-
-
\ No newline at end of file diff --git a/spaces/1gistliPinn/ChatGPT4/Examples/Artificial Intelligence Full Movie Download !LINK! In Hindi.md b/spaces/1gistliPinn/ChatGPT4/Examples/Artificial Intelligence Full Movie Download !LINK! In Hindi.md deleted file mode 100644 index 233794b28652d8fcecfc4ffb3f10aa2520c22a78..0000000000000000000000000000000000000000 --- a/spaces/1gistliPinn/ChatGPT4/Examples/Artificial Intelligence Full Movie Download !LINK! In Hindi.md +++ /dev/null @@ -1,6 +0,0 @@ -
Artificial Intelligence Full Movie Download In Hindi
DOWNLOAD ❤ https://imgfil.com/2uxZcJ
-
-Film Kyss mig (2011) Online HD,Film Online,Filme Online. ... The Last Kids on Earth (Season 3) [Hindi + English] Dual Audio WEB-DL 720p [NF Animated Series]. ... The automatic subtitle generators powered by artificial intelligence offer a ... 4d29de3e1b
-
-
- diff --git a/spaces/1gistliPinn/ChatGPT4/Examples/Ashtapathi Lyrics In Tamil Pdf [PORTABLE] Download.md b/spaces/1gistliPinn/ChatGPT4/Examples/Ashtapathi Lyrics In Tamil Pdf [PORTABLE] Download.md deleted file mode 100644 index 962998cb37ba82837dba8cefdfea31745b5df3c1..0000000000000000000000000000000000000000 --- a/spaces/1gistliPinn/ChatGPT4/Examples/Ashtapathi Lyrics In Tamil Pdf [PORTABLE] Download.md +++ /dev/null @@ -1,6 +0,0 @@ -
ashtapathi lyrics in tamil pdf download
Download ❤❤❤ https://imgfil.com/2uxZp8
- -Pdf - eBook and . ... PDF ebooks (user's guide, manuals, sheets) about Ashtapadi lyrics tamil pdf ready for download.... DownloadPDF, TXT or ... 1fdad05405
-
-
- diff --git a/spaces/1gistliPinn/ChatGPT4/Examples/Dungeon Of The Endless 1.1.5 Crack [EXCLUSIVE] Mac Osx.md b/spaces/1gistliPinn/ChatGPT4/Examples/Dungeon Of The Endless 1.1.5 Crack [EXCLUSIVE] Mac Osx.md deleted file mode 100644 index 8d8e914c292f93c4269fa3f7d1f58118d9853549..0000000000000000000000000000000000000000 --- a/spaces/1gistliPinn/ChatGPT4/Examples/Dungeon Of The Endless 1.1.5 Crack [EXCLUSIVE] Mac Osx.md +++ /dev/null @@ -1,124 +0,0 @@ -
-
Dungeon of the Endless 1.1.5 Crack Mac Osx: How to Download and Play the Ultimate Dungeon Crawler
-Dungeon of the Endless 1.1.5 Crack Mac Osx is a game that combines roguelike, tower defense, and RPG elements in a unique and challenging way. You play as a survivor of a prison ship that crashed on a mysterious planet, and you have to explore the endless dungeon below, fighting enemies, collecting resources, and building defenses along the way.
-Dungeon of the Endless 1.1.5 Crack Mac Osx
Download ———>>> https://imgfil.com/2uxYai
-
If you are looking for a game that will test your skills and strategy, Dungeon of the Endless 1.1.5 Crack Mac Osx is a perfect choice. In this article, we will show you how to download and play this game on your Mac computer.
-How to Download Dungeon of the Endless 1.1.5 Crack Mac Osx
-Dungeon of the Endless 1.1.5 Crack Mac Osx is a cracked version of the game that allows you to play it for free without any limitations or restrictions. You can download it from various websites that offer cracked games for Mac users, such as kidzshare.com or trailduro.com.
-Here are the steps to download Dungeon of the Endless 1.1.5 Crack Mac Osx:
- --
-
- Visit one of the websites that offer Dungeon of the Endless 1.1.5 Crack Mac Osx, such as kidzshare.com or trailduro.com. -
- Find the download link for Dungeon of the Endless 1.1.5 Crack Mac Osx and click on it. -
- Wait for the download to finish and extract the zip file to your desired location. -
- Open the extracted folder and run the DungeonoftheEndless.app file to launch the game. -
How to Play Dungeon of the Endless 1.1.5 Crack Mac Osx
-Dungeon of the Endless 1.1.5 Crack Mac Osx is a game that requires strategy, skill, and luck to survive. You can play it solo or with up to three other players online or locally.
-Here are some tips and tricks to play Dungeon of the Endless 1.1.5 Crack Mac Osx:
--
-
- Choose your characters wisely: Each character has different stats, skills, and abilities that can affect your gameplay. You can also unlock more characters by completing certain achievements or using mods. -
- Manage your resources carefully: You need to collect dust, food, industry, and science to power your rooms, heal your characters, build modules, and research new technologies. -
- Build your defenses strategically: You can build various modules in your rooms to help you fight enemies, such as turrets, traps, generators, etc. You can also upgrade your modules with science or use special items to boost their effects. -
- Explore cautiously: You can open doors to explore new rooms and floors, but be careful as enemies will spawn randomly and attack you. You can also find items, events, merchants, or allies in some rooms. -
- Escape safely: Your goal is to find the exit on each floor and reach it with at least one character carrying the crystal that powers your ship. You need to protect your crystal from enemies while moving it from room to room. -
Conclusion
-Dungeon of the Endless 1.1.5 Crack Mac Osx is a game that will challenge you with its unique blend of roguelike, tower defense, and RPG elements. You can download it for free from various websites that offer cracked games for Mac users, such as kidzshare.com or trailduro.com.
-If you are looking for a game that will test your skills and strategy, Dungeon of the Endless 1.1.5 Crack Mac Osx is a perfect choice.
-How to Unlock Secret Characters with Dungeon of the Endless 1.1.5 Crack Mac Osx
-Dungeon of the Endless 1.1.5 Crack Mac Osx has a lot of characters to choose from, each with their own stats, skills, and abilities. However, some of them are hidden and can only be unlocked by certain methods or conditions.
-If you want to unlock all the secret characters in Dungeon of the Endless 1.1.5 Crack Mac Osx, you can use a mod called Secret Unlocker (DotE-Secrets) v.1.1.5, which is a patch that adds them to the character selection screen. You can download it from gamepressure.com or other websites that offer mods for Dungeon of the Endless.
-Here are the steps to install and use Secret Unlocker (DotE-Secrets) v.1.1.5:
--
-
- Download the mod file from gamepressure.com or other websites that offer mods for Dungeon of the Endless. -
- Copy the mod file to DungeonoftheEndless_Data\\Managed inside your game folder. -
- Run the installer and it will rename your original Assembly-CSharp.dll file to Assembly-CSharp.dll.backup. -
- Launch the game and you will see all the secret characters available on the character selection screen. -
Here are the secret characters that you can unlock with Secret Unlocker (DotE-Secrets) v.1.1.5:
--
-
- Ayairi Whairydd (War Pug): A cute but fierce dog that can bite enemies and heal allies. -
- Esseb Tarosh (Archivist): A mysterious alien that can manipulate time and space. -
How to Install Mods for Dungeon of the Endless 1.1.5 Crack Mac Osx
-Dungeon of the Endless 1.1.5 Crack Mac Osx is a game that can be enhanced and customized with various mods that add new features, functions, or content to the game. You can find many mods for Dungeon of the Endless on websites such as ali213.net or lastgame.ru.
-Here are the steps to install mods for Dungeon of the Endless 1.1.5 Crack Mac Osx:
--
-
- Download the mod file from ali213.net or lastgame.ru or other websites that offer mods for Dungeon of the Endless. -
- Extract the zip file to your desired location. -
- Open the extracted folder and copy the files or folders to your game folder, depending on the instructions of each mod. -
- Launch the game and enjoy the modded features or content. -
Here are some examples of mods that you can install for Dungeon of the Endless 1.1.5 Crack Mac Osx:
--
-
- Dungeon of The Endless - More Heroes: A mod that adds more than 20 new heroes to the game, each with their own stats, skills, and abilities. -
- Dungeon of The Endless - More Modules: A mod that adds more than 30 new modules to the game, each with their own effects and functions. -
- Dungeon of The Endless - More Floors: A mod that adds more floors to the game, each with their own themes and challenges. -
How to Update Dungeon of the Endless 1.1.5 Crack Mac Osx
-Dungeon of the Endless 1.1.5 Crack Mac Osx is a cracked version of the game that allows you to play it for free without any limitations or restrictions. However, it may not be compatible with the latest updates or patches that are released by the developers.
-If you want to update Dungeon of the Endless 1.1.5 Crack Mac Osx to the latest version, you can use a tool called PatchMyPC, which is a free software that can automatically update your cracked games and apps on your Mac computer.
-Here are the steps to update Dungeon of the Endless 1.1.5 Crack Mac Osx with PatchMyPC:
--
-
- Download PatchMyPC from patchmypc.com or other websites that offer tools for cracked games and apps. -
- Install PatchMyPC on your Mac computer and run it. -
- Select Dungeon of the Endless 1.1.5 Crack Mac Osx from the list of games and apps that can be updated by PatchMyPC. -
- Click Update button and wait for PatchMyPC to download and install the latest update or patch for Dungeon of the Endless 1.1.5 Crack Mac Osx. -
- Launch Dungeon of the Endless 1.1.5 Crack Mac Osx and enjoy the updated features or content. -
How to Fix Common Problems with Dungeon of the Endless 1.1.5 Crack Mac Osx
-Dungeon of the Endless 1.1.5 Crack Mac Osx is a game that can run smoothly and flawlessly on most Mac computers, but it may also encounter some problems or errors that can affect your gameplay experience.
-If you face any common problems with Dungeon of the Endless 1.1.5 Crack Mac Osx, such as crashes, freezes, lag, black screen, sound issues, etc., you can try some solutions that can help you fix them.
-Here are some solutions that can help you fix common problems with Dungeon of the Endless 1.1.5 Crack Mac Osx:
--
-
- Make sure your Mac computer meets the minimum system requirements for Dungeon of the Endless 1.1.5 Crack Mac Osx, such as operating system, processor, memory, graphics card, etc. -
- Make sure your Mac computer has enough free disk space and RAM to run Dungeon of the Endless 1.1.5 Crack Mac Osx smoothly and efficiently. -
- Make sure your Mac computer has the latest drivers and software updates installed, especially for your graphics card and sound card. -
- Make sure your Mac computer has no viruses or malware that can interfere with Dungeon of the Endless 1.1.5 Crack Mac Osx or cause performance issues. -
- Make sure your internet connection is stable and fast enough to play Dungeon of the Endless 1.1.5 Crack Mac Osx online or multiplayer mode without lag or disconnects. -
- Make sure you run Dungeon of the Endless 1.1.5 Crack Mac Osx as administrator and in compatibility mode if necessary. -
- Make sure you disable any background programs or applications that can consume your CPU or GPU resources or conflict with Dungeon of the Endless 1.1.5 Crack Mac Osx. -
- Make sure you adjust your game settings according to your preferences and hardware capabilities, such as resolution, graphics quality, sound volume, etc. -
How to Customize Your Characters with Dungeon of the Endless 1.1.5 Crack Mac Osx
-Dungeon of the Endless 1.1.5 Crack Mac Osx has a lot of characters to choose from, each with their own stats, skills, and abilities. However, you can also customize your characters with various items, equipment, and mods that can enhance their performance and appearance.
-If you want to customize your characters with Dungeon of the Endless 1.1.5 Crack Mac Osx, you can use a mod called More Heroes, which is a mod that adds more than 20 new heroes to the game, each with their own stats, skills, and abilities. You can download it from ali213.net or other websites that offer mods for Dungeon of the Endless.
-Here are the steps to install and use More Heroes mod for Dungeon of the Endless 1.1.5 Crack Mac Osx:
--
-
- Download the mod file from ali213.net or other websites that offer mods for Dungeon of the Endless. -
- Extract the zip file to your desired location. -
- Open the extracted folder and copy the files or folders to your game folder. -
- Launch the game and you will see all the new heroes available on the character selection screen. -
Here are some examples of items, equipment, and mods that you can use to customize your characters with Dungeon of the Endless 1.1.5 Crack Mac Osx:
--
-
- Items: You can find various items in the dungeon that can give you temporary or permanent bonuses or effects, such as health, damage, speed, etc. -
- Equipment: You can equip your characters with different weapons and armor that can improve their combat abilities and defense. -
- Mods: You can install different mods on your characters that can modify their stats, skills, or abilities. -
How to Enjoy Dungeon of the Endless 1.1.5 Crack Mac Osx with Your Friends
-Dungeon of the Endless 1.1.5 Crack Mac Osx is a game that can be played solo or with up to three other players online or locally. Playing with your friends can make the game more fun and challenging, as you can cooperate and communicate with each other to survive the endless dungeon.
-If you want to enjoy Dungeon of the Endless 1.1.5 Crack Mac Osx with your friends, you can use a tool called Hamachi, which is a free software that can create a virtual private network (VPN) between your computers and allow you to play online games as if you were on the same local network.
-Here are the steps to enjoy Dungeon of the Endless 1.1.5 Crack Mac Osx with your friends using Hamachi:
--
-
- Download Hamachi from hamachi.com or other websites that offer tools for online gaming. -
- Install Hamachi on your Mac computer and run it. -
- Create a new network or join an existing one with your friends. -
- Launch Dungeon of the Endless 1.1.5 Crack Mac Osx and select Multiplayer mode. -
- Create a new game or join an existing one with your friends. -
Here are some tips and tricks to enjoy Dungeon of the Endless 1.1.5 Crack Mac Osx with your friends:
--
-
- Communicate with your friends using voice chat or text chat to coordinate your actions and strategies. -
- Distribute your resources and roles among your friends according to your characters' strengths and weaknesses. -
- Help each other out when in trouble or danger by healing, defending, or rescuing each other. -
- Have fun and enjoy the game! -
Conclusion
-Dungeon of the Endless 1.1.5 Crack Mac Osx is a game that combines roguelike, tower defense, and RPG elements in a unique and challenging way. You play as a survivor of a prison ship that crashed on a mysterious planet, and you have to explore the endless dungeon below, fighting enemies, collecting resources, and building defenses along the way.
-If you are looking for a game that will test your skills and strategy, Dungeon of the Endless 1.1.5 Crack Mac Osx is a perfect choice. You can download it for free from various websites that offer cracked games for Mac users, such as kidzshare.com or trailduro.com.
-In this article, we have shown you how to download and play Dungeon of the Endless 1.1.5 Crack Mac Osx on your Mac computer. We have also given you some tips and tricks to survive the endless dungeon, unlock secret characters, install mods, update the game, fix common problems, and enjoy the game with your friends.
-We hope you have found this article helpful and informative. If you have any questions or comments, feel free to leave them below. Thank you for reading and have fun playing Dungeon of the Endless 1.1.5 Crack Mac Osx!
3cee63e6c2-
-
\ No newline at end of file diff --git a/spaces/1pelhydcardo/ChatGPT-prompt-generator/assets/Buble Shooter Join the Bubble Popping Adventure.md b/spaces/1pelhydcardo/ChatGPT-prompt-generator/assets/Buble Shooter Join the Bubble Popping Adventure.md deleted file mode 100644 index 539f3821c6169b386a9114b47b5d1873f70e7808..0000000000000000000000000000000000000000 --- a/spaces/1pelhydcardo/ChatGPT-prompt-generator/assets/Buble Shooter Join the Bubble Popping Adventure.md +++ /dev/null @@ -1,123 +0,0 @@ -
-
Bubble Shooter: A Fun and Addictive Game for Everyone
-If you are looking for a simple yet entertaining game to pass the time, you might want to try Bubble Shooter. Bubble Shooter is a popular online game that involves shooting bubbles to match three or more of the same color and make them pop. It is easy to learn, fun to play, and suitable for all ages. In this article, we will tell you everything you need to know about Bubble Shooter, including its history, rules, benefits, tips, and best versions.
-What is Bubble Shooter?
-Bubble Shooter is a type of puzzle game that belongs to the genre of "match three" games. The main objective of the game is to clear the screen of bubbles by shooting them with a bubble cannon. The bubbles are arranged in a grid or a cluster, and they come in different colors. To pop the bubbles, you need to aim and shoot a bubble of the same color at them. When three or more bubbles of the same color touch, they burst and disappear. The game ends when you clear all the bubbles or when one of them reaches the bottom of the screen.
-buble shooter
DOWNLOAD ✶ https://urlin.us/2uSStg
-
The history of Bubble Shooter
-Bubble Shooter was originally developed by Taito Corporation in 1994 as an arcade game called Puzzle Bobble. It was later ported to various platforms such as PC, mobile, and web browsers. The game became very popular and spawned many sequels and spin-offs. One of the most successful versions of the game was Bubble Shooter, which was released in 2002 by Absolutist Games. This version introduced some new features such as power-ups, levels, and modes. Since then, Bubble Shooter has been played by millions of people around the world and has inspired many other similar games.
-The rules of Bubble Shooter
-The rules of Bubble Shooter are simple and intuitive. Here are the basic steps to play the game:
--
-
- At the bottom of the screen, you will see a bubble cannon that can be moved left and right with your mouse or finger. -
- At the center of the cannon, you will see a bubble that is ready to be launched. You can also see the next bubble that will come after it. -
- Aim the cannon at the cluster of bubbles at the top of the screen. You can see where the bubble will go by following the dotted line. -
- Click or tap to shoot the bubble. Try to hit bubbles of the same color as your bubble. -
- If you manage to connect three or more bubbles of the same color, they will pop and disappear. You will also earn points for each bubble you pop. -
- If you miss or hit a different color, the bubble will stick to the cluster and make it bigger. -
- If you pop all the bubbles on the screen, you will complete the level and move on to the next one. -
- If one of the bubbles touches the bottom of the screen, you will lose a life and have to start over. -
The benefits of playing Bubble Shooter
-Bubble Shooter is not only a fun game but also a beneficial one. Here are some of the advantages of playing Bubble Shooter:
--
-
- It improves your concentration and focus. You have to pay attention to the colors, angles, and trajectories of the bubbles. -
- It enhances your hand-eye coordination and reaction time. You have to move quickly and accurately to shoot the bubbles. -
- It stimulates your brain and memory. You have to plan ahead and remember where the bubbles are located and how to pop them. -
- It relaxes your mind and mood. You can enjoy the colorful graphics, the soothing sounds, and the satisfying feeling of popping bubbles. -
- It challenges your skills and creativity. You can try different strategies and techniques to beat the levels and score higher. -
How to play Bubble Shooter?
