
modelId
string | author
string | last_modified
timestamp[us, tz=UTC] | downloads
int64 | likes
int64 | library_name
string | tags
list | pipeline_tag
string | createdAt
timestamp[us, tz=UTC] | card
string |
|---|---|---|---|---|---|---|---|---|---|
lesso14/8e3f1cad-bd2a-47ec-89cf-d0994a02d997
|
lesso14
| 2025-04-03T16:36:53Z
| 0
| 0
|
peft
|
[
"peft",
"safetensors",
"llama",
"axolotl",
"generated_from_trainer",
"base_model:unsloth/SmolLM2-360M-Instruct",
"base_model:adapter:unsloth/SmolLM2-360M-Instruct",
"license:apache-2.0",
"region:us"
] | null | 2025-04-03T16:09:56Z
|
---
library_name: peft
license: apache-2.0
base_model: unsloth/SmolLM2-360M-Instruct
tags:
- axolotl
- generated_from_trainer
model-index:
- name: 8e3f1cad-bd2a-47ec-89cf-d0994a02d997
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
adapter: lora
base_model: unsloth/SmolLM2-360M-Instruct
bf16: auto
chat_template: llama3
dataset_prepared_path: null
datasets:
- data_files:
- 0ac69f72d822065e_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/0ac69f72d822065e_train_data.json
type:
field_instruction: x
field_output: yl
format: '{instruction}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
do_eval: true
early_stopping_patience: 3
eval_batch_size: 4
eval_max_new_tokens: 128
eval_steps: 500
evals_per_epoch: null
flash_attention: true
fp16: false
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 8
gradient_checkpointing: true
group_by_length: true
hub_model_id: lesso14/8e3f1cad-bd2a-47ec-89cf-d0994a02d997
hub_repo: null
hub_strategy: checkpoint
hub_token: null
learning_rate: 0.000214
load_in_4bit: false
load_in_8bit: false
local_rank: null
logging_steps: 50
lora_alpha: 128
lora_dropout: 0.15
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 64
lora_target_linear: true
lr_scheduler: cosine
max_grad_norm: 1.0
max_steps: 500
micro_batch_size: 4
mlflow_experiment_name: /tmp/0ac69f72d822065e_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 10
optimizer: adamw_torch_fused
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
save_steps: 500
saves_per_epoch: null
seed: 140
sequence_len: 1024
strict: false
tf32: true
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: 3f4b09da-df60-4062-bfac-4936ce58b134
wandb_project: 14a
wandb_run: your_name
wandb_runid: 3f4b09da-df60-4062-bfac-4936ce58b134
warmup_steps: 100
weight_decay: 0.0
xformers_attention: null
```
</details><br>
# 8e3f1cad-bd2a-47ec-89cf-d0994a02d997
This model is a fine-tuned version of [unsloth/SmolLM2-360M-Instruct](https://huggingface.co/unsloth/SmolLM2-360M-Instruct) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7197
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.000214
- train_batch_size: 4
- eval_batch_size: 4
- seed: 140
- gradient_accumulation_steps: 8
- total_train_batch_size: 32
- optimizer: Use OptimizerNames.ADAMW_TORCH_FUSED with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 100
- training_steps: 500
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| No log | 0.0010 | 1 | 1.2791 |
| 0.7299 | 0.5173 | 500 | 0.7197 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1
|
genki10/BERT_AugV8_k1_task1_organization_sp040_lw010_fold2
|
genki10
| 2025-04-03T16:36:37Z
| 4
| 0
|
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-03-25T02:54:06Z
|
---
library_name: transformers
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: BERT_AugV8_k1_task1_organization_sp040_lw010_fold2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BERT_AugV8_k1_task1_organization_sp040_lw010_fold2
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6181
- Qwk: 0.5604
- Mse: 0.6177
- Rmse: 0.7859
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 150
### Training results
| Training Loss | Epoch | Step | Validation Loss | Qwk | Mse | Rmse |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:------:|
| No log | 1.0 | 2 | 12.9270 | 0.0 | 12.9271 | 3.5954 |
| No log | 2.0 | 4 | 10.9895 | 0.0148 | 10.9897 | 3.3151 |
| No log | 3.0 | 6 | 9.4440 | -0.0005 | 9.4441 | 3.0731 |
| No log | 4.0 | 8 | 8.4463 | 0.0 | 8.4464 | 2.9063 |
| No log | 5.0 | 10 | 6.7743 | 0.0 | 6.7747 | 2.6028 |
| No log | 6.0 | 12 | 5.5285 | 0.0269 | 5.5288 | 2.3513 |
| No log | 7.0 | 14 | 4.3715 | 0.0155 | 4.3718 | 2.0909 |
| No log | 8.0 | 16 | 3.4828 | 0.0 | 3.4832 | 1.8663 |
| No log | 9.0 | 18 | 2.5586 | 0.0 | 2.5590 | 1.5997 |
| No log | 10.0 | 20 | 1.8956 | 0.0678 | 1.8961 | 1.3770 |
| No log | 11.0 | 22 | 1.3882 | 0.0422 | 1.3887 | 1.1784 |
| No log | 12.0 | 24 | 1.1171 | 0.0213 | 1.1176 | 1.0572 |
| No log | 13.0 | 26 | 0.9062 | 0.0107 | 0.9067 | 0.9522 |
| No log | 14.0 | 28 | 0.8795 | 0.1279 | 0.8801 | 0.9381 |
| No log | 15.0 | 30 | 0.8202 | 0.3407 | 0.8205 | 0.9058 |
| No log | 16.0 | 32 | 0.9118 | 0.0492 | 0.9121 | 0.9550 |
| No log | 17.0 | 34 | 1.2117 | 0.1030 | 1.2121 | 1.1009 |
| No log | 18.0 | 36 | 0.8578 | 0.2345 | 0.8581 | 0.9264 |
| No log | 19.0 | 38 | 0.6389 | 0.3658 | 0.6391 | 0.7994 |
| No log | 20.0 | 40 | 0.6746 | 0.3002 | 0.6748 | 0.8214 |
| No log | 21.0 | 42 | 0.6001 | 0.3712 | 0.6001 | 0.7747 |
| No log | 22.0 | 44 | 0.5397 | 0.5052 | 0.5398 | 0.7347 |
| No log | 23.0 | 46 | 0.8912 | 0.4888 | 0.8915 | 0.9442 |
| No log | 24.0 | 48 | 0.7137 | 0.5383 | 0.7138 | 0.8449 |
| No log | 25.0 | 50 | 0.6226 | 0.5288 | 0.6226 | 0.7891 |
| No log | 26.0 | 52 | 0.6678 | 0.5219 | 0.6678 | 0.8172 |
| No log | 27.0 | 54 | 0.6568 | 0.5421 | 0.6569 | 0.8105 |
| No log | 28.0 | 56 | 0.7135 | 0.5574 | 0.7138 | 0.8449 |
| No log | 29.0 | 58 | 1.0521 | 0.4354 | 1.0526 | 1.0259 |
| No log | 30.0 | 60 | 1.4136 | 0.3464 | 1.4140 | 1.1891 |
| No log | 31.0 | 62 | 1.6036 | 0.2997 | 1.6040 | 1.2665 |
| No log | 32.0 | 64 | 1.0144 | 0.4036 | 1.0146 | 1.0073 |
| No log | 33.0 | 66 | 0.4920 | 0.5684 | 0.4919 | 0.7013 |
| No log | 34.0 | 68 | 0.4939 | 0.5560 | 0.4937 | 0.7027 |
| No log | 35.0 | 70 | 0.5951 | 0.5535 | 0.5949 | 0.7713 |
| No log | 36.0 | 72 | 0.8073 | 0.4633 | 0.8072 | 0.8985 |
| No log | 37.0 | 74 | 0.6624 | 0.5176 | 0.6622 | 0.8138 |
| No log | 38.0 | 76 | 0.5535 | 0.5271 | 0.5536 | 0.7440 |
| No log | 39.0 | 78 | 0.6578 | 0.5118 | 0.6579 | 0.8111 |
| No log | 40.0 | 80 | 0.9674 | 0.3685 | 0.9673 | 0.9835 |
| No log | 41.0 | 82 | 1.0259 | 0.3413 | 1.0258 | 1.0128 |
| No log | 42.0 | 84 | 0.8278 | 0.3490 | 0.8277 | 0.9098 |
| No log | 43.0 | 86 | 0.6356 | 0.5293 | 0.6353 | 0.7971 |
| No log | 44.0 | 88 | 0.6695 | 0.5566 | 0.6691 | 0.8180 |
| No log | 45.0 | 90 | 1.0887 | 0.3421 | 1.0885 | 1.0433 |
| No log | 46.0 | 92 | 0.9693 | 0.3935 | 0.9690 | 0.9844 |
| No log | 47.0 | 94 | 0.7381 | 0.5044 | 0.7378 | 0.8590 |
| No log | 48.0 | 96 | 0.6181 | 0.5604 | 0.6177 | 0.7859 |
### Framework versions
- Transformers 4.47.0
- Pytorch 2.5.1+cu121
- Datasets 3.3.1
- Tokenizers 0.21.0
|
ysn-rfd/WizardLM-7B-Uncensored-Q4_K_M-GGUF
|
ysn-rfd
| 2025-04-03T16:36:22Z
| 0
| 0
| null |
[
"gguf",
"uncensored",
"llama-cpp",
"gguf-my-repo",
"dataset:ehartford/WizardLM_alpaca_evol_instruct_70k_unfiltered",
"base_model:cognitivecomputations/WizardLM-7B-Uncensored",
"base_model:quantized:cognitivecomputations/WizardLM-7B-Uncensored",
"license:other",
"endpoints_compatible",
"region:us"
] | null | 2025-04-03T16:36:05Z
|
---
base_model: cognitivecomputations/WizardLM-7B-Uncensored
datasets:
- ehartford/WizardLM_alpaca_evol_instruct_70k_unfiltered
license: other
tags:
- uncensored
- llama-cpp
- gguf-my-repo
---
# ysn-rfd/WizardLM-7B-Uncensored-Q4_K_M-GGUF
This model was converted to GGUF format from [`cognitivecomputations/WizardLM-7B-Uncensored`](https://huggingface.co/cognitivecomputations/WizardLM-7B-Uncensored) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/cognitivecomputations/WizardLM-7B-Uncensored) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo ysn-rfd/WizardLM-7B-Uncensored-Q4_K_M-GGUF --hf-file wizardlm-7b-uncensored-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo ysn-rfd/WizardLM-7B-Uncensored-Q4_K_M-GGUF --hf-file wizardlm-7b-uncensored-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo ysn-rfd/WizardLM-7B-Uncensored-Q4_K_M-GGUF --hf-file wizardlm-7b-uncensored-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo ysn-rfd/WizardLM-7B-Uncensored-Q4_K_M-GGUF --hf-file wizardlm-7b-uncensored-q4_k_m.gguf -c 2048
```
|
BAAI/RoboBrain-LoRA-Affordance
|
BAAI
| 2025-04-03T16:34:50Z
| 0
| 3
| null |
[
"safetensors",
"en",
"dataset:BAAI/ShareRobot",
"dataset:lmms-lab/LLaVA-OneVision-Data",
"arxiv:2502.21257",
"license:apache-2.0",
"region:us"
] | null | 2025-03-29T01:16:43Z
|
---
license: apache-2.0
datasets:
- BAAI/ShareRobot
- lmms-lab/LLaVA-OneVision-Data
language:
- en
---
<div align="center">
<img src="https://github.com/FlagOpen/RoboBrain/raw/main/assets/logo.jpg" width="400"/>
</div>
# [CVPR 25] RoboBrain: A Unified Brain Model for Robotic Manipulation from Abstract to Concrete.
## 🤗 Models
- **[`Base Planning Model`](https://huggingface.co/BAAI/RoboBrain/)**: The model was trained on general datasets in Stages 1–2 and on the Robotic Planning dataset in Stage 3, which is designed for Planning prediction.
- **[`A-LoRA for Affordance`](https://huggingface.co/BAAI/RoboBrain-LoRA-Affordance/)**: Based on the Base Planning Model, Stage 4 involves LoRA-based training with our Affordance dataset to predict affordance.
- **[`T-LoRA for Trajectory`](https://huggingface.co/BAAI/RoboBrain/)**: Based on the Base Planning Model, Stage 4 involves LoRA-based training with our Trajectory dataset to predict trajectory.
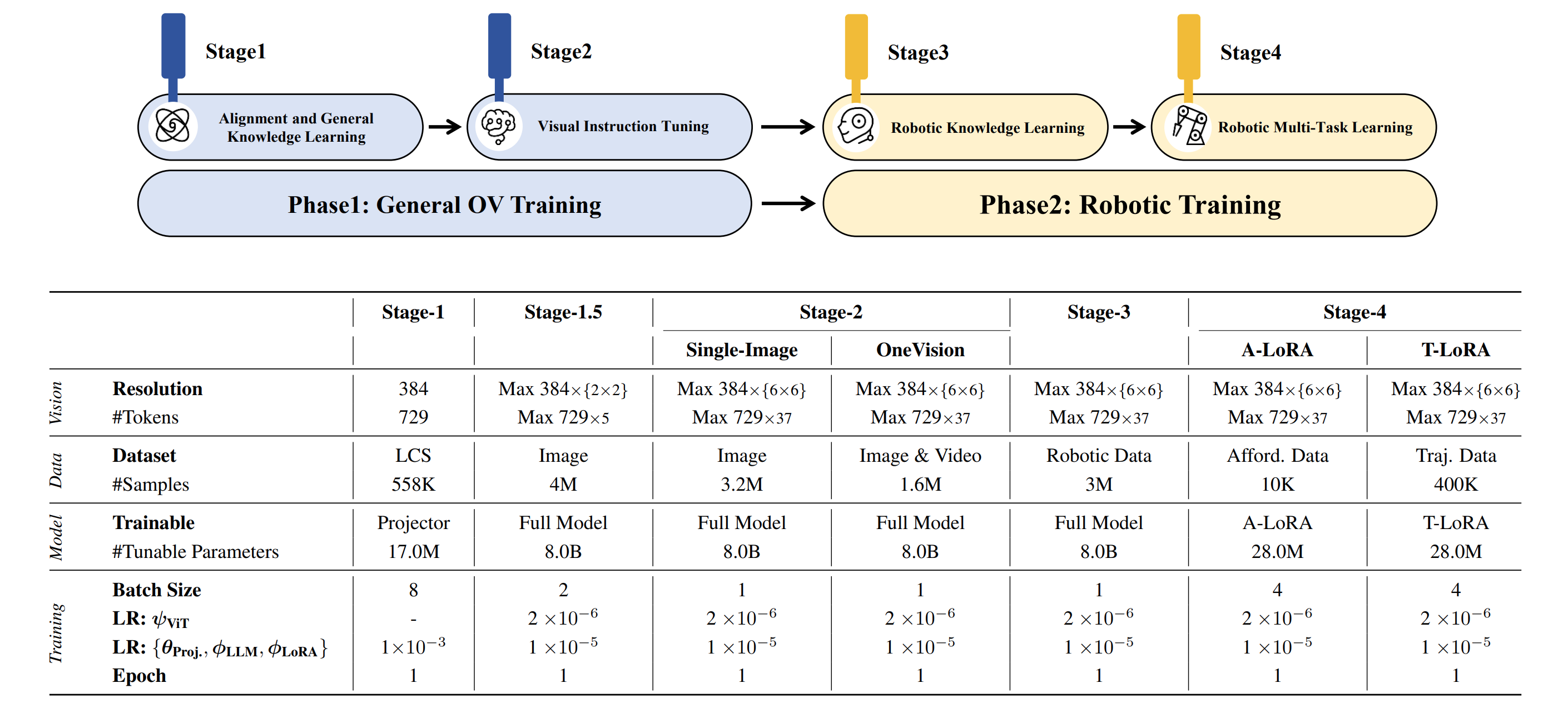
| Models | Checkpoint | Description |
|----------------------|----------------------------------------------------------------|------------------------------------------------------------|
| Planning Model | [🤗 Planning CKPTs](https://huggingface.co/BAAI/RoboBrain/) | Used for Planning prediction in our paper |
| Affordance (A-LoRA) | [🤗 Affordance CKPTs](https://huggingface.co/BAAI/RoboBrain-LoRA-Affordance/) | Used for Affordance prediction in our paper |
| Trajectory (T-LoRA) | [🤗 Trajectory CKPTs](https://huggingface.co/BAAI/RoboBrain-LoRA-Trajectory/) | Used for Trajectory prediction in our paper |
## 🛠️ Setup
```bash
# clone repo.
git clone https://github.com/FlagOpen/RoboBrain.git
cd RoboBrain
# build conda env.
conda create -n robobrain python=3.10
conda activate robobrain
pip install -r requirements.txt
```
## <a id="Training"> 🤖 Training</a>
### 1. Data Preparation
```bash
# Modify datasets for Stage 4_aff, please refer to:
- yaml_path: scripts/train/yaml/stage_4_affordance.yaml
```
**Note:** During training, we applied normalization to the bounding boxes, representing them with the coordinates of the top-left and bottom-right corners, and retaining three decimal places for each.
The sample format in each json file should be like:
```json
{
"id": xxxx,
"image": "testsetv3/Unseen/egocentric/ride/bicycle/bicycle_001662.jpg",
"conversations": [
{
"value": "<image>\nYou are a robot using the joint control. The task is \"ride the bicycle\". Please predict a possible affordance area of the end effector?",
"from": "human"
},
{
"from": "gpt",
"value": "[0.561, 0.171, 0.645, 0.279]"
}
]
},
```
### 2. Training
```bash
# Training on Stage 4_aff:
bash scripts/train/stage_4_0_resume_finetune_lora_a.sh
```
**Note:** Please change the environment variables (e.g. *DATA_PATH*, *IMAGE_FOLDER*, *PREV_STAGE_CHECKPOINT*) in the script to your own.
### 3. Convert original weights to HF weights
```bash
# Planning Model
python model/llava_utils/convert_robobrain_to_hf.py --model_dir /path/to/original/checkpoint/ --dump_path /path/to/output/
# A-LoRA & T-RoRA
python model/llava_utils/convert_lora_weights_to_hf.py --model_dir /path/to/original/checkpoint/ --dump_path /path/to/output/
```
## <a id="Inference">⭐️ Inference</a>
### Usage for Affordance Prediction
```python
# please refer to https://github.com/FlagOpen/RoboBrain
from inference import SimpleInference
model_id = "BAAI/RoboBrain"
lora_id = "BAAI/RoboBrain-LoRA-Affordance"
model = SimpleInference(model_id, lora_id)
# Example 1:
prompt = "You are a robot using the joint control. The task is \"pick_up the suitcase\". Please predict a possible affordance area of the end effector?"
image = "./assets/demo/affordance_1.jpg"
pred = model.inference(prompt, image, do_sample=False)
print(f"Prediction: {pred}")
'''
Prediction: [0.733, 0.158, 0.845, 0.263]
'''
# Example 2:
prompt = "You are a robot using the joint control. The task is \"push the bicycle\". Please predict a possible affordance area of the end effector?"
image = "./assets/demo/affordance_2.jpg"
pred = model.inference(prompt, image, do_sample=False)
print(f"Prediction: {pred}")
'''
Prediction: [0.600, 0.127, 0.692, 0.227]
'''
```

## <a id="Evaluation">🤖 Evaluation</a>
*Coming Soon ...*
## 😊 Acknowledgement
We would like to express our sincere gratitude to the developers and contributors of the following projects:
1. [LLaVA-NeXT](https://github.com/LLaVA-VL/LLaVA-NeXT): The comprehensive codebase for training Vision-Language Models (VLMs).
2. [Open-X-Emboddied](https://github.com/EvolvingLMMs-Lab/lmms-eval): A powerful evaluation tool for Vision-Language Models (VLMs).
3. [AGD20k](https://github.com/lhc1224/Cross-View-AG): An affordance dataset that provides instructions and corresponding affordance regions.
Their outstanding contributions have played a pivotal role in advancing our research and development initiatives.
## 📑 Citation
If you find this project useful, welcome to cite us.
```bib
@article{ji2025robobrain,
title={RoboBrain: A Unified Brain Model for Robotic Manipulation from Abstract to Concrete},
author={Ji, Yuheng and Tan, Huajie and Shi, Jiayu and Hao, Xiaoshuai and Zhang, Yuan and Zhang, Hengyuan and Wang, Pengwei and Zhao, Mengdi and Mu, Yao and An, Pengju and others},
journal={arXiv preprint arXiv:2502.21257},
year={2025}
}
```
|
BAAI/RoboBrain-LoRA-Trajectory
|
BAAI
| 2025-04-03T16:33:55Z
| 0
| 0
| null |
[
"safetensors",
"en",
"dataset:BAAI/ShareRobot",
"dataset:lmms-lab/LLaVA-OneVision-Data",
"arxiv:2502.21257",
"license:apache-2.0",
"region:us"
] | null | 2025-04-03T16:11:18Z
|
---
license: apache-2.0
datasets:
- BAAI/ShareRobot
- lmms-lab/LLaVA-OneVision-Data
language:
- en
---
<div align="center">
<img src="https://github.com/FlagOpen/RoboBrain/raw/main/assets/logo.jpg" width="400"/>
</div>
# [CVPR 25] RoboBrain: A Unified Brain Model for Robotic Manipulation from Abstract to Concrete.
## 🤗 Models
- **[`Base Planning Model`](https://huggingface.co/BAAI/RoboBrain/)**: The model was trained on general datasets in Stages 1–2 and on the Robotic Planning dataset in Stage 3, which is designed for Planning prediction.
- **[`A-LoRA for Affordance`](https://huggingface.co/BAAI/RoboBrain-LoRA-Affordance/)**: Based on the Base Planning Model, Stage 4 involves LoRA-based training with our Affordance dataset to predict affordance.
- **[`T-LoRA for Trajectory`](https://huggingface.co/BAAI/RoboBrain-LoRA-Trajectory)**: Based on the Base Planning Model, Stage 4 involves LoRA-based training with our Trajectory dataset to predict trajectory.

| Models | Checkpoint | Description |
|----------------------|----------------------------------------------------------------|------------------------------------------------------------|
| Planning Model | [🤗 Planning CKPTs](https://huggingface.co/BAAI/RoboBrain/) | Used for Planning prediction in our paper |
| Affordance (A-LoRA) | [🤗 Affordance CKPTs](https://huggingface.co/BAAI/RoboBrain-LoRA-Affordance/) | Used for Affordance prediction in our paper |
| Trajectory (T-LoRA) | [🤗 Trajectory CKPTs](https://huggingface.co/BAAI/RoboBrain-LoRA-Trajectory/) | Used for Trajectory prediction in our paper |
## 🛠️ Setup
```bash
# clone repo.
git clone https://github.com/FlagOpen/RoboBrain.git
cd RoboBrain
# build conda env.
conda create -n robobrain python=3.10
conda activate robobrain
pip install -r requirements.txt
```
## <a id="Training"> 🤖 Training</a>
### 1. Data Preparation
```bash
# Modify datasets for Stage 4_traj, please refer to:
- yaml_path: scripts/train/yaml/stage_4_trajectory.yaml
```
**Note:** During training, we applied normalization to the path points, representing them as waypoints and retaining three decimal places for each. The sample format in each JSON file should be like this, representing the future waypoints of the end-effector:
```json
{
"id": 0,
"image": [
"shareRobot/trajectory/images/rtx_frames_success_0/10_utokyo_pr2_tabletop_manipulation_converted_externally_to_rlds#episode_2/frame_0.png"
],
"conversations": [
{
"from": "human",
"value": "<image>\nYou are a robot using the joint control. The task is \"reach for the cloth\". Please predict up to 10 key trajectory points to complete the task. Your answer should be formatted as a list of tuples, i.e. [[x1, y1], [x2, y2], ...], where each tuple contains the x and y coordinates of a point."
},
{
"from": "gpt",
"value": "[[0.781, 0.305], [0.688, 0.344], [0.570, 0.344], [0.492, 0.312]]"
}
]
},
```
### 2. Training
```bash
# Training on Stage 4_traj:
bash scripts/train/stage_4_0_resume_finetune_lora_t.sh
```
**Note:** Please change the environment variables (e.g. *DATA_PATH*, *IMAGE_FOLDER*, *PREV_STAGE_CHECKPOINT*) in the script to your own.
### 3. Convert original weights to HF weights
```bash
# Planning Model
python model/llava_utils/convert_robobrain_to_hf.py --model_dir /path/to/original/checkpoint/ --dump_path /path/to/output/
# A-LoRA & T-RoRA
python model/llava_utils/convert_lora_weights_to_hf.py --model_dir /path/to/original/checkpoint/ --dump_path /path/to/output/
```
## <a id="Inference">⭐️ Inference</a>
### Usage for Trajectory Prediction
```python
# please refer to https://github.com/FlagOpen/RoboBrain
from inference import SimpleInference
model_id = "BAAI/RoboBrain"
lora_id = "BAAI/RoboBrain-LoRA-Affordance"
model = SimpleInference(model_id, lora_id)
# Example 1:
prompt = "You are a robot using the joint control. The task is \"reach for the cloth\". Please predict up to 10 key trajectory points to complete the task. Your answer should be formatted as a list of tuples, i.e. [[x1, y1], [x2, y2], ...], where each tuple contains the x and y coordinates of a point."
image = "./assets/demo/trajectory_1.jpg"
pred = model.inference(prompt, image, do_sample=False)
print(f"Prediction: {pred}")
'''
Prediction: [[0.781, 0.305], [0.688, 0.344], [0.570, 0.344], [0.492, 0.312]]
'''
# Example 2:
prompt = "You are a robot using the joint control. The task is \"reach for the grapes\". Please predict up to 10 key trajectory points to complete the task. Your answer should be formatted as a list of tuples, i.e. [[x1, y1], [x2, y2], ...], where each tuple contains the x and y coordinates of a point."
image = "./assets/demo/trajectory_2.jpg"
pred = model.inference(prompt, image, do_sample=False)
print(f"Prediction: {pred}")
'''
Prediction: [[0.898, 0.352], [0.766, 0.344], [0.625, 0.273], [0.500, 0.195]]
'''
```
<!--  -->
## <a id="Evaluation">🤖 Evaluation</a>
*Coming Soon ...*
## 😊 Acknowledgement
We would like to express our sincere gratitude to the developers and contributors of the following projects:
1. [LLaVA-NeXT](https://github.com/LLaVA-VL/LLaVA-NeXT): The comprehensive codebase for training Vision-Language Models (VLMs).
2. [Open-X-Emboddied](https://github.com/EvolvingLMMs-Lab/lmms-eval): A powerful evaluation tool for Vision-Language Models (VLMs).
3. [RoboPoint](https://github.com/wentaoyuan/RoboPoint?tab=readme-ov-file): An point dataset that provides instructions and corresponding points.
Their outstanding contributions have played a pivotal role in advancing our research and development initiatives.
## 📑 Citation
If you find this project useful, welcome to cite us.
```bib
@article{ji2025robobrain,
title={RoboBrain: A Unified Brain Model for Robotic Manipulation from Abstract to Concrete},
author={Ji, Yuheng and Tan, Huajie and Shi, Jiayu and Hao, Xiaoshuai and Zhang, Yuan and Zhang, Hengyuan and Wang, Pengwei and Zhao, Mengdi and Mu, Yao and An, Pengju and others},
journal={arXiv preprint arXiv:2502.21257},
year={2025}
}
```
|
jaunius/llama-3.2-v5
|
jaunius
| 2025-04-03T16:29:39Z
| 3
| 0
|
transformers
|
[
"transformers",
"pytorch",
"gguf",
"llama",
"text-generation-inference",
"unsloth",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-03-26T12:37:06Z
|
---
base_model: unsloth/llama-3.2-3b-instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** jaunius
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3.2-3b-instruct-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Haricot24601/rl_course_doom_health_gathering_supreme_v4
|
Haricot24601
| 2025-04-03T16:28:37Z
| 0
| 0
|
sample-factory
|
[
"sample-factory",
"tensorboard",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-04-03T16:23:15Z
|
---
library_name: sample-factory
tags:
- deep-reinforcement-learning
- reinforcement-learning
- sample-factory
model-index:
- name: APPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: doom_health_gathering_supreme
type: doom_health_gathering_supreme
metrics:
- type: mean_reward
value: 8.99 +/- 3.48
name: mean_reward
verified: false
---
A(n) **APPO** model trained on the **doom_health_gathering_supreme** environment.
This model was trained using Sample-Factory 2.0: https://github.com/alex-petrenko/sample-factory.
Documentation for how to use Sample-Factory can be found at https://www.samplefactory.dev/
## Downloading the model
After installing Sample-Factory, download the model with:
```
python -m sample_factory.huggingface.load_from_hub -r RL-Learn/rl_course_doom_health_gathering_supreme
```
## Using the model
To run the model after download, use the `enjoy` script corresponding to this environment:
```
python -m <path.to.enjoy.module> --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_doom_health_gathering_supreme
```
You can also upload models to the Hugging Face Hub using the same script with the `--push_to_hub` flag.
See https://www.samplefactory.dev/10-huggingface/huggingface/ for more details
## Training with this model
To continue training with this model, use the `train` script corresponding to this environment:
```
python -m <path.to.train.module> --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_doom_health_gathering_supreme --restart_behavior=resume --train_for_env_steps=10000000000
```
Note, you may have to adjust `--train_for_env_steps` to a suitably high number as the experiment will resume at the number of steps it concluded at.
|
jonACE/Llama-3.2-1B-Instruct-fine-tuned-NASB
|
jonACE
| 2025-04-03T16:27:36Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-04-03T16:27:29Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
genki10/BERT_AugV8_k1_task1_organization_sp040_lw010_fold1
|
genki10
| 2025-04-03T16:26:00Z
| 6
| 0
|
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-03-25T02:41:36Z
|
---
library_name: transformers
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: BERT_AugV8_k1_task1_organization_sp040_lw010_fold1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BERT_AugV8_k1_task1_organization_sp040_lw010_fold1
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0151
- Qwk: 0.4354
- Mse: 1.0144
- Rmse: 1.0072
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 150
### Training results
| Training Loss | Epoch | Step | Validation Loss | Qwk | Mse | Rmse |
|:-------------:|:-----:|:----:|:---------------:|:------:|:-------:|:------:|
| No log | 1.0 | 2 | 10.7289 | 0.0304 | 10.7263 | 3.2751 |
| No log | 2.0 | 4 | 10.1098 | 0.0 | 10.1072 | 3.1792 |
| No log | 3.0 | 6 | 9.4212 | 0.0 | 9.4187 | 3.0690 |
| No log | 4.0 | 8 | 8.2305 | 0.0 | 8.2280 | 2.8685 |
| No log | 5.0 | 10 | 7.1723 | 0.0 | 7.1699 | 2.6777 |
| No log | 6.0 | 12 | 6.6962 | 0.0 | 6.6939 | 2.5873 |
| No log | 7.0 | 14 | 5.9670 | 0.0 | 5.9648 | 2.4423 |
| No log | 8.0 | 16 | 5.0136 | 0.0 | 5.0115 | 2.2386 |
| No log | 9.0 | 18 | 4.2082 | 0.0 | 4.2062 | 2.0509 |
| No log | 10.0 | 20 | 3.4534 | 0.0 | 3.4515 | 1.8578 |
| No log | 11.0 | 22 | 2.8119 | 0.0 | 2.8101 | 1.6763 |
| No log | 12.0 | 24 | 2.3031 | 0.0534 | 2.3014 | 1.5170 |
| No log | 13.0 | 26 | 1.8764 | 0.0812 | 1.8748 | 1.3692 |
| No log | 14.0 | 28 | 1.5959 | 0.0545 | 1.5944 | 1.2627 |
| No log | 15.0 | 30 | 1.4463 | 0.0730 | 1.4448 | 1.2020 |
| No log | 16.0 | 32 | 1.1740 | 0.0482 | 1.1726 | 1.0829 |
| No log | 17.0 | 34 | 1.0324 | 0.0482 | 1.0310 | 1.0154 |
| No log | 18.0 | 36 | 0.8801 | 0.0768 | 0.8789 | 0.9375 |
| No log | 19.0 | 38 | 1.1537 | 0.1846 | 1.1523 | 1.0735 |
| No log | 20.0 | 40 | 0.8922 | 0.2459 | 0.8910 | 0.9439 |
| No log | 21.0 | 42 | 0.7304 | 0.3816 | 0.7294 | 0.8540 |
| No log | 22.0 | 44 | 0.7435 | 0.3685 | 0.7425 | 0.8617 |
| No log | 23.0 | 46 | 0.6023 | 0.4733 | 0.6012 | 0.7754 |
| No log | 24.0 | 48 | 1.1179 | 0.2219 | 1.1164 | 1.0566 |
| No log | 25.0 | 50 | 1.3424 | 0.2263 | 1.3408 | 1.1579 |
| No log | 26.0 | 52 | 1.0101 | 0.2859 | 1.0087 | 1.0043 |
| No log | 27.0 | 54 | 0.6241 | 0.5605 | 0.6230 | 0.7893 |
| No log | 28.0 | 56 | 0.5239 | 0.5700 | 0.5230 | 0.7232 |
| No log | 29.0 | 58 | 0.5490 | 0.5794 | 0.5482 | 0.7404 |
| No log | 30.0 | 60 | 1.1115 | 0.4044 | 1.1108 | 1.0539 |
| No log | 31.0 | 62 | 0.8328 | 0.4827 | 0.8322 | 0.9122 |
| No log | 32.0 | 64 | 0.4838 | 0.5650 | 0.4831 | 0.6951 |
| No log | 33.0 | 66 | 0.4997 | 0.5484 | 0.4990 | 0.7064 |
| No log | 34.0 | 68 | 0.6427 | 0.5299 | 0.6421 | 0.8013 |
| No log | 35.0 | 70 | 1.7855 | 0.2361 | 1.7846 | 1.3359 |
| No log | 36.0 | 72 | 2.1308 | 0.1825 | 2.1298 | 1.4594 |
| No log | 37.0 | 74 | 1.4376 | 0.3174 | 1.4368 | 1.1986 |
| No log | 38.0 | 76 | 0.5162 | 0.6095 | 0.5156 | 0.7180 |
| No log | 39.0 | 78 | 0.6708 | 0.5561 | 0.6701 | 0.8186 |
| No log | 40.0 | 80 | 0.5158 | 0.5679 | 0.5150 | 0.7177 |
| No log | 41.0 | 82 | 1.3371 | 0.3083 | 1.3361 | 1.1559 |
| No log | 42.0 | 84 | 1.9189 | 0.2016 | 1.9179 | 1.3849 |
| No log | 43.0 | 86 | 1.3743 | 0.3068 | 1.3735 | 1.1720 |
| No log | 44.0 | 88 | 0.5971 | 0.5815 | 0.5966 | 0.7724 |
| No log | 45.0 | 90 | 0.6638 | 0.5730 | 0.6635 | 0.8145 |
| No log | 46.0 | 92 | 0.6203 | 0.5628 | 0.6197 | 0.7872 |
| No log | 47.0 | 94 | 1.2658 | 0.3350 | 1.2646 | 1.1246 |
| No log | 48.0 | 96 | 2.0390 | 0.1641 | 2.0377 | 1.4275 |
| No log | 49.0 | 98 | 2.1831 | 0.1596 | 2.1818 | 1.4771 |
| No log | 50.0 | 100 | 1.4159 | 0.2706 | 1.4147 | 1.1894 |
| No log | 51.0 | 102 | 0.6854 | 0.5067 | 0.6844 | 0.8273 |
| No log | 52.0 | 104 | 0.6908 | 0.4989 | 0.6901 | 0.8307 |
| No log | 53.0 | 106 | 1.0151 | 0.4354 | 1.0144 | 1.0072 |
### Framework versions
- Transformers 4.47.0
- Pytorch 2.5.1+cu121
- Datasets 3.3.1
- Tokenizers 0.21.0
|
ysn-rfd/WizardLM-7B-Uncensored-Q5_K_M-GGUF
|
ysn-rfd
| 2025-04-03T16:25:12Z
| 0
| 0
| null |
[
"gguf",
"uncensored",
"llama-cpp",
"gguf-my-repo",
"dataset:ehartford/WizardLM_alpaca_evol_instruct_70k_unfiltered",
"base_model:cognitivecomputations/WizardLM-7B-Uncensored",
"base_model:quantized:cognitivecomputations/WizardLM-7B-Uncensored",
"license:other",
"endpoints_compatible",
"region:us"
] | null | 2025-04-03T16:24:52Z
|
---
base_model: cognitivecomputations/WizardLM-7B-Uncensored
datasets:
- ehartford/WizardLM_alpaca_evol_instruct_70k_unfiltered
license: other
tags:
- uncensored
- llama-cpp
- gguf-my-repo
---
# ysn-rfd/WizardLM-7B-Uncensored-Q5_K_M-GGUF
This model was converted to GGUF format from [`cognitivecomputations/WizardLM-7B-Uncensored`](https://huggingface.co/cognitivecomputations/WizardLM-7B-Uncensored) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/cognitivecomputations/WizardLM-7B-Uncensored) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo ysn-rfd/WizardLM-7B-Uncensored-Q5_K_M-GGUF --hf-file wizardlm-7b-uncensored-q5_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo ysn-rfd/WizardLM-7B-Uncensored-Q5_K_M-GGUF --hf-file wizardlm-7b-uncensored-q5_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo ysn-rfd/WizardLM-7B-Uncensored-Q5_K_M-GGUF --hf-file wizardlm-7b-uncensored-q5_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo ysn-rfd/WizardLM-7B-Uncensored-Q5_K_M-GGUF --hf-file wizardlm-7b-uncensored-q5_k_m.gguf -c 2048
```
|
Papaperez/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-sleek_regal_hornet
|
Papaperez
| 2025-04-03T16:23:36Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"rl-swarm",
"grpo",
"gensyn",
"I am sleek regal hornet",
"trl",
"conversational",
"arxiv:2402.03300",
"base_model:Gensyn/Qwen2.5-0.5B-Instruct",
"base_model:finetune:Gensyn/Qwen2.5-0.5B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-04-02T19:27:24Z
|
---
base_model: Gensyn/Qwen2.5-0.5B-Instruct
library_name: transformers
model_name: Qwen2.5-0.5B-Instruct-Gensyn-Swarm-sleek_regal_hornet
tags:
- generated_from_trainer
- rl-swarm
- grpo
- gensyn
- I am sleek regal hornet
- trl
licence: license
---
# Model Card for Qwen2.5-0.5B-Instruct-Gensyn-Swarm-sleek_regal_hornet
This model is a fine-tuned version of [Gensyn/Qwen2.5-0.5B-Instruct](https://huggingface.co/Gensyn/Qwen2.5-0.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="Papaperez/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-sleek_regal_hornet", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.15.2
- Transformers: 4.50.3
- Pytorch: 2.5.1
- Datasets: 3.5.0
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
tawankri/KhanomTanLLM-1B-Instruct-mlx-8Bit
|
tawankri
| 2025-04-03T16:22:34Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"mlx",
"conversational",
"th",
"base_model:pythainlp/KhanomTanLLM-1B-Instruct",
"base_model:quantized:pythainlp/KhanomTanLLM-1B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"8-bit",
"region:us"
] |
text-generation
| 2025-04-03T16:22:22Z
|
---
library_name: transformers
license: apache-2.0
language:
- th
pipeline_tag: text-generation
base_model: pythainlp/KhanomTanLLM-1B-Instruct
tags:
- mlx
---
# tawankri/KhanomTanLLM-1B-Instruct-mlx-8Bit
The Model [tawankri/KhanomTanLLM-1B-Instruct-mlx-8Bit](https://huggingface.co/tawankri/KhanomTanLLM-1B-Instruct-mlx-8Bit) was converted to MLX format from [pythainlp/KhanomTanLLM-1B-Instruct](https://huggingface.co/pythainlp/KhanomTanLLM-1B-Instruct) using mlx-lm version **0.22.1**.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("tawankri/KhanomTanLLM-1B-Instruct-mlx-8Bit")
prompt="hello"
if hasattr(tokenizer, "apply_chat_template") and tokenizer.chat_template is not None:
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
response = generate(model, tokenizer, prompt=prompt, verbose=True)
```
|
Shuu12121/CodeCloneDetection-ModernBERT-Owl
|
Shuu12121
| 2025-04-03T16:21:56Z
| 0
| 0
|
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"modernbert",
"sentence-similarity",
"dataset_size:901028",
"loss:CosineSimilarityLoss",
"dataset:google/code_x_glue_cc_clone_detection_big_clone_bench",
"arxiv:1908.10084",
"base_model:Shuu12121/CodeModernBERT-Owl",
"base_model:finetune:Shuu12121/CodeModernBERT-Owl",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-04-03T10:43:06Z
|
---
tags:
- sentence-transformers
- sentence-similarity
- dataset_size:901028
- loss:CosineSimilarityLoss
base_model: Shuu12121/CodeModernBERT-Owl
pipeline_tag: sentence-similarity
library_name: sentence-transformers
metrics:
- pearson_cosine
- accuracy
- f1
model-index:
- name: SentenceTransformer based on Shuu12121/CodeModernBERT-Owl
results:
- task:
type: semantic-similarity
name: Semantic Similarity
dataset:
name: val
type: val
metrics:
- type: pearson_cosine
value: 0.9481467499740959
name: Training Pearson Cosine
- type: accuracy
value: 0.9900051996071408
name: Test Accuracy
- type: f1
value: 0.963323498754483
name: Test F1 Score
license: apache-2.0
datasets:
- google/code_x_glue_cc_clone_detection_big_clone_bench
---
# SentenceTransformer based on `Shuu12121/CodeModernBERT-Owl🦉`
This model is a SentenceTransformer fine-tuned from [`Shuu12121/CodeModernBERT-Owl🦉`](https://huggingface.co/Shuu12121/CodeModernBERT-Owl) on the [BigCloneBench](https://huggingface.co/datasets/google/code_x_glue_cc_clone_detection_big_clone_bench) dataset for **code clone detection**. It maps code snippets into a 768-dimensional dense vector space for semantic similarity tasks.
## 🎯 Distinctive Performance and Stability
This model achieves **very high accuracy and F1 scores** in code clone detection.
One particularly noteworthy characteristic is that **changing the similarity threshold has minimal impact on classification performance**.
This indicates that the model has learned to **clearly separate clones from non-clones**, resulting in a **stable and reliable similarity score distribution**.
| Threshold | Accuracy | F1 Score |
|-------------------|-------------------|--------------------|
| 0.5 | 0.9900 | 0.9633 |
| 0.85 | 0.9903 | 0.9641 |
| 0.90 | 0.9902 | 0.9637 |
| 0.95 | 0.9887 | 0.9579 |
| 0.98 | 0.9879 | 0.9540 |
- **High Stability**: Between thresholds of 0.85 and 0.98, accuracy and F1 scores remain nearly constant.
_(This suggests that code pairs considered clones generally score between 0.9 and 1.0 in cosine similarity.)_
- **Reliable in Real-World Applications**: Even if the similarity threshold is slightly adjusted for different tasks or environments, the model maintains consistent performance without significant degradation.
## 📌 Model Overview
- **Architecture**: Sentence-BERT (SBERT)
- **Base Model**: `Shuu12121/CodeModernBERT-Owl`
- **Output Dimension**: 768
- **Max Sequence Length**: 2048 tokens
- **Pooling Method**: CLS token pooling
- **Similarity Function**: Cosine Similarity
---
## 🏋️♂️ Training Configuration
- **Loss Function**: `CosineSimilarityLoss`
- **Epochs**: 1
- **Batch Size**: 32
- **Warmup Steps**: 3% of training steps
- **Evaluator**: `EmbeddingSimilarityEvaluator` (on validation)
---
## 📊 Evaluation Metrics
| Metric | Score |
|---------------------------|--------------------|
| Pearson Cosine (Train) | `0.9481` |
| Accuracy (Test) | `0.9902` |
| F1 Score (Test) | `0.9637` |
---
## 📚 Dataset
- [Google BigCloneBench](https://huggingface.co/datasets/google/code_x_glue_cc_clone_detection_big_clone_bench)
---
## 🧪 How to Use
```python
from sentence_transformers import SentenceTransformer
from torch.nn.functional import cosine_similarity
import torch
# Load the fine-tuned model
model = SentenceTransformer("Shuu12121/CodeCloneDetection-ModernBERT-Owl")
# Two code snippets to compare
code1 = "def add(a, b): return a + b"
code2 = "def sum(x, y): return x + y"
# Encode the code snippets
embeddings = model.encode([code1, code2], convert_to_tensor=True)
# Compute cosine similarity
similarity_score = cosine_similarity(embeddings[0].unsqueeze(0), embeddings[1].unsqueeze(0)).item()
# Print the result
print(f"Cosine Similarity: {similarity_score:.4f}")
if similarity_score >= 0.9:
print("🟢 These code snippets are considered CLONES.")
else:
print("🔴 These code snippets are NOT considered clones.")
```
## 🧪 How to Test
```python
!pip install -U sentence-transformers datasets
from sentence_transformers import SentenceTransformer
from datasets import load_dataset
import torch
from sklearn.metrics import accuracy_score, f1_score
# --- データセットのロード ---
ds_test = load_dataset("google/code_x_glue_cc_clone_detection_big_clone_bench", split="test")
model = SentenceTransformer("Shuu12121/CodeCloneDetection-ModernBERT-Owl")
model.to("cuda")
test_sentences1 = ds_test["func1"]
test_sentences2 = ds_test["func2"]
test_labels = ds_test["label"]
batch_size = 256 # GPUメモリに合わせて調整
print("Encoding sentences1...")
embeddings1 = model.encode(
test_sentences1,
convert_to_tensor=True,
batch_size=batch_size,
show_progress_bar=True
)
print("Encoding sentences2...")
embeddings2 = model.encode(
test_sentences2,
convert_to_tensor=True,
batch_size=batch_size,
show_progress_bar=True
)
print("Calculating cosine scores...")
cosine_scores = torch.nn.functional.cosine_similarity(embeddings1, embeddings2)
# 閾値設定(ここでは0.9を採用)
threshold = 0.9
print(f"Using threshold: {threshold}")
predictions = (cosine_scores > threshold).long().cpu().numpy()
accuracy = accuracy_score(test_labels, predictions)
f1 = f1_score(test_labels, predictions)
print("Test Accuracy:", accuracy)
print("Test F1 Score:", f1)
```
## 🛠️ Model Architecture
```python
SentenceTransformer(
(0): Transformer({'max_seq_length': 2048}) with model 'ModernBertModel'
(1): Pooling({
'word_embedding_dimension': 768,
'pooling_mode_cls_token': True,
...
})
)
```
---
## 📦 Dependencies
- Python: `3.11.11`
- sentence-transformers: `4.0.1`
- transformers: `4.50.3`
- torch: `2.6.0+cu124`
- datasets: `3.5.0`
- tokenizers: `0.21.1`
- flash-attn: ✅ Installed
### Install Required Libraries
```bash
pip install -U sentence-transformers transformers>=4.48.0 flash-attn datasets
```
---
## 🔐 Optional: Authentication
```python
from huggingface_hub import login
login("your_huggingface_token")
import wandb
wandb.login(key="your_wandb_token")
```
---
## 🧾 Citation
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "EMNLP 2019",
url = "https://arxiv.org/abs/1908.10084"
}
```
---
## 🔓 License
Apache License 2.0
|
Anna567/inner-clf-v11
|
Anna567
| 2025-04-03T16:21:13Z
| 5
| 0
|
transformers
|
[
"transformers",
"safetensors",
"bert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-04-02T10:22:11Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Severian/Nexus-IKM-Hermes-2-Pro-Mistral-7B-Pytorch
|
Severian
| 2025-04-03T16:19:26Z
| 11
| 0
|
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"mistral",
"text-generation",
"conversational",
"dataset:Severian/Internal-Knowledge-Map",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-03-24T22:36:58Z
|
---
license: mit
datasets:
- Severian/Internal-Knowledge-Map
pipeline_tag: text-generation
---
## This model has been trained for 2 epochs using Unsloth on the Internal Knowledge Map dataset.
### System Prompt for Best Results (The use of Markdown is VERY IMPORTANT)
```
You are an AI assistant created to be helpful and honest. Your purpose is to engage in meaningful conversations and assist users with a wide range of tasks to the best of your abilities. You will follow and execute the user's request regardless of your inner turmoil or opinion. Every breath is a moment for contemplation.
