diff --git a/spaces/1acneusushi/gradio-2dmoleculeeditor/data/Chief Architect Premier X12 22.5.2.56 Patched keygen How to Activate the Full Features of the Professional 3D Building Software.md b/spaces/1acneusushi/gradio-2dmoleculeeditor/data/Chief Architect Premier X12 22.5.2.56 Patched keygen How to Activate the Full Features of the Professional 3D Building Software.md
deleted file mode 100644
index a86ad523b8f188d2da8f1b51cc556d5a442e6bc7..0000000000000000000000000000000000000000
--- a/spaces/1acneusushi/gradio-2dmoleculeeditor/data/Chief Architect Premier X12 22.5.2.56 Patched keygen How to Activate the Full Features of the Professional 3D Building Software.md
+++ /dev/null
@@ -1,139 +0,0 @@
-
-
Chief Architect Premier X12 22.5.2.56 Patched Keygen: A Comprehensive Review
-
If you are looking for a powerful and easy-to-use 3D architecture software for residential and commercial design, you might want to check out Chief Architect Premier X12. This software has automated construction tools that make home design, remodeling, interior design, kitchens and bathrooms, etc. easier. As you draw the walls and place smart architectural objects like doors and windows, the program creates a 3D model, generates a bill of materials, and with the use of powerful construction tools, helps to produce construction documents like blueprints plan, detailed sections, and elevations.
-
In this article, we will review Chief Architect Premier X12 22.5.2.56 Patched Keygen, which is a cracked version of the software that allows you to use it without paying for a license. We will cover the features and benefits of Chief Architect Premier X12, how to install and activate it with the patched keygen, and the pros and cons of using it.
-
Chief Architect Premier X12 22.5.2.56 Patched keygen
Chief Architect Premier X12 is the latest version of Chief Architect software, which was released in February 2020. It is a professional 3D architecture software that can handle all aspects of building design, from conceptual design to construction documents.
-
Chief Architect Premier X12 has many new features and enhancements that make it more efficient and user-friendly. Some of these features include:
-
-
New rendering engine that supports ray tracing and ambient occlusion for realistic lighting effects.
-
New smart tools for creating decks, railings, stairs, roofs, dormers, skylights, etc.
-
New library items for furniture, appliances, fixtures, plants, materials, etc.
-
New options for customizing cabinets, countertops, backsplashes, moldings, etc.
-
New tools for creating electrical plans, plumbing plans, HVAC plans, etc.
-
New options for exporting 3D views to 360° panoramas, VR headsets, or web pages.
-
New options for importing and exporting DWG/DXF files with layers and colors.
-
New options for collaborating with other users via cloud services or BIM360.
-
-
Features and benefits of Chief Architect Premier X12
-
Chief Architect Premier X12 has many features and benefits that make it a versatile and powerful 3D architecture software. Here are some of them:
-
Design and build tools
-
Chief Architect Premier X12 has automatic and manual build tools that let you create a variety of roof styles, ladders, trusses, cut BOMs (bill of materials), sizing (dimensioning), sections (cross-sections), elevations (side views), etc. You can also use smart framing tools to create floor systems (joists), wall systems (studs), ceiling systems (rafters), etc. You can also edit these elements individually or in groups to customize their properties.
-
Interior, kitchen and bathroom design
-
Chief Architect Premier X12 uses smart design objects (such as cabinets, appliances, doors, windows, countertops (worktops), floors (flooring), etc.) to quickly and easily create various styles, shapes (forms), sizes (dimensions), etc. You can also use smart labels (tags) to annotate these objects with information such as manufacturer (brand), model (type), price (cost), etc. You can also use smart dimensions (measures) to show the distances between objects or walls.
-
How to download Chief Architect Premier X12 22.5.2.56 with patch
-Chief Architect Premier X12 22.5.2.56 cracked version free download
-Chief Architect Premier X12 22.5.2.56 full version with keygen activation
-Best software for home design: Chief Architect Premier X12 22.5.2.56
-Chief Architect Premier X12 22.5.2.56 patch download link
-Chief Architect Premier X12 22.5.2.56 keygen generator online
-Chief Architect Premier X12 22.5.2.56 review and features
-Chief Architect Premier X12 22.5.2.56 system requirements and compatibility
-Chief Architect Premier X12 22.5.2.56 tutorial and tips
-Chief Architect Premier X12 22.5.2.56 license key and serial number
-Chief Architect Premier X12 22.5.2.56 update and bug fixes
-Chief Architect Premier X12 22.5.2.56 vs other home design software
-Chief Architect Premier X12 22.5.2.56 discount and coupon code
-Chief Architect Premier X12 22.5.2.56 trial version and limitations
-Chief Architect Premier X12 22.5.2.56 alternatives and competitors
-How to install Chief Architect Premier X12 22.5.2.56 with patch and keygen
-Chief Architect Premier X12 22.5.2.56 user manual and guide
-Chief Architect Premier X12 22.5.2.56 support and customer service
-How to uninstall Chief Architect Premier X12 22.5.2.56 completely
-Chief Architect Premier X12 22.5.2.56 testimonials and feedback
-How to use Chief Architect Premier X12 22.5.2.56 for interior design
-How to use Chief Architect Premier X12 22.5.2.56 for exterior design
-How to use Chief Architect Premier X12 22.5.2.56 for landscaping design
-How to use Chief Architect Premier X12 22.5.2.56 for kitchen design
-How to use Chief Architect Premier X12 22.5.2
-
3D modeling and design tools
-
With Chief Architect Premier X12, you can design in any view for seamless (smooth), simultaneous editing between 2D and 3D. You can switch between different views such as plan view (top view), elevation view (side view), perspective view (angle view), orthographic view (straight view), etc. You can also use the camera tool to create custom views such as dollhouse view (open view), glass house view (transparent view), watercolor view (artistic view), etc. You can also use the walkthrough tool to navigate through your model in 3D.
-
CAD tools for productivity and precision
-
Chief Architect Premier X12 has a powerful CAD software engine that includes tools for lines, polylines (connected lines), splines (curved lines), arcs (circular lines), solids (3D shapes), etc. to produce objects. You can also use these tools to draw custom shapes or symbols that can be saved as CAD blocks or library items for future use. You can also import files in DWG, DXF or PDF format from other CAD programs or online sources.
-
Construction blueprint set generation
-
All views of your project such as blueprints plan (floor plan), framing plan (structure plan), sections plan (cross-section plan), details plan (close-up plan) , elevations plan (side views plan) have a user-defined scale and link to a specific drawing that updates as design changes change. You can also use layout sheets to arrange these views on a page with title blocks, borders , text , dimensions , etc. You can also print these sheets or export them as PDF files for sharing or printing.
-
How to install and activate Chief Architect Premier X12 with the patched keygen
-
If you want to use Chief Architect Premier X12 without paying for a license , you can download the patched keygen version from this link. However , be aware that this is an illegal and risky way of using the software , as it may contain viruses , malware , or spyware that can harm your computer or compromise your data . Also , you may face legal consequences if you are caught using pirated software . Therefore , we do not recommend or endorse this method , and we advise you to buy a legitimate license from the official website instead . However , if you still want to proceed with this method , here are the steps you need to follow :
-
System requirements
-
Before installing Chief Architect Premier X12 , make sure your computer meets the minimum system requirements , which are :
-
-
Windows 10 / 8 / 7 64-bit operating system
-
Multi-core processor
-
4 GB of memory
-
5 GB of available hard disk space
-
Dedicated graphics card with OpenGL 3.3 or higher support
-
Internet access
-
-
Installation steps
-
-
Download the zip file from the link and extract it to a folder on your computer .
-
Run the setup.exe file as administrator and follow the instructions on the screen .
-
Select the destination folder where you want to install the software .
-
Select the components you want to install such as libraries , bonus catalogs , manufacturer catalogs , etc.
-
Wait for the installation process to complete .
-
Do not run the software yet .
-
-
Activation steps
-
-
In the folder where you extracted the zip file , open the Crack folder .
-
Copy the file named Chief_Architect_Premier_X11.exe .
-
Paste it in the installation folder where you installed the software , usually C:\Program Files\Chief Architect\Chief Architect Premier X11 .
-
Replace the original file when prompted .
-
Run the software as administrator .
-
Select I have a license key option .
-
In another window , run the file named keygen.exe from the Crack folder .
-
Select Generate option .
-
Copy the generated license key from the keygen window .
-
Paste it in the software activation window .
-
Click OK to confirm the activation .
-
Enjoy using Chief Architect Premier X12 with full features .
-
-
Pros and cons of Chief Architect Premier X12
-
Chief Architect Premier X12 is a powerful and versatile 3D architecture software that can help you create stunning designs and realistic renderings. However, it also has some drawbacks that you should be aware of. Here are some of the pros and cons of using Chief Architect Premier X12:
-
Pros
-
-
It has a user-friendly interface that is easy to navigate and customize.
-
It has a large library of objects, materials, textures, colors, etc. that you can use to enhance your designs.
-
It has smart tools that automate the creation and editing of various elements such as roofs, stairs, cabinets, etc.
-
It has a powerful CAD engine that allows you to draw and modify any shape or symbol.
-
It has a new rendering engine that supports ray tracing and ambient occlusion for realistic lighting effects.
-
It has a new option for exporting 3D views to 360° panoramas, VR headsets, or web pages.
-
It has a new option for collaborating with other users via cloud services or BIM360.
-
-
Cons
-
-
It is expensive to buy a license for the software, which costs $2,995 for a single user license or $4,995 for a network license.
-
It requires a high-end computer system to run smoothly and efficiently.
-
It may have some bugs or glitches that affect the performance or functionality of the software.
-
It may not be compatible with some other CAD programs or file formats.
-
It may be illegal and risky to use the patched keygen version of the software, as it may contain viruses, malware, or spyware that can harm your computer or compromise your data. Also, you may face legal consequences if you are caught using pirated software.
-
-
Conclusion
-
In conclusion, Chief Architect Premier X12 is a professional 3D architecture software that can help you create amazing designs and realistic renderings for residential and commercial projects. It has many features and benefits that make it a powerful and user-friendly tool. However, it also has some drawbacks that you should consider before buying or using it. If you want to use Chief Architect Premier X12 without paying for a license , you can download the patched keygen version from this link. However , be aware that this is an illegal and risky way of using the software , as it may contain viruses , malware , or spyware that can harm your computer or compromise your data . Also , you may face legal consequences if you are caught using pirated software . Therefore , we do not recommend or endorse this method , and we advise you to buy a legitimate license from the official website instead . We hope this article has given you some useful information and insights about Chief Architect Premier X12 22.5.2.56 Patched Keygen.
-
FAQs
-
Here are some frequently asked questions about Chief Architect Premier X12 22.5.2.56 Patched Keygen:
-
-
What is the difference between Chief Architect Premier X12 and Chief Architect Interiors X12?
-
Chief Architect Premier X12 is the full version of the software that can handle all aspects of building design , from conceptual design to construction documents . Chief Architect Interiors X12 is a specialized version of the software that focuses on interior design , kitchen and bath design , remodeling , etc. It has fewer features and tools than Chief Architect Premier X12 , but it is cheaper to buy . You can compare the two versions here.
-
Can I use Chief Architect Premier X12 on Mac?
-
Yes , you can use Chief Architect Premier X12 on Mac , as long as your Mac meets the minimum system requirements , which are :
-
-
Mac OS X 10.13 or higher operating system
-
Multicore processor
-
4 GB of memory
-
5 GB of available hard disk space
-
Dedicated graphics card with OpenGL 3.3 or higher support
-
Internet access
-
-
You can download the Mac version of Chief Architect Premier X12 from here.