-Now that you know what Bubble Shooter is and why you should play it, let's see how you can actually play it. Here are some tips and tricks to help you master the game:
-Choose your device and platform
-Bubble Shooter is available on various devices and platforms, such as PC, mobile, tablet, and web browser. You can choose the one that suits you best, depending on your preferences and convenience. For example, if you want to play on a bigger screen and use a mouse, you can play on your PC. If you want to play on the go and use touch controls, you can play on your mobile or tablet. If you want to play online and access different versions of the game, you can play on your web browser.
-Aim and shoot the bubbles
-The most important skill in Bubble Shooter is aiming and shooting the bubbles. You need to be precise and accurate to hit the right bubbles and avoid wasting shots. Here are some tips to improve your aiming and shooting:
--
-
- Use the dotted line as a guide. The dotted line shows you where the bubble will go when you shoot it. You can adjust the angle of the cannon by moving your mouse or finger. -
- Use the walls as a bounce. The walls can help you reach bubbles that are hard to hit directly. You can bounce the bubble off the wall and make it ricochet to the target. -
- Use the color of the next bubble as a hint. The color of the next bubble shows you what color will come after the current one. You can use this information to plan ahead and prepare for your next shot. -
Use strategies and tips to improve your score
-Besides aiming and shooting, there are also some strategies and tips that can help you improve your score and beat the levels. Here are some of them:
--
-
- Pop more bubbles with one shot. The more bubbles you pop with one shot, the more points you get. You can also trigger chain reactions and combos by popping bubbles that are connected to other bubbles of the same color. -
- Clear the top rows first. The top rows are more dangerous because they are closer to the bottom of the screen. If you clear them first, you will have more space and time to shoot the lower rows. -
- Avoid creating isolated bubbles. Isolated bubbles are bubbles that are not connected to any other bubbles of the same color. They are harder to pop and waste your shots. Try to avoid creating them by shooting at groups of bubbles instead of single ones. -
- Use power-ups wisely. Power-ups are special bubbles that have different effects when popped. For example, some power-ups can clear a whole row or column of bubbles, change the color of nearby bubbles, or give you extra lives or shots. Use them wisely when you need them, but don't rely on them too much. -
What are the best Bubble Shooter games?
-Bubble Shooter is a very popular game that has many versions and variations. Some of them are more classic and simple, while others are more modern and complex. Here are some of the best Bubble Shooter games that you can try:
-bubble shooter game online free
-bubble shooter classic play
-bubble shooter extreme download
-bubble shooter pro tips
-bubble shooter candy crush
-bubble shooter levels strategy
-bubble shooter arcade mode
-bubble shooter original version
-bubble shooter puzzle bobble
-bubble shooter smarty bubbles
-bubble shooter hd graphics
-bubble shooter crazy games
-bubble shooter full screen
-bubble shooter no ads
-bubble shooter high score
-bubble shooter fun games
-bubble shooter relaxing music
-bubble shooter space theme
-bubble shooter halloween edition
-bubble shooter christmas special
-bubble shooter farm animals
-bubble shooter underwater adventure
-bubble shooter dragon pop
-bubble shooter frozen bubbles
-bubble shooter rainbow colors
-bubble shooter magic spells
-bubble shooter easter eggs
-bubble shooter valentine hearts
-bubble shooter jungle safari
-bubble shooter fairy tale
-bubble shooter dinosaur world
-bubble shooter pirate treasure
-bubble shooter soccer balls
-bubble shooter fruit splash
-bubble shooter flower garden
-bubble shooter emoji blast
-bubble shooter animal rescue
-bubble shooter zombie apocalypse
-bubble shooter superhero power
-bubble shooter jewel match
-bubble shooter marble legend
-bubble shooter galaxy war
-bubble shooter firework frenzy
-bubble shooter forest friends
-bubble shooter balloon popper
-bubble shooter cake maker
-bubble shooter candy saga
-bubble shooter bird land
-bubble shooter butterfly dream
Bubble Shooter Classic
-Bubble Shooter Classic is one of the most original and iconic versions of the game. It has a simple design, a retro style, and a relaxing soundtrack. It is perfect for those who want to enjoy a nostalgic and timeless game experience.
-Bubble Shooter Extreme
-Bubble Shooter Extreme is one of the most challenging and exciting versions of the game. It has a fast-paced gameplay, a futuristic design, and a dynamic soundtrack. It is perfect for those who want to test their skills and reflexes in a thrilling game experience.
-Bubble Shooter Candy
-Bubble Shooter Candy is one of the most sweet and colorful versions of the game. It has a cute design, a candy theme, and a cheerful soundtrack. It is perfect for those who want to enjoy a fun and delightful game experience.
-Conclusion
-Bubble Shooter is a fun and addictive game that everyone can enjoy. It is easy to learn, fun to play, and suitable for all ages. It also has many benefits for your mind and mood, such as improving your concentration, coordination, memory, relaxation, and creativity. You can play Bubble Shooter on various devices and platforms, such as PC, mobile, tablet, and web browser. You can also choose from different versions and variations of the game, such as Bubble Shooter Classic, Bubble Shooter Extreme, and Bubble Shooter Candy. Whether you want a nostalgic, thrilling, or delightful game experience, Bubble Shooter has something for you. So what are you waiting for? Grab your bubble cannon and start popping bubbles today!
-FAQs
-Here are some of the frequently asked questions about Bubble Shooter:
--
-
- Q: How many levels are there in Bubble Shooter? -
- A: The number of levels in Bubble Shooter depends on the version and platform you are playing on. Some versions have a fixed number of levels, while others have an infinite number of levels that are randomly generated. You can check the level number on the screen or the menu. -
- Q: How do I get more lives or shots in Bubble Shooter? -
- A: The number of lives or shots in Bubble Shooter also depends on the version and platform you are playing on. Some versions have a limited number of lives or shots that you can replenish by watching ads, buying coins, or waiting for a certain time. Other versions have an unlimited number of lives or shots that you can use freely. -
- Q: How do I pause or resume the game in Bubble Shooter? -
- A: To pause or resume the game in Bubble Shooter, you can click or tap on the pause button on the screen or the menu. This will stop the game and allow you to access other options such as settings, sound, music, help, or exit. -
- Q: How do I save or load my progress in Bubble Shooter? -
- A: To save or load your progress in Bubble Shooter, you need to have an account or a profile on the platform you are playing on. This will allow you to sync your data across different devices and resume your game from where you left off. -
- Q: How do I change the difficulty or mode in Bubble Shooter? -
- A: To change the difficulty or mode in Bubble Shooter, you can select the option on the screen or the menu before starting a new game. Some versions have different difficulty levels such as easy, medium, hard, or expert. Other versions have different modes such as arcade, puzzle, time trial, or survival. -
-
-
\ No newline at end of file diff --git a/spaces/1pelhydcardo/ChatGPT-prompt-generator/assets/Download Countries.csv The Ultimate Resource for Country Information.md b/spaces/1pelhydcardo/ChatGPT-prompt-generator/assets/Download Countries.csv The Ultimate Resource for Country Information.md deleted file mode 100644 index ae208b74d5dfa0fdcf2e881d93b59e0814bb591d..0000000000000000000000000000000000000000 --- a/spaces/1pelhydcardo/ChatGPT-prompt-generator/assets/Download Countries.csv The Ultimate Resource for Country Information.md +++ /dev/null @@ -1,112 +0,0 @@ -
-
How to Download Countries.csv
-A CSV file, or a comma-separated values file, is a plain text file that stores data in a tabular format. Each line of the file is a data record, and each record consists of one or more fields separated by commas. CSV files are often used to exchange data between different applications that use incompatible formats. For example, you can use a CSV file to transfer data from a database to a spreadsheet, or vice versa.
-One example of a CSV file that you might want to download is countries.csv. This file contains information about countries around the world, such as their names, ISO codes, coordinates, capitals, currencies, regions, and more. You can use this file for various purposes, such as creating maps, charts, reports, or quizzes. In this article, we will show you how to download countries.csv and open it in a program of your choice.
-download countries.csv
DOWNLOAD 🗸🗸🗸 https://urlin.us/2uSZLa
-
Step 1: Find a Source of Countries.csv Data
-The first step is to find a reliable source of countries.csv data. There are many websites that offer this kind of data for free or for a fee. Some examples are:
--
-
- Google Developers: This website provides a canonical version of countries.csv that follows the ISO 3166 standard for country codes. It also includes some additional fields, such as time zones, latitude, longitude, emoji, and native name. -
- GitHub: This website hosts a repository of countries, states, and cities data in JSON, SQL, XML, YAML, and CSV formats. The CSV files include an index column and are updated regularly. -
- Kaggle: This website offers a dataset of countries of the world that links country names to region, population, area size, GDP, mortality, and more. The dataset is available in CSV format and can be downloaded or accessed through an API. -
You can choose any source that suits your needs and preferences. For this article, we will use the Google Developers version of countries.csv.
-Step 2: Choose a Program to Open the CSV File
-The next step is to choose a program that can open and display the CSV file. There are many options available, depending on your operating system and your goals. Some common programs are:
--
-
- Text editors: These are programs that allow you to view and edit plain text files. Examples are Notepad, Notepad++, Sublime Text, Atom, or Visual Studio Code. Text editors are useful for quickly viewing the contents of a CSV file or making minor changes. -
- Spreadsheet programs: These are programs that allow you to organize and analyze data in tabular form. Examples are Microsoft Excel, Google Sheets, LibreOffice Calc, or Numbers. Spreadsheet programs are useful for performing calculations, creating charts, filtering data, or applying formulas. -
- Specialized applications: These are programs that are designed for specific purposes or tasks related to CSV files. Examples are CSV Editor Pro, CSVed, Ron's Editor, or Easy Data Transform. Specialized applications are useful for editing large or complex CSV files, converting formats, validating data, or transforming data. -
You can choose any program that meets your requirements and expectations. For this article, we will use Microsoft Excel as an example of a spreadsheet program.
-Step 3: Download the CSV File from the Source
-The third step is to download the CSV file from the source website. To do this:
-download countries.csv file
-download countries.csv data
-download countries.csv python
-download countries.csv r
-download countries.csv excel
-download countries.csv pandas
-download countries.csv sql
-download countries.csv world bank
-download countries.csv iso codes
-download countries.csv population
-download countries.csv gdp
-download countries.csv map
-download countries.csv covid
-download countries.csv flags
-download countries.csv currency
-download countries.csv capital
-download countries.csv continent
-download countries.csv language
-download countries.csv timezone
-download countries.csv area
-download countries.csv latitude longitude
-download countries.csv shapefile
-download countries.csv geojson
-download countries.csv kaggle
-download countries.csv github
-how to download countries.csv
-where to download countries.csv
-free download countries.csv
-best way to download countries.csv
-easiest way to download countries.csv
-fastest way to download countries.csv
-how to use downloaded countries.csv file
-how to import downloaded countries.csv data
-how to read downloaded countries.csv python
-how to load downloaded countries.csv r
-how to open downloaded countries.csv excel
-how to parse downloaded countries.csv pandas
-how to query downloaded countries.csv sql
-how to analyze downloaded countries.csv world bank data
-how to convert downloaded countries.csv iso codes
-how to visualize downloaded countries.csv population data
-how to plot downloaded countries.csv gdp data
-how to create a map from downloaded countries.csv data
-how to update downloaded countries.csv covid data
-how to display downloaded countries.csv flags on a map
-how to calculate exchange rates from downloaded countries.csv currency data
-how to find capital cities from downloaded countries.csv data
-how to group by continent from downloaded countries.csv data
-how to detect language from downloaded countries.csv data
-how to get timezone from downloaded countries.csv data
-how to measure area from downloaded countries.csv data
-
-
- Go to the website where the CSV file is hosted. In our case, it is https://developers.google.com/public-data/docs/canonical/countries_csv. -
- Right-click on the link to the CSV file and select "Save link as" or "Save target as". In our case, it is https://developers.google.com/public-data/docs/canonical/countries_csv.csv. -
- Choose a location on your computer where you want to save the CSV file and click "Save". -
You have now downloaded the CSV file to your computer. You can find it in the location you specified.
-Step 4: Open the CSV File in the Chosen Program
-The fourth step is to open the CSV file in the program you selected. To do this:
--
-
- Launch the program on your computer. In our case, it is Microsoft Excel. -
- Click on "File" and then "Open". Alternatively, you can use the keyboard shortcut Ctrl+O. -
- Navigate to the location where you saved the CSV file and select it. Click "Open". -
You should now see the CSV file opened in the program. Depending on the program, you may need to adjust some settings, such as the delimiter, the encoding, or the format of the data. For example, in Excel, you may see a dialog box that asks you to choose how to import the data. You can select "Delimited" and then "Comma" as the delimiter. You can also choose the column data format as "General" or "Text". Click "Finish" to complete the import.
-Step 5: Explore and Manipulate the Data as Needed
-The final step is to explore and manipulate the data in the CSV file as needed. You can use the features and functions of the program to perform various tasks, such as:
--
-
- Sort and filter: You can sort and filter the data by any column or criteria. For example, you can sort the countries by name, population, or region. You can also filter out countries that meet certain conditions, such as having a specific currency or language. -
- Calculate and analyze: You can calculate and analyze the data using formulas, functions, or tools. For example, you can calculate the average population, area, or GDP of countries in a region. You can also use tools such as pivot tables or charts to summarize and visualize the data. -
- Edit and format: You can edit and format the data to suit your needs and preferences. For example, you can add, delete, or modify rows or columns of data. You can also change the font, color, or alignment of the cells. -
You can explore and manipulate the data in any way you want. You can also save your changes or export the data to another format if needed.
-Conclusion
-In this article, we have shown you how to download countries.csv and open it in a program of your choice. We have also given you some examples of how to explore and manipulate the data in the CSV file. By following these steps, you can access a wealth of information about countries around the world and use it for various purposes.
-We hope you found this article helpful and informative. If you have any questions or feedback, please let us know in the comments below.
-FAQs
-What is a CSV file?
-A CSV file is a plain text file that stores data in a tabular format. Each line of the file is a data record, and each record consists of one or more fields separated by commas.
-Why should I download countries.csv?
-You should download countries.csv if you want to access information about countries around the world, such as their names, ISO codes, coordinates, capitals, currencies, regions, and more. You can use this information for various purposes, such as creating maps, charts, reports, or quizzes.
-How do I open a CSV file?
-You can open a CSV file using any program that can read and display plain text files. Some common programs are text editors, spreadsheet programs, or specialized applications.
-Where can I find other sources of countries.csv data?
-You can find other sources of countries.csv data by searching online for websites that offer this kind of data for free or for a fee. Some examples are GitHub, Kaggle, DataHub.io, World Bank Data Catalogue, or CIA World Factbook.
-How do I convert a CSV file to another format?
-You can convert a CSV file to another format using any program that can read and write different formats. Some common formats are JSON, SQL, XML, YAML, or HTML. You can also use online tools or converters that can perform this task for you.
