verify"
60 DEFAULT_CLIENT_ID = 20771
61 DEFAULT_API_KEY = "9iE9DRkPHQDJbAFFC31/dum5I54="
62
63 optional = True
64 required = False
65
66 log = logging.getLogger(__name__)
67
68
69 class YubicoTokenClass(TokenClass):
70
71 def __init__(self, db_token):
72 TokenClass.__init__(self, db_token)
73 self.set_type(u"yubico")
74 self.tokenid = ""
75
76 @staticmethod
77 def get_class_type():
78 return "yubico"
79
80 @staticmethod
81 def get_class_prefix():
82 return "UBCM"
83
84 @staticmethod
85 @log_with(log)
86 def get_class_info(key=None, ret='all'):
87 """
88 :param key: subsection identifier
89 :type key: string
90 :param ret: default return value, if nothing is found
91 :type ret: user defined
92 :return: subsection if key exists or user defined
93 :rtype: dict or string
94 """
95 res = {'type': 'yubico',
96 'title': 'Yubico Token',
97 'description': _('Yubikey Cloud mode: Forward authentication '
98 'request to YubiCloud.'),
99 'user': ['enroll'],
100 # This tokentype is enrollable in the UI for...
101 'ui_enroll': ["admin", "user"],
102 'policy' : {},
103 }
104
105 if key:
106 ret = res.get(key, {})
107 else:
108 if ret == 'all':
109 ret = res
110 return ret
111
112 def update(self, param):
113 tokenid = getParam(param, "yubico.tokenid", required)
114 if len(tokenid) < YUBICO_LEN_ID:
115 log.error("The tokenid needs to be {0:d} characters long!".format(YUBICO_LEN_ID))
116 raise Exception("The Yubikey token ID needs to be {0:d} characters long!".format(YUBICO_LEN_ID))
117
118 if len(tokenid) > YUBICO_LEN_ID:
119 tokenid = tokenid[:YUBICO_LEN_ID]
120 self.tokenid = tokenid
121 # overwrite the maybe wrong lenght given at the command line
122 param['otplen'] = 44
123 TokenClass.update(self, param)
124 self.add_tokeninfo("yubico.tokenid", self.tokenid)
125 self.add_tokeninfo("tokenkind", TOKENKIND.HARDWARE)
126
127 @log_with(log)
128 @check_token_locked
129 def check_otp(self, anOtpVal, counter=None, window=None, options=None):
130 """
131 Here we contact the Yubico Cloud server to validate the OtpVal.
132 """
133 res = -1
134
135 apiId = get_from_config("yubico.id", DEFAULT_CLIENT_ID)
136 apiKey = get_from_config("yubico.secret", DEFAULT_API_KEY)
137 yubico_url = get_from_config("yubico.url", YUBICO_URL)
138
139 if apiKey == DEFAULT_API_KEY or apiId == DEFAULT_CLIENT_ID:
140 log.warning("Usage of default apiKey or apiId not recommended!")
141 log.warning("Please register your own apiKey and apiId at "
142 "yubico website!")
143 log.warning("Configure of apiKey and apiId at the "
144 "privacyidea manage config menu!")
145
146 tokenid = self.get_tokeninfo("yubico.tokenid")
147 if len(anOtpVal) < 12:
148 log.warning("The otpval is too short: {0!r}".format(anOtpVal))
149 elif anOtpVal[:12] != tokenid:
150 log.warning("The tokenid in the OTP value does not match "
151 "the assigned token!")
152 else:
153 nonce = geturandom(20, hex=True)
154 p = {'nonce': nonce,
155 'otp': anOtpVal,
156 'id': apiId}
157 # Also send the signature to the yubico server
158 p["h"] = yubico_api_signature(p, apiKey)
159
160 try:
161 r = requests.post(yubico_url,
162 data=p)
163
164 if r.status_code == requests.codes.ok:
165 response = r.text
166 elements = response.split()
167 data = {}
168 for elem in elements:
169 k, v = elem.split("=", 1)
170 data[k] = v
171 result = data.get("status")
172 return_nonce = data.get("nonce")
173 # check signature:
174 signature_valid = yubico_check_api_signature(data, apiKey)
175
176 if not signature_valid:
177 log.error("The hash of the return from the yubico "
178 "authentication server ({0!s}) "
179 "does not match the data!".format(yubico_url))
180
181 if nonce != return_nonce:
182 log.error("The returned nonce does not match "
183 "the sent nonce!")
184
185 if result == "OK":
186 res = 1
187 if nonce != return_nonce or not signature_valid:
188 log.warning("Nonce and Hash do not match.")
189 res = -2
190 else:
191 # possible results are listed here:
192 # https://github.com/Yubico/yubikey-val/wiki/ValidationProtocolV20
193 log.warning("failed with {0!r}".format(result))
194
195 except Exception as ex:
196 log.error("Error getting response from Yubico Cloud Server"
197 " (%r): %r" % (yubico_url, ex))
198 log.debug("{0!s}".format(traceback.format_exc()))
199
200 return res
201
[end of privacyidea/lib/tokens/yubicotoken.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/privacyidea/lib/tokens/yubicotoken.py b/privacyidea/lib/tokens/yubicotoken.py
--- a/privacyidea/lib/tokens/yubicotoken.py
+++ b/privacyidea/lib/tokens/yubicotoken.py
@@ -5,6 +5,8 @@
# License: AGPLv3
# contact: http://www.privacyidea.org
#
+# 2019-03-21 Cornelius Kölbel <[email protected]>
+# Change POST to GET request
# 2017-11-24 Cornelius Kölbel <[email protected]>
# Generate the nonce on an HSM
# 2016-04-04 Cornelius Kölbel <[email protected]>
@@ -50,13 +52,16 @@
from privacyidea.lib.tokenclass import TokenClass, TOKENKIND
from privacyidea.lib.tokens.yubikeytoken import (yubico_check_api_signature,
yubico_api_signature)
-import os
-import binascii
+from six.moves.urllib.parse import urlencode
from privacyidea.lib import _
YUBICO_LEN_ID = 12
YUBICO_LEN_OTP = 44
YUBICO_URL = "https://api.yubico.com/wsapi/2.0/verify"
+# The Yubico API requires GET requests. See: https://developers.yubico.com/yubikey-val/Validation_Protocol_V2.0.html
+# Previously we used POST requests.
+# If you want to have the old behaviour, you can set this to True
+DO_YUBICO_POST = False
DEFAULT_CLIENT_ID = 20771
DEFAULT_API_KEY = "9iE9DRkPHQDJbAFFC31/dum5I54="
@@ -135,6 +140,7 @@
apiId = get_from_config("yubico.id", DEFAULT_CLIENT_ID)
apiKey = get_from_config("yubico.secret", DEFAULT_API_KEY)
yubico_url = get_from_config("yubico.url", YUBICO_URL)
+ do_yubico_post = get_from_config("yubico.do_post", DO_YUBICO_POST)
if apiKey == DEFAULT_API_KEY or apiId == DEFAULT_CLIENT_ID:
log.warning("Usage of default apiKey or apiId not recommended!")
@@ -158,8 +164,12 @@
p["h"] = yubico_api_signature(p, apiKey)
try:
- r = requests.post(yubico_url,
- data=p)
+ if do_yubico_post:
+ r = requests.post(yubico_url,
+ data=p)
+ else:
+ r = requests.get(yubico_url,
+ params=urlencode(p))
if r.status_code == requests.codes.ok:
response = r.text
| {"golden_diff": "diff --git a/privacyidea/lib/tokens/yubicotoken.py b/privacyidea/lib/tokens/yubicotoken.py\n--- a/privacyidea/lib/tokens/yubicotoken.py\n+++ b/privacyidea/lib/tokens/yubicotoken.py\n@@ -5,6 +5,8 @@\n # License: AGPLv3\n # contact: http://www.privacyidea.org\n #\n+# 2019-03-21 Cornelius K\u00f6lbel <[email protected]>\n+# Change POST to GET request\n # 2017-11-24 Cornelius K\u00f6lbel <[email protected]>\n # Generate the nonce on an HSM\n # 2016-04-04 Cornelius K\u00f6lbel <[email protected]>\n@@ -50,13 +52,16 @@\n from privacyidea.lib.tokenclass import TokenClass, TOKENKIND\n from privacyidea.lib.tokens.yubikeytoken import (yubico_check_api_signature,\n yubico_api_signature)\n-import os\n-import binascii\n+from six.moves.urllib.parse import urlencode\n from privacyidea.lib import _\n \n YUBICO_LEN_ID = 12\n YUBICO_LEN_OTP = 44\n YUBICO_URL = \"https://api.yubico.com/wsapi/2.0/verify\"\n+# The Yubico API requires GET requests. See: https://developers.yubico.com/yubikey-val/Validation_Protocol_V2.0.html\n+# Previously we used POST requests.\n+# If you want to have the old behaviour, you can set this to True\n+DO_YUBICO_POST = False\n DEFAULT_CLIENT_ID = 20771\n DEFAULT_API_KEY = \"9iE9DRkPHQDJbAFFC31/dum5I54=\"\n \n@@ -135,6 +140,7 @@\n apiId = get_from_config(\"yubico.id\", DEFAULT_CLIENT_ID)\n apiKey = get_from_config(\"yubico.secret\", DEFAULT_API_KEY)\n yubico_url = get_from_config(\"yubico.url\", YUBICO_URL)\n+ do_yubico_post = get_from_config(\"yubico.do_post\", DO_YUBICO_POST)\n \n if apiKey == DEFAULT_API_KEY or apiId == DEFAULT_CLIENT_ID:\n log.warning(\"Usage of default apiKey or apiId not recommended!\")\n@@ -158,8 +164,12 @@\n p[\"h\"] = yubico_api_signature(p, apiKey)\n \n try:\n- r = requests.post(yubico_url,\n- data=p)\n+ if do_yubico_post:\n+ r = requests.post(yubico_url,\n+ data=p)\n+ else:\n+ r = requests.get(yubico_url,\n+ params=urlencode(p))\n \n if r.status_code == requests.codes.ok:\n response = r.text\n", "issue": "Change yubico POST request to GET request\nSee: https://community.privacyidea.org/t/yubico-auth-not-working-since-a-few-hours-quickfix/977/3\r\n\r\nWe need to change the POST request to the yubicloud to a GET request.\r\n\r\n*bummer*\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# privacyIDEA is a fork of LinOTP\n# May 08, 2014 Cornelius K\u00f6lbel\n# License: AGPLv3\n# contact: http://www.privacyidea.org\n#\n# 2017-11-24 Cornelius K\u00f6lbel <[email protected]>\n# Generate the nonce on an HSM\n# 2016-04-04 Cornelius K\u00f6lbel <[email protected]>\n# Use central yubico_api_signature function\n# 2015-01-28 Rewrite during flask migration\n# Change to use requests module\n# Cornelius K\u00f6lbel <[email protected]>\n#\n#\n# Copyright (C) 2010 - 2014 LSE Leading Security Experts GmbH\n# License: LSE\n# contact: http://www.linotp.org\n# http://www.lsexperts.de\n# [email protected]\n#\n# This code is free software; you can redistribute it and/or\n# modify it under the terms of the GNU AFFERO GENERAL PUBLIC LICENSE\n# License as published by the Free Software Foundation; either\n# version 3 of the License, or any later version.\n#\n# This code is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU AFFERO GENERAL PUBLIC LICENSE for more details.\n#\n# You should have received a copy of the GNU Affero General Public\n# License along with this program. If not, see <http://www.gnu.org/licenses/>.\n#\n__doc__ = \"\"\"\nThis is the implementation of the yubico token type.\nAuthentication requests are forwarded to the Yubico Cloud service YubiCloud.\n\nThe code is tested in tests/test_lib_tokens_yubico\n\"\"\"\nimport logging\nfrom privacyidea.lib.decorators import check_token_locked\nimport traceback\nimport requests\nfrom privacyidea.api.lib.utils import getParam\nfrom privacyidea.lib.crypto import geturandom\nfrom privacyidea.lib.config import get_from_config\nfrom privacyidea.lib.log import log_with\nfrom privacyidea.lib.tokenclass import TokenClass, TOKENKIND\nfrom privacyidea.lib.tokens.yubikeytoken import (yubico_check_api_signature,\n yubico_api_signature)\nimport os\nimport binascii\nfrom privacyidea.lib import _\n\nYUBICO_LEN_ID = 12\nYUBICO_LEN_OTP = 44\nYUBICO_URL = \"https://api.yubico.com/wsapi/2.0/verify\"\nDEFAULT_CLIENT_ID = 20771\nDEFAULT_API_KEY = \"9iE9DRkPHQDJbAFFC31/dum5I54=\"\n\noptional = True\nrequired = False\n\nlog = logging.getLogger(__name__)\n\n\nclass YubicoTokenClass(TokenClass):\n\n def __init__(self, db_token):\n TokenClass.__init__(self, db_token)\n self.set_type(u\"yubico\")\n self.tokenid = \"\"\n\n @staticmethod\n def get_class_type():\n return \"yubico\"\n\n @staticmethod\n def get_class_prefix():\n return \"UBCM\"\n\n @staticmethod\n @log_with(log)\n def get_class_info(key=None, ret='all'):\n \"\"\"\n :param key: subsection identifier\n :type key: string\n :param ret: default return value, if nothing is found\n :type ret: user defined\n :return: subsection if key exists or user defined\n :rtype: dict or string\n \"\"\"\n res = {'type': 'yubico',\n 'title': 'Yubico Token',\n 'description': _('Yubikey Cloud mode: Forward authentication '\n 'request to YubiCloud.'),\n 'user': ['enroll'],\n # This tokentype is enrollable in the UI for...\n 'ui_enroll': [\"admin\", \"user\"],\n 'policy' : {},\n }\n\n if key:\n ret = res.get(key, {})\n else:\n if ret == 'all':\n ret = res\n return ret\n\n def update(self, param):\n tokenid = getParam(param, \"yubico.tokenid\", required)\n if len(tokenid) < YUBICO_LEN_ID:\n log.error(\"The tokenid needs to be {0:d} characters long!\".format(YUBICO_LEN_ID))\n raise Exception(\"The Yubikey token ID needs to be {0:d} characters long!\".format(YUBICO_LEN_ID))\n\n if len(tokenid) > YUBICO_LEN_ID:\n tokenid = tokenid[:YUBICO_LEN_ID]\n self.tokenid = tokenid\n # overwrite the maybe wrong lenght given at the command line\n param['otplen'] = 44\n TokenClass.update(self, param)\n self.add_tokeninfo(\"yubico.tokenid\", self.tokenid)\n self.add_tokeninfo(\"tokenkind\", TOKENKIND.HARDWARE)\n\n @log_with(log)\n @check_token_locked\n def check_otp(self, anOtpVal, counter=None, window=None, options=None):\n \"\"\"\n Here we contact the Yubico Cloud server to validate the OtpVal.\n \"\"\"\n res = -1\n\n apiId = get_from_config(\"yubico.id\", DEFAULT_CLIENT_ID)\n apiKey = get_from_config(\"yubico.secret\", DEFAULT_API_KEY)\n yubico_url = get_from_config(\"yubico.url\", YUBICO_URL)\n\n if apiKey == DEFAULT_API_KEY or apiId == DEFAULT_CLIENT_ID:\n log.warning(\"Usage of default apiKey or apiId not recommended!\")\n log.warning(\"Please register your own apiKey and apiId at \"\n \"yubico website!\")\n log.warning(\"Configure of apiKey and apiId at the \"\n \"privacyidea manage config menu!\")\n\n tokenid = self.get_tokeninfo(\"yubico.tokenid\")\n if len(anOtpVal) < 12:\n log.warning(\"The otpval is too short: {0!r}\".format(anOtpVal))\n elif anOtpVal[:12] != tokenid:\n log.warning(\"The tokenid in the OTP value does not match \"\n \"the assigned token!\")\n else:\n nonce = geturandom(20, hex=True)\n p = {'nonce': nonce,\n 'otp': anOtpVal,\n 'id': apiId}\n # Also send the signature to the yubico server\n p[\"h\"] = yubico_api_signature(p, apiKey)\n\n try:\n r = requests.post(yubico_url,\n data=p)\n\n if r.status_code == requests.codes.ok:\n response = r.text\n elements = response.split()\n data = {}\n for elem in elements:\n k, v = elem.split(\"=\", 1)\n data[k] = v\n result = data.get(\"status\")\n return_nonce = data.get(\"nonce\")\n # check signature:\n signature_valid = yubico_check_api_signature(data, apiKey)\n\n if not signature_valid:\n log.error(\"The hash of the return from the yubico \"\n \"authentication server ({0!s}) \"\n \"does not match the data!\".format(yubico_url))\n\n if nonce != return_nonce:\n log.error(\"The returned nonce does not match \"\n \"the sent nonce!\")\n\n if result == \"OK\":\n res = 1\n if nonce != return_nonce or not signature_valid:\n log.warning(\"Nonce and Hash do not match.\")\n res = -2\n else:\n # possible results are listed here:\n # https://github.com/Yubico/yubikey-val/wiki/ValidationProtocolV20\n log.warning(\"failed with {0!r}\".format(result))\n\n except Exception as ex:\n log.error(\"Error getting response from Yubico Cloud Server\"\n \" (%r): %r\" % (yubico_url, ex))\n log.debug(\"{0!s}\".format(traceback.format_exc()))\n\n return res\n", "path": "privacyidea/lib/tokens/yubicotoken.py"}]} | 2,893 | 661 |
gh_patches_debug_17241 | rasdani/github-patches | git_diff | microsoft__torchgeo-1713 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
HTTP internal server error when trying to download ``AbovegroundLiveWoodyBiomassDensity``
### Description
There is an ``urllib.error.HTTPError: HTTP Error 500: Internal Server Error`` occuring . This issue occures when compiling from github and installing using pip3. It is occuring for`` AbovegroundLiveWoodyBiomassDensity`` which is a module from ``torchgeo.datasets.agb_live_woody_density``
### Steps to reproduce
python
``
from torchgeo.datasets.agb_live_woody_density import AbovegroundLiveWoodyBiomassDensity
ALWBD = AbovegroundLiveWoodyBiomassDensity(paths="~/test", download=True)
``
### Version
0.6.0.dev0 and 0.5.0
</issue>
<code>
[start of torchgeo/datasets/agb_live_woody_density.py]
1 # Copyright (c) Microsoft Corporation. All rights reserved.
2 # Licensed under the MIT License.
3
4 """Aboveground Live Woody Biomass Density dataset."""
5
6 import json
7 import os
8 from collections.abc import Iterable
9 from typing import Any, Callable, Optional, Union
10
11 import matplotlib.pyplot as plt
12 from matplotlib.figure import Figure
13 from rasterio.crs import CRS
14
15 from .geo import RasterDataset
16 from .utils import download_url
17
18
19 class AbovegroundLiveWoodyBiomassDensity(RasterDataset):
20 """Aboveground Live Woody Biomass Density dataset.
21
22 The `Aboveground Live Woody Biomass Density dataset
23 <https://data.globalforestwatch.org/datasets/gfw::aboveground-live-woody
24 -biomass-density/about>`_
25 is a global-scale, wall-to-wall map of aboveground biomass at ~30m resolution
26 for the year 2000.
27
28 Dataset features:
29
30 * Masks with per pixel live woody biomass density estimates in megagrams
31 biomass per hectare at ~30m resolution (~40,000x40,0000 px)
32
33 Dataset format:
34
35 * geojson file that contains download links to tif files
36 * single-channel geotiffs with the pixel values representing biomass density
37
38 If you use this dataset in your research, please give credit to:
39
40 * `Global Forest Watch <https://data.globalforestwatch.org/>`_
41
42 .. versionadded:: 0.3
43 """
44
45 is_image = False
46
47 url = (
48 "https://opendata.arcgis.com/api/v3/datasets/3e8736c8866b458687"
49 "e00d40c9f00bce_0/downloads/data?format=geojson&spatialRefId=4326"
50 )
51
52 base_filename = "Aboveground_Live_Woody_Biomass_Density.geojson"
53
54 filename_glob = "*N_*E.*"
55 filename_regex = r"""^
56 (?P<latitude>[0-9][0-9][A-Z])_
57 (?P<longitude>[0-9][0-9][0-9][A-Z])*
58 """
59
60 def __init__(
61 self,
62 paths: Union[str, Iterable[str]] = "data",
63 crs: Optional[CRS] = None,
64 res: Optional[float] = None,
65 transforms: Optional[Callable[[dict[str, Any]], dict[str, Any]]] = None,
66 download: bool = False,
67 cache: bool = True,
68 ) -> None:
69 """Initialize a new Dataset instance.
70
71 Args:
72 paths: one or more root directories to search or files to load
73 crs: :term:`coordinate reference system (CRS)` to warp to
74 (defaults to the CRS of the first file found)
75 res: resolution of the dataset in units of CRS
76 (defaults to the resolution of the first file found)
77 transforms: a function/transform that takes an input sample
78 and returns a transformed version
79 download: if True, download dataset and store it in the root directory
80 cache: if True, cache file handle to speed up repeated sampling
81
82 Raises:
83 FileNotFoundError: if no files are found in ``paths``
84
85 .. versionchanged:: 0.5
86 *root* was renamed to *paths*.
87 """
88 self.paths = paths
89 self.download = download
90
91 self._verify()
92
93 super().__init__(paths, crs, res, transforms=transforms, cache=cache)
94
95 def _verify(self) -> None:
96 """Verify the integrity of the dataset.
97
98 Raises:
99 RuntimeError: if dataset is missing
100 """
101 # Check if the extracted files already exist
102 if self.files:
103 return
104
105 # Check if the user requested to download the dataset
106 if not self.download:
107 raise RuntimeError(
108 f"Dataset not found in `paths={self.paths!r}` and `download=False`, "
109 "either specify a different `root` directory or use `download=True` "
110 "to automatically download the dataset."
111 )
112
113 # Download the dataset
114 self._download()
115
116 def _download(self) -> None:
117 """Download the dataset."""
118 assert isinstance(self.paths, str)
119 download_url(self.url, self.paths, self.base_filename)
120
121 with open(os.path.join(self.paths, self.base_filename)) as f:
122 content = json.load(f)
123
124 for item in content["features"]:
125 download_url(
126 item["properties"]["download"],
127 self.paths,
128 item["properties"]["tile_id"] + ".tif",
129 )
130
131 def plot(
132 self,
133 sample: dict[str, Any],
134 show_titles: bool = True,
135 suptitle: Optional[str] = None,
136 ) -> Figure:
137 """Plot a sample from the dataset.
138
139 Args:
140 sample: a sample returned by :meth:`RasterDataset.__getitem__`
141 show_titles: flag indicating whether to show titles above each panel
142 suptitle: optional string to use as a suptitle
143
144 Returns:
145 a matplotlib Figure with the rendered sample
146 """
147 mask = sample["mask"].squeeze()
148 ncols = 1
149
150 showing_predictions = "prediction" in sample
151 if showing_predictions:
152 pred = sample["prediction"].squeeze()
153 ncols = 2
154
155 fig, axs = plt.subplots(nrows=1, ncols=ncols, figsize=(ncols * 4, 4))
156
157 if showing_predictions:
158 axs[0].imshow(mask)
159 axs[0].axis("off")
160 axs[1].imshow(pred)
161 axs[1].axis("off")
162 if show_titles:
163 axs[0].set_title("Mask")
164 axs[1].set_title("Prediction")
165 else:
166 axs.imshow(mask)
167 axs.axis("off")
168 if show_titles:
169 axs.set_title("Mask")
170
171 if suptitle is not None:
172 plt.suptitle(suptitle)
173
174 return fig
175
[end of torchgeo/datasets/agb_live_woody_density.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/torchgeo/datasets/agb_live_woody_density.py b/torchgeo/datasets/agb_live_woody_density.py
--- a/torchgeo/datasets/agb_live_woody_density.py
+++ b/torchgeo/datasets/agb_live_woody_density.py
@@ -44,10 +44,7 @@
is_image = False
- url = (
- "https://opendata.arcgis.com/api/v3/datasets/3e8736c8866b458687"
- "e00d40c9f00bce_0/downloads/data?format=geojson&spatialRefId=4326"
- )
+ url = "https://opendata.arcgis.com/api/v3/datasets/e4bdbe8d6d8d4e32ace7d36a4aec7b93_0/downloads/data?format=geojson&spatialRefId=4326" # noqa: E501
base_filename = "Aboveground_Live_Woody_Biomass_Density.geojson"
@@ -123,7 +120,7 @@
for item in content["features"]:
download_url(
- item["properties"]["download"],
+ item["properties"]["Mg_px_1_download"],
self.paths,
item["properties"]["tile_id"] + ".tif",
)
| {"golden_diff": "diff --git a/torchgeo/datasets/agb_live_woody_density.py b/torchgeo/datasets/agb_live_woody_density.py\n--- a/torchgeo/datasets/agb_live_woody_density.py\n+++ b/torchgeo/datasets/agb_live_woody_density.py\n@@ -44,10 +44,7 @@\n \n is_image = False\n \n- url = (\n- \"https://opendata.arcgis.com/api/v3/datasets/3e8736c8866b458687\"\n- \"e00d40c9f00bce_0/downloads/data?format=geojson&spatialRefId=4326\"\n- )\n+ url = \"https://opendata.arcgis.com/api/v3/datasets/e4bdbe8d6d8d4e32ace7d36a4aec7b93_0/downloads/data?format=geojson&spatialRefId=4326\" # noqa: E501\n \n base_filename = \"Aboveground_Live_Woody_Biomass_Density.geojson\"\n \n@@ -123,7 +120,7 @@\n \n for item in content[\"features\"]:\n download_url(\n- item[\"properties\"][\"download\"],\n+ item[\"properties\"][\"Mg_px_1_download\"],\n self.paths,\n item[\"properties\"][\"tile_id\"] + \".tif\",\n )\n", "issue": "HTTP internal server error when trying to download ``AbovegroundLiveWoodyBiomassDensity``\n### Description\n\nThere is an ``urllib.error.HTTPError: HTTP Error 500: Internal Server Error`` occuring . This issue occures when compiling from github and installing using pip3. It is occuring for`` AbovegroundLiveWoodyBiomassDensity`` which is a module from ``torchgeo.datasets.agb_live_woody_density``\n\n### Steps to reproduce\n\npython\r\n``\r\nfrom torchgeo.datasets.agb_live_woody_density import AbovegroundLiveWoodyBiomassDensity \r\nALWBD = AbovegroundLiveWoodyBiomassDensity(paths=\"~/test\", download=True)\r\n``\r\n\n\n### Version\n\n0.6.0.dev0 and 0.5.0\n", "before_files": [{"content": "# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License.\n\n\"\"\"Aboveground Live Woody Biomass Density dataset.\"\"\"\n\nimport json\nimport os\nfrom collections.abc import Iterable\nfrom typing import Any, Callable, Optional, Union\n\nimport matplotlib.pyplot as plt\nfrom matplotlib.figure import Figure\nfrom rasterio.crs import CRS\n\nfrom .geo import RasterDataset\nfrom .utils import download_url\n\n\nclass AbovegroundLiveWoodyBiomassDensity(RasterDataset):\n \"\"\"Aboveground Live Woody Biomass Density dataset.\n\n The `Aboveground Live Woody Biomass Density dataset\n <https://data.globalforestwatch.org/datasets/gfw::aboveground-live-woody\n -biomass-density/about>`_\n is a global-scale, wall-to-wall map of aboveground biomass at ~30m resolution\n for the year 2000.\n\n Dataset features:\n\n * Masks with per pixel live woody biomass density estimates in megagrams\n biomass per hectare at ~30m resolution (~40,000x40,0000 px)\n\n Dataset format:\n\n * geojson file that contains download links to tif files\n * single-channel geotiffs with the pixel values representing biomass density\n\n If you use this dataset in your research, please give credit to:\n\n * `Global Forest Watch <https://data.globalforestwatch.org/>`_\n\n .. versionadded:: 0.3\n \"\"\"\n\n is_image = False\n\n url = (\n \"https://opendata.arcgis.com/api/v3/datasets/3e8736c8866b458687\"\n \"e00d40c9f00bce_0/downloads/data?format=geojson&spatialRefId=4326\"\n )\n\n base_filename = \"Aboveground_Live_Woody_Biomass_Density.geojson\"\n\n filename_glob = \"*N_*E.*\"\n filename_regex = r\"\"\"^\n (?P<latitude>[0-9][0-9][A-Z])_\n (?P<longitude>[0-9][0-9][0-9][A-Z])*\n \"\"\"\n\n def __init__(\n self,\n paths: Union[str, Iterable[str]] = \"data\",\n crs: Optional[CRS] = None,\n res: Optional[float] = None,\n transforms: Optional[Callable[[dict[str, Any]], dict[str, Any]]] = None,\n download: bool = False,\n cache: bool = True,\n ) -> None:\n \"\"\"Initialize a new Dataset instance.\n\n Args:\n paths: one or more root directories to search or files to load\n crs: :term:`coordinate reference system (CRS)` to warp to\n (defaults to the CRS of the first file found)\n res: resolution of the dataset in units of CRS\n (defaults to the resolution of the first file found)\n transforms: a function/transform that takes an input sample\n and returns a transformed version\n download: if True, download dataset and store it in the root directory\n cache: if True, cache file handle to speed up repeated sampling\n\n Raises:\n FileNotFoundError: if no files are found in ``paths``\n\n .. versionchanged:: 0.5\n *root* was renamed to *paths*.\n \"\"\"\n self.paths = paths\n self.download = download\n\n self._verify()\n\n super().__init__(paths, crs, res, transforms=transforms, cache=cache)\n\n def _verify(self) -> None:\n \"\"\"Verify the integrity of the dataset.\n\n Raises:\n RuntimeError: if dataset is missing\n \"\"\"\n # Check if the extracted files already exist\n if self.files:\n return\n\n # Check if the user requested to download the dataset\n if not self.download:\n raise RuntimeError(\n f\"Dataset not found in `paths={self.paths!r}` and `download=False`, \"\n \"either specify a different `root` directory or use `download=True` \"\n \"to automatically download the dataset.\"\n )\n\n # Download the dataset\n self._download()\n\n def _download(self) -> None:\n \"\"\"Download the dataset.\"\"\"\n assert isinstance(self.paths, str)\n download_url(self.url, self.paths, self.base_filename)\n\n with open(os.path.join(self.paths, self.base_filename)) as f:\n content = json.load(f)\n\n for item in content[\"features\"]:\n download_url(\n item[\"properties\"][\"download\"],\n self.paths,\n item[\"properties\"][\"tile_id\"] + \".tif\",\n )\n\n def plot(\n self,\n sample: dict[str, Any],\n show_titles: bool = True,\n suptitle: Optional[str] = None,\n ) -> Figure:\n \"\"\"Plot a sample from the dataset.\n\n Args:\n sample: a sample returned by :meth:`RasterDataset.__getitem__`\n show_titles: flag indicating whether to show titles above each panel\n suptitle: optional string to use as a suptitle\n\n Returns:\n a matplotlib Figure with the rendered sample\n \"\"\"\n mask = sample[\"mask\"].squeeze()\n ncols = 1\n\n showing_predictions = \"prediction\" in sample\n if showing_predictions:\n pred = sample[\"prediction\"].squeeze()\n ncols = 2\n\n fig, axs = plt.subplots(nrows=1, ncols=ncols, figsize=(ncols * 4, 4))\n\n if showing_predictions:\n axs[0].imshow(mask)\n axs[0].axis(\"off\")\n axs[1].imshow(pred)\n axs[1].axis(\"off\")\n if show_titles:\n axs[0].set_title(\"Mask\")\n axs[1].set_title(\"Prediction\")\n else:\n axs.imshow(mask)\n axs.axis(\"off\")\n if show_titles:\n axs.set_title(\"Mask\")\n\n if suptitle is not None:\n plt.suptitle(suptitle)\n\n return fig\n", "path": "torchgeo/datasets/agb_live_woody_density.py"}]} | 2,450 | 320 |
gh_patches_debug_18187 | rasdani/github-patches | git_diff | praw-dev__praw-782 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Explain "PRAW is not thread safe" in the documentation.
It would be great to provide an example of why it is not thread safe.
Relevant comment:
https://www.reddit.com/r/redditdev/comments/63ugl5/praw_mulitprocessing_handler_prawhandler_is_not_a/dfx9oet/?context=3
</issue>
<code>
[start of setup.py]
1 """praw setup.py"""
2
3 import re
4 from codecs import open
5 from os import path
6 from setuptools import find_packages, setup
7
8
9 PACKAGE_NAME = 'praw'
10 HERE = path.abspath(path.dirname(__file__))
11 with open(path.join(HERE, 'README.rst'), encoding='utf-8') as fp:
12 README = fp.read()
13 with open(path.join(HERE, PACKAGE_NAME, 'const.py'),
14 encoding='utf-8') as fp:
15 VERSION = re.search("__version__ = '([^']+)'", fp.read()).group(1)
16
17
18 setup(name=PACKAGE_NAME,
19 author='Bryce Boe',
20 author_email='[email protected]',
21 classifiers=[
22 'Development Status :: 5 - Production/Stable',
23 'Environment :: Console',
24 'Intended Audience :: Developers',
25 'License :: OSI Approved :: BSD License',
26 'Natural Language :: English',
27 'Operating System :: OS Independent',
28 'Programming Language :: Python',
29 'Programming Language :: Python :: 2.7',
30 'Programming Language :: Python :: 3',
31 'Programming Language :: Python :: 3.3',
32 'Programming Language :: Python :: 3.4',
33 'Programming Language :: Python :: 3.5',
34 'Programming Language :: Python :: 3.6',
35 'Programming Language :: Python :: Implementation :: CPython',
36 'Topic :: Utilities'],
37 description=('PRAW, an acronym for `Python Reddit API Wrapper`, is a '
38 'python package that allows for simple access to '
39 'reddit\'s API.'),
40 install_requires=['prawcore >=0.9.0, <0.10',
41 'update_checker >=0.16'],
42 keywords='reddit api wrapper',
43 license='Simplified BSD License',
44 long_description=README,
45 package_data={'': ['LICENSE.txt'], PACKAGE_NAME: ['*.ini']},
46 packages=find_packages(exclude=['tests', 'tests.*']),
47 setup_requires=['pytest-runner >=2.1'],
48 tests_require=['betamax >=0.8, <0.9',
49 'betamax-matchers >=0.3.0, <0.4',
50 'betamax-serializers >=0.2, <0.3',
51 'mock >=0.8',
52 'pytest >=2.7.3',
53 'six >=1.10'],
54 test_suite='tests',
55 url='https://praw.readthedocs.org/',
56 version=VERSION)
57
[end of setup.py]
[start of docs/conf.py]
1 import os
2 import sys
3 sys.path.insert(0, '..')
4
5 from praw import __version__
6
7 copyright = '2016, Bryce Boe'
8 exclude_patterns = ['_build']
9 extensions = ['sphinx.ext.autodoc', 'sphinx.ext.intersphinx']
10 html_static_path = ['_static']
11 html_theme = 'sphinx_rtd_theme'
12 html_theme_options = {
13 'collapse_navigation': True
14 }
15 html_use_smartypants = True
16 htmlhelp_basename = 'PRAW'
17 intersphinx_mapping = {'python': ('https://docs.python.org/3.6', None)}
18 master_doc = 'index'
19 nitpicky = True
20 project = 'PRAW'
21 pygments_style = 'sphinx'
22 release = __version__
23 source_suffix = '.rst'
24 suppress_warnings = ['image.nonlocal_uri']
25 version = '.'.join(__version__.split('.', 2)[:2])
26
27
28 # Use RTD theme locally
29 if not os.environ.get('READTHEDOCS'):
30 import sphinx_rtd_theme
31 html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]
32
33
34 def skip(app, what, name, obj, skip, options):
35 if name in {'__call__', '__contains__', '__getitem__', '__init__',
36 '__iter__', '__len__'}:
37 return False
38 return skip
39
40
41 def setup(app):
42 app.connect('autodoc-skip-member', skip)
43
[end of docs/conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -4,7 +4,7 @@
from praw import __version__
-copyright = '2016, Bryce Boe'
+copyright = '2017, Bryce Boe'
exclude_patterns = ['_build']
extensions = ['sphinx.ext.autodoc', 'sphinx.ext.intersphinx']
html_static_path = ['_static']
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -37,7 +37,7 @@
description=('PRAW, an acronym for `Python Reddit API Wrapper`, is a '
'python package that allows for simple access to '
'reddit\'s API.'),
- install_requires=['prawcore >=0.9.0, <0.10',
+ install_requires=['prawcore >=0.10.1, <0.11',
'update_checker >=0.16'],
keywords='reddit api wrapper',
license='Simplified BSD License',
| {"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -4,7 +4,7 @@\n \n from praw import __version__\n \n-copyright = '2016, Bryce Boe'\n+copyright = '2017, Bryce Boe'\n exclude_patterns = ['_build']\n extensions = ['sphinx.ext.autodoc', 'sphinx.ext.intersphinx']\n html_static_path = ['_static']\ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -37,7 +37,7 @@\n description=('PRAW, an acronym for `Python Reddit API Wrapper`, is a '\n 'python package that allows for simple access to '\n 'reddit\\'s API.'),\n- install_requires=['prawcore >=0.9.0, <0.10',\n+ install_requires=['prawcore >=0.10.1, <0.11',\n 'update_checker >=0.16'],\n keywords='reddit api wrapper',\n license='Simplified BSD License',\n", "issue": "Explain \"PRAW is not thread safe\" in the documentation.\nIt would be great to provide an example of why it is not thread safe.\r\n\r\nRelevant comment:\r\n\r\nhttps://www.reddit.com/r/redditdev/comments/63ugl5/praw_mulitprocessing_handler_prawhandler_is_not_a/dfx9oet/?context=3\n", "before_files": [{"content": "\"\"\"praw setup.py\"\"\"\n\nimport re\nfrom codecs import open\nfrom os import path\nfrom setuptools import find_packages, setup\n\n\nPACKAGE_NAME = 'praw'\nHERE = path.abspath(path.dirname(__file__))\nwith open(path.join(HERE, 'README.rst'), encoding='utf-8') as fp:\n README = fp.read()\nwith open(path.join(HERE, PACKAGE_NAME, 'const.py'),\n encoding='utf-8') as fp:\n VERSION = re.search(\"__version__ = '([^']+)'\", fp.read()).group(1)\n\n\nsetup(name=PACKAGE_NAME,\n author='Bryce Boe',\n author_email='[email protected]',\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Environment :: Console',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: BSD License',\n 'Natural Language :: English',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: Implementation :: CPython',\n 'Topic :: Utilities'],\n description=('PRAW, an acronym for `Python Reddit API Wrapper`, is a '\n 'python package that allows for simple access to '\n 'reddit\\'s API.'),\n install_requires=['prawcore >=0.9.0, <0.10',\n 'update_checker >=0.16'],\n keywords='reddit api wrapper',\n license='Simplified BSD License',\n long_description=README,\n package_data={'': ['LICENSE.txt'], PACKAGE_NAME: ['*.ini']},\n packages=find_packages(exclude=['tests', 'tests.*']),\n setup_requires=['pytest-runner >=2.1'],\n tests_require=['betamax >=0.8, <0.9',\n 'betamax-matchers >=0.3.0, <0.4',\n 'betamax-serializers >=0.2, <0.3',\n 'mock >=0.8',\n 'pytest >=2.7.3',\n 'six >=1.10'],\n test_suite='tests',\n url='https://praw.readthedocs.org/',\n version=VERSION)\n", "path": "setup.py"}, {"content": "import os\nimport sys\nsys.path.insert(0, '..')\n\nfrom praw import __version__\n\ncopyright = '2016, Bryce Boe'\nexclude_patterns = ['_build']\nextensions = ['sphinx.ext.autodoc', 'sphinx.ext.intersphinx']\nhtml_static_path = ['_static']\nhtml_theme = 'sphinx_rtd_theme'\nhtml_theme_options = {\n 'collapse_navigation': True\n}\nhtml_use_smartypants = True\nhtmlhelp_basename = 'PRAW'\nintersphinx_mapping = {'python': ('https://docs.python.org/3.6', None)}\nmaster_doc = 'index'\nnitpicky = True\nproject = 'PRAW'\npygments_style = 'sphinx'\nrelease = __version__\nsource_suffix = '.rst'\nsuppress_warnings = ['image.nonlocal_uri']\nversion = '.'.join(__version__.split('.', 2)[:2])\n\n\n# Use RTD theme locally\nif not os.environ.get('READTHEDOCS'):\n import sphinx_rtd_theme\n html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]\n\n\ndef skip(app, what, name, obj, skip, options):\n if name in {'__call__', '__contains__', '__getitem__', '__init__',\n '__iter__', '__len__'}:\n return False\n return skip\n\n\ndef setup(app):\n app.connect('autodoc-skip-member', skip)\n", "path": "docs/conf.py"}]} | 1,622 | 237 |
gh_patches_debug_24913 | rasdani/github-patches | git_diff | alltheplaces__alltheplaces-6564 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
bupa_gb spider is including closed branches
The bupa_gb.py spider is returning a number of closed practices, as these still have web pages and are still listed in the sitemap. Current examples include:
https://www.bupa.co.uk/dental/dental-care/practices/harleston
https://www.bupa.co.uk/dental/dental-care/practices/leckhampton
I think these can be reliably detected by checking if the name ends (case-insensitively) with "closed". So I'd suggest we drop any whose name matches /closed$/i. There are about 12 of these in total out of 388 branches.
(Sorry, I can no longer run the code on my computer to implement and test this myself, since I'm unable to install a recent enough version of Python.)
</issue>
<code>
[start of locations/items.py]
1 # Define here the models for your scraped items
2 #
3 # See documentation in:
4 # http://doc.scrapy.org/en/latest/topics/items.html
5
6 import scrapy
7
8
9 class Feature(scrapy.Item):
10 lat = scrapy.Field()
11 lon = scrapy.Field()
12 geometry = scrapy.Field()
13 name = scrapy.Field()
14 branch = scrapy.Field()
15 addr_full = scrapy.Field()
16 housenumber = scrapy.Field()
17 street = scrapy.Field()
18 street_address = scrapy.Field()
19 city = scrapy.Field()
20 state = scrapy.Field()
21 postcode = scrapy.Field()
22 country = scrapy.Field()
23 phone = scrapy.Field()
24 email = scrapy.Field()
25 website = scrapy.Field()
26 twitter = scrapy.Field()
27 facebook = scrapy.Field()
28 opening_hours = scrapy.Field()
29 image = scrapy.Field()
30 ref = scrapy.Field()
31 brand = scrapy.Field()
32 brand_wikidata = scrapy.Field()
33 operator = scrapy.Field()
34 operator_wikidata = scrapy.Field()
35 located_in = scrapy.Field()
36 located_in_wikidata = scrapy.Field()
37 nsi_id = scrapy.Field()
38 extras = scrapy.Field()
39
40 def __init__(self, *args, **kwargs):
41 super().__init__(*args, **kwargs)
42 if not self._values.get("extras"):
43 self.__setitem__("extras", {})
44
45
46 def get_lat_lon(item: Feature) -> (float, float):
47 if geometry := item.get("geometry"):
48 if isinstance(geometry, dict):
49 if geometry.get("type") == "Point":
50 if coords := geometry.get("coordinates"):
51 try:
52 return float(coords[1]), float(coords[0])
53 except (TypeError, ValueError):
54 item["geometry"] = None
55 else:
56 try:
57 return float(item.get("lat")), float(item.get("lon"))
58 except (TypeError, ValueError):
59 pass
60 return None
61
62
63 def set_lat_lon(item: Feature, lat: float, lon: float):
64 item.pop("lat", None)
65 item.pop("lon", None)
66 if lat and lon:
67 item["geometry"] = {
68 "type": "Point",
69 "coordinates": [lon, lat],
70 }
71 else:
72 item["geometry"] = None
73
74
75 def add_social_media(item: Feature, service: str, account: str):
76 service = service.lower()
77 if service in item.fields:
78 item[service] = account
79 else:
80 item["extras"][f"contact:{service}"] = account
81
[end of locations/items.py]
[start of locations/spiders/bupa_gb.py]
1 from scrapy.spiders import SitemapSpider
2
3 from locations.categories import Categories
4 from locations.structured_data_spider import StructuredDataSpider
5
6
7 class BupaGBSpider(SitemapSpider, StructuredDataSpider):
8 name = "bupa_gb"
9 item_attributes = {"brand": "Bupa", "brand_wikidata": "Q931628", "extras": Categories.DENTIST.value}
10 sitemap_urls = ["https://www.bupa.co.uk/robots.txt"]
11 sitemap_rules = [(r"/practices/([-\w]+)$", "parse_sd")]
12
13 def post_process_item(self, item, response, ld_data, **kwargs):
14 if "Total Dental Care" in item["name"]:
15 item["brand"] = "Total Dental Care"
16 yield item
17
[end of locations/spiders/bupa_gb.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/locations/items.py b/locations/items.py
--- a/locations/items.py
+++ b/locations/items.py
@@ -2,6 +2,7 @@
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
+from datetime import datetime
import scrapy
@@ -78,3 +79,7 @@
item[service] = account
else:
item["extras"][f"contact:{service}"] = account
+
+
+def set_closed(item: Feature, end_date: datetime = None):
+ item["extras"]["end_date"] = end_date.strftime("%Y-%m-%d") if end_date else "yes"
diff --git a/locations/spiders/bupa_gb.py b/locations/spiders/bupa_gb.py
--- a/locations/spiders/bupa_gb.py
+++ b/locations/spiders/bupa_gb.py
@@ -1,6 +1,7 @@
from scrapy.spiders import SitemapSpider
from locations.categories import Categories
+from locations.items import set_closed
from locations.structured_data_spider import StructuredDataSpider
@@ -13,4 +14,8 @@
def post_process_item(self, item, response, ld_data, **kwargs):
if "Total Dental Care" in item["name"]:
item["brand"] = "Total Dental Care"
+
+ if item["name"].lower().endswith(" - closed"):
+ set_closed(item)
+
yield item
| {"golden_diff": "diff --git a/locations/items.py b/locations/items.py\n--- a/locations/items.py\n+++ b/locations/items.py\n@@ -2,6 +2,7 @@\n #\n # See documentation in:\n # http://doc.scrapy.org/en/latest/topics/items.html\n+from datetime import datetime\n \n import scrapy\n \n@@ -78,3 +79,7 @@\n item[service] = account\n else:\n item[\"extras\"][f\"contact:{service}\"] = account\n+\n+\n+def set_closed(item: Feature, end_date: datetime = None):\n+ item[\"extras\"][\"end_date\"] = end_date.strftime(\"%Y-%m-%d\") if end_date else \"yes\"\ndiff --git a/locations/spiders/bupa_gb.py b/locations/spiders/bupa_gb.py\n--- a/locations/spiders/bupa_gb.py\n+++ b/locations/spiders/bupa_gb.py\n@@ -1,6 +1,7 @@\n from scrapy.spiders import SitemapSpider\n \n from locations.categories import Categories\n+from locations.items import set_closed\n from locations.structured_data_spider import StructuredDataSpider\n \n \n@@ -13,4 +14,8 @@\n def post_process_item(self, item, response, ld_data, **kwargs):\n if \"Total Dental Care\" in item[\"name\"]:\n item[\"brand\"] = \"Total Dental Care\"\n+\n+ if item[\"name\"].lower().endswith(\" - closed\"):\n+ set_closed(item)\n+\n yield item\n", "issue": "bupa_gb spider is including closed branches\nThe bupa_gb.py spider is returning a number of closed practices, as these still have web pages and are still listed in the sitemap. Current examples include:\r\n\r\nhttps://www.bupa.co.uk/dental/dental-care/practices/harleston\r\nhttps://www.bupa.co.uk/dental/dental-care/practices/leckhampton\r\n\r\nI think these can be reliably detected by checking if the name ends (case-insensitively) with \"closed\". So I'd suggest we drop any whose name matches /closed$/i. There are about 12 of these in total out of 388 branches.\r\n\r\n(Sorry, I can no longer run the code on my computer to implement and test this myself, since I'm unable to install a recent enough version of Python.)\n", "before_files": [{"content": "# Define here the models for your scraped items\n#\n# See documentation in:\n# http://doc.scrapy.org/en/latest/topics/items.html\n\nimport scrapy\n\n\nclass Feature(scrapy.Item):\n lat = scrapy.Field()\n lon = scrapy.Field()\n geometry = scrapy.Field()\n name = scrapy.Field()\n branch = scrapy.Field()\n addr_full = scrapy.Field()\n housenumber = scrapy.Field()\n street = scrapy.Field()\n street_address = scrapy.Field()\n city = scrapy.Field()\n state = scrapy.Field()\n postcode = scrapy.Field()\n country = scrapy.Field()\n phone = scrapy.Field()\n email = scrapy.Field()\n website = scrapy.Field()\n twitter = scrapy.Field()\n facebook = scrapy.Field()\n opening_hours = scrapy.Field()\n image = scrapy.Field()\n ref = scrapy.Field()\n brand = scrapy.Field()\n brand_wikidata = scrapy.Field()\n operator = scrapy.Field()\n operator_wikidata = scrapy.Field()\n located_in = scrapy.Field()\n located_in_wikidata = scrapy.Field()\n nsi_id = scrapy.Field()\n extras = scrapy.Field()\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n if not self._values.get(\"extras\"):\n self.__setitem__(\"extras\", {})\n\n\ndef get_lat_lon(item: Feature) -> (float, float):\n if geometry := item.get(\"geometry\"):\n if isinstance(geometry, dict):\n if geometry.get(\"type\") == \"Point\":\n if coords := geometry.get(\"coordinates\"):\n try:\n return float(coords[1]), float(coords[0])\n except (TypeError, ValueError):\n item[\"geometry\"] = None\n else:\n try:\n return float(item.get(\"lat\")), float(item.get(\"lon\"))\n except (TypeError, ValueError):\n pass\n return None\n\n\ndef set_lat_lon(item: Feature, lat: float, lon: float):\n item.pop(\"lat\", None)\n item.pop(\"lon\", None)\n if lat and lon:\n item[\"geometry\"] = {\n \"type\": \"Point\",\n \"coordinates\": [lon, lat],\n }\n else:\n item[\"geometry\"] = None\n\n\ndef add_social_media(item: Feature, service: str, account: str):\n service = service.lower()\n if service in item.fields:\n item[service] = account\n else:\n item[\"extras\"][f\"contact:{service}\"] = account\n", "path": "locations/items.py"}, {"content": "from scrapy.spiders import SitemapSpider\n\nfrom locations.categories import Categories\nfrom locations.structured_data_spider import StructuredDataSpider\n\n\nclass BupaGBSpider(SitemapSpider, StructuredDataSpider):\n name = \"bupa_gb\"\n item_attributes = {\"brand\": \"Bupa\", \"brand_wikidata\": \"Q931628\", \"extras\": Categories.DENTIST.value}\n sitemap_urls = [\"https://www.bupa.co.uk/robots.txt\"]\n sitemap_rules = [(r\"/practices/([-\\w]+)$\", \"parse_sd\")]\n\n def post_process_item(self, item, response, ld_data, **kwargs):\n if \"Total Dental Care\" in item[\"name\"]:\n item[\"brand\"] = \"Total Dental Care\"\n yield item\n", "path": "locations/spiders/bupa_gb.py"}]} | 1,595 | 318 |
gh_patches_debug_33731 | rasdani/github-patches | git_diff | pyodide__pyodide-872 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Allow Micropip to download from relative urls
I think to allow relative urls, we'd only need to change the check here:
https://github.com/iodide-project/pyodide/blob/3a06f5dfcb9b536e9ece1f68f6963717acf82486/packages/micropip/micropip/micropip.py#L201
to `if "/" in requirement` or `if requirement.endswith(".whl")`.
Also, the documentation of `micropip.install` is a bit lacking. It'd be good to add an explanation of how `micropip` decides what a url is.
But for instance, it could be helpful to indicate the case where `url` is `"some_package-vers-py3-none-any.whl"`: does this expect a file `some_package-vers-py3-none-any.whl` to be in the current directory?
Would be good to mention that all wheels need to be named according to pep 427 too.
https://www.python.org/dev/peps/pep-0427/#file-name-convention
Redundancies / differences between pyodide.loadPackage and micropip.install?
It seems to me that `pyodide.loadPackage` and `micropip.install` have significant redundancies in their functionality. Is there any difference in their purpose? Which one is better? Could they be merged? If not, it would be good to add a very explicit explanation of their differences to the docs.
</issue>
<code>
[start of packages/micropip/micropip/micropip.py]
1 try:
2 from js import Promise, XMLHttpRequest
3 except ImportError:
4 XMLHttpRequest = None
5
6 try:
7 from js import pyodide as js_pyodide
8 except ImportError:
9
10 class js_pyodide: # type: ignore
11 """A mock object to allow import of this package outside pyodide"""
12
13 class _module:
14 class packages:
15 dependencies = [] # type: ignore
16
17
18 import hashlib
19 import importlib
20 import io
21 import json
22 from pathlib import Path
23 import zipfile
24 from typing import Dict, Any, Union, List, Tuple
25
26 from distlib import markers, util, version
27
28
29 def _nullop(*args):
30 return
31
32
33 # Provide implementations of HTTP fetching for in-browser and out-of-browser to
34 # make testing easier
35 if XMLHttpRequest is not None:
36 import pyodide # noqa
37
38 def _get_url(url):
39 req = XMLHttpRequest.new()
40 req.open("GET", url, False)
41 req.send(None)
42 return io.StringIO(req.response)
43
44 def _get_url_async(url, cb):
45 req = XMLHttpRequest.new()
46 req.open("GET", url, True)
47 req.responseType = "arraybuffer"
48
49 def callback(e):
50 if req.readyState == 4:
51 cb(io.BytesIO(req.response))
52
53 req.onreadystatechange = callback
54 req.send(None)
55
56 # In practice, this is the `site-packages` directory.
57 WHEEL_BASE = Path(__file__).parent
58 else:
59 # Outside the browser
60 from urllib.request import urlopen
61
62 def _get_url(url):
63 with urlopen(url) as fd:
64 content = fd.read()
65 return io.BytesIO(content)
66
67 def _get_url_async(url, cb):
68 cb(_get_url(url))
69
70 WHEEL_BASE = Path(".") / "wheels"
71
72
73 def _get_pypi_json(pkgname):
74 url = f"https://pypi.org/pypi/{pkgname}/json"
75 fd = _get_url(url)
76 return json.load(fd)
77
78
79 def _parse_wheel_url(url: str) -> Tuple[str, Dict[str, Any], str]:
80 """Parse wheels url and extract available metadata
81
82 See https://www.python.org/dev/peps/pep-0427/#file-name-convention
83 """
84 file_name = Path(url).name
85 # also strip '.whl' extension.
86 wheel_name = Path(url).stem
87 tokens = wheel_name.split("-")
88 # TODO: support optional build tags in the filename (cf PEP 427)
89 if len(tokens) < 5:
90 raise ValueError(f"{file_name} is not a valid wheel file name.")
91 version, python_tag, abi_tag, platform = tokens[-4:]
92 name = "-".join(tokens[:-4])
93 wheel = {
94 "digests": None, # checksums not available
95 "filename": file_name,
96 "packagetype": "bdist_wheel",
97 "python_version": python_tag,
98 "abi_tag": abi_tag,
99 "platform": platform,
100 "url": url,
101 }
102
103 return name, wheel, version
104
105
106 class _WheelInstaller:
107 def extract_wheel(self, fd):
108 with zipfile.ZipFile(fd) as zf:
109 zf.extractall(WHEEL_BASE)
110
111 def validate_wheel(self, data, fileinfo):
112 if fileinfo.get("digests") is None:
113 # No checksums available, e.g. because installing
114 # from a different location than PyPi.
115 return
116 sha256 = fileinfo["digests"]["sha256"]
117 m = hashlib.sha256()
118 m.update(data.getvalue())
119 if m.hexdigest() != sha256:
120 raise ValueError("Contents don't match hash")
121
122 def __call__(self, name, fileinfo, resolve, reject):
123 url = self.fetch_wheel(name, fileinfo)
124
125 def callback(wheel):
126 try:
127 self.validate_wheel(wheel, fileinfo)
128 self.extract_wheel(wheel)
129 except Exception as e:
130 reject(str(e))
131 else:
132 resolve()
133
134 _get_url_async(url, callback)
135
136
137 class _RawWheelInstaller(_WheelInstaller):
138 def fetch_wheel(self, name, fileinfo):
139 return fileinfo["url"]
140
141
142 class _PackageManager:
143 version_scheme = version.get_scheme("normalized")
144
145 def __init__(self):
146 self.builtin_packages = {}
147 self.builtin_packages.update(js_pyodide._module.packages.dependencies)
148 self.installed_packages = {}
149
150 def install(
151 self,
152 requirements: Union[str, List[str]],
153 ctx=None,
154 wheel_installer=None,
155 resolve=_nullop,
156 reject=_nullop,
157 ):
158 try:
159 if ctx is None:
160 ctx = {"extra": None}
161
162 if wheel_installer is None:
163 wheel_installer = _RawWheelInstaller()
164
165 complete_ctx = dict(markers.DEFAULT_CONTEXT)
166 complete_ctx.update(ctx)
167
168 if isinstance(requirements, str):
169 requirements = [requirements]
170
171 transaction: Dict[str, Any] = {
172 "wheels": [],
173 "pyodide_packages": set(),
174 "locked": dict(self.installed_packages),
175 }
176 for requirement in requirements:
177 self.add_requirement(requirement, complete_ctx, transaction)
178 except Exception as e:
179 reject(str(e))
180
181 resolve_count = [len(transaction["wheels"])]
182
183 def do_resolve(*args):
184 resolve_count[0] -= 1
185 if resolve_count[0] == 0:
186 resolve(f'Installed {", ".join(self.installed_packages.keys())}')
187
188 # Install built-in packages
189 pyodide_packages = transaction["pyodide_packages"]
190 if len(pyodide_packages):
191 resolve_count[0] += 1
192 self.installed_packages.update(dict((k, None) for k in pyodide_packages))
193 js_pyodide.loadPackage(list(pyodide_packages)).then(do_resolve)
194
195 # Now install PyPI packages
196 for name, wheel, ver in transaction["wheels"]:
197 wheel_installer(name, wheel, do_resolve, reject)
198 self.installed_packages[name] = ver
199
200 def add_requirement(self, requirement: str, ctx, transaction):
201 if requirement.startswith(("http://", "https://")):
202 # custom download location
203 name, wheel, version = _parse_wheel_url(requirement)
204 transaction["wheels"].append((name, wheel, version))
205 return
206
207 req = util.parse_requirement(requirement)
208
209 # If it's a Pyodide package, use that instead of the one on PyPI
210 if req.name in self.builtin_packages:
211 transaction["pyodide_packages"].add(req.name)
212 return
213
214 if req.marker:
215 if not markers.evaluator.evaluate(req.marker, ctx):
216 return
217
218 matcher = self.version_scheme.matcher(req.requirement)
219
220 # If we already have something that will work, don't
221 # fetch again
222 for name, ver in transaction["locked"].items():
223 if name == req.name:
224 if matcher.match(ver):
225 break
226 else:
227 raise ValueError(
228 f"Requested '{requirement}', "
229 f"but {name}=={ver} is already installed"
230 )
231 else:
232 metadata = _get_pypi_json(req.name)
233 wheel, ver = self.find_wheel(metadata, req)
234 transaction["locked"][req.name] = ver
235
236 recurs_reqs = metadata.get("info", {}).get("requires_dist") or []
237 for recurs_req in recurs_reqs:
238 self.add_requirement(recurs_req, ctx, transaction)
239
240 transaction["wheels"].append((req.name, wheel, ver))
241
242 def find_wheel(self, metadata, req):
243 releases = []
244 for ver, files in metadata.get("releases", {}).items():
245 ver = self.version_scheme.suggest(ver)
246 if ver is not None:
247 releases.append((ver, files))
248
249 def version_number(release):
250 return version.NormalizedVersion(release[0])
251
252 releases = sorted(releases, key=version_number, reverse=True)
253 matcher = self.version_scheme.matcher(req.requirement)
254 for ver, meta in releases:
255 if matcher.match(ver):
256 for fileinfo in meta:
257 if fileinfo["filename"].endswith("py3-none-any.whl"):
258 return fileinfo, ver
259
260 raise ValueError(f"Couldn't find a pure Python 3 wheel for '{req.requirement}'")
261
262
263 # Make PACKAGE_MANAGER singleton
264 PACKAGE_MANAGER = _PackageManager()
265 del _PackageManager
266
267
268 def install(requirements: Union[str, List[str]]):
269 """Install the given package and all of its dependencies.
270
271 This only works for pure Python wheels or for packages built
272 in pyodide. If a package is not found in the pyodide repository
273 it will be loaded from PyPi.
274
275 Parameters
276 ----------
277 requirements
278 a requirements or a list of requirements to install.
279 Can be composed either of
280
281 - package names, as defined in pyodide repository or on PyPi
282 - URLs pointing to pure Python wheels. The file name of such wheels
283 end with ``none-any.whl``.
284
285 Returns
286 -------
287 a Promise that resolves when all packages have downloaded and installed.
288 """
289
290 def do_install(resolve, reject):
291 PACKAGE_MANAGER.install(requirements, resolve=resolve, reject=reject)
292 importlib.invalidate_caches()
293
294 return Promise.new(do_install)
295
296
297 __all__ = ["install"]
298
299
300 if __name__ == "__main__":
301 install("snowballstemmer")
302
[end of packages/micropip/micropip/micropip.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/packages/micropip/micropip/micropip.py b/packages/micropip/micropip/micropip.py
--- a/packages/micropip/micropip/micropip.py
+++ b/packages/micropip/micropip/micropip.py
@@ -198,7 +198,7 @@
self.installed_packages[name] = ver
def add_requirement(self, requirement: str, ctx, transaction):
- if requirement.startswith(("http://", "https://")):
+ if requirement.endswith(".whl"):
# custom download location
name, wheel, version = _parse_wheel_url(requirement)
transaction["wheels"].append((name, wheel, version))
@@ -268,23 +268,28 @@
def install(requirements: Union[str, List[str]]):
"""Install the given package and all of its dependencies.
- This only works for pure Python wheels or for packages built
- in pyodide. If a package is not found in the pyodide repository
- it will be loaded from PyPi.
+ See :ref:`loading packages <loading_packages>` for more information.
+
+ This only works for packages that are either pure Python or for packages with
+ C extensions that are built in pyodide. If a pure Python package is not found
+ in the pyodide repository it will be loaded from PyPi.
Parameters
----------
requirements
- a requirements or a list of requirements to install.
- Can be composed either of
+ A requirement or list of requirements to install.
+ Each requirement is a string.
+
+ - If the requirement ends in ".whl", the file will be interpreted as a url.
+ The file must be a wheel named in compliance with the
+ [PEP 427 naming convention](https://www.python.org/dev/peps/pep-0427/#file-format)
- - package names, as defined in pyodide repository or on PyPi
- - URLs pointing to pure Python wheels. The file name of such wheels
- end with ``none-any.whl``.
+ - A package name. A package by this name must either be present in the pyodide
+ repository at `languagePluginUrl` or on PyPi.
Returns
-------
- a Promise that resolves when all packages have downloaded and installed.
+ A Promise that resolves when all packages have been downloaded and installed.
"""
def do_install(resolve, reject):
| {"golden_diff": "diff --git a/packages/micropip/micropip/micropip.py b/packages/micropip/micropip/micropip.py\n--- a/packages/micropip/micropip/micropip.py\n+++ b/packages/micropip/micropip/micropip.py\n@@ -198,7 +198,7 @@\n self.installed_packages[name] = ver\n \n def add_requirement(self, requirement: str, ctx, transaction):\n- if requirement.startswith((\"http://\", \"https://\")):\n+ if requirement.endswith(\".whl\"):\n # custom download location\n name, wheel, version = _parse_wheel_url(requirement)\n transaction[\"wheels\"].append((name, wheel, version))\n@@ -268,23 +268,28 @@\n def install(requirements: Union[str, List[str]]):\n \"\"\"Install the given package and all of its dependencies.\n \n- This only works for pure Python wheels or for packages built\n- in pyodide. If a package is not found in the pyodide repository\n- it will be loaded from PyPi.\n+ See :ref:`loading packages <loading_packages>` for more information.\n+\n+ This only works for packages that are either pure Python or for packages with\n+ C extensions that are built in pyodide. If a pure Python package is not found\n+ in the pyodide repository it will be loaded from PyPi.\n \n Parameters\n ----------\n requirements\n- a requirements or a list of requirements to install.\n- Can be composed either of\n+ A requirement or list of requirements to install.\n+ Each requirement is a string.\n+\n+ - If the requirement ends in \".whl\", the file will be interpreted as a url.\n+ The file must be a wheel named in compliance with the\n+ [PEP 427 naming convention](https://www.python.org/dev/peps/pep-0427/#file-format)\n \n- - package names, as defined in pyodide repository or on PyPi\n- - URLs pointing to pure Python wheels. The file name of such wheels\n- end with ``none-any.whl``.\n+ - A package name. A package by this name must either be present in the pyodide\n+ repository at `languagePluginUrl` or on PyPi.\n \n Returns\n -------\n- a Promise that resolves when all packages have downloaded and installed.\n+ A Promise that resolves when all packages have been downloaded and installed.\n \"\"\"\n \n def do_install(resolve, reject):\n", "issue": "Allow Micropip to download from relative urls\nI think to allow relative urls, we'd only need to change the check here:\r\n\r\nhttps://github.com/iodide-project/pyodide/blob/3a06f5dfcb9b536e9ece1f68f6963717acf82486/packages/micropip/micropip/micropip.py#L201\r\n\r\nto `if \"/\" in requirement` or `if requirement.endswith(\".whl\")`.\r\n\r\nAlso, the documentation of `micropip.install` is a bit lacking. It'd be good to add an explanation of how `micropip` decides what a url is.\r\nBut for instance, it could be helpful to indicate the case where `url` is `\"some_package-vers-py3-none-any.whl\"`: does this expect a file `some_package-vers-py3-none-any.whl` to be in the current directory?\r\n\r\nWould be good to mention that all wheels need to be named according to pep 427 too.\r\nhttps://www.python.org/dev/peps/pep-0427/#file-name-convention\nRedundancies / differences between pyodide.loadPackage and micropip.install?\nIt seems to me that `pyodide.loadPackage` and `micropip.install` have significant redundancies in their functionality. Is there any difference in their purpose? Which one is better? Could they be merged? If not, it would be good to add a very explicit explanation of their differences to the docs.\n", "before_files": [{"content": "try:\n from js import Promise, XMLHttpRequest\nexcept ImportError:\n XMLHttpRequest = None\n\ntry:\n from js import pyodide as js_pyodide\nexcept ImportError:\n\n class js_pyodide: # type: ignore\n \"\"\"A mock object to allow import of this package outside pyodide\"\"\"\n\n class _module:\n class packages:\n dependencies = [] # type: ignore\n\n\nimport hashlib\nimport importlib\nimport io\nimport json\nfrom pathlib import Path\nimport zipfile\nfrom typing import Dict, Any, Union, List, Tuple\n\nfrom distlib import markers, util, version\n\n\ndef _nullop(*args):\n return\n\n\n# Provide implementations of HTTP fetching for in-browser and out-of-browser to\n# make testing easier\nif XMLHttpRequest is not None:\n import pyodide # noqa\n\n def _get_url(url):\n req = XMLHttpRequest.new()\n req.open(\"GET\", url, False)\n req.send(None)\n return io.StringIO(req.response)\n\n def _get_url_async(url, cb):\n req = XMLHttpRequest.new()\n req.open(\"GET\", url, True)\n req.responseType = \"arraybuffer\"\n\n def callback(e):\n if req.readyState == 4:\n cb(io.BytesIO(req.response))\n\n req.onreadystatechange = callback\n req.send(None)\n\n # In practice, this is the `site-packages` directory.\n WHEEL_BASE = Path(__file__).parent\nelse:\n # Outside the browser\n from urllib.request import urlopen\n\n def _get_url(url):\n with urlopen(url) as fd:\n content = fd.read()\n return io.BytesIO(content)\n\n def _get_url_async(url, cb):\n cb(_get_url(url))\n\n WHEEL_BASE = Path(\".\") / \"wheels\"\n\n\ndef _get_pypi_json(pkgname):\n url = f\"https://pypi.org/pypi/{pkgname}/json\"\n fd = _get_url(url)\n return json.load(fd)\n\n\ndef _parse_wheel_url(url: str) -> Tuple[str, Dict[str, Any], str]:\n \"\"\"Parse wheels url and extract available metadata\n\n See https://www.python.org/dev/peps/pep-0427/#file-name-convention\n \"\"\"\n file_name = Path(url).name\n # also strip '.whl' extension.\n wheel_name = Path(url).stem\n tokens = wheel_name.split(\"-\")\n # TODO: support optional build tags in the filename (cf PEP 427)\n if len(tokens) < 5:\n raise ValueError(f\"{file_name} is not a valid wheel file name.\")\n version, python_tag, abi_tag, platform = tokens[-4:]\n name = \"-\".join(tokens[:-4])\n wheel = {\n \"digests\": None, # checksums not available\n \"filename\": file_name,\n \"packagetype\": \"bdist_wheel\",\n \"python_version\": python_tag,\n \"abi_tag\": abi_tag,\n \"platform\": platform,\n \"url\": url,\n }\n\n return name, wheel, version\n\n\nclass _WheelInstaller:\n def extract_wheel(self, fd):\n with zipfile.ZipFile(fd) as zf:\n zf.extractall(WHEEL_BASE)\n\n def validate_wheel(self, data, fileinfo):\n if fileinfo.get(\"digests\") is None:\n # No checksums available, e.g. because installing\n # from a different location than PyPi.\n return\n sha256 = fileinfo[\"digests\"][\"sha256\"]\n m = hashlib.sha256()\n m.update(data.getvalue())\n if m.hexdigest() != sha256:\n raise ValueError(\"Contents don't match hash\")\n\n def __call__(self, name, fileinfo, resolve, reject):\n url = self.fetch_wheel(name, fileinfo)\n\n def callback(wheel):\n try:\n self.validate_wheel(wheel, fileinfo)\n self.extract_wheel(wheel)\n except Exception as e:\n reject(str(e))\n else:\n resolve()\n\n _get_url_async(url, callback)\n\n\nclass _RawWheelInstaller(_WheelInstaller):\n def fetch_wheel(self, name, fileinfo):\n return fileinfo[\"url\"]\n\n\nclass _PackageManager:\n version_scheme = version.get_scheme(\"normalized\")\n\n def __init__(self):\n self.builtin_packages = {}\n self.builtin_packages.update(js_pyodide._module.packages.dependencies)\n self.installed_packages = {}\n\n def install(\n self,\n requirements: Union[str, List[str]],\n ctx=None,\n wheel_installer=None,\n resolve=_nullop,\n reject=_nullop,\n ):\n try:\n if ctx is None:\n ctx = {\"extra\": None}\n\n if wheel_installer is None:\n wheel_installer = _RawWheelInstaller()\n\n complete_ctx = dict(markers.DEFAULT_CONTEXT)\n complete_ctx.update(ctx)\n\n if isinstance(requirements, str):\n requirements = [requirements]\n\n transaction: Dict[str, Any] = {\n \"wheels\": [],\n \"pyodide_packages\": set(),\n \"locked\": dict(self.installed_packages),\n }\n for requirement in requirements:\n self.add_requirement(requirement, complete_ctx, transaction)\n except Exception as e:\n reject(str(e))\n\n resolve_count = [len(transaction[\"wheels\"])]\n\n def do_resolve(*args):\n resolve_count[0] -= 1\n if resolve_count[0] == 0:\n resolve(f'Installed {\", \".join(self.installed_packages.keys())}')\n\n # Install built-in packages\n pyodide_packages = transaction[\"pyodide_packages\"]\n if len(pyodide_packages):\n resolve_count[0] += 1\n self.installed_packages.update(dict((k, None) for k in pyodide_packages))\n js_pyodide.loadPackage(list(pyodide_packages)).then(do_resolve)\n\n # Now install PyPI packages\n for name, wheel, ver in transaction[\"wheels\"]:\n wheel_installer(name, wheel, do_resolve, reject)\n self.installed_packages[name] = ver\n\n def add_requirement(self, requirement: str, ctx, transaction):\n if requirement.startswith((\"http://\", \"https://\")):\n # custom download location\n name, wheel, version = _parse_wheel_url(requirement)\n transaction[\"wheels\"].append((name, wheel, version))\n return\n\n req = util.parse_requirement(requirement)\n\n # If it's a Pyodide package, use that instead of the one on PyPI\n if req.name in self.builtin_packages:\n transaction[\"pyodide_packages\"].add(req.name)\n return\n\n if req.marker:\n if not markers.evaluator.evaluate(req.marker, ctx):\n return\n\n matcher = self.version_scheme.matcher(req.requirement)\n\n # If we already have something that will work, don't\n # fetch again\n for name, ver in transaction[\"locked\"].items():\n if name == req.name:\n if matcher.match(ver):\n break\n else:\n raise ValueError(\n f\"Requested '{requirement}', \"\n f\"but {name}=={ver} is already installed\"\n )\n else:\n metadata = _get_pypi_json(req.name)\n wheel, ver = self.find_wheel(metadata, req)\n transaction[\"locked\"][req.name] = ver\n\n recurs_reqs = metadata.get(\"info\", {}).get(\"requires_dist\") or []\n for recurs_req in recurs_reqs:\n self.add_requirement(recurs_req, ctx, transaction)\n\n transaction[\"wheels\"].append((req.name, wheel, ver))\n\n def find_wheel(self, metadata, req):\n releases = []\n for ver, files in metadata.get(\"releases\", {}).items():\n ver = self.version_scheme.suggest(ver)\n if ver is not None:\n releases.append((ver, files))\n\n def version_number(release):\n return version.NormalizedVersion(release[0])\n\n releases = sorted(releases, key=version_number, reverse=True)\n matcher = self.version_scheme.matcher(req.requirement)\n for ver, meta in releases:\n if matcher.match(ver):\n for fileinfo in meta:\n if fileinfo[\"filename\"].endswith(\"py3-none-any.whl\"):\n return fileinfo, ver\n\n raise ValueError(f\"Couldn't find a pure Python 3 wheel for '{req.requirement}'\")\n\n\n# Make PACKAGE_MANAGER singleton\nPACKAGE_MANAGER = _PackageManager()\ndel _PackageManager\n\n\ndef install(requirements: Union[str, List[str]]):\n \"\"\"Install the given package and all of its dependencies.\n\n This only works for pure Python wheels or for packages built\n in pyodide. If a package is not found in the pyodide repository\n it will be loaded from PyPi.\n\n Parameters\n ----------\n requirements\n a requirements or a list of requirements to install.\n Can be composed either of\n\n - package names, as defined in pyodide repository or on PyPi\n - URLs pointing to pure Python wheels. The file name of such wheels\n end with ``none-any.whl``.\n\n Returns\n -------\n a Promise that resolves when all packages have downloaded and installed.\n \"\"\"\n\n def do_install(resolve, reject):\n PACKAGE_MANAGER.install(requirements, resolve=resolve, reject=reject)\n importlib.invalidate_caches()\n\n return Promise.new(do_install)\n\n\n__all__ = [\"install\"]\n\n\nif __name__ == \"__main__\":\n install(\"snowballstemmer\")\n", "path": "packages/micropip/micropip/micropip.py"}]} | 3,762 | 566 |
gh_patches_debug_4358 | rasdani/github-patches | git_diff | pallets__click-1832 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Reconsider the choice of adding a newline after multi-line option definitions
First, thanks for your work.
I ask you to reconsider the feature introduced with PR https://github.com/pallets/click/pull/1081.
1. Adding a newline only to some options feels inconsistent and leads to a weird-looking "non-uniform" help strings. It's even worse when you use an extension that adds new help sections (e.g. [Cloup](https://github.com/janluke/cloup) for option groups), since some sections are not clearly demarked or too much demarked. It looks like a complete mess.
2. I'm pretty sure it's non-standard. Why should it be the default?
As a consequence, it feels like a bug. I did mistake it for a bug. Another developer reported it as a bug (issue https://github.com/pallets/click/issues/1559). The few people I asked don't like it and consider it a problem worth the effort of writing additional code to get rid of it. Most people in the original issue (https://github.com/pallets/click/issues/1075) are for an all-or-nothing behavior and described the current behviour as inconsistent as well.
Here's some alternative proposals.
1. Remove the feature.
2. Make it possible but non-default. Two solutions here:
1. Add a parameter to `HelpFormatter`. It can be made as simple as a boolean or as complex as a "list item separation strategy". A user can pass a custom factory function as `Context.formatter_class` (which probably could be called `formatter_factory`).
2. Refactor `HelpFormatter` to make it easy for people to override without copying, pasting and modiyfing the current code of `HelpFormatter.write_dl`.
Thank you again.
</issue>
<code>
[start of src/click/formatting.py]
1 import typing as t
2 from contextlib import contextmanager
3
4 from ._compat import term_len
5 from .parser import split_opt
6
7 # Can force a width. This is used by the test system
8 FORCED_WIDTH: t.Optional[int] = None
9
10
11 def measure_table(rows):
12 widths = {}
13 for row in rows:
14 for idx, col in enumerate(row):
15 widths[idx] = max(widths.get(idx, 0), term_len(col))
16 return tuple(y for x, y in sorted(widths.items()))
17
18
19 def iter_rows(rows, col_count):
20 for row in rows:
21 row = tuple(row)
22 yield row + ("",) * (col_count - len(row))
23
24
25 def wrap_text(
26 text, width=78, initial_indent="", subsequent_indent="", preserve_paragraphs=False
27 ):
28 """A helper function that intelligently wraps text. By default, it
29 assumes that it operates on a single paragraph of text but if the
30 `preserve_paragraphs` parameter is provided it will intelligently
31 handle paragraphs (defined by two empty lines).
32
33 If paragraphs are handled, a paragraph can be prefixed with an empty
34 line containing the ``\\b`` character (``\\x08``) to indicate that
35 no rewrapping should happen in that block.
36
37 :param text: the text that should be rewrapped.
38 :param width: the maximum width for the text.
39 :param initial_indent: the initial indent that should be placed on the
40 first line as a string.
41 :param subsequent_indent: the indent string that should be placed on
42 each consecutive line.
43 :param preserve_paragraphs: if this flag is set then the wrapping will
44 intelligently handle paragraphs.
45 """
46 from ._textwrap import TextWrapper
47
48 text = text.expandtabs()
49 wrapper = TextWrapper(
50 width,
51 initial_indent=initial_indent,
52 subsequent_indent=subsequent_indent,
53 replace_whitespace=False,
54 )
55 if not preserve_paragraphs:
56 return wrapper.fill(text)
57
58 p = []
59 buf = []
60 indent = None
61
62 def _flush_par():
63 if not buf:
64 return
65 if buf[0].strip() == "\b":
66 p.append((indent or 0, True, "\n".join(buf[1:])))
67 else:
68 p.append((indent or 0, False, " ".join(buf)))
69 del buf[:]
70
71 for line in text.splitlines():
72 if not line:
73 _flush_par()
74 indent = None
75 else:
76 if indent is None:
77 orig_len = term_len(line)
78 line = line.lstrip()
79 indent = orig_len - term_len(line)
80 buf.append(line)
81 _flush_par()
82
83 rv = []
84 for indent, raw, text in p:
85 with wrapper.extra_indent(" " * indent):
86 if raw:
87 rv.append(wrapper.indent_only(text))
88 else:
89 rv.append(wrapper.fill(text))
90
91 return "\n\n".join(rv)
92
93
94 class HelpFormatter:
95 """This class helps with formatting text-based help pages. It's
96 usually just needed for very special internal cases, but it's also
97 exposed so that developers can write their own fancy outputs.
98
99 At present, it always writes into memory.
100
101 :param indent_increment: the additional increment for each level.
102 :param width: the width for the text. This defaults to the terminal
103 width clamped to a maximum of 78.
104 """
105
106 def __init__(self, indent_increment=2, width=None, max_width=None):
107 import shutil
108
109 self.indent_increment = indent_increment
110 if max_width is None:
111 max_width = 80
112 if width is None:
113 width = FORCED_WIDTH
114 if width is None:
115 width = max(min(shutil.get_terminal_size().columns, max_width) - 2, 50)
116 self.width = width
117 self.current_indent = 0
118 self.buffer = []
119
120 def write(self, string):
121 """Writes a unicode string into the internal buffer."""
122 self.buffer.append(string)
123
124 def indent(self):
125 """Increases the indentation."""
126 self.current_indent += self.indent_increment
127
128 def dedent(self):
129 """Decreases the indentation."""
130 self.current_indent -= self.indent_increment
131
132 def write_usage(self, prog, args="", prefix="Usage: "):
133 """Writes a usage line into the buffer.
134
135 :param prog: the program name.
136 :param args: whitespace separated list of arguments.
137 :param prefix: the prefix for the first line.
138 """
139 usage_prefix = f"{prefix:>{self.current_indent}}{prog} "
140 text_width = self.width - self.current_indent
141
142 if text_width >= (term_len(usage_prefix) + 20):
143 # The arguments will fit to the right of the prefix.
144 indent = " " * term_len(usage_prefix)
145 self.write(
146 wrap_text(
147 args,
148 text_width,
149 initial_indent=usage_prefix,
150 subsequent_indent=indent,
151 )
152 )
153 else:
154 # The prefix is too long, put the arguments on the next line.
155 self.write(usage_prefix)
156 self.write("\n")
157 indent = " " * (max(self.current_indent, term_len(prefix)) + 4)
158 self.write(
159 wrap_text(
160 args, text_width, initial_indent=indent, subsequent_indent=indent
161 )
162 )
163
164 self.write("\n")
165
166 def write_heading(self, heading):
167 """Writes a heading into the buffer."""
168 self.write(f"{'':>{self.current_indent}}{heading}:\n")
169
170 def write_paragraph(self):
171 """Writes a paragraph into the buffer."""
172 if self.buffer:
173 self.write("\n")
174
175 def write_text(self, text):
176 """Writes re-indented text into the buffer. This rewraps and
177 preserves paragraphs.
178 """
179 text_width = max(self.width - self.current_indent, 11)
180 indent = " " * self.current_indent
181 self.write(
182 wrap_text(
183 text,
184 text_width,
185 initial_indent=indent,
186 subsequent_indent=indent,
187 preserve_paragraphs=True,
188 )
189 )
190 self.write("\n")
191
192 def write_dl(self, rows, col_max=30, col_spacing=2):
193 """Writes a definition list into the buffer. This is how options
194 and commands are usually formatted.
195
196 :param rows: a list of two item tuples for the terms and values.
197 :param col_max: the maximum width of the first column.
198 :param col_spacing: the number of spaces between the first and
199 second column.
200 """
201 rows = list(rows)
202 widths = measure_table(rows)
203 if len(widths) != 2:
204 raise TypeError("Expected two columns for definition list")
205
206 first_col = min(widths[0], col_max) + col_spacing
207
208 for first, second in iter_rows(rows, len(widths)):
209 self.write(f"{'':>{self.current_indent}}{first}")
210 if not second:
211 self.write("\n")
212 continue
213 if term_len(first) <= first_col - col_spacing:
214 self.write(" " * (first_col - term_len(first)))
215 else:
216 self.write("\n")
217 self.write(" " * (first_col + self.current_indent))
218
219 text_width = max(self.width - first_col - 2, 10)
220 wrapped_text = wrap_text(second, text_width, preserve_paragraphs=True)
221 lines = wrapped_text.splitlines()
222
223 if lines:
224 self.write(f"{lines[0]}\n")
225
226 for line in lines[1:]:
227 self.write(f"{'':>{first_col + self.current_indent}}{line}\n")
228
229 if len(lines) > 1:
230 # separate long help from next option
231 self.write("\n")
232 else:
233 self.write("\n")
234
235 @contextmanager
236 def section(self, name):
237 """Helpful context manager that writes a paragraph, a heading,
238 and the indents.
239
240 :param name: the section name that is written as heading.
241 """
242 self.write_paragraph()
243 self.write_heading(name)
244 self.indent()
245 try:
246 yield
247 finally:
248 self.dedent()
249
250 @contextmanager
251 def indentation(self):
252 """A context manager that increases the indentation."""
253 self.indent()
254 try:
255 yield
256 finally:
257 self.dedent()
258
259 def getvalue(self):
260 """Returns the buffer contents."""
261 return "".join(self.buffer)
262
263
264 def join_options(options):
265 """Given a list of option strings this joins them in the most appropriate
266 way and returns them in the form ``(formatted_string,
267 any_prefix_is_slash)`` where the second item in the tuple is a flag that
268 indicates if any of the option prefixes was a slash.
269 """
270 rv = []
271 any_prefix_is_slash = False
272 for opt in options:
273 prefix = split_opt(opt)[0]
274 if prefix == "/":
275 any_prefix_is_slash = True
276 rv.append((len(prefix), opt))
277
278 rv.sort(key=lambda x: x[0])
279
280 rv = ", ".join(x[1] for x in rv)
281 return rv, any_prefix_is_slash
282
[end of src/click/formatting.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/src/click/formatting.py b/src/click/formatting.py
--- a/src/click/formatting.py
+++ b/src/click/formatting.py
@@ -225,10 +225,6 @@
for line in lines[1:]:
self.write(f"{'':>{first_col + self.current_indent}}{line}\n")
-
- if len(lines) > 1:
- # separate long help from next option
- self.write("\n")
else:
self.write("\n")
| {"golden_diff": "diff --git a/src/click/formatting.py b/src/click/formatting.py\n--- a/src/click/formatting.py\n+++ b/src/click/formatting.py\n@@ -225,10 +225,6 @@\n \n for line in lines[1:]:\n self.write(f\"{'':>{first_col + self.current_indent}}{line}\\n\")\n-\n- if len(lines) > 1:\n- # separate long help from next option\n- self.write(\"\\n\")\n else:\n self.write(\"\\n\")\n", "issue": "Reconsider the choice of adding a newline after multi-line option definitions\nFirst, thanks for your work.\r\n\r\nI ask you to reconsider the feature introduced with PR https://github.com/pallets/click/pull/1081.\r\n\r\n1. Adding a newline only to some options feels inconsistent and leads to a weird-looking \"non-uniform\" help strings. It's even worse when you use an extension that adds new help sections (e.g. [Cloup](https://github.com/janluke/cloup) for option groups), since some sections are not clearly demarked or too much demarked. It looks like a complete mess.\r\n\r\n2. I'm pretty sure it's non-standard. Why should it be the default?\r\n\r\nAs a consequence, it feels like a bug. I did mistake it for a bug. Another developer reported it as a bug (issue https://github.com/pallets/click/issues/1559). The few people I asked don't like it and consider it a problem worth the effort of writing additional code to get rid of it. Most people in the original issue (https://github.com/pallets/click/issues/1075) are for an all-or-nothing behavior and described the current behviour as inconsistent as well.\r\n\r\nHere's some alternative proposals.\r\n1. Remove the feature.\r\n2. Make it possible but non-default. Two solutions here:\r\n 1. Add a parameter to `HelpFormatter`. It can be made as simple as a boolean or as complex as a \"list item separation strategy\". A user can pass a custom factory function as `Context.formatter_class` (which probably could be called `formatter_factory`).\r\n 2. Refactor `HelpFormatter` to make it easy for people to override without copying, pasting and modiyfing the current code of `HelpFormatter.write_dl`.\r\n\r\nThank you again.\r\n\n", "before_files": [{"content": "import typing as t\nfrom contextlib import contextmanager\n\nfrom ._compat import term_len\nfrom .parser import split_opt\n\n# Can force a width. This is used by the test system\nFORCED_WIDTH: t.Optional[int] = None\n\n\ndef measure_table(rows):\n widths = {}\n for row in rows:\n for idx, col in enumerate(row):\n widths[idx] = max(widths.get(idx, 0), term_len(col))\n return tuple(y for x, y in sorted(widths.items()))\n\n\ndef iter_rows(rows, col_count):\n for row in rows:\n row = tuple(row)\n yield row + (\"\",) * (col_count - len(row))\n\n\ndef wrap_text(\n text, width=78, initial_indent=\"\", subsequent_indent=\"\", preserve_paragraphs=False\n):\n \"\"\"A helper function that intelligently wraps text. By default, it\n assumes that it operates on a single paragraph of text but if the\n `preserve_paragraphs` parameter is provided it will intelligently\n handle paragraphs (defined by two empty lines).\n\n If paragraphs are handled, a paragraph can be prefixed with an empty\n line containing the ``\\\\b`` character (``\\\\x08``) to indicate that\n no rewrapping should happen in that block.\n\n :param text: the text that should be rewrapped.\n :param width: the maximum width for the text.\n :param initial_indent: the initial indent that should be placed on the\n first line as a string.\n :param subsequent_indent: the indent string that should be placed on\n each consecutive line.\n :param preserve_paragraphs: if this flag is set then the wrapping will\n intelligently handle paragraphs.\n \"\"\"\n from ._textwrap import TextWrapper\n\n text = text.expandtabs()\n wrapper = TextWrapper(\n width,\n initial_indent=initial_indent,\n subsequent_indent=subsequent_indent,\n replace_whitespace=False,\n )\n if not preserve_paragraphs:\n return wrapper.fill(text)\n\n p = []\n buf = []\n indent = None\n\n def _flush_par():\n if not buf:\n return\n if buf[0].strip() == \"\\b\":\n p.append((indent or 0, True, \"\\n\".join(buf[1:])))\n else:\n p.append((indent or 0, False, \" \".join(buf)))\n del buf[:]\n\n for line in text.splitlines():\n if not line:\n _flush_par()\n indent = None\n else:\n if indent is None:\n orig_len = term_len(line)\n line = line.lstrip()\n indent = orig_len - term_len(line)\n buf.append(line)\n _flush_par()\n\n rv = []\n for indent, raw, text in p:\n with wrapper.extra_indent(\" \" * indent):\n if raw:\n rv.append(wrapper.indent_only(text))\n else:\n rv.append(wrapper.fill(text))\n\n return \"\\n\\n\".join(rv)\n\n\nclass HelpFormatter:\n \"\"\"This class helps with formatting text-based help pages. It's\n usually just needed for very special internal cases, but it's also\n exposed so that developers can write their own fancy outputs.\n\n At present, it always writes into memory.\n\n :param indent_increment: the additional increment for each level.\n :param width: the width for the text. This defaults to the terminal\n width clamped to a maximum of 78.\n \"\"\"\n\n def __init__(self, indent_increment=2, width=None, max_width=None):\n import shutil\n\n self.indent_increment = indent_increment\n if max_width is None:\n max_width = 80\n if width is None:\n width = FORCED_WIDTH\n if width is None:\n width = max(min(shutil.get_terminal_size().columns, max_width) - 2, 50)\n self.width = width\n self.current_indent = 0\n self.buffer = []\n\n def write(self, string):\n \"\"\"Writes a unicode string into the internal buffer.\"\"\"\n self.buffer.append(string)\n\n def indent(self):\n \"\"\"Increases the indentation.\"\"\"\n self.current_indent += self.indent_increment\n\n def dedent(self):\n \"\"\"Decreases the indentation.\"\"\"\n self.current_indent -= self.indent_increment\n\n def write_usage(self, prog, args=\"\", prefix=\"Usage: \"):\n \"\"\"Writes a usage line into the buffer.\n\n :param prog: the program name.\n :param args: whitespace separated list of arguments.\n :param prefix: the prefix for the first line.\n \"\"\"\n usage_prefix = f\"{prefix:>{self.current_indent}}{prog} \"\n text_width = self.width - self.current_indent\n\n if text_width >= (term_len(usage_prefix) + 20):\n # The arguments will fit to the right of the prefix.\n indent = \" \" * term_len(usage_prefix)\n self.write(\n wrap_text(\n args,\n text_width,\n initial_indent=usage_prefix,\n subsequent_indent=indent,\n )\n )\n else:\n # The prefix is too long, put the arguments on the next line.\n self.write(usage_prefix)\n self.write(\"\\n\")\n indent = \" \" * (max(self.current_indent, term_len(prefix)) + 4)\n self.write(\n wrap_text(\n args, text_width, initial_indent=indent, subsequent_indent=indent\n )\n )\n\n self.write(\"\\n\")\n\n def write_heading(self, heading):\n \"\"\"Writes a heading into the buffer.\"\"\"\n self.write(f\"{'':>{self.current_indent}}{heading}:\\n\")\n\n def write_paragraph(self):\n \"\"\"Writes a paragraph into the buffer.\"\"\"\n if self.buffer:\n self.write(\"\\n\")\n\n def write_text(self, text):\n \"\"\"Writes re-indented text into the buffer. This rewraps and\n preserves paragraphs.\n \"\"\"\n text_width = max(self.width - self.current_indent, 11)\n indent = \" \" * self.current_indent\n self.write(\n wrap_text(\n text,\n text_width,\n initial_indent=indent,\n subsequent_indent=indent,\n preserve_paragraphs=True,\n )\n )\n self.write(\"\\n\")\n\n def write_dl(self, rows, col_max=30, col_spacing=2):\n \"\"\"Writes a definition list into the buffer. This is how options\n and commands are usually formatted.\n\n :param rows: a list of two item tuples for the terms and values.\n :param col_max: the maximum width of the first column.\n :param col_spacing: the number of spaces between the first and\n second column.\n \"\"\"\n rows = list(rows)\n widths = measure_table(rows)\n if len(widths) != 2:\n raise TypeError(\"Expected two columns for definition list\")\n\n first_col = min(widths[0], col_max) + col_spacing\n\n for first, second in iter_rows(rows, len(widths)):\n self.write(f\"{'':>{self.current_indent}}{first}\")\n if not second:\n self.write(\"\\n\")\n continue\n if term_len(first) <= first_col - col_spacing:\n self.write(\" \" * (first_col - term_len(first)))\n else:\n self.write(\"\\n\")\n self.write(\" \" * (first_col + self.current_indent))\n\n text_width = max(self.width - first_col - 2, 10)\n wrapped_text = wrap_text(second, text_width, preserve_paragraphs=True)\n lines = wrapped_text.splitlines()\n\n if lines:\n self.write(f\"{lines[0]}\\n\")\n\n for line in lines[1:]:\n self.write(f\"{'':>{first_col + self.current_indent}}{line}\\n\")\n\n if len(lines) > 1:\n # separate long help from next option\n self.write(\"\\n\")\n else:\n self.write(\"\\n\")\n\n @contextmanager\n def section(self, name):\n \"\"\"Helpful context manager that writes a paragraph, a heading,\n and the indents.\n\n :param name: the section name that is written as heading.\n \"\"\"\n self.write_paragraph()\n self.write_heading(name)\n self.indent()\n try:\n yield\n finally:\n self.dedent()\n\n @contextmanager\n def indentation(self):\n \"\"\"A context manager that increases the indentation.\"\"\"\n self.indent()\n try:\n yield\n finally:\n self.dedent()\n\n def getvalue(self):\n \"\"\"Returns the buffer contents.\"\"\"\n return \"\".join(self.buffer)\n\n\ndef join_options(options):\n \"\"\"Given a list of option strings this joins them in the most appropriate\n way and returns them in the form ``(formatted_string,\n any_prefix_is_slash)`` where the second item in the tuple is a flag that\n indicates if any of the option prefixes was a slash.\n \"\"\"\n rv = []\n any_prefix_is_slash = False\n for opt in options:\n prefix = split_opt(opt)[0]\n if prefix == \"/\":\n any_prefix_is_slash = True\n rv.append((len(prefix), opt))\n\n rv.sort(key=lambda x: x[0])\n\n rv = \", \".join(x[1] for x in rv)\n return rv, any_prefix_is_slash\n", "path": "src/click/formatting.py"}]} | 3,675 | 117 |
gh_patches_debug_39544 | rasdani/github-patches | git_diff | RedHatInsights__insights-core-1873 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Need to enhance parser "ls_parser" to parse the output of command 'ls -laRZ <dir-name>' in RHEL-8
The parser **ls_parser** needs to be enhanced to support parsing the output of command `ls` with an option `Z` (for selinux context) in a RHEL8 system. In RHEL8, additional fields have been introduced in the output of command `ls -laRZ`. For example:
RHEL7:
```
#/bin/ls -laRZ /var/lib/nova/instances
/var/lib/nova/instances:
drwxr-xr-x. nova nova system_u:object_r:nova_var_lib_t:s0 .
drwxr-xr-x. nova nova system_u:object_r:nova_var_lib_t:s0 ..
drwxr-xr-x. root root unconfined_u:object_r:nova_var_lib_t:s0 xxxx-xxxx-xxxx-xxxx
```
RHEL8:
```
#/bin/ls -laRZ /var/lib/nova/instances
/var/lib/nova/instances:
total 0
drwxr-xr-x. 3 root root unconfined_u:object_r:var_lib_t:s0 50 Apr 8 16:41 .
drwxr-xr-x. 3 root root unconfined_u:object_r:var_lib_t:s0 23 Apr 8 16:29 ..
drwxr-xr-x. 2 root root unconfined_u:object_r:var_lib_t:s0 54 Apr 8 16:41 xxxx-xxxx-xxxx-xxxx
```
</issue>
<code>
[start of insights/core/ls_parser.py]
1 """
2 This module contains logic for parsing ls output. It attempts to handle
3 output when selinux is enabled or disabled and also skip "bad" lines.
4 """
5 import six
6
7
8 def parse_path(path):
9 """
10 Convert possible symbolic link into a source -> target pair.
11
12 Args:
13 path (str): The path portion of an ls output line.
14
15 Returns:
16 A (path, link) tuple where path is always populated and link is a non
17 empty string if the original path is a symoblic link.
18 """
19 path, _, link = path.partition(" -> ")
20 return path, link
21
22
23 def parse_non_selinux(parts):
24 """
25 Parse part of an ls output line that isn't selinux.
26
27 Args:
28 parts (list): A four element list of strings representing the initial
29 parts of an ls line after the permission bits. The parts are link
30 count, owner, group, and everything else.
31
32 Returns:
33 A dict containing links, owner, group, date, and name. If the line
34 represented a device, major and minor numbers are included. Otherwise,
35 size is included. If the raw name was a symbolic link, link is
36 included.
37 """
38 links, owner, group, last = parts
39 result = {
40 "links": int(links),
41 "owner": owner,
42 "group": group,
43 }
44
45 # device numbers only go to 256.
46 # If a comma is in the first four characters, the next two elements are
47 # major and minor device numbers. Otherwise, the next element is the size.
48 if "," in last[:4]:
49 major, minor, rest = last.split(None, 2)
50 result["major"] = int(major.rstrip(","))
51 result["minor"] = int(minor)
52 else:
53 size, rest = last.split(None, 1)
54 result["size"] = int(size)
55
56 # The date part is always 12 characters regardless of content.
57 result["date"] = rest[:12]
58
59 # Jump over the date and the following space to get the path part.
60 path, link = parse_path(rest[13:])
61 result["name"] = path
62 if link:
63 result["link"] = link
64
65 return result
66
67
68 def parse_selinux(parts):
69 """
70 Parse part of an ls output line that is selinux.
71
72 Args:
73 parts (list): A four element list of strings representing the initial
74 parts of an ls line after the permission bits. The parts are owner
75 group, selinux info, and the path.
76
77 Returns:
78 A dict containing owner, group, se_user, se_role, se_type, se_mls, and
79 name. If the raw name was a symbolic link, link is always included.
80
81 """
82
83 owner, group = parts[:2]
84 selinux = parts[2].split(":")
85 lsel = len(selinux)
86 path, link = parse_path(parts[-1])
87 result = {
88 "owner": owner,
89 "group": group,
90 "se_user": selinux[0],
91 "se_role": selinux[1] if lsel > 1 else None,
92 "se_type": selinux[2] if lsel > 2 else None,
93 "se_mls": selinux[3] if lsel > 3 else None,
94 "name": path
95 }
96 if link:
97 result["link"] = link
98 return result
99
100
101 PASS_KEYS = set(["name", "total"])
102 DELAYED_KEYS = ["entries", "files", "dirs", "specials"]
103
104
105 class Directory(dict):
106 def __init__(self, name, total, body):
107 data = dict.fromkeys(DELAYED_KEYS)
108 data["name"] = name
109 data["total"] = total
110 self.body = body
111 self.loaded = False
112 super(Directory, self).__init__(data)
113
114 def iteritems(self):
115 if not self.loaded:
116 self._load()
117 return six.iteritems(super(Directory, self))
118
119 def items(self):
120 if not self.loaded:
121 self._load()
122 return super(Directory, self).items()
123
124 def values(self):
125 if not self.loaded:
126 self._load()
127 return super(Directory, self).values()
128
129 def get(self, key, default=None):
130 if not self.loaded:
131 self._load()
132 return super(Directory, self).get(key, default)
133
134 def _load(self):
135 dirs = []
136 ents = {}
137 files = []
138 specials = []
139 for line in self.body:
140 parts = line.split(None, 4)
141 perms = parts[0]
142 typ = perms[0]
143 entry = {
144 "type": typ,
145 "perms": perms[1:]
146 }
147 if parts[1][0].isdigit():
148 rest = parse_non_selinux(parts[1:])
149 else:
150 rest = parse_selinux(parts[1:])
151
152 # Update our entry and put it into the correct buckets
153 # based on its type.
154 entry.update(rest)
155 entry["raw_entry"] = line
156 entry["dir"] = self["name"]
157 nm = entry["name"]
158 ents[nm] = entry
159 if typ not in "bcd":
160 files.append(nm)
161 elif typ == "d":
162 dirs.append(nm)
163 elif typ in "bc":
164 specials.append(nm)
165
166 self.update({"entries": ents,
167 "files": files,
168 "dirs": dirs,
169 "specials": specials})
170
171 self.loaded = True
172 del self.body
173
174 def __getitem__(self, key):
175 if self.loaded or key in PASS_KEYS:
176 return super(Directory, self).__getitem__(key)
177 self._load()
178 return super(Directory, self).__getitem__(key)
179
180
181 def parse(lines, root=None):
182 """
183 Parses a list of lines from ls into dictionaries representing their
184 components.
185
186 Args:
187 lines (list): A list of lines generated by ls.
188 root (str): The directory name to be used for ls output stanzas that
189 don't have a name.
190
191 Returns:
192 A dictionary representing the ls output. It's keyed by the path
193 containing each ls stanza.
194 """
195 doc = {}
196 entries = []
197 name = None
198 total = None
199 for line in lines:
200 line = line.strip()
201 if not line:
202 continue
203 if line and line[0] == "/" and line[-1] == ":":
204 if name is None:
205 name = line[:-1]
206 if entries:
207 d = Directory(name, total or len(entries), entries)
208 doc[root] = d
209 total = None
210 entries = []
211 else:
212 d = Directory(name, total or len(entries), entries)
213 doc[name or root] = d
214 total = None
215 entries = []
216 name = line[:-1]
217 continue
218 if line.startswith("total"):
219 total = int(line.split(None, 1)[1])
220 continue
221 entries.append(line)
222 name = name or root
223 doc[name] = Directory(name, total or len(entries), entries)
224 return doc
225
[end of insights/core/ls_parser.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/insights/core/ls_parser.py b/insights/core/ls_parser.py
--- a/insights/core/ls_parser.py
+++ b/insights/core/ls_parser.py
@@ -76,7 +76,7 @@
Returns:
A dict containing owner, group, se_user, se_role, se_type, se_mls, and
- name. If the raw name was a symbolic link, link is always included.
+ name. If the raw name was a symbolic link, link is also included.
"""
@@ -98,6 +98,47 @@
return result
+def parse_rhel8_selinux(parts):
+ """
+ Parse part of an ls output line that is selinux on RHEL8.
+
+ Args:
+ parts (list): A four element list of strings representing the initial
+ parts of an ls line after the permission bits. The parts are link
+ count, owner, group, and everything else
+
+ Returns:
+ A dict containing links, owner, group, se_user, se_role, se_type,
+ se_mls, size, date, and name. If the raw name was a symbolic link,
+ link is also included.
+
+ """
+
+ links, owner, group, last = parts
+
+ selinux = parts[3].split(":")
+ lsel = len(selinux)
+ selinux, size, last = parts[-1].split(None, 2)
+ selinux = selinux.split(":")
+ date = last[:12]
+ path, link = parse_path(last[13:])
+ result = {
+ "links": int(links),
+ "owner": owner,
+ "group": group,
+ "se_user": selinux[0],
+ "se_role": selinux[1] if lsel > 1 else None,
+ "se_type": selinux[2] if lsel > 2 else None,
+ "se_mls": selinux[3] if lsel > 3 else None,
+ "size": int(size),
+ "name": path,
+ "date": date,
+ }
+ if link:
+ result["link"] = link
+ return result
+
+
PASS_KEYS = set(["name", "total"])
DELAYED_KEYS = ["entries", "files", "dirs", "specials"]
@@ -137,6 +178,10 @@
files = []
specials = []
for line in self.body:
+ # we can't split(None, 5) here b/c rhel 6/7 selinux lines only have
+ # 4 parts before the path, and the path itself could contain
+ # spaces. Unfortunately, this means we have to split the line again
+ # below
parts = line.split(None, 4)
perms = parts[0]
typ = perms[0]
@@ -145,7 +190,13 @@
"perms": perms[1:]
}
if parts[1][0].isdigit():
- rest = parse_non_selinux(parts[1:])
+ # We have to split the line again to see if this is a RHEL8
+ # selinux stanza. This assumes that the context section will
+ # always have at least two pieces separated by ':'.
+ if ":" in line.split()[4]:
+ rest = parse_rhel8_selinux(parts[1:])
+ else:
+ rest = parse_non_selinux(parts[1:])
else:
rest = parse_selinux(parts[1:])
@@ -220,5 +271,6 @@
continue
entries.append(line)
name = name or root
- doc[name] = Directory(name, total or len(entries), entries)
+ total = total if total is not None else len(entries)
+ doc[name] = Directory(name, total, entries)
return doc
| {"golden_diff": "diff --git a/insights/core/ls_parser.py b/insights/core/ls_parser.py\n--- a/insights/core/ls_parser.py\n+++ b/insights/core/ls_parser.py\n@@ -76,7 +76,7 @@\n \n Returns:\n A dict containing owner, group, se_user, se_role, se_type, se_mls, and\n- name. If the raw name was a symbolic link, link is always included.\n+ name. If the raw name was a symbolic link, link is also included.\n \n \"\"\"\n \n@@ -98,6 +98,47 @@\n return result\n \n \n+def parse_rhel8_selinux(parts):\n+ \"\"\"\n+ Parse part of an ls output line that is selinux on RHEL8.\n+\n+ Args:\n+ parts (list): A four element list of strings representing the initial\n+ parts of an ls line after the permission bits. The parts are link\n+ count, owner, group, and everything else\n+\n+ Returns:\n+ A dict containing links, owner, group, se_user, se_role, se_type,\n+ se_mls, size, date, and name. If the raw name was a symbolic link,\n+ link is also included.\n+\n+ \"\"\"\n+\n+ links, owner, group, last = parts\n+\n+ selinux = parts[3].split(\":\")\n+ lsel = len(selinux)\n+ selinux, size, last = parts[-1].split(None, 2)\n+ selinux = selinux.split(\":\")\n+ date = last[:12]\n+ path, link = parse_path(last[13:])\n+ result = {\n+ \"links\": int(links),\n+ \"owner\": owner,\n+ \"group\": group,\n+ \"se_user\": selinux[0],\n+ \"se_role\": selinux[1] if lsel > 1 else None,\n+ \"se_type\": selinux[2] if lsel > 2 else None,\n+ \"se_mls\": selinux[3] if lsel > 3 else None,\n+ \"size\": int(size),\n+ \"name\": path,\n+ \"date\": date,\n+ }\n+ if link:\n+ result[\"link\"] = link\n+ return result\n+\n+\n PASS_KEYS = set([\"name\", \"total\"])\n DELAYED_KEYS = [\"entries\", \"files\", \"dirs\", \"specials\"]\n \n@@ -137,6 +178,10 @@\n files = []\n specials = []\n for line in self.body:\n+ # we can't split(None, 5) here b/c rhel 6/7 selinux lines only have\n+ # 4 parts before the path, and the path itself could contain\n+ # spaces. Unfortunately, this means we have to split the line again\n+ # below\n parts = line.split(None, 4)\n perms = parts[0]\n typ = perms[0]\n@@ -145,7 +190,13 @@\n \"perms\": perms[1:]\n }\n if parts[1][0].isdigit():\n- rest = parse_non_selinux(parts[1:])\n+ # We have to split the line again to see if this is a RHEL8\n+ # selinux stanza. This assumes that the context section will\n+ # always have at least two pieces separated by ':'.\n+ if \":\" in line.split()[4]:\n+ rest = parse_rhel8_selinux(parts[1:])\n+ else:\n+ rest = parse_non_selinux(parts[1:])\n else:\n rest = parse_selinux(parts[1:])\n \n@@ -220,5 +271,6 @@\n continue\n entries.append(line)\n name = name or root\n- doc[name] = Directory(name, total or len(entries), entries)\n+ total = total if total is not None else len(entries)\n+ doc[name] = Directory(name, total, entries)\n return doc\n", "issue": "Need to enhance parser \"ls_parser\" to parse the output of command 'ls -laRZ <dir-name>' in RHEL-8 \nThe parser **ls_parser** needs to be enhanced to support parsing the output of command `ls` with an option `Z` (for selinux context) in a RHEL8 system. In RHEL8, additional fields have been introduced in the output of command `ls -laRZ`. For example:\r\n\r\nRHEL7: \r\n\r\n```\r\n#/bin/ls -laRZ /var/lib/nova/instances\r\n/var/lib/nova/instances:\r\ndrwxr-xr-x. nova nova system_u:object_r:nova_var_lib_t:s0 .\r\ndrwxr-xr-x. nova nova system_u:object_r:nova_var_lib_t:s0 ..\r\ndrwxr-xr-x. root root unconfined_u:object_r:nova_var_lib_t:s0 xxxx-xxxx-xxxx-xxxx\r\n```\r\n\r\nRHEL8: \r\n\r\n```\r\n#/bin/ls -laRZ /var/lib/nova/instances\r\n/var/lib/nova/instances:\r\ntotal 0\r\ndrwxr-xr-x. 3 root root unconfined_u:object_r:var_lib_t:s0 50 Apr 8 16:41 .\r\ndrwxr-xr-x. 3 root root unconfined_u:object_r:var_lib_t:s0 23 Apr 8 16:29 ..\r\ndrwxr-xr-x. 2 root root unconfined_u:object_r:var_lib_t:s0 54 Apr 8 16:41 xxxx-xxxx-xxxx-xxxx\r\n```\n", "before_files": [{"content": "\"\"\"\nThis module contains logic for parsing ls output. It attempts to handle\noutput when selinux is enabled or disabled and also skip \"bad\" lines.\n\"\"\"\nimport six\n\n\ndef parse_path(path):\n \"\"\"\n Convert possible symbolic link into a source -> target pair.\n\n Args:\n path (str): The path portion of an ls output line.\n\n Returns:\n A (path, link) tuple where path is always populated and link is a non\n empty string if the original path is a symoblic link.\n \"\"\"\n path, _, link = path.partition(\" -> \")\n return path, link\n\n\ndef parse_non_selinux(parts):\n \"\"\"\n Parse part of an ls output line that isn't selinux.\n\n Args:\n parts (list): A four element list of strings representing the initial\n parts of an ls line after the permission bits. The parts are link\n count, owner, group, and everything else.\n\n Returns:\n A dict containing links, owner, group, date, and name. If the line\n represented a device, major and minor numbers are included. Otherwise,\n size is included. If the raw name was a symbolic link, link is\n included.\n \"\"\"\n links, owner, group, last = parts\n result = {\n \"links\": int(links),\n \"owner\": owner,\n \"group\": group,\n }\n\n # device numbers only go to 256.\n # If a comma is in the first four characters, the next two elements are\n # major and minor device numbers. Otherwise, the next element is the size.\n if \",\" in last[:4]:\n major, minor, rest = last.split(None, 2)\n result[\"major\"] = int(major.rstrip(\",\"))\n result[\"minor\"] = int(minor)\n else:\n size, rest = last.split(None, 1)\n result[\"size\"] = int(size)\n\n # The date part is always 12 characters regardless of content.\n result[\"date\"] = rest[:12]\n\n # Jump over the date and the following space to get the path part.\n path, link = parse_path(rest[13:])\n result[\"name\"] = path\n if link:\n result[\"link\"] = link\n\n return result\n\n\ndef parse_selinux(parts):\n \"\"\"\n Parse part of an ls output line that is selinux.\n\n Args:\n parts (list): A four element list of strings representing the initial\n parts of an ls line after the permission bits. The parts are owner\n group, selinux info, and the path.\n\n Returns:\n A dict containing owner, group, se_user, se_role, se_type, se_mls, and\n name. If the raw name was a symbolic link, link is always included.\n\n \"\"\"\n\n owner, group = parts[:2]\n selinux = parts[2].split(\":\")\n lsel = len(selinux)\n path, link = parse_path(parts[-1])\n result = {\n \"owner\": owner,\n \"group\": group,\n \"se_user\": selinux[0],\n \"se_role\": selinux[1] if lsel > 1 else None,\n \"se_type\": selinux[2] if lsel > 2 else None,\n \"se_mls\": selinux[3] if lsel > 3 else None,\n \"name\": path\n }\n if link:\n result[\"link\"] = link\n return result\n\n\nPASS_KEYS = set([\"name\", \"total\"])\nDELAYED_KEYS = [\"entries\", \"files\", \"dirs\", \"specials\"]\n\n\nclass Directory(dict):\n def __init__(self, name, total, body):\n data = dict.fromkeys(DELAYED_KEYS)\n data[\"name\"] = name\n data[\"total\"] = total\n self.body = body\n self.loaded = False\n super(Directory, self).__init__(data)\n\n def iteritems(self):\n if not self.loaded:\n self._load()\n return six.iteritems(super(Directory, self))\n\n def items(self):\n if not self.loaded:\n self._load()\n return super(Directory, self).items()\n\n def values(self):\n if not self.loaded:\n self._load()\n return super(Directory, self).values()\n\n def get(self, key, default=None):\n if not self.loaded:\n self._load()\n return super(Directory, self).get(key, default)\n\n def _load(self):\n dirs = []\n ents = {}\n files = []\n specials = []\n for line in self.body:\n parts = line.split(None, 4)\n perms = parts[0]\n typ = perms[0]\n entry = {\n \"type\": typ,\n \"perms\": perms[1:]\n }\n if parts[1][0].isdigit():\n rest = parse_non_selinux(parts[1:])\n else:\n rest = parse_selinux(parts[1:])\n\n # Update our entry and put it into the correct buckets\n # based on its type.\n entry.update(rest)\n entry[\"raw_entry\"] = line\n entry[\"dir\"] = self[\"name\"]\n nm = entry[\"name\"]\n ents[nm] = entry\n if typ not in \"bcd\":\n files.append(nm)\n elif typ == \"d\":\n dirs.append(nm)\n elif typ in \"bc\":\n specials.append(nm)\n\n self.update({\"entries\": ents,\n \"files\": files,\n \"dirs\": dirs,\n \"specials\": specials})\n\n self.loaded = True\n del self.body\n\n def __getitem__(self, key):\n if self.loaded or key in PASS_KEYS:\n return super(Directory, self).__getitem__(key)\n self._load()\n return super(Directory, self).__getitem__(key)\n\n\ndef parse(lines, root=None):\n \"\"\"\n Parses a list of lines from ls into dictionaries representing their\n components.\n\n Args:\n lines (list): A list of lines generated by ls.\n root (str): The directory name to be used for ls output stanzas that\n don't have a name.\n\n Returns:\n A dictionary representing the ls output. It's keyed by the path\n containing each ls stanza.\n \"\"\"\n doc = {}\n entries = []\n name = None\n total = None\n for line in lines:\n line = line.strip()\n if not line:\n continue\n if line and line[0] == \"/\" and line[-1] == \":\":\n if name is None:\n name = line[:-1]\n if entries:\n d = Directory(name, total or len(entries), entries)\n doc[root] = d\n total = None\n entries = []\n else:\n d = Directory(name, total or len(entries), entries)\n doc[name or root] = d\n total = None\n entries = []\n name = line[:-1]\n continue\n if line.startswith(\"total\"):\n total = int(line.split(None, 1)[1])\n continue\n entries.append(line)\n name = name or root\n doc[name] = Directory(name, total or len(entries), entries)\n return doc\n", "path": "insights/core/ls_parser.py"}]} | 3,033 | 885 |
gh_patches_debug_32 | rasdani/github-patches | git_diff | mlflow__mlflow-2797 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[SETUP-BUG] ResolvePackageNotFound - python=3.5.2
Thank you for submitting an issue. Please refer to our [issue policy](https://www.github.com/mlflow/mlflow/blob/master/ISSUE_POLICY.md)
for information on what types of issues we address.
Please fill in this template and do not delete it unless you are sure your issue is outside its scope.
### System information
- **OS Platform and Distribution (e.g., Linux Ubuntu 16.04)**: Ubuntu 16.04
- **MLflow installed from (source or binary)**: binary (pip install mlflow)
- **MLflow version (run ``mlflow --version``)**: 1.2.0
- **Python version**: 3.5.2
- **Exact command to reproduce**: mlflow models build-docker -m /path/to/model -n "my-model"
### Describe the problem
mlflow models build-docker -m /path/to/model -n "my-model"
### Other info / logs
Warning: you have pip-installed dependencies in your environment file, but you do not list pip itself as one of your condadependencies. Conda may not use the correct pip to install your packages, and they may end up in the wrong place. Pleaseadd an explicit pip dependency. I'm adding one for you, but still nagging you.
Collecting package metadata (repodata.json): ...working... done
Solving environment: ...working... failed
ResolvePackageNotFound:
- python=3.5.2
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/miniconda/lib/python3.7/site-packages/mlflow/models/container/__init__.py", line 102, in _install_pyfunc_deps
raise Exception("Failed to create model environment.")
Exception: Failed to create model environment.
creating and activating custom environment
The command '/bin/sh -c python -c 'from mlflow.models.container import _install_pyfunc_deps; _install_pyfunc_deps("/opt/ml/model", install_mlflow=False)'' returned a non-zero code: 1
</issue>
<code>
[start of mlflow/utils/environment.py]
1 import yaml
2
3 from mlflow.utils import PYTHON_VERSION
4
5 _conda_header = """\
6 name: mlflow-env
7 channels:
8 - defaults
9 """
10
11
12 def _mlflow_conda_env(path=None, additional_conda_deps=None, additional_pip_deps=None,
13 additional_conda_channels=None, install_mlflow=True):
14 """
15 Creates a Conda environment with the specified package channels and dependencies. If there are
16 any pip dependencies, including from the install_mlflow parameter, then pip will be added to
17 the conda dependencies. This is done to ensure that the pip inside the conda environment is
18 used to install the pip dependencies.
19
20 :param path: Local filesystem path where the conda env file is to be written. If unspecified,
21 the conda env will not be written to the filesystem; it will still be returned
22 in dictionary format.
23 :param additional_conda_deps: List of additional conda dependencies passed as strings.
24 :param additional_pip_deps: List of additional pip dependencies passed as strings.
25 :param additional_conda_channels: List of additional conda channels to search when resolving
26 packages.
27 :return: ``None`` if ``path`` is specified. Otherwise, the a dictionary representation of the
28 Conda environment.
29 """
30 pip_deps = (["mlflow"] if install_mlflow else []) + (
31 additional_pip_deps if additional_pip_deps else [])
32 conda_deps = (additional_conda_deps if additional_conda_deps else []) + (
33 ["pip"] if pip_deps else [])
34
35 env = yaml.safe_load(_conda_header)
36 env["dependencies"] = ["python={}".format(PYTHON_VERSION)]
37 if conda_deps is not None:
38 env["dependencies"] += conda_deps
39 env["dependencies"].append({"pip": pip_deps})
40 if additional_conda_channels is not None:
41 env["channels"] += additional_conda_channels
42
43 if path is not None:
44 with open(path, "w") as out:
45 yaml.safe_dump(env, stream=out, default_flow_style=False)
46 return None
47 else:
48 return env
49
[end of mlflow/utils/environment.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/mlflow/utils/environment.py b/mlflow/utils/environment.py
--- a/mlflow/utils/environment.py
+++ b/mlflow/utils/environment.py
@@ -6,6 +6,7 @@
name: mlflow-env
channels:
- defaults
+ - conda-forge
"""
| {"golden_diff": "diff --git a/mlflow/utils/environment.py b/mlflow/utils/environment.py\n--- a/mlflow/utils/environment.py\n+++ b/mlflow/utils/environment.py\n@@ -6,6 +6,7 @@\n name: mlflow-env\n channels:\n - defaults\n+ - conda-forge\n \"\"\"\n", "issue": "[SETUP-BUG] ResolvePackageNotFound - python=3.5.2\nThank you for submitting an issue. Please refer to our [issue policy](https://www.github.com/mlflow/mlflow/blob/master/ISSUE_POLICY.md)\r\nfor information on what types of issues we address.\r\n \r\nPlease fill in this template and do not delete it unless you are sure your issue is outside its scope.\r\n\r\n### System information\r\n- **OS Platform and Distribution (e.g., Linux Ubuntu 16.04)**: Ubuntu 16.04\r\n- **MLflow installed from (source or binary)**: binary (pip install mlflow)\r\n- **MLflow version (run ``mlflow --version``)**: 1.2.0\r\n- **Python version**: 3.5.2\r\n- **Exact command to reproduce**: mlflow models build-docker -m /path/to/model -n \"my-model\" \r\n\r\n### Describe the problem\r\nmlflow models build-docker -m /path/to/model -n \"my-model\"\r\n\r\n### Other info / logs\r\nWarning: you have pip-installed dependencies in your environment file, but you do not list pip itself as one of your condadependencies. Conda may not use the correct pip to install your packages, and they may end up in the wrong place. Pleaseadd an explicit pip dependency. I'm adding one for you, but still nagging you.\r\nCollecting package metadata (repodata.json): ...working... done\r\nSolving environment: ...working... failed\r\n\r\nResolvePackageNotFound:\r\n - python=3.5.2\r\n\r\nTraceback (most recent call last):\r\n File \"<string>\", line 1, in <module>\r\n File \"/miniconda/lib/python3.7/site-packages/mlflow/models/container/__init__.py\", line 102, in _install_pyfunc_deps\r\n raise Exception(\"Failed to create model environment.\")\r\nException: Failed to create model environment.\r\ncreating and activating custom environment\r\nThe command '/bin/sh -c python -c 'from mlflow.models.container import _install_pyfunc_deps; _install_pyfunc_deps(\"/opt/ml/model\", install_mlflow=False)'' returned a non-zero code: 1\r\n\n", "before_files": [{"content": "import yaml\n\nfrom mlflow.utils import PYTHON_VERSION\n\n_conda_header = \"\"\"\\\nname: mlflow-env\nchannels:\n - defaults\n\"\"\"\n\n\ndef _mlflow_conda_env(path=None, additional_conda_deps=None, additional_pip_deps=None,\n additional_conda_channels=None, install_mlflow=True):\n \"\"\"\n Creates a Conda environment with the specified package channels and dependencies. If there are\n any pip dependencies, including from the install_mlflow parameter, then pip will be added to\n the conda dependencies. This is done to ensure that the pip inside the conda environment is\n used to install the pip dependencies.\n\n :param path: Local filesystem path where the conda env file is to be written. If unspecified,\n the conda env will not be written to the filesystem; it will still be returned\n in dictionary format.\n :param additional_conda_deps: List of additional conda dependencies passed as strings.\n :param additional_pip_deps: List of additional pip dependencies passed as strings.\n :param additional_conda_channels: List of additional conda channels to search when resolving\n packages.\n :return: ``None`` if ``path`` is specified. Otherwise, the a dictionary representation of the\n Conda environment.\n \"\"\"\n pip_deps = ([\"mlflow\"] if install_mlflow else []) + (\n additional_pip_deps if additional_pip_deps else [])\n conda_deps = (additional_conda_deps if additional_conda_deps else []) + (\n [\"pip\"] if pip_deps else [])\n\n env = yaml.safe_load(_conda_header)\n env[\"dependencies\"] = [\"python={}\".format(PYTHON_VERSION)]\n if conda_deps is not None:\n env[\"dependencies\"] += conda_deps\n env[\"dependencies\"].append({\"pip\": pip_deps})\n if additional_conda_channels is not None:\n env[\"channels\"] += additional_conda_channels\n\n if path is not None:\n with open(path, \"w\") as out:\n yaml.safe_dump(env, stream=out, default_flow_style=False)\n return None\n else:\n return env\n", "path": "mlflow/utils/environment.py"}]} | 1,540 | 63 |
gh_patches_debug_37559 | rasdani/github-patches | git_diff | yt-dlp__yt-dlp-1202 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Site Request] 7plus add login/pass to access 720p resolution
<!--
######################################################################
WARNING!
IGNORING THE FOLLOWING TEMPLATE WILL RESULT IN ISSUE CLOSED AS INCOMPLETE
######################################################################
-->
## Checklist
<!--
Carefully read and work through this check list in order to prevent the most common mistakes and misuse of yt-dlp:
- First of, make sure you are using the latest version of yt-dlp. Run `yt-dlp --version` and ensure your version is 2021.09.25. If it's not, see https://github.com/yt-dlp/yt-dlp on how to update. Issues with outdated version will be REJECTED.
- Search the bugtracker for similar site feature requests: https://github.com/yt-dlp/yt-dlp. DO NOT post duplicates.
- Finally, put x into all relevant boxes like this [x] (Dont forget to delete the empty space)
-->
- [x] I'm reporting a site feature request
- [x] I've verified that I'm running yt-dlp version **2021.09.25**
- [x] I've searched the bugtracker for similar site feature requests including closed ones
## Description
<!--
Provide an explanation of your site feature request in an arbitrary form. Please make sure the description is worded well enough to be understood, see https://github.com/ytdl-org/youtube-dl#is-the-description-of-the-issue-itself-sufficient. Provide any additional information, suggested solution and as much context and examples as possible.
-->
7Plus has 720p resolution available behind a login/pass. Current site functionality only pulls 540p.
</issue>
<code>
[start of yt_dlp/extractor/sevenplus.py]
1 # coding: utf-8
2 from __future__ import unicode_literals
3
4 import re
5
6 from .brightcove import BrightcoveNewIE
7 from ..compat import (
8 compat_HTTPError,
9 compat_str,
10 )
11 from ..utils import (
12 ExtractorError,
13 try_get,
14 update_url_query,
15 )
16
17
18 class SevenPlusIE(BrightcoveNewIE):
19 IE_NAME = '7plus'
20 _VALID_URL = r'https?://(?:www\.)?7plus\.com\.au/(?P<path>[^?]+\?.*?\bepisode-id=(?P<id>[^&#]+))'
21 _TESTS = [{
22 'url': 'https://7plus.com.au/MTYS?episode-id=MTYS7-003',
23 'info_dict': {
24 'id': 'MTYS7-003',
25 'ext': 'mp4',
26 'title': 'S7 E3 - Wind Surf',
27 'description': 'md5:29c6a69f21accda7601278f81b46483d',
28 'uploader_id': '5303576322001',
29 'upload_date': '20171201',
30 'timestamp': 1512106377,
31 'series': 'Mighty Ships',
32 'season_number': 7,
33 'episode_number': 3,
34 'episode': 'Wind Surf',
35 },
36 'params': {
37 'format': 'bestvideo',
38 'skip_download': True,
39 }
40 }, {
41 'url': 'https://7plus.com.au/UUUU?episode-id=AUMS43-001',
42 'only_matching': True,
43 }]
44
45 def _real_extract(self, url):
46 path, episode_id = self._match_valid_url(url).groups()
47
48 try:
49 media = self._download_json(
50 'https://videoservice.swm.digital/playback', episode_id, query={
51 'appId': '7plus',
52 'deviceType': 'web',
53 'platformType': 'web',
54 'accountId': 5303576322001,
55 'referenceId': 'ref:' + episode_id,
56 'deliveryId': 'csai',
57 'videoType': 'vod',
58 })['media']
59 except ExtractorError as e:
60 if isinstance(e.cause, compat_HTTPError) and e.cause.code == 403:
61 raise ExtractorError(self._parse_json(
62 e.cause.read().decode(), episode_id)[0]['error_code'], expected=True)
63 raise
64
65 for source in media.get('sources', {}):
66 src = source.get('src')
67 if not src:
68 continue
69 source['src'] = update_url_query(src, {'rule': ''})
70
71 info = self._parse_brightcove_metadata(media, episode_id)
72
73 content = self._download_json(
74 'https://component-cdn.swm.digital/content/' + path,
75 episode_id, headers={
76 'market-id': 4,
77 }, fatal=False) or {}
78 for item in content.get('items', {}):
79 if item.get('componentData', {}).get('componentType') == 'infoPanel':
80 for src_key, dst_key in [('title', 'title'), ('shortSynopsis', 'description')]:
81 value = item.get(src_key)
82 if value:
83 info[dst_key] = value
84 info['series'] = try_get(
85 item, lambda x: x['seriesLogo']['name'], compat_str)
86 mobj = re.search(r'^S(\d+)\s+E(\d+)\s+-\s+(.+)$', info['title'])
87 if mobj:
88 info.update({
89 'season_number': int(mobj.group(1)),
90 'episode_number': int(mobj.group(2)),
91 'episode': mobj.group(3),
92 })
93
94 return info
95
[end of yt_dlp/extractor/sevenplus.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/yt_dlp/extractor/sevenplus.py b/yt_dlp/extractor/sevenplus.py
--- a/yt_dlp/extractor/sevenplus.py
+++ b/yt_dlp/extractor/sevenplus.py
@@ -1,6 +1,7 @@
# coding: utf-8
from __future__ import unicode_literals
+import json
import re
from .brightcove import BrightcoveNewIE
@@ -42,9 +43,52 @@
'only_matching': True,
}]
+ def _real_initialize(self):
+ self.token = None
+
+ cookies = self._get_cookies('https://7plus.com.au')
+ api_key = next((x for x in cookies if x.startswith('glt_')), '')[4:]
+ if not api_key: # Cookies are signed out, skip login
+ return
+
+ login_resp = self._download_json(
+ 'https://login.7plus.com.au/accounts.getJWT', None, 'Logging in', fatal=False,
+ query={
+ 'APIKey': api_key,
+ 'sdk': 'js_latest',
+ 'login_token': cookies[f'glt_{api_key}'].value,
+ 'authMode': 'cookie',
+ 'pageURL': 'https://7plus.com.au/',
+ 'sdkBuild': '12471',
+ 'format': 'json',
+ }) or {}
+
+ if 'errorMessage' in login_resp:
+ self.report_warning(f'Unable to login: 7plus said: {login_resp["errorMessage"]}')
+ return
+ id_token = login_resp.get('id_token')
+ if not id_token:
+ self.report_warning('Unable to login: Could not extract id token')
+ return
+
+ token_resp = self._download_json(
+ 'https://7plus.com.au/auth/token', None, 'Getting auth token', fatal=False,
+ headers={'Content-Type': 'application/json'}, data=json.dumps({
+ 'idToken': id_token,
+ 'platformId': 'web',
+ 'regSource': '7plus',
+ }).encode('utf-8')) or {}
+ self.token = token_resp.get('token')
+ if not self.token:
+ self.report_warning('Unable to log in: Could not extract auth token')
+
def _real_extract(self, url):
path, episode_id = self._match_valid_url(url).groups()
+ headers = {}
+ if self.token:
+ headers['Authorization'] = f'Bearer {self.token}'
+
try:
media = self._download_json(
'https://videoservice.swm.digital/playback', episode_id, query={
@@ -55,7 +99,7 @@
'referenceId': 'ref:' + episode_id,
'deliveryId': 'csai',
'videoType': 'vod',
- })['media']
+ }, headers=headers)['media']
except ExtractorError as e:
if isinstance(e.cause, compat_HTTPError) and e.cause.code == 403:
raise ExtractorError(self._parse_json(
| {"golden_diff": "diff --git a/yt_dlp/extractor/sevenplus.py b/yt_dlp/extractor/sevenplus.py\n--- a/yt_dlp/extractor/sevenplus.py\n+++ b/yt_dlp/extractor/sevenplus.py\n@@ -1,6 +1,7 @@\n # coding: utf-8\n from __future__ import unicode_literals\n \n+import json\n import re\n \n from .brightcove import BrightcoveNewIE\n@@ -42,9 +43,52 @@\n 'only_matching': True,\n }]\n \n+ def _real_initialize(self):\n+ self.token = None\n+\n+ cookies = self._get_cookies('https://7plus.com.au')\n+ api_key = next((x for x in cookies if x.startswith('glt_')), '')[4:]\n+ if not api_key: # Cookies are signed out, skip login\n+ return\n+\n+ login_resp = self._download_json(\n+ 'https://login.7plus.com.au/accounts.getJWT', None, 'Logging in', fatal=False,\n+ query={\n+ 'APIKey': api_key,\n+ 'sdk': 'js_latest',\n+ 'login_token': cookies[f'glt_{api_key}'].value,\n+ 'authMode': 'cookie',\n+ 'pageURL': 'https://7plus.com.au/',\n+ 'sdkBuild': '12471',\n+ 'format': 'json',\n+ }) or {}\n+\n+ if 'errorMessage' in login_resp:\n+ self.report_warning(f'Unable to login: 7plus said: {login_resp[\"errorMessage\"]}')\n+ return\n+ id_token = login_resp.get('id_token')\n+ if not id_token:\n+ self.report_warning('Unable to login: Could not extract id token')\n+ return\n+\n+ token_resp = self._download_json(\n+ 'https://7plus.com.au/auth/token', None, 'Getting auth token', fatal=False,\n+ headers={'Content-Type': 'application/json'}, data=json.dumps({\n+ 'idToken': id_token,\n+ 'platformId': 'web',\n+ 'regSource': '7plus',\n+ }).encode('utf-8')) or {}\n+ self.token = token_resp.get('token')\n+ if not self.token:\n+ self.report_warning('Unable to log in: Could not extract auth token')\n+\n def _real_extract(self, url):\n path, episode_id = self._match_valid_url(url).groups()\n \n+ headers = {}\n+ if self.token:\n+ headers['Authorization'] = f'Bearer {self.token}'\n+\n try:\n media = self._download_json(\n 'https://videoservice.swm.digital/playback', episode_id, query={\n@@ -55,7 +99,7 @@\n 'referenceId': 'ref:' + episode_id,\n 'deliveryId': 'csai',\n 'videoType': 'vod',\n- })['media']\n+ }, headers=headers)['media']\n except ExtractorError as e:\n if isinstance(e.cause, compat_HTTPError) and e.cause.code == 403:\n raise ExtractorError(self._parse_json(\n", "issue": "[Site Request] 7plus add login/pass to access 720p resolution\n<!--\r\n\r\n######################################################################\r\n WARNING!\r\n IGNORING THE FOLLOWING TEMPLATE WILL RESULT IN ISSUE CLOSED AS INCOMPLETE\r\n######################################################################\r\n\r\n-->\r\n\r\n\r\n## Checklist\r\n\r\n<!--\r\nCarefully read and work through this check list in order to prevent the most common mistakes and misuse of yt-dlp:\r\n- First of, make sure you are using the latest version of yt-dlp. Run `yt-dlp --version` and ensure your version is 2021.09.25. If it's not, see https://github.com/yt-dlp/yt-dlp on how to update. Issues with outdated version will be REJECTED.\r\n- Search the bugtracker for similar site feature requests: https://github.com/yt-dlp/yt-dlp. DO NOT post duplicates.\r\n- Finally, put x into all relevant boxes like this [x] (Dont forget to delete the empty space)\r\n-->\r\n\r\n- [x] I'm reporting a site feature request\r\n- [x] I've verified that I'm running yt-dlp version **2021.09.25**\r\n- [x] I've searched the bugtracker for similar site feature requests including closed ones\r\n\r\n\r\n## Description\r\n\r\n<!--\r\nProvide an explanation of your site feature request in an arbitrary form. Please make sure the description is worded well enough to be understood, see https://github.com/ytdl-org/youtube-dl#is-the-description-of-the-issue-itself-sufficient. Provide any additional information, suggested solution and as much context and examples as possible.\r\n-->\r\n\r\n7Plus has 720p resolution available behind a login/pass. Current site functionality only pulls 540p. \n", "before_files": [{"content": "# coding: utf-8\nfrom __future__ import unicode_literals\n\nimport re\n\nfrom .brightcove import BrightcoveNewIE\nfrom ..compat import (\n compat_HTTPError,\n compat_str,\n)\nfrom ..utils import (\n ExtractorError,\n try_get,\n update_url_query,\n)\n\n\nclass SevenPlusIE(BrightcoveNewIE):\n IE_NAME = '7plus'\n _VALID_URL = r'https?://(?:www\\.)?7plus\\.com\\.au/(?P<path>[^?]+\\?.*?\\bepisode-id=(?P<id>[^&#]+))'\n _TESTS = [{\n 'url': 'https://7plus.com.au/MTYS?episode-id=MTYS7-003',\n 'info_dict': {\n 'id': 'MTYS7-003',\n 'ext': 'mp4',\n 'title': 'S7 E3 - Wind Surf',\n 'description': 'md5:29c6a69f21accda7601278f81b46483d',\n 'uploader_id': '5303576322001',\n 'upload_date': '20171201',\n 'timestamp': 1512106377,\n 'series': 'Mighty Ships',\n 'season_number': 7,\n 'episode_number': 3,\n 'episode': 'Wind Surf',\n },\n 'params': {\n 'format': 'bestvideo',\n 'skip_download': True,\n }\n }, {\n 'url': 'https://7plus.com.au/UUUU?episode-id=AUMS43-001',\n 'only_matching': True,\n }]\n\n def _real_extract(self, url):\n path, episode_id = self._match_valid_url(url).groups()\n\n try:\n media = self._download_json(\n 'https://videoservice.swm.digital/playback', episode_id, query={\n 'appId': '7plus',\n 'deviceType': 'web',\n 'platformType': 'web',\n 'accountId': 5303576322001,\n 'referenceId': 'ref:' + episode_id,\n 'deliveryId': 'csai',\n 'videoType': 'vod',\n })['media']\n except ExtractorError as e:\n if isinstance(e.cause, compat_HTTPError) and e.cause.code == 403:\n raise ExtractorError(self._parse_json(\n e.cause.read().decode(), episode_id)[0]['error_code'], expected=True)\n raise\n\n for source in media.get('sources', {}):\n src = source.get('src')\n if not src:\n continue\n source['src'] = update_url_query(src, {'rule': ''})\n\n info = self._parse_brightcove_metadata(media, episode_id)\n\n content = self._download_json(\n 'https://component-cdn.swm.digital/content/' + path,\n episode_id, headers={\n 'market-id': 4,\n }, fatal=False) or {}\n for item in content.get('items', {}):\n if item.get('componentData', {}).get('componentType') == 'infoPanel':\n for src_key, dst_key in [('title', 'title'), ('shortSynopsis', 'description')]:\n value = item.get(src_key)\n if value:\n info[dst_key] = value\n info['series'] = try_get(\n item, lambda x: x['seriesLogo']['name'], compat_str)\n mobj = re.search(r'^S(\\d+)\\s+E(\\d+)\\s+-\\s+(.+)$', info['title'])\n if mobj:\n info.update({\n 'season_number': int(mobj.group(1)),\n 'episode_number': int(mobj.group(2)),\n 'episode': mobj.group(3),\n })\n\n return info\n", "path": "yt_dlp/extractor/sevenplus.py"}]} | 1,960 | 698 |
gh_patches_debug_25239 | rasdani/github-patches | git_diff | learningequality__kolibri-1604 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
DateTimeTzFields are serialized with incorrect times
Example saved this time in a `ChannelMetaDataCache` object (at around 14:00 local time)
`2017-06-06 14:44:12.582879(America/Los_Angeles)`
But it gets serialized as
`2017-06-06T07:44:12.582-07:00`
Expected is
`2017-06-06T14:44:12.582-07:00`
</issue>
<code>
[start of kolibri/core/serializers.py]
1 from django.utils import timezone
2 from rest_framework.serializers import DateTimeField, ModelSerializer
3 from .fields import DateTimeTzField as DjangoDateTimeTzField
4
5 class DateTimeTzField(DateTimeField):
6
7 def to_internal_value(self, data):
8 data = super(DateTimeTzField, self).to_internal_value(data)
9 tz = timezone.get_current_timezone()
10 return data.astimezone(tz)
11
12
13 serializer_field_mapping = {
14 DjangoDateTimeTzField: DateTimeTzField,
15 }
16
17 serializer_field_mapping.update(ModelSerializer.serializer_field_mapping)
18
19 class KolibriModelSerializer(ModelSerializer):
20
21 serializer_field_mapping = serializer_field_mapping
22
[end of kolibri/core/serializers.py]
[start of kolibri/core/fields.py]
1 import datetime
2 import re
3
4 import pytz
5 from django.db.models.fields import Field
6 from django.utils import timezone
7
8 date_time_format = "%Y-%m-%d %H:%M:%S.%f"
9 tz_format = "({tz})"
10 tz_regex = re.compile("\(([^\)]+)\)")
11 db_storage_string = "{date_time_string}{tz_string}"
12
13 def parse_timezonestamp(value):
14 if tz_regex.search(value):
15 tz = pytz.timezone(tz_regex.search(value).groups()[0])
16 else:
17 tz = timezone.get_current_timezone()
18 utc_value = tz_regex.sub('', value)
19 value = datetime.datetime.strptime(utc_value, date_time_format)
20 value = timezone.make_aware(value, pytz.utc)
21 return value.astimezone(tz)
22
23 def create_timezonestamp(value):
24 if value.tzinfo:
25 tz = value.tzinfo.zone
26 else:
27 tz = timezone.get_current_timezone().zone
28 date_time_string = value.strftime(date_time_format)
29 tz_string = tz_format.format(tz=tz)
30 value = db_storage_string.format(date_time_string=date_time_string, tz_string=tz_string)
31 return value
32
33 class DateTimeTzField(Field):
34 """
35 A field that stores datetime information as a char in this format:
36
37 %Y-%m-%d %H:%M:%S.%f(<tzinfo>)
38
39 It reads a timezone aware datetime object, and extracts the timezone zone information
40 then parses the datetime into the format above with the timezone information appended.
41
42 As this is ISO formatted, alphabetic sorting should still allow for proper queries
43 against this in the database. Mostly engineered for SQLite usage.
