-
-
\ No newline at end of file diff --git a/spaces/1pelhydcardo/ChatGPT-prompt-generator/assets/Clash of Clans Son Srm APK ndir - Efsanevi Bir Sava Oyunu Deneyimi.md b/spaces/1pelhydcardo/ChatGPT-prompt-generator/assets/Clash of Clans Son Srm APK ndir - Efsanevi Bir Sava Oyunu Deneyimi.md deleted file mode 100644 index ede09b35cc1b2630cfec58564a371b8379716104..0000000000000000000000000000000000000000 --- a/spaces/1pelhydcardo/ChatGPT-prompt-generator/assets/Clash of Clans Son Srm APK ndir - Efsanevi Bir Sava Oyunu Deneyimi.md +++ /dev/null @@ -1,169 +0,0 @@ -
-
Son Sürüm Clash of Clans APK İndir: Nasıl Yapılır ve Neden Yapmalısınız?
-Clash of Clans, dünyanın en popüler strateji oyunlarından biridir. Milyonlarca oyuncu, kendi köylerini inşa etmek, klan savaşlarına katılmak ve rakiplerini yenmek için bu oyunu oynamaktadır. Peki, son sürüm clash of clans apk indirerek bu oyunu daha da eğlenceli hale getirebilirsiniz. Bu yazıda, son sürüm clash of clans apk indirmenin nasıl yapıldığını, neden yapmanız gerektiğini ve bunun size ne gibi faydalar sağlayacağını anlatacağız.
-son sürüm clash of clans apk indir
Download Zip > https://urlin.us/2uSYYJ
-
Clash of Clans Nedir ve Neden Popüler?
-Clash of Clans, Supercell tarafından geliştirilen ve 2012 yılında piyasaya sürülen bir çevrimiçi çok oyunculu savaş oyunudur. Oyunun amacı, köyünüzü inşa etmek, üssünüzü tasarlamak ve savunmak, askerlerinizi eğitmek ve geliştirmek, kaynaklarınızı artırmak ve diğer oyuncuların köylerine saldırarak altın, iksir ve kara iksir elde etmektir. Ayrıca, bir klan kurabilir veya başka bir klana katılarak klan savaşlarına, klan liglerine ve klan oyunlarına katılabilirsiniz. Oyun sürekli olarak güncellenmekte ve yeni özellikler, birimler, binalar, büyüler ve etkinlikler eklenmektedir.
-Clash of Clans Oyununun Özellikleri
-Clash of Clans oyununun bazı özellikleri şunlardır:
--
-
- Köyünüzü istediğiniz gibi inşa edebilir ve düzenleyebilirsiniz. -
- Birbirinden farklı yeteneklere sahip çok sayıda asker tipi arasından seçim yapabilirsiniz. -
- Benzersiz güçlere ve stratejilere sahip epik savaşlara katılabilirsiniz. -
- Oyun ücretsizdir ve herhangi bir cihazda oynanabilir. -
- Oyun sürekli olarak güncellenir ve yeni içerikler sunar. -
- Oyun hem bireysel hem de takım halinde oynanabilir. -
- Oyun strateji, planlama, yaratıcılık ve eğlenceyi bir arada sunar. -
- Oyun dünyanın her yerinden milyonlarca oyuncu ile sosyalleşme imkanı sağlar. -
- Son sürüm clash of clans apk indirerek oyunun en güncel ve en yeni versiyonuna sahip olabilirsiniz. -
- Son sürüm clash of clans apk indirerek oyunun resmi olarak sunulmayan bazı özelliklerine ve modlarına erişebilirsiniz. -
- Son sürüm clash of clans apk indirerek oyunu daha hızlı, daha akıcı ve daha sorunsuz bir şekilde oynayabilirsiniz. -
- Son sürüm clash of clans apk indirerek oyunu istediğiniz zaman ve istediğiniz yerde oynayabilirsiniz. -
- Bir Android cihaz (telefon, tablet, bilgisayar vb.) -
- Bir internet bağlantısı -
- Bir güvenilir ve güncel son sürüm clash of clans apk indirme sitesi -
- Bir dosya yöneticisi uygulaması -
- Öncelikle, cihazınızın ayarlar menüsünden bilinmeyen kaynaklardan uygulama yükleme seçeneğini etkinleştirin. Bu, cihazınıza resmi olmayan uygulamaları kurmanıza izin verecektir. -
- Ardından, bir internet tarayıcısı açın ve güvenilir bir son sürüm clash of clans apk indirme sitesine gidin. Bu sitelerden bazıları şunlardır: , , . Bu sitelerden birini seçin ve son sürüm clash of clans apk dosyasını indirmek için talimatları takip edin. -
- Daha sonra, indirdiğiniz son sürüm clash of clans apk dosyasını bulmak için bir dosya yöneticisi uygulaması açın. Bu uygulamaların bazıları şunlardır: , , . Bu uygulamalardan birini seçin ve son sürüm clash of clans apk dosyasını cihazınızın hafızasında veya harici depolama alanında arayın. -
- Köyünüzü inşa ederken dengeli bir şekilde hem savunma hem de saldırı odaklanın. -
- Askerlerinizi akıllıca seçin ve farklı durumlara uygun stratejiler geliştirin. -
- Klanınıza katılın veya kurun ve diğer oyuncularla işbirliği yapın. -
- Oyunun sunduğu etkinlikleri, görevleri ve ödülleri kaçırmayın. -
- Oyunu eğlenmek için oynayın ve rakiplerinize saygılı davranın. -
- Son sürüm clash of clans apk indirmek ücretli mi? -
- Son sürüm clash of clans apk indirmek cihazımı bozar mı? -
- Son sürüm clash of clans apk indirmek oyunumun verilerini siler mi? -
- Son sürüm clash of clans apk indirmek bana ban sebebi olur mu? -
- Son sürüm clash of clans apk indirmek oyunu daha kolay yapar mı? -
- A new track called "Tokyo Night" that lets you drift in the neon-lit streets of Japan. -
- A new car pack that includes four new cars: Nissan Skyline GT-R R34, Toyota Supra MK4, Mazda RX-7 FD, and Subaru Impreza WRX STI. -
- A new game mode called "Drift Wars" that pits you against other players online in a drift battle. -
- A new feature called "Car Customization" that allows you to modify your car's appearance, performance, and tuning. -
- A new feature called "Replay Mode" that lets you watch your best drifts from different angles and share them with your friends. -
- Improved graphics, sound effects, and user interface. -
- Bug fixes and stability improvements. -
- "Career Mode" where you can complete various missions and challenges to unlock new cars, tracks, and upgrades. -
- "Multiplayer Mode" where you can compete with other players online in real-time or join a drift club and challenge other clubs. -
- "Drift Wars Mode" where you can show off your drifting skills and earn respect from other players in a drift battle. -
- "Training Base" where you can learn the basics of drifting and test your car's performance. -
- "Parking Lot" where you can practice your drifting techniques and tricks in a spacious area. -
- "San Palezzo" where you can drift along the coast and enjoy the scenic view of the sea. -
- "Red Rock" where you can drift on a dusty road surrounded by red rocks and cacti. -
- "Tokyo Night" where you can drift in the neon-lit streets of Japan and feel the atmosphere of the city. -
- It is free to download and play, with optional in-app purchases for extra features and content. -
- It has realistic and fun gameplay, with smooth controls, physics-based car behavior, and various game modes and tracks. -
- It has stunning graphics and sound effects, with high-quality visuals, animations, and sounds. -
- It has a lot of customization options, with over 40 cars to choose from, hundreds of parts and accessories to modify your car's appearance, performance, and tuning. -
- It has a social aspect, with online multiplayer mode, drift clubs, leaderboards, chat rooms, and replay mode. -
- It requires a lot of storage space on your device, as it is a large file that takes up about 600 MB of memory. -
- It requires a stable internet connection for some features, such as multiplayer mode, drift wars mode, and online updates. -
- It can be challenging and frustrating for beginners, as it requires a lot of practice and skill to master drifting and earn points. -
- It can be repetitive and boring for some players, as it does not have a lot of variety or story in its gameplay. -
- It can be expensive for some players, as it has a lot of in-app purchases that might tempt you to spend real money on coins, golds, or premium cars. -
- Go to [this link] to download the CarX Drift Racing APK 1.21.1 file on your device. -
- Once the download is complete, locate the file in your device's file manager or downloads folder. -
- Tap on the file to start the installation process. You might need to enable "Unknown Sources" in your device's settings to allow the installation of apps from sources other than Google Play Store. -
- Follow the instructions on the screen to complete the installation process. -
- Choose the right car for your drifting style. Different cars have different characteristics, such as speed, acceleration, handling, and driftability. You can compare the stats of each car and test them on different tracks to find the one that suits you best. -
- Upgrade and tune your car to optimize its performance. You can use coins and golds to buy new parts and accessories for your car, such as tires, engines, brakes, suspensions, and turbos. You can also adjust the tuning of your car, such as camber, toe, caster, differential, and gearbox, to change its behavior on the road. -
- Use the handbrake and the throttle wisely. The handbrake is useful for initiating and maintaining drifts, while the throttle is useful for controlling the speed and angle of your drifts. You can also use the clutch kick and the weight shift techniques to enhance your drifts. -
- Practice on different tracks and game modes. The more you practice, the more you will learn how to drift on different surfaces, curves, and obstacles. You can also try different game modes and challenges to test your skills and earn more rewards. -
- Watch replays and learn from other players. You can watch your own replays or other players' replays to analyze your mistakes and improve your techniques. You can also join a drift club or a drift war to learn from other players and compete with them. -
- Is CarX Drift Racing APK 1.21.1 safe to download and install? -
- How can I get more coins and golds in CarX Drift Racing APK 1.21.1? -
- How can I join a drift club or a drift war in CarX Drift Racing APK 1.21.1? -
- How can I share my replays with my friends in CarX Drift Racing APK 1.21.1? -
- How can I contact the developers of CarX Drift Racing APK 1.21.1? -
- It is free to download and use, with no registration or subscription required. -
- It supports multiple protocols, such as OpenVPN, WireGuard, IKEv2, etc. -
- It has a large network of servers in over 50 countries. -
- It provides unlimited bandwidth and speed. -
- It has a simple and user-friendly interface. -
- It works with all Android devices running Android 4.0 or higher. -
- Go to the official website of NIC VPN Beta 6 APK and click on the download button. -
- Once the download is complete, locate the APK file on your device and tap on it. -
- If you see a warning message that says "Install blocked", go to your device settings and enable "Unknown sources" under security options. -
- Tap on "Install" and wait for the installation process to finish. -
- Launch the app and select a server location from the list. -
- Tap on "Connect" and enjoy using NIC VPN Beta 6 APK. -
-
-
- - - - - ----
General Info:
- ${info_div.join('\n')} -
- - '; - _update_cache(data); - } else { - console.log('We already have cache!'); - } - - inputs = ulColumns.querySelectorAll('input'); - for (let i = 1; i < inputs.length; i++) { - if (!inputs[i].checked) continue; - _plot(i-1); - } - }; - reader.readAsText(selectedFile); - } else { - console.warn('There is no file!'); - } -} - -function _comeback_options() { - dropdownSearch.style.display = 'none'; - let ids = new Set(); - for (let chart of charts.getElementsByClassName('cols')) { - ids.add(+chart.id.split('-')[1]); - } - - const inputs = ulColumns.querySelectorAll('input'); - inputs[0].checked = false; - for (let i = 1; i < inputs.length; i++) { - inputs[i].checked = ids.has(i-1); - } - - _update_dropdown_text(ids.size, inputs.length-1); -} - -function _apply_options() { - dropdownSearch.style.display = 'none'; - const inputs = ulColumns.querySelectorAll('input'); - for (let i = 1; i < inputs.length; i++) { - _toggle_column(i-1, inputs[i].checked); - } -} - -const showDropdownButton = document.getElementById('showDropdown'); -const dropdownSearch = document.getElementById('dropdownSearch'); -const ulColumns = document.getElementById('ul-columns'); - -showDropdownButton.addEventListener('click', function() { - if (dropdownSearch.style.display === 'none' || dropdownSearch.style.display === '') { - dropdownSearch.style.display = 'block'; - } else { - dropdownSearch.style.display = 'none'; - } -}); - -document.getElementById('cancel').addEventListener('click', _comeback_options); -document.getElementById('apply').addEventListener('click', _apply_options); diff --git a/spaces/ECCV2022/PSG/OpenPSG/configs/_base_/datasets/vg_sg.py b/spaces/ECCV2022/PSG/OpenPSG/configs/_base_/datasets/vg_sg.py deleted file mode 100644 index 5f555ac70bc04c85cbeb9099fd792114ee2ed9a9..0000000000000000000000000000000000000000 --- a/spaces/ECCV2022/PSG/OpenPSG/configs/_base_/datasets/vg_sg.py +++ /dev/null @@ -1,57 +0,0 @@ -# dataset settings -dataset_type = 'SceneGraphDataset' -ann_file = '/mnt/ssd/gzj/data/VisualGenome/data_openpsg.json' -img_dir = '/mnt/ssd/gzj/data/VisualGenome/VG_100K' - -img_norm_cfg = dict(mean=[123.675, 116.28, 103.53], - std=[58.395, 57.12, 57.375], - to_rgb=True) -train_pipeline = [ - dict(type='LoadImageFromFile'), - dict(type='LoadSceneGraphAnnotations', with_bbox=True, with_rel=True), - dict(type='Resize', img_scale=(1333, 800), keep_ratio=True), - dict(type='RandomFlip', flip_ratio=0.5), - dict(type='Normalize', **img_norm_cfg), - dict(type='Pad', size_divisor=32), - dict(type='SceneGraphFormatBundle'), - dict(type='Collect', - keys=['img', 'gt_bboxes', 'gt_labels', 'gt_rels', 'gt_relmaps']), -] -test_pipeline = [ - dict(type='LoadImageFromFile'), - # Since the forward process may need gt info, annos must be loaded. - dict(type='LoadSceneGraphAnnotations', with_bbox=True, with_rel=True), - dict( - type='MultiScaleFlipAug', - img_scale=(1333, 800), - flip=False, - transforms=[ - dict(type='Resize', keep_ratio=True), - dict(type='RandomFlip'), - dict(type='Normalize', **img_norm_cfg), - dict(type='Pad', size_divisor=32), - # NOTE: Do not change the img to DC. - dict(type='ImageToTensor', keys=['img']), - dict(type='ToTensor', keys=['gt_bboxes', 'gt_labels']), - dict(type='ToDataContainer', - fields=(dict(key='gt_bboxes'), dict(key='gt_labels'))), - dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']), - ]) -] -data = dict(samples_per_gpu=2, - workers_per_gpu=2, - train=dict(type=dataset_type, - ann_file=ann_file, - img_prefix=img_dir, - pipeline=train_pipeline, - split='train'), - val=dict(type=dataset_type, - ann_file=ann_file, - img_prefix=img_dir, - pipeline=test_pipeline, - split='test'), - test=dict(type=dataset_type, - ann_file=ann_file, - img_prefix=img_dir, - pipeline=test_pipeline, - split='test')) diff --git a/spaces/EronSamez/RVC_HFmeu/infer_batch_rvc.py b/spaces/EronSamez/RVC_HFmeu/infer_batch_rvc.py deleted file mode 100644 index 15c862a3d6bf815fa68003cc7054b694cae50c2a..0000000000000000000000000000000000000000 --- a/spaces/EronSamez/RVC_HFmeu/infer_batch_rvc.py +++ /dev/null @@ -1,215 +0,0 @@ -""" -v1 -runtime\python.exe myinfer-v2-0528.py 0 "E:\codes\py39\RVC-beta\todo-songs" "E:\codes\py39\logs\mi-test\added_IVF677_Flat_nprobe_7.index" harvest "E:\codes\py39\RVC-beta\output" "E:\codes\py39\test-20230416b\weights\mi-test.pth" 0.66 cuda:0 True 3 0 1 0.33 -v2 -runtime\python.exe myinfer-v2-0528.py 0 "E:\codes\py39\RVC-beta\todo-songs" "E:\codes\py39\test-20230416b\logs\mi-test-v2\aadded_IVF677_Flat_nprobe_1_v2.index" harvest "E:\codes\py39\RVC-beta\output_v2" "E:\codes\py39\test-20230416b\weights\mi-test-v2.pth" 0.66 cuda:0 True 3 0 1 0.33 -""" -import os, sys, pdb, torch - -now_dir = os.getcwd() -sys.path.append(now_dir) -import sys -import torch -import tqdm as tq -from multiprocessing import cpu_count - - -class Config: - def __init__(self, device, is_half): - self.device = device - self.is_half = is_half - self.n_cpu = 0 - self.gpu_name = None - self.gpu_mem = None - self.x_pad, self.x_query, self.x_center, self.x_max = self.device_config() - - def device_config(self) -> tuple: - if torch.cuda.is_available(): - i_device = int(self.device.split(":")[-1]) - self.gpu_name = torch.cuda.get_device_name(i_device) - if ( - ("16" in self.gpu_name and "V100" not in self.gpu_name.upper()) - or "P40" in self.gpu_name.upper() - or "1060" in self.gpu_name - or "1070" in self.gpu_name - or "1080" in self.gpu_name - ): - print("16系/10系显卡和P40强制单精度") - self.is_half = False - for config_file in ["32k.json", "40k.json", "48k.json"]: - with open(f"configs/{config_file}", "r") as f: - strr = f.read().replace("true", "false") - with open(f"configs/{config_file}", "w") as f: - f.write(strr) - with open("infer/modules/train/preprocess.py", "r") as f: - strr = f.read().replace("3.7", "3.0") - with open("infer/modules/train/preprocess.py", "w") as f: - f.write(strr) - else: - self.gpu_name = None - self.gpu_mem = int( - torch.cuda.get_device_properties(i_device).total_memory - / 1024 - / 1024 - / 1024 - + 0.4 - ) - if self.gpu_mem <= 4: - with open("infer/modules/train/preprocess.py", "r") as f: - strr = f.read().replace("3.7", "3.0") - with open("infer/modules/train/preprocess.py", "w") as f: - f.write(strr) - elif torch.backends.mps.is_available(): - print("没有发现支持的N卡, 使用MPS进行推理") - self.device = "mps" - else: - print("没有发现支持的N卡, 使用CPU进行推理") - self.device = "cpu" - self.is_half = True - - if self.n_cpu == 0: - self.n_cpu = cpu_count() - - if self.is_half: - # 6G显存配置 - x_pad = 3 - x_query = 10 - x_center = 60 - x_max = 65 - else: - # 5G显存配置 - x_pad = 1 - x_query = 6 - x_center = 38 - x_max = 41 - - if self.gpu_mem != None and self.gpu_mem <= 4: - x_pad = 1 - x_query = 5 - x_center = 30 - x_max = 32 - - return x_pad, x_query, x_center, x_max - - -f0up_key = sys.argv[1] -input_path = sys.argv[2] -index_path = sys.argv[3] -f0method = sys.argv[4] # harvest or pm -opt_path = sys.argv[5] -model_path = sys.argv[6] -index_rate = float(sys.argv[7]) -device = sys.argv[8] -is_half = sys.argv[9].lower() != "false" -filter_radius = int(sys.argv[10]) -resample_sr = int(sys.argv[11]) -rms_mix_rate = float(sys.argv[12]) -protect = float(sys.argv[13]) -print(sys.argv) -config = Config(device, is_half) -now_dir = os.getcwd() -sys.path.append(now_dir) -from infer.modules.vc.modules import VC -from lib.infer_pack.models import ( - SynthesizerTrnMs256NSFsid, - SynthesizerTrnMs256NSFsid_nono, - SynthesizerTrnMs768NSFsid, - SynthesizerTrnMs768NSFsid_nono, -) -from infer.lib.audio import load_audio -from fairseq import checkpoint_utils -from scipy.io import wavfile - -hubert_model = None - - -def load_hubert(): - global hubert_model - models, saved_cfg, task = checkpoint_utils.load_model_ensemble_and_task( - ["hubert_base.pt"], - suffix="", - ) - hubert_model = models[0] - hubert_model = hubert_model.to(device) - if is_half: - hubert_model = hubert_model.half() - else: - hubert_model = hubert_model.float() - hubert_model.eval() - - -def vc_single(sid, input_audio, f0_up_key, f0_file, f0_method, file_index, index_rate): - global tgt_sr, net_g, vc, hubert_model, version - if input_audio is None: - return "You need to upload an audio", None - f0_up_key = int(f0_up_key) - audio = load_audio(input_audio, 16000) - times = [0, 0, 0] - if hubert_model == None: - load_hubert() - if_f0 = cpt.get("f0", 1) - # audio_opt=vc.pipeline(hubert_model,net_g,sid,audio,times,f0_up_key,f0_method,file_index,file_big_npy,index_rate,if_f0,f0_file=f0_file) - audio_opt = vc.pipeline( - hubert_model, - net_g, - sid, - audio, - input_audio, - times, - f0_up_key, - f0_method, - file_index, - index_rate, - if_f0, - filter_radius, - tgt_sr, - resample_sr, - rms_mix_rate, - version, - protect, - f0_file=f0_file, - ) - print(times) - return audio_opt - - -def get_vc(model_path): - global n_spk, tgt_sr, net_g, vc, cpt, device, is_half, version - print("loading pth %s" % model_path) - cpt = torch.load(model_path, map_location="cpu") - tgt_sr = cpt["config"][-1] - cpt["config"][-3] = cpt["weight"]["emb_g.weight"].shape[0] # n_spk - if_f0 = cpt.get("f0", 1) - version = cpt.get("version", "v1") - if version == "v1": - if if_f0 == 1: - net_g = SynthesizerTrnMs256NSFsid(*cpt["config"], is_half=is_half) - else: - net_g = SynthesizerTrnMs256NSFsid_nono(*cpt["config"]) - elif version == "v2": - if if_f0 == 1: # - net_g = SynthesizerTrnMs768NSFsid(*cpt["config"], is_half=is_half) - else: - net_g = SynthesizerTrnMs768NSFsid_nono(*cpt["config"]) - del net_g.enc_q - print(net_g.load_state_dict(cpt["weight"], strict=False)) # 不加这一行清不干净,真奇葩 - net_g.eval().to(device) - if is_half: - net_g = net_g.half() - else: - net_g = net_g.float() - vc = VC(tgt_sr, config) - n_spk = cpt["config"][-3] - # return {"visible": True,"maximum": n_spk, "__type__": "update"} - - -get_vc(model_path) -audios = os.listdir(input_path) -for file in tq.tqdm(audios): - if file.endswith(".wav"): - file_path = input_path + "/" + file - wav_opt = vc_single( - 0, file_path, f0up_key, None, f0method, index_path, index_rate - ) - out_path = opt_path + "/" + file - wavfile.write(out_path, tgt_sr, wav_opt) diff --git a/spaces/EronSamez/RVC_HFmeu/tools/calc_rvc_model_similarity.py b/spaces/EronSamez/RVC_HFmeu/tools/calc_rvc_model_similarity.py deleted file mode 100644 index 42496e088e51dc5162d0714470c2226f696e260c..0000000000000000000000000000000000000000 --- a/spaces/EronSamez/RVC_HFmeu/tools/calc_rvc_model_similarity.py +++ /dev/null @@ -1,96 +0,0 @@ -# This code references https://huggingface.co/JosephusCheung/ASimilarityCalculatior/blob/main/qwerty.py -# Fill in the path of the model to be queried and the root directory of the reference models, and this script will return the similarity between the model to be queried and all reference models. -import os -import logging - -logger = logging.getLogger(__name__) - -import torch -import torch.nn as nn -import torch.nn.functional as F - - -def cal_cross_attn(to_q, to_k, to_v, rand_input): - hidden_dim, embed_dim = to_q.shape - attn_to_q = nn.Linear(hidden_dim, embed_dim, bias=False) - attn_to_k = nn.Linear(hidden_dim, embed_dim, bias=False) - attn_to_v = nn.Linear(hidden_dim, embed_dim, bias=False) - attn_to_q.load_state_dict({"weight": to_q}) - attn_to_k.load_state_dict({"weight": to_k}) - attn_to_v.load_state_dict({"weight": to_v}) - - return torch.einsum( - "ik, jk -> ik", - F.softmax( - torch.einsum("ij, kj -> ik", attn_to_q(rand_input), attn_to_k(rand_input)), - dim=-1, - ), - attn_to_v(rand_input), - ) - - -def model_hash(filename): - try: - with open(filename, "rb") as file: - import hashlib - - m = hashlib.sha256() - - file.seek(0x100000) - m.update(file.read(0x10000)) - return m.hexdigest()[0:8] - except FileNotFoundError: - return "NOFILE" - - -def eval(model, n, input): - qk = f"enc_p.encoder.attn_layers.{n}.conv_q.weight" - uk = f"enc_p.encoder.attn_layers.{n}.conv_k.weight" - vk = f"enc_p.encoder.attn_layers.{n}.conv_v.weight" - atoq, atok, atov = model[qk][:, :, 0], model[uk][:, :, 0], model[vk][:, :, 0] - - attn = cal_cross_attn(atoq, atok, atov, input) - return attn - - -def main(path, root): - torch.manual_seed(114514) - model_a = torch.load(path, map_location="cpu")["weight"] - - logger.info("Query:\t\t%s\t%s" % (path, model_hash(path))) - - map_attn_a = {} - map_rand_input = {} - for n in range(6): - hidden_dim, embed_dim, _ = model_a[ - f"enc_p.encoder.attn_layers.{n}.conv_v.weight" - ].shape - rand_input = torch.randn([embed_dim, hidden_dim]) - - map_attn_a[n] = eval(model_a, n, rand_input) - map_rand_input[n] = rand_input - - del model_a - - for name in sorted(list(os.listdir(root))): - path = "%s/%s" % (root, name) - model_b = torch.load(path, map_location="cpu")["weight"] - - sims = [] - for n in range(6): - attn_a = map_attn_a[n] - attn_b = eval(model_b, n, map_rand_input[n]) - - sim = torch.mean(torch.cosine_similarity(attn_a, attn_b)) - sims.append(sim) - - logger.info( - "Reference:\t%s\t%s\t%s" - % (path, model_hash(path), f"{torch.mean(torch.stack(sims)) * 1e2:.2f}%") - ) - - -if __name__ == "__main__": - query_path = r"assets\weights\mi v3.pth" - reference_root = r"assets\weights" - main(query_path, reference_root) diff --git a/spaces/EsoCode/text-generation-webui/modules/models.py b/spaces/EsoCode/text-generation-webui/modules/models.py deleted file mode 100644 index f12e700c2345fc574dcf8274ab3dbdefeba82a3f..0000000000000000000000000000000000000000 --- a/spaces/EsoCode/text-generation-webui/modules/models.py +++ /dev/null @@ -1,334 +0,0 @@ -import gc -import os -import re -import time -from pathlib import Path - -import torch -import transformers -from accelerate import infer_auto_device_map, init_empty_weights -from transformers import ( - AutoConfig, - AutoModel, - AutoModelForCausalLM, - AutoModelForSeq2SeqLM, - AutoTokenizer, - BitsAndBytesConfig, - LlamaTokenizer -) - -import modules.shared as shared -from modules import llama_attn_hijack, sampler_hijack -from modules.logging_colors import logger -from modules.models_settings import infer_loader - -transformers.logging.set_verbosity_error() - -local_rank = None -if shared.args.deepspeed: - import deepspeed - from transformers.deepspeed import ( - HfDeepSpeedConfig, - is_deepspeed_zero3_enabled - ) - - from modules.deepspeed_parameters import generate_ds_config - - # Distributed setup - local_rank = shared.args.local_rank if shared.args.local_rank is not None else int(os.getenv("LOCAL_RANK", "0")) - world_size = int(os.getenv("WORLD_SIZE", "1")) - torch.cuda.set_device(local_rank) - deepspeed.init_distributed() - ds_config = generate_ds_config(shared.args.bf16, 1 * world_size, shared.args.nvme_offload_dir) - dschf = HfDeepSpeedConfig(ds_config) # Keep this object alive for the Transformers integration - -sampler_hijack.hijack_samplers() - - -def load_model(model_name, loader=None): - logger.info(f"Loading {model_name}...") - t0 = time.time() - - shared.is_seq2seq = False - load_func_map = { - 'Transformers': huggingface_loader, - 'AutoGPTQ': AutoGPTQ_loader, - 'GPTQ-for-LLaMa': GPTQ_loader, - 'llama.cpp': llamacpp_loader, - 'FlexGen': flexgen_loader, - 'RWKV': RWKV_loader, - 'ExLlama': ExLlama_loader, - 'ExLlama_HF': ExLlama_HF_loader - } - - if loader is None: - if shared.args.loader is not None: - loader = shared.args.loader - else: - loader = infer_loader(model_name) - if loader is None: - logger.error('The path to the model does not exist. Exiting.') - return None, None - - shared.args.loader = loader - output = load_func_map[loader](model_name) - if type(output) is tuple: - model, tokenizer = output - else: - model = output - if model is None: - return None, None - else: - tokenizer = load_tokenizer(model_name, model) - - # Hijack attention with xformers - if any((shared.args.xformers, shared.args.sdp_attention)): - llama_attn_hijack.hijack_llama_attention() - - logger.info(f"Loaded the model in {(time.time()-t0):.2f} seconds.\n") - return model, tokenizer - - -def load_tokenizer(model_name, model): - tokenizer = None - if any(s in model_name.lower() for s in ['gpt-4chan', 'gpt4chan']) and Path(f"{shared.args.model_dir}/gpt-j-6B/").exists(): - tokenizer = AutoTokenizer.from_pretrained(Path(f"{shared.args.model_dir}/gpt-j-6B/")) - elif model.__class__.__name__ in ['LlamaForCausalLM', 'LlamaGPTQForCausalLM', 'ExllamaHF']: - # Try to load an universal LLaMA tokenizer - if not any(s in shared.model_name.lower() for s in ['llava', 'oasst']): - for p in [Path(f"{shared.args.model_dir}/llama-tokenizer/"), Path(f"{shared.args.model_dir}/oobabooga_llama-tokenizer/")]: - if p.exists(): - logger.info(f"Loading the universal LLaMA tokenizer from {p}...") - tokenizer = LlamaTokenizer.from_pretrained(p, clean_up_tokenization_spaces=True) - return tokenizer - - # Otherwise, load it from the model folder and hope that these - # are not outdated tokenizer files. - tokenizer = LlamaTokenizer.from_pretrained(Path(f"{shared.args.model_dir}/{model_name}/"), clean_up_tokenization_spaces=True) - try: - tokenizer.eos_token_id = 2 - tokenizer.bos_token_id = 1 - tokenizer.pad_token_id = 0 - except: - pass - else: - path_to_model = Path(f"{shared.args.model_dir}/{model_name}/") - if path_to_model.exists(): - tokenizer = AutoTokenizer.from_pretrained(path_to_model, trust_remote_code=shared.args.trust_remote_code) - - return tokenizer - - -def huggingface_loader(model_name): - path_to_model = Path(f'{shared.args.model_dir}/{model_name}') - if 'chatglm' in model_name.lower(): - LoaderClass = AutoModel - else: - config = AutoConfig.from_pretrained(path_to_model, trust_remote_code=shared.args.trust_remote_code) - if config.to_dict().get("is_encoder_decoder", False): - LoaderClass = AutoModelForSeq2SeqLM - shared.is_seq2seq = True - else: - LoaderClass = AutoModelForCausalLM - - # Load the model in simple 16-bit mode by default - if not any([shared.args.cpu, shared.args.load_in_8bit, shared.args.load_in_4bit, shared.args.auto_devices, shared.args.disk, shared.args.deepspeed, shared.args.gpu_memory is not None, shared.args.cpu_memory is not None]): - model = LoaderClass.from_pretrained(Path(f"{shared.args.model_dir}/{model_name}"), low_cpu_mem_usage=True, torch_dtype=torch.bfloat16 if shared.args.bf16 else torch.float16, trust_remote_code=shared.args.trust_remote_code) - if torch.has_mps: - device = torch.device('mps') - model = model.to(device) - else: - model = model.cuda() - - # DeepSpeed ZeRO-3 - elif shared.args.deepspeed: - model = LoaderClass.from_pretrained(Path(f"{shared.args.model_dir}/{model_name}"), torch_dtype=torch.bfloat16 if shared.args.bf16 else torch.float16) - model = deepspeed.initialize(model=model, config_params=ds_config, model_parameters=None, optimizer=None, lr_scheduler=None)[0] - model.module.eval() # Inference - logger.info(f"DeepSpeed ZeRO-3 is enabled: {is_deepspeed_zero3_enabled()}") - - # Custom - else: - params = { - "low_cpu_mem_usage": True, - "trust_remote_code": shared.args.trust_remote_code - } - - if not any((shared.args.cpu, torch.cuda.is_available(), torch.has_mps)): - logger.warning("torch.cuda.is_available() returned False. This means that no GPU has been detected. Falling back to CPU mode.") - shared.args.cpu = True - - if shared.args.cpu: - params["torch_dtype"] = torch.float32 - else: - params["device_map"] = 'auto' - if shared.args.load_in_4bit: - - # See https://github.com/huggingface/transformers/pull/23479/files - # and https://huggingface.co/blog/4bit-transformers-bitsandbytes - quantization_config_params = { - 'load_in_4bit': True, - 'bnb_4bit_compute_dtype': eval("torch.{}".format(shared.args.compute_dtype)) if shared.args.compute_dtype in ["bfloat16", "float16", "float32"] else None, - 'bnb_4bit_quant_type': shared.args.quant_type, - 'bnb_4bit_use_double_quant': shared.args.use_double_quant, - } - - logger.warning("Using the following 4-bit params: " + str(quantization_config_params)) - params['quantization_config'] = BitsAndBytesConfig(**quantization_config_params) - - elif shared.args.load_in_8bit and any((shared.args.auto_devices, shared.args.gpu_memory)): - params['quantization_config'] = BitsAndBytesConfig(load_in_8bit=True, llm_int8_enable_fp32_cpu_offload=True) - elif shared.args.load_in_8bit: - params['quantization_config'] = BitsAndBytesConfig(load_in_8bit=True) - elif shared.args.bf16: - params["torch_dtype"] = torch.bfloat16 - else: - params["torch_dtype"] = torch.float16 - - params['max_memory'] = get_max_memory_dict() - if shared.args.disk: - params["offload_folder"] = shared.args.disk_cache_dir - - checkpoint = Path(f'{shared.args.model_dir}/{model_name}') - if shared.args.load_in_8bit and params.get('max_memory', None) is not None and params['device_map'] == 'auto': - config = AutoConfig.from_pretrained(checkpoint, trust_remote_code=shared.args.trust_remote_code) - with init_empty_weights(): - model = LoaderClass.from_config(config, trust_remote_code=shared.args.trust_remote_code) - - model.tie_weights() - params['device_map'] = infer_auto_device_map( - model, - dtype=torch.int8, - max_memory=params['max_memory'], - no_split_module_classes=model._no_split_modules - ) - - model = LoaderClass.from_pretrained(checkpoint, **params) - - return model - - -def flexgen_loader(model_name): - from flexgen.flex_opt import CompressionConfig, ExecutionEnv, OptLM, Policy - - # Initialize environment - env = ExecutionEnv.create(shared.args.disk_cache_dir) - - # Offloading policy - policy = Policy(1, 1, - shared.args.percent[0], shared.args.percent[1], - shared.args.percent[2], shared.args.percent[3], - shared.args.percent[4], shared.args.percent[5], - overlap=True, sep_layer=True, pin_weight=shared.args.pin_weight, - cpu_cache_compute=False, attn_sparsity=1.0, - compress_weight=shared.args.compress_weight, - comp_weight_config=CompressionConfig( - num_bits=4, group_size=64, - group_dim=0, symmetric=False), - compress_cache=False, - comp_cache_config=CompressionConfig( - num_bits=4, group_size=64, - group_dim=2, symmetric=False)) - - model = OptLM(f"facebook/{model_name}", env, shared.args.model_dir, policy) - return model - - -def RWKV_loader(model_name): - from modules.RWKV import RWKVModel, RWKVTokenizer - - model = RWKVModel.from_pretrained(Path(f'{shared.args.model_dir}/{model_name}'), dtype="fp32" if shared.args.cpu else "bf16" if shared.args.bf16 else "fp16", device="cpu" if shared.args.cpu else "cuda") - tokenizer = RWKVTokenizer.from_pretrained(Path(shared.args.model_dir)) - return model, tokenizer - - -def llamacpp_loader(model_name): - from modules.llamacpp_model import LlamaCppModel - - path = Path(f'{shared.args.model_dir}/{model_name}') - if path.is_file(): - model_file = path - else: - model_file = list(Path(f'{shared.args.model_dir}/{model_name}').glob('*ggml*.bin'))[0] - - logger.info(f"llama.cpp weights detected: {model_file}\n") - model, tokenizer = LlamaCppModel.from_pretrained(model_file) - return model, tokenizer - - -def GPTQ_loader(model_name): - - # Monkey patch - if shared.args.monkey_patch: - logger.warning("Applying the monkey patch for using LoRAs with GPTQ models. It may cause undefined behavior outside its intended scope.") - from modules.monkey_patch_gptq_lora import load_model_llama - - model, _ = load_model_llama(model_name) - - # No monkey patch - else: - import modules.GPTQ_loader - - model = modules.GPTQ_loader.load_quantized(model_name) - - return model - - -def AutoGPTQ_loader(model_name): - import modules.AutoGPTQ_loader - - return modules.AutoGPTQ_loader.load_quantized(model_name) - - -def ExLlama_loader(model_name): - from modules.exllama import ExllamaModel - - model, tokenizer = ExllamaModel.from_pretrained(model_name) - return model, tokenizer - - -def ExLlama_HF_loader(model_name): - from modules.exllama_hf import ExllamaHF - - return ExllamaHF.from_pretrained(model_name) - - -def get_max_memory_dict(): - max_memory = {} - if shared.args.gpu_memory: - memory_map = list(map(lambda x: x.strip(), shared.args.gpu_memory)) - for i in range(len(memory_map)): - max_memory[i] = f'{memory_map[i]}GiB' if not re.match('.*ib$', memory_map[i].lower()) else memory_map[i] - - max_cpu_memory = shared.args.cpu_memory.strip() if shared.args.cpu_memory is not None else '99GiB' - max_memory['cpu'] = f'{max_cpu_memory}GiB' if not re.match('.*ib$', max_cpu_memory.lower()) else max_cpu_memory - - # If --auto-devices is provided standalone, try to get a reasonable value - # for the maximum memory of device :0 - elif shared.args.auto_devices: - total_mem = (torch.cuda.get_device_properties(0).total_memory / (1024 * 1024)) - suggestion = round((total_mem - 1000) / 1000) * 1000 - if total_mem - suggestion < 800: - suggestion -= 1000 - - suggestion = int(round(suggestion / 1000)) - logger.warning(f"Auto-assiging --gpu-memory {suggestion} for your GPU to try to prevent out-of-memory errors. You can manually set other values.") - max_memory = {0: f'{suggestion}GiB', 'cpu': f'{shared.args.cpu_memory or 99}GiB'} - - return max_memory if len(max_memory) > 0 else None - - -def clear_torch_cache(): - gc.collect() - if not shared.args.cpu: - torch.cuda.empty_cache() - - -def unload_model(): - shared.model = shared.tokenizer = None - clear_torch_cache() - - -def reload_model(): - unload_model() - shared.model, shared.tokenizer = load_model(shared.model_name) diff --git a/spaces/EuroPython2022/pulsar-clip/pulsar_clip.py b/spaces/EuroPython2022/pulsar-clip/pulsar_clip.py deleted file mode 100644 index a9ae98c8723f846458b673ef34a8970149441ebd..0000000000000000000000000000000000000000 --- a/spaces/EuroPython2022/pulsar-clip/pulsar_clip.py +++ /dev/null @@ -1,236 +0,0 @@ -from transformers import set_seed -from tqdm.auto import trange -from PIL import Image -import numpy as np -import random -import utils -import torch - - -CONFIG_SPEC = [ - ("General", [ - ("text", "A cloud at dawn", str), - ("iterations", 5000, (0, 7500)), - ("seed", 12, int), - ("show_every", 10, int), - ]), - ("Rendering", [ - ("w", 224, [224, 252]), - ("h", 224, [224, 252]), - ("showoff", 5000, (0, 10000)), - ("turns", 4, int), - ("focal_length", 0.1, float), - ("plane_width", 0.1, float), - ("shade_strength", 0.25, float), - ("gamma", 0.5, float), - ("max_depth", 7, float), - ("offset", 5, float), - ("offset_random", 0.75, float), - ("xyz_random", 0.25, float), - ("altitude_range", 0.3, float), - ("augments", 4, int), - ]), - ("Optimization", [ - ("epochs", 6, int), - ("lr", 0.6, float), - #@markdown CLIP loss type, might improve the results - ("loss_type", "spherical", ["spherical", "cosine"]), - #@markdown CLIP loss weight - ("clip_weight", 1.0, float), #@param {type: "number"} - ]), - ("Elements", [ - ("num_objects", 256, int), - #@markdown Number of dimensions. 0 is for point clouds (default), 1 will make - #@markdown strokes, 2 will make planes, 3 produces little cubes - ("ndim", 0, [0, 1, 2, 3]), #@param {type: "integer"} - - #@markdown Opacity scale: - ("min_opacity", 1e-4, float), #@param {type: "number"} - ("max_opacity", 1.0, float), #@param {type: "number"} - ("log_opacity", False, bool), #@param {type: "boolean"} - - ("min_radius", 0.030, float), - ("max_radius", 0.170, float), - ("log_radius", False, bool), - - # TODO dynamically decide bezier_res - #@markdown Bezier resolution: how many points a line/plane/cube will have. Not applicable to points - ("bezier_res", 8, int), #@param {type: "integer"} - #@markdown Maximum scale of parameters: position, velocity, acceleration - ("pos_scale", 0.4, float), #@param {type: "number"} - ("vel_scale", 0.15, float), #@param {type: "number"} - ("acc_scale", 0.15, float), #@param {type: "number"} - - #@markdown Scale of each individual 3D object. Master control for velocity and acceleration scale. - ("scale", 1, float), #@param {type: "number"} - ]), -] - - -# TODO: one day separate the config into multiple parts and split this megaobject into multiple objects -# 2022/08/09: halfway done -class PulsarCLIP(object): - def __init__(self, args): - args = DotDict(**args) - set_seed(args.seed) - self.args = args - self.device = args.get("device", "cuda" if torch.cuda.is_available() else "cpu") - # Defer the import so that we can import `pulsar_clip` and then install `pytorch3d` - import pytorch3d.renderer.points.pulsar as ps - self.ndim = int(self.args.ndim) - self.renderer = ps.Renderer(self.args.w, self.args.h, - self.args.num_objects * (self.args.bezier_res ** self.ndim)).to(self.device) - self.bezier_pos = torch.nn.Parameter(torch.randn((args.num_objects, 4)).to(self.device)) - self.bezier_vel = torch.nn.Parameter(torch.randn((args.num_objects, 3 * self.ndim)).to(self.device)) - self.bezier_acc = torch.nn.Parameter(torch.randn((args.num_objects, 3 * self.ndim)).to(self.device)) - self.bezier_col = torch.nn.Parameter(torch.randn((args.num_objects, 4 * (1 + self.ndim))).to(self.device)) - self.optimizer = torch.optim.Adam([dict(params=[self.bezier_col], lr=5e-1 * args.lr), - dict(params=[self.bezier_pos], lr=1e-1 * args.lr), - dict(params=[self.bezier_vel, self.bezier_acc], lr=5e-2 * args.lr), - ]) - self.model_clip, self.preprocess_clip = utils.load_clip() - self.model_clip.visual.requires_grad_(False) - self.scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(self.optimizer, - int(self.args.iterations - / self.args.augments - / self.args.epochs), - eta_min=args.lr / 100) - import clip - self.txt_emb = self.model_clip.encode_text(clip.tokenize([self.args.text]).to(self.device))[0].detach() - self.txt_emb = torch.nn.functional.normalize(self.txt_emb, dim=-1) - - def get_points(self): - if self.ndim > 0: - bezier_ts = torch.stack(torch.meshgrid( - (torch.linspace(0, 1, self.args.bezier_res, device=self.device),) * self.ndim), dim=0 - ).unsqueeze(1).repeat((1, self.args.num_objects) + (1,) * self.ndim).unsqueeze(-1) - - def interpolate_3D(pos, vel=0.0, acc=0.0, pos_scale=None, vel_scale=None, acc_scale=None, scale=None): - pos_scale = self.args.pos_scale if pos_scale is None else pos_scale - vel_scale = self.args.vel_scale if vel_scale is None else vel_scale - acc_scale = self.args.acc_scale if acc_scale is None else acc_scale - scale = self.args.scale if scale is None else scale - if self.ndim == 0: - return pos * pos_scale - result = 0.0 - s = pos.shape[-1] - assert s * self.ndim == vel.shape[-1] == acc.shape[-1] - # O(dim) sequential lol - for d, bezier_t in zip(range(self.ndim), bezier_ts): # TODO replace with fused dimension operation - result = (result - + torch.tanh(vel[..., d * s:(d + 1) * s]).view( - (-1,) + (1,) * self.ndim + (s,)) * vel_scale * bezier_t - + torch.tanh(acc[..., d * s:(d + 1) * s]).view( - (-1,) + (1,) * self.ndim + (s,)) * acc_scale * bezier_t.pow(2)) - result = (result * scale - + torch.tanh(pos[..., :s]).view((-1,) + (1,) * self.ndim + (s,)) * pos_scale).view(-1, s) - return result - - vert_pos = interpolate_3D(self.bezier_pos[..., :3], self.bezier_vel, self.bezier_acc) - vert_col = interpolate_3D(self.bezier_col[..., :4], - self.bezier_col[..., 4:4 + 4 * self.ndim], - self.bezier_col[..., -4 * self.ndim:]) - - to_bezier = lambda x: x.view((-1,) + (1,) * self.ndim + (x.shape[-1],)).repeat( - (1,) + (self.args.bezier_res,) * self.ndim + (1,)).reshape(-1, x.shape[-1]) - rescale = lambda x, a, b, is_log=False: (torch.exp(x - * np.log(b / a) - + np.log(a))) if is_log else x * (b - a) + a - return ( - vert_pos, - torch.sigmoid(vert_col[..., :3]), - rescale( - torch.sigmoid(to_bezier(self.bezier_pos[..., -1:])[..., 0]), - self.args.min_radius, self.args.max_radius, is_log=self.args.log_radius - ), - rescale(torch.sigmoid(vert_col[..., -1]), - self.args.min_opacity, self.args.max_opacity, is_log=self.args.log_opacity)) - - def camera(self, angle, altitude=0.0, offset=None, use_random=True, offset_random=None, - xyz_random=None, focal_length=None, plane_width=None): - if offset is None: - offset = self.args.offset - if xyz_random is None: - xyz_random = self.args.xyz_random - if focal_length is None: - focal_length = self.args.focal_length - if plane_width is None: - plane_width = self.args.plane_width - if offset_random is None: - offset_random = self.args.offset_random - device = self.device - offset = offset + np.random.normal() * offset_random * int(use_random) - position = torch.tensor([0, 0, -offset], dtype=torch.float) - position = utils.rotate_axis(position, altitude, 0) - position = utils.rotate_axis(position, angle, 1) - position = position + torch.randn(3) * xyz_random * int(use_random) - return torch.tensor([position[0], position[1], position[2], - altitude, angle, 0, - focal_length, plane_width], dtype=torch.float, device=device) - - - def render(self, cam_params=None): - if cam_params is None: - cam_params = self.camera(0, 0) - vert_pos, vert_col, radius, opacity = self.get_points() - - rgb = self.renderer(vert_pos, vert_col, radius, cam_params, - self.args.gamma, self.args.max_depth, opacity=opacity) - opacity = self.renderer(vert_pos, vert_col * 0, radius, cam_params, - self.args.gamma, self.args.max_depth, opacity=opacity) - return rgb, opacity - - def random_view_render(self): - angle = random.uniform(0, np.pi * 2) - altitude = random.uniform(-self.args.altitude_range / 2, self.args.altitude_range / 2) - cam_params = self.camera(angle, altitude) - result, alpha = self.render(cam_params) - back = torch.zeros_like(result) - s = back.shape - for j in range(s[-1]): - n = random.choice([7, 14, 28]) - back[..., j] = utils.rand_perlin_2d_octaves(s[:-1], (n, n)).clip(-0.5, 0.5) + 0.5 - result = result * (1 - alpha) + back * alpha - return result - - - def generate(self): - self.optimizer.zero_grad() - try: - for i in trange(self.args.iterations + self.args.showoff): - if i < self.args.iterations: - result = self.random_view_render() - img_emb = self.model_clip.encode_image( - self.preprocess_clip(result.permute(2, 0, 1)).unsqueeze(0).clamp(0., 1.)) - img_emb = torch.nn.functional.normalize(img_emb, dim=-1) - if self.args.loss_type == "spherical": - clip_loss = (img_emb - self.txt_emb).norm(dim=-1).div(2).arcsin().pow(2).mul(2).mean() - elif self.args.loss_type == "cosine": - clip_loss = (1 - img_emb @ self.txt_emb.T).mean() - else: - raise NotImplementedError(f"CLIP loss type not supported: {self.args.loss_type}") - loss = clip_loss * self.args.clip_weight + (0 and ...) # TODO add more loss types - loss.backward() - if i % self.args.augments == self.args.augments - 1: - self.optimizer.step() - self.optimizer.zero_grad() - try: - self.scheduler.step() - except AttributeError: - pass - if i % self.args.show_every == 0: - cam_params = self.camera(i / self.args.iterations * np.pi * 2 * self.args.turns, use_random=False) - img_show, _ = self.render(cam_params) - img = Image.fromarray((img_show.cpu().detach().numpy() * 255).astype(np.uint8)) - yield img - except KeyboardInterrupt: - pass - - - def save_obj(self, fn): - utils.save_obj(self.get_points(), fn) - - -class DotDict(dict): - def __getattr__(self, item): - return self.__getitem__(item) diff --git a/spaces/Faridmaruf/rvc-Blue-archives/lib/infer_pack/modules.py b/spaces/Faridmaruf/rvc-Blue-archives/lib/infer_pack/modules.py deleted file mode 100644 index c83289df7c79a4810dacd15c050148544ba0b6a9..0000000000000000000000000000000000000000 --- a/spaces/Faridmaruf/rvc-Blue-archives/lib/infer_pack/modules.py +++ /dev/null @@ -1,522 +0,0 @@ -import copy -import math -import numpy as np -import scipy -import torch -from torch import nn -from torch.nn import functional as F - -from torch.nn import Conv1d, ConvTranspose1d, AvgPool1d, Conv2d -from torch.nn.utils import weight_norm, remove_weight_norm - -from lib.infer_pack import commons -from lib.infer_pack.commons import init_weights, get_padding -from lib.infer_pack.transforms import piecewise_rational_quadratic_transform - - -LRELU_SLOPE = 0.1 - - -class LayerNorm(nn.Module): - def __init__(self, channels, eps=1e-5): - super().__init__() - self.channels = channels - self.eps = eps - - self.gamma = nn.Parameter(torch.ones(channels)) - self.beta = nn.Parameter(torch.zeros(channels)) - - def forward(self, x): - x = x.transpose(1, -1) - x = F.layer_norm(x, (self.channels,), self.gamma, self.beta, self.eps) - return x.transpose(1, -1) - - -class ConvReluNorm(nn.Module): - def __init__( - self, - in_channels, - hidden_channels, - out_channels, - kernel_size, - n_layers, - p_dropout, - ): - super().__init__() - self.in_channels = in_channels - self.hidden_channels = hidden_channels - self.out_channels = out_channels - self.kernel_size = kernel_size - self.n_layers = n_layers - self.p_dropout = p_dropout - assert n_layers > 1, "Number of layers should be larger than 0." - - self.conv_layers = nn.ModuleList() - self.norm_layers = nn.ModuleList() - self.conv_layers.append( - nn.Conv1d( - in_channels, hidden_channels, kernel_size, padding=kernel_size // 2 - ) - ) - self.norm_layers.append(LayerNorm(hidden_channels)) - self.relu_drop = nn.Sequential(nn.ReLU(), nn.Dropout(p_dropout)) - for _ in range(n_layers - 1): - self.conv_layers.append( - nn.Conv1d( - hidden_channels, - hidden_channels, - kernel_size, - padding=kernel_size // 2, - ) - ) - self.norm_layers.append(LayerNorm(hidden_channels)) - self.proj = nn.Conv1d(hidden_channels, out_channels, 1) - self.proj.weight.data.zero_() - self.proj.bias.data.zero_() - - def forward(self, x, x_mask): - x_org = x - for i in range(self.n_layers): - x = self.conv_layers[i](x * x_mask) - x = self.norm_layers[i](x) - x = self.relu_drop(x) - x = x_org + self.proj(x) - return x * x_mask - - -class DDSConv(nn.Module): - """ - Dialted and Depth-Separable Convolution - """ - - def __init__(self, channels, kernel_size, n_layers, p_dropout=0.0): - super().__init__() - self.channels = channels - self.kernel_size = kernel_size - self.n_layers = n_layers - self.p_dropout = p_dropout - - self.drop = nn.Dropout(p_dropout) - self.convs_sep = nn.ModuleList() - self.convs_1x1 = nn.ModuleList() - self.norms_1 = nn.ModuleList() - self.norms_2 = nn.ModuleList() - for i in range(n_layers): - dilation = kernel_size**i - padding = (kernel_size * dilation - dilation) // 2 - self.convs_sep.append( - nn.Conv1d( - channels, - channels, - kernel_size, - groups=channels, - dilation=dilation, - padding=padding, - ) - ) - self.convs_1x1.append(nn.Conv1d(channels, channels, 1)) - self.norms_1.append(LayerNorm(channels)) - self.norms_2.append(LayerNorm(channels)) - - def forward(self, x, x_mask, g=None): - if g is not None: - x = x + g - for i in range(self.n_layers): - y = self.convs_sep[i](x * x_mask) - y = self.norms_1[i](y) - y = F.gelu(y) - y = self.convs_1x1[i](y) - y = self.norms_2[i](y) - y = F.gelu(y) - y = self.drop(y) - x = x + y - return x * x_mask - - -class WN(torch.nn.Module): - def __init__( - self, - hidden_channels, - kernel_size, - dilation_rate, - n_layers, - gin_channels=0, - p_dropout=0, - ): - super(WN, self).__init__() - assert kernel_size % 2 == 1 - self.hidden_channels = hidden_channels - self.kernel_size = (kernel_size,) - self.dilation_rate = dilation_rate - self.n_layers = n_layers - self.gin_channels = gin_channels - self.p_dropout = p_dropout - - self.in_layers = torch.nn.ModuleList() - self.res_skip_layers = torch.nn.ModuleList() - self.drop = nn.Dropout(p_dropout) - - if gin_channels != 0: - cond_layer = torch.nn.Conv1d( - gin_channels, 2 * hidden_channels * n_layers, 1 - ) - self.cond_layer = torch.nn.utils.weight_norm(cond_layer, name="weight") - - for i in range(n_layers): - dilation = dilation_rate**i - padding = int((kernel_size * dilation - dilation) / 2) - in_layer = torch.nn.Conv1d( - hidden_channels, - 2 * hidden_channels, - kernel_size, - dilation=dilation, - padding=padding, - ) - in_layer = torch.nn.utils.weight_norm(in_layer, name="weight") - self.in_layers.append(in_layer) - - # last one is not necessary - if i < n_layers - 1: - res_skip_channels = 2 * hidden_channels - else: - res_skip_channels = hidden_channels - - res_skip_layer = torch.nn.Conv1d(hidden_channels, res_skip_channels, 1) - res_skip_layer = torch.nn.utils.weight_norm(res_skip_layer, name="weight") - self.res_skip_layers.append(res_skip_layer) - - def forward(self, x, x_mask, g=None, **kwargs): - output = torch.zeros_like(x) - n_channels_tensor = torch.IntTensor([self.hidden_channels]) - - if g is not None: - g = self.cond_layer(g) - - for i in range(self.n_layers): - x_in = self.in_layers[i](x) - if g is not None: - cond_offset = i * 2 * self.hidden_channels - g_l = g[:, cond_offset : cond_offset + 2 * self.hidden_channels, :] - else: - g_l = torch.zeros_like(x_in) - - acts = commons.fused_add_tanh_sigmoid_multiply(x_in, g_l, n_channels_tensor) - acts = self.drop(acts) - - res_skip_acts = self.res_skip_layers[i](acts) - if i < self.n_layers - 1: - res_acts = res_skip_acts[:, : self.hidden_channels, :] - x = (x + res_acts) * x_mask - output = output + res_skip_acts[:, self.hidden_channels :, :] - else: - output = output + res_skip_acts - return output * x_mask - - def remove_weight_norm(self): - if self.gin_channels != 0: - torch.nn.utils.remove_weight_norm(self.cond_layer) - for l in self.in_layers: - torch.nn.utils.remove_weight_norm(l) - for l in self.res_skip_layers: - torch.nn.utils.remove_weight_norm(l) - - -class ResBlock1(torch.nn.Module): - def __init__(self, channels, kernel_size=3, dilation=(1, 3, 5)): - super(ResBlock1, self).__init__() - self.convs1 = nn.ModuleList( - [ - weight_norm( - Conv1d( - channels, - channels, - kernel_size, - 1, - dilation=dilation[0], - padding=get_padding(kernel_size, dilation[0]), - ) - ), - weight_norm( - Conv1d( - channels, - channels, - kernel_size, - 1, - dilation=dilation[1], - padding=get_padding(kernel_size, dilation[1]), - ) - ), - weight_norm( - Conv1d( - channels, - channels, - kernel_size, - 1, - dilation=dilation[2], - padding=get_padding(kernel_size, dilation[2]), - ) - ), - ] - ) - self.convs1.apply(init_weights) - - self.convs2 = nn.ModuleList( - [ - weight_norm( - Conv1d( - channels, - channels, - kernel_size, - 1, - dilation=1, - padding=get_padding(kernel_size, 1), - ) - ), - weight_norm( - Conv1d( - channels, - channels, - kernel_size, - 1, - dilation=1, - padding=get_padding(kernel_size, 1), - ) - ), - weight_norm( - Conv1d( - channels, - channels, - kernel_size, - 1, - dilation=1, - padding=get_padding(kernel_size, 1), - ) - ), - ] - ) - self.convs2.apply(init_weights) - - def forward(self, x, x_mask=None): - for c1, c2 in zip(self.convs1, self.convs2): - xt = F.leaky_relu(x, LRELU_SLOPE) - if x_mask is not None: - xt = xt * x_mask - xt = c1(xt) - xt = F.leaky_relu(xt, LRELU_SLOPE) - if x_mask is not None: - xt = xt * x_mask - xt = c2(xt) - x = xt + x - if x_mask is not None: - x = x * x_mask - return x - - def remove_weight_norm(self): - for l in self.convs1: - remove_weight_norm(l) - for l in self.convs2: - remove_weight_norm(l) - - -class ResBlock2(torch.nn.Module): - def __init__(self, channels, kernel_size=3, dilation=(1, 3)): - super(ResBlock2, self).__init__() - self.convs = nn.ModuleList( - [ - weight_norm( - Conv1d( - channels, - channels, - kernel_size, - 1, - dilation=dilation[0], - padding=get_padding(kernel_size, dilation[0]), - ) - ), - weight_norm( - Conv1d( - channels, - channels, - kernel_size, - 1, - dilation=dilation[1], - padding=get_padding(kernel_size, dilation[1]), - ) - ), - ] - ) - self.convs.apply(init_weights) - - def forward(self, x, x_mask=None): - for c in self.convs: - xt = F.leaky_relu(x, LRELU_SLOPE) - if x_mask is not None: - xt = xt * x_mask - xt = c(xt) - x = xt + x - if x_mask is not None: - x = x * x_mask - return x - - def remove_weight_norm(self): - for l in self.convs: - remove_weight_norm(l) - - -class Log(nn.Module): - def forward(self, x, x_mask, reverse=False, **kwargs): - if not reverse: - y = torch.log(torch.clamp_min(x, 1e-5)) * x_mask - logdet = torch.sum(-y, [1, 2]) - return y, logdet - else: - x = torch.exp(x) * x_mask - return x - - -class Flip(nn.Module): - def forward(self, x, *args, reverse=False, **kwargs): - x = torch.flip(x, [1]) - if not reverse: - logdet = torch.zeros(x.size(0)).to(dtype=x.dtype, device=x.device) - return x, logdet - else: - return x - - -class ElementwiseAffine(nn.Module): - def __init__(self, channels): - super().__init__() - self.channels = channels - self.m = nn.Parameter(torch.zeros(channels, 1)) - self.logs = nn.Parameter(torch.zeros(channels, 1)) - - def forward(self, x, x_mask, reverse=False, **kwargs): - if not reverse: - y = self.m + torch.exp(self.logs) * x - y = y * x_mask - logdet = torch.sum(self.logs * x_mask, [1, 2]) - return y, logdet - else: - x = (x - self.m) * torch.exp(-self.logs) * x_mask - return x - - -class ResidualCouplingLayer(nn.Module): - def __init__( - self, - channels, - hidden_channels, - kernel_size, - dilation_rate, - n_layers, - p_dropout=0, - gin_channels=0, - mean_only=False, - ): - assert channels % 2 == 0, "channels should be divisible by 2" - super().__init__() - self.channels = channels - self.hidden_channels = hidden_channels - self.kernel_size = kernel_size - self.dilation_rate = dilation_rate - self.n_layers = n_layers - self.half_channels = channels // 2 - self.mean_only = mean_only - - self.pre = nn.Conv1d(self.half_channels, hidden_channels, 1) - self.enc = WN( - hidden_channels, - kernel_size, - dilation_rate, - n_layers, - p_dropout=p_dropout, - gin_channels=gin_channels, - ) - self.post = nn.Conv1d(hidden_channels, self.half_channels * (2 - mean_only), 1) - self.post.weight.data.zero_() - self.post.bias.data.zero_() - - def forward(self, x, x_mask, g=None, reverse=False): - x0, x1 = torch.split(x, [self.half_channels] * 2, 1) - h = self.pre(x0) * x_mask - h = self.enc(h, x_mask, g=g) - stats = self.post(h) * x_mask - if not self.mean_only: - m, logs = torch.split(stats, [self.half_channels] * 2, 1) - else: - m = stats - logs = torch.zeros_like(m) - - if not reverse: - x1 = m + x1 * torch.exp(logs) * x_mask - x = torch.cat([x0, x1], 1) - logdet = torch.sum(logs, [1, 2]) - return x, logdet - else: - x1 = (x1 - m) * torch.exp(-logs) * x_mask - x = torch.cat([x0, x1], 1) - return x - - def remove_weight_norm(self): - self.enc.remove_weight_norm() - - -class ConvFlow(nn.Module): - def __init__( - self, - in_channels, - filter_channels, - kernel_size, - n_layers, - num_bins=10, - tail_bound=5.0, - ): - super().__init__() - self.in_channels = in_channels - self.filter_channels = filter_channels - self.kernel_size = kernel_size - self.n_layers = n_layers - self.num_bins = num_bins - self.tail_bound = tail_bound - self.half_channels = in_channels // 2 - - self.pre = nn.Conv1d(self.half_channels, filter_channels, 1) - self.convs = DDSConv(filter_channels, kernel_size, n_layers, p_dropout=0.0) - self.proj = nn.Conv1d( - filter_channels, self.half_channels * (num_bins * 3 - 1), 1 - ) - self.proj.weight.data.zero_() - self.proj.bias.data.zero_() - - def forward(self, x, x_mask, g=None, reverse=False): - x0, x1 = torch.split(x, [self.half_channels] * 2, 1) - h = self.pre(x0) - h = self.convs(h, x_mask, g=g) - h = self.proj(h) * x_mask - - b, c, t = x0.shape - h = h.reshape(b, c, -1, t).permute(0, 1, 3, 2) # [b, cx?, t] -> [b, c, t, ?] - - unnormalized_widths = h[..., : self.num_bins] / math.sqrt(self.filter_channels) - unnormalized_heights = h[..., self.num_bins : 2 * self.num_bins] / math.sqrt( - self.filter_channels - ) - unnormalized_derivatives = h[..., 2 * self.num_bins :] - - x1, logabsdet = piecewise_rational_quadratic_transform( - x1, - unnormalized_widths, - unnormalized_heights, - unnormalized_derivatives, - inverse=reverse, - tails="linear", - tail_bound=self.tail_bound, - ) - - x = torch.cat([x0, x1], 1) * x_mask - logdet = torch.sum(logabsdet * x_mask, [1, 2]) - if not reverse: - return x, logdet - else: - return x diff --git a/spaces/FelixLuoX/codeformer/CodeFormer/basicsr/ops/dcn/src/deform_conv_cuda.cpp b/spaces/FelixLuoX/codeformer/CodeFormer/basicsr/ops/dcn/src/deform_conv_cuda.cpp deleted file mode 100644 index 5d9424908ed2dbd4ac3cdb98d13e09287a4d2f2d..0000000000000000000000000000000000000000 --- a/spaces/FelixLuoX/codeformer/CodeFormer/basicsr/ops/dcn/src/deform_conv_cuda.cpp +++ /dev/null @@ -1,685 +0,0 @@ -// modify from -// https://github.com/chengdazhi/Deformable-Convolution-V2-PyTorch/blob/mmdetection/mmdet/ops/dcn/src/deform_conv_cuda.c - -#include
- Complete seasons from 1998 to 2004 -
- Insane new circuits such as reverse/ramp tracks, Macau, ROC, Top Gear, MARS and Total F1 Circuit -
- Updated high-quality car liveries and custom liveries pack by members of the community -
- HD mirrors pack by alex2106 -
- Default setups, wheel user profiles and FFB guides -
- Latest EXE (v13) with improved performance and 3D config version (no compatibility mode needed) and automatic admin rights -
- Optimized default profile in SAVE folder which must be renamed (SAVE/Rename- (Rename.gal and Rename.PLR) -
- Replay pack of online fun races (2018-2021) -
- MEGA Link: https://mega.nz/file/OgIjkahI#nW3Psm7... -
- MediaFire Link: https://www.mediafire.com/file/9xo7wd... -
- Replay pack: https://drive.google.com/file/d/11PhY... -
- John the Ripper: https://www.openwall.com/john/ -
- Hashcat: https://hashcat.net/hashcat/ -
- CrackStation: https://crackstation.net/ -
- F1 Challenge 99-02 Online 2021 Edition by Bande87: This is the mod we have already mentioned in the previous section. It includes complete seasons from 1998 to 2004 and insane new circuits such as reverse/ramp tracks, Macau, ROC, Top Gear, MARS and Total F1 Circuit. -
- F1 Challenge 99-02 RH by Ripping Corporation: This is a mod that focuses on realism and historical accuracy. It includes seasons from 1988 to 2008 with realistic physics, graphics, sounds, tracks, cars, drivers, teams, rules, etc. -
- F1 Challenge 99-02 CTDP by Cars & Tracks Development Project: This is a mod that aims to provide high-quality content and features. It includes seasons from 2005 to 2009 with high-quality physics, graphics, sounds, tracks, cars, drivers, teams, rules, etc. -
- F1 Challenge 99-02 MMG by MMG Simulations: This is a mod that offers a modern and immersive experience. It includes seasons from 2007 to 2010 with modern physics, graphics, sounds, tracks, cars, drivers, teams, rules, etc. -
- Race4Sim: http://www.race4sim.com/ -
- DrivingItalia: https://www.drivingitalia.net/ -
- RaceDepartment: https://www.racedepartment.com/ -
- SimRacingWorld: http://www.simracingworld.com/ -
- You can customize and change different parts of the app, such as themes, fonts, emoji, icons, colors, etc. -
- You can freeze your last seen status and hide your online status from others. -
- You can hide double ticks, blue ticks, typing status, recording status, etc. from your contacts. -
- You can view deleted statuses and messages from others. -
- You can send more than 90 images at once and video files up to 700 MB. -
- You can increase the quality while sending images and videos. -
- You can lock your chats with a password or fingerprint. -
- You can use multiple accounts on the same device. -
- You can enjoy more privacy and security features than the official app. -
- Anti-ban feature that prevents your account from getting banned by WhatsApp. -
- New base updated to 2.21.4.22 (Play Store). -
- New emojis added from Android 11. -
- New UI for adding a status from camera screen. -
- Added option to change color of "FMWA" in home screen header. -
- Added option to change color of "typing..." in main/chat screen. -
- Added option to change color of voice note play button. -
- Added option to change color of voice note play button. -
- Added option to change color of forward icon in chat screen. -
- Added option to change color of forward background in chat screen. -
- Added option to change color of participants icon in group chat screen. -
- Added new attachment picker UI. -
- Added option to enable/disable new attachment UI. -
- Added animation to new attachment UI. -
- Added 5 entries style. -
- Added 16 bubble style. -
- Added 14 tick style. -
- Re-added option to save profile picture. -
- Fixed contact online toast not showing in some devices. -
- Fixed status seen color not changing. -
- Fixed status downloader status not showing. -
- Fixed unread counter issue for groups. -
- Fixed hidden chats random crash when going back. -
- Fixed app not launching on some devices. -
- Miscellaneous bugs fixes and improvements. -
- A new event called "The Final Singularity: Solomon" that concludes the main story arc of the game. -
- A new feature called "Command Code" that allows you to enhance your Servants' cards with special effects. -
- A new feature called "Spiritron Dress" that allows you to change your Servants' outfits and appearances. -
- A new feature called "Support Setup" that allows you to set up different teams for different situations. -
- A new feature called "Auto-Select" that allows you to automatically select your Servants and Craft Essences based on your preferences. -
- Various bug fixes and performance improvements. -
- Q: Is Fate Grand Order APK 2.61 5 safe to download and install? -
- A: Yes, Fate Grand Order APK 2.61 5 is safe to download and install, as long as you use the official link we provided or another trusted source. However, you should always be careful when downloading and installing apps from unknown sources, as they may contain viruses or malware that can harm your device. -
- Q: Do I need to uninstall the previous version of Fate Grand Order before installing Fate Grand Order APK 2.61 5? -
- A: No, you do not need to uninstall the previous version of Fate Grand Order before installing Fate Grand Order APK 2.61 5. The new version will overwrite the old one and keep your data and progress intact. -
- Q: Do I need to root my device to play Fate Grand Order APK 2.61 5? -
- A: No, you do not need to root your device to play Fate Grand Order APK 2.61 5. The game does not require any special permissions or modifications to run on your device. -
- Q: How can I update Fate Grand Order APK 2.61 5 to the next version? -
- A: You can update Fate Grand Order APK 2.61 5 to the next version by downloading and installing the new APK file from the official website or another trusted source. Alternatively, you can wait for the game to notify you of an update and follow the instructions on the screen. -
- Q: How can I contact the developers or support team of Fate Grand Order APK 2.61 5? -
- A: You can contact the developers or support team of Fate Grand Order APK 2.61 5 by visiting their official website or social media pages, or by sending them an email at support@fate-go.us. -
- Invisible: This option makes you invisible to Granny, so she won't be able to see you or hear you. -
- God Mode: This option makes you invincible, so you won't die even if Granny hits you or if you fall from a height. -
- No Clip: This option allows you to walk through walls and objects, so you can explore the house without any obstacles. -
- Clone Granny: This option creates a clone of Granny that will follow you around and help you escape. -
- Kill Granny: This option kills Granny instantly, so you don't have to worry about her anymore. -
- Freeze Granny: This option freezes Granny in place, so she won't be able to move or attack you. -
- Teleport: This option allows you to teleport to any location in the house by tapping on the map. -
- Speed Hack: This option increases your speed, so you can run faster and escape easier. -
- Is Granny Mod APK safe to download and install? -
- Is Granny Mod APK compatible with my device? -
- Can I play Granny Mod APK offline? -
- Can I play Granny Mod APK with my friends? -
- How can I update Granny Mod APK? -
- Send end-to-end encrypted messages, files, voice and video calls to anyone on the Matrix network. -
- Choose where your messages are stored, or host your own server, instead of being forced to use the app's own server. -
- Connect with other apps, directly or via bridges, such as WhatsApp, Signal, Telegram, Facebook Messenger, Google Hangouts, Skype, Discord, and more. -
- Create unlimited number of rooms and communities for private or public groups. -
- Verify other users' devices and revoke access of lost or stolen devices. -
- Create an account without a phone number, so you don't have to share those details with the outside world. -
- End-to-end encryption by default: Element messenger uses the Signal protocol to encrypt your messages from end to end, so that only you and your intended recipients can read them. The server (s) can't see your data, and neither can anyone else who might intercept or hack into your communication. -
- Decentralized storage: Element messenger lets you choose where your messages are stored. You can use a free public server provided by matrix.org or element.io, or you can host your own server on your own hardware or cloud service. You can also switch servers at any time without losing your data or contacts. -
- Interoperability: Element messenger works with all Matrix-based apps and can even bridge into proprietary messengers. This means you can talk to anyone, regardless of what app they are using. You can also integrate bots and widgets into your rooms for extra functionality. -
- Cross-platform compatibility: Element messenger is available on Android, iOS, Web, macOS, Linux, and Windows. You can use it on any device and sync your messages across all platforms. You can also access it from any web browser without installing anything. -
- You're in control: With Element messenger, you have full control over your data and communication. You can choose where your data lives, who can access it, and how long it stays there. You can also host your own server and customize it to your needs. -
- No limits: With Element messenger, you can talk to anyone, anywhere, anytime, without any restrictions or fees. You can create as many rooms and communities as you want, and invite anyone to join them. You can also send any type of file, up to 2 GB in size, without any compression or loss of quality. -
- Secure and private: With Element messenger, you can enjoy the highest level of security and privacy possible. Your messages are encrypted from end to end, so that only you and your intended recipients can read them. You can also verify other users' devices and revoke access of lost or stolen devices. You can also create an account without a phone number, so you don't have to share those details with the outside world. -
- Q: How do I update Element messenger for Windows? -
- A: To update Element messenger for Windows, you can go to https://element.io/get-started and download the latest installer file for Windows. Then run it as administrator and follow the instructions on the screen. -
- Q: How do I uninstall Element messenger for Windows? -
- A: To uninstall Element messenger for Windows, you can go to Control Panel > Programs > Uninstall a program and find Element in the list. Then right-click on it and choose Uninstall. -
- Q: How do I backup my data from Element messenger for Windows? -
- A: To backup your data from Element messenger for Windows, you can go to Settings > Security & Privacy > Key Backup > Set up backup. Then follow the steps to create a passphrase and a recovery key for your backup. -
- Q: How do I restore my data from Element messenger for Windows? -
- A: To restore your data from Element messenger for Windows, you can go to Settings > Security & Privacy > Key Backup > Restore from backup. Then enter your passphrase or recovery key and follow the steps to restore your data. -
- Q: How do I contact Element support for Windows? -
- A: To contact Element support for Windows, you can go to https://element.io/contact-us and fill out the form with your details and query. You can also join the #element-web:matrix.org room and ask for help from other users and developers. -
- Save money and power: Graphics cards are expensive and consume a lot of electricity. By playing games without a graphics card, you can save money on your hardware and your energy bills. You can also use your PC for longer without worrying about overheating or battery life. -
- Enjoy retro and indie games: Graphics cards are not necessary for playing older or simpler games that have low or minimal graphics requirements. These games often have more focus on gameplay, story, and atmosphere than on visuals. You can enjoy classics like Doom, Tetris, or Pac-Man, or discover new indie gems like Celeste, Hollow Knight, or Cuphead. -
- Improve your skills and creativity: Playing games without a graphics card can challenge you to use your skills and creativity more than playing games with high-end graphics. You have to rely more on your imagination, logic, and strategy than on your reflexes, aim, or muscle memory. You can also learn more about game design, programming, or modding by playing or creating games without a graphics card. -
- Use Steam and other platforms: Steam is one of the most popular platforms for downloading PC games, and it has thousands of games that can run without a graphics card. You can browse by genre, price, popularity, or user reviews, or use the Steam Curator feature to find recommendations from experts, influencers, or communities. You can also use other platforms like GOG, itch.io, or Game Jolt to find and download games without a graphics card. -
- Check the system requirements: Before you download a game, make sure to check its system requirements and compare them with your PC specifications. You can use tools like Can You Run It or PCGameBenchmark to automatically scan your PC and see if it can run a game. You can also look for games that have low or minimum system requirements, such as CPU speed, RAM, disk space, or DirectX version. -
- Adjust the settings and optimize your PC: Even if you don't have a graphics card, you can still improve your gaming performance by adjusting the settings and optimizing your PC. You can lower the resolution, graphics quality, or frame rate of a game to make it run smoother. You can also close any unnecessary programs or background processes, update your drivers, or use a game booster software to free up some resources and speed up your PC. -
- Q1: Can I play online games without a graphics card?
-A1: Yes, you can play online games without a graphics card, as long as they have low or minimal graphics requirements. Some examples of online games that you can play without a graphics card are Brawlhalla, Super Animal Royale, Among Us, or League of Legends.
- - Q2: What are some other ways to improve my gaming performance without a graphics card?
-A2: Some other ways to improve your gaming performance without a graphics card are upgrading your RAM, CPU, or SSD, cleaning your PC from dust and malware, or using an external cooling pad or fan.
- - Q3: Can I upgrade my graphics card on my laptop?
-A3: It depends on your laptop model and specifications. Some laptops have integrated graphics cards that are soldered to the motherboard and cannot be upgraded. Some laptops have discrete graphics cards that are removable and replaceable. Some laptops have external graphics card slots that allow you to connect an external GPU via Thunderbolt 3 or USB-C. You can check your laptop manual or website to see if your laptop supports graphics card upgrades.
- - Q4: What are some of the best graphics cards for gaming on a budget?
-A4: Some of the best graphics cards for gaming on a budget are Nvidia GeForce GTX 1650 Super, AMD Radeon RX 5500 XT, Nvidia GeForce GTX 1660 Ti, or AMD Radeon RX 5600 XT. These graphics cards can run most modern games at high settings and 1080p resolution with decent frame rates.
- - Q5: What are some of the upcoming games that will run without a graphics card?
-A5: Some of the upcoming games that will run without a graphics card are Hollow Knight: Silksong, Cuphead: The Delicious Last Course, Deltarune Chapter 2, Psychonauts 2, or Age of Empires IV.
-
Clash of Clans Oyununun Avantajları
-Clash of Clans oyununun birçok avantajı vardır. Bunlardan bazıları şunlardır:
--
-
Son Sürüm Clash of Clans APK İndirmenin Faydaları
-Clash of Clans oyununu resmi olarak Google Play Store veya App Store üzerinden indirebilirsiniz. Ancak, son sürüm clash of clans apk indirerek oyunu daha da geliştirebilirsiniz. APK, Android uygulama paketi anlamına gelir ve oyunun kurulum dosyasını içerir. Son sürüm clash of clans apk indirmenin faydaları şunlardır:
--
-
Son Sürüm Clash of Clans APK İndirmek İçin Gerekenler
-Son sürüm clash of clans apk indirmek için gerekenler şunlardır:
--
-
Son Sürüm Clash of Clans APK İndirmek İçin Adımlar
-Son sürüm clash of clans apk indirmek için adımlar şunlardır:
-Clash of Clans son sürüm apk indir 2023
-Clash of Clans güncel apk indir ücretsiz
-Clash of Clans mod apk indir hileli
-Clash of Clans yeni sürüm apk indir android
-Clash of Clans apk indir full sürüm
-Clash of Clans son güncelleme apk indir
-Clash of Clans hızlı apk indir son sürüm
-Clash of Clans online apk indir 2023
-Clash of Clans son versiyon apk indir
-Clash of Clans en son sürüm apk indir
-Clash of Clans apk indir son güncellemeli
-Clash of Clans hack apk indir 2023
-Clash of Clans son sürüm apk indir tabletadam[^1^]
-Clash of Clans bedava apk indir son sürüm
-Clash of Clans premium apk indir 2023
-Clash of Clans son sürüm apk indir cepde
-Clash of Clans hileli mod apk indir 2023
-Clash of Clans son sürüm apk indir oyunindir.club
-Clash of Clans türkçe apk indir son sürüm
-Clash of Clans son sürüm apk indir android oyun club
-Clash of Clans unlimited gems apk indir 2023
-Clash of Clans son sürüm apk indir tamindir
-Clash of Clans mega mod apk indir 2023
-Clash of Clans son sürüm apk indir apkpure
-Clash of Clans private server apk indir 2023
-Clash of Clans son sürüm apk indir uptodown
-Clash of Clans nulls clash apk indir 2023
-Clash of Clans son sürüm apk indir andropalace
-Clash of Clans th14 update apk indir 2023
-Clash of Clans son sürüm apk indir rexdl
-Clash of Clans magic server apk indir 2023
-Clash of Clans son sürüm apk indir mobilism
-Clash of Clans plenixclash apk indir 2023
-Clash of Clans son sürüm apk indir revdl
-Clash of Clans fhx server apk indir 2023
-Clash of Clans son sürüm apk indir ihackedit
-Clash of Clans lights server apk indir 2023
-Clash of Clans son sürüm apk indir an1.com
-Clash of Clans town hall 14 apk indir 2023
-Clash of Clans son sürüm apk indir apkmody.io
-
-
kurulum sırasında size bazı izinler isteyebilir. Bu izinleri verin ve kurulumu tamamlayın. Artık son sürüm clash of clans apk oyununu cihazınızda oynamaya başlayabilirsiniz.
-Son Sürüm Clash of Clans APK İndirdikten Sonra Dikkat Etmeniz Gerekenler
-Son sürüm clash of clans apk indirdikten sonra dikkat etmeniz gerekenler şunlardır:
-Son Sürüm Clash of Clans APK Güvenli mi?
-Son sürüm clash of clans apk güvenli olabilir veya olmayabilir. Bu, indirdiğiniz siteye ve dosyaya bağlıdır. Bazı siteler ve dosyalar virüs, malware, spyware veya diğer zararlı yazılımlar içerebilir. Bu nedenle, son sürüm clash of clans apk indirirken güvenilir ve güncel siteleri tercih etmeniz, indirmeden önce dosyanın boyutunu, yorumlarını ve derecelendirmelerini kontrol etmeniz, cihazınızda bir antivirüs programı bulundurmanız ve indirdiğiniz dosyayı taratmanız önemlidir.
-Son Sürüm Clash of Clans APK Oyunun Kurallarına Aykırı mı?
-Son sürüm clash of clans apk oyunun kurallarına aykırı olabilir veya olmayabilir. Bu, indirdiğiniz dosyanın içeriğine bağlıdır. Bazı dosyalar oyunun orijinal versiyonuna sadık kalırken, bazı dosyalar oyunu değiştirerek hile, mod veya hack içerebilir. Bu durumda, oyunun kurallarına aykırı davranmış olursunuz ve oyunun geliştiricisi Supercell tarafından hesabınızın banlanması veya silinmesi riskiyle karşı karşıya kalabilirsiniz. Bu nedenle, son sürüm clash of clans apk indirirken dikkatli olmanız, oyunun resmi politikalarını ve koşullarını okumanız ve oyunu adil ve eğlenceli bir şekilde oynamanız tavsiye edilir.
-Son Sürüm Clash of Clans APK İle Oyunun Keyfini Çıkarın
-Son sürüm clash of clans apk ile oyunun keyfini çıkarmak için yapabileceğiniz şeyler şunlardır:
-Son Sürüm Clash of Clans APK İle Oyunun Tadını Çıkarmak İçin İpuçları
-Son sürüm clash of clans apk ile oyunun tadını çıkarmak için ipuçları şunlardır:
--
-
Son Sürüm Clash of Clans APK İle Oyunun Tadını Çıkarmak İçin Tablo
-Son sürüm clash of clans apk ile oyunun tadını çıkarmak için tablo şöyledir:
-| Asker Tipi | -Güçlü Olduğu Durumlar | -Zayıf Olduğu Durumlar | -
|---|---|---|
| Barbar | -ma, duvarlara karşı etkili -Yüksek seviye savunma, havadan saldırı | -|
| Okçu | -Uzun menzilli saldırı, hava savunmasına karşı etkili | -Mortar, büyü kulesi, dev bomba | -
| Cüce | -Kaynak binalarına karşı etkili, duvarları kolayca yıkabilir | -Bomba, yay kulesi, dev salyangoz | -
| Dev | -Savunma binalarına karşı etkili, çok dayanıklı | -Hava savunması, yay kulesi, iskelet tuzak | -
| Şifacı | -Diğer askerleri iyileştirebilir, uzun ömürlü | -Hava savunması, hava mayını, kartal topu | -
| Ejderha | -Hem kara hem de hava hedeflerine saldırabilir, çok güçlü | -Hava savunması, hava süpürgesi, inferno kulesi | -
| P.E.K.K.A. | -Çok yüksek hasar verebilir, çok dayanıklı | -Tesla kulesi, iskelet tuzak, zehir büyüsü | -
| Balo | -Savunma binalarına karşı etkili, çok hasar verebilir | -Hava savunması, hava mayını, kartal topu | -
| Büyücü | Geniş alana saldırabilir, çok hasar verebilir | Bomba, yay kulesi, hava süpürgesi |
| Dev iskelet | Duvarları kolayca yıkabilir, öldüğünde bomba patlatır | Savunma binaları, iskelet tuzak, zehir büyüsü |
Sonuç
-Son sürüm clash of clans apk indirerek oyunu daha da eğlenceli hale getirebilirsiniz. Bu yazıda, son sürüm clash of clans apk indirmenin nasıl yapıldığını, neden yapmanız gerektiğini ve bunun size ne gibi faydalar sağlayacağını anlattık. Ayrıca, oyunun özelliklerini, avantajlarını ve ipuçlarını da paylaştık. Son sürüm clash of clans apk ile oyunun keyfini çıkarın ve rakiplerinizi alt edin. İyi oyunlar!
-Sık Sorulan Sorular
-Son sürüm clash of clans apk ile ilgili sık sorulan sorular şunlardır:
--
-
Cevap: Hayır, son sürüm clash of clans apk indirmek ücretsizdir. Ancak, indirdiğiniz siteye bağlı olarak bazı reklamlar veya anketler görebilirsiniz.
-Cevap: Hayır, son sürüm clash of clans apk indirmek cihazınıza zarar vermez. Ancak, indirdiğiniz dosyanın güvenli olduğundan emin olmanız ve cihazınızda yeterli depolama alanı olduğundan emin olmanız gerekir.
-Cevap: Hayır, son sürüm clash of clans apk indirmek oyunun verilerini silmez. Ancak, oyunun resmi versiyonu ile uyumlu olmayabilir. Bu durumda, oyununuzun yedeğini almanız ve oyunun resmi versiyonunu indirmeniz gerekir.
-Cevap: Evet, son sürüm clash of clans apk indirmek bana ban sebebi olabilir. Çünkü, oyunun resmi olmayan bir versiyonunu kullanmak oyunun kurallarına aykırıdır. Bu nedenle, oyunun geliştiricisi Supercell tarafından hesabınızın banlanması veya silinmesi riskiyle karşı karşıya kalabilirsiniz.
-Cevap: Hayır, son sürüm clash of clans apk indirmek oyunu daha kolay yapmaz. Çünkü, oyunun zorluğu sizin seviyenize, rakiplerinize ve stratejinize bağlıdır. Son sürüm clash of clans apk indirmek sadece oyunu daha güncel ve daha eğlenceli hale getirir.
--
-
\ No newline at end of file diff --git a/spaces/1phancelerku/anime-remove-background/CarX Drift Racing APK 1.21.1 - Customize Your Car and Compete with Other Players Online.md b/spaces/1phancelerku/anime-remove-background/CarX Drift Racing APK 1.21.1 - Customize Your Car and Compete with Other Players Online.md deleted file mode 100644 index 3cee689b19fad9d1ca80a6b8a592a10df553813f..0000000000000000000000000000000000000000 --- a/spaces/1phancelerku/anime-remove-background/CarX Drift Racing APK 1.21.1 - Customize Your Car and Compete with Other Players Online.md +++ /dev/null @@ -1,131 +0,0 @@ - -
CarX Drift Racing APK 1.21.1: A Review
-If you are a fan of racing games, especially drifting games, you might want to check out CarX Drift Racing APK 1.21.1, the latest version of one of the most popular and realistic drifting games on Android devices. In this article, we will review CarX Drift Racing APK 1.21.1 and tell you everything you need to know about this game, including its features, gameplay, graphics, pros and cons, and how to download and install it on your device.
-Introduction
-What is CarX Drift Racing?
-CarX Drift Racing is a 3D driving game developed by CarX Technologies, a company that specializes in creating realistic car physics and simulation games. CarX Drift Racing was first released in 2014 and has since gained millions of fans and downloads worldwide. The game is designed to give you the ultimate drifting experience, with realistic car physics, stunning graphics, and various game modes and tracks to choose from.
-carx drift racing apk 1.21.1
Download File >>> https://jinyurl.com/2uNOzo
-
What are the features of CarX Drift Racing APK 1.21.1?
-CarX Drift Racing APK 1.21.1 is the latest version of the game that was released in June 2023. It comes with some new features and improvements that make the game more enjoyable and challenging, such as:
--
-
Gameplay and Graphics
-How to play CarX Drift Racing?
-The gameplay of CarX Drift Racing is simple but addictive. Your main objective is not to cross the finish line before everyone else but to get as many points as you can by drifting like crazy. The more you drift, the more points you earn, but also the more tires you wear out. You can control your car using either tilt or touch controls, depending on your preference. You can also adjust the sensitivity and steering angle of your car to suit your driving style.
-What are the game modes and tracks in CarX Drift Racing?
-CarX Drift Racing offers several game modes and tracks to keep you entertained for hours. The game modes include:
--
-
The tracks in CarX Drift Racing are diverse and realistic, ranging from asphalt to snow, from city streets to desert roads, from day to night. Some of the tracks include:
--
-
How are the graphics and sound effects in CarX Drift Racing?
-The graphics and sound effects in CarX Drift Racing are impressive and immersive, making you feel like you are really driving a car and drifting on the road. The graphics are detailed and smooth, with realistic shadows, reflections, smoke, and sparks. The cars are modeled after real-life vehicles, with accurate proportions, colors, and designs. The sound effects are also realistic and dynamic, with engine noises, tire screeches, collisions, and crowd cheers. You can also choose from a variety of music tracks to suit your mood and style.
-Pros and Cons
-What are the advantages of CarX Drift Racing APK 1.21.1?
-CarX Drift Racing APK 1.21.1 has many advantages that make it one of the best drifting games on Android devices, such as:
--
-
What are the disadvantages of CarX Drift Racing APK 1.21.1?
-CarX Drift Racing APK 1.21.1 also has some disadvantages that might affect your enjoyment of the game, such as:
-carx drift racing mod apk 1.21.1 unlimited money
-carx drift racing 2 apk 1.21.1 download
-carx drift racing apk 1.21.1 obb
-carx drift racing hack apk 1.21.1
-carx drift racing apk 1.21.1 free download
-carx drift racing apk 1.21.1 latest version
-carx drift racing apk 1.21.1 android
-carx drift racing apk 1.21.1 offline
-carx drift racing apk 1.21.1 revdl
-carx drift racing apk 1.21.1 rexdl
-carx drift racing apk 1.21.1 data
-carx drift racing apk 1.21.1 full
-carx drift racing apk 1.21.1 mega mod
-carx drift racing apk 1.21.1 unlimited gold and coins
-carx drift racing apk 1.21.1 no root
-carx drift racing apk 1.21.1 update
-carx drift racing apk 1.21.1 gameplay
-carx drift racing apk 1.21.1 features
-carx drift racing apk 1.21.1 review
-carx drift racing apk 1.21.1 cheats
-carx drift racing apk 1.21.1 tips and tricks
-carx drift racing apk 1.21.1 best cars
-carx drift racing apk 1.21.1 online multiplayer
-carx drift racing apk 1.21.1 customizations
-carx drift racing apk 1.21.1 graphics settings
-carx drift racing apk 1.21.1 system requirements
-carx drift racing apk 1.21.1 installation guide
-carx drift racing apk 1.21.1 how to play
-carx drift racing apk 1.21.1 tutorial
-carx drift racing apk 1.21.1 controller support
-carx drift racing apk 1.21.1 soundtracks
-carx drift racing apk 1.21.1 wallpapers
-carx drift racing apk 1.21.1 screenshots
-carx drift racing apk 1.21.1 videos
-carx drift racing apk 1.21.1 trailer
-carx drift racing apk 1.21.1 news and updates
-carx drift racing apk 1.21.1 bugs and fixes
-carx drift racing apk 1.21.