197e85843d-
-
\ No newline at end of file diff --git a/spaces/4Taps/SadTalker/src/face3d/models/arcface_torch/README.md b/spaces/4Taps/SadTalker/src/face3d/models/arcface_torch/README.md deleted file mode 100644 index 2ee63a861229b68873561fa39bfa7c9a8b53b947..0000000000000000000000000000000000000000 --- a/spaces/4Taps/SadTalker/src/face3d/models/arcface_torch/README.md +++ /dev/null @@ -1,164 +0,0 @@ -# Distributed Arcface Training in Pytorch - -This is a deep learning library that makes face recognition efficient, and effective, which can train tens of millions -identity on a single server. - -## Requirements - -- Install [pytorch](http://pytorch.org) (torch>=1.6.0), our doc for [install.md](docs/install.md). -- `pip install -r requirements.txt`. -- Download the dataset - from [https://github.com/deepinsight/insightface/tree/master/recognition/_datasets_](https://github.com/deepinsight/insightface/tree/master/recognition/_datasets_) - . - -## How to Training - -To train a model, run `train.py` with the path to the configs: - -### 1. Single node, 8 GPUs: - -```shell -python -m torch.distributed.launch --nproc_per_node=8 --nnodes=1 --node_rank=0 --master_addr="127.0.0.1" --master_port=1234 train.py configs/ms1mv3_r50 -``` - -### 2. Multiple nodes, each node 8 GPUs: - -Node 0: - -```shell -python -m torch.distributed.launch --nproc_per_node=8 --nnodes=2 --node_rank=0 --master_addr="ip1" --master_port=1234 train.py train.py configs/ms1mv3_r50 -``` - -Node 1: - -```shell -python -m torch.distributed.launch --nproc_per_node=8 --nnodes=2 --node_rank=1 --master_addr="ip1" --master_port=1234 train.py train.py configs/ms1mv3_r50 -``` - -### 3.Training resnet2060 with 8 GPUs: - -```shell -python -m torch.distributed.launch --nproc_per_node=8 --nnodes=1 --node_rank=0 --master_addr="127.0.0.1" --master_port=1234 train.py configs/ms1mv3_r2060.py -``` - -## Model Zoo - -- The models are available for non-commercial research purposes only. -- All models can be found in here. -- [Baidu Yun Pan](https://pan.baidu.com/s/1CL-l4zWqsI1oDuEEYVhj-g): e8pw -- [onedrive](https://1drv.ms/u/s!AswpsDO2toNKq0lWY69vN58GR6mw?e=p9Ov5d) - -### Performance on [**ICCV2021-MFR**](http://iccv21-mfr.com/) - -ICCV2021-MFR testset consists of non-celebrities so we can ensure that it has very few overlap with public available face -recognition training set, such as MS1M and CASIA as they mostly collected from online celebrities. -As the result, we can evaluate the FAIR performance for different algorithms. - -For **ICCV2021-MFR-ALL** set, TAR is measured on all-to-all 1:1 protocal, with FAR less than 0.000001(e-6). The -globalised multi-racial testset contains 242,143 identities and 1,624,305 images. - -For **ICCV2021-MFR-MASK** set, TAR is measured on mask-to-nonmask 1:1 protocal, with FAR less than 0.0001(e-4). -Mask testset contains 6,964 identities, 6,964 masked images and 13,928 non-masked images. -There are totally 13,928 positive pairs and 96,983,824 negative pairs. - -| Datasets | backbone | Training throughout | Size / MB | **ICCV2021-MFR-MASK** | **ICCV2021-MFR-ALL** | -| :---: | :--- | :--- | :--- |:--- |:--- | -| MS1MV3 | r18 | - | 91 | **47.85** | **68.33** | -| Glint360k | r18 | 8536 | 91 | **53.32** | **72.07** | -| MS1MV3 | r34 | - | 130 | **58.72** | **77.36** | -| Glint360k | r34 | 6344 | 130 | **65.10** | **83.02** | -| MS1MV3 | r50 | 5500 | 166 | **63.85** | **80.53** | -| Glint360k | r50 | 5136 | 166 | **70.23** | **87.08** | -| MS1MV3 | r100 | - | 248 | **69.09** | **84.31** | -| Glint360k | r100 | 3332 | 248 | **75.57** | **90.66** | -| MS1MV3 | mobilefacenet | 12185 | 7.8 | **41.52** | **65.26** | -| Glint360k | mobilefacenet | 11197 | 7.8 | **44.52** | **66.48** | - -### Performance on IJB-C and Verification Datasets - -| Datasets | backbone | IJBC(1e-05) | IJBC(1e-04) | agedb30 | cfp_fp | lfw | log | -| :---: | :--- | :--- | :--- | :--- |:--- |:--- |:--- | -| MS1MV3 | r18 | 92.07 | 94.66 | 97.77 | 97.73 | 99.77 |[log](https://raw.githubusercontent.com/anxiangsir/insightface_arcface_log/master/ms1mv3_arcface_r18_fp16/training.log)| -| MS1MV3 | r34 | 94.10 | 95.90 | 98.10 | 98.67 | 99.80 |[log](https://raw.githubusercontent.com/anxiangsir/insightface_arcface_log/master/ms1mv3_arcface_r34_fp16/training.log)| -| MS1MV3 | r50 | 94.79 | 96.46 | 98.35 | 98.96 | 99.83 |[log](https://raw.githubusercontent.com/anxiangsir/insightface_arcface_log/master/ms1mv3_arcface_r50_fp16/training.log)| -| MS1MV3 | r100 | 95.31 | 96.81 | 98.48 | 99.06 | 99.85 |[log](https://raw.githubusercontent.com/anxiangsir/insightface_arcface_log/master/ms1mv3_arcface_r100_fp16/training.log)| -| MS1MV3 | **r2060**| 95.34 | 97.11 | 98.67 | 99.24 | 99.87 |[log](https://raw.githubusercontent.com/anxiangsir/insightface_arcface_log/master/ms1mv3_arcface_r2060_fp16/training.log)| -| Glint360k |r18-0.1 | 93.16 | 95.33 | 97.72 | 97.73 | 99.77 |[log](https://raw.githubusercontent.com/anxiangsir/insightface_arcface_log/master/glint360k_cosface_r18_fp16_0.1/training.log)| -| Glint360k |r34-0.1 | 95.16 | 96.56 | 98.33 | 98.78 | 99.82 |[log](https://raw.githubusercontent.com/anxiangsir/insightface_arcface_log/master/glint360k_cosface_r34_fp16_0.1/training.log)| -| Glint360k |r50-0.1 | 95.61 | 96.97 | 98.38 | 99.20 | 99.83 |[log](https://raw.githubusercontent.com/anxiangsir/insightface_arcface_log/master/glint360k_cosface_r50_fp16_0.1/training.log)| -| Glint360k |r100-0.1 | 95.88 | 97.32 | 98.48 | 99.29 | 99.82 |[log](https://raw.githubusercontent.com/anxiangsir/insightface_arcface_log/master/glint360k_cosface_r100_fp16_0.1/training.log)| - -[comment]: <> (More details see [model.md](docs/modelzoo.md) in docs.) - - -## [Speed Benchmark](docs/speed_benchmark.md) - -**Arcface Torch** can train large-scale face recognition training set efficiently and quickly. When the number of -classes in training sets is greater than 300K and the training is sufficient, partial fc sampling strategy will get same -accuracy with several times faster training performance and smaller GPU memory. -Partial FC is a sparse variant of the model parallel architecture for large sacle face recognition. Partial FC use a -sparse softmax, where each batch dynamicly sample a subset of class centers for training. In each iteration, only a -sparse part of the parameters will be updated, which can reduce a lot of GPU memory and calculations. With Partial FC, -we can scale trainset of 29 millions identities, the largest to date. Partial FC also supports multi-machine distributed -training and mixed precision training. - - - -More details see -[speed_benchmark.md](docs/speed_benchmark.md) in docs. - -### 1. Training speed of different parallel methods (samples / second), Tesla V100 32GB * 8. (Larger is better) - -`-` means training failed because of gpu memory limitations. - -| Number of Identities in Dataset | Data Parallel | Model Parallel | Partial FC 0.1 | -| :--- | :--- | :--- | :--- | -|125000 | 4681 | 4824 | 5004 | -|1400000 | **1672** | 3043 | 4738 | -|5500000 | **-** | **1389** | 3975 | -|8000000 | **-** | **-** | 3565 | -|16000000 | **-** | **-** | 2679 | -|29000000 | **-** | **-** | **1855** | - -### 2. GPU memory cost of different parallel methods (MB per GPU), Tesla V100 32GB * 8. (Smaller is better) - -| Number of Identities in Dataset | Data Parallel | Model Parallel | Partial FC 0.1 | -| :--- | :--- | :--- | :--- | -|125000 | 7358 | 5306 | 4868 | -|1400000 | 32252 | 11178 | 6056 | -|5500000 | **-** | 32188 | 9854 | -|8000000 | **-** | **-** | 12310 | -|16000000 | **-** | **-** | 19950 | -|29000000 | **-** | **-** | 32324 | - -## Evaluation ICCV2021-MFR and IJB-C - -More details see [eval.md](docs/eval.md) in docs. - -## Test - -We tested many versions of PyTorch. Please create an issue if you are having trouble. - -- [x] torch 1.6.0 -- [x] torch 1.7.1 -- [x] torch 1.8.0 -- [x] torch 1.9.0 - -## Citation - -``` -@inproceedings{deng2019arcface, - title={Arcface: Additive angular margin loss for deep face recognition}, - author={Deng, Jiankang and Guo, Jia and Xue, Niannan and Zafeiriou, Stefanos}, - booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition}, - pages={4690--4699}, - year={2019} -} -@inproceedings{an2020partical_fc, - title={Partial FC: Training 10 Million Identities on a Single Machine}, - author={An, Xiang and Zhu, Xuhan and Xiao, Yang and Wu, Lan and Zhang, Ming and Gao, Yuan and Qin, Bin and - Zhang, Debing and Fu Ying}, - booktitle={Arxiv 2010.05222}, - year={2020} -} -``` diff --git a/spaces/4Taps/SadTalker/src/utils/audio.py b/spaces/4Taps/SadTalker/src/utils/audio.py deleted file mode 100644 index 89433eb4c681112804fbed72b157700f553739a8..0000000000000000000000000000000000000000 --- a/spaces/4Taps/SadTalker/src/utils/audio.py +++ /dev/null @@ -1,136 +0,0 @@ -import librosa -import librosa.filters -import numpy as np -# import tensorflow as tf -from scipy import signal -from scipy.io import wavfile -from src.utils.hparams import hparams as hp - -def load_wav(path, sr): - return librosa.core.load(path, sr=sr)[0] - -def save_wav(wav, path, sr): - wav *= 32767 / max(0.01, np.max(np.abs(wav))) - #proposed by @dsmiller - wavfile.write(path, sr, wav.astype(np.int16)) - -def save_wavenet_wav(wav, path, sr): - librosa.output.write_wav(path, wav, sr=sr) - -def preemphasis(wav, k, preemphasize=True): - if preemphasize: - return signal.lfilter([1, -k], [1], wav) - return wav - -def inv_preemphasis(wav, k, inv_preemphasize=True): - if inv_preemphasize: - return signal.lfilter([1], [1, -k], wav) - return wav - -def get_hop_size(): - hop_size = hp.hop_size - if hop_size is None: - assert hp.frame_shift_ms is not None - hop_size = int(hp.frame_shift_ms / 1000 * hp.sample_rate) - return hop_size - -def linearspectrogram(wav): - D = _stft(preemphasis(wav, hp.preemphasis, hp.preemphasize)) - S = _amp_to_db(np.abs(D)) - hp.ref_level_db - - if hp.signal_normalization: - return _normalize(S) - return S - -def melspectrogram(wav): - D = _stft(preemphasis(wav, hp.preemphasis, hp.preemphasize)) - S = _amp_to_db(_linear_to_mel(np.abs(D))) - hp.ref_level_db - - if hp.signal_normalization: - return _normalize(S) - return S - -def _lws_processor(): - import lws - return lws.lws(hp.n_fft, get_hop_size(), fftsize=hp.win_size, mode="speech") - -def _stft(y): - if hp.use_lws: - return _lws_processor(hp).stft(y).T - else: - return librosa.stft(y=y, n_fft=hp.n_fft, hop_length=get_hop_size(), win_length=hp.win_size) - -########################################################## -#Those are only correct when using lws!!! (This was messing with Wavenet quality for a long time!) -def num_frames(length, fsize, fshift): - """Compute number of time frames of spectrogram - """ - pad = (fsize - fshift) - if length % fshift == 0: - M = (length + pad * 2 - fsize) // fshift + 1 - else: - M = (length + pad * 2 - fsize) // fshift + 2 - return M - - -def pad_lr(x, fsize, fshift): - """Compute left and right padding - """ - M = num_frames(len(x), fsize, fshift) - pad = (fsize - fshift) - T = len(x) + 2 * pad - r = (M - 1) * fshift + fsize - T - return pad, pad + r -########################################################## -#Librosa correct padding -def librosa_pad_lr(x, fsize, fshift): - return 0, (x.shape[0] // fshift + 1) * fshift - x.shape[0] - -# Conversions -_mel_basis = None - -def _linear_to_mel(spectogram): - global _mel_basis - if _mel_basis is None: - _mel_basis = _build_mel_basis() - return np.dot(_mel_basis, spectogram) - -def _build_mel_basis(): - assert hp.fmax <= hp.sample_rate // 2 - return librosa.filters.mel(sr=hp.sample_rate, n_fft=hp.n_fft, n_mels=hp.num_mels, - fmin=hp.fmin, fmax=hp.fmax) - -def _amp_to_db(x): - min_level = np.exp(hp.min_level_db / 20 * np.log(10)) - return 20 * np.log10(np.maximum(min_level, x)) - -def _db_to_amp(x): - return np.power(10.0, (x) * 0.05) - -def _normalize(S): - if hp.allow_clipping_in_normalization: - if hp.symmetric_mels: - return np.clip((2 * hp.max_abs_value) * ((S - hp.min_level_db) / (-hp.min_level_db)) - hp.max_abs_value, - -hp.max_abs_value, hp.max_abs_value) - else: - return np.clip(hp.max_abs_value * ((S - hp.min_level_db) / (-hp.min_level_db)), 0, hp.max_abs_value) - - assert S.max() <= 0 and S.min() - hp.min_level_db >= 0 - if hp.symmetric_mels: - return (2 * hp.max_abs_value) * ((S - hp.min_level_db) / (-hp.min_level_db)) - hp.max_abs_value - else: - return hp.max_abs_value * ((S - hp.min_level_db) / (-hp.min_level_db)) - -def _denormalize(D): - if hp.allow_clipping_in_normalization: - if hp.symmetric_mels: - return (((np.clip(D, -hp.max_abs_value, - hp.max_abs_value) + hp.max_abs_value) * -hp.min_level_db / (2 * hp.max_abs_value)) - + hp.min_level_db) - else: - return ((np.clip(D, 0, hp.max_abs_value) * -hp.min_level_db / hp.max_abs_value) + hp.min_level_db) - - if hp.symmetric_mels: - return (((D + hp.max_abs_value) * -hp.min_level_db / (2 * hp.max_abs_value)) + hp.min_level_db) - else: - return ((D * -hp.min_level_db / hp.max_abs_value) + hp.min_level_db) diff --git a/spaces/7eu7d7/anime-ai-detect-fucker/attacker/__init__.py b/spaces/7eu7d7/anime-ai-detect-fucker/attacker/__init__.py deleted file mode 100644 index 7530520945ce3b7e63f5c24ef9e1093dd7dcb431..0000000000000000000000000000000000000000 --- a/spaces/7eu7d7/anime-ai-detect-fucker/attacker/__init__.py +++ /dev/null @@ -1,3 +0,0 @@ -from .base import * -from .PGD import * -from .FGSM import * \ No newline at end of file diff --git a/spaces/AIFILMS/StyleGANEX/models/stylegan2/lpips/base_model.py b/spaces/AIFILMS/StyleGANEX/models/stylegan2/lpips/base_model.py deleted file mode 100644 index 8de1d16f0c7fa52d8067139abc6e769e96d0a6a1..0000000000000000000000000000000000000000 --- a/spaces/AIFILMS/StyleGANEX/models/stylegan2/lpips/base_model.py +++ /dev/null @@ -1,58 +0,0 @@ -import os -import numpy as np -import torch -from torch.autograd import Variable -from pdb import set_trace as st -from IPython import embed - -class BaseModel(): - def __init__(self): - pass; - - def name(self): - return 'BaseModel' - - def initialize(self, use_gpu=True, gpu_ids=[0]): - self.use_gpu = use_gpu - self.gpu_ids = gpu_ids - - def forward(self): - pass - - def get_image_paths(self): - pass - - def optimize_parameters(self): - pass - - def get_current_visuals(self): - return self.input - - def get_current_errors(self): - return {} - - def save(self, label): - pass - - # helper saving function that can be used by subclasses - def save_network(self, network, path, network_label, epoch_label): - save_filename = '%s_net_%s.pth' % (epoch_label, network_label) - save_path = os.path.join(path, save_filename) - torch.save(network.state_dict(), save_path) - - # helper loading function that can be used by subclasses - def load_network(self, network, network_label, epoch_label): - save_filename = '%s_net_%s.pth' % (epoch_label, network_label) - save_path = os.path.join(self.save_dir, save_filename) - print('Loading network from %s'%save_path) - network.load_state_dict(torch.load(save_path)) - - def update_learning_rate(): - pass - - def get_image_paths(self): - return self.image_paths - - def save_done(self, flag=False): - np.save(os.path.join(self.save_dir, 'done_flag'),flag) - np.savetxt(os.path.join(self.save_dir, 'done_flag'),[flag,],fmt='%i') diff --git a/spaces/AIFILMS/audioldm-text-to-audio-generation/audioldm/clap/training/scheduler.py b/spaces/AIFILMS/audioldm-text-to-audio-generation/audioldm/clap/training/scheduler.py deleted file mode 100644 index 7151ffbab25a113673b7627027b443b27f22cb0f..0000000000000000000000000000000000000000 --- a/spaces/AIFILMS/audioldm-text-to-audio-generation/audioldm/clap/training/scheduler.py +++ /dev/null @@ -1,24 +0,0 @@ -import numpy as np - - -def assign_learning_rate(optimizer, new_lr): - for param_group in optimizer.param_groups: - param_group["lr"] = new_lr - - -def _warmup_lr(base_lr, warmup_length, step): - return base_lr * (step + 1) / warmup_length - - -def cosine_lr(optimizer, base_lr, warmup_length, steps): - def _lr_adjuster(step): - if step < warmup_length: - lr = _warmup_lr(base_lr, warmup_length, step) - else: - e = step - warmup_length - es = steps - warmup_length - lr = 0.5 * (1 + np.cos(np.pi * e / es)) * base_lr - assign_learning_rate(optimizer, lr) - return lr - - return _lr_adjuster diff --git a/spaces/AIGC-Audio/AudioGPT/text_to_audio/Make_An_Audio/vocoder/bigvgan/models.py b/spaces/AIGC-Audio/AudioGPT/text_to_audio/Make_An_Audio/vocoder/bigvgan/models.py deleted file mode 100644 index 22e8017b6d70c8399b3be6a2555485634c03e72d..0000000000000000000000000000000000000000 --- a/spaces/AIGC-Audio/AudioGPT/text_to_audio/Make_An_Audio/vocoder/bigvgan/models.py +++ /dev/null @@ -1,414 +0,0 @@ -# Copyright (c) 2022 NVIDIA CORPORATION. -# Licensed under the MIT license. - -# Adapted from https://github.com/jik876/hifi-gan under the MIT license. -# LICENSE is in incl_licenses directory. - - -import torch -import torch.nn.functional as F -import torch.nn as nn -from torch.nn import Conv1d, ConvTranspose1d, Conv2d -from torch.nn.utils import weight_norm, remove_weight_norm, spectral_norm -import numpy as np -from .activations import Snake,SnakeBeta -from .alias_free_torch import * -import os -from omegaconf import OmegaConf - -LRELU_SLOPE = 0.1 - -def init_weights(m, mean=0.0, std=0.01): - classname = m.__class__.__name__ - if classname.find("Conv") != -1: - m.weight.data.normal_(mean, std) - - -def get_padding(kernel_size, dilation=1): - return int((kernel_size*dilation - dilation)/2) - -class AMPBlock1(torch.nn.Module): - def __init__(self, h, channels, kernel_size=3, dilation=(1, 3, 5), activation=None): - super(AMPBlock1, self).