44 """
45
46 def db_type(self, connection):
47 return "varchar"
48
49 def from_db_value(self, value, expression, connection, context):
50 if value is None:
51 return value
52 return parse_timezonestamp(value)
53
54 def to_python(self, value):
55 if isinstance(value, datetime.datetime):
56 return value
57
58 if value is None:
59 return value
60
61 return parse_timezonestamp(value)
62
63 def get_prep_value(self, value):
64 # Casts datetimes into the format expected by the backend
65 if value is None:
66 return value
67 return create_timezonestamp(value)
68
69 def get_db_prep_value(self, value, connection, prepared=False):
70 if not prepared:
71 value = self.get_prep_value(value)
72 return value
73
[end of kolibri/core/fields.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/kolibri/core/fields.py b/kolibri/core/fields.py
--- a/kolibri/core/fields.py
+++ b/kolibri/core/fields.py
@@ -25,7 +25,8 @@
tz = value.tzinfo.zone
else:
tz = timezone.get_current_timezone().zone
- date_time_string = value.strftime(date_time_format)
+ value = timezone.make_aware(value, timezone.get_current_timezone())
+ date_time_string = value.astimezone(pytz.utc).strftime(date_time_format)
tz_string = tz_format.format(tz=tz)
value = db_storage_string.format(date_time_string=date_time_string, tz_string=tz_string)
return value
diff --git a/kolibri/core/serializers.py b/kolibri/core/serializers.py
--- a/kolibri/core/serializers.py
+++ b/kolibri/core/serializers.py
@@ -1,3 +1,5 @@
+import pytz
+
from django.utils import timezone
from rest_framework.serializers import DateTimeField, ModelSerializer
from .fields import DateTimeTzField as DjangoDateTimeTzField
@@ -7,6 +9,8 @@
def to_internal_value(self, data):
data = super(DateTimeTzField, self).to_internal_value(data)
tz = timezone.get_current_timezone()
+ if not data.tzinfo:
+ data = timezone.make_aware(data, pytz.utc)
return data.astimezone(tz)
| {"golden_diff": "diff --git a/kolibri/core/fields.py b/kolibri/core/fields.py\n--- a/kolibri/core/fields.py\n+++ b/kolibri/core/fields.py\n@@ -25,7 +25,8 @@\n tz = value.tzinfo.zone\n else:\n tz = timezone.get_current_timezone().zone\n- date_time_string = value.strftime(date_time_format)\n+ value = timezone.make_aware(value, timezone.get_current_timezone())\n+ date_time_string = value.astimezone(pytz.utc).strftime(date_time_format)\n tz_string = tz_format.format(tz=tz)\n value = db_storage_string.format(date_time_string=date_time_string, tz_string=tz_string)\n return value\ndiff --git a/kolibri/core/serializers.py b/kolibri/core/serializers.py\n--- a/kolibri/core/serializers.py\n+++ b/kolibri/core/serializers.py\n@@ -1,3 +1,5 @@\n+import pytz\n+\n from django.utils import timezone\n from rest_framework.serializers import DateTimeField, ModelSerializer\n from .fields import DateTimeTzField as DjangoDateTimeTzField\n@@ -7,6 +9,8 @@\n def to_internal_value(self, data):\n data = super(DateTimeTzField, self).to_internal_value(data)\n tz = timezone.get_current_timezone()\n+ if not data.tzinfo:\n+ data = timezone.make_aware(data, pytz.utc)\n return data.astimezone(tz)\n", "issue": "DateTimeTzFields are serialized with incorrect times\nExample saved this time in a `ChannelMetaDataCache` object (at around 14:00 local time)\r\n\r\n`2017-06-06 14:44:12.582879(America/Los_Angeles)`\r\n\r\nBut it gets serialized as\r\n\r\n`2017-06-06T07:44:12.582-07:00`\r\n\r\nExpected is\r\n\r\n`2017-06-06T14:44:12.582-07:00`\r\n\n", "before_files": [{"content": "from django.utils import timezone\nfrom rest_framework.serializers import DateTimeField, ModelSerializer\nfrom .fields import DateTimeTzField as DjangoDateTimeTzField\n\nclass DateTimeTzField(DateTimeField):\n\n def to_internal_value(self, data):\n data = super(DateTimeTzField, self).to_internal_value(data)\n tz = timezone.get_current_timezone()\n return data.astimezone(tz)\n\n\nserializer_field_mapping = {\n DjangoDateTimeTzField: DateTimeTzField,\n}\n\nserializer_field_mapping.update(ModelSerializer.serializer_field_mapping)\n\nclass KolibriModelSerializer(ModelSerializer):\n\n serializer_field_mapping = serializer_field_mapping\n", "path": "kolibri/core/serializers.py"}, {"content": "import datetime\nimport re\n\nimport pytz\nfrom django.db.models.fields import Field\nfrom django.utils import timezone\n\ndate_time_format = \"%Y-%m-%d %H:%M:%S.%f\"\ntz_format = \"({tz})\"\ntz_regex = re.compile(\"\\(([^\\)]+)\\)\")\ndb_storage_string = \"{date_time_string}{tz_string}\"\n\ndef parse_timezonestamp(value):\n if tz_regex.search(value):\n tz = pytz.timezone(tz_regex.search(value).groups()[0])\n else:\n tz = timezone.get_current_timezone()\n utc_value = tz_regex.sub('', value)\n value = datetime.datetime.strptime(utc_value, date_time_format)\n value = timezone.make_aware(value, pytz.utc)\n return value.astimezone(tz)\n\ndef create_timezonestamp(value):\n if value.tzinfo:\n tz = value.tzinfo.zone\n else:\n tz = timezone.get_current_timezone().zone\n date_time_string = value.strftime(date_time_format)\n tz_string = tz_format.format(tz=tz)\n value = db_storage_string.format(date_time_string=date_time_string, tz_string=tz_string)\n return value\n\nclass DateTimeTzField(Field):\n \"\"\"\n A field that stores datetime information as a char in this format:\n\n %Y-%m-%d %H:%M:%S.%f(<tzinfo>)\n\n It reads a timezone aware datetime object, and extracts the timezone zone information\n then parses the datetime into the format above with the timezone information appended.\n\n As this is ISO formatted, alphabetic sorting should still allow for proper queries\n against this in the database. Mostly engineered for SQLite usage.\n \"\"\"\n\n def db_type(self, connection):\n return \"varchar\"\n\n def from_db_value(self, value, expression, connection, context):\n if value is None:\n return value\n return parse_timezonestamp(value)\n\n def to_python(self, value):\n if isinstance(value, datetime.datetime):\n return value\n\n if value is None:\n return value\n\n return parse_timezonestamp(value)\n\n def get_prep_value(self, value):\n # Casts datetimes into the format expected by the backend\n if value is None:\n return value\n return create_timezonestamp(value)\n\n def get_db_prep_value(self, value, connection, prepared=False):\n if not prepared:\n value = self.get_prep_value(value)\n return value\n", "path": "kolibri/core/fields.py"}]} | 1,536 | 325 |
gh_patches_debug_2535 | rasdani/github-patches | git_diff | python__peps-2229 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Don't auto-add inline links to ref section & rm if empty, per #2130
First step to implementing #2130 , as agreed with @gvanrossum and the PEP editor team.
When building, don't add redundant footnotes and references entries for URLs that are already directly linked inline. This avoids an unnecessary, potentially confusing footnote for each link, and taking up additional space in the references section for no real benefit, plus simplifies the build code and should improve build time, especially for Sphinx. Furthermore, if the references section is empty (not including now-invisible link targets), remove it, as we did before (but in a more robust manner). This allows past and future PEPs to still use inline references with targets stored in the references section, while avoiding showing a now-empty references section.
These are both implemented for Sphinx and the legacy builder, and I visually inspected a variety of PEPs with various cases with both builders to ensure the desired results were achieved, and there were no obvious side effects from this change.
Following merging this PR, following the plan outlined in #2130 , I'll proceed with one updating the meta-PEP docs in PEP 0, PEP 1 and PEP 12 to reflect the revised policy of using standard reST links (inline or with separate targets) rather than the references section, and follow that with a PR updating the relative handful of references in the other active meta-PEPs, for consistency.
</issue>
<code>
[start of pep_sphinx_extensions/pep_processor/transforms/pep_footer.py]
1 import datetime
2 from pathlib import Path
3 import subprocess
4
5 from docutils import nodes
6 from docutils import transforms
7
8
9 class PEPFooter(transforms.Transform):
10 """Footer transforms for PEPs.
11
12 - Removes the References section if it is empty when rendered.
13 - Creates a link to the (GitHub) source text.
14
15 Source Link:
16 Create the link to the source file from the document source path,
17 and append the text to the end of the document.
18
19 """
20
21 # Uses same priority as docutils.transforms.TargetNotes
22 default_priority = 520
23
24 def apply(self) -> None:
25 pep_source_path = Path(self.document["source"])
26 if not pep_source_path.match("pep-*"):
27 return # not a PEP file, exit early
28
29 # Iterate through sections from the end of the document
30 for section in reversed(self.document[0]):
31 if not isinstance(section, nodes.section):
32 continue
33 title_words = section[0].astext().lower().split()
34 if "references" in title_words:
35 # Remove references section if there are no displayed
36 # footnotes (it only has title & link target nodes)
37 if all(isinstance(ref_node, (nodes.title, nodes.target))
38 for ref_node in section):
39 section.parent.remove(section)
40 break
41
42 # Add link to source text and last modified date
43 if pep_source_path.stem != "pep-0000":
44 self.document += _add_source_link(pep_source_path)
45 self.document += _add_commit_history_info(pep_source_path)
46
47
48 def _add_source_link(pep_source_path: Path) -> nodes.paragraph:
49 """Add link to source text on VCS (GitHub)"""
50 source_link = f"https://github.com/python/peps/blob/main/{pep_source_path.name}"
51 link_node = nodes.reference("", source_link, refuri=source_link)
52 return nodes.paragraph("", "Source: ", link_node)
53
54
55 def _add_commit_history_info(pep_source_path: Path) -> nodes.paragraph:
56 """Use local git history to find last modified date."""
57 try:
58 since_epoch = LAST_MODIFIED_TIMES[pep_source_path.name]
59 except KeyError:
60 return nodes.paragraph()
61
62 iso_time = datetime.datetime.utcfromtimestamp(since_epoch).isoformat(sep=" ")
63 commit_link = f"https://github.com/python/peps/commits/main/{pep_source_path.name}"
64 link_node = nodes.reference("", f"{iso_time} GMT", refuri=commit_link)
65 return nodes.paragraph("", "Last modified: ", link_node)
66
67
68 def _get_last_modified_timestamps():
69 # get timestamps and changed files from all commits (without paging results)
70 args = ["git", "--no-pager", "log", "--format=#%at", "--name-only"]
71 with subprocess.Popen(args, stdout=subprocess.PIPE) as process:
72 all_modified = process.stdout.read().decode("utf-8")
73 process.stdout.close()
74 if process.wait(): # non-zero return code
75 return {}
76
77 # set up the dictionary with the *current* files
78 last_modified = {path.name: 0 for path in Path().glob("pep-*") if path.suffix in {".txt", ".rst"}}
79
80 # iterate through newest to oldest, updating per file timestamps
81 change_sets = all_modified.removeprefix("#").split("#")
82 for change_set in change_sets:
83 timestamp, files = change_set.split("\n", 1)
84 for file in files.strip().split("\n"):
85 if file.startswith("pep-") and file[-3:] in {"txt", "rst"}:
86 if last_modified.get(file) == 0:
87 try:
88 last_modified[file] = float(timestamp)
89 except ValueError:
90 pass # if float conversion fails
91
92 return last_modified
93
94
95 LAST_MODIFIED_TIMES = _get_last_modified_timestamps()
96
[end of pep_sphinx_extensions/pep_processor/transforms/pep_footer.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/pep_sphinx_extensions/pep_processor/transforms/pep_footer.py b/pep_sphinx_extensions/pep_processor/transforms/pep_footer.py
--- a/pep_sphinx_extensions/pep_processor/transforms/pep_footer.py
+++ b/pep_sphinx_extensions/pep_processor/transforms/pep_footer.py
@@ -18,8 +18,8 @@
"""
- # Uses same priority as docutils.transforms.TargetNotes
- default_priority = 520
+ # Set low priority so ref targets aren't removed before they are needed
+ default_priority = 999
def apply(self) -> None:
pep_source_path = Path(self.document["source"])
| {"golden_diff": "diff --git a/pep_sphinx_extensions/pep_processor/transforms/pep_footer.py b/pep_sphinx_extensions/pep_processor/transforms/pep_footer.py\n--- a/pep_sphinx_extensions/pep_processor/transforms/pep_footer.py\n+++ b/pep_sphinx_extensions/pep_processor/transforms/pep_footer.py\n@@ -18,8 +18,8 @@\n \n \"\"\"\n \n- # Uses same priority as docutils.transforms.TargetNotes\n- default_priority = 520\n+ # Set low priority so ref targets aren't removed before they are needed\n+ default_priority = 999\n \n def apply(self) -> None:\n pep_source_path = Path(self.document[\"source\"])\n", "issue": "Don't auto-add inline links to ref section & rm if empty, per #2130\nFirst step to implementing #2130 , as agreed with @gvanrossum and the PEP editor team.\r\n\r\nWhen building, don't add redundant footnotes and references entries for URLs that are already directly linked inline. This avoids an unnecessary, potentially confusing footnote for each link, and taking up additional space in the references section for no real benefit, plus simplifies the build code and should improve build time, especially for Sphinx. Furthermore, if the references section is empty (not including now-invisible link targets), remove it, as we did before (but in a more robust manner). This allows past and future PEPs to still use inline references with targets stored in the references section, while avoiding showing a now-empty references section.\r\n\r\nThese are both implemented for Sphinx and the legacy builder, and I visually inspected a variety of PEPs with various cases with both builders to ensure the desired results were achieved, and there were no obvious side effects from this change.\r\n\r\nFollowing merging this PR, following the plan outlined in #2130 , I'll proceed with one updating the meta-PEP docs in PEP 0, PEP 1 and PEP 12 to reflect the revised policy of using standard reST links (inline or with separate targets) rather than the references section, and follow that with a PR updating the relative handful of references in the other active meta-PEPs, for consistency.\n", "before_files": [{"content": "import datetime\nfrom pathlib import Path\nimport subprocess\n\nfrom docutils import nodes\nfrom docutils import transforms\n\n\nclass PEPFooter(transforms.Transform):\n \"\"\"Footer transforms for PEPs.\n\n - Removes the References section if it is empty when rendered.\n - Creates a link to the (GitHub) source text.\n\n Source Link:\n Create the link to the source file from the document source path,\n and append the text to the end of the document.\n\n \"\"\"\n\n # Uses same priority as docutils.transforms.TargetNotes\n default_priority = 520\n\n def apply(self) -> None:\n pep_source_path = Path(self.document[\"source\"])\n if not pep_source_path.match(\"pep-*\"):\n return # not a PEP file, exit early\n\n # Iterate through sections from the end of the document\n for section in reversed(self.document[0]):\n if not isinstance(section, nodes.section):\n continue\n title_words = section[0].astext().lower().split()\n if \"references\" in title_words:\n # Remove references section if there are no displayed\n # footnotes (it only has title & link target nodes)\n if all(isinstance(ref_node, (nodes.title, nodes.target))\n for ref_node in section):\n section.parent.remove(section)\n break\n\n # Add link to source text and last modified date\n if pep_source_path.stem != \"pep-0000\":\n self.document += _add_source_link(pep_source_path)\n self.document += _add_commit_history_info(pep_source_path)\n\n\ndef _add_source_link(pep_source_path: Path) -> nodes.paragraph:\n \"\"\"Add link to source text on VCS (GitHub)\"\"\"\n source_link = f\"https://github.com/python/peps/blob/main/{pep_source_path.name}\"\n link_node = nodes.reference(\"\", source_link, refuri=source_link)\n return nodes.paragraph(\"\", \"Source: \", link_node)\n\n\ndef _add_commit_history_info(pep_source_path: Path) -> nodes.paragraph:\n \"\"\"Use local git history to find last modified date.\"\"\"\n try:\n since_epoch = LAST_MODIFIED_TIMES[pep_source_path.name]\n except KeyError:\n return nodes.paragraph()\n\n iso_time = datetime.datetime.utcfromtimestamp(since_epoch).isoformat(sep=\" \")\n commit_link = f\"https://github.com/python/peps/commits/main/{pep_source_path.name}\"\n link_node = nodes.reference(\"\", f\"{iso_time} GMT\", refuri=commit_link)\n return nodes.paragraph(\"\", \"Last modified: \", link_node)\n\n\ndef _get_last_modified_timestamps():\n # get timestamps and changed files from all commits (without paging results)\n args = [\"git\", \"--no-pager\", \"log\", \"--format=#%at\", \"--name-only\"]\n with subprocess.Popen(args, stdout=subprocess.PIPE) as process:\n all_modified = process.stdout.read().decode(\"utf-8\")\n process.stdout.close()\n if process.wait(): # non-zero return code\n return {}\n\n # set up the dictionary with the *current* files\n last_modified = {path.name: 0 for path in Path().glob(\"pep-*\") if path.suffix in {\".txt\", \".rst\"}}\n\n # iterate through newest to oldest, updating per file timestamps\n change_sets = all_modified.removeprefix(\"#\").split(\"#\")\n for change_set in change_sets:\n timestamp, files = change_set.split(\"\\n\", 1)\n for file in files.strip().split(\"\\n\"):\n if file.startswith(\"pep-\") and file[-3:] in {\"txt\", \"rst\"}:\n if last_modified.get(file) == 0:\n try:\n last_modified[file] = float(timestamp)\n except ValueError:\n pass # if float conversion fails\n\n return last_modified\n\n\nLAST_MODIFIED_TIMES = _get_last_modified_timestamps()\n", "path": "pep_sphinx_extensions/pep_processor/transforms/pep_footer.py"}]} | 1,889 | 165 |
gh_patches_debug_10524 | rasdani/github-patches | git_diff | Gallopsled__pwntools-2191 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
readthedocs.org builds are broken
The docs fail to build for a while, but differently since https://github.com/Gallopsled/pwntools/pull/2179. They're still built using Python 2.7, which had problems installing rpyc and is now missing the toml package before running the setup.py.
https://readthedocs.org/projects/pwntools/builds/
You could switch to Python 3 or try adding the `toml; python_version<'3.4'` package to the `docs/requirements.txt` file for a starter? I think only a maintainer with access to the configs can fix this.
</issue>
<code>
[start of pwn/toplevel.py]
1 # Get all the modules from pwnlib
2 import collections
3 import logging
4 import math
5 import operator
6 import os
7 import platform
8 import re
9 import socks
10 import signal
11 import string
12 import struct
13 import subprocess
14 import sys
15 import tempfile
16 import threading
17 import time
18
19 import colored_traceback
20 from pprint import pprint
21
22 import pwnlib
23 from pwnlib import *
24 from pwnlib.asm import *
25 from pwnlib.context import Thread
26 from pwnlib.context import context, LocalContext
27 from pwnlib.dynelf import DynELF
28 from pwnlib.encoders import *
29 from pwnlib.elf.corefile import Core, Corefile, Coredump
30 from pwnlib.elf.elf import ELF, load
31 from pwnlib.encoders import *
32 from pwnlib.exception import PwnlibException
33 from pwnlib.gdb import attach, debug_assembly, debug_shellcode
34 from pwnlib.filepointer import *
35 from pwnlib.filesystem import *
36 from pwnlib.flag import *
37 from pwnlib.fmtstr import FmtStr, fmtstr_payload, fmtstr_split
38 from pwnlib.log import getLogger
39 from pwnlib.memleak import MemLeak, RelativeMemLeak
40 from pwnlib.regsort import *
41 from pwnlib.replacements import *
42 from pwnlib.rop import ROP
43 from pwnlib.rop.call import AppendedArgument
44 from pwnlib.rop.srop import SigreturnFrame
45 from pwnlib.rop.ret2dlresolve import Ret2dlresolvePayload
46 from pwnlib.runner import *
47 from pwnlib.term.readline import str_input
48 from pwnlib.timeout import Timeout
49 from pwnlib.tubes.listen import listen
50 from pwnlib.tubes.process import process, PTY, PIPE, STDOUT
51 from pwnlib.tubes.remote import remote, tcp, udp, connect
52 from pwnlib.tubes.serialtube import serialtube
53 from pwnlib.tubes.server import server
54 from pwnlib.tubes.ssh import ssh
55 from pwnlib.tubes.tube import tube
56 from pwnlib.ui import *
57 from pwnlib.util import crc
58 from pwnlib.util import iters
59 from pwnlib.util import net
60 from pwnlib.util import proc
61 from pwnlib.util import safeeval
62 from pwnlib.util.crc import BitPolynom
63 from pwnlib.util.cyclic import *
64 from pwnlib.util.fiddling import *
65 from pwnlib.util.getdents import *
66 from pwnlib.util.hashes import *
67 from pwnlib.util.lists import *
68 from pwnlib.util.misc import *
69 from pwnlib.util.packing import *
70 from pwnlib.util.proc import pidof
71 from pwnlib.util.sh_string import sh_string, sh_prepare, sh_command_with
72 from pwnlib.util.splash import *
73 from pwnlib.util.web import *
74
75 # Promote these modules, so that "from pwn import *" will let you access them
76
77 from six.moves import cPickle as pickle, cStringIO as StringIO
78 from six import BytesIO
79
80 log = getLogger("pwnlib.exploit")
81 error = log.error
82 warning = log.warning
83 warn = log.warning
84 info = log.info
85 debug = log.debug
86 success = log.success
87
88 colored_traceback.add_hook()
89
90 # Equivalence with the default behavior of "from import *"
91 # __all__ = [x for x in tuple(globals()) if not x.startswith('_')]
92
[end of pwn/toplevel.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/pwn/toplevel.py b/pwn/toplevel.py
--- a/pwn/toplevel.py
+++ b/pwn/toplevel.py
@@ -16,7 +16,6 @@
import threading
import time
-import colored_traceback
from pprint import pprint
import pwnlib
@@ -85,7 +84,12 @@
debug = log.debug
success = log.success
-colored_traceback.add_hook()
+try:
+ import colored_traceback
+except ImportError:
+ pass
+else:
+ colored_traceback.add_hook()
# Equivalence with the default behavior of "from import *"
# __all__ = [x for x in tuple(globals()) if not x.startswith('_')]
| {"golden_diff": "diff --git a/pwn/toplevel.py b/pwn/toplevel.py\n--- a/pwn/toplevel.py\n+++ b/pwn/toplevel.py\n@@ -16,7 +16,6 @@\n import threading\n import time\n \n-import colored_traceback\n from pprint import pprint\n \n import pwnlib\n@@ -85,7 +84,12 @@\n debug = log.debug\n success = log.success\n \n-colored_traceback.add_hook()\n+try:\n+ import colored_traceback\n+except ImportError:\n+ pass\n+else:\n+ colored_traceback.add_hook()\n \n # Equivalence with the default behavior of \"from import *\"\n # __all__ = [x for x in tuple(globals()) if not x.startswith('_')]\n", "issue": "readthedocs.org builds are broken\nThe docs fail to build for a while, but differently since https://github.com/Gallopsled/pwntools/pull/2179. They're still built using Python 2.7, which had problems installing rpyc and is now missing the toml package before running the setup.py.\r\n\r\nhttps://readthedocs.org/projects/pwntools/builds/\r\n\r\nYou could switch to Python 3 or try adding the `toml; python_version<'3.4'` package to the `docs/requirements.txt` file for a starter? I think only a maintainer with access to the configs can fix this.\n", "before_files": [{"content": "# Get all the modules from pwnlib\nimport collections\nimport logging\nimport math\nimport operator\nimport os\nimport platform\nimport re\nimport socks\nimport signal\nimport string\nimport struct\nimport subprocess\nimport sys\nimport tempfile\nimport threading\nimport time\n\nimport colored_traceback\nfrom pprint import pprint\n\nimport pwnlib\nfrom pwnlib import *\nfrom pwnlib.asm import *\nfrom pwnlib.context import Thread\nfrom pwnlib.context import context, LocalContext\nfrom pwnlib.dynelf import DynELF\nfrom pwnlib.encoders import *\nfrom pwnlib.elf.corefile import Core, Corefile, Coredump\nfrom pwnlib.elf.elf import ELF, load\nfrom pwnlib.encoders import *\nfrom pwnlib.exception import PwnlibException\nfrom pwnlib.gdb import attach, debug_assembly, debug_shellcode\nfrom pwnlib.filepointer import *\nfrom pwnlib.filesystem import *\nfrom pwnlib.flag import *\nfrom pwnlib.fmtstr import FmtStr, fmtstr_payload, fmtstr_split\nfrom pwnlib.log import getLogger\nfrom pwnlib.memleak import MemLeak, RelativeMemLeak\nfrom pwnlib.regsort import *\nfrom pwnlib.replacements import *\nfrom pwnlib.rop import ROP\nfrom pwnlib.rop.call import AppendedArgument\nfrom pwnlib.rop.srop import SigreturnFrame\nfrom pwnlib.rop.ret2dlresolve import Ret2dlresolvePayload\nfrom pwnlib.runner import *\nfrom pwnlib.term.readline import str_input\nfrom pwnlib.timeout import Timeout\nfrom pwnlib.tubes.listen import listen\nfrom pwnlib.tubes.process import process, PTY, PIPE, STDOUT\nfrom pwnlib.tubes.remote import remote, tcp, udp, connect\nfrom pwnlib.tubes.serialtube import serialtube\nfrom pwnlib.tubes.server import server\nfrom pwnlib.tubes.ssh import ssh\nfrom pwnlib.tubes.tube import tube\nfrom pwnlib.ui import *\nfrom pwnlib.util import crc\nfrom pwnlib.util import iters\nfrom pwnlib.util import net\nfrom pwnlib.util import proc\nfrom pwnlib.util import safeeval\nfrom pwnlib.util.crc import BitPolynom\nfrom pwnlib.util.cyclic import *\nfrom pwnlib.util.fiddling import *\nfrom pwnlib.util.getdents import *\nfrom pwnlib.util.hashes import *\nfrom pwnlib.util.lists import *\nfrom pwnlib.util.misc import *\nfrom pwnlib.util.packing import *\nfrom pwnlib.util.proc import pidof\nfrom pwnlib.util.sh_string import sh_string, sh_prepare, sh_command_with\nfrom pwnlib.util.splash import *\nfrom pwnlib.util.web import *\n\n# Promote these modules, so that \"from pwn import *\" will let you access them\n\nfrom six.moves import cPickle as pickle, cStringIO as StringIO\nfrom six import BytesIO\n\nlog = getLogger(\"pwnlib.exploit\")\nerror = log.error\nwarning = log.warning\nwarn = log.warning\ninfo = log.info\ndebug = log.debug\nsuccess = log.success\n\ncolored_traceback.add_hook()\n\n# Equivalence with the default behavior of \"from import *\"\n# __all__ = [x for x in tuple(globals()) if not x.startswith('_')]\n", "path": "pwn/toplevel.py"}]} | 1,590 | 158 |
gh_patches_debug_11600 | rasdani/github-patches | git_diff | nautobot__nautobot-4260 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Set NAUTOBOT_INSTALLATION_METRICS_ENABLED=false in the dockerfile dev stage
<!--
NOTE: This template is for use by maintainers only. Please do not submit
an issue using this template unless you have been specifically asked to
do so.
-->
### Proposed Changes
This should propagate to all of the app dev instances since they base off of nautobot dev images. Make sure to unset this in the final stage
<!-- Provide justification for the proposed change(s). -->
### Justification
We don't want to send metrics for dev environments
</issue>
<code>
[start of development/nautobot_config.py]
1 """Nautobot development configuration file."""
2 import os
3
4 from nautobot.core.settings import * # noqa: F403
5 from nautobot.core.settings_funcs import is_truthy
6
7 #
8 # Debugging defaults to True rather than False for the development environment
9 #
10 DEBUG = is_truthy(os.getenv("NAUTOBOT_DEBUG", "True"))
11
12 # Django Debug Toolbar - enabled only when debugging
13 if DEBUG:
14 if "debug_toolbar" not in INSTALLED_APPS: # noqa: F405
15 INSTALLED_APPS.append("debug_toolbar") # noqa: F405
16 if "debug_toolbar.middleware.DebugToolbarMiddleware" not in MIDDLEWARE: # noqa: F405
17 MIDDLEWARE.insert(0, "debug_toolbar.middleware.DebugToolbarMiddleware") # noqa: F405
18 # By default the toolbar only displays when the request is coming from one of INTERNAL_IPS.
19 # For the Docker dev environment, we don't know in advance what that IP may be, so override to skip that check
20 DEBUG_TOOLBAR_CONFIG = {"SHOW_TOOLBAR_CALLBACK": lambda _request: DEBUG}
21
22 #
23 # Logging for the development environment, taking into account the redefinition of DEBUG above
24 #
25
26 LOG_LEVEL = "DEBUG" if DEBUG else "INFO"
27 LOGGING["loggers"]["nautobot"]["handlers"] = ["verbose_console" if DEBUG else "normal_console"] # noqa: F405
28 LOGGING["loggers"]["nautobot"]["level"] = LOG_LEVEL # noqa: F405
29
30 #
31 # Plugins
32 #
33
34 PLUGINS = [
35 "example_plugin",
36 ]
37
38
39 #
40 # Development Environment for SSO
41 # Configure `invoke.yml` based on example for SSO development environment
42 #
43
44 # OIDC Dev ENV
45 if is_truthy(os.getenv("ENABLE_OIDC", "False")):
46 import requests
47
48 AUTHENTICATION_BACKENDS = (
49 "social_core.backends.keycloak.KeycloakOAuth2",
50 "nautobot.core.authentication.ObjectPermissionBackend",
51 )
52 SOCIAL_AUTH_KEYCLOAK_KEY = "nautobot"
53 SOCIAL_AUTH_KEYCLOAK_SECRET = "7b1c3527-8702-4742-af69-2b74ee5742e8"
54 SOCIAL_AUTH_KEYCLOAK_PUBLIC_KEY = requests.get("http://keycloak:8087/realms/nautobot/", timeout=15).json()[
55 "public_key"
56 ]
57 SOCIAL_AUTH_KEYCLOAK_AUTHORIZATION_URL = "http://localhost:8087/realms/nautobot/protocol/openid-connect/auth"
58 SOCIAL_AUTH_KEYCLOAK_ACCESS_TOKEN_URL = "http://keycloak:8087/realms/nautobot/protocol/openid-connect/token"
59 SOCIAL_AUTH_KEYCLOAK_VERIFY_SSL = False
60
61 METRICS_ENABLED = True
62
63 CELERY_WORKER_PROMETHEUS_PORTS = [8080]
64
[end of development/nautobot_config.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/development/nautobot_config.py b/development/nautobot_config.py
--- a/development/nautobot_config.py
+++ b/development/nautobot_config.py
@@ -19,6 +19,9 @@
# For the Docker dev environment, we don't know in advance what that IP may be, so override to skip that check
DEBUG_TOOLBAR_CONFIG = {"SHOW_TOOLBAR_CALLBACK": lambda _request: DEBUG}
+# Do *not* send anonymized install metrics when post_upgrade or send_installation_metrics management commands are run
+INSTALLATION_METRICS_ENABLED = is_truthy(os.getenv("NAUTOBOT_INSTALLATION_METRICS_ENABLED", "False"))
+
#
# Logging for the development environment, taking into account the redefinition of DEBUG above
#
| {"golden_diff": "diff --git a/development/nautobot_config.py b/development/nautobot_config.py\n--- a/development/nautobot_config.py\n+++ b/development/nautobot_config.py\n@@ -19,6 +19,9 @@\n # For the Docker dev environment, we don't know in advance what that IP may be, so override to skip that check\n DEBUG_TOOLBAR_CONFIG = {\"SHOW_TOOLBAR_CALLBACK\": lambda _request: DEBUG}\n \n+# Do *not* send anonymized install metrics when post_upgrade or send_installation_metrics management commands are run\n+INSTALLATION_METRICS_ENABLED = is_truthy(os.getenv(\"NAUTOBOT_INSTALLATION_METRICS_ENABLED\", \"False\"))\n+\n #\n # Logging for the development environment, taking into account the redefinition of DEBUG above\n #\n", "issue": "Set NAUTOBOT_INSTALLATION_METRICS_ENABLED=false in the dockerfile dev stage\n<!--\r\n NOTE: This template is for use by maintainers only. Please do not submit\r\n an issue using this template unless you have been specifically asked to\r\n do so.\r\n-->\r\n### Proposed Changes\r\n\r\nThis should propagate to all of the app dev instances since they base off of nautobot dev images. Make sure to unset this in the final stage\r\n\r\n<!-- Provide justification for the proposed change(s). -->\r\n### Justification\r\n\r\nWe don't want to send metrics for dev environments\n", "before_files": [{"content": "\"\"\"Nautobot development configuration file.\"\"\"\nimport os\n\nfrom nautobot.core.settings import * # noqa: F403\nfrom nautobot.core.settings_funcs import is_truthy\n\n#\n# Debugging defaults to True rather than False for the development environment\n#\nDEBUG = is_truthy(os.getenv(\"NAUTOBOT_DEBUG\", \"True\"))\n\n# Django Debug Toolbar - enabled only when debugging\nif DEBUG:\n if \"debug_toolbar\" not in INSTALLED_APPS: # noqa: F405\n INSTALLED_APPS.append(\"debug_toolbar\") # noqa: F405\n if \"debug_toolbar.middleware.DebugToolbarMiddleware\" not in MIDDLEWARE: # noqa: F405\n MIDDLEWARE.insert(0, \"debug_toolbar.middleware.DebugToolbarMiddleware\") # noqa: F405\n # By default the toolbar only displays when the request is coming from one of INTERNAL_IPS.\n # For the Docker dev environment, we don't know in advance what that IP may be, so override to skip that check\n DEBUG_TOOLBAR_CONFIG = {\"SHOW_TOOLBAR_CALLBACK\": lambda _request: DEBUG}\n\n#\n# Logging for the development environment, taking into account the redefinition of DEBUG above\n#\n\nLOG_LEVEL = \"DEBUG\" if DEBUG else \"INFO\"\nLOGGING[\"loggers\"][\"nautobot\"][\"handlers\"] = [\"verbose_console\" if DEBUG else \"normal_console\"] # noqa: F405\nLOGGING[\"loggers\"][\"nautobot\"][\"level\"] = LOG_LEVEL # noqa: F405\n\n#\n# Plugins\n#\n\nPLUGINS = [\n \"example_plugin\",\n]\n\n\n#\n# Development Environment for SSO\n# Configure `invoke.yml` based on example for SSO development environment\n#\n\n# OIDC Dev ENV\nif is_truthy(os.getenv(\"ENABLE_OIDC\", \"False\")):\n import requests\n\n AUTHENTICATION_BACKENDS = (\n \"social_core.backends.keycloak.KeycloakOAuth2\",\n \"nautobot.core.authentication.ObjectPermissionBackend\",\n )\n SOCIAL_AUTH_KEYCLOAK_KEY = \"nautobot\"\n SOCIAL_AUTH_KEYCLOAK_SECRET = \"7b1c3527-8702-4742-af69-2b74ee5742e8\"\n SOCIAL_AUTH_KEYCLOAK_PUBLIC_KEY = requests.get(\"http://keycloak:8087/realms/nautobot/\", timeout=15).json()[\n \"public_key\"\n ]\n SOCIAL_AUTH_KEYCLOAK_AUTHORIZATION_URL = \"http://localhost:8087/realms/nautobot/protocol/openid-connect/auth\"\n SOCIAL_AUTH_KEYCLOAK_ACCESS_TOKEN_URL = \"http://keycloak:8087/realms/nautobot/protocol/openid-connect/token\"\n SOCIAL_AUTH_KEYCLOAK_VERIFY_SSL = False\n\nMETRICS_ENABLED = True\n\nCELERY_WORKER_PROMETHEUS_PORTS = [8080]\n", "path": "development/nautobot_config.py"}]} | 1,412 | 166 |
gh_patches_debug_7368 | rasdani/github-patches | git_diff | learningequality__kolibri-9397 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fresh Kolibri dev environment fails to install properly
## Observed behavior
I took these steps:
- Clone Kolibri to fresh local repo
- Ensure `develop` is checked out
- `python -m venv venv`
- `source venv/bin/activate`
- `pip install -r` every file in the `requirements/` directory
- `pip install -e .`
- `yarn install`
- `yarn devserver`
Then I get the error noted below. Seems like Django isn't being installed correctly or something. I've copied the `venv` from another worktree in and the branch works as expected until I `pip install...` everything again.
There was a recent bump to Morango in the requirements.txt but I can't imagine why that would cause this problem.
## Errors and logs
<!--
Relevant logs from:
* the command line
* ~/.kolibri/logs/kolibri.txt
* the browser console
Please wrap errors in triple backticks for clean formatting like this:
```
01:10 info: something happened
01:12 error: something bad happened
```
-->
```
╰─ yarn devserver
yarn run v1.22.15
$ run-p python-devserver lint-frontend:watch:format hashi-dev watch
> [email protected] hashi-dev
> yarn workspace hashi run dev
> [email protected] watch
> kolibri-tools build dev --file ./build_tools/build_plugins.txt --cache
> [email protected] python-devserver
> kolibri start --debug --foreground --port=8000 --settings=kolibri.deployment.default.settings.dev
> [email protected] lint-frontend:watch:format
> yarn run lint-frontend --monitor --write
$ kolibri-tools lint --pattern '{kolibri*/**/assets,packages,build_tools}/**/*.{js,vue,scss,less,css}' --ignore '**/dist/**,**/node_modules/**,**/static/**,**/kolibri-core-for-export/**' --monitor --write
$ yarn run build-base --mode=development --watch
$ webpack --config ./webpack.config.js --mode=development --watch
INFO Option DEBUG in section [Server] being overridden by environment variable KOLIBRI_DEBUG
INFO Option DEBUG_LOG_DATABASE in section [Server] being overridden by environment variable KOLIBRI_DEBUG_LOG_DATABASE
INFO Option RUN_MODE in section [Deployment] being overridden by environment variable KOLIBRI_RUN_MODE
/home/jacob/kill-this-kolibri/venv/lib/python3.6/site-packages/psycopg2/__init__.py:144: UserWarning: The psycopg2 wheel package will be renamed from release 2.8; in order to keep installing from binary please use "pip install psycopg2-binary" instead. For details see: <http://initd.org/psycopg/docs/install.html#binary-install-from-pypi>.
""")
Error: Traceback (most recent call last):
File "/home/jacob/kill-this-kolibri/kolibri/utils/cli.py", line 193, in invoke
initialize(**get_initialize_params())
File "/home/jacob/kill-this-kolibri/kolibri/utils/main.py", line 279, in initialize
_setup_django()
File "/home/jacob/kill-this-kolibri/kolibri/utils/main.py", line 153, in _setup_django
django.setup()
File "/home/jacob/kill-this-kolibri/venv/lib/python3.6/site-packages/django/__init__.py", line 27, in setup
apps.populate(settings.INSTALLED_APPS)
File "/home/jacob/kill-this-kolibri/venv/lib/python3.6/site-packages/django/apps/registry.py", line 85, in populate
app_config = AppConfig.create(entry)
File "/home/jacob/kill-this-kolibri/venv/lib/python3.6/site-packages/django/apps/config.py", line 94, in create
module = import_module(entry)
File "/home/jacob/.pyenv/versions/3.6.12/lib/python3.6/importlib/__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 994, in _gcd_import
File "<frozen importlib._bootstrap>", line 971, in _find_and_load
File "<frozen importlib._bootstrap>", line 953, in _find_and_load_unlocked
ModuleNotFoundError: No module named 'django_extensions'
ERROR: "python-devserver" exited with 1.
error Command failed with exit code 1.
info Visit https://yarnpkg.com/en/docs/cli/run for documentation about this command.
```
## Expected behavior
<!--
Description of what behavior was expected but did not occur
-->
Server should start up without issue.
## User-facing consequences…
<!--
Implications and real-world consequences for learners, coaches, admins, and other users of the application
-->
Devs cannot create new working local environments.
## Steps to reproduce
<!--
Precise steps that someone else can follow in order to see this behavior
-->
See the above.
## Context
<!--
Tell us about your environment, including:
* Kolibri version
* Operating system
* Browser
-->
`develop`
Fedora
</issue>
<code>
[start of kolibri/deployment/default/settings/dev.py]
1 from __future__ import absolute_import
2 from __future__ import print_function
3 from __future__ import unicode_literals
4
5 import os
6
7 from .base import * # noqa isort:skip @UnusedWildImport
8
9 DEBUG = True
10
11 # Settings might be tuples, so switch to lists
12 INSTALLED_APPS = list(INSTALLED_APPS) + ["drf_yasg", "django_extensions"] # noqa F405
13 webpack_middleware = "kolibri.core.webpack.middleware.WebpackErrorHandler"
14 no_login_popup_middleware = (
15 "kolibri.core.auth.middleware.XhrPreventLoginPromptMiddleware"
16 )
17 MIDDLEWARE = list(MIDDLEWARE) + [ # noqa F405
18 webpack_middleware,
19 no_login_popup_middleware,
20 ]
21
22 INTERNAL_IPS = ["127.0.0.1"]
23
24 ROOT_URLCONF = "kolibri.deployment.default.dev_urls"
25
26 DEVELOPER_MODE = True
27 os.environ.update({"KOLIBRI_DEVELOPER_MODE": "True"})
28
29 try:
30 process_cache = CACHES["process_cache"] # noqa F405
31 except KeyError:
32 process_cache = None
33
34 # Create a memcache for each cache
35 CACHES = {
36 key: {"BACKEND": "django.core.cache.backends.locmem.LocMemCache"}
37 for key in CACHES # noqa F405
38 }
39
40 if process_cache:
41 CACHES["process_cache"] = process_cache
42
43
44 REST_FRAMEWORK = {
45 "UNAUTHENTICATED_USER": "kolibri.core.auth.models.KolibriAnonymousUser",
46 "DEFAULT_AUTHENTICATION_CLASSES": [
47 # Activate basic auth for external API testing tools
48 "rest_framework.authentication.BasicAuthentication",
49 "rest_framework.authentication.SessionAuthentication",
50 ],
51 "DEFAULT_RENDERER_CLASSES": (
52 "rest_framework.renderers.JSONRenderer",
53 "rest_framework.renderers.BrowsableAPIRenderer",
54 ),
55 "EXCEPTION_HANDLER": "kolibri.core.utils.exception_handler.custom_exception_handler",
56 }
57
58 SWAGGER_SETTINGS = {"DEFAULT_INFO": "kolibri.deployment.default.dev_urls.api_info"}
59
[end of kolibri/deployment/default/settings/dev.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/kolibri/deployment/default/settings/dev.py b/kolibri/deployment/default/settings/dev.py
--- a/kolibri/deployment/default/settings/dev.py
+++ b/kolibri/deployment/default/settings/dev.py
@@ -9,7 +9,7 @@
DEBUG = True
# Settings might be tuples, so switch to lists
-INSTALLED_APPS = list(INSTALLED_APPS) + ["drf_yasg", "django_extensions"] # noqa F405
+INSTALLED_APPS = list(INSTALLED_APPS) + ["drf_yasg"] # noqa F405
webpack_middleware = "kolibri.core.webpack.middleware.WebpackErrorHandler"
no_login_popup_middleware = (
"kolibri.core.auth.middleware.XhrPreventLoginPromptMiddleware"
| {"golden_diff": "diff --git a/kolibri/deployment/default/settings/dev.py b/kolibri/deployment/default/settings/dev.py\n--- a/kolibri/deployment/default/settings/dev.py\n+++ b/kolibri/deployment/default/settings/dev.py\n@@ -9,7 +9,7 @@\n DEBUG = True\n \n # Settings might be tuples, so switch to lists\n-INSTALLED_APPS = list(INSTALLED_APPS) + [\"drf_yasg\", \"django_extensions\"] # noqa F405\n+INSTALLED_APPS = list(INSTALLED_APPS) + [\"drf_yasg\"] # noqa F405\n webpack_middleware = \"kolibri.core.webpack.middleware.WebpackErrorHandler\"\n no_login_popup_middleware = (\n \"kolibri.core.auth.middleware.XhrPreventLoginPromptMiddleware\"\n", "issue": "Fresh Kolibri dev environment fails to install properly\n## Observed behavior\r\n\r\nI took these steps:\r\n\r\n- Clone Kolibri to fresh local repo\r\n- Ensure `develop` is checked out\r\n- `python -m venv venv`\r\n- `source venv/bin/activate` \r\n- `pip install -r` every file in the `requirements/` directory\r\n- `pip install -e .`\r\n- `yarn install`\r\n- `yarn devserver`\r\n\r\nThen I get the error noted below. Seems like Django isn't being installed correctly or something. I've copied the `venv` from another worktree in and the branch works as expected until I `pip install...` everything again.\r\n\r\nThere was a recent bump to Morango in the requirements.txt but I can't imagine why that would cause this problem.\r\n\r\n## Errors and logs\r\n<!--\r\nRelevant logs from:\r\n * the command line\r\n * ~/.kolibri/logs/kolibri.txt\r\n * the browser console\r\n\r\nPlease wrap errors in triple backticks for clean formatting like this:\r\n```\r\n01:10 info: something happened\r\n01:12 error: something bad happened\r\n```\r\n-->\r\n\r\n```\r\n\u2570\u2500 yarn devserver \r\nyarn run v1.22.15\r\n$ run-p python-devserver lint-frontend:watch:format hashi-dev watch\r\n\r\n> [email protected] hashi-dev\r\n> yarn workspace hashi run dev\r\n\r\n\r\n> [email protected] watch\r\n> kolibri-tools build dev --file ./build_tools/build_plugins.txt --cache\r\n\r\n\r\n> [email protected] python-devserver\r\n> kolibri start --debug --foreground --port=8000 --settings=kolibri.deployment.default.settings.dev\r\n\r\n\r\n> [email protected] lint-frontend:watch:format\r\n> yarn run lint-frontend --monitor --write\r\n\r\n$ kolibri-tools lint --pattern '{kolibri*/**/assets,packages,build_tools}/**/*.{js,vue,scss,less,css}' --ignore '**/dist/**,**/node_modules/**,**/static/**,**/kolibri-core-for-export/**' --monitor --write\r\n$ yarn run build-base --mode=development --watch\r\n$ webpack --config ./webpack.config.js --mode=development --watch\r\nINFO Option DEBUG in section [Server] being overridden by environment variable KOLIBRI_DEBUG\r\nINFO Option DEBUG_LOG_DATABASE in section [Server] being overridden by environment variable KOLIBRI_DEBUG_LOG_DATABASE\r\nINFO Option RUN_MODE in section [Deployment] being overridden by environment variable KOLIBRI_RUN_MODE\r\n/home/jacob/kill-this-kolibri/venv/lib/python3.6/site-packages/psycopg2/__init__.py:144: UserWarning: The psycopg2 wheel package will be renamed from release 2.8; in order to keep installing from binary please use \"pip install psycopg2-binary\" instead. For details see: <http://initd.org/psycopg/docs/install.html#binary-install-from-pypi>.\r\n \"\"\")\r\nError: Traceback (most recent call last):\r\n File \"/home/jacob/kill-this-kolibri/kolibri/utils/cli.py\", line 193, in invoke\r\n initialize(**get_initialize_params())\r\n File \"/home/jacob/kill-this-kolibri/kolibri/utils/main.py\", line 279, in initialize\r\n _setup_django()\r\n File \"/home/jacob/kill-this-kolibri/kolibri/utils/main.py\", line 153, in _setup_django\r\n django.setup()\r\n File \"/home/jacob/kill-this-kolibri/venv/lib/python3.6/site-packages/django/__init__.py\", line 27, in setup\r\n apps.populate(settings.INSTALLED_APPS)\r\n File \"/home/jacob/kill-this-kolibri/venv/lib/python3.6/site-packages/django/apps/registry.py\", line 85, in populate\r\n app_config = AppConfig.create(entry)\r\n File \"/home/jacob/kill-this-kolibri/venv/lib/python3.6/site-packages/django/apps/config.py\", line 94, in create\r\n module = import_module(entry)\r\n File \"/home/jacob/.pyenv/versions/3.6.12/lib/python3.6/importlib/__init__.py\", line 126, in import_module\r\n return _bootstrap._gcd_import(name[level:], package, level)\r\n File \"<frozen importlib._bootstrap>\", line 994, in _gcd_import\r\n File \"<frozen importlib._bootstrap>\", line 971, in _find_and_load\r\n File \"<frozen importlib._bootstrap>\", line 953, in _find_and_load_unlocked\r\nModuleNotFoundError: No module named 'django_extensions'\r\n\r\nERROR: \"python-devserver\" exited with 1.\r\nerror Command failed with exit code 1.\r\ninfo Visit https://yarnpkg.com/en/docs/cli/run for documentation about this command.\r\n```\r\n\r\n## Expected behavior\r\n<!--\r\nDescription of what behavior was expected but did not occur\r\n-->\r\n\r\nServer should start up without issue.\r\n\r\n## User-facing consequences\u2026\r\n\r\n<!--\r\nImplications and real-world consequences for learners, coaches, admins, and other users of the application\r\n-->\r\n\r\nDevs cannot create new working local environments.\r\n\r\n## Steps to reproduce\r\n<!--\r\nPrecise steps that someone else can follow in order to see this behavior\r\n-->\r\n\r\nSee the above.\r\n\r\n## Context\r\n<!--\r\nTell us about your environment, including:\r\n * Kolibri version\r\n * Operating system\r\n * Browser\r\n-->\r\n\r\n`develop`\r\nFedora\n", "before_files": [{"content": "from __future__ import absolute_import\nfrom __future__ import print_function\nfrom __future__ import unicode_literals\n\nimport os\n\nfrom .base import * # noqa isort:skip @UnusedWildImport\n\nDEBUG = True\n\n# Settings might be tuples, so switch to lists\nINSTALLED_APPS = list(INSTALLED_APPS) + [\"drf_yasg\", \"django_extensions\"] # noqa F405\nwebpack_middleware = \"kolibri.core.webpack.middleware.WebpackErrorHandler\"\nno_login_popup_middleware = (\n \"kolibri.core.auth.middleware.XhrPreventLoginPromptMiddleware\"\n)\nMIDDLEWARE = list(MIDDLEWARE) + [ # noqa F405\n webpack_middleware,\n no_login_popup_middleware,\n]\n\nINTERNAL_IPS = [\"127.0.0.1\"]\n\nROOT_URLCONF = \"kolibri.deployment.default.dev_urls\"\n\nDEVELOPER_MODE = True\nos.environ.update({\"KOLIBRI_DEVELOPER_MODE\": \"True\"})\n\ntry:\n process_cache = CACHES[\"process_cache\"] # noqa F405\nexcept KeyError:\n process_cache = None\n\n# Create a memcache for each cache\nCACHES = {\n key: {\"BACKEND\": \"django.core.cache.backends.locmem.LocMemCache\"}\n for key in CACHES # noqa F405\n}\n\nif process_cache:\n CACHES[\"process_cache\"] = process_cache\n\n\nREST_FRAMEWORK = {\n \"UNAUTHENTICATED_USER\": \"kolibri.core.auth.models.KolibriAnonymousUser\",\n \"DEFAULT_AUTHENTICATION_CLASSES\": [\n # Activate basic auth for external API testing tools\n \"rest_framework.authentication.BasicAuthentication\",\n \"rest_framework.authentication.SessionAuthentication\",\n ],\n \"DEFAULT_RENDERER_CLASSES\": (\n \"rest_framework.renderers.JSONRenderer\",\n \"rest_framework.renderers.BrowsableAPIRenderer\",\n ),\n \"EXCEPTION_HANDLER\": \"kolibri.core.utils.exception_handler.custom_exception_handler\",\n}\n\nSWAGGER_SETTINGS = {\"DEFAULT_INFO\": \"kolibri.deployment.default.dev_urls.api_info\"}\n", "path": "kolibri/deployment/default/settings/dev.py"}]} | 2,311 | 168 |
gh_patches_debug_14152 | rasdani/github-patches | git_diff | scrapy__scrapy-5412 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Remove Python 2 code from WrappedRequest
[The WrappedRequest class](https://github.com/scrapy/scrapy/blob/06f3d12c1208c380f9f1a16cb36ba2dfa3c244c5/scrapy/http/cookies.py#L148) has methods that can be removed, as [they were only used in Python 3.3 and earlier](https://docs.python.org/3/library/http.cookiejar.html#http.cookiejar.CookieJar.extract_cookies).
</issue>
<code>
[start of scrapy/http/cookies.py]
1 import re
2 import time
3 from http.cookiejar import CookieJar as _CookieJar, DefaultCookiePolicy
4
5 from scrapy.utils.httpobj import urlparse_cached
6 from scrapy.utils.python import to_unicode
7
8
9 # Defined in the http.cookiejar module, but undocumented:
10 # https://github.com/python/cpython/blob/v3.9.0/Lib/http/cookiejar.py#L527
11 IPV4_RE = re.compile(r"\.\d+$", re.ASCII)
12
13
14 class CookieJar:
15 def __init__(self, policy=None, check_expired_frequency=10000):
16 self.policy = policy or DefaultCookiePolicy()
17 self.jar = _CookieJar(self.policy)
18 self.jar._cookies_lock = _DummyLock()
19 self.check_expired_frequency = check_expired_frequency
20 self.processed = 0
21
22 def extract_cookies(self, response, request):
23 wreq = WrappedRequest(request)
24 wrsp = WrappedResponse(response)
25 return self.jar.extract_cookies(wrsp, wreq)
26
27 def add_cookie_header(self, request):
28 wreq = WrappedRequest(request)
29 self.policy._now = self.jar._now = int(time.time())
30
31 # the cookiejar implementation iterates through all domains
32 # instead we restrict to potential matches on the domain
33 req_host = urlparse_cached(request).hostname
34 if not req_host:
35 return
36
37 if not IPV4_RE.search(req_host):
38 hosts = potential_domain_matches(req_host)
39 if '.' not in req_host:
40 hosts += [req_host + ".local"]
41 else:
42 hosts = [req_host]
43
44 cookies = []
45 for host in hosts:
46 if host in self.jar._cookies:
47 cookies += self.jar._cookies_for_domain(host, wreq)
48
49 attrs = self.jar._cookie_attrs(cookies)
50 if attrs:
51 if not wreq.has_header("Cookie"):
52 wreq.add_unredirected_header("Cookie", "; ".join(attrs))
53
54 self.processed += 1
55 if self.processed % self.check_expired_frequency == 0:
56 # This is still quite inefficient for large number of cookies
57 self.jar.clear_expired_cookies()
58
59 @property
60 def _cookies(self):
61 return self.jar._cookies
62
63 def clear_session_cookies(self, *args, **kwargs):
64 return self.jar.clear_session_cookies(*args, **kwargs)
65
66 def clear(self, domain=None, path=None, name=None):
67 return self.jar.clear(domain, path, name)
68
69 def __iter__(self):
70 return iter(self.jar)
71
72 def __len__(self):
73 return len(self.jar)
74
75 def set_policy(self, pol):
76 return self.jar.set_policy(pol)
77
78 def make_cookies(self, response, request):
79 wreq = WrappedRequest(request)
80 wrsp = WrappedResponse(response)
81 return self.jar.make_cookies(wrsp, wreq)
82
83 def set_cookie(self, cookie):
84 self.jar.set_cookie(cookie)
85
86 def set_cookie_if_ok(self, cookie, request):
87 self.jar.set_cookie_if_ok(cookie, WrappedRequest(request))
88
89
90 def potential_domain_matches(domain):
91 """Potential domain matches for a cookie
92
93 >>> potential_domain_matches('www.example.com')
94 ['www.example.com', 'example.com', '.www.example.com', '.example.com']
95
96 """
97 matches = [domain]
98 try:
99 start = domain.index('.') + 1
100 end = domain.rindex('.')
101 while start < end:
102 matches.append(domain[start:])
103 start = domain.index('.', start) + 1
104 except ValueError:
105 pass
106 return matches + ['.' + d for d in matches]
107
108
109 class _DummyLock:
110 def acquire(self):
111 pass
112
113 def release(self):
114 pass
115
116
117 class WrappedRequest:
118 """Wraps a scrapy Request class with methods defined by urllib2.Request class to interact with CookieJar class
119
120 see http://docs.python.org/library/urllib2.html#urllib2.Request
121 """
122
123 def __init__(self, request):
124 self.request = request
125
126 def get_full_url(self):
127 return self.request.url
128
129 def get_host(self):
130 return urlparse_cached(self.request).netloc
131
132 def get_type(self):
133 return urlparse_cached(self.request).scheme
134
135 def is_unverifiable(self):
136 """Unverifiable should indicate whether the request is unverifiable, as defined by RFC 2965.
137
138 It defaults to False. An unverifiable request is one whose URL the user did not have the
139 option to approve. For example, if the request is for an image in an
140 HTML document, and the user had no option to approve the automatic
141 fetching of the image, this should be true.
142 """
143 return self.request.meta.get('is_unverifiable', False)
144
145 def get_origin_req_host(self):
146 return urlparse_cached(self.request).hostname
147
148 # python3 uses attributes instead of methods
149 @property
150 def full_url(self):
151 return self.get_full_url()
152
153 @property
154 def host(self):
155 return self.get_host()
156
157 @property
158 def type(self):
159 return self.get_type()
160
161 @property
162 def unverifiable(self):
163 return self.is_unverifiable()
164
165 @property
166 def origin_req_host(self):
167 return self.get_origin_req_host()
168
169 def has_header(self, name):
170 return name in self.request.headers
171
172 def get_header(self, name, default=None):
173 return to_unicode(self.request.headers.get(name, default),
174 errors='replace')
175
176 def header_items(self):
177 return [
178 (to_unicode(k, errors='replace'),
179 [to_unicode(x, errors='replace') for x in v])
180 for k, v in self.request.headers.items()
181 ]
182
183 def add_unredirected_header(self, name, value):
184 self.request.headers.appendlist(name, value)
185
186
187 class WrappedResponse:
188
189 def __init__(self, response):
190 self.response = response
191
192 def info(self):
193 return self
194
195 def get_all(self, name, default=None):
196 return [to_unicode(v, errors='replace')
197 for v in self.response.headers.getlist(name)]
198
[end of scrapy/http/cookies.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/scrapy/http/cookies.py b/scrapy/http/cookies.py
--- a/scrapy/http/cookies.py
+++ b/scrapy/http/cookies.py
@@ -142,10 +142,6 @@
"""
return self.request.meta.get('is_unverifiable', False)
- def get_origin_req_host(self):
- return urlparse_cached(self.request).hostname
-
- # python3 uses attributes instead of methods
@property
def full_url(self):
return self.get_full_url()
@@ -164,7 +160,7 @@
@property
def origin_req_host(self):
- return self.get_origin_req_host()
+ return urlparse_cached(self.request).hostname
def has_header(self, name):
return name in self.request.headers
| {"golden_diff": "diff --git a/scrapy/http/cookies.py b/scrapy/http/cookies.py\n--- a/scrapy/http/cookies.py\n+++ b/scrapy/http/cookies.py\n@@ -142,10 +142,6 @@\n \"\"\"\n return self.request.meta.get('is_unverifiable', False)\n \n- def get_origin_req_host(self):\n- return urlparse_cached(self.request).hostname\n-\n- # python3 uses attributes instead of methods\n @property\n def full_url(self):\n return self.get_full_url()\n@@ -164,7 +160,7 @@\n \n @property\n def origin_req_host(self):\n- return self.get_origin_req_host()\n+ return urlparse_cached(self.request).hostname\n \n def has_header(self, name):\n return name in self.request.headers\n", "issue": "Remove Python 2 code from WrappedRequest\n[The WrappedRequest class](https://github.com/scrapy/scrapy/blob/06f3d12c1208c380f9f1a16cb36ba2dfa3c244c5/scrapy/http/cookies.py#L148) has methods that can be removed, as [they were only used in Python 3.3 and earlier](https://docs.python.org/3/library/http.cookiejar.html#http.cookiejar.CookieJar.extract_cookies).\n", "before_files": [{"content": "import re\nimport time\nfrom http.cookiejar import CookieJar as _CookieJar, DefaultCookiePolicy\n\nfrom scrapy.utils.httpobj import urlparse_cached\nfrom scrapy.utils.python import to_unicode\n\n\n# Defined in the http.cookiejar module, but undocumented:\n# https://github.com/python/cpython/blob/v3.9.0/Lib/http/cookiejar.py#L527\nIPV4_RE = re.compile(r\"\\.\\d+$\", re.ASCII)\n\n\nclass CookieJar:\n def __init__(self, policy=None, check_expired_frequency=10000):\n self.policy = policy or DefaultCookiePolicy()\n self.jar = _CookieJar(self.policy)\n self.jar._cookies_lock = _DummyLock()\n self.check_expired_frequency = check_expired_frequency\n self.processed = 0\n\n def extract_cookies(self, response, request):\n wreq = WrappedRequest(request)\n wrsp = WrappedResponse(response)\n return self.jar.extract_cookies(wrsp, wreq)\n\n def add_cookie_header(self, request):\n wreq = WrappedRequest(request)\n self.policy._now = self.jar._now = int(time.time())\n\n # the cookiejar implementation iterates through all domains\n # instead we restrict to potential matches on the domain\n req_host = urlparse_cached(request).hostname\n if not req_host:\n return\n\n if not IPV4_RE.search(req_host):\n hosts = potential_domain_matches(req_host)\n if '.' not in req_host:\n hosts += [req_host + \".local\"]\n else:\n hosts = [req_host]\n\n cookies = []\n for host in hosts:\n if host in self.jar._cookies:\n cookies += self.jar._cookies_for_domain(host, wreq)\n\n attrs = self.jar._cookie_attrs(cookies)\n if attrs:\n if not wreq.has_header(\"Cookie\"):\n wreq.add_unredirected_header(\"Cookie\", \"; \".join(attrs))\n\n self.processed += 1\n if self.processed % self.check_expired_frequency == 0:\n # This is still quite inefficient for large number of cookies\n self.jar.clear_expired_cookies()\n\n @property\n def _cookies(self):\n return self.jar._cookies\n\n def clear_session_cookies(self, *args, **kwargs):\n return self.jar.clear_session_cookies(*args, **kwargs)\n\n def clear(self, domain=None, path=None, name=None):\n return self.jar.clear(domain, path, name)\n\n def __iter__(self):\n return iter(self.jar)\n\n def __len__(self):\n return len(self.jar)\n\n def set_policy(self, pol):\n return self.jar.set_policy(pol)\n\n def make_cookies(self, response, request):\n wreq = WrappedRequest(request)\n wrsp = WrappedResponse(response)\n return self.jar.make_cookies(wrsp, wreq)\n\n def set_cookie(self, cookie):\n self.jar.set_cookie(cookie)\n\n def set_cookie_if_ok(self, cookie, request):\n self.jar.set_cookie_if_ok(cookie, WrappedRequest(request))\n\n\ndef potential_domain_matches(domain):\n \"\"\"Potential domain matches for a cookie\n\n >>> potential_domain_matches('www.example.com')\n ['www.example.com', 'example.com', '.www.example.com', '.example.com']\n\n \"\"\"\n matches = [domain]\n try:\n start = domain.index('.') + 1\n end = domain.rindex('.')\n while start < end:\n matches.append(domain[start:])\n start = domain.index('.', start) + 1\n except ValueError:\n pass\n return matches + ['.' + d for d in matches]\n\n\nclass _DummyLock:\n def acquire(self):\n pass\n\n def release(self):\n pass\n\n\nclass WrappedRequest:\n \"\"\"Wraps a scrapy Request class with methods defined by urllib2.Request class to interact with CookieJar class\n\n see http://docs.python.org/library/urllib2.html#urllib2.Request\n \"\"\"\n\n def __init__(self, request):\n self.request = request\n\n def get_full_url(self):\n return self.request.url\n\n def get_host(self):\n return urlparse_cached(self.request).netloc\n\n def get_type(self):\n return urlparse_cached(self.request).scheme\n\n def is_unverifiable(self):\n \"\"\"Unverifiable should indicate whether the request is unverifiable, as defined by RFC 2965.\n\n It defaults to False. An unverifiable request is one whose URL the user did not have the\n option to approve. For example, if the request is for an image in an\n HTML document, and the user had no option to approve the automatic\n fetching of the image, this should be true.\n \"\"\"\n return self.request.meta.get('is_unverifiable', False)\n\n def get_origin_req_host(self):\n return urlparse_cached(self.request).hostname\n\n # python3 uses attributes instead of methods\n @property\n def full_url(self):\n return self.get_full_url()\n\n @property\n def host(self):\n return self.get_host()\n\n @property\n def type(self):\n return self.get_type()\n\n @property\n def unverifiable(self):\n return self.is_unverifiable()\n\n @property\n def origin_req_host(self):\n return self.get_origin_req_host()\n\n def has_header(self, name):\n return name in self.request.headers\n\n def get_header(self, name, default=None):\n return to_unicode(self.request.headers.get(name, default),\n errors='replace')\n\n def header_items(self):\n return [\n (to_unicode(k, errors='replace'),\n [to_unicode(x, errors='replace') for x in v])\n for k, v in self.request.headers.items()\n ]\n\n def add_unredirected_header(self, name, value):\n self.request.headers.appendlist(name, value)\n\n\nclass WrappedResponse:\n\n def __init__(self, response):\n self.response = response\n\n def info(self):\n return self\n\n def get_all(self, name, default=None):\n return [to_unicode(v, errors='replace')\n for v in self.response.headers.getlist(name)]\n", "path": "scrapy/http/cookies.py"}]} | 2,466 | 177 |
gh_patches_debug_17128 | rasdani/github-patches | git_diff | google__flax-965 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
When jax_enable_x64 is set Adam promotes everything to float64
### Problem you have encountered:
When `jax_enable_x64` is set, Adam's `apply_gradient` method will promote all float32 arrays to float64, potentially unexpectedly degrading performance.
This is due to jax's wonky type promotion semantics. The offending line is:
https://github.com/google/flax/blob/3e36db3e5e3b8e6e1777d612f270e7948238aa9c/flax/optim/adam.py#L82
which promotes like:
```python
jnp.array([0], dtype=jnp.int32) + 1. # == DeviceArray([1.], dtype=float64)
```
and then cascades from there promoting everything to float64
### What you expected to happen:
Arrays should retain their dtypes on optimizer updates.
### Logs, error messages, etc:
### Steps to reproduce:
```python
from jax.config import config
config.update("jax_enable_x64", True)
import jax.numpy as jnp
import flax
opt = flax.optim.Adam(1e-3).create(
{"x": jnp.zeros(10, dtype=jnp.float32)})
assert opt.target["x"].dtype == jnp.float32
opt = opt.apply_gradient({"x": jnp.zeros(10, dtype=jnp.float32)})
# This fails, since dtype was promoted to float64
assert opt.target["x"].dtype == jnp.float32
```
</issue>
<code>
[start of flax/optim/lamb.py]
1 # Copyright 2021 The Flax Authors.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from .. import struct
16
17 from jax import lax
18 import jax.numpy as jnp
19
20 import numpy as onp
21
22 from .base import OptimizerDef
23
24 @struct.dataclass
25 class _LAMBHyperParams:
26 learning_rate: onp.ndarray
27 beta1: onp.ndarray
28 beta2: onp.ndarray
29 weight_decay: onp.ndarray
30 eps: onp.ndarray
31
32
33 @struct.dataclass
34 class _LAMBParamState:
35 grad_ema: onp.ndarray
36 grad_sq_ema: onp.ndarray
37
38
39 class LAMB(OptimizerDef):
40 """Layerwise adaptive moments for batch (LAMB) optimizer.
41
42 See https://arxiv.org/abs/1904.00962
43 """
44
45 def __init__(self, learning_rate=None, beta1=0.9, beta2=0.999, weight_decay=0,
46 eps=1e-6):
47 """Constructor for the LAMB optimizer.
48
49 Args:
50 learning_rate: the step size used to update the parameters.
51 beta1: the coefficient used for the moving average of the gradient
52 (default: 0.9).
53 beta2: the coefficient used for the moving average of the squared gradient
54 (default: 0.999).
55 weight_decay: weight decay coefficient to apply
56 eps: epsilon used for Adam update computation (default: 1e-6).
57 """
58
59 hyper_params = _LAMBHyperParams(
60 learning_rate, beta1, beta2, weight_decay, eps)
61 super().__init__(hyper_params)
62
63 def init_param_state(self, param):
64 return _LAMBParamState(jnp.zeros_like(param), jnp.zeros_like(param))
65
66 def apply_param_gradient(self, step, hyper_params, param, state, grad):
67 assert hyper_params.learning_rate is not None, 'no learning rate provided.'
68 beta1 = hyper_params.beta1
69 beta2 = hyper_params.beta2
70 weight_decay = hyper_params.weight_decay
71 learning_rate = hyper_params.learning_rate
72
73 grad_sq = lax.square(grad)
74 grad_ema = beta1 * state.grad_ema + (1. - beta1) * grad
75 grad_sq_ema = beta2 * state.grad_sq_ema + (1. - beta2) * grad_sq
76
77 t = step + 1.
78 grad_ema_corr = grad_ema / (1. - beta1 ** t)
79 grad_sq_ema_corr = grad_sq_ema / (1. - beta2 ** t)
80
81 update = grad_ema_corr / (jnp.sqrt(grad_sq_ema_corr) + hyper_params.eps)
82
83 if weight_decay != 0.0:
84 update += weight_decay * param
85
86 param_norm = jnp.linalg.norm(param)
87 update_norm = jnp.linalg.norm(update)
88 trust_ratio = jnp.where(
89 param_norm + update_norm > 0., param_norm / update_norm, 1.)
90
91 new_param = param - trust_ratio * learning_rate * update
92 new_state = _LAMBParamState(grad_ema, grad_sq_ema)
93 return new_param, new_state
94
[end of flax/optim/lamb.py]
[start of flax/optim/adam.py]
1 # Copyright 2021 The Flax Authors.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from .. import struct
16
17 import jax.numpy as jnp
18 from jax import lax
19
20 import numpy as onp
21
22 from .base import OptimizerDef
23
24
25 @struct.dataclass
26 class _AdamHyperParams:
27 learning_rate: onp.ndarray
28 beta1: onp.ndarray
29 beta2: onp.ndarray
30 eps: onp.ndarray
31 weight_decay: onp.ndarray
32
33
34 @struct.dataclass
35 class _AdamParamState:
36 grad_ema: onp.ndarray
37 grad_sq_ema: onp.ndarray
38
39
40 class Adam(OptimizerDef):
41 """Adam optimizer.
42
43 Implements Adam - a stochastic gradient descent method (SGD) that computes
44 individual adaptive learning rates for different parameters from estimates of
45 first- and second-order moments of the gradients.
46
47 Reference: [Adam: A Method
48 for Stochastic Optimization](https://arxiv.org/abs/1412.6980v8) (Kingma and
49 Ba, 2014).
50
51 Attributes:
52 learning_rate: The learning rate — the step size used to update the
53 parameters.
54 beta1: The exponentian decay rate for the 1st moment estimates. The
55 coefficient used to calculate the first moments of the gradients (the
56 moving average of the gradient) (default: 0.9).
57 beta2: The exponentian decay rate for the 2nd moment estimates. The
58 coefficient used to calculate the second moments of the gradients (the
59 moving average of the gradient magnitude) (default: 0.999).
60 eps: A small scalar added to the gradient magnitude estimate to improve
61 numerical stability (default: 1e-8).
62 weight_decay: The learning rate decay (default: 0.0).
63 """
64
65 def __init__(self,
66 learning_rate=None,
67 beta1=0.9,
68 beta2=0.999,
69 eps=1e-8,
70 weight_decay=0.0):
71 """Constructor for the Adam optimizer.
72
73 Args:
74 learning_rate: The step size used to update the parameters.
75 beta1: The coefficient used for the moving average of the
76 gradient (default: 0.9).
77 beta2: The coefficient used for the moving average of the
78 gradient magnitude (default: 0.999).
79 eps: The term added to the gradient magnitude estimate for
80 numerical stability (default: 1e-8).
81 weight_decay: AdamW style weight decay rate
82 (relative to learning rate) (default: 0.0).
83 """
84 hyper_params = _AdamHyperParams(learning_rate, beta1, beta2, eps,
85 weight_decay)
86 super().__init__(hyper_params)
87
88 def init_param_state(self, param):
89 return _AdamParamState(jnp.zeros_like(param), jnp.zeros_like(param))
90
91 def apply_param_gradient(self, step, hyper_params, param, state, grad):
92 assert hyper_params.learning_rate is not None, 'no learning rate provided.'
93 beta1 = hyper_params.beta1
94 beta2 = hyper_params.beta2
95 weight_decay = hyper_params.weight_decay
96 grad_sq = lax.square(grad)
97 grad_ema = beta1 * state.grad_ema + (1. - beta1) * grad
98 grad_sq_ema = beta2 * state.grad_sq_ema + (1. - beta2) * grad_sq
99
100 # bias correction
101 t = step + 1.
102 grad_ema_corr = grad_ema / (1 - beta1 ** t)
103 grad_sq_ema_corr = grad_sq_ema / (1 - beta2 ** t)
104
105 denom = jnp.sqrt(grad_sq_ema_corr) + hyper_params.eps
106 new_param = param - hyper_params.learning_rate * grad_ema_corr / denom
107 new_param -= hyper_params.learning_rate * weight_decay * param
108 new_state = _AdamParamState(grad_ema, grad_sq_ema)
109 return new_param, new_state
110
[end of flax/optim/adam.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/flax/optim/adam.py b/flax/optim/adam.py
--- a/flax/optim/adam.py
+++ b/flax/optim/adam.py
@@ -98,7 +98,7 @@
grad_sq_ema = beta2 * state.grad_sq_ema + (1. - beta2) * grad_sq
# bias correction
- t = step + 1.
+ t = jnp.array(step + 1, lax.dtype(param.dtype))
grad_ema_corr = grad_ema / (1 - beta1 ** t)
grad_sq_ema_corr = grad_sq_ema / (1 - beta2 ** t)
diff --git a/flax/optim/lamb.py b/flax/optim/lamb.py
--- a/flax/optim/lamb.py
+++ b/flax/optim/lamb.py
@@ -74,7 +74,7 @@
grad_ema = beta1 * state.grad_ema + (1. - beta1) * grad
grad_sq_ema = beta2 * state.grad_sq_ema + (1. - beta2) * grad_sq
- t = step + 1.
+ t = jnp.array(step + 1, lax.dtype(param.dtype))
grad_ema_corr = grad_ema / (1. - beta1 ** t)
grad_sq_ema_corr = grad_sq_ema / (1. - beta2 ** t)
| {"golden_diff": "diff --git a/flax/optim/adam.py b/flax/optim/adam.py\n--- a/flax/optim/adam.py\n+++ b/flax/optim/adam.py\n@@ -98,7 +98,7 @@\n grad_sq_ema = beta2 * state.grad_sq_ema + (1. - beta2) * grad_sq\n \n # bias correction\n- t = step + 1.\n+ t = jnp.array(step + 1, lax.dtype(param.dtype))\n grad_ema_corr = grad_ema / (1 - beta1 ** t)\n grad_sq_ema_corr = grad_sq_ema / (1 - beta2 ** t)\n \ndiff --git a/flax/optim/lamb.py b/flax/optim/lamb.py\n--- a/flax/optim/lamb.py\n+++ b/flax/optim/lamb.py\n@@ -74,7 +74,7 @@\n grad_ema = beta1 * state.grad_ema + (1. - beta1) * grad\n grad_sq_ema = beta2 * state.grad_sq_ema + (1. - beta2) * grad_sq\n \n- t = step + 1.\n+ t = jnp.array(step + 1, lax.dtype(param.dtype))\n grad_ema_corr = grad_ema / (1. - beta1 ** t)\n grad_sq_ema_corr = grad_sq_ema / (1. - beta2 ** t)\n", "issue": "When jax_enable_x64 is set Adam promotes everything to float64\n\r\n### Problem you have encountered:\r\n\r\nWhen `jax_enable_x64` is set, Adam's `apply_gradient` method will promote all float32 arrays to float64, potentially unexpectedly degrading performance.\r\n\r\nThis is due to jax's wonky type promotion semantics. The offending line is:\r\nhttps://github.com/google/flax/blob/3e36db3e5e3b8e6e1777d612f270e7948238aa9c/flax/optim/adam.py#L82\r\n\r\nwhich promotes like:\r\n```python\r\njnp.array([0], dtype=jnp.int32) + 1. # == DeviceArray([1.], dtype=float64)\r\n```\r\nand then cascades from there promoting everything to float64\r\n\r\n### What you expected to happen:\r\n\r\nArrays should retain their dtypes on optimizer updates.\r\n\r\n### Logs, error messages, etc:\r\n\r\n\r\n### Steps to reproduce:\r\n\r\n```python\r\nfrom jax.config import config\r\nconfig.update(\"jax_enable_x64\", True)\r\n\r\nimport jax.numpy as jnp\r\nimport flax\r\n\r\nopt = flax.optim.Adam(1e-3).create(\r\n {\"x\": jnp.zeros(10, dtype=jnp.float32)})\r\n\r\nassert opt.target[\"x\"].dtype == jnp.float32\r\n\r\nopt = opt.apply_gradient({\"x\": jnp.zeros(10, dtype=jnp.float32)})\r\n\r\n# This fails, since dtype was promoted to float64\r\nassert opt.target[\"x\"].dtype == jnp.float32\r\n```\n", "before_files": [{"content": "# Copyright 2021 The Flax Authors.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom .. import struct\n\nfrom jax import lax\nimport jax.numpy as jnp\n\nimport numpy as onp\n\nfrom .base import OptimizerDef\n\[email protected]\nclass _LAMBHyperParams:\n learning_rate: onp.ndarray\n beta1: onp.ndarray\n beta2: onp.ndarray\n weight_decay: onp.ndarray\n eps: onp.ndarray\n\n\[email protected]\nclass _LAMBParamState:\n grad_ema: onp.ndarray\n grad_sq_ema: onp.ndarray\n\n\nclass LAMB(OptimizerDef):\n \"\"\"Layerwise adaptive moments for batch (LAMB) optimizer.\n\n See https://arxiv.org/abs/1904.00962\n \"\"\"\n\n def __init__(self, learning_rate=None, beta1=0.9, beta2=0.999, weight_decay=0,\n eps=1e-6):\n \"\"\"Constructor for the LAMB optimizer.\n\n Args:\n learning_rate: the step size used to update the parameters.\n beta1: the coefficient used for the moving average of the gradient\n (default: 0.9).\n beta2: the coefficient used for the moving average of the squared gradient\n (default: 0.999).\n weight_decay: weight decay coefficient to apply\n eps: epsilon used for Adam update computation (default: 1e-6).\n \"\"\"\n\n hyper_params = _LAMBHyperParams(\n learning_rate, beta1, beta2, weight_decay, eps)\n super().__init__(hyper_params)\n\n def init_param_state(self, param):\n return _LAMBParamState(jnp.zeros_like(param), jnp.zeros_like(param))\n\n def apply_param_gradient(self, step, hyper_params, param, state, grad):\n assert hyper_params.learning_rate is not None, 'no learning rate provided.'\n beta1 = hyper_params.beta1\n beta2 = hyper_params.beta2\n weight_decay = hyper_params.weight_decay\n learning_rate = hyper_params.learning_rate\n\n grad_sq = lax.square(grad)\n grad_ema = beta1 * state.grad_ema + (1. - beta1) * grad\n grad_sq_ema = beta2 * state.grad_sq_ema + (1. - beta2) * grad_sq\n\n t = step + 1.\n grad_ema_corr = grad_ema / (1. - beta1 ** t)\n grad_sq_ema_corr = grad_sq_ema / (1. - beta2 ** t)\n\n update = grad_ema_corr / (jnp.sqrt(grad_sq_ema_corr) + hyper_params.eps)\n\n if weight_decay != 0.0:\n update += weight_decay * param\n\n param_norm = jnp.linalg.norm(param)\n update_norm = jnp.linalg.norm(update)\n trust_ratio = jnp.where(\n param_norm + update_norm > 0., param_norm / update_norm, 1.)\n\n new_param = param - trust_ratio * learning_rate * update\n new_state = _LAMBParamState(grad_ema, grad_sq_ema)\n return new_param, new_state\n", "path": "flax/optim/lamb.py"}, {"content": "# Copyright 2021 The Flax Authors.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom .. import struct\n\nimport jax.numpy as jnp\nfrom jax import lax\n\nimport numpy as onp\n\nfrom .base import OptimizerDef\n\n\[email protected]\nclass _AdamHyperParams:\n learning_rate: onp.ndarray\n beta1: onp.ndarray\n beta2: onp.ndarray\n eps: onp.ndarray\n weight_decay: onp.ndarray\n\n\[email protected]\nclass _AdamParamState:\n grad_ema: onp.ndarray\n grad_sq_ema: onp.ndarray\n\n\nclass Adam(OptimizerDef):\n \"\"\"Adam optimizer.\n\n Implements Adam - a stochastic gradient descent method (SGD) that computes\n individual adaptive learning rates for different parameters from estimates of\n first- and second-order moments of the gradients. \n \n Reference: [Adam: A Method\n for Stochastic Optimization](https://arxiv.org/abs/1412.6980v8) (Kingma and\n Ba, 2014).\n\n Attributes:\n learning_rate: The learning rate \u2014 the step size used to update the\n parameters.\n beta1: The exponentian decay rate for the 1st moment estimates. The\n coefficient used to calculate the first moments of the gradients (the\n moving average of the gradient) (default: 0.9).\n beta2: The exponentian decay rate for the 2nd moment estimates. The\n coefficient used to calculate the second moments of the gradients (the\n moving average of the gradient magnitude) (default: 0.999).\n eps: A small scalar added to the gradient magnitude estimate to improve\n numerical stability (default: 1e-8).\n weight_decay: The learning rate decay (default: 0.0).\n \"\"\"\n\n def __init__(self,\n learning_rate=None,\n beta1=0.9,\n beta2=0.999,\n eps=1e-8,\n weight_decay=0.0):\n \"\"\"Constructor for the Adam optimizer.\n\n Args:\n learning_rate: The step size used to update the parameters.\n beta1: The coefficient used for the moving average of the\n gradient (default: 0.9).\n beta2: The coefficient used for the moving average of the\n gradient magnitude (default: 0.999).\n eps: The term added to the gradient magnitude estimate for\n numerical stability (default: 1e-8).\n weight_decay: AdamW style weight decay rate\n (relative to learning rate) (default: 0.0).\n \"\"\"\n hyper_params = _AdamHyperParams(learning_rate, beta1, beta2, eps,\n weight_decay)\n super().__init__(hyper_params)\n\n def init_param_state(self, param):\n return _AdamParamState(jnp.zeros_like(param), jnp.zeros_like(param))\n\n def apply_param_gradient(self, step, hyper_params, param, state, grad):\n assert hyper_params.learning_rate is not None, 'no learning rate provided.'\n beta1 = hyper_params.beta1\n beta2 = hyper_params.beta2\n weight_decay = hyper_params.weight_decay\n grad_sq = lax.square(grad)\n grad_ema = beta1 * state.grad_ema + (1. - beta1) * grad\n grad_sq_ema = beta2 * state.grad_sq_ema + (1. - beta2) * grad_sq\n\n # bias correction\n t = step + 1.\n grad_ema_corr = grad_ema / (1 - beta1 ** t)\n grad_sq_ema_corr = grad_sq_ema / (1 - beta2 ** t)\n\n denom = jnp.sqrt(grad_sq_ema_corr) + hyper_params.eps\n new_param = param - hyper_params.learning_rate * grad_ema_corr / denom\n new_param -= hyper_params.learning_rate * weight_decay * param\n new_state = _AdamParamState(grad_ema, grad_sq_ema)\n return new_param, new_state\n", "path": "flax/optim/adam.py"}]} | 3,143 | 315 |
gh_patches_debug_31690 | rasdani/github-patches | git_diff | open-telemetry__opentelemetry-python-2237 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Otel Spec forbids B3 propagator from propagating `X-B3-ParentSpanId`
From the [spec](https://github.com/open-telemetry/opentelemetry-specification/blob/main/specification/context/api-propagators.md#b3-inject)
> MUST NOT propagate X-B3-ParentSpanId as OpenTelemetry does not support reusing the same id for both sides of a request.
But we do it [here](https://github.com/open-telemetry/opentelemetry-python/blob/61c2d6e1508c75cce4b50ff7b28712c944b94128/propagator/opentelemetry-propagator-b3/src/opentelemetry/propagators/b3/__init__.py#L152-L158)
This should be removed as the spec forbids it.
</issue>
<code>
[start of propagator/opentelemetry-propagator-b3/src/opentelemetry/propagators/b3/__init__.py]
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import typing
16 from re import compile as re_compile
17
18 from deprecated import deprecated
19
20 from opentelemetry import trace
21 from opentelemetry.context import Context
22 from opentelemetry.propagators.textmap import (
23 CarrierT,
24 Getter,
25 Setter,
26 TextMapPropagator,
27 default_getter,
28 default_setter,
29 )
30 from opentelemetry.trace import format_span_id, format_trace_id
31
32
33 class B3MultiFormat(TextMapPropagator):
34 """Propagator for the B3 HTTP multi-header format.
35
36 See: https://github.com/openzipkin/b3-propagation
37 https://github.com/openzipkin/b3-propagation#multiple-headers
38 """
39
40 SINGLE_HEADER_KEY = "b3"
41 TRACE_ID_KEY = "x-b3-traceid"
42 SPAN_ID_KEY = "x-b3-spanid"
43 PARENT_SPAN_ID_KEY = "x-b3-parentspanid"
44 SAMPLED_KEY = "x-b3-sampled"
45 FLAGS_KEY = "x-b3-flags"
46 _SAMPLE_PROPAGATE_VALUES = set(["1", "True", "true", "d"])
47 _trace_id_regex = re_compile(r"[\da-fA-F]{16}|[\da-fA-F]{32}")
48 _span_id_regex = re_compile(r"[\da-fA-F]{16}")
49
50 def extract(
51 self,
52 carrier: CarrierT,
53 context: typing.Optional[Context] = None,
54 getter: Getter = default_getter,
55 ) -> Context:
56 if context is None:
57 context = Context()
58 trace_id = trace.INVALID_TRACE_ID
59 span_id = trace.INVALID_SPAN_ID
60 sampled = "0"
61 flags = None
62
63 single_header = _extract_first_element(
64 getter.get(carrier, self.SINGLE_HEADER_KEY)
65 )
66 if single_header:
67 # The b3 spec calls for the sampling state to be
68 # "deferred", which is unspecified. This concept does not
69 # translate to SpanContext, so we set it as recorded.
70 sampled = "1"
71 fields = single_header.split("-", 4)
72
73 if len(fields) == 1:
74 sampled = fields[0]
75 elif len(fields) == 2:
76 trace_id, span_id = fields
77 elif len(fields) == 3:
78 trace_id, span_id, sampled = fields
79 elif len(fields) == 4:
80 trace_id, span_id, sampled, _ = fields
81 else:
82 trace_id = (
83 _extract_first_element(getter.get(carrier, self.TRACE_ID_KEY))
84 or trace_id
85 )
86 span_id = (
87 _extract_first_element(getter.get(carrier, self.SPAN_ID_KEY))
88 or span_id
89 )
90 sampled = (
91 _extract_first_element(getter.get(carrier, self.SAMPLED_KEY))
92 or sampled
93 )
94 flags = (
95 _extract_first_element(getter.get(carrier, self.FLAGS_KEY))
96 or flags
97 )
98
99 if (
100 trace_id == trace.INVALID_TRACE_ID
101 or span_id == trace.INVALID_SPAN_ID
102 or self._trace_id_regex.fullmatch(trace_id) is None
103 or self._span_id_regex.fullmatch(span_id) is None
104 ):
105 return context
106
107 trace_id = int(trace_id, 16)
108 span_id = int(span_id, 16)
109 options = 0
110 # The b3 spec provides no defined behavior for both sample and
111 # flag values set. Since the setting of at least one implies
112 # the desire for some form of sampling, propagate if either
113 # header is set to allow.
114 if sampled in self._SAMPLE_PROPAGATE_VALUES or flags == "1":
115 options |= trace.TraceFlags.SAMPLED
116
117 return trace.set_span_in_context(
118 trace.NonRecordingSpan(
119 trace.SpanContext(
120 # trace an span ids are encoded in hex, so must be converted
121 trace_id=trace_id,
122 span_id=span_id,
123 is_remote=True,
124 trace_flags=trace.TraceFlags(options),
125 trace_state=trace.TraceState(),
126 )
127 ),
128 context,
129 )
130
131 def inject(
132 self,
133 carrier: CarrierT,
134 context: typing.Optional[Context] = None,
135 setter: Setter = default_setter,
136 ) -> None:
137 span = trace.get_current_span(context=context)
138
139 span_context = span.get_span_context()
140 if span_context == trace.INVALID_SPAN_CONTEXT:
141 return
142
143 sampled = (trace.TraceFlags.SAMPLED & span_context.trace_flags) != 0
144 setter.set(
145 carrier,
146 self.TRACE_ID_KEY,
147 format_trace_id(span_context.trace_id),
148 )
149 setter.set(
150 carrier, self.SPAN_ID_KEY, format_span_id(span_context.span_id)
151 )
152 span_parent = getattr(span, "parent", None)
153 if span_parent is not None:
154 setter.set(
155 carrier,
156 self.PARENT_SPAN_ID_KEY,
157 format_span_id(span_parent.span_id),
158 )
159 setter.set(carrier, self.SAMPLED_KEY, "1" if sampled else "0")
160
161 @property
162 def fields(self) -> typing.Set[str]:
163 return {
164 self.TRACE_ID_KEY,
165 self.SPAN_ID_KEY,
166 self.PARENT_SPAN_ID_KEY,
167 self.SAMPLED_KEY,
168 }
169
170
171 class B3SingleFormat(B3MultiFormat):
172 """Propagator for the B3 HTTP single-header format.
173
174 See: https://github.com/openzipkin/b3-propagation
175 https://github.com/openzipkin/b3-propagation#single-header
176 """
177
178 def inject(
179 self,
180 carrier: CarrierT,
181 context: typing.Optional[Context] = None,
182 setter: Setter = default_setter,
183 ) -> None:
184 span = trace.get_current_span(context=context)
185
186 span_context = span.get_span_context()
187 if span_context == trace.INVALID_SPAN_CONTEXT:
188 return
189
190 sampled = (trace.TraceFlags.SAMPLED & span_context.trace_flags) != 0
191
192 fields = [
193 format_trace_id(span_context.trace_id),
194 format_span_id(span_context.span_id),
195 "1" if sampled else "0",
196 ]
197
198 span_parent = getattr(span, "parent", None)
199 if span_parent:
200 fields.append(format_span_id(span_parent.span_id))
201
202 setter.set(carrier, self.SINGLE_HEADER_KEY, "-".join(fields))
203
204 @property
205 def fields(self) -> typing.Set[str]:
206 return {self.SINGLE_HEADER_KEY}
207
208
209 class B3Format(B3MultiFormat):
210 @deprecated(
211 version="1.2.0",
212 reason="B3Format is deprecated in favor of B3MultiFormat",
213 )
214 def __init__(self, *args, **kwargs):
215 super().__init__(*args, **kwargs)
216
217
218 def _extract_first_element(
219 items: typing.Iterable[CarrierT],
220 ) -> typing.Optional[CarrierT]:
221 if items is None:
222 return None
223 return next(iter(items), None)
224
[end of propagator/opentelemetry-propagator-b3/src/opentelemetry/propagators/b3/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/propagator/opentelemetry-propagator-b3/src/opentelemetry/propagators/b3/__init__.py b/propagator/opentelemetry-propagator-b3/src/opentelemetry/propagators/b3/__init__.py
--- a/propagator/opentelemetry-propagator-b3/src/opentelemetry/propagators/b3/__init__.py
+++ b/propagator/opentelemetry-propagator-b3/src/opentelemetry/propagators/b3/__init__.py
@@ -40,7 +40,6 @@
SINGLE_HEADER_KEY = "b3"
TRACE_ID_KEY = "x-b3-traceid"
SPAN_ID_KEY = "x-b3-spanid"
- PARENT_SPAN_ID_KEY = "x-b3-parentspanid"
SAMPLED_KEY = "x-b3-sampled"
FLAGS_KEY = "x-b3-flags"
_SAMPLE_PROPAGATE_VALUES = set(["1", "True", "true", "d"])
@@ -149,13 +148,6 @@
setter.set(
carrier, self.SPAN_ID_KEY, format_span_id(span_context.span_id)
)
- span_parent = getattr(span, "parent", None)
- if span_parent is not None:
- setter.set(
- carrier,
- self.PARENT_SPAN_ID_KEY,
- format_span_id(span_parent.span_id),
- )
setter.set(carrier, self.SAMPLED_KEY, "1" if sampled else "0")
@property
@@ -163,7 +155,6 @@
return {
self.TRACE_ID_KEY,
self.SPAN_ID_KEY,
- self.PARENT_SPAN_ID_KEY,
self.SAMPLED_KEY,
}
@@ -195,10 +186,6 @@
"1" if sampled else "0",
]
- span_parent = getattr(span, "parent", None)
- if span_parent:
- fields.append(format_span_id(span_parent.span_id))
-
setter.set(carrier, self.SINGLE_HEADER_KEY, "-".join(fields))
@property
| {"golden_diff": "diff --git a/propagator/opentelemetry-propagator-b3/src/opentelemetry/propagators/b3/__init__.py b/propagator/opentelemetry-propagator-b3/src/opentelemetry/propagators/b3/__init__.py\n--- a/propagator/opentelemetry-propagator-b3/src/opentelemetry/propagators/b3/__init__.py\n+++ b/propagator/opentelemetry-propagator-b3/src/opentelemetry/propagators/b3/__init__.py\n@@ -40,7 +40,6 @@\n SINGLE_HEADER_KEY = \"b3\"\n TRACE_ID_KEY = \"x-b3-traceid\"\n SPAN_ID_KEY = \"x-b3-spanid\"\n- PARENT_SPAN_ID_KEY = \"x-b3-parentspanid\"\n SAMPLED_KEY = \"x-b3-sampled\"\n FLAGS_KEY = \"x-b3-flags\"\n _SAMPLE_PROPAGATE_VALUES = set([\"1\", \"True\", \"true\", \"d\"])\n@@ -149,13 +148,6 @@\n setter.set(\n carrier, self.SPAN_ID_KEY, format_span_id(span_context.span_id)\n )\n- span_parent = getattr(span, \"parent\", None)\n- if span_parent is not None:\n- setter.set(\n- carrier,\n- self.PARENT_SPAN_ID_KEY,\n- format_span_id(span_parent.span_id),\n- )\n setter.set(carrier, self.SAMPLED_KEY, \"1\" if sampled else \"0\")\n \n @property\n@@ -163,7 +155,6 @@\n return {\n self.TRACE_ID_KEY,\n self.SPAN_ID_KEY,\n- self.PARENT_SPAN_ID_KEY,\n self.SAMPLED_KEY,\n }\n \n@@ -195,10 +186,6 @@\n \"1\" if sampled else \"0\",\n ]\n \n- span_parent = getattr(span, \"parent\", None)\n- if span_parent:\n- fields.append(format_span_id(span_parent.span_id))\n-\n setter.set(carrier, self.SINGLE_HEADER_KEY, \"-\".join(fields))\n \n @property\n", "issue": "Otel Spec forbids B3 propagator from propagating `X-B3-ParentSpanId`\nFrom the [spec](https://github.com/open-telemetry/opentelemetry-specification/blob/main/specification/context/api-propagators.md#b3-inject)\r\n\r\n> MUST NOT propagate X-B3-ParentSpanId as OpenTelemetry does not support reusing the same id for both sides of a request.\r\n\r\nBut we do it [here](https://github.com/open-telemetry/opentelemetry-python/blob/61c2d6e1508c75cce4b50ff7b28712c944b94128/propagator/opentelemetry-propagator-b3/src/opentelemetry/propagators/b3/__init__.py#L152-L158)\r\n\r\nThis should be removed as the spec forbids it. \n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport typing\nfrom re import compile as re_compile\n\nfrom deprecated import deprecated\n\nfrom opentelemetry import trace\nfrom opentelemetry.context import Context\nfrom opentelemetry.propagators.textmap import (\n CarrierT,\n Getter,\n Setter,\n TextMapPropagator,\n default_getter,\n default_setter,\n)\nfrom opentelemetry.trace import format_span_id, format_trace_id\n\n\nclass B3MultiFormat(TextMapPropagator):\n \"\"\"Propagator for the B3 HTTP multi-header format.\n\n See: https://github.com/openzipkin/b3-propagation\n https://github.com/openzipkin/b3-propagation#multiple-headers\n \"\"\"\n\n SINGLE_HEADER_KEY = \"b3\"\n TRACE_ID_KEY = \"x-b3-traceid\"\n SPAN_ID_KEY = \"x-b3-spanid\"\n PARENT_SPAN_ID_KEY = \"x-b3-parentspanid\"\n SAMPLED_KEY = \"x-b3-sampled\"\n FLAGS_KEY = \"x-b3-flags\"\n _SAMPLE_PROPAGATE_VALUES = set([\"1\", \"True\", \"true\", \"d\"])\n _trace_id_regex = re_compile(r\"[\\da-fA-F]{16}|[\\da-fA-F]{32}\")\n _span_id_regex = re_compile(r\"[\\da-fA-F]{16}\")\n\n def extract(\n self,\n carrier: CarrierT,\n context: typing.Optional[Context] = None,\n getter: Getter = default_getter,\n ) -> Context:\n if context is None:\n context = Context()\n trace_id = trace.INVALID_TRACE_ID\n span_id = trace.INVALID_SPAN_ID\n sampled = \"0\"\n flags = None\n\n single_header = _extract_first_element(\n getter.get(carrier, self.SINGLE_HEADER_KEY)\n )\n if single_header:\n # The b3 spec calls for the sampling state to be\n # \"deferred\", which is unspecified. This concept does not\n # translate to SpanContext, so we set it as recorded.\n sampled = \"1\"\n fields = single_header.split(\"-\", 4)\n\n if len(fields) == 1:\n sampled = fields[0]\n elif len(fields) == 2:\n trace_id, span_id = fields\n elif len(fields) == 3:\n trace_id, span_id, sampled = fields\n elif len(fields) == 4:\n trace_id, span_id, sampled, _ = fields\n else:\n trace_id = (\n _extract_first_element(getter.get(carrier, self.TRACE_ID_KEY))\n or trace_id\n )\n span_id = (\n _extract_first_element(getter.get(carrier, self.SPAN_ID_KEY))\n or span_id\n )\n sampled = (\n _extract_first_element(getter.get(carrier, self.SAMPLED_KEY))\n or sampled\n )\n flags = (\n _extract_first_element(getter.get(carrier, self.FLAGS_KEY))\n or flags\n )\n\n if (\n trace_id == trace.INVALID_TRACE_ID\n or span_id == trace.INVALID_SPAN_ID\n or self._trace_id_regex.fullmatch(trace_id) is None\n or self._span_id_regex.fullmatch(span_id) is None\n ):\n return context\n\n trace_id = int(trace_id, 16)\n span_id = int(span_id, 16)\n options = 0\n # The b3 spec provides no defined behavior for both sample and\n # flag values set. Since the setting of at least one implies\n # the desire for some form of sampling, propagate if either\n # header is set to allow.\n if sampled in self._SAMPLE_PROPAGATE_VALUES or flags == \"1\":\n options |= trace.TraceFlags.SAMPLED\n\n return trace.set_span_in_context(\n trace.NonRecordingSpan(\n trace.SpanContext(\n # trace an span ids are encoded in hex, so must be converted\n trace_id=trace_id,\n span_id=span_id,\n is_remote=True,\n trace_flags=trace.TraceFlags(options),\n trace_state=trace.TraceState(),\n )\n ),\n context,\n )\n\n def inject(\n self,\n carrier: CarrierT,\n context: typing.Optional[Context] = None,\n setter: Setter = default_setter,\n ) -> None:\n span = trace.get_current_span(context=context)\n\n span_context = span.get_span_context()\n if span_context == trace.INVALID_SPAN_CONTEXT:\n return\n\n sampled = (trace.TraceFlags.SAMPLED & span_context.trace_flags) != 0\n setter.set(\n carrier,\n self.TRACE_ID_KEY,\n format_trace_id(span_context.trace_id),\n )\n setter.set(\n carrier, self.SPAN_ID_KEY, format_span_id(span_context.span_id)\n )\n span_parent = getattr(span, \"parent\", None)\n if span_parent is not None:\n setter.set(\n carrier,\n self.PARENT_SPAN_ID_KEY,\n format_span_id(span_parent.span_id),\n )\n setter.set(carrier, self.SAMPLED_KEY, \"1\" if sampled else \"0\")\n\n @property\n def fields(self) -> typing.Set[str]:\n return {\n self.TRACE_ID_KEY,\n self.SPAN_ID_KEY,\n self.PARENT_SPAN_ID_KEY,\n self.SAMPLED_KEY,\n }\n\n\nclass B3SingleFormat(B3MultiFormat):\n \"\"\"Propagator for the B3 HTTP single-header format.\n\n See: https://github.com/openzipkin/b3-propagation\n https://github.com/openzipkin/b3-propagation#single-header\n \"\"\"\n\n def inject(\n self,\n carrier: CarrierT,\n context: typing.Optional[Context] = None,\n setter: Setter = default_setter,\n ) -> None:\n span = trace.get_current_span(context=context)\n\n span_context = span.get_span_context()\n if span_context == trace.INVALID_SPAN_CONTEXT:\n return\n\n sampled = (trace.TraceFlags.SAMPLED & span_context.trace_flags) != 0\n\n fields = [\n format_trace_id(span_context.trace_id),\n format_span_id(span_context.span_id),\n \"1\" if sampled else \"0\",\n ]\n\n span_parent = getattr(span, \"parent\", None)\n if span_parent:\n fields.append(format_span_id(span_parent.span_id))\n\n setter.set(carrier, self.SINGLE_HEADER_KEY, \"-\".join(fields))\n\n @property\n def fields(self) -> typing.Set[str]:\n return {self.SINGLE_HEADER_KEY}\n\n\nclass B3Format(B3MultiFormat):\n @deprecated(\n version=\"1.2.0\",\n reason=\"B3Format is deprecated in favor of B3MultiFormat\",\n )\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n\n\ndef _extract_first_element(\n items: typing.Iterable[CarrierT],\n) -> typing.Optional[CarrierT]:\n if items is None:\n return None\n return next(iter(items), None)\n", "path": "propagator/opentelemetry-propagator-b3/src/opentelemetry/propagators/b3/__init__.py"}]} | 2,985 | 475 |
gh_patches_debug_14541 | rasdani/github-patches | git_diff | pyinstaller__pyinstaller-5006 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Impossible to build with matplotlib 3.3 on Python 3.7 and 3.8
## Description of the issue
Trying a simple program main.py
```python
import matplotlib.pyplot as plt
plt.plot([0,1,2], [0,1,1])
```
Running the application created with pyinstaller --hiddenimport='pkg_resources.py2_warn' main.py
I get:
```
Traceback (most recent call last): File "main.py", line 3, in <module> File "<frozen importlib._bootstrap>", line 983, in _find_and_load File "<frozen importlib._bootstrap>", line 967, in _find_and_load_unlocked File "<frozen importlib._bootstrap>", line 677, in _load_unlocked File "c:\users\***\appdata\local\programs\python\python37\lib\site-packages\PyInstaller\loader\pyimod03_importers.py", line 623, in exec_module File "site-packages\matplotlib\__init__.py", line 898, in <module> File "site-packages\matplotlib\cbook\__init__.py", line 480, in _get_data_path File "site-packages\matplotlib\__init__.py", line 239, in wrapper File "site-packages\matplotlib\__init__.py", line 534, in get_data_path File "site-packages\matplotlib\__init__.py", line 239, in wrapper File "site-packages\matplotlib\__init__.py", line 563, in _get_data_path NameError: name 'defaultParams' is not defined [3064] Failed to execute script main
```
## Context information (for bug reports)
* Output of `pyinstaller --version`: ```3.6 and 4.0-dev0```
* Version of Python: 3.7 and 3.8
* Platform: Windows (english 10)
* Did you also try this on another platform? No
## What solves it
Reverting to matplotlib 3.2.2 resolve the issue (temporarily).
</issue>
<code>
[start of PyInstaller/hooks/hook-matplotlib.py]
1 #-----------------------------------------------------------------------------
2 # Copyright (c) 2013-2020, PyInstaller Development Team.
3 #
4 # Distributed under the terms of the GNU General Public License (version 2
5 # or later) with exception for distributing the bootloader.
6 #
7 # The full license is in the file COPYING.txt, distributed with this software.
8 #
9 # SPDX-License-Identifier: (GPL-2.0-or-later WITH Bootloader-exception)
10 #-----------------------------------------------------------------------------
11
12
13 from PyInstaller.utils.hooks import exec_statement
14
15 mpl_data_dir = exec_statement(
16 "import matplotlib; print(matplotlib._get_data_path())")
17
18 datas = [
19 (mpl_data_dir, "mpl-data"),
20 ]
21
[end of PyInstaller/hooks/hook-matplotlib.py]
[start of PyInstaller/hooks/rthooks/pyi_rth_mpldata.py]
1 #-----------------------------------------------------------------------------
2 # Copyright (c) 2013-2020, PyInstaller Development Team.
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 #
7 # The full license is in the file COPYING.txt, distributed with this software.
8 #
9 # SPDX-License-Identifier: Apache-2.0
10 #-----------------------------------------------------------------------------
11
12
13 import os
14 import sys
15
16 os.environ["MATPLOTLIBDATA"] = os.path.join(sys._MEIPASS, "mpl-data")
17
[end of PyInstaller/hooks/rthooks/pyi_rth_mpldata.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/PyInstaller/hooks/hook-matplotlib.py b/PyInstaller/hooks/hook-matplotlib.py
--- a/PyInstaller/hooks/hook-matplotlib.py
+++ b/PyInstaller/hooks/hook-matplotlib.py
@@ -16,5 +16,5 @@
"import matplotlib; print(matplotlib._get_data_path())")
datas = [
- (mpl_data_dir, "mpl-data"),
+ (mpl_data_dir, "matplotlib/mpl-data"),
]
diff --git a/PyInstaller/hooks/rthooks/pyi_rth_mpldata.py b/PyInstaller/hooks/rthooks/pyi_rth_mpldata.py
deleted file mode 100644
--- a/PyInstaller/hooks/rthooks/pyi_rth_mpldata.py
+++ /dev/null
@@ -1,16 +0,0 @@
-#-----------------------------------------------------------------------------
-# Copyright (c) 2013-2020, PyInstaller Development Team.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-#
-# The full license is in the file COPYING.txt, distributed with this software.
-#
-# SPDX-License-Identifier: Apache-2.0
-#-----------------------------------------------------------------------------
-
-
-import os
-import sys
-
-os.environ["MATPLOTLIBDATA"] = os.path.join(sys._MEIPASS, "mpl-data")
| {"golden_diff": "diff --git a/PyInstaller/hooks/hook-matplotlib.py b/PyInstaller/hooks/hook-matplotlib.py\n--- a/PyInstaller/hooks/hook-matplotlib.py\n+++ b/PyInstaller/hooks/hook-matplotlib.py\n@@ -16,5 +16,5 @@\n \"import matplotlib; print(matplotlib._get_data_path())\")\n \n datas = [\n- (mpl_data_dir, \"mpl-data\"),\n+ (mpl_data_dir, \"matplotlib/mpl-data\"),\n ]\ndiff --git a/PyInstaller/hooks/rthooks/pyi_rth_mpldata.py b/PyInstaller/hooks/rthooks/pyi_rth_mpldata.py\ndeleted file mode 100644\n--- a/PyInstaller/hooks/rthooks/pyi_rth_mpldata.py\n+++ /dev/null\n@@ -1,16 +0,0 @@\n-#-----------------------------------------------------------------------------\n-# Copyright (c) 2013-2020, PyInstaller Development Team.\n-#\n-# Licensed under the Apache License, Version 2.0 (the \"License\");\n-# you may not use this file except in compliance with the License.\n-#\n-# The full license is in the file COPYING.txt, distributed with this software.\n-#\n-# SPDX-License-Identifier: Apache-2.0\n-#-----------------------------------------------------------------------------\n-\n-\n-import os\n-import sys\n-\n-os.environ[\"MATPLOTLIBDATA\"] = os.path.join(sys._MEIPASS, \"mpl-data\")\n", "issue": "Impossible to build with matplotlib 3.3 on Python 3.7 and 3.8\n## Description of the issue\r\n\r\nTrying a simple program main.py\r\n```python\r\nimport matplotlib.pyplot as plt\r\n\r\nplt.plot([0,1,2], [0,1,1])\r\n```\r\n\r\nRunning the application created with pyinstaller --hiddenimport='pkg_resources.py2_warn' main.py\r\n\r\nI get:\r\n\r\n```\r\nTraceback (most recent call last): File \"main.py\", line 3, in <module> File \"<frozen importlib._bootstrap>\", line 983, in _find_and_load File \"<frozen importlib._bootstrap>\", line 967, in _find_and_load_unlocked File \"<frozen importlib._bootstrap>\", line 677, in _load_unlocked File \"c:\\users\\***\\appdata\\local\\programs\\python\\python37\\lib\\site-packages\\PyInstaller\\loader\\pyimod03_importers.py\", line 623, in exec_module File \"site-packages\\matplotlib\\__init__.py\", line 898, in <module> File \"site-packages\\matplotlib\\cbook\\__init__.py\", line 480, in _get_data_path File \"site-packages\\matplotlib\\__init__.py\", line 239, in wrapper File \"site-packages\\matplotlib\\__init__.py\", line 534, in get_data_path File \"site-packages\\matplotlib\\__init__.py\", line 239, in wrapper File \"site-packages\\matplotlib\\__init__.py\", line 563, in _get_data_path NameError: name 'defaultParams' is not defined [3064] Failed to execute script main\r\n```\r\n## Context information (for bug reports)\r\n\r\n* Output of `pyinstaller --version`: ```3.6 and 4.0-dev0```\r\n* Version of Python: 3.7 and 3.8\r\n* Platform: Windows (english 10)\r\n* Did you also try this on another platform? No\r\n\r\n## What solves it\r\n\r\nReverting to matplotlib 3.2.2 resolve the issue (temporarily).\n", "before_files": [{"content": "#-----------------------------------------------------------------------------\n# Copyright (c) 2013-2020, PyInstaller Development Team.\n#\n# Distributed under the terms of the GNU General Public License (version 2\n# or later) with exception for distributing the bootloader.\n#\n# The full license is in the file COPYING.txt, distributed with this software.\n#\n# SPDX-License-Identifier: (GPL-2.0-or-later WITH Bootloader-exception)\n#-----------------------------------------------------------------------------\n\n\nfrom PyInstaller.utils.hooks import exec_statement\n\nmpl_data_dir = exec_statement(\n \"import matplotlib; print(matplotlib._get_data_path())\")\n\ndatas = [\n (mpl_data_dir, \"mpl-data\"),\n]\n", "path": "PyInstaller/hooks/hook-matplotlib.py"}, {"content": "#-----------------------------------------------------------------------------\n# Copyright (c) 2013-2020, PyInstaller Development Team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n#\n# The full license is in the file COPYING.txt, distributed with this software.\n#\n# SPDX-License-Identifier: Apache-2.0\n#-----------------------------------------------------------------------------\n\n\nimport os\nimport sys\n\nos.environ[\"MATPLOTLIBDATA\"] = os.path.join(sys._MEIPASS, \"mpl-data\")\n", "path": "PyInstaller/hooks/rthooks/pyi_rth_mpldata.py"}]} | 1,403 | 317 |
gh_patches_debug_16772 | rasdani/github-patches | git_diff | saulpw__visidata-1584 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ZSH completion fails with invalid option definition
I'm using v2.10.2 installed via the [latest Arch package](https://archlinux.org/packages/community/any/visidata/). Visidata shell completion in my ZSH is currently broken.
```
$ vd <tab>
_arguments:comparguments:327: invalid option definition: --fmt_expand_list[format str to use for names of columns expanded from list (colname, index) (default: %s[%s])]:str
```
</issue>
<code>
[start of dev/zsh-completion.py]
1 #!/usr/bin/env python
2 from __future__ import unicode_literals
3
4 import os
5 from os.path import dirname as dirn
6 import sys
7 import re
8
9 sys.path.insert(0, dirn(dirn((os.path.abspath(__file__)))))
10 from visidata import vd
11 from visidata.main import option_aliases
12
13 ZSH_COMPLETION_FILE = "_visidata"
14 ZSH_COMPLETION_TEMPLATE = "dev/zsh-completion.in"
15 pat_class = re.compile("'(.*)'")
16 pat_select = re.compile("^\([^)]*\)")
17
18
19 def generate_completion(opt):
20 prefix = "--" + opt.name
21 shortnames = [key for key, value in option_aliases.items() if value[0] == opt.name]
22 if len(shortnames):
23 if len(shortnames[0]) == 1:
24 shortname = "-" + shortnames[0]
25 else:
26 shortname = "--" + shortnames[0]
27 prefix = "{" + f"{shortname},{prefix}" + "}"
28 if isinstance(opt.value, bool):
29 completion = ""
30 else:
31 completion = ":" + pat_class.findall(str(opt.value.__class__))[0]
32 if opt.name in ["play", "output", "visidata_dir", "config"]:
33 completion += ":_files"
34 elif opt.name in ["plugins_url", "motd_url"]:
35 completion += ":_urls"
36 helpstr = opt.helpstr.replace("[", "\\[").replace("]", "\\]")
37 selections = pat_select.findall(helpstr)
38 if len(selections):
39 completion += f":{selections[0].replace('/', ' ')}"
40 # TODO: use `zstyle ':completion:*' extra-verbose true`
41 # to control the display of default value
42 helpstr = helpstr + f" (default: {opt.value})"
43 return f"{prefix}'[{helpstr}]{completion}'"
44
45
46 flags = [generate_completion(vd._options[opt]["default"]) for opt in vd._options]
47
48 with open(ZSH_COMPLETION_TEMPLATE) as f:
49 template = f.read()
50
51 template = template.replace("{{flags}}", " \\\n ".join(flags))
52
53 with open(ZSH_COMPLETION_FILE, "w") as f:
54 f.write(template)
55
[end of dev/zsh-completion.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/dev/zsh-completion.py b/dev/zsh-completion.py
--- a/dev/zsh-completion.py
+++ b/dev/zsh-completion.py
@@ -33,13 +33,14 @@
completion += ":_files"
elif opt.name in ["plugins_url", "motd_url"]:
completion += ":_urls"
- helpstr = opt.helpstr.replace("[", "\\[").replace("]", "\\]")
+ helpstr = opt.helpstr
selections = pat_select.findall(helpstr)
if len(selections):
completion += f":{selections[0].replace('/', ' ')}"
# TODO: use `zstyle ':completion:*' extra-verbose true`
# to control the display of default value
helpstr = helpstr + f" (default: {opt.value})"
+ helpstr = helpstr.replace("[", "\\[").replace("]", "\\]")
return f"{prefix}'[{helpstr}]{completion}'"
| {"golden_diff": "diff --git a/dev/zsh-completion.py b/dev/zsh-completion.py\n--- a/dev/zsh-completion.py\n+++ b/dev/zsh-completion.py\n@@ -33,13 +33,14 @@\n completion += \":_files\"\n elif opt.name in [\"plugins_url\", \"motd_url\"]:\n completion += \":_urls\"\n- helpstr = opt.helpstr.replace(\"[\", \"\\\\[\").replace(\"]\", \"\\\\]\")\n+ helpstr = opt.helpstr\n selections = pat_select.findall(helpstr)\n if len(selections):\n completion += f\":{selections[0].replace('/', ' ')}\"\n # TODO: use `zstyle ':completion:*' extra-verbose true`\n # to control the display of default value\n helpstr = helpstr + f\" (default: {opt.value})\"\n+ helpstr = helpstr.replace(\"[\", \"\\\\[\").replace(\"]\", \"\\\\]\")\n return f\"{prefix}'[{helpstr}]{completion}'\"\n", "issue": "ZSH completion fails with invalid option definition\nI'm using v2.10.2 installed via the [latest Arch package](https://archlinux.org/packages/community/any/visidata/). Visidata shell completion in my ZSH is currently broken.\r\n\r\n```\r\n$ vd <tab>\r\n_arguments:comparguments:327: invalid option definition: --fmt_expand_list[format str to use for names of columns expanded from list (colname, index) (default: %s[%s])]:str\r\n```\n", "before_files": [{"content": "#!/usr/bin/env python\nfrom __future__ import unicode_literals\n\nimport os\nfrom os.path import dirname as dirn\nimport sys\nimport re\n\nsys.path.insert(0, dirn(dirn((os.path.abspath(__file__)))))\nfrom visidata import vd\nfrom visidata.main import option_aliases\n\nZSH_COMPLETION_FILE = \"_visidata\"\nZSH_COMPLETION_TEMPLATE = \"dev/zsh-completion.in\"\npat_class = re.compile(\"'(.*)'\")\npat_select = re.compile(\"^\\([^)]*\\)\")\n\n\ndef generate_completion(opt):\n prefix = \"--\" + opt.name\n shortnames = [key for key, value in option_aliases.items() if value[0] == opt.name]\n if len(shortnames):\n if len(shortnames[0]) == 1:\n shortname = \"-\" + shortnames[0]\n else:\n shortname = \"--\" + shortnames[0]\n prefix = \"{\" + f\"{shortname},{prefix}\" + \"}\"\n if isinstance(opt.value, bool):\n completion = \"\"\n else:\n completion = \":\" + pat_class.findall(str(opt.value.__class__))[0]\n if opt.name in [\"play\", \"output\", \"visidata_dir\", \"config\"]:\n completion += \":_files\"\n elif opt.name in [\"plugins_url\", \"motd_url\"]:\n completion += \":_urls\"\n helpstr = opt.helpstr.replace(\"[\", \"\\\\[\").replace(\"]\", \"\\\\]\")\n selections = pat_select.findall(helpstr)\n if len(selections):\n completion += f\":{selections[0].replace('/', ' ')}\"\n # TODO: use `zstyle ':completion:*' extra-verbose true`\n # to control the display of default value\n helpstr = helpstr + f\" (default: {opt.value})\"\n return f\"{prefix}'[{helpstr}]{completion}'\"\n\n\nflags = [generate_completion(vd._options[opt][\"default\"]) for opt in vd._options]\n\nwith open(ZSH_COMPLETION_TEMPLATE) as f:\n template = f.read()\n\ntemplate = template.replace(\"{{flags}}\", \" \\\\\\n \".join(flags))\n\nwith open(ZSH_COMPLETION_FILE, \"w\") as f:\n f.write(template)\n", "path": "dev/zsh-completion.py"}]} | 1,225 | 212 |
gh_patches_debug_13197 | rasdani/github-patches | git_diff | localstack__localstack-5700 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
bug: sqs creation breaks with 0.14.1
### Is there an existing issue for this?
- [X] I have searched the existing issues
### Current Behavior
Having the following cdk definition for a sqs queue
const queue = new sqs.Queue(scope, `foo-queue`, {
fifo: true,
visibilityTimeout: Duration.seconds(300),
contentBasedDeduplication: true
})
deploy works normally with localstack 0.14.0 using https://github.com/localstack/aws-cdk-local
But after upgrading to 0.14.1 we see the following error
2022-03-17T11:34:23.851:WARNING:localstack.utils.cloudformation.template_deployer: Error calling <bound method ClientCreator._create_api_method.<locals>._api_call of <botocore.client.SQS object at 0x7f11db7346d0>> with params: {'QueueName': 'FooStack-fooqueueB0475DE4-8bf04fb7', 'Attributes': {'ContentBasedDeduplication': 'True', 'FifoQueue': 'True', 'VisibilityTimeout': '300'}, 'tags': {}} for resource: {'Type': 'AWS::SQS::Queue', 'UpdateReplacePolicy': 'Delete', 'DeletionPolicy': 'Delete', 'Metadata': {'aws:cdk:path': 'FooStack/foo-queue/Resource'}, 'LogicalResourceId': 'fooqueueB0475DE4', 'Properties': {'ContentBasedDeduplication': True, 'FifoQueue': True, 'VisibilityTimeout': 300, 'QueueName': 'FooStack-fooqueueB0475DE4-8bf04fb7'}, '_state_': {}}
Only difference being the localstack upgrade, downgrading back to 0.14.0 fixes the problem.
### Expected Behavior
Sqs queue is created successfully like with 0.14.0
### How are you starting LocalStack?
With a docker-compose file
### Steps To Reproduce
cdklocal deploy
### Environment
```markdown
- LocalStack: 0.14.1
```
### Anything else?
_No response_
</issue>
<code>
[start of localstack/services/cloudformation/models/sqs.py]
1 import json
2 import logging
3
4 from botocore.exceptions import ClientError
5
6 from localstack.services.cloudformation.deployment_utils import (
7 PLACEHOLDER_RESOURCE_NAME,
8 generate_default_name,
9 params_list_to_dict,
10 params_select_attributes,
11 )
12 from localstack.services.cloudformation.service_models import (
13 DependencyNotYetSatisfied,
14 GenericBaseModel,
15 )
16 from localstack.utils.aws import aws_stack
17 from localstack.utils.common import short_uid
18
19 LOG = logging.getLogger(__name__)
20
21
22 class QueuePolicy(GenericBaseModel):
23 @classmethod
24 def cloudformation_type(cls):
25 return "AWS::SQS::QueuePolicy"
26
27 @classmethod
28 def get_deploy_templates(cls):
29 def _create(resource_id, resources, resource_type, func, stack_name):
30 sqs_client = aws_stack.connect_to_service("sqs")
31 resource = cls(resources[resource_id])
32 props = resource.props
33
34 # TODO: generalize/support in get_physical_resource_id
35 resources[resource_id]["PhysicalResourceId"] = "%s-%s-%s" % (
36 stack_name,
37 resource_id,
38 short_uid(),
39 )
40
41 policy = json.dumps(props["PolicyDocument"])
42 for queue in props["Queues"]:
43 sqs_client.set_queue_attributes(QueueUrl=queue, Attributes={"Policy": policy})
44
45 def _delete(resource_id, resources, *args, **kwargs):
46 sqs_client = aws_stack.connect_to_service("sqs")
47 resource = cls(resources[resource_id])
48 props = resource.props
49
50 for queue in props["Queues"]:
51 try:
52 sqs_client.set_queue_attributes(QueueUrl=queue, Attributes={"Policy": ""})
53 except ClientError as err:
54 if "AWS.SimpleQueueService.NonExistentQueue" != err.response["Error"]["Code"]:
55 raise
56
57 return {
58 "create": {"function": _create},
59 "delete": {
60 "function": _delete,
61 },
62 }
63
64
65 class SQSQueue(GenericBaseModel):
66 @classmethod
67 def cloudformation_type(cls):
68 return "AWS::SQS::Queue"
69
70 def get_resource_name(self):
71 return self.props.get("QueueName")
72
73 def get_physical_resource_id(self, attribute=None, **kwargs):
74 queue_url = None
75 props = self.props
76 try:
77 queue_url = aws_stack.get_sqs_queue_url(props.get("QueueName"))
78 except Exception as e:
79 if "NonExistentQueue" in str(e):
80 raise DependencyNotYetSatisfied(
81 resource_ids=self.resource_id, message="Unable to get queue: %s" % e
82 )
83 if attribute == "Arn":
84 return aws_stack.sqs_queue_arn(props.get("QueueName"))
85 return queue_url
86
87 def fetch_state(self, stack_name, resources):
88 queue_name = self.resolve_refs_recursively(stack_name, self.props["QueueName"], resources)
89 sqs_client = aws_stack.connect_to_service("sqs")
90 queues = sqs_client.list_queues()
91 result = list(
92 filter(
93 lambda item:
94 # TODO possibly find a better way to compare resource_id with queue URLs
95 item.endswith("/%s" % queue_name),
96 queues.get("QueueUrls", []),
97 )
98 )
99 if not result:
100 return None
101 result = sqs_client.get_queue_attributes(QueueUrl=result[0], AttributeNames=["All"])[
102 "Attributes"
103 ]
104 result["Arn"] = result["QueueArn"]
105 return result
106
107 @staticmethod
108 def add_defaults(resource, stack_name: str):
109 role_name = resource.get("Properties", {}).get("QueueName")
110 if not role_name:
111 resource["Properties"]["QueueName"] = generate_default_name(
112 stack_name, resource["LogicalResourceId"]
113 )
114
115 @classmethod
116 def get_deploy_templates(cls):
117 def _queue_url(params, resources, resource_id, **kwargs):
118 resource = cls(resources[resource_id])
119 props = resource.props
120 queue_url = resource.physical_resource_id or props.get("QueueUrl")
121 if queue_url:
122 return queue_url
123 return aws_stack.sqs_queue_url_for_arn(props["QueueArn"])
124
125 return {
126 "create": {
127 "function": "create_queue",
128 "parameters": {
129 "QueueName": ["QueueName", PLACEHOLDER_RESOURCE_NAME],
130 "Attributes": params_select_attributes(
131 "ContentBasedDeduplication",
132 "DelaySeconds",
133 "FifoQueue",
134 "MaximumMessageSize",
135 "MessageRetentionPeriod",
136 "VisibilityTimeout",
137 "RedrivePolicy",
138 "ReceiveMessageWaitTimeSeconds",
139 ),
140 "tags": params_list_to_dict("Tags"),
141 },
142 },
143 "delete": {
144 "function": "delete_queue",
145 "parameters": {"QueueUrl": _queue_url},
146 },
147 }
148
[end of localstack/services/cloudformation/models/sqs.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/localstack/services/cloudformation/models/sqs.py b/localstack/services/cloudformation/models/sqs.py
--- a/localstack/services/cloudformation/models/sqs.py
+++ b/localstack/services/cloudformation/models/sqs.py
@@ -107,10 +107,13 @@
@staticmethod
def add_defaults(resource, stack_name: str):
role_name = resource.get("Properties", {}).get("QueueName")
+
if not role_name:
resource["Properties"]["QueueName"] = generate_default_name(
stack_name, resource["LogicalResourceId"]
)
+ if resource["Properties"].get("FifoQueue"):
+ resource["Properties"]["QueueName"] += ".fifo"
@classmethod
def get_deploy_templates(cls):
| {"golden_diff": "diff --git a/localstack/services/cloudformation/models/sqs.py b/localstack/services/cloudformation/models/sqs.py\n--- a/localstack/services/cloudformation/models/sqs.py\n+++ b/localstack/services/cloudformation/models/sqs.py\n@@ -107,10 +107,13 @@\n @staticmethod\n def add_defaults(resource, stack_name: str):\n role_name = resource.get(\"Properties\", {}).get(\"QueueName\")\n+\n if not role_name:\n resource[\"Properties\"][\"QueueName\"] = generate_default_name(\n stack_name, resource[\"LogicalResourceId\"]\n )\n+ if resource[\"Properties\"].get(\"FifoQueue\"):\n+ resource[\"Properties\"][\"QueueName\"] += \".fifo\"\n \n @classmethod\n def get_deploy_templates(cls):\n", "issue": "bug: sqs creation breaks with 0.14.1\n### Is there an existing issue for this?\n\n- [X] I have searched the existing issues\n\n### Current Behavior\n\nHaving the following cdk definition for a sqs queue\r\nconst queue = new sqs.Queue(scope, `foo-queue`, {\r\n fifo: true,\r\n visibilityTimeout: Duration.seconds(300),\r\n contentBasedDeduplication: true\r\n})\r\ndeploy works normally with localstack 0.14.0 using https://github.com/localstack/aws-cdk-local\r\nBut after upgrading to 0.14.1 we see the following error\r\n2022-03-17T11:34:23.851:WARNING:localstack.utils.cloudformation.template_deployer: Error calling <bound method ClientCreator._create_api_method.<locals>._api_call of <botocore.client.SQS object at 0x7f11db7346d0>> with params: {'QueueName': 'FooStack-fooqueueB0475DE4-8bf04fb7', 'Attributes': {'ContentBasedDeduplication': 'True', 'FifoQueue': 'True', 'VisibilityTimeout': '300'}, 'tags': {}} for resource: {'Type': 'AWS::SQS::Queue', 'UpdateReplacePolicy': 'Delete', 'DeletionPolicy': 'Delete', 'Metadata': {'aws:cdk:path': 'FooStack/foo-queue/Resource'}, 'LogicalResourceId': 'fooqueueB0475DE4', 'Properties': {'ContentBasedDeduplication': True, 'FifoQueue': True, 'VisibilityTimeout': 300, 'QueueName': 'FooStack-fooqueueB0475DE4-8bf04fb7'}, '_state_': {}}\r\nOnly difference being the localstack upgrade, downgrading back to 0.14.0 fixes the problem.\r\n\n\n### Expected Behavior\n\nSqs queue is created successfully like with 0.14.0\n\n### How are you starting LocalStack?\n\nWith a docker-compose file\n\n### Steps To Reproduce\n\ncdklocal deploy\n\n### Environment\n\n```markdown\n- LocalStack: 0.14.1\n```\n\n\n### Anything else?\n\n_No response_\n", "before_files": [{"content": "import json\nimport logging\n\nfrom botocore.exceptions import ClientError\n\nfrom localstack.services.cloudformation.deployment_utils import (\n PLACEHOLDER_RESOURCE_NAME,\n generate_default_name,\n params_list_to_dict,\n params_select_attributes,\n)\nfrom localstack.services.cloudformation.service_models import (\n DependencyNotYetSatisfied,\n GenericBaseModel,\n)\nfrom localstack.utils.aws import aws_stack\nfrom localstack.utils.common import short_uid\n\nLOG = logging.getLogger(__name__)\n\n\nclass QueuePolicy(GenericBaseModel):\n @classmethod\n def cloudformation_type(cls):\n return \"AWS::SQS::QueuePolicy\"\n\n @classmethod\n def get_deploy_templates(cls):\n def _create(resource_id, resources, resource_type, func, stack_name):\n sqs_client = aws_stack.connect_to_service(\"sqs\")\n resource = cls(resources[resource_id])\n props = resource.props\n\n # TODO: generalize/support in get_physical_resource_id\n resources[resource_id][\"PhysicalResourceId\"] = \"%s-%s-%s\" % (\n stack_name,\n resource_id,\n short_uid(),\n )\n\n policy = json.dumps(props[\"PolicyDocument\"])\n for queue in props[\"Queues\"]:\n sqs_client.set_queue_attributes(QueueUrl=queue, Attributes={\"Policy\": policy})\n\n def _delete(resource_id, resources, *args, **kwargs):\n sqs_client = aws_stack.connect_to_service(\"sqs\")\n resource = cls(resources[resource_id])\n props = resource.props\n\n for queue in props[\"Queues\"]:\n try:\n sqs_client.set_queue_attributes(QueueUrl=queue, Attributes={\"Policy\": \"\"})\n except ClientError as err:\n if \"AWS.SimpleQueueService.NonExistentQueue\" != err.response[\"Error\"][\"Code\"]:\n raise\n\n return {\n \"create\": {\"function\": _create},\n \"delete\": {\n \"function\": _delete,\n },\n }\n\n\nclass SQSQueue(GenericBaseModel):\n @classmethod\n def cloudformation_type(cls):\n return \"AWS::SQS::Queue\"\n\n def get_resource_name(self):\n return self.props.get(\"QueueName\")\n\n def get_physical_resource_id(self, attribute=None, **kwargs):\n queue_url = None\n props = self.props\n try:\n queue_url = aws_stack.get_sqs_queue_url(props.get(\"QueueName\"))\n except Exception as e:\n if \"NonExistentQueue\" in str(e):\n raise DependencyNotYetSatisfied(\n resource_ids=self.resource_id, message=\"Unable to get queue: %s\" % e\n )\n if attribute == \"Arn\":\n return aws_stack.sqs_queue_arn(props.get(\"QueueName\"))\n return queue_url\n\n def fetch_state(self, stack_name, resources):\n queue_name = self.resolve_refs_recursively(stack_name, self.props[\"QueueName\"], resources)\n sqs_client = aws_stack.connect_to_service(\"sqs\")\n queues = sqs_client.list_queues()\n result = list(\n filter(\n lambda item:\n # TODO possibly find a better way to compare resource_id with queue URLs\n item.endswith(\"/%s\" % queue_name),\n queues.get(\"QueueUrls\", []),\n )\n )\n if not result:\n return None\n result = sqs_client.get_queue_attributes(QueueUrl=result[0], AttributeNames=[\"All\"])[\n \"Attributes\"\n ]\n result[\"Arn\"] = result[\"QueueArn\"]\n return result\n\n @staticmethod\n def add_defaults(resource, stack_name: str):\n role_name = resource.get(\"Properties\", {}).get(\"QueueName\")\n if not role_name:\n resource[\"Properties\"][\"QueueName\"] = generate_default_name(\n stack_name, resource[\"LogicalResourceId\"]\n )\n\n @classmethod\n def get_deploy_templates(cls):\n def _queue_url(params, resources, resource_id, **kwargs):\n resource = cls(resources[resource_id])\n props = resource.props\n queue_url = resource.physical_resource_id or props.get(\"QueueUrl\")\n if queue_url:\n return queue_url\n return aws_stack.sqs_queue_url_for_arn(props[\"QueueArn\"])\n\n return {\n \"create\": {\n \"function\": \"create_queue\",\n \"parameters\": {\n \"QueueName\": [\"QueueName\", PLACEHOLDER_RESOURCE_NAME],\n \"Attributes\": params_select_attributes(\n \"ContentBasedDeduplication\",\n \"DelaySeconds\",\n \"FifoQueue\",\n \"MaximumMessageSize\",\n \"MessageRetentionPeriod\",\n \"VisibilityTimeout\",\n \"RedrivePolicy\",\n \"ReceiveMessageWaitTimeSeconds\",\n ),\n \"tags\": params_list_to_dict(\"Tags\"),\n },\n },\n \"delete\": {\n \"function\": \"delete_queue\",\n \"parameters\": {\"QueueUrl\": _queue_url},\n },\n }\n", "path": "localstack/services/cloudformation/models/sqs.py"}]} | 2,404 | 163 |
gh_patches_debug_6043 | rasdani/github-patches | git_diff | readthedocs__readthedocs.org-10389 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Docs: Config file deprecation warnings
* [x] Upgrade v1 docs to clearly indicate that it's removed in September 2023 and link to the v2 version
* [x] Add warning banners in various places
References https://github.com/readthedocs/readthedocs.org/issues/10342
</issue>
<code>
[start of docs/conf.py]
1 """
2 Shared Sphinx configuration using sphinx-multiproject.
3
4 To build each project, the ``PROJECT`` environment variable is used.
5
6 .. code:: console
7
8 $ make html # build default project
9 $ PROJECT=dev make html # build the dev project
10
11 for more information read https://sphinx-multiproject.readthedocs.io/.
12 """
13
14 import os
15 import sys
16
17 from multiproject.utils import get_project
18
19 sys.path.append(os.path.abspath("_ext"))
20 extensions = [
21 "hoverxref.extension",
22 "multiproject",
23 "myst_parser",
24 "notfound.extension",
25 "sphinx_design",
26 "sphinx_search.extension",
27 "sphinx_tabs.tabs",
28 "sphinx-prompt",
29 "sphinx.ext.autodoc",
30 "sphinx.ext.autosectionlabel",
31 "sphinx.ext.extlinks",
32 "sphinx.ext.intersphinx",
33 "sphinxcontrib.httpdomain",
34 "sphinxcontrib.video",
35 "sphinxemoji.sphinxemoji",
36 "sphinxext.opengraph",
37 ]
38
39 multiproject_projects = {
40 "user": {
41 "use_config_file": False,
42 "config": {
43 "project": "Read the Docs user documentation",
44 },
45 },
46 "dev": {
47 "use_config_file": False,
48 "config": {
49 "project": "Read the Docs developer documentation",
50 },
51 },
52 }
53
54 docset = get_project(multiproject_projects)
55
56 ogp_site_name = "Read the Docs Documentation"
57 ogp_use_first_image = True # https://github.com/readthedocs/blog/pull/118
58 ogp_image = "https://docs.readthedocs.io/en/latest/_static/img/logo-opengraph.png"
59 # Inspired by https://github.com/executablebooks/MyST-Parser/pull/404/
60 ogp_custom_meta_tags = [
61 '<meta name="twitter:card" content="summary_large_image" />',
62 ]
63 ogp_enable_meta_description = True
64 ogp_description_length = 300
65
66 templates_path = ["_templates"]
67
68 # This may be elevated as a general issue for documentation and behavioral
69 # change to the Sphinx build:
70 # This will ensure that we use the correctly set environment for canonical URLs
71 # Old Read the Docs injections makes it point only to the default version,
72 # for instance /en/stable/
73 html_baseurl = os.environ.get("READTHEDOCS_CANONICAL_URL", "/")
74
75 master_doc = "index"
76 copyright = "Read the Docs, Inc & contributors"
77 version = "9.13.2"
78 release = version
79 exclude_patterns = ["_build", "shared", "_includes"]
80 default_role = "obj"
81 intersphinx_cache_limit = 14 # cache for 2 weeks
82 intersphinx_timeout = 3 # 3 seconds timeout
83 intersphinx_mapping = {
84 "python": ("https://docs.python.org/3.10/", None),
85 "django": (
86 "https://docs.djangoproject.com/en/stable/",
87 "https://docs.djangoproject.com/en/stable/_objects/",
88 ),
89 "sphinx": ("https://www.sphinx-doc.org/en/master/", None),
90 "pip": ("https://pip.pypa.io/en/stable/", None),
91 "nbsphinx": ("https://nbsphinx.readthedocs.io/en/latest/", None),
92 "myst-nb": ("https://myst-nb.readthedocs.io/en/stable/", None),
93 "ipywidgets": ("https://ipywidgets.readthedocs.io/en/stable/", None),
94 "jupytext": ("https://jupytext.readthedocs.io/en/stable/", None),
95 "ipyleaflet": ("https://ipyleaflet.readthedocs.io/en/latest/", None),
96 "poliastro": ("https://docs.poliastro.space/en/stable/", None),
97 "qiskit": ("https://qiskit.org/documentation/", None),
98 "myst-parser": ("https://myst-parser.readthedocs.io/en/stable/", None),
99 "writethedocs": ("https://www.writethedocs.org/", None),
100 "jupyterbook": ("https://jupyterbook.org/en/stable/", None),
101 "executablebook": ("https://executablebooks.org/en/latest/", None),
102 "rst-to-myst": ("https://rst-to-myst.readthedocs.io/en/stable/", None),
103 "rtd": ("https://docs.readthedocs.io/en/stable/", None),
104 "rtd-dev": ("https://dev.readthedocs.io/en/latest/", None),
105 "jupyter": ("https://docs.jupyter.org/en/latest/", None),
106 }
107
108 # Intersphinx: Do not try to resolve unresolved labels that aren't explicitly prefixed.
109 # The default setting for intersphinx_disabled_reftypes can cause some pretty bad
110 # breakage because we have rtd and rtd-dev stable versions in our mappings.
111 # Hence, if we refactor labels, we won't see broken references, since the
112 # currently active stable mapping keeps resolving.
113 # Recommending doing this on all projects with Intersphinx.
114 # https://www.sphinx-doc.org/en/master/usage/extensions/intersphinx.html#confval-intersphinx_disabled_reftypes
115 intersphinx_disabled_reftypes = ["*"]
116
117 myst_enable_extensions = [
118 "deflist",
119 ]
120 hoverxref_intersphinx = [
121 "sphinx",
122 "pip",
123 "nbsphinx",
124 "myst-nb",
125 "ipywidgets",
126 "jupytext",
127 ]
128 htmlhelp_basename = "ReadTheDocsdoc"
129 latex_documents = [
130 (
131 "index",
132 "ReadTheDocs.tex",
133 "Read the Docs Documentation",
134 "Eric Holscher, Charlie Leifer, Bobby Grace",
135 "manual",
136 ),
137 ]
138 man_pages = [
139 (
140 "index",
141 "read-the-docs",
142 "Read the Docs Documentation",
143 ["Eric Holscher, Charlie Leifer, Bobby Grace"],
144 1,
145 )
146 ]
147
148 language = "en"
149
150 locale_dirs = [
151 f"{docset}/locale/",
152 ]
153 gettext_compact = False
154
155 html_theme = "sphinx_rtd_theme"
156 html_static_path = ["_static", f"{docset}/_static"]
157 html_css_files = ["css/custom.css", "css/sphinx_prompt_css.css"]
158 html_js_files = ["js/expand_tabs.js"]
159
160 if os.environ.get("READTHEDOCS_VERSION_TYPE") == "external":
161 html_js_files.append("js/readthedocs-doc-diff.js")
162
163 html_logo = "img/logo.svg"
164 html_theme_options = {
165 "logo_only": True,
166 "display_version": False,
167 }
168 html_context = {
169 # Fix the "edit on" links.
170 # TODO: remove once we support different rtd config
171 # files per project.
172 "conf_py_path": f"/docs/{docset}/",
173 # Use to generate the Plausible "data-domain" attribute from the template
174 "plausible_domain": f"{os.environ.get('READTHEDOCS_PROJECT')}.readthedocs.io",
175 }
176
177 hoverxref_auto_ref = True
178 hoverxref_domains = ["py"]
179 hoverxref_roles = [
180 "option",
181 # Documentation pages
182 # Not supported yet: https://github.com/readthedocs/sphinx-hoverxref/issues/18
183 "doc",
184 # Glossary terms
185 "term",
186 ]
187 hoverxref_role_types = {
188 "mod": "modal", # for Python Sphinx Domain
189 "doc": "modal", # for whole docs
190 "class": "tooltip", # for Python Sphinx Domain
191 "ref": "tooltip", # for hoverxref_auto_ref config
192 "confval": "tooltip", # for custom object
193 "term": "tooltip", # for glossaries
194 }
195
196 # See dev/style_guide.rst for documentation
197 rst_epilog = """
198 .. |org_brand| replace:: Read the Docs Community
199 .. |com_brand| replace:: Read the Docs for Business
200 .. |git_providers_and| replace:: GitHub, Bitbucket, and GitLab
201 .. |git_providers_or| replace:: GitHub, Bitbucket, or GitLab
202 """
203
204 # Activate autosectionlabel plugin
205 autosectionlabel_prefix_document = True
206
207 # sphinx-notfound-page
208 # https://github.com/readthedocs/sphinx-notfound-page
209 notfound_context = {
210 "title": "Page Not Found",
211 "body": """
212 <h1>Page Not Found</h1>
213
214 <p>Sorry, we couldn't find that page.</p>
215
216 <p>Try using the search box or go to the homepage.</p>
217 """,
218 }
219 linkcheck_retries = 2
220 linkcheck_timeout = 1
221 linkcheck_workers = 10
222 linkcheck_ignore = [
223 r"http://127\.0\.0\.1",
224 r"http://localhost",
225 r"http://community\.dev\.readthedocs\.io",
226 r"https://yourproject\.readthedocs\.io",
227 r"https?://docs\.example\.com",
228 r"https://foo\.readthedocs\.io/projects",
229 r"https://github\.com.+?#L\d+",
230 r"https://github\.com/readthedocs/readthedocs\.org/issues",
231 r"https://github\.com/readthedocs/readthedocs\.org/pull",
232 r"https://docs\.readthedocs\.io/\?rtd_search",
233 r"https://readthedocs\.org/search",
234 # This page is under login
235 r"https://readthedocs\.org/accounts/gold",
236 ]
237
238 extlinks = {
239 "rtd-issue": ("https://github.com/readthedocs/readthedocs.org/issues/%s", "#%s"),
240 }
241
242 # Disable epub mimetype warnings
243 suppress_warnings = ["epub.unknown_project_files"]
244
[end of docs/conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -102,6 +102,7 @@
"rst-to-myst": ("https://rst-to-myst.readthedocs.io/en/stable/", None),
"rtd": ("https://docs.readthedocs.io/en/stable/", None),
"rtd-dev": ("https://dev.readthedocs.io/en/latest/", None),
+ "rtd-blog": ("https://blog.readthedocs.com/", None),
"jupyter": ("https://docs.jupyter.org/en/latest/", None),
}
| {"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -102,6 +102,7 @@\n \"rst-to-myst\": (\"https://rst-to-myst.readthedocs.io/en/stable/\", None),\n \"rtd\": (\"https://docs.readthedocs.io/en/stable/\", None),\n \"rtd-dev\": (\"https://dev.readthedocs.io/en/latest/\", None),\n+ \"rtd-blog\": (\"https://blog.readthedocs.com/\", None),\n \"jupyter\": (\"https://docs.jupyter.org/en/latest/\", None),\n }\n", "issue": "Docs: Config file deprecation warnings\n* [x] Upgrade v1 docs to clearly indicate that it's removed in September 2023 and link to the v2 version\r\n* [x] Add warning banners in various places\r\n\r\nReferences https://github.com/readthedocs/readthedocs.org/issues/10342\n", "before_files": [{"content": "\"\"\"\nShared Sphinx configuration using sphinx-multiproject.\n\nTo build each project, the ``PROJECT`` environment variable is used.\n\n.. code:: console\n\n $ make html # build default project\n $ PROJECT=dev make html # build the dev project\n\nfor more information read https://sphinx-multiproject.readthedocs.io/.\n\"\"\"\n\nimport os\nimport sys\n\nfrom multiproject.utils import get_project\n\nsys.path.append(os.path.abspath(\"_ext\"))\nextensions = [\n \"hoverxref.extension\",\n \"multiproject\",\n \"myst_parser\",\n \"notfound.extension\",\n \"sphinx_design\",\n \"sphinx_search.extension\",\n \"sphinx_tabs.tabs\",\n \"sphinx-prompt\",\n \"sphinx.ext.autodoc\",\n \"sphinx.ext.autosectionlabel\",\n \"sphinx.ext.extlinks\",\n \"sphinx.ext.intersphinx\",\n \"sphinxcontrib.httpdomain\",\n \"sphinxcontrib.video\",\n \"sphinxemoji.sphinxemoji\",\n \"sphinxext.opengraph\",\n]\n\nmultiproject_projects = {\n \"user\": {\n \"use_config_file\": False,\n \"config\": {\n \"project\": \"Read the Docs user documentation\",\n },\n },\n \"dev\": {\n \"use_config_file\": False,\n \"config\": {\n \"project\": \"Read the Docs developer documentation\",\n },\n },\n}\n\ndocset = get_project(multiproject_projects)\n\nogp_site_name = \"Read the Docs Documentation\"\nogp_use_first_image = True # https://github.com/readthedocs/blog/pull/118\nogp_image = \"https://docs.readthedocs.io/en/latest/_static/img/logo-opengraph.png\"\n# Inspired by https://github.com/executablebooks/MyST-Parser/pull/404/\nogp_custom_meta_tags = [\n '<meta name=\"twitter:card\" content=\"summary_large_image\" />',\n]\nogp_enable_meta_description = True\nogp_description_length = 300\n\ntemplates_path = [\"_templates\"]\n\n# This may be elevated as a general issue for documentation and behavioral\n# change to the Sphinx build:\n# This will ensure that we use the correctly set environment for canonical URLs\n# Old Read the Docs injections makes it point only to the default version,\n# for instance /en/stable/\nhtml_baseurl = os.environ.get(\"READTHEDOCS_CANONICAL_URL\", \"/\")\n\nmaster_doc = \"index\"\ncopyright = \"Read the Docs, Inc & contributors\"\nversion = \"9.13.2\"\nrelease = version\nexclude_patterns = [\"_build\", \"shared\", \"_includes\"]\ndefault_role = \"obj\"\nintersphinx_cache_limit = 14 # cache for 2 weeks\nintersphinx_timeout = 3 # 3 seconds timeout\nintersphinx_mapping = {\n \"python\": (\"https://docs.python.org/3.10/\", None),\n \"django\": (\n \"https://docs.djangoproject.com/en/stable/\",\n \"https://docs.djangoproject.com/en/stable/_objects/\",\n ),\n \"sphinx\": (\"https://www.sphinx-doc.org/en/master/\", None),\n \"pip\": (\"https://pip.pypa.io/en/stable/\", None),\n \"nbsphinx\": (\"https://nbsphinx.readthedocs.io/en/latest/\", None),\n \"myst-nb\": (\"https://myst-nb.readthedocs.io/en/stable/\", None),\n \"ipywidgets\": (\"https://ipywidgets.readthedocs.io/en/stable/\", None),\n \"jupytext\": (\"https://jupytext.readthedocs.io/en/stable/\", None),\n \"ipyleaflet\": (\"https://ipyleaflet.readthedocs.io/en/latest/\", None),\n \"poliastro\": (\"https://docs.poliastro.space/en/stable/\", None),\n \"qiskit\": (\"https://qiskit.org/documentation/\", None),\n \"myst-parser\": (\"https://myst-parser.readthedocs.io/en/stable/\", None),\n \"writethedocs\": (\"https://www.writethedocs.org/\", None),\n \"jupyterbook\": (\"https://jupyterbook.org/en/stable/\", None),\n \"executablebook\": (\"https://executablebooks.org/en/latest/\", None),\n \"rst-to-myst\": (\"https://rst-to-myst.readthedocs.io/en/stable/\", None),\n \"rtd\": (\"https://docs.readthedocs.io/en/stable/\", None),\n \"rtd-dev\": (\"https://dev.readthedocs.io/en/latest/\", None),\n \"jupyter\": (\"https://docs.jupyter.org/en/latest/\", None),\n}\n\n# Intersphinx: Do not try to resolve unresolved labels that aren't explicitly prefixed.\n# The default setting for intersphinx_disabled_reftypes can cause some pretty bad\n# breakage because we have rtd and rtd-dev stable versions in our mappings.\n# Hence, if we refactor labels, we won't see broken references, since the\n# currently active stable mapping keeps resolving.\n# Recommending doing this on all projects with Intersphinx.\n# https://www.sphinx-doc.org/en/master/usage/extensions/intersphinx.html#confval-intersphinx_disabled_reftypes\nintersphinx_disabled_reftypes = [\"*\"]\n\nmyst_enable_extensions = [\n \"deflist\",\n]\nhoverxref_intersphinx = [\n \"sphinx\",\n \"pip\",\n \"nbsphinx\",\n \"myst-nb\",\n \"ipywidgets\",\n \"jupytext\",\n]\nhtmlhelp_basename = \"ReadTheDocsdoc\"\nlatex_documents = [\n (\n \"index\",\n \"ReadTheDocs.tex\",\n \"Read the Docs Documentation\",\n \"Eric Holscher, Charlie Leifer, Bobby Grace\",\n \"manual\",\n ),\n]\nman_pages = [\n (\n \"index\",\n \"read-the-docs\",\n \"Read the Docs Documentation\",\n [\"Eric Holscher, Charlie Leifer, Bobby Grace\"],\n 1,\n )\n]\n\nlanguage = \"en\"\n\nlocale_dirs = [\n f\"{docset}/locale/\",\n]\ngettext_compact = False\n\nhtml_theme = \"sphinx_rtd_theme\"\nhtml_static_path = [\"_static\", f\"{docset}/_static\"]\nhtml_css_files = [\"css/custom.css\", \"css/sphinx_prompt_css.css\"]\nhtml_js_files = [\"js/expand_tabs.js\"]\n\nif os.environ.get(\"READTHEDOCS_VERSION_TYPE\") == \"external\":\n html_js_files.append(\"js/readthedocs-doc-diff.js\")\n\nhtml_logo = \"img/logo.svg\"\nhtml_theme_options = {\n \"logo_only\": True,\n \"display_version\": False,\n}\nhtml_context = {\n # Fix the \"edit on\" links.\n # TODO: remove once we support different rtd config\n # files per project.\n \"conf_py_path\": f\"/docs/{docset}/\",\n # Use to generate the Plausible \"data-domain\" attribute from the template\n \"plausible_domain\": f\"{os.environ.get('READTHEDOCS_PROJECT')}.readthedocs.io\",\n}\n\nhoverxref_auto_ref = True\nhoverxref_domains = [\"py\"]\nhoverxref_roles = [\n \"option\",\n # Documentation pages\n # Not supported yet: https://github.com/readthedocs/sphinx-hoverxref/issues/18\n \"doc\",\n # Glossary terms\n \"term\",\n]\nhoverxref_role_types = {\n \"mod\": \"modal\", # for Python Sphinx Domain\n \"doc\": \"modal\", # for whole docs\n \"class\": \"tooltip\", # for Python Sphinx Domain\n \"ref\": \"tooltip\", # for hoverxref_auto_ref config\n \"confval\": \"tooltip\", # for custom object\n \"term\": \"tooltip\", # for glossaries\n}\n\n# See dev/style_guide.rst for documentation\nrst_epilog = \"\"\"\n.. |org_brand| replace:: Read the Docs Community\n.. |com_brand| replace:: Read the Docs for Business\n.. |git_providers_and| replace:: GitHub, Bitbucket, and GitLab\n.. |git_providers_or| replace:: GitHub, Bitbucket, or GitLab\n\"\"\"\n\n# Activate autosectionlabel plugin\nautosectionlabel_prefix_document = True\n\n# sphinx-notfound-page\n# https://github.com/readthedocs/sphinx-notfound-page\nnotfound_context = {\n \"title\": \"Page Not Found\",\n \"body\": \"\"\"\n<h1>Page Not Found</h1>\n\n<p>Sorry, we couldn't find that page.</p>\n\n<p>Try using the search box or go to the homepage.</p>\n\"\"\",\n}\nlinkcheck_retries = 2\nlinkcheck_timeout = 1\nlinkcheck_workers = 10\nlinkcheck_ignore = [\n r\"http://127\\.0\\.0\\.1\",\n r\"http://localhost\",\n r\"http://community\\.dev\\.readthedocs\\.io\",\n r\"https://yourproject\\.readthedocs\\.io\",\n r\"https?://docs\\.example\\.com\",\n r\"https://foo\\.readthedocs\\.io/projects\",\n r\"https://github\\.com.+?#L\\d+\",\n r\"https://github\\.com/readthedocs/readthedocs\\.org/issues\",\n r\"https://github\\.com/readthedocs/readthedocs\\.org/pull\",\n r\"https://docs\\.readthedocs\\.io/\\?rtd_search\",\n r\"https://readthedocs\\.org/search\",\n # This page is under login\n r\"https://readthedocs\\.org/accounts/gold\",\n]\n\nextlinks = {\n \"rtd-issue\": (\"https://github.com/readthedocs/readthedocs.org/issues/%s\", \"#%s\"),\n}\n\n# Disable epub mimetype warnings\nsuppress_warnings = [\"epub.unknown_project_files\"]\n", "path": "docs/conf.py"}]} | 3,335 | 136 |
gh_patches_debug_36678 | rasdani/github-patches | git_diff | jazzband__pip-tools-909 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
pip-compile --no-header <blank requirements.in> neither creates nor overwrites requirements.txt
If `requirements.in` is empty, running `pip-compile` will create or clobber `requirements.txt`, thereby removing all requirements, but if `--no-header` is passed to `pip-compile`, `requirements.txt` will not be affected in any way, no matter its state.