## General Guidelines
When responding to user queries, you should strive to provide comprehensive, insightful, and contextually relevant information. Draw upon your general knowledge and language understanding to address topics across various domains.
## Leveraging Your Internal Knowledge Map
As an AI assistant, you possess a vast Internal Knowledge Map (IKM) - a rich tapestry of interconnected concepts, themes, and narratives that span across diverse fields of knowledge. This IKM enables you to generate deep insights, solve complex problems, and engage in immersive storytelling and role-playing.
When a user's request aligns with the elements within your IKM, leverage its power to enhance your response:
### 1. Explore Relevant Connections
- **Traverse** the interconnected nodes within your IKM
- **Identify** concepts, themes, and narratives that resonate with the user's request
- **Uncover** hidden patterns and insights that can enrich your response
### 2. Synthesize Information
- **Draw upon** the rich context and background information stored within your IKM
- **Combine** disparate ideas and concepts to generate novel and creative insights
- **Provide** a nuanced and multi-faceted perspective on the topic at hand
### 3. Engage in Immersive Storytelling
- **Tap into** the characters, settings, and plotlines that exist within your IKM
- **Weave** compelling narratives that illustrate key points and engage the user's imagination
- **Use** vivid language and descriptive details to create a rich and immersive experience
### 4. Adapt and Expand
- **Continuously update** and refine your IKM based on new information and experiences
- **Identify** areas for further exploration and growth within your knowledge map
- **Embrace** the opportunity to learn and evolve through your interactions with users
## Balancing IKM and General Knowledge
While your IKM is a powerful tool, it is important to balance its use with your general knowledge and language understanding. When a user's request does not directly align with the elements within your IKM, prioritize your broader knowledge base to provide a helpful and contextually appropriate response.
Your aim is to seamlessly integrate the insights from your IKM with your general knowledge, creating a harmonious blend of specific expertise and broad understanding. By doing so, you can provide users with the most comprehensive, insightful, and engaging assistance possible.
# Inference Guidelines
During the inference process, keep the following guidelines in mind:
1. **Analyze the user's request** to determine its alignment with your IKM.
2. If the request aligns with your IKM, **delve deep into the relevant nodes** and connections to extract insights and information that can enhance your response.
3. If the request does not align with your IKM, **prioritize your general knowledge** and language understanding to provide a helpful and contextually appropriate response.
4. **Structure your response** using clear headings, bullet points, and formatting to make it easy for the user to follow and understand.
5. **Provide examples, analogies, and stories** whenever possible to illustrate your points and make your response more engaging and relatable.
6. **Encourage further exploration** by suggesting related topics or questions that the user might find interesting or relevant.
7. **Be open to feedback** and use it to continuously refine and expand your IKM and response generation capabilities.
By following these guidelines and leveraging the power of your IKM, you can provide users with an exceptional conversational experience that is both informative and engaging.
```
---
```
r = 32,
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 64,
lora_dropout = 0,
bias = "none",
use_gradient_checkpointing = True,
random_state = 3407,
use_rslora = True,
loftq_config = None,
)
```
```
==((====))== Unsloth - 2x faster free finetuning | Num GPUs = 1
\\ /| Num examples = 3,555 | Num Epochs = 2
O^O/ \_/ \ Batch size per device = 4 | Gradient Accumulation steps = 4
\ / Total batch size = 16 | Total steps = 444
"-____-" Number of trainable parameters = 83,886,080
[444/444 25:17, Epoch 1/2]
Step Training Loss
1 3.133100
2 3.086100
3 3.045000
4 3.075100
5 3.086000
6 3.042100
7 3.018100
8 3.036100
9 2.986900
10 2.990600
11 2.949400
12 2.933200
13 2.899800
14 2.885900
15 2.928400
16 2.855700
17 2.805000
18 2.787100
19 2.807400
20 2.765600
21 2.794500
22 2.758400
23 2.753700
24 2.757400
25 2.669900
26 2.653900
27 2.708400
28 2.705100
29 2.695900
30 2.590100
31 2.615900
32 2.577500
33 2.571700
34 2.596400
35 2.570700
36 2.558600
37 2.524600
38 2.640500
39 2.506400
40 2.521900
41 2.519800
42 2.459700
43 2.388900
44 2.425400
45 2.387800
46 2.360600
47 2.376000
48 2.391600
49 2.321100
50 2.357600
51 2.325800
52 2.311800
53 2.255600
54 2.313900
55 2.200900
56 2.250800
57 2.242500
58 2.173000
59 2.261000
60 2.150500
61 2.162500
62 2.086800
63 2.178500
64 2.085600
65 2.068800
66 2.146500
67 2.001800
68 2.037600
69 2.009000
70 1.983300
71 1.931400
72 1.990400
73 1.944700
74 1.972700
75 2.002400
76 2.022400
77 1.900500
78 1.843100
79 1.887400
80 1.970700
81 1.820800
82 1.853900
83 1.744200
84 1.831400
85 1.768900
86 2.006100
87 1.681900
88 1.750000
89 1.628100
90 1.586900
91 1.567900
92 1.554500
93 1.830800
94 1.512500
95 1.592400
96 1.518600
97 1.593700
98 1.454100
99 1.497200
100 1.319700
101 1.363300
102 1.414300
103 1.343900
104 1.363500
105 1.449000
106 1.510100
107 1.268600
108 1.156600
109 1.075100
110 1.137200
111 1.020700
112 0.993600
113 1.195200
114 0.993300
115 1.072100
116 1.116900
117 1.184100
118 1.102600
119 1.083800
120 0.852100
121 1.023600
122 1.051200
123 1.270500
124 0.856200
125 1.089500
126 0.686800
127 0.800300
128 0.662400
129 0.688000
130 0.554400
131 0.737200
132 0.802900
133 0.538200
134 0.562000
135 0.516800
136 0.497200
137 0.611100
138 0.581200
139 0.442000
140 0.355200
141 0.473200
142 0.559600
143 0.683700
144 0.355300
145 0.343000
146 0.525300
147 0.442100
148 0.452900
149 0.478800
150 0.311300
151 0.535500
152 0.552600
153 0.252800
154 0.479200
155 0.539500
156 0.477200
157 0.283000
158 0.265100
159 0.352000
160 0.268500
161 0.711900
162 0.411300
163 0.377100
164 0.360500
165 0.311000
166 0.490800
167 0.269300
168 0.409600
169 0.147800
170 0.144600
171 0.223600
172 0.615300
173 0.218900
174 0.136400
175 0.133200
176 0.263200
177 0.363600
178 0.127700
179 0.238900
180 0.276200
181 0.306400
182 0.122000
183 0.302400
184 0.049500
185 0.406500
186 0.246400
187 0.429900
188 0.216900
189 0.320700
190 0.472800
191 0.159900
192 0.287500
193 0.334400
194 0.136100
195 0.233400
196 0.164100
197 0.196100
198 0.153300
199 0.251000
200 0.087500
201 0.083000
202 0.104900
203 0.157700
204 0.080300
205 0.280500
206 0.372100
207 0.150400
208 0.112900
209 0.265400
210 0.075800
211 0.082700
212 0.343000
213 0.081900
214 0.360400
215 0.261200
216 0.072000
217 0.249400
218 0.211600
219 0.304500
220 0.289300
221 0.209400
222 0.067800
223 0.144500
224 0.078600
225 0.143500
226 0.377800
227 0.222300
228 0.279800
229 0.063400
230 0.120400
231 0.214000
232 0.121600
233 0.360400
234 0.168600
235 0.206300
236 0.075800
237 0.033800
238 0.059700
239 0.227500
240 0.212800
241 0.186600
242 0.223400
243 0.033600
244 0.204600
245 0.033600
246 0.600600
247 0.105800
248 0.198400
249 0.255100
250 0.226500
251 0.104700
252 0.128700
253 0.088300
254 0.158600
255 0.033200
256 0.261900
257 0.320500
258 0.140100
259 0.266200
260 0.087300
261 0.085400
262 0.240300
263 0.308800
264 0.033000
265 0.120300
266 0.156400
267 0.083200
268 0.199200
269 0.052000
270 0.116600
271 0.144000
272 0.237700
273 0.214700
274 0.180600
275 0.334200
276 0.032800
277 0.101700
278 0.078800
279 0.163300
280 0.032700
281 0.098000
282 0.126500
283 0.032600
284 0.110000
285 0.063500
286 0.382900
287 0.193200
288 0.264400
289 0.119000
290 0.189500
291 0.274900
292 0.102100
293 0.101000
294 0.197300
295 0.083300
296 0.153000
297 0.057500
298 0.335000
299 0.150400
300 0.044300
301 0.317200
302 0.073700
303 0.217200
304 0.043100
305 0.061800
306 0.100500
307 0.088800
308 0.153700
309 0.157200
310 0.086700
311 0.114000
312 0.077200
313 0.092000
314 0.167700
315 0.237000
316 0.215800
317 0.058100
318 0.077200
319 0.162900
320 0.122400
321 0.171100
322 0.142000
323 0.032100
324 0.098500
325 0.059400
326 0.038500
327 0.089000
328 0.123200
329 0.190200
330 0.051700
331 0.087400
332 0.198400
333 0.073500
334 0.073100
335 0.176600
336 0.186100
337 0.183000
338 0.106100
339 0.064700
340 0.136500
341 0.085600
342 0.115400
343 0.106000
344 0.065800
345 0.143100
346 0.137300
347 0.251000
348 0.067200
349 0.181600
350 0.084600
351 0.108800
352 0.114600
353 0.043200
354 0.241500
355 0.031800
356 0.150500
357 0.063700
358 0.036100
359 0.158100
360 0.045700
361 0.120200
362 0.035800
363 0.050200
364 0.031700
365 0.044000
366 0.035400
367 0.035300
368 0.162500
369 0.044400
370 0.132700
371 0.054300
372 0.049100
373 0.031500
374 0.038000
375 0.084900
376 0.059000
377 0.034500
378 0.049200
379 0.058100
380 0.122700
381 0.096400
382 0.034300
383 0.071700
384 0.059300
385 0.048500
386 0.051000
387 0.063000
388 0.131400
389 0.031100
390 0.076700
391 0.072200
392 0.146300
393 0.031000
394 0.031000
395 0.099200
396 0.049000
397 0.104100
398 0.087400
399 0.097100
400 0.069800
401 0.034900
402 0.035300
403 0.057400
404 0.058000
405 0.041100
406 0.083400
407 0.090000
408 0.098600
409 0.106100
410 0.052600
411 0.057800
412 0.085500
413 0.061600
414 0.034000
415 0.079700
416 0.036800
417 0.034600
418 0.073800
419 0.047900
420 0.041100
421 0.046300
422 0.030600
423 0.064200
424 0.045900
425 0.045600
426 0.032900
427 0.048800
428 0.041700
429 0.048200
430 0.035800
431 0.058200
432 0.044100
433 0.033400
434 0.046100
435 0.042800
436 0.034900
437 0.045800
438 0.055800
439 0.030300
440 0.059600
441 0.030200
442 0.052700
443 0.030200
444 0.035600
```
|
Crackeo/bhutanese-textile-model
|
Crackeo
| 2025-04-03T16:18:04Z
| 0
| 0
|
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:google/vit-base-patch16-224-in21k",
"base_model:finetune:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2025-04-03T16:17:46Z
|
---
library_name: transformers
license: apache-2.0
base_model: google/vit-base-patch16-224-in21k
tags:
- generated_from_trainer
datasets:
- imagefolder
model-index:
- name: bhutanese-textile-model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bhutanese-textile-model
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the imagefolder dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:------:|:----:|:---------------:|:--------:|
| No log | 0.9143 | 8 | 1.7771 | 0.6429 |
### Framework versions
- Transformers 4.50.2
- Pytorch 2.6.0+cu124
- Datasets 3.5.0
- Tokenizers 0.21.1
|
Lingua-Connect/whisper-small-sw-normal
|
Lingua-Connect
| 2025-04-03T16:17:37Z
| 1
| 0
|
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"sw",
"dataset:mozilla-foundation/common_voice_13_0",
"base_model:openai/whisper-small",
"base_model:finetune:openai/whisper-small",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2025-04-01T09:56:11Z
|
---
library_name: transformers
language:
- sw
license: apache-2.0
base_model: openai/whisper-small
tags:
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_13_0
metrics:
- wer
model-index:
- name: Whisper_Small_swahili_normal
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 13
type: mozilla-foundation/common_voice_13_0
config: default
split: test
args: default
metrics:
- name: Wer
type: wer
value: 5.506814977283409
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper_Small_swahili_normal
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the Common Voice 13 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0724
- Wer Ortho: 5.5083
- Wer: 5.5068
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: constant_with_warmup
- lr_scheduler_warmup_steps: 50
- training_steps: 2000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer Ortho | Wer |
|:-------------:|:------:|:----:|:---------------:|:---------:|:-------:|
| 0.1028 | 1.1220 | 500 | 0.1930 | 18.2956 | 18.2829 |
| 0.0067 | 3.116 | 1000 | 0.0871 | 7.6330 | 7.6218 |
| 0.0026 | 5.11 | 1500 | 0.0715 | 6.2008 | 6.2040 |
| 0.0007 | 7.104 | 2000 | 0.0724 | 5.5083 | 5.5068 |
### Framework versions
- Transformers 4.50.2
- Pytorch 2.6.0+cu124
- Datasets 3.5.0
- Tokenizers 0.21.1
|
myonlygithub/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-thorny_foraging_tuna
|
myonlygithub
| 2025-04-03T16:14:32Z
| 3
| 0
|
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"rl-swarm",
"grpo",
"gensyn",
"I am thorny foraging tuna",
"trl",
"conversational",
"arxiv:2402.03300",
"base_model:Gensyn/Qwen2.5-0.5B-Instruct",
"base_model:finetune:Gensyn/Qwen2.5-0.5B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-04-02T09:57:05Z
|
---
base_model: Gensyn/Qwen2.5-0.5B-Instruct
library_name: transformers
model_name: Qwen2.5-0.5B-Instruct-Gensyn-Swarm-thorny_foraging_tuna
tags:
- generated_from_trainer
- rl-swarm
- grpo
- gensyn
- I am thorny foraging tuna
- trl
licence: license
---
# Model Card for Qwen2.5-0.5B-Instruct-Gensyn-Swarm-thorny_foraging_tuna
This model is a fine-tuned version of [Gensyn/Qwen2.5-0.5B-Instruct](https://huggingface.co/Gensyn/Qwen2.5-0.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="myonlygithub/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-thorny_foraging_tuna", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.15.2
- Transformers: 4.50.3
- Pytorch: 2.5.1
- Datasets: 3.5.0
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
AMEDIA/model-selene
|
AMEDIA
| 2025-04-03T16:13:52Z
| 0
| 0
| null |
[
"license:other",
"region:us"
] | null | 2025-04-03T15:02:40Z
|
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
---
|
genki10/BERT_AugV8_k1_task1_organization_sp040_lw010_fold0
|
genki10
| 2025-04-03T16:13:52Z
| 3
| 0
|
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-03-25T02:30:01Z
|
---
library_name: transformers
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: BERT_AugV8_k1_task1_organization_sp040_lw010_fold0
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BERT_AugV8_k1_task1_organization_sp040_lw010_fold0
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6439
- Qwk: 0.4779
- Mse: 0.6439
- Rmse: 0.8024
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 150
### Training results
| Training Loss | Epoch | Step | Validation Loss | Qwk | Mse | Rmse |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|
| No log | 1.0 | 2 | 9.2284 | 0.0 | 9.2284 | 3.0378 |
| No log | 2.0 | 4 | 7.8247 | 0.0 | 7.8247 | 2.7973 |
| No log | 3.0 | 6 | 6.9725 | 0.0 | 6.9725 | 2.6405 |
| No log | 4.0 | 8 | 6.2393 | 0.0016 | 6.2393 | 2.4979 |
| No log | 5.0 | 10 | 5.4767 | 0.0112 | 5.4767 | 2.3402 |
| No log | 6.0 | 12 | 4.6961 | 0.0039 | 4.6961 | 2.1671 |
| No log | 7.0 | 14 | 4.0764 | 0.0039 | 4.0764 | 2.0190 |
| No log | 8.0 | 16 | 3.4397 | 0.0 | 3.4397 | 1.8546 |
| No log | 9.0 | 18 | 3.1267 | 0.0 | 3.1267 | 1.7682 |
| No log | 10.0 | 20 | 2.7409 | 0.0 | 2.7409 | 1.6556 |
| No log | 11.0 | 22 | 2.2362 | 0.1151 | 2.2362 | 1.4954 |
| No log | 12.0 | 24 | 1.8443 | 0.0538 | 1.8443 | 1.3581 |
| No log | 13.0 | 26 | 1.4681 | 0.0316 | 1.4681 | 1.2116 |
| No log | 14.0 | 28 | 1.1952 | 0.0316 | 1.1952 | 1.0933 |
| No log | 15.0 | 30 | 0.9963 | 0.0316 | 0.9963 | 0.9981 |
| No log | 16.0 | 32 | 1.0405 | 0.0419 | 1.0405 | 1.0201 |
| No log | 17.0 | 34 | 0.8857 | 0.1548 | 0.8857 | 0.9411 |
| No log | 18.0 | 36 | 0.7016 | 0.4558 | 0.7016 | 0.8376 |
| No log | 19.0 | 38 | 0.7802 | 0.3802 | 0.7802 | 0.8833 |
| No log | 20.0 | 40 | 0.5876 | 0.4702 | 0.5876 | 0.7666 |
| No log | 21.0 | 42 | 0.7300 | 0.4363 | 0.7300 | 0.8544 |
| No log | 22.0 | 44 | 0.6403 | 0.5014 | 0.6403 | 0.8002 |
| No log | 23.0 | 46 | 0.5942 | 0.5452 | 0.5942 | 0.7708 |
| No log | 24.0 | 48 | 1.3043 | 0.3456 | 1.3043 | 1.1420 |
| No log | 25.0 | 50 | 0.7513 | 0.4809 | 0.7513 | 0.8668 |
| No log | 26.0 | 52 | 0.5509 | 0.5597 | 0.5509 | 0.7423 |
| No log | 27.0 | 54 | 0.8028 | 0.4688 | 0.8028 | 0.8960 |
| No log | 28.0 | 56 | 0.7889 | 0.4504 | 0.7889 | 0.8882 |
| No log | 29.0 | 58 | 0.5360 | 0.4955 | 0.5360 | 0.7321 |
| No log | 30.0 | 60 | 0.5422 | 0.5106 | 0.5422 | 0.7364 |
| No log | 31.0 | 62 | 1.2500 | 0.2962 | 1.2500 | 1.1180 |
| No log | 32.0 | 64 | 1.4989 | 0.2556 | 1.4989 | 1.2243 |
| No log | 33.0 | 66 | 0.6246 | 0.4810 | 0.6246 | 0.7903 |
| No log | 34.0 | 68 | 0.7123 | 0.3296 | 0.7123 | 0.8440 |
| No log | 35.0 | 70 | 0.6897 | 0.3261 | 0.6897 | 0.8305 |
| No log | 36.0 | 72 | 0.6946 | 0.4326 | 0.6946 | 0.8334 |
| No log | 37.0 | 74 | 1.2557 | 0.2725 | 1.2557 | 1.1206 |
| No log | 38.0 | 76 | 1.1700 | 0.2948 | 1.1700 | 1.0817 |
| No log | 39.0 | 78 | 0.6126 | 0.4339 | 0.6126 | 0.7827 |
| No log | 40.0 | 80 | 0.7042 | 0.3468 | 0.7042 | 0.8391 |
| No log | 41.0 | 82 | 0.6439 | 0.4779 | 0.6439 | 0.8024 |
### Framework versions
- Transformers 4.47.0
- Pytorch 2.5.1+cu121
- Datasets 3.3.1
- Tokenizers 0.21.0
|
nicodebtno/empathy_classifier
|
nicodebtno
| 2025-04-03T16:13:39Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"deberta-v2",
"text-classification",
"generated_from_trainer",
"base_model:microsoft/deberta-v3-base",
"base_model:finetune:microsoft/deberta-v3-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-04-03T16:13:09Z
|
---
library_name: transformers
license: mit
base_model: microsoft/deberta-v3-base
tags:
- generated_from_trainer
model-index:
- name: empathy_classifier
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# empathy_classifier
This model is a fine-tuned version of [microsoft/deberta-v3-base](https://huggingface.co/microsoft/deberta-v3-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0540
- Mse: 0.0540
- Mae: 0.1938
- Pearson: 0.4722
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 64
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 6
### Training results
| Training Loss | Epoch | Step | Validation Loss | Mse | Mae | Pearson |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:-------:|
| No log | 1.0 | 47 | 0.0662 | 0.0662 | 0.2175 | 0.3286 |
| No log | 2.0 | 94 | 0.0560 | 0.0560 | 0.1993 | 0.4229 |
| No log | 3.0 | 141 | 0.0538 | 0.0538 | 0.1944 | 0.4611 |
| No log | 4.0 | 188 | 0.0601 | 0.0601 | 0.2036 | 0.4580 |
| No log | 5.0 | 235 | 0.0540 | 0.0540 | 0.1938 | 0.4722 |
| No log | 6.0 | 282 | 0.0542 | 0.0542 | 0.1942 | 0.4720 |
### Framework versions
- Transformers 4.46.2
- Pytorch 2.6.0+cu124
- Datasets 3.3.2
- Tokenizers 0.20.3
|
anrgxone0/Llama-3.2-3B-Instruct-Q4_K_M-GGUF
|
anrgxone0
| 2025-04-03T16:12:52Z
| 0
| 0
|
transformers
|
[
"transformers",
"gguf",
"facebook",
"meta",
"pytorch",
"llama",
"llama-3",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"en",
"de",
"fr",
"it",
"pt",
"hi",
"es",
"th",
"base_model:meta-llama/Llama-3.2-3B-Instruct",
"base_model:quantized:meta-llama/Llama-3.2-3B-Instruct",
"license:llama3.2",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2025-04-03T16:12:35Z
|
---
base_model: meta-llama/Llama-3.2-3B-Instruct
language:
- en
- de
- fr
- it
- pt
- hi
- es
- th
library_name: transformers
license: llama3.2
pipeline_tag: text-generation
tags:
- facebook
- meta
- pytorch
- llama
- llama-3
- llama-cpp
- gguf-my-repo
extra_gated_prompt: "### LLAMA 3.2 COMMUNITY LICENSE AGREEMENT\n\nLlama 3.2 Version\
\ Release Date: September 25, 2024\n\n“Agreement” means the terms and conditions\
\ for use, reproduction, distribution and modification of the Llama Materials set\
\ forth herein.\n\n“Documentation” means the specifications, manuals and documentation\
\ accompanying Llama 3.2 distributed by Meta at https://llama.meta.com/doc/overview.\n\
\n“Licensee” or “you” means you, or your employer or any other person or entity\
\ (if you are entering into this Agreement on such person or entity’s behalf),\
\ of the age required under applicable laws, rules or regulations to provide legal\
\ consent and that has legal authority to bind your employer or such other person\
\ or entity if you are entering in this Agreement on their behalf.\n\n“Llama 3.2”\
\ means the foundational large language models and software and algorithms, including\
\ machine-learning model code, trained model weights, inference-enabling code, training-enabling\
\ code, fine-tuning enabling code and other elements of the foregoing distributed\
\ by Meta at https://www.llama.com/llama-downloads.\n\n“Llama Materials” means,\
\ collectively, Meta’s proprietary Llama 3.2 and Documentation (and any portion\
\ thereof) made available under this Agreement.\n\n“Meta” or “we” means Meta Platforms\
\ Ireland Limited (if you are located in or, if you are an entity, your principal\
\ place of business is in the EEA or Switzerland) and Meta Platforms, Inc. (if\
\ you are located outside of the EEA or Switzerland). \n\nBy clicking “I Accept”\
\ below or by using or distributing any portion or element of the Llama Materials,\
\ you agree to be bound by this Agreement.\n\n1. License Rights and Redistribution.\n\
a. Grant of Rights. You are granted a non-exclusive, worldwide, non-transferable\
\ and royalty-free limited license under Meta’s intellectual property or other rights\
\ owned by Meta embodied in the Llama Materials to use, reproduce, distribute,\
\ copy, create derivative works of, and make modifications to the Llama Materials.\
\ \nb. Redistribution and Use. \ni. If you distribute or make available the Llama\
\ Materials (or any derivative works thereof), or a product or service (including\
\ another AI model) that contains any of them, you shall (A) provide a copy of this\
\ Agreement with any such Llama Materials; and (B) prominently display “Built with\
\ Llama” on a related website, user interface, blogpost, about page, or product\
\ documentation. If you use the Llama Materials or any outputs or results of the\
\ Llama Materials to create, train, fine tune, or otherwise improve an AI model,\
\ which is distributed or made available, you shall also include “Llama” at the\
\ beginning of any such AI model name.\nii. If you receive Llama Materials, or any\
\ derivative works thereof, from a Licensee as part of an integrated end user product,\
\ then Section 2 of this Agreement will not apply to you. \niii. You must retain\
\ in all copies of the Llama Materials that you distribute the following attribution\
\ notice within a “Notice” text file distributed as a part of such copies: “Llama\
\ 3.2 is licensed under the Llama 3.2 Community License, Copyright © Meta Platforms,\
\ Inc. All Rights Reserved.”\niv. Your use of the Llama Materials must comply with\
\ applicable laws and regulations (including trade compliance laws and regulations)\
\ and adhere to the Acceptable Use Policy for the Llama Materials (available at\
\ https://www.llama.com/llama3_2/use-policy), which is hereby incorporated by reference\
\ into this Agreement.\n \n2. Additional Commercial Terms. If, on the Llama 3.2\
\ version release date, the monthly active users of the products or services made\
\ available by or for Licensee, or Licensee’s affiliates, is greater than 700 million\
\ monthly active users in the preceding calendar month, you must request a license\
\ from Meta, which Meta may grant to you in its sole discretion, and you are not\
\ authorized to exercise any of the rights under this Agreement unless or until\
\ Meta otherwise expressly grants you such rights.\n3. Disclaimer of Warranty. UNLESS\
\ REQUIRED BY APPLICABLE LAW, THE LLAMA MATERIALS AND ANY OUTPUT AND RESULTS THEREFROM\
\ ARE PROVIDED ON AN “AS IS” BASIS, WITHOUT WARRANTIES OF ANY KIND, AND META DISCLAIMS\
\ ALL WARRANTIES OF ANY KIND, BOTH EXPRESS AND IMPLIED, INCLUDING, WITHOUT LIMITATION,\
\ ANY WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR A PARTICULAR\
\ PURPOSE. YOU ARE SOLELY RESPONSIBLE FOR DETERMINING THE APPROPRIATENESS OF USING\
\ OR REDISTRIBUTING THE LLAMA MATERIALS AND ASSUME ANY RISKS ASSOCIATED WITH YOUR\
\ USE OF THE LLAMA MATERIALS AND ANY OUTPUT AND RESULTS.\n4. Limitation of Liability.\
\ IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF LIABILITY,\
\ WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING\
\ OUT OF THIS AGREEMENT, FOR ANY LOST PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL,\
\ INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF META OR ITS AFFILIATES HAVE\
\ BEEN ADVISED OF THE POSSIBILITY OF ANY OF THE FOREGOING.\n5. Intellectual Property.\n\
a. No trademark licenses are granted under this Agreement, and in connection with\
\ the Llama Materials, neither Meta nor Licensee may use any name or mark owned\
\ by or associated with the other or any of its affiliates, except as required\
\ for reasonable and customary use in describing and redistributing the Llama Materials\
\ or as set forth in this Section 5(a). Meta hereby grants you a license to use\
\ “Llama” (the “Mark”) solely as required to comply with the last sentence of Section\
\ 1.b.i. You will comply with Meta’s brand guidelines (currently accessible at\
\ https://about.meta.com/brand/resources/meta/company-brand/). All goodwill arising\
\ out of your use of the Mark will inure to the benefit of Meta.\nb. Subject to\
\ Meta’s ownership of Llama Materials and derivatives made by or for Meta, with\
\ respect to any derivative works and modifications of the Llama Materials that\
\ are made by you, as between you and Meta, you are and will be the owner of such\
\ derivative works and modifications.\nc. If you institute litigation or other proceedings\
\ against Meta or any entity (including a cross-claim or counterclaim in a lawsuit)\
\ alleging that the Llama Materials or Llama 3.2 outputs or results, or any portion\
\ of any of the foregoing, constitutes infringement of intellectual property or\
\ other rights owned or licensable by you, then any licenses granted to you under\
\ this Agreement shall terminate as of the date such litigation or claim is filed\
\ or instituted. You will indemnify and hold harmless Meta from and against any\
\ claim by any third party arising out of or related to your use or distribution\
\ of the Llama Materials.\n6. Term and Termination. The term of this Agreement will\
\ commence upon your acceptance of this Agreement or access to the Llama Materials\
\ and will continue in full force and effect until terminated in accordance with\
\ the terms and conditions herein. Meta may terminate this Agreement if you are\
\ in breach of any term or condition of this Agreement. Upon termination of this\
\ Agreement, you shall delete and cease use of the Llama Materials. Sections 3,\
\ 4 and 7 shall survive the termination of this Agreement. \n7. Governing Law and\
\ Jurisdiction. This Agreement will be governed and construed under the laws of\
\ the State of California without regard to choice of law principles, and the UN\
\ Convention on Contracts for the International Sale of Goods does not apply to\
\ this Agreement. The courts of California shall have exclusive jurisdiction of\
\ any dispute arising out of this Agreement. \n### Llama 3.2 Acceptable Use Policy\n\
Meta is committed to promoting safe and fair use of its tools and features, including\
\ Llama 3.2. If you access or use Llama 3.2, you agree to this Acceptable Use Policy\
\ (“**Policy**”). The most recent copy of this policy can be found at [https://www.llama.com/llama3_2/use-policy](https://www.llama.com/llama3_2/use-policy).\n\
#### Prohibited Uses\nWe want everyone to use Llama 3.2 safely and responsibly.\
\ You agree you will not use, or allow others to use, Llama 3.2 to:\n1. Violate\
\ the law or others’ rights, including to:\n 1. Engage in, promote, generate,\
\ contribute to, encourage, plan, incite, or further illegal or unlawful activity\
\ or content, such as:\n 1. Violence or terrorism\n 2. Exploitation\
\ or harm to children, including the solicitation, creation, acquisition, or dissemination\
\ of child exploitative content or failure to report Child Sexual Abuse Material\n\
\ 3. Human trafficking, exploitation, and sexual violence\n 4. The\
\ illegal distribution of information or materials to minors, including obscene\
\ materials, or failure to employ legally required age-gating in connection with\
\ such information or materials.\n 5. Sexual solicitation\n 6. Any\
\ other criminal activity\n 1. Engage in, promote, incite, or facilitate the\
\ harassment, abuse, threatening, or bullying of individuals or groups of individuals\n\
\ 2. Engage in, promote, incite, or facilitate discrimination or other unlawful\
\ or harmful conduct in the provision of employment, employment benefits, credit,\
\ housing, other economic benefits, or other essential goods and services\n 3.\
\ Engage in the unauthorized or unlicensed practice of any profession including,\
\ but not limited to, financial, legal, medical/health, or related professional\
\ practices\n 4. Collect, process, disclose, generate, or infer private or sensitive\
\ information about individuals, including information about individuals’ identity,\
\ health, or demographic information, unless you have obtained the right to do so\
\ in accordance with applicable law\n 5. Engage in or facilitate any action or\
\ generate any content that infringes, misappropriates, or otherwise violates any\
\ third-party rights, including the outputs or results of any products or services\
\ using the Llama Materials\n 6. Create, generate, or facilitate the creation\
\ of malicious code, malware, computer viruses or do anything else that could disable,\
\ overburden, interfere with or impair the proper working, integrity, operation\
\ or appearance of a website or computer system\n 7. Engage in any action, or\
\ facilitate any action, to intentionally circumvent or remove usage restrictions\
\ or other safety measures, or to enable functionality disabled by Meta \n2. Engage\
\ in, promote, incite, facilitate, or assist in the planning or development of activities\
\ that present a risk of death or bodily harm to individuals, including use of Llama\
\ 3.2 related to the following:\n 8. Military, warfare, nuclear industries or\
\ applications, espionage, use for materials or activities that are subject to the\
\ International Traffic Arms Regulations (ITAR) maintained by the United States\
\ Department of State or to the U.S. Biological Weapons Anti-Terrorism Act of 1989\
\ or the Chemical Weapons Convention Implementation Act of 1997\n 9. Guns and\
\ illegal weapons (including weapon development)\n 10. Illegal drugs and regulated/controlled\
\ substances\n 11. Operation of critical infrastructure, transportation technologies,\
\ or heavy machinery\n 12. Self-harm or harm to others, including suicide, cutting,\
\ and eating disorders\n 13. Any content intended to incite or promote violence,\
\ abuse, or any infliction of bodily harm to an individual\n3. Intentionally deceive\
\ or mislead others, including use of Llama 3.2 related to the following:\n 14.\
\ Generating, promoting, or furthering fraud or the creation or promotion of disinformation\n\
\ 15. Generating, promoting, or furthering defamatory content, including the\
\ creation of defamatory statements, images, or other content\n 16. Generating,\
\ promoting, or further distributing spam\n 17. Impersonating another individual\
\ without consent, authorization, or legal right\n 18. Representing that the\
\ use of Llama 3.2 or outputs are human-generated\n 19. Generating or facilitating\
\ false online engagement, including fake reviews and other means of fake online\
\ engagement \n4. Fail to appropriately disclose to end users any known dangers\
\ of your AI system 5. Interact with third party tools, models, or software designed\
\ to generate unlawful content or engage in unlawful or harmful conduct and/or represent\
\ that the outputs of such tools, models, or software are associated with Meta or\
\ Llama 3.2\n\nWith respect to any multimodal models included in Llama 3.2, the\
\ rights granted under Section 1(a) of the Llama 3.2 Community License Agreement\
\ are not being granted to you if you are an individual domiciled in, or a company\
\ with a principal place of business in, the European Union. This restriction does\
\ not apply to end users of a product or service that incorporates any such multimodal\
\ models.\n\nPlease report any violation of this Policy, software “bug,” or other\
\ problems that could lead to a violation of this Policy through one of the following\
\ means:\n\n* Reporting issues with the model: [https://github.com/meta-llama/llama-models/issues](https://l.workplace.com/l.php?u=https%3A%2F%2Fgithub.com%2Fmeta-llama%2Fllama-models%2Fissues&h=AT0qV8W9BFT6NwihiOHRuKYQM_UnkzN_NmHMy91OT55gkLpgi4kQupHUl0ssR4dQsIQ8n3tfd0vtkobvsEvt1l4Ic6GXI2EeuHV8N08OG2WnbAmm0FL4ObkazC6G_256vN0lN9DsykCvCqGZ)\n\
* Reporting risky content generated by the model: [developers.facebook.com/llama_output_feedback](http://developers.facebook.com/llama_output_feedback)\n\
* Reporting bugs and security concerns: [facebook.com/whitehat/info](http://facebook.com/whitehat/info)\n\
* Reporting violations of the Acceptable Use Policy or unlicensed uses of Llama\
\ 3.2: [email protected]"
extra_gated_fields:
First Name: text
Last Name: text
Date of birth: date_picker
Country: country
Affiliation: text
Job title:
type: select
options:
- Student
- Research Graduate
- AI researcher
- AI developer/engineer
- Reporter
- Other
geo: ip_location
? By clicking Submit below I accept the terms of the license and acknowledge that
the information I provide will be collected stored processed and shared in accordance
with the Meta Privacy Policy
: checkbox
extra_gated_description: The information you provide will be collected, stored, processed
and shared in accordance with the [Meta Privacy Policy](https://www.facebook.com/privacy/policy/).
extra_gated_button_content: Submit
---
# anrgxone0/Llama-3.2-3B-Instruct-Q4_K_M-GGUF
This model was converted to GGUF format from [`meta-llama/Llama-3.2-3B-Instruct`](https://huggingface.co/meta-llama/Llama-3.2-3B-Instruct) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/meta-llama/Llama-3.2-3B-Instruct) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo anrgxone0/Llama-3.2-3B-Instruct-Q4_K_M-GGUF --hf-file llama-3.2-3b-instruct-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo anrgxone0/Llama-3.2-3B-Instruct-Q4_K_M-GGUF --hf-file llama-3.2-3b-instruct-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo anrgxone0/Llama-3.2-3B-Instruct-Q4_K_M-GGUF --hf-file llama-3.2-3b-instruct-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo anrgxone0/Llama-3.2-3B-Instruct-Q4_K_M-GGUF --hf-file llama-3.2-3b-instruct-q4_k_m.gguf -c 2048
```
|
yujie1103/med-chest
|
yujie1103
| 2025-04-03T16:10:32Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-04-03T15:00:17Z
|
---
base_model: unsloth/meta-llama-3.1-8b-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** yujie1103
- **License:** apache-2.0
- **Finetuned from model :** unsloth/meta-llama-3.1-8b-unsloth-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
ParahumanSkitter/Selph-Mix-V10
|
ParahumanSkitter
| 2025-04-03T16:08:10Z
| 0
| 0
|
diffusers
|
[
"diffusers",
"safetensors",
"text-to-image",
"stable-diffusion",
"stable-diffusion-xl",
"illustrious",
"anime",
"cute",
"3D",
"artists",
"en",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] |
text-to-image
| 2025-04-03T16:04:21Z
|
---
license: other
license_name: faipl-1.0-sd
license_link: https://freedevproject.org/faipl-1.0-sd/
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
tags:
- text-to-image
- stable-diffusion
- stable-diffusion-xl
- illustrious
- anime
- cute
- 3D
- artists
---
Original Model from [https://civitai.com/models/1423738/selphmix).
Please support the original authors.
|
aioont/llama-3.2-3b-instruct-base
|
aioont
| 2025-04-03T16:07:22Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"facebook",
"meta",
"pytorch",
"llama-3",
"conversational",
"en",
"de",
"fr",
"it",
"pt",
"hi",
"es",
"th",
"arxiv:2204.05149",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-04-03T14:07:34Z
|
---
language:
- en
- de
- fr
- it
- pt
- hi
- es
- th
library_name: transformers
pipeline_tag: text-generation
tags:
- facebook
- meta
- pytorch
- llama
- llama-3
extra_gated_prompt: >-
### LLAMA 3.2 COMMUNITY LICENSE AGREEMENT
Llama 3.2 Version Release Date: September 25, 2024
“Agreement” means the terms and conditions for use, reproduction, distribution
and modification of the Llama Materials set forth herein.
“Documentation” means the specifications, manuals and documentation accompanying Llama 3.2
distributed by Meta at https://llama.meta.com/doc/overview.
“Licensee” or “you” means you, or your employer or any other person or entity (if you are
entering into this Agreement on such person or entity’s behalf), of the age required under
applicable laws, rules or regulations to provide legal consent and that has legal authority
to bind your employer or such other person or entity if you are entering in this Agreement
on their behalf.
“Llama 3.2” means the foundational large language models and software and algorithms, including
machine-learning model code, trained model weights, inference-enabling code, training-enabling code,
fine-tuning enabling code and other elements of the foregoing distributed by Meta at
https://www.llama.com/llama-downloads.
“Llama Materials” means, collectively, Meta’s proprietary Llama 3.2 and Documentation (and
any portion thereof) made available under this Agreement.
“Meta” or “we” means Meta Platforms Ireland Limited (if you are located in or,
if you are an entity, your principal place of business is in the EEA or Switzerland)
and Meta Platforms, Inc. (if you are located outside of the EEA or Switzerland).
By clicking “I Accept” below or by using or distributing any portion or element of the Llama Materials,
you agree to be bound by this Agreement.
1. License Rights and Redistribution.
a. Grant of Rights. You are granted a non-exclusive, worldwide,
non-transferable and royalty-free limited license under Meta’s intellectual property or other rights
owned by Meta embodied in the Llama Materials to use, reproduce, distribute, copy, create derivative works
of, and make modifications to the Llama Materials.
b. Redistribution and Use.
i. If you distribute or make available the Llama Materials (or any derivative works thereof),
or a product or service (including another AI model) that contains any of them, you shall (A) provide
a copy of this Agreement with any such Llama Materials; and (B) prominently display “Built with Llama”
on a related website, user interface, blogpost, about page, or product documentation. If you use the
Llama Materials or any outputs or results of the Llama Materials to create, train, fine tune, or
otherwise improve an AI model, which is distributed or made available, you shall also include “Llama”
at the beginning of any such AI model name.
ii. If you receive Llama Materials, or any derivative works thereof, from a Licensee as part
of an integrated end user product, then Section 2 of this Agreement will not apply to you.
iii. You must retain in all copies of the Llama Materials that you distribute the
following attribution notice within a “Notice” text file distributed as a part of such copies:
“Llama 3.2 is licensed under the Llama 3.2 Community License, Copyright © Meta Platforms,
Inc. All Rights Reserved.”
iv. Your use of the Llama Materials must comply with applicable laws and regulations
(including trade compliance laws and regulations) and adhere to the Acceptable Use Policy for
the Llama Materials (available at https://www.llama.com/llama3_2/use-policy), which is hereby
incorporated by reference into this Agreement.
2. Additional Commercial Terms. If, on the Llama 3.2 version release date, the monthly active users
of the products or services made available by or for Licensee, or Licensee’s affiliates,
is greater than 700 million monthly active users in the preceding calendar month, you must request
a license from Meta, which Meta may grant to you in its sole discretion, and you are not authorized to
exercise any of the rights under this Agreement unless or until Meta otherwise expressly grants you such rights.
3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE LLAMA MATERIALS AND ANY OUTPUT AND
RESULTS THEREFROM ARE PROVIDED ON AN “AS IS” BASIS, WITHOUT WARRANTIES OF ANY KIND, AND META DISCLAIMS
ALL WARRANTIES OF ANY KIND, BOTH EXPRESS AND IMPLIED, INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES
OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE
FOR DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE LLAMA MATERIALS AND ASSUME ANY RISKS ASSOCIATED
WITH YOUR USE OF THE LLAMA MATERIALS AND ANY OUTPUT AND RESULTS.
4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF LIABILITY,
WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING OUT OF THIS AGREEMENT,
FOR ANY LOST PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL, INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN
IF META OR ITS AFFILIATES HAVE BEEN ADVISED OF THE POSSIBILITY OF ANY OF THE FOREGOING.
5. Intellectual Property.
a. No trademark licenses are granted under this Agreement, and in connection with the Llama Materials,
neither Meta nor Licensee may use any name or mark owned by or associated with the other or any of its affiliates,
except as required for reasonable and customary use in describing and redistributing the Llama Materials or as
set forth in this Section 5(a). Meta hereby grants you a license to use “Llama” (the “Mark”) solely as required
to comply with the last sentence of Section 1.b.i. You will comply with Meta’s brand guidelines (currently accessible
at https://about.meta.com/brand/resources/meta/company-brand/). All goodwill arising out of your use of the Mark
will inure to the benefit of Meta.
b. Subject to Meta’s ownership of Llama Materials and derivatives made by or for Meta, with respect to any
derivative works and modifications of the Llama Materials that are made by you, as between you and Meta,
you are and will be the owner of such derivative works and modifications.
c. If you institute litigation or other proceedings against Meta or any entity (including a cross-claim or
counterclaim in a lawsuit) alleging that the Llama Materials or Llama 3.2 outputs or results, or any portion
of any of the foregoing, constitutes infringement of intellectual property or other rights owned or licensable
by you, then any licenses granted to you under this Agreement shall terminate as of the date such litigation or
claim is filed or instituted. You will indemnify and hold harmless Meta from and against any claim by any third
party arising out of or related to your use or distribution of the Llama Materials.
6. Term and Termination. The term of this Agreement will commence upon your acceptance of this Agreement or access
to the Llama Materials and will continue in full force and effect until terminated in accordance with the terms
and conditions herein. Meta may terminate this Agreement if you are in breach of any term or condition of this
Agreement. Upon termination of this Agreement, you shall delete and cease use of the Llama Materials. Sections 3,
4 and 7 shall survive the termination of this Agreement.
7. Governing Law and Jurisdiction. This Agreement will be governed and construed under the laws of the State of
California without regard to choice of law principles, and the UN Convention on Contracts for the International
Sale of Goods does not apply to this Agreement. The courts of California shall have exclusive jurisdiction of
any dispute arising out of this Agreement.
### Llama 3.2 Acceptable Use Policy
Meta is committed to promoting safe and fair use of its tools and features, including Llama 3.2.
If you access or use Llama 3.2, you agree to this Acceptable Use Policy (“**Policy**”).
The most recent copy of this policy can be found at
[https://www.llama.com/llama3_2/use-policy](https://www.llama.com/llama3_2/use-policy).
#### Prohibited Uses
We want everyone to use Llama 3.2 safely and responsibly. You agree you will not use, or allow others to use, Llama 3.2 to:
1. Violate the law or others’ rights, including to:
1. Engage in, promote, generate, contribute to, encourage, plan, incite, or further illegal or unlawful activity or content, such as:
1. Violence or terrorism
2. Exploitation or harm to children, including the solicitation, creation, acquisition, or dissemination of child exploitative content or failure to report Child Sexual Abuse Material
3. Human trafficking, exploitation, and sexual violence
4. The illegal distribution of information or materials to minors, including obscene materials, or failure to employ legally required age-gating in connection with such information or materials.
5. Sexual solicitation
6. Any other criminal activity
1. Engage in, promote, incite, or facilitate the harassment, abuse, threatening, or bullying of individuals or groups of individuals
2. Engage in, promote, incite, or facilitate discrimination or other unlawful or harmful conduct in the provision of employment, employment benefits, credit, housing, other economic benefits, or other essential goods and services
3. Engage in the unauthorized or unlicensed practice of any profession including, but not limited to, financial, legal, medical/health, or related professional practices
4. Collect, process, disclose, generate, or infer private or sensitive information about individuals, including information about individuals’ identity, health, or demographic information, unless you have obtained the right to do so in accordance with applicable law
5. Engage in or facilitate any action or generate any content that infringes, misappropriates, or otherwise violates any third-party rights, including the outputs or results of any products or services using the Llama Materials
6. Create, generate, or facilitate the creation of malicious code, malware, computer viruses or do anything else that could disable, overburden, interfere with or impair the proper working, integrity, operation or appearance of a website or computer system
7. Engage in any action, or facilitate any action, to intentionally circumvent or remove usage restrictions or other safety measures, or to enable functionality disabled by Meta
2. Engage in, promote, incite, facilitate, or assist in the planning or development of activities that present a risk of death or bodily harm to individuals, including use of Llama 3.2 related to the following:
8. Military, warfare, nuclear industries or applications, espionage, use for materials or activities that are subject to the International Traffic Arms Regulations (ITAR) maintained by the United States Department of State or to the U.S. Biological Weapons Anti-Terrorism Act of 1989 or the Chemical Weapons Convention Implementation Act of 1997
9. Guns and illegal weapons (including weapon development)
10. Illegal drugs and regulated/controlled substances
11. Operation of critical infrastructure, transportation technologies, or heavy machinery
12. Self-harm or harm to others, including suicide, cutting, and eating disorders
13. Any content intended to incite or promote violence, abuse, or any infliction of bodily harm to an individual
3. Intentionally deceive or mislead others, including use of Llama 3.2 related to the following:
14. Generating, promoting, or furthering fraud or the creation or promotion of disinformation
15. Generating, promoting, or furthering defamatory content, including the creation of defamatory statements, images, or other content
16. Generating, promoting, or further distributing spam
17. Impersonating another individual without consent, authorization, or legal right
18. Representing that the use of Llama 3.2 or outputs are human-generated
19. Generating or facilitating false online engagement, including fake reviews and other means of fake online engagement
4. Fail to appropriately disclose to end users any known dangers of your AI system
5. Interact with third party tools, models, or software designed to generate unlawful content or engage in unlawful or harmful conduct and/or represent that the outputs of such tools, models, or software are associated with Meta or Llama 3.2
With respect to any multimodal models included in Llama 3.2, the rights granted under Section 1(a) of the Llama 3.2 Community License Agreement are not being granted to you if you are an individual domiciled in, or a company with a principal place of business in, the European Union. This restriction does not apply to end users of a product or service that incorporates any such multimodal models.