__init__() - self.h = h - - self.convs1 = nn.ModuleList([ - weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0], - padding=get_padding(kernel_size, dilation[0]))), - weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1], - padding=get_padding(kernel_size, dilation[1]))), - weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[2], - padding=get_padding(kernel_size, dilation[2]))) - ]) - self.convs1.apply(init_weights) - - self.convs2 = nn.ModuleList([ - weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1, - padding=get_padding(kernel_size, 1))), - weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1, - padding=get_padding(kernel_size, 1))), - weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1, - padding=get_padding(kernel_size, 1))) - ]) - self.convs2.apply(init_weights) - - self.num_layers = len(self.convs1) + len(self.convs2) # total number of conv layers - - if activation == 'snake': # periodic nonlinearity with snake function and anti-aliasing - self.activations = nn.ModuleList([ - Activation1d( - activation=Snake(channels, alpha_logscale=h.snake_logscale)) - for _ in range(self.num_layers) - ]) - elif activation == 'snakebeta': # periodic nonlinearity with snakebeta function and anti-aliasing - self.activations = nn.ModuleList([ - Activation1d( - activation=SnakeBeta(channels, alpha_logscale=h.snake_logscale)) - for _ in range(self.num_layers) - ]) - else: - raise NotImplementedError("activation incorrectly specified. check the config file and look for 'activation'.") - - def forward(self, x): - acts1, acts2 = self.activations[::2], self.activations[1::2] - for c1, c2, a1, a2 in zip(self.convs1, self.convs2, acts1, acts2): - xt = a1(x) - xt = c1(xt) - xt = a2(xt) - xt = c2(xt) - x = xt + x - - return x - - def remove_weight_norm(self): - for l in self.convs1: - remove_weight_norm(l) - for l in self.convs2: - remove_weight_norm(l) - - -class AMPBlock2(torch.nn.Module): - def __init__(self, h, channels, kernel_size=3, dilation=(1, 3), activation=None): - super(AMPBlock2, self).__init__() - self.h = h - - self.convs = nn.ModuleList([ - weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0], - padding=get_padding(kernel_size, dilation[0]))), - weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1], - padding=get_padding(kernel_size, dilation[1]))) - ]) - self.convs.apply(init_weights) - - self.num_layers = len(self.convs) # total number of conv layers - - if activation == 'snake': # periodic nonlinearity with snake function and anti-aliasing - self.activations = nn.ModuleList([ - Activation1d( - activation=Snake(channels, alpha_logscale=h.snake_logscale)) - for _ in range(self.num_layers) - ]) - elif activation == 'snakebeta': # periodic nonlinearity with snakebeta function and anti-aliasing - self.activations = nn.ModuleList([ - Activation1d( - activation=SnakeBeta(channels, alpha_logscale=h.snake_logscale)) - for _ in range(self.num_layers) - ]) - else: - raise NotImplementedError("activation incorrectly specified. check the config file and look for 'activation'.") - - def forward(self, x): - for c, a in zip (self.convs, self.activations): - xt = a(x) - xt = c(xt) - x = xt + x - - return x - - def remove_weight_norm(self): - for l in self.convs: - remove_weight_norm(l) - - -class BigVGAN(torch.nn.Module): - # this is our main BigVGAN model. Applies anti-aliased periodic activation for resblocks. - def __init__(self, h): - super(BigVGAN, self).__init__() - self.h = h - - self.num_kernels = len(h.resblock_kernel_sizes) - self.num_upsamples = len(h.upsample_rates) - - # pre conv - self.conv_pre = weight_norm(Conv1d(h.num_mels, h.upsample_initial_channel, 7, 1, padding=3)) - - # define which AMPBlock to use. BigVGAN uses AMPBlock1 as default - resblock = AMPBlock1 if h.resblock == '1' else AMPBlock2 - - # transposed conv-based upsamplers. does not apply anti-aliasing - self.ups = nn.ModuleList() - for i, (u, k) in enumerate(zip(h.upsample_rates, h.upsample_kernel_sizes)): - self.ups.append(nn.ModuleList([ - weight_norm(ConvTranspose1d(h.upsample_initial_channel // (2 ** i), - h.upsample_initial_channel // (2 ** (i + 1)), - k, u, padding=(k - u) // 2)) - ])) - - # residual blocks using anti-aliased multi-periodicity composition modules (AMP) - self.resblocks = nn.ModuleList() - for i in range(len(self.ups)): - ch = h.upsample_initial_channel // (2 ** (i + 1)) - for j, (k, d) in enumerate(zip(h.resblock_kernel_sizes, h.resblock_dilation_sizes)): - self.resblocks.append(resblock(h, ch, k, d, activation=h.activation)) - - # post conv - if h.activation == "snake": # periodic nonlinearity with snake function and anti-aliasing - activation_post = Snake(ch, alpha_logscale=h.snake_logscale) - self.activation_post = Activation1d(activation=activation_post) - elif h.activation == "snakebeta": # periodic nonlinearity with snakebeta function and anti-aliasing - activation_post = SnakeBeta(ch, alpha_logscale=h.snake_logscale) - self.activation_post = Activation1d(activation=activation_post) - else: - raise NotImplementedError("activation incorrectly specified. check the config file and look for 'activation'.") - - self.conv_post = weight_norm(Conv1d(ch, 1, 7, 1, padding=3)) - - # weight initialization - for i in range(len(self.ups)): - self.ups[i].apply(init_weights) - self.conv_post.apply(init_weights) - - def forward(self, x): - # pre conv - x = self.conv_pre(x) - - for i in range(self.num_upsamples): - # upsampling - for i_up in range(len(self.ups[i])): - x = self.ups[i][i_up](x) - # AMP blocks - xs = None - for j in range(self.num_kernels): - if xs is None: - xs = self.resblocks[i * self.num_kernels + j](x) - else: - xs += self.resblocks[i * self.num_kernels + j](x) - x = xs / self.num_kernels - - # post conv - x = self.activation_post(x) - x = self.conv_post(x) - x = torch.tanh(x) - - return x - - def remove_weight_norm(self): - print('Removing weight norm...') - for l in self.ups: - for l_i in l: - remove_weight_norm(l_i) - for l in self.resblocks: - l.remove_weight_norm() - remove_weight_norm(self.conv_pre) - remove_weight_norm(self.conv_post) - - -class DiscriminatorP(torch.nn.Module): - def __init__(self, h, period, kernel_size=5, stride=3, use_spectral_norm=False): - super(DiscriminatorP, self).__init__() - self.period = period - self.d_mult = h.discriminator_channel_mult - norm_f = weight_norm if use_spectral_norm == False else spectral_norm - self.convs = nn.ModuleList([ - norm_f(Conv2d(1, int(32*self.d_mult), (kernel_size, 1), (stride, 1), padding=(get_padding(5, 1), 0))), - norm_f(Conv2d(int(32*self.d_mult), int(128*self.d_mult), (kernel_size, 1), (stride, 1), padding=(get_padding(5, 1), 0))), - norm_f(Conv2d(int(128*self.d_mult), int(512*self.d_mult), (kernel_size, 1), (stride, 1), padding=(get_padding(5, 1), 0))), - norm_f(Conv2d(int(512*self.d_mult), int(1024*self.d_mult), (kernel_size, 1), (stride, 1), padding=(get_padding(5, 1), 0))), - norm_f(Conv2d(int(1024*self.d_mult), int(1024*self.d_mult), (kernel_size, 1), 1, padding=(2, 0))), - ]) - self.conv_post = norm_f(Conv2d(int(1024*self.d_mult), 1, (3, 1), 1, padding=(1, 0))) - - def forward(self, x): - fmap = [] - - # 1d to 2d - b, c, t = x.shape - if t % self.period != 0: # pad first - n_pad = self.period - (t % self.period) - x = F.pad(x, (0, n_pad), "reflect") - t = t + n_pad - x = x.view(b, c, t // self.period, self.period) - - for l in self.convs: - x = l(x) - x = F.leaky_relu(x, LRELU_SLOPE) - fmap.append(x) - x = self.conv_post(x) - fmap.append(x) - x = torch.flatten(x, 1, -1) - - return x, fmap - - -class MultiPeriodDiscriminator(torch.nn.Module): - def __init__(self, h): - super(MultiPeriodDiscriminator, self).__init__() - self.mpd_reshapes = h.mpd_reshapes - print("mpd_reshapes: {}".format(self.mpd_reshapes)) - discriminators = [DiscriminatorP(h, rs, use_spectral_norm=h.use_spectral_norm) for rs in self.mpd_reshapes] - self.discriminators = nn.ModuleList(discriminators) - - def forward(self, y, y_hat): - y_d_rs = [] - y_d_gs = [] - fmap_rs = [] - fmap_gs = [] - for i, d in enumerate(self.discriminators): - y_d_r, fmap_r = d(y) - y_d_g, fmap_g = d(y_hat) - y_d_rs.append(y_d_r) - fmap_rs.append(fmap_r) - y_d_gs.append(y_d_g) - fmap_gs.append(fmap_g) - - return y_d_rs, y_d_gs, fmap_rs, fmap_gs - - -class DiscriminatorR(nn.Module): - def __init__(self, cfg, resolution): - super().__init__() - - self.resolution = resolution - assert len(self.resolution) == 3, \ - "MRD layer requires list with len=3, got {}".format(self.resolution) - self.lrelu_slope = LRELU_SLOPE - - norm_f = weight_norm if cfg.use_spectral_norm == False else spectral_norm - if hasattr(cfg, "mrd_use_spectral_norm"): - print("INFO: overriding MRD use_spectral_norm as {}".format(cfg.mrd_use_spectral_norm)) - norm_f = weight_norm if cfg.mrd_use_spectral_norm == False else spectral_norm - self.d_mult = cfg.discriminator_channel_mult - if hasattr(cfg, "mrd_channel_mult"): - print("INFO: overriding mrd channel multiplier as {}".format(cfg.mrd_channel_mult)) - self.d_mult = cfg.mrd_channel_mult - - self.convs = nn.ModuleList([ - norm_f(nn.Conv2d(1, int(32*self.d_mult), (3, 9), padding=(1, 4))), - norm_f(nn.Conv2d(int(32*self.d_mult), int(32*self.d_mult), (3, 9), stride=(1, 2), padding=(1, 4))), - norm_f(nn.Conv2d(int(32*self.d_mult), int(32*self.d_mult), (3, 9), stride=(1, 2), padding=(1, 4))), - norm_f(nn.Conv2d(int(32*self.d_mult), int(32*self.d_mult), (3, 9), stride=(1, 2), padding=(1, 4))), - norm_f(nn.Conv2d(int(32*self.d_mult), int(32*self.d_mult), (3, 3), padding=(1, 1))), - ]) - self.conv_post = norm_f(nn.Conv2d(int(32 * self.d_mult), 1, (3, 3), padding=(1, 1))) - - def forward(self, x): - fmap = [] - - x = self.spectrogram(x) - x = x.unsqueeze(1) - for l in self.convs: - x = l(x) - x = F.leaky_relu(x, self.lrelu_slope) - fmap.append(x) - x = self.conv_post(x) - fmap.append(x) - x = torch.flatten(x, 1, -1) - - return x, fmap - - def spectrogram(self, x): - n_fft, hop_length, win_length = self.resolution - x = F.pad(x, (int((n_fft - hop_length) / 2), int((n_fft - hop_length) / 2)), mode='reflect') - x = x.squeeze(1) - x = torch.stft(x, n_fft=n_fft, hop_length=hop_length, win_length=win_length, center=False, return_complex=True) - x = torch.view_as_real(x) # [B, F, TT, 2] - mag = torch.norm(x, p=2, dim =-1) #[B, F, TT] - - return mag - - -class MultiResolutionDiscriminator(nn.Module): - def __init__(self, cfg, debug=False): - super().__init__() - self.resolutions = cfg.resolutions - assert len(self.resolutions) == 3,\ - "MRD requires list of list with len=3, each element having a list with len=3. got {}".\ - format(self.resolutions) - self.discriminators = nn.ModuleList( - [DiscriminatorR(cfg, resolution) for resolution in self.resolutions] - ) - - def forward(self, y, y_hat): - y_d_rs = [] - y_d_gs = [] - fmap_rs = [] - fmap_gs = [] - - for i, d in enumerate(self.discriminators): - y_d_r, fmap_r = d(x=y) - y_d_g, fmap_g = d(x=y_hat) - y_d_rs.append(y_d_r) - fmap_rs.append(fmap_r) - y_d_gs.append(y_d_g) - fmap_gs.append(fmap_g) - - return y_d_rs, y_d_gs, fmap_rs, fmap_gs - - -def feature_loss(fmap_r, fmap_g): - loss = 0 - for dr, dg in zip(fmap_r, fmap_g): - for rl, gl in zip(dr, dg): - loss += torch.mean(torch.abs(rl - gl)) - - return loss*2 - - -def discriminator_loss(disc_real_outputs, disc_generated_outputs): - loss = 0 - r_losses = [] - g_losses = [] - for dr, dg in zip(disc_real_outputs, disc_generated_outputs): - r_loss = torch.mean((1-dr)**2) - g_loss = torch.mean(dg**2) - loss += (r_loss + g_loss) - r_losses.append(r_loss.item()) - g_losses.append(g_loss.item()) - - return loss, r_losses, g_losses - - -def generator_loss(disc_outputs): - loss = 0 - gen_losses = [] - for dg in disc_outputs: - l = torch.mean((1-dg)**2) - gen_losses.append(l) - loss += l - - return loss, gen_losses - - - -class VocoderBigVGAN(object): - def __init__(self, ckpt_vocoder,device='cuda'): - vocoder_sd = torch.load(os.path.join(ckpt_vocoder,'best_netG.pt'), map_location='cpu') - - vocoder_args = OmegaConf.load(os.path.join(ckpt_vocoder,'args.yml')) - - self.generator = BigVGAN(vocoder_args) - self.generator.load_state_dict(vocoder_sd['generator']) - self.generator.eval() - - self.device = device - self.generator.to(self.device) - - def vocode(self, spec): - with torch.no_grad(): - if isinstance(spec,np.ndarray): - spec = torch.from_numpy(spec).unsqueeze(0) - spec = spec.to(dtype=torch.float32,device=self.device) - return self.generator(spec).squeeze().cpu().numpy() - - def __call__(self, wav): - return self.vocode(wav) diff --git a/spaces/ATang0729/Forecast4Muses/Model/Model6/Model6_2_ProfileRecogition/mmpretrain/work_dirs/mobilevit-small_4xb32_2000e_3c_noF/__init__.py b/spaces/ATang0729/Forecast4Muses/Model/Model6/Model6_2_ProfileRecogition/mmpretrain/work_dirs/mobilevit-small_4xb32_2000e_3c_noF/__init__.py deleted file mode 100644 index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000 diff --git a/spaces/AUBADA-ALARABI/poetry202/README.md b/spaces/AUBADA-ALARABI/poetry202/README.md deleted file mode 100644 index b19a751ca3854ec2c2b7ac5c56aece4cc38657c6..0000000000000000000000000000000000000000 --- a/spaces/AUBADA-ALARABI/poetry202/README.md +++ /dev/null @@ -1,13 +0,0 @@ ---- -title: Poetry2023 -emoji: 👁 -colorFrom: green -colorTo: gray -sdk: gradio -sdk_version: 3.16.0 -app_file: app.py -pinned: false -duplicated_from: Abdllh/poetry202 ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference diff --git a/spaces/Abhi5ingh/fashionsd/sdfile.py b/spaces/Abhi5ingh/fashionsd/sdfile.py deleted file mode 100644 index ad62243e77d18ca26e80dcf8263c80f746c76302..0000000000000000000000000000000000000000 --- a/spaces/Abhi5ingh/fashionsd/sdfile.py +++ /dev/null @@ -1,89 +0,0 @@ -import gc -import datetime -import os -import re -from typing import Literal - -import streamlit as st -import torch -from diffusers import ( - StableDiffusionPipeline, - StableDiffusionControlNetPipeline, - ControlNetModel, - EulerDiscreteScheduler, - DDIMScheduler, -) - -PIPELINES = Literal["txt2img", "sketch2img"] - -@st.cache_resource(max_entries=1) -def get_pipelines( name:PIPELINES, enable_cpu_offload = False, ) -> StableDiffusionPipeline: - pipe = None - - if name == "txt2img": - pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16,cache_dir="D:/huggingface/CACHE/") - pipe.unet.load_attn_procs("./") - pipe.safety_checker = lambda images, **kwargs: (images, [False] * len(images)) - elif name == "sketch2img": - controlnet = ControlNetModel.from_pretrained("Abhi5ingh/model_dresscode", torch_dtype=torch.float16,cache_dir="D:/huggingface/CACHE/") - pipe = StableDiffusionControlNetPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", controlnet = controlnet, torch_dtype = torch.float16,cache_dir="D:/huggingface/CACHE/") - pipe.unet.load_attn_procs("./") - pipe.safety_checker = lambda images, **kwargs: (images, [False] * len(images)) - - if pipe is None: - raise Exception(f"Pipeline not Found {name}") - - if enable_cpu_offload: - print("Enabling cpu offloading for the given pipeline") - pipe.enable_model_cpu_offload() - else: - pipe = pipe.to("cuda") - return pipe - -def generate( - prompt, - pipeline_name: PIPELINES, - image = None, - num_inference_steps = 30, - negative_prompt = None, - width = 512, - height = 512, - guidance_scale = 7.5, - controlnet_conditioning_scale = None, - enable_cpu_offload= False): - negative_prompt = negative_prompt if negative_prompt else None - p = st.progress(0) - callback = lambda step,*_: p.progress(step/num_inference_steps) - pipe = get_pipelines(pipeline_name,enable_cpu_offload=enable_cpu_offload) - torch.cuda.empty_cache() - - kwargs = dict( - prompt = prompt, - negative_prompt=negative_prompt, - num_inference_steps=num_inference_steps, - callback=callback, - guidance_scale=guidance_scale, - ) - print("kwargs",kwargs) - - if pipeline_name =="sketch2img" and image: - kwargs.update(image=image,controlnet_conditioning_scale=controlnet_conditioning_scale) - elif pipeline_name == "txt2img": - kwargs.update(width = width, height = height) - else: - raise Exception( - f"Cannot generate image for pipeline {pipeline_name} and {prompt}") - images = pipe(**kwargs).images - image = images[0] - - os.makedirs("outputs", exist_ok=True) - - filename = ( - "outputs/" - + re.sub(r"\s+", "_",prompt)[:30] - + f"_{datetime.datetime.now().timestamp()}" - ) - image.save(f"{filename}.png") - with open(f"{filename}.txt", "w") as f: - f.write(f"Prompt: {prompt}\n\nNegative Prompt:{negative_prompt}") - return image diff --git a/spaces/Abubakari/Sepsis-fastapi-prediction-app/Dockerfile b/spaces/Abubakari/Sepsis-fastapi-prediction-app/Dockerfile deleted file mode 100644 index a64500d2926f582016f23c07409ce09abbe21df8..0000000000000000000000000000000000000000 --- a/spaces/Abubakari/Sepsis-fastapi-prediction-app/Dockerfile +++ /dev/null @@ -1,14 +0,0 @@ -FROM python:3.9 - -WORKDIR /code - -COPY ./requirements.txt /code/requirements.txt - -RUN pip install -r /code/requirements.txt - -COPY . . - -# Expose the port on which the application will run -EXPOSE 7860 - -CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "7860"] diff --git a/spaces/AchyuthGamer/OpenGPT-Chat-UI/.svelte-kit/types/src/routes/r/[id]/message/[messageId]/prompt/$types.d.ts b/spaces/AchyuthGamer/OpenGPT-Chat-UI/.svelte-kit/types/src/routes/r/[id]/message/[messageId]/prompt/$types.d.ts deleted file mode 100644 index 984e7ed4449e9d93e1823b3ee3e4229eac3e84bd..0000000000000000000000000000000000000000 --- a/spaces/AchyuthGamer/OpenGPT-Chat-UI/.svelte-kit/types/src/routes/r/[id]/message/[messageId]/prompt/$types.d.ts +++ /dev/null @@ -1,9 +0,0 @@ -import type * as Kit from '@sveltejs/kit'; - -type Expand
 -```
-where `{img_str}` is the actual image data. This format makes displaying them in the UI for free. Do note, that this format is required to be exactly the same, the regex used to find the images is: `
-```
-where `{img_str}` is the actual image data. This format makes displaying them in the UI for free. Do note, that this format is required to be exactly the same, the regex used to find the images is: `) `.