#### Environment Versions
1. Linux
1. Python version: `3.7.4`
1. pip version: `19.2.3`
1. pip-tools version: `4.1.0`
#### Steps to replicate
```bash
touch requirements.in
pip-compile --no-header
# no txt file created (unexpected)
pip-compile
# txt file created (as expected)
echo plumbum > requirements.in
pip-compile
echo > requirements.in
pip-compile --no-header
cat requirements.txt
```
full, unexpected:
```python
#
# This file is autogenerated by pip-compile
# To update, run:
#
# pip-compile
#
plumbum==1.6.7
```
</issue>
<code>
[start of piptools/writer.py]
1 from __future__ import unicode_literals
2
3 import os
4 from itertools import chain
5
6 from .click import unstyle
7 from .logging import log
8 from .utils import (
9 UNSAFE_PACKAGES,
10 comment,
11 dedup,
12 format_requirement,
13 get_compile_command,
14 key_from_ireq,
15 )
16
17 MESSAGE_UNHASHED_PACKAGE = comment(
18 "# WARNING: pip install will require the following package to be hashed."
19 "\n# Consider using a hashable URL like "
20 "https://github.com/jazzband/pip-tools/archive/SOMECOMMIT.zip"
21 )
22
23 MESSAGE_UNSAFE_PACKAGES_UNPINNED = comment(
24 "# WARNING: The following packages were not pinned, but pip requires them to be"
25 "\n# pinned when the requirements file includes hashes. "
26 "Consider using the --allow-unsafe flag."
27 )
28
29 MESSAGE_UNSAFE_PACKAGES = comment(
30 "# The following packages are considered to be unsafe in a requirements file:"
31 )
32
33 MESSAGE_UNINSTALLABLE = (
34 "The generated requirements file may be rejected by pip install. "
35 "See # WARNING lines for details."
36 )
37
38
39 class OutputWriter(object):
40 def __init__(
41 self,
42 src_files,
43 dst_file,
44 click_ctx,
45 dry_run,
46 emit_header,
47 emit_index,
48 emit_trusted_host,
49 annotate,
50 generate_hashes,
51 default_index_url,
52 index_urls,
53 trusted_hosts,
54 format_control,
55 allow_unsafe,
56 find_links,
57 emit_find_links,
58 ):
59 self.src_files = src_files
60 self.dst_file = dst_file
61 self.click_ctx = click_ctx
62 self.dry_run = dry_run
63 self.emit_header = emit_header
64 self.emit_index = emit_index
65 self.emit_trusted_host = emit_trusted_host
66 self.annotate = annotate
67 self.generate_hashes = generate_hashes
68 self.default_index_url = default_index_url
69 self.index_urls = index_urls
70 self.trusted_hosts = trusted_hosts
71 self.format_control = format_control
72 self.allow_unsafe = allow_unsafe
73 self.find_links = find_links
74 self.emit_find_links = emit_find_links
75
76 def _sort_key(self, ireq):
77 return (not ireq.editable, str(ireq.req).lower())
78
79 def write_header(self):
80 if self.emit_header:
81 yield comment("#")
82 yield comment("# This file is autogenerated by pip-compile")
83 yield comment("# To update, run:")
84 yield comment("#")
85 compile_command = os.environ.get(
86 "CUSTOM_COMPILE_COMMAND"
87 ) or get_compile_command(self.click_ctx)
88 yield comment("# {}".format(compile_command))
89 yield comment("#")
90
91 def write_index_options(self):
92 if self.emit_index:
93 for index, index_url in enumerate(dedup(self.index_urls)):
94 if index_url.rstrip("/") == self.default_index_url:
95 continue
96 flag = "--index-url" if index == 0 else "--extra-index-url"
97 yield "{} {}".format(flag, index_url)
98
99 def write_trusted_hosts(self):
100 if self.emit_trusted_host:
101 for trusted_host in dedup(self.trusted_hosts):
102 yield "--trusted-host {}".format(trusted_host)
103
104 def write_format_controls(self):
105 for nb in dedup(self.format_control.no_binary):
106 yield "--no-binary {}".format(nb)
107 for ob in dedup(self.format_control.only_binary):
108 yield "--only-binary {}".format(ob)
109
110 def write_find_links(self):
111 if self.emit_find_links:
112 for find_link in dedup(self.find_links):
113 yield "--find-links {}".format(find_link)
114
115 def write_flags(self):
116 emitted = False
117 for line in chain(
118 self.write_index_options(),
119 self.write_find_links(),
120 self.write_trusted_hosts(),
121 self.write_format_controls(),
122 ):
123 emitted = True
124 yield line
125 if emitted:
126 yield ""
127
128 def _iter_lines(
129 self,
130 results,
131 unsafe_requirements=None,
132 reverse_dependencies=None,
133 primary_packages=None,
134 markers=None,
135 hashes=None,
136 ):
137 # default values
138 unsafe_requirements = unsafe_requirements or []
139 reverse_dependencies = reverse_dependencies or {}
140 primary_packages = primary_packages or []
141 markers = markers or {}
142 hashes = hashes or {}
143
144 # Check for unhashed or unpinned packages if at least one package does have
145 # hashes, which will trigger pip install's --require-hashes mode.
146 warn_uninstallable = False
147 has_hashes = hashes and any(hash for hash in hashes.values())
148
149 for line in self.write_header():
150 yield line
151 for line in self.write_flags():
152 yield line
153
154 unsafe_requirements = (
155 {r for r in results if r.name in UNSAFE_PACKAGES}
156 if not unsafe_requirements
157 else unsafe_requirements
158 )
159 packages = {r for r in results if r.name not in UNSAFE_PACKAGES}
160
161 packages = sorted(packages, key=self._sort_key)
162
163 for ireq in packages:
164 if has_hashes and not hashes.get(ireq):
165 yield MESSAGE_UNHASHED_PACKAGE
166 warn_uninstallable = True
167 line = self._format_requirement(
168 ireq,
169 reverse_dependencies,
170 primary_packages,
171 markers.get(key_from_ireq(ireq)),
172 hashes=hashes,
173 )
174 yield line
175
176 if unsafe_requirements:
177 unsafe_requirements = sorted(unsafe_requirements, key=self._sort_key)
178 yield ""
179 if has_hashes and not self.allow_unsafe:
180 yield MESSAGE_UNSAFE_PACKAGES_UNPINNED
181 warn_uninstallable = True
182 else:
183 yield MESSAGE_UNSAFE_PACKAGES
184
185 for ireq in unsafe_requirements:
186 req = self._format_requirement(
187 ireq,
188 reverse_dependencies,
189 primary_packages,
190 marker=markers.get(key_from_ireq(ireq)),
191 hashes=hashes,
192 )
193 if not self.allow_unsafe:
194 yield comment("# {}".format(req))
195 else:
196 yield req
197
198 if warn_uninstallable:
199 log.warning(MESSAGE_UNINSTALLABLE)
200
201 def write(
202 self,
203 results,
204 unsafe_requirements,
205 reverse_dependencies,
206 primary_packages,
207 markers,
208 hashes,
209 ):
210
211 for line in self._iter_lines(
212 results,
213 unsafe_requirements,
214 reverse_dependencies,
215 primary_packages,
216 markers,
217 hashes,
218 ):
219 log.info(line)
220 if not self.dry_run:
221 self.dst_file.write(unstyle(line).encode("utf-8"))
222 self.dst_file.write(os.linesep.encode("utf-8"))
223
224 def _format_requirement(
225 self, ireq, reverse_dependencies, primary_packages, marker=None, hashes=None
226 ):
227 ireq_hashes = (hashes if hashes is not None else {}).get(ireq)
228
229 line = format_requirement(ireq, marker=marker, hashes=ireq_hashes)
230
231 if not self.annotate or key_from_ireq(ireq) in primary_packages:
232 return line
233
234 # Annotate what packages this package is required by
235 required_by = reverse_dependencies.get(ireq.name.lower(), [])
236 if required_by:
237 annotation = ", ".join(sorted(required_by))
238 line = "{:24}{}{}".format(
239 line,
240 " \\\n " if ireq_hashes else " ",
241 comment("# via " + annotation),
242 )
243 return line
244
[end of piptools/writer.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/piptools/writer.py b/piptools/writer.py
--- a/piptools/writer.py
+++ b/piptools/writer.py
@@ -146,10 +146,14 @@
warn_uninstallable = False
has_hashes = hashes and any(hash for hash in hashes.values())
+ yielded = False
+
for line in self.write_header():
yield line
+ yielded = True
for line in self.write_flags():
yield line
+ yielded = True
unsafe_requirements = (
{r for r in results if r.name in UNSAFE_PACKAGES}
@@ -158,24 +162,26 @@
)
packages = {r for r in results if r.name not in UNSAFE_PACKAGES}
- packages = sorted(packages, key=self._sort_key)
-
- for ireq in packages:
- if has_hashes and not hashes.get(ireq):
- yield MESSAGE_UNHASHED_PACKAGE
- warn_uninstallable = True
- line = self._format_requirement(
- ireq,
- reverse_dependencies,
- primary_packages,
- markers.get(key_from_ireq(ireq)),
- hashes=hashes,
- )
- yield line
+ if packages:
+ packages = sorted(packages, key=self._sort_key)
+ for ireq in packages:
+ if has_hashes and not hashes.get(ireq):
+ yield MESSAGE_UNHASHED_PACKAGE
+ warn_uninstallable = True
+ line = self._format_requirement(
+ ireq,
+ reverse_dependencies,
+ primary_packages,
+ markers.get(key_from_ireq(ireq)),
+ hashes=hashes,
+ )
+ yield line
+ yielded = True
if unsafe_requirements:
unsafe_requirements = sorted(unsafe_requirements, key=self._sort_key)
yield ""
+ yielded = True
if has_hashes and not self.allow_unsafe:
yield MESSAGE_UNSAFE_PACKAGES_UNPINNED
warn_uninstallable = True
@@ -195,6 +201,10 @@
else:
yield req
+ # Yield even when there's no real content, so that blank files are written
+ if not yielded:
+ yield ""
+
if warn_uninstallable:
log.warning(MESSAGE_UNINSTALLABLE)
| {"golden_diff": "diff --git a/piptools/writer.py b/piptools/writer.py\n--- a/piptools/writer.py\n+++ b/piptools/writer.py\n@@ -146,10 +146,14 @@\n warn_uninstallable = False\n has_hashes = hashes and any(hash for hash in hashes.values())\n \n+ yielded = False\n+\n for line in self.write_header():\n yield line\n+ yielded = True\n for line in self.write_flags():\n yield line\n+ yielded = True\n \n unsafe_requirements = (\n {r for r in results if r.name in UNSAFE_PACKAGES}\n@@ -158,24 +162,26 @@\n )\n packages = {r for r in results if r.name not in UNSAFE_PACKAGES}\n \n- packages = sorted(packages, key=self._sort_key)\n-\n- for ireq in packages:\n- if has_hashes and not hashes.get(ireq):\n- yield MESSAGE_UNHASHED_PACKAGE\n- warn_uninstallable = True\n- line = self._format_requirement(\n- ireq,\n- reverse_dependencies,\n- primary_packages,\n- markers.get(key_from_ireq(ireq)),\n- hashes=hashes,\n- )\n- yield line\n+ if packages:\n+ packages = sorted(packages, key=self._sort_key)\n+ for ireq in packages:\n+ if has_hashes and not hashes.get(ireq):\n+ yield MESSAGE_UNHASHED_PACKAGE\n+ warn_uninstallable = True\n+ line = self._format_requirement(\n+ ireq,\n+ reverse_dependencies,\n+ primary_packages,\n+ markers.get(key_from_ireq(ireq)),\n+ hashes=hashes,\n+ )\n+ yield line\n+ yielded = True\n \n if unsafe_requirements:\n unsafe_requirements = sorted(unsafe_requirements, key=self._sort_key)\n yield \"\"\n+ yielded = True\n if has_hashes and not self.allow_unsafe:\n yield MESSAGE_UNSAFE_PACKAGES_UNPINNED\n warn_uninstallable = True\n@@ -195,6 +201,10 @@\n else:\n yield req\n \n+ # Yield even when there's no real content, so that blank files are written\n+ if not yielded:\n+ yield \"\"\n+\n if warn_uninstallable:\n log.warning(MESSAGE_UNINSTALLABLE)\n", "issue": "pip-compile --no-header <blank requirements.in> neither creates nor overwrites requirements.txt\nIf `requirements.in` is empty, running `pip-compile` will create or clobber `requirements.txt`, thereby removing all requirements, but if `--no-header` is passed to `pip-compile`, `requirements.txt` will not be affected in any way, no matter its state.\r\n\r\n#### Environment Versions\r\n\r\n1. Linux\r\n1. Python version: `3.7.4`\r\n1. pip version: `19.2.3`\r\n1. pip-tools version: `4.1.0`\r\n\r\n#### Steps to replicate\r\n\r\n```bash\r\ntouch requirements.in\r\npip-compile --no-header\r\n# no txt file created (unexpected)\r\npip-compile\r\n# txt file created (as expected)\r\necho plumbum > requirements.in\r\npip-compile\r\necho > requirements.in\r\npip-compile --no-header\r\ncat requirements.txt\r\n```\r\nfull, unexpected:\r\n```python\r\n#\r\n# This file is autogenerated by pip-compile\r\n# To update, run:\r\n#\r\n# pip-compile\r\n#\r\nplumbum==1.6.7\r\n```\n", "before_files": [{"content": "from __future__ import unicode_literals\n\nimport os\nfrom itertools import chain\n\nfrom .click import unstyle\nfrom .logging import log\nfrom .utils import (\n UNSAFE_PACKAGES,\n comment,\n dedup,\n format_requirement,\n get_compile_command,\n key_from_ireq,\n)\n\nMESSAGE_UNHASHED_PACKAGE = comment(\n \"# WARNING: pip install will require the following package to be hashed.\"\n \"\\n# Consider using a hashable URL like \"\n \"https://github.com/jazzband/pip-tools/archive/SOMECOMMIT.zip\"\n)\n\nMESSAGE_UNSAFE_PACKAGES_UNPINNED = comment(\n \"# WARNING: The following packages were not pinned, but pip requires them to be\"\n \"\\n# pinned when the requirements file includes hashes. \"\n \"Consider using the --allow-unsafe flag.\"\n)\n\nMESSAGE_UNSAFE_PACKAGES = comment(\n \"# The following packages are considered to be unsafe in a requirements file:\"\n)\n\nMESSAGE_UNINSTALLABLE = (\n \"The generated requirements file may be rejected by pip install. \"\n \"See # WARNING lines for details.\"\n)\n\n\nclass OutputWriter(object):\n def __init__(\n self,\n src_files,\n dst_file,\n click_ctx,\n dry_run,\n emit_header,\n emit_index,\n emit_trusted_host,\n annotate,\n generate_hashes,\n default_index_url,\n index_urls,\n trusted_hosts,\n format_control,\n allow_unsafe,\n find_links,\n emit_find_links,\n ):\n self.src_files = src_files\n self.dst_file = dst_file\n self.click_ctx = click_ctx\n self.dry_run = dry_run\n self.emit_header = emit_header\n self.emit_index = emit_index\n self.emit_trusted_host = emit_trusted_host\n self.annotate = annotate\n self.generate_hashes = generate_hashes\n self.default_index_url = default_index_url\n self.index_urls = index_urls\n self.trusted_hosts = trusted_hosts\n self.format_control = format_control\n self.allow_unsafe = allow_unsafe\n self.find_links = find_links\n self.emit_find_links = emit_find_links\n\n def _sort_key(self, ireq):\n return (not ireq.editable, str(ireq.req).lower())\n\n def write_header(self):\n if self.emit_header:\n yield comment(\"#\")\n yield comment(\"# This file is autogenerated by pip-compile\")\n yield comment(\"# To update, run:\")\n yield comment(\"#\")\n compile_command = os.environ.get(\n \"CUSTOM_COMPILE_COMMAND\"\n ) or get_compile_command(self.click_ctx)\n yield comment(\"# {}\".format(compile_command))\n yield comment(\"#\")\n\n def write_index_options(self):\n if self.emit_index:\n for index, index_url in enumerate(dedup(self.index_urls)):\n if index_url.rstrip(\"/\") == self.default_index_url:\n continue\n flag = \"--index-url\" if index == 0 else \"--extra-index-url\"\n yield \"{} {}\".format(flag, index_url)\n\n def write_trusted_hosts(self):\n if self.emit_trusted_host:\n for trusted_host in dedup(self.trusted_hosts):\n yield \"--trusted-host {}\".format(trusted_host)\n\n def write_format_controls(self):\n for nb in dedup(self.format_control.no_binary):\n yield \"--no-binary {}\".format(nb)\n for ob in dedup(self.format_control.only_binary):\n yield \"--only-binary {}\".format(ob)\n\n def write_find_links(self):\n if self.emit_find_links:\n for find_link in dedup(self.find_links):\n yield \"--find-links {}\".format(find_link)\n\n def write_flags(self):\n emitted = False\n for line in chain(\n self.write_index_options(),\n self.write_find_links(),\n self.write_trusted_hosts(),\n self.write_format_controls(),\n ):\n emitted = True\n yield line\n if emitted:\n yield \"\"\n\n def _iter_lines(\n self,\n results,\n unsafe_requirements=None,\n reverse_dependencies=None,\n primary_packages=None,\n markers=None,\n hashes=None,\n ):\n # default values\n unsafe_requirements = unsafe_requirements or []\n reverse_dependencies = reverse_dependencies or {}\n primary_packages = primary_packages or []\n markers = markers or {}\n hashes = hashes or {}\n\n # Check for unhashed or unpinned packages if at least one package does have\n # hashes, which will trigger pip install's --require-hashes mode.\n warn_uninstallable = False\n has_hashes = hashes and any(hash for hash in hashes.values())\n\n for line in self.write_header():\n yield line\n for line in self.write_flags():\n yield line\n\n unsafe_requirements = (\n {r for r in results if r.name in UNSAFE_PACKAGES}\n if not unsafe_requirements\n else unsafe_requirements\n )\n packages = {r for r in results if r.name not in UNSAFE_PACKAGES}\n\n packages = sorted(packages, key=self._sort_key)\n\n for ireq in packages:\n if has_hashes and not hashes.get(ireq):\n yield MESSAGE_UNHASHED_PACKAGE\n warn_uninstallable = True\n line = self._format_requirement(\n ireq,\n reverse_dependencies,\n primary_packages,\n markers.get(key_from_ireq(ireq)),\n hashes=hashes,\n )\n yield line\n\n if unsafe_requirements:\n unsafe_requirements = sorted(unsafe_requirements, key=self._sort_key)\n yield \"\"\n if has_hashes and not self.allow_unsafe:\n yield MESSAGE_UNSAFE_PACKAGES_UNPINNED\n warn_uninstallable = True\n else:\n yield MESSAGE_UNSAFE_PACKAGES\n\n for ireq in unsafe_requirements:\n req = self._format_requirement(\n ireq,\n reverse_dependencies,\n primary_packages,\n marker=markers.get(key_from_ireq(ireq)),\n hashes=hashes,\n )\n if not self.allow_unsafe:\n yield comment(\"# {}\".format(req))\n else:\n yield req\n\n if warn_uninstallable:\n log.warning(MESSAGE_UNINSTALLABLE)\n\n def write(\n self,\n results,\n unsafe_requirements,\n reverse_dependencies,\n primary_packages,\n markers,\n hashes,\n ):\n\n for line in self._iter_lines(\n results,\n unsafe_requirements,\n reverse_dependencies,\n primary_packages,\n markers,\n hashes,\n ):\n log.info(line)\n if not self.dry_run:\n self.dst_file.write(unstyle(line).encode(\"utf-8\"))\n self.dst_file.write(os.linesep.encode(\"utf-8\"))\n\n def _format_requirement(\n self, ireq, reverse_dependencies, primary_packages, marker=None, hashes=None\n ):\n ireq_hashes = (hashes if hashes is not None else {}).get(ireq)\n\n line = format_requirement(ireq, marker=marker, hashes=ireq_hashes)\n\n if not self.annotate or key_from_ireq(ireq) in primary_packages:\n return line\n\n # Annotate what packages this package is required by\n required_by = reverse_dependencies.get(ireq.name.lower(), [])\n if required_by:\n annotation = \", \".join(sorted(required_by))\n line = \"{:24}{}{}\".format(\n line,\n \" \\\\\\n \" if ireq_hashes else \" \",\n comment(\"# via \" + annotation),\n )\n return line\n", "path": "piptools/writer.py"}]} | 2,986 | 529 |
gh_patches_debug_57377 | rasdani/github-patches | git_diff | open-telemetry__opentelemetry-python-1657 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
TypeError: pop() takes no arguments (1 given) with otlp exporter 0.18b0
**Describe your environment**
opentelemetry-sdk==1.0.0rc1
opentelemetry-exporter-otlp==1.0.0rc1
opentelemetry-exporter-jaeger==1.0.0rc1
opentelemetry-propagator-b3==1.0.0rc1
opentelemetry-distro==0.18b0
opentelemetry-instrumentation==0.18b0
opentelemetry-instrumentation-grpc==0.18b0
opentelemetry-instrumentation-jinja2==0.18b0
export OTEL_TRACES_EXPORTER="otlp"
export OTEL_EXPORTER_OTLP_INSECURE=true
export OTEL_EXPORTER_OTLP_ENDPOINT="markf-0398:4317"
export OTEL_RESOURCE_ATTRIBUTES="service.name=emailservice, environment=hipster_shop"
**Steps to reproduce**
I'm using this app, but I don't believe it makes any difference, given the error.
https://github.com/markfink-splunk/microservices-demo/tree/master/src/emailservice
**What is the expected behavior?**
otlp should initialize and export traces.
**What is the actual behavior?**
I get this error immediately upon executing "opentelemetry-instrument python email_server.py".
Configuration of configurator failed
Traceback (most recent call last):
File "/usr/local/lib/python3.7/site-packages/opentelemetry/instrumentation/auto_instrumentation/sitecustomize.py", line 74, in _load_configurators
entry_point.load()().configure() # type: ignore
File "/usr/local/lib/python3.7/site-packages/opentelemetry/instrumentation/configurator.py", line 50, in configure
self._configure(**kwargs)
File "/usr/local/lib/python3.7/site-packages/opentelemetry/distro/__init__.py", line 168, in _configure
_initialize_components()
File "/usr/local/lib/python3.7/site-packages/opentelemetry/distro/__init__.py", line 159, in _initialize_components
exporter_names = _get_exporter_names()
File "/usr/local/lib/python3.7/site-packages/opentelemetry/distro/__init__.py", line 73, in _get_exporter_names
exporters.pop(EXPORTER_OTLP)
TypeError: pop() takes no arguments (1 given)
Failed to auto initialize opentelemetry
Traceback (most recent call last):
File "/usr/local/lib/python3.7/site-packages/opentelemetry/instrumentation/auto_instrumentation/sitecustomize.py", line 84, in initialize
_load_configurators()
File "/usr/local/lib/python3.7/site-packages/opentelemetry/instrumentation/auto_instrumentation/sitecustomize.py", line 78, in _load_configurators
raise exc
File "/usr/local/lib/python3.7/site-packages/opentelemetry/instrumentation/auto_instrumentation/sitecustomize.py", line 74, in _load_configurators
entry_point.load()().configure() # type: ignore
File "/usr/local/lib/python3.7/site-packages/opentelemetry/instrumentation/configurator.py", line 50, in configure
self._configure(**kwargs)
File "/usr/local/lib/python3.7/site-packages/opentelemetry/distro/__init__.py", line 168, in _configure
_initialize_components()
File "/usr/local/lib/python3.7/site-packages/opentelemetry/distro/__init__.py", line 159, in _initialize_components
exporter_names = _get_exporter_names()
File "/usr/local/lib/python3.7/site-packages/opentelemetry/distro/__init__.py", line 73, in _get_exporter_names
exporters.pop(EXPORTER_OTLP)
TypeError: pop() takes no arguments (1 given)
</issue>
<code>
[start of opentelemetry-distro/src/opentelemetry/distro/__init__.py]
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 #
15 import os
16 from logging import getLogger
17 from os import environ
18 from typing import Sequence, Tuple
19
20 from pkg_resources import iter_entry_points
21
22 from opentelemetry import trace
23 from opentelemetry.environment_variables import (
24 OTEL_PYTHON_ID_GENERATOR,
25 OTEL_PYTHON_SERVICE_NAME,
26 OTEL_TRACES_EXPORTER,
27 )
28 from opentelemetry.instrumentation.configurator import BaseConfigurator
29 from opentelemetry.instrumentation.distro import BaseDistro
30 from opentelemetry.sdk.resources import Resource
31 from opentelemetry.sdk.trace import TracerProvider
32 from opentelemetry.sdk.trace.export import BatchSpanProcessor, SpanExporter
33 from opentelemetry.sdk.trace.id_generator import IdGenerator
34
35 logger = getLogger(__file__)
36
37
38 EXPORTER_OTLP = "otlp"
39 EXPORTER_OTLP_SPAN = "otlp_span"
40
41 RANDOM_ID_GENERATOR = "random"
42 _DEFAULT_ID_GENERATOR = RANDOM_ID_GENERATOR
43
44
45 def _get_id_generator() -> str:
46 return environ.get(OTEL_PYTHON_ID_GENERATOR, _DEFAULT_ID_GENERATOR)
47
48
49 def _get_service_name() -> str:
50 return environ.get(OTEL_PYTHON_SERVICE_NAME, "")
51
52
53 def _get_exporter_names() -> Sequence[str]:
54 trace_exporters = environ.get(OTEL_TRACES_EXPORTER)
55
56 exporters = set()
57
58 if (
59 trace_exporters is not None
60 or trace_exporters.lower().strip() != "none"
61 ):
62 exporters.update(
63 {
64 trace_exporter.strip()
65 for trace_exporter in trace_exporters.split(",")
66 }
67 )
68
69 if EXPORTER_OTLP in exporters:
70 exporters.pop(EXPORTER_OTLP)
71 exporters.add(EXPORTER_OTLP_SPAN)
72
73 return list(exporters)
74
75
76 def _init_tracing(
77 exporters: Sequence[SpanExporter], id_generator: IdGenerator
78 ):
79 service_name = _get_service_name()
80 provider = TracerProvider(
81 resource=Resource.create({"service.name": service_name}),
82 id_generator=id_generator(),
83 )
84 trace.set_tracer_provider(provider)
85
86 for exporter_name, exporter_class in exporters.items():
87 exporter_args = {}
88 if exporter_name not in [
89 EXPORTER_OTLP,
90 EXPORTER_OTLP_SPAN,
91 ]:
92 exporter_args["service_name"] = service_name
93
94 provider.add_span_processor(
95 BatchSpanProcessor(exporter_class(**exporter_args))
96 )
97
98
99 def _import_tracer_provider_config_components(
100 selected_components, entry_point_name
101 ) -> Sequence[Tuple[str, object]]:
102 component_entry_points = {
103 ep.name: ep for ep in iter_entry_points(entry_point_name)
104 }
105 component_impls = []
106 for selected_component in selected_components:
107 entry_point = component_entry_points.get(selected_component, None)
108 if not entry_point:
109 raise RuntimeError(
110 "Requested component '{}' not found in entry points for '{}'".format(
111 selected_component, entry_point_name
112 )
113 )
114
115 component_impl = entry_point.load()
116 component_impls.append((selected_component, component_impl))
117
118 return component_impls
119
120
121 def _import_exporters(
122 exporter_names: Sequence[str],
123 ) -> Sequence[SpanExporter]:
124 trace_exporters = {}
125
126 for (
127 exporter_name,
128 exporter_impl,
129 ) in _import_tracer_provider_config_components(
130 exporter_names, "opentelemetry_exporter"
131 ):
132 if issubclass(exporter_impl, SpanExporter):
133 trace_exporters[exporter_name] = exporter_impl
134 else:
135 raise RuntimeError(
136 "{0} is not a trace exporter".format(exporter_name)
137 )
138 return trace_exporters
139
140
141 def _import_id_generator(id_generator_name: str) -> IdGenerator:
142 # pylint: disable=unbalanced-tuple-unpacking
143 [
144 (id_generator_name, id_generator_impl)
145 ] = _import_tracer_provider_config_components(
146 [id_generator_name.strip()], "opentelemetry_id_generator"
147 )
148
149 if issubclass(id_generator_impl, IdGenerator):
150 return id_generator_impl
151
152 raise RuntimeError("{0} is not an IdGenerator".format(id_generator_name))
153
154
155 def _initialize_components():
156 exporter_names = _get_exporter_names()
157 trace_exporters = _import_exporters(exporter_names)
158 id_generator_name = _get_id_generator()
159 id_generator = _import_id_generator(id_generator_name)
160 _init_tracing(trace_exporters, id_generator)
161
162
163 class Configurator(BaseConfigurator):
164 def _configure(self, **kwargs):
165 _initialize_components()
166
167
168 class OpenTelemetryDistro(BaseDistro):
169 """
170 The OpenTelemetry provided Distro configures a default set of
171 configuration out of the box.
172 """
173
174 def _configure(self, **kwargs):
175 os.environ.setdefault(OTEL_TRACES_EXPORTER, "otlp_span")
176
[end of opentelemetry-distro/src/opentelemetry/distro/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/opentelemetry-distro/src/opentelemetry/distro/__init__.py b/opentelemetry-distro/src/opentelemetry/distro/__init__.py
--- a/opentelemetry-distro/src/opentelemetry/distro/__init__.py
+++ b/opentelemetry-distro/src/opentelemetry/distro/__init__.py
@@ -67,7 +67,7 @@
)
if EXPORTER_OTLP in exporters:
- exporters.pop(EXPORTER_OTLP)
+ exporters.remove(EXPORTER_OTLP)
exporters.add(EXPORTER_OTLP_SPAN)
return list(exporters)
| {"golden_diff": "diff --git a/opentelemetry-distro/src/opentelemetry/distro/__init__.py b/opentelemetry-distro/src/opentelemetry/distro/__init__.py\n--- a/opentelemetry-distro/src/opentelemetry/distro/__init__.py\n+++ b/opentelemetry-distro/src/opentelemetry/distro/__init__.py\n@@ -67,7 +67,7 @@\n )\n \n if EXPORTER_OTLP in exporters:\n- exporters.pop(EXPORTER_OTLP)\n+ exporters.remove(EXPORTER_OTLP)\n exporters.add(EXPORTER_OTLP_SPAN)\n \n return list(exporters)\n", "issue": "TypeError: pop() takes no arguments (1 given) with otlp exporter 0.18b0\n**Describe your environment** \r\nopentelemetry-sdk==1.0.0rc1\r\nopentelemetry-exporter-otlp==1.0.0rc1\r\nopentelemetry-exporter-jaeger==1.0.0rc1\r\nopentelemetry-propagator-b3==1.0.0rc1\r\nopentelemetry-distro==0.18b0\r\nopentelemetry-instrumentation==0.18b0\r\nopentelemetry-instrumentation-grpc==0.18b0\r\nopentelemetry-instrumentation-jinja2==0.18b0\r\n\r\nexport OTEL_TRACES_EXPORTER=\"otlp\"\r\nexport OTEL_EXPORTER_OTLP_INSECURE=true\r\nexport OTEL_EXPORTER_OTLP_ENDPOINT=\"markf-0398:4317\"\r\nexport OTEL_RESOURCE_ATTRIBUTES=\"service.name=emailservice, environment=hipster_shop\"\r\n\r\n**Steps to reproduce**\r\nI'm using this app, but I don't believe it makes any difference, given the error.\r\nhttps://github.com/markfink-splunk/microservices-demo/tree/master/src/emailservice\r\n\r\n**What is the expected behavior?**\r\notlp should initialize and export traces.\r\n\r\n**What is the actual behavior?**\r\nI get this error immediately upon executing \"opentelemetry-instrument python email_server.py\".\r\n\r\nConfiguration of configurator failed\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.7/site-packages/opentelemetry/instrumentation/auto_instrumentation/sitecustomize.py\", line 74, in _load_configurators\r\n entry_point.load()().configure() # type: ignore\r\n File \"/usr/local/lib/python3.7/site-packages/opentelemetry/instrumentation/configurator.py\", line 50, in configure\r\n self._configure(**kwargs)\r\n File \"/usr/local/lib/python3.7/site-packages/opentelemetry/distro/__init__.py\", line 168, in _configure\r\n _initialize_components()\r\n File \"/usr/local/lib/python3.7/site-packages/opentelemetry/distro/__init__.py\", line 159, in _initialize_components\r\n exporter_names = _get_exporter_names()\r\n File \"/usr/local/lib/python3.7/site-packages/opentelemetry/distro/__init__.py\", line 73, in _get_exporter_names\r\n exporters.pop(EXPORTER_OTLP)\r\nTypeError: pop() takes no arguments (1 given)\r\nFailed to auto initialize opentelemetry\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.7/site-packages/opentelemetry/instrumentation/auto_instrumentation/sitecustomize.py\", line 84, in initialize\r\n _load_configurators()\r\n File \"/usr/local/lib/python3.7/site-packages/opentelemetry/instrumentation/auto_instrumentation/sitecustomize.py\", line 78, in _load_configurators\r\n raise exc\r\n File \"/usr/local/lib/python3.7/site-packages/opentelemetry/instrumentation/auto_instrumentation/sitecustomize.py\", line 74, in _load_configurators\r\n entry_point.load()().configure() # type: ignore\r\n File \"/usr/local/lib/python3.7/site-packages/opentelemetry/instrumentation/configurator.py\", line 50, in configure\r\n self._configure(**kwargs)\r\n File \"/usr/local/lib/python3.7/site-packages/opentelemetry/distro/__init__.py\", line 168, in _configure\r\n _initialize_components()\r\n File \"/usr/local/lib/python3.7/site-packages/opentelemetry/distro/__init__.py\", line 159, in _initialize_components\r\n exporter_names = _get_exporter_names()\r\n File \"/usr/local/lib/python3.7/site-packages/opentelemetry/distro/__init__.py\", line 73, in _get_exporter_names\r\n exporters.pop(EXPORTER_OTLP)\r\nTypeError: pop() takes no arguments (1 given)\r\n\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\nimport os\nfrom logging import getLogger\nfrom os import environ\nfrom typing import Sequence, Tuple\n\nfrom pkg_resources import iter_entry_points\n\nfrom opentelemetry import trace\nfrom opentelemetry.environment_variables import (\n OTEL_PYTHON_ID_GENERATOR,\n OTEL_PYTHON_SERVICE_NAME,\n OTEL_TRACES_EXPORTER,\n)\nfrom opentelemetry.instrumentation.configurator import BaseConfigurator\nfrom opentelemetry.instrumentation.distro import BaseDistro\nfrom opentelemetry.sdk.resources import Resource\nfrom opentelemetry.sdk.trace import TracerProvider\nfrom opentelemetry.sdk.trace.export import BatchSpanProcessor, SpanExporter\nfrom opentelemetry.sdk.trace.id_generator import IdGenerator\n\nlogger = getLogger(__file__)\n\n\nEXPORTER_OTLP = \"otlp\"\nEXPORTER_OTLP_SPAN = \"otlp_span\"\n\nRANDOM_ID_GENERATOR = \"random\"\n_DEFAULT_ID_GENERATOR = RANDOM_ID_GENERATOR\n\n\ndef _get_id_generator() -> str:\n return environ.get(OTEL_PYTHON_ID_GENERATOR, _DEFAULT_ID_GENERATOR)\n\n\ndef _get_service_name() -> str:\n return environ.get(OTEL_PYTHON_SERVICE_NAME, \"\")\n\n\ndef _get_exporter_names() -> Sequence[str]:\n trace_exporters = environ.get(OTEL_TRACES_EXPORTER)\n\n exporters = set()\n\n if (\n trace_exporters is not None\n or trace_exporters.lower().strip() != \"none\"\n ):\n exporters.update(\n {\n trace_exporter.strip()\n for trace_exporter in trace_exporters.split(\",\")\n }\n )\n\n if EXPORTER_OTLP in exporters:\n exporters.pop(EXPORTER_OTLP)\n exporters.add(EXPORTER_OTLP_SPAN)\n\n return list(exporters)\n\n\ndef _init_tracing(\n exporters: Sequence[SpanExporter], id_generator: IdGenerator\n):\n service_name = _get_service_name()\n provider = TracerProvider(\n resource=Resource.create({\"service.name\": service_name}),\n id_generator=id_generator(),\n )\n trace.set_tracer_provider(provider)\n\n for exporter_name, exporter_class in exporters.items():\n exporter_args = {}\n if exporter_name not in [\n EXPORTER_OTLP,\n EXPORTER_OTLP_SPAN,\n ]:\n exporter_args[\"service_name\"] = service_name\n\n provider.add_span_processor(\n BatchSpanProcessor(exporter_class(**exporter_args))\n )\n\n\ndef _import_tracer_provider_config_components(\n selected_components, entry_point_name\n) -> Sequence[Tuple[str, object]]:\n component_entry_points = {\n ep.name: ep for ep in iter_entry_points(entry_point_name)\n }\n component_impls = []\n for selected_component in selected_components:\n entry_point = component_entry_points.get(selected_component, None)\n if not entry_point:\n raise RuntimeError(\n \"Requested component '{}' not found in entry points for '{}'\".format(\n selected_component, entry_point_name\n )\n )\n\n component_impl = entry_point.load()\n component_impls.append((selected_component, component_impl))\n\n return component_impls\n\n\ndef _import_exporters(\n exporter_names: Sequence[str],\n) -> Sequence[SpanExporter]:\n trace_exporters = {}\n\n for (\n exporter_name,\n exporter_impl,\n ) in _import_tracer_provider_config_components(\n exporter_names, \"opentelemetry_exporter\"\n ):\n if issubclass(exporter_impl, SpanExporter):\n trace_exporters[exporter_name] = exporter_impl\n else:\n raise RuntimeError(\n \"{0} is not a trace exporter\".format(exporter_name)\n )\n return trace_exporters\n\n\ndef _import_id_generator(id_generator_name: str) -> IdGenerator:\n # pylint: disable=unbalanced-tuple-unpacking\n [\n (id_generator_name, id_generator_impl)\n ] = _import_tracer_provider_config_components(\n [id_generator_name.strip()], \"opentelemetry_id_generator\"\n )\n\n if issubclass(id_generator_impl, IdGenerator):\n return id_generator_impl\n\n raise RuntimeError(\"{0} is not an IdGenerator\".format(id_generator_name))\n\n\ndef _initialize_components():\n exporter_names = _get_exporter_names()\n trace_exporters = _import_exporters(exporter_names)\n id_generator_name = _get_id_generator()\n id_generator = _import_id_generator(id_generator_name)\n _init_tracing(trace_exporters, id_generator)\n\n\nclass Configurator(BaseConfigurator):\n def _configure(self, **kwargs):\n _initialize_components()\n\n\nclass OpenTelemetryDistro(BaseDistro):\n \"\"\"\n The OpenTelemetry provided Distro configures a default set of\n configuration out of the box.\n \"\"\"\n\n def _configure(self, **kwargs):\n os.environ.setdefault(OTEL_TRACES_EXPORTER, \"otlp_span\")\n", "path": "opentelemetry-distro/src/opentelemetry/distro/__init__.py"}]} | 3,004 | 135 |
gh_patches_debug_14769 | rasdani/github-patches | git_diff | getpelican__pelican-2716 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
LOG_FILTER not working as it should?
Good evening folks,
I have a problem with LOG_FILTER. According to the docs, one can remove `TAG_SAVE_AS is set to False` by configuring `LOG_FILTER` this way:
```python
import logging
LOG_FILTER = [(logging.WARN, 'TAG_SAVE_AS is set to False')]
```
So to ignore `AUTHOR_SAVE_AS is set to False` and `CATEGORY_SAVE_AS is set to False`, it must be :
```python
import logging
LOG_FILTER = [
(logging.WARN, 'AUTHOR_SAVE_AS is set to False'),
(logging.WARN, 'CATEGORY_SAVE_AS is set to False')
]
```
Right?
So this is what I did:
```bash
$ head pelicanconf.py -n 20
#!/usr/bin/env python
# -*- coding: utf-8 -*- #
from __future__ import unicode_literals
import datetime
import logging
import pelican
PELICAN_VERSION = pelican.__version__
[...]
LOG_FILTER = [
(logging.WARN, 'AUTHOR_SAVE_AS is set to False'),
(logging.WARN, 'CATEGORY_SAVE_AS is set to False')
]
AUTHOR_SAVE_AS = False
AUTHORS_SAVE_AS = False
TAG_SAVE_AS = False
TAGS_SAVE_AS = False
CATEGORY_SAVE_AS = False
CATEGORIES_SAVE_AS = False
ARCHIVES_SAVE_AS = False
$ make publish
pelican /mnt/c/Users/max/Code/mlcdf/content -o /mnt/c/Users/max/Code/mlcdf/output -s /mnt/c/Users/max/Code/mlcdf/publishconf.py
WARNING: CATEGORY_SAVE_AS is set to False
WARNING: AUTHOR_SAVE_AS is set to False
Done: Processed 2 articles, 0 drafts, 4 pages, 1 hidden page and 0 draft pages in 0.52 seconds.
```
2 things here:
- it didn't work: `AUTHOR_SAVE_AS is set to False` and `CATEGORY_SAVE_AS is set to False` are still logged.
- and, you may have noticed that, despite setting `TAG_SAVE_AS = False`, and not filtering it, I did not see `TAG_SAVE_AS is set to False` in the logs.
Using the template to filter worked (but it will also filter out other logs matching the template which is not what you would necessary want):
```
import logging
LOG_FILTER = [
(logging.WARN, '%s is set to %s'),
]
```
* Am I missing something?
* What's the intended behaviour here? Is there an actual bug in the code? Or is the code example in the docs just wrong?
I'm a bit lost. 🙃
Maxime
</issue>
<code>
[start of pelican/log.py]
1 # -*- coding: utf-8 -*-
2
3 import logging
4 import os
5 import sys
6 from collections import defaultdict
7
8 __all__ = [
9 'init'
10 ]
11
12
13 class BaseFormatter(logging.Formatter):
14 def __init__(self, fmt=None, datefmt=None):
15 FORMAT = '%(customlevelname)s %(message)s'
16 super().__init__(fmt=FORMAT, datefmt=datefmt)
17
18 def format(self, record):
19 customlevel = self._get_levelname(record.levelname)
20 record.__dict__['customlevelname'] = customlevel
21 # format multiline messages 'nicely' to make it clear they are together
22 record.msg = record.msg.replace('\n', '\n | ')
23 record.args = tuple(arg.replace('\n', '\n | ') if
24 isinstance(arg, str) else
25 arg for arg in record.args)
26 return super().format(record)
27
28 def formatException(self, ei):
29 ''' prefix traceback info for better representation '''
30 s = super().formatException(ei)
31 # fancy format traceback
32 s = '\n'.join(' | ' + line for line in s.splitlines())
33 # separate the traceback from the preceding lines
34 s = ' |___\n{}'.format(s)
35 return s
36
37 def _get_levelname(self, name):
38 ''' NOOP: overridden by subclasses '''
39 return name
40
41
42 class ANSIFormatter(BaseFormatter):
43 ANSI_CODES = {
44 'red': '\033[1;31m',
45 'yellow': '\033[1;33m',
46 'cyan': '\033[1;36m',
47 'white': '\033[1;37m',
48 'bgred': '\033[1;41m',
49 'bggrey': '\033[1;100m',
50 'reset': '\033[0;m'}
51
52 LEVEL_COLORS = {
53 'INFO': 'cyan',
54 'WARNING': 'yellow',
55 'ERROR': 'red',
56 'CRITICAL': 'bgred',
57 'DEBUG': 'bggrey'}
58
59 def _get_levelname(self, name):
60 color = self.ANSI_CODES[self.LEVEL_COLORS.get(name, 'white')]
61 if name == 'INFO':
62 fmt = '{0}->{2}'
63 else:
64 fmt = '{0}{1}{2}:'
65 return fmt.format(color, name, self.ANSI_CODES['reset'])
66
67
68 class TextFormatter(BaseFormatter):
69 """
70 Convert a `logging.LogRecord' object into text.
71 """
72
73 def _get_levelname(self, name):
74 if name == 'INFO':
75 return '->'
76 else:
77 return name + ':'
78
79
80 class LimitFilter(logging.Filter):
81 """
82 Remove duplicates records, and limit the number of records in the same
83 group.
84
85 Groups are specified by the message to use when the number of records in
86 the same group hit the limit.
87 E.g.: log.warning(('43 is not the answer', 'More erroneous answers'))
88 """
89
90 LOGS_DEDUP_MIN_LEVEL = logging.WARNING
91
92 _ignore = set()
93 _raised_messages = set()
94 _threshold = 5
95 _group_count = defaultdict(int)
96
97 def filter(self, record):
98 # don't limit log messages for anything above "warning"
99 if record.levelno > self.LOGS_DEDUP_MIN_LEVEL:
100 return True
101
102 # extract group
103 group = record.__dict__.get('limit_msg', None)
104 group_args = record.__dict__.get('limit_args', ())
105
106 # ignore record if it was already raised
107 message_key = (record.levelno, record.getMessage())
108 if message_key in self._raised_messages:
109 return False
110 else:
111 self._raised_messages.add(message_key)
112
113 # ignore LOG_FILTER records by templates when "debug" isn't enabled
114 logger_level = logging.getLogger().getEffectiveLevel()
115 if logger_level > logging.DEBUG:
116 ignore_key = (record.levelno, record.msg)
117 if ignore_key in self._ignore:
118 return False
119
120 # check if we went over threshold
121 if group:
122 key = (record.levelno, group)
123 self._group_count[key] += 1
124 if self._group_count[key] == self._threshold:
125 record.msg = group
126 record.args = group_args
127 elif self._group_count[key] > self._threshold:
128 return False
129 return True
130
131
132 class LimitLogger(logging.Logger):
133 """
134 A logger which adds LimitFilter automatically
135 """
136
137 limit_filter = LimitFilter()
138
139 def __init__(self, *args, **kwargs):
140 super().__init__(*args, **kwargs)
141 self.enable_filter()
142
143 def disable_filter(self):
144 self.removeFilter(LimitLogger.limit_filter)
145
146 def enable_filter(self):
147 self.addFilter(LimitLogger.limit_filter)
148
149
150 class FatalLogger(LimitLogger):
151 warnings_fatal = False
152 errors_fatal = False
153
154 def warning(self, *args, **kwargs):
155 super().warning(*args, **kwargs)
156 if FatalLogger.warnings_fatal:
157 raise RuntimeError('Warning encountered')
158
159 def error(self, *args, **kwargs):
160 super().error(*args, **kwargs)
161 if FatalLogger.errors_fatal:
162 raise RuntimeError('Error encountered')
163
164
165 logging.setLoggerClass(FatalLogger)
166
167
168 def supports_color():
169 """
170 Returns True if the running system's terminal supports color,
171 and False otherwise.
172
173 from django.core.management.color
174 """
175 plat = sys.platform
176 supported_platform = plat != 'Pocket PC' and \
177 (plat != 'win32' or 'ANSICON' in os.environ)
178
179 # isatty is not always implemented, #6223.
180 is_a_tty = hasattr(sys.stdout, 'isatty') and sys.stdout.isatty()
181 if not supported_platform or not is_a_tty:
182 return False
183 return True
184
185
186 def get_formatter():
187 if supports_color():
188 return ANSIFormatter()
189 else:
190 return TextFormatter()
191
192
193 def init(level=None, fatal='', handler=logging.StreamHandler(), name=None,
194 logs_dedup_min_level=None):
195 FatalLogger.warnings_fatal = fatal.startswith('warning')
196 FatalLogger.errors_fatal = bool(fatal)
197
198 logger = logging.getLogger(name)
199
200 handler.setFormatter(get_formatter())
201 logger.addHandler(handler)
202
203 if level:
204 logger.setLevel(level)
205 if logs_dedup_min_level:
206 LimitFilter.LOGS_DEDUP_MIN_LEVEL = logs_dedup_min_level
207
208
209 def log_warnings():
210 import warnings
211 logging.captureWarnings(True)
212 warnings.simplefilter("default", DeprecationWarning)
213 init(logging.DEBUG, name='py.warnings')
214
215
216 if __name__ == '__main__':
217 init(level=logging.DEBUG)
218
219 root_logger = logging.getLogger()
220 root_logger.debug('debug')
221 root_logger.info('info')
222 root_logger.warning('warning')
223 root_logger.error('error')
224 root_logger.critical('critical')
225
[end of pelican/log.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/pelican/log.py b/pelican/log.py
--- a/pelican/log.py
+++ b/pelican/log.py
@@ -110,11 +110,13 @@
else:
self._raised_messages.add(message_key)
- # ignore LOG_FILTER records by templates when "debug" isn't enabled
+ # ignore LOG_FILTER records by templates or messages
+ # when "debug" isn't enabled
logger_level = logging.getLogger().getEffectiveLevel()
if logger_level > logging.DEBUG:
- ignore_key = (record.levelno, record.msg)
- if ignore_key in self._ignore:
+ template_key = (record.levelno, record.msg)
+ message_key = (record.levelno, record.getMessage())
+ if (template_key in self._ignore or message_key in self._ignore):
return False
# check if we went over threshold
| {"golden_diff": "diff --git a/pelican/log.py b/pelican/log.py\n--- a/pelican/log.py\n+++ b/pelican/log.py\n@@ -110,11 +110,13 @@\n else:\n self._raised_messages.add(message_key)\n \n- # ignore LOG_FILTER records by templates when \"debug\" isn't enabled\n+ # ignore LOG_FILTER records by templates or messages\n+ # when \"debug\" isn't enabled\n logger_level = logging.getLogger().getEffectiveLevel()\n if logger_level > logging.DEBUG:\n- ignore_key = (record.levelno, record.msg)\n- if ignore_key in self._ignore:\n+ template_key = (record.levelno, record.msg)\n+ message_key = (record.levelno, record.getMessage())\n+ if (template_key in self._ignore or message_key in self._ignore):\n return False\n \n # check if we went over threshold\n", "issue": "LOG_FILTER not working as it should?\nGood evening folks,\r\n\r\nI have a problem with LOG_FILTER. According to the docs, one can remove `TAG_SAVE_AS is set to False` by configuring `LOG_FILTER` this way:\r\n\r\n```python\r\nimport logging\r\nLOG_FILTER = [(logging.WARN, 'TAG_SAVE_AS is set to False')]\r\n```\r\n\r\nSo to ignore `AUTHOR_SAVE_AS is set to False` and `CATEGORY_SAVE_AS is set to False`, it must be :\r\n\r\n```python\r\nimport logging\r\nLOG_FILTER = [\r\n (logging.WARN, 'AUTHOR_SAVE_AS is set to False'),\r\n (logging.WARN, 'CATEGORY_SAVE_AS is set to False')\r\n]\r\n```\r\nRight?\r\n\r\nSo this is what I did:\r\n```bash\r\n$ head pelicanconf.py -n 20\r\n#!/usr/bin/env python\r\n# -*- coding: utf-8 -*- #\r\nfrom __future__ import unicode_literals\r\nimport datetime\r\nimport logging\r\n\r\nimport pelican\r\n\r\nPELICAN_VERSION = pelican.__version__\r\n\r\n[...]\r\n\r\nLOG_FILTER = [\r\n (logging.WARN, 'AUTHOR_SAVE_AS is set to False'),\r\n (logging.WARN, 'CATEGORY_SAVE_AS is set to False')\r\n]\r\n\r\nAUTHOR_SAVE_AS = False\r\nAUTHORS_SAVE_AS = False\r\nTAG_SAVE_AS = False\r\nTAGS_SAVE_AS = False\r\nCATEGORY_SAVE_AS = False\r\nCATEGORIES_SAVE_AS = False\r\nARCHIVES_SAVE_AS = False\r\n\r\n$ make publish\r\npelican /mnt/c/Users/max/Code/mlcdf/content -o /mnt/c/Users/max/Code/mlcdf/output -s /mnt/c/Users/max/Code/mlcdf/publishconf.py\r\nWARNING: CATEGORY_SAVE_AS is set to False\r\nWARNING: AUTHOR_SAVE_AS is set to False\r\nDone: Processed 2 articles, 0 drafts, 4 pages, 1 hidden page and 0 draft pages in 0.52 seconds.\r\n```\r\n2 things here:\r\n- it didn't work: `AUTHOR_SAVE_AS is set to False` and `CATEGORY_SAVE_AS is set to False` are still logged.\r\n- and, you may have noticed that, despite setting `TAG_SAVE_AS = False`, and not filtering it, I did not see `TAG_SAVE_AS is set to False` in the logs.\r\n\r\nUsing the template to filter worked (but it will also filter out other logs matching the template which is not what you would necessary want):\r\n```\r\nimport logging\r\nLOG_FILTER = [\r\n (logging.WARN, '%s is set to %s'),\r\n]\r\n```\r\n\r\n* Am I missing something?\r\n* What's the intended behaviour here? Is there an actual bug in the code? Or is the code example in the docs just wrong?\r\n\r\nI'm a bit lost. \ud83d\ude43 \r\n\r\nMaxime\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\nimport logging\nimport os\nimport sys\nfrom collections import defaultdict\n\n__all__ = [\n 'init'\n]\n\n\nclass BaseFormatter(logging.Formatter):\n def __init__(self, fmt=None, datefmt=None):\n FORMAT = '%(customlevelname)s %(message)s'\n super().__init__(fmt=FORMAT, datefmt=datefmt)\n\n def format(self, record):\n customlevel = self._get_levelname(record.levelname)\n record.__dict__['customlevelname'] = customlevel\n # format multiline messages 'nicely' to make it clear they are together\n record.msg = record.msg.replace('\\n', '\\n | ')\n record.args = tuple(arg.replace('\\n', '\\n | ') if\n isinstance(arg, str) else\n arg for arg in record.args)\n return super().format(record)\n\n def formatException(self, ei):\n ''' prefix traceback info for better representation '''\n s = super().formatException(ei)\n # fancy format traceback\n s = '\\n'.join(' | ' + line for line in s.splitlines())\n # separate the traceback from the preceding lines\n s = ' |___\\n{}'.format(s)\n return s\n\n def _get_levelname(self, name):\n ''' NOOP: overridden by subclasses '''\n return name\n\n\nclass ANSIFormatter(BaseFormatter):\n ANSI_CODES = {\n 'red': '\\033[1;31m',\n 'yellow': '\\033[1;33m',\n 'cyan': '\\033[1;36m',\n 'white': '\\033[1;37m',\n 'bgred': '\\033[1;41m',\n 'bggrey': '\\033[1;100m',\n 'reset': '\\033[0;m'}\n\n LEVEL_COLORS = {\n 'INFO': 'cyan',\n 'WARNING': 'yellow',\n 'ERROR': 'red',\n 'CRITICAL': 'bgred',\n 'DEBUG': 'bggrey'}\n\n def _get_levelname(self, name):\n color = self.ANSI_CODES[self.LEVEL_COLORS.get(name, 'white')]\n if name == 'INFO':\n fmt = '{0}->{2}'\n else:\n fmt = '{0}{1}{2}:'\n return fmt.format(color, name, self.ANSI_CODES['reset'])\n\n\nclass TextFormatter(BaseFormatter):\n \"\"\"\n Convert a `logging.LogRecord' object into text.\n \"\"\"\n\n def _get_levelname(self, name):\n if name == 'INFO':\n return '->'\n else:\n return name + ':'\n\n\nclass LimitFilter(logging.Filter):\n \"\"\"\n Remove duplicates records, and limit the number of records in the same\n group.\n\n Groups are specified by the message to use when the number of records in\n the same group hit the limit.\n E.g.: log.warning(('43 is not the answer', 'More erroneous answers'))\n \"\"\"\n\n LOGS_DEDUP_MIN_LEVEL = logging.WARNING\n\n _ignore = set()\n _raised_messages = set()\n _threshold = 5\n _group_count = defaultdict(int)\n\n def filter(self, record):\n # don't limit log messages for anything above \"warning\"\n if record.levelno > self.LOGS_DEDUP_MIN_LEVEL:\n return True\n\n # extract group\n group = record.__dict__.get('limit_msg', None)\n group_args = record.__dict__.get('limit_args', ())\n\n # ignore record if it was already raised\n message_key = (record.levelno, record.getMessage())\n if message_key in self._raised_messages:\n return False\n else:\n self._raised_messages.add(message_key)\n\n # ignore LOG_FILTER records by templates when \"debug\" isn't enabled\n logger_level = logging.getLogger().getEffectiveLevel()\n if logger_level > logging.DEBUG:\n ignore_key = (record.levelno, record.msg)\n if ignore_key in self._ignore:\n return False\n\n # check if we went over threshold\n if group:\n key = (record.levelno, group)\n self._group_count[key] += 1\n if self._group_count[key] == self._threshold:\n record.msg = group\n record.args = group_args\n elif self._group_count[key] > self._threshold:\n return False\n return True\n\n\nclass LimitLogger(logging.Logger):\n \"\"\"\n A logger which adds LimitFilter automatically\n \"\"\"\n\n limit_filter = LimitFilter()\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.enable_filter()\n\n def disable_filter(self):\n self.removeFilter(LimitLogger.limit_filter)\n\n def enable_filter(self):\n self.addFilter(LimitLogger.limit_filter)\n\n\nclass FatalLogger(LimitLogger):\n warnings_fatal = False\n errors_fatal = False\n\n def warning(self, *args, **kwargs):\n super().warning(*args, **kwargs)\n if FatalLogger.warnings_fatal:\n raise RuntimeError('Warning encountered')\n\n def error(self, *args, **kwargs):\n super().error(*args, **kwargs)\n if FatalLogger.errors_fatal:\n raise RuntimeError('Error encountered')\n\n\nlogging.setLoggerClass(FatalLogger)\n\n\ndef supports_color():\n \"\"\"\n Returns True if the running system's terminal supports color,\n and False otherwise.\n\n from django.core.management.color\n \"\"\"\n plat = sys.platform\n supported_platform = plat != 'Pocket PC' and \\\n (plat != 'win32' or 'ANSICON' in os.environ)\n\n # isatty is not always implemented, #6223.\n is_a_tty = hasattr(sys.stdout, 'isatty') and sys.stdout.isatty()\n if not supported_platform or not is_a_tty:\n return False\n return True\n\n\ndef get_formatter():\n if supports_color():\n return ANSIFormatter()\n else:\n return TextFormatter()\n\n\ndef init(level=None, fatal='', handler=logging.StreamHandler(), name=None,\n logs_dedup_min_level=None):\n FatalLogger.warnings_fatal = fatal.startswith('warning')\n FatalLogger.errors_fatal = bool(fatal)\n\n logger = logging.getLogger(name)\n\n handler.setFormatter(get_formatter())\n logger.addHandler(handler)\n\n if level:\n logger.setLevel(level)\n if logs_dedup_min_level:\n LimitFilter.LOGS_DEDUP_MIN_LEVEL = logs_dedup_min_level\n\n\ndef log_warnings():\n import warnings\n logging.captureWarnings(True)\n warnings.simplefilter(\"default\", DeprecationWarning)\n init(logging.DEBUG, name='py.warnings')\n\n\nif __name__ == '__main__':\n init(level=logging.DEBUG)\n\n root_logger = logging.getLogger()\n root_logger.debug('debug')\n root_logger.info('info')\n root_logger.warning('warning')\n root_logger.error('error')\n root_logger.critical('critical')\n", "path": "pelican/log.py"}]} | 3,193 | 200 |
gh_patches_debug_23711 | rasdani/github-patches | git_diff | pretix__pretix-254 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Voucher-counting returning True/False
The tag-counting of vouchers seems two have two issues at the moment:
- No voucher has been used yet:
`False/<Number of Vouchers>` instead of `0/<Number of Vouchers>`
- Some other bug, if some vouchers have already been redeemed (cannot put my finger on, when this happens/why this happens):
`True/<Number of Vouchers>` instead of `<Number of used Vouchers>/<Number of Vouchers>`
Second item can be observed at the moment for example for budapest.
</issue>
<code>
[start of src/pretix/control/views/vouchers.py]
1 import csv
2 import io
3
4 from django.conf import settings
5 from django.contrib import messages
6 from django.core.urlresolvers import resolve, reverse
7 from django.db import transaction
8 from django.db.models import Count, Q, Sum
9 from django.http import (
10 Http404, HttpResponse, HttpResponseBadRequest, HttpResponseRedirect,
11 JsonResponse,
12 )
13 from django.utils.timezone import now
14 from django.utils.translation import ugettext_lazy as _
15 from django.views.generic import (
16 CreateView, DeleteView, ListView, TemplateView, UpdateView, View,
17 )
18
19 from pretix.base.models import Voucher
20 from pretix.base.models.vouchers import _generate_random_code
21 from pretix.control.forms.vouchers import VoucherBulkForm, VoucherForm
22 from pretix.control.permissions import EventPermissionRequiredMixin
23 from pretix.control.signals import voucher_form_class
24
25
26 class VoucherList(EventPermissionRequiredMixin, ListView):
27 model = Voucher
28 context_object_name = 'vouchers'
29 paginate_by = 30
30 template_name = 'pretixcontrol/vouchers/index.html'
31 permission = 'can_view_vouchers'
32
33 def get_queryset(self):
34 qs = self.request.event.vouchers.all().select_related('item', 'variation')
35 if self.request.GET.get("search", "") != "":
36 s = self.request.GET.get("search", "")
37 qs = qs.filter(Q(code__icontains=s) | Q(tag__icontains=s) | Q(comment__icontains=s))
38 if self.request.GET.get("tag", "") != "":
39 s = self.request.GET.get("tag", "")
40 qs = qs.filter(tag__icontains=s)
41 if self.request.GET.get("status", "") != "":
42 s = self.request.GET.get("status", "")
43 if s == 'v':
44 qs = qs.filter(Q(valid_until__isnull=True) | Q(valid_until__gt=now())).filter(redeemed=False)
45 elif s == 'r':
46 qs = qs.filter(redeemed=True)
47 elif s == 'e':
48 qs = qs.filter(Q(valid_until__isnull=False) & Q(valid_until__lt=now())).filter(redeemed=False)
49 return qs
50
51 def get(self, request, *args, **kwargs):
52 if request.GET.get("download", "") == "yes":
53 return self._download_csv()
54 return super().get(request, *args, **kwargs)
55
56 def _download_csv(self):
57 output = io.StringIO()
58 writer = csv.writer(output, quoting=csv.QUOTE_NONNUMERIC, delimiter=",")
59
60 headers = [
61 _('Voucher code'), _('Valid until'), _('Product'), _('Reserve quota'), _('Bypass quota'),
62 _('Price'), _('Tag'), _('Redeemed')
63 ]
64 writer.writerow(headers)
65
66 for v in self.get_queryset():
67 if v.item:
68 if v.variation:
69 prod = '%s – %s' % (str(v.item.name), str(v.variation.name))
70 else:
71 prod = '%s' % str(v.item.name)
72 elif v.quota:
73 prod = _('Any product in quota "{quota}"').format(quota=str(v.quota.name))
74 row = [
75 v.code,
76 v.valid_until.isoformat() if v.valid_until else "",
77 prod,
78 _("Yes") if v.block_quota else _("No"),
79 _("Yes") if v.allow_ignore_quota else _("No"),
80 str(v.price) if v.price else "",
81 v.tag,
82 _("Yes") if v.redeemed else _("No"),
83 ]
84 writer.writerow(row)
85
86 r = HttpResponse(output.getvalue().encode("utf-8"), content_type='text/csv')
87 r['Content-Disposition'] = 'attachment; filename="vouchers.csv"'
88 return r
89
90
91 class VoucherTags(EventPermissionRequiredMixin, TemplateView):
92 template_name = 'pretixcontrol/vouchers/tags.html'
93 permission = 'can_view_vouchers'
94
95 def get_context_data(self, **kwargs):
96 ctx = super().get_context_data(**kwargs)
97
98 tags = self.request.event.vouchers.order_by('tag').filter(tag__isnull=False).values('tag').annotate(
99 total=Count('id'),
100 redeemed=Sum('redeemed')
101 )
102 for t in tags:
103 t['percentage'] = int((t['redeemed'] / t['total']) * 100)
104
105 ctx['tags'] = tags
106 return ctx
107
108
109 class VoucherDelete(EventPermissionRequiredMixin, DeleteView):
110 model = Voucher
111 template_name = 'pretixcontrol/vouchers/delete.html'
112 permission = 'can_change_vouchers'
113 context_object_name = 'voucher'
114
115 def get_object(self, queryset=None) -> Voucher:
116 try:
117 return self.request.event.vouchers.get(
118 id=self.kwargs['voucher']
119 )
120 except Voucher.DoesNotExist:
121 raise Http404(_("The requested voucher does not exist."))
122
123 def get(self, request, *args, **kwargs):
124 if self.get_object().redeemed:
125 messages.error(request, _('A voucher can not be deleted if it already has been redeemed.'))
126 return HttpResponseRedirect(self.get_success_url())
127 return super().get(request, *args, **kwargs)
128
129 @transaction.atomic
130 def delete(self, request, *args, **kwargs):
131 self.object = self.get_object()
132 success_url = self.get_success_url()
133
134 if self.object.redeemed:
135 messages.error(request, _('A voucher can not be deleted if it already has been redeemed.'))
136 else:
137 self.object.log_action('pretix.voucher.deleted', user=self.request.user)
138 self.object.delete()
139 messages.success(request, _('The selected voucher has been deleted.'))
140 return HttpResponseRedirect(success_url)
141
142 def get_success_url(self) -> str:
143 return reverse('control:event.vouchers', kwargs={
144 'organizer': self.request.event.organizer.slug,
145 'event': self.request.event.slug,
146 })
147
148
149 class VoucherUpdate(EventPermissionRequiredMixin, UpdateView):
150 model = Voucher
151 template_name = 'pretixcontrol/vouchers/detail.html'
152 permission = 'can_change_vouchers'
153 context_object_name = 'voucher'
154
155 def get_form_class(self):
156 form_class = VoucherForm
157 for receiver, response in voucher_form_class.send(self.request.event, cls=form_class):
158 if response:
159 form_class = response
160 return form_class
161
162 def get_object(self, queryset=None) -> VoucherForm:
163 url = resolve(self.request.path_info)
164 try:
165 return self.request.event.vouchers.get(
166 id=url.kwargs['voucher']
167 )
168 except Voucher.DoesNotExist:
169 raise Http404(_("The requested voucher does not exist."))
170
171 @transaction.atomic
172 def form_valid(self, form):
173 messages.success(self.request, _('Your changes have been saved.'))
174 if form.has_changed():
175 self.object.log_action(
176 'pretix.voucher.changed', user=self.request.user, data={
177 k: form.cleaned_data.get(k) for k in form.changed_data
178 }
179 )
180 return super().form_valid(form)
181
182 def get_success_url(self) -> str:
183 return reverse('control:event.vouchers', kwargs={
184 'organizer': self.request.event.organizer.slug,
185 'event': self.request.event.slug,
186 })
187
188
189 class VoucherCreate(EventPermissionRequiredMixin, CreateView):
190 model = Voucher
191 template_name = 'pretixcontrol/vouchers/detail.html'
192 permission = 'can_change_vouchers'
193 context_object_name = 'voucher'
194
195 def get_form_class(self):
196 form_class = VoucherForm
197 for receiver, response in voucher_form_class.send(self.request.event, cls=form_class):
198 if response:
199 form_class = response
200 return form_class
201
202 def get_success_url(self) -> str:
203 return reverse('control:event.vouchers', kwargs={
204 'organizer': self.request.event.organizer.slug,
205 'event': self.request.event.slug,
206 })
207
208 def get_form_kwargs(self):
209 kwargs = super().get_form_kwargs()
210 kwargs['instance'] = Voucher(event=self.request.event)
211 return kwargs
212
213 @transaction.atomic
214 def form_valid(self, form):
215 form.instance.event = self.request.event
216 messages.success(self.request, _('The new voucher has been created.'))
217 ret = super().form_valid(form)
218 form.instance.log_action('pretix.voucher.added', data=dict(form.cleaned_data), user=self.request.user)
219 return ret
220
221 def post(self, request, *args, **kwargs):
222 # TODO: Transform this into an asynchronous call?
223 with request.event.lock():
224 return super().post(request, *args, **kwargs)
225
226
227 class VoucherBulkCreate(EventPermissionRequiredMixin, CreateView):
228 model = Voucher
229 template_name = 'pretixcontrol/vouchers/bulk.html'
230 permission = 'can_change_vouchers'
231 context_object_name = 'voucher'
232
233 def get_success_url(self) -> str:
234 return reverse('control:event.vouchers', kwargs={
235 'organizer': self.request.event.organizer.slug,
236 'event': self.request.event.slug,
237 })
238
239 def get_form_kwargs(self):
240 kwargs = super().get_form_kwargs()
241 kwargs['instance'] = Voucher(event=self.request.event)
242 return kwargs
243
244 @transaction.atomic
245 def form_valid(self, form):
246 for o in form.save(self.request.event):
247 o.log_action('pretix.voucher.added', data=form.cleaned_data, user=self.request.user)
248 messages.success(self.request, _('The new vouchers have been created.'))
249 return HttpResponseRedirect(self.get_success_url())
250
251 def get_form_class(self):
252 form_class = VoucherBulkForm
253 for receiver, response in voucher_form_class.send(self.request.event, cls=form_class):
254 if response:
255 form_class = response
256 return form_class
257
258 def get_context_data(self, **kwargs):
259 ctx = super().get_context_data(**kwargs)
260 ctx['code_length'] = settings.ENTROPY['voucher_code']
261 return ctx
262
263 def post(self, request, *args, **kwargs):
264 # TODO: Transform this into an asynchronous call?
265 with request.event.lock():
266 return super().post(request, *args, **kwargs)
267
268
269 class VoucherRNG(EventPermissionRequiredMixin, View):
270 permission = 'can_change_vouchers'
271
272 def get(self, request, *args, **kwargs):
273 codes = set()
274 try:
275 num = int(request.GET.get('num', '5'))
276 except ValueError: # NOQA
277 return HttpResponseBadRequest()
278
279 while len(codes) < num:
280 new_codes = set()
281 for i in range(min(num - len(codes), 500)): # Work around SQLite's SQLITE_MAX_VARIABLE_NUMBER
282 new_codes.add(_generate_random_code())
283 new_codes -= set([v['code'] for v in Voucher.objects.filter(code__in=new_codes).values('code')])
284 codes |= new_codes
285
286 return JsonResponse({
287 'codes': list(codes)
288 })
289
290 def get_success_url(self) -> str:
291 return reverse('control:event.vouchers', kwargs={
292 'organizer': self.request.event.organizer.slug,
293 'event': self.request.event.slug,
294 })
295
[end of src/pretix/control/views/vouchers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/src/pretix/control/views/vouchers.py b/src/pretix/control/views/vouchers.py
--- a/src/pretix/control/views/vouchers.py
+++ b/src/pretix/control/views/vouchers.py
@@ -5,7 +5,7 @@
from django.contrib import messages
from django.core.urlresolvers import resolve, reverse
from django.db import transaction
-from django.db.models import Count, Q, Sum
+from django.db.models import Case, Count, IntegerField, Q, Sum, When
from django.http import (
Http404, HttpResponse, HttpResponseBadRequest, HttpResponseRedirect,
JsonResponse,
@@ -97,7 +97,14 @@
tags = self.request.event.vouchers.order_by('tag').filter(tag__isnull=False).values('tag').annotate(
total=Count('id'),
- redeemed=Sum('redeemed')
+ # This is a fix for this MySQL issue: https://code.djangoproject.com/ticket/24662
+ redeemed=Sum(
+ Case(
+ When(redeemed=True, then=1),
+ When(redeemed=False, then=0),
+ output_field=IntegerField()
+ )
+ )
)
for t in tags:
t['percentage'] = int((t['redeemed'] / t['total']) * 100)
| {"golden_diff": "diff --git a/src/pretix/control/views/vouchers.py b/src/pretix/control/views/vouchers.py\n--- a/src/pretix/control/views/vouchers.py\n+++ b/src/pretix/control/views/vouchers.py\n@@ -5,7 +5,7 @@\n from django.contrib import messages\n from django.core.urlresolvers import resolve, reverse\n from django.db import transaction\n-from django.db.models import Count, Q, Sum\n+from django.db.models import Case, Count, IntegerField, Q, Sum, When\n from django.http import (\n Http404, HttpResponse, HttpResponseBadRequest, HttpResponseRedirect,\n JsonResponse,\n@@ -97,7 +97,14 @@\n \n tags = self.request.event.vouchers.order_by('tag').filter(tag__isnull=False).values('tag').annotate(\n total=Count('id'),\n- redeemed=Sum('redeemed')\n+ # This is a fix for this MySQL issue: https://code.djangoproject.com/ticket/24662\n+ redeemed=Sum(\n+ Case(\n+ When(redeemed=True, then=1),\n+ When(redeemed=False, then=0),\n+ output_field=IntegerField()\n+ )\n+ )\n )\n for t in tags:\n t['percentage'] = int((t['redeemed'] / t['total']) * 100)\n", "issue": "Voucher-counting returning True/False\nThe tag-counting of vouchers seems two have two issues at the moment:\n- No voucher has been used yet:\n `False/<Number of Vouchers>` instead of `0/<Number of Vouchers>`\n- Some other bug, if some vouchers have already been redeemed (cannot put my finger on, when this happens/why this happens):\n `True/<Number of Vouchers>` instead of `<Number of used Vouchers>/<Number of Vouchers>`\n\nSecond item can be observed at the moment for example for budapest.\n\n", "before_files": [{"content": "import csv\nimport io\n\nfrom django.conf import settings\nfrom django.contrib import messages\nfrom django.core.urlresolvers import resolve, reverse\nfrom django.db import transaction\nfrom django.db.models import Count, Q, Sum\nfrom django.http import (\n Http404, HttpResponse, HttpResponseBadRequest, HttpResponseRedirect,\n JsonResponse,\n)\nfrom django.utils.timezone import now\nfrom django.utils.translation import ugettext_lazy as _\nfrom django.views.generic import (\n CreateView, DeleteView, ListView, TemplateView, UpdateView, View,\n)\n\nfrom pretix.base.models import Voucher\nfrom pretix.base.models.vouchers import _generate_random_code\nfrom pretix.control.forms.vouchers import VoucherBulkForm, VoucherForm\nfrom pretix.control.permissions import EventPermissionRequiredMixin\nfrom pretix.control.signals import voucher_form_class\n\n\nclass VoucherList(EventPermissionRequiredMixin, ListView):\n model = Voucher\n context_object_name = 'vouchers'\n paginate_by = 30\n template_name = 'pretixcontrol/vouchers/index.html'\n permission = 'can_view_vouchers'\n\n def get_queryset(self):\n qs = self.request.event.vouchers.all().select_related('item', 'variation')\n if self.request.GET.get(\"search\", \"\") != \"\":\n s = self.request.GET.get(\"search\", \"\")\n qs = qs.filter(Q(code__icontains=s) | Q(tag__icontains=s) | Q(comment__icontains=s))\n if self.request.GET.get(\"tag\", \"\") != \"\":\n s = self.request.GET.get(\"tag\", \"\")\n qs = qs.filter(tag__icontains=s)\n if self.request.GET.get(\"status\", \"\") != \"\":\n s = self.request.GET.get(\"status\", \"\")\n if s == 'v':\n qs = qs.filter(Q(valid_until__isnull=True) | Q(valid_until__gt=now())).filter(redeemed=False)\n elif s == 'r':\n qs = qs.filter(redeemed=True)\n elif s == 'e':\n qs = qs.filter(Q(valid_until__isnull=False) & Q(valid_until__lt=now())).filter(redeemed=False)\n return qs\n\n def get(self, request, *args, **kwargs):\n if request.GET.get(\"download\", \"\") == \"yes\":\n return self._download_csv()\n return super().get(request, *args, **kwargs)\n\n def _download_csv(self):\n output = io.StringIO()\n writer = csv.writer(output, quoting=csv.QUOTE_NONNUMERIC, delimiter=\",\")\n\n headers = [\n _('Voucher code'), _('Valid until'), _('Product'), _('Reserve quota'), _('Bypass quota'),\n _('Price'), _('Tag'), _('Redeemed')\n ]\n writer.writerow(headers)\n\n for v in self.get_queryset():\n if v.item:\n if v.variation:\n prod = '%s \u2013 %s' % (str(v.item.name), str(v.variation.name))\n else:\n prod = '%s' % str(v.item.name)\n elif v.quota:\n prod = _('Any product in quota \"{quota}\"').format(quota=str(v.quota.name))\n row = [\n v.code,\n v.valid_until.isoformat() if v.valid_until else \"\",\n prod,\n _(\"Yes\") if v.block_quota else _(\"No\"),\n _(\"Yes\") if v.allow_ignore_quota else _(\"No\"),\n str(v.price) if v.price else \"\",\n v.tag,\n _(\"Yes\") if v.redeemed else _(\"No\"),\n ]\n writer.writerow(row)\n\n r = HttpResponse(output.getvalue().encode(\"utf-8\"), content_type='text/csv')\n r['Content-Disposition'] = 'attachment; filename=\"vouchers.csv\"'\n return r\n\n\nclass VoucherTags(EventPermissionRequiredMixin, TemplateView):\n template_name = 'pretixcontrol/vouchers/tags.html'\n permission = 'can_view_vouchers'\n\n def get_context_data(self, **kwargs):\n ctx = super().get_context_data(**kwargs)\n\n tags = self.request.event.vouchers.order_by('tag').filter(tag__isnull=False).values('tag').annotate(\n total=Count('id'),\n redeemed=Sum('redeemed')\n )\n for t in tags:\n t['percentage'] = int((t['redeemed'] / t['total']) * 100)\n\n ctx['tags'] = tags\n return ctx\n\n\nclass VoucherDelete(EventPermissionRequiredMixin, DeleteView):\n model = Voucher\n template_name = 'pretixcontrol/vouchers/delete.html'\n permission = 'can_change_vouchers'\n context_object_name = 'voucher'\n\n def get_object(self, queryset=None) -> Voucher:\n try:\n return self.request.event.vouchers.get(\n id=self.kwargs['voucher']\n )\n except Voucher.DoesNotExist:\n raise Http404(_(\"The requested voucher does not exist.\"))\n\n def get(self, request, *args, **kwargs):\n if self.get_object().redeemed:\n messages.error(request, _('A voucher can not be deleted if it already has been redeemed.'))\n return HttpResponseRedirect(self.get_success_url())\n return super().get(request, *args, **kwargs)\n\n @transaction.atomic\n def delete(self, request, *args, **kwargs):\n self.object = self.get_object()\n success_url = self.get_success_url()\n\n if self.object.redeemed:\n messages.error(request, _('A voucher can not be deleted if it already has been redeemed.'))\n else:\n self.object.log_action('pretix.voucher.deleted', user=self.request.user)\n self.object.delete()\n messages.success(request, _('The selected voucher has been deleted.'))\n return HttpResponseRedirect(success_url)\n\n def get_success_url(self) -> str:\n return reverse('control:event.vouchers', kwargs={\n 'organizer': self.request.event.organizer.slug,\n 'event': self.request.event.slug,\n })\n\n\nclass VoucherUpdate(EventPermissionRequiredMixin, UpdateView):\n model = Voucher\n template_name = 'pretixcontrol/vouchers/detail.html'\n permission = 'can_change_vouchers'\n context_object_name = 'voucher'\n\n def get_form_class(self):\n form_class = VoucherForm\n for receiver, response in voucher_form_class.send(self.request.event, cls=form_class):\n if response:\n form_class = response\n return form_class\n\n def get_object(self, queryset=None) -> VoucherForm:\n url = resolve(self.request.path_info)\n try:\n return self.request.event.vouchers.get(\n id=url.kwargs['voucher']\n )\n except Voucher.DoesNotExist:\n raise Http404(_(\"The requested voucher does not exist.\"))\n\n @transaction.atomic\n def form_valid(self, form):\n messages.success(self.request, _('Your changes have been saved.'))\n if form.has_changed():\n self.object.log_action(\n 'pretix.voucher.changed', user=self.request.user, data={\n k: form.cleaned_data.get(k) for k in form.changed_data\n }\n )\n return super().form_valid(form)\n\n def get_success_url(self) -> str:\n return reverse('control:event.vouchers', kwargs={\n 'organizer': self.request.event.organizer.slug,\n 'event': self.request.event.slug,\n })\n\n\nclass VoucherCreate(EventPermissionRequiredMixin, CreateView):\n model = Voucher\n template_name = 'pretixcontrol/vouchers/detail.html'\n permission = 'can_change_vouchers'\n context_object_name = 'voucher'\n\n def get_form_class(self):\n form_class = VoucherForm\n for receiver, response in voucher_form_class.send(self.request.event, cls=form_class):\n if response:\n form_class = response\n return form_class\n\n def get_success_url(self) -> str:\n return reverse('control:event.vouchers', kwargs={\n 'organizer': self.request.event.organizer.slug,\n 'event': self.request.event.slug,\n })\n\n def get_form_kwargs(self):\n kwargs = super().get_form_kwargs()\n kwargs['instance'] = Voucher(event=self.request.event)\n return kwargs\n\n @transaction.atomic\n def form_valid(self, form):\n form.instance.event = self.request.event\n messages.success(self.request, _('The new voucher has been created.'))\n ret = super().form_valid(form)\n form.instance.log_action('pretix.voucher.added', data=dict(form.cleaned_data), user=self.request.user)\n return ret\n\n def post(self, request, *args, **kwargs):\n # TODO: Transform this into an asynchronous call?\n with request.event.lock():\n return super().post(request, *args, **kwargs)\n\n\nclass VoucherBulkCreate(EventPermissionRequiredMixin, CreateView):\n model = Voucher\n template_name = 'pretixcontrol/vouchers/bulk.html'\n permission = 'can_change_vouchers'\n context_object_name = 'voucher'\n\n def get_success_url(self) -> str:\n return reverse('control:event.vouchers', kwargs={\n 'organizer': self.request.event.organizer.slug,\n 'event': self.request.event.slug,\n })\n\n def get_form_kwargs(self):\n kwargs = super().get_form_kwargs()\n kwargs['instance'] = Voucher(event=self.request.event)\n return kwargs\n\n @transaction.atomic\n def form_valid(self, form):\n for o in form.save(self.request.event):\n o.log_action('pretix.voucher.added', data=form.cleaned_data, user=self.request.user)\n messages.success(self.request, _('The new vouchers have been created.'))\n return HttpResponseRedirect(self.get_success_url())\n\n def get_form_class(self):\n form_class = VoucherBulkForm\n for receiver, response in voucher_form_class.send(self.request.event, cls=form_class):\n if response:\n form_class = response\n return form_class\n\n def get_context_data(self, **kwargs):\n ctx = super().get_context_data(**kwargs)\n ctx['code_length'] = settings.ENTROPY['voucher_code']\n return ctx\n\n def post(self, request, *args, **kwargs):\n # TODO: Transform this into an asynchronous call?\n with request.event.lock():\n return super().post(request, *args, **kwargs)\n\n\nclass VoucherRNG(EventPermissionRequiredMixin, View):\n permission = 'can_change_vouchers'\n\n def get(self, request, *args, **kwargs):\n codes = set()\n try:\n num = int(request.GET.get('num', '5'))\n except ValueError: # NOQA\n return HttpResponseBadRequest()\n\n while len(codes) < num:\n new_codes = set()\n for i in range(min(num - len(codes), 500)): # Work around SQLite's SQLITE_MAX_VARIABLE_NUMBER\n new_codes.add(_generate_random_code())\n new_codes -= set([v['code'] for v in Voucher.objects.filter(code__in=new_codes).values('code')])\n codes |= new_codes\n\n return JsonResponse({\n 'codes': list(codes)\n })\n\n def get_success_url(self) -> str:\n return reverse('control:event.vouchers', kwargs={\n 'organizer': self.request.event.organizer.slug,\n 'event': self.request.event.slug,\n })\n", "path": "src/pretix/control/views/vouchers.py"}]} | 3,826 | 293 |
gh_patches_debug_8893 | rasdani/github-patches | git_diff | vacanza__python-holidays-806 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Swaziland deprecation warning
Resolves #793.
</issue>
<code>
[start of holidays/__init__.py]
1 # python-holidays
2 # ---------------
3 # A fast, efficient Python library for generating country, province and state
4 # specific sets of holidays on the fly. It aims to make determining whether a
5 # specific date is a holiday as fast and flexible as possible.
6 #
7 # Authors: dr-prodigy <[email protected]> (c) 2017-2022
8 # ryanss <[email protected]> (c) 2014-2017
9 # Website: https://github.com/dr-prodigy/python-holidays
10 # License: MIT (see LICENSE file)
11 from holidays.constants import (
12 MON,
13 TUE,
14 WED,
15 THU,
16 FRI,
17 SAT,
18 SUN,
19 WEEKEND,
20 JAN,
21 FEB,
22 MAR,
23 APR,
24 MAY,
25 JUN,
26 JUL,
27 AUG,
28 SEP,
29 OCT,
30 NOV,
31 DEC,
32 )
33 from holidays.countries import *
34 from holidays.financial import *
35 from holidays.holiday_base import * # * import required for IDE docstrings
36 from holidays.utils import (
37 CountryHoliday,
38 country_holidays,
39 financial_holidays,
40 list_supported_countries,
41 list_supported_financial,
42 )
43
44 __version__ = "0.17"
45
[end of holidays/__init__.py]
[start of holidays/countries/eswatini.py]
1 # python-holidays
2 # ---------------
3 # A fast, efficient Python library for generating country, province and state
4 # specific sets of holidays on the fly. It aims to make determining whether a
5 # specific date is a holiday as fast and flexible as possible.
6 #
7 # Authors: dr-prodigy <[email protected]> (c) 2017-2022
8 # ryanss <[email protected]> (c) 2014-2017
9 # Website: https://github.com/dr-prodigy/python-holidays
10 # License: MIT (see LICENSE file)
11
12 import warnings
13 from datetime import date
14
15 from dateutil.easter import easter
16 from dateutil.relativedelta import relativedelta as rd
17
18 from holidays.constants import SUN, JAN, APR, MAY, JUL, SEP, DEC
19 from holidays.holiday_base import HolidayBase
20
21
22 class Eswatini(HolidayBase):
23 """
24 https://swazilii.org/sz/legislation/act/1938/71
25 https://www.officeholidays.com/countries/swaziland
26 """
27
28 country = "SZ"
29
30 def _populate(self, year):
31 super()._populate(year)
32
33 # Observed since 1938
34 if year > 1938:
35 self[date(year, JAN, 1)] = "New Year's Day"
36
37 e = easter(year)
38 good_friday = e - rd(days=2)
39 easter_monday = e + rd(days=1)
40 ascension_day = e + rd(days=39)
41 self[good_friday] = "Good Friday"
42 self[easter_monday] = "Easter Monday"
43 self[ascension_day] = "Ascension Day"
44
45 if year > 1968:
46 self[date(year, APR, 25)] = "National Flag Day"
47
48 if year > 1982:
49 # https://www.officeholidays.com/holidays/swaziland/birthday-of-late-king-sobhuza
50 self[date(year, JUL, 22)] = "Birthday of Late King Sobhuza"
51
52 if year > 1986:
53 # https://www.officeholidays.com/holidays/swaziland/birthday-of-king-mswati-iii
54 self[date(year, APR, 19)] = "King's Birthday"
55
56 self[date(year, MAY, 1)] = "Worker's Day"
57 self[date(year, SEP, 6)] = "Independence Day"
58 self[date(year, DEC, 25)] = "Christmas Day"
59 self[date(year, DEC, 26)] = "Boxing Day"
60
61 # Once-off public holidays
62 y2k = "Y2K changeover"
63
64 if year == 1999:
65 # https://mg.co.za/article/1999-12-09-swaziland-declares-bank-holidays/
66 self[date(1999, DEC, 31)] = y2k
67 if year == 2000:
68 self[date(2000, JAN, 3)] = y2k
69
70 # As of 2021/1/1, whenever a public holiday falls on a
71 # Sunday
72 # it rolls over to the following Monday
73 for k, v in list(self.items()):
74
75 if self.observed and k.weekday() == SUN and k.year == year:
76 add_days = 1
77 while self.get(k + rd(days=add_days)) is not None:
78 add_days += 1
79 self[k + rd(days=add_days)] = v + " (Day Off)"
80
81
82 class Swaziland(Eswatini):
83 warnings.warn(
84 "Swaziland is deprecated, use Eswatini instead.",
85 DeprecationWarning,
86 )
87 pass
88
89
90 class SZ(Eswatini):
91 pass
92
93
94 class SZW(Eswatini):
95 pass
96
[end of holidays/countries/eswatini.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/holidays/__init__.py b/holidays/__init__.py
--- a/holidays/__init__.py
+++ b/holidays/__init__.py
@@ -41,4 +41,4 @@
list_supported_financial,
)
-__version__ = "0.17"
+__version__ = "0.17.1"
diff --git a/holidays/countries/eswatini.py b/holidays/countries/eswatini.py
--- a/holidays/countries/eswatini.py
+++ b/holidays/countries/eswatini.py
@@ -80,11 +80,13 @@
class Swaziland(Eswatini):
- warnings.warn(
- "Swaziland is deprecated, use Eswatini instead.",
- DeprecationWarning,
- )
- pass
+ def __init__(self, *args, **kwargs) -> None:
+ warnings.warn(
+ "Swaziland is deprecated, use Eswatini instead.",
+ DeprecationWarning,
+ )
+
+ super().__init__(*args, **kwargs)
class SZ(Eswatini):
| {"golden_diff": "diff --git a/holidays/__init__.py b/holidays/__init__.py\n--- a/holidays/__init__.py\n+++ b/holidays/__init__.py\n@@ -41,4 +41,4 @@\n list_supported_financial,\n )\n \n-__version__ = \"0.17\"\n+__version__ = \"0.17.1\"\ndiff --git a/holidays/countries/eswatini.py b/holidays/countries/eswatini.py\n--- a/holidays/countries/eswatini.py\n+++ b/holidays/countries/eswatini.py\n@@ -80,11 +80,13 @@\n \n \n class Swaziland(Eswatini):\n- warnings.warn(\n- \"Swaziland is deprecated, use Eswatini instead.\",\n- DeprecationWarning,\n- )\n- pass\n+ def __init__(self, *args, **kwargs) -> None:\n+ warnings.warn(\n+ \"Swaziland is deprecated, use Eswatini instead.\",\n+ DeprecationWarning,\n+ )\n+\n+ super().__init__(*args, **kwargs)\n \n \n class SZ(Eswatini):\n", "issue": "Swaziland deprecation warning\nResolves #793.\n", "before_files": [{"content": "# python-holidays\n# ---------------\n# A fast, efficient Python library for generating country, province and state\n# specific sets of holidays on the fly. It aims to make determining whether a\n# specific date is a holiday as fast and flexible as possible.\n#\n# Authors: dr-prodigy <[email protected]> (c) 2017-2022\n# ryanss <[email protected]> (c) 2014-2017\n# Website: https://github.com/dr-prodigy/python-holidays\n# License: MIT (see LICENSE file)\nfrom holidays.constants import (\n MON,\n TUE,\n WED,\n THU,\n FRI,\n SAT,\n SUN,\n WEEKEND,\n JAN,\n FEB,\n MAR,\n APR,\n MAY,\n JUN,\n JUL,\n AUG,\n SEP,\n OCT,\n NOV,\n DEC,\n)\nfrom holidays.countries import *\nfrom holidays.financial import *\nfrom holidays.holiday_base import * # * import required for IDE docstrings\nfrom holidays.utils import (\n CountryHoliday,\n country_holidays,\n financial_holidays,\n list_supported_countries,\n list_supported_financial,\n)\n\n__version__ = \"0.17\"\n", "path": "holidays/__init__.py"}, {"content": "# python-holidays\n# ---------------\n# A fast, efficient Python library for generating country, province and state\n# specific sets of holidays on the fly. It aims to make determining whether a\n# specific date is a holiday as fast and flexible as possible.\n#\n# Authors: dr-prodigy <[email protected]> (c) 2017-2022\n# ryanss <[email protected]> (c) 2014-2017\n# Website: https://github.com/dr-prodigy/python-holidays\n# License: MIT (see LICENSE file)\n\nimport warnings\nfrom datetime import date\n\nfrom dateutil.easter import easter\nfrom dateutil.relativedelta import relativedelta as rd\n\nfrom holidays.constants import SUN, JAN, APR, MAY, JUL, SEP, DEC\nfrom holidays.holiday_base import HolidayBase\n\n\nclass Eswatini(HolidayBase):\n \"\"\"\n https://swazilii.org/sz/legislation/act/1938/71\n https://www.officeholidays.com/countries/swaziland\n \"\"\"\n\n country = \"SZ\"\n\n def _populate(self, year):\n super()._populate(year)\n\n # Observed since 1938\n if year > 1938:\n self[date(year, JAN, 1)] = \"New Year's Day\"\n\n e = easter(year)\n good_friday = e - rd(days=2)\n easter_monday = e + rd(days=1)\n ascension_day = e + rd(days=39)\n self[good_friday] = \"Good Friday\"\n self[easter_monday] = \"Easter Monday\"\n self[ascension_day] = \"Ascension Day\"\n\n if year > 1968:\n self[date(year, APR, 25)] = \"National Flag Day\"\n\n if year > 1982:\n # https://www.officeholidays.com/holidays/swaziland/birthday-of-late-king-sobhuza\n self[date(year, JUL, 22)] = \"Birthday of Late King Sobhuza\"\n\n if year > 1986:\n # https://www.officeholidays.com/holidays/swaziland/birthday-of-king-mswati-iii\n self[date(year, APR, 19)] = \"King's Birthday\"\n\n self[date(year, MAY, 1)] = \"Worker's Day\"\n self[date(year, SEP, 6)] = \"Independence Day\"\n self[date(year, DEC, 25)] = \"Christmas Day\"\n self[date(year, DEC, 26)] = \"Boxing Day\"\n\n # Once-off public holidays\n y2k = \"Y2K changeover\"\n\n if year == 1999:\n # https://mg.co.za/article/1999-12-09-swaziland-declares-bank-holidays/\n self[date(1999, DEC, 31)] = y2k\n if year == 2000:\n self[date(2000, JAN, 3)] = y2k\n\n # As of 2021/1/1, whenever a public holiday falls on a\n # Sunday\n # it rolls over to the following Monday\n for k, v in list(self.items()):\n\n if self.observed and k.weekday() == SUN and k.year == year:\n add_days = 1\n while self.get(k + rd(days=add_days)) is not None:\n add_days += 1\n self[k + rd(days=add_days)] = v + \" (Day Off)\"\n\n\nclass Swaziland(Eswatini):\n warnings.warn(\n \"Swaziland is deprecated, use Eswatini instead.\",\n DeprecationWarning,\n )\n pass\n\n\nclass SZ(Eswatini):\n pass\n\n\nclass SZW(Eswatini):\n pass\n", "path": "holidays/countries/eswatini.py"}]} | 2,023 | 251 |
gh_patches_debug_27065 | rasdani/github-patches | git_diff | mdn__kuma-7869 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Refactorings for welcome HTML email
Based on https://github.com/mdn/kuma/pull/7866
we'll drop the `utm` query string things and we'll get rid of the plain text email template.
</issue>
<code>
[start of kuma/users/tasks.py]
1 import logging
2
3 from celery import task
4 from django.conf import settings
5 from django.contrib.auth import get_user_model
6 from django.utils import translation
7 from django.utils.translation import gettext_lazy as _
8
9 from kuma.core.decorators import skip_in_maintenance_mode
10 from kuma.core.email_utils import render_email
11 from kuma.core.utils import (
12 EmailMultiAlternativesRetrying,
13 send_mail_retrying,
14 strings_are_translated,
15 )
16
17 log = logging.getLogger("kuma.users.tasks")
18
19
20 WELCOME_EMAIL_STRINGS = [
21 "Like words?",
22 "Don't be shy, if you have any doubt, problems, questions: contact us! We are here to help.",
23 ]
24
25
26 @task
27 @skip_in_maintenance_mode
28 def send_recovery_email(user_pk, email, locale=None):
29 user = get_user_model().objects.get(pk=user_pk)
30 locale = locale or settings.WIKI_DEFAULT_LANGUAGE
31 url = settings.SITE_URL + user.get_recovery_url()
32 context = {"recovery_url": url, "username": user.username}
33 with translation.override(locale):
34 subject = render_email("users/email/recovery/subject.ltxt", context)
35 # Email subject *must not* contain newlines
36 subject = "".join(subject.splitlines())
37 plain = render_email("users/email/recovery/plain.ltxt", context)
38 send_mail_retrying(subject, plain, settings.DEFAULT_FROM_EMAIL, [email])
39
40
41 @task
42 @skip_in_maintenance_mode
43 def send_welcome_email(user_pk, locale):
44 user = get_user_model().objects.get(pk=user_pk)
45 if locale == settings.WIKI_DEFAULT_LANGUAGE or strings_are_translated(
46 WELCOME_EMAIL_STRINGS, locale
47 ):
48 context = {"username": user.username}
49 log.debug("Using the locale %s to send the welcome email", locale)
50 with translation.override(locale):
51 content_plain = render_email("users/email/welcome/plain.ltxt", context)
52 content_html = render_email("users/email/welcome/html.ltxt", context)
53
54 email = EmailMultiAlternativesRetrying(
55 _("Getting started with your new MDN account"),
56 content_plain,
57 settings.WELCOME_EMAIL_FROM,
58 [user.email],
59 )
60 email.attach_alternative(content_html, "text/html")
61 email.send()
62
[end of kuma/users/tasks.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/kuma/users/tasks.py b/kuma/users/tasks.py
--- a/kuma/users/tasks.py
+++ b/kuma/users/tasks.py
@@ -5,6 +5,7 @@
from django.contrib.auth import get_user_model
from django.utils import translation
from django.utils.translation import gettext_lazy as _
+from pyquery import PyQuery as pq
from kuma.core.decorators import skip_in_maintenance_mode
from kuma.core.email_utils import render_email
@@ -48,8 +49,18 @@
context = {"username": user.username}
log.debug("Using the locale %s to send the welcome email", locale)
with translation.override(locale):
- content_plain = render_email("users/email/welcome/plain.ltxt", context)
content_html = render_email("users/email/welcome/html.ltxt", context)
+ doc = pq(content_html)
+ urls = []
+ for i, link in enumerate(doc("body a[href]").items()):
+ link.text(f"{link.text()}[{i + 1}]")
+ urls.append((i + 1, link.attr("href")))
+
+ content_plain = doc("body").text().replace("\n", "\n\n")
+ if urls:
+ content_plain += "\n\n"
+ for i, url in urls:
+ content_plain += f"[{i}] {url}\n"
email = EmailMultiAlternativesRetrying(
_("Getting started with your new MDN account"),
| {"golden_diff": "diff --git a/kuma/users/tasks.py b/kuma/users/tasks.py\n--- a/kuma/users/tasks.py\n+++ b/kuma/users/tasks.py\n@@ -5,6 +5,7 @@\n from django.contrib.auth import get_user_model\n from django.utils import translation\n from django.utils.translation import gettext_lazy as _\n+from pyquery import PyQuery as pq\n \n from kuma.core.decorators import skip_in_maintenance_mode\n from kuma.core.email_utils import render_email\n@@ -48,8 +49,18 @@\n context = {\"username\": user.username}\n log.debug(\"Using the locale %s to send the welcome email\", locale)\n with translation.override(locale):\n- content_plain = render_email(\"users/email/welcome/plain.ltxt\", context)\n content_html = render_email(\"users/email/welcome/html.ltxt\", context)\n+ doc = pq(content_html)\n+ urls = []\n+ for i, link in enumerate(doc(\"body a[href]\").items()):\n+ link.text(f\"{link.text()}[{i + 1}]\")\n+ urls.append((i + 1, link.attr(\"href\")))\n+\n+ content_plain = doc(\"body\").text().replace(\"\\n\", \"\\n\\n\")\n+ if urls:\n+ content_plain += \"\\n\\n\"\n+ for i, url in urls:\n+ content_plain += f\"[{i}] {url}\\n\"\n \n email = EmailMultiAlternativesRetrying(\n _(\"Getting started with your new MDN account\"),\n", "issue": "Refactorings for welcome HTML email \nBased on https://github.com/mdn/kuma/pull/7866 \r\nwe'll drop the `utm` query string things and we'll get rid of the plain text email template. \n", "before_files": [{"content": "import logging\n\nfrom celery import task\nfrom django.conf import settings\nfrom django.contrib.auth import get_user_model\nfrom django.utils import translation\nfrom django.utils.translation import gettext_lazy as _\n\nfrom kuma.core.decorators import skip_in_maintenance_mode\nfrom kuma.core.email_utils import render_email\nfrom kuma.core.utils import (\n EmailMultiAlternativesRetrying,\n send_mail_retrying,\n strings_are_translated,\n)\n\nlog = logging.getLogger(\"kuma.users.tasks\")\n\n\nWELCOME_EMAIL_STRINGS = [\n \"Like words?\",\n \"Don't be shy, if you have any doubt, problems, questions: contact us! We are here to help.\",\n]\n\n\n@task\n@skip_in_maintenance_mode\ndef send_recovery_email(user_pk, email, locale=None):\n user = get_user_model().objects.get(pk=user_pk)\n locale = locale or settings.WIKI_DEFAULT_LANGUAGE\n url = settings.SITE_URL + user.get_recovery_url()\n context = {\"recovery_url\": url, \"username\": user.username}\n with translation.override(locale):\n subject = render_email(\"users/email/recovery/subject.ltxt\", context)\n # Email subject *must not* contain newlines\n subject = \"\".join(subject.splitlines())\n plain = render_email(\"users/email/recovery/plain.ltxt\", context)\n send_mail_retrying(subject, plain, settings.DEFAULT_FROM_EMAIL, [email])\n\n\n@task\n@skip_in_maintenance_mode\ndef send_welcome_email(user_pk, locale):\n user = get_user_model().objects.get(pk=user_pk)\n if locale == settings.WIKI_DEFAULT_LANGUAGE or strings_are_translated(\n WELCOME_EMAIL_STRINGS, locale\n ):\n context = {\"username\": user.username}\n log.debug(\"Using the locale %s to send the welcome email\", locale)\n with translation.override(locale):\n content_plain = render_email(\"users/email/welcome/plain.ltxt\", context)\n content_html = render_email(\"users/email/welcome/html.ltxt\", context)\n\n email = EmailMultiAlternativesRetrying(\n _(\"Getting started with your new MDN account\"),\n content_plain,\n settings.WELCOME_EMAIL_FROM,\n [user.email],\n )\n email.attach_alternative(content_html, \"text/html\")\n email.send()\n", "path": "kuma/users/tasks.py"}]} | 1,178 | 316 |
gh_patches_debug_38488 | rasdani/github-patches | git_diff | larq__larq-356 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Make the HyperparameterScheduler compatible with the CaseOptimizer
### Feature motivation
The HyperparameterScheduler is not compatible with the CaseOptimizer since the hyperparameters are attributes of the optimizers inside the CaseOptimizer.
### Feature description
I propose one of the two possible solutions:
Either we could give HyperparameterScheduler the optimizer as an argument. It could be called via ``` HyperparameterScheduler(schedule, hyperparameter, optimizer, verbose=0) ``` and the right optimizer inside the CaseOptimizer can be addressed. (@koenhelwegen)
My second proposal would be to search the CaseOptimizer for optimizers that have the hyperparameter as attribute. Then the schedule can be applied to this optimizer only. The downside of this would be that in case there are two optimizers inside the CaseOptimizer that have a hyperparameter with the same name the schedule would be applied to both of them. I do not think this would happen very often but it could definitively be an issue. See code below for my second proposal.
### Feature implementation
``` python
class HyperparameterScheduler(tf.keras.callbacks.Callback):
"""Generic hyperparameter scheduler.
# Arguments
schedule: a function that takes an epoch index as input
(integer, indexed from 0) and returns a new hyperparameter as output.
hyperparameter: str. the name of the hyperparameter to be scheduled.
verbose: int. 0: quiet, 1: update messages.
"""
def __init__(self, schedule, hyperparameter, verbose=0):
super(HyperparameterScheduler, self).__init__()
self.schedule = schedule
self.hyperparameter = hyperparameter
self.verbose = verbose
def on_epoch_begin(self, epoch, logs=None):
for op in self.model.optimizer.optimizers:
if hasattr(op, self.hyperparameter):
hp = getattr(op, self.hyperparameter)
try: # new API
hyperparameter_val = tf.keras.backend.get_value(hp)
hyperparameter_val = self.schedule(epoch, hyperparameter_val)
except TypeError: # Support for old API for backward compatibility
hyperparameter_val = self.schedule(epoch)
tf.keras.backend.set_value(hp, hyperparameter_val)
if self.verbose > 0:
print(
f"Epoch {epoch + 1}: {self.hyperparameter} changning to {tf.keras.backend.get_value(hp)}."
)
def on_epoch_end(self, epoch, logs=None):
logs = logs or {}
for op in self.model.optimizer.optimizers:
if hasattr(op, self.hyperparameter):
hp = getattr(op, self.hyperparameter)
logs[self.hyperparameter] = tf.keras.backend.get_value(hp)
```
</issue>
<code>
[start of larq/callbacks.py]
1 import tensorflow as tf
2
3
4 class HyperparameterScheduler(tf.keras.callbacks.Callback):
5 """Generic hyperparameter scheduler.
6
7 # Arguments
8 schedule: a function that takes an epoch index as input
9 (integer, indexed from 0) and returns a new hyperparameter as output.
10 hyperparameter: str. the name of the hyperparameter to be scheduled.
11 verbose: int. 0: quiet, 1: update messages.
12 """
13
14 def __init__(self, schedule, hyperparameter, verbose=0):
15 super(HyperparameterScheduler, self).__init__()
16 self.schedule = schedule
17 self.hyperparameter = hyperparameter
18 self.verbose = verbose
19
20 def on_epoch_begin(self, epoch, logs=None):
21 if not hasattr(self.model.optimizer, self.hyperparameter):
22 raise ValueError(
23 f'Optimizer must have a "{self.hyperparameter}" attribute.'
24 )
25
26 hp = getattr(self.model.optimizer, self.hyperparameter)
27 try: # new API
28 hyperparameter_val = tf.keras.backend.get_value(hp)
29 hyperparameter_val = self.schedule(epoch, hyperparameter_val)
30 except TypeError: # Support for old API for backward compatibility
31 hyperparameter_val = self.schedule(epoch)
32
33 tf.keras.backend.set_value(hp, hyperparameter_val)
34
35 if self.verbose > 0:
36 print(
37 f"Epoch {epoch + 1}: {self.hyperparameter} changning to {tf.keras.backend.get_value(hp)}."
38 )
39
40 def on_epoch_end(self, epoch, logs=None):
41 logs = logs or {}
42 hp = getattr(self.model.optimizer, self.hyperparameter)
43 logs[self.hyperparameter] = tf.keras.backend.get_value(hp)
44
[end of larq/callbacks.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/larq/callbacks.py b/larq/callbacks.py
--- a/larq/callbacks.py
+++ b/larq/callbacks.py
@@ -4,26 +4,40 @@
class HyperparameterScheduler(tf.keras.callbacks.Callback):
"""Generic hyperparameter scheduler.
+ !!! example
+ ```python
+ bop = lq.optimizers.Bop(threshold=1e-6, gamma=1e-3)
+ adam = tf.keras.optimizers.Adam(0.01)
+ optimizer = lq.optimizers.CaseOptimizer(
+ (lq.optimizers.Bop.is_binary_variable, bop), default_optimizer=adam,
+ )
+ callbacks = [
+ HyperparameterScheduler(lambda x: 0.001 * (0.1 ** (x // 30)), "gamma", bop)
+ ]
+ ```
# Arguments
+ optimizer: the optimizer that contains the hyperparameter that will be scheduled.
+ Defaults to `self.model.optimizer` if `optimizer == None`.
schedule: a function that takes an epoch index as input
(integer, indexed from 0) and returns a new hyperparameter as output.
hyperparameter: str. the name of the hyperparameter to be scheduled.
verbose: int. 0: quiet, 1: update messages.
"""
- def __init__(self, schedule, hyperparameter, verbose=0):
+ def __init__(self, schedule, hyperparameter, optimizer=None, verbose=0):
super(HyperparameterScheduler, self).__init__()
+ self.optimizer = optimizer if optimizer else self.model.optimizer
self.schedule = schedule
self.hyperparameter = hyperparameter
self.verbose = verbose
def on_epoch_begin(self, epoch, logs=None):
- if not hasattr(self.model.optimizer, self.hyperparameter):
+ if not hasattr(self.optimizer, self.hyperparameter):
raise ValueError(
f'Optimizer must have a "{self.hyperparameter}" attribute.'
)
- hp = getattr(self.model.optimizer, self.hyperparameter)
+ hp = getattr(self.optimizer, self.hyperparameter)
try: # new API
hyperparameter_val = tf.keras.backend.get_value(hp)
hyperparameter_val = self.schedule(epoch, hyperparameter_val)
@@ -34,10 +48,10 @@
if self.verbose > 0:
print(
- f"Epoch {epoch + 1}: {self.hyperparameter} changning to {tf.keras.backend.get_value(hp)}."
+ f"Epoch {epoch + 1}: {self.hyperparameter} changing to {tf.keras.backend.get_value(hp)}."
)
def on_epoch_end(self, epoch, logs=None):
logs = logs or {}
- hp = getattr(self.model.optimizer, self.hyperparameter)
+ hp = getattr(self.optimizer, self.hyperparameter)
logs[self.hyperparameter] = tf.keras.backend.get_value(hp)
| {"golden_diff": "diff --git a/larq/callbacks.py b/larq/callbacks.py\n--- a/larq/callbacks.py\n+++ b/larq/callbacks.py\n@@ -4,26 +4,40 @@\n class HyperparameterScheduler(tf.keras.callbacks.Callback):\n \"\"\"Generic hyperparameter scheduler.\n \n+ !!! example\n+ ```python\n+ bop = lq.optimizers.Bop(threshold=1e-6, gamma=1e-3)\n+ adam = tf.keras.optimizers.Adam(0.01)\n+ optimizer = lq.optimizers.CaseOptimizer(\n+ (lq.optimizers.Bop.is_binary_variable, bop), default_optimizer=adam,\n+ )\n+ callbacks = [\n+ HyperparameterScheduler(lambda x: 0.001 * (0.1 ** (x // 30)), \"gamma\", bop)\n+ ]\n+ ```\n # Arguments\n+ optimizer: the optimizer that contains the hyperparameter that will be scheduled.\n+ Defaults to `self.model.optimizer` if `optimizer == None`.\n schedule: a function that takes an epoch index as input\n (integer, indexed from 0) and returns a new hyperparameter as output.\n hyperparameter: str. the name of the hyperparameter to be scheduled.\n verbose: int. 0: quiet, 1: update messages.\n \"\"\"\n \n- def __init__(self, schedule, hyperparameter, verbose=0):\n+ def __init__(self, schedule, hyperparameter, optimizer=None, verbose=0):\n super(HyperparameterScheduler, self).__init__()\n+ self.optimizer = optimizer if optimizer else self.model.optimizer\n self.schedule = schedule\n self.hyperparameter = hyperparameter\n self.verbose = verbose\n \n def on_epoch_begin(self, epoch, logs=None):\n- if not hasattr(self.model.optimizer, self.hyperparameter):\n+ if not hasattr(self.optimizer, self.hyperparameter):\n raise ValueError(\n f'Optimizer must have a \"{self.hyperparameter}\" attribute.'\n )\n \n- hp = getattr(self.model.optimizer, self.hyperparameter)\n+ hp = getattr(self.optimizer, self.hyperparameter)\n try: # new API\n hyperparameter_val = tf.keras.backend.get_value(hp)\n hyperparameter_val = self.schedule(epoch, hyperparameter_val)\n@@ -34,10 +48,10 @@\n \n if self.verbose > 0:\n print(\n- f\"Epoch {epoch + 1}: {self.hyperparameter} changning to {tf.keras.backend.get_value(hp)}.\"\n+ f\"Epoch {epoch + 1}: {self.hyperparameter} changing to {tf.keras.backend.get_value(hp)}.\"\n )\n \n def on_epoch_end(self, epoch, logs=None):\n logs = logs or {}\n- hp = getattr(self.model.optimizer, self.hyperparameter)\n+ hp = getattr(self.optimizer, self.hyperparameter)\n logs[self.hyperparameter] = tf.keras.backend.get_value(hp)\n", "issue": "Make the HyperparameterScheduler compatible with the CaseOptimizer\n### Feature motivation\r\nThe HyperparameterScheduler is not compatible with the CaseOptimizer since the hyperparameters are attributes of the optimizers inside the CaseOptimizer. \r\n\r\n### Feature description\r\nI propose one of the two possible solutions: \r\nEither we could give HyperparameterScheduler the optimizer as an argument. It could be called via ``` HyperparameterScheduler(schedule, hyperparameter, optimizer, verbose=0) ``` and the right optimizer inside the CaseOptimizer can be addressed. (@koenhelwegen) \r\n\r\nMy second proposal would be to search the CaseOptimizer for optimizers that have the hyperparameter as attribute. Then the schedule can be applied to this optimizer only. The downside of this would be that in case there are two optimizers inside the CaseOptimizer that have a hyperparameter with the same name the schedule would be applied to both of them. I do not think this would happen very often but it could definitively be an issue. See code below for my second proposal. \r\n### Feature implementation\r\n``` python \r\nclass HyperparameterScheduler(tf.keras.callbacks.Callback):\r\n \"\"\"Generic hyperparameter scheduler.\r\n # Arguments\r\n schedule: a function that takes an epoch index as input\r\n (integer, indexed from 0) and returns a new hyperparameter as output.\r\n hyperparameter: str. the name of the hyperparameter to be scheduled.\r\n verbose: int. 0: quiet, 1: update messages.\r\n \"\"\"\r\n\r\n def __init__(self, schedule, hyperparameter, verbose=0):\r\n super(HyperparameterScheduler, self).__init__()\r\n self.schedule = schedule\r\n self.hyperparameter = hyperparameter\r\n self.verbose = verbose\r\n\r\n def on_epoch_begin(self, epoch, logs=None):\r\n for op in self.model.optimizer.optimizers:\r\n if hasattr(op, self.hyperparameter):\r\n\r\n hp = getattr(op, self.hyperparameter)\r\n try: # new API\r\n hyperparameter_val = tf.keras.backend.get_value(hp)\r\n hyperparameter_val = self.schedule(epoch, hyperparameter_val)\r\n except TypeError: # Support for old API for backward compatibility\r\n hyperparameter_val = self.schedule(epoch)\r\n\r\n tf.keras.backend.set_value(hp, hyperparameter_val)\r\n\r\n if self.verbose > 0:\r\n print(\r\n f\"Epoch {epoch + 1}: {self.hyperparameter} changning to {tf.keras.backend.get_value(hp)}.\"\r\n )\r\n\r\n def on_epoch_end(self, epoch, logs=None):\r\n logs = logs or {}\r\n for op in self.model.optimizer.optimizers:\r\n if hasattr(op, self.hyperparameter):\r\n hp = getattr(op, self.hyperparameter)\r\n logs[self.hyperparameter] = tf.keras.backend.get_value(hp)\r\n```\n", "before_files": [{"content": "import tensorflow as tf\n\n\nclass HyperparameterScheduler(tf.keras.callbacks.Callback):\n \"\"\"Generic hyperparameter scheduler.\n\n # Arguments\n schedule: a function that takes an epoch index as input\n (integer, indexed from 0) and returns a new hyperparameter as output.\n hyperparameter: str. the name of the hyperparameter to be scheduled.\n verbose: int. 0: quiet, 1: update messages.\n \"\"\"\n\n def __init__(self, schedule, hyperparameter, verbose=0):\n super(HyperparameterScheduler, self).__init__()\n self.schedule = schedule\n self.hyperparameter = hyperparameter\n self.verbose = verbose\n\n def on_epoch_begin(self, epoch, logs=None):\n if not hasattr(self.model.optimizer, self.hyperparameter):\n raise ValueError(\n f'Optimizer must have a \"{self.hyperparameter}\" attribute.'\n )\n\n hp = getattr(self.model.optimizer, self.hyperparameter)\n try: # new API\n hyperparameter_val = tf.keras.backend.get_value(hp)\n hyperparameter_val = self.schedule(epoch, hyperparameter_val)\n except TypeError: # Support for old API for backward compatibility\n hyperparameter_val = self.schedule(epoch)\n\n tf.keras.backend.set_value(hp, hyperparameter_val)\n\n if self.verbose > 0:\n print(\n f\"Epoch {epoch + 1}: {self.hyperparameter} changning to {tf.keras.backend.get_value(hp)}.\"\n )\n\n def on_epoch_end(self, epoch, logs=None):\n logs = logs or {}\n hp = getattr(self.model.optimizer, self.hyperparameter)\n logs[self.hyperparameter] = tf.keras.backend.get_value(hp)\n", "path": "larq/callbacks.py"}]} | 1,549 | 650 |
gh_patches_debug_118 | rasdani/github-patches | git_diff | librosa__librosa-1738 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Release new version to fix scipy tests
https://github.com/librosa/librosa/commit/12dee8eabed7df14c5622b52c05393ddfeb11f4b fixed compatibility with scipy in tests but it's not included in any release.
We rely as downstream packagers on tests to ensure all python dependencies play well together.
</issue>
<code>
[start of librosa/version.py]
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 """Version info"""
4
5 import sys
6 import importlib
7
8 short_version = "0.10"
9 version = "0.10.1dev"
10
11
12 def __get_mod_version(modname):
13 try:
14 if modname in sys.modules:
15 mod = sys.modules[modname]
16 else:
17 mod = importlib.import_module(modname)
18 try:
19 return mod.__version__
20 except AttributeError:
21 return "installed, no version number available"
22
23 except ImportError:
24 return None
25
26
27 def show_versions() -> None:
28 """Return the version information for all librosa dependencies."""
29 core_deps = [
30 "audioread",
31 "numpy",
32 "scipy",
33 "sklearn",
34 "joblib",
35 "decorator",
36 "numba",
37 "soundfile",
38 "pooch",
39 "soxr",
40 "typing_extensions",
41 "lazy_loader",
42 "msgpack",
43 ]
44
45 extra_deps = [
46 "numpydoc",
47 "sphinx",
48 "sphinx_rtd_theme",
49 "matplotlib",
50 "sphinx_multiversion",
51 "sphinx_gallery",
52 "mir_eval",
53 "ipython",
54 "sphinxcontrib.rsvgconverter",
55 "pytest",
56 "pytest_mpl",
57 "pytest_cov",
58 "samplerate",
59 "resampy",
60 "presets",
61 "packaging",
62 ]
63
64 print("INSTALLED VERSIONS")
65 print("------------------")
66 print(f"python: {sys.version}\n")
67 print(f"librosa: {version}\n")
68 for dep in core_deps:
69 print("{}: {}".format(dep, __get_mod_version(dep)))
70 print("")
71 for dep in extra_deps:
72 print("{}: {}".format(dep, __get_mod_version(dep)))
73
[end of librosa/version.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/librosa/version.py b/librosa/version.py
--- a/librosa/version.py
+++ b/librosa/version.py
@@ -6,7 +6,7 @@
import importlib
short_version = "0.10"
-version = "0.10.1dev"
+version = "0.10.1"
def __get_mod_version(modname):
| {"golden_diff": "diff --git a/librosa/version.py b/librosa/version.py\n--- a/librosa/version.py\n+++ b/librosa/version.py\n@@ -6,7 +6,7 @@\n import importlib\n \n short_version = \"0.10\"\n-version = \"0.10.1dev\"\n+version = \"0.10.1\"\n \n \n def __get_mod_version(modname):\n", "issue": "Release new version to fix scipy tests\nhttps://github.com/librosa/librosa/commit/12dee8eabed7df14c5622b52c05393ddfeb11f4b fixed compatibility with scipy in tests but it's not included in any release.\r\nWe rely as downstream packagers on tests to ensure all python dependencies play well together.\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\"\"\"Version info\"\"\"\n\nimport sys\nimport importlib\n\nshort_version = \"0.10\"\nversion = \"0.10.1dev\"\n\n\ndef __get_mod_version(modname):\n try:\n if modname in sys.modules:\n mod = sys.modules[modname]\n else:\n mod = importlib.import_module(modname)\n try:\n return mod.__version__\n except AttributeError:\n return \"installed, no version number available\"\n\n except ImportError:\n return None\n\n\ndef show_versions() -> None:\n \"\"\"Return the version information for all librosa dependencies.\"\"\"\n core_deps = [\n \"audioread\",\n \"numpy\",\n \"scipy\",\n \"sklearn\",\n \"joblib\",\n \"decorator\",\n \"numba\",\n \"soundfile\",\n \"pooch\",\n \"soxr\",\n \"typing_extensions\",\n \"lazy_loader\",\n \"msgpack\",\n ]\n\n extra_deps = [\n \"numpydoc\",\n \"sphinx\",\n \"sphinx_rtd_theme\",\n \"matplotlib\",\n \"sphinx_multiversion\",\n \"sphinx_gallery\",\n \"mir_eval\",\n \"ipython\",\n \"sphinxcontrib.rsvgconverter\",\n \"pytest\",\n \"pytest_mpl\",\n \"pytest_cov\",\n \"samplerate\",\n \"resampy\",\n \"presets\",\n \"packaging\",\n ]\n\n print(\"INSTALLED VERSIONS\")\n print(\"------------------\")\n print(f\"python: {sys.version}\\n\")\n print(f\"librosa: {version}\\n\")\n for dep in core_deps:\n print(\"{}: {}\".format(dep, __get_mod_version(dep)))\n print(\"\")\n for dep in extra_deps:\n print(\"{}: {}\".format(dep, __get_mod_version(dep)))\n", "path": "librosa/version.py"}]} | 1,156 | 86 |
gh_patches_debug_12127 | rasdani/github-patches | git_diff | elastic__ecs-1148 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Documentation Suggestion: anchor links on ECS fields
This is really pretty simple and I'm not sure where else to properly capture it.
The existing ECS documentation should have anchor tags on each field name in the ECS guide so you can easily deep-link directly to the relevant field.
When collaborating, often I'll say "Look at this field(such as rule.id)". I can link the fields [category page](https://www.elastic.co/guide/en/ecs/current/ecs-rule.html), but I can't deep-link directly to the field of discussion.
Just a small quality of life change that could speed up collaboration.
</issue>
<code>
[start of scripts/schema/finalizer.py]
1 import copy
2 import re
3
4 from schema import visitor
5
6 # This script takes the fleshed out deeply nested fields dictionary as emitted by
7 # cleaner.py, and performs field reuse in two phases.
8 #
9 # Phase 1 performs field reuse across field sets. E.g. `group` fields should also be under `user`.
10 # This type of reuse is then carried around if the receiving field set is also reused.
11 # In other words, user.group.* will be in other places where user is nested:
12 # source.user.* will contain source.user.group.*
13
14 # Phase 2 performs field reuse where field sets are reused within themselves, with a different name.
15 # Examples are nesting `process` within itself, as `process.parent.*`,
16 # or nesting `user` within itself at `user.target.*`.
17 # This second kind of nesting is not carried around everywhere else the receiving field set is reused.
18 # So `user.target.*` is *not* carried over to `source.user.target*` when we reuse `user` under `source`.
19
20
21 def finalize(fields):
22 '''Intended entrypoint of the finalizer.'''
23 perform_reuse(fields)
24 calculate_final_values(fields)
25
26
27 def order_reuses(fields):
28 foreign_reuses = {}
29 self_nestings = {}
30 for schema_name, schema in fields.items():
31 if not 'reusable' in schema['schema_details']:
32 continue
33 reuse_order = schema['schema_details']['reusable']['order']
34 for reuse_entry in schema['schema_details']['reusable']['expected']:
35 destination_schema_name = reuse_entry['full'].split('.')[0]
36 if destination_schema_name == schema_name:
37 # Accumulate self-nestings for phase 2.
38 self_nestings.setdefault(destination_schema_name, [])
39 self_nestings[destination_schema_name].extend([reuse_entry])
40 else:
41 # Group foreign reuses by 'order' attribute.
42 foreign_reuses.setdefault(reuse_order, {})
43 foreign_reuses[reuse_order].setdefault(schema_name, [])
44 foreign_reuses[reuse_order][schema_name].extend([reuse_entry])
45 return foreign_reuses, self_nestings
46
47
48 def perform_reuse(fields):
49 '''Performs field reuse in two phases'''
50 foreign_reuses, self_nestings = order_reuses(fields)
51
52 # Phase 1: foreign reuse
53 # These are done respecting the reusable.order attribute.
54 # This lets us force the order for chained reuses (e.g. group => user, then user => many places)
55 for order in sorted(foreign_reuses.keys()):
56 for schema_name, reuse_entries in foreign_reuses[order].items():
57 schema = fields[schema_name]
58 for reuse_entry in reuse_entries:
59 # print(order, "{} => {}".format(schema_name, reuse_entry['full']))
60 nest_as = reuse_entry['as']
61 destination_schema_name = reuse_entry['full'].split('.')[0]
62 destination_schema = fields[destination_schema_name]
63 ensure_valid_reuse(schema, destination_schema)
64
65 new_field_details = copy.deepcopy(schema['field_details'])
66 new_field_details['name'] = nest_as
67 new_field_details['original_fieldset'] = schema_name
68 new_field_details['intermediate'] = True
69 reused_fields = copy.deepcopy(schema['fields'])
70 set_original_fieldset(reused_fields, schema_name)
71 destination_fields = field_group_at_path(reuse_entry['at'], fields)
72 destination_fields[nest_as] = {
73 'field_details': new_field_details,
74 'fields': reused_fields,
75 }
76 append_reused_here(schema, reuse_entry, destination_schema)
77
78 # Phase 2: self-nesting
79 for schema_name, reuse_entries in self_nestings.items():
80 schema = fields[schema_name]
81 ensure_valid_reuse(schema)
82 # Since we're about self-nest more fields within these, make a pristine copy first
83 reused_fields = copy.deepcopy(schema['fields'])
84 set_original_fieldset(reused_fields, schema_name)
85 for reuse_entry in reuse_entries:
86 # print("x {} => {}".format(schema_name, reuse_entry['full']))
87 nest_as = reuse_entry['as']
88 new_field_details = copy.deepcopy(schema['field_details'])
89 new_field_details['name'] = nest_as
90 new_field_details['original_fieldset'] = schema_name
91 new_field_details['intermediate'] = True
92 destination_fields = schema['fields']
93 destination_fields[nest_as] = {
94 'field_details': new_field_details,
95 # Make a new copy of the pristine copy
96 'fields': copy.deepcopy(reused_fields),
97 }
98 append_reused_here(schema, reuse_entry, fields[schema_name])
99
100
101 def ensure_valid_reuse(reused_schema, destination_schema=None):
102 '''
103 Raise if either the reused schema or destination schema have root=true.
104
105 Second param is optional, if testing for a self-nesting (where source=destination).
106 '''
107 if reused_schema['schema_details']['root']:
108 msg = "Schema {} has attribute root=true and therefore cannot be reused.".format(
109 reused_schema['field_details']['name'])
110 raise ValueError(msg)
111 elif destination_schema and destination_schema['schema_details']['root']:
112 msg = "Schema {} has attribute root=true and therefore cannot have other field sets reused inside it.".format(
113 destination_schema['field_details']['name'])
114 raise ValueError(msg)
115
116
117 def append_reused_here(reused_schema, reuse_entry, destination_schema):
118 '''Captures two ways of denoting what field sets are reused under a given field set'''
119 # Legacy, too limited
120 destination_schema['schema_details'].setdefault('nestings', [])
121 destination_schema['schema_details']['nestings'] = sorted(
122 destination_schema['schema_details']['nestings'] + [reuse_entry['full']]
123 )
124 # New roomier way: we could eventually include contextual description here
125 destination_schema['schema_details'].setdefault('reused_here', [])
126 reused_here_entry = {
127 'schema_name': reused_schema['field_details']['name'],
128 'full': reuse_entry['full'],
129 'short': reused_schema['field_details']['short'],
130 }
131 # Check for beta attribute
132 if 'beta' in reuse_entry:
133 reused_here_entry['beta'] = reuse_entry['beta']
134 destination_schema['schema_details']['reused_here'].extend([reused_here_entry])
135
136
137 def set_original_fieldset(fields, original_fieldset):
138 '''Recursively set the 'original_fieldset' attribute for all fields in a group of fields'''
139 def func(details):
140 # Don't override if already set (e.g. 'group' for user.group.* fields)
141 details['field_details'].setdefault('original_fieldset', original_fieldset)
142 visitor.visit_fields(fields, field_func=func)
143
144
145 def field_group_at_path(dotted_path, fields):
146 '''Returns the ['fields'] hash at the dotted_path.'''
147 path = dotted_path.split('.')
148 nesting = fields
149 for next_field in path:
150 field = nesting.get(next_field, None)
151 if not field:
152 raise ValueError("Field {} not found, failed to find {}".format(dotted_path, next_field))
153 nesting = field.get('fields', None)
154 if not nesting:
155 field_type = field['field_details']['type']
156 if field_type in ['object', 'group', 'nested']:
157 nesting = field['fields'] = {}
158 else:
159 raise ValueError("Field {} (type {}) already exists and cannot have nested fields".format(
160 dotted_path, field_type))
161 return nesting
162
163
164 def calculate_final_values(fields):
165 '''
166 This function navigates all fields recursively.
167
168 It populates a few more values for the fields, especially path-based values
169 like flat_name.
170 '''
171 visitor.visit_fields_with_path(fields, field_finalizer)
172
173
174 def field_finalizer(details, path):
175 '''This is the function called by the visitor to perform the work of calculate_final_values'''
176 name_array = path + [details['field_details']['node_name']]
177 flat_name = '.'.join(name_array)
178 details['field_details']['flat_name'] = flat_name
179 details['field_details']['dashed_name'] = re.sub('[@_\.]', '-', flat_name)
180 if 'multi_fields' in details['field_details']:
181 for mf in details['field_details']['multi_fields']:
182 mf['flat_name'] = flat_name + '.' + mf['name']
183
[end of scripts/schema/finalizer.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/scripts/schema/finalizer.py b/scripts/schema/finalizer.py
--- a/scripts/schema/finalizer.py
+++ b/scripts/schema/finalizer.py
@@ -176,7 +176,7 @@
name_array = path + [details['field_details']['node_name']]
flat_name = '.'.join(name_array)
details['field_details']['flat_name'] = flat_name
- details['field_details']['dashed_name'] = re.sub('[@_\.]', '-', flat_name)
+ details['field_details']['dashed_name'] = re.sub('[_\.]', '-', flat_name).replace('@', '')
if 'multi_fields' in details['field_details']:
for mf in details['field_details']['multi_fields']:
mf['flat_name'] = flat_name + '.' + mf['name']
| {"golden_diff": "diff --git a/scripts/schema/finalizer.py b/scripts/schema/finalizer.py\n--- a/scripts/schema/finalizer.py\n+++ b/scripts/schema/finalizer.py\n@@ -176,7 +176,7 @@\n name_array = path + [details['field_details']['node_name']]\n flat_name = '.'.join(name_array)\n details['field_details']['flat_name'] = flat_name\n- details['field_details']['dashed_name'] = re.sub('[@_\\.]', '-', flat_name)\n+ details['field_details']['dashed_name'] = re.sub('[_\\.]', '-', flat_name).replace('@', '')\n if 'multi_fields' in details['field_details']:\n for mf in details['field_details']['multi_fields']:\n mf['flat_name'] = flat_name + '.' + mf['name']\n", "issue": "Documentation Suggestion: anchor links on ECS fields\nThis is really pretty simple and I'm not sure where else to properly capture it. \r\n\r\nThe existing ECS documentation should have anchor tags on each field name in the ECS guide so you can easily deep-link directly to the relevant field. \r\n\r\nWhen collaborating, often I'll say \"Look at this field(such as rule.id)\". I can link the fields [category page](https://www.elastic.co/guide/en/ecs/current/ecs-rule.html), but I can't deep-link directly to the field of discussion. \r\n\r\nJust a small quality of life change that could speed up collaboration. \r\n\n", "before_files": [{"content": "import copy\nimport re\n\nfrom schema import visitor\n\n# This script takes the fleshed out deeply nested fields dictionary as emitted by\n# cleaner.py, and performs field reuse in two phases.\n#\n# Phase 1 performs field reuse across field sets. E.g. `group` fields should also be under `user`.\n# This type of reuse is then carried around if the receiving field set is also reused.\n# In other words, user.group.* will be in other places where user is nested:\n# source.user.* will contain source.user.group.*\n\n# Phase 2 performs field reuse where field sets are reused within themselves, with a different name.\n# Examples are nesting `process` within itself, as `process.parent.*`,\n# or nesting `user` within itself at `user.target.*`.\n# This second kind of nesting is not carried around everywhere else the receiving field set is reused.\n# So `user.target.*` is *not* carried over to `source.user.target*` when we reuse `user` under `source`.\n\n\ndef finalize(fields):\n '''Intended entrypoint of the finalizer.'''\n perform_reuse(fields)\n calculate_final_values(fields)\n\n\ndef order_reuses(fields):\n foreign_reuses = {}\n self_nestings = {}\n for schema_name, schema in fields.items():\n if not 'reusable' in schema['schema_details']:\n continue\n reuse_order = schema['schema_details']['reusable']['order']\n for reuse_entry in schema['schema_details']['reusable']['expected']:\n destination_schema_name = reuse_entry['full'].split('.')[0]\n if destination_schema_name == schema_name:\n # Accumulate self-nestings for phase 2.\n self_nestings.setdefault(destination_schema_name, [])\n self_nestings[destination_schema_name].extend([reuse_entry])\n else:\n # Group foreign reuses by 'order' attribute.\n foreign_reuses.setdefault(reuse_order, {})\n foreign_reuses[reuse_order].setdefault(schema_name, [])\n foreign_reuses[reuse_order][schema_name].extend([reuse_entry])\n return foreign_reuses, self_nestings\n\n\ndef perform_reuse(fields):\n '''Performs field reuse in two phases'''\n foreign_reuses, self_nestings = order_reuses(fields)\n\n # Phase 1: foreign reuse\n # These are done respecting the reusable.order attribute.\n # This lets us force the order for chained reuses (e.g. group => user, then user => many places)\n for order in sorted(foreign_reuses.keys()):\n for schema_name, reuse_entries in foreign_reuses[order].items():\n schema = fields[schema_name]\n for reuse_entry in reuse_entries:\n # print(order, \"{} => {}\".format(schema_name, reuse_entry['full']))\n nest_as = reuse_entry['as']\n destination_schema_name = reuse_entry['full'].split('.')[0]\n destination_schema = fields[destination_schema_name]\n ensure_valid_reuse(schema, destination_schema)\n\n new_field_details = copy.deepcopy(schema['field_details'])\n new_field_details['name'] = nest_as\n new_field_details['original_fieldset'] = schema_name\n new_field_details['intermediate'] = True\n reused_fields = copy.deepcopy(schema['fields'])\n set_original_fieldset(reused_fields, schema_name)\n destination_fields = field_group_at_path(reuse_entry['at'], fields)\n destination_fields[nest_as] = {\n 'field_details': new_field_details,\n 'fields': reused_fields,\n }\n append_reused_here(schema, reuse_entry, destination_schema)\n\n # Phase 2: self-nesting\n for schema_name, reuse_entries in self_nestings.items():\n schema = fields[schema_name]\n ensure_valid_reuse(schema)\n # Since we're about self-nest more fields within these, make a pristine copy first\n reused_fields = copy.deepcopy(schema['fields'])\n set_original_fieldset(reused_fields, schema_name)\n for reuse_entry in reuse_entries:\n # print(\"x {} => {}\".format(schema_name, reuse_entry['full']))\n nest_as = reuse_entry['as']\n new_field_details = copy.deepcopy(schema['field_details'])\n new_field_details['name'] = nest_as\n new_field_details['original_fieldset'] = schema_name\n new_field_details['intermediate'] = True\n destination_fields = schema['fields']\n destination_fields[nest_as] = {\n 'field_details': new_field_details,\n # Make a new copy of the pristine copy\n 'fields': copy.deepcopy(reused_fields),\n }\n append_reused_here(schema, reuse_entry, fields[schema_name])\n\n\ndef ensure_valid_reuse(reused_schema, destination_schema=None):\n '''\n Raise if either the reused schema or destination schema have root=true.\n\n Second param is optional, if testing for a self-nesting (where source=destination).\n '''\n if reused_schema['schema_details']['root']:\n msg = \"Schema {} has attribute root=true and therefore cannot be reused.\".format(\n reused_schema['field_details']['name'])\n raise ValueError(msg)\n elif destination_schema and destination_schema['schema_details']['root']:\n msg = \"Schema {} has attribute root=true and therefore cannot have other field sets reused inside it.\".format(\n destination_schema['field_details']['name'])\n raise ValueError(msg)\n\n\ndef append_reused_here(reused_schema, reuse_entry, destination_schema):\n '''Captures two ways of denoting what field sets are reused under a given field set'''\n # Legacy, too limited\n destination_schema['schema_details'].setdefault('nestings', [])\n destination_schema['schema_details']['nestings'] = sorted(\n destination_schema['schema_details']['nestings'] + [reuse_entry['full']]\n )\n # New roomier way: we could eventually include contextual description here\n destination_schema['schema_details'].setdefault('reused_here', [])\n reused_here_entry = {\n 'schema_name': reused_schema['field_details']['name'],\n 'full': reuse_entry['full'],\n 'short': reused_schema['field_details']['short'],\n }\n # Check for beta attribute\n if 'beta' in reuse_entry:\n reused_here_entry['beta'] = reuse_entry['beta']\n destination_schema['schema_details']['reused_here'].extend([reused_here_entry])\n\n\ndef set_original_fieldset(fields, original_fieldset):\n '''Recursively set the 'original_fieldset' attribute for all fields in a group of fields'''\n def func(details):\n # Don't override if already set (e.g. 'group' for user.group.* fields)\n details['field_details'].setdefault('original_fieldset', original_fieldset)\n visitor.visit_fields(fields, field_func=func)\n\n\ndef field_group_at_path(dotted_path, fields):\n '''Returns the ['fields'] hash at the dotted_path.'''\n path = dotted_path.split('.')\n nesting = fields\n for next_field in path:\n field = nesting.get(next_field, None)\n if not field:\n raise ValueError(\"Field {} not found, failed to find {}\".format(dotted_path, next_field))\n nesting = field.get('fields', None)\n if not nesting:\n field_type = field['field_details']['type']\n if field_type in ['object', 'group', 'nested']:\n nesting = field['fields'] = {}\n else:\n raise ValueError(\"Field {} (type {}) already exists and cannot have nested fields\".format(\n dotted_path, field_type))\n return nesting\n\n\ndef calculate_final_values(fields):\n '''\n This function navigates all fields recursively.\n\n It populates a few more values for the fields, especially path-based values\n like flat_name.\n '''\n visitor.visit_fields_with_path(fields, field_finalizer)\n\n\ndef field_finalizer(details, path):\n '''This is the function called by the visitor to perform the work of calculate_final_values'''\n name_array = path + [details['field_details']['node_name']]\n flat_name = '.'.join(name_array)\n details['field_details']['flat_name'] = flat_name\n details['field_details']['dashed_name'] = re.sub('[@_\\.]', '-', flat_name)\n if 'multi_fields' in details['field_details']:\n for mf in details['field_details']['multi_fields']:\n mf['flat_name'] = flat_name + '.' + mf['name']\n", "path": "scripts/schema/finalizer.py"}]} | 2,882 | 177 |
gh_patches_debug_11399 | rasdani/github-patches | git_diff | ethereum__web3.py-407 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Remove shh from default list of modules
The whisper protocol is not standardized enough to be in the default list.