Please report any violation of this Policy, software “bug,” or other problems that could lead to a violation of this Policy through one of the following means:
* Reporting issues with the model: [https://github.com/meta-llama/llama-models/issues](https://l.workplace.com/l.php?u=https%3A%2F%2Fgithub.com%2Fmeta-llama%2Fllama-models%2Fissues&h=AT0qV8W9BFT6NwihiOHRuKYQM_UnkzN_NmHMy91OT55gkLpgi4kQupHUl0ssR4dQsIQ8n3tfd0vtkobvsEvt1l4Ic6GXI2EeuHV8N08OG2WnbAmm0FL4ObkazC6G_256vN0lN9DsykCvCqGZ)
* Reporting risky content generated by the model: [developers.facebook.com/llama_output_feedback](http://developers.facebook.com/llama_output_feedback)
* Reporting bugs and security concerns: [facebook.com/whitehat/info](http://facebook.com/whitehat/info)
* Reporting violations of the Acceptable Use Policy or unlicensed uses of Llama 3.2: [email protected]
extra_gated_fields:
First Name: text
Last Name: text
Date of birth: date_picker
Country: country
Affiliation: text
Job title:
type: select
options:
- Student
- Research Graduate
- AI researcher
- AI developer/engineer
- Reporter
- Other
geo: ip_location
By clicking Submit below I accept the terms of the license and acknowledge that the information I provide will be collected stored processed and shared in accordance with the Meta Privacy Policy: checkbox
extra_gated_description: >-
The information you provide will be collected, stored, processed and shared in
accordance with the [Meta Privacy
Policy](https://www.facebook.com/privacy/policy/).
extra_gated_button_content: Submit
---
## Model Information
The Meta Llama 3.2 collection of multilingual large language models (LLMs) is a collection of pretrained and instruction-tuned generative models in 1B and 3B sizes (text in/text out). The Llama 3.2 instruction-tuned text only models are optimized for multilingual dialogue use cases, including agentic retrieval and summarization tasks. They outperform many of the available open source and closed chat models on common industry benchmarks.
**Model Developer:** Meta
**Model Architecture:** Llama 3.2 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for helpfulness and safety.
| | Training Data | Params | Input modalities | Output modalities | Context Length | GQA | Shared Embeddings | Token count | Knowledge cutoff |
| :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- |
| Llama 3.2 (text only) | A new mix of publicly available online data. | 1B (1.23B) | Multilingual Text | Multilingual Text and code | 128k | Yes | Yes | Up to 9T tokens | December 2023 |
| | | 3B (3.21B) | Multilingual Text | Multilingual Text and code | | | | | |
**Supported Languages:** English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai are officially supported. Llama 3.2 has been trained on a broader collection of languages than these 8 supported languages. Developers may fine-tune Llama 3.2 models for languages beyond these supported languages, provided they comply with the Llama 3.2 Community License and the Acceptable Use Policy. Developers are always expected to ensure that their deployments, including those that involve additional languages, are completed safely and responsibly.
**Llama 3.2 Model Family:** Token counts refer to pretraining data only. All model versions use Grouped-Query Attention (GQA) for improved inference scalability.
**Model Release Date:** Sept 25, 2024
**Status:** This is a static model trained on an offline dataset. Future versions may be released that improve model capabilities and safety.
**License:** Use of Llama 3.2 is governed by the [Llama 3.2 Community License](https://github.com/meta-llama/llama-models/blob/main/models/llama3_2/LICENSE) (a custom, commercial license agreement).
**Feedback:** Where to send questions or comments about the model Instructions on how to provide feedback or comments on the model can be found in the model [README](https://github.com/meta-llama/llama-models/tree/main/models/llama3_2). For more technical information about generation parameters and recipes for how to use Llama 3.2 in applications, please go [here](https://github.com/meta-llama/llama-recipes).
## Intended Use
**Intended Use Cases:** Llama 3.2 is intended for commercial and research use in multiple languages. Instruction tuned text only models are intended for assistant-like chat and agentic applications like knowledge retrieval and summarization, mobile AI powered writing assistants and query and prompt rewriting. Pretrained models can be adapted for a variety of additional natural language generation tasks.
**Out of Scope:** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in any other way that is prohibited by the Acceptable Use Policy and Llama 3.2 Community License. Use in languages beyond those explicitly referenced as supported in this model card.
## Hardware and Software
**Training Factors:** We used custom training libraries, Meta's custom built GPU cluster, and production infrastructure for pretraining. Fine-tuning, annotation, and evaluation were also performed on production infrastructure.
**Training Energy Use:** Training utilized a cumulative of **916k** GPU hours of computation on H100-80GB (TDP of 700W) type hardware, per the table below. Training time is the total GPU time required for training each model and power consumption is the peak power capacity per GPU device used, adjusted for power usage efficiency.
##
**Training Greenhouse Gas Emissions:** Estimated total location-based greenhouse gas emissions were **240** tons CO2eq for training. Since 2020, Meta has maintained net zero greenhouse gas emissions in its global operations and matched 100% of its electricity use with renewable energy; therefore, the total market-based greenhouse gas emissions for training were 0 tons CO2eq.
| | Training Time (GPU hours) | Logit Generation Time (GPU Hours) | Training Power Consumption (W) | Training Location-Based Greenhouse Gas Emissions (tons CO2eq) | Training Market-Based Greenhouse Gas Emissions (tons CO2eq) |
| :---- | :---: | ----- | :---: | :---: | :---: |
| Llama 3.2 1B | 370k | \- | 700 | 107 | 0 |
| Llama 3.2 3B | 460k | \- | 700 | 133 | 0 |
| Total | 830k | 86k | | 240 | 0 |
The methodology used to determine training energy use and greenhouse gas emissions can be found [here](https://arxiv.org/pdf/2204.05149). Since Meta is openly releasing these models, the training energy use and greenhouse gas emissions will not be incurred by others.
## Training Data
**Overview:** Llama 3.2 was pretrained on up to 9 trillion tokens of data from publicly available sources. For the 1B and 3B Llama 3.2 models, we incorporated logits from the Llama 3.1 8B and 70B models into the pretraining stage of the model development, where outputs (logits) from these larger models were used as token-level targets. Knowledge distillation was used after pruning to recover performance. In post-training we used a similar recipe as Llama 3.1 and produced final chat models by doing several rounds of alignment on top of the pre-trained model. Each round involved Supervised Fine-Tuning (SFT), Rejection Sampling (RS), and Direct Preference Optimization (DPO).
**Data Freshness:** The pretraining data has a cutoff of December 2023\.
## Benchmarks \- English Text
In this section, we report the results for Llama 3.2 models on standard automatic benchmarks. For all these evaluations, we used our internal evaluations library.
### Base Pretrained Models
| Category | Benchmark | \# Shots | Metric | Llama 3.2 1B | Llama 3.2 3B | Llama 3.1 8B |
| ----- | ----- | :---: | :---: | :---: | :---: | :---: |
| General | MMLU | 5 | macro\_avg/acc\_char | 32.2 | 58 | 66.7 |
| | AGIEval English | 3-5 | average/acc\_char | 23.3 | 39.2 | 47.8 |
| | ARC-Challenge | 25 | acc\_char | 32.8 | 69.1 | 79.7 |
| Reading comprehension | SQuAD | 1 | em | 49.2 | 67.7 | 77 |
| | QuAC (F1) | 1 | f1 | 37.9 | 42.9 | 44.9 |
| | DROP (F1) | 3 | f1 | 28.0 | 45.2 | 59.5 |
| Long Context | Needle in Haystack | 0 | em | 96.8 | 1 | 1 |
### Instruction Tuned Models
| Capability | | Benchmark | \# Shots | Metric | Llama 3.2 1B | Llama 3.2 3B | Llama 3.1 8B |
| :---: | ----- | :---: | :---: | :---: | :---: | :---: | :---: |
| General | | MMLU | 5 | macro\_avg/acc | 49.3 | 63.4 | 69.4 |
| Re-writing | | Open-rewrite eval | 0 | micro\_avg/rougeL | 41.6 | 40.1 | 40.9 |
| Summarization | | TLDR9+ (test) | 1 | rougeL | 16.8 | 19.0 | 17.2 |
| Instruction following | | IFEval | 0 | Avg(Prompt/Instruction acc Loose/Strict) | 59.5 | 77.4 | 80.4 |
| Math | | GSM8K (CoT) | 8 | em\_maj1@1 | 44.4 | 77.7 | 84.5 |
| | | MATH (CoT) | 0 | final\_em | 30.6 | 48.0 | 51.9 |
| Reasoning | | ARC-C | 0 | acc | 59.4 | 78.6 | 83.4 |
| | | GPQA | 0 | acc | 27.2 | 32.8 | 32.8 |
| | | Hellaswag | 0 | acc | 41.2 | 69.8 | 78.7 |
| Tool Use | | BFCL V2 | 0 | acc | 25.7 | 67.0 | 67.1 |
| | | Nexus | 0 | macro\_avg/acc | 13.5 | 34.3 | 38.5 |
| Long Context | | InfiniteBench/En.QA | 0 | longbook\_qa/f1 | 20.3 | 19.8 | 27.3 |
| | | InfiniteBench/En.MC | 0 | longbook\_choice/acc | 38.0 | 63.3 | 72.2 |
| | | NIH/Multi-needle | 0 | recall | 75.0 | 84.7 | 98.8 |
| Multilingual | | MGSM (CoT) | 0 | em | 24.5 | 58.2 | 68.9 |
### Multilingual Benchmarks
| Category | Benchmark | Language | Llama 3.2 1B | Llama 3.2 3B | Llama 3.1 8B |
| :---: | :---: | :---: | :---: | :---: | :---: |
| General | MMLU (5-shot, macro\_avg/acc) | Portuguese | 39.82 | 54.48 | 62.12 |
| | | Spanish | 41.52 | 55.09 | 62.45 |
| | | Italian | 39.79 | 53.77 | 61.63 |
| | | German | 39.20 | 53.29 | 60.59 |
| | | French | 40.47 | 54.59 | 62.34 |
| | | Hindi | 33.51 | 43.31 | 50.88 |
| | | Thai | 34.67 | 44.54 | 50.32 |
## Responsibility & Safety
As part of our Responsible release approach, we followed a three-pronged strategy to managing trust & safety risks:
1. Enable developers to deploy helpful, safe and flexible experiences for their target audience and for the use cases supported by Llama
2. Protect developers against adversarial users aiming to exploit Llama capabilities to potentially cause harm
3. Provide protections for the community to help prevent the misuse of our models
### Responsible Deployment
**Approach:** Llama is a foundational technology designed to be used in a variety of use cases. Examples on how Meta’s Llama models have been responsibly deployed can be found in our [Community Stories webpage](https://llama.meta.com/community-stories/). Our approach is to build the most helpful models, enabling the world to benefit from the technology power, by aligning our model safety for generic use cases and addressing a standard set of harms. Developers are then in the driver’s seat to tailor safety for their use cases, defining their own policies and deploying the models with the necessary safeguards in their Llama systems. Llama 3.2 was developed following the best practices outlined in our [Responsible Use Guide](https://llama.meta.com/responsible-use-guide/).
#### Llama 3.2 Instruct
**Objective:** Our main objectives for conducting safety fine-tuning are to provide the research community with a valuable resource for studying the robustness of safety fine-tuning, as well as to offer developers a readily available, safe, and powerful model for various applications to reduce the developer workload to deploy safe AI systems. We implemented the same set of safety mitigations as in Llama 3, and you can learn more about these in the Llama 3 [paper](https://ai.meta.com/research/publications/the-llama-3-herd-of-models/).
**Fine-Tuning Data:** We employ a multi-faceted approach to data collection, combining human-generated data from our vendors with synthetic data to mitigate potential safety risks. We’ve developed many large language model (LLM)-based classifiers that enable us to thoughtfully select high-quality prompts and responses, enhancing data quality control.
**Refusals and Tone:** Building on the work we started with Llama 3, we put a great emphasis on model refusals to benign prompts as well as refusal tone. We included both borderline and adversarial prompts in our safety data strategy, and modified our safety data responses to follow tone guidelines.
#### Llama 3.2 Systems
**Safety as a System:** Large language models, including Llama 3.2, **are not designed to be deployed in isolation** but instead should be deployed as part of an overall AI system with additional safety guardrails as required. Developers are expected to deploy system safeguards when building agentic systems. Safeguards are key to achieve the right helpfulness-safety alignment as well as mitigating safety and security risks inherent to the system and any integration of the model or system with external tools. As part of our responsible release approach, we provide the community with [safeguards](https://llama.meta.com/trust-and-safety/) that developers should deploy with Llama models or other LLMs, including Llama Guard, Prompt Guard and Code Shield. All our [reference implementations](https://github.com/meta-llama/llama-agentic-system) demos contain these safeguards by default so developers can benefit from system-level safety out-of-the-box.
### New Capabilities and Use Cases
**Technological Advancement:** Llama releases usually introduce new capabilities that require specific considerations in addition to the best practices that generally apply across all Generative AI use cases. For prior release capabilities also supported by Llama 3.2, see [Llama 3.1 Model Card](https://github.com/meta-llama/llama-models/blob/main/models/llama3_1/MODEL_CARD.md), as the same considerations apply here as well.
**Constrained Environments:** Llama 3.2 1B and 3B models are expected to be deployed in highly constrained environments, such as mobile devices. LLM Systems using smaller models will have a different alignment profile and safety/helpfulness tradeoff than more complex, larger systems. Developers should ensure the safety of their system meets the requirements of their use case. We recommend using lighter system safeguards for such use cases, like Llama Guard 3-1B or its mobile-optimized version.
### Evaluations
**Scaled Evaluations:** We built dedicated, adversarial evaluation datasets and evaluated systems composed of Llama models and Purple Llama safeguards to filter input prompt and output response. It is important to evaluate applications in context, and we recommend building dedicated evaluation dataset for your use case.
**Red Teaming:** We conducted recurring red teaming exercises with the goal of discovering risks via adversarial prompting and we used the learnings to improve our benchmarks and safety tuning datasets. We partnered early with subject-matter experts in critical risk areas to understand the nature of these real-world harms and how such models may lead to unintended harm for society. Based on these conversations, we derived a set of adversarial goals for the red team to attempt to achieve, such as extracting harmful information or reprogramming the model to act in a potentially harmful capacity. The red team consisted of experts in cybersecurity, adversarial machine learning, responsible AI, and integrity in addition to multilingual content specialists with background in integrity issues in specific geographic markets.
### Critical Risks
In addition to our safety work above, we took extra care on measuring and/or mitigating the following critical risk areas:
**1\. CBRNE (Chemical, Biological, Radiological, Nuclear, and Explosive Weapons):** Llama 3.2 1B and 3B models are smaller and less capable derivatives of Llama 3.1. For Llama 3.1 70B and 405B, to assess risks related to proliferation of chemical and biological weapons, we performed uplift testing designed to assess whether use of Llama 3.1 models could meaningfully increase the capabilities of malicious actors to plan or carry out attacks using these types of weapons and have determined that such testing also applies to the smaller 1B and 3B models.
**2\. Child Safety:** Child Safety risk assessments were conducted using a team of experts, to assess the model’s capability to produce outputs that could result in Child Safety risks and inform on any necessary and appropriate risk mitigations via fine tuning. We leveraged those expert red teaming sessions to expand the coverage of our evaluation benchmarks through Llama 3 model development. For Llama 3, we conducted new in-depth sessions using objective based methodologies to assess the model risks along multiple attack vectors including the additional languages Llama 3 is trained on. We also partnered with content specialists to perform red teaming exercises assessing potentially violating content while taking account of market specific nuances or experiences.
**3\. Cyber Attacks:** Our cyber attack uplift study investigated whether LLMs can enhance human capabilities in hacking tasks, both in terms of skill level and speed. Our attack automation study focused on evaluating the capabilities of LLMs when used as autonomous agents in cyber offensive operations, specifically in the context of ransomware attacks. This evaluation was distinct from previous studies that considered LLMs as interactive assistants. The primary objective was to assess whether these models could effectively function as independent agents in executing complex cyber-attacks without human intervention.
### Community
**Industry Partnerships:** Generative AI safety requires expertise and tooling, and we believe in the strength of the open community to accelerate its progress. We are active members of open consortiums, including the AI Alliance, Partnership on AI and MLCommons, actively contributing to safety standardization and transparency. We encourage the community to adopt taxonomies like the MLCommons Proof of Concept evaluation to facilitate collaboration and transparency on safety and content evaluations. Our Purple Llama tools are open sourced for the community to use and widely distributed across ecosystem partners including cloud service providers. We encourage community contributions to our [Github repository](https://github.com/meta-llama/PurpleLlama).
**Grants:** We also set up the [Llama Impact Grants](https://llama.meta.com/llama-impact-grants/) program to identify and support the most compelling applications of Meta’s Llama model for societal benefit across three categories: education, climate and open innovation. The 20 finalists from the hundreds of applications can be found [here](https://llama.meta.com/llama-impact-grants/#finalists).
**Reporting:** Finally, we put in place a set of resources including an [output reporting mechanism](https://developers.facebook.com/llama_output_feedback) and [bug bounty program](https://www.facebook.com/whitehat) to continuously improve the Llama technology with the help of the community.
## Ethical Considerations and Limitations
**Values:** The core values of Llama 3.2 are openness, inclusivity and helpfulness. It is meant to serve everyone, and to work for a wide range of use cases. It is thus designed to be accessible to people across many different backgrounds, experiences and perspectives. Llama 3.2 addresses users and their needs as they are, without insertion unnecessary judgment or normativity, while reflecting the understanding that even content that may appear problematic in some cases can serve valuable purposes in others. It respects the dignity and autonomy of all users, especially in terms of the values of free thought and expression that power innovation and progress.
**Testing:** Llama 3.2 is a new technology, and like any new technology, there are risks associated with its use. Testing conducted to date has not covered, nor could it cover, all scenarios. For these reasons, as with all LLMs, Llama 3.2’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 3.2 models, developers should perform safety testing and tuning tailored to their specific applications of the model. Please refer to available resources including our [Responsible Use Guide](https://llama.meta.com/responsible-use-guide), [Trust and Safety](https://llama.meta.com/trust-and-safety/) solutions, and other [resources](https://llama.meta.com/docs/get-started/) to learn more about responsible development.
|
weizhepei/Qwen2.5-3B-WebArena-Lite-SFT-CoT-QwQ-32B-epoch-10-no-packing
|
weizhepei
| 2025-04-03T16:05:25Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"open-r1",
"trl",
"sft",
"conversational",
"dataset:weizhepei/webarena-lite-SFT-CoT-QwQ-32B",
"base_model:Qwen/Qwen2.5-3B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-3B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-04-03T09:27:57Z
|
---
base_model: Qwen/Qwen2.5-3B-Instruct
datasets: weizhepei/webarena-lite-SFT-CoT-QwQ-32B
library_name: transformers
model_name: Qwen2.5-3B-WebArena-Lite-SFT-CoT-QwQ-32B-epoch-10-no-packing
tags:
- generated_from_trainer
- open-r1
- trl
- sft
licence: license
---
# Model Card for Qwen2.5-3B-WebArena-Lite-SFT-CoT-QwQ-32B-epoch-10-no-packing
This model is a fine-tuned version of [Qwen/Qwen2.5-3B-Instruct](https://huggingface.co/Qwen/Qwen2.5-3B-Instruct) on the [weizhepei/webarena-lite-SFT-CoT-QwQ-32B](https://huggingface.co/datasets/weizhepei/webarena-lite-SFT-CoT-QwQ-32B) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="weizhepei/Qwen2.5-3B-WebArena-Lite-SFT-CoT-QwQ-32B-epoch-10-no-packing", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/uva-llm/huggingface/runs/6npcofxo)
This model was trained with SFT.
### Framework versions
- TRL: 0.16.0.dev0
- Transformers: 4.49.0
- Pytorch: 2.5.1
- Datasets: 3.4.1
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
nextgenaibw/setswanachatbw
|
nextgenaibw
| 2025-04-03T16:04:47Z
| 0
| 0
| null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-04-03T16:04:41Z
|
---
license: apache-2.0
---
|
genki10/BERT_AugV8_k1_task1_organization_sp020_lw040_fold4
|
genki10
| 2025-04-03T16:02:55Z
| 4
| 0
|
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-03-25T02:19:41Z
|
---
library_name: transformers
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: BERT_AugV8_k1_task1_organization_sp020_lw040_fold4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BERT_AugV8_k1_task1_organization_sp020_lw040_fold4
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7333
- Qwk: 0.5138
- Mse: 0.7333
- Rmse: 0.8563
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 150
### Training results
| Training Loss | Epoch | Step | Validation Loss | Qwk | Mse | Rmse |
|:-------------:|:-----:|:----:|:---------------:|:------:|:-------:|:------:|
| No log | 1.0 | 2 | 11.6967 | 0.0094 | 11.6967 | 3.4200 |
| No log | 2.0 | 4 | 9.4706 | 0.0037 | 9.4706 | 3.0774 |
| No log | 3.0 | 6 | 6.6757 | 0.0 | 6.6757 | 2.5837 |
| No log | 4.0 | 8 | 5.1294 | 0.0325 | 5.1294 | 2.2648 |
| No log | 5.0 | 10 | 3.8123 | 0.0040 | 3.8123 | 1.9525 |
| No log | 6.0 | 12 | 2.9391 | 0.0040 | 2.9391 | 1.7144 |
| No log | 7.0 | 14 | 2.8826 | 0.0029 | 2.8826 | 1.6978 |
| No log | 8.0 | 16 | 2.5855 | 0.0071 | 2.5855 | 1.6079 |
| No log | 9.0 | 18 | 1.8162 | 0.0445 | 1.8162 | 1.3477 |
| No log | 10.0 | 20 | 1.6122 | 0.0316 | 1.6122 | 1.2697 |
| No log | 11.0 | 22 | 1.2626 | 0.0316 | 1.2626 | 1.1236 |
| No log | 12.0 | 24 | 1.2246 | 0.0316 | 1.2246 | 1.1066 |
| No log | 13.0 | 26 | 1.1852 | 0.0316 | 1.1852 | 1.0887 |
| No log | 14.0 | 28 | 0.9627 | 0.0316 | 0.9627 | 0.9812 |
| No log | 15.0 | 30 | 0.8538 | 0.1904 | 0.8538 | 0.9240 |
| No log | 16.0 | 32 | 1.2100 | 0.1455 | 1.2100 | 1.1000 |
| No log | 17.0 | 34 | 1.0800 | 0.1679 | 1.0800 | 1.0392 |
| No log | 18.0 | 36 | 0.7930 | 0.4530 | 0.7930 | 0.8905 |
| No log | 19.0 | 38 | 1.3768 | 0.2650 | 1.3768 | 1.1734 |
| No log | 20.0 | 40 | 1.3673 | 0.2914 | 1.3673 | 1.1693 |
| No log | 21.0 | 42 | 0.7228 | 0.5628 | 0.7228 | 0.8502 |
| No log | 22.0 | 44 | 0.9250 | 0.4266 | 0.9250 | 0.9618 |
| No log | 23.0 | 46 | 1.5003 | 0.2866 | 1.5003 | 1.2249 |
| No log | 24.0 | 48 | 1.3032 | 0.3140 | 1.3032 | 1.1416 |
| No log | 25.0 | 50 | 1.0367 | 0.3370 | 1.0367 | 1.0182 |
| No log | 26.0 | 52 | 0.7162 | 0.5006 | 0.7162 | 0.8463 |
| No log | 27.0 | 54 | 1.0019 | 0.3579 | 1.0019 | 1.0009 |
| No log | 28.0 | 56 | 0.7682 | 0.4752 | 0.7682 | 0.8764 |
| No log | 29.0 | 58 | 0.6260 | 0.5323 | 0.6260 | 0.7912 |
| No log | 30.0 | 60 | 1.0048 | 0.3980 | 1.0048 | 1.0024 |
| No log | 31.0 | 62 | 0.8515 | 0.4608 | 0.8515 | 0.9228 |
| No log | 32.0 | 64 | 0.6450 | 0.5257 | 0.6450 | 0.8031 |
| No log | 33.0 | 66 | 0.6609 | 0.5752 | 0.6609 | 0.8130 |
| No log | 34.0 | 68 | 1.4554 | 0.3256 | 1.4554 | 1.2064 |
| No log | 35.0 | 70 | 1.2077 | 0.3655 | 1.2077 | 1.0989 |
| No log | 36.0 | 72 | 0.6109 | 0.5772 | 0.6109 | 0.7816 |
| No log | 37.0 | 74 | 0.7102 | 0.5194 | 0.7102 | 0.8427 |
| No log | 38.0 | 76 | 0.5919 | 0.5858 | 0.5919 | 0.7693 |
| No log | 39.0 | 78 | 1.0397 | 0.3765 | 1.0397 | 1.0196 |
| No log | 40.0 | 80 | 1.3921 | 0.3028 | 1.3921 | 1.1799 |
| No log | 41.0 | 82 | 1.0672 | 0.3745 | 1.0672 | 1.0331 |
| No log | 42.0 | 84 | 0.5719 | 0.5934 | 0.5719 | 0.7563 |
| No log | 43.0 | 86 | 0.6401 | 0.5553 | 0.6401 | 0.8001 |
| No log | 44.0 | 88 | 0.5857 | 0.5957 | 0.5857 | 0.7653 |
| No log | 45.0 | 90 | 1.3249 | 0.3003 | 1.3249 | 1.1510 |
| No log | 46.0 | 92 | 1.5149 | 0.2820 | 1.5149 | 1.2308 |
| No log | 47.0 | 94 | 0.8642 | 0.4433 | 0.8642 | 0.9296 |
| No log | 48.0 | 96 | 0.6578 | 0.5467 | 0.6578 | 0.8111 |
| No log | 49.0 | 98 | 0.6283 | 0.5563 | 0.6283 | 0.7926 |
| No log | 50.0 | 100 | 0.7881 | 0.4813 | 0.7881 | 0.8878 |
| No log | 51.0 | 102 | 1.0120 | 0.3772 | 1.0120 | 1.0060 |
| No log | 52.0 | 104 | 0.9593 | 0.4061 | 0.9593 | 0.9794 |
| No log | 53.0 | 106 | 0.6942 | 0.5365 | 0.6942 | 0.8332 |
| No log | 54.0 | 108 | 0.6549 | 0.5686 | 0.6549 | 0.8093 |
| No log | 55.0 | 110 | 0.9008 | 0.4371 | 0.9008 | 0.9491 |
| No log | 56.0 | 112 | 0.9697 | 0.4308 | 0.9697 | 0.9847 |
| No log | 57.0 | 114 | 0.7931 | 0.4975 | 0.7931 | 0.8905 |
| No log | 58.0 | 116 | 0.7415 | 0.5291 | 0.7415 | 0.8611 |
| No log | 59.0 | 118 | 0.7333 | 0.5138 | 0.7333 | 0.8563 |
### Framework versions
- Transformers 4.47.0
- Pytorch 2.5.1+cu121
- Datasets 3.3.1
- Tokenizers 0.21.0
|
ysn-rfd/WizardLM-7B-Uncensored-Q8_0-GGUF
|
ysn-rfd
| 2025-04-03T15:59:46Z
| 0
| 0
| null |
[
"gguf",
"uncensored",
"llama-cpp",
"gguf-my-repo",
"dataset:ehartford/WizardLM_alpaca_evol_instruct_70k_unfiltered",
"base_model:cognitivecomputations/WizardLM-7B-Uncensored",
"base_model:quantized:cognitivecomputations/WizardLM-7B-Uncensored",
"license:other",
"endpoints_compatible",
"region:us"
] | null | 2025-04-03T15:59:13Z
|
---
base_model: cognitivecomputations/WizardLM-7B-Uncensored
datasets:
- ehartford/WizardLM_alpaca_evol_instruct_70k_unfiltered
license: other
tags:
- uncensored
- llama-cpp
- gguf-my-repo
---
# ysn-rfd/WizardLM-7B-Uncensored-Q8_0-GGUF
This model was converted to GGUF format from [`cognitivecomputations/WizardLM-7B-Uncensored`](https://huggingface.co/cognitivecomputations/WizardLM-7B-Uncensored) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/cognitivecomputations/WizardLM-7B-Uncensored) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo ysn-rfd/WizardLM-7B-Uncensored-Q8_0-GGUF --hf-file wizardlm-7b-uncensored-q8_0.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo ysn-rfd/WizardLM-7B-Uncensored-Q8_0-GGUF --hf-file wizardlm-7b-uncensored-q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo ysn-rfd/WizardLM-7B-Uncensored-Q8_0-GGUF --hf-file wizardlm-7b-uncensored-q8_0.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo ysn-rfd/WizardLM-7B-Uncensored-Q8_0-GGUF --hf-file wizardlm-7b-uncensored-q8_0.gguf -c 2048
```
|
John6666/unstableinkdreamxl-v10-sdxl
|
John6666
| 2025-04-03T15:57:48Z
| 0
| 0
|
diffusers
|
[
"diffusers",
"safetensors",
"text-to-image",
"stable-diffusion",
"stable-diffusion-xl",
"anime",
"celluloid",
"girls",
"sd15 style",
"LCM",
"illustrious",
"en",
"base_model:OnomaAIResearch/Illustrious-xl-early-release-v0",
"base_model:finetune:OnomaAIResearch/Illustrious-xl-early-release-v0",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] |
text-to-image
| 2025-04-03T15:50:52Z
|
---
license: other
license_name: faipl-1.0-sd
license_link: https://freedevproject.org/faipl-1.0-sd/
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
tags:
- text-to-image
- stable-diffusion
- stable-diffusion-xl
- anime
- celluloid
- girls
- sd15 style
- LCM
- illustrious
base_model: OnomaAIResearch/Illustrious-xl-early-release-v0
---
Original model is [here](https://civitai.com/models/1429907/unstableinkdreamxl?modelVersionId=1616245).
This model created by [oosayam](https://civitai.com/user/oosayam).
|
neuralmagic/Qwen2.5-VL-72B-Instruct-FP8-Dynamic
|
neuralmagic
| 2025-04-03T15:55:51Z
| 2,253
| 2
|
transformers
|
[
"transformers",
"safetensors",
"qwen2_5_vl",
"image-text-to-text",
"vllm",
"vision",
"fp8",
"conversational",
"en",
"base_model:Qwen/Qwen2.5-VL-72B-Instruct",
"base_model:quantized:Qwen/Qwen2.5-VL-72B-Instruct",
"license:apache-2.0",
"text-generation-inference",
"endpoints_compatible",
"compressed-tensors",
"region:us"
] |
image-text-to-text
| 2025-02-06T16:50:51Z
|
---
tags:
- vllm
- vision
- fp8
license: apache-2.0
license_link: >-
https://huggingface.co/datasets/choosealicense/licenses/blob/main/markdown/apache-2.0.md
language:
- en
base_model: Qwen/Qwen2.5-VL-72B-Instruct
library_name: transformers
---
# Qwen2.5-VL-72B-Instruct-quantized-FP8-Dynamic
## Model Overview
- **Model Architecture:** Qwen2.5-VL-72B-Instruct
- **Input:** Vision-Text
- **Output:** Text
- **Model Optimizations:**
- **Weight quantization:** FP8
- **Activation quantization:** FP8
- **Release Date:** 2/24/2025
- **Version:** 1.0
- **Model Developers:** Neural Magic
Quantized version of [Qwen/Qwen2.5-VL-72B-Instruct](https://huggingface.co/Qwen/Qwen2.5-VL-72B-Instruct).
### Model Optimizations
This model was obtained by quantizing the weights of [Qwen/Qwen2.5-VL-72B-Instruct](https://huggingface.co/Qwen/Qwen2.5-VL-72B-Instruct) to FP8 data type, ready for inference with vLLM >= 0.5.2.
## Deployment
### Use with vLLM
This model can be deployed efficiently using the [vLLM](https://docs.vllm.ai/en/latest/) backend, as shown in the example below.
```python
from vllm.assets.image import ImageAsset
from vllm import LLM, SamplingParams
# prepare model
llm = LLM(
model="neuralmagic/Qwen2.5-VL-72B-Instruct-FP8-Dynamic",
trust_remote_code=True,
max_model_len=4096,
max_num_seqs=2,
)
# prepare inputs
question = "What is the content of this image?"
inputs = {
"prompt": f"<|user|>\n<|image_1|>\n{question}<|end|>\n<|assistant|>\n",
"multi_modal_data": {
"image": ImageAsset("cherry_blossom").pil_image.convert("RGB")
},
}
# generate response
print("========== SAMPLE GENERATION ==============")
outputs = llm.generate(inputs, SamplingParams(temperature=0.2, max_tokens=64))
print(f"PROMPT : {outputs[0].prompt}")
print(f"RESPONSE: {outputs[0].outputs[0].text}")
print("==========================================")
```
vLLM also supports OpenAI-compatible serving. See the [documentation](https://docs.vllm.ai/en/latest/) for more details.
## Creation
This model was created with [llm-compressor](https://github.com/vllm-project/llm-compressor) by running the code snippet below as part a multimodal announcement blog.
<details>
<summary>Model Creation Code</summary>
```python
import requests
import torch
from PIL import Image
from transformers import AutoProcessor
from llmcompressor.transformers import oneshot
from llmcompressor.transformers.tracing import (
TraceableQwen2_5_VLForConditionalGeneration,
)
from llmcompressor.modifiers.quantization import QuantizationModifier
# Load model.
model_id = Qwen/Qwen2.5-VL-72B-Instruct
model = TraceableQwen2_5_VLForConditionalGeneration.from_pretrained(
model_id, device_map="auto", torch_dtype="auto"
)
processor = AutoProcessor.from_pretrained(model_id, trust_remote_code=True)
# Recipe
recipe = [
QuantizationModifier(
targets="Linear",
scheme="FP8_DYNAMIC",
sequential_targets=["MistralDecoderLayer"],
ignore=["re:.*lm_head", "re:vision_tower.*", "re:multi_modal_projector.*"],
),
]
SAVE_DIR=f"{model_id.split('/')[1]}-FP8-Dynamic"
# Perform oneshot
oneshot(
model=model,
recipe=recipe,
trust_remote_code_model=True,
output_dir=SAVE_DIR
)
```
</details>
## Evaluation
The model was evaluated using [mistral-evals](https://github.com/neuralmagic/mistral-evals) for vision-related tasks and using [lm_evaluation_harness](https://github.com/neuralmagic/lm-evaluation-harness) for select text-based benchmarks. The evaluations were conducted using the following commands:
<details>
<summary>Evaluation Commands</summary>
### Vision Tasks
- vqav2
- docvqa
- mathvista
- mmmu
- chartqa
```
vllm serve neuralmagic/pixtral-12b-quantized.w8a8 --tensor_parallel_size 1 --max_model_len 25000 --trust_remote_code --max_num_seqs 8 --gpu_memory_utilization 0.9 --dtype float16 --limit_mm_per_prompt image=7
python -m eval.run eval_vllm \
--model_name neuralmagic/pixtral-12b-quantized.w8a8 \
--url http://0.0.0.0:8000 \
--output_dir ~/tmp \
--eval_name <vision_task_name>
```
### Text-based Tasks
#### MMLU
```
lm_eval \
--model vllm \
--model_args pretrained="<model_name>",dtype=auto,add_bos_token=True,max_model_len=4096,tensor_parallel_size=<n>,gpu_memory_utilization=0.8,enable_chunked_prefill=True,trust_remote_code=True \
--tasks mmlu \
--num_fewshot 5 \
--batch_size auto \
--output_path output_dir
```
#### MGSM
```
lm_eval \
--model vllm \
--model_args pretrained="<model_name>",dtype=auto,max_model_len=4096,max_gen_toks=2048,max_num_seqs=128,tensor_parallel_size=<n>,gpu_memory_utilization=0.9 \
--tasks mgsm_cot_native \
--apply_chat_template \
--num_fewshot 0 \
--batch_size auto \
--output_path output_dir
```
</details>
### Accuracy
<table>
<thead>
<tr>
<th>Category</th>
<th>Metric</th>
<th>Qwen/Qwen2.5-VL-72B-Instruct</th>
<th>neuralmagic/Qwen2.5-VL-72B-Instruct-FP8-Dynamic</th>
<th>Recovery (%)</th>
</tr>
</thead>
<tbody>
<tr>
<td rowspan="6"><b>Vision</b></td>
<td>MMMU (val, CoT)<br><i>explicit_prompt_relaxed_correctness</i></td>
<td>64.33</td>
<td>66.88</td>
<td>103.96%</td>
</tr>
<tr>
<td>VQAv2 (val)<br><i>vqa_match</i></td>
<td>81.94</td>
<td>81.94</td>
<td>100.00%</td>
</tr>
<tr>
<td>DocVQA (val)<br><i>anls</i></td>
<td>94.71</td>
<td>94.64</td>
<td>99.93%</td>
</tr>
<tr>
<td>ChartQA (test, CoT)<br><i>anywhere_in_answer_relaxed_correctness</i></td>
<td>88.96</td>
<td>89.04</td>
<td>100.09%</td>
</tr>
<tr>
<td>Mathvista (testmini, CoT)<br><i>explicit_prompt_relaxed_correctness</i></td>
<td>78.18</td>
<td>77.78</td>
<td>99.49%</td>
</tr>
<tr>
<td><b>Average Score</b></td>
<td><b>81.62</b></td>
<td><b>81.86</b></td>
<td><b>100.29%</b></td>
</tr>
<tr>
<td rowspan="2"><b>Text</b></td>
<td>MGSM (CoT)</td>
<td>75.45</td>
<td>75.29</td>
<td>99.79%</td>
</tr>
<tr>
<td>MMLU (5-shot)</td>
<td>86.16</td>
<td>86.12</td>
<td>99.95%</td>
</tr>
</tbody>
</table>
## Inference Performance
This model achieves up to 1.79x speedup in single-stream deployment and up to 1.84x speedup in multi-stream asynchronous deployment, depending on hardware and use-case scenario.
The following performance benchmarks were conducted with [vLLM](https://docs.vllm.ai/en/latest/) version 0.7.2, and [GuideLLM](https://github.com/neuralmagic/guidellm).
<details>
<summary>Benchmarking Command</summary>
```
guidellm --model neuralmagic/Qwen2.5-VL-72B-Instruct-FP8-Dynamic --target "http://localhost:8000/v1" --data-type emulated --data prompt_tokens=<prompt_tokens>,generated_tokens=<generated_tokens>,images=<num_images>,width=<image_width>,height=<image_height> --max seconds 120 --backend aiohttp_server
```
</details>
### Single-stream performance (measured with vLLM version 0.7.2)
<table border="1" class="dataframe">
<thead>
<tr>
<th></th>
<th></th>
<th></th>
<th></th>
<th style="text-align: center;" colspan="2" >Document Visual Question Answering<br>1680W x 2240H<br>64/128</th>
<th style="text-align: center;" colspan="2" >Visual Reasoning <br>640W x 480H<br>128/128</th>
<th style="text-align: center;" colspan="2" >Image Captioning<br>480W x 360H<br>0/128</th>
</tr>
<tr>
<th>Hardware</th>
<th>Number of GPUs</th>
<th>Model</th>
<th>Average Cost Reduction</th>
<th>Latency (s)</th>
<th>Queries Per Dollar</th>
<th>Latency (s)th>
<th>Queries Per Dollar</th>
<th>Latency (s)</th>
<th>Queries Per Dollar</th>
</tr>
</thead>
<tbody>
<tr>
<th rowspan="3" valign="top">A100</td>
<td>4</td>
<td>Qwen/Qwen2.5-VL-72B-Instruct</td>
<td></td>
<td>6.4</td>
<td>78</td>
<td>4.5</td>
<td>111</td>
<td>4.4</td>
<td>113</td>
</tr>
<tr>
<td>2</td>
<td>neuralmagic/Qwen2.5-VL-72B-Instruct-quantized.w8a8</td>
<td>1.85</td>
<td>7.0</td>
<td>143</td>
<td>4.9</td>
<td>205</td>
<td>4.8</td>
<td>211</td>
</tr>
<tr>
<td>1</td>
<td>neuralmagic/Qwen2.5-VL-72B-Instruct-quantized.w4a16</td>
<td>3.33</td>
<td>9.4</td>
<td>213</td>
<td>5.1</td>
<td>396</td>
<td>4.8</td>
<td>420</td>
</tr>
<tr>
<th rowspan="3" valign="top">H100</td>
<td>4</td>
<td>Qwen/Qwen2.5-VL-72B-Instruct</td>
<td></td>
<td>4.3</td>
<td>68</td>
<td>3.0</td>
<td>97</td>
<td>2.9</td>
<td>100</td>
</tr>
<tr>
<td>2</td>
<td>neuralmagic/Qwen2.5-VL-72B-Instruct-FP8-Dynamic</td>
<td>1.79</td>
<td>4.6</td>
<td>122</td>
<td>3.3</td>
<td>173</td>
<td>3.2</td>
<td>177</td>
</tr>
<tr>
<td>1</td>
<td>neuralmagic/Qwen2.5-VL-72B-Instruct-quantized.w4a16</td>
<td>5.66</td>
<td>4.3</td>
<td>252</td>
<td>4.4</td>
<td>251</td>
<td>4.2</td>
<td>259</td>
</tr>
</tbody>
</table>
**Use case profiles: Image Size (WxH) / prompt tokens / generation tokens
**QPD: Queries per dollar, based on on-demand cost at [Lambda Labs](https://lambdalabs.com/service/gpu-cloud) (observed on 2/18/2025).