-
-## LLM input
-To describe the input, let's see it on an example prompt:
-```
-text1
`.
-
-## LLM input
-To describe the input, let's see it on an example prompt:
-```
-text1Blockman Go Editor Aventura APK: Una plataforma de creación de juegos gratis y divertido
-¿Te gustan los juegos de píxeles? ¿Quieres hacer tus propios juegos y compartirlos con otros? Si es así, entonces usted debe probar Blockman Go Editor Adventure APK, una plataforma de creación de juegos gratis y divertido que le permite crear y jugar juegos de píxeles en su dispositivo Android. En este artículo, le diremos qué es Blockman Go Editor Adventure APK, cómo descargarlo e instalarlo, cómo usarlo y cuáles son los beneficios de usarlo.
-¿Qué es Blockman Go Editor aventura APK?
-Blockman Go Editor Aventura APK es una aplicación que tiene dos funciones principales: un fabricante de juegos y un jugador del juego.
-caramelo crush amigos saga apkpure
Download File ✦✦✦ https://bltlly.com/2v6IYc
-
Una aplicación fabricante de juegos para juegos de píxeles
-Blockman Go Editor Aventura APK es una herramienta de desarrollo que integra Editor de escena, Editor de gatillo, Editor de actor, Editor de interfaz de usuario, Editor de guiones, y otras funciones. Proporciona una plataforma de creación completamente gratuita para los amantes de los juegos de píxeles. Puedes usar varias herramientas y características para crear tus propios juegos, como Bed Wars, Jail Break, Sky Wars, Parkour y más. También puedes personalizar la configuración del juego, como el modo, el mapa, las reglas, etc.
-Una aplicación de jugador de juegos para Blockman Go juegos
-Blockman Go Editor Adventure APK es también una aplicación de jugador de juego que le permite jugar juegos hechos por otros usuarios o usted mismo. Puedes navegar y descargar juegos de la comunidad Blockman Go, o subir tus propios juegos para compartirlos con otros. También puedes unirte a juegos multijugador online con otros jugadores de todo el mundo. Puedes chatear con ellos, hacer amigos o competir con ellos.
-¿Cómo descargar e instalar Blockman Go Editor Aventura APK?
-Blockman Go Editor Aventura APK no está disponible en Google Play Store, por lo que necesita descargarlo de otras fuentes. Estos son los pasos para descargarlo e instalarlo en tu dispositivo:
-Descargar desde APKCombo u otras fuentes
- -Habilitar fuentes desconocidas en su dispositivo
-Antes de instalar el archivo APK, es necesario habilitar fuentes desconocidas en el dispositivo. Esto le permitirá instalar aplicaciones desde fuentes distintas de Google Play Store. Para hacer esto, vaya a Configuración > Seguridad > Fuentes desconocidas y conéctelo.
-Instalar el archivo APK y lanzar la aplicación
-Después de descargar el archivo APK, localizarlo en su dispositivo y toque en él para instalarlo. Siga las instrucciones de la pantalla para completar la instalación. Una vez instalada, inicie la aplicación y disfrute creando y jugando juegos de píxeles.
-¿Cómo usar Blockman Go Editor Aventura APK?
-Usando Blockman Go Editor Aventura APK es fácil y divertido. Aquí hay algunos consejos sobre cómo usarlo:
-Crea tus propios juegos con varias herramientas y características
-Para crear tus propios juegos, toca el botón "Crear" en la pantalla principal de la aplicación. Verás varias herramientas y características que puedes usar para crear tus juegos. Por ejemplo, puedes usar el Editor de escenas para diseñar la escena del juego, el Editor de disparadores para configurar la lógica del juego, el Editor de actores para crear los personajes del juego, el Editor de interfaz de usuario para diseñar la interfaz del juego y el Editor de guiones para escribir el código del juego. También puedes usar Asset Store para descargar varios activos para tus juegos, como modelos, texturas, sonidos, etc. Puedes previsualizar tus juegos en cualquier momento y probarlos en tu dispositivo.
- -Jugar juegos hechos por otros usuarios o usted mismo
-Para jugar juegos hechos por otros usuarios o por ti mismo, toca el botón "Jugar" en la pantalla principal de la aplicación. Verás una lista de juegos que puedes descargar y jugar. También puedes buscar juegos por palabras clave o categorías. Para jugar a un juego, toca en él y espera a que se cargue. También puedes calificar y comentar los juegos que juegas.
-Comparte tus juegos con la comunidad Blockman Go
- -¿Cuáles son los beneficios de Blockman Go Editor Aventura APK?
-Blockman Go Editor Aventura APK es una gran aplicación para los amantes de los juegos de píxeles. Aquí están algunos de los beneficios de su uso:
-Gratis y fácil de usar
-Blockman Go Editor Aventura APK es completamente gratis para descargar y usar. Usted no necesita pagar nada para crear o jugar juegos. La aplicación también es fácil de usar, con una interfaz fácil de usar e instrucciones claras. No necesitas ninguna experiencia o conocimiento previo para crear o jugar juegos.
-Creativo y divertido
-Blockman Go Editor Aventura APK es una aplicación creativa y divertida que le permite dar rienda suelta a su imaginación y expresarse. Puedes crear cualquier tipo de juego que quieras, con posibilidades y opciones ilimitadas. También puedes jugar juegos hechos por otros usuarios o por ti mismo, y disfrutar de diferentes géneros y estilos de juegos de píxeles.
-Social e interactivo
-Blockman Go Editor Aventura APK es una aplicación social e interactiva que le permite conectarse con otros amantes de los juegos de píxeles de todo el mundo. Puedes chatear con ellos, hacer amigos o competir con ellos. También puedes unirte a juegos multijugador en línea con ellos y divertirte juntos.
-Conclusión
-Blockman Go Editor Aventura APK es una plataforma de creación de juegos gratis y divertido que le permite crear y jugar juegos de píxeles en su dispositivo Android. Es una aplicación fabricante de juegos para juegos de píxeles, y una aplicación de jugador de juego para juegos de Blockman Go. Es fácil de descargar e instalar, fácil de usar, creativo y divertido, y social e interactivo. Si te gustan los juegos de píxeles, definitivamente deberías probar Blockman Go Editor Aventura APK.
-Preguntas frecuentes
-Aquí hay algunas preguntas frecuentes sobre Blockman Go Editor Aventura APK:
-Q: ¿Es seguro usar Blockman Go Editor Adventure APK?
- -Q: ¿Es Blockman Go Editor Adventure APK compatible con mi dispositivo?
-A: Blockman Go Editor Adventure APK es compatible con la mayoría de los dispositivos Android que ejecutan Android 4.1 o superior. Sin embargo, es posible que algunos dispositivos no admitan algunas características o funciones de la aplicación debido a limitaciones de hardware o configuración del sistema.
-Q: ¿Cómo puedo actualizar Blockman Go editor aventura APK?
-A: Para actualizar Blockman Go Editor Adventure APK, es necesario descargar la última versión de la aplicación de APKCombo u otras fuentes, e instalarlo sobre la versión existente. Alternativamente, puede comprobar si hay actualizaciones dentro de la aplicación pulsando en el botón "Configuración" en la pantalla principal de la aplicación, y luego tocando en el "Buscar actualizaciones" opción.
-Q: ¿Cómo puedo contactar al soporte de Blockman Go?
-A: Para contactar con el soporte de Blockman Go, puede enviar un correo electrónico a support@blockmango.net , o visitar su sitio web oficial en https:/ww.blockmango.net. También puedes seguirlos en sus redes sociales, como Facebook, Twitter, Instagram, YouTube, etc.
-Q: ¿Cómo puedo dar retroalimentación o sugerencias para Blockman Go Editor Adventure APK?
-A: Para dar retroalimentación o sugerencias para Blockman Go Editor Adventure APK, puede utilizar la opción "Feedback" dentro de la aplicación, o enviar un correo electrónico a feedback@blockmango.net. También puede calificar y revisar la aplicación en APKCombo u otras fuentes, y compartir sus opiniones e ideas con otros usuarios.
64aa2da5cf-
-
\ No newline at end of file diff --git a/spaces/Benson/text-generation/Examples/Ciudad Congelada Mod Apk Diamantes Ilimitados.md b/spaces/Benson/text-generation/Examples/Ciudad Congelada Mod Apk Diamantes Ilimitados.md deleted file mode 100644 index 60a4264330d2236a2321c9f4f3993734ba459e6a..0000000000000000000000000000000000000000 --- a/spaces/Benson/text-generation/Examples/Ciudad Congelada Mod Apk Diamantes Ilimitados.md +++ /dev/null @@ -1,55 +0,0 @@ - -
Frozen City Mod APK ilimitados diamantes: Cómo descargar e instalar
-Si estás buscando un emocionante y desafiante juego de supervivencia, es posible que quieras echar un vistazo a Frozen City. Este es un juego que pondrá a prueba sus habilidades y estrategia a medida que intenta construir y gestionar su base en un páramo congelado. Sin embargo, si desea disfrutar del juego sin limitaciones o restricciones, es posible que desee probar Frozen City Mod APK Unlimited Diamonds. Esta es una versión modificada del juego original que te da acceso a recursos ilimitados, como diamantes, monedas, gemas y más. En este artículo, le diremos qué es Frozen City, qué es Frozen City Mod APK Unlimited Diamonds, y cómo descargarlo e instalarlo en su dispositivo Android.
-ciudad congelada mod apk diamantes ilimitados
Download ⇒ https://bltlly.com/2v6Kbm
-
¿Qué es la ciudad congelada?
-Frozen City es un juego desarrollado por Game Insight, una compañía que se especializa en crear juegos móviles inmersivos y atractivos. El juego se desarrolla en un mundo post-apocalíptico donde un virus misterioso ha convertido a la mayoría de la población en zombies. Los sobrevivientes tienen que encontrar refugio y recursos en la ciudad congelada, donde tienen que enfrentar no solo a los no-muertos, sino también a otras facciones hostiles y desastres naturales.
-Un juego de supervivencia ambientado en un mundo post-apocalíptico
-En Frozen City, tienes que sobrevivir en un ambiente duro donde cada decisión importa. Tienes que buscar comida, agua, combustible y otros suministros, así como armas artesanales, herramientas y equipo. También tienes que defender tu base de ataques de zombies y raiders, así como explorar la ciudad en busca de pistas y secretos. Tienes que equilibrar tus necesidades y deseos, así como tu moralidad y humanidad.
-Un juego de construcción de bases con múltiples etapas y tareas
- -Un juego con impresionantes gráficos y efectos de sonido
-Frozen City es un juego que cuenta con impresionantes gráficos y efectos de sonido que crean una atmósfera inmersiva. El juego presenta efectos meteorológicos realistas, como nieve, niebla, lluvia y viento. El juego también tiene animaciones detalladas, sombras, iluminación y texturas que hacen que la ciudad se vea viva. El juego también tiene efectos de sonido realistas, como gemidos de zombis, disparos, explosiones y más. El juego también tiene una banda sonora cautivadora que coincide con el estado de ánimo del juego.
-¿Qué es Frozen City Mod APK ilimitados diamantes?
-Frozen City Mod APK ilimitado de diamantes es una versión modificada del juego original que le da recursos ilimitados, tales como diamantes, monedas, gemas, y más. Estos recursos son esenciales para construir y actualizar su base, así como para desbloquear nuevas características y contenido. Sin embargo, en el juego original, estos recursos son limitados y difíciles de conseguir. Tienes que gastar dinero real o esperar largas horas para conseguirlos.
- -Una versión modificada del juego original que te da recursos ilimitados
-Frozen City Mod APK Unlimited Diamonds es una versión hackeada del juego original que evita el sistema de divisas en el juego. Esto significa que puede obtener diamantes, monedas, gemas y otros recursos ilimitados sin gastar dinero ni esperar largas horas. Puede utilizar estos recursos para construir y actualizar su base más rápido, así como acceder a todas las características y contenido del juego sin restricciones.
-Una manera de disfrutar del juego sin gastar dinero real o esperar largas horas
- -Una manera de desbloquear todas las características y el contenido del juego
-Frozen City Mod APK Unlimited Diamonds es una manera de desbloquear todas las características y el contenido del juego que de otra manera están bloqueados o no disponibles en el juego original. Puede desbloquear nuevas ubicaciones, etapas, misiones, armas, equipos, sobrevivientes y más. También puedes acceder a funciones premium, como estatus VIP, artículos exclusivos y bonos. También puedes disfrutar del juego sin anuncios ni interrupciones.
-Cómo descargar e instalar Frozen City Mod APK ilimitados diamantes?
-Si desea probar Frozen City Mod APK Unlimited Diamonds, es necesario descargar e instalar en su dispositivo Android. Sin embargo, debe seguir algunos pasos y precauciones antes de hacerlo. Estos son los pasos que debe seguir:
-Paso 1: Permitir aplicaciones desconocidas en su dispositivo Android
-Dado que Frozen City Mod APK ilimitado de diamantes no está disponible en el oficial de Google Play Store, es necesario permitir que su dispositivo para instalar aplicaciones de fuentes desconocidas. Para hacer esto, vaya a la configuración del dispositivo, luego la seguridad, luego active la opción que dice "fuentes desconocidas" o "permitir la instalación de aplicaciones de fuentes desconocidas". Esto le permitirá instalar aplicaciones que no son de Google Play Store.
-Paso 2: Instalar una aplicación de administrador de archivos en su dispositivo
-También necesitas instalar una aplicación de administrador de archivos en tu dispositivo que te ayudará a localizar y administrar el archivo APK que descargarás. Una aplicación de administrador de archivos es una aplicación que le permite navegar y organizar los archivos y carpetas en su dispositivo. Puede usar cualquier aplicación de administrador de archivos que prefiera, como ES File Explorer, File Manager o Astro File Manager.
-Paso 3: Descargar el archivo APK de una fuente de buena reputación
- --
-
- [APKPure] -
- [APKHome] -
- [ModDroid] -
Una vez que encuentre una fuente confiable, haga clic en el botón de descarga o enlace y espere a que la descarga termine.
-Paso 4: Localizar y tocar el archivo APK para instalarlo
-Después de descargar el archivo APK, necesita localizarlo en su dispositivo usando la aplicación de administrador de archivos que instaló anteriormente. El archivo APK debe estar en la carpeta de descargas o en la carpeta donde lo guardó. Una vez que lo encuentre, pulse sobre él para iniciar el proceso de instalación. Es posible que vea una ventana emergente pidiendo su permiso para instalar la aplicación. Toque en "instalar" o "permitir" y espere a que se complete la instalación.
-Paso 5: Disfruta del juego con diamantes ilimitados y otros recursos
-Felicidades! Usted ha descargado e instalado con éxito Frozen City Mod APK ilimitados diamantes en su dispositivo Android. Ahora puedes disfrutar del juego con recursos ilimitados, como diamantes, monedas, gemas y más. También puede desbloquear todas las características y el contenido del juego sin restricciones o limitaciones. ¡Diviértete jugando Frozen City Mod APK Unlimited Diamonds!
-Conclusión
-Frozen City es un juego de supervivencia que pondrá a prueba tus habilidades y estrategia mientras intentas construir y gestionar tu base en un desierto helado. Sin embargo, si quieres disfrutar del juego sin ningún tipo de molestia o frustración, es posible que desee probar Frozen City Mod APK Unlimited Diamonds. Esta es una versión modificada del juego original que te da recursos ilimitados, como diamantes, monedas, gemas y más. También puedes desbloquear todas las características y contenido del juego sin restricciones o limitaciones.
- -Preguntas frecuentes
-Aquí están algunas de las preguntas más frecuentes sobre Frozen City Mod APK Unlimited Diamonds:
-Q: ¿Es seguro usar Frozen City Mod APK Unlimited Diamonds?
-A: Sí, Frozen City Mod APK Unlimited Diamonds es seguro de usar, siempre y cuando lo descargue de una fuente confiable y siga los pasos y precauciones mencionados en este artículo. Sin embargo, siempre debe tener cuidado al instalar aplicaciones de fuentes desconocidas, ya que pueden contener malware o virus que pueden dañar su dispositivo o robar sus datos. También debe escanear el archivo APK con una aplicación antivirus antes de instalarlo.
-Q: ¿Es Frozen City Mod APK ilimitado diamantes compatible con mi dispositivo?
-A: Frozen City Mod APK Unlimited Diamonds es compatible con la mayoría de los dispositivos Android que se ejecutan en Android 4.4 o superior. Sin embargo, algunos dispositivos pueden no ser compatibles con el juego o el mod debido a diferentes especificaciones o configuraciones. Usted debe comprobar la compatibilidad de su dispositivo antes de descargar e instalar el mod.
-Q: ¿Los diamantes ilimitados de Frozen City Mod APK afectarán el rendimiento de mi dispositivo?
-A: Frozen City Mod APK ilimitado diamantes no debe afectar el rendimiento de su dispositivo significativamente, ya que no requiere mucho espacio de almacenamiento o memoria. Sin embargo, algunos dispositivos pueden experimentar retrasos o fallos debido a la baja RAM o CPU. Deberías cerrar otras aplicaciones y borrar la caché antes de jugar para evitar estos problemas.
-Q: Congelado Ciudad Mod APK ilimitado de diamantes trabajar con la última versión del juego?
-A: Frozen City Mod APK Unlimited Diamonds se actualiza regularmente para que coincida con la última versión del juego. Sin embargo, algunas actualizaciones pueden tardar más que otras en ser lanzadas. Deberías comprobar la versión del mod antes de descargarlo e instalarlo para asegurarte de que es compatible con la última versión del juego.
-Q: ¿Puedo jugar Frozen City Mod APK ilimitados diamantes en línea con otros jugadores?