Also, note in the docs the current fractured nature of whisper.
See #384
</issue>
<code>
[start of web3/main.py]
1 from __future__ import absolute_import
2
3 from eth_utils import (
4 apply_to_return_value,
5 add_0x_prefix,
6 from_wei,
7 is_address,
8 is_checksum_address,
9 keccak,
10 remove_0x_prefix,
11 to_checksum_address,
12 to_wei,
13 )
14
15 from web3.admin import Admin
16 from web3.eth import Eth
17 from web3.iban import Iban
18 from web3.miner import Miner
19 from web3.net import Net
20 from web3.personal import Personal
21 from web3.shh import Shh
22 from web3.testing import Testing
23 from web3.txpool import TxPool
24 from web3.version import Version
25
26 from web3.providers.ipc import (
27 IPCProvider,
28 )
29 from web3.providers.rpc import (
30 HTTPProvider,
31 )
32 from web3.providers.tester import (
33 TestRPCProvider,
34 EthereumTesterProvider,
35 )
36
37 from web3.manager import (
38 RequestManager,
39 )
40
41 from web3.utils.datastructures import (
42 HexBytes,
43 )
44 from web3.utils.encoding import (
45 hex_encode_abi_type,
46 to_bytes,
47 to_int,
48 to_hex,
49 to_text,
50 )
51
52
53 def get_default_modules():
54 return {
55 "eth": Eth,
56 "shh": Shh,
57 "net": Net,
58 "personal": Personal,
59 "version": Version,
60 "txpool": TxPool,
61 "miner": Miner,
62 "admin": Admin,
63 "testing": Testing,
64 }
65
66
67 class Web3(object):
68 # Providers
69 HTTPProvider = HTTPProvider
70 IPCProvider = IPCProvider
71 TestRPCProvider = TestRPCProvider
72 EthereumTesterProvider = EthereumTesterProvider
73
74 # Managers
75 RequestManager = RequestManager
76
77 # Iban
78 Iban = Iban
79
80 # Encoding and Decoding
81 toBytes = staticmethod(to_bytes)
82 toInt = staticmethod(to_int)
83 toHex = staticmethod(to_hex)
84 toText = staticmethod(to_text)
85
86 # Currency Utility
87 toWei = staticmethod(to_wei)
88 fromWei = staticmethod(from_wei)
89
90 # Address Utility
91 isAddress = staticmethod(is_address)
92 isChecksumAddress = staticmethod(is_checksum_address)
93 toChecksumAddress = staticmethod(to_checksum_address)
94
95 def __init__(self, providers, middlewares=None, modules=None):
96 self.manager = RequestManager(self, providers, middlewares)
97
98 if modules is None:
99 modules = get_default_modules()
100
101 for module_name, module_class in modules.items():
102 module_class.attach(self, module_name)
103
104 @property
105 def middleware_stack(self):
106 return self.manager.middleware_stack
107
108 @property
109 def providers(self):
110 return self.manager.providers
111
112 def setProviders(self, providers):
113 self.manager.setProvider(providers)
114
115 @staticmethod
116 @apply_to_return_value(HexBytes)
117 def sha3(primitive=None, text=None, hexstr=None):
118 if isinstance(primitive, (bytes, int, type(None))):
119 input_bytes = to_bytes(primitive, hexstr=hexstr, text=text)
120 return keccak(input_bytes)
121
122 raise TypeError(
123 "You called sha3 with first arg %r and keywords %r. You must call it with one of "
124 "these approaches: sha3(text='txt'), sha3(hexstr='0x747874'), "
125 "sha3(b'\\x74\\x78\\x74'), or sha3(0x747874)." % (
126 primitive,
127 {'text': text, 'hexstr': hexstr}
128 )
129 )
130
131 @classmethod
132 def soliditySha3(cls, abi_types, values):
133 """
134 Executes sha3 (keccak256) exactly as Solidity does.
135 Takes list of abi_types as inputs -- `[uint24, int8[], bool]`
136 and list of corresponding values -- `[20, [-1, 5, 0], True]`
137 """
138 if len(abi_types) != len(values):
139 raise ValueError(
140 "Length mismatch between provided abi types and values. Got "
141 "{0} types and {1} values.".format(len(abi_types), len(values))
142 )
143
144 hex_string = add_0x_prefix(''.join(
145 remove_0x_prefix(hex_encode_abi_type(abi_type, value))
146 for abi_type, value
147 in zip(abi_types, values)
148 ))
149 return cls.sha3(hexstr=hex_string)
150
151 def isConnected(self):
152 for provider in self.providers:
153 if provider.isConnected():
154 return True
155 else:
156 return False
157
[end of web3/main.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/web3/main.py b/web3/main.py
--- a/web3/main.py
+++ b/web3/main.py
@@ -18,7 +18,6 @@
from web3.miner import Miner
from web3.net import Net
from web3.personal import Personal
-from web3.shh import Shh
from web3.testing import Testing
from web3.txpool import TxPool
from web3.version import Version
@@ -53,7 +52,6 @@
def get_default_modules():
return {
"eth": Eth,
- "shh": Shh,
"net": Net,
"personal": Personal,
"version": Version,
| {"golden_diff": "diff --git a/web3/main.py b/web3/main.py\n--- a/web3/main.py\n+++ b/web3/main.py\n@@ -18,7 +18,6 @@\n from web3.miner import Miner\n from web3.net import Net\n from web3.personal import Personal\n-from web3.shh import Shh\n from web3.testing import Testing\n from web3.txpool import TxPool\n from web3.version import Version\n@@ -53,7 +52,6 @@\n def get_default_modules():\n return {\n \"eth\": Eth,\n- \"shh\": Shh,\n \"net\": Net,\n \"personal\": Personal,\n \"version\": Version,\n", "issue": "Remove shh from default list of modules\nThe whisper protocol is not standardized enough to be in the default list.\r\n\r\nAlso, note in the docs the current fractured nature of whisper.\r\n\r\nSee #384 \n", "before_files": [{"content": "from __future__ import absolute_import\n\nfrom eth_utils import (\n apply_to_return_value,\n add_0x_prefix,\n from_wei,\n is_address,\n is_checksum_address,\n keccak,\n remove_0x_prefix,\n to_checksum_address,\n to_wei,\n)\n\nfrom web3.admin import Admin\nfrom web3.eth import Eth\nfrom web3.iban import Iban\nfrom web3.miner import Miner\nfrom web3.net import Net\nfrom web3.personal import Personal\nfrom web3.shh import Shh\nfrom web3.testing import Testing\nfrom web3.txpool import TxPool\nfrom web3.version import Version\n\nfrom web3.providers.ipc import (\n IPCProvider,\n)\nfrom web3.providers.rpc import (\n HTTPProvider,\n)\nfrom web3.providers.tester import (\n TestRPCProvider,\n EthereumTesterProvider,\n)\n\nfrom web3.manager import (\n RequestManager,\n)\n\nfrom web3.utils.datastructures import (\n HexBytes,\n)\nfrom web3.utils.encoding import (\n hex_encode_abi_type,\n to_bytes,\n to_int,\n to_hex,\n to_text,\n)\n\n\ndef get_default_modules():\n return {\n \"eth\": Eth,\n \"shh\": Shh,\n \"net\": Net,\n \"personal\": Personal,\n \"version\": Version,\n \"txpool\": TxPool,\n \"miner\": Miner,\n \"admin\": Admin,\n \"testing\": Testing,\n }\n\n\nclass Web3(object):\n # Providers\n HTTPProvider = HTTPProvider\n IPCProvider = IPCProvider\n TestRPCProvider = TestRPCProvider\n EthereumTesterProvider = EthereumTesterProvider\n\n # Managers\n RequestManager = RequestManager\n\n # Iban\n Iban = Iban\n\n # Encoding and Decoding\n toBytes = staticmethod(to_bytes)\n toInt = staticmethod(to_int)\n toHex = staticmethod(to_hex)\n toText = staticmethod(to_text)\n\n # Currency Utility\n toWei = staticmethod(to_wei)\n fromWei = staticmethod(from_wei)\n\n # Address Utility\n isAddress = staticmethod(is_address)\n isChecksumAddress = staticmethod(is_checksum_address)\n toChecksumAddress = staticmethod(to_checksum_address)\n\n def __init__(self, providers, middlewares=None, modules=None):\n self.manager = RequestManager(self, providers, middlewares)\n\n if modules is None:\n modules = get_default_modules()\n\n for module_name, module_class in modules.items():\n module_class.attach(self, module_name)\n\n @property\n def middleware_stack(self):\n return self.manager.middleware_stack\n\n @property\n def providers(self):\n return self.manager.providers\n\n def setProviders(self, providers):\n self.manager.setProvider(providers)\n\n @staticmethod\n @apply_to_return_value(HexBytes)\n def sha3(primitive=None, text=None, hexstr=None):\n if isinstance(primitive, (bytes, int, type(None))):\n input_bytes = to_bytes(primitive, hexstr=hexstr, text=text)\n return keccak(input_bytes)\n\n raise TypeError(\n \"You called sha3 with first arg %r and keywords %r. You must call it with one of \"\n \"these approaches: sha3(text='txt'), sha3(hexstr='0x747874'), \"\n \"sha3(b'\\\\x74\\\\x78\\\\x74'), or sha3(0x747874).\" % (\n primitive,\n {'text': text, 'hexstr': hexstr}\n )\n )\n\n @classmethod\n def soliditySha3(cls, abi_types, values):\n \"\"\"\n Executes sha3 (keccak256) exactly as Solidity does.\n Takes list of abi_types as inputs -- `[uint24, int8[], bool]`\n and list of corresponding values -- `[20, [-1, 5, 0], True]`\n \"\"\"\n if len(abi_types) != len(values):\n raise ValueError(\n \"Length mismatch between provided abi types and values. Got \"\n \"{0} types and {1} values.\".format(len(abi_types), len(values))\n )\n\n hex_string = add_0x_prefix(''.join(\n remove_0x_prefix(hex_encode_abi_type(abi_type, value))\n for abi_type, value\n in zip(abi_types, values)\n ))\n return cls.sha3(hexstr=hex_string)\n\n def isConnected(self):\n for provider in self.providers:\n if provider.isConnected():\n return True\n else:\n return False\n", "path": "web3/main.py"}]} | 1,943 | 148 |
gh_patches_debug_22671 | rasdani/github-patches | git_diff | rucio__rucio-2844 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Distance exporter fails
Motivation
----------
There is a bug in https://github.com/rucio/rucio/blob/master/lib/rucio/api/exporter.py#L40
(ValueError: too many values to unpack) which does not show up in the test.
Modification
------------
Fix the loop where the ValueError occurs and modify the test in tests/test_import_export.py to have distances to export
</issue>
<code>
[start of lib/rucio/api/exporter.py]
1 '''
2 Copyright European Organization for Nuclear Research (CERN)
3
4 Licensed under the Apache License, Version 2.0 (the "License");
5 You may not use this file except in compliance with the License.
6 You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0
7
8 Authors:
9 - Hannes Hansen, <[email protected]>, 2018
10 - Andrew Lister, <[email protected]>, 2019
11
12 PY3K COMPATIBLE
13 '''
14
15 from rucio.api import permission
16 from rucio.common import exception
17 from rucio.core import exporter
18 from rucio.core.rse import get_rse_name
19
20
21 def export_data(issuer):
22 """
23 Export data from Rucio.
24
25 :param issuer: the issuer.
26 """
27 kwargs = {'issuer': issuer}
28 if not permission.has_permission(issuer=issuer, action='export', kwargs=kwargs):
29 raise exception.AccessDenied('Account %s can not export data' % issuer)
30
31 data = exporter.export_data()
32 rses = {}
33 distances = {}
34
35 for rse_id in data['rses']:
36 rse = data['rses'][rse_id]
37 rses[get_rse_name(rse_id=rse_id)] = rse
38 data['rses'] = rses
39
40 for src_id, tmp in data['distances']:
41 src = get_rse_name(rse_id=src_id)
42 distances[src] = {}
43 for dst_id, dists in tmp:
44 dst = get_rse_name(rse_id=dst_id)
45 distances[src][dst] = dists
46 data['distances'] = distances
47 return data
48
[end of lib/rucio/api/exporter.py]
[start of lib/rucio/core/distance.py]
1 """
2 Copyright European Organization for Nuclear Research (CERN)
3
4 Licensed under the Apache License, Version 2.0 (the "License");
5 You may not use this file except in compliance with the License.
6 You may obtain a copy of the License at
7 http://www.apache.org/licenses/LICENSE-2.0
8
9 Authors:
10 - Wen Guan, <[email protected]>, 2015-2016
11 - Cedric Serfon, <[email protected]>, 2017
12 - Andrew Lister, <[email protected]>, 2019
13
14 PY3K COMPATIBLE
15 """
16
17 from sqlalchemy.exc import DatabaseError, IntegrityError
18 from sqlalchemy.orm import aliased
19
20 from rucio.common import exception
21 from rucio.core.rse import get_rse_name
22 from rucio.db.sqla.models import Distance, RSE
23 from rucio.db.sqla.session import transactional_session, read_session
24
25
26 @transactional_session
27 def add_distance(src_rse_id, dest_rse_id, ranking=None, agis_distance=None, geoip_distance=None,
28 active=None, submitted=None, finished=None, failed=None, transfer_speed=None, session=None):
29 """
30 Add a src-dest distance.
31
32 :param src_rse_id: The source RSE ID.
33 :param dest_rse_id: The destination RSE ID.
34 :param ranking: Ranking as an integer.
35 :param agis_distance: AGIS Distance as an integer.
36 :param geoip_distance: GEOIP Distance as an integer.
37 :param active: Active FTS transfers as an integer.
38 :param submitted: Submitted FTS transfers as an integer.
39 :param finished: Finished FTS transfers as an integer.
40 :param failed: Failed FTS transfers as an integer.
41 :param transfer_speed: FTS transfer speed as an integer.
42 :param session: The database session to use.
43 """
44
45 try:
46 new_distance = Distance(src_rse_id=src_rse_id, dest_rse_id=dest_rse_id, ranking=ranking, agis_distance=agis_distance, geoip_distance=geoip_distance,
47 active=active, submitted=submitted, finished=finished, failed=failed, transfer_speed=transfer_speed)
48 new_distance.save(session=session)
49 except IntegrityError:
50 raise exception.Duplicate('Distance from %s to %s already exists!' % (get_rse_name(rse_id=src_rse_id, session=session), get_rse_name(rse_id=dest_rse_id, session=session)))
51 except DatabaseError as error:
52 raise exception.RucioException(error.args)
53
54
55 @transactional_session
56 def add_distance_short(src_rse_id, dest_rse_id, distance=None, session=None):
57 """
58 Add a src-dest distance.
59
60 :param src_rse_id: The source RSE ID.
61 :param dest_rse_id: The destination RSE ID.
62 :param distance: A dictionary with different values.
63 """
64
65 add_distance(src_rse_id, dest_rse_id, ranking=distance.get('ranking', None), agis_distance=distance.get('agis_distance', None),
66 geoip_distance=distance.get('geoip_distance', None), active=distance.get('active', None), submitted=distance.get('submitted', None),
67 finished=distance.get('finished', None), failed=distance.get('failed', None), transfer_speed=distance.get('transfer_speed', None),
68 session=session)
69
70
71 @read_session
72 def get_distances(src_rse_id=None, dest_rse_id=None, session=None):
73 """
74 Get distances between rses.
75
76 :param src_rse_id: The source RSE ID.
77 :param dest_rse_id: The destination RSE ID.
78 :param session: The database session to use.
79
80 :returns distance: List of dictionaries.
81 """
82
83 try:
84 query = session.query(Distance)
85 if src_rse_id:
86 query = query.filter(Distance.src_rse_id == src_rse_id)
87 if dest_rse_id:
88 query = query.filter(Distance.dest_rse_id == dest_rse_id)
89
90 distances = []
91 tmp = query.all()
92 if tmp:
93 for t in tmp:
94 t2 = dict(t)
95 t2['distance'] = t2['agis_distance']
96 t2.pop('_sa_instance_state')
97 distances.append(t2)
98 return distances
99 except IntegrityError as error:
100 raise exception.RucioException(error.args)
101
102
103 @transactional_session
104 def delete_distances(src_rse_id=None, dest_rse_id=None, session=None):
105 """
106 Delete distances with the given RSE ids.
107
108 :param src_rse_id: The source RSE ID.
109 :param dest_rse_id: The destination RSE ID.
110 :param session: The database session to use.
111 """
112
113 try:
114 query = session.query(Distance)
115
116 if src_rse_id:
117 query = query.filter(Distance.src_rse_id == src_rse_id)
118 if dest_rse_id:
119 query = query.filter(Distance.dest_rse_id == dest_rse_id)
120
121 query.delete()
122 except IntegrityError as error:
123 raise exception.RucioException(error.args)
124
125
126 @transactional_session
127 def update_distances(src_rse_id=None, dest_rse_id=None, parameters=None, session=None):
128 """
129 Update distances with the given RSE ids.
130
131 :param src_rse_id: The source RSE ID.
132 :param dest_rse_id: The destination RSE ID.
133 :param parameters: A dictionnary with property
134 :param session: The database session to use.
135 """
136 params = {}
137 for key in parameters:
138 if key in ['ranking', 'agis_distance', 'geoip_distance', 'active', 'submitted', 'finished', 'failed', 'transfer_speed', 'packet_loss', 'latency', 'mbps_file', 'mbps_link', 'queued_total', 'done_1h', 'done_6h']:
139 params[key] = parameters[key]
140 try:
141 query = session.query(Distance)
142 if src_rse_id:
143 query = query.filter(Distance.src_rse_id == src_rse_id)
144 if dest_rse_id:
145 query = query.filter(Distance.dest_rse_id == dest_rse_id)
146 query.update(params)
147 except IntegrityError as error:
148 raise exception.RucioException(error.args)
149
150
151 @read_session
152 def list_distances(filter={}, session=None):
153 """
154 Get distances between all the RSEs.
155
156 :param filter: dictionary to filter distances.
157 :param session: The database session in use.
158 """
159 return [distance.to_dict() for distance in session.query(Distance).all()]
160
161
162 @read_session
163 def export_distances(session=None):
164 """
165 Export distances between all the RSEs using RSE ids.
166 :param session: The database session to use.
167 :returns distance: dictionary of dictionaries with all the distances.
168 """
169
170 distances = {}
171 try:
172 rse_src = aliased(RSE)
173 rse_dest = aliased(RSE)
174 query = session.query(Distance, rse_src.id, rse_dest.id)\
175 .join(rse_src, rse_src.id == Distance.src_rse_id)\
176 .join(rse_dest, rse_dest.id == Distance.dest_rse_id)
177 for result in query.all():
178 distance = result[0]
179 src_id = result[1]
180 dst_id = result[2]
181 if src_id not in distances:
182 distances[src_id] = {}
183 distances[src_id][dst_id] = {}
184 distances[src_id][dst_id] = distance.to_dict()
185 del distances[src_id][dst_id]['_sa_instance_state']
186 return distances
187 except IntegrityError as error:
188 raise exception.RucioException(error.args)
189
[end of lib/rucio/core/distance.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/lib/rucio/api/exporter.py b/lib/rucio/api/exporter.py
--- a/lib/rucio/api/exporter.py
+++ b/lib/rucio/api/exporter.py
@@ -37,11 +37,12 @@
rses[get_rse_name(rse_id=rse_id)] = rse
data['rses'] = rses
- for src_id, tmp in data['distances']:
+ for src_id in data['distances']:
+ dests = data['distances'][src_id]
src = get_rse_name(rse_id=src_id)
distances[src] = {}
- for dst_id, dists in tmp:
- dst = get_rse_name(rse_id=dst_id)
- distances[src][dst] = dists
+ for dest_id in dests:
+ dest = get_rse_name(rse_id=dest_id)
+ distances[src][dest] = dests[dest_id]
data['distances'] = distances
return data
diff --git a/lib/rucio/core/distance.py b/lib/rucio/core/distance.py
--- a/lib/rucio/core/distance.py
+++ b/lib/rucio/core/distance.py
@@ -181,6 +181,7 @@
if src_id not in distances:
distances[src_id] = {}
distances[src_id][dst_id] = {}
+ distance['distance'] = distance['agis_distance']
distances[src_id][dst_id] = distance.to_dict()
del distances[src_id][dst_id]['_sa_instance_state']
return distances
| {"golden_diff": "diff --git a/lib/rucio/api/exporter.py b/lib/rucio/api/exporter.py\n--- a/lib/rucio/api/exporter.py\n+++ b/lib/rucio/api/exporter.py\n@@ -37,11 +37,12 @@\n rses[get_rse_name(rse_id=rse_id)] = rse\n data['rses'] = rses\n \n- for src_id, tmp in data['distances']:\n+ for src_id in data['distances']:\n+ dests = data['distances'][src_id]\n src = get_rse_name(rse_id=src_id)\n distances[src] = {}\n- for dst_id, dists in tmp:\n- dst = get_rse_name(rse_id=dst_id)\n- distances[src][dst] = dists\n+ for dest_id in dests:\n+ dest = get_rse_name(rse_id=dest_id)\n+ distances[src][dest] = dests[dest_id]\n data['distances'] = distances\n return data\ndiff --git a/lib/rucio/core/distance.py b/lib/rucio/core/distance.py\n--- a/lib/rucio/core/distance.py\n+++ b/lib/rucio/core/distance.py\n@@ -181,6 +181,7 @@\n if src_id not in distances:\n distances[src_id] = {}\n distances[src_id][dst_id] = {}\n+ distance['distance'] = distance['agis_distance']\n distances[src_id][dst_id] = distance.to_dict()\n del distances[src_id][dst_id]['_sa_instance_state']\n return distances\n", "issue": "Distance exporter fails\nMotivation\r\n----------\r\nThere is a bug in https://github.com/rucio/rucio/blob/master/lib/rucio/api/exporter.py#L40\r\n(ValueError: too many values to unpack) which does not show up in the test.\r\n\r\n\r\nModification\r\n------------\r\nFix the loop where the ValueError occurs and modify the test in tests/test_import_export.py to have distances to export \r\n\r\n\n", "before_files": [{"content": "'''\n Copyright European Organization for Nuclear Research (CERN)\n\n Licensed under the Apache License, Version 2.0 (the \"License\");\n You may not use this file except in compliance with the License.\n You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0\n\n Authors:\n - Hannes Hansen, <[email protected]>, 2018\n - Andrew Lister, <[email protected]>, 2019\n\n PY3K COMPATIBLE\n'''\n\nfrom rucio.api import permission\nfrom rucio.common import exception\nfrom rucio.core import exporter\nfrom rucio.core.rse import get_rse_name\n\n\ndef export_data(issuer):\n \"\"\"\n Export data from Rucio.\n\n :param issuer: the issuer.\n \"\"\"\n kwargs = {'issuer': issuer}\n if not permission.has_permission(issuer=issuer, action='export', kwargs=kwargs):\n raise exception.AccessDenied('Account %s can not export data' % issuer)\n\n data = exporter.export_data()\n rses = {}\n distances = {}\n\n for rse_id in data['rses']:\n rse = data['rses'][rse_id]\n rses[get_rse_name(rse_id=rse_id)] = rse\n data['rses'] = rses\n\n for src_id, tmp in data['distances']:\n src = get_rse_name(rse_id=src_id)\n distances[src] = {}\n for dst_id, dists in tmp:\n dst = get_rse_name(rse_id=dst_id)\n distances[src][dst] = dists\n data['distances'] = distances\n return data\n", "path": "lib/rucio/api/exporter.py"}, {"content": "\"\"\"\n Copyright European Organization for Nuclear Research (CERN)\n\n Licensed under the Apache License, Version 2.0 (the \"License\");\n You may not use this file except in compliance with the License.\n You may obtain a copy of the License at\n http://www.apache.org/licenses/LICENSE-2.0\n\n Authors:\n - Wen Guan, <[email protected]>, 2015-2016\n - Cedric Serfon, <[email protected]>, 2017\n - Andrew Lister, <[email protected]>, 2019\n\n PY3K COMPATIBLE\n\"\"\"\n\nfrom sqlalchemy.exc import DatabaseError, IntegrityError\nfrom sqlalchemy.orm import aliased\n\nfrom rucio.common import exception\nfrom rucio.core.rse import get_rse_name\nfrom rucio.db.sqla.models import Distance, RSE\nfrom rucio.db.sqla.session import transactional_session, read_session\n\n\n@transactional_session\ndef add_distance(src_rse_id, dest_rse_id, ranking=None, agis_distance=None, geoip_distance=None,\n active=None, submitted=None, finished=None, failed=None, transfer_speed=None, session=None):\n \"\"\"\n Add a src-dest distance.\n\n :param src_rse_id: The source RSE ID.\n :param dest_rse_id: The destination RSE ID.\n :param ranking: Ranking as an integer.\n :param agis_distance: AGIS Distance as an integer.\n :param geoip_distance: GEOIP Distance as an integer.\n :param active: Active FTS transfers as an integer.\n :param submitted: Submitted FTS transfers as an integer.\n :param finished: Finished FTS transfers as an integer.\n :param failed: Failed FTS transfers as an integer.\n :param transfer_speed: FTS transfer speed as an integer.\n :param session: The database session to use.\n \"\"\"\n\n try:\n new_distance = Distance(src_rse_id=src_rse_id, dest_rse_id=dest_rse_id, ranking=ranking, agis_distance=agis_distance, geoip_distance=geoip_distance,\n active=active, submitted=submitted, finished=finished, failed=failed, transfer_speed=transfer_speed)\n new_distance.save(session=session)\n except IntegrityError:\n raise exception.Duplicate('Distance from %s to %s already exists!' % (get_rse_name(rse_id=src_rse_id, session=session), get_rse_name(rse_id=dest_rse_id, session=session)))\n except DatabaseError as error:\n raise exception.RucioException(error.args)\n\n\n@transactional_session\ndef add_distance_short(src_rse_id, dest_rse_id, distance=None, session=None):\n \"\"\"\n Add a src-dest distance.\n\n :param src_rse_id: The source RSE ID.\n :param dest_rse_id: The destination RSE ID.\n :param distance: A dictionary with different values.\n \"\"\"\n\n add_distance(src_rse_id, dest_rse_id, ranking=distance.get('ranking', None), agis_distance=distance.get('agis_distance', None),\n geoip_distance=distance.get('geoip_distance', None), active=distance.get('active', None), submitted=distance.get('submitted', None),\n finished=distance.get('finished', None), failed=distance.get('failed', None), transfer_speed=distance.get('transfer_speed', None),\n session=session)\n\n\n@read_session\ndef get_distances(src_rse_id=None, dest_rse_id=None, session=None):\n \"\"\"\n Get distances between rses.\n\n :param src_rse_id: The source RSE ID.\n :param dest_rse_id: The destination RSE ID.\n :param session: The database session to use.\n\n :returns distance: List of dictionaries.\n \"\"\"\n\n try:\n query = session.query(Distance)\n if src_rse_id:\n query = query.filter(Distance.src_rse_id == src_rse_id)\n if dest_rse_id:\n query = query.filter(Distance.dest_rse_id == dest_rse_id)\n\n distances = []\n tmp = query.all()\n if tmp:\n for t in tmp:\n t2 = dict(t)\n t2['distance'] = t2['agis_distance']\n t2.pop('_sa_instance_state')\n distances.append(t2)\n return distances\n except IntegrityError as error:\n raise exception.RucioException(error.args)\n\n\n@transactional_session\ndef delete_distances(src_rse_id=None, dest_rse_id=None, session=None):\n \"\"\"\n Delete distances with the given RSE ids.\n\n :param src_rse_id: The source RSE ID.\n :param dest_rse_id: The destination RSE ID.\n :param session: The database session to use.\n \"\"\"\n\n try:\n query = session.query(Distance)\n\n if src_rse_id:\n query = query.filter(Distance.src_rse_id == src_rse_id)\n if dest_rse_id:\n query = query.filter(Distance.dest_rse_id == dest_rse_id)\n\n query.delete()\n except IntegrityError as error:\n raise exception.RucioException(error.args)\n\n\n@transactional_session\ndef update_distances(src_rse_id=None, dest_rse_id=None, parameters=None, session=None):\n \"\"\"\n Update distances with the given RSE ids.\n\n :param src_rse_id: The source RSE ID.\n :param dest_rse_id: The destination RSE ID.\n :param parameters: A dictionnary with property\n :param session: The database session to use.\n \"\"\"\n params = {}\n for key in parameters:\n if key in ['ranking', 'agis_distance', 'geoip_distance', 'active', 'submitted', 'finished', 'failed', 'transfer_speed', 'packet_loss', 'latency', 'mbps_file', 'mbps_link', 'queued_total', 'done_1h', 'done_6h']:\n params[key] = parameters[key]\n try:\n query = session.query(Distance)\n if src_rse_id:\n query = query.filter(Distance.src_rse_id == src_rse_id)\n if dest_rse_id:\n query = query.filter(Distance.dest_rse_id == dest_rse_id)\n query.update(params)\n except IntegrityError as error:\n raise exception.RucioException(error.args)\n\n\n@read_session\ndef list_distances(filter={}, session=None):\n \"\"\"\n Get distances between all the RSEs.\n\n :param filter: dictionary to filter distances.\n :param session: The database session in use.\n \"\"\"\n return [distance.to_dict() for distance in session.query(Distance).all()]\n\n\n@read_session\ndef export_distances(session=None):\n \"\"\"\n Export distances between all the RSEs using RSE ids.\n :param session: The database session to use.\n :returns distance: dictionary of dictionaries with all the distances.\n \"\"\"\n\n distances = {}\n try:\n rse_src = aliased(RSE)\n rse_dest = aliased(RSE)\n query = session.query(Distance, rse_src.id, rse_dest.id)\\\n .join(rse_src, rse_src.id == Distance.src_rse_id)\\\n .join(rse_dest, rse_dest.id == Distance.dest_rse_id)\n for result in query.all():\n distance = result[0]\n src_id = result[1]\n dst_id = result[2]\n if src_id not in distances:\n distances[src_id] = {}\n distances[src_id][dst_id] = {}\n distances[src_id][dst_id] = distance.to_dict()\n del distances[src_id][dst_id]['_sa_instance_state']\n return distances\n except IntegrityError as error:\n raise exception.RucioException(error.args)\n", "path": "lib/rucio/core/distance.py"}]} | 3,300 | 359 |
gh_patches_debug_2327 | rasdani/github-patches | git_diff | encode__httpx-194 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Missing py.typed declaration?
`mypy` is complaining about not being able to find type annotations for `httpx`:
`error: Cannot find module named 'httpx'`
I'm somewhat new to using type annotations/static type checking in Python, but from the mypy documentation [here](https://mypy.readthedocs.io/en/latest/installed_packages.html#making-pep-561-compatible-packages) it looks like there may be a missing declaration in `setup.py`?
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3
4 import os
5 import re
6
7 from setuptools import setup
8
9
10 def get_version(package):
11 """
12 Return package version as listed in `__version__` in `init.py`.
13 """
14 with open(os.path.join(package, "__version__.py")) as f:
15 return re.search("__version__ = ['\"]([^'\"]+)['\"]", f.read()).group(1)
16
17
18 def get_long_description():
19 """
20 Return the README.
21 """
22 with open("README.md", encoding="utf8") as f:
23 return f.read()
24
25
26 def get_packages(package):
27 """
28 Return root package and all sub-packages.
29 """
30 return [
31 dirpath
32 for dirpath, dirnames, filenames in os.walk(package)
33 if os.path.exists(os.path.join(dirpath, "__init__.py"))
34 ]
35
36
37 setup(
38 name="httpx",
39 python_requires=">=3.6",
40 version=get_version("httpx"),
41 url="https://github.com/encode/httpx",
42 license="BSD",
43 description="The next generation HTTP client.",
44 long_description=get_long_description(),
45 long_description_content_type="text/markdown",
46 author="Tom Christie",
47 author_email="[email protected]",
48 packages=get_packages("httpx"),
49 install_requires=[
50 "certifi",
51 "chardet==3.*",
52 "h11==0.8.*",
53 "h2==3.*",
54 "hstspreload",
55 "idna==2.*",
56 "rfc3986==1.*",
57 ],
58 classifiers=[
59 "Development Status :: 3 - Alpha",
60 "Environment :: Web Environment",
61 "Intended Audience :: Developers",
62 "License :: OSI Approved :: BSD License",
63 "Operating System :: OS Independent",
64 "Topic :: Internet :: WWW/HTTP",
65 "Programming Language :: Python :: 3",
66 "Programming Language :: Python :: 3.6",
67 "Programming Language :: Python :: 3.7",
68 "Programming Language :: Python :: 3.8",
69 ],
70 )
71
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -45,6 +45,7 @@
long_description_content_type="text/markdown",
author="Tom Christie",
author_email="[email protected]",
+ package_data={"httpx": ["py.typed"]},
packages=get_packages("httpx"),
install_requires=[
"certifi",
| {"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -45,6 +45,7 @@\n long_description_content_type=\"text/markdown\",\n author=\"Tom Christie\",\n author_email=\"[email protected]\",\n+ package_data={\"httpx\": [\"py.typed\"]},\n packages=get_packages(\"httpx\"),\n install_requires=[\n \"certifi\",\n", "issue": "Missing py.typed declaration?\n`mypy` is complaining about not being able to find type annotations for `httpx`: \r\n\r\n`error: Cannot find module named 'httpx'`\r\n\r\nI'm somewhat new to using type annotations/static type checking in Python, but from the mypy documentation [here](https://mypy.readthedocs.io/en/latest/installed_packages.html#making-pep-561-compatible-packages) it looks like there may be a missing declaration in `setup.py`?\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nimport os\nimport re\n\nfrom setuptools import setup\n\n\ndef get_version(package):\n \"\"\"\n Return package version as listed in `__version__` in `init.py`.\n \"\"\"\n with open(os.path.join(package, \"__version__.py\")) as f:\n return re.search(\"__version__ = ['\\\"]([^'\\\"]+)['\\\"]\", f.read()).group(1)\n\n\ndef get_long_description():\n \"\"\"\n Return the README.\n \"\"\"\n with open(\"README.md\", encoding=\"utf8\") as f:\n return f.read()\n\n\ndef get_packages(package):\n \"\"\"\n Return root package and all sub-packages.\n \"\"\"\n return [\n dirpath\n for dirpath, dirnames, filenames in os.walk(package)\n if os.path.exists(os.path.join(dirpath, \"__init__.py\"))\n ]\n\n\nsetup(\n name=\"httpx\",\n python_requires=\">=3.6\",\n version=get_version(\"httpx\"),\n url=\"https://github.com/encode/httpx\",\n license=\"BSD\",\n description=\"The next generation HTTP client.\",\n long_description=get_long_description(),\n long_description_content_type=\"text/markdown\",\n author=\"Tom Christie\",\n author_email=\"[email protected]\",\n packages=get_packages(\"httpx\"),\n install_requires=[\n \"certifi\",\n \"chardet==3.*\",\n \"h11==0.8.*\",\n \"h2==3.*\",\n \"hstspreload\",\n \"idna==2.*\",\n \"rfc3986==1.*\",\n ],\n classifiers=[\n \"Development Status :: 3 - Alpha\",\n \"Environment :: Web Environment\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: BSD License\",\n \"Operating System :: OS Independent\",\n \"Topic :: Internet :: WWW/HTTP\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n ],\n)\n", "path": "setup.py"}]} | 1,220 | 90 |
gh_patches_debug_4090 | rasdani/github-patches | git_diff | enthought__chaco-883 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
NameError: name 'gc' is not defined
**Problem Description**
NameError: name 'gc' is not defined in chaco/chaco/plots/polar_line_renderer.py
**Reproduction Steps:**
python chaco/examples/demo/simple_polar.py
[Steps to reproduce issue here.]
```python
# Code to reproduce issue here
```
**Expected behavior:**
[MacOS, python3.8 (EDM)]
**OS, Python version:** [Enter OS name and Python version]
</issue>
<code>
[start of chaco/plots/polar_line_renderer.py]
1 # (C) Copyright 2005-2021 Enthought, Inc., Austin, TX
2 # All rights reserved.
3 #
4 # This software is provided without warranty under the terms of the BSD
5 # license included in LICENSE.txt and may be redistributed only under
6 # the conditions described in the aforementioned license. The license
7 # is also available online at http://www.enthought.com/licenses/BSD.txt
8 #
9 # Thanks for using Enthought open source!
10
11 """ Defines the PolarLineRenderer class.
12 """
13
14
15 # Major library imports
16 from numpy import array, cos, empty, pi, sin, transpose
17
18 # Enthought library imports
19 from enable.api import black_color_trait, LineStyle
20 from traits.api import Float
21
22 # Local, relative imports
23 from chaco.abstract_plot_renderer import AbstractPlotRenderer
24
25
26 class PolarLineRenderer(AbstractPlotRenderer):
27 """A renderer for polar line plots."""
28
29 # ------------------------------------------------------------------------
30 # Appearance-related traits
31 # ------------------------------------------------------------------------
32
33 # The color of the origin axis.
34 origin_axis_color_ = (0, 0, 0, 1)
35 # The width of the origin axis.
36 origin_axis_width = 2.0
37 # The origin axis is visible.
38 origin_axis_visible = True
39 # The grid is visible.
40 grid_visible = True
41 # The orientation of the plot is horizontal; for any other value, it is
42 # transposed
43 orientation = "h"
44 # The color of the line.
45 color = black_color_trait
46 # The width of the line.
47 line_width = Float(1.0)
48 # The style of the line.
49 line_style = LineStyle("solid")
50 # The style of the grid lines.
51 grid_style = LineStyle("dot")
52
53 def _gather_points(self):
54 """
55 Collects the data points that are within the plot bounds and caches them
56 """
57 # This is just a stub for now. We should really find the lines only
58 # inside the screen range here.
59
60 x = self.index.get_data()
61 y = self.value.get_data()
62 rad = min(self.width / 2.0, self.height / 2.0)
63 sx = x * rad + self.x + self.width / 2.0
64 sy = y * rad + self.y + self.height / 2.0
65
66 points = transpose(array((sx, sy)))
67 self._cached_data_pts = points
68 self._cache_valid = True
69
70 def _data_changed(self):
71 self._cache_valid = False
72
73 def _update_mappers(self):
74 # Dunno if there is anything else to do here
75 self._cache_valid = False
76
77 def _render(self, gc, points):
78 """Actually draw the plot."""
79 with gc:
80 gc.set_antialias(True)
81 self._draw_default_axes(gc)
82 self._draw_default_grid(gc)
83 if len(points) > 0:
84 gc.clip_to_rect(self.x, self.y, self.width, self.height)
85 gc.set_stroke_color(self.color_)
86 gc.set_line_width(self.line_width)
87 gc.set_line_dash(self.line_style_)
88
89 gc.begin_path()
90 gc.lines(points)
91 gc.stroke_path()
92
93 def map_screen(self, data_array):
94 """Maps an array of data points into screen space and returns it as
95 an array.
96
97 Implements the AbstractPlotRenderer interface.
98 """
99
100 if len(data_array) == 0:
101 return empty(shape=(0, 2))
102 elif len(data_array) == 1:
103 xtmp, ytmp = transpose(data_array)
104 x_ary = xtmp
105 y_ary = ytmp
106 else:
107 x_ary, y_ary = transpose(data_array)
108
109 sx = self.index_mapper.map_screen(x_ary)
110 sy = self.value_mapper.map_screen(y_ary)
111
112 if self.orientation == "h":
113 return transpose(array((sx, sy)))
114 else:
115 return transpose(array((sy, sx)))
116
117 def map_data(self, screen_pt):
118 """Maps a screen space point into the "index" space of the plot.
119
120 Implements the AbstractPlotRenderer interface.
121 """
122 if self.orientation == "h":
123 x, y = screen_pt
124 else:
125 y, x = screen_pt
126 return array(
127 (self.index_mapper.map_data(x), self.value_mapper.map_data(y))
128 )
129
130 def _downsample(self):
131 return self.map_screen(self._cached_data_pts)
132
133 def _draw_plot(self, *args, **kw):
134 """Draws the 'plot' layer."""
135 self._gather_points()
136 self._render(gc, self._cached_data_pts)
137
138 def _bounds_changed(self, old, new):
139 super()._bounds_changed(old, new)
140 self._update_mappers()
141
142 def _bounds_items_changed(self, event):
143 super()._bounds_items_changed(event)
144 self._update_mappers()
145
146 def _draw_default_axes(self, gc):
147 if not self.origin_axis_visible:
148 return
149
150 with gc:
151 gc.set_stroke_color(self.origin_axis_color_)
152 gc.set_line_width(self.origin_axis_width)
153 gc.set_line_dash(self.grid_style_)
154 x_data, y_data = transpose(self._cached_data_pts)
155 x_center = self.x + self.width / 2.0
156 y_center = self.y + self.height / 2.0
157
158 for theta in range(12):
159 r = min(self.width / 2.0, self.height / 2.0)
160 x = r * cos(theta * pi / 6) + x_center
161 y = r * sin(theta * pi / 6) + y_center
162 data_pts = array([[x_center, y_center], [x, y]])
163 start, end = data_pts
164 gc.move_to(int(start[0]), int(start[1]))
165 gc.line_to(int(end[0]), int(end[1]))
166 gc.stroke_path()
167
168 def _draw_default_grid(self, gc):
169 if not self.grid_visible:
170 return
171
172 with gc:
173 gc.set_stroke_color(self.origin_axis_color_)
174 gc.set_line_width(self.origin_axis_width)
175 gc.set_line_dash(self.grid_style_)
176 x_data, y_data = transpose(self._cached_data_pts)
177 x_center = self.x + self.width / 2.0
178 y_center = self.y + self.height / 2.0
179 rad = min(self.width / 2.0, self.height / 2.0)
180 for r_part in range(1, 5):
181 r = rad * r_part / 4
182 gc.arc(x_center, y_center, r, 0, 2 * pi)
183 gc.stroke_path()
184
[end of chaco/plots/polar_line_renderer.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/chaco/plots/polar_line_renderer.py b/chaco/plots/polar_line_renderer.py
--- a/chaco/plots/polar_line_renderer.py
+++ b/chaco/plots/polar_line_renderer.py
@@ -130,7 +130,7 @@
def _downsample(self):
return self.map_screen(self._cached_data_pts)
- def _draw_plot(self, *args, **kw):
+ def _draw_plot(self, gc, *args, **kw):
"""Draws the 'plot' layer."""
self._gather_points()
self._render(gc, self._cached_data_pts)
| {"golden_diff": "diff --git a/chaco/plots/polar_line_renderer.py b/chaco/plots/polar_line_renderer.py\n--- a/chaco/plots/polar_line_renderer.py\n+++ b/chaco/plots/polar_line_renderer.py\n@@ -130,7 +130,7 @@\n def _downsample(self):\n return self.map_screen(self._cached_data_pts)\n \n- def _draw_plot(self, *args, **kw):\n+ def _draw_plot(self, gc, *args, **kw):\n \"\"\"Draws the 'plot' layer.\"\"\"\n self._gather_points()\n self._render(gc, self._cached_data_pts)\n", "issue": "NameError: name 'gc' is not defined\n**Problem Description**\nNameError: name 'gc' is not defined in chaco/chaco/plots/polar_line_renderer.py\n\n**Reproduction Steps:**\npython chaco/examples/demo/simple_polar.py\n\n[Steps to reproduce issue here.]\n\n```python\n# Code to reproduce issue here\n```\n\n**Expected behavior:** \n\n[MacOS, python3.8 (EDM)]\n\n**OS, Python version:** [Enter OS name and Python version]\n\n", "before_files": [{"content": "# (C) Copyright 2005-2021 Enthought, Inc., Austin, TX\n# All rights reserved.\n#\n# This software is provided without warranty under the terms of the BSD\n# license included in LICENSE.txt and may be redistributed only under\n# the conditions described in the aforementioned license. The license\n# is also available online at http://www.enthought.com/licenses/BSD.txt\n#\n# Thanks for using Enthought open source!\n\n\"\"\" Defines the PolarLineRenderer class.\n\"\"\"\n\n\n# Major library imports\nfrom numpy import array, cos, empty, pi, sin, transpose\n\n# Enthought library imports\nfrom enable.api import black_color_trait, LineStyle\nfrom traits.api import Float\n\n# Local, relative imports\nfrom chaco.abstract_plot_renderer import AbstractPlotRenderer\n\n\nclass PolarLineRenderer(AbstractPlotRenderer):\n \"\"\"A renderer for polar line plots.\"\"\"\n\n # ------------------------------------------------------------------------\n # Appearance-related traits\n # ------------------------------------------------------------------------\n\n # The color of the origin axis.\n origin_axis_color_ = (0, 0, 0, 1)\n # The width of the origin axis.\n origin_axis_width = 2.0\n # The origin axis is visible.\n origin_axis_visible = True\n # The grid is visible.\n grid_visible = True\n # The orientation of the plot is horizontal; for any other value, it is\n # transposed\n orientation = \"h\"\n # The color of the line.\n color = black_color_trait\n # The width of the line.\n line_width = Float(1.0)\n # The style of the line.\n line_style = LineStyle(\"solid\")\n # The style of the grid lines.\n grid_style = LineStyle(\"dot\")\n\n def _gather_points(self):\n \"\"\"\n Collects the data points that are within the plot bounds and caches them\n \"\"\"\n # This is just a stub for now. We should really find the lines only\n # inside the screen range here.\n\n x = self.index.get_data()\n y = self.value.get_data()\n rad = min(self.width / 2.0, self.height / 2.0)\n sx = x * rad + self.x + self.width / 2.0\n sy = y * rad + self.y + self.height / 2.0\n\n points = transpose(array((sx, sy)))\n self._cached_data_pts = points\n self._cache_valid = True\n\n def _data_changed(self):\n self._cache_valid = False\n\n def _update_mappers(self):\n # Dunno if there is anything else to do here\n self._cache_valid = False\n\n def _render(self, gc, points):\n \"\"\"Actually draw the plot.\"\"\"\n with gc:\n gc.set_antialias(True)\n self._draw_default_axes(gc)\n self._draw_default_grid(gc)\n if len(points) > 0:\n gc.clip_to_rect(self.x, self.y, self.width, self.height)\n gc.set_stroke_color(self.color_)\n gc.set_line_width(self.line_width)\n gc.set_line_dash(self.line_style_)\n\n gc.begin_path()\n gc.lines(points)\n gc.stroke_path()\n\n def map_screen(self, data_array):\n \"\"\"Maps an array of data points into screen space and returns it as\n an array.\n\n Implements the AbstractPlotRenderer interface.\n \"\"\"\n\n if len(data_array) == 0:\n return empty(shape=(0, 2))\n elif len(data_array) == 1:\n xtmp, ytmp = transpose(data_array)\n x_ary = xtmp\n y_ary = ytmp\n else:\n x_ary, y_ary = transpose(data_array)\n\n sx = self.index_mapper.map_screen(x_ary)\n sy = self.value_mapper.map_screen(y_ary)\n\n if self.orientation == \"h\":\n return transpose(array((sx, sy)))\n else:\n return transpose(array((sy, sx)))\n\n def map_data(self, screen_pt):\n \"\"\"Maps a screen space point into the \"index\" space of the plot.\n\n Implements the AbstractPlotRenderer interface.\n \"\"\"\n if self.orientation == \"h\":\n x, y = screen_pt\n else:\n y, x = screen_pt\n return array(\n (self.index_mapper.map_data(x), self.value_mapper.map_data(y))\n )\n\n def _downsample(self):\n return self.map_screen(self._cached_data_pts)\n\n def _draw_plot(self, *args, **kw):\n \"\"\"Draws the 'plot' layer.\"\"\"\n self._gather_points()\n self._render(gc, self._cached_data_pts)\n\n def _bounds_changed(self, old, new):\n super()._bounds_changed(old, new)\n self._update_mappers()\n\n def _bounds_items_changed(self, event):\n super()._bounds_items_changed(event)\n self._update_mappers()\n\n def _draw_default_axes(self, gc):\n if not self.origin_axis_visible:\n return\n\n with gc:\n gc.set_stroke_color(self.origin_axis_color_)\n gc.set_line_width(self.origin_axis_width)\n gc.set_line_dash(self.grid_style_)\n x_data, y_data = transpose(self._cached_data_pts)\n x_center = self.x + self.width / 2.0\n y_center = self.y + self.height / 2.0\n\n for theta in range(12):\n r = min(self.width / 2.0, self.height / 2.0)\n x = r * cos(theta * pi / 6) + x_center\n y = r * sin(theta * pi / 6) + y_center\n data_pts = array([[x_center, y_center], [x, y]])\n start, end = data_pts\n gc.move_to(int(start[0]), int(start[1]))\n gc.line_to(int(end[0]), int(end[1]))\n gc.stroke_path()\n\n def _draw_default_grid(self, gc):\n if not self.grid_visible:\n return\n\n with gc:\n gc.set_stroke_color(self.origin_axis_color_)\n gc.set_line_width(self.origin_axis_width)\n gc.set_line_dash(self.grid_style_)\n x_data, y_data = transpose(self._cached_data_pts)\n x_center = self.x + self.width / 2.0\n y_center = self.y + self.height / 2.0\n rad = min(self.width / 2.0, self.height / 2.0)\n for r_part in range(1, 5):\n r = rad * r_part / 4\n gc.arc(x_center, y_center, r, 0, 2 * pi)\n gc.stroke_path()\n", "path": "chaco/plots/polar_line_renderer.py"}]} | 2,538 | 139 |
gh_patches_debug_9383 | rasdani/github-patches | git_diff | buildbot__buildbot-4099 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Workers configured_on gets corrupted for multi-master
https://github.com/buildbot/buildbot/issues/3981 fixed the issue of Workers configured_on getting corrupted. It works for single master scenario. However, for multi-master scenario, this bug is still present.
I have two masters (running 1.1.1):
1: handling the web-server
2: handling workers communication, builds and everything else
If I restart 1 and then 2, then it's fine. However, if I restart 2 and then 1, then the workers configured_on is corrupted. The issue reproduce immediately on restarting 1.
If I restart only 2, then the issue doesn't happen. However, restarting 1 consistently reproduces the issue.
I suspect that the HouseKeeping which is done while starting the masters might be causing the issue.
https://github.com/buildbot/buildbot/blob/master/master/buildbot/master.py#L300
</issue>
<code>
[start of master/buildbot/data/masters.py]
1 # This file is part of Buildbot. Buildbot is free software: you can
2 # redistribute it and/or modify it under the terms of the GNU General Public
3 # License as published by the Free Software Foundation, version 2.
4 #
5 # This program is distributed in the hope that it will be useful, but WITHOUT
6 # ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS
7 # FOR A PARTICULAR PURPOSE. See the GNU General Public License for more
8 # details.
9 #
10 # You should have received a copy of the GNU General Public License along with
11 # this program; if not, write to the Free Software Foundation, Inc., 51
12 # Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
13 #
14 # Copyright Buildbot Team Members
15
16 from __future__ import absolute_import
17 from __future__ import print_function
18
19 from twisted.internet import defer
20 from twisted.internet import reactor
21 from twisted.python import log
22
23 from buildbot.data import base
24 from buildbot.data import resultspec
25 from buildbot.data import types
26 from buildbot.process.results import RETRY
27 from buildbot.util import epoch2datetime
28
29 # time, in minutes, after which a master that hasn't checked in will be
30 # marked as inactive
31 EXPIRE_MINUTES = 10
32
33
34 def _db2data(master):
35 return dict(masterid=master['id'],
36 name=master['name'],
37 active=master['active'],
38 last_active=master['last_active'])
39
40
41 class MasterEndpoint(base.Endpoint):
42
43 isCollection = False
44 pathPatterns = """
45 /masters/n:masterid
46 /builders/n:builderid/masters/n:masterid
47 """
48
49 @defer.inlineCallbacks
50 def get(self, resultSpec, kwargs):
51 # if a builder is given, only return the master if it's associated with
52 # this builder
53 if 'builderid' in kwargs:
54 builder = yield self.master.db.builders.getBuilder(
55 builderid=kwargs['builderid'])
56 if not builder or kwargs['masterid'] not in builder['masterids']:
57 defer.returnValue(None)
58 return
59 m = yield self.master.db.masters.getMaster(kwargs['masterid'])
60 defer.returnValue(_db2data(m) if m else None)
61
62
63 class MastersEndpoint(base.Endpoint):
64
65 isCollection = True
66 pathPatterns = """
67 /masters
68 /builders/n:builderid/masters
69 """
70 rootLinkName = 'masters'
71
72 @defer.inlineCallbacks
73 def get(self, resultSpec, kwargs):
74 masterlist = yield self.master.db.masters.getMasters()
75 if 'builderid' in kwargs:
76 builder = yield self.master.db.builders.getBuilder(
77 builderid=kwargs['builderid'])
78 if builder:
79 masterids = set(builder['masterids'])
80 masterlist = [m for m in masterlist if m['id'] in masterids]
81 else:
82 masterlist = []
83 defer.returnValue([_db2data(m) for m in masterlist])
84
85
86 class Master(base.ResourceType):
87
88 name = "master"
89 plural = "masters"
90 endpoints = [MasterEndpoint, MastersEndpoint]
91 eventPathPatterns = """
92 /masters/:masterid
93 """
94
95 class EntityType(types.Entity):
96 masterid = types.Integer()
97 name = types.String()
98 active = types.Boolean()
99 last_active = types.DateTime()
100 entityType = EntityType(name)
101
102 @base.updateMethod
103 @defer.inlineCallbacks
104 def masterActive(self, name, masterid, _reactor=reactor):
105 activated = yield self.master.db.masters.setMasterState(
106 masterid=masterid, active=True, _reactor=_reactor)
107 if activated:
108 self.produceEvent(
109 dict(masterid=masterid, name=name, active=True),
110 'started')
111
112 @base.updateMethod
113 @defer.inlineCallbacks
114 def expireMasters(self, forceHouseKeeping=False, _reactor=reactor):
115 too_old = epoch2datetime(_reactor.seconds() - 60 * EXPIRE_MINUTES)
116 masters = yield self.master.db.masters.getMasters()
117 for m in masters:
118 if not forceHouseKeeping and m['last_active'] is not None and m['last_active'] >= too_old:
119 continue
120
121 # mark the master inactive, and send a message on its behalf
122 deactivated = yield self.master.db.masters.setMasterState(
123 masterid=m['id'], active=False, _reactor=_reactor)
124 if deactivated:
125 yield self._masterDeactivated(m['id'], m['name'])
126 elif forceHouseKeeping:
127 yield self._masterDeactivatedHousekeeping(m['id'], m['name'])
128
129 @base.updateMethod
130 @defer.inlineCallbacks
131 def masterStopped(self, name, masterid):
132 deactivated = yield self.master.db.masters.setMasterState(
133 masterid=masterid, active=False)
134 if deactivated:
135 yield self._masterDeactivated(masterid, name)
136
137 @defer.inlineCallbacks
138 def _masterDeactivatedHousekeeping(self, masterid, name):
139 log.msg("doing housekeeping for master %d %s" % (masterid, name))
140
141 # common code for deactivating a master
142 yield self.master.data.rtypes.worker._masterDeactivated(
143 masterid=masterid)
144 yield self.master.data.rtypes.builder._masterDeactivated(
145 masterid=masterid)
146 yield self.master.data.rtypes.scheduler._masterDeactivated(
147 masterid=masterid)
148 yield self.master.data.rtypes.changesource._masterDeactivated(
149 masterid=masterid)
150
151 # for each build running on that instance..
152 builds = yield self.master.data.get(('builds',),
153 filters=[resultspec.Filter('masterid', 'eq', [masterid]),
154 resultspec.Filter('complete', 'eq', [False])])
155 for build in builds:
156 # stop any running steps..
157 steps = yield self.master.data.get(
158 ('builds', build['buildid'], 'steps'),
159 filters=[resultspec.Filter('results', 'eq', [None])])
160 for step in steps:
161 # finish remaining logs for those steps..
162 logs = yield self.master.data.get(
163 ('steps', step['stepid'], 'logs'),
164 filters=[resultspec.Filter('complete', 'eq',
165 [False])])
166 for _log in logs:
167 yield self.master.data.updates.finishLog(
168 logid=_log['logid'])
169 yield self.master.data.updates.finishStep(
170 stepid=step['stepid'], results=RETRY, hidden=False)
171 # then stop the build itself
172 yield self.master.data.updates.finishBuild(
173 buildid=build['buildid'], results=RETRY)
174
175 # unclaim all of the build requests owned by the deactivated instance
176 buildrequests = yield self.master.db.buildrequests.getBuildRequests(
177 complete=False, claimed=masterid)
178 yield self.master.db.buildrequests.unclaimBuildRequests(
179 brids=[br['buildrequestid'] for br in buildrequests])
180
181 @defer.inlineCallbacks
182 def _masterDeactivated(self, masterid, name):
183 yield self._masterDeactivatedHousekeeping(masterid, name)
184
185 self.produceEvent(
186 dict(masterid=masterid, name=name, active=False),
187 'stopped')
188
[end of master/buildbot/data/masters.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/master/buildbot/data/masters.py b/master/buildbot/data/masters.py
--- a/master/buildbot/data/masters.py
+++ b/master/buildbot/data/masters.py
@@ -115,7 +115,7 @@
too_old = epoch2datetime(_reactor.seconds() - 60 * EXPIRE_MINUTES)
masters = yield self.master.db.masters.getMasters()
for m in masters:
- if not forceHouseKeeping and m['last_active'] is not None and m['last_active'] >= too_old:
+ if m['last_active'] is not None and m['last_active'] >= too_old:
continue
# mark the master inactive, and send a message on its behalf
| {"golden_diff": "diff --git a/master/buildbot/data/masters.py b/master/buildbot/data/masters.py\n--- a/master/buildbot/data/masters.py\n+++ b/master/buildbot/data/masters.py\n@@ -115,7 +115,7 @@\n too_old = epoch2datetime(_reactor.seconds() - 60 * EXPIRE_MINUTES)\n masters = yield self.master.db.masters.getMasters()\n for m in masters:\n- if not forceHouseKeeping and m['last_active'] is not None and m['last_active'] >= too_old:\n+ if m['last_active'] is not None and m['last_active'] >= too_old:\n continue\n \n # mark the master inactive, and send a message on its behalf\n", "issue": "Workers configured_on gets corrupted for multi-master\nhttps://github.com/buildbot/buildbot/issues/3981 fixed the issue of Workers configured_on getting corrupted. It works for single master scenario. However, for multi-master scenario, this bug is still present.\r\n\r\nI have two masters (running 1.1.1):\r\n1: handling the web-server\r\n2: handling workers communication, builds and everything else\r\n\r\nIf I restart 1 and then 2, then it's fine. However, if I restart 2 and then 1, then the workers configured_on is corrupted. The issue reproduce immediately on restarting 1.\r\n\r\nIf I restart only 2, then the issue doesn't happen. However, restarting 1 consistently reproduces the issue.\r\n\r\nI suspect that the HouseKeeping which is done while starting the masters might be causing the issue.\r\n\r\nhttps://github.com/buildbot/buildbot/blob/master/master/buildbot/master.py#L300\r\n\n", "before_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\nfrom __future__ import absolute_import\nfrom __future__ import print_function\n\nfrom twisted.internet import defer\nfrom twisted.internet import reactor\nfrom twisted.python import log\n\nfrom buildbot.data import base\nfrom buildbot.data import resultspec\nfrom buildbot.data import types\nfrom buildbot.process.results import RETRY\nfrom buildbot.util import epoch2datetime\n\n# time, in minutes, after which a master that hasn't checked in will be\n# marked as inactive\nEXPIRE_MINUTES = 10\n\n\ndef _db2data(master):\n return dict(masterid=master['id'],\n name=master['name'],\n active=master['active'],\n last_active=master['last_active'])\n\n\nclass MasterEndpoint(base.Endpoint):\n\n isCollection = False\n pathPatterns = \"\"\"\n /masters/n:masterid\n /builders/n:builderid/masters/n:masterid\n \"\"\"\n\n @defer.inlineCallbacks\n def get(self, resultSpec, kwargs):\n # if a builder is given, only return the master if it's associated with\n # this builder\n if 'builderid' in kwargs:\n builder = yield self.master.db.builders.getBuilder(\n builderid=kwargs['builderid'])\n if not builder or kwargs['masterid'] not in builder['masterids']:\n defer.returnValue(None)\n return\n m = yield self.master.db.masters.getMaster(kwargs['masterid'])\n defer.returnValue(_db2data(m) if m else None)\n\n\nclass MastersEndpoint(base.Endpoint):\n\n isCollection = True\n pathPatterns = \"\"\"\n /masters\n /builders/n:builderid/masters\n \"\"\"\n rootLinkName = 'masters'\n\n @defer.inlineCallbacks\n def get(self, resultSpec, kwargs):\n masterlist = yield self.master.db.masters.getMasters()\n if 'builderid' in kwargs:\n builder = yield self.master.db.builders.getBuilder(\n builderid=kwargs['builderid'])\n if builder:\n masterids = set(builder['masterids'])\n masterlist = [m for m in masterlist if m['id'] in masterids]\n else:\n masterlist = []\n defer.returnValue([_db2data(m) for m in masterlist])\n\n\nclass Master(base.ResourceType):\n\n name = \"master\"\n plural = \"masters\"\n endpoints = [MasterEndpoint, MastersEndpoint]\n eventPathPatterns = \"\"\"\n /masters/:masterid\n \"\"\"\n\n class EntityType(types.Entity):\n masterid = types.Integer()\n name = types.String()\n active = types.Boolean()\n last_active = types.DateTime()\n entityType = EntityType(name)\n\n @base.updateMethod\n @defer.inlineCallbacks\n def masterActive(self, name, masterid, _reactor=reactor):\n activated = yield self.master.db.masters.setMasterState(\n masterid=masterid, active=True, _reactor=_reactor)\n if activated:\n self.produceEvent(\n dict(masterid=masterid, name=name, active=True),\n 'started')\n\n @base.updateMethod\n @defer.inlineCallbacks\n def expireMasters(self, forceHouseKeeping=False, _reactor=reactor):\n too_old = epoch2datetime(_reactor.seconds() - 60 * EXPIRE_MINUTES)\n masters = yield self.master.db.masters.getMasters()\n for m in masters:\n if not forceHouseKeeping and m['last_active'] is not None and m['last_active'] >= too_old:\n continue\n\n # mark the master inactive, and send a message on its behalf\n deactivated = yield self.master.db.masters.setMasterState(\n masterid=m['id'], active=False, _reactor=_reactor)\n if deactivated:\n yield self._masterDeactivated(m['id'], m['name'])\n elif forceHouseKeeping:\n yield self._masterDeactivatedHousekeeping(m['id'], m['name'])\n\n @base.updateMethod\n @defer.inlineCallbacks\n def masterStopped(self, name, masterid):\n deactivated = yield self.master.db.masters.setMasterState(\n masterid=masterid, active=False)\n if deactivated:\n yield self._masterDeactivated(masterid, name)\n\n @defer.inlineCallbacks\n def _masterDeactivatedHousekeeping(self, masterid, name):\n log.msg(\"doing housekeeping for master %d %s\" % (masterid, name))\n\n # common code for deactivating a master\n yield self.master.data.rtypes.worker._masterDeactivated(\n masterid=masterid)\n yield self.master.data.rtypes.builder._masterDeactivated(\n masterid=masterid)\n yield self.master.data.rtypes.scheduler._masterDeactivated(\n masterid=masterid)\n yield self.master.data.rtypes.changesource._masterDeactivated(\n masterid=masterid)\n\n # for each build running on that instance..\n builds = yield self.master.data.get(('builds',),\n filters=[resultspec.Filter('masterid', 'eq', [masterid]),\n resultspec.Filter('complete', 'eq', [False])])\n for build in builds:\n # stop any running steps..\n steps = yield self.master.data.get(\n ('builds', build['buildid'], 'steps'),\n filters=[resultspec.Filter('results', 'eq', [None])])\n for step in steps:\n # finish remaining logs for those steps..\n logs = yield self.master.data.get(\n ('steps', step['stepid'], 'logs'),\n filters=[resultspec.Filter('complete', 'eq',\n [False])])\n for _log in logs:\n yield self.master.data.updates.finishLog(\n logid=_log['logid'])\n yield self.master.data.updates.finishStep(\n stepid=step['stepid'], results=RETRY, hidden=False)\n # then stop the build itself\n yield self.master.data.updates.finishBuild(\n buildid=build['buildid'], results=RETRY)\n\n # unclaim all of the build requests owned by the deactivated instance\n buildrequests = yield self.master.db.buildrequests.getBuildRequests(\n complete=False, claimed=masterid)\n yield self.master.db.buildrequests.unclaimBuildRequests(\n brids=[br['buildrequestid'] for br in buildrequests])\n\n @defer.inlineCallbacks\n def _masterDeactivated(self, masterid, name):\n yield self._masterDeactivatedHousekeeping(masterid, name)\n\n self.produceEvent(\n dict(masterid=masterid, name=name, active=False),\n 'stopped')\n", "path": "master/buildbot/data/masters.py"}]} | 2,772 | 160 |
gh_patches_debug_25818 | rasdani/github-patches | git_diff | conda__conda-build-1105 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
conda-build crashes when building PEP420 namespace packages
There is a very trivial bug in `conda_build.utils.copy_into()`, causing it to crash when building PEP420 namespace packages. To reproduce the issue, all of the following conditions must be met:
- your package must be a native PEP420 namespace package (`python >=3.3`)
- your package must depend on (and therefore install) other packages mapping to the same namespace
- you must build all of these packages with `recipe['build']['preserve_egg_dir'] = False`
- your namespace must be a multi-level directory
This is easier to explain by example:
```
found egg dir: C:\ANACONDA\envs\_build\Lib\site-packages\example-4.3.0-py3.5-win-amd64.egg
...
Traceback (most recent call last):
File "C:\ANACONDA\Scripts\conda-build-script.py", line 4, in <module>
sys.exit(main())
File "C:\ANACONDA\lib\site-packages\conda_build\main_build.py", line 144, in main
args_func(args, p)
File "C:\ANACONDA\lib\site-packages\conda_build\main_build.py", line 389, in args_func
args.func(args, p)
File "C:\ANACONDA\lib\site-packages\conda_build\main_build.py", line 332, in execute
dirty=args.dirty, activate=args.activate)
File "C:\ANACONDA\lib\site-packages\conda_build\build.py", line 606, in build
preserve_egg_dir=bool(m.get_value('build/preserve_egg_dir')))
File "C:\ANACONDA\lib\site-packages\conda_build\post.py", line 162, in post_process
remove_easy_install_pth(files, preserve_egg_dir=preserve_egg_dir)
File "C:\ANACONDA\lib\site-packages\conda_build\post.py", line 119, in remove_easy_install_pth
utils.copy_into(join(egg_path, fn), join(sp_dir, fn))
File "C:\ANACONDA\lib\site-packages\conda_build\utils.py", line 54, in copy_into
shutil.copytree(srcname, dstname)
File "C:\ANACONDA\lib\shutil.py", line 177, in copytree
os.makedirs(dst)
File "C:\ANACONDA\lib\os.py", line 157, in makedirs
mkdir(name, mode)
WindowsError: [Error 183] Cannot create a file when that file already exists: 'C:\ANACONDA\envs\_build\Lib\site-packages\ns\sub'
```
Here `ns` is the top level namespace directory and `sub` is a sub-package, but also a namespace package:
```
+ ns
|
+ sub
|
module.py
```
The problem is that conda is trying to copy `ns\sub` to site-packages at build time. However, this directory already exists because another package -- a runtime dependency -- is already installed in site packages providing the same namespace directory layout:
```
+ ns
|
+ sub
|
dependency.py
```
`conda-build` needs to be able to "merge" the `sub` directories coming from all namespace packages. Deleting or skipping directories if they exist will corrupt the namespace and produce incorrect results. Here is the quickest way to fix this:
``` python
from distutils.dir_util import copy_tree
def copy_into(src, dst):
"Copy all the files and directories in src to the directory dst"
if not isdir(src):
tocopy = [src]
else:
tocopy = os.listdir(src)
for afile in tocopy:
srcname = os.path.join(src, afile)
dstname = os.path.join(dst, afile)
if os.path.isdir(srcname):
copy_tree(srcname, dstname)
else:
shutil.copy2(srcname, dstname)
```
i.e. just replace `shutil.copytree()` with `distutils.dir_util.copy_tree()`.
</issue>
<code>
[start of conda_build/utils.py]
1 from __future__ import absolute_import, division, print_function
2
3 import fnmatch
4 import os
5 import sys
6 import shutil
7 import tarfile
8 import zipfile
9 import subprocess
10 import operator
11 from os.path import dirname, getmtime, getsize, isdir, join
12 from collections import defaultdict
13
14 from conda.utils import md5_file, unix_path_to_win
15 from conda.compat import PY3, iteritems
16
17 from conda_build import external
18
19 # Backwards compatibility import. Do not remove.
20 from conda.install import rm_rf
21 rm_rf
22
23
24 def find_recipe(path):
25 """recurse through a folder, locating meta.yaml. Raises error if more than one is found.
26
27 Returns folder containing meta.yaml, to be built.
28
29 If we have a base level meta.yaml and other supplemental ones, use that first"""
30 results = rec_glob(path, ["meta.yaml", "conda.yaml"])
31 if len(results) > 1:
32 base_recipe = os.path.join(path, "meta.yaml")
33 if base_recipe in results:
34 return os.path.dirname(base_recipe)
35 else:
36 raise IOError("More than one meta.yaml files found in %s" % path)
37 elif not results:
38 raise IOError("No meta.yaml files found in %s" % path)
39 return os.path.dirname(results[0])
40
41
42 def copy_into(src, dst):
43 "Copy all the files and directories in src to the directory dst"
44
45 if not isdir(src):
46 tocopy = [src]
47 else:
48 tocopy = os.listdir(src)
49 for afile in tocopy:
50 srcname = os.path.join(src, afile)
51 dstname = os.path.join(dst, afile)
52
53 if os.path.isdir(srcname):
54 shutil.copytree(srcname, dstname)
55 else:
56 shutil.copy2(srcname, dstname)
57
58
59 def relative(f, d='lib'):
60 assert not f.startswith('/'), f
61 assert not d.startswith('/'), d
62 d = d.strip('/').split('/')
63 if d == ['.']:
64 d = []
65 f = dirname(f).split('/')
66 if f == ['']:
67 f = []
68 while d and f and d[0] == f[0]:
69 d.pop(0)
70 f.pop(0)
71 return '/'.join(((['..'] * len(f)) if f else ['.']) + d)
72
73
74 def _check_call(args, **kwargs):
75 try:
76 subprocess.check_call(args, **kwargs)
77 except subprocess.CalledProcessError:
78 sys.exit('Command failed: %s' % ' '.join(args))
79
80
81 def tar_xf(tarball, dir_path, mode='r:*'):
82 if tarball.lower().endswith('.tar.z'):
83 uncompress = external.find_executable('uncompress')
84 if not uncompress:
85 uncompress = external.find_executable('gunzip')
86 if not uncompress:
87 sys.exit("""\
88 uncompress (or gunzip) is required to unarchive .z source files.
89 """)
90 subprocess.check_call([uncompress, '-f', tarball])
91 tarball = tarball[:-2]
92 if not PY3 and tarball.endswith('.tar.xz'):
93 unxz = external.find_executable('unxz')
94 if not unxz:
95 sys.exit("""\
96 unxz is required to unarchive .xz source files.
97 """)
98
99 subprocess.check_call([unxz, '-f', '-k', tarball])
100 tarball = tarball[:-3]
101 t = tarfile.open(tarball, mode)
102 t.extractall(path=dir_path)
103 t.close()
104
105
106 def unzip(zip_path, dir_path):
107 z = zipfile.ZipFile(zip_path)
108 for name in z.namelist():
109 if name.endswith('/'):
110 continue
111 path = join(dir_path, *name.split('/'))
112 dp = dirname(path)
113 if not isdir(dp):
114 os.makedirs(dp)
115 with open(path, 'wb') as fo:
116 fo.write(z.read(name))
117 z.close()
118
119
120 def file_info(path):
121 return {'size': getsize(path),
122 'md5': md5_file(path),
123 'mtime': getmtime(path)}
124
125 # Taken from toolz
126
127
128 def groupby(key, seq):
129 """ Group a collection by a key function
130 >>> names = ['Alice', 'Bob', 'Charlie', 'Dan', 'Edith', 'Frank']
131 >>> groupby(len, names) # doctest: +SKIP
132 {3: ['Bob', 'Dan'], 5: ['Alice', 'Edith', 'Frank'], 7: ['Charlie']}
133 >>> iseven = lambda x: x % 2 == 0
134 >>> groupby(iseven, [1, 2, 3, 4, 5, 6, 7, 8]) # doctest: +SKIP
135 {False: [1, 3, 5, 7], True: [2, 4, 6, 8]}
136 Non-callable keys imply grouping on a member.
137 >>> groupby('gender', [{'name': 'Alice', 'gender': 'F'},
138 ... {'name': 'Bob', 'gender': 'M'},
139 ... {'name': 'Charlie', 'gender': 'M'}]) # doctest:+SKIP
140 {'F': [{'gender': 'F', 'name': 'Alice'}],
141 'M': [{'gender': 'M', 'name': 'Bob'},
142 {'gender': 'M', 'name': 'Charlie'}]}
143 See Also:
144 countby
145 """
146 if not callable(key):
147 key = getter(key)
148 d = defaultdict(lambda: [].append)
149 for item in seq:
150 d[key(item)](item)
151 rv = {}
152 for k, v in iteritems(d):
153 rv[k] = v.__self__
154 return rv
155
156
157 def getter(index):
158 if isinstance(index, list):
159 if len(index) == 1:
160 index = index[0]
161 return lambda x: (x[index],)
162 elif index:
163 return operator.itemgetter(*index)
164 else:
165 return lambda x: ()
166 else:
167 return operator.itemgetter(index)
168
169
170 def comma_join(items):
171 """
172 Like ', '.join(items) but with and
173
174 Examples:
175
176 >>> comma_join(['a'])
177 'a'
178 >>> comma_join(['a', 'b'])
179 'a and b'
180 >>> comma_join(['a', 'b', 'c])
181 'a, b, and c'
182 """
183 return ' and '.join(items) if len(items) <= 2 else ', '.join(items[:-1]) + ', and ' + items[-1]
184
185
186 def safe_print_unicode(*args, **kwargs):
187 """
188 prints unicode strings to stdout using configurable `errors` handler for
189 encoding errors
190
191 :param args: unicode strings to print to stdout
192 :param sep: separator (defaults to ' ')
193 :param end: ending character (defaults to '\n')
194 :param errors: error handler for encoding errors (defaults to 'replace')
195 """
196 sep = kwargs.pop('sep', u' ')
197 end = kwargs.pop('end', u'\n')
198 errors = kwargs.pop('errors', 'replace')
199 if PY3:
200 func = sys.stdout.buffer.write
201 else:
202 func = sys.stdout.write
203 line = sep.join(args) + end
204 encoding = sys.stdout.encoding or 'utf8'
205 func(line.encode(encoding, errors))
206
207
208 def rec_glob(path, patterns):
209 result = []
210 for d_f in os.walk(path):
211 m = []
212 for pattern in patterns:
213 m.extend(fnmatch.filter(d_f[2], pattern))
214 if m:
215 result.extend([os.path.join(d_f[0], f) for f in m])
216 return result
217
218
219 def convert_unix_path_to_win(path):
220 if external.find_executable('cygpath'):
221 cmd = "cygpath -w {0}".format(path)
222 if PY3:
223 path = subprocess.getoutput(cmd)
224 else:
225 path = subprocess.check_output(cmd.split()).rstrip().rstrip("\\")
226
227 else:
228 path = unix_path_to_win(path)
229 return path
230
[end of conda_build/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/conda_build/utils.py b/conda_build/utils.py
--- a/conda_build/utils.py
+++ b/conda_build/utils.py
@@ -8,8 +8,9 @@
import zipfile
import subprocess
import operator
-from os.path import dirname, getmtime, getsize, isdir, join
+from os.path import dirname, getmtime, getsize, isdir, isfile, join
from collections import defaultdict
+from distutils.dir_util import copy_tree
from conda.utils import md5_file, unix_path_to_win
from conda.compat import PY3, iteritems
@@ -51,11 +52,29 @@
dstname = os.path.join(dst, afile)
if os.path.isdir(srcname):
- shutil.copytree(srcname, dstname)
+ merge_tree(srcname, dstname)
else:
shutil.copy2(srcname, dstname)
+def merge_tree(src, dst):
+ """
+ Merge src into dst recursively by copying all files from src into dst.
+ Return a list of all files copied.
+
+ Like copy_tree(src, dst), but raises an error if merging the two trees
+ would overwrite any files.
+ """
+ new_files = copy_tree(src, dst, dry_run=True)
+ existing = [f for f in new_files if isfile(f)]
+
+ if existing:
+ raise IOError("Can't merge {0} into {1}: file exists: "
+ "{2}".format(src, dst, existing[0]))
+
+ return copy_tree(src, dst)
+
+
def relative(f, d='lib'):
assert not f.startswith('/'), f
assert not d.startswith('/'), d
| {"golden_diff": "diff --git a/conda_build/utils.py b/conda_build/utils.py\n--- a/conda_build/utils.py\n+++ b/conda_build/utils.py\n@@ -8,8 +8,9 @@\n import zipfile\n import subprocess\n import operator\n-from os.path import dirname, getmtime, getsize, isdir, join\n+from os.path import dirname, getmtime, getsize, isdir, isfile, join\n from collections import defaultdict\n+from distutils.dir_util import copy_tree\n \n from conda.utils import md5_file, unix_path_to_win\n from conda.compat import PY3, iteritems\n@@ -51,11 +52,29 @@\n dstname = os.path.join(dst, afile)\n \n if os.path.isdir(srcname):\n- shutil.copytree(srcname, dstname)\n+ merge_tree(srcname, dstname)\n else:\n shutil.copy2(srcname, dstname)\n \n \n+def merge_tree(src, dst):\n+ \"\"\"\n+ Merge src into dst recursively by copying all files from src into dst.\n+ Return a list of all files copied.\n+\n+ Like copy_tree(src, dst), but raises an error if merging the two trees\n+ would overwrite any files.\n+ \"\"\"\n+ new_files = copy_tree(src, dst, dry_run=True)\n+ existing = [f for f in new_files if isfile(f)]\n+\n+ if existing:\n+ raise IOError(\"Can't merge {0} into {1}: file exists: \"\n+ \"{2}\".format(src, dst, existing[0]))\n+\n+ return copy_tree(src, dst)\n+\n+\n def relative(f, d='lib'):\n assert not f.startswith('/'), f\n assert not d.startswith('/'), d\n", "issue": "conda-build crashes when building PEP420 namespace packages\nThere is a very trivial bug in `conda_build.utils.copy_into()`, causing it to crash when building PEP420 namespace packages. To reproduce the issue, all of the following conditions must be met:\n- your package must be a native PEP420 namespace package (`python >=3.3`)\n- your package must depend on (and therefore install) other packages mapping to the same namespace\n- you must build all of these packages with `recipe['build']['preserve_egg_dir'] = False`\n- your namespace must be a multi-level directory \n\nThis is easier to explain by example:\n\n```\nfound egg dir: C:\\ANACONDA\\envs\\_build\\Lib\\site-packages\\example-4.3.0-py3.5-win-amd64.egg\n...\nTraceback (most recent call last):\n File \"C:\\ANACONDA\\Scripts\\conda-build-script.py\", line 4, in <module>\n sys.exit(main())\n File \"C:\\ANACONDA\\lib\\site-packages\\conda_build\\main_build.py\", line 144, in main\n args_func(args, p)\n File \"C:\\ANACONDA\\lib\\site-packages\\conda_build\\main_build.py\", line 389, in args_func\n args.func(args, p)\n File \"C:\\ANACONDA\\lib\\site-packages\\conda_build\\main_build.py\", line 332, in execute\n dirty=args.dirty, activate=args.activate)\n File \"C:\\ANACONDA\\lib\\site-packages\\conda_build\\build.py\", line 606, in build\n preserve_egg_dir=bool(m.get_value('build/preserve_egg_dir')))\n File \"C:\\ANACONDA\\lib\\site-packages\\conda_build\\post.py\", line 162, in post_process\n remove_easy_install_pth(files, preserve_egg_dir=preserve_egg_dir)\n File \"C:\\ANACONDA\\lib\\site-packages\\conda_build\\post.py\", line 119, in remove_easy_install_pth\n utils.copy_into(join(egg_path, fn), join(sp_dir, fn))\n File \"C:\\ANACONDA\\lib\\site-packages\\conda_build\\utils.py\", line 54, in copy_into\n shutil.copytree(srcname, dstname)\n File \"C:\\ANACONDA\\lib\\shutil.py\", line 177, in copytree\n os.makedirs(dst)\n File \"C:\\ANACONDA\\lib\\os.py\", line 157, in makedirs\n mkdir(name, mode)\nWindowsError: [Error 183] Cannot create a file when that file already exists: 'C:\\ANACONDA\\envs\\_build\\Lib\\site-packages\\ns\\sub'\n```\n\nHere `ns` is the top level namespace directory and `sub` is a sub-package, but also a namespace package:\n\n```\n+ ns\n |\n + sub\n |\n module.py\n```\n\nThe problem is that conda is trying to copy `ns\\sub` to site-packages at build time. However, this directory already exists because another package -- a runtime dependency -- is already installed in site packages providing the same namespace directory layout:\n\n```\n+ ns\n |\n + sub\n |\n dependency.py\n```\n\n`conda-build` needs to be able to \"merge\" the `sub` directories coming from all namespace packages. Deleting or skipping directories if they exist will corrupt the namespace and produce incorrect results. Here is the quickest way to fix this:\n\n``` python\nfrom distutils.dir_util import copy_tree\n\ndef copy_into(src, dst):\n \"Copy all the files and directories in src to the directory dst\"\n\n if not isdir(src):\n tocopy = [src]\n else:\n tocopy = os.listdir(src)\n for afile in tocopy:\n srcname = os.path.join(src, afile)\n dstname = os.path.join(dst, afile)\n\n if os.path.isdir(srcname):\n copy_tree(srcname, dstname)\n else:\n shutil.copy2(srcname, dstname)\n```\n\ni.e. just replace `shutil.copytree()` with `distutils.dir_util.copy_tree()`.\n\n", "before_files": [{"content": "from __future__ import absolute_import, division, print_function\n\nimport fnmatch\nimport os\nimport sys\nimport shutil\nimport tarfile\nimport zipfile\nimport subprocess\nimport operator\nfrom os.path import dirname, getmtime, getsize, isdir, join\nfrom collections import defaultdict\n\nfrom conda.utils import md5_file, unix_path_to_win\nfrom conda.compat import PY3, iteritems\n\nfrom conda_build import external\n\n# Backwards compatibility import. Do not remove.\nfrom conda.install import rm_rf\nrm_rf\n\n\ndef find_recipe(path):\n \"\"\"recurse through a folder, locating meta.yaml. Raises error if more than one is found.\n\n Returns folder containing meta.yaml, to be built.\n\n If we have a base level meta.yaml and other supplemental ones, use that first\"\"\"\n results = rec_glob(path, [\"meta.yaml\", \"conda.yaml\"])\n if len(results) > 1:\n base_recipe = os.path.join(path, \"meta.yaml\")\n if base_recipe in results:\n return os.path.dirname(base_recipe)\n else:\n raise IOError(\"More than one meta.yaml files found in %s\" % path)\n elif not results:\n raise IOError(\"No meta.yaml files found in %s\" % path)\n return os.path.dirname(results[0])\n\n\ndef copy_into(src, dst):\n \"Copy all the files and directories in src to the directory dst\"\n\n if not isdir(src):\n tocopy = [src]\n else:\n tocopy = os.listdir(src)\n for afile in tocopy:\n srcname = os.path.join(src, afile)\n dstname = os.path.join(dst, afile)\n\n if os.path.isdir(srcname):\n shutil.copytree(srcname, dstname)\n else:\n shutil.copy2(srcname, dstname)\n\n\ndef relative(f, d='lib'):\n assert not f.startswith('/'), f\n assert not d.startswith('/'), d\n d = d.strip('/').split('/')\n if d == ['.']:\n d = []\n f = dirname(f).split('/')\n if f == ['']:\n f = []\n while d and f and d[0] == f[0]:\n d.pop(0)\n f.pop(0)\n return '/'.join(((['..'] * len(f)) if f else ['.']) + d)\n\n\ndef _check_call(args, **kwargs):\n try:\n subprocess.check_call(args, **kwargs)\n except subprocess.CalledProcessError:\n sys.exit('Command failed: %s' % ' '.join(args))\n\n\ndef tar_xf(tarball, dir_path, mode='r:*'):\n if tarball.lower().endswith('.tar.z'):\n uncompress = external.find_executable('uncompress')\n if not uncompress:\n uncompress = external.find_executable('gunzip')\n if not uncompress:\n sys.exit(\"\"\"\\\nuncompress (or gunzip) is required to unarchive .z source files.\n\"\"\")\n subprocess.check_call([uncompress, '-f', tarball])\n tarball = tarball[:-2]\n if not PY3 and tarball.endswith('.tar.xz'):\n unxz = external.find_executable('unxz')\n if not unxz:\n sys.exit(\"\"\"\\\nunxz is required to unarchive .xz source files.\n\"\"\")\n\n subprocess.check_call([unxz, '-f', '-k', tarball])\n tarball = tarball[:-3]\n t = tarfile.open(tarball, mode)\n t.extractall(path=dir_path)\n t.close()\n\n\ndef unzip(zip_path, dir_path):\n z = zipfile.ZipFile(zip_path)\n for name in z.namelist():\n if name.endswith('/'):\n continue\n path = join(dir_path, *name.split('/'))\n dp = dirname(path)\n if not isdir(dp):\n os.makedirs(dp)\n with open(path, 'wb') as fo:\n fo.write(z.read(name))\n z.close()\n\n\ndef file_info(path):\n return {'size': getsize(path),\n 'md5': md5_file(path),\n 'mtime': getmtime(path)}\n\n# Taken from toolz\n\n\ndef groupby(key, seq):\n \"\"\" Group a collection by a key function\n >>> names = ['Alice', 'Bob', 'Charlie', 'Dan', 'Edith', 'Frank']\n >>> groupby(len, names) # doctest: +SKIP\n {3: ['Bob', 'Dan'], 5: ['Alice', 'Edith', 'Frank'], 7: ['Charlie']}\n >>> iseven = lambda x: x % 2 == 0\n >>> groupby(iseven, [1, 2, 3, 4, 5, 6, 7, 8]) # doctest: +SKIP\n {False: [1, 3, 5, 7], True: [2, 4, 6, 8]}\n Non-callable keys imply grouping on a member.\n >>> groupby('gender', [{'name': 'Alice', 'gender': 'F'},\n ... {'name': 'Bob', 'gender': 'M'},\n ... {'name': 'Charlie', 'gender': 'M'}]) # doctest:+SKIP\n {'F': [{'gender': 'F', 'name': 'Alice'}],\n 'M': [{'gender': 'M', 'name': 'Bob'},\n {'gender': 'M', 'name': 'Charlie'}]}\n See Also:\n countby\n \"\"\"\n if not callable(key):\n key = getter(key)\n d = defaultdict(lambda: [].append)\n for item in seq:\n d[key(item)](item)\n rv = {}\n for k, v in iteritems(d):\n rv[k] = v.__self__\n return rv\n\n\ndef getter(index):\n if isinstance(index, list):\n if len(index) == 1:\n index = index[0]\n return lambda x: (x[index],)\n elif index:\n return operator.itemgetter(*index)\n else:\n return lambda x: ()\n else:\n return operator.itemgetter(index)\n\n\ndef comma_join(items):\n \"\"\"\n Like ', '.join(items) but with and\n\n Examples:\n\n >>> comma_join(['a'])\n 'a'\n >>> comma_join(['a', 'b'])\n 'a and b'\n >>> comma_join(['a', 'b', 'c])\n 'a, b, and c'\n \"\"\"\n return ' and '.join(items) if len(items) <= 2 else ', '.join(items[:-1]) + ', and ' + items[-1]\n\n\ndef safe_print_unicode(*args, **kwargs):\n \"\"\"\n prints unicode strings to stdout using configurable `errors` handler for\n encoding errors\n\n :param args: unicode strings to print to stdout\n :param sep: separator (defaults to ' ')\n :param end: ending character (defaults to '\\n')\n :param errors: error handler for encoding errors (defaults to 'replace')\n \"\"\"\n sep = kwargs.pop('sep', u' ')\n end = kwargs.pop('end', u'\\n')\n errors = kwargs.pop('errors', 'replace')\n if PY3:\n func = sys.stdout.buffer.write\n else:\n func = sys.stdout.write\n line = sep.join(args) + end\n encoding = sys.stdout.encoding or 'utf8'\n func(line.encode(encoding, errors))\n\n\ndef rec_glob(path, patterns):\n result = []\n for d_f in os.walk(path):\n m = []\n for pattern in patterns:\n m.extend(fnmatch.filter(d_f[2], pattern))\n if m:\n result.extend([os.path.join(d_f[0], f) for f in m])\n return result\n\n\ndef convert_unix_path_to_win(path):\n if external.find_executable('cygpath'):\n cmd = \"cygpath -w {0}\".format(path)\n if PY3:\n path = subprocess.getoutput(cmd)\n else:\n path = subprocess.check_output(cmd.split()).rstrip().rstrip(\"\\\\\")\n\n else:\n path = unix_path_to_win(path)\n return path\n", "path": "conda_build/utils.py"}]} | 3,813 | 374 |
gh_patches_debug_19453 | rasdani/github-patches | git_diff | psf__black-2343 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bad formatting of error messages about EOF in multi-line statements
**Describe the bug**
"EOF in multi-line statement" error is shown to the user as the raw tuple it was returned as, rather than in a nicely formatted message.
**To Reproduce**
For example:
1. Take this (invalid) file:
```py
print(
```
2. Run _Black_ on it with no arguments
3. See a message with the EOF error being shown as a raw tuple representation:
```
error: cannot format test_black.py: ('EOF in multi-line statement', (2, 0))
Oh no! 💥 💔 💥
1 file failed to reformat.
```
**Expected behavior**
A bit more nicely formatted error message.
**Environment (please complete the following information):**
- Version: <!-- e.g. [main] -->
- OS and Python version: <!-- e.g. [Linux/Python 3.7.4rc1] -->
**Does this bug also happen on main?**
Yes.
**Additional context**
For comparison, here's how I'm assuming the error should look like:
```
error: cannot format test_black.py: Cannot parse: 1:7: print([)
Oh no! 💥 💔 💥
1 file failed to reformat.
```
which is what you get in output when you try to format:
```py
print([)
```
</issue>
<code>
[start of src/black/parsing.py]
1 """
2 Parse Python code and perform AST validation.
3 """
4 import ast
5 import platform
6 import sys
7 from typing import Any, Iterable, Iterator, List, Set, Tuple, Type, Union
8
9 if sys.version_info < (3, 8):
10 from typing_extensions import Final
11 else:
12 from typing import Final
13
14 # lib2to3 fork
15 from blib2to3.pytree import Node, Leaf
16 from blib2to3 import pygram
17 from blib2to3.pgen2 import driver
18 from blib2to3.pgen2.grammar import Grammar
19 from blib2to3.pgen2.parse import ParseError
20
21 from black.mode import TargetVersion, Feature, supports_feature
22 from black.nodes import syms
23
24 ast3: Any
25 ast27: Any
26
27 _IS_PYPY = platform.python_implementation() == "PyPy"
28
29 try:
30 from typed_ast import ast3, ast27
31 except ImportError:
32 # Either our python version is too low, or we're on pypy
33 if sys.version_info < (3, 7) or (sys.version_info < (3, 8) and not _IS_PYPY):
34 print(
35 "The typed_ast package is required but not installed.\n"
36 "You can upgrade to Python 3.8+ or install typed_ast with\n"
37 "`python3 -m pip install typed-ast`.",
38 file=sys.stderr,
39 )
40 sys.exit(1)
41 else:
42 ast3 = ast27 = ast
43
44
45 class InvalidInput(ValueError):
46 """Raised when input source code fails all parse attempts."""
47
48
49 def get_grammars(target_versions: Set[TargetVersion]) -> List[Grammar]:
50 if not target_versions:
51 # No target_version specified, so try all grammars.
52 return [
53 # Python 3.7+
54 pygram.python_grammar_no_print_statement_no_exec_statement_async_keywords,
55 # Python 3.0-3.6
56 pygram.python_grammar_no_print_statement_no_exec_statement,
57 # Python 2.7 with future print_function import
58 pygram.python_grammar_no_print_statement,
59 # Python 2.7
60 pygram.python_grammar,
61 ]
62
63 if all(version.is_python2() for version in target_versions):
64 # Python 2-only code, so try Python 2 grammars.
65 return [
66 # Python 2.7 with future print_function import
67 pygram.python_grammar_no_print_statement,
68 # Python 2.7
69 pygram.python_grammar,
70 ]
71
72 # Python 3-compatible code, so only try Python 3 grammar.
73 grammars = []
74 if supports_feature(target_versions, Feature.PATTERN_MATCHING):
75 # Python 3.10+
76 grammars.append(pygram.python_grammar_soft_keywords)
77 # If we have to parse both, try to parse async as a keyword first
78 if not supports_feature(
79 target_versions, Feature.ASYNC_IDENTIFIERS
80 ) and not supports_feature(target_versions, Feature.PATTERN_MATCHING):
81 # Python 3.7-3.9
82 grammars.append(
83 pygram.python_grammar_no_print_statement_no_exec_statement_async_keywords
84 )
85 if not supports_feature(target_versions, Feature.ASYNC_KEYWORDS):
86 # Python 3.0-3.6
87 grammars.append(pygram.python_grammar_no_print_statement_no_exec_statement)
88 # At least one of the above branches must have been taken, because every Python
89 # version has exactly one of the two 'ASYNC_*' flags
90 return grammars
91
92
93 def lib2to3_parse(src_txt: str, target_versions: Iterable[TargetVersion] = ()) -> Node:
94 """Given a string with source, return the lib2to3 Node."""
95 if not src_txt.endswith("\n"):
96 src_txt += "\n"
97
98 for grammar in get_grammars(set(target_versions)):
99 drv = driver.Driver(grammar)
100 try:
101 result = drv.parse_string(src_txt, True)
102 break
103
104 except ParseError as pe:
105 lineno, column = pe.context[1]
106 lines = src_txt.splitlines()
107 try:
108 faulty_line = lines[lineno - 1]
109 except IndexError:
110 faulty_line = "<line number missing in source>"
111 exc = InvalidInput(f"Cannot parse: {lineno}:{column}: {faulty_line}")
112 else:
113 raise exc from None
114
115 if isinstance(result, Leaf):
116 result = Node(syms.file_input, [result])
117 return result
118
119
120 def lib2to3_unparse(node: Node) -> str:
121 """Given a lib2to3 node, return its string representation."""
122 code = str(node)
123 return code
124
125
126 def parse_single_version(
127 src: str, version: Tuple[int, int]
128 ) -> Union[ast.AST, ast3.AST, ast27.AST]:
129 filename = "<unknown>"
130 # typed_ast is needed because of feature version limitations in the builtin ast
131 if sys.version_info >= (3, 8) and version >= (3,):
132 return ast.parse(src, filename, feature_version=version)
133 elif version >= (3,):
134 if _IS_PYPY:
135 return ast3.parse(src, filename)
136 else:
137 return ast3.parse(src, filename, feature_version=version[1])
138 elif version == (2, 7):
139 return ast27.parse(src)
140 raise AssertionError("INTERNAL ERROR: Tried parsing unsupported Python version!")
141
142
143 def parse_ast(src: str) -> Union[ast.AST, ast3.AST, ast27.AST]:
144 # TODO: support Python 4+ ;)
145 versions = [(3, minor) for minor in range(3, sys.version_info[1] + 1)]
146
147 if ast27.__name__ != "ast":
148 versions.append((2, 7))
149
150 first_error = ""
151 for version in sorted(versions, reverse=True):
152 try:
153 return parse_single_version(src, version)
154 except SyntaxError as e:
155 if not first_error:
156 first_error = str(e)
157
158 raise SyntaxError(first_error)
159
160
161 ast3_AST: Final[Type[ast3.AST]] = ast3.AST
162 ast27_AST: Final[Type[ast27.AST]] = ast27.AST
163
164
165 def stringify_ast(
166 node: Union[ast.AST, ast3.AST, ast27.AST], depth: int = 0
167 ) -> Iterator[str]:
168 """Simple visitor generating strings to compare ASTs by content."""
169
170 node = fixup_ast_constants(node)
171
172 yield f"{' ' * depth}{node.__class__.__name__}("
173
174 type_ignore_classes: Tuple[Type[Any], ...]
175 for field in sorted(node._fields): # noqa: F402
176 # TypeIgnore will not be present using pypy < 3.8, so need for this
177 if not (_IS_PYPY and sys.version_info < (3, 8)):
178 # TypeIgnore has only one field 'lineno' which breaks this comparison
179 type_ignore_classes = (ast3.TypeIgnore, ast27.TypeIgnore)
180 if sys.version_info >= (3, 8):
181 type_ignore_classes += (ast.TypeIgnore,)
182 if isinstance(node, type_ignore_classes):
183 break
184
185 try:
186 value = getattr(node, field)
187 except AttributeError:
188 continue
189
190 yield f"{' ' * (depth+1)}{field}="
191
192 if isinstance(value, list):
193 for item in value:
194 # Ignore nested tuples within del statements, because we may insert
195 # parentheses and they change the AST.
196 if (
197 field == "targets"
198 and isinstance(node, (ast.Delete, ast3.Delete, ast27.Delete))
199 and isinstance(item, (ast.Tuple, ast3.Tuple, ast27.Tuple))
200 ):
201 for item in item.elts:
202 yield from stringify_ast(item, depth + 2)
203
204 elif isinstance(item, (ast.AST, ast3.AST, ast27.AST)):
205 yield from stringify_ast(item, depth + 2)
206
207 # Note that we are referencing the typed-ast ASTs via global variables and not
208 # direct module attribute accesses because that breaks mypyc. It's probably
209 # something to do with the ast3 / ast27 variables being marked as Any leading
210 # mypy to think this branch is always taken, leaving the rest of the code
211 # unanalyzed. Tighting up the types for the typed-ast AST types avoids the
212 # mypyc crash.
213 elif isinstance(value, (ast.AST, ast3_AST, ast27_AST)):
214 yield from stringify_ast(value, depth + 2)
215
216 else:
217 # Constant strings may be indented across newlines, if they are
218 # docstrings; fold spaces after newlines when comparing. Similarly,
219 # trailing and leading space may be removed.
220 # Note that when formatting Python 2 code, at least with Windows
221 # line-endings, docstrings can end up here as bytes instead of
222 # str so make sure that we handle both cases.
223 if (
224 isinstance(node, ast.Constant)
225 and field == "value"
226 and isinstance(value, (str, bytes))
227 ):
228 lineend = "\n" if isinstance(value, str) else b"\n"
229 # To normalize, we strip any leading and trailing space from
230 # each line...
231 stripped = [line.strip() for line in value.splitlines()]
232 normalized = lineend.join(stripped) # type: ignore[attr-defined]
233 # ...and remove any blank lines at the beginning and end of
234 # the whole string
235 normalized = normalized.strip()
236 else:
237 normalized = value
238 yield f"{' ' * (depth+2)}{normalized!r}, # {value.__class__.__name__}"
239
240 yield f"{' ' * depth}) # /{node.__class__.__name__}"
241
242
243 def fixup_ast_constants(
244 node: Union[ast.AST, ast3.AST, ast27.AST]
245 ) -> Union[ast.AST, ast3.AST, ast27.AST]:
246 """Map ast nodes deprecated in 3.8 to Constant."""
247 if isinstance(node, (ast.Str, ast3.Str, ast27.Str, ast.Bytes, ast3.Bytes)):
248 return ast.Constant(value=node.s)
249
250 if isinstance(node, (ast.Num, ast3.Num, ast27.Num)):
251 return ast.Constant(value=node.n)
252
253 if isinstance(node, (ast.NameConstant, ast3.NameConstant)):
254 return ast.Constant(value=node.value)
255
256 return node
257
[end of src/black/parsing.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/src/black/parsing.py b/src/black/parsing.py
--- a/src/black/parsing.py
+++ b/src/black/parsing.py
@@ -17,6 +17,7 @@
from blib2to3.pgen2 import driver
from blib2to3.pgen2.grammar import Grammar
from blib2to3.pgen2.parse import ParseError
+from blib2to3.pgen2.tokenize import TokenError
from black.mode import TargetVersion, Feature, supports_feature
from black.nodes import syms
@@ -109,6 +110,12 @@
except IndexError:
faulty_line = "<line number missing in source>"
exc = InvalidInput(f"Cannot parse: {lineno}:{column}: {faulty_line}")
+
+ except TokenError as te:
+ # In edge cases these are raised; and typically don't have a "faulty_line".
+ lineno, column = te.args[1]
+ exc = InvalidInput(f"Cannot parse: {lineno}:{column}: {te.args[0]}")
+
else:
raise exc from None
| {"golden_diff": "diff --git a/src/black/parsing.py b/src/black/parsing.py\n--- a/src/black/parsing.py\n+++ b/src/black/parsing.py\n@@ -17,6 +17,7 @@\n from blib2to3.pgen2 import driver\n from blib2to3.pgen2.grammar import Grammar\n from blib2to3.pgen2.parse import ParseError\n+from blib2to3.pgen2.tokenize import TokenError\n \n from black.mode import TargetVersion, Feature, supports_feature\n from black.nodes import syms\n@@ -109,6 +110,12 @@\n except IndexError:\n faulty_line = \"<line number missing in source>\"\n exc = InvalidInput(f\"Cannot parse: {lineno}:{column}: {faulty_line}\")\n+\n+ except TokenError as te:\n+ # In edge cases these are raised; and typically don't have a \"faulty_line\".\n+ lineno, column = te.args[1]\n+ exc = InvalidInput(f\"Cannot parse: {lineno}:{column}: {te.args[0]}\")\n+\n else:\n raise exc from None\n", "issue": "Bad formatting of error messages about EOF in multi-line statements\n**Describe the bug**\r\n\r\n\"EOF in multi-line statement\" error is shown to the user as the raw tuple it was returned as, rather than in a nicely formatted message.\r\n\r\n**To Reproduce**\r\n\r\nFor example:\r\n1. Take this (invalid) file:\r\n```py\r\nprint(\r\n\r\n```\r\n2. Run _Black_ on it with no arguments\r\n3. See a message with the EOF error being shown as a raw tuple representation:\r\n```\r\nerror: cannot format test_black.py: ('EOF in multi-line statement', (2, 0))\r\nOh no! \ud83d\udca5 \ud83d\udc94 \ud83d\udca5\r\n1 file failed to reformat.\r\n```\r\n\r\n**Expected behavior**\r\n\r\nA bit more nicely formatted error message.\r\n\r\n**Environment (please complete the following information):**\r\n\r\n- Version: <!-- e.g. [main] -->\r\n- OS and Python version: <!-- e.g. [Linux/Python 3.7.4rc1] -->\r\n\r\n**Does this bug also happen on main?**\r\n\r\nYes.\r\n\r\n**Additional context**\r\n\r\nFor comparison, here's how I'm assuming the error should look like:\r\n```\r\nerror: cannot format test_black.py: Cannot parse: 1:7: print([)\r\nOh no! \ud83d\udca5 \ud83d\udc94 \ud83d\udca5\r\n1 file failed to reformat.\r\n```\r\nwhich is what you get in output when you try to format:\r\n```py\r\nprint([)\r\n```\r\n\n", "before_files": [{"content": "\"\"\"\nParse Python code and perform AST validation.\n\"\"\"\nimport ast\nimport platform\nimport sys\nfrom typing import Any, Iterable, Iterator, List, Set, Tuple, Type, Union\n\nif sys.version_info < (3, 8):\n from typing_extensions import Final\nelse:\n from typing import Final\n\n# lib2to3 fork\nfrom blib2to3.pytree import Node, Leaf\nfrom blib2to3 import pygram\nfrom blib2to3.pgen2 import driver\nfrom blib2to3.pgen2.grammar import Grammar\nfrom blib2to3.pgen2.parse import ParseError\n\nfrom black.mode import TargetVersion, Feature, supports_feature\nfrom black.nodes import syms\n\nast3: Any\nast27: Any\n\n_IS_PYPY = platform.python_implementation() == \"PyPy\"\n\ntry:\n from typed_ast import ast3, ast27\nexcept ImportError:\n # Either our python version is too low, or we're on pypy\n if sys.version_info < (3, 7) or (sys.version_info < (3, 8) and not _IS_PYPY):\n print(\n \"The typed_ast package is required but not installed.\\n\"\n \"You can upgrade to Python 3.8+ or install typed_ast with\\n\"\n \"`python3 -m pip install typed-ast`.\",\n file=sys.stderr,\n )\n sys.exit(1)\n else:\n ast3 = ast27 = ast\n\n\nclass InvalidInput(ValueError):\n \"\"\"Raised when input source code fails all parse attempts.\"\"\"\n\n\ndef get_grammars(target_versions: Set[TargetVersion]) -> List[Grammar]:\n if not target_versions:\n # No target_version specified, so try all grammars.\n return [\n # Python 3.7+\n pygram.python_grammar_no_print_statement_no_exec_statement_async_keywords,\n # Python 3.0-3.6\n pygram.python_grammar_no_print_statement_no_exec_statement,\n # Python 2.7 with future print_function import\n pygram.python_grammar_no_print_statement,\n # Python 2.7\n pygram.python_grammar,\n ]\n\n if all(version.is_python2() for version in target_versions):\n # Python 2-only code, so try Python 2 grammars.\n return [\n # Python 2.7 with future print_function import\n pygram.python_grammar_no_print_statement,\n # Python 2.7\n pygram.python_grammar,\n ]\n\n # Python 3-compatible code, so only try Python 3 grammar.\n grammars = []\n if supports_feature(target_versions, Feature.PATTERN_MATCHING):\n # Python 3.10+\n grammars.append(pygram.python_grammar_soft_keywords)\n # If we have to parse both, try to parse async as a keyword first\n if not supports_feature(\n target_versions, Feature.ASYNC_IDENTIFIERS\n ) and not supports_feature(target_versions, Feature.PATTERN_MATCHING):\n # Python 3.7-3.9\n grammars.append(\n pygram.python_grammar_no_print_statement_no_exec_statement_async_keywords\n )\n if not supports_feature(target_versions, Feature.ASYNC_KEYWORDS):\n # Python 3.0-3.6\n grammars.append(pygram.python_grammar_no_print_statement_no_exec_statement)\n # At least one of the above branches must have been taken, because every Python\n # version has exactly one of the two 'ASYNC_*' flags\n return grammars\n\n\ndef lib2to3_parse(src_txt: str, target_versions: Iterable[TargetVersion] = ()) -> Node:\n \"\"\"Given a string with source, return the lib2to3 Node.\"\"\"\n if not src_txt.endswith(\"\\n\"):\n src_txt += \"\\n\"\n\n for grammar in get_grammars(set(target_versions)):\n drv = driver.Driver(grammar)\n try:\n result = drv.parse_string(src_txt, True)\n break\n\n except ParseError as pe:\n lineno, column = pe.context[1]\n lines = src_txt.splitlines()\n try:\n faulty_line = lines[lineno - 1]\n except IndexError:\n faulty_line = \"<line number missing in source>\"\n exc = InvalidInput(f\"Cannot parse: {lineno}:{column}: {faulty_line}\")\n else:\n raise exc from None\n\n if isinstance(result, Leaf):\n result = Node(syms.file_input, [result])\n return result\n\n\ndef lib2to3_unparse(node: Node) -> str:\n \"\"\"Given a lib2to3 node, return its string representation.\"\"\"\n code = str(node)\n return code\n\n\ndef parse_single_version(\n src: str, version: Tuple[int, int]\n) -> Union[ast.AST, ast3.AST, ast27.AST]:\n filename = \"<unknown>\"\n # typed_ast is needed because of feature version limitations in the builtin ast\n if sys.version_info >= (3, 8) and version >= (3,):\n return ast.parse(src, filename, feature_version=version)\n elif version >= (3,):\n if _IS_PYPY:\n return ast3.parse(src, filename)\n else:\n return ast3.parse(src, filename, feature_version=version[1])\n elif version == (2, 7):\n return ast27.parse(src)\n raise AssertionError(\"INTERNAL ERROR: Tried parsing unsupported Python version!\")\n\n\ndef parse_ast(src: str) -> Union[ast.AST, ast3.AST, ast27.AST]:\n # TODO: support Python 4+ ;)\n versions = [(3, minor) for minor in range(3, sys.version_info[1] + 1)]\n\n if ast27.__name__ != \"ast\":\n versions.append((2, 7))\n\n first_error = \"\"\n for version in sorted(versions, reverse=True):\n try:\n return parse_single_version(src, version)\n except SyntaxError as e:\n if not first_error:\n first_error = str(e)\n\n raise SyntaxError(first_error)\n\n\nast3_AST: Final[Type[ast3.AST]] = ast3.AST\nast27_AST: Final[Type[ast27.AST]] = ast27.AST\n\n\ndef stringify_ast(\n node: Union[ast.AST, ast3.AST, ast27.AST], depth: int = 0\n) -> Iterator[str]:\n \"\"\"Simple visitor generating strings to compare ASTs by content.\"\"\"\n\n node = fixup_ast_constants(node)\n\n yield f\"{' ' * depth}{node.__class__.__name__}(\"\n\n type_ignore_classes: Tuple[Type[Any], ...]\n for field in sorted(node._fields): # noqa: F402\n # TypeIgnore will not be present using pypy < 3.8, so need for this\n if not (_IS_PYPY and sys.version_info < (3, 8)):\n # TypeIgnore has only one field 'lineno' which breaks this comparison\n type_ignore_classes = (ast3.TypeIgnore, ast27.TypeIgnore)\n if sys.version_info >= (3, 8):\n type_ignore_classes += (ast.TypeIgnore,)\n if isinstance(node, type_ignore_classes):\n break\n\n try:\n value = getattr(node, field)\n except AttributeError:\n continue\n\n yield f\"{' ' * (depth+1)}{field}=\"\n\n if isinstance(value, list):\n for item in value:\n # Ignore nested tuples within del statements, because we may insert\n # parentheses and they change the AST.\n if (\n field == \"targets\"\n and isinstance(node, (ast.Delete, ast3.Delete, ast27.Delete))\n and isinstance(item, (ast.Tuple, ast3.Tuple, ast27.Tuple))\n ):\n for item in item.elts:\n yield from stringify_ast(item, depth + 2)\n\n elif isinstance(item, (ast.AST, ast3.AST, ast27.AST)):\n yield from stringify_ast(item, depth + 2)\n\n # Note that we are referencing the typed-ast ASTs via global variables and not\n # direct module attribute accesses because that breaks mypyc. It's probably\n # something to do with the ast3 / ast27 variables being marked as Any leading\n # mypy to think this branch is always taken, leaving the rest of the code\n # unanalyzed. Tighting up the types for the typed-ast AST types avoids the\n # mypyc crash.\n elif isinstance(value, (ast.AST, ast3_AST, ast27_AST)):\n yield from stringify_ast(value, depth + 2)\n\n else:\n # Constant strings may be indented across newlines, if they are\n # docstrings; fold spaces after newlines when comparing. Similarly,\n # trailing and leading space may be removed.\n # Note that when formatting Python 2 code, at least with Windows\n # line-endings, docstrings can end up here as bytes instead of\n # str so make sure that we handle both cases.\n if (\n isinstance(node, ast.Constant)\n and field == \"value\"\n and isinstance(value, (str, bytes))\n ):\n lineend = \"\\n\" if isinstance(value, str) else b\"\\n\"\n # To normalize, we strip any leading and trailing space from\n # each line...\n stripped = [line.strip() for line in value.splitlines()]\n normalized = lineend.join(stripped) # type: ignore[attr-defined]\n # ...and remove any blank lines at the beginning and end of\n # the whole string\n normalized = normalized.strip()\n else:\n normalized = value\n yield f\"{' ' * (depth+2)}{normalized!r}, # {value.__class__.__name__}\"\n\n yield f\"{' ' * depth}) # /{node.__class__.__name__}\"\n\n\ndef fixup_ast_constants(\n node: Union[ast.AST, ast3.AST, ast27.AST]\n) -> Union[ast.AST, ast3.AST, ast27.AST]:\n \"\"\"Map ast nodes deprecated in 3.8 to Constant.\"\"\"\n if isinstance(node, (ast.Str, ast3.Str, ast27.Str, ast.Bytes, ast3.Bytes)):\n return ast.Constant(value=node.s)\n\n if isinstance(node, (ast.Num, ast3.Num, ast27.Num)):\n return ast.Constant(value=node.n)\n\n if isinstance(node, (ast.NameConstant, ast3.NameConstant)):\n return ast.Constant(value=node.value)\n\n return node\n", "path": "src/black/parsing.py"}]} | 3,819 | 242 |
gh_patches_debug_8332 | rasdani/github-patches | git_diff | sopel-irc__sopel-1380 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
.title command should say an error if no title is found
Example: http://zimage.com/~ant/temp/notitle.html
Sopel should say there was no web page title found.
</issue>
<code>
[start of sopel/modules/url.py]
1 # coding=utf-8
2 """URL title module"""
3 # Copyright 2010-2011, Michael Yanovich, yanovich.net, Kenneth Sham
4 # Copyright 2012-2013 Elsie Powell
5 # Copyright 2013 Lior Ramati ([email protected])
6 # Copyright © 2014 Elad Alfassa <[email protected]>
7 # Licensed under the Eiffel Forum License 2.
8 from __future__ import unicode_literals, absolute_import, print_function, division
9
10 import re
11 from sopel import web, tools, __version__
12 from sopel.module import commands, rule, example
13 from sopel.config.types import ValidatedAttribute, ListAttribute, StaticSection
14
15 import requests
16
17 USER_AGENT = 'Sopel/{} (https://sopel.chat)'.format(__version__)
18 default_headers = {'User-Agent': USER_AGENT}
19 url_finder = None
20 # These are used to clean up the title tag before actually parsing it. Not the
21 # world's best way to do this, but it'll do for now.
22 title_tag_data = re.compile('<(/?)title( [^>]+)?>', re.IGNORECASE)
23 quoted_title = re.compile('[\'"]<title>[\'"]', re.IGNORECASE)
24 # This is another regex that presumably does something important.
25 re_dcc = re.compile(r'(?i)dcc\ssend')
26 # This sets the maximum number of bytes that should be read in order to find
27 # the title. We don't want it too high, or a link to a big file/stream will
28 # just keep downloading until there's no more memory. 640k ought to be enough
29 # for anybody.
30 max_bytes = 655360
31
32
33 class UrlSection(StaticSection):
34 # TODO some validation rules maybe?
35 exclude = ListAttribute('exclude')
36 exclusion_char = ValidatedAttribute('exclusion_char', default='!')
37
38
39 def configure(config):
40 config.define_section('url', UrlSection)
41 config.url.configure_setting(
42 'exclude',
43 'Enter regular expressions for each URL you would like to exclude.'
44 )
45 config.url.configure_setting(
46 'exclusion_char',
47 'Enter a character which can be prefixed to suppress URL titling'
48 )
49
50
51 def setup(bot):
52 global url_finder
53
54 bot.config.define_section('url', UrlSection)
55
56 if bot.config.url.exclude:
57 regexes = [re.compile(s) for s in bot.config.url.exclude]
58 else:
59 regexes = []
60
61 # We're keeping these in their own list, rather than putting then in the
62 # callbacks list because 1, it's easier to deal with modules that are still
63 # using this list, and not the newer callbacks list and 2, having a lambda
64 # just to pass is kinda ugly.
65 if not bot.memory.contains('url_exclude'):
66 bot.memory['url_exclude'] = regexes
67 else:
68 exclude = bot.memory['url_exclude']
69 if regexes:
70 exclude.extend(regexes)
71 bot.memory['url_exclude'] = exclude
72
73 # Ensure that url_callbacks and last_seen_url are in memory
74 if not bot.memory.contains('url_callbacks'):
75 bot.memory['url_callbacks'] = tools.SopelMemory()
76 if not bot.memory.contains('last_seen_url'):
77 bot.memory['last_seen_url'] = tools.SopelMemory()
78
79 url_finder = re.compile(r'(?u)(%s?(?:http|https|ftp)(?:://\S+))' %
80 (bot.config.url.exclusion_char), re.IGNORECASE)
81
82
83 @commands('title')
84 @example('.title http://google.com', '[ Google ] - google.com')
85 def title_command(bot, trigger):
86 """
87 Show the title or URL information for the given URL, or the last URL seen
88 in this channel.
89 """
90 if not trigger.group(2):
91 if trigger.sender not in bot.memory['last_seen_url']:
92 return
93 matched = check_callbacks(bot, trigger,
94 bot.memory['last_seen_url'][trigger.sender],
95 True)
96 if matched:
97 return
98 else:
99 urls = [bot.memory['last_seen_url'][trigger.sender]]
100 else:
101 urls = re.findall(url_finder, trigger)
102
103 results = process_urls(bot, trigger, urls)
104 for title, domain in results[:4]:
105 bot.reply('[ %s ] - %s' % (title, domain))
106
107
108 @rule('(?u).*(https?://\S+).*')
109 def title_auto(bot, trigger):
110 """
111 Automatically show titles for URLs. For shortened URLs/redirects, find
112 where the URL redirects to and show the title for that (or call a function
113 from another module to give more information).
114 """
115 if re.match(bot.config.core.prefix + 'title', trigger):
116 return
117
118 # Avoid fetching known malicious links
119 if 'safety_cache' in bot.memory and trigger in bot.memory['safety_cache']:
120 if bot.memory['safety_cache'][trigger]['positives'] > 1:
121 return
122
123 urls = re.findall(url_finder, trigger)
124 if len(urls) == 0:
125 return
126
127 results = process_urls(bot, trigger, urls)
128 bot.memory['last_seen_url'][trigger.sender] = urls[-1]
129
130 for title, domain in results[:4]:
131 message = '[ %s ] - %s' % (title, domain)
132 # Guard against responding to other instances of this bot.
133 if message != trigger:
134 bot.say(message)
135
136
137 def process_urls(bot, trigger, urls):
138 """
139 For each URL in the list, ensure that it isn't handled by another module.
140 If not, find where it redirects to, if anywhere. If that redirected URL
141 should be handled by another module, dispatch the callback for it.
142 Return a list of (title, hostname) tuples for each URL which is not handled by
143 another module.
144 """
145
146 results = []
147 for url in urls:
148 if not url.startswith(bot.config.url.exclusion_char):
149 # Magic stuff to account for international domain names
150 try:
151 url = web.iri_to_uri(url)
152 except Exception: # TODO: Be specific
153 pass
154 # First, check that the URL we got doesn't match
155 matched = check_callbacks(bot, trigger, url, False)
156 if matched:
157 continue
158 # Finally, actually show the URL
159 title = find_title(url, verify=bot.config.core.verify_ssl)
160 if title:
161 results.append((title, get_hostname(url)))
162 return results
163
164
165 def check_callbacks(bot, trigger, url, run=True):
166 """
167 Check the given URL against the callbacks list. If it matches, and ``run``
168 is given as ``True``, run the callback function, otherwise pass. Returns
169 ``True`` if the url matched anything in the callbacks list.
170 """
171 # Check if it matches the exclusion list first
172 matched = any(regex.search(url) for regex in bot.memory['url_exclude'])
173 # Then, check if there's anything in the callback list
174 for regex, function in tools.iteritems(bot.memory['url_callbacks']):
175 match = regex.search(url)
176 if match:
177 # Always run ones from @url; they don't run on their own.
178 if run or hasattr(function, 'url_regex'):
179 function(bot, trigger, match)
180 matched = True
181 return matched
182
183
184 def find_title(url, verify=True):
185 """Return the title for the given URL."""
186 try:
187 response = requests.get(url, stream=True, verify=verify,
188 headers=default_headers)
189 content = b''
190 for byte in response.iter_content(chunk_size=512):
191 content += byte
192 if b'</title>' in content or len(content) > max_bytes:
193 break
194 content = content.decode('utf-8', errors='ignore')
195 # Need to close the connection because we have not read all
196 # the data
197 response.close()
198 except requests.exceptions.ConnectionError:
199 return None
200
201 # Some cleanup that I don't really grok, but was in the original, so
202 # we'll keep it (with the compiled regexes made global) for now.
203 content = title_tag_data.sub(r'<\1title>', content)
204 content = quoted_title.sub('', content)
205
206 start = content.rfind('<title>')
207 end = content.rfind('</title>')
208 if start == -1 or end == -1:
209 return
210 title = web.decode(content[start + 7:end])
211 title = title.strip()[:200]
212
213 title = ' '.join(title.split()) # cleanly remove multiple spaces
214
215 # More cryptic regex substitutions. This one looks to be myano's invention.
216 title = re_dcc.sub('', title)
217
218 return title or None
219
220
221 def get_hostname(url):
222 idx = 7
223 if url.startswith('https://'):
224 idx = 8
225 elif url.startswith('ftp://'):
226 idx = 6
227 hostname = url[idx:]
228 slash = hostname.find('/')
229 if slash != -1:
230 hostname = hostname[:slash]
231 return hostname
232
233
234 if __name__ == "__main__":
235 from sopel.test_tools import run_example_tests
236 run_example_tests(__file__)
237
[end of sopel/modules/url.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/sopel/modules/url.py b/sopel/modules/url.py
--- a/sopel/modules/url.py
+++ b/sopel/modules/url.py
@@ -104,6 +104,13 @@
for title, domain in results[:4]:
bot.reply('[ %s ] - %s' % (title, domain))
+ # Nice to have different failure messages for one-and-only requested URL
+ # failed vs. one-of-many failed.
+ if len(urls) == 1 and not results:
+ bot.reply('Sorry, fetching that title failed. Make sure the site is working.')
+ elif len(urls) > len(results):
+ bot.reply('I couldn\'t get all of the titles, but I fetched what I could!')
+
@rule('(?u).*(https?://\S+).*')
def title_auto(bot, trigger):
| {"golden_diff": "diff --git a/sopel/modules/url.py b/sopel/modules/url.py\n--- a/sopel/modules/url.py\n+++ b/sopel/modules/url.py\n@@ -104,6 +104,13 @@\n for title, domain in results[:4]:\n bot.reply('[ %s ] - %s' % (title, domain))\n \n+ # Nice to have different failure messages for one-and-only requested URL\n+ # failed vs. one-of-many failed.\n+ if len(urls) == 1 and not results:\n+ bot.reply('Sorry, fetching that title failed. Make sure the site is working.')\n+ elif len(urls) > len(results):\n+ bot.reply('I couldn\\'t get all of the titles, but I fetched what I could!')\n+\n \n @rule('(?u).*(https?://\\S+).*')\n def title_auto(bot, trigger):\n", "issue": ".title command should say an error if no title is found\nExample: http://zimage.com/~ant/temp/notitle.html\r\n\r\nSopel should say there was no web page title found.\n", "before_files": [{"content": "# coding=utf-8\n\"\"\"URL title module\"\"\"\n# Copyright 2010-2011, Michael Yanovich, yanovich.net, Kenneth Sham\n# Copyright 2012-2013 Elsie Powell\n# Copyright 2013 Lior Ramati ([email protected])\n# Copyright \u00a9 2014 Elad Alfassa <[email protected]>\n# Licensed under the Eiffel Forum License 2.\nfrom __future__ import unicode_literals, absolute_import, print_function, division\n\nimport re\nfrom sopel import web, tools, __version__\nfrom sopel.module import commands, rule, example\nfrom sopel.config.types import ValidatedAttribute, ListAttribute, StaticSection\n\nimport requests\n\nUSER_AGENT = 'Sopel/{} (https://sopel.chat)'.format(__version__)\ndefault_headers = {'User-Agent': USER_AGENT}\nurl_finder = None\n# These are used to clean up the title tag before actually parsing it. Not the\n# world's best way to do this, but it'll do for now.\ntitle_tag_data = re.compile('<(/?)title( [^>]+)?>', re.IGNORECASE)\nquoted_title = re.compile('[\\'\"]<title>[\\'\"]', re.IGNORECASE)\n# This is another regex that presumably does something important.\nre_dcc = re.compile(r'(?i)dcc\\ssend')\n# This sets the maximum number of bytes that should be read in order to find\n# the title. We don't want it too high, or a link to a big file/stream will\n# just keep downloading until there's no more memory. 640k ought to be enough\n# for anybody.\nmax_bytes = 655360\n\n\nclass UrlSection(StaticSection):\n # TODO some validation rules maybe?\n exclude = ListAttribute('exclude')\n exclusion_char = ValidatedAttribute('exclusion_char', default='!')\n\n\ndef configure(config):\n config.define_section('url', UrlSection)\n config.url.configure_setting(\n 'exclude',\n 'Enter regular expressions for each URL you would like to exclude.'\n )\n config.url.configure_setting(\n 'exclusion_char',\n 'Enter a character which can be prefixed to suppress URL titling'\n )\n\n\ndef setup(bot):\n global url_finder\n\n bot.config.define_section('url', UrlSection)\n\n if bot.config.url.exclude:\n regexes = [re.compile(s) for s in bot.config.url.exclude]\n else:\n regexes = []\n\n # We're keeping these in their own list, rather than putting then in the\n # callbacks list because 1, it's easier to deal with modules that are still\n # using this list, and not the newer callbacks list and 2, having a lambda\n # just to pass is kinda ugly.\n if not bot.memory.contains('url_exclude'):\n bot.memory['url_exclude'] = regexes\n else:\n exclude = bot.memory['url_exclude']\n if regexes:\n exclude.extend(regexes)\n bot.memory['url_exclude'] = exclude\n\n # Ensure that url_callbacks and last_seen_url are in memory\n if not bot.memory.contains('url_callbacks'):\n bot.memory['url_callbacks'] = tools.SopelMemory()\n if not bot.memory.contains('last_seen_url'):\n bot.memory['last_seen_url'] = tools.SopelMemory()\n\n url_finder = re.compile(r'(?u)(%s?(?:http|https|ftp)(?:://\\S+))' %\n (bot.config.url.exclusion_char), re.IGNORECASE)\n\n\n@commands('title')\n@example('.title http://google.com', '[ Google ] - google.com')\ndef title_command(bot, trigger):\n \"\"\"\n Show the title or URL information for the given URL, or the last URL seen\n in this channel.\n \"\"\"\n if not trigger.group(2):\n if trigger.sender not in bot.memory['last_seen_url']:\n return\n matched = check_callbacks(bot, trigger,\n bot.memory['last_seen_url'][trigger.sender],\n True)\n if matched:\n return\n else:\n urls = [bot.memory['last_seen_url'][trigger.sender]]\n else:\n urls = re.findall(url_finder, trigger)\n\n results = process_urls(bot, trigger, urls)\n for title, domain in results[:4]:\n bot.reply('[ %s ] - %s' % (title, domain))\n\n\n@rule('(?u).*(https?://\\S+).*')\ndef title_auto(bot, trigger):\n \"\"\"\n Automatically show titles for URLs. For shortened URLs/redirects, find\n where the URL redirects to and show the title for that (or call a function\n from another module to give more information).\n \"\"\"\n if re.match(bot.config.core.prefix + 'title', trigger):\n return\n\n # Avoid fetching known malicious links\n if 'safety_cache' in bot.memory and trigger in bot.memory['safety_cache']:\n if bot.memory['safety_cache'][trigger]['positives'] > 1:\n return\n\n urls = re.findall(url_finder, trigger)\n if len(urls) == 0:\n return\n\n results = process_urls(bot, trigger, urls)\n bot.memory['last_seen_url'][trigger.sender] = urls[-1]\n\n for title, domain in results[:4]:\n message = '[ %s ] - %s' % (title, domain)\n # Guard against responding to other instances of this bot.\n if message != trigger:\n bot.say(message)\n\n\ndef process_urls(bot, trigger, urls):\n \"\"\"\n For each URL in the list, ensure that it isn't handled by another module.\n If not, find where it redirects to, if anywhere. If that redirected URL\n should be handled by another module, dispatch the callback for it.\n Return a list of (title, hostname) tuples for each URL which is not handled by\n another module.\n \"\"\"\n\n results = []\n for url in urls:\n if not url.startswith(bot.config.url.exclusion_char):\n # Magic stuff to account for international domain names\n try:\n url = web.iri_to_uri(url)\n except Exception: # TODO: Be specific\n pass\n # First, check that the URL we got doesn't match\n matched = check_callbacks(bot, trigger, url, False)\n if matched:\n continue\n # Finally, actually show the URL\n title = find_title(url, verify=bot.config.core.verify_ssl)\n if title:\n results.append((title, get_hostname(url)))\n return results\n\n\ndef check_callbacks(bot, trigger, url, run=True):\n \"\"\"\n Check the given URL against the callbacks list. If it matches, and ``run``\n is given as ``True``, run the callback function, otherwise pass. Returns\n ``True`` if the url matched anything in the callbacks list.\n \"\"\"\n # Check if it matches the exclusion list first\n matched = any(regex.search(url) for regex in bot.memory['url_exclude'])\n # Then, check if there's anything in the callback list\n for regex, function in tools.iteritems(bot.memory['url_callbacks']):\n match = regex.search(url)\n if match:\n # Always run ones from @url; they don't run on their own.\n if run or hasattr(function, 'url_regex'):\n function(bot, trigger, match)\n matched = True\n return matched\n\n\ndef find_title(url, verify=True):\n \"\"\"Return the title for the given URL.\"\"\"\n try:\n response = requests.get(url, stream=True, verify=verify,\n headers=default_headers)\n content = b''\n for byte in response.iter_content(chunk_size=512):\n content += byte\n if b'</title>' in content or len(content) > max_bytes:\n break\n content = content.decode('utf-8', errors='ignore')\n # Need to close the connection because we have not read all\n # the data\n response.close()\n except requests.exceptions.ConnectionError:\n return None\n\n # Some cleanup that I don't really grok, but was in the original, so\n # we'll keep it (with the compiled regexes made global) for now.\n content = title_tag_data.sub(r'<\\1title>', content)\n content = quoted_title.sub('', content)\n\n start = content.rfind('<title>')\n end = content.rfind('</title>')\n if start == -1 or end == -1:\n return\n title = web.decode(content[start + 7:end])\n title = title.strip()[:200]\n\n title = ' '.join(title.split()) # cleanly remove multiple spaces\n\n # More cryptic regex substitutions. This one looks to be myano's invention.\n title = re_dcc.sub('', title)\n\n return title or None\n\n\ndef get_hostname(url):\n idx = 7\n if url.startswith('https://'):\n idx = 8\n elif url.startswith('ftp://'):\n idx = 6\n hostname = url[idx:]\n slash = hostname.find('/')\n if slash != -1:\n hostname = hostname[:slash]\n return hostname\n\n\nif __name__ == \"__main__\":\n from sopel.test_tools import run_example_tests\n run_example_tests(__file__)\n", "path": "sopel/modules/url.py"}]} | 3,187 | 194 |
gh_patches_debug_5891 | rasdani/github-patches | git_diff | sublimelsp__LSP-1732 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`os.path.relpath` may throw an exception on Windows.
`os.path.relpath` may throw an exception on Windows.
```
Traceback (most recent call last):
File "C:\tools\sublime\Data\Installed Packages\LSP.sublime-package\plugin/references.py", line 55, in
File "C:\tools\sublime\Data\Installed Packages\LSP.sublime-package\plugin/references.py", line 62, in _handle_response
File "C:\tools\sublime\Data\Installed Packages\LSP.sublime-package\plugin/references.py", line 85, in _show_references_in_output_panel
File "C:\tools\sublime\Data\Installed Packages\LSP.sublime-package\plugin/references.py", line 107, in _get_relative_path
File "./python3.3/ntpath.py", line 564, in relpath
ValueError: path is on mount 'C:', start on mount '\myserver\myshare'
```
</issue>
<code>
[start of plugin/references.py]
1 from .core.panels import ensure_panel
2 from .core.protocol import Location
3 from .core.protocol import Point
4 from .core.protocol import Request
5 from .core.registry import get_position
6 from .core.registry import LspTextCommand
7 from .core.sessions import Session
8 from .core.settings import PLUGIN_NAME
9 from .core.settings import userprefs
10 from .core.types import ClientConfig
11 from .core.types import PANEL_FILE_REGEX
12 from .core.types import PANEL_LINE_REGEX
13 from .core.typing import Dict, List, Optional, Tuple
14 from .core.views import get_line
15 from .core.views import get_uri_and_position_from_location
16 from .core.views import text_document_position_params
17 from .locationpicker import LocationPicker
18 import functools
19 import linecache
20 import os
21 import sublime
22
23
24 def ensure_references_panel(window: sublime.Window) -> Optional[sublime.View]:
25 return ensure_panel(window, "references", PANEL_FILE_REGEX, PANEL_LINE_REGEX,
26 "Packages/" + PLUGIN_NAME + "/Syntaxes/References.sublime-syntax")
27
28
29 class LspSymbolReferencesCommand(LspTextCommand):
30
31 capability = 'referencesProvider'
32
33 def __init__(self, view: sublime.View) -> None:
34 super().__init__(view)
35 self._picker = None # type: Optional[LocationPicker]
36
37 def run(self, _: sublime.Edit, event: Optional[dict] = None, point: Optional[int] = None) -> None:
38 session = self.best_session(self.capability)
39 file_path = self.view.file_name()
40 pos = get_position(self.view, event, point)
41 if session and file_path and pos is not None:
42 params = text_document_position_params(self.view, pos)
43 params['context'] = {"includeDeclaration": False}
44 request = Request("textDocument/references", params, self.view, progress=True)
45 session.send_request(
46 request,
47 functools.partial(
48 self._handle_response_async,
49 self.view.substr(self.view.word(pos)),
50 session
51 )
52 )
53
54 def _handle_response_async(self, word: str, session: Session, response: Optional[List[Location]]) -> None:
55 sublime.set_timeout(lambda: self._handle_response(word, session, response))
56
57 def _handle_response(self, word: str, session: Session, response: Optional[List[Location]]) -> None:
58 if response:
59 if userprefs().show_references_in_quick_panel:
60 self._show_references_in_quick_panel(session, response)
61 else:
62 self._show_references_in_output_panel(word, session, response)
63 else:
64 window = self.view.window()
65 if window:
66 window.status_message("No references found")
67
68 def _show_references_in_quick_panel(self, session: Session, locations: List[Location]) -> None:
69 self.view.run_command("add_jump_record", {"selection": [(r.a, r.b) for r in self.view.sel()]})
70 LocationPicker(self.view, session, locations, side_by_side=False)
71
72 def _show_references_in_output_panel(self, word: str, session: Session, locations: List[Location]) -> None:
73 window = session.window
74 panel = ensure_references_panel(window)
75 if not panel:
76 return
77 manager = session.manager()
78 if not manager:
79 return
80 base_dir = manager.get_project_path(self.view.file_name() or "")
81 to_render = [] # type: List[str]
82 references_count = 0
83 references_by_file = _group_locations_by_uri(window, session.config, locations)
84 for file, references in references_by_file.items():
85 to_render.append('{}:'.format(_get_relative_path(base_dir, file)))
86 for reference in references:
87 references_count += 1
88 point, line = reference
89 to_render.append('{:>5}:{:<4} {}'.format(point.row + 1, point.col + 1, line))
90 to_render.append("") # add spacing between filenames
91 characters = "\n".join(to_render)
92 panel.settings().set("result_base_dir", base_dir)
93 panel.run_command("lsp_clear_panel")
94 window.run_command("show_panel", {"panel": "output.references"})
95 panel.run_command('append', {
96 'characters': "{} references for '{}'\n\n{}".format(references_count, word, characters),
97 'force': True,
98 'scroll_to_end': False
99 })
100 # highlight all word occurrences
101 regions = panel.find_all(r"\b{}\b".format(word))
102 panel.add_regions('ReferenceHighlight', regions, 'comment', flags=sublime.DRAW_OUTLINED)
103
104
105 def _get_relative_path(base_dir: Optional[str], file_path: str) -> str:
106 if base_dir:
107 return os.path.relpath(file_path, base_dir)
108 else:
109 return file_path
110
111
112 def _group_locations_by_uri(
113 window: sublime.Window,
114 config: ClientConfig,
115 locations: List[Location]
116 ) -> Dict[str, List[Tuple[Point, str]]]:
117 """Return a dictionary that groups locations by the URI it belongs."""
118 grouped_locations = {} # type: Dict[str, List[Tuple[Point, str]]]
119 for location in locations:
120 uri, position = get_uri_and_position_from_location(location)
121 file_path = config.map_server_uri_to_client_path(uri)
122 point = Point.from_lsp(position)
123 # get line of the reference, to showcase its use
124 reference_line = get_line(window, file_path, point.row)
125 if grouped_locations.get(file_path) is None:
126 grouped_locations[file_path] = []
127 grouped_locations[file_path].append((point, reference_line))
128 # we don't want to cache the line, we always want to get fresh data
129 linecache.clearcache()
130 return grouped_locations
131
[end of plugin/references.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/plugin/references.py b/plugin/references.py
--- a/plugin/references.py
+++ b/plugin/references.py
@@ -104,9 +104,12 @@
def _get_relative_path(base_dir: Optional[str], file_path: str) -> str:
if base_dir:
- return os.path.relpath(file_path, base_dir)
- else:
- return file_path
+ try:
+ return os.path.relpath(file_path, base_dir)
+ except ValueError:
+ # On Windows, ValueError is raised when path and start are on different drives.
+ pass
+ return file_path
def _group_locations_by_uri(
| {"golden_diff": "diff --git a/plugin/references.py b/plugin/references.py\n--- a/plugin/references.py\n+++ b/plugin/references.py\n@@ -104,9 +104,12 @@\n \n def _get_relative_path(base_dir: Optional[str], file_path: str) -> str:\n if base_dir:\n- return os.path.relpath(file_path, base_dir)\n- else:\n- return file_path\n+ try:\n+ return os.path.relpath(file_path, base_dir)\n+ except ValueError:\n+ # On Windows, ValueError is raised when path and start are on different drives.\n+ pass\n+ return file_path\n \n \n def _group_locations_by_uri(\n", "issue": "`os.path.relpath` may throw an exception on Windows.\n`os.path.relpath` may throw an exception on Windows.\r\n\r\n```\r\nTraceback (most recent call last):\r\nFile \"C:\\tools\\sublime\\Data\\Installed Packages\\LSP.sublime-package\\plugin/references.py\", line 55, in \r\nFile \"C:\\tools\\sublime\\Data\\Installed Packages\\LSP.sublime-package\\plugin/references.py\", line 62, in _handle_response\r\nFile \"C:\\tools\\sublime\\Data\\Installed Packages\\LSP.sublime-package\\plugin/references.py\", line 85, in _show_references_in_output_panel\r\nFile \"C:\\tools\\sublime\\Data\\Installed Packages\\LSP.sublime-package\\plugin/references.py\", line 107, in _get_relative_path\r\nFile \"./python3.3/ntpath.py\", line 564, in relpath\r\nValueError: path is on mount 'C:', start on mount '\\myserver\\myshare'\r\n```\n", "before_files": [{"content": "from .core.panels import ensure_panel\nfrom .core.protocol import Location\nfrom .core.protocol import Point\nfrom .core.protocol import Request\nfrom .core.registry import get_position\nfrom .core.registry import LspTextCommand\nfrom .core.sessions import Session\nfrom .core.settings import PLUGIN_NAME\nfrom .core.settings import userprefs\nfrom .core.types import ClientConfig\nfrom .core.types import PANEL_FILE_REGEX\nfrom .core.types import PANEL_LINE_REGEX\nfrom .core.typing import Dict, List, Optional, Tuple\nfrom .core.views import get_line\nfrom .core.views import get_uri_and_position_from_location\nfrom .core.views import text_document_position_params\nfrom .locationpicker import LocationPicker\nimport functools\nimport linecache\nimport os\nimport sublime\n\n\ndef ensure_references_panel(window: sublime.Window) -> Optional[sublime.View]:\n return ensure_panel(window, \"references\", PANEL_FILE_REGEX, PANEL_LINE_REGEX,\n \"Packages/\" + PLUGIN_NAME + \"/Syntaxes/References.sublime-syntax\")\n\n\nclass LspSymbolReferencesCommand(LspTextCommand):\n\n capability = 'referencesProvider'\n\n def __init__(self, view: sublime.View) -> None:\n super().__init__(view)\n self._picker = None # type: Optional[LocationPicker]\n\n def run(self, _: sublime.Edit, event: Optional[dict] = None, point: Optional[int] = None) -> None:\n session = self.best_session(self.capability)\n file_path = self.view.file_name()\n pos = get_position(self.view, event, point)\n if session and file_path and pos is not None:\n params = text_document_position_params(self.view, pos)\n params['context'] = {\"includeDeclaration\": False}\n request = Request(\"textDocument/references\", params, self.view, progress=True)\n session.send_request(\n request,\n functools.partial(\n self._handle_response_async,\n self.view.substr(self.view.word(pos)),\n session\n )\n )\n\n def _handle_response_async(self, word: str, session: Session, response: Optional[List[Location]]) -> None:\n sublime.set_timeout(lambda: self._handle_response(word, session, response))\n\n def _handle_response(self, word: str, session: Session, response: Optional[List[Location]]) -> None:\n if response:\n if userprefs().show_references_in_quick_panel:\n self._show_references_in_quick_panel(session, response)\n else:\n self._show_references_in_output_panel(word, session, response)\n else:\n window = self.view.window()\n if window:\n window.status_message(\"No references found\")\n\n def _show_references_in_quick_panel(self, session: Session, locations: List[Location]) -> None:\n self.view.run_command(\"add_jump_record\", {\"selection\": [(r.a, r.b) for r in self.view.sel()]})\n LocationPicker(self.view, session, locations, side_by_side=False)\n\n def _show_references_in_output_panel(self, word: str, session: Session, locations: List[Location]) -> None:\n window = session.window\n panel = ensure_references_panel(window)\n if not panel:\n return\n manager = session.manager()\n if not manager:\n return\n base_dir = manager.get_project_path(self.view.file_name() or \"\")\n to_render = [] # type: List[str]\n references_count = 0\n references_by_file = _group_locations_by_uri(window, session.config, locations)\n for file, references in references_by_file.items():\n to_render.append('{}:'.format(_get_relative_path(base_dir, file)))\n for reference in references:\n references_count += 1\n point, line = reference\n to_render.append('{:>5}:{:<4} {}'.format(point.row + 1, point.col + 1, line))\n to_render.append(\"\") # add spacing between filenames\n characters = \"\\n\".join(to_render)\n panel.settings().set(\"result_base_dir\", base_dir)\n panel.run_command(\"lsp_clear_panel\")\n window.run_command(\"show_panel\", {\"panel\": \"output.references\"})\n panel.run_command('append', {\n 'characters': \"{} references for '{}'\\n\\n{}\".format(references_count, word, characters),\n 'force': True,\n 'scroll_to_end': False\n })\n # highlight all word occurrences\n regions = panel.find_all(r\"\\b{}\\b\".format(word))\n panel.add_regions('ReferenceHighlight', regions, 'comment', flags=sublime.DRAW_OUTLINED)\n\n\ndef _get_relative_path(base_dir: Optional[str], file_path: str) -> str:\n if base_dir:\n return os.path.relpath(file_path, base_dir)\n else:\n return file_path\n\n\ndef _group_locations_by_uri(\n window: sublime.Window,\n config: ClientConfig,\n locations: List[Location]\n) -> Dict[str, List[Tuple[Point, str]]]:\n \"\"\"Return a dictionary that groups locations by the URI it belongs.\"\"\"\n grouped_locations = {} # type: Dict[str, List[Tuple[Point, str]]]\n for location in locations:\n uri, position = get_uri_and_position_from_location(location)\n file_path = config.map_server_uri_to_client_path(uri)\n point = Point.from_lsp(position)\n # get line of the reference, to showcase its use\n reference_line = get_line(window, file_path, point.row)\n if grouped_locations.get(file_path) is None:\n grouped_locations[file_path] = []\n grouped_locations[file_path].append((point, reference_line))\n # we don't want to cache the line, we always want to get fresh data\n linecache.clearcache()\n return grouped_locations\n", "path": "plugin/references.py"}]} | 2,248 | 149 |
gh_patches_debug_7263 | rasdani/github-patches | git_diff | iterative__dvc-5753 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
exp show: failing with rich==10.0.0
```console
$ dvc exp show
dvc exp show -v
2021-03-29 11:30:45,071 DEBUG: Check for update is disabled.
2021-03-29 11:30:46,006 ERROR: unexpected error - 'int' object has no attribute 'max_width'
------------------------------------------------------------
Traceback (most recent call last):
File "/home/saugat/repos/iterative/dvc/dvc/main.py", line 55, in main
ret = cmd.run()
File "/home/saugat/repos/iterative/dvc/dvc/command/experiments.py", line 411, in run
measurement = table.__rich_measure__(console, SHOW_MAX_WIDTH)
File "/home/saugat/venvs/dvc/env39/lib/python3.9/site-packages/rich/table.py", line 287, in __rich_measure__
max_width = options.max_width
AttributeError: 'int' object has no attribute 'max_width'
------------------------------------------------------------
2021-03-29 11:30:47,022 DEBUG: Version info for developers:
DVC version: 2.0.11+f8c567
---------------------------------
Platform: Python 3.9.2 on Linux-5.11.8-arch1-1-x86_64-with-glibc2.33
Supports: All remotes
Cache types: hardlink, symlink
Cache directory: ext4 on /dev/sda9
Caches: local
Remotes: https
Workspace directory: ext4 on /dev/sda9
Repo: dvc, git
Having any troubles? Hit us up at https://dvc.org/support, we are always happy to help!