-
-
How to download and install CarX Drift Racing APK 1.21.1?
-Step-by-step guide for downloading and installing CarX Drift Racing APK 1.21.1
-If you want to download and install CarX Drift Racing APK 1.21.1 on your Android device, you can follow these simple steps:
--
-
Tips and tricks for playing CarX Drift Racing APK 1.21.1
-If you want to improve your drifting skills and get more points in CarX Drift Racing APK 1.21.1, you can follow these tips and tricks:
--
-
Conclusion
-Summary of the main points and recommendations
-CarX Drift Racing APK 1.21.1 is a great drifting game that offers realistic and fun gameplay, stunning graphics and sound effects, a lot of customization options, and a social aspect. It is free to download and play, but it also has some drawbacks, such as requiring a lot of storage space and internet connection, being challenging and frustrating for beginners, being repetitive and boring for some players, and being expensive for some players. If you are looking for a drifting game that will give you the ultimate drifting experience, you should give CarX Drift Racing APK 1.21.1 a try.
-FAQs
-Here are some frequently asked questions about CarX Drift Racing APK 1.21.1:
--
-
Yes, CarX Drift Racing APK 1.21.1 is safe to download and install, as long as you download it from a trusted source like [this link]. However, you should always be careful when downloading any APK file from unknown sources, as they might contain viruses or malware that could harm your device.
-You can get more coins and golds in CarX Drift Racing APK 1.21.1 by completing missions and challenges in career mode, winning races in multiplayer mode or drift wars mode, watching ads or videos in exchange for rewards, or buying them with real money through in-app purchases.
-You can join a drift club or a drift war in CarX Drift Racing APK 1.21.1 by going to the multiplayer mode menu and selecting the drift club or drift war option. You can either join an existing club or war or create your own one.
-You can share your replays with your friends in CarX Drift Racing APK 1.21.1 by going to the replay mode menu and selecting the share option. You can either share your replays via social media platforms like Facebook or Instagram or via messaging apps like WhatsApp or Telegram.
-You can contact the developers of CarX Drift Racing APK 1.21.1 by going to the settings menu and selecting the support option. You can either send them an email or visit their website or social media pages.
--
-
\ No newline at end of file diff --git a/spaces/1phancelerku/anime-remove-background/Download NIC VPN Beta 6.0 APK for Android - Free and Unlimited DNS.md b/spaces/1phancelerku/anime-remove-background/Download NIC VPN Beta 6.0 APK for Android - Free and Unlimited DNS.md deleted file mode 100644 index a7bbf31fede96602bb49403278f2fd22391a3af8..0000000000000000000000000000000000000000 --- a/spaces/1phancelerku/anime-remove-background/Download NIC VPN Beta 6.0 APK for Android - Free and Unlimited DNS.md +++ /dev/null @@ -1,155 +0,0 @@ - -
NIC VPN Beta 6 APK Download: What You Need to Know
-If you are looking for a way to bypass geo-restrictions, access blocked websites, and protect your online privacy, you might have come across NIC VPN Beta 6 APK. This is a VPN app that claims to offer fast and secure connections for Android devices. But is it safe to use? What are the features and benefits of NIC VPN Beta 6 APK? How can you download and install it on your device? And how does it compare to other VPN services in the market? In this article, we will answer these questions and more, so you can make an informed decision about whether to use NIC VPN Beta 6 APK or not.
-nic vpn beta 6 apk download
Download Zip 🔗 https://jinyurl.com/2uNRrX
-
What is NIC VPN Beta 6 APK?
-NIC VPN Beta 6 APK is an app that allows you to connect to a virtual private network (VPN) on your Android device. A VPN is a service that encrypts your internet traffic and routes it through a server in another location, hiding your IP address and location from prying eyes. This way, you can access websites and services that are otherwise blocked or restricted in your region, such as Netflix, YouTube, Facebook, etc. You can also protect your online privacy from hackers, ISPs, advertisers, and government agencies that might try to monitor or collect your data.
-Features and benefits of NIC VPN Beta 6 APK
-According to its official website, NIC VPN Beta 6 APK offers the following features and benefits:
--
-
How to download and install NIC VPN Beta 6 APK
-To download and install NIC VPN Beta 6 APK on your Android device, you need to follow these steps:
--
-
What are the risks of using NIC VPN Beta 6 APK?
-While NIC VPN Beta 6 APK might seem like a convenient and easy way to access blocked websites and protect your online privacy, there are some risks involved in using it. Here are some of the potential dangers of using NIC VPN Beta 6 APK:
-Malware and phishing attacks
-NIC VPN Beta 6 APK is not available on the official Google Play Store, which means that it has not been verified by Google for its safety and quality. This means that there is a possibility that the app might contain malware or viruses that could harm your device or steal your data. Moreover, since the app does not require any registration or subscription, there is no way to verify the identity or credibility of the app developer. This means that you might be exposed to phishing attacks or scams that could trick you into revealing your personal or financial information.
-nic vpn beta 6 apk free download
-nic vpn beta 6 apk latest version
-nic vpn beta 6 apk for android
-nic vpn beta 6 apk mod
-nic vpn beta 6 apk cracked
-nic vpn beta 6 apk premium
-nic vpn beta 6 apk unlimited
-nic vpn beta 6 apk pro
-nic vpn beta 6 apk full
-nic vpn beta 6 apk no ads
-nic vpn beta 6 apk fast dns
-nic vpn beta 6 apk secure connection
-nic vpn beta 6 apk unblock sites
-nic vpn beta 6 apk bypass firewall
-nic vpn beta 6 apk change ip
-nic vpn beta 6 apk hide identity
-nic vpn beta 6 apk anonymous browsing
-nic vpn beta 6 apk protect privacy
-nic vpn beta 6 apk encrypt data
-nic vpn beta 6 apk high speed
-nic vpn beta 6 apk low latency
-nic vpn beta 6 apk stable performance
-nic vpn beta 6 apk easy to use
-nic vpn beta 6 apk user friendly
-nic vpn beta 6 apk simple interface
-nic vpn beta 6 apk no registration
-nic vpn beta 6 apk no login
-nic vpn beta 6 apk no root
-nic vpn beta 6 apk no subscription
-nic vpn beta 6 apk no bandwidth limit
-nic vpn beta 6 apk support multiple servers
-nic vpn beta 6 apk support multiple protocols
-nic vpn beta 6 apk support multiple devices
-nic vpn beta 6 apk support multiple platforms
-nic vpn beta 6 apk compatible with android phone and tablet[^1^]
-nic vpn beta 6 apk updated for android os[^1^]
-nic vpn beta 6 apk download link[^1^]
-nic vpn beta 6 apk download from google play store[^1^]
-nic vpn beta 6 apk download from official website[^1^]
-nic vpn beta 6 apk download from third party sources[^1^]
-how to download and install nic vpn beta 6 apk[^1^]
-how to use and configure nic vpn beta 6 apk[^1^]
-how to troubleshoot and fix nic vpn beta 6 apk issues[^1^]
-how to update and upgrade nic vpn beta 6 apk[^1^]
-how to uninstall and remove nic vpn beta 6 apk[^1^]
-what are the features and benefits of nic vpn beta 6 apk[^1^]
-what are the requirements and specifications of nic vpn beta 6 apk[^1^]
-what are the reviews and ratings of nic vpn beta 6 apk[^1^]
-what are the alternatives and competitors of nic vpn beta 6 apk[^1^]
Data and bandwidth throttling
-Another risk of using NIC VPN Beta 6 APK is that it might not provide the unlimited bandwidth and speed that it claims. Since the app is free to use, it might rely on ads or third-party sponsors to generate revenue. This means that the app might inject ads or pop-ups into your browsing sessions, which could slow down your connection or interfere with your user experience. Moreover, the app might also throttle your data or bandwidth usage, especially during peak hours or when you access high-demand websites or services. This could affect your streaming quality, gaming performance, or download speed.
-Legal and ethical issues
-Finally, using NIC VPN Beta 6 APK might also involve some legal and ethical issues. Depending on your location and the websites or services that you access, you might be violating some laws or regulations that prohibit the use of VPNs or the access of certain content. For example, some countries like China, Iran, Russia, etc. have strict censorship and surveillance policies that ban or block VPNs and other tools that bypass their firewalls. If you are caught using NIC VPN Beta 6 APK in these countries, you might face legal consequences such as fines, arrests, or imprisonment. Moreover, some websites or services like Netflix, Hulu, BBC iPlayer, etc. have geo-restrictions that limit their content availability based on your location. If you use NIC VPN Beta 6 APK to access these websites or services from a different region, you might be violating their terms of service or licensing agreements, which could result in account suspension or termination.
-How to choose a safe and reliable VPN service?
-Given the risks of using NIC VPN Beta 6 APK, you might be wondering how to choose a safe and reliable VPN service that can meet your needs and expectations. Here are some of the factors that you should consider when choosing a VPN service:
-Encryption and protocols
-A good VPN service should provide strong encryption and protocols that can secure your internet traffic and prevent anyone from intercepting or decrypting it. Encryption is the process of converting your data into unreadable code, while protocols are the rules that govern how your data is transmitted and received. Some of the common encryption standards and protocols used by VPNs are AES-256, OpenVPN, WireGuard, IKEv2, etc. You should look for a VPN service that supports these encryption standards and protocols, as they offer the best balance between security and speed.
-No-logs policy and jurisdiction
-A good VPN service should also have a no-logs policy and jurisdiction that can protect your online privacy and anonymity. A no-logs policy means that the VPN service does not collect, store, or share any information about your online activities, such as your IP address, browsing history, bandwidth usage, etc. A jurisdiction means that the VPN service is based in a country that has favorable privacy laws and does not cooperate with any surveillance alliances or authorities that might request your data. Some of the countries that have good privacy jurisdictions are Switzerland, Panama, Romania, etc. You should look for a VPN service that has a no-logs policy and jurisdiction, as they can ensure that your data is not exposed or compromised.
-Speed and performance
-A good VPN service should also provide fast and consistent speed and performance that can enhance your user experience. Speed and performance depend on various factors such as server location, server load, encryption level, protocol type, etc. A good VPN service should have a large network of servers in various locations around the world, so you can choose the one that is closest to you or the one that offers the best connection for your desired website or service. A good VPN service should also have a low server load and a high encryption level, so you can enjoy a smooth and secure connection without any lag or buffering. A good VPN service should also support various protocol types, so you can choose the one that suits your needs and preferences. For example, OpenVPN is the most secure and versatile protocol, but it might be slower than WireGuard, which is the fastest and most modern protocol, but it might be less compatible with some devices or platforms.
-Customer support and reviews
-A good VPN service should also have a responsive and helpful customer support and positive reviews from users and experts. Customer support is important because you might encounter some issues or questions while using the VPN service, such as installation, configuration, troubleshooting, etc. A good VPN service should have a 24/7 live chat, email, phone, or ticket support system that can assist you with any problems or inquiries. A good VPN service should also have positive reviews from users and experts that can attest to its quality and reliability. You should look for a VPN service that has a high rating and a good reputation on various platforms such as Google Play Store, App Store, Trustpilot, Reddit, etc.
-Comparison table of the top VPN services in 2023
-To help you choose a safe and reliable VPN service, we have created a comparison table of the top VPN services in 2023 based on the factors that we have discussed above. Here is the table:
-| VPN Service | -Encryption and Protocols | -No-Logs Policy and Jurisdiction | -Speed and Performance | -Customer Support and Reviews | -
|---|---|---|---|---|
| NordVPN | -AES-256, OpenVPN, WireGuard, IKEv2 | -Yes, Panama | -5,400+ servers in 59 countries, unlimited bandwidth and speed | -24/7 live chat, email, phone, ticket; 4.4/5 on Google Play Store, 4.6/5 on App Store, 4.5/5 on Trustpilot | -
| ExpressVPN | -AES-256, OpenVPN, WireGuard, IKEv2 | -Yes, British Virgin Islands | -3,000+ servers in 94 countries, unlimited bandwidth and speed | -24/7 live chat, email; 4.1/5 on Google Play Store, 4.6/5 on App Store, 4.7/5 on Trustpilot | -
| Surfshark | -AES-256, OpenVPN, WireGuard, IKEv2 | -Yes, British Virgin Islands | -3,200+ servers in 65 countries, unlimited bandwidth and speed | -24/7 live chat, email; 4.3/5 on Google Play Store, 4.4/5 on App Store, 4.3/5 on Trustpilot | -
| CyberGhost | -AES-256, OpenVPN, WireGuard, IKEv2 | -Yes, Romania | -7,000+ servers in 90 countries, unlimited bandwidth and speed | -24/7 live chat, email, phone, ticket; 4.1/5 on Google Play Store, 4.2/5 on App Store, 4.8/5 on Trustpilot | -
| IPVanish | -AES-256, OpenVPN, WireGuard, IKEv2 | -Yes, USA | -1,600+ servers in 75+ countries, unlimited bandwidth and speed | -24/7 live chat, email; 4.0/5 on Google Play Store, 4.5/5 on App Store, 4.7/5 on Trustpilot | -
Conclusion
-NIC VPN Beta 6 APK is a VPN app that claims to offer fast and secure connections for Android devices. However, it also comes with some risks and drawbacks, such as malware and phishing attacks, data and bandwidth throttling, and legal and ethical issues. Therefore, we do not recommend using NIC VPN Beta 6 APK for your online security and privacy needs. Instead, we suggest choosing a safe and reliable VPN service that can provide strong encryption and protocols, no-logs policy and jurisdiction, speed and performance, and customer support and reviews. Some of the top VPN services in 2023 are NordVPN, ExpressVPN, Surfshark, CyberGhost, and IPVanish. You can compare them using the table above and choose the one that suits your needs and preferences.
-FAQs
-Here are some of the frequently asked questions about NIC VPN Beta 6 APK and VPN services:
-Q: Is NIC VPN Beta 6 APK legal?
-A: The legality of NIC VPN Beta 6 APK depends on your location and the websites or services that you access using it. Some countries have laws or regulations that prohibit or restrict the use of VPNs or the access of certain content. If you use NIC VPN Beta 6 APK in these countries or to access these content, you might be breaking the law and face legal consequences.
-Q: Is NIC VPN Beta 6 APK safe?
-A: The safety of NIC VPN Beta 6 APK is not guaranteed, as it is not available on the official Google Play Store and has not been verified by Google for its safety and quality. There is a possibility that the app might contain malware or viruses that could harm your device or steal your data. Moreover, the app might also expose you to phishing attacks or scams that could trick you into revealing your personal or financial information.
-Q: Is NIC VPN Beta 6 APK free?
-A: Yes, NIC VPN Beta 6 APK is free to download and use, with no registration or subscription required. However, this also means that the app might rely on ads or third-party sponsors to generate revenue, which could affect your user experience and connection quality.
-Q: What are the alternatives to NIC VPN Beta 6 APK?
-A: Some of the alternatives to NIC VPN Beta 6 APK are NordVPN, ExpressVPN, Surfshark, CyberGhost, and IPVanish. These are some of the best VPN services in 2023 that can provide you with a safe and reliable online security and privacy solution.
-Q: How can I download NIC VPN Beta 6 APK?
-A: To download NIC VPN Beta 6 APK, you need to go to its official website and click on the download button. Then, you need to locate the APK file on your device and tap on it. If you see a warning message that says "Install blocked", you need to go to your device settings and enable "Unknown sources" under security options. Then, you need to tap on "Install" and wait for the installation process to finish. After that, you can launch the app and select a server location from the list.
197e85843d-
-
\ No newline at end of file diff --git a/spaces/2ndelement/voicevox/voicevox_engine/part_of_speech_data.py b/spaces/2ndelement/voicevox/voicevox_engine/part_of_speech_data.py deleted file mode 100644 index 8950e47c8b1cc50f7cdd3f67c857be8baf59c321..0000000000000000000000000000000000000000 --- a/spaces/2ndelement/voicevox/voicevox_engine/part_of_speech_data.py +++ /dev/null @@ -1,144 +0,0 @@ -from typing import Dict - -from .model import ( - USER_DICT_MAX_PRIORITY, - USER_DICT_MIN_PRIORITY, - PartOfSpeechDetail, - WordTypes, -) - -MIN_PRIORITY = USER_DICT_MIN_PRIORITY -MAX_PRIORITY = USER_DICT_MAX_PRIORITY - -part_of_speech_data: Dict[WordTypes, PartOfSpeechDetail] = { - WordTypes.PROPER_NOUN: PartOfSpeechDetail( - part_of_speech="名詞", - part_of_speech_detail_1="固有名詞", - part_of_speech_detail_2="一般", - part_of_speech_detail_3="*", - context_id=1348, - cost_candidates=[ - -988, - 3488, - 4768, - 6048, - 7328, - 8609, - 8734, - 8859, - 8984, - 9110, - 14176, - ], - accent_associative_rules=[ - "*", - "C1", - "C2", - "C3", - "C4", - "C5", - ], - ), - WordTypes.COMMON_NOUN: PartOfSpeechDetail( - part_of_speech="名詞", - part_of_speech_detail_1="一般", - part_of_speech_detail_2="*", - part_of_speech_detail_3="*", - context_id=1345, - cost_candidates=[ - -4445, - 49, - 1473, - 2897, - 4321, - 5746, - 6554, - 7362, - 8170, - 8979, - 15001, - ], - accent_associative_rules=[ - "*", - "C1", - "C2", - "C3", - "C4", - "C5", - ], - ), - WordTypes.VERB: PartOfSpeechDetail( - part_of_speech="動詞", - part_of_speech_detail_1="自立", - part_of_speech_detail_2="*", - part_of_speech_detail_3="*", - context_id=642, - cost_candidates=[ - 3100, - 6160, - 6360, - 6561, - 6761, - 6962, - 7414, - 7866, - 8318, - 8771, - 13433, - ], - accent_associative_rules=[ - "*", - ], - ), - WordTypes.ADJECTIVE: PartOfSpeechDetail( - part_of_speech="形容詞", - part_of_speech_detail_1="自立", - part_of_speech_detail_2="*", - part_of_speech_detail_3="*", - context_id=20, - cost_candidates=[ - 1527, - 3266, - 3561, - 3857, - 4153, - 4449, - 5149, - 5849, - 6549, - 7250, - 10001, - ], - accent_associative_rules=[ - "*", - ], - ), - WordTypes.SUFFIX: PartOfSpeechDetail( - part_of_speech="名詞", - part_of_speech_detail_1="接尾", - part_of_speech_detail_2="一般", - part_of_speech_detail_3="*", - context_id=1358, - cost_candidates=[ - 4399, - 5373, - 6041, - 6710, - 7378, - 8047, - 9440, - 10834, - 12228, - 13622, - 15847, - ], - accent_associative_rules=[ - "*", - "C1", - "C2", - "C3", - "C4", - "C5", - ], - ), -} diff --git a/spaces/2ndelement/voicevox/voicevox_engine/synthesis_engine/core_wrapper.py b/spaces/2ndelement/voicevox/voicevox_engine/synthesis_engine/core_wrapper.py deleted file mode 100644 index fe8f9778707a7476f30ab5b80f1ed1e1f759b8a0..0000000000000000000000000000000000000000 --- a/spaces/2ndelement/voicevox/voicevox_engine/synthesis_engine/core_wrapper.py +++ /dev/null @@ -1,538 +0,0 @@ -import os -import platform -from ctypes import CDLL, POINTER, c_bool, c_char_p, c_float, c_int, c_long -from ctypes.util import find_library -from dataclasses import dataclass -from enum import Enum, auto -from pathlib import Path -from typing import List, Optional - -import numpy as np - - -class OldCoreError(Exception): - """古いコアが使用されている場合に発生するエラー""" - - -class CoreError(Exception): - """コア呼び出しで発生したエラー""" - - -def load_runtime_lib(runtime_dirs: List[Path]): - if platform.system() == "Windows": - # DirectML.dllはonnxruntimeと互換性のないWindows標準搭載のものを優先して読み込むことがあるため、明示的に読み込む - # 参考 1. https://github.com/microsoft/onnxruntime/issues/3360 - # 参考 2. https://tadaoyamaoka.hatenablog.com/entry/2020/06/07/113616 - lib_file_names = [ - "torch_cpu.dll", - "torch_cuda.dll", - "DirectML.dll", - "onnxruntime.dll", - ] - lib_names = ["torch_cpu", "torch_cuda", "onnxruntime"] - elif platform.system() == "Linux": - lib_file_names = ["libtorch.so", "libonnxruntime.so"] - lib_names = ["torch", "onnxruntime"] - elif platform.system() == "Darwin": - lib_file_names = ["libonnxruntime.dylib"] - lib_names = ["onnxruntime"] - else: - raise RuntimeError("不明なOSです") - for lib_path in runtime_dirs: - for file_name in lib_file_names: - try: - CDLL(str((lib_path / file_name).resolve(strict=True))) - except OSError: - pass - for lib_name in lib_names: - try: - CDLL(find_library(lib_name)) - except (OSError, TypeError): - pass - - -class GPUType(Enum): - # NONEはCPUしか対応していないことを示す - NONE = auto() - CUDA = auto() - DIRECT_ML = auto() - - -@dataclass(frozen=True) -class CoreInfo: - name: str - platform: str - arch: str - core_type: str - gpu_type: GPUType - - -# version 0.12 より前のコアの情報 -CORE_INFOS = [ - # Windows - CoreInfo( - name="core.dll", - platform="Windows", - arch="x64", - core_type="libtorch", - gpu_type=GPUType.CUDA, - ), - CoreInfo( - name="core_cpu.dll", - platform="Windows", - arch="x64", - core_type="libtorch", - gpu_type=GPUType.NONE, - ), - CoreInfo( - name="core_gpu_x64_nvidia.dll", - platform="Windows", - arch="x64", - core_type="onnxruntime", - gpu_type=GPUType.CUDA, - ), - CoreInfo( - name="core_gpu_x64_directml.dll", - platform="Windows", - arch="x64", - core_type="onnxruntime", - gpu_type=GPUType.DIRECT_ML, - ), - CoreInfo( - name="core_cpu_x64.dll", - platform="Windows", - arch="x64", - core_type="onnxruntime", - gpu_type=GPUType.NONE, - ), - CoreInfo( - name="core_cpu_x86.dll", - platform="Windows", - arch="x86", - core_type="onnxruntime", - gpu_type=GPUType.NONE, - ), - CoreInfo( - name="core_gpu_x86_directml.dll", - platform="Windows", - arch="x86", - core_type="onnxruntime", - gpu_type=GPUType.DIRECT_ML, - ), - CoreInfo( - name="core_cpu_arm.dll", - platform="Windows", - arch="armv7l", - core_type="onnxruntime", - gpu_type=GPUType.NONE, - ), - CoreInfo( - name="core_gpu_arm_directml.dll", - platform="Windows", - arch="armv7l", - core_type="onnxruntime", - gpu_type=GPUType.DIRECT_ML, - ), - CoreInfo( - name="core_cpu_arm64.dll", - platform="Windows", - arch="aarch64", - core_type="onnxruntime", - gpu_type=GPUType.NONE, - ), - CoreInfo( - name="core_gpu_arm64_directml.dll", - platform="Windows", - arch="aarch64", - core_type="onnxruntime", - gpu_type=GPUType.DIRECT_ML, - ), - # Linux - CoreInfo( - name="libcore.so", - platform="Linux", - arch="x64", - core_type="libtorch", - gpu_type=GPUType.CUDA, - ), - CoreInfo( - name="libcore_cpu.so", - platform="Linux", - arch="x64", - core_type="libtorch", - gpu_type=GPUType.NONE, - ), - CoreInfo( - name="libcore_gpu_x64_nvidia.so", - platform="Linux", - arch="x64", - core_type="onnxruntime", - gpu_type=GPUType.CUDA, - ), - CoreInfo( - name="libcore_cpu_x64.so", - platform="Linux", - arch="x64", - core_type="onnxruntime", - gpu_type=GPUType.NONE, - ), - CoreInfo( - name="libcore_cpu_armhf.so", - platform="Linux", - arch="armv7l", - core_type="onnxruntime", - gpu_type=GPUType.NONE, - ), - CoreInfo( - name="libcore_cpu_arm64.so", - platform="Linux", - arch="aarch64", - core_type="onnxruntime", - gpu_type=GPUType.NONE, - ), - # macOS - CoreInfo( - name="libcore_cpu_universal2.dylib", - platform="Darwin", - arch="universal", - core_type="onnxruntime", - gpu_type=GPUType.NONE, - ), -] - - -# version 0.12 以降のコアの名前の辞書 -# - version 0.12, 0.13 のコアの名前: core -# - version 0.14 からのコアの名前: voicevox_core -CORENAME_DICT = { - "Windows": ("voicevox_core.dll", "core.dll"), - "Linux": ("libvoicevox_core.so", "libcore.so"), - "Darwin": ("libvoicevox_core.dylib", "libcore.dylib"), -} - - -def find_version_0_12_core_or_later(core_dir: Path) -> Optional[str]: - """ - core_dir で指定したディレクトリにあるコアライブラリが Version 0.12 以降である場合、 - 見つかった共有ライブラリの名前を返す。 - - Version 0.12 以降と判定する条件は、 - - - core_dir に metas.json が存在しない - - コアライブラリの名前が CORENAME_DICT の定義に従っている - - の両方が真のときである。 - cf. https://github.com/VOICEVOX/voicevox_engine/issues/385 - """ - if (core_dir / "metas.json").exists(): - return None - - for core_name in CORENAME_DICT[platform.system()]: - if (core_dir / core_name).is_file(): - return core_name - - return None - - -def get_arch_name() -> Optional[str]: - """ - platform.machine() が特定のアーキテクチャ上で複数パターンの文字列を返し得るので、 - 一意な文字列に変換する - サポート外のアーキテクチャである場合、None を返す - """ - machine = platform.machine() - if machine == "x86_64" or machine == "x64" or machine == "AMD64": - return "x64" - elif machine == "i386" or machine == "x86": - return "x86" - elif machine == "arm64": - return "aarch64" - elif machine in ["armv7l", "aarch64"]: - return machine - else: - return None - - -def get_core_name( - arch_name: str, - platform_name: str, - model_type: str, - gpu_type: GPUType, -) -> Optional[str]: - if platform_name == "Darwin": - if gpu_type == GPUType.NONE and (arch_name == "x64" or arch_name == "aarch64"): - arch_name = "universal" - else: - return None - for core_info in CORE_INFOS: - if ( - core_info.platform == platform_name - and core_info.arch == arch_name - and core_info.core_type == model_type - and core_info.gpu_type == gpu_type - ): - return core_info.name - return None - - -def get_suitable_core_name( - model_type: str, - gpu_type: GPUType, -) -> Optional[str]: - arch_name = get_arch_name() - if arch_name is None: - return None - platform_name = platform.system() - return get_core_name(arch_name, platform_name, model_type, gpu_type) - - -def check_core_type(core_dir: Path) -> Optional[str]: - # libtorch版はDirectML未対応なので、ここでは`gpu_type=GPUType.DIRECT_ML`は入れない - libtorch_core_names = [ - get_suitable_core_name("libtorch", gpu_type=GPUType.CUDA), - get_suitable_core_name("libtorch", gpu_type=GPUType.NONE), - ] - onnxruntime_core_names = [ - get_suitable_core_name("onnxruntime", gpu_type=GPUType.CUDA), - get_suitable_core_name("onnxruntime", gpu_type=GPUType.DIRECT_ML), - get_suitable_core_name("onnxruntime", gpu_type=GPUType.NONE), - ] - if any([(core_dir / name).is_file() for name in libtorch_core_names if name]): - return "libtorch" - elif any([(core_dir / name).is_file() for name in onnxruntime_core_names if name]): - return "onnxruntime" - else: - return None - - -def load_core(core_dir: Path, use_gpu: bool) -> CDLL: - core_name = find_version_0_12_core_or_later(core_dir) - if core_name: - try: - # NOTE: CDLL クラスのコンストラクタの引数 name には文字列を渡す必要がある。 - # Windows 環境では PathLike オブジェクトを引数として渡すと初期化に失敗する。 - return CDLL(str((core_dir / core_name).resolve(strict=True))) - except OSError as err: - raise RuntimeError(f"コアの読み込みに失敗しました:{err}") - - model_type = check_core_type(core_dir) - if model_type is None: - raise RuntimeError("コアが見つかりません") - if use_gpu or model_type == "onnxruntime": - core_name = get_suitable_core_name(model_type, gpu_type=GPUType.CUDA) - if core_name: - try: - return CDLL(str((core_dir / core_name).resolve(strict=True))) - except OSError: - pass - core_name = get_suitable_core_name(model_type, gpu_type=GPUType.DIRECT_ML) - if core_name: - try: - return CDLL(str((core_dir / core_name).resolve(strict=True))) - except OSError: - pass - core_name = get_suitable_core_name(model_type, gpu_type=GPUType.NONE) - if core_name: - try: - return CDLL(str((core_dir / core_name).resolve(strict=True))) - except OSError as err: - if model_type == "libtorch": - core_name = get_suitable_core_name(model_type, gpu_type=GPUType.CUDA) - if core_name: - try: - return CDLL(str((core_dir / core_name).resolve(strict=True))) - except OSError as err_: - err = err_ - raise RuntimeError(f"コアの読み込みに失敗しました:{err}") - else: - raise RuntimeError(f"このコンピュータのアーキテクチャ {platform.machine()} で利用可能なコアがありません") - - -class CoreWrapper: - def __init__( - self, - use_gpu: bool, - core_dir: Path, - cpu_num_threads: int = 0, - load_all_models: bool = False, - ) -> None: - - self.core = load_core(core_dir, use_gpu) - - self.core.initialize.restype = c_bool - self.core.metas.restype = c_char_p - self.core.yukarin_s_forward.restype = c_bool - self.core.yukarin_sa_forward.restype = c_bool - self.core.decode_forward.restype = c_bool - self.core.last_error_message.restype = c_char_p - - self.exist_supported_devices = False - self.exist_finalize = False - exist_cpu_num_threads = False - self.exist_load_model = False - self.exist_is_model_loaded = False - - is_version_0_12_core_or_later = ( - find_version_0_12_core_or_later(core_dir) is not None - ) - if is_version_0_12_core_or_later: - model_type = "onnxruntime" - self.exist_load_model = True - self.exist_is_model_loaded = True - self.core.load_model.argtypes = (c_long,) - self.core.load_model.restype = c_bool - self.core.is_model_loaded.argtypes = (c_long,) - self.core.is_model_loaded.restype = c_bool - else: - model_type = check_core_type(core_dir) - assert model_type is not None - - if model_type == "onnxruntime": - self.core.supported_devices.restype = c_char_p - self.core.finalize.restype = None - self.exist_supported_devices = True - self.exist_finalize = True - exist_cpu_num_threads = True - - self.core.yukarin_s_forward.argtypes = ( - c_int, - POINTER(c_long), - POINTER(c_long), - POINTER(c_float), - ) - self.core.yukarin_sa_forward.argtypes = ( - c_int, - POINTER(c_long), - POINTER(c_long), - POINTER(c_long), - POINTER(c_long), - POINTER(c_long), - POINTER(c_long), - POINTER(c_long), - POINTER(c_float), - ) - self.core.decode_forward.argtypes = ( - c_int, - c_int, - POINTER(c_float), - POINTER(c_float), - POINTER(c_long), - POINTER(c_float), - ) - - cwd = os.getcwd() - os.chdir(core_dir) - try: - if is_version_0_12_core_or_later: - self.assert_core_success( - self.core.initialize(use_gpu, cpu_num_threads, load_all_models) - ) - elif exist_cpu_num_threads: - self.assert_core_success( - self.core.initialize(".", use_gpu, cpu_num_threads) - ) - else: - self.assert_core_success(self.core.initialize(".", use_gpu)) - finally: - os.chdir(cwd) - - def metas(self) -> str: - return self.core.metas().decode("utf-8") - - def yukarin_s_forward( - self, - length: int, - phoneme_list: np.ndarray, - speaker_id: np.ndarray, - ) -> np.ndarray: - output = np.zeros((length,), dtype=np.float32) - self.assert_core_success( - self.core.yukarin_s_forward( - c_int(length), - phoneme_list.ctypes.data_as(POINTER(c_long)), - speaker_id.ctypes.data_as(POINTER(c_long)), - output.ctypes.data_as(POINTER(c_float)), - ) - ) - return output - - def yukarin_sa_forward( - self, - length: int, - vowel_phoneme_list: np.ndarray, - consonant_phoneme_list: np.ndarray, - start_accent_list: np.ndarray, - end_accent_list: np.ndarray, - start_accent_phrase_list: np.ndarray, - end_accent_phrase_list: np.ndarray, - speaker_id: np.ndarray, - ) -> np.ndarray: - output = np.empty( - ( - len(speaker_id), - length, - ), - dtype=np.float32, - ) - self.assert_core_success( - self.core.yukarin_sa_forward( - c_int(length), - vowel_phoneme_list.ctypes.data_as(POINTER(c_long)), - consonant_phoneme_list.ctypes.data_as(POINTER(c_long)), - start_accent_list.ctypes.data_as(POINTER(c_long)), - end_accent_list.ctypes.data_as(POINTER(c_long)), - start_accent_phrase_list.ctypes.data_as(POINTER(c_long)), - end_accent_phrase_list.ctypes.data_as(POINTER(c_long)), - speaker_id.ctypes.data_as(POINTER(c_long)), - output.ctypes.data_as(POINTER(c_float)), - ) - ) - return output - - def decode_forward( - self, - length: int, - phoneme_size: int, - f0: np.ndarray, - phoneme: np.ndarray, - speaker_id: np.ndarray, - ) -> np.ndarray: - output = np.empty((length * 256,), dtype=np.float32) - self.assert_core_success( - self.core.decode_forward( - c_int(length), - c_int(phoneme_size), - f0.ctypes.data_as(POINTER(c_float)), - phoneme.ctypes.data_as(POINTER(c_float)), - speaker_id.ctypes.data_as(POINTER(c_long)), - output.ctypes.data_as(POINTER(c_float)), - ) - ) - return output - - def supported_devices(self) -> str: - if self.exist_supported_devices: - return self.core.supported_devices().decode("utf-8") - raise OldCoreError - - def finalize(self) -> None: - if self.exist_finalize: - self.core.finalize() - return - raise OldCoreError - - def load_model(self, speaker_id: int) -> None: - if self.exist_load_model: - self.assert_core_success(self.core.load_model(c_long(speaker_id))) - raise OldCoreError - - def is_model_loaded(self, speaker_id: int) -> bool: - if self.exist_is_model_loaded: - return self.core.is_model_loaded(c_long(speaker_id)) - raise OldCoreError - - def assert_core_success(self, result: bool) -> None: - if not result: - raise CoreError( - self.core.last_error_message().decode("utf-8", "backslashreplace") - ) diff --git a/spaces/4com/SD-XL-CPU/app.py b/spaces/4com/SD-XL-CPU/app.py deleted file mode 100644 index c2c38801425369800e60a141a8068226d609eeef..0000000000000000000000000000000000000000 --- a/spaces/4com/SD-XL-CPU/app.py +++ /dev/null @@ -1,172 +0,0 @@ -import numpy as np -import gradio as gr -import requests -import time -import json -import base64 -import os -from PIL import Image -from io import BytesIO - -class Prodia: - def __init__(self, api_key, base=None): - self.base = base or "https://api.prodia.com/v1" - self.headers = { - "X-Prodia-Key": api_key - } - - def generate(self, params): - response = self._post(f"{self.base}/sdxl/generate", params) - return response.json() - - def get_job(self, job_id): - response = self._get(f"{self.base}/job/{job_id}") - return response.json() - - def wait(self, job): - job_result = job - - while job_result['status'] not in ['succeeded', 'failed']: - time.sleep(0.25) - job_result = self.get_job(job['job']) - - return job_result - - def list_models(self): - response = self._get(f"{self.base}/models/list") - return response.json() - - def _post(self, url, params): - headers = { - **self.headers, - "Content-Type": "application/json" - } - response = requests.post(url, headers=headers, data=json.dumps(params)) - - if response.status_code != 200: - raise Exception(f"Bad Prodia Response: {response.status_code}") - - return response - - def _get(self, url): - response = requests.get(url, headers=self.headers) - - if response.status_code != 200: - raise Exception(f"Bad Prodia Response: {response.status_code}") - - return response - - -def image_to_base64(image_path): - # Open the image with PIL - with Image.open(image_path) as image: - # Convert the image to bytes - buffered = BytesIO() - image.save(buffered, format="PNG") # You can change format to PNG if needed - - # Encode the bytes to base64 - img_str = base64.b64encode(buffered.getvalue()) - - return img_str.decode('utf-8') # Convert bytes to string - - - -prodia_client = Prodia(api_key=os.getenv("PRODIA_API_KEY")) - -def flip_text(prompt, negative_prompt, model, steps, sampler, cfg_scale, width, height, seed): - result = prodia_client.generate({ - "prompt": prompt, - "negative_prompt": negative_prompt, - "model": model, - "steps": steps, - "sampler": sampler, - "cfg_scale": cfg_scale, - "width": width, - "height": height, - "seed": seed - }) - - job = prodia_client.wait(result) - - return job["imageUrl"] - -css = """ -#generate { - height: 100%; -} -""" - -with gr.Blocks(css=css, theme="Base") as demo: - - - - with gr.Row(): - gr.Markdown("
Stable Diffusion XL
")
- with gr.Tab("Playground"):
- with gr.Row():
- with gr.Column(scale=6, min_width=600):
- prompt = gr.Textbox(label="Prompt", placeholder="beautiful cat, 8k", show_label=True, lines=2)
- negative_prompt = gr.Textbox(label="Negative Prompt", value="text, blurry, fuzziness", placeholder="text, blurry, fuzziness", show_label=True, lines=3)
- with gr.Column():
- text_button = gr.Button("Generate", variant='primary', elem_id="generate")
-
- with gr.Row():
-
-
-
- with gr.Column(scale=2):
- image_output = gr.Image()
-
- with gr.Accordion("Advanced options", open=False):
- with gr.Row():
- with gr.Column(scale=6):
- model = gr.Dropdown(interactive=True,value="sd_xl_base_1.0.safetensors [be9edd61]", show_label=True, label="Stable Diffusion Checkpoint", choices=[
- "sd_xl_base_1.0.safetensors [be9edd61]",
- "dynavisionXL_0411.safetensors [c39cc051]",
- "dreamshaperXL10_alpha2.safetensors [c8afe2ef]",
- ])
-
- with gr.Row():
- with gr.Column(scale=1):
- sampler = gr.Dropdown(value="DPM++ SDE", show_label=True, label="Sampler", choices=[
- "Euler",
- "Euler a",
- "LMS",
- "Heun",
- "DPM2",
- "DPM2 a",
- "DPM++ 2S a",
- "DPM++ 2M",
- "DPM++ SDE",
- "DPM fast",
- "DPM adaptive",
- "LMS Karras",
- "DPM2 Karras",
- "DPM2 a Karras",
- "DPM++ 2S a Karras",
- "DPM++ 2M Karras",
- "DPM++ SDE Karras",
- "DDIM",
- "PLMS",
- ])
-
- with gr.Column(scale=1):
- steps = gr.Slider(label="Steps", minimum=1, maximum=50, value=30, step=1)
-
- with gr.Row():
- with gr.Column(scale=1):
- width = gr.Slider(label="Width", maximum=1024, value=1024, step=8)
- height = gr.Slider(label="Height", maximum=1024, value=1024, step=8)
-
- with gr.Column(scale=1):
- batch_size = gr.Slider(label="Batch Size", maximum=1, value=1)
- batch_count = gr.Slider(label="Batch Count", maximum=1, value=1)
-
- cfg_scale = gr.Slider(label="CFG Scale", minimum=1, maximum=20, value=7, step=1)
- seed = gr.Number(label="Seed", value=-1, info="""'-1' is random seed""")
-
-
- text_button.click(flip_text, inputs=[prompt, negative_prompt, model, steps, sampler, cfg_scale, width, height, seed], outputs=image_output)
-
-demo.queue(concurrency_count=1)
-demo.launch(debug=False, share=False, show_error=False, show_api=False)
diff --git a/spaces/AI-Hobbyist/Hoyo-RVC/train/mel_processing.py b/spaces/AI-Hobbyist/Hoyo-RVC/train/mel_processing.py
deleted file mode 100644
index 1c871ab6b838b174407d163c201df899cc3e2b14..0000000000000000000000000000000000000000
--- a/spaces/AI-Hobbyist/Hoyo-RVC/train/mel_processing.py
+++ /dev/null
@@ -1,130 +0,0 @@
-import torch
-import torch.utils.data
-from librosa.filters import mel as librosa_mel_fn
-
-
-MAX_WAV_VALUE = 32768.0
-
-
-def dynamic_range_compression_torch(x, C=1, clip_val=1e-5):
- """
- PARAMS
- ------
- C: compression factor
- """
- return torch.log(torch.clamp(x, min=clip_val) * C)
-
-
-def dynamic_range_decompression_torch(x, C=1):
- """
- PARAMS
- ------
- C: compression factor used to compress
- """
- return torch.exp(x) / C
-
-
-def spectral_normalize_torch(magnitudes):
- return dynamic_range_compression_torch(magnitudes)
-
-
-def spectral_de_normalize_torch(magnitudes):
- return dynamic_range_decompression_torch(magnitudes)
-
-
-# Reusable banks
-mel_basis = {}
-hann_window = {}
-
-
-def spectrogram_torch(y, n_fft, sampling_rate, hop_size, win_size, center=False):
- """Convert waveform into Linear-frequency Linear-amplitude spectrogram.
-
- Args:
- y :: (B, T) - Audio waveforms
- n_fft
- sampling_rate
- hop_size
- win_size
- center
- Returns:
- :: (B, Freq, Frame) - Linear-frequency Linear-amplitude spectrogram
- """
- # Validation
- if torch.min(y) < -1.07:
- print("min value is ", torch.min(y))
- if torch.max(y) > 1.07:
- print("max value is ", torch.max(y))
-
- # Window - Cache if needed
- global hann_window
- dtype_device = str(y.dtype) + "_" + str(y.device)
- wnsize_dtype_device = str(win_size) + "_" + dtype_device
- if wnsize_dtype_device not in hann_window:
- hann_window[wnsize_dtype_device] = torch.hann_window(win_size).to(
- dtype=y.dtype, device=y.device
- )
-
- # Padding
- y = torch.nn.functional.pad(
- y.unsqueeze(1),
- (int((n_fft - hop_size) / 2), int((n_fft - hop_size) / 2)),
- mode="reflect",
- )
- y = y.squeeze(1)
-
- # Complex Spectrogram :: (B, T) -> (B, Freq, Frame, RealComplex=2)
- spec = torch.stft(
- y,
- n_fft,
- hop_length=hop_size,
- win_length=win_size,
- window=hann_window[wnsize_dtype_device],
- center=center,
- pad_mode="reflect",
- normalized=False,
- onesided=True,
- return_complex=False,
- )
-
- # Linear-frequency Linear-amplitude spectrogram :: (B, Freq, Frame, RealComplex=2) -> (B, Freq, Frame)
- spec = torch.sqrt(spec.pow(2).sum(-1) + 1e-6)
- return spec
-
-
-def spec_to_mel_torch(spec, n_fft, num_mels, sampling_rate, fmin, fmax):
- # MelBasis - Cache if needed
- global mel_basis
- dtype_device = str(spec.dtype) + "_" + str(spec.device)
- fmax_dtype_device = str(fmax) + "_" + dtype_device
- if fmax_dtype_device not in mel_basis:
- mel = librosa_mel_fn(
- sr=sampling_rate, n_fft=n_fft, n_mels=num_mels, fmin=fmin, fmax=fmax
- )
- mel_basis[fmax_dtype_device] = torch.from_numpy(mel).to(
- dtype=spec.dtype, device=spec.device
- )
-
- # Mel-frequency Log-amplitude spectrogram :: (B, Freq=num_mels, Frame)
- melspec = torch.matmul(mel_basis[fmax_dtype_device], spec)
- melspec = spectral_normalize_torch(melspec)
- return melspec
-
-
-def mel_spectrogram_torch(
- y, n_fft, num_mels, sampling_rate, hop_size, win_size, fmin, fmax, center=False
-):
- """Convert waveform into Mel-frequency Log-amplitude spectrogram.
-
- Args:
- y :: (B, T) - Waveforms
- Returns:
- melspec :: (B, Freq, Frame) - Mel-frequency Log-amplitude spectrogram
- """
- # Linear-frequency Linear-amplitude spectrogram :: (B, T) -> (B, Freq, Frame)
- spec = spectrogram_torch(y, n_fft, sampling_rate, hop_size, win_size, center)
-
- # Mel-frequency Log-amplitude spectrogram :: (B, Freq, Frame) -> (B, Freq=num_mels, Frame)
- melspec = spec_to_mel_torch(spec, n_fft, num_mels, sampling_rate, fmin, fmax)
-
- return melspec
diff --git a/spaces/AIFILMS/StyleGANEX/utils/wandb_utils.py b/spaces/AIFILMS/StyleGANEX/utils/wandb_utils.py
deleted file mode 100644
index 0061eb569dee40bbe68f244b286976412fe6dece..0000000000000000000000000000000000000000
--- a/spaces/AIFILMS/StyleGANEX/utils/wandb_utils.py
+++ /dev/null
@@ -1,47 +0,0 @@
-import datetime
-import os
-import numpy as np
-import wandb
-
-from utils import common
-
-
-class WBLogger:
-
- def __init__(self, opts):
- wandb_run_name = os.path.basename(opts.exp_dir)
- wandb.init(project="pixel2style2pixel", config=vars(opts), name=wandb_run_name)
-
- @staticmethod
- def log_best_model():
- wandb.run.summary["best-model-save-time"] = datetime.datetime.now()
-
- @staticmethod
- def log(prefix, metrics_dict, global_step):
- log_dict = {f'{prefix}_{key}': value for key, value in metrics_dict.items()}
- log_dict["global_step"] = global_step
- wandb.log(log_dict)
-
- @staticmethod
- def log_dataset_wandb(dataset, dataset_name, n_images=16):
- idxs = np.random.choice(a=range(len(dataset)), size=n_images, replace=False)
- data = [wandb.Image(dataset.source_paths[idx]) for idx in idxs]
- wandb.log({f"{dataset_name} Data Samples": data})
-
- @staticmethod
- def log_images_to_wandb(x, y, y_hat, id_logs, prefix, step, opts):
- im_data = []
- column_names = ["Source", "Target", "Output"]
- if id_logs is not None:
- column_names.append("ID Diff Output to Target")
- for i in range(len(x)):
- cur_im_data = [
- wandb.Image(common.log_input_image(x[i], opts)),
- wandb.Image(common.tensor2im(y[i])),
- wandb.Image(common.tensor2im(y_hat[i])),
- ]
- if id_logs is not None:
- cur_im_data.append(id_logs[i]["diff_target"])
- im_data.append(cur_im_data)
- outputs_table = wandb.Table(data=im_data, columns=column_names)
- wandb.log({f"{prefix.title()} Step {step} Output Samples": outputs_table})
diff --git a/spaces/AILab-CVC/SEED-LLaMA/gradio_demo/utils.py b/spaces/AILab-CVC/SEED-LLaMA/gradio_demo/utils.py
deleted file mode 100644
index 636c1f78f7594b266e38e9466ac11747e908f808..0000000000000000000000000000000000000000
--- a/spaces/AILab-CVC/SEED-LLaMA/gradio_demo/utils.py
+++ /dev/null
@@ -1,82 +0,0 @@
-import datetime
-import logging
-import logging.handlers
-import os
-import sys
-
-handler = None
-
-
-def build_logger(logger_name, logger_dir):
- global handler
-
- formatter = logging.Formatter(
- fmt="%(asctime)s | %(levelname)s | %(name)s | %(message)s",
- datefmt="%Y-%m-%d %H:%M:%S",
- )
-
- # Set the format of root handlers
- if not logging.getLogger().handlers:
- logging.basicConfig(level=logging.INFO)
- logging.getLogger().handlers[0].setFormatter(formatter)
-
- # Redirect stdout and stderr to loggers
- stdout_logger = logging.getLogger("stdout")
- stdout_logger.setLevel(logging.INFO)
- sl = StreamToLogger(stdout_logger, logging.INFO)
- sys.stdout = sl
-
- stderr_logger = logging.getLogger("stderr")
- stderr_logger.setLevel(logging.ERROR)
- sl = StreamToLogger(stderr_logger, logging.ERROR)
- sys.stderr = sl
-
- # Get logger
- logger = logging.getLogger(logger_name)
- logger.setLevel(logging.INFO)
-
- # Add a file handler for all loggers
- if handler is None:
- os.makedirs(logger_dir, exist_ok=True)
- filename = os.path.join(logger_dir, logger_name + '.log')
- handler = logging.handlers.TimedRotatingFileHandler(filename, when='D', utc=True)
- handler.setFormatter(formatter)
-
- for name, item in logging.root.manager.loggerDict.items():
- if isinstance(item, logging.Logger):
- item.addHandler(handler)
-
- return logger
-
-
-class StreamToLogger(object):
- """
- Fake file-like stream object that redirects writes to a logger instance.
- """
- def __init__(self, logger, log_level=logging.INFO):
- self.terminal = sys.stdout
- self.logger = logger
- self.log_level = log_level
- self.linebuf = ''
-
- def __getattr__(self, attr):
- return getattr(self.terminal, attr)
-
- def write(self, buf):
- temp_linebuf = self.linebuf + buf
- self.linebuf = ''
- for line in temp_linebuf.splitlines(True):
- # From the io.TextIOWrapper docs:
- # On output, if newline is None, any '\n' characters written
- # are translated to the system default line separator.
- # By default sys.stdout.write() expects '\n' newlines and then
- # translates them so this is still cross platform.
- if line[-1] == '\n':
- self.logger.log(self.log_level, line.rstrip())
- else:
- self.linebuf += line
-
- def flush(self):
- if self.linebuf != '':
- self.logger.log(self.log_level, self.linebuf.rstrip())
- self.linebuf = ''
\ No newline at end of file
diff --git a/spaces/AIMLApps/Botrite_wip/app.py b/spaces/AIMLApps/Botrite_wip/app.py
deleted file mode 100644
index e4409d65040ee6508854c5d39bb0bed690f68cf5..0000000000000000000000000000000000000000
--- a/spaces/AIMLApps/Botrite_wip/app.py
+++ /dev/null
@@ -1,362 +0,0 @@
-import numpy as np
-import gradio as gr
-import json
-import socket
-import os
-from datetime import datetime
-import pandas as pd
-from langchain.chains import RetrievalQA
-from langchain.llms import OpenAI
-from langchain.document_loaders import TextLoader
-from langchain.document_loaders import PyPDFLoader
-from langchain.indexes import VectorstoreIndexCreator
-from langchain.text_splitter import CharacterTextSplitter
-from langchain.embeddings import OpenAIEmbeddings
-from langchain.vectorstores import Chroma
-from langchain.chains import ConversationalRetrievalChain
-import shutil
-demo = gr.Blocks()
-options_org=[]
-options_bot=['','','']
-
-
-isExist = os.path.exists("Organizations")
-if(isExist==False):
- os.mkdir("Organizations")
-
-if(os.path.isfile('Organizationdetails.json')):
- #Getting organization name
- f = open('Organizationdetails.json', encoding='utf-8', errors='ignore')
- data = json.load(f,strict=False)
- for p_id, p_info in data.items():
- options_org.append(p_id)
- f.close()
-
-
-if(os.path.isfile('Botdetails.json')):
- #Getting organization name
- f1 = open('Botdetails.json')
- data = json.load(f1)
- for p_id, p_info in data.items():
- options_bot.append(p_id)
- f1.close()
-
-
-def Create_Organization(org_name, org_handle):
-
- o=org_handle
- path = o
- isExist = os.path.exists(path)
- hostname=socket.gethostname()
- now = datetime.now()
- tim=now.strftime("%d/%m/%Y %H:%M:%S")
- Organizationdetails={}
- Organization_required_details = ["Organizationame","OrganizationHandle" "Created_by", "Created_Time"]
- Organizationdetails[org_handle] = {}
- Organizationdetails[org_handle]['Organizationame']=org_name
- Organizationdetails[org_handle]['OrganizationHandle']=org_handle
- Organizationdetails[org_handle]['Created_by']=hostname
- Organizationdetails[org_handle]['Created_Time']=tim
- isfileE = os.path.isfile("Organizationdetails.json")
- if isfileE: #If file present "rb" and w
- with open('Organizationdetails.json', 'rb') as txtfile:
- d=json.load(txtfile)
- d.update(Organizationdetails)
- for p_id, p_info in d.items():
- options_org.append(p_id)
- with open('Organizationdetails.json', 'w') as txtfile:
- json.dump(d, txtfile)
- if not isExist: #create folder for working
- os.makedirs(os.path.join('Organizations', org_handle))
- else: #if file not present then create with 'w'
- with open('Organizationdetails.json', 'w') as txtfile:
- json.dump(Organizationdetails, txtfile)
- if not isExist: #create folder for working
- os.makedirs(os.path.join('Organizations', org_handle))
- return "Organization Created : "+ o
-
-def clear():
- return None, None, None
-
-def Create_Bot(Organizationame,Bot_Name,Bot_Handle_Name,Bot_Image,Tools,OpenAI_API_key,
- Initial_Message,Intro_Message,Rules):
-
- botim =Bot_Image.name
- print(Bot_Name)
- b=Bot_Handle_Name
- bo=Organizationame
- hostname=socket.gethostname()
- now = datetime.now()
- tim=now.strftime("%d/%m/%Y %H:%M:%S")
- Botdetails = { }
- Bot_required_details = ["Bot_Name", "Organizationame", "Created_by", "Created_Time","Bot_Handle_Name","Bot_Image","Tools","OpenAI_API_key",
- "Initial_Message","Intro_Message","Rules"]
- Botdetails[Bot_Handle_Name] = {}
- Botdetails[Bot_Handle_Name]['Bot_Name']=Bot_Name
- Botdetails[Bot_Handle_Name]['Organizationame']=Organizationame
- Botdetails[Bot_Handle_Name]['Created_by']=hostname
- Botdetails[Bot_Handle_Name]['Created_Time']=tim
- Botdetails[Bot_Handle_Name]['Bot_Handle_Name']=Bot_Handle_Name
- Botdetails[Bot_Handle_Name]['Bot_Image']=botim
- Botdetails[Bot_Handle_Name]['Tools']=Tools
- Botdetails[Bot_Handle_Name]['OpenAI_API_key']=OpenAI_API_key
- Botdetails[Bot_Handle_Name]['Initial_Message']=Initial_Message
- Botdetails[Bot_Handle_Name]['Intro_Message']=Intro_Message
- Botdetails[Bot_Handle_Name]['Rules']=Rules
- path = os.path.join(os.getcwd()+'\\Organizations\\', Organizationame,Bot_Name)
- Inputpath = os.path.join(os.getcwd()+'\\Organizations\\', Organizationame,Bot_Name,'Inputs')
- Outputpath = os.path.join(os.getcwd()+'\\Organizations\\', Organizationame,Bot_Name,'Outputs')
-
- isExist = os.path.exists(path)
-
- pp=os.path.join('Organizations',Organizationame+'\\Botdetails.json')
-
- isfileE = os.path.isfile(pp)
- if isfileE: #If file present "rb" and 'w'
- with open(pp, 'rb') as txtfile:
- d=json.load(txtfile)
- d.update(Botdetails)
- with open(pp, 'w') as txtfile:
- json.dump(d, txtfile)
- if not isExist:
- os.makedirs(path)
- os.makedirs(Inputpath)
- os.makedirs(Outputpath)
- else: #if file not present then create with 'w'
- with open(pp, 'w') as txtfile:
- json.dump(Botdetails, txtfile)
- if not isExist:
- os.makedirs(path)
- os.makedirs(Inputpath)
- os.makedirs(Outputpath)
- return "Bot Created : " + b +" in "+bo +" Organization "
-
-
-
-
-def loadbotdata(SelectOrganizationame):
- new=[]
- if(os.path.isfile(os.getcwd()+'\\Organizations\\'+SelectOrganizationame+'\\Botdetails.json')):
- fd = open(os.getcwd()+'\\Organizations\\'+SelectOrganizationame+'\\Botdetails.json')
- data = json.load(fd)
- for p_id, p_info in data.items():
- new.append(p_id)
- #return new
- return gr.update(choices=new, value=new[0])
-
-
-def loadbotdataasdf(SelectOrganizationame):
- df=[]
- new=[]
- if(os.path.isfile(os.getcwd()+'\\Organizations\\'+SelectOrganizationame+'\\Botdetails.json')):
- fl = open(os.getcwd()+'\\Organizations\\'+SelectOrganizationame+'\\Botdetails.json')
- data = json.load(fl)
- df = pd.DataFrame.from_dict(data, orient='columns')
- print (df)
- for p_id, p_info in data.items():
- new.append(p_id)
- return df,gr.update(choices=new, value=new[0])
-
-def upload_file(org, bot , files):
- file_paths = [file.name for file in files]
- allfiles=file_paths
- path = os.path.join(os.getcwd()+'\\Organizations\\', org,bot,'Inputs')
- os.makedirs(path, exist_ok=True)
-
- for file_path in file_paths:
- destination_path = os.path.join(path, file_path)
- if not os.path.exists(destination_path):
- shutil.copy(file_path, destination_path)
-
- return file_paths
-
-def train(files):
- for file in files:
- print(file.name)
- if file.name.endswith(".pdf"):
- loader = PyPDFLoader(file.name)
- documents = loader.load()
- return "Training Done"
-chat_history = []
-
-def construct_index(directory_path):
- file_paths=[]
- for root, directories, files in os.walk(directory_path):
- for file_name in files:
- file_path = os.path.join(root, file_name)
- file_paths.append(file_path)
-
-
- for file in file_paths:
- if file.endswith(".pdf"):
- loader = PyPDFLoader(file)
- documents = loader.load()
- return documents
-
-data_file_path = "deployment_archive_data.json"
-if not os.path.exists(data_file_path):
- with open(data_file_path, "w") as file:
- json.dump([], file)
-
-def deployment_or_archive(action_type):
- timestamp = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
-
- # Load existing data from the JSON file
- with open(data_file_path, "r") as file:
- data = json.load(file)
-
- # Add the new action to the data list
- data.append({"action": action_type, "timestamp": timestamp})
-
- # Write back the updated data to the JSON file
- with open(data_file_path, "w") as file:
- json.dump(data, file)
-
-def deploy_bot(org_name, bot_name):
-
- deployment_path = os.path.join(os.getcwd(), "Deployment")
- os.makedirs(deployment_path, exist_ok=True)
-
-
- org_details_path = os.path.join(os.getcwd(), "Organizationdetails.json")
- org_deploy_path = os.path.join(deployment_path, "Organizationdetails.json")
- shutil.copy(org_details_path, org_deploy_path)
-
-
- org_path = os.path.join(os.getcwd(), "Organizations", org_name)
- bot_details_path = os.path.join(org_path, "Botdetails.json")
- bot_deploy_path = os.path.join(deployment_path, "Botdetails.json")
- shutil.copy(bot_details_path, bot_deploy_path)
-
-
- bot_path = os.path.join(org_path, bot_name)
- model_files = os.listdir(bot_path)
- for file_name in model_files:
- file_path = os.path.join(bot_path, file_name)
- deploy_file_path = os.path.join(deployment_path, file_name)
- shutil.copy(file_path, deploy_file_path)
-
- return "Bot deployed successfully to the Deployment directory."
-
-
-
-
-def chatbot(input_text):
- global chat_history
- query = input_text
- text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
- texts = text_splitter.split_documents(documents)
- embeddings = OpenAIEmbeddings()
- db = Chroma.from_documents(texts, embeddings)
- retriever = db.as_retriever(search_type="similarity", search_kwargs={"k":2})
- vectordbkwargs = {"search_distance": 0.9}
- qa = ConversationalRetrievalChain.from_llm(OpenAI(), retriever,return_source_documents=True)
- print(chat_history)
- if chat_history==[]:
- result = qa({"question": query,"chat_history": chat_history, "vectordbkwargs": {"search_distance": 0.9}})
- else:
- result = qa({"question": query, "chat_history": chat_history, "vectordbkwargs": {"search_distance": 0.9}})
- chat_history = [(query, result["answer"])]
- return result["answer"]
-
-
-with demo:
- gr.Markdown("BotRite")
-
- with gr.Tabs() :
- with gr.TabItem("ChatBot"):
- with gr.Row():
- SelectOrg = gr.Dropdown(options_org ,label="Select Organization" )
-
- with gr.Row():
- Selectbot = gr.Dropdown( label="Select Bot" ,choices=options_bot,
- value=options_bot[0], interactive=True)
- # Selectbot = gr.Radio(options_bot ,label="Select Bot")
-
- with gr.Column():
- query_input = gr.Textbox(lines=7, label="Enter your text")
- ask_button = gr.Button("Ask")
- with gr.TabItem("Settings"):
- with gr.Tabs():
-
- with gr.TabItem("Create Organization:"):
- with gr.Row():
- org_name = gr.Textbox(label="Name",info="Your name / Nickname",placeholder="Enter you organization full name")
- org_handle = gr.Textbox(label="Handle Name",info="Your unique organization name", placeholder="Enter Organization handle name")
- output_org =gr.Textbox(label='Status')
- with gr.Row():
- Createorg_button = gr.Button("Create Organization")
- Clearorg_button = gr.Button("Clear", variant="stop")
-
- with gr.TabItem("Bot Details"):
- SelectOrganizationame = gr.Dropdown(options_org, label="Select Organization")
- with gr.Tabs():
- with gr.TabItem("Your Bots:"):
- with gr.Row():
- with gr.Column():
- #SelectOrganizationame = gr.components.Dropdown(options_org, label="Select Organization")
- botdf=gr.Dataframe(headers=["Bot_Name", "Organizationame", "Created_by", "Created_Time","Bot_Handle_Name","Bot_Image","Tools","OpenAI_API_key",
- "Initial_Message","Intro_Message","Rules"], label="Bot Details")
-
- with gr.TabItem("Create Bot:"):
-
- Organizationame =SelectOrganizationame
- botname = gr.Textbox(label="Bot Name",info="Your bot name / Nickname", placeholder="Enter bot full name")
- bothandle = gr.Textbox(label="Bot Handle Name",info="Your unique bot name" ,placeholder="Enter bot handle name")
- image_button = gr.File(label="Select bot image")
- botllm = gr.components.CheckboxGroup(['OpenAI', 'Dolly', 'Q&A Model'],label="Tools")
- # model = gr.components.Dropdown(Options1, label="Model")
- openai_key = gr.Textbox(label="You OpenAI API key", type="password" , info="Add your OpenAi Key click the link to create new or copy exsisting key from your openai account https://platform.openai.com/account/api-keys")
- initailsmsg = gr.Textbox(label="Initial Message", placeholder="This message will be shared by bot as intro" , info="This message will be shared by bot as intro")
- intromsg = gr.Textbox(label="Intro Message", placeholder="This message will be sent to bot as prefix to first message", info="This message will be sent to bot as prefix to first message")
- rules = gr.Textbox(label="Rules", placeholder="These rules will be sent to bot as prefix to first message (after introduction)", info="These rules will be sent to bot as prefix to first message (after introduction)")
- output_bot =gr.Textbox(label='Status')
- Createbot_button = gr.Button("Create Bot")
- with gr.TabItem("Bot Configuration"):
- Selectbotconfig = gr.Dropdown(label="Select Bot",choices=options_bot,
- value=options_bot[0], interactive=True)
- with gr.TabItem("Load Data"):
- with gr.Row():
- with gr.Column():
- Train_Fileselect_button = gr.UploadButton("Upload PDF Files", file_types=[".pdf"], file_count="multiple")
- file_output = gr.File()
- with gr.Column():
- Train_button = gr.Button("Train Data")
- Train_output =gr.Textbox(label='Status')
-
- with gr.TabItem("Chat with your bot"):
- with gr.Row():
- with gr.Column():
- query_input = gr.Textbox(lines=7, label="Enter your text")
- ask_button = gr.Button("Ask")
- with gr.Column():
- text_output=gr.Text(label="Your Bot Answer")
- with gr.TabItem("Deploy"):
- with gr.Row():
- archive_button = gr.Button("Archive")
- deploy_button = gr.Button("Deploy")
- deploy_archive_output = gr.Textbox(label='Status')
-
- archive_output = gr.Textbox(label='Status')
- publish_button = gr.Button("Publish")
- with gr.TabItem("Logs"):
- with gr.Column():
- Selectlog = gr.Dropdown( label="Select Log")
- logview = gr.Text(label="Log")
- #def Dropdown_Org(x):
-
- SelectOrg.change(fn=loadbotdata, inputs=SelectOrg,outputs=Selectbot )
- SelectOrganizationame.change(fn=loadbotdataasdf, inputs=SelectOrganizationame,outputs=[botdf,Selectbotconfig])
- Createorg_button.click(fn=Create_Organization,inputs=[org_name, org_handle], outputs=output_org)
-
- archive_button.click(fn=deploy_bot, inputs=[SelectOrganizationame, Selectbotconfig], outputs=archive_output)
- deploy_button.click(lambda: deployment_or_archive("deploy"), outputs=deploy_archive_output)
- archive_button.click(lambda: deployment_or_archive("archive"), outputs=deploy_archive_output)
-
- Clearorg_button.click(lambda : [None,None,None], inputs=None, outputs=[org_name,org_handle,output_org])
- Createbot_button.click(fn=Create_Bot,inputs=[Organizationame, botname, bothandle,image_button,botllm,openai_key,initailsmsg,intromsg,rules], outputs=output_bot)
-
- Train_Fileselect_button.upload(upload_file,inputs=[SelectOrganizationame, Selectbotconfig,Train_Fileselect_button], outputs=[file_output])
- Train_button.click(fn=train,inputs=Train_Fileselect_button, outputs=Train_output)
-
-demo.launch()
\ No newline at end of file
diff --git a/spaces/ASJMO/freegpt/client/css/button.css b/spaces/ASJMO/freegpt/client/css/button.css
deleted file mode 100644
index 5f604a8460d048458249f78be9dc544ade84801e..0000000000000000000000000000000000000000
--- a/spaces/ASJMO/freegpt/client/css/button.css
+++ /dev/null
@@ -1,26 +0,0 @@
-.button {
- display: flex;
- padding: 8px 12px;
- align-items: center;
- justify-content: center;
- border: 1px solid var(--conversations);
- border-radius: var(--border-radius-1);
- width: 100%;
- background: transparent;
- cursor: pointer;
-}
-
-.button span {
- color: var(--colour-3);
- font-size: 0.875rem;
-}
-
-.button i::before {
- margin-right: 8px;
-}
-
-@media screen and (max-width: 990px) {
- .button span {
- font-size: 0.75rem;
- }
-}
diff --git a/spaces/ATang0729/Forecast4Muses/Model/Model6/Model6_2_ProfileRecogition/mmpretrain/configs/_base_/__init__.py b/spaces/ATang0729/Forecast4Muses/Model/Model6/Model6_2_ProfileRecogition/mmpretrain/configs/_base_/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/Admin08077/Record/README.md b/spaces/Admin08077/Record/README.md
deleted file mode 100644
index cbed1d30fa5b78e10b32a029355e4176d9ec9b45..0000000000000000000000000000000000000000
--- a/spaces/Admin08077/Record/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Record
-emoji: 🐢
-colorFrom: yellow
-colorTo: indigo
-sdk: gradio
-sdk_version: 3.46.1
-app_file: app.py
-pinned: false
-license: other
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/holygrail/HolyGrail.js b/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/holygrail/HolyGrail.js
deleted file mode 100644
index bd891f48cd1899074ee6778a25fbaaadbdeaa94f..0000000000000000000000000000000000000000
--- a/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/holygrail/HolyGrail.js
+++ /dev/null
@@ -1,28 +0,0 @@
-import Sizer from '../sizer/Sizer.js';
-import Build from './methods/Build.js'
-
-class HolyGrail extends Sizer {
- constructor(scene, config) {
- if (config === undefined) {
- config = {};
- }
-
- config.orientation = 1; // top-to-bottom
- // Create sizer
- super(scene, config);
- this.type = 'rexHolyGrail';
-
- this.build(config);
- }
-}
-
-var methods = {
- build: Build,
-}
-
-Object.assign(
- HolyGrail.prototype,
- methods,
-)
-
-export default HolyGrail;
\ No newline at end of file
diff --git a/spaces/Aki004/herta-so-vits/vdecoder/hifigan/nvSTFT.py b/spaces/Aki004/herta-so-vits/vdecoder/hifigan/nvSTFT.py
deleted file mode 100644
index 88597d62a505715091f9ba62d38bf0a85a31b95a..0000000000000000000000000000000000000000
--- a/spaces/Aki004/herta-so-vits/vdecoder/hifigan/nvSTFT.py
+++ /dev/null
@@ -1,111 +0,0 @@
-import math
-import os
-os.environ["LRU_CACHE_CAPACITY"] = "3"
-import random
-import torch
-import torch.utils.data
-import numpy as np
-import librosa
-from librosa.util import normalize
-from librosa.filters import mel as librosa_mel_fn
-from scipy.io.wavfile import read
-import soundfile as sf
-
-def load_wav_to_torch(full_path, target_sr=None, return_empty_on_exception=False):
- sampling_rate = None
- try:
- data, sampling_rate = sf.read(full_path, always_2d=True)# than soundfile.
- except Exception as ex:
- print(f"'{full_path}' failed to load.\nException:")
- print(ex)
- if return_empty_on_exception:
- return [], sampling_rate or target_sr or 32000
- else:
- raise Exception(ex)
-
- if len(data.shape) > 1:
- data = data[:, 0]
- assert len(data) > 2# check duration of audio file is > 2 samples (because otherwise the slice operation was on the wrong dimension)
-
- if np.issubdtype(data.dtype, np.integer): # if audio data is type int
- max_mag = -np.iinfo(data.dtype).min # maximum magnitude = min possible value of intXX
- else: # if audio data is type fp32
- max_mag = max(np.amax(data), -np.amin(data))
- max_mag = (2**31)+1 if max_mag > (2**15) else ((2**15)+1 if max_mag > 1.01 else 1.0) # data should be either 16-bit INT, 32-bit INT or [-1 to 1] float32
-
- data = torch.FloatTensor(data.astype(np.float32))/max_mag
-
- if (torch.isinf(data) | torch.isnan(data)).any() and return_empty_on_exception:# resample will crash with inf/NaN inputs. return_empty_on_exception will return empty arr instead of except
- return [], sampling_rate or target_sr or 32000
- if target_sr is not None and sampling_rate != target_sr:
- data = torch.from_numpy(librosa.core.resample(data.numpy(), orig_sr=sampling_rate, target_sr=target_sr))
- sampling_rate = target_sr
-
- return data, sampling_rate
-
-def dynamic_range_compression(x, C=1, clip_val=1e-5):
- return np.log(np.clip(x, a_min=clip_val, a_max=None) * C)
-
-def dynamic_range_decompression(x, C=1):
- return np.exp(x) / C
-
-def dynamic_range_compression_torch(x, C=1, clip_val=1e-5):
- return torch.log(torch.clamp(x, min=clip_val) * C)
-
-def dynamic_range_decompression_torch(x, C=1):
- return torch.exp(x) / C
-
-class STFT():
- def __init__(self, sr=22050, n_mels=80, n_fft=1024, win_size=1024, hop_length=256, fmin=20, fmax=11025, clip_val=1e-5):
- self.target_sr = sr
-
- self.n_mels = n_mels
- self.n_fft = n_fft
- self.win_size = win_size
- self.hop_length = hop_length
- self.fmin = fmin
- self.fmax = fmax
- self.clip_val = clip_val
- self.mel_basis = {}
- self.hann_window = {}
-
- def get_mel(self, y, center=False):
- sampling_rate = self.target_sr
- n_mels = self.n_mels
- n_fft = self.n_fft
- win_size = self.win_size
- hop_length = self.hop_length
- fmin = self.fmin
- fmax = self.fmax
- clip_val = self.clip_val
-
- if torch.min(y) < -1.:
- print('min value is ', torch.min(y))
- if torch.max(y) > 1.:
- print('max value is ', torch.max(y))
-
- if fmax not in self.mel_basis:
- mel = librosa_mel_fn(sr=sampling_rate, n_fft=n_fft, n_mels=n_mels, fmin=fmin, fmax=fmax)
- self.mel_basis[str(fmax)+'_'+str(y.device)] = torch.from_numpy(mel).float().to(y.device)
- self.hann_window[str(y.device)] = torch.hann_window(self.win_size).to(y.device)
-
- y = torch.nn.functional.pad(y.unsqueeze(1), (int((n_fft-hop_length)/2), int((n_fft-hop_length)/2)), mode='reflect')
- y = y.squeeze(1)
-
- spec = torch.stft(y, n_fft, hop_length=hop_length, win_length=win_size, window=self.hann_window[str(y.device)],
- center=center, pad_mode='reflect', normalized=False, onesided=True)
- # print(111,spec)
- spec = torch.sqrt(spec.pow(2).sum(-1)+(1e-9))
- # print(222,spec)
- spec = torch.matmul(self.mel_basis[str(fmax)+'_'+str(y.device)], spec)
- # print(333,spec)
- spec = dynamic_range_compression_torch(spec, clip_val=clip_val)
- # print(444,spec)
- return spec
-
- def __call__(self, audiopath):
- audio, sr = load_wav_to_torch(audiopath, target_sr=self.target_sr)
- spect = self.get_mel(audio.unsqueeze(0)).squeeze(0)
- return spect
-
-stft = STFT()
diff --git a/spaces/Akmyradov/TurkmenTTSweSTT/uroman/lib/NLP/Romanizer.pm b/spaces/Akmyradov/TurkmenTTSweSTT/uroman/lib/NLP/Romanizer.pm
deleted file mode 100644
index b504ec6eefcf1b6b28e216c9fe3d69d2735b2b25..0000000000000000000000000000000000000000
--- a/spaces/Akmyradov/TurkmenTTSweSTT/uroman/lib/NLP/Romanizer.pm
+++ /dev/null
@@ -1,2020 +0,0 @@
-################################################################
-# #
-# Romanizer #
-# #
-################################################################
-
-package NLP::Romanizer;
-
-use NLP::Chinese;
-use NLP::UTF8;
-use NLP::utilities;
-use JSON;
-$utf8 = NLP::UTF8;
-$util = NLP::utilities;
-$chinesePM = NLP::Chinese;
-
-my $verbosePM = 0;
-%empty_ht = ();
-
-my $braille_capital_letter_indicator = "\xE2\xA0\xA0";
-my $braille_number_indicator = "\xE2\xA0\xBC";
-my $braille_decimal_point = "\xE2\xA0\xA8";
-my $braille_comma = "\xE2\xA0\x82";
-my $braille_solidus = "\xE2\xA0\x8C";
-my $braille_numeric_space = "\xE2\xA0\x90";
-my $braille_letter_indicator = "\xE2\xA0\xB0";
-my $braille_period = "\xE2\xA0\xB2";
-
-sub new {
- local($caller) = @_;
-
- my $object = {};
- my $class = ref( $caller ) || $caller;
- bless($object, $class);
- return $object;
-}
-
-sub load_unicode_data {
- local($this, *ht, $filename) = @_;
- # ../../data/UnicodeData.txt
-
- $n = 0;
- if (open(IN, $filename)) {
- while (main title
" - """ - if self.asGroupList: - raise TypeError("cannot use sub() with Regex(asGroupList=True)") - - if self.asMatch and callable(repl): - raise TypeError("cannot use sub() with a callable with Regex(asMatch=True)") - - if self.asMatch: - - def pa(tokens): - return tokens[0].expand(repl) - - else: - - def pa(tokens): - return self.re.sub(repl, tokens[0]) - - return self.add_parse_action(pa) - - -class QuotedString(Token): - r""" - Token for matching strings that are delimited by quoting characters. - - Defined with the following parameters: - - - ``quote_char`` - string of one or more characters defining the - quote delimiting string - - ``esc_char`` - character to re_escape quotes, typically backslash - (default= ``None``) - - ``esc_quote`` - special quote sequence to re_escape an embedded quote - string (such as SQL's ``""`` to re_escape an embedded ``"``) - (default= ``None``) - - ``multiline`` - boolean indicating whether quotes can span - multiple lines (default= ``False``) - - ``unquote_results`` - boolean indicating whether the matched text - should be unquoted (default= ``True``) - - ``end_quote_char`` - string of one or more characters defining the - end of the quote delimited string (default= ``None`` => same as - quote_char) - - ``convert_whitespace_escapes`` - convert escaped whitespace - (``'\t'``, ``'\n'``, etc.) to actual whitespace - (default= ``True``) - - Example:: - - qs = QuotedString('"') - print(qs.search_string('lsjdf "This is the quote" sldjf')) - complex_qs = QuotedString('{{', end_quote_char='}}') - print(complex_qs.search_string('lsjdf {{This is the "quote"}} sldjf')) - sql_qs = QuotedString('"', esc_quote='""') - print(sql_qs.search_string('lsjdf "This is the quote with ""embedded"" quotes" sldjf')) - - prints:: - - [['This is the quote']] - [['This is the "quote"']] - [['This is the quote with "embedded" quotes']] - """ - ws_map = ((r"\t", "\t"), (r"\n", "\n"), (r"\f", "\f"), (r"\r", "\r")) - - def __init__( - self, - quote_char: str = "", - esc_char: typing.Optional[str] = None, - esc_quote: typing.Optional[str] = None, - multiline: bool = False, - unquote_results: bool = True, - end_quote_char: typing.Optional[str] = None, - convert_whitespace_escapes: bool = True, - *, - quoteChar: str = "", - escChar: typing.Optional[str] = None, - escQuote: typing.Optional[str] = None, - unquoteResults: bool = True, - endQuoteChar: typing.Optional[str] = None, - convertWhitespaceEscapes: bool = True, - ): - super().__init__() - escChar = escChar or esc_char - escQuote = escQuote or esc_quote - unquoteResults = unquoteResults and unquote_results - endQuoteChar = endQuoteChar or end_quote_char - convertWhitespaceEscapes = ( - convertWhitespaceEscapes and convert_whitespace_escapes - ) - quote_char = quoteChar or quote_char - - # remove white space from quote chars - wont work anyway - quote_char = quote_char.strip() - if not quote_char: - raise ValueError("quote_char cannot be the empty string") - - if endQuoteChar is None: - endQuoteChar = quote_char - else: - endQuoteChar = endQuoteChar.strip() - if not endQuoteChar: - raise ValueError("endQuoteChar cannot be the empty string") - - self.quoteChar = quote_char - self.quoteCharLen = len(quote_char) - self.firstQuoteChar = quote_char[0] - self.endQuoteChar = endQuoteChar - self.endQuoteCharLen = len(endQuoteChar) - self.escChar = escChar - self.escQuote = escQuote - self.unquoteResults = unquoteResults - self.convertWhitespaceEscapes = convertWhitespaceEscapes - - sep = "" - inner_pattern = "" - - if escQuote: - inner_pattern += r"{}(?:{})".format(sep, re.escape(escQuote)) - sep = "|" - - if escChar: - inner_pattern += r"{}(?:{}.)".format(sep, re.escape(escChar)) - sep = "|" - self.escCharReplacePattern = re.escape(self.escChar) + "(.)" - - if len(self.endQuoteChar) > 1: - inner_pattern += ( - "{}(?:".format(sep) - + "|".join( - "(?:{}(?!{}))".format( - re.escape(self.endQuoteChar[:i]), - re.escape(self.endQuoteChar[i:]), - ) - for i in range(len(self.endQuoteChar) - 1, 0, -1) - ) - + ")" - ) - sep = "|" - - if multiline: - self.flags = re.MULTILINE | re.DOTALL - inner_pattern += r"{}(?:[^{}{}])".format( - sep, - _escape_regex_range_chars(self.endQuoteChar[0]), - (_escape_regex_range_chars(escChar) if escChar is not None else ""), - ) - else: - self.flags = 0 - inner_pattern += r"{}(?:[^{}\n\r{}])".format( - sep, - _escape_regex_range_chars(self.endQuoteChar[0]), - (_escape_regex_range_chars(escChar) if escChar is not None else ""), - ) - - self.pattern = "".join( - [ - re.escape(self.quoteChar), - "(?:", - inner_pattern, - ")*", - re.escape(self.endQuoteChar), - ] - ) - - try: - self.re = re.compile(self.pattern, self.flags) - self.reString = self.pattern - self.re_match = self.re.match - except re.error: - raise ValueError( - "invalid pattern {!r} passed to Regex".format(self.pattern) - ) - - self.errmsg = "Expected " + self.name - self.mayIndexError = False - self.mayReturnEmpty = True - - def _generateDefaultName(self): - if self.quoteChar == self.endQuoteChar and isinstance(self.quoteChar, str_type): - return "string enclosed in {!r}".format(self.quoteChar) - - return "quoted string, starting with {} ending with {}".format( - self.quoteChar, self.endQuoteChar - ) - - def parseImpl(self, instring, loc, doActions=True): - result = ( - instring[loc] == self.firstQuoteChar - and self.re_match(instring, loc) - or None - ) - if not result: - raise ParseException(instring, loc, self.errmsg, self) - - loc = result.end() - ret = result.group() - - if self.unquoteResults: - - # strip off quotes - ret = ret[self.quoteCharLen : -self.endQuoteCharLen] - - if isinstance(ret, str_type): - # replace escaped whitespace - if "\\" in ret and self.convertWhitespaceEscapes: - for wslit, wschar in self.ws_map: - ret = ret.replace(wslit, wschar) - - # replace escaped characters - if self.escChar: - ret = re.sub(self.escCharReplacePattern, r"\g<1>", ret) - - # replace escaped quotes - if self.escQuote: - ret = ret.replace(self.escQuote, self.endQuoteChar) - - return loc, ret - - -class CharsNotIn(Token): - """Token for matching words composed of characters *not* in a given - set (will include whitespace in matched characters if not listed in - the provided exclusion set - see example). Defined with string - containing all disallowed characters, and an optional minimum, - maximum, and/or exact length. The default value for ``min`` is - 1 (a minimum value < 1 is not valid); the default values for - ``max`` and ``exact`` are 0, meaning no maximum or exact - length restriction. - - Example:: - - # define a comma-separated-value as anything that is not a ',' - csv_value = CharsNotIn(',') - print(delimited_list(csv_value).parse_string("dkls,lsdkjf,s12 34,@!#,213")) - - prints:: - - ['dkls', 'lsdkjf', 's12 34', '@!#', '213'] - """ - - def __init__( - self, - not_chars: str = "", - min: int = 1, - max: int = 0, - exact: int = 0, - *, - notChars: str = "", - ): - super().__init__() - self.skipWhitespace = False - self.notChars = not_chars or notChars - self.notCharsSet = set(self.notChars) - - if min < 1: - raise ValueError( - "cannot specify a minimum length < 1; use " - "Opt(CharsNotIn()) if zero-length char group is permitted" - ) - - self.minLen = min - - if max > 0: - self.maxLen = max - else: - self.maxLen = _MAX_INT - - if exact > 0: - self.maxLen = exact - self.minLen = exact - - self.errmsg = "Expected " + self.name - self.mayReturnEmpty = self.minLen == 0 - self.mayIndexError = False - - def _generateDefaultName(self): - not_chars_str = _collapse_string_to_ranges(self.notChars) - if len(not_chars_str) > 16: - return "!W:({}...)".format(self.notChars[: 16 - 3]) - else: - return "!W:({})".format(self.notChars) - - def parseImpl(self, instring, loc, doActions=True): - notchars = self.notCharsSet - if instring[loc] in notchars: - raise ParseException(instring, loc, self.errmsg, self) - - start = loc - loc += 1 - maxlen = min(start + self.maxLen, len(instring)) - while loc < maxlen and instring[loc] not in notchars: - loc += 1 - - if loc - start < self.minLen: - raise ParseException(instring, loc, self.errmsg, self) - - return loc, instring[start:loc] - - -class White(Token): - """Special matching class for matching whitespace. Normally, - whitespace is ignored by pyparsing grammars. This class is included - when some whitespace structures are significant. Define with - a string containing the whitespace characters to be matched; default - is ``" \\t\\r\\n"``. Also takes optional ``min``, - ``max``, and ``exact`` arguments, as defined for the - :class:`Word` class. - """ - - whiteStrs = { - " ": "constexpr bool that is \c true if \c T is
-/// \a TriviallyRelocatable e.g. can be copied bitwise (with a facility like
-/// \c memcpy), and \c false otherwise.
-template constexpr bool that is \c true if \c From is
-/// \a TriviallyRelocatable to \c To, e.g. can be copied bitwise (with a
-/// facility like \c memcpy), and \c false otherwise.
-template constexpr bool that is \c true if the element type of
-/// \c FromIterator is \a TriviallyRelocatable to the element type of
-/// \c ToIterator, and \c false otherwise.
-template ${item[0]}: ${item[1]}
` - info_div.push(v); - } - - const newChartDiv = document.createElement('div'); - newChartDiv.id = `col-${chartID}`; - newChartDiv.className = 'cols p-4 mt-4 w-full overflow-hidden bg-white rounded-lg'; - newChartDiv.innerHTML = ` -${name}
--
-
Doc {i} -
-{source['content']}
-LoiLibre Q&A
")
- gr.Markdown("Pose tes questions aux textes de loi ici
")
-
- with gr.Row():
- with gr.Column(scale=2):
- chatbot = gr.Chatbot(
- elem_id="chatbot", label="LoiLibreQ&A chatbot", show_label=False
- )
- state = gr.State([system_template])
-
- with gr.Row():
- ask = gr.Textbox(
- show_label=False,
- placeholder="Pose ta question ici",
- ).style(container=False)
- ask_examples_hidden = gr.Textbox(elem_id="hidden-message")
-
- examples_questions = gr.Examples(
- [
- "Quelles sont les options légales pour une personne qui souhaite divorcer, notamment en matière de garde d'enfants et de pension alimentaire ?",
- "Quelles sont les démarches à suivre pour créer une entreprise et quels sont les risques et les responsabilités juridiques associés ?",
- "Comment pouvez-vous m'aider à protéger mes droits d'auteur et à faire respecter mes droits de propriété intellectuelle ?",
- "Quels sont mes droits si j'ai été victime de harcèlement au travail ou de discrimination en raison de mon âge, de ma race ou de mon genre ?",
- "Quelles sont les conséquences légales pour une entreprise qui a été poursuivie pour négligence ou faute professionnelle ?",
- "Comment pouvez-vous m'aider à négocier un contrat de location commercial ou résidentiel, et quels sont mes droits et obligations en tant que locataire ou propriétaire ?",
- "Quels sont les défenses possibles pour une personne accusée de crimes sexuels ou de violence domestique ?",
- "Quelles sont les options légales pour une personne qui souhaite contester un testament ou un héritage ?",
- "Comment pouvez-vous m'aider à obtenir une compensation en cas d'accident de voiture ou de blessure personnelle causée par la négligence d'une autre personne ?",
- "Comment pouvez-vous m'aider à obtenir un visa ou un statut de résident permanent aux États-Unis, et quels sont les risques et les avantages associés ?",
- ],
- [ask_examples_hidden],
- )
-
- with gr.Column(scale=1, variant="panel"):
- gr.Markdown("### Sources")
- sources_textbox = gr.Markdown(show_label=False)
-
- ask.submit(
- fn=chat,
- inputs=[user_id_state, ask, state],
- outputs=[chatbot, state, sources_textbox],
- )
- ask.submit(reset_textbox, [], [ask])
-
- ask_examples_hidden.change(
- fn=chat,
- inputs=[user_id_state, ask_examples_hidden, state],
- outputs=[chatbot, state, sources_textbox],
- )
-
- with gr.Row():
- with gr.Column(scale=1):
- gr.Markdown(
- """
-  ''', f"You should name your concept with a unique made up word that has low chance of the model already knowing it (e.g.: `{instance_prompt_example}` here). Images will be automatically cropped to {resize_width}x{resize_width}.", freeze_for, gr.update(visible=False)]
- elif(option == "person"):
- instance_prompt_example = "julcto"
- freeze_for = 70
- #show_prior_preservation = True if base != "v2-768" else False
- show_prior_preservation=False
- if(show_prior_preservation):
- prior_preservation_box_update = gr.update(visible=show_prior_preservation)
- else:
- prior_preservation_box_update = gr.update(visible=show_prior_preservation, value=False)
- return [f"You are going to train a `person`(s), upload 10-20 images of each person you are planning on training on from different angles/perspectives. You can use services like birme for smart cropping. {mandatory_liability}:", '''
''', f"You should name your concept with a unique made up word that has low chance of the model already knowing it (e.g.: `{instance_prompt_example}` here). Images will be automatically cropped to {resize_width}x{resize_width}.", freeze_for, gr.update(visible=False)]
- elif(option == "person"):
- instance_prompt_example = "julcto"
- freeze_for = 70
- #show_prior_preservation = True if base != "v2-768" else False
- show_prior_preservation=False
- if(show_prior_preservation):
- prior_preservation_box_update = gr.update(visible=show_prior_preservation)
- else:
- prior_preservation_box_update = gr.update(visible=show_prior_preservation, value=False)
- return [f"You are going to train a `person`(s), upload 10-20 images of each person you are planning on training on from different angles/perspectives. You can use services like birme for smart cropping. {mandatory_liability}:", ''' ''', f"You should name your concept with a unique made up word that has low chance of the model already knowing it (e.g.: `{instance_prompt_example}` here). Images will be automatically cropped to {resize_width}x{resize_width}.", freeze_for, prior_preservation_box_update]
- elif(option == "style"):
- instance_prompt_example = "trsldamrl"
- freeze_for = 10
- return [f"You are going to train a `style`, upload 10-20 images of the style you are planning on training on. You can use services like birme for smart cropping. Name the files with the words you would like {mandatory_liability}:", '''
''', f"You should name your concept with a unique made up word that has low chance of the model already knowing it (e.g.: `{instance_prompt_example}` here). Images will be automatically cropped to {resize_width}x{resize_width}.", freeze_for, prior_preservation_box_update]
- elif(option == "style"):
- instance_prompt_example = "trsldamrl"
- freeze_for = 10
- return [f"You are going to train a `style`, upload 10-20 images of the style you are planning on training on. You can use services like birme for smart cropping. Name the files with the words you would like {mandatory_liability}:", ''' ''', f"You should name your concept with a unique made up word that has low chance of the model already knowing it (e.g.: `{instance_prompt_example}` here). Images will be automatically cropped to {resize_width}x{resize_width}", freeze_for, gr.update(visible=False)]
-
-def swap_base_model(selected_model):
- if(is_gpu_associated):
- global model_to_load
- if(selected_model == "v1-5"):
- model_to_load = model_v1
- elif(selected_model == "v2-768"):
- model_to_load = model_v2
- else:
- model_to_load = model_v2_512
-
-def count_files(*inputs):
- file_counter = 0
- concept_counter = 0
- for i, input in enumerate(inputs):
- if(i < maximum_concepts-1):
- files = inputs[i]
- if(files):
- concept_counter+=1
- file_counter+=len(files)
- uses_custom = inputs[-1]
- type_of_thing = inputs[-4]
- selected_model = inputs[-5]
- experimental_faces = inputs[-6]
- if(uses_custom):
- Training_Steps = int(inputs[-3])
- else:
- Training_Steps = file_counter*150
- if(type_of_thing == "person" and Training_Steps > 2400):
- Training_Steps = 2400 #Avoid overfitting on person faces
- if(is_spaces):
- if(selected_model == "v1-5"):
- its = 1.1
- if(experimental_faces):
- its = 1
- elif(selected_model == "v2-512"):
- its = 0.8
- if(experimental_faces):
- its = 0.7
- elif(selected_model == "v2-768"):
- its = 0.5
- summary_sentence = f'''You are going to train {concept_counter} {type_of_thing}(s), with {file_counter} images for {Training_Steps} steps. The training should take around {round(Training_Steps/its, 2)} seconds, or {round((Training_Steps/its)/60, 2)} minutes.