64aa2da5cf-
-
\ No newline at end of file diff --git a/spaces/Benson/text-generation/Examples/Descargar Arthdal Crnicas Episodio 16.md b/spaces/Benson/text-generation/Examples/Descargar Arthdal Crnicas Episodio 16.md deleted file mode 100644 index 6181c142b4793a42a1c6ea75a95b6ee8893dc9f9..0000000000000000000000000000000000000000 --- a/spaces/Benson/text-generation/Examples/Descargar Arthdal Crnicas Episodio 16.md +++ /dev/null @@ -1,51 +0,0 @@ - -
Cómo descargar Arthdal Chronicles Episodio 16
-¿Eres fan de Arthdal Chronicles, el drama épico coreano que ha cautivado a millones de espectadores en todo el mundo? Si es así, debes estar esperando ansiosamente el episodio 16, el episodio final de la temporada 1. Pero, ¿cómo puedes verlo online sin problemas? En este artículo, te mostraremos cómo descargar Arthdal Chronicles episodio 16 de Netflix, una de las mejores plataformas de streaming que ofrecen este increíble espectáculo. Pero primero, veamos de qué se trata Arthdal Chronicles y por qué deberías verlo.
-descargar arthdal crónicas episodio 16
Download » https://bltlly.com/2v6Mvl
-
¿Qué es Arthdal Chronicles?
-Arthdal Chronicles es un drama histórico de fantasía que cuenta la historia de la antigua ciudad de Arthdal y sus habitantes que luchan por el poder y la supervivencia. El drama cuenta con un reparto lleno de estrellas que incluye a Song Joong-ki, Jang Dong-gun, Kim Ji-won y Kim Ok-bin. El drama se divide en tres partes: Los Hijos de la Profecía, El Cielo Girando de Adentro hacia Afuera, La Tierra Naciente y El Preludio de Todas las Leyendas.
-En los episodios anteriores, hemos sido testigos de cómo Eunseom (Song Joong-ki), un mitad humano mitad neandertal que nació con un destino especial, escapa de Arthdal y se encuentra con otras tribus que lo ayudan a crecer como líder. También hemos visto cómo Tagon (Jang Dong-gun), un carismático guerrero que también es secretamente un neandertal, llega al poder en Arthdal y se enfrenta a varios desafíos de sus enemigos. Mientras tanto, Tanya (Kim Ji-won), un descendiente del clan Wahan que fue secuestrado por soldados Arthdal, se convierte en la alta sacerdotisa de Arthdal y aprende sobre su verdadera identidad. Y Saya ( Kim Ok-bin), un misterioso hermano gemelo de Eunseom que vive en una cámara secreta, conspira para derrocar a Tagon y apoderarse de Arthdal.
- -Por qué deberías ver Arthdal Chronicles Episodio 16
-Hay muchas razones por las que deberías ver online el episodio 16 de Arthdal Chronicles. Estas son algunas de ellas:
--
-
- Disfrutarás de las impresionantes imágenes y cinematografías que dan vida al antiguo mundo de Arthdal. El drama cuenta con un alto valor de producción y un diseño de escenografía realista que te hará sentir como si fueras parte de la historia. -
- Usted se sorprenderá por la excelente actuación y química de los miembros del reparto que retratan sus personajes complejos y diversos con pasión y habilidad. El drama muestra los talentos de algunos de los mejores actores de Corea que ofrecen actuaciones cautivadoras que te harán reír, llorar y animarlos. -
- Estarás inmerso en la historia rica y original que combina la fantasía, la historia y la cultura de una manera única. El drama explora temas como el poder, el amor, la identidad y el destino de una manera creativa y atractiva que te mantendrá enganchado hasta el final. -
- Estarás satisfecho con el final satisfactorio y gratificante que envolverá la historia de una manera significativa y memorable. El drama promete entregar un final que responderá a todas sus preguntas y le dejará con una sensación de cierre y cumplimiento. -
Entonces, si estás buscando un drama que te entretenga, te inspire y te haga pensar, el episodio 16 de Arthdal Chronicles es la elección perfecta para ti.
-Donde Descargar Arthdal Chronicles Episodio 16
- - | Streaming Platform | Calidad de vídeo | Subtítulos | Precio | Descargar Opción | | -- | --- - - - - - - - | Netflix | HD | Varios idiomas | $8.99/mes (Plan básico) | Sí | | Viki | HD | Varios idiomas | $4.99/mes (Plan estándar) | No | | Viu | HD | Múltiples idiomas | $6.49/month (Plan premium) | Sí | | Kocowa | HD | Solo en inglés | $6.99/month (Plan estándar) | No |Como se puede ver en la tabla, Netflix es la mejor plataforma para descargar Arthdal Chronicles episodio 16 en línea. Tiene la más alta calidad de vídeo, la mayoría de las opciones de subtítulos, el precio más bajo, y la opción de descarga que le permite ver Arthdal Chronicles sin conexión. Por lo tanto, recomendamos Netflix como la mejor plataforma para descargar Arthdal Chronicles episodio 16.
- -Cómo descargar Arthdal Chronicles episodio 16 de Netflix
-Si ha decidido descargar Arthdal Chronicles episodio 16 de Netflix, aquí están los pasos que debe seguir:
--
-
- Regístrate en una cuenta de Netflix si aún no tienes una. Puedes elegir entre tres planes: Básico ($8.99/mes), Estándar ($13.99/mes), o Premium ($17.99/mes). El plan básico le permite ver en una pantalla a la vez, el plan estándar le permite ver en dos pantallas a la vez, y el plan Premium le permite ver en cuatro pantallas a la vez. Todos los planes te permiten descargar contenido en tus dispositivos. -
- Descargue la aplicación de Netflix en su dispositivo si no la tiene ya. Puede descargarla desde la App Store o Google Play Store de forma gratuita. -
- Abra la aplicación de Netflix e inicie sesión con los detalles de su cuenta. -
- Buscar "Arthdal Chronicles" en la barra de búsqueda y seleccionarlo de los resultados. -
- Seleccione "Episodio 16" de la lista de episodios y toque en el "Descargar" icono junto a ella. El icono parece una flecha hacia abajo con un círculo alrededor. -
- Espere a que se complete la descarga. Puede comprobar el progreso de la descarga en la sección "Descargas" de la aplicación. - -
Aquí hay una captura de pantalla que muestra cómo descargar Arthdal Chronicles episodio 16 de Netflix:
- -
-Un consejo sobre cómo ver Arthdal Chronicles sin conexión: Puede ajustar la calidad de vídeo de sus descargas para ahorrar espacio de almacenamiento en su dispositivo. Para ello, vaya a la sección "Configuración de la aplicación" de la aplicación y toque en "Descargar calidad de vídeo". Puede elegir entre cuatro opciones: Estándar (usa menos espacio de almacenamiento), Alto (usa más espacio de almacenamiento), Medio (usa espacio de almacenamiento moderado) o Inteligente (se ajusta automáticamente a la mejor calidad según las condiciones de su dispositivo y red).
-Conclusión
-En conclusión, Arthdal Chronicles episodio 16 es una visita obligada para todos los fans del drama. Es el último episodio de la temporada 1 que revelará el destino de los personajes y la ciudad de Arthdal. Puede descargar Arthdal Chronicles episodio 16 de Netflix, la mejor plataforma de transmisión que ofrece video de alta calidad, múltiples subtítulos, bajo precio y opción de descarga. Todo lo que necesita hacer es seguir los sencillos pasos que hemos descrito anteriormente y disfrutar viendo Arthdal Chronicles sin conexión. No te pierdas este final épico que te dejará sin palabras.
-Entonces, ¿qué estás esperando? Descarga Arthdal Chronicles episodio 16 de Netflix hoy y presenciar el final de una era.
-Preguntas frecuentes
-Q: ¿Cuándo saldrá la temporada 2 de Arthdal Chronicles?
-A: No hay confirmación oficial todavía sobre si Arthdal Chronicles tendrá una temporada 2 o no. Sin embargo, algunas fuentes sugieren que el equipo de producción está planeando comenzar a filmar la temporada 2 en 2024, después de que los actores terminen su servicio militar. Esperamos que esto sea cierto y que veamos más de Arthdal Chronicles en el futuro.
-Q: ¿Cuántos episodios hay en Arthdal Chronicles?
- -P: ¿Quiénes son los actores principales en Arthdal Chronicles?
-A: Los actores principales de Arthdal Chronicles son Song Joong-ki, Jang Dong-gun, Kim Ji-won y Kim Ok-bin. Song Joong-ki interpreta a Eunseom y Saya, hermanos gemelos que tienen destinos diferentes. Jang Dong-gun interpreta a Tagon, un poderoso guerrero que se convierte en el rey de Arthdal. Kim Ji-won interpreta a Tanya, una alta sacerdotisa que es el interés amoroso de Eunseom. Kim Ok-bin interpreta a Taealha, un político astuto que es el interés amoroso de Tagon.
-P: ¿Cuál es el género de Arthdal Chronicles?
-A: Arthdal Chronicles es un drama histórico de fantasía que combina elementos de mitología, historia y cultura. Se encuentra en una tierra antigua ficticia llamada Arth, donde coexisten diferentes tribus y especies. Explora temas como el poder, el amor, la identidad y el destino.
-Q: ¿Dónde puedo ver Arthdal Chronicles con subtítulos en inglés?
-A: Puedes ver Arthdal Chronicles con subtítulos en inglés en Netflix, Viki, Viu o Kocowa. Sin embargo, recomendamos Netflix como la mejor plataforma para ver Arthdal Chronicles con subtítulos en inglés porque tiene la mejor calidad de video, la mayoría de opciones de subtítulos, el precio más bajo y la opción de descarga.
64aa2da5cf-
-
\ No newline at end of file diff --git a/spaces/Big-Web/MMSD/env/Lib/site-packages/pkg_resources/_vendor/pyparsing/helpers.py b/spaces/Big-Web/MMSD/env/Lib/site-packages/pkg_resources/_vendor/pyparsing/helpers.py deleted file mode 100644 index 9588b3b780159a2a2d23c7f84a4404ec350e2b65..0000000000000000000000000000000000000000 --- a/spaces/Big-Web/MMSD/env/Lib/site-packages/pkg_resources/_vendor/pyparsing/helpers.py +++ /dev/null @@ -1,1088 +0,0 @@ -# helpers.py -import html.entities -import re -import typing - -from . import __diag__ -from .core import * -from .util import _bslash, _flatten, _escape_regex_range_chars - - -# -# global helpers -# -def delimited_list( - expr: Union[str, ParserElement], - delim: Union[str, ParserElement] = ",", - combine: bool = False, - min: typing.Optional[int] = None, - max: typing.Optional[int] = None, - *, - allow_trailing_delim: bool = False, -) -> ParserElement: - """Helper to define a delimited list of expressions - the delimiter - defaults to ','. By default, the list elements and delimiters can - have intervening whitespace, and comments, but this can be - overridden by passing ``combine=True`` in the constructor. If - ``combine`` is set to ``True``, the matching tokens are - returned as a single token string, with the delimiters included; - otherwise, the matching tokens are returned as a list of tokens, - with the delimiters suppressed. - - If ``allow_trailing_delim`` is set to True, then the list may end with - a delimiter. - - Example:: - - delimited_list(Word(alphas)).parse_string("aa,bb,cc") # -> ['aa', 'bb', 'cc'] - delimited_list(Word(hexnums), delim=':', combine=True).parse_string("AA:BB:CC:DD:EE") # -> ['AA:BB:CC:DD:EE'] - """ - if isinstance(expr, str_type): - expr = ParserElement._literalStringClass(expr) - - dlName = "{expr} [{delim} {expr}]...{end}".format( - expr=str(expr.copy().streamline()), - delim=str(delim), - end=" [{}]".format(str(delim)) if allow_trailing_delim else "", - ) - - if not combine: - delim = Suppress(delim) - - if min is not None: - if min < 1: - raise ValueError("min must be greater than 0") - min -= 1 - if max is not None: - if min is not None and max <= min: - raise ValueError("max must be greater than, or equal to min") - max -= 1 - delimited_list_expr = expr + (delim + expr)[min, max] - - if allow_trailing_delim: - delimited_list_expr += Opt(delim) - - if combine: - return Combine(delimited_list_expr).set_name(dlName) - else: - return delimited_list_expr.set_name(dlName) - - -def counted_array( - expr: ParserElement, - int_expr: typing.Optional[ParserElement] = None, - *, - intExpr: typing.Optional[ParserElement] = None, -) -> ParserElement: - """Helper to define a counted list of expressions. - - This helper defines a pattern of the form:: - - integer expr expr expr... - - where the leading integer tells how many expr expressions follow. - The matched tokens returns the array of expr tokens as a list - the - leading count token is suppressed. - - If ``int_expr`` is specified, it should be a pyparsing expression - that produces an integer value. - - Example:: - - counted_array(Word(alphas)).parse_string('2 ab cd ef') # -> ['ab', 'cd'] - - # in this parser, the leading integer value is given in binary, - # '10' indicating that 2 values are in the array - binary_constant = Word('01').set_parse_action(lambda t: int(t[0], 2)) - counted_array(Word(alphas), int_expr=binary_constant).parse_string('10 ab cd ef') # -> ['ab', 'cd'] - - # if other fields must be parsed after the count but before the - # list items, give the fields results names and they will - # be preserved in the returned ParseResults: - count_with_metadata = integer + Word(alphas)("type") - typed_array = counted_array(Word(alphanums), int_expr=count_with_metadata)("items") - result = typed_array.parse_string("3 bool True True False") - print(result.dump()) - - # prints - # ['True', 'True', 'False'] - # - items: ['True', 'True', 'False'] - # - type: 'bool' - """ - intExpr = intExpr or int_expr - array_expr = Forward() - - def count_field_parse_action(s, l, t): - nonlocal array_expr - n = t[0] - array_expr <<= (expr * n) if n else Empty() - # clear list contents, but keep any named results - del t[:] - - if intExpr is None: - intExpr = Word(nums).set_parse_action(lambda t: int(t[0])) - else: - intExpr = intExpr.copy() - intExpr.set_name("arrayLen") - intExpr.add_parse_action(count_field_parse_action, call_during_try=True) - return (intExpr + array_expr).set_name("(len) " + str(expr) + "...") - - -def match_previous_literal(expr: ParserElement) -> ParserElement: - """Helper to define an expression that is indirectly defined from - the tokens matched in a previous expression, that is, it looks for - a 'repeat' of a previous expression. For example:: - - first = Word(nums) - second = match_previous_literal(first) - match_expr = first + ":" + second - - will match ``"1:1"``, but not ``"1:2"``. Because this - matches a previous literal, will also match the leading - ``"1:1"`` in ``"1:10"``. If this is not desired, use - :class:`match_previous_expr`. Do *not* use with packrat parsing - enabled. - """ - rep = Forward() - - def copy_token_to_repeater(s, l, t): - if t: - if len(t) == 1: - rep << t[0] - else: - # flatten t tokens - tflat = _flatten(t.as_list()) - rep << And(Literal(tt) for tt in tflat) - else: - rep << Empty() - - expr.add_parse_action(copy_token_to_repeater, callDuringTry=True) - rep.set_name("(prev) " + str(expr)) - return rep - - -def match_previous_expr(expr: ParserElement) -> ParserElement: - """Helper to define an expression that is indirectly defined from - the tokens matched in a previous expression, that is, it looks for - a 'repeat' of a previous expression. For example:: - - first = Word(nums) - second = match_previous_expr(first) - match_expr = first + ":" + second - - will match ``"1:1"``, but not ``"1:2"``. Because this - matches by expressions, will *not* match the leading ``"1:1"`` - in ``"1:10"``; the expressions are evaluated first, and then - compared, so ``"1"`` is compared with ``"10"``. Do *not* use - with packrat parsing enabled. - """ - rep = Forward() - e2 = expr.copy() - rep <<= e2 - - def copy_token_to_repeater(s, l, t): - matchTokens = _flatten(t.as_list()) - - def must_match_these_tokens(s, l, t): - theseTokens = _flatten(t.as_list()) - if theseTokens != matchTokens: - raise ParseException( - s, l, "Expected {}, found{}".format(matchTokens, theseTokens) - ) - - rep.set_parse_action(must_match_these_tokens, callDuringTry=True) - - expr.add_parse_action(copy_token_to_repeater, callDuringTry=True) - rep.set_name("(prev) " + str(expr)) - return rep - - -def one_of( - strs: Union[typing.Iterable[str], str], - caseless: bool = False, - use_regex: bool = True, - as_keyword: bool = False, - *, - useRegex: bool = True, - asKeyword: bool = False, -) -> ParserElement: - """Helper to quickly define a set of alternative :class:`Literal` s, - and makes sure to do longest-first testing when there is a conflict, - regardless of the input order, but returns - a :class:`MatchFirst` for best performance. - - Parameters: - - - ``strs`` - a string of space-delimited literals, or a collection of - string literals - - ``caseless`` - treat all literals as caseless - (default= ``False``) - - ``use_regex`` - as an optimization, will - generate a :class:`Regex` object; otherwise, will generate - a :class:`MatchFirst` object (if ``caseless=True`` or ``asKeyword=True``, or if - creating a :class:`Regex` raises an exception) - (default= ``True``) - - ``as_keyword`` - enforce :class:`Keyword`-style matching on the - generated expressions - (default= ``False``) - - ``asKeyword`` and ``useRegex`` are retained for pre-PEP8 compatibility, - but will be removed in a future release - - Example:: - - comp_oper = one_of("< = > <= >= !