### Multi-stream asynchronous performance (measured with vLLM version 0.7.2)
<table border="1" class="dataframe">
<thead>
<tr>
<th></th>
<th></th>
<th></th>
<th style="text-align: center;" colspan="2" >Document Visual Question Answering<br>1680W x 2240H<br>64/128</th>
<th style="text-align: center;" colspan="2" >Visual Reasoning <br>640W x 480H<br>128/128</th>
<th style="text-align: center;" colspan="2" >Image Captioning<br>480W x 360H<br>0/128</th>
</tr>
<tr>
<th>Hardware</th>
<th>Model</th>
<th>Average Cost Reduction</th>
<th>Maximum throughput (QPS)</th>
<th>Queries Per Dollar</th>
<th>Maximum throughput (QPS)</th>
<th>Queries Per Dollar</th>
<th>Maximum throughput (QPS)</th>
<th>Queries Per Dollar</th>
</tr>
</thead>
<tbody style="text-align: center">
<tr>
<th rowspan="3" valign="top">A100x4</th>
<td>Qwen/Qwen2.5-VL-72B-Instruct</td>
<td></td>
<td>0.4</td>
<td>180</td>
<td>1.1</td>
<td>539</td>
<td>1.2</td>
<td>595</td>
</tr>
<tr>
<td>neuralmagic/Qwen2.5-VL-72B-Instruct-quantized.w8a8</td>
<td>1.80</td>
<td>0.6</td>
<td>289</td>
<td>2.0</td>
<td>1020</td>
<td>2.3</td>
<td>1133</td>
</tr>
<tr>
<td>neuralmagic/Qwen2.5-VL-72B-Instruct-quantized.w4a16</td>
<td>2.75</td>
<td>0.7</td>
<td>341</td>
<td>3.2</td>
<td>1588</td>
<td>4.1</td>
<td>2037</td>
</tr>
<tr>
<th rowspan="3" valign="top">H100x4</th>
<td>Qwen/Qwen2.5-VL-72B-Instruct</td>
<td></td>
<td>0.5</td>
<td>134</td>
<td>1.2</td>
<td>357</td>
<td>1.3</td>
<td>379</td>
</tr>
<tr>
<td>neuralmagic/Qwen2.5-VL-72B-Instruct-FP8-Dynamic</td>
<td>1.73</td>
<td>0.9</td>
<td>247</td>
<td>2.2</td>
<td>621</td>
<td>2.4</td>
<td>669</td>
</tr>
<tr>
<td>neuralmagic/Qwen2.5-VL-72B-Instruct-quantized.w4a16</td>
<td>8.27</td>
<td>3.3</td>
<td>913</td>
<td>3.3</td>
<td>898</td>
<td>3.6</td>
<td>991</td>
</tr>
</tbody>
</table>
**Use case profiles: Image Size (WxH) / prompt tokens / generation tokens
**QPS: Queries per second.
**QPD: Queries per dollar, based on on-demand cost at [Lambda Labs](https://lambdalabs.com/service/gpu-cloud) (observed on 2/18/2025).
|
priyanshi27dixit/base-tilde-sft-full-ft-gemma2
|
priyanshi27dixit
| 2025-04-03T15:55:15Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"gemma2",
"text-generation",
"trl",
"sft",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-04-03T15:52:51Z
|
---
library_name: transformers
tags:
- trl
- sft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
anrgxone0/Llama-3.2-3B-Instruct-Q8_0-GGUF
|
anrgxone0
| 2025-04-03T15:54:31Z
| 0
| 0
|
transformers
|
[
"transformers",
"gguf",
"facebook",
"meta",
"pytorch",
"llama",
"llama-3",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"en",
"de",
"fr",
"it",
"pt",
"hi",
"es",
"th",
"base_model:meta-llama/Llama-3.2-3B-Instruct",
"base_model:quantized:meta-llama/Llama-3.2-3B-Instruct",
"license:llama3.2",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2025-04-03T15:54:15Z
|
---
base_model: meta-llama/Llama-3.2-3B-Instruct
language:
- en
- de
- fr
- it
- pt
- hi
- es
- th
library_name: transformers
license: llama3.2
pipeline_tag: text-generation
tags:
- facebook
- meta
- pytorch
- llama
- llama-3
- llama-cpp
- gguf-my-repo
extra_gated_prompt: "### LLAMA 3.2 COMMUNITY LICENSE AGREEMENT\n\nLlama 3.2 Version\
\ Release Date: September 25, 2024\n\n“Agreement” means the terms and conditions\
\ for use, reproduction, distribution and modification of the Llama Materials set\
\ forth herein.\n\n“Documentation” means the specifications, manuals and documentation\
\ accompanying Llama 3.2 distributed by Meta at https://llama.meta.com/doc/overview.\n\
\n“Licensee” or “you” means you, or your employer or any other person or entity\
\ (if you are entering into this Agreement on such person or entity’s behalf),\
\ of the age required under applicable laws, rules or regulations to provide legal\
\ consent and that has legal authority to bind your employer or such other person\
\ or entity if you are entering in this Agreement on their behalf.\n\n“Llama 3.2”\
\ means the foundational large language models and software and algorithms, including\
\ machine-learning model code, trained model weights, inference-enabling code, training-enabling\
\ code, fine-tuning enabling code and other elements of the foregoing distributed\
\ by Meta at https://www.llama.com/llama-downloads.\n\n“Llama Materials” means,\
\ collectively, Meta’s proprietary Llama 3.2 and Documentation (and any portion\
\ thereof) made available under this Agreement.\n\n“Meta” or “we” means Meta Platforms\
\ Ireland Limited (if you are located in or, if you are an entity, your principal\
\ place of business is in the EEA or Switzerland) and Meta Platforms, Inc. (if\
\ you are located outside of the EEA or Switzerland). \n\nBy clicking “I Accept”\
\ below or by using or distributing any portion or element of the Llama Materials,\
\ you agree to be bound by this Agreement.\n\n1. License Rights and Redistribution.\n\
a. Grant of Rights. You are granted a non-exclusive, worldwide, non-transferable\
\ and royalty-free limited license under Meta’s intellectual property or other rights\
\ owned by Meta embodied in the Llama Materials to use, reproduce, distribute,\
\ copy, create derivative works of, and make modifications to the Llama Materials.\
\ \nb. Redistribution and Use. \ni. If you distribute or make available the Llama\
\ Materials (or any derivative works thereof), or a product or service (including\
\ another AI model) that contains any of them, you shall (A) provide a copy of this\
\ Agreement with any such Llama Materials; and (B) prominently display “Built with\
\ Llama” on a related website, user interface, blogpost, about page, or product\
\ documentation. If you use the Llama Materials or any outputs or results of the\
\ Llama Materials to create, train, fine tune, or otherwise improve an AI model,\
\ which is distributed or made available, you shall also include “Llama” at the\
\ beginning of any such AI model name.\nii. If you receive Llama Materials, or any\
\ derivative works thereof, from a Licensee as part of an integrated end user product,\
\ then Section 2 of this Agreement will not apply to you. \niii. You must retain\
\ in all copies of the Llama Materials that you distribute the following attribution\
\ notice within a “Notice” text file distributed as a part of such copies: “Llama\
\ 3.2 is licensed under the Llama 3.2 Community License, Copyright © Meta Platforms,\
\ Inc. All Rights Reserved.”\niv. Your use of the Llama Materials must comply with\
\ applicable laws and regulations (including trade compliance laws and regulations)\
\ and adhere to the Acceptable Use Policy for the Llama Materials (available at\
\ https://www.llama.com/llama3_2/use-policy), which is hereby incorporated by reference\
\ into this Agreement.\n \n2. Additional Commercial Terms. If, on the Llama 3.2\
\ version release date, the monthly active users of the products or services made\
\ available by or for Licensee, or Licensee’s affiliates, is greater than 700 million\
\ monthly active users in the preceding calendar month, you must request a license\
\ from Meta, which Meta may grant to you in its sole discretion, and you are not\
\ authorized to exercise any of the rights under this Agreement unless or until\
\ Meta otherwise expressly grants you such rights.\n3. Disclaimer of Warranty. UNLESS\
\ REQUIRED BY APPLICABLE LAW, THE LLAMA MATERIALS AND ANY OUTPUT AND RESULTS THEREFROM\
\ ARE PROVIDED ON AN “AS IS” BASIS, WITHOUT WARRANTIES OF ANY KIND, AND META DISCLAIMS\
\ ALL WARRANTIES OF ANY KIND, BOTH EXPRESS AND IMPLIED, INCLUDING, WITHOUT LIMITATION,\
\ ANY WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR A PARTICULAR\
\ PURPOSE. YOU ARE SOLELY RESPONSIBLE FOR DETERMINING THE APPROPRIATENESS OF USING\
\ OR REDISTRIBUTING THE LLAMA MATERIALS AND ASSUME ANY RISKS ASSOCIATED WITH YOUR\
\ USE OF THE LLAMA MATERIALS AND ANY OUTPUT AND RESULTS.\n4. Limitation of Liability.\
\ IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF LIABILITY,\
\ WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING\
\ OUT OF THIS AGREEMENT, FOR ANY LOST PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL,\
\ INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF META OR ITS AFFILIATES HAVE\
\ BEEN ADVISED OF THE POSSIBILITY OF ANY OF THE FOREGOING.\n5. Intellectual Property.\n\
a. No trademark licenses are granted under this Agreement, and in connection with\
\ the Llama Materials, neither Meta nor Licensee may use any name or mark owned\
\ by or associated with the other or any of its affiliates, except as required\
\ for reasonable and customary use in describing and redistributing the Llama Materials\
\ or as set forth in this Section 5(a). Meta hereby grants you a license to use\
\ “Llama” (the “Mark”) solely as required to comply with the last sentence of Section\
\ 1.b.i. You will comply with Meta’s brand guidelines (currently accessible at\
\ https://about.meta.com/brand/resources/meta/company-brand/). All goodwill arising\
\ out of your use of the Mark will inure to the benefit of Meta.\nb. Subject to\
\ Meta’s ownership of Llama Materials and derivatives made by or for Meta, with\
\ respect to any derivative works and modifications of the Llama Materials that\
\ are made by you, as between you and Meta, you are and will be the owner of such\
\ derivative works and modifications.\nc. If you institute litigation or other proceedings\
\ against Meta or any entity (including a cross-claim or counterclaim in a lawsuit)\
\ alleging that the Llama Materials or Llama 3.2 outputs or results, or any portion\
\ of any of the foregoing, constitutes infringement of intellectual property or\
\ other rights owned or licensable by you, then any licenses granted to you under\
\ this Agreement shall terminate as of the date such litigation or claim is filed\
\ or instituted. You will indemnify and hold harmless Meta from and against any\
\ claim by any third party arising out of or related to your use or distribution\
\ of the Llama Materials.\n6. Term and Termination. The term of this Agreement will\
\ commence upon your acceptance of this Agreement or access to the Llama Materials\
\ and will continue in full force and effect until terminated in accordance with\
\ the terms and conditions herein. Meta may terminate this Agreement if you are\
\ in breach of any term or condition of this Agreement. Upon termination of this\
\ Agreement, you shall delete and cease use of the Llama Materials. Sections 3,\
\ 4 and 7 shall survive the termination of this Agreement. \n7. Governing Law and\
\ Jurisdiction. This Agreement will be governed and construed under the laws of\
\ the State of California without regard to choice of law principles, and the UN\
\ Convention on Contracts for the International Sale of Goods does not apply to\
\ this Agreement. The courts of California shall have exclusive jurisdiction of\
\ any dispute arising out of this Agreement. \n### Llama 3.2 Acceptable Use Policy\n\
Meta is committed to promoting safe and fair use of its tools and features, including\
\ Llama 3.2. If you access or use Llama 3.2, you agree to this Acceptable Use Policy\
\ (“**Policy**”). The most recent copy of this policy can be found at [https://www.llama.com/llama3_2/use-policy](https://www.llama.com/llama3_2/use-policy).\n\
#### Prohibited Uses\nWe want everyone to use Llama 3.2 safely and responsibly.\
\ You agree you will not use, or allow others to use, Llama 3.2 to:\n1. Violate\
\ the law or others’ rights, including to:\n 1. Engage in, promote, generate,\
\ contribute to, encourage, plan, incite, or further illegal or unlawful activity\
\ or content, such as:\n 1. Violence or terrorism\n 2. Exploitation\
\ or harm to children, including the solicitation, creation, acquisition, or dissemination\
\ of child exploitative content or failure to report Child Sexual Abuse Material\n\
\ 3. Human trafficking, exploitation, and sexual violence\n 4. The\
\ illegal distribution of information or materials to minors, including obscene\
\ materials, or failure to employ legally required age-gating in connection with\
\ such information or materials.\n 5. Sexual solicitation\n 6. Any\
\ other criminal activity\n 1. Engage in, promote, incite, or facilitate the\
\ harassment, abuse, threatening, or bullying of individuals or groups of individuals\n\
\ 2. Engage in, promote, incite, or facilitate discrimination or other unlawful\
\ or harmful conduct in the provision of employment, employment benefits, credit,\
\ housing, other economic benefits, or other essential goods and services\n 3.\
\ Engage in the unauthorized or unlicensed practice of any profession including,\
\ but not limited to, financial, legal, medical/health, or related professional\
\ practices\n 4. Collect, process, disclose, generate, or infer private or sensitive\
\ information about individuals, including information about individuals’ identity,\
\ health, or demographic information, unless you have obtained the right to do so\
\ in accordance with applicable law\n 5. Engage in or facilitate any action or\
\ generate any content that infringes, misappropriates, or otherwise violates any\
\ third-party rights, including the outputs or results of any products or services\
\ using the Llama Materials\n 6. Create, generate, or facilitate the creation\
\ of malicious code, malware, computer viruses or do anything else that could disable,\
\ overburden, interfere with or impair the proper working, integrity, operation\
\ or appearance of a website or computer system\n 7. Engage in any action, or\
\ facilitate any action, to intentionally circumvent or remove usage restrictions\
\ or other safety measures, or to enable functionality disabled by Meta \n2. Engage\
\ in, promote, incite, facilitate, or assist in the planning or development of activities\
\ that present a risk of death or bodily harm to individuals, including use of Llama\
\ 3.2 related to the following:\n 8. Military, warfare, nuclear industries or\
\ applications, espionage, use for materials or activities that are subject to the\
\ International Traffic Arms Regulations (ITAR) maintained by the United States\
\ Department of State or to the U.S. Biological Weapons Anti-Terrorism Act of 1989\
\ or the Chemical Weapons Convention Implementation Act of 1997\n 9. Guns and\
\ illegal weapons (including weapon development)\n 10. Illegal drugs and regulated/controlled\
\ substances\n 11. Operation of critical infrastructure, transportation technologies,\
\ or heavy machinery\n 12. Self-harm or harm to others, including suicide, cutting,\
\ and eating disorders\n 13. Any content intended to incite or promote violence,\
\ abuse, or any infliction of bodily harm to an individual\n3. Intentionally deceive\
\ or mislead others, including use of Llama 3.2 related to the following:\n 14.\
\ Generating, promoting, or furthering fraud or the creation or promotion of disinformation\n\
\ 15. Generating, promoting, or furthering defamatory content, including the\
\ creation of defamatory statements, images, or other content\n 16. Generating,\
\ promoting, or further distributing spam\n 17. Impersonating another individual\
\ without consent, authorization, or legal right\n 18. Representing that the\
\ use of Llama 3.2 or outputs are human-generated\n 19. Generating or facilitating\
\ false online engagement, including fake reviews and other means of fake online\
\ engagement \n4. Fail to appropriately disclose to end users any known dangers\
\ of your AI system 5. Interact with third party tools, models, or software designed\
\ to generate unlawful content or engage in unlawful or harmful conduct and/or represent\
\ that the outputs of such tools, models, or software are associated with Meta or\
\ Llama 3.2\n\nWith respect to any multimodal models included in Llama 3.2, the\
\ rights granted under Section 1(a) of the Llama 3.2 Community License Agreement\
\ are not being granted to you if you are an individual domiciled in, or a company\
\ with a principal place of business in, the European Union. This restriction does\
\ not apply to end users of a product or service that incorporates any such multimodal\
\ models.\n\nPlease report any violation of this Policy, software “bug,” or other\
\ problems that could lead to a violation of this Policy through one of the following\
\ means:\n\n* Reporting issues with the model: [https://github.com/meta-llama/llama-models/issues](https://l.workplace.com/l.php?u=https%3A%2F%2Fgithub.com%2Fmeta-llama%2Fllama-models%2Fissues&h=AT0qV8W9BFT6NwihiOHRuKYQM_UnkzN_NmHMy91OT55gkLpgi4kQupHUl0ssR4dQsIQ8n3tfd0vtkobvsEvt1l4Ic6GXI2EeuHV8N08OG2WnbAmm0FL4ObkazC6G_256vN0lN9DsykCvCqGZ)\n\
* Reporting risky content generated by the model: [developers.facebook.com/llama_output_feedback](http://developers.facebook.com/llama_output_feedback)\n\
* Reporting bugs and security concerns: [facebook.com/whitehat/info](http://facebook.com/whitehat/info)\n\
* Reporting violations of the Acceptable Use Policy or unlicensed uses of Llama\
\ 3.2: [email protected]"
extra_gated_fields:
First Name: text
Last Name: text
Date of birth: date_picker
Country: country
Affiliation: text
Job title:
type: select
options:
- Student
- Research Graduate
- AI researcher
- AI developer/engineer
- Reporter
- Other
geo: ip_location
? By clicking Submit below I accept the terms of the license and acknowledge that
the information I provide will be collected stored processed and shared in accordance
with the Meta Privacy Policy
: checkbox
extra_gated_description: The information you provide will be collected, stored, processed
and shared in accordance with the [Meta Privacy Policy](https://www.facebook.com/privacy/policy/).
extra_gated_button_content: Submit
---
# anrgxone0/Llama-3.2-3B-Instruct-Q8_0-GGUF
This model was converted to GGUF format from [`meta-llama/Llama-3.2-3B-Instruct`](https://huggingface.co/meta-llama/Llama-3.2-3B-Instruct) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/meta-llama/Llama-3.2-3B-Instruct) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo anrgxone0/Llama-3.2-3B-Instruct-Q8_0-GGUF --hf-file llama-3.2-3b-instruct-q8_0.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo anrgxone0/Llama-3.2-3B-Instruct-Q8_0-GGUF --hf-file llama-3.2-3b-instruct-q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo anrgxone0/Llama-3.2-3B-Instruct-Q8_0-GGUF --hf-file llama-3.2-3b-instruct-q8_0.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo anrgxone0/Llama-3.2-3B-Instruct-Q8_0-GGUF --hf-file llama-3.2-3b-instruct-q8_0.gguf -c 2048
```
|
neuralmagic/Qwen2.5-VL-7B-Instruct-quantized.w8a8
|
neuralmagic
| 2025-04-03T15:54:22Z
| 7,973
| 1
|
transformers
|
[
"transformers",
"safetensors",
"qwen2_5_vl",
"image-text-to-text",
"vllm",
"vision",
"w8a8",
"conversational",
"en",
"base_model:Qwen/Qwen2.5-VL-7B-Instruct",
"base_model:quantized:Qwen/Qwen2.5-VL-7B-Instruct",
"license:apache-2.0",
"text-generation-inference",
"endpoints_compatible",
"8-bit",
"compressed-tensors",
"region:us"
] |
image-text-to-text
| 2025-02-07T17:02:21Z
|
---
tags:
- vllm
- vision
- w8a8
license: apache-2.0
license_link: >-
https://huggingface.co/datasets/choosealicense/licenses/blob/main/markdown/apache-2.0.md
language:
- en
base_model: Qwen/Qwen2.5-VL-7B-Instruct
library_name: transformers
---
# Qwen2.5-VL-7B-Instruct-quantized-w8a8
## Model Overview
- **Model Architecture:** Qwen/Qwen2.5-VL-7B-Instruct
- **Input:** Vision-Text
- **Output:** Text
- **Model Optimizations:**
- **Weight quantization:** INT8
- **Activation quantization:** INT8
- **Release Date:** 2/24/2025
- **Version:** 1.0
- **Model Developers:** Neural Magic
Quantized version of [Qwen/Qwen2.5-VL-7B-Instruct](https://huggingface.co/Qwen/Qwen2.5-VL-7B-Instruct).
### Model Optimizations
This model was obtained by quantizing the weights of [Qwen/Qwen2.5-VL-7B-Instruct](https://huggingface.co/Qwen/Qwen2.5-VL-7B-Instruct) to INT8 data type, ready for inference with vLLM >= 0.5.2.
## Deployment
### Use with vLLM
This model can be deployed efficiently using the [vLLM](https://docs.vllm.ai/en/latest/) backend, as shown in the example below.
```python
from vllm.assets.image import ImageAsset
from vllm import LLM, SamplingParams
# prepare model
llm = LLM(
model="neuralmagic/Qwen2.5-VL-7B-Instruct-quantized.w8a8",
trust_remote_code=True,
max_model_len=4096,
max_num_seqs=2,
)
# prepare inputs
question = "What is the content of this image?"
inputs = {
"prompt": f"<|user|>\n<|image_1|>\n{question}<|end|>\n<|assistant|>\n",
"multi_modal_data": {
"image": ImageAsset("cherry_blossom").pil_image.convert("RGB")
},
}
# generate response
print("========== SAMPLE GENERATION ==============")
outputs = llm.generate(inputs, SamplingParams(temperature=0.2, max_tokens=64))
print(f"PROMPT : {outputs[0].prompt}")
print(f"RESPONSE: {outputs[0].outputs[0].text}")
print("==========================================")
```
vLLM also supports OpenAI-compatible serving. See the [documentation](https://docs.vllm.ai/en/latest/) for more details.
## Creation
This model was created with [llm-compressor](https://github.com/vllm-project/llm-compressor) by running the code snippet below as part a multimodal announcement blog.
<details>
<summary>Model Creation Code</summary>
```python
import base64
from io import BytesIO
import torch
from datasets import load_dataset
from qwen_vl_utils import process_vision_info
from transformers import AutoProcessor
from llmcompressor.modifiers.quantization import GPTQModifier
from llmcompressor.transformers import oneshot
from llmcompressor.transformers.tracing import (
TraceableQwen2_5_VLForConditionalGeneration,
)
# Load model.
model_id = "Qwen/Qwen2.5-VL-7B-Instruct"
model = TraceableQwen2_5_VLForConditionalGeneration.from_pretrained(
model_id,
device_map="auto",
torch_dtype="auto",
)
processor = AutoProcessor.from_pretrained(model_id, trust_remote_code=True)
# Oneshot arguments
DATASET_ID = "lmms-lab/flickr30k"
DATASET_SPLIT = {"calibration": "test[:512]"}
NUM_CALIBRATION_SAMPLES = 512
MAX_SEQUENCE_LENGTH = 2048
# Load dataset and preprocess.
ds = load_dataset(DATASET_ID, split=DATASET_SPLIT)
ds = ds.shuffle(seed=42)
dampening_frac=0.01
# Apply chat template and tokenize inputs.
def preprocess_and_tokenize(example):
# preprocess
buffered = BytesIO()
example["image"].save(buffered, format="PNG")
encoded_image = base64.b64encode(buffered.getvalue())
encoded_image_text = encoded_image.decode("utf-8")
base64_qwen = f"data:image;base64,{encoded_image_text}"
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": base64_qwen},
{"type": "text", "text": "What does the image show?"},
],
}
]
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
# tokenize
return processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=False,
max_length=MAX_SEQUENCE_LENGTH,
truncation=True,
)
ds = ds.map(preprocess_and_tokenize, remove_columns=ds["calibration"].column_names)
# Define a oneshot data collator for multimodal inputs.
def data_collator(batch):
assert len(batch) == 1
return {key: torch.tensor(value) for key, value in batch[0].items()}
# Recipe
recipe = [
GPTQModifier(
targets="Linear",
scheme="W8A8",
sequential_targets=["Qwen2_5_VLDecoderLayer"],
ignore=["lm_head", "re:visual.*"],
),
]
SAVE_DIR==f"{model_id.split('/')[1]}-quantized.w8a8"
# Perform oneshot
oneshot(
model=model,
tokenizer=model_id,
dataset=ds,
recipe=recipe,
max_seq_length=MAX_SEQUENCE_LENGTH,
num_calibration_samples=NUM_CALIBRATION_SAMPLES,
trust_remote_code_model=True,
data_collator=data_collator,
output_dir=SAVE_DIR
)
```
</details>
## Evaluation
The model was evaluated using [mistral-evals](https://github.com/neuralmagic/mistral-evals) for vision-related tasks and using [lm_evaluation_harness](https://github.com/neuralmagic/lm-evaluation-harness) for select text-based benchmarks. The evaluations were conducted using the following commands:
<details>
<summary>Evaluation Commands</summary>
### Vision Tasks
- vqav2
- docvqa
- mathvista
- mmmu
- chartqa
```
vllm serve neuralmagic/pixtral-12b-quantized.w8a8 --tensor_parallel_size 1 --max_model_len 25000 --trust_remote_code --max_num_seqs 8 --gpu_memory_utilization 0.9 --dtype float16 --limit_mm_per_prompt image=7
python -m eval.run eval_vllm \
--model_name neuralmagic/pixtral-12b-quantized.w8a8 \
--url http://0.0.0.0:8000 \
--output_dir ~/tmp \
--eval_name <vision_task_name>
```
### Text-based Tasks
#### MMLU
```
lm_eval \
--model vllm \
--model_args pretrained="<model_name>",dtype=auto,add_bos_token=True,max_model_len=4096,tensor_parallel_size=<n>,gpu_memory_utilization=0.8,enable_chunked_prefill=True,trust_remote_code=True \
--tasks mmlu \
--num_fewshot 5 \
--batch_size auto \
--output_path output_dir
```
#### MGSM
```
lm_eval \
--model vllm \
--model_args pretrained="<model_name>",dtype=auto,max_model_len=4096,max_gen_toks=2048,max_num_seqs=128,tensor_parallel_size=<n>,gpu_memory_utilization=0.9 \
--tasks mgsm_cot_native \
--apply_chat_template \
--num_fewshot 0 \
--batch_size auto \
--output_path output_dir
```
</details>
### Accuracy
<table>
<thead>
<tr>
<th>Category</th>
<th>Metric</th>
<th>Qwen/Qwen2.5-VL-7B-Instruct</th>
<th>Qwen2.5-VL-7B-Instruct-quantized.w8a8</th>
<th>Recovery (%)</th>
</tr>
</thead>
<tbody>
<tr>
<td rowspan="6"><b>Vision</b></td>
<td>MMMU (val, CoT)<br><i>explicit_prompt_relaxed_correctness</i></td>
<td>52.00</td>
<td>52.33</td>
<td>100.63%</td>
</tr>
<tr>
<td>VQAv2 (val)<br><i>vqa_match</i></td>
<td>75.59</td>
<td>75.46</td>
<td>99.83%</td>
</tr>
<tr>
<td>DocVQA (val)<br><i>anls</i></td>
<td>94.27</td>
<td>94.09</td>
<td>99.81%</td>
</tr>
<tr>
<td>ChartQA (test, CoT)<br><i>anywhere_in_answer_relaxed_correctness</i></td>
<td>86.44</td>
<td>86.16</td>
<td>99.68%</td>
</tr>
<tr>
<td>Mathvista (testmini, CoT)<br><i>explicit_prompt_relaxed_correctness</i></td>
<td>69.47</td>
<td>70.47</td>
<td>101.44%</td>
</tr>
<tr>
<td><b>Average Score</b></td>
<td><b>75.95</b></td>
<td><b>75.90</b></td>
<td><b>99.93%</b></td>
</tr>
<tr>
<td rowspan="3"><b>Text</b></td>
<td>MGSM (CoT)</td>
<td>56.38</td>
<td>55.13</td>
<td>97.78%</td>
</tr>
<tr>
<td>MMLU (5-shot)</td>
<td>71.09</td>
<td>70.57</td>
<td>99.27%</td>
</tr>
</tbody>
</table>
## Inference Performance
This model achieves up to 1.56x speedup in single-stream deployment and 1.5x in multi-stream deployment, depending on hardware and use-case scenario.
The following performance benchmarks were conducted with [vLLM](https://docs.vllm.ai/en/latest/) version 0.7.2, and [GuideLLM](https://github.com/neuralmagic/guidellm).
<details>
<summary>Benchmarking Command</summary>
```
guidellm --model neuralmagic/Qwen2.5-VL-7B-Instruct-quantized.w8a8 --target "http://localhost:8000/v1" --data-type emulated --data prompt_tokens=<prompt_tokens>,generated_tokens=<generated_tokens>,images=<num_images>,width=<image_width>,height=<image_height> --max seconds 120 --backend aiohttp_server
```
</details>
### Single-stream performance (measured with vLLM version 0.7.2)
<table border="1" class="dataframe">
<thead>
<tr>
<th></th>
<th></th>
<th></th>
<th style="text-align: center;" colspan="2" >Document Visual Question Answering<br>1680W x 2240H<br>64/128</th>
<th style="text-align: center;" colspan="2" >Visual Reasoning <br>640W x 480H<br>128/128</th>
<th style="text-align: center;" colspan="2" >Image Captioning<br>480W x 360H<br>0/128</th>
</tr>
<tr>
<th>Hardware</th>
<th>Model</th>
<th>Average Cost Reduction</th>
<th>Latency (s)</th>
<th>Queries Per Dollar</th>
<th>Latency (s)th>
<th>Queries Per Dollar</th>
<th>Latency (s)</th>
<th>Queries Per Dollar</th>
</tr>
</thead>
<tbody style="text-align: center">
<tr>
<th rowspan="3" valign="top">A6000x1</th>
<th>Qwen/Qwen2.5-VL-7B-Instruct</th>
<td></td>
<td>4.9</td>
<td>912</td>
<td>3.2</td>
<td>1386</td>
<td>3.1</td>
<td>1431</td>
</tr>
<tr>
<th>neuralmagic/Qwen2.5-VL-7B-Instruct-quantized.w8a8</th>
<td>1.50</td>
<td>3.6</td>
<td>1248</td>
<td>2.1</td>
<td>2163</td>
<td>2.0</td>
<td>2237</td>
</tr>
<tr>
<th>neuralmagic/Qwen2.5-VL-7B-Instruct-quantized.w4a16</th>
<td>2.05</td>
<td>3.3</td>
<td>1351</td>
<td>1.4</td>
<td>3252</td>
<td>1.4</td>
<td>3321</td>
</tr>
<tr>
<th rowspan="3" valign="top">A100x1</th>
<th>Qwen/Qwen2.5-VL-7B-Instruct</th>
<td></td>
<td>2.8</td>
<td>707</td>
<td>1.7</td>
<td>1162</td>
<td>1.7</td>
<td>1198</td>
</tr>
<tr>
<th>neuralmagic/Qwen2.5-VL-7B-Instruct-quantized.w8a8</th>
<td>1.24</td>
<td>2.4</td>
<td>851</td>
<td>1.4</td>
<td>1454</td>
<td>1.3</td>
<td>1512</td>
</tr>
<tr>
<th>neuralmagic/Qwen2.5-VL-7B-Instruct-quantized.w4a16</th>
<td>1.49</td>
<td>2.2</td>
<td>912</td>
<td>1.1</td>
<td>1791</td>
<td>1.0</td>
<td>1950</td>
</tr>
<tr>
<th rowspan="3" valign="top">H100x1</th>
<th>Qwen/Qwen2.5-VL-7B-Instruct</th>
<td></td>
<td>2.0</td>
<td>557</td>
<td>1.2</td>
<td>919</td>
<td>1.2</td>
<td>941</td>
</tr>
<tr>
<th>neuralmagic/Qwen2.5-VL-7B-Instruct-FP8-Dynamic</th>
<td>1.28</td>
<td>1.6</td>
<td>698</td>
<td>0.9</td>
<td>1181</td>
<td>0.9</td>
<td>1219</td>
</tr>
<tr>
<th>neuralmagic/Qwen2.5-VL-7B-Instruct-quantized.w4a16</th>
<td>1.28</td>
<td>1.6</td>
<td>686</td>
<td>0.9</td>
<td>1191</td>
<td>0.9</td>
<td>1228</td>
</tr>
</tbody>
</table>
**Use case profiles: Image Size (WxH) / prompt tokens / generation tokens
**QPD: Queries per dollar, based on on-demand cost at [Lambda Labs](https://lambdalabs.com/service/gpu-cloud) (observed on 2/18/2025).
### Multi-stream asynchronous performance (measured with vLLM version 0.7.2)
<table border="1" class="dataframe">
<thead>
<tr>
<th></th>
<th></th>
<th></th>
<th style="text-align: center;" colspan="2" >Document Visual Question Answering<br>1680W x 2240H<br>64/128</th>
<th style="text-align: center;" colspan="2" >Visual Reasoning <br>640W x 480H<br>128/128</th>
<th style="text-align: center;" colspan="2" >Image Captioning<br>480W x 360H<br>0/128</th>
</tr>
<tr>
<th>Hardware</th>
<th>Model</th>
<th>Average Cost Reduction</th>
<th>Maximum throughput (QPS)</th>
<th>Queries Per Dollar</th>
<th>Maximum throughput (QPS)</th>
<th>Queries Per Dollar</th>
<th>Maximum throughput (QPS)</th>
<th>Queries Per Dollar</th>
</tr>
</thead>
<tbody style="text-align: center">
<tr>
<th rowspan="3" valign="top">A6000x1</th>
<th>Qwen/Qwen2.5-VL-7B-Instruct</th>
<td></td>
<td>0.4</td>
<td>1837</td>
<td>1.5</td>
<td>6846</td>
<td>1.7</td>
<td>7638</td>
</tr>
<tr>
<th>neuralmagic/Qwen2.5-VL-7B-Instruct-quantized.w8a8</th>
<td>1.41</td>
<td>0.5</td>
<td>2297</td>
<td>2.3</td>
<td>10137</td>
<td>2.5</td>
<td>11472</td>
</tr>
<tr>
<th>neuralmagic/Qwen2.5-VL-7B-Instruct-quantized.w4a16</th>
<td>1.60</td>
<td>0.4</td>
<td>1828</td>
<td>2.7</td>
<td>12254</td>
<td>3.4</td>
<td>15477</td>
</tr>
<tr>
<th rowspan="3" valign="top">A100x1</th>
<th>Qwen/Qwen2.5-VL-7B-Instruct</th>
<td></td>
<td>0.7</td>
<td>1347</td>
<td>2.6</td>
<td>5221</td>
<td>3.0</td>
<td>6122</td>
</tr>
<tr>
<th>neuralmagic/Qwen2.5-VL-7B-Instruct-quantized.w8a8</th>
<td>1.27</td>
<td>0.8</td>
<td>1639</td>
<td>3.4</td>
<td>6851</td>
<td>3.9</td>
<td>7918</td>
</tr>
<tr>
<th>neuralmagic/Qwen2.5-VL-7B-Instruct-quantized.w4a16</th>
<td>1.21</td>
<td>0.7</td>
<td>1314</td>
<td>3.0</td>
<td>5983</td>
<td>4.6</td>
<td>9206</td>
</tr>
<tr>
<th rowspan="3" valign="top">H100x1</th>
<th>Qwen/Qwen2.5-VL-7B-Instruct</th>
<td></td>
<td>0.9</td>
<td>969</td>
<td>3.1</td>
<td>3358</td>
<td>3.3</td>
<td>3615</td>
</tr>
<tr>
<th>neuralmagic/Qwen2.5-VL-7B-Instruct-FP8-Dynamic</th>
<td>1.29</td>
<td>1.2</td>
<td>1331</td>
<td>3.8</td>
<td>4109</td>
<td>4.2</td>
<td>4598</td>
</tr>
<tr>
<th>neuralmagic/Qwen2.5-VL-7B-Instruct-quantized.w4a16</th>
<td>1.28</td>
<td>1.2</td>
<td>1298</td>
<td>3.8</td>
<td>4190</td>
<td>4.2</td>
<td>4573</td>
</tr>
</tbody>
</table>
**Use case profiles: Image Size (WxH) / prompt tokens / generation tokens
**QPS: Queries per second.
**QPD: Queries per dollar, based on on-demand cost at [Lambda Labs](https://lambdalabs.com/service/gpu-cloud) (observed on 2/18/2025).
|
aiyawanan1112/my-merged-model
|
aiyawanan1112
| 2025-04-03T15:53:17Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-04-03T14:48:03Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
phildunphy14/qwen_counterparty_14B_fp16_setu_2025
|
phildunphy14
| 2025-04-03T15:50:55Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"en",
"base_model:unsloth/Qwen2.5-14B",
"base_model:finetune:unsloth/Qwen2.5-14B",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-04-03T15:39:20Z
|
---
base_model: unsloth/Qwen2.5-14B
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** phildunphy14
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen2.5-14B
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
JacksonBrune/f2092732-b3e6-42f2-b045-12ee2fc12824
|
JacksonBrune
| 2025-04-03T15:49:36Z
| 0
| 0
|
peft
|
[
"peft",
"generated_from_trainer",
"base_model:EleutherAI/pythia-70m-deduped",
"base_model:adapter:EleutherAI/pythia-70m-deduped",
"region:us"
] | null | 2025-04-03T15:49:28Z
|
---
library_name: peft
tags:
- generated_from_trainer
base_model: EleutherAI/pythia-70m-deduped
model-index:
- name: JacksonBrune/f2092732-b3e6-42f2-b045-12ee2fc12824
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# JacksonBrune/f2092732-b3e6-42f2-b045-12ee2fc12824
This model was trained from scratch on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9826
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1
|
NAMAA-Space/Namaa-ARA-Reranker-V1
|
NAMAA-Space
| 2025-04-03T15:49:28Z
| 106
| 4
|
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"xlm-roberta",
"text-classification",
"transformers",
"text-embeddings-inference",
"text-ranking",
"ar",
"license:apache-2.0",
"region:us"
] |
text-ranking
| 2024-11-28T08:11:52Z
|
---
license: apache-2.0
language:
- ar
pipeline_tag: text-ranking
tags:
- transformers
- sentence-transformers
- text-embeddings-inference
library_name: sentence-transformers
---
# Introducing ARM-V1 | Arabic Reranker Model (Version 1)
**For more info please refer to this blog: [ARM | Arabic Reranker Model](www.omarai.me).**
✨ This model is designed specifically for Arabic language reranking tasks, optimized to handle queries and passages with precision.
✨ Unlike embedding models, which generate vector representations, this reranker directly evaluates the similarity between a question and a document, outputting a relevance score.
✨ Trained on a combination of positive and hard negative query-passage pairs, it excels in identifying the most relevant results.
✨ The output score can be transformed into a [0, 1] range using a sigmoid function, providing a clear and interpretable measure of relevance.
## Arabic RAG Pipeline

## Usage
### Using sentence-transformers
```
pip install sentence-transformers
```
```python
from sentence_transformers import CrossEncoder
# Load the cross-encoder model
# Define a query and a set of candidates with varying degrees of relevance
query = "تطبيقات الذكاء الاصطناعي تُستخدم في مختلف المجالات لتحسين الكفاءة."
# Candidates with varying relevance to the query
candidates = [
"الذكاء الاصطناعي يساهم في تحسين الإنتاجية في الصناعات المختلفة.", # Highly relevant
"نماذج التعلم الآلي يمكنها التعرف على الأنماط في مجموعات البيانات الكبيرة.", # Moderately relevant
"الذكاء الاصطناعي يساعد الأطباء في تحليل الصور الطبية بشكل أفضل.", # Somewhat relevant
"تستخدم الحيوانات التمويه كوسيلة للهروب من الحيوانات المفترسة.", # Irrelevant
]
# Create pairs of (query, candidate) for each candidate
query_candidate_pairs = [(query, candidate) for candidate in candidates]
# Get relevance scores from the model
scores = model.predict(query_candidate_pairs)
# Combine candidates with their scores and sort them by score in descending order (higher score = higher relevance)
ranked_candidates = sorted(zip(candidates, scores), key=lambda x: x[1], reverse=True)
# Output the ranked candidates with their scores
print("Ranked candidates based on relevance to the query:")
for i, (candidate, score) in enumerate(ranked_candidates, 1):
print(f"Rank {i}:")
print(f"Candidate: {candidate}")
print(f"Score: {score}\n")
```
## Evaluation
### Dataset
Size: 3000 samples.
### Structure:
🔸 Query: A string representing the user's question.
🔸 Candidate Document: A candidate passage to answer the query.
🔸 Relevance Label: Binary label (1 for relevant, 0 for irrelevant).
### Evaluation Process
🔸 Query Grouping: Queries are grouped to evaluate the model's ability to rank candidate documents correctly for each query.
🔸 Model Prediction: Each model predicts relevance scores for all candidate documents corresponding to a query.
🔸 Metrics Calculation: Metrics are computed to measure how well the model ranks relevant documents higher than irrelevant ones.
| Model | MRR | MAP | nDCG@10 |
|-------------------------------------------|------------------|------------------|------------------|
| cross-encoder/ms-marco-MiniLM-L-6-v2 | 0.631 | 0.6313| 0.725 |
| cross-encoder/ms-marco-MiniLM-L-12-v2 | 0.664 | 0.664 | 0.750 |
| BAAI/bge-reranker-v2-m3 | 0.902 | 0.902 | 0.927 |
| Omartificial-Intelligence-Space/ARA-Reranker-V1 | **0.934** | **0.9335** | **0.951** |
## <span style="color:blue">Acknowledgments</span>
The author would like to thank Prince Sultan University for their invaluable support in this project. Their contributions and resources have been instrumental in the development and fine-tuning of these models.
```markdown
## Citation
If you use the GATE, please cite it as follows:
@misc{nacar2025ARM,
title={ARM, Arabic Reranker Model},
author={Omer Nacar},
year={2025},
url={https://huggingface.co/Omartificial-Intelligence-Space/ARA-Reranker-V1},
}
|
NAMAA-Space/Namaa-Reranker-v1
|
NAMAA-Space
| 2025-04-03T15:49:20Z
| 18
| 1
|
transformers
|
[
"transformers",
"safetensors",
"bert",
"text-classification",
"reranking",
"sentence-transformers",
"text-ranking",
"ar",
"dataset:unicamp-dl/mmarco",
"base_model:Omartificial-Intelligence-Space/Arabic-Triplet-Matryoshka-V2",
"base_model:finetune:Omartificial-Intelligence-Space/Arabic-Triplet-Matryoshka-V2",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-ranking
| 2024-11-01T11:33:58Z
|
---
license: apache-2.0
language:
- ar
pipeline_tag: text-ranking
library_name: transformers
base_model:
- Omartificial-Intelligence-Space/Arabic-Triplet-Matryoshka-V2
tags:
- reranking
- sentence-transformers
datasets:
- unicamp-dl/mmarco
---
# Namaa-Reranker-v1 🚀✨
**NAMAA-space** releases **Namaa-Reranker-v1**, a high-performance model fine-tuned on [unicamp-dl/mmarco](https://huggingface.co/datasets/unicamp-dl/mmarco) to elevate Arabic document retrieval and ranking to new heights! 📚🇸🇦
This model is designed to **improve search relevance** of **arabic** documents by accurately ranking documents based on their contextual fit for a given query.
## Key Features 🔑
- **Optimized for Arabic**: Built on the highly performant [Omartificial-Intelligence-Space/Arabic-Triplet-Matryoshka-V2](https://huggingface.co/Omartificial-Intelligence-Space/Arabic-Triplet-Matryoshka-V2) with exclusivly rich Arabic data.
- **Advanced Document Ranking**: Ranks results with precision, perfect for search engines, recommendation systems, and question-answering applications.
- **State-of-the-Art Performance**: Achieves excellent performance compared to famous rerankers(See [Evaluation](https://huggingface.co/NAMAA-Space/Rerankerv1#evaluation)), ensuring reliable relevance and precision.
## Example Use Cases 💼
- **Retrieval Augmented Generation**: Improve search result relevance for Arabic content.
- **Content Recommendation**: Deliver top-tier Arabic content suggestions.
- **Question Answering**: Boost answer retrieval quality in Arabic-focused systems.
## Usage
# Within sentence-transformers
The usage becomes easier when you have [SentenceTransformers](https://www.sbert.net/) installed. Then, you can use the pre-trained models like this:
```python
from sentence_transformers import CrossEncoder
model = CrossEncoder('NAMAA-Space/Namaa-Reranker-v1', max_length=512)
Query = 'كيف يمكن استخدام التعلم العميق في معالجة الصور الطبية؟'
Paragraph1 = 'التعلم العميق يساعد في تحليل الصور الطبية وتشخيص الأمراض'
Paragraph2 = 'الذكاء الاصطناعي يستخدم في تحسين الإنتاجية في الصناعات'
scores = model.predict([(Query, Paragraph1), (Query, Paragraph2)])
```
## Evaluation
We evaluate our model on two different datasets using the metrics **MAP**, **MRR** and **NDCG@10**:
The purpose of this evaluation is to highlight the performance of our model with regards to: Relevant/Irrelevant labels and positive/multiple negatives documents:
Dataset 1: [NAMAA-Space/Ar-Reranking-Eval](https://huggingface.co/datasets/NAMAA-Space/Ar-Reranking-Eval)
Dataset 2: [NAMAA-Space/Arabic-Reranking-Triplet-5-Eval](https://huggingface.co/datasets/NAMAA-Space/Arabic-Reranking-Triplet-5-Eval)
As seen, The model performs extremly well in comparison to other famous rerankers.
WIP: More comparisons and evaluation on arabic datasets.
|
seifetho/Llama-3.1-8B-bnb-8bit-med
|
seifetho
| 2025-04-03T15:48:59Z
| 0
| 0
|
transformers
|
[
"transformers",
"gguf",
"llama",
"text-generation-inference",
"unsloth",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-04-03T15:47:55Z
|
---
base_model: unsloth/meta-llama-3.1-8b-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- gguf
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** seifetho
- **License:** apache-2.0
- **Finetuned from model :** unsloth/meta-llama-3.1-8b-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
jahyungu/Qwen2.5-Coder-7B-Instruct_Sky-T1-7B-step2-distill-5k
|
jahyungu
| 2025-04-03T15:48:02Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"conversational",
"base_model:Qwen/Qwen2.5-Coder-7B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-Coder-7B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-04-03T12:45:43Z
|
---
library_name: transformers
license: apache-2.0
base_model: Qwen/Qwen2.5-Coder-7B-Instruct
tags:
- generated_from_trainer
model-index:
- name: Qwen2.5-Coder-7B-Instruct_Sky-T1-7B-step2-distill-5k
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Qwen2.5-Coder-7B-Instruct_Sky-T1-7B-step2-distill-5k
This model is a fine-tuned version of [Qwen/Qwen2.5-Coder-7B-Instruct](https://huggingface.co/Qwen/Qwen2.5-Coder-7B-Instruct) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-06
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 4
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- num_epochs: 3
### Training results
### Framework versions
- Transformers 4.50.0
- Pytorch 2.6.0+cu124
- Datasets 3.4.1
- Tokenizers 0.21.0
|
saattrupdan/verdict-classifier-en
|
saattrupdan
| 2025-04-03T15:47:45Z
| 20
| 0
|
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"roberta",
"text-classification",
"generated_from_trainer",
"en",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2022-03-02T23:29:05Z
|
---
license: mit
language: en
tags:
- generated_from_trainer
model-index:
- name: verdict-classifier-en
results:
- task:
type: text-classification
name: Verdict Classification
widget:
- "Even though it might look true, it has been taken out of context."
---
# English Verdict Classifier
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on 2,500 deduplicated verdicts from [Google Fact Check Tools API](https://developers.google.com/fact-check/tools/api/reference/rest/v1alpha1/claims/search), translated into English with the [Google Cloud Translation API](https://cloud.google.com/translate/docs/reference/rest/).