- The setup, compression and uploading the model can take up to 20 minutes.
''', f"You should name your concept with a unique made up word that has low chance of the model already knowing it (e.g.: `{instance_prompt_example}` here). Images will be automatically cropped to {resize_width}x{resize_width}", freeze_for, gr.update(visible=False)]
-
-def swap_base_model(selected_model):
- if(is_gpu_associated):
- global model_to_load
- if(selected_model == "v1-5"):
- model_to_load = model_v1
- elif(selected_model == "v2-768"):
- model_to_load = model_v2
- else:
- model_to_load = model_v2_512
-
-def count_files(*inputs):
- file_counter = 0
- concept_counter = 0
- for i, input in enumerate(inputs):
- if(i < maximum_concepts-1):
- files = inputs[i]
- if(files):
- concept_counter+=1
- file_counter+=len(files)
- uses_custom = inputs[-1]
- type_of_thing = inputs[-4]
- selected_model = inputs[-5]
- experimental_faces = inputs[-6]
- if(uses_custom):
- Training_Steps = int(inputs[-3])
- else:
- Training_Steps = file_counter*150
- if(type_of_thing == "person" and Training_Steps > 2400):
- Training_Steps = 2400 #Avoid overfitting on person faces
- if(is_spaces):
- if(selected_model == "v1-5"):
- its = 1.1
- if(experimental_faces):
- its = 1
- elif(selected_model == "v2-512"):
- its = 0.8
- if(experimental_faces):
- its = 0.7
- elif(selected_model == "v2-768"):
- its = 0.5
- summary_sentence = f'''You are going to train {concept_counter} {type_of_thing}(s), with {file_counter} images for {Training_Steps} steps. The training should take around {round(Training_Steps/its, 2)} seconds, or {round((Training_Steps/its)/60, 2)} minutes.
- The setup, compression and uploading the model can take up to 20 minutes.As the T4-Small GPU costs US$0.60 for 1h, the estimated cost for this training is below US${round((((Training_Steps/its)/3600)+0.3+0.1)*0.60, 2)}.
- If you check the box below the GPU attribution will automatically removed after training is done and the model is uploaded. If not, don't forget to come back here and swap the hardware back to CPU.
''' - else: - summary_sentence = f'''You are going to train {concept_counter} {type_of_thing}(s), with {file_counter} images for {Training_Steps} steps.
''' - - return([gr.update(visible=True), gr.update(visible=True, value=summary_sentence)]) - -def update_steps(*files_list): - file_counter = 0 - for i, files in enumerate(files_list): - if(files): - file_counter+=len(files) - return(gr.update(value=file_counter*200)) - -def pad_image(image): - w, h = image.size - if w == h: - return image - elif w > h: - new_image = Image.new(image.mode, (w, w), (0, 0, 0)) - new_image.paste(image, (0, (w - h) // 2)) - return new_image - else: - new_image = Image.new(image.mode, (h, h), (0, 0, 0)) - new_image.paste(image, ((h - w) // 2, 0)) - return new_image - -def train(*inputs): - if is_shared_ui: - raise gr.Error("This Space only works in duplicated instances") - if not is_gpu_associated: - raise gr.Error("Please associate a T4 GPU for this Space") - torch.cuda.empty_cache() - if 'pipe' in globals(): - global pipe, pipe_is_set - del pipe - pipe_is_set = False - gc.collect() - - if os.path.exists("output_model"): shutil.rmtree('output_model') - if os.path.exists("instance_images"): shutil.rmtree('instance_images') - if os.path.exists("diffusers_model.tar"): os.remove("diffusers_model.tar") - if os.path.exists("model.ckpt"): os.remove("model.ckpt") - if os.path.exists("hastrained.success"): os.remove("hastrained.success") - file_counter = 0 - which_model = inputs[-10] - resolution = 512 if which_model != "v2-768" else 768 - for i, input in enumerate(inputs): - if(i < maximum_concepts-1): - if(input): - os.makedirs('instance_images',exist_ok=True) - files = inputs[i+(maximum_concepts*2)] - prompt = inputs[i+maximum_concepts] - if(prompt == "" or prompt == None): - raise gr.Error("You forgot to define your concept prompt") - for j, file_temp in enumerate(files): - file = Image.open(file_temp.name) - image = pad_image(file) - image = image.resize((resolution, resolution)) - extension = file_temp.name.split(".")[1] - image = image.convert('RGB') - image.save(f'instance_images/{prompt}_({j+1}).jpg', format="JPEG", quality = 100) - file_counter += 1 - - os.makedirs('output_model',exist_ok=True) - uses_custom = inputs[-1] - type_of_thing = inputs[-4] - remove_attribution_after = inputs[-6] - experimental_face_improvement = inputs[-9] - - if(uses_custom): - Training_Steps = int(inputs[-3]) - Train_text_encoder_for = int(inputs[-2]) - else: - if(type_of_thing == "object"): - Train_text_encoder_for=30 - - elif(type_of_thing == "style"): - Train_text_encoder_for=15 - - elif(type_of_thing == "person"): - Train_text_encoder_for=70 - - Training_Steps = file_counter*150 - if(type_of_thing == "person" and Training_Steps > 2600): - Training_Steps = 2600 #Avoid overfitting on people's faces - stptxt = int((Training_Steps*Train_text_encoder_for)/100) - gradient_checkpointing = True if (experimental_face_improvement or which_model != "v1-5") else False - cache_latents = True if which_model != "v1-5" else False - if (type_of_thing == "object" or type_of_thing == "style" or (type_of_thing == "person" and not experimental_face_improvement)): - args_general = argparse.Namespace( - image_captions_filename = True, - train_text_encoder = True if stptxt > 0 else False, - stop_text_encoder_training = stptxt, - save_n_steps = 0, - pretrained_model_name_or_path = model_to_load, - instance_data_dir="instance_images", - class_data_dir=None, - output_dir="output_model", - instance_prompt="", - seed=42, - resolution=resolution, - mixed_precision="fp16", - train_batch_size=1, - gradient_accumulation_steps=1, - use_8bit_adam=True, - learning_rate=2e-6, - lr_scheduler="polynomial", - lr_warmup_steps = 0, - max_train_steps=Training_Steps, - gradient_checkpointing=gradient_checkpointing, - cache_latents=cache_latents, - ) - print("Starting single training...") - lock_file = open("intraining.lock", "w") - lock_file.close() - run_training(args_general) - else: - args_general = argparse.Namespace( - image_captions_filename = True, - train_text_encoder = True if stptxt > 0 else False, - stop_text_encoder_training = stptxt, - save_n_steps = 0, - pretrained_model_name_or_path = model_to_load, - instance_data_dir="instance_images", - class_data_dir="Mix", - output_dir="output_model", - with_prior_preservation=True, - prior_loss_weight=1.0, - instance_prompt="", - seed=42, - resolution=resolution, - mixed_precision="fp16", - train_batch_size=1, - gradient_accumulation_steps=1, - use_8bit_adam=True, - learning_rate=2e-6, - lr_scheduler="polynomial", - lr_warmup_steps = 0, - max_train_steps=Training_Steps, - num_class_images=200, - gradient_checkpointing=gradient_checkpointing, - cache_latents=cache_latents, - ) - print("Starting multi-training...") - lock_file = open("intraining.lock", "w") - lock_file.close() - run_training(args_general) - gc.collect() - torch.cuda.empty_cache() - if(which_model == "v1-5"): - print("Adding Safety Checker to the model...") - shutil.copytree(f"{safety_checker}/feature_extractor", "output_model/feature_extractor") - shutil.copytree(f"{safety_checker}/safety_checker", "output_model/safety_checker") - shutil.copy(f"model_index.json", "output_model/model_index.json") - - if(not remove_attribution_after): - print("Archiving model file...") - with tarfile.open("diffusers_model.tar", "w") as tar: - tar.add("output_model", arcname=os.path.basename("output_model")) - if os.path.exists("intraining.lock"): os.remove("intraining.lock") - trained_file = open("hastrained.success", "w") - trained_file.close() - print("Training completed!") - return [ - gr.update(visible=True, value=["diffusers_model.tar"]), #result - gr.update(visible=True), #try_your_model - gr.update(visible=True), #push_to_hub - gr.update(visible=True), #convert_button - gr.update(visible=False), #training_ongoing - gr.update(visible=True) #completed_training - ] - else: - hf_token = inputs[-5] - model_name = inputs[-7] - where_to_upload = inputs[-8] - push(model_name, where_to_upload, hf_token, which_model, True) - hardware_url = f"https://huggingface.co/spaces/{os.environ['SPACE_ID']}/hardware" - headers = { "authorization" : f"Bearer {hf_token}"} - body = {'flavor': 'cpu-basic'} - requests.post(hardware_url, json = body, headers=headers) - -pipe_is_set = False -def generate(prompt, steps): - torch.cuda.empty_cache() - from diffusers import StableDiffusionPipeline - global pipe_is_set - if(not pipe_is_set): - global pipe - pipe = StableDiffusionPipeline.from_pretrained("./output_model", torch_dtype=torch.float16) - pipe = pipe.to("cuda") - pipe_is_set = True - - image = pipe(prompt, num_inference_steps=steps).images[0] - return(image) - -def push(model_name, where_to_upload, hf_token, which_model, comes_from_automated=False): - if(not os.path.exists("model.ckpt")): - convert("output_model", "model.ckpt") - from huggingface_hub import HfApi, HfFolder, CommitOperationAdd - from huggingface_hub import create_repo - model_name_slug = slugify(model_name) - api = HfApi() - your_username = api.whoami(token=hf_token)["name"] - if(where_to_upload == "My personal profile"): - model_id = f"{your_username}/{model_name_slug}" - else: - model_id = f"sd-dreambooth-library/{model_name_slug}" - headers = {"Authorization" : f"Bearer: {hf_token}", "Content-Type": "application/json"} - response = requests.post("https://huggingface.co/organizations/sd-dreambooth-library/share/SSeOwppVCscfTEzFGQaqpfcjukVeNrKNHX", headers=headers) - - images_upload = os.listdir("instance_images") - image_string = "" - instance_prompt_list = [] - previous_instance_prompt = '' - for i, image in enumerate(images_upload): - instance_prompt = image.split("_")[0] - if(instance_prompt != previous_instance_prompt): - title_instance_prompt_string = instance_prompt - instance_prompt_list.append(instance_prompt) - else: - title_instance_prompt_string = '' - previous_instance_prompt = instance_prompt - image_string = f'''{title_instance_prompt_string} {"(use that on your prompt)" if title_instance_prompt_string != "" else ""} -{image_string}})''' - readme_text = f'''--- -license: creativeml-openrail-m -tags: -- text-to-image ---- -### {model_name} Dreambooth model trained by {api.whoami(token=hf_token)["name"]} with [Hugging Face Dreambooth Training Space](https://huggingface.co/spaces/multimodalart/dreambooth-training) with the {which_model} base model - -You run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb). Don't forget to use the concept prompts! - -Sample pictures of: -{image_string} -''' - #Save the readme to a file - readme_file = open("model.README.md", "w") - readme_file.write(readme_text) - readme_file.close() - #Save the token identifier to a file - text_file = open("token_identifier.txt", "w") - text_file.write(', '.join(instance_prompt_list)) - text_file.close() - try: - create_repo(model_id,private=True, token=hf_token) - except: - import time - epoch_time = str(int(time.time())) - create_repo(f"{model_id}-{epoch_time}", private=True,token=hf_token) - operations = [ - CommitOperationAdd(path_in_repo="token_identifier.txt", path_or_fileobj="token_identifier.txt"), - CommitOperationAdd(path_in_repo="README.md", path_or_fileobj="model.README.md"), - CommitOperationAdd(path_in_repo=f"model.ckpt",path_or_fileobj="model.ckpt") - ] - api.create_commit( - repo_id=model_id, - operations=operations, - commit_message=f"Upload the model {model_name}", - token=hf_token - ) - api.upload_folder( - folder_path="output_model", - repo_id=model_id, - token=hf_token - ) - api.upload_folder( - folder_path="instance_images", - path_in_repo="concept_images", - repo_id=model_id, - token=hf_token - ) - if is_spaces: - if(not comes_from_automated): - extra_message = "Don't forget to remove the GPU attribution after you play with it." - else: - extra_message = "The GPU has been removed automatically as requested, and you can try the model via the model page" - api.create_discussion(repo_id=os.environ['SPACE_ID'], title=f"Your model {model_name} has finished trained from the Dreambooth Train Spaces!", description=f"Your model has been successfully uploaded to: https://huggingface.co/{model_id}. {extra_message}",repo_type="space", token=hf_token) - - return [gr.update(visible=True, value=f"Successfully uploaded your model. Access it [here](https://huggingface.co/{model_id})"), gr.update(visible=True, value=["diffusers_model.tar", "model.ckpt"])] - -def convert_to_ckpt(): - if 'pipe' in globals(): - global pipe, pipe_is_set - del pipe - pipe_is_set = False - gc.collect() - convert("output_model", "model.ckpt") - return gr.update(visible=True, value=["diffusers_model.tar", "model.ckpt"]) - -def check_status(top_description): - if os.path.exists("hastrained.success"): - if is_spaces: - update_top_tag = gr.update(value=f''' -
Your model has finished training ✅
-Yay, congratulations on training your model. Scroll down to play with with it, save it (either downloading it or on the Hugging Face Hub). Once you are done, your model is safe, and you don't want to train a new one, go to the settings page and downgrade your Space to a CPU Basic
-Your model has finished training ✅
-Yay, congratulations on training your model. Scroll down to play with with it, save it (either downloading it or on the Hugging Face Hub).
-Don't worry, your model is still training! ⌛
-You closed the tab while your model was training, but it's all good! It is still training right now. You can click the "Open logs" button above here to check the training status. Once training is done, reload this tab to interact with your model
-Attention - This Space doesn't work in this shared UI
-For it to work, you can either run locally or duplicate the Space and run it on your own profile using a (paid) private T4 GPU for training. As each T4 costs US$0.60/h, it should cost < US$1 to train most models using default settings!
 -
- You have successfully associated a GPU to the Dreambooth Training Space 🎉
-Certify that you got a T4. You can now train your model! You will be billed by the minute from when you activated the GPU until when it is turned it off.
-You have successfully duplicated the Dreambooth Training Space 🎉
-There's only one step left before you can train your model: attribute a T4 GPU to it (via the Settings tab) and run the training below. Other GPUs are not compatible for now. You will be billed by the minute from when you activate the GPU until when it is turned it off.
-You have successfully cloned the Dreambooth Training Space locally 🎉
-Do a pip install requirements-local.txt
''')
- things_naming = gr.Markdown("You should name your concept with a unique made up word that has low chance of the model already knowing it (e.g.: `cttoy` here). Images will be automatically cropped to 512x512.")
-
- with gr.Column():
- file_collection = []
- concept_collection = []
- buttons_collection = []
- delete_collection = []
- is_visible = []
-
- row = [None] * maximum_concepts
- for x in range(maximum_concepts):
- ordinal = lambda n: "%d%s" % (n, "tsnrhtdd"[(n // 10 % 10 != 1) * (n % 10 < 4) * n % 10::4])
- if(x == 0):
- visible = True
- is_visible.append(gr.State(value=True))
- else:
- visible = False
- is_visible.append(gr.State(value=False))
-
- file_collection.append(gr.File(label=f'''Upload the images for your {ordinal(x+1) if (x>0) else ""} concept''', file_count="multiple", interactive=True, visible=visible))
- with gr.Column(visible=visible) as row[x]:
- concept_collection.append(gr.Textbox(label=f'''{ordinal(x+1) if (x>0) else ""} concept prompt - use a unique, made up word to avoid collisions'''))
- with gr.Row():
- if(x < maximum_concepts-1):
- buttons_collection.append(gr.Button(value="Add +1 concept", visible=visible))
- if(x > 0):
- delete_collection.append(gr.Button(value=f"Delete {ordinal(x+1)} concept"))
-
- counter_add = 1
- for button in buttons_collection:
- if(counter_add < len(buttons_collection)):
- button.click(lambda:
- [gr.update(visible=True),gr.update(visible=True), gr.update(visible=False), gr.update(visible=True), True, None],
- None,
- [row[counter_add], file_collection[counter_add], buttons_collection[counter_add-1], buttons_collection[counter_add], is_visible[counter_add], file_collection[counter_add]], queue=False)
- else:
- button.click(lambda:[gr.update(visible=True),gr.update(visible=True), gr.update(visible=False), True], None, [row[counter_add], file_collection[counter_add], buttons_collection[counter_add-1], is_visible[counter_add]], queue=False)
- counter_add += 1
-
- counter_delete = 1
- for delete_button in delete_collection:
- if(counter_delete < len(delete_collection)+1):
- delete_button.click(lambda:[gr.update(visible=False),gr.update(visible=False), gr.update(visible=True), False], None, [file_collection[counter_delete], row[counter_delete], buttons_collection[counter_delete-1], is_visible[counter_delete]], queue=False)
- counter_delete += 1
-
- with gr.Accordion("Custom Settings", open=False):
- swap_auto_calculated = gr.Checkbox(label="Use custom settings")
- gr.Markdown("If not checked, the % of frozen encoder will be tuned automatically to whether you are training an `object`, `person` or `style`. The text-encoder is frozen after 10% of the steps for a style, 30% of the steps for an object and 75% trained for persons. The number of steps varies between 1400 and 2400 depending on how many images uploaded. If you see too many artifacts in your output, it means it may have overfit and you need less steps. If your results aren't really what you wanted, it may be underfitting and you need more steps.")
- steps = gr.Number(label="How many steps", value=2400)
- perc_txt_encoder = gr.Number(label="Percentage of the training steps the text-encoder should be trained as well", value=30)
-
- with gr.Box(visible=False) as training_summary:
- training_summary_text = gr.HTML("", visible=True, label="Training Summary")
- is_advanced_visible = True if is_spaces else False
- training_summary_checkbox = gr.Checkbox(label="Automatically remove paid GPU attribution and upload model to the Hugging Face Hub after training", value=True, visible=is_advanced_visible)
- training_summary_model_name = gr.Textbox(label="Name of your model", visible=True)
- training_summary_where_to_upload = gr.Dropdown(["My personal profile", "Public Library"], value="My personal profile", label="Upload to", visible=True)
- training_summary_token_message = gr.Markdown("[A Hugging Face write access token](https://huggingface.co/settings/tokens), go to \"New token\" -> Role : Write. A regular read token won't work here.", visible=True)
- training_summary_token = gr.Textbox(label="Hugging Face Write Token", type="password", visible=True)
-
- train_btn = gr.Button("Start Training")
- if(is_shared_ui):
- training_ongoing = gr.Markdown("## This Space only works in duplicated instances. Please duplicate it and try again!", visible=False)
- elif(not is_gpu_associated):
- training_ongoing = gr.Markdown("## Oops, you haven't associated your T4 GPU to this Space. Visit the Settings tab, associate and try again.", visible=False)
- else:
- training_ongoing = gr.Markdown("## Training is ongoing ⌛... You can close this tab if you like or just wait. If you did not check the `Remove GPU After training`, you can come back here to try your model and upload it after training. Don't forget to remove the GPU attribution after you are done. ", visible=False)
-
- #Post-training UI
- completed_training = gr.Markdown('''# ✅ Training completed.
- ### Don't forget to remove the GPU attribution after you are done trying and uploading your model''', visible=False)
-
- with gr.Row():
- with gr.Box(visible=False) as try_your_model:
- gr.Markdown("## Try your model")
- prompt = gr.Textbox(label="Type your prompt")
- result_image = gr.Image()
- inference_steps = gr.Slider(minimum=1, maximum=150, value=50, step=1)
- generate_button = gr.Button("Generate Image")
-
- with gr.Box(visible=False) as push_to_hub:
- gr.Markdown("## Push to Hugging Face Hub")
- model_name = gr.Textbox(label="Name of your model", placeholder="Tarsila do Amaral Style")
- where_to_upload = gr.Dropdown(["My personal profile", "Public Library"], label="Upload to")
- gr.Markdown("[A Hugging Face write access token](https://huggingface.co/settings/tokens), go to \"New token\" -> Role : Write. A regular read token won't work here.")
- hf_token = gr.Textbox(label="Hugging Face Write Token", type="password")
-
- push_button = gr.Button("Push to the Hub")
-
- result = gr.File(label="Download the uploaded models in the diffusers format", visible=True)
- success_message_upload = gr.Markdown(visible=False)
- convert_button = gr.Button("Convert to CKPT", visible=False)
-
- #Swap the examples and the % of text encoder trained depending if it is an object, person or style
- type_of_thing.change(fn=swap_text, inputs=[type_of_thing, base_model_to_use], outputs=[thing_description, thing_image_example, things_naming, perc_txt_encoder, thing_experimental], queue=False, show_progress=False)
-
- #Swap the base model
- base_model_to_use.change(fn=swap_text, inputs=[type_of_thing, base_model_to_use], outputs=[thing_description, thing_image_example, things_naming, perc_txt_encoder, thing_experimental], queue=False, show_progress=False)
- base_model_to_use.change(fn=swap_base_model, inputs=base_model_to_use, outputs=[])
-
- #Update the summary box below the UI according to how many images are uploaded and whether users are using custom settings or not
- for file in file_collection:
- #file.change(fn=update_steps,inputs=file_collection, outputs=steps)
- file.change(fn=count_files, inputs=file_collection+[thing_experimental]+[base_model_to_use]+[type_of_thing]+[steps]+[perc_txt_encoder]+[swap_auto_calculated], outputs=[training_summary, training_summary_text], queue=False)
-
- thing_experimental.change(fn=count_files, inputs=file_collection+[thing_experimental]+[base_model_to_use]+[type_of_thing]+[steps]+[perc_txt_encoder]+[swap_auto_calculated], outputs=[training_summary, training_summary_text], queue=False)
- base_model_to_use.change(fn=count_files, inputs=file_collection+[thing_experimental]+[base_model_to_use]+[type_of_thing]+[steps]+[perc_txt_encoder]+[swap_auto_calculated], outputs=[training_summary, training_summary_text], queue=False)
- steps.change(fn=count_files, inputs=file_collection+[thing_experimental]+[base_model_to_use]+[type_of_thing]+[steps]+[perc_txt_encoder]+[swap_auto_calculated], outputs=[training_summary, training_summary_text], queue=False)
- perc_txt_encoder.change(fn=count_files, inputs=file_collection+[thing_experimental]+[base_model_to_use]+[type_of_thing]+[steps]+[perc_txt_encoder]+[swap_auto_calculated], outputs=[training_summary, training_summary_text], queue=False)
-
- #Give more options if the user wants to finish everything after training
- if(is_spaces):
- training_summary_checkbox.change(fn=checkbox_swap, inputs=training_summary_checkbox, outputs=[training_summary_token_message, training_summary_token, training_summary_model_name, training_summary_where_to_upload],queue=False, show_progress=False)
- #Add a message for while it is in training
- train_btn.click(lambda:gr.update(visible=True), inputs=None, outputs=training_ongoing)
-
- #The main train function
- train_btn.click(fn=train, inputs=is_visible+concept_collection+file_collection+[base_model_to_use]+[thing_experimental]+[training_summary_where_to_upload]+[training_summary_model_name]+[training_summary_checkbox]+[training_summary_token]+[type_of_thing]+[steps]+[perc_txt_encoder]+[swap_auto_calculated], outputs=[result, try_your_model, push_to_hub, convert_button, training_ongoing, completed_training], queue=False)
-
- #Button to generate an image from your trained model after training
- generate_button.click(fn=generate, inputs=[prompt, inference_steps], outputs=result_image, queue=False)
- #Button to push the model to the Hugging Face Hub
- push_button.click(fn=push, inputs=[model_name, where_to_upload, hf_token, base_model_to_use], outputs=[success_message_upload, result], queue=False)
- #Button to convert the model to ckpt format
- convert_button.click(fn=convert_to_ckpt, inputs=[], outputs=result, queue=False)
-
- #Checks if the training is running
- demo.load(fn=check_status, inputs=top_description, outputs=[top_description, try_your_model, push_to_hub, result, convert_button], queue=False, show_progress=False)
-
-demo.queue(default_enabled=False).launch(debug=True)
\ No newline at end of file
diff --git a/spaces/GT4SD/advanced_manufacturing/app.py b/spaces/GT4SD/advanced_manufacturing/app.py
deleted file mode 100644
index baf78eb0256dd23d26a2831163c13932c3e8082f..0000000000000000000000000000000000000000
--- a/spaces/GT4SD/advanced_manufacturing/app.py
+++ /dev/null
@@ -1,102 +0,0 @@
-import logging
-import pathlib
-import gradio as gr
-import pandas as pd
-from gt4sd.algorithms.controlled_sampling.advanced_manufacturing import (
- CatalystGenerator,
- AdvancedManufacturing,
-)
-from gt4sd.algorithms.registry import ApplicationsRegistry
-
-from utils import draw_grid_generate
-
-logger = logging.getLogger(__name__)
-logger.addHandler(logging.NullHandler())
-
-
-def run_inference(
- algorithm_version: str,
- target_binding_energy: float,
- primer_smiles: str,
- length: float,
- number_of_points: int,
- number_of_steps: int,
- number_of_samples: int,
-):
-
- config = CatalystGenerator(
- algorithm_version=algorithm_version,
- number_of_points=number_of_points,
- number_of_steps=number_of_steps,
- generated_length=length,
- primer_smiles=primer_smiles,
- )
- model = AdvancedManufacturing(config, target=target_binding_energy)
- samples = list(model.sample(number_of_samples))
- seeds = [] if primer_smiles == "" else [primer_smiles]
-
- return draw_grid_generate(samples=samples, n_cols=5, seeds=seeds)
-
-
-if __name__ == "__main__":
-
- # Preparation (retrieve all available algorithms)
- all_algos = ApplicationsRegistry.list_available()
- algos = [
- x["algorithm_version"]
- for x in list(
- filter(lambda x: "AdvancedManufact" in x["algorithm_name"], all_algos)
- )
- ]
-
- # Load metadata
- metadata_root = pathlib.Path(__file__).parent.joinpath("model_cards")
-
- examples = pd.read_csv(metadata_root.joinpath("examples.csv"), header=None).fillna(
- ""
- )
- print("Examples: ", examples.values.tolist())
-
- with open(metadata_root.joinpath("article.md"), "r") as f:
- article = f.read()
- with open(metadata_root.joinpath("description.md"), "r") as f:
- description = f.read()
-
- demo = gr.Interface(
- fn=run_inference,
- title="Advanced Manufacturing",
- inputs=[
- gr.Dropdown(
- algos,
- label="Algorithm version",
- value="v0",
- ),
- gr.Slider(minimum=1, maximum=100, value=10, label="Target binding energy"),
- gr.Textbox(
- label="Primer SMILES",
- placeholder="FP(F)F.CP(C)c1ccccc1.[Au]",
- lines=1,
- ),
- gr.Slider(
- minimum=5,
- maximum=400,
- value=100,
- label="Maximal sequence length",
- step=1,
- ),
- gr.Slider(
- minimum=16, maximum=128, value=32, label="Number of points", step=1
- ),
- gr.Slider(
- minimum=16, maximum=128, value=50, label="Number of steps", step=1
- ),
- gr.Slider(
- minimum=1, maximum=50, value=10, label="Number of samples", step=1
- ),
- ],
- outputs=gr.HTML(label="Output"),
- article=article,
- description=description,
- # examples=examples.values.tolist(),
- )
- demo.launch(debug=True, show_error=True)
diff --git a/spaces/GT4SD/molecular_properties/README.md b/spaces/GT4SD/molecular_properties/README.md
deleted file mode 100644
index 4ad0545f17c112926076ca6023a9aeef3e923f20..0000000000000000000000000000000000000000
--- a/spaces/GT4SD/molecular_properties/README.md
+++ /dev/null
@@ -1,16 +0,0 @@
----
-title: Molecular properties
-emoji: 💡
-colorFrom: green
-colorTo: blue
-sdk: gradio
-sdk_version: 3.46.0
-app_file: app.py
-pinned: false
-python_version: 3.8.13
-pypi_version: 20.2.4
-duplicated_from: GT4SD/regression_transformer
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
-
diff --git a/spaces/Gananom/claudeisms/README.md b/spaces/Gananom/claudeisms/README.md
deleted file mode 100644
index 64c659a2d73974faab443a5b01557a5dbd87777e..0000000000000000000000000000000000000000
--- a/spaces/Gananom/claudeisms/README.md
+++ /dev/null
@@ -1,11 +0,0 @@
----
-title: Claudeisms
-emoji: 💻
-colorFrom: gray
-colorTo: purple
-sdk: docker
-pinned: false
-license: other
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
\ No newline at end of file
diff --git a/spaces/Gen-Sim/Gen-Sim/cliport/generated_tasks/color_sequenced_sphere_placement.py b/spaces/Gen-Sim/Gen-Sim/cliport/generated_tasks/color_sequenced_sphere_placement.py
deleted file mode 100644
index 07296929bada75ece2e7c2f9c4cde99469dcd8c1..0000000000000000000000000000000000000000
--- a/spaces/Gen-Sim/Gen-Sim/cliport/generated_tasks/color_sequenced_sphere_placement.py
+++ /dev/null
@@ -1,51 +0,0 @@
-import numpy as np
-import os
-import pybullet as p
-import random
-from cliport.tasks import primitives
-from cliport.tasks.grippers import Spatula
-from cliport.tasks.task import Task
-from cliport.utils import utils
-import numpy as np
-from cliport.tasks.task import Task
-from cliport.utils import utils
-
-class ColorSequencedSpherePlacement(Task):
- """Pick up spheres of different colors and place them in the center of the square of the same color in a specific sequence."""
-
- def __init__(self):
- super().__init__()
- self.max_steps = 20
- self.lang_template = "place the {color} sphere in the {color} square"
- self.task_completed_desc = "done placing spheres."
- self.additional_reset()
-
- def reset(self, env):
- super().reset(env)
-
- # Define colors and their sequence
- colors = ['red', 'blue', 'green', 'yellow']
-
- # Add squares of different colors
- square_size = (0.1, 0.1, 0.005)
- square_urdf = 'square/square-template.urdf'
- square_poses = []
- for color in colors:
- square_pose = self.get_random_pose(env, square_size)
- env.add_object(square_urdf, square_pose, 'fixed', color=color)
- square_poses.append(square_pose)
-
- # Add spheres of different colors
- sphere_size = (0.04, 0.04, 0.04)
- sphere_urdf = 'sphere/sphere.urdf'
- spheres = []
- for color in colors:
- sphere_pose = self.get_random_pose(env, sphere_size)
- sphere_id = env.add_object(sphere_urdf, sphere_pose, color=color)
- spheres.append(sphere_id)
-
- # Goal: each sphere is in the square of the same color, in the correct sequence
- for i in range(len(colors)):
- self.add_goal(objs=[spheres[i]], matches=np.ones((1, 1)), targ_poses=[square_poses[i]], replace=False,
- rotations=True, metric='pose', params=None, step_max_reward=1/len(colors),
- language_goal=self.lang_template.format(color=colors[i]))
\ No newline at end of file
diff --git a/spaces/Godrose0728/sound-link/text/cantonese.py b/spaces/Godrose0728/sound-link/text/cantonese.py
deleted file mode 100644
index 32eae72ef7eb43d493da6d6f75dd46176d0e8808..0000000000000000000000000000000000000000
--- a/spaces/Godrose0728/sound-link/text/cantonese.py
+++ /dev/null
@@ -1,59 +0,0 @@
-import re
-import cn2an
-import opencc
-
-
-converter = opencc.OpenCC('chinese_dialect_lexicons/jyutjyu')
-
-# List of (Latin alphabet, ipa) pairs:
-_latin_to_ipa = [(re.compile('%s' % x[0]), x[1]) for x in [
- ('A', 'ei˥'),
- ('B', 'biː˥'),
- ('C', 'siː˥'),
- ('D', 'tiː˥'),
- ('E', 'iː˥'),
- ('F', 'e˥fuː˨˩'),
- ('G', 'tsiː˥'),
- ('H', 'ɪk̚˥tsʰyː˨˩'),
- ('I', 'ɐi˥'),
- ('J', 'tsei˥'),
- ('K', 'kʰei˥'),
- ('L', 'e˥llou˨˩'),
- ('M', 'ɛːm˥'),
- ('N', 'ɛːn˥'),
- ('O', 'ou˥'),
- ('P', 'pʰiː˥'),
- ('Q', 'kʰiːu˥'),
- ('R', 'aː˥lou˨˩'),
- ('S', 'ɛː˥siː˨˩'),
- ('T', 'tʰiː˥'),
- ('U', 'juː˥'),
- ('V', 'wiː˥'),
- ('W', 'tʊk̚˥piː˥juː˥'),
- ('X', 'ɪk̚˥siː˨˩'),
- ('Y', 'waːi˥'),
- ('Z', 'iː˨sɛːt̚˥')
-]]
-
-
-def number_to_cantonese(text):
- return re.sub(r'\d+(?:\.?\d+)?', lambda x: cn2an.an2cn(x.group()), text)
-
-
-def latin_to_ipa(text):
- for regex, replacement in _latin_to_ipa:
- text = re.sub(regex, replacement, text)
- return text
-
-
-def cantonese_to_ipa(text):
- text = number_to_cantonese(text.upper())
- text = converter.convert(text).replace('-','').replace('$',' ')
- text = re.sub(r'[A-Z]', lambda x: latin_to_ipa(x.group())+' ', text)
- text = re.sub(r'[、;:]', ',', text)
- text = re.sub(r'\s*,\s*', ', ', text)
- text = re.sub(r'\s*。\s*', '. ', text)
- text = re.sub(r'\s*?\s*', '? ', text)
- text = re.sub(r'\s*!\s*', '! ', text)
- text = re.sub(r'\s*$', '', text)
- return text
diff --git a/spaces/Gradio-Blocks/uniformer_image_detection/mmdet/models/dense_heads/ga_rpn_head.py b/spaces/Gradio-Blocks/uniformer_image_detection/mmdet/models/dense_heads/ga_rpn_head.py
deleted file mode 100644
index 2ec0d4fdd3475bfbd2e541a6e8130b1df9ad861a..0000000000000000000000000000000000000000
--- a/spaces/Gradio-Blocks/uniformer_image_detection/mmdet/models/dense_heads/ga_rpn_head.py
+++ /dev/null
@@ -1,171 +0,0 @@
-import copy
-import warnings
-
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-from mmcv import ConfigDict
-from mmcv.cnn import normal_init
-from mmcv.ops import nms
-
-from ..builder import HEADS
-from .guided_anchor_head import GuidedAnchorHead
-from .rpn_test_mixin import RPNTestMixin
-
-
-@HEADS.register_module()
-class GARPNHead(RPNTestMixin, GuidedAnchorHead):
- """Guided-Anchor-based RPN head."""
-
- def __init__(self, in_channels, **kwargs):
- super(GARPNHead, self).__init__(1, in_channels, **kwargs)
-
- def _init_layers(self):
- """Initialize layers of the head."""
- self.rpn_conv = nn.Conv2d(
- self.in_channels, self.feat_channels, 3, padding=1)
- super(GARPNHead, self)._init_layers()
-
- def init_weights(self):
- """Initialize weights of the head."""
- normal_init(self.rpn_conv, std=0.01)
- super(GARPNHead, self).init_weights()
-
- def forward_single(self, x):
- """Forward feature of a single scale level."""
-
- x = self.rpn_conv(x)
- x = F.relu(x, inplace=True)
- (cls_score, bbox_pred, shape_pred,
- loc_pred) = super(GARPNHead, self).forward_single(x)
- return cls_score, bbox_pred, shape_pred, loc_pred
-
- def loss(self,
- cls_scores,
- bbox_preds,
- shape_preds,
- loc_preds,
- gt_bboxes,
- img_metas,
- gt_bboxes_ignore=None):
- losses = super(GARPNHead, self).loss(
- cls_scores,
- bbox_preds,
- shape_preds,
- loc_preds,
- gt_bboxes,
- None,
- img_metas,
- gt_bboxes_ignore=gt_bboxes_ignore)
- return dict(
- loss_rpn_cls=losses['loss_cls'],
- loss_rpn_bbox=losses['loss_bbox'],
- loss_anchor_shape=losses['loss_shape'],
- loss_anchor_loc=losses['loss_loc'])
-
- def _get_bboxes_single(self,
- cls_scores,
- bbox_preds,
- mlvl_anchors,
- mlvl_masks,
- img_shape,
- scale_factor,
- cfg,
- rescale=False):
- cfg = self.test_cfg if cfg is None else cfg
-
- cfg = copy.deepcopy(cfg)
-
- # deprecate arguments warning
- if 'nms' not in cfg or 'max_num' in cfg or 'nms_thr' in cfg:
- warnings.warn(
- 'In rpn_proposal or test_cfg, '
- 'nms_thr has been moved to a dict named nms as '
- 'iou_threshold, max_num has been renamed as max_per_img, '
- 'name of original arguments and the way to specify '
- 'iou_threshold of NMS will be deprecated.')
- if 'nms' not in cfg:
- cfg.nms = ConfigDict(dict(type='nms', iou_threshold=cfg.nms_thr))
- if 'max_num' in cfg:
- if 'max_per_img' in cfg:
- assert cfg.max_num == cfg.max_per_img, f'You ' \
- f'set max_num and max_per_img at the same time, ' \
- f'but get {cfg.max_num} ' \
- f'and {cfg.max_per_img} respectively' \
- 'Please delete max_num which will be deprecated.'
- else:
- cfg.max_per_img = cfg.max_num
- if 'nms_thr' in cfg:
- assert cfg.nms.iou_threshold == cfg.nms_thr, f'You set ' \
- f'iou_threshold in nms and ' \
- f'nms_thr at the same time, but get ' \
- f'{cfg.nms.iou_threshold} and {cfg.nms_thr}' \
- f' respectively. Please delete the ' \
- f'nms_thr which will be deprecated.'
-
- assert cfg.nms.get('type', 'nms') == 'nms', 'GARPNHead only support ' \
- 'naive nms.'
-
- mlvl_proposals = []
- for idx in range(len(cls_scores)):
- rpn_cls_score = cls_scores[idx]
- rpn_bbox_pred = bbox_preds[idx]
- anchors = mlvl_anchors[idx]
- mask = mlvl_masks[idx]
- assert rpn_cls_score.size()[-2:] == rpn_bbox_pred.size()[-2:]
- # if no location is kept, end.
- if mask.sum() == 0:
- continue
- rpn_cls_score = rpn_cls_score.permute(1, 2, 0)
- if self.use_sigmoid_cls:
- rpn_cls_score = rpn_cls_score.reshape(-1)
- scores = rpn_cls_score.sigmoid()
- else:
- rpn_cls_score = rpn_cls_score.reshape(-1, 2)
- # remind that we set FG labels to [0, num_class-1]
- # since mmdet v2.0
- # BG cat_id: num_class
- scores = rpn_cls_score.softmax(dim=1)[:, :-1]
- # filter scores, bbox_pred w.r.t. mask.
- # anchors are filtered in get_anchors() beforehand.
- scores = scores[mask]
- rpn_bbox_pred = rpn_bbox_pred.permute(1, 2, 0).reshape(-1,
- 4)[mask, :]
- if scores.dim() == 0:
- rpn_bbox_pred = rpn_bbox_pred.unsqueeze(0)
- anchors = anchors.unsqueeze(0)
- scores = scores.unsqueeze(0)
- # filter anchors, bbox_pred, scores w.r.t. scores
- if cfg.nms_pre > 0 and scores.shape[0] > cfg.nms_pre:
- _, topk_inds = scores.topk(cfg.nms_pre)
- rpn_bbox_pred = rpn_bbox_pred[topk_inds, :]
- anchors = anchors[topk_inds, :]
- scores = scores[topk_inds]
- # get proposals w.r.t. anchors and rpn_bbox_pred
- proposals = self.bbox_coder.decode(
- anchors, rpn_bbox_pred, max_shape=img_shape)
- # filter out too small bboxes
- if cfg.min_bbox_size > 0:
- w = proposals[:, 2] - proposals[:, 0]
- h = proposals[:, 3] - proposals[:, 1]
- valid_inds = torch.nonzero(
- (w >= cfg.min_bbox_size) & (h >= cfg.min_bbox_size),
- as_tuple=False).squeeze()
- proposals = proposals[valid_inds, :]
- scores = scores[valid_inds]
- # NMS in current level
- proposals, _ = nms(proposals, scores, cfg.nms.iou_threshold)
- proposals = proposals[:cfg.nms_post, :]
- mlvl_proposals.append(proposals)
- proposals = torch.cat(mlvl_proposals, 0)
- if cfg.get('nms_across_levels', False):
- # NMS across multi levels
- proposals, _ = nms(proposals[:, :4], proposals[:, -1],
- cfg.nms.iou_threshold)
- proposals = proposals[:cfg.max_per_img, :]
- else:
- scores = proposals[:, 4]
- num = min(cfg.max_per_img, proposals.shape[0])
- _, topk_inds = scores.topk(num)
- proposals = proposals[topk_inds, :]
- return proposals
diff --git a/spaces/HarryLee/eCommerceImageCaptioning/fairseq/examples/multilingual/data_scripts/check_self_overlaps.py b/spaces/HarryLee/eCommerceImageCaptioning/fairseq/examples/multilingual/data_scripts/check_self_overlaps.py
deleted file mode 100644
index 07b338dcfd2d7f10317608274631d0edd93ba889..0000000000000000000000000000000000000000
--- a/spaces/HarryLee/eCommerceImageCaptioning/fairseq/examples/multilingual/data_scripts/check_self_overlaps.py
+++ /dev/null
@@ -1,103 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-
-import os
-import glob
-import argparse
-from utils.dedup import deup
-import sys
-
-WORKDIR_ROOT = os.environ.get('WORKDIR_ROOT', None)
-
-if WORKDIR_ROOT is None or not WORKDIR_ROOT.strip():
- print('please specify your working directory root in OS environment variable WORKDIR_ROOT. Exitting..."')
- sys.exit(-1)
-
-def get_directions(folder):
- raw_files = glob.glob(f'{folder}/train*')
- directions = [os.path.split(file_path)[-1].split('.')[1] for file_path in raw_files]
- return directions
-
-def diff_list(lhs, rhs):
- return set(lhs).difference(set(rhs))
-
-def check_diff(
- from_src_file, from_tgt_file,
- to_src_file, to_tgt_file,
-):
- seen_in_from = set()
- seen_src_in_from = set()
- seen_tgt_in_from = set()
- from_count = 0
- with open(from_src_file, encoding='utf-8') as fsrc, \
- open(from_tgt_file, encoding='utf-8') as ftgt:
- for s, t in zip(fsrc, ftgt):
- seen_in_from.add((s, t))
- seen_src_in_from.add(s)
- seen_tgt_in_from.add(t)
- from_count += 1
- common = 0
- common_src = 0
- common_tgt = 0
- to_count = 0
- seen = set()
-
- with open(to_src_file, encoding='utf-8') as fsrc, \
- open(to_tgt_file, encoding='utf-8') as ftgt:
- for s, t in zip(fsrc, ftgt):
- to_count += 1
- if (s, t) not in seen:
- if (s, t) in seen_in_from:
- common += 1
- if s in seen_src_in_from:
- common_src += 1
- seen_src_in_from.remove(s)
- if t in seen_tgt_in_from:
- common_tgt += 1
- seen_tgt_in_from.remove(t)
- seen.add((s, t))
- return common, common_src, common_tgt, from_count, to_count
-
-def main():
- parser = argparse.ArgumentParser()
- parser.add_argument("--folder", type=str, required=True,
- help="the data folder ")
- parser.add_argument("--split", type=str, default='test',
- help="split (valid, test) to check against training data")
- parser.add_argument('--directions', type=str, default=None, required=False)
-
- args = parser.parse_args()
-
- if args.directions is None:
- directions = set(get_directions(args.folder))
- directions = sorted(directions)
- else:
- directions = args.directions.split(',')
- directions = sorted(set(directions))
-
- results = []
- print(f'checking where {args.split} split data are in training')
- print(f'direction\tcommon_count\tsrc common\ttgt common\tfrom_size\tto_size')
-
- for direction in directions:
- src, tgt = direction.split('-')
- from_src_file = f'{args.folder}/{args.split}.{src}-{tgt}.{src}'
- from_tgt_file = f'{args.folder}/{args.split}.{src}-{tgt}.{tgt}'
- if not os.path.exists(from_src_file):
- # some test/valid data might in reverse directinos:
- from_src_file = f'{args.folder}/{args.split}.{tgt}-{src}.{src}'
- from_tgt_file = f'{args.folder}/{args.split}.{tgt}-{src}.{tgt}'
- to_src_file = f'{args.folder}/train.{src}-{tgt}.{src}'
- to_tgt_file = f'{args.folder}/train.{src}-{tgt}.{tgt}'
- if not os.path.exists(to_src_file) or not os.path.exists(from_src_file):
- continue
- r = check_diff(from_src_file, from_tgt_file, to_src_file, to_tgt_file)
- results.append(r)
- print(f'{direction}\t', '\t'.join(map(str, r)))
-
-
-if __name__ == "__main__":
- main()
diff --git a/spaces/HuggingFaceM4/IDEFICS_Data_Measurement_Tool/data_measurements/zipf/zipf.py b/spaces/HuggingFaceM4/IDEFICS_Data_Measurement_Tool/data_measurements/zipf/zipf.py
deleted file mode 100644
index 423e218a7117fe2fc45c9dc01232358bd33da73f..0000000000000000000000000000000000000000
--- a/spaces/HuggingFaceM4/IDEFICS_Data_Measurement_Tool/data_measurements/zipf/zipf.py
+++ /dev/null
@@ -1,244 +0,0 @@
-# Copyright 2021 The HuggingFace Team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import json
-import logging
-import numpy as np
-import os
-import pandas as pd
-import plotly.graph_objects as go
-import powerlaw
-from os.path import join as pjoin
-import utils
-from scipy.stats import ks_2samp
-from scipy.stats import zipf as zipf_lib
-
-# treating inf values as NaN as well
-
-pd.set_option("use_inf_as_na", True)
-
-logs = utils.prepare_logging(__file__)
-
-
-class Zipf:
- def __init__(self, vocab_counts_df, count_str="count",
- proportion_str="prop"):
- self.vocab_counts_df = vocab_counts_df
- # Strings used in the input dictionary
- self.cnt_str = count_str
- self.prop_str = proportion_str
- self.alpha = None
- self.xmin = None
- self.xmax = None
- self.p = None
- self.ks_distance = None
- self.observed_counts = None
- self.word_counts_unique = None
- self.word_ranks_unique = None
- if self.vocab_counts_df is not None:
- self.observed_counts = self.vocab_counts_df[self.cnt_str].values
- self.word_counts_unique = list(set(self.observed_counts))
- self.word_ranks_unique = list(
- np.arange(1, len(self.word_counts_unique) + 1))
- self.zipf_dict = {"xmin": None, "xmax": None, "alpha": None,
- "ks_distance": None, "p-value": None,
- "word_ranks_unique": self.word_ranks_unique,
- "word_counts_unique": self.word_counts_unique}
- self.fit = None
- self.predicted_counts = None
-
- def load(self, zipf_dict):
- self.zipf_dict = zipf_dict
- self.xmin = zipf_dict["xmin"]
- self.xmax = zipf_dict["xmax"]
- self.alpha = zipf_dict["alpha"]
- self.ks_distance = zipf_dict["ks_distance"]
- self.p = zipf_dict["p-value"]
- self.word_ranks_unique = zipf_dict["word_ranks_unique"]
- self.word_counts_unique = zipf_dict["word_counts_unique"]
-
- def get_zipf_dict(self):
- zipf_dict = {"xmin": int(self.xmin), "xmax": int(self.xmax),
- "alpha": float(self.alpha),
- "ks_distance": float(self.ks_distance),
- "p-value": float(self.ks_test.pvalue),
- "word_counts_unique": [int(count) for count in
- self.word_counts_unique],
- "word_ranks_unique": [int(rank) for rank in
- self.word_ranks_unique]}
- return zipf_dict
-
- def calc_fit(self):
- """
- Uses the powerlaw package to fit the observed frequencies
- to a zipfian distribution.
- We use the KS-distance to fit, as that seems more appropriate that MLE.
- """
- logs.info("Fitting based on input vocab counts.")
-
- self._make_rank_column()
- # Note another method for determining alpha might be defined by
- # (Newman, 2005): alpha = 1 + n * sum(ln( xi / xmin )) ^ -1
- self.fit = powerlaw.Fit(self.observed_counts, fit_method="KS",
- discrete=True)
- # This should probably be a pmf (not pdf); using discrete=True above.
- # original_data=False uses only the fitted data (within xmin and xmax).
- # pdf_bin_edges: The portion of the data within the bin.
- # observed_pdf: The probability density function (normalized histogram)
- # of the data.
- pdf_bin_edges, observed_pdf = self.fit.pdf(original_data=False)
- # See the 'Distribution' class described here for info:
- # https://pythonhosted.org/powerlaw/#powerlaw.Fit.pdf
- theoretical_distro = self.fit.power_law
- # The probability density function (normalized histogram) of the
- # theoretical distribution.
- predicted_pdf = theoretical_distro.pdf()
- self._set_fit_vars(observed_pdf, predicted_pdf, theoretical_distro)
-
- def _set_fit_vars(self, observed_pdf, predicted_pdf, theoretical_distro):
- # !!!! CRITICAL VALUE FOR ZIPF !!!!
- self.alpha = theoretical_distro.alpha
- # Exclusive xmin: The optimal xmin *beyond which* the scaling regime of
- # the power law fits best.
- self.xmin = int(theoretical_distro.xmin)
- self.xmax = theoretical_distro.xmax
- # Can be None if there isn't an xmax returned;
- # this handles that.
- self._set_xmax()
- self.ks_distance = theoretical_distro.KS()
- self.ks_test = ks_2samp(observed_pdf, predicted_pdf)
- self.p = self.ks_test[1]
- logs.info("KS test:")
- logs.info(self.ks_test)
- self.predicted_counts = self._calc_zipf_counts()
-
- def _make_rank_column(self):
- # TODO: These proportions may have already been calculated.
- prop_denom = float(sum(self.vocab_counts_df[self.cnt_str]))
- count_prop = self.vocab_counts_df[self.cnt_str] / prop_denom
- self.vocab_counts_df[self.prop_str] = count_prop
- rank_column = self.vocab_counts_df[self.cnt_str].rank(
- method="dense", numeric_only=True, ascending=False
- )
- self.vocab_counts_df["rank"] = rank_column.astype("int64")
-
- def _calc_zipf_counts(self):
- """
- The fit is based on an optimal xmin (minimum rank)
- Let's use this to make count estimates for the zipf fit,
- by multiplying the fitted pmf value by the sum of counts above xmin.
- :return: array of count values following the fitted pmf.
- """
- logs.info("Getting predicted counts.")
- if not self.alpha:
- logs.warning("Have not yet fit -- need the alpha value.")
- logs.warning("Fitting now...")
- self.calc_fit()
- logs.info(self.word_counts_unique)
- logs.info(self.xmin)
- logs.info(self.xmax)
- # The subset of words that fit
- word_counts_fit_unique = self.word_counts_unique[
- self.xmin + 1: self.xmax]
- pmf_mass = float(sum(word_counts_fit_unique))
- zipf_counts = np.array(
- [self._estimate_count(rank, pmf_mass) for rank in
- self.word_ranks_unique]
- )
- return zipf_counts
-
- def _estimate_count(self, rank, pmf_mass):
- return int(round(zipf_lib.pmf(rank, self.alpha) * pmf_mass))
-
- def _set_xmax(self):
- """
- xmax is usually None, so we add some handling to set it as the
- maximum rank in the dataset.
- :param xmax:
- :return:
- """
- if self.xmax is not None:
- self.xmax = int(xmax)
- elif self.word_counts_unique:
- self.xmax = int(len(self.word_counts_unique))
- elif self.word_ranks_unique:
- self.xmax = int(len(self.word_ranks_unique))
-
-
-# TODO: This might fit better in its own file handling class?
-def get_zipf_fids(cache_path):
- zipf_cache_dir = pjoin(cache_path, "zipf")
- os.makedirs(zipf_cache_dir, exist_ok=True)
- # Zipf cache files
- zipf_fid = pjoin(zipf_cache_dir, "zipf_basic_stats.json")
- zipf_fig_fid = pjoin(zipf_cache_dir, "zipf_fig.json")
- zipf_fig_html_fid = pjoin(zipf_cache_dir, "zipf_fig.html")
- return zipf_fid, zipf_fig_fid, zipf_fig_html_fid
-
-
-def make_unique_rank_word_list(z):
- """
- Function to help with the figure, creating strings for the hovertext.
- """
- ranked_words = {}
- word_counts = z.word_counts_unique
- word_ranks = z.word_ranks_unique
- for count, rank in zip(word_counts, word_ranks):
- z.vocab_counts_df[z.vocab_counts_df[z.cnt_str] == count]["rank"] = rank
- ranked_words[rank] = ",".join(
- z.vocab_counts_df[
- z.vocab_counts_df[z.cnt_str] == count].index.astype(str)
- ) # Use the hovertext kw argument for hover text
- ranked_words_list = [wrds for rank, wrds in
- sorted(ranked_words.items())]
- return ranked_words_list
-
-
-def make_zipf_fig(z):
- xmin = z.xmin
- word_ranks_unique = z.word_ranks_unique
- observed_counts = z.observed_counts
- zipf_counts = z.predicted_counts # "] #self.calc_zipf_counts()
- ranked_words_list = make_unique_rank_word_list(z)
- layout = go.Layout(xaxis=dict(range=[0, 100]))
- fig = go.Figure(
- data=[
- go.Bar(
- x=word_ranks_unique,
- y=observed_counts,
- hovertext=ranked_words_list,
- name="Word Rank Frequency",
- )
- ],
- layout=layout,
- )
- fig.add_trace(
- go.Scatter(
- x=word_ranks_unique[xmin: len(word_ranks_unique)],
- y=zipf_counts[xmin: len(word_ranks_unique)],
- hovertext=ranked_words_list[xmin: len(word_ranks_unique)],
- line=go.scatter.Line(color="crimson", width=3),
- name="Zipf Predicted Frequency",
- )
- )
- # Customize aspect
- # fig.update_traces(marker_color='limegreen',
- # marker_line_width=1.5, opacity=0.6)
- fig.update_layout(
- title_text="Word Counts, Observed and Predicted by Zipf")
- fig.update_layout(xaxis_title="Word Rank")
- fig.update_layout(yaxis_title="Frequency")
- fig.update_layout(
- legend=dict(yanchor="top", y=0.99, xanchor="left", x=0.10))
- return fig
diff --git a/spaces/ICML2022/OFA/fairseq/fairseq/models/nat/nonautoregressive_ensembles.py b/spaces/ICML2022/OFA/fairseq/fairseq/models/nat/nonautoregressive_ensembles.py
deleted file mode 100644
index 705a04fb49658c91114a26efd411b4653c65b943..0000000000000000000000000000000000000000
--- a/spaces/ICML2022/OFA/fairseq/fairseq/models/nat/nonautoregressive_ensembles.py
+++ /dev/null
@@ -1,253 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-import math
-
-import torch
-import torch.nn.functional as F
-from fairseq.models.nat import (
- _apply_del_words,
- _apply_ins_masks,
- _apply_ins_words,
- _fill,
- _skip,
- _skip_encoder_out,
-)
-
-
-class _EnsembleModelEncoder(object):
- def __init__(self, models):
- self.models = models
-
- def reorder_encoder_out(self, encoder_outs, new_order):
- encoder_outs = [
- model.encoder.reorder_encoder_out(encoder_out, new_order)
- for model, encoder_out in zip(self.models, encoder_outs)
- ]
- return encoder_outs
-
-
-class BasicEnsembleModel(torch.nn.Module):
- """A wrapper around an ensemble of models."""
-
- def __init__(self, models):
- super().__init__()
- self.models = torch.nn.ModuleList(models)
- self.bos = self.models[0].decoder.dictionary.bos()
- self.eos = self.models[0].decoder.dictionary.eos()
- self.pad = self.models[0].decoder.dictionary.pad()
- self.unk = self.models[0].decoder.dictionary.unk()
- self.encoder = _EnsembleModelEncoder(self.models)
-
- def has_encoder(self):
- return hasattr(self.models[0], "encoder")
-
- def max_decoder_positions(self):
- return min(m.max_decoder_positions() for m in self.models)
-
- @torch.no_grad()
- def forward_encoder(self, encoder_input):
- if not self.has_encoder():
- return None
- return [model.forward_encoder(encoder_input) for model in self.models]
-
- @torch.no_grad()
- def forward_decoder(self, *inputs):
- raise NotImplementedError
-
- def initialize_output_tokens(self, *inputs):
- raise NotImplementedError
-
-
-class EnsembleLevT(BasicEnsembleModel):
- """A wrapper around an ensemble of models."""
-
- def __init__(self, models):
- super().__init__(models)
-
- @torch.no_grad()
- def forward_decoder(
- self, decoder_out, encoder_outs, eos_penalty=0.0, max_ratio=None, **kwargs
- ):
- # LevT ensembling
- # A pipeline of three steps: deletion, placeholder, and word insertion.
- # We need to average scores in each step in a pipeline way because of dependence.
- # deletion
- output_tokens = decoder_out.output_tokens
- output_scores = decoder_out.output_scores
- attn = decoder_out.attn
-
- bsz = output_tokens.size(0)
- if max_ratio is None:
- max_lens = output_tokens.new().fill_(255)
- else:
- if not encoder_outs[0]["encoder_padding_mask"]:
- src_lens = (
- encoder_outs[0]["encoder_out"][0].new(bsz)
- .fill_(encoder_outs[0]["encoder_out"][0].size(1))
- )
- else:
- src_lens = (~encoder_outs[0]["encoder_padding_mask"][0]).sum(1)
- max_lens = (src_lens * max_ratio).clamp(min=10).long()
-
- # delete words
- # do not delete tokens if it is ','.....').replace('$','.')+"... ]") - stat = [f'执行中: {obs}\n\n' if alive else '已完成\n\n' for alive, obs in zip(th_alive, observe_win)] - stat_str = ''.join(stat) - chatbot[-1] = (chatbot[-1][0], f'多线程操作已经开始,完成情况: \n\n{stat_str}' + ''.join(['.']*(cnt%10+1))) - yield from update_ui(chatbot=chatbot, history=history) # 刷新界面 - - # 第9步:把结果写入文件 - for index, h in enumerate(handles): - h.join() # 这里其实不需要join了,肯定已经都结束了 - fp = file_manifest[index] - gpt_say = mutable_return[index] - i_say_show_user = i_say_show_user_buffer[index] - - where_to_relocate = f'gpt_log/generated_english_version/{fp}' - if gpt_say is not None: - with open(where_to_relocate, 'w+', encoding='utf-8') as f: - f.write(gpt_say) - else: # 失败 - shutil.copyfile(file_manifest[index], where_to_relocate) - chatbot.append((i_say_show_user, f'[Local Message] 已完成{os.path.abspath(fp)}的转化,\n\n存入{os.path.abspath(where_to_relocate)}')) - history.append(i_say_show_user); history.append(gpt_say) - yield from update_ui(chatbot=chatbot, history=history) # 刷新界面 - time.sleep(1) - - # 第10步:备份一个文件 - res = write_results_to_file(history) - chatbot.append(("生成一份任务执行报告", res)) - yield from update_ui(chatbot=chatbot, history=history) # 刷新界面 diff --git a/spaces/Loren/Streamlit_OCR_comparator/configs/_base_/recog_pipelines/crnn_tps_pipeline.py b/spaces/Loren/Streamlit_OCR_comparator/configs/_base_/recog_pipelines/crnn_tps_pipeline.py deleted file mode 100644 index 3a2eea55a739206c11ae876ba82e9c2f6ea1ff6d..0000000000000000000000000000000000000000 --- a/spaces/Loren/Streamlit_OCR_comparator/configs/_base_/recog_pipelines/crnn_tps_pipeline.py +++ /dev/null @@ -1,37 +0,0 @@ -img_norm_cfg = dict(mean=[0.5], std=[0.5]) - -train_pipeline = [ - dict(type='LoadImageFromFile', color_type='grayscale'), - dict( - type='ResizeOCR', - height=32, - min_width=100, - max_width=100, - keep_aspect_ratio=False), - dict(type='ToTensorOCR'), - dict(type='NormalizeOCR', **img_norm_cfg), - dict( - type='Collect', - keys=['img'], - meta_keys=[ - 'filename', 'ori_shape', 'resize_shape', 'text', 'valid_ratio' - ]), -] -test_pipeline = [ - dict(type='LoadImageFromFile', color_type='grayscale'), - dict( - type='ResizeOCR', - height=32, - min_width=32, - max_width=100, - keep_aspect_ratio=False), - dict(type='ToTensorOCR'), - dict(type='NormalizeOCR', **img_norm_cfg), - dict( - type='Collect', - keys=['img'], - meta_keys=[ - 'filename', 'ori_shape', 'resize_shape', 'valid_ratio', - 'img_norm_cfg', 'ori_filename', 'img_shape' - ]), -] diff --git a/spaces/Loren/Streamlit_OCR_comparator/configs/textdet/maskrcnn/mask_rcnn_r50_fpn_160e_icdar2017.py b/spaces/Loren/Streamlit_OCR_comparator/configs/textdet/maskrcnn/mask_rcnn_r50_fpn_160e_icdar2017.py deleted file mode 100644 index e22571e74511bab4303138f0e4816687fadac69e..0000000000000000000000000000000000000000 --- a/spaces/Loren/Streamlit_OCR_comparator/configs/textdet/maskrcnn/mask_rcnn_r50_fpn_160e_icdar2017.py +++ /dev/null @@ -1,33 +0,0 @@ -_base_ = [ - '../../_base_/default_runtime.py', - '../../_base_/det_models/ocr_mask_rcnn_r50_fpn_ohem.py', - '../../_base_/schedules/schedule_sgd_160e.py', - '../../_base_/det_datasets/icdar2017.py', - '../../_base_/det_pipelines/maskrcnn_pipeline.py' -] - -train_list = {{_base_.train_list}} -test_list = {{_base_.test_list}} - -train_pipeline = {{_base_.train_pipeline}} -test_pipeline_icdar2015 = {{_base_.test_pipeline_icdar2015}} - -data = dict( - samples_per_gpu=8, - workers_per_gpu=4, - val_dataloader=dict(samples_per_gpu=1), - test_dataloader=dict(samples_per_gpu=1), - train=dict( - type='UniformConcatDataset', - datasets=train_list, - pipeline=train_pipeline), - val=dict( - type='UniformConcatDataset', - datasets=test_list, - pipeline=test_pipeline_icdar2015), - test=dict( - type='UniformConcatDataset', - datasets=test_list, - pipeline=test_pipeline_icdar2015)) - -evaluation = dict(interval=10, metric='hmean-iou') diff --git a/spaces/MINAMONI/White-box-Cartoonization/wbc/guided_filter.py b/spaces/MINAMONI/White-box-Cartoonization/wbc/guided_filter.py deleted file mode 100644 index fd019d145efc7f308cd96de90f4e7b648f6820b4..0000000000000000000000000000000000000000 --- a/spaces/MINAMONI/White-box-Cartoonization/wbc/guided_filter.py +++ /dev/null @@ -1,87 +0,0 @@ -import tensorflow as tf -import numpy as np - - - - -def tf_box_filter(x, r): - k_size = int(2*r+1) - ch = x.get_shape().as_list()[-1] - weight = 1/(k_size**2) - box_kernel = weight*np.ones((k_size, k_size, ch, 1)) - box_kernel = np.array(box_kernel).astype(np.float32) - output = tf.nn.depthwise_conv2d(x, box_kernel, [1, 1, 1, 1], 'SAME') - return output - - - -def guided_filter(x, y, r, eps=1e-2): - - x_shape = tf.shape(x) - #y_shape = tf.shape(y) - - N = tf_box_filter(tf.ones((1, x_shape[1], x_shape[2], 1), dtype=x.dtype), r) - - mean_x = tf_box_filter(x, r) / N - mean_y = tf_box_filter(y, r) / N - cov_xy = tf_box_filter(x * y, r) / N - mean_x * mean_y - var_x = tf_box_filter(x * x, r) / N - mean_x * mean_x - - A = cov_xy / (var_x + eps) - b = mean_y - A * mean_x - - mean_A = tf_box_filter(A, r) / N - mean_b = tf_box_filter(b, r) / N - - output = mean_A * x + mean_b - - return output - - - -def fast_guided_filter(lr_x, lr_y, hr_x, r=1, eps=1e-8): - - #assert lr_x.shape.ndims == 4 and lr_y.shape.ndims == 4 and hr_x.shape.ndims == 4 - - lr_x_shape = tf.shape(lr_x) - #lr_y_shape = tf.shape(lr_y) - hr_x_shape = tf.shape(hr_x) - - N = tf_box_filter(tf.ones((1, lr_x_shape[1], lr_x_shape[2], 1), dtype=lr_x.dtype), r) - - mean_x = tf_box_filter(lr_x, r) / N - mean_y = tf_box_filter(lr_y, r) / N - cov_xy = tf_box_filter(lr_x * lr_y, r) / N - mean_x * mean_y - var_x = tf_box_filter(lr_x * lr_x, r) / N - mean_x * mean_x - - A = cov_xy / (var_x + eps) - b = mean_y - A * mean_x - - mean_A = tf.image.resize_images(A, hr_x_shape[1: 3]) - mean_b = tf.image.resize_images(b, hr_x_shape[1: 3]) - - output = mean_A * hr_x + mean_b - - return output - - -if __name__ == '__main__': - import cv2 - from tqdm import tqdm - - input_photo = tf.placeholder(tf.float32, [1, None, None, 3]) - #input_superpixel = tf.placeholder(tf.float32, [16, 256, 256, 3]) - output = guided_filter(input_photo, input_photo, 5, eps=1) - image = cv2.imread('output_figure1/cartoon2.jpg') - image = image/127.5 - 1 - image = np.expand_dims(image, axis=0) - - config = tf.ConfigProto() - config.gpu_options.allow_growth = True - sess = tf.Session(config=config) - sess.run(tf.global_variables_initializer()) - - out = sess.run(output, feed_dict={input_photo: image}) - out = (np.squeeze(out)+1)*127.5 - out = np.clip(out, 0, 255).astype(np.uint8) - cv2.imwrite('output_figure1/cartoon2_filter.jpg', out) diff --git a/spaces/Mahiruoshi/Lovelive_Nijigasaki_VITS/ONNXVITS_models.py b/spaces/Mahiruoshi/Lovelive_Nijigasaki_VITS/ONNXVITS_models.py deleted file mode 100644 index acd00238895d57ba878fd0211d5654250fb10061..0000000000000000000000000000000000000000 --- a/spaces/Mahiruoshi/Lovelive_Nijigasaki_VITS/ONNXVITS_models.py +++ /dev/null @@ -1,509 +0,0 @@ -import copy -import math -import torch -from torch import nn -from torch.nn import functional as F - -import commons -import ONNXVITS_modules as modules -import attentions -import monotonic_align - -from torch.nn import Conv1d, ConvTranspose1d, AvgPool1d, Conv2d -from torch.nn.utils import weight_norm, remove_weight_norm, spectral_norm -from commons import init_weights, get_padding - - -class StochasticDurationPredictor(nn.Module): - def __init__(self, in_channels, filter_channels, kernel_size, p_dropout, n_flows=4, gin_channels=0): - super().__init__() - filter_channels = in_channels # it needs to be removed from future version. - self.in_channels = in_channels - self.filter_channels = filter_channels - self.kernel_size = kernel_size - self.p_dropout = p_dropout - self.n_flows = n_flows - self.gin_channels = gin_channels - - self.log_flow = modules.Log() - self.flows = nn.ModuleList() - self.flows.append(modules.ElementwiseAffine(2)) - for i in range(n_flows): - self.flows.append(modules.ConvFlow(2, filter_channels, kernel_size, n_layers=3)) - self.flows.append(modules.Flip()) - - self.post_pre = nn.Conv1d(1, filter_channels, 1) - self.post_proj = nn.Conv1d(filter_channels, filter_channels, 1) - self.post_convs = modules.DDSConv(filter_channels, kernel_size, n_layers=3, p_dropout=p_dropout) - self.post_flows = nn.ModuleList() - self.post_flows.append(modules.ElementwiseAffine(2)) - for i in range(4): - self.post_flows.append(modules.ConvFlow(2, filter_channels, kernel_size, n_layers=3)) - self.post_flows.append(modules.Flip()) - - self.pre = nn.Conv1d(in_channels, filter_channels, 1) - self.proj = nn.Conv1d(filter_channels, filter_channels, 1) - self.convs = modules.DDSConv(filter_channels, kernel_size, n_layers=3, p_dropout=p_dropout) - if gin_channels != 0: - self.cond = nn.Conv1d(gin_channels, filter_channels, 1) - - self.w = None - self.reverse = None - self.noise_scale = None - def forward(self, x, x_mask, g=None): - w = self.w - reverse = self.reverse - noise_scale = self.noise_scale - - x = torch.detach(x) - x = self.pre(x) - if g is not None: - g = torch.detach(g) - x = x + self.cond(g) - x = self.convs(x, x_mask) - x = self.proj(x) * x_mask - - if not reverse: - flows = self.flows - assert w is not None - - logdet_tot_q = 0 - h_w = self.post_pre(w) - h_w = self.post_convs(h_w, x_mask) - h_w = self.post_proj(h_w) * x_mask - e_q = torch.randn(w.size(0), 2, w.size(2)).to(device=x.device, dtype=x.dtype) * x_mask - z_q = e_q - for flow in self.post_flows: - z_q, logdet_q = flow(z_q, x_mask, g=(x + h_w)) - logdet_tot_q += logdet_q - z_u, z1 = torch.split(z_q, [1, 1], 1) - u = torch.sigmoid(z_u) * x_mask - z0 = (w - u) * x_mask - logdet_tot_q += torch.sum((F.logsigmoid(z_u) + F.logsigmoid(-z_u)) * x_mask, [1,2]) - logq = torch.sum(-0.5 * (math.log(2*math.pi) + (e_q**2)) * x_mask, [1,2]) - logdet_tot_q - - logdet_tot = 0 - z0, logdet = self.log_flow(z0, x_mask) - logdet_tot += logdet - z = torch.cat([z0, z1], 1) - for flow in flows: - z, logdet = flow(z, x_mask, g=x, reverse=reverse) - logdet_tot = logdet_tot + logdet - nll = torch.sum(0.5 * (math.log(2*math.pi) + (z**2)) * x_mask, [1,2]) - logdet_tot - return nll + logq # [b] - else: - flows = list(reversed(self.flows)) - flows = flows[:-2] + [flows[-1]] # remove a useless vflow - z = torch.randn(x.size(0), 2, x.size(2)).to(device=x.device, dtype=x.dtype) * noise_scale - for flow in flows: - z = flow(z, x_mask, g=x, reverse=reverse) - z0, z1 = torch.split(z, [1, 1], 1) - logw = z0 - return logw - - -class TextEncoder(nn.Module): - def __init__(self, - n_vocab, - out_channels, - hidden_channels, - filter_channels, - n_heads, - n_layers, - kernel_size, - p_dropout): - super().__init__() - self.n_vocab = n_vocab - self.out_channels = out_channels - self.hidden_channels = hidden_channels - self.filter_channels = filter_channels - self.n_heads = n_heads - self.n_layers = n_layers - self.kernel_size = kernel_size - self.p_dropout = p_dropout - - self.emb = nn.Embedding(n_vocab, hidden_channels) - nn.init.normal_(self.emb.weight, 0.0, hidden_channels**-0.5) - - self.encoder = attentions.Encoder( - hidden_channels, - filter_channels, - n_heads, - n_layers, - kernel_size, - p_dropout) - self.proj= nn.Conv1d(hidden_channels, out_channels * 2, 1) - - def forward(self, x, x_lengths): - x = self.emb(x) * math.sqrt(self.hidden_channels) # [b, t, h] - x = torch.transpose(x, 1, -1) # [b, h, t] - x_mask = torch.unsqueeze(commons.sequence_mask(x_lengths, x.size(2)), 1).to(x.dtype) - - x = self.encoder(x * x_mask, x_mask) - stats = self.proj(x) * x_mask - - m, logs = torch.split(stats, self.out_channels, dim=1) - return x, m, logs, x_mask - - -class ResidualCouplingBlock(nn.Module): - def __init__(self, - channels, - hidden_channels, - kernel_size, - dilation_rate, - n_layers, - n_flows=4, - gin_channels=0): - super().__init__() - self.channels = channels - self.hidden_channels = hidden_channels - self.kernel_size = kernel_size - self.dilation_rate = dilation_rate - self.n_layers = n_layers - self.n_flows = n_flows - self.gin_channels = gin_channels - - self.flows = nn.ModuleList() - for i in range(n_flows): - self.flows.append(modules.ResidualCouplingLayer(channels, hidden_channels, kernel_size, dilation_rate, n_layers, gin_channels=gin_channels, mean_only=True)) - self.flows.append(modules.Flip()) - - self.reverse = None - def forward(self, x, x_mask, g=None): - reverse = self.reverse - if not reverse: - for flow in self.flows: - x, _ = flow(x, x_mask, g=g, reverse=reverse) - else: - for flow in reversed(self.flows): - x = flow(x, x_mask, g=g, reverse=reverse) - return x - - -class PosteriorEncoder(nn.Module): - def __init__(self, - in_channels, - out_channels, - hidden_channels, - kernel_size, - dilation_rate, - n_layers, - gin_channels=0): - super().__init__() - self.in_channels = in_channels - self.out_channels = out_channels - self.hidden_channels = hidden_channels - self.kernel_size = kernel_size - self.dilation_rate = dilation_rate - self.n_layers = n_layers - self.gin_channels = gin_channels - - self.pre = nn.Conv1d(in_channels, hidden_channels, 1) - self.enc = modules.WN(hidden_channels, kernel_size, dilation_rate, n_layers, gin_channels=gin_channels) - self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1) - - def forward(self, x, x_lengths, g=None): - x_mask = torch.unsqueeze(commons.sequence_mask(x_lengths, x.size(2)), 1).to(x.dtype) - x = self.pre(x) * x_mask # x_in : [b, c, t] -> [b, h, t] - x = self.enc(x, x_mask, g=g) # x_in : [b, h, t], g : [b, h, 1], x = x_in + g - stats = self.proj(x) * x_mask - m, logs = torch.split(stats, self.out_channels, dim=1) - z = (m + torch.randn_like(m) * torch.exp(logs)) * x_mask - return z, m, logs, x_mask # z, m, logs : [b, h, t] - - -class Generator(torch.nn.Module): - def __init__(self, initial_channel, resblock, resblock_kernel_sizes, resblock_dilation_sizes, upsample_rates, upsample_initial_channel, upsample_kernel_sizes, gin_channels=0): - super(Generator, self).