---
license: cc-by-nc-nd-4.0
task_categories:
- audio-classification
language:
- zh
- en
tags:
- music
- art
pretty_name: Guzheng Technique 99 Dataset
size_categories:
- n<1K
viewer: false
---
If you want to view the dataset, please visit [here](https://www.modelscope.cn/datasets/ccmusic-database/Guzheng_Tech99/dataPeview)
# Dataset Card for Guzheng Technique 99 Dataset
## Original Content
This dataset is created and used by [[1]](https://arxiv.org/pdf/2303.13272) for frame-level Guzheng playing technique detection. The original dataset encompasses 99 solo compositions for Guzheng, recorded by professional musicians within a studio environment. Each composition is annotated for every note, indicating the onset, offset, pitch, and playing techniques. This is different from the GZ IsoTech, which is annotated at the clip-level. Also, its playing technique categories differ slightly, encompassing a total of seven techniques. They are: _Vibrato (chanyin 颤音), Plucks (boxian 拨弦), Upward Portamento (shanghua 上滑), Downward Portamento (xiahua 下滑), Glissando (huazhi\guazou\lianmo\liantuo 花指\刮奏\连抹\连托), Tremolo (yaozhi 摇指), and Point Note (dianyin 点音)_. This meticulous annotation results in a total of 63,352 annotated labels.
## Integration
In the original dataset, the labels were stored in a separate CSV file. This posed usability challenges, as researchers had to perform time-consuming operations on CSV parsing and label-audio alignment. After our integration, the data structure has been streamlined and optimized. It now contains three columns: audio sampled at 44,100 Hz, pre-processed mel spectrograms, and a dictionary. This dictionary contains onset, offset, technique numeric labels, and pitch. The number of data entries after integration remains 99, with a cumulative duration amounting to 151.08 minutes. The average audio duration is 91.56 seconds.
We performed data processing and constructed the [default subset](#default-subset) of the current integrated version of the dataset, and the details of its data structure can be viewed through the [viewer](https://www.modelscope.cn/datasets/ccmusic-database/Guzheng_Tech99/dataPeview). In light of the fact that the current dataset has been referenced and evaluated in a published article, we transcribe here the details of the dataset processing during the evaluation in the said article: each audio clip is a 3-second segment sampled at 44,100Hz, which is then converted into a log Constant-Q Transform (CQT) spectrogram. A CQT accompanied by a label constitutes a single data entry, forming the first and second columns, respectively. The CQT is a 3-dimensional array with dimensions of 88x258x1, representing the frequency-time structure of the audio. The label, on the other hand, is a 2-dimensional array with dimensions of 7x258, indicating the presence of seven distinct techniques across each time frame. Ultimately, given that the original dataset has already been divided into train, valid, and test sets, we have integrated the feature extraction method mentioned in this article's evaluation process into the API, thereby constructing the [eval subset](#eval-subset), which is not embodied in our paper.