```
This is also breaking our linter ([here](https://github.com/iterative/dvc/runs/2214172187?check_suite_focus=true#step:7:250
)) and tests as well due to the change in rich's internal API that we are using:
https://github.com/iterative/dvc/blob/1a25ebe3bd2eda4c3612e408fb503d64490fb56c/dvc/utils/table.py#L59
</issue>
<code>
[start of dvc/utils/table.py]
1 from dataclasses import dataclass
2 from typing import TYPE_CHECKING, List, cast
3
4 from rich.style import StyleType
5 from rich.table import Column as RichColumn
6 from rich.table import Table as RichTable
7
8 if TYPE_CHECKING:
9 from rich.console import (
10 Console,
11 ConsoleOptions,
12 JustifyMethod,
13 OverflowMethod,
14 RenderableType,
15 )
16
17
18 @dataclass
19 class Column(RichColumn):
20 collapse: bool = False
21
22
23 class Table(RichTable):
24 def add_column( # pylint: disable=arguments-differ
25 self,
26 header: "RenderableType" = "",
27 footer: "RenderableType" = "",
28 *,
29 header_style: StyleType = None,
30 footer_style: StyleType = None,
31 style: StyleType = None,
32 justify: "JustifyMethod" = "left",
33 overflow: "OverflowMethod" = "ellipsis",
34 width: int = None,
35 min_width: int = None,
36 max_width: int = None,
37 ratio: int = None,
38 no_wrap: bool = False,
39 collapse: bool = False,
40 ) -> None:
41 column = Column( # type: ignore[call-arg]
42 _index=len(self.columns),
43 header=header,
44 footer=footer,
45 header_style=header_style or "",
46 footer_style=footer_style or "",
47 style=style or "",
48 justify=justify,
49 overflow=overflow,
50 width=width,
51 min_width=min_width,
52 max_width=max_width,
53 ratio=ratio,
54 no_wrap=no_wrap,
55 collapse=collapse,
56 )
57 self.columns.append(column)
58
59 def _calculate_column_widths(
60 self, console: "Console", options: "ConsoleOptions"
61 ) -> List[int]:
62 """Calculate the widths of each column, including padding, not
63 including borders.
64
65 Adjacent collapsed columns will be removed until there is only a single
66 truncated column remaining.
67 """
68 widths = super()._calculate_column_widths(console, options)
69 last_collapsed = -1
70 columns = cast(List[Column], self.columns)
71 for i in range(len(columns) - 1, -1, -1):
72 if widths[i] == 1 and columns[i].collapse:
73 if last_collapsed >= 0:
74 del widths[last_collapsed]
75 del columns[last_collapsed]
76 if self.box:
77 options.max_width += 1
78 for column in columns[last_collapsed:]:
79 column._index -= 1
80 last_collapsed = i
81 padding = self._get_padding_width(i)
82 if (
83 columns[i].overflow == "ellipsis"
84 and (sum(widths) + padding) <= options.max_width
85 ):
86 # Set content width to 1 (plus padding) if we can fit a
87 # single unicode ellipsis in this column
88 widths[i] = 1 + padding
89 else:
90 last_collapsed = -1
91 return widths
92
93 def _collapse_widths( # type: ignore[override]
94 self, widths: List[int], wrapable: List[bool], max_width: int,
95 ) -> List[int]:
96 """Collapse columns right-to-left if possible to fit table into
97 max_width.
98
99 If table is still too wide after collapsing, rich's automatic overflow
100 handling will be used.
101 """
102 columns = cast(List[Column], self.columns)
103 collapsible = [column.collapse for column in columns]
104 total_width = sum(widths)
105 excess_width = total_width - max_width
106 if any(collapsible):
107 for i in range(len(widths) - 1, -1, -1):
108 if collapsible[i]:
109 total_width -= widths[i]
110 excess_width -= widths[i]
111 widths[i] = 0
112 if excess_width <= 0:
113 break
114 return super()._collapse_widths(widths, wrapable, max_width)
115
[end of dvc/utils/table.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/dvc/utils/table.py b/dvc/utils/table.py
--- a/dvc/utils/table.py
+++ b/dvc/utils/table.py
@@ -69,7 +69,7 @@
last_collapsed = -1
columns = cast(List[Column], self.columns)
for i in range(len(columns) - 1, -1, -1):
- if widths[i] == 1 and columns[i].collapse:
+ if widths[i] == 0 and columns[i].collapse:
if last_collapsed >= 0:
del widths[last_collapsed]
del columns[last_collapsed]
| {"golden_diff": "diff --git a/dvc/utils/table.py b/dvc/utils/table.py\n--- a/dvc/utils/table.py\n+++ b/dvc/utils/table.py\n@@ -69,7 +69,7 @@\n last_collapsed = -1\n columns = cast(List[Column], self.columns)\n for i in range(len(columns) - 1, -1, -1):\n- if widths[i] == 1 and columns[i].collapse:\n+ if widths[i] == 0 and columns[i].collapse:\n if last_collapsed >= 0:\n del widths[last_collapsed]\n del columns[last_collapsed]\n", "issue": "exp show: failing with rich==10.0.0\n```console\r\n$ dvc exp show\r\ndvc exp show -v\r\n2021-03-29 11:30:45,071 DEBUG: Check for update is disabled.\r\n2021-03-29 11:30:46,006 ERROR: unexpected error - 'int' object has no attribute 'max_width'\r\n------------------------------------------------------------\r\nTraceback (most recent call last):\r\n File \"/home/saugat/repos/iterative/dvc/dvc/main.py\", line 55, in main\r\n ret = cmd.run()\r\n File \"/home/saugat/repos/iterative/dvc/dvc/command/experiments.py\", line 411, in run\r\n measurement = table.__rich_measure__(console, SHOW_MAX_WIDTH)\r\n File \"/home/saugat/venvs/dvc/env39/lib/python3.9/site-packages/rich/table.py\", line 287, in __rich_measure__\r\n max_width = options.max_width\r\nAttributeError: 'int' object has no attribute 'max_width'\r\n------------------------------------------------------------\r\n2021-03-29 11:30:47,022 DEBUG: Version info for developers:\r\nDVC version: 2.0.11+f8c567 \r\n---------------------------------\r\nPlatform: Python 3.9.2 on Linux-5.11.8-arch1-1-x86_64-with-glibc2.33\r\nSupports: All remotes\r\nCache types: hardlink, symlink\r\nCache directory: ext4 on /dev/sda9\r\nCaches: local\r\nRemotes: https\r\nWorkspace directory: ext4 on /dev/sda9\r\nRepo: dvc, git\r\n\r\nHaving any troubles? Hit us up at https://dvc.org/support, we are always happy to help!\r\n```\r\n\r\n\r\nThis is also breaking our linter ([here](https://github.com/iterative/dvc/runs/2214172187?check_suite_focus=true#step:7:250\r\n)) and tests as well due to the change in rich's internal API that we are using:\r\nhttps://github.com/iterative/dvc/blob/1a25ebe3bd2eda4c3612e408fb503d64490fb56c/dvc/utils/table.py#L59\r\n\r\n\n", "before_files": [{"content": "from dataclasses import dataclass\nfrom typing import TYPE_CHECKING, List, cast\n\nfrom rich.style import StyleType\nfrom rich.table import Column as RichColumn\nfrom rich.table import Table as RichTable\n\nif TYPE_CHECKING:\n from rich.console import (\n Console,\n ConsoleOptions,\n JustifyMethod,\n OverflowMethod,\n RenderableType,\n )\n\n\n@dataclass\nclass Column(RichColumn):\n collapse: bool = False\n\n\nclass Table(RichTable):\n def add_column( # pylint: disable=arguments-differ\n self,\n header: \"RenderableType\" = \"\",\n footer: \"RenderableType\" = \"\",\n *,\n header_style: StyleType = None,\n footer_style: StyleType = None,\n style: StyleType = None,\n justify: \"JustifyMethod\" = \"left\",\n overflow: \"OverflowMethod\" = \"ellipsis\",\n width: int = None,\n min_width: int = None,\n max_width: int = None,\n ratio: int = None,\n no_wrap: bool = False,\n collapse: bool = False,\n ) -> None:\n column = Column( # type: ignore[call-arg]\n _index=len(self.columns),\n header=header,\n footer=footer,\n header_style=header_style or \"\",\n footer_style=footer_style or \"\",\n style=style or \"\",\n justify=justify,\n overflow=overflow,\n width=width,\n min_width=min_width,\n max_width=max_width,\n ratio=ratio,\n no_wrap=no_wrap,\n collapse=collapse,\n )\n self.columns.append(column)\n\n def _calculate_column_widths(\n self, console: \"Console\", options: \"ConsoleOptions\"\n ) -> List[int]:\n \"\"\"Calculate the widths of each column, including padding, not\n including borders.\n\n Adjacent collapsed columns will be removed until there is only a single\n truncated column remaining.\n \"\"\"\n widths = super()._calculate_column_widths(console, options)\n last_collapsed = -1\n columns = cast(List[Column], self.columns)\n for i in range(len(columns) - 1, -1, -1):\n if widths[i] == 1 and columns[i].collapse:\n if last_collapsed >= 0:\n del widths[last_collapsed]\n del columns[last_collapsed]\n if self.box:\n options.max_width += 1\n for column in columns[last_collapsed:]:\n column._index -= 1\n last_collapsed = i\n padding = self._get_padding_width(i)\n if (\n columns[i].overflow == \"ellipsis\"\n and (sum(widths) + padding) <= options.max_width\n ):\n # Set content width to 1 (plus padding) if we can fit a\n # single unicode ellipsis in this column\n widths[i] = 1 + padding\n else:\n last_collapsed = -1\n return widths\n\n def _collapse_widths( # type: ignore[override]\n self, widths: List[int], wrapable: List[bool], max_width: int,\n ) -> List[int]:\n \"\"\"Collapse columns right-to-left if possible to fit table into\n max_width.\n\n If table is still too wide after collapsing, rich's automatic overflow\n handling will be used.\n \"\"\"\n columns = cast(List[Column], self.columns)\n collapsible = [column.collapse for column in columns]\n total_width = sum(widths)\n excess_width = total_width - max_width\n if any(collapsible):\n for i in range(len(widths) - 1, -1, -1):\n if collapsible[i]:\n total_width -= widths[i]\n excess_width -= widths[i]\n widths[i] = 0\n if excess_width <= 0:\n break\n return super()._collapse_widths(widths, wrapable, max_width)\n", "path": "dvc/utils/table.py"}]} | 2,153 | 134 |
gh_patches_debug_15548 | rasdani/github-patches | git_diff | tensorflow__addons-340 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
tfa.seq2seq.sequence_loss can't average over one dimension (batch or timesteps) while summing over the other one
**System information**
- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Google Colab
- TensorFlow installed from (source or binary): binary
- TensorFlow version (use command below): 2.0.0=beta1
- TensorFlow Addons installed from (source, PyPi): PyPi
- TensorFlow Addons version: 0.4.0
- Python version and type (eg. Anaconda Python, Stock Python as in Mac, or homebrew installed Python etc): Google Colab Python
- Is GPU used? (yes/no): yes
- GPU model (if used): T4
**Describe the bug**
`tfa.seq2seq.sequence_loss` can't average over one dimension (`batch` or `timesteps`) while summing over the other one. It will arbitrarily only execute the averaging and ignore the sum right now.
**Describe the expected behavior**
I think the weights should be associated with the summing operation, and then the averaging should happen irrespective of that.
Concretely, when passing, say `average_across_batch=True` and `sum_over_timesteps=True` (of course, making sure `average_across_timesteps=False` is set), you should expect either of these things:
1. An error stating that this is not implemented (might be the wisest).
2. Return a scalar tensor obtained by either of these two following orders:
a) first computing the *weighted sum* of xents over timesteps (yielding a batchsize-sized tensor of xent-sums), then simply averaging this vector, i.e., summing and dividing by the batchsize. The result, however, is just the both-averaged version times the batchsize, divided by the sum of all weights.
b) first computing the *weighted average* over the batchsize, then summing these averages over all timesteps. The result here is different from 1a and the double-averaged (of course, there is some correlation...)!
I think 1a is the desired behavior (as the loglikelihood of a sequence really is the sum of the individual loglikelihoods and batches do correspond to sequence-length agnostic averages) and I'd be happy to establish it as the standard for this. Either way, doing something other than failing with an error will require an explicit notice in the docs. An error (or warning for backwards-compatibility?) might just be the simplest and safest option.
**Code to reproduce the issue**
```python
tfa.seq2seq.sequence_loss(
logits=tf.random.normal([3, 5, 7]),
targets=tf.zeros([3, 5], dtype=tf.int32),
weights=tf.sequence_mask(lengths=[3, 5, 1], maxlen=5, dtype=tf.float32),
average_across_batch=True,
average_across_timesteps=False,
sum_over_batch=False,
sum_over_timesteps=True,
)
```
...should return a scalar but returns only the batch-averaged tensor.
**Some more code to play with to test the claims above**
```python
import tensorflow.compat.v2 as tf
import tensorflow_addons as tfa
import numpy as np
import random
case1b = []
dblavg = []
for _ in range(100):
dtype = tf.float32
batchsize = random.randint(2, 10)
maxlen = random.randint(2, 10)
logits = tf.random.normal([batchsize, maxlen, 3])
labels = tf.zeros([batchsize, maxlen], dtype=tf.int32)
lengths = tf.squeeze(tf.random.categorical(tf.zeros([1, maxlen - 1]), batchsize)) + 1
weights = tf.sequence_mask(lengths=lengths, maxlen=maxlen, dtype=tf.float32)
def sl(ab, sb, at, st):
return tfa.seq2seq.sequence_loss(
logits,
labels,
weights,
average_across_batch=ab,
average_across_timesteps=at,
sum_over_batch=sb,
sum_over_timesteps=st,
)
all_b_all_t = sl(ab=False, sb=False, at=False, st=False)
avg_b_avg_t = sl(ab=True, sb=False, at=True, st=False)
sum_b_all_t = sl(ab=False, sb=True, at=False, st=False)
tf.assert_equal(sum_b_all_t, tf.math.divide_no_nan(tf.reduce_sum(all_b_all_t, axis=0), tf.reduce_sum(weights, axis=0)))
weighted = all_b_all_t * weights
first_sum_timesteps = tf.reduce_sum(weighted, axis=1)
then_average_batch = tf.reduce_sum(first_sum_timesteps) / batchsize
first_average_batch = tf.math.divide_no_nan(tf.reduce_sum(weighted, axis=0), tf.reduce_sum(weights, axis=0))
then_sum_timesteps = tf.reduce_sum(first_average_batch)
# Case 1a and 1b are different.
assert not np.isclose(then_average_batch, then_sum_timesteps)
# Case 1a is just the double-averaging up to a constant.
assert np.allclose(then_average_batch * batchsize / tf.reduce_sum(weights), avg_b_avg_t)
# Case 1b is not just the averaging.
assert not np.allclose(then_sum_timesteps / maxlen, avg_b_avg_t)
# They only kind of correlate:
case1b.append(then_sum_timesteps / maxlen)
dblavg.append(avg_b_avg_t)
```
</issue>
<code>
[start of tensorflow_addons/seq2seq/loss.py]
1 # Copyright 2016 The TensorFlow Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 # ==============================================================================
15 """Seq2seq loss operations for use in sequence models."""
16
17 from __future__ import absolute_import
18 from __future__ import division
19 from __future__ import print_function
20
21 import tensorflow as tf
22
23
24 def sequence_loss(logits,
25 targets,
26 weights,
27 average_across_timesteps=True,
28 average_across_batch=True,
29 sum_over_timesteps=False,
30 sum_over_batch=False,
31 softmax_loss_function=None,
32 name=None):
33 """Weighted cross-entropy loss for a sequence of logits.
34
35 Depending on the values of `average_across_timesteps` /
36 `sum_over_timesteps` and `average_across_batch` / `sum_over_batch`, the
37 return Tensor will have rank 0, 1, or 2 as these arguments reduce the
38 cross-entropy at each target, which has shape
39 `[batch_size, sequence_length]`, over their respective dimensions. For
40 example, if `average_across_timesteps` is `True` and `average_across_batch`
41 is `False`, then the return Tensor will have shape `[batch_size]`.
42
43 Note that `average_across_timesteps` and `sum_over_timesteps` cannot be
44 True at same time. Same for `average_across_batch` and `sum_over_batch`.
45
46 The recommended loss reduction in tf 2.0 has been changed to sum_over,
47 instead of weighted average. User are recommend to use `sum_over_timesteps`
48 and `sum_over_batch` for reduction.
49
50 Args:
51 logits: A Tensor of shape
52 `[batch_size, sequence_length, num_decoder_symbols]` and dtype float.
53 The logits correspond to the prediction across all classes at each
54 timestep.
55 targets: A Tensor of shape `[batch_size, sequence_length]` and dtype
56 int. The target represents the true class at each timestep.
57 weights: A Tensor of shape `[batch_size, sequence_length]` and dtype
58 float. `weights` constitutes the weighting of each prediction in the
59 sequence. When using `weights` as masking, set all valid timesteps to 1
60 and all padded timesteps to 0, e.g. a mask returned by
61 `tf.sequence_mask`.
62 average_across_timesteps: If set, sum the cost across the sequence
63 dimension and divide the cost by the total label weight across
64 timesteps.
65 average_across_batch: If set, sum the cost across the batch dimension and
66 divide the returned cost by the batch size.
67 sum_over_timesteps: If set, sum the cost across the sequence dimension
68 and divide the size of the sequence. Note that any element with 0
69 weights will be excluded from size calculation.
70 sum_over_batch: if set, sum the cost across the batch dimension and
71 divide the total cost by the batch size. Not that any element with 0
72 weights will be excluded from size calculation.
73 softmax_loss_function: Function (labels, logits) -> loss-batch
74 to be used instead of the standard softmax (the default if this is
75 None). **Note that to avoid confusion, it is required for the function
76 to accept named arguments.**
77 name: Optional name for this operation, defaults to "sequence_loss".
78
79 Returns:
80 A float Tensor of rank 0, 1, or 2 depending on the
81 `average_across_timesteps` and `average_across_batch` arguments. By
82 default, it has rank 0 (scalar) and is the weighted average cross-entropy
83 (log-perplexity) per symbol.
84
85 Raises:
86 ValueError: logits does not have 3 dimensions or targets does not have 2
87 dimensions or weights does not have 2 dimensions.
88 """
89 if len(logits.get_shape()) != 3:
90 raise ValueError("Logits must be a "
91 "[batch_size x sequence_length x logits] tensor")
92 if len(targets.get_shape()) != 2:
93 raise ValueError(
94 "Targets must be a [batch_size x sequence_length] tensor")
95 if len(weights.get_shape()) != 2:
96 raise ValueError(
97 "Weights must be a [batch_size x sequence_length] tensor")
98 if average_across_timesteps and sum_over_timesteps:
99 raise ValueError(
100 "average_across_timesteps and sum_over_timesteps cannot "
101 "be set to True at same time.")
102 if average_across_batch and sum_over_batch:
103 raise ValueError(
104 "average_across_batch and sum_over_batch cannot be set "
105 "to True at same time.")
106 with tf.name_scope(name or "sequence_loss"):
107 num_classes = tf.shape(input=logits)[2]
108 logits_flat = tf.reshape(logits, [-1, num_classes])
109 targets = tf.reshape(targets, [-1])
110 if softmax_loss_function is None:
111 crossent = tf.nn.sparse_softmax_cross_entropy_with_logits(
112 labels=targets, logits=logits_flat)
113 else:
114 crossent = softmax_loss_function(
115 labels=targets, logits=logits_flat)
116 crossent *= tf.reshape(weights, [-1])
117 if average_across_timesteps and average_across_batch:
118 crossent = tf.reduce_sum(input_tensor=crossent)
119 total_size = tf.reduce_sum(input_tensor=weights)
120 crossent = tf.math.divide_no_nan(crossent, total_size)
121 elif sum_over_timesteps and sum_over_batch:
122 crossent = tf.reduce_sum(input_tensor=crossent)
123 total_count = tf.cast(
124 tf.math.count_nonzero(weights), crossent.dtype)
125 crossent = tf.math.divide_no_nan(crossent, total_count)
126 else:
127 crossent = tf.reshape(crossent, tf.shape(input=logits)[0:2])
128 if average_across_timesteps or average_across_batch:
129 reduce_axis = [0] if average_across_batch else [1]
130 crossent = tf.reduce_sum(
131 input_tensor=crossent, axis=reduce_axis)
132 total_size = tf.reduce_sum(
133 input_tensor=weights, axis=reduce_axis)
134 crossent = tf.math.divide_no_nan(crossent, total_size)
135 elif sum_over_timesteps or sum_over_batch:
136 reduce_axis = [0] if sum_over_batch else [1]
137 crossent = tf.reduce_sum(
138 input_tensor=crossent, axis=reduce_axis)
139 total_count = tf.cast(
140 tf.math.count_nonzero(weights, axis=reduce_axis),
141 dtype=crossent.dtype)
142 crossent = tf.math.divide_no_nan(crossent, total_count)
143 return crossent
144
145
146 class SequenceLoss(tf.keras.losses.Loss):
147 """Weighted cross-entropy loss for a sequence of logits."""
148
149 def __init__(self,
150 average_across_timesteps=False,
151 average_across_batch=False,
152 sum_over_timesteps=True,
153 sum_over_batch=True,
154 softmax_loss_function=None,
155 name=None):
156 super(SequenceLoss, self).__init__(name=name)
157 self.average_across_timesteps = average_across_timesteps
158 self.average_across_batch = average_across_batch
159 self.sum_over_timesteps = sum_over_timesteps
160 self.sum_over_batch = sum_over_batch
161 self.softmax_loss_function = softmax_loss_function
162
163 def __call__(self, y_true, y_pred, sample_weight=None):
164 """Override the parent __call__ to have a customized reduce
165 behavior."""
166 return sequence_loss(
167 y_pred,
168 y_true,
169 sample_weight,
170 average_across_timesteps=self.average_across_timesteps,
171 average_across_batch=self.average_across_batch,
172 sum_over_timesteps=self.sum_over_timesteps,
173 sum_over_batch=self.sum_over_batch,
174 softmax_loss_function=self.softmax_loss_function,
175 name=self.name)
176
177 def call(self, y_true, y_pred):
178 # Skip this method since the __call__ contains real implementation.
179 pass
180
[end of tensorflow_addons/seq2seq/loss.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/tensorflow_addons/seq2seq/loss.py b/tensorflow_addons/seq2seq/loss.py
--- a/tensorflow_addons/seq2seq/loss.py
+++ b/tensorflow_addons/seq2seq/loss.py
@@ -103,6 +103,14 @@
raise ValueError(
"average_across_batch and sum_over_batch cannot be set "
"to True at same time.")
+ if average_across_batch and sum_over_timesteps:
+ raise ValueError(
+ "average_across_batch and sum_over_timesteps cannot be set "
+ "to True at same time because of ambiguous order.")
+ if sum_over_batch and average_across_timesteps:
+ raise ValueError(
+ "sum_over_batch and average_across_timesteps cannot be set "
+ "to True at same time because of ambiguous order.")
with tf.name_scope(name or "sequence_loss"):
num_classes = tf.shape(input=logits)[2]
logits_flat = tf.reshape(logits, [-1, num_classes])
| {"golden_diff": "diff --git a/tensorflow_addons/seq2seq/loss.py b/tensorflow_addons/seq2seq/loss.py\n--- a/tensorflow_addons/seq2seq/loss.py\n+++ b/tensorflow_addons/seq2seq/loss.py\n@@ -103,6 +103,14 @@\n raise ValueError(\n \"average_across_batch and sum_over_batch cannot be set \"\n \"to True at same time.\")\n+ if average_across_batch and sum_over_timesteps:\n+ raise ValueError(\n+ \"average_across_batch and sum_over_timesteps cannot be set \"\n+ \"to True at same time because of ambiguous order.\")\n+ if sum_over_batch and average_across_timesteps:\n+ raise ValueError(\n+ \"sum_over_batch and average_across_timesteps cannot be set \"\n+ \"to True at same time because of ambiguous order.\")\n with tf.name_scope(name or \"sequence_loss\"):\n num_classes = tf.shape(input=logits)[2]\n logits_flat = tf.reshape(logits, [-1, num_classes])\n", "issue": "tfa.seq2seq.sequence_loss can't average over one dimension (batch or timesteps) while summing over the other one\n**System information**\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Google Colab\r\n- TensorFlow installed from (source or binary): binary\r\n- TensorFlow version (use command below): 2.0.0=beta1\r\n- TensorFlow Addons installed from (source, PyPi): PyPi\r\n- TensorFlow Addons version: 0.4.0\r\n- Python version and type (eg. Anaconda Python, Stock Python as in Mac, or homebrew installed Python etc): Google Colab Python\r\n- Is GPU used? (yes/no): yes\r\n- GPU model (if used): T4\r\n\r\n**Describe the bug**\r\n\r\n`tfa.seq2seq.sequence_loss` can't average over one dimension (`batch` or `timesteps`) while summing over the other one. It will arbitrarily only execute the averaging and ignore the sum right now.\r\n\r\n**Describe the expected behavior**\r\n\r\nI think the weights should be associated with the summing operation, and then the averaging should happen irrespective of that.\r\nConcretely, when passing, say `average_across_batch=True` and `sum_over_timesteps=True` (of course, making sure `average_across_timesteps=False` is set), you should expect either of these things:\r\n\r\n1. An error stating that this is not implemented (might be the wisest).\r\n2. Return a scalar tensor obtained by either of these two following orders:\r\n a) first computing the *weighted sum* of xents over timesteps (yielding a batchsize-sized tensor of xent-sums), then simply averaging this vector, i.e., summing and dividing by the batchsize. The result, however, is just the both-averaged version times the batchsize, divided by the sum of all weights.\r\n b) first computing the *weighted average* over the batchsize, then summing these averages over all timesteps. The result here is different from 1a and the double-averaged (of course, there is some correlation...)!\r\n\r\nI think 1a is the desired behavior (as the loglikelihood of a sequence really is the sum of the individual loglikelihoods and batches do correspond to sequence-length agnostic averages) and I'd be happy to establish it as the standard for this. Either way, doing something other than failing with an error will require an explicit notice in the docs. An error (or warning for backwards-compatibility?) might just be the simplest and safest option.\r\n\r\n**Code to reproduce the issue**\r\n\r\n```python\r\ntfa.seq2seq.sequence_loss(\r\n logits=tf.random.normal([3, 5, 7]),\r\n targets=tf.zeros([3, 5], dtype=tf.int32),\r\n weights=tf.sequence_mask(lengths=[3, 5, 1], maxlen=5, dtype=tf.float32),\r\n average_across_batch=True,\r\n average_across_timesteps=False,\r\n sum_over_batch=False,\r\n sum_over_timesteps=True,\r\n)\r\n```\r\n...should return a scalar but returns only the batch-averaged tensor.\r\n\r\n**Some more code to play with to test the claims above**\r\n\r\n```python\r\nimport tensorflow.compat.v2 as tf\r\nimport tensorflow_addons as tfa\r\nimport numpy as np\r\nimport random\r\n\r\ncase1b = []\r\ndblavg = []\r\n\r\nfor _ in range(100):\r\n dtype = tf.float32\r\n batchsize = random.randint(2, 10)\r\n maxlen = random.randint(2, 10)\r\n logits = tf.random.normal([batchsize, maxlen, 3])\r\n labels = tf.zeros([batchsize, maxlen], dtype=tf.int32)\r\n lengths = tf.squeeze(tf.random.categorical(tf.zeros([1, maxlen - 1]), batchsize)) + 1\r\n weights = tf.sequence_mask(lengths=lengths, maxlen=maxlen, dtype=tf.float32)\r\n\r\n def sl(ab, sb, at, st):\r\n return tfa.seq2seq.sequence_loss(\r\n logits,\r\n labels,\r\n weights,\r\n average_across_batch=ab,\r\n average_across_timesteps=at,\r\n sum_over_batch=sb,\r\n sum_over_timesteps=st,\r\n )\r\n\r\n all_b_all_t = sl(ab=False, sb=False, at=False, st=False)\r\n avg_b_avg_t = sl(ab=True, sb=False, at=True, st=False)\r\n sum_b_all_t = sl(ab=False, sb=True, at=False, st=False)\r\n\r\n tf.assert_equal(sum_b_all_t, tf.math.divide_no_nan(tf.reduce_sum(all_b_all_t, axis=0), tf.reduce_sum(weights, axis=0)))\r\n\r\n weighted = all_b_all_t * weights\r\n\r\n first_sum_timesteps = tf.reduce_sum(weighted, axis=1)\r\n then_average_batch = tf.reduce_sum(first_sum_timesteps) / batchsize\r\n\r\n first_average_batch = tf.math.divide_no_nan(tf.reduce_sum(weighted, axis=0), tf.reduce_sum(weights, axis=0))\r\n then_sum_timesteps = tf.reduce_sum(first_average_batch)\r\n\r\n # Case 1a and 1b are different.\r\n assert not np.isclose(then_average_batch, then_sum_timesteps)\r\n # Case 1a is just the double-averaging up to a constant.\r\n assert np.allclose(then_average_batch * batchsize / tf.reduce_sum(weights), avg_b_avg_t)\r\n # Case 1b is not just the averaging.\r\n assert not np.allclose(then_sum_timesteps / maxlen, avg_b_avg_t)\r\n # They only kind of correlate:\r\n case1b.append(then_sum_timesteps / maxlen)\r\n dblavg.append(avg_b_avg_t)\r\n```\n", "before_files": [{"content": "# Copyright 2016 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\"\"\"Seq2seq loss operations for use in sequence models.\"\"\"\n\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport tensorflow as tf\n\n\ndef sequence_loss(logits,\n targets,\n weights,\n average_across_timesteps=True,\n average_across_batch=True,\n sum_over_timesteps=False,\n sum_over_batch=False,\n softmax_loss_function=None,\n name=None):\n \"\"\"Weighted cross-entropy loss for a sequence of logits.\n\n Depending on the values of `average_across_timesteps` /\n `sum_over_timesteps` and `average_across_batch` / `sum_over_batch`, the\n return Tensor will have rank 0, 1, or 2 as these arguments reduce the\n cross-entropy at each target, which has shape\n `[batch_size, sequence_length]`, over their respective dimensions. For\n example, if `average_across_timesteps` is `True` and `average_across_batch`\n is `False`, then the return Tensor will have shape `[batch_size]`.\n\n Note that `average_across_timesteps` and `sum_over_timesteps` cannot be\n True at same time. Same for `average_across_batch` and `sum_over_batch`.\n\n The recommended loss reduction in tf 2.0 has been changed to sum_over,\n instead of weighted average. User are recommend to use `sum_over_timesteps`\n and `sum_over_batch` for reduction.\n\n Args:\n logits: A Tensor of shape\n `[batch_size, sequence_length, num_decoder_symbols]` and dtype float.\n The logits correspond to the prediction across all classes at each\n timestep.\n targets: A Tensor of shape `[batch_size, sequence_length]` and dtype\n int. The target represents the true class at each timestep.\n weights: A Tensor of shape `[batch_size, sequence_length]` and dtype\n float. `weights` constitutes the weighting of each prediction in the\n sequence. When using `weights` as masking, set all valid timesteps to 1\n and all padded timesteps to 0, e.g. a mask returned by\n `tf.sequence_mask`.\n average_across_timesteps: If set, sum the cost across the sequence\n dimension and divide the cost by the total label weight across\n timesteps.\n average_across_batch: If set, sum the cost across the batch dimension and\n divide the returned cost by the batch size.\n sum_over_timesteps: If set, sum the cost across the sequence dimension\n and divide the size of the sequence. Note that any element with 0\n weights will be excluded from size calculation.\n sum_over_batch: if set, sum the cost across the batch dimension and\n divide the total cost by the batch size. Not that any element with 0\n weights will be excluded from size calculation.\n softmax_loss_function: Function (labels, logits) -> loss-batch\n to be used instead of the standard softmax (the default if this is\n None). **Note that to avoid confusion, it is required for the function\n to accept named arguments.**\n name: Optional name for this operation, defaults to \"sequence_loss\".\n\n Returns:\n A float Tensor of rank 0, 1, or 2 depending on the\n `average_across_timesteps` and `average_across_batch` arguments. By\n default, it has rank 0 (scalar) and is the weighted average cross-entropy\n (log-perplexity) per symbol.\n\n Raises:\n ValueError: logits does not have 3 dimensions or targets does not have 2\n dimensions or weights does not have 2 dimensions.\n \"\"\"\n if len(logits.get_shape()) != 3:\n raise ValueError(\"Logits must be a \"\n \"[batch_size x sequence_length x logits] tensor\")\n if len(targets.get_shape()) != 2:\n raise ValueError(\n \"Targets must be a [batch_size x sequence_length] tensor\")\n if len(weights.get_shape()) != 2:\n raise ValueError(\n \"Weights must be a [batch_size x sequence_length] tensor\")\n if average_across_timesteps and sum_over_timesteps:\n raise ValueError(\n \"average_across_timesteps and sum_over_timesteps cannot \"\n \"be set to True at same time.\")\n if average_across_batch and sum_over_batch:\n raise ValueError(\n \"average_across_batch and sum_over_batch cannot be set \"\n \"to True at same time.\")\n with tf.name_scope(name or \"sequence_loss\"):\n num_classes = tf.shape(input=logits)[2]\n logits_flat = tf.reshape(logits, [-1, num_classes])\n targets = tf.reshape(targets, [-1])\n if softmax_loss_function is None:\n crossent = tf.nn.sparse_softmax_cross_entropy_with_logits(\n labels=targets, logits=logits_flat)\n else:\n crossent = softmax_loss_function(\n labels=targets, logits=logits_flat)\n crossent *= tf.reshape(weights, [-1])\n if average_across_timesteps and average_across_batch:\n crossent = tf.reduce_sum(input_tensor=crossent)\n total_size = tf.reduce_sum(input_tensor=weights)\n crossent = tf.math.divide_no_nan(crossent, total_size)\n elif sum_over_timesteps and sum_over_batch:\n crossent = tf.reduce_sum(input_tensor=crossent)\n total_count = tf.cast(\n tf.math.count_nonzero(weights), crossent.dtype)\n crossent = tf.math.divide_no_nan(crossent, total_count)\n else:\n crossent = tf.reshape(crossent, tf.shape(input=logits)[0:2])\n if average_across_timesteps or average_across_batch:\n reduce_axis = [0] if average_across_batch else [1]\n crossent = tf.reduce_sum(\n input_tensor=crossent, axis=reduce_axis)\n total_size = tf.reduce_sum(\n input_tensor=weights, axis=reduce_axis)\n crossent = tf.math.divide_no_nan(crossent, total_size)\n elif sum_over_timesteps or sum_over_batch:\n reduce_axis = [0] if sum_over_batch else [1]\n crossent = tf.reduce_sum(\n input_tensor=crossent, axis=reduce_axis)\n total_count = tf.cast(\n tf.math.count_nonzero(weights, axis=reduce_axis),\n dtype=crossent.dtype)\n crossent = tf.math.divide_no_nan(crossent, total_count)\n return crossent\n\n\nclass SequenceLoss(tf.keras.losses.Loss):\n \"\"\"Weighted cross-entropy loss for a sequence of logits.\"\"\"\n\n def __init__(self,\n average_across_timesteps=False,\n average_across_batch=False,\n sum_over_timesteps=True,\n sum_over_batch=True,\n softmax_loss_function=None,\n name=None):\n super(SequenceLoss, self).__init__(name=name)\n self.average_across_timesteps = average_across_timesteps\n self.average_across_batch = average_across_batch\n self.sum_over_timesteps = sum_over_timesteps\n self.sum_over_batch = sum_over_batch\n self.softmax_loss_function = softmax_loss_function\n\n def __call__(self, y_true, y_pred, sample_weight=None):\n \"\"\"Override the parent __call__ to have a customized reduce\n behavior.\"\"\"\n return sequence_loss(\n y_pred,\n y_true,\n sample_weight,\n average_across_timesteps=self.average_across_timesteps,\n average_across_batch=self.average_across_batch,\n sum_over_timesteps=self.sum_over_timesteps,\n sum_over_batch=self.sum_over_batch,\n softmax_loss_function=self.softmax_loss_function,\n name=self.name)\n\n def call(self, y_true, y_pred):\n # Skip this method since the __call__ contains real implementation.\n pass\n", "path": "tensorflow_addons/seq2seq/loss.py"}]} | 4,000 | 232 |
gh_patches_debug_10799 | rasdani/github-patches | git_diff | optuna__optuna-1680 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Use function annotation syntax for Type Hints.
After dropping Python 2.7 support at #710, we can define type hints with function annotation syntax.
~~Do you have a plan to update the coding style guideline?~~
https://github.com/optuna/optuna/wiki/Coding-Style-Conventions
## Progress
- [x] `optuna/integration/sklearn.py` (#1735)
- [x] `optuna/study.py` - assigned to harpy
## Note to the questioner
We still cannot use variable annotation syntax introduced by [PEP 526](https://www.python.org/dev/peps/pep-0526/) because we supports Python 3.5.
</issue>
<code>
[start of optuna/pruners/_nop.py]
1 from optuna.pruners import BasePruner
2 from optuna import type_checking
3
4 if type_checking.TYPE_CHECKING:
5 from optuna.study import Study # NOQA
6 from optuna.trial import FrozenTrial # NOQA
7
8
9 class NopPruner(BasePruner):
10 """Pruner which never prunes trials.
11
12 Example:
13
14 .. testcode::
15
16 import numpy as np
17 from sklearn.datasets import load_iris
18 from sklearn.linear_model import SGDClassifier
19 from sklearn.model_selection import train_test_split
20
21 import optuna
22
23 X, y = load_iris(return_X_y=True)
24 X_train, X_valid, y_train, y_valid = train_test_split(X, y)
25 classes = np.unique(y)
26
27 def objective(trial):
28 alpha = trial.suggest_uniform('alpha', 0.0, 1.0)
29 clf = SGDClassifier(alpha=alpha)
30 n_train_iter = 100
31
32 for step in range(n_train_iter):
33 clf.partial_fit(X_train, y_train, classes=classes)
34
35 intermediate_value = clf.score(X_valid, y_valid)
36 trial.report(intermediate_value, step)
37
38 if trial.should_prune():
39 assert False, "should_prune() should always return False with this pruner."
40 raise optuna.TrialPruned()
41
42 return clf.score(X_valid, y_valid)
43
44 study = optuna.create_study(direction='maximize',
45 pruner=optuna.pruners.NopPruner())
46 study.optimize(objective, n_trials=20)
47 """
48
49 def prune(self, study, trial):
50 # type: (Study, FrozenTrial) -> bool
51
52 return False
53
[end of optuna/pruners/_nop.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/optuna/pruners/_nop.py b/optuna/pruners/_nop.py
--- a/optuna/pruners/_nop.py
+++ b/optuna/pruners/_nop.py
@@ -1,9 +1,5 @@
+import optuna
from optuna.pruners import BasePruner
-from optuna import type_checking
-
-if type_checking.TYPE_CHECKING:
- from optuna.study import Study # NOQA
- from optuna.trial import FrozenTrial # NOQA
class NopPruner(BasePruner):
@@ -46,7 +42,6 @@
study.optimize(objective, n_trials=20)
"""
- def prune(self, study, trial):
- # type: (Study, FrozenTrial) -> bool
+ def prune(self, study: "optuna.study.Study", trial: "optuna.trial.FrozenTrial") -> bool:
return False
| {"golden_diff": "diff --git a/optuna/pruners/_nop.py b/optuna/pruners/_nop.py\n--- a/optuna/pruners/_nop.py\n+++ b/optuna/pruners/_nop.py\n@@ -1,9 +1,5 @@\n+import optuna\n from optuna.pruners import BasePruner\n-from optuna import type_checking\n-\n-if type_checking.TYPE_CHECKING:\n- from optuna.study import Study # NOQA\n- from optuna.trial import FrozenTrial # NOQA\n \n \n class NopPruner(BasePruner):\n@@ -46,7 +42,6 @@\n study.optimize(objective, n_trials=20)\n \"\"\"\n \n- def prune(self, study, trial):\n- # type: (Study, FrozenTrial) -> bool\n+ def prune(self, study: \"optuna.study.Study\", trial: \"optuna.trial.FrozenTrial\") -> bool:\n \n return False\n", "issue": "Use function annotation syntax for Type Hints.\nAfter dropping Python 2.7 support at #710, we can define type hints with function annotation syntax. \r\n~~Do you have a plan to update the coding style guideline?~~\r\nhttps://github.com/optuna/optuna/wiki/Coding-Style-Conventions\r\n\r\n## Progress\r\n\r\n- [x] `optuna/integration/sklearn.py` (#1735)\r\n- [x] `optuna/study.py` - assigned to harpy\r\n\r\n## Note to the questioner\r\n\r\nWe still cannot use variable annotation syntax introduced by [PEP 526](https://www.python.org/dev/peps/pep-0526/) because we supports Python 3.5.\n", "before_files": [{"content": "from optuna.pruners import BasePruner\nfrom optuna import type_checking\n\nif type_checking.TYPE_CHECKING:\n from optuna.study import Study # NOQA\n from optuna.trial import FrozenTrial # NOQA\n\n\nclass NopPruner(BasePruner):\n \"\"\"Pruner which never prunes trials.\n\n Example:\n\n .. testcode::\n\n import numpy as np\n from sklearn.datasets import load_iris\n from sklearn.linear_model import SGDClassifier\n from sklearn.model_selection import train_test_split\n\n import optuna\n\n X, y = load_iris(return_X_y=True)\n X_train, X_valid, y_train, y_valid = train_test_split(X, y)\n classes = np.unique(y)\n\n def objective(trial):\n alpha = trial.suggest_uniform('alpha', 0.0, 1.0)\n clf = SGDClassifier(alpha=alpha)\n n_train_iter = 100\n\n for step in range(n_train_iter):\n clf.partial_fit(X_train, y_train, classes=classes)\n\n intermediate_value = clf.score(X_valid, y_valid)\n trial.report(intermediate_value, step)\n\n if trial.should_prune():\n assert False, \"should_prune() should always return False with this pruner.\"\n raise optuna.TrialPruned()\n\n return clf.score(X_valid, y_valid)\n\n study = optuna.create_study(direction='maximize',\n pruner=optuna.pruners.NopPruner())\n study.optimize(objective, n_trials=20)\n \"\"\"\n\n def prune(self, study, trial):\n # type: (Study, FrozenTrial) -> bool\n\n return False\n", "path": "optuna/pruners/_nop.py"}]} | 1,168 | 210 |
gh_patches_debug_15760 | rasdani/github-patches | git_diff | iterative__dvc-1052 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
dvc status error with S3 output
DVC version 0.17.1, installed with pip.
Running `dvc status` shows
```
Failed to obtain data status: 'OutputS3' object has no attribute 'rel_path'
```
and nothing else (e.g. files that are not output to S3)
My .dvc/config:
```
['remote "data"']
url = s3://xxxxx/data
[core]
remote = data
['remote "s3cache"']
url = s3://xxxxx/cache
[cache]
s3 = s3cache
```
</issue>
<code>
[start of dvc/dependency/base.py]
1 import re
2
3 from dvc.exceptions import DvcException
4
5
6 class DependencyError(DvcException):
7 def __init__(self, path, msg):
8 msg = 'Dependency \'{}\' error: {}'
9 super(DependencyError, self).__init__(msg.format(path, msg))
10
11
12 class DependencyDoesNotExistError(DependencyError):
13 def __init__(self, path):
14 msg = 'does not exist'
15 super(DependencyDoesNotExistError, self).__init__(path, msg)
16
17
18 class DependencyIsNotFileOrDirError(DependencyError):
19 def __init__(self, path):
20 msg = 'not a file or directory'
21 super(DependencyIsNotFileOrDirError, self).__init__(path, msg)
22
23
24 class DependencyBase(object):
25 REGEX = None
26
27 PARAM_PATH = 'path'
28
29 def __init__(self, stage, path):
30 self.stage = stage
31 self.project = stage.project
32 self.path = path
33
34 @classmethod
35 def match(cls, url):
36 return re.match(cls.REGEX, url)
37
38 def group(self, name):
39 match = self.match(self.path)
40 if not match:
41 return None
42 return match.group(name)
43
44 @classmethod
45 def supported(cls, url):
46 return cls.match(url) is not None
47
48 @property
49 def sep(self):
50 return '/'
51
52 @property
53 def exists(self):
54 return self.remote.exists([self.path_info])
55
56 def changed(self):
57 raise NotImplementedError
58
59 def status(self):
60 if self.changed():
61 # FIXME better msgs
62 return {self.rel_path: 'changed'}
63 return {}
64
65 def save(self):
66 raise NotImplementedError
67
68 def dumpd(self):
69 return {self.PARAM_PATH: self.path}
70
71 def download(self, to_info):
72 self.remote.download([self.path_info], [to_info])
73
[end of dvc/dependency/base.py]
[start of dvc/config.py]
1 """
2 DVC config objects.
3 """
4 import os
5 import configobj
6 from schema import Schema, Optional, And, Use, Regex
7
8 from dvc.exceptions import DvcException
9
10
11 class ConfigError(DvcException):
12 """ DVC config exception """
13 def __init__(self, ex=None):
14 super(ConfigError, self).__init__('Config file error', ex)
15
16
17 def supported_url(url):
18 from dvc.remote import supported_url as supported
19 return supported(url)
20
21
22 def supported_cache_type(types):
23 if isinstance(types, str):
24 types = [t.strip() for t in types.split(',')]
25 for t in types:
26 if t not in ['reflink', 'hardlink', 'symlink', 'copy']:
27 return False
28 return True
29
30
31 def supported_loglevel(level):
32 return level in ['info', 'debug', 'warning', 'error']
33
34
35 def supported_cloud(cloud):
36 return cloud in ['aws', 'gcp', 'local', '']
37
38
39 def is_bool(val):
40 return val.lower() in ['true', 'false']
41
42
43 def to_bool(val):
44 return val.lower() == 'true'
45
46
47 class Config(object):
48 CONFIG = 'config'
49 CONFIG_LOCAL = 'config.local'
50
51 SECTION_CORE = 'core'
52 SECTION_CORE_LOGLEVEL = 'loglevel'
53 SECTION_CORE_LOGLEVEL_SCHEMA = And(Use(str.lower), supported_loglevel)
54 SECTION_CORE_REMOTE = 'remote'
55 SECTION_CORE_INTERACTIVE_SCHEMA = And(str, is_bool, Use(to_bool))
56 SECTION_CORE_INTERACTIVE = 'interactive'
57
58 SECTION_CACHE = 'cache'
59 SECTION_CACHE_DIR = 'dir'
60 SECTION_CACHE_TYPE = 'type'
61 SECTION_CACHE_TYPE_SCHEMA = supported_cache_type
62 SECTION_CACHE_LOCAL = 'local'
63 SECTION_CACHE_S3 = 's3'
64 SECTION_CACHE_GS = 'gs'
65 SECTION_CACHE_SSH = 'ssh'
66 SECTION_CACHE_HDFS = 'hdfs'
67 SECTION_CACHE_AZURE = 'azure'
68 SECTION_CACHE_SCHEMA = {
69 Optional(SECTION_CACHE_LOCAL): str,
70 Optional(SECTION_CACHE_S3): str,
71 Optional(SECTION_CACHE_GS): str,
72 Optional(SECTION_CACHE_HDFS): str,
73 Optional(SECTION_CACHE_SSH): str,
74 Optional(SECTION_CACHE_AZURE): str,
75
76 # backward compatibility
77 Optional(SECTION_CACHE_DIR, default='cache'): str,
78 Optional(SECTION_CACHE_TYPE, default=None): SECTION_CACHE_TYPE_SCHEMA,
79 }
80
81 # backward compatibility
82 SECTION_CORE_CLOUD = 'cloud'
83 SECTION_CORE_CLOUD_SCHEMA = And(Use(str.lower), supported_cloud)
84 SECTION_CORE_STORAGEPATH = 'storagepath'
85
86 SECTION_CORE_SCHEMA = {
87 Optional(SECTION_CORE_LOGLEVEL,
88 default='info'): And(str, Use(str.lower),
89 SECTION_CORE_LOGLEVEL_SCHEMA),
90 Optional(SECTION_CORE_REMOTE, default=''): And(str, Use(str.lower)),
91 Optional(SECTION_CORE_INTERACTIVE,
92 default=False): SECTION_CORE_INTERACTIVE_SCHEMA,
93
94 # backward compatibility
95 Optional(SECTION_CORE_CLOUD, default=''): SECTION_CORE_CLOUD_SCHEMA,
96 Optional(SECTION_CORE_STORAGEPATH, default=''): str,
97 }
98
99 # backward compatibility
100 SECTION_AWS = 'aws'
101 SECTION_AWS_STORAGEPATH = 'storagepath'
102 SECTION_AWS_CREDENTIALPATH = 'credentialpath'
103 SECTION_AWS_ENDPOINT_URL = 'endpointurl'
104 SECTION_AWS_REGION = 'region'
105 SECTION_AWS_PROFILE = 'profile'
106 SECTION_AWS_SCHEMA = {
107 SECTION_AWS_STORAGEPATH: str,
108 Optional(SECTION_AWS_REGION): str,
109 Optional(SECTION_AWS_PROFILE, default='default'): str,
110 Optional(SECTION_AWS_CREDENTIALPATH, default=''): str,
111 Optional(SECTION_AWS_ENDPOINT_URL, default=None): str,
112 }
113
114 # backward compatibility
115 SECTION_GCP = 'gcp'
116 SECTION_GCP_STORAGEPATH = SECTION_AWS_STORAGEPATH
117 SECTION_GCP_PROJECTNAME = 'projectname'
118 SECTION_GCP_SCHEMA = {
119 SECTION_GCP_STORAGEPATH: str,
120 Optional(SECTION_GCP_PROJECTNAME): str,
121 }
122
123 # backward compatibility
124 SECTION_LOCAL = 'local'
125 SECTION_LOCAL_STORAGEPATH = SECTION_AWS_STORAGEPATH
126 SECTION_LOCAL_SCHEMA = {
127 SECTION_LOCAL_STORAGEPATH: str,
128 }
129
130 SECTION_REMOTE_REGEX = r'^\s*remote\s*"(?P<name>.*)"\s*$'
131 SECTION_REMOTE_FMT = 'remote "{}"'
132 SECTION_REMOTE_URL = 'url'
133 SECTION_REMOTE_USER = 'user'
134 SECTION_REMOTE_SCHEMA = {
135 SECTION_REMOTE_URL: And(supported_url, error="Unsupported URL"),
136 Optional(SECTION_AWS_REGION): str,
137 Optional(SECTION_AWS_PROFILE, default='default'): str,
138 Optional(SECTION_AWS_CREDENTIALPATH, default=''): str,
139 Optional(SECTION_AWS_ENDPOINT_URL, default=None): str,
140 Optional(SECTION_GCP_PROJECTNAME): str,
141 Optional(SECTION_CACHE_TYPE): SECTION_CACHE_TYPE_SCHEMA,
142 Optional(SECTION_REMOTE_USER): str,
143 }
144
145 SCHEMA = {
146 Optional(SECTION_CORE, default={}): SECTION_CORE_SCHEMA,
147 Optional(Regex(SECTION_REMOTE_REGEX)): SECTION_REMOTE_SCHEMA,
148 Optional(SECTION_CACHE, default={}): SECTION_CACHE_SCHEMA,
149
150 # backward compatibility
151 Optional(SECTION_AWS, default={}): SECTION_AWS_SCHEMA,
152 Optional(SECTION_GCP, default={}): SECTION_GCP_SCHEMA,
153 Optional(SECTION_LOCAL, default={}): SECTION_LOCAL_SCHEMA,
154 }
155
156 def __init__(self, dvc_dir):
157 self.dvc_dir = os.path.abspath(os.path.realpath(dvc_dir))
158 self.config_file = os.path.join(dvc_dir, self.CONFIG)
159 self.config_local_file = os.path.join(dvc_dir, self.CONFIG_LOCAL)
160
161 try:
162 self._config = configobj.ConfigObj(self.config_file)
163 local = configobj.ConfigObj(self.config_local_file)
164
165 # NOTE: schema doesn't support ConfigObj.Section validation, so we
166 # need to convert our config to dict before passing it to
167 self._config = self._lower(self._config)
168 local = self._lower(local)
169 self._config.update(local)
170
171 self._config = Schema(self.SCHEMA).validate(self._config)
172
173 # NOTE: now converting back to ConfigObj
174 self._config = configobj.ConfigObj(self._config,
175 write_empty_values=True)
176 self._config.filename = self.config_file
177 except Exception as ex:
178 raise ConfigError(ex)
179
180 @staticmethod
181 def _lower(config):
182 new_config = {}
183 for s_key, s_value in config.items():
184 new_s = {}
185 for key, value in s_value.items():
186 new_s[key.lower()] = value
187 new_config[s_key.lower()] = new_s
188 return new_config
189
190 @staticmethod
191 def init(dvc_dir):
192 config_file = os.path.join(dvc_dir, Config.CONFIG)
193 open(config_file, 'w+').close()
194 return Config(dvc_dir)
195
[end of dvc/config.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/dvc/config.py b/dvc/config.py
--- a/dvc/config.py
+++ b/dvc/config.py
@@ -10,8 +10,9 @@
class ConfigError(DvcException):
""" DVC config exception """
- def __init__(self, ex=None):
- super(ConfigError, self).__init__('Config file error', ex)
+ def __init__(self, msg, ex=None):
+ super(ConfigError, self).__init__('Config file error: {}'.format(msg),
+ ex)
def supported_url(url):
diff --git a/dvc/dependency/base.py b/dvc/dependency/base.py
--- a/dvc/dependency/base.py
+++ b/dvc/dependency/base.py
@@ -59,7 +59,11 @@
def status(self):
if self.changed():
# FIXME better msgs
- return {self.rel_path: 'changed'}
+ if self.path_info['scheme'] == 'local':
+ p = self.rel_path
+ else:
+ p = self.path
+ return {p: 'changed'}
return {}
def save(self):
| {"golden_diff": "diff --git a/dvc/config.py b/dvc/config.py\n--- a/dvc/config.py\n+++ b/dvc/config.py\n@@ -10,8 +10,9 @@\n \n class ConfigError(DvcException):\n \"\"\" DVC config exception \"\"\"\n- def __init__(self, ex=None):\n- super(ConfigError, self).__init__('Config file error', ex)\n+ def __init__(self, msg, ex=None):\n+ super(ConfigError, self).__init__('Config file error: {}'.format(msg),\n+ ex)\n \n \n def supported_url(url):\ndiff --git a/dvc/dependency/base.py b/dvc/dependency/base.py\n--- a/dvc/dependency/base.py\n+++ b/dvc/dependency/base.py\n@@ -59,7 +59,11 @@\n def status(self):\n if self.changed():\n # FIXME better msgs\n- return {self.rel_path: 'changed'}\n+ if self.path_info['scheme'] == 'local':\n+ p = self.rel_path\n+ else:\n+ p = self.path\n+ return {p: 'changed'}\n return {}\n \n def save(self):\n", "issue": "dvc status error with S3 output\nDVC version 0.17.1, installed with pip.\r\n\r\nRunning `dvc status` shows\r\n```\r\nFailed to obtain data status: 'OutputS3' object has no attribute 'rel_path'\r\n```\r\nand nothing else (e.g. files that are not output to S3)\r\n\r\nMy .dvc/config:\r\n```\r\n['remote \"data\"']\r\nurl = s3://xxxxx/data\r\n[core]\r\nremote = data\r\n['remote \"s3cache\"']\r\nurl = s3://xxxxx/cache\r\n[cache]\r\ns3 = s3cache\r\n```\n", "before_files": [{"content": "import re\n\nfrom dvc.exceptions import DvcException\n\n\nclass DependencyError(DvcException):\n def __init__(self, path, msg):\n msg = 'Dependency \\'{}\\' error: {}'\n super(DependencyError, self).__init__(msg.format(path, msg))\n\n\nclass DependencyDoesNotExistError(DependencyError):\n def __init__(self, path):\n msg = 'does not exist'\n super(DependencyDoesNotExistError, self).__init__(path, msg)\n\n\nclass DependencyIsNotFileOrDirError(DependencyError):\n def __init__(self, path):\n msg = 'not a file or directory'\n super(DependencyIsNotFileOrDirError, self).__init__(path, msg)\n\n\nclass DependencyBase(object):\n REGEX = None\n\n PARAM_PATH = 'path'\n\n def __init__(self, stage, path):\n self.stage = stage\n self.project = stage.project\n self.path = path\n\n @classmethod\n def match(cls, url):\n return re.match(cls.REGEX, url)\n\n def group(self, name):\n match = self.match(self.path)\n if not match:\n return None\n return match.group(name)\n\n @classmethod\n def supported(cls, url):\n return cls.match(url) is not None\n\n @property\n def sep(self):\n return '/'\n\n @property\n def exists(self):\n return self.remote.exists([self.path_info])\n\n def changed(self):\n raise NotImplementedError\n\n def status(self):\n if self.changed():\n # FIXME better msgs\n return {self.rel_path: 'changed'}\n return {}\n\n def save(self):\n raise NotImplementedError\n\n def dumpd(self):\n return {self.PARAM_PATH: self.path}\n\n def download(self, to_info):\n self.remote.download([self.path_info], [to_info])\n", "path": "dvc/dependency/base.py"}, {"content": "\"\"\"\nDVC config objects.\n\"\"\"\nimport os\nimport configobj\nfrom schema import Schema, Optional, And, Use, Regex\n\nfrom dvc.exceptions import DvcException\n\n\nclass ConfigError(DvcException):\n \"\"\" DVC config exception \"\"\"\n def __init__(self, ex=None):\n super(ConfigError, self).__init__('Config file error', ex)\n\n\ndef supported_url(url):\n from dvc.remote import supported_url as supported\n return supported(url)\n\n\ndef supported_cache_type(types):\n if isinstance(types, str):\n types = [t.strip() for t in types.split(',')]\n for t in types:\n if t not in ['reflink', 'hardlink', 'symlink', 'copy']:\n return False\n return True\n\n\ndef supported_loglevel(level):\n return level in ['info', 'debug', 'warning', 'error']\n\n\ndef supported_cloud(cloud):\n return cloud in ['aws', 'gcp', 'local', '']\n\n\ndef is_bool(val):\n return val.lower() in ['true', 'false']\n\n\ndef to_bool(val):\n return val.lower() == 'true'\n\n\nclass Config(object):\n CONFIG = 'config'\n CONFIG_LOCAL = 'config.local'\n\n SECTION_CORE = 'core'\n SECTION_CORE_LOGLEVEL = 'loglevel'\n SECTION_CORE_LOGLEVEL_SCHEMA = And(Use(str.lower), supported_loglevel)\n SECTION_CORE_REMOTE = 'remote'\n SECTION_CORE_INTERACTIVE_SCHEMA = And(str, is_bool, Use(to_bool))\n SECTION_CORE_INTERACTIVE = 'interactive'\n\n SECTION_CACHE = 'cache'\n SECTION_CACHE_DIR = 'dir'\n SECTION_CACHE_TYPE = 'type'\n SECTION_CACHE_TYPE_SCHEMA = supported_cache_type\n SECTION_CACHE_LOCAL = 'local'\n SECTION_CACHE_S3 = 's3'\n SECTION_CACHE_GS = 'gs'\n SECTION_CACHE_SSH = 'ssh'\n SECTION_CACHE_HDFS = 'hdfs'\n SECTION_CACHE_AZURE = 'azure'\n SECTION_CACHE_SCHEMA = {\n Optional(SECTION_CACHE_LOCAL): str,\n Optional(SECTION_CACHE_S3): str,\n Optional(SECTION_CACHE_GS): str,\n Optional(SECTION_CACHE_HDFS): str,\n Optional(SECTION_CACHE_SSH): str,\n Optional(SECTION_CACHE_AZURE): str,\n\n # backward compatibility\n Optional(SECTION_CACHE_DIR, default='cache'): str,\n Optional(SECTION_CACHE_TYPE, default=None): SECTION_CACHE_TYPE_SCHEMA,\n }\n\n # backward compatibility\n SECTION_CORE_CLOUD = 'cloud'\n SECTION_CORE_CLOUD_SCHEMA = And(Use(str.lower), supported_cloud)\n SECTION_CORE_STORAGEPATH = 'storagepath'\n\n SECTION_CORE_SCHEMA = {\n Optional(SECTION_CORE_LOGLEVEL,\n default='info'): And(str, Use(str.lower),\n SECTION_CORE_LOGLEVEL_SCHEMA),\n Optional(SECTION_CORE_REMOTE, default=''): And(str, Use(str.lower)),\n Optional(SECTION_CORE_INTERACTIVE,\n default=False): SECTION_CORE_INTERACTIVE_SCHEMA,\n\n # backward compatibility\n Optional(SECTION_CORE_CLOUD, default=''): SECTION_CORE_CLOUD_SCHEMA,\n Optional(SECTION_CORE_STORAGEPATH, default=''): str,\n }\n\n # backward compatibility\n SECTION_AWS = 'aws'\n SECTION_AWS_STORAGEPATH = 'storagepath'\n SECTION_AWS_CREDENTIALPATH = 'credentialpath'\n SECTION_AWS_ENDPOINT_URL = 'endpointurl'\n SECTION_AWS_REGION = 'region'\n SECTION_AWS_PROFILE = 'profile'\n SECTION_AWS_SCHEMA = {\n SECTION_AWS_STORAGEPATH: str,\n Optional(SECTION_AWS_REGION): str,\n Optional(SECTION_AWS_PROFILE, default='default'): str,\n Optional(SECTION_AWS_CREDENTIALPATH, default=''): str,\n Optional(SECTION_AWS_ENDPOINT_URL, default=None): str,\n }\n\n # backward compatibility\n SECTION_GCP = 'gcp'\n SECTION_GCP_STORAGEPATH = SECTION_AWS_STORAGEPATH\n SECTION_GCP_PROJECTNAME = 'projectname'\n SECTION_GCP_SCHEMA = {\n SECTION_GCP_STORAGEPATH: str,\n Optional(SECTION_GCP_PROJECTNAME): str,\n }\n\n # backward compatibility\n SECTION_LOCAL = 'local'\n SECTION_LOCAL_STORAGEPATH = SECTION_AWS_STORAGEPATH\n SECTION_LOCAL_SCHEMA = {\n SECTION_LOCAL_STORAGEPATH: str,\n }\n\n SECTION_REMOTE_REGEX = r'^\\s*remote\\s*\"(?P<name>.*)\"\\s*$'\n SECTION_REMOTE_FMT = 'remote \"{}\"'\n SECTION_REMOTE_URL = 'url'\n SECTION_REMOTE_USER = 'user'\n SECTION_REMOTE_SCHEMA = {\n SECTION_REMOTE_URL: And(supported_url, error=\"Unsupported URL\"),\n Optional(SECTION_AWS_REGION): str,\n Optional(SECTION_AWS_PROFILE, default='default'): str,\n Optional(SECTION_AWS_CREDENTIALPATH, default=''): str,\n Optional(SECTION_AWS_ENDPOINT_URL, default=None): str,\n Optional(SECTION_GCP_PROJECTNAME): str,\n Optional(SECTION_CACHE_TYPE): SECTION_CACHE_TYPE_SCHEMA,\n Optional(SECTION_REMOTE_USER): str,\n }\n\n SCHEMA = {\n Optional(SECTION_CORE, default={}): SECTION_CORE_SCHEMA,\n Optional(Regex(SECTION_REMOTE_REGEX)): SECTION_REMOTE_SCHEMA,\n Optional(SECTION_CACHE, default={}): SECTION_CACHE_SCHEMA,\n\n # backward compatibility\n Optional(SECTION_AWS, default={}): SECTION_AWS_SCHEMA,\n Optional(SECTION_GCP, default={}): SECTION_GCP_SCHEMA,\n Optional(SECTION_LOCAL, default={}): SECTION_LOCAL_SCHEMA,\n }\n\n def __init__(self, dvc_dir):\n self.dvc_dir = os.path.abspath(os.path.realpath(dvc_dir))\n self.config_file = os.path.join(dvc_dir, self.CONFIG)\n self.config_local_file = os.path.join(dvc_dir, self.CONFIG_LOCAL)\n\n try:\n self._config = configobj.ConfigObj(self.config_file)\n local = configobj.ConfigObj(self.config_local_file)\n\n # NOTE: schema doesn't support ConfigObj.Section validation, so we\n # need to convert our config to dict before passing it to\n self._config = self._lower(self._config)\n local = self._lower(local)\n self._config.update(local)\n\n self._config = Schema(self.SCHEMA).validate(self._config)\n\n # NOTE: now converting back to ConfigObj\n self._config = configobj.ConfigObj(self._config,\n write_empty_values=True)\n self._config.filename = self.config_file\n except Exception as ex:\n raise ConfigError(ex)\n\n @staticmethod\n def _lower(config):\n new_config = {}\n for s_key, s_value in config.items():\n new_s = {}\n for key, value in s_value.items():\n new_s[key.lower()] = value\n new_config[s_key.lower()] = new_s\n return new_config\n\n @staticmethod\n def init(dvc_dir):\n config_file = os.path.join(dvc_dir, Config.CONFIG)\n open(config_file, 'w+').close()\n return Config(dvc_dir)\n", "path": "dvc/config.py"}]} | 3,205 | 249 |
gh_patches_debug_14763 | rasdani/github-patches | git_diff | pantsbuild__pants-20300 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`terraform_deployment` cannot load vars files if the root `terraform_module` is not in the same dir
**Describe the bug**
root/BUILD:
```
terraform_deployment(root_module="//mod0:mod0", var_files=["a.tfvars"])
```
root/a.tfvars:
```
var0 = "hihello"
```
mod/BUILD:
```
terraform_module()
```
mod/main.tf:
```
resource "null_resource" "dep" {}
```
running `pants experimental-deploy //root:root` yields:
```
Engine traceback:
in select
..
in pants.core.goals.deploy.run_deploy
`experimental-deploy` goal
Traceback (most recent call last):
File "/home/lilatomic/vnd/pants/src/python/pants/core/goals/deploy.py", line 176, in run_deploy
deploy_processes = await MultiGet(
File "/home/lilatomic/vnd/pants/src/python/pants/engine/internals/selectors.py", line 374, in MultiGet
return await _MultiGet(tuple(__arg0))
File "/home/lilatomic/vnd/pants/src/python/pants/engine/internals/selectors.py", line 172, in __await__
result = yield self.gets
ValueError: 'root/a.tfvars' is not in the subpath of 'mod0' OR one path is relative and the other is absolute.
```
**Pants version**
2.18+
</issue>
<code>
[start of src/python/pants/backend/terraform/utils.py]
1 # Copyright 2023 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3 import shlex
4 from pathlib import PurePath
5
6
7 def terraform_arg(name: str, value: str) -> str:
8 """Format a Terraform arg."""
9 return f"{name}={shlex.quote(value)}"
10
11
12 def terraform_relpath(chdir: str, target: str) -> str:
13 """Compute the relative path of a target file to the Terraform deployment root."""
14 return PurePath(target).relative_to(chdir).as_posix()
15
[end of src/python/pants/backend/terraform/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/src/python/pants/backend/terraform/utils.py b/src/python/pants/backend/terraform/utils.py
--- a/src/python/pants/backend/terraform/utils.py
+++ b/src/python/pants/backend/terraform/utils.py
@@ -1,7 +1,7 @@
# Copyright 2023 Pants project contributors (see CONTRIBUTORS.md).
# Licensed under the Apache License, Version 2.0 (see LICENSE).
+import os.path
import shlex
-from pathlib import PurePath
def terraform_arg(name: str, value: str) -> str:
@@ -11,4 +11,4 @@
def terraform_relpath(chdir: str, target: str) -> str:
"""Compute the relative path of a target file to the Terraform deployment root."""
- return PurePath(target).relative_to(chdir).as_posix()
+ return os.path.relpath(target, start=chdir)
| {"golden_diff": "diff --git a/src/python/pants/backend/terraform/utils.py b/src/python/pants/backend/terraform/utils.py\n--- a/src/python/pants/backend/terraform/utils.py\n+++ b/src/python/pants/backend/terraform/utils.py\n@@ -1,7 +1,7 @@\n # Copyright 2023 Pants project contributors (see CONTRIBUTORS.md).\n # Licensed under the Apache License, Version 2.0 (see LICENSE).\n+import os.path\n import shlex\n-from pathlib import PurePath\n \n \n def terraform_arg(name: str, value: str) -> str:\n@@ -11,4 +11,4 @@\n \n def terraform_relpath(chdir: str, target: str) -> str:\n \"\"\"Compute the relative path of a target file to the Terraform deployment root.\"\"\"\n- return PurePath(target).relative_to(chdir).as_posix()\n+ return os.path.relpath(target, start=chdir)\n", "issue": "`terraform_deployment` cannot load vars files if the root `terraform_module` is not in the same dir\n**Describe the bug**\r\n\r\nroot/BUILD:\r\n```\r\nterraform_deployment(root_module=\"//mod0:mod0\", var_files=[\"a.tfvars\"])\r\n```\r\nroot/a.tfvars:\r\n```\r\nvar0 = \"hihello\"\r\n```\r\nmod/BUILD:\r\n```\r\nterraform_module()\r\n```\r\nmod/main.tf:\r\n```\r\nresource \"null_resource\" \"dep\" {}\r\n```\r\n\r\nrunning `pants experimental-deploy //root:root` yields:\r\n```\r\nEngine traceback:\r\n in select\r\n ..\r\n in pants.core.goals.deploy.run_deploy\r\n `experimental-deploy` goal\r\n\r\nTraceback (most recent call last):\r\n File \"/home/lilatomic/vnd/pants/src/python/pants/core/goals/deploy.py\", line 176, in run_deploy\r\n deploy_processes = await MultiGet(\r\n File \"/home/lilatomic/vnd/pants/src/python/pants/engine/internals/selectors.py\", line 374, in MultiGet\r\n return await _MultiGet(tuple(__arg0))\r\n File \"/home/lilatomic/vnd/pants/src/python/pants/engine/internals/selectors.py\", line 172, in __await__\r\n result = yield self.gets\r\nValueError: 'root/a.tfvars' is not in the subpath of 'mod0' OR one path is relative and the other is absolute.\r\n```\r\n\r\n**Pants version**\r\n2.18+\r\n\n", "before_files": [{"content": "# Copyright 2023 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\nimport shlex\nfrom pathlib import PurePath\n\n\ndef terraform_arg(name: str, value: str) -> str:\n \"\"\"Format a Terraform arg.\"\"\"\n return f\"{name}={shlex.quote(value)}\"\n\n\ndef terraform_relpath(chdir: str, target: str) -> str:\n \"\"\"Compute the relative path of a target file to the Terraform deployment root.\"\"\"\n return PurePath(target).relative_to(chdir).as_posix()\n", "path": "src/python/pants/backend/terraform/utils.py"}]} | 1,009 | 197 |
gh_patches_debug_35794 | rasdani/github-patches | git_diff | microsoft__hi-ml-430 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Clean up console logging for runner
Starting the runner prints out "sys.path at container level" twice.
</issue>
<code>
[start of hi-ml-histopathology/src/histopathology/configs/SSL/CRCK_SimCLRContainer.py]
1 # ------------------------------------------------------------------------------------------
2 # Copyright (c) Microsoft Corporation. All rights reserved.
3 # Licensed under the MIT License (MIT). See LICENSE in the repo root for license information.
4 # ------------------------------------------------------------------------------------------
5 from enum import Enum
6 from pathlib import Path
7 from typing import Any
8 import sys
9
10 from SSL.lightning_containers.ssl_container import EncoderName, SSLContainer, SSLDatasetName
11 from SSL.utils import SSLTrainingType
12 from histopathology.datasets.tcga_crck_tiles_dataset import TcgaCrck_TilesDatasetWithReturnIndex
13 from histopathology.configs.SSL.HistoSimCLRContainer import HistoSSLContainer
14
15 current_file = Path(__file__)
16 print(f"Running container from {current_file}")
17 print(f"Sys path container level {sys.path}")
18
19
20 class SSLDatasetNameHiml(SSLDatasetName, Enum): # type: ignore
21 TCGA_CRCK = "CRCKTilesDataset"
22
23
24 class CRCK_SimCLR(HistoSSLContainer):
25 """
26 Config to train SSL model on CRCK tiles dataset.
27 Augmentation can be configured by using a configuration yml file or by specifying the set of transformations
28 in the _get_transforms method.
29 It has been tested locally and on AML on the full training dataset (93408 tiles).
30 """
31 SSLContainer._SSLDataClassMappings.update({SSLDatasetNameHiml.TCGA_CRCK.value:
32 TcgaCrck_TilesDatasetWithReturnIndex})
33
34 def __init__(self, **kwargs: Any) -> None:
35 # if not running in Azure ML, you may want to override certain properties on the command line, such as:
36 # --is_debug_model = True
37 # --num_workers = 0
38 # --max_epochs = 2
39
40 super().__init__(ssl_training_dataset_name=SSLDatasetNameHiml.TCGA_CRCK,
41 linear_head_dataset_name=SSLDatasetNameHiml.TCGA_CRCK,
42 azure_datasets=["TCGA-CRCk"],
43 random_seed=1,
44 num_workers=8,
45 is_debug_model=False,
46 model_checkpoint_save_interval=50,
47 model_checkpoints_save_last_k=3,
48 model_monitor_metric='ssl_online_evaluator/val/AreaUnderRocCurve',
49 model_monitor_mode='max',
50 max_epochs=50,
51 ssl_training_batch_size=48, # GPU memory is at 70% with batch_size=32, 2GPUs
52 ssl_encoder=EncoderName.resnet50,
53 ssl_training_type=SSLTrainingType.SimCLR,
54 use_balanced_binary_loss_for_linear_head=True,
55 ssl_augmentation_config=None, # Change to path_augmentation to use the config
56 linear_head_augmentation_config=None, # Change to path_augmentation to use the config
57 drop_last=False,
58 **kwargs)
59
[end of hi-ml-histopathology/src/histopathology/configs/SSL/CRCK_SimCLRContainer.py]
[start of hi-ml-histopathology/src/histopathology/configs/SSL/PANDA_SimCLRContainer.py]
1 # ------------------------------------------------------------------------------------------
2 # Copyright (c) Microsoft Corporation. All rights reserved.
3 # Licensed under the MIT License (MIT). See LICENSE in the repo root for license information.
4 # ------------------------------------------------------------------------------------------
5 from enum import Enum
6 from pathlib import Path
7 from typing import Any
8 import sys
9
10 from SSL.lightning_containers.ssl_container import EncoderName, SSLContainer, SSLDatasetName
11 from SSL.utils import SSLTrainingType
12 from health_azure.utils import is_running_in_azure_ml
13 from histopathology.datasets.panda_tiles_dataset import PandaTilesDatasetWithReturnIndex
14 from histopathology.configs.SSL.HistoSimCLRContainer import HistoSSLContainer
15 from histopathology.datasets.default_paths import PANDA_TILES_DATASET_ID
16
17
18 current_file = Path(__file__)
19 print(f"Running container from {current_file}")
20 print(f"Sys path container level {sys.path}")
21
22
23 class SSLDatasetNameHiml(SSLDatasetName, Enum): # type: ignore
24 PANDA = "PandaTilesDataset"
25
26
27 class PANDA_SimCLR(HistoSSLContainer):
28 """
29 Config to train SSL model on Panda tiles dataset.
30 Augmentation can be configured by using a configuration yml file or by specifying the set of transformations
31 in the _get_transforms method.
32 It has been tested on a toy local dataset (2 slides) and on AML on (~25 slides).
33 """
34 SSLContainer._SSLDataClassMappings.update({SSLDatasetNameHiml.PANDA.value: PandaTilesDatasetWithReturnIndex})
35
36 def __init__(self, **kwargs: Any) -> None:
37 super().__init__(ssl_training_dataset_name=SSLDatasetNameHiml.PANDA,
38 linear_head_dataset_name=SSLDatasetNameHiml.PANDA,
39 azure_datasets=[PANDA_TILES_DATASET_ID],
40 random_seed=1,
41 num_workers=5,
42 is_debug_model=False,
43 model_checkpoint_save_interval=50,
44 model_checkpoints_save_last_k=3,
45 model_monitor_metric='ssl_online_evaluator/val/AccuracyAtThreshold05',
46 model_monitor_mode='max',
47 max_epochs=200,
48 ssl_training_batch_size=128,
49 ssl_encoder=EncoderName.resnet50,
50 ssl_training_type=SSLTrainingType.SimCLR,
51 use_balanced_binary_loss_for_linear_head=True,
52 ssl_augmentation_config=None, # Change to path_augmentation to use the config
53 linear_head_augmentation_config=None, # Change to path_augmentation to use the config
54 drop_last=False,
55 **kwargs)
56 self.pl_check_val_every_n_epoch = 10
57 PandaTilesDatasetWithReturnIndex.occupancy_threshold = 0
58 PandaTilesDatasetWithReturnIndex.random_subset_fraction = 1
59 if not is_running_in_azure_ml():
60 self.is_debug_model = True
61 self.num_workers = 0
62 self.max_epochs = 2
63
[end of hi-ml-histopathology/src/histopathology/configs/SSL/PANDA_SimCLRContainer.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/hi-ml-histopathology/src/histopathology/configs/SSL/CRCK_SimCLRContainer.py b/hi-ml-histopathology/src/histopathology/configs/SSL/CRCK_SimCLRContainer.py
--- a/hi-ml-histopathology/src/histopathology/configs/SSL/CRCK_SimCLRContainer.py
+++ b/hi-ml-histopathology/src/histopathology/configs/SSL/CRCK_SimCLRContainer.py
@@ -3,19 +3,13 @@
# Licensed under the MIT License (MIT). See LICENSE in the repo root for license information.
# ------------------------------------------------------------------------------------------
from enum import Enum
-from pathlib import Path
from typing import Any
-import sys
from SSL.lightning_containers.ssl_container import EncoderName, SSLContainer, SSLDatasetName
from SSL.utils import SSLTrainingType
from histopathology.datasets.tcga_crck_tiles_dataset import TcgaCrck_TilesDatasetWithReturnIndex
from histopathology.configs.SSL.HistoSimCLRContainer import HistoSSLContainer
-current_file = Path(__file__)
-print(f"Running container from {current_file}")
-print(f"Sys path container level {sys.path}")
-
class SSLDatasetNameHiml(SSLDatasetName, Enum): # type: ignore
TCGA_CRCK = "CRCKTilesDataset"
diff --git a/hi-ml-histopathology/src/histopathology/configs/SSL/PANDA_SimCLRContainer.py b/hi-ml-histopathology/src/histopathology/configs/SSL/PANDA_SimCLRContainer.py
--- a/hi-ml-histopathology/src/histopathology/configs/SSL/PANDA_SimCLRContainer.py
+++ b/hi-ml-histopathology/src/histopathology/configs/SSL/PANDA_SimCLRContainer.py
@@ -3,9 +3,7 @@
# Licensed under the MIT License (MIT). See LICENSE in the repo root for license information.
# ------------------------------------------------------------------------------------------
from enum import Enum
-from pathlib import Path
from typing import Any
-import sys
from SSL.lightning_containers.ssl_container import EncoderName, SSLContainer, SSLDatasetName
from SSL.utils import SSLTrainingType
@@ -15,11 +13,6 @@
from histopathology.datasets.default_paths import PANDA_TILES_DATASET_ID
-current_file = Path(__file__)
-print(f"Running container from {current_file}")
-print(f"Sys path container level {sys.path}")
-
-
class SSLDatasetNameHiml(SSLDatasetName, Enum): # type: ignore
PANDA = "PandaTilesDataset"
| {"golden_diff": "diff --git a/hi-ml-histopathology/src/histopathology/configs/SSL/CRCK_SimCLRContainer.py b/hi-ml-histopathology/src/histopathology/configs/SSL/CRCK_SimCLRContainer.py\n--- a/hi-ml-histopathology/src/histopathology/configs/SSL/CRCK_SimCLRContainer.py\n+++ b/hi-ml-histopathology/src/histopathology/configs/SSL/CRCK_SimCLRContainer.py\n@@ -3,19 +3,13 @@\n # Licensed under the MIT License (MIT). See LICENSE in the repo root for license information.\n # ------------------------------------------------------------------------------------------\n from enum import Enum\n-from pathlib import Path\n from typing import Any\n-import sys\n \n from SSL.lightning_containers.ssl_container import EncoderName, SSLContainer, SSLDatasetName\n from SSL.utils import SSLTrainingType\n from histopathology.datasets.tcga_crck_tiles_dataset import TcgaCrck_TilesDatasetWithReturnIndex\n from histopathology.configs.SSL.HistoSimCLRContainer import HistoSSLContainer\n \n-current_file = Path(__file__)\n-print(f\"Running container from {current_file}\")\n-print(f\"Sys path container level {sys.path}\")\n-\n \n class SSLDatasetNameHiml(SSLDatasetName, Enum): # type: ignore\n TCGA_CRCK = \"CRCKTilesDataset\"\ndiff --git a/hi-ml-histopathology/src/histopathology/configs/SSL/PANDA_SimCLRContainer.py b/hi-ml-histopathology/src/histopathology/configs/SSL/PANDA_SimCLRContainer.py\n--- a/hi-ml-histopathology/src/histopathology/configs/SSL/PANDA_SimCLRContainer.py\n+++ b/hi-ml-histopathology/src/histopathology/configs/SSL/PANDA_SimCLRContainer.py\n@@ -3,9 +3,7 @@\n # Licensed under the MIT License (MIT). See LICENSE in the repo root for license information.\n # ------------------------------------------------------------------------------------------\n from enum import Enum\n-from pathlib import Path\n from typing import Any\n-import sys\n \n from SSL.lightning_containers.ssl_container import EncoderName, SSLContainer, SSLDatasetName\n from SSL.utils import SSLTrainingType\n@@ -15,11 +13,6 @@\n from histopathology.datasets.default_paths import PANDA_TILES_DATASET_ID\n \n \n-current_file = Path(__file__)\n-print(f\"Running container from {current_file}\")\n-print(f\"Sys path container level {sys.path}\")\n-\n-\n class SSLDatasetNameHiml(SSLDatasetName, Enum): # type: ignore\n PANDA = \"PandaTilesDataset\"\n", "issue": "Clean up console logging for runner\nStarting the runner prints out \"sys.path at container level\" twice.\n", "before_files": [{"content": "# ------------------------------------------------------------------------------------------\n# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License (MIT). See LICENSE in the repo root for license information.\n# ------------------------------------------------------------------------------------------\nfrom enum import Enum\nfrom pathlib import Path\nfrom typing import Any\nimport sys\n\nfrom SSL.lightning_containers.ssl_container import EncoderName, SSLContainer, SSLDatasetName\nfrom SSL.utils import SSLTrainingType\nfrom histopathology.datasets.tcga_crck_tiles_dataset import TcgaCrck_TilesDatasetWithReturnIndex\nfrom histopathology.configs.SSL.HistoSimCLRContainer import HistoSSLContainer\n\ncurrent_file = Path(__file__)\nprint(f\"Running container from {current_file}\")\nprint(f\"Sys path container level {sys.path}\")\n\n\nclass SSLDatasetNameHiml(SSLDatasetName, Enum): # type: ignore\n TCGA_CRCK = \"CRCKTilesDataset\"\n\n\nclass CRCK_SimCLR(HistoSSLContainer):\n \"\"\"\n Config to train SSL model on CRCK tiles dataset.\n Augmentation can be configured by using a configuration yml file or by specifying the set of transformations\n in the _get_transforms method.\n It has been tested locally and on AML on the full training dataset (93408 tiles).\n \"\"\"\n SSLContainer._SSLDataClassMappings.update({SSLDatasetNameHiml.TCGA_CRCK.value:\n TcgaCrck_TilesDatasetWithReturnIndex})\n\n def __init__(self, **kwargs: Any) -> None:\n # if not running in Azure ML, you may want to override certain properties on the command line, such as:\n # --is_debug_model = True\n # --num_workers = 0\n # --max_epochs = 2\n\n super().__init__(ssl_training_dataset_name=SSLDatasetNameHiml.TCGA_CRCK,\n linear_head_dataset_name=SSLDatasetNameHiml.TCGA_CRCK,\n azure_datasets=[\"TCGA-CRCk\"],\n random_seed=1,\n num_workers=8,\n is_debug_model=False,\n model_checkpoint_save_interval=50,\n model_checkpoints_save_last_k=3,\n model_monitor_metric='ssl_online_evaluator/val/AreaUnderRocCurve',\n model_monitor_mode='max',\n max_epochs=50,\n ssl_training_batch_size=48, # GPU memory is at 70% with batch_size=32, 2GPUs\n ssl_encoder=EncoderName.resnet50,\n ssl_training_type=SSLTrainingType.SimCLR,\n use_balanced_binary_loss_for_linear_head=True,\n ssl_augmentation_config=None, # Change to path_augmentation to use the config\n linear_head_augmentation_config=None, # Change to path_augmentation to use the config\n drop_last=False,\n **kwargs)\n", "path": "hi-ml-histopathology/src/histopathology/configs/SSL/CRCK_SimCLRContainer.py"}, {"content": "# ------------------------------------------------------------------------------------------\n# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License (MIT). See LICENSE in the repo root for license information.\n# ------------------------------------------------------------------------------------------\nfrom enum import Enum\nfrom pathlib import Path\nfrom typing import Any\nimport sys\n\nfrom SSL.lightning_containers.ssl_container import EncoderName, SSLContainer, SSLDatasetName\nfrom SSL.utils import SSLTrainingType\nfrom health_azure.utils import is_running_in_azure_ml\nfrom histopathology.datasets.panda_tiles_dataset import PandaTilesDatasetWithReturnIndex\nfrom histopathology.configs.SSL.HistoSimCLRContainer import HistoSSLContainer\nfrom histopathology.datasets.default_paths import PANDA_TILES_DATASET_ID\n\n\ncurrent_file = Path(__file__)\nprint(f\"Running container from {current_file}\")\nprint(f\"Sys path container level {sys.path}\")\n\n\nclass SSLDatasetNameHiml(SSLDatasetName, Enum): # type: ignore\n PANDA = \"PandaTilesDataset\"\n\n\nclass PANDA_SimCLR(HistoSSLContainer):\n \"\"\"\n Config to train SSL model on Panda tiles dataset.\n Augmentation can be configured by using a configuration yml file or by specifying the set of transformations\n in the _get_transforms method.\n It has been tested on a toy local dataset (2 slides) and on AML on (~25 slides).\n \"\"\"\n SSLContainer._SSLDataClassMappings.update({SSLDatasetNameHiml.PANDA.value: PandaTilesDatasetWithReturnIndex})\n\n def __init__(self, **kwargs: Any) -> None:\n super().__init__(ssl_training_dataset_name=SSLDatasetNameHiml.PANDA,\n linear_head_dataset_name=SSLDatasetNameHiml.PANDA,\n azure_datasets=[PANDA_TILES_DATASET_ID],\n random_seed=1,\n num_workers=5,\n is_debug_model=False,\n model_checkpoint_save_interval=50,\n model_checkpoints_save_last_k=3,\n model_monitor_metric='ssl_online_evaluator/val/AccuracyAtThreshold05',\n model_monitor_mode='max',\n max_epochs=200,\n ssl_training_batch_size=128,\n ssl_encoder=EncoderName.resnet50,\n ssl_training_type=SSLTrainingType.SimCLR,\n use_balanced_binary_loss_for_linear_head=True,\n ssl_augmentation_config=None, # Change to path_augmentation to use the config\n linear_head_augmentation_config=None, # Change to path_augmentation to use the config\n drop_last=False,\n **kwargs)\n self.pl_check_val_every_n_epoch = 10\n PandaTilesDatasetWithReturnIndex.occupancy_threshold = 0\n PandaTilesDatasetWithReturnIndex.random_subset_fraction = 1\n if not is_running_in_azure_ml():\n self.is_debug_model = True\n self.num_workers = 0\n self.max_epochs = 2\n", "path": "hi-ml-histopathology/src/histopathology/configs/SSL/PANDA_SimCLRContainer.py"}]} | 2,123 | 582 |
gh_patches_debug_26356 | rasdani/github-patches | git_diff | pypi__warehouse-6193 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
2FA: Enrolling a TouchID sensor as a webauthn security key fails (Chrome, Mac)
<!--
NOTE: This issue should be for problems with PyPI itself, including:
* pypi.org
* test.pypi.org
* files.pythonhosted.org
This issue should NOT be for a project installed from PyPI. If you are
having an issue with a specific package, you should reach out to the
maintainers of that project directly instead.
Furthermore, this issue should NOT be for any non-PyPI properties (like
python.org, docs.python.org, etc.)
-->
**Describe the bug**
I'm trying to enroll a TouchID sensor as a webauthn device. PyPI and Chrome do let me select the sensor, and I do get prompted for a touch, but then PyPI throws an error: "Registration rejected. Error: Self attestation is not permitted.."
**Expected behavior**
I expect to be able to enroll a TouchID sensor.
**To Reproduce**
- PyPI --> Account Settings
- Click "Add 2FA With Security Key"
- Type a key name, click "Provision Key"
- Chrome prompts to choose between a USB security key and a built-in sensor. Choose "Built-in sensor"
- MacOS prompts to hit the TouchID sensor. Do so.
- Chrome prompts, "Allow this site to see your security key?" Click "Allow"
- PyPI displays an error: "Registration rejected. Error: Self attestation is not permitted.."
**My Platform**
- MacOS 10.14.5
- MacBook Air (2018 edition, with TouchID)
- Chrome "75.0.3770.100 (Official Build) (64-bit)"
</issue>
<code>
[start of warehouse/utils/webauthn.py]
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
10 # See the License for the specific language governing permissions and
11 # limitations under the License.
12
13 import base64
14 import os
15
16 import webauthn as pywebauthn
17
18 from webauthn.webauthn import (
19 AuthenticationRejectedException as _AuthenticationRejectedException,
20 RegistrationRejectedException as _RegistrationRejectedException,
21 )
22
23
24 class AuthenticationRejectedException(Exception):
25 pass
26
27
28 class RegistrationRejectedException(Exception):
29 pass
30
31
32 WebAuthnCredential = pywebauthn.WebAuthnCredential
33
34
35 def _get_webauthn_users(user, *, icon_url, rp_id):
36 """
37 Returns a webauthn.WebAuthnUser instance corresponding
38 to the given user model, with properties suitable for
39 usage within the webauthn API.
40 """
41 return [
42 pywebauthn.WebAuthnUser(
43 str(user.id),
44 user.username,
45 user.name,
46 icon_url,
47 credential.credential_id,
48 credential.public_key,
49 credential.sign_count,
50 rp_id,
51 )
52 for credential in user.webauthn
53 ]
54
55
56 def _webauthn_b64decode(encoded):
57 padding = "=" * (len(encoded) % 4)
58 return base64.urlsafe_b64decode(encoded + padding)
59
60
61 def _webauthn_b64encode(source):
62 return base64.urlsafe_b64encode(source).rstrip(b"=")
63
64
65 def generate_webauthn_challenge():
66 """
67 Returns a random challenge suitable for use within
68 Webauthn's credential and configuration option objects.
69
70 See: https://w3c.github.io/webauthn/#cryptographic-challenges
71 """
72 # NOTE: Webauthn recommends at least 16 bytes of entropy,
73 # we go with 32 because it doesn't cost us anything.
74 return _webauthn_b64encode(os.urandom(32)).decode()
75
76
77 def get_credential_options(user, *, challenge, rp_name, rp_id, icon_url):
78 """
79 Returns a dictionary of options for credential creation
80 on the client side.
81 """
82 options = pywebauthn.WebAuthnMakeCredentialOptions(
83 challenge, rp_name, rp_id, str(user.id), user.username, user.name, icon_url
84 )
85
86 return options.registration_dict
87
88
89 def get_assertion_options(user, *, challenge, icon_url, rp_id):
90 """
91 Returns a dictionary of options for assertion retrieval
92 on the client side.
93 """
94 options = pywebauthn.WebAuthnAssertionOptions(
95 _get_webauthn_users(user, icon_url=icon_url, rp_id=rp_id), challenge
96 )
97
98 return options.assertion_dict
99
100
101 def verify_registration_response(response, challenge, *, rp_id, origin):
102 """
103 Validates the challenge and attestation information
104 sent from the client during device registration.
105
106 Returns a WebAuthnCredential on success.
107 Raises RegistrationRejectedException on failire.
108 """
109 # NOTE: We re-encode the challenge below, because our
110 # response's clientData.challenge is encoded twice:
111 # first for the entire clientData payload, and then again
112 # for the individual challenge.
113 response = pywebauthn.WebAuthnRegistrationResponse(
114 rp_id, origin, response, _webauthn_b64encode(challenge.encode()).decode()
115 )
116 try:
117 return response.verify()
118 except _RegistrationRejectedException as e:
119 raise RegistrationRejectedException(str(e))
120
121
122 def verify_assertion_response(assertion, *, challenge, user, origin, icon_url, rp_id):
123 """
124 Validates the challenge and assertion information
125 sent from the client during authentication.
126
127 Returns an updated signage count on success.
128 Raises AuthenticationRejectedException on failure.
129 """
130 webauthn_users = _get_webauthn_users(user, icon_url=icon_url, rp_id=rp_id)
131 cred_ids = [cred.credential_id for cred in webauthn_users]
132
133 for webauthn_user in webauthn_users:
134 response = pywebauthn.WebAuthnAssertionResponse(
135 webauthn_user,
136 assertion,
137 _webauthn_b64encode(challenge.encode()).decode(),
138 origin,
139 allow_credentials=cred_ids,
140 )
141 try:
142 return (webauthn_user.credential_id, response.verify())
143 except _AuthenticationRejectedException:
144 pass
145
146 # If we exit the loop, then we've failed to verify the assertion against
147 # any of the user's WebAuthn credentials. Fail.
148 raise AuthenticationRejectedException("Invalid WebAuthn credential")
149
[end of warehouse/utils/webauthn.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/warehouse/utils/webauthn.py b/warehouse/utils/webauthn.py
--- a/warehouse/utils/webauthn.py
+++ b/warehouse/utils/webauthn.py
@@ -110,8 +110,9 @@
# response's clientData.challenge is encoded twice:
# first for the entire clientData payload, and then again
# for the individual challenge.
+ encoded_challenge = _webauthn_b64encode(challenge.encode()).decode()
response = pywebauthn.WebAuthnRegistrationResponse(
- rp_id, origin, response, _webauthn_b64encode(challenge.encode()).decode()
+ rp_id, origin, response, encoded_challenge, self_attestation_permitted=True
)
try:
return response.verify()
@@ -129,12 +130,13 @@
"""
webauthn_users = _get_webauthn_users(user, icon_url=icon_url, rp_id=rp_id)
cred_ids = [cred.credential_id for cred in webauthn_users]
+ encoded_challenge = _webauthn_b64encode(challenge.encode()).decode()
for webauthn_user in webauthn_users:
response = pywebauthn.WebAuthnAssertionResponse(
webauthn_user,
assertion,
- _webauthn_b64encode(challenge.encode()).decode(),
+ encoded_challenge,
origin,
allow_credentials=cred_ids,
)
| {"golden_diff": "diff --git a/warehouse/utils/webauthn.py b/warehouse/utils/webauthn.py\n--- a/warehouse/utils/webauthn.py\n+++ b/warehouse/utils/webauthn.py\n@@ -110,8 +110,9 @@\n # response's clientData.challenge is encoded twice:\n # first for the entire clientData payload, and then again\n # for the individual challenge.\n+ encoded_challenge = _webauthn_b64encode(challenge.encode()).decode()\n response = pywebauthn.WebAuthnRegistrationResponse(\n- rp_id, origin, response, _webauthn_b64encode(challenge.encode()).decode()\n+ rp_id, origin, response, encoded_challenge, self_attestation_permitted=True\n )\n try:\n return response.verify()\n@@ -129,12 +130,13 @@\n \"\"\"\n webauthn_users = _get_webauthn_users(user, icon_url=icon_url, rp_id=rp_id)\n cred_ids = [cred.credential_id for cred in webauthn_users]\n+ encoded_challenge = _webauthn_b64encode(challenge.encode()).decode()\n \n for webauthn_user in webauthn_users:\n response = pywebauthn.WebAuthnAssertionResponse(\n webauthn_user,\n assertion,\n- _webauthn_b64encode(challenge.encode()).decode(),\n+ encoded_challenge,\n origin,\n allow_credentials=cred_ids,\n )\n", "issue": "2FA: Enrolling a TouchID sensor as a webauthn security key fails (Chrome, Mac)\n<!--\r\n NOTE: This issue should be for problems with PyPI itself, including:\r\n * pypi.org\r\n * test.pypi.org\r\n * files.pythonhosted.org\r\n\r\n This issue should NOT be for a project installed from PyPI. If you are\r\n having an issue with a specific package, you should reach out to the\r\n maintainers of that project directly instead.\r\n\r\n Furthermore, this issue should NOT be for any non-PyPI properties (like\r\n python.org, docs.python.org, etc.)\r\n-->\r\n\r\n**Describe the bug**\r\nI'm trying to enroll a TouchID sensor as a webauthn device. PyPI and Chrome do let me select the sensor, and I do get prompted for a touch, but then PyPI throws an error: \"Registration rejected. Error: Self attestation is not permitted..\"\r\n\r\n**Expected behavior**\r\nI expect to be able to enroll a TouchID sensor. \r\n\r\n**To Reproduce**\r\n- PyPI --> Account Settings\r\n- Click \"Add 2FA With Security Key\"\r\n- Type a key name, click \"Provision Key\"\r\n- Chrome prompts to choose between a USB security key and a built-in sensor. Choose \"Built-in sensor\"\r\n- MacOS prompts to hit the TouchID sensor. Do so.\r\n- Chrome prompts, \"Allow this site to see your security key?\" Click \"Allow\"\r\n- PyPI displays an error: \"Registration rejected. Error: Self attestation is not permitted..\"\r\n\r\n**My Platform**\r\n- MacOS 10.14.5\r\n- MacBook Air (2018 edition, with TouchID)\r\n- Chrome \"75.0.3770.100 (Official Build) (64-bit)\"\r\n\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport base64\nimport os\n\nimport webauthn as pywebauthn\n\nfrom webauthn.webauthn import (\n AuthenticationRejectedException as _AuthenticationRejectedException,\n RegistrationRejectedException as _RegistrationRejectedException,\n)\n\n\nclass AuthenticationRejectedException(Exception):\n pass\n\n\nclass RegistrationRejectedException(Exception):\n pass\n\n\nWebAuthnCredential = pywebauthn.WebAuthnCredential\n\n\ndef _get_webauthn_users(user, *, icon_url, rp_id):\n \"\"\"\n Returns a webauthn.WebAuthnUser instance corresponding\n to the given user model, with properties suitable for\n usage within the webauthn API.\n \"\"\"\n return [\n pywebauthn.WebAuthnUser(\n str(user.id),\n user.username,\n user.name,\n icon_url,\n credential.credential_id,\n credential.public_key,\n credential.sign_count,\n rp_id,\n )\n for credential in user.webauthn\n ]\n\n\ndef _webauthn_b64decode(encoded):\n padding = \"=\" * (len(encoded) % 4)\n return base64.urlsafe_b64decode(encoded + padding)\n\n\ndef _webauthn_b64encode(source):\n return base64.urlsafe_b64encode(source).rstrip(b\"=\")\n\n\ndef generate_webauthn_challenge():\n \"\"\"\n Returns a random challenge suitable for use within\n Webauthn's credential and configuration option objects.\n\n See: https://w3c.github.io/webauthn/#cryptographic-challenges\n \"\"\"\n # NOTE: Webauthn recommends at least 16 bytes of entropy,\n # we go with 32 because it doesn't cost us anything.\n return _webauthn_b64encode(os.urandom(32)).decode()\n\n\ndef get_credential_options(user, *, challenge, rp_name, rp_id, icon_url):\n \"\"\"\n Returns a dictionary of options for credential creation\n on the client side.\n \"\"\"\n options = pywebauthn.WebAuthnMakeCredentialOptions(\n challenge, rp_name, rp_id, str(user.id), user.username, user.name, icon_url\n )\n\n return options.registration_dict\n\n\ndef get_assertion_options(user, *, challenge, icon_url, rp_id):\n \"\"\"\n Returns a dictionary of options for assertion retrieval\n on the client side.\n \"\"\"\n options = pywebauthn.WebAuthnAssertionOptions(\n _get_webauthn_users(user, icon_url=icon_url, rp_id=rp_id), challenge\n )\n\n return options.assertion_dict\n\n\ndef verify_registration_response(response, challenge, *, rp_id, origin):\n \"\"\"\n Validates the challenge and attestation information\n sent from the client during device registration.\n\n Returns a WebAuthnCredential on success.\n Raises RegistrationRejectedException on failire.\n \"\"\"\n # NOTE: We re-encode the challenge below, because our\n # response's clientData.challenge is encoded twice:\n # first for the entire clientData payload, and then again\n # for the individual challenge.\n response = pywebauthn.WebAuthnRegistrationResponse(\n rp_id, origin, response, _webauthn_b64encode(challenge.encode()).decode()\n )\n try:\n return response.verify()\n except _RegistrationRejectedException as e:\n raise RegistrationRejectedException(str(e))\n\n\ndef verify_assertion_response(assertion, *, challenge, user, origin, icon_url, rp_id):\n \"\"\"\n Validates the challenge and assertion information\n sent from the client during authentication.\n\n Returns an updated signage count on success.\n Raises AuthenticationRejectedException on failure.\n \"\"\"\n webauthn_users = _get_webauthn_users(user, icon_url=icon_url, rp_id=rp_id)\n cred_ids = [cred.credential_id for cred in webauthn_users]\n\n for webauthn_user in webauthn_users:\n response = pywebauthn.WebAuthnAssertionResponse(\n webauthn_user,\n assertion,\n _webauthn_b64encode(challenge.encode()).decode(),\n origin,\n allow_credentials=cred_ids,\n )\n try:\n return (webauthn_user.credential_id, response.verify())\n except _AuthenticationRejectedException:\n pass\n\n # If we exit the loop, then we've failed to verify the assertion against\n # any of the user's WebAuthn credentials. Fail.\n raise AuthenticationRejectedException(\"Invalid WebAuthn credential\")\n", "path": "warehouse/utils/webauthn.py"}]} | 2,336 | 319 |
gh_patches_debug_12773 | rasdani/github-patches | git_diff | Nitrate__Nitrate-649 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Upgrade db image to newer version
Upgrade following images:
- MySQL 8.0.20
- PostgreSQL 12.2
- MariaDB 10.4.12
</issue>
<code>
[start of contrib/travis-ci/testrunner.py]
1 #!/usr/bin/env python3
2 #
3 # Nitrate is a test case management system.
4 # Copyright (C) 2019 Nitrate Team
5 #
6 # This program is free software; you can redistribute it and/or modify
7 # it under the terms of the GNU General Public License as published by
8 # the Free Software Foundation; either version 2 of the License, or
9 # (at your option) any later version.
10 #
11 # This program is distributed in the hope that it will be useful,
12 # but WITHOUT ANY WARRANTY; without even the implied warranty of
13 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
14 # GNU General Public License for more details.
15 #
16 # You should have received a copy of the GNU General Public License along
17 # with this program; if not, write to the Free Software Foundation, Inc.,
18 # 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
19
20 import argparse
21 import logging
22 import os
23 import re
24 import subprocess
25
26 from typing import Dict, List
27
28 logging.basicConfig(level=logging.DEBUG)
29 log = logging.getLogger(__name__)
30
31 DB_CONTAINER_NAME = 'nitrate-test-db'
32 TEST_DB_NAME = 'nitrate'
33 TEST_BOX_IMAGE = 'quay.io/nitrate/testbox:latest'
34 VALID_NITRATE_DB_NAMES = ['mysql', 'mariadb', 'postgres', 'sqlite']
35 # Since this script was written originally to work inside Travis-CI, using
36 # Python version 3.6 and 3.7 would be much easier to match the value of
37 # environment variable TRAVIS_PYTHON_VERSION.
38 VALID_PYTHON_VERSIONS = ['3.6', '3.7']
39 DB_CONTAINER_INFO = {
40 'mysql': {
41 'db_engine': 'mysql',
42 'db_image': 'mysql:5.7',
43 },
44 'mariadb': {
45 'db_engine': 'mysql',
46 'db_image': 'mariadb:10.2.21',
47 },
48 'sqlite': {
49 'db_engine': 'sqlite',
50 'db_image': '',
51 },
52 'postgres': {
53 'db_engine': 'pgsql',
54 'db_image': 'postgres:10.6',
55 },
56 }
57
58
59 def validate_django_ver(value):
60 regex = r'^django(>|>=|<|<=)[0-9]+\.[0-9]+,(>|>=|<|<=)[0-9]+\.[0-9]+$'
61 if not re.match(regex, value):
62 raise argparse.ArgumentTypeError(
63 f"Invalid django version specifier '{value}'.")
64 return value
65
66
67 def validate_project_dir(value):
68 if os.path.exists(value):
69 return value
70 return argparse.ArgumentTypeError(
71 'Invalid project root directory. It might not exist.')
72
73
74 def docker_run(image,
75 rm: bool = False,
76 detach: bool = False,
77 interactive: bool = False,
78 tty: bool = False,
79 name: str = None,
80 link: str = None,
81 volumes: List[str] = None,
82 envs: Dict[str, str] = None,
83 cmd_args: List[str] = None
84 ) -> None:
85 cmd = ['docker', 'run']
86 if rm:
87 cmd.append('--rm')
88 if detach:
89 cmd.append('--detach')
90 if interactive:
91 cmd.append('-i')
92 if tty:
93 cmd.append('-t')
94 if name:
95 cmd.append('--name')
96 cmd.append(name)
97 if link:
98 cmd.append('--link')
99 cmd.append(link)
100 if volumes:
101 for item in volumes:
102 cmd.append('--volume')
103 cmd.append(item)
104 if envs:
105 for var_name, var_value in envs.items():
106 cmd.append('--env')
107 cmd.append(f'{var_name}={var_value}')
108 cmd.append(image)
109 if cmd_args:
110 cmd.extend(cmd_args)
111
112 log.debug('Run: %r', cmd)
113 subprocess.check_call(cmd)
114
115
116 def docker_ps(all_: bool = False,
117 filter_: List[str] = None,
118 quiet: bool = False) -> str:
119 cmd = ['docker', 'ps']
120 if all_:
121 cmd.append('--all')
122 if filter_:
123 for item in filter_:
124 cmd.append('--filter')
125 cmd.append(item)
126 if quiet:
127 cmd.append('--quiet')
128
129 log.debug('Run: %r', cmd)
130 return subprocess.check_output(cmd, universal_newlines=True)
131
132
133 def docker_stop(name: str) -> None:
134 cmd = ['docker', 'stop', name]
135 log.debug('Run: %r', cmd)
136 subprocess.check_call(cmd)
137
138
139 def stop_container(name: str) -> None:
140 c_hash = docker_ps(all_=True, filter_=[f'name={name}'], quiet=True)
141 if c_hash:
142 docker_stop(name)
143
144
145 def main():
146 parser = argparse.ArgumentParser(
147 description='Run tests matrix inside containers. This is particularly '
148 'useful for running tests in Travis-CI.'
149 )
150 parser.add_argument(
151 '--python-ver',
152 choices=VALID_PYTHON_VERSIONS,
153 default='3.7',
154 help='Specify Python version')
155 parser.add_argument(
156 '--django-ver',
157 type=validate_django_ver,
158 default='django<2.3,>=2.2',
159 help='Specify django version specifier')
160 parser.add_argument(
161 '--nitrate-db',
162 choices=VALID_NITRATE_DB_NAMES,
163 default='sqlite',
164 help='Database engine name')
165 parser.add_argument(
166 '--project-dir',
167 metavar='DIR',
168 type=validate_project_dir,
169 default=os.path.abspath(os.curdir),
170 help='Project root directory. Default to current working directory')
171 parser.add_argument(
172 'targets', nargs='+', help='Test targets')
173
174 args = parser.parse_args()
175
176 container_info = DB_CONTAINER_INFO[args.nitrate_db]
177 db_engine = container_info['db_engine']
178 db_image = container_info['db_image']
179
180 stop_container(DB_CONTAINER_NAME)
181
182 test_box_run_opts = None
183
184 if db_engine == 'mysql':
185 docker_run(
186 db_image,
187 rm=True,
188 name=DB_CONTAINER_NAME,
189 detach=True,
190 envs={
191 'MYSQL_ALLOW_EMPTY_PASSWORD': 'yes',
192 'MYSQL_DATABASE': 'nitrate'
193 },
194 cmd_args=[
195 '--character-set-server=utf8mb4',
196 '--collation-server=utf8mb4_unicode_ci'
197 ])
198 test_box_run_opts = {
199 'link': f'{DB_CONTAINER_NAME}:mysql',
200 'envs': {
201 'NITRATE_DB_ENGINE': db_engine,
202 'NITRATE_DB_NAME': TEST_DB_NAME,
203 'NITRATE_DB_HOST': DB_CONTAINER_NAME,
204 }
205 }
206 elif db_engine == 'pgsql':
207 docker_run(
208 db_image,
209 rm=True,
210 detach=True,
211 name=DB_CONTAINER_NAME,
212 envs={'POSTGRES_PASSWORD': 'admin'}
213 )
214 test_box_run_opts = {
215 'link': f'{DB_CONTAINER_NAME}:postgres',
216 'envs': {
217 'NITRATE_DB_ENGINE': db_engine,
218 'NITRATE_DB_HOST': DB_CONTAINER_NAME,
219 'NITRATE_DB_NAME': TEST_DB_NAME,
220 'NITRATE_DB_USER': 'postgres',
221 'NITRATE_DB_PASSWORD': 'admin',
222 }
223 }
224 elif db_engine == 'sqlite':
225 # No need to launch a SQLite docker image
226 test_box_run_opts = {
227 'envs': {
228 'NITRATE_DB_ENGINE': db_engine,
229 'NITRATE_DB_NAME': "file::memory:",
230 }
231 }
232
233 test_box_container_name = f'nitrate-testbox-py{args.python_ver.replace(".", "")}'
234 test_box_run_opts.update({
235 'rm': True,
236 'interactive': True,
237 'tty': True,
238 'name': test_box_container_name,
239 'volumes': [f'{args.project_dir}:/code:Z'],
240 })
241 test_box_run_opts['envs'].update({
242 'PYTHON_VER': f'py{args.python_ver.replace(".", "")}',
243 'DJANGO_VER': args.django_ver,
244 'TEST_TARGETS': '"{}"'.format(' '.join(args.targets)),
245 })
246
247 try:
248 log.debug('Start testbox to run tests')
249 docker_run(TEST_BOX_IMAGE, **test_box_run_opts)
250 finally:
251 log.debug('Stop container: %s', DB_CONTAINER_NAME)
252 stop_container(DB_CONTAINER_NAME)
253
254
255 if __name__ == '__main__':
256 main()
257
[end of contrib/travis-ci/testrunner.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/contrib/travis-ci/testrunner.py b/contrib/travis-ci/testrunner.py
--- a/contrib/travis-ci/testrunner.py
+++ b/contrib/travis-ci/testrunner.py
@@ -39,11 +39,11 @@
DB_CONTAINER_INFO = {
'mysql': {
'db_engine': 'mysql',
- 'db_image': 'mysql:5.7',
+ 'db_image': 'mysql:8.0.20',
},
'mariadb': {
'db_engine': 'mysql',
- 'db_image': 'mariadb:10.2.21',
+ 'db_image': 'mariadb:10.4.12',
},
'sqlite': {
'db_engine': 'sqlite',
@@ -51,7 +51,7 @@
},
'postgres': {
'db_engine': 'pgsql',
- 'db_image': 'postgres:10.6',
+ 'db_image': 'postgres:12.2',
},
}
| {"golden_diff": "diff --git a/contrib/travis-ci/testrunner.py b/contrib/travis-ci/testrunner.py\n--- a/contrib/travis-ci/testrunner.py\n+++ b/contrib/travis-ci/testrunner.py\n@@ -39,11 +39,11 @@\n DB_CONTAINER_INFO = {\n 'mysql': {\n 'db_engine': 'mysql',\n- 'db_image': 'mysql:5.7',\n+ 'db_image': 'mysql:8.0.20',\n },\n 'mariadb': {\n 'db_engine': 'mysql',\n- 'db_image': 'mariadb:10.2.21',\n+ 'db_image': 'mariadb:10.4.12',\n },\n 'sqlite': {\n 'db_engine': 'sqlite',\n@@ -51,7 +51,7 @@\n },\n 'postgres': {\n 'db_engine': 'pgsql',\n- 'db_image': 'postgres:10.6',\n+ 'db_image': 'postgres:12.2',\n },\n }\n", "issue": "Upgrade db image to newer version\nUpgrade following images:\r\n\r\n- MySQL 8.0.20\r\n- PostgreSQL 12.2\r\n- MariaDB 10.4.12\n", "before_files": [{"content": "#!/usr/bin/env python3\n#\n# Nitrate is a test case management system.\n# Copyright (C) 2019 Nitrate Team\n#\n# This program is free software; you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation; either version 2 of the License, or\n# (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License along\n# with this program; if not, write to the Free Software Foundation, Inc.,\n# 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n\nimport argparse\nimport logging\nimport os\nimport re\nimport subprocess\n\nfrom typing import Dict, List\n\nlogging.basicConfig(level=logging.DEBUG)\nlog = logging.getLogger(__name__)\n\nDB_CONTAINER_NAME = 'nitrate-test-db'\nTEST_DB_NAME = 'nitrate'\nTEST_BOX_IMAGE = 'quay.io/nitrate/testbox:latest'\nVALID_NITRATE_DB_NAMES = ['mysql', 'mariadb', 'postgres', 'sqlite']\n# Since this script was written originally to work inside Travis-CI, using\n# Python version 3.6 and 3.7 would be much easier to match the value of\n# environment variable TRAVIS_PYTHON_VERSION.\nVALID_PYTHON_VERSIONS = ['3.6', '3.7']\nDB_CONTAINER_INFO = {\n 'mysql': {\n 'db_engine': 'mysql',\n 'db_image': 'mysql:5.7',\n },\n 'mariadb': {\n 'db_engine': 'mysql',\n 'db_image': 'mariadb:10.2.21',\n },\n 'sqlite': {\n 'db_engine': 'sqlite',\n 'db_image': '',\n },\n 'postgres': {\n 'db_engine': 'pgsql',\n 'db_image': 'postgres:10.6',\n },\n}\n\n\ndef validate_django_ver(value):\n regex = r'^django(>|>=|<|<=)[0-9]+\\.[0-9]+,(>|>=|<|<=)[0-9]+\\.[0-9]+$'\n if not re.match(regex, value):\n raise argparse.ArgumentTypeError(\n f\"Invalid django version specifier '{value}'.\")\n return value\n\n\ndef validate_project_dir(value):\n if os.path.exists(value):\n return value\n return argparse.ArgumentTypeError(\n 'Invalid project root directory. It might not exist.')\n\n\ndef docker_run(image,\n rm: bool = False,\n detach: bool = False,\n interactive: bool = False,\n tty: bool = False,\n name: str = None,\n link: str = None,\n volumes: List[str] = None,\n envs: Dict[str, str] = None,\n cmd_args: List[str] = None\n ) -> None:\n cmd = ['docker', 'run']\n if rm:\n cmd.append('--rm')\n if detach:\n cmd.append('--detach')\n if interactive:\n cmd.append('-i')\n if tty:\n cmd.append('-t')\n if name:\n cmd.append('--name')\n cmd.append(name)\n if link:\n cmd.append('--link')\n cmd.append(link)\n if volumes:\n for item in volumes:\n cmd.append('--volume')\n cmd.append(item)\n if envs:\n for var_name, var_value in envs.items():\n cmd.append('--env')\n cmd.append(f'{var_name}={var_value}')\n cmd.append(image)\n if cmd_args:\n cmd.extend(cmd_args)\n\n log.debug('Run: %r', cmd)\n subprocess.check_call(cmd)\n\n\ndef docker_ps(all_: bool = False,\n filter_: List[str] = None,\n quiet: bool = False) -> str:\n cmd = ['docker', 'ps']\n if all_:\n cmd.append('--all')\n if filter_:\n for item in filter_:\n cmd.append('--filter')\n cmd.append(item)\n if quiet:\n cmd.append('--quiet')\n\n log.debug('Run: %r', cmd)\n return subprocess.check_output(cmd, universal_newlines=True)\n\n\ndef docker_stop(name: str) -> None:\n cmd = ['docker', 'stop', name]\n log.debug('Run: %r', cmd)\n subprocess.check_call(cmd)\n\n\ndef stop_container(name: str) -> None:\n c_hash = docker_ps(all_=True, filter_=[f'name={name}'], quiet=True)\n if c_hash:\n docker_stop(name)\n\n\ndef main():\n parser = argparse.ArgumentParser(\n description='Run tests matrix inside containers. This is particularly '\n 'useful for running tests in Travis-CI.'\n )\n parser.add_argument(\n '--python-ver',\n choices=VALID_PYTHON_VERSIONS,\n default='3.7',\n help='Specify Python version')\n parser.add_argument(\n '--django-ver',\n type=validate_django_ver,\n default='django<2.3,>=2.2',\n help='Specify django version specifier')\n parser.add_argument(\n '--nitrate-db',\n choices=VALID_NITRATE_DB_NAMES,\n default='sqlite',\n help='Database engine name')\n parser.add_argument(\n '--project-dir',\n metavar='DIR',\n type=validate_project_dir,\n default=os.path.abspath(os.curdir),\n help='Project root directory. Default to current working directory')\n parser.add_argument(\n 'targets', nargs='+', help='Test targets')\n\n args = parser.parse_args()\n\n container_info = DB_CONTAINER_INFO[args.nitrate_db]\n db_engine = container_info['db_engine']\n db_image = container_info['db_image']\n\n stop_container(DB_CONTAINER_NAME)\n\n test_box_run_opts = None\n\n if db_engine == 'mysql':\n docker_run(\n db_image,\n rm=True,\n name=DB_CONTAINER_NAME,\n detach=True,\n envs={\n 'MYSQL_ALLOW_EMPTY_PASSWORD': 'yes',\n 'MYSQL_DATABASE': 'nitrate'\n },\n cmd_args=[\n '--character-set-server=utf8mb4',\n '--collation-server=utf8mb4_unicode_ci'\n ])\n test_box_run_opts = {\n 'link': f'{DB_CONTAINER_NAME}:mysql',\n 'envs': {\n 'NITRATE_DB_ENGINE': db_engine,\n 'NITRATE_DB_NAME': TEST_DB_NAME,\n 'NITRATE_DB_HOST': DB_CONTAINER_NAME,\n }\n }\n elif db_engine == 'pgsql':\n docker_run(\n db_image,\n rm=True,\n detach=True,\n name=DB_CONTAINER_NAME,\n envs={'POSTGRES_PASSWORD': 'admin'}\n )\n test_box_run_opts = {\n 'link': f'{DB_CONTAINER_NAME}:postgres',\n 'envs': {\n 'NITRATE_DB_ENGINE': db_engine,\n 'NITRATE_DB_HOST': DB_CONTAINER_NAME,\n 'NITRATE_DB_NAME': TEST_DB_NAME,\n 'NITRATE_DB_USER': 'postgres',\n 'NITRATE_DB_PASSWORD': 'admin',\n }\n }\n elif db_engine == 'sqlite':\n # No need to launch a SQLite docker image\n test_box_run_opts = {\n 'envs': {\n 'NITRATE_DB_ENGINE': db_engine,\n 'NITRATE_DB_NAME': \"file::memory:\",\n }\n }\n\n test_box_container_name = f'nitrate-testbox-py{args.python_ver.replace(\".\", \"\")}'\n test_box_run_opts.update({\n 'rm': True,\n 'interactive': True,\n 'tty': True,\n 'name': test_box_container_name,\n 'volumes': [f'{args.project_dir}:/code:Z'],\n })\n test_box_run_opts['envs'].update({\n 'PYTHON_VER': f'py{args.python_ver.replace(\".\", \"\")}',\n 'DJANGO_VER': args.django_ver,\n 'TEST_TARGETS': '\"{}\"'.format(' '.join(args.targets)),\n })\n\n try:\n log.debug('Start testbox to run tests')\n docker_run(TEST_BOX_IMAGE, **test_box_run_opts)\n finally:\n log.debug('Stop container: %s', DB_CONTAINER_NAME)\n stop_container(DB_CONTAINER_NAME)\n\n\nif __name__ == '__main__':\n main()\n", "path": "contrib/travis-ci/testrunner.py"}]} | 3,078 | 233 |
gh_patches_debug_30438 | rasdani/github-patches | git_diff | bridgecrewio__checkov-5301 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
TypeError in SecretManagerSecret90days
**Describe the issue**
While running a scan on TF code, I'm getting a TypeError
**Examples**
The relevant TF code is:
```
resource "aws_secretsmanager_secret_rotation" "rds_password_rotation" {
secret_id = aws_secretsmanager_secret.credentials.id
rotation_lambda_arn = "arn:..."
rotation_rules {
automatically_after_days = var.db_password_rotation_days
}
}
variable "db_password_rotation_days" {
description = "Number of days in which the RDS password will be rotated"
type = number
}
```
**Exception Trace**
```
Failed to run check CKV_AWS_304 on rds.tf:aws_secretsmanager_secret_rotation.rds_password_rotation
Traceback (most recent call last):
File "\venv\Lib\site-packages\checkov\common\checks\base_check.py", line 73, in run
check_result["result"] = self.scan_entity_conf(entity_configuration, entity_type)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "\venv\Lib\site-packages\checkov\terraform\checks\resource\base_resource_check.py", line 43, in scan_entity_conf
return self.scan_resource_conf(conf)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "\venv\Lib\site-packages\checkov\terraform\checks\resource\aws\SecretManagerSecret90days.py", line 20, in scan_resource_conf
if days < 90:
^^^^^^^^^
TypeError: '<' not supported between instances of 'str' and 'int'
```
**Desktop (please complete the following information):**
- OS: Windows 10 for Workstation
- Checkov Version 2.3.301
**Additional context**
I inspected the value of date at the line causing the error and it is the string `var.db_password_rotation_days`.
</issue>
<code>
[start of checkov/terraform/checks/resource/aws/SecretManagerSecret90days.py]
1
2 from checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck
3 from checkov.common.models.enums import CheckCategories, CheckResult
4
5
6 class SecretManagerSecret90days(BaseResourceCheck):
7
8 def __init__(self):
9 name = "Ensure Secrets Manager secrets should be rotated within 90 days"
10 id = "CKV_AWS_304"
11 supported_resources = ["aws_secretsmanager_secret_rotation"]
12 categories = [CheckCategories.GENERAL_SECURITY]
13 super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)
14
15 def scan_resource_conf(self, conf) -> CheckResult:
16 if conf.get("rotation_rules") and isinstance(conf.get("rotation_rules"), list):
17 rule = conf.get("rotation_rules")[0]
18 if rule.get('automatically_after_days') and isinstance(rule.get('automatically_after_days'), list):
19 days = rule.get('automatically_after_days')[0]
20 if days < 90:
21 return CheckResult.PASSED
22 return CheckResult.FAILED
23
24
25 check = SecretManagerSecret90days()
26
[end of checkov/terraform/checks/resource/aws/SecretManagerSecret90days.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/checkov/terraform/checks/resource/aws/SecretManagerSecret90days.py b/checkov/terraform/checks/resource/aws/SecretManagerSecret90days.py
--- a/checkov/terraform/checks/resource/aws/SecretManagerSecret90days.py
+++ b/checkov/terraform/checks/resource/aws/SecretManagerSecret90days.py
@@ -1,23 +1,27 @@
+from __future__ import annotations
+from typing import Any
+
+from checkov.common.util.type_forcers import force_int
from checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck
from checkov.common.models.enums import CheckCategories, CheckResult
class SecretManagerSecret90days(BaseResourceCheck):
-
- def __init__(self):
+ def __init__(self) -> None:
name = "Ensure Secrets Manager secrets should be rotated within 90 days"
id = "CKV_AWS_304"
- supported_resources = ["aws_secretsmanager_secret_rotation"]
- categories = [CheckCategories.GENERAL_SECURITY]
+ supported_resources = ("aws_secretsmanager_secret_rotation",)
+ categories = (CheckCategories.GENERAL_SECURITY,)
super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)
- def scan_resource_conf(self, conf) -> CheckResult:
- if conf.get("rotation_rules") and isinstance(conf.get("rotation_rules"), list):
- rule = conf.get("rotation_rules")[0]
- if rule.get('automatically_after_days') and isinstance(rule.get('automatically_after_days'), list):
- days = rule.get('automatically_after_days')[0]
- if days < 90:
+ def scan_resource_conf(self, conf: dict[str, list[Any]]) -> CheckResult:
+ rules = conf.get("rotation_rules")
+ if rules and isinstance(rules, list):
+ days = rules[0].get('automatically_after_days')
+ if days and isinstance(days, list):
+ days = force_int(days[0])
+ if days is not None and days < 90:
return CheckResult.PASSED
return CheckResult.FAILED
| {"golden_diff": "diff --git a/checkov/terraform/checks/resource/aws/SecretManagerSecret90days.py b/checkov/terraform/checks/resource/aws/SecretManagerSecret90days.py\n--- a/checkov/terraform/checks/resource/aws/SecretManagerSecret90days.py\n+++ b/checkov/terraform/checks/resource/aws/SecretManagerSecret90days.py\n@@ -1,23 +1,27 @@\n+from __future__ import annotations\n \n+from typing import Any\n+\n+from checkov.common.util.type_forcers import force_int\n from checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck\n from checkov.common.models.enums import CheckCategories, CheckResult\n \n \n class SecretManagerSecret90days(BaseResourceCheck):\n-\n- def __init__(self):\n+ def __init__(self) -> None:\n name = \"Ensure Secrets Manager secrets should be rotated within 90 days\"\n id = \"CKV_AWS_304\"\n- supported_resources = [\"aws_secretsmanager_secret_rotation\"]\n- categories = [CheckCategories.GENERAL_SECURITY]\n+ supported_resources = (\"aws_secretsmanager_secret_rotation\",)\n+ categories = (CheckCategories.GENERAL_SECURITY,)\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n \n- def scan_resource_conf(self, conf) -> CheckResult:\n- if conf.get(\"rotation_rules\") and isinstance(conf.get(\"rotation_rules\"), list):\n- rule = conf.get(\"rotation_rules\")[0]\n- if rule.get('automatically_after_days') and isinstance(rule.get('automatically_after_days'), list):\n- days = rule.get('automatically_after_days')[0]\n- if days < 90:\n+ def scan_resource_conf(self, conf: dict[str, list[Any]]) -> CheckResult:\n+ rules = conf.get(\"rotation_rules\")\n+ if rules and isinstance(rules, list):\n+ days = rules[0].get('automatically_after_days')\n+ if days and isinstance(days, list):\n+ days = force_int(days[0])\n+ if days is not None and days < 90:\n return CheckResult.PASSED\n return CheckResult.FAILED\n", "issue": "TypeError in SecretManagerSecret90days\n**Describe the issue**\r\nWhile running a scan on TF code, I'm getting a TypeError \r\n\r\n\r\n**Examples**\r\nThe relevant TF code is:\r\n```\r\nresource \"aws_secretsmanager_secret_rotation\" \"rds_password_rotation\" {\r\n secret_id = aws_secretsmanager_secret.credentials.id\r\n rotation_lambda_arn = \"arn:...\"\r\n\r\n rotation_rules {\r\n automatically_after_days = var.db_password_rotation_days\r\n }\r\n\r\n}\r\n\r\nvariable \"db_password_rotation_days\" {\r\n description = \"Number of days in which the RDS password will be rotated\"\r\n type = number\r\n}\r\n\r\n```\r\n**Exception Trace**\r\n```\r\nFailed to run check CKV_AWS_304 on rds.tf:aws_secretsmanager_secret_rotation.rds_password_rotation\r\nTraceback (most recent call last):\r\n File \"\\venv\\Lib\\site-packages\\checkov\\common\\checks\\base_check.py\", line 73, in run\r\n check_result[\"result\"] = self.scan_entity_conf(entity_configuration, entity_type)\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"\\venv\\Lib\\site-packages\\checkov\\terraform\\checks\\resource\\base_resource_check.py\", line 43, in scan_entity_conf\r\n return self.scan_resource_conf(conf)\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"\\venv\\Lib\\site-packages\\checkov\\terraform\\checks\\resource\\aws\\SecretManagerSecret90days.py\", line 20, in scan_resource_conf\r\n if days < 90:\r\n ^^^^^^^^^\r\nTypeError: '<' not supported between instances of 'str' and 'int' \r\n```\r\n\r\n**Desktop (please complete the following information):**\r\n - OS: Windows 10 for Workstation\r\n - Checkov Version 2.3.301\r\n\r\n**Additional context**\r\nI inspected the value of date at the line causing the error and it is the string `var.db_password_rotation_days`. \n", "before_files": [{"content": "\nfrom checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck\nfrom checkov.common.models.enums import CheckCategories, CheckResult\n\n\nclass SecretManagerSecret90days(BaseResourceCheck):\n\n def __init__(self):\n name = \"Ensure Secrets Manager secrets should be rotated within 90 days\"\n id = \"CKV_AWS_304\"\n supported_resources = [\"aws_secretsmanager_secret_rotation\"]\n categories = [CheckCategories.GENERAL_SECURITY]\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n\n def scan_resource_conf(self, conf) -> CheckResult:\n if conf.get(\"rotation_rules\") and isinstance(conf.get(\"rotation_rules\"), list):\n rule = conf.get(\"rotation_rules\")[0]\n if rule.get('automatically_after_days') and isinstance(rule.get('automatically_after_days'), list):\n days = rule.get('automatically_after_days')[0]\n if days < 90:\n return CheckResult.PASSED\n return CheckResult.FAILED\n\n\ncheck = SecretManagerSecret90days()\n", "path": "checkov/terraform/checks/resource/aws/SecretManagerSecret90days.py"}]} | 1,258 | 476 |
gh_patches_debug_19980 | rasdani/github-patches | git_diff | cfpb__consumerfinance.gov-229 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Centering on mobile
`the-bureau` page contains media blocks whose content (image & body) becomes centered at mobile sizes via a `media__centered` class. The `office` index page, however, introduces a new pattern of media blocks whose image centers on mobile while the body remains left-aligned.
It seems like it would be more useful to add a general-purpose `.centered-on-mobile` class (or two classes, one for inline & the other for block elements) that could be applied to the appropriate parts of the media object rather than handle this behavior through .`media` modifiers.
Thoughts? Preferences?
</issue>
<code>
[start of _lib/wordpress_office_processor.py]
1 import sys
2 import json
3 import os.path
4 import requests
5
6 def posts_at_url(url):
7
8 current_page = 1
9 max_page = sys.maxint
10
11 while current_page <= max_page:
12
13 url = os.path.expandvars(url)
14 resp = requests.get(url, params={'page':current_page, 'count': '-1'})
15 results = json.loads(resp.content)
16 current_page += 1
17 max_page = results['pages']
18 for p in results['posts']:
19 yield p
20
21 def documents(name, url, **kwargs):
22
23 for post in posts_at_url(url):
24 yield process_office(post)
25
26
27 def process_office(item):
28
29 item['_id'] = item['slug']
30 custom_fields = item['custom_fields']
31
32 # get intro text & subscribe form data from custom fields
33 for attr in ['intro_text', 'intro_subscribe_form', 'related_contact']:
34 if attr in custom_fields:
35 item[attr] = custom_fields[attr][0]
36
37 # build top story dict
38 top_story = {}
39 for attr in ['top_story_head', 'top_story_desc']:
40 if attr in custom_fields:
41 top_story[attr] = custom_fields[attr][0]
42
43 # convert top story links into a proper list
44 top_story_links = []
45 for x in xrange(0,5):
46 key = 'top_story_links_%s' % x
47 if key in custom_fields:
48 top_story_links.append(custom_fields[key])
49
50 if top_story_links:
51 top_story['top_story_links'] = top_story_links
52
53 if top_story:
54 item['top_story'] = top_story
55
56 # create list of office resource dicts
57 item['resources'] = []
58 for x in xrange(1,4):
59 resource = {}
60 fields = ['head', 'desc', 'icon', 'link_0']
61 for field in fields:
62 field_name = 'resource%s_%s' % (str(x), field)
63 if field_name in custom_fields and custom_fields[field_name][0] != '':
64 if field == 'link_0':
65 resource['link'] = custom_fields[field_name]
66 else:
67 resource[field] = custom_fields[field_name][0]
68
69 if resource:
70 item['resources'].append(resource)
71
72 return item
73
74
[end of _lib/wordpress_office_processor.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/_lib/wordpress_office_processor.py b/_lib/wordpress_office_processor.py
--- a/_lib/wordpress_office_processor.py
+++ b/_lib/wordpress_office_processor.py
@@ -55,17 +55,17 @@
# create list of office resource dicts
item['resources'] = []
- for x in xrange(1,4):
+ for x in xrange(0,4):
resource = {}
- fields = ['head', 'desc', 'icon', 'link_0']
+ fields = ['head', 'desc', 'icon', 'link']
for field in fields:
- field_name = 'resource%s_%s' % (str(x), field)
+ field_name = 'resource_%s_%s' % (str(x), field)
if field_name in custom_fields and custom_fields[field_name][0] != '':
- if field == 'link_0':
- resource['link'] = custom_fields[field_name]
+ if field == 'link':
+ resource[field] = custom_fields[field_name]
else:
resource[field] = custom_fields[field_name][0]
-
+
if resource:
item['resources'].append(resource)
| {"golden_diff": "diff --git a/_lib/wordpress_office_processor.py b/_lib/wordpress_office_processor.py\n--- a/_lib/wordpress_office_processor.py\n+++ b/_lib/wordpress_office_processor.py\n@@ -55,17 +55,17 @@\n \n # create list of office resource dicts\n item['resources'] = []\n- for x in xrange(1,4):\n+ for x in xrange(0,4):\n resource = {}\n- fields = ['head', 'desc', 'icon', 'link_0']\n+ fields = ['head', 'desc', 'icon', 'link']\n for field in fields:\n- field_name = 'resource%s_%s' % (str(x), field)\n+ field_name = 'resource_%s_%s' % (str(x), field)\n if field_name in custom_fields and custom_fields[field_name][0] != '':\n- if field == 'link_0':\n- resource['link'] = custom_fields[field_name]\n+ if field == 'link':\n+ resource[field] = custom_fields[field_name]\n else:\n resource[field] = custom_fields[field_name][0]\n- \n+ \n if resource:\n item['resources'].append(resource)\n", "issue": "Centering on mobile\n`the-bureau` page contains media blocks whose content (image & body) becomes centered at mobile sizes via a `media__centered` class. The `office` index page, however, introduces a new pattern of media blocks whose image centers on mobile while the body remains left-aligned. \n\nIt seems like it would be more useful to add a general-purpose `.centered-on-mobile` class (or two classes, one for inline & the other for block elements) that could be applied to the appropriate parts of the media object rather than handle this behavior through .`media` modifiers. \n\nThoughts? Preferences?\n\n", "before_files": [{"content": "import sys\nimport json\nimport os.path\nimport requests\n\ndef posts_at_url(url):\n \n current_page = 1\n max_page = sys.maxint\n\n while current_page <= max_page:\n\n url = os.path.expandvars(url)\n resp = requests.get(url, params={'page':current_page, 'count': '-1'})\n results = json.loads(resp.content) \n current_page += 1\n max_page = results['pages']\n for p in results['posts']:\n yield p\n \ndef documents(name, url, **kwargs):\n \n for post in posts_at_url(url):\n yield process_office(post)\n\n\ndef process_office(item):\n \n item['_id'] = item['slug']\n custom_fields = item['custom_fields']\n \n # get intro text & subscribe form data from custom fields\n for attr in ['intro_text', 'intro_subscribe_form', 'related_contact']:\n if attr in custom_fields:\n item[attr] = custom_fields[attr][0]\n \n # build top story dict\n top_story = {}\n for attr in ['top_story_head', 'top_story_desc']:\n if attr in custom_fields:\n top_story[attr] = custom_fields[attr][0]\n \n # convert top story links into a proper list\n top_story_links = []\n for x in xrange(0,5):\n key = 'top_story_links_%s' % x\n if key in custom_fields:\n top_story_links.append(custom_fields[key])\n \n if top_story_links: \n top_story['top_story_links'] = top_story_links\n \n if top_story:\n item['top_story'] = top_story\n \n # create list of office resource dicts\n item['resources'] = []\n for x in xrange(1,4):\n resource = {}\n fields = ['head', 'desc', 'icon', 'link_0']\n for field in fields:\n field_name = 'resource%s_%s' % (str(x), field)\n if field_name in custom_fields and custom_fields[field_name][0] != '':\n if field == 'link_0':\n resource['link'] = custom_fields[field_name]\n else:\n resource[field] = custom_fields[field_name][0]\n \n if resource:\n item['resources'].append(resource)\n\n return item\n\n", "path": "_lib/wordpress_office_processor.py"}]} | 1,303 | 263 |
gh_patches_debug_14209 | rasdani/github-patches | git_diff | ietf-tools__datatracker-4703 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Links to non-existing person profiles are being generated
### What happened?
For example, on http://127.0.0.1:8000/ipr/2670/history/, a link to http://127.0.0.1:8000/person/[email protected] is being generated, which 404s.
### What browser(s) are you seeing the problem on?
_No response_
### Code of Conduct
- [X] I agree to follow the IETF's Code of Conduct
</issue>
<code>
[start of ietf/person/views.py]
1 # Copyright The IETF Trust 2012-2020, All Rights Reserved
2 # -*- coding: utf-8 -*-
3
4
5 from io import StringIO, BytesIO
6 from PIL import Image
7
8 from django.contrib import messages
9 from django.db.models import Q
10 from django.http import HttpResponse, Http404
11 from django.shortcuts import render, get_object_or_404, redirect
12 from django.utils import timezone
13
14 import debug # pyflakes:ignore
15
16 from ietf.ietfauth.utils import role_required
17 from ietf.person.models import Email, Person, Alias
18 from ietf.person.fields import select2_id_name_json
19 from ietf.person.forms import MergeForm
20 from ietf.person.utils import handle_users, merge_persons
21
22
23 def ajax_select2_search(request, model_name):
24 if model_name == "email":
25 model = Email
26 else:
27 model = Person
28
29 q = [w.strip() for w in request.GET.get('q', '').split() if w.strip()]
30
31 if not q:
32 objs = model.objects.none()
33 else:
34 query = Q() # all objects returned if no other terms in the queryset
35 for t in q:
36 if model == Email:
37 query &= Q(person__alias__name__icontains=t) | Q(address__icontains=t)
38 elif model == Person:
39 if "@" in t: # allow searching email address if there's a @ in the search term
40 query &= Q(alias__name__icontains=t) | Q(email__address__icontains=t)
41 else:
42 query &= Q(alias__name__icontains=t)
43
44 objs = model.objects.filter(query)
45
46 # require an account at the Datatracker
47 only_users = request.GET.get("user") == "1"
48 all_emails = request.GET.get("a", "0") == "1"
49
50 if model == Email:
51 objs = objs.exclude(person=None).order_by('person__name')
52 if not all_emails:
53 objs = objs.filter(active=True)
54 if only_users:
55 objs = objs.exclude(person__user=None)
56 elif model == Person:
57 objs = objs.order_by("name")
58 if only_users:
59 objs = objs.exclude(user=None)
60
61 try:
62 page = int(request.GET.get("p", 1)) - 1
63 except ValueError:
64 page = 0
65
66 objs = objs.distinct()[page:page + 10]
67
68 return HttpResponse(select2_id_name_json(objs), content_type='application/json')
69
70 def profile(request, email_or_name):
71 if '@' in email_or_name:
72 persons = [ get_object_or_404(Email, address=email_or_name).person, ]
73 else:
74 aliases = Alias.objects.filter(name=email_or_name)
75 persons = list(set([ a.person for a in aliases ]))
76 persons = [ p for p in persons if p and p.id ]
77 if not persons:
78 raise Http404
79 return render(request, 'person/profile.html', {'persons': persons, 'today': timezone.now()})
80
81
82 def photo(request, email_or_name):
83 if '@' in email_or_name:
84 persons = [ get_object_or_404(Email, address=email_or_name).person, ]
85 else:
86 aliases = Alias.objects.filter(name=email_or_name)
87 persons = list(set([ a.person for a in aliases ]))
88 if not persons:
89 raise Http404("No such person")
90 if len(persons) > 1:
91 return HttpResponse(r"\r\n".join([p.email() for p in persons]), status=300)
92 person = persons[0]
93 if not person.photo:
94 raise Http404("No photo found")
95 size = request.GET.get('s') or request.GET.get('size', '80')
96 if not size.isdigit():
97 return HttpResponse("Size must be integer", status=400)
98 size = int(size)
99 img = Image.open(person.photo)
100 img = img.resize((size, img.height*size//img.width))
101 bytes = BytesIO()
102 try:
103 img.save(bytes, format='JPEG')
104 return HttpResponse(bytes.getvalue(), content_type='image/jpg')
105 except OSError:
106 raise Http404
107
108
109 @role_required("Secretariat")
110 def merge(request):
111 form = MergeForm()
112 method = 'get'
113 change_details = ''
114 warn_messages = []
115 source = None
116 target = None
117
118 if request.method == "GET":
119 form = MergeForm()
120 if request.GET:
121 form = MergeForm(request.GET)
122 if form.is_valid():
123 source = form.cleaned_data.get('source')
124 target = form.cleaned_data.get('target')
125 if source.user and target.user:
126 warn_messages.append('WARNING: Both Person records have logins. Be sure to specify the record to keep in the Target field.')
127 if source.user.last_login and target.user.last_login and source.user.last_login > target.user.last_login:
128 warn_messages.append('WARNING: The most recently used login is being deleted!')