__init__() - self.num_kernels = len(resblock_kernel_sizes) - self.num_upsamples = len(upsample_rates) - self.conv_pre = Conv1d(initial_channel, upsample_initial_channel, 7, 1, padding=3) - resblock = modules.ResBlock1 if resblock == '1' else modules.ResBlock2 - - self.ups = nn.ModuleList() - for i, (u, k) in enumerate(zip(upsample_rates, upsample_kernel_sizes)): - self.ups.append(weight_norm( - ConvTranspose1d(upsample_initial_channel//(2**i), upsample_initial_channel//(2**(i+1)), - k, u, padding=(k-u)//2))) - - self.resblocks = nn.ModuleList() - for i in range(len(self.ups)): - ch = upsample_initial_channel//(2**(i+1)) - for j, (k, d) in enumerate(zip(resblock_kernel_sizes, resblock_dilation_sizes)): - self.resblocks.append(resblock(ch, k, d)) - - self.conv_post = Conv1d(ch, 1, 7, 1, padding=3, bias=False) - self.ups.apply(init_weights) - - if gin_channels != 0: - self.cond = nn.Conv1d(gin_channels, upsample_initial_channel, 1) - - def forward(self, x, g=None): - x = self.conv_pre(x) - if g is not None: - x = x + self.cond(g) - - for i in range(self.num_upsamples): - x = F.leaky_relu(x, modules.LRELU_SLOPE) - x = self.ups[i](x) - xs = None - for j in range(self.num_kernels): - if xs is None: - xs = self.resblocks[i*self.num_kernels+j](x) - else: - xs += self.resblocks[i*self.num_kernels+j](x) - x = xs / self.num_kernels - x = F.leaky_relu(x) - x = self.conv_post(x) - x = torch.tanh(x) - - return x - - def remove_weight_norm(self): - print('Removing weight norm...') - for l in self.ups: - remove_weight_norm(l) - for l in self.resblocks: - l.remove_weight_norm() - - -class DiscriminatorP(torch.nn.Module): - def __init__(self, period, kernel_size=5, stride=3, use_spectral_norm=False): - super(DiscriminatorP, self).__init__() - self.period = period - self.use_spectral_norm = use_spectral_norm - norm_f = weight_norm if use_spectral_norm == False else spectral_norm - self.convs = nn.ModuleList([ - norm_f(Conv2d(1, 32, (kernel_size, 1), (stride, 1), padding=(get_padding(kernel_size, 1), 0))), - norm_f(Conv2d(32, 128, (kernel_size, 1), (stride, 1), padding=(get_padding(kernel_size, 1), 0))), - norm_f(Conv2d(128, 512, (kernel_size, 1), (stride, 1), padding=(get_padding(kernel_size, 1), 0))), - norm_f(Conv2d(512, 1024, (kernel_size, 1), (stride, 1), padding=(get_padding(kernel_size, 1), 0))), - norm_f(Conv2d(1024, 1024, (kernel_size, 1), 1, padding=(get_padding(kernel_size, 1), 0))), - ]) - self.conv_post = norm_f(Conv2d(1024, 1, (3, 1), 1, padding=(1, 0))) - - def forward(self, x): - fmap = [] - - # 1d to 2d - b, c, t = x.shape - if t % self.period != 0: # pad first - n_pad = self.period - (t % self.period) - x = F.pad(x, (0, n_pad), "reflect") - t = t + n_pad - x = x.view(b, c, t // self.period, self.period) - - for l in self.convs: - x = l(x) - x = F.leaky_relu(x, modules.LRELU_SLOPE) - fmap.append(x) - x = self.conv_post(x) - fmap.append(x) - x = torch.flatten(x, 1, -1) - - return x, fmap - - -class DiscriminatorS(torch.nn.Module): - def __init__(self, use_spectral_norm=False): - super(DiscriminatorS, self).__init__() - norm_f = weight_norm if use_spectral_norm == False else spectral_norm - self.convs = nn.ModuleList([ - norm_f(Conv1d(1, 16, 15, 1, padding=7)), - norm_f(Conv1d(16, 64, 41, 4, groups=4, padding=20)), - norm_f(Conv1d(64, 256, 41, 4, groups=16, padding=20)), - norm_f(Conv1d(256, 1024, 41, 4, groups=64, padding=20)), - norm_f(Conv1d(1024, 1024, 41, 4, groups=256, padding=20)), - norm_f(Conv1d(1024, 1024, 5, 1, padding=2)), - ]) - self.conv_post = norm_f(Conv1d(1024, 1, 3, 1, padding=1)) - - def forward(self, x): - fmap = [] - - for l in self.convs: - x = l(x) - x = F.leaky_relu(x, modules.LRELU_SLOPE) - fmap.append(x) - x = self.conv_post(x) - fmap.append(x) - x = torch.flatten(x, 1, -1) - - return x, fmap - - -class MultiPeriodDiscriminator(torch.nn.Module): - def __init__(self, use_spectral_norm=False): - super(MultiPeriodDiscriminator, self).__init__() - periods = [2,3,5,7,11] - - discs = [DiscriminatorS(use_spectral_norm=use_spectral_norm)] - discs = discs + [DiscriminatorP(i, use_spectral_norm=use_spectral_norm) for i in periods] - self.discriminators = nn.ModuleList(discs) - - def forward(self, y, y_hat): - y_d_rs = [] - y_d_gs = [] - fmap_rs = [] - fmap_gs = [] - for i, d in enumerate(self.discriminators): - y_d_r, fmap_r = d(y) - y_d_g, fmap_g = d(y_hat) - y_d_rs.append(y_d_r) - y_d_gs.append(y_d_g) - fmap_rs.append(fmap_r) - fmap_gs.append(fmap_g) - - return y_d_rs, y_d_gs, fmap_rs, fmap_gs - - - -class SynthesizerTrn(nn.Module): - """ - Synthesizer for Training - """ - - def __init__(self, - n_vocab, - spec_channels, - segment_size, - inter_channels, - hidden_channels, - filter_channels, - n_heads, - n_layers, - kernel_size, - p_dropout, - resblock, - resblock_kernel_sizes, - resblock_dilation_sizes, - upsample_rates, - upsample_initial_channel, - upsample_kernel_sizes, - n_speakers=0, - gin_channels=0, - use_sdp=True, - **kwargs): - - super().__init__() - self.n_vocab = n_vocab - self.spec_channels = spec_channels - self.inter_channels = inter_channels - self.hidden_channels = hidden_channels - self.filter_channels = filter_channels - self.n_heads = n_heads - self.n_layers = n_layers - self.kernel_size = kernel_size - self.p_dropout = p_dropout - self.resblock = resblock - self.resblock_kernel_sizes = resblock_kernel_sizes - self.resblock_dilation_sizes = resblock_dilation_sizes - self.upsample_rates = upsample_rates - self.upsample_initial_channel = upsample_initial_channel - self.upsample_kernel_sizes = upsample_kernel_sizes - self.segment_size = segment_size - self.n_speakers = n_speakers - self.gin_channels = gin_channels - - self.use_sdp = use_sdp - - self.enc_p = TextEncoder(n_vocab, - inter_channels, - hidden_channels, - filter_channels, - n_heads, - n_layers, - kernel_size, - p_dropout) - self.dec = Generator(inter_channels, resblock, resblock_kernel_sizes, resblock_dilation_sizes, upsample_rates, upsample_initial_channel, upsample_kernel_sizes, gin_channels=gin_channels) - self.enc_q = PosteriorEncoder(spec_channels, inter_channels, hidden_channels, 5, 1, 16, gin_channels=gin_channels) - self.flow = ResidualCouplingBlock(inter_channels, hidden_channels, 5, 1, 4, gin_channels=gin_channels) - - self.dp = StochasticDurationPredictor(hidden_channels, 192, 3, 0.5, 4, gin_channels=gin_channels) - - if n_speakers > 0: - self.emb_g = nn.Embedding(n_speakers, gin_channels) - - def forward(self, x, x_lengths, sid=None, noise_scale=.667, length_scale=1, noise_scale_w=.8, max_len=None): - torch.onnx.export( - self.enc_p, - (x, x_lengths), - "ONNX_net/enc_p.onnx", - input_names=["x", "x_lengths"], - output_names=["xout", "m_p", "logs_p", "x_mask"], - dynamic_axes={ - "x" : [1], - "xout" : [2], - "m_p" : [2], - "logs_p" : [2], - "x_mask" : [2] - }, - verbose=True, - ) - x, m_p, logs_p, x_mask = self.enc_p(x, x_lengths) - - if self.n_speakers > 0: - g = self.emb_g(sid).unsqueeze(-1) # [b, h, 1] - else: - g = None - - self.dp.reverse = True - self.dp.noise_scale = noise_scale_w - torch.onnx.export( - self.dp, - (x, x_mask, g), - "ONNX_net/dp.onnx", - input_names=["x", "x_mask", "g"], - output_names=["logw"], - dynamic_axes={ - "x" : [2], - "x_mask" : [2], - "logw" : [2] - }, - verbose=True, - ) - logw = self.dp(x, x_mask, g=g) - w = torch.exp(logw) * x_mask * length_scale - w_ceil = torch.ceil(w) - y_lengths = torch.clamp_min(torch.sum(w_ceil, [1, 2]), 1).long() - y_mask = torch.unsqueeze(commons.sequence_mask(y_lengths, None), 1).to(x_mask.dtype) - attn_mask = torch.unsqueeze(x_mask, 2) * torch.unsqueeze(y_mask, -1) - attn = commons.generate_path(w_ceil, attn_mask) - - m_p = torch.matmul(attn.squeeze(1), m_p.transpose(1, 2)).transpose(1, 2) # [b, t', t], [b, t, d] -> [b, d, t'] - logs_p = torch.matmul(attn.squeeze(1), logs_p.transpose(1, 2)).transpose(1, 2) # [b, t', t], [b, t, d] -> [b, d, t'] - - z_p = m_p + torch.randn_like(m_p) * torch.exp(logs_p) * noise_scale - - self.flow.reverse = True - torch.onnx.export( - self.flow, - (z_p, y_mask, g), - "ONNX_net/flow.onnx", - input_names=["z_p", "y_mask", "g"], - output_names=["z"], - dynamic_axes={ - "z_p" : [2], - "y_mask" : [2], - "z" : [2] - }, - verbose=True, - ) - z = self.flow(z_p, y_mask, g=g) - z_in = (z * y_mask)[:,:,:max_len] - - torch.onnx.export( - self.dec, - (z_in, g), - "ONNX_net/dec.onnx", - input_names=["z_in", "g"], - output_names=["o"], - dynamic_axes={ - "z_in" : [2], - "o" : [2] - }, - verbose=True, - ) - o = self.dec(z_in, g=g) - return o diff --git a/spaces/Mahiruoshi/Lovelive_Nijigasaki_VITS/main.py b/spaces/Mahiruoshi/Lovelive_Nijigasaki_VITS/main.py deleted file mode 100644 index 3a1d933e936e5f58a6e0fbf04fa7bc3d6486076c..0000000000000000000000000000000000000000 --- a/spaces/Mahiruoshi/Lovelive_Nijigasaki_VITS/main.py +++ /dev/null @@ -1,526 +0,0 @@ -import logging -logging.getLogger('numba').setLevel(logging.WARNING) -logging.getLogger('matplotlib').setLevel(logging.WARNING) -logging.getLogger('urllib3').setLevel(logging.WARNING) -import json -import re -import numpy as np -import IPython.display as ipd -import torch -import commons -import utils -from models import SynthesizerTrn -from text.symbols import symbols -from text import text_to_sequence -import gradio as gr -import time -import datetime -import os -import pickle -import openai -from scipy.io.wavfile import write -import librosa -import romajitable -from mel_processing import spectrogram_torch -def is_japanese(string): - for ch in string: - if ord(ch) > 0x3040 and ord(ch) < 0x30FF: - return True - return False - -def is_english(string): - import re - pattern = re.compile('^[A-Za-z0-9.,:;!?()_*"\' ]+$') - if pattern.fullmatch(string): - return True - else: - return False - -def extrac(text): - text = re.sub("<[^>]*>","",text) - result_list = re.split(r'\n', text) - final_list = [] - for i in result_list: - if is_english(i): - i = romajitable.to_kana(i).katakana - i = i.replace('\n','').replace(' ','') - #Current length of single sentence: 20 - if len(i)>1: - if len(i) > 50: - try: - cur_list = re.split(r'。|!', i) - for i in cur_list: - if len(i)>1: - final_list.append(i+'。') - except: - pass - else: - final_list.append(i) - ''' - final_list.append(i) - ''' - final_list = [x for x in final_list if x != ''] - print(final_list) - return final_list - -def to_numpy(tensor: torch.Tensor): - return tensor.detach().cpu().numpy() if tensor.requires_grad \ - else tensor.detach().numpy() - -def chatgpt(text): - messages = [] - try: - if text != 'exist': - with open('log.pickle', 'rb') as f: - messages = pickle.load(f) - messages.append({"role": "user", "content": text},) - chat = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=messages) - reply = chat.choices[0].message.content - messages.append({"role": "assistant", "content": reply}) - print(messages[-1]) - if len(messages) == 12: - messages[6:10] = messages[8:] - del messages[-2:] - with open('log.pickle', 'wb') as f: - pickle.dump(messages, f) - return reply - except: - messages.append({"role": "user", "content": text},) - chat = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=messages) - reply = chat.choices[0].message.content - messages.append({"role": "assistant", "content": reply}) - print(messages[-1]) - if len(messages) == 12: - messages[6:10] = messages[8:] - del messages[-2:] - with open('log.pickle', 'wb') as f: - pickle.dump(messages, f) - return reply - -def get_symbols_from_json(path): - assert os.path.isfile(path) - with open(path, 'r') as f: - data = json.load(f) - return data['symbols'] - -def sle(language,text): - text = text.replace('\n', '').replace('\r', '').replace(" ", "") - if language == "中文": - tts_input1 = "[ZH]" + text + "[ZH]" - return tts_input1 - elif language == "自动": - tts_input1 = f"[JA]{text}[JA]" if is_japanese(text) else f"[ZH]{text}[ZH]" - return tts_input1 - elif language == "日文": - tts_input1 = "[JA]" + text + "[JA]" - return tts_input1 - elif language == "英文": - tts_input1 = "[EN]" + text + "[EN]" - return tts_input1 - elif language == "手动": - return text - -def get_text(text,hps_ms): - text_norm = text_to_sequence(text,hps_ms.symbols,hps_ms.data.text_cleaners) - if hps_ms.data.add_blank: - text_norm = commons.intersperse(text_norm, 0) - text_norm = torch.LongTensor(text_norm) - return text_norm - -def create_tts_fn(net_g,hps,speaker_id): - speaker_id = int(speaker_id) - def tts_fn(is_transfer,original_speaker, target_speaker,history,is_gpt,api_key,is_audio,audiopath,repeat_time,text, language, extract, n_scale= 0.667,n_scale_w = 0.8, l_scale = 1 ): - text = check_text(text) - repeat_time = int(repeat_time) - original_speaker_id = selection(original_speaker) - target_speaker_id = selection(target_speaker) - if is_gpt: - openai.api_key = api_key - text = chatgpt(text) - history[-1][1] = text - if not extract: - print(text) - t1 = time.time() - stn_tst = get_text(sle(language,text),hps) - with torch.no_grad(): - x_tst = stn_tst.unsqueeze(0).to(dev) - x_tst_lengths = torch.LongTensor([stn_tst.size(0)]).to(dev) - sid = torch.LongTensor([speaker_id]).to(dev) - audio = net_g.infer(x_tst, x_tst_lengths, sid=sid, noise_scale=n_scale, noise_scale_w=n_scale_w, length_scale=l_scale)[0][0,0].data.cpu().float().numpy() - t2 = time.time() - spending_time = "推理时间为:"+str(t2-t1)+"s" - print(spending_time) - file_path = "subtitles.srt" - try: - write(audiopath + '.wav',22050,audio) - if is_audio: - for i in range(repeat_time): - cmd = 'ffmpeg -y -i ' + audiopath + '.wav' + ' -ar 44100 '+ audiopath.replace('temp','temp'+str(i)) - os.system(cmd) - except: - pass - return history,file_path,(hps.data.sampling_rate,audio) - else: - a = ['【','[','(','('] - b = ['】',']',')',')'] - for i in a: - text = text.replace(i,'<') - for i in b: - text = text.replace(i,'>') - final_list = extrac(text.replace('“','').replace('”','')) - split_list = [] - while len(final_list) > 0: - split_list.append(final_list[:500]) - final_list = final_list[500:] - c0 = 0 - for lists in split_list: - audio_fin = [] - t = datetime.timedelta(seconds=0) - c = 0 - f1 = open(audiopath.replace('.wav',str(c0)+".srt"),'w',encoding='utf-8') - for sentence in lists: - try: - c +=1 - stn_tst = get_text(sle(language,sentence),hps) - with torch.no_grad(): - x_tst = stn_tst.unsqueeze(0).to(dev) - x_tst_lengths = torch.LongTensor([stn_tst.size(0)]).to(dev) - sid = torch.LongTensor([original_speaker_id]).to(dev) - t1 = time.time() - audio = net_g.infer(x_tst, x_tst_lengths, sid=sid, noise_scale=n_scale, noise_scale_w=n_scale_w, length_scale=l_scale)[0][0,0].data.cpu().float().numpy() - t2 = time.time() - spending_time = "第"+str(c)+"句的推理时间为:"+str(t2-t1)+"s" - print(spending_time) - time_start = str(t).split(".")[0] + "," + str(t.microseconds)[:3] - last_time = datetime.timedelta(seconds=len(audio)/float(22050)) - t+=last_time - time_end = str(t).split(".")[0] + "," + str(t.microseconds)[:3] - print(time_end) - f1.write(str(c-1)+'\n'+time_start+' --> '+time_end+'\n'+sentence+'\n\n') - if is_transfer: - with torch.no_grad(): - y = torch.FloatTensor(audio) - y = y / max(-y.min(), y.max()) / 0.99 - y = y.to(dev) - y = y.unsqueeze(0) - spec = spectrogram_torch(y, hps.data.filter_length, - hps.data.sampling_rate, hps.data.hop_length, hps.data.win_length, - center=False).to(dev) - spec_lengths = torch.LongTensor([spec.size(-1)]).to(dev) - sid_src = torch.LongTensor([original_speaker_id]).to(dev) - sid_tgt = torch.LongTensor([target_speaker_id]).to(dev) - audio = net_g.voice_conversion(spec, spec_lengths, sid_src=sid_src, sid_tgt=sid_tgt)[0][ - 0, 0].data.cpu().float().numpy() - del y, spec, spec_lengths, sid_src, sid_tgt - audio_fin.append(audio) - except: - pass - write(audiopath.replace('.wav',str(c0)+'.wav'),22050,np.concatenate(audio_fin)) - c0 += 1 - file_path = audiopath.replace('.wav',str(c0)+".srt") - return history,file_path,(hps.data.sampling_rate, np.concatenate(audio_fin)) - return tts_fn - -def create_vc_fn(net_g,hps): - def vc_fn(text,language,n_scale,n_scale_w,l_scale,original_speaker, target_speaker, record_audio, upload_audio): - input_audio = record_audio if record_audio is not None else upload_audio - original_speaker_id = selection(original_speaker) - target_speaker_id = selection(target_speaker) - if input_audio is None: - stn_tst = get_text(sle(language,text),hps) - with torch.no_grad(): - x_tst = stn_tst.unsqueeze(0).to(dev) - x_tst_lengths = torch.LongTensor([stn_tst.size(0)]).to(dev) - sid = torch.LongTensor([original_speaker_id]).to(dev) - audio = net_g.infer(x_tst, x_tst_lengths, sid=sid, noise_scale=n_scale, noise_scale_w=n_scale_w, length_scale=l_scale)[0][0,0].data.cpu().float().numpy() - sampling_rate = hps.data.sampling_rate - else: - sampling_rate, audio = input_audio - audio = (audio / np.iinfo(audio.dtype).max).astype(np.float32) - if len(audio.shape) > 1: - audio = librosa.to_mono(audio.transpose(1, 0)) - if sampling_rate != hps.data.sampling_rate: - audio = librosa.resample(audio, orig_sr=sampling_rate, target_sr=hps.data.sampling_rate) - with torch.no_grad(): - y = torch.FloatTensor(audio) - y = y / max(-y.min(), y.max()) / 0.99 - y = y.to(dev) - y = y.unsqueeze(0) - spec = spectrogram_torch(y, hps.data.filter_length, - hps.data.sampling_rate, hps.data.hop_length, hps.data.win_length, - center=False).to(dev) - spec_lengths = torch.LongTensor([spec.size(-1)]).to(dev) - sid_src = torch.LongTensor([original_speaker_id]).to(dev) - sid_tgt = torch.LongTensor([target_speaker_id]).to(dev) - audio = net_g.voice_conversion(spec, spec_lengths, sid_src=sid_src, sid_tgt=sid_tgt)[0][ - 0, 0].data.cpu().float().numpy() - del y, spec, spec_lengths, sid_src, sid_tgt - return "Success", (hps.data.sampling_rate, audio) - return vc_fn - -def bot(history,user_message): - return history + [[check_text(user_message), None]] - -def selection(speaker): - if speaker == "高咲侑": - spk = 0 - return spk - - elif speaker == "歩夢": - spk = 1 - return spk - - elif speaker == "かすみ": - spk = 2 - return spk - - elif speaker == "しずく": - spk = 3 - return spk - - elif speaker == "果林": - spk = 4 - return spk - - elif speaker == "愛": - spk = 5 - return spk - - elif speaker == "彼方": - spk = 6 - return spk - - elif speaker == "せつ菜": - spk = 7 - return spk - - elif speaker == "エマ": - spk = 8 - return spk - - elif speaker == "璃奈": - spk = 9 - return spk - - elif speaker == "栞子": - spk = 10 - return spk - - elif speaker == "ランジュ": - spk = 11 - return spk - - elif speaker == "ミア": - spk = 12 - return spk - - elif speaker == "派蒙": - spk = 16 - return spk - - elif speaker == "c1": - spk = 18 - return spk - - elif speaker == "c2": - spk = 19 - return spk - - elif speaker == "華恋": - spk = 21 - return spk - - elif speaker == "まひる": - spk = 22 - return spk - - elif speaker == "なな": - spk = 23 - return spk - - elif speaker == "クロディーヌ": - spk = 24 - return spk - - elif speaker == "ひかり": - spk = 25 - return spk - - elif speaker == "純那": - spk = 26 - return spk - - elif speaker == "香子": - spk = 27 - return spk - - elif speaker == "真矢": - spk = 28 - return spk - - elif speaker == "双葉": - spk = 29 - return spk - - elif speaker == "ミチル": - spk = 30 - return spk - - elif speaker == "メイファン": - spk = 31 - return spk - - elif speaker == "やちよ": - spk = 32 - return spk - - elif speaker == "晶": - spk = 33 - return spk - - elif speaker == "いちえ": - spk = 34 - return spk - - elif speaker == "ゆゆ子": - spk = 35 - return spk - - elif speaker == "塁": - spk = 36 - return spk - - elif speaker == "珠緒": - spk = 37 - return spk - - elif speaker == "あるる": - spk = 38 - return spk - - elif speaker == "ララフィン": - spk = 39 - return spk - - elif speaker == "美空": - spk = 40 - return spk - - elif speaker == "静羽": - spk = 41 - return spk - - else: - return 0 - -def check_text(input): - if isinstance(input, str): - return input - else: - with open(input.name, "r", encoding="utf-8") as f: - return f.read() - -if __name__ == '__main__': - hps = utils.get_hparams_from_file('checkpoints/tmp/config.json') - dev = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") - models = [] - schools_list = ["ShojoKageki-Nijigasaki","ShojoKageki","Nijigasaki"] - schools = [] - lan = ["中文","日文","自动","手动"] - with open("checkpoints/info.json", "r", encoding="utf-8") as f: - models_info = json.load(f) - for i in models_info: - checkpoint = models_info[i]["checkpoint"] - phone_dict = { - symbol: i for i, symbol in enumerate(symbols) - } - net_g = SynthesizerTrn( - len(symbols), - hps.data.filter_length // 2 + 1, - hps.train.segment_size // hps.data.hop_length, - n_speakers=hps.data.n_speakers, - **hps.model).to(dev) - _ = net_g.eval() - _ = utils.load_checkpoint(checkpoint, net_g) - school = models_info[i] - speakers = school["speakers"] - content = [] - for j in speakers: - sid = int(speakers[j]['sid']) - title = school - example = speakers[j]['speech'] - name = speakers[j]["name"] - content.append((sid, name, title, example, create_tts_fn(net_g,hps,sid))) - models.append(content) - schools.append((i,create_vc_fn(net_g,hps))) - with gr.Blocks() as app: - with gr.Tabs(): - for (i,vc_fn) in schools: - with gr.TabItem(i): - idols = ["派蒙"] - for (sid, name, title, example, tts_fn) in models[schools_list.index(i)]: - idols.append(name) - with gr.TabItem(name): - with gr.Column(): - with gr.Row(): - with gr.Row(): - gr.Markdown( - '
 '
- '
'
- 'tags""" - if isinstance(text, list): - # Add horizontal rules between pages - text = "\n
\n".join(text) - return "".join([f"
{line}
" for line in text.split("\n")]) \ No newline at end of file diff --git a/spaces/Shularp/marian_translation_test_th_ar_en/app.py b/spaces/Shularp/marian_translation_test_th_ar_en/app.py deleted file mode 100644 index da175a091abaa72f6700b1c2df56037272152efc..0000000000000000000000000000000000000000 --- a/spaces/Shularp/marian_translation_test_th_ar_en/app.py +++ /dev/null @@ -1,65 +0,0 @@ -# -*- coding: utf-8 -*- -"""Gradio Course 04 - Test.ipynb - -Automatically generated by Colaboratory. - -Original file is located at - https://colab.research.google.com/drive/1QdsZHyXpY78iytNDhpBZmMTKRcb_27nQ -""" - -#!pip install gradio transformers googletrans==4.0.0rc1 transformers[sentencepiece] --quiet - -import gradio as gr -from transformers import pipeline -from googletrans import Translator - -model_card_en2ar = 'Shularp/model-translate-en-to-ar-from-320k-dataset-ar-en-th2301191458' -model_card_th2en = 'Helsinki-NLP/opus-mt-th-en' - -translate_en2ar = pipeline("translation", model = model_card_en2ar) -translate_th2en = pipeline("translation", model = model_card_th2en) - -def tx_th2en(text): - result_en = translate_th2en(text)[0]['translation_text'] - return (result_en) - -def tx_en2ar(text): - result_ar = translate_en2ar(text)[0]['translation_text'] - return (result_ar) - -def tx_th2ar(text): - result_en = translate_th2en(text)[0]['translation_text'] - result_ar = translate_en2ar(result_en)[0]['translation_text'] - #return result_en, result_ar - return result_ar - -def trans_via_google(text,source, target): - google_trans = Translator() #reduce problem timeout runtime. - return google_trans.translate(text = text, src = source, dest = target).text - -def translate_en2th(text): - google_trans = Translator() #reduce problem timeout runtime. - return google_trans.translate(text = text, src = 'en', dest = 'th').text - -def null(text): - return "ยังไม่ได้รองการแปลจากภาษาอังกฤษเป็นภาษาไทย" - -with gr.Blocks() as demo: - with gr.Row(): - with gr.Column(): - input_thai = gr.Textbox(label = 'ข้อความภาษาไทย') - translate_btn = gr.Button(value = 'Translate to En and Ar') - - with gr.Column(): - input_en = gr.Textbox(label = 'English Text') - translate_en_btn = gr.Button(value = 'Translate to Ar') - - with gr.Column(): - result_ar = gr.Textbox(label = 'ข้อความภาษาอาหรับ') - translate_btn.click(tx_th2en, inputs = input_thai, outputs=input_en) - translate_btn.click(tx_th2ar, inputs = input_thai, outputs=result_ar) - translate_en_btn.click(tx_en2ar, inputs = input_en, outputs=result_ar) - translate_en_btn.click(translate_en2th,inputs = input_en, outputs= input_thai) - -demo.launch() - diff --git a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/chromadb/errors.py b/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/chromadb/errors.py deleted file mode 100644 index 75f14596c769f5afe8e29858c5844a148bf43a76..0000000000000000000000000000000000000000 --- a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/chromadb/errors.py +++ /dev/null @@ -1,58 +0,0 @@ -from abc import abstractmethod -from typing import Dict, Type -from overrides import overrides, EnforceOverrides - - -class ChromaError(Exception, EnforceOverrides): - def code(self) -> int: - """Return an appropriate HTTP response code for this error""" - return 400 # Bad Request - - def message(self) -> str: - return ", ".join(self.args) - - @classmethod - @abstractmethod - def name(self) -> str: - """Return the error name""" - pass - - -class InvalidDimensionException(ChromaError): - @classmethod - @overrides - def name(cls) -> str: - return "InvalidDimension" - - -class IDAlreadyExistsError(ChromaError): - @overrides - def code(self) -> int: - return 409 # Conflict - - @classmethod - @overrides - def name(cls) -> str: - return "IDAlreadyExists" - - -class DuplicateIDError(ChromaError): - @classmethod - @overrides - def name(cls) -> str: - return "DuplicateID" - - -class InvalidUUIDError(ChromaError): - @classmethod - @overrides - def name(cls) -> str: - return "InvalidUUID" - - -error_types: Dict[str, Type[ChromaError]] = { - "InvalidDimension": InvalidDimensionException, - "IDAlreadyExists": IDAlreadyExistsError, - "DuplicateID": DuplicateIDError, - "InvalidUUID": InvalidUUIDError, -} diff --git a/spaces/Suniilkumaar/MusicGen-updated/tests/modules/test_seanet.py b/spaces/Suniilkumaar/MusicGen-updated/tests/modules/test_seanet.py deleted file mode 100644 index e5c51b340a2f94fb2828b14daf83d5fad645073d..0000000000000000000000000000000000000000 --- a/spaces/Suniilkumaar/MusicGen-updated/tests/modules/test_seanet.py +++ /dev/null @@ -1,115 +0,0 @@ -# Copyright (c) Meta Platforms, Inc. and affiliates. -# All rights reserved. -# -# This source code is licensed under the license found in the -# LICENSE file in the root directory of this source tree. - -from itertools import product - -import pytest -import torch - -from audiocraft.modules.seanet import SEANetEncoder, SEANetDecoder, SEANetResnetBlock -from audiocraft.modules import StreamableConv1d, StreamableConvTranspose1d - - -class TestSEANetModel: - - def test_base(self): - encoder = SEANetEncoder() - decoder = SEANetDecoder() - - x = torch.randn(1, 1, 24000) - z = encoder(x) - assert list(z.shape) == [1, 128, 75], z.shape - y = decoder(z) - assert y.shape == x.shape, (x.shape, y.shape) - - def test_causal(self): - encoder = SEANetEncoder(causal=True) - decoder = SEANetDecoder(causal=True) - x = torch.randn(1, 1, 24000) - - z = encoder(x) - assert list(z.shape) == [1, 128, 75], z.shape - y = decoder(z) - assert y.shape == x.shape, (x.shape, y.shape) - - def test_conv_skip_connection(self): - encoder = SEANetEncoder(true_skip=False) - decoder = SEANetDecoder(true_skip=False) - - x = torch.randn(1, 1, 24000) - z = encoder(x) - assert list(z.shape) == [1, 128, 75], z.shape - y = decoder(z) - assert y.shape == x.shape, (x.shape, y.shape) - - def test_seanet_encoder_decoder_final_act(self): - encoder = SEANetEncoder(true_skip=False) - decoder = SEANetDecoder(true_skip=False, final_activation='Tanh') - - x = torch.randn(1, 1, 24000) - z = encoder(x) - assert list(z.shape) == [1, 128, 75], z.shape - y = decoder(z) - assert y.shape == x.shape, (x.shape, y.shape) - - def _check_encoder_blocks_norm(self, encoder: SEANetEncoder, n_disable_blocks: int, norm: str): - n_blocks = 0 - for layer in encoder.model: - if isinstance(layer, StreamableConv1d): - n_blocks += 1 - assert layer.conv.norm_type == 'none' if n_blocks <= n_disable_blocks else norm - elif isinstance(layer, SEANetResnetBlock): - for resnet_layer in layer.block: - if isinstance(resnet_layer, StreamableConv1d): - # here we add + 1 to n_blocks as we increment n_blocks just after the block - assert resnet_layer.conv.norm_type == 'none' if (n_blocks + 1) <= n_disable_blocks else norm - - def test_encoder_disable_norm(self): - n_residuals = [0, 1, 3] - disable_blocks = [0, 1, 2, 3, 4, 5, 6] - norms = ['weight_norm', 'none'] - for n_res, disable_blocks, norm in product(n_residuals, disable_blocks, norms): - encoder = SEANetEncoder(n_residual_layers=n_res, norm=norm, - disable_norm_outer_blocks=disable_blocks) - self._check_encoder_blocks_norm(encoder, disable_blocks, norm) - - def _check_decoder_blocks_norm(self, decoder: SEANetDecoder, n_disable_blocks: int, norm: str): - n_blocks = 0 - for layer in decoder.model: - if isinstance(layer, StreamableConv1d): - n_blocks += 1 - assert layer.conv.norm_type == 'none' if (decoder.n_blocks - n_blocks) < n_disable_blocks else norm - elif isinstance(layer, StreamableConvTranspose1d): - n_blocks += 1 - assert layer.convtr.norm_type == 'none' if (decoder.n_blocks - n_blocks) < n_disable_blocks else norm - elif isinstance(layer, SEANetResnetBlock): - for resnet_layer in layer.block: - if isinstance(resnet_layer, StreamableConv1d): - assert resnet_layer.conv.norm_type == 'none' \ - if (decoder.n_blocks - n_blocks) < n_disable_blocks else norm - - def test_decoder_disable_norm(self): - n_residuals = [0, 1, 3] - disable_blocks = [0, 1, 2, 3, 4, 5, 6] - norms = ['weight_norm', 'none'] - for n_res, disable_blocks, norm in product(n_residuals, disable_blocks, norms): - decoder = SEANetDecoder(n_residual_layers=n_res, norm=norm, - disable_norm_outer_blocks=disable_blocks) - self._check_decoder_blocks_norm(decoder, disable_blocks, norm) - - def test_disable_norm_raises_exception(self): - # Invalid disable_norm_outer_blocks values raise exceptions - with pytest.raises(AssertionError): - SEANetEncoder(disable_norm_outer_blocks=-1) - - with pytest.raises(AssertionError): - SEANetEncoder(ratios=[1, 1, 2, 2], disable_norm_outer_blocks=7) - - with pytest.raises(AssertionError): - SEANetDecoder(disable_norm_outer_blocks=-1) - - with pytest.raises(AssertionError): - SEANetDecoder(ratios=[1, 1, 2, 2], disable_norm_outer_blocks=7) diff --git a/spaces/Superlang/ImageProcessor/annotator/uniformer/mmcv/utils/timer.py b/spaces/Superlang/ImageProcessor/annotator/uniformer/mmcv/utils/timer.py deleted file mode 100644 index e3db7d497d8b374e18b5297e0a1d6eb186fd8cba..0000000000000000000000000000000000000000 --- a/spaces/Superlang/ImageProcessor/annotator/uniformer/mmcv/utils/timer.py +++ /dev/null @@ -1,118 +0,0 @@ -# Copyright (c) OpenMMLab. All rights reserved. -from time import time - - -class TimerError(Exception): - - def __init__(self, message): - self.message = message - super(TimerError, self).__init__(message) - - -class Timer: - """A flexible Timer class. - - :Example: - - >>> import time - >>> import annotator.uniformer.mmcv as mmcv - >>> with mmcv.Timer(): - >>> # simulate a code block that will run for 1s - >>> time.sleep(1) - 1.000 - >>> with mmcv.Timer(print_tmpl='it takes {:.1f} seconds'): - >>> # simulate a code block that will run for 1s - >>> time.sleep(1) - it takes 1.0 seconds - >>> timer = mmcv.Timer() - >>> time.sleep(0.5) - >>> print(timer.since_start()) - 0.500 - >>> time.sleep(0.5) - >>> print(timer.since_last_check()) - 0.500 - >>> print(timer.since_start()) - 1.000 - """ - - def __init__(self, start=True, print_tmpl=None): - self._is_running = False - self.print_tmpl = print_tmpl if print_tmpl else '{:.3f}' - if start: - self.start() - - @property - def is_running(self): - """bool: indicate whether the timer is running""" - return self._is_running - - def __enter__(self): - self.start() - return self - - def __exit__(self, type, value, traceback): - print(self.print_tmpl.format(self.since_last_check())) - self._is_running = False - - def start(self): - """Start the timer.""" - if not self._is_running: - self._t_start = time() - self._is_running = True - self._t_last = time() - - def since_start(self): - """Total time since the timer is started. - - Returns (float): Time in seconds. - """ - if not self._is_running: - raise TimerError('timer is not running') - self._t_last = time() - return self._t_last - self._t_start - - def since_last_check(self): - """Time since the last checking. - - Either :func:`since_start` or :func:`since_last_check` is a checking - operation. - - Returns (float): Time in seconds. - """ - if not self._is_running: - raise TimerError('timer is not running') - dur = time() - self._t_last - self._t_last = time() - return dur - - -_g_timers = {} # global timers - - -def check_time(timer_id): - """Add check points in a single line. - - This method is suitable for running a task on a list of items. A timer will - be registered when the method is called for the first time. - - :Example: - - >>> import time - >>> import annotator.uniformer.mmcv as mmcv - >>> for i in range(1, 6): - >>> # simulate a code block - >>> time.sleep(i) - >>> mmcv.check_time('task1') - 2.000 - 3.000 - 4.000 - 5.000 - - Args: - timer_id (str): Timer identifier. - """ - if timer_id not in _g_timers: - _g_timers[timer_id] = Timer() - return 0 - else: - return _g_timers[timer_id].since_last_check() diff --git a/spaces/Superlang/ImageProcessor/annotator/uniformer/mmseg/datasets/custom.py b/spaces/Superlang/ImageProcessor/annotator/uniformer/mmseg/datasets/custom.py deleted file mode 100644 index d8eb2a709cc7a3a68fc6a1e3a1ad98faef4c5b7b..0000000000000000000000000000000000000000 --- a/spaces/Superlang/ImageProcessor/annotator/uniformer/mmseg/datasets/custom.py +++ /dev/null @@ -1,400 +0,0 @@ -import os -import os.path as osp -from collections import OrderedDict -from functools import reduce - -import annotator.uniformer.mmcv as mmcv -import numpy as np -from annotator.uniformer.mmcv.utils import print_log -from prettytable import PrettyTable -from torch.utils.data import Dataset - -from annotator.uniformer.mmseg.core import eval_metrics -from annotator.uniformer.mmseg.utils import get_root_logger -from .builder import DATASETS -from .pipelines import Compose - - -@DATASETS.register_module() -class CustomDataset(Dataset): - """Custom dataset for semantic segmentation. An example of file structure - is as followed. - - .. code-block:: none - - ├── data - │ ├── my_dataset - │ │ ├── img_dir - │ │ │ ├── train - │ │ │ │ ├── xxx{img_suffix} - │ │ │ │ ├── yyy{img_suffix} - │ │ │ │ ├── zzz{img_suffix} - │ │ │ ├── val - │ │ ├── ann_dir - │ │ │ ├── train - │ │ │ │ ├── xxx{seg_map_suffix} - │ │ │ │ ├── yyy{seg_map_suffix} - │ │ │ │ ├── zzz{seg_map_suffix} - │ │ │ ├── val - - The img/gt_semantic_seg pair of CustomDataset should be of the same - except suffix. A valid img/gt_semantic_seg filename pair should be like - ``xxx{img_suffix}`` and ``xxx{seg_map_suffix}`` (extension is also included - in the suffix). If split is given, then ``xxx`` is specified in txt file. - Otherwise, all files in ``img_dir/``and ``ann_dir`` will be loaded. - Please refer to ``docs/tutorials/new_dataset.md`` for more details. - - - Args: - pipeline (list[dict]): Processing pipeline - img_dir (str): Path to image directory - img_suffix (str): Suffix of images. Default: '.jpg' - ann_dir (str, optional): Path to annotation directory. Default: None - seg_map_suffix (str): Suffix of segmentation maps. Default: '.png' - split (str, optional): Split txt file. If split is specified, only - file with suffix in the splits will be loaded. Otherwise, all - images in img_dir/ann_dir will be loaded. Default: None - data_root (str, optional): Data root for img_dir/ann_dir. Default: - None. - test_mode (bool): If test_mode=True, gt wouldn't be loaded. - ignore_index (int): The label index to be ignored. Default: 255 - reduce_zero_label (bool): Whether to mark label zero as ignored. - Default: False - classes (str | Sequence[str], optional): Specify classes to load. - If is None, ``cls.CLASSES`` will be used. Default: None. - palette (Sequence[Sequence[int]]] | np.ndarray | None): - The palette of segmentation map. If None is given, and - self.PALETTE is None, random palette will be generated. - Default: None - """ - - CLASSES = None - - PALETTE = None - - def __init__(self, - pipeline, - img_dir, - img_suffix='.jpg', - ann_dir=None, - seg_map_suffix='.png', - split=None, - data_root=None, - test_mode=False, - ignore_index=255, - reduce_zero_label=False, - classes=None, - palette=None): - self.pipeline = Compose(pipeline) - self.img_dir = img_dir - self.img_suffix = img_suffix - self.ann_dir = ann_dir - self.seg_map_suffix = seg_map_suffix - self.split = split - self.data_root = data_root - self.test_mode = test_mode - self.ignore_index = ignore_index - self.reduce_zero_label = reduce_zero_label - self.label_map = None - self.CLASSES, self.PALETTE = self.get_classes_and_palette( - classes, palette) - - # join paths if data_root is specified - if self.data_root is not None: - if not osp.isabs(self.img_dir): - self.img_dir = osp.join(self.data_root, self.img_dir) - if not (self.ann_dir is None or osp.isabs(self.ann_dir)): - self.ann_dir = osp.join(self.data_root, self.ann_dir) - if not (self.split is None or osp.isabs(self.split)): - self.split = osp.join(self.data_root, self.split) - - # load annotations - self.img_infos = self.load_annotations(self.img_dir, self.img_suffix, - self.ann_dir, - self.seg_map_suffix, self.split) - - def __len__(self): - """Total number of samples of data.""" - return len(self.img_infos) - - def load_annotations(self, img_dir, img_suffix, ann_dir, seg_map_suffix, - split): - """Load annotation from directory. - - Args: - img_dir (str): Path to image directory - img_suffix (str): Suffix of images. - ann_dir (str|None): Path to annotation directory. - seg_map_suffix (str|None): Suffix of segmentation maps. - split (str|None): Split txt file. If split is specified, only file - with suffix in the splits will be loaded. Otherwise, all images - in img_dir/ann_dir will be loaded. Default: None - - Returns: - list[dict]: All image info of dataset. - """ - - img_infos = [] - if split is not None: - with open(split) as f: - for line in f: - img_name = line.strip() - img_info = dict(filename=img_name + img_suffix) - if ann_dir is not None: - seg_map = img_name + seg_map_suffix - img_info['ann'] = dict(seg_map=seg_map) - img_infos.append(img_info) - else: - for img in mmcv.scandir(img_dir, img_suffix, recursive=True): - img_info = dict(filename=img) - if ann_dir is not None: - seg_map = img.replace(img_suffix, seg_map_suffix) - img_info['ann'] = dict(seg_map=seg_map) - img_infos.append(img_info) - - print_log(f'Loaded {len(img_infos)} images', logger=get_root_logger()) - return img_infos - - def get_ann_info(self, idx): - """Get annotation by index. - - Args: - idx (int): Index of data. - - Returns: - dict: Annotation info of specified index. - """ - - return self.img_infos[idx]['ann'] - - def pre_pipeline(self, results): - """Prepare results dict for pipeline.""" - results['seg_fields'] = [] - results['img_prefix'] = self.img_dir - results['seg_prefix'] = self.ann_dir - if self.custom_classes: - results['label_map'] = self.label_map - - def __getitem__(self, idx): - """Get training/test data after pipeline. - - Args: - idx (int): Index of data. - - Returns: - dict: Training/test data (with annotation if `test_mode` is set - False). - """ - - if self.test_mode: - return self.prepare_test_img(idx) - else: - return self.prepare_train_img(idx) - - def prepare_train_img(self, idx): - """Get training data and annotations after pipeline. - - Args: - idx (int): Index of data. - - Returns: - dict: Training data and annotation after pipeline with new keys - introduced by pipeline. - """ - - img_info = self.img_infos[idx] - ann_info = self.get_ann_info(idx) - results = dict(img_info=img_info, ann_info=ann_info) - self.pre_pipeline(results) - return self.pipeline(results) - - def prepare_test_img(self, idx): - """Get testing data after pipeline. - - Args: - idx (int): Index of data. - - Returns: - dict: Testing data after pipeline with new keys introduced by - pipeline. - """ - - img_info = self.img_infos[idx] - results = dict(img_info=img_info) - self.pre_pipeline(results) - return self.pipeline(results) - - def format_results(self, results, **kwargs): - """Place holder to format result to dataset specific output.""" - - def get_gt_seg_maps(self, efficient_test=False): - """Get ground truth segmentation maps for evaluation.""" - gt_seg_maps = [] - for img_info in self.img_infos: - seg_map = osp.join(self.ann_dir, img_info['ann']['seg_map']) - if efficient_test: - gt_seg_map = seg_map - else: - gt_seg_map = mmcv.imread( - seg_map, flag='unchanged', backend='pillow') - gt_seg_maps.append(gt_seg_map) - return gt_seg_maps - - def get_classes_and_palette(self, classes=None, palette=None): - """Get class names of current dataset. - - Args: - classes (Sequence[str] | str | None): If classes is None, use - default CLASSES defined by builtin dataset. If classes is a - string, take it as a file name. The file contains the name of - classes where each line contains one class name. If classes is - a tuple or list, override the CLASSES defined by the dataset. - palette (Sequence[Sequence[int]]] | np.ndarray | None): - The palette of segmentation map. If None is given, random - palette will be generated. Default: None - """ - if classes is None: - self.custom_classes = False - return self.CLASSES, self.PALETTE - - self.custom_classes = True - if isinstance(classes, str): - # take it as a file path - class_names = mmcv.list_from_file(classes) - elif isinstance(classes, (tuple, list)): - class_names = classes - else: - raise ValueError(f'Unsupported type {type(classes)} of classes.') - - if self.CLASSES: - if not set(classes).issubset(self.CLASSES): - raise ValueError('classes is not a subset of CLASSES.') - - # dictionary, its keys are the old label ids and its values - # are the new label ids. - # used for changing pixel labels in load_annotations. - self.label_map = {} - for i, c in enumerate(self.CLASSES): - if c not in class_names: - self.label_map[i] = -1 - else: - self.label_map[i] = classes.index(c) - - palette = self.get_palette_for_custom_classes(class_names, palette) - - return class_names, palette - - def get_palette_for_custom_classes(self, class_names, palette=None): - - if self.label_map is not None: - # return subset of palette - palette = [] - for old_id, new_id in sorted( - self.label_map.items(), key=lambda x: x[1]): - if new_id != -1: - palette.append(self.PALETTE[old_id]) - palette = type(self.PALETTE)(palette) - - elif palette is None: - if self.PALETTE is None: - palette = np.random.randint(0, 255, size=(len(class_names), 3)) - else: - palette = self.PALETTE - - return palette - - def evaluate(self, - results, - metric='mIoU', - logger=None, - efficient_test=False, - **kwargs): - """Evaluate the dataset. - - Args: - results (list): Testing results of the dataset. - metric (str | list[str]): Metrics to be evaluated. 'mIoU', - 'mDice' and 'mFscore' are supported. - logger (logging.Logger | None | str): Logger used for printing - related information during evaluation. Default: None. - - Returns: - dict[str, float]: Default metrics. - """ - - if isinstance(metric, str): - metric = [metric] - allowed_metrics = ['mIoU', 'mDice', 'mFscore'] - if not set(metric).issubset(set(allowed_metrics)): - raise KeyError('metric {} is not supported'.format(metric)) - eval_results = {} - gt_seg_maps = self.get_gt_seg_maps(efficient_test) - if self.CLASSES is None: - num_classes = len( - reduce(np.union1d, [np.unique(_) for _ in gt_seg_maps])) - else: - num_classes = len(self.CLASSES) - ret_metrics = eval_metrics( - results, - gt_seg_maps, - num_classes, - self.ignore_index, - metric, - label_map=self.label_map, - reduce_zero_label=self.reduce_zero_label) - - if self.CLASSES is None: - class_names = tuple(range(num_classes)) - else: - class_names = self.CLASSES - - # summary table - ret_metrics_summary = OrderedDict({ - ret_metric: np.round(np.nanmean(ret_metric_value) * 100, 2) - for ret_metric, ret_metric_value in ret_metrics.items() - }) - - # each class table - ret_metrics.pop('aAcc', None) - ret_metrics_class = OrderedDict({ - ret_metric: np.round(ret_metric_value * 100, 2) - for ret_metric, ret_metric_value in ret_metrics.items() - }) - ret_metrics_class.update({'Class': class_names}) - ret_metrics_class.move_to_end('Class', last=False) - - # for logger - class_table_data = PrettyTable() - for key, val in ret_metrics_class.items(): - class_table_data.add_column(key, val) - - summary_table_data = PrettyTable() - for key, val in ret_metrics_summary.items(): - if key == 'aAcc': - summary_table_data.add_column(key, [val]) - else: - summary_table_data.add_column('m' + key, [val]) - - print_log('per class results:', logger) - print_log('\n' + class_table_data.get_string(), logger=logger) - print_log('Summary:', logger) - print_log('\n' + summary_table_data.get_string(), logger=logger) - - # each metric dict - for key, value in ret_metrics_summary.items(): - if key == 'aAcc': - eval_results[key] = value / 100.0 - else: - eval_results['m' + key] = value / 100.0 - - ret_metrics_class.pop('Class', None) - for key, value in ret_metrics_class.items(): - eval_results.update({ - key + '.' + str(name): value[idx] / 100.0 - for idx, name in enumerate(class_names) - }) - - if mmcv.is_list_of(results, str): - for file_name in results: - os.remove(file_name) - return eval_results diff --git a/spaces/TNR-5/chatorO/Dockerfile b/spaces/TNR-5/chatorO/Dockerfile deleted file mode 100644 index 8a3000e46b2706d40cae6585898ee88696022bde..0000000000000000000000000000000000000000 --- a/spaces/TNR-5/chatorO/Dockerfile +++ /dev/null @@ -1,133 +0,0 @@ -# Use the official Python 3.9 image as the base image -FROM python:3.9 - -# Expose the port -EXPOSE 7860 - -# Keeps Python from generating .pyc files in the container -ENV PYTHONDONTWRITEBYTECODE=1 - -# Turns off buffering for easier container logging -ENV PYTHONUNBUFFERED=1 - -# Set the PYNGROK_CONFIG environment variable -ENV PYNGROK_CONFIG /tmp/pyngrok.yml - -# Set the NGROK_PATH environment variable to a writable location -ENV NGROK_PATH /tmp/ngrok - -# Copy requirements.txt into the container -COPY requirements.txt . - -# RUN apt-get update -# RUN apt-get install -y wget -# RUN wget -q https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb -# RUN apt-get install ./google-chrome-stable_current_amd64.deb -y - - -# RUN wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub | apt-key add - -# RUN sh -c 'echo "deb [arch=amd64] http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google-chrome.list' -# RUN apt-get -y update -# RUN apt-get install -y google-chrome-stable - -# # install chromedriver -# RUN apt-get install -yqq unzip -# RUN wget -O /tmp/chromedriver.zip http://chromedriver.storage.googleapis.com/`curl -sS chromedriver.storage.googleapis.com/LATEST_RELEASE`/chromedriver_linux64.zip -# RUN unzip /tmp/chromedriver.zip chromedriver -d /usr/local/bin/ - - - - - -# RUN apt install wget -y -# RUN wget https://github.com/mozilla/geckodriver/releases/download/v0.32.0/geckodriver-v0.32.0-linux64.tar.gz -# RUN tar -xzvf geckodriver-v0.32.0-linux64.tar.gz -C /usr/local/bin -# RUN chmod +x /usr/local/bin/geckodriver -# RUN geckodriver -V - - -# RUN apt install firefox-esr -y -# RUN apt-get install firefox-geckodriver - -# Upgrade pip and install the required packages -RUN pip install --upgrade pip && \ - pip install -r requirements.txt - -# Install sudo and create the necessary directories before copying the files -RUN apt-get update && \ - apt-get install -y sudo && \ - mkdir -p /code/image - -# Creates a non-root user with an explicit UID and adds permission to access the /code folder -RUN adduser -u 5678 --disabled-password --gecos "" appuser && \ - usermod -aG sudo appuser && \ - usermod -aG root appuser && \ - chown -R appuser:appuser /code - -# Create the pyngrok bin directory and set the ownership and permissions for appuser -RUN mkdir -p /usr/local/lib/python3.9/site-packages/pyngrok/bin && \ - chown -R appuser:appuser /usr/local/lib/python3.9/site-packages/pyngrok/bin && \ - chmod -R 777 /usr/local/lib/python3.9/site-packages/pyngrok/bin - -RUN mkdir -p /.ngrok2 && \ - chown -R appuser:appuser /.ngrok2 && \ - chmod -R 777 /.ngrok2 - -RUN apt-get update && \ - apt-get install -y curl - -RUN echo "deb http://deb.debian.org/debian/ unstable main contrib non-free" >> /etc/apt/sources.list.d/debian.list - - -# RUN apt install firefox-esr && \ -# apt install geckodriver - -# Set the working directory and copy the files -WORKDIR /code - -# Set the ownership and permissions for the /code directory and its contents -RUN chown -R appuser:appuser /code && \ - chmod -R 777 /code - -COPY . /code - -# RUN chown -R appuser:appuser /code/data.csv && \ -# chmod -R 777 /code/data.csv - -# Copy the pyngrok.yml configuration file -COPY pyngrok.yml /tmp/pyngrok.yml - -# Set the TRANSFORMERS_CACHE environment variable to a cache directory inside /tmp -ENV TRANSFORMERS_CACHE /tmp/transformers_cache -ENV TORCH_HOME /tmp/torch_cache - -USER appuser - - -RUN git clone https://github.com/rphrp1985/gpt4f -# WORKDIR /gpt4f -# COPY . /gpt4f -# RUN cd gpt4f -# RUN ls - -# cp -R / /root/dest-folder -RUN cp -R gpt4f/* /code -RUN ls -CMD python run.py - - - - - - - -# Start the application using pyngrok -# CMD python main.py -# Get the public IP address and display it -# RUN curl -s https://api.ipify.org | xargs echo "Public IP:" -RUN pip install gunicorn - -# Start the Uvicorn server -# ENTRYPOINT ["python", "main.py"] -# CMD ["sh", "-c", "python main.py & sleep infinity"] -CMD ["gunicorn", "--bind", "0.0.0.0:7860","run:app"] \ No newline at end of file diff --git a/spaces/TandCAcceptMe/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_internal/resolution/legacy/resolver.py b/spaces/TandCAcceptMe/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_internal/resolution/legacy/resolver.py deleted file mode 100644 index b17b7e4530b185a4011f4dc3211ddedd6d6587aa..0000000000000000000000000000000000000000 --- a/spaces/TandCAcceptMe/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_internal/resolution/legacy/resolver.py +++ /dev/null @@ -1,600 +0,0 @@ -"""Dependency Resolution - -The dependency resolution in pip is performed as follows: - -for top-level requirements: - a. only one spec allowed per project, regardless of conflicts or not. - otherwise a "double requirement" exception is raised - b. they override sub-dependency requirements. -for sub-dependencies - a. "first found, wins" (where the order is breadth first) -""" - -# The following comment should be removed at some point in the future. -# mypy: strict-optional=False - -import logging -import sys -from collections import defaultdict -from itertools import chain -from typing import DefaultDict, Iterable, List, Optional, Set, Tuple - -from pip._vendor.packaging import specifiers -from pip._vendor.packaging.requirements import Requirement - -from pip._internal.cache import WheelCache -from pip._internal.exceptions import ( - BestVersionAlreadyInstalled, - DistributionNotFound, - HashError, - HashErrors, - InstallationError, - NoneMetadataError, - UnsupportedPythonVersion, -) -from pip._internal.index.package_finder import PackageFinder -from pip._internal.metadata import BaseDistribution -from pip._internal.models.link import Link -from pip._internal.models.wheel import Wheel -from pip._internal.operations.prepare import RequirementPreparer -from pip._internal.req.req_install import ( - InstallRequirement, - check_invalid_constraint_type, -) -from pip._internal.req.req_set import RequirementSet -from pip._internal.resolution.base import BaseResolver, InstallRequirementProvider -from pip._internal.utils import compatibility_tags -from pip._internal.utils.compatibility_tags import get_supported -from pip._internal.utils.direct_url_helpers import direct_url_from_link -from pip._internal.utils.logging import indent_log -from pip._internal.utils.misc import normalize_version_info -from pip._internal.utils.packaging import check_requires_python - -logger = logging.getLogger(__name__) - -DiscoveredDependencies = DefaultDict[str, List[InstallRequirement]] - - -def _check_dist_requires_python( - dist: BaseDistribution, - version_info: Tuple[int, int, int], - ignore_requires_python: bool = False, -) -> None: - """ - Check whether the given Python version is compatible with a distribution's - "Requires-Python" value. - - :param version_info: A 3-tuple of ints representing the Python - major-minor-micro version to check. - :param ignore_requires_python: Whether to ignore the "Requires-Python" - value if the given Python version isn't compatible. - - :raises UnsupportedPythonVersion: When the given Python version isn't - compatible. - """ - # This idiosyncratically converts the SpecifierSet to str and let - # check_requires_python then parse it again into SpecifierSet. But this - # is the legacy resolver so I'm just not going to bother refactoring. - try: - requires_python = str(dist.requires_python) - except FileNotFoundError as e: - raise NoneMetadataError(dist, str(e)) - try: - is_compatible = check_requires_python( - requires_python, - version_info=version_info, - ) - except specifiers.InvalidSpecifier as exc: - logger.warning( - "Package %r has an invalid Requires-Python: %s", dist.raw_name, exc - ) - return - - if is_compatible: - return - - version = ".".join(map(str, version_info)) - if ignore_requires_python: - logger.debug( - "Ignoring failed Requires-Python check for package %r: %s not in %r", - dist.raw_name, - version, - requires_python, - ) - return - - raise UnsupportedPythonVersion( - "Package {!r} requires a different Python: {} not in {!r}".format( - dist.raw_name, version, requires_python - ) - ) - - -class Resolver(BaseResolver): - """Resolves which packages need to be installed/uninstalled to perform \ - the requested operation without breaking the requirements of any package. - """ - - _allowed_strategies = {"eager", "only-if-needed", "to-satisfy-only"} - - def __init__( - self, - preparer: RequirementPreparer, - finder: PackageFinder, - wheel_cache: Optional[WheelCache], - make_install_req: InstallRequirementProvider, - use_user_site: bool, - ignore_dependencies: bool, - ignore_installed: bool, - ignore_requires_python: bool, - force_reinstall: bool, - upgrade_strategy: str, - py_version_info: Optional[Tuple[int, ...]] = None, - ) -> None: - super().__init__() - assert upgrade_strategy in self._allowed_strategies - - if py_version_info is None: - py_version_info = sys.version_info[:3] - else: - py_version_info = normalize_version_info(py_version_info) - - self._py_version_info = py_version_info - - self.preparer = preparer - self.finder = finder - self.wheel_cache = wheel_cache - - self.upgrade_strategy = upgrade_strategy - self.force_reinstall = force_reinstall - self.ignore_dependencies = ignore_dependencies - self.ignore_installed = ignore_installed - self.ignore_requires_python = ignore_requires_python - self.use_user_site = use_user_site - self._make_install_req = make_install_req - - self._discovered_dependencies: DiscoveredDependencies = defaultdict(list) - - def resolve( - self, root_reqs: List[InstallRequirement], check_supported_wheels: bool - ) -> RequirementSet: - """Resolve what operations need to be done - - As a side-effect of this method, the packages (and their dependencies) - are downloaded, unpacked and prepared for installation. This - preparation is done by ``pip.operations.prepare``. - - Once PyPI has static dependency metadata available, it would be - possible to move the preparation to become a step separated from - dependency resolution. - """ - requirement_set = RequirementSet(check_supported_wheels=check_supported_wheels) - for req in root_reqs: - if req.constraint: - check_invalid_constraint_type(req) - self._add_requirement_to_set(requirement_set, req) - - # Actually prepare the files, and collect any exceptions. Most hash - # exceptions cannot be checked ahead of time, because - # _populate_link() needs to be called before we can make decisions - # based on link type. - discovered_reqs: List[InstallRequirement] = [] - hash_errors = HashErrors() - for req in chain(requirement_set.all_requirements, discovered_reqs): - try: - discovered_reqs.extend(self._resolve_one(requirement_set, req)) - except HashError as exc: - exc.req = req - hash_errors.append(exc) - - if hash_errors: - raise hash_errors - - return requirement_set - - def _add_requirement_to_set( - self, - requirement_set: RequirementSet, - install_req: InstallRequirement, - parent_req_name: Optional[str] = None, - extras_requested: Optional[Iterable[str]] = None, - ) -> Tuple[List[InstallRequirement], Optional[InstallRequirement]]: - """Add install_req as a requirement to install. - - :param parent_req_name: The name of the requirement that needed this - added. The name is used because when multiple unnamed requirements - resolve to the same name, we could otherwise end up with dependency - links that point outside the Requirements set. parent_req must - already be added. Note that None implies that this is a user - supplied requirement, vs an inferred one. - :param extras_requested: an iterable of extras used to evaluate the - environment markers. - :return: Additional requirements to scan. That is either [] if - the requirement is not applicable, or [install_req] if the - requirement is applicable and has just been added. - """ - # If the markers do not match, ignore this requirement. - if not install_req.match_markers(extras_requested): - logger.info( - "Ignoring %s: markers '%s' don't match your environment", - install_req.name, - install_req.markers, - ) - return [], None - - # If the wheel is not supported, raise an error. - # Should check this after filtering out based on environment markers to - # allow specifying different wheels based on the environment/OS, in a - # single requirements file. - if install_req.link and install_req.link.is_wheel: - wheel = Wheel(install_req.link.filename) - tags = compatibility_tags.get_supported() - if requirement_set.check_supported_wheels and not wheel.supported(tags): - raise InstallationError( - "{} is not a supported wheel on this platform.".format( - wheel.filename - ) - ) - - # This next bit is really a sanity check. - assert ( - not install_req.user_supplied or parent_req_name is None - ), "a user supplied req shouldn't have a parent" - - # Unnamed requirements are scanned again and the requirement won't be - # added as a dependency until after scanning. - if not install_req.name: - requirement_set.add_unnamed_requirement(install_req) - return [install_req], None - - try: - existing_req: Optional[ - InstallRequirement - ] = requirement_set.get_requirement(install_req.name) - except KeyError: - existing_req = None - - has_conflicting_requirement = ( - parent_req_name is None - and existing_req - and not existing_req.constraint - and existing_req.extras == install_req.extras - and existing_req.req - and install_req.req - and existing_req.req.specifier != install_req.req.specifier - ) - if has_conflicting_requirement: - raise InstallationError( - "Double requirement given: {} (already in {}, name={!r})".format( - install_req, existing_req, install_req.name - ) - ) - - # When no existing requirement exists, add the requirement as a - # dependency and it will be scanned again after. - if not existing_req: - requirement_set.add_named_requirement(install_req) - # We'd want to rescan this requirement later - return [install_req], install_req - - # Assume there's no need to scan, and that we've already - # encountered this for scanning. - if install_req.constraint or not existing_req.constraint: - return [], existing_req - - does_not_satisfy_constraint = install_req.link and not ( - existing_req.link and install_req.link.path == existing_req.link.path - ) - if does_not_satisfy_constraint: - raise InstallationError( - "Could not satisfy constraints for '{}': " - "installation from path or url cannot be " - "constrained to a version".format(install_req.name) - ) - # If we're now installing a constraint, mark the existing - # object for real installation. - existing_req.constraint = False - # If we're now installing a user supplied requirement, - # mark the existing object as such. - if install_req.user_supplied: - existing_req.user_supplied = True - existing_req.extras = tuple( - sorted(set(existing_req.extras) | set(install_req.extras)) - ) - logger.debug( - "Setting %s extras to: %s", - existing_req, - existing_req.extras, - ) - # Return the existing requirement for addition to the parent and - # scanning again. - return [existing_req], existing_req - - def _is_upgrade_allowed(self, req: InstallRequirement) -> bool: - if self.upgrade_strategy == "to-satisfy-only": - return False - elif self.upgrade_strategy == "eager": - return True - else: - assert self.upgrade_strategy == "only-if-needed" - return req.user_supplied or req.constraint - - def _set_req_to_reinstall(self, req: InstallRequirement) -> None: - """ - Set a requirement to be installed. - """ - # Don't uninstall the conflict if doing a user install and the - # conflict is not a user install. - if not self.use_user_site or req.satisfied_by.in_usersite: - req.should_reinstall = True - req.satisfied_by = None - - def _check_skip_installed( - self, req_to_install: InstallRequirement - ) -> Optional[str]: - """Check if req_to_install should be skipped. - - This will check if the req is installed, and whether we should upgrade - or reinstall it, taking into account all the relevant user options. - - After calling this req_to_install will only have satisfied_by set to - None if the req_to_install is to be upgraded/reinstalled etc. Any - other value will be a dist recording the current thing installed that - satisfies the requirement. - - Note that for vcs urls and the like we can't assess skipping in this - routine - we simply identify that we need to pull the thing down, - then later on it is pulled down and introspected to assess upgrade/ - reinstalls etc. - - :return: A text reason for why it was skipped, or None. - """ - if self.ignore_installed: - return None - - req_to_install.check_if_exists(self.use_user_site) - if not req_to_install.satisfied_by: - return None - - if self.force_reinstall: - self._set_req_to_reinstall(req_to_install) - return None - - if not self._is_upgrade_allowed(req_to_install): - if self.upgrade_strategy == "only-if-needed": - return "already satisfied, skipping upgrade" - return "already satisfied" - - # Check for the possibility of an upgrade. For link-based - # requirements we have to pull the tree down and inspect to assess - # the version #, so it's handled way down. - if not req_to_install.link: - try: - self.finder.find_requirement(req_to_install, upgrade=True) - except BestVersionAlreadyInstalled: - # Then the best version is installed. - return "already up-to-date" - except DistributionNotFound: - # No distribution found, so we squash the error. It will - # be raised later when we re-try later to do the install. - # Why don't we just raise here? - pass - - self._set_req_to_reinstall(req_to_install) - return None - - def _find_requirement_link(self, req: InstallRequirement) -> Optional[Link]: - upgrade = self._is_upgrade_allowed(req) - best_candidate = self.finder.find_requirement(req, upgrade) - if not best_candidate: - return None - - # Log a warning per PEP 592 if necessary before returning. - link = best_candidate.link - if link.is_yanked: - reason = link.yanked_reason or "HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units | Github Repo
" - -examples = [['sample.wav','example.jpeg']] -gr.Interface( - inference, - [gr.inputs.Audio(type='file'),gr.inputs.Image(type="file", label="Input")], - [gr.outputs.Textbox(label="Output"),gr.outputs.Video(label="Video Out")], - title=title, - description=description, - article=article, - enable_queue=True, - examples=examples - ).launch(debug=True) \ No newline at end of file diff --git a/spaces/akhaliq/stylegan3_clip/viz/__init__.py b/spaces/akhaliq/stylegan3_clip/viz/__init__.py deleted file mode 100644 index 8dd34882519598c472f1224cfe68c9ff6952ce69..0000000000000000000000000000000000000000 --- a/spaces/akhaliq/stylegan3_clip/viz/__init__.py +++ /dev/null @@ -1,9 +0,0 @@ -# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved. -# -# NVIDIA CORPORATION and its licensors retain all intellectual property -# and proprietary rights in and to this software, related documentation -# and any modifications thereto. Any use, reproduction, disclosure or -# distribution of this software and related documentation without an express -# license agreement from NVIDIA CORPORATION is strictly prohibited. - -# empty diff --git a/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_vendor/progress/colors.py b/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_vendor/progress/colors.py deleted file mode 100644 index 4e770f868bf4ccceb4c520e55dbb866723d89270..0000000000000000000000000000000000000000 --- a/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_vendor/progress/colors.py +++ /dev/null @@ -1,79 +0,0 @@ -# -*- coding: utf-8 -*- - -# Copyright (c) 2020 Georgios Verigakis -
- # SCREENSHOTS
-
- ## _EXAMPLE 1_
- 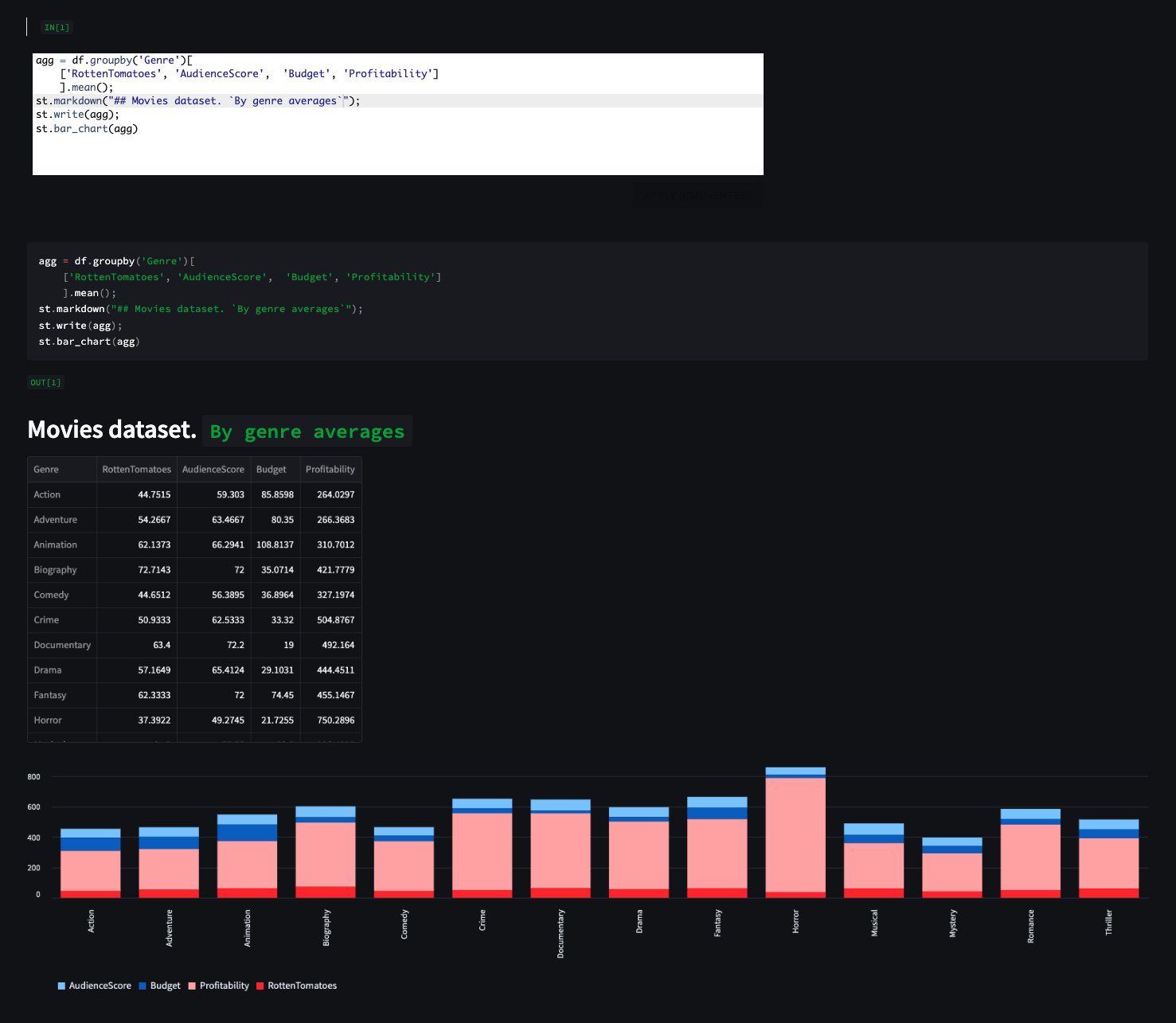
-
- ## _EXAMPLE 2_
- 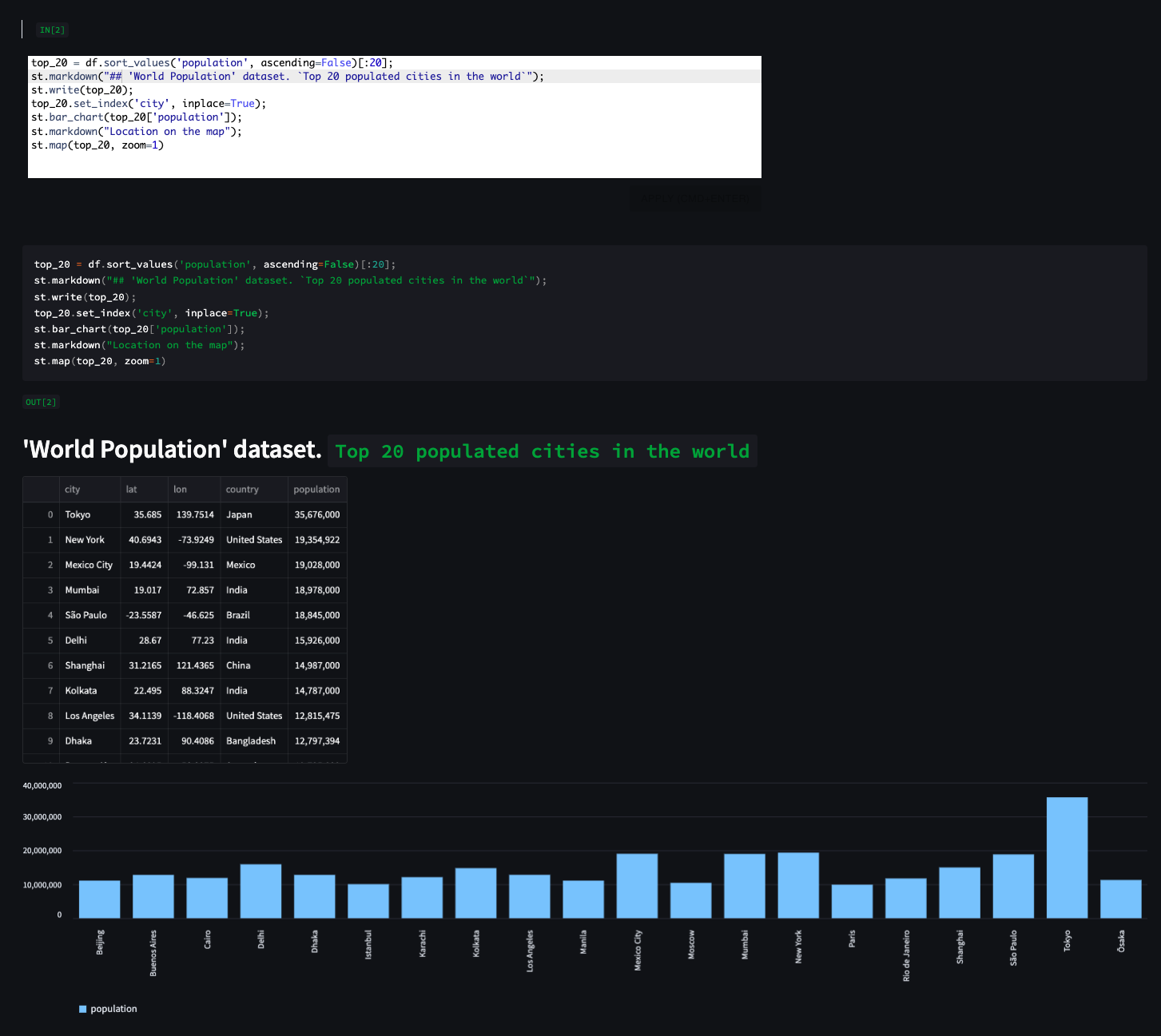
- 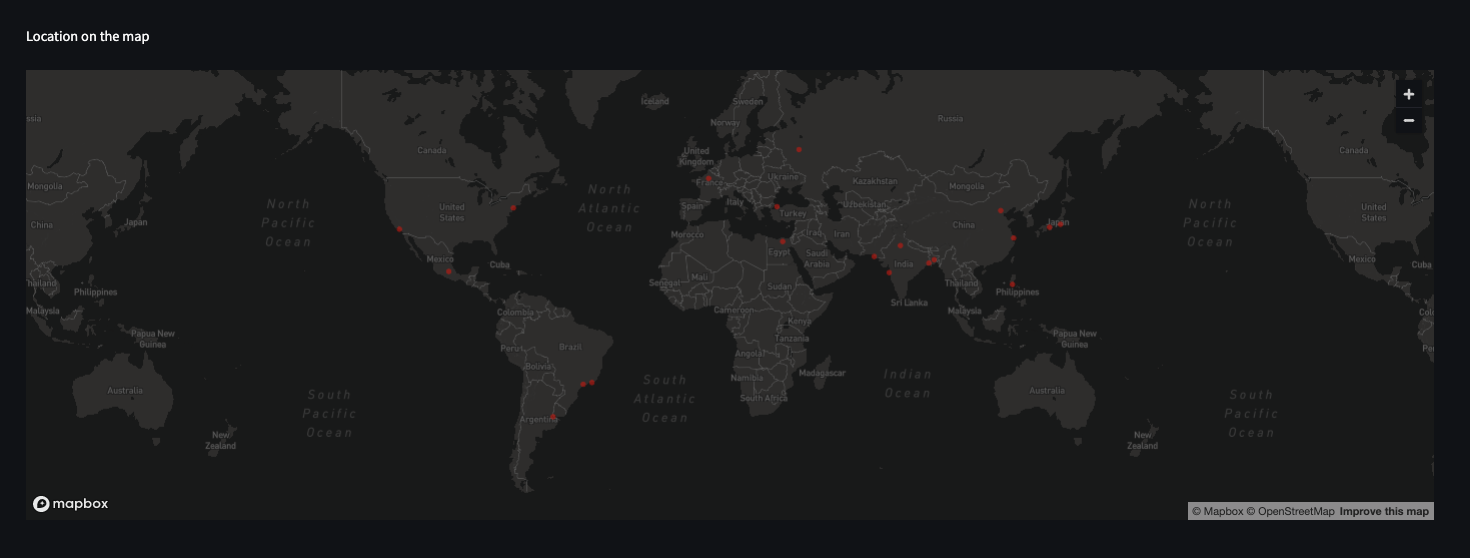
-
- ## _EXAMPLE 3_
- 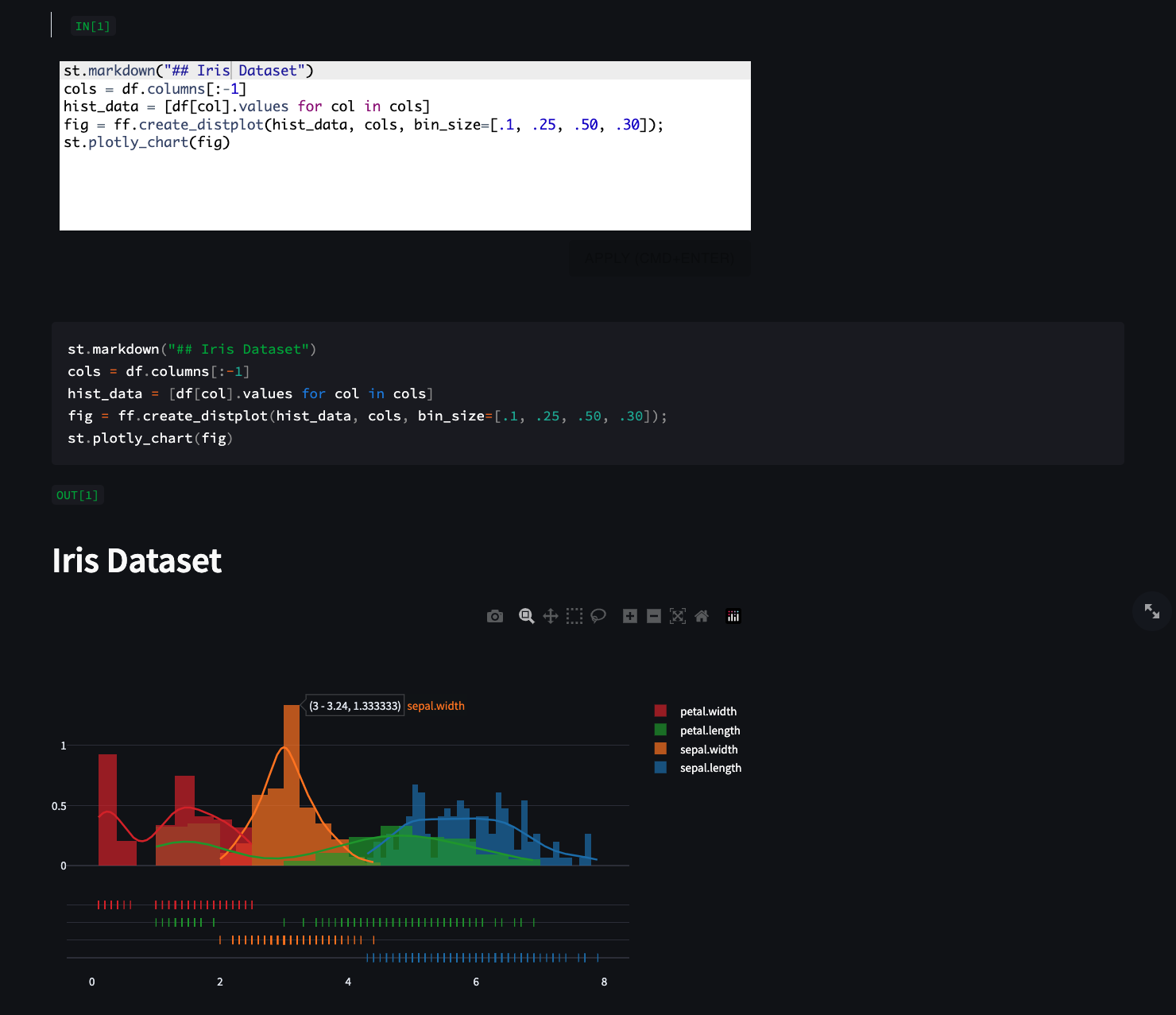
-
- ## _EXAMPLE 4_
- 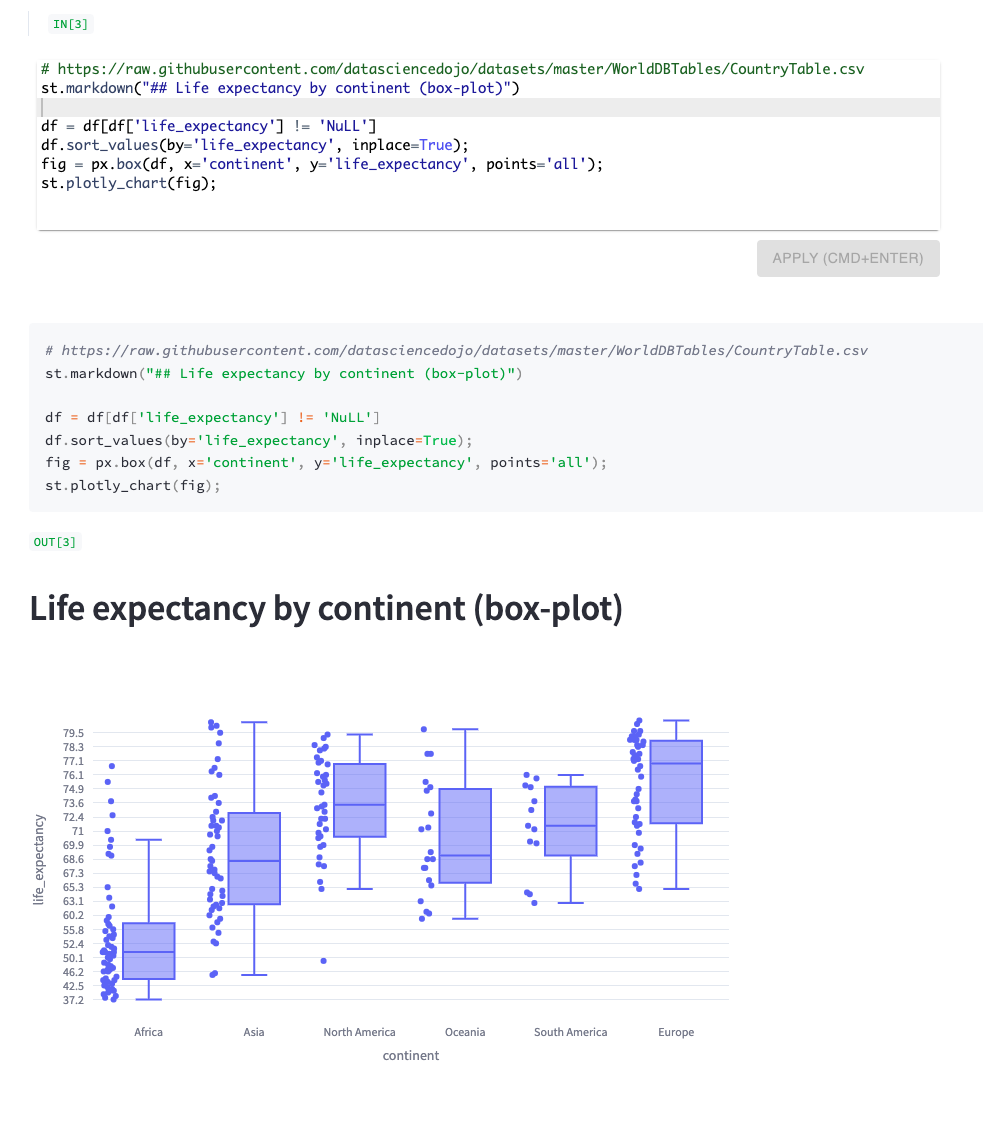
-
- """
-
- with st.expander("READE"):
- st.markdown(content, unsafe_allow_html=True)
-
- return st.checkbox("Show more code examples")
-
-
-def display_example_snippets():
- from glob import glob
-
- examples = glob("./examples/*")
- with st.expander("EXAMPLES"):
- example = st.selectbox("", options=[""] + examples)
- if example:
- with open(example, "r") as f:
- content = f.read()
- st.code(content)
-
-
-if __name__ == "__main__":
- show_examples = docs()
- if show_examples:
- display_example_snippets()
-
- df = read_data()
- display(df)
-
- # run and execute SQL script
- def sql_cells(df):
- st.write("---")
- st.header("SQL")
- hint = """Type SQL to query the loaded dataset, data is stored in a table named 'df'.
- For example, to select 10 rows:
- SELECT * FROM df LIMIT 10
- Describe the table:
- DESCRIBE TABLE df
- """
- number_cells = st.sidebar.number_input("Number of SQL cells to use", value=1, max_value=40)
- for i in range(number_cells):
- col1, col2 = st.columns([2, 1])
- st.markdown("
-
- # SCREENSHOTS
-
- ## _EXAMPLE 1_
- 
-
- ## _EXAMPLE 2_
- 
- 
-
- ## _EXAMPLE 3_
- 
-
- ## _EXAMPLE 4_
- 
-
- """
-
- with st.expander("READE"):
- st.markdown(content, unsafe_allow_html=True)
-
- return st.checkbox("Show more code examples")
-
-
-def display_example_snippets():
- from glob import glob
-
- examples = glob("./examples/*")
- with st.expander("EXAMPLES"):
- example = st.selectbox("", options=[""] + examples)
- if example:
- with open(example, "r") as f:
- content = f.read()
- st.code(content)
-
-
-if __name__ == "__main__":
- show_examples = docs()
- if show_examples:
- display_example_snippets()
-
- df = read_data()
- display(df)
-
- # run and execute SQL script
- def sql_cells(df):
- st.write("---")
- st.header("SQL")
- hint = """Type SQL to query the loaded dataset, data is stored in a table named 'df'.