## Statistics
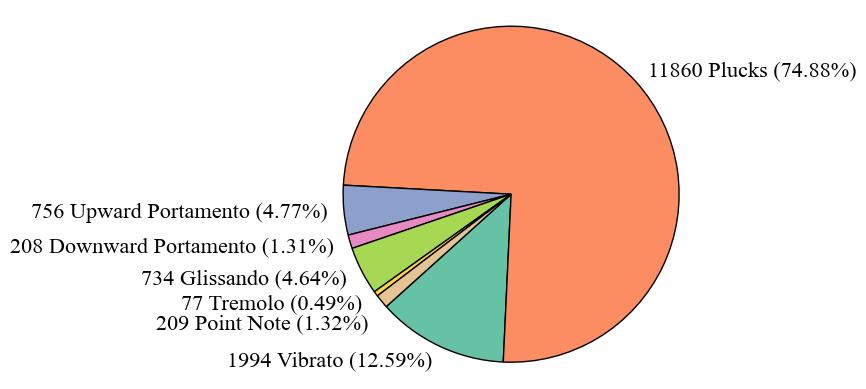
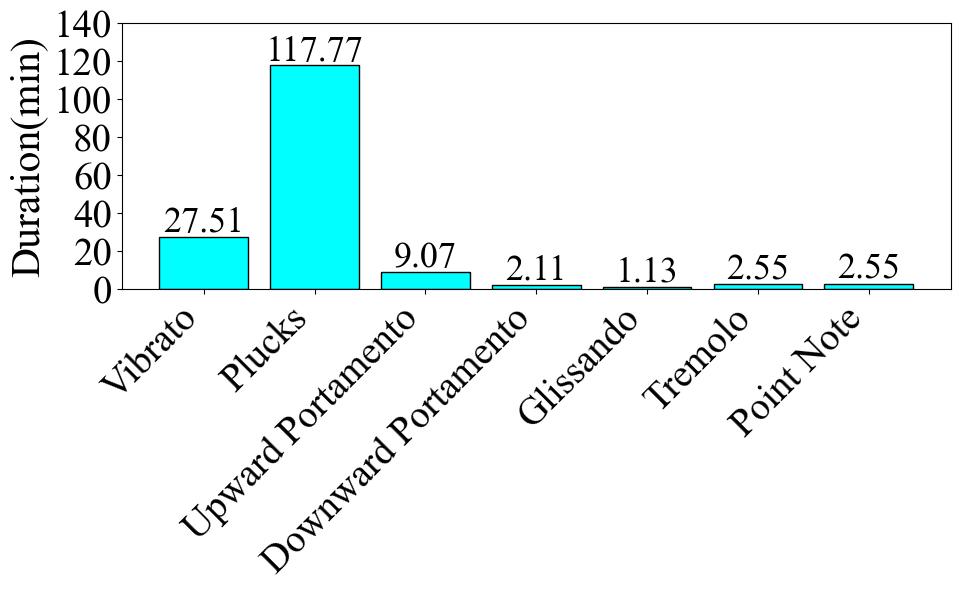
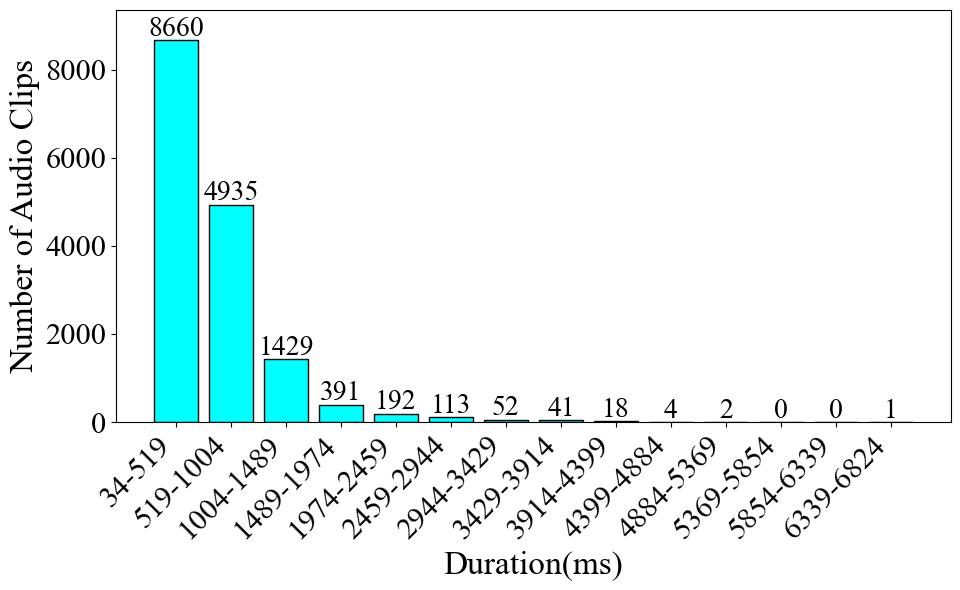
In this part, we present statistics at the label-level. The number of audio clips is equivalent to the count of either onset or offset occurrences. The duration of an audio clip is determined by calculating the offset time minus the onset time. At this level, the average audio duration is 0.62 seconds, with the shortest being 0.03 seconds and the longest 6.82 seconds.
|  |  |  |
| :--------------------------------------------------------------------------------------------------------: | :----------------------------------------------------------------------------------------------------: | :--------------------------------------------------------------------------------------------------------: |
| **Fig. 1** | **Fig. 2** | **Fig. 3** |
In this part, we present statistics at label level. The number of audio clips is equivalent to the count of either onset or offset occurrences. The duration of an audio clip is determined by calculating the offset time minus the onset time. At this level, the average audio duration is 0.62 seconds, with the shortest being 0.03 seconds and the longest 6.82 seconds. Firstly, **Fig. 1** illustrates the number and proportion of audio clips in each category. The *Plucks* category accounts for a significantly larger proportion than all other categories, comprising 74.88% of the dataset. The category with the smallest proportion is *Tremolo*, which accounts for only 0.49%, resulting in a difference of 74.39% between the largest and smallest categories. Next, **Fig. 2** presents the audio duration of each category. The total duration of *Plucks* audio is also significantly longer than all other categories, with a total duration of 117.77 minutes. In contrast, the category with the shortest total duration is *Glissando*, with only 1.13 minutes. This differs from the pie chart, where the smallest category was *Tremolo*. The difference between the longest and shortest durations is 116.64 minutes. From both the pie chart and the duration chart, it is evident that this dataset suffers from a severe data imbalance problem. In the end, **Fig. 3** gives the audio clip number across various duration intervals. Most of the audio clips are concentrated in the 34-1004 millisecond range. Among them, 8,660 audio clips fall within the 34-519 millisecond range, 4,935 clips fall within the 519-1004 millisecond range, and only 2,243 clips exceed 1004 milliseconds in length.