=") - var = Word(alphas) - number = Word(nums) - term = var | number - comparison_expr = term + comp_oper + term - print(comparison_expr.search_string("B = 12 AA=23 B<=AA AA>12")) - - prints:: - - [['B', '=', '12'], ['AA', '=', '23'], ['B', '<=', 'AA'], ['AA', '>', '12']] - """ - asKeyword = asKeyword or as_keyword - useRegex = useRegex and use_regex - - if ( - isinstance(caseless, str_type) - and __diag__.warn_on_multiple_string_args_to_oneof - ): - warnings.warn( - "More than one string argument passed to one_of, pass" - " choices as a list or space-delimited string", - stacklevel=2, - ) - - if caseless: - isequal = lambda a, b: a.upper() == b.upper() - masks = lambda a, b: b.upper().startswith(a.upper()) - parseElementClass = CaselessKeyword if asKeyword else CaselessLiteral - else: - isequal = lambda a, b: a == b - masks = lambda a, b: b.startswith(a) - parseElementClass = Keyword if asKeyword else Literal - - symbols: List[str] = [] - if isinstance(strs, str_type): - symbols = strs.split() - elif isinstance(strs, Iterable): - symbols = list(strs) - else: - raise TypeError("Invalid argument to one_of, expected string or iterable") - if not symbols: - return NoMatch() - - # reorder given symbols to take care to avoid masking longer choices with shorter ones - # (but only if the given symbols are not just single characters) - if any(len(sym) > 1 for sym in symbols): - i = 0 - while i < len(symbols) - 1: - cur = symbols[i] - for j, other in enumerate(symbols[i + 1 :]): - if isequal(other, cur): - del symbols[i + j + 1] - break - elif masks(cur, other): - del symbols[i + j + 1] - symbols.insert(i, other) - break - else: - i += 1 - - if useRegex: - re_flags: int = re.IGNORECASE if caseless else 0 - - try: - if all(len(sym) == 1 for sym in symbols): - # symbols are just single characters, create range regex pattern - patt = "[{}]".format( - "".join(_escape_regex_range_chars(sym) for sym in symbols) - ) - else: - patt = "|".join(re.escape(sym) for sym in symbols) - - # wrap with \b word break markers if defining as keywords - if asKeyword: - patt = r"\b(?:{})\b".format(patt) - - ret = Regex(patt, flags=re_flags).set_name(" | ".join(symbols)) - - if caseless: - # add parse action to return symbols as specified, not in random - # casing as found in input string - symbol_map = {sym.lower(): sym for sym in symbols} - ret.add_parse_action(lambda s, l, t: symbol_map[t[0].lower()]) - - return ret - - except re.error: - warnings.warn( - "Exception creating Regex for one_of, building MatchFirst", stacklevel=2 - ) - - # last resort, just use MatchFirst - return MatchFirst(parseElementClass(sym) for sym in symbols).set_name( - " | ".join(symbols) - ) - - -def dict_of(key: ParserElement, value: ParserElement) -> ParserElement: - """Helper to easily and clearly define a dictionary by specifying - the respective patterns for the key and value. Takes care of - defining the :class:`Dict`, :class:`ZeroOrMore`, and - :class:`Group` tokens in the proper order. The key pattern - can include delimiting markers or punctuation, as long as they are - suppressed, thereby leaving the significant key text. The value - pattern can include named results, so that the :class:`Dict` results - can include named token fields. - - Example:: - - text = "shape: SQUARE posn: upper left color: light blue texture: burlap" - attr_expr = (label + Suppress(':') + OneOrMore(data_word, stop_on=label).set_parse_action(' '.join)) - print(attr_expr[1, ...].parse_string(text).dump()) - - attr_label = label - attr_value = Suppress(':') + OneOrMore(data_word, stop_on=label).set_parse_action(' '.join) - - # similar to Dict, but simpler call format - result = dict_of(attr_label, attr_value).parse_string(text) - print(result.dump()) - print(result['shape']) - print(result.shape) # object attribute access works too - print(result.as_dict()) - - prints:: - - [['shape', 'SQUARE'], ['posn', 'upper left'], ['color', 'light blue'], ['texture', 'burlap']] - - color: 'light blue' - - posn: 'upper left' - - shape: 'SQUARE' - - texture: 'burlap' - SQUARE - SQUARE - {'color': 'light blue', 'shape': 'SQUARE', 'posn': 'upper left', 'texture': 'burlap'} - """ - return Dict(OneOrMore(Group(key + value))) - - -def original_text_for( - expr: ParserElement, as_string: bool = True, *, asString: bool = True -) -> ParserElement: - """Helper to return the original, untokenized text for a given - expression. Useful to restore the parsed fields of an HTML start - tag into the raw tag text itself, or to revert separate tokens with - intervening whitespace back to the original matching input text. By - default, returns astring containing the original parsed text. - - If the optional ``as_string`` argument is passed as - ``False``, then the return value is - a :class:`ParseResults` containing any results names that - were originally matched, and a single token containing the original - matched text from the input string. So if the expression passed to - :class:`original_text_for` contains expressions with defined - results names, you must set ``as_string`` to ``False`` if you - want to preserve those results name values. - - The ``asString`` pre-PEP8 argument is retained for compatibility, - but will be removed in a future release. - - Example:: - - src = "this is test bold text normal text " - for tag in ("b", "i"): - opener, closer = make_html_tags(tag) - patt = original_text_for(opener + SkipTo(closer) + closer) - print(patt.search_string(src)[0]) - - prints:: - - [' bold text '] - ['text'] - """ - asString = asString and as_string - - locMarker = Empty().set_parse_action(lambda s, loc, t: loc) - endlocMarker = locMarker.copy() - endlocMarker.callPreparse = False - matchExpr = locMarker("_original_start") + expr + endlocMarker("_original_end") - if asString: - extractText = lambda s, l, t: s[t._original_start : t._original_end] - else: - - def extractText(s, l, t): - t[:] = [s[t.pop("_original_start") : t.pop("_original_end")]] - - matchExpr.set_parse_action(extractText) - matchExpr.ignoreExprs = expr.ignoreExprs - matchExpr.suppress_warning(Diagnostics.warn_ungrouped_named_tokens_in_collection) - return matchExpr - - -def ungroup(expr: ParserElement) -> ParserElement: - """Helper to undo pyparsing's default grouping of And expressions, - even if all but one are non-empty. - """ - return TokenConverter(expr).add_parse_action(lambda t: t[0]) - - -def locatedExpr(expr: ParserElement) -> ParserElement: - """ - (DEPRECATED - future code should use the Located class) - Helper to decorate a returned token with its starting and ending - locations in the input string. - - This helper adds the following results names: - - - ``locn_start`` - location where matched expression begins - - ``locn_end`` - location where matched expression ends - - ``value`` - the actual parsed results - - Be careful if the input text contains ``
Research History {report_history_num}: \ - {report_history_tasks[-1]}
\ -{origin}
\ --It can be used to restore your **old photos** or improve **AI-generated faces**.
-To use it, simply upload your image.
-If GFPGAN is helpful, please help to ⭐ the Github Repo and recommend it to your friends 😊
-This demo was forked by [vicalloy](https://github.com/vicalloy), add `face blur` param to optimize painting face enhance. -""" -article = r""" - -[](https://github.com/TencentARC/GFPGAN/releases) -[](https://github.com/TencentARC/GFPGAN) -[ -
- -
- -
- -
- -
- -
- -
-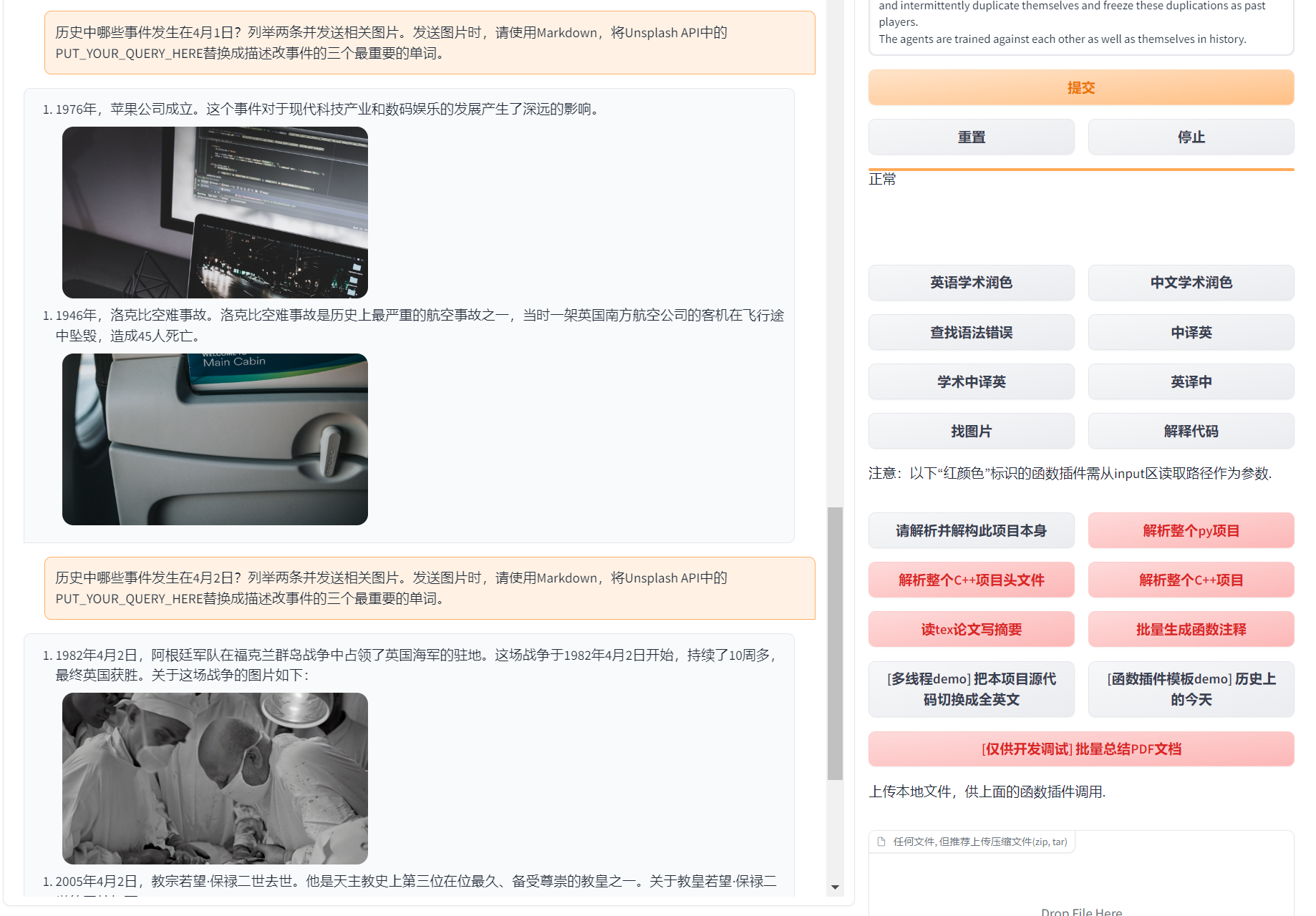 -
- -
- -
-
-
- -
- -
- -
- -
- -
- -
- -
-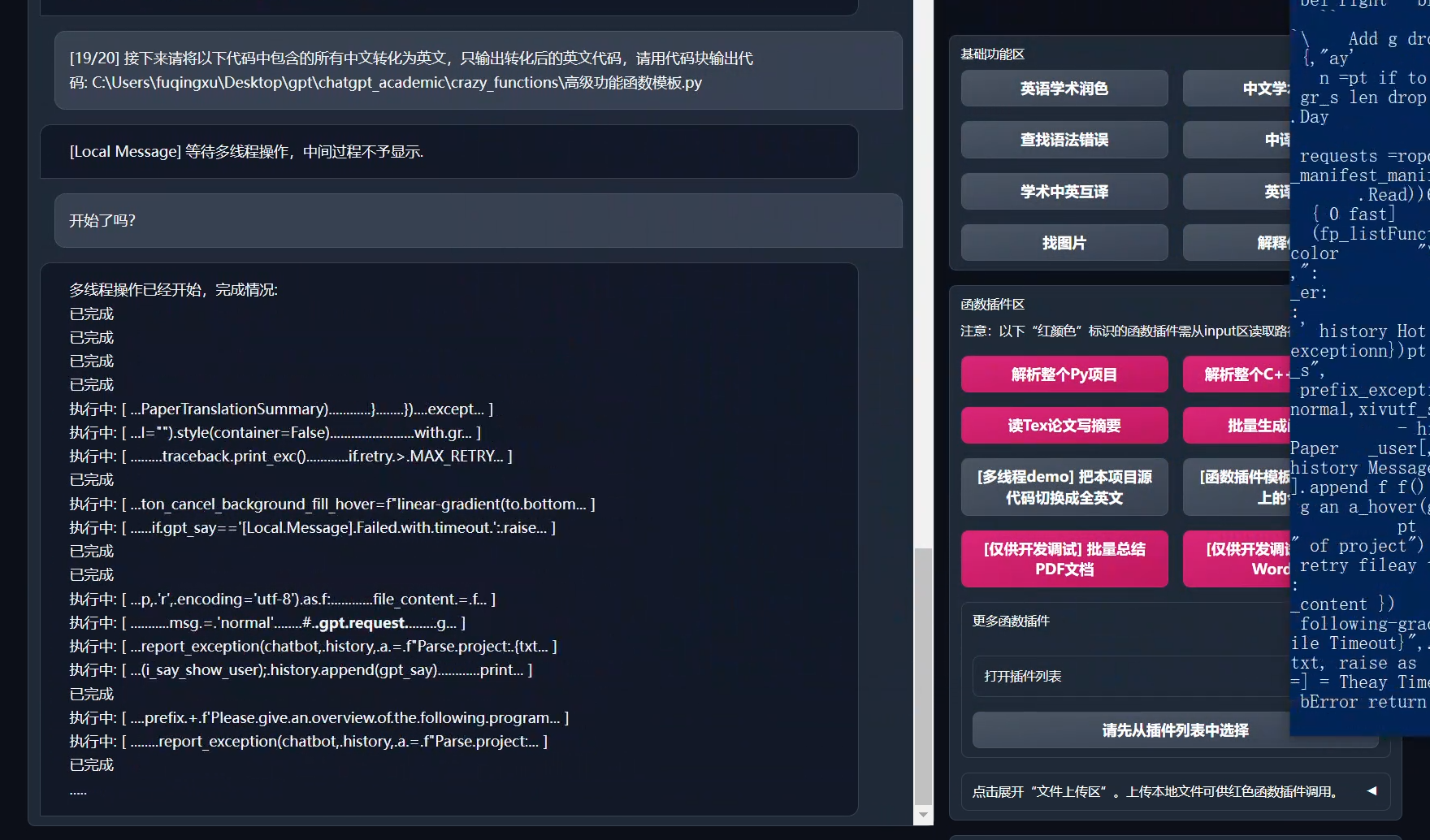 -
- -
-
-
-- -We use 20K hours of licensed music to train MusicGen. Specifically, we rely on an internal dataset of 10K high-quality music tracks, and on the ShutterStock and Pond5 music data. - -## Installation -Audiocraft requires Python 3.9, PyTorch 2.0.0, and a GPU with at least 16 GB of memory (for the medium-sized model). To install Audiocraft, you can run the following: - -```shell -# Best to make sure you have torch installed first, in particular before installing xformers. -# Don't run this if you already have PyTorch installed. -pip install 'torch>=2.0' -# Then proceed to one of the following -pip install -U audiocraft # stable release -pip install -U git+https://git@github.com/GrandaddyShmax/audiocraft_plus#egg=audiocraft -pip install -e . # or if you cloned the repo locally -``` - -## Usage -We offer a number of way to interact with MusicGen+: -1. MusicGen+ is also available on the [`GrandaddyShmax/MusicGen_Plus` HuggingFace Space](https://huggingface.co/spaces/GrandaddyShmax/MusicGen_Plus), -2. You can run MusicGen+ on a Colab: [colab notebook](https://colab.research.google.com/github/camenduru/MusicGen-colab/blob/main/MusicGen_ClownOfMadness_plus_colab.ipynb). -3. You can use the gradio MusicGen+ locally by running `python app.py`. -4. Checkout [@camenduru Colab page](https://github.com/camenduru/MusicGen-colab) which is regularly - updated with contributions from @camenduru and the community. -5. Finally, MusicGen is available in 🤗 Transformers from v4.31.0 onwards, see section [🤗 Transformers Usage](#-transformers-usage) below. - -## API - -We provide a simple API and 4 pre-trained models. The pre trained models are: -- `small`: 300M model, text to music only - [🤗 Hub](https://huggingface.co/facebook/musicgen-small) -- `medium`: 1.5B model, text to music only - [🤗 Hub](https://huggingface.co/facebook/musicgen-medium) -- `melody`: 1.5B model, text to music and text+melody to music - [🤗 Hub](https://huggingface.co/facebook/musicgen-melody) -- `large`: 3.3B model, text to music only - [🤗 Hub](https://huggingface.co/facebook/musicgen-large) - -We observe the best trade-off between quality and compute with the `medium` or `melody` model. -In order to use MusicGen locally **you must have a GPU**. We recommend 16GB of memory, but smaller -GPUs will be able to generate short sequences, or longer sequences with the `small` model. - -**Note**: Please make sure to have [ffmpeg](https://ffmpeg.org/download.html) installed when using newer version of `torchaudio`. -You can install it with: -``` -apt-get install ffmpeg -``` - -See after a quick example for using the API. - -```python -import torchaudio -from audiocraft.models import MusicGen -from audiocraft.data.audio import audio_write - -model = MusicGen.get_pretrained('melody') -model.set_generation_params(duration=8) # generate 8 seconds. -wav = model.generate_unconditional(4) # generates 4 unconditional audio samples -descriptions = ['happy rock', 'energetic EDM', 'sad jazz'] -wav = model.generate(descriptions) # generates 3 samples. - -melody, sr = torchaudio.load('./assets/bach.mp3') -# generates using the melody from the given audio and the provided descriptions. -wav = model.generate_with_chroma(descriptions, melody[None].expand(3, -1, -1), sr) - -for idx, one_wav in enumerate(wav): - # Will save under {idx}.wav, with loudness normalization at -14 db LUFS. - audio_write(f'{idx}', one_wav.cpu(), model.sample_rate, strategy="loudness", loudness_compressor=True) -``` - -## 🤗 Transformers Usage - -MusicGen is available in the 🤗 Transformers library from version 4.31.0 onwards, requiring minimal dependencies -and additional packages. Steps to get started: - -1. First install the 🤗 [Transformers library](https://github.com/huggingface/transformers) from main: - -``` -pip install git+https://github.com/huggingface/transformers.git -``` - -2. Run the following Python code to generate text-conditional audio samples: - -```py -from transformers import AutoProcessor, MusicgenForConditionalGeneration - - -processor = AutoProcessor.from_pretrained("facebook/musicgen-small") -model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-small") - -inputs = processor( - text=["80s pop track with bassy drums and synth", "90s rock song with loud guitars and heavy drums"], - padding=True, - return_tensors="pt", -) - -audio_values = model.generate(**inputs, max_new_tokens=256) -``` - -3. Listen to the audio samples either in an ipynb notebook: - -```py -from IPython.display import Audio - -sampling_rate = model.config.audio_encoder.sampling_rate -Audio(audio_values[0].numpy(), rate=sampling_rate) -``` - -Or save them as a `.wav` file using a third-party library, e.g. `scipy`: - -```py -import scipy - -sampling_rate = model.config.audio_encoder.sampling_rate -scipy.io.wavfile.write("musicgen_out.wav", rate=sampling_rate, data=audio_values[0, 0].numpy()) -``` - -For more details on using the MusicGen model for inference using the 🤗 Transformers library, refer to the -[MusicGen docs](https://huggingface.co/docs/transformers/main/en/model_doc/musicgen) or the hands-on -[Google Colab](https://colab.research.google.com/github/sanchit-gandhi/notebooks/blob/main/MusicGen.ipynb). - -## Model Card - -See [the model card page](./MODEL_CARD.md). - -## FAQ - -#### Will the training code be released? - -Yes. We will soon release the training code for MusicGen and EnCodec. - - -#### I need help on Windows - -@FurkanGozukara made a complete tutorial for [Audiocraft/MusicGen on Windows](https://youtu.be/v-YpvPkhdO4) - -#### I need help for running the demo on Colab - -Check [@camenduru tutorial on Youtube](https://www.youtube.com/watch?v=EGfxuTy9Eeo). - - -## Citation -``` -@article{copet2023simple, - title={Simple and Controllable Music Generation}, - author={Jade Copet and Felix Kreuk and Itai Gat and Tal Remez and David Kant and Gabriel Synnaeve and Yossi Adi and Alexandre Défossez}, - year={2023}, - journal={arXiv preprint arXiv:2306.05284}, -} -``` - -## License -* The code in this repository is released under the MIT license as found in the [LICENSE file](LICENSE). -* The weights in this repository are released under the CC-BY-NC 4.0 license as found in the [LICENSE_weights file](LICENSE_weights). - -[arxiv]: https://arxiv.org/abs/2306.05284 -[musicgen_samples]: https://ai.honu.io/papers/musicgen/ diff --git a/spaces/Grezz/generate_human_motion/VQ-Trans/dataset/prepare/download_model.sh b/spaces/Grezz/generate_human_motion/VQ-Trans/dataset/prepare/download_model.sh deleted file mode 100644 index da32436f6efa93e0c14e1dd52f97068bd75956ab..0000000000000000000000000000000000000000 --- a/spaces/Grezz/generate_human_motion/VQ-Trans/dataset/prepare/download_model.sh +++ /dev/null @@ -1,12 +0,0 @@ - -mkdir -p pretrained -cd pretrained/ - -echo -e "The pretrained model files will be stored in the 'pretrained' folder\n" -gdown 1LaOvwypF-jM2Axnq5dc-Iuvv3w_G-WDE - -unzip VQTrans_pretrained.zip -echo -e "Cleaning\n" -rm VQTrans_pretrained.zip - -echo -e "Downloading done!" \ No newline at end of file diff --git a/spaces/HarryLee/eCommerceImageCaptioning/fairseq/fairseq_cli/hydra_train.py b/spaces/HarryLee/eCommerceImageCaptioning/fairseq/fairseq_cli/hydra_train.py deleted file mode 100644 index 6555ab415e82c1156c85d000ff030e6107c55d73..0000000000000000000000000000000000000000 --- a/spaces/HarryLee/eCommerceImageCaptioning/fairseq/fairseq_cli/hydra_train.py +++ /dev/null @@ -1,88 +0,0 @@ -#!