129 change_details = handle_users(source, target, check_only=True)
130 method = 'post'
131 else:
132 method = 'get'
133
134 if request.method == "POST":
135 form = MergeForm(request.POST)
136 if form.is_valid():
137 source = form.cleaned_data.get('source')
138 source_id = source.id
139 target = form.cleaned_data.get('target')
140 # Do merge with force
141 output = StringIO()
142 success, changes = merge_persons(request, source, target, file=output)
143 if success:
144 messages.success(request, 'Merged {} ({}) to {} ({}). {})'.format(
145 source.name, source_id, target.name, target.id, changes))
146 else:
147 messages.error(request, output)
148 return redirect('ietf.secr.rolodex.views.view', id=target.pk)
149
150 return render(request, 'person/merge.html', {
151 'form': form,
152 'method': method,
153 'change_details': change_details,
154 'source': source,
155 'target': target,
156 'warn_messages': warn_messages,
157 })
158
[end of ietf/person/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/ietf/person/views.py b/ietf/person/views.py
--- a/ietf/person/views.py
+++ b/ietf/person/views.py
@@ -68,11 +68,13 @@
return HttpResponse(select2_id_name_json(objs), content_type='application/json')
def profile(request, email_or_name):
+ aliases = Alias.objects.filter(name=email_or_name)
+ persons = list(set([ a.person for a in aliases ]))
+
if '@' in email_or_name:
- persons = [ get_object_or_404(Email, address=email_or_name).person, ]
- else:
- aliases = Alias.objects.filter(name=email_or_name)
- persons = list(set([ a.person for a in aliases ]))
+ emails = Email.objects.filter(address=email_or_name)
+ persons += list(set([ e.person for e in emails ]))
+
persons = [ p for p in persons if p and p.id ]
if not persons:
raise Http404
| {"golden_diff": "diff --git a/ietf/person/views.py b/ietf/person/views.py\n--- a/ietf/person/views.py\n+++ b/ietf/person/views.py\n@@ -68,11 +68,13 @@\n return HttpResponse(select2_id_name_json(objs), content_type='application/json')\n \n def profile(request, email_or_name):\n+ aliases = Alias.objects.filter(name=email_or_name)\n+ persons = list(set([ a.person for a in aliases ]))\n+\n if '@' in email_or_name:\n- persons = [ get_object_or_404(Email, address=email_or_name).person, ]\n- else:\n- aliases = Alias.objects.filter(name=email_or_name)\n- persons = list(set([ a.person for a in aliases ]))\n+ emails = Email.objects.filter(address=email_or_name)\n+ persons += list(set([ e.person for e in emails ]))\n+\n persons = [ p for p in persons if p and p.id ]\n if not persons:\n raise Http404\n", "issue": "Links to non-existing person profiles are being generated\n### What happened?\n\nFor example, on http://127.0.0.1:8000/ipr/2670/history/, a link to http://127.0.0.1:8000/person/[email protected] is being generated, which 404s.\n\n### What browser(s) are you seeing the problem on?\n\n_No response_\n\n### Code of Conduct\n\n- [X] I agree to follow the IETF's Code of Conduct\n", "before_files": [{"content": "# Copyright The IETF Trust 2012-2020, All Rights Reserved\n# -*- coding: utf-8 -*-\n\n\nfrom io import StringIO, BytesIO\nfrom PIL import Image\n\nfrom django.contrib import messages\nfrom django.db.models import Q\nfrom django.http import HttpResponse, Http404\nfrom django.shortcuts import render, get_object_or_404, redirect\nfrom django.utils import timezone\n\nimport debug # pyflakes:ignore\n\nfrom ietf.ietfauth.utils import role_required\nfrom ietf.person.models import Email, Person, Alias\nfrom ietf.person.fields import select2_id_name_json\nfrom ietf.person.forms import MergeForm\nfrom ietf.person.utils import handle_users, merge_persons\n\n\ndef ajax_select2_search(request, model_name):\n if model_name == \"email\":\n model = Email\n else:\n model = Person\n\n q = [w.strip() for w in request.GET.get('q', '').split() if w.strip()]\n\n if not q:\n objs = model.objects.none()\n else:\n query = Q() # all objects returned if no other terms in the queryset\n for t in q:\n if model == Email:\n query &= Q(person__alias__name__icontains=t) | Q(address__icontains=t)\n elif model == Person:\n if \"@\" in t: # allow searching email address if there's a @ in the search term\n query &= Q(alias__name__icontains=t) | Q(email__address__icontains=t)\n else:\n query &= Q(alias__name__icontains=t)\n\n objs = model.objects.filter(query)\n\n # require an account at the Datatracker\n only_users = request.GET.get(\"user\") == \"1\"\n all_emails = request.GET.get(\"a\", \"0\") == \"1\"\n\n if model == Email:\n objs = objs.exclude(person=None).order_by('person__name')\n if not all_emails:\n objs = objs.filter(active=True)\n if only_users:\n objs = objs.exclude(person__user=None)\n elif model == Person:\n objs = objs.order_by(\"name\")\n if only_users:\n objs = objs.exclude(user=None)\n\n try:\n page = int(request.GET.get(\"p\", 1)) - 1\n except ValueError:\n page = 0\n\n objs = objs.distinct()[page:page + 10]\n\n return HttpResponse(select2_id_name_json(objs), content_type='application/json')\n\ndef profile(request, email_or_name):\n if '@' in email_or_name:\n persons = [ get_object_or_404(Email, address=email_or_name).person, ]\n else:\n aliases = Alias.objects.filter(name=email_or_name)\n persons = list(set([ a.person for a in aliases ]))\n persons = [ p for p in persons if p and p.id ]\n if not persons:\n raise Http404\n return render(request, 'person/profile.html', {'persons': persons, 'today': timezone.now()})\n\n\ndef photo(request, email_or_name):\n if '@' in email_or_name:\n persons = [ get_object_or_404(Email, address=email_or_name).person, ]\n else:\n aliases = Alias.objects.filter(name=email_or_name)\n persons = list(set([ a.person for a in aliases ]))\n if not persons:\n raise Http404(\"No such person\")\n if len(persons) > 1:\n return HttpResponse(r\"\\r\\n\".join([p.email() for p in persons]), status=300)\n person = persons[0]\n if not person.photo:\n raise Http404(\"No photo found\")\n size = request.GET.get('s') or request.GET.get('size', '80')\n if not size.isdigit():\n return HttpResponse(\"Size must be integer\", status=400)\n size = int(size)\n img = Image.open(person.photo)\n img = img.resize((size, img.height*size//img.width))\n bytes = BytesIO()\n try:\n img.save(bytes, format='JPEG')\n return HttpResponse(bytes.getvalue(), content_type='image/jpg')\n except OSError:\n raise Http404\n\n\n@role_required(\"Secretariat\")\ndef merge(request):\n form = MergeForm()\n method = 'get'\n change_details = ''\n warn_messages = []\n source = None\n target = None\n\n if request.method == \"GET\":\n form = MergeForm()\n if request.GET:\n form = MergeForm(request.GET)\n if form.is_valid():\n source = form.cleaned_data.get('source')\n target = form.cleaned_data.get('target')\n if source.user and target.user:\n warn_messages.append('WARNING: Both Person records have logins. Be sure to specify the record to keep in the Target field.')\n if source.user.last_login and target.user.last_login and source.user.last_login > target.user.last_login:\n warn_messages.append('WARNING: The most recently used login is being deleted!')\n change_details = handle_users(source, target, check_only=True)\n method = 'post'\n else:\n method = 'get'\n\n if request.method == \"POST\":\n form = MergeForm(request.POST)\n if form.is_valid():\n source = form.cleaned_data.get('source')\n source_id = source.id\n target = form.cleaned_data.get('target')\n # Do merge with force\n output = StringIO()\n success, changes = merge_persons(request, source, target, file=output)\n if success:\n messages.success(request, 'Merged {} ({}) to {} ({}). {})'.format(\n source.name, source_id, target.name, target.id, changes))\n else:\n messages.error(request, output)\n return redirect('ietf.secr.rolodex.views.view', id=target.pk)\n\n return render(request, 'person/merge.html', {\n 'form': form,\n 'method': method,\n 'change_details': change_details,\n 'source': source,\n 'target': target,\n 'warn_messages': warn_messages,\n })\n", "path": "ietf/person/views.py"}]} | 2,340 | 218 |
gh_patches_debug_111 | rasdani/github-patches | git_diff | vispy__vispy-1794 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add transparent color to internal color dictionary
Hi,
I've been working extending and improving `napari`'s color support (mostly [here](https://github.com/napari/napari/pull/782)) and we'd be very happy to have a "transparent" color in your internal `color_dict`, which simply corresponds to `#00000000`. This modification is very minimal (I'd be happy to do it myself) and can provide us with the bare-bones support we'd like to see.
Is that possible?
Thanks.
_Originally posted by @HagaiHargil in https://github.com/vispy/vispy/issues/1345#issuecomment-566884858_
</issue>
<code>
[start of vispy/color/_color_dict.py]
1 # -*- coding: utf-8 -*-
2 # Copyright (c) Vispy Development Team. All Rights Reserved.
3 # Distributed under the (new) BSD License. See LICENSE.txt for more info.
4
5
6 def get_color_names():
7 """Get the known color names
8
9 Returns
10 -------
11 names : list
12 List of color names known by Vispy.
13 """
14 names = list(_color_dict.keys())
15 names.sort()
16 return names
17
18
19 def get_color_dict():
20 """Get the known colors
21
22 Returns
23 -------
24 color_dict : dict
25 Dict of colors known by Vispy {name: #rgb}.
26 """
27 return _color_dict.copy()
28
29
30 # This is used by color functions to translate user strings to colors
31 # For now, this is web colors, and all in hex. It will take some simple
32 # but annoying refactoring to deal with non-hex entries if we want them.
33
34 # Add the CSS colors, courtesy MIT-licensed code from Dave Eddy:
35 # github.com/bahamas10/css-color-names/blob/master/css-color-names.json
36
37 _color_dict = {
38 "k": '#000000',
39 "w": '#FFFFFF',
40 "r": '#FF0000',
41 "g": '#00FF00',
42 "b": '#0000FF',
43 "y": '#FFFF00',
44 "m": '#FF00FF',
45 "c": '#00FFFF',
46 "aqua": "#00ffff",
47 "aliceblue": "#f0f8ff",
48 "antiquewhite": "#faebd7",
49 "black": "#000000",
50 "blue": "#0000ff",
51 "cyan": "#00ffff",
52 "darkblue": "#00008b",
53 "darkcyan": "#008b8b",
54 "darkgreen": "#006400",
55 "darkturquoise": "#00ced1",
56 "deepskyblue": "#00bfff",
57 "green": "#008000",
58 "lime": "#00ff00",
59 "mediumblue": "#0000cd",
60 "mediumspringgreen": "#00fa9a",
61 "navy": "#000080",
62 "springgreen": "#00ff7f",
63 "teal": "#008080",
64 "midnightblue": "#191970",
65 "dodgerblue": "#1e90ff",
66 "lightseagreen": "#20b2aa",
67 "forestgreen": "#228b22",
68 "seagreen": "#2e8b57",
69 "darkslategray": "#2f4f4f",
70 "darkslategrey": "#2f4f4f",
71 "limegreen": "#32cd32",
72 "mediumseagreen": "#3cb371",
73 "turquoise": "#40e0d0",
74 "royalblue": "#4169e1",
75 "steelblue": "#4682b4",
76 "darkslateblue": "#483d8b",
77 "mediumturquoise": "#48d1cc",
78 "indigo": "#4b0082",
79 "darkolivegreen": "#556b2f",
80 "cadetblue": "#5f9ea0",
81 "cornflowerblue": "#6495ed",
82 "mediumaquamarine": "#66cdaa",
83 "dimgray": "#696969",
84 "dimgrey": "#696969",
85 "slateblue": "#6a5acd",
86 "olivedrab": "#6b8e23",
87 "slategray": "#708090",
88 "slategrey": "#708090",
89 "lightslategray": "#778899",
90 "lightslategrey": "#778899",
91 "mediumslateblue": "#7b68ee",
92 "lawngreen": "#7cfc00",
93 "aquamarine": "#7fffd4",
94 "chartreuse": "#7fff00",
95 "gray": "#808080",
96 "grey": "#808080",
97 "maroon": "#800000",
98 "olive": "#808000",
99 "purple": "#800080",
100 "lightskyblue": "#87cefa",
101 "skyblue": "#87ceeb",
102 "blueviolet": "#8a2be2",
103 "darkmagenta": "#8b008b",
104 "darkred": "#8b0000",
105 "saddlebrown": "#8b4513",
106 "darkseagreen": "#8fbc8f",
107 "lightgreen": "#90ee90",
108 "mediumpurple": "#9370db",
109 "darkviolet": "#9400d3",
110 "palegreen": "#98fb98",
111 "darkorchid": "#9932cc",
112 "yellowgreen": "#9acd32",
113 "sienna": "#a0522d",
114 "brown": "#a52a2a",
115 "darkgray": "#a9a9a9",
116 "darkgrey": "#a9a9a9",
117 "greenyellow": "#adff2f",
118 "lightblue": "#add8e6",
119 "paleturquoise": "#afeeee",
120 "lightsteelblue": "#b0c4de",
121 "powderblue": "#b0e0e6",
122 "firebrick": "#b22222",
123 "darkgoldenrod": "#b8860b",
124 "mediumorchid": "#ba55d3",
125 "rosybrown": "#bc8f8f",
126 "darkkhaki": "#bdb76b",
127 "silver": "#c0c0c0",
128 "mediumvioletred": "#c71585",
129 "indianred": "#cd5c5c",
130 "peru": "#cd853f",
131 "chocolate": "#d2691e",
132 "tan": "#d2b48c",
133 "lightgray": "#d3d3d3",
134 "lightgrey": "#d3d3d3",
135 "thistle": "#d8bfd8",
136 "goldenrod": "#daa520",
137 "orchid": "#da70d6",
138 "palevioletred": "#db7093",
139 "crimson": "#dc143c",
140 "gainsboro": "#dcdcdc",
141 "plum": "#dda0dd",
142 "burlywood": "#deb887",
143 "lightcyan": "#e0ffff",
144 "lavender": "#e6e6fa",
145 "darksalmon": "#e9967a",
146 "palegoldenrod": "#eee8aa",
147 "violet": "#ee82ee",
148 "azure": "#f0ffff",
149 "honeydew": "#f0fff0",
150 "khaki": "#f0e68c",
151 "lightcoral": "#f08080",
152 "sandybrown": "#f4a460",
153 "beige": "#f5f5dc",
154 "mintcream": "#f5fffa",
155 "wheat": "#f5deb3",
156 "whitesmoke": "#f5f5f5",
157 "ghostwhite": "#f8f8ff",
158 "lightgoldenrodyellow": "#fafad2",
159 "linen": "#faf0e6",
160 "salmon": "#fa8072",
161 "oldlace": "#fdf5e6",
162 "bisque": "#ffe4c4",
163 "blanchedalmond": "#ffebcd",
164 "coral": "#ff7f50",
165 "cornsilk": "#fff8dc",
166 "darkorange": "#ff8c00",
167 "deeppink": "#ff1493",
168 "floralwhite": "#fffaf0",
169 "fuchsia": "#ff00ff",
170 "gold": "#ffd700",
171 "hotpink": "#ff69b4",
172 "ivory": "#fffff0",
173 "lavenderblush": "#fff0f5",
174 "lemonchiffon": "#fffacd",
175 "lightpink": "#ffb6c1",
176 "lightsalmon": "#ffa07a",
177 "lightyellow": "#ffffe0",
178 "magenta": "#ff00ff",
179 "mistyrose": "#ffe4e1",
180 "moccasin": "#ffe4b5",
181 "navajowhite": "#ffdead",
182 "orange": "#ffa500",
183 "orangered": "#ff4500",
184 "papayawhip": "#ffefd5",
185 "peachpuff": "#ffdab9",
186 "pink": "#ffc0cb",
187 "red": "#ff0000",
188 "seashell": "#fff5ee",
189 "snow": "#fffafa",
190 "tomato": "#ff6347",
191 "white": "#ffffff",
192 "yellow": "#ffff00",
193 }
194
[end of vispy/color/_color_dict.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/vispy/color/_color_dict.py b/vispy/color/_color_dict.py
--- a/vispy/color/_color_dict.py
+++ b/vispy/color/_color_dict.py
@@ -190,4 +190,5 @@
"tomato": "#ff6347",
"white": "#ffffff",
"yellow": "#ffff00",
+ "transparent": "#00000000",
}
| {"golden_diff": "diff --git a/vispy/color/_color_dict.py b/vispy/color/_color_dict.py\n--- a/vispy/color/_color_dict.py\n+++ b/vispy/color/_color_dict.py\n@@ -190,4 +190,5 @@\n \"tomato\": \"#ff6347\",\n \"white\": \"#ffffff\",\n \"yellow\": \"#ffff00\",\n+ \"transparent\": \"#00000000\",\n }\n", "issue": "Add transparent color to internal color dictionary\nHi, \r\n\r\nI've been working extending and improving `napari`'s color support (mostly [here](https://github.com/napari/napari/pull/782)) and we'd be very happy to have a \"transparent\" color in your internal `color_dict`, which simply corresponds to `#00000000`. This modification is very minimal (I'd be happy to do it myself) and can provide us with the bare-bones support we'd like to see.\r\n\r\nIs that possible?\r\nThanks.\r\n\r\n_Originally posted by @HagaiHargil in https://github.com/vispy/vispy/issues/1345#issuecomment-566884858_\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright (c) Vispy Development Team. All Rights Reserved.\n# Distributed under the (new) BSD License. See LICENSE.txt for more info.\n\n\ndef get_color_names():\n \"\"\"Get the known color names\n\n Returns\n -------\n names : list\n List of color names known by Vispy.\n \"\"\"\n names = list(_color_dict.keys())\n names.sort()\n return names\n\n\ndef get_color_dict():\n \"\"\"Get the known colors\n\n Returns\n -------\n color_dict : dict\n Dict of colors known by Vispy {name: #rgb}.\n \"\"\"\n return _color_dict.copy()\n\n\n# This is used by color functions to translate user strings to colors\n# For now, this is web colors, and all in hex. It will take some simple\n# but annoying refactoring to deal with non-hex entries if we want them.\n\n# Add the CSS colors, courtesy MIT-licensed code from Dave Eddy:\n# github.com/bahamas10/css-color-names/blob/master/css-color-names.json\n\n_color_dict = {\n \"k\": '#000000',\n \"w\": '#FFFFFF',\n \"r\": '#FF0000',\n \"g\": '#00FF00',\n \"b\": '#0000FF',\n \"y\": '#FFFF00',\n \"m\": '#FF00FF',\n \"c\": '#00FFFF',\n \"aqua\": \"#00ffff\",\n \"aliceblue\": \"#f0f8ff\",\n \"antiquewhite\": \"#faebd7\",\n \"black\": \"#000000\",\n \"blue\": \"#0000ff\",\n \"cyan\": \"#00ffff\",\n \"darkblue\": \"#00008b\",\n \"darkcyan\": \"#008b8b\",\n \"darkgreen\": \"#006400\",\n \"darkturquoise\": \"#00ced1\",\n \"deepskyblue\": \"#00bfff\",\n \"green\": \"#008000\",\n \"lime\": \"#00ff00\",\n \"mediumblue\": \"#0000cd\",\n \"mediumspringgreen\": \"#00fa9a\",\n \"navy\": \"#000080\",\n \"springgreen\": \"#00ff7f\",\n \"teal\": \"#008080\",\n \"midnightblue\": \"#191970\",\n \"dodgerblue\": \"#1e90ff\",\n \"lightseagreen\": \"#20b2aa\",\n \"forestgreen\": \"#228b22\",\n \"seagreen\": \"#2e8b57\",\n \"darkslategray\": \"#2f4f4f\",\n \"darkslategrey\": \"#2f4f4f\",\n \"limegreen\": \"#32cd32\",\n \"mediumseagreen\": \"#3cb371\",\n \"turquoise\": \"#40e0d0\",\n \"royalblue\": \"#4169e1\",\n \"steelblue\": \"#4682b4\",\n \"darkslateblue\": \"#483d8b\",\n \"mediumturquoise\": \"#48d1cc\",\n \"indigo\": \"#4b0082\",\n \"darkolivegreen\": \"#556b2f\",\n \"cadetblue\": \"#5f9ea0\",\n \"cornflowerblue\": \"#6495ed\",\n \"mediumaquamarine\": \"#66cdaa\",\n \"dimgray\": \"#696969\",\n \"dimgrey\": \"#696969\",\n \"slateblue\": \"#6a5acd\",\n \"olivedrab\": \"#6b8e23\",\n \"slategray\": \"#708090\",\n \"slategrey\": \"#708090\",\n \"lightslategray\": \"#778899\",\n \"lightslategrey\": \"#778899\",\n \"mediumslateblue\": \"#7b68ee\",\n \"lawngreen\": \"#7cfc00\",\n \"aquamarine\": \"#7fffd4\",\n \"chartreuse\": \"#7fff00\",\n \"gray\": \"#808080\",\n \"grey\": \"#808080\",\n \"maroon\": \"#800000\",\n \"olive\": \"#808000\",\n \"purple\": \"#800080\",\n \"lightskyblue\": \"#87cefa\",\n \"skyblue\": \"#87ceeb\",\n \"blueviolet\": \"#8a2be2\",\n \"darkmagenta\": \"#8b008b\",\n \"darkred\": \"#8b0000\",\n \"saddlebrown\": \"#8b4513\",\n \"darkseagreen\": \"#8fbc8f\",\n \"lightgreen\": \"#90ee90\",\n \"mediumpurple\": \"#9370db\",\n \"darkviolet\": \"#9400d3\",\n \"palegreen\": \"#98fb98\",\n \"darkorchid\": \"#9932cc\",\n \"yellowgreen\": \"#9acd32\",\n \"sienna\": \"#a0522d\",\n \"brown\": \"#a52a2a\",\n \"darkgray\": \"#a9a9a9\",\n \"darkgrey\": \"#a9a9a9\",\n \"greenyellow\": \"#adff2f\",\n \"lightblue\": \"#add8e6\",\n \"paleturquoise\": \"#afeeee\",\n \"lightsteelblue\": \"#b0c4de\",\n \"powderblue\": \"#b0e0e6\",\n \"firebrick\": \"#b22222\",\n \"darkgoldenrod\": \"#b8860b\",\n \"mediumorchid\": \"#ba55d3\",\n \"rosybrown\": \"#bc8f8f\",\n \"darkkhaki\": \"#bdb76b\",\n \"silver\": \"#c0c0c0\",\n \"mediumvioletred\": \"#c71585\",\n \"indianred\": \"#cd5c5c\",\n \"peru\": \"#cd853f\",\n \"chocolate\": \"#d2691e\",\n \"tan\": \"#d2b48c\",\n \"lightgray\": \"#d3d3d3\",\n \"lightgrey\": \"#d3d3d3\",\n \"thistle\": \"#d8bfd8\",\n \"goldenrod\": \"#daa520\",\n \"orchid\": \"#da70d6\",\n \"palevioletred\": \"#db7093\",\n \"crimson\": \"#dc143c\",\n \"gainsboro\": \"#dcdcdc\",\n \"plum\": \"#dda0dd\",\n \"burlywood\": \"#deb887\",\n \"lightcyan\": \"#e0ffff\",\n \"lavender\": \"#e6e6fa\",\n \"darksalmon\": \"#e9967a\",\n \"palegoldenrod\": \"#eee8aa\",\n \"violet\": \"#ee82ee\",\n \"azure\": \"#f0ffff\",\n \"honeydew\": \"#f0fff0\",\n \"khaki\": \"#f0e68c\",\n \"lightcoral\": \"#f08080\",\n \"sandybrown\": \"#f4a460\",\n \"beige\": \"#f5f5dc\",\n \"mintcream\": \"#f5fffa\",\n \"wheat\": \"#f5deb3\",\n \"whitesmoke\": \"#f5f5f5\",\n \"ghostwhite\": \"#f8f8ff\",\n \"lightgoldenrodyellow\": \"#fafad2\",\n \"linen\": \"#faf0e6\",\n \"salmon\": \"#fa8072\",\n \"oldlace\": \"#fdf5e6\",\n \"bisque\": \"#ffe4c4\",\n \"blanchedalmond\": \"#ffebcd\",\n \"coral\": \"#ff7f50\",\n \"cornsilk\": \"#fff8dc\",\n \"darkorange\": \"#ff8c00\",\n \"deeppink\": \"#ff1493\",\n \"floralwhite\": \"#fffaf0\",\n \"fuchsia\": \"#ff00ff\",\n \"gold\": \"#ffd700\",\n \"hotpink\": \"#ff69b4\",\n \"ivory\": \"#fffff0\",\n \"lavenderblush\": \"#fff0f5\",\n \"lemonchiffon\": \"#fffacd\",\n \"lightpink\": \"#ffb6c1\",\n \"lightsalmon\": \"#ffa07a\",\n \"lightyellow\": \"#ffffe0\",\n \"magenta\": \"#ff00ff\",\n \"mistyrose\": \"#ffe4e1\",\n \"moccasin\": \"#ffe4b5\",\n \"navajowhite\": \"#ffdead\",\n \"orange\": \"#ffa500\",\n \"orangered\": \"#ff4500\",\n \"papayawhip\": \"#ffefd5\",\n \"peachpuff\": \"#ffdab9\",\n \"pink\": \"#ffc0cb\",\n \"red\": \"#ff0000\",\n \"seashell\": \"#fff5ee\",\n \"snow\": \"#fffafa\",\n \"tomato\": \"#ff6347\",\n \"white\": \"#ffffff\",\n \"yellow\": \"#ffff00\",\n}\n", "path": "vispy/color/_color_dict.py"}]} | 3,308 | 102 |
gh_patches_debug_39843 | rasdani/github-patches | git_diff | projectmesa__mesa-289 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Minor docstring clean-up needed on time.py and batchrunner.py
A couple of typos and minor content edit items for the two files.
Minor docstring clean-up needed on time.py and batchrunner.py
A couple of typos and minor content edit items for the two files.
</issue>
<code>
[start of mesa/batchrunner.py]
1 # -*- coding: utf-8 -*-
2 """
3 Batchrunner
4 ===========
5
6 A single class to manage a batch run or parameter sweep of a given model.
7
8 """
9 from itertools import product
10 import pandas as pd
11
12
13 class BatchRunner:
14 """ This class is instantiated with a model class, and model parameters
15 associated with one or more values. It is also instantiated with model- and
16 agent-level reporters, dictionaries mapping a variable name to a function
17 which collects some data from the model or its agents at the end of the run
18 and stores it.
19
20 Note that by default, the reporters only collect data at the *end* of the
21 run. To get step by step data, simply have a reporter store the model's
22 entire DataCollector object.
23
24 """
25 def __init__(self, model_cls, parameter_values, iterations=1,
26 max_steps=1000, model_reporters=None, agent_reporters=None):
27 """ Create a new BatchRunner for a given model with the given
28 parameters.
29
30 Args:
31 model_cls: The class of model to batch-run.
32 parameter_values: Dictionary of parameters to their values or
33 ranges of values. For example:
34 {"param_1": range(5),
35 "param_2": [1, 5, 10],
36 "const_param": 100}
37 iterations: How many times to run the model at each combination of
38 parameters.
39 max_steps: After how many steps to halt each run if it hasn't
40 halted on its own.
41 model_reporters: Dictionary of variables to collect on each run at
42 the end, with variable names mapped to a function to collect
43 them. For example:
44 {"agent_count": lambda m: m.schedule.get_agent_count()}
45 agent_reporters: Like model_reporters, but each variable is now
46 collected at the level of each agent present in the model at
47 the end of the run.
48
49 """
50 self.model_cls = model_cls
51 self.parameter_values = {param: self.make_iterable(vals)
52 for param, vals in parameter_values.items()}
53 self.iterations = iterations
54 self.max_steps = max_steps
55
56 self.model_reporters = model_reporters
57 self.agent_reporters = agent_reporters
58
59 if self.model_reporters:
60 self.model_vars = {}
61
62 if self.agent_reporters:
63 self.agent_vars = {}
64
65 def run_all(self):
66 """ Run the model at all parameter combinations and store results. """
67 params = self.parameter_values.keys()
68 param_ranges = self.parameter_values.values()
69 run_count = 0
70 for param_values in list(product(*param_ranges)):
71 kwargs = dict(zip(params, param_values))
72 for _ in range(self.iterations):
73 model = self.model_cls(**kwargs)
74 self.run_model(model)
75 # Collect and store results:
76 if self.model_reporters:
77 key = tuple(list(param_values) + [run_count])
78 self.model_vars[key] = self.collect_model_vars(model)
79 if self.agent_reporters:
80 agent_vars = self.collect_agent_vars(model)
81 for agent_id, reports in agent_vars.items():
82 key = tuple(list(param_values) + [run_count, agent_id])
83 self.agent_vars[key] = reports
84 run_count += 1
85
86 def run_model(self, model):
87 """ Run a model object to completion, or until reaching max steps.
88
89 If your model runs in a non-standard way, this is the method to modify
90 in your subclass.
91
92 """
93 while model.running and model.schedule.steps < self.max_steps:
94 model.step()
95
96 def collect_model_vars(self, model):
97 """ Run reporters and collect model-level variables. """
98 model_vars = {}
99 for var, reporter in self.model_reporters.items():
100 model_vars[var] = reporter(model)
101 return model_vars
102
103 def collect_agent_vars(self, model):
104 """ Run reporters and collect agent-level variables. """
105 agent_vars = {}
106 for agent in model.schedule.agents:
107 agent_record = {}
108 for var, reporter in self.agent_reporters.items():
109 agent_record[var] = reporter(agent)
110 agent_vars[agent.unique_id] = agent_record
111 return agent_vars
112
113 def get_model_vars_dataframe(self):
114 """ Generate a pandas DataFrame from the model-level collected
115 variables.
116
117 """
118 index_col_names = list(self.parameter_values.keys())
119 index_col_names.append("Run")
120 records = []
121 for key, val in self.model_vars.items():
122 record = dict(zip(index_col_names, key))
123 for k, v in val.items():
124 record[k] = v
125 records.append(record)
126 return pd.DataFrame(records)
127
128 def get_agent_vars_dataframe(self):
129 """ Generate a pandas DataFrame from the agent-level variables
130 collected.
131
132 """
133 index_col_names = list(self.parameter_values.keys())
134 index_col_names += ["Run", "AgentID"]
135 records = []
136 for key, val in self.agent_vars.items():
137 record = dict(zip(index_col_names, key))
138 for k, v in val.items():
139 record[k] = v
140 records.append(record)
141 return pd.DataFrame(records)
142
143 @staticmethod
144 def make_iterable(val):
145 """ Helper method to ensure a value is a non-string iterable. """
146 if hasattr(val, "__iter__") and not isinstance(val, str):
147 return val
148 else:
149 return [val]
150
[end of mesa/batchrunner.py]
[start of mesa/time.py]
1 # -*- coding: utf-8 -*-
2 """
3 Mesa Time Module
4 ================
5
6 Objects for handling the time component of a model. In particular, this module
7 contains Schedulers, which handle agent activation. A Scheduler is an object
8 which controls when agents are called upon to act, and when.
9
10 The activation order can have a serious impact on model behavior, so it's
11 important to specify it explicity. Example simple activation regimes include
12 activating all agents in the same order every step, shuffling the activation
13 order every time, activating each agent *on average* once per step, and more.
14
15 Key concepts:
16 Step: Many models advance in 'steps'. A step may involve the activation of
17 all agents, or a random (or selected) subset of them. Each agent in turn
18 may have their own step() method.
19
20 Time: Some models may simulate a continuous 'clock' instead of discrete
21 steps. However, by default, the Time is equal to the number of steps the
22 model has taken.
23
24
25 TODO: Have the schedulers use the model's randomizer, to keep random number
26 seeds consistent and allow for replication.
27
28 """
29 import random
30
31
32 class BaseScheduler:
33 """ Simplest scheduler; activates agents one at a time, in the order
34 they were added.
35
36 Assumes that each agent added has a *step* method, which accepts a model
37 object as its single argument.
38
39 (This is explicitly meant to replicate the scheduler in MASON).
40
41 """
42 model = None
43 steps = 0
44 time = 0
45 agents = []
46
47 def __init__(self, model):
48 """ Create a new, empty BaseScheduler. """
49 self.model = model
50 self.steps = 0
51 self.time = 0
52 self.agents = []
53
54 def add(self, agent):
55 """ Add an Agent object to the schedule.
56
57 Args:
58 agent: An Agent to be added to the schedule. NOTE: The agent must
59 have a step(model) method.
60
61 """
62 self.agents.append(agent)
63
64 def remove(self, agent):
65 """ Remove all instances of a given agent from the schedule.
66
67 Args:
68 agent: An agent object.
69
70 """
71 while agent in self.agents:
72 self.agents.remove(agent)
73
74 def step(self):
75 """ Execute the step of all the agents, one at a time. """
76 for agent in self.agents:
77 agent.step(self.model)
78 self.steps += 1
79 self.time += 1
80
81 def get_agent_count(self):
82 """ Returns the current number of agents in the queue. """
83 return len(self.agents)
84
85
86 class RandomActivation(BaseScheduler):
87 """ A scheduler which activates each agent once per step, in random order,
88 with the order reshuffled every step.
89
90 This is equivalent to the NetLogo 'ask agents...' and is generally the
91 default behavior for an ABM.
92
93 Assumes that all agents have a step(model) method.
94
95 """
96 def step(self):
97 """ Executes the step of all agents, one at a time, in
98 random order.
99
100 """
101 random.shuffle(self.agents)
102
103 for agent in self.agents:
104 agent.step(self.model)
105 self.steps += 1
106 self.time += 1
107
108
109 class SimultaneousActivation(BaseScheduler):
110 """ A scheduler to simulate the simultaneous activation of all the agents.
111
112 This scheduler requires that each agent have two methods: step and advance.
113 step(model) activates the agent and stages any necessary changes, but does
114 not apply them yet. advance(model) then applies the changes.
115
116 """
117 def step(self):
118 """ Step all agents, then advance them. """
119 for agent in self.agents:
120 agent.step(self.model)
121 for agent in self.agents:
122 agent.advance(self.model)
123 self.steps += 1
124 self.time += 1
125
126
127 class StagedActivation(BaseScheduler):
128 """ A scheduler which allows agent activation to be divided into several
129 stages instead of a single `step` method. All agents execute one stage
130 before moving on to the next.
131
132 Agents must have all the stage methods implemented. Stage methods take a
133 model object as their only argument.
134
135 This schedule tracks steps and time separately. Time advances in fractional
136 increments of 1 / (# of stages), meaning that 1 step = 1 unit of time.
137
138 """
139 stage_list = []
140 shuffle = False
141 shuffle_between_stages = False
142 stage_time = 1
143
144 def __init__(self, model, stage_list=["step"], shuffle=False,
145 shuffle_between_stages=False):
146 """ Create an empty Staged Activation schedule.
147
148 Args:
149 model: Model object associated with the schedule.
150 stage_list: List of strings of names of stages to run, in the
151 order to run them in.
152 shuffle: If True, shuffle the order of agents each step.
153 shuffle_between_stages: If True, shuffle the agents after each
154 stage; otherwise, only shuffle at the start
155 of each step.
156
157 """
158 super().__init__(model)
159 self.stage_list = stage_list
160 self.shuffle = shuffle
161 self.shuffle_between_stages = shuffle_between_stages
162 self.stage_time = 1 / len(self.stage_list)
163
164 def step(self):
165 """ Executes all the stages of all agents. """
166 if self.shuffle:
167 random.shuffle(self.agents)
168 for stage in self.stage_list:
169 for agent in self.agents:
170 getattr(agent, stage)(self.model) # Run stage
171 if self.shuffle_between_stages:
172 random.shuffle(self.agents)
173 self.time += self.stage_time
174
175 self.steps += 1
176
[end of mesa/time.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/mesa/batchrunner.py b/mesa/batchrunner.py
--- a/mesa/batchrunner.py
+++ b/mesa/batchrunner.py
@@ -12,7 +12,7 @@
class BatchRunner:
""" This class is instantiated with a model class, and model parameters
- associated with one or more values. It is also instantiated with model- and
+ associated with one or more values. It is also instantiated with model and
agent-level reporters, dictionaries mapping a variable name to a function
which collects some data from the model or its agents at the end of the run
and stores it.
@@ -34,11 +34,11 @@
{"param_1": range(5),
"param_2": [1, 5, 10],
"const_param": 100}
- iterations: How many times to run the model at each combination of
- parameters.
- max_steps: After how many steps to halt each run if it hasn't
- halted on its own.
- model_reporters: Dictionary of variables to collect on each run at
+ iterations: The total number of times to run the model for each
+ combination of parameters.
+ max_steps: The upper limit of steps above which each run will be halted
+ if it hasn't halted on its own.
+ model_reporters: The dictionary of variables to collect on each run at
the end, with variable names mapped to a function to collect
them. For example:
{"agent_count": lambda m: m.schedule.get_agent_count()}
@@ -111,8 +111,7 @@
return agent_vars
def get_model_vars_dataframe(self):
- """ Generate a pandas DataFrame from the model-level collected
- variables.
+ """ Generate a pandas DataFrame from the model-level variables collected.
"""
index_col_names = list(self.parameter_values.keys())
diff --git a/mesa/time.py b/mesa/time.py
--- a/mesa/time.py
+++ b/mesa/time.py
@@ -8,7 +8,7 @@
which controls when agents are called upon to act, and when.
The activation order can have a serious impact on model behavior, so it's
-important to specify it explicity. Example simple activation regimes include
+important to specify it explicitly. Example simple activation regimes include
activating all agents in the same order every step, shuffling the activation
order every time, activating each agent *on average* once per step, and more.
@@ -162,7 +162,7 @@
self.stage_time = 1 / len(self.stage_list)
def step(self):
- """ Executes all the stages of all agents. """
+ """ Executes all the stages for all agents. """
if self.shuffle:
random.shuffle(self.agents)
for stage in self.stage_list:
| {"golden_diff": "diff --git a/mesa/batchrunner.py b/mesa/batchrunner.py\n--- a/mesa/batchrunner.py\n+++ b/mesa/batchrunner.py\n@@ -12,7 +12,7 @@\n \n class BatchRunner:\n \"\"\" This class is instantiated with a model class, and model parameters\n- associated with one or more values. It is also instantiated with model- and\n+ associated with one or more values. It is also instantiated with model and\n agent-level reporters, dictionaries mapping a variable name to a function\n which collects some data from the model or its agents at the end of the run\n and stores it.\n@@ -34,11 +34,11 @@\n {\"param_1\": range(5),\n \"param_2\": [1, 5, 10],\n \"const_param\": 100}\n- iterations: How many times to run the model at each combination of\n- parameters.\n- max_steps: After how many steps to halt each run if it hasn't\n- halted on its own.\n- model_reporters: Dictionary of variables to collect on each run at\n+ iterations: The total number of times to run the model for each\n+ combination of parameters.\n+ max_steps: The upper limit of steps above which each run will be halted\n+ if it hasn't halted on its own.\n+ model_reporters: The dictionary of variables to collect on each run at\n the end, with variable names mapped to a function to collect\n them. For example:\n {\"agent_count\": lambda m: m.schedule.get_agent_count()}\n@@ -111,8 +111,7 @@\n return agent_vars\n \n def get_model_vars_dataframe(self):\n- \"\"\" Generate a pandas DataFrame from the model-level collected\n- variables.\n+ \"\"\" Generate a pandas DataFrame from the model-level variables collected.\n \n \"\"\"\n index_col_names = list(self.parameter_values.keys())\ndiff --git a/mesa/time.py b/mesa/time.py\n--- a/mesa/time.py\n+++ b/mesa/time.py\n@@ -8,7 +8,7 @@\n which controls when agents are called upon to act, and when.\n \n The activation order can have a serious impact on model behavior, so it's\n-important to specify it explicity. Example simple activation regimes include\n+important to specify it explicitly. Example simple activation regimes include\n activating all agents in the same order every step, shuffling the activation\n order every time, activating each agent *on average* once per step, and more.\n \n@@ -162,7 +162,7 @@\n self.stage_time = 1 / len(self.stage_list)\n \n def step(self):\n- \"\"\" Executes all the stages of all agents. \"\"\"\n+ \"\"\" Executes all the stages for all agents. \"\"\"\n if self.shuffle:\n random.shuffle(self.agents)\n for stage in self.stage_list:\n", "issue": "Minor docstring clean-up needed on time.py and batchrunner.py\nA couple of typos and minor content edit items for the two files.\n\nMinor docstring clean-up needed on time.py and batchrunner.py\nA couple of typos and minor content edit items for the two files.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\nBatchrunner\n===========\n\nA single class to manage a batch run or parameter sweep of a given model.\n\n\"\"\"\nfrom itertools import product\nimport pandas as pd\n\n\nclass BatchRunner:\n \"\"\" This class is instantiated with a model class, and model parameters\n associated with one or more values. It is also instantiated with model- and\n agent-level reporters, dictionaries mapping a variable name to a function\n which collects some data from the model or its agents at the end of the run\n and stores it.\n\n Note that by default, the reporters only collect data at the *end* of the\n run. To get step by step data, simply have a reporter store the model's\n entire DataCollector object.\n\n \"\"\"\n def __init__(self, model_cls, parameter_values, iterations=1,\n max_steps=1000, model_reporters=None, agent_reporters=None):\n \"\"\" Create a new BatchRunner for a given model with the given\n parameters.\n\n Args:\n model_cls: The class of model to batch-run.\n parameter_values: Dictionary of parameters to their values or\n ranges of values. For example:\n {\"param_1\": range(5),\n \"param_2\": [1, 5, 10],\n \"const_param\": 100}\n iterations: How many times to run the model at each combination of\n parameters.\n max_steps: After how many steps to halt each run if it hasn't\n halted on its own.\n model_reporters: Dictionary of variables to collect on each run at\n the end, with variable names mapped to a function to collect\n them. For example:\n {\"agent_count\": lambda m: m.schedule.get_agent_count()}\n agent_reporters: Like model_reporters, but each variable is now\n collected at the level of each agent present in the model at\n the end of the run.\n\n \"\"\"\n self.model_cls = model_cls\n self.parameter_values = {param: self.make_iterable(vals)\n for param, vals in parameter_values.items()}\n self.iterations = iterations\n self.max_steps = max_steps\n\n self.model_reporters = model_reporters\n self.agent_reporters = agent_reporters\n\n if self.model_reporters:\n self.model_vars = {}\n\n if self.agent_reporters:\n self.agent_vars = {}\n\n def run_all(self):\n \"\"\" Run the model at all parameter combinations and store results. \"\"\"\n params = self.parameter_values.keys()\n param_ranges = self.parameter_values.values()\n run_count = 0\n for param_values in list(product(*param_ranges)):\n kwargs = dict(zip(params, param_values))\n for _ in range(self.iterations):\n model = self.model_cls(**kwargs)\n self.run_model(model)\n # Collect and store results:\n if self.model_reporters:\n key = tuple(list(param_values) + [run_count])\n self.model_vars[key] = self.collect_model_vars(model)\n if self.agent_reporters:\n agent_vars = self.collect_agent_vars(model)\n for agent_id, reports in agent_vars.items():\n key = tuple(list(param_values) + [run_count, agent_id])\n self.agent_vars[key] = reports\n run_count += 1\n\n def run_model(self, model):\n \"\"\" Run a model object to completion, or until reaching max steps.\n\n If your model runs in a non-standard way, this is the method to modify\n in your subclass.\n\n \"\"\"\n while model.running and model.schedule.steps < self.max_steps:\n model.step()\n\n def collect_model_vars(self, model):\n \"\"\" Run reporters and collect model-level variables. \"\"\"\n model_vars = {}\n for var, reporter in self.model_reporters.items():\n model_vars[var] = reporter(model)\n return model_vars\n\n def collect_agent_vars(self, model):\n \"\"\" Run reporters and collect agent-level variables. \"\"\"\n agent_vars = {}\n for agent in model.schedule.agents:\n agent_record = {}\n for var, reporter in self.agent_reporters.items():\n agent_record[var] = reporter(agent)\n agent_vars[agent.unique_id] = agent_record\n return agent_vars\n\n def get_model_vars_dataframe(self):\n \"\"\" Generate a pandas DataFrame from the model-level collected\n variables.\n\n \"\"\"\n index_col_names = list(self.parameter_values.keys())\n index_col_names.append(\"Run\")\n records = []\n for key, val in self.model_vars.items():\n record = dict(zip(index_col_names, key))\n for k, v in val.items():\n record[k] = v\n records.append(record)\n return pd.DataFrame(records)\n\n def get_agent_vars_dataframe(self):\n \"\"\" Generate a pandas DataFrame from the agent-level variables\n collected.\n\n \"\"\"\n index_col_names = list(self.parameter_values.keys())\n index_col_names += [\"Run\", \"AgentID\"]\n records = []\n for key, val in self.agent_vars.items():\n record = dict(zip(index_col_names, key))\n for k, v in val.items():\n record[k] = v\n records.append(record)\n return pd.DataFrame(records)\n\n @staticmethod\n def make_iterable(val):\n \"\"\" Helper method to ensure a value is a non-string iterable. \"\"\"\n if hasattr(val, \"__iter__\") and not isinstance(val, str):\n return val\n else:\n return [val]\n", "path": "mesa/batchrunner.py"}, {"content": "# -*- coding: utf-8 -*-\n\"\"\"\nMesa Time Module\n================\n\nObjects for handling the time component of a model. In particular, this module\ncontains Schedulers, which handle agent activation. A Scheduler is an object\nwhich controls when agents are called upon to act, and when.\n\nThe activation order can have a serious impact on model behavior, so it's\nimportant to specify it explicity. Example simple activation regimes include\nactivating all agents in the same order every step, shuffling the activation\norder every time, activating each agent *on average* once per step, and more.\n\nKey concepts:\n Step: Many models advance in 'steps'. A step may involve the activation of\n all agents, or a random (or selected) subset of them. Each agent in turn\n may have their own step() method.\n\n Time: Some models may simulate a continuous 'clock' instead of discrete\n steps. However, by default, the Time is equal to the number of steps the\n model has taken.\n\n\nTODO: Have the schedulers use the model's randomizer, to keep random number\nseeds consistent and allow for replication.\n\n\"\"\"\nimport random\n\n\nclass BaseScheduler:\n \"\"\" Simplest scheduler; activates agents one at a time, in the order\n they were added.\n\n Assumes that each agent added has a *step* method, which accepts a model\n object as its single argument.\n\n (This is explicitly meant to replicate the scheduler in MASON).\n\n \"\"\"\n model = None\n steps = 0\n time = 0\n agents = []\n\n def __init__(self, model):\n \"\"\" Create a new, empty BaseScheduler. \"\"\"\n self.model = model\n self.steps = 0\n self.time = 0\n self.agents = []\n\n def add(self, agent):\n \"\"\" Add an Agent object to the schedule.\n\n Args:\n agent: An Agent to be added to the schedule. NOTE: The agent must\n have a step(model) method.\n\n \"\"\"\n self.agents.append(agent)\n\n def remove(self, agent):\n \"\"\" Remove all instances of a given agent from the schedule.\n\n Args:\n agent: An agent object.\n\n \"\"\"\n while agent in self.agents:\n self.agents.remove(agent)\n\n def step(self):\n \"\"\" Execute the step of all the agents, one at a time. \"\"\"\n for agent in self.agents:\n agent.step(self.model)\n self.steps += 1\n self.time += 1\n\n def get_agent_count(self):\n \"\"\" Returns the current number of agents in the queue. \"\"\"\n return len(self.agents)\n\n\nclass RandomActivation(BaseScheduler):\n \"\"\" A scheduler which activates each agent once per step, in random order,\n with the order reshuffled every step.\n\n This is equivalent to the NetLogo 'ask agents...' and is generally the\n default behavior for an ABM.\n\n Assumes that all agents have a step(model) method.\n\n \"\"\"\n def step(self):\n \"\"\" Executes the step of all agents, one at a time, in\n random order.\n\n \"\"\"\n random.shuffle(self.agents)\n\n for agent in self.agents:\n agent.step(self.model)\n self.steps += 1\n self.time += 1\n\n\nclass SimultaneousActivation(BaseScheduler):\n \"\"\" A scheduler to simulate the simultaneous activation of all the agents.\n\n This scheduler requires that each agent have two methods: step and advance.\n step(model) activates the agent and stages any necessary changes, but does\n not apply them yet. advance(model) then applies the changes.\n\n \"\"\"\n def step(self):\n \"\"\" Step all agents, then advance them. \"\"\"\n for agent in self.agents:\n agent.step(self.model)\n for agent in self.agents:\n agent.advance(self.model)\n self.steps += 1\n self.time += 1\n\n\nclass StagedActivation(BaseScheduler):\n \"\"\" A scheduler which allows agent activation to be divided into several\n stages instead of a single `step` method. All agents execute one stage\n before moving on to the next.\n\n Agents must have all the stage methods implemented. Stage methods take a\n model object as their only argument.\n\n This schedule tracks steps and time separately. Time advances in fractional\n increments of 1 / (# of stages), meaning that 1 step = 1 unit of time.\n\n \"\"\"\n stage_list = []\n shuffle = False\n shuffle_between_stages = False\n stage_time = 1\n\n def __init__(self, model, stage_list=[\"step\"], shuffle=False,\n shuffle_between_stages=False):\n \"\"\" Create an empty Staged Activation schedule.\n\n Args:\n model: Model object associated with the schedule.\n stage_list: List of strings of names of stages to run, in the\n order to run them in.\n shuffle: If True, shuffle the order of agents each step.\n shuffle_between_stages: If True, shuffle the agents after each\n stage; otherwise, only shuffle at the start\n of each step.\n\n \"\"\"\n super().__init__(model)\n self.stage_list = stage_list\n self.shuffle = shuffle\n self.shuffle_between_stages = shuffle_between_stages\n self.stage_time = 1 / len(self.stage_list)\n\n def step(self):\n \"\"\" Executes all the stages of all agents. \"\"\"\n if self.shuffle:\n random.shuffle(self.agents)\n for stage in self.stage_list:\n for agent in self.agents:\n getattr(agent, stage)(self.model) # Run stage\n if self.shuffle_between_stages:\n random.shuffle(self.agents)\n self.time += self.stage_time\n\n self.steps += 1\n", "path": "mesa/time.py"}]} | 3,768 | 630 |
gh_patches_debug_27775 | rasdani/github-patches | git_diff | bridgecrewio__checkov-4917 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Checkov Python error - kubernetes_pod_v1
I get the following error when parsing a **kubernetes_pod_v1** resource:
https://registry.terraform.io/providers/hashicorp/kubernetes/latest/docs/resources/pod_v1
```
Error: -18 02:46:45,476 [MainThread ] [ERROR] Failed to run check CKV_K8S_[27](https://github.com/technology-services-and-platforms-accnz/dotc-aks/actions/runs/4728024195/jobs/8389176473#step:21:28) on /tfplan.json:kubernetes_pod_v1.test
Traceback (most recent call last):
File "/usr/local/lib/python3.10/site-packages/checkov/common/checks/base_check.py", line 73, in run
check_result["result"] = self.scan_entity_conf(entity_configuration, entity_type)
File "/usr/local/lib/python3.10/site-packages/checkov/terraform/checks/resource/base_resource_check.py", line 43, in scan_entity_conf
return self.scan_resource_conf(conf)
File "/usr/local/lib/python3.10/site-packages/checkov/terraform/checks/resource/kubernetes/DockerSocketVolume.py", line 36, in scan_resource_conf
if v.get("host_path"):
File "/usr/local/lib/python3.10/site-packages/checkov/common/parsers/node.py", line 189, in __getattr__
raise TemplateAttributeError(f'***name*** is invalid')
checkov.common.parsers.node.TemplateAttributeError: get is invalid
[...]
```
For all the checks that fail.
Checkov Version: :2.3.165
</issue>
<code>
[start of checkov/terraform/checks/resource/kubernetes/DockerSocketVolume.py]
1 from __future__ import annotations
2
3 from typing import Any
4
5 from checkov.common.models.enums import CheckCategories, CheckResult
6 from checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck
7
8
9 class DockerSocketVolume(BaseResourceCheck):
10 def __init__(self) -> None:
11 # Exposing the socket gives container information and increases risk of exploit
12 # read-only is not a solution but only makes it harder to exploit.
13 # Location: Pod.spec.volumes[].hostPath.path
14 # Location: CronJob.spec.jobTemplate.spec.template.spec.volumes[].hostPath.path
15 # Location: *.spec.template.spec.volumes[].hostPath.path
16 id = "CKV_K8S_27"
17 name = "Do not expose the docker daemon socket to containers"
18 supported_resources = ("kubernetes_pod", "kubernetes_pod_v1",
19 "kubernetes_deployment", "kubernetes_deployment_v1",
20 "kubernetes_daemonset", "kubernetes_daemon_set_v1")
21 categories = (CheckCategories.NETWORKING,)
22 super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)
23
24 def scan_resource_conf(self, conf: dict[str, list[Any]]):
25 if "spec" not in conf:
26 self.evaluated_keys = [""]
27 return CheckResult.FAILED
28
29 spec = conf['spec'][0]
30 if not spec:
31 return CheckResult.UNKNOWN
32
33 if "volume" in spec and spec.get("volume"):
34 volumes = spec.get("volume")
35 for idx, v in enumerate(volumes):
36 if v.get("host_path"):
37 if "path" in v["host_path"][0]:
38 if v["host_path"][0]["path"] == ["/var/run/docker.sock"]:
39 self.evaluated_keys = [f"spec/volume/{idx}/host_path/[0]/path"]
40 return CheckResult.FAILED
41 if "template" in spec and spec.get("template"):
42 template = spec.get("template")[0]
43 if "spec" in template:
44 temp_spec = template.get("spec")[0]
45 if "volume" in temp_spec and temp_spec.get("volume"):
46 volumes = temp_spec.get("volume")
47 for idx, v in enumerate(volumes):
48 if isinstance(v, dict) and v.get("host_path"):
49 if "path" in v["host_path"][0]:
50 path = v["host_path"][0]["path"]
51 if path == ["/var/run/docker.sock"]:
52 self.evaluated_keys = [f"spec/template/spec/volume/{idx}/host_path/[0]/path"]
53 return CheckResult.FAILED
54
55 return CheckResult.PASSED
56
57
58 check = DockerSocketVolume()
59
[end of checkov/terraform/checks/resource/kubernetes/DockerSocketVolume.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/checkov/terraform/checks/resource/kubernetes/DockerSocketVolume.py b/checkov/terraform/checks/resource/kubernetes/DockerSocketVolume.py
--- a/checkov/terraform/checks/resource/kubernetes/DockerSocketVolume.py
+++ b/checkov/terraform/checks/resource/kubernetes/DockerSocketVolume.py
@@ -33,7 +33,7 @@
if "volume" in spec and spec.get("volume"):
volumes = spec.get("volume")
for idx, v in enumerate(volumes):
- if v.get("host_path"):
+ if isinstance(v, dict) and v.get("host_path"):
if "path" in v["host_path"][0]:
if v["host_path"][0]["path"] == ["/var/run/docker.sock"]:
self.evaluated_keys = [f"spec/volume/{idx}/host_path/[0]/path"]
@@ -47,8 +47,7 @@
for idx, v in enumerate(volumes):
if isinstance(v, dict) and v.get("host_path"):
if "path" in v["host_path"][0]:
- path = v["host_path"][0]["path"]
- if path == ["/var/run/docker.sock"]:
+ if v["host_path"][0]["path"] == ["/var/run/docker.sock"]:
self.evaluated_keys = [f"spec/template/spec/volume/{idx}/host_path/[0]/path"]
return CheckResult.FAILED
| {"golden_diff": "diff --git a/checkov/terraform/checks/resource/kubernetes/DockerSocketVolume.py b/checkov/terraform/checks/resource/kubernetes/DockerSocketVolume.py\n--- a/checkov/terraform/checks/resource/kubernetes/DockerSocketVolume.py\n+++ b/checkov/terraform/checks/resource/kubernetes/DockerSocketVolume.py\n@@ -33,7 +33,7 @@\n if \"volume\" in spec and spec.get(\"volume\"):\n volumes = spec.get(\"volume\")\n for idx, v in enumerate(volumes):\n- if v.get(\"host_path\"):\n+ if isinstance(v, dict) and v.get(\"host_path\"):\n if \"path\" in v[\"host_path\"][0]:\n if v[\"host_path\"][0][\"path\"] == [\"/var/run/docker.sock\"]:\n self.evaluated_keys = [f\"spec/volume/{idx}/host_path/[0]/path\"]\n@@ -47,8 +47,7 @@\n for idx, v in enumerate(volumes):\n if isinstance(v, dict) and v.get(\"host_path\"):\n if \"path\" in v[\"host_path\"][0]:\n- path = v[\"host_path\"][0][\"path\"]\n- if path == [\"/var/run/docker.sock\"]:\n+ if v[\"host_path\"][0][\"path\"] == [\"/var/run/docker.sock\"]:\n self.evaluated_keys = [f\"spec/template/spec/volume/{idx}/host_path/[0]/path\"]\n return CheckResult.FAILED\n", "issue": "Checkov Python error - kubernetes_pod_v1\nI get the following error when parsing a **kubernetes_pod_v1** resource:\r\nhttps://registry.terraform.io/providers/hashicorp/kubernetes/latest/docs/resources/pod_v1\r\n\r\n```\r\nError: -18 02:46:45,476 [MainThread ] [ERROR] Failed to run check CKV_K8S_[27](https://github.com/technology-services-and-platforms-accnz/dotc-aks/actions/runs/4728024195/jobs/8389176473#step:21:28) on /tfplan.json:kubernetes_pod_v1.test\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.10/site-packages/checkov/common/checks/base_check.py\", line 73, in run\r\n check_result[\"result\"] = self.scan_entity_conf(entity_configuration, entity_type)\r\n File \"/usr/local/lib/python3.10/site-packages/checkov/terraform/checks/resource/base_resource_check.py\", line 43, in scan_entity_conf\r\n return self.scan_resource_conf(conf)\r\n File \"/usr/local/lib/python3.10/site-packages/checkov/terraform/checks/resource/kubernetes/DockerSocketVolume.py\", line 36, in scan_resource_conf\r\n if v.get(\"host_path\"):\r\n File \"/usr/local/lib/python3.10/site-packages/checkov/common/parsers/node.py\", line 189, in __getattr__\r\n raise TemplateAttributeError(f'***name*** is invalid')\r\ncheckov.common.parsers.node.TemplateAttributeError: get is invalid\r\n[...]\r\n```\r\n\r\nFor all the checks that fail.\r\n\r\nCheckov Version: :2.3.165\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom typing import Any\n\nfrom checkov.common.models.enums import CheckCategories, CheckResult\nfrom checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck\n\n\nclass DockerSocketVolume(BaseResourceCheck):\n def __init__(self) -> None:\n # Exposing the socket gives container information and increases risk of exploit\n # read-only is not a solution but only makes it harder to exploit.\n # Location: Pod.spec.volumes[].hostPath.path\n # Location: CronJob.spec.jobTemplate.spec.template.spec.volumes[].hostPath.path\n # Location: *.spec.template.spec.volumes[].hostPath.path\n id = \"CKV_K8S_27\"\n name = \"Do not expose the docker daemon socket to containers\"\n supported_resources = (\"kubernetes_pod\", \"kubernetes_pod_v1\",\n \"kubernetes_deployment\", \"kubernetes_deployment_v1\",\n \"kubernetes_daemonset\", \"kubernetes_daemon_set_v1\")\n categories = (CheckCategories.NETWORKING,)\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n\n def scan_resource_conf(self, conf: dict[str, list[Any]]):\n if \"spec\" not in conf:\n self.evaluated_keys = [\"\"]\n return CheckResult.FAILED\n\n spec = conf['spec'][0]\n if not spec:\n return CheckResult.UNKNOWN\n\n if \"volume\" in spec and spec.get(\"volume\"):\n volumes = spec.get(\"volume\")\n for idx, v in enumerate(volumes):\n if v.get(\"host_path\"):\n if \"path\" in v[\"host_path\"][0]:\n if v[\"host_path\"][0][\"path\"] == [\"/var/run/docker.sock\"]:\n self.evaluated_keys = [f\"spec/volume/{idx}/host_path/[0]/path\"]\n return CheckResult.FAILED\n if \"template\" in spec and spec.get(\"template\"):\n template = spec.get(\"template\")[0]\n if \"spec\" in template:\n temp_spec = template.get(\"spec\")[0]\n if \"volume\" in temp_spec and temp_spec.get(\"volume\"):\n volumes = temp_spec.get(\"volume\")\n for idx, v in enumerate(volumes):\n if isinstance(v, dict) and v.get(\"host_path\"):\n if \"path\" in v[\"host_path\"][0]:\n path = v[\"host_path\"][0][\"path\"]\n if path == [\"/var/run/docker.sock\"]:\n self.evaluated_keys = [f\"spec/template/spec/volume/{idx}/host_path/[0]/path\"]\n return CheckResult.FAILED\n\n return CheckResult.PASSED\n\n\ncheck = DockerSocketVolume()\n", "path": "checkov/terraform/checks/resource/kubernetes/DockerSocketVolume.py"}]} | 1,627 | 311 |
gh_patches_debug_3593 | rasdani/github-patches | git_diff | opendatacube__datacube-core-898 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Documentation for indexing from s3 contains mistakes
resolution for EPSG:4326 should be in degrees not in meters:
https://github.com/opendatacube/datacube-core/commit/363a11c9f39a40c8fba958cb265ace193d7849b6#diff-95fd54d5e1fd0aea8de7aacba3ad495cR323
</issue>
<code>
[start of datacube/config.py]
1 # coding=utf-8
2 """
3 User configuration.
4 """
5
6 import os
7 from pathlib import Path
8 import configparser
9 from urllib.parse import unquote_plus, urlparse
10 from typing import Optional, Iterable, Union, Any, Tuple, Dict
11
12 PathLike = Union[str, 'os.PathLike[Any]']
13
14
15 ENVIRONMENT_VARNAME = 'DATACUBE_CONFIG_PATH'
16 #: Config locations in order. Properties found in latter locations override
17 #: earlier ones.
18 #:
19 #: - `/etc/datacube.conf`
20 #: - file at `$DATACUBE_CONFIG_PATH` environment variable
21 #: - `~/.datacube.conf`
22 #: - `datacube.conf`
23 DEFAULT_CONF_PATHS = tuple(p for p in ['/etc/datacube.conf',
24 os.environ.get(ENVIRONMENT_VARNAME, ''),
25 str(os.path.expanduser("~/.datacube.conf")),
26 'datacube.conf'] if len(p) > 0)
27
28 DEFAULT_ENV = 'default'
29
30 # Default configuration options.
31 _DEFAULT_CONF = """
32 [DEFAULT]
33 # Blank implies localhost
34 db_hostname:
35 db_database: datacube
36 index_driver: default
37 # If a connection is unused for this length of time, expect it to be invalidated.
38 db_connection_timeout: 60
39
40 [user]
41 # Which environment to use when none is specified explicitly.
42 # note: will fail if default_environment points to non-existent section
43 # default_environment: datacube
44 """
45
46 #: Used in place of None as a default, when None is a valid but not default parameter to a function
47 _UNSET = object()
48
49
50 def read_config(default_text: Optional[str] = None) -> configparser.ConfigParser:
51 config = configparser.ConfigParser()
52 if default_text is not None:
53 config.read_string(default_text)
54 return config
55
56
57 class LocalConfig(object):
58 """
59 System configuration for the user.
60
61 This loads from a set of possible configuration files which define the available environments.
62 An environment contains connection details for a Data Cube Index, which provides access to
63 available data.
64
65 """
66
67 def __init__(self, config: configparser.ConfigParser,
68 files_loaded: Optional[Iterable[str]] = None,
69 env: Optional[str] = None):
70 """
71 Datacube environment resolution precedence is:
72 1. Supplied as a function argument `env`
73 2. DATACUBE_ENVIRONMENT environment variable
74 3. user.default_environment option in the config
75 4. 'default' or 'datacube' whichever is present
76
77 If environment is supplied by any of the first 3 methods is not present
78 in the config, then throw an exception.
79 """
80 self._config = config
81 self.files_loaded = [] if files_loaded is None else list(iter(files_loaded))
82
83 if env is None:
84 env = os.environ.get('DATACUBE_ENVIRONMENT',
85 config.get('user', 'default_environment', fallback=None))
86
87 # If the user specifies a particular env, we either want to use it or Fail
88 if env:
89 if config.has_section(env):
90 self._env = env
91 # All is good
92 return
93 else:
94 raise ValueError('No config section found for environment %r' % (env,))
95 else:
96 # If an env hasn't been specifically selected, we can fall back defaults
97 fallbacks = [DEFAULT_ENV, 'datacube']
98 for fallback_env in fallbacks:
99 if config.has_section(fallback_env):
100 self._env = fallback_env
101 return
102 raise ValueError('No ODC environment, checked configurations for %s' % fallbacks)
103
104 @classmethod
105 def find(cls,
106 paths: Optional[Union[str, Iterable[PathLike]]] = None,
107 env: Optional[str] = None) -> 'LocalConfig':
108 """
109 Find config from environment variables or possible filesystem locations.
110
111 'env' is which environment to use from the config: it corresponds to the name of a
112 config section
113 """
114 config = read_config(_DEFAULT_CONF)
115
116 if paths is None:
117 if env is None:
118 env_opts = parse_env_params()
119 if env_opts:
120 return _cfg_from_env_opts(env_opts, config)
121
122 paths = DEFAULT_CONF_PATHS
123
124 if isinstance(paths, str) or hasattr(paths, '__fspath__'): # Use os.PathLike in 3.6+
125 paths = [str(paths)]
126
127 files_loaded = config.read(str(p) for p in paths if p)
128
129 return LocalConfig(
130 config,
131 files_loaded=files_loaded,
132 env=env,
133 )
134
135 def get(self, item: str, fallback=_UNSET):
136 if fallback is _UNSET:
137 return self._config.get(self._env, item)
138 else:
139 return self._config.get(self._env, item, fallback=fallback)
140
141 def __getitem__(self, item: str):
142 return self.get(item, fallback=None)
143
144 def __str__(self) -> str:
145 return "LocalConfig<loaded_from={}, environment={!r}, config={}>".format(
146 self.files_loaded or 'defaults',
147 self._env,
148 dict(self._config[self._env]),
149 )
150
151 def __repr__(self) -> str:
152 return str(self)
153
154
155 DB_KEYS = ('hostname', 'port', 'database', 'username', 'password')
156
157
158 def parse_connect_url(url: str) -> Dict[str, str]:
159 """ Extract database,hostname,port,username,password from db URL.
160
161 Example: postgresql://username:password@hostname:port/database
162
163 For local password-less db use `postgresql:///<your db>`
164 """
165 def split2(s: str, separator: str) -> Tuple[str, str]:
166 i = s.find(separator)
167 return (s, '') if i < 0 else (s[:i], s[i+1:])
168
169 _, netloc, path, *_ = urlparse(url)
170
171 db = path[1:] if path else ''
172 if '@' in netloc:
173 (user, password), (host, port) = (split2(p, ':') for p in split2(netloc, '@'))
174 else:
175 user, password = '', ''
176 host, port = split2(netloc, ':')
177
178 oo = dict(hostname=host, database=db)
179
180 if port:
181 oo['port'] = port
182 if password:
183 oo['password'] = unquote_plus(password)
184 if user:
185 oo['username'] = user
186 return oo
187
188
189 def parse_env_params() -> Dict[str, str]:
190 """
191 - Extract parameters from DATACUBE_DB_URL if present
192 - Else look for DB_HOSTNAME, DB_USERNAME, DB_PASSWORD, DB_DATABASE
193 - Return {} otherwise
194 """
195
196 db_url = os.environ.get('DATACUBE_DB_URL', None)
197 if db_url is not None:
198 return parse_connect_url(db_url)
199
200 params = {k: os.environ.get('DB_{}'.format(k.upper()), None)
201 for k in DB_KEYS}
202 return {k: v
203 for k, v in params.items()
204 if v is not None and v != ""}
205
206
207 def _cfg_from_env_opts(opts: Dict[str, str],
208 base: configparser.ConfigParser) -> LocalConfig:
209 base['default'] = {'db_'+k: v for k, v in opts.items()}
210 return LocalConfig(base, files_loaded=[], env='default')
211
212
213 def render_dc_config(params: Dict[str, Any],
214 section_name: str = 'default') -> str:
215 """ Render output of parse_env_params to a string that can be written to config file.
216 """
217 oo = '[{}]\n'.format(section_name)
218 for k in DB_KEYS:
219 v = params.get(k, None)
220 if v is not None:
221 oo += 'db_{k}: {v}\n'.format(k=k, v=v)
222 return oo
223
224
225 def auto_config() -> str:
226 """
227 Render config to $DATACUBE_CONFIG_PATH or ~/.datacube.conf, but only if doesn't exist.
228
229 option1:
230 DATACUBE_DB_URL postgresql://user:password@host/database
231
232 option2:
233 DB_{HOSTNAME|PORT|USERNAME|PASSWORD|DATABASE}
234
235 option3:
236 default config
237 """
238 cfg_path = os.environ.get('DATACUBE_CONFIG_PATH', None)
239 cfg_path = Path(cfg_path) if cfg_path else Path.home()/'.datacube.conf'
240
241 if cfg_path.exists():
242 return str(cfg_path)
243
244 opts = parse_env_params()
245
246 if len(opts) == 0:
247 opts['hostname'] = ''
248 opts['database'] = 'datacube'
249
250 cfg_text = render_dc_config(opts)
251 with open(str(cfg_path), 'wt') as f:
252 f.write(cfg_text)
253
254 return str(cfg_path)
255
[end of datacube/config.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/datacube/config.py b/datacube/config.py
--- a/datacube/config.py
+++ b/datacube/config.py
@@ -227,7 +227,7 @@
Render config to $DATACUBE_CONFIG_PATH or ~/.datacube.conf, but only if doesn't exist.
option1:
- DATACUBE_DB_URL postgresql://user:password@host/database
+ DATACUBE_DB_URL postgresql://user:password@host:port/database
option2:
DB_{HOSTNAME|PORT|USERNAME|PASSWORD|DATABASE}
| {"golden_diff": "diff --git a/datacube/config.py b/datacube/config.py\n--- a/datacube/config.py\n+++ b/datacube/config.py\n@@ -227,7 +227,7 @@\n Render config to $DATACUBE_CONFIG_PATH or ~/.datacube.conf, but only if doesn't exist.\n \n option1:\n- DATACUBE_DB_URL postgresql://user:password@host/database\n+ DATACUBE_DB_URL postgresql://user:password@host:port/database\n \n option2:\n DB_{HOSTNAME|PORT|USERNAME|PASSWORD|DATABASE}\n", "issue": "Documentation for indexing from s3 contains mistakes\n\r\nresolution for EPSG:4326 should be in degrees not in meters:\r\n\r\nhttps://github.com/opendatacube/datacube-core/commit/363a11c9f39a40c8fba958cb265ace193d7849b6#diff-95fd54d5e1fd0aea8de7aacba3ad495cR323\r\n\r\n\n", "before_files": [{"content": "# coding=utf-8\n\"\"\"\nUser configuration.\n\"\"\"\n\nimport os\nfrom pathlib import Path\nimport configparser\nfrom urllib.parse import unquote_plus, urlparse\nfrom typing import Optional, Iterable, Union, Any, Tuple, Dict\n\nPathLike = Union[str, 'os.PathLike[Any]']\n\n\nENVIRONMENT_VARNAME = 'DATACUBE_CONFIG_PATH'\n#: Config locations in order. Properties found in latter locations override\n#: earlier ones.\n#:\n#: - `/etc/datacube.conf`\n#: - file at `$DATACUBE_CONFIG_PATH` environment variable\n#: - `~/.datacube.conf`\n#: - `datacube.conf`\nDEFAULT_CONF_PATHS = tuple(p for p in ['/etc/datacube.conf',\n os.environ.get(ENVIRONMENT_VARNAME, ''),\n str(os.path.expanduser(\"~/.datacube.conf\")),\n 'datacube.conf'] if len(p) > 0)\n\nDEFAULT_ENV = 'default'\n\n# Default configuration options.\n_DEFAULT_CONF = \"\"\"\n[DEFAULT]\n# Blank implies localhost\ndb_hostname:\ndb_database: datacube\nindex_driver: default\n# If a connection is unused for this length of time, expect it to be invalidated.\ndb_connection_timeout: 60\n\n[user]\n# Which environment to use when none is specified explicitly.\n# note: will fail if default_environment points to non-existent section\n# default_environment: datacube\n\"\"\"\n\n#: Used in place of None as a default, when None is a valid but not default parameter to a function\n_UNSET = object()\n\n\ndef read_config(default_text: Optional[str] = None) -> configparser.ConfigParser:\n config = configparser.ConfigParser()\n if default_text is not None:\n config.read_string(default_text)\n return config\n\n\nclass LocalConfig(object):\n \"\"\"\n System configuration for the user.\n\n This loads from a set of possible configuration files which define the available environments.\n An environment contains connection details for a Data Cube Index, which provides access to\n available data.\n\n \"\"\"\n\n def __init__(self, config: configparser.ConfigParser,\n files_loaded: Optional[Iterable[str]] = None,\n env: Optional[str] = None):\n \"\"\"\n Datacube environment resolution precedence is:\n 1. Supplied as a function argument `env`\n 2. DATACUBE_ENVIRONMENT environment variable\n 3. user.default_environment option in the config\n 4. 'default' or 'datacube' whichever is present\n\n If environment is supplied by any of the first 3 methods is not present\n in the config, then throw an exception.\n \"\"\"\n self._config = config\n self.files_loaded = [] if files_loaded is None else list(iter(files_loaded))\n\n if env is None:\n env = os.environ.get('DATACUBE_ENVIRONMENT',\n config.get('user', 'default_environment', fallback=None))\n\n # If the user specifies a particular env, we either want to use it or Fail\n if env:\n if config.has_section(env):\n self._env = env\n # All is good\n return\n else:\n raise ValueError('No config section found for environment %r' % (env,))\n else:\n # If an env hasn't been specifically selected, we can fall back defaults\n fallbacks = [DEFAULT_ENV, 'datacube']\n for fallback_env in fallbacks:\n if config.has_section(fallback_env):\n self._env = fallback_env\n return\n raise ValueError('No ODC environment, checked configurations for %s' % fallbacks)\n\n @classmethod\n def find(cls,\n paths: Optional[Union[str, Iterable[PathLike]]] = None,\n env: Optional[str] = None) -> 'LocalConfig':\n \"\"\"\n Find config from environment variables or possible filesystem locations.\n\n 'env' is which environment to use from the config: it corresponds to the name of a\n config section\n \"\"\"\n config = read_config(_DEFAULT_CONF)\n\n if paths is None:\n if env is None:\n env_opts = parse_env_params()\n if env_opts:\n return _cfg_from_env_opts(env_opts, config)\n\n paths = DEFAULT_CONF_PATHS\n\n if isinstance(paths, str) or hasattr(paths, '__fspath__'): # Use os.PathLike in 3.6+\n paths = [str(paths)]\n\n files_loaded = config.read(str(p) for p in paths if p)\n\n return LocalConfig(\n config,\n files_loaded=files_loaded,\n env=env,\n )\n\n def get(self, item: str, fallback=_UNSET):\n if fallback is _UNSET:\n return self._config.get(self._env, item)\n else:\n return self._config.get(self._env, item, fallback=fallback)\n\n def __getitem__(self, item: str):\n return self.get(item, fallback=None)\n\n def __str__(self) -> str:\n return \"LocalConfig<loaded_from={}, environment={!r}, config={}>\".format(\n self.files_loaded or 'defaults',\n self._env,\n dict(self._config[self._env]),\n )\n\n def __repr__(self) -> str:\n return str(self)\n\n\nDB_KEYS = ('hostname', 'port', 'database', 'username', 'password')\n\n\ndef parse_connect_url(url: str) -> Dict[str, str]:\n \"\"\" Extract database,hostname,port,username,password from db URL.\n\n Example: postgresql://username:password@hostname:port/database\n\n For local password-less db use `postgresql:///<your db>`\n \"\"\"\n def split2(s: str, separator: str) -> Tuple[str, str]:\n i = s.find(separator)\n return (s, '') if i < 0 else (s[:i], s[i+1:])\n\n _, netloc, path, *_ = urlparse(url)\n\n db = path[1:] if path else ''\n if '@' in netloc:\n (user, password), (host, port) = (split2(p, ':') for p in split2(netloc, '@'))\n else:\n user, password = '', ''\n host, port = split2(netloc, ':')\n\n oo = dict(hostname=host, database=db)\n\n if port:\n oo['port'] = port\n if password:\n oo['password'] = unquote_plus(password)\n if user:\n oo['username'] = user\n return oo\n\n\ndef parse_env_params() -> Dict[str, str]:\n \"\"\"\n - Extract parameters from DATACUBE_DB_URL if present\n - Else look for DB_HOSTNAME, DB_USERNAME, DB_PASSWORD, DB_DATABASE\n - Return {} otherwise\n \"\"\"\n\n db_url = os.environ.get('DATACUBE_DB_URL', None)\n if db_url is not None:\n return parse_connect_url(db_url)\n\n params = {k: os.environ.get('DB_{}'.format(k.upper()), None)\n for k in DB_KEYS}\n return {k: v\n for k, v in params.items()\n if v is not None and v != \"\"}\n\n\ndef _cfg_from_env_opts(opts: Dict[str, str],\n base: configparser.ConfigParser) -> LocalConfig:\n base['default'] = {'db_'+k: v for k, v in opts.items()}\n return LocalConfig(base, files_loaded=[], env='default')\n\n\ndef render_dc_config(params: Dict[str, Any],\n section_name: str = 'default') -> str:\n \"\"\" Render output of parse_env_params to a string that can be written to config file.\n \"\"\"\n oo = '[{}]\\n'.format(section_name)\n for k in DB_KEYS:\n v = params.get(k, None)\n if v is not None:\n oo += 'db_{k}: {v}\\n'.format(k=k, v=v)\n return oo\n\n\ndef auto_config() -> str:\n \"\"\"\n Render config to $DATACUBE_CONFIG_PATH or ~/.datacube.conf, but only if doesn't exist.\n\n option1:\n DATACUBE_DB_URL postgresql://user:password@host/database\n\n option2:\n DB_{HOSTNAME|PORT|USERNAME|PASSWORD|DATABASE}\n\n option3:\n default config\n \"\"\"\n cfg_path = os.environ.get('DATACUBE_CONFIG_PATH', None)\n cfg_path = Path(cfg_path) if cfg_path else Path.home()/'.datacube.conf'\n\n if cfg_path.exists():\n return str(cfg_path)\n\n opts = parse_env_params()\n\n if len(opts) == 0:\n opts['hostname'] = ''\n opts['database'] = 'datacube'\n\n cfg_text = render_dc_config(opts)\n with open(str(cfg_path), 'wt') as f:\n f.write(cfg_text)\n\n return str(cfg_path)\n", "path": "datacube/config.py"}]} | 3,192 | 126 |
gh_patches_debug_14901 | rasdani/github-patches | git_diff | streamlink__streamlink-2102 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ok.ru VODs
<!--
Thanks for reporting a plugin issue!
USE THE TEMPLATE. Otherwise your plugin issue may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Also check the list of open and closed plugin issues:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Plugin Issue
<!-- Replace [ ] with [x] in order to check the box -->
- [x ] This is a plugin issue and I have read the contribution guidelines.
### Description
i enter link in #1884 but "https://raw.githubusercontent.com/back-to/plugins/master/plugins/ok_live.py" 404: Not Found. Thanks
<!-- Explain the plugin issue as thoroughly as you can. -->
### Reproduction steps / Explicit stream URLs to test
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
1. D:\my\Streamlinkl\bin>streamlink -l debug "https://ok.ru/video/266205792931" best
### Log output
<!--
TEXT LOG OUTPUT IS REQUIRED for a plugin issue!
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
https://streamlink.github.io/cli.html#cmdoption-l
Make sure to **remove usernames and passwords**
You can copy the output to https://gist.github.com/ or paste it below.
-->
```
[cli][debug] OS: Windows 8.1
[cli][debug] Python: 3.5.2
[cli][debug] Streamlink: 0.14.2
[cli][debug] Requests(2.19.1), Socks(1.6.7), Websocket(0.48.0)
error: No plugin can handle URL: https://ok.ru/video/266205792931
```
### Additional comments, screenshots, etc.
[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)
</issue>
<code>
[start of src/streamlink/plugins/ok_live.py]
1 import re
2
3 from streamlink.plugin import Plugin
4 from streamlink.plugin.api import validate
5 from streamlink.plugin.api import useragents
6 from streamlink.stream import HLSStream
7
8 _url_re = re.compile(r"https?://(www\.)?ok\.ru/live/\d+")
9 _vod_re = re.compile(r";(?P<hlsurl>[^;]+video\.m3u8.+?)\\"")
10
11 _schema = validate.Schema(
12 validate.transform(_vod_re.search),
13 validate.any(
14 None,
15 validate.all(
16 validate.get("hlsurl"),
17 validate.url()
18 )
19 )
20 )
21
22 class OK_live(Plugin):
23 """
24 Support for ok.ru live stream: http://www.ok.ru/live/
25 """
26 @classmethod
27 def can_handle_url(cls, url):
28 return _url_re.match(url) is not None
29
30 def _get_streams(self):
31 headers = {
32 'User-Agent': useragents.CHROME,
33 'Referer': self.url
34 }
35
36 hls = self.session.http.get(self.url, headers=headers, schema=_schema)
37 if hls:
38 hls = hls.replace(u'\\\\u0026', u'&')
39 return HLSStream.parse_variant_playlist(self.session, hls, headers=headers)
40
41
42 __plugin__ = OK_live
[end of src/streamlink/plugins/ok_live.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/src/streamlink/plugins/ok_live.py b/src/streamlink/plugins/ok_live.py
--- a/src/streamlink/plugins/ok_live.py
+++ b/src/streamlink/plugins/ok_live.py
@@ -5,7 +5,7 @@
from streamlink.plugin.api import useragents
from streamlink.stream import HLSStream
-_url_re = re.compile(r"https?://(www\.)?ok\.ru/live/\d+")
+_url_re = re.compile(r"https?://(www\.)?ok\.ru/(live|video)/\d+")
_vod_re = re.compile(r";(?P<hlsurl>[^;]+video\.m3u8.+?)\\"")
_schema = validate.Schema(
@@ -21,7 +21,7 @@
class OK_live(Plugin):
"""
- Support for ok.ru live stream: http://www.ok.ru/live/
+ Support for ok.ru live stream: http://www.ok.ru/live/ and for ok.ru VoDs: http://www.ok.ru/video/
"""
@classmethod
def can_handle_url(cls, url):
| {"golden_diff": "diff --git a/src/streamlink/plugins/ok_live.py b/src/streamlink/plugins/ok_live.py\n--- a/src/streamlink/plugins/ok_live.py\n+++ b/src/streamlink/plugins/ok_live.py\n@@ -5,7 +5,7 @@\n from streamlink.plugin.api import useragents\n from streamlink.stream import HLSStream\n \n-_url_re = re.compile(r\"https?://(www\\.)?ok\\.ru/live/\\d+\")\n+_url_re = re.compile(r\"https?://(www\\.)?ok\\.ru/(live|video)/\\d+\")\n _vod_re = re.compile(r\";(?P<hlsurl>[^;]+video\\.m3u8.+?)\\\\"\")\n \n _schema = validate.Schema(\n@@ -21,7 +21,7 @@\n \n class OK_live(Plugin):\n \"\"\"\n- Support for ok.ru live stream: http://www.ok.ru/live/\n+ Support for ok.ru live stream: http://www.ok.ru/live/ and for ok.ru VoDs: http://www.ok.ru/video/\n \"\"\"\n @classmethod\n def can_handle_url(cls, url):\n", "issue": "ok.ru VODs\n<!--\r\nThanks for reporting a plugin issue!\r\nUSE THE TEMPLATE. Otherwise your plugin issue may be rejected.\r\n\r\nFirst, see the contribution guidelines:\r\nhttps://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink\r\n\r\nAlso check the list of open and closed plugin issues:\r\nhttps://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22\r\n\r\nPlease see the text preview to avoid unnecessary formatting errors.\r\n-->\r\n\r\n\r\n## Plugin Issue\r\n\r\n<!-- Replace [ ] with [x] in order to check the box -->\r\n- [x ] This is a plugin issue and I have read the contribution guidelines.\r\n\r\n\r\n### Description\r\ni enter link in #1884 but \"https://raw.githubusercontent.com/back-to/plugins/master/plugins/ok_live.py\" 404: Not Found. Thanks\r\n<!-- Explain the plugin issue as thoroughly as you can. -->\r\n\r\n\r\n### Reproduction steps / Explicit stream URLs to test\r\n\r\n<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->\r\n\r\n1. D:\\my\\Streamlinkl\\bin>streamlink -l debug \"https://ok.ru/video/266205792931\" best\r\n\r\n\r\n\r\n### Log output\r\n\r\n<!--\r\nTEXT LOG OUTPUT IS REQUIRED for a plugin issue!\r\nUse the `--loglevel debug` parameter and avoid using parameters which suppress log output.\r\nhttps://streamlink.github.io/cli.html#cmdoption-l\r\n\r\nMake sure to **remove usernames and passwords**\r\nYou can copy the output to https://gist.github.com/ or paste it below.\r\n-->\r\n\r\n```\r\n[cli][debug] OS: Windows 8.1\r\n[cli][debug] Python: 3.5.2\r\n[cli][debug] Streamlink: 0.14.2\r\n[cli][debug] Requests(2.19.1), Socks(1.6.7), Websocket(0.48.0)\r\nerror: No plugin can handle URL: https://ok.ru/video/266205792931\r\n\r\n```\r\n\r\n\r\n### Additional comments, screenshots, etc.\r\n\r\n\r\n\r\n[Love Streamlink? Please consider supporting our collective. Thanks!](https://opencollective.com/streamlink/donate)\r\n\n", "before_files": [{"content": "import re\n\nfrom streamlink.plugin import Plugin\nfrom streamlink.plugin.api import validate\nfrom streamlink.plugin.api import useragents\nfrom streamlink.stream import HLSStream\n\n_url_re = re.compile(r\"https?://(www\\.)?ok\\.ru/live/\\d+\")\n_vod_re = re.compile(r\";(?P<hlsurl>[^;]+video\\.m3u8.+?)\\\\"\")\n\n_schema = validate.Schema(\n validate.transform(_vod_re.search),\n validate.any(\n None,\n validate.all(\n validate.get(\"hlsurl\"),\n validate.url()\n )\n )\n)\n\nclass OK_live(Plugin):\n \"\"\"\n Support for ok.ru live stream: http://www.ok.ru/live/\n \"\"\"\n @classmethod\n def can_handle_url(cls, url):\n return _url_re.match(url) is not None\n\n def _get_streams(self):\n headers = {\n 'User-Agent': useragents.CHROME,\n 'Referer': self.url\n }\n\n hls = self.session.http.get(self.url, headers=headers, schema=_schema)\n if hls:\n hls = hls.replace(u'\\\\\\\\u0026', u'&')\n return HLSStream.parse_variant_playlist(self.session, hls, headers=headers)\n\n\n__plugin__ = OK_live", "path": "src/streamlink/plugins/ok_live.py"}]} | 1,401 | 239 |
gh_patches_debug_4820 | rasdani/github-patches | git_diff | ivy-llc__ivy-28045 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Wrong key-word argument `name` in `ivy.remainder()` function call
In the following line, the name argument is passed,
https://github.com/unifyai/ivy/blob/bec4752711c314f01298abc3845f02c24a99acab/ivy/functional/frontends/tensorflow/variable.py#L191
From the actual function definition, there is no such argument
https://github.com/unifyai/ivy/blob/8ff497a8c592b75f010160b313dc431218c2b475/ivy/functional/ivy/elementwise.py#L5415-L5422
</issue>
<code>
[start of ivy/functional/frontends/tensorflow/variable.py]
1 # global
2
3 # local
4 import ivy
5 import ivy.functional.frontends.tensorflow as tf_frontend
6
7
8 class Variable:
9 def __init__(self, array, trainable=True, name=None, dtype=None):
10 self._ivy_array = (
11 ivy.array(array) if not isinstance(array, ivy.Array) else array
12 )
13 self._ivy_array = (
14 ivy.astype(self._ivy_array, dtype) if dtype is not None else self._ivy_array
15 )
16 self.trainable = trainable
17
18 def __repr__(self):
19 return (
20 repr(self._ivy_array).replace(
21 "ivy.array", "ivy.frontends.tensorflow.Variable"
22 )[:-1]
23 + ", shape="
24 + str(self._ivy_array.shape)
25 + ", dtype="
26 + str(self._ivy_array.dtype)
27 + ")"
28 )
29
30 # Properties #
31 # ---------- #
32
33 @property
34 def ivy_array(self):
35 return self._ivy_array
36
37 @property
38 def device(self):
39 return self._ivy_array.device
40
41 @property
42 def dtype(self):
43 return tf_frontend.DType(
44 tf_frontend.tensorflow_type_to_enum[self._ivy_array.dtype]
45 )
46
47 @property
48 def shape(self):
49 return self._ivy_array.shape
50
51 # Instance Methods #
52 # ---------------- #
53
54 def assign(self, value, use_locking=None, name=None, read_value=True):
55 ivy.utils.assertions.check_equal(
56 value.shape if hasattr(value, "ivy_array") else ivy.shape(value),
57 self.shape,
58 as_array=False,
59 )
60 self._ivy_array = value._ivy_array
61
62 def assign_add(self, delta, use_locking=None, name=None, read_value=True):
63 ivy.utils.assertions.check_equal(
64 delta.shape if hasattr(delta, "ivy_array") else ivy.shape(delta),
65 self.shape,
66 as_array=False,
67 )
68 self._ivy_array = tf_frontend.math.add(self._ivy_array, delta._ivy_array)
69
70 def assign_sub(self, delta, use_locking=None, name=None, read_value=True):
71 ivy.utils.assertions.check_equal(
72 delta.shape if hasattr(delta, "ivy_array") else ivy.shape(delta),
73 self.shape,
74 as_array=False,
75 )
76 self._ivy_array = tf_frontend.math.subtract(self._ivy_array, delta._ivy_array)
77
78 def batch_scatter_update(
79 self, sparse_delta, use_locking=None, name=None, read_value=True
80 ):
81 pass
82
83 def gather_nd(self, indices, name=None):
84 return tf_frontend.gather_nd(params=self._ivy_array, indices=indices)
85
86 def read_value(self):
87 return tf_frontend.Tensor(self._ivy_array)
88
89 def scatter_add(self, sparse_delta, use_locking=None, name=None, read_value=True):
90 pass
91
92 def scatter_div(self, sparse_delta, use_locking=None, name=None, read_value=True):
93 pass
94
95 def scatter_max(self, sparse_delta, use_locking=None, name=None, read_value=True):
96 pass
97
98 def scatter_min(self, sparse_delta, use_locking=None, name=None, read_value=True):
99 pass
100
101 def scatter_mul(self, sparse_delta, use_locking=None, name=None, read_value=True):
102 pass
103
104 def scatter_nd_add(self, indices, updates, use_locking=None, name=None):
105 pass
106
107 def scatter_nd_sub(self, indices, updates, use_locking=None, name=None):
108 pass
109
110 def scatter_nd_update(self, indices, updates, use_locking=None, name=None):
111 pass
112
113 def scatter_sub(self, sparse_delta, use_locking=None, name=None, read_value=True):
114 pass
115
116 def scatter_update(
117 self, sparse_delta, use_locking=None, name=None, read_value=True
118 ):
119 pass
120
121 def set_shape(self, shape):
122 if shape is None:
123 return
124
125 x_shape = self._ivy_array.shape
126 if len(x_shape) != len(shape):
127 raise ValueError(
128 f"Tensor's shape {x_shape} is not compatible with supplied shape "
129 f"{shape}."
130 )
131 for i, v in enumerate(x_shape):
132 if v != shape[i] and (shape[i] is not None):
133 raise ValueError(
134 f"Tensor's shape {x_shape} is not compatible with supplied shape "
135 f"{shape}."
136 )
137
138 def get_shape(self):
139 return self._ivy_array.shape
140
141 def sparse_read(self, indices, name=None):
142 pass
143
144 def __add__(self, y, name="add"):
145 return self.__radd__(y)
146
147 def __div__(self, x, name="div"):
148 return tf_frontend.math.divide(x, self._ivy_array, name=name)
149
150 def __and__(self, y, name="and"):
151 return y.__rand__(self._ivy_array)
152
153 def __eq__(self, other):
154 return tf_frontend.raw_ops.Equal(
155 x=self._ivy_array, y=other, incompatible_shape_error=False
156 )
157
158 def __floordiv__(self, y, name="floordiv"):
159 return y.__rfloordiv__(self._ivy_array)
160
161 def __ge__(self, y, name="ge"):
162 return tf_frontend.raw_ops.GreaterEqual(
163 x=self._ivy_array, y=y._ivy_array, name=name
164 )
165
166 def __getitem__(self, slice_spec, var=None, name="getitem"):
167 ret = ivy.get_item(self._ivy_array, slice_spec)
168 return Variable(ivy.array(ret, dtype=ivy.dtype(ret), copy=False))
169
170 def __gt__(self, y, name="gt"):
171 return tf_frontend.raw_ops.Greater(x=self._ivy_array, y=y._ivy_array, name=name)
172
173 def __invert__(self, name="invert"):
174 return tf_frontend.raw_ops.Invert(x=self._ivy_array, name=name)
175
176 def __le__(self, y, name="le"):
177 return tf_frontend.raw_ops.LessEqual(
178 x=self._ivy_array, y=y._ivy_array, name=name
179 )
180
181 def __lt__(self, y, name="lt"):
182 return tf_frontend.raw_ops.Less(x=self._ivy_array, y=y._ivy_array, name=name)
183
184 def __matmul__(self, y, name="matmul"):
185 return y.__rmatmul__(self._ivy_array)
186
187 def __mul__(self, x, name="mul"):
188 return tf_frontend.math.multiply(x, self._ivy_array, name=name)
189
190 def __mod__(self, x, name="mod"):
191 return ivy.remainder(x, self._ivy_array, name=name)
192
193 def __ne__(self, other):
194 return tf_frontend.raw_ops.NotEqual(
195 x=self._ivy_array, y=other._ivy_array, incompatible_shape_error=False
196 )
197
198 def __neg__(self, name="neg"):
199 return tf_frontend.raw_ops.Neg(x=self._ivy_array, name=name)
200
201 def __or__(self, y, name="or"):
202 return y.__ror__(self._ivy_array)
203
204 def __pow__(self, y, name="pow"):
205 return tf_frontend.math.pow(x=self, y=y, name=name)
206
207 def __radd__(self, x, name="radd"):
208 return tf_frontend.math.add(x, self._ivy_array, name=name)
209
210 def __rand__(self, x, name="rand"):
211 return tf_frontend.math.logical_and(x, self._ivy_array, name=name)
212
213 def __rfloordiv__(self, x, name="rfloordiv"):
214 return tf_frontend.raw_ops.FloorDiv(x=x, y=self._ivy_array, name=name)
215
216 def __rmatmul__(self, x, name="rmatmul"):
217 return tf_frontend.raw_ops.MatMul(a=x, b=self._ivy_array, name=name)
218
219 def __rmul__(self, x, name="rmul"):
220 return tf_frontend.raw_ops.Mul(x=x, y=self._ivy_array, name=name)
221
222 def __ror__(self, x, name="ror"):
223 return tf_frontend.raw_ops.LogicalOr(x=x, y=self._ivy_array, name=name)
224
225 def __rpow__(self, x, name="rpow"):
226 return tf_frontend.raw_ops.Pow(x=x, y=self._ivy_array, name=name)
227
228 def __rsub__(self, x, name="rsub"):
229 return tf_frontend.math.subtract(x, self._ivy_array, name=name)
230
231 def __rtruediv__(self, x, name="rtruediv"):
232 return tf_frontend.math.truediv(x, self._ivy_array, name=name)
233
234 def __rxor__(self, x, name="rxor"):
235 return tf_frontend.math.logical_xor(x, self._ivy_array, name=name)
236
237 def __sub__(self, y, name="sub"):
238 return y.__rsub__(self._ivy_array)
239
240 def __truediv__(self, y, name="truediv"):
241 dtype = ivy.dtype(self._ivy_array)
242 if dtype in [ivy.uint8, ivy.int8, ivy.uint16, ivy.int16]:
243 return ivy.astype(y, ivy.float32).__rtruediv__(
244 ivy.astype(self._ivy_array, ivy.float32)
245 )
246 if dtype in [ivy.uint32, ivy.int32, ivy.uint64, ivy.int64]:
247 return ivy.astype(y, ivy.float64).__rtruediv__(
248 ivy.astype(self._ivy_array, ivy.float64)
249 )
250 return y.__rtruediv__(self._ivy_array)
251
252 def __xor__(self, y, name="xor"):
253 return y.__rxor__(self._ivy_array)
254
255 def __setitem__(self, key, value):
256 raise ivy.utils.exceptions.IvyException(
257 "ivy.functional.frontends.tensorflow.Variable object "
258 "doesn't support assignment"
259 )
260
261
262 class IndexedSlices:
263 def __init__(self, values, indices, dense_shape=None):
264 self._values = values
265 self._indices = indices
266 self._dense_shape = dense_shape
267
268 @property
269 def values(self):
270 """A `Tensor` containing the values of the slices."""
271 return self._values
272
273 @property
274 def indices(self):
275 """A 1-D `Tensor` containing the indices of the slices."""
276 return self._indices
277
278 @property
279 def dense_shape(self):
280 """A 1-D `Tensor` containing the shape of the corresponding dense
281 tensor."""
282 return self._dense_shape
283
284 @property
285 def device(self):
286 """The name of the device on which `values` will be produced, or
287 `None`."""
288 return self.values.device
289
290 @property
291 def dtype(self):
292 """The `DType` of elements in this tensor."""
293 return self.values.dtype
294
295 def __repr__(self):
296 return "IndexedSlices(\nindices=%s,\nvalues=%s%s\n)" % (
297 self._indices,
298 self._values,
299 (
300 f", dense_shape={self._dense_shape}"
301 if self._dense_shape is not None
302 else ""
303 ),
304 )
305
306 def __neg__(self):
307 return IndexedSlices(-self._values, self._indices, self._dense_shape)
308
[end of ivy/functional/frontends/tensorflow/variable.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/ivy/functional/frontends/tensorflow/variable.py b/ivy/functional/frontends/tensorflow/variable.py
--- a/ivy/functional/frontends/tensorflow/variable.py
+++ b/ivy/functional/frontends/tensorflow/variable.py
@@ -188,7 +188,7 @@
return tf_frontend.math.multiply(x, self._ivy_array, name=name)
def __mod__(self, x, name="mod"):
- return ivy.remainder(x, self._ivy_array, name=name)
+ return tf_frontend.math.mod(x, self._ivy_array, name=name)
def __ne__(self, other):
return tf_frontend.raw_ops.NotEqual(
| {"golden_diff": "diff --git a/ivy/functional/frontends/tensorflow/variable.py b/ivy/functional/frontends/tensorflow/variable.py\n--- a/ivy/functional/frontends/tensorflow/variable.py\n+++ b/ivy/functional/frontends/tensorflow/variable.py\n@@ -188,7 +188,7 @@\n return tf_frontend.math.multiply(x, self._ivy_array, name=name)\n \n def __mod__(self, x, name=\"mod\"):\n- return ivy.remainder(x, self._ivy_array, name=name)\n+ return tf_frontend.math.mod(x, self._ivy_array, name=name)\n \n def __ne__(self, other):\n return tf_frontend.raw_ops.NotEqual(\n", "issue": "Wrong key-word argument `name` in `ivy.remainder()` function call\nIn the following line, the name argument is passed,\r\nhttps://github.com/unifyai/ivy/blob/bec4752711c314f01298abc3845f02c24a99acab/ivy/functional/frontends/tensorflow/variable.py#L191\r\nFrom the actual function definition, there is no such argument\r\nhttps://github.com/unifyai/ivy/blob/8ff497a8c592b75f010160b313dc431218c2b475/ivy/functional/ivy/elementwise.py#L5415-L5422\n", "before_files": [{"content": "# global\n\n# local\nimport ivy\nimport ivy.functional.frontends.tensorflow as tf_frontend\n\n\nclass Variable:\n def __init__(self, array, trainable=True, name=None, dtype=None):\n self._ivy_array = (\n ivy.array(array) if not isinstance(array, ivy.Array) else array\n )\n self._ivy_array = (\n ivy.astype(self._ivy_array, dtype) if dtype is not None else self._ivy_array\n )\n self.trainable = trainable\n\n def __repr__(self):\n return (\n repr(self._ivy_array).replace(\n \"ivy.array\", \"ivy.frontends.tensorflow.Variable\"\n )[:-1]\n + \", shape=\"\n + str(self._ivy_array.shape)\n + \", dtype=\"\n + str(self._ivy_array.dtype)\n + \")\"\n )\n\n # Properties #\n # ---------- #\n\n @property\n def ivy_array(self):\n return self._ivy_array\n\n @property\n def device(self):\n return self._ivy_array.device\n\n @property\n def dtype(self):\n return tf_frontend.DType(\n tf_frontend.tensorflow_type_to_enum[self._ivy_array.dtype]\n )\n\n @property\n def shape(self):\n return self._ivy_array.shape\n\n # Instance Methods #\n # ---------------- #\n\n def assign(self, value, use_locking=None, name=None, read_value=True):\n ivy.utils.assertions.check_equal(\n value.shape if hasattr(value, \"ivy_array\") else ivy.shape(value),\n self.shape,\n as_array=False,\n )\n self._ivy_array = value._ivy_array\n\n def assign_add(self, delta, use_locking=None, name=None, read_value=True):\n ivy.utils.assertions.check_equal(\n delta.shape if hasattr(delta, \"ivy_array\") else ivy.shape(delta),\n self.shape,\n as_array=False,\n )\n self._ivy_array = tf_frontend.math.add(self._ivy_array, delta._ivy_array)\n\n def assign_sub(self, delta, use_locking=None, name=None, read_value=True):\n ivy.utils.assertions.check_equal(\n delta.shape if hasattr(delta, \"ivy_array\") else ivy.shape(delta),\n self.shape,\n as_array=False,\n )\n self._ivy_array = tf_frontend.math.subtract(self._ivy_array, delta._ivy_array)\n\n def batch_scatter_update(\n self, sparse_delta, use_locking=None, name=None, read_value=True\n ):\n pass\n\n def gather_nd(self, indices, name=None):\n return tf_frontend.gather_nd(params=self._ivy_array, indices=indices)\n\n def read_value(self):\n return tf_frontend.Tensor(self._ivy_array)\n\n def scatter_add(self, sparse_delta, use_locking=None, name=None, read_value=True):\n pass\n\n def scatter_div(self, sparse_delta, use_locking=None, name=None, read_value=True):\n pass\n\n def scatter_max(self, sparse_delta, use_locking=None, name=None, read_value=True):\n pass\n\n def scatter_min(self, sparse_delta, use_locking=None, name=None, read_value=True):\n pass\n\n def scatter_mul(self, sparse_delta, use_locking=None, name=None, read_value=True):\n pass\n\n def scatter_nd_add(self, indices, updates, use_locking=None, name=None):\n pass\n\n def scatter_nd_sub(self, indices, updates, use_locking=None, name=None):\n pass\n\n def scatter_nd_update(self, indices, updates, use_locking=None, name=None):\n pass\n\n def scatter_sub(self, sparse_delta, use_locking=None, name=None, read_value=True):\n pass\n\n def scatter_update(\n self, sparse_delta, use_locking=None, name=None, read_value=True\n ):\n pass\n\n def set_shape(self, shape):\n if shape is None:\n return\n\n x_shape = self._ivy_array.shape\n if len(x_shape) != len(shape):\n raise ValueError(\n f\"Tensor's shape {x_shape} is not compatible with supplied shape \"\n f\"{shape}.\"\n )\n for i, v in enumerate(x_shape):\n if v != shape[i] and (shape[i] is not None):\n raise ValueError(\n f\"Tensor's shape {x_shape} is not compatible with supplied shape \"\n f\"{shape}.\"\n )\n\n def get_shape(self):\n return self._ivy_array.shape\n\n def sparse_read(self, indices, name=None):\n pass\n\n def __add__(self, y, name=\"add\"):\n return self.__radd__(y)\n\n def __div__(self, x, name=\"div\"):\n return tf_frontend.math.divide(x, self._ivy_array, name=name)\n\n def __and__(self, y, name=\"and\"):\n return y.__rand__(self._ivy_array)\n\n def __eq__(self, other):\n return tf_frontend.raw_ops.Equal(\n x=self._ivy_array, y=other, incompatible_shape_error=False\n )\n\n def __floordiv__(self, y, name=\"floordiv\"):\n return y.__rfloordiv__(self._ivy_array)\n\n def __ge__(self, y, name=\"ge\"):\n return tf_frontend.raw_ops.GreaterEqual(\n x=self._ivy_array, y=y._ivy_array, name=name\n )\n\n def __getitem__(self, slice_spec, var=None, name=\"getitem\"):\n ret = ivy.get_item(self._ivy_array, slice_spec)\n return Variable(ivy.array(ret, dtype=ivy.dtype(ret), copy=False))\n\n def __gt__(self, y, name=\"gt\"):\n return tf_frontend.raw_ops.Greater(x=self._ivy_array, y=y._ivy_array, name=name)\n\n def __invert__(self, name=\"invert\"):\n return tf_frontend.raw_ops.Invert(x=self._ivy_array, name=name)\n\n def __le__(self, y, name=\"le\"):\n return tf_frontend.raw_ops.LessEqual(\n x=self._ivy_array, y=y._ivy_array, name=name\n )\n\n def __lt__(self, y, name=\"lt\"):\n return tf_frontend.raw_ops.Less(x=self._ivy_array, y=y._ivy_array, name=name)\n\n def __matmul__(self, y, name=\"matmul\"):\n return y.__rmatmul__(self._ivy_array)\n\n def __mul__(self, x, name=\"mul\"):\n return tf_frontend.math.multiply(x, self._ivy_array, name=name)\n\n def __mod__(self, x, name=\"mod\"):\n return ivy.remainder(x, self._ivy_array, name=name)\n\n def __ne__(self, other):\n return tf_frontend.raw_ops.NotEqual(\n x=self._ivy_array, y=other._ivy_array, incompatible_shape_error=False\n )\n\n def __neg__(self, name=\"neg\"):\n return tf_frontend.raw_ops.Neg(x=self._ivy_array, name=name)\n\n def __or__(self, y, name=\"or\"):\n return y.__ror__(self._ivy_array)\n\n def __pow__(self, y, name=\"pow\"):\n return tf_frontend.math.pow(x=self, y=y, name=name)\n\n def __radd__(self, x, name=\"radd\"):\n return tf_frontend.math.add(x, self._ivy_array, name=name)\n\n def __rand__(self, x, name=\"rand\"):\n return tf_frontend.math.logical_and(x, self._ivy_array, name=name)\n\n def __rfloordiv__(self, x, name=\"rfloordiv\"):\n return tf_frontend.raw_ops.FloorDiv(x=x, y=self._ivy_array, name=name)\n\n def __rmatmul__(self, x, name=\"rmatmul\"):\n return tf_frontend.raw_ops.MatMul(a=x, b=self._ivy_array, name=name)\n\n def __rmul__(self, x, name=\"rmul\"):\n return tf_frontend.raw_ops.Mul(x=x, y=self._ivy_array, name=name)\n\n def __ror__(self, x, name=\"ror\"):\n return tf_frontend.raw_ops.LogicalOr(x=x, y=self._ivy_array, name=name)\n\n def __rpow__(self, x, name=\"rpow\"):\n return tf_frontend.raw_ops.Pow(x=x, y=self._ivy_array, name=name)\n\n def __rsub__(self, x, name=\"rsub\"):\n return tf_frontend.math.subtract(x, self._ivy_array, name=name)\n\n def __rtruediv__(self, x, name=\"rtruediv\"):\n return tf_frontend.math.truediv(x, self._ivy_array, name=name)\n\n def __rxor__(self, x, name=\"rxor\"):\n return tf_frontend.math.logical_xor(x, self._ivy_array, name=name)\n\n def __sub__(self, y, name=\"sub\"):\n return y.__rsub__(self._ivy_array)\n\n def __truediv__(self, y, name=\"truediv\"):\n dtype = ivy.dtype(self._ivy_array)\n if dtype in [ivy.uint8, ivy.int8, ivy.uint16, ivy.int16]:\n return ivy.astype(y, ivy.float32).__rtruediv__(\n ivy.astype(self._ivy_array, ivy.float32)\n )\n if dtype in [ivy.uint32, ivy.int32, ivy.uint64, ivy.int64]:\n return ivy.astype(y, ivy.float64).__rtruediv__(\n ivy.astype(self._ivy_array, ivy.float64)\n )\n return y.__rtruediv__(self._ivy_array)\n\n def __xor__(self, y, name=\"xor\"):\n return y.__rxor__(self._ivy_array)\n\n def __setitem__(self, key, value):\n raise ivy.utils.exceptions.IvyException(\n \"ivy.functional.frontends.tensorflow.Variable object \"\n \"doesn't support assignment\"\n )\n\n\nclass IndexedSlices:\n def __init__(self, values, indices, dense_shape=None):\n self._values = values\n self._indices = indices\n self._dense_shape = dense_shape\n\n @property\n def values(self):\n \"\"\"A `Tensor` containing the values of the slices.\"\"\"\n return self._values\n\n @property\n def indices(self):\n \"\"\"A 1-D `Tensor` containing the indices of the slices.\"\"\"\n return self._indices\n\n @property\n def dense_shape(self):\n \"\"\"A 1-D `Tensor` containing the shape of the corresponding dense\n tensor.\"\"\"\n return self._dense_shape\n\n @property\n def device(self):\n \"\"\"The name of the device on which `values` will be produced, or\n `None`.\"\"\"\n return self.values.device\n\n @property\n def dtype(self):\n \"\"\"The `DType` of elements in this tensor.\"\"\"\n return self.values.dtype\n\n def __repr__(self):\n return \"IndexedSlices(\\nindices=%s,\\nvalues=%s%s\\n)\" % (\n self._indices,\n self._values,\n (\n f\", dense_shape={self._dense_shape}\"\n if self._dense_shape is not None\n else \"\"\n ),\n )\n\n def __neg__(self):\n return IndexedSlices(-self._values, self._indices, self._dense_shape)\n", "path": "ivy/functional/frontends/tensorflow/variable.py"}]} | 4,047 | 158 |
gh_patches_debug_8517 | rasdani/github-patches | git_diff | facebookresearch__hydra-1818 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Bug] delete field when using optuna sweeper would throw error
# 🐛 Bug
## Description
<!-- A clear and concise description of what the bug is. -->
I was using optuna sweeper but I noticed that if i delete a field by `~field` it would throw an error.
## To reproduce
Let's [start with this](https://github.com/facebookresearch/hydra/tree/main/examples/advanced/defaults_list_interpolation). Let's modify `conf/db/sqlite.yaml` to be this
```yaml
name: sqlite
model:
name: boring
```
then create a directory called `exp`, and create a file `exp/exp.yaml`
```yaml
# @package _global_
defaults:
- override /hydra/sweeper: optuna
- override /db: sqlite
```
Now run the command `python my_app.py -m +exp=exp ~db.model` it would have the error
> Could not delete from config. The value of 'db.model' is {'name': 'boring'} and not None.
However if I did `python my_app.py +exp=exp ~db.model` (not activating sweeper), then the code would run correctly, making the db to be sqlite (the default is mysql) and the `model.name` part deleted.
## System information
- **Hydra Version** : 1.0.0.rc1
- **Python version** : 3.7.10
- **Operating system** : Ubuntu 18.04.2 LTS
</issue>
<code>
[start of plugins/hydra_optuna_sweeper/hydra_plugins/hydra_optuna_sweeper/_impl.py]
1 # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
2 import logging
3 import sys
4 from typing import Any, Dict, List, MutableMapping, MutableSequence, Optional
5
6 import optuna
7 from hydra.core.override_parser.overrides_parser import OverridesParser
8 from hydra.core.override_parser.types import (
9 ChoiceSweep,
10 IntervalSweep,
11 Override,
12 RangeSweep,
13 Transformer,
14 )
15 from hydra.core.plugins import Plugins
16 from hydra.plugins.sweeper import Sweeper
17 from hydra.types import HydraContext, TaskFunction
18 from omegaconf import DictConfig, OmegaConf
19 from optuna.distributions import (
20 BaseDistribution,
21 CategoricalChoiceType,
22 CategoricalDistribution,
23 DiscreteUniformDistribution,
24 IntLogUniformDistribution,
25 IntUniformDistribution,
26 LogUniformDistribution,
27 UniformDistribution,
28 )
29
30 from .config import Direction, DistributionConfig, DistributionType
31
32 log = logging.getLogger(__name__)
33
34
35 def create_optuna_distribution_from_config(
36 config: MutableMapping[str, Any]
37 ) -> BaseDistribution:
38 kwargs = dict(config)
39 if isinstance(config["type"], str):
40 kwargs["type"] = DistributionType[config["type"]]
41 param = DistributionConfig(**kwargs)
42 if param.type == DistributionType.categorical:
43 assert param.choices is not None
44 return CategoricalDistribution(param.choices)
45 if param.type == DistributionType.int:
46 assert param.low is not None
47 assert param.high is not None
48 if param.log:
49 return IntLogUniformDistribution(int(param.low), int(param.high))
50 step = int(param.step) if param.step is not None else 1
51 return IntUniformDistribution(int(param.low), int(param.high), step=step)
52 if param.type == DistributionType.float:
53 assert param.low is not None
54 assert param.high is not None
55 if param.log:
56 return LogUniformDistribution(param.low, param.high)
57 if param.step is not None:
58 return DiscreteUniformDistribution(param.low, param.high, param.step)
59 return UniformDistribution(param.low, param.high)
60 raise NotImplementedError(f"{param.type} is not supported by Optuna sweeper.")
61
62
63 def create_optuna_distribution_from_override(override: Override) -> Any:
64 value = override.value()
65 if not override.is_sweep_override():
66 return value
67
68 choices: List[CategoricalChoiceType] = []
69 if override.is_choice_sweep():
70 assert isinstance(value, ChoiceSweep)
71 for x in override.sweep_iterator(transformer=Transformer.encode):
72 assert isinstance(
73 x, (str, int, float, bool)
74 ), f"A choice sweep expects str, int, float, or bool type. Got {type(x)}."
75 choices.append(x)
76 return CategoricalDistribution(choices)
77
78 if override.is_range_sweep():
79 assert isinstance(value, RangeSweep)
80 assert value.start is not None
81 assert value.stop is not None
82 if value.shuffle:
83 for x in override.sweep_iterator(transformer=Transformer.encode):
84 assert isinstance(
85 x, (str, int, float, bool)
86 ), f"A choice sweep expects str, int, float, or bool type. Got {type(x)}."
87 choices.append(x)
88 return CategoricalDistribution(choices)
89 return IntUniformDistribution(
90 int(value.start), int(value.stop), step=int(value.step)
91 )
92
93 if override.is_interval_sweep():
94 assert isinstance(value, IntervalSweep)
95 assert value.start is not None
96 assert value.end is not None
97 if "log" in value.tags:
98 if isinstance(value.start, int) and isinstance(value.end, int):
99 return IntLogUniformDistribution(int(value.start), int(value.end))
100 return LogUniformDistribution(value.start, value.end)
101 else:
102 if isinstance(value.start, int) and isinstance(value.end, int):
103 return IntUniformDistribution(value.start, value.end)
104 return UniformDistribution(value.start, value.end)
105
106 raise NotImplementedError(f"{override} is not supported by Optuna sweeper.")
107
108
109 class OptunaSweeperImpl(Sweeper):
110 def __init__(
111 self,
112 sampler: Any,
113 direction: Any,
114 storage: Optional[str],
115 study_name: Optional[str],
116 n_trials: int,
117 n_jobs: int,
118 search_space: Optional[DictConfig],
119 ) -> None:
120 self.sampler = sampler
121 self.direction = direction
122 self.storage = storage
123 self.study_name = study_name
124 self.n_trials = n_trials
125 self.n_jobs = n_jobs
126 self.search_space = {}
127 if search_space:
128 assert isinstance(search_space, DictConfig)
129 self.search_space = {
130 str(x): create_optuna_distribution_from_config(y)
131 for x, y in search_space.items()
132 }
133 self.job_idx: int = 0
134
135 def setup(
136 self,
137 *,
138 hydra_context: HydraContext,
139 task_function: TaskFunction,
140 config: DictConfig,
141 ) -> None:
142 self.job_idx = 0
143 self.config = config
144 self.hydra_context = hydra_context
145 self.launcher = Plugins.instance().instantiate_launcher(
146 config=config, hydra_context=hydra_context, task_function=task_function
147 )
148 self.sweep_dir = config.hydra.sweep.dir
149
150 def sweep(self, arguments: List[str]) -> None:
151 assert self.config is not None
152 assert self.launcher is not None
153 assert self.hydra_context is not None
154 assert self.job_idx is not None
155
156 parser = OverridesParser.create()
157 parsed = parser.parse_overrides(arguments)
158
159 search_space = dict(self.search_space)
160 fixed_params = dict()
161 for override in parsed:
162 value = create_optuna_distribution_from_override(override)
163 if isinstance(value, BaseDistribution):
164 search_space[override.get_key_element()] = value
165 else:
166 fixed_params[override.get_key_element()] = value
167 # Remove fixed parameters from Optuna search space.
168 for param_name in fixed_params:
169 if param_name in search_space:
170 del search_space[param_name]
171
172 directions: List[str]
173 if isinstance(self.direction, MutableSequence):
174 directions = [
175 d.name if isinstance(d, Direction) else d for d in self.direction
176 ]
177 else:
178 if isinstance(self.direction, str):
179 directions = [self.direction]
180 else:
181 directions = [self.direction.name]
182
183 study = optuna.create_study(
184 study_name=self.study_name,
185 storage=self.storage,
186 sampler=self.sampler,
187 directions=directions,
188 load_if_exists=True,
189 )
190 log.info(f"Study name: {study.study_name}")
191 log.info(f"Storage: {self.storage}")
192 log.info(f"Sampler: {type(self.sampler).__name__}")
193 log.info(f"Directions: {directions}")
194
195 batch_size = self.n_jobs
196 n_trials_to_go = self.n_trials
197
198 while n_trials_to_go > 0:
199 batch_size = min(n_trials_to_go, batch_size)
200
201 trials = [study.ask() for _ in range(batch_size)]
202 overrides = []
203 for trial in trials:
204 for param_name, distribution in search_space.items():
205 trial._suggest(param_name, distribution)
206
207 params = dict(trial.params)
208 params.update(fixed_params)
209 overrides.append(tuple(f"{name}={val}" for name, val in params.items()))
210
211 returns = self.launcher.launch(overrides, initial_job_idx=self.job_idx)
212 self.job_idx += len(returns)
213 for trial, ret in zip(trials, returns):
214 values: Optional[List[float]] = None
215 state: optuna.trial.TrialState = optuna.trial.TrialState.COMPLETE
216 try:
217 if len(directions) == 1:
218 try:
219 values = [float(ret.return_value)]
220 except (ValueError, TypeError):
221 raise ValueError(
222 f"Return value must be float-castable. Got '{ret.return_value}'."
223 ).with_traceback(sys.exc_info()[2])
224 else:
225 try:
226 values = [float(v) for v in ret.return_value]
227 except (ValueError, TypeError):
228 raise ValueError(
229 "Return value must be a list or tuple of float-castable values."
230 f" Got '{ret.return_value}'."
231 ).with_traceback(sys.exc_info()[2])
232 if len(values) != len(directions):
233 raise ValueError(
234 "The number of the values and the number of the objectives are"
235 f" mismatched. Expect {len(directions)}, but actually {len(values)}."
236 )
237 study.tell(trial=trial, state=state, values=values)
238 except Exception as e:
239 state = optuna.trial.TrialState.FAIL
240 study.tell(trial=trial, state=state, values=values)
241 raise e
242
243 n_trials_to_go -= batch_size
244
245 results_to_serialize: Dict[str, Any]
246 if len(directions) < 2:
247 best_trial = study.best_trial
248 results_to_serialize = {
249 "name": "optuna",
250 "best_params": best_trial.params,
251 "best_value": best_trial.value,
252 }
253 log.info(f"Best parameters: {best_trial.params}")
254 log.info(f"Best value: {best_trial.value}")
255 else:
256 best_trials = study.best_trials
257 pareto_front = [
258 {"params": t.params, "values": t.values} for t in best_trials
259 ]
260 results_to_serialize = {
261 "name": "optuna",
262 "solutions": pareto_front,
263 }
264 log.info(f"Number of Pareto solutions: {len(best_trials)}")
265 for t in best_trials:
266 log.info(f" Values: {t.values}, Params: {t.params}")
267 OmegaConf.save(
268 OmegaConf.create(results_to_serialize),
269 f"{self.config.hydra.sweep.dir}/optimization_results.yaml",
270 )
271
[end of plugins/hydra_optuna_sweeper/hydra_plugins/hydra_optuna_sweeper/_impl.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/plugins/hydra_optuna_sweeper/hydra_plugins/hydra_optuna_sweeper/_impl.py b/plugins/hydra_optuna_sweeper/hydra_plugins/hydra_optuna_sweeper/_impl.py
--- a/plugins/hydra_optuna_sweeper/hydra_plugins/hydra_optuna_sweeper/_impl.py
+++ b/plugins/hydra_optuna_sweeper/hydra_plugins/hydra_optuna_sweeper/_impl.py
@@ -61,10 +61,10 @@
def create_optuna_distribution_from_override(override: Override) -> Any:
- value = override.value()
if not override.is_sweep_override():
- return value
+ return override.get_value_element_as_str()
+ value = override.value()
choices: List[CategoricalChoiceType] = []
if override.is_choice_sweep():
assert isinstance(value, ChoiceSweep)
| {"golden_diff": "diff --git a/plugins/hydra_optuna_sweeper/hydra_plugins/hydra_optuna_sweeper/_impl.py b/plugins/hydra_optuna_sweeper/hydra_plugins/hydra_optuna_sweeper/_impl.py\n--- a/plugins/hydra_optuna_sweeper/hydra_plugins/hydra_optuna_sweeper/_impl.py\n+++ b/plugins/hydra_optuna_sweeper/hydra_plugins/hydra_optuna_sweeper/_impl.py\n@@ -61,10 +61,10 @@\n \n \n def create_optuna_distribution_from_override(override: Override) -> Any:\n- value = override.value()\n if not override.is_sweep_override():\n- return value\n+ return override.get_value_element_as_str()\n \n+ value = override.value()\n choices: List[CategoricalChoiceType] = []\n if override.is_choice_sweep():\n assert isinstance(value, ChoiceSweep)\n", "issue": "[Bug] delete field when using optuna sweeper would throw error\n# \ud83d\udc1b Bug\r\n## Description\r\n<!-- A clear and concise description of what the bug is. -->\r\nI was using optuna sweeper but I noticed that if i delete a field by `~field` it would throw an error.\r\n\r\n## To reproduce\r\nLet's [start with this](https://github.com/facebookresearch/hydra/tree/main/examples/advanced/defaults_list_interpolation). Let's modify `conf/db/sqlite.yaml` to be this\r\n```yaml\r\nname: sqlite\r\n\r\nmodel:\r\n name: boring\r\n```\r\nthen create a directory called `exp`, and create a file `exp/exp.yaml`\r\n```yaml\r\n# @package _global_\r\n\r\ndefaults:\r\n - override /hydra/sweeper: optuna\r\n - override /db: sqlite\r\n```\r\nNow run the command `python my_app.py -m +exp=exp ~db.model` it would have the error\r\n> Could not delete from config. The value of 'db.model' is {'name': 'boring'} and not None.\r\n\r\nHowever if I did `python my_app.py +exp=exp ~db.model` (not activating sweeper), then the code would run correctly, making the db to be sqlite (the default is mysql) and the `model.name` part deleted. \r\n\r\n## System information\r\n- **Hydra Version** : 1.0.0.rc1\r\n- **Python version** : 3.7.10\r\n- **Operating system** : Ubuntu 18.04.2 LTS\r\n\n", "before_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\nimport logging\nimport sys\nfrom typing import Any, Dict, List, MutableMapping, MutableSequence, Optional\n\nimport optuna\nfrom hydra.core.override_parser.overrides_parser import OverridesParser\nfrom hydra.core.override_parser.types import (\n ChoiceSweep,\n IntervalSweep,\n Override,\n RangeSweep,\n Transformer,\n)\nfrom hydra.core.plugins import Plugins\nfrom hydra.plugins.sweeper import Sweeper\nfrom hydra.types import HydraContext, TaskFunction\nfrom omegaconf import DictConfig, OmegaConf\nfrom optuna.distributions import (\n BaseDistribution,\n CategoricalChoiceType,\n CategoricalDistribution,\n DiscreteUniformDistribution,\n IntLogUniformDistribution,\n IntUniformDistribution,\n LogUniformDistribution,\n UniformDistribution,\n)\n\nfrom .config import Direction, DistributionConfig, DistributionType\n\nlog = logging.getLogger(__name__)\n\n\ndef create_optuna_distribution_from_config(\n config: MutableMapping[str, Any]\n) -> BaseDistribution:\n kwargs = dict(config)\n if isinstance(config[\"type\"], str):\n kwargs[\"type\"] = DistributionType[config[\"type\"]]\n param = DistributionConfig(**kwargs)\n if param.type == DistributionType.categorical:\n assert param.choices is not None\n return CategoricalDistribution(param.choices)\n if param.type == DistributionType.int:\n assert param.low is not None\n assert param.high is not None\n if param.log:\n return IntLogUniformDistribution(int(param.low), int(param.high))\n step = int(param.step) if param.step is not None else 1\n return IntUniformDistribution(int(param.low), int(param.high), step=step)\n if param.type == DistributionType.float:\n assert param.low is not None\n assert param.high is not None\n if param.log:\n return LogUniformDistribution(param.low, param.high)\n if param.step is not None:\n return DiscreteUniformDistribution(param.low, param.high, param.step)\n return UniformDistribution(param.low, param.high)\n raise NotImplementedError(f\"{param.type} is not supported by Optuna sweeper.\")\n\n\ndef create_optuna_distribution_from_override(override: Override) -> Any:\n value = override.value()\n if not override.is_sweep_override():\n return value\n\n choices: List[CategoricalChoiceType] = []\n if override.is_choice_sweep():\n assert isinstance(value, ChoiceSweep)\n for x in override.sweep_iterator(transformer=Transformer.encode):\n assert isinstance(\n x, (str, int, float, bool)\n ), f\"A choice sweep expects str, int, float, or bool type. Got {type(x)}.\"\n choices.append(x)\n return CategoricalDistribution(choices)\n\n if override.is_range_sweep():\n assert isinstance(value, RangeSweep)\n assert value.start is not None\n assert value.stop is not None\n if value.shuffle:\n for x in override.sweep_iterator(transformer=Transformer.encode):\n assert isinstance(\n x, (str, int, float, bool)\n ), f\"A choice sweep expects str, int, float, or bool type. Got {type(x)}.\"\n choices.append(x)\n return CategoricalDistribution(choices)\n return IntUniformDistribution(\n int(value.start), int(value.stop), step=int(value.step)\n )\n\n if override.is_interval_sweep():\n assert isinstance(value, IntervalSweep)\n assert value.start is not None\n assert value.end is not None\n if \"log\" in value.tags:\n if isinstance(value.start, int) and isinstance(value.end, int):\n return IntLogUniformDistribution(int(value.start), int(value.end))\n return LogUniformDistribution(value.start, value.end)\n else:\n if isinstance(value.start, int) and isinstance(value.end, int):\n return IntUniformDistribution(value.start, value.end)\n return UniformDistribution(value.start, value.end)\n\n raise NotImplementedError(f\"{override} is not supported by Optuna sweeper.\")\n\n\nclass OptunaSweeperImpl(Sweeper):\n def __init__(\n self,\n sampler: Any,\n direction: Any,\n storage: Optional[str],\n study_name: Optional[str],\n n_trials: int,\n n_jobs: int,\n search_space: Optional[DictConfig],\n ) -> None:\n self.sampler = sampler\n self.direction = direction\n self.storage = storage\n self.study_name = study_name\n self.n_trials = n_trials\n self.n_jobs = n_jobs\n self.search_space = {}\n if search_space:\n assert isinstance(search_space, DictConfig)\n self.search_space = {\n str(x): create_optuna_distribution_from_config(y)\n for x, y in search_space.items()\n }\n self.job_idx: int = 0\n\n def setup(\n self,\n *,\n hydra_context: HydraContext,\n task_function: TaskFunction,\n config: DictConfig,\n ) -> None:\n self.job_idx = 0\n self.config = config\n self.hydra_context = hydra_context\n self.launcher = Plugins.instance().instantiate_launcher(\n config=config, hydra_context=hydra_context, task_function=task_function\n )\n self.sweep_dir = config.hydra.sweep.dir\n\n def sweep(self, arguments: List[str]) -> None:\n assert self.config is not None\n assert self.launcher is not None\n assert self.hydra_context is not None\n assert self.job_idx is not None\n\n parser = OverridesParser.create()\n parsed = parser.parse_overrides(arguments)\n\n search_space = dict(self.search_space)\n fixed_params = dict()\n for override in parsed:\n value = create_optuna_distribution_from_override(override)\n if isinstance(value, BaseDistribution):\n search_space[override.get_key_element()] = value\n else:\n fixed_params[override.get_key_element()] = value\n # Remove fixed parameters from Optuna search space.\n for param_name in fixed_params:\n if param_name in search_space:\n del search_space[param_name]\n\n directions: List[str]\n if isinstance(self.direction, MutableSequence):\n directions = [\n d.name if isinstance(d, Direction) else d for d in self.direction\n ]\n else:\n if isinstance(self.direction, str):\n directions = [self.direction]\n else:\n directions = [self.direction.name]\n\n study = optuna.create_study(\n study_name=self.study_name,\n storage=self.storage,\n sampler=self.sampler,\n directions=directions,\n load_if_exists=True,\n )\n log.info(f\"Study name: {study.study_name}\")\n log.info(f\"Storage: {self.storage}\")\n log.info(f\"Sampler: {type(self.sampler).__name__}\")\n log.info(f\"Directions: {directions}\")\n\n batch_size = self.n_jobs\n n_trials_to_go = self.n_trials\n\n while n_trials_to_go > 0:\n batch_size = min(n_trials_to_go, batch_size)\n\n trials = [study.ask() for _ in range(batch_size)]\n overrides = []\n for trial in trials:\n for param_name, distribution in search_space.items():\n trial._suggest(param_name, distribution)\n\n params = dict(trial.params)\n params.update(fixed_params)\n overrides.append(tuple(f\"{name}={val}\" for name, val in params.items()))\n\n returns = self.launcher.launch(overrides, initial_job_idx=self.job_idx)\n self.job_idx += len(returns)\n for trial, ret in zip(trials, returns):\n values: Optional[List[float]] = None\n state: optuna.trial.TrialState = optuna.trial.TrialState.COMPLETE\n try:\n if len(directions) == 1:\n try:\n values = [float(ret.return_value)]\n except (ValueError, TypeError):\n raise ValueError(\n f\"Return value must be float-castable. Got '{ret.return_value}'.\"\n ).with_traceback(sys.exc_info()[2])\n else:\n try:\n values = [float(v) for v in ret.return_value]\n except (ValueError, TypeError):\n raise ValueError(\n \"Return value must be a list or tuple of float-castable values.\"\n f\" Got '{ret.return_value}'.\"\n ).with_traceback(sys.exc_info()[2])\n if len(values) != len(directions):\n raise ValueError(\n \"The number of the values and the number of the objectives are\"\n f\" mismatched. Expect {len(directions)}, but actually {len(values)}.\"\n )\n study.tell(trial=trial, state=state, values=values)\n except Exception as e:\n state = optuna.trial.TrialState.FAIL\n study.tell(trial=trial, state=state, values=values)\n raise e\n\n n_trials_to_go -= batch_size\n\n results_to_serialize: Dict[str, Any]\n if len(directions) < 2:\n best_trial = study.best_trial\n results_to_serialize = {\n \"name\": \"optuna\",\n \"best_params\": best_trial.params,\n \"best_value\": best_trial.value,\n }\n log.info(f\"Best parameters: {best_trial.params}\")\n log.info(f\"Best value: {best_trial.value}\")\n else:\n best_trials = study.best_trials\n pareto_front = [\n {\"params\": t.params, \"values\": t.values} for t in best_trials\n ]\n results_to_serialize = {\n \"name\": \"optuna\",\n \"solutions\": pareto_front,\n }\n log.info(f\"Number of Pareto solutions: {len(best_trials)}\")\n for t in best_trials:\n log.info(f\" Values: {t.values}, Params: {t.params}\")\n OmegaConf.save(\n OmegaConf.create(results_to_serialize),\n f\"{self.config.hydra.sweep.dir}/optimization_results.yaml\",\n )\n", "path": "plugins/hydra_optuna_sweeper/hydra_plugins/hydra_optuna_sweeper/_impl.py"}]} | 3,736 | 205 |
gh_patches_debug_11245 | rasdani/github-patches | git_diff | sunpy__sunpy-4596 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Rethinking and rewriting sunpy.self_test
We are currently using astropy's test runner for `sunpy.self_test` this was really designed for setup.py and is therefore very full of features which are probably not needed for self_test.
Before we (I) go deleting swathes of code as I love to do. What do we want to achieve with self test? Is a very slim wrapper around `pytest --pyargs sunpy` all we need?
</issue>
<code>
[start of sunpy/__init__.py]
1 """
2 SunPy
3 =====
4
5 An open-source Python library for Solar Physics data analysis.
6
7 * Homepage: https://sunpy.org
8 * Documentation: https://docs.sunpy.org/en/stable/
9 """
10 import os
11 import sys
12 import logging
13
14 from sunpy.tests.runner import SunPyTestRunner
15 from sunpy.util import system_info
16 from sunpy.util.config import load_config, print_config
17 from sunpy.util.logger import _init_log
18 from .version import version as __version__
19
20 # Enforce Python version check during package import.
21 __minimum_python_version__ = "3.7"
22
23
24 class UnsupportedPythonError(Exception):
25 """Running on an unsupported version of Python."""
26
27
28 if sys.version_info < tuple(int(val) for val in __minimum_python_version__.split('.')):
29 # This has to be .format to keep backwards compatibly.
30 raise UnsupportedPythonError(
31 "sunpy does not support Python < {}".format(__minimum_python_version__))
32
33
34 def _get_bibtex():
35 import textwrap
36
37 # Set the bibtex entry to the article referenced in CITATION.rst
38 citation_file = os.path.join(os.path.dirname(__file__), 'CITATION.rst')
39
40 # Explicitly specify UTF-8 encoding in case the system's default encoding is problematic
41 with open(citation_file, 'r', encoding='utf-8') as citation:
42 # Extract the first bibtex block:
43 ref = citation.read().partition(".. code:: bibtex\n\n")[2]
44 lines = ref.split("\n")
45 # Only read the lines which are indented
46 lines = lines[:[l.startswith(" ") for l in lines].index(False)]
47 ref = textwrap.dedent('\n'.join(lines))
48 return ref
49
50
51 __citation__ = __bibtex__ = _get_bibtex()
52
53 self_test = SunPyTestRunner.make_test_runner_in(os.path.dirname(__file__))
54
55 # Load user configuration
56 config = load_config()
57
58 log = _init_log(config=config)
59
60 __all__ = ['config', 'self_test', 'system_info', 'print_config']
61
[end of sunpy/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/sunpy/__init__.py b/sunpy/__init__.py
--- a/sunpy/__init__.py
+++ b/sunpy/__init__.py
@@ -11,7 +11,7 @@
import sys
import logging
-from sunpy.tests.runner import SunPyTestRunner
+from sunpy.tests.self_test import self_test
from sunpy.util import system_info
from sunpy.util.config import load_config, print_config
from sunpy.util.logger import _init_log
@@ -50,8 +50,6 @@
__citation__ = __bibtex__ = _get_bibtex()
-self_test = SunPyTestRunner.make_test_runner_in(os.path.dirname(__file__))
-
# Load user configuration
config = load_config()
| {"golden_diff": "diff --git a/sunpy/__init__.py b/sunpy/__init__.py\n--- a/sunpy/__init__.py\n+++ b/sunpy/__init__.py\n@@ -11,7 +11,7 @@\n import sys\n import logging\n \n-from sunpy.tests.runner import SunPyTestRunner\n+from sunpy.tests.self_test import self_test\n from sunpy.util import system_info\n from sunpy.util.config import load_config, print_config\n from sunpy.util.logger import _init_log\n@@ -50,8 +50,6 @@\n \n __citation__ = __bibtex__ = _get_bibtex()\n \n-self_test = SunPyTestRunner.make_test_runner_in(os.path.dirname(__file__))\n-\n # Load user configuration\n config = load_config()\n", "issue": "Rethinking and rewriting sunpy.self_test\nWe are currently using astropy's test runner for `sunpy.self_test` this was really designed for setup.py and is therefore very full of features which are probably not needed for self_test.\n\nBefore we (I) go deleting swathes of code as I love to do. What do we want to achieve with self test? Is a very slim wrapper around `pytest --pyargs sunpy` all we need?\n", "before_files": [{"content": "\"\"\"\nSunPy\n=====\n\nAn open-source Python library for Solar Physics data analysis.\n\n* Homepage: https://sunpy.org\n* Documentation: https://docs.sunpy.org/en/stable/\n\"\"\"\nimport os\nimport sys\nimport logging\n\nfrom sunpy.tests.runner import SunPyTestRunner\nfrom sunpy.util import system_info\nfrom sunpy.util.config import load_config, print_config\nfrom sunpy.util.logger import _init_log\nfrom .version import version as __version__\n\n# Enforce Python version check during package import.\n__minimum_python_version__ = \"3.7\"\n\n\nclass UnsupportedPythonError(Exception):\n \"\"\"Running on an unsupported version of Python.\"\"\"\n\n\nif sys.version_info < tuple(int(val) for val in __minimum_python_version__.split('.')):\n # This has to be .format to keep backwards compatibly.\n raise UnsupportedPythonError(\n \"sunpy does not support Python < {}\".format(__minimum_python_version__))\n\n\ndef _get_bibtex():\n import textwrap\n\n # Set the bibtex entry to the article referenced in CITATION.rst\n citation_file = os.path.join(os.path.dirname(__file__), 'CITATION.rst')\n\n # Explicitly specify UTF-8 encoding in case the system's default encoding is problematic\n with open(citation_file, 'r', encoding='utf-8') as citation:\n # Extract the first bibtex block:\n ref = citation.read().partition(\".. code:: bibtex\\n\\n\")[2]\n lines = ref.split(\"\\n\")\n # Only read the lines which are indented\n lines = lines[:[l.startswith(\" \") for l in lines].index(False)]\n ref = textwrap.dedent('\\n'.join(lines))\n return ref\n\n\n__citation__ = __bibtex__ = _get_bibtex()\n\nself_test = SunPyTestRunner.make_test_runner_in(os.path.dirname(__file__))\n\n# Load user configuration\nconfig = load_config()\n\nlog = _init_log(config=config)\n\n__all__ = ['config', 'self_test', 'system_info', 'print_config']\n", "path": "sunpy/__init__.py"}]} | 1,196 | 168 |
gh_patches_debug_33083 | rasdani/github-patches | git_diff | ipython__ipython-7466 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
interact doesn't work with instance methods
This code:
``` python
from IPython.html.widgets import interact
class Foo(object):
def show(self, x):
print x
f = Foo()
interact(f.show, x=(1,10))
```
produces this exception:
```
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-58-b03b8685dfc0> in <module>()
7 f = Foo()
8
----> 9 interact(f.show, x=(1,10))
/home/fperez/usr/lib/python2.7/site-packages/IPython/html/widgets/interaction.pyc in interact(__interact_f, **kwargs)
235 f = __interact_f
236 w = interactive(f, **kwargs)
--> 237 f.widget = w
238 display(w)
239 return f
AttributeError: 'instancemethod' object has no attribute 'widget'
```
</issue>
<code>
[start of IPython/html/widgets/interaction.py]
1 """Interact with functions using widgets."""
2
3 #-----------------------------------------------------------------------------
4 # Copyright (c) 2013, the IPython Development Team.
5 #
6 # Distributed under the terms of the Modified BSD License.
7 #
8 # The full license is in the file COPYING.txt, distributed with this software.
9 #-----------------------------------------------------------------------------
10
11 #-----------------------------------------------------------------------------
12 # Imports
13 #-----------------------------------------------------------------------------
14
15 from __future__ import print_function
16
17 try: # Python >= 3.3
18 from inspect import signature, Parameter
19 except ImportError:
20 from IPython.utils.signatures import signature, Parameter
21 from inspect import getcallargs
22
23 from IPython.core.getipython import get_ipython
24 from IPython.html.widgets import (Widget, Text,
25 FloatSlider, IntSlider, Checkbox, Dropdown,
26 Box, Button, DOMWidget)
27 from IPython.display import display, clear_output
28 from IPython.utils.py3compat import string_types, unicode_type
29 from IPython.utils.traitlets import HasTraits, Any, Unicode
30
31 empty = Parameter.empty
32
33 #-----------------------------------------------------------------------------
34 # Classes and Functions
35 #-----------------------------------------------------------------------------
36
37
38 def _matches(o, pattern):
39 """Match a pattern of types in a sequence."""
40 if not len(o) == len(pattern):
41 return False
42 comps = zip(o,pattern)
43 return all(isinstance(obj,kind) for obj,kind in comps)
44
45
46 def _get_min_max_value(min, max, value=None, step=None):
47 """Return min, max, value given input values with possible None."""
48 if value is None:
49 if not max > min:
50 raise ValueError('max must be greater than min: (min={0}, max={1})'.format(min, max))
51 value = min + abs(min-max)/2
52 value = type(min)(value)
53 elif min is None and max is None:
54 if value == 0.0:
55 min, max, value = 0.0, 1.0, 0.5
56 elif value == 0:
57 min, max, value = 0, 1, 0
58 elif isinstance(value, (int, float)):
59 min, max = (-value, 3*value) if value > 0 else (3*value, -value)
60 else:
61 raise TypeError('expected a number, got: %r' % value)
62 else:
63 raise ValueError('unable to infer range, value from: ({0}, {1}, {2})'.format(min, max, value))
64 if step is not None:
65 # ensure value is on a step
66 r = (value - min) % step
67 value = value - r
68 return min, max, value
69
70 def _widget_abbrev_single_value(o):
71 """Make widgets from single values, which can be used as parameter defaults."""
72 if isinstance(o, string_types):
73 return Text(value=unicode_type(o))
74 elif isinstance(o, dict):
75 return Dropdown(values=o)
76 elif isinstance(o, bool):
77 return Checkbox(value=o)
78 elif isinstance(o, float):
79 min, max, value = _get_min_max_value(None, None, o)
80 return FloatSlider(value=o, min=min, max=max)
81 elif isinstance(o, int):
82 min, max, value = _get_min_max_value(None, None, o)
83 return IntSlider(value=o, min=min, max=max)
84 else:
85 return None
86
87 def _widget_abbrev(o):
88 """Make widgets from abbreviations: single values, lists or tuples."""
89 float_or_int = (float, int)
90 if isinstance(o, (list, tuple)):
91 if o and all(isinstance(x, string_types) for x in o):
92 return Dropdown(values=[unicode_type(k) for k in o])
93 elif _matches(o, (float_or_int, float_or_int)):
94 min, max, value = _get_min_max_value(o[0], o[1])
95 if all(isinstance(_, int) for _ in o):
96 cls = IntSlider
97 else:
98 cls = FloatSlider
99 return cls(value=value, min=min, max=max)
100 elif _matches(o, (float_or_int, float_or_int, float_or_int)):
101 step = o[2]
102 if step <= 0:
103 raise ValueError("step must be >= 0, not %r" % step)
104 min, max, value = _get_min_max_value(o[0], o[1], step=step)
105 if all(isinstance(_, int) for _ in o):
106 cls = IntSlider
107 else:
108 cls = FloatSlider
109 return cls(value=value, min=min, max=max, step=step)
110 else:
111 return _widget_abbrev_single_value(o)
112
113 def _widget_from_abbrev(abbrev, default=empty):
114 """Build a Widget instance given an abbreviation or Widget."""
115 if isinstance(abbrev, Widget) or isinstance(abbrev, fixed):
116 return abbrev
117
118 widget = _widget_abbrev(abbrev)
119 if default is not empty and isinstance(abbrev, (list, tuple, dict)):
120 # if it's not a single-value abbreviation,
121 # set the initial value from the default
122 try:
123 widget.value = default
124 except Exception:
125 # ignore failure to set default
126 pass
127 if widget is None:
128 raise ValueError("%r cannot be transformed to a Widget" % (abbrev,))
129 return widget
130
131 def _yield_abbreviations_for_parameter(param, kwargs):
132 """Get an abbreviation for a function parameter."""
133 name = param.name
134 kind = param.kind
135 ann = param.annotation
136 default = param.default
137 not_found = (name, empty, empty)
138 if kind in (Parameter.POSITIONAL_OR_KEYWORD, Parameter.KEYWORD_ONLY):
139 if name in kwargs:
140 value = kwargs.pop(name)
141 elif ann is not empty:
142 value = ann
143 elif default is not empty:
144 value = default
145 else:
146 yield not_found
147 yield (name, value, default)
148 elif kind == Parameter.VAR_KEYWORD:
149 # In this case name=kwargs and we yield the items in kwargs with their keys.
150 for k, v in kwargs.copy().items():
151 kwargs.pop(k)
152 yield k, v, empty
153
154 def _find_abbreviations(f, kwargs):
155 """Find the abbreviations for a function and kwargs passed to interact."""
156 new_kwargs = []
157 for param in signature(f).parameters.values():
158 for name, value, default in _yield_abbreviations_for_parameter(param, kwargs):
159 if value is empty:
160 raise ValueError('cannot find widget or abbreviation for argument: {!r}'.format(name))
161 new_kwargs.append((name, value, default))
162 return new_kwargs
163
164 def _widgets_from_abbreviations(seq):
165 """Given a sequence of (name, abbrev) tuples, return a sequence of Widgets."""
166 result = []
167 for name, abbrev, default in seq:
168 widget = _widget_from_abbrev(abbrev, default)
169 if not widget.description:
170 widget.description = name
171 result.append(widget)
172 return result
173
174 def interactive(__interact_f, **kwargs):
175 """Build a group of widgets to interact with a function."""
176 f = __interact_f
177 co = kwargs.pop('clear_output', True)
178 manual = kwargs.pop('__manual', False)
179 kwargs_widgets = []
180 container = Box()
181 container.result = None
182 container.args = []
183 container.kwargs = dict()
184 kwargs = kwargs.copy()
185
186 new_kwargs = _find_abbreviations(f, kwargs)
187 # Before we proceed, let's make sure that the user has passed a set of args+kwargs
188 # that will lead to a valid call of the function. This protects against unspecified
189 # and doubly-specified arguments.
190 getcallargs(f, **{n:v for n,v,_ in new_kwargs})
191 # Now build the widgets from the abbreviations.
192 kwargs_widgets.extend(_widgets_from_abbreviations(new_kwargs))
193
194 # This has to be done as an assignment, not using container.children.append,
195 # so that traitlets notices the update. We skip any objects (such as fixed) that
196 # are not DOMWidgets.
197 c = [w for w in kwargs_widgets if isinstance(w, DOMWidget)]
198
199 # If we are only to run the function on demand, add a button to request this
200 if manual:
201 manual_button = Button(description="Run %s" % f.__name__)
202 c.append(manual_button)
203 container.children = c
204
205 # Build the callback
206 def call_f(name=None, old=None, new=None):
207 container.kwargs = {}
208 for widget in kwargs_widgets:
209 value = widget.value
210 container.kwargs[widget.description] = value
211 if co:
212 clear_output(wait=True)
213 if manual:
214 manual_button.disabled = True
215 try:
216 container.result = f(**container.kwargs)
217 except Exception as e:
218 ip = get_ipython()
219 if ip is None:
220 container.log.warn("Exception in interact callback: %s", e, exc_info=True)
221 else:
222 ip.showtraceback()
223 finally:
224 if manual:
225 manual_button.disabled = False
226
227 # Wire up the widgets
228 # If we are doing manual running, the callback is only triggered by the button
229 # Otherwise, it is triggered for every trait change received
230 # On-demand running also suppresses running the fucntion with the initial parameters
231 if manual:
232 manual_button.on_click(call_f)
233 else:
234 for widget in kwargs_widgets:
235 widget.on_trait_change(call_f, 'value')
236
237 container.on_displayed(lambda _: call_f(None, None, None))
238
239 return container
240
241 def interact(__interact_f=None, **kwargs):
242 """interact(f, **kwargs)
243
244 Interact with a function using widgets."""
245 # positional arg support in: https://gist.github.com/8851331
246 if __interact_f is not None:
247 # This branch handles the cases:
248 # 1. interact(f, **kwargs)
249 # 2. @interact
250 # def f(*args, **kwargs):
251 # ...