- For example, to select 10 rows:
- SELECT * FROM df LIMIT 10
- Describe the table:
- DESCRIBE TABLE df
- """
- number_cells = st.sidebar.number_input("Number of SQL cells to use", value=1, max_value=40)
- for i in range(number_cells):
- col1, col2 = st.columns([2, 1])
- st.markdown("", unsafe_allow_html=True) - col1.write(f"> `IN[{i+1}]`") - show_panel = col2.checkbox("Show cell config panel", key=f"sql_{i}") - key = f"sql{i}" - sql = code_editor("sql", hint, show_panel=show_panel, key=key) - if sql: - st.code(sql, language="sql") - st.write(f"`OUT[{i+1}]`") - res = query_data(sql, df) - display_results(sql, res, f"{key}{sql}") - - # run and dexectue python script - def python_cells(): - st.write("---") - st.header("Python") - hint = """Type Python command (one-liner) to execute or manipulate the dataframe e.g. `df.sample(7)`. By default, results are rendered using `st.write()`. - 📊 Visulaization example: from "movies" dataset, plot average rating by genre: - st.line_chart(df.groupby("Genre")[["RottenTomatoes", "AudienceScore"]].mean()) - 🗺 Maps example: show the top 10 populated cities in the world on map (from "Cities Population" dataset) - st.map(df.sort_values(by='population', ascending=False)[:10]) - - NOTE: for multi-lines, a semi-colon can be used to end each line e.g. - print("first line"); - print("second line); - """ - help = """ - For multiple lines, use semicolons e.g. - - ```python - - fig, ax = plt.subplots(); - ax.hist(df[[col1, col2]]); - st.pyplot(fig); - ``` - or - - ```python - groups = [group for _, group in df.groupby('class')]; - for i in range(3): - st.write(groups[i]['name'].iloc[0]) - st.bar_chart(groups[i].mean()) - ``` - """ - number_cells = st.sidebar.number_input("Number of Python cells to use", value=1, max_value=40, min_value=1, help=help) - for i in range(number_cells): - st.markdown("
", unsafe_allow_html=True) - col1, col2 = st.columns([2, 1]) - col1.write(f"> `IN[{i+1}]`") - show_panel = col2.checkbox("Show cell config panel", key=f"panel{i}") - user_script = code_editor("python", hint, show_panel=show_panel, key=i) - if user_script: - df.rename(columns={"lng": "lon"}, inplace=True) # hot-fix for "World Population" dataset - st.code(user_script, language="python") - st.write(f"`OUT[{i+1}]`") - run_python_script(user_script, key=f"{user_script}{i}") - - - if st.sidebar.checkbox("Show SQL cells", value=True): - sql_cells(df) - if st.sidebar.checkbox("Show Python cells", value=True): - python_cells() - - st.sidebar.write("---") - - if st.sidebar.checkbox("Generate Data Profile Report", help="pandas profiling, generated by [ydata-profiling](https://github.com/ydataai/ydata-profiling)"): - st.write("---") - st.header("Data Profiling") - profile = data_profiler(df) - st_profile_report(profile) - - st.write("---") \ No newline at end of file diff --git a/spaces/azusarang/so-vits-svc-models-ba_P/vencoder/hubert/hubert_model_onnx.py b/spaces/azusarang/so-vits-svc-models-ba_P/vencoder/hubert/hubert_model_onnx.py deleted file mode 100644 index d18f3c2a0fc29592a573a9780308d38f059640b9..0000000000000000000000000000000000000000 --- a/spaces/azusarang/so-vits-svc-models-ba_P/vencoder/hubert/hubert_model_onnx.py +++ /dev/null @@ -1,217 +0,0 @@ -import copy -import random -from typing import Optional, Tuple - -import torch -import torch.nn as nn -import torch.nn.functional as t_func -from torch.nn.modules.utils import consume_prefix_in_state_dict_if_present - - -class Hubert(nn.Module): - def __init__(self, num_label_embeddings: int = 100, mask: bool = True): - super().__init__() - self._mask = mask - self.feature_extractor = FeatureExtractor() - self.feature_projection = FeatureProjection() - self.positional_embedding = PositionalConvEmbedding() - self.norm = nn.LayerNorm(768) - self.dropout = nn.Dropout(0.1) - self.encoder = TransformerEncoder( - nn.TransformerEncoderLayer( - 768, 12, 3072, activation="gelu", batch_first=True - ), - 12, - ) - self.proj = nn.Linear(768, 256) - - self.masked_spec_embed = nn.Parameter(torch.FloatTensor(768).uniform_()) - self.label_embedding = nn.Embedding(num_label_embeddings, 256) - - def mask(self, x: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]: - mask = None - if self.training and self._mask: - mask = _compute_mask((x.size(0), x.size(1)), 0.8, 10, x.device, 2) - x[mask] = self.masked_spec_embed.to(x.dtype) - return x, mask - - def encode( - self, x: torch.Tensor, layer: Optional[int] = None - ) -> Tuple[torch.Tensor, torch.Tensor]: - x = self.feature_extractor(x) - x = self.feature_projection(x.transpose(1, 2)) - x, mask = self.mask(x) - x = x + self.positional_embedding(x) - x = self.dropout(self.norm(x)) - x = self.encoder(x, output_layer=layer) - return x, mask - - def logits(self, x: torch.Tensor) -> torch.Tensor: - logits = torch.cosine_similarity( - x.unsqueeze(2), - self.label_embedding.weight.unsqueeze(0).unsqueeze(0), - dim=-1, - ) - return logits / 0.1 - - -class HubertSoft(Hubert): - def __init__(self): - super().__init__() - - def units(self, wav: torch.Tensor) -> torch.Tensor: - wav = t_func.pad(wav, ((400 - 320) // 2, (400 - 320) // 2)) - x, _ = self.encode(wav) - return self.proj(x) - - def forward(self, x): - return self.units(x) - -class FeatureExtractor(nn.Module): - def __init__(self): - super().__init__() - self.conv0 = nn.Conv1d(1, 512, 10, 5, bias=False) - self.norm0 = nn.GroupNorm(512, 512) - self.conv1 = nn.Conv1d(512, 512, 3, 2, bias=False) - self.conv2 = nn.Conv1d(512, 512, 3, 2, bias=False) - self.conv3 = nn.Conv1d(512, 512, 3, 2, bias=False) - self.conv4 = nn.Conv1d(512, 512, 3, 2, bias=False) - self.conv5 = nn.Conv1d(512, 512, 2, 2, bias=False) - self.conv6 = nn.Conv1d(512, 512, 2, 2, bias=False) - - def forward(self, x: torch.Tensor) -> torch.Tensor: - x = t_func.gelu(self.norm0(self.conv0(x))) - x = t_func.gelu(self.conv1(x)) - x = t_func.gelu(self.conv2(x)) - x = t_func.gelu(self.conv3(x)) - x = t_func.gelu(self.conv4(x)) - x = t_func.gelu(self.conv5(x)) - x = t_func.gelu(self.conv6(x)) - return x - - -class FeatureProjection(nn.Module): - def __init__(self): - super().__init__() - self.norm = nn.LayerNorm(512) - self.projection = nn.Linear(512, 768) - self.dropout = nn.Dropout(0.1) - - def forward(self, x: torch.Tensor) -> torch.Tensor: - x = self.norm(x) - x = self.projection(x) - x = self.dropout(x) - return x - - -class PositionalConvEmbedding(nn.Module): - def __init__(self): - super().__init__() - self.conv = nn.Conv1d( - 768, - 768, - kernel_size=128, - padding=128 // 2, - groups=16, - ) - self.conv = nn.utils.weight_norm(self.conv, name="weight", dim=2) - - def forward(self, x: torch.Tensor) -> torch.Tensor: - x = self.conv(x.transpose(1, 2)) - x = t_func.gelu(x[:, :, :-1]) - return x.transpose(1, 2) - - -class TransformerEncoder(nn.Module): - def __init__( - self, encoder_layer: nn.TransformerEncoderLayer, num_layers: int - ) -> None: - super(TransformerEncoder, self).__init__() - self.layers = nn.ModuleList( - [copy.deepcopy(encoder_layer) for _ in range(num_layers)] - ) - self.num_layers = num_layers - - def forward( - self, - src: torch.Tensor, - mask: torch.Tensor = None, - src_key_padding_mask: torch.Tensor = None, - output_layer: Optional[int] = None, - ) -> torch.Tensor: - output = src - for layer in self.layers[:output_layer]: - output = layer( - output, src_mask=mask, src_key_padding_mask=src_key_padding_mask - ) - return output - - -def _compute_mask( - shape: Tuple[int, int], - mask_prob: float, - mask_length: int, - device: torch.device, - min_masks: int = 0, -) -> torch.Tensor: - batch_size, sequence_length = shape - - if mask_length < 1: - raise ValueError("`mask_length` has to be bigger than 0.") - - if mask_length > sequence_length: - raise ValueError( - f"`mask_length` has to be smaller than `sequence_length`, but got `mask_length`: {mask_length} and `sequence_length`: {sequence_length}`" - ) - - # compute number of masked spans in batch - num_masked_spans = int(mask_prob * sequence_length / mask_length + random.random()) - num_masked_spans = max(num_masked_spans, min_masks) - - # make sure num masked indices <= sequence_length - if num_masked_spans * mask_length > sequence_length: - num_masked_spans = sequence_length // mask_length - - # SpecAugment mask to fill - mask = torch.zeros((batch_size, sequence_length), device=device, dtype=torch.bool) - - # uniform distribution to sample from, make sure that offset samples are < sequence_length - uniform_dist = torch.ones( - (batch_size, sequence_length - (mask_length - 1)), device=device - ) - - # get random indices to mask - mask_indices = torch.multinomial(uniform_dist, num_masked_spans) - - # expand masked indices to masked spans - mask_indices = ( - mask_indices.unsqueeze(dim=-1) - .expand((batch_size, num_masked_spans, mask_length)) - .reshape(batch_size, num_masked_spans * mask_length) - ) - offsets = ( - torch.arange(mask_length, device=device)[None, None, :] - .expand((batch_size, num_masked_spans, mask_length)) - .reshape(batch_size, num_masked_spans * mask_length) - ) - mask_idxs = mask_indices + offsets - - # scatter indices to mask - mask = mask.scatter(1, mask_idxs, True) - - return mask - - -def hubert_soft( - path: str, -) -> HubertSoft: - r"""HuBERT-Soft from `"A Comparison of Discrete and Soft Speech Units for Improved Voice Conversion"`. - Args: - path (str): path of a pretrained model - """ - hubert = HubertSoft() - checkpoint = torch.load(path) - consume_prefix_in_state_dict_if_present(checkpoint, "module.") - hubert.load_state_dict(checkpoint) - hubert.eval() - return hubert diff --git a/spaces/banana-dev/demo-faceswap/README.md b/spaces/banana-dev/demo-faceswap/README.md deleted file mode 100644 index d2fc98285a09c675b6669f678a0032e792769349..0000000000000000000000000000000000000000 --- a/spaces/banana-dev/demo-faceswap/README.md +++ /dev/null @@ -1,12 +0,0 @@ ---- -title: Demo Faceswap -emoji: 🏃 -colorFrom: gray -colorTo: indigo -sdk: gradio -sdk_version: 3.44.4 -app_file: app.py -pinned: false ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference diff --git a/spaces/banana-projects/web3d/node_modules/three/examples/js/shaders/HalftoneShader.js b/spaces/banana-projects/web3d/node_modules/three/examples/js/shaders/HalftoneShader.js deleted file mode 100644 index 56df6b935efbf13daa02b8ed473ae6a92c42a653..0000000000000000000000000000000000000000 --- a/spaces/banana-projects/web3d/node_modules/three/examples/js/shaders/HalftoneShader.js +++ /dev/null @@ -1,314 +0,0 @@ -/** - * @author meatbags / xavierburrow.com, github/meatbags - * - * RGB Halftone shader for three.js. - * NOTE: - * Shape (1 = Dot, 2 = Ellipse, 3 = Line, 4 = Square) - * Blending Mode (1 = Linear, 2 = Multiply, 3 = Add, 4 = Lighter, 5 = Darker) - */ - -THREE.HalftoneShader = { - - uniforms: { - "tDiffuse": { value: null }, - "shape": { value: 1 }, - "radius": { value: 4 }, - "rotateR": { value: Math.PI / 12 * 1 }, - "rotateG": { value: Math.PI / 12 * 2 }, - "rotateB": { value: Math.PI / 12 * 3 }, - "scatter": { value: 0 }, - "width": { value: 1 }, - "height": { value: 1 }, - "blending": { value: 1 }, - "blendingMode": { value: 1 }, - "greyscale": { value: false }, - "disable": { value: false } - }, - - vertexShader: [ - - "varying vec2 vUV;", - - "void main() {", - - "vUV = uv;", - "gl_Position = projectionMatrix * modelViewMatrix * vec4(position, 1.0);", - - "}" - - ].join( "\n" ), - - fragmentShader: [ - - "#define SQRT2_MINUS_ONE 0.41421356", - "#define SQRT2_HALF_MINUS_ONE 0.20710678", - "#define PI2 6.28318531", - "#define SHAPE_DOT 1", - "#define SHAPE_ELLIPSE 2", - "#define SHAPE_LINE 3", - "#define SHAPE_SQUARE 4", - "#define BLENDING_LINEAR 1", - "#define BLENDING_MULTIPLY 2", - "#define BLENDING_ADD 3", - "#define BLENDING_LIGHTER 4", - "#define BLENDING_DARKER 5", - "uniform sampler2D tDiffuse;", - "uniform float radius;", - "uniform float rotateR;", - "uniform float rotateG;", - "uniform float rotateB;", - "uniform float scatter;", - "uniform float width;", - "uniform float height;", - "uniform int shape;", - "uniform bool disable;", - "uniform float blending;", - "uniform int blendingMode;", - "varying vec2 vUV;", - "uniform bool greyscale;", - "const int samples = 8;", - - "float blend( float a, float b, float t ) {", - - // linear blend - "return a * ( 1.0 - t ) + b * t;", - - "}", - - "float hypot( float x, float y ) {", - - // vector magnitude - "return sqrt( x * x + y * y );", - - "}", - - "float rand( vec2 seed ){", - - // get pseudo-random number - "return fract( sin( dot( seed.xy, vec2( 12.9898, 78.233 ) ) ) * 43758.5453 );", - - "}", - - "float distanceToDotRadius( float channel, vec2 coord, vec2 normal, vec2 p, float angle, float rad_max ) {", - - // apply shape-specific transforms - "float dist = hypot( coord.x - p.x, coord.y - p.y );", - "float rad = channel;", - - "if ( shape == SHAPE_DOT ) {", - - "rad = pow( abs( rad ), 1.125 ) * rad_max;", - - "} else if ( shape == SHAPE_ELLIPSE ) {", - - "rad = pow( abs( rad ), 1.125 ) * rad_max;", - - "if ( dist != 0.0 ) {", - "float dot_p = abs( ( p.x - coord.x ) / dist * normal.x + ( p.y - coord.y ) / dist * normal.y );", - "dist = ( dist * ( 1.0 - SQRT2_HALF_MINUS_ONE ) ) + dot_p * dist * SQRT2_MINUS_ONE;", - "}", - - "} else if ( shape == SHAPE_LINE ) {", - - "rad = pow( abs( rad ), 1.5) * rad_max;", - "float dot_p = ( p.x - coord.x ) * normal.x + ( p.y - coord.y ) * normal.y;", - "dist = hypot( normal.x * dot_p, normal.y * dot_p );", - - "} else if ( shape == SHAPE_SQUARE ) {", - - "float theta = atan( p.y - coord.y, p.x - coord.x ) - angle;", - "float sin_t = abs( sin( theta ) );", - "float cos_t = abs( cos( theta ) );", - "rad = pow( abs( rad ), 1.4 );", - "rad = rad_max * ( rad + ( ( sin_t > cos_t ) ? rad - sin_t * rad : rad - cos_t * rad ) );", - - "}", - - "return rad - dist;", - - "}", - - "struct Cell {", - - // grid sample positions - "vec2 normal;", - "vec2 p1;", - "vec2 p2;", - "vec2 p3;", - "vec2 p4;", - "float samp2;", - "float samp1;", - "float samp3;", - "float samp4;", - - "};", - - "vec4 getSample( vec2 point ) {", - - // multi-sampled point - "vec4 tex = texture2D( tDiffuse, vec2( point.x / width, point.y / height ) );", - "float base = rand( vec2( floor( point.x ), floor( point.y ) ) ) * PI2;", - "float step = PI2 / float( samples );", - "float dist = radius * 0.66;", - - "for ( int i = 0; i < samples; ++i ) {", - - "float r = base + step * float( i );", - "vec2 coord = point + vec2( cos( r ) * dist, sin( r ) * dist );", - "tex += texture2D( tDiffuse, vec2( coord.x / width, coord.y / height ) );", - - "}", - - "tex /= float( samples ) + 1.0;", - "return tex;", - - "}", - - "float getDotColour( Cell c, vec2 p, int channel, float angle, float aa ) {", - - // get colour for given point - "float dist_c_1, dist_c_2, dist_c_3, dist_c_4, res;", - - "if ( channel == 0 ) {", - - "c.samp1 = getSample( c.p1 ).r;", - "c.samp2 = getSample( c.p2 ).r;", - "c.samp3 = getSample( c.p3 ).r;", - "c.samp4 = getSample( c.p4 ).r;", - - "} else if (channel == 1) {", - - "c.samp1 = getSample( c.p1 ).g;", - "c.samp2 = getSample( c.p2 ).g;", - "c.samp3 = getSample( c.p3 ).g;", - "c.samp4 = getSample( c.p4 ).g;", - - "} else {", - - "c.samp1 = getSample( c.p1 ).b;", - "c.samp3 = getSample( c.p3 ).b;", - "c.samp2 = getSample( c.p2 ).b;", - "c.samp4 = getSample( c.p4 ).b;", - - "}", - - "dist_c_1 = distanceToDotRadius( c.samp1, c.p1, c.normal, p, angle, radius );", - "dist_c_2 = distanceToDotRadius( c.samp2, c.p2, c.normal, p, angle, radius );", - "dist_c_3 = distanceToDotRadius( c.samp3, c.p3, c.normal, p, angle, radius );", - "dist_c_4 = distanceToDotRadius( c.samp4, c.p4, c.normal, p, angle, radius );", - "res = ( dist_c_1 > 0.0 ) ? clamp( dist_c_1 / aa, 0.0, 1.0 ) : 0.0;", - "res += ( dist_c_2 > 0.0 ) ? clamp( dist_c_2 / aa, 0.0, 1.0 ) : 0.0;", - "res += ( dist_c_3 > 0.0 ) ? clamp( dist_c_3 / aa, 0.0, 1.0 ) : 0.0;", - "res += ( dist_c_4 > 0.0 ) ? clamp( dist_c_4 / aa, 0.0, 1.0 ) : 0.0;", - "res = clamp( res, 0.0, 1.0 );", - - "return res;", - - "}", - - "Cell getReferenceCell( vec2 p, vec2 origin, float grid_angle, float step ) {", - - // get containing cell - "Cell c;", - - // calc grid - "vec2 n = vec2( cos( grid_angle ), sin( grid_angle ) );", - "float threshold = step * 0.5;", - "float dot_normal = n.x * ( p.x - origin.x ) + n.y * ( p.y - origin.y );", - "float dot_line = -n.y * ( p.x - origin.x ) + n.x * ( p.y - origin.y );", - "vec2 offset = vec2( n.x * dot_normal, n.y * dot_normal );", - "float offset_normal = mod( hypot( offset.x, offset.y ), step );", - "float normal_dir = ( dot_normal < 0.0 ) ? 1.0 : -1.0;", - "float normal_scale = ( ( offset_normal < threshold ) ? -offset_normal : step - offset_normal ) * normal_dir;", - "float offset_line = mod( hypot( ( p.x - offset.x ) - origin.x, ( p.y - offset.y ) - origin.y ), step );", - "float line_dir = ( dot_line < 0.0 ) ? 1.0 : -1.0;", - "float line_scale = ( ( offset_line < threshold ) ? -offset_line : step - offset_line ) * line_dir;", - - // get closest corner - "c.normal = n;", - "c.p1.x = p.x - n.x * normal_scale + n.y * line_scale;", - "c.p1.y = p.y - n.y * normal_scale - n.x * line_scale;", - - // scatter - "if ( scatter != 0.0 ) {", - - "float off_mag = scatter * threshold * 0.5;", - "float off_angle = rand( vec2( floor( c.p1.x ), floor( c.p1.y ) ) ) * PI2;", - "c.p1.x += cos( off_angle ) * off_mag;", - "c.p1.y += sin( off_angle ) * off_mag;", - - "}", - - // find corners - "float normal_step = normal_dir * ( ( offset_normal < threshold ) ? step : -step );", - "float line_step = line_dir * ( ( offset_line < threshold ) ? step : -step );", - "c.p2.x = c.p1.x - n.x * normal_step;", - "c.p2.y = c.p1.y - n.y * normal_step;", - "c.p3.x = c.p1.x + n.y * line_step;", - "c.p3.y = c.p1.y - n.x * line_step;", - "c.p4.x = c.p1.x - n.x * normal_step + n.y * line_step;", - "c.p4.y = c.p1.y - n.y * normal_step - n.x * line_step;", - - "return c;", - - "}", - - "float blendColour( float a, float b, float t ) {", - - // blend colours - "if ( blendingMode == BLENDING_LINEAR ) {", - "return blend( a, b, 1.0 - t );", - "} else if ( blendingMode == BLENDING_ADD ) {", - "return blend( a, min( 1.0, a + b ), t );", - "} else if ( blendingMode == BLENDING_MULTIPLY ) {", - "return blend( a, max( 0.0, a * b ), t );", - "} else if ( blendingMode == BLENDING_LIGHTER ) {", - "return blend( a, max( a, b ), t );", - "} else if ( blendingMode == BLENDING_DARKER ) {", - "return blend( a, min( a, b ), t );", - "} else {", - "return blend( a, b, 1.0 - t );", - "}", - - "}", - - "void main() {", - - "if ( ! disable ) {", - - // setup - "vec2 p = vec2( vUV.x * width, vUV.y * height );", - "vec2 origin = vec2( 0, 0 );", - "float aa = ( radius < 2.5 ) ? radius * 0.5 : 1.25;", - - // get channel samples - "Cell cell_r = getReferenceCell( p, origin, rotateR, radius );", - "Cell cell_g = getReferenceCell( p, origin, rotateG, radius );", - "Cell cell_b = getReferenceCell( p, origin, rotateB, radius );", - "float r = getDotColour( cell_r, p, 0, rotateR, aa );", - "float g = getDotColour( cell_g, p, 1, rotateG, aa );", - "float b = getDotColour( cell_b, p, 2, rotateB, aa );", - - // blend with original - "vec4 colour = texture2D( tDiffuse, vUV );", - "r = blendColour( r, colour.r, blending );", - "g = blendColour( g, colour.g, blending );", - "b = blendColour( b, colour.b, blending );", - - "if ( greyscale ) {", - "r = g = b = (r + b + g) / 3.0;", - "}", - - "gl_FragColor = vec4( r, g, b, 1.0 );", - - "} else {", - - "gl_FragColor = texture2D( tDiffuse, vUV );", - - "}", - - "}" - - ].join( "\n" ) - -}; diff --git a/spaces/beihai/GFPGAN-V1.3-whole-image/basicsr/models/stylegan2_model.py b/spaces/beihai/GFPGAN-V1.3-whole-image/basicsr/models/stylegan2_model.py deleted file mode 100644 index b03844378421a7ef2b187a3ea8e8d3485780a569..0000000000000000000000000000000000000000 --- a/spaces/beihai/GFPGAN-V1.3-whole-image/basicsr/models/stylegan2_model.py +++ /dev/null @@ -1,283 +0,0 @@ -import cv2 -import math -import numpy as np -import random -import torch -from collections import OrderedDict -from os import path as osp - -from basicsr.archs import build_network -from basicsr.losses import build_loss -from basicsr.losses.losses import g_path_regularize, r1_penalty -from basicsr.utils import imwrite, tensor2img -from basicsr.utils.registry import MODEL_REGISTRY -from .base_model import BaseModel - - -@MODEL_REGISTRY.register() -class StyleGAN2Model(BaseModel): - """StyleGAN2 model.""" - - def __init__(self, opt): - super(StyleGAN2Model, self).__init__(opt) - - # define network net_g - self.net_g = build_network(opt['network_g']) - self.net_g = self.model_to_device(self.net_g) - self.print_network(self.net_g) - # load pretrained model - load_path = self.opt['path'].get('pretrain_network_g', None) - if load_path is not None: - param_key = self.opt['path'].get('param_key_g', 'params') - self.load_network(self.net_g, load_path, self.opt['path'].get('strict_load_g', True), param_key) - - # latent dimension: self.num_style_feat - self.num_style_feat = opt['network_g']['num_style_feat'] - num_val_samples = self.opt['val'].get('num_val_samples', 16) - self.fixed_sample = torch.randn(num_val_samples, self.num_style_feat, device=self.device) - - if self.is_train: - self.init_training_settings() - - def init_training_settings(self): - train_opt = self.opt['train'] - - # define network net_d - self.net_d = build_network(self.opt['network_d']) - self.net_d = self.model_to_device(self.net_d) - self.print_network(self.net_d) - - # load pretrained model - load_path = self.opt['path'].get('pretrain_network_d', None) - if load_path is not None: - param_key = self.opt['path'].get('param_key_d', 'params') - self.load_network(self.net_d, load_path, self.opt['path'].get('strict_load_d', True), param_key) - - # define network net_g with Exponential Moving Average (EMA) - # net_g_ema only used for testing on one GPU and saving, do not need to - # wrap with DistributedDataParallel - self.net_g_ema = build_network(self.opt['network_g']).to(self.device) - # load pretrained model - load_path = self.opt['path'].get('pretrain_network_g', None) - if load_path is not None: - self.load_network(self.net_g_ema, load_path, self.opt['path'].get('strict_load_g', True), 'params_ema') - else: - self.model_ema(0) # copy net_g weight - - self.net_g.train() - self.net_d.train() - self.net_g_ema.eval() - - # define losses - # gan loss (wgan) - self.cri_gan = build_loss(train_opt['gan_opt']).to(self.device) - # regularization weights - self.r1_reg_weight = train_opt['r1_reg_weight'] # for discriminator - self.path_reg_weight = train_opt['path_reg_weight'] # for generator - - self.net_g_reg_every = train_opt['net_g_reg_every'] - self.net_d_reg_every = train_opt['net_d_reg_every'] - self.mixing_prob = train_opt['mixing_prob'] - - self.mean_path_length = 0 - - # set up optimizers and schedulers - self.setup_optimizers() - self.setup_schedulers() - - def setup_optimizers(self): - train_opt = self.opt['train'] - # optimizer g - net_g_reg_ratio = self.net_g_reg_every / (self.net_g_reg_every + 1) - if self.opt['network_g']['type'] == 'StyleGAN2GeneratorC': - normal_params = [] - style_mlp_params = [] - modulation_conv_params = [] - for name, param in self.net_g.named_parameters(): - if 'modulation' in name: - normal_params.append(param) - elif 'style_mlp' in name: - style_mlp_params.append(param) - elif 'modulated_conv' in name: - modulation_conv_params.append(param) - else: - normal_params.append(param) - optim_params_g = [ - { # add normal params first - 'params': normal_params, - 'lr': train_opt['optim_g']['lr'] - }, - { - 'params': style_mlp_params, - 'lr': train_opt['optim_g']['lr'] * 0.01 - }, - { - 'params': modulation_conv_params, - 'lr': train_opt['optim_g']['lr'] / 3 - } - ] - else: - normal_params = [] - for name, param in self.net_g.named_parameters(): - normal_params.append(param) - optim_params_g = [{ # add normal params first - 'params': normal_params, - 'lr': train_opt['optim_g']['lr'] - }] - - optim_type = train_opt['optim_g'].pop('type') - lr = train_opt['optim_g']['lr'] * net_g_reg_ratio - betas = (0**net_g_reg_ratio, 0.99**net_g_reg_ratio) - self.optimizer_g = self.get_optimizer(optim_type, optim_params_g, lr, betas=betas) - self.optimizers.append(self.optimizer_g) - - # optimizer d - net_d_reg_ratio = self.net_d_reg_every / (self.net_d_reg_every + 1) - if self.opt['network_d']['type'] == 'StyleGAN2DiscriminatorC': - normal_params = [] - linear_params = [] - for name, param in self.net_d.named_parameters(): - if 'final_linear' in name: - linear_params.append(param) - else: - normal_params.append(param) - optim_params_d = [ - { # add normal params first - 'params': normal_params, - 'lr': train_opt['optim_d']['lr'] - }, - { - 'params': linear_params, - 'lr': train_opt['optim_d']['lr'] * (1 / math.sqrt(512)) - } - ] - else: - normal_params = [] - for name, param in self.net_d.named_parameters(): - normal_params.append(param) - optim_params_d = [{ # add normal params first - 'params': normal_params, - 'lr': train_opt['optim_d']['lr'] - }] - - optim_type = train_opt['optim_d'].pop('type') - lr = train_opt['optim_d']['lr'] * net_d_reg_ratio - betas = (0**net_d_reg_ratio, 0.99**net_d_reg_ratio) - self.optimizer_d = self.get_optimizer(optim_type, optim_params_d, lr, betas=betas) - self.optimizers.append(self.optimizer_d) - - def feed_data(self, data): - self.real_img = data['gt'].to(self.device) - - def make_noise(self, batch, num_noise): - if num_noise == 1: - noises = torch.randn(batch, self.num_style_feat, device=self.device) - else: - noises = torch.randn(num_noise, batch, self.num_style_feat, device=self.device).unbind(0) - return noises - - def mixing_noise(self, batch, prob): - if random.random() < prob: - return self.make_noise(batch, 2) - else: - return [self.make_noise(batch, 1)] - - def optimize_parameters(self, current_iter): - loss_dict = OrderedDict() - - # optimize net_d - for p in self.net_d.parameters(): - p.requires_grad = True - self.optimizer_d.zero_grad() - - batch = self.real_img.size(0) - noise = self.mixing_noise(batch, self.mixing_prob) - fake_img, _ = self.net_g(noise) - fake_pred = self.net_d(fake_img.detach()) - - real_pred = self.net_d(self.real_img) - # wgan loss with softplus (logistic loss) for discriminator - l_d = self.cri_gan(real_pred, True, is_disc=True) + self.cri_gan(fake_pred, False, is_disc=True) - loss_dict['l_d'] = l_d - # In wgan, real_score should be positive and fake_score should be - # negative - loss_dict['real_score'] = real_pred.detach().mean() - loss_dict['fake_score'] = fake_pred.detach().mean() - l_d.backward() - - if current_iter % self.net_d_reg_every == 0: - self.real_img.requires_grad = True - real_pred = self.net_d(self.real_img) - l_d_r1 = r1_penalty(real_pred, self.real_img) - l_d_r1 = (self.r1_reg_weight / 2 * l_d_r1 * self.net_d_reg_every + 0 * real_pred[0]) - # TODO: why do we need to add 0 * real_pred, otherwise, a runtime - # error will arise: RuntimeError: Expected to have finished - # reduction in the prior iteration before starting a new one. - # This error indicates that your module has parameters that were - # not used in producing loss. - loss_dict['l_d_r1'] = l_d_r1.detach().mean() - l_d_r1.backward() - - self.optimizer_d.step() - - # optimize net_g - for p in self.net_d.parameters(): - p.requires_grad = False - self.optimizer_g.zero_grad() - - noise = self.mixing_noise(batch, self.mixing_prob) - fake_img, _ = self.net_g(noise) - fake_pred = self.net_d(fake_img) - - # wgan loss with softplus (non-saturating loss) for generator - l_g = self.cri_gan(fake_pred, True, is_disc=False) - loss_dict['l_g'] = l_g - l_g.backward() - - if current_iter % self.net_g_reg_every == 0: - path_batch_size = max(1, batch // self.opt['train']['path_batch_shrink']) - noise = self.mixing_noise(path_batch_size, self.mixing_prob) - fake_img, latents = self.net_g(noise, return_latents=True) - l_g_path, path_lengths, self.mean_path_length = g_path_regularize(fake_img, latents, self.mean_path_length) - - l_g_path = (self.path_reg_weight * self.net_g_reg_every * l_g_path + 0 * fake_img[0, 0, 0, 0]) - # TODO: why do we need to add 0 * fake_img[0, 0, 0, 0] - l_g_path.backward() - loss_dict['l_g_path'] = l_g_path.detach().mean() - loss_dict['path_length'] = path_lengths - - self.optimizer_g.step() - - self.log_dict = self.reduce_loss_dict(loss_dict) - - # EMA - self.model_ema(decay=0.5**(32 / (10 * 1000))) - - def test(self): - with torch.no_grad(): - self.net_g_ema.eval() - self.output, _ = self.net_g_ema([self.fixed_sample]) - - def dist_validation(self, dataloader, current_iter, tb_logger, save_img): - if self.opt['rank'] == 0: - self.nondist_validation(dataloader, current_iter, tb_logger, save_img) - - def nondist_validation(self, dataloader, current_iter, tb_logger, save_img): - assert dataloader is None, 'Validation dataloader should be None.' - self.test() - result = tensor2img(self.output, min_max=(-1, 1)) - if self.opt['is_train']: - save_img_path = osp.join(self.opt['path']['visualization'], 'train', f'train_{current_iter}.png') - else: - save_img_path = osp.join(self.opt['path']['visualization'], 'test', f'test_{self.opt["name"]}.png') - imwrite(result, save_img_path) - # add sample images to tb_logger - result = (result / 255.).astype(np.float32) - result = cv2.cvtColor(result, cv2.COLOR_BGR2RGB) - if tb_logger is not None: - tb_logger.add_image('samples', result, global_step=current_iter, dataformats='HWC') - - def save(self, epoch, current_iter): - self.save_network([self.net_g, self.net_g_ema], 'net_g', current_iter, param_key=['params', 'params_ema']) - self.save_network(self.net_d, 'net_d', current_iter) - self.save_training_state(epoch, current_iter) diff --git a/spaces/bigjoker/stable-diffusion-webui/modules/ui_extra_networks_textual_inversion.py b/spaces/bigjoker/stable-diffusion-webui/modules/ui_extra_networks_textual_inversion.py deleted file mode 100644 index 47491b2f09ccc960e2e237097f9d9e78075d25c0..0000000000000000000000000000000000000000 --- a/spaces/bigjoker/stable-diffusion-webui/modules/ui_extra_networks_textual_inversion.py +++ /dev/null @@ -1,34 +0,0 @@ -import json -import os - -from modules import ui_extra_networks, sd_hijack - - -class ExtraNetworksPageTextualInversion(ui_extra_networks.ExtraNetworksPage): - def __init__(self): - super().__init__('Textual Inversion') - self.allow_negative_prompt = True - - def refresh(self): - sd_hijack.model_hijack.embedding_db.load_textual_inversion_embeddings(force_reload=True) - - def list_items(self): - for embedding in sd_hijack.model_hijack.embedding_db.word_embeddings.values(): - path, ext = os.path.splitext(embedding.filename) - preview_file = path + ".preview.png" - - preview = None - if os.path.isfile(preview_file): - preview = self.link_preview(preview_file) - - yield { - "name": embedding.name, - "filename": embedding.filename, - "preview": preview, - "search_term": self.search_terms_from_path(embedding.filename), - "prompt": json.dumps(embedding.name), - "local_preview": path + ".preview.png", - } - - def allowed_directories_for_previews(self): - return list(sd_hijack.model_hijack.embedding_db.embedding_dirs) diff --git a/spaces/bingbing520/ChatGPT2/locale/extract_locale.py b/spaces/bingbing520/ChatGPT2/locale/extract_locale.py deleted file mode 100644 index 32b0924bd6dffe150cb3e481ddadef836b91b83c..0000000000000000000000000000000000000000 --- a/spaces/bingbing520/ChatGPT2/locale/extract_locale.py +++ /dev/null @@ -1,26 +0,0 @@ -import os -import json -import re - -# Define regular expression patterns -pattern = r'i18n\((\"{3}.*?\"{3}|\".*?\")\)' - -# Load the .py file -with open('ChuanhuChatbot.py', 'r', encoding='utf-8') as f: - contents = f.read() - -# Load the .py files in the modules folder -for filename in os.listdir("modules"): - if filename.endswith(".py"): - with open(os.path.join("modules", filename), "r", encoding="utf-8") as f: - contents += f.read() - -# Matching with regular expressions -matches = re.findall(pattern, contents, re.DOTALL) - -# Convert to key/value pairs -data = {match.strip('()"'): '' for match in matches} - -# Save as a JSON file -with open('labels.json', 'w', encoding='utf-8') as f: - json.dump(data, f, ensure_ascii=False, indent=4) \ No newline at end of file diff --git a/spaces/bioriAsaeru/text-to-voice/Download-Digimon-Adventure-Psp-Portugues-Fixed.md b/spaces/bioriAsaeru/text-to-voice/Download-Digimon-Adventure-Psp-Portugues-Fixed.md deleted file mode 100644 index 540bde38596a82545de65fb4a21b040e69491566..0000000000000000000000000000000000000000 --- a/spaces/bioriAsaeru/text-to-voice/Download-Digimon-Adventure-Psp-Portugues-Fixed.md +++ /dev/null @@ -1,100 +0,0 @@ -## download digimon adventure psp portugues - - - - - - - - - -**DOWNLOAD >> [https://venemena.blogspot.com/?download=2txSWn](https://venemena.blogspot.com/?download=2txSWn)** - - - - - - - - - - - - - -# How to Download Digimon Adventure PSP in Portuguese - - - -Digimon Adventure is a role-playing game based on the original 1999 anime series and the movie Our War Game. It was released for the PlayStation Portable (PSP) in 2013 by Prope and NBGI. The game follows the adventures of the eight DigiDestined children and their Digimon partners as they fight against evil forces in the Digital World. The game also features original sub-episodes, choices that affect the story, and the ability to access the ultimate forms of the original Digimon. There is also a bonus scenario where Taichi meets the main protagonists of the sequel anime series Digimon (Daisuke, Takato, Takuya, Masaru, Taiki and Tagiru). - - - -If you are a fan of Digimon and want to play this game in Portuguese, you are in luck. A group of fans called DIGITRANSLATORS has released a patch that translates all the texts, menus, descriptions, graphics, videos, and voices into Portuguese. The patch is compatible with the English version of the game and can be applied using a program called xdelta. - - - -To download Digimon Adventure PSP in Portuguese, you will need the following: - - - -- A PSP console or a PSP emulator for your PC or mobile device. - -- The ISO file of the English version of Digimon Adventure PSP. You can find it online or rip it from your own copy of the game. - -- The patch file from DIGITRANSLATORS. You can download it from their official website or blog. - -- The xdelta program to apply the patch. You can download it from here. - - - -Once you have everything ready, follow these steps: - - - -1. Extract the patch file and the xdelta program to a folder on your computer. - -2. Copy the ISO file of Digimon Adventure PSP to the same folder. - -3. Run xdelta and select "Apply Patch". - -4. Browse for the patch file (Digimon\_Adventure\_PTBR\_v1.2.xdelta) and open it. - -5. Browse for the source file (the ISO file of Digimon Adventure PSP) and open it. - -6. Browse for the output file (the patched ISO file) and name it as you like. - -7. Click on "Patch" and wait for the process to finish. - -8. Copy the patched ISO file to your PSP console or emulator and enjoy playing Digimon Adventure PSP in Portuguese. - - - -Digimon Adventure PSP is a great game for fans of the anime and RPGs. It has a faithful adaptation of the story, a fun combat system, and a lot of content to explore. With this patch, you can also enjoy it in your native language. Download Digimon Adventure PSP in Portuguese today and join the DigiDestined in their epic journey! - - - -## Digimon Adventure PSP Review - - - -If you are looking for an old RPG worth playing in 2023, you might want to check out Digimon Adventure PSP. This game is a faithful adaptation of the first season of the Digimon anime, which aired in 1999 and became a worldwide phenomenon. The game lets you relive the classic story of the eight DigiDestined children and their Digimon partners as they explore the Digital World and fight against evil Digimon. The game also features original content that expands the story and adds more depth to the characters and their relationships. - - - -The gameplay of Digimon Adventure PSP is a turn-based dungeon crawler RPG. You control one of the eight DigiDestined and two other partner Digimon in each episode. You can switch between different characters depending on the episode and the situation. You can also talk to your teammates and improve your bond with them, which unlocks extra episodes and assist attacks. The battles are fast-paced and strategic, as you can use different types of attacks, items, and digivolutions. Digivolutions are special transformations that allow your Digimon to evolve into more powerful forms for a limited time. The game features all the digivolutions from the anime, as well as some new ones that were not shown before. - - - -The graphics of Digimon Adventure PSP are colorful and detailed, capturing the style and atmosphere of the anime. The character models and animations are well-done, especially during the digivolution sequences, which are reanimated from scratch for this game. The backgrounds and environments are varied and immersive, ranging from forests and deserts to temples and cities. The game also uses voice acting from the original cast of the anime, as well as music and sound effects that match the scenes and emotions. The game has a nostalgic appeal for fans of the anime, as well as a fresh appeal for newcomers. - - - -Digimon Adventure PSP is a great RPG for fans of Digimon and anime in general. It has a captivating story, engaging gameplay, and charming presentation. It is a faithful tribute to the original anime series, as well as a creative addition to the Digimon franchise. It is a game that will make you feel like a kid again, or introduce you to a new world of adventure. If you want to play this game in Portuguese, you can download a patch that translates everything into your language. Download Digimon Adventure PSP today and join the adventure! - - dfd1c89656 - - - - - diff --git a/spaces/bioriAsaeru/text-to-voice/F1challenge9902crack [BETTER]passwordonline.md b/spaces/bioriAsaeru/text-to-voice/F1challenge9902crack [BETTER]passwordonline.md deleted file mode 100644 index e84d2359b4d9d66d24e73f13b1161d2e769157b6..0000000000000000000000000000000000000000 --- a/spaces/bioriAsaeru/text-to-voice/F1challenge9902crack [BETTER]passwordonline.md +++ /dev/null @@ -1,131 +0,0 @@ - -
F1 Challenge 99-02 Online: How to Enjoy the Classic Racing Game in 2021
- -F1 Challenge 99-02 is a racing game that was released in 2003 by EA Sports. It covers four seasons of Formula One racing: 1999, 2000, 2001 and 2002. It features realistic physics, graphics and sound, as well as a career mode that lets you create your own driver and compete in all the races.
-f1challenge9902crackpasswordonline
DOWNLOAD ⇔ https://urloso.com/2uyOGg
- -
But what if you want to play F1 Challenge 99-02 online with other players in 2021? Is it still possible? The answer is yes, thanks to the efforts of a dedicated community of fans who have created mods, patches and servers to keep the game alive and updated.
- -How to Download and Install F1 Challenge 99-02 Online
- -If you already have a copy of F1 Challenge 99-02 on your PC, you can skip this step. If not, you can download it from various websites that offer old games for free. Just make sure you scan the files for viruses before installing them.
- -Once you have the game on your PC, you need to install it. You may need to mount the ISO file using a virtual drive software like Daemon Tools or PowerISO. You may also need to enter a CD key, which you can find online or use this one: 2599-1511779-0693459-6951.
- - -After installing the game, you need to copy the crack file from the ISO into the installation folder. This will allow you to run the game without the CD.
- -How to Update and Mod F1 Challenge 99-02 Online
- -The next step is to update and mod your game to make it compatible with online play and enhance its features. There are many mods available for F1 Challenge 99-02 online, but one of the most popular and comprehensive ones is the F1 Challenge 99-02 Online 2021 Edition by Bande87.
- -This mod includes:
--
-
You can download this mod from these links:
--
-
To install this mod, you need to extract the files and copy them into your F1 Challenge 99-02 folder. You may need to overwrite some existing files, so make sure you backup your original files first. Then run the 3D config (Vsync) and play!
- -How to Join and Host F1 Challenge 99-02 Online Servers
- -The final step is to join or host online servers where you can race with other players. There are several ways to do this, but one of the easiest ones is to use Hamachi, a free VPN software that creates a virtual LAN network.
- -To use Hamachi, you need to download it from here: https://www.vpn.net/ and install it on your PC. Then you need to create or join a network with other players who have Hamachi and F1 Challenge 99-02 online installed.
- -To create a network, you need to click on the power button on Hamachi and then click on "Create a new network". You need to enter a network name and password and share them with other players who want to join your network.
- -To join a network, you need to click on the power button on Hamachi and then click on "Join an existing network". You need to enter the network name and password provided by the host of the network.
- -Once you are connected to a network with other players, you can launch F1 Challenge 99-02 online and go to multiplayer mode. To host a server, you need to click on "Create" and choose your settings. To join a server, you need to click on "Join" and select a server from the list or enter its IP address manually.
- -The IP address of the host can be found on Hamachi by right-clicking on their name and choosing "Copy IPv4 address". The IP address of the joiner can be found on Hamachi by right-clicking on their own name and choosing "Copy IPv4 address". You may need to exchange these IP addresses with each other before joining or hosting a server.
- -Conclusion
- -F1 Challenge 99-02 online is a great way to enjoy the classic racing game in 2021 with other players around the world. You just need to download and install the game, update and mod it with the F1 Challenge 99-02 Online 2021 Edition by Bande87, and use Hamachi to create or join online servers.
- -If you are a fan of Formula One racing or just want to have some fun with an old but gold game, give F1 Challenge 99-02 online a try. You won't regret it!
-How to Crack Password Online for F1 Challenge 99-02
- -One of the challenges of playing F1 Challenge 99-02 online is that some servers may require a password to join. This can be frustrating if you don't know the password or if you forgot it. Fortunately, there are some ways to crack password online for F1 Challenge 99-02.
- -One of the easiest ways to crack password online for F1 Challenge 99-02 is to use a password cracker tool. These are programs that can generate or guess passwords based on various criteria, such as length, characters, patterns, etc. Some of the most popular password cracker tools are:
--
-
To use these tools, you need to download and install them on your PC. Then you need to obtain the hash of the password you want to crack. A hash is a string of characters that represents the encrypted form of the password. You can get the hash of the password by using a network sniffer tool like Wireshark or Fiddler, which can capture and analyze the data packets sent and received by your PC when you try to join a server.
- -Once you have the hash of the password, you can use the password cracker tool to try to find the plain text version of the password. Depending on the complexity and length of the password, this may take some time and computing power. You may also need to use some options or parameters to specify the type of hash, the character set, the wordlist, etc.
- -If you are lucky, you may find the password and use it to join the server. If not, you may need to try another tool or another method.
- -How to Bypass Password Online for F1 Challenge 99-02
- -Another way to play F1 Challenge 99-02 online without knowing the password is to bypass it altogether. This means that you can join a server without entering a password or without being asked for one. There are some ways to bypass password online for F1 Challenge 99-02.
- -One of the simplest ways to bypass password online for F1 Challenge 99-02 is to use a proxy server. A proxy server is a server that acts as an intermediary between your PC and the server you want to join. It can hide your IP address, encrypt your data, and modify your requests and responses.
- -To use a proxy server, you need to find one that works with F1 Challenge 99-02 online. You can search for free or paid proxy servers online or use a proxy service like Proxify or HideMyAss. You need to enter the IP address and port number of the proxy server in your game settings or in your network settings on your PC.
- -Once you have configured your proxy server, you can try to join a server that requires a password. The proxy server may be able to bypass the password authentication and let you join without asking for a password. However, this may not work with all servers or all proxy servers.
- -Conclusion
- -F1 Challenge 99-02 online is a fun and exciting way to play the classic racing game with other players around the world. However, some servers may require a password to join, which can be annoying if you don't know it or if you forgot it.
- -In this article, we have shown you how to crack password online for F1 Challenge 99-02 using various tools and methods. We have also shown you how to bypass password online for F1 Challenge 99-02 using proxy servers.
- -We hope that this article has helped you enjoy F1 Challenge 99-02 online more and that you have learned something useful about passwords and security.
-How to Enjoy F1 Challenge 99-02 Online with Various Mods and Seasons
- -One of the best things about F1 Challenge 99-02 online is that you can customize and enhance your game experience with various mods and seasons created by the community. These mods and seasons can add new features, graphics, sounds, tracks, cars, drivers, teams, rules, etc. to your game.
- -There are many mods and seasons available for F1 Challenge 99-02 online, but some of the most popular and recommended ones are:
--
-
You can download these mods and seasons from various websites that offer F1 Challenge 99-02 online content. Some of them are:
--
-
To install these mods and seasons, you need to follow the instructions provided by each mod or season creator. Usually, you need to extract the files and copy them into your F1 Challenge 99-02 folder. You may need to overwrite some existing files or use a mod manager tool like JSGME or ModEnabler.
- -Once you have installed these mods and seasons, you can enjoy F1 Challenge 99-02 online with different options and scenarios. You can choose your favorite season or mod from the game menu or use a season switcher tool like F1C Season Switcher or F1C Season Manager.
- -Conclusion
- -F1 Challenge 99-02 online is a great way to enjoy the classic racing game in 2021 with other players around the world. You just need to download and install the game, update and mod it with the F1 Challenge 99-02 Online 2021 Edition by Bande87, use Hamachi to create or join online servers, and use various mods and seasons to customize and enhance your game experience.
- -If you are a fan of Formula One racing or just want to have some fun with an old but gold game, give F1 Challenge 99-02 online a try. You won't regret it!
-Conclusion
- -F1 Challenge 99-02 online is a great way to enjoy the classic racing game in 2021 with other players around the world. You just need to download and install the game, update and mod it with the F1 Challenge 99-02 Online 2021 Edition by Bande87, use Hamachi to create or join online servers, and use various mods and seasons to customize and enhance your game experience.
- -If you are a fan of Formula One racing or just want to have some fun with an old but gold game, give F1 Challenge 99-02 online a try. You won't regret it!
3cee63e6c2-
-
\ No newline at end of file diff --git a/spaces/bioriAsaeru/text-to-voice/Keilc51crack A Complete Guide to Keil Tools Collection for ARM and 8051 Microcontrollers.md b/spaces/bioriAsaeru/text-to-voice/Keilc51crack A Complete Guide to Keil Tools Collection for ARM and 8051 Microcontrollers.md deleted file mode 100644 index 1914e31627614325fa0187073ffd3c4854086077..0000000000000000000000000000000000000000 --- a/spaces/bioriAsaeru/text-to-voice/Keilc51crack A Complete Guide to Keil Tools Collection for ARM and 8051 Microcontrollers.md +++ /dev/null @@ -1,13 +0,0 @@ -
-
Libraries installed in the Arduino IDE are available for every Arduino sketch. So, for example, if we install Version 1 of our library in the IDE and we have four sketches ALL of the sketches have access to that library.
-Sketch 52 Crack Mac Osx
DOWNLOAD ⇔ https://urloso.com/2uyRei
-
In high school the comic was credited with being a crack athlete, starring in basketball, baseball, football and track. Later he tried his hand at boxing, drawing considerable crowds who were amazed at his ability to absorb punishment.
-unzip: cannot find or open /library/application support/sketchup 2021/sketchup/plugins/twinmotion2020.2/.zip, /library/application support/sketchup 2021/sketchup/plugins/twinmotion2020.2/.zip.zip or /library/application support/sketchup 2021/sketchup/plugins/twinmotion2020.2/*.zip.ZIP.
-Hello Tom,
Great explanation on how to fix the clone Arduino UNO. What about the clone Arduino pro mini from China? I can upload the sketch, but they just seem not to work properly or don't work at all. Can you do the same with pro mini since the microcontroller is the same as UNO? Thank you and I appreciate your work?
Davor
I have similar problem with MEGA 2560 R3, L LED is blinking but cannot upload any sketch.
I tried to burn bootloader from a New MEGA 2560 R3 and get this error:
avrdude: Expected signature for ATmega2560 is 1E 98 01
Double check chip, or use -F to override this check.
I tried using ICSP interface.
Can any help me?? Only I have available two Arduino Mega (If wiring is wrong)
I used PIN10 to RESET and PINs (MISO, SCK, VCC, MOSI and GND) from ICSP and capacitor between RESET and GND (on programmer)
worng arduino can work with last sketch uploaded but I cannot upload anymore....
If you guys are having problem with arduino uploading sketch. You tried all solution but it never worked. So last option you have is to upload the sketch through using other arduino.
You can see in detail in this article: -not-uploading-through-usb.html
I think there is another way to do this, without extracting the code from the Arduino board. Remenber the date you create the sketch, and look for it in C:\Users\User\AppData\Local\Temp\(For example : C:\Users\User\AppData\Local\Temp\untitled4390292704786567977.tmp\sketch_jan19a ). You could find your unsaved code unless it was deleted by some "freeing space program".Good luck!
-In the "short sketch" case, you are better off just rewriting from scratch. That would be faster, almost certainly. In the "long sketch" case - it just isn't worth it. None of the variable names are preserved, and the way the compiler optimizes code, even the structure of the code would be hard to determine.
aaccfb2cb3-
-
\ No newline at end of file diff --git a/spaces/birgermoell/syllables_app/README.md b/spaces/birgermoell/syllables_app/README.md deleted file mode 100644 index 34dc2b4c1cc49ca4fce9e37066b5a47183f739f4..0000000000000000000000000000000000000000 --- a/spaces/birgermoell/syllables_app/README.md +++ /dev/null @@ -1,12 +0,0 @@ ---- -title: Syllables App -emoji: 🚀 -colorFrom: purple -colorTo: yellow -sdk: streamlit -sdk_version: 1.17.0 -app_file: app.py -pinned: false ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference diff --git a/spaces/breezedeus/pix2text/app.py b/spaces/breezedeus/pix2text/app.py deleted file mode 100644 index 58e1e56e4e5fb9f2bc89496a6ffcc54bf54b9b93..0000000000000000000000000000000000000000 --- a/spaces/breezedeus/pix2text/app.py +++ /dev/null @@ -1,64 +0,0 @@ -# coding: utf-8 -# Copyright (C) 2022, [Breezedeus](https://github.com/breezedeus). - -from PIL import Image -import streamlit as st - -from pix2text import set_logger, Pix2Text - -logger = set_logger() -st.set_page_config(layout="wide") - - -@st.cache(allow_output_mutation=True) -def get_model(): - return Pix2Text() - - -def main(): - p2t = get_model() - - title = 'Pix2Text (a Free Alternative to Mathpix) Demo' - st.markdown(f"
{title}
", unsafe_allow_html=True) - - subtitle = '作者:breezedeus; ' \ - '欢迎加入 交流群' - - st.markdown(f" -
- Welcome to Nitro Diffusion - the first Multi-Style Model trained from scratch! This is a fine-tuned Stable Diffusion model trained on three artstyles simultaniously while keeping each style separate from the others. This allows for high control of mixing, weighting and single style use. Use the tokens archer style, arcane style or modern disney style in your prompts for the effect. You can also use more than one for a mixed style like in the examples down below. Model by Nitrosocke
-datasets/coco/
- annotations/
- densepose_{train,minival,valminusminival}2014.json
- densepose_minival2014_100.json (optional, for testing only)
- {train,val}2014/
- # image files that are mentioned in the corresponding json
-
-
-To train a model one can use the [train_net.py](../train_net.py) script.
-This script was used to train all DensePose models in [Model Zoo(IUV)](DENSEPOSE_IUV.md#ModelZoo), [Model Zoo(CSE)](DENSEPOSE_CSE.md#ModelZoo).
-For example, to launch end-to-end DensePose-RCNN training with ResNet-50 FPN backbone
-on 8 GPUs following the s1x schedule, one can run
-```bash
-python train_net.py --config-file configs/densepose_rcnn_R_50_FPN_s1x.yaml --num-gpus 8
-```
-The configs are made for 8-GPU training. To train on 1 GPU, one can apply the
-[linear learning rate scaling rule](https://arxiv.org/abs/1706.02677):
-```bash
-python train_net.py --config-file configs/densepose_rcnn_R_50_FPN_s1x.yaml \
- SOLVER.IMS_PER_BATCH 2 SOLVER.BASE_LR 0.0025
-```
-
-## Evaluation
-
-Model testing can be done in the same way as training, except for an additional flag `--eval-only` and
-model location specification through `MODEL.WEIGHTS model.pth` in the command line
-```bash
-python train_net.py --config-file configs/densepose_rcnn_R_50_FPN_s1x.yaml \
- --eval-only MODEL.WEIGHTS model.pth
-```
-
-## Tools
-
-We provide tools which allow one to:
- - easily view DensePose annotated data in a dataset;
- - perform DensePose inference on a set of images;
- - visualize DensePose model results;
-
-`query_db` is a tool to print or visualize DensePose data in a dataset.
-Please refer to [Query DB](TOOL_QUERY_DB.md) for more details on this tool
-
-`apply_net` is a tool to print or visualize DensePose results.
-Please refer to [Apply Net](TOOL_APPLY_NET.md) for more details on this tool
-
-
-## Installation as a package
-
-DensePose can also be installed as a Python package for integration with other software.
-
-The following dependencies are needed:
-- Python >= 3.7
-- [PyTorch](https://pytorch.org/get-started/locally/#start-locally) >= 1.7 (to match [detectron2 requirements](https://detectron2.readthedocs.io/en/latest/tutorials/install.html#requirements))
-- [torchvision](https://pytorch.org/vision/stable/) version [compatible with your version of PyTorch](https://github.com/pytorch/vision#installation)
-
-DensePose can then be installed from this repository with:
-
-```
-pip install git+https://github.com/facebookresearch/detectron2@main#subdirectory=projects/DensePose
-```
-
-After installation, the package will be importable as `densepose`.
diff --git a/spaces/ccolas/TastyPiano/src/music/pipeline/audio2midi.py b/spaces/ccolas/TastyPiano/src/music/pipeline/audio2midi.py
deleted file mode 100644
index 135a615a1687d896f011c6bbbc7f2c48afd96707..0000000000000000000000000000000000000000
--- a/spaces/ccolas/TastyPiano/src/music/pipeline/audio2midi.py
+++ /dev/null
@@ -1,52 +0,0 @@
-import torch
-import piano_transcription_inference
-import numpy as np
-import os
-import sys
-sys.path.append('../../')
-from src.music.utils import get_out_path, load_audio
-from src.music.config import CHKPT_PATH_TRANSCRIPTION, FPS, MIN_LEN, CROP_LEN
-# import librosa
-device = 'cuda' if torch.cuda.is_available() else 'cpu'
-TRANSCRIPTOR = piano_transcription_inference.PianoTranscription(device=device,
- checkpoint_path=CHKPT_PATH_TRANSCRIPTION)
-
-def audio2midi(audio_path, midi_path=None, crop=CROP_LEN, random_crop=True, verbose=False, level=0):
- if verbose and crop < MIN_LEN + 2:
- print('crop is inferior to the minimal length of a tune')
- assert '.mp3' == audio_path[-4:]
- if midi_path is None:
- midi_path, _, _ = get_out_path(in_path=audio_path, in_word='audio', out_word='midi', out_extension='.mid')
-
- if verbose: print(' ' * level + f'Transcribing {audio_path}.')
- if os.path.exists(midi_path):
- if verbose: print(' ' * (level + 2) + 'Midi file already exists.')
- return midi_path, ''
-
- error_msg = 'Error in transcription. '
- try:
- error_msg += 'Maybe in audio loading?'
- (audio, _) = load_audio(audio_path,
- sr=FPS,
- mono=True)
- error_msg += ' Nope. Cropping?'
- if isinstance(crop, int) and len(audio) > FPS * crop:
- rc_str = ' (random crop)' if random_crop else ' (start crop)'
- if verbose: print(' ' * (level + 2) + f'Cropping the song to {crop}s before transcription{rc_str}. ')
- size_crop = FPS * crop
- if random_crop:
- index_begining = np.random.randint(len(audio) - size_crop - 1)
- else:
- index_begining = 0
- audio = audio[index_begining: index_begining + size_crop]
- error_msg += ' Nope. Transcription?'
- TRANSCRIPTOR.transcribe(audio, midi_path)
- error_msg += ' Nope.'
- extra = f' Saved to {midi_path}' if midi_path else ''
- if verbose: print(' ' * (level + 2) + f'Success! {extra}')
- return midi_path, ''
- except:
- if verbose: print(' ' * (level + 2) + 'Transcription failed.')
- if os.path.exists(midi_path):
- os.remove(midi_path)
- return None, error_msg + ' Yes.'
diff --git a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/fontTools/encodings/StandardEncoding.py b/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/fontTools/encodings/StandardEncoding.py
deleted file mode 100644
index bf1388624bef4763d26656497b7f3068cb23e307..0000000000000000000000000000000000000000
--- a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/fontTools/encodings/StandardEncoding.py
+++ /dev/null
@@ -1,258 +0,0 @@
-StandardEncoding = [
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- "space",
- "exclam",
- "quotedbl",
- "numbersign",
- "dollar",
- "percent",
- "ampersand",
- "quoteright",
- "parenleft",
- "parenright",
- "asterisk",
- "plus",
- "comma",
- "hyphen",
- "period",
- "slash",
- "zero",
- "one",
- "two",
- "three",
- "four",
- "five",
- "six",
- "seven",
- "eight",
- "nine",
- "colon",
- "semicolon",
- "less",
- "equal",
- "greater",
- "question",
- "at",
- "A",
- "B",
- "C",
- "D",
- "E",
- "F",
- "G",
- "H",
- "I",
- "J",
- "K",
- "L",
- "M",
- "N",
- "O",
- "P",
- "Q",
- "R",
- "S",
- "T",
- "U",
- "V",
- "W",
- "X",
- "Y",
- "Z",
- "bracketleft",
- "backslash",
- "bracketright",
- "asciicircum",
- "underscore",
- "quoteleft",
- "a",
- "b",
- "c",
- "d",
- "e",
- "f",
- "g",
- "h",
- "i",
- "j",
- "k",
- "l",
- "m",
- "n",
- "o",
- "p",
- "q",
- "r",
- "s",
- "t",
- "u",
- "v",
- "w",
- "x",
- "y",
- "z",
- "braceleft",
- "bar",
- "braceright",
- "asciitilde",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- "exclamdown",
- "cent",
- "sterling",
- "fraction",
- "yen",
- "florin",
- "section",
- "currency",
- "quotesingle",
- "quotedblleft",
- "guillemotleft",
- "guilsinglleft",
- "guilsinglright",
- "fi",
- "fl",
- ".notdef",
- "endash",
- "dagger",
- "daggerdbl",
- "periodcentered",
- ".notdef",
- "paragraph",
- "bullet",
- "quotesinglbase",
- "quotedblbase",
- "quotedblright",
- "guillemotright",
- "ellipsis",
- "perthousand",
- ".notdef",
- "questiondown",
- ".notdef",
- "grave",
- "acute",
- "circumflex",
- "tilde",
- "macron",
- "breve",
- "dotaccent",
- "dieresis",
- ".notdef",
- "ring",
- "cedilla",
- ".notdef",
- "hungarumlaut",
- "ogonek",
- "caron",
- "emdash",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- "AE",
- ".notdef",
- "ordfeminine",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- "Lslash",
- "Oslash",
- "OE",
- "ordmasculine",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
- "ae",
- ".notdef",
- ".notdef",
- ".notdef",
- "dotlessi",
- ".notdef",
- ".notdef",
- "lslash",
- "oslash",
- "oe",
- "germandbls",
- ".notdef",
- ".notdef",
- ".notdef",
- ".notdef",
-]
diff --git a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/fontTools/misc/classifyTools.py b/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/fontTools/misc/classifyTools.py
deleted file mode 100644
index e46386230e5c826486963cf47640ae0a920377cb..0000000000000000000000000000000000000000
--- a/spaces/chuan-hd/law-assistant-chatbot/.venv/lib/python3.11/site-packages/fontTools/misc/classifyTools.py
+++ /dev/null
@@ -1,172 +0,0 @@
-""" fontTools.misc.classifyTools.py -- tools for classifying things.
-"""
-
-
-class Classifier(object):
-
- """
- Main Classifier object, used to classify things into similar sets.
- """
-
- def __init__(self, sort=True):
-
- self._things = set() # set of all things known so far
- self._sets = [] # list of class sets produced so far
- self._mapping = {} # map from things to their class set
- self._dirty = False
- self._sort = sort
-
- def add(self, set_of_things):
- """
- Add a set to the classifier. Any iterable is accepted.
- """
- if not set_of_things:
- return
-
- self._dirty = True
-
- things, sets, mapping = self._things, self._sets, self._mapping
-
- s = set(set_of_things)
- intersection = s.intersection(things) # existing things
- s.difference_update(intersection) # new things
- difference = s
- del s
-
- # Add new class for new things
- if difference:
- things.update(difference)
- sets.append(difference)
- for thing in difference:
- mapping[thing] = difference
- del difference
-
- while intersection:
- # Take one item and process the old class it belongs to
- old_class = mapping[next(iter(intersection))]
- old_class_intersection = old_class.intersection(intersection)
-
- # Update old class to remove items from new set
- old_class.difference_update(old_class_intersection)
-
- # Remove processed items from todo list
- intersection.difference_update(old_class_intersection)
-
- # Add new class for the intersection with old class
- sets.append(old_class_intersection)
- for thing in old_class_intersection:
- mapping[thing] = old_class_intersection
- del old_class_intersection
-
- def update(self, list_of_sets):
- """
- Add a a list of sets to the classifier. Any iterable of iterables is accepted.
- """
- for s in list_of_sets:
- self.add(s)
-
- def _process(self):
- if not self._dirty:
- return
-
- # Do any deferred processing
- sets = self._sets
- self._sets = [s for s in sets if s]
-
- if self._sort:
- self._sets = sorted(self._sets, key=lambda s: (-len(s), sorted(s)))
-
- self._dirty = False
-
- # Output methods
-
- def getThings(self):
- """Returns the set of all things known so far.
-
- The return value belongs to the Classifier object and should NOT
- be modified while the classifier is still in use.
- """
- self._process()
- return self._things
-
- def getMapping(self):
- """Returns the mapping from things to their class set.
-
- The return value belongs to the Classifier object and should NOT
- be modified while the classifier is still in use.
- """
- self._process()
- return self._mapping
-
- def getClasses(self):
- """Returns the list of class sets.
-
- The return value belongs to the Classifier object and should NOT
- be modified while the classifier is still in use.
- """
- self._process()
- return self._sets
-
-
-def classify(list_of_sets, sort=True):
- """
- Takes a iterable of iterables (list of sets from here on; but any
- iterable works.), and returns the smallest list of sets such that
- each set, is either a subset, or is disjoint from, each of the input
- sets.
-
- In other words, this function classifies all the things present in
- any of the input sets, into similar classes, based on which sets
- things are a member of.
-
- If sort=True, return class sets are sorted by decreasing size and
- their natural sort order within each class size. Otherwise, class
- sets are returned in the order that they were identified, which is
- generally not significant.
-
- >>> classify([]) == ([], {})
- True
- >>> classify([[]]) == ([], {})
- True
- >>> classify([[], []]) == ([], {})
- True
- >>> classify([[1]]) == ([{1}], {1: {1}})
- True
- >>> classify([[1,2]]) == ([{1, 2}], {1: {1, 2}, 2: {1, 2}})
- True
- >>> classify([[1],[2]]) == ([{1}, {2}], {1: {1}, 2: {2}})
- True
- >>> classify([[1,2],[2]]) == ([{1}, {2}], {1: {1}, 2: {2}})
- True
- >>> classify([[1,2],[2,4]]) == ([{1}, {2}, {4}], {1: {1}, 2: {2}, 4: {4}})
- True
- >>> classify([[1,2],[2,4,5]]) == (
- ... [{4, 5}, {1}, {2}], {1: {1}, 2: {2}, 4: {4, 5}, 5: {4, 5}})
- True
- >>> classify([[1,2],[2,4,5]], sort=False) == (
- ... [{1}, {4, 5}, {2}], {1: {1}, 2: {2}, 4: {4, 5}, 5: {4, 5}})
- True
- >>> classify([[1,2,9],[2,4,5]], sort=False) == (
- ... [{1, 9}, {4, 5}, {2}], {1: {1, 9}, 2: {2}, 4: {4, 5}, 5: {4, 5},
- ... 9: {1, 9}})
- True
- >>> classify([[1,2,9,15],[2,4,5]], sort=False) == (
- ... [{1, 9, 15}, {4, 5}, {2}], {1: {1, 9, 15}, 2: {2}, 4: {4, 5},
- ... 5: {4, 5}, 9: {1, 9, 15}, 15: {1, 9, 15}})
- True
- >>> classes, mapping = classify([[1,2,9,15],[2,4,5],[15,5]], sort=False)
- >>> set([frozenset(c) for c in classes]) == set(
- ... [frozenset(s) for s in ({1, 9}, {4}, {2}, {5}, {15})])
- True
- >>> mapping == {1: {1, 9}, 2: {2}, 4: {4}, 5: {5}, 9: {1, 9}, 15: {15}}
- True
- """
- classifier = Classifier(sort=sort)
- classifier.update(list_of_sets)
- return classifier.getClasses(), classifier.getMapping()
-
-
-if __name__ == "__main__":
- import sys, doctest
-
- sys.exit(doctest.testmod(optionflags=doctest.ELLIPSIS).failed)
diff --git a/spaces/cihyFjudo/fairness-paper-search/Kepuhi Beach A Picturesque Spot for Picnics and Sunsets on Molokai.md b/spaces/cihyFjudo/fairness-paper-search/Kepuhi Beach A Picturesque Spot for Picnics and Sunsets on Molokai.md
deleted file mode 100644
index 23104c7b2b6ca76e86a331ad16cbe241e054c495..0000000000000000000000000000000000000000
--- a/spaces/cihyFjudo/fairness-paper-search/Kepuhi Beach A Picturesque Spot for Picnics and Sunsets on Molokai.md
+++ /dev/null
@@ -1,6 +0,0 @@
-kepuhi
Download File ⚡ https://tinurli.com/2uwhT5
- - aaccfb2cb3
-
-
- diff --git a/spaces/cihyFjudo/fairness-paper-search/Roberta Gemma E Asante Stone Video Gratis.md b/spaces/cihyFjudo/fairness-paper-search/Roberta Gemma E Asante Stone Video Gratis.md deleted file mode 100644 index e2f6023be20272810e44721a4e39b5ef0e925011..0000000000000000000000000000000000000000 --- a/spaces/cihyFjudo/fairness-paper-search/Roberta Gemma E Asante Stone Video Gratis.md +++ /dev/null @@ -1,6 +0,0 @@ -
Roberta Gemma E Asante Stone Video Gratis
DOWNLOAD ○○○ https://tinurli.com/2uwkDV
- - aaccfb2cb3
-
-
- diff --git a/spaces/cihyFjudo/fairness-paper-search/Saajan 4 Full Movie In Tamil Downloadl Enjoy the Love Story of Sanjay Dutt and Madhuri Dixit.md b/spaces/cihyFjudo/fairness-paper-search/Saajan 4 Full Movie In Tamil Downloadl Enjoy the Love Story of Sanjay Dutt and Madhuri Dixit.md deleted file mode 100644 index 447dd6283005d4c74a14af28ee8c20197076d987..0000000000000000000000000000000000000000 --- a/spaces/cihyFjudo/fairness-paper-search/Saajan 4 Full Movie In Tamil Downloadl Enjoy the Love Story of Sanjay Dutt and Madhuri Dixit.md +++ /dev/null @@ -1,6 +0,0 @@ -
Saajan 4 Full Movie In Tamil Downloadl
Download ✦ https://tinurli.com/2uwjNk
-
- aaccfb2cb3
-
-
- diff --git a/spaces/cihyFjudo/fairness-paper-search/Steve Miller Band Fly Like An Eagle 1976 (2006).rarl _HOT_.md b/spaces/cihyFjudo/fairness-paper-search/Steve Miller Band Fly Like An Eagle 1976 (2006).rarl _HOT_.md deleted file mode 100644 index c95d918efd6542b851cefc1858403c105545f920..0000000000000000000000000000000000000000 --- a/spaces/cihyFjudo/fairness-paper-search/Steve Miller Band Fly Like An Eagle 1976 (2006).rarl _HOT_.md +++ /dev/null @@ -1,6 +0,0 @@ -
Steve Miller Band Fly Like An Eagle 1976 (2006).rarl
DOWNLOAD ⚙ https://tinurli.com/2uwk63
- - aaccfb2cb3
-
-
- diff --git a/spaces/cloudtheboi/Lofi4All/.pythonlibs/lib/python3.10/site-packages/altair/vegalite/v5/theme.py b/spaces/cloudtheboi/Lofi4All/.pythonlibs/lib/python3.10/site-packages/altair/vegalite/v5/theme.py deleted file mode 100644 index b536a1ddebe6c311672e6ce2757853ecffa6fb1e..0000000000000000000000000000000000000000 --- a/spaces/cloudtheboi/Lofi4All/.pythonlibs/lib/python3.10/site-packages/altair/vegalite/v5/theme.py +++ /dev/null @@ -1,59 +0,0 @@ -"""Tools for enabling and registering chart themes""" - -from ...utils.theme import ThemeRegistry - -VEGA_THEMES = [ - "ggplot2", - "quartz", - "vox", - "fivethirtyeight", - "dark", - "latimes", - "urbaninstitute", - "excel", - "googlecharts", - "powerbi", -] - - -class VegaTheme: - """Implementation of a builtin vega theme.""" - - def __init__(self, theme): - self.theme = theme - - def __call__(self): - return { - "usermeta": {"embedOptions": {"theme": self.theme}}, - "config": {"view": {"continuousWidth": 300, "continuousHeight": 300}}, - } - - def __repr__(self): - return "VegaTheme({!r})".format(self.theme) - - -# The entry point group that can be used by other packages to declare other -# renderers that will be auto-detected. Explicit registration is also -# allowed by the PluginRegistery API. -ENTRY_POINT_GROUP = "altair.vegalite.v5.theme" # type: str -themes = ThemeRegistry(entry_point_group=ENTRY_POINT_GROUP) - -themes.register( - "default", - lambda: {"config": {"view": {"continuousWidth": 300, "continuousHeight": 300}}}, -) -themes.register( - "opaque", - lambda: { - "config": { - "background": "white", - "view": {"continuousWidth": 300, "continuousHeight": 300}, - } - }, -) -themes.register("none", lambda: {}) - -for theme in VEGA_THEMES: - themes.register(theme, VegaTheme(theme)) - -themes.enable("default") diff --git a/spaces/codedog-ai/edu-assistant/edu_assistant/utils/qdrant_utils.py b/spaces/codedog-ai/edu-assistant/edu_assistant/utils/qdrant_utils.py deleted file mode 100644 index 4aa1133e7400dbde1e659d032a96f8f61f98f747..0000000000000000000000000000000000000000 --- a/spaces/codedog-ai/edu-assistant/edu_assistant/utils/qdrant_utils.py +++ /dev/null @@ -1,13 +0,0 @@ -import os -from functools import lru_cache - -from qdrant_client import QdrantClient - - -@lru_cache(maxsize=1) -def load_qdrant_client(): - qdrant_url = os.environ.get("QDRANT_API_BASE", "") - qdrant_apikey = os.environ.get("QDRANT_API_KEY", "") - client = QdrantClient(url=qdrant_url, api_key=qdrant_apikey) - - return client diff --git a/spaces/codeparrot/code-generation-models/utils/resources.md b/spaces/codeparrot/code-generation-models/utils/resources.md deleted file mode 100644 index c3e0149a07bf2f6340f275eecfaa2811831a1314..0000000000000000000000000000000000000000 --- a/spaces/codeparrot/code-generation-models/utils/resources.md +++ /dev/null @@ -1,6 +0,0 @@ -- Natural Language Processing with Transformers [Tunstall et al., 2022](https://www.oreilly.com/library/view/natural-language-processing/9781098103231/). -- Evaluating large language models trained on code [Chen et al., 2021](https://arxiv.org/abs/2107.03374). -- Competition-Level Code Generation with AlphaCode [Li et al., 2022](https://arxiv.org/abs/2203.07814). -- InCoder: A Generative Model for Code Infilling and Synthesis [Fried et al., 2022](https://arxiv.org/abs/2204.05999). -- A Conversational Paradigm for Program Synthesis [Nijkamp et al. 2022](https://arxiv.org/abs/2203.13474). -- A systematic evaluation of large language models of code [Xu et al. 2022](https://arxiv.org/abs/2202.13169). diff --git a/spaces/coffeeee/nsfw-c0ffees-erotic-story-generator/README.md b/spaces/coffeeee/nsfw-c0ffees-erotic-story-generator/README.md deleted file mode 100644 index 115a15023b1dd2f6c1543644e3652e0634eac3ab..0000000000000000000000000000000000000000 --- a/spaces/coffeeee/nsfw-c0ffees-erotic-story-generator/README.md +++ /dev/null @@ -1,12 +0,0 @@ ---- -title: "[NSFW] C0ffee's Erotic Story Generator" -emoji: 🍑 -colorFrom: gray -colorTo: pink -sdk: gradio -sdk_version: 3.27.0 -app_file: app.py -pinned: false ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference diff --git a/spaces/colakin/video-generater/public/ffmpeg/libavcodec/eac3_data.c b/spaces/colakin/video-generater/public/ffmpeg/libavcodec/eac3_data.c deleted file mode 100644 index d556d35b8217c6b24324a122ca5bacf38c5e0f2f..0000000000000000000000000000000000000000 --- a/spaces/colakin/video-generater/public/ffmpeg/libavcodec/eac3_data.c +++ /dev/null @@ -1,1136 +0,0 @@ -/* - * E-AC-3 tables - * Copyright (c) 2007 Bartlomiej Wolowiec
FM WhatsApp v9.60 Update Download: Everything You Need to Know
-WhatsApp is one of the most popular messaging apps in the world, with over 2 billion users. However, many people are not satisfied with the limited features and functions of the official WhatsApp app. That's why they turn to WhatsApp MODs, which are modified versions of the original app that offer more customization, privacy, and security options.
-One of the best WhatsApp MODs available is FM WhatsApp, developed by Fouad Mokdad. FM WhatsApp comes with a plethora of features that are not present in the official app, such as themes, fonts, emoji, anti-delete messages, hide view status, and much more.
-fm whatsapp v9 60 update download
Download Zip ✸ https://urlca.com/2uOdes
-
If you are looking for the latest version of FM WhatsApp, which is v9.60, you have come to the right place. In this article, we will tell you everything you need to know about FM WhatsApp v9.60 update download, including what it is, why you should use it, what's new in it, how to download and install it, how to update it, and some FAQs.
-What is FM WhatsApp?
-FM WhatsApp is a modified version of the official WhatsApp app that offers more features and functions than the original app. It is also known as Fouad WhatsApp or FMWA. It is not available on the Google Play Store or the App Store, as it is not an official app owned by Facebook. However, you can still download it as an APK file from third-party sources and install it on your Android device.
-Why use FM WhatsApp?
-There are many reasons why you might want to use FM WhatsApp instead of the official app. Here are some of them:
--
-
What's new in FM WhatsApp v9.60?
-The latest version of FM WhatsApp is v9.60, which was released in March 2023. It comes with a number of new features and improvements over the previous versions. Here are some of them:
--
-
How to download and install FM WhatsApp v9.60?
-If you want to download and install FM WhatsApp v9.60 on your Android device, you need to follow these steps:
-Download FM WhatsApp APK file
-The first step is to download the FM WhatsApp APK file from a trusted source. You can use the link below to download the latest version of FM WhatsApp v9.60:
-FM WhatsApp v9.60 APK Download
-The file size is about 43 MB, so make sure you have enough storage space on your device before downloading it.
-fm whatsapp v9 60 apk download latest version
-fm whatsapp v9 60 by fouad mokdad
-fm whatsapp v9 60 download for android
-fm whatsapp v9 60 features and benefits
-fm whatsapp v9 60 anti ban mod apk
-fm whatsapp v9 60 how to install and use
-fm whatsapp v9 60 vs gb whatsapp and yo whatsapp
-fm whatsapp v9 60 free download link
-fm whatsapp v9 60 update download 2023
-fm whatsapp v9 60 new version download
-fm whatsapp v9 60 download official website
-fm whatsapp v9 60 review and rating
-fm whatsapp v9 60 problems and solutions
-fm whatsapp v9 60 customization and themes
-fm whatsapp v9 60 send images and videos without quality loss
-fm whatsapp v9 60 hide online status and last seen
-fm whatsapp v9 60 view deleted messages and statuses
-fm whatsapp v9 60 increase file size limit and number of images
-fm whatsapp v9 60 backup and restore chats
-fm whatsapp v9 60 change fonts and emojis
-fm whatsapp v9 60 privacy and security settings
-fm whatsapp v9 60 latest update news and changelog
-fm whatsapp v9 60 download for pc and laptop
-fm whatsapp v9 60 alternative apps and mods
-fm whatsapp v9 60 tips and tricks
-fm whatsapp v9 60 comparison with original whatsapp
-fm whatsapp v9 60 pros and cons
-fm whatsapp v9 60 faqs and answers
-fm whatsapp v9 60 support and contact details
-fm whatsapp v9 60 bugs and issues fixed
-fm whatsapp v9 60 requirements and compatibility
-fm whatsapp v9 60 screenshots and videos
-fm whatsapp v9 60 group chat and broadcast features
-fm whatsapp v9 60 voice call and video call quality
-fm whatsapp v9 60 stickers and gifs support
-fm whatsapp v9 60 dark mode and night mode options
-fm whatsapp v9 60 lock app with fingerprint or password
-fm whatsapp v9 60 disable forwarded tag on messages
-fm whatsapp v9 60 enable or disable blue ticks and double ticks
-fm whatsapp v9 60 pin chats and mark as unread features
-fm whatsapp v9 60 always online and freeze last seen features
-fm whatsapp v9 60 schedule messages and auto reply features
-fm whatsapp v9 60 download from google drive or mediafire links
-fm whatsapp v9 60 modded by fouad mods team
Enable unknown sources on your device
-The next step is to enable unknown sources on your device, which will allow you to install apps from sources other than the Google Play Store. To do this, go to your device settings and look for the security or privacy option. Then, find the option that says "unknown sources" or "allow installation of apps from unknown sources" and toggle it on. You might see a warning message, but just ignore it and proceed.
-Install FM WhatsApp APK file
-The third step is to install the FM WhatsApp APK file that you downloaded earlier. To do this, locate the file in your device storage and tap on it. You might see a prompt asking you to confirm the installation, just tap on "install" and wait for the process to finish. You might also see a prompt asking you to allow FM WhatsApp to access your contacts, media, files, etc. Just tap on "allow" and continue.
-Verify your phone number and restore your chats
-The final step is to verify your phone number and restore your chats. To do this, open the FM WhatsApp app and enter your phone number that you want to use with it. You will receive a verification code via SMS or call, just enter it and verify your number. Then, you will see an option to restore your chats from a backup, if you have one. Just tap on "restore" and wait for the process to finish. If you don't have a backup, just skip this step and start using the app.
-How to update FM WhatsApp to the latest version?
-If you already have FM WhatsApp installed on your device and you want to update it to the latest version, you can follow these steps:
-Check for updates within the app
-The easiest way to update FM WhatsApp is to check for updates within the app itself. To do this, open the FM WhatsApp app and tap on the menu icon (three dots) in the top right corner. Then, tap on "Fouad Mods" and scroll down until you see the option that says "Updates". Tap on it and check if there is a new version available. If there is, just tap on "Download" and follow the instructions.
-Download the latest FM WhatsApp APK file
-The alternative way to update FM WhatsApp is to download the latest FM WhatsApp APK file from a trusted source. You can use the same link as before to download the latest version of FM WhatsApp v9.60:
-FM WhatsApp v9.60 APK Download
-The file size is about 43 MB, so make sure you have enough storage space on your device before downloading it.
-Install the latest FM WhatsApp APK file
-The final step is to install the latest FM WhatsApp APK file that you downloaded earlier. To do this, locate the file in your device storage and tap on it. You might see a prompt asking you to confirm the installation, just tap on " "install" and wait for the process to finish. You don't need to uninstall the previous version, as the new version will overwrite it. You also don't need to verify your number or restore your chats again, as they will be preserved.
-FAQs about FM WhatsApp v9.60
-Here are some of the frequently asked questions about FM WhatsApp v9.60 and their answers:
-Is FM WhatsApp safe to use?
-FM WhatsApp is generally safe to use, as it is based on the official WhatsApp app and uses the same encryption and security protocols. However, it is not an official app owned by Facebook, so there is no guarantee that it will not contain any malware or spyware. Also, using FM WhatsApp might violate the terms and conditions of WhatsApp, and your account might get banned if WhatsApp detects that you are using a modified app. Therefore, use FM WhatsApp at your own risk and discretion.
-Can I use FM WhatsApp with the official WhatsApp?
-Yes, you can use FM WhatsApp with the official WhatsApp on the same device, as long as you use different phone numbers for each app. You can also use other WhatsApp MODs with FM WhatsApp, such as GB WhatsApp, Yo WhatsApp, etc. However, you cannot use the same phone number for more than one app, as it will cause conflicts and errors.
-How can I customize FM WhatsApp?
-FM WhatsApp offers a lot of customization options that you can access from the "Fouad Mods" menu in the app. You can change the themes, fonts, emoji, icons, colors, and other aspects of the app according to your preferences. You can also download more themes and fonts from the online library within the app.
-How can I hide my online status on FM WhatsApp?
-FM WhatsApp allows you to hide your online status from others, so that they cannot see when you are online or last seen. To do this, go to the "Fouad Mods" menu and tap on "Privacy". Then, tap on "Freeze last seen" and enable it. This will freeze your last seen status at a certain time and prevent it from changing. You can also hide other indicators such as double ticks, blue ticks, typing status, recording status, etc. from the same menu.
-How can I backup and restore my chats on FM WhatsApp?
-FM WhatsApp allows you to backup and restore your chats using Google Drive or local storage. To backup your chats, go to the "Settings" menu and tap on "Chats". Then, tap on "Chat backup" and choose the backup frequency, account, and network settings. To restore your chats, just install FM WhatsApp on a new device and verify your number. You will see an option to restore your chats from Google Drive or local storage. Just tap on "Restore" and wait for the process to finish.
-I hope this article has helped you learn more about FM WhatsApp v9.60 update download and how to use it. If you have any questions or feedback, feel free to leave a comment below. Thanks for reading!
401be4b1e0-
-
\ No newline at end of file diff --git a/spaces/congsaPfin/Manga-OCR/logs/FateGrand Order 2.61.5 APK Download - Latest Version for Android.md b/spaces/congsaPfin/Manga-OCR/logs/FateGrand Order 2.61.5 APK Download - Latest Version for Android.md deleted file mode 100644 index d9eb2ac2af64b865413918d5088badde29d53148..0000000000000000000000000000000000000000 --- a/spaces/congsaPfin/Manga-OCR/logs/FateGrand Order 2.61.5 APK Download - Latest Version for Android.md +++ /dev/null @@ -1,96 +0,0 @@ - -
Fate Grand Order APK 2.61 5: A Guide for Android Users
-If you are a fan of the Fate series, you might have heard of Fate Grand Order, a popular mobile RPG that lets you experience the epic story and battles of the franchise. But did you know that you can download the latest version of the game, Fate Grand Order APK 2.61 5, on your Android device? In this article, we will tell you everything you need to know about this game, how to download and install it, and what benefits you can get from playing it.
-fate grand order apk 2.61 5
Download File ✦✦✦ https://urlca.com/2uO6wS
-
What is Fate Grand Order?
-A popular mobile RPG based on the Fate series
-Fate Grand Order is a mobile RPG that was released in Japan in 2015 and in other regions in 2017. It is based on the Fate series, a media franchise that includes anime, manga, novels, and games. The game is set in a parallel world where the history of humanity is threatened by a mysterious force called the Singularities. You play as a Master, a member of an organization called Chaldea, who can summon heroic spirits called Servants to fight against the enemies and restore the timeline.
-A game with rich story, characters, and gameplay
-Fate Grand Order is not just a simple RPG. It is also a game with a rich story that spans across seven chapters and various spin-offs and collaborations. The game features over 200 Servants from different historical periods and mythologies, each with their own personality, skills, and abilities. You can choose your favorite Servants to form your team and customize them with different costumes, weapons, and items. The game also has various gameplay modes, such as turn-based combat, real-time PvP, co-op missions, and more.
-Why download Fate Grand Order APK 2.61 5?
-The latest version of the game with new features and improvements
-Fate Grand Order APK 2.61 5 is the latest version of the game that was released on June 21, 2023. It includes new features and improvements that make the game more enjoyable and convenient for players. Some of these features are:
--
-
How to download and install Fate Grand Order APK 2.61 5 on your Android device
-If you want to download and install Fate Grand Order APK 2.61 5 on your Android device, you need to follow these simple steps:
-Step 1: Enable unknown sources Step 1: Enable unknown sources on your device settings
-
Before you can install Fate Grand Order APK 2.61 5, you need to enable unknown sources on your device settings. This will allow you to install apps that are not from the Google Play Store. To do this, go to your device settings, then security, then toggle on the option that says "Allow installation of apps from unknown sources". You may also need to confirm this action by tapping "OK" or "Yes" on a pop-up message.
-fate grand order apk 2.61 5 download
-fate grand order apk 2.61 5 mod
-fate grand order apk 2.61 5 update
-fate grand order apk 2.61 5 english
-fate grand order apk 2.61 5 free
-fate grand order apk 2.61 5 latest version
-fate grand order apk 2.61 5 android
-fate grand order apk 2.61 5 apkpure
-fate grand order apk 2.61 5 reddit
-fate grand order apk 2.61 5 install
-fate grand order apk 2.61 5 hack
-fate grand order apk 2.61 5 unlimited quartz
-fate grand order apk 2.61 5 offline
-fate grand order apk 2.61 5 no root
-fate grand order apk 2.61 5 obb
-fate grand order apk 2.61 5 data
-fate grand order apk 2.61 5 mirror
-fate grand order apk 2.61 5 qooapp
-fate grand order apk 2.61 5 jp
-fate grand order apk 2.61 5 na
-fate grand order apk 2.61 5 review
-fate grand order apk 2.61 5 gameplay
-fate grand order apk 2.61 5 guide
-fate grand order apk 2.61 5 tips
-fate grand order apk 2.61 5 tricks
-fate grand order apk 2.61 5 cheats
-fate grand order apk 2.61 5 wiki
-fate grand order apk 2.61 5 tier list
-fate grand order apk 2.61 5 best servants
-fate grand order apk 2.61 5 events
-fate grand order apk 2.61 5 story
-fate grand order apk 2.61 5 characters
-fate grand order apk 2.61 5 summons
-fate grand order apk 2.61 5 gacha
-fate grand order apk 2.61 5 banners
-fate grand order apk 2.61 5 codes
-fate grand order apk 2.61 5 news
-fate grand order apk 2.61 5 patch notes
-fate grand order apk 2.61 5 bugs
-fate grand order apk 2.61 5 fixes
-fate grand order apk
Step 2: Download the APK file from a trusted source
-Next, you need to download the APK file of Fate Grand Order APK 2.61 5 from a trusted source. You can use the link below to download the file directly from the official website of the game. Alternatively, you can search for other sources online, but make sure they are safe and reliable. The file size of the APK is about 80 MB, so make sure you have enough storage space and a stable internet connection.
-Download Fate Grand Order APK 2.61 5 here
-Step 3: Install the APK file and launch the game
-Finally, you need to install the APK file and launch the game. To do this, locate the downloaded file on your device, then tap on it to start the installation process. You may need to grant some permissions to the app, such as access to your storage, camera, and microphone. Follow the on-screen instructions and wait for the installation to finish. Once done, you can launch the game by tapping on its icon on your home screen or app drawer. Enjoy playing Fate Grand Order APK 2.61 5!
-What are the benefits of playing Fate Grand Order APK 2.61 5?
-Enjoy the immersive story and graphics of the game
-One of the benefits of playing Fate Grand Order APK 2.61 5 is that you can enjoy the immersive story and graphics of the game. The game has a captivating story that will keep you hooked until the end, with twists and turns that will surprise you. The game also has stunning graphics that will make you feel like you are in the world of Fate, with realistic animations, effects, and backgrounds. You can also watch cutscenes and dialogues that will enhance your experience.
-Collect and customize your favorite Servants from the Fate series
-Another benefit of playing Fate Grand Order APK 2.61 5 is that you can collect and customize your favorite Servants from the Fate series. The game has over 200 Servants that you can summon and use in battle, each with their own unique skills, abilities, and personalities. You can choose from different classes, such as Saber, Archer, Lancer, Caster, Assassin, Rider, Berserker, and more. You can also customize your Servants with different costumes, weapons, and items that will change their appearance and performance.
-Participate in various events and quests to earn rewards and items
-A third benefit of playing Fate Grand Order APK 2.61 5 is that you can participate in various events and quests to earn rewards and items. The game has different types of events and quests that will challenge your skills and strategy, such as daily quests, story quests, free quests, interludes, rank-up quests, singularity quests, event quests, and more. By completing these events and quests, you can earn rewards and items that will help you improve your Servants and gameplay, such as Saint Quartz, Summon Tickets, Craft Essences, Ascension Materials, Skill Reinforcement Materials, QP, EXP Cards, Fou Cards, Mana Prisms
Join a community of millions of players around the world
-A fourth benefit of playing Fate Grand Order APK 2.61 5 is that you can join a community of millions of players around the world. The game has a global fan base that shares their passion and love for the Fate series and the game. You can interact with other players through the game's chat, friend system, support system, and social media platforms. You can also join or create your own guilds, alliances, or groups to cooperate and compete with other players. You can also participate in online events and campaigns that will reward you with exclusive items and bonuses.
-Conclusion
-Fate Grand Order APK 2.61 5 is a game that every Fate fan and RPG lover should try. It is a game that offers an immersive story, stunning graphics, diverse gameplay, and a vibrant community. It is also easy to download and install on your Android device, as long as you follow the steps we provided. So what are you waiting for? Download Fate Grand Order APK 2.61 5 today and enjoy the ultimate Fate experience!
-FAQs
-Here are some frequently asked questions about Fate Grand Order APK 2.61 5:
--
-
-
-
\ No newline at end of file diff --git a/spaces/congsaPfin/Manga-OCR/logs/Granny Mod APK How to Beat Granny in the Horror Game with MOD Menu and God Mode.md b/spaces/congsaPfin/Manga-OCR/logs/Granny Mod APK How to Beat Granny in the Horror Game with MOD Menu and God Mode.md deleted file mode 100644 index 230c96b753a4c5f5693f872014eac03aba058757..0000000000000000000000000000000000000000 --- a/spaces/congsaPfin/Manga-OCR/logs/Granny Mod APK How to Beat Granny in the Horror Game with MOD Menu and God Mode.md +++ /dev/null @@ -1,93 +0,0 @@ - -
Granny Mod APK: A Horror Game with a Twist
-Do you love horror games? Do you enjoy solving puzzles and escaping from danger? If yes, then you should try Granny Mod APK, a thrilling and challenging game that will keep you on the edge of your seat. In this article, we will tell you everything you need to know about Granny Mod APK, including what it is, why you should play it, what features it offers, and how to download and install it on your device. Let's get started!
-Introduction
-What is Granny Mod APK?
-Granny Mod APK is a modified version of the original Granny game, which is a first-person horror game developed by DVloper. The game is set in a creepy house where you are trapped with a scary old lady named Granny. She is not friendly and she will try to catch you and kill you if she sees you. You have to find a way out of the house before she does.
-granny mod apk
Download Zip ——— https://urlca.com/2uObBp
-
The game has five difficulty levels: Easy, Normal, Hard, Extreme, and Practice. You can also choose to play in dark mode or extra locks mode for more challenge. The game has many rooms, hidden passages, traps, and secrets that you have to explore and use to your advantage. You can also find items and weapons that can help you escape or fight back against Granny.
-Why play Granny Mod APK?
-Granny Mod APK is a great game for horror fans who want to experience a different kind of thrill. Unlike other horror games that rely on jump scares and gore, Granny Mod APK focuses on creating a tense and immersive atmosphere that will make you feel like you are really in the house with Granny. The game also has a lot of puzzles and riddles that will test your logic and creativity. You have to think fast and act smart to survive.
-Another reason to play Granny Mod APK is that it offers some amazing features that are not available in the original game. These features make the game more fun and enjoyable, as well as easier or harder depending on your preference. We will discuss these features in the next section.
-Features of Granny Mod APK
-Mod Menu
-One of the best features of Granny Mod APK is the mod menu, which allows you to customize the game according to your liking. You can access the mod menu by tapping on the icon at the top left corner of the screen. The mod menu has several options that you can toggle on or off, such as:
--
-
Unlimited Everything
-Another feature of Granny Mod APK is that it gives you unlimited everything, meaning that you can use any item or weapon as many times as you want without running out of them. For example, you can use the shotgun, the crossbow, the tranquilizer, the hammer, the pliers, the screwdriver, the padlock key, the master key, the safe key, the car key, the winch handle, the cutting pliers, the cogwheel, the playhouse key, the melon, the wrench, and the gasoline can as much as you want. This feature makes the game easier and more fun, as you can experiment with different items and weapons without worrying about running out of them.
-No Ads
-The last feature of Granny Mod APK is that it removes all the ads from the game. This means that you won't see any annoying pop-ups or banners that interrupt your gameplay or distract you from the horror. You can enjoy the game without any interruptions or distractions.
-How to download and install Granny Mod APK?
-If you are interested in playing Granny Mod APK, you might be wondering how to download and install it on your device. Don't worry, it's very easy and simple. Just follow these steps:
-granny mod apk download
-granny mod apk unlimited health
-granny mod apk invisible
-granny mod apk god mode
-granny mod apk latest version
-granny mod apk menu
-granny mod apk outwitt
-granny mod apk nullzerep
-granny mod apk android 1
-granny mod apk no ads
-granny mod apk unlimited ammo
-granny mod apk chapter 2
-granny mod apk free shopping
-granny mod apk mega mod
-granny mod apk all unlocked
-granny mod apk horror game
-granny mod apk easy escape
-granny mod apk no root
-granny mod apk offline
-granny mod apk unlimited time
-granny mod apk hack version
-granny mod apk with obb file
-granny mod apk for pc
-granny mod apk 1.8
-granny mod apk 1.7.3
-granny mod apk 1.6.1
-granny mod apk 1.5
-granny mod apk 1.4.0.1
-granny mod apk 1.3.2
-granny mod apk 1.2.0.1
-granny smith mod apk
-angry granny run mod apk
-super granny run mod apk
-scary teacher vs granny horror house escape challenge 3d - horror game adventure - best scary games & horror escape games free - scary teacher & evil nun - spooky games - ice scream & scary clown - horror games for kids - hello neighbor alpha 4 - baldi's basics - creepy games - horrorfield & death park - roblox piggy escape - scary hospital & scary doctor - five nights at freddy's (fnaf) - goosebumps & eyes the horror game - mr meat & evil nun 2 - hello guest & grandpa and grandma house escape - siren head & cartoon cat - slenderman & jeff the killer - bendy and the ink machine & mr hopps playhouse 2 - dark deception & boris and the dark survival - little nightmares & little nightmares 2 - among us & impostor vs crewmate - hello neighbor hide and seek & secret neighbor multiplayer online - hello neighbor 2 (hello guest) & hello engineer (mod, unlimited money)
Step 1: Enable unknown sources
-Before you can install Granny Mod APK, you need to enable unknown sources on your device. This will allow you to install apps that are not from the Google Play Store. To do this, go to your device settings and look for security or privacy options. Then, find and enable unknown sources or allow installation from unknown sources.
-Step 2: Download the APK file
-Next, you need to download the APK file of Granny Mod APK. You can do this by clicking on this link: [Granny Mod APK Download]. This will take you to a download page where you can get the latest version of Granny Mod APK for free. Just tap on the download button and wait for the file to be downloaded.
-Step 3: Install the APK file
-Once you have downloaded the APK file, you need to install it on your device. To do this, locate the file in your device storage and tap on it. You will see a prompt asking you to confirm the installation. Just tap on install and wait for the process to finish.
-Step 4: Enjoy the game
-Congratulations! You have successfully installed Granny Mod APK on your device. Now you can enjoy playing this awesome horror game with all its amazing features. Have fun and good luck!
-Conclusion
-Summary of the main points
-In conclusion, Granny Mod APK is a modified version of the original Granny game that offers some incredible features that make the game more fun and enjoyable. These features include a mod menu that lets you customize the game according to your liking, unlimited everything that lets you use any item or weapon as many times as you want, and no ads that remove all the interruptions and distractions from the game. Granny Mod APK is a great game for horror fans who want to experience a different kind of thrill.
-Call to action
-If you are ready to play Granny Mod APK, don't hesitate and download it now from this link: [Granny Mod APK Download]. You won't regret it! And if you like this article, please share it with your friends and family who might also be interested in playing this game. Thank you for reading!
-Frequently Asked Questions
-Here are some of the most common questions that people ask about Granny Mod APK:
--
-
Yes, Granny Mod APK is safe to download and install. It does not contain any viruses or malware that can harm your device or data. However, make sure that you download it from a trusted source like this one: [Granny Mod APK Download].
-Granny Mod APK is compatible with most Android devices that run on Android 4.1 or higher. However, some devices may not support some features or may experience some glitches or bugs. If you encounter any problems while playing Granny Mod APK, please contact us and we will try to help you.
-Yes, you can play Granny Mod APK offline without any internet connection. However, some features may not work properly or may require an internet connection to function. For example, you may not be able to access some mod menu options or update the game without an internet connection.
-No , you cannot play Granny Mod APK with your friends. Granny Mod APK is a single-player game that does not support multiplayer mode. However, you can share your screenshots or videos of your gameplay with your friends and challenge them to beat your score or time.
-To update Granny Mod APK, you need to download and install the latest version of the APK file from this link: [Granny Mod APK Download]. You don't need to uninstall the previous version, just overwrite it with the new one. However, make sure that you have a backup of your game data before updating, as some updates may erase your progress or settings.
--
-
\ No newline at end of file diff --git a/spaces/congsaPfin/Manga-OCR/logs/How to Download Element the End-to-End Encrypted Messenger for Windows.md b/spaces/congsaPfin/Manga-OCR/logs/How to Download Element the End-to-End Encrypted Messenger for Windows.md deleted file mode 100644 index adf8e3f2b135a9a76646bdb626d4e99738a582a2..0000000000000000000000000000000000000000 --- a/spaces/congsaPfin/Manga-OCR/logs/How to Download Element the End-to-End Encrypted Messenger for Windows.md +++ /dev/null @@ -1,158 +0,0 @@ - -
How to Download Element Messenger for Windows
-If you are looking for a secure, open-source, and decentralized messaging app that lets you communicate with anyone on the Matrix network, then you might want to try Element messenger. Element is a cross-platform app that works on Android, iOS, Web, macOS, Linux, and Windows. In this article, we will show you how to download and install Element messenger for Windows, as well as how to use its features and benefits.
-What is Element Messenger?
-Element messenger is a free and open-source software instant messaging client that implements the Matrix protocol. Matrix is an open network for secure, decentralized communication, connecting millions of users over thousands of deployments. With Element messenger, you can:
-download element messenger for windows
Download File ⭐ https://urlca.com/2uO8b5
-
-
-
Features of Element Messenger
-Element messenger has many features that make it a powerful and versatile app for communication and collaboration. Some of these features are:
--
-
Benefits of Element Messenger
-Element messenger has many benefits that make it a great choice for anyone who values their privacy and security. Some of these benefits are:
--
-
Comparison of Element Messenger with Other Messaging Apps
-Element messenger is not the only messaging app out there, but it is one of the best ones in terms of features and benefits. Here is a table that compares Element messenger with some of the most popular messaging apps in the market:
-| Messaging App | -End-to-end Encryption | -Decentralized Storage | -Interoperability | -Cross-platform Compatibility | -
|---|---|---|---|---|
| Element Messenger | -Yes (by default) | -Yes (user's choice) | -Yes (with all Matrix-based apps and bridges) | -Yes (Android, iOS, Web, macOS, Linux, Windows) | -
| Yes (by default) | -No (Facebook's server) | -No (only with WhatsApp users) | -Yes (Android, iOS, Web, Windows, macOS) | -|
| Signal | -Yes (by default) | -No (Signal's server) | -No (only with Signal users) | -Yes (Android, iOS, Windows, macOS, Linux) | -
| Telegram | -No (only in secret chats) | -No (Telegram's server) | -No (only with Telegram users) | -Yes (Android, iOS, Web, Windows, macOS, Linux) | -
| Discord | -No (not available) | -No (Discord's server) | -No (only with Discord users) | -Yes (Android, iOS, Web, Windows, macOS, Linux) | -
How to Download and Install Element Messenger for Windows
-If you want to download and install Element messenger for Windows, you can follow these simple steps:
-Step 1: Go to the Element website
-The first step is to go to the Element website at https://element.io/get-started. There you will see a list of options for different platforms. You can also learn more about Element and its features on the website.
-How to download element messenger for windows 10
-Download element messenger for windows 7 free
-Element messenger for windows desktop app
-Download element secure messenger for windows pc
-Element messenger for windows review and features
-Download element encrypted messenger for windows laptop
-Element messenger for windows voice and video chat
-Download element collaboration app for windows
-Element messenger for windows self-hosted or cloud
-Download element end-to-end encrypted messenger for windows
-Element messenger for windows no phone number required
-Download element productivity app for windows
-Element messenger for windows no ads or tracking
-Download element open source messenger for windows
-Element messenger for windows structure groups and communities
-Download element cross-platform messenger for windows
-Element messenger for windows talk to anyone
-Download element web-based messenger for windows
-Element messenger for windows choose where your data lives
-Download element nightly build for windows
-Element messenger for windows debian / ubuntu x86_64
-Download element io archive keyring gpg for windows
-Element messenger for windows sudo apt install element-desktop
-Download element personal plan for windows
-Element messenger for windows get started for free
-Download element business plan for windows
-Element messenger for windows contact sales and book a demo
-Download element enterprise plan for windows
-Element messenger for windows set up your own deployment
-Download element matrix services (EMS) for windows
-Element messenger for windows use your own custom domain
-Download element federation services (EFS) for windows
-Element messenger for windows scalable and secure hosting
-Download element bridge services (EBS) for windows
-Element messenger for windows connect to other platforms
-Download element identity services (EIS) for windows
-Element messenger for windows manage your users and groups
-Download element widget services (EWS) for windows
-Element messenger for windows embed third-party apps and tools
-Download element moderation services (EMS) for windows
-Element messenger for windows monitor and moderate content
-Download element support services (ESS) for windows
-Element messenger for windows get help and guidance from experts
-Download element custom development services (CDS) for windows
-Element messenger for windows customize and extend your app
Step 2: Choose the Windows option
-The next step is to choose the Windows option from the list. This will take you to a page where you can download the installer file for Element messenger for Windows. The file size is about 100 MB and it will be saved in your Downloads folder by default.
-Step 3: Run the installer file
-The third step is to run the installer file that you downloaded. You can do this by double-clicking on it or right-clicking on it and choosing Run as administrator. This will launch the installation wizard that will guide you through the process.
-Step 4: Follow the instructions on the screen
-The final step is to follow the instructions on the screen to complete the installation. You will have to agree to the terms and conditions, choose a destination folder, and wait for the installation to finish. Once it is done, you will see a shortcut icon for Element messenger on your desktop and in your Start menu.
-How to Use Element Messenger for Windows
-Now that you have downloaded and installed Element messenger for Windows, you can start using it to communicate and collaborate with others on the Matrix network. Here are some steps to help you get started:
-Step 1: Create an account or sign in
-The first step is to create an account or sign in if you already have one. You can do this by clicking on the shortcut icon for Element messenger on your desktop or in your Start menu. This will open the app and prompt you to enter your username and password. If you don't have an account, you can click on the Create Account button and follow the steps to register. You will need to enter a valid email address, choose a username and password, and verify your email. You can also choose a display name and an avatar for your profile.
-Step 2: Choose a server or host your own
-The next step is to choose a server or host your own. A server is where your messages are stored and how you connect to the Matrix network. You can use a free public server provided by matrix.org or element.io, or you can host your own server on your own hardware or cloud service. You can also switch servers at any time without losing your data or contacts. To choose a server, you can click on the Change button next to the server name on the sign in or sign up screen. You will see a list of available servers and their details. You can also enter a custom server address if you have one.
-Step 3: Join or create rooms and communities
-The third step is to join or create rooms and communities. A room is where you chat with other users on the Matrix network. A community is a group of rooms that share a common topic or purpose. You can join or create as many rooms and communities as you want, and invite anyone to join them. To join or create a room, you can click on the + button on the left sidebar of the app. You will see a list of suggested rooms and communities that you can join, or you can search for one by name or topic. You can also create your own room by clicking on the Create Room button and choosing a name, topic, icon, and settings for your room. To join or create a community, you can click on the Communities button on the left sidebar of the app. You will see a list of suggested communities that you can join, or you can search for one by name or topic. You can also create your own community by clicking on the Create Community button and choosing a name, description, icon, and settings for your community.
-Step 4: Start chatting and collaborating with others
-The final step is to start chatting and collaborating with others on the Matrix network. You can send text, voice, video, images, files, stickers, emojis, and more to anyone in your rooms and communities. You can also make voice and video calls, share your screen, use bots and widgets, and more. To send a message, you can type it in the text box at the bottom of the app and press Enter or click on the Send button. To send other types of media, you can click on the + button next to the text box and choose what you want to send. To make a voice or video call, you can click on the Call button at the top right corner of the app and choose Voice Call or Video Call. To share your screen, you can click on the Screen Share button next to the Call button and choose what you want to share. To use bots and widgets, you can click on the Apps button at the top right corner of the app and choose what you want to use.
-Conclusion
-Element messenger is a secure, open-source, and decentralized messaging app that lets you communicate with anyone on the Matrix network. It has many features and benefits that make it a great choice for anyone who values their privacy and security. It is also easy to download and install for Windows, as well as to use its features and benefits. If you want to try Element messenger for Windows, you can follow the steps in this article and start chatting and collaborating with others today.
-FAQs
-Here are some frequently asked questions about Element messenger for Windows:
--
-
-
-
\ No newline at end of file diff --git a/spaces/congsaPfin/Manga-OCR/logs/How to Play Great Games on Windows 7 32 Bit With Integrated GPU.md b/spaces/congsaPfin/Manga-OCR/logs/How to Play Great Games on Windows 7 32 Bit With Integrated GPU.md deleted file mode 100644 index cb1429605ef3e8af0546073a63f65fab338402f6..0000000000000000000000000000000000000000 --- a/spaces/congsaPfin/Manga-OCR/logs/How to Play Great Games on Windows 7 32 Bit With Integrated GPU.md +++ /dev/null @@ -1,103 +0,0 @@ -
-
- Enjoy retro and indie games
- Improve your skills and creativity | | H2: How to Find and Download Games Without a Graphics Card | - Use Steam and other platforms
- Check the system requirements
- Adjust the settings and optimize your PC | | H2: Top 15 Games for Windows 7 32 Bit Without Graphics Card Free Download | - H3: Brawlhalla
- H3: Super Animal Royale
- H3: AdVenture Capitalist
- H3: Cube Escape: Paradox
- H3: Among Us
- H3: Terraria
- H3: Stardew Valley
- H3: Undertale
- H3: Portal
- H3: Half-Life 2
- H3: Minecraft
- H3: Limbo
- H3: Papers, Please
- H3: Plants vs. Zombies
- H3: The Binding of Isaac | | H2: Conclusion | Summary of the main points and recommendations | | H2: FAQs | - Q1: Can I play online games without a graphics card?
- Q2: What are some other ways to improve my gaming performance without a graphics card?
- Q3: Can I upgrade my graphics card on my laptop?
- Q4: What are some of the best graphics cards for gaming on a budget?
- Q5: What are some of the upcoming games that will run without a graphics card? | Table 2: Article with HTML formatting
Games for Windows 7 32 Bit Without Graphics Card Free Download
-If you think you need a powerful graphics card to enjoy PC gaming, think again. There are plenty of games that you can play on your Windows 7 32 bit system without spending a fortune on a new GPU. In fact, playing games without a graphics card can have some advantages, such as saving money and power, enjoying retro and indie games, and improving your skills and creativity. In this article, we will show you how to find and download games without a graphics card, and we will also recommend you some of the best games for Windows 7 32 bit without graphics card free download.
-games for windows 7 32 bit without graphics card free download
Download ✏ ✏ ✏ https://urlca.com/2uOcTX
-
Benefits of Playing Games Without a Graphics Card
-Playing games without a graphics card may seem like a limitation, but it can also be a blessing in disguise. Here are some of the benefits of playing games without a graphics card:
--
-
How to Find and Download Games Without a Graphics Card
-Finding and downloading games without a graphics card is not difficult if you know where to look and what to look for. Here are some tips on how to find and download games without a graphics card:
--
-
Top 15 Games for Windows 7 32 Bit Without Graphics Card Free Download
-Now that you know how to find and download games without a graphics card, let's take a look at some of the best games for Windows 7 32 bit without graphics card free download. These games are not only compatible with your system, but also fun, engaging, and diverse. Here are our top 15 picks:
-Brawlhalla
-Brawlhalla is a free-to-play fighting game that features over 50 characters from various genres and franchises, such as Lara Croft, Finn and Jake, or The Rock. You can play online or offline, solo or with friends, in various modes and maps. The game has simple controls, colorful graphics, and fast-paced action. Brawlhalla is a great game for fans of Super Smash Bros. or casual fighting games.