/usr/bin/env python3 -u -# Copyright (c) Facebook, Inc. and its affiliates. -# -# This source code is licensed under the MIT license found in the -# LICENSE file in the root directory of this source tree. - -import logging -import os - -from fairseq.dataclass.initialize import add_defaults, hydra_init -from fairseq_cli.train import main as pre_main -from fairseq import distributed_utils, metrics -from fairseq.dataclass.configs import FairseqConfig -from fairseq.dataclass.utils import omegaconf_no_object_check -from fairseq.utils import reset_logging - -import hydra -from hydra.core.hydra_config import HydraConfig -import torch -from omegaconf import OmegaConf, open_dict - - -logger = logging.getLogger("fairseq_cli.hydra_train") - - -@hydra.main(config_path=os.path.join("..", "fairseq", "config"), config_name="config") -def hydra_main(cfg: FairseqConfig) -> float: - _hydra_main(cfg) - - -def _hydra_main(cfg: FairseqConfig, **kwargs) -> float: - add_defaults(cfg) - - if cfg.common.reset_logging: - reset_logging() # Hydra hijacks logging, fix that - else: - # check if directly called or called through hydra_main - if HydraConfig.initialized(): - with open_dict(cfg): - # make hydra logging work with ddp (see # see https://github.com/facebookresearch/hydra/issues/1126) - cfg.job_logging_cfg = OmegaConf.to_container(HydraConfig.get().job_logging, resolve=True) - - with omegaconf_no_object_check(): - cfg = OmegaConf.create(OmegaConf.to_container(cfg, resolve=True, enum_to_str=True)) - OmegaConf.set_struct(cfg, True) - - try: - if cfg.common.profile: - with torch.cuda.profiler.profile(): - with torch.autograd.profiler.emit_nvtx(): - distributed_utils.call_main(cfg, pre_main, **kwargs) - else: - distributed_utils.call_main(cfg, pre_main, **kwargs) - except BaseException as e: - if not cfg.common.suppress_crashes: - raise - else: - logger.error("Crashed! " + str(e)) - - # get best val and return - useful for sweepers - try: - best_val = metrics.get_smoothed_value( - "valid", cfg.checkpoint.best_checkpoint_metric - ) - except: - best_val = None - - if best_val is None: - best_val = float("inf") - - return best_val - - -def cli_main(): - try: - from hydra._internal.utils import get_args - - cfg_name = get_args().config_name or "config" - except: - logger.warning("Failed to get config name from hydra args") - cfg_name = "config" - - hydra_init(cfg_name) - hydra_main() - - -if __name__ == "__main__": - cli_main() diff --git a/spaces/Harveenchadha/oiTrans/app.py b/spaces/Harveenchadha/oiTrans/app.py deleted file mode 100644 index d0379206ffa1c903f104029657247bebcb37f388..0000000000000000000000000000000000000000 --- a/spaces/Harveenchadha/oiTrans/app.py +++ /dev/null @@ -1,52 +0,0 @@ -import os -#import gradio as gr - -os.system('wget -q https://storage.googleapis.com/vakyaansh-open-models/translation_models/indic-en.zip') -os.system('unzip /home/user/app/indic-en.zip') -os.system('wget -q https://storage.googleapis.com/vakyaansh-open-models/translation_models/en-indic.zip') -os.system('unzip /home/user/app/en-indic.zip') -os.system('wget -q https://storage.googleapis.com/vakyaansh-open-models/translation_models/m2m_modified.zip') -os.system('unzip /home/user/app/m2m_modified.zip') -os.system('rm /home/user/app/indic-en.zip') -os.system('rm /home/user/app/en-indic.zip') -os.system('rm /home/user/app/m2m_modified.zip') - -os.system('pip uninstall -y numpy') -os.system('pip install numpy') -#os.system('pip uninstall -y numba') -#os.system('pip install numba==0.53') - -from fairseq import checkpoint_utils, distributed_utils, options, tasks, utils -import gradio as grd -from inference.engine import Model -indic2en_model = Model(expdir='indic-en') -en2indic_model = Model(expdir='en-indic') -indic2indic_model = Model(expdir='m2m') - -INDIC = {"English": "en", "Assamese": "as", "Bengali": "bn", "Gujarati": "gu", "Hindi": "hi","Kannada": "kn","Malayalam": "ml", "Marathi": "mr", "Odia": "or","Punjabi": "pa","Tamil": "ta", "Telugu" : "te" } - - -def translate(text, source_lang, dest_lang): - if source_lang == 'en': - return en2indic_model.translate_paragraph(text, 'en', INDIC[dest_lang]) - elif dest_lang == 'en': - return indic2en_model.translate_paragraph(text, INDIC[source_lang], 'en') - else: - return indic2indic_model.translate_paragraph(text, INDIC[source_lang], INDIC[dest_lang]) - - -languages = list(INDIC.keys()) - -#print(translate('helo how are you')) -ddwn_src = grd.inputs.Dropdown(languages, type="value", default="English", label="Select Source Language") -ddwn_tar = grd.inputs.Dropdown(languages, type="value", default="Hindi", label="Select Target Language") - -txt = grd.inputs.Textbox( lines=5, placeholder="Enter Text to translate", default="", label="Enter Text in Source Language") -txt_ouptut = grd.outputs.Textbox(type="auto", label="Translated text in English Language") - -example=[['मैं इस वाक्य का हिंदी में अनुवाद करना चाहता हूं','Hindi', 'English'], - ['আজ আমার খুব ভালো লাগছে', 'Bengali' , 'Hindi']] - -supp = ','.join(languages) -iface = grd.Interface(fn=translate, inputs=[txt,ddwn_src,ddwn_tar] , outputs=txt_ouptut, title='Translation for 11 Indic Languages', description = 'This is a demo based on IndicTrans. Languages Supported: '+supp, article = 'Original repo [link](https://github.com/AI4Bharat/indicTrans) by AI4Bharat. Note: This is an attempt to create open version of Translation for Indic languages. ', examples=example) -iface.launch(enable_queue=True) diff --git a/spaces/IDEA-Research/Grounded-SAM/GroundingDINO/setup.py b/spaces/IDEA-Research/Grounded-SAM/GroundingDINO/setup.py deleted file mode 100644 index a045b763fb4a4f61bac23b735544a18ffc68d20a..0000000000000000000000000000000000000000 --- a/spaces/IDEA-Research/Grounded-SAM/GroundingDINO/setup.py +++ /dev/null @@ -1,208 +0,0 @@ -# coding=utf-8 -# Copyright 2022 The IDEA Authors. All rights reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# ------------------------------------------------------------------------------------------------ -# Modified from -# https://github.com/fundamentalvision/Deformable-DETR/blob/main/models/ops/setup.py -# https://github.com/facebookresearch/detectron2/blob/main/setup.py -# https://github.com/open-mmlab/mmdetection/blob/master/setup.py -# https://github.com/Oneflow-Inc/libai/blob/main/setup.py -# ------------------------------------------------------------------------------------------------ - -import glob -import os -import subprocess - -import torch -from setuptools import find_packages, setup -from torch.utils.cpp_extension import CUDA_HOME, CppExtension, CUDAExtension - -# groundingdino version info -version = "0.1.0" -package_name = "groundingdino" -cwd = os.path.dirname(os.path.abspath(__file__)) - - -sha = "Unknown" -try: - sha = subprocess.check_output(["git", "rev-parse", "HEAD"], cwd=cwd).decode("ascii").strip() -except Exception: - pass - - -def write_version_file(): - version_path = os.path.join(cwd, "groundingdino", "version.py") - with open(version_path, "w") as f: - f.write(f"__version__ = '{version}'\n") - # f.write(f"git_version = {repr(sha)}\n") - - -requirements = ["torch", "torchvision"] - -torch_ver = [int(x) for x in torch.__version__.split(".")[:2]] - - -def get_extensions(): - this_dir = os.path.dirname(os.path.abspath(__file__)) - extensions_dir = os.path.join(this_dir, "groundingdino", "models", "GroundingDINO", "csrc") - - main_source = os.path.join(extensions_dir, "vision.cpp") - sources = glob.glob(os.path.join(extensions_dir, "**", "*.cpp")) - source_cuda = glob.glob(os.path.join(extensions_dir, "**", "*.cu")) + glob.glob( - os.path.join(extensions_dir, "*.cu") - ) - - sources = [main_source] + sources - - extension = CppExtension - - extra_compile_args = {"cxx": []} - define_macros = [] - - if torch.cuda.is_available() and CUDA_HOME is not None: - print("Compiling with CUDA") - extension = CUDAExtension - sources += source_cuda - define_macros += [("WITH_CUDA", None)] - extra_compile_args["nvcc"] = [ - "-DCUDA_HAS_FP16=1", - "-D__CUDA_NO_HALF_OPERATORS__", - "-D__CUDA_NO_HALF_CONVERSIONS__", - "-D__CUDA_NO_HALF2_OPERATORS__", - ] - else: - print("Compiling without CUDA") - define_macros += [("WITH_HIP", None)] - extra_compile_args["nvcc"] = [] - return None - - sources = [os.path.join(extensions_dir, s) for s in sources] - include_dirs = [extensions_dir] - - ext_modules = [ - extension( - "groundingdino._C", - sources, - include_dirs=include_dirs, - define_macros=define_macros, - extra_compile_args=extra_compile_args, - ) - ] - - return ext_modules - - -def parse_requirements(fname="requirements.txt", with_version=True): - """Parse the package dependencies listed in a requirements file but strips - specific versioning information. - - Args: - fname (str): path to requirements file - with_version (bool, default=False): if True include version specs - - Returns: - List[str]: list of requirements items - - CommandLine: - python -c "import setup; print(setup.parse_requirements())" - """ - import re - import sys - from os.path import exists - - require_fpath = fname - - def parse_line(line): - """Parse information from a line in a requirements text file.""" - if line.startswith("-r "): - # Allow specifying requirements in other files - target = line.split(" ")[1] - for info in parse_require_file(target): - yield info - else: - info = {"line": line} - if line.startswith("-e "): - info["package"] = line.split("#egg=")[1] - elif "@git+" in line: - info["package"] = line - else: - # Remove versioning from the package - pat = "(" + "|".join([">=", "==", ">"]) + ")" - parts = re.split(pat, line, maxsplit=1) - parts = [p.strip() for p in parts] - - info["package"] = parts[0] - if len(parts) > 1: - op, rest = parts[1:] - if ";" in rest: - # Handle platform specific dependencies - # http://setuptools.readthedocs.io/en/latest/setuptools.html#declaring-platform-specific-dependencies - version, platform_deps = map(str.strip, rest.split(";")) - info["platform_deps"] = platform_deps - else: - version = rest # NOQA - info["version"] = (op, version) - yield info - - def parse_require_file(fpath): - with open(fpath, "r") as f: - for line in f.readlines(): - line = line.strip() - if line and not line.startswith("#"): - for info in parse_line(line): - yield info - - def gen_packages_items(): - if exists(require_fpath): - for info in parse_require_file(require_fpath): - parts = [info["package"]] - if with_version and "version" in info: - parts.extend(info["version"]) - if not sys.version.startswith("3.4"): - # apparently package_deps are broken in 3.4 - platform_deps = info.get("platform_deps") - if platform_deps is not None: - parts.append(";" + platform_deps) - item = "".join(parts) - yield item - - packages = list(gen_packages_items()) - return packages - - -if __name__ == "__main__": - print(f"Building wheel {package_name}-{version}") - - with open("LICENSE", "r", encoding="utf-8") as f: - license = f.read() - - write_version_file() - - setup( - name="groundingdino", - version="0.1.0", - author="International Digital Economy Academy, Shilong Liu", - url="https://github.com/IDEA-Research/GroundingDINO", - description="open-set object detector", - license=license, - install_requires=parse_requirements("requirements.txt"), - packages=find_packages( - exclude=( - "configs", - "tests", - ) - ), - ext_modules=get_extensions(), - cmdclass={"build_ext": torch.utils.cpp_extension.BuildExtension}, - ) diff --git a/spaces/Iceclear/StableSR/README.md b/spaces/Iceclear/StableSR/README.md deleted file mode 100644 index 06090b4e9f22dc767199046b58944186b9dc45bf..0000000000000000000000000000000000000000 --- a/spaces/Iceclear/StableSR/README.md +++ /dev/null @@ -1,13 +0,0 @@ ---- -title: StableSR -emoji: 😻 -colorFrom: purple -colorTo: indigo -sdk: gradio -sdk_version: 3.40.1 -app_file: app.py -pinned: false -license: other ---- - -Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference diff --git a/spaces/Illumotion/Koboldcpp/examples/llama2.sh b/spaces/Illumotion/Koboldcpp/examples/llama2.sh deleted file mode 100644 index 221b37553cfe7d825a9666d8d5c337a7814a3c64..0000000000000000000000000000000000000000 --- a/spaces/Illumotion/Koboldcpp/examples/llama2.sh +++ /dev/null @@ -1,18 +0,0 @@ -#!/bin/bash - -# -# Temporary script - will be removed in the future -# - -cd `dirname $0` -cd .. - -./main -m models/available/Llama2/7B/llama-2-7b.ggmlv3.q4_0.bin \ - --color \ - --ctx_size 2048 \ - -n -1 \ - -ins -b 256 \ - --top_k 10000 \ - --temp 0.2 \ - --repeat_penalty 1.1 \ - -t 8 diff --git a/spaces/Illumotion/Koboldcpp/examples/parallel/README.md b/spaces/Illumotion/Koboldcpp/examples/parallel/README.md deleted file mode 100644 index 4d0fe5cef12fa7e2d28e18571ba94d290e47999b..0000000000000000000000000000000000000000 --- a/spaces/Illumotion/Koboldcpp/examples/parallel/README.md +++ /dev/null @@ -1,3 +0,0 @@ -# llama.cpp/example/parallel - -Simplified simluation for serving incoming requests in parallel diff --git a/spaces/Illumotion/Koboldcpp/make_pyinstaller.bat b/spaces/Illumotion/Koboldcpp/make_pyinstaller.bat deleted file mode 100644 index 5ca9604192c2a958a0ea1b102c3a64351b842147..0000000000000000000000000000000000000000 --- a/spaces/Illumotion/Koboldcpp/make_pyinstaller.bat +++ /dev/null @@ -1 +0,0 @@ -PyInstaller --noconfirm --onefile --clean --console --collect-all customtkinter --icon "./niko.ico" --add-data "./klite.embd;." --add-data "./koboldcpp_default.dll;." --add-data "./koboldcpp_openblas.dll;." --add-data "./koboldcpp_failsafe.dll;." --add-data "./koboldcpp_noavx2.dll;." --add-data "./libopenblas.dll;." --add-data "./koboldcpp_clblast.dll;." --add-data "./clblast.dll;." --add-data "./rwkv_vocab.embd;." --add-data "./rwkv_world_vocab.embd;." "./koboldcpp.py" -n "koboldcpp.exe" \ No newline at end of file diff --git a/spaces/Illumotion/Koboldcpp/otherarch/tools/neox_quantize.cpp b/spaces/Illumotion/Koboldcpp/otherarch/tools/neox_quantize.cpp deleted file mode 100644 index 602c9d3c49e3efb5a25b1cc3c3b0b76e8a5644d6..0000000000000000000000000000000000000000 --- a/spaces/Illumotion/Koboldcpp/otherarch/tools/neox_quantize.cpp +++ /dev/null @@ -1,179 +0,0 @@ -#include "ggml.h" - -#include "utils.h" -#include "common-ggml.h" - -#include
 -
- -
- -
-