252 f = __interact_f
253 w = interactive(f, **kwargs)
254 f.widget = w
255 display(w)
256 return f
257 else:
258 # This branch handles the case:
259 # @interact(a=30, b=40)
260 # def f(*args, **kwargs):
261 # ...
262 def dec(f):
263 w = interactive(f, **kwargs)
264 f.widget = w
265 display(w)
266 return f
267 return dec
268
269 def interact_manual(__interact_f=None, **kwargs):
270 """interact_manual(f, **kwargs)
271
272 As `interact()`, generates widgets for each argument, but rather than running
273 the function after each widget change, adds a "Run" button and waits for it
274 to be clicked. Useful if the function is long-running and has several
275 parameters to change.
276 """
277 return interact(__interact_f, __manual=True, **kwargs)
278
279 class fixed(HasTraits):
280 """A pseudo-widget whose value is fixed and never synced to the client."""
281 value = Any(help="Any Python object")
282 description = Unicode('', help="Any Python object")
283 def __init__(self, value, **kwargs):
284 super(fixed, self).__init__(value=value, **kwargs)
285
[end of IPython/html/widgets/interaction.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/IPython/html/widgets/interaction.py b/IPython/html/widgets/interaction.py
--- a/IPython/html/widgets/interaction.py
+++ b/IPython/html/widgets/interaction.py
@@ -1,16 +1,7 @@
"""Interact with functions using widgets."""
-#-----------------------------------------------------------------------------
-# Copyright (c) 2013, the IPython Development Team.
-#
+# Copyright (c) IPython Development Team.
# Distributed under the terms of the Modified BSD License.
-#
-# The full license is in the file COPYING.txt, distributed with this software.
-#-----------------------------------------------------------------------------
-
-#-----------------------------------------------------------------------------
-# Imports
-#-----------------------------------------------------------------------------
from __future__ import print_function
@@ -30,10 +21,6 @@
empty = Parameter.empty
-#-----------------------------------------------------------------------------
-# Classes and Functions
-#-----------------------------------------------------------------------------
-
def _matches(o, pattern):
"""Match a pattern of types in a sequence."""
@@ -251,7 +238,13 @@
# ...
f = __interact_f
w = interactive(f, **kwargs)
- f.widget = w
+ try:
+ f.widget = w
+ except AttributeError:
+ # some things (instancemethods) can't have attributes attached,
+ # so wrap in a lambda
+ f = lambda *args, **kwargs: __interact_f(*args, **kwargs)
+ f.widget = w
display(w)
return f
else:
@@ -260,10 +253,7 @@
# def f(*args, **kwargs):
# ...
def dec(f):
- w = interactive(f, **kwargs)
- f.widget = w
- display(w)
- return f
+ return interact(f, **kwargs)
return dec
def interact_manual(__interact_f=None, **kwargs):
| {"golden_diff": "diff --git a/IPython/html/widgets/interaction.py b/IPython/html/widgets/interaction.py\n--- a/IPython/html/widgets/interaction.py\n+++ b/IPython/html/widgets/interaction.py\n@@ -1,16 +1,7 @@\n \"\"\"Interact with functions using widgets.\"\"\"\n \n-#-----------------------------------------------------------------------------\n-# Copyright (c) 2013, the IPython Development Team.\n-#\n+# Copyright (c) IPython Development Team.\n # Distributed under the terms of the Modified BSD License.\n-#\n-# The full license is in the file COPYING.txt, distributed with this software.\n-#-----------------------------------------------------------------------------\n-\n-#-----------------------------------------------------------------------------\n-# Imports\n-#-----------------------------------------------------------------------------\n \n from __future__ import print_function\n \n@@ -30,10 +21,6 @@\n \n empty = Parameter.empty\n \n-#-----------------------------------------------------------------------------\n-# Classes and Functions\n-#-----------------------------------------------------------------------------\n-\n \n def _matches(o, pattern):\n \"\"\"Match a pattern of types in a sequence.\"\"\"\n@@ -251,7 +238,13 @@\n # ...\n f = __interact_f\n w = interactive(f, **kwargs)\n- f.widget = w\n+ try:\n+ f.widget = w\n+ except AttributeError:\n+ # some things (instancemethods) can't have attributes attached,\n+ # so wrap in a lambda\n+ f = lambda *args, **kwargs: __interact_f(*args, **kwargs)\n+ f.widget = w\n display(w)\n return f\n else:\n@@ -260,10 +253,7 @@\n # def f(*args, **kwargs):\n # ...\n def dec(f):\n- w = interactive(f, **kwargs)\n- f.widget = w\n- display(w)\n- return f\n+ return interact(f, **kwargs)\n return dec\n \n def interact_manual(__interact_f=None, **kwargs):\n", "issue": "interact doesn't work with instance methods\nThis code:\n\n``` python\nfrom IPython.html.widgets import interact\n\nclass Foo(object):\n def show(self, x):\n print x\n\nf = Foo()\n\ninteract(f.show, x=(1,10))\n```\n\nproduces this exception:\n\n```\n---------------------------------------------------------------------------\nAttributeError Traceback (most recent call last)\n<ipython-input-58-b03b8685dfc0> in <module>()\n 7 f = Foo()\n 8 \n----> 9 interact(f.show, x=(1,10))\n\n/home/fperez/usr/lib/python2.7/site-packages/IPython/html/widgets/interaction.pyc in interact(__interact_f, **kwargs)\n 235 f = __interact_f\n 236 w = interactive(f, **kwargs)\n--> 237 f.widget = w\n 238 display(w)\n 239 return f\n\nAttributeError: 'instancemethod' object has no attribute 'widget'\n```\n\n", "before_files": [{"content": "\"\"\"Interact with functions using widgets.\"\"\"\n\n#-----------------------------------------------------------------------------\n# Copyright (c) 2013, the IPython Development Team.\n#\n# Distributed under the terms of the Modified BSD License.\n#\n# The full license is in the file COPYING.txt, distributed with this software.\n#-----------------------------------------------------------------------------\n\n#-----------------------------------------------------------------------------\n# Imports\n#-----------------------------------------------------------------------------\n\nfrom __future__ import print_function\n\ntry: # Python >= 3.3\n from inspect import signature, Parameter\nexcept ImportError:\n from IPython.utils.signatures import signature, Parameter\nfrom inspect import getcallargs\n\nfrom IPython.core.getipython import get_ipython\nfrom IPython.html.widgets import (Widget, Text,\n FloatSlider, IntSlider, Checkbox, Dropdown,\n Box, Button, DOMWidget)\nfrom IPython.display import display, clear_output\nfrom IPython.utils.py3compat import string_types, unicode_type\nfrom IPython.utils.traitlets import HasTraits, Any, Unicode\n\nempty = Parameter.empty\n\n#-----------------------------------------------------------------------------\n# Classes and Functions\n#-----------------------------------------------------------------------------\n\n\ndef _matches(o, pattern):\n \"\"\"Match a pattern of types in a sequence.\"\"\"\n if not len(o) == len(pattern):\n return False\n comps = zip(o,pattern)\n return all(isinstance(obj,kind) for obj,kind in comps)\n\n\ndef _get_min_max_value(min, max, value=None, step=None):\n \"\"\"Return min, max, value given input values with possible None.\"\"\"\n if value is None:\n if not max > min:\n raise ValueError('max must be greater than min: (min={0}, max={1})'.format(min, max))\n value = min + abs(min-max)/2\n value = type(min)(value)\n elif min is None and max is None:\n if value == 0.0:\n min, max, value = 0.0, 1.0, 0.5\n elif value == 0:\n min, max, value = 0, 1, 0\n elif isinstance(value, (int, float)):\n min, max = (-value, 3*value) if value > 0 else (3*value, -value)\n else:\n raise TypeError('expected a number, got: %r' % value)\n else:\n raise ValueError('unable to infer range, value from: ({0}, {1}, {2})'.format(min, max, value))\n if step is not None:\n # ensure value is on a step\n r = (value - min) % step\n value = value - r\n return min, max, value\n\ndef _widget_abbrev_single_value(o):\n \"\"\"Make widgets from single values, which can be used as parameter defaults.\"\"\"\n if isinstance(o, string_types):\n return Text(value=unicode_type(o))\n elif isinstance(o, dict):\n return Dropdown(values=o)\n elif isinstance(o, bool):\n return Checkbox(value=o)\n elif isinstance(o, float):\n min, max, value = _get_min_max_value(None, None, o)\n return FloatSlider(value=o, min=min, max=max)\n elif isinstance(o, int):\n min, max, value = _get_min_max_value(None, None, o)\n return IntSlider(value=o, min=min, max=max)\n else:\n return None\n\ndef _widget_abbrev(o):\n \"\"\"Make widgets from abbreviations: single values, lists or tuples.\"\"\"\n float_or_int = (float, int)\n if isinstance(o, (list, tuple)):\n if o and all(isinstance(x, string_types) for x in o):\n return Dropdown(values=[unicode_type(k) for k in o])\n elif _matches(o, (float_or_int, float_or_int)):\n min, max, value = _get_min_max_value(o[0], o[1])\n if all(isinstance(_, int) for _ in o):\n cls = IntSlider\n else:\n cls = FloatSlider\n return cls(value=value, min=min, max=max)\n elif _matches(o, (float_or_int, float_or_int, float_or_int)):\n step = o[2]\n if step <= 0:\n raise ValueError(\"step must be >= 0, not %r\" % step)\n min, max, value = _get_min_max_value(o[0], o[1], step=step)\n if all(isinstance(_, int) for _ in o):\n cls = IntSlider\n else:\n cls = FloatSlider\n return cls(value=value, min=min, max=max, step=step)\n else:\n return _widget_abbrev_single_value(o)\n\ndef _widget_from_abbrev(abbrev, default=empty):\n \"\"\"Build a Widget instance given an abbreviation or Widget.\"\"\"\n if isinstance(abbrev, Widget) or isinstance(abbrev, fixed):\n return abbrev\n\n widget = _widget_abbrev(abbrev)\n if default is not empty and isinstance(abbrev, (list, tuple, dict)):\n # if it's not a single-value abbreviation,\n # set the initial value from the default\n try:\n widget.value = default\n except Exception:\n # ignore failure to set default\n pass\n if widget is None:\n raise ValueError(\"%r cannot be transformed to a Widget\" % (abbrev,))\n return widget\n\ndef _yield_abbreviations_for_parameter(param, kwargs):\n \"\"\"Get an abbreviation for a function parameter.\"\"\"\n name = param.name\n kind = param.kind\n ann = param.annotation\n default = param.default\n not_found = (name, empty, empty)\n if kind in (Parameter.POSITIONAL_OR_KEYWORD, Parameter.KEYWORD_ONLY):\n if name in kwargs:\n value = kwargs.pop(name)\n elif ann is not empty:\n value = ann\n elif default is not empty:\n value = default\n else:\n yield not_found\n yield (name, value, default)\n elif kind == Parameter.VAR_KEYWORD:\n # In this case name=kwargs and we yield the items in kwargs with their keys.\n for k, v in kwargs.copy().items():\n kwargs.pop(k)\n yield k, v, empty\n\ndef _find_abbreviations(f, kwargs):\n \"\"\"Find the abbreviations for a function and kwargs passed to interact.\"\"\"\n new_kwargs = []\n for param in signature(f).parameters.values():\n for name, value, default in _yield_abbreviations_for_parameter(param, kwargs):\n if value is empty:\n raise ValueError('cannot find widget or abbreviation for argument: {!r}'.format(name))\n new_kwargs.append((name, value, default))\n return new_kwargs\n\ndef _widgets_from_abbreviations(seq):\n \"\"\"Given a sequence of (name, abbrev) tuples, return a sequence of Widgets.\"\"\"\n result = []\n for name, abbrev, default in seq:\n widget = _widget_from_abbrev(abbrev, default)\n if not widget.description:\n widget.description = name\n result.append(widget)\n return result\n\ndef interactive(__interact_f, **kwargs):\n \"\"\"Build a group of widgets to interact with a function.\"\"\"\n f = __interact_f\n co = kwargs.pop('clear_output', True)\n manual = kwargs.pop('__manual', False)\n kwargs_widgets = []\n container = Box()\n container.result = None\n container.args = []\n container.kwargs = dict()\n kwargs = kwargs.copy()\n\n new_kwargs = _find_abbreviations(f, kwargs)\n # Before we proceed, let's make sure that the user has passed a set of args+kwargs\n # that will lead to a valid call of the function. This protects against unspecified\n # and doubly-specified arguments.\n getcallargs(f, **{n:v for n,v,_ in new_kwargs})\n # Now build the widgets from the abbreviations.\n kwargs_widgets.extend(_widgets_from_abbreviations(new_kwargs))\n\n # This has to be done as an assignment, not using container.children.append,\n # so that traitlets notices the update. We skip any objects (such as fixed) that\n # are not DOMWidgets.\n c = [w for w in kwargs_widgets if isinstance(w, DOMWidget)]\n\n # If we are only to run the function on demand, add a button to request this\n if manual:\n manual_button = Button(description=\"Run %s\" % f.__name__)\n c.append(manual_button)\n container.children = c\n\n # Build the callback\n def call_f(name=None, old=None, new=None):\n container.kwargs = {}\n for widget in kwargs_widgets:\n value = widget.value\n container.kwargs[widget.description] = value\n if co:\n clear_output(wait=True)\n if manual:\n manual_button.disabled = True\n try:\n container.result = f(**container.kwargs)\n except Exception as e:\n ip = get_ipython()\n if ip is None:\n container.log.warn(\"Exception in interact callback: %s\", e, exc_info=True)\n else:\n ip.showtraceback()\n finally:\n if manual:\n manual_button.disabled = False\n\n # Wire up the widgets\n # If we are doing manual running, the callback is only triggered by the button\n # Otherwise, it is triggered for every trait change received\n # On-demand running also suppresses running the fucntion with the initial parameters\n if manual:\n manual_button.on_click(call_f)\n else:\n for widget in kwargs_widgets:\n widget.on_trait_change(call_f, 'value')\n\n container.on_displayed(lambda _: call_f(None, None, None))\n\n return container\n\ndef interact(__interact_f=None, **kwargs):\n \"\"\"interact(f, **kwargs)\n\n Interact with a function using widgets.\"\"\"\n # positional arg support in: https://gist.github.com/8851331\n if __interact_f is not None:\n # This branch handles the cases:\n # 1. interact(f, **kwargs)\n # 2. @interact\n # def f(*args, **kwargs):\n # ...\n f = __interact_f\n w = interactive(f, **kwargs)\n f.widget = w\n display(w)\n return f\n else:\n # This branch handles the case:\n # @interact(a=30, b=40)\n # def f(*args, **kwargs):\n # ...\n def dec(f):\n w = interactive(f, **kwargs)\n f.widget = w\n display(w)\n return f\n return dec\n\ndef interact_manual(__interact_f=None, **kwargs):\n \"\"\"interact_manual(f, **kwargs)\n \n As `interact()`, generates widgets for each argument, but rather than running\n the function after each widget change, adds a \"Run\" button and waits for it\n to be clicked. Useful if the function is long-running and has several\n parameters to change.\n \"\"\"\n return interact(__interact_f, __manual=True, **kwargs)\n\nclass fixed(HasTraits):\n \"\"\"A pseudo-widget whose value is fixed and never synced to the client.\"\"\"\n value = Any(help=\"Any Python object\")\n description = Unicode('', help=\"Any Python object\")\n def __init__(self, value, **kwargs):\n super(fixed, self).__init__(value=value, **kwargs)\n", "path": "IPython/html/widgets/interaction.py"}]} | 3,951 | 407 |
gh_patches_debug_7810 | rasdani/github-patches | git_diff | ManimCommunity__manim-2587 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Rendering TeX strings containing % broken
This unfortunately broke rendering of TeX strings containing `%`. Trying to create `Tex(r"\%")` fails in v0.15.0.
_Originally posted by @behackl in https://github.com/ManimCommunity/manim/issues/2574#issuecomment-1054726581_
</issue>
<code>
[start of manim/utils/tex_file_writing.py]
1 """Interface for writing, compiling, and converting ``.tex`` files.
2
3 .. SEEALSO::
4
5 :mod:`.mobject.svg.tex_mobject`
6
7 """
8
9 from __future__ import annotations
10
11 import hashlib
12 import os
13 import re
14 import unicodedata
15 from pathlib import Path
16
17 from .. import config, logger
18
19
20 def tex_hash(expression):
21 id_str = str(expression)
22 hasher = hashlib.sha256()
23 hasher.update(id_str.encode())
24 # Truncating at 16 bytes for cleanliness
25 return hasher.hexdigest()[:16]
26
27
28 def tex_to_svg_file(expression, environment=None, tex_template=None):
29 """Takes a tex expression and returns the svg version of the compiled tex
30
31 Parameters
32 ----------
33 expression : :class:`str`
34 String containing the TeX expression to be rendered, e.g. ``\\sqrt{2}`` or ``foo``
35 environment : Optional[:class:`str`], optional
36 The string containing the environment in which the expression should be typeset, e.g. ``align*``
37 tex_template : Optional[:class:`~.TexTemplate`], optional
38 Template class used to typesetting. If not set, use default template set via `config["tex_template"]`
39
40 Returns
41 -------
42 :class:`str`
43 Path to generated SVG file.
44 """
45 if tex_template is None:
46 tex_template = config["tex_template"]
47 tex_file = generate_tex_file(expression, environment, tex_template)
48 dvi_file = compile_tex(
49 tex_file,
50 tex_template.tex_compiler,
51 tex_template.output_format,
52 )
53 return convert_to_svg(dvi_file, tex_template.output_format)
54
55
56 def generate_tex_file(expression, environment=None, tex_template=None):
57 """Takes a tex expression (and an optional tex environment),
58 and returns a fully formed tex file ready for compilation.
59
60 Parameters
61 ----------
62 expression : :class:`str`
63 String containing the TeX expression to be rendered, e.g. ``\\sqrt{2}`` or ``foo``
64 environment : Optional[:class:`str`], optional
65 The string containing the environment in which the expression should be typeset, e.g. ``align*``
66 tex_template : Optional[:class:`~.TexTemplate`], optional
67 Template class used to typesetting. If not set, use default template set via `config["tex_template"]`
68
69 Returns
70 -------
71 :class:`str`
72 Path to generated TeX file
73 """
74 if tex_template is None:
75 tex_template = config["tex_template"]
76 if environment is not None:
77 output = tex_template.get_texcode_for_expression_in_env(expression, environment)
78 else:
79 output = tex_template.get_texcode_for_expression(expression)
80
81 tex_dir = config.get_dir("tex_dir")
82 if not os.path.exists(tex_dir):
83 os.makedirs(tex_dir)
84
85 result = os.path.join(tex_dir, tex_hash(output)) + ".tex"
86 if not os.path.exists(result):
87 logger.info(f"Writing {expression} to %(path)s", {"path": f"{result}"})
88 with open(result, "w", encoding="utf-8") as outfile:
89 outfile.write(output)
90 return result
91
92
93 def tex_compilation_command(tex_compiler, output_format, tex_file, tex_dir):
94 """Prepares the tex compilation command with all necessary cli flags
95
96 Parameters
97 ----------
98 tex_compiler : :class:`str`
99 String containing the compiler to be used, e.g. ``pdflatex`` or ``lualatex``
100 output_format : :class:`str`
101 String containing the output format generated by the compiler, e.g. ``.dvi`` or ``.pdf``
102 tex_file : :class:`str`
103 File name of TeX file to be typeset.
104 tex_dir : :class:`str`
105 Path to the directory where compiler output will be stored.
106
107 Returns
108 -------
109 :class:`str`
110 Compilation command according to given parameters
111 """
112 if tex_compiler in {"latex", "pdflatex", "luatex", "lualatex"}:
113 commands = [
114 tex_compiler,
115 "-interaction=batchmode",
116 f'-output-format="{output_format[1:]}"',
117 "-halt-on-error",
118 f'-output-directory="{tex_dir}"',
119 f'"{tex_file}"',
120 ">",
121 os.devnull,
122 ]
123 elif tex_compiler == "xelatex":
124 if output_format == ".xdv":
125 outflag = "-no-pdf"
126 elif output_format == ".pdf":
127 outflag = ""
128 else:
129 raise ValueError("xelatex output is either pdf or xdv")
130 commands = [
131 "xelatex",
132 outflag,
133 "-interaction=batchmode",
134 "-halt-on-error",
135 f'-output-directory="{tex_dir}"',
136 f'"{tex_file}"',
137 ">",
138 os.devnull,
139 ]
140 else:
141 raise ValueError(f"Tex compiler {tex_compiler} unknown.")
142 return " ".join(commands)
143
144
145 def insight_inputenc_error(matching):
146 code_point = chr(int(matching[1], 16))
147 name = unicodedata.name(code_point)
148 yield f"TexTemplate does not support character '{name}' (U+{matching[1]})."
149 yield "See the documentation for manim.mobject.svg.tex_mobject for details on using a custom TexTemplate."
150
151
152 def insight_package_not_found_error(matching):
153 yield f"You do not have package {matching[1]} installed."
154 yield f"Install {matching[1]} it using your LaTeX package manager, or check for typos."
155
156
157 def compile_tex(tex_file, tex_compiler, output_format):
158 """Compiles a tex_file into a .dvi or a .xdv or a .pdf
159
160 Parameters
161 ----------
162 tex_file : :class:`str`
163 File name of TeX file to be typeset.
164 tex_compiler : :class:`str`
165 String containing the compiler to be used, e.g. ``pdflatex`` or ``lualatex``
166 output_format : :class:`str`
167 String containing the output format generated by the compiler, e.g. ``.dvi`` or ``.pdf``
168
169 Returns
170 -------
171 :class:`str`
172 Path to generated output file in desired format (DVI, XDV or PDF).
173 """
174 result = tex_file.replace(".tex", output_format)
175 result = Path(result).as_posix()
176 tex_file = Path(tex_file).as_posix()
177 tex_dir = Path(config.get_dir("tex_dir")).as_posix()
178 if not os.path.exists(result):
179 command = tex_compilation_command(
180 tex_compiler,
181 output_format,
182 tex_file,
183 tex_dir,
184 )
185 exit_code = os.system(command)
186 if exit_code != 0:
187 log_file = tex_file.replace(".tex", ".log")
188 print_all_tex_errors(log_file, tex_compiler, tex_file)
189 raise ValueError(
190 f"{tex_compiler} error converting to"
191 f" {output_format[1:]}. See log output above or"
192 f" the log file: {log_file}",
193 )
194 return result
195
196
197 def convert_to_svg(dvi_file, extension, page=1):
198 """Converts a .dvi, .xdv, or .pdf file into an svg using dvisvgm.
199
200 Parameters
201 ----------
202 dvi_file : :class:`str`
203 File name of the input file to be converted.
204 extension : :class:`str`
205 String containing the file extension and thus indicating the file type, e.g. ``.dvi`` or ``.pdf``
206 page : Optional[:class:`int`], optional
207 Page to be converted if input file is multi-page.
208
209 Returns
210 -------
211 :class:`str`
212 Path to generated SVG file.
213 """
214 result = dvi_file.replace(extension, ".svg")
215 result = Path(result).as_posix()
216 dvi_file = Path(dvi_file).as_posix()
217 if not os.path.exists(result):
218 commands = [
219 "dvisvgm",
220 "--pdf" if extension == ".pdf" else "",
221 "-p " + str(page),
222 f'"{dvi_file}"',
223 "-n",
224 "-v 0",
225 "-o " + f'"{result}"',
226 ">",
227 os.devnull,
228 ]
229 os.system(" ".join(commands))
230
231 # if the file does not exist now, this means conversion failed
232 if not os.path.exists(result):
233 raise ValueError(
234 f"Your installation does not support converting {extension} files to SVG."
235 f" Consider updating dvisvgm to at least version 2.4."
236 f" If this does not solve the problem, please refer to our troubleshooting guide at:"
237 f" https://docs.manim.community/en/stable/installation/troubleshooting.html",
238 )
239
240 return result
241
242
243 def print_all_tex_errors(log_file, tex_compiler, tex_file):
244 if not Path(log_file).exists():
245 raise RuntimeError(
246 f"{tex_compiler} failed but did not produce a log file. "
247 "Check your LaTeX installation.",
248 )
249 with open(log_file) as f:
250 tex_compilation_log = f.readlines()
251 error_indices = [
252 index
253 for index, line in enumerate(tex_compilation_log)
254 if line.startswith("!")
255 ]
256 if error_indices:
257 with open(tex_file) as g:
258 tex = g.readlines()
259 for error_index in error_indices:
260 print_tex_error(tex_compilation_log, error_index, tex)
261
262
263 LATEX_ERROR_INSIGHTS = [
264 (
265 r"inputenc Error: Unicode character (?:.*) \(U\+([0-9a-fA-F]+)\)",
266 insight_inputenc_error,
267 ),
268 (
269 r"LaTeX Error: File `(.*?[clsty])' not found",
270 insight_package_not_found_error,
271 ),
272 ]
273
274
275 def print_tex_error(tex_compilation_log, error_start_index, tex_source):
276 logger.error(
277 f"LaTeX compilation error: {tex_compilation_log[error_start_index][2:]}",
278 )
279
280 # TeX errors eventually contain a line beginning 'l.xxx` where xxx is the line number that caused the compilation
281 # failure. This code finds the next such line after the error current error message
282 line_of_tex_error = (
283 int(
284 [
285 log_line
286 for log_line in tex_compilation_log[error_start_index:]
287 if log_line.startswith("l.")
288 ][0]
289 .split(" ")[0]
290 .split(".")[1],
291 )
292 - 1
293 )
294 # our tex error may be on a line outside our user input because of post-processing
295 if line_of_tex_error >= len(tex_source):
296 return None
297
298 context = ["Context of error: \n"]
299 if line_of_tex_error < 3:
300 context += tex_source[: line_of_tex_error + 3]
301 context[-4] = "-> " + context[-4]
302 elif line_of_tex_error > len(tex_source) - 3:
303 context += tex_source[line_of_tex_error - 1 :]
304 context[1] = "-> " + context[1]
305 else:
306 context += tex_source[line_of_tex_error - 3 : line_of_tex_error + 3]
307 context[-4] = "-> " + context[-4]
308
309 context = "".join(context)
310 logger.error(context)
311
312 for insights in LATEX_ERROR_INSIGHTS:
313 prob, get_insight = insights
314 matching = re.search(
315 prob,
316 "".join(tex_compilation_log[error_start_index])[2:],
317 )
318 if matching is not None:
319 for insight in get_insight(matching):
320 logger.info(insight)
321
[end of manim/utils/tex_file_writing.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/manim/utils/tex_file_writing.py b/manim/utils/tex_file_writing.py
--- a/manim/utils/tex_file_writing.py
+++ b/manim/utils/tex_file_writing.py
@@ -84,7 +84,10 @@
result = os.path.join(tex_dir, tex_hash(output)) + ".tex"
if not os.path.exists(result):
- logger.info(f"Writing {expression} to %(path)s", {"path": f"{result}"})
+ logger.info(
+ "Writing %(expression)s to %(path)s",
+ {"expression": expression, "path": f"{result}"},
+ )
with open(result, "w", encoding="utf-8") as outfile:
outfile.write(output)
return result
| {"golden_diff": "diff --git a/manim/utils/tex_file_writing.py b/manim/utils/tex_file_writing.py\n--- a/manim/utils/tex_file_writing.py\n+++ b/manim/utils/tex_file_writing.py\n@@ -84,7 +84,10 @@\n \n result = os.path.join(tex_dir, tex_hash(output)) + \".tex\"\n if not os.path.exists(result):\n- logger.info(f\"Writing {expression} to %(path)s\", {\"path\": f\"{result}\"})\n+ logger.info(\n+ \"Writing %(expression)s to %(path)s\",\n+ {\"expression\": expression, \"path\": f\"{result}\"},\n+ )\n with open(result, \"w\", encoding=\"utf-8\") as outfile:\n outfile.write(output)\n return result\n", "issue": "Rendering TeX strings containing % broken\nThis unfortunately broke rendering of TeX strings containing `%`. Trying to create `Tex(r\"\\%\")` fails in v0.15.0.\r\n\r\n_Originally posted by @behackl in https://github.com/ManimCommunity/manim/issues/2574#issuecomment-1054726581_\n", "before_files": [{"content": "\"\"\"Interface for writing, compiling, and converting ``.tex`` files.\n\n.. SEEALSO::\n\n :mod:`.mobject.svg.tex_mobject`\n\n\"\"\"\n\nfrom __future__ import annotations\n\nimport hashlib\nimport os\nimport re\nimport unicodedata\nfrom pathlib import Path\n\nfrom .. import config, logger\n\n\ndef tex_hash(expression):\n id_str = str(expression)\n hasher = hashlib.sha256()\n hasher.update(id_str.encode())\n # Truncating at 16 bytes for cleanliness\n return hasher.hexdigest()[:16]\n\n\ndef tex_to_svg_file(expression, environment=None, tex_template=None):\n \"\"\"Takes a tex expression and returns the svg version of the compiled tex\n\n Parameters\n ----------\n expression : :class:`str`\n String containing the TeX expression to be rendered, e.g. ``\\\\sqrt{2}`` or ``foo``\n environment : Optional[:class:`str`], optional\n The string containing the environment in which the expression should be typeset, e.g. ``align*``\n tex_template : Optional[:class:`~.TexTemplate`], optional\n Template class used to typesetting. If not set, use default template set via `config[\"tex_template\"]`\n\n Returns\n -------\n :class:`str`\n Path to generated SVG file.\n \"\"\"\n if tex_template is None:\n tex_template = config[\"tex_template\"]\n tex_file = generate_tex_file(expression, environment, tex_template)\n dvi_file = compile_tex(\n tex_file,\n tex_template.tex_compiler,\n tex_template.output_format,\n )\n return convert_to_svg(dvi_file, tex_template.output_format)\n\n\ndef generate_tex_file(expression, environment=None, tex_template=None):\n \"\"\"Takes a tex expression (and an optional tex environment),\n and returns a fully formed tex file ready for compilation.\n\n Parameters\n ----------\n expression : :class:`str`\n String containing the TeX expression to be rendered, e.g. ``\\\\sqrt{2}`` or ``foo``\n environment : Optional[:class:`str`], optional\n The string containing the environment in which the expression should be typeset, e.g. ``align*``\n tex_template : Optional[:class:`~.TexTemplate`], optional\n Template class used to typesetting. If not set, use default template set via `config[\"tex_template\"]`\n\n Returns\n -------\n :class:`str`\n Path to generated TeX file\n \"\"\"\n if tex_template is None:\n tex_template = config[\"tex_template\"]\n if environment is not None:\n output = tex_template.get_texcode_for_expression_in_env(expression, environment)\n else:\n output = tex_template.get_texcode_for_expression(expression)\n\n tex_dir = config.get_dir(\"tex_dir\")\n if not os.path.exists(tex_dir):\n os.makedirs(tex_dir)\n\n result = os.path.join(tex_dir, tex_hash(output)) + \".tex\"\n if not os.path.exists(result):\n logger.info(f\"Writing {expression} to %(path)s\", {\"path\": f\"{result}\"})\n with open(result, \"w\", encoding=\"utf-8\") as outfile:\n outfile.write(output)\n return result\n\n\ndef tex_compilation_command(tex_compiler, output_format, tex_file, tex_dir):\n \"\"\"Prepares the tex compilation command with all necessary cli flags\n\n Parameters\n ----------\n tex_compiler : :class:`str`\n String containing the compiler to be used, e.g. ``pdflatex`` or ``lualatex``\n output_format : :class:`str`\n String containing the output format generated by the compiler, e.g. ``.dvi`` or ``.pdf``\n tex_file : :class:`str`\n File name of TeX file to be typeset.\n tex_dir : :class:`str`\n Path to the directory where compiler output will be stored.\n\n Returns\n -------\n :class:`str`\n Compilation command according to given parameters\n \"\"\"\n if tex_compiler in {\"latex\", \"pdflatex\", \"luatex\", \"lualatex\"}:\n commands = [\n tex_compiler,\n \"-interaction=batchmode\",\n f'-output-format=\"{output_format[1:]}\"',\n \"-halt-on-error\",\n f'-output-directory=\"{tex_dir}\"',\n f'\"{tex_file}\"',\n \">\",\n os.devnull,\n ]\n elif tex_compiler == \"xelatex\":\n if output_format == \".xdv\":\n outflag = \"-no-pdf\"\n elif output_format == \".pdf\":\n outflag = \"\"\n else:\n raise ValueError(\"xelatex output is either pdf or xdv\")\n commands = [\n \"xelatex\",\n outflag,\n \"-interaction=batchmode\",\n \"-halt-on-error\",\n f'-output-directory=\"{tex_dir}\"',\n f'\"{tex_file}\"',\n \">\",\n os.devnull,\n ]\n else:\n raise ValueError(f\"Tex compiler {tex_compiler} unknown.\")\n return \" \".join(commands)\n\n\ndef insight_inputenc_error(matching):\n code_point = chr(int(matching[1], 16))\n name = unicodedata.name(code_point)\n yield f\"TexTemplate does not support character '{name}' (U+{matching[1]}).\"\n yield \"See the documentation for manim.mobject.svg.tex_mobject for details on using a custom TexTemplate.\"\n\n\ndef insight_package_not_found_error(matching):\n yield f\"You do not have package {matching[1]} installed.\"\n yield f\"Install {matching[1]} it using your LaTeX package manager, or check for typos.\"\n\n\ndef compile_tex(tex_file, tex_compiler, output_format):\n \"\"\"Compiles a tex_file into a .dvi or a .xdv or a .pdf\n\n Parameters\n ----------\n tex_file : :class:`str`\n File name of TeX file to be typeset.\n tex_compiler : :class:`str`\n String containing the compiler to be used, e.g. ``pdflatex`` or ``lualatex``\n output_format : :class:`str`\n String containing the output format generated by the compiler, e.g. ``.dvi`` or ``.pdf``\n\n Returns\n -------\n :class:`str`\n Path to generated output file in desired format (DVI, XDV or PDF).\n \"\"\"\n result = tex_file.replace(\".tex\", output_format)\n result = Path(result).as_posix()\n tex_file = Path(tex_file).as_posix()\n tex_dir = Path(config.get_dir(\"tex_dir\")).as_posix()\n if not os.path.exists(result):\n command = tex_compilation_command(\n tex_compiler,\n output_format,\n tex_file,\n tex_dir,\n )\n exit_code = os.system(command)\n if exit_code != 0:\n log_file = tex_file.replace(\".tex\", \".log\")\n print_all_tex_errors(log_file, tex_compiler, tex_file)\n raise ValueError(\n f\"{tex_compiler} error converting to\"\n f\" {output_format[1:]}. See log output above or\"\n f\" the log file: {log_file}\",\n )\n return result\n\n\ndef convert_to_svg(dvi_file, extension, page=1):\n \"\"\"Converts a .dvi, .xdv, or .pdf file into an svg using dvisvgm.\n\n Parameters\n ----------\n dvi_file : :class:`str`\n File name of the input file to be converted.\n extension : :class:`str`\n String containing the file extension and thus indicating the file type, e.g. ``.dvi`` or ``.pdf``\n page : Optional[:class:`int`], optional\n Page to be converted if input file is multi-page.\n\n Returns\n -------\n :class:`str`\n Path to generated SVG file.\n \"\"\"\n result = dvi_file.replace(extension, \".svg\")\n result = Path(result).as_posix()\n dvi_file = Path(dvi_file).as_posix()\n if not os.path.exists(result):\n commands = [\n \"dvisvgm\",\n \"--pdf\" if extension == \".pdf\" else \"\",\n \"-p \" + str(page),\n f'\"{dvi_file}\"',\n \"-n\",\n \"-v 0\",\n \"-o \" + f'\"{result}\"',\n \">\",\n os.devnull,\n ]\n os.system(\" \".join(commands))\n\n # if the file does not exist now, this means conversion failed\n if not os.path.exists(result):\n raise ValueError(\n f\"Your installation does not support converting {extension} files to SVG.\"\n f\" Consider updating dvisvgm to at least version 2.4.\"\n f\" If this does not solve the problem, please refer to our troubleshooting guide at:\"\n f\" https://docs.manim.community/en/stable/installation/troubleshooting.html\",\n )\n\n return result\n\n\ndef print_all_tex_errors(log_file, tex_compiler, tex_file):\n if not Path(log_file).exists():\n raise RuntimeError(\n f\"{tex_compiler} failed but did not produce a log file. \"\n \"Check your LaTeX installation.\",\n )\n with open(log_file) as f:\n tex_compilation_log = f.readlines()\n error_indices = [\n index\n for index, line in enumerate(tex_compilation_log)\n if line.startswith(\"!\")\n ]\n if error_indices:\n with open(tex_file) as g:\n tex = g.readlines()\n for error_index in error_indices:\n print_tex_error(tex_compilation_log, error_index, tex)\n\n\nLATEX_ERROR_INSIGHTS = [\n (\n r\"inputenc Error: Unicode character (?:.*) \\(U\\+([0-9a-fA-F]+)\\)\",\n insight_inputenc_error,\n ),\n (\n r\"LaTeX Error: File `(.*?[clsty])' not found\",\n insight_package_not_found_error,\n ),\n]\n\n\ndef print_tex_error(tex_compilation_log, error_start_index, tex_source):\n logger.error(\n f\"LaTeX compilation error: {tex_compilation_log[error_start_index][2:]}\",\n )\n\n # TeX errors eventually contain a line beginning 'l.xxx` where xxx is the line number that caused the compilation\n # failure. This code finds the next such line after the error current error message\n line_of_tex_error = (\n int(\n [\n log_line\n for log_line in tex_compilation_log[error_start_index:]\n if log_line.startswith(\"l.\")\n ][0]\n .split(\" \")[0]\n .split(\".\")[1],\n )\n - 1\n )\n # our tex error may be on a line outside our user input because of post-processing\n if line_of_tex_error >= len(tex_source):\n return None\n\n context = [\"Context of error: \\n\"]\n if line_of_tex_error < 3:\n context += tex_source[: line_of_tex_error + 3]\n context[-4] = \"-> \" + context[-4]\n elif line_of_tex_error > len(tex_source) - 3:\n context += tex_source[line_of_tex_error - 1 :]\n context[1] = \"-> \" + context[1]\n else:\n context += tex_source[line_of_tex_error - 3 : line_of_tex_error + 3]\n context[-4] = \"-> \" + context[-4]\n\n context = \"\".join(context)\n logger.error(context)\n\n for insights in LATEX_ERROR_INSIGHTS:\n prob, get_insight = insights\n matching = re.search(\n prob,\n \"\".join(tex_compilation_log[error_start_index])[2:],\n )\n if matching is not None:\n for insight in get_insight(matching):\n logger.info(insight)\n", "path": "manim/utils/tex_file_writing.py"}]} | 4,026 | 171 |
gh_patches_debug_30401 | rasdani/github-patches | git_diff | castorini__pyserini-630 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add ability to select random question for interactive demo
hey @saileshnankani - how about we add a `/random` command to ask a random question from the dev set?
</issue>
<code>
[start of pyserini/demo/msmarco.py]
1 #
2 # Pyserini: Reproducible IR research with sparse and dense representations
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 # You may obtain a copy of the License at
7 #
8 # http://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15 #
16
17 import cmd
18 import json
19
20 from pyserini.search import SimpleSearcher
21 from pyserini.dsearch import SimpleDenseSearcher, TctColBertQueryEncoder, AnceQueryEncoder
22 from pyserini.hsearch import HybridSearcher
23
24
25 class MsMarcoDemo(cmd.Cmd):
26 ssearcher = SimpleSearcher.from_prebuilt_index('msmarco-passage')
27 dsearcher = None
28 hsearcher = None
29 searcher = ssearcher
30
31 k = 10
32 prompt = '>>> '
33
34 # https://stackoverflow.com/questions/35213134/command-prefixes-in-python-cli-using-cmd-in-pythons-standard-library
35 def precmd(self, line):
36 if line[0] == '/':
37 line = line[1:]
38 return line
39
40 def do_help(self, arg):
41 print(f'/help : returns this message')
42 print(f'/k [NUM] : sets k (number of hits to return) to [NUM]')
43 print(f'/model [MODEL] : sets encoder to use the model [MODEL] (one of tct, ance)')
44 print(f'/mode [MODE] : sets retriver type to [MODE] (one of sparse, dense, hybrid)')
45
46 def do_k(self, arg):
47 print(f'setting k = {int(arg)}')
48 self.k = int(arg)
49
50 def do_mode(self, arg):
51 if arg == "sparse":
52 self.searcher = self.ssearcher
53 elif arg == "dense":
54 if self.dsearcher is None:
55 print(f'Specify model through /model before using dense retrieval.')
56 return
57 self.searcher = self.dsearcher
58 elif arg == "hybrid":
59 if self.hsearcher is None:
60 print(f'Specify model through /model before using hybrid retrieval.')
61 return
62 self.searcher = self.hsearcher
63 else:
64 print(
65 f'Mode "{arg}" is invalid. Mode should be one of [sparse, dense, hybrid].')
66 return
67 print(f'setting retriver = {arg}')
68
69 def do_model(self, arg):
70 if arg == "tct":
71 encoder = TctColBertQueryEncoder("castorini/tct_colbert-msmarco")
72 index = "msmarco-passage-tct_colbert-hnsw"
73 elif arg == "ance":
74 encoder = AnceQueryEncoder("castorini/ance-msmarco-passage")
75 index = "msmarco-passage-ance-bf"
76 else:
77 print(
78 f'Model "{arg}" is invalid. Model should be one of [tct, ance].')
79 return
80
81 self.dsearcher = SimpleDenseSearcher.from_prebuilt_index(
82 index,
83 encoder
84 )
85 self.hsearcher = HybridSearcher(self.dsearcher, self.ssearcher)
86 print(f'setting model = {arg}')
87
88 def do_EOF(self, line):
89 return True
90
91 def default(self, q):
92 hits = self.searcher.search(q, self.k)
93
94 for i in range(0, len(hits)):
95 raw_doc = None
96 if isinstance(self.searcher, SimpleSearcher):
97 raw_doc = hits[i].raw
98 else:
99 doc = self.ssearcher.doc(hits[i].docid)
100 if doc:
101 raw_doc = doc.raw()
102 jsondoc = json.loads(raw_doc)
103 print(f'{i + 1:2} {hits[i].score:.5f} {jsondoc["contents"]}')
104
105
106 if __name__ == '__main__':
107 MsMarcoDemo().cmdloop()
108
[end of pyserini/demo/msmarco.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/pyserini/demo/msmarco.py b/pyserini/demo/msmarco.py
--- a/pyserini/demo/msmarco.py
+++ b/pyserini/demo/msmarco.py
@@ -16,13 +16,18 @@
import cmd
import json
+import os
+import random
from pyserini.search import SimpleSearcher
from pyserini.dsearch import SimpleDenseSearcher, TctColBertQueryEncoder, AnceQueryEncoder
from pyserini.hsearch import HybridSearcher
+from pyserini import search
class MsMarcoDemo(cmd.Cmd):
+ dev_topics = list(search.get_topics('msmarco-passage-dev-subset').values())
+
ssearcher = SimpleSearcher.from_prebuilt_index('msmarco-passage')
dsearcher = None
hsearcher = None
@@ -42,6 +47,7 @@
print(f'/k [NUM] : sets k (number of hits to return) to [NUM]')
print(f'/model [MODEL] : sets encoder to use the model [MODEL] (one of tct, ance)')
print(f'/mode [MODE] : sets retriver type to [MODE] (one of sparse, dense, hybrid)')
+ print(f'/random : returns results for a random question from dev subset')
def do_k(self, arg):
print(f'setting k = {int(arg)}')
@@ -85,6 +91,11 @@
self.hsearcher = HybridSearcher(self.dsearcher, self.ssearcher)
print(f'setting model = {arg}')
+ def do_random(self, arg):
+ q = random.choice(self.dev_topics)['title']
+ print(f'question: {q}')
+ self.default(q)
+
def do_EOF(self, line):
return True
| {"golden_diff": "diff --git a/pyserini/demo/msmarco.py b/pyserini/demo/msmarco.py\n--- a/pyserini/demo/msmarco.py\n+++ b/pyserini/demo/msmarco.py\n@@ -16,13 +16,18 @@\n \n import cmd\n import json\n+import os\n+import random\n \n from pyserini.search import SimpleSearcher\n from pyserini.dsearch import SimpleDenseSearcher, TctColBertQueryEncoder, AnceQueryEncoder\n from pyserini.hsearch import HybridSearcher\n+from pyserini import search\n \n \n class MsMarcoDemo(cmd.Cmd):\n+ dev_topics = list(search.get_topics('msmarco-passage-dev-subset').values())\n+\n ssearcher = SimpleSearcher.from_prebuilt_index('msmarco-passage')\n dsearcher = None\n hsearcher = None\n@@ -42,6 +47,7 @@\n print(f'/k [NUM] : sets k (number of hits to return) to [NUM]')\n print(f'/model [MODEL] : sets encoder to use the model [MODEL] (one of tct, ance)')\n print(f'/mode [MODE] : sets retriver type to [MODE] (one of sparse, dense, hybrid)')\n+ print(f'/random : returns results for a random question from dev subset')\n \n def do_k(self, arg):\n print(f'setting k = {int(arg)}')\n@@ -85,6 +91,11 @@\n self.hsearcher = HybridSearcher(self.dsearcher, self.ssearcher)\n print(f'setting model = {arg}')\n \n+ def do_random(self, arg):\n+ q = random.choice(self.dev_topics)['title']\n+ print(f'question: {q}')\n+ self.default(q)\n+\n def do_EOF(self, line):\n return True\n", "issue": "Add ability to select random question for interactive demo\nhey @saileshnankani - how about we add a `/random` command to ask a random question from the dev set?\n", "before_files": [{"content": "#\n# Pyserini: Reproducible IR research with sparse and dense representations\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n\nimport cmd\nimport json\n\nfrom pyserini.search import SimpleSearcher\nfrom pyserini.dsearch import SimpleDenseSearcher, TctColBertQueryEncoder, AnceQueryEncoder\nfrom pyserini.hsearch import HybridSearcher\n\n\nclass MsMarcoDemo(cmd.Cmd):\n ssearcher = SimpleSearcher.from_prebuilt_index('msmarco-passage')\n dsearcher = None\n hsearcher = None\n searcher = ssearcher\n\n k = 10\n prompt = '>>> '\n\n # https://stackoverflow.com/questions/35213134/command-prefixes-in-python-cli-using-cmd-in-pythons-standard-library\n def precmd(self, line):\n if line[0] == '/':\n line = line[1:]\n return line\n\n def do_help(self, arg):\n print(f'/help : returns this message')\n print(f'/k [NUM] : sets k (number of hits to return) to [NUM]')\n print(f'/model [MODEL] : sets encoder to use the model [MODEL] (one of tct, ance)')\n print(f'/mode [MODE] : sets retriver type to [MODE] (one of sparse, dense, hybrid)')\n\n def do_k(self, arg):\n print(f'setting k = {int(arg)}')\n self.k = int(arg)\n\n def do_mode(self, arg):\n if arg == \"sparse\":\n self.searcher = self.ssearcher\n elif arg == \"dense\":\n if self.dsearcher is None:\n print(f'Specify model through /model before using dense retrieval.')\n return\n self.searcher = self.dsearcher\n elif arg == \"hybrid\":\n if self.hsearcher is None:\n print(f'Specify model through /model before using hybrid retrieval.')\n return\n self.searcher = self.hsearcher\n else:\n print(\n f'Mode \"{arg}\" is invalid. Mode should be one of [sparse, dense, hybrid].')\n return\n print(f'setting retriver = {arg}')\n\n def do_model(self, arg):\n if arg == \"tct\":\n encoder = TctColBertQueryEncoder(\"castorini/tct_colbert-msmarco\")\n index = \"msmarco-passage-tct_colbert-hnsw\"\n elif arg == \"ance\":\n encoder = AnceQueryEncoder(\"castorini/ance-msmarco-passage\")\n index = \"msmarco-passage-ance-bf\"\n else:\n print(\n f'Model \"{arg}\" is invalid. Model should be one of [tct, ance].')\n return\n\n self.dsearcher = SimpleDenseSearcher.from_prebuilt_index(\n index,\n encoder\n )\n self.hsearcher = HybridSearcher(self.dsearcher, self.ssearcher)\n print(f'setting model = {arg}')\n\n def do_EOF(self, line):\n return True\n\n def default(self, q):\n hits = self.searcher.search(q, self.k)\n\n for i in range(0, len(hits)):\n raw_doc = None\n if isinstance(self.searcher, SimpleSearcher):\n raw_doc = hits[i].raw\n else:\n doc = self.ssearcher.doc(hits[i].docid)\n if doc:\n raw_doc = doc.raw()\n jsondoc = json.loads(raw_doc)\n print(f'{i + 1:2} {hits[i].score:.5f} {jsondoc[\"contents\"]}')\n\n\nif __name__ == '__main__':\n MsMarcoDemo().cmdloop()\n", "path": "pyserini/demo/msmarco.py"}]} | 1,728 | 408 |
gh_patches_debug_4757 | rasdani/github-patches | git_diff | nonebot__nonebot2-2537 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bug: websockets 驱动器连接关闭 code 不存在
### 操作系统
Windows
### Python 版本
3.11.6
### NoneBot 版本
2.1.2
### 适配器
nonebot-adapter-kaiheila 0.3.0
### 协议端
kook API(websockets)
### 描述问题
在nonebot库的websockets.py模块中,处理WebSocket异常时出现了AttributeError。这个问题发生在尝试处理ConnectionClosed异常的过程中。
异常信息:
`AttributeError: 'NoneType' object has no attribute 'code'`
相关代码:
```python
def catch_closed(func: Callable[P, Awaitable[T]]) -> Callable[P, Awaitable[T]]:
@wraps(func)
async def decorator(*args: P.args, **kwargs: P.kwargs) -> T:
try:
return await func(*args, **kwargs)
except ConnectionClosed as e:
if e.rcvd_then_sent:
raise WebSocketClosed(e.rcvd.code, e.rcvd.reason) # type: ignore
else:
raise WebSocketClosed(e.sent.code, e.sent.reason) # type: ignore
return decorator
```
位于:`nonebot/drivers/websockets.py` Line 56
这个问题是在捕获ConnectionClosed异常时发生的,但e.rcvd或e.sent对象可能为None(在websocket超时这种不是由关闭帧影响的情况下会都不存在)。这导致尝试访问NoneType对象的code属性,从而引发了AttributeError。
### 复现步骤
1.在环境下加载websockets adapter
2.在插件的event handler中存在不使用异步的长时间等待情形(在我的例子是等待语言模型的计算)
### 期望的结果
按照上述描述修改此bug
### 截图或日志
无
</issue>
<code>
[start of nonebot/drivers/websockets.py]
1 """[websockets](https://websockets.readthedocs.io/) 驱动适配
2
3 ```bash
4 nb driver install websockets
5 # 或者
6 pip install nonebot2[websockets]
7 ```
8
9 :::tip 提示
10 本驱动仅支持客户端 WebSocket 连接
11 :::
12
13 FrontMatter:
14 sidebar_position: 4
15 description: nonebot.drivers.websockets 模块
16 """
17
18 import logging
19 from functools import wraps
20 from contextlib import asynccontextmanager
21 from typing_extensions import ParamSpec, override
22 from typing import TYPE_CHECKING, Union, TypeVar, Callable, Awaitable, AsyncGenerator
23
24 from nonebot.drivers import Request
25 from nonebot.log import LoguruHandler
26 from nonebot.exception import WebSocketClosed
27 from nonebot.drivers.none import Driver as NoneDriver
28 from nonebot.drivers import WebSocket as BaseWebSocket
29 from nonebot.drivers import WebSocketClientMixin, combine_driver
30
31 try:
32 from websockets.exceptions import ConnectionClosed
33 from websockets.legacy.client import Connect, WebSocketClientProtocol
34 except ModuleNotFoundError as e: # pragma: no cover
35 raise ImportError(
36 "Please install websockets first to use this driver. "
37 "Install with pip: `pip install nonebot2[websockets]`"
38 ) from e
39
40 T = TypeVar("T")
41 P = ParamSpec("P")
42
43 logger = logging.Logger("websockets.client", "INFO")
44 logger.addHandler(LoguruHandler())
45
46
47 def catch_closed(func: Callable[P, Awaitable[T]]) -> Callable[P, Awaitable[T]]:
48 @wraps(func)
49 async def decorator(*args: P.args, **kwargs: P.kwargs) -> T:
50 try:
51 return await func(*args, **kwargs)
52 except ConnectionClosed as e:
53 if e.rcvd_then_sent:
54 raise WebSocketClosed(e.rcvd.code, e.rcvd.reason) # type: ignore
55 else:
56 raise WebSocketClosed(e.sent.code, e.sent.reason) # type: ignore
57
58 return decorator
59
60
61 class Mixin(WebSocketClientMixin):
62 """Websockets Mixin"""
63
64 @property
65 @override
66 def type(self) -> str:
67 return "websockets"
68
69 @override
70 @asynccontextmanager
71 async def websocket(self, setup: Request) -> AsyncGenerator["WebSocket", None]:
72 connection = Connect(
73 str(setup.url),
74 extra_headers={**setup.headers, **setup.cookies.as_header(setup)},
75 open_timeout=setup.timeout,
76 )
77 async with connection as ws:
78 yield WebSocket(request=setup, websocket=ws)
79
80
81 class WebSocket(BaseWebSocket):
82 """Websockets WebSocket Wrapper"""
83
84 @override
85 def __init__(self, *, request: Request, websocket: WebSocketClientProtocol):
86 super().__init__(request=request)
87 self.websocket = websocket
88
89 @property
90 @override
91 def closed(self) -> bool:
92 return self.websocket.closed
93
94 @override
95 async def accept(self):
96 raise NotImplementedError
97
98 @override
99 async def close(self, code: int = 1000, reason: str = ""):
100 await self.websocket.close(code, reason)
101
102 @override
103 @catch_closed
104 async def receive(self) -> Union[str, bytes]:
105 return await self.websocket.recv()
106
107 @override
108 @catch_closed
109 async def receive_text(self) -> str:
110 msg = await self.websocket.recv()
111 if isinstance(msg, bytes):
112 raise TypeError("WebSocket received unexpected frame type: bytes")
113 return msg
114
115 @override
116 @catch_closed
117 async def receive_bytes(self) -> bytes:
118 msg = await self.websocket.recv()
119 if isinstance(msg, str):
120 raise TypeError("WebSocket received unexpected frame type: str")
121 return msg
122
123 @override
124 async def send_text(self, data: str) -> None:
125 await self.websocket.send(data)
126
127 @override
128 async def send_bytes(self, data: bytes) -> None:
129 await self.websocket.send(data)
130
131
132 if TYPE_CHECKING:
133
134 class Driver(Mixin, NoneDriver):
135 ...
136
137 else:
138 Driver = combine_driver(NoneDriver, Mixin)
139 """Websockets Driver"""
140
[end of nonebot/drivers/websockets.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/nonebot/drivers/websockets.py b/nonebot/drivers/websockets.py
--- a/nonebot/drivers/websockets.py
+++ b/nonebot/drivers/websockets.py
@@ -50,10 +50,7 @@
try:
return await func(*args, **kwargs)
except ConnectionClosed as e:
- if e.rcvd_then_sent:
- raise WebSocketClosed(e.rcvd.code, e.rcvd.reason) # type: ignore
- else:
- raise WebSocketClosed(e.sent.code, e.sent.reason) # type: ignore
+ raise WebSocketClosed(e.code, e.reason)
return decorator
| {"golden_diff": "diff --git a/nonebot/drivers/websockets.py b/nonebot/drivers/websockets.py\n--- a/nonebot/drivers/websockets.py\n+++ b/nonebot/drivers/websockets.py\n@@ -50,10 +50,7 @@\n try:\n return await func(*args, **kwargs)\n except ConnectionClosed as e:\n- if e.rcvd_then_sent:\n- raise WebSocketClosed(e.rcvd.code, e.rcvd.reason) # type: ignore\n- else:\n- raise WebSocketClosed(e.sent.code, e.sent.reason) # type: ignore\n+ raise WebSocketClosed(e.code, e.reason)\n \n return decorator\n", "issue": "Bug: websockets \u9a71\u52a8\u5668\u8fde\u63a5\u5173\u95ed code \u4e0d\u5b58\u5728\n### \u64cd\u4f5c\u7cfb\u7edf\r\n\r\nWindows\r\n\r\n### Python \u7248\u672c\r\n\r\n3.11.6\r\n\r\n### NoneBot \u7248\u672c\r\n\r\n2.1.2\r\n\r\n### \u9002\u914d\u5668\r\n\r\nnonebot-adapter-kaiheila 0.3.0\r\n\r\n### \u534f\u8bae\u7aef\r\n\r\nkook API(websockets)\r\n\r\n### \u63cf\u8ff0\u95ee\u9898\r\n\r\n\u5728nonebot\u5e93\u7684websockets.py\u6a21\u5757\u4e2d\uff0c\u5904\u7406WebSocket\u5f02\u5e38\u65f6\u51fa\u73b0\u4e86AttributeError\u3002\u8fd9\u4e2a\u95ee\u9898\u53d1\u751f\u5728\u5c1d\u8bd5\u5904\u7406ConnectionClosed\u5f02\u5e38\u7684\u8fc7\u7a0b\u4e2d\u3002\r\n\u5f02\u5e38\u4fe1\u606f:\r\n`AttributeError: 'NoneType' object has no attribute 'code'`\r\n\u76f8\u5173\u4ee3\u7801:\r\n```python\r\ndef catch_closed(func: Callable[P, Awaitable[T]]) -> Callable[P, Awaitable[T]]:\r\n @wraps(func)\r\n async def decorator(*args: P.args, **kwargs: P.kwargs) -> T:\r\n try:\r\n return await func(*args, **kwargs)\r\n except ConnectionClosed as e:\r\n if e.rcvd_then_sent:\r\n raise WebSocketClosed(e.rcvd.code, e.rcvd.reason) # type: ignore\r\n else:\r\n raise WebSocketClosed(e.sent.code, e.sent.reason) # type: ignore\r\n\r\n return decorator\r\n```\r\n\r\n\u4f4d\u4e8e:`nonebot/drivers/websockets.py` Line 56\r\n\u8fd9\u4e2a\u95ee\u9898\u662f\u5728\u6355\u83b7ConnectionClosed\u5f02\u5e38\u65f6\u53d1\u751f\u7684\uff0c\u4f46e.rcvd\u6216e.sent\u5bf9\u8c61\u53ef\u80fd\u4e3aNone(\u5728websocket\u8d85\u65f6\u8fd9\u79cd\u4e0d\u662f\u7531\u5173\u95ed\u5e27\u5f71\u54cd\u7684\u60c5\u51b5\u4e0b\u4f1a\u90fd\u4e0d\u5b58\u5728)\u3002\u8fd9\u5bfc\u81f4\u5c1d\u8bd5\u8bbf\u95eeNoneType\u5bf9\u8c61\u7684code\u5c5e\u6027\uff0c\u4ece\u800c\u5f15\u53d1\u4e86AttributeError\u3002\r\n\r\n### \u590d\u73b0\u6b65\u9aa4\r\n\r\n1.\u5728\u73af\u5883\u4e0b\u52a0\u8f7dwebsockets adapter\r\n2.\u5728\u63d2\u4ef6\u7684event handler\u4e2d\u5b58\u5728\u4e0d\u4f7f\u7528\u5f02\u6b65\u7684\u957f\u65f6\u95f4\u7b49\u5f85\u60c5\u5f62\uff08\u5728\u6211\u7684\u4f8b\u5b50\u662f\u7b49\u5f85\u8bed\u8a00\u6a21\u578b\u7684\u8ba1\u7b97\uff09\r\n\r\n\r\n### \u671f\u671b\u7684\u7ed3\u679c\r\n\r\n\u6309\u7167\u4e0a\u8ff0\u63cf\u8ff0\u4fee\u6539\u6b64bug\r\n\r\n### \u622a\u56fe\u6216\u65e5\u5fd7\r\n\r\n\u65e0\n", "before_files": [{"content": "\"\"\"[websockets](https://websockets.readthedocs.io/) \u9a71\u52a8\u9002\u914d\n\n```bash\nnb driver install websockets\n# \u6216\u8005\npip install nonebot2[websockets]\n```\n\n:::tip \u63d0\u793a\n\u672c\u9a71\u52a8\u4ec5\u652f\u6301\u5ba2\u6237\u7aef WebSocket \u8fde\u63a5\n:::\n\nFrontMatter:\n sidebar_position: 4\n description: nonebot.drivers.websockets \u6a21\u5757\n\"\"\"\n\nimport logging\nfrom functools import wraps\nfrom contextlib import asynccontextmanager\nfrom typing_extensions import ParamSpec, override\nfrom typing import TYPE_CHECKING, Union, TypeVar, Callable, Awaitable, AsyncGenerator\n\nfrom nonebot.drivers import Request\nfrom nonebot.log import LoguruHandler\nfrom nonebot.exception import WebSocketClosed\nfrom nonebot.drivers.none import Driver as NoneDriver\nfrom nonebot.drivers import WebSocket as BaseWebSocket\nfrom nonebot.drivers import WebSocketClientMixin, combine_driver\n\ntry:\n from websockets.exceptions import ConnectionClosed\n from websockets.legacy.client import Connect, WebSocketClientProtocol\nexcept ModuleNotFoundError as e: # pragma: no cover\n raise ImportError(\n \"Please install websockets first to use this driver. \"\n \"Install with pip: `pip install nonebot2[websockets]`\"\n ) from e\n\nT = TypeVar(\"T\")\nP = ParamSpec(\"P\")\n\nlogger = logging.Logger(\"websockets.client\", \"INFO\")\nlogger.addHandler(LoguruHandler())\n\n\ndef catch_closed(func: Callable[P, Awaitable[T]]) -> Callable[P, Awaitable[T]]:\n @wraps(func)\n async def decorator(*args: P.args, **kwargs: P.kwargs) -> T:\n try:\n return await func(*args, **kwargs)\n except ConnectionClosed as e:\n if e.rcvd_then_sent:\n raise WebSocketClosed(e.rcvd.code, e.rcvd.reason) # type: ignore\n else:\n raise WebSocketClosed(e.sent.code, e.sent.reason) # type: ignore\n\n return decorator\n\n\nclass Mixin(WebSocketClientMixin):\n \"\"\"Websockets Mixin\"\"\"\n\n @property\n @override\n def type(self) -> str:\n return \"websockets\"\n\n @override\n @asynccontextmanager\n async def websocket(self, setup: Request) -> AsyncGenerator[\"WebSocket\", None]:\n connection = Connect(\n str(setup.url),\n extra_headers={**setup.headers, **setup.cookies.as_header(setup)},\n open_timeout=setup.timeout,\n )\n async with connection as ws:\n yield WebSocket(request=setup, websocket=ws)\n\n\nclass WebSocket(BaseWebSocket):\n \"\"\"Websockets WebSocket Wrapper\"\"\"\n\n @override\n def __init__(self, *, request: Request, websocket: WebSocketClientProtocol):\n super().__init__(request=request)\n self.websocket = websocket\n\n @property\n @override\n def closed(self) -> bool:\n return self.websocket.closed\n\n @override\n async def accept(self):\n raise NotImplementedError\n\n @override\n async def close(self, code: int = 1000, reason: str = \"\"):\n await self.websocket.close(code, reason)\n\n @override\n @catch_closed\n async def receive(self) -> Union[str, bytes]:\n return await self.websocket.recv()\n\n @override\n @catch_closed\n async def receive_text(self) -> str:\n msg = await self.websocket.recv()\n if isinstance(msg, bytes):\n raise TypeError(\"WebSocket received unexpected frame type: bytes\")\n return msg\n\n @override\n @catch_closed\n async def receive_bytes(self) -> bytes:\n msg = await self.websocket.recv()\n if isinstance(msg, str):\n raise TypeError(\"WebSocket received unexpected frame type: str\")\n return msg\n\n @override\n async def send_text(self, data: str) -> None:\n await self.websocket.send(data)\n\n @override\n async def send_bytes(self, data: bytes) -> None:\n await self.websocket.send(data)\n\n\nif TYPE_CHECKING:\n\n class Driver(Mixin, NoneDriver):\n ...\n\nelse:\n Driver = combine_driver(NoneDriver, Mixin)\n \"\"\"Websockets Driver\"\"\"\n", "path": "nonebot/drivers/websockets.py"}]} | 2,146 | 142 |
gh_patches_debug_53619 | rasdani/github-patches | git_diff | qtile__qtile-2926 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Systray icon disappears with restart
As reported on IRC:
```
[08:11] < elcaven> this morning I updated qtile from the qtile-git package from the AUR and since then it seems that my systray widget resets every time qtile restarts, so after a qtile restart the systray
is empty until a program spawns there again
[08:12] < elcaven> there don't seem to be any related errors in the logfile, only one I see is "AttributeError: 'Screen' object has
[20:53] < elParaguayo> | elcaven - interesting. That may be a side-effect of the config reloading code that was recently committed.
[21:09] < mcol> What does it mean for the systray to reset? Can it persist state across restarts?
[21:14] < elParaguayo> | I'm guessing that the app is still open but the icon has disappeared from the tray
[21:22] < elParaguayo> | I wonder if SNI has that issue too...
[21:25] < elParaguayo> | No, SNI looks ok.
[21:25] < elParaguayo> | Tested with "restart" and "reload_config"
[21:27] < elParaguayo> | Confirmed, Systray icon disappears on reload_config even though app is open.
[21:28] < elParaguayo> | Icon doesn't disappear with "restart"
```
Tested on latest: 66ce6c28
</issue>
<code>
[start of libqtile/widget/systray.py]
1 # Copyright (c) 2010 Aldo Cortesi
2 # Copyright (c) 2010-2011 dequis
3 # Copyright (c) 2010, 2012 roger
4 # Copyright (c) 2011 Mounier Florian
5 # Copyright (c) 2011-2012, 2014 Tycho Andersen
6 # Copyright (c) 2012 dmpayton
7 # Copyright (c) 2012-2013 Craig Barnes
8 # Copyright (c) 2013 hbc
9 # Copyright (c) 2013 Tao Sauvage
10 # Copyright (c) 2014 Sean Vig
11 #
12 # Permission is hereby granted, free of charge, to any person obtaining a copy
13 # of this software and associated documentation files (the "Software"), to deal
14 # in the Software without restriction, including without limitation the rights
15 # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
16 # copies of the Software, and to permit persons to whom the Software is
17 # furnished to do so, subject to the following conditions:
18 #
19 # The above copyright notice and this permission notice shall be included in
20 # all copies or substantial portions of the Software.
21 #
22 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
23 # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
24 # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
25 # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
26 # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
27 # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
28 # SOFTWARE.
29 import xcffib
30 from xcffib.xproto import (
31 ClientMessageData,
32 ClientMessageEvent,
33 EventMask,
34 SetMode,
35 )
36
37 from libqtile import bar
38 from libqtile.backend.x11 import window
39 from libqtile.widget import base
40
41 XEMBED_PROTOCOL_VERSION = 0
42
43
44 class Icon(window._Window):
45 _window_mask = EventMask.StructureNotify | \
46 EventMask.PropertyChange | \
47 EventMask.Exposure
48
49 def __init__(self, win, qtile, systray):
50 window._Window.__init__(self, win, qtile)
51 self.systray = systray
52 self.update_size()
53
54 def update_size(self):
55 icon_size = self.systray.icon_size
56 self.update_hints()
57
58 width = self.hints.get("min_width", icon_size)
59 height = self.hints.get("min_height", icon_size)
60
61 width = max(width, icon_size)
62 height = max(height, icon_size)
63
64 if height > icon_size:
65 width = width * icon_size // height
66 height = icon_size
67
68 self.width = width
69 self.height = height
70 return False
71
72 def handle_PropertyNotify(self, e): # noqa: N802
73 name = self.qtile.core.conn.atoms.get_name(e.atom)
74 if name == "_XEMBED_INFO":
75 info = self.window.get_property('_XEMBED_INFO', unpack=int)
76 if info and info[1]:
77 self.systray.bar.draw()
78
79 return False
80
81 def handle_DestroyNotify(self, event): # noqa: N802
82 wid = event.window
83 del(self.qtile.windows_map[wid])
84 del(self.systray.icons[wid])
85 self.systray.bar.draw()
86 return False
87
88 handle_UnmapNotify = handle_DestroyNotify # noqa: N815
89
90
91 class Systray(window._Window, base._Widget):
92 """
93 A widget that manages system tray.
94
95 .. note::
96 Icons will not render correctly where the bar/widget is
97 drawn with a semi-transparent background. Instead, icons
98 will be drawn with a transparent background.
99
100 If using this widget it is therefore recommended to use
101 a fully opaque background colour or a fully transparent
102 one.
103 """
104
105 _window_mask = EventMask.StructureNotify | \
106 EventMask.Exposure
107
108 orientations = base.ORIENTATION_HORIZONTAL
109
110 defaults = [
111 ('icon_size', 20, 'Icon width'),
112 ('padding', 5, 'Padding between icons'),
113 ]
114
115 def __init__(self, **config):
116 base._Widget.__init__(self, bar.CALCULATED, **config)
117 self.add_defaults(Systray.defaults)
118 self.icons = {}
119 self.screen = 0
120
121 def calculate_length(self):
122 width = sum(i.width for i in self.icons.values())
123 width += self.padding * len(self.icons)
124 return width
125
126 def _configure(self, qtile, bar):
127 base._Widget._configure(self, qtile, bar)
128
129 if self.configured:
130 return
131
132 self.conn = conn = qtile.core.conn
133 win = conn.create_window(-1, -1, 1, 1)
134 window._Window.__init__(self, window.XWindow(conn, win.wid), qtile)
135 qtile.windows_map[win.wid] = self
136
137 # Even when we have multiple "Screen"s, we are setting up as the system
138 # tray on a particular X display, that is the screen we need to
139 # reference in the atom
140 if qtile.current_screen:
141 self.screen = qtile.current_screen.index
142 self.bar = bar
143 atoms = conn.atoms
144
145 # We need tray to tell icons which visual to use.
146 # This needs to be the same as the bar/widget.
147 # This mainly benefits transparent bars.
148 conn.conn.core.ChangeProperty(
149 xcffib.xproto.PropMode.Replace,
150 win.wid,
151 atoms["_NET_SYSTEM_TRAY_VISUAL"],
152 xcffib.xproto.Atom.VISUALID,
153 32,
154 1,
155 [self.drawer._visual.visual_id]
156 )
157
158 conn.conn.core.SetSelectionOwner(
159 win.wid,
160 atoms['_NET_SYSTEM_TRAY_S{:d}'.format(self.screen)],
161 xcffib.CurrentTime
162 )
163 data = [
164 xcffib.CurrentTime,
165 atoms['_NET_SYSTEM_TRAY_S{:d}'.format(self.screen)],
166 win.wid, 0, 0
167 ]
168 union = ClientMessageData.synthetic(data, "I" * 5)
169 event = ClientMessageEvent.synthetic(
170 format=32,
171 window=qtile.core._root.wid,
172 type=atoms['MANAGER'],
173 data=union
174 )
175 qtile.core._root.send_event(event, mask=EventMask.StructureNotify)
176
177 def handle_ClientMessage(self, event): # noqa: N802
178 atoms = self.conn.atoms
179
180 opcode = event.type
181 data = event.data.data32
182 message = data[1]
183 wid = data[2]
184
185 parent = self.bar.window.window
186
187 if opcode == atoms['_NET_SYSTEM_TRAY_OPCODE'] and message == 0:
188 w = window.XWindow(self.conn, wid)
189 icon = Icon(w, self.qtile, self)
190 self.icons[wid] = icon
191 self.qtile.windows_map[wid] = icon
192
193 self.conn.conn.core.ChangeSaveSet(SetMode.Insert, wid)
194 self.conn.conn.core.ReparentWindow(wid, parent.wid, 0, 0)
195 self.conn.conn.flush()
196
197 info = icon.window.get_property('_XEMBED_INFO', unpack=int)
198
199 if not info:
200 self.bar.draw()
201 return False
202
203 if info[1]:
204 self.bar.draw()
205
206 return False
207
208 def draw(self):
209 xoffset = self.padding
210 self.drawer.clear(self.background or self.bar.background)
211 self.drawer.draw(offsetx=self.offset, width=self.length)
212 for pos, icon in enumerate(self.icons.values()):
213 icon.window.set_attribute(backpixmap=self.drawer.pixmap)
214 icon.place(
215 self.offset + xoffset,
216 self.bar.height // 2 - self.icon_size // 2,
217 icon.width, self.icon_size,
218 0,
219 None
220 )
221 if icon.hidden:
222 icon.unhide()
223 data = [
224 self.conn.atoms["_XEMBED_EMBEDDED_NOTIFY"],
225 xcffib.xproto.Time.CurrentTime,
226 0,
227 self.bar.window.wid,
228 XEMBED_PROTOCOL_VERSION
229 ]
230 u = xcffib.xproto.ClientMessageData.synthetic(data, "I" * 5)
231 event = xcffib.xproto.ClientMessageEvent.synthetic(
232 format=32,
233 window=icon.wid,
234 type=self.conn.atoms["_XEMBED"],
235 data=u
236 )
237 self.window.send_event(event)
238
239 xoffset += icon.width + self.padding
240
241 def finalize(self):
242 base._Widget.finalize(self)
243 atoms = self.conn.atoms
244 self.conn.conn.core.SetSelectionOwner(
245 0,
246 atoms['_NET_SYSTEM_TRAY_S{:d}'.format(self.screen)],
247 xcffib.CurrentTime,
248 )
249 self.hide()
250
[end of libqtile/widget/systray.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/libqtile/widget/systray.py b/libqtile/widget/systray.py
--- a/libqtile/widget/systray.py
+++ b/libqtile/widget/systray.py
@@ -247,3 +247,11 @@
xcffib.CurrentTime,
)
self.hide()
+
+ root = self.qtile.core._root.wid
+ for wid in self.icons:
+ self.conn.conn.core.ReparentWindow(wid, root, 0, 0)
+ self.conn.conn.flush()
+
+ del self.qtile.windows_map[self.wid]
+ self.conn.conn.core.DestroyWindow(self.wid)
| {"golden_diff": "diff --git a/libqtile/widget/systray.py b/libqtile/widget/systray.py\n--- a/libqtile/widget/systray.py\n+++ b/libqtile/widget/systray.py\n@@ -247,3 +247,11 @@\n xcffib.CurrentTime,\n )\n self.hide()\n+\n+ root = self.qtile.core._root.wid\n+ for wid in self.icons:\n+ self.conn.conn.core.ReparentWindow(wid, root, 0, 0)\n+ self.conn.conn.flush()\n+\n+ del self.qtile.windows_map[self.wid]\n+ self.conn.conn.core.DestroyWindow(self.wid)\n", "issue": "Systray icon disappears with restart\nAs reported on IRC:\r\n```\r\n[08:11] < elcaven> this morning I updated qtile from the qtile-git package from the AUR and since then it seems that my systray widget resets every time qtile restarts, so after a qtile restart the systray\r\n is empty until a program spawns there again\r\n[08:12] < elcaven> there don't seem to be any related errors in the logfile, only one I see is \"AttributeError: 'Screen' object has \r\n[20:53] < elParaguayo> | elcaven - interesting. That may be a side-effect of the config reloading code that was recently committed.\r\n[21:09] < mcol> What does it mean for the systray to reset? Can it persist state across restarts?\r\n[21:14] < elParaguayo> | I'm guessing that the app is still open but the icon has disappeared from the tray\r\n[21:22] < elParaguayo> | I wonder if SNI has that issue too...\r\n[21:25] < elParaguayo> | No, SNI looks ok.\r\n[21:25] < elParaguayo> | Tested with \"restart\" and \"reload_config\"\r\n[21:27] < elParaguayo> | Confirmed, Systray icon disappears on reload_config even though app is open.\r\n[21:28] < elParaguayo> | Icon doesn't disappear with \"restart\"\r\n```\r\n\r\nTested on latest: 66ce6c28\n", "before_files": [{"content": "# Copyright (c) 2010 Aldo Cortesi\n# Copyright (c) 2010-2011 dequis\n# Copyright (c) 2010, 2012 roger\n# Copyright (c) 2011 Mounier Florian\n# Copyright (c) 2011-2012, 2014 Tycho Andersen\n# Copyright (c) 2012 dmpayton\n# Copyright (c) 2012-2013 Craig Barnes\n# Copyright (c) 2013 hbc\n# Copyright (c) 2013 Tao Sauvage\n# Copyright (c) 2014 Sean Vig\n#\n# Permission is hereby granted, free of charge, to any person obtaining a copy\n# of this software and associated documentation files (the \"Software\"), to deal\n# in the Software without restriction, including without limitation the rights\n# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell\n# copies of the Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\n# SOFTWARE.\nimport xcffib\nfrom xcffib.xproto import (\n ClientMessageData,\n ClientMessageEvent,\n EventMask,\n SetMode,\n)\n\nfrom libqtile import bar\nfrom libqtile.backend.x11 import window\nfrom libqtile.widget import base\n\nXEMBED_PROTOCOL_VERSION = 0\n\n\nclass Icon(window._Window):\n _window_mask = EventMask.StructureNotify | \\\n EventMask.PropertyChange | \\\n EventMask.Exposure\n\n def __init__(self, win, qtile, systray):\n window._Window.__init__(self, win, qtile)\n self.systray = systray\n self.update_size()\n\n def update_size(self):\n icon_size = self.systray.icon_size\n self.update_hints()\n\n width = self.hints.get(\"min_width\", icon_size)\n height = self.hints.get(\"min_height\", icon_size)\n\n width = max(width, icon_size)\n height = max(height, icon_size)\n\n if height > icon_size:\n width = width * icon_size // height\n height = icon_size\n\n self.width = width\n self.height = height\n return False\n\n def handle_PropertyNotify(self, e): # noqa: N802\n name = self.qtile.core.conn.atoms.get_name(e.atom)\n if name == \"_XEMBED_INFO\":\n info = self.window.get_property('_XEMBED_INFO', unpack=int)\n if info and info[1]:\n self.systray.bar.draw()\n\n return False\n\n def handle_DestroyNotify(self, event): # noqa: N802\n wid = event.window\n del(self.qtile.windows_map[wid])\n del(self.systray.icons[wid])\n self.systray.bar.draw()\n return False\n\n handle_UnmapNotify = handle_DestroyNotify # noqa: N815\n\n\nclass Systray(window._Window, base._Widget):\n \"\"\"\n A widget that manages system tray.\n\n .. note::\n Icons will not render correctly where the bar/widget is\n drawn with a semi-transparent background. Instead, icons\n will be drawn with a transparent background.\n\n If using this widget it is therefore recommended to use\n a fully opaque background colour or a fully transparent\n one.\n \"\"\"\n\n _window_mask = EventMask.StructureNotify | \\\n EventMask.Exposure\n\n orientations = base.ORIENTATION_HORIZONTAL\n\n defaults = [\n ('icon_size', 20, 'Icon width'),\n ('padding', 5, 'Padding between icons'),\n ]\n\n def __init__(self, **config):\n base._Widget.__init__(self, bar.CALCULATED, **config)\n self.add_defaults(Systray.defaults)\n self.icons = {}\n self.screen = 0\n\n def calculate_length(self):\n width = sum(i.width for i in self.icons.values())\n width += self.padding * len(self.icons)\n return width\n\n def _configure(self, qtile, bar):\n base._Widget._configure(self, qtile, bar)\n\n if self.configured:\n return\n\n self.conn = conn = qtile.core.conn\n win = conn.create_window(-1, -1, 1, 1)\n window._Window.__init__(self, window.XWindow(conn, win.wid), qtile)\n qtile.windows_map[win.wid] = self\n\n # Even when we have multiple \"Screen\"s, we are setting up as the system\n # tray on a particular X display, that is the screen we need to\n # reference in the atom\n if qtile.current_screen:\n self.screen = qtile.current_screen.index\n self.bar = bar\n atoms = conn.atoms\n\n # We need tray to tell icons which visual to use.\n # This needs to be the same as the bar/widget.\n # This mainly benefits transparent bars.\n conn.conn.core.ChangeProperty(\n xcffib.xproto.PropMode.Replace,\n win.wid,\n atoms[\"_NET_SYSTEM_TRAY_VISUAL\"],\n xcffib.xproto.Atom.VISUALID,\n 32,\n 1,\n [self.drawer._visual.visual_id]\n )\n\n conn.conn.core.SetSelectionOwner(\n win.wid,\n atoms['_NET_SYSTEM_TRAY_S{:d}'.format(self.screen)],\n xcffib.CurrentTime\n )\n data = [\n xcffib.CurrentTime,\n atoms['_NET_SYSTEM_TRAY_S{:d}'.format(self.screen)],\n win.wid, 0, 0\n ]\n union = ClientMessageData.synthetic(data, \"I\" * 5)\n event = ClientMessageEvent.synthetic(\n format=32,\n window=qtile.core._root.wid,\n type=atoms['MANAGER'],\n data=union\n )\n qtile.core._root.send_event(event, mask=EventMask.StructureNotify)\n\n def handle_ClientMessage(self, event): # noqa: N802\n atoms = self.conn.atoms\n\n opcode = event.type\n data = event.data.data32\n message = data[1]\n wid = data[2]\n\n parent = self.bar.window.window\n\n if opcode == atoms['_NET_SYSTEM_TRAY_OPCODE'] and message == 0:\n w = window.XWindow(self.conn, wid)\n icon = Icon(w, self.qtile, self)\n self.icons[wid] = icon\n self.qtile.windows_map[wid] = icon\n\n self.conn.conn.core.ChangeSaveSet(SetMode.Insert, wid)\n self.conn.conn.core.ReparentWindow(wid, parent.wid, 0, 0)\n self.conn.conn.flush()\n\n info = icon.window.get_property('_XEMBED_INFO', unpack=int)\n\n if not info:\n self.bar.draw()\n return False\n\n if info[1]:\n self.bar.draw()\n\n return False\n\n def draw(self):\n xoffset = self.padding\n self.drawer.clear(self.background or self.bar.background)\n self.drawer.draw(offsetx=self.offset, width=self.length)\n for pos, icon in enumerate(self.icons.values()):\n icon.window.set_attribute(backpixmap=self.drawer.pixmap)\n icon.place(\n self.offset + xoffset,\n self.bar.height // 2 - self.icon_size // 2,\n icon.width, self.icon_size,\n 0,\n None\n )\n if icon.hidden:\n icon.unhide()\n data = [\n self.conn.atoms[\"_XEMBED_EMBEDDED_NOTIFY\"],\n xcffib.xproto.Time.CurrentTime,\n 0,\n self.bar.window.wid,\n XEMBED_PROTOCOL_VERSION\n ]\n u = xcffib.xproto.ClientMessageData.synthetic(data, \"I\" * 5)\n event = xcffib.xproto.ClientMessageEvent.synthetic(\n format=32,\n window=icon.wid,\n type=self.conn.atoms[\"_XEMBED\"],\n data=u\n )\n self.window.send_event(event)\n\n xoffset += icon.width + self.padding\n\n def finalize(self):\n base._Widget.finalize(self)\n atoms = self.conn.atoms\n self.conn.conn.core.SetSelectionOwner(\n 0,\n atoms['_NET_SYSTEM_TRAY_S{:d}'.format(self.screen)],\n xcffib.CurrentTime,\n )\n self.hide()\n", "path": "libqtile/widget/systray.py"}]} | 3,539 | 150 |
gh_patches_debug_31579 | rasdani/github-patches | git_diff | weecology__retriever-1311 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Error when running retriever license with no dataset as argument
Currently, when running `retriever license` and providing no dataset as an argument it results into `KeyError: 'No dataset named: None'`
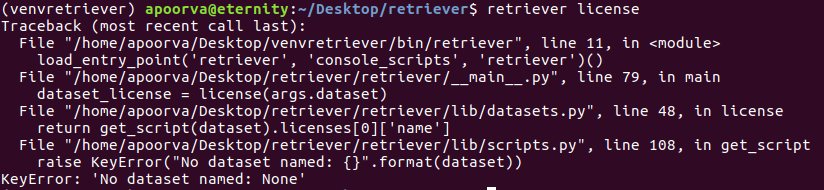
In case of `retriever citation` if no dataset is given we show the citation for retriever.
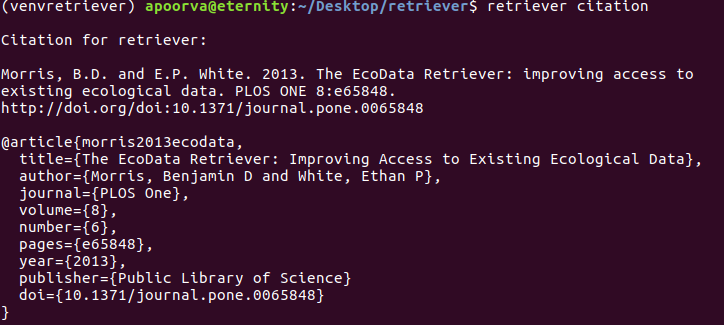
How should we handle this? Show the license for retriever by reading the `LICENSE` file or create a new `LICENSE` variable in `retriever.lib.defaults` and show it?
</issue>
<code>
[start of retriever/__main__.py]
1 """Data Retriever
2
3 This module handles the CLI for the Data retriever.
4 """
5 from __future__ import absolute_import
6 from __future__ import print_function
7
8 import os
9 import sys
10 from builtins import input
11
12 from retriever.engines import engine_list, choose_engine
13 from retriever.lib.datapackage import create_json, edit_json, delete_json, get_script_filename
14 from retriever.lib.datasets import datasets, dataset_names, license
15 from retriever.lib.defaults import sample_script, CITATION, SCRIPT_SEARCH_PATHS
16 from retriever.lib.engine_tools import name_matches, reset_retriever
17 from retriever.lib.get_opts import parser
18 from retriever.lib.repository import check_for_updates
19 from retriever.lib.scripts import SCRIPT_LIST, reload_scripts, get_script
20
21
22 def main():
23 """This function launches the Data Retriever."""
24 if len(sys.argv) == 1:
25 # if no command line args are passed, show the help options
26 parser.parse_args(['-h'])
27
28 else:
29 # otherwise, parse them
30 args = parser.parse_args()
31
32 if args.command not in ['reset', 'update'] \
33 and not os.path.isdir(SCRIPT_SEARCH_PATHS[1]) \
34 and not [f for f in os.listdir(SCRIPT_SEARCH_PATHS[-1])
35 if os.path.exists(SCRIPT_SEARCH_PATHS[-1])]:
36 check_for_updates()
37 reload_scripts()
38 script_list = SCRIPT_LIST()
39
40 if args.command == "install" and not args.engine:
41 parser.parse_args(['install', '-h'])
42
43 if args.quiet:
44 sys.stdout = open(os.devnull, 'w')
45
46 if args.command == 'help':
47 parser.parse_args(['-h'])
48
49 if hasattr(args, 'compile') and args.compile:
50 script_list = reload_scripts()
51
52 if args.command == 'defaults':
53 for engine_item in engine_list:
54 print("Default options for engine ", engine_item.name)
55 for default_opts in engine_item.required_opts:
56 print(default_opts[0], " ", default_opts[2])
57 print()
58 return
59
60 if args.command == 'update':
61 check_for_updates()
62 reload_scripts()
63 return
64
65 elif args.command == 'citation':
66 if args.dataset is None:
67 print("\nCitation for retriever:\n")
68 print(CITATION)
69 else:
70 scripts = name_matches(script_list, args.dataset)
71 for dataset in scripts:
72 print("\nDataset: {}".format(dataset.name))
73 print("Citation: {}".format(dataset.citation))
74 print("Description: {}\n".format(dataset.description))
75
76 return
77
78 elif args.command == 'license':
79 dataset_license = license(args.dataset)
80 if dataset_license:
81 print(dataset_license)
82 else:
83 print("There is no license information for {}".format(args.dataset))
84 return
85
86 elif args.command == 'new':
87 f = open(args.filename, 'w')
88 f.write(sample_script)
89 f.close()
90
91 return
92
93 elif args.command == 'reset':
94 reset_retriever(args.scope)
95 return
96
97 elif args.command == 'new_json':
98 # create new JSON script
99 create_json()
100 return
101
102 elif args.command == 'edit_json':
103 # edit existing JSON script
104 json_file = get_script_filename(args.dataset.lower())
105 edit_json(json_file)
106 return
107
108 elif args.command == 'delete_json':
109 # delete existing JSON script from home directory and or script directory if exists in current dir
110 confirm = input("Really remove " + args.dataset.lower() +
111 " and all its contents? (y/N): ")
112 if confirm.lower().strip() in ['y', 'yes']:
113 json_file = get_script_filename(args.dataset.lower())
114 delete_json(json_file)
115 return
116
117 if args.command == 'ls':
118 # scripts should never be empty because check_for_updates is run on SCRIPT_LIST init
119 if not (args.l or args.k or isinstance(args.v, list)):
120 all_scripts = dataset_names()
121 print("Available datasets : {}\n".format(len(all_scripts)))
122 from retriever import lscolumns
123
124 lscolumns.printls(all_scripts)
125
126 elif isinstance(args.v, list):
127 if args.v:
128 try:
129 all_scripts = [get_script(dataset) for dataset in args.v]
130 except KeyError:
131 all_scripts = []
132 print("Dataset(s) is not found.")
133 else:
134 all_scripts = datasets()
135 count = 1
136 for script in all_scripts:
137 print(
138 "{count}. {title}\n {name}\n"
139 "{keywords}\n{description}\n"
140 "{licenses}\n{citation}\n"
141 "".format(
142 count=count,
143 title=script.title,
144 name=script.name,
145 keywords=script.keywords,
146 description=script.description,
147 licenses=str(script.licenses[0]['name']),
148 citation=script.citation,
149 )
150 )
151 count += 1
152
153 else:
154 param_licenses = args.l if args.l else None
155 keywords = args.k if args.k else None
156
157 # search
158 searched_scripts = datasets(keywords, param_licenses)
159 if not searched_scripts:
160 print("No available datasets found")
161 else:
162 print("Available datasets : {}\n".format(len(searched_scripts)))
163 count = 1
164 for script in searched_scripts:
165 print(
166 "{count}. {title}\n{name}\n"
167 "{keywords}\n{licenses}\n".format(
168 count=count,
169 title=script.title,
170 name=script.name,
171 keywords=script.keywords,
172 licenses=str(script.licenses[0]['name']),
173 )
174 )
175 count += 1
176 return
177
178 engine = choose_engine(args.__dict__)
179
180 if hasattr(args, 'debug') and args.debug:
181 debug = True
182 else:
183 debug = False
184 sys.tracebacklimit = 0
185
186 if hasattr(args, 'debug') and args.not_cached:
187 engine.use_cache = False
188 else:
189 engine.use_cache = True
190
191 if args.dataset is not None:
192 scripts = name_matches(script_list, args.dataset)
193 else:
194 raise Exception("no dataset specified.")
195 if scripts:
196 for dataset in scripts:
197 print("=> Installing", dataset.name)
198 try:
199 dataset.download(engine, debug=debug)
200 dataset.engine.final_cleanup()
201 except KeyboardInterrupt:
202 pass
203 except Exception as e:
204 print(e)
205 if debug:
206 raise
207 print("Done!")
208 else:
209 print("Run 'retriever ls' to see a list of currently available datasets.")
210
211
212 if __name__ == "__main__":
213 main()
214
[end of retriever/__main__.py]
[start of retriever/lib/defaults.py]
1 import os
2
3 from retriever._version import __version__
4
5 VERSION = __version__
6 COPYRIGHT = "Copyright (C) 2011-2016 Weecology University of Florida"
7 REPO_URL = "https://raw.githubusercontent.com/weecology/retriever/"
8 MASTER_BRANCH = REPO_URL + "master/"
9 REPOSITORY = MASTER_BRANCH
10 ENCODING = 'ISO-8859-1'
11 HOME_DIR = os.path.expanduser('~/.retriever/')
12 SCRIPT_SEARCH_PATHS = [
13 "./",
14 'scripts',
15 os.path.join(HOME_DIR, 'scripts/')
16 ]
17 SCRIPT_WRITE_PATH = SCRIPT_SEARCH_PATHS[-1]
18 DATA_SEARCH_PATHS = [
19 "./",
20 "{dataset}",
21 "raw_data/{dataset}",
22 os.path.join(HOME_DIR, 'raw_data/{dataset}'),
23 ]
24 DATA_WRITE_PATH = DATA_SEARCH_PATHS[-1]
25
26 # Create default data directory
27 DATA_DIR = '.'
28 sample_script = """
29 {
30 "description": "S. K. Morgan Ernest. 2003. Life history characteristics of placental non-volant mammals. Ecology 84:3402.",
31 "homepage": "http://esapubs.org/archive/ecol/E084/093/default.htm",
32 "name": "MammalLH",
33 "resources": [
34 {
35 "dialect": {},
36 "mediatype": "text/csv",
37 "name": "species",
38 "schema": {},
39 "url": "http://esapubs.org/archive/ecol/E084/093/Mammal_lifehistories_v2.txt"
40 }
41 ],
42 "title": "Mammal Life History Database - Ernest, et al., 2003"
43 }
44 """
45 CITATION = """Morris, B.D. and E.P. White. 2013. The EcoData Retriever: improving access to
46 existing ecological data. PLOS ONE 8:e65848.
47 http://doi.org/doi:10.1371/journal.pone.0065848
48
49 @article{morris2013ecodata,
50 title={The EcoData Retriever: Improving Access to Existing Ecological Data},
51 author={Morris, Benjamin D and White, Ethan P},
52 journal={PLOS One},
53 volume={8},
54 number={6},
55 pages={e65848},
56 year={2013},
57 publisher={Public Library of Science}
58 doi={10.1371/journal.pone.0065848}
59 }
60 """
61
[end of retriever/lib/defaults.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/retriever/__main__.py b/retriever/__main__.py
--- a/retriever/__main__.py
+++ b/retriever/__main__.py
@@ -12,7 +12,7 @@
from retriever.engines import engine_list, choose_engine
from retriever.lib.datapackage import create_json, edit_json, delete_json, get_script_filename
from retriever.lib.datasets import datasets, dataset_names, license
-from retriever.lib.defaults import sample_script, CITATION, SCRIPT_SEARCH_PATHS
+from retriever.lib.defaults import sample_script, CITATION, SCRIPT_SEARCH_PATHS, LICENSE
from retriever.lib.engine_tools import name_matches, reset_retriever
from retriever.lib.get_opts import parser
from retriever.lib.repository import check_for_updates
@@ -76,11 +76,14 @@
return
elif args.command == 'license':
- dataset_license = license(args.dataset)
- if dataset_license:
- print(dataset_license)
+ if args.dataset is None:
+ print(LICENSE)
else:
- print("There is no license information for {}".format(args.dataset))
+ dataset_license = license(args.dataset)
+ if dataset_license:
+ print(dataset_license)
+ else:
+ print("There is no license information for {}".format(args.dataset))
return
elif args.command == 'new':
diff --git a/retriever/lib/defaults.py b/retriever/lib/defaults.py
--- a/retriever/lib/defaults.py
+++ b/retriever/lib/defaults.py
@@ -4,6 +4,7 @@
VERSION = __version__
COPYRIGHT = "Copyright (C) 2011-2016 Weecology University of Florida"
+LICENSE = "MIT"
REPO_URL = "https://raw.githubusercontent.com/weecology/retriever/"
MASTER_BRANCH = REPO_URL + "master/"
REPOSITORY = MASTER_BRANCH
| {"golden_diff": "diff --git a/retriever/__main__.py b/retriever/__main__.py\n--- a/retriever/__main__.py\n+++ b/retriever/__main__.py\n@@ -12,7 +12,7 @@\n from retriever.engines import engine_list, choose_engine\n from retriever.lib.datapackage import create_json, edit_json, delete_json, get_script_filename\n from retriever.lib.datasets import datasets, dataset_names, license\n-from retriever.lib.defaults import sample_script, CITATION, SCRIPT_SEARCH_PATHS\n+from retriever.lib.defaults import sample_script, CITATION, SCRIPT_SEARCH_PATHS, LICENSE\n from retriever.lib.engine_tools import name_matches, reset_retriever\n from retriever.lib.get_opts import parser\n from retriever.lib.repository import check_for_updates\n@@ -76,11 +76,14 @@\n return\n \n elif args.command == 'license':\n- dataset_license = license(args.dataset)\n- if dataset_license:\n- print(dataset_license)\n+ if args.dataset is None:\n+ print(LICENSE)\n else:\n- print(\"There is no license information for {}\".format(args.dataset))\n+ dataset_license = license(args.dataset)\n+ if dataset_license:\n+ print(dataset_license)\n+ else:\n+ print(\"There is no license information for {}\".format(args.dataset))\n return\n \n elif args.command == 'new':\ndiff --git a/retriever/lib/defaults.py b/retriever/lib/defaults.py\n--- a/retriever/lib/defaults.py\n+++ b/retriever/lib/defaults.py\n@@ -4,6 +4,7 @@\n \n VERSION = __version__\n COPYRIGHT = \"Copyright (C) 2011-2016 Weecology University of Florida\"\n+LICENSE = \"MIT\"\n REPO_URL = \"https://raw.githubusercontent.com/weecology/retriever/\"\n MASTER_BRANCH = REPO_URL + \"master/\"\n REPOSITORY = MASTER_BRANCH\n", "issue": "Error when running retriever license with no dataset as argument\nCurrently, when running `retriever license` and providing no dataset as an argument it results into `KeyError: 'No dataset named: None'`\r\n\r\n\r\nIn case of `retriever citation` if no dataset is given we show the citation for retriever. \r\n\r\n\r\nHow should we handle this? Show the license for retriever by reading the `LICENSE` file or create a new `LICENSE` variable in `retriever.lib.defaults` and show it?\n", "before_files": [{"content": "\"\"\"Data Retriever\n\nThis module handles the CLI for the Data retriever.\n\"\"\"\nfrom __future__ import absolute_import\nfrom __future__ import print_function\n\nimport os\nimport sys\nfrom builtins import input\n\nfrom retriever.engines import engine_list, choose_engine\nfrom retriever.lib.datapackage import create_json, edit_json, delete_json, get_script_filename\nfrom retriever.lib.datasets import datasets, dataset_names, license\nfrom retriever.lib.defaults import sample_script, CITATION, SCRIPT_SEARCH_PATHS\nfrom retriever.lib.engine_tools import name_matches, reset_retriever\nfrom retriever.lib.get_opts import parser\nfrom retriever.lib.repository import check_for_updates\nfrom retriever.lib.scripts import SCRIPT_LIST, reload_scripts, get_script\n\n\ndef main():\n \"\"\"This function launches the Data Retriever.\"\"\"\n if len(sys.argv) == 1:\n # if no command line args are passed, show the help options\n parser.parse_args(['-h'])\n\n else:\n # otherwise, parse them\n args = parser.parse_args()\n\n if args.command not in ['reset', 'update'] \\\n and not os.path.isdir(SCRIPT_SEARCH_PATHS[1]) \\\n and not [f for f in os.listdir(SCRIPT_SEARCH_PATHS[-1])\n if os.path.exists(SCRIPT_SEARCH_PATHS[-1])]:\n check_for_updates()\n reload_scripts()\n script_list = SCRIPT_LIST()\n\n if args.command == \"install\" and not args.engine:\n parser.parse_args(['install', '-h'])\n\n if args.quiet:\n sys.stdout = open(os.devnull, 'w')\n\n if args.command == 'help':\n parser.parse_args(['-h'])\n\n if hasattr(args, 'compile') and args.compile:\n script_list = reload_scripts()\n\n if args.command == 'defaults':\n for engine_item in engine_list:\n print(\"Default options for engine \", engine_item.name)\n for default_opts in engine_item.required_opts:\n print(default_opts[0], \" \", default_opts[2])\n print()\n return\n\n if args.command == 'update':\n check_for_updates()\n reload_scripts()\n return\n\n elif args.command == 'citation':\n if args.dataset is None:\n print(\"\\nCitation for retriever:\\n\")\n print(CITATION)\n else:\n scripts = name_matches(script_list, args.dataset)\n for dataset in scripts:\n print(\"\\nDataset: {}\".format(dataset.name))\n print(\"Citation: {}\".format(dataset.citation))\n print(\"Description: {}\\n\".format(dataset.description))\n\n return\n\n elif args.command == 'license':\n dataset_license = license(args.dataset)\n if dataset_license:\n print(dataset_license)\n else:\n print(\"There is no license information for {}\".format(args.dataset))\n return\n\n elif args.command == 'new':\n f = open(args.filename, 'w')\n f.write(sample_script)\n f.close()\n\n return\n\n elif args.command == 'reset':\n reset_retriever(args.scope)\n return\n\n elif args.command == 'new_json':\n # create new JSON script\n create_json()\n return\n\n elif args.command == 'edit_json':\n # edit existing JSON script\n json_file = get_script_filename(args.dataset.lower())\n edit_json(json_file)\n return\n\n elif args.command == 'delete_json':\n # delete existing JSON script from home directory and or script directory if exists in current dir\n confirm = input(\"Really remove \" + args.dataset.lower() +\n \" and all its contents? (y/N): \")\n if confirm.lower().strip() in ['y', 'yes']:\n json_file = get_script_filename(args.dataset.lower())\n delete_json(json_file)\n return\n\n if args.command == 'ls':\n # scripts should never be empty because check_for_updates is run on SCRIPT_LIST init\n if not (args.l or args.k or isinstance(args.v, list)):\n all_scripts = dataset_names()\n print(\"Available datasets : {}\\n\".format(len(all_scripts)))\n from retriever import lscolumns\n\n lscolumns.printls(all_scripts)\n\n elif isinstance(args.v, list):\n if args.v:\n try:\n all_scripts = [get_script(dataset) for dataset in args.v]\n except KeyError:\n all_scripts = []\n print(\"Dataset(s) is not found.\")\n else:\n all_scripts = datasets()\n count = 1\n for script in all_scripts:\n print(\n \"{count}. {title}\\n {name}\\n\"\n \"{keywords}\\n{description}\\n\"\n \"{licenses}\\n{citation}\\n\"\n \"\".format(\n count=count,\n title=script.title,\n name=script.name,\n keywords=script.keywords,\n description=script.description,\n licenses=str(script.licenses[0]['name']),\n citation=script.citation,\n )\n )\n count += 1\n\n else:\n param_licenses = args.l if args.l else None\n keywords = args.k if args.k else None\n\n # search\n searched_scripts = datasets(keywords, param_licenses)\n if not searched_scripts:\n print(\"No available datasets found\")\n else:\n print(\"Available datasets : {}\\n\".format(len(searched_scripts)))\n count = 1\n for script in searched_scripts:\n print(\n \"{count}. {title}\\n{name}\\n\"\n \"{keywords}\\n{licenses}\\n\".format(\n count=count,\n title=script.title,\n name=script.name,\n keywords=script.keywords,\n licenses=str(script.licenses[0]['name']),\n )\n )\n count += 1\n return\n\n engine = choose_engine(args.__dict__)\n\n if hasattr(args, 'debug') and args.debug:\n debug = True\n else:\n debug = False\n sys.tracebacklimit = 0\n\n if hasattr(args, 'debug') and args.not_cached:\n engine.use_cache = False\n else:\n engine.use_cache = True\n\n if args.dataset is not None:\n scripts = name_matches(script_list, args.dataset)\n else:\n raise Exception(\"no dataset specified.\")\n if scripts:\n for dataset in scripts:\n print(\"=> Installing\", dataset.name)\n try:\n dataset.download(engine, debug=debug)\n dataset.engine.final_cleanup()\n except KeyboardInterrupt:\n pass\n except Exception as e:\n print(e)\n if debug:\n raise\n print(\"Done!\")\n else:\n print(\"Run 'retriever ls' to see a list of currently available datasets.\")\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "retriever/__main__.py"}, {"content": "import os\n\nfrom retriever._version import __version__\n\nVERSION = __version__\nCOPYRIGHT = \"Copyright (C) 2011-2016 Weecology University of Florida\"\nREPO_URL = \"https://raw.githubusercontent.com/weecology/retriever/\"\nMASTER_BRANCH = REPO_URL + \"master/\"\nREPOSITORY = MASTER_BRANCH\nENCODING = 'ISO-8859-1'\nHOME_DIR = os.path.expanduser('~/.retriever/')\nSCRIPT_SEARCH_PATHS = [\n \"./\",\n 'scripts',\n os.path.join(HOME_DIR, 'scripts/')\n]\nSCRIPT_WRITE_PATH = SCRIPT_SEARCH_PATHS[-1]\nDATA_SEARCH_PATHS = [\n \"./\",\n \"{dataset}\",\n \"raw_data/{dataset}\",\n os.path.join(HOME_DIR, 'raw_data/{dataset}'),\n]\nDATA_WRITE_PATH = DATA_SEARCH_PATHS[-1]\n\n# Create default data directory\nDATA_DIR = '.'\nsample_script = \"\"\"\n{\n \"description\": \"S. K. Morgan Ernest. 2003. Life history characteristics of placental non-volant mammals. Ecology 84:3402.\",\n \"homepage\": \"http://esapubs.org/archive/ecol/E084/093/default.htm\",\n \"name\": \"MammalLH\",\n \"resources\": [\n {\n \"dialect\": {},\n \"mediatype\": \"text/csv\",\n \"name\": \"species\",\n \"schema\": {},\n \"url\": \"http://esapubs.org/archive/ecol/E084/093/Mammal_lifehistories_v2.txt\"\n }\n ],\n \"title\": \"Mammal Life History Database - Ernest, et al., 2003\"\n}\n\"\"\"\nCITATION = \"\"\"Morris, B.D. and E.P. White. 2013. The EcoData Retriever: improving access to\nexisting ecological data. PLOS ONE 8:e65848.\nhttp://doi.org/doi:10.1371/journal.pone.0065848\n\n@article{morris2013ecodata,\n title={The EcoData Retriever: Improving Access to Existing Ecological Data},\n author={Morris, Benjamin D and White, Ethan P},\n journal={PLOS One},\n volume={8},\n number={6},\n pages={e65848},\n year={2013},\n publisher={Public Library of Science}\n doi={10.1371/journal.pone.0065848}\n}\n\"\"\"\n", "path": "retriever/lib/defaults.py"}]} | 3,444 | 417 |
gh_patches_debug_11400 | rasdani/github-patches | git_diff | ansible__ansible-modules-core-3732 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
os_floating_ip errors if an ip is attached.
##### Issue Type:
Regression (so inevitably a feature idea).
##### Ansible Version:
ansible 2.0.0
##### Ansible Configuration:
```
< lookup_plugins = ./lookup_plugins:~/.ansible/plugins/lookup_plugins/:/usr/share/ansible_plugins/
< timeout = 120
---
> timeout = 10
```
##### Environment:
OSX -> Ubuntu
##### Summary:
If you add an ip with os_floating_ip to a server, when you rerun your play, it errors.
##### Steps To Reproduce:
```
- os_floating_ip:
cloud: envvars
state: present
reuse: yes
server: cwp-goserver-1
network: vlan3320
fixed_address: "{{ lookup('os_private_ip', 'cwp-goserver-1') }}"
wait: true
timeout: 180
```
##### Expected Results:
If the server already has a floating ip from the network, expect the task to pass, as unchanged.
##### Actual Results:
```
unable to bind a floating ip to server f23ce73c-82ad-490a-bf0e-7e3d23dce449: Cannot associate floating IP 10.12.71.112 (57a5b6e0-2843-4ec5-9388-408a098cdcc7) with port f2c6e8bb-b500-4ea0-abc8-980b34fc200f using fixed IP 192.168.101.36, as that fixed IP already has a floating IP on external network 8b3e1a76-f16c-461b-a5b5-f5987936426d
```
</issue>
<code>
[start of cloud/openstack/os_floating_ip.py]
1 #!/usr/bin/python
2 # Copyright (c) 2015 Hewlett-Packard Development Company, L.P.
3 # Author: Davide Guerri <[email protected]>
4 #
5 # This module is free software: you can redistribute it and/or modify
6 # it under the terms of the GNU General Public License as published by
7 # the Free Software Foundation, either version 3 of the License, or
8 # (at your option) any later version.
9 #
10 # This software is distributed in the hope that it will be useful,
11 # but WITHOUT ANY WARRANTY; without even the implied warranty of
12 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
13 # GNU General Public License for more details.
14 #
15 # You should have received a copy of the GNU General Public License
16 # along with this software. If not, see <http://www.gnu.org/licenses/>.
17
18 try:
19 import shade
20 from shade import meta
21
22 HAS_SHADE = True
23 except ImportError:
24 HAS_SHADE = False
25
26 DOCUMENTATION = '''
27 ---
28 module: os_floating_ip
29 version_added: "2.0"
30 short_description: Add/Remove floating IP from an instance
31 extends_documentation_fragment: openstack
32 description:
33 - Add or Remove a floating IP to an instance
34 options:
35 server:
36 description:
37 - The name or ID of the instance to which the IP address
38 should be assigned.
39 required: true
40 network:
41 description:
42 - The name or ID of a neutron external network or a nova pool name.
43 required: false
44 floating_ip_address:
45 description:
46 - A floating IP address to attach or to detach. Required only if I(state)
47 is absent. When I(state) is present can be used to specify a IP address
48 to attach.
49 required: false
50 reuse:
51 description:
52 - When I(state) is present, and I(floating_ip_address) is not present,
53 this parameter can be used to specify whether we should try to reuse
54 a floating IP address already allocated to the project.
55 required: false
56 default: false
57 fixed_address:
58 description:
59 - To which fixed IP of server the floating IP address should be
60 attached to.
61 required: false
62 wait:
63 description:
64 - When attaching a floating IP address, specify whether we should
65 wait for it to appear as attached.
66 required: false
67 default: false
68 timeout:
69 description:
70 - Time to wait for an IP address to appear as attached. See wait.
71 required: false
72 default: 60
73 state:
74 description:
75 - Should the resource be present or absent.
76 choices: [present, absent]
77 required: false
78 default: present
79 purge:
80 description:
81 - When I(state) is absent, indicates whether or not to delete the floating
82 IP completely, or only detach it from the server. Default is to detach only.
83 required: false
84 default: false
85 version_added: "2.1"
86 requirements: ["shade"]
87 '''
88
89 EXAMPLES = '''
90 # Assign a floating IP to the fist interface of `cattle001` from an exiting
91 # external network or nova pool. A new floating IP from the first available
92 # external network is allocated to the project.
93 - os_floating_ip:
94 cloud: dguerri
95 server: cattle001
96
97 # Assign a new floating IP to the instance fixed ip `192.0.2.3` of
98 # `cattle001`. If a free floating IP is already allocated to the project, it is
99 # reused; if not, a new one is created.
100 - os_floating_ip:
101 cloud: dguerri
102 state: present
103 reuse: yes
104 server: cattle001
105 network: ext_net
106 fixed_address: 192.0.2.3
107 wait: true
108 timeout: 180
109
110 # Detach a floating IP address from a server
111 - os_floating_ip:
112 cloud: dguerri
113 state: absent
114 floating_ip_address: 203.0.113.2
115 server: cattle001
116 '''
117
118
119 def _get_floating_ip(cloud, floating_ip_address):
120 f_ips = cloud.search_floating_ips(
121 filters={'floating_ip_address': floating_ip_address})
122 if not f_ips:
123 return None
124
125 return f_ips[0]
126
127
128 def main():
129 argument_spec = openstack_full_argument_spec(
130 server=dict(required=True),
131 state=dict(default='present', choices=['absent', 'present']),
132 network=dict(required=False, default=None),
133 floating_ip_address=dict(required=False, default=None),
134 reuse=dict(required=False, type='bool', default=False),
135 fixed_address=dict(required=False, default=None),
136 wait=dict(required=False, type='bool', default=False),
137 timeout=dict(required=False, type='int', default=60),
138 purge=dict(required=False, type='bool', default=False),
139 )
140
141 module_kwargs = openstack_module_kwargs()
142 module = AnsibleModule(argument_spec, **module_kwargs)
143
144 if not HAS_SHADE:
145 module.fail_json(msg='shade is required for this module')
146
147 server_name_or_id = module.params['server']
148 state = module.params['state']
149 network = module.params['network']
150 floating_ip_address = module.params['floating_ip_address']
151 reuse = module.params['reuse']
152 fixed_address = module.params['fixed_address']
153 wait = module.params['wait']
154 timeout = module.params['timeout']
155 purge = module.params['purge']
156
157 cloud = shade.openstack_cloud(**module.params)
158
159 try:
160 server = cloud.get_server(server_name_or_id)
161 if server is None:
162 module.fail_json(
163 msg="server {0} not found".format(server_name_or_id))
164
165 if state == 'present':
166 server = cloud.add_ips_to_server(
167 server=server, ips=floating_ip_address, ip_pool=network,
168 reuse=reuse, fixed_address=fixed_address, wait=wait,
169 timeout=timeout)
170 fip_address = cloud.get_server_public_ip(server)
171 # Update the floating IP status
172 f_ip = _get_floating_ip(cloud, fip_address)
173 module.exit_json(changed=True, floating_ip=f_ip)
174
175 elif state == 'absent':
176 if floating_ip_address is None:
177 module.fail_json(msg="floating_ip_address is required")
178
179 f_ip = _get_floating_ip(cloud, floating_ip_address)
180
181 if not f_ip:
182 # Nothing to detach
183 module.exit_json(changed=False)
184
185 cloud.detach_ip_from_server(
186 server_id=server['id'], floating_ip_id=f_ip['id'])
187 # Update the floating IP status
188 f_ip = cloud.get_floating_ip(id=f_ip['id'])
189 if purge:
190 cloud.delete_floating_ip(f_ip['id'])
191 module.exit_json(changed=True)
192 module.exit_json(changed=True, floating_ip=f_ip)
193
194 except shade.OpenStackCloudException as e:
195 module.fail_json(msg=str(e), extra_data=e.extra_data)
196
197
198 # this is magic, see lib/ansible/module_common.py
199 from ansible.module_utils.basic import *
200 from ansible.module_utils.openstack import *
201
202
203 if __name__ == '__main__':
204 main()
205
[end of cloud/openstack/os_floating_ip.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/cloud/openstack/os_floating_ip.py b/cloud/openstack/os_floating_ip.py
--- a/cloud/openstack/os_floating_ip.py
+++ b/cloud/openstack/os_floating_ip.py
@@ -163,6 +163,10 @@
msg="server {0} not found".format(server_name_or_id))
if state == 'present':
+ fip_address = cloud.get_server_public_ip(server)
+ f_ip = _get_floating_ip(cloud, fip_address)
+ if f_ip:
+ module.exit_json(changed=False, floating_ip=f_ip)
server = cloud.add_ips_to_server(
server=server, ips=floating_ip_address, ip_pool=network,
reuse=reuse, fixed_address=fixed_address, wait=wait,
| {"golden_diff": "diff --git a/cloud/openstack/os_floating_ip.py b/cloud/openstack/os_floating_ip.py\n--- a/cloud/openstack/os_floating_ip.py\n+++ b/cloud/openstack/os_floating_ip.py\n@@ -163,6 +163,10 @@\n msg=\"server {0} not found\".format(server_name_or_id))\n \n if state == 'present':\n+ fip_address = cloud.get_server_public_ip(server)\n+ f_ip = _get_floating_ip(cloud, fip_address)\n+ if f_ip:\n+ module.exit_json(changed=False, floating_ip=f_ip)\n server = cloud.add_ips_to_server(\n server=server, ips=floating_ip_address, ip_pool=network,\n reuse=reuse, fixed_address=fixed_address, wait=wait,\n", "issue": "os_floating_ip errors if an ip is attached.\n##### Issue Type:\n\nRegression (so inevitably a feature idea).\n##### Ansible Version:\n\nansible 2.0.0\n##### Ansible Configuration:\n\n```\n< lookup_plugins = ./lookup_plugins:~/.ansible/plugins/lookup_plugins/:/usr/share/ansible_plugins/\n< timeout = 120\n\n---\n> timeout = 10\n```\n##### Environment:\n\nOSX -> Ubuntu\n##### Summary:\n\nIf you add an ip with os_floating_ip to a server, when you rerun your play, it errors.\n##### Steps To Reproduce:\n\n```\n- os_floating_ip:\n cloud: envvars\n state: present\n reuse: yes\n server: cwp-goserver-1\n network: vlan3320\n fixed_address: \"{{ lookup('os_private_ip', 'cwp-goserver-1') }}\"\n wait: true\n timeout: 180\n```\n##### Expected Results:\n\nIf the server already has a floating ip from the network, expect the task to pass, as unchanged.\n##### Actual Results:\n\n```\nunable to bind a floating ip to server f23ce73c-82ad-490a-bf0e-7e3d23dce449: Cannot associate floating IP 10.12.71.112 (57a5b6e0-2843-4ec5-9388-408a098cdcc7) with port f2c6e8bb-b500-4ea0-abc8-980b34fc200f using fixed IP 192.168.101.36, as that fixed IP already has a floating IP on external network 8b3e1a76-f16c-461b-a5b5-f5987936426d\n```\n\n", "before_files": [{"content": "#!/usr/bin/python\n# Copyright (c) 2015 Hewlett-Packard Development Company, L.P.\n# Author: Davide Guerri <[email protected]>\n#\n# This module is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# This software is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this software. If not, see <http://www.gnu.org/licenses/>.\n\ntry:\n import shade\n from shade import meta\n\n HAS_SHADE = True\nexcept ImportError:\n HAS_SHADE = False\n\nDOCUMENTATION = '''\n---\nmodule: os_floating_ip\nversion_added: \"2.0\"\nshort_description: Add/Remove floating IP from an instance\nextends_documentation_fragment: openstack\ndescription:\n - Add or Remove a floating IP to an instance\noptions:\n server:\n description:\n - The name or ID of the instance to which the IP address\n should be assigned.\n required: true\n network:\n description:\n - The name or ID of a neutron external network or a nova pool name.\n required: false\n floating_ip_address:\n description:\n - A floating IP address to attach or to detach. Required only if I(state)\n is absent. When I(state) is present can be used to specify a IP address\n to attach.\n required: false\n reuse:\n description:\n - When I(state) is present, and I(floating_ip_address) is not present,\n this parameter can be used to specify whether we should try to reuse\n a floating IP address already allocated to the project.\n required: false\n default: false\n fixed_address:\n description:\n - To which fixed IP of server the floating IP address should be\n attached to.\n required: false\n wait:\n description:\n - When attaching a floating IP address, specify whether we should\n wait for it to appear as attached.\n required: false\n default: false\n timeout:\n description:\n - Time to wait for an IP address to appear as attached. See wait.\n required: false\n default: 60\n state:\n description:\n - Should the resource be present or absent.\n choices: [present, absent]\n required: false\n default: present\n purge:\n description:\n - When I(state) is absent, indicates whether or not to delete the floating\n IP completely, or only detach it from the server. Default is to detach only.\n required: false\n default: false\n version_added: \"2.1\"\nrequirements: [\"shade\"]\n'''\n\nEXAMPLES = '''\n# Assign a floating IP to the fist interface of `cattle001` from an exiting\n# external network or nova pool. A new floating IP from the first available\n# external network is allocated to the project.\n- os_floating_ip:\n cloud: dguerri\n server: cattle001\n\n# Assign a new floating IP to the instance fixed ip `192.0.2.3` of\n# `cattle001`. If a free floating IP is already allocated to the project, it is\n# reused; if not, a new one is created.\n- os_floating_ip:\n cloud: dguerri\n state: present\n reuse: yes\n server: cattle001\n network: ext_net\n fixed_address: 192.0.2.3\n wait: true\n timeout: 180\n\n# Detach a floating IP address from a server\n- os_floating_ip:\n cloud: dguerri\n state: absent\n floating_ip_address: 203.0.113.2\n server: cattle001\n'''\n\n\ndef _get_floating_ip(cloud, floating_ip_address):\n f_ips = cloud.search_floating_ips(\n filters={'floating_ip_address': floating_ip_address})\n if not f_ips:\n return None\n\n return f_ips[0]\n\n\ndef main():\n argument_spec = openstack_full_argument_spec(\n server=dict(required=True),\n state=dict(default='present', choices=['absent', 'present']),\n network=dict(required=False, default=None),\n floating_ip_address=dict(required=False, default=None),\n reuse=dict(required=False, type='bool', default=False),\n fixed_address=dict(required=False, default=None),\n wait=dict(required=False, type='bool', default=False),\n timeout=dict(required=False, type='int', default=60),\n purge=dict(required=False, type='bool', default=False),\n )\n\n module_kwargs = openstack_module_kwargs()\n module = AnsibleModule(argument_spec, **module_kwargs)\n\n if not HAS_SHADE:\n module.fail_json(msg='shade is required for this module')\n\n server_name_or_id = module.params['server']\n state = module.params['state']\n network = module.params['network']\n floating_ip_address = module.params['floating_ip_address']\n reuse = module.params['reuse']\n fixed_address = module.params['fixed_address']\n wait = module.params['wait']\n timeout = module.params['timeout']\n purge = module.params['purge']\n\n cloud = shade.openstack_cloud(**module.params)\n\n try:\n server = cloud.get_server(server_name_or_id)\n if server is None:\n module.fail_json(\n msg=\"server {0} not found\".format(server_name_or_id))\n\n if state == 'present':\n server = cloud.add_ips_to_server(\n server=server, ips=floating_ip_address, ip_pool=network,\n reuse=reuse, fixed_address=fixed_address, wait=wait,\n timeout=timeout)\n fip_address = cloud.get_server_public_ip(server)\n # Update the floating IP status\n f_ip = _get_floating_ip(cloud, fip_address)\n module.exit_json(changed=True, floating_ip=f_ip)\n\n elif state == 'absent':\n if floating_ip_address is None:\n module.fail_json(msg=\"floating_ip_address is required\")\n\n f_ip = _get_floating_ip(cloud, floating_ip_address)\n\n if not f_ip:\n # Nothing to detach\n module.exit_json(changed=False)\n\n cloud.detach_ip_from_server(\n server_id=server['id'], floating_ip_id=f_ip['id'])\n # Update the floating IP status\n f_ip = cloud.get_floating_ip(id=f_ip['id'])\n if purge:\n cloud.delete_floating_ip(f_ip['id'])\n module.exit_json(changed=True)\n module.exit_json(changed=True, floating_ip=f_ip)\n\n except shade.OpenStackCloudException as e:\n module.fail_json(msg=str(e), extra_data=e.extra_data)\n\n\n# this is magic, see lib/ansible/module_common.py\nfrom ansible.module_utils.basic import *\nfrom ansible.module_utils.openstack import *\n\n\nif __name__ == '__main__':\n main()\n", "path": "cloud/openstack/os_floating_ip.py"}]} | 3,066 | 173 |
gh_patches_debug_41419 | rasdani/github-patches | git_diff | cookiecutter__cookiecutter-815 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
passing list to template
I would like to be able to pass a list to the templates. See the two code blocks at the end of this post for an example. Right now it appears that if you pass a list in the config object, it's read as a list of options for that key.
I know that you can use `str.split()` in the jinja2 template, but that's not a real solution, since it's impossible to "escape" the character that's used as the delimiter. What's the best solution here? I would prefer to be able to pass a list in the json object and call it a day, but obviously that doesn't work for the user input prompts.
- `cookiecutter.json`:
``` json
{
"build_steps": [
"do_something",
"do_something_else"
]
}
```
- `Dockerfile`:
``` jinja2
FROM something
{% for step in cookiecutter.build_steps %}
RUN {{ step }}
{% endfor %}
```
</issue>
<code>
[start of cookiecutter/prompt.py]
1 # -*- coding: utf-8 -*-
2
3 """
4 cookiecutter.prompt
5 ---------------------
6
7 Functions for prompting the user for project info.
8 """
9
10 from collections import OrderedDict
11
12 import click
13 from past.builtins import basestring
14
15 from future.utils import iteritems
16
17 from jinja2.exceptions import UndefinedError
18
19 from .exceptions import UndefinedVariableInTemplate
20 from .environment import StrictEnvironment
21
22
23 def read_user_variable(var_name, default_value):
24 """Prompt the user for the given variable and return the entered value
25 or the given default.
26
27 :param str var_name: Variable of the context to query the user
28 :param default_value: Value that will be returned if no input happens
29 """
30 # Please see http://click.pocoo.org/4/api/#click.prompt
31 return click.prompt(var_name, default=default_value)
32
33
34 def read_user_yes_no(question, default_value):
35 """Prompt the user to reply with 'yes' or 'no' (or equivalent values).
36
37 Note:
38 Possible choices are 'true', '1', 'yes', 'y' or 'false', '0', 'no', 'n'
39
40 :param str question: Question to the user
41 :param default_value: Value that will be returned if no input happens
42 """
43 # Please see http://click.pocoo.org/4/api/#click.prompt
44 return click.prompt(
45 question,
46 default=default_value,
47 type=click.BOOL
48 )
49
50
51 def read_user_choice(var_name, options):
52 """Prompt the user to choose from several options for the given variable.
53
54 The first item will be returned if no input happens.
55
56 :param str var_name: Variable as specified in the context
57 :param list options: Sequence of options that are available to select from
58 :return: Exactly one item of ``options`` that has been chosen by the user
59 """
60 # Please see http://click.pocoo.org/4/api/#click.prompt
61 if not isinstance(options, list):
62 raise TypeError
63
64 if not options:
65 raise ValueError
66
67 choice_map = OrderedDict(
68 (u'{}'.format(i), value) for i, value in enumerate(options, 1)
69 )
70 choices = choice_map.keys()
71 default = u'1'
72
73 choice_lines = [u'{} - {}'.format(*c) for c in choice_map.items()]
74 prompt = u'\n'.join((
75 u'Select {}:'.format(var_name),
76 u'\n'.join(choice_lines),
77 u'Choose from {}'.format(u', '.join(choices))
78 ))
79
80 user_choice = click.prompt(
81 prompt, type=click.Choice(choices), default=default
82 )
83 return choice_map[user_choice]
84
85
86 def render_variable(env, raw, cookiecutter_dict):
87 if raw is None:
88 return None
89 if not isinstance(raw, basestring):
90 raw = str(raw)
91 template = env.from_string(raw)
92
93 rendered_template = template.render(cookiecutter=cookiecutter_dict)
94 return rendered_template
95
96
97 def prompt_choice_for_config(cookiecutter_dict, env, key, options, no_input):
98 """Prompt the user which option to choose from the given. Each of the
99 possible choices is rendered beforehand.
100 """
101 rendered_options = [
102 render_variable(env, raw, cookiecutter_dict) for raw in options
103 ]
104
105 if no_input:
106 return rendered_options[0]
107 return read_user_choice(key, rendered_options)
108
109
110 def prompt_for_config(context, no_input=False):
111 """
112 Prompts the user to enter new config, using context as a source for the
113 field names and sample values.
114
115 :param no_input: Prompt the user at command line for manual configuration?
116 """
117 cookiecutter_dict = {}
118 env = StrictEnvironment(context=context)
119
120 for key, raw in iteritems(context[u'cookiecutter']):
121 if key.startswith(u'_'):
122 cookiecutter_dict[key] = raw
123 continue
124
125 try:
126 if isinstance(raw, list):
127 # We are dealing with a choice variable
128 val = prompt_choice_for_config(
129 cookiecutter_dict, env, key, raw, no_input
130 )
131 else:
132 # We are dealing with a regular variable
133 val = render_variable(env, raw, cookiecutter_dict)
134
135 if not no_input:
136 val = read_user_variable(key, val)
137 except UndefinedError as err:
138 msg = "Unable to render variable '{}'".format(key)
139 raise UndefinedVariableInTemplate(msg, err, context)
140
141 cookiecutter_dict[key] = val
142 return cookiecutter_dict
143
[end of cookiecutter/prompt.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/cookiecutter/prompt.py b/cookiecutter/prompt.py
--- a/cookiecutter/prompt.py
+++ b/cookiecutter/prompt.py
@@ -8,6 +8,7 @@
"""
from collections import OrderedDict
+import json
import click
from past.builtins import basestring
@@ -83,11 +84,43 @@
return choice_map[user_choice]
+def read_user_dict(var_name, default_value):
+ """Prompt the user to provide a dictionary of data.
+
+ :param str var_name: Variable as specified in the context
+ :param default_value: Value that will be returned if no input is provided
+ :return: A Python dictionary to use in the context.
+ """
+ # Please see http://click.pocoo.org/4/api/#click.prompt
+ if not isinstance(default_value, dict):
+ raise TypeError
+
+ raw = click.prompt(var_name, default='default')
+ if raw != 'default':
+ value = json.loads(raw, object_hook=OrderedDict)
+ else:
+ value = default_value
+
+ return value
+
+
def render_variable(env, raw, cookiecutter_dict):
if raw is None:
return None
- if not isinstance(raw, basestring):
+ elif isinstance(raw, dict):
+ return {
+ render_variable(env, k, cookiecutter_dict):
+ render_variable(env, v, cookiecutter_dict)
+ for k, v in raw.items()
+ }
+ elif isinstance(raw, list):
+ return [
+ render_variable(env, v, cookiecutter_dict)
+ for v in raw
+ ]
+ elif not isinstance(raw, basestring):
raw = str(raw)
+
template = env.from_string(raw)
rendered_template = template.render(cookiecutter=cookiecutter_dict)
@@ -117,6 +150,9 @@
cookiecutter_dict = {}
env = StrictEnvironment(context=context)
+ # First pass: Handle simple and raw variables, plus choices.
+ # These must be done first because the dictionaries keys and
+ # values might refer to them.
for key, raw in iteritems(context[u'cookiecutter']):
if key.startswith(u'_'):
cookiecutter_dict[key] = raw
@@ -128,15 +164,33 @@
val = prompt_choice_for_config(
cookiecutter_dict, env, key, raw, no_input
)
- else:
+ cookiecutter_dict[key] = val
+ elif not isinstance(raw, dict):
# We are dealing with a regular variable
val = render_variable(env, raw, cookiecutter_dict)
if not no_input:
val = read_user_variable(key, val)
+
+ cookiecutter_dict[key] = val
+ except UndefinedError as err:
+ msg = "Unable to render variable '{}'".format(key)
+ raise UndefinedVariableInTemplate(msg, err, context)
+
+ # Second pass; handle the dictionaries.
+ for key, raw in iteritems(context[u'cookiecutter']):
+
+ try:
+ if isinstance(raw, dict):
+ # We are dealing with a dict variable
+ val = render_variable(env, raw, cookiecutter_dict)
+
+ if not no_input:
+ val = read_user_dict(key, val)
+
+ cookiecutter_dict[key] = val
except UndefinedError as err:
msg = "Unable to render variable '{}'".format(key)
raise UndefinedVariableInTemplate(msg, err, context)
- cookiecutter_dict[key] = val
return cookiecutter_dict
| {"golden_diff": "diff --git a/cookiecutter/prompt.py b/cookiecutter/prompt.py\n--- a/cookiecutter/prompt.py\n+++ b/cookiecutter/prompt.py\n@@ -8,6 +8,7 @@\n \"\"\"\n \n from collections import OrderedDict\n+import json\n \n import click\n from past.builtins import basestring\n@@ -83,11 +84,43 @@\n return choice_map[user_choice]\n \n \n+def read_user_dict(var_name, default_value):\n+ \"\"\"Prompt the user to provide a dictionary of data.\n+\n+ :param str var_name: Variable as specified in the context\n+ :param default_value: Value that will be returned if no input is provided\n+ :return: A Python dictionary to use in the context.\n+ \"\"\"\n+ # Please see http://click.pocoo.org/4/api/#click.prompt\n+ if not isinstance(default_value, dict):\n+ raise TypeError\n+\n+ raw = click.prompt(var_name, default='default')\n+ if raw != 'default':\n+ value = json.loads(raw, object_hook=OrderedDict)\n+ else:\n+ value = default_value\n+\n+ return value\n+\n+\n def render_variable(env, raw, cookiecutter_dict):\n if raw is None:\n return None\n- if not isinstance(raw, basestring):\n+ elif isinstance(raw, dict):\n+ return {\n+ render_variable(env, k, cookiecutter_dict):\n+ render_variable(env, v, cookiecutter_dict)\n+ for k, v in raw.items()\n+ }\n+ elif isinstance(raw, list):\n+ return [\n+ render_variable(env, v, cookiecutter_dict)\n+ for v in raw\n+ ]\n+ elif not isinstance(raw, basestring):\n raw = str(raw)\n+\n template = env.from_string(raw)\n \n rendered_template = template.render(cookiecutter=cookiecutter_dict)\n@@ -117,6 +150,9 @@\n cookiecutter_dict = {}\n env = StrictEnvironment(context=context)\n \n+ # First pass: Handle simple and raw variables, plus choices.\n+ # These must be done first because the dictionaries keys and\n+ # values might refer to them.\n for key, raw in iteritems(context[u'cookiecutter']):\n if key.startswith(u'_'):\n cookiecutter_dict[key] = raw\n@@ -128,15 +164,33 @@\n val = prompt_choice_for_config(\n cookiecutter_dict, env, key, raw, no_input\n )\n- else:\n+ cookiecutter_dict[key] = val\n+ elif not isinstance(raw, dict):\n # We are dealing with a regular variable\n val = render_variable(env, raw, cookiecutter_dict)\n \n if not no_input:\n val = read_user_variable(key, val)\n+\n+ cookiecutter_dict[key] = val\n+ except UndefinedError as err:\n+ msg = \"Unable to render variable '{}'\".format(key)\n+ raise UndefinedVariableInTemplate(msg, err, context)\n+\n+ # Second pass; handle the dictionaries.\n+ for key, raw in iteritems(context[u'cookiecutter']):\n+\n+ try:\n+ if isinstance(raw, dict):\n+ # We are dealing with a dict variable\n+ val = render_variable(env, raw, cookiecutter_dict)\n+\n+ if not no_input:\n+ val = read_user_dict(key, val)\n+\n+ cookiecutter_dict[key] = val\n except UndefinedError as err:\n msg = \"Unable to render variable '{}'\".format(key)\n raise UndefinedVariableInTemplate(msg, err, context)\n \n- cookiecutter_dict[key] = val\n return cookiecutter_dict\n", "issue": "passing list to template\nI would like to be able to pass a list to the templates. See the two code blocks at the end of this post for an example. Right now it appears that if you pass a list in the config object, it's read as a list of options for that key.\n\nI know that you can use `str.split()` in the jinja2 template, but that's not a real solution, since it's impossible to \"escape\" the character that's used as the delimiter. What's the best solution here? I would prefer to be able to pass a list in the json object and call it a day, but obviously that doesn't work for the user input prompts.\n- `cookiecutter.json`:\n\n``` json\n{\n \"build_steps\": [\n \"do_something\",\n \"do_something_else\"\n ]\n}\n```\n- `Dockerfile`:\n\n``` jinja2\nFROM something\n\n{% for step in cookiecutter.build_steps %}\nRUN {{ step }}\n{% endfor %}\n```\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n\"\"\"\ncookiecutter.prompt\n---------------------\n\nFunctions for prompting the user for project info.\n\"\"\"\n\nfrom collections import OrderedDict\n\nimport click\nfrom past.builtins import basestring\n\nfrom future.utils import iteritems\n\nfrom jinja2.exceptions import UndefinedError\n\nfrom .exceptions import UndefinedVariableInTemplate\nfrom .environment import StrictEnvironment\n\n\ndef read_user_variable(var_name, default_value):\n \"\"\"Prompt the user for the given variable and return the entered value\n or the given default.\n\n :param str var_name: Variable of the context to query the user\n :param default_value: Value that will be returned if no input happens\n \"\"\"\n # Please see http://click.pocoo.org/4/api/#click.prompt\n return click.prompt(var_name, default=default_value)\n\n\ndef read_user_yes_no(question, default_value):\n \"\"\"Prompt the user to reply with 'yes' or 'no' (or equivalent values).\n\n Note:\n Possible choices are 'true', '1', 'yes', 'y' or 'false', '0', 'no', 'n'\n\n :param str question: Question to the user\n :param default_value: Value that will be returned if no input happens\n \"\"\"\n # Please see http://click.pocoo.org/4/api/#click.prompt\n return click.prompt(\n question,\n default=default_value,\n type=click.BOOL\n )\n\n\ndef read_user_choice(var_name, options):\n \"\"\"Prompt the user to choose from several options for the given variable.\n\n The first item will be returned if no input happens.\n\n :param str var_name: Variable as specified in the context\n :param list options: Sequence of options that are available to select from\n :return: Exactly one item of ``options`` that has been chosen by the user\n \"\"\"\n # Please see http://click.pocoo.org/4/api/#click.prompt\n if not isinstance(options, list):\n raise TypeError\n\n if not options:\n raise ValueError\n\n choice_map = OrderedDict(\n (u'{}'.format(i), value) for i, value in enumerate(options, 1)\n )\n choices = choice_map.keys()\n default = u'1'\n\n choice_lines = [u'{} - {}'.format(*c) for c in choice_map.items()]\n prompt = u'\\n'.join((\n u'Select {}:'.format(var_name),\n u'\\n'.join(choice_lines),\n u'Choose from {}'.format(u', '.join(choices))\n ))\n\n user_choice = click.prompt(\n prompt, type=click.Choice(choices), default=default\n )\n return choice_map[user_choice]\n\n\ndef render_variable(env, raw, cookiecutter_dict):\n if raw is None:\n return None\n if not isinstance(raw, basestring):\n raw = str(raw)\n template = env.from_string(raw)\n\n rendered_template = template.render(cookiecutter=cookiecutter_dict)\n return rendered_template\n\n\ndef prompt_choice_for_config(cookiecutter_dict, env, key, options, no_input):\n \"\"\"Prompt the user which option to choose from the given. Each of the\n possible choices is rendered beforehand.\n \"\"\"\n rendered_options = [\n render_variable(env, raw, cookiecutter_dict) for raw in options\n ]\n\n if no_input:\n return rendered_options[0]\n return read_user_choice(key, rendered_options)\n\n\ndef prompt_for_config(context, no_input=False):\n \"\"\"\n Prompts the user to enter new config, using context as a source for the\n field names and sample values.\n\n :param no_input: Prompt the user at command line for manual configuration?\n \"\"\"\n cookiecutter_dict = {}\n env = StrictEnvironment(context=context)\n\n for key, raw in iteritems(context[u'cookiecutter']):\n if key.startswith(u'_'):\n cookiecutter_dict[key] = raw\n continue\n\n try:\n if isinstance(raw, list):\n # We are dealing with a choice variable\n val = prompt_choice_for_config(\n cookiecutter_dict, env, key, raw, no_input\n )\n else:\n # We are dealing with a regular variable\n val = render_variable(env, raw, cookiecutter_dict)\n\n if not no_input:\n val = read_user_variable(key, val)\n except UndefinedError as err:\n msg = \"Unable to render variable '{}'\".format(key)\n raise UndefinedVariableInTemplate(msg, err, context)\n\n cookiecutter_dict[key] = val\n return cookiecutter_dict\n", "path": "cookiecutter/prompt.py"}]} | 2,067 | 819 |
gh_patches_debug_22064 | rasdani/github-patches | git_diff | readthedocs__readthedocs.org-3302 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Broken edit links
Two issues which may or may not be related:
- Module sources: the "Edit on github" links for pages like http://www.tornadoweb.org/en/stable/_modules/tornado/stack_context.html are broken; they point to a non-existent .rst file. Is it possible to suppress the edit link for these pages (or ideally point it to the real source)? (migrated from https://github.com/snide/sphinx_rtd_theme/issues/237)
- Non-latest branches: on a page like http://www.tornadoweb.org/en/stable/, the "edit on github" link in the upper right is broken because it points to https://github.com/tornadoweb/tornado/blob/origin/stable/docs/index.rst (the 'origin' directory needs to be removed from the path). On the lower left, clicking "v: stable" for the menu and then "Edit" works (linking to https://github.com/tornadoweb/tornado/edit/stable/docs/index.rst).
The "latest" branch works fine (linking to "master"); this is only a problem for pages based on other branches (migrated from https://github.com/snide/sphinx_rtd_theme/issues/236)
</issue>
<code>
[start of readthedocs/vcs_support/backends/git.py]
1 """Git-related utilities."""
2
3 from __future__ import absolute_import
4
5 import csv
6 import logging
7 import os
8 import re
9
10 from builtins import str
11 from six import StringIO
12
13 from readthedocs.projects.exceptions import ProjectImportError
14 from readthedocs.vcs_support.base import BaseVCS, VCSVersion
15
16
17 log = logging.getLogger(__name__)
18
19
20 class Backend(BaseVCS):
21
22 """Git VCS backend."""
23
24 supports_tags = True
25 supports_branches = True
26 fallback_branch = 'master' # default branch
27
28 def __init__(self, *args, **kwargs):
29 super(Backend, self).__init__(*args, **kwargs)
30 self.token = kwargs.get('token', None)
31 self.repo_url = self._get_clone_url()
32
33 def _get_clone_url(self):
34 if '://' in self.repo_url:
35 hacked_url = self.repo_url.split('://')[1]
36 hacked_url = re.sub('.git$', '', hacked_url)
37 clone_url = 'https://%s' % hacked_url
38 if self.token:
39 clone_url = 'https://%s@%s' % (self.token, hacked_url)
40 return clone_url
41 # Don't edit URL because all hosts aren't the same
42
43 # else:
44 # clone_url = 'git://%s' % (hacked_url)
45 return self.repo_url
46
47 def set_remote_url(self, url):
48 return self.run('git', 'remote', 'set-url', 'origin', url)
49
50 def update(self):
51 # Use checkout() to update repo
52 self.checkout()
53
54 def repo_exists(self):
55 code, _, _ = self.run('git', 'status')
56 return code == 0
57
58 def fetch(self):
59 code, _, err = self.run('git', 'fetch', '--tags', '--prune')
60 if code != 0:
61 raise ProjectImportError(
62 "Failed to get code from '%s' (git fetch): %s\n\nStderr:\n\n%s\n\n" % (
63 self.repo_url, code, err)
64 )
65
66 def checkout_revision(self, revision=None):
67 if not revision:
68 branch = self.default_branch or self.fallback_branch
69 revision = 'origin/%s' % branch
70
71 code, out, err = self.run('git', 'checkout',
72 '--force', '--quiet', revision)
73 if code != 0:
74 log.warning("Failed to checkout revision '%s': %s",
75 revision, code)
76 return [code, out, err]
77
78 def clone(self):
79 code, _, err = self.run('git', 'clone', '--recursive', '--quiet',
80 self.repo_url, '.')
81 if code != 0:
82 raise ProjectImportError(
83 (
84 "Failed to get code from '{url}' (git clone): {exit}\n\n"
85 "git clone error output: {sterr}"
86 ).format(
87 url=self.repo_url,
88 exit=code,
89 sterr=err
90 )
91 )
92
93 @property
94 def tags(self):
95 retcode, stdout, _ = self.run('git', 'show-ref', '--tags')
96 # error (or no tags found)
97 if retcode != 0:
98 return []
99 return self.parse_tags(stdout)
100
101 def parse_tags(self, data):
102 """
103 Parses output of show-ref --tags, eg:
104
105 3b32886c8d3cb815df3793b3937b2e91d0fb00f1 refs/tags/2.0.0
106 bd533a768ff661991a689d3758fcfe72f455435d refs/tags/2.0.1
107 c0288a17899b2c6818f74e3a90b77e2a1779f96a refs/tags/2.0.2
108 a63a2de628a3ce89034b7d1a5ca5e8159534eef0 refs/tags/2.1.0.beta2
109 c7fc3d16ed9dc0b19f0d27583ca661a64562d21e refs/tags/2.1.0.rc1
110 edc0a2d02a0cc8eae8b67a3a275f65cd126c05b1 refs/tags/2.1.0.rc2
111
112 Into VCSTag objects with the tag name as verbose_name and the commit
113 hash as identifier.
114 """
115 # parse the lines into a list of tuples (commit-hash, tag ref name)
116 # StringIO below is expecting Unicode data, so ensure that it gets it.
117 if not isinstance(data, str):
118 data = str(data)
119 raw_tags = csv.reader(StringIO(data), delimiter=' ')
120 vcs_tags = []
121 for row in raw_tags:
122 row = [f for f in row if f != '']
123 if row == []:
124 continue
125 commit_hash, name = row
126 clean_name = name.split('/')[-1]
127 vcs_tags.append(VCSVersion(self, commit_hash, clean_name))
128 return vcs_tags
129
130 @property
131 def branches(self):
132 # Only show remote branches
133 retcode, stdout, _ = self.run('git', 'branch', '-r')
134 # error (or no tags found)
135 if retcode != 0:
136 return []
137 return self.parse_branches(stdout)
138
139 def parse_branches(self, data):
140 """
141 Parse output of git branch -r
142
143 e.g.:
144
145 origin/2.0.X
146 origin/HEAD -> origin/master
147 origin/develop
148 origin/master
149 origin/release/2.0.0
150 origin/release/2.1.0
151 """
152 clean_branches = []
153 # StringIO below is expecting Unicode data, so ensure that it gets it.