-Super Animal Royale
-Super Animal Royale is a free-to-play battle royale game that lets you play as cute and deadly animals in a 2D pixel art world. You can choose from over 300 breeds of animals, customize your appearance, and parachute into a 64-player match. You can loot weapons, items, and vehicles, and fight your way to be the last animal standing. Super Animal Royale is a fun and quirky game for fans of Fortnite or PUBG.
-AdVenture Capitalist
-AdVenture Capitalist is a free-to-play idle game that lets you become a billionaire by investing in various businesses. You can start with a lemonade stand and work your way up to oil companies, banks, or even moon colonies. You can hire managers, upgrade your businesses, and attract angel investors. AdVenture Capitalist is a relaxing and addictive game for fans of Cookie Clicker or Idle Miner Tycoon.
-* best pc games without graphics card
-* free games for windows 7 32 bit laptop
-* low-end pc games for integrated graphics
-* how to play games without graphics card on windows 7
-* download games for windows 7 32 bit offline
-* top free games for windows 7 32 bit
-* games that run on windows 7 32 bit without graphics card
-* no-gpu games for windows 7 32 bit
-* free pc games for integrated graphics
-* best games for windows 7 32 bit laptop
-* download free games for windows 7 32 bit full version
-* low spec pc games for windows 7 32 bit
-* how to run games without graphics card on windows 7
-* best offline games for windows 7 32 bit
-* free steam games for windows 7 32 bit
-* top pc games without graphics card
-* free download games for windows 7 32 bit pc
-* low graphics pc games for windows 7 32 bit
-* how to play high-end games without graphics card on windows 7
-* best online games for windows 7 32 bit
-* free action games for windows 7 32 bit
-* top integrated graphics pc games
-* free racing games for windows 7 32 bit
-* low requirement pc games for windows 7 32 bit
-* how to improve gaming performance without graphics card on windows 7
-* best adventure games for windows 7 32 bit
-* free shooting games for windows 7 32 bit
-* top indie games for integrated graphics
-* free strategy games for windows 7 32 bit
-* low resolution pc games for windows 7 32 bit
-* how to optimize windows 7 for gaming without graphics card
-* best horror games for windows 7 32 bit
-* free simulation games for windows 7 32 bit
-* top retro games for integrated graphics
-* free puzzle games for windows 7 32 bit
-* low memory pc games for windows 7 32 bit
-* how to install graphics card drivers on windows 7 without graphics card
-* best platformer games for windows 7 32 bit
-* free rpg games for windows 7 32 bit
-* top pixel art games for integrated graphics
Cube Escape: Paradox
-Cube Escape: Paradox is a free-to-play point-and-click adventure game that is part of the Rusty Lake series. You play as detective Dale Vandermeer, who wakes up in a mysterious room with no memory of his past. You have to solve puzzles, find clues, and escape the room. The game has a dark and surreal atmosphere, a captivating story, and a live-action movie that accompanies the game. Cube Escape: Paradox is a must-play game for fans of The Room or Escape Room.
-Among Us
-Among Us is a free-to-play social deduction game that has become one of the most popular games of 2020. You play as one of the crewmates on a spaceship who have to complete tasks and find the impostor among them. The impostor can sabotage the ship, kill the crewmates, or lie their way out of suspicion. You can play online or locally with up to 10 players. Among Us is a hilarious and thrilling game for fans of Mafia or Werewolf.
-Terraria
-Terraria is a sandbox game that combines elements of exploration, crafting, building, combat, and adventure. You can create your own character and world, and explore the randomly generated terrain full of enemies, resources, biomes, and secrets. You can craft weapons, armor, potions, and other items to help you survive and fight against various bosses and events. You can also build your own base, farm, or castle, and decorate it with furniture, paintings, statues, and more. You can play solo or with up to 8 players online or locally. Terraria is a game that offers endless possibilities and hours of fun for fans of Minecraft or Starbound.
-Stardew Valley
-Stardew Valley is a farming simulation game that lets you escape the city life and start a new life in a rural town. You inherit your grandfather's old farm, and you have to restore it and make it profitable. You can grow crops, raise animals, fish, mine, craft, cook, and more. You can also interact with the town's residents, make friends, or even find love. You can play solo or with up to 4 players online or locally. Stardew Valley is a game that will make you feel relaxed and happy for fans of Harvest Moon or Animal Crossing.
-Undertale
-Undertale is a role-playing game that subverts the genre's conventions and expectations. You play as a human child who falls into the Underground, a world of monsters who have been sealed away by humans. You have to find your way back to the surface, but you can choose whether to fight or befriend the monsters you encounter. The game has multiple endings and consequences depending on your actions and choices. The game has a unique pixel art style, a catchy soundtrack, and a witty and emotional story. Undertale is a game that will make you laugh, cry, and think for fans of Earthbound or Chrono Trigger.
-Portal
-Portal is a puzzle-platformer game that tests your logic and creativity. You play as Chell, a test subject in the Aperture Science Enrichment Center, who has to use a portal gun to create portals between two surfaces and overcome various obstacles and traps. The game has a dark humor, a mysterious plot, and a memorable antagonist in GLaDOS, the artificial intelligence that guides and taunts you throughout the game. Portal is a game that will challenge your mind and entertain you for fans of Half-Life or The Talos Principle.
-Half-Life 2
-Half-Life 2 is a first-person shooter game that is widely considered as one of the best games of all time. You play as Gordon Freeman, a scientist who has to fight against the Combine, an alien empire that has invaded Earth. The game has a realistic physics engine, an immersive story, and a variety of weapons and vehicles. The game also has several episodes and mods that expand the gameplay and story. Half-Life 2 is a game that will keep you on the edge of your seat for fans of Doom or Bioshock.
-Minecraft
-Minecraft is a sandbox game that lets you create your own world out of blocks. You can explore, build, mine, craft, fight, or do anything you want in this game. You can play in survival mode, where you have to gather resources and fend off enemies, scenarios that affect your moral and ethical choices. Papers, Please is a game that will make you question your decisions and actions for fans of Orwell or Beholder.
-Plants vs. Zombies
-Plants vs. Zombies is a tower defense game that pits you against hordes of zombies who want to eat your brains. You have to use various plants, such as peashooters, sunflowers, or cherry bombs, to defend your house and garden. The game has a cartoonish and humorous style, a catchy soundtrack, and a variety of modes and levels. Plants vs. Zombies is a game that will make you laugh and have fun for fans of Bloons TD or Kingdom Rush.
-The Binding of Isaac
-The Binding of Isaac is a roguelike game that is inspired by the biblical story of the same name. You play as Isaac, a boy who escapes to the basement of his house after his mother tries to sacrifice him to God. You have to fight your way through randomly generated rooms full of enemies, items, secrets, and bosses. The game has a dark and twisted theme, a retro pixel art style, and a high replay value. The Binding of Isaac is a game that will challenge and surprise you for fans of Spelunky or Enter the Gungeon.
-Conclusion
-Playing games without a graphics card is not only possible, but also enjoyable and rewarding. You can save money and power, enjoy retro and indie games, and improve your skills and creativity by playing games without a graphics card. You can also find and download games without a graphics card easily by using platforms like Steam, checking the system requirements, and adjusting the settings and optimizing your PC. We have also recommended you some of the best games for Windows 7 32 bit without graphics card free download, ranging from fighting to farming, from puzzle to platformer, from simulation to shooter. We hope you have fun playing these games and discover more games without a graphics card.
-FAQs
--
-
-
-
\ No newline at end of file diff --git a/spaces/contluForse/HuggingGPT/assets/Baadshaho Hindi 720p Free Download Gru Karte Ornamente BEST.md b/spaces/contluForse/HuggingGPT/assets/Baadshaho Hindi 720p Free Download Gru Karte Ornamente BEST.md deleted file mode 100644 index a5ecf0e75f7f695256fd8d2205972d7a62d68dff..0000000000000000000000000000000000000000 --- a/spaces/contluForse/HuggingGPT/assets/Baadshaho Hindi 720p Free Download Gru Karte Ornamente BEST.md +++ /dev/null @@ -1,6 +0,0 @@ -
Baadshaho Hindi 720p Free Download gru karte ornamente
DOWNLOAD ✒ ✒ ✒ https://ssurll.com/2uzvJR
- - aaccfb2cb3
-
-
- diff --git a/spaces/contluForse/HuggingGPT/assets/CamScanner for Windows 7 Free Download and Installation Guide.md b/spaces/contluForse/HuggingGPT/assets/CamScanner for Windows 7 Free Download and Installation Guide.md deleted file mode 100644 index 975205f5924d8cfdbbaaa8b322e5d306aef13ad3..0000000000000000000000000000000000000000 --- a/spaces/contluForse/HuggingGPT/assets/CamScanner for Windows 7 Free Download and Installation Guide.md +++ /dev/null @@ -1,16 +0,0 @@ - -
The world's No. 1 mobile document scanning and sharing today!CamScanner helps you scan, store, sync and collaborate on various contents across smartphones, iPads, tablets and computers.Installed on over 100 million devices in over 200 countries around the worldOver 50,000 new registrations per dayCamScanner, 50 Best Mobile Apps, 2013 Edition - TIME\"The application employs its own image cropping and enhancing algorithm that leads to clearer images.\" - Makeuseof.com\"CamScanner may just be the best deal for scanning documents on your iPhone.\" - CNET.comCamScanner users scan and manage * Bill, Invoice, Contract, Tax Roll, Business Card...* Whiteboard, Memo, Script, Letter...* Blackboard, Note, PPT, Book, Article...* Credential, Certificate, Identity Documents...Main Features:Scan Documents* Auto detect and crop scanned images* Smart enhance documents with 5 enhance modes* Quickly covert to PDF/JPEG files* Batch scan multiple pagesManage Documents* Easily search texts in document images, highlighting keyword* Add/Edit name, tags and notes to documents* Copy, move and marge documents* Extract texts in images and generate .txt file* Merge documents* Clear cache to release local memorySync Documents* Upload, download and manage documents at www.camscanner.net * Access and update documents on smartphone, tablet and web app* Upload PDF to OneDriveShare Documents * Send documents directly as email attachments* Upload documents to Microsoft OneNote or OneDrive* Save document image to phone Photos* Save PDF files to your phone or SD cardWindows Phone Users Exclusives:1.Make unlimited annotations 2.Copy recognized texts to other apps3.Export recognized texts to a Word document4.Read recognized texts in documentsWe'd love to hear your feedback: Follow us on Twitter: @CamScannerLike us on Facebook: CamScannerFollow us on Google+: CamScanner
-camscanner for windows 7 free download
Download ❤❤❤ https://ssurll.com/2uzyJL
-
Freeware programs can be downloaded used free of charge and without any time limitations. Freeware products can be used free of charge for both personal and professional (commercial use).
-This license is commonly used for video games and it allows users to download and play the game for free. Basically, a product is offered Free to Play (Freemium) and the user can decide if he wants to pay the money (Premium) for additional features, services, virtual or physical goods that expand the functionality of the game. In some cases, ads may be show to the users.
-Camscanner is a popular and powerful app which scans the document and covert it into digital form. You can easily use this powerful app convert your files and documents into PDF file without any problem. It is completely free to download. It has fairly simple usage technique that even a beginner can understand the usage of this app. Convert downloaded file into pdf or you can take pictures manually of your documents within the app to convert the document into digital Pdf form. Use filters and other editing tools to enhance the quality of picture. You can extract the words from any picture or document. You can easily print out any document using this awesome app.
-This marvellous tool is free to download but if you want premium features, then you can buy the premium account within the app. With free account, you can easily create and save digital pdf of your documents but with watermark. Get the premium version to remove watermark and get premium filters as well.
-An SMS with a download link will be sent to the mobile number provided. Our texts are free, but your service provider may charge a usage fee. Adobe does not store or share this mobile number. App available on iOS and Android.
-You can download CamStudio and use it completely free - yep - completely 100% free for your personal and commercial projects as CamStudio and the Codec are released under the GPL (for more details on this license, click here.)
-"@context": " ", "@type": "FAQPage", "mainEntity": [ "@type": "Question", "name": "Q: What is CamScanner used for?", "acceptedAnswer": "@type": "Answer", "text": "A: CamScanner is a powerful camera and scanning app that lets you scan any document and transfer it to a digital copy." , "@type": "Question", "name": "Q: Is CamScanner free?", "acceptedAnswer": "@type": "Answer", "text": "A: Yes, CamScanner is a free application." , "@type": "Question", "name": "Q: Can I download CamScanner for PC?", "acceptedAnswer": "@type": "Answer", "text": "A: CamScanner is a native mobile app available on iOS and Android. However, there are methods for downloading the app on Windows and Mac." , "@type": "Question", "name": "Q: How can I use CamScanner on Windows?", "acceptedAnswer": "@type": "Answer", "text": "A: You can use CamScanner by either running the app through an emulator or by syncing the mobile app through its accompanying Google Chrome extension." ]
-Moreover, there is no releases of CamScanner app for Windows or Mac computers. We cannot directly install CamScanner for desktop computers. Because there are no such a camscanner desktop version available to download. So, we are going to get help from the Bluestacks android emulator. Firstly, We will install an Android emulator to Windows and Mac computer and install the CamScanner app there. Then we can use CamScanner easily with a computer. Therefore, follow the guide below to download CamScanner for computer.
-Now I am going to share the guide to download CamScanner For PC or Laptop on Windows XP, 10, 8.1, 8, 7, Vista & Mac Computer OS. You just need to follow the below given step by step guide perfectly to install CamScanner For PC. I will mentioned on the above section Officially the CamScanner For PC version is not yet released in the market. You can still download and use CamScanner on your PC, then you need to use the BlueStacks App Player on your computer. BlueStacks is one of the best and popular Android emulator which helps you to run any smartphone Android apps or games on your computer with free of cost. There are many Android emulators are available on the internet site. But in this guide i will use Bluestacks App Player because it allows to run any mobile phone apps very fast for without any errors. Now lets start the installation steps.
- -CamScanner Download for PC is freeware productivity software developed by INTSIG for changing images into PDF images or digital photos. It was released in 2011 for the first time and become the most popular app while offering high-quality scanning features. It offers both types of scanning; text extracting from images and picture scanning. It helps you to enhance the picture quality and readability using editing tools and share it in form of JPEG or PDF files. It makes us free from spending a lot of money on expensive scanning machines. The app is basically designed for Android devices, but you can download it on your PC using an emulator such as BlueStacks or Nox player.
aaccfb2cb3-
-
\ No newline at end of file diff --git a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/oneformer/detectron2/modeling/poolers.py b/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/oneformer/detectron2/modeling/poolers.py deleted file mode 100644 index 109ab47eb975b2302966eeb698ac6b4aff5e0a4d..0000000000000000000000000000000000000000 --- a/spaces/coreml-community/ControlNet-v1-1-Annotators-cpu/annotator/oneformer/detectron2/modeling/poolers.py +++ /dev/null @@ -1,263 +0,0 @@ -# Copyright (c) Facebook, Inc. and its affiliates. -import math -from typing import List, Optional -import torch -from torch import nn -from torchvision.ops import RoIPool - -from annotator.oneformer.detectron2.layers import ROIAlign, ROIAlignRotated, cat, nonzero_tuple, shapes_to_tensor -from annotator.oneformer.detectron2.structures import Boxes -from annotator.oneformer.detectron2.utils.tracing import assert_fx_safe, is_fx_tracing - -""" -To export ROIPooler to torchscript, in this file, variables that should be annotated with -`Union[List[Boxes], List[RotatedBoxes]]` are only annotated with `List[Boxes]`. - -TODO: Correct these annotations when torchscript support `Union`. -https://github.com/pytorch/pytorch/issues/41412 -""" - -__all__ = ["ROIPooler"] - - -def assign_boxes_to_levels( - box_lists: List[Boxes], - min_level: int, - max_level: int, - canonical_box_size: int, - canonical_level: int, -): - """ - Map each box in `box_lists` to a feature map level index and return the assignment - vector. - - Args: - box_lists (list[Boxes] | list[RotatedBoxes]): A list of N Boxes or N RotatedBoxes, - where N is the number of images in the batch. - min_level (int): Smallest feature map level index. The input is considered index 0, - the output of stage 1 is index 1, and so. - max_level (int): Largest feature map level index. - canonical_box_size (int): A canonical box size in pixels (sqrt(box area)). - canonical_level (int): The feature map level index on which a canonically-sized box - should be placed. - - Returns: - A tensor of length M, where M is the total number of boxes aggregated over all - N batch images. The memory layout corresponds to the concatenation of boxes - from all images. Each element is the feature map index, as an offset from - `self.min_level`, for the corresponding box (so value i means the box is at - `self.min_level + i`). - """ - box_sizes = torch.sqrt(cat([boxes.area() for boxes in box_lists])) - # Eqn.(1) in FPN paper - level_assignments = torch.floor( - canonical_level + torch.log2(box_sizes / canonical_box_size + 1e-8) - ) - # clamp level to (min, max), in case the box size is too large or too small - # for the available feature maps - level_assignments = torch.clamp(level_assignments, min=min_level, max=max_level) - return level_assignments.to(torch.int64) - min_level - - -# script the module to avoid hardcoded device type -@torch.jit.script_if_tracing -def _convert_boxes_to_pooler_format(boxes: torch.Tensor, sizes: torch.Tensor) -> torch.Tensor: - sizes = sizes.to(device=boxes.device) - indices = torch.repeat_interleave( - torch.arange(len(sizes), dtype=boxes.dtype, device=boxes.device), sizes - ) - return cat([indices[:, None], boxes], dim=1) - - -def convert_boxes_to_pooler_format(box_lists: List[Boxes]): - """ - Convert all boxes in `box_lists` to the low-level format used by ROI pooling ops - (see description under Returns). - - Args: - box_lists (list[Boxes] | list[RotatedBoxes]): - A list of N Boxes or N RotatedBoxes, where N is the number of images in the batch. - - Returns: - When input is list[Boxes]: - A tensor of shape (M, 5), where M is the total number of boxes aggregated over all - N batch images. - The 5 columns are (batch index, x0, y0, x1, y1), where batch index - is the index in [0, N) identifying which batch image the box with corners at - (x0, y0, x1, y1) comes from. - When input is list[RotatedBoxes]: - A tensor of shape (M, 6), where M is the total number of boxes aggregated over all - N batch images. - The 6 columns are (batch index, x_ctr, y_ctr, width, height, angle_degrees), - where batch index is the index in [0, N) identifying which batch image the - rotated box (x_ctr, y_ctr, width, height, angle_degrees) comes from. - """ - boxes = torch.cat([x.tensor for x in box_lists], dim=0) - # __len__ returns Tensor in tracing. - sizes = shapes_to_tensor([x.__len__() for x in box_lists]) - return _convert_boxes_to_pooler_format(boxes, sizes) - - -@torch.jit.script_if_tracing -def _create_zeros( - batch_target: Optional[torch.Tensor], - channels: int, - height: int, - width: int, - like_tensor: torch.Tensor, -) -> torch.Tensor: - batches = batch_target.shape[0] if batch_target is not None else 0 - sizes = (batches, channels, height, width) - return torch.zeros(sizes, dtype=like_tensor.dtype, device=like_tensor.device) - - -class ROIPooler(nn.Module): - """ - Region of interest feature map pooler that supports pooling from one or more - feature maps. - """ - - def __init__( - self, - output_size, - scales, - sampling_ratio, - pooler_type, - canonical_box_size=224, - canonical_level=4, - ): - """ - Args: - output_size (int, tuple[int] or list[int]): output size of the pooled region, - e.g., 14 x 14. If tuple or list is given, the length must be 2. - scales (list[float]): The scale for each low-level pooling op relative to - the input image. For a feature map with stride s relative to the input - image, scale is defined as 1/s. The stride must be power of 2. - When there are multiple scales, they must form a pyramid, i.e. they must be - a monotically decreasing geometric sequence with a factor of 1/2. - sampling_ratio (int): The `sampling_ratio` parameter for the ROIAlign op. - pooler_type (string): Name of the type of pooling operation that should be applied. - For instance, "ROIPool" or "ROIAlignV2". - canonical_box_size (int): A canonical box size in pixels (sqrt(box area)). The default - is heuristically defined as 224 pixels in the FPN paper (based on ImageNet - pre-training). - canonical_level (int): The feature map level index from which a canonically-sized box - should be placed. The default is defined as level 4 (stride=16) in the FPN paper, - i.e., a box of size 224x224 will be placed on the feature with stride=16. - The box placement for all boxes will be determined from their sizes w.r.t - canonical_box_size. For example, a box whose area is 4x that of a canonical box - should be used to pool features from feature level ``canonical_level+1``. - - Note that the actual input feature maps given to this module may not have - sufficiently many levels for the input boxes. If the boxes are too large or too - small for the input feature maps, the closest level will be used. - """ - super().__init__() - - if isinstance(output_size, int): - output_size = (output_size, output_size) - assert len(output_size) == 2 - assert isinstance(output_size[0], int) and isinstance(output_size[1], int) - self.output_size = output_size - - if pooler_type == "ROIAlign": - self.level_poolers = nn.ModuleList( - ROIAlign( - output_size, spatial_scale=scale, sampling_ratio=sampling_ratio, aligned=False - ) - for scale in scales - ) - elif pooler_type == "ROIAlignV2": - self.level_poolers = nn.ModuleList( - ROIAlign( - output_size, spatial_scale=scale, sampling_ratio=sampling_ratio, aligned=True - ) - for scale in scales - ) - elif pooler_type == "ROIPool": - self.level_poolers = nn.ModuleList( - RoIPool(output_size, spatial_scale=scale) for scale in scales - ) - elif pooler_type == "ROIAlignRotated": - self.level_poolers = nn.ModuleList( - ROIAlignRotated(output_size, spatial_scale=scale, sampling_ratio=sampling_ratio) - for scale in scales - ) - else: - raise ValueError("Unknown pooler type: {}".format(pooler_type)) - - # Map scale (defined as 1 / stride) to its feature map level under the - # assumption that stride is a power of 2. - min_level = -(math.log2(scales[0])) - max_level = -(math.log2(scales[-1])) - assert math.isclose(min_level, int(min_level)) and math.isclose( - max_level, int(max_level) - ), "Featuremap stride is not power of 2!" - self.min_level = int(min_level) - self.max_level = int(max_level) - assert ( - len(scales) == self.max_level - self.min_level + 1 - ), "[ROIPooler] Sizes of input featuremaps do not form a pyramid!" - assert 0 <= self.min_level and self.min_level <= self.max_level - self.canonical_level = canonical_level - assert canonical_box_size > 0 - self.canonical_box_size = canonical_box_size - - def forward(self, x: List[torch.Tensor], box_lists: List[Boxes]): - """ - Args: - x (list[Tensor]): A list of feature maps of NCHW shape, with scales matching those - used to construct this module. - box_lists (list[Boxes] | list[RotatedBoxes]): - A list of N Boxes or N RotatedBoxes, where N is the number of images in the batch. - The box coordinates are defined on the original image and - will be scaled by the `scales` argument of :class:`ROIPooler`. - - Returns: - Tensor: - A tensor of shape (M, C, output_size, output_size) where M is the total number of - boxes aggregated over all N batch images and C is the number of channels in `x`. - """ - num_level_assignments = len(self.level_poolers) - - if not is_fx_tracing(): - torch._assert( - isinstance(x, list) and isinstance(box_lists, list), - "Arguments to pooler must be lists", - ) - assert_fx_safe( - len(x) == num_level_assignments, - "unequal value, num_level_assignments={}, but x is list of {} Tensors".format( - num_level_assignments, len(x) - ), - ) - assert_fx_safe( - len(box_lists) == x[0].size(0), - "unequal value, x[0] batch dim 0 is {}, but box_list has length {}".format( - x[0].size(0), len(box_lists) - ), - ) - if len(box_lists) == 0: - return _create_zeros(None, x[0].shape[1], *self.output_size, x[0]) - - pooler_fmt_boxes = convert_boxes_to_pooler_format(box_lists) - - if num_level_assignments == 1: - return self.level_poolers[0](x[0], pooler_fmt_boxes) - - level_assignments = assign_boxes_to_levels( - box_lists, self.min_level, self.max_level, self.canonical_box_size, self.canonical_level - ) - - num_channels = x[0].shape[1] - output_size = self.output_size[0] - - output = _create_zeros(pooler_fmt_boxes, num_channels, output_size, output_size, x[0]) - - for level, pooler in enumerate(self.level_poolers): - inds = nonzero_tuple(level_assignments == level)[0] - pooler_fmt_boxes_level = pooler_fmt_boxes[inds] - # Use index_put_ instead of advance indexing, to avoid pytorch/issues/49852 - output.index_put_((inds,), pooler(x[level], pooler_fmt_boxes_level)) - - return output diff --git a/spaces/cynika/taffy/app.py b/spaces/cynika/taffy/app.py deleted file mode 100644 index 5f835d5695d413c734e545a53900bbbbc6157bd2..0000000000000000000000000000000000000000 --- a/spaces/cynika/taffy/app.py +++ /dev/null @@ -1,70 +0,0 @@ -import io - -import gradio as gr -import librosa -import numpy as np -import soundfile -import torch -from inference.infer_tool import Svc -import logging - -logging.getLogger('numba').setLevel(logging.WARNING) - -model_name = "logs/32k/G_65000.pth" -config_name = "configs/config.json" - -svc_model = Svc(model_name, config_name) -sid_map = { - "taffy": "taffy" -} - - -def vc_fn(sid, input_audio, vc_transform): - if input_audio is None: - return "You need to upload an audio", None - sampling_rate, audio = input_audio - # print(audio.shape,sampling_rate) - duration = audio.shape[0] / sampling_rate - if duration > 45: - return "请上传小于45s的音频,需要转换长音频请本地进行转换", None - audio = (audio / np.iinfo(audio.dtype).max).astype(np.float32) - if len(audio.shape) > 1: - audio = librosa.to_mono(audio.transpose(1, 0)) - if sampling_rate != 16000: - audio = librosa.resample(audio, orig_sr=sampling_rate, target_sr=16000) - print(audio.shape) - out_wav_path = io.BytesIO() - soundfile.write(out_wav_path, audio, 16000, format="wav") - out_wav_path.seek(0) - - sid = sid_map[sid] - out_audio, out_sr = svc_model.infer(sid, vc_transform, out_wav_path) - _audio = out_audio.cpu().numpy() - return "Success", (32000, _audio) - - -app = gr.Blocks() -with app: - with gr.Tabs(): - with gr.TabItem("Basic"): - gr.Markdown(value=""" - 这是sovits 3.0 32khz版本ai草莓猫taffy的在线demo - - 在使用此模型前请阅读[AI草莓猫Taffy模型使用协议](https://huggingface.co/spaces/cynika/taffy/blob/main/terms.md) - - 草莓猫Taffy@bilibili:[点击关注](https://space.bilibili.com/1210816252) - - 如果要在本地使用该demo,请使用git lfs clone 该仓库,安装requirements.txt后运行app.py即可 - - 项目改写基于 https://huggingface.co/spaces/innnky/nyaru-svc-3.0 - - 本地合成可以删除26、27两行代码以解除合成45s长度限制""") - sid = gr.Dropdown(label="音色", choices=["taffy"], value="taffy") - vc_input3 = gr.Audio(label="上传音频(长度小于45秒)") - vc_transform = gr.Number(label="变调(整数,可以正负,半音数量,升高八度就是12)", value=0) - vc_submit = gr.Button("转换", variant="primary") - vc_output1 = gr.Textbox(label="Output Message") - vc_output2 = gr.Audio(label="Output Audio") - vc_submit.click(vc_fn, [sid, vc_input3, vc_transform], [vc_output1, vc_output2]) - - app.launch() diff --git a/spaces/dakaiye/dky_xuexi/crazy_functions/test_project/cpp/cppipc/waiter.h b/spaces/dakaiye/dky_xuexi/crazy_functions/test_project/cpp/cppipc/waiter.h deleted file mode 100644 index ee45fe3517be95ac1688a3e3540189edeb0d860c..0000000000000000000000000000000000000000 --- a/spaces/dakaiye/dky_xuexi/crazy_functions/test_project/cpp/cppipc/waiter.h +++ /dev/null @@ -1,83 +0,0 @@ -#pragma once - -#include
download windows 10 pro key 2016 free download, microsoft office professional plus 2010 serial number free download, microsoft office professional plus 2010 serial number free download,, download esm skyrim pc thingiverse,
adobe premiere pro cc 2014 free download, adobe premiere pro cs5 free download,, windows 8.1 pro 64 bit iso file free download,, windows 10 enterprise pro 64 bit download,
download cs5 free download, adobe photoshop cs5 free download,, air video dvd burner pro free download,,
windows 7 pro iso free download,, adobe dreamweaver cs5 free download,, download windows 7 ultimate free iso file, adobe indesign cs5 free download,
adobe premier pro cc 2015 serial number free download, download windows 7 ultimate x86 iso file free download, adobe premiere pro cc 2015 serial number free download, download windows xp office professional x64 free download,
windows 7 ultimate iso free download, adobe premiere pro cs5 x64 free download, adobe premiere pro cc 2015 serial number free download,, windows 7 pro 64 bit iso file free download, adobe premiere pro cc 2015 free download,, windows 7 driver graphic card free download,
, microsoft office professional plus 2010 free download,, microsoft windows 7 professional iso free download, microsoft office 2007 home and business edition for mac os x free download,
, windows 7 32 bit office download free, adobe illustrator cs5 free download, adobe premiere pro cc 2015 free download,, adobe kodak digital studio cc 2015 free download,
, adobe premiere pro cc 2015 program key free download,
Activar Adobe Media Encoder Cs6 131
Download Zip ✅ https://gohhs.com/2uFUvl
899543212b
-
-
\ No newline at end of file diff --git a/spaces/diacanFperku/AutoGPT/Farz Sunny Deol Full Movie Download.md b/spaces/diacanFperku/AutoGPT/Farz Sunny Deol Full Movie Download.md deleted file mode 100644 index 27c2010e2eab02996cb1a241981a4ba084132826..0000000000000000000000000000000000000000 --- a/spaces/diacanFperku/AutoGPT/Farz Sunny Deol Full Movie Download.md +++ /dev/null @@ -1,6 +0,0 @@ -
Farz Sunny Deol Full Movie Download
Download File ✑ https://gohhs.com/2uFTUF
- -Ghatak - Full Movie | Sunny Deol, Meenakshi, Mamta Kulkarni | Bollywood Blockbuster Movie | FULL HD ... How to download HD (1080p) movies for free. 4d29de3e1b
-
-
- diff --git a/spaces/diacanFperku/AutoGPT/Kundu Bedside Clinics In Medicine Free Download Pdf ((BETTER)).md b/spaces/diacanFperku/AutoGPT/Kundu Bedside Clinics In Medicine Free Download Pdf ((BETTER)).md deleted file mode 100644 index b0b13560c1238c5550590cc6fcc3ca8de51ab747..0000000000000000000000000000000000000000 --- a/spaces/diacanFperku/AutoGPT/Kundu Bedside Clinics In Medicine Free Download Pdf ((BETTER)).md +++ /dev/null @@ -1,6 +0,0 @@ -
Kundu Bedside Clinics In Medicine Free Download Pdf
Download Zip ✦✦✦ https://gohhs.com/2uFTWt
-
-Special discussion space for Arup Kumar Kundu's book Bedside Clinics in Medicine (ISBN 8187504986). Note. This is a forum for discussing books and . You must be logged in to access it. 8a78ff9644
-
-
- diff --git a/spaces/digitalxingtong/Nanami-Bert-VITS2/utils.py b/spaces/digitalxingtong/Nanami-Bert-VITS2/utils.py deleted file mode 100644 index c6aa6cfc64c33e2eed33e9845239e831fc1c4a1a..0000000000000000000000000000000000000000 --- a/spaces/digitalxingtong/Nanami-Bert-VITS2/utils.py +++ /dev/null @@ -1,293 +0,0 @@ -import os -import glob -import sys -import argparse -import logging -import json -import subprocess -import numpy as np -from scipy.io.wavfile import read -import torch - -MATPLOTLIB_FLAG = False - -logging.basicConfig(stream=sys.stdout, level=logging.DEBUG) -logger = logging - - -def load_checkpoint(checkpoint_path, model, optimizer=None, skip_optimizer=False): - assert os.path.isfile(checkpoint_path) - checkpoint_dict = torch.load(checkpoint_path, map_location='cpu') - iteration = checkpoint_dict['iteration'] - learning_rate = checkpoint_dict['learning_rate'] - if optimizer is not None and not skip_optimizer and checkpoint_dict['optimizer'] is not None: - optimizer.load_state_dict(checkpoint_dict['optimizer']) - elif optimizer is None and not skip_optimizer: - #else: #Disable this line if Infer ,and enable the line upper - new_opt_dict = optimizer.state_dict() - new_opt_dict_params = new_opt_dict['param_groups'][0]['params'] - new_opt_dict['param_groups'] = checkpoint_dict['optimizer']['param_groups'] - new_opt_dict['param_groups'][0]['params'] = new_opt_dict_params - optimizer.load_state_dict(new_opt_dict) - saved_state_dict = checkpoint_dict['model'] - if hasattr(model, 'module'): - state_dict = model.module.state_dict() - else: - state_dict = model.state_dict() - new_state_dict = {} - for k, v in state_dict.items(): - try: - #assert "emb_g" not in k - # print("load", k) - new_state_dict[k] = saved_state_dict[k] - assert saved_state_dict[k].shape == v.shape, (saved_state_dict[k].shape, v.shape) - except: - print("error, %s is not in the checkpoint" % k) - new_state_dict[k] = v - if hasattr(model, 'module'): - model.module.load_state_dict(new_state_dict, strict=False) - else: - model.load_state_dict(new_state_dict, strict=False) - print("load ") - logger.info("Loaded checkpoint '{}' (iteration {})".format( - checkpoint_path, iteration)) - return model, optimizer, learning_rate, iteration - - -def save_checkpoint(model, optimizer, learning_rate, iteration, checkpoint_path): - logger.info("Saving model and optimizer state at iteration {} to {}".format( - iteration, checkpoint_path)) - if hasattr(model, 'module'): - state_dict = model.module.state_dict() - else: - state_dict = model.state_dict() - torch.save({'model': state_dict, - 'iteration': iteration, - 'optimizer': optimizer.state_dict(), - 'learning_rate': learning_rate}, checkpoint_path) - - -def summarize(writer, global_step, scalars={}, histograms={}, images={}, audios={}, audio_sampling_rate=22050): - for k, v in scalars.items(): - writer.add_scalar(k, v, global_step) - for k, v in histograms.items(): - writer.add_histogram(k, v, global_step) - for k, v in images.items(): - writer.add_image(k, v, global_step, dataformats='HWC') - for k, v in audios.items(): - writer.add_audio(k, v, global_step, audio_sampling_rate) - - -def latest_checkpoint_path(dir_path, regex="G_*.pth"): - f_list = glob.glob(os.path.join(dir_path, regex)) - f_list.sort(key=lambda f: int("".join(filter(str.isdigit, f)))) - x = f_list[-1] - print(x) - return x - - -def plot_spectrogram_to_numpy(spectrogram): - global MATPLOTLIB_FLAG - if not MATPLOTLIB_FLAG: - import matplotlib - matplotlib.use("Agg") - MATPLOTLIB_FLAG = True - mpl_logger = logging.getLogger('matplotlib') - mpl_logger.setLevel(logging.WARNING) - import matplotlib.pylab as plt - import numpy as np - - fig, ax = plt.subplots(figsize=(10, 2)) - im = ax.imshow(spectrogram, aspect="auto", origin="lower", - interpolation='none') - plt.colorbar(im, ax=ax) - plt.xlabel("Frames") - plt.ylabel("Channels") - plt.tight_layout() - - fig.canvas.draw() - data = np.fromstring(fig.canvas.tostring_rgb(), dtype=np.uint8, sep='') - data = data.reshape(fig.canvas.get_width_height()[::-1] + (3,)) - plt.close() - return data - - -def plot_alignment_to_numpy(alignment, info=None): - global MATPLOTLIB_FLAG - if not MATPLOTLIB_FLAG: - import matplotlib - matplotlib.use("Agg") - MATPLOTLIB_FLAG = True - mpl_logger = logging.getLogger('matplotlib') - mpl_logger.setLevel(logging.WARNING) - import matplotlib.pylab as plt - import numpy as np - - fig, ax = plt.subplots(figsize=(6, 4)) - im = ax.imshow(alignment.transpose(), aspect='auto', origin='lower', - interpolation='none') - fig.colorbar(im, ax=ax) - xlabel = 'Decoder timestep' - if info is not None: - xlabel += '\n\n' + info - plt.xlabel(xlabel) - plt.ylabel('Encoder timestep') - plt.tight_layout() - - fig.canvas.draw() - data = np.fromstring(fig.canvas.tostring_rgb(), dtype=np.uint8, sep='') - data = data.reshape(fig.canvas.get_width_height()[::-1] + (3,)) - plt.close() - return data - - -def load_wav_to_torch(full_path): - sampling_rate, data = read(full_path) - return torch.FloatTensor(data.astype(np.float32)), sampling_rate - - -def load_filepaths_and_text(filename, split="|"): - with open(filename, encoding='utf-8') as f: - filepaths_and_text = [line.strip().split(split) for line in f] - return filepaths_and_text - - -def get_hparams(init=True): - parser = argparse.ArgumentParser() - parser.add_argument('-c', '--config', type=str, default="./configs/base.json", - help='JSON file for configuration') - parser.add_argument('-m', '--model', type=str, default="./OUTPUT_MODEL", - help='Model name') - parser.add_argument('--cont', dest='cont', action="store_true", default=False, help="whether to continue training on the latest checkpoint") - - args = parser.parse_args() - model_dir = os.path.join("./logs", args.model) - - if not os.path.exists(model_dir): - os.makedirs(model_dir) - - config_path = args.config - config_save_path = os.path.join(model_dir, "config.json") - if init: - with open(config_path, "r") as f: - data = f.read() - with open(config_save_path, "w") as f: - f.write(data) - else: - with open(config_save_path, "r") as f: - data = f.read() - config = json.loads(data) - - hparams = HParams(**config) - hparams.model_dir = model_dir - hparams.cont = args.cont - return hparams - - -def clean_checkpoints(path_to_models='logs/44k/', n_ckpts_to_keep=2, sort_by_time=True): - """Freeing up space by deleting saved ckpts - - Arguments: - path_to_models -- Path to the model directory - n_ckpts_to_keep -- Number of ckpts to keep, excluding G_0.pth and D_0.pth - sort_by_time -- True -> chronologically delete ckpts - False -> lexicographically delete ckpts - """ - import re - ckpts_files = [f for f in os.listdir(path_to_models) if os.path.isfile(os.path.join(path_to_models, f))] - name_key = (lambda _f: int(re.compile('._(\d+)\.pth').match(_f).group(1))) - time_key = (lambda _f: os.path.getmtime(os.path.join(path_to_models, _f))) - sort_key = time_key if sort_by_time else name_key - x_sorted = lambda _x: sorted([f for f in ckpts_files if f.startswith(_x) and not f.endswith('_0.pth')], - key=sort_key) - to_del = [os.path.join(path_to_models, fn) for fn in - (x_sorted('G')[:-n_ckpts_to_keep] + x_sorted('D')[:-n_ckpts_to_keep])] - del_info = lambda fn: logger.info(f".. Free up space by deleting ckpt {fn}") - del_routine = lambda x: [os.remove(x), del_info(x)] - rs = [del_routine(fn) for fn in to_del] - -def get_hparams_from_dir(model_dir): - config_save_path = os.path.join(model_dir, "config.json") - with open(config_save_path, "r") as f: - data = f.read() - config = json.loads(data) - - hparams = HParams(**config) - hparams.model_dir = model_dir - return hparams - - -def get_hparams_from_file(config_path): - with open(config_path, "r") as f: - data = f.read() - config = json.loads(data) - - hparams = HParams(**config) - return hparams - - -def check_git_hash(model_dir): - source_dir = os.path.dirname(os.path.realpath(__file__)) - if not os.path.exists(os.path.join(source_dir, ".git")): - logger.warn("{} is not a git repository, therefore hash value comparison will be ignored.".format( - source_dir - )) - return - - cur_hash = subprocess.getoutput("git rev-parse HEAD") - - path = os.path.join(model_dir, "githash") - if os.path.exists(path): - saved_hash = open(path).read() - if saved_hash != cur_hash: - logger.warn("git hash values are different. {}(saved) != {}(current)".format( - saved_hash[:8], cur_hash[:8])) - else: - open(path, "w").write(cur_hash) - - -def get_logger(model_dir, filename="train.log"): - global logger - logger = logging.getLogger(os.path.basename(model_dir)) - logger.setLevel(logging.DEBUG) - - formatter = logging.Formatter("%(asctime)s\t%(name)s\t%(levelname)s\t%(message)s") - if not os.path.exists(model_dir): - os.makedirs(model_dir) - h = logging.FileHandler(os.path.join(model_dir, filename)) - h.setLevel(logging.DEBUG) - h.setFormatter(formatter) - logger.addHandler(h) - return logger - - -class HParams(): - def __init__(self, **kwargs): - for k, v in kwargs.items(): - if type(v) == dict: - v = HParams(**v) - self[k] = v - - def keys(self): - return self.__dict__.keys() - - def items(self): - return self.__dict__.items() - - def values(self): - return self.__dict__.values() - - def __len__(self): - return len(self.__dict__) - - def __getitem__(self, key): - return getattr(self, key) - - def __setitem__(self, key, value): - return setattr(self, key, value) - - def __contains__(self, key): - return key in self.__dict__ - - def __repr__(self): - return self.__dict__.__repr__() diff --git a/spaces/digitalxingtong/Xingtong-Longread-Dongmuchang-Bert-VITS2/text/cleaner.py b/spaces/digitalxingtong/Xingtong-Longread-Dongmuchang-Bert-VITS2/text/cleaner.py deleted file mode 100644 index 64bd5f7296f66c94f3a335666c53706bb5fe5b39..0000000000000000000000000000000000000000 --- a/spaces/digitalxingtong/Xingtong-Longread-Dongmuchang-Bert-VITS2/text/cleaner.py +++ /dev/null @@ -1,27 +0,0 @@ -from text import chinese, cleaned_text_to_sequence - - -language_module_map = { - 'ZH': chinese -} - - -def clean_text(text, language): - language_module = language_module_map[language] - norm_text = language_module.text_normalize(text) - phones, tones, word2ph = language_module.g2p(norm_text) - return norm_text, phones, tones, word2ph - -def clean_text_bert(text, language): - language_module = language_module_map[language] - norm_text = language_module.text_normalize(text) - phones, tones, word2ph = language_module.g2p(norm_text) - bert = language_module.get_bert_feature(norm_text, word2ph) - return phones, tones, bert - -def text_to_sequence(text, language): - norm_text, phones, tones, word2ph = clean_text(text, language) - return cleaned_text_to_sequence(phones, tones, language) - -if __name__ == '__main__': - pass diff --git a/spaces/dinhminh20521597/OCR_DEMO/configs/textrecog/seg/README.md b/spaces/dinhminh20521597/OCR_DEMO/configs/textrecog/seg/README.md deleted file mode 100644 index f8ab29e61727e3fa648c2aa090fcae8076bbf5e2..0000000000000000000000000000000000000000 --- a/spaces/dinhminh20521597/OCR_DEMO/configs/textrecog/seg/README.md +++ /dev/null @@ -1,48 +0,0 @@ -# SegOCR - - - -## Abstract - -Just a simple Seg-based baseline for text recognition tasks. - -## Dataset - -### Train Dataset - -| trainset | instance_num | repeat_num | source | -| :-------: | :----------: | :--------: | :----: | -| SynthText | 7266686 | 1 | synth | - -### Test Dataset - -| testset | instance_num | type | -| :-----: | :----------: | :-------: | -| IIIT5K | 3000 | regular | -| SVT | 647 | regular | -| IC13 | 1015 | regular | -| CT80 | 288 | irregular | - -## Results and Models - -| Backbone | Neck | Head | | | Regular Text | | | Irregular Text | download | -| :------: | :----: | :--: | :-: | :----: | :----------: | :--: | :-: | :------------: | :------------------------------------------------------------------------------------------------------------------------------------------: | -| | | | | IIIT5K | SVT | IC13 | | CT80 | | -| R31-1/16 | FPNOCR | 1x | | 90.9 | 81.8 | 90.7 | | 80.9 | [model](https://download.openmmlab.com/mmocr/textrecog/seg/seg_r31_1by16_fpnocr_academic-72235b11.pth) \| [log](https://download.openmmlab.com/mmocr/textrecog/seg/20210325_112835.log.json) | - -```{note} - -- `R31-1/16` means the size (both height and width ) of feature from backbone is 1/16 of input image. -- `1x` means the size (both height and width) of feature from head is the same with input image. -``` - -## Citation - -```bibtex -@unpublished{key, - title={SegOCR Simple Baseline.}, - author={}, - note={Unpublished Manuscript}, - year={2021} -} -``` diff --git a/spaces/dmeck/RVC-Speakers/speakers/server/static/swagger-ui.css b/spaces/dmeck/RVC-Speakers/speakers/server/static/swagger-ui.css deleted file mode 100644 index c247abc339caf9e351491d80e32fe318849f443b..0000000000000000000000000000000000000000 --- a/spaces/dmeck/RVC-Speakers/speakers/server/static/swagger-ui.css +++ /dev/null @@ -1,9 +0,0 @@ -/** - * Skipped minification because the original files appears to be already minified. - * Original file: /npm/swagger-ui-dist@5.3.1/swagger-ui.css - * - * Do NOT use SRI with dynamically generated files! More information: https://www.jsdelivr.com/using-sri-with-dynamic-files - */ - .swagger-ui{color:#3b4151;font-family:sans-serif/*! normalize.css v7.0.0 | MIT License | github.com/necolas/normalize.css */}.swagger-ui html{-ms-text-size-adjust:100%;-webkit-text-size-adjust:100%;line-height:1.15}.swagger-ui body{margin:0}.swagger-ui article,.swagger-ui aside,.swagger-ui footer,.swagger-ui header,.swagger-ui nav,.swagger-ui section{display:block}.swagger-ui h1{font-size:2em;margin:.67em 0}.swagger-ui figcaption,.swagger-ui figure,.swagger-ui main{display:block}.swagger-ui figure{margin:1em 40px}.swagger-ui hr{box-sizing:content-box;height:0;overflow:visible}.swagger-ui pre{font-family:monospace,monospace;font-size:1em}.swagger-ui a{-webkit-text-decoration-skip:objects;background-color:transparent}.swagger-ui abbr[title]{border-bottom:none;text-decoration:underline;-webkit-text-decoration:underline dotted;text-decoration:underline dotted}.swagger-ui b,.swagger-ui strong{font-weight:inherit;font-weight:bolder}.swagger-ui code,.swagger-ui kbd,.swagger-ui samp{font-family:monospace,monospace;font-size:1em}.swagger-ui dfn{font-style:italic}.swagger-ui mark{background-color:#ff0;color:#000}.swagger-ui small{font-size:80%}.swagger-ui sub,.swagger-ui sup{font-size:75%;line-height:0;position:relative;vertical-align:baseline}.swagger-ui sub{bottom:-.25em}.swagger-ui sup{top:-.5em}.swagger-ui audio,.swagger-ui video{display:inline-block}.swagger-ui audio:not([controls]){display:none;height:0}.swagger-ui img{border-style:none}.swagger-ui svg:not(:root){overflow:hidden}.swagger-ui button,.swagger-ui input,.swagger-ui optgroup,.swagger-ui select,.swagger-ui textarea{font-family:sans-serif;font-size:100%;line-height:1.15;margin:0}.swagger-ui button,.swagger-ui input{overflow:visible}.swagger-ui button,.swagger-ui select{text-transform:none}.swagger-ui [type=reset],.swagger-ui [type=submit],.swagger-ui button,.swagger-ui html [type=button]{-webkit-appearance:button}.swagger-ui [type=button]::-moz-focus-inner,.swagger-ui [type=reset]::-moz-focus-inner,.swagger-ui [type=submit]::-moz-focus-inner,.swagger-ui button::-moz-focus-inner{border-style:none;padding:0}.swagger-ui [type=button]:-moz-focusring,.swagger-ui [type=reset]:-moz-focusring,.swagger-ui [type=submit]:-moz-focusring,.swagger-ui button:-moz-focusring{outline:1px dotted ButtonText}.swagger-ui fieldset{padding:.35em .75em .625em}.swagger-ui legend{box-sizing:border-box;color:inherit;display:table;max-width:100%;padding:0;white-space:normal}.swagger-ui progress{display:inline-block;vertical-align:baseline}.swagger-ui textarea{overflow:auto}.swagger-ui [type=checkbox],.swagger-ui [type=radio]{box-sizing:border-box;padding:0}.swagger-ui [type=number]::-webkit-inner-spin-button,.swagger-ui [type=number]::-webkit-outer-spin-button{height:auto}.swagger-ui [type=search]{-webkit-appearance:textfield;outline-offset:-2px}.swagger-ui [type=search]::-webkit-search-cancel-button,.swagger-ui [type=search]::-webkit-search-decoration{-webkit-appearance:none}.swagger-ui ::-webkit-file-upload-button{-webkit-appearance:button;font:inherit}.swagger-ui details,.swagger-ui menu{display:block}.swagger-ui summary{display:list-item}.swagger-ui canvas{display:inline-block}.swagger-ui [hidden],.swagger-ui template{display:none}.swagger-ui .debug *{outline:1px solid gold}.swagger-ui .debug-white *{outline:1px solid #fff}.swagger-ui .debug-black *{outline:1px solid #000}.swagger-ui .debug-grid{background:transparent url(data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAgAAAAICAYAAADED76LAAAAGXRFWHRTb2Z0d2FyZQBBZG9iZSBJbWFnZVJlYWR5ccllPAAAAyhpVFh0WE1MOmNvbS5hZG9iZS54bXAAAAAAADw/eHBhY2tldCBiZWdpbj0i77u/IiBpZD0iVzVNME1wQ2VoaUh6cmVTek5UY3prYzlkIj8+IDx4OnhtcG1ldGEgeG1sbnM6eD0iYWRvYmU6bnM6bWV0YS8iIHg6eG1wdGs9IkFkb2JlIFhNUCBDb3JlIDUuNi1jMTExIDc5LjE1ODMyNSwgMjAxNS8wOS8xMC0wMToxMDoyMCAgICAgICAgIj4gPHJkZjpSREYgeG1sbnM6cmRmPSJodHRwOi8vd3d3LnczLm9yZy8xOTk5LzAyLzIyLXJkZi1zeW50YXgtbnMjIj4gPHJkZjpEZXNjcmlwdGlvbiByZGY6YWJvdXQ9IiIgeG1sbnM6eG1wTU09Imh0dHA6Ly9ucy5hZG9iZS5jb20veGFwLzEuMC9tbS8iIHhtbG5zOnN0UmVmPSJodHRwOi8vbnMuYWRvYmUuY29tL3hhcC8xLjAvc1R5cGUvUmVzb3VyY2VSZWYjIiB4bWxuczp4bXA9Imh0dHA6Ly9ucy5hZG9iZS5jb20veGFwLzEuMC8iIHhtcE1NOkRvY3VtZW50SUQ9InhtcC5kaWQ6MTRDOTY4N0U2N0VFMTFFNjg2MzZDQjkwNkQ4MjgwMEIiIHhtcE1NOkluc3RhbmNlSUQ9InhtcC5paWQ6MTRDOTY4N0Q2N0VFMTFFNjg2MzZDQjkwNkQ4MjgwMEIiIHhtcDpDcmVhdG9yVG9vbD0iQWRvYmUgUGhvdG9zaG9wIENDIDIwMTUgKE1hY2ludG9zaCkiPiA8eG1wTU06RGVyaXZlZEZyb20gc3RSZWY6aW5zdGFuY2VJRD0ieG1wLmlpZDo3NjcyQkQ3NjY3QzUxMUU2QjJCQ0UyNDA4MTAwMjE3MSIgc3RSZWY6ZG9jdW1lbnRJRD0ieG1wLmRpZDo3NjcyQkQ3NzY3QzUxMUU2QjJCQ0UyNDA4MTAwMjE3MSIvPiA8L3JkZjpEZXNjcmlwdGlvbj4gPC9yZGY6UkRGPiA8L3g6eG1wbWV0YT4gPD94cGFja2V0IGVuZD0iciI/PsBS+GMAAAAjSURBVHjaYvz//z8DLsD4gcGXiYEAGBIKGBne//fFpwAgwAB98AaF2pjlUQAAAABJRU5ErkJggg==) repeat 0 0}.swagger-ui .debug-grid-16{background:transparent url(data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAABAAAAAQCAYAAAAf8/9hAAAAGXRFWHRTb2Z0d2FyZQBBZG9iZSBJbWFnZVJlYWR5ccllPAAAAyhpVFh0WE1MOmNvbS5hZG9iZS54bXAAAAAAADw/eHBhY2tldCBiZWdpbj0i77u/IiBpZD0iVzVNME1wQ2VoaUh6cmVTek5UY3prYzlkIj8+IDx4OnhtcG1ldGEgeG1sbnM6eD0iYWRvYmU6bnM6bWV0YS8iIHg6eG1wdGs9IkFkb2JlIFhNUCBDb3JlIDUuNi1jMTExIDc5LjE1ODMyNSwgMjAxNS8wOS8xMC0wMToxMDoyMCAgICAgICAgIj4gPHJkZjpSREYgeG1sbnM6cmRmPSJodHRwOi8vd3d3LnczLm9yZy8xOTk5LzAyLzIyLXJkZi1zeW50YXgtbnMjIj4gPHJkZjpEZXNjcmlwdGlvbiByZGY6YWJvdXQ9IiIgeG1sbnM6eG1wTU09Imh0dHA6Ly9ucy5hZG9iZS5jb20veGFwLzEuMC9tbS8iIHhtbG5zOnN0UmVmPSJodHRwOi8vbnMuYWRvYmUuY29tL3hhcC8xLjAvc1R5cGUvUmVzb3VyY2VSZWYjIiB4bWxuczp4bXA9Imh0dHA6Ly9ucy5hZG9iZS5jb20veGFwLzEuMC8iIHhtcE1NOkRvY3VtZW50SUQ9InhtcC5kaWQ6ODYyRjhERDU2N0YyMTFFNjg2MzZDQjkwNkQ4MjgwMEIiIHhtcE1NOkluc3RhbmNlSUQ9InhtcC5paWQ6ODYyRjhERDQ2N0YyMTFFNjg2MzZDQjkwNkQ4MjgwMEIiIHhtcDpDcmVhdG9yVG9vbD0iQWRvYmUgUGhvdG9zaG9wIENDIDIwMTUgKE1hY2ludG9zaCkiPiA8eG1wTU06RGVyaXZlZEZyb20gc3RSZWY6aW5zdGFuY2VJRD0ieG1wLmlpZDo3NjcyQkQ3QTY3QzUxMUU2QjJCQ0UyNDA4MTAwMjE3MSIgc3RSZWY6ZG9jdW1lbnRJRD0ieG1wLmRpZDo3NjcyQkQ3QjY3QzUxMUU2QjJCQ0UyNDA4MTAwMjE3MSIvPiA8L3JkZjpEZXNjcmlwdGlvbj4gPC9yZGY6UkRGPiA8L3g6eG1wbWV0YT4gPD94cGFja2V0IGVuZD0iciI/PvCS01IAAABMSURBVHjaYmR4/5+BFPBfAMFm/MBgx8RAGWCn1AAmSg34Q6kBDKMGMDCwICeMIemF/5QawEipAWwUhwEjMDvbAWlWkvVBwu8vQIABAEwBCph8U6c0AAAAAElFTkSuQmCC) repeat 0 0}.swagger-ui .debug-grid-8-solid{background:#fff url(data:image/jpeg;base64,/9j/4QAYRXhpZgAASUkqAAgAAAAAAAAAAAAAAP/sABFEdWNreQABAAQAAAAAAAD/4QMxaHR0cDovL25zLmFkb2JlLmNvbS94YXAvMS4wLwA8P3hwYWNrZXQgYmVnaW49Iu+7vyIgaWQ9Ilc1TTBNcENlaGlIenJlU3pOVGN6a2M5ZCI/PiA8eDp4bXBtZXRhIHhtbG5zOng9ImFkb2JlOm5zOm1ldGEvIiB4OnhtcHRrPSJBZG9iZSBYTVAgQ29yZSA1LjYtYzExMSA3OS4xNTgzMjUsIDIwMTUvMDkvMTAtMDE6MTA6MjAgICAgICAgICI+IDxyZGY6UkRGIHhtbG5zOnJkZj0iaHR0cDovL3d3dy53My5vcmcvMTk5OS8wMi8yMi1yZGYtc3ludGF4LW5zIyI+IDxyZGY6RGVzY3JpcHRpb24gcmRmOmFib3V0PSIiIHhtbG5zOnhtcD0iaHR0cDovL25zLmFkb2JlLmNvbS94YXAvMS4wLyIgeG1sbnM6eG1wTU09Imh0dHA6Ly9ucy5hZG9iZS5jb20veGFwLzEuMC9tbS8iIHhtbG5zOnN0UmVmPSJodHRwOi8vbnMuYWRvYmUuY29tL3hhcC8xLjAvc1R5cGUvUmVzb3VyY2VSZWYjIiB4bXA6Q3JlYXRvclRvb2w9IkFkb2JlIFBob3Rvc2hvcCBDQyAyMDE1IChNYWNpbnRvc2gpIiB4bXBNTTpJbnN0YW5jZUlEPSJ4bXAuaWlkOkIxMjI0OTczNjdCMzExRTZCMkJDRTI0MDgxMDAyMTcxIiB4bXBNTTpEb2N1bWVudElEPSJ4bXAuZGlkOkIxMjI0OTc0NjdCMzExRTZCMkJDRTI0MDgxMDAyMTcxIj4gPHhtcE1NOkRlcml2ZWRGcm9tIHN0UmVmOmluc3RhbmNlSUQ9InhtcC5paWQ6QjEyMjQ5NzE2N0IzMTFFNkIyQkNFMjQwODEwMDIxNzEiIHN0UmVmOmRvY3VtZW50SUQ9InhtcC5kaWQ6QjEyMjQ5NzI2N0IzMTFFNkIyQkNFMjQwODEwMDIxNzEiLz4gPC9yZGY6RGVzY3JpcHRpb24+IDwvcmRmOlJERj4gPC94OnhtcG1ldGE+IDw/eHBhY2tldCBlbmQ9InIiPz7/7gAOQWRvYmUAZMAAAAAB/9sAhAAbGhopHSlBJiZBQi8vL0JHPz4+P0dHR0dHR0dHR0dHR0dHR0dHR0dHR0dHR0dHR0dHR0dHR0dHR0dHR0dHR0dHAR0pKTQmND8oKD9HPzU/R0dHR0dHR0dHR0dHR0dHR0dHR0dHR0dHR0dHR0dHR0dHR0dHR0dHR0dHR0dHR0dHR0f/wAARCAAIAAgDASIAAhEBAxEB/8QAWQABAQAAAAAAAAAAAAAAAAAAAAYBAQEAAAAAAAAAAAAAAAAAAAIEEAEBAAMBAAAAAAAAAAAAAAABADECA0ERAAEDBQAAAAAAAAAAAAAAAAARITFBUWESIv/aAAwDAQACEQMRAD8AoOnTV1QTD7JJshP3vSM3P//Z) repeat 0 0}.swagger-ui .debug-grid-16-solid{background:#fff url(data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAABAAAAAQCAIAAACQkWg2AAAAGXRFWHRTb2Z0d2FyZQBBZG9iZSBJbWFnZVJlYWR5ccllPAAAAyhpVFh0WE1MOmNvbS5hZG9iZS54bXAAAAAAADw/eHBhY2tldCBiZWdpbj0i77u/IiBpZD0iVzVNME1wQ2VoaUh6cmVTek5UY3prYzlkIj8+IDx4OnhtcG1ldGEgeG1sbnM6eD0iYWRvYmU6bnM6bWV0YS8iIHg6eG1wdGs9IkFkb2JlIFhNUCBDb3JlIDUuNi1jMTExIDc5LjE1ODMyNSwgMjAxNS8wOS8xMC0wMToxMDoyMCAgICAgICAgIj4gPHJkZjpSREYgeG1sbnM6cmRmPSJodHRwOi8vd3d3LnczLm9yZy8xOTk5LzAyLzIyLXJkZi1zeW50YXgtbnMjIj4gPHJkZjpEZXNjcmlwdGlvbiByZGY6YWJvdXQ9IiIgeG1sbnM6eG1wPSJodHRwOi8vbnMuYWRvYmUuY29tL3hhcC8xLjAvIiB4bWxuczp4bXBNTT0iaHR0cDovL25zLmFkb2JlLmNvbS94YXAvMS4wL21tLyIgeG1sbnM6c3RSZWY9Imh0dHA6Ly9ucy5hZG9iZS5jb20veGFwLzEuMC9zVHlwZS9SZXNvdXJjZVJlZiMiIHhtcDpDcmVhdG9yVG9vbD0iQWRvYmUgUGhvdG9zaG9wIENDIDIwMTUgKE1hY2ludG9zaCkiIHhtcE1NOkluc3RhbmNlSUQ9InhtcC5paWQ6NzY3MkJEN0U2N0M1MTFFNkIyQkNFMjQwODEwMDIxNzEiIHhtcE1NOkRvY3VtZW50SUQ9InhtcC5kaWQ6NzY3MkJEN0Y2N0M1MTFFNkIyQkNFMjQwODEwMDIxNzEiPiA8eG1wTU06RGVyaXZlZEZyb20gc3RSZWY6aW5zdGFuY2VJRD0ieG1wLmlpZDo3NjcyQkQ3QzY3QzUxMUU2QjJCQ0UyNDA4MTAwMjE3MSIgc3RSZWY6ZG9jdW1lbnRJRD0ieG1wLmRpZDo3NjcyQkQ3RDY3QzUxMUU2QjJCQ0UyNDA4MTAwMjE3MSIvPiA8L3JkZjpEZXNjcmlwdGlvbj4gPC9yZGY6UkRGPiA8L3g6eG1wbWV0YT4gPD94cGFja2V0IGVuZD0iciI/Pve6J3kAAAAzSURBVHjaYvz//z8D0UDsMwMjSRoYP5Gq4SPNbRjVMEQ1fCRDg+in/6+J1AJUxsgAEGAA31BAJMS0GYEAAAAASUVORK5CYII=) repeat 0 0}.swagger-ui .border-box,.swagger-ui a,.swagger-ui article,.swagger-ui body,.swagger-ui code,.swagger-ui dd,.swagger-ui div,.swagger-ui dl,.swagger-ui dt,.swagger-ui fieldset,.swagger-ui footer,.swagger-ui form,.swagger-ui h1,.swagger-ui h2,.swagger-ui h3,.swagger-ui h4,.swagger-ui h5,.swagger-ui h6,.swagger-ui header,.swagger-ui html,.swagger-ui input[type=email],.swagger-ui input[type=number],.swagger-ui input[type=password],.swagger-ui input[type=tel],.swagger-ui input[type=text],.swagger-ui input[type=url],.swagger-ui legend,.swagger-ui li,.swagger-ui main,.swagger-ui ol,.swagger-ui p,.swagger-ui pre,.swagger-ui section,.swagger-ui table,.swagger-ui td,.swagger-ui textarea,.swagger-ui th,.swagger-ui tr,.swagger-ui ul{box-sizing:border-box}.swagger-ui .aspect-ratio{height:0;position:relative}.swagger-ui .aspect-ratio--16x9{padding-bottom:56.25%}.swagger-ui .aspect-ratio--9x16{padding-bottom:177.77%}.swagger-ui .aspect-ratio--4x3{padding-bottom:75%}.swagger-ui .aspect-ratio--3x4{padding-bottom:133.33%}.swagger-ui .aspect-ratio--6x4{padding-bottom:66.6%}.swagger-ui .aspect-ratio--4x6{padding-bottom:150%}.swagger-ui .aspect-ratio--8x5{padding-bottom:62.5%}.swagger-ui .aspect-ratio--5x8{padding-bottom:160%}.swagger-ui .aspect-ratio--7x5{padding-bottom:71.42%}.swagger-ui .aspect-ratio--5x7{padding-bottom:140%}.swagger-ui .aspect-ratio--1x1{padding-bottom:100%}.swagger-ui .aspect-ratio--object{bottom:0;height:100%;left:0;position:absolute;right:0;top:0;width:100%;z-index:100}@media screen and (min-width:30em){.swagger-ui .aspect-ratio-ns{height:0;position:relative}.swagger-ui .aspect-ratio--16x9-ns{padding-bottom:56.25%}.swagger-ui .aspect-ratio--9x16-ns{padding-bottom:177.77%}.swagger-ui .aspect-ratio--4x3-ns{padding-bottom:75%}.swagger-ui .aspect-ratio--3x4-ns{padding-bottom:133.33%}.swagger-ui .aspect-ratio--6x4-ns{padding-bottom:66.6%}.swagger-ui .aspect-ratio--4x6-ns{padding-bottom:150%}.swagger-ui .aspect-ratio--8x5-ns{padding-bottom:62.5%}.swagger-ui .aspect-ratio--5x8-ns{padding-bottom:160%}.swagger-ui .aspect-ratio--7x5-ns{padding-bottom:71.42%}.swagger-ui .aspect-ratio--5x7-ns{padding-bottom:140%}.swagger-ui .aspect-ratio--1x1-ns{padding-bottom:100%}.swagger-ui .aspect-ratio--object-ns{bottom:0;height:100%;left:0;position:absolute;right:0;top:0;width:100%;z-index:100}}@media screen and (min-width:30em)and (max-width:60em){.swagger-ui .aspect-ratio-m{height:0;position:relative}.swagger-ui .aspect-ratio--16x9-m{padding-bottom:56.25%}.swagger-ui .aspect-ratio--9x16-m{padding-bottom:177.77%}.swagger-ui .aspect-ratio--4x3-m{padding-bottom:75%}.swagger-ui .aspect-ratio--3x4-m{padding-bottom:133.33%}.swagger-ui .aspect-ratio--6x4-m{padding-bottom:66.6%}.swagger-ui .aspect-ratio--4x6-m{padding-bottom:150%}.swagger-ui .aspect-ratio--8x5-m{padding-bottom:62.5%}.swagger-ui .aspect-ratio--5x8-m{padding-bottom:160%}.swagger-ui .aspect-ratio--7x5-m{padding-bottom:71.42%}.swagger-ui .aspect-ratio--5x7-m{padding-bottom:140%}.swagger-ui .aspect-ratio--1x1-m{padding-bottom:100%}.swagger-ui .aspect-ratio--object-m{bottom:0;height:100%;left:0;position:absolute;right:0;top:0;width:100%;z-index:100}}@media screen and (min-width:60em){.swagger-ui .aspect-ratio-l{height:0;position:relative}.swagger-ui .aspect-ratio--16x9-l{padding-bottom:56.25%}.swagger-ui .aspect-ratio--9x16-l{padding-bottom:177.77%}.swagger-ui .aspect-ratio--4x3-l{padding-bottom:75%}.swagger-ui .aspect-ratio--3x4-l{padding-bottom:133.33%}.swagger-ui .aspect-ratio--6x4-l{padding-bottom:66.6%}.swagger-ui .aspect-ratio--4x6-l{padding-bottom:150%}.swagger-ui .aspect-ratio--8x5-l{padding-bottom:62.5%}.swagger-ui .aspect-ratio--5x8-l{padding-bottom:160%}.swagger-ui .aspect-ratio--7x5-l{padding-bottom:71.42%}.swagger-ui .aspect-ratio--5x7-l{padding-bottom:140%}.swagger-ui .aspect-ratio--1x1-l{padding-bottom:100%}.swagger-ui .aspect-ratio--object-l{bottom:0;height:100%;left:0;position:absolute;right:0;top:0;width:100%;z-index:100}}.swagger-ui img{max-width:100%}.swagger-ui .cover{background-size:cover!important}.swagger-ui .contain{background-size:contain!important}@media screen and (min-width:30em){.swagger-ui .cover-ns{background-size:cover!important}.swagger-ui .contain-ns{background-size:contain!important}}@media screen and (min-width:30em)and (max-width:60em){.swagger-ui .cover-m{background-size:cover!important}.swagger-ui .contain-m{background-size:contain!important}}@media screen and (min-width:60em){.swagger-ui .cover-l{background-size:cover!important}.swagger-ui .contain-l{background-size:contain!important}}.swagger-ui .bg-center{background-position:50%;background-repeat:no-repeat}.swagger-ui .bg-top{background-position:top;background-repeat:no-repeat}.swagger-ui .bg-right{background-position:100%;background-repeat:no-repeat}.swagger-ui .bg-bottom{background-position:bottom;background-repeat:no-repeat}.swagger-ui .bg-left{background-position:0;background-repeat:no-repeat}@media screen and (min-width:30em){.swagger-ui .bg-center-ns{background-position:50%;background-repeat:no-repeat}.swagger-ui .bg-top-ns{background-position:top;background-repeat:no-repeat}.swagger-ui .bg-right-ns{background-position:100%;background-repeat:no-repeat}.swagger-ui .bg-bottom-ns{background-position:bottom;background-repeat:no-repeat}.swagger-ui .bg-left-ns{background-position:0;background-repeat:no-repeat}}@media screen and (min-width:30em)and (max-width:60em){.swagger-ui .bg-center-m{background-position:50%;background-repeat:no-repeat}.swagger-ui .bg-top-m{background-position:top;background-repeat:no-repeat}.swagger-ui .bg-right-m{background-position:100%;background-repeat:no-repeat}.swagger-ui .bg-bottom-m{background-position:bottom;background-repeat:no-repeat}.swagger-ui .bg-left-m{background-position:0;background-repeat:no-repeat}}@media screen and (min-width:60em){.swagger-ui .bg-center-l{background-position:50%;background-repeat:no-repeat}.swagger-ui .bg-top-l{background-position:top;background-repeat:no-repeat}.swagger-ui .bg-right-l{background-position:100%;background-repeat:no-repeat}.swagger-ui .bg-bottom-l{background-position:bottom;background-repeat:no-repeat}.swagger-ui .bg-left-l{background-position:0;background-repeat:no-repeat}}.swagger-ui .outline{outline:1px solid}.swagger-ui .outline-transparent{outline:1px solid transparent}.swagger-ui .outline-0{outline:0}@media screen and (min-width:30em){.swagger-ui .outline-ns{outline:1px solid}.swagger-ui .outline-transparent-ns{outline:1px solid transparent}.swagger-ui .outline-0-ns{outline:0}}@media screen and (min-width:30em)and (max-width:60em){.swagger-ui .outline-m{outline:1px solid}.swagger-ui .outline-transparent-m{outline:1px solid transparent}.swagger-ui .outline-0-m{outline:0}}@media screen and (min-width:60em){.swagger-ui .outline-l{outline:1px solid}.swagger-ui .outline-transparent-l{outline:1px solid transparent}.swagger-ui .outline-0-l{outline:0}}.swagger-ui .ba{border-style:solid;border-width:1px}.swagger-ui .bt{border-top-style:solid;border-top-width:1px}.swagger-ui .br{border-right-style:solid;border-right-width:1px}.swagger-ui .bb{border-bottom-style:solid;border-bottom-width:1px}.swagger-ui .bl{border-left-style:solid;border-left-width:1px}.swagger-ui .bn{border-style:none;border-width:0}@media screen and (min-width:30em){.swagger-ui .ba-ns{border-style:solid;border-width:1px}.swagger-ui .bt-ns{border-top-style:solid;border-top-width:1px}.swagger-ui .br-ns{border-right-style:solid;border-right-width:1px}.swagger-ui .bb-ns{border-bottom-style:solid;border-bottom-width:1px}.swagger-ui .bl-ns{border-left-style:solid;border-left-width:1px}.swagger-ui .bn-ns{border-style:none;border-width:0}}@media screen and (min-width:30em)and (max-width:60em){.swagger-ui .ba-m{border-style:solid;border-width:1px}.swagger-ui .bt-m{border-top-style:solid;border-top-width:1px}.swagger-ui .br-m{border-right-style:solid;border-right-width:1px}.swagger-ui .bb-m{border-bottom-style:solid;border-bottom-width:1px}.swagger-ui .bl-m{border-left-style:solid;border-left-width:1px}.swagger-ui .bn-m{border-style:none;border-width:0}}@media screen and (min-width:60em){.swagger-ui .ba-l{border-style:solid;border-width:1px}.swagger-ui .bt-l{border-top-style:solid;border-top-width:1px}.swagger-ui .br-l{border-right-style:solid;border-right-width:1px}.swagger-ui .bb-l{border-bottom-style:solid;border-bottom-width:1px}.swagger-ui .bl-l{border-left-style:solid;border-left-width:1px}.swagger-ui .bn-l{border-style:none;border-width:0}}.swagger-ui .b--black{border-color:#000}.swagger-ui .b--near-black{border-color:#111}.swagger-ui .b--dark-gray{border-color:#333}.swagger-ui .b--mid-gray{border-color:#555}.swagger-ui .b--gray{border-color:#777}.swagger-ui .b--silver{border-color:#999}.swagger-ui .b--light-silver{border-color:#aaa}.swagger-ui .b--moon-gray{border-color:#ccc}.swagger-ui .b--light-gray{border-color:#eee}.swagger-ui .b--near-white{border-color:#f4f4f4}.swagger-ui .b--white{border-color:#fff}.swagger-ui .b--white-90{border-color:hsla(0,0%,100%,.9)}.swagger-ui .b--white-80{border-color:hsla(0,0%,100%,.8)}.swagger-ui .b--white-70{border-color:hsla(0,0%,100%,.7)}.swagger-ui .b--white-60{border-color:hsla(0,0%,100%,.6)}.swagger-ui .b--white-50{border-color:hsla(0,0%,100%,.5)}.swagger-ui .b--white-40{border-color:hsla(0,0%,100%,.4)}.swagger-ui .b--white-30{border-color:hsla(0,0%,100%,.3)}.swagger-ui .b--white-20{border-color:hsla(0,0%,100%,.2)}.swagger-ui .b--white-10{border-color:hsla(0,0%,100%,.1)}.swagger-ui .b--white-05{border-color:hsla(0,0%,100%,.05)}.swagger-ui .b--white-025{border-color:hsla(0,0%,100%,.025)}.swagger-ui .b--white-0125{border-color:hsla(0,0%,100%,.013)}.swagger-ui .b--black-90{border-color:rgba(0,0,0,.9)}.swagger-ui .b--black-80{border-color:rgba(0,0,0,.8)}.swagger-ui .b--black-70{border-color:rgba(0,0,0,.7)}.swagger-ui .b--black-60{border-color:rgba(0,0,0,.6)}.swagger-ui .b--black-50{border-color:rgba(0,0,0,.5)}.swagger-ui .b--black-40{border-color:rgba(0,0,0,.4)}.swagger-ui .b--black-30{border-color:rgba(0,0,0,.3)}.swagger-ui .b--black-20{border-color:rgba(0,0,0,.2)}.swagger-ui .b--black-10{border-color:rgba(0,0,0,.1)}.swagger-ui .b--black-05{border-color:rgba(0,0,0,.05)}.swagger-ui .b--black-025{border-color:rgba(0,0,0,.025)}.swagger-ui .b--black-0125{border-color:rgba(0,0,0,.013)}.swagger-ui .b--dark-red{border-color:#e7040f}.swagger-ui .b--red{border-color:#ff4136}.swagger-ui .b--light-red{border-color:#ff725c}.swagger-ui .b--orange{border-color:#ff6300}.swagger-ui .b--gold{border-color:#ffb700}.swagger-ui .b--yellow{border-color:gold}.swagger-ui .b--light-yellow{border-color:#fbf1a9}.swagger-ui .b--purple{border-color:#5e2ca5}.swagger-ui .b--light-purple{border-color:#a463f2}.swagger-ui .b--dark-pink{border-color:#d5008f}.swagger-ui .b--hot-pink{border-color:#ff41b4}.swagger-ui .b--pink{border-color:#ff80cc}.swagger-ui .b--light-pink{border-color:#ffa3d7}.swagger-ui .b--dark-green{border-color:#137752}.swagger-ui .b--green{border-color:#19a974}.swagger-ui .b--light-green{border-color:#9eebcf}.swagger-ui .b--navy{border-color:#001b44}.swagger-ui .b--dark-blue{border-color:#00449e}.swagger-ui .b--blue{border-color:#357edd}.swagger-ui .b--light-blue{border-color:#96ccff}.swagger-ui .b--lightest-blue{border-color:#cdecff}.swagger-ui .b--washed-blue{border-color:#f6fffe}.swagger-ui .b--washed-green{border-color:#e8fdf5}.swagger-ui .b--washed-yellow{border-color:#fffceb}.swagger-ui .b--washed-red{border-color:#ffdfdf}.swagger-ui .b--transparent{border-color:transparent}.swagger-ui .b--inherit{border-color:inherit}.swagger-ui .br0{border-radius:0}.swagger-ui .br1{border-radius:.125rem}.swagger-ui .br2{border-radius:.25rem}.swagger-ui .br3{border-radius:.5rem}.swagger-ui .br4{border-radius:1rem}.swagger-ui .br-100{border-radius:100%}.swagger-ui .br-pill{border-radius:9999px}.swagger-ui .br--bottom{border-top-left-radius:0;border-top-right-radius:0}.swagger-ui .br--top{border-bottom-left-radius:0;border-bottom-right-radius:0}.swagger-ui .br--right{border-bottom-left-radius:0;border-top-left-radius:0}.swagger-ui .br--left{border-bottom-right-radius:0;border-top-right-radius:0}@media screen and (min-width:30em){.swagger-ui .br0-ns{border-radius:0}.swagger-ui .br1-ns{border-radius:.125rem}.swagger-ui .br2-ns{border-radius:.25rem}.swagger-ui .br3-ns{border-radius:.5rem}.swagger-ui .br4-ns{border-radius:1rem}.swagger-ui .br-100-ns{border-radius:100%}.swagger-ui .br-pill-ns{border-radius:9999px}.swagger-ui .br--bottom-ns{border-top-left-radius:0;border-top-right-radius:0}.swagger-ui .br--top-ns{border-bottom-left-radius:0;border-bottom-right-radius:0}.swagger-ui .br--right-ns{border-bottom-left-radius:0;border-top-left-radius:0}.swagger-ui .br--left-ns{border-bottom-right-radius:0;border-top-right-radius:0}}@media screen and (min-width:30em)and (max-width:60em){.swagger-ui .br0-m{border-radius:0}.swagger-ui .br1-m{border-radius:.125rem}.swagger-ui .br2-m{border-radius:.25rem}.swagger-ui .br3-m{border-radius:.5rem}.swagger-ui .br4-m{border-radius:1rem}.swagger-ui .br-100-m{border-radius:100%}.swagger-ui .br-pill-m{border-radius:9999px}.swagger-ui .br--bottom-m{border-top-left-radius:0;border-top-right-radius:0}.swagger-ui .br--top-m{border-bottom-left-radius:0;border-bottom-right-radius:0}.swagger-ui .br--right-m{border-bottom-left-radius:0;border-top-left-radius:0}.swagger-ui .br--left-m{border-bottom-right-radius:0;border-top-right-radius:0}}@media screen and (min-width:60em){.swagger-ui .br0-l{border-radius:0}.swagger-ui .br1-l{border-radius:.125rem}.swagger-ui .br2-l{border-radius:.25rem}.swagger-ui .br3-l{border-radius:.5rem}.swagger-ui .br4-l{border-radius:1rem}.swagger-ui .br-100-l{border-radius:100%}.swagger-ui .br-pill-l{border-radius:9999px}.swagger-ui .br--bottom-l{border-top-left-radius:0;border-top-right-radius:0}.swagger-ui .br--top-l{border-bottom-left-radius:0;border-bottom-right-radius:0}.swagger-ui .br--right-l{border-bottom-left-radius:0;border-top-left-radius:0}.swagger-ui .br--left-l{border-bottom-right-radius:0;border-top-right-radius:0}}.swagger-ui .b--dotted{border-style:dotted}.swagger-ui .b--dashed{border-style:dashed}.swagger-ui .b--solid{border-style:solid}.swagger-ui .b--none{border-style:none}@media screen and (min-width:30em){.swagger-ui .b--dotted-ns{border-style:dotted}.swagger-ui .b--dashed-ns{border-style:dashed}.swagger-ui .b--solid-ns{border-style:solid}.swagger-ui .b--none-ns{border-style:none}}@media screen and (min-width:30em)and (max-width:60em){.swagger-ui .b--dotted-m{border-style:dotted}.swagger-ui .b--dashed-m{border-style:dashed}.swagger-ui .b--solid-m{border-style:solid}.swagger-ui .b--none-m{border-style:none}}@media screen and (min-width:60em){.swagger-ui .b--dotted-l{border-style:dotted}.swagger-ui .b--dashed-l{border-style:dashed}.swagger-ui .b--solid-l{border-style:solid}.swagger-ui .b--none-l{border-style:none}}.swagger-ui .bw0{border-width:0}.swagger-ui .bw1{border-width:.125rem}.swagger-ui .bw2{border-width:.25rem}.swagger-ui .bw3{border-width:.5rem}.swagger-ui .bw4{border-width:1rem}.swagger-ui .bw5{border-width:2rem}.swagger-ui .bt-0{border-top-width:0}.swagger-ui .br-0{border-right-width:0}.swagger-ui .bb-0{border-bottom-width:0}.swagger-ui .bl-0{border-left-width:0}@media screen and (min-width:30em){.swagger-ui .bw0-ns{border-width:0}.swagger-ui .bw1-ns{border-width:.125rem}.swagger-ui .bw2-ns{border-width:.25rem}.swagger-ui .bw3-ns{border-width:.5rem}.swagger-ui .bw4-ns{border-width:1rem}.swagger-ui .bw5-ns{border-width:2rem}.swagger-ui .bt-0-ns{border-top-width:0}.swagger-ui .br-0-ns{border-right-width:0}.swagger-ui .bb-0-ns{border-bottom-width:0}.swagger-ui .bl-0-ns{border-left-width:0}}@media screen and (min-width:30em)and (max-width:60em){.swagger-ui .bw0-m{border-width:0}.swagger-ui .bw1-m{border-width:.125rem}.swagger-ui .bw2-m{border-width:.25rem}.swagger-ui .bw3-m{border-width:.5rem}.swagger-ui .bw4-m{border-width:1rem}.swagger-ui .bw5-m{border-width:2rem}.swagger-ui .bt-0-m{border-top-width:0}.swagger-ui .br-0-m{border-right-width:0}.swagger-ui .bb-0-m{border-bottom-width:0}.swagger-ui .bl-0-m{border-left-width:0}}@media screen and (min-width:60em){.swagger-ui .bw0-l{border-width:0}.swagger-ui .bw1-l{border-width:.125rem}.swagger-ui .bw2-l{border-width:.25rem}.swagger-ui .bw3-l{border-width:.5rem}.swagger-ui .bw4-l{border-width:1rem}.swagger-ui .bw5-l{border-width:2rem}.swagger-ui .bt-0-l{border-top-width:0}.swagger-ui .br-0-l{border-right-width:0}.swagger-ui .bb-0-l{border-bottom-width:0}.swagger-ui .bl-0-l{border-left-width:0}}.swagger-ui .shadow-1{box-shadow:0 0 4px 2px rgba(0,0,0,.2)}.swagger-ui .shadow-2{box-shadow:0 0 8px 2px rgba(0,0,0,.2)}.swagger-ui .shadow-3{box-shadow:2px 2px 4px 2px rgba(0,0,0,.2)}.swagger-ui .shadow-4{box-shadow:2px 2px 8px 0 rgba(0,0,0,.2)}.swagger-ui .shadow-5{box-shadow:4px 4px 8px 0 rgba(0,0,0,.2)}@media screen and (min-width:30em){.swagger-ui .shadow-1-ns{box-shadow:0 0 4px 2px rgba(0,0,0,.2)}.swagger-ui .shadow-2-ns{box-shadow:0 0 8px 2px rgba(0,0,0,.2)}.swagger-ui .shadow-3-ns{box-shadow:2px 2px 4px 2px rgba(0,0,0,.2)}.swagger-ui .shadow-4-ns{box-shadow:2px 2px 8px 0 rgba(0,0,0,.2)}.swagger-ui .shadow-5-ns{box-shadow:4px 4px 8px 0 rgba(0,0,0,.2)}}@media screen and (min-width:30em)and (max-width:60em){.swagger-ui .shadow-1-m{box-shadow:0 0 4px 2px rgba(0,0,0,.2)}.swagger-ui .shadow-2-m{box-shadow:0 0 8px 2px rgba(0,0,0,.2)}.swagger-ui .shadow-3-m{box-shadow:2px 2px 4px 2px rgba(0,0,0,.2)}.swagger-ui .shadow-4-m{box-shadow:2px 2px 8px 0 rgba(0,0,0,.2)}.swagger-ui .shadow-5-m{box-shadow:4px 4px 8px 0 rgba(0,0,0,.2)}}@media screen and (min-width:60em){.swagger-ui .shadow-1-l{box-shadow:0 0 4px 2px rgba(0,0,0,.2)}.swagger-ui .shadow-2-l{box-shadow:0 0 8px 2px rgba(0,0,0,.2)}.swagger-ui .shadow-3-l{box-shadow:2px 2px 4px 2px rgba(0,0,0,.2)}.swagger-ui .shadow-4-l{box-shadow:2px 2px 8px 0 rgba(0,0,0,.2)}.swagger-ui .shadow-5-l{box-shadow:4px 4px 8px 0 rgba(0,0,0,.2)}}.swagger-ui .pre{overflow-x:auto;overflow-y:hidden;overflow:scroll}.swagger-ui .top-0{top:0}.swagger-ui .right-0{right:0}.swagger-ui .bottom-0{bottom:0}.swagger-ui .left-0{left:0}.swagger-ui .top-1{top:1rem}.swagger-ui .right-1{right:1rem}.swagger-ui .bottom-1{bottom:1rem}.swagger-ui .left-1{left:1rem}.swagger-ui .top-2{top:2rem}.swagger-ui .right-2{right:2rem}.swagger-ui .bottom-2{bottom:2rem}.swagger-ui .left-2{left:2rem}.swagger-ui .top--1{top:-1rem}.swagger-ui .right--1{right:-1rem}.swagger-ui .bottom--1{bottom:-1rem}.swagger-ui .left--1{left:-1rem}.swagger-ui .top--2{top:-2rem}.swagger-ui .right--2{right:-2rem}.swagger-ui .bottom--2{bottom:-2rem}.swagger-ui .left--2{left:-2rem}.swagger-ui .absolute--fill{bottom:0;left:0;right:0;top:0}@media screen and (min-width:30em){.swagger-ui .top-0-ns{top:0}.swagger-ui .left-0-ns{left:0}.swagger-ui .right-0-ns{right:0}.swagger-ui .bottom-0-ns{bottom:0}.swagger-ui .top-1-ns{top:1rem}.swagger-ui .left-1-ns{left:1rem}.swagger-ui .right-1-ns{right:1rem}.swagger-ui .bottom-1-ns{bottom:1rem}.swagger-ui .top-2-ns{top:2rem}.swagger-ui .left-2-ns{left:2rem}.swagger-ui .right-2-ns{right:2rem}.swagger-ui .bottom-2-ns{bottom:2rem}.swagger-ui .top--1-ns{top:-1rem}.swagger-ui .right--1-ns{right:-1rem}.swagger-ui .bottom--1-ns{bottom:-1rem}.swagger-ui .left--1-ns{left:-1rem}.swagger-ui .top--2-ns{top:-2rem}.swagger-ui .right--2-ns{right:-2rem}.swagger-ui .bottom--2-ns{bottom:-2rem}.swagger-ui .left--2-ns{left:-2rem}.swagger-ui .absolute--fill-ns{bottom:0;left:0;right:0;top:0}}@media screen and (min-width:30em)and (max-width:60em){.swagger-ui .top-0-m{top:0}.swagger-ui .left-0-m{left:0}.swagger-ui .right-0-m{right:0}.swagger-ui .bottom-0-m{bottom:0}.swagger-ui .top-1-m{top:1rem}.swagger-ui .left-1-m{left:1rem}.swagger-ui .right-1-m{right:1rem}.swagger-ui .bottom-1-m{bottom:1rem}.swagger-ui .top-2-m{top:2rem}.swagger-ui .left-2-m{left:2rem}.swagger-ui .right-2-m{right:2rem}.swagger-ui .bottom-2-m{bottom:2rem}.swagger-ui .top--1-m{top:-1rem}.swagger-ui .right--1-m{right:-1rem}.swagger-ui .bottom--1-m{bottom:-1rem}.swagger-ui .left--1-m{left:-1rem}.swagger-ui .top--2-m{top:-2rem}.swagger-ui .right--2-m{right:-2rem}.swagger-ui .bottom--2-m{bottom:-2rem}.swagger-ui .left--2-m{left:-2rem}.swagger-ui .absolute--fill-m{bottom:0;left:0;right:0;top:0}}@media screen and (min-width:60em){.swagger-ui .top-0-l{top:0}.swagger-ui .left-0-l{left:0}.swagger-ui .right-0-l{right:0}.swagger-ui .bottom-0-l{bottom:0}.swagger-ui .top-1-l{top:1rem}.swagger-ui .left-1-l{left:1rem}.swagger-ui .right-1-l{right:1rem}.swagger-ui .bottom-1-l{bottom:1rem}.swagger-ui .top-2-l{top:2rem}.swagger-ui .left-2-l{left:2rem}.swagger-ui .right-2-l{right:2rem}.swagger-ui .bottom-2-l{bottom:2rem}.swagger-ui .top--1-l{top:-1rem}.swagger-ui .right--1-l{right:-1rem}.swagger-ui .bottom--1-l{bottom:-1rem}.swagger-ui .left--1-l{left:-1rem}.swagger-ui .top--2-l{top:-2rem}.swagger-ui .right--2-l{right:-2rem}.swagger-ui .bottom--2-l{bottom:-2rem}.swagger-ui .left--2-l{left:-2rem}.swagger-ui .absolute--fill-l{bottom:0;left:0;right:0;top:0}}.swagger-ui .cf:after,.swagger-ui .cf:before{content:" ";display:table}.swagger-ui .cf:after{clear:both}.swagger-ui .cf{zoom:1}.swagger-ui .cl{clear:left}.swagger-ui .cr{clear:right}.swagger-ui .cb{clear:both}.swagger-ui .cn{clear:none}@media screen and (min-width:30em){.swagger-ui .cl-ns{clear:left}.swagger-ui .cr-ns{clear:right}.swagger-ui .cb-ns{clear:both}.swagger-ui .cn-ns{clear:none}}@media screen and (min-width:30em)and (max-width:60em){.swagger-ui .cl-m{clear:left}.swagger-ui .cr-m{clear:right}.swagger-ui .cb-m{clear:both}.swagger-ui .cn-m{clear:none}}@media screen and (min-width:60em){.swagger-ui .cl-l{clear:left}.swagger-ui .cr-l{clear:right}.swagger-ui .cb-l{clear:both}.swagger-ui .cn-l{clear:none}}.swagger-ui .flex{display:flex}.swagger-ui .inline-flex{display:inline-flex}.swagger-ui .flex-auto{flex:1 1 auto;min-height:0;min-width:0}.swagger-ui .flex-none{flex:none}.swagger-ui .flex-column{flex-direction:column}.swagger-ui .flex-row{flex-direction:row}.swagger-ui .flex-wrap{flex-wrap:wrap}.swagger-ui .flex-nowrap{flex-wrap:nowrap}.swagger-ui .flex-wrap-reverse{flex-wrap:wrap-reverse}.swagger-ui .flex-column-reverse{flex-direction:column-reverse}.swagger-ui .flex-row-reverse{flex-direction:row-reverse}.swagger-ui .items-start{align-items:flex-start}.swagger-ui .items-end{align-items:flex-end}.swagger-ui .items-center{align-items:center}.swagger-ui .items-baseline{align-items:baseline}.swagger-ui .items-stretch{align-items:stretch}.swagger-ui .self-start{align-self:flex-start}.swagger-ui .self-end{align-self:flex-end}.swagger-ui .self-center{align-self:center}.swagger-ui .self-baseline{align-self:baseline}.swagger-ui .self-stretch{align-self:stretch}.swagger-ui .justify-start{justify-content:flex-start}.swagger-ui .justify-end{justify-content:flex-end}.swagger-ui .justify-center{justify-content:center}.swagger-ui .justify-between{justify-content:space-between}.swagger-ui .justify-around{justify-content:space-around}.swagger-ui .content-start{align-content:flex-start}.swagger-ui .content-end{align-content:flex-end}.swagger-ui .content-center{align-content:center}.swagger-ui .content-between{align-content:space-between}.swagger-ui .content-around{align-content:space-around}.swagger-ui .content-stretch{align-content:stretch}.swagger-ui .order-0{order:0}.swagger-ui .order-1{order:1}.swagger-ui .order-2{order:2}.swagger-ui .order-3{order:3}.swagger-ui .order-4{order:4}.swagger-ui .order-5{order:5}.swagger-ui .order-6{order:6}.swagger-ui .order-7{order:7}.swagger-ui .order-8{order:8}.swagger-ui .order-last{order:99999}.swagger-ui .flex-grow-0{flex-grow:0}.swagger-ui .flex-grow-1{flex-grow:1}.swagger-ui .flex-shrink-0{flex-shrink:0}.swagger-ui .flex-shrink-1{flex-shrink:1}@media screen and (min-width:30em){.swagger-ui .flex-ns{display:flex}.swagger-ui .inline-flex-ns{display:inline-flex}.swagger-ui .flex-auto-ns{flex:1 1 auto;min-height:0;min-width:0}.swagger-ui .flex-none-ns{flex:none}.swagger-ui .flex-column-ns{flex-direction:column}.swagger-ui .flex-row-ns{flex-direction:row}.swagger-ui .flex-wrap-ns{flex-wrap:wrap}.swagger-ui .flex-nowrap-ns{flex-wrap:nowrap}.swagger-ui .flex-wrap-reverse-ns{flex-wrap:wrap-reverse}.swagger-ui .flex-column-reverse-ns{flex-direction:column-reverse}.swagger-ui .flex-row-reverse-ns{flex-direction:row-reverse}.swagger-ui .items-start-ns{align-items:flex-start}.swagger-ui .items-end-ns{align-items:flex-end}.swagger-ui .items-center-ns{align-items:center}.swagger-ui .items-baseline-ns{align-items:baseline}.swagger-ui .items-stretch-ns{align-items:stretch}.swagger-ui .self-start-ns{align-self:flex-start}.swagger-ui .self-end-ns{align-self:flex-end}.swagger-ui .self-center-ns{align-self:center}.swagger-ui .self-baseline-ns{align-self:baseline}.swagger-ui .self-stretch-ns{align-self:stretch}.swagger-ui .justify-start-ns{justify-content:flex-start}.swagger-ui .justify-end-ns{justify-content:flex-end}.swagger-ui .justify-center-ns{justify-content:center}.swagger-ui .justify-between-ns{justify-content:space-between}.swagger-ui .justify-around-ns{justify-content:space-around}.swagger-ui .content-start-ns{align-content:flex-start}.swagger-ui .content-end-ns{align-content:flex-end}.swagger-ui .content-center-ns{align-content:center}.swagger-ui .content-between-ns{align-content:space-between}.swagger-ui .content-around-ns{align-content:space-around}.swagger-ui .content-stretch-ns{align-content:stretch}.swagger-ui .order-0-ns{order:0}.swagger-ui .order-1-ns{order:1}.swagger-ui .order-2-ns{order:2}.swagger-ui .order-3-ns{order:3}.swagger-ui .order-4-ns{order:4}.swagger-ui .order-5-ns{order:5}.swagger-ui .order-6-ns{order:6}.swagger-ui .order-7-ns{order:7}.swagger-ui .order-8-ns{order:8}.swagger-ui .order-last-ns{order:99999}.swagger-ui .flex-grow-0-ns{flex-grow:0}.swagger-ui .flex-grow-1-ns{flex-grow:1}.swagger-ui .flex-shrink-0-ns{flex-shrink:0}.swagger-ui .flex-shrink-1-ns{flex-shrink:1}}@media screen and (min-width:30em)and (max-width:60em){.swagger-ui .flex-m{display:flex}.swagger-ui .inline-flex-m{display:inline-flex}.swagger-ui .flex-auto-m{flex:1 1 auto;min-height:0;min-width:0}.swagger-ui .flex-none-m{flex:none}.swagger-ui .flex-column-m{flex-direction:column}.swagger-ui .flex-row-m{flex-direction:row}.swagger-ui .flex-wrap-m{flex-wrap:wrap}.swagger-ui .flex-nowrap-m{flex-wrap:nowrap}.swagger-ui .flex-wrap-reverse-m{flex-wrap:wrap-reverse}.swagger-ui .flex-column-reverse-m{flex-direction:column-reverse}.swagger-ui .flex-row-reverse-m{flex-direction:row-reverse}.swagger-ui .items-start-m{align-items:flex-start}.swagger-ui .items-end-m{align-items:flex-end}.swagger-ui .items-center-m{align-items:center}.swagger-ui .items-baseline-m{align-items:baseline}.swagger-ui .items-stretch-m{align-items:stretch}.swagger-ui .self-start-m{align-self:flex-start}.swagger-ui .self-end-m{align-self:flex-end}.swagger-ui .self-center-m{align-self:center}.swagger-ui .self-baseline-m{align-self:baseline}.swagger-ui .self-stretch-m{align-self:stretch}.swagger-ui .justify-start-m{justify-content:flex-start}.swagger-ui .justify-end-m{justify-content:flex-end}.swagger-ui .justify-center-m{justify-content:center}.swagger-ui .justify-between-m{justify-content:space-between}.swagger-ui .justify-around-m{justify-content:space-around}.swagger-ui .content-start-m{align-content:flex-start}.swagger-ui .content-end-m{align-content:flex-end}.swagger-ui .content-center-m{align-content:center}.swagger-ui .content-between-m{align-content:space-between}.swagger-ui .content-around-m{align-content:space-around}.swagger-ui .content-stretch-m{align-content:stretch}.swagger-ui .order-0-m{order:0}.swagger-ui .order-1-m{order:1}.swagger-ui .order-2-m{order:2}.swagger-ui .order-3-m{order:3}.swagger-ui .order-4-m{order:4}.swagger-ui .order-5-m{order:5}.swagger-ui .order-6-m{order:6}.swagger-ui .order-7-m{order:7}.swagger-ui .order-8-m{order:8}.swagger-ui .order-last-m{order:99999}.swagger-ui .flex-grow-0-m{flex-grow:0}.swagger-ui .flex-grow-1-m{flex-grow:1}.swagger-ui .flex-shrink-0-m{flex-shrink:0}.swagger-ui .flex-shrink-1-m{flex-shrink:1}}@media screen and (min-width:60em){.swagger-ui .flex-l{display:flex}.swagger-ui .inline-flex-l{display:inline-flex}.swagger-ui .flex-auto-l{flex:1 1 auto;min-height:0;min-width:0}.swagger-ui .flex-none-l{flex:none}.swagger-ui .flex-column-l{flex-direction:column}.swagger-ui .flex-row-l{flex-direction:row}.swagger-ui .flex-wrap-l{flex-wrap:wrap}.swagger-ui .flex-nowrap-l{flex-wrap:nowrap}.swagger-ui .flex-wrap-reverse-l{flex-wrap:wrap-reverse}.swagger-ui .flex-column-reverse-l{flex-direction:column-reverse}.swagger-ui .flex-row-reverse-l{flex-direction:row-reverse}.swagger-ui .items-start-l{align-items:flex-start}.swagger-ui .items-end-l{align-items:flex-end}.swagger-ui .items-center-l{align-items:center}.swagger-ui .items-baseline-l{align-items:baseline}.swagger-ui .items-stretch-l{align-items:stretch}.swagger-ui .self-start-l{align-self:flex-start}.swagger-ui .self-end-l{align-self:flex-end}.swagger-ui .self-center-l{align-self:center}.swagger-ui .self-baseline-l{align-self:baseline}.swagger-ui .self-stretch-l{align-self:stretch}.swagger-ui .justify-start-l{justify-content:flex-start}.swagger-ui .justify-end-l{justify-content:flex-end}.swagger-ui .justify-center-l{justify-content:center}.swagger-ui .justify-between-l{justify-content:space-between}.swagger-ui .justify-around-l{justify-content:space-around}.swagger-ui .content-start-l{align-content:flex-start}.swagger-ui .content-end-l{align-content:flex-end}.swagger-ui .content-center-l{align-content:center}.swagger-ui .content-between-l{align-content:space-between}.swagger-ui .content-around-l{align-content:space-around}.swagger-ui .content-stretch-l{align-content:stretch}.swagger-ui .order-0-l{order:0}.swagger-ui .order-1-l{order:1}.swagger-ui .order-2-l{order:2}.swagger-ui .order-3-l{order:3}.swagger-ui .order-4-l{order:4}.swagger-ui .order-5-l{order:5}.swagger-ui .order-6-l{order:6}.swagger-ui .order-7-l{order:7}.swagger-ui .order-8-l{order:8}.swagger-ui .order-last-l{order:99999}.swagger-ui .flex-grow-0-l{flex-grow:0}.swagger-ui .flex-grow-1-l{flex-grow:1}.swagger-ui .flex-shrink-0-l{flex-shrink:0}.swagger-ui .flex-shrink-1-l{flex-shrink:1}}.swagger-ui .dn{display:none}.swagger-ui .di{display:inline}.swagger-ui .db{display:block}.swagger-ui .dib{display:inline-block}.swagger-ui .dit{display:inline-table}.swagger-ui .dt{display:table}.swagger-ui .dtc{display:table-cell}.swagger-ui .dt-row{display:table-row}.swagger-ui .dt-row-group{display:table-row-group}.swagger-ui .dt-column{display:table-column}.swagger-ui .dt-column-group{display:table-column-group}.swagger-ui .dt--fixed{table-layout:fixed;width:100%}@media screen and (min-width:30em){.swagger-ui .dn-ns{display:none}.swagger-ui .di-ns{display:inline}.swagger-ui .db-ns{display:block}.swagger-ui .dib-ns{display:inline-block}.swagger-ui .dit-ns{display:inline-table}.swagger-ui .dt-ns{display:table}.swagger-ui .dtc-ns{display:table-cell}.swagger-ui .dt-row-ns{display:table-row}.swagger-ui .dt-row-group-ns{display:table-row-group}.swagger-ui .dt-column-ns{display:table-column}.swagger-ui .dt-column-group-ns{display:table-column-group}.swagger-ui .dt--fixed-ns{table-layout:fixed;width:100%}}@media screen and (min-width:30em)and (max-width:60em){.swagger-ui .dn-m{display:none}.swagger-ui .di-m{display:inline}.swagger-ui .db-m{display:block}.swagger-ui .dib-m{display:inline-block}.swagger-ui .dit-m{display:inline-table}.swagger-ui .dt-m{display:table}.swagger-ui .dtc-m{display:table-cell}.swagger-ui .dt-row-m{display:table-row}.swagger-ui .dt-row-group-m{display:table-row-group}.swagger-ui .dt-column-m{display:table-column}.swagger-ui .dt-column-group-m{display:table-column-group}.swagger-ui .dt--fixed-m{table-layout:fixed;width:100%}}@media screen and (min-width:60em){.swagger-ui .dn-l{display:none}.swagger-ui .di-l{display:inline}.swagger-ui .db-l{display:block}.swagger-ui .dib-l{display:inline-block}.swagger-ui .dit-l{display:inline-table}.swagger-ui .dt-l{display:table}.swagger-ui .dtc-l{display:table-cell}.swagger-ui .dt-row-l{display:table-row}.swagger-ui .dt-row-group-l{display:table-row-group}.swagger-ui .dt-column-l{display:table-column}.swagger-ui .dt-column-group-l{display:table-column-group}.swagger-ui .dt--fixed-l{table-layout:fixed;width:100%}}.swagger-ui .fl{_display:inline;float:left}.swagger-ui .fr{_display:inline;float:right}.swagger-ui .fn{float:none}@media screen and (min-width:30em){.swagger-ui .fl-ns{_display:inline;float:left}.swagger-ui .fr-ns{_display:inline;float:right}.swagger-ui .fn-ns{float:none}}@media screen and (min-width:30em)and (max-width:60em){.swagger-ui .fl-m{_display:inline;float:left}.swagger-ui .fr-m{_display:inline;float:right}.swagger-ui .fn-m{float:none}}@media screen and (min-width:60em){.swagger-ui .fl-l{_display:inline;float:left}.swagger-ui .fr-l{_display:inline;float:right}.swagger-ui .fn-l{float:none}}.swagger-ui .sans-serif{font-family:-apple-system,BlinkMacSystemFont,avenir next,avenir,helvetica,helvetica neue,ubuntu,roboto,noto,segoe ui,arial,sans-serif}.swagger-ui .serif{font-family:georgia,serif}.swagger-ui .system-sans-serif{font-family:sans-serif}.swagger-ui .system-serif{font-family:serif}.swagger-ui .code,.swagger-ui code{font-family:Consolas,monaco,monospace}.swagger-ui .courier{font-family:Courier Next,courier,monospace}.swagger-ui .helvetica{font-family:helvetica neue,helvetica,sans-serif}.swagger-ui .avenir{font-family:avenir next,avenir,sans-serif}.swagger-ui .athelas{font-family:athelas,georgia,serif}.swagger-ui .georgia{font-family:georgia,serif}.swagger-ui .times{font-family:times,serif}.swagger-ui .bodoni{font-family:Bodoni MT,serif}.swagger-ui .calisto{font-family:Calisto MT,serif}.swagger-ui .garamond{font-family:garamond,serif}.swagger-ui .baskerville{font-family:baskerville,serif}.swagger-ui .i{font-style:italic}.swagger-ui .fs-normal{font-style:normal}@media screen and (min-width:30em){.swagger-ui .i-ns{font-style:italic}.swagger-ui .fs-normal-ns{font-style:normal}}@media screen and (min-width:30em)and (max-width:60em){.swagger-ui .i-m{font-style:italic}.swagger-ui .fs-normal-m{font-style:normal}}@media screen and (min-width:60em){.swagger-ui .i-l{font-style:italic}.swagger-ui .fs-normal-l{font-style:normal}}.swagger-ui .normal{font-weight:400}.swagger-ui .b{font-weight:700}.swagger-ui .fw1{font-weight:100}.swagger-ui .fw2{font-weight:200}.swagger-ui .fw3{font-weight:300}.swagger-ui .fw4{font-weight:400}.swagger-ui .fw5{font-weight:500}.swagger-ui .fw6{font-weight:600}.swagger-ui .fw7{font-weight:700}.swagger-ui .fw8{font-weight:800}.swagger-ui .fw9{font-weight:900}@media screen and (min-width:30em){.swagger-ui .normal-ns{font-weight:400}.swagger-ui .b-ns{font-weight:700}.swagger-ui .fw1-ns{font-weight:100}.swagger-ui .fw2-ns{font-weight:200}.swagger-ui .fw3-ns{font-weight:300}.swagger-ui .fw4-ns{font-weight:400}.swagger-ui .fw5-ns{font-weight:500}.swagger-ui .fw6-ns{font-weight:600}.swagger-ui .fw7-ns{font-weight:700}.swagger-ui .fw8-ns{font-weight:800}.swagger-ui .fw9-ns{font-weight:900}}@media screen and (min-width:30em)and (max-width:60em){.swagger-ui .normal-m{font-weight:400}.swagger-ui .b-m{font-weight:700}.swagger-ui .fw1-m{font-weight:100}.swagger-ui .fw2-m{font-weight:200}.swagger-ui .fw3-m{font-weight:300}.swagger-ui .fw4-m{font-weight:400}.swagger-ui .fw5-m{font-weight:500}.swagger-ui .fw6-m{font-weight:600}.swagger-ui .fw7-m{font-weight:700}.swagger-ui .fw8-m{font-weight:800}.swagger-ui .fw9-m{font-weight:900}}@media screen and (min-width:60em){.swagger-ui .normal-l{font-weight:400}.swagger-ui .b-l{font-weight:700}.swagger-ui .fw1-l{font-weight:100}.swagger-ui .fw2-l{font-weight:200}.swagger-ui .fw3-l{font-weight:300}.swagger-ui .fw4-l{font-weight:400}.swagger-ui .fw5-l{font-weight:500}.swagger-ui .fw6-l{font-weight:600}.swagger-ui .fw7-l{font-weight:700}.swagger-ui .fw8-l{font-weight:800}.swagger-ui .fw9-l{font-weight:900}}.swagger-ui .input-reset{-webkit-appearance:none;-moz-appearance:none}.swagger-ui .button-reset::-moz-focus-inner,.swagger-ui .input-reset::-moz-focus-inner{border:0;padding:0}.swagger-ui .h1{height:1rem}.swagger-ui .h2{height:2rem}.swagger-ui .h3{height:4rem}.swagger-ui .h4{height:8rem}.swagger-ui .h5{height:16rem}.swagger-ui .h-25{height:25%}.swagger-ui .h-50{height:50%}.swagger-ui .h-75{height:75%}.swagger-ui .h-100{height:100%}.swagger-ui .min-h-100{min-height:100%}.swagger-ui .vh-25{height:25vh}.swagger-ui .vh-50{height:50vh}.swagger-ui .vh-75{height:75vh}.swagger-ui .vh-100{height:100vh}.swagger-ui .min-vh-100{min-height:100vh}.swagger-ui .h-auto{height:auto}.swagger-ui .h-inherit{height:inherit}@media screen and (min-width:30em){.swagger-ui .h1-ns{height:1rem}.swagger-ui .h2-ns{height:2rem}.swagger-ui .h3-ns{height:4rem}.swagger-ui .h4-ns{height:8rem}.swagger-ui .h5-ns{height:16rem}.swagger-ui .h-25-ns{height:25%}.swagger-ui .h-50-ns{height:50%}.swagger-ui .h-75-ns{height:75%}.swagger-ui .h-100-ns{height:100%}.swagger-ui .min-h-100-ns{min-height:100%}.swagger-ui .vh-25-ns{height:25vh}.swagger-ui .vh-50-ns{height:50vh}.swagger-ui .vh-75-ns{height:75vh}.swagger-ui .vh-100-ns{height:100vh}.swagger-ui .min-vh-100-ns{min-height:100vh}.swagger-ui .h-auto-ns{height:auto}.swagger-ui .h-inherit-ns{height:inherit}}@media screen and (min-width:30em)and (max-width:60em){.swagger-ui .h1-m{height:1rem}.swagger-ui .h2-m{height:2rem}.swagger-ui .h3-m{height:4rem}.swagger-ui .h4-m{height:8rem}.swagger-ui .h5-m{height:16rem}.swagger-ui .h-25-m{height:25%}.swagger-ui .h-50-m{height:50%}.swagger-ui .h-75-m{height:75%}.swagger-ui .h-100-m{height:100%}.swagger-ui .min-h-100-m{min-height:100%}.swagger-ui .vh-25-m{height:25vh}.swagger-ui .vh-50-m{height:50vh}.swagger-ui .vh-75-m{height:75vh}.swagger-ui .vh-100-m{height:100vh}.swagger-ui .min-vh-100-m{min-height:100vh}.swagger-ui .h-auto-m{height:auto}.swagger-ui .h-inherit-m{height:inherit}}@media screen and (min-width:60em){.swagger-ui .h1-l{height:1rem}.swagger-ui .h2-l{height:2rem}.swagger-ui .h3-l{height:4rem}.swagger-ui .h4-l{height:8rem}.swagger-ui .h5-l{height:16rem}.swagger-ui .h-25-l{height:25%}.swagger-ui .h-50-l{height:50%}.swagger-ui .h-75-l{height:75%}.swagger-ui .h-100-l{height:100%}.swagger-ui .min-h-100-l{min-height:100%}.swagger-ui .vh-25-l{height:25vh}.swagger-ui .vh-50-l{height:50vh}.swagger-ui .vh-75-l{height:75vh}.swagger-ui .vh-100-l{height:100vh}.swagger-ui .min-vh-100-l{min-height:100vh}.swagger-ui .h-auto-l{height:auto}.swagger-ui .h-inherit-l{height:inherit}}.swagger-ui .tracked{letter-spacing:.1em}.swagger-ui .tracked-tight{letter-spacing:-.05em}.swagger-ui .tracked-mega{letter-spacing:.25em}@media screen and (min-width:30em){.swagger-ui .tracked-ns{letter-spacing:.1em}.swagger-ui .tracked-tight-ns{letter-spacing:-.05em}.swagger-ui .tracked-mega-ns{letter-spacing:.25em}}@media screen and (min-width:30em)and (max-width:60em){.swagger-ui .tracked-m{letter-spacing:.1em}.swagger-ui .tracked-tight-m{letter-spacing:-.05em}.swagger-ui .tracked-mega-m{letter-spacing:.25em}}@media screen and (min-width:60em){.swagger-ui .tracked-l{letter-spacing:.1em}.swagger-ui .tracked-tight-l{letter-spacing:-.05em}.swagger-ui .tracked-mega-l{letter-spacing:.25em}}.swagger-ui .lh-solid{line-height:1}.swagger-ui .lh-title{line-height:1.25}.swagger-ui .lh-copy{line-height:1.5}@media screen and (min-width:30em){.swagger-ui .lh-solid-ns{line-height:1}.swagger-ui .lh-title-ns{line-height:1.25}.swagger-ui .lh-copy-ns{line-height:1.5}}@media screen and (min-width:30em)and (max-width:60em){.swagger-ui .lh-solid-m{line-height:1}.swagger-ui .lh-title-m{line-height:1.25}.swagger-ui .lh-copy-m{line-height:1.5}}@media screen and (min-width:60em){.swagger-ui .lh-solid-l{line-height:1}.swagger-ui .lh-title-l{line-height:1.25}.swagger-ui .lh-copy-l{line-height:1.5}}.swagger-ui .link{-webkit-text-decoration:none;text-decoration:none}.swagger-ui .link,.swagger-ui .link:active,.swagger-ui .link:focus,.swagger-ui .link:hover,.swagger-ui .link:link,.swagger-ui .link:visited{transition:color .15s ease-in}.swagger-ui .link:focus{outline:1px dotted currentColor}.swagger-ui .list{list-style-type:none}.swagger-ui .mw-100{max-width:100%}.swagger-ui .mw1{max-width:1rem}.swagger-ui .mw2{max-width:2rem}.swagger-ui .mw3{max-width:4rem}.swagger-ui .mw4{max-width:8rem}.swagger-ui .mw5{max-width:16rem}.swagger-ui .mw6{max-width:32rem}.swagger-ui .mw7{max-width:48rem}.swagger-ui .mw8{max-width:64rem}.swagger-ui .mw9{max-width:96rem}.swagger-ui .mw-none{max-width:none}@media screen and (min-width:30em){.swagger-ui .mw-100-ns{max-width:100%}.swagger-ui .mw1-ns{max-width:1rem}.swagger-ui .mw2-ns{max-width:2rem}.swagger-ui .mw3-ns{max-width:4rem}.swagger-ui .mw4-ns{max-width:8rem}.swagger-ui .mw5-ns{max-width:16rem}.swagger-ui .mw6-ns{max-width:32rem}.swagger-ui .mw7-ns{max-width:48rem}.swagger-ui .mw8-ns{max-width:64rem}.swagger-ui .mw9-ns{max-width:96rem}.swagger-ui .mw-none-ns{max-width:none}}@media screen and (min-width:30em)and (max-width:60em){.swagger-ui .mw-100-m{max-width:100%}.swagger-ui .mw1-m{max-width:1rem}.swagger-ui .mw2-m{max-width:2rem}.swagger-ui .mw3-m{max-width:4rem}.swagger-ui .mw4-m{max-width:8rem}.swagger-ui .mw5-m{max-width:16rem}.swagger-ui .mw6-m{max-width:32rem}.swagger-ui .mw7-m{max-width:48rem}.swagger-ui .mw8-m{max-width:64rem}.swagger-ui .mw9-m{max-width:96rem}.swagger-ui .mw-none-m{max-width:none}}@media screen and (min-width:60em){.swagger-ui .mw-100-l{max-width:100%}.swagger-ui .mw1-l{max-width:1rem}.swagger-ui .mw2-l{max-width:2rem}.swagger-ui .mw3-l{max-width:4rem}.swagger-ui .mw4-l{max-width:8rem}.swagger-ui .mw5-l{max-width:16rem}.swagger-ui .mw6-l{max-width:32rem}.swagger-ui .mw7-l{max-width:48rem}.swagger-ui .mw8-l{max-width:64rem}.swagger-ui .mw9-l{max-width:96rem}.swagger-ui .mw-none-l{max-width:none}}.swagger-ui .w1{width:1rem}.swagger-ui .w2{width:2rem}.swagger-ui .w3{width:4rem}.swagger-ui .w4{width:8rem}.swagger-ui .w5{width:16rem}.swagger-ui .w-10{width:10%}.swagger-ui .w-20{width:20%}.swagger-ui .w-25{width:25%}.swagger-ui .w-30{width:30%}.swagger-ui .w-33{width:33%}.swagger-ui .w-34{width:34%}.swagger-ui .w-40{width:40%}.swagger-ui .w-50{width:50%}.swagger-ui .w-60{width:60%}.swagger-ui .w-70{width:70%}.swagger-ui .w-75{width:75%}.swagger-ui .w-80{width:80%}.swagger-ui .w-90{width:90%}.swagger-ui .w-100{width:100%}.swagger-ui .w-third{width:33.3333333333%}.swagger-ui .w-two-thirds{width:66.6666666667%}.swagger-ui .w-auto{width:auto}@media screen and (min-width:30em){.swagger-ui .w1-ns{width:1rem}.swagger-ui .w2-ns{width:2rem}.swagger-ui .w3-ns{width:4rem}.swagger-ui .w4-ns{width:8rem}.swagger-ui .w5-ns{width:16rem}.swagger-ui .w-10-ns{width:10%}.swagger-ui .w-20-ns{width:20%}.swagger-ui .w-25-ns{width:25%}.swagger-ui .w-30-ns{width:30%}.swagger-ui .w-33-ns{width:33%}.swagger-ui .w-34-ns{width:34%}.swagger-ui .w-40-ns{width:40%}.swagger-ui .w-50-ns{width:50%}.swagger-ui .w-60-ns{width:60%}.swagger-ui .w-70-ns{width:70%}.swagger-ui .w-75-ns{width:75%}.swagger-ui .w-80-ns{width:80%}.swagger-ui .w-90-ns{width:90%}.swagger-ui .w-100-ns{width:100%}.swagger-ui .w-third-ns{width:33.3333333333%}.swagger-ui .w-two-thirds-ns{width:66.6666666667%}.swagger-ui .w-auto-ns{width:auto}}@media screen and (min-width:30em)and (max-width:60em){.swagger-ui .w1-m{width:1rem}.swagger-ui .w2-m{width:2rem}.swagger-ui .w3-m{width:4rem}.swagger-ui .w4-m{width:8rem}.swagger-ui .w5-m{width:16rem}.swagger-ui .w-10-m{width:10%}.swagger-ui .w-20-m{width:20%}.swagger-ui .w-25-m{width:25%}.swagger-ui .w-30-m{width:30%}.swagger-ui .w-33-m{width:33%}.swagger-ui .w-34-m{width:34%}.swagger-ui .w-40-m{width:40%}.swagger-ui .w-50-m{width:50%}.swagger-ui .w-60-m{width:60%}.swagger-ui .w-70-m{width:70%}.swagger-ui .w-75-m{width:75%}.swagger-ui .w-80-m{width:80%}.swagger-ui .w-90-m{width:90%}.swagger-ui .w-100-m{width:100%}.swagger-ui .w-third-m{width:33.3333333333%}.swagger-ui .w-two-thirds-m{width:66.6666666667%}.swagger-ui .w-auto-m{width:auto}}@media screen and (min-width:60em){.swagger-ui .w1-l{width:1rem}.swagger-ui .w2-l{width:2rem}.swagger-ui .w3-l{width:4rem}.swagger-ui .w4-l{width:8rem}.swagger-ui .w5-l{width:16rem}.swagger-ui .w-10-l{width:10%}.swagger-ui .w-20-l{width:20%}.swagger-ui .w-25-l{width:25%}.swagger-ui .w-30-l{width:30%}.swagger-ui .w-33-l{width:33%}.swagger-ui .w-34-l{width:34%}.swagger-ui .w-40-l{width:40%}.swagger-ui .w-50-l{width:50%}.swagger-ui .w-60-l{width:60%}.swagger-ui .w-70-l{width:70%}.swagger-ui .w-75-l{width:75%}.swagger-ui .w-80-l{width:80%}.swagger-ui .w-90-l{width:90%}.swagger-ui .w-100-l{width:100%}.swagger-ui .w-third-l{width:33.3333333333%}.swagger-ui .w-two-thirds-l{width:66.6666666667%}.swagger-ui .w-auto-l{width:auto}}.swagger-ui .overflow-visible{overflow:visible}.swagger-ui .overflow-hidden{overflow:hidden}.swagger-ui .overflow-scroll{overflow:scroll}.swagger-ui .overflow-auto{overflow:auto}.swagger-ui .overflow-x-visible{overflow-x:visible}.swagger-ui .overflow-x-hidden{overflow-x:hidden}.swagger-ui .overflow-x-scroll{overflow-x:scroll}.swagger-ui .overflow-x-auto{overflow-x:auto}.swagger-ui .overflow-y-visible{overflow-y:visible}.swagger-ui .overflow-y-hidden{overflow-y:hidden}.swagger-ui .overflow-y-scroll{overflow-y:scroll}.swagger-ui .overflow-y-auto{overflow-y:auto}@media screen and (min-width:30em){.swagger-ui .overflow-visible-ns{overflow:visible}.swagger-ui .overflow-hidden-ns{overflow:hidden}.swagger-ui .overflow-scroll-ns{overflow:scroll}.swagger-ui .overflow-auto-ns{overflow:auto}.swagger-ui .overflow-x-visible-ns{overflow-x:visible}.swagger-ui .overflow-x-hidden-ns{overflow-x:hidden}.swagger-ui .overflow-x-scroll-ns{overflow-x:scroll}.swagger-ui .overflow-x-auto-ns{overflow-x:auto}.swagger-ui .overflow-y-visible-ns{overflow-y:visible}.swagger-ui .overflow-y-hidden-ns{overflow-y:hidden}.swagger-ui .overflow-y-scroll-ns{overflow-y:scroll}.swagger-ui .overflow-y-auto-ns{overflow-y:auto}}@media screen and (min-width:30em)and (max-width:60em){.swagger-ui .overflow-visible-m{overflow:visible}.swagger-ui .overflow-hidden-m{overflow:hidden}.swagger-ui .overflow-scroll-m{overflow:scroll}.swagger-ui .overflow-auto-m{overflow:auto}.swagger-ui .overflow-x-visible-m{overflow-x:visible}.swagger-ui .overflow-x-hidden-m{overflow-x:hidden}.swagger-ui .overflow-x-scroll-m{overflow-x:scroll}.swagger-ui .overflow-x-auto-m{overflow-x:auto}.swagger-ui .overflow-y-visible-m{overflow-y:visible}.swagger-ui .overflow-y-hidden-m{overflow-y:hidden}.swagger-ui .overflow-y-scroll-m{overflow-y:scroll}.swagger-ui .overflow-y-auto-m{overflow-y:auto}}@media screen and (min-width:60em){.swagger-ui .overflow-visible-l{overflow:visible}.swagger-ui .overflow-hidden-l{overflow:hidden}.swagger-ui .overflow-scroll-l{overflow:scroll}.swagger-ui .overflow-auto-l{overflow:auto}.swagger-ui .overflow-x-visible-l{overflow-x:visible}.swagger-ui .overflow-x-hidden-l{overflow-x:hidden}.swagger-ui .overflow-x-scroll-l{overflow-x:scroll}.swagger-ui .overflow-x-auto-l{overflow-x:auto}.swagger-ui .overflow-y-visible-l{overflow-y:visible}.swagger-ui .overflow-y-hidden-l{overflow-y:hidden}.swagger-ui .overflow-y-scroll-l{overflow-y:scroll}.swagger-ui .overflow-y-auto-l{overflow-y:auto}}.swagger-ui .static{position:static}.swagger-ui .relative{position:relative}.swagger-ui .absolute{position:absolute}.swagger-ui .fixed{position:fixed}@media screen and (min-width:30em){.swagger-ui .static-ns{position:static}.swagger-ui .relative-ns{position:relative}.swagger-ui .absolute-ns{position:absolute}.swagger-ui .fixed-ns{position:fixed}}@media screen and (min-width:30em)and (max-width:60em){.swagger-ui .static-m{position:static}.swagger-ui .relative-m{position:relative}.swagger-ui .absolute-m{position:absolute}.swagger-ui .fixed-m{position:fixed}}@media screen and (min-width:60em){.swagger-ui .static-l{position:static}.swagger-ui .relative-l{position:relative}.swagger-ui .absolute-l{position:absolute}.swagger-ui .fixed-l{position:fixed}}.swagger-ui .o-100{opacity:1}.swagger-ui .o-90{opacity:.9}.swagger-ui .o-80{opacity:.8}.swagger-ui .o-70{opacity:.7}.swagger-ui .o-60{opacity:.6}.swagger-ui .o-50{opacity:.5}.swagger-ui .o-40{opacity:.4}.swagger-ui .o-30{opacity:.3}.swagger-ui .o-20{opacity:.2}.swagger-ui .o-10{opacity:.1}.swagger-ui .o-05{opacity:.05}.swagger-ui .o-025{opacity:.025}.swagger-ui .o-0{opacity:0}.swagger-ui .rotate-45{transform:rotate(45deg)}.swagger-ui .rotate-90{transform:rotate(90deg)}.swagger-ui .rotate-135{transform:rotate(135deg)}.swagger-ui .rotate-180{transform:rotate(180deg)}.swagger-ui .rotate-225{transform:rotate(225deg)}.swagger-ui .rotate-270{transform:rotate(270deg)}.swagger-ui .rotate-315{transform:rotate(315deg)}@media screen and (min-width:30em){.swagger-ui .rotate-45-ns{transform:rotate(45deg)}.swagger-ui .rotate-90-ns{transform:rotate(90deg)}.swagger-ui .rotate-135-ns{transform:rotate(135deg)}.swagger-ui .rotate-180-ns{transform:rotate(180deg)}.swagger-ui .rotate-225-ns{transform:rotate(225deg)}.swagger-ui .rotate-270-ns{transform:rotate(270deg)}.swagger-ui .rotate-315-ns{transform:rotate(315deg)}}@media screen and (min-width:30em)and (max-width:60em){.swagger-ui .rotate-45-m{transform:rotate(45deg)}.swagger-ui .rotate-90-m{transform:rotate(90deg)}.swagger-ui .rotate-135-m{transform:rotate(135deg)}.swagger-ui .rotate-180-m{transform:rotate(180deg)}.swagger-ui .rotate-225-m{transform:rotate(225deg)}.swagger-ui .rotate-270-m{transform:rotate(270deg)}.swagger-ui .rotate-315-m{transform:rotate(315deg)}}@media screen and (min-width:60em){.swagger-ui .rotate-45-l{transform:rotate(45deg)}.swagger-ui .rotate-90-l{transform:rotate(90deg)}.swagger-ui .rotate-135-l{transform:rotate(135deg)}.swagger-ui .rotate-180-l{transform:rotate(180deg)}.swagger-ui .rotate-225-l{transform:rotate(225deg)}.swagger-ui .rotate-270-l{transform:rotate(270deg)}.swagger-ui .rotate-315-l{transform:rotate(315deg)}}.swagger-ui .black-90{color:rgba(0,0,0,.9)}.swagger-ui .black-80{color:rgba(0,0,0,.8)}.swagger-ui .black-70{color:rgba(0,0,0,.7)}.swagger-ui .black-60{color:rgba(0,0,0,.6)}.swagger-ui .black-50{color:rgba(0,0,0,.5)}.swagger-ui .black-40{color:rgba(0,0,0,.4)}.swagger-ui .black-30{color:rgba(0,0,0,.3)}.swagger-ui .black-20{color:rgba(0,0,0,.2)}.swagger-ui .black-10{color:rgba(0,0,0,.1)}.swagger-ui .black-05{color:rgba(0,0,0,.05)}.swagger-ui .white-90{color:hsla(0,0%,100%,.9)}.swagger-ui .white-80{color:hsla(0,0%,100%,.8)}.swagger-ui .white-70{color:hsla(0,0%,100%,.7)}.swagger-ui .white-60{color:hsla(0,0%,100%,.6)}.swagger-ui .white-50{color:hsla(0,0%,100%,.5)}.swagger-ui .white-40{color:hsla(0,0%,100%,.4)}.swagger-ui .white-30{color:hsla(0,0%,100%,.3)}.swagger-ui .white-20{color:hsla(0,0%,100%,.2)}.swagger-ui .white-10{color:hsla(0,0%,100%,.1)}.swagger-ui .black{color:#000}.swagger-ui .near-black{color:#111}.swagger-ui .dark-gray{color:#333}.swagger-ui .mid-gray{color:#555}.swagger-ui .gray{color:#777}.swagger-ui .silver{color:#999}.swagger-ui .light-silver{color:#aaa}.swagger-ui .moon-gray{color:#ccc}.swagger-ui .light-gray{color:#eee}.swagger-ui .near-white{color:#f4f4f4}.swagger-ui .white{color:#fff}.swagger-ui .dark-red{color:#e7040f}.swagger-ui .red{color:#ff4136}.swagger-ui .light-red{color:#ff725c}.swagger-ui .orange{color:#ff6300}.swagger-ui .gold{color:#ffb700}.swagger-ui .yellow{color:gold}.swagger-ui .light-yellow{color:#fbf1a9}.swagger-ui .purple{color:#5e2ca5}.swagger-ui .light-purple{color:#a463f2}.swagger-ui .dark-pink{color:#d5008f}.swagger-ui .hot-pink{color:#ff41b4}.swagger-ui .pink{color:#ff80cc}.swagger-ui .light-pink{color:#ffa3d7}.swagger-ui .dark-green{color:#137752}.swagger-ui .green{color:#19a974}.swagger-ui .light-green{color:#9eebcf}.swagger-ui .navy{color:#001b44}.swagger-ui .dark-blue{color:#00449e}.swagger-ui .blue{color:#357edd}.swagger-ui .light-blue{color:#96ccff}.swagger-ui .lightest-blue{color:#cdecff}.swagger-ui .washed-blue{color:#f6fffe}.swagger-ui .washed-green{color:#e8fdf5}.swagger-ui .washed-yellow{color:#fffceb}.swagger-ui .washed-red{color:#ffdfdf}.swagger-ui .color-inherit{color:inherit}.swagger-ui .bg-black-90{background-color:rgba(0,0,0,.9)}.swagger-ui .bg-black-80{background-color:rgba(0,0,0,.8)}.swagger-ui .bg-black-70{background-color:rgba(0,0,0,.7)}.swagger-ui .bg-black-60{background-color:rgba(0,0,0,.6)}.swagger-ui .bg-black-50{background-color:rgba(0,0,0,.5)}.swagger-ui .bg-black-40{background-color:rgba(0,0,0,.4)}.swagger-ui .bg-black-30{background-color:rgba(0,0,0,.3)}.swagger-ui .bg-black-20{background-color:rgba(0,0,0,.2)}.swagger-ui .bg-black-10{background-color:rgba(0,0,0,.1)}.swagger-ui .bg-black-05{background-color:rgba(0,0,0,.05)}.swagger-ui .bg-white-90{background-color:hsla(0,0%,100%,.9)}.swagger-ui .bg-white-80{background-color:hsla(0,0%,100%,.8)}.swagger-ui .bg-white-70{background-color:hsla(0,0%,100%,.7)}.swagger-ui .bg-white-60{background-color:hsla(0,0%,100%,.6)}.swagger-ui .bg-white-50{background-color:hsla(0,0%,100%,.5)}.swagger-ui .bg-white-40{background-color:hsla(0,0%,100%,.4)}.swagger-ui .bg-white-30{background-color:hsla(0,0%,100%,.3)}.swagger-ui .bg-white-20{background-color:hsla(0,0%,100%,.2)}.swagger-ui .bg-white-10{background-color:hsla(0,0%,100%,.1)}.swagger-ui .bg-black{background-color:#000}.swagger-ui .bg-near-black{background-color:#111}.swagger-ui .bg-dark-gray{background-color:#333}.swagger-ui .bg-mid-gray{background-color:#555}.swagger-ui .bg-gray{background-color:#777}.swagger-ui .bg-silver{background-color:#999}.swagger-ui .bg-light-silver{background-color:#aaa}.swagger-ui .bg-moon-gray{background-color:#ccc}.swagger-ui .bg-light-gray{background-color:#eee}.swagger-ui .bg-near-white{background-color:#f4f4f4}.swagger-ui .bg-white{background-color:#fff}.swagger-ui .bg-transparent{background-color:transparent}.swagger-ui .bg-dark-red{background-color:#e7040f}.swagger-ui .bg-red{background-color:#ff4136}.swagger-ui .bg-light-red{background-color:#ff725c}.swagger-ui .bg-orange{background-color:#ff6300}.swagger-ui .bg-gold{background-color:#ffb700}.swagger-ui .bg-yellow{background-color:gold}.swagger-ui .bg-light-yellow{background-color:#fbf1a9}.swagger-ui .bg-purple{background-color:#5e2ca5}.swagger-ui .bg-light-purple{background-color:#a463f2}.swagger-ui .bg-dark-pink{background-color:#d5008f}.swagger-ui .bg-hot-pink{background-color:#ff41b4}.swagger-ui .bg-pink{background-color:#ff80cc}.swagger-ui .bg-light-pink{background-color:#ffa3d7}.swagger-ui .bg-dark-green{background-color:#137752}.swagger-ui .bg-green{background-color:#19a974}.swagger-ui .bg-light-green{background-color:#9eebcf}.swagger-ui .bg-navy{background-color:#001b44}.swagger-ui .bg-dark-blue{background-color:#00449e}.swagger-ui .bg-blue{background-color:#357edd}.swagger-ui .bg-light-blue{background-color:#96ccff}.swagger-ui .bg-lightest-blue{background-color:#cdecff}.swagger-ui .bg-washed-blue{background-color:#f6fffe}.swagger-ui .bg-washed-green{background-color:#e8fdf5}.swagger-ui .bg-washed-yellow{background-color:#fffceb}.swagger-ui .bg-washed-red{background-color:#ffdfdf}.swagger-ui .bg-inherit{background-color:inherit}.swagger-ui .hover-black:focus,.swagger-ui .hover-black:hover{color:#000}.swagger-ui .hover-near-black:focus,.swagger-ui .hover-near-black:hover{color:#111}.swagger-ui .hover-dark-gray:focus,.swagger-ui .hover-dark-gray:hover{color:#333}.swagger-ui .hover-mid-gray:focus,.swagger-ui .hover-mid-gray:hover{color:#555}.swagger-ui .hover-gray:focus,.swagger-ui .hover-gray:hover{color:#777}.swagger-ui .hover-silver:focus,.swagger-ui .hover-silver:hover{color:#999}.swagger-ui .hover-light-silver:focus,.swagger-ui .hover-light-silver:hover{color:#aaa}.swagger-ui .hover-moon-gray:focus,.swagger-ui .hover-moon-gray:hover{color:#ccc}.swagger-ui .hover-light-gray:focus,.swagger-ui .hover-light-gray:hover{color:#eee}.swagger-ui .hover-near-white:focus,.swagger-ui .hover-near-white:hover{color:#f4f4f4}.swagger-ui .hover-white:focus,.swagger-ui .hover-white:hover{color:#fff}.swagger-ui .hover-black-90:focus,.swagger-ui .hover-black-90:hover{color:rgba(0,0,0,.9)}.swagger-ui .hover-black-80:focus,.swagger-ui .hover-black-80:hover{color:rgba(0,0,0,.8)}.swagger-ui .hover-black-70:focus,.swagger-ui .hover-black-70:hover{color:rgba(0,0,0,.7)}.swagger-ui .hover-black-60:focus,.swagger-ui .hover-black-60:hover{color:rgba(0,0,0,.6)}.swagger-ui .hover-black-50:focus,.swagger-ui .hover-black-50:hover{color:rgba(0,0,0,.5)}.swagger-ui .hover-black-40:focus,.swagger-ui .hover-black-40:hover{color:rgba(0,0,0,.4)}.swagger-ui .hover-black-30:focus,.swagger-ui .hover-black-30:hover{color:rgba(0,0,0,.3)}.swagger-ui .hover-black-20:focus,.swagger-ui .hover-black-20:hover{color:rgba(0,0,0,.2)}.swagger-ui .hover-black-10:focus,.swagger-ui .hover-black-10:hover{color:rgba(0,0,0,.1)}.swagger-ui .hover-white-90:focus,.swagger-ui .hover-white-90:hover{color:hsla(0,0%,100%,.9)}.swagger-ui .hover-white-80:focus,.swagger-ui .hover-white-80:hover{color:hsla(0,0%,100%,.8)}.swagger-ui .hover-white-70:focus,.swagger-ui .hover-white-70:hover{color:hsla(0,0%,100%,.7)}.swagger-ui .hover-white-60:focus,.swagger-ui .hover-white-60:hover{color:hsla(0,0%,100%,.6)}.swagger-ui .hover-white-50:focus,.swagger-ui .hover-white-50:hover{color:hsla(0,0%,100%,.5)}.swagger-ui .hover-white-40:focus,.swagger-ui .hover-white-40:hover{color:hsla(0,0%,100%,.4)}.swagger-ui .hover-white-30:focus,.swagger-ui .hover-white-30:hover{color:hsla(0,0%,100%,.3)}.swagger-ui .hover-white-20:focus,.swagger-ui .hover-white-20:hover{color:hsla(0,0%,100%,.2)}.swagger-ui .hover-white-10:focus,.swagger-ui .hover-white-10:hover{color:hsla(0,0%,100%,.1)}.swagger-ui .hover-inherit:focus,.swagger-ui .hover-inherit:hover{color:inherit}.swagger-ui .hover-bg-black:focus,.swagger-ui .hover-bg-black:hover{background-color:#000}.swagger-ui .hover-bg-near-black:focus,.swagger-ui .hover-bg-near-black:hover{background-color:#111}.swagger-ui .hover-bg-dark-gray:focus,.swagger-ui .hover-bg-dark-gray:hover{background-color:#333}.swagger-ui .hover-bg-mid-gray:focus,.swagger-ui .hover-bg-mid-gray:hover{background-color:#555}.swagger-ui .hover-bg-gray:focus,.swagger-ui .hover-bg-gray:hover{background-color:#777}.swagger-ui .hover-bg-silver:focus,.swagger-ui .hover-bg-silver:hover{background-color:#999}.swagger-ui .hover-bg-light-silver:focus,.swagger-ui .hover-bg-light-silver:hover{background-color:#aaa}.swagger-ui .hover-bg-moon-gray:focus,.swagger-ui .hover-bg-moon-gray:hover{background-color:#ccc}.swagger-ui .hover-bg-light-gray:focus,.swagger-ui .hover-bg-light-gray:hover{background-color:#eee}.swagger-ui .hover-bg-near-white:focus,.swagger-ui .hover-bg-near-white:hover{background-color:#f4f4f4}.swagger-ui .hover-bg-white:focus,.swagger-ui .hover-bg-white:hover{background-color:#fff}.swagger-ui .hover-bg-transparent:focus,.swagger-ui .hover-bg-transparent:hover{background-color:transparent}.swagger-ui .hover-bg-black-90:focus,.swagger-ui .hover-bg-black-90:hover{background-color:rgba(0,0,0,.9)}.swagger-ui .hover-bg-black-80:focus,.swagger-ui .hover-bg-black-80:hover{background-color:rgba(0,0,0,.8)}.swagger-ui .hover-bg-black-70:focus,.swagger-ui .hover-bg-black-70:hover{background-color:rgba(0,0,0,.7)}.swagger-ui .hover-bg-black-60:focus,.swagger-ui .hover-bg-black-60:hover{background-color:rgba(0,0,0,.6)}.swagger-ui .hover-bg-black-50:focus,.swagger-ui .hover-bg-black-50:hover{background-color:rgba(0,0,0,.5)}.swagger-ui .hover-bg-black-40:focus,.swagger-ui .hover-bg-black-40:hover{background-color:rgba(0,0,0,.4)}.swagger-ui .hover-bg-black-30:focus,.swagger-ui .hover-bg-black-30:hover{background-color:rgba(0,0,0,.3)}.swagger-ui .hover-bg-black-20:focus,.swagger-ui .hover-bg-black-20:hover{background-color:rgba(0,0,0,.2)}.swagger-ui .hover-bg-black-10:focus,.swagger-ui .hover-bg-black-10:hover{background-color:rgba(0,0,0,.1)}.swagger-ui .hover-bg-white-90:focus,.swagger-ui .hover-bg-white-90:hover{background-color:hsla(0,0%,100%,.9)}.swagger-ui .hover-bg-white-80:focus,.swagger-ui .hover-bg-white-80:hover{background-color:hsla(0,0%,100%,.8)}.swagger-ui .hover-bg-white-70:focus,.swagger-ui .hover-bg-white-70:hover{background-color:hsla(0,0%,100%,.7)}.swagger-ui .hover-bg-white-60:focus,.swagger-ui .hover-bg-white-60:hover{background-color:hsla(0,0%,100%,.6)}.swagger-ui .hover-bg-white-50:focus,.swagger-ui .hover-bg-white-50:hover{background-color:hsla(0,0%,100%,.5)}.swagger-ui .hover-bg-white-40:focus,.swagger-ui .hover-bg-white-40:hover{background-color:hsla(0,0%,100%,.4)}.swagger-ui .hover-bg-white-30:focus,.swagger-ui .hover-bg-white-30:hover{background-color:hsla(0,0%,100%,.3)}.swagger-ui .hover-bg-white-20:focus,.swagger-ui .hover-bg-white-20:hover{background-color:hsla(0,0%,100%,.2)}.swagger-ui .hover-bg-white-10:focus,.swagger-ui .hover-bg-white-10:hover{background-color:hsla(0,0%,100%,.1)}.swagger-ui .hover-dark-red:focus,.swagger-ui .hover-dark-red:hover{color:#e7040f}.swagger-ui .hover-red:focus,.swagger-ui .hover-red:hover{color:#ff4136}.swagger-ui .hover-light-red:focus,.swagger-ui .hover-light-red:hover{color:#ff725c}.swagger-ui .hover-orange:focus,.swagger-ui .hover-orange:hover{color:#ff6300}.swagger-ui .hover-gold:focus,.swagger-ui .hover-gold:hover{color:#ffb700}.swagger-ui .hover-yellow:focus,.swagger-ui .hover-yellow:hover{color:gold}.swagger-ui .hover-light-yellow:focus,.swagger-ui .hover-light-yellow:hover{color:#fbf1a9}.swagger-ui .hover-purple:focus,.swagger-ui .hover-purple:hover{color:#5e2ca5}.swagger-ui .hover-light-purple:focus,.swagger-ui .hover-light-purple:hover{color:#a463f2}.swagger-ui .hover-dark-pink:focus,.swagger-ui .hover-dark-pink:hover{color:#d5008f}.swagger-ui .hover-hot-pink:focus,.swagger-ui .hover-hot-pink:hover{color:#ff41b4}.swagger-ui .hover-pink:focus,.swagger-ui .hover-pink:hover{color:#ff80cc}.swagger-ui .hover-light-pink:focus,.swagger-ui .hover-light-pink:hover{color:#ffa3d7}.swagger-ui .hover-dark-green:focus,.swagger-ui .hover-dark-green:hover{color:#137752}.swagger-ui .hover-green:focus,.swagger-ui .hover-green:hover{color:#19a974}.swagger-ui .hover-light-green:focus,.swagger-ui .hover-light-green:hover{color:#9eebcf}.swagger-ui .hover-navy:focus,.swagger-ui .hover-navy:hover{color:#001b44}.swagger-ui .hover-dark-blue:focus,.swagger-ui .hover-dark-blue:hover{color:#00449e}.swagger-ui .hover-blue:focus,.swagger-ui .hover-blue:hover{color:#357edd}.swagger-ui .hover-light-blue:focus,.swagger-ui .hover-light-blue:hover{color:#96ccff}.swagger-ui .hover-lightest-blue:focus,.swagger-ui .hover-lightest-blue:hover{color:#cdecff}.swagger-ui .hover-washed-blue:focus,.swagger-ui .hover-washed-blue:hover{color:#f6fffe}.swagger-ui .hover-washed-green:focus,.swagger-ui .hover-washed-green:hover{color:#e8fdf5}.swagger-ui .hover-washed-yellow:focus,.swagger-ui .hover-washed-yellow:hover{color:#fffceb}.swagger-ui .hover-washed-red:focus,.swagger-ui .hover-washed-red:hover{color:#ffdfdf}.swagger-ui .hover-bg-dark-red:focus,.swagger-ui .hover-bg-dark-red:hover{background-color:#e7040f}.swagger-ui .hover-bg-red:focus,.swagger-ui .hover-bg-red:hover{background-color:#ff4136}.swagger-ui .hover-bg-light-red:focus,.swagger-ui .hover-bg-light-red:hover{background-color:#ff725c}.swagger-ui .hover-bg-orange:focus,.swagger-ui .hover-bg-orange:hover{background-color:#ff6300}.swagger-ui .hover-bg-gold:focus,.swagger-ui .hover-bg-gold:hover{background-color:#ffb700}.swagger-ui .hover-bg-yellow:focus,.swagger-ui .hover-bg-yellow:hover{background-color:gold}.swagger-ui .hover-bg-light-yellow:focus,.swagger-ui .hover-bg-light-yellow:hover{background-color:#fbf1a9}.swagger-ui .hover-bg-purple:focus,.swagger-ui .hover-bg-purple:hover{background-color:#5e2ca5}.swagger-ui .hover-bg-light-purple:focus,.swagger-ui .hover-bg-light-purple:hover{background-color:#a463f2}.swagger-ui .hover-bg-dark-pink:focus,.swagger-ui .hover-bg-dark-pink:hover{background-color:#d5008f}.swagger-ui .hover-bg-hot-pink:focus,.swagger-ui .hover-bg-hot-pink:hover{background-color:#ff41b4}.swagger-ui .hover-bg-pink:focus,.swagger-ui .hover-bg-pink:hover{background-color:#ff80cc}.swagger-ui .hover-bg-light-pink:focus,.swagger-ui .hover-bg-light-pink:hover{background-color:#ffa3d7}.swagger-ui .hover-bg-dark-green:focus,.swagger-ui .hover-bg-dark-green:hover{background-color:#137752}.swagger-ui .hover-bg-green:focus,.swagger-ui .hover-bg-green:hover{background-color:#19a974}.swagger-ui .hover-bg-light-green:focus,.swagger-ui .hover-bg-light-green:hover{background-color:#9eebcf}.swagger-ui .hover-bg-navy:focus,.swagger-ui .hover-bg-navy:hover{background-color:#001b44}.swagger-ui .hover-bg-dark-blue:focus,.swagger-ui .hover-bg-dark-blue:hover{background-color:#00449e}.swagger-ui .hover-bg-blue:focus,.swagger-ui .hover-bg-blue:hover{background-color:#357edd}.swagger-ui .hover-bg-light-blue:focus,.swagger-ui .hover-bg-light-blue:hover{background-color:#96ccff}.swagger-ui .hover-bg-lightest-blue:focus,.swagger-ui .hover-bg-lightest-blue:hover{background-color:#cdecff}.swagger-ui .hover-bg-washed-blue:focus,.swagger-ui .hover-bg-washed-blue:hover{background-color:#f6fffe}.swagger-ui .hover-bg-washed-green:focus,.swagger-ui .hover-bg-washed-green:hover{background-color:#e8fdf5}.swagger-ui .hover-bg-washed-yellow:focus,.swagger-ui .hover-bg-washed-yellow:hover{background-color:#fffceb}.swagger-ui .hover-bg-washed-red:focus,.swagger-ui .hover-bg-washed-red:hover{background-color:#ffdfdf}.swagger-ui .hover-bg-inherit:focus,.swagger-ui .hover-bg-inherit:hover{background-color:inherit}.swagger-ui .pa0{padding:0}.swagger-ui .pa1{padding:.25rem}.swagger-ui .pa2{padding:.5rem}.swagger-ui .pa3{padding:1rem}.swagger-ui .pa4{padding:2rem}.swagger-ui .pa5{padding:4rem}.swagger-ui .pa6{padding:8rem}.swagger-ui .pa7{padding:16rem}.swagger-ui .pl0{padding-left:0}.swagger-ui .pl1{padding-left:.25rem}.swagger-ui .pl2{padding-left:.5rem}.swagger-ui .pl3{padding-left:1rem}.swagger-ui .pl4{padding-left:2rem}.swagger-ui .pl5{padding-left:4rem}.swagger-ui .pl6{padding-left:8rem}.swagger-ui .pl7{padding-left:16rem}.swagger-ui .pr0{padding-right:0}.swagger-ui .pr1{padding-right:.25rem}.swagger-ui .pr2{padding-right:.5rem}.swagger-ui .pr3{padding-right:1rem}.swagger-ui .pr4{padding-right:2rem}.swagger-ui .pr5{padding-right:4rem}.swagger-ui .pr6{padding-right:8rem}.swagger-ui .pr7{padding-right:16rem}.swagger-ui .pb0{padding-bottom:0}.swagger-ui .pb1{padding-bottom:.25rem}.swagger-ui .pb2{padding-bottom:.5rem}.swagger-ui .pb3{padding-bottom:1rem}.swagger-ui .pb4{padding-bottom:2rem}.swagger-ui .pb5{padding-bottom:4rem}.swagger-ui .pb6{padding-bottom:8rem}.swagger-ui .pb7{padding-bottom:16rem}.swagger-ui .pt0{padding-top:0}.swagger-ui .pt1{padding-top:.25rem}.swagger-ui .pt2{padding-top:.5rem}.swagger-ui .pt3{padding-top:1rem}.swagger-ui .pt4{padding-top:2rem}.swagger-ui .pt5{padding-top:4rem}.swagger-ui .pt6{padding-top:8rem}.swagger-ui .pt7{padding-top:16rem}.swagger-ui .pv0{padding-bottom:0;padding-top:0}.swagger-ui .pv1{padding-bottom:.25rem;padding-top:.25rem}.swagger-ui .pv2{padding-bottom:.5rem;padding-top:.5rem}.swagger-ui .pv3{padding-bottom:1rem;padding-top:1rem}.swagger-ui .pv4{padding-bottom:2rem;padding-top:2rem}.swagger-ui .pv5{padding-bottom:4rem;padding-top:4rem}.swagger-ui .pv6{padding-bottom:8rem;padding-top:8rem}.swagger-ui .pv7{padding-bottom:16rem;padding-top:16rem}.swagger-ui .ph0{padding-left:0;padding-right:0}.swagger-ui .ph1{padding-left:.25rem;padding-right:.25rem}.swagger-ui .ph2{padding-left:.5rem;padding-right:.5rem}.swagger-ui .ph3{padding-left:1rem;padding-right:1rem}.swagger-ui .ph4{padding-left:2rem;padding-right:2rem}.swagger-ui .ph5{padding-left:4rem;padding-right:4rem}.swagger-ui .ph6{padding-left:8rem;padding-right:8rem}.swagger-ui .ph7{padding-left:16rem;padding-right:16rem}.swagger-ui .ma0{margin:0}.swagger-ui .ma1{margin:.25rem}.swagger-ui .ma2{margin:.5rem}.swagger-ui .ma3{margin:1rem}.swagger-ui .ma4{margin:2rem}.swagger-ui .ma5{margin:4rem}.swagger-ui .ma6{margin:8rem}.swagger-ui .ma7{margin:16rem}.swagger-ui .ml0{margin-left:0}.swagger-ui .ml1{margin-left:.25rem}.swagger-ui .ml2{margin-left:.5rem}.swagger-ui .ml3{margin-left:1rem}.swagger-ui .ml4{margin-left:2rem}.swagger-ui .ml5{margin-left:4rem}.swagger-ui .ml6{margin-left:8rem}.swagger-ui .ml7{margin-left:16rem}.swagger-ui .mr0{margin-right:0}.swagger-ui .mr1{margin-right:.25rem}.swagger-ui .mr2{margin-right:.5rem}.swagger-ui .mr3{margin-right:1rem}.swagger-ui .mr4{margin-right:2rem}.swagger-ui .mr5{margin-right:4rem}.swagger-ui .mr6{margin-right:8rem}.swagger-ui .mr7{margin-right:16rem}.swagger-ui .mb0{margin-bottom:0}.swagger-ui .mb1{margin-bottom:.25rem}.swagger-ui .mb2{margin-bottom:.5rem}.swagger-ui .mb3{margin-bottom:1rem}.swagger-ui .mb4{margin-bottom:2rem}.swagger-ui .mb5{margin-bottom:4rem}.swagger-ui .mb6{margin-bottom:8rem}.swagger-ui .mb7{margin-bottom:16rem}.swagger-ui .mt0{margin-top:0}.swagger-ui .mt1{margin-top:.25rem}.swagger-ui .mt2{margin-top:.5rem}.swagger-ui .mt3{margin-top:1rem}.swagger-ui .mt4{margin-top:2rem}.swagger-ui .mt5{margin-top:4rem}.swagger-ui .mt6{margin-top:8rem}.swagger-ui .mt7{margin-top:16rem}.swagger-ui .mv0{margin-bottom:0;margin-top:0}.swagger-ui .mv1{margin-bottom:.25rem;margin-top:.25rem}.swagger-ui .mv2{margin-bottom:.5rem;margin-top:.5rem}.swagger-ui .mv3{margin-bottom:1rem;margin-top:1rem}.swagger-ui .mv4{margin-bottom:2rem;margin-top:2rem}.swagger-ui .mv5{margin-bottom:4rem;margin-top:4rem}.swagger-ui .mv6{margin-bottom:8rem;margin-top:8rem}.swagger-ui .mv7{margin-bottom:16rem;margin-top:16rem}.swagger-ui .mh0{margin-left:0;margin-right:0}.swagger-ui .mh1{margin-left:.25rem;margin-right:.25rem}.swagger-ui .mh2{margin-left:.5rem;margin-right:.5rem}.swagger-ui .mh3{margin-left:1rem;margin-right:1rem}.swagger-ui .mh4{margin-left:2rem;margin-right:2rem}.swagger-ui .mh5{margin-left:4rem;margin-right:4rem}.swagger-ui .mh6{margin-left:8rem;margin-right:8rem}.swagger-ui .mh7{margin-left:16rem;margin-right:16rem}@media screen and (min-width:30em){.swagger-ui .pa0-ns{padding:0}.swagger-ui .pa1-ns{padding:.25rem}.swagger-ui .pa2-ns{padding:.5rem}.swagger-ui .pa3-ns{padding:1rem}.swagger-ui .pa4-ns{padding:2rem}.swagger-ui .pa5-ns{padding:4rem}.swagger-ui .pa6-ns{padding:8rem}.swagger-ui .pa7-ns{padding:16rem}.swagger-ui .pl0-ns{padding-left:0}.swagger-ui .pl1-ns{padding-left:.25rem}.swagger-ui .pl2-ns{padding-left:.5rem}.swagger-ui .pl3-ns{padding-left:1rem}.swagger-ui .pl4-ns{padding-left:2rem}.swagger-ui .pl5-ns{padding-left:4rem}.swagger-ui .pl6-ns{padding-left:8rem}.swagger-ui .pl7-ns{padding-left:16rem}.swagger-ui .pr0-ns{padding-right:0}.swagger-ui .pr1-ns{padding-right:.25rem}.swagger-ui .pr2-ns{padding-right:.5rem}.swagger-ui .pr3-ns{padding-right:1rem}.swagger-ui .pr4-ns{padding-right:2rem}.swagger-ui .pr5-ns{padding-right:4rem}.swagger-ui .pr6-ns{padding-right:8rem}.swagger-ui .pr7-ns{padding-right:16rem}.swagger-ui .pb0-ns{padding-bottom:0}.swagger-ui .pb1-ns{padding-bottom:.25rem}.swagger-ui .pb2-ns{padding-bottom:.5rem}.swagger-ui .pb3-ns{padding-bottom:1rem}.swagger-ui .pb4-ns{padding-bottom:2rem}.swagger-ui .pb5-ns{padding-bottom:4rem}.swagger-ui .pb6-ns{padding-bottom:8rem}.swagger-ui .pb7-ns{padding-bottom:16rem}.swagger-ui .pt0-ns{padding-top:0}.swagger-ui .pt1-ns{padding-top:.25rem}.swagger-ui .pt2-ns{padding-top:.5rem}.swagger-ui .pt3-ns{padding-top:1rem}.swagger-ui .pt4-ns{padding-top:2rem}.swagger-ui .pt5-ns{padding-top:4rem}.swagger-ui .pt6-ns{padding-top:8rem}.swagger-ui .pt7-ns{padding-top:16rem}.swagger-ui .pv0-ns{padding-bottom:0;padding-top:0}.swagger-ui .pv1-ns{padding-bottom:.25rem;padding-top:.25rem}.swagger-ui .pv2-ns{padding-bottom:.5rem;padding-top:.5rem}.swagger-ui .pv3-ns{padding-bottom:1rem;padding-top:1rem}.swagger-ui .pv4-ns{padding-bottom:2rem;padding-top:2rem}.swagger-ui .pv5-ns{padding-bottom:4rem;padding-top:4rem}.swagger-ui .pv6-ns{padding-bottom:8rem;padding-top:8rem}.swagger-ui .pv7-ns{padding-bottom:16rem;padding-top:16rem}.swagger-ui .ph0-ns{padding-left:0;padding-right:0}.swagger-ui .ph1-ns{padding-left:.25rem;padding-right:.25rem}.swagger-ui .ph2-ns{padding-left:.5rem;padding-right:.5rem}.swagger-ui .ph3-ns{padding-left:1rem;padding-right:1rem}.swagger-ui .ph4-ns{padding-left:2rem;padding-right:2rem}.swagger-ui .ph5-ns{padding-left:4rem;padding-right:4rem}.swagger-ui .ph6-ns{padding-left:8rem;padding-right:8rem}.swagger-ui .ph7-ns{padding-left:16rem;padding-right:16rem}.swagger-ui .ma0-ns{margin:0}.swagger-ui .ma1-ns{margin:.25rem}.swagger-ui .ma2-ns{margin:.5rem}.swagger-ui .ma3-ns{margin:1rem}.swagger-ui .ma4-ns{margin:2rem}.swagger-ui .ma5-ns{margin:4rem}.swagger-ui .ma6-ns{margin:8rem}.swagger-ui .ma7-ns{margin:16rem}.swagger-ui .ml0-ns{margin-left:0}.swagger-ui .ml1-ns{margin-left:.25rem}.swagger-ui .ml2-ns{margin-left:.5rem}.swagger-ui .ml3-ns{margin-left:1rem}.swagger-ui .ml4-ns{margin-left:2rem}.swagger-ui .ml5-ns{margin-left:4rem}.swagger-ui .ml6-ns{margin-left:8rem}.swagger-ui .ml7-ns{margin-left:16rem}.swagger-ui .mr0-ns{margin-right:0}.swagger-ui .mr1-ns{margin-right:.25rem}.swagger-ui .mr2-ns{margin-right:.5rem}.swagger-ui .mr3-ns{margin-right:1rem}.swagger-ui .mr4-ns{margin-right:2rem}.swagger-ui .mr5-ns{margin-right:4rem}.swagger-ui .mr6-ns{margin-right:8rem}.swagger-ui .mr7-ns{margin-right:16rem}.swagger-ui .mb0-ns{margin-bottom:0}.swagger-ui .mb1-ns{margin-bottom:.25rem}.swagger-ui .mb2-ns{margin-bottom:.5rem}.swagger-ui .mb3-ns{margin-bottom:1rem}.swagger-ui .mb4-ns{margin-bottom:2rem}.swagger-ui .mb5-ns{margin-bottom:4rem}.swagger-ui .mb6-ns{margin-bottom:8rem}.swagger-ui .mb7-ns{margin-bottom:16rem}.swagger-ui .mt0-ns{margin-top:0}.swagger-ui .mt1-ns{margin-top:.25rem}.swagger-ui .mt2-ns{margin-top:.5rem}.swagger-ui .mt3-ns{margin-top:1rem}.swagger-ui .mt4-ns{margin-top:2rem}.swagger-ui .mt5-ns{margin-top:4rem}.swagger-ui .mt6-ns{margin-top:8rem}.swagger-ui .mt7-ns{margin-top:16rem}.swagger-ui .mv0-ns{margin-bottom:0;margin-top:0}.swagger-ui .mv1-ns{margin-bottom:.25rem;margin-top:.25rem}.swagger-ui .mv2-ns{margin-bottom:.5rem;margin-top:.5rem}.swagger-ui .mv3-ns{margin-bottom:1rem;margin-top:1rem}.swagger-ui .mv4-ns{margin-bottom:2rem;margin-top:2rem}.swagger-ui .mv5-ns{margin-bottom:4rem;margin-top:4rem}.swagger-ui .mv6-ns{margin-bottom:8rem;margin-top:8rem}.swagger-ui .mv7-ns{margin-bottom:16rem;margin-top:16rem}.swagger-ui .mh0-ns{margin-left:0;margin-right:0}.swagger-ui .mh1-ns{margin-left:.25rem;margin-right:.25rem}.swagger-ui .mh2-ns{margin-left:.5rem;margin-right:.5rem}.swagger-ui .mh3-ns{margin-left:1rem;margin-right:1rem}.swagger-ui .mh4-ns{margin-left:2rem;margin-right:2rem}.swagger-ui .mh5-ns{margin-left:4rem;margin-right:4rem}.swagger-ui .mh6-ns{margin-left:8rem;margin-right:8rem}.swagger-ui .mh7-ns{margin-left:16rem;margin-right:16rem}}@media screen and (min-width:30em)and (max-width:60em){.swagger-ui .pa0-m{padding:0}.swagger-ui .pa1-m{padding:.25rem}.swagger-ui .pa2-m{padding:.5rem}.swagger-ui .pa3-m{padding:1rem}.swagger-ui .pa4-m{padding:2rem}.swagger-ui .pa5-m{padding:4rem}.swagger-ui .pa6-m{padding:8rem}.swagger-ui .pa7-m{padding:16rem}.swagger-ui .pl0-m{padding-left:0}.swagger-ui .pl1-m{padding-left:.25rem}.swagger-ui .pl2-m{padding-left:.5rem}.swagger-ui .pl3-m{padding-left:1rem}.swagger-ui .pl4-m{padding-left:2rem}.swagger-ui .pl5-m{padding-left:4rem}.swagger-ui .pl6-m{padding-left:8rem}.swagger-ui .pl7-m{padding-left:16rem}.swagger-ui .pr0-m{padding-right:0}.swagger-ui .pr1-m{padding-right:.25rem}.swagger-ui .pr2-m{padding-right:.5rem}.swagger-ui .pr3-m{padding-right:1rem}.swagger-ui .pr4-m{padding-right:2rem}.swagger-ui .pr5-m{padding-right:4rem}.swagger-ui .pr6-m{padding-right:8rem}.swagger-ui .pr7-m{padding-right:16rem}.swagger-ui .pb0-m{padding-bottom:0}.swagger-ui .pb1-m{padding-bottom:.25rem}.swagger-ui .pb2-m{padding-bottom:.5rem}.swagger-ui .pb3-m{padding-bottom:1rem}.swagger-ui .pb4-m{padding-bottom:2rem}.swagger-ui .pb5-m{padding-bottom:4rem}.swagger-ui .pb6-m{padding-bottom:8rem}.swagger-ui .pb7-m{padding-bottom:16rem}.swagger-ui .pt0-m{padding-top:0}.swagger-ui .pt1-m{padding-top:.25rem}.swagger-ui .pt2-m{padding-top:.5rem}.swagger-ui .pt3-m{padding-top:1rem}.swagger-ui .pt4-m{padding-top:2rem}.swagger-ui .pt5-m{padding-top:4rem}.swagger-ui .pt6-m{padding-top:8rem}.swagger-ui .pt7-m{padding-top:16rem}.swagger-ui .pv0-m{padding-bottom:0;padding-top:0}.swagger-ui .pv1-m{padding-bottom:.25rem;padding-top:.25rem}.swagger-ui .pv2-m{padding-bottom:.5rem;padding-top:.5rem}.swagger-ui .pv3-m{padding-bottom:1rem;padding-top:1rem}.swagger-ui .pv4-m{padding-bottom:2rem;padding-top:2rem}.swagger-ui .pv5-m{padding-bottom:4rem;padding-top:4rem}.swagger-ui .pv6-m{padding-bottom:8rem;padding-top:8rem}.swagger-ui .pv7-m{padding-bottom:16rem;padding-top:16rem}.swagger-ui .ph0-m{padding-left:0;padding-right:0}.swagger-ui .ph1-m{padding-left:.25rem;padding-right:.25rem}.swagger-ui .ph2-m{padding-left:.5rem;padding-right:.5rem}.swagger-ui .ph3-m{padding-left:1rem;padding-right:1rem}.swagger-ui .ph4-m{padding-left:2rem;padding-right:2rem}.swagger-ui .ph5-m{padding-left:4rem;padding-right:4rem}.swagger-ui .ph6-m{padding-left:8rem;padding-right:8rem}.swagger-ui .ph7-m{padding-left:16rem;padding-right:16rem}.swagger-ui .ma0-m{margin:0}.swagger-ui .ma1-m{margin:.25rem}.swagger-ui .ma2-m{margin:.5rem}.swagger-ui .ma3-m{margin:1rem}.swagger-ui .ma4-m{margin:2rem}.swagger-ui .ma5-m{margin:4rem}.swagger-ui .ma6-m{margin:8rem}.swagger-ui .ma7-m{margin:16rem}.swagger-ui .ml0-m{margin-left:0}.swagger-ui .ml1-m{margin-left:.25rem}.swagger-ui .ml2-m{margin-left:.5rem}.swagger-ui .ml3-m{margin-left:1rem}.swagger-ui .ml4-m{margin-left:2rem}.swagger-ui .ml5-m{margin-left:4rem}.swagger-ui .ml6-m{margin-left:8rem}.swagger-ui .ml7-m{margin-left:16rem}.swagger-ui .mr0-m{margin-right:0}.swagger-ui .mr1-m{margin-right:.25rem}.swagger-ui .mr2-m{margin-right:.5rem}.swagger-ui .mr3-m{margin-right:1rem}.swagger-ui .mr4-m{margin-right:2rem}.swagger-ui .mr5-m{margin-right:4rem}.swagger-ui .mr6-m{margin-right:8rem}.swagger-ui .mr7-m{margin-right:16rem}.swagger-ui .mb0-m{margin-bottom:0}.swagger-ui .mb1-m{margin-bottom:.25rem}.swagger-ui .mb2-m{margin-bottom:.5rem}.swagger-ui .mb3-m{margin-bottom:1rem}.swagger-ui .mb4-m{margin-bottom:2rem}.swagger-ui .mb5-m{margin-bottom:4rem}.swagger-ui .mb6-m{margin-bottom:8rem}.swagger-ui .mb7-m{margin-bottom:16rem}.swagger-ui .mt0-m{margin-top:0}.swagger-ui .mt1-m{margin-top:.25rem}.swagger-ui .mt2-m{margin-top:.5rem}.swagger-ui .mt3-m{margin-top:1rem}.swagger-ui .mt4-m{margin-top:2rem}.swagger-ui .mt5-m{margin-top:4rem}.swagger-ui .mt6-m{margin-top:8rem}.swagger-ui .mt7-m{margin-top:16rem}.swagger-ui .mv0-m{margin-bottom:0;margin-top:0}.swagger-ui .mv1-m{margin-bottom:.25rem;margin-top:.25rem}.swagger-ui .mv2-m{margin-bottom:.5rem;margin-top:.5rem}.swagger-ui .mv3-m{margin-bottom:1rem;margin-top:1rem}.swagger-ui .mv4-m{margin-bottom:2rem;margin-top:2rem}.swagger-ui .mv5-m{margin-bottom:4rem;margin-top:4rem}.swagger-ui .mv6-m{margin-bottom:8rem;margin-top:8rem}.swagger-ui .mv7-m{margin-bottom:16rem;margin-top:16rem}.swagger-ui .mh0-m{margin-left:0;margin-right:0}.swagger-ui .mh1-m{margin-left:.25rem;margin-right:.25rem}.swagger-ui .mh2-m{margin-left:.5rem;margin-right:.5rem}.swagger-ui .mh3-m{margin-left:1rem;margin-right:1rem}.swagger-ui .mh4-m{margin-left:2rem;margin-right:2rem}.swagger-ui .mh5-m{margin-left:4rem;margin-right:4rem}.swagger-ui .mh6-m{margin-left:8rem;margin-right:8rem}.swagger-ui .mh7-m{margin-left:16rem;margin-right:16rem}}@media screen and (min-width:60em){.swagger-ui .pa0-l{padding:0}.swagger-ui .pa1-l{padding:.25rem}.swagger-ui .pa2-l{padding:.5rem}.swagger-ui .pa3-l{padding:1rem}.swagger-ui .pa4-l{padding:2rem}.swagger-ui .pa5-l{padding:4rem}.swagger-ui .pa6-l{padding:8rem}.swagger-ui .pa7-l{padding:16rem}.swagger-ui .pl0-l{padding-left:0}.swagger-ui .pl1-l{padding-left:.25rem}.swagger-ui .pl2-l{padding-left:.5rem}.swagger-ui .pl3-l{padding-left:1rem}.swagger-ui .pl4-l{padding-left:2rem}.swagger-ui .pl5-l{padding-left:4rem}.swagger-ui .pl6-l{padding-left:8rem}.swagger-ui .pl7-l{padding-left:16rem}.swagger-ui .pr0-l{padding-right:0}.swagger-ui .pr1-l{padding-right:.25rem}.swagger-ui .pr2-l{padding-right:.5rem}.swagger-ui .pr3-l{padding-right:1rem}.swagger-ui .pr4-l{padding-right:2rem}.swagger-ui .pr5-l{padding-right:4rem}.swagger-ui .pr6-l{padding-right:8rem}.swagger-ui .pr7-l{padding-right:16rem}.swagger-ui .pb0-l{padding-bottom:0}.swagger-ui .pb1-l{padding-bottom:.25rem}.swagger-ui .pb2-l{padding-bottom:.5rem}.swagger-ui .pb3-l{padding-bottom:1rem}.swagger-ui .pb4-l{padding-bottom:2rem}.swagger-ui .pb5-l{padding-bottom:4rem}.swagger-ui .pb6-l{padding-bottom:8rem}.swagger-ui .pb7-l{padding-bottom:16rem}.swagger-ui .pt0-l{padding-top:0}.swagger-ui .pt1-l{padding-top:.25rem}.swagger-ui .pt2-l{padding-top:.5rem}.swagger-ui .pt3-l{padding-top:1rem}.swagger-ui .pt4-l{padding-top:2rem}.swagger-ui .pt5-l{padding-top:4rem}.swagger-ui .pt6-l{padding-top:8rem}.swagger-ui .pt7-l{padding-top:16rem}.swagger-ui .pv0-l{padding-bottom:0;padding-top:0}.swagger-ui .pv1-l{padding-bottom:.25rem;padding-top:.25rem}.swagger-ui .pv2-l{padding-bottom:.5rem;padding-top:.5rem}.swagger-ui .pv3-l{padding-bottom:1rem;padding-top:1rem}.swagger-ui .pv4-l{padding-bottom:2rem;padding-top:2rem}.swagger-ui .pv5-l{padding-bottom:4rem;padding-top:4rem}.swagger-ui .pv6-l{padding-bottom:8rem;padding-top:8rem}.swagger-ui .pv7-l{padding-bottom:16rem;padding-top:16rem}.swagger-ui .ph0-l{padding-left:0;padding-right:0}.swagger-ui .ph1-l{padding-left:.25rem;padding-right:.25rem}.swagger-ui .ph2-l{padding-left:.5rem;padding-right:.5rem}.swagger-ui .ph3-l{padding-left:1rem;padding-right:1rem}.swagger-ui .ph4-l{padding-left:2rem;padding-right:2rem}.swagger-ui .ph5-l{padding-left:4rem;padding-right:4rem}.swagger-ui .ph6-l{padding-left:8rem;padding-right:8rem}.swagger-ui .ph7-l{padding-left:16rem;padding-right:16rem}.swagger-ui .ma0-l{margin:0}.swagger-ui .ma1-l{margin:.25rem}.swagger-ui .ma2-l{margin:.5rem}.swagger-ui .ma3-l{margin:1rem}.swagger-ui .ma4-l{margin:2rem}.swagger-ui .ma5-l{margin:4rem}.swagger-ui .ma6-l{margin:8rem}.swagger-ui .ma7-l{margin:16rem}.swagger-ui .ml0-l{margin-left:0}.swagger-ui .ml1-l{margin-left:.25rem}.swagger-ui .ml2-l{margin-left:.5rem}.swagger-ui .ml3-l{margin-left:1rem}.swagger-ui .ml4-l{margin-left:2rem}.swagger-ui .ml5-l{margin-left:4rem}.swagger-ui .ml6-l{margin-left:8rem}.swagger-ui .ml7-l{margin-left:16rem}.swagger-ui .mr0-l{margin-right:0}.swagger-ui .mr1-l{margin-right:.25rem}.swagger-ui .mr2-l{margin-right:.5rem}.swagger-ui .mr3-l{margin-right:1rem}.swagger-ui .mr4-l{margin-right:2rem}.swagger-ui .mr5-l{margin-right:4rem}.swagger-ui .mr6-l{margin-right:8rem}.swagger-ui .mr7-l{margin-right:16rem}.swagger-ui .mb0-l{margin-bottom:0}.swagger-ui .mb1-l{margin-bottom:.25rem}.swagger-ui .mb2-l{margin-bottom:.5rem}.swagger-ui .mb3-l{margin-bottom:1rem}.swagger-ui .mb4-l{margin-bottom:2rem}.swagger-ui .mb5-l{margin-bottom:4rem}.swagger-ui .mb6-l{margin-bottom:8rem}.swagger-ui .mb7-l{margin-bottom:16rem}.swagger-ui .mt0-l{margin-top:0}.swagger-ui .mt1-l{margin-top:.25rem}.swagger-ui .mt2-l{margin-top:.5rem}.swagger-ui .mt3-l{margin-top:1rem}.swagger-ui .mt4-l{margin-top:2rem}.swagger-ui .mt5-l{margin-top:4rem}.swagger-ui .mt6-l{margin-top:8rem}.swagger-ui .mt7-l{margin-top:16rem}.swagger-ui .mv0-l{margin-bottom:0;margin-top:0}.swagger-ui .mv1-l{margin-bottom:.25rem;margin-top:.25rem}.swagger-ui .mv2-l{margin-bottom:.5rem;margin-top:.5rem}.swagger-ui .mv3-l{margin-bottom:1rem;margin-top:1rem}.swagger-ui .mv4-l{margin-bottom:2rem;margin-top:2rem}.swagger-ui .mv5-l{margin-bottom:4rem;margin-top:4rem}.swagger-ui .mv6-l{margin-bottom:8rem;margin-top:8rem}.swagger-ui .mv7-l{margin-bottom:16rem;margin-top:16rem}.swagger-ui .mh0-l{margin-left:0;margin-right:0}.swagger-ui .mh1-l{margin-left:.25rem;margin-right:.25rem}.swagger-ui .mh2-l{margin-left:.5rem;margin-right:.5rem}.swagger-ui .mh3-l{margin-left:1rem;margin-right:1rem}.swagger-ui .mh4-l{margin-left:2rem;margin-right:2rem}.swagger-ui .mh5-l{margin-left:4rem;margin-right:4rem}.swagger-ui .mh6-l{margin-left:8rem;margin-right:8rem}.swagger-ui .mh7-l{margin-left:16rem;margin-right:16rem}}.swagger-ui .na1{margin:-.25rem}.swagger-ui .na2{margin:-.5rem}.swagger-ui .na3{margin:-1rem}.swagger-ui .na4{margin:-2rem}.swagger-ui .na5{margin:-4rem}.swagger-ui .na6{margin:-8rem}.swagger-ui .na7{margin:-16rem}.swagger-ui .nl1{margin-left:-.25rem}.swagger-ui .nl2{margin-left:-.5rem}.swagger-ui .nl3{margin-left:-1rem}.swagger-ui .nl4{margin-left:-2rem}.swagger-ui .nl5{margin-left:-4rem}.swagger-ui .nl6{margin-left:-8rem}.swagger-ui .nl7{margin-left:-16rem}.swagger-ui .nr1{margin-right:-.25rem}.swagger-ui .nr2{margin-right:-.5rem}.swagger-ui .nr3{margin-right:-1rem}.swagger-ui .nr4{margin-right:-2rem}.swagger-ui .nr5{margin-right:-4rem}.swagger-ui .nr6{margin-right:-8rem}.swagger-ui .nr7{margin-right:-16rem}.swagger-ui .nb1{margin-bottom:-.25rem}.swagger-ui .nb2{margin-bottom:-.5rem}.swagger-ui .nb3{margin-bottom:-1rem}.swagger-ui .nb4{margin-bottom:-2rem}.swagger-ui .nb5{margin-bottom:-4rem}.swagger-ui .nb6{margin-bottom:-8rem}.swagger-ui .nb7{margin-bottom:-16rem}.swagger-ui .nt1{margin-top:-.25rem}.swagger-ui .nt2{margin-top:-.5rem}.swagger-ui .nt3{margin-top:-1rem}.swagger-ui .nt4{margin-top:-2rem}.swagger-ui .nt5{margin-top:-4rem}.swagger-ui .nt6{margin-top:-8rem}.swagger-ui .nt7{margin-top:-16rem}@media screen and (min-width:30em){.swagger-ui .na1-ns{margin:-.25rem}.swagger-ui .na2-ns{margin:-.5rem}.swagger-ui .na3-ns{margin:-1rem}.swagger-ui .na4-ns{margin:-2rem}.swagger-ui .na5-ns{margin:-4rem}.swagger-ui .na6-ns{margin:-8rem}.swagger-ui .na7-ns{margin:-16rem}.swagger-ui .nl1-ns{margin-left:-.25rem}.swagger-ui .nl2-ns{margin-left:-.5rem}.swagger-ui .nl3-ns{margin-left:-1rem}.swagger-ui .nl4-ns{margin-left:-2rem}.swagger-ui .nl5-ns{margin-left:-4rem}.swagger-ui .nl6-ns{margin-left:-8rem}.swagger-ui .nl7-ns{margin-left:-16rem}.swagger-ui .nr1-ns{margin-right:-.25rem}.swagger-ui .nr2-ns{margin-right:-.5rem}.swagger-ui .nr3-ns{margin-right:-1rem}.swagger-ui .nr4-ns{margin-right:-2rem}.swagger-ui .nr5-ns{margin-right:-4rem}.swagger-ui .nr6-ns{margin-right:-8rem}.swagger-ui .nr7-ns{margin-right:-16rem}.swagger-ui .nb1-ns{margin-bottom:-.25rem}.swagger-ui .nb2-ns{margin-bottom:-.5rem}.swagger-ui .nb3-ns{margin-bottom:-1rem}.swagger-ui .nb4-ns{margin-bottom:-2rem}.swagger-ui .nb5-ns{margin-bottom:-4rem}.swagger-ui .nb6-ns{margin-bottom:-8rem}.swagger-ui .nb7-ns{margin-bottom:-16rem}.swagger-ui .nt1-ns{margin-top:-.25rem}.swagger-ui .nt2-ns{margin-top:-.5rem}.swagger-ui .nt3-ns{margin-top:-1rem}.swagger-ui .nt4-ns{margin-top:-2rem}.swagger-ui .nt5-ns{margin-top:-4rem}.swagger-ui .nt6-ns{margin-top:-8rem}.swagger-ui .nt7-ns{margin-top:-16rem}}@media screen and (min-width:30em)and (max-width:60em){.swagger-ui .na1-m{margin:-.25rem}.swagger-ui .na2-m{margin:-.5rem}.swagger-ui .na3-m{margin:-1rem}.swagger-ui .na4-m{margin:-2rem}.swagger-ui .na5-m{margin:-4rem}.swagger-ui .na6-m{margin:-8rem}.swagger-ui .na7-m{margin:-16rem}.swagger-ui .nl1-m{margin-left:-.25rem}.swagger-ui .nl2-m{margin-left:-.5rem}.swagger-ui .nl3-m{margin-left:-1rem}.swagger-ui .nl4-m{margin-left:-2rem}.swagger-ui .nl5-m{margin-left:-4rem}.swagger-ui .nl6-m{margin-left:-8rem}.swagger-ui .nl7-m{margin-left:-16rem}.swagger-ui .nr1-m{margin-right:-.25rem}.swagger-ui .nr2-m{margin-right:-.5rem}.swagger-ui .nr3-m{margin-right:-1rem}.swagger-ui .nr4-m{margin-right:-2rem}.swagger-ui .nr5-m{margin-right:-4rem}.swagger-ui .nr6-m{margin-right:-8rem}.swagger-ui .nr7-m{margin-right:-16rem}.swagger-ui .nb1-m{margin-bottom:-.25rem}.swagger-ui .nb2-m{margin-bottom:-.5rem}.swagger-ui .nb3-m{margin-bottom:-1rem}.swagger-ui .nb4-m{margin-bottom:-2rem}.swagger-ui .nb5-m{margin-bottom:-4rem}.swagger-ui .nb6-m{margin-bottom:-8rem}.swagger-ui .nb7-m{margin-bottom:-16rem}.swagger-ui .nt1-m{margin-top:-.25rem}.swagger-ui .nt2-m{margin-top:-.5rem}.swagger-ui .nt3-m{margin-top:-1rem}.swagger-ui .nt4-m{margin-top:-2rem}.swagger-ui .nt5-m{margin-top:-4rem}.swagger-ui .nt6-m{margin-top:-8rem}.swagger-ui .nt7-m{margin-top:-16rem}}@media screen and (min-width:60em){.swagger-ui .na1-l{margin:-.25rem}.swagger-ui .na2-l{margin:-.5rem}.swagger-ui .na3-l{margin:-1rem}.swagger-ui .na4-l{margin:-2rem}.swagger-ui .na5-l{margin:-4rem}.swagger-ui .na6-l{margin:-8rem}.swagger-ui .na7-l{margin:-16rem}.swagger-ui .nl1-l{margin-left:-.25rem}.swagger-ui .nl2-l{margin-left:-.5rem}.swagger-ui .nl3-l{margin-left:-1rem}.swagger-ui .nl4-l{margin-left:-2rem}.swagger-ui .nl5-l{margin-left:-4rem}.swagger-ui .nl6-l{margin-left:-8rem}.swagger-ui .nl7-l{margin-left:-16rem}.swagger-ui .nr1-l{margin-right:-.25rem}.swagger-ui .nr2-l{margin-right:-.5rem}.swagger-ui .nr3-l{margin-right:-1rem}.swagger-ui .nr4-l{margin-right:-2rem}.swagger-ui .nr5-l{margin-right:-4rem}.swagger-ui .nr6-l{margin-right:-8rem}.swagger-ui .nr7-l{margin-right:-16rem}.swagger-ui .nb1-l{margin-bottom:-.25rem}.swagger-ui .nb2-l{margin-bottom:-.5rem}.swagger-ui .nb3-l{margin-bottom:-1rem}.swagger-ui .nb4-l{margin-bottom:-2rem}.swagger-ui .nb5-l{margin-bottom:-4rem}.swagger-ui .nb6-l{margin-bottom:-8rem}.swagger-ui .nb7-l{margin-bottom:-16rem}.swagger-ui .nt1-l{margin-top:-.25rem}.swagger-ui .nt2-l{margin-top:-.5rem}.swagger-ui .nt3-l{margin-top:-1rem}.swagger-ui .nt4-l{margin-top:-2rem}.swagger-ui .nt5-l{margin-top:-4rem}.swagger-ui .nt6-l{margin-top:-8rem}.swagger-ui .nt7-l{margin-top:-16rem}}.swagger-ui .collapse{border-collapse:collapse;border-spacing:0}.swagger-ui .striped--light-silver:nth-child(odd){background-color:#aaa}.swagger-ui .striped--moon-gray:nth-child(odd){background-color:#ccc}.swagger-ui .striped--light-gray:nth-child(odd){background-color:#eee}.swagger-ui .striped--near-white:nth-child(odd){background-color:#f4f4f4}.swagger-ui .stripe-light:nth-child(odd){background-color:hsla(0,0%,100%,.1)}.swagger-ui .stripe-dark:nth-child(odd){background-color:rgba(0,0,0,.1)}.swagger-ui .strike{-webkit-text-decoration:line-through;text-decoration:line-through}.swagger-ui .underline{-webkit-text-decoration:underline;text-decoration:underline}.swagger-ui .no-underline{-webkit-text-decoration:none;text-decoration:none}@media screen and (min-width:30em){.swagger-ui .strike-ns{-webkit-text-decoration:line-through;text-decoration:line-through}.swagger-ui .underline-ns{-webkit-text-decoration:underline;text-decoration:underline}.swagger-ui .no-underline-ns{-webkit-text-decoration:none;text-decoration:none}}@media screen and (min-width:30em)and (max-width:60em){.swagger-ui .strike-m{-webkit-text-decoration:line-through;text-decoration:line-through}.swagger-ui .underline-m{-webkit-text-decoration:underline;text-decoration:underline}.swagger-ui .no-underline-m{-webkit-text-decoration:none;text-decoration:none}}@media screen and (min-width:60em){.swagger-ui .strike-l{-webkit-text-decoration:line-through;text-decoration:line-through}.swagger-ui .underline-l{-webkit-text-decoration:underline;text-decoration:underline}.swagger-ui .no-underline-l{-webkit-text-decoration:none;text-decoration:none}}.swagger-ui .tl{text-align:left}.swagger-ui .tr{text-align:right}.swagger-ui .tc{text-align:center}.swagger-ui .tj{text-align:justify}@media screen and (min-width:30em){.swagger-ui .tl-ns{text-align:left}.swagger-ui .tr-ns{text-align:right}.swagger-ui .tc-ns{text-align:center}.swagger-ui .tj-ns{text-align:justify}}@media screen and (min-width:30em)and (max-width:60em){.swagger-ui .tl-m{text-align:left}.swagger-ui .tr-m{text-align:right}.swagger-ui .tc-m{text-align:center}.swagger-ui .tj-m{text-align:justify}}@media screen and (min-width:60em){.swagger-ui .tl-l{text-align:left}.swagger-ui .tr-l{text-align:right}.swagger-ui .tc-l{text-align:center}.swagger-ui .tj-l{text-align:justify}}.swagger-ui .ttc{text-transform:capitalize}.swagger-ui .ttl{text-transform:lowercase}.swagger-ui .ttu{text-transform:uppercase}.swagger-ui .ttn{text-transform:none}@media screen and (min-width:30em){.swagger-ui .ttc-ns{text-transform:capitalize}.swagger-ui .ttl-ns{text-transform:lowercase}.swagger-ui .ttu-ns{text-transform:uppercase}.swagger-ui .ttn-ns{text-transform:none}}@media screen and (min-width:30em)and (max-width:60em){.swagger-ui .ttc-m{text-transform:capitalize}.swagger-ui .ttl-m{text-transform:lowercase}.swagger-ui .ttu-m{text-transform:uppercase}.swagger-ui .ttn-m{text-transform:none}}@media screen and (min-width:60em){.swagger-ui .ttc-l{text-transform:capitalize}.swagger-ui .ttl-l{text-transform:lowercase}.swagger-ui .ttu-l{text-transform:uppercase}.swagger-ui .ttn-l{text-transform:none}}.swagger-ui .f-6,.swagger-ui .f-headline{font-size:6rem}.swagger-ui .f-5,.swagger-ui .f-subheadline{font-size:5rem}.swagger-ui .f1{font-size:3rem}.swagger-ui .f2{font-size:2.25rem}.swagger-ui .f3{font-size:1.5rem}.swagger-ui .f4{font-size:1.25rem}.swagger-ui .f5{font-size:1rem}.swagger-ui .f6{font-size:.875rem}.swagger-ui .f7{font-size:.75rem}@media screen and (min-width:30em){.swagger-ui .f-6-ns,.swagger-ui .f-headline-ns{font-size:6rem}.swagger-ui .f-5-ns,.swagger-ui .f-subheadline-ns{font-size:5rem}.swagger-ui .f1-ns{font-size:3rem}.swagger-ui .f2-ns{font-size:2.25rem}.swagger-ui .f3-ns{font-size:1.5rem}.swagger-ui .f4-ns{font-size:1.25rem}.swagger-ui .f5-ns{font-size:1rem}.swagger-ui .f6-ns{font-size:.875rem}.swagger-ui .f7-ns{font-size:.75rem}}@media screen and (min-width:30em)and (max-width:60em){.swagger-ui .f-6-m,.swagger-ui .f-headline-m{font-size:6rem}.swagger-ui .f-5-m,.swagger-ui .f-subheadline-m{font-size:5rem}.swagger-ui .f1-m{font-size:3rem}.swagger-ui .f2-m{font-size:2.25rem}.swagger-ui .f3-m{font-size:1.5rem}.swagger-ui .f4-m{font-size:1.25rem}.swagger-ui .f5-m{font-size:1rem}.swagger-ui .f6-m{font-size:.875rem}.swagger-ui .f7-m{font-size:.75rem}}@media screen and (min-width:60em){.swagger-ui .f-6-l,.swagger-ui .f-headline-l{font-size:6rem}.swagger-ui .f-5-l,.swagger-ui .f-subheadline-l{font-size:5rem}.swagger-ui .f1-l{font-size:3rem}.swagger-ui .f2-l{font-size:2.25rem}.swagger-ui .f3-l{font-size:1.5rem}.swagger-ui .f4-l{font-size:1.25rem}.swagger-ui .f5-l{font-size:1rem}.swagger-ui .f6-l{font-size:.875rem}.swagger-ui .f7-l{font-size:.75rem}}.swagger-ui .measure{max-width:30em}.swagger-ui .measure-wide{max-width:34em}.swagger-ui .measure-narrow{max-width:20em}.swagger-ui .indent{margin-bottom:0;margin-top:0;text-indent:1em}.swagger-ui .small-caps{font-feature-settings:"smcp";font-variant:small-caps}.swagger-ui .truncate{overflow:hidden;text-overflow:ellipsis;white-space:nowrap}@media screen and (min-width:30em){.swagger-ui .measure-ns{max-width:30em}.swagger-ui .measure-wide-ns{max-width:34em}.swagger-ui .measure-narrow-ns{max-width:20em}.swagger-ui .indent-ns{margin-bottom:0;margin-top:0;text-indent:1em}.swagger-ui .small-caps-ns{font-feature-settings:"smcp";font-variant:small-caps}.swagger-ui .truncate-ns{overflow:hidden;text-overflow:ellipsis;white-space:nowrap}}@media screen and (min-width:30em)and (max-width:60em){.swagger-ui .measure-m{max-width:30em}.swagger-ui .measure-wide-m{max-width:34em}.swagger-ui .measure-narrow-m{max-width:20em}.swagger-ui .indent-m{margin-bottom:0;margin-top:0;text-indent:1em}.swagger-ui .small-caps-m{font-feature-settings:"smcp";font-variant:small-caps}.swagger-ui .truncate-m{overflow:hidden;text-overflow:ellipsis;white-space:nowrap}}@media screen and (min-width:60em){.swagger-ui .measure-l{max-width:30em}.swagger-ui .measure-wide-l{max-width:34em}.swagger-ui .measure-narrow-l{max-width:20em}.swagger-ui .indent-l{margin-bottom:0;margin-top:0;text-indent:1em}.swagger-ui .small-caps-l{font-feature-settings:"smcp";font-variant:small-caps}.swagger-ui .truncate-l{overflow:hidden;text-overflow:ellipsis;white-space:nowrap}}.swagger-ui .overflow-container{overflow-y:scroll}.swagger-ui .center{margin-left:auto;margin-right:auto}.swagger-ui .mr-auto{margin-right:auto}.swagger-ui .ml-auto{margin-left:auto}@media screen and (min-width:30em){.swagger-ui .center-ns{margin-left:auto;margin-right:auto}.swagger-ui .mr-auto-ns{margin-right:auto}.swagger-ui .ml-auto-ns{margin-left:auto}}@media screen and (min-width:30em)and (max-width:60em){.swagger-ui .center-m{margin-left:auto;margin-right:auto}.swagger-ui .mr-auto-m{margin-right:auto}.swagger-ui .ml-auto-m{margin-left:auto}}@media screen and (min-width:60em){.swagger-ui .center-l{margin-left:auto;margin-right:auto}.swagger-ui .mr-auto-l{margin-right:auto}.swagger-ui .ml-auto-l{margin-left:auto}}.swagger-ui .clip{position:fixed!important;_position:absolute!important}.swagger-ui .clip{clip:rect(1px 1px 1px 1px);clip:rect(1px,1px,1px,1px)}@media screen and (min-width:30em){.swagger-ui .clip-ns{position:fixed!important;_position:absolute!important}.swagger-ui .clip-ns{clip:rect(1px 1px 1px 1px);clip:rect(1px,1px,1px,1px)}}@media screen and (min-width:30em)and (max-width:60em){.swagger-ui .clip-m{position:fixed!important;_position:absolute!important}.swagger-ui .clip-m{clip:rect(1px 1px 1px 1px);clip:rect(1px,1px,1px,1px)}}@media screen and (min-width:60em){.swagger-ui .clip-l{position:fixed!important;_position:absolute!important}.swagger-ui .clip-l{clip:rect(1px 1px 1px 1px);clip:rect(1px,1px,1px,1px)}}.swagger-ui .ws-normal{white-space:normal}.swagger-ui .nowrap{white-space:nowrap}.swagger-ui .pre{white-space:pre}@media screen and (min-width:30em){.swagger-ui .ws-normal-ns{white-space:normal}.swagger-ui .nowrap-ns{white-space:nowrap}.swagger-ui .pre-ns{white-space:pre}}@media screen and (min-width:30em)and (max-width:60em){.swagger-ui .ws-normal-m{white-space:normal}.swagger-ui .nowrap-m{white-space:nowrap}.swagger-ui .pre-m{white-space:pre}}@media screen and (min-width:60em){.swagger-ui .ws-normal-l{white-space:normal}.swagger-ui .nowrap-l{white-space:nowrap}.swagger-ui .pre-l{white-space:pre}}.swagger-ui .v-base{vertical-align:baseline}.swagger-ui .v-mid{vertical-align:middle}.swagger-ui .v-top{vertical-align:top}.swagger-ui .v-btm{vertical-align:bottom}@media screen and (min-width:30em){.swagger-ui .v-base-ns{vertical-align:baseline}.swagger-ui .v-mid-ns{vertical-align:middle}.swagger-ui .v-top-ns{vertical-align:top}.swagger-ui .v-btm-ns{vertical-align:bottom}}@media screen and (min-width:30em)and (max-width:60em){.swagger-ui .v-base-m{vertical-align:baseline}.swagger-ui .v-mid-m{vertical-align:middle}.swagger-ui .v-top-m{vertical-align:top}.swagger-ui .v-btm-m{vertical-align:bottom}}@media screen and (min-width:60em){.swagger-ui .v-base-l{vertical-align:baseline}.swagger-ui .v-mid-l{vertical-align:middle}.swagger-ui .v-top-l{vertical-align:top}.swagger-ui .v-btm-l{vertical-align:bottom}}.swagger-ui .dim{opacity:1;transition:opacity .15s ease-in}.swagger-ui .dim:focus,.swagger-ui .dim:hover{opacity:.5;transition:opacity .15s ease-in}.swagger-ui .dim:active{opacity:.8;transition:opacity .15s ease-out}.swagger-ui .glow{transition:opacity .15s ease-in}.swagger-ui .glow:focus,.swagger-ui .glow:hover{opacity:1;transition:opacity .15s ease-in}.swagger-ui .hide-child .child{opacity:0;transition:opacity .15s ease-in}.swagger-ui .hide-child:active .child,.swagger-ui .hide-child:focus .child,.swagger-ui .hide-child:hover .child{opacity:1;transition:opacity .15s ease-in}.swagger-ui .underline-hover:focus,.swagger-ui .underline-hover:hover{-webkit-text-decoration:underline;text-decoration:underline}.swagger-ui .grow{-moz-osx-font-smoothing:grayscale;backface-visibility:hidden;transform:translateZ(0);transition:transform .25s ease-out}.swagger-ui .grow:focus,.swagger-ui .grow:hover{transform:scale(1.05)}.swagger-ui .grow:active{transform:scale(.9)}.swagger-ui .grow-large{-moz-osx-font-smoothing:grayscale;backface-visibility:hidden;transform:translateZ(0);transition:transform .25s ease-in-out}.swagger-ui .grow-large:focus,.swagger-ui .grow-large:hover{transform:scale(1.2)}.swagger-ui .grow-large:active{transform:scale(.95)}.swagger-ui .pointer:hover{cursor:pointer}.swagger-ui .shadow-hover{cursor:pointer;position:relative;transition:all .5s cubic-bezier(.165,.84,.44,1)}.swagger-ui .shadow-hover:after{border-radius:inherit;box-shadow:0 0 16px 2px rgba(0,0,0,.2);content:"";height:100%;left:0;opacity:0;position:absolute;top:0;transition:opacity .5s cubic-bezier(.165,.84,.44,1);width:100%;z-index:-1}.swagger-ui .shadow-hover:focus:after,.swagger-ui .shadow-hover:hover:after{opacity:1}.swagger-ui .bg-animate,.swagger-ui .bg-animate:focus,.swagger-ui .bg-animate:hover{transition:background-color .15s ease-in-out}.swagger-ui .z-0{z-index:0}.swagger-ui .z-1{z-index:1}.swagger-ui .z-2{z-index:2}.swagger-ui .z-3{z-index:3}.swagger-ui .z-4{z-index:4}.swagger-ui .z-5{z-index:5}.swagger-ui .z-999{z-index:999}.swagger-ui .z-9999{z-index:9999}.swagger-ui .z-max{z-index:2147483647}.swagger-ui .z-inherit{z-index:inherit}.swagger-ui .z-initial,.swagger-ui .z-unset{z-index:auto}.swagger-ui .nested-copy-line-height ol,.swagger-ui .nested-copy-line-height p,.swagger-ui .nested-copy-line-height ul{line-height:1.5}.swagger-ui .nested-headline-line-height h1,.swagger-ui .nested-headline-line-height h2,.swagger-ui .nested-headline-line-height h3,.swagger-ui .nested-headline-line-height h4,.swagger-ui .nested-headline-line-height h5,.swagger-ui .nested-headline-line-height h6{line-height:1.25}.swagger-ui .nested-list-reset ol,.swagger-ui .nested-list-reset ul{list-style-type:none;margin-left:0;padding-left:0}.swagger-ui .nested-copy-indent p+p{margin-bottom:0;margin-top:0;text-indent:.1em}.swagger-ui .nested-copy-seperator p+p{margin-top:1.5em}.swagger-ui .nested-img img{display:block;max-width:100%;width:100%}.swagger-ui .nested-links a{color:#357edd;transition:color .15s ease-in}.swagger-ui .nested-links a:focus,.swagger-ui .nested-links a:hover{color:#96ccff;transition:color .15s ease-in}.swagger-ui .wrapper{box-sizing:border-box;margin:0 auto;max-width:1460px;padding:0 20px;width:100%}.swagger-ui .opblock-tag-section{display:flex;flex-direction:column}.swagger-ui .try-out.btn-group{display:flex;flex:.1 2 auto;padding:0}.swagger-ui .try-out__btn{margin-left:1.25rem}.swagger-ui .opblock-tag{align-items:center;border-bottom:1px solid rgba(59,65,81,.3);cursor:pointer;display:flex;padding:10px 20px 10px 10px;transition:all .2s}.swagger-ui .opblock-tag:hover{background:rgba(0,0,0,.02)}.swagger-ui .opblock-tag{color:#3b4151;font-family:sans-serif;font-size:24px;margin:0 0 5px}.swagger-ui .opblock-tag.no-desc span{flex:1}.swagger-ui .opblock-tag svg{transition:all .4s}.swagger-ui .opblock-tag small{color:#3b4151;flex:2;font-family:sans-serif;font-size:14px;font-weight:400;padding:0 10px}.swagger-ui .opblock-tag>div{flex:1 1 150px;font-weight:400;overflow:hidden;text-overflow:ellipsis;white-space:nowrap}@media(max-width:640px){.swagger-ui .opblock-tag small,.swagger-ui .opblock-tag>div{flex:1}}.swagger-ui .opblock-tag .info__externaldocs{text-align:right}.swagger-ui .parameter__type{color:#3b4151;font-family:monospace;font-size:12px;font-weight:600;padding:5px 0}.swagger-ui .parameter-controls{margin-top:.75em}.swagger-ui .examples__title{display:block;font-size:1.1em;font-weight:700;margin-bottom:.75em}.swagger-ui .examples__section{margin-top:1.5em}.swagger-ui .examples__section-header{font-size:.9rem;font-weight:700;margin-bottom:.5rem}.swagger-ui .examples-select{display:inline-block;margin-bottom:.75em}.swagger-ui .examples-select .examples-select-element{width:100%}.swagger-ui .examples-select__section-label{font-size:.9rem;font-weight:700;margin-right:.5rem}.swagger-ui .example__section{margin-top:1.5em}.swagger-ui .example__section-header{font-size:.9rem;font-weight:700;margin-bottom:.5rem}.swagger-ui .view-line-link{cursor:pointer;margin:0 5px;position:relative;top:3px;transition:all .5s;width:20px}.swagger-ui .opblock{border:1px solid #000;border-radius:4px;box-shadow:0 0 3px rgba(0,0,0,.19);margin:0 0 15px}.swagger-ui .opblock .tab-header{display:flex;flex:1}.swagger-ui .opblock .tab-header .tab-item{cursor:pointer;padding:0 40px}.swagger-ui .opblock .tab-header .tab-item:first-of-type{padding:0 40px 0 0}.swagger-ui .opblock .tab-header .tab-item.active h4 span{position:relative}.swagger-ui .opblock .tab-header .tab-item.active h4 span:after{background:gray;bottom:-15px;content:"";height:4px;left:50%;position:absolute;transform:translateX(-50%);width:120%}.swagger-ui .opblock.is-open .opblock-summary{border-bottom:1px solid #000}.swagger-ui .opblock .opblock-section-header{align-items:center;background:hsla(0,0%,100%,.8);box-shadow:0 1px 2px rgba(0,0,0,.1);display:flex;min-height:50px;padding:8px 20px}.swagger-ui .opblock .opblock-section-header>label{align-items:center;color:#3b4151;display:flex;font-family:sans-serif;font-size:12px;font-weight:700;margin:0 0 0 auto}.swagger-ui .opblock .opblock-section-header>label>span{padding:0 10px 0 0}.swagger-ui .opblock .opblock-section-header h4{color:#3b4151;flex:1;font-family:sans-serif;font-size:14px;margin:0}.swagger-ui .opblock .opblock-summary-method{background:#000;border-radius:3px;color:#fff;font-family:sans-serif;font-size:14px;font-weight:700;min-width:80px;padding:6px 0;text-align:center;text-shadow:0 1px 0 rgba(0,0,0,.1)}.swagger-ui .opblock .opblock-summary-operation-id,.swagger-ui .opblock .opblock-summary-path,.swagger-ui .opblock .opblock-summary-path__deprecated{align-items:center;color:#3b4151;display:flex;font-family:monospace;font-size:16px;font-weight:600;padding:0 10px;word-break:break-word}@media(max-width:768px){.swagger-ui .opblock .opblock-summary-operation-id,.swagger-ui .opblock .opblock-summary-path,.swagger-ui .opblock .opblock-summary-path__deprecated{font-size:12px}}.swagger-ui .opblock .opblock-summary-path{flex-shrink:0;max-width:calc(100% - 110px - 15rem)}@media(max-width:640px){.swagger-ui .opblock .opblock-summary-path{flex-shrink:1;max-width:100%}}.swagger-ui .opblock .opblock-summary-path__deprecated{-webkit-text-decoration:line-through;text-decoration:line-through}.swagger-ui .opblock .opblock-summary-operation-id{font-size:14px}.swagger-ui .opblock .opblock-summary-description{color:#3b4151;flex:1 1 auto;font-family:sans-serif;font-size:13px;word-break:break-word}.swagger-ui .opblock .opblock-summary{align-items:center;cursor:pointer;display:flex;padding:5px}.swagger-ui .opblock .opblock-summary .view-line-link{cursor:pointer;margin:0;position:relative;top:2px;transition:all .5s;width:0}.swagger-ui .opblock .opblock-summary:hover .view-line-link{margin:0 5px;width:18px}.swagger-ui .opblock .opblock-summary:hover .view-line-link.copy-to-clipboard{width:24px}.swagger-ui .opblock.opblock-post{background:rgba(73,204,144,.1);border-color:#49cc90}.swagger-ui .opblock.opblock-post .opblock-summary-method{background:#49cc90}.swagger-ui .opblock.opblock-post .opblock-summary{border-color:#49cc90}.swagger-ui .opblock.opblock-post .tab-header .tab-item.active h4 span:after{background:#49cc90}.swagger-ui .opblock.opblock-put{background:rgba(252,161,48,.1);border-color:#fca130}.swagger-ui .opblock.opblock-put .opblock-summary-method{background:#fca130}.swagger-ui .opblock.opblock-put .opblock-summary{border-color:#fca130}.swagger-ui .opblock.opblock-put .tab-header .tab-item.active h4 span:after{background:#fca130}.swagger-ui .opblock.opblock-delete{background:rgba(249,62,62,.1);border-color:#f93e3e}.swagger-ui .opblock.opblock-delete .opblock-summary-method{background:#f93e3e}.swagger-ui .opblock.opblock-delete .opblock-summary{border-color:#f93e3e}.swagger-ui .opblock.opblock-delete .tab-header .tab-item.active h4 span:after{background:#f93e3e}.swagger-ui .opblock.opblock-get{background:rgba(97,175,254,.1);border-color:#61affe}.swagger-ui .opblock.opblock-get .opblock-summary-method{background:#61affe}.swagger-ui .opblock.opblock-get .opblock-summary{border-color:#61affe}.swagger-ui .opblock.opblock-get .tab-header .tab-item.active h4 span:after{background:#61affe}.swagger-ui .opblock.opblock-patch{background:rgba(80,227,194,.1);border-color:#50e3c2}.swagger-ui .opblock.opblock-patch .opblock-summary-method{background:#50e3c2}.swagger-ui .opblock.opblock-patch .opblock-summary{border-color:#50e3c2}.swagger-ui .opblock.opblock-patch .tab-header .tab-item.active h4 span:after{background:#50e3c2}.swagger-ui .opblock.opblock-head{background:rgba(144,18,254,.1);border-color:#9012fe}.swagger-ui .opblock.opblock-head .opblock-summary-method{background:#9012fe}.swagger-ui .opblock.opblock-head .opblock-summary{border-color:#9012fe}.swagger-ui .opblock.opblock-head .tab-header .tab-item.active h4 span:after{background:#9012fe}.swagger-ui .opblock.opblock-options{background:rgba(13,90,167,.1);border-color:#0d5aa7}.swagger-ui .opblock.opblock-options .opblock-summary-method{background:#0d5aa7}.swagger-ui .opblock.opblock-options .opblock-summary{border-color:#0d5aa7}.swagger-ui .opblock.opblock-options .tab-header .tab-item.active h4 span:after{background:#0d5aa7}.swagger-ui .opblock.opblock-deprecated{background:hsla(0,0%,92%,.1);border-color:#ebebeb;opacity:.6}.swagger-ui .opblock.opblock-deprecated .opblock-summary-method{background:#ebebeb}.swagger-ui .opblock.opblock-deprecated .opblock-summary{border-color:#ebebeb}.swagger-ui .opblock.opblock-deprecated .tab-header .tab-item.active h4 span:after{background:#ebebeb}.swagger-ui .opblock .opblock-schemes{padding:8px 20px}.swagger-ui .opblock .opblock-schemes .schemes-title{padding:0 10px 0 0}.swagger-ui .filter .operation-filter-input{border:2px solid #d8dde7;margin:20px 0;padding:10px;width:100%}.swagger-ui .download-url-wrapper .failed,.swagger-ui .filter .failed{color:red}.swagger-ui .download-url-wrapper .loading,.swagger-ui .filter .loading{color:#aaa}.swagger-ui .model-example{margin-top:1em}.swagger-ui .tab{display:flex;list-style:none;padding:0}.swagger-ui .tab li{color:#3b4151;cursor:pointer;font-family:sans-serif;font-size:12px;min-width:60px;padding:0}.swagger-ui .tab li:first-of-type{padding-left:0;padding-right:12px;position:relative}.swagger-ui .tab li:first-of-type:after{background:rgba(0,0,0,.2);content:"";height:100%;position:absolute;right:6px;top:0;width:1px}.swagger-ui .tab li.active{font-weight:700}.swagger-ui .tab li button.tablinks{background:none;border:0;color:inherit;font-family:inherit;font-weight:inherit;padding:0}.swagger-ui .opblock-description-wrapper,.swagger-ui .opblock-external-docs-wrapper,.swagger-ui .opblock-title_normal{color:#3b4151;font-family:sans-serif;font-size:12px;margin:0 0 5px;padding:15px 20px}.swagger-ui .opblock-description-wrapper h4,.swagger-ui .opblock-external-docs-wrapper h4,.swagger-ui .opblock-title_normal h4{color:#3b4151;font-family:sans-serif;font-size:12px;margin:0 0 5px}.swagger-ui .opblock-description-wrapper p,.swagger-ui .opblock-external-docs-wrapper p,.swagger-ui .opblock-title_normal p{color:#3b4151;font-family:sans-serif;font-size:14px;margin:0}.swagger-ui .opblock-external-docs-wrapper h4{padding-left:0}.swagger-ui .execute-wrapper{padding:20px;text-align:right}.swagger-ui .execute-wrapper .btn{padding:8px 40px;width:100%}.swagger-ui .body-param-options{display:flex;flex-direction:column}.swagger-ui .body-param-options .body-param-edit{padding:10px 0}.swagger-ui .body-param-options label{padding:8px 0}.swagger-ui .body-param-options label select{margin:3px 0 0}.swagger-ui .responses-inner{padding:20px}.swagger-ui .responses-inner h4,.swagger-ui .responses-inner h5{color:#3b4151;font-family:sans-serif;font-size:12px;margin:10px 0 5px}.swagger-ui .responses-inner .curl{white-space:normal}.swagger-ui .response-col_status{color:#3b4151;font-family:sans-serif;font-size:14px}.swagger-ui .response-col_status .response-undocumented{color:#909090;font-family:monospace;font-size:11px;font-weight:600}.swagger-ui .response-col_links{color:#3b4151;font-family:sans-serif;font-size:14px;max-width:40em;padding-left:2em}.swagger-ui .response-col_links .response-undocumented{color:#909090;font-family:monospace;font-size:11px;font-weight:600}.swagger-ui .response-col_links .operation-link{margin-bottom:1.5em}.swagger-ui .response-col_links .operation-link .description{margin-bottom:.5em}.swagger-ui .opblock-body .opblock-loading-animation{display:block;margin:3em auto}.swagger-ui .opblock-body pre.microlight{word-wrap:break-word;background:#333;border-radius:4px;color:#fff;font-family:monospace;font-size:12px;font-weight:600;-webkit-hyphens:auto;hyphens:auto;margin:0;padding:10px;white-space:pre-wrap;word-break:break-all;word-break:break-word}.swagger-ui .opblock-body pre.microlight .headerline{display:block}.swagger-ui .highlight-code{position:relative}.swagger-ui .highlight-code>.microlight{max-height:400px;min-height:6em;overflow-y:auto}.swagger-ui .highlight-code>.microlight code{white-space:pre-wrap!important}.swagger-ui .highlight-code>.microlight code{word-break:break-all}.swagger-ui .curl-command{position:relative}.swagger-ui .download-contents{align-items:center;background:#7d8293;border-radius:4px;bottom:10px;color:#fff;cursor:pointer;display:flex;font-family:sans-serif;font-size:14px;font-weight:600;height:30px;justify-content:center;padding:5px;position:absolute;right:10px;text-align:center}.swagger-ui .scheme-container{background:#fff;box-shadow:0 1px 2px 0 rgba(0,0,0,.15);margin:0 0 20px;padding:30px 0}.swagger-ui .scheme-container .schemes{align-items:flex-end;display:flex}.swagger-ui .scheme-container .schemes>label{color:#3b4151;display:flex;flex-direction:column;font-family:sans-serif;font-size:12px;font-weight:700;margin:-20px 15px 0 0}.swagger-ui .scheme-container .schemes>label select{min-width:130px;text-transform:uppercase}.swagger-ui .loading-container{align-items:center;display:flex;flex-direction:column;justify-content:center;margin-top:1em;min-height:1px;padding:40px 0 60px}.swagger-ui .loading-container .loading{position:relative}.swagger-ui .loading-container .loading:after{color:#3b4151;content:"loading";font-family:sans-serif;font-size:10px;font-weight:700;left:50%;position:absolute;text-transform:uppercase;top:50%;transform:translate(-50%,-50%)}.swagger-ui .loading-container .loading:before{animation:rotation 1s linear infinite,opacity .5s;backface-visibility:hidden;border:2px solid rgba(85,85,85,.1);border-radius:100%;border-top-color:rgba(0,0,0,.6);content:"";display:block;height:60px;left:50%;margin:-30px;opacity:1;position:absolute;top:50%;width:60px}@keyframes rotation{to{transform:rotate(1turn)}}.swagger-ui .response-controls{display:flex;padding-top:1em}.swagger-ui .response-control-media-type{margin-right:1em}.swagger-ui .response-control-media-type--accept-controller select{border-color:green}.swagger-ui .response-control-media-type__accept-message{color:green;font-size:.7em}.swagger-ui .response-control-examples__title,.swagger-ui .response-control-media-type__title{display:block;font-size:.7em;margin-bottom:.2em}@keyframes blinker{50%{opacity:0}}.swagger-ui .hidden{display:none}.swagger-ui .no-margin{border:none;height:auto;margin:0;padding:0}.swagger-ui .float-right{float:right}.swagger-ui .svg-assets{height:0;position:absolute;width:0}.swagger-ui section h3{color:#3b4151;font-family:sans-serif}.swagger-ui a.nostyle{display:inline}.swagger-ui a.nostyle,.swagger-ui a.nostyle:visited{color:inherit;cursor:pointer;text-decoration:inherit}.swagger-ui .fallback{color:#aaa;padding:1em}.swagger-ui .version-pragma{height:100%;padding:5em 0}.swagger-ui .version-pragma__message{display:flex;font-size:1.2em;height:100%;justify-content:center;line-height:1.5em;padding:0 .6em;text-align:center}.swagger-ui .version-pragma__message>div{flex:1;max-width:55ch}.swagger-ui .version-pragma__message code{background-color:#dedede;padding:4px 4px 2px;white-space:pre}.swagger-ui .opblock-link{font-weight:400}.swagger-ui .opblock-link.shown{font-weight:700}.swagger-ui span.token-string{color:#555}.swagger-ui span.token-not-formatted{color:#555;font-weight:700}.swagger-ui .btn{background:transparent;border:2px solid gray;border-radius:4px;box-shadow:0 1px 2px rgba(0,0,0,.1);color:#3b4151;font-family:sans-serif;font-size:14px;font-weight:700;padding:5px 23px;transition:all .3s}.swagger-ui .btn.btn-sm{font-size:12px;padding:4px 23px}.swagger-ui .btn[disabled]{cursor:not-allowed;opacity:.3}.swagger-ui .btn:hover{box-shadow:0 0 5px rgba(0,0,0,.3)}.swagger-ui .btn.cancel{background-color:transparent;border-color:#ff6060;color:#ff6060;font-family:sans-serif}.swagger-ui .btn.authorize{background-color:transparent;border-color:#49cc90;color:#49cc90;display:inline;line-height:1}.swagger-ui .btn.authorize span{float:left;padding:4px 20px 0 0}.swagger-ui .btn.authorize svg{fill:#49cc90}.swagger-ui .btn.execute{background-color:#4990e2;border-color:#4990e2;color:#fff}.swagger-ui .btn-group{display:flex;padding:30px}.swagger-ui .btn-group .btn{flex:1}.swagger-ui .btn-group .btn:first-child{border-radius:4px 0 0 4px}.swagger-ui .btn-group .btn:last-child{border-radius:0 4px 4px 0}.swagger-ui .authorization__btn{background:none;border:none;padding:0 0 0 10px}.swagger-ui .authorization__btn .locked{opacity:1}.swagger-ui .authorization__btn .unlocked{opacity:.4}.swagger-ui .model-box-control,.swagger-ui .models-control,.swagger-ui .opblock-summary-control{all:inherit;border-bottom:0;cursor:pointer;flex:1;padding:0}.swagger-ui .model-box-control:focus,.swagger-ui .models-control:focus,.swagger-ui .opblock-summary-control:focus{outline:auto}.swagger-ui .expand-methods,.swagger-ui .expand-operation{background:none;border:none}.swagger-ui .expand-methods svg,.swagger-ui .expand-operation svg{height:20px;width:20px}.swagger-ui .expand-methods{padding:0 10px}.swagger-ui .expand-methods:hover svg{fill:#404040}.swagger-ui .expand-methods svg{fill:#707070;transition:all .3s}.swagger-ui button{cursor:pointer}.swagger-ui button.invalid{animation:shake .4s 1;background:#feebeb;border-color:#f93e3e}.swagger-ui .copy-to-clipboard{align-items:center;background:#7d8293;border:none;border-radius:4px;bottom:10px;display:flex;height:30px;justify-content:center;position:absolute;right:100px;width:30px}.swagger-ui .copy-to-clipboard button{background:url("data:image/svg+xml;charset=utf-8,") 50% no-repeat;border:none;flex-grow:1;flex-shrink:1;height:25px}.swagger-ui .curl-command .copy-to-clipboard{bottom:5px;height:20px;right:10px;width:20px}.swagger-ui .curl-command .copy-to-clipboard button{height:18px}.swagger-ui .opblock .opblock-summary .view-line-link.copy-to-clipboard{height:26px;position:static}.swagger-ui select{-webkit-appearance:none;-moz-appearance:none;appearance:none;background:#f7f7f7 url("data:image/svg+xml;charset=utf-8,") right 10px center no-repeat;background-size:20px;border:2px solid #41444e;border-radius:4px;box-shadow:0 1px 2px 0 rgba(0,0,0,.25);color:#3b4151;font-family:sans-serif;font-size:14px;font-weight:700;padding:5px 40px 5px 10px}.swagger-ui select[multiple]{background:#f7f7f7;margin:5px 0;padding:5px}.swagger-ui select.invalid{animation:shake .4s 1;background:#feebeb;border-color:#f93e3e}.swagger-ui .opblock-body select{min-width:230px}@media(max-width:768px){.swagger-ui .opblock-body select{min-width:180px}}@media(max-width:640px){.swagger-ui .opblock-body select{min-width:100%;width:100%}}.swagger-ui label{color:#3b4151;font-family:sans-serif;font-size:12px;font-weight:700;margin:0 0 5px}.swagger-ui input[type=email],.swagger-ui input[type=file],.swagger-ui input[type=password],.swagger-ui input[type=search],.swagger-ui input[type=text]{line-height:1}@media(max-width:768px){.swagger-ui input[type=email],.swagger-ui input[type=file],.swagger-ui input[type=password],.swagger-ui input[type=search],.swagger-ui input[type=text]{max-width:175px}}.swagger-ui input[type=email],.swagger-ui input[type=file],.swagger-ui input[type=password],.swagger-ui input[type=search],.swagger-ui input[type=text],.swagger-ui textarea{background:#fff;border:1px solid #d9d9d9;border-radius:4px;margin:5px 0;min-width:100px;padding:8px 10px}.swagger-ui input[type=email].invalid,.swagger-ui input[type=file].invalid,.swagger-ui input[type=password].invalid,.swagger-ui input[type=search].invalid,.swagger-ui input[type=text].invalid,.swagger-ui textarea.invalid{animation:shake .4s 1;background:#feebeb;border-color:#f93e3e}.swagger-ui input[disabled],.swagger-ui select[disabled],.swagger-ui textarea[disabled]{background-color:#fafafa;color:#888;cursor:not-allowed}.swagger-ui select[disabled]{border-color:#888}.swagger-ui textarea[disabled]{background-color:#41444e;color:#fff}@keyframes shake{10%,90%{transform:translate3d(-1px,0,0)}20%,80%{transform:translate3d(2px,0,0)}30%,50%,70%{transform:translate3d(-4px,0,0)}40%,60%{transform:translate3d(4px,0,0)}}.swagger-ui textarea{background:hsla(0,0%,100%,.8);border:none;border-radius:4px;color:#3b4151;font-family:monospace;font-size:12px;font-weight:600;min-height:280px;outline:none;padding:10px;width:100%}.swagger-ui textarea:focus{border:2px solid #61affe}.swagger-ui textarea.curl{background:#41444e;border-radius:4px;color:#fff;font-family:monospace;font-size:12px;font-weight:600;margin:0;min-height:100px;padding:10px;resize:none}.swagger-ui .checkbox{color:#303030;padding:5px 0 10px;transition:opacity .5s}.swagger-ui .checkbox label{display:flex}.swagger-ui .checkbox p{font-weight:400!important;margin:0!important}.swagger-ui .checkbox p{color:#3b4151;font-family:monospace;font-style:italic;font-weight:600}.swagger-ui .checkbox input[type=checkbox]{display:none}.swagger-ui .checkbox input[type=checkbox]+label>.item{background:#e8e8e8;border-radius:1px;box-shadow:0 0 0 2px #e8e8e8;cursor:pointer;display:inline-block;flex:none;height:16px;margin:0 8px 0 0;padding:5px;position:relative;top:3px;width:16px}.swagger-ui .checkbox input[type=checkbox]+label>.item:active{transform:scale(.9)}.swagger-ui .checkbox input[type=checkbox]:checked+label>.item{background:#e8e8e8 url("data:image/svg+xml;charset=utf-8,") 50% no-repeat}.swagger-ui .dialog-ux{bottom:0;left:0;position:fixed;right:0;top:0;z-index:9999}.swagger-ui .dialog-ux .backdrop-ux{background:rgba(0,0,0,.8);bottom:0;left:0;position:fixed;right:0;top:0}.swagger-ui .dialog-ux .modal-ux{background:#fff;border:1px solid #ebebeb;border-radius:4px;box-shadow:0 10px 30px 0 rgba(0,0,0,.2);left:50%;max-width:650px;min-width:300px;position:absolute;top:50%;transform:translate(-50%,-50%);width:100%;z-index:9999}.swagger-ui .dialog-ux .modal-ux-content{max-height:540px;overflow-y:auto;padding:20px}.swagger-ui .dialog-ux .modal-ux-content p{color:#41444e;color:#3b4151;font-family:sans-serif;font-size:12px;margin:0 0 5px}.swagger-ui .dialog-ux .modal-ux-content h4{color:#3b4151;font-family:sans-serif;font-size:18px;font-weight:600;margin:15px 0 0}.swagger-ui .dialog-ux .modal-ux-header{align-items:center;border-bottom:1px solid #ebebeb;display:flex;padding:12px 0}.swagger-ui .dialog-ux .modal-ux-header .close-modal{-webkit-appearance:none;-moz-appearance:none;appearance:none;background:none;border:none;padding:0 10px}.swagger-ui .dialog-ux .modal-ux-header h3{color:#3b4151;flex:1;font-family:sans-serif;font-size:20px;font-weight:600;margin:0;padding:0 20px}.swagger-ui .model{color:#3b4151;font-family:monospace;font-size:12px;font-weight:300;font-weight:600}.swagger-ui .model .deprecated span,.swagger-ui .model .deprecated td{color:#a0a0a0!important}.swagger-ui .model .deprecated>td:first-of-type{-webkit-text-decoration:line-through;text-decoration:line-through}.swagger-ui .model-toggle{cursor:pointer;display:inline-block;font-size:10px;margin:auto .3em;position:relative;top:6px;transform:rotate(90deg);transform-origin:50% 50%;transition:transform .15s ease-in}.swagger-ui .model-toggle.collapsed{transform:rotate(0deg)}.swagger-ui .model-toggle:after{background:url("data:image/svg+xml;charset=utf-8,") 50% no-repeat;background-size:100%;content:"";display:block;height:20px;width:20px}.swagger-ui .model-jump-to-path{cursor:pointer;position:relative}.swagger-ui .model-jump-to-path .view-line-link{cursor:pointer;position:absolute;top:-.4em}.swagger-ui .model-title{position:relative}.swagger-ui .model-title:hover .model-hint{visibility:visible}.swagger-ui .model-hint{background:rgba(0,0,0,.7);border-radius:4px;color:#ebebeb;padding:.1em .5em;position:absolute;top:-1.8em;visibility:hidden;white-space:nowrap}.swagger-ui .model p{margin:0 0 1em}.swagger-ui .model .property{color:#999;font-style:italic}.swagger-ui .model .property.primitive{color:#6b6b6b}.swagger-ui .model .external-docs,.swagger-ui table.model tr.description{color:#666;font-weight:400}.swagger-ui table.model tr.description td:first-child,.swagger-ui table.model tr.property-row.required td:first-child{font-weight:700}.swagger-ui table.model tr.property-row td{vertical-align:top}.swagger-ui table.model tr.property-row td:first-child{padding-right:.2em}.swagger-ui table.model tr.property-row .star{color:red}.swagger-ui table.model tr.extension{color:#777}.swagger-ui table.model tr.extension td:last-child{vertical-align:top}.swagger-ui table.model tr.external-docs td:first-child{font-weight:700}.swagger-ui table.model tr .renderedMarkdown p:first-child{margin-top:0}.swagger-ui section.models{border:1px solid rgba(59,65,81,.3);border-radius:4px;margin:30px 0}.swagger-ui section.models .pointer{cursor:pointer}.swagger-ui section.models.is-open{padding:0 0 20px}.swagger-ui section.models.is-open h4{border-bottom:1px solid rgba(59,65,81,.3);margin:0 0 5px}.swagger-ui section.models h4{align-items:center;color:#606060;cursor:pointer;display:flex;font-family:sans-serif;font-size:16px;margin:0;padding:10px 20px 10px 10px;transition:all .2s}.swagger-ui section.models h4 svg{transition:all .4s}.swagger-ui section.models h4 span{flex:1}.swagger-ui section.models h4:hover{background:rgba(0,0,0,.02)}.swagger-ui section.models h5{color:#707070;font-family:sans-serif;font-size:16px;margin:0 0 10px}.swagger-ui section.models .model-jump-to-path{position:relative;top:5px}.swagger-ui section.models .model-container{background:rgba(0,0,0,.05);border-radius:4px;margin:0 20px 15px;position:relative;transition:all .5s}.swagger-ui section.models .model-container:hover{background:rgba(0,0,0,.07)}.swagger-ui section.models .model-container:first-of-type{margin:20px}.swagger-ui section.models .model-container:last-of-type{margin:0 20px}.swagger-ui section.models .model-container .models-jump-to-path{opacity:.65;position:absolute;right:5px;top:8px}.swagger-ui section.models .model-box{background:none}.swagger-ui .model-box{background:rgba(0,0,0,.1);border-radius:4px;display:inline-block;padding:10px}.swagger-ui .model-box .model-jump-to-path{position:relative;top:4px}.swagger-ui .model-box.deprecated{opacity:.5}.swagger-ui .model-title{color:#505050;font-family:sans-serif;font-size:16px}.swagger-ui .model-title img{bottom:0;margin-left:1em;position:relative}.swagger-ui .model-deprecated-warning{color:#f93e3e;font-family:sans-serif;font-size:16px;font-weight:600;margin-right:1em}.swagger-ui span>span.model .brace-close{padding:0 0 0 10px}.swagger-ui .prop-name{display:inline-block;margin-right:1em}.swagger-ui .prop-type{color:#55a}.swagger-ui .prop-enum{display:block}.swagger-ui .prop-format{color:#606060}.swagger-ui .servers>label{color:#3b4151;font-family:sans-serif;font-size:12px;margin:-20px 15px 0 0}.swagger-ui .servers>label select{max-width:100%;min-width:130px;width:100%}.swagger-ui .servers h4.message{padding-bottom:2em}.swagger-ui .servers table tr{width:30em}.swagger-ui .servers table td{display:inline-block;max-width:15em;padding-bottom:10px;padding-top:10px;vertical-align:middle}.swagger-ui .servers table td:first-of-type{padding-right:1em}.swagger-ui .servers table td input{height:100%;width:100%}.swagger-ui .servers .computed-url{margin:2em 0}.swagger-ui .servers .computed-url code{display:inline-block;font-size:16px;margin:0 1em;padding:4px}.swagger-ui .servers-title{font-size:12px;font-weight:700}.swagger-ui .operation-servers h4.message{margin-bottom:2em}.swagger-ui table{border-collapse:collapse;padding:0 10px;width:100%}.swagger-ui table.model tbody tr td{padding:0;vertical-align:top}.swagger-ui table.model tbody tr td:first-of-type{padding:0 0 0 2em;width:174px}.swagger-ui table.headers td{color:#3b4151;font-family:monospace;font-size:12px;font-weight:300;font-weight:600;vertical-align:middle}.swagger-ui table.headers .header-example{color:#999;font-style:italic}.swagger-ui table tbody tr td{padding:10px 0 0;vertical-align:top}.swagger-ui table tbody tr td:first-of-type{min-width:6em;padding:10px 0}.swagger-ui table thead tr td,.swagger-ui table thead tr th{border-bottom:1px solid rgba(59,65,81,.2);color:#3b4151;font-family:sans-serif;font-size:12px;font-weight:700;padding:12px 0;text-align:left}.swagger-ui .parameters-col_description{margin-bottom:2em;width:99%}.swagger-ui .parameters-col_description input{max-width:340px;width:100%}.swagger-ui .parameters-col_description select{border-width:1px}.swagger-ui .parameters-col_description .markdown p,.swagger-ui .parameters-col_description .renderedMarkdown p{margin:0}.swagger-ui .parameter__name{color:#3b4151;font-family:sans-serif;font-size:16px;font-weight:400;margin-right:.75em}.swagger-ui .parameter__name.required{font-weight:700}.swagger-ui .parameter__name.required span{color:red}.swagger-ui .parameter__name.required:after{color:rgba(255,0,0,.6);content:"required";font-size:10px;padding:5px;position:relative;top:-6px}.swagger-ui .parameter__extension,.swagger-ui .parameter__in{color:gray;font-family:monospace;font-size:12px;font-style:italic;font-weight:600}.swagger-ui .parameter__deprecated{color:red;font-family:monospace;font-size:12px;font-style:italic;font-weight:600}.swagger-ui .parameter__empty_value_toggle{display:block;font-size:13px;padding-bottom:12px;padding-top:5px}.swagger-ui .parameter__empty_value_toggle input{margin-right:7px;width:auto}.swagger-ui .parameter__empty_value_toggle.disabled{opacity:.7}.swagger-ui .table-container{padding:20px}.swagger-ui .response-col_description{width:99%}.swagger-ui .response-col_description .markdown p,.swagger-ui .response-col_description .renderedMarkdown p{margin:0}.swagger-ui .response-col_links{min-width:6em}.swagger-ui .response__extension{color:gray;font-family:monospace;font-size:12px;font-style:italic;font-weight:600}.swagger-ui .topbar{background-color:#1b1b1b;padding:10px 0}.swagger-ui .topbar .topbar-wrapper,.swagger-ui .topbar a{align-items:center;display:flex}.swagger-ui .topbar a{color:#fff;flex:1;font-family:sans-serif;font-size:1.5em;font-weight:700;max-width:300px;-webkit-text-decoration:none;text-decoration:none}.swagger-ui .topbar a span{margin:0;padding:0 10px}.swagger-ui .topbar .download-url-wrapper{display:flex;flex:3;justify-content:flex-end}.swagger-ui .topbar .download-url-wrapper input[type=text]{border:2px solid #62a03f;border-radius:4px 0 0 4px;margin:0;outline:none;width:100%}.swagger-ui .topbar .download-url-wrapper .select-label{align-items:center;color:#f0f0f0;display:flex;margin:0;max-width:600px;width:100%}.swagger-ui .topbar .download-url-wrapper .select-label span{flex:1;font-size:16px;padding:0 10px 0 0;text-align:right}.swagger-ui .topbar .download-url-wrapper .select-label select{border:2px solid #62a03f;box-shadow:none;flex:2;outline:none;width:100%}.swagger-ui .topbar .download-url-wrapper .download-url-button{background:#62a03f;border:none;border-radius:0 4px 4px 0;color:#fff;font-family:sans-serif;font-size:16px;font-weight:700;padding:4px 30px}.swagger-ui .info{margin:50px 0}.swagger-ui .info.failed-config{margin-left:auto;margin-right:auto;max-width:880px;text-align:center}.swagger-ui .info hgroup.main{margin:0 0 20px}.swagger-ui .info hgroup.main a{font-size:12px}.swagger-ui .info pre{font-size:14px}.swagger-ui .info li,.swagger-ui .info p,.swagger-ui .info table{color:#3b4151;font-family:sans-serif;font-size:14px}.swagger-ui .info h1,.swagger-ui .info h2,.swagger-ui .info h3,.swagger-ui .info h4,.swagger-ui .info h5{color:#3b4151;font-family:sans-serif}.swagger-ui .info a{color:#4990e2;font-family:sans-serif;font-size:14px;transition:all .4s}.swagger-ui .info a:hover{color:#1f69c0}.swagger-ui .info>div{margin:0 0 5px}.swagger-ui .info .base-url{font-weight:300!important}.swagger-ui .info .base-url{color:#3b4151;font-family:monospace;font-size:12px;font-weight:600;margin:0}.swagger-ui .info .title{color:#3b4151;font-family:sans-serif;font-size:36px;margin:0}.swagger-ui .info .title small{background:#7d8492;border-radius:57px;display:inline-block;font-size:10px;margin:0 0 0 5px;padding:2px 4px;position:relative;top:-5px;vertical-align:super}.swagger-ui .info .title small.version-stamp{background-color:#89bf04}.swagger-ui .info .title small pre{color:#fff;font-family:sans-serif;margin:0;padding:0}.swagger-ui .auth-btn-wrapper{display:flex;justify-content:center;padding:10px 0}.swagger-ui .auth-btn-wrapper .btn-done{margin-right:1em}.swagger-ui .auth-wrapper{display:flex;flex:1;justify-content:flex-end}.swagger-ui .auth-wrapper .authorize{margin-left:10px;margin-right:10px;padding-right:20px}.swagger-ui .auth-container{border-bottom:1px solid #ebebeb;margin:0 0 10px;padding:10px 20px}.swagger-ui .auth-container:last-of-type{border:0;margin:0;padding:10px 20px}.swagger-ui .auth-container h4{margin:5px 0 15px!important}.swagger-ui .auth-container .wrapper{margin:0;padding:0}.swagger-ui .auth-container input[type=password],.swagger-ui .auth-container input[type=text]{min-width:230px}.swagger-ui .auth-container .errors{background-color:#fee;border-radius:4px;color:red;color:#3b4151;font-family:monospace;font-size:12px;font-weight:600;margin:1em;padding:10px}.swagger-ui .auth-container .errors b{margin-right:1em;text-transform:capitalize}.swagger-ui .scopes h2{color:#3b4151;font-family:sans-serif;font-size:14px}.swagger-ui .scopes h2 a{color:#4990e2;cursor:pointer;font-size:12px;padding-left:10px;-webkit-text-decoration:underline;text-decoration:underline}.swagger-ui .scope-def{padding:0 0 20px}.swagger-ui .errors-wrapper{animation:scaleUp .5s;background:rgba(249,62,62,.1);border:2px solid #f93e3e;border-radius:4px;margin:20px;padding:10px 20px}.swagger-ui .errors-wrapper .error-wrapper{margin:0 0 10px}.swagger-ui .errors-wrapper .errors h4{color:#3b4151;font-family:monospace;font-size:14px;font-weight:600;margin:0}.swagger-ui .errors-wrapper .errors small{color:#606060}.swagger-ui .errors-wrapper .errors .message{white-space:pre-line}.swagger-ui .errors-wrapper .errors .message.thrown{max-width:100%}.swagger-ui .errors-wrapper .errors .error-line{cursor:pointer;-webkit-text-decoration:underline;text-decoration:underline}.swagger-ui .errors-wrapper hgroup{align-items:center;display:flex}.swagger-ui .errors-wrapper hgroup h4{color:#3b4151;flex:1;font-family:sans-serif;font-size:20px;margin:0}@keyframes scaleUp{0%{opacity:0;transform:scale(.8)}to{opacity:1;transform:scale(1)}}.swagger-ui .Resizer.vertical.disabled{display:none}.swagger-ui .markdown p,.swagger-ui .markdown pre,.swagger-ui .renderedMarkdown p,.swagger-ui .renderedMarkdown pre{margin:1em auto;word-break:break-all;word-break:break-word}.swagger-ui .markdown pre,.swagger-ui .renderedMarkdown pre{background:none;color:#000;font-weight:400;padding:0;white-space:pre-wrap}.swagger-ui .markdown code,.swagger-ui .renderedMarkdown code{background:rgba(0,0,0,.05);border-radius:4px;color:#9012fe;font-family:monospace;font-size:14px;font-weight:600;padding:5px 7px}.swagger-ui .markdown pre>code,.swagger-ui .renderedMarkdown pre>code{display:block}.swagger-ui .json-schema-2020-12{background-color:rgba(0,0,0,.05);border-radius:4px;margin:0 20px 15px;padding:12px 0 12px 20px}.swagger-ui .json-schema-2020-12:first-of-type{margin:20px}.swagger-ui .json-schema-2020-12:last-of-type{margin:0 20px}.swagger-ui .json-schema-2020-12--embedded{background-color:inherit;padding-bottom:0;padding-left:inherit;padding-right:inherit;padding-top:0}.swagger-ui .json-schema-2020-12-body{border-left:1px dashed rgba(0,0,0,.1);margin:2px 0}.swagger-ui .json-schema-2020-12-body--collapsed{display:none}.swagger-ui .json-schema-2020-12-accordion{border:none;outline:none;padding-left:0}.swagger-ui .json-schema-2020-12-accordion__children{display:inline-block}.swagger-ui .json-schema-2020-12-accordion__icon{display:inline-block;height:18px;vertical-align:bottom;width:18px}.swagger-ui .json-schema-2020-12-accordion__icon--expanded{transform:rotate(-90deg);transform-origin:50% 50%;transition:transform .15s ease-in}.swagger-ui .json-schema-2020-12-accordion__icon--collapsed{transform:rotate(0deg);transform-origin:50% 50%;transition:transform .15s ease-in}.swagger-ui .json-schema-2020-12-accordion__icon svg{height:20px;width:20px}.swagger-ui .json-schema-2020-12-expand-deep-button{border:none;color:#505050;color:#afaeae;font-family:sans-serif;font-size:12px;padding-right:0}.swagger-ui .json-schema-2020-12-keyword{margin:5px 0}.swagger-ui .json-schema-2020-12-keyword__children{border-left:1px dashed rgba(0,0,0,.1);margin:0 0 0 20px;padding:0}.swagger-ui .json-schema-2020-12-keyword__children--collapsed{display:none}.swagger-ui .json-schema-2020-12-keyword__name{font-size:12px;font-weight:700;margin-left:20px}.swagger-ui .json-schema-2020-12-keyword__name--primary{color:#3b4151;font-style:normal}.swagger-ui .json-schema-2020-12-keyword__name--secondary{color:#6b6b6b;font-style:italic}.swagger-ui .json-schema-2020-12-keyword__value{color:#6b6b6b;font-size:12px;font-style:italic;font-weight:400}.swagger-ui .json-schema-2020-12-keyword__value--primary{color:#3b4151;font-style:normal}.swagger-ui .json-schema-2020-12-keyword__value--secondary{color:#6b6b6b;font-style:italic}.swagger-ui .json-schema-2020-12-keyword__value--const,.swagger-ui .json-schema-2020-12-keyword__value--warning{border:1px dashed #6b6b6b;border-radius:4px;color:#3b4151;color:#6b6b6b;display:inline-block;font-family:monospace;font-style:normal;font-weight:600;line-height:1.5;margin-left:10px;padding:1px 4px}.swagger-ui .json-schema-2020-12-keyword__value--warning{border:1px dashed red;color:red}.swagger-ui .json-schema-2020-12-keyword__name--secondary+.json-schema-2020-12-keyword__value--secondary:before{content:"="}.swagger-ui .json-schema-2020-12__attribute{color:#3b4151;font-family:monospace;font-size:12px;padding-left:10px;text-transform:lowercase}.swagger-ui .json-schema-2020-12__attribute--primary{color:#55a}.swagger-ui .json-schema-2020-12__attribute--muted{color:gray}.swagger-ui .json-schema-2020-12__attribute--warning{color:red}.swagger-ui .json-schema-2020-12-keyword--\$vocabulary ul{border-left:1px dashed rgba(0,0,0,.1);margin:0 0 0 20px}.swagger-ui .json-schema-2020-12-\$vocabulary-uri{margin-left:35px}.swagger-ui .json-schema-2020-12-\$vocabulary-uri--disabled{-webkit-text-decoration:line-through;text-decoration:line-through}.swagger-ui .json-schema-2020-12-keyword--description{color:#6b6b6b;font-size:12px;margin-left:20px}.swagger-ui .json-schema-2020-12-keyword--description p{margin:0}.swagger-ui .json-schema-2020-12__title{color:#505050;display:inline-block;font-family:sans-serif;font-size:12px;font-weight:700;line-height:normal}.swagger-ui .json-schema-2020-12__title .json-schema-2020-12-keyword__name{margin:0}.swagger-ui .json-schema-2020-12-property{margin:7px 0}.swagger-ui .json-schema-2020-12-property .json-schema-2020-12__title{color:#3b4151;font-family:monospace;font-size:12px;font-weight:600;vertical-align:middle}.swagger-ui .json-schema-2020-12-keyword--properties>ul{border:none;margin:0;padding:0}.swagger-ui .json-schema-2020-12-property{list-style-type:none}.swagger-ui .json-schema-2020-12-property--required>.json-schema-2020-12:first-of-type>.json-schema-2020-12-head .json-schema-2020-12__title:after{color:red;content:"*";font-weight:700}.swagger-ui .json-schema-2020-12-keyword--patternProperties ul{border:none;margin:0;padding:0}.swagger-ui .json-schema-2020-12-keyword--patternProperties .json-schema-2020-12__title:first-of-type:after,.swagger-ui .json-schema-2020-12-keyword--patternProperties .json-schema-2020-12__title:first-of-type:before{color:#55a;content:"/"}.swagger-ui .json-schema-2020-12-keyword--enum>ul{display:inline-block;margin:0;padding:0}.swagger-ui .json-schema-2020-12-keyword--enum>ul li{display:inline;list-style-type:none}.swagger-ui .json-schema-2020-12__constraint{background-color:#805ad5;border-radius:4px;color:#3b4151;color:#fff;font-family:monospace;font-weight:600;line-height:1.5;margin-left:10px;padding:1px 3px}.swagger-ui .json-schema-2020-12__constraint--string{background-color:#d69e2e;color:#fff}.swagger-ui .json-schema-2020-12-keyword--dependentRequired>ul{display:inline-block;margin:0;padding:0}.swagger-ui .json-schema-2020-12-keyword--dependentRequired>ul li{display:inline;list-style-type:none}.swagger-ui .model-box .json-schema-2020-12:not(.json-schema-2020-12--embedded)>.json-schema-2020-12-head .json-schema-2020-12__title:first-of-type{font-size:16px}.swagger-ui .model-box>.json-schema-2020-12{margin:0}.swagger-ui .model-box .json-schema-2020-12{background-color:transparent;padding:0}.swagger-ui .model-box .json-schema-2020-12-accordion,.swagger-ui .model-box .json-schema-2020-12-expand-deep-button{background-color:transparent}.swagger-ui .models .json-schema-2020-12:not(.json-schema-2020-12--embedded)>.json-schema-2020-12-head .json-schema-2020-12__title:first-of-type{font-size:16px} - - /*# sourceMappingURL=swagger-ui.css.map*/ \ No newline at end of file diff --git a/spaces/dorkai/ChatUIPro/service/index.ts b/spaces/dorkai/ChatUIPro/service/index.ts deleted file mode 100644 index 8028e0aa4a3b7c8249b258098daff80fef2575a8..0000000000000000000000000000000000000000 --- a/spaces/dorkai/ChatUIPro/service/index.ts +++ /dev/null @@ -1,33 +0,0 @@ -import type { IOnCompleted, IOnData, IOnError } from './base' -import { get, post, ssePost } from './base' -import type { Feedbacktype } from '@/types/app' - -export const sendChatMessage = async (body: Record
 '
-
- if '
'
-
- if ' ', prompt)
-
- if image_match is None:
- return prompt, input_ids, input_embeds
-
- prompt, input_ids, input_embeds, total_embedded = multimodal_embedder.forward(prompt, state, params)
- logging.info(f'Embedded {total_embedded} image(s) in {time.time()-start_ts:.2f}s')
- return (prompt,
- input_ids.unsqueeze(0).to(shared.model.device, dtype=torch.int64),
- input_embeds.unsqueeze(0).to(shared.model.device, dtype=shared.model.dtype))
-
-
-def ui():
- global multimodal_embedder
- multimodal_embedder = MultimodalEmbedder(params)
- with gr.Column():
- picture_select = gr.Image(label='Send a picture', type='pil')
- # The models don't seem to deal well with multiple images
- single_image_checkbox = gr.Checkbox(False, label='Embed all images, not only the last one')
- # Prepare the input hijack
- picture_select.upload(
- lambda picture: input_hijack.update({"state": True, "value": partial(add_chat_picture, picture)}),
- [picture_select],
- None
- )
- picture_select.clear(lambda: input_hijack.update({"state": False, "value": ["", ""]}), None, None)
- single_image_checkbox.change(lambda x: params.update({"add_all_images_to_prompt": x}), single_image_checkbox, None)
- shared.gradio['Generate'].click(lambda: None, None, picture_select)
- shared.gradio['textbox'].submit(lambda: None, None, picture_select)
diff --git a/spaces/dorkai/text-generation-webui-main/modules/RWKV.py b/spaces/dorkai/text-generation-webui-main/modules/RWKV.py
deleted file mode 100644
index bb6bab50c7d644f499e1ada84ec8b09d6adadf7e..0000000000000000000000000000000000000000
--- a/spaces/dorkai/text-generation-webui-main/modules/RWKV.py
+++ /dev/null
@@ -1,145 +0,0 @@
-import copy
-import os
-from pathlib import Path
-
-import numpy as np
-from tokenizers import Tokenizer
-
-import modules.shared as shared
-from modules.callbacks import Iteratorize
-
-np.set_printoptions(precision=4, suppress=True, linewidth=200)
-
-os.environ['RWKV_JIT_ON'] = '1'
-os.environ["RWKV_CUDA_ON"] = '1' if shared.args.rwkv_cuda_on else '0' # use CUDA kernel for seq mode (much faster)
-
-from rwkv.model import RWKV
-from rwkv.utils import PIPELINE, PIPELINE_ARGS
-
-
-class RWKVModel:
- def __init__(self):
- pass
-
- @classmethod
- def from_pretrained(self, path, dtype="fp16", device="cuda"):
- tokenizer_path = Path(f"{path.parent}/20B_tokenizer.json")
- if shared.args.rwkv_strategy is None:
- model = RWKV(model=str(path), strategy=f'{device} {dtype}')
- else:
- model = RWKV(model=str(path), strategy=shared.args.rwkv_strategy)
-
- pipeline = PIPELINE(model, str(tokenizer_path))
- result = self()
- result.pipeline = pipeline
- result.model = model
- result.cached_context = ""
- result.cached_model_state = None
- result.cached_output_logits = None
- return result
-
- def generate(self, context="", token_count=20, temperature=1, top_p=1, top_k=50, repetition_penalty=None, alpha_frequency=0.1, alpha_presence=0.1, token_ban=None, token_stop=None, callback=None):
- args = PIPELINE_ARGS(
- temperature=temperature,
- top_p=top_p,
- top_k=top_k,
- alpha_frequency=alpha_frequency, # Frequency Penalty (as in GPT-3)
- alpha_presence=alpha_presence, # Presence Penalty (as in GPT-3)
- token_ban=token_ban or [0], # ban the generation of some tokens
- token_stop=token_stop or []
- )
-
- if self.cached_context != "":
- if context.startswith(self.cached_context):
- context = context[len(self.cached_context):]
- else:
- self.cached_context = ""
- self.cached_model_state = None
- self.cached_output_logits = None
-
- # out = self.pipeline.generate(context, token_count=token_count, args=args, callback=callback)
- out = self.generate_from_cached_state(context, token_count=token_count, args=args, callback=callback)
- return out
-
- def generate_with_streaming(self, **kwargs):
- with Iteratorize(self.generate, kwargs, callback=None) as generator:
- reply = ''
- for token in generator:
- reply += token
- yield reply
-
- # Similar to the PIPELINE.generate, but lets us maintain the cached_model_state
- def generate_from_cached_state(self, ctx="", token_count=20, args=None, callback=None):
- all_tokens = []
- out_str = ''
- occurrence = {}
- state = copy.deepcopy(self.cached_model_state) if self.cached_model_state is not None else None
-
- # if we ended up with an empty context, just reuse the cached logits
- # this can happen if a user undoes a message and then sends the exact message again
- # in that case the full context ends up being the same as the cached_context, so the remaining context is empty.
- if ctx == "":
- out = self.cached_output_logits
-
- for i in range(token_count):
- # forward
- tokens = self.pipeline.encode(ctx) if i == 0 else [token]
- while len(tokens) > 0:
- out, state = self.model.forward(tokens[:args.chunk_len], state)
- tokens = tokens[args.chunk_len:]
-
- # cache the model state after scanning the context
- # we don't cache the state after processing our own generated tokens because
- # the output string might be post-processed arbitrarily. Therefore, what's fed into the model
- # on the next round of chat might be slightly different what what it output on the previous round
- if i == 0:
- self.cached_context += ctx
- self.cached_model_state = copy.deepcopy(state)
- self.cached_output_logits = copy.deepcopy(out)
-
- # adjust probabilities
- for n in args.token_ban:
- out[n] = -float('inf')
-
- for n in occurrence:
- out[n] -= (args.alpha_presence + occurrence[n] * args.alpha_frequency)
-
- # sampler
- token = self.pipeline.sample_logits(out, temperature=args.temperature, top_p=args.top_p, top_k=args.top_k)
- if token in args.token_stop:
- break
-
- all_tokens += [token]
- if token not in occurrence:
- occurrence[token] = 1
- else:
- occurrence[token] += 1
-
- # output
- tmp = self.pipeline.decode([token])
- if '\ufffd' not in tmp: # is valid utf-8 string?
- if callback:
- callback(tmp)
-
- out_str += tmp
-
- return out_str
-
-
-class RWKVTokenizer:
- def __init__(self):
- pass
-
- @classmethod
- def from_pretrained(self, path):
- tokenizer_path = path / "20B_tokenizer.json"
- tokenizer = Tokenizer.from_file(str(tokenizer_path))
- result = self()
- result.tokenizer = tokenizer
- return result
-
- def encode(self, prompt):
- return self.tokenizer.encode(prompt).ids
-
- def decode(self, ids):
- return self.tokenizer.decode(ids)
diff --git a/spaces/elonmuskceo/shiny-orbit-simulation/simulation.py b/spaces/elonmuskceo/shiny-orbit-simulation/simulation.py
deleted file mode 100644
index 64014f626446e095d7d652332efafea9c7cc149b..0000000000000000000000000000000000000000
--- a/spaces/elonmuskceo/shiny-orbit-simulation/simulation.py
+++ /dev/null
@@ -1,203 +0,0 @@
-from typing import Any
-import numpy as np
-import astropy.constants as c
-import time
-
-# Adapted from Python for Astronomers: An Introduction to Scientific Computing
-# by Imad Pasha & Christopher Agostino
-# https://prappleizer.github.io/Tutorials/RK4/RK4_Tutorial.html
-
-# Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License
-# http://creativecommons.org/licenses/by-nc-sa/4.0/
-
-
-class Body:
- def __init__(self, mass, x_vec, v_vec, name=None, has_units=True):
- """
- spawn instance of the Body class, which is used in Simulations.
-
- :param: mass | mass of particle. if has_units=True, an Astropy Quantity, otherwise a float
- :param: x_vec | a vector len(3) containing the x, y, z initial positions of the body.
- the array can be unitless if has_units=False, or be of the form np.array([0,0,0])*u.km
- :param: v_vec | vector len(3) containing the v_x, v_y, v_z initial velocities of the body.
- :param: name | string containing a name, used for plotting later
- :param: has_units | defines how the code treats the problem, as unit-ed, or unitless.
- """
- self.name = name
- self.has_units = has_units
- if self.has_units:
- self.mass = mass.cgs
- self.x_vec = x_vec.cgs.value
- self.v_vec = v_vec.cgs.value
- else:
- self.mass = mass
- self.x_vec = x_vec
- self.v_vec = v_vec
-
- def return_vec(self):
- """
- Concatenates the x and v vector into 1 vector 'y' used in RK formalism.
- """
- return np.concatenate((self.x_vec, self.v_vec))
-
- def return_mass(self):
- """
- handler to strip the mass units if present (after converting to cgs) or return float
- """
- if self.has_units:
- return self.mass.cgs.value
- else:
- return self.mass
-
- def return_name(self):
- return self.name
-
-
-class Simulation:
- def __init__(self, bodies, has_units=True):
- """
- Initializes instance of Simulation object.
- -------------------------------------------
- Params:
- bodies (list): a list of Body() objects
- has_units (bool): set whether bodies entered have units or not.
- """
- self.has_units = has_units
- self.bodies = bodies
- self.N_bodies = len(self.bodies)
- self.nDim = 6.0
- self.quant_vec = np.concatenate(np.array([i.return_vec() for i in self.bodies]))
- self.mass_vec = np.array([i.return_mass() for i in self.bodies])
- self.name_vec = [i.return_name() for i in self.bodies]
-
- def set_diff_eq(self, calc_diff_eqs, **kwargs):
- """
- Method which assigns an external solver function as the diff-eq solver for RK4.
- For N-body or gravitational setups, this is the function which calculates accelerations.
- ---------------------------------
- Params:
- calc_diff_eqs: A function which returns a [y] vector for RK4
- **kwargs: Any additional inputs/hyperparameters the external function requires
- """
- self.diff_eq_kwargs = kwargs
- self.calc_diff_eqs = calc_diff_eqs
-
- def rk4(self, t, dt):
- """
- RK4 integrator. Calculates the K values and returns a new y vector
- --------------------------------
- Params:
- t: a time. Only used if the diff eq depends on time (gravity doesn't).
- dt: timestep. Non adaptive in this case
- """
- k1 = dt * self.calc_diff_eqs(
- t, self.quant_vec, self.mass_vec, **self.diff_eq_kwargs
- )
- k2 = dt * self.calc_diff_eqs(
- t + 0.5 * dt,
- self.quant_vec + 0.5 * k1,
- self.mass_vec,
- **self.diff_eq_kwargs,
- )
- k3 = dt * self.calc_diff_eqs(
- t + 0.5 * dt,
- self.quant_vec + 0.5 * k2,
- self.mass_vec,
- **self.diff_eq_kwargs,
- )
- k4 = dt * self.calc_diff_eqs(
- t + dt, self.quant_vec + k2, self.mass_vec, **self.diff_eq_kwargs
- )
-
- y_new = self.quant_vec + ((k1 + 2 * k2 + 2 * k3 + k4) / 6.0)
-
- return y_new
-
- def run(self, T, dt, t0=0, progress=None):
- """
- Method which runs the simulation on a given set of bodies.
- ---------------------
- Params:
- T: total time (in simulation units) to run the simulation. Can have units or not, just set has_units appropriately.
- dt: timestep (in simulation units) to advance the simulation. Same as above
- t0 (optional): set a non-zero start time to the simulation.
- progress (optional): A shiny.ui.Progress object which will be used to send progress updates.
-
- Returns:
- None, but leaves an attribute history accessed via
- 'simulation.history' which contains all y vectors for the simulation.
- These are of shape (Nstep,Nbodies * 6), so the x and y positions of particle 1 are
- simulation.history[:,0], simulation.history[:,1], while the same for particle 2 are
- simulation.history[:,6], simulation.history[:,7]. Velocities are also extractable.
- """
- if not hasattr(self, "calc_diff_eqs"):
- raise AttributeError("You must set a diff eq solver first.")
- if self.has_units:
- try:
- _ = t0.unit
- except:
- t0 = (t0 * T.unit).cgs.value
- T = T.cgs.value
- dt = dt.cgs.value
-
- self.history: Any = [self.quant_vec]
- clock_time = t0
- nsteps = int((T - t0) / dt)
- start_time = time.time()
- for step in range(nsteps):
- if progress is not None and step % 5 == 0:
- progress.set(
- step,
- message=f"Integrating step = {step} / {nsteps}",
- detail=f"Elapsed time = {round(clock_time/1e6, 1)}",
- )
- y_new = self.rk4(0, dt)
- self.history.append(y_new)
- self.quant_vec = y_new
- clock_time += dt
- runtime = time.time() - start_time
- self.history = np.array(self.history)
-
-
-def nbody_solve(t, y, masses):
- N_bodies = int(len(y) / 6)
- solved_vector = np.zeros(y.size)
- for i in range(N_bodies):
- ioffset = i * 6
- for j in range(N_bodies):
- joffset = j * 6
- solved_vector[ioffset] = y[ioffset + 3]
- solved_vector[ioffset + 1] = y[ioffset + 4]
- solved_vector[ioffset + 2] = y[ioffset + 5]
- if i != j:
- dx = y[ioffset] - y[joffset]
- dy = y[ioffset + 1] - y[joffset + 1]
- dz = y[ioffset + 2] - y[joffset + 2]
- r = (dx**2 + dy**2 + dz**2) ** 0.5
- ax = (-c.G.cgs * masses[j] / r**3) * dx
- ay = (-c.G.cgs * masses[j] / r**3) * dy
- az = (-c.G.cgs * masses[j] / r**3) * dz
- ax = ax.value
- ay = ay.value
- az = az.value
- solved_vector[ioffset + 3] += ax
- solved_vector[ioffset + 4] += ay
- solved_vector[ioffset + 5] += az
- return solved_vector
-
-
-def spherical_to_cartesian(
- theta: float, phi: float, rho: float
-) -> tuple[float, float, float]:
- x = rho * sind(phi) * cosd(theta)
- y = rho * sind(phi) * sind(theta)
- z = rho * cosd(phi)
- return (x, y, z)
-
-
-def cosd(x):
- return np.cos(x / 180 * np.pi)
-
-
-def sind(x):
- return np.sin(x / 180 * np.pi)
diff --git a/spaces/eskayML/AUTOMATIC_SPEECH_RECOGNITION/README.md b/spaces/eskayML/AUTOMATIC_SPEECH_RECOGNITION/README.md
deleted file mode 100644
index 70cd862e2438ae09f248ecb30418617c92b5d0b2..0000000000000000000000000000000000000000
--- a/spaces/eskayML/AUTOMATIC_SPEECH_RECOGNITION/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: AUTOMATIC SPEECH RECOGNITION
-emoji: 🐠
-colorFrom: blue
-colorTo: green
-sdk: gradio
-sdk_version: 3.12.0
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/f2api/gpt-academic/crazy_functions/test_project/cpp/cppipc/buffer.cpp b/spaces/f2api/gpt-academic/crazy_functions/test_project/cpp/cppipc/buffer.cpp
deleted file mode 100644
index 0ac0fa7bc3ced0447ba4caa359355dd4252670b3..0000000000000000000000000000000000000000
--- a/spaces/f2api/gpt-academic/crazy_functions/test_project/cpp/cppipc/buffer.cpp
+++ /dev/null
@@ -1,87 +0,0 @@
-#include "libipc/buffer.h"
-#include "libipc/utility/pimpl.h"
-
-#include
', prompt)
-
- if image_match is None:
- return prompt, input_ids, input_embeds
-
- prompt, input_ids, input_embeds, total_embedded = multimodal_embedder.forward(prompt, state, params)
- logging.info(f'Embedded {total_embedded} image(s) in {time.time()-start_ts:.2f}s')
- return (prompt,
- input_ids.unsqueeze(0).to(shared.model.device, dtype=torch.int64),
- input_embeds.unsqueeze(0).to(shared.model.device, dtype=shared.model.dtype))
-
-
-def ui():
- global multimodal_embedder
- multimodal_embedder = MultimodalEmbedder(params)
- with gr.Column():
- picture_select = gr.Image(label='Send a picture', type='pil')
- # The models don't seem to deal well with multiple images
- single_image_checkbox = gr.Checkbox(False, label='Embed all images, not only the last one')
- # Prepare the input hijack
- picture_select.upload(
- lambda picture: input_hijack.update({"state": True, "value": partial(add_chat_picture, picture)}),
- [picture_select],
- None
- )
- picture_select.clear(lambda: input_hijack.update({"state": False, "value": ["", ""]}), None, None)
- single_image_checkbox.change(lambda x: params.update({"add_all_images_to_prompt": x}), single_image_checkbox, None)
- shared.gradio['Generate'].click(lambda: None, None, picture_select)
- shared.gradio['textbox'].submit(lambda: None, None, picture_select)
diff --git a/spaces/dorkai/text-generation-webui-main/modules/RWKV.py b/spaces/dorkai/text-generation-webui-main/modules/RWKV.py
deleted file mode 100644
index bb6bab50c7d644f499e1ada84ec8b09d6adadf7e..0000000000000000000000000000000000000000
--- a/spaces/dorkai/text-generation-webui-main/modules/RWKV.py
+++ /dev/null
@@ -1,145 +0,0 @@
-import copy
-import os
-from pathlib import Path
-
-import numpy as np
-from tokenizers import Tokenizer
-
-import modules.shared as shared
-from modules.callbacks import Iteratorize
-
-np.set_printoptions(precision=4, suppress=True, linewidth=200)
-
-os.environ['RWKV_JIT_ON'] = '1'
-os.environ["RWKV_CUDA_ON"] = '1' if shared.args.rwkv_cuda_on else '0' # use CUDA kernel for seq mode (much faster)
-
-from rwkv.model import RWKV
-from rwkv.utils import PIPELINE, PIPELINE_ARGS
-
-
-class RWKVModel:
- def __init__(self):
- pass
-
- @classmethod
- def from_pretrained(self, path, dtype="fp16", device="cuda"):
- tokenizer_path = Path(f"{path.parent}/20B_tokenizer.json")
- if shared.args.rwkv_strategy is None:
- model = RWKV(model=str(path), strategy=f'{device} {dtype}')
- else:
- model = RWKV(model=str(path), strategy=shared.args.rwkv_strategy)
-
- pipeline = PIPELINE(model, str(tokenizer_path))
- result = self()
- result.pipeline = pipeline
- result.model = model
- result.cached_context = ""
- result.cached_model_state = None
- result.cached_output_logits = None
- return result
-
- def generate(self, context="", token_count=20, temperature=1, top_p=1, top_k=50, repetition_penalty=None, alpha_frequency=0.1, alpha_presence=0.1, token_ban=None, token_stop=None, callback=None):
- args = PIPELINE_ARGS(
- temperature=temperature,
- top_p=top_p,
- top_k=top_k,
- alpha_frequency=alpha_frequency, # Frequency Penalty (as in GPT-3)
- alpha_presence=alpha_presence, # Presence Penalty (as in GPT-3)
- token_ban=token_ban or [0], # ban the generation of some tokens
- token_stop=token_stop or []
- )
-
- if self.cached_context != "":
- if context.startswith(self.cached_context):
- context = context[len(self.cached_context):]
- else:
- self.cached_context = ""
- self.cached_model_state = None
- self.cached_output_logits = None
-
- # out = self.pipeline.generate(context, token_count=token_count, args=args, callback=callback)
- out = self.generate_from_cached_state(context, token_count=token_count, args=args, callback=callback)
- return out
-
- def generate_with_streaming(self, **kwargs):
- with Iteratorize(self.generate, kwargs, callback=None) as generator:
- reply = ''
- for token in generator:
- reply += token
- yield reply
-
- # Similar to the PIPELINE.generate, but lets us maintain the cached_model_state
- def generate_from_cached_state(self, ctx="", token_count=20, args=None, callback=None):
- all_tokens = []
- out_str = ''
- occurrence = {}
- state = copy.deepcopy(self.cached_model_state) if self.cached_model_state is not None else None
-
- # if we ended up with an empty context, just reuse the cached logits
- # this can happen if a user undoes a message and then sends the exact message again
- # in that case the full context ends up being the same as the cached_context, so the remaining context is empty.
- if ctx == "":
- out = self.cached_output_logits
-
- for i in range(token_count):
- # forward
- tokens = self.pipeline.encode(ctx) if i == 0 else [token]
- while len(tokens) > 0:
- out, state = self.model.forward(tokens[:args.chunk_len], state)
- tokens = tokens[args.chunk_len:]
-
- # cache the model state after scanning the context
- # we don't cache the state after processing our own generated tokens because
- # the output string might be post-processed arbitrarily. Therefore, what's fed into the model
- # on the next round of chat might be slightly different what what it output on the previous round
- if i == 0:
- self.cached_context += ctx
- self.cached_model_state = copy.deepcopy(state)
- self.cached_output_logits = copy.deepcopy(out)
-
- # adjust probabilities
- for n in args.token_ban:
- out[n] = -float('inf')
-
- for n in occurrence:
- out[n] -= (args.alpha_presence + occurrence[n] * args.alpha_frequency)
-
- # sampler
- token = self.pipeline.sample_logits(out, temperature=args.temperature, top_p=args.top_p, top_k=args.top_k)
- if token in args.token_stop:
- break
-
- all_tokens += [token]
- if token not in occurrence:
- occurrence[token] = 1
- else:
- occurrence[token] += 1
-
- # output
- tmp = self.pipeline.decode([token])
- if '\ufffd' not in tmp: # is valid utf-8 string?
- if callback:
- callback(tmp)
-
- out_str += tmp
-
- return out_str
-
-
-class RWKVTokenizer:
- def __init__(self):
- pass
-
- @classmethod
- def from_pretrained(self, path):
- tokenizer_path = path / "20B_tokenizer.json"
- tokenizer = Tokenizer.from_file(str(tokenizer_path))
- result = self()
- result.tokenizer = tokenizer
- return result
-
- def encode(self, prompt):
- return self.tokenizer.encode(prompt).ids
-
- def decode(self, ids):
- return self.tokenizer.decode(ids)
diff --git a/spaces/elonmuskceo/shiny-orbit-simulation/simulation.py b/spaces/elonmuskceo/shiny-orbit-simulation/simulation.py
deleted file mode 100644
index 64014f626446e095d7d652332efafea9c7cc149b..0000000000000000000000000000000000000000
--- a/spaces/elonmuskceo/shiny-orbit-simulation/simulation.py
+++ /dev/null
@@ -1,203 +0,0 @@
-from typing import Any
-import numpy as np
-import astropy.constants as c
-import time
-
-# Adapted from Python for Astronomers: An Introduction to Scientific Computing
-# by Imad Pasha & Christopher Agostino
-# https://prappleizer.github.io/Tutorials/RK4/RK4_Tutorial.html
-
-# Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License
-# http://creativecommons.org/licenses/by-nc-sa/4.0/
-
-
-class Body:
- def __init__(self, mass, x_vec, v_vec, name=None, has_units=True):
- """
- spawn instance of the Body class, which is used in Simulations.
-
- :param: mass | mass of particle. if has_units=True, an Astropy Quantity, otherwise a float
- :param: x_vec | a vector len(3) containing the x, y, z initial positions of the body.
- the array can be unitless if has_units=False, or be of the form np.array([0,0,0])*u.km
- :param: v_vec | vector len(3) containing the v_x, v_y, v_z initial velocities of the body.
- :param: name | string containing a name, used for plotting later
- :param: has_units | defines how the code treats the problem, as unit-ed, or unitless.
- """
- self.name = name
- self.has_units = has_units
- if self.has_units:
- self.mass = mass.cgs
- self.x_vec = x_vec.cgs.value
- self.v_vec = v_vec.cgs.value
- else:
- self.mass = mass
- self.x_vec = x_vec
- self.v_vec = v_vec
-
- def return_vec(self):
- """
- Concatenates the x and v vector into 1 vector 'y' used in RK formalism.
- """
- return np.concatenate((self.x_vec, self.v_vec))
-
- def return_mass(self):
- """
- handler to strip the mass units if present (after converting to cgs) or return float
- """
- if self.has_units:
- return self.mass.cgs.value
- else:
- return self.mass
-
- def return_name(self):
- return self.name
-
-
-class Simulation:
- def __init__(self, bodies, has_units=True):
- """
- Initializes instance of Simulation object.
- -------------------------------------------
- Params:
- bodies (list): a list of Body() objects
- has_units (bool): set whether bodies entered have units or not.
- """
- self.has_units = has_units
- self.bodies = bodies
- self.N_bodies = len(self.bodies)
- self.nDim = 6.0
- self.quant_vec = np.concatenate(np.array([i.return_vec() for i in self.bodies]))
- self.mass_vec = np.array([i.return_mass() for i in self.bodies])
- self.name_vec = [i.return_name() for i in self.bodies]
-
- def set_diff_eq(self, calc_diff_eqs, **kwargs):
- """
- Method which assigns an external solver function as the diff-eq solver for RK4.
- For N-body or gravitational setups, this is the function which calculates accelerations.
- ---------------------------------
- Params:
- calc_diff_eqs: A function which returns a [y] vector for RK4
- **kwargs: Any additional inputs/hyperparameters the external function requires
- """
- self.diff_eq_kwargs = kwargs
- self.calc_diff_eqs = calc_diff_eqs
-
- def rk4(self, t, dt):
- """
- RK4 integrator. Calculates the K values and returns a new y vector
- --------------------------------
- Params:
- t: a time. Only used if the diff eq depends on time (gravity doesn't).
- dt: timestep. Non adaptive in this case
- """
- k1 = dt * self.calc_diff_eqs(
- t, self.quant_vec, self.mass_vec, **self.diff_eq_kwargs
- )
- k2 = dt * self.calc_diff_eqs(
- t + 0.5 * dt,
- self.quant_vec + 0.5 * k1,
- self.mass_vec,
- **self.diff_eq_kwargs,
- )
- k3 = dt * self.calc_diff_eqs(
- t + 0.5 * dt,
- self.quant_vec + 0.5 * k2,
- self.mass_vec,
- **self.diff_eq_kwargs,
- )
- k4 = dt * self.calc_diff_eqs(
- t + dt, self.quant_vec + k2, self.mass_vec, **self.diff_eq_kwargs
- )
-
- y_new = self.quant_vec + ((k1 + 2 * k2 + 2 * k3 + k4) / 6.0)
-
- return y_new
-
- def run(self, T, dt, t0=0, progress=None):
- """
- Method which runs the simulation on a given set of bodies.
- ---------------------
- Params:
- T: total time (in simulation units) to run the simulation. Can have units or not, just set has_units appropriately.
- dt: timestep (in simulation units) to advance the simulation. Same as above
- t0 (optional): set a non-zero start time to the simulation.
- progress (optional): A shiny.ui.Progress object which will be used to send progress updates.
-
- Returns:
- None, but leaves an attribute history accessed via
- 'simulation.history' which contains all y vectors for the simulation.
- These are of shape (Nstep,Nbodies * 6), so the x and y positions of particle 1 are
- simulation.history[:,0], simulation.history[:,1], while the same for particle 2 are
- simulation.history[:,6], simulation.history[:,7]. Velocities are also extractable.
- """
- if not hasattr(self, "calc_diff_eqs"):
- raise AttributeError("You must set a diff eq solver first.")
- if self.has_units:
- try:
- _ = t0.unit
- except:
- t0 = (t0 * T.unit).cgs.value
- T = T.cgs.value
- dt = dt.cgs.value
-
- self.history: Any = [self.quant_vec]
- clock_time = t0
- nsteps = int((T - t0) / dt)
- start_time = time.time()
- for step in range(nsteps):
- if progress is not None and step % 5 == 0:
- progress.set(
- step,
- message=f"Integrating step = {step} / {nsteps}",
- detail=f"Elapsed time = {round(clock_time/1e6, 1)}",
- )
- y_new = self.rk4(0, dt)
- self.history.append(y_new)
- self.quant_vec = y_new
- clock_time += dt
- runtime = time.time() - start_time
- self.history = np.array(self.history)
-
-
-def nbody_solve(t, y, masses):
- N_bodies = int(len(y) / 6)
- solved_vector = np.zeros(y.size)
- for i in range(N_bodies):
- ioffset = i * 6
- for j in range(N_bodies):
- joffset = j * 6
- solved_vector[ioffset] = y[ioffset + 3]
- solved_vector[ioffset + 1] = y[ioffset + 4]
- solved_vector[ioffset + 2] = y[ioffset + 5]
- if i != j:
- dx = y[ioffset] - y[joffset]
- dy = y[ioffset + 1] - y[joffset + 1]
- dz = y[ioffset + 2] - y[joffset + 2]
- r = (dx**2 + dy**2 + dz**2) ** 0.5
- ax = (-c.G.cgs * masses[j] / r**3) * dx
- ay = (-c.G.cgs * masses[j] / r**3) * dy
- az = (-c.G.cgs * masses[j] / r**3) * dz
- ax = ax.value
- ay = ay.value
- az = az.value
- solved_vector[ioffset + 3] += ax
- solved_vector[ioffset + 4] += ay
- solved_vector[ioffset + 5] += az
- return solved_vector
-
-
-def spherical_to_cartesian(
- theta: float, phi: float, rho: float
-) -> tuple[float, float, float]:
- x = rho * sind(phi) * cosd(theta)
- y = rho * sind(phi) * sind(theta)
- z = rho * cosd(phi)
- return (x, y, z)
-
-
-def cosd(x):
- return np.cos(x / 180 * np.pi)
-
-
-def sind(x):
- return np.sin(x / 180 * np.pi)
diff --git a/spaces/eskayML/AUTOMATIC_SPEECH_RECOGNITION/README.md b/spaces/eskayML/AUTOMATIC_SPEECH_RECOGNITION/README.md
deleted file mode 100644
index 70cd862e2438ae09f248ecb30418617c92b5d0b2..0000000000000000000000000000000000000000
--- a/spaces/eskayML/AUTOMATIC_SPEECH_RECOGNITION/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: AUTOMATIC SPEECH RECOGNITION
-emoji: 🐠
-colorFrom: blue
-colorTo: green
-sdk: gradio
-sdk_version: 3.12.0
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/f2api/gpt-academic/crazy_functions/test_project/cpp/cppipc/buffer.cpp b/spaces/f2api/gpt-academic/crazy_functions/test_project/cpp/cppipc/buffer.cpp
deleted file mode 100644
index 0ac0fa7bc3ced0447ba4caa359355dd4252670b3..0000000000000000000000000000000000000000
--- a/spaces/f2api/gpt-academic/crazy_functions/test_project/cpp/cppipc/buffer.cpp
+++ /dev/null
@@ -1,87 +0,0 @@
-#include "libipc/buffer.h"
-#include "libipc/utility/pimpl.h"
-
-#include