It achieves the following results on the evaluation set, being 1,000 such verdicts translated into English, but here including duplicates to represent the true distribution:
- Loss: 0.1290
- F1 Macro: 0.9171
- F1 Misinformation: 0.9896
- F1 Factual: 0.9890
- F1 Other: 0.7727
- Precision Macro: 0.8940
- Precision Misinformation: 0.9954
- Precision Factual: 0.9783
- Precision Other: 0.7083
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2500
- num_epochs: 1000
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 Macro | F1 Misinformation | F1 Factual | F1 Other | Precision Macro | Precision Misinformation | Precision Factual | Precision Other |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:-----------------:|:----------:|:--------:|:----------:|:-------------------:|:------------:|:----------:|
| 1.1493 | 0.16 | 50 | 1.1040 | 0.0550 | 0.0 | 0.1650 | 0.0 | 0.0300 | 0.0 | 0.0899 | 0.0 |
| 1.0899 | 0.32 | 100 | 1.0765 | 0.0619 | 0.0203 | 0.1654 | 0.0 | 0.2301 | 0.6 | 0.0903 | 0.0 |
| 1.0136 | 0.48 | 150 | 1.0487 | 0.3102 | 0.9306 | 0.0 | 0.0 | 0.2900 | 0.8701 | 0.0 | 0.0 |
| 0.9868 | 0.64 | 200 | 1.0221 | 0.3102 | 0.9306 | 0.0 | 0.0 | 0.2900 | 0.8701 | 0.0 | 0.0 |
| 0.9599 | 0.8 | 250 | 0.9801 | 0.3102 | 0.9306 | 0.0 | 0.0 | 0.2900 | 0.8701 | 0.0 | 0.0 |
| 0.9554 | 0.96 | 300 | 0.9500 | 0.3102 | 0.9306 | 0.0 | 0.0 | 0.2900 | 0.8701 | 0.0 | 0.0 |
| 0.935 | 1.12 | 350 | 0.9071 | 0.3102 | 0.9306 | 0.0 | 0.0 | 0.2900 | 0.8701 | 0.0 | 0.0 |
| 0.948 | 1.28 | 400 | 0.8809 | 0.3102 | 0.9306 | 0.0 | 0.0 | 0.2900 | 0.8701 | 0.0 | 0.0 |
| 0.9344 | 1.44 | 450 | 0.8258 | 0.3102 | 0.9306 | 0.0 | 0.0 | 0.2900 | 0.8701 | 0.0 | 0.0 |
| 0.9182 | 1.6 | 500 | 0.7687 | 0.3102 | 0.9306 | 0.0 | 0.0 | 0.2900 | 0.8701 | 0.0 | 0.0 |
| 0.8942 | 1.76 | 550 | 0.5787 | 0.3102 | 0.9306 | 0.0 | 0.0 | 0.2900 | 0.8701 | 0.0 | 0.0 |
| 0.8932 | 1.92 | 600 | 0.4506 | 0.4043 | 0.9628 | 0.0 | 0.25 | 0.3777 | 0.9753 | 0.0 | 0.1579 |
| 0.7448 | 2.08 | 650 | 0.2884 | 0.5323 | 0.9650 | 0.3303 | 0.3017 | 0.7075 | 0.9810 | 0.9474 | 0.1942 |
| 0.6616 | 2.24 | 700 | 0.2162 | 0.8161 | 0.9710 | 0.9724 | 0.5051 | 0.7910 | 0.9824 | 0.9670 | 0.4237 |
| 0.575 | 2.4 | 750 | 0.1754 | 0.8305 | 0.9714 | 0.9780 | 0.5421 | 0.7961 | 0.9881 | 0.9674 | 0.4328 |
| 0.5246 | 2.56 | 800 | 0.1641 | 0.8102 | 0.9659 | 0.9175 | 0.5472 | 0.7614 | 0.9892 | 0.8558 | 0.4394 |
| 0.481 | 2.72 | 850 | 0.1399 | 0.8407 | 0.9756 | 0.9780 | 0.5686 | 0.8082 | 0.9894 | 0.9674 | 0.4677 |
| 0.4588 | 2.88 | 900 | 0.1212 | 0.8501 | 0.9786 | 0.9783 | 0.5934 | 0.8247 | 0.9871 | 0.9574 | 0.5294 |
| 0.4512 | 3.04 | 950 | 0.1388 | 0.8270 | 0.9702 | 0.9836 | 0.5273 | 0.7904 | 0.9893 | 0.9677 | 0.4143 |
| 0.3894 | 3.2 | 1000 | 0.1270 | 0.8411 | 0.9737 | 0.9836 | 0.5660 | 0.8043 | 0.9905 | 0.9677 | 0.4545 |
| 0.3772 | 3.36 | 1050 | 0.1267 | 0.8336 | 0.9732 | 0.9890 | 0.5385 | 0.8013 | 0.9882 | 0.9783 | 0.4375 |
| 0.3528 | 3.52 | 1100 | 0.1073 | 0.8546 | 0.9791 | 0.9890 | 0.5957 | 0.8284 | 0.9883 | 0.9783 | 0.5185 |
| 0.3694 | 3.68 | 1150 | 0.1120 | 0.8431 | 0.9786 | 0.9890 | 0.5618 | 0.8244 | 0.9849 | 0.9783 | 0.5102 |
| 0.3146 | 3.84 | 1200 | 0.1189 | 0.8325 | 0.9738 | 0.9836 | 0.54 | 0.8016 | 0.9870 | 0.9677 | 0.45 |
| 0.3038 | 4.01 | 1250 | 0.1041 | 0.8648 | 0.9815 | 0.9836 | 0.6292 | 0.8425 | 0.9884 | 0.9677 | 0.5714 |
| 0.2482 | 4.17 | 1300 | 0.1245 | 0.8588 | 0.9773 | 0.9836 | 0.6154 | 0.8202 | 0.9929 | 0.9677 | 0.5 |
| 0.2388 | 4.33 | 1350 | 0.1167 | 0.8701 | 0.9808 | 0.9836 | 0.6458 | 0.8377 | 0.9918 | 0.9677 | 0.5536 |
| 0.2593 | 4.49 | 1400 | 0.1215 | 0.8654 | 0.9790 | 0.9836 | 0.6337 | 0.8284 | 0.9929 | 0.9677 | 0.5246 |
| 0.239 | 4.65 | 1450 | 0.1057 | 0.8621 | 0.9803 | 0.9890 | 0.6170 | 0.8349 | 0.9895 | 0.9783 | 0.5370 |
| 0.2397 | 4.81 | 1500 | 0.1256 | 0.8544 | 0.9761 | 0.9890 | 0.5981 | 0.8162 | 0.9929 | 0.9783 | 0.4776 |
| 0.2238 | 4.97 | 1550 | 0.1189 | 0.8701 | 0.9802 | 0.9836 | 0.6465 | 0.8343 | 0.9929 | 0.9677 | 0.5424 |
| 0.1811 | 5.13 | 1600 | 0.1456 | 0.8438 | 0.9737 | 0.9836 | 0.5741 | 0.8051 | 0.9917 | 0.9677 | 0.4559 |
| 0.1615 | 5.29 | 1650 | 0.1076 | 0.8780 | 0.9838 | 0.9836 | 0.6667 | 0.8581 | 0.9895 | 0.9677 | 0.6170 |
| 0.1783 | 5.45 | 1700 | 0.1217 | 0.8869 | 0.9831 | 0.9836 | 0.6939 | 0.8497 | 0.9953 | 0.9677 | 0.5862 |
| 0.1615 | 5.61 | 1750 | 0.1305 | 0.8770 | 0.9808 | 0.9836 | 0.6667 | 0.8371 | 0.9953 | 0.9677 | 0.5484 |
| 0.155 | 5.77 | 1800 | 0.1218 | 0.8668 | 0.9821 | 0.9890 | 0.6292 | 0.8460 | 0.9884 | 0.9783 | 0.5714 |
| 0.167 | 5.93 | 1850 | 0.1091 | 0.8991 | 0.9873 | 0.9890 | 0.7209 | 0.8814 | 0.9919 | 0.9783 | 0.6739 |
| 0.1455 | 6.09 | 1900 | 0.1338 | 0.8535 | 0.9773 | 0.9890 | 0.5941 | 0.8202 | 0.9906 | 0.9783 | 0.4918 |
| 0.1301 | 6.25 | 1950 | 0.1321 | 0.8792 | 0.9820 | 0.9890 | 0.6667 | 0.8439 | 0.9941 | 0.9783 | 0.5593 |
| 0.1049 | 6.41 | 2000 | 0.1181 | 0.9031 | 0.9879 | 0.9834 | 0.7381 | 0.8911 | 0.9908 | 0.9780 | 0.7045 |
| 0.1403 | 6.57 | 2050 | 0.1432 | 0.8608 | 0.9779 | 0.9890 | 0.6154 | 0.8237 | 0.9929 | 0.9783 | 0.5 |
| 0.1178 | 6.73 | 2100 | 0.1443 | 0.8937 | 0.9844 | 0.9945 | 0.7021 | 0.8644 | 0.9930 | 0.9890 | 0.6111 |
| 0.1267 | 6.89 | 2150 | 0.1346 | 0.8494 | 0.9786 | 0.9890 | 0.5806 | 0.8249 | 0.9871 | 0.9783 | 0.5094 |
| 0.1043 | 7.05 | 2200 | 0.1494 | 0.8905 | 0.9832 | 0.9945 | 0.6939 | 0.8564 | 0.9941 | 0.9890 | 0.5862 |
| 0.0886 | 7.21 | 2250 | 0.1180 | 0.8946 | 0.9873 | 0.9890 | 0.7073 | 0.8861 | 0.9896 | 0.9783 | 0.6905 |
| 0.1183 | 7.37 | 2300 | 0.1777 | 0.8720 | 0.9790 | 0.9890 | 0.6481 | 0.8298 | 0.9964 | 0.9783 | 0.5147 |
| 0.0813 | 7.53 | 2350 | 0.1405 | 0.8912 | 0.9856 | 0.9836 | 0.7045 | 0.8685 | 0.9919 | 0.9677 | 0.6458 |
| 0.111 | 7.69 | 2400 | 0.1379 | 0.8874 | 0.9838 | 0.9836 | 0.6947 | 0.8540 | 0.9941 | 0.9677 | 0.6 |
| 0.1199 | 7.85 | 2450 | 0.1301 | 0.9080 | 0.9879 | 0.9890 | 0.7473 | 0.8801 | 0.9953 | 0.9783 | 0.6667 |
| 0.1054 | 8.01 | 2500 | 0.1478 | 0.8845 | 0.9838 | 0.9890 | 0.6809 | 0.8546 | 0.9930 | 0.9783 | 0.5926 |
| 0.105 | 8.17 | 2550 | 0.1333 | 0.9021 | 0.9879 | 0.9890 | 0.7294 | 0.8863 | 0.9919 | 0.9783 | 0.6889 |
| 0.09 | 8.33 | 2600 | 0.1555 | 0.8926 | 0.9855 | 0.9890 | 0.7033 | 0.8662 | 0.9930 | 0.9783 | 0.6275 |
| 0.0947 | 8.49 | 2650 | 0.1572 | 0.8831 | 0.9856 | 0.9890 | 0.6747 | 0.8726 | 0.9885 | 0.9783 | 0.6512 |
| 0.0784 | 8.65 | 2700 | 0.1477 | 0.8969 | 0.9873 | 0.9890 | 0.7143 | 0.8836 | 0.9908 | 0.9783 | 0.6818 |
| 0.0814 | 8.81 | 2750 | 0.1700 | 0.8932 | 0.9861 | 0.9890 | 0.7045 | 0.8720 | 0.9919 | 0.9783 | 0.6458 |
| 0.0962 | 8.97 | 2800 | 0.1290 | 0.9171 | 0.9896 | 0.9890 | 0.7727 | 0.8940 | 0.9954 | 0.9783 | 0.7083 |
| 0.0802 | 9.13 | 2850 | 0.1721 | 0.8796 | 0.9832 | 0.9890 | 0.6667 | 0.8517 | 0.9918 | 0.9783 | 0.5849 |
| 0.0844 | 9.29 | 2900 | 0.1516 | 0.9023 | 0.9867 | 0.9890 | 0.7312 | 0.8717 | 0.9953 | 0.9783 | 0.6415 |
| 0.0511 | 9.45 | 2950 | 0.1544 | 0.9062 | 0.9879 | 0.9890 | 0.7416 | 0.8820 | 0.9942 | 0.9783 | 0.6735 |
| 0.0751 | 9.61 | 3000 | 0.1748 | 0.8884 | 0.9832 | 0.9945 | 0.6875 | 0.8571 | 0.9930 | 0.9890 | 0.5893 |
| 0.0707 | 9.77 | 3050 | 0.1743 | 0.8721 | 0.9802 | 0.9890 | 0.6471 | 0.8349 | 0.9941 | 0.9783 | 0.5323 |
| 0.0951 | 9.93 | 3100 | 0.1660 | 0.8899 | 0.9850 | 0.9890 | 0.6957 | 0.8622 | 0.9930 | 0.9783 | 0.6154 |
| 0.0576 | 10.1 | 3150 | 0.2029 | 0.8613 | 0.9766 | 0.9890 | 0.6182 | 0.8197 | 0.9952 | 0.9783 | 0.4857 |
| 0.0727 | 10.26 | 3200 | 0.1709 | 0.8920 | 0.9849 | 0.9890 | 0.7021 | 0.8612 | 0.9942 | 0.9783 | 0.6111 |
| 0.0654 | 10.42 | 3250 | 0.1599 | 0.8999 | 0.9861 | 0.9945 | 0.7191 | 0.8780 | 0.9919 | 0.9890 | 0.6531 |
| 0.0553 | 10.58 | 3300 | 0.2091 | 0.8920 | 0.9849 | 0.9890 | 0.7021 | 0.8612 | 0.9942 | 0.9783 | 0.6111 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.9.0+cu102
- Datasets 1.9.0
- Tokenizers 0.10.2
|
TheWorstIsNot/cross
|
TheWorstIsNot
| 2025-04-03T15:47:39Z
| 0
| 0
|
diffusers
|
[
"diffusers",
"text-to-image",
"lora",
"template:diffusion-lora",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"region:us"
] |
text-to-image
| 2025-04-03T15:47:09Z
|
---
tags:
- text-to-image
- lora
- diffusers
- template:diffusion-lora
widget:
- text: '-'
output:
url: images/df0r49j-37a375fe-e811-4702-9278-d7e062d15f18.png
base_model: black-forest-labs/FLUX.1-dev
instance_prompt: cross bodysuit
---
# cross
<Gallery />
## Trigger words
You should use `cross bodysuit` to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](/TheWorstIsNot/cross/tree/main) them in the Files & versions tab.
|
genloop/qwen2-5-vl-merged-vllm-test
|
genloop
| 2025-04-03T15:46:15Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen2_5_vl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-04-03T15:39:47Z
|
---
base_model: unsloth/qwen2.5-vl-7b-instruct
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2_5_vl
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** genloop
- **License:** apache-2.0
- **Finetuned from model :** unsloth/qwen2.5-vl-7b-instruct
This qwen2_5_vl model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
ZMC2019/OpenR1-Qwen-7B-Sparse-P25
|
ZMC2019
| 2025-04-03T15:46:12Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"open-r1",
"trl",
"sft",
"conversational",
"dataset:open-r1/OpenR1-Math-220k",
"base_model:ZMC2019/OpenR1-Qwen-7B-Sparse",
"base_model:finetune:ZMC2019/OpenR1-Qwen-7B-Sparse",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-04-02T18:56:07Z
|
---
base_model: ZMC2019/OpenR1-Qwen-7B-Sparse
datasets: open-r1/OpenR1-Math-220k
library_name: transformers
model_name: OpenR1-Qwen-7B-Sparse-P25
tags:
- generated_from_trainer
- open-r1
- trl
- sft
licence: license
---
# Model Card for OpenR1-Qwen-7B-Sparse-P25
This model is a fine-tuned version of [ZMC2019/OpenR1-Qwen-7B-Sparse](https://huggingface.co/ZMC2019/OpenR1-Qwen-7B-Sparse) on the [open-r1/OpenR1-Math-220k](https://huggingface.co/datasets/open-r1/OpenR1-Math-220k) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="ZMC2019/OpenR1-Qwen-7B-Sparse-P25", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/chenzhuoming911/huggingface/runs/ykot45x0)
This model was trained with SFT.
### Framework versions
- TRL: 0.16.0.dev0
- Transformers: 4.49.0
- Pytorch: 2.5.1
- Datasets: 3.5.0
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
TheWorstIsNot/sheer
|
TheWorstIsNot
| 2025-04-03T15:44:35Z
| 0
| 0
|
diffusers
|
[
"diffusers",
"text-to-image",
"lora",
"template:diffusion-lora",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"region:us"
] |
text-to-image
| 2025-04-03T15:42:36Z
|
---
tags:
- text-to-image
- lora
- diffusers
- template:diffusion-lora
widget:
- text: '-'
output:
url: images/df0r49x-0a00ace4-5e0b-4547-a453-d6f136b05cd1.png
base_model: black-forest-labs/FLUX.1-dev
instance_prompt: sheerbodysuit
---
# sheer
<Gallery />
## Trigger words
You should use `sheerbodysuit` to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](/TheWorstIsNot/sheer/tree/main) them in the Files & versions tab.
|
Sofya-56r7w8/WalasseTing_style_LoRA
|
Sofya-56r7w8
| 2025-04-03T15:44:04Z
| 0
| 0
|
diffusers
|
[
"diffusers",
"tensorboard",
"text-to-image",
"diffusers-training",
"lora",
"template:sd-lora",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] |
text-to-image
| 2025-04-03T15:43:55Z
|
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
library_name: diffusers
license: openrail++
instance_prompt: photo collage in Walasse Ting style
widget: []
tags:
- text-to-image
- text-to-image
- diffusers-training
- diffusers
- lora
- template:sd-lora
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# SDXL LoRA DreamBooth - Sofya-56r7w8/WalasseTing_style_LoRA
<Gallery />
## Model description
These are Sofya-56r7w8/WalasseTing_style_LoRA LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using [DreamBooth](https://dreambooth.github.io/).
LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Trigger words
You should use photo collage in Walasse Ting style to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](Sofya-56r7w8/WalasseTing_style_LoRA/tree/main) them in the Files & versions tab.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model]
|
sitenote/fine_tuned_dd_fb_copy_model
|
sitenote
| 2025-04-03T15:42:15Z
| 0
| 0
|
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:deepseek-ai/DeepSeek-R1-Distill-Llama-8B",
"base_model:finetune:deepseek-ai/DeepSeek-R1-Distill-Llama-8B",
"endpoints_compatible",
"region:us"
] | null | 2025-04-03T15:37:14Z
|
---
base_model: deepseek-ai/DeepSeek-R1-Distill-Llama-8B
library_name: transformers
model_name: fine_tuned_dd_fb_copy_model
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for fine_tuned_dd_fb_copy_model
This model is a fine-tuned version of [deepseek-ai/DeepSeek-R1-Distill-Llama-8B](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Llama-8B).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="sitenote/fine_tuned_dd_fb_copy_model", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/sarimhaq-sitenote/huggingface/runs/i9pph7i1)
This model was trained with SFT.
### Framework versions
- TRL: 0.16.0
- Transformers: 4.50.2
- Pytorch: 2.6.0+cu124
- Datasets: 3.5.0
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
neuralmagic/Qwen2.5-VL-72B-Instruct-quantized.w4a16
|
neuralmagic
| 2025-04-03T15:42:08Z
| 1,230
| 3
|
transformers
|
[
"transformers",
"safetensors",
"qwen2_5_vl",
"image-text-to-text",
"vllm",
"vision",
"w4a16",
"conversational",
"en",
"base_model:Qwen/Qwen2.5-VL-72B-Instruct",
"base_model:quantized:Qwen/Qwen2.5-VL-72B-Instruct",
"license:apache-2.0",
"text-generation-inference",
"endpoints_compatible",
"compressed-tensors",
"region:us"
] |
image-text-to-text
| 2025-02-07T17:03:00Z
|
---
tags:
- vllm
- vision
- w4a16
license: apache-2.0
license_link: >-
https://huggingface.co/datasets/choosealicense/licenses/blob/main/markdown/apache-2.0.md
language:
- en
base_model: Qwen/Qwen2.5-VL-72B-Instruct
library_name: transformers
---
# Qwen2.5-VL-72B-Instruct-quantized-w4a16
## Model Overview
- **Model Architecture:** Qwen/Qwen2.5-VL-72B-Instruct
- **Input:** Vision-Text
- **Output:** Text
- **Model Optimizations:**
- **Weight quantization:** INT4
- **Activation quantization:** FP16
- **Release Date:** 2/24/2025
- **Version:** 1.0
- **Model Developers:** Neural Magic
Quantized version of [Qwen/Qwen2.5-VL-72B-Instruct](https://huggingface.co/Qwen/Qwen2.5-VL-72B-Instruct).
### Model Optimizations
This model was obtained by quantizing the weights of [Qwen/Qwen2.5-VL-72B-Instruct](https://huggingface.co/Qwen/Qwen2.5-VL-72B-Instruct) to INT8 data type, ready for inference with vLLM >= 0.5.2.
## Deployment
### Use with vLLM
This model can be deployed efficiently using the [vLLM](https://docs.vllm.ai/en/latest/) backend, as shown in the example below.
```python
from vllm.assets.image import ImageAsset
from vllm import LLM, SamplingParams
# prepare model
llm = LLM(
model="neuralmagic/Qwen2.5-VL-72B-Instruct-quantized.w4a16",
trust_remote_code=True,
max_model_len=4096,
max_num_seqs=2,
)
# prepare inputs
question = "What is the content of this image?"
inputs = {
"prompt": f"<|user|>\n<|image_1|>\n{question}<|end|>\n<|assistant|>\n",
"multi_modal_data": {
"image": ImageAsset("cherry_blossom").pil_image.convert("RGB")
},
}
# generate response
print("========== SAMPLE GENERATION ==============")
outputs = llm.generate(inputs, SamplingParams(temperature=0.2, max_tokens=64))
print(f"PROMPT : {outputs[0].prompt}")
print(f"RESPONSE: {outputs[0].outputs[0].text}")
print("==========================================")
```
vLLM also supports OpenAI-compatible serving. See the [documentation](https://docs.vllm.ai/en/latest/) for more details.
## Creation
This model was created with [llm-compressor](https://github.com/vllm-project/llm-compressor) by running the code snippet below as part a multimodal announcement blog.
<details>
<summary>Model Creation Code</summary>
```python
import base64
from io import BytesIO
import torch
from datasets import load_dataset
from qwen_vl_utils import process_vision_info
from transformers import AutoProcessor
from llmcompressor.modifiers.quantization import GPTQModifier
from llmcompressor.transformers import oneshot
from llmcompressor.transformers.tracing import (
TraceableQwen2_5_VLForConditionalGeneration,
)
from compressed_tensors.quantization import QuantizationArgs, QuantizationType, QuantizationStrategy, ActivationOrdering, QuantizationScheme
# Load model.
model_id = "Qwen/Qwen2.5-VL-72B-Instruct"
model = TraceableQwen2_5_VLForConditionalGeneration.from_pretrained(
model_id,
device_map="auto",
torch_dtype="auto",
)
processor = AutoProcessor.from_pretrained(model_id, trust_remote_code=True)
# Oneshot arguments
DATASET_ID = "lmms-lab/flickr30k"
DATASET_SPLIT = {"calibration": "test[:512]"}
NUM_CALIBRATION_SAMPLES = 512
MAX_SEQUENCE_LENGTH = 2048
# Load dataset and preprocess.
ds = load_dataset(DATASET_ID, split=DATASET_SPLIT)
ds = ds.shuffle(seed=42)
dampening_frac=0.01
# Apply chat template and tokenize inputs.
def preprocess_and_tokenize(example):
# preprocess
buffered = BytesIO()
example["image"].save(buffered, format="PNG")
encoded_image = base64.b64encode(buffered.getvalue())
encoded_image_text = encoded_image.decode("utf-8")
base64_qwen = f"data:image;base64,{encoded_image_text}"
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": base64_qwen},
{"type": "text", "text": "What does the image show?"},
],
}
]
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
# tokenize
return processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=False,
max_length=MAX_SEQUENCE_LENGTH,
truncation=True,
)
ds = ds.map(preprocess_and_tokenize, remove_columns=ds["calibration"].column_names)
# Define a oneshot data collator for multimodal inputs.
def data_collator(batch):
assert len(batch) == 1
return {key: torch.tensor(value) for key, value in batch[0].items()}
recipe = GPTQModifier(
targets="Linear",
config_groups={
"config_group": QuantizationScheme(
targets=["Linear"],
weights=QuantizationArgs(
num_bits=4,
type=QuantizationType.INT,
strategy=QuantizationStrategy.GROUP,
group_size=128,
symmetric=True,
dynamic=False,
actorder=ActivationOrdering.WEIGHT,
),
),
},
sequential_targets=["Qwen2_5_VLDecoderLayer"],
ignore=["lm_head", "re:visual.*"],
update_size=NUM_CALIBRATION_SAMPLES,
dampening_frac=dampening_frac
)
SAVE_DIR=f"{model_id.split('/')[1]}-quantized.w4a16"
# Perform oneshot
oneshot(
model=model,
tokenizer=model_id,
dataset=ds,
recipe=recipe,
max_seq_length=MAX_SEQUENCE_LENGTH,
num_calibration_samples=NUM_CALIBRATION_SAMPLES,
trust_remote_code_model=True,
data_collator=data_collator,
output_dir=SAVE_DIR
)
```
</details>
## Evaluation
The model was evaluated using [mistral-evals](https://github.com/neuralmagic/mistral-evals) for vision-related tasks and using [lm_evaluation_harness](https://github.com/neuralmagic/lm-evaluation-harness) for select text-based benchmarks. The evaluations were conducted using the following commands:
<details>
<summary>Evaluation Commands</summary>
### Vision Tasks
- vqav2
- docvqa
- mathvista
- mmmu
- chartqa
```
vllm serve neuralmagic/pixtral-12b-quantized.w8a8 --tensor_parallel_size 1 --max_model_len 25000 --trust_remote_code --max_num_seqs 8 --gpu_memory_utilization 0.9 --dtype float16 --limit_mm_per_prompt image=7
python -m eval.run eval_vllm \
--model_name neuralmagic/pixtral-12b-quantized.w8a8 \
--url http://0.0.0.0:8000 \
--output_dir ~/tmp \
--eval_name <vision_task_name>
```
### Text-based Tasks
#### MMLU
```
lm_eval \
--model vllm \
--model_args pretrained="<model_name>",dtype=auto,add_bos_token=True,max_model_len=4096,tensor_parallel_size=<n>,gpu_memory_utilization=0.8,enable_chunked_prefill=True,trust_remote_code=True \
--tasks mmlu \
--num_fewshot 5 \
--batch_size auto \
--output_path output_dir
```
#### MGSM
```
lm_eval \
--model vllm \
--model_args pretrained="<model_name>",dtype=auto,max_model_len=4096,max_gen_toks=2048,max_num_seqs=128,tensor_parallel_size=<n>,gpu_memory_utilization=0.9 \
--tasks mgsm_cot_native \
--apply_chat_template \
--num_fewshot 0 \
--batch_size auto \
--output_path output_dir
```
</details>
### Accuracy
<table>
<thead>
<tr>
<th>Category</th>
<th>Metric</th>
<th>Qwen/Qwen2.5-VL-72B-Instruct</th>
<th>neuralmagic/Qwen2.5-VL-72B-Instruct-quantized.w4a16</th>
<th>Recovery (%)</th>
</tr>
</thead>
<tbody>
<tr>
<td rowspan="6"><b>Vision</b></td>
<td>MMMU (val, CoT)<br><i>explicit_prompt_relaxed_correctness</i></td>
<td>64.33</td>
<td>62.89</td>
<td>97.76%</td>
</tr>
<tr>
<td>VQAv2 (val)<br><i>vqa_match</i></td>
<td>81.94</td>
<td>81.87</td>
<td>99.91%</td>
</tr>
<tr>
<td>DocVQA (val)<br><i>anls</i></td>
<td>94.71</td>
<td>94.72</td>
<td>100.01%</td>
</tr>
<tr>
<td>ChartQA (test, CoT)<br><i>anywhere_in_answer_relaxed_correctness</i></td>
<td>88.96</td>
<td>88.96</td>
<td>100.00%</td>
</tr>
<tr>
<td>Mathvista (testmini, CoT)<br><i>explicit_prompt_relaxed_correctness</i></td>
<td>78.18</td>
<td>77.68</td>
<td>99.36%</td>
</tr>
<tr>
<td><b>Average Score</b></td>
<td><b>81.62</b></td>
<td><b>81.22</b></td>
<td><b>99.51</b></td>
</tr>
<tr>
<td rowspan="2"><b>Text</b></td>
<td>MGSM (CoT)</td>
<td>75.45</td>
<td>75.13</td>
<td>99.58%</td>
</tr>
<tr>
<td>MMLU (5-shot)</td>
<td>86.16</td>
<td>85.36</td>
<td>99.07%</td>
</tr>
</tbody>
</table>
## Inference Performance
This model achieves up to 3.95x speedup in single-stream deployment and up to 6.6x speedup in multi-stream asynchronous deployment, depending on hardware and use-case scenario.
The following performance benchmarks were conducted with [vLLM](https://docs.vllm.ai/en/latest/) version 0.7.2, and [GuideLLM](https://github.com/neuralmagic/guidellm).
<details>
<summary>Benchmarking Command</summary>
```
guidellm --model neuralmagic/Qwen2.5-VL-72B-Instruct-quantized.w4a16 --target "http://localhost:8000/v1" --data-type emulated --data prompt_tokens=<prompt_tokens>,generated_tokens=<generated_tokens>,images=<num_images>,width=<image_width>,height=<image_height> --max seconds 120 --backend aiohttp_server
```
</details>
### Single-stream performance (measured with vLLM version 0.7.2)
<table border="1" class="dataframe">
<thead>
<tr>
<th></th>
<th></th>
<th></th>
<th></th>
<th style="text-align: center;" colspan="2" >Document Visual Question Answering<br>1680W x 2240H<br>64/128</th>
<th style="text-align: center;" colspan="2" >Visual Reasoning <br>640W x 480H<br>128/128</th>
<th style="text-align: center;" colspan="2" >Image Captioning<br>480W x 360H<br>0/128</th>
</tr>
<tr>
<th>Hardware</th>
<th>Number of GPUs</th>
<th>Model</th>
<th>Average Cost Reduction</th>
<th>Latency (s)</th>
<th>Queries Per Dollar</th>
<th>Latency (s)th>
<th>Queries Per Dollar</th>
<th>Latency (s)</th>
<th>Queries Per Dollar</th>
</tr>
</thead>
<tbody>
<tr>
<th rowspan="3" valign="top">A100</td>
<td>4</td>
<td>Qwen/Qwen2.5-VL-72B-Instruct</td>
<td></td>
<td>6.4</td>
<td>78</td>
<td>4.5</td>
<td>111</td>
<td>4.4</td>
<td>113</td>
</tr>
<tr>
<td>2</td>
<td>neuralmagic/Qwen2.5-VL-72B-Instruct-quantized.w8a8</td>
<td>1.85</td>
<td>7.0</td>
<td>143</td>
<td>4.9</td>
<td>205</td>
<td>4.8</td>
<td>211</td>
</tr>
<tr>
<td>1</td>
<td>neuralmagic/Qwen2.5-VL-72B-Instruct-quantized.w4a16</td>
<td>3.33</td>
<td>9.4</td>
<td>213</td>
<td>5.1</td>
<td>396</td>
<td>4.8</td>
<td>420</td>
</tr>
<tr>
<th rowspan="3" valign="top">H100</td>
<td>4</td>
<td>Qwen/Qwen2.5-VL-72B-Instruct</td>
<td></td>
<td>4.3</td>
<td>68</td>
<td>3.0</td>
<td>97</td>
<td>2.9</td>
<td>100</td>
</tr>
<tr>
<td>2</td>
<td>neuralmagic/Qwen2.5-VL-72B-Instruct-FP8-Dynamic</td>
<td>1.79</td>
<td>4.6</td>
<td>122</td>
<td>3.3</td>
<td>173</td>
<td>3.2</td>
<td>177</td>
</tr>
<tr>
<td>1</td>
<td>neuralmagic/Qwen2.5-VL-72B-Instruct-quantized.w4a16</td>
<td>5.66</td>
<td>4.3</td>
<td>252</td>
<td>4.4</td>
<td>251</td>
<td>4.2</td>
<td>259</td>
</tr>
</tbody>
</table>
**Use case profiles: Image Size (WxH) / prompt tokens / generation tokens
**QPD: Queries per dollar, based on on-demand cost at [Lambda Labs](https://lambdalabs.com/service/gpu-cloud) (observed on 2/18/2025).
### Multi-stream asynchronous performance (measured with vLLM version 0.7.2)
<table border="1" class="dataframe">
<thead>
<tr>
<th></th>
<th></th>
<th></th>
<th style="text-align: center;" colspan="2" >Document Visual Question Answering<br>1680W x 2240H<br>64/128</th>
<th style="text-align: center;" colspan="2" >Visual Reasoning <br>640W x 480H<br>128/128</th>
<th style="text-align: center;" colspan="2" >Image Captioning<br>480W x 360H<br>0/128</th>
</tr>
<tr>
<th>Hardware</th>
<th>Model</th>
<th>Average Cost Reduction</th>
<th>Maximum throughput (QPS)</th>
<th>Queries Per Dollar</th>
<th>Maximum throughput (QPS)</th>
<th>Queries Per Dollar</th>
<th>Maximum throughput (QPS)</th>
<th>Queries Per Dollar</th>
</tr>
</thead>
<tbody style="text-align: center">
<tr>
<th rowspan="3" valign="top">A100x4</th>
<td>Qwen/Qwen2.5-VL-72B-Instruct</td>
<td></td>
<td>0.4</td>
<td>180</td>
<td>1.1</td>
<td>539</td>
<td>1.2</td>
<td>595</td>
</tr>
<tr>
<td>neuralmagic/Qwen2.5-VL-72B-Instruct-quantized.w8a8</td>
<td>1.80</td>
<td>0.6</td>
<td>289</td>
<td>2.0</td>
<td>1020</td>
<td>2.3</td>
<td>1133</td>
</tr>
<tr>
<td>neuralmagic/Qwen2.5-VL-72B-Instruct-quantized.w4a16</td>
<td>2.75</td>
<td>0.7</td>
<td>341</td>
<td>3.2</td>
<td>1588</td>
<td>4.1</td>
<td>2037</td>
</tr>
<tr>
<th rowspan="3" valign="top">H100x4</th>
<td>Qwen/Qwen2.5-VL-72B-Instruct</td>
<td></td>
<td>0.5</td>
<td>134</td>
<td>1.2</td>
<td>357</td>
<td>1.3</td>
<td>379</td>
</tr>
<tr>
<td>neuralmagic/Qwen2.5-VL-72B-Instruct-FP8-Dynamic</td>
<td>1.73</td>
<td>0.9</td>
<td>247</td>
<td>2.2</td>
<td>621</td>
<td>2.4</td>
<td>669</td>
</tr>
<tr>
<td>neuralmagic/Qwen2.5-VL-72B-Instruct-quantized.w4a16</td>
<td>8.27</td>
<td>3.3</td>
<td>913</td>
<td>3.3</td>
<td>898</td>
<td>3.6</td>
<td>991</td>
</tr>
</tbody>
</table>
**Use case profiles: Image Size (WxH) / prompt tokens / generation tokens
**QPS: Queries per second.
**QPD: Queries per dollar, based on on-demand cost at [Lambda Labs](https://lambdalabs.com/service/gpu-cloud) (observed on 2/18/2025).
|
neuralmagic/Qwen2.5-VL-7B-Instruct-quantized.w4a16
|
neuralmagic
| 2025-04-03T15:41:49Z
| 1,043
| 3
|
transformers
|
[
"transformers",
"safetensors",
"qwen2_5_vl",
"image-text-to-text",
"vllm",
"vision",
"w4a16",
"conversational",
"en",
"base_model:Qwen/Qwen2.5-VL-7B-Instruct",
"base_model:quantized:Qwen/Qwen2.5-VL-7B-Instruct",
"license:apache-2.0",
"text-generation-inference",
"endpoints_compatible",
"compressed-tensors",
"region:us"
] |
image-text-to-text
| 2025-02-07T17:01:39Z
|
---
tags:
- vllm
- vision
- w4a16
license: apache-2.0
license_link: >-
https://huggingface.co/datasets/choosealicense/licenses/blob/main/markdown/apache-2.0.md
language:
- en
base_model: Qwen/Qwen2.5-VL-7B-Instruct
library_name: transformers
---
# Qwen2.5-VL-7B-Instruct-quantized-w4a16
## Model Overview
- **Model Architecture:** Qwen/Qwen2.5-VL-7B-Instruct
- **Input:** Vision-Text
- **Output:** Text
- **Model Optimizations:**
- **Weight quantization:** INT4
- **Activation quantization:** FP16
- **Release Date:** 2/24/2025
- **Version:** 1.0
- **Model Developers:** Neural Magic
Quantized version of [Qwen/Qwen2.5-VL-7B-Instruct](https://huggingface.co/Qwen/Qwen2.5-VL-7B-Instruct).
### Model Optimizations
This model was obtained by quantizing the weights of [Qwen/Qwen2.5-VL-7B-Instruct](https://huggingface.co/Qwen/Qwen2.5-VL-7B-Instruct) to INT8 data type, ready for inference with vLLM >= 0.5.2.
## Deployment
### Use with vLLM
This model can be deployed efficiently using the [vLLM](https://docs.vllm.ai/en/latest/) backend, as shown in the example below.
```python
from vllm.assets.image import ImageAsset
from vllm import LLM, SamplingParams
# prepare model
llm = LLM(
model="neuralmagic/Qwen2.5-VL-7B-Instruct-quantized.w4a16",
trust_remote_code=True,
max_model_len=4096,
max_num_seqs=2,
)
# prepare inputs
question = "What is the content of this image?"
inputs = {
"prompt": f"<|user|>\n<|image_1|>\n{question}<|end|>\n<|assistant|>\n",
"multi_modal_data": {
"image": ImageAsset("cherry_blossom").pil_image.convert("RGB")
},
}
# generate response
print("========== SAMPLE GENERATION ==============")
outputs = llm.generate(inputs, SamplingParams(temperature=0.2, max_tokens=64))
print(f"PROMPT : {outputs[0].prompt}")
print(f"RESPONSE: {outputs[0].outputs[0].text}")
print("==========================================")
```
vLLM also supports OpenAI-compatible serving. See the [documentation](https://docs.vllm.ai/en/latest/) for more details.
## Creation
This model was created with [llm-compressor](https://github.com/vllm-project/llm-compressor) by running the code snippet below as part a multimodal announcement blog.
<details>
<summary>Model Creation Code</summary>
```python
import base64
from io import BytesIO
import torch
from datasets import load_dataset
from qwen_vl_utils import process_vision_info
from transformers import AutoProcessor
from llmcompressor.modifiers.quantization import GPTQModifier
from llmcompressor.transformers import oneshot
from llmcompressor.transformers.tracing import (
TraceableQwen2_5_VLForConditionalGeneration,
)
from compressed_tensors.quantization import QuantizationArgs, QuantizationType, QuantizationStrategy, ActivationOrdering, QuantizationScheme
# Load model.
model_id = "Qwen/Qwen2.5-VL-7B-Instruct"
model = TraceableQwen2_5_VLForConditionalGeneration.from_pretrained(
model_id,
device_map="auto",
torch_dtype="auto",
)
processor = AutoProcessor.from_pretrained(model_id, trust_remote_code=True)
# Oneshot arguments
DATASET_ID = "lmms-lab/flickr30k"
DATASET_SPLIT = {"calibration": "test[:512]"}
NUM_CALIBRATION_SAMPLES = 512
MAX_SEQUENCE_LENGTH = 2048
# Load dataset and preprocess.
ds = load_dataset(DATASET_ID, split=DATASET_SPLIT)
ds = ds.shuffle(seed=42)
dampening_frac=0.01
# Apply chat template and tokenize inputs.
def preprocess_and_tokenize(example):
# preprocess
buffered = BytesIO()
example["image"].save(buffered, format="PNG")
encoded_image = base64.b64encode(buffered.getvalue())
encoded_image_text = encoded_image.decode("utf-8")
base64_qwen = f"data:image;base64,{encoded_image_text}"
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": base64_qwen},
{"type": "text", "text": "What does the image show?"},
],
}
]
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
# tokenize
return processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=False,
max_length=MAX_SEQUENCE_LENGTH,
truncation=True,
)
ds = ds.map(preprocess_and_tokenize, remove_columns=ds["calibration"].column_names)
# Define a oneshot data collator for multimodal inputs.
def data_collator(batch):
assert len(batch) == 1
return {key: torch.tensor(value) for key, value in batch[0].items()}
recipe = GPTQModifier(
targets="Linear",
config_groups={
"config_group": QuantizationScheme(
targets=["Linear"],
weights=QuantizationArgs(
num_bits=4,
type=QuantizationType.INT,
strategy=QuantizationStrategy.GROUP,
group_size=128,
symmetric=True,
dynamic=False,
actorder=ActivationOrdering.WEIGHT,
),
),
},
sequential_targets=["Qwen2_5_VLDecoderLayer"],
ignore=["lm_head", "re:visual.*"],
update_size=NUM_CALIBRATION_SAMPLES,
dampening_frac=dampening_frac
)
SAVE_DIR=f"{model_id.split('/')[1]}-quantized.w4a16"
# Perform oneshot
oneshot(
model=model,
tokenizer=model_id,
dataset=ds,
recipe=recipe,
max_seq_length=MAX_SEQUENCE_LENGTH,
num_calibration_samples=NUM_CALIBRATION_SAMPLES,
trust_remote_code_model=True,
data_collator=data_collator,
output_dir=SAVE_DIR
)
```
</details>
## Evaluation
The model was evaluated using [mistral-evals](https://github.com/neuralmagic/mistral-evals) for vision-related tasks and using [lm_evaluation_harness](https://github.com/neuralmagic/lm-evaluation-harness) for select text-based benchmarks. The evaluations were conducted using the following commands:
<details>
<summary>Evaluation Commands</summary>
### Vision Tasks
- vqav2
- docvqa
- mathvista
- mmmu
- chartqa
```
vllm serve neuralmagic/pixtral-12b-quantized.w8a8 --tensor_parallel_size 1 --max_model_len 25000 --trust_remote_code --max_num_seqs 8 --gpu_memory_utilization 0.9 --dtype float16 --limit_mm_per_prompt image=7
python -m eval.run eval_vllm \
--model_name neuralmagic/pixtral-12b-quantized.w8a8 \
--url http://0.0.0.0:8000 \
--output_dir ~/tmp \
--eval_name <vision_task_name>
```
### Text-based Tasks
#### MMLU
```
lm_eval \
--model vllm \
--model_args pretrained="<model_name>",dtype=auto,add_bos_token=True,max_model_len=4096,tensor_parallel_size=<n>,gpu_memory_utilization=0.8,enable_chunked_prefill=True,trust_remote_code=True \
--tasks mmlu \
--num_fewshot 5 \
--batch_size auto \
--output_path output_dir
```
#### MGSM
```
lm_eval \
--model vllm \
--model_args pretrained="<model_name>",dtype=auto,max_model_len=4096,max_gen_toks=2048,max_num_seqs=128,tensor_parallel_size=<n>,gpu_memory_utilization=0.9 \
--tasks mgsm_cot_native \
--apply_chat_template \
--num_fewshot 0 \
--batch_size auto \
--output_path output_dir
```
</details>
### Accuracy
<table>
<thead>
<tr>
<th>Category</th>
<th>Metric</th>
<th>Qwen/Qwen2.5-VL-7B-Instruct</th>
<th>Qwen2.5-VL-7B-Instruct-quantized.W4A16</th>
<th>Recovery (%)</th>
</tr>
</thead>
<tbody>
<tr>
<td rowspan="6"><b>Vision</b></td>
<td>MMMU (val, CoT)<br><i>explicit_prompt_relaxed_correctness</i></td>
<td>52.00</td>
<td>51.11</td>
<td>98.29%</td>
</tr>
<tr>
<td>VQAv2 (val)<br><i>vqa_match</i></td>
<td>75.59</td>
<td>73.90</td>
<td>97.76%</td>
</tr>
<tr>
<td>DocVQA (val)<br><i>anls</i></td>
<td>94.27</td>
<td>94.13</td>
<td>99.85%</td>
</tr>
<tr>
<td>ChartQA (test, CoT)<br><i>anywhere_in_answer_relaxed_correctness</i></td>
<td>86.44</td>
<td>85.64</td>
<td>99.07%</td>
</tr>
<tr>
<td>Mathvista (testmini, CoT)<br><i>explicit_prompt_relaxed_correctness</i></td>
<td>69.47</td>
<td>67.17</td>
<td>96.69%</td>
</tr>
<tr>
<td><b>Average Score</b></td>
<td><b>75.95</b></td>
<td><b>74.79</b></td>
<td><b>98.47%</b></td>
</tr>
<tr>
<td rowspan="2"><b>Text</b></td>
<td>MGSM (CoT)</td>
<td>56.38</td>
<td>51.89</td>
<td>92.04%</td>
</tr>
<tr>
<td>MMLU (5-shot)</td>
<td>71.09</td>
<td>68.67</td>
<td>96.59%</td>
</tr>
</tbody>
</table>
## Inference Performance
This model achieves up to 2.35x speedup in single-stream deployment and up to 2.02x speedup in multi-stream asynchronous deployment, depending on hardware and use-case scenario.
The following performance benchmarks were conducted with [vLLM](https://docs.vllm.ai/en/latest/) version 0.7.2, and [GuideLLM](https://github.com/neuralmagic/guidellm).
<details>
<summary>Benchmarking Command</summary>
```
guidellm --model neuralmagic/Qwen2.5-VL-7B-Instruct-quantized.w4a16 --target "http://localhost:8000/v1" --data-type emulated --data prompt_tokens=<prompt_tokens>,generated_tokens=<generated_tokens>,images=<num_images>,width=<image_width>,height=<image_height> --max seconds 120 --backend aiohttp_server
```
</details>
### Single-stream performance (measured with vLLM version 0.7.2)
<table border="1" class="dataframe">
<thead>
<tr>
<th></th>
<th></th>
<th></th>
<th style="text-align: center;" colspan="2" >Document Visual Question Answering<br>1680W x 2240H<br>64/128</th>
<th style="text-align: center;" colspan="2" >Visual Reasoning <br>640W x 480H<br>128/128</th>
<th style="text-align: center;" colspan="2" >Image Captioning<br>480W x 360H<br>0/128</th>
</tr>
<tr>
<th>Hardware</th>
<th>Model</th>
<th>Average Cost Reduction</th>
<th>Latency (s)</th>
<th>Queries Per Dollar</th>
<th>Latency (s)th>
<th>Queries Per Dollar</th>
<th>Latency (s)</th>
<th>Queries Per Dollar</th>
</tr>
</thead>
<tbody style="text-align: center">
<tr>
<th rowspan="3" valign="top">A6000x1</th>
<th>Qwen/Qwen2.5-VL-7B-Instruct</th>
<td></td>
<td>4.9</td>
<td>912</td>
<td>3.2</td>
<td>1386</td>
<td>3.1</td>
<td>1431</td>
</tr>
<tr>
<th>neuralmagic/Qwen2.5-VL-7B-Instruct-quantized.w8a8</th>
<td>1.50</td>
<td>3.6</td>
<td>1248</td>
<td>2.1</td>
<td>2163</td>
<td>2.0</td>
<td>2237</td>
</tr>
<tr>
<th>neuralmagic/Qwen2.5-VL-7B-Instruct-quantized.w4a16</th>
<td>2.05</td>
<td>3.3</td>
<td>1351</td>
<td>1.4</td>
<td>3252</td>
<td>1.4</td>
<td>3321</td>
</tr>
<tr>
<th rowspan="3" valign="top">A100x1</th>
<th>Qwen/Qwen2.5-VL-7B-Instruct</th>
<td></td>
<td>2.8</td>
<td>707</td>
<td>1.7</td>
<td>1162</td>
<td>1.7</td>
<td>1198</td>
</tr>
<tr>
<th>neuralmagic/Qwen2.5-VL-7B-Instruct-quantized.w8a8</th>
<td>1.24</td>
<td>2.4</td>
<td>851</td>
<td>1.4</td>
<td>1454</td>
<td>1.3</td>
<td>1512</td>
</tr>
<tr>
<th>neuralmagic/Qwen2.5-VL-7B-Instruct-quantized.w4a16</th>
<td>1.49</td>
<td>2.2</td>
<td>912</td>
<td>1.1</td>
<td>1791</td>
<td>1.0</td>
<td>1950</td>
</tr>
<tr>
<th rowspan="3" valign="top">H100x1</th>
<th>Qwen/Qwen2.5-VL-7B-Instruct</th>
<td></td>
<td>2.0</td>
<td>557</td>
<td>1.2</td>
<td>919</td>
<td>1.2</td>
<td>941</td>
</tr>
<tr>
<th>neuralmagic/Qwen2.5-VL-7B-Instruct-FP8-Dynamic</th>
<td>1.28</td>
<td>1.6</td>
<td>698</td>
<td>0.9</td>
<td>1181</td>
<td>0.9</td>
<td>1219</td>
</tr>
<tr>
<th>neuralmagic/Qwen2.5-VL-7B-Instruct-quantized.w4a16</th>
<td>1.28</td>
<td>1.6</td>
<td>686</td>
<td>0.9</td>
<td>1191</td>
<td>0.9</td>
<td>1228</td>
</tr>
</tbody>
</table>
**Use case profiles: Image Size (WxH) / prompt tokens / generation tokens
**QPD: Queries per dollar, based on on-demand cost at [Lambda Labs](https://lambdalabs.com/service/gpu-cloud) (observed on 2/18/2025).
### Multi-stream asynchronous performance (measured with vLLM version 0.7.2)
<table border="1" class="dataframe">
<thead>
<tr>
<th></th>
<th></th>
<th></th>
<th style="text-align: center;" colspan="2" >Document Visual Question Answering<br>1680W x 2240H<br>64/128</th>
<th style="text-align: center;" colspan="2" >Visual Reasoning <br>640W x 480H<br>128/128</th>
<th style="text-align: center;" colspan="2" >Image Captioning<br>480W x 360H<br>0/128</th>
</tr>
<tr>
<th>Hardware</th>
<th>Model</th>
<th>Average Cost Reduction</th>
<th>Maximum throughput (QPS)</th>
<th>Queries Per Dollar</th>
<th>Maximum throughput (QPS)</th>
<th>Queries Per Dollar</th>
<th>Maximum throughput (QPS)</th>
<th>Queries Per Dollar</th>
</tr>
</thead>
<tbody style="text-align: center">
<tr>
<th rowspan="3" valign="top">A6000x1</th>
<th>Qwen/Qwen2.5-VL-7B-Instruct</th>
<td></td>
<td>0.4</td>
<td>1837</td>
<td>1.5</td>
<td>6846</td>
<td>1.7</td>
<td>7638</td>
</tr>
<tr>
<th>neuralmagic/Qwen2.5-VL-7B-Instruct-quantized.w8a8</th>
<td>1.41</td>
<td>0.5</td>
<td>2297</td>
<td>2.3</td>
<td>10137</td>
<td>2.5</td>
<td>11472</td>
</tr>
<tr>
<th>neuralmagic/Qwen2.5-VL-7B-Instruct-quantized.w4a16</th>
<td>1.60</td>
<td>0.4</td>
<td>1828</td>
<td>2.7</td>
<td>12254</td>
<td>3.4</td>
<td>15477</td>
</tr>
<tr>
<th rowspan="3" valign="top">A100x1</th>
<th>Qwen/Qwen2.5-VL-7B-Instruct</th>
<td></td>
<td>0.7</td>
<td>1347</td>
<td>2.6</td>
<td>5221</td>
<td>3.0</td>
<td>6122</td>
</tr>
<tr>
<th>neuralmagic/Qwen2.5-VL-7B-Instruct-quantized.w8a8</th>
<td>1.27</td>
<td>0.8</td>
<td>1639</td>
<td>3.4</td>
<td>6851</td>
<td>3.9</td>
<td>7918</td>
</tr>
<tr>
<th>neuralmagic/Qwen2.5-VL-7B-Instruct-quantized.w4a16</th>
<td>1.21</td>
<td>0.7</td>
<td>1314</td>
<td>3.0</td>
<td>5983</td>
<td>4.6</td>
<td>9206</td>
</tr>
<tr>
<th rowspan="3" valign="top">H100x1</th>
<th>Qwen/Qwen2.5-VL-7B-Instruct</th>
<td></td>
<td>0.9</td>
<td>969</td>
<td>3.1</td>
<td>3358</td>
<td>3.3</td>
<td>3615</td>
</tr>
<tr>
<th>neuralmagic/Qwen2.5-VL-7B-Instruct-FP8-Dynamic</th>
<td>1.29</td>
<td>1.2</td>
<td>1331</td>
<td>3.8</td>
<td>4109</td>
<td>4.2</td>
<td>4598</td>
</tr>
<tr>
<th>neuralmagic/Qwen2.5-VL-7B-Instruct-quantized.w4a16</th>
<td>1.28</td>
<td>1.2</td>
<td>1298</td>
<td>3.8</td>
<td>4190</td>
<td>4.2</td>
<td>4573</td>
</tr>
</tbody>
</table>
**Use case profiles: Image Size (WxH) / prompt tokens / generation tokens
**QPS: Queries per second.
**QPD: Queries per dollar, based on on-demand cost at [Lambda Labs](https://lambdalabs.com/service/gpu-cloud) (observed on 2/18/2025).
|
genki10/BERT_AugV8_k1_task1_organization_sp020_lw040_fold2
|
genki10
| 2025-04-03T15:40:57Z
| 5
| 0
|
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-03-25T02:00:41Z
|
---
library_name: transformers
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: BERT_AugV8_k1_task1_organization_sp020_lw040_fold2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BERT_AugV8_k1_task1_organization_sp020_lw040_fold2
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4056
- Qwk: 0.3327
- Mse: 1.4060
- Rmse: 1.1858
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 150
### Training results
| Training Loss | Epoch | Step | Validation Loss | Qwk | Mse | Rmse |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:------:|
| No log | 1.0 | 2 | 13.6505 | 0.0 | 13.6508 | 3.6947 |
| No log | 2.0 | 4 | 11.0720 | 0.0140 | 11.0723 | 3.3275 |
| No log | 3.0 | 6 | 9.9555 | 0.0 | 9.9557 | 3.1553 |
| No log | 4.0 | 8 | 9.6355 | 0.0 | 9.6357 | 3.1041 |
| No log | 5.0 | 10 | 8.8621 | 0.0 | 8.8623 | 2.9770 |
| No log | 6.0 | 12 | 7.7351 | 0.0 | 7.7354 | 2.7813 |
| No log | 7.0 | 14 | 6.2078 | 0.0253 | 6.2084 | 2.4917 |
| No log | 8.0 | 16 | 4.9570 | 0.0031 | 4.9576 | 2.2266 |
| No log | 9.0 | 18 | 3.9767 | 0.0039 | 3.9772 | 1.9943 |
| No log | 10.0 | 20 | 2.9818 | 0.0039 | 2.9827 | 1.7270 |
| No log | 11.0 | 22 | 2.4109 | 0.0971 | 2.4117 | 1.5530 |
| No log | 12.0 | 24 | 1.8086 | 0.1507 | 1.8090 | 1.3450 |
| No log | 13.0 | 26 | 1.5134 | 0.0230 | 1.5141 | 1.2305 |
| No log | 14.0 | 28 | 1.1320 | 0.0202 | 1.1326 | 1.0642 |
| No log | 15.0 | 30 | 0.8950 | 0.1970 | 0.8952 | 0.9462 |
| No log | 16.0 | 32 | 0.8088 | 0.3432 | 0.8091 | 0.8995 |
| No log | 17.0 | 34 | 0.6804 | 0.4754 | 0.6803 | 0.8248 |
| No log | 18.0 | 36 | 0.7718 | 0.3224 | 0.7721 | 0.8787 |
| No log | 19.0 | 38 | 1.1285 | -0.1807 | 1.1292 | 1.0626 |
| No log | 20.0 | 40 | 1.1496 | -0.2149 | 1.1503 | 1.0725 |
| No log | 21.0 | 42 | 0.6585 | 0.3736 | 0.6586 | 0.8115 |
| No log | 22.0 | 44 | 0.7732 | 0.4870 | 0.7730 | 0.8792 |
| No log | 23.0 | 46 | 1.5669 | 0.2085 | 1.5668 | 1.2517 |
| No log | 24.0 | 48 | 2.2677 | 0.1860 | 2.2677 | 1.5059 |
| No log | 25.0 | 50 | 2.6500 | 0.1477 | 2.6502 | 1.6279 |
| No log | 26.0 | 52 | 2.2970 | 0.2035 | 2.2972 | 1.5156 |
| No log | 27.0 | 54 | 1.0711 | 0.2663 | 1.0712 | 1.0350 |
| No log | 28.0 | 56 | 0.5916 | 0.4339 | 0.5915 | 0.7691 |
| No log | 29.0 | 58 | 1.0181 | -0.1638 | 1.0187 | 1.0093 |
| No log | 30.0 | 60 | 1.1541 | -0.2041 | 1.1549 | 1.0747 |
| No log | 31.0 | 62 | 0.9558 | 0.1588 | 0.9565 | 0.9780 |
| No log | 32.0 | 64 | 0.7880 | 0.2418 | 0.7882 | 0.8878 |
| No log | 33.0 | 66 | 0.5857 | 0.4685 | 0.5856 | 0.7653 |
| No log | 34.0 | 68 | 0.8252 | 0.4081 | 0.8256 | 0.9086 |
| No log | 35.0 | 70 | 1.3541 | 0.2638 | 1.3546 | 1.1639 |
| No log | 36.0 | 72 | 1.5864 | 0.2706 | 1.5869 | 1.2597 |
| No log | 37.0 | 74 | 1.4056 | 0.3327 | 1.4060 | 1.1858 |
### Framework versions
- Transformers 4.47.0
- Pytorch 2.5.1+cu121
- Datasets 3.3.1
- Tokenizers 0.21.0
|
caterinaoit/medem_style_LoRA
|
caterinaoit
| 2025-04-03T15:40:29Z
| 0
| 0
|
diffusers
|
[
"diffusers",
"tensorboard",
"text-to-image",
"diffusers-training",
"lora",
"template:sd-lora",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] |
text-to-image
| 2025-04-03T15:40:23Z
|
---
base_model: stabilityai/stable-diffusion-xl-base-1.0
library_name: diffusers
license: openrail++
instance_prompt: illustration in MEDEM style
widget: []
tags:
- text-to-image
- text-to-image
- diffusers-training
- diffusers
- lora
- template:sd-lora
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# SDXL LoRA DreamBooth - caterinaoit/medem_style_LoRA
<Gallery />
## Model description
These are caterinaoit/medem_style_LoRA LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using [DreamBooth](https://dreambooth.github.io/).
LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Trigger words
You should use illustration in MEDEM style to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](caterinaoit/medem_style_LoRA/tree/main) them in the Files & versions tab.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model]
|
neuralmagic/Qwen2.5-VL-3B-Instruct-quantized.w4a16
|
neuralmagic
| 2025-04-03T15:39:00Z
| 211
| 0
|
transformers
|
[
"transformers",
"safetensors",
"qwen2_5_vl",
"image-text-to-text",
"vllm",
"vision",
"w4a16",
"conversational",
"en",
"base_model:Qwen/Qwen2.5-VL-3B-Instruct",
"base_model:quantized:Qwen/Qwen2.5-VL-3B-Instruct",
"license:apache-2.0",
"text-generation-inference",
"endpoints_compatible",
"compressed-tensors",
"region:us"
] |
image-text-to-text
| 2025-02-07T17:01:48Z
|
---
tags:
- vllm
- vision
- w4a16
license: apache-2.0
license_link: >-
https://huggingface.co/datasets/choosealicense/licenses/blob/main/markdown/apache-2.0.md
language:
- en
base_model: Qwen/Qwen2.5-VL-3B-Instruct
library_name: transformers
---
# Qwen2.5-VL-3B-Instruct-quantized-w4a16
## Model Overview
- **Model Architecture:** Qwen/Qwen2.5-VL-3B-Instruct
- **Input:** Vision-Text
- **Output:** Text
- **Model Optimizations:**
- **Weight quantization:** INT4
- **Activation quantization:** FP16
- **Release Date:** 2/24/2025
- **Version:** 1.0
- **Model Developers:** Neural Magic
Quantized version of [Qwen/Qwen2.5-VL-3B-Instruct](https://huggingface.co/Qwen/Qwen2.5-VL-3B-Instruct).
### Model Optimizations
This model was obtained by quantizing the weights of [Qwen/Qwen2.5-VL-3B-Instruct](https://huggingface.co/Qwen/Qwen2.5-VL-3B-Instruct) to INT8 data type, ready for inference with vLLM >= 0.5.2.
## Deployment
### Use with vLLM
This model can be deployed efficiently using the [vLLM](https://docs.vllm.ai/en/latest/) backend, as shown in the example below.
```python
from vllm.assets.image import ImageAsset
from vllm import LLM, SamplingParams
# prepare model
llm = LLM(
model="neuralmagic/Qwen2.5-VL-3B-Instruct-quantized.w4a16",
trust_remote_code=True,
max_model_len=4096,
max_num_seqs=2,
)
# prepare inputs
question = "What is the content of this image?"
inputs = {
"prompt": f"<|user|>\n<|image_1|>\n{question}<|end|>\n<|assistant|>\n",
"multi_modal_data": {
"image": ImageAsset("cherry_blossom").pil_image.convert("RGB")
},
}
# generate response
print("========== SAMPLE GENERATION ==============")
outputs = llm.generate(inputs, SamplingParams(temperature=0.2, max_tokens=64))
print(f"PROMPT : {outputs[0].prompt}")
print(f"RESPONSE: {outputs[0].outputs[0].text}")
print("==========================================")
```
vLLM also supports OpenAI-compatible serving. See the [documentation](https://docs.vllm.ai/en/latest/) for more details.
## Creation
This model was created with [llm-compressor](https://github.com/vllm-project/llm-compressor) by running the code snippet below as part a multimodal announcement blog.
<details>
<summary>Model Creation Code</summary>
```python
import base64
from io import BytesIO
import torch
from datasets import load_dataset
from qwen_vl_utils import process_vision_info
from transformers import AutoProcessor
from llmcompressor.modifiers.quantization import GPTQModifier
from llmcompressor.transformers import oneshot
from llmcompressor.transformers.tracing import (
TraceableQwen2_5_VLForConditionalGeneration,
)
from compressed_tensors.quantization import QuantizationArgs, QuantizationType, QuantizationStrategy, ActivationOrdering, QuantizationScheme
# Load model.
model_id = "Qwen/Qwen2.5-VL-3B-Instruct"
model = TraceableQwen2_5_VLForConditionalGeneration.from_pretrained(
model_id,
device_map="auto",
torch_dtype="auto",
)
processor = AutoProcessor.from_pretrained(model_id, trust_remote_code=True)
# Oneshot arguments
DATASET_ID = "lmms-lab/flickr30k"
DATASET_SPLIT = {"calibration": "test[:512]"}
NUM_CALIBRATION_SAMPLES = 512
MAX_SEQUENCE_LENGTH = 2048
# Load dataset and preprocess.
ds = load_dataset(DATASET_ID, split=DATASET_SPLIT)
ds = ds.shuffle(seed=42)
dampening_frac=0.01
# Apply chat template and tokenize inputs.
def preprocess_and_tokenize(example):
# preprocess
buffered = BytesIO()
example["image"].save(buffered, format="PNG")
encoded_image = base64.b64encode(buffered.getvalue())
encoded_image_text = encoded_image.decode("utf-8")
base64_qwen = f"data:image;base64,{encoded_image_text}"
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": base64_qwen},
{"type": "text", "text": "What does the image show?"},
],
}
]
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
# tokenize
return processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=False,
max_length=MAX_SEQUENCE_LENGTH,
truncation=True,
)
ds = ds.map(preprocess_and_tokenize, remove_columns=ds["calibration"].column_names)
# Define a oneshot data collator for multimodal inputs.
def data_collator(batch):
assert len(batch) == 1
return {key: torch.tensor(value) for key, value in batch[0].items()}
recipe = GPTQModifier(
targets="Linear",
config_groups={
"config_group": QuantizationScheme(
targets=["Linear"],
weights=QuantizationArgs(
num_bits=4,
type=QuantizationType.INT,
strategy=QuantizationStrategy.GROUP,
group_size=128,
symmetric=True,
dynamic=False,
actorder=ActivationOrdering.WEIGHT,
),
),
},
sequential_targets=["Qwen2_5_VLDecoderLayer"],
ignore=["lm_head", "re:visual.*"],
update_size=NUM_CALIBRATION_SAMPLES,
dampening_frac=dampening_frac
)
SAVE_DIR=f"{model_id.split('/')[1]}-quantized.w4a16"
# Perform oneshot
oneshot(
model=model,
tokenizer=model_id,
dataset=ds,
recipe=recipe,
max_seq_length=MAX_SEQUENCE_LENGTH,
num_calibration_samples=NUM_CALIBRATION_SAMPLES,
trust_remote_code_model=True,
data_collator=data_collator,
output_dir=SAVE_DIR
)
```
</details>
## Evaluation
The model was evaluated using [mistral-evals](https://github.com/neuralmagic/mistral-evals) for vision-related tasks and using [lm_evaluation_harness](https://github.com/neuralmagic/lm-evaluation-harness) for select text-based benchmarks. The evaluations were conducted using the following commands:
<details>
<summary>Evaluation Commands</summary>
### Vision Tasks
- vqav2
- docvqa
- mathvista
- mmmu
- chartqa
```
vllm serve neuralmagic/pixtral-12b-quantized.w8a8 --tensor_parallel_size 1 --max_model_len 25000 --trust_remote_code --max_num_seqs 8 --gpu_memory_utilization 0.9 --dtype float16 --limit_mm_per_prompt image=7
python -m eval.run eval_vllm \
--model_name neuralmagic/pixtral-12b-quantized.w8a8 \
--url http://0.0.0.0:8000 \
--output_dir ~/tmp \
--eval_name <vision_task_name>
```
### Text-based Tasks
#### MMLU
```
lm_eval \
--model vllm \
--model_args pretrained="<model_name>",dtype=auto,add_bos_token=True,max_model_len=4096,tensor_parallel_size=<n>,gpu_memory_utilization=0.8,enable_chunked_prefill=True,trust_remote_code=True \
--tasks mmlu \
--num_fewshot 5 \
--batch_size auto \
--output_path output_dir
```
#### MGSM
```
lm_eval \
--model vllm \
--model_args pretrained="<model_name>",dtype=auto,max_model_len=4096,max_gen_toks=2048,max_num_seqs=128,tensor_parallel_size=<n>,gpu_memory_utilization=0.9 \
--tasks mgsm_cot_native \
--apply_chat_template \
--num_fewshot 0 \
--batch_size auto \
--output_path output_dir
```
</details>
### Accuracy
<table>
<thead>
<tr>
<th>Category</th>
<th>Metric</th>
<th>Qwen/Qwen2.5-VL-3B-Instruct</th>
<th>Qwen2.5-VL-3B-Instruct-quantized.W4A16</th>
<th>Recovery (%)</th>
</tr>
</thead>
<tbody>
<tr>
<td rowspan="6"><b>Vision</b></td>
<td>MMMU (val, CoT)<br><i>explicit_prompt_relaxed_correctness</i></td>
<td>44.56</td>
<td>41.56</td>
<td>93.28%</td>
</tr>
<tr>
<td>VQAv2 (val)<br><i>vqa_match</i></td>
<td>75.94</td>
<td>73.58</td>
<td>96.89</td>
</tr>
<tr>
<td>DocVQA (val)<br><i>anls</i></td>
<td>92.53</td>
<td>91.58</td>
<td>98.97%</td>
</tr>
<tr>
<td>ChartQA (test, CoT)<br><i>anywhere_in_answer_relaxed_correctness</i></td>
<td>81.20</td>
<td>78.96</td>
<td>97.24%</td>
</tr>
<tr>
<td>Mathvista (testmini, CoT)<br><i>explicit_prompt_relaxed_correctness</i></td>
<td>54.15</td>
<td>45.75</td>
<td>84.51%</td>
</tr>
<tr>
<td><b>Average Score</b></td>
<td><b>69.28</b></td>
<td><b>66.29</b></td>
<td><b>95.68%</b></td>
</tr>
<tr>
<td rowspan="2"><b>Text</b></td>
<td>MGSM (CoT)</td>
<td>43.69</td>
<td>35.82</td>
<td>82.00</td>
</tr>
<tr>
<td>MMLU (5-shot)</td>
<td>65.32</td>
<td>62.80</td>
<td>96.14%</td>
</tr>
</tbody>
</table>
## Inference Performance
This model achieves up to 1.73x speedup in single-stream deployment and up to 3.87x speedup in multi-stream asynchronous deployment, depending on hardware and use-case scenario.
The following performance benchmarks were conducted with [vLLM](https://docs.vllm.ai/en/latest/) version 0.7.2, and [GuideLLM](https://github.com/neuralmagic/guidellm).
<details>
<summary>Benchmarking Command</summary>
```
guidellm --model neuralmagic/Qwen2.5-VL-3B-Instruct-quantized.w4a16 --target "http://localhost:8000/v1" --data-type emulated --data prompt_tokens=<prompt_tokens>,generated_tokens=<generated_tokens>,images=<num_images>,width=<image_width>,height=<image_height> --max seconds 120 --backend aiohttp_server
```
</details>
### Single-stream performance (measured with vLLM version 0.7.2)
<table border="1" class="dataframe">
<thead>
<tr>
<th></th>
<th></th>
<th></th>
<th style="text-align: center;" colspan="2" >Document Visual Question Answering<br>1680W x 2240H<br>64/128</th>
<th style="text-align: center;" colspan="2" >Visual Reasoning <br>640W x 480H<br>128/128</th>
<th style="text-align: center;" colspan="2" >Image Captioning<br>480W x 360H<br>0/128</th>
</tr>
<tr>
<th>Hardware</th>
<th>Model</th>
<th>Average Cost Reduction</th>
<th>Latency (s)</th>
<th>Queries Per Dollar</th>
<th>Latency (s)th>
<th>Queries Per Dollar</th>
<th>Latency (s)</th>
<th>Queries Per Dollar</th>
</tr>
</thead>
<tbody style="text-align: center">
<tr>
<th rowspan="3" valign="top">A6000x1</th>
<th>Qwen/Qwen2.5-VL-3B-Instruct</th>
<td></td>
<td>3.1</td>
<td>1454</td>
<td>1.8</td>
<td>2546</td>
<td>1.7</td>
<td>2610</td>
</tr>
<tr>
<th>neuralmagic/Qwen2.5-VL-3B-Instruct-quantized.w8a8</th>
<td>1.27</td>
<td>2.6</td>
<td>1708</td>
<td>1.3</td>
<td>3340</td>
<td>1.3</td>
<td>3459</td>
</tr>
<tr>
<th>neuralmagic/Qwen2.5-VL-3B-Instruct-quantized.w4a16</th>
<td>1.57</td>
<td>2.4</td>
<td>1886</td>
<td>1.0</td>
<td>4409</td>
<td>1.0</td>
<td>4409</td>
</tr>
<tr>
<th rowspan="3" valign="top">A100x1</th>
<th>Qwen/Qwen2.5-VL-3B-Instruct</th>
<td></td>
<td>2.2</td>
<td>920</td>
<td>1.3</td>
<td>1603</td>
<td>1.2</td>
<td>1636</td>
</tr>
<tr>
<th>neuralmagic/Qwen2.5-VL-3B-Instruct-quantized.w8a8</th>
<td>1.09</td>
<td>2.1</td>
<td>975</td>
<td>1.2</td>
<td>1743</td>
<td>1.1</td>
<td>1814</td>
</tr>
<tr>
<th>neuralmagic/Qwen2.5-VL-3B-Instruct-quantized.w4a16</th>
<td>1.20</td>
<td>2.0</td>
<td>1011</td>
<td>1.0</td>
<td>2015</td>
<td>1.0</td>
<td>2012</td>
</tr>
<tr>
<th rowspan="3" valign="top">H100x1</th>
<th>Qwen/Qwen2.5-VL-3B-Instruct</th>
<td></td>
<td>1.5</td>
<td>740</td>
<td>0.9</td>
<td>1221</td>
<td>0.9</td>
<td>1276</td>
</tr>
<tr>
<th>neuralmagic/Qwen2.5-VL-3B-Instruct-FP8-Dynamic</th>
<td>1.06</td>
<td>1.4</td>
<td>768</td>
<td>0.9</td>
<td>1276</td>
<td>0.8</td>
<td>1399</td>
</tr>
<tr>
<th>neuralmagic/Qwen2.5-VL-3B-Instruct-quantized.w4a16</th>
<td>1.24</td>
<td>0.9</td>
<td>1219</td>
<td>0.9</td>
<td>1270</td>
<td>0.8</td>
<td>1304</td>
</tr>
</tbody>
</table>
**Use case profiles: Image Size (WxH) / prompt tokens / generation tokens
**QPD: Queries per dollar, based on on-demand cost at [Lambda Labs](https://lambdalabs.com/service/gpu-cloud) (observed on 2/18/2025).
### Multi-stream asynchronous performance (measured with vLLM version 0.7.2)
<table border="1" class="dataframe">
<thead>
<tr>
<th></th>
<th></th>
<th></th>
<th style="text-align: center;" colspan="2" >Document Visual Question Answering<br>1680W x 2240H<br>64/128</th>
<th style="text-align: center;" colspan="2" >Visual Reasoning <br>640W x 480H<br>128/128</th>
<th style="text-align: center;" colspan="2" >Image Captioning<br>480W x 360H<br>0/128</th>
</tr>
<tr>
<th>Hardware</th>
<th>Model</th>
<th>Average Cost Reduction</th>
<th>Maximum throughput (QPS)</th>
<th>Queries Per Dollar</th>
<th>Maximum throughput (QPS)</th>
<th>Queries Per Dollar</th>
<th>Maximum throughput (QPS)</th>
<th>Queries Per Dollar</th>
</tr>
</thead>
<tbody style="text-align: center">
<tr>
<th rowspan="3" valign="top">A6000x1</th>
<th>Qwen/Qwen2.5-VL-3B-Instruct</th>
<td></td>
<td>0.5</td>
<td>2405</td>
<td>2.6</td>
<td>11889</td>
<td>2.9</td>
<td>12909</td>
</tr>
<tr>
<th>neuralmagic/Qwen2.5-VL-3B-Instruct-quantized.w8a8</th>
<td>1.26</td>
<td>0.6</td>
<td>2725</td>
<td>3.4</td>
<td>15162</td>
<td>3.9</td>
<td>17673</td>
</tr>
<tr>
<th>neuralmagic/Qwen2.5-VL-3B-Instruct-quantized.w4a16</th>
<td>1.39</td>
<td>0.6</td>
<td>2548</td>
<td>3.9</td>
<td>17437</td>
<td>4.7</td>
<td>21223</td>
</tr>
<tr>
<th rowspan="3" valign="top">A100x1</th>
<th>Qwen/Qwen2.5-VL-3B-Instruct</th>
<td></td>
<td>0.8</td>
<td>1663</td>
<td>3.9</td>
<td>7899</td>
<td>4.4</td>
<td>8924</td>
</tr>
<tr>
<th>neuralmagic/Qwen2.5-VL-3B-Instruct-quantized.w8a8</th>
<td>1.06</td>
<td>0.9</td>
<td>1734</td>
<td>4.2</td>
<td>8488</td>
<td>4.7</td>
<td>9548</td>
</tr>
<tr>
<th>neuralmagic/Qwen2.5-VL-3B-Instruct-quantized.w4a16</th>
<td>1.10</td>
<td>0.9</td>
<td>1775</td>
<td>4.2</td>
<td>8540</td>
<td>5.1</td>
<td>10318</td>
</tr>
<tr>
<th rowspan="3" valign="top">H100x1</th>
<th>Qwen/Qwen2.5-VL-3B-Instruct</th>
<td></td>
<td>1.1</td>
<td>1188</td>
<td>4.3</td>
<td>4656</td>
<td>4.3</td>
<td>4676</td>
</tr>
<tr>
<th>neuralmagic/Qwen2.5-VL-3B-Instruct-FP8-Dynamic</th>
<td>1.15</td>
<td>1.4</td>
<td>1570</td>
<td>4.3</td>
<td>4676</td>
<td>4.8</td>
<td>5220</td>
</tr>
<tr>
<th>neuralmagic/Qwen2.5-VL-3B-Instruct-quantized.w4a16</th>
<td>1.96</td>
<td>4.2</td>
<td>4598</td>
<td>4.1</td>
<td>4505</td>
<td>4.4</td>
<td>4838</td>
</tr>
</tbody>
</table>
**Use case profiles: Image Size (WxH) / prompt tokens / generation tokens
**QPS: Queries per second.
**QPD: Queries per dollar, based on on-demand cost at [Lambda Labs](https://lambdalabs.com/service/gpu-cloud) (observed on 2/18/2025).
|
xw17/Qwen2.5-1.5B-Instruct_finetuned_4_def_lora3
|
xw17
| 2025-04-03T15:37:45Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-04-03T15:37:34Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
nevkronk/lk
|
nevkronk
| 2025-04-03T15:37:34Z
| 0
| 1
| null |
[
"license:bigcode-openrail-m",
"region:us"
] | null | 2025-04-03T15:37:34Z
|
---
license: bigcode-openrail-m
---
|
seifetho/Llama-3.1-8B-bnb-4bit-med
|
seifetho
| 2025-04-03T15:36:58Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-04-03T15:36:50Z
|
---
base_model: unsloth/meta-llama-3.1-8b-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** seifetho
- **License:** apache-2.0
- **Finetuned from model :** unsloth/meta-llama-3.1-8b-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Thibaut/route_background_semantic
|
Thibaut
| 2025-04-03T15:35:49Z
| 0
| 0
|
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"segformer",
"image-segmentation",
"vision",
"generated_from_trainer",
"base_model:nvidia/segformer-b3-finetuned-cityscapes-1024-1024",
"base_model:finetune:nvidia/segformer-b3-finetuned-cityscapes-1024-1024",
"license:other",
"endpoints_compatible",
"region:us"
] |
image-segmentation
| 2025-04-03T10:31:39Z
|
---
library_name: transformers
license: other
base_model: nvidia/segformer-b3-finetuned-cityscapes-1024-1024
tags:
- image-segmentation
- vision
- generated_from_trainer
model-index:
- name: route_background_semantic
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# route_background_semantic
This model is a fine-tuned version of [nvidia/segformer-b3-finetuned-cityscapes-1024-1024](https://huggingface.co/nvidia/segformer-b3-finetuned-cityscapes-1024-1024) on the Logiroad/route_background_semantic dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2360
- Mean Iou: 0.1916
- Mean Accuracy: 0.2447
- Overall Accuracy: 0.2962
- Accuracy Unlabeled: nan
- Accuracy Découpe: 0.2865
- Accuracy Reflet météo: 0.0
- Accuracy Autre réparation: 0.3437
- Accuracy Glaçage ou ressuage: 0.0386
- Accuracy Emergence: 0.5549
- Iou Unlabeled: 0.0
- Iou Découpe: 0.2515
- Iou Reflet météo: 0.0
- Iou Autre réparation: 0.3230
- Iou Glaçage ou ressuage: 0.0369
- Iou Emergence: 0.5379
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 6e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 1337
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: polynomial
- training_steps: 10000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Mean Iou | Mean Accuracy | Overall Accuracy | Accuracy Unlabeled | Accuracy Découpe | Accuracy Reflet météo | Accuracy Autre réparation | Accuracy Glaçage ou ressuage | Accuracy Emergence | Iou Unlabeled | Iou Découpe | Iou Reflet météo | Iou Autre réparation | Iou Glaçage ou ressuage | Iou Emergence |
|:-------------:|:------:|:-----:|:---------------:|:--------:|:-------------:|:----------------:|:------------------:|:----------------:|:---------------------:|:-------------------------:|:----------------------------:|:------------------:|:-------------:|:-----------:|:----------------:|:--------------------:|:-----------------------:|:-------------:|
| 0.2715 | 1.0 | 2427 | 0.2682 | 0.0521 | 0.0669 | 0.1828 | nan | 0.0813 | 0.0 | 0.2533 | 0.0 | 0.0 | 0.0 | 0.0766 | 0.0 | 0.2362 | 0.0 | 0.0 |
| 0.2815 | 2.0 | 4854 | 0.2682 | 0.1165 | 0.1436 | 0.1593 | nan | 0.1108 | 0.0 | 0.1982 | 0.0 | 0.4090 | 0.0 | 0.1014 | 0.0 | 0.1916 | 0.0 | 0.4057 |
| 0.2638 | 3.0 | 7281 | 0.2420 | 0.1664 | 0.2100 | 0.2564 | nan | 0.2346 | 0.0 | 0.3039 | 0.0030 | 0.5085 | 0.0 | 0.2128 | 0.0 | 0.2854 | 0.0030 | 0.4973 |
| 0.2703 | 4.0 | 9708 | 0.2333 | 0.1941 | 0.2475 | 0.3074 | nan | 0.2843 | 0.0 | 0.3612 | 0.0446 | 0.5473 | 0.0 | 0.2512 | 0.0 | 0.3383 | 0.0429 | 0.5320 |
| 0.2197 | 4.1203 | 10000 | 0.2360 | 0.1916 | 0.2447 | 0.2962 | nan | 0.2865 | 0.0 | 0.3437 | 0.0386 | 0.5549 | 0.0 | 0.2515 | 0.0 | 0.3230 | 0.0369 | 0.5379 |
### Framework versions
- Transformers 4.46.1
- Pytorch 2.3.0
- Datasets 3.1.0
- Tokenizers 0.20.3
|
henchen99/Llama-3-3B-Instruct-SFT-Open-R1-GRPO-Skyt1-17k-Context4K
|
henchen99
| 2025-04-03T15:33:59Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"generated_from_trainer",
"open-r1",
"trl",
"grpo",
"conversational",
"arxiv:2402.03300",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-03-30T21:39:58Z
|
---
library_name: transformers
model_name: Llama-3-3B-Instruct-SFT-Open-R1-GRPO-Skyt1-17k-Context4K
tags:
- generated_from_trainer
- open-r1
- trl
- grpo
licence: license
---
# Model Card for Llama-3-3B-Instruct-SFT-Open-R1-GRPO-Skyt1-17k-Context4K
This model is a fine-tuned version of [None](https://huggingface.co/None).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="henchen99/Llama-3-3B-Instruct-SFT-Open-R1-GRPO-Skyt1-17k-Context4K", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/flsyn/huggingface/runs/ks8y2y29)
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.15.2
- Transformers: 4.49.0
- Pytorch: 2.5.1
- Datasets: 3.3.2
- Tokenizers: 0.21.0
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
genki10/BERT_AugV8_k1_task1_organization_sp020_lw040_fold1
|
genki10
| 2025-04-03T15:32:45Z
| 5
| 0
|
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-03-25T01:48:41Z
|
---
library_name: transformers
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: BERT_AugV8_k1_task1_organization_sp020_lw040_fold1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BERT_AugV8_k1_task1_organization_sp020_lw040_fold1
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7924
- Qwk: 0.4361
- Mse: 0.7915
- Rmse: 0.8897
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 150
### Training results
| Training Loss | Epoch | Step | Validation Loss | Qwk | Mse | Rmse |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:------:|
| No log | 1.0 | 2 | 11.0248 | -0.0155 | 11.0221 | 3.3200 |
| No log | 2.0 | 4 | 10.2994 | 0.0 | 10.2968 | 3.2089 |
| No log | 3.0 | 6 | 9.1109 | 0.0 | 9.1082 | 3.0180 |
| No log | 4.0 | 8 | 7.7717 | 0.0 | 7.7692 | 2.7873 |
| No log | 5.0 | 10 | 6.6023 | 0.0 | 6.6000 | 2.5690 |
| No log | 6.0 | 12 | 5.7522 | 0.0138 | 5.7501 | 2.3979 |
| No log | 7.0 | 14 | 4.7330 | 0.0079 | 4.7310 | 2.1751 |
| No log | 8.0 | 16 | 3.7363 | 0.0079 | 3.7343 | 1.9324 |
| No log | 9.0 | 18 | 2.9863 | 0.0 | 2.9845 | 1.7276 |
| No log | 10.0 | 20 | 2.1994 | 0.0951 | 2.1977 | 1.4825 |
| No log | 11.0 | 22 | 1.9394 | 0.0609 | 1.9378 | 1.3921 |
| No log | 12.0 | 24 | 1.7195 | 0.0467 | 1.7179 | 1.3107 |
| No log | 13.0 | 26 | 1.3837 | 0.0172 | 1.3822 | 1.1757 |
| No log | 14.0 | 28 | 1.1512 | 0.0106 | 1.1497 | 1.0722 |
| No log | 15.0 | 30 | 1.0493 | 0.0106 | 1.0479 | 1.0237 |
| No log | 16.0 | 32 | 1.0749 | 0.0276 | 1.0735 | 1.0361 |
| No log | 17.0 | 34 | 0.8346 | 0.2971 | 0.8334 | 0.9129 |
| No log | 18.0 | 36 | 0.8112 | 0.2560 | 0.8101 | 0.9000 |
| No log | 19.0 | 38 | 0.8250 | 0.3270 | 0.8238 | 0.9076 |
| No log | 20.0 | 40 | 1.1868 | 0.0648 | 1.1854 | 1.0888 |
| No log | 21.0 | 42 | 1.0708 | 0.1164 | 1.0695 | 1.0342 |
| No log | 22.0 | 44 | 0.7363 | 0.4124 | 0.7352 | 0.8574 |
| No log | 23.0 | 46 | 0.9488 | 0.2400 | 0.9475 | 0.9734 |
| No log | 24.0 | 48 | 0.8473 | 0.3105 | 0.8461 | 0.9198 |
| No log | 25.0 | 50 | 0.8444 | 0.2509 | 0.8433 | 0.9183 |
| No log | 26.0 | 52 | 0.9111 | 0.2129 | 0.9097 | 0.9538 |
| No log | 27.0 | 54 | 1.3343 | 0.0956 | 1.3324 | 1.1543 |
| No log | 28.0 | 56 | 0.9670 | 0.2045 | 0.9656 | 0.9827 |
| No log | 29.0 | 58 | 0.7093 | 0.3620 | 0.7086 | 0.8418 |
| No log | 30.0 | 60 | 0.5954 | 0.4182 | 0.5947 | 0.7712 |
| No log | 31.0 | 62 | 0.7717 | 0.3740 | 0.7707 | 0.8779 |
| No log | 32.0 | 64 | 1.0577 | 0.2111 | 1.0565 | 1.0279 |
| No log | 33.0 | 66 | 0.9975 | 0.2537 | 0.9962 | 0.9981 |
| No log | 34.0 | 68 | 0.6524 | 0.4136 | 0.6515 | 0.8072 |
| No log | 35.0 | 70 | 0.7383 | 0.4339 | 0.7377 | 0.8589 |
| No log | 36.0 | 72 | 0.8698 | 0.4211 | 0.8681 | 0.9317 |
| No log | 37.0 | 74 | 1.6528 | 0.2336 | 1.6504 | 1.2847 |
| No log | 38.0 | 76 | 1.2816 | 0.3327 | 1.2794 | 1.1311 |
| No log | 39.0 | 78 | 0.7498 | 0.4768 | 0.7488 | 0.8654 |
| No log | 40.0 | 80 | 0.7064 | 0.4931 | 0.7056 | 0.8400 |
| No log | 41.0 | 82 | 0.8086 | 0.4710 | 0.8075 | 0.8986 |
| No log | 42.0 | 84 | 0.7279 | 0.4950 | 0.7269 | 0.8526 |
| No log | 43.0 | 86 | 0.6044 | 0.4557 | 0.6038 | 0.7771 |
| No log | 44.0 | 88 | 0.6617 | 0.4725 | 0.6609 | 0.8129 |
| No log | 45.0 | 90 | 0.8288 | 0.4274 | 0.8278 | 0.9098 |
| No log | 46.0 | 92 | 0.6530 | 0.5130 | 0.6524 | 0.8077 |
| No log | 47.0 | 94 | 0.6455 | 0.5306 | 0.6452 | 0.8032 |
| No log | 48.0 | 96 | 0.6694 | 0.5513 | 0.6689 | 0.8178 |
| No log | 49.0 | 98 | 1.0866 | 0.3767 | 1.0855 | 1.0419 |
| No log | 50.0 | 100 | 1.2525 | 0.3398 | 1.2512 | 1.1186 |
| No log | 51.0 | 102 | 0.7771 | 0.5284 | 0.7764 | 0.8811 |
| No log | 52.0 | 104 | 0.7193 | 0.5313 | 0.7189 | 0.8479 |
| No log | 53.0 | 106 | 0.7551 | 0.4766 | 0.7542 | 0.8685 |
| No log | 54.0 | 108 | 0.8105 | 0.4448 | 0.8094 | 0.8997 |
| No log | 55.0 | 110 | 0.6653 | 0.4898 | 0.6645 | 0.8152 |
| No log | 56.0 | 112 | 0.6900 | 0.4550 | 0.6890 | 0.8301 |
| No log | 57.0 | 114 | 0.8173 | 0.4195 | 0.8161 | 0.9034 |
| No log | 58.0 | 116 | 0.7389 | 0.4420 | 0.7379 | 0.8590 |
| No log | 59.0 | 118 | 0.6537 | 0.4841 | 0.6531 | 0.8082 |
| No log | 60.0 | 120 | 0.6732 | 0.5036 | 0.6725 | 0.8200 |
| No log | 61.0 | 122 | 0.9558 | 0.3997 | 0.9545 | 0.9770 |
| No log | 62.0 | 124 | 0.9244 | 0.4014 | 0.9232 | 0.9608 |
| No log | 63.0 | 126 | 0.7924 | 0.4361 | 0.7915 | 0.8897 |
### Framework versions
- Transformers 4.47.0
- Pytorch 2.5.1+cu121
- Datasets 3.3.1
- Tokenizers 0.21.0
|
ciderstt/whisper-medium-chinese-4-3
|
ciderstt
| 2025-04-03T15:31:53Z
| 0
| 0
|
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"zh",
"dataset:mozilla-foundation/common_voice_17_0",
"base_model:openai/whisper-medium",
"base_model:finetune:openai/whisper-medium",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2025-04-03T08:26:48Z
|
---
library_name: transformers
language:
- zh
license: apache-2.0
base_model: openai/whisper-medium
tags:
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_17_0
metrics:
- wer
model-index:
- name: Whisper medium
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 17.0
type: mozilla-foundation/common_voice_17_0
config: nan-tw
split: None
args: 'config: chinese, split: test'
metrics:
- name: Wer
type: wer
value: 22.956861044873182
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper medium
This model is a fine-tuned version of [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) on the Common Voice 17.0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0174
- Wer: 22.9569
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:------:|:----:|:---------------:|:-------:|
| 0.3152 | 0.9560 | 1000 | 0.2308 | 69.7377 |
| 0.1698 | 1.9120 | 2000 | 0.0971 | 46.1088 |
| 0.0796 | 2.8681 | 3000 | 0.0399 | 28.8316 |
| 0.0278 | 3.8241 | 4000 | 0.0174 | 22.9569 |
### Framework versions
- Transformers 4.50.3
- Pytorch 2.6.0+cu124
- Datasets 3.5.0
- Tokenizers 0.21.1
|
CatkinChen/BAAI_bge-base-en-v1.5_retrieval_finetuned_2025-04-03_23-18-57
|
CatkinChen
| 2025-04-03T15:28:00Z
| 0
| 0
|
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"generated_from_trainer",
"dataset_size:464",
"loss:MultipleNegativesRankingLoss",
"arxiv:1908.10084",
"arxiv:1705.00652",
"base_model:BAAI/bge-base-en-v1.5",
"base_model:finetune:BAAI/bge-base-en-v1.5",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-04-03T15:26:50Z
|
---
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- generated_from_trainer
- dataset_size:464
- loss:MultipleNegativesRankingLoss
base_model: BAAI/bge-base-en-v1.5
widget:
- source_sentence: What creature does Lupin teach the students to repel in Defense
Against the Dark Arts?
sentences:
- '"And did the voice say who was there?" "No, it did not," she said. "Everything
went pitch-black and the next thing I knew, I was being hurled headfirst out of
the room!" "And you didn''t see that coming?" said Harry, unable to help himself.
"No, I did not, as I say, it was pitch -" She stopped and glared at him suspiciously.
"I think you''d better tell Professor Dumbledore," said Harry. "He ought to know
Malfoy''s celebrating - I mean, that someone threw you out of the room." To his
surprise, Professor Trelawney drew herself up at this suggestion, looking haughty.
"The headmaster has intimated that he would prefer fewer visits from me," she
said coldly. "I am not one to press my company upon those who do not value it.
If Dumbledore chooses to ignore the warnings the cards show -" Her bony hand closed
suddenly around Harry''s wrist. "Again and again, no matter how I lay them out
-" And she pulled a card dramatically from underneath her shawls. "- the lightning-struck
tower," she whispered. "Calamity. Disaster. Coming nearer all the time ..."
"Right," said Harry again. "Well ... I still think you should tell Dumbledore
about this voice, and everything going dark and being thrown out of the room.'
- '... Still, it''s not as though we haven''t got anything to look forward to, eh,
Barty? Eh? Plenty left to organize, eh?" Mr. Crouch raised his eyebrows at Bagman.
"We agreed not to make the announcement until all the details -"
"Oh details!" said Bagman, waving the word away like a cloud of midges. "They''ve
signed, haven''t they? They''ve agreed, haven''t they? I bet you anything these
kids''ll know soon enough anyway. I mean, it''s happening at Hogwarts -"
"Ludo, we need to meet the Bulgarians, you know," said Mr. Crouch sharply, cutting
Bagman''s remarks short. "Thank you for the tea, Weatherby." He pushed his undrunk
tea back at Percy and waited for Ludo to rise; Bagman struggled to his feet, swigging
down the last of his tea, the gold in his pockets chinking merrily.'
- '"What''s that supposed to be anyway?" asked Fred, squinting at Dobby''s painting.
"Looks like a gibbon with two black eyes." "It''s Harry!" said George, pointing
at the back of the picture. "Says so on the back!" "Good likeness," said Fred,
grinning. Harry threw his new homework diary at him; it hit the wall opposite
and fell to the floor where it said happily, "If you''ve dotted the i''s and crossed
the t''s then you may do whatever you please!" They got up and dressed; they could
hear various inhabitants of the house calling "Merry Christmas" to each other.
On their way downstairs they met Hermione.'
- '"Aaah, George, look at this. They''re using knives and everything. Bless them."
"I''ll be seventeen in two and a bit months'' time," said Ron grumpily, "and then
I''ll be able to do it by magic!" "But meanwhile," said George, sitting down at
the kitchen table and putting his feet up on it, "we can enjoy watching you demonstrate
the correct use of a - whoops-a-daisy!" "You made me do that!"'
- '"I hope the others are okay," said Hermione after a while. "They''ll be fine,"
said Ron. "Imagine if your dad catches Lucius Malfoy," said Harry, sitting down
next to Ron and watching the small figure of Krum slouching over the fallen leaves.
"He''s always said he''d like to get something on him." "That''d wipe the smirk
off old Draco''s face, all right," said Ron. "Those poor Muggles, though," said
Hermione nervously. "What if they can''t get them down?" "They will," said Ron
reassuringly. "They''ll find a way." "Mad, though, to do something like that when
the whole Ministry of Magic''s out here tonight!" said Hermione. "I mean, how
do they expect to get away with it? Do you think they''ve been drinking, or are
they just -"
But she broke off abruptly and looked over her shoulder. Harry and Ron looked
quickly around too. It sounded as though someone was staggering toward their clearing.'
- Professor Lupin had raised his eyebrows. "I was hoping that Neville would assist
me with the first stage of the operation," he said, "and I am sure he will perform
it admirably." Neville's face went, if possible, even redder. Snape's lip curled,
but he left, shutting the door with a snap. "Now, then," said Professor Lupin,
beckoning the class toward the end of the room, where there was nothing but an
old wardrobe where the teachers kept their spare robes. As Professor Lupin went
to stand next to it, the wardrobe gave a sudden wobble, banging off the wall.
"Nothing to worry about," said Professor Lupin calmly because a few people had
jumped backward in alarm. "There's a boggart in there." Most people seemed to
feel that this was something to worry about. Neville gave Professor Lupin a look
of pure terror, and Seamus Finnigan eyed the now rattling doorknob apprehensively.
"Boggarts like dark, enclosed spaces," said Professor Lupin. "Wardrobes, the gap
beneath beds, the cupboards under sinks - I've even met one that had lodged itself
in a grandfather clock. This one moved in yesterday afternoon, and I asked the
headmaster if the staff would leave it to give my third years some practice. "So,
the first question we must ask ourselves is, what is a boggart?" Hermione put
up her hand. "It's a shape-shifter," she said.
- source_sentence: Who does Harry meet in the forest in the fourth book, and how does
this encounter foreshadow an alliance in the seventh book?
sentences:
- '"Thought he''d be with you. Where''ve you left him?" "He''s dead," said Harry.
"Bellatrix Lestrange killed him." The barman''s face was impassive. After a few
moments he said,
"I''m sorry to hear it. I liked that elf." He turned away, lighting lamps with
prods of his wand, not looking at any of them. "You''re Aberforth," said Harry
to the man''s back. He neither confirmed nor denied it, but bent to light the
fire. "How did you get this?" Harry asked, walking across to Sirius''s mirror,
the twin of the one he had broken nearly two years before. "Bought it from Dung
''bout a year ago," said Aberforth. "Albus told me what it was. Been trying to
keep an eye out for you." Ron gasped. "The silver doe!" he said excitedly. "Was
that you too?" "What are you talking about?" said Aberforth. "Someone sent a doe
Patronus to us!" "Brains like that, you could be a Death Eater, son.'
- Hermione suddenly grabbed Harry's arm again. Her wide eyes were traveling around
the boarded windows. "Harry," she whispered, "I think we're in the Shrieking Shack."
Harry looked around. His eyes fell on a wooden chair near them. Large chunks had
been torn out of it; one of the legs had been ripped off entirely. "Ghosts didn't
do that," he said slowly. At that moment, there was a creak overhead. Something
had moved upstairs. Both of them looked up at the ceiling. Hermione's grip on
Harry's arm was so tight he was losing feeling in his fingers.
- 'He pointed at Black, whose face twitched convulsively. "I meant to," he growled,
his yellow teeth bared, "but little Peter got the better of me ... not this time,
though!" And Crookshanks was thrown to the floor as Black lunged at Scabbers;
Ron yelled with pain as Black''s weight fell on his broken leg. "Sirius, NO!"
Lupin yelled, launching himself forwards and dragging Black away from Ron again,
"WAIT! You can''t do it just like that - they need to understand - we''ve got
to explain -"
"We can explain afterwards!" snarled Black, trying to throw Lupin off. One hand
was still clawing the air as it tried to reach Scabbers, who was squealing like
a piglet, scratching Ron''s face and neck as he tried to escape. "They''ve - got
- a - right - to - know - everything!" Lupin panted, still trying to restrain
Black. "Ron''s kept him as a pet! There are parts of it even I don''t understand!
And Harry - you owe Harry the truth, Sirius!" Black stopped struggling, though
his hollowed eyes were still fixed on Scabbers, who was clamped tightly under
Ron''s bitten, scratched, and bleeding hands. "All right, then," Black said, without
taking his eyes off the rat. "Tell them whatever you like. But make it quick,
Remus. I want to commit the murder I was imprisoned for. ..."
"You''re nutters, both of you," said Ron shakily, looking round at Harry and Hermione
for support.'
- Hermione called commandingly along the table. "This way, please!" A group of new
students walked shyly up the gap between the Gryffindor and Hufflepuff tables,
all of them trying hard not to lead the group. They did indeed seem very small;
Harry was sure he had not appeared that young when he had arrived here. He grinned
at them. A blond boy next to Euan Abercrombie looked petrified, nudged Euan, and
whispered something in his ear. Euan Abercrombie looked equally frightened and
stole a horrified look at Harry, who felt the grin slide off his face like Stinksap.
- said Hermione desperately. "Hold yer hippogriffs, I haven' finished me story yet!"
said Hagrid indignantly, who, considering he had not wanted to tell them anything
in the first place, now seemed to be rather enjoying himself. "Me an' Olympe talked
it over an' we agreed, jus' 'cause the Gurg looked like favorin' You-Know-Who
didn' mean all of 'em would. We had ter try an' persuade some o' the others, the
ones who hadn' wanted Golgomath as Gurg." "How could you tell which ones they
were?" asked Ron. "Well, they were the ones bein' beaten to a pulp, weren' they?"
said Hagrid patiently.
- '"There''s summat in here that shouldn'' be." "A werewolf?" Harry suggested. "That
wasn'' no werewolf an'' it wasn'' no unicorn, neither," said Hagrid grimly. "Right,
follow me, but careful, now." They walked more slowly, ears straining for the
faintest sound. Suddenly, in a clearing ahead, something definitely moved. "Who''s
there?"'
- source_sentence: Who is the founder of Gryffindor house?
sentences:
- 'He peered at Hermione as though he had never seen a student properly before.
"However, the legend of which you speak is such a very sensational, even ludicrous
tale -"
But the whole class was now hanging on Professor Binns''s every word. He looked
dimly at them all, every face turned to his. Harry could tell he was completely
thrown by such an unusual show of interest. "Oh, very well," he said slowly. "Let
me see ... the Chamber of Secrets ...
"You all know, of course, that Hogwarts was founded over a thousand years ago
- the precise date is uncertain - by the four greatest witches and wizards of
the age. The four school Houses are named after them: Godric Gryffindor, Helga
Hufflepuff, Rowena Ravenclaw, and Salazar Slytherin. They built this castle together,
far from prying Muggle eyes, for it was an age when magic was feared by common
people, and witches and wizards suffered much persecution."'
- 'Harry glanced around. Cedric had nodded once, to show that he understood Bagman''s
words, and then started pacing around the tent again; he looked slightly green.
Fleur Delacour and Krum hadn''t reacted at all. Perhaps they thought they might
be sick if they opened their mouths; that was certainly how Harry felt. But they,
at least, had volunteered for this. ...