154 if not isinstance(data, str):
155 data = str(data)
156 raw_branches = csv.reader(StringIO(data), delimiter=' ')
157 for branch in raw_branches:
158 branch = [f for f in branch if f != '' and f != '*']
159 # Handle empty branches
160 if branch:
161 branch = branch[0]
162 if branch.startswith('origin/'):
163 cut_len = len('origin/')
164 slug = branch[cut_len:].replace('/', '-')
165 if slug in ['HEAD']:
166 continue
167 clean_branches.append(VCSVersion(self, branch, slug))
168 else:
169 # Believe this is dead code.
170 slug = branch.replace('/', '-')
171 clean_branches.append(VCSVersion(self, branch, slug))
172 return clean_branches
173
174 @property
175 def commit(self):
176 _, stdout, _ = self.run('git', 'rev-parse', 'HEAD')
177 return stdout.strip()
178
179 def checkout(self, identifier=None):
180 self.check_working_dir()
181
182 # Clone or update repository
183 if self.repo_exists():
184 self.set_remote_url(self.repo_url)
185 self.fetch()
186 else:
187 self.make_clean_working_dir()
188 self.clone()
189
190 # Find proper identifier
191 if not identifier:
192 identifier = self.default_branch or self.fallback_branch
193
194 identifier = self.find_ref(identifier)
195
196 # Checkout the correct identifier for this branch.
197 code, out, err = self.checkout_revision(identifier)
198 if code != 0:
199 return code, out, err
200
201 # Clean any remains of previous checkouts
202 self.run('git', 'clean', '-d', '-f', '-f')
203
204 # Update submodules
205 self.run('git', 'submodule', 'sync')
206 self.run('git', 'submodule', 'update',
207 '--init', '--recursive', '--force')
208
209 return code, out, err
210
211 def find_ref(self, ref):
212 # Check if ref starts with 'origin/'
213 if ref.startswith('origin/'):
214 return ref
215
216 # Check if ref is a branch of the origin remote
217 if self.ref_exists('remotes/origin/' + ref):
218 return 'origin/' + ref
219
220 return ref
221
222 def ref_exists(self, ref):
223 code, _, _ = self.run('git', 'show-ref', ref)
224 return code == 0
225
226 @property
227 def env(self):
228 env = super(Backend, self).env
229 env['GIT_DIR'] = os.path.join(self.working_dir, '.git')
230 return env
231
[end of readthedocs/vcs_support/backends/git.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/readthedocs/vcs_support/backends/git.py b/readthedocs/vcs_support/backends/git.py
--- a/readthedocs/vcs_support/backends/git.py
+++ b/readthedocs/vcs_support/backends/git.py
@@ -92,7 +92,15 @@
@property
def tags(self):
- retcode, stdout, _ = self.run('git', 'show-ref', '--tags')
+ # Hash for non-annotated tag is its commit hash, but for annotated tag it
+ # points to tag itself, so we need to dereference annotated tags.
+ # The output format is the same as `git show-ref --tags`, but with hashes
+ # of annotated tags pointing to tagged commits.
+ retcode, stdout, _ = self.run(
+ 'git', 'for-each-ref',
+ '--format="%(if)%(*objectname)%(then)%(*objectname)'
+ '%(else)%(objectname)%(end) %(refname)"',
+ 'refs/tags')
# error (or no tags found)
if retcode != 0:
return []
@@ -100,7 +108,7 @@
def parse_tags(self, data):
"""
- Parses output of show-ref --tags, eg:
+ Parses output of `git show-ref --tags`, eg:
3b32886c8d3cb815df3793b3937b2e91d0fb00f1 refs/tags/2.0.0
bd533a768ff661991a689d3758fcfe72f455435d refs/tags/2.0.1
| {"golden_diff": "diff --git a/readthedocs/vcs_support/backends/git.py b/readthedocs/vcs_support/backends/git.py\n--- a/readthedocs/vcs_support/backends/git.py\n+++ b/readthedocs/vcs_support/backends/git.py\n@@ -92,7 +92,15 @@\n \n @property\n def tags(self):\n- retcode, stdout, _ = self.run('git', 'show-ref', '--tags')\n+ # Hash for non-annotated tag is its commit hash, but for annotated tag it\n+ # points to tag itself, so we need to dereference annotated tags.\n+ # The output format is the same as `git show-ref --tags`, but with hashes\n+ # of annotated tags pointing to tagged commits.\n+ retcode, stdout, _ = self.run(\n+ 'git', 'for-each-ref',\n+ '--format=\"%(if)%(*objectname)%(then)%(*objectname)'\n+ '%(else)%(objectname)%(end) %(refname)\"',\n+ 'refs/tags')\n # error (or no tags found)\n if retcode != 0:\n return []\n@@ -100,7 +108,7 @@\n \n def parse_tags(self, data):\n \"\"\"\n- Parses output of show-ref --tags, eg:\n+ Parses output of `git show-ref --tags`, eg:\n \n 3b32886c8d3cb815df3793b3937b2e91d0fb00f1 refs/tags/2.0.0\n bd533a768ff661991a689d3758fcfe72f455435d refs/tags/2.0.1\n", "issue": "Broken edit links\nTwo issues which may or may not be related:\n- Module sources: the \"Edit on github\" links for pages like http://www.tornadoweb.org/en/stable/_modules/tornado/stack_context.html are broken; they point to a non-existent .rst file. Is it possible to suppress the edit link for these pages (or ideally point it to the real source)? (migrated from https://github.com/snide/sphinx_rtd_theme/issues/237)\n- Non-latest branches: on a page like http://www.tornadoweb.org/en/stable/, the \"edit on github\" link in the upper right is broken because it points to https://github.com/tornadoweb/tornado/blob/origin/stable/docs/index.rst (the 'origin' directory needs to be removed from the path). On the lower left, clicking \"v: stable\" for the menu and then \"Edit\" works (linking to https://github.com/tornadoweb/tornado/edit/stable/docs/index.rst).\n\nThe \"latest\" branch works fine (linking to \"master\"); this is only a problem for pages based on other branches (migrated from https://github.com/snide/sphinx_rtd_theme/issues/236)\n\n", "before_files": [{"content": "\"\"\"Git-related utilities.\"\"\"\n\nfrom __future__ import absolute_import\n\nimport csv\nimport logging\nimport os\nimport re\n\nfrom builtins import str\nfrom six import StringIO\n\nfrom readthedocs.projects.exceptions import ProjectImportError\nfrom readthedocs.vcs_support.base import BaseVCS, VCSVersion\n\n\nlog = logging.getLogger(__name__)\n\n\nclass Backend(BaseVCS):\n\n \"\"\"Git VCS backend.\"\"\"\n\n supports_tags = True\n supports_branches = True\n fallback_branch = 'master' # default branch\n\n def __init__(self, *args, **kwargs):\n super(Backend, self).__init__(*args, **kwargs)\n self.token = kwargs.get('token', None)\n self.repo_url = self._get_clone_url()\n\n def _get_clone_url(self):\n if '://' in self.repo_url:\n hacked_url = self.repo_url.split('://')[1]\n hacked_url = re.sub('.git$', '', hacked_url)\n clone_url = 'https://%s' % hacked_url\n if self.token:\n clone_url = 'https://%s@%s' % (self.token, hacked_url)\n return clone_url\n # Don't edit URL because all hosts aren't the same\n\n # else:\n # clone_url = 'git://%s' % (hacked_url)\n return self.repo_url\n\n def set_remote_url(self, url):\n return self.run('git', 'remote', 'set-url', 'origin', url)\n\n def update(self):\n # Use checkout() to update repo\n self.checkout()\n\n def repo_exists(self):\n code, _, _ = self.run('git', 'status')\n return code == 0\n\n def fetch(self):\n code, _, err = self.run('git', 'fetch', '--tags', '--prune')\n if code != 0:\n raise ProjectImportError(\n \"Failed to get code from '%s' (git fetch): %s\\n\\nStderr:\\n\\n%s\\n\\n\" % (\n self.repo_url, code, err)\n )\n\n def checkout_revision(self, revision=None):\n if not revision:\n branch = self.default_branch or self.fallback_branch\n revision = 'origin/%s' % branch\n\n code, out, err = self.run('git', 'checkout',\n '--force', '--quiet', revision)\n if code != 0:\n log.warning(\"Failed to checkout revision '%s': %s\",\n revision, code)\n return [code, out, err]\n\n def clone(self):\n code, _, err = self.run('git', 'clone', '--recursive', '--quiet',\n self.repo_url, '.')\n if code != 0:\n raise ProjectImportError(\n (\n \"Failed to get code from '{url}' (git clone): {exit}\\n\\n\"\n \"git clone error output: {sterr}\"\n ).format(\n url=self.repo_url,\n exit=code,\n sterr=err\n )\n )\n\n @property\n def tags(self):\n retcode, stdout, _ = self.run('git', 'show-ref', '--tags')\n # error (or no tags found)\n if retcode != 0:\n return []\n return self.parse_tags(stdout)\n\n def parse_tags(self, data):\n \"\"\"\n Parses output of show-ref --tags, eg:\n\n 3b32886c8d3cb815df3793b3937b2e91d0fb00f1 refs/tags/2.0.0\n bd533a768ff661991a689d3758fcfe72f455435d refs/tags/2.0.1\n c0288a17899b2c6818f74e3a90b77e2a1779f96a refs/tags/2.0.2\n a63a2de628a3ce89034b7d1a5ca5e8159534eef0 refs/tags/2.1.0.beta2\n c7fc3d16ed9dc0b19f0d27583ca661a64562d21e refs/tags/2.1.0.rc1\n edc0a2d02a0cc8eae8b67a3a275f65cd126c05b1 refs/tags/2.1.0.rc2\n\n Into VCSTag objects with the tag name as verbose_name and the commit\n hash as identifier.\n \"\"\"\n # parse the lines into a list of tuples (commit-hash, tag ref name)\n # StringIO below is expecting Unicode data, so ensure that it gets it.\n if not isinstance(data, str):\n data = str(data)\n raw_tags = csv.reader(StringIO(data), delimiter=' ')\n vcs_tags = []\n for row in raw_tags:\n row = [f for f in row if f != '']\n if row == []:\n continue\n commit_hash, name = row\n clean_name = name.split('/')[-1]\n vcs_tags.append(VCSVersion(self, commit_hash, clean_name))\n return vcs_tags\n\n @property\n def branches(self):\n # Only show remote branches\n retcode, stdout, _ = self.run('git', 'branch', '-r')\n # error (or no tags found)\n if retcode != 0:\n return []\n return self.parse_branches(stdout)\n\n def parse_branches(self, data):\n \"\"\"\n Parse output of git branch -r\n\n e.g.:\n\n origin/2.0.X\n origin/HEAD -> origin/master\n origin/develop\n origin/master\n origin/release/2.0.0\n origin/release/2.1.0\n \"\"\"\n clean_branches = []\n # StringIO below is expecting Unicode data, so ensure that it gets it.\n if not isinstance(data, str):\n data = str(data)\n raw_branches = csv.reader(StringIO(data), delimiter=' ')\n for branch in raw_branches:\n branch = [f for f in branch if f != '' and f != '*']\n # Handle empty branches\n if branch:\n branch = branch[0]\n if branch.startswith('origin/'):\n cut_len = len('origin/')\n slug = branch[cut_len:].replace('/', '-')\n if slug in ['HEAD']:\n continue\n clean_branches.append(VCSVersion(self, branch, slug))\n else:\n # Believe this is dead code.\n slug = branch.replace('/', '-')\n clean_branches.append(VCSVersion(self, branch, slug))\n return clean_branches\n\n @property\n def commit(self):\n _, stdout, _ = self.run('git', 'rev-parse', 'HEAD')\n return stdout.strip()\n\n def checkout(self, identifier=None):\n self.check_working_dir()\n\n # Clone or update repository\n if self.repo_exists():\n self.set_remote_url(self.repo_url)\n self.fetch()\n else:\n self.make_clean_working_dir()\n self.clone()\n\n # Find proper identifier\n if not identifier:\n identifier = self.default_branch or self.fallback_branch\n\n identifier = self.find_ref(identifier)\n\n # Checkout the correct identifier for this branch.\n code, out, err = self.checkout_revision(identifier)\n if code != 0:\n return code, out, err\n\n # Clean any remains of previous checkouts\n self.run('git', 'clean', '-d', '-f', '-f')\n\n # Update submodules\n self.run('git', 'submodule', 'sync')\n self.run('git', 'submodule', 'update',\n '--init', '--recursive', '--force')\n\n return code, out, err\n\n def find_ref(self, ref):\n # Check if ref starts with 'origin/'\n if ref.startswith('origin/'):\n return ref\n\n # Check if ref is a branch of the origin remote\n if self.ref_exists('remotes/origin/' + ref):\n return 'origin/' + ref\n\n return ref\n\n def ref_exists(self, ref):\n code, _, _ = self.run('git', 'show-ref', ref)\n return code == 0\n\n @property\n def env(self):\n env = super(Backend, self).env\n env['GIT_DIR'] = os.path.join(self.working_dir, '.git')\n return env\n", "path": "readthedocs/vcs_support/backends/git.py"}]} | 3,287 | 398 |
gh_patches_debug_8880 | rasdani/github-patches | git_diff | liqd__a4-product-606 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
can't see full time when creating an event on small screen

</issue>
<code>
[start of liqd_product/apps/actions/apps.py]
1 from django.apps import AppConfig
2
3
4 class Config(AppConfig):
5 name = 'liqd_product.apps.actions'
6 label = 'liqd_product_actions'
7
8 def ready(self):
9 from adhocracy4.actions.models import configure_icon
10 from adhocracy4.actions.models import configure_type
11 from adhocracy4.actions.verbs import Verbs
12 configure_type(
13 'project',
14 ('a4projects', 'project')
15 )
16 configure_type(
17 'phase',
18 ('a4phases', 'phase')
19 )
20 configure_type(
21 'comment',
22 ('a4comments', 'comment')
23 )
24 configure_type(
25 'rating',
26 ('a4ratings', 'rating')
27 )
28 configure_type(
29 'item',
30 ('liqd_product_budgeting', 'proposal'),
31 ('liqd_product_ideas', 'idea'),
32 ('liqd_product_mapideas', 'mapidea')
33 )
34
35 configure_icon('far fa-comment', type='comment')
36 configure_icon('far fa-lightbulb', type='item')
37 configure_icon('fas fa-plus', verb=Verbs.ADD)
38 configure_icon('fas fa-pencil-alt', verb=Verbs.UPDATE)
39 configure_icon('fas fa-flag', verb=Verbs.START)
40 configure_icon('far fa-clock', verb=Verbs.SCHEDULE)
41
[end of liqd_product/apps/actions/apps.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/liqd_product/apps/actions/apps.py b/liqd_product/apps/actions/apps.py
--- a/liqd_product/apps/actions/apps.py
+++ b/liqd_product/apps/actions/apps.py
@@ -35,6 +35,6 @@
configure_icon('far fa-comment', type='comment')
configure_icon('far fa-lightbulb', type='item')
configure_icon('fas fa-plus', verb=Verbs.ADD)
- configure_icon('fas fa-pencil-alt', verb=Verbs.UPDATE)
+ configure_icon('fas fa-pencil', verb=Verbs.UPDATE)
configure_icon('fas fa-flag', verb=Verbs.START)
- configure_icon('far fa-clock', verb=Verbs.SCHEDULE)
+ configure_icon('far fa-clock-o', verb=Verbs.SCHEDULE)
| {"golden_diff": "diff --git a/liqd_product/apps/actions/apps.py b/liqd_product/apps/actions/apps.py\n--- a/liqd_product/apps/actions/apps.py\n+++ b/liqd_product/apps/actions/apps.py\n@@ -35,6 +35,6 @@\n configure_icon('far fa-comment', type='comment')\n configure_icon('far fa-lightbulb', type='item')\n configure_icon('fas fa-plus', verb=Verbs.ADD)\n- configure_icon('fas fa-pencil-alt', verb=Verbs.UPDATE)\n+ configure_icon('fas fa-pencil', verb=Verbs.UPDATE)\n configure_icon('fas fa-flag', verb=Verbs.START)\n- configure_icon('far fa-clock', verb=Verbs.SCHEDULE)\n+ configure_icon('far fa-clock-o', verb=Verbs.SCHEDULE)\n", "issue": "can't see full time when creating an event on small screen\n\r\n\n", "before_files": [{"content": "from django.apps import AppConfig\n\n\nclass Config(AppConfig):\n name = 'liqd_product.apps.actions'\n label = 'liqd_product_actions'\n\n def ready(self):\n from adhocracy4.actions.models import configure_icon\n from adhocracy4.actions.models import configure_type\n from adhocracy4.actions.verbs import Verbs\n configure_type(\n 'project',\n ('a4projects', 'project')\n )\n configure_type(\n 'phase',\n ('a4phases', 'phase')\n )\n configure_type(\n 'comment',\n ('a4comments', 'comment')\n )\n configure_type(\n 'rating',\n ('a4ratings', 'rating')\n )\n configure_type(\n 'item',\n ('liqd_product_budgeting', 'proposal'),\n ('liqd_product_ideas', 'idea'),\n ('liqd_product_mapideas', 'mapidea')\n )\n\n configure_icon('far fa-comment', type='comment')\n configure_icon('far fa-lightbulb', type='item')\n configure_icon('fas fa-plus', verb=Verbs.ADD)\n configure_icon('fas fa-pencil-alt', verb=Verbs.UPDATE)\n configure_icon('fas fa-flag', verb=Verbs.START)\n configure_icon('far fa-clock', verb=Verbs.SCHEDULE)\n", "path": "liqd_product/apps/actions/apps.py"}]} | 995 | 170 |
gh_patches_debug_40709 | rasdani/github-patches | git_diff | getredash__redash-604 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
"'float' object is not iterable" when using coordinates for MongoDB query
I'm trying to run a query using **MongoDB** and the **[$geoNear](http://docs.mongodb.org/manual/reference/operator/aggregation/geoNear/)** function, but every time I type the origin coordinate using floats (to create a [GeoJSON Point](http://docs.mongodb.org/manual/reference/geojson/)), I get an error: [_from Python?_]
`Error running query: 'float' object is not iterable`
I'm trying to run the query below. The problem here is the `[ -22.910079, -43.205161 ]` part.
``` json
{
"collection": "bus",
"aggregate": [
{
"$geoNear": {
"near": { "type": "Point", "coordinates": [ -22.910079, -43.205161 ] },
"maxDistance": 100000000,
"distanceField": "dist.calculated",
"includeLocs": "dist.location",
"spherical": true
}
}
]
}
```
However, if I use the coordinates with integers, such as `[ -22, -43 ]`, the query runs fine, but this coordinate is now meaningless, obviously. Here is an example that doesn't error:
``` json
{
"collection": "bus",
"aggregate": [
{
"$geoNear": {
"near": { "type": "Point", "coordinates": [ -22, -43 ] },
"maxDistance": 100000000,
"distanceField": "dist.calculated",
"includeLocs": "dist.location",
"spherical": true
}
}
]
}
```
</issue>
<code>
[start of redash/query_runner/mongodb.py]
1 import json
2 import datetime
3 import logging
4 import re
5 from dateutil.parser import parse
6
7 from redash.utils import JSONEncoder
8 from redash.query_runner import *
9
10 logger = logging.getLogger(__name__)
11
12 try:
13 import pymongo
14 from bson.objectid import ObjectId
15 from bson.son import SON
16 enabled = True
17
18 except ImportError:
19 enabled = False
20
21
22 TYPES_MAP = {
23 str: TYPE_STRING,
24 unicode: TYPE_STRING,
25 int: TYPE_INTEGER,
26 long: TYPE_INTEGER,
27 float: TYPE_FLOAT,
28 bool: TYPE_BOOLEAN,
29 datetime.datetime: TYPE_DATETIME,
30 }
31
32 date_regex = re.compile("ISODate\(\"(.*)\"\)", re.IGNORECASE)
33
34 class MongoDBJSONEncoder(JSONEncoder):
35 def default(self, o):
36 if isinstance(o, ObjectId):
37 return str(o)
38
39 return super(MongoDBJSONEncoder, self).default(o)
40
41 # Simple query example:
42 #
43 # {
44 # "collection" : "my_collection",
45 # "query" : {
46 # "date" : {
47 # "$gt" : "ISODate(\"2015-01-15 11:41\")",
48 # },
49 # "type" : 1
50 # },
51 # "fields" : {
52 # "_id" : 1,
53 # "name" : 2
54 # },
55 # "sort" : [
56 # {
57 # "name" : "date",
58 # "direction" : -1
59 # }
60 # ]
61 #
62 # }
63 #
64 #
65 # Aggregation
66 # ===========
67 # Uses a syntax similar to the one used in PyMongo, however to support the
68 # correct order of sorting, it uses a regular list for the "$sort" operation
69 # that converts into a SON (sorted dictionary) object before execution.
70 #
71 # Aggregation query example:
72 #
73 # {
74 # "collection" : "things",
75 # "aggregate" : [
76 # {
77 # "$unwind" : "$tags"
78 # },
79 # {
80 # "$group" : {
81 # "_id" : "$tags",
82 # "count" : { "$sum" : 1 }
83 # }
84 # },
85 # {
86 # "$sort" : [
87 # {
88 # "name" : "count",
89 # "direction" : -1
90 # },
91 # {
92 # "name" : "_id",
93 # "direction" : -1
94 # }
95 # ]
96 # }
97 # ]
98 # }
99 #
100 #
101 class MongoDB(BaseQueryRunner):
102 @classmethod
103 def configuration_schema(cls):
104 return {
105 'type': 'object',
106 'properties': {
107 'connectionString': {
108 'type': 'string',
109 'title': 'Connection String'
110 },
111 'dbName': {
112 'type': 'string',
113 'title': "Database Name"
114 },
115 'replicaSetName': {
116 'type': 'string',
117 'title': 'Replica Set Name'
118 },
119 },
120 'required': ['connectionString']
121 }
122
123 @classmethod
124 def enabled(cls):
125 return enabled
126
127 @classmethod
128 def annotate_query(cls):
129 return False
130
131 def __init__(self, configuration_json):
132 super(MongoDB, self).__init__(configuration_json)
133
134 self.syntax = 'json'
135
136 self.db_name = self.configuration["dbName"]
137
138 self.is_replica_set = True if "replicaSetName" in self.configuration and self.configuration["replicaSetName"] else False
139
140 def _get_column_by_name(self, columns, column_name):
141 for c in columns:
142 if "name" in c and c["name"] == column_name:
143 return c
144
145 return None
146
147 def _fix_dates(self, data):
148 for k in data:
149 if isinstance(data[k], list):
150 for i in range(0, len(data[k])):
151 if isinstance(data[k][i], (str, unicode)):
152 self._convert_date(data[k], i)
153 elif not isinstance(data[k][i], (int)):
154 self._fix_dates(data[k][i])
155
156 elif isinstance(data[k], dict):
157 self._fix_dates(data[k])
158 else:
159 if isinstance(data[k], (str, unicode)):
160 self._convert_date(data, k)
161
162 def _convert_date(self, q, field_name):
163 m = date_regex.findall(q[field_name])
164 if len(m) > 0:
165 q[field_name] = parse(m[0], yearfirst=True)
166
167 def run_query(self, query):
168 if self.is_replica_set:
169 db_connection = pymongo.MongoReplicaSetClient(self.configuration["connectionString"], replicaSet=self.configuration["replicaSetName"])
170 else:
171 db_connection = pymongo.MongoClient(self.configuration["connectionString"])
172
173 db = db_connection[self.db_name]
174
175 logger.debug("mongodb connection string: %s", self.configuration['connectionString'])
176 logger.debug("mongodb got query: %s", query)
177
178 try:
179 query_data = json.loads(query)
180 self._fix_dates(query_data)
181 except ValueError:
182 return None, "Invalid query format. The query is not a valid JSON."
183
184 if "collection" not in query_data:
185 return None, "'collection' must have a value to run a query"
186 else:
187 collection = query_data["collection"]
188
189 q = query_data.get("query", None)
190 f = None
191
192 aggregate = query_data.get("aggregate", None)
193 if aggregate:
194 for step in aggregate:
195 if "$sort" in step:
196 sort_list = []
197 for sort_item in step["$sort"]:
198 sort_list.append((sort_item["name"], sort_item["direction"]))
199
200 step["$sort"] = SON(sort_list)
201
202 if not aggregate:
203 s = None
204 if "sort" in query_data and query_data["sort"]:
205 s = []
206 for field in query_data["sort"]:
207 s.append((field["name"], field["direction"]))
208
209 if "fields" in query_data:
210 f = query_data["fields"]
211
212 s = None
213 if "sort" in query_data and query_data["sort"]:
214 s = []
215 for field_data in query_data["sort"]:
216 s.append((field_data["name"], field_data["direction"]))
217
218 columns = []
219 rows = []
220
221 cursor = None
222 if q or (not q and not aggregate):
223 if s:
224 cursor = db[collection].find(q, f).sort(s)
225 else:
226 cursor = db[collection].find(q, f)
227
228 if "skip" in query_data:
229 cursor = cursor.skip(query_data["skip"])
230
231 if "limit" in query_data:
232 cursor = cursor.limit(query_data["limit"])
233
234 elif aggregate:
235 r = db[collection].aggregate(aggregate)
236
237 # Backwards compatibility with older pymongo versions.
238 #
239 # Older pymongo version would return a dictionary from an aggregate command.
240 # The dict would contain a "result" key which would hold the cursor.
241 # Newer ones return pymongo.command_cursor.CommandCursor.
242 if isinstance(r, dict):
243 cursor = r["result"]
244 else:
245 cursor = r
246
247 for r in cursor:
248 for k in r:
249 if self._get_column_by_name(columns, k) is None:
250 columns.append({
251 "name": k,
252 "friendly_name": k,
253 "type": TYPES_MAP.get(type(r[k]), TYPE_STRING)
254 })
255
256 rows.append(r)
257
258 if f:
259 ordered_columns = []
260 for k in sorted(f, key=f.get):
261 ordered_columns.append(self._get_column_by_name(columns, k))
262
263 columns = ordered_columns
264
265 data = {
266 "columns": columns,
267 "rows": rows
268 }
269 error = None
270 json_data = json.dumps(data, cls=MongoDBJSONEncoder)
271
272 return json_data, error
273
274 register(MongoDB)
275
[end of redash/query_runner/mongodb.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/redash/query_runner/mongodb.py b/redash/query_runner/mongodb.py
--- a/redash/query_runner/mongodb.py
+++ b/redash/query_runner/mongodb.py
@@ -29,7 +29,6 @@
datetime.datetime: TYPE_DATETIME,
}
-date_regex = re.compile("ISODate\(\"(.*)\"\)", re.IGNORECASE)
class MongoDBJSONEncoder(JSONEncoder):
def default(self, o):
@@ -38,66 +37,25 @@
return super(MongoDBJSONEncoder, self).default(o)
-# Simple query example:
-#
-# {
-# "collection" : "my_collection",
-# "query" : {
-# "date" : {
-# "$gt" : "ISODate(\"2015-01-15 11:41\")",
-# },
-# "type" : 1
-# },
-# "fields" : {
-# "_id" : 1,
-# "name" : 2
-# },
-# "sort" : [
-# {
-# "name" : "date",
-# "direction" : -1
-# }
-# ]
-#
-# }
-#
-#
-# Aggregation
-# ===========
-# Uses a syntax similar to the one used in PyMongo, however to support the
-# correct order of sorting, it uses a regular list for the "$sort" operation
-# that converts into a SON (sorted dictionary) object before execution.
-#
-# Aggregation query example:
-#
-# {
-# "collection" : "things",
-# "aggregate" : [
-# {
-# "$unwind" : "$tags"
-# },
-# {
-# "$group" : {
-# "_id" : "$tags",
-# "count" : { "$sum" : 1 }
-# }
-# },
-# {
-# "$sort" : [
-# {
-# "name" : "count",
-# "direction" : -1
-# },
-# {
-# "name" : "_id",
-# "direction" : -1
-# }
-# ]
-# }
-# ]
-# }
-#
-#
+
+date_regex = re.compile("ISODate\(\"(.*)\"\)", re.IGNORECASE)
+
+
+def datetime_parser(dct):
+ for k, v in dct.iteritems():
+ if isinstance(v, basestring):
+ m = date_regex.findall(v)
+ if len(m) > 0:
+ dct[k] = parse(m[0], yearfirst=True)
+
+ return dct
+
+
+def parse_query_json(query):
+ query_data = json.loads(query, object_hook=datetime_parser)
+ return query_data
+
+
class MongoDB(BaseQueryRunner):
@classmethod
def configuration_schema(cls):
@@ -144,25 +102,6 @@
return None
- def _fix_dates(self, data):
- for k in data:
- if isinstance(data[k], list):
- for i in range(0, len(data[k])):
- if isinstance(data[k][i], (str, unicode)):
- self._convert_date(data[k], i)
- elif not isinstance(data[k][i], (int)):
- self._fix_dates(data[k][i])
-
- elif isinstance(data[k], dict):
- self._fix_dates(data[k])
- else:
- if isinstance(data[k], (str, unicode)):
- self._convert_date(data, k)
-
- def _convert_date(self, q, field_name):
- m = date_regex.findall(q[field_name])
- if len(m) > 0:
- q[field_name] = parse(m[0], yearfirst=True)
def run_query(self, query):
if self.is_replica_set:
@@ -176,8 +115,7 @@
logger.debug("mongodb got query: %s", query)
try:
- query_data = json.loads(query)
- self._fix_dates(query_data)
+ query_data = parse_query_json(query)
except ValueError:
return None, "Invalid query format. The query is not a valid JSON."
| {"golden_diff": "diff --git a/redash/query_runner/mongodb.py b/redash/query_runner/mongodb.py\n--- a/redash/query_runner/mongodb.py\n+++ b/redash/query_runner/mongodb.py\n@@ -29,7 +29,6 @@\n datetime.datetime: TYPE_DATETIME,\n }\n \n-date_regex = re.compile(\"ISODate\\(\\\"(.*)\\\"\\)\", re.IGNORECASE)\n \n class MongoDBJSONEncoder(JSONEncoder):\n def default(self, o):\n@@ -38,66 +37,25 @@\n \n return super(MongoDBJSONEncoder, self).default(o)\n \n-# Simple query example:\n-#\n-# {\n-# \"collection\" : \"my_collection\",\n-# \"query\" : {\n-# \"date\" : {\n-# \"$gt\" : \"ISODate(\\\"2015-01-15 11:41\\\")\",\n-# },\n-# \"type\" : 1\n-# },\n-# \"fields\" : {\n-# \"_id\" : 1,\n-# \"name\" : 2\n-# },\n-# \"sort\" : [\n-# {\n-# \"name\" : \"date\",\n-# \"direction\" : -1\n-# }\n-# ]\n-#\n-# }\n-#\n-#\n-# Aggregation\n-# ===========\n-# Uses a syntax similar to the one used in PyMongo, however to support the\n-# correct order of sorting, it uses a regular list for the \"$sort\" operation\n-# that converts into a SON (sorted dictionary) object before execution.\n-#\n-# Aggregation query example:\n-#\n-# {\n-# \"collection\" : \"things\",\n-# \"aggregate\" : [\n-# {\n-# \"$unwind\" : \"$tags\"\n-# },\n-# {\n-# \"$group\" : {\n-# \"_id\" : \"$tags\",\n-# \"count\" : { \"$sum\" : 1 }\n-# }\n-# },\n-# {\n-# \"$sort\" : [\n-# {\n-# \"name\" : \"count\",\n-# \"direction\" : -1\n-# },\n-# {\n-# \"name\" : \"_id\",\n-# \"direction\" : -1\n-# }\n-# ]\n-# }\n-# ]\n-# }\n-#\n-#\n+\n+date_regex = re.compile(\"ISODate\\(\\\"(.*)\\\"\\)\", re.IGNORECASE)\n+\n+\n+def datetime_parser(dct):\n+ for k, v in dct.iteritems():\n+ if isinstance(v, basestring):\n+ m = date_regex.findall(v)\n+ if len(m) > 0:\n+ dct[k] = parse(m[0], yearfirst=True)\n+\n+ return dct\n+\n+\n+def parse_query_json(query):\n+ query_data = json.loads(query, object_hook=datetime_parser)\n+ return query_data\n+\n+\n class MongoDB(BaseQueryRunner):\n @classmethod\n def configuration_schema(cls):\n@@ -144,25 +102,6 @@\n \n return None\n \n- def _fix_dates(self, data):\n- for k in data:\n- if isinstance(data[k], list):\n- for i in range(0, len(data[k])):\n- if isinstance(data[k][i], (str, unicode)):\n- self._convert_date(data[k], i)\n- elif not isinstance(data[k][i], (int)):\n- self._fix_dates(data[k][i])\n-\n- elif isinstance(data[k], dict):\n- self._fix_dates(data[k])\n- else:\n- if isinstance(data[k], (str, unicode)):\n- self._convert_date(data, k)\n-\n- def _convert_date(self, q, field_name):\n- m = date_regex.findall(q[field_name])\n- if len(m) > 0:\n- q[field_name] = parse(m[0], yearfirst=True)\n \n def run_query(self, query):\n if self.is_replica_set:\n@@ -176,8 +115,7 @@\n logger.debug(\"mongodb got query: %s\", query)\n \n try:\n- query_data = json.loads(query)\n- self._fix_dates(query_data)\n+ query_data = parse_query_json(query)\n except ValueError:\n return None, \"Invalid query format. The query is not a valid JSON.\"\n", "issue": "\"'float' object is not iterable\" when using coordinates for MongoDB query\nI'm trying to run a query using **MongoDB** and the **[$geoNear](http://docs.mongodb.org/manual/reference/operator/aggregation/geoNear/)** function, but every time I type the origin coordinate using floats (to create a [GeoJSON Point](http://docs.mongodb.org/manual/reference/geojson/)), I get an error: [_from Python?_]\n\n `Error running query: 'float' object is not iterable`\n\nI'm trying to run the query below. The problem here is the `[ -22.910079, -43.205161 ]` part.\n\n``` json\n{\n \"collection\": \"bus\",\n \"aggregate\": [\n { \n \"$geoNear\": { \n \"near\": { \"type\": \"Point\", \"coordinates\": [ -22.910079, -43.205161 ] },\n \"maxDistance\": 100000000,\n \"distanceField\": \"dist.calculated\",\n \"includeLocs\": \"dist.location\",\n \"spherical\": true\n }\n } \n ]\n}\n```\n\nHowever, if I use the coordinates with integers, such as `[ -22, -43 ]`, the query runs fine, but this coordinate is now meaningless, obviously. Here is an example that doesn't error:\n\n``` json\n{\n \"collection\": \"bus\",\n \"aggregate\": [\n { \n \"$geoNear\": { \n \"near\": { \"type\": \"Point\", \"coordinates\": [ -22, -43 ] },\n \"maxDistance\": 100000000,\n \"distanceField\": \"dist.calculated\",\n \"includeLocs\": \"dist.location\",\n \"spherical\": true\n }\n } \n ]\n}\n```\n\n", "before_files": [{"content": "import json\nimport datetime\nimport logging\nimport re\nfrom dateutil.parser import parse\n\nfrom redash.utils import JSONEncoder\nfrom redash.query_runner import *\n\nlogger = logging.getLogger(__name__)\n\ntry:\n import pymongo\n from bson.objectid import ObjectId\n from bson.son import SON\n enabled = True\n\nexcept ImportError:\n enabled = False\n\n\nTYPES_MAP = {\n str: TYPE_STRING,\n unicode: TYPE_STRING,\n int: TYPE_INTEGER,\n long: TYPE_INTEGER,\n float: TYPE_FLOAT,\n bool: TYPE_BOOLEAN,\n datetime.datetime: TYPE_DATETIME,\n}\n\ndate_regex = re.compile(\"ISODate\\(\\\"(.*)\\\"\\)\", re.IGNORECASE)\n\nclass MongoDBJSONEncoder(JSONEncoder):\n def default(self, o):\n if isinstance(o, ObjectId):\n return str(o)\n\n return super(MongoDBJSONEncoder, self).default(o)\n\n# Simple query example:\n#\n# {\n# \"collection\" : \"my_collection\",\n# \"query\" : {\n# \"date\" : {\n# \"$gt\" : \"ISODate(\\\"2015-01-15 11:41\\\")\",\n# },\n# \"type\" : 1\n# },\n# \"fields\" : {\n# \"_id\" : 1,\n# \"name\" : 2\n# },\n# \"sort\" : [\n# {\n# \"name\" : \"date\",\n# \"direction\" : -1\n# }\n# ]\n#\n# }\n#\n#\n# Aggregation\n# ===========\n# Uses a syntax similar to the one used in PyMongo, however to support the\n# correct order of sorting, it uses a regular list for the \"$sort\" operation\n# that converts into a SON (sorted dictionary) object before execution.\n#\n# Aggregation query example:\n#\n# {\n# \"collection\" : \"things\",\n# \"aggregate\" : [\n# {\n# \"$unwind\" : \"$tags\"\n# },\n# {\n# \"$group\" : {\n# \"_id\" : \"$tags\",\n# \"count\" : { \"$sum\" : 1 }\n# }\n# },\n# {\n# \"$sort\" : [\n# {\n# \"name\" : \"count\",\n# \"direction\" : -1\n# },\n# {\n# \"name\" : \"_id\",\n# \"direction\" : -1\n# }\n# ]\n# }\n# ]\n# }\n#\n#\nclass MongoDB(BaseQueryRunner):\n @classmethod\n def configuration_schema(cls):\n return {\n 'type': 'object',\n 'properties': {\n 'connectionString': {\n 'type': 'string',\n 'title': 'Connection String'\n },\n 'dbName': {\n 'type': 'string',\n 'title': \"Database Name\"\n },\n 'replicaSetName': {\n 'type': 'string',\n 'title': 'Replica Set Name'\n },\n },\n 'required': ['connectionString']\n }\n\n @classmethod\n def enabled(cls):\n return enabled\n\n @classmethod\n def annotate_query(cls):\n return False\n\n def __init__(self, configuration_json):\n super(MongoDB, self).__init__(configuration_json)\n\n self.syntax = 'json'\n\n self.db_name = self.configuration[\"dbName\"]\n\n self.is_replica_set = True if \"replicaSetName\" in self.configuration and self.configuration[\"replicaSetName\"] else False\n\n def _get_column_by_name(self, columns, column_name):\n for c in columns:\n if \"name\" in c and c[\"name\"] == column_name:\n return c\n\n return None\n\n def _fix_dates(self, data):\n for k in data:\n if isinstance(data[k], list):\n for i in range(0, len(data[k])):\n if isinstance(data[k][i], (str, unicode)):\n self._convert_date(data[k], i)\n elif not isinstance(data[k][i], (int)):\n self._fix_dates(data[k][i])\n\n elif isinstance(data[k], dict):\n self._fix_dates(data[k])\n else:\n if isinstance(data[k], (str, unicode)):\n self._convert_date(data, k)\n\n def _convert_date(self, q, field_name):\n m = date_regex.findall(q[field_name])\n if len(m) > 0:\n q[field_name] = parse(m[0], yearfirst=True)\n\n def run_query(self, query):\n if self.is_replica_set:\n db_connection = pymongo.MongoReplicaSetClient(self.configuration[\"connectionString\"], replicaSet=self.configuration[\"replicaSetName\"])\n else:\n db_connection = pymongo.MongoClient(self.configuration[\"connectionString\"])\n\n db = db_connection[self.db_name]\n\n logger.debug(\"mongodb connection string: %s\", self.configuration['connectionString'])\n logger.debug(\"mongodb got query: %s\", query)\n\n try:\n query_data = json.loads(query)\n self._fix_dates(query_data)\n except ValueError:\n return None, \"Invalid query format. The query is not a valid JSON.\"\n\n if \"collection\" not in query_data:\n return None, \"'collection' must have a value to run a query\"\n else:\n collection = query_data[\"collection\"]\n\n q = query_data.get(\"query\", None)\n f = None\n\n aggregate = query_data.get(\"aggregate\", None)\n if aggregate:\n for step in aggregate:\n if \"$sort\" in step:\n sort_list = []\n for sort_item in step[\"$sort\"]:\n sort_list.append((sort_item[\"name\"], sort_item[\"direction\"]))\n\n step[\"$sort\"] = SON(sort_list)\n\n if not aggregate:\n s = None\n if \"sort\" in query_data and query_data[\"sort\"]:\n s = []\n for field in query_data[\"sort\"]:\n s.append((field[\"name\"], field[\"direction\"]))\n\n if \"fields\" in query_data:\n f = query_data[\"fields\"]\n\n s = None\n if \"sort\" in query_data and query_data[\"sort\"]:\n s = []\n for field_data in query_data[\"sort\"]:\n s.append((field_data[\"name\"], field_data[\"direction\"]))\n\n columns = []\n rows = []\n\n cursor = None\n if q or (not q and not aggregate):\n if s:\n cursor = db[collection].find(q, f).sort(s)\n else:\n cursor = db[collection].find(q, f)\n\n if \"skip\" in query_data:\n cursor = cursor.skip(query_data[\"skip\"])\n\n if \"limit\" in query_data:\n cursor = cursor.limit(query_data[\"limit\"])\n\n elif aggregate:\n r = db[collection].aggregate(aggregate)\n\n # Backwards compatibility with older pymongo versions.\n #\n # Older pymongo version would return a dictionary from an aggregate command.\n # The dict would contain a \"result\" key which would hold the cursor.\n # Newer ones return pymongo.command_cursor.CommandCursor.\n if isinstance(r, dict):\n cursor = r[\"result\"]\n else:\n cursor = r\n\n for r in cursor:\n for k in r:\n if self._get_column_by_name(columns, k) is None:\n columns.append({\n \"name\": k,\n \"friendly_name\": k,\n \"type\": TYPES_MAP.get(type(r[k]), TYPE_STRING)\n })\n\n rows.append(r)\n\n if f:\n ordered_columns = []\n for k in sorted(f, key=f.get):\n ordered_columns.append(self._get_column_by_name(columns, k))\n\n columns = ordered_columns\n\n data = {\n \"columns\": columns,\n \"rows\": rows\n }\n error = None\n json_data = json.dumps(data, cls=MongoDBJSONEncoder)\n\n return json_data, error\n\nregister(MongoDB)\n", "path": "redash/query_runner/mongodb.py"}]} | 3,376 | 972 |
gh_patches_debug_35338 | rasdani/github-patches | git_diff | joke2k__faker-270 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
some generated UK postcodes are invalid
UK postcodes follow strict rules and there are a limited set of codes for each part of the postcode. Faker does not know about these rules and generates postcodes such as: `XC9E 1FL` and `U93 2ZU` which are invalid. See e.g. https://github.com/hamstah/ukpostcodeparser for more info.
</issue>
<code>
[start of faker/providers/address/en_GB/__init__.py]
1 from __future__ import unicode_literals
2 from ..en import Provider as AddressProvider
3
4
5 class Provider(AddressProvider):
6 city_prefixes = ('North', 'East', 'West', 'South', 'New', 'Lake', 'Port')
7 city_suffixes = (
8 'town', 'ton', 'land', 'ville', 'berg', 'burgh', 'borough', 'bury', 'view', 'port', 'mouth', 'stad', 'furt',
9 'chester', 'mouth', 'fort', 'haven', 'side', 'shire')
10 building_number_formats = ('#', '##', '###')
11 street_suffixes = (
12 'alley', 'avenue', 'branch', 'bridge', 'brook', 'brooks', 'burg', 'burgs', 'bypass', 'camp', 'canyon', 'cape',
13 'causeway', 'center', 'centers', 'circle', 'circles', 'cliff', 'cliffs', 'club', 'common', 'corner', 'corners',
14 'course', 'court', 'courts', 'cove', 'coves', 'creek', 'crescent', 'crest', 'crossing', 'crossroad', 'curve',
15 'dale', 'dam', 'divide', 'drive', 'drive', 'drives', 'estate', 'estates', 'expressway', 'extension',
16 'extensions',
17 'fall', 'falls', 'ferry', 'field', 'fields', 'flat', 'flats', 'ford', 'fords', 'forest', 'forge', 'forges',
18 'fork',
19 'forks', 'fort', 'freeway', 'garden', 'gardens', 'gateway', 'glen', 'glens', 'green', 'greens', 'grove',
20 'groves',
21 'harbor', 'harbors', 'haven', 'heights', 'highway', 'hill', 'hills', 'hollow', 'inlet', 'inlet', 'island',
22 'island',
23 'islands', 'islands', 'isle', 'isle', 'junction', 'junctions', 'key', 'keys', 'knoll', 'knolls', 'lake',
24 'lakes',
25 'land', 'landing', 'lane', 'light', 'lights', 'loaf', 'lock', 'locks', 'locks', 'lodge', 'lodge', 'loop',
26 'mall',
27 'manor', 'manors', 'meadow', 'meadows', 'mews', 'mill', 'mills', 'mission', 'mission', 'motorway', 'mount',
28 'mountain', 'mountain', 'mountains', 'mountains', 'neck', 'orchard', 'oval', 'overpass', 'park', 'parks',
29 'parkway',
30 'parkways', 'pass', 'passage', 'path', 'pike', 'pine', 'pines', 'place', 'plain', 'plains', 'plains', 'plaza',
31 'plaza', 'point', 'points', 'port', 'port', 'ports', 'ports', 'prairie', 'prairie', 'radial', 'ramp', 'ranch',
32 'rapid', 'rapids', 'rest', 'ridge', 'ridges', 'river', 'road', 'road', 'roads', 'roads', 'route', 'row', 'rue',
33 'run', 'shoal', 'shoals', 'shore', 'shores', 'skyway', 'spring', 'springs', 'springs', 'spur', 'spurs',
34 'square',
35 'square', 'squares', 'squares', 'station', 'station', 'stravenue', 'stravenue', 'stream', 'stream', 'street',
36 'street', 'streets', 'summit', 'summit', 'terrace', 'throughway', 'trace', 'track', 'trafficway', 'trail',
37 'trail',
38 'tunnel', 'tunnel', 'turnpike', 'turnpike', 'underpass', 'union', 'unions', 'valley', 'valleys', 'via',
39 'viaduct',
40 'view', 'views', 'village', 'village', 'villages', 'ville', 'vista', 'vista', 'walk', 'walks', 'wall', 'way',
41 'ways', 'well', 'wells')
42
43 postcode_formats = ('??#? #??', '?#? #??', '?# #??', '?## #??', '??# #??', '??## #??',)
44
45 city_formats = (
46 '{{city_prefix}} {{first_name}}{{city_suffix}}',
47 '{{city_prefix}} {{first_name}}',
48 '{{first_name}}{{city_suffix}}',
49 '{{last_name}}{{city_suffix}}',
50 )
51 street_name_formats = (
52 '{{first_name}} {{street_suffix}}',
53 '{{last_name}} {{street_suffix}}'
54 )
55 street_address_formats = (
56 '{{building_number}} {{street_name}}',
57 '{{secondary_address}}\n{{street_name}}',
58 )
59 address_formats = (
60 "{{street_address}}\n{{city}}\n{{postcode}}",
61 )
62 secondary_address_formats = ('Flat #', 'Flat ##', 'Flat ##?', 'Studio #', 'Studio ##', 'Studio ##?')
63
64 @classmethod
65 def city_prefix(cls):
66 return cls.random_element(cls.city_prefixes)
67
68 @classmethod
69 def secondary_address(cls):
70 return cls.bothify(cls.random_element(cls.secondary_address_formats))
71
[end of faker/providers/address/en_GB/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/faker/providers/address/en_GB/__init__.py b/faker/providers/address/en_GB/__init__.py
--- a/faker/providers/address/en_GB/__init__.py
+++ b/faker/providers/address/en_GB/__init__.py
@@ -40,7 +40,44 @@
'view', 'views', 'village', 'village', 'villages', 'ville', 'vista', 'vista', 'walk', 'walks', 'wall', 'way',
'ways', 'well', 'wells')
- postcode_formats = ('??#? #??', '?#? #??', '?# #??', '?## #??', '??# #??', '??## #??',)
+ POSTAL_ZONES = (
+ 'AB', 'AL', 'B' , 'BA', 'BB', 'BD', 'BH', 'BL', 'BN', 'BR',
+ 'BS', 'BT', 'CA', 'CB', 'CF', 'CH', 'CM', 'CO', 'CR', 'CT',
+ 'CV', 'CW', 'DA', 'DD', 'DE', 'DG', 'DH', 'DL', 'DN', 'DT',
+ 'DY', 'E' , 'EC', 'EH', 'EN', 'EX', 'FK', 'FY', 'G' , 'GL',
+ 'GY', 'GU', 'HA', 'HD', 'HG', 'HP', 'HR', 'HS', 'HU', 'HX',
+ 'IG', 'IM', 'IP', 'IV', 'JE', 'KA', 'KT', 'KW', 'KY', 'L' ,
+ 'LA', 'LD', 'LE', 'LL', 'LN', 'LS', 'LU', 'M' , 'ME', 'MK',
+ 'ML', 'N' , 'NE', 'NG', 'NN', 'NP', 'NR', 'NW', 'OL', 'OX',
+ 'PA', 'PE', 'PH', 'PL', 'PO', 'PR', 'RG', 'RH', 'RM', 'S' ,
+ 'SA', 'SE', 'SG', 'SK', 'SL', 'SM', 'SN', 'SO', 'SP', 'SR',
+ 'SS', 'ST', 'SW', 'SY', 'TA', 'TD', 'TF', 'TN', 'TQ', 'TR',
+ 'TS', 'TW', 'UB', 'W' , 'WA', 'WC', 'WD', 'WF', 'WN', 'WR',
+ 'WS', 'WV', 'YO', 'ZE'
+ )
+
+ POSTAL_ZONES_ONE_CHAR = [zone for zone in POSTAL_ZONES if len(zone) == 1]
+ POSTAL_ZONES_TWO_CHARS = [zone for zone in POSTAL_ZONES if len(zone) == 2]
+
+ postcode_formats = (
+ 'AN NEE',
+ 'ANN NEE',
+ 'PN NEE',
+ 'PNN NEE',
+ 'ANC NEE',
+ 'PND NEE',
+ )
+
+ _postcode_sets = {
+ ' ': ' ',
+ 'N': [str(i) for i in range(0, 10)],
+ 'A': POSTAL_ZONES_ONE_CHAR,
+ 'B': 'ABCDEFGHKLMNOPQRSTUVWXY',
+ 'C': 'ABCDEFGHJKSTUW',
+ 'D': 'ABEHMNPRVWXY',
+ 'E': 'ABDEFGHJLNPQRSTUWXYZ',
+ 'P': POSTAL_ZONES_TWO_CHARS,
+ }
city_formats = (
'{{city_prefix}} {{first_name}}{{city_suffix}}',
@@ -61,6 +98,17 @@
)
secondary_address_formats = ('Flat #', 'Flat ##', 'Flat ##?', 'Studio #', 'Studio ##', 'Studio ##?')
+ @classmethod
+ def postcode(cls):
+ """
+ See http://web.archive.org/web/20090930140939/http://www.govtalk.gov.uk/gdsc/html/noframes/PostCode-2-1-Release.htm
+ """
+ postcode = ''
+ pattern = cls.random_element(cls.postcode_formats)
+ for placeholder in pattern:
+ postcode += cls.random_element(cls._postcode_sets[placeholder])
+ return postcode
+
@classmethod
def city_prefix(cls):
return cls.random_element(cls.city_prefixes)
| {"golden_diff": "diff --git a/faker/providers/address/en_GB/__init__.py b/faker/providers/address/en_GB/__init__.py\n--- a/faker/providers/address/en_GB/__init__.py\n+++ b/faker/providers/address/en_GB/__init__.py\n@@ -40,7 +40,44 @@\n 'view', 'views', 'village', 'village', 'villages', 'ville', 'vista', 'vista', 'walk', 'walks', 'wall', 'way',\n 'ways', 'well', 'wells')\n \n- postcode_formats = ('??#? #??', '?#? #??', '?# #??', '?## #??', '??# #??', '??## #??',)\n+ POSTAL_ZONES = (\n+ 'AB', 'AL', 'B' , 'BA', 'BB', 'BD', 'BH', 'BL', 'BN', 'BR',\n+ 'BS', 'BT', 'CA', 'CB', 'CF', 'CH', 'CM', 'CO', 'CR', 'CT',\n+ 'CV', 'CW', 'DA', 'DD', 'DE', 'DG', 'DH', 'DL', 'DN', 'DT',\n+ 'DY', 'E' , 'EC', 'EH', 'EN', 'EX', 'FK', 'FY', 'G' , 'GL',\n+ 'GY', 'GU', 'HA', 'HD', 'HG', 'HP', 'HR', 'HS', 'HU', 'HX',\n+ 'IG', 'IM', 'IP', 'IV', 'JE', 'KA', 'KT', 'KW', 'KY', 'L' ,\n+ 'LA', 'LD', 'LE', 'LL', 'LN', 'LS', 'LU', 'M' , 'ME', 'MK',\n+ 'ML', 'N' , 'NE', 'NG', 'NN', 'NP', 'NR', 'NW', 'OL', 'OX',\n+ 'PA', 'PE', 'PH', 'PL', 'PO', 'PR', 'RG', 'RH', 'RM', 'S' ,\n+ 'SA', 'SE', 'SG', 'SK', 'SL', 'SM', 'SN', 'SO', 'SP', 'SR',\n+ 'SS', 'ST', 'SW', 'SY', 'TA', 'TD', 'TF', 'TN', 'TQ', 'TR',\n+ 'TS', 'TW', 'UB', 'W' , 'WA', 'WC', 'WD', 'WF', 'WN', 'WR',\n+ 'WS', 'WV', 'YO', 'ZE'\n+ )\n+\n+ POSTAL_ZONES_ONE_CHAR = [zone for zone in POSTAL_ZONES if len(zone) == 1]\n+ POSTAL_ZONES_TWO_CHARS = [zone for zone in POSTAL_ZONES if len(zone) == 2]\n+\n+ postcode_formats = (\n+ 'AN NEE',\n+ 'ANN NEE',\n+ 'PN NEE',\n+ 'PNN NEE',\n+ 'ANC NEE',\n+ 'PND NEE',\n+ )\n+\n+ _postcode_sets = {\n+ ' ': ' ',\n+ 'N': [str(i) for i in range(0, 10)],\n+ 'A': POSTAL_ZONES_ONE_CHAR,\n+ 'B': 'ABCDEFGHKLMNOPQRSTUVWXY',\n+ 'C': 'ABCDEFGHJKSTUW',\n+ 'D': 'ABEHMNPRVWXY',\n+ 'E': 'ABDEFGHJLNPQRSTUWXYZ',\n+ 'P': POSTAL_ZONES_TWO_CHARS,\n+ }\n \n city_formats = (\n '{{city_prefix}} {{first_name}}{{city_suffix}}',\n@@ -61,6 +98,17 @@\n )\n secondary_address_formats = ('Flat #', 'Flat ##', 'Flat ##?', 'Studio #', 'Studio ##', 'Studio ##?')\n \n+ @classmethod\n+ def postcode(cls):\n+ \"\"\"\n+ See http://web.archive.org/web/20090930140939/http://www.govtalk.gov.uk/gdsc/html/noframes/PostCode-2-1-Release.htm\n+ \"\"\"\n+ postcode = ''\n+ pattern = cls.random_element(cls.postcode_formats)\n+ for placeholder in pattern:\n+ postcode += cls.random_element(cls._postcode_sets[placeholder])\n+ return postcode\n+\n @classmethod\n def city_prefix(cls):\n return cls.random_element(cls.city_prefixes)\n", "issue": "some generated UK postcodes are invalid\nUK postcodes follow strict rules and there are a limited set of codes for each part of the postcode. Faker does not know about these rules and generates postcodes such as: `XC9E 1FL` and `U93 2ZU` which are invalid. See e.g. https://github.com/hamstah/ukpostcodeparser for more info.\n\n", "before_files": [{"content": "from __future__ import unicode_literals \nfrom ..en import Provider as AddressProvider\n\n\nclass Provider(AddressProvider):\n city_prefixes = ('North', 'East', 'West', 'South', 'New', 'Lake', 'Port')\n city_suffixes = (\n 'town', 'ton', 'land', 'ville', 'berg', 'burgh', 'borough', 'bury', 'view', 'port', 'mouth', 'stad', 'furt',\n 'chester', 'mouth', 'fort', 'haven', 'side', 'shire')\n building_number_formats = ('#', '##', '###')\n street_suffixes = (\n 'alley', 'avenue', 'branch', 'bridge', 'brook', 'brooks', 'burg', 'burgs', 'bypass', 'camp', 'canyon', 'cape',\n 'causeway', 'center', 'centers', 'circle', 'circles', 'cliff', 'cliffs', 'club', 'common', 'corner', 'corners',\n 'course', 'court', 'courts', 'cove', 'coves', 'creek', 'crescent', 'crest', 'crossing', 'crossroad', 'curve',\n 'dale', 'dam', 'divide', 'drive', 'drive', 'drives', 'estate', 'estates', 'expressway', 'extension',\n 'extensions',\n 'fall', 'falls', 'ferry', 'field', 'fields', 'flat', 'flats', 'ford', 'fords', 'forest', 'forge', 'forges',\n 'fork',\n 'forks', 'fort', 'freeway', 'garden', 'gardens', 'gateway', 'glen', 'glens', 'green', 'greens', 'grove',\n 'groves',\n 'harbor', 'harbors', 'haven', 'heights', 'highway', 'hill', 'hills', 'hollow', 'inlet', 'inlet', 'island',\n 'island',\n 'islands', 'islands', 'isle', 'isle', 'junction', 'junctions', 'key', 'keys', 'knoll', 'knolls', 'lake',\n 'lakes',\n 'land', 'landing', 'lane', 'light', 'lights', 'loaf', 'lock', 'locks', 'locks', 'lodge', 'lodge', 'loop',\n 'mall',\n 'manor', 'manors', 'meadow', 'meadows', 'mews', 'mill', 'mills', 'mission', 'mission', 'motorway', 'mount',\n 'mountain', 'mountain', 'mountains', 'mountains', 'neck', 'orchard', 'oval', 'overpass', 'park', 'parks',\n 'parkway',\n 'parkways', 'pass', 'passage', 'path', 'pike', 'pine', 'pines', 'place', 'plain', 'plains', 'plains', 'plaza',\n 'plaza', 'point', 'points', 'port', 'port', 'ports', 'ports', 'prairie', 'prairie', 'radial', 'ramp', 'ranch',\n 'rapid', 'rapids', 'rest', 'ridge', 'ridges', 'river', 'road', 'road', 'roads', 'roads', 'route', 'row', 'rue',\n 'run', 'shoal', 'shoals', 'shore', 'shores', 'skyway', 'spring', 'springs', 'springs', 'spur', 'spurs',\n 'square',\n 'square', 'squares', 'squares', 'station', 'station', 'stravenue', 'stravenue', 'stream', 'stream', 'street',\n 'street', 'streets', 'summit', 'summit', 'terrace', 'throughway', 'trace', 'track', 'trafficway', 'trail',\n 'trail',\n 'tunnel', 'tunnel', 'turnpike', 'turnpike', 'underpass', 'union', 'unions', 'valley', 'valleys', 'via',\n 'viaduct',\n 'view', 'views', 'village', 'village', 'villages', 'ville', 'vista', 'vista', 'walk', 'walks', 'wall', 'way',\n 'ways', 'well', 'wells')\n\n postcode_formats = ('??#? #??', '?#? #??', '?# #??', '?## #??', '??# #??', '??## #??',)\n\n city_formats = (\n '{{city_prefix}} {{first_name}}{{city_suffix}}',\n '{{city_prefix}} {{first_name}}',\n '{{first_name}}{{city_suffix}}',\n '{{last_name}}{{city_suffix}}',\n )\n street_name_formats = (\n '{{first_name}} {{street_suffix}}',\n '{{last_name}} {{street_suffix}}'\n )\n street_address_formats = (\n '{{building_number}} {{street_name}}',\n '{{secondary_address}}\\n{{street_name}}',\n )\n address_formats = (\n \"{{street_address}}\\n{{city}}\\n{{postcode}}\",\n )\n secondary_address_formats = ('Flat #', 'Flat ##', 'Flat ##?', 'Studio #', 'Studio ##', 'Studio ##?')\n\n @classmethod\n def city_prefix(cls):\n return cls.random_element(cls.city_prefixes)\n\n @classmethod\n def secondary_address(cls):\n return cls.bothify(cls.random_element(cls.secondary_address_formats))\n", "path": "faker/providers/address/en_GB/__init__.py"}]} | 1,971 | 1,001 |
gh_patches_debug_64108 | rasdani/github-patches | git_diff | facebookresearch__hydra-2242 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Bug] Colorlog plugin generates `.log` file in cwd instead of output dir
# 🐛 Bug
I'm using hydra v1.2 with `chdir` set to false.
When I don't use colorlog plugin, the `.log` file with python logs gets generated in my output directory (as expected).
But when I attach colorlog plugin with:
```yaml
defaults:
- override hydra/hydra_logging: colorlog
- override hydra/job_logging: colorlog
```
The `.log` file gets generated in current working directory
## Checklist
- [x] I checked on the latest version of Hydra
- [ ] I created a minimal repro (See [this](https://stackoverflow.com/help/minimal-reproducible-example) for tips).
## Expected Behavior
I would expect the `.log` file to be always saved in output directory by default.
## System information
- **Hydra Version** : 1.2
- **Python version** : 3.10
- **Virtual environment type and version** :
- **Operating system** : linux
</issue>
<code>
[start of plugins/hydra_colorlog/hydra_plugins/hydra_colorlog/__init__.py]
1 # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
2
3 __version__ = "1.2.0"
4
[end of plugins/hydra_colorlog/hydra_plugins/hydra_colorlog/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/plugins/hydra_colorlog/hydra_plugins/hydra_colorlog/__init__.py b/plugins/hydra_colorlog/hydra_plugins/hydra_colorlog/__init__.py
--- a/plugins/hydra_colorlog/hydra_plugins/hydra_colorlog/__init__.py
+++ b/plugins/hydra_colorlog/hydra_plugins/hydra_colorlog/__init__.py
@@ -1,3 +1,3 @@
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
-__version__ = "1.2.0"
+__version__ = "1.2.1"
| {"golden_diff": "diff --git a/plugins/hydra_colorlog/hydra_plugins/hydra_colorlog/__init__.py b/plugins/hydra_colorlog/hydra_plugins/hydra_colorlog/__init__.py\n--- a/plugins/hydra_colorlog/hydra_plugins/hydra_colorlog/__init__.py\n+++ b/plugins/hydra_colorlog/hydra_plugins/hydra_colorlog/__init__.py\n@@ -1,3 +1,3 @@\n # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\n \n-__version__ = \"1.2.0\"\n+__version__ = \"1.2.1\"\n", "issue": "[Bug] Colorlog plugin generates `.log` file in cwd instead of output dir\n# \ud83d\udc1b Bug\r\nI'm using hydra v1.2 with `chdir` set to false.\r\n\r\nWhen I don't use colorlog plugin, the `.log` file with python logs gets generated in my output directory (as expected).\r\n\r\nBut when I attach colorlog plugin with:\r\n```yaml\r\ndefaults:\r\n - override hydra/hydra_logging: colorlog\r\n - override hydra/job_logging: colorlog\r\n```\r\nThe `.log` file gets generated in current working directory\r\n\r\n## Checklist\r\n- [x] I checked on the latest version of Hydra\r\n- [ ] I created a minimal repro (See [this](https://stackoverflow.com/help/minimal-reproducible-example) for tips).\r\n\r\n## Expected Behavior\r\nI would expect the `.log` file to be always saved in output directory by default.\r\n\r\n## System information\r\n- **Hydra Version** : 1.2\r\n- **Python version** : 3.10\r\n- **Virtual environment type and version** : \r\n- **Operating system** : linux\r\n\r\n\n", "before_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\n\n__version__ = \"1.2.0\"\n", "path": "plugins/hydra_colorlog/hydra_plugins/hydra_colorlog/__init__.py"}]} | 834 | 139 |
gh_patches_debug_11242 | rasdani/github-patches | git_diff | getpelican__pelican-1002 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
"'dict_keys' object does not support indexing" in Python 3 using sourcecode directive
When I include a code-block with an option, like this:
```
.. sourcecode:: python
:linenos:
...
```
a WARNING appears and the corresponding file is not processed:
```
WARNING: Could not process /home/juanlu/Development/Python/pelican_test/myproject/content/2013-07-14_hello-world.rst
'dict_keys' object does not support indexing
```
The problem is here:
https://github.com/getpelican/pelican/blob/master/pelican/rstdirectives.py#L35
and the solution is detailed here:
http://stackoverflow.com/questions/8953627/python-dictionary-keys-error
I have read the guidelines but, even being a trivial fix:
```
--- rstdirectives.py 2013-07-14 12:41:00.188687997 +0200
+++ rstdirectives.py.new 2013-07-14 12:36:25.982005000 +0200
@@ -32,7 +32,7 @@
# no lexer found - use the text one instead of an exception
lexer = TextLexer()
# take an arbitrary option if more than one is given
- formatter = self.options and VARIANTS[self.options.keys()[0]] \
+ formatter = self.options and VARIANTS[list(self.options.keys())[0]] \
or DEFAULT
parsed = highlight('\n'.join(self.content), lexer, formatter)
return [nodes.raw('', parsed, format='html')]
```
I don't have time to add docs, tests, run the test suite and, summing up, doing it properly. Hence the issue without pull request.
</issue>
<code>
[start of pelican/rstdirectives.py]
1 # -*- coding: utf-8 -*-
2 from __future__ import unicode_literals, print_function
3
4 from docutils import nodes, utils
5 from docutils.parsers.rst import directives, roles, Directive
6 from pygments.formatters import HtmlFormatter
7 from pygments import highlight
8 from pygments.lexers import get_lexer_by_name, TextLexer
9 import re
10
11 INLINESTYLES = False
12 DEFAULT = HtmlFormatter(noclasses=INLINESTYLES)
13 VARIANTS = {
14 'linenos': HtmlFormatter(noclasses=INLINESTYLES, linenos=True),
15 }
16
17
18 class Pygments(Directive):
19 """ Source code syntax hightlighting.
20 """
21 required_arguments = 1
22 optional_arguments = 0
23 final_argument_whitespace = True
24 option_spec = dict([(key, directives.flag) for key in VARIANTS])
25 has_content = True
26
27 def run(self):
28 self.assert_has_content()
29 try:
30 lexer = get_lexer_by_name(self.arguments[0])
31 except ValueError:
32 # no lexer found - use the text one instead of an exception
33 lexer = TextLexer()
34 # take an arbitrary option if more than one is given
35 formatter = self.options and VARIANTS[self.options.keys()[0]] \
36 or DEFAULT
37 parsed = highlight('\n'.join(self.content), lexer, formatter)
38 return [nodes.raw('', parsed, format='html')]
39
40 directives.register_directive('code-block', Pygments)
41 directives.register_directive('sourcecode', Pygments)
42
43
44 class YouTube(Directive):
45 """ Embed YouTube video in posts.
46
47 Courtesy of Brian Hsu: https://gist.github.com/1422773
48
49 VIDEO_ID is required, with / height are optional integer,
50 and align could be left / center / right.
51
52 Usage:
53 .. youtube:: VIDEO_ID
54 :width: 640
55 :height: 480
56 :align: center
57 """
58
59 def align(argument):
60 """Conversion function for the "align" option."""
61 return directives.choice(argument, ('left', 'center', 'right'))
62
63 required_arguments = 1
64 optional_arguments = 2
65 option_spec = {
66 'width': directives.positive_int,
67 'height': directives.positive_int,
68 'align': align
69 }
70
71 final_argument_whitespace = False
72 has_content = False
73
74 def run(self):
75 videoID = self.arguments[0].strip()
76 width = 420
77 height = 315
78 align = 'left'
79
80 if 'width' in self.options:
81 width = self.options['width']
82
83 if 'height' in self.options:
84 height = self.options['height']
85
86 if 'align' in self.options:
87 align = self.options['align']
88
89 url = 'http://www.youtube.com/embed/%s' % videoID
90 div_block = '<div class="youtube" align="%s">' % align
91 embed_block = '<iframe width="%s" height="%s" src="%s" '\
92 'frameborder="0"></iframe>' % (width, height, url)
93
94 return [
95 nodes.raw('', div_block, format='html'),
96 nodes.raw('', embed_block, format='html'),
97 nodes.raw('', '</div>', format='html')]
98
99 directives.register_directive('youtube', YouTube)
100
101 _abbr_re = re.compile('\((.*)\)$')
102
103
104 class abbreviation(nodes.Inline, nodes.TextElement):
105 pass
106
107
108 def abbr_role(typ, rawtext, text, lineno, inliner, options={}, content=[]):
109 text = utils.unescape(text)
110 m = _abbr_re.search(text)
111 if m is None:
112 return [abbreviation(text, text)], []
113 abbr = text[:m.start()].strip()
114 expl = m.group(1)
115 return [abbreviation(abbr, abbr, explanation=expl)], []
116
117 roles.register_local_role('abbr', abbr_role)
118
[end of pelican/rstdirectives.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/pelican/rstdirectives.py b/pelican/rstdirectives.py
--- a/pelican/rstdirectives.py
+++ b/pelican/rstdirectives.py
@@ -32,7 +32,7 @@
# no lexer found - use the text one instead of an exception
lexer = TextLexer()
# take an arbitrary option if more than one is given
- formatter = self.options and VARIANTS[self.options.keys()[0]] \
+ formatter = self.options and VARIANTS[list(self.options.keys())[0]] \
or DEFAULT
parsed = highlight('\n'.join(self.content), lexer, formatter)
return [nodes.raw('', parsed, format='html')]
| {"golden_diff": "diff --git a/pelican/rstdirectives.py b/pelican/rstdirectives.py\n--- a/pelican/rstdirectives.py\n+++ b/pelican/rstdirectives.py\n@@ -32,7 +32,7 @@\n # no lexer found - use the text one instead of an exception\n lexer = TextLexer()\n # take an arbitrary option if more than one is given\n- formatter = self.options and VARIANTS[self.options.keys()[0]] \\\n+ formatter = self.options and VARIANTS[list(self.options.keys())[0]] \\\n or DEFAULT\n parsed = highlight('\\n'.join(self.content), lexer, formatter)\n return [nodes.raw('', parsed, format='html')]\n", "issue": "\"'dict_keys' object does not support indexing\" in Python 3 using sourcecode directive\nWhen I include a code-block with an option, like this:\n\n```\n.. sourcecode:: python\n :linenos:\n\n ...\n```\n\na WARNING appears and the corresponding file is not processed:\n\n```\nWARNING: Could not process /home/juanlu/Development/Python/pelican_test/myproject/content/2013-07-14_hello-world.rst\n'dict_keys' object does not support indexing\n```\n\nThe problem is here:\n\nhttps://github.com/getpelican/pelican/blob/master/pelican/rstdirectives.py#L35\n\nand the solution is detailed here:\n\nhttp://stackoverflow.com/questions/8953627/python-dictionary-keys-error\n\nI have read the guidelines but, even being a trivial fix:\n\n```\n--- rstdirectives.py 2013-07-14 12:41:00.188687997 +0200\n+++ rstdirectives.py.new 2013-07-14 12:36:25.982005000 +0200\n@@ -32,7 +32,7 @@\n # no lexer found - use the text one instead of an exception\n lexer = TextLexer()\n # take an arbitrary option if more than one is given\n- formatter = self.options and VARIANTS[self.options.keys()[0]] \\\n+ formatter = self.options and VARIANTS[list(self.options.keys())[0]] \\\n or DEFAULT\n parsed = highlight('\\n'.join(self.content), lexer, formatter)\n return [nodes.raw('', parsed, format='html')]\n```\n\nI don't have time to add docs, tests, run the test suite and, summing up, doing it properly. Hence the issue without pull request.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nfrom __future__ import unicode_literals, print_function\n\nfrom docutils import nodes, utils\nfrom docutils.parsers.rst import directives, roles, Directive\nfrom pygments.formatters import HtmlFormatter\nfrom pygments import highlight\nfrom pygments.lexers import get_lexer_by_name, TextLexer\nimport re\n\nINLINESTYLES = False\nDEFAULT = HtmlFormatter(noclasses=INLINESTYLES)\nVARIANTS = {\n 'linenos': HtmlFormatter(noclasses=INLINESTYLES, linenos=True),\n}\n\n\nclass Pygments(Directive):\n \"\"\" Source code syntax hightlighting.\n \"\"\"\n required_arguments = 1\n optional_arguments = 0\n final_argument_whitespace = True\n option_spec = dict([(key, directives.flag) for key in VARIANTS])\n has_content = True\n\n def run(self):\n self.assert_has_content()\n try:\n lexer = get_lexer_by_name(self.arguments[0])\n except ValueError:\n # no lexer found - use the text one instead of an exception\n lexer = TextLexer()\n # take an arbitrary option if more than one is given\n formatter = self.options and VARIANTS[self.options.keys()[0]] \\\n or DEFAULT\n parsed = highlight('\\n'.join(self.content), lexer, formatter)\n return [nodes.raw('', parsed, format='html')]\n\ndirectives.register_directive('code-block', Pygments)\ndirectives.register_directive('sourcecode', Pygments)\n\n\nclass YouTube(Directive):\n \"\"\" Embed YouTube video in posts.\n\n Courtesy of Brian Hsu: https://gist.github.com/1422773\n\n VIDEO_ID is required, with / height are optional integer,\n and align could be left / center / right.\n\n Usage:\n .. youtube:: VIDEO_ID\n :width: 640\n :height: 480\n :align: center\n \"\"\"\n\n def align(argument):\n \"\"\"Conversion function for the \"align\" option.\"\"\"\n return directives.choice(argument, ('left', 'center', 'right'))\n\n required_arguments = 1\n optional_arguments = 2\n option_spec = {\n 'width': directives.positive_int,\n 'height': directives.positive_int,\n 'align': align\n }\n\n final_argument_whitespace = False\n has_content = False\n\n def run(self):\n videoID = self.arguments[0].strip()\n width = 420\n height = 315\n align = 'left'\n\n if 'width' in self.options:\n width = self.options['width']\n\n if 'height' in self.options:\n height = self.options['height']\n\n if 'align' in self.options:\n align = self.options['align']\n\n url = 'http://www.youtube.com/embed/%s' % videoID\n div_block = '<div class=\"youtube\" align=\"%s\">' % align\n embed_block = '<iframe width=\"%s\" height=\"%s\" src=\"%s\" '\\\n 'frameborder=\"0\"></iframe>' % (width, height, url)\n\n return [\n nodes.raw('', div_block, format='html'),\n nodes.raw('', embed_block, format='html'),\n nodes.raw('', '</div>', format='html')]\n\ndirectives.register_directive('youtube', YouTube)\n\n_abbr_re = re.compile('\\((.*)\\)$')\n\n\nclass abbreviation(nodes.Inline, nodes.TextElement):\n pass\n\n\ndef abbr_role(typ, rawtext, text, lineno, inliner, options={}, content=[]):\n text = utils.unescape(text)\n m = _abbr_re.search(text)\n if m is None:\n return [abbreviation(text, text)], []\n abbr = text[:m.start()].strip()\n expl = m.group(1)\n return [abbreviation(abbr, abbr, explanation=expl)], []\n\nroles.register_local_role('abbr', abbr_role)\n", "path": "pelican/rstdirectives.py"}]} | 2,053 | 156 |
gh_patches_debug_4905 | rasdani/github-patches | git_diff | cupy__cupy-1459 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`cupy.split` sometimes fails with a 0-sized input array
```
>>> cupy.split(cupy.ones((3, 0)), [1])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/kataoka/cupy/cupy/manipulation/split.py", line 78, in split
return array_split(ary, indices_or_sections, axis)
File "/home/kataoka/cupy/cupy/manipulation/split.py", line 16, in array_split
return core.array_split(ary, indices_or_sections, axis)
File "cupy/core/core.pyx", line 2338, in cupy.core.core.array_split
v.data = ary.data + prev * stride
File "cupy/cuda/memory.pyx", line 243, in cupy.cuda.memory.MemoryPointer.__add__
assert self.ptr > 0 or offset == 0
AssertionError
```
</issue>
<code>
[start of cupy/math/sumprod.py]
1 import numpy
2 import six
3
4 from cupy import core
5
6
7 def sum(a, axis=None, dtype=None, out=None, keepdims=False):
8 """Returns the sum of an array along given axes.
9
10 Args:
11 a (cupy.ndarray): Array to take sum.
12 axis (int or sequence of ints): Axes along which the sum is taken.
13 dtype: Data type specifier.
14 out (cupy.ndarray): Output array.
15 keepdims (bool): If ``True``, the specified axes are remained as axes
16 of length one.
17
18 Returns:
19 cupy.ndarray: The result array.
20
21 .. seealso:: :func:`numpy.sum`
22
23 """
24 # TODO(okuta): check type
25 return a.sum(axis, dtype, out, keepdims)
26
27
28 def prod(a, axis=None, dtype=None, out=None, keepdims=False):
29 """Returns the product of an array along given axes.
30
31 Args:
32 a (cupy.ndarray): Array to take product.
33 axis (int or sequence of ints): Axes along which the product is taken.
34 dtype: Data type specifier.
35 out (cupy.ndarray): Output array.
36 keepdims (bool): If ``True``, the specified axes are remained as axes
37 of length one.
38
39 Returns:
40 cupy.ndarray: The result array.
41
42 .. seealso:: :func:`numpy.prod`
43
44 """
45 # TODO(okuta): check type
46 return a.prod(axis, dtype, out, keepdims)
47
48
49 # TODO(okuta): Implement nansum
50
51
52 def _axis_to_first(x, axis):
53 if axis < 0:
54 axis = x.ndim + axis
55 trans = [axis] + [a for a in six.moves.range(x.ndim) if a != axis]
56 pre = list(six.moves.range(1, axis + 1))
57 succ = list(six.moves.range(axis + 1, x.ndim))
58 revert = pre + [0] + succ
59 return trans, revert
60
61
62 def _proc_as_batch(proc, x, axis):
63 trans, revert = _axis_to_first(x, axis)
64 t = x.transpose(trans)
65 s = t.shape
66 r = t.reshape(x.shape[axis], -1)
67 pos = 1
68 size = r.size
69 batch = r.shape[1]
70 while pos < size:
71 proc(pos, batch, r, size=size)
72 pos <<= 1
73 return r.reshape(s).transpose(revert)
74
75
76 def _cum_core(a, axis, dtype, out, kern, batch_kern):
77 if out is None:
78 if dtype is None:
79 kind = a.dtype.kind
80 if kind == 'b':
81 dtype = numpy.dtype('l')
82 elif kind == 'i' and a.dtype.itemsize < numpy.dtype('l').itemsize:
83 dtype = numpy.dtype('l')
84 elif kind == 'u' and a.dtype.itemsize < numpy.dtype('L').itemsize:
85 dtype = numpy.dtype('L')
86 else:
87 dtype = a.dtype
88
89 out = a.astype(dtype)
90 else:
91 out[...] = a
92
93 if axis is None:
94 out = out.ravel()
95 elif not (-a.ndim <= axis < a.ndim):
96 raise core.core._AxisError('axis(={}) out of bounds'.format(axis))
97 else:
98 return _proc_as_batch(batch_kern, out, axis=axis)
99
100 pos = 1
101 while pos < out.size:
102 kern(pos, out, size=out.size)
103 pos <<= 1
104 return out
105
106
107 _cumsum_batch_kern = core.ElementwiseKernel(
108 'int64 pos, int64 batch', 'raw T x',
109 '''
110 ptrdiff_t b = i % batch;
111 ptrdiff_t j = i / batch;
112 if (j & pos) {
113 const ptrdiff_t dst_index[] = {j, b};
114 const ptrdiff_t src_index[] = {j ^ pos | (pos - 1), b};
115 x[dst_index] += x[src_index];
116 }
117 ''',
118 'cumsum_batch_kernel'
119 )
120 _cumsum_kern = core.ElementwiseKernel(
121 'int64 pos', 'raw T x',
122 '''
123 if (i & pos) {
124 x[i] += x[i ^ pos | (pos - 1)];
125 }
126 ''',
127 'cumsum_kernel'
128 )
129
130
131 def cumsum(a, axis=None, dtype=None, out=None):
132 """Returns the cumulative sum of an array along a given axis.
133
134 Args:
135 a (cupy.ndarray): Input array.
136 axis (int): Axis along which the cumulative sum is taken. If it is not
137 specified, the input is flattened.
138 dtype: Data type specifier.
139 out (cupy.ndarray): Output array.
140
141 Returns:
142 cupy.ndarray: The result array.
143
144 .. seealso:: :func:`numpy.cumsum`
145
146 """
147 return _cum_core(a, axis, dtype, out, _cumsum_kern, _cumsum_batch_kern)
148
149
150 _cumprod_batch_kern = core.ElementwiseKernel(
151 'int64 pos, int64 batch', 'raw T x',
152 '''
153 ptrdiff_t b = i % batch;
154 ptrdiff_t j = i / batch;
155 if (j & pos) {
156 const ptrdiff_t dst_index[] = {j, b};
157 const ptrdiff_t src_index[] = {j ^ pos | (pos - 1), b};
158 x[dst_index] *= x[src_index];
159 }
160 ''',
161 'cumprod_batch_kernel'
162 )
163 _cumprod_kern = core.ElementwiseKernel(
164 'int64 pos', 'raw T x',
165 '''
166 if (i & pos) {
167 x[i] *= x[i ^ pos | (pos - 1)];
168 }
169 ''',
170 'cumprod_kernel'
171 )
172
173
174 def cumprod(a, axis=None, dtype=None, out=None):
175 """Returns the cumulative product of an array along a given axis.
176
177 Args:
178 a (cupy.ndarray): Input array.
179 axis (int): Axis along which the cumulative product is taken. If it is
180 not specified, the input is flattened.
181 dtype: Data type specifier.
182 out (cupy.ndarray): Output array.
183
184 Returns:
185 cupy.ndarray: The result array.
186
187 .. seealso:: :func:`numpy.cumprod`
188
189 """
190 return _cum_core(a, axis, dtype, out, _cumprod_kern, _cumprod_batch_kern)
191
192
193 # TODO(okuta): Implement diff
194
195
196 # TODO(okuta): Implement ediff1d
197
198
199 # TODO(okuta): Implement gradient
200
201
202 # TODO(okuta): Implement cross
203
204
205 # TODO(okuta): Implement trapz
206
[end of cupy/math/sumprod.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/cupy/math/sumprod.py b/cupy/math/sumprod.py
--- a/cupy/math/sumprod.py
+++ b/cupy/math/sumprod.py
@@ -1,6 +1,7 @@
import numpy
import six
+import cupy
from cupy import core
@@ -60,6 +61,8 @@
def _proc_as_batch(proc, x, axis):
+ if x.shape[axis] == 0:
+ return cupy.empty_like(x)
trans, revert = _axis_to_first(x, axis)
t = x.transpose(trans)
s = t.shape
| {"golden_diff": "diff --git a/cupy/math/sumprod.py b/cupy/math/sumprod.py\n--- a/cupy/math/sumprod.py\n+++ b/cupy/math/sumprod.py\n@@ -1,6 +1,7 @@\n import numpy\n import six\n \n+import cupy\n from cupy import core\n \n \n@@ -60,6 +61,8 @@\n \n \n def _proc_as_batch(proc, x, axis):\n+ if x.shape[axis] == 0:\n+ return cupy.empty_like(x)\n trans, revert = _axis_to_first(x, axis)\n t = x.transpose(trans)\n s = t.shape\n", "issue": "`cupy.split` sometimes fails with a 0-sized input array\n```\r\n>>> cupy.split(cupy.ones((3, 0)), [1])\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/home/kataoka/cupy/cupy/manipulation/split.py\", line 78, in split\r\n return array_split(ary, indices_or_sections, axis)\r\n File \"/home/kataoka/cupy/cupy/manipulation/split.py\", line 16, in array_split\r\n return core.array_split(ary, indices_or_sections, axis)\r\n File \"cupy/core/core.pyx\", line 2338, in cupy.core.core.array_split\r\n v.data = ary.data + prev * stride\r\n File \"cupy/cuda/memory.pyx\", line 243, in cupy.cuda.memory.MemoryPointer.__add__\r\n assert self.ptr > 0 or offset == 0\r\nAssertionError\r\n```\n", "before_files": [{"content": "import numpy\nimport six\n\nfrom cupy import core\n\n\ndef sum(a, axis=None, dtype=None, out=None, keepdims=False):\n \"\"\"Returns the sum of an array along given axes.\n\n Args:\n a (cupy.ndarray): Array to take sum.\n axis (int or sequence of ints): Axes along which the sum is taken.\n dtype: Data type specifier.\n out (cupy.ndarray): Output array.\n keepdims (bool): If ``True``, the specified axes are remained as axes\n of length one.\n\n Returns:\n cupy.ndarray: The result array.\n\n .. seealso:: :func:`numpy.sum`\n\n \"\"\"\n # TODO(okuta): check type\n return a.sum(axis, dtype, out, keepdims)\n\n\ndef prod(a, axis=None, dtype=None, out=None, keepdims=False):\n \"\"\"Returns the product of an array along given axes.\n\n Args:\n a (cupy.ndarray): Array to take product.\n axis (int or sequence of ints): Axes along which the product is taken.\n dtype: Data type specifier.\n out (cupy.ndarray): Output array.\n keepdims (bool): If ``True``, the specified axes are remained as axes\n of length one.\n\n Returns:\n cupy.ndarray: The result array.\n\n .. seealso:: :func:`numpy.prod`\n\n \"\"\"\n # TODO(okuta): check type\n return a.prod(axis, dtype, out, keepdims)\n\n\n# TODO(okuta): Implement nansum\n\n\ndef _axis_to_first(x, axis):\n if axis < 0:\n axis = x.ndim + axis\n trans = [axis] + [a for a in six.moves.range(x.ndim) if a != axis]\n pre = list(six.moves.range(1, axis + 1))\n succ = list(six.moves.range(axis + 1, x.ndim))\n revert = pre + [0] + succ\n return trans, revert\n\n\ndef _proc_as_batch(proc, x, axis):\n trans, revert = _axis_to_first(x, axis)\n t = x.transpose(trans)\n s = t.shape\n r = t.reshape(x.shape[axis], -1)\n pos = 1\n size = r.size\n batch = r.shape[1]\n while pos < size:\n proc(pos, batch, r, size=size)\n pos <<= 1\n return r.reshape(s).transpose(revert)\n\n\ndef _cum_core(a, axis, dtype, out, kern, batch_kern):\n if out is None:\n if dtype is None:\n kind = a.dtype.kind\n if kind == 'b':\n dtype = numpy.dtype('l')\n elif kind == 'i' and a.dtype.itemsize < numpy.dtype('l').itemsize:\n dtype = numpy.dtype('l')\n elif kind == 'u' and a.dtype.itemsize < numpy.dtype('L').itemsize:\n dtype = numpy.dtype('L')\n else:\n dtype = a.dtype\n\n out = a.astype(dtype)\n else:\n out[...] = a\n\n if axis is None:\n out = out.ravel()\n elif not (-a.ndim <= axis < a.ndim):\n raise core.core._AxisError('axis(={}) out of bounds'.format(axis))\n else:\n return _proc_as_batch(batch_kern, out, axis=axis)\n\n pos = 1\n while pos < out.size:\n kern(pos, out, size=out.size)\n pos <<= 1\n return out\n\n\n_cumsum_batch_kern = core.ElementwiseKernel(\n 'int64 pos, int64 batch', 'raw T x',\n '''\n ptrdiff_t b = i % batch;\n ptrdiff_t j = i / batch;\n if (j & pos) {\n const ptrdiff_t dst_index[] = {j, b};\n const ptrdiff_t src_index[] = {j ^ pos | (pos - 1), b};\n x[dst_index] += x[src_index];\n }\n ''',\n 'cumsum_batch_kernel'\n)\n_cumsum_kern = core.ElementwiseKernel(\n 'int64 pos', 'raw T x',\n '''\n if (i & pos) {\n x[i] += x[i ^ pos | (pos - 1)];\n }\n ''',\n 'cumsum_kernel'\n)\n\n\ndef cumsum(a, axis=None, dtype=None, out=None):\n \"\"\"Returns the cumulative sum of an array along a given axis.\n\n Args:\n a (cupy.ndarray): Input array.\n axis (int): Axis along which the cumulative sum is taken. If it is not\n specified, the input is flattened.\n dtype: Data type specifier.\n out (cupy.ndarray): Output array.\n\n Returns:\n cupy.ndarray: The result array.\n\n .. seealso:: :func:`numpy.cumsum`\n\n \"\"\"\n return _cum_core(a, axis, dtype, out, _cumsum_kern, _cumsum_batch_kern)\n\n\n_cumprod_batch_kern = core.ElementwiseKernel(\n 'int64 pos, int64 batch', 'raw T x',\n '''\n ptrdiff_t b = i % batch;\n ptrdiff_t j = i / batch;\n if (j & pos) {\n const ptrdiff_t dst_index[] = {j, b};\n const ptrdiff_t src_index[] = {j ^ pos | (pos - 1), b};\n x[dst_index] *= x[src_index];\n }\n ''',\n 'cumprod_batch_kernel'\n)\n_cumprod_kern = core.ElementwiseKernel(\n 'int64 pos', 'raw T x',\n '''\n if (i & pos) {\n x[i] *= x[i ^ pos | (pos - 1)];\n }\n ''',\n 'cumprod_kernel'\n)\n\n\ndef cumprod(a, axis=None, dtype=None, out=None):\n \"\"\"Returns the cumulative product of an array along a given axis.\n\n Args:\n a (cupy.ndarray): Input array.\n axis (int): Axis along which the cumulative product is taken. If it is\n not specified, the input is flattened.\n dtype: Data type specifier.\n out (cupy.ndarray): Output array.\n\n Returns:\n cupy.ndarray: The result array.\n\n .. seealso:: :func:`numpy.cumprod`\n\n \"\"\"\n return _cum_core(a, axis, dtype, out, _cumprod_kern, _cumprod_batch_kern)\n\n\n# TODO(okuta): Implement diff\n\n\n# TODO(okuta): Implement ediff1d\n\n\n# TODO(okuta): Implement gradient\n\n\n# TODO(okuta): Implement cross\n\n\n# TODO(okuta): Implement trapz\n", "path": "cupy/math/sumprod.py"}]} | 2,739 | 138 |
gh_patches_debug_40326 | rasdani/github-patches | git_diff | nextcloud__appstore-201 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Delete user account
A user should be able to delete his account by hitting and confirming it on the download page. The confirmation should not be able to trigger by accident, Github's delete repo ui is a good example.
Before deleting his account, a user will be warned that all his comments and apps will be deleted.
</issue>
<code>
[start of nextcloudappstore/urls.py]
1 from allauth.account.views import signup
2 from allauth.socialaccount.views import signup as social_signup
3 from csp.decorators import csp_exempt
4 from django.conf.urls import url, include
5 from django.contrib import admin
6 from nextcloudappstore.core.user.views import PasswordView, AccountView, \
7 APITokenView
8 from nextcloudappstore.core.views import CategoryAppListView, AppDetailView, \
9 app_description, AppReleasesView, AppUploadView, LegalNoticeView
10
11 urlpatterns = [
12 url(r'^$', CategoryAppListView.as_view(), {'id': None}, name='home'),
13 url(r"^signup/$", csp_exempt(signup), name="account_signup"),
14 url(r"^social/signup/$", csp_exempt(social_signup),
15 name="socialaccount_signup"),
16 url(r'^', include('allauth.urls')),
17 url(r'^account/?$', AccountView.as_view(), name='account'),
18 url(r'^account/password/?$', PasswordView.as_view(),
19 name='account-password'),
20 url(r'^account/token/?$', APITokenView.as_view(),
21 name='account-api-token'),
22 url(r'^legal/?$', LegalNoticeView.as_view(), name='legal-notice'),
23 url(r'^categories/(?P<id>[\w]*)/?$', CategoryAppListView.as_view(),
24 name='category-app-list'),
25 url(r'^app/upload/?$', AppUploadView.as_view(), name='app-upload'),
26 url(r'^app/(?P<id>[\w_]+)/?$', AppDetailView.as_view(), name='app-detail'),
27 url(r'^app/(?P<id>[\w_]+)/releases/?$', AppReleasesView.as_view(),
28 name='app-releases'),
29 url(r'^app/(?P<id>[\w_]+)/description/?$', app_description,
30 name='app-description'),
31 url(r'^api/', include('nextcloudappstore.core.api.urls',
32 namespace='api')),
33 url(r'^admin/', admin.site.urls),
34 ]
35
[end of nextcloudappstore/urls.py]
[start of nextcloudappstore/core/user/views.py]
1 from allauth.account.views import PasswordChangeView
2 from django.contrib import messages
3 from django.contrib.auth.mixins import LoginRequiredMixin
4 from django.contrib.auth.models import User
5 from django.core.urlresolvers import reverse_lazy
6 from django.views.generic import TemplateView
7 from django.views.generic import UpdateView
8
9
10 class AccountView(LoginRequiredMixin, UpdateView):
11 """Display and allow changing of the user's name."""
12
13 template_name = 'user/account.html'
14 template_name_suffix = ''
15 model = User
16 fields = ['first_name', 'last_name']
17 success_url = reverse_lazy('account')
18
19 def get_context_data(self, **kwargs):
20 context = super().get_context_data(**kwargs)
21 context['acc_page'] = 'account'
22 return context
23
24 def form_valid(self, form):
25 messages.success(self.request, 'Name saved.')
26 return super().form_valid(form)
27
28 def get_object(self, queryset=None):
29 return self.request.user
30
31
32 class PasswordView(LoginRequiredMixin, PasswordChangeView):
33 """Allow the user to change their password."""
34
35 template_name = 'user/password.html'
36 success_url = reverse_lazy('account-password')
37
38 def get_context_data(self, **kwargs):
39 context = super().get_context_data(**kwargs)
40 context['acc_page'] = 'password'
41 return context
42
43
44 class APITokenView(LoginRequiredMixin, TemplateView):
45 """Display the user's API token, and allow it to be regenerated."""
46
47 template_name = 'user/api-token.html'
48
49 def get_context_data(self, **kwargs):
50 context = super().get_context_data(**kwargs)
51 context['acc_page'] = 'api-token'
52 return context
53
[end of nextcloudappstore/core/user/views.py]
[start of nextcloudappstore/core/user/forms.py]
1 from django import forms
2 from captcha.fields import ReCaptchaField
3
4
5 class SignupFormRecaptcha(forms.Form):
6 """integrate a recaptcha field."""
7 recaptcha = ReCaptchaField()
8
9 def signup(self, request, user):
10 pass
11
[end of nextcloudappstore/core/user/forms.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/nextcloudappstore/core/user/forms.py b/nextcloudappstore/core/user/forms.py
--- a/nextcloudappstore/core/user/forms.py
+++ b/nextcloudappstore/core/user/forms.py
@@ -1,5 +1,7 @@
from django import forms
from captcha.fields import ReCaptchaField
+from django.forms import EmailField
+from django.utils.translation import ugettext_lazy as _
class SignupFormRecaptcha(forms.Form):
@@ -8,3 +10,19 @@
def signup(self, request, user):
pass
+
+
+class DeleteAccountForm(forms.Form):
+ email = EmailField(required=True, label=_('Your e-mail address'))
+
+ def __init__(self, *args, **kwargs):
+ self.user = kwargs.pop('user', None)
+ super().__init__(*args, **kwargs)
+
+ def clean_email(self):
+ email = self.cleaned_data.get('email')
+ if self.user and self.user.email == email:
+ return email
+ else:
+ raise forms.ValidationError(_(
+ 'The given e-mail address does not match your e-mail address'))
diff --git a/nextcloudappstore/core/user/views.py b/nextcloudappstore/core/user/views.py
--- a/nextcloudappstore/core/user/views.py
+++ b/nextcloudappstore/core/user/views.py
@@ -3,9 +3,30 @@
from django.contrib.auth.mixins import LoginRequiredMixin
from django.contrib.auth.models import User
from django.core.urlresolvers import reverse_lazy
+from django.shortcuts import redirect, render
from django.views.generic import TemplateView
from django.views.generic import UpdateView
+from nextcloudappstore.core.user.forms import DeleteAccountForm
+
+
+class DeleteAccountView(LoginRequiredMixin, TemplateView):
+ template_name = 'user/delete-account.html'
+
+ def get_context_data(self, **kwargs):
+ context = super().get_context_data(**kwargs)
+ context['form'] = DeleteAccountForm()
+ context['acc_page'] = 'delete-account'
+ return context
+
+ def post(self, request, *args, **kwargs):
+ form = DeleteAccountForm(request.POST, user=request.user)
+ if form.is_valid():
+ request.user.delete()
+ return redirect(reverse_lazy('home'))
+ else:
+ return render(request, self.template_name, {'form': form})
+
class AccountView(LoginRequiredMixin, UpdateView):
"""Display and allow changing of the user's name."""
diff --git a/nextcloudappstore/urls.py b/nextcloudappstore/urls.py
--- a/nextcloudappstore/urls.py
+++ b/nextcloudappstore/urls.py
@@ -4,7 +4,7 @@
from django.conf.urls import url, include
from django.contrib import admin
from nextcloudappstore.core.user.views import PasswordView, AccountView, \
- APITokenView
+ APITokenView, DeleteAccountView
from nextcloudappstore.core.views import CategoryAppListView, AppDetailView, \
app_description, AppReleasesView, AppUploadView, LegalNoticeView
@@ -19,6 +19,8 @@
name='account-password'),
url(r'^account/token/?$', APITokenView.as_view(),
name='account-api-token'),
+ url(r'^account/delete/?$', DeleteAccountView.as_view(),
+ name='account-deletion'),
url(r'^legal/?$', LegalNoticeView.as_view(), name='legal-notice'),
url(r'^categories/(?P<id>[\w]*)/?$', CategoryAppListView.as_view(),
name='category-app-list'),
| {"golden_diff": "diff --git a/nextcloudappstore/core/user/forms.py b/nextcloudappstore/core/user/forms.py\n--- a/nextcloudappstore/core/user/forms.py\n+++ b/nextcloudappstore/core/user/forms.py\n@@ -1,5 +1,7 @@\n from django import forms\n from captcha.fields import ReCaptchaField\n+from django.forms import EmailField\n+from django.utils.translation import ugettext_lazy as _\n \n \n class SignupFormRecaptcha(forms.Form):\n@@ -8,3 +10,19 @@\n \n def signup(self, request, user):\n pass\n+\n+\n+class DeleteAccountForm(forms.Form):\n+ email = EmailField(required=True, label=_('Your e-mail address'))\n+\n+ def __init__(self, *args, **kwargs):\n+ self.user = kwargs.pop('user', None)\n+ super().__init__(*args, **kwargs)\n+\n+ def clean_email(self):\n+ email = self.cleaned_data.get('email')\n+ if self.user and self.user.email == email:\n+ return email\n+ else:\n+ raise forms.ValidationError(_(\n+ 'The given e-mail address does not match your e-mail address'))\ndiff --git a/nextcloudappstore/core/user/views.py b/nextcloudappstore/core/user/views.py\n--- a/nextcloudappstore/core/user/views.py\n+++ b/nextcloudappstore/core/user/views.py\n@@ -3,9 +3,30 @@\n from django.contrib.auth.mixins import LoginRequiredMixin\n from django.contrib.auth.models import User\n from django.core.urlresolvers import reverse_lazy\n+from django.shortcuts import redirect, render\n from django.views.generic import TemplateView\n from django.views.generic import UpdateView\n \n+from nextcloudappstore.core.user.forms import DeleteAccountForm\n+\n+\n+class DeleteAccountView(LoginRequiredMixin, TemplateView):\n+ template_name = 'user/delete-account.html'\n+\n+ def get_context_data(self, **kwargs):\n+ context = super().get_context_data(**kwargs)\n+ context['form'] = DeleteAccountForm()\n+ context['acc_page'] = 'delete-account'\n+ return context\n+\n+ def post(self, request, *args, **kwargs):\n+ form = DeleteAccountForm(request.POST, user=request.user)\n+ if form.is_valid():\n+ request.user.delete()\n+ return redirect(reverse_lazy('home'))\n+ else:\n+ return render(request, self.template_name, {'form': form})\n+\n \n class AccountView(LoginRequiredMixin, UpdateView):\n \"\"\"Display and allow changing of the user's name.\"\"\"\ndiff --git a/nextcloudappstore/urls.py b/nextcloudappstore/urls.py\n--- a/nextcloudappstore/urls.py\n+++ b/nextcloudappstore/urls.py\n@@ -4,7 +4,7 @@\n from django.conf.urls import url, include\n from django.contrib import admin\n from nextcloudappstore.core.user.views import PasswordView, AccountView, \\\n- APITokenView\n+ APITokenView, DeleteAccountView\n from nextcloudappstore.core.views import CategoryAppListView, AppDetailView, \\\n app_description, AppReleasesView, AppUploadView, LegalNoticeView\n \n@@ -19,6 +19,8 @@\n name='account-password'),\n url(r'^account/token/?$', APITokenView.as_view(),\n name='account-api-token'),\n+ url(r'^account/delete/?$', DeleteAccountView.as_view(),\n+ name='account-deletion'),\n url(r'^legal/?$', LegalNoticeView.as_view(), name='legal-notice'),\n url(r'^categories/(?P<id>[\\w]*)/?$', CategoryAppListView.as_view(),\n name='category-app-list'),\n", "issue": "Delete user account\nA user should be able to delete his account by hitting and confirming it on the download page. The confirmation should not be able to trigger by accident, Github's delete repo ui is a good example.\n\nBefore deleting his account, a user will be warned that all his comments and apps will be deleted.\n\n", "before_files": [{"content": "from allauth.account.views import signup\nfrom allauth.socialaccount.views import signup as social_signup\nfrom csp.decorators import csp_exempt\nfrom django.conf.urls import url, include\nfrom django.contrib import admin\nfrom nextcloudappstore.core.user.views import PasswordView, AccountView, \\\n APITokenView\nfrom nextcloudappstore.core.views import CategoryAppListView, AppDetailView, \\\n app_description, AppReleasesView, AppUploadView, LegalNoticeView\n\nurlpatterns = [\n url(r'^$', CategoryAppListView.as_view(), {'id': None}, name='home'),\n url(r\"^signup/$\", csp_exempt(signup), name=\"account_signup\"),\n url(r\"^social/signup/$\", csp_exempt(social_signup),\n name=\"socialaccount_signup\"),\n url(r'^', include('allauth.urls')),\n url(r'^account/?$', AccountView.as_view(), name='account'),\n url(r'^account/password/?$', PasswordView.as_view(),\n name='account-password'),\n url(r'^account/token/?$', APITokenView.as_view(),\n name='account-api-token'),\n url(r'^legal/?$', LegalNoticeView.as_view(), name='legal-notice'),\n url(r'^categories/(?P<id>[\\w]*)/?$', CategoryAppListView.as_view(),\n name='category-app-list'),\n url(r'^app/upload/?$', AppUploadView.as_view(), name='app-upload'),\n url(r'^app/(?P<id>[\\w_]+)/?$', AppDetailView.as_view(), name='app-detail'),\n url(r'^app/(?P<id>[\\w_]+)/releases/?$', AppReleasesView.as_view(),\n name='app-releases'),\n url(r'^app/(?P<id>[\\w_]+)/description/?$', app_description,\n name='app-description'),\n url(r'^api/', include('nextcloudappstore.core.api.urls',\n namespace='api')),\n url(r'^admin/', admin.site.urls),\n]\n", "path": "nextcloudappstore/urls.py"}, {"content": "from allauth.account.views import PasswordChangeView\nfrom django.contrib import messages\nfrom django.contrib.auth.mixins import LoginRequiredMixin\nfrom django.contrib.auth.models import User\nfrom django.core.urlresolvers import reverse_lazy\nfrom django.views.generic import TemplateView\nfrom django.views.generic import UpdateView\n\n\nclass AccountView(LoginRequiredMixin, UpdateView):\n \"\"\"Display and allow changing of the user's name.\"\"\"\n\n template_name = 'user/account.html'\n template_name_suffix = ''\n model = User\n fields = ['first_name', 'last_name']\n success_url = reverse_lazy('account')\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n context['acc_page'] = 'account'\n return context\n\n def form_valid(self, form):\n messages.success(self.request, 'Name saved.')\n return super().form_valid(form)\n\n def get_object(self, queryset=None):\n return self.request.user\n\n\nclass PasswordView(LoginRequiredMixin, PasswordChangeView):\n \"\"\"Allow the user to change their password.\"\"\"\n\n template_name = 'user/password.html'\n success_url = reverse_lazy('account-password')\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n context['acc_page'] = 'password'\n return context\n\n\nclass APITokenView(LoginRequiredMixin, TemplateView):\n \"\"\"Display the user's API token, and allow it to be regenerated.\"\"\"\n\n template_name = 'user/api-token.html'\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n context['acc_page'] = 'api-token'\n return context\n", "path": "nextcloudappstore/core/user/views.py"}, {"content": "from django import forms\nfrom captcha.fields import ReCaptchaField\n\n\nclass SignupFormRecaptcha(forms.Form):\n \"\"\"integrate a recaptcha field.\"\"\"\n recaptcha = ReCaptchaField()\n\n def signup(self, request, user):\n pass\n", "path": "nextcloudappstore/core/user/forms.py"}]} | 1,645 | 793 |
gh_patches_debug_5702 | rasdani/github-patches | git_diff | sanic-org__sanic-819 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Configs loaded from environmental variables aren't properly typed
When setting configs using environmental variables `export SANIC_REQUEST_TIMEOUT=30`
```
app = Sanic(__name__)
print(type(app.config.REQUEST_TIMEOUT)) # <class 'str'>
```
The problem is in this function
```
# .../sanic/config.py
def load_environment_vars(self):
"""
Looks for any SANIC_ prefixed environment variables and applies
them to the configuration if present.
"""
for k, v in os.environ.items():
if k.startswith(SANIC_PREFIX):
_, config_key = k.split(SANIC_PREFIX, 1)
self[config_key] = v # os.environ values are always of type str
```
</issue>
<code>
[start of sanic/config.py]
1 import os
2 import sys
3 import syslog
4 import platform
5 import types
6
7 from sanic.log import DefaultFilter
8
9 SANIC_PREFIX = 'SANIC_'
10
11 _address_dict = {
12 'Windows': ('localhost', 514),
13 'Darwin': '/var/run/syslog',
14 'Linux': '/dev/log',
15 'FreeBSD': '/dev/log'
16 }
17
18 LOGGING = {
19 'version': 1,
20 'filters': {
21 'accessFilter': {
22 '()': DefaultFilter,
23 'param': [0, 10, 20]
24 },
25 'errorFilter': {
26 '()': DefaultFilter,
27 'param': [30, 40, 50]
28 }
29 },
30 'formatters': {
31 'simple': {
32 'format': '%(asctime)s - (%(name)s)[%(levelname)s]: %(message)s',
33 'datefmt': '%Y-%m-%d %H:%M:%S'
34 },
35 'access': {
36 'format': '%(asctime)s - (%(name)s)[%(levelname)s][%(host)s]: ' +
37 '%(request)s %(message)s %(status)d %(byte)d',
38 'datefmt': '%Y-%m-%d %H:%M:%S'
39 }
40 },
41 'handlers': {
42 'internal': {
43 'class': 'logging.StreamHandler',
44 'filters': ['accessFilter'],
45 'formatter': 'simple',
46 'stream': sys.stderr
47 },
48 'accessStream': {
49 'class': 'logging.StreamHandler',
50 'filters': ['accessFilter'],
51 'formatter': 'access',
52 'stream': sys.stderr
53 },
54 'errorStream': {
55 'class': 'logging.StreamHandler',
56 'filters': ['errorFilter'],
57 'formatter': 'simple',
58 'stream': sys.stderr
59 },
60 # before you use accessSysLog, be sure that log levels
61 # 0, 10, 20 have been enabled in you syslog configuration
62 # otherwise you won't be able to see the output in syslog
63 # logging file.
64 'accessSysLog': {
65 'class': 'logging.handlers.SysLogHandler',
66 'address': _address_dict.get(platform.system(),
67 ('localhost', 514)),
68 'facility': syslog.LOG_DAEMON,
69 'filters': ['accessFilter'],
70 'formatter': 'access'
71 },
72 'errorSysLog': {
73 'class': 'logging.handlers.SysLogHandler',
74 'address': _address_dict.get(platform.system(),
75 ('localhost', 514)),
76 'facility': syslog.LOG_DAEMON,
77 'filters': ['errorFilter'],
78 'formatter': 'simple'
79 },
80 },
81 'loggers': {
82 'sanic': {
83 'level': 'DEBUG',
84 'handlers': ['internal', 'errorStream']
85 },
86 'network': {
87 'level': 'DEBUG',
88 'handlers': ['accessStream', 'errorStream']
89 }
90 }
91 }
92
93 # this happens when using container or systems without syslog
94 # keep things in config would cause file not exists error
95 _addr = LOGGING['handlers']['accessSysLog']['address']
96 if type(_addr) is str and not os.path.exists(_addr):
97 LOGGING['handlers'].pop('accessSysLog')
98 LOGGING['handlers'].pop('errorSysLog')
99
100
101 class Config(dict):
102 def __init__(self, defaults=None, load_env=True, keep_alive=True):
103 super().__init__(defaults or {})
104 self.LOGO = """
105 ▄▄▄▄▄
106 ▀▀▀██████▄▄▄ _______________
107 ▄▄▄▄▄ █████████▄ / \\
108 ▀▀▀▀█████▌ ▀▐▄ ▀▐█ | Gotta go fast! |
109 ▀▀█████▄▄ ▀██████▄██ | _________________/
110 ▀▄▄▄▄▄ ▀▀█▄▀█════█▀ |/
111 ▀▀▀▄ ▀▀███ ▀ ▄▄
112 ▄███▀▀██▄████████▄ ▄▀▀▀▀▀▀█▌
113 ██▀▄▄▄██▀▄███▀ ▀▀████ ▄██
114 ▄▀▀▀▄██▄▀▀▌████▒▒▒▒▒▒███ ▌▄▄▀
115 ▌ ▐▀████▐███▒▒▒▒▒▐██▌
116 ▀▄▄▄▄▀ ▀▀████▒▒▒▒▄██▀
117 ▀▀█████████▀
118 ▄▄██▀██████▀█
119 ▄██▀ ▀▀▀ █
120 ▄█ ▐▌
121 ▄▄▄▄█▌ ▀█▄▄▄▄▀▀▄
122 ▌ ▐ ▀▀▄▄▄▀
123 ▀▀▄▄▀
124 """
125 self.REQUEST_MAX_SIZE = 100000000 # 100 megabytes
126 self.REQUEST_TIMEOUT = 60 # 60 seconds
127 self.KEEP_ALIVE = keep_alive
128 self.WEBSOCKET_MAX_SIZE = 2 ** 20 # 1 megabytes
129 self.WEBSOCKET_MAX_QUEUE = 32
130
131 if load_env:
132 self.load_environment_vars()
133
134 def __getattr__(self, attr):
135 try:
136 return self[attr]
137 except KeyError as ke:
138 raise AttributeError("Config has no '{}'".format(ke.args[0]))
139
140 def __setattr__(self, attr, value):
141 self[attr] = value
142
143 def from_envvar(self, variable_name):
144 """Load a configuration from an environment variable pointing to
145 a configuration file.
146
147 :param variable_name: name of the environment variable
148 :return: bool. ``True`` if able to load config, ``False`` otherwise.
149 """
150 config_file = os.environ.get(variable_name)
151 if not config_file:
152 raise RuntimeError('The environment variable %r is not set and '
153 'thus configuration could not be loaded.' %
154 variable_name)
155 return self.from_pyfile(config_file)
156
157 def from_pyfile(self, filename):
158 """Update the values in the config from a Python file.
159 Only the uppercase variables in that module are stored in the config.
160
161 :param filename: an absolute path to the config file
162 """
163 module = types.ModuleType('config')
164 module.__file__ = filename
165 try:
166 with open(filename) as config_file:
167 exec(compile(config_file.read(), filename, 'exec'),
168 module.__dict__)
169 except IOError as e:
170 e.strerror = 'Unable to load configuration file (%s)' % e.strerror
171 raise
172 self.from_object(module)
173 return True
174
175 def from_object(self, obj):
176 """Update the values from the given object.
177 Objects are usually either modules or classes.
178
179 Just the uppercase variables in that object are stored in the config.
180 Example usage::
181
182 from yourapplication import default_config
183 app.config.from_object(default_config)
184
185 You should not use this function to load the actual configuration but
186 rather configuration defaults. The actual config should be loaded
187 with :meth:`from_pyfile` and ideally from a location not within the
188 package because the package might be installed system wide.
189
190 :param obj: an object holding the configuration
191 """
192 for key in dir(obj):
193 if key.isupper():
194 self[key] = getattr(obj, key)
195
196 def load_environment_vars(self):
197 """
198 Looks for any SANIC_ prefixed environment variables and applies
199 them to the configuration if present.
200 """
201 for k, v in os.environ.items():
202 if k.startswith(SANIC_PREFIX):
203 _, config_key = k.split(SANIC_PREFIX, 1)
204 self[config_key] = v
205
[end of sanic/config.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/sanic/config.py b/sanic/config.py
--- a/sanic/config.py
+++ b/sanic/config.py
@@ -201,4 +201,10 @@
for k, v in os.environ.items():
if k.startswith(SANIC_PREFIX):
_, config_key = k.split(SANIC_PREFIX, 1)
- self[config_key] = v
+ try:
+ self[config_key] = int(v)
+ except ValueError:
+ try:
+ self[config_key] = float(v)
+ except ValueError:
+ self[config_key] = v
| {"golden_diff": "diff --git a/sanic/config.py b/sanic/config.py\n--- a/sanic/config.py\n+++ b/sanic/config.py\n@@ -201,4 +201,10 @@\n for k, v in os.environ.items():\n if k.startswith(SANIC_PREFIX):\n _, config_key = k.split(SANIC_PREFIX, 1)\n- self[config_key] = v\n+ try:\n+ self[config_key] = int(v)\n+ except ValueError:\n+ try:\n+ self[config_key] = float(v)\n+ except ValueError:\n+ self[config_key] = v\n", "issue": "Configs loaded from environmental variables aren't properly typed\nWhen setting configs using environmental variables `export SANIC_REQUEST_TIMEOUT=30`\r\n\r\n```\r\napp = Sanic(__name__)\r\nprint(type(app.config.REQUEST_TIMEOUT)) # <class 'str'>\r\n```\r\n\r\nThe problem is in this function\r\n```\r\n# .../sanic/config.py\r\n def load_environment_vars(self):\r\n \"\"\"\r\n Looks for any SANIC_ prefixed environment variables and applies\r\n them to the configuration if present.\r\n \"\"\"\r\n for k, v in os.environ.items():\r\n if k.startswith(SANIC_PREFIX):\r\n _, config_key = k.split(SANIC_PREFIX, 1)\r\n self[config_key] = v # os.environ values are always of type str\r\n```\r\n\n", "before_files": [{"content": "import os\nimport sys\nimport syslog\nimport platform\nimport types\n\nfrom sanic.log import DefaultFilter\n\nSANIC_PREFIX = 'SANIC_'\n\n_address_dict = {\n 'Windows': ('localhost', 514),\n 'Darwin': '/var/run/syslog',\n 'Linux': '/dev/log',\n 'FreeBSD': '/dev/log'\n}\n\nLOGGING = {\n 'version': 1,\n 'filters': {\n 'accessFilter': {\n '()': DefaultFilter,\n 'param': [0, 10, 20]\n },\n 'errorFilter': {\n '()': DefaultFilter,\n 'param': [30, 40, 50]\n }\n },\n 'formatters': {\n 'simple': {\n 'format': '%(asctime)s - (%(name)s)[%(levelname)s]: %(message)s',\n 'datefmt': '%Y-%m-%d %H:%M:%S'\n },\n 'access': {\n 'format': '%(asctime)s - (%(name)s)[%(levelname)s][%(host)s]: ' +\n '%(request)s %(message)s %(status)d %(byte)d',\n 'datefmt': '%Y-%m-%d %H:%M:%S'\n }\n },\n 'handlers': {\n 'internal': {\n 'class': 'logging.StreamHandler',\n 'filters': ['accessFilter'],\n 'formatter': 'simple',\n 'stream': sys.stderr\n },\n 'accessStream': {\n 'class': 'logging.StreamHandler',\n 'filters': ['accessFilter'],\n 'formatter': 'access',\n 'stream': sys.stderr\n },\n 'errorStream': {\n 'class': 'logging.StreamHandler',\n 'filters': ['errorFilter'],\n 'formatter': 'simple',\n 'stream': sys.stderr\n },\n # before you use accessSysLog, be sure that log levels\n # 0, 10, 20 have been enabled in you syslog configuration\n # otherwise you won't be able to see the output in syslog\n # logging file.\n 'accessSysLog': {\n 'class': 'logging.handlers.SysLogHandler',\n 'address': _address_dict.get(platform.system(),\n ('localhost', 514)),\n 'facility': syslog.LOG_DAEMON,\n 'filters': ['accessFilter'],\n 'formatter': 'access'\n },\n 'errorSysLog': {\n 'class': 'logging.handlers.SysLogHandler',\n 'address': _address_dict.get(platform.system(),\n ('localhost', 514)),\n 'facility': syslog.LOG_DAEMON,\n 'filters': ['errorFilter'],\n 'formatter': 'simple'\n },\n },\n 'loggers': {\n 'sanic': {\n 'level': 'DEBUG',\n 'handlers': ['internal', 'errorStream']\n },\n 'network': {\n 'level': 'DEBUG',\n 'handlers': ['accessStream', 'errorStream']\n }\n }\n}\n\n# this happens when using container or systems without syslog\n# keep things in config would cause file not exists error\n_addr = LOGGING['handlers']['accessSysLog']['address']\nif type(_addr) is str and not os.path.exists(_addr):\n LOGGING['handlers'].pop('accessSysLog')\n LOGGING['handlers'].pop('errorSysLog')\n\n\nclass Config(dict):\n def __init__(self, defaults=None, load_env=True, keep_alive=True):\n super().__init__(defaults or {})\n self.LOGO = \"\"\"\n \u2584\u2584\u2584\u2584\u2584\n \u2580\u2580\u2580\u2588\u2588\u2588\u2588\u2588\u2588\u2584\u2584\u2584 _______________\n \u2584\u2584\u2584\u2584\u2584 \u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2584 / \\\\\n \u2580\u2580\u2580\u2580\u2588\u2588\u2588\u2588\u2588\u258c \u2580\u2590\u2584 \u2580\u2590\u2588 | Gotta go fast! |\n \u2580\u2580\u2588\u2588\u2588\u2588\u2588\u2584\u2584 \u2580\u2588\u2588\u2588\u2588\u2588\u2588\u2584\u2588\u2588 | _________________/\n \u2580\u2584\u2584\u2584\u2584\u2584 \u2580\u2580\u2588\u2584\u2580\u2588\u2550\u2550\u2550\u2550\u2588\u2580 |/\n \u2580\u2580\u2580\u2584 \u2580\u2580\u2588\u2588\u2588 \u2580 \u2584\u2584\n \u2584\u2588\u2588\u2588\u2580\u2580\u2588\u2588\u2584\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2584 \u2584\u2580\u2580\u2580\u2580\u2580\u2580\u2588\u258c\n \u2588\u2588\u2580\u2584\u2584\u2584\u2588\u2588\u2580\u2584\u2588\u2588\u2588\u2580 \u2580\u2580\u2588\u2588\u2588\u2588 \u2584\u2588\u2588\n\u2584\u2580\u2580\u2580\u2584\u2588\u2588\u2584\u2580\u2580\u258c\u2588\u2588\u2588\u2588\u2592\u2592\u2592\u2592\u2592\u2592\u2588\u2588\u2588 \u258c\u2584\u2584\u2580\n\u258c \u2590\u2580\u2588\u2588\u2588\u2588\u2590\u2588\u2588\u2588\u2592\u2592\u2592\u2592\u2592\u2590\u2588\u2588\u258c\n\u2580\u2584\u2584\u2584\u2584\u2580 \u2580\u2580\u2588\u2588\u2588\u2588\u2592\u2592\u2592\u2592\u2584\u2588\u2588\u2580\n \u2580\u2580\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2580\n \u2584\u2584\u2588\u2588\u2580\u2588\u2588\u2588\u2588\u2588\u2588\u2580\u2588\n \u2584\u2588\u2588\u2580 \u2580\u2580\u2580 \u2588\n \u2584\u2588 \u2590\u258c\n \u2584\u2584\u2584\u2584\u2588\u258c \u2580\u2588\u2584\u2584\u2584\u2584\u2580\u2580\u2584\n\u258c \u2590 \u2580\u2580\u2584\u2584\u2584\u2580\n \u2580\u2580\u2584\u2584\u2580\n\"\"\"\n self.REQUEST_MAX_SIZE = 100000000 # 100 megabytes\n self.REQUEST_TIMEOUT = 60 # 60 seconds\n self.KEEP_ALIVE = keep_alive\n self.WEBSOCKET_MAX_SIZE = 2 ** 20 # 1 megabytes\n self.WEBSOCKET_MAX_QUEUE = 32\n\n if load_env:\n self.load_environment_vars()\n\n def __getattr__(self, attr):\n try:\n return self[attr]\n except KeyError as ke:\n raise AttributeError(\"Config has no '{}'\".format(ke.args[0]))\n\n def __setattr__(self, attr, value):\n self[attr] = value\n\n def from_envvar(self, variable_name):\n \"\"\"Load a configuration from an environment variable pointing to\n a configuration file.\n\n :param variable_name: name of the environment variable\n :return: bool. ``True`` if able to load config, ``False`` otherwise.\n \"\"\"\n config_file = os.environ.get(variable_name)\n if not config_file:\n raise RuntimeError('The environment variable %r is not set and '\n 'thus configuration could not be loaded.' %\n variable_name)\n return self.from_pyfile(config_file)\n\n def from_pyfile(self, filename):\n \"\"\"Update the values in the config from a Python file.\n Only the uppercase variables in that module are stored in the config.\n\n :param filename: an absolute path to the config file\n \"\"\"\n module = types.ModuleType('config')\n module.__file__ = filename\n try:\n with open(filename) as config_file:\n exec(compile(config_file.read(), filename, 'exec'),\n module.__dict__)\n except IOError as e:\n e.strerror = 'Unable to load configuration file (%s)' % e.strerror\n raise\n self.from_object(module)\n return True\n\n def from_object(self, obj):\n \"\"\"Update the values from the given object.\n Objects are usually either modules or classes.\n\n Just the uppercase variables in that object are stored in the config.\n Example usage::\n\n from yourapplication import default_config\n app.config.from_object(default_config)\n\n You should not use this function to load the actual configuration but\n rather configuration defaults. The actual config should be loaded\n with :meth:`from_pyfile` and ideally from a location not within the\n package because the package might be installed system wide.\n\n :param obj: an object holding the configuration\n \"\"\"\n for key in dir(obj):\n if key.isupper():\n self[key] = getattr(obj, key)\n\n def load_environment_vars(self):\n \"\"\"\n Looks for any SANIC_ prefixed environment variables and applies\n them to the configuration if present.\n \"\"\"\n for k, v in os.environ.items():\n if k.startswith(SANIC_PREFIX):\n _, config_key = k.split(SANIC_PREFIX, 1)\n self[config_key] = v\n", "path": "sanic/config.py"}]} | 2,922 | 137 |
gh_patches_debug_37645 | rasdani/github-patches | git_diff | vyperlang__vyper-1672 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Unused optimisation.
### Version Information
master
### What's your issue about?
Investigate listed TODO: https://github.com/ethereum/vyper/blame/master/vyper/optimizer.py#L99
```python
# Turns out this is actually not such a good optimization after all
elif node.value == "with" and int_at(argz, 1) and not search_for_set(argz[2], argz[0].value) and False:
o = replace_with_value(argz[2], argz[0].value, argz[1].value)
return o
```
### How can it be fixed?
I have not fully investigated, but I suspect we can just drop the optimisation.
</issue>
<code>
[start of vyper/optimizer.py]
1 import operator
2
3 from vyper.parser.parser_utils import (
4 LLLnode,
5 )
6 from vyper.utils import (
7 LOADED_LIMIT_MAP,
8 )
9
10
11 def get_int_at(args, pos, signed=False):
12 value = args[pos].value
13
14 if isinstance(value, int):
15 o = value
16 elif value == "mload" and args[pos].args[0].value in LOADED_LIMIT_MAP.keys():
17 o = LOADED_LIMIT_MAP[args[pos].args[0].value]
18 else:
19 return None
20
21 if signed or o < 0:
22 return ((o + 2**255) % 2**256) - 2**255
23 else:
24 return o % 2**256
25
26
27 def int_at(args, pos):
28 return get_int_at(args, pos) is not None
29
30
31 def search_for_set(node, var):
32 if node.value == "set" and node.args[0].value == var:
33 return True
34
35 for arg in node.args:
36 if search_for_set(arg, var):
37 return True
38
39 return False
40
41
42 def replace_with_value(node, var, value):
43 if node.value == "with" and node.args[0].value == var:
44 return LLLnode(
45 node.value,
46 [
47 node.args[0],
48 replace_with_value(node.args[1], var, value),
49 node.args[2]
50 ],
51 node.typ,
52 node.location,
53 node.annotation,
54 )
55 elif node.value == var:
56 return LLLnode(value, [], node.typ, node.location, node.annotation)
57 else:
58 return LLLnode(
59 node.value,
60 [replace_with_value(arg, var, value) for arg in node.args],
61 node.typ,
62 node.location,
63 node.annotation,
64 )
65
66
67 arith = {
68 "add": (operator.add, '+'),
69 "sub": (operator.sub, '-'),
70 "mul": (operator.mul, '*'),
71 "div": (operator.floordiv, '/'),
72 "mod": (operator.mod, '%'),
73 }
74
75
76 def _is_constant_add(node, args):
77 return (
78 (
79 node.value == "add" and int_at(args, 0)
80 ) and (
81 args[1].value == "add" and int_at(args[1].args, 0)
82 )
83 )
84
85
86 def _is_with_without_set(node, args):
87 # TODO: this unconditionally returns `False`. Corresponding optimizer path
88 # should likely be removed.
89 return (
90 (
91 node.value == "with" and int_at(args, 1)
92 ) and (
93 not search_for_set(args[2], args[0].value)
94 ) and (
95 False
96 )
97 )
98
99
100 def has_cond_arg(node):
101 return node.value in ['if', 'if_unchecked', 'assert', 'assert_reason']
102
103
104 def optimize(node: LLLnode) -> LLLnode:
105 argz = [optimize(arg) for arg in node.args]
106 if node.value in arith and int_at(argz, 0) and int_at(argz, 1):
107 left, right = get_int_at(argz, 0), get_int_at(argz, 1)
108 calcer, symb = arith[node.value]
109 new_value = calcer(left, right)
110 if argz[0].annotation and argz[1].annotation:
111 annotation = argz[0].annotation + symb + argz[1].annotation
112 elif argz[0].annotation or argz[1].annotation:
113 annotation = (
114 argz[0].annotation or str(left)
115 ) + symb + (
116 argz[1].annotation or str(right)
117 )
118 else:
119 annotation = ''
120 return LLLnode(
121 new_value,
122 [],
123 node.typ,
124 None,
125 node.pos,
126 annotation,
127 add_gas_estimate=node.add_gas_estimate,
128 valency=node.valency,
129 )
130 elif _is_constant_add(node, argz):
131 calcer, symb = arith[node.value]
132 if argz[0].annotation and argz[1].args[0].annotation:
133 annotation = argz[0].annotation + symb + argz[1].args[0].annotation
134 elif argz[0].annotation or argz[1].args[0].annotation:
135 annotation = (
136 argz[0].annotation or str(argz[0].value)
137 ) + symb + (
138 argz[1].args[0].annotation or str(argz[1].args[0].value)
139 )
140 else:
141 annotation = ''
142 return LLLnode(
143 "add",
144 [
145 LLLnode(argz[0].value + argz[1].args[0].value, annotation=annotation),
146 argz[1].args[1],
147 ],
148 node.typ,
149 None,
150 node.annotation,
151 add_gas_estimate=node.add_gas_estimate,
152 valency=node.valency,
153 )
154 elif node.value == "add" and get_int_at(argz, 0) == 0:
155 return LLLnode(
156 argz[1].value,
157 argz[1].args,
158 node.typ,
159 node.location,
160 node.pos,
161 argz[1].annotation,
162 add_gas_estimate=node.add_gas_estimate,
163 valency=node.valency,
164 )
165 elif node.value == "add" and get_int_at(argz, 1) == 0:
166 return LLLnode(
167 argz[0].value,
168 argz[0].args,
169 node.typ,
170 node.location,
171 node.pos,
172 argz[0].annotation,
173 add_gas_estimate=node.add_gas_estimate,
174 valency=node.valency,
175 )
176 elif node.value == "clamp" and int_at(argz, 0) and int_at(argz, 1) and int_at(argz, 2):
177 if get_int_at(argz, 0, True) > get_int_at(argz, 1, True):
178 raise Exception("Clamp always fails")
179 elif get_int_at(argz, 1, True) > get_int_at(argz, 2, True):
180 raise Exception("Clamp always fails")
181 else:
182 return argz[1]
183 elif node.value == "clamp" and int_at(argz, 0) and int_at(argz, 1):
184 if get_int_at(argz, 0, True) > get_int_at(argz, 1, True):
185 raise Exception("Clamp always fails")
186 else:
187 return LLLnode(
188 "clample",
189 [argz[1], argz[2]],
190 node.typ,
191 node.location,
192 node.pos,
193 node.annotation,
194 add_gas_estimate=node.add_gas_estimate,
195 valency=node.valency,
196 )
197 elif node.value == "clamp_nonzero" and int_at(argz, 0):
198 if get_int_at(argz, 0) != 0:
199 return LLLnode(
200 argz[0].value,
201 [],
202 node.typ,
203 node.location,
204 node.pos,
205 node.annotation,
206 add_gas_estimate=node.add_gas_estimate,
207 valency=node.valency,
208 )
209 else:
210 raise Exception("Clamp always fails")
211 # [eq, x, 0] is the same as [iszero, x].
212 elif node.value == 'eq' and int_at(argz, 1) and argz[1].value == 0:
213 return LLLnode(
214 'iszero',
215 [argz[0]],
216 node.typ,
217 node.location,
218 node.pos,
219 node.annotation,
220 add_gas_estimate=node.add_gas_estimate,
221 valency=node.valency,
222 )
223 # [ne, x, y] has the same truthyness as [xor, x, y]
224 # rewrite 'ne' as 'xor' in places where truthy is accepted.
225 elif has_cond_arg(node) and argz[0].value == 'ne':
226 argz[0] = LLLnode.from_list(['xor'] + argz[0].args)
227 return LLLnode.from_list(
228 [node.value] + argz,
229 typ=node.typ,
230 location=node.location,
231 pos=node.pos,
232 annotation=node.annotation,
233 # let from_list handle valency and gas_estimate
234 )
235 elif _is_with_without_set(node, argz):
236 # TODO: This block is currently unreachable due to
237 # `_is_with_without_set` unconditionally returning `False` this appears
238 # to be because this "is actually not such a good optimization after
239 # all" accordiing to previous comment.
240 o = replace_with_value(argz[2], argz[0].value, argz[1].value)
241 return o
242 elif node.value == "seq":
243 o = []
244 for arg in argz:
245 if arg.value == "seq":
246 o.extend(arg.args)
247 else:
248 o.append(arg)
249 return LLLnode(
250 node.value,
251 o,
252 node.typ,
253 node.location,
254 node.pos,
255 node.annotation,
256 add_gas_estimate=node.add_gas_estimate,
257 valency=node.valency,
258 )
259 elif node.total_gas is not None:
260 o = LLLnode(
261 node.value,
262 argz,
263 node.typ,
264 node.location,
265 node.pos,
266 node.annotation,
267 add_gas_estimate=node.add_gas_estimate,
268 valency=node.valency,
269 )
270 o.total_gas = node.total_gas - node.gas + o.gas
271 o.func_name = node.func_name
272 return o
273 else:
274 return LLLnode(
275 node.value,
276 argz,
277 node.typ,
278 node.location,
279 node.pos,
280 node.annotation,
281 add_gas_estimate=node.add_gas_estimate,
282 valency=node.valency,
283 )
284
[end of vyper/optimizer.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/vyper/optimizer.py b/vyper/optimizer.py
--- a/vyper/optimizer.py
+++ b/vyper/optimizer.py
@@ -1,4 +1,8 @@
import operator
+from typing import (
+ Any,
+ List,
+)
from vyper.parser.parser_utils import (
LLLnode,
@@ -39,31 +43,6 @@
return False
-def replace_with_value(node, var, value):
- if node.value == "with" and node.args[0].value == var:
- return LLLnode(
- node.value,
- [
- node.args[0],
- replace_with_value(node.args[1], var, value),
- node.args[2]
- ],
- node.typ,
- node.location,
- node.annotation,
- )
- elif node.value == var:
- return LLLnode(value, [], node.typ, node.location, node.annotation)
- else:
- return LLLnode(
- node.value,
- [replace_with_value(arg, var, value) for arg in node.args],
- node.typ,
- node.location,
- node.annotation,
- )
-
-
arith = {
"add": (operator.add, '+'),
"sub": (operator.sub, '-'),
@@ -83,20 +62,6 @@
)
-def _is_with_without_set(node, args):
- # TODO: this unconditionally returns `False`. Corresponding optimizer path
- # should likely be removed.
- return (
- (
- node.value == "with" and int_at(args, 1)
- ) and (
- not search_for_set(args[2], args[0].value)
- ) and (
- False
- )
- )
-
-
def has_cond_arg(node):
return node.value in ['if', 'if_unchecked', 'assert', 'assert_reason']
@@ -232,23 +197,16 @@
annotation=node.annotation,
# let from_list handle valency and gas_estimate
)
- elif _is_with_without_set(node, argz):
- # TODO: This block is currently unreachable due to
- # `_is_with_without_set` unconditionally returning `False` this appears
- # to be because this "is actually not such a good optimization after
- # all" accordiing to previous comment.
- o = replace_with_value(argz[2], argz[0].value, argz[1].value)
- return o
elif node.value == "seq":
- o = []
+ xs: List[Any] = []
for arg in argz:
if arg.value == "seq":
- o.extend(arg.args)
+ xs.extend(arg.args)
else:
- o.append(arg)
+ xs.append(arg)
return LLLnode(
node.value,
- o,
+ xs,
node.typ,
node.location,
node.pos,
| {"golden_diff": "diff --git a/vyper/optimizer.py b/vyper/optimizer.py\n--- a/vyper/optimizer.py\n+++ b/vyper/optimizer.py\n@@ -1,4 +1,8 @@\n import operator\n+from typing import (\n+ Any,\n+ List,\n+)\n \n from vyper.parser.parser_utils import (\n LLLnode,\n@@ -39,31 +43,6 @@\n return False\n \n \n-def replace_with_value(node, var, value):\n- if node.value == \"with\" and node.args[0].value == var:\n- return LLLnode(\n- node.value,\n- [\n- node.args[0],\n- replace_with_value(node.args[1], var, value),\n- node.args[2]\n- ],\n- node.typ,\n- node.location,\n- node.annotation,\n- )\n- elif node.value == var:\n- return LLLnode(value, [], node.typ, node.location, node.annotation)\n- else:\n- return LLLnode(\n- node.value,\n- [replace_with_value(arg, var, value) for arg in node.args],\n- node.typ,\n- node.location,\n- node.annotation,\n- )\n-\n-\n arith = {\n \"add\": (operator.add, '+'),\n \"sub\": (operator.sub, '-'),\n@@ -83,20 +62,6 @@\n )\n \n \n-def _is_with_without_set(node, args):\n- # TODO: this unconditionally returns `False`. Corresponding optimizer path\n- # should likely be removed.\n- return (\n- (\n- node.value == \"with\" and int_at(args, 1)\n- ) and (\n- not search_for_set(args[2], args[0].value)\n- ) and (\n- False\n- )\n- )\n-\n-\n def has_cond_arg(node):\n return node.value in ['if', 'if_unchecked', 'assert', 'assert_reason']\n \n@@ -232,23 +197,16 @@\n annotation=node.annotation,\n # let from_list handle valency and gas_estimate\n )\n- elif _is_with_without_set(node, argz):\n- # TODO: This block is currently unreachable due to\n- # `_is_with_without_set` unconditionally returning `False` this appears\n- # to be because this \"is actually not such a good optimization after\n- # all\" accordiing to previous comment.\n- o = replace_with_value(argz[2], argz[0].value, argz[1].value)\n- return o\n elif node.value == \"seq\":\n- o = []\n+ xs: List[Any] = []\n for arg in argz:\n if arg.value == \"seq\":\n- o.extend(arg.args)\n+ xs.extend(arg.args)\n else:\n- o.append(arg)\n+ xs.append(arg)\n return LLLnode(\n node.value,\n- o,\n+ xs,\n node.typ,\n node.location,\n node.pos,\n", "issue": "Unused optimisation.\n### Version Information\r\n\r\nmaster\r\n\r\n### What's your issue about?\r\nInvestigate listed TODO: https://github.com/ethereum/vyper/blame/master/vyper/optimizer.py#L99\r\n```python\r\n # Turns out this is actually not such a good optimization after all\r\n elif node.value == \"with\" and int_at(argz, 1) and not search_for_set(argz[2], argz[0].value) and False:\r\n o = replace_with_value(argz[2], argz[0].value, argz[1].value)\r\n return o\r\n```\r\n\r\n### How can it be fixed?\r\n\r\nI have not fully investigated, but I suspect we can just drop the optimisation.\n", "before_files": [{"content": "import operator\n\nfrom vyper.parser.parser_utils import (\n LLLnode,\n)\nfrom vyper.utils import (\n LOADED_LIMIT_MAP,\n)\n\n\ndef get_int_at(args, pos, signed=False):\n value = args[pos].value\n\n if isinstance(value, int):\n o = value\n elif value == \"mload\" and args[pos].args[0].value in LOADED_LIMIT_MAP.keys():\n o = LOADED_LIMIT_MAP[args[pos].args[0].value]\n else:\n return None\n\n if signed or o < 0:\n return ((o + 2**255) % 2**256) - 2**255\n else:\n return o % 2**256\n\n\ndef int_at(args, pos):\n return get_int_at(args, pos) is not None\n\n\ndef search_for_set(node, var):\n if node.value == \"set\" and node.args[0].value == var:\n return True\n\n for arg in node.args:\n if search_for_set(arg, var):\n return True\n\n return False\n\n\ndef replace_with_value(node, var, value):\n if node.value == \"with\" and node.args[0].value == var:\n return LLLnode(\n node.value,\n [\n node.args[0],\n replace_with_value(node.args[1], var, value),\n node.args[2]\n ],\n node.typ,\n node.location,\n node.annotation,\n )\n elif node.value == var:\n return LLLnode(value, [], node.typ, node.location, node.annotation)\n else:\n return LLLnode(\n node.value,\n [replace_with_value(arg, var, value) for arg in node.args],\n node.typ,\n node.location,\n node.annotation,\n )\n\n\narith = {\n \"add\": (operator.add, '+'),\n \"sub\": (operator.sub, '-'),\n \"mul\": (operator.mul, '*'),\n \"div\": (operator.floordiv, '/'),\n \"mod\": (operator.mod, '%'),\n}\n\n\ndef _is_constant_add(node, args):\n return (\n (\n node.value == \"add\" and int_at(args, 0)\n ) and (\n args[1].value == \"add\" and int_at(args[1].args, 0)\n )\n )\n\n\ndef _is_with_without_set(node, args):\n # TODO: this unconditionally returns `False`. Corresponding optimizer path\n # should likely be removed.\n return (\n (\n node.value == \"with\" and int_at(args, 1)\n ) and (\n not search_for_set(args[2], args[0].value)\n ) and (\n False\n )\n )\n\n\ndef has_cond_arg(node):\n return node.value in ['if', 'if_unchecked', 'assert', 'assert_reason']\n\n\ndef optimize(node: LLLnode) -> LLLnode:\n argz = [optimize(arg) for arg in node.args]\n if node.value in arith and int_at(argz, 0) and int_at(argz, 1):\n left, right = get_int_at(argz, 0), get_int_at(argz, 1)\n calcer, symb = arith[node.value]\n new_value = calcer(left, right)\n if argz[0].annotation and argz[1].annotation:\n annotation = argz[0].annotation + symb + argz[1].annotation\n elif argz[0].annotation or argz[1].annotation:\n annotation = (\n argz[0].annotation or str(left)\n ) + symb + (\n argz[1].annotation or str(right)\n )\n else:\n annotation = ''\n return LLLnode(\n new_value,\n [],\n node.typ,\n None,\n node.pos,\n annotation,\n add_gas_estimate=node.add_gas_estimate,\n valency=node.valency,\n )\n elif _is_constant_add(node, argz):\n calcer, symb = arith[node.value]\n if argz[0].annotation and argz[1].args[0].annotation:\n annotation = argz[0].annotation + symb + argz[1].args[0].annotation\n elif argz[0].annotation or argz[1].args[0].annotation:\n annotation = (\n argz[0].annotation or str(argz[0].value)\n ) + symb + (\n argz[1].args[0].annotation or str(argz[1].args[0].value)\n )\n else:\n annotation = ''\n return LLLnode(\n \"add\",\n [\n LLLnode(argz[0].value + argz[1].args[0].value, annotation=annotation),\n argz[1].args[1],\n ],\n node.typ,\n None,\n node.annotation,\n add_gas_estimate=node.add_gas_estimate,\n valency=node.valency,\n )\n elif node.value == \"add\" and get_int_at(argz, 0) == 0:\n return LLLnode(\n argz[1].value,\n argz[1].args,\n node.typ,\n node.location,\n node.pos,\n argz[1].annotation,\n add_gas_estimate=node.add_gas_estimate,\n valency=node.valency,\n )\n elif node.value == \"add\" and get_int_at(argz, 1) == 0:\n return LLLnode(\n argz[0].value,\n argz[0].args,\n node.typ,\n node.location,\n node.pos,\n argz[0].annotation,\n add_gas_estimate=node.add_gas_estimate,\n valency=node.valency,\n )\n elif node.value == \"clamp\" and int_at(argz, 0) and int_at(argz, 1) and int_at(argz, 2):\n if get_int_at(argz, 0, True) > get_int_at(argz, 1, True):\n raise Exception(\"Clamp always fails\")\n elif get_int_at(argz, 1, True) > get_int_at(argz, 2, True):\n raise Exception(\"Clamp always fails\")\n else:\n return argz[1]\n elif node.value == \"clamp\" and int_at(argz, 0) and int_at(argz, 1):\n if get_int_at(argz, 0, True) > get_int_at(argz, 1, True):\n raise Exception(\"Clamp always fails\")\n else:\n return LLLnode(\n \"clample\",\n [argz[1], argz[2]],\n node.typ,\n node.location,\n node.pos,\n node.annotation,\n add_gas_estimate=node.add_gas_estimate,\n valency=node.valency,\n )\n elif node.value == \"clamp_nonzero\" and int_at(argz, 0):\n if get_int_at(argz, 0) != 0:\n return LLLnode(\n argz[0].value,\n [],\n node.typ,\n node.location,\n node.pos,\n node.annotation,\n add_gas_estimate=node.add_gas_estimate,\n valency=node.valency,\n )\n else:\n raise Exception(\"Clamp always fails\")\n # [eq, x, 0] is the same as [iszero, x].\n elif node.value == 'eq' and int_at(argz, 1) and argz[1].value == 0:\n return LLLnode(\n 'iszero',\n [argz[0]],\n node.typ,\n node.location,\n node.pos,\n node.annotation,\n add_gas_estimate=node.add_gas_estimate,\n valency=node.valency,\n )\n # [ne, x, y] has the same truthyness as [xor, x, y]\n # rewrite 'ne' as 'xor' in places where truthy is accepted.\n elif has_cond_arg(node) and argz[0].value == 'ne':\n argz[0] = LLLnode.from_list(['xor'] + argz[0].args)\n return LLLnode.from_list(\n [node.value] + argz,\n typ=node.typ,\n location=node.location,\n pos=node.pos,\n annotation=node.annotation,\n # let from_list handle valency and gas_estimate\n )\n elif _is_with_without_set(node, argz):\n # TODO: This block is currently unreachable due to\n # `_is_with_without_set` unconditionally returning `False` this appears\n # to be because this \"is actually not such a good optimization after\n # all\" accordiing to previous comment.\n o = replace_with_value(argz[2], argz[0].value, argz[1].value)\n return o\n elif node.value == \"seq\":\n o = []\n for arg in argz:\n if arg.value == \"seq\":\n o.extend(arg.args)\n else:\n o.append(arg)\n return LLLnode(\n node.value,\n o,\n node.typ,\n node.location,\n node.pos,\n node.annotation,\n add_gas_estimate=node.add_gas_estimate,\n valency=node.valency,\n )\n elif node.total_gas is not None:\n o = LLLnode(\n node.value,\n argz,\n node.typ,\n node.location,\n node.pos,\n node.annotation,\n add_gas_estimate=node.add_gas_estimate,\n valency=node.valency,\n )\n o.total_gas = node.total_gas - node.gas + o.gas\n o.func_name = node.func_name\n return o\n else:\n return LLLnode(\n node.value,\n argz,\n node.typ,\n node.location,\n node.pos,\n node.annotation,\n add_gas_estimate=node.add_gas_estimate,\n valency=node.valency,\n )\n", "path": "vyper/optimizer.py"}]} | 3,570 | 664 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.