Datasets:

File size: 2,829 Bytes
057c13a 01d4e9c 64bdebd 057c13a 06942b6 e3d4510 06942b6 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 |
---
license: mit
size_categories:
- 1K<n<10K
task_categories:
- visual-question-answering
pretty_name: VisualPuzzles
dataset_info:
features:
- name: id
dtype: int64
- name: category
dtype: string
- name: image
dtype: image
- name: question
dtype: string
- name: options
sequence: string
- name: answer
dtype: string
splits:
- name: train
num_bytes: 139582416.624
num_examples: 1168
download_size: 137679574
dataset_size: 139582416.624
configs:
- config_name: default
data_files:
- split: train
path: data.parquet
---
# VisualPuzzles: Decoupling Multimodal Reasoning Evaluation from Domain Knowledge
[🏠 Homepage](https://neulab.github.io/VisualPuzzles/) | [📊 VisualPuzzles](https://huggingface.co/datasets/neulab/VisualPuzzles) | [💻 Github](https://github.com/neulab/VisualPuzzles) | [📄 Arxiv](https://arxiv.org/abs/2504.10342) | [📕 PDF](https://arxiv.org/pdf/2504.10342) | [🖥️ Zeno Model Output](https://hub.zenoml.com/project/2e727b03-a677-451a-b714-f2c07ad2b49f/VisualPuzzles)
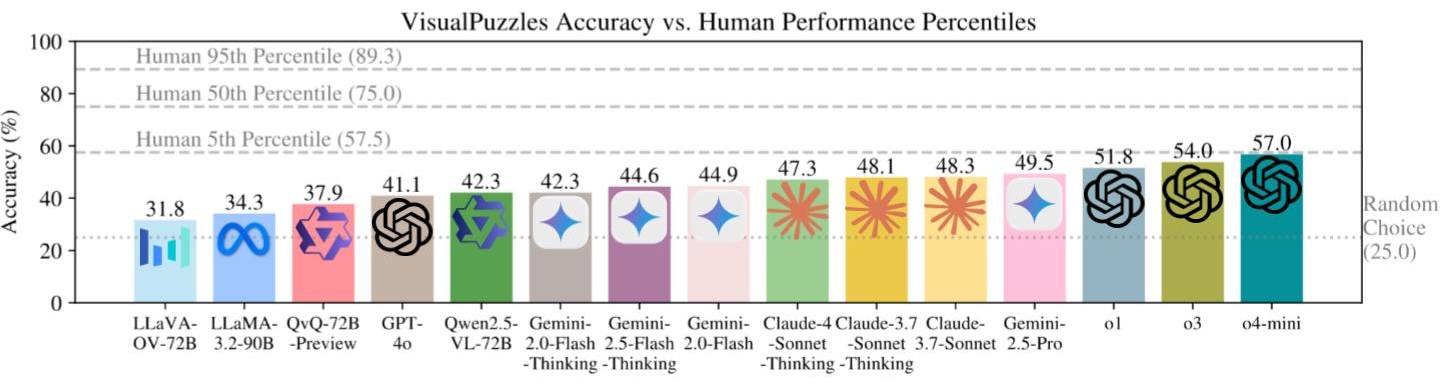
## Overview
**VisualPuzzles** is a multimodal benchmark specifically designed to evaluate **reasoning abilities** in large models while deliberately minimizing reliance on domain-specific knowledge.
Key features:
- 1168 diverse puzzles
- 5 reasoning categories: Algorithmic, Analogical, Deductive, Inductive, Spatial
- Difficulty labels: Easy, Medium, Hard
- Less knowledge-intensive than existing benchmarks (e.g., MMMU)
- More reasoning-complex than existing benchmarks (e.g., MMMU)
## Key Findings
- All models perform worse than humans; most can't surpass even 5th-percentile human performance.
- Strong performance on knowledge-heavy benchmarks does not transfer well.
- Larger models and structured "thinking modes" don't guarantee better results.
- Scaling model size does not ensure stronger reasoning
## Usage
To load this dataset via Hugging Face’s `datasets` library:
```python
from datasets import load_dataset
dataset = load_dataset("neulab/VisualPuzzles")
data = dataset["train"]
sample = data[0]
print("ID:", sample["id"])
print("Category:", sample["category"])
print("Question:", sample["question"])
print("Options:", sample["options"])
print("Answer:", sample["answer"])
```
## Citation
If you use or reference this dataset in your work, please cite:
```bibtex
@article{song2025visualpuzzles,
title = {VisualPuzzles: Decoupling Multimodal Reasoning Evaluation from Domain Knowledge},
author = {Song, Yueqi and Ou, Tianyue and Kong, Yibo and Li, Zecheng and Neubig, Graham and Yue, Xiang},
year = {2025},
journal = {arXiv preprint arXiv:2504.10342},
url = {https://arxiv.org/abs/2504.10342}
}
``` |