| Statistical items | Values |
| :------------------------------------------: | :------------------: |
| Total audio count | `99` |
| Total audio duration(s) | `9064.61260770975` |
| Avg audio duration(s) | `91.5617435122197` |
| Shortest audio duration(s) | `32.888004535147395` |
| Longest audio duration(s) | `327.7973469387755` |
| Total data count | `15838` |
| Total data duration(s) | `9760.579138441011` |
| Mean data duration(ms) | `616.2759905569524` |
| Min data duration(ms) | `34.81292724609375` |
| Max data duration(ms) | `6823.249816894531` |
| Class in the longest audio duartion interval | `boxian` |
## Dataset Structure
### Default Subset Structure
### Eval Subset Structure
| data(logCQT spectrogram) | label |
| :----------------------: | :--------------: |
| float64, 88 x 258 x 1 | float64, 7 x 258 |
### Data Instances
.zip(.flac, .csv)
### Data Fields
The dataset comprises 99 Guzheng solo compositions, recorded by professionals in a studio, totaling 9064.6 seconds. It includes seven playing techniques labeled for each note (onset, offset, pitch, vibrato, point note, upward portamento, downward portamento, plucks, glissando, and tremolo), resulting in 63,352 annotated labels. The dataset is divided into 79, 10, and 10 songs for the training, validation, and test sets, respectively.
### Data Splits
train, validation, test
## Dataset Description
### Dataset Summary
The integrated version provides the original content and the spectrogram generated in the experimental part of the paper cited above. For the second part, the pre-process in the paper is replicated. Each audio clip is a 3-second segment sampled at 44,100Hz, which is subsequently converted into a log Constant-Q Transform (CQT) spectrogram. A CQT accompanied by a label constitutes a single data entry, forming the first and second columns, respectively. The CQT is a 3-dimensional array with the dimension of 88 x 258 x 1, representing the frequency-time structure of the audio. The label, on the other hand, is a 2-dimensional array with dimensions of 7 x 258, which indicates the presence of seven distinct techniques across each time frame. indicating the existence of the seven techniques in each time frame. In the end, given that the raw dataset has already been split into train, valid, and test sets, the integrated dataset maintains the same split method. This dataset can be used for frame-level guzheng playing technique detection.
### Supported Tasks and Leaderboards
MIR, audio classification
### Languages
Chinese, English
## Usage
### Default Subset
```python
from datasets import load_dataset
ds = load_dataset("ccmusic-database/Guzheng_Tech99", split="train")
for item in ds:
print(item)
```
### Eval Subset
```python
from datasets import load_dataset
ds = load_dataset("ccmusic-database/Guzheng_Tech99", name="eval")
for item in ds["train"]:
print(item)
for item in ds["validation"]:
print(item)
for item in ds["test"]:
print(item)
```
## Maintenance
```bash
git clone git@hf.co:datasets/ccmusic-database/Guzheng_Tech99
cd Guzheng_Tech99
```
## Dataset Creation
### Curation Rationale
Instrument playing technique (IPT) is a key element of musical presentation.
### Source Data
#### Initial Data Collection and Normalization
Dichucheng Li, Monan Zhou
#### Who are the source language producers?
Students from FD-LAMT
### Annotations
#### Annotation process
Guzheng is a polyphonic instrument. In Guzheng performance, notes with different IPTs are usually overlapped and mixed IPTs that can be decomposed into multiple independent IPTs are usually used. Most existing work on IPT detection typically uses datasets with monophonic instrumental solo pieces. This dataset fills a gap in the research field.
#### Who are the annotators?
Students from FD-LAMT
## Considerations for Using the Data
### Social Impact of Dataset
Promoting the development of the music AI industry
### Discussion of Biases
Only for Traditional Chinese Instruments
### Other Known Limitations
Insufficient sample
## Additional Information
### Dataset Curators
Dichucheng Li
### Evaluation
[1] [Dichucheng Li, Mingjin Che, Wenwu Meng, Yulun Wu, Yi Yu, Fan Xia and Wei Li. "Frame-Level Multi-Label Playing Technique Detection Using Multi-Scale Network and Self-Attention Mechanism", in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2023).](https://arxiv.org/pdf/2303.13272.pdf)
[2]
### Citation Information
```bibtex
@dataset{zhaorui_liu_2021_5676893,
author = {Monan Zhou, Shenyang Xu, Zhaorui Liu, Zhaowen Wang, Feng Yu, Wei Li and Baoqiang Han},
title = {CCMusic: an Open and Diverse Database for Chinese Music Information Retrieval Research},
month = {mar},
year = {2024},
publisher = {HuggingFace},
version = {1.2},
url = {https://huggingface.co/ccmusic-database}
}
```
### Contributions
Promoting the development of the music AI industry