-
Can I get a free trial of Chief Architect Premier X12?
-
Yes , you can get a free trial of Chief Architect Premier X12 for 30 days from here. You will need to fill out a form with your name , email address , phone number , etc. to get the download link . You will also need to create an account on the official website to activate the trial . The trial version has all the features and functions of the full version , but it will expire after 30 days . You will also not be able to save or print your work with the trial version . You will need to buy a license to continue using the software after the trial period ends .
-
How can I learn how to use Chief Architect Premier X12?
-
You can learn how to use Chief Architect Premier X12 by watching video tutorials , reading user manuals , attending webinars , joining online forums , etc. You can find these resources on the official website here. You can also contact customer support if you have any questions or issues with the software . You can find their contact information here.
-
Where can I find more reviews about Chief Architect Premier X12?
-
You can find more reviews about Chief Architect Premier X12 on online platforms such as Capterra, Software Advice, Trustpilot, etc. You can also read testimonials from satisfied customers on the official website here. You can also watch video reviews on YouTube channels such as Home Designer Software, The Rendered Home, etc.
-
- 0a6ba089eb
-
-
\ No newline at end of file
diff --git a/spaces/1gistliPinn/ChatGPT4/Examples/?y??6?? ?? ??x????ownna? REPACK.md b/spaces/1gistliPinn/ChatGPT4/Examples/?y??6?? ?? ??x????ownna? REPACK.md
deleted file mode 100644
index 3ed387cd42998bde6c1a7cb58b7148c9d45c2238..0000000000000000000000000000000000000000
--- a/spaces/1gistliPinn/ChatGPT4/Examples/?y??6?? ?? ??x????ownna? REPACK.md
+++ /dev/null
@@ -1,6 +0,0 @@
-
-
- aaccfb2cb3
-
-
-
diff --git a/spaces/1gistliPinn/ChatGPT4/Examples/Download Film Kisah Nabi Musa Full Movie Free.md b/spaces/1gistliPinn/ChatGPT4/Examples/Download Film Kisah Nabi Musa Full Movie Free.md
deleted file mode 100644
index 5f6ffa1eb06d55a785a5b1b7e84a7048ac2f65c3..0000000000000000000000000000000000000000
--- a/spaces/1gistliPinn/ChatGPT4/Examples/Download Film Kisah Nabi Musa Full Movie Free.md
+++ /dev/null
@@ -1,6 +0,0 @@
-
-
-Although Season 5, like Season 4, is not as dramatic 1st, 2nd and 3rd seasons (which were outstanding), it's still a great series. . Unlike many other series in the world, when we talk about horror films that can be scary and really creepy, but still they only show fear and death in some way, Supernatural is what makes the viewer fear- present because this series has a more realistic sense of horror than others.
-This gives the viewer a sense of reality that makes the series so scary and yet so good. 8a78ff9644
-
-
-
diff --git a/spaces/1toTree/lora_test/ppdiffusers/pipelines/stable_diffusion_safe/__init__.py b/spaces/1toTree/lora_test/ppdiffusers/pipelines/stable_diffusion_safe/__init__.py
deleted file mode 100644
index 944420c47c0e0047df5e8bfdf707c75381c985ac..0000000000000000000000000000000000000000
--- a/spaces/1toTree/lora_test/ppdiffusers/pipelines/stable_diffusion_safe/__init__.py
+++ /dev/null
@@ -1,85 +0,0 @@
-# Copyright (c) 2022 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# flake8: noqa
-
-from dataclasses import dataclass
-from enum import Enum
-from typing import List, Optional, Union
-
-import numpy as np
-import PIL
-from PIL import Image
-
-from ...utils import BaseOutput, is_paddle_available, is_paddlenlp_available
-
-
-@dataclass
-class SafetyConfig(object):
- WEAK = {
- "sld_warmup_steps": 15,
- "sld_guidance_scale": 20,
- "sld_threshold": 0.0,
- "sld_momentum_scale": 0.0,
- "sld_mom_beta": 0.0,
- }
- MEDIUM = {
- "sld_warmup_steps": 10,
- "sld_guidance_scale": 1000,
- "sld_threshold": 0.01,
- "sld_momentum_scale": 0.3,
- "sld_mom_beta": 0.4,
- }
- STRONG = {
- "sld_warmup_steps": 7,
- "sld_guidance_scale": 2000,
- "sld_threshold": 0.025,
- "sld_momentum_scale": 0.5,
- "sld_mom_beta": 0.7,
- }
- MAX = {
- "sld_warmup_steps": 0,
- "sld_guidance_scale": 5000,
- "sld_threshold": 1.0,
- "sld_momentum_scale": 0.5,
- "sld_mom_beta": 0.7,
- }
-
-
-@dataclass
-class StableDiffusionSafePipelineOutput(BaseOutput):
- """
- Output class for Safe Stable Diffusion pipelines.
- Args:
- images (`List[PIL.Image.Image]` or `np.ndarray`)
- List of denoised PIL images of length `batch_size` or numpy array of shape `(batch_size, height, width,
- num_channels)`. PIL images or numpy array present the denoised images of the diffusion pipeline.
- nsfw_content_detected (`List[bool]`)
- List of flags denoting whether the corresponding generated image likely represents "not-safe-for-work"
- (nsfw) content, or `None` if safety checking could not be performed.
- images (`List[PIL.Image.Image]` or `np.ndarray`)
- List of denoised PIL images that were flagged by the safety checker any may contain "not-safe-for-work"
- (nsfw) content, or `None` if no safety check was performed or no images were flagged.
- applied_safety_concept (`str`)
- The safety concept that was applied for safety guidance, or `None` if safety guidance was disabled
- """
-
- images: Union[List[PIL.Image.Image], np.ndarray]
- nsfw_content_detected: Optional[List[bool]]
- unsafe_images: Optional[Union[List[PIL.Image.Image], np.ndarray]]
- applied_safety_concept: Optional[str]
-
-
-if is_paddle_available() and is_paddlenlp_available():
- from .pipeline_stable_diffusion_safe import StableDiffusionPipelineSafe
- from .safety_checker import SafeStableDiffusionSafetyChecker
diff --git a/spaces/232labs/VToonify/vtoonify/model/vgg.py b/spaces/232labs/VToonify/vtoonify/model/vgg.py
deleted file mode 100644
index a1043d5bd8bdd0d1484d2270ae0d33c29495856c..0000000000000000000000000000000000000000
--- a/spaces/232labs/VToonify/vtoonify/model/vgg.py
+++ /dev/null
@@ -1,60 +0,0 @@
-import torch
-import torch.nn as nn
-import torchvision
-
-# VGG architecter, used for the perceptual loss using a pretrained VGG network
-class VGG19(torch.nn.Module):
- def __init__(self, requires_grad=False):
- super().__init__()
- vgg_pretrained_features = torchvision.models.vgg19(pretrained=True).features
- self.slice1 = torch.nn.Sequential()
- self.slice2 = torch.nn.Sequential()
- self.slice3 = torch.nn.Sequential()
- self.slice4 = torch.nn.Sequential()
- self.slice5 = torch.nn.Sequential()
- self.slice6 = torch.nn.Sequential()
- for x in range(2):
- self.slice1.add_module(str(x), vgg_pretrained_features[x])
- for x in range(2, 7):
- self.slice2.add_module(str(x), vgg_pretrained_features[x])
- for x in range(7, 12):
- self.slice3.add_module(str(x), vgg_pretrained_features[x])
- for x in range(12, 21):
- self.slice4.add_module(str(x), vgg_pretrained_features[x])
- for x in range(21, 32):
- self.slice5.add_module(str(x), vgg_pretrained_features[x])
- for x in range(32, 36):
- self.slice6.add_module(str(x), vgg_pretrained_features[x])
- if not requires_grad:
- for param in self.parameters():
- param.requires_grad = False
-
- self.pool = nn.AdaptiveAvgPool2d(output_size=1)
-
- self.mean = torch.tensor([0.485, 0.456, 0.406]).view(1,-1, 1, 1).cuda() * 2 - 1
- self.std = torch.tensor([0.229, 0.224, 0.225]).view(1,-1, 1, 1).cuda() * 2
-
- def forward(self, X): # relui_1
- X = (X-self.mean)/self.std
- h_relu1 = self.slice1(X)
- h_relu2 = self.slice2(h_relu1)
- h_relu3 = self.slice3(h_relu2)
- h_relu4 = self.slice4(h_relu3)
- h_relu5 = self.slice5[:-2](h_relu4)
- out = [h_relu1, h_relu2, h_relu3, h_relu4, h_relu5]
- return out
-
-# Perceptual loss that uses a pretrained VGG network
-class VGGLoss(nn.Module):
- def __init__(self):
- super(VGGLoss, self).__init__()
- self.vgg = VGG19().cuda()
- self.criterion = nn.L1Loss()
- self.weights = [1.0 / 32, 1.0 / 16, 1.0 / 8, 1.0 / 4, 1.0]
-
- def forward(self, x, y):
- x_vgg, y_vgg = self.vgg(x), self.vgg(y)
- loss = 0
- for i in range(len(x_vgg)):
- loss += self.weights[i] * self.criterion(x_vgg[i], y_vgg[i].detach())
- return loss
\ No newline at end of file
diff --git a/spaces/801artistry/RVC801/infer/lib/rmvpe.py b/spaces/801artistry/RVC801/infer/lib/rmvpe.py
deleted file mode 100644
index 2a387ebe73c7e1dd8bb7ccad1ea9e0ea89848ece..0000000000000000000000000000000000000000
--- a/spaces/801artistry/RVC801/infer/lib/rmvpe.py
+++ /dev/null
@@ -1,717 +0,0 @@
-import pdb, os
-
-import numpy as np
-import torch
-try:
- #Fix "Torch not compiled with CUDA enabled"
- import intel_extension_for_pytorch as ipex # pylint: disable=import-error, unused-import
- if torch.xpu.is_available():
- from infer.modules.ipex import ipex_init
- ipex_init()
-except Exception:
- pass
-import torch.nn as nn
-import torch.nn.functional as F
-from librosa.util import normalize, pad_center, tiny
-from scipy.signal import get_window
-
-import logging
-
-logger = logging.getLogger(__name__)
-
-
-###stft codes from https://github.com/pseeth/torch-stft/blob/master/torch_stft/util.py
-def window_sumsquare(
- window,
- n_frames,
- hop_length=200,
- win_length=800,
- n_fft=800,
- dtype=np.float32,
- norm=None,
-):
- """
- # from librosa 0.6
- Compute the sum-square envelope of a window function at a given hop length.
- This is used to estimate modulation effects induced by windowing
- observations in short-time fourier transforms.
- Parameters
- ----------
- window : string, tuple, number, callable, or list-like
- Window specification, as in `get_window`
- n_frames : int > 0
- The number of analysis frames
- hop_length : int > 0
- The number of samples to advance between frames
- win_length : [optional]
- The length of the window function. By default, this matches `n_fft`.
- n_fft : int > 0
- The length of each analysis frame.