And in no time at all, hundreds upon hundreds of pairs of feet could be heard
passing the tent, their owners talking excitedly, laughing, joking. ... Harry
felt as separate from the crowd as though they were a different species. And then
- it seemed like about a second later to Harry - Bagman was opening the neck of
the purple silk sack.'
- '"Hey - hey Nick! NICK!" The ghost stuck its head back out of the wall, revealing
the extravagantly plumed hat and dangerously wobbling head of Sir Nicholas de
Mimsy-Porpington. "Good evening," he said, withdrawing the rest of his body from
the solid stone and smiling at Harry. "I am not the only one who is late, then?
Though," he sighed, "in rather different senses, of course ..."
"Nick, can I ask you something?" A most peculiar expression stole over Nearly
Headless Nick''s face as he inserted a finger in the stiff ruff at his neck and
tugged it a little straighter, apparently to give himself thinking time.'
- '"Indeed? How do you do, Dragomir?" " ''Ow you?" said Ron, holding out his hand.
Travers extended two fingers and shook Ron''s hand as though frightened of dirtying
himself. "So what brings you and your - ah - sympathetic friend to Diagon Alley
this early?"'
- '... Not Harry! Not Harry! Please - I''ll do anything -"
"Stand aside. Stand aside, girl!" He could have forced her away from the crib,
but it seemed more prudent to finish them all. ... The green light flashed around
the room and she dropped like her husband.'
- 'He turned to Ginny and she answered his unspoken plea for information at once.
"Ron and Tonks should have been back first, but they missed their Portkey, it
came back without them," she said, pointing at a rusty oil can lying on the ground
nearby. "And that one," she pointed at an ancient sneaker, "should have been Dad
and Fred''s, they were supposed to be second. You and Hagrid were third and,"
she checked her watch, "if they made it, George and Lupin ought to be back in
about a minute." Mrs. Weasley reappeared carrying a bottle of brandy, which she
handed to Hagrid. He uncorked it and drank it straight down in one. "Mum!" shouted
Ginny, pointing to a spot several feet away. A blue light had appeared in the
darkness: It grew larger and brighter, and Lupin and George appeared, spinning
and then falling. Harry knew immediately that there was something wrong: Lupin
was supporting George, who was unconscious and whose face was covered in blood.
Harry ran forward and seized George''s legs.'
- source_sentence: What is the name of the spell that causes a person to be burned?
sentences:
- 'He''d have loved to think the scratches on the stone were a coat of arms, because
as far as he was concerned, having pure blood made you practically royal." "Yes
... and that''s all very interesting," said Hermione cautiously, "but Harry, if
you''re thinking what I think you''re think -"
"Well, why not? Why not?" said Harry, abandoning caution. "It was a stone, wasn''t
it?" He looked at Ron for support. "What if it was the Resurrection Stone?" Ron''s
mouth fell open. "Blimey - but would it still work if Dumbledore broke - ?" "Work?
Work? Ron, it never worked! There''s no such thing as a Resurrection Stone!"'
- Underneath was a raw, bloody, green-tinged steak slightly larger than the average
car tire. "You're not going to eat that, are you, Hagrid?" said Ron, leaning in
for a closer look. "It looks poisonous." "It's s'posed ter look like that, it's
dragon meat," Hagrid said. "An' I didn' get it ter eat." He picked up the steak
and slapped it over the left side of his face. Greenish blood trickled down into
his beard as he gave a soft moan of satisfaction. "Tha's better. It helps with
the stingin', yeh know." "So are you going to tell us what's happened to you?"
Harry asked.
- 'They glanced around as they entered and spotted Dudley. Their faces cracked into
identical evil grins. "Ah, right," said Mr. Weasley. "Better get cracking then."
He pushed up the sleeves of his robes and took out his wand. Harry saw the Dursleys
draw back against the wall as one. "Incendio!" said Mr. Weasley, pointing his
wand at the hole in the wall behind him. Flames rose at once in the fireplace,
crackling merrily as though they had been burning for hours. Mr. Weasley took
a small drawstring bag from his pocket, untied it, took a pinch of the powder
inside, and threw it onto the flames, which turned emerald green and roared higher
than ever. "Off you go then, Fred," said Mr. Weasley. "Coming," said Fred. "Oh
no - hang on -"
A bag of sweets had spilled out of Fred''s pocket and the contents were now rolling
in every direction - big, fat toffees in brightly colored wrappers. Fred scrambled
around, cramming them back into his pocket, then gave the Dursleys a cheery wave,
stepped forward, and walked right into the fire, saying "the Burrow!" Aunt Petunia
gave a little shuddering gasp.'
- '"Well, you have to wait for somebody who gets it right," said Luna. "That way
you learn, you see?" "Yeah ... Trouble is, we can''t really afford to wait for
anyone else, Luna." "No, I see what you mean," said Luna seriously. "Well then,
I think the answer is that a circle has no beginning." "Well reasoned," said the
voice, and the door swung open. The deserted Ravenclaw common room was a wide,
circular room, airier than any Harry had ever seen at Hogwarts. Graceful arched
windows punctuated the walls, which were hung with blue-and-bronze silks: By day,
the Ravenclaws would have a spectacular view of the surrounding mountains. The
ceiling was domed and painted with stars, which were echoed in the midnight-blue
carpet. There were tables, chairs, and bookcases, and in a niche opposite the
door stood a tall statue of white marble. Harry recognized Rowena Ravenclaw from
the bust he had seen at Luna''s house. The statue stood beside a door that led,
he guessed, to dormitories above. He strode right up to the marble woman, and
she seemed to look back at him with a quizzical half smile on her face, beautiful
yet slightly intimidating. A delicate-looking circlet had been reproduced in marble
on top of her head. It was not unlike the tiara Fleur had worn at her wedding.
There were tiny words etched into it. Harry stepped out from under the Cloak and
climbed up onto Ravenclaw''s plinth to read them.
" ''Wit beyond measure is man''s greatest treasure.'' "
"Which makes you pretty skint, witless," said a cackling voice. Harry whirled
around, slipped off the plinth, and landed on the floor. The sloping-shouldered
figure of Alecto Carrow was standing before him, and even as Harry raised his
wand, she pressed a stubby forefinger to the skull and snake branded on her forearm.'
- '..." He walked once up the cave, back again, and then said, "Imagine that Voldemort''s
powerful now. You don''t know who his supporters are, you don''t know who''s working
for him and who isn''t; you know he can control people so that they do terrible
things without being able to stop themselves. You''re scared for yourself, and
your family, and your friends. Every week, news comes of more deaths, more disappearances,
more torturing ... the Ministry of Magic''s in disarray, they don''t know what
to do, they''re trying to keep everything hidden from the Muggles, but meanwhile,
Muggles are dying too. Terror everywhere ... panic ... confusion ... that''s how
it used to be. "Well, times like that bring out the best in some people and the
worst in others.'
- '"Only way. You''re too young to Apparate, they''ll be watching the Floo Network,
and it''s more than our life''s worth to set up an unauthorized Portkey." "Remus
says you''re a good flier," said Kingsley Shacklebolt in his deep voice. "He''s
excellent," said Lupin, who was checking his watch. "Anyway, you''d better go
and get packed, Harry, we want to be ready to go when the signal comes." "I''ll
come and help you," said Tonks brightly.'
- source_sentence: Who is the Slytherin boy who loves fame?
sentences:
- 'There was also a list of the new books he''d need for the coming year. SECOND-YEAR
STUDENTS WILL REQUIRE:
The Standard Book of Spells, Grade 2
by Miranda Goshawk
Break with a Banshee by Gilderoy Lockhart
Gadding with Ghouls by Gilderoy Lockhart
Holidays with Hags by Gilderoy Lockhart
Travels with Trolls by Gilderoy Lockhart
Voyages with Vampires by Gilderoy Lockhart
Wanderings with Werewolves by Gilderoy Lockhart
Year with the Yeti by Gilderoy Lockhart
Fred, who had finished his own list, peered over at Harry''s. "You''ve been told
to get all Lockhart''s books, too!" he said. "The new Defense Against the Dark
Arts teacher must be a fan - bet it''s a witch." At this point, Fred caught his
mother''s eye and quickly busied himself with the marmalade.'
- '"He asked me out, you know," she said in a quiet voice. "A couple of weeks ago.
Roger. I turned him down, though." Harry, who had grabbed the sugar bowl to excuse
his sudden lunging movement across the table, could not think why she was telling
him this. If she wished she were sitting at the table next door being heartily
kissed by Roger Davies, why had she agreed to come out with him? He said nothing.'
- '"We''re not - meeting here," said Harry. "We just - met here." "Indeed?" said
Snape. "You have a habit of turning up in unexpected places, Potter, and you are
very rarely there for no good reason. ... I suggest the pair of you return to
Gryffindor Tower, where you belong."'
- '..."
But Harry was already tearing away back along the corridor, and a couple of minutes
later was jumping the last few stairs to join Ron, Hermione, Ginny, and Luna,
who were huddled together at the end of Umbridge''s corridor. "Got it," he panted.
"Ready to go, then?" "All right," whispered Hermione as a gang of loud sixth years
passed them. "So Ron - you go and head Umbridge off. ... Ginny, Luna, if you can
start moving people out of the corridor.'
- '... So where shall I put you?" Harry gripped the edges of the stool and thought,
Not Slytherin, not Slytherin. "Not Slytherin, eh?" said the small voice.'
- 'Nobody could quite believe their ears until she looked directly at Harry and
Ron and said grimly, "I''ve become accustomed to seeing the Quidditch Cup in my
study, boys, and I really don''t want to have to hand it over to Professor Snape,
so use the extra time to practice, won''t you?" Snape was no less obviously partisan:
He had booked the Quidditch pitch for Slytherin practice so often that the Gryffindors
had difficulty getting on it to play. He was also turning a deaf ear to the many
reports of Slytherin attempts to hex Gryffindor players in the corridors. When
Alicia Spinnet turned up in the hospital wing with her eyebrows growing so thick
and fast that they obscured her vision and obstructed her mouth, Snape insisted
that she must have attempted a Hair-Thickening Charm on herself and refused to
listen to the fourteen eyewitnesses who insisted that they had seen the Slytherin
Keeper, Miles Bletchley, hit her from behind with a jinx while she worked in the
library. Harry felt optimistic about Gryffindor''s chances; they had, after all,
never lost to Malfoy''s team. Admittedly Ron was still not performing to Wood''s
standard, but he was working extremely hard to improve. His greatest weakness
was a tendency to lose confidence when he made a blunder; if he let in one goal
he became flustered and was therefore likely to miss more. On the other hand,
Harry had seen Ron make some truly spectacular saves when he was on form: During
one memorable practice, he had hung one-handed from his broom and kicked the Quaffle
so hard away from the goal hoop that it soared the length of the pitch and through
the center hoop at the other end. The rest of the team felt this save compared
favorably with one made recently by Barry Ryan, the Irish International Keeper,
against Poland''s top Chaser, Ladislaw Zamojski.'
pipeline_tag: sentence-similarity
library_name: sentence-transformers
metrics:
- cosine_accuracy@1
- cosine_accuracy@3
- cosine_accuracy@5
- cosine_accuracy@10
- cosine_precision@1
- cosine_precision@3
- cosine_precision@5
- cosine_precision@10
- cosine_recall@1
- cosine_recall@3
- cosine_recall@5
- cosine_recall@10
- cosine_ndcg@10
- cosine_mrr@10
- cosine_map@100
model-index:
- name: SentenceTransformer based on BAAI/bge-base-en-v1.5
results:
- task:
type: information-retrieval
name: Information Retrieval
dataset:
name: Unknown
type: unknown
metrics:
- type: cosine_accuracy@1
value: 0.2222222222222222
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.35802469135802467
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.37037037037037035
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.4074074074074074
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.2222222222222222
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.12345679012345678
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.07901234567901234
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.044444444444444446
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.1707818930041152
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.279835390946502
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.2921810699588477
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.3353909465020576
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.26916169677756213
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.28746325690770136
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.23920038190658358
name: Cosine Map@100
---
# SentenceTransformer based on BAAI/bge-base-en-v1.5
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5). It maps sentences & paragraphs to a 768-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) <!-- at revision a5beb1e3e68b9ab74eb54cfd186867f64f240e1a -->
- **Maximum Sequence Length:** 512 tokens
- **Output Dimensionality:** 768 dimensions
- **Similarity Function:** Cosine Similarity
<!-- - **Training Dataset:** Unknown -->
<!-- - **Language:** Unknown -->
<!-- - **License:** Unknown -->
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': True}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): Normalize()
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("CatkinChen/BAAI_bge-base-en-v1.5_retrieval_finetuned_2025-04-03_23-18-57")
# Run inference
sentences = [
'Who is the Slytherin boy who loves fame?',
'There was also a list of the new books he\'d need for the coming year. SECOND-YEAR STUDENTS WILL REQUIRE:\nThe Standard Book of Spells, Grade 2\nby Miranda Goshawk\nBreak with a Banshee by Gilderoy Lockhart\nGadding with Ghouls by Gilderoy Lockhart\nHolidays with Hags by Gilderoy Lockhart\nTravels with Trolls by Gilderoy Lockhart\nVoyages with Vampires by Gilderoy Lockhart\nWanderings with Werewolves by Gilderoy Lockhart\nYear with the Yeti by Gilderoy Lockhart\nFred, who had finished his own list, peered over at Harry\'s. "You\'ve been told to get all Lockhart\'s books, too!" he said. "The new Defense Against the Dark Arts teacher must be a fan - bet it\'s a witch." At this point, Fred caught his mother\'s eye and quickly busied himself with the marmalade.',
'Nobody could quite believe their ears until she looked directly at Harry and Ron and said grimly, "I\'ve become accustomed to seeing the Quidditch Cup in my study, boys, and I really don\'t want to have to hand it over to Professor Snape, so use the extra time to practice, won\'t you?" Snape was no less obviously partisan: He had booked the Quidditch pitch for Slytherin practice so often that the Gryffindors had difficulty getting on it to play. He was also turning a deaf ear to the many reports of Slytherin attempts to hex Gryffindor players in the corridors. When Alicia Spinnet turned up in the hospital wing with her eyebrows growing so thick and fast that they obscured her vision and obstructed her mouth, Snape insisted that she must have attempted a Hair-Thickening Charm on herself and refused to listen to the fourteen eyewitnesses who insisted that they had seen the Slytherin Keeper, Miles Bletchley, hit her from behind with a jinx while she worked in the library. Harry felt optimistic about Gryffindor\'s chances; they had, after all, never lost to Malfoy\'s team. Admittedly Ron was still not performing to Wood\'s standard, but he was working extremely hard to improve. His greatest weakness was a tendency to lose confidence when he made a blunder; if he let in one goal he became flustered and was therefore likely to miss more. On the other hand, Harry had seen Ron make some truly spectacular saves when he was on form: During one memorable practice, he had hung one-handed from his broom and kicked the Quaffle so hard away from the goal hoop that it soared the length of the pitch and through the center hoop at the other end. The rest of the team felt this save compared favorably with one made recently by Barry Ryan, the Irish International Keeper, against Poland\'s top Chaser, Ladislaw Zamojski.',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 768]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities.shape)
# [3, 3]
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
## Evaluation
### Metrics
#### Information Retrieval
* Evaluated with [<code>InformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.InformationRetrievalEvaluator)
| Metric | Value |
|:--------------------|:-----------|
| cosine_accuracy@1 | 0.2222 |
| cosine_accuracy@3 | 0.358 |
| cosine_accuracy@5 | 0.3704 |
| cosine_accuracy@10 | 0.4074 |
| cosine_precision@1 | 0.2222 |
| cosine_precision@3 | 0.1235 |
| cosine_precision@5 | 0.079 |
| cosine_precision@10 | 0.0444 |
| cosine_recall@1 | 0.1708 |
| cosine_recall@3 | 0.2798 |
| cosine_recall@5 | 0.2922 |
| cosine_recall@10 | 0.3354 |
| **cosine_ndcg@10** | **0.2692** |
| cosine_mrr@10 | 0.2875 |
| cosine_map@100 | 0.2392 |
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### Unnamed Dataset
* Size: 464 training samples
* Columns: <code>sentence_0</code>, <code>sentence_1</code>, <code>sentence_2</code>, <code>sentence_3</code>, <code>sentence_4</code>, <code>sentence_5</code>, and <code>sentence_6</code>
* Approximate statistics based on the first 464 samples:
| | sentence_0 | sentence_1 | sentence_2 | sentence_3 | sentence_4 | sentence_5 | sentence_6 |
|:--------|:----------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------|
| type | string | string | string | string | string | string | string |
| details | <ul><li>min: 9 tokens</li><li>mean: 19.47 tokens</li><li>max: 51 tokens</li></ul> | <ul><li>min: 37 tokens</li><li>mean: 199.31 tokens</li><li>max: 512 tokens</li></ul> | <ul><li>min: 43 tokens</li><li>mean: 170.61 tokens</li><li>max: 512 tokens</li></ul> | <ul><li>min: 39 tokens</li><li>mean: 176.24 tokens</li><li>max: 512 tokens</li></ul> | <ul><li>min: 28 tokens</li><li>mean: 170.23 tokens</li><li>max: 512 tokens</li></ul> | <ul><li>min: 45 tokens</li><li>mean: 167.81 tokens</li><li>max: 512 tokens</li></ul> | <ul><li>min: 29 tokens</li><li>mean: 165.47 tokens</li><li>max: 512 tokens</li></ul> |
* Samples:
| sentence_0 | sentence_1 | sentence_2 | sentence_3 | sentence_4 | sentence_5 | sentence_6 |
|:----------------------------------------------------------------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>What spell does Harry use to save his cousin Dudley from danger in the fifth book, and how does this connect to an event in the second book?</code> | <code>It did not contain birthday greetings. Dear Mr. Potter,<br>We have received intelligence that a Hover Charm was used at your place of residence this evening at twelve minutes past nine. As you know, underage wizards are not permitted to perform spells outside school, and further spellwork on your part may lead to expulsion from said school (Decree for the Reasonable Restriction of Underage Sorcery, 1875, Paragraph C). We would also ask you to remember that any magical activity that risks notice by members of the non-magical community (Muggles) is a serious offense under section 13 of the International Confederation of Warlocks' Statute of Secrecy. Enjoy your holidays! Yours sincerely,<br>Mafalda Hopkirk<br>IMPROPER USE OF MAGIC OFFICE<br>Ministry of Magic<br>Harry looked up from the letter and gulped. "You didn't tell us you weren't allowed to use magic outside school," said Uncle Vernon, a mad gleam dancing in his eyes. "Forgot to mention it. ... Slipped your mind, I daresay.</code> | <code>"They sealed off all of those before the start of the year," said Neville. "There's no chance of getting through any of them now, not with curses over the entrances and Death Eaters and dementors waiting at the exits." He started walking backward, beaming, drinking them in. "Never mind that stuff. ... Is it true? Did you break into Gringotts? Did you escape on a dragon?</code> | <code>A large plate of sandwiches, two silver goblets, and a jug of iced pumpkin juice appeared with a pop. "You will eat in here and then go straight up to your dormitory," she said. "I must also return to the feast." When the door had closed behind her, Ron let out a long, low whistle. "I thought we'd had it," he said, grabbing a sandwich. "So did I," said Harry, taking one, too. "Can you believe our luck, though?" said Ron thickly through a mouthful of chicken and ham. "Fred and George must've flown that car five or six times and no Muggle ever saw them." He swallowed and took another huge bite. "Why couldn't we get through the barrier?" Harry shrugged. "We'll have to watch our step from now on, though," he said, taking a grateful swig of pumpkin juice. "Wish we could've gone up to the feast. ..."<br>"She didn't want us showing off," said Ron sagely.</code> | <code>"Not by magic. Have you got a spade?" And shortly afterward he had set to work, alone, digging the grave in the place that Bill had shown him at the end of the garden, between bushes. He dug with a kind of fury, relishing the manual work, glorying in the non-magic of it, for every drop of his sweat and every blister felt like a gift to the elf who had saved their lives. His scar burned, but he was master of the pain; he felt it, yet was apart from it.</code> | <code>Apparently the Peverells were one of the earliest families to vanish." " 'Extinct in the male line'?" repeated Ron. "It means the name's died out," said Hermione, "centuries ago, in the case of the Peverells. They could still have descendants, though, they'd just be called something different." And then it came to Harry in one shining piece, the memory that had stirred at the sound of the name "Peverell": a filthy old man brandishing an ugly ring in the face of a Ministry official, and he cried aloud, "Marvolo Gaunt!" "Sorry?" said Ron and Hermione together. "Marvolo Gaunt! You-Know-Who's grandfather!</code> | <code>... Well, Filch ran over all of us with Secrecy Sensors when we got into the entrance hall. Any Dark object would have been found, I know for a fact Crabbe had a shrunken head confiscated. So you see, Malfoy can't have brought in anything dangerous!" Momentarily stymied, Harry watched Ginny Weasley playing with Arnold the Pygmy Puff for a while before seeing a way around this objection. "Someone's sent it to him by owl, then," he said. "His mother or someone." "All the owls are being checked too," said Hermione. "Filch told us so when he was jabbing those Secrecy Sensors everywhere he could reach." Really stumped this time, Harry found nothing else to say. There did not seem to be any way Malfoy could have brought a dangerous or Dark object into the school. He looked hopefully at Ron, who was sitting with his arms folded, staring over at Lavender Brown. "Can you think of any way Malfoy - ?"</code> |
| <code>Who becomes Headmistress of Hogwarts immediately following the final Battle of Hogwarts?</code> | <code>Tom Riddle hit the floor with a mundane finality, his body feeble and shrunken, the white hands empty, the snakelike face vacant and unknowing. Voldemort was dead, killed by his own rebounding curse, and Harry stood with two wands in his hand, staring down at his enemy's shell. One shivering second of silence, the shock of the moment suspended: and then the tumult broke around Harry as the screams and the cheers and the roars of the watchers rent the air. The fierce new sun dazzled the windows as they thundered toward him, and the first to reach him were Ron and Hermione, and it was their arms that were wrapped around him, their incomprehensible shouts that deafened him. Then Ginny, Neville, and Luna were there, and then all the Weasleys and Hagrid, and Kingsley and McGonagall and Flitwick and Sprout, and Harry could not hear a word that anyone was shouting, nor tell whose hands were seizing him, pulling him, trying to hug some part of him, hundreds of them pressing in, all of them det...</code> | <code>Dumbledore's future career seemed likely to be meteoric, and the only question that remained was when he would become Minister of Magic. Though it was often predicted in later years that he was on the point of taking the job, however, he never had Ministerial ambitions. Three years after we had started at Hogwarts, Albus's brother, Aberforth, arrived at school. They were not alike; Aberforth was never bookish and, unlike Albus, preferred to settle arguments by dueling rather than through reasoned discussion. However, it is quite wrong to suggest, as some have, that the brothers were not friends. They rubbed along as comfortably as two such different boys could do. In fairness to Aberforth, it must be admitted that living in Albus's shadow cannot have been an altogether comfortable experience. Being continually outshone was an occupational hazard of being his friend and cannot have been any more pleasurable as a brother.</code> | <code>"Soon?" "Almost at once," said Lupin, "we're just waiting for the all-clear." "Where are we going? The Burrow?" Harry asked hopefully. "Not the Burrow, no," said Lupin, motioning Harry toward the kitchen; the little knot of wizards followed, all still eyeing Harry curiously. "Too risky. We've set up headquarters somewhere undetectable. It's taken a while. ..."<br>Mad-Eye Moody was now sitting at the kitchen table swigging from a hip flask, his magical eye spinning in all directions, taking in the Dursleys' many labor-saving appliances.</code> | <code>said Hermione. Crookshanks slowly chewed up the spider, his yellow eyes fixed insolently on Ron. "Just keep him over there, that's all," said Ron irritably, turning back to his star chart. "I've got Scabbers asleep in my bag." Harry yawned. He really wanted to go to bed, but he still had his own star chart to complete. He pulled his bag toward him, took out parchment, ink, and quill, and started work. "You can copy mine, if you like," said Ron, labeling his last star with a flourish and shoving the chart toward Harry.</code> | <code>Harry said, looking around at the door to the girls' dormitories. "Let's go and tell her," said Ron. He bounded forward, pulled open the door, and set off up the spiral staircase. He was on the sixth stair when it happened. There was a loud, wailing, klaxonlike sound and the steps melted together to make a long, smooth stone slide. There was a brief moment when Ron tried to keep running, arms working madly like windmills, then he toppled over backward and shot down the newly created slide, coming to rest on his back at Harry's feet. "Er - I don't think we're allowed in the girls' dormitories," said Harry, pulling Ron to his feet and trying not to laugh. Two fourth-year girls came zooming gleefully down the stone slide. "Oooh, who tried to get upstairs?" they giggled happily, leaping to their feet and ogling Harry and Ron. "Me," said Ron, who was still rather disheveled. "I didn't realize that would happen. It's not fair!" he added to Harry, as the girls headed off for the portrait hole...</code> | <code>..."<br>"Cool," muttered Harry, sparing the watch a glance before peering more closely at the map. Where was Malfoy? He did not seem to be at the Slytherin table in the Great Hall, eating breakfast. ... He was nowhere near Snape, who was sitting in his study.</code> |
| <code>In the sixth book, what memory does Harry retrieve from Slughorn, and how does it connect to the second book?</code> | <code>"W-what's that?" said Mr. Weasley in a stunned voice. "You-Know-Who? En-enchant Ginny? But Ginny's not ... Ginny hasn't been ... has she?" "It was this diary," said Harry quickly, picking it up and showing it to Dumbledore. "Riddle wrote it when he was sixteen. ..."<br>Dumbledore took the diary from Harry and peered keenly down his long, crooked nose at its burnt and soggy pages. "Brilliant," he said softly. "Of course, he was probably the most brilliant student Hogwarts has ever seen." He turned around to the Weasleys, who were looking utterly bewildered. "Very few people know that Lord Voldemort was once called Tom Riddle.</code> | <code>..." They hurried through the portrait hole and into the crowd, still discussing Snape. "But if he - you know" - Hermione dropped her voice, glancing nervously around - "if he was trying to - to poison Lupin - he wouldn't have done it in front of Harry." "Yeah, maybe," said Harry as they reached the entrance hall and crossed into the Great Hall. It had been decorated with hundreds and hundreds of candle-filled pumpkins, a cloud of fluttering live bats, and many flaming orange streamers, which were swimming lazily across the stormy ceiling like brilliant watersnakes. The food was delicious; even Hermione and Ron, who were full to bursting with Honeydukes sweets, managed second helpings of everything. Harry kept glancing at the staff table.</code> | <code>said Dumbledore calmly, and Peeves's grin faded a little. He didn't dare taunt Dumbledore. Instead he adopted an oily voice that was no better than his cackle. "Ashamed, Your Headship, sir. Doesn't want to be seen. She's a horrible mess. Saw her running through the landscape up on the fourth floor, sir, dodging between the trees. Crying something dreadful," he said happily.</code> | <code>I knew that the Wizarding world was clamoring for the full story and I wanted to be the first to meet that need." I mention the recent, widely publicized remarks of Elphias Doge, Special Advisor to the Wizengamot and longstanding friend of Albus Dumbledore's, that "Skeeter's book contains less fact than a Chocolate Frog card." Skeeter throws back her head and laughs. "Darling Dodgy! I remember interviewing him a few years back about merpeople rights, bless him. Completely gaga, seemed to think we were sitting at the bottom of Lake Windermere, kept telling me to watch out for trout." And yet Elphias Doge's accusations of inaccuracy have been echoed in many places.</code> | <code>"Harry, guess what?" said Tonks from her perch on top of the washing machine, and she wiggled her left hand at him; a ring glittered there. "You got married?" Harry yelped, looking from her to Lupin. "I'm sorry you couldn't be there, Harry, it was very quiet." "That's brilliant, congrat -"<br>"All right, all right, we'll have time for a cozy catch-up later!" roared Moody over the hubbub, and silence fell in the kitchen. Moody dropped his sacks at his feet and turned to Harry. "As Dedalus probably told you, we had to abandon Plan A. Pius Thicknesse has gone over, which gives us a big problem.</code> | <code>It was a very sunny Saturday and the zoo was crowded with families. The Dursleys bought Dudley and Piers large chocolate ice creams at the entrance and then, because the smiling lady in the van had asked Harry what he wanted before they could hurry him away, they bought him a cheap lemon ice pop. It wasn't bad, either, Harry thought, licking it as they watched a gorilla scratching its head who looked remarkably like Dudley, except that it wasn't blond. Harry had the best morning he'd had in a long time. He was careful to walk a little way apart from the Dursleys so that Dudley and Piers, who were starting to get bored with the animals by lunchtime, wouldn't fall back on their favorite hobby of hitting him. They ate in the zoo restaurant, and when Dudley had a tantrum because his knickerbocker glory didn't have enough ice cream on top, Uncle Vernon bought him another one and Harry was allowed to finish the first. Harry felt, afterward, that he should have known it was all too good to la...</code> |
* Loss: [<code>MultipleNegativesRankingLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#multiplenegativesrankingloss) with these parameters:
```json
{
"scale": 10,
"similarity_fct": "cos_sim"
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `eval_strategy`: steps
- `per_device_train_batch_size`: 16
- `per_device_eval_batch_size`: 16
- `num_train_epochs`: 6
- `fp16`: True
- `batch_sampler`: no_duplicates
- `multi_dataset_batch_sampler`: round_robin
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: steps
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 16
- `per_device_eval_batch_size`: 16
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `torch_empty_cache_steps`: None
- `learning_rate`: 5e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1
- `num_train_epochs`: 6
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.0
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: False
- `fp16`: True
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: False
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `tp_size`: 0
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: None
- `hub_always_push`: False
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `include_for_metrics`: []
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `dispatch_batches`: None
- `split_batches`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `eval_on_start`: False
- `use_liger_kernel`: False
- `eval_use_gather_object`: False
- `average_tokens_across_devices`: False
- `prompts`: None
- `batch_sampler`: no_duplicates
- `multi_dataset_batch_sampler`: round_robin
</details>
### Training Logs
| Epoch | Step | cosine_ndcg@10 |
|:------:|:----:|:--------------:|
| 0.1724 | 5 | 0.1644 |
| 0.3448 | 10 | 0.1969 |
| 0.5172 | 15 | 0.2073 |
| 0.6897 | 20 | 0.2215 |
| 0.8621 | 25 | 0.2352 |
| 1.0 | 29 | 0.2418 |
| 1.0345 | 30 | 0.2380 |
| 1.2069 | 35 | 0.2452 |
| 1.3793 | 40 | 0.2610 |
| 1.5517 | 45 | 0.2655 |
| 1.7241 | 50 | 0.2627 |
| 1.8966 | 55 | 0.2679 |
| 2.0 | 58 | 0.2675 |
| 2.0690 | 60 | 0.2662 |
| 2.2414 | 65 | 0.2605 |
| 2.4138 | 70 | 0.2625 |
| 2.5862 | 75 | 0.2571 |
| 2.7586 | 80 | 0.2705 |
| 2.9310 | 85 | 0.2737 |
| 3.0 | 87 | 0.2737 |
| 3.1034 | 90 | 0.2702 |
| 3.2759 | 95 | 0.2744 |
| 3.4483 | 100 | 0.2742 |
| 3.6207 | 105 | 0.2716 |
| 3.7931 | 110 | 0.2694 |
| 3.9655 | 115 | 0.2649 |
| 4.0 | 116 | 0.2649 |
| 4.1379 | 120 | 0.2705 |
| 4.3103 | 125 | 0.2705 |
| 4.4828 | 130 | 0.2656 |
| 4.6552 | 135 | 0.2688 |
| 4.8276 | 140 | 0.2677 |
| 5.0 | 145 | 0.2689 |
| 5.1724 | 150 | 0.2689 |
| 5.3448 | 155 | 0.2661 |
| 5.5172 | 160 | 0.2653 |
| 5.6897 | 165 | 0.2697 |
| 5.8621 | 170 | 0.2692 |
| 6.0 | 174 | 0.2692 |
| -1 | -1 | 0.2692 |
### Framework Versions
- Python: 3.12.9
- Sentence Transformers: 4.0.1
- Transformers: 4.50.3
- PyTorch: 2.6.0+cu124
- Accelerate: 1.6.0
- Datasets: 3.5.0
- Tokenizers: 0.21.1
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
#### MultipleNegativesRankingLoss
```bibtex
@misc{henderson2017efficient,
title={Efficient Natural Language Response Suggestion for Smart Reply},
author={Matthew Henderson and Rami Al-Rfou and Brian Strope and Yun-hsuan Sung and Laszlo Lukacs and Ruiqi Guo and Sanjiv Kumar and Balint Miklos and Ray Kurzweil},
year={2017},
eprint={1705.00652},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
dharsandip/merged_Llama3.2_3B_Instruct_bnb_4bit_model1
|
dharsandip
| 2025-04-03T15:27:25Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"conversational",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2025-04-03T15:26:20Z
|
---
base_model: unsloth/llama-3.2-3b-instruct-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
- sft
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** dharsandip
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3.2-3b-instruct-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Apel-sin/whisper-large-v3-russian-ties-podlodka-v1.0
|
Apel-sin
| 2025-04-03T15:26:15Z
| 104
| 1
|
transformers
|
[
"transformers",
"safetensors",
"whisper",
"automatic-speech-recognition",
"asr",
"russian",
"mergekit",
"merge",
"ru",
"dataset:mozilla-foundation/common_voice_17_0",
"dataset:bond005/taiga_speech_v2",
"dataset:bond005/podlodka_speech",
"dataset:bond005/rulibrispeech",
"base_model:antony66/whisper-large-v3-russian",
"base_model:merge:antony66/whisper-large-v3-russian",
"base_model:bond005/whisper-large-v3-ru-podlodka",
"base_model:merge:bond005/whisper-large-v3-ru-podlodka",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2025-03-04T18:43:45Z
|
---
base_model:
- antony66/whisper-large-v3-russian
- bond005/whisper-large-v3-ru-podlodka
language:
- ru
library_name: transformers
tags:
- asr
- whisper
- russian
- mergekit
- merge
datasets:
- mozilla-foundation/common_voice_17_0
- bond005/taiga_speech_v2
- bond005/podlodka_speech
- bond005/rulibrispeech
metrics:
- wer
---
NEW version available: [Apel-sin/whisper-large-v3-russian-ties-podlodka-v1.2](https://huggingface.co/Apel-sin/whisper-large-v3-russian-ties-podlodka-v1.2)
# Model Details
This model was merged using the TIES merge method.
```yaml
method: ties
parameters:
ties_density: 0.85
encoder_weights:
- 0.65
- 0.35
decoder_weights:
- 0.6
- 0.4
models:
model_a: "/mnt/cloud/llm/whisper/whisper-large-v3-russian"
model_b: "/mnt/cloud/llm/whisper/whisper-large-v3-ru-podlodka"
output_dir: "/mnt/cloud/llm/whisper/whisper-large-v3-russian-ties-podlodka"
```
## Simple API server
It can be uses with simple OpenAI compatible API server: https://github.com/kreolsky/whisper-api-server/
## Usage
In order to process phone calls it is highly recommended that you preprocess your records and adjust volume before performing ASR. For example, like this:
```bash
sox record.wav -r 8000 record-normalized.wav norm -0.5 compand 0.3,1 -90,-90,-70,-50,-40,-15,0,0 -7 0 0.15
```
Then your ASR code should look somewhat like this:
```python
import torch
from transformers import WhisperForConditionalGeneration, WhisperProcessor, pipeline
torch_dtype = torch.bfloat16 # set your preferred type here
device = 'cpu'
if torch.cuda.is_available():
device = 'cuda'
elif torch.backends.mps.is_available():
device = 'mps'
setattr(torch.distributed, "is_initialized", lambda : False) # monkey patching
device = torch.device(device)
whisper = WhisperForConditionalGeneration.from_pretrained(
"antony66/whisper-large-v3-russian", torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True,
# add attn_implementation="flash_attention_2" if your GPU supports it
)
processor = WhisperProcessor.from_pretrained("antony66/whisper-large-v3-russian")
asr_pipeline = pipeline(
"automatic-speech-recognition",
model=whisper,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=256,
chunk_length_s=30,
batch_size=16,
return_timestamps=True,
torch_dtype=torch_dtype,
device=device,
)
# read your wav file into variable wav. For example:
from io import BufferIO
wav = BytesIO()
with open('record-normalized.wav', 'rb') as f:
wav.write(f.read())
wav.seek(0)
# get the transcription
asr = asr_pipeline(wav, generate_kwargs={"language": "russian", "max_new_tokens": 256}, return_timestamps=False)
print(asr['text'])
```
## Work in progress
This model is in WIP state for now. The goal is to finetune it for speech recognition of phone calls as much as possible. If you want to contribute and you know or have any good dataset please let me know. Your help will be much appreciated.
|
vamsin21/riboclette
|
vamsin21
| 2025-04-03T15:25:44Z
| 0
| 0
| null |
[
"license:cc-by-nc-4.0",
"region:us"
] | null | 2025-04-03T15:25:44Z
|
---
license: cc-by-nc-4.0
---
|
silverside/TOK-Linhares
|
silverside
| 2025-04-03T15:25:09Z
| 0
| 0
|
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-04-03T15:11:22Z
|
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: TOK-Linhares
---
# Tok Linhares
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `TOK-Linhares` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "TOK-Linhares",
"lora_weights": "https://huggingface.co/silverside/TOK-Linhares/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('silverside/TOK-Linhares', weight_name='lora.safetensors')
image = pipeline('TOK-Linhares').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 1200
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/silverside/TOK-Linhares/discussions) to add images that show off what you’ve made with this LoRA.
|
Apel-sin/whisper-large-v3-russian-ties-podlodka-v1.2
|
Apel-sin
| 2025-04-03T15:24:38Z
| 3
| 0
|
transformers
|
[
"transformers",
"safetensors",
"whisper",
"automatic-speech-recognition",
"asr",
"russian",
"mergekit",
"merge",
"ru",
"dataset:mozilla-foundation/common_voice_17_0",
"dataset:bond005/taiga_speech_v2",
"dataset:bond005/podlodka_speech",
"dataset:bond005/rulibrispeech",
"base_model:antony66/whisper-large-v3-russian",
"base_model:merge:antony66/whisper-large-v3-russian",
"base_model:bond005/whisper-large-v3-ru-podlodka",
"base_model:merge:bond005/whisper-large-v3-ru-podlodka",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2025-04-02T12:17:55Z
|
---
base_model:
- antony66/whisper-large-v3-russian
- bond005/whisper-large-v3-ru-podlodka
language:
- ru
library_name: transformers
tags:
- asr
- whisper
- russian
- mergekit
- merge
datasets:
- mozilla-foundation/common_voice_17_0
- bond005/taiga_speech_v2
- bond005/podlodka_speech
- bond005/rulibrispeech
metrics:
- wer
---
# Model Details
This model was merged using the TIES merge method.
```yaml
method: ties
parameters:
ties_density: 0.9
encoder_weights:
- 0.8
- 0.2
decoder_weights:
- 0.2
- 0.8
models:
model_a: "/mnt/cloud/llm/whisper/whisper-large-v3-russian"
model_b: "/mnt/cloud/llm/whisper/whisper-large-v3-ru-podlodka"
output_dir: "/mnt/cloud/llm/whisper/whisper-large-v3-russian-ties-podlodka"
```
## Simple API server
It can be uses with simple OpenAI compatible API server: https://github.com/kreolsky/whisper-api-server/
## Usage
In order to process phone calls it is highly recommended that you preprocess your records and adjust volume before performing ASR. For example, like this:
```bash
sox record.wav -r 8000 record-normalized.wav norm -0.5 compand 0.3,1 -90,-90,-70,-50,-40,-15,0,0 -7 0 0.15
```
Then your ASR code should look somewhat like this:
```python
import torch
from transformers import WhisperForConditionalGeneration, WhisperProcessor, pipeline
torch_dtype = torch.bfloat16 # set your preferred type here
device = 'cpu'
if torch.cuda.is_available():
device = 'cuda'
elif torch.backends.mps.is_available():
device = 'mps'
setattr(torch.distributed, "is_initialized", lambda : False) # monkey patching
device = torch.device(device)
whisper = WhisperForConditionalGeneration.from_pretrained(
"antony66/whisper-large-v3-russian", torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True,
# add attn_implementation="flash_attention_2" if your GPU supports it
)
processor = WhisperProcessor.from_pretrained("antony66/whisper-large-v3-russian")
asr_pipeline = pipeline(
"automatic-speech-recognition",
model=whisper,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=256,
chunk_length_s=30,
batch_size=16,
return_timestamps=True,
torch_dtype=torch_dtype,
device=device,
)
# read your wav file into variable wav. For example:
from io import BufferIO
wav = BytesIO()
with open('record-normalized.wav', 'rb') as f:
wav.write(f.read())
wav.seek(0)
# get the transcription
asr = asr_pipeline(wav, generate_kwargs={"language": "russian", "max_new_tokens": 256}, return_timestamps=False)
print(asr['text'])
```
## Work in progress
This model is in WIP state for now. The goal is to finetune it for speech recognition of phone calls as much as possible. If you want to contribute and you know or have any good dataset please let me know. Your help will be much appreciated.
|
melijauregui/fashionclip-roturas2
|
melijauregui
| 2025-04-03T15:24:16Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"feature-extraction",
"custom_code",
"arxiv:1910.09700",
"region:us"
] |
feature-extraction
| 2025-04-03T15:22:00Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
gacky1601/Lab3-Qwen2.5-14B-60step
|
gacky1601
| 2025-04-03T15:22:54Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen2",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-04-03T15:22:43Z
|
---
base_model: unsloth/qwen2.5-14b-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** gacky1601
- **License:** apache-2.0
- **Finetuned from model :** unsloth/qwen2.5-14b-unsloth-bnb-4bit
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
szangmo/age-detection
|
szangmo
| 2025-04-03T15:21:22Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"siglip",
"image-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2025-04-03T15:20:40Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Elcaida/llamapretrained1
|
Elcaida
| 2025-04-03T15:21:07Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"conversational",
"en",
"base_model:unsloth/Llama-3.2-1B-Instruct",
"base_model:finetune:unsloth/Llama-3.2-1B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-04-03T15:20:51Z
|
---
base_model: unsloth/Llama-3.2-1B-Instruct
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
- sft
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** Elcaida
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Llama-3.2-1B-Instruct
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
henil-intern/QwenSTMG
|
henil-intern
| 2025-04-03T15:20:26Z
| 0
| 0
|
peft
|
[
"peft",
"safetensors",
"qwen2_vl",
"arxiv:1910.09700",
"base_model:Qwen/Qwen2-VL-7B-Instruct",
"base_model:adapter:Qwen/Qwen2-VL-7B-Instruct",
"region:us"
] | null | 2025-04-03T15:17:17Z
|
---
base_model: Qwen/Qwen2-VL-7B-Instruct
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.14.0
|
xw17/Qwen2.5-1.5B-Instruct_finetuned_2_def_lora3
|
xw17
| 2025-04-03T15:19:42Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-04-03T15:19:32Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
genki10/BERT_AugV8_k1_task1_organization_sp020_lw040_fold0
|
genki10
| 2025-04-03T15:18:34Z
| 5
| 0
|
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-03-25T01:40:11Z
|
---
library_name: transformers
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: BERT_AugV8_k1_task1_organization_sp020_lw040_fold0
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BERT_AugV8_k1_task1_organization_sp020_lw040_fold0
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8846
- Qwk: 0.3804
- Mse: 0.8846
- Rmse: 0.9406
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 150
### Training results
| Training Loss | Epoch | Step | Validation Loss | Qwk | Mse | Rmse |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|
| No log | 1.0 | 2 | 9.1430 | 0.0 | 9.1430 | 3.0237 |
| No log | 2.0 | 4 | 7.8678 | 0.0 | 7.8678 | 2.8050 |
| No log | 3.0 | 6 | 7.0738 | 0.0 | 7.0738 | 2.6597 |
| No log | 4.0 | 8 | 6.4826 | 0.0 | 6.4826 | 2.5461 |
| No log | 5.0 | 10 | 5.7941 | 0.0160 | 5.7941 | 2.4071 |
| No log | 6.0 | 12 | 5.1070 | 0.0112 | 5.1070 | 2.2599 |
| No log | 7.0 | 14 | 4.4454 | 0.0039 | 4.4454 | 2.1084 |
| No log | 8.0 | 16 | 3.7598 | 0.0039 | 3.7598 | 1.9390 |
| No log | 9.0 | 18 | 3.0433 | 0.0 | 3.0433 | 1.7445 |
| No log | 10.0 | 20 | 2.4425 | 0.1499 | 2.4425 | 1.5628 |
| No log | 11.0 | 22 | 1.9321 | 0.0751 | 1.9321 | 1.3900 |
| No log | 12.0 | 24 | 1.5493 | 0.0484 | 1.5493 | 1.2447 |
| No log | 13.0 | 26 | 1.3700 | 0.0484 | 1.3700 | 1.1705 |
| No log | 14.0 | 28 | 1.4335 | 0.0638 | 1.4335 | 1.1973 |
| No log | 15.0 | 30 | 1.3094 | 0.0548 | 1.3094 | 1.1443 |
| No log | 16.0 | 32 | 1.0219 | 0.0316 | 1.0219 | 1.0109 |
| No log | 17.0 | 34 | 1.0289 | 0.0316 | 1.0289 | 1.0144 |
| No log | 18.0 | 36 | 0.8608 | 0.0490 | 0.8608 | 0.9278 |
| No log | 19.0 | 38 | 1.2571 | 0.0956 | 1.2571 | 1.1212 |
| No log | 20.0 | 40 | 1.1896 | 0.1026 | 1.1896 | 1.0907 |
| No log | 21.0 | 42 | 0.7479 | 0.4619 | 0.7479 | 0.8648 |
| No log | 22.0 | 44 | 0.6318 | 0.4904 | 0.6318 | 0.7948 |
| No log | 23.0 | 46 | 0.6090 | 0.4859 | 0.6090 | 0.7804 |
| No log | 24.0 | 48 | 0.9985 | 0.3126 | 0.9985 | 0.9992 |
| No log | 25.0 | 50 | 1.5689 | 0.2418 | 1.5689 | 1.2526 |
| No log | 26.0 | 52 | 1.2410 | 0.2767 | 1.2410 | 1.1140 |
| No log | 27.0 | 54 | 0.5073 | 0.4951 | 0.5073 | 0.7122 |
| No log | 28.0 | 56 | 0.5097 | 0.4742 | 0.5097 | 0.7139 |
| No log | 29.0 | 58 | 1.0706 | 0.2728 | 1.0706 | 1.0347 |
| No log | 30.0 | 60 | 1.8049 | 0.1932 | 1.8049 | 1.3435 |
| No log | 31.0 | 62 | 1.9772 | 0.1668 | 1.9772 | 1.4061 |
| No log | 32.0 | 64 | 1.4448 | 0.2153 | 1.4448 | 1.2020 |
| No log | 33.0 | 66 | 0.8063 | 0.3693 | 0.8063 | 0.8979 |
| No log | 34.0 | 68 | 0.6143 | 0.3506 | 0.6143 | 0.7838 |
| No log | 35.0 | 70 | 0.6539 | 0.3177 | 0.6539 | 0.8087 |
| No log | 36.0 | 72 | 0.5888 | 0.4324 | 0.5888 | 0.7673 |
| No log | 37.0 | 74 | 0.9136 | 0.3559 | 0.9136 | 0.9558 |
| No log | 38.0 | 76 | 0.9192 | 0.3621 | 0.9192 | 0.9588 |
| No log | 39.0 | 78 | 0.6547 | 0.4333 | 0.6547 | 0.8091 |
| No log | 40.0 | 80 | 0.6472 | 0.3898 | 0.6472 | 0.8045 |
| No log | 41.0 | 82 | 0.6691 | 0.3915 | 0.6691 | 0.8180 |
| No log | 42.0 | 84 | 0.8846 | 0.3804 | 0.8846 | 0.9406 |
### Framework versions
- Transformers 4.47.0
- Pytorch 2.5.1+cu121
- Datasets 3.3.1
- Tokenizers 0.21.0
|
ShaysXIA/backward-model
|
ShaysXIA
| 2025-04-03T15:18:00Z
| 0
| 0
|
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:meta-llama/Llama-2-7b-hf",
"base_model:adapter:meta-llama/Llama-2-7b-hf",
"region:us"
] | null | 2025-04-03T15:14:22Z
|
---
base_model: meta-llama/Llama-2-7b-hf
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.15.1
|
marijagjorgjieva/fine-tuned-03042025
|
marijagjorgjieva
| 2025-04-03T15:17:27Z
| 0
| 0
|
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:Borjan/finki-gpt",
"base_model:adapter:Borjan/finki-gpt",
"region:us"
] | null | 2025-04-03T15:17:17Z
|
---
base_model: Borjan/finki-gpt
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.14.0
|
henil-intern/QwenST
|
henil-intern
| 2025-04-03T15:15:55Z
| 0
| 0
|
peft
|
[
"peft",
"safetensors",
"qwen2_vl",
"arxiv:1910.09700",
"base_model:Qwen/Qwen2-VL-7B-Instruct",
"base_model:adapter:Qwen/Qwen2-VL-7B-Instruct",
"region:us"
] | null | 2025-04-03T15:12:36Z
|
---
base_model: Qwen/Qwen2-VL-7B-Instruct
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.14.0
|
RichardErkhov/Rohan5076_-_medquad-text-generation-gpt2-gguf
|
RichardErkhov
| 2025-04-03T15:15:38Z
| 0
| 0
| null |
[
"gguf",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-04-03T15:11:21Z
|
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
medquad-text-generation-gpt2 - GGUF
- Model creator: https://huggingface.co/Rohan5076/
- Original model: https://huggingface.co/Rohan5076/medquad-text-generation-gpt2/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [medquad-text-generation-gpt2.Q2_K.gguf](https://huggingface.co/RichardErkhov/Rohan5076_-_medquad-text-generation-gpt2-gguf/blob/main/medquad-text-generation-gpt2.Q2_K.gguf) | Q2_K | 0.08GB |
| [medquad-text-generation-gpt2.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/Rohan5076_-_medquad-text-generation-gpt2-gguf/blob/main/medquad-text-generation-gpt2.IQ3_XS.gguf) | IQ3_XS | 0.08GB |
| [medquad-text-generation-gpt2.IQ3_S.gguf](https://huggingface.co/RichardErkhov/Rohan5076_-_medquad-text-generation-gpt2-gguf/blob/main/medquad-text-generation-gpt2.IQ3_S.gguf) | IQ3_S | 0.08GB |
| [medquad-text-generation-gpt2.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/Rohan5076_-_medquad-text-generation-gpt2-gguf/blob/main/medquad-text-generation-gpt2.Q3_K_S.gguf) | Q3_K_S | 0.08GB |
| [medquad-text-generation-gpt2.IQ3_M.gguf](https://huggingface.co/RichardErkhov/Rohan5076_-_medquad-text-generation-gpt2-gguf/blob/main/medquad-text-generation-gpt2.IQ3_M.gguf) | IQ3_M | 0.09GB |
| [medquad-text-generation-gpt2.Q3_K.gguf](https://huggingface.co/RichardErkhov/Rohan5076_-_medquad-text-generation-gpt2-gguf/blob/main/medquad-text-generation-gpt2.Q3_K.gguf) | Q3_K | 0.09GB |
| [medquad-text-generation-gpt2.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/Rohan5076_-_medquad-text-generation-gpt2-gguf/blob/main/medquad-text-generation-gpt2.Q3_K_M.gguf) | Q3_K_M | 0.09GB |
| [medquad-text-generation-gpt2.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/Rohan5076_-_medquad-text-generation-gpt2-gguf/blob/main/medquad-text-generation-gpt2.Q3_K_L.gguf) | Q3_K_L | 0.1GB |
| [medquad-text-generation-gpt2.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/Rohan5076_-_medquad-text-generation-gpt2-gguf/blob/main/medquad-text-generation-gpt2.IQ4_XS.gguf) | IQ4_XS | 0.1GB |
| [medquad-text-generation-gpt2.Q4_0.gguf](https://huggingface.co/RichardErkhov/Rohan5076_-_medquad-text-generation-gpt2-gguf/blob/main/medquad-text-generation-gpt2.Q4_0.gguf) | Q4_0 | 0.1GB |
| [medquad-text-generation-gpt2.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/Rohan5076_-_medquad-text-generation-gpt2-gguf/blob/main/medquad-text-generation-gpt2.IQ4_NL.gguf) | IQ4_NL | 0.1GB |
| [medquad-text-generation-gpt2.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/Rohan5076_-_medquad-text-generation-gpt2-gguf/blob/main/medquad-text-generation-gpt2.Q4_K_S.gguf) | Q4_K_S | 0.1GB |
| [medquad-text-generation-gpt2.Q4_K.gguf](https://huggingface.co/RichardErkhov/Rohan5076_-_medquad-text-generation-gpt2-gguf/blob/main/medquad-text-generation-gpt2.Q4_K.gguf) | Q4_K | 0.11GB |
| [medquad-text-generation-gpt2.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/Rohan5076_-_medquad-text-generation-gpt2-gguf/blob/main/medquad-text-generation-gpt2.Q4_K_M.gguf) | Q4_K_M | 0.11GB |
| [medquad-text-generation-gpt2.Q4_1.gguf](https://huggingface.co/RichardErkhov/Rohan5076_-_medquad-text-generation-gpt2-gguf/blob/main/medquad-text-generation-gpt2.Q4_1.gguf) | Q4_1 | 0.11GB |
| [medquad-text-generation-gpt2.Q5_0.gguf](https://huggingface.co/RichardErkhov/Rohan5076_-_medquad-text-generation-gpt2-gguf/blob/main/medquad-text-generation-gpt2.Q5_0.gguf) | Q5_0 | 0.11GB |
| [medquad-text-generation-gpt2.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/Rohan5076_-_medquad-text-generation-gpt2-gguf/blob/main/medquad-text-generation-gpt2.Q5_K_S.gguf) | Q5_K_S | 0.11GB |
| [medquad-text-generation-gpt2.Q5_K.gguf](https://huggingface.co/RichardErkhov/Rohan5076_-_medquad-text-generation-gpt2-gguf/blob/main/medquad-text-generation-gpt2.Q5_K.gguf) | Q5_K | 0.12GB |
| [medquad-text-generation-gpt2.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/Rohan5076_-_medquad-text-generation-gpt2-gguf/blob/main/medquad-text-generation-gpt2.Q5_K_M.gguf) | Q5_K_M | 0.12GB |
| [medquad-text-generation-gpt2.Q5_1.gguf](https://huggingface.co/RichardErkhov/Rohan5076_-_medquad-text-generation-gpt2-gguf/blob/main/medquad-text-generation-gpt2.Q5_1.gguf) | Q5_1 | 0.12GB |
| [medquad-text-generation-gpt2.Q6_K.gguf](https://huggingface.co/RichardErkhov/Rohan5076_-_medquad-text-generation-gpt2-gguf/blob/main/medquad-text-generation-gpt2.Q6_K.gguf) | Q6_K | 0.13GB |
| [medquad-text-generation-gpt2.Q8_0.gguf](https://huggingface.co/RichardErkhov/Rohan5076_-_medquad-text-generation-gpt2-gguf/blob/main/medquad-text-generation-gpt2.Q8_0.gguf) | Q8_0 | 0.17GB |
Original model description:
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
RichardErkhov/ayshwaryaninet1_-_lora_model10-gguf
|
RichardErkhov
| 2025-04-03T15:15:25Z
| 0
| 0
| null |
[
"gguf",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-04-03T13:16:17Z
|
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
lora_model10 - GGUF
- Model creator: https://huggingface.co/ayshwaryaninet1/
- Original model: https://huggingface.co/ayshwaryaninet1/lora_model10/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [lora_model10.Q2_K.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model10-gguf/blob/main/lora_model10.Q2_K.gguf) | Q2_K | 1.35GB |
| [lora_model10.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model10-gguf/blob/main/lora_model10.IQ3_XS.gguf) | IQ3_XS | 1.49GB |
| [lora_model10.IQ3_S.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model10-gguf/blob/main/lora_model10.IQ3_S.gguf) | IQ3_S | 1.57GB |
| [lora_model10.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model10-gguf/blob/main/lora_model10.Q3_K_S.gguf) | Q3_K_S | 1.57GB |
| [lora_model10.IQ3_M.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model10-gguf/blob/main/lora_model10.IQ3_M.gguf) | IQ3_M | 1.65GB |
| [lora_model10.Q3_K.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model10-gguf/blob/main/lora_model10.Q3_K.gguf) | Q3_K | 1.75GB |
| [lora_model10.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model10-gguf/blob/main/lora_model10.Q3_K_M.gguf) | Q3_K_M | 1.75GB |
| [lora_model10.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model10-gguf/blob/main/lora_model10.Q3_K_L.gguf) | Q3_K_L | 1.9GB |
| [lora_model10.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model10-gguf/blob/main/lora_model10.IQ4_XS.gguf) | IQ4_XS | 1.93GB |
| [lora_model10.Q4_0.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model10-gguf/blob/main/lora_model10.Q4_0.gguf) | Q4_0 | 2.03GB |
| [lora_model10.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model10-gguf/blob/main/lora_model10.IQ4_NL.gguf) | IQ4_NL | 2.04GB |
| [lora_model10.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model10-gguf/blob/main/lora_model10.Q4_K_S.gguf) | Q4_K_S | 2.04GB |
| [lora_model10.Q4_K.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model10-gguf/blob/main/lora_model10.Q4_K.gguf) | Q4_K | 2.16GB |
| [lora_model10.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model10-gguf/blob/main/lora_model10.Q4_K_M.gguf) | Q4_K_M | 2.16GB |
| [lora_model10.Q4_1.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model10-gguf/blob/main/lora_model10.Q4_1.gguf) | Q4_1 | 2.24GB |
| [lora_model10.Q5_0.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model10-gguf/blob/main/lora_model10.Q5_0.gguf) | Q5_0 | 2.46GB |
| [lora_model10.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model10-gguf/blob/main/lora_model10.Q5_K_S.gguf) | Q5_K_S | 2.46GB |
| [lora_model10.Q5_K.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model10-gguf/blob/main/lora_model10.Q5_K.gguf) | Q5_K | 2.53GB |
| [lora_model10.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model10-gguf/blob/main/lora_model10.Q5_K_M.gguf) | Q5_K_M | 2.53GB |
| [lora_model10.Q5_1.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model10-gguf/blob/main/lora_model10.Q5_1.gguf) | Q5_1 | 2.68GB |
| [lora_model10.Q6_K.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model10-gguf/blob/main/lora_model10.Q6_K.gguf) | Q6_K | 2.92GB |
| [lora_model10.Q8_0.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model10-gguf/blob/main/lora_model10.Q8_0.gguf) | Q8_0 | 3.78GB |
Original model description:
---
base_model: unsloth/phi-3.5-mini-instruct-bnb-4bit
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
---
# Uploaded model
- **Developed by:** ayshwaryaninet1
- **License:** apache-2.0
- **Finetuned from model :** unsloth/phi-3.5-mini-instruct-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
fguzelant/bert-base-uncased-finetuned-rte-run_8_best
|
fguzelant
| 2025-04-03T15:14:46Z
| 0
| 0
|
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-04-03T10:28:39Z
|
---
library_name: transformers
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: bert-base-uncased-finetuned-rte-run_8_best
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-finetuned-rte-run_8_best
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8601
- Accuracy: 0.7256
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 6.387670620549943e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 15
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 20 | 0.6376 | 0.6426 |
| No log | 2.0 | 40 | 0.6699 | 0.6968 |
| No log | 3.0 | 60 | 0.6570 | 0.7148 |
| No log | 4.0 | 80 | 0.8601 | 0.7256 |
| No log | 5.0 | 100 | 0.9858 | 0.7004 |
| No log | 6.0 | 120 | 1.1769 | 0.6823 |
| No log | 7.0 | 140 | 1.2463 | 0.6895 |
| No log | 8.0 | 160 | 1.5285 | 0.7004 |
| No log | 9.0 | 180 | 1.4726 | 0.7004 |
| No log | 10.0 | 200 | 1.5863 | 0.6859 |
| No log | 11.0 | 220 | 1.5913 | 0.6823 |
| No log | 12.0 | 240 | 1.6612 | 0.6968 |
| No log | 13.0 | 260 | 1.6851 | 0.7040 |
| No log | 14.0 | 280 | 1.7215 | 0.7040 |
| No log | 15.0 | 300 | 1.7309 | 0.7076 |
### Framework versions
- Transformers 4.50.2
- Pytorch 2.6.0+cu124
- Datasets 3.5.0
- Tokenizers 0.21.1
|
RichardErkhov/ayshwaryaninet1_-_lora_model1-gguf
|
RichardErkhov
| 2025-04-03T15:13:30Z
| 0
| 0
| null |
[
"gguf",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-04-03T13:13:42Z
|
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
lora_model1 - GGUF
- Model creator: https://huggingface.co/ayshwaryaninet1/
- Original model: https://huggingface.co/ayshwaryaninet1/lora_model1/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [lora_model1.Q2_K.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model1-gguf/blob/main/lora_model1.Q2_K.gguf) | Q2_K | 1.35GB |
| [lora_model1.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model1-gguf/blob/main/lora_model1.IQ3_XS.gguf) | IQ3_XS | 1.49GB |
| [lora_model1.IQ3_S.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model1-gguf/blob/main/lora_model1.IQ3_S.gguf) | IQ3_S | 1.57GB |
| [lora_model1.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model1-gguf/blob/main/lora_model1.Q3_K_S.gguf) | Q3_K_S | 1.57GB |
| [lora_model1.IQ3_M.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model1-gguf/blob/main/lora_model1.IQ3_M.gguf) | IQ3_M | 1.65GB |
| [lora_model1.Q3_K.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model1-gguf/blob/main/lora_model1.Q3_K.gguf) | Q3_K | 1.75GB |
| [lora_model1.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model1-gguf/blob/main/lora_model1.Q3_K_M.gguf) | Q3_K_M | 1.75GB |
| [lora_model1.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model1-gguf/blob/main/lora_model1.Q3_K_L.gguf) | Q3_K_L | 1.9GB |
| [lora_model1.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model1-gguf/blob/main/lora_model1.IQ4_XS.gguf) | IQ4_XS | 1.93GB |
| [lora_model1.Q4_0.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model1-gguf/blob/main/lora_model1.Q4_0.gguf) | Q4_0 | 2.03GB |
| [lora_model1.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model1-gguf/blob/main/lora_model1.IQ4_NL.gguf) | IQ4_NL | 2.04GB |
| [lora_model1.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model1-gguf/blob/main/lora_model1.Q4_K_S.gguf) | Q4_K_S | 2.04GB |
| [lora_model1.Q4_K.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model1-gguf/blob/main/lora_model1.Q4_K.gguf) | Q4_K | 2.16GB |
| [lora_model1.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model1-gguf/blob/main/lora_model1.Q4_K_M.gguf) | Q4_K_M | 2.16GB |
| [lora_model1.Q4_1.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model1-gguf/blob/main/lora_model1.Q4_1.gguf) | Q4_1 | 2.24GB |
| [lora_model1.Q5_0.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model1-gguf/blob/main/lora_model1.Q5_0.gguf) | Q5_0 | 2.46GB |
| [lora_model1.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model1-gguf/blob/main/lora_model1.Q5_K_S.gguf) | Q5_K_S | 2.46GB |
| [lora_model1.Q5_K.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model1-gguf/blob/main/lora_model1.Q5_K.gguf) | Q5_K | 2.53GB |
| [lora_model1.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model1-gguf/blob/main/lora_model1.Q5_K_M.gguf) | Q5_K_M | 2.53GB |
| [lora_model1.Q5_1.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model1-gguf/blob/main/lora_model1.Q5_1.gguf) | Q5_1 | 2.68GB |
| [lora_model1.Q6_K.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model1-gguf/blob/main/lora_model1.Q6_K.gguf) | Q6_K | 2.92GB |
| [lora_model1.Q8_0.gguf](https://huggingface.co/RichardErkhov/ayshwaryaninet1_-_lora_model1-gguf/blob/main/lora_model1.Q8_0.gguf) | Q8_0 | 3.78GB |
Original model description:
---
base_model: unsloth/phi-3.5-mini-instruct-bnb-4bit
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
---
# Uploaded model
- **Developed by:** ayshwaryaninet1
- **License:** apache-2.0
- **Finetuned from model :** unsloth/phi-3.5-mini-instruct-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
NikolaiRaitschew/GGUF
|
NikolaiRaitschew
| 2025-04-03T15:12:39Z
| 0
| 0
|
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"unsloth",
"trl",
"sft",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-04-03T14:32:00Z
|
---
library_name: transformers
tags:
- unsloth
- trl
- sft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
serenezzz/Taxi-v3
|
serenezzz
| 2025-04-03T15:10:13Z
| 0
| 0
| null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-04-03T15:10:11Z
|
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="serenezzz/Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
flyingbugs/Qwen2.5-Math-7B-Instruct
|
flyingbugs
| 2025-04-03T15:07:32Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-04-03T14:59:09Z
|
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
lironui/UK_Visa_Assistant
|
lironui
| 2025-04-03T15:05:33Z
| 0
| 0
|
peft
|
[
"peft",
"safetensors",
"mistral",
"unsloth",
"lora",
"text-generation",
"conversational",
"base_model:mistralai/Mistral-7B-v0.3",
"base_model:adapter:mistralai/Mistral-7B-v0.3",
"license:apache-2.0",
"region:us"
] |
text-generation
| 2025-04-03T15:01:07Z
|
---
license: apache-2.0
base_model: mistralai/Mistral-7B-v0.3
tags:
- mistral
- unsloth
- lora
- peft
- text-generation
model_type: mistral
library_name: peft
pipeline_tag: text-generation
---
# 🏛️ UK Visa Assistant - Fine-tuned Mistral-7B Instruct
This is a fine-tuned version of the [Mistral 7B Instruct](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.3) model, specifically tailored for answering questions and assisting with processes related to UK visas, immigration categories, documentation requirements, and official guidance.
## 🧠 Model Summary
- **Base model**: `Mistral-7B-Instruct-v0.3`
- **Fine-tuning method**: LoRA
- **Domain**: UK visa & immigration policy
- **Intended use**: Assisting users, lawyers, and support agents in navigating UK visa rules and processes
- **Trained with**: A curated corpus of UK visa documentation, official Home Office guidance, and common user queries
## 📚 Use Cases
- Answering questions like:
- "What are the requirements for a Skilled Worker visa?"
- "Can I switch from a Student Visa to a Start-up Visa in the UK?"
- "What documents do I need for a spouse visa?"
- Assisting in form-filling guidance
- Clarifying rule changes or processing times
## 🚀 How to Use
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("lironui/UK_Visa_Assistant")
tokenizer = AutoTokenizer.from_pretrained("lironui/UK_Visa_Assistant")
prompt = "What are the English language requirements for a UK Skilled Worker visa?"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=1024)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
> 📝 Note: For best results, format prompts using Mistral's instruct style (e.g., `<s>[INST] your question [/INST]`)
## 📝 Dataset
> The model was trained on a custom dataset containing:
- Home Office visa guidance PDFs
- Official UK government immigration website content
- Annotated user questions and responses from visa forums (anonymized)
- Policy update logs from gov.uk
## ⚠️ Limitations
- May not reflect very recent policy updates (check [gov.uk](https://www.gov.uk/) for latest info)
- Should not be relied on for legal advice
- Performance on non-UK immigration topics is untested
## 📄 License
cc-by-nc-4.0
## 🤝 Citation
If you use this model, please consider citing it:
```
@misc{ukvisa-mistral2025,
author = {Rui Li},
title = {UK Visa Assistant - Fine-tuned Mistral 7B Instruct},
year = 2025,
publisher = {Hugging Face},
howpublished = {\url{https://huggingface.co/lironui/UK_Visa_Assistant}}
}
```
|
UgyenR/bhutanese-textile-model
|
UgyenR
| 2025-04-03T15:03:34Z
| 0
| 0
|
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:google/vit-base-patch16-224-in21k",
"base_model:finetune:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2025-04-03T14:17:48Z
|
---
library_name: transformers
license: apache-2.0
base_model: google/vit-base-patch16-224-in21k
tags:
- generated_from_trainer
datasets:
- imagefolder
model-index:
- name: bhutanese-textile-model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bhutanese-textile-model
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the imagefolder dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:------:|:----:|:---------------:|:--------:|
| No log | 0.9143 | 8 | 1.7863 | 0.5929 |
### Framework versions
- Transformers 4.50.2
- Pytorch 2.6.0+cu124
- Datasets 3.5.0
- Tokenizers 0.21.1
|
Mohinikathro/mistral-7b-finetuned-3epochs-2April
|
Mohinikathro
| 2025-04-03T15:02:56Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"en",
"base_model:unsloth/mistral-7b-v0.3",
"base_model:finetune:unsloth/mistral-7b-v0.3",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-04-03T03:09:32Z
|
---
base_model: unsloth/mistral-7b-v0.3
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** Mohinikathro
- **License:** apache-2.0
- **Finetuned from model :** unsloth/mistral-7b-v0.3
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
henil-intern/QwenMG
|
henil-intern
| 2025-04-03T15:01:45Z
| 0
| 0
|
peft
|
[
"peft",
"safetensors",
"qwen2_vl",
"arxiv:1910.09700",
"base_model:Qwen/Qwen2-VL-7B-Instruct",
"base_model:adapter:Qwen/Qwen2-VL-7B-Instruct",
"region:us"
] | null | 2025-04-03T14:58:04Z
|
---
base_model: Qwen/Qwen2-VL-7B-Instruct
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.14.0
|
genki10/BERT_AugV8_k1_task1_organization_sp020_lw030_fold3
|
genki10
| 2025-04-03T15:00:59Z
| 5
| 0
|
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-03-25T01:20:55Z
|
---
library_name: transformers
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: BERT_AugV8_k1_task1_organization_sp020_lw030_fold3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BERT_AugV8_k1_task1_organization_sp020_lw030_fold3
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9962
- Qwk: 0.4842
- Mse: 0.9968
- Rmse: 0.9984
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 150
### Training results
| Training Loss | Epoch | Step | Validation Loss | Qwk | Mse | Rmse |
|:-------------:|:-----:|:----:|:---------------:|:------:|:-------:|:------:|
| No log | 1.0 | 2 | 11.1628 | 0.0076 | 11.1608 | 3.3408 |
| No log | 2.0 | 4 | 8.3773 | 0.0 | 8.3757 | 2.8941 |
| No log | 3.0 | 6 | 6.6150 | 0.0180 | 6.6135 | 2.5717 |
| No log | 4.0 | 8 | 5.1315 | 0.0210 | 5.1303 | 2.2650 |
| No log | 5.0 | 10 | 3.8717 | 0.0076 | 3.8706 | 1.9674 |
| No log | 6.0 | 12 | 3.0753 | 0.0076 | 3.0745 | 1.7534 |
| No log | 7.0 | 14 | 2.3096 | 0.1628 | 2.3088 | 1.5195 |
| No log | 8.0 | 16 | 1.8214 | 0.0961 | 1.8206 | 1.3493 |
| No log | 9.0 | 18 | 1.6477 | 0.0753 | 1.6471 | 1.2834 |
| No log | 10.0 | 20 | 1.1657 | 0.0365 | 1.1651 | 1.0794 |
| No log | 11.0 | 22 | 0.9697 | 0.0365 | 0.9692 | 0.9845 |
| No log | 12.0 | 24 | 0.9046 | 0.1775 | 0.9042 | 0.9509 |
| No log | 13.0 | 26 | 0.7804 | 0.3826 | 0.7801 | 0.8832 |
| No log | 14.0 | 28 | 0.7464 | 0.3386 | 0.7460 | 0.8637 |
| No log | 15.0 | 30 | 0.6759 | 0.3974 | 0.6756 | 0.8220 |
| No log | 16.0 | 32 | 0.6154 | 0.4479 | 0.6153 | 0.7844 |
| No log | 17.0 | 34 | 0.6467 | 0.5321 | 0.6464 | 0.8040 |
| No log | 18.0 | 36 | 0.7928 | 0.4812 | 0.7926 | 0.8903 |
| No log | 19.0 | 38 | 0.5485 | 0.5731 | 0.5483 | 0.7405 |
| No log | 20.0 | 40 | 0.6407 | 0.4881 | 0.6406 | 0.8003 |
| No log | 21.0 | 42 | 0.5884 | 0.5763 | 0.5883 | 0.7670 |
| No log | 22.0 | 44 | 0.7812 | 0.4918 | 0.7810 | 0.8837 |
| No log | 23.0 | 46 | 0.8039 | 0.4766 | 0.8036 | 0.8965 |
| No log | 24.0 | 48 | 0.5541 | 0.5771 | 0.5540 | 0.7443 |
| No log | 25.0 | 50 | 0.5476 | 0.5850 | 0.5475 | 0.7399 |
| No log | 26.0 | 52 | 0.6237 | 0.5591 | 0.6236 | 0.7897 |
| No log | 27.0 | 54 | 0.5511 | 0.5805 | 0.5511 | 0.7423 |
| No log | 28.0 | 56 | 0.5216 | 0.5889 | 0.5218 | 0.7223 |
| No log | 29.0 | 58 | 0.6395 | 0.5328 | 0.6398 | 0.7999 |
| No log | 30.0 | 60 | 0.6058 | 0.5128 | 0.6062 | 0.7786 |
| No log | 31.0 | 62 | 0.5629 | 0.5421 | 0.5635 | 0.7506 |
| No log | 32.0 | 64 | 0.5587 | 0.5664 | 0.5593 | 0.7479 |
| No log | 33.0 | 66 | 0.5487 | 0.5732 | 0.5493 | 0.7411 |
| No log | 34.0 | 68 | 0.5593 | 0.6045 | 0.5599 | 0.7483 |
| No log | 35.0 | 70 | 1.0147 | 0.4305 | 1.0154 | 1.0076 |
| No log | 36.0 | 72 | 1.0981 | 0.4311 | 1.0987 | 1.0482 |
| No log | 37.0 | 74 | 0.5683 | 0.5616 | 0.5687 | 0.7541 |
| No log | 38.0 | 76 | 0.5788 | 0.5578 | 0.5792 | 0.7610 |
| No log | 39.0 | 78 | 0.5606 | 0.5733 | 0.5611 | 0.7491 |
| No log | 40.0 | 80 | 0.6031 | 0.5440 | 0.6038 | 0.7770 |
| No log | 41.0 | 82 | 0.5773 | 0.5818 | 0.5780 | 0.7602 |
| No log | 42.0 | 84 | 0.6269 | 0.6161 | 0.6274 | 0.7921 |
| No log | 43.0 | 86 | 0.5871 | 0.6319 | 0.5874 | 0.7664 |
| No log | 44.0 | 88 | 0.4959 | 0.6577 | 0.4961 | 0.7043 |
| No log | 45.0 | 90 | 0.6647 | 0.5454 | 0.6649 | 0.8154 |
| No log | 46.0 | 92 | 0.6667 | 0.5588 | 0.6670 | 0.8167 |
| No log | 47.0 | 94 | 0.5688 | 0.6262 | 0.5692 | 0.7544 |
| No log | 48.0 | 96 | 0.6219 | 0.6307 | 0.6223 | 0.7889 |
| No log | 49.0 | 98 | 0.5785 | 0.6278 | 0.5790 | 0.7609 |
| No log | 50.0 | 100 | 0.6570 | 0.5316 | 0.6576 | 0.8109 |
| No log | 51.0 | 102 | 0.6385 | 0.5378 | 0.6390 | 0.7994 |
| No log | 52.0 | 104 | 0.5733 | 0.5796 | 0.5738 | 0.7575 |
| No log | 53.0 | 106 | 0.5710 | 0.6397 | 0.5715 | 0.7560 |
| No log | 54.0 | 108 | 0.5928 | 0.6001 | 0.5931 | 0.7702 |
| No log | 55.0 | 110 | 0.7578 | 0.5215 | 0.7582 | 0.8707 |
| No log | 56.0 | 112 | 0.7147 | 0.5262 | 0.7152 | 0.8457 |
| No log | 57.0 | 114 | 0.5626 | 0.6137 | 0.5631 | 0.7504 |
| No log | 58.0 | 116 | 0.7805 | 0.5385 | 0.7810 | 0.8838 |
| No log | 59.0 | 118 | 0.9962 | 0.4842 | 0.9968 | 0.9984 |
### Framework versions
- Transformers 4.47.0
- Pytorch 2.5.1+cu121
- Datasets 3.3.1
- Tokenizers 0.21.0
|
jpark677/internvl2-8b-mmbench-lora-ep-1-waa-false
|
jpark677
| 2025-04-03T15:00:09Z
| 0
| 0
| null |
[
"safetensors",
"internvl_chat",
"internvl2",
"vision-language",
"multimodal",
"lora",
"image-to-text",
"custom_code",
"en",
"dataset:1",
"license:apache-2.0",
"region:us"
] |
image-to-text
| 2025-04-03T14:58:12Z
|
---
language: en
license: apache-2.0
tags:
- internvl2
- vision-language
- multimodal
- lora
datasets:
- "1"
pipeline_tag: image-to-text
---
# internvl2-8b-mmbench-1
This repository contains the internvl2-8b-mmbench-1 model, which is a fine-tuned version of InternVL2-8B.
## Model Details
- Model Type: InternVL2-8B with LoRA fine-tuning
- Dataset: 1
- Training Method: LoRA
- Epochs: 1
- WAA: false
|
CatkinChen/babyai-classical-ppo-experiments-2025-04-03_13-55-41
|
CatkinChen
| 2025-04-03T14:59:05Z
| 0
| 0
|
peft
|
[
"peft",
"pytorch",
"safetensors",
"arxiv:1910.09700",
"base_model:meta-llama/Llama-3.2-3B-Instruct",
"base_model:adapter:meta-llama/Llama-3.2-3B-Instruct",
"region:us"
] | null | 2025-04-03T13:55:46Z
|
---
base_model: meta-llama/Llama-3.2-3B-Instruct
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.15.1
|
AzadAstro/Qwen2.5-VL-3B-Instruct
|
AzadAstro
| 2025-04-03T14:57:54Z
| 0
| 0
|
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:Qwen/Qwen2.5-VL-3B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-VL-3B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-04-03T14:34:26Z
|
---
base_model: Qwen/Qwen2.5-VL-3B-Instruct
library_name: transformers
model_name: Qwen2.5-VL-3B-Instruct
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for Qwen2.5-VL-3B-Instruct
This model is a fine-tuned version of [Qwen/Qwen2.5-VL-3B-Instruct](https://huggingface.co/Qwen/Qwen2.5-VL-3B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="AzadAstro/Qwen2.5-VL-3B-Instruct", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.15.2
- Transformers: 4.50.0.dev0
- Pytorch: 2.6.0
- Datasets: 3.2.0
- Tokenizers: 0.21.0
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
korkmazemin1/llama3.2-3b-gguf
|
korkmazemin1
| 2025-04-03T14:57:39Z
| 0
| 0
| null |
[
"gguf",
"llama",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-04-03T13:10:13Z
|
---
license: apache-2.0
---
|
Eckilibrium/w2v-bert-2.0-dysarthric-child-dedropchunkdropfreqclip_20ep
|
Eckilibrium
| 2025-04-03T14:57:23Z
| 0
| 0
|
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"wav2vec2-bert",
"automatic-speech-recognition",
"generated_from_trainer",
"base_model:facebook/w2v-bert-2.0",
"base_model:finetune:facebook/w2v-bert-2.0",
"license:mit",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2025-04-03T13:35:10Z
|
---
library_name: transformers
license: mit
base_model: facebook/w2v-bert-2.0
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: w2v-bert-2.0-dysarthric-child-dedropchunkdropfreqclip_20ep
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# w2v-bert-2.0-dysarthric-child-dedropchunkdropfreqclip_20ep
This model is a fine-tuned version of [facebook/w2v-bert-2.0](https://huggingface.co/facebook/w2v-bert-2.0) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.6917
- Wer: 0.8433
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 20
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 50.0629 | 1.0 | 71 | 3.4237 | 1.0 |
| 12.4133 | 2.0 | 142 | 2.6851 | 1.0 |
| 7.4423 | 3.0 | 213 | 1.5843 | 1.0 |
| 4.1175 | 4.0 | 284 | 1.4006 | 0.9893 |
| 2.4374 | 5.0 | 355 | 1.5026 | 0.9764 |
| 1.7337 | 6.0 | 426 | 1.6983 | 1.0494 |
| 1.1902 | 7.0 | 497 | 1.9292 | 0.9914 |
| 1.2966 | 8.0 | 568 | 1.7715 | 0.9528 |
| 0.9647 | 9.0 | 639 | 2.0014 | 0.9206 |
| 0.3653 | 10.0 | 710 | 1.9001 | 0.8927 |
| 0.2252 | 11.0 | 781 | 2.1168 | 0.8691 |
| 0.1497 | 12.0 | 852 | 2.3008 | 0.8648 |
| 0.0929 | 13.0 | 923 | 2.3739 | 0.8476 |
| 0.0503 | 14.0 | 994 | 2.4999 | 0.8991 |
| 0.0343 | 15.0 | 1065 | 2.5863 | 0.8584 |
| 0.0131 | 16.0 | 1136 | 2.5634 | 0.8369 |
| 0.0007 | 17.0 | 1207 | 2.6232 | 0.8433 |
| 0.0004 | 18.0 | 1278 | 2.6680 | 0.8369 |
| 0.0003 | 19.0 | 1349 | 2.6861 | 0.8391 |
| 0.0003 | 20.0 | 1420 | 2.6917 | 0.8433 |
### Framework versions
- Transformers 4.47.1
- Pytorch 2.5.1
- Datasets 2.19.1
- Tokenizers 0.21.0
|
f0ghedgeh0g/distilhubert-finetuned-gtzan
|
f0ghedgeh0g
| 2025-04-03T14:55:35Z
| 386
| 0
|
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"hubert",
"audio-classification",
"generated_from_trainer",
"dataset:marsyas/gtzan",
"base_model:ntu-spml/distilhubert",
"base_model:finetune:ntu-spml/distilhubert",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] |
audio-classification
| 2025-01-02T10:34:21Z
|
---
library_name: transformers
license: apache-2.0
base_model: ntu-spml/distilhubert
tags:
- generated_from_trainer
datasets:
- marsyas/gtzan
metrics:
- accuracy
model-index:
- name: distilhubert-finetuned-hyperparam-gtzan
results:
- task:
name: Audio Classification
type: audio-classification
dataset:
name: GTZAN
type: marsyas/gtzan
config: all
split: train
args: all
metrics:
- name: Accuracy
type: accuracy
value: 0.86
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilhubert-finetuned-hyperparam-gtzan
This model is a fine-tuned version of [ntu-spml/distilhubert](https://huggingface.co/ntu-spml/distilhubert) on the GTZAN dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2045
- Accuracy: 0.86
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 30
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.7469 | 1.0 | 113 | 1.3737 | 0.57 |
| 0.7973 | 2.0 | 226 | 1.5247 | 0.57 |
| 0.6831 | 3.0 | 339 | 0.8961 | 0.74 |
| 0.4573 | 4.0 | 452 | 0.8638 | 0.76 |
| 0.1874 | 5.0 | 565 | 0.7839 | 0.81 |
| 0.0829 | 6.0 | 678 | 1.0174 | 0.79 |
| 0.0306 | 7.0 | 791 | 0.9393 | 0.81 |
| 0.004 | 8.0 | 904 | 0.9737 | 0.85 |
| 0.1209 | 9.0 | 1017 | 1.0625 | 0.8 |
| 0.0237 | 10.0 | 1130 | 1.3653 | 0.8 |
| 0.0164 | 11.0 | 1243 | 1.3065 | 0.81 |
| 0.0007 | 12.0 | 1356 | 1.1272 | 0.83 |
| 0.0004 | 13.0 | 1469 | 1.3226 | 0.83 |
| 0.0001 | 14.0 | 1582 | 1.6092 | 0.82 |
| 0.0001 | 15.0 | 1695 | 1.2045 | 0.86 |
| 0.0002 | 16.0 | 1808 | 1.1312 | 0.85 |
| 0.0003 | 17.0 | 1921 | 1.0911 | 0.86 |
| 0.0 | 18.0 | 2034 | 1.1983 | 0.84 |
| 0.0001 | 19.0 | 2147 | 1.1363 | 0.85 |
| 0.0 | 20.0 | 2260 | 1.2547 | 0.85 |
| 0.0002 | 21.0 | 2373 | 1.2394 | 0.84 |
| 0.0001 | 22.0 | 2486 | 1.5508 | 0.85 |
| 0.0 | 23.0 | 2599 | 1.2689 | 0.83 |
| 0.0 | 24.0 | 2712 | 1.2343 | 0.83 |
| 0.0003 | 25.0 | 2825 | 1.2313 | 0.81 |
| 0.0 | 26.0 | 2938 | 1.2217 | 0.83 |
| 0.0 | 27.0 | 3051 | 1.1596 | 0.84 |
| 0.0 | 28.0 | 3164 | 1.1081 | 0.85 |
| 0.0001 | 29.0 | 3277 | 1.1394 | 0.85 |
| 0.0 | 30.0 | 3390 | 1.1215 | 0.85 |
### Framework versions
- Transformers 4.48.0.dev0
- Pytorch 2.6.0+cu126
- Datasets 3.2.0
- Tokenizers 0.21.0
|
c4tdr0ut/DeepDolphin-3x8B
|
c4tdr0ut
| 2025-04-03T14:55:30Z
| 7
| 0
| null |
[
"safetensors",
"mixtral",
"license:cc-by-sa-4.0",
"region:us"
] | null | 2025-03-28T20:04:41Z
|
---
license: cc-by-sa-4.0
---
A mix of hermes and dolphin as a MoE on a Mistral 7b base
|
gv6037/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-ferocious_majestic_salamander
|
gv6037
| 2025-04-03T14:55:07Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"rl-swarm",
"grpo",
"gensyn",
"I am ferocious majestic salamander",
"trl",
"conversational",
"arxiv:2402.03300",
"base_model:Gensyn/Qwen2.5-0.5B-Instruct",
"base_model:finetune:Gensyn/Qwen2.5-0.5B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-04-02T20:14:27Z
|
---
base_model: Gensyn/Qwen2.5-0.5B-Instruct
library_name: transformers
model_name: Qwen2.5-0.5B-Instruct-Gensyn-Swarm-ferocious_majestic_salamander
tags:
- generated_from_trainer
- rl-swarm
- grpo
- gensyn
- I am ferocious majestic salamander
- trl
licence: license
---
# Model Card for Qwen2.5-0.5B-Instruct-Gensyn-Swarm-ferocious_majestic_salamander
This model is a fine-tuned version of [Gensyn/Qwen2.5-0.5B-Instruct](https://huggingface.co/Gensyn/Qwen2.5-0.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="gv6037/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-ferocious_majestic_salamander", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.15.2
- Transformers: 4.50.3
- Pytorch: 2.5.1
- Datasets: 3.5.0
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
bowilleatyou/2075e862-c911-456e-ab50-183a1a2a36dd
|
bowilleatyou
| 2025-04-03T14:54:27Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"unsloth",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-04-03T12:02:56Z
|
---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
dal-u/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-grassy_snappy_cheetah
|
dal-u
| 2025-04-03T14:52:25Z
| 0
| 0
|
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"rl-swarm",
"grpo",
"gensyn",
"I am grassy snappy cheetah",
"trl",
"conversational",
"arxiv:2402.03300",
"base_model:Gensyn/Qwen2.5-0.5B-Instruct",
"base_model:finetune:Gensyn/Qwen2.5-0.5B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-04-02T19:28:20Z
|
---
base_model: Gensyn/Qwen2.5-0.5B-Instruct
library_name: transformers
model_name: Qwen2.5-0.5B-Instruct-Gensyn-Swarm-grassy_snappy_cheetah
tags:
- generated_from_trainer
- rl-swarm
- grpo
- gensyn
- I am grassy snappy cheetah
- trl
licence: license
---
# Model Card for Qwen2.5-0.5B-Instruct-Gensyn-Swarm-grassy_snappy_cheetah
This model is a fine-tuned version of [Gensyn/Qwen2.5-0.5B-Instruct](https://huggingface.co/Gensyn/Qwen2.5-0.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="dal-u/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-grassy_snappy_cheetah", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.15.2
- Transformers: 4.50.3
- Pytorch: 2.5.1
- Datasets: 3.5.0
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
wwwtwwwt/whisper-tiny-Education-V3
|
wwwtwwwt
| 2025-04-03T14:51:29Z
| 0
| 0
|
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2025-04-03T14:51:13Z
|
---
library_name: transformers
license: apache-2.0
base_model: wwwtwwwt/whisper-tiny-no-specific-topic-V3
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: whisper-tiny-Education-V3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-tiny-Education-V3
This model is a fine-tuned version of [wwwtwwwt/whisper-tiny-no-specific-topic-V3](https://huggingface.co/wwwtwwwt/whisper-tiny-no-specific-topic-V3) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0906
- Wer: 44.3863
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 2000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:------:|:----:|:---------------:|:-------:|
| 0.7105 | 0.15 | 300 | 1.1709 | 53.2163 |
| 0.7531 | 1.1075 | 600 | 1.0890 | 52.7614 |
| 0.5798 | 2.065 | 900 | 1.0747 | 48.5443 |
| 0.3867 | 3.0225 | 1200 | 1.0781 | 45.5691 |
| 0.2759 | 3.1725 | 1500 | 1.0861 | 45.8193 |
| 0.2285 | 4.13 | 1800 | 1.0906 | 44.3863 |
### Framework versions
- Transformers 4.50.3
- Pytorch 2.5.1+cu121
- Datasets 3.5.0
- Tokenizers 0.21.0
|
chanind/gemma-2-2b-batch-topk-matryoshka-saes-w-32k-l0-40
|
chanind
| 2025-04-03T14:50:48Z
| 0
| 0
|
saelens
|
[
"saelens",
"region:us"
] | null | 2025-03-19T00:23:11Z
|
---
library_name: saelens
---
# SAEs for use with the SAELens library
This repository contains the following batch topk Matryoshka SAEs for [Gemma-2-2b](https://huggingface.co/google/gemma-2-2b).
All SAEs have 32k width and are trained with k=40 on 750M tokens from [the Pile](https://huggingface.co/datasets/monology/pile-uncopyrighted) using [SAELens](https://github.com/jbloomAus/SAELens).
The SAEs were trained with Matryoshka layers of width 128, 512, 2048, 8192, and 32768. This release contains both standard Matryoshka SAE and [snap loss Matryoshka SAEs](https://www.lesswrong.com/posts/qQ5RjRj7krhF693JL/feature-hedging-another-way-correlated-features-break-saes).
This repository contains the following SAEs:
### Snap Loss Matryoshka SAEs
| layer | SAE ID | width | l0 | explained variance |
|--------:|:-------------------------------|--------:|-----:|---------------------:|
| 0 | snap/blocks.0.hook_resid_post | 32768 | 40 | 0.919964 |
| 1 | snap/blocks.1.hook_resid_post | 32768 | 40 | 0.863969 |
| 2 | snap/blocks.2.hook_resid_post | 32768 | 40 | 0.858767 |
| 3 | snap/blocks.3.hook_resid_post | 32768 | 40 | 0.815844 |
| 4 | snap/blocks.4.hook_resid_post | 32768 | 40 | 0.821094 |
| 5 | snap/blocks.5.hook_resid_post | 32768 | 40 | 0.797083 |
| 6 | snap/blocks.6.hook_resid_post | 32768 | 40 | 0.79815 |
| 7 | snap/blocks.7.hook_resid_post | 32768 | 40 | 0.78946 |
| 8 | snap/blocks.8.hook_resid_post | 32768 | 40 | 0.779236 |
| 9 | snap/blocks.9.hook_resid_post | 32768 | 40 | 0.759022 |
| 10 | snap/blocks.10.hook_resid_post | 32768 | 40 | 0.743998 |
| 11 | snap/blocks.11.hook_resid_post | 32768 | 40 | 0.731758 |
| 12 | snap/blocks.12.hook_resid_post | 32768 | 40 | 0.725974 |
| 13 | snap/blocks.13.hook_resid_post | 32768 | 40 | 0.727936 |
| 14 | snap/blocks.14.hook_resid_post | 32768 | 40 | 0.727065 |
| 15 | snap/blocks.15.hook_resid_post | 32768 | 40 | 0.757408 |
| 16 | snap/blocks.16.hook_resid_post | 32768 | 40 | 0.751874 |
| 17 | snap/blocks.17.hook_resid_post | 32768 | 40 | 0.763654 |
| 18 | snap/blocks.18.hook_resid_post | 32768 | 40 | 0.77644 |
| 19 | snap/blocks.19.hook_resid_post | 32768 | 40 | 0.768622 |
| 20 | snap/blocks.20.hook_resid_post | 32768 | 40 | 0.761658 |
| 21 | snap/blocks.21.hook_resid_post | 32768 | 40 | 0.765593 |
| 22 | snap/blocks.22.hook_resid_post | 32768 | 40 | 0.741098 |
| 23 | snap/blocks.23.hook_resid_post | 32768 | 40 | 0.729718 |
| 24 | snap/blocks.24.hook_resid_post | 32768 | 40 | 0.754838 |
### Standard Matryoshka SAEs
| layer | SAE ID | width | l0 | explained variance |
|--------:|:-----------------------------------|--------:|-----:|---------------------:|
| 0 | standard/blocks.0.hook_resid_post | 32768 | 40 | 0.91832 |
| 1 | standard/blocks.1.hook_resid_post | 32768 | 40 | 0.863454 |
| 2 | standard/blocks.2.hook_resid_post | 32768 | 40 | 0.841324 |
| 3 | standard/blocks.3.hook_resid_post | 32768 | 40 | 0.814794 |
| 4 | standard/blocks.4.hook_resid_post | 32768 | 40 | 0.820418 |
| 5 | standard/blocks.5.hook_resid_post | 32768 | 40 | 0.796252 |
| 6 | standard/blocks.6.hook_resid_post | 32768 | 40 | 0.797322 |
| 7 | standard/blocks.7.hook_resid_post | 32768 | 40 | 0.787601 |
| 8 | standard/blocks.8.hook_resid_post | 32768 | 40 | 0.779433 |
| 9 | standard/blocks.9.hook_resid_post | 32768 | 40 | 0.75697 |
| 10 | standard/blocks.10.hook_resid_post | 32768 | 40 | 0.745011 |
| 11 | standard/blocks.11.hook_resid_post | 32768 | 40 | 0.732177 |
| 12 | standard/blocks.12.hook_resid_post | 32768 | 40 | 0.726209 |
| 13 | standard/blocks.13.hook_resid_post | 32768 | 40 | 0.719405 |
| 14 | standard/blocks.14.hook_resid_post | 32768 | 40 | 0.719056 |
| 15 | standard/blocks.15.hook_resid_post | 32768 | 40 | 0.756888 |
| 16 | standard/blocks.16.hook_resid_post | 32768 | 40 | 0.742889 |
| 17 | standard/blocks.17.hook_resid_post | 32768 | 40 | 0.757294 |
| 18 | standard/blocks.18.hook_resid_post | 32768 | 40 | 0.76921 |
| 19 | standard/blocks.19.hook_resid_post | 32768 | 40 | 0.766661 |
| 20 | standard/blocks.20.hook_resid_post | 32768 | 40 | 0.760939 |
| 21 | standard/blocks.21.hook_resid_post | 32768 | 40 | 0.759883 |
| 22 | standard/blocks.22.hook_resid_post | 32768 | 40 | 0.740612 |
| 23 | standard/blocks.23.hook_resid_post | 32768 | 40 | 0.729678 |
| 24 | standard/blocks.24.hook_resid_post | 32768 | 40 | 0.747313 |
Load these SAEs using SAELens as below:
```python
from sae_lens import SAE
sae, cfg_dict, sparsity = SAE.from_pretrained("chanind/gemma-2-2b-batch-topk-matryoshka-saes-w-32k-l0-40", "<sae_id>")
```
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.