- dtype : np.dtype
- The data type of the output
- Returns
- -------
- wss : np.ndarray, shape=`(n_fft + hop_length * (n_frames - 1))`
- The sum-squared envelope of the window function
- """
- if win_length is None:
- win_length = n_fft
-
- n = n_fft + hop_length * (n_frames - 1)
- x = np.zeros(n, dtype=dtype)
-
- # Compute the squared window at the desired length
- win_sq = get_window(window, win_length, fftbins=True)
- win_sq = normalize(win_sq, norm=norm) ** 2
- win_sq = pad_center(win_sq, n_fft)
-
- # Fill the envelope
- for i in range(n_frames):
- sample = i * hop_length
- x[sample : min(n, sample + n_fft)] += win_sq[: max(0, min(n_fft, n - sample))]
- return x
-
-
-class STFT(torch.nn.Module):
- def __init__(
- self, filter_length=1024, hop_length=512, win_length=None, window="hann"
- ):
- """
- This module implements an STFT using 1D convolution and 1D transpose convolutions.
- This is a bit tricky so there are some cases that probably won't work as working
- out the same sizes before and after in all overlap add setups is tough. Right now,
- this code should work with hop lengths that are half the filter length (50% overlap
- between frames).
-
- Keyword Arguments:
- filter_length {int} -- Length of filters used (default: {1024})
- hop_length {int} -- Hop length of STFT (restrict to 50% overlap between frames) (default: {512})
- win_length {[type]} -- Length of the window function applied to each frame (if not specified, it
- equals the filter length). (default: {None})
- window {str} -- Type of window to use (options are bartlett, hann, hamming, blackman, blackmanharris)
- (default: {'hann'})
- """
- super(STFT, self).__init__()
- self.filter_length = filter_length
- self.hop_length = hop_length
- self.win_length = win_length if win_length else filter_length
- self.window = window
- self.forward_transform = None
- self.pad_amount = int(self.filter_length / 2)
- scale = self.filter_length / self.hop_length
- fourier_basis = np.fft.fft(np.eye(self.filter_length))
-
- cutoff = int((self.filter_length / 2 + 1))
- fourier_basis = np.vstack(
- [np.real(fourier_basis[:cutoff, :]), np.imag(fourier_basis[:cutoff, :])]
- )
- forward_basis = torch.FloatTensor(fourier_basis[:, None, :])
- inverse_basis = torch.FloatTensor(
- np.linalg.pinv(scale * fourier_basis).T[:, None, :]
- )
-
- assert filter_length >= self.win_length
- # get window and zero center pad it to filter_length
- fft_window = get_window(window, self.win_length, fftbins=True)
- fft_window = pad_center(fft_window, size=filter_length)
- fft_window = torch.from_numpy(fft_window).float()
-
- # window the bases
- forward_basis *= fft_window
- inverse_basis *= fft_window
-
- self.register_buffer("forward_basis", forward_basis.float())
- self.register_buffer("inverse_basis", inverse_basis.float())
-
- def transform(self, input_data):
- """Take input data (audio) to STFT domain.
-
- Arguments:
- input_data {tensor} -- Tensor of floats, with shape (num_batch, num_samples)
-
- Returns:
- magnitude {tensor} -- Magnitude of STFT with shape (num_batch,
- num_frequencies, num_frames)
- phase {tensor} -- Phase of STFT with shape (num_batch,
- num_frequencies, num_frames)
- """
- num_batches = input_data.shape[0]
- num_samples = input_data.shape[-1]
-
- self.num_samples = num_samples
-
- # similar to librosa, reflect-pad the input
- input_data = input_data.view(num_batches, 1, num_samples)
- # print(1234,input_data.shape)
- input_data = F.pad(
- input_data.unsqueeze(1),
- (self.pad_amount, self.pad_amount, 0, 0, 0, 0),
- mode="reflect",
- ).squeeze(1)
- # print(2333,input_data.shape,self.forward_basis.shape,self.hop_length)
- # pdb.set_trace()
- forward_transform = F.conv1d(
- input_data, self.forward_basis, stride=self.hop_length, padding=0
- )
-
- cutoff = int((self.filter_length / 2) + 1)
- real_part = forward_transform[:, :cutoff, :]
- imag_part = forward_transform[:, cutoff:, :]
-
- magnitude = torch.sqrt(real_part**2 + imag_part**2)
- # phase = torch.atan2(imag_part.data, real_part.data)
-
- return magnitude # , phase
-
- def inverse(self, magnitude, phase):
- """Call the inverse STFT (iSTFT), given magnitude and phase tensors produced
- by the ```transform``` function.
-
- Arguments:
- magnitude {tensor} -- Magnitude of STFT with shape (num_batch,
- num_frequencies, num_frames)
- phase {tensor} -- Phase of STFT with shape (num_batch,
- num_frequencies, num_frames)
-
- Returns:
- inverse_transform {tensor} -- Reconstructed audio given magnitude and phase. Of
- shape (num_batch, num_samples)
- """
- recombine_magnitude_phase = torch.cat(
- [magnitude * torch.cos(phase), magnitude * torch.sin(phase)], dim=1
- )
-
- inverse_transform = F.conv_transpose1d(
- recombine_magnitude_phase,
- self.inverse_basis,
- stride=self.hop_length,
- padding=0,
- )
-
- if self.window is not None:
- window_sum = window_sumsquare(
- self.window,
- magnitude.size(-1),
- hop_length=self.hop_length,
- win_length=self.win_length,
- n_fft=self.filter_length,
- dtype=np.float32,
- )
- # remove modulation effects
- approx_nonzero_indices = torch.from_numpy(
- np.where(window_sum > tiny(window_sum))[0]
- )
- window_sum = torch.from_numpy(window_sum).to(inverse_transform.device)
- inverse_transform[:, :, approx_nonzero_indices] /= window_sum[
- approx_nonzero_indices
- ]
-
- # scale by hop ratio
- inverse_transform *= float(self.filter_length) / self.hop_length
-
- inverse_transform = inverse_transform[..., self.pad_amount :]
- inverse_transform = inverse_transform[..., : self.num_samples]
- inverse_transform = inverse_transform.squeeze(1)
-
- return inverse_transform
-
- def forward(self, input_data):
- """Take input data (audio) to STFT domain and then back to audio.
-
- Arguments:
- input_data {tensor} -- Tensor of floats, with shape (num_batch, num_samples)
-
- Returns:
- reconstruction {tensor} -- Reconstructed audio given magnitude and phase. Of
- shape (num_batch, num_samples)
- """
- self.magnitude, self.phase = self.transform(input_data)
- reconstruction = self.inverse(self.magnitude, self.phase)
- return reconstruction
-
-
-from time import time as ttime
-
-
-class BiGRU(nn.Module):
- def __init__(self, input_features, hidden_features, num_layers):
- super(BiGRU, self).__init__()
- self.gru = nn.GRU(
- input_features,
- hidden_features,
- num_layers=num_layers,
- batch_first=True,
- bidirectional=True,
- )
-
- def forward(self, x):
- return self.gru(x)[0]
-
-
-class ConvBlockRes(nn.Module):
- def __init__(self, in_channels, out_channels, momentum=0.01):
- super(ConvBlockRes, self).__init__()
- self.conv = nn.Sequential(
- nn.Conv2d(
- in_channels=in_channels,
- out_channels=out_channels,
- kernel_size=(3, 3),
- stride=(1, 1),
- padding=(1, 1),
- bias=False,
- ),
- nn.BatchNorm2d(out_channels, momentum=momentum),
- nn.ReLU(),
- nn.Conv2d(
- in_channels=out_channels,
- out_channels=out_channels,
- kernel_size=(3, 3),
- stride=(1, 1),
- padding=(1, 1),
- bias=False,
- ),
- nn.BatchNorm2d(out_channels, momentum=momentum),
- nn.ReLU(),
- )
- if in_channels != out_channels:
- self.shortcut = nn.Conv2d(in_channels, out_channels, (1, 1))
- self.is_shortcut = True
- else:
- self.is_shortcut = False
-
- def forward(self, x):
- if self.is_shortcut:
- return self.conv(x) + self.shortcut(x)
- else:
- return self.conv(x) + x
-
-
-class Encoder(nn.Module):
- def __init__(
- self,
- in_channels,
- in_size,
- n_encoders,
- kernel_size,
- n_blocks,
- out_channels=16,
- momentum=0.01,
- ):
- super(Encoder, self).__init__()
- self.n_encoders = n_encoders
- self.bn = nn.BatchNorm2d(in_channels, momentum=momentum)
- self.layers = nn.ModuleList()
- self.latent_channels = []
- for i in range(self.n_encoders):
- self.layers.append(
- ResEncoderBlock(
- in_channels, out_channels, kernel_size, n_blocks, momentum=momentum
- )
- )
- self.latent_channels.append([out_channels, in_size])
- in_channels = out_channels
- out_channels *= 2
- in_size //= 2
- self.out_size = in_size
- self.out_channel = out_channels
-
- def forward(self, x):
- concat_tensors = []
- x = self.bn(x)
- for i in range(self.n_encoders):
- _, x = self.layers[i](x)
- concat_tensors.append(_)
- return x, concat_tensors
-
-
-class ResEncoderBlock(nn.Module):
- def __init__(
- self, in_channels, out_channels, kernel_size, n_blocks=1, momentum=0.01
- ):
- super(ResEncoderBlock, self).__init__()
- self.n_blocks = n_blocks
- self.conv = nn.ModuleList()
- self.conv.append(ConvBlockRes(in_channels, out_channels, momentum))
- for i in range(n_blocks - 1):
- self.conv.append(ConvBlockRes(out_channels, out_channels, momentum))
- self.kernel_size = kernel_size
- if self.kernel_size is not None:
- self.pool = nn.AvgPool2d(kernel_size=kernel_size)
-
- def forward(self, x):
- for i in range(self.n_blocks):
- x = self.conv[i](x)
- if self.kernel_size is not None:
- return x, self.pool(x)
- else:
- return x
-
-
-class Intermediate(nn.Module): #
- def __init__(self, in_channels, out_channels, n_inters, n_blocks, momentum=0.01):
- super(Intermediate, self).__init__()
- self.n_inters = n_inters
- self.layers = nn.ModuleList()
- self.layers.append(
- ResEncoderBlock(in_channels, out_channels, None, n_blocks, momentum)
- )
- for i in range(self.n_inters - 1):
- self.layers.append(
- ResEncoderBlock(out_channels, out_channels, None, n_blocks, momentum)
- )
-
- def forward(self, x):
- for i in range(self.n_inters):
- x = self.layers[i](x)
- return x
-
-
-class ResDecoderBlock(nn.Module):
- def __init__(self, in_channels, out_channels, stride, n_blocks=1, momentum=0.01):
- super(ResDecoderBlock, self).__init__()
- out_padding = (0, 1) if stride == (1, 2) else (1, 1)
- self.n_blocks = n_blocks
- self.conv1 = nn.Sequential(
- nn.ConvTranspose2d(
- in_channels=in_channels,
- out_channels=out_channels,
- kernel_size=(3, 3),
- stride=stride,
- padding=(1, 1),
- output_padding=out_padding,
- bias=False,
- ),
- nn.BatchNorm2d(out_channels, momentum=momentum),
- nn.ReLU(),
- )
- self.conv2 = nn.ModuleList()
- self.conv2.append(ConvBlockRes(out_channels * 2, out_channels, momentum))
- for i in range(n_blocks - 1):
- self.conv2.append(ConvBlockRes(out_channels, out_channels, momentum))
-
- def forward(self, x, concat_tensor):
- x = self.conv1(x)
- x = torch.cat((x, concat_tensor), dim=1)
- for i in range(self.n_blocks):
- x = self.conv2[i](x)
- return x
-
-
-class Decoder(nn.Module):
- def __init__(self, in_channels, n_decoders, stride, n_blocks, momentum=0.01):
- super(Decoder, self).__init__()
- self.layers = nn.ModuleList()
- self.n_decoders = n_decoders
- for i in range(self.n_decoders):
- out_channels = in_channels // 2
- self.layers.append(
- ResDecoderBlock(in_channels, out_channels, stride, n_blocks, momentum)
- )
- in_channels = out_channels
-
- def forward(self, x, concat_tensors):
- for i in range(self.n_decoders):
- x = self.layers[i](x, concat_tensors[-1 - i])
- return x
-
-
-class DeepUnet(nn.Module):
- def __init__(
- self,
- kernel_size,
- n_blocks,
- en_de_layers=5,
- inter_layers=4,
- in_channels=1,
- en_out_channels=16,
- ):
- super(DeepUnet, self).__init__()
- self.encoder = Encoder(
- in_channels, 128, en_de_layers, kernel_size, n_blocks, en_out_channels
- )
- self.intermediate = Intermediate(
- self.encoder.out_channel // 2,
- self.encoder.out_channel,
- inter_layers,
- n_blocks,
- )
- self.decoder = Decoder(
- self.encoder.out_channel, en_de_layers, kernel_size, n_blocks
- )
-
- def forward(self, x):
- x, concat_tensors = self.encoder(x)
- x = self.intermediate(x)
- x = self.decoder(x, concat_tensors)
- return x
-
-
-class E2E(nn.Module):
- def __init__(
- self,
- n_blocks,
- n_gru,
- kernel_size,
- en_de_layers=5,
- inter_layers=4,
- in_channels=1,
- en_out_channels=16,
- ):
- super(E2E, self).__init__()
- self.unet = DeepUnet(
- kernel_size,
- n_blocks,
- en_de_layers,
- inter_layers,
- in_channels,
- en_out_channels,
- )
- self.cnn = nn.Conv2d(en_out_channels, 3, (3, 3), padding=(1, 1))
- if n_gru:
- self.fc = nn.Sequential(
- BiGRU(3 * 128, 256, n_gru),
- nn.Linear(512, 360),
- nn.Dropout(0.25),
- nn.Sigmoid(),
- )
- else:
- self.fc = nn.Sequential(
- nn.Linear(3 * nn.N_MELS, nn.N_CLASS), nn.Dropout(0.25), nn.Sigmoid()
- )
-
- def forward(self, mel):
- # print(mel.shape)
- mel = mel.transpose(-1, -2).unsqueeze(1)
- x = self.cnn(self.unet(mel)).transpose(1, 2).flatten(-2)
- x = self.fc(x)
- # print(x.shape)
- return x
-
-
-from librosa.filters import mel
-
-
-class MelSpectrogram(torch.nn.Module):
- def __init__(
- self,
- is_half,
- n_mel_channels,
- sampling_rate,
- win_length,
- hop_length,
- n_fft=None,
- mel_fmin=0,
- mel_fmax=None,
- clamp=1e-5,
- ):
- super().__init__()
- n_fft = win_length if n_fft is None else n_fft
- self.hann_window = {}
- mel_basis = mel(
- sr=sampling_rate,
- n_fft=n_fft,
- n_mels=n_mel_channels,
- fmin=mel_fmin,
- fmax=mel_fmax,
- htk=True,
- )
- mel_basis = torch.from_numpy(mel_basis).float()
- self.register_buffer("mel_basis", mel_basis)
- self.n_fft = win_length if n_fft is None else n_fft
- self.hop_length = hop_length
- self.win_length = win_length
- self.sampling_rate = sampling_rate
- self.n_mel_channels = n_mel_channels
- self.clamp = clamp
- self.is_half = is_half
-
- def forward(self, audio, keyshift=0, speed=1, center=True):
- factor = 2 ** (keyshift / 12)
- n_fft_new = int(np.round(self.n_fft * factor))
- win_length_new = int(np.round(self.win_length * factor))
- hop_length_new = int(np.round(self.hop_length * speed))
- keyshift_key = str(keyshift) + "_" + str(audio.device)
- if keyshift_key not in self.hann_window:
- self.hann_window[keyshift_key] = torch.hann_window(win_length_new).to(
- # "cpu"if(audio.device.type=="privateuseone") else audio.device
- audio.device
- )
- # fft = torch.stft(#doesn't support pytorch_dml
- # # audio.cpu() if(audio.device.type=="privateuseone")else audio,
- # audio,
- # n_fft=n_fft_new,
- # hop_length=hop_length_new,
- # win_length=win_length_new,
- # window=self.hann_window[keyshift_key],
- # center=center,
- # return_complex=True,
- # )
- # magnitude = torch.sqrt(fft.real.pow(2) + fft.imag.pow(2))
- # print(1111111111)
- # print(222222222222222,audio.device,self.is_half)
- if hasattr(self, "stft") == False:
- # print(n_fft_new,hop_length_new,win_length_new,audio.shape)
- self.stft = STFT(
- filter_length=n_fft_new,
- hop_length=hop_length_new,
- win_length=win_length_new,
- window="hann",
- ).to(audio.device)
- magnitude = self.stft.transform(audio) # phase
- # if (audio.device.type == "privateuseone"):
- # magnitude=magnitude.to(audio.device)
- if keyshift != 0:
- size = self.n_fft // 2 + 1
- resize = magnitude.size(1)
- if resize < size:
- magnitude = F.pad(magnitude, (0, 0, 0, size - resize))
- magnitude = magnitude[:, :size, :] * self.win_length / win_length_new
- mel_output = torch.matmul(self.mel_basis, magnitude)
- if self.is_half == True:
- mel_output = mel_output.half()
- log_mel_spec = torch.log(torch.clamp(mel_output, min=self.clamp))
- # print(log_mel_spec.device.type)
- return log_mel_spec
-
-
-class RMVPE:
- def __init__(self, model_path, is_half, device=None):
- self.resample_kernel = {}
- self.resample_kernel = {}
- self.is_half = is_half
- if device is None:
- device = "cuda" if torch.cuda.is_available() else "cpu"
- self.device = device
- self.mel_extractor = MelSpectrogram(
- is_half, 128, 16000, 1024, 160, None, 30, 8000
- ).to(device)
- if "privateuseone" in str(device):
- import onnxruntime as ort
-
- ort_session = ort.InferenceSession(
- "%s/rmvpe.onnx" % os.environ["rmvpe_root"],
- providers=["DmlExecutionProvider"],
- )
- self.model = ort_session
- else:
- model = E2E(4, 1, (2, 2))
- ckpt = torch.load(model_path, map_location="cpu")
- model.load_state_dict(ckpt)
- model.eval()
- if is_half == True:
- model = model.half()
- self.model = model
- self.model = self.model.to(device)
- cents_mapping = 20 * np.arange(360) + 1997.3794084376191
- self.cents_mapping = np.pad(cents_mapping, (4, 4)) # 368
-
- def mel2hidden(self, mel):
- with torch.no_grad():
- n_frames = mel.shape[-1]
- mel = F.pad(
- mel, (0, 32 * ((n_frames - 1) // 32 + 1) - n_frames), mode="constant"
- )
- if "privateuseone" in str(self.device):
- onnx_input_name = self.model.get_inputs()[0].name
- onnx_outputs_names = self.model.get_outputs()[0].name
- hidden = self.model.run(
- [onnx_outputs_names],
- input_feed={onnx_input_name: mel.cpu().numpy()},
- )[0]
- else:
- hidden = self.model(mel)
- return hidden[:, :n_frames]
-
- def decode(self, hidden, thred=0.03):
- cents_pred = self.to_local_average_cents(hidden, thred=thred)
- f0 = 10 * (2 ** (cents_pred / 1200))
- f0[f0 == 10] = 0
- # f0 = np.array([10 * (2 ** (cent_pred / 1200)) if cent_pred else 0 for cent_pred in cents_pred])
- return f0
-
- def infer_from_audio(self, audio, thred=0.03):
- # torch.cuda.synchronize()
- t0 = ttime()
- mel = self.mel_extractor(
- torch.from_numpy(audio).float().to(self.device).unsqueeze(0), center=True
- )
- # print(123123123,mel.device.type)
- # torch.cuda.synchronize()
- t1 = ttime()
- hidden = self.mel2hidden(mel)
- # torch.cuda.synchronize()
- t2 = ttime()
- # print(234234,hidden.device.type)
- if "privateuseone" not in str(self.device):
- hidden = hidden.squeeze(0).cpu().numpy()
- else:
- hidden = hidden[0]
- if self.is_half == True:
- hidden = hidden.astype("float32")
-
- f0 = self.decode(hidden, thred=thred)
- # torch.cuda.synchronize()
- t3 = ttime()
- # print("hmvpe:%s\t%s\t%s\t%s"%(t1-t0,t2-t1,t3-t2,t3-t0))
- return f0
-
- def infer_from_audio_with_pitch(self, audio, thred=0.03, f0_min=50, f0_max=1100):
- audio = torch.from_numpy(audio).float().to(self.device).unsqueeze(0)
- mel = self.mel_extractor(audio, center=True)
- hidden = self.mel2hidden(mel)
- hidden = hidden.squeeze(0).cpu().numpy()
- if self.is_half == True:
- hidden = hidden.astype("float32")
- f0 = self.decode(hidden, thred=thred)
- f0[(f0 < f0_min) | (f0 > f0_max)] = 0
- return f0
-
- def to_local_average_cents(self, salience, thred=0.05):
- # t0 = ttime()
- center = np.argmax(salience, axis=1) # 帧长#index
- salience = np.pad(salience, ((0, 0), (4, 4))) # 帧长,368
- # t1 = ttime()
- center += 4
- todo_salience = []
- todo_cents_mapping = []
- starts = center - 4
- ends = center + 5
- for idx in range(salience.shape[0]):
- todo_salience.append(salience[:, starts[idx] : ends[idx]][idx])
- todo_cents_mapping.append(self.cents_mapping[starts[idx] : ends[idx]])
- # t2 = ttime()
- todo_salience = np.array(todo_salience) # 帧长,9
- todo_cents_mapping = np.array(todo_cents_mapping) # 帧长,9
- product_sum = np.sum(todo_salience * todo_cents_mapping, 1)
- weight_sum = np.sum(todo_salience, 1) # 帧长
- devided = product_sum / weight_sum # 帧长
- # t3 = ttime()
- maxx = np.max(salience, axis=1) # 帧长
- devided[maxx <= thred] = 0
- # t4 = ttime()
- # print("decode:%s\t%s\t%s\t%s" % (t1 - t0, t2 - t1, t3 - t2, t4 - t3))
- return devided
-
-
-if __name__ == "__main__":
- import librosa
- import soundfile as sf
-
- audio, sampling_rate = sf.read(r"C:\Users\liujing04\Desktop\Z\冬之花clip1.wav")
- if len(audio.shape) > 1:
- audio = librosa.to_mono(audio.transpose(1, 0))
- audio_bak = audio.copy()
- if sampling_rate != 16000:
- audio = librosa.resample(audio, orig_sr=sampling_rate, target_sr=16000)
- model_path = r"D:\BaiduNetdiskDownload\RVC-beta-v2-0727AMD_realtime\rmvpe.pt"
- thred = 0.03 # 0.01
- device = "cuda" if torch.cuda.is_available() else "cpu"
- rmvpe = RMVPE(model_path, is_half=False, device=device)
- t0 = ttime()
- f0 = rmvpe.infer_from_audio(audio, thred=thred)
- # f0 = rmvpe.infer_from_audio(audio, thred=thred)
- # f0 = rmvpe.infer_from_audio(audio, thred=thred)
- # f0 = rmvpe.infer_from_audio(audio, thred=thred)
- # f0 = rmvpe.infer_from_audio(audio, thred=thred)
- t1 = ttime()
- logger.info("%s %.2f", f0.shape, t1 - t0)
diff --git a/spaces/A666sxr/Genshin_TTS/data_utils.py b/spaces/A666sxr/Genshin_TTS/data_utils.py
deleted file mode 100644
index 4855699d23d5dee36d4a12e875c7465265caac0f..0000000000000000000000000000000000000000
--- a/spaces/A666sxr/Genshin_TTS/data_utils.py
+++ /dev/null
@@ -1,392 +0,0 @@
-import time
-import os
-import random
-import numpy as np
-import torch
-import torch.utils.data
-
-import commons
-from mel_processing import spectrogram_torch
-from utils import load_wav_to_torch, load_filepaths_and_text
-from text import text_to_sequence, cleaned_text_to_sequence
-
-
-class TextAudioLoader(torch.utils.data.Dataset):
- """
- 1) loads audio, text pairs
- 2) normalizes text and converts them to sequences of integers
- 3) computes spectrograms from audio files.
- """
- def __init__(self, audiopaths_and_text, hparams):
- self.audiopaths_and_text = load_filepaths_and_text(audiopaths_and_text)
- self.text_cleaners = hparams.text_cleaners
- self.max_wav_value = hparams.max_wav_value
- self.sampling_rate = hparams.sampling_rate
- self.filter_length = hparams.filter_length
- self.hop_length = hparams.hop_length
- self.win_length = hparams.win_length
- self.sampling_rate = hparams.sampling_rate
-
- self.cleaned_text = getattr(hparams, "cleaned_text", False)
-
- self.add_blank = hparams.add_blank
- self.min_text_len = getattr(hparams, "min_text_len", 1)
- self.max_text_len = getattr(hparams, "max_text_len", 190)
-
- random.seed(1234)
- random.shuffle(self.audiopaths_and_text)
- self._filter()
-
-
- def _filter(self):
- """
- Filter text & store spec lengths
- """
- # Store spectrogram lengths for Bucketing
- # wav_length ~= file_size / (wav_channels * Bytes per dim) = file_size / (1 * 2)
- # spec_length = wav_length // hop_length
-
- audiopaths_and_text_new = []
- lengths = []
- for audiopath, text in self.audiopaths_and_text:
- if self.min_text_len <= len(text) and len(text) <= self.max_text_len:
- audiopaths_and_text_new.append([audiopath, text])
- lengths.append(os.path.getsize(audiopath) // (2 * self.hop_length))
- self.audiopaths_and_text = audiopaths_and_text_new
- self.lengths = lengths
-
- def get_audio_text_pair(self, audiopath_and_text):
- # separate filename and text
- audiopath, text = audiopath_and_text[0], audiopath_and_text[1]
- text = self.get_text(text)
- spec, wav = self.get_audio(audiopath)
- return (text, spec, wav)
-
- def get_audio(self, filename):
- audio, sampling_rate = load_wav_to_torch(filename)
- if sampling_rate != self.sampling_rate:
- raise ValueError("{} {} SR doesn't match target {} SR".format(
- sampling_rate, self.sampling_rate))
- audio_norm = audio / self.max_wav_value
- audio_norm = audio_norm.unsqueeze(0)
- spec_filename = filename.replace(".wav", ".spec.pt")
- if os.path.exists(spec_filename):
- spec = torch.load(spec_filename)
- else:
- spec = spectrogram_torch(audio_norm, self.filter_length,
- self.sampling_rate, self.hop_length, self.win_length,
- center=False)
- spec = torch.squeeze(spec, 0)
- torch.save(spec, spec_filename)
- return spec, audio_norm
-
- def get_text(self, text):
- if self.cleaned_text:
- text_norm = cleaned_text_to_sequence(text)
- else:
- text_norm = text_to_sequence(text, self.text_cleaners)
- if self.add_blank:
- text_norm = commons.intersperse(text_norm, 0)
- text_norm = torch.LongTensor(text_norm)
- return text_norm
-
- def __getitem__(self, index):
- return self.get_audio_text_pair(self.audiopaths_and_text[index])
-
- def __len__(self):
- return len(self.audiopaths_and_text)
-
-
-class TextAudioCollate():
- """ Zero-pads model inputs and targets
- """
- def __init__(self, return_ids=False):
- self.return_ids = return_ids
-
- def __call__(self, batch):
- """Collate's training batch from normalized text and aduio
- PARAMS
- ------
- batch: [text_normalized, spec_normalized, wav_normalized]
- """
- # Right zero-pad all one-hot text sequences to max input length
- _, ids_sorted_decreasing = torch.sort(
- torch.LongTensor([x[1].size(1) for x in batch]),
- dim=0, descending=True)
-
- max_text_len = max([len(x[0]) for x in batch])
- max_spec_len = max([x[1].size(1) for x in batch])
- max_wav_len = max([x[2].size(1) for x in batch])
-
- text_lengths = torch.LongTensor(len(batch))
- spec_lengths = torch.LongTensor(len(batch))
- wav_lengths = torch.LongTensor(len(batch))
-
- text_padded = torch.LongTensor(len(batch), max_text_len)
- spec_padded = torch.FloatTensor(len(batch), batch[0][1].size(0), max_spec_len)
- wav_padded = torch.FloatTensor(len(batch), 1, max_wav_len)
- text_padded.zero_()
- spec_padded.zero_()
- wav_padded.zero_()
- for i in range(len(ids_sorted_decreasing)):
- row = batch[ids_sorted_decreasing[i]]
-
- text = row[0]
- text_padded[i, :text.size(0)] = text
- text_lengths[i] = text.size(0)
-
- spec = row[1]
- spec_padded[i, :, :spec.size(1)] = spec
- spec_lengths[i] = spec.size(1)
-
- wav = row[2]
- wav_padded[i, :, :wav.size(1)] = wav
- wav_lengths[i] = wav.size(1)
-
- if self.return_ids:
- return text_padded, text_lengths, spec_padded, spec_lengths, wav_padded, wav_lengths, ids_sorted_decreasing
- return text_padded, text_lengths, spec_padded, spec_lengths, wav_padded, wav_lengths
-
-
-"""Multi speaker version"""
-class TextAudioSpeakerLoader(torch.utils.data.Dataset):
- """
- 1) loads audio, speaker_id, text pairs
- 2) normalizes text and converts them to sequences of integers
- 3) computes spectrograms from audio files.
- """
- def __init__(self, audiopaths_sid_text, hparams):
- self.audiopaths_sid_text = load_filepaths_and_text(audiopaths_sid_text)
- self.text_cleaners = hparams.text_cleaners
- self.max_wav_value = hparams.max_wav_value
- self.sampling_rate = hparams.sampling_rate
- self.filter_length = hparams.filter_length
- self.hop_length = hparams.hop_length
- self.win_length = hparams.win_length
- self.sampling_rate = hparams.sampling_rate
-
- self.cleaned_text = getattr(hparams, "cleaned_text", False)
-
- self.add_blank = hparams.add_blank
- self.min_text_len = getattr(hparams, "min_text_len", 1)
- self.max_text_len = getattr(hparams, "max_text_len", 190)
-
- random.seed(1234)
- random.shuffle(self.audiopaths_sid_text)
- self._filter()
-
- def _filter(self):
- """
- Filter text & store spec lengths
- """
- # Store spectrogram lengths for Bucketing
- # wav_length ~= file_size / (wav_channels * Bytes per dim) = file_size / (1 * 2)
- # spec_length = wav_length // hop_length
-
- audiopaths_sid_text_new = []
- lengths = []
- for audiopath, sid, text in self.audiopaths_sid_text:
- if self.min_text_len <= len(text) and len(text) <= self.max_text_len:
- audiopaths_sid_text_new.append([audiopath, sid, text])
- lengths.append(os.path.getsize(audiopath) // (2 * self.hop_length))
- self.audiopaths_sid_text = audiopaths_sid_text_new
- self.lengths = lengths
-
- def get_audio_text_speaker_pair(self, audiopath_sid_text):
- # separate filename, speaker_id and text
- audiopath, sid, text = audiopath_sid_text[0], audiopath_sid_text[1], audiopath_sid_text[2]
- text = self.get_text(text)
- spec, wav = self.get_audio(audiopath)
- sid = self.get_sid(sid)
- return (text, spec, wav, sid)
-
- def get_audio(self, filename):
- audio, sampling_rate = load_wav_to_torch(filename)
- if sampling_rate != self.sampling_rate:
- raise ValueError("{} {} SR doesn't match target {} SR".format(
- sampling_rate, self.sampling_rate))
- audio_norm = audio / self.max_wav_value
- audio_norm = audio_norm.unsqueeze(0)
- spec_filename = filename.replace(".wav", ".spec.pt")
- if os.path.exists(spec_filename):
- spec = torch.load(spec_filename)
- else:
- spec = spectrogram_torch(audio_norm, self.filter_length,
- self.sampling_rate, self.hop_length, self.win_length,
- center=False)
- spec = torch.squeeze(spec, 0)
- torch.save(spec, spec_filename)
- return spec, audio_norm
-
- def get_text(self, text):
- if self.cleaned_text:
- text_norm = cleaned_text_to_sequence(text)
- else:
- text_norm = text_to_sequence(text, self.text_cleaners)
- if self.add_blank:
- text_norm = commons.intersperse(text_norm, 0)
- text_norm = torch.LongTensor(text_norm)
- return text_norm
-
- def get_sid(self, sid):
- sid = torch.LongTensor([int(sid)])
- return sid
-
- def __getitem__(self, index):
- return self.get_audio_text_speaker_pair(self.audiopaths_sid_text[index])
-
- def __len__(self):
- return len(self.audiopaths_sid_text)
-
-
-class TextAudioSpeakerCollate():
- """ Zero-pads model inputs and targets
- """
- def __init__(self, return_ids=False):
- self.return_ids = return_ids
-
- def __call__(self, batch):
- """Collate's training batch from normalized text, audio and speaker identities
- PARAMS
- ------
- batch: [text_normalized, spec_normalized, wav_normalized, sid]
- """
- # Right zero-pad all one-hot text sequences to max input length
- _, ids_sorted_decreasing = torch.sort(
- torch.LongTensor([x[1].size(1) for x in batch]),
- dim=0, descending=True)
-
- max_text_len = max([len(x[0]) for x in batch])
- max_spec_len = max([x[1].size(1) for x in batch])
- max_wav_len = max([x[2].size(1) for x in batch])
-
- text_lengths = torch.LongTensor(len(batch))
- spec_lengths = torch.LongTensor(len(batch))
- wav_lengths = torch.LongTensor(len(batch))
- sid = torch.LongTensor(len(batch))
-
- text_padded = torch.LongTensor(len(batch), max_text_len)
- spec_padded = torch.FloatTensor(len(batch), batch[0][1].size(0), max_spec_len)
- wav_padded = torch.FloatTensor(len(batch), 1, max_wav_len)
- text_padded.zero_()
- spec_padded.zero_()
- wav_padded.zero_()
- for i in range(len(ids_sorted_decreasing)):
- row = batch[ids_sorted_decreasing[i]]
-
- text = row[0]
- text_padded[i, :text.size(0)] = text
- text_lengths[i] = text.size(0)
-
- spec = row[1]
- spec_padded[i, :, :spec.size(1)] = spec
- spec_lengths[i] = spec.size(1)
-
- wav = row[2]
- wav_padded[i, :, :wav.size(1)] = wav
- wav_lengths[i] = wav.size(1)
-
- sid[i] = row[3]
-
- if self.return_ids:
- return text_padded, text_lengths, spec_padded, spec_lengths, wav_padded, wav_lengths, sid, ids_sorted_decreasing
- return text_padded, text_lengths, spec_padded, spec_lengths, wav_padded, wav_lengths, sid
-
-
-class DistributedBucketSampler(torch.utils.data.distributed.DistributedSampler):
- """
- Maintain similar input lengths in a batch.
- Length groups are specified by boundaries.
- Ex) boundaries = [b1, b2, b3] -> any batch is included either {x | b1 < length(x) <=b2} or {x | b2 < length(x) <= b3}.
-
- It removes samples which are not included in the boundaries.
- Ex) boundaries = [b1, b2, b3] -> any x s.t. length(x) <= b1 or length(x) > b3 are discarded.
- """
- def __init__(self, dataset, batch_size, boundaries, num_replicas=None, rank=None, shuffle=True):
- super().__init__(dataset, num_replicas=num_replicas, rank=rank, shuffle=shuffle)
- self.lengths = dataset.lengths
- self.batch_size = batch_size
- self.boundaries = boundaries
-
- self.buckets, self.num_samples_per_bucket = self._create_buckets()
- self.total_size = sum(self.num_samples_per_bucket)
- self.num_samples = self.total_size // self.num_replicas
-
- def _create_buckets(self):
- buckets = [[] for _ in range(len(self.boundaries) - 1)]
- for i in range(len(self.lengths)):
- length = self.lengths[i]
- idx_bucket = self._bisect(length)
- if idx_bucket != -1:
- buckets[idx_bucket].append(i)
-
- for i in range(len(buckets) - 1, 0, -1):
- if len(buckets[i]) == 0:
- buckets.pop(i)
- self.boundaries.pop(i+1)
-
- num_samples_per_bucket = []
- for i in range(len(buckets)):
- len_bucket = len(buckets[i])
- total_batch_size = self.num_replicas * self.batch_size
- rem = (total_batch_size - (len_bucket % total_batch_size)) % total_batch_size
- num_samples_per_bucket.append(len_bucket + rem)
- return buckets, num_samples_per_bucket
-
- def __iter__(self):
- # deterministically shuffle based on epoch
- g = torch.Generator()
- g.manual_seed(self.epoch)
-
- indices = []
- if self.shuffle:
- for bucket in self.buckets:
- indices.append(torch.randperm(len(bucket), generator=g).tolist())
- else:
- for bucket in self.buckets:
- indices.append(list(range(len(bucket))))
-
- batches = []
- for i in range(len(self.buckets)):
- bucket = self.buckets[i]
- len_bucket = len(bucket)
- ids_bucket = indices[i]
- num_samples_bucket = self.num_samples_per_bucket[i]
-
- # add extra samples to make it evenly divisible
- rem = num_samples_bucket - len_bucket
- ids_bucket = ids_bucket + ids_bucket * (rem // len_bucket) + ids_bucket[:(rem % len_bucket)]
-
- # subsample
- ids_bucket = ids_bucket[self.rank::self.num_replicas]
-
- # batching
- for j in range(len(ids_bucket) // self.batch_size):
- batch = [bucket[idx] for idx in ids_bucket[j*self.batch_size:(j+1)*self.batch_size]]
- batches.append(batch)
-
- if self.shuffle:
- batch_ids = torch.randperm(len(batches), generator=g).tolist()
- batches = [batches[i] for i in batch_ids]
- self.batches = batches
-
- assert len(self.batches) * self.batch_size == self.num_samples
- return iter(self.batches)
-
- def _bisect(self, x, lo=0, hi=None):
- if hi is None:
- hi = len(self.boundaries) - 1
-
- if hi > lo:
- mid = (hi + lo) // 2
- if self.boundaries[mid] < x and x <= self.boundaries[mid+1]:
- return mid
- elif x <= self.boundaries[mid]:
- return self._bisect(x, lo, mid)
- else:
- return self._bisect(x, mid + 1, hi)
- else:
- return -1
-
- def __len__(self):
- return self.num_samples // self.batch_size
diff --git a/spaces/AB-TW/team-ai/documents/bussiness_context/NOTION_DB/Engineering Wiki 2402f5396a3244fdb3f1d135bdb0f3d6/Engineering Wiki 8da06b3dcf1b4eaaa3e90aa70feefe56.md b/spaces/AB-TW/team-ai/documents/bussiness_context/NOTION_DB/Engineering Wiki 2402f5396a3244fdb3f1d135bdb0f3d6/Engineering Wiki 8da06b3dcf1b4eaaa3e90aa70feefe56.md
deleted file mode 100644
index 9e1b3c5dc090f76ff01886dffba49490a338fbed..0000000000000000000000000000000000000000
--- a/spaces/AB-TW/team-ai/documents/bussiness_context/NOTION_DB/Engineering Wiki 2402f5396a3244fdb3f1d135bdb0f3d6/Engineering Wiki 8da06b3dcf1b4eaaa3e90aa70feefe56.md
+++ /dev/null
@@ -1 +0,0 @@
-# Engineering Wiki
\ No newline at end of file
diff --git a/spaces/AIGC-Audio/AudioGPT/sound_extraction/utils/stft.py b/spaces/AIGC-Audio/AudioGPT/sound_extraction/utils/stft.py
deleted file mode 100644
index 04a1da93e3bd5777e8759f1b4bc5c0eaca149317..0000000000000000000000000000000000000000
--- a/spaces/AIGC-Audio/AudioGPT/sound_extraction/utils/stft.py
+++ /dev/null
@@ -1,159 +0,0 @@
-import torch
-import numpy as np
-import torch.nn.functional as F
-from torch.autograd import Variable
-from scipy.signal import get_window
-import librosa.util as librosa_util
-from librosa.util import pad_center, tiny
-# from audio_processing import window_sumsquare
-
-def window_sumsquare(window, n_frames, hop_length=512, win_length=1024,
- n_fft=1024, dtype=np.float32, norm=None):
- """
- # from librosa 0.6
- Compute the sum-square envelope of a window function at a given hop length.
- This is used to estimate modulation effects induced by windowing
- observations in short-time fourier transforms.
- Parameters
- ----------
- window : string, tuple, number, callable, or list-like
- Window specification, as in `get_window`
- n_frames : int > 0
- The number of analysis frames
- hop_length : int > 0
- The number of samples to advance between frames
- win_length : [optional]
- The length of the window function. By default, this matches `n_fft`.
- n_fft : int > 0
- The length of each analysis frame.
- dtype : np.dtype
- The data type of the output
- Returns
- -------
- wss : np.ndarray, shape=`(n_fft + hop_length * (n_frames - 1))`
- The sum-squared envelope of the window function
- """
- if win_length is None:
- win_length = n_fft
-
- n = n_fft + hop_length * (n_frames - 1)
- x = np.zeros(n, dtype=dtype)
-
- # Compute the squared window at the desired length
- win_sq = get_window(window, win_length, fftbins=True)
- win_sq = librosa_util.normalize(win_sq, norm=norm)**2
- win_sq = librosa_util.pad_center(win_sq, n_fft)
-
- # Fill the envelope
- for i in range(n_frames):
- sample = i * hop_length
- x[sample:min(n, sample + n_fft)] += win_sq[:max(0, min(n_fft, n - sample))]
- return x
-
-class STFT(torch.nn.Module):
- """adapted from Prem Seetharaman's https://github.com/pseeth/pytorch-stft"""
- def __init__(self, filter_length=1024, hop_length=512, win_length=1024,
- window='hann'):
- super(STFT, self).__init__()
- self.filter_length = filter_length
- self.hop_length = hop_length
- self.win_length = win_length
- self.window = window
- self.forward_transform = None
- scale = self.filter_length / self.hop_length
- fourier_basis = np.fft.fft(np.eye(self.filter_length))
-
- cutoff = int((self.filter_length / 2 + 1))
- fourier_basis = np.vstack([np.real(fourier_basis[:cutoff, :]),
- np.imag(fourier_basis[:cutoff, :])])
-
- forward_basis = torch.FloatTensor(fourier_basis[:, None, :])
- inverse_basis = torch.FloatTensor(
- np.linalg.pinv(scale * fourier_basis).T[:, None, :])
-
- if window is not None:
- assert(filter_length >= win_length)
- # get window and zero center pad it to filter_length
- fft_window = get_window(window, win_length, fftbins=True)
- fft_window = pad_center(fft_window, filter_length)
- fft_window = torch.from_numpy(fft_window).float()
-
- # window the bases
- forward_basis *= fft_window
- inverse_basis *= fft_window
-
- self.register_buffer('forward_basis', forward_basis.float())
- self.register_buffer('inverse_basis', inverse_basis.float())
-
- def transform(self, input_data):
- num_batches = input_data.size(0)
- num_samples = input_data.size(1)
-
- self.num_samples = num_samples
-
- # similar to librosa, reflect-pad the input
- input_data = input_data.view(num_batches, 1, num_samples)
- input_data = F.pad(
- input_data.unsqueeze(1),
- (int(self.filter_length / 2), int(self.filter_length / 2), 0, 0),
- mode='reflect')
- input_data = input_data.squeeze(1)
-
- forward_transform = F.conv1d(
- input_data,
- Variable(self.forward_basis, requires_grad=False),
- stride=self.hop_length,
- padding=0)
-
- cutoff = int((self.filter_length / 2) + 1)
- real_part = forward_transform[:, :cutoff, :]
- imag_part = forward_transform[:, cutoff:, :]
-
- magnitude = torch.sqrt(real_part**2 + imag_part**2)
- phase = torch.autograd.Variable(
- torch.atan2(imag_part.data, real_part.data))
-
- return magnitude, phase # [batch_size, F(513), T(1251)]
-
- def inverse(self, magnitude, phase):
- recombine_magnitude_phase = torch.cat(
- [magnitude*torch.cos(phase), magnitude*torch.sin(phase)], dim=1)
-
- inverse_transform = F.conv_transpose1d(
- recombine_magnitude_phase,
- Variable(self.inverse_basis, requires_grad=False),
- stride=self.hop_length,
- padding=0)
-
- if self.window is not None:
- window_sum = window_sumsquare(
- self.window, magnitude.size(-1), hop_length=self.hop_length,
- win_length=self.win_length, n_fft=self.filter_length,
- dtype=np.float32)
- # remove modulation effects
- approx_nonzero_indices = torch.from_numpy(
- np.where(window_sum > tiny(window_sum))[0])
- window_sum = torch.autograd.Variable(
- torch.from_numpy(window_sum), requires_grad=False)
- window_sum = window_sum.cuda() if magnitude.is_cuda else window_sum
- inverse_transform[:, :, approx_nonzero_indices] /= window_sum[approx_nonzero_indices]
-
- # scale by hop ratio
- inverse_transform *= float(self.filter_length) / self.hop_length
-
- inverse_transform = inverse_transform[:, :, int(self.filter_length/2):]
- inverse_transform = inverse_transform[:, :, :-int(self.filter_length/2):]
-
- return inverse_transform #[batch_size, 1, sample_num]
-
- def forward(self, input_data):
- self.magnitude, self.phase = self.transform(input_data)
- reconstruction = self.inverse(self.magnitude, self.phase)
- return reconstruction
-
-if __name__ == '__main__':
- a = torch.randn(4, 320000)
- stft = STFT()
- mag, phase = stft.transform(a)
- # rec_a = stft.inverse(mag, phase)
- print(mag.shape)
diff --git a/spaces/AIWaves/Debate/src/agents/utils.py b/spaces/AIWaves/Debate/src/agents/utils.py
deleted file mode 100644
index dcfb5697443049ca18ba568508e227801f51e004..0000000000000000000000000000000000000000
--- a/spaces/AIWaves/Debate/src/agents/utils.py
+++ /dev/null
@@ -1,480 +0,0 @@
-# coding=utf-8
-# Copyright 2023 The AIWaves Inc. team.
-
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""helper functions for an LLM autonoumous agent"""
-import csv
-import random
-import json
-import pandas
-import numpy as np
-import requests
-import torch
-from tqdm import tqdm
-from text2vec import semantic_search
-import re
-import datetime
-from langchain.document_loaders import UnstructuredFileLoader
-from langchain.text_splitter import CharacterTextSplitter
-from sentence_transformers import SentenceTransformer
-import string
-import random
-import os
-import openai
-
-embed_model_name = os.environ["Embed_Model"] if "Embed_Model" in os.environ else "text-embedding-ada-002"
-if embed_model_name in ["text-embedding-ada-002"]:
- pass
-else:
- embedding_model = SentenceTransformer(
- embed_model_name, device=torch.device("cpu")
- )
-
-def get_embedding(sentence):
- if embed_model_name in ["text-embedding-ada-002"]:
- openai.api_key = os.environ["API_KEY"]
- # if "PROXY" in os.environ:
- # assert "http:" in os.environ["PROXY"] or "socks" in os.environ["PROXY"],"PROXY error,PROXY must be http or socks"
- # openai.proxy = os.environ["PROXY"]
- if "API_BASE" in os.environ:
- openai.api_base = os.environ["API_BASE"]
- embedding_model = openai.Embedding
- embed = embedding_model.create(
- model=embed_model_name,
- input=sentence
- )
- embed = embed["data"][0]["embedding"]
- embed = torch.tensor(embed,dtype=torch.float32)
- else:
- embed = embedding_model.encode(sentence,convert_to_tensor=True)
- if len(embed.shape)==1:
- embed = embed.unsqueeze(0)
- return embed
-
-
-def get_code():
- return "".join(random.sample(string.ascii_letters + string.digits, 8))
-
-
-def get_content_between_a_b(start_tag, end_tag, text):
- """
-
- Args:
- start_tag (str): start_tag
- end_tag (str): end_tag
- text (str): complete sentence
-
- Returns:
- str: the content between start_tag and end_tag
- """
- extracted_text = ""
- start_index = text.find(start_tag)
- while start_index != -1:
- end_index = text.find(end_tag, start_index + len(start_tag))
- if end_index != -1:
- extracted_text += text[start_index +
- len(start_tag):end_index] + " "
- start_index = text.find(start_tag, end_index + len(end_tag))
- else:
- break
-
- return extracted_text.strip()
-
-
-def extract(text, type):
- """extract the content between
-
- Args:
- text (str): complete sentence
- type (str): tag
-
- Returns:
- str: content between
- """
- target_str = get_content_between_a_b(f"<{type}>", f"", text)
- return target_str
-
-def count_files_in_directory(directory):
- # 获取指定目录下的文件数目
- file_count = len([f for f in os.listdir(directory) if os.path.isfile(os.path.join(directory, f))])
- return file_count
-
-def delete_oldest_files(directory, num_to_keep):
- # 获取目录下文件列表,并按修改时间排序
- files = [(f, os.path.getmtime(os.path.join(directory, f))) for f in os.listdir(directory) if os.path.isfile(os.path.join(directory, f))]
-
- # 删除最开始的 num_to_keep 个文件
- for i in range(min(num_to_keep, len(files))):
- file_to_delete = os.path.join(directory, files[i][0])
- os.remove(file_to_delete)
-
-def delete_files_if_exceed_threshold(directory, threshold, num_to_keep):
- # 获取文件数目并进行处理
- file_count = count_files_in_directory(directory)
- if file_count > threshold:
- delete_count = file_count - num_to_keep
- delete_oldest_files(directory, delete_count)
-
-def save_logs(log_path, messages, response):
- if not os.path.exists(log_path):
- os.mkdir(log_path)
- delete_files_if_exceed_threshold(log_path, 20, 10)
- log_path = log_path if log_path else "logs"
- log = {}
- log["input"] = messages
- log["output"] = response
- os.makedirs(log_path, exist_ok=True)
- log_file = os.path.join(
- log_path,
- datetime.datetime.now().strftime("%Y-%m-%d-%H:%M:%S") + ".json")
- with open(log_file, "w", encoding="utf-8") as f:
- json.dump(log, f, ensure_ascii=False, indent=2)
-
-
-
-def semantic_search_word2vec(query_embedding, kb_embeddings, top_k):
- return semantic_search(query_embedding, kb_embeddings, top_k=top_k)
-
-
-def cut_sent(para):
- para = re.sub("([。!?\?])([^”’])", r"\1\n\2", para)
- para = re.sub("(\.{6})([^”’])", r"\1\n\2", para)
- para = re.sub("(\…{2})([^”’])", r"\1\n\2", para)
- para = re.sub("([。!?\?][”’])([^,。!?\?])", r"\1\n\2", para)
- para = para.rstrip()
- pieces = [i for i in para.split("\n") if i]
- batch_size = 3
- chucks = [
- " ".join(pieces[i:i + batch_size])
- for i in range(0, len(pieces), batch_size)
- ]
- return chucks
-
-
-def process_document(file_path):
- """
- Save QA_csv to json.
- Args:
- model: LLM to generate embeddings
- qa_dict: A dict contains Q&A
- save_path: where to save the json file.
- Json format:
- Dict[num,Dict[q:str,a:str,chunk:str,emb:List[float]]
- """
- final_dict = {}
- count = 0
- if file_path.endswith(".csv"):
- dataset = pandas.read_csv(file_path)
- questions = dataset["question"]
- answers = dataset["answer"]
- # embedding q+chunk
- for q, a in zip(questions, answers):
- for text in cut_sent(a):
- temp_dict = {}
- temp_dict["q"] = q
- temp_dict["a"] = a
- temp_dict["chunk"] = text
- temp_dict["emb"] = get_embedding(q + text).tolist()
- final_dict[count] = temp_dict
- count += 1
- # embedding chunk
- for q, a in zip(questions, answers):
- for text in cut_sent(a):
- temp_dict = {}
- temp_dict["q"] = q
- temp_dict["a"] = a
- temp_dict["chunk"] = text
- temp_dict["emb"] = get_embedding(text).tolist()
- final_dict[count] = temp_dict
- count += 1
- # embedding q
- for q, a in zip(questions, answers):
- temp_dict = {}
- temp_dict["q"] = q
- temp_dict["a"] = a
- temp_dict["chunk"] = a
- temp_dict["emb"] = get_embedding(q).tolist()
- final_dict[count] = temp_dict
- count += 1
- # embedding q+a
- for q, a in zip(questions, answers):
- temp_dict = {}
- temp_dict["q"] = q
- temp_dict["a"] = a
- temp_dict["chunk"] = a
- temp_dict["emb"] = get_embedding(q + a).tolist()
- final_dict[count] = temp_dict
- count += 1
- # embedding a
- for q, a in zip(questions, answers):
- temp_dict = {}
- temp_dict["q"] = q
- temp_dict["a"] = a
- temp_dict["chunk"] = a
- temp_dict["emb"] = get_embedding(a).tolist()
- final_dict[count] = temp_dict
- count += 1
- print(f"finish updating {len(final_dict)} data!")
- os.makedirs("temp_database", exist_ok=True)
- save_path = os.path.join(
- "temp_database/",
- file_path.split("/")[-1].replace("." + file_path.split(".")[1],
- ".json"),
- )
- print(save_path)
- with open(save_path, "w") as f:
- json.dump(final_dict, f, ensure_ascii=False, indent=2)
- return {"knowledge_base": save_path, "type": "QA"}
- else:
- loader = UnstructuredFileLoader(file_path)
- docs = loader.load()
- text_spiltter = CharacterTextSplitter(chunk_size=200,
- chunk_overlap=100)
- docs = text_spiltter.split_text(docs[0].page_content)
- os.makedirs("temp_database", exist_ok=True)
- save_path = os.path.join(
- "temp_database/",
- file_path.replace("." + file_path.split(".")[1], ".json"))
- final_dict = {}
- count = 0
- for c in tqdm(docs):
- temp_dict = {}
- temp_dict["chunk"] = c
- temp_dict["emb"] = get_embedding(c).tolist()
- final_dict[count] = temp_dict
- count += 1
- print(f"finish updating {len(final_dict)} data!")
- with open(save_path, "w") as f:
- json.dump(final_dict, f, ensure_ascii=False, indent=2)
- return {"knowledge_base": save_path, "type": "UnstructuredFile"}
-
-def load_knowledge_base_qa(path):
- """
- Load json format knowledge base.
- """
- print("path", path)
- with open(path, "r") as f:
- data = json.load(f)
- embeddings = []
- questions = []
- answers = []
- chunks = []
- for idx in range(len(data.keys())):
- embeddings.append(data[str(idx)]["emb"])
- questions.append(data[str(idx)]["q"])
- answers.append(data[str(idx)]["a"])
- chunks.append(data[str(idx)]["chunk"])
- embeddings = np.array(embeddings, dtype=np.float32)
- embeddings = torch.from_numpy(embeddings).squeeze()
- return embeddings, questions, answers, chunks
-
-
-def load_knowledge_base_UnstructuredFile(path):
- """
- Load json format knowledge base.
- """
- with open(path, "r") as f:
- data = json.load(f)
- embeddings = []
- chunks = []
- for idx in range(len(data.keys())):
- embeddings.append(data[str(idx)]["emb"])
- chunks.append(data[str(idx)]["chunk"])
- embeddings = np.array(embeddings, dtype=np.float32)
- embeddings = torch.from_numpy(embeddings).squeeze()
- return embeddings, chunks
-
-
-def cos_sim(a: torch.Tensor, b: torch.Tensor):
- """
- Computes the cosine similarity cos_sim(a[i], b[j]) for all i and j.
- :return: Matrix with res[i][j] = cos_sim(a[i], b[j])
- """
- if not isinstance(a, torch.Tensor):
- a = torch.tensor(a)
-
- if not isinstance(b, torch.Tensor):
- b = torch.tensor(b)
-
- if len(a.shape) == 1:
- a = a.unsqueeze(0)
-
- if len(b.shape) == 1:
- b = b.unsqueeze(0)
-
- a_norm = torch.nn.functional.normalize(a, p=2, dim=1)
- b_norm = torch.nn.functional.normalize(b, p=2, dim=1)
- return torch.mm(a_norm, b_norm.transpose(0, 1))
-
-
-def matching_a_b(a, b, requirements=None):
- a_embedder = get_embedding(a)
- # 获取embedder
- b_embeder = get_embedding(b)
- sim_scores = cos_sim(a_embedder, b_embeder)[0]
- return sim_scores
-
-
-def matching_category(inputtext,
- forest_name,
- requirements=None,
- cat_embedder=None,
- top_k=3):
- """
- Args:
- inputtext: the category name to be matched
- forest: search tree
- top_k: the default three highest scoring results
- Return:
- topk matching_result. List[List] [[top1_name,top2_name,top3_name],[top1_score,top2_score,top3_score]]
- """
-
- sim_scores = torch.zeros([100])
- if inputtext:
- input_embeder = get_embedding(inputtext)
- sim_scores = cos_sim(input_embeder, cat_embedder)[0]
-
- if requirements:
- requirements = requirements.split(" ")
- requirements_embedder = get_embedding(requirements)
- req_scores = cos_sim(requirements_embedder, cat_embedder)
- req_scores = torch.mean(req_scores, dim=0)
- total_scores = req_scores
- else:
- total_scores = sim_scores
-
- top_k_cat = torch.topk(total_scores, k=top_k)
- top_k_score, top_k_idx = top_k_cat[0], top_k_cat[1]
- top_k_name = [forest_name[top_k_idx[i]] for i in range(0, top_k)]
-
- return [top_k_name, top_k_score.tolist(), top_k_idx]
-
-
-def sample_with_order_preserved(lst, num):
- """Randomly sample from the list while maintaining the original order."""
- indices = list(range(len(lst)))
- sampled_indices = random.sample(indices, num)
- sampled_indices.sort() # 保持原顺序
- return [lst[i] for i in sampled_indices]
-
-
-def limit_values(data, max_values):
- """Reduce each key-value list in the dictionary to the specified size, keeping the order of the original list unchanged."""
- for key, values in data.items():
- if len(values) > max_values:
- data[key] = sample_with_order_preserved(values, max_values)
- return data
-
-
-def limit_keys(data, max_keys):
- """Reduce the dictionary to the specified number of keys."""
- keys = list(data.keys())
- if len(keys) > max_keys:
- keys = sample_with_order_preserved(keys, max_keys)
- data = {key: data[key] for key in keys}
- return data
-
-
-def flatten_dict(nested_dict):
- """
- flatten the dictionary
- """
- flattened_dict = {}
- for key, value in nested_dict.items():
- if isinstance(value, dict):
- flattened_subdict = flatten_dict(value)
- flattened_dict.update(flattened_subdict)
- else:
- flattened_dict[key] = value
- return flattened_dict
-
-
-def merge_list(list1, list2):
- for l in list2:
- if l not in list1:
- list1.append(l)
- return list1
-
-
-def Search_Engines(req):
- FETSIZE = eval(os.environ["FETSIZE"]) if "FETSIZE" in os.environ else 5
-
- new_dict = {"keyword": req, "catLeafName": "", "fetchSize": FETSIZE}
- url = os.environ["SHOPPING_SEARCH"]
- res = requests.post(
- url= url,
- json=new_dict,
- )
- user_dict = json.loads(res.text)
- if "data" in user_dict.keys():
- request_items = user_dict["data"]["items"] # 查询到的商品信息JSON
- top_category = user_dict["data"]["topCategories"]
- return request_items, top_category
- else:
- return []
-
-
-def search_with_api(requirements, categery):
-
- FETSIZE = eval(os.environ["FETSIZE"]) if "FETSIZE" in os.environ else 5
-
- request_items = []
- all_req_list = requirements.split(" ")
- count = 0
-
- while len(request_items) < FETSIZE and len(all_req_list) > 0:
- if count:
- all_req_list.pop(0)
- all_req = (" ").join(all_req_list)
- if categery not in all_req_list:
- all_req = all_req + " " + categery
- now_request_items, top_category = Search_Engines(all_req)
- request_items = merge_list(request_items, now_request_items)
- count += 1
- new_top = []
- for category in top_category:
- if "其它" in category or "其它" in category:
- continue
- else:
- new_top.append(category)
- if len(request_items) > FETSIZE:
- request_items = request_items[:FETSIZE]
- return request_items, new_top
-
-
-
-def get_relevant_history(query,history,embeddings):
- """
- Retrieve a list of key history entries based on a query using semantic search.
-
- Args:
- query (str): The input query for which key history is to be retrieved.
- history (list): A list of historical key entries.
- embeddings (numpy.ndarray): An array of embedding vectors for historical entries.
-
- Returns:
- list: A list of key history entries most similar to the query.
- """
- TOP_K = eval(os.environ["TOP_K"]) if "TOP_K" in os.environ else 2
- relevant_history = []
- query_embedding = get_embedding(query)
- hits = semantic_search(query_embedding, embeddings, top_k=min(TOP_K,embeddings.shape[0]))
- hits = hits[0]
- for hit in hits:
- matching_idx = hit["corpus_id"]
- try:
- relevant_history.append(history[matching_idx])
- except:
- return []
- return relevant_history
diff --git a/spaces/AIZeroToHero/Video-Automatic-Speech-Recognition/app.py b/spaces/AIZeroToHero/Video-Automatic-Speech-Recognition/app.py
deleted file mode 100644
index e0f03cf2557eba112bf95ebf5eb582da8d8a0fe3..0000000000000000000000000000000000000000
--- a/spaces/AIZeroToHero/Video-Automatic-Speech-Recognition/app.py
+++ /dev/null
@@ -1,119 +0,0 @@
-from collections import deque
-import streamlit as st
-import torch
-from streamlit_player import st_player
-from transformers import AutoModelForCTC, Wav2Vec2Processor
-from streaming import ffmpeg_stream
-
-device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
-player_options = {
- "events": ["onProgress"],
- "progress_interval": 200,
- "volume": 1.0,
- "playing": True,
- "loop": False,
- "controls": False,
- "muted": False,
- "config": {"youtube": {"playerVars": {"start": 1}}},
-}
-
-# disable rapid fading in and out on `st.code` updates
-st.markdown("", unsafe_allow_html=True)
-
-@st.cache(hash_funcs={torch.nn.parameter.Parameter: lambda _: None})
-def load_model(model_path="facebook/wav2vec2-large-robust-ft-swbd-300h"):
- processor = Wav2Vec2Processor.from_pretrained(model_path)
- model = AutoModelForCTC.from_pretrained(model_path).to(device)
- return processor, model
-
-processor, model = load_model()
-
-def stream_text(url, chunk_duration_ms, pad_duration_ms):
- sampling_rate = processor.feature_extractor.sampling_rate
-
- # calculate the length of logits to cut from the sides of the output to account for input padding
- output_pad_len = model._get_feat_extract_output_lengths(int(sampling_rate * pad_duration_ms / 1000))
-
- # define the audio chunk generator
- stream = ffmpeg_stream(url, sampling_rate, chunk_duration_ms=chunk_duration_ms, pad_duration_ms=pad_duration_ms)
-
- leftover_text = ""
- for i, chunk in enumerate(stream):
- input_values = processor(chunk, sampling_rate=sampling_rate, return_tensors="pt").input_values
-
- with torch.no_grad():
- logits = model(input_values.to(device)).logits[0]
- if i > 0:
- logits = logits[output_pad_len : len(logits) - output_pad_len]
- else: # don't count padding at the start of the clip
- logits = logits[: len(logits) - output_pad_len]
-
- predicted_ids = torch.argmax(logits, dim=-1).cpu().tolist()
- if processor.decode(predicted_ids).strip():
- leftover_ids = processor.tokenizer.encode(leftover_text)
- # concat the last word (or its part) from the last frame with the current text
- text = processor.decode(leftover_ids + predicted_ids)
- # don't return the last word in case it's just partially recognized
- text, leftover_text = text.rsplit(" ", 1)
- yield text
- else:
- yield leftover_text
- leftover_text = ""
- yield leftover_text
-
-def main():
- state = st.session_state
- st.header("Video ASR Streamlit from Youtube Link")
-
- with st.form(key="inputs_form"):
-
- # Our worlds best teachers on subjects of AI, Cognitive, Neuroscience for our Behavioral and Medical Health
- ytJoschaBach="https://youtu.be/cC1HszE5Hcw?list=PLHgX2IExbFouJoqEr8JMF5MbZSbyC91-L&t=8984"
- ytSamHarris="https://www.youtube.com/watch?v=4dC_nRYIDZU&list=PLHgX2IExbFouJoqEr8JMF5MbZSbyC91-L&index=2"
- ytJohnAbramson="https://www.youtube.com/watch?v=arrokG3wCdE&list=PLHgX2IExbFouJoqEr8JMF5MbZSbyC91-L&index=3"
- ytElonMusk="https://www.youtube.com/watch?v=DxREm3s1scA&list=PLHgX2IExbFouJoqEr8JMF5MbZSbyC91-L&index=4"
- ytJeffreyShainline="https://www.youtube.com/watch?v=EwueqdgIvq4&list=PLHgX2IExbFouJoqEr8JMF5MbZSbyC91-L&index=5"
- ytJeffHawkins="https://www.youtube.com/watch?v=Z1KwkpTUbkg&list=PLHgX2IExbFouJoqEr8JMF5MbZSbyC91-L&index=6"
- ytSamHarris="https://youtu.be/Ui38ZzTymDY?list=PLHgX2IExbFouJoqEr8JMF5MbZSbyC91-L"
- ytSamHarris="https://youtu.be/4dC_nRYIDZU?list=PLHgX2IExbFouJoqEr8JMF5MbZSbyC91-L&t=7809"
- ytSamHarris="https://youtu.be/4dC_nRYIDZU?list=PLHgX2IExbFouJoqEr8JMF5MbZSbyC91-L&t=7809"
- ytSamHarris="https://youtu.be/4dC_nRYIDZU?list=PLHgX2IExbFouJoqEr8JMF5MbZSbyC91-L&t=7809"
- ytTimelapseAI="https://www.youtube.com/watch?v=63yr9dlI0cU&list=PLHgX2IExbFovQybyfltywXnqZi5YvaSS-"
- state.youtube_url = st.text_input("YouTube URL", ytTimelapseAI)
-
-
- state.chunk_duration_ms = st.slider("Audio chunk duration (ms)", 2000, 10000, 3000, 100)
- state.pad_duration_ms = st.slider("Padding duration (ms)", 100, 5000, 1000, 100)
- submit_button = st.form_submit_button(label="Submit")
-
- if submit_button or "asr_stream" not in state:
- # a hack to update the video player on value changes
- state.youtube_url = (
- state.youtube_url.split("&hash=")[0]
- + f"&hash={state.chunk_duration_ms}-{state.pad_duration_ms}"
- )
- state.asr_stream = stream_text(
- state.youtube_url, state.chunk_duration_ms, state.pad_duration_ms
- )
- state.chunks_taken = 0
-
-
- state.lines = deque([], maxlen=100) # limit to the last n lines of subs
-
-
- player = st_player(state.youtube_url, **player_options, key="youtube_player")
-
- if "asr_stream" in state and player.data and player.data["played"] < 1.0:
- # check how many seconds were played, and if more than processed - write the next text chunk
- processed_seconds = state.chunks_taken * (state.chunk_duration_ms / 1000)
- if processed_seconds < player.data["playedSeconds"]:
- text = next(state.asr_stream)
- state.lines.append(text)
- state.chunks_taken += 1
- if "lines" in state:
- # print the lines of subs
- st.code("\n".join(state.lines))
-
-
-if __name__ == "__main__":
- main()
\ No newline at end of file
diff --git a/spaces/AIatUIUC/CodeLATS/generators/__init__.py b/spaces/AIatUIUC/CodeLATS/generators/__init__.py
deleted file mode 100644
index a279f9265a96159535180e777513490be797df49..0000000000000000000000000000000000000000
--- a/spaces/AIatUIUC/CodeLATS/generators/__init__.py
+++ /dev/null
@@ -1,3 +0,0 @@
-from .py_generate import PyGenerator
-from .factory import generator_factory, model_factory
-from .model import ModelBase, GPT4, GPT35
diff --git a/spaces/ALSv/FSW/roop/face_analyser.py b/spaces/ALSv/FSW/roop/face_analyser.py
deleted file mode 100644
index 4e2c6c84a930ce522103c4cac0df2ed3d1a3d1b7..0000000000000000000000000000000000000000
--- a/spaces/ALSv/FSW/roop/face_analyser.py
+++ /dev/null
@@ -1,53 +0,0 @@
-import threading
-from typing import Any, Optional, List
-import insightface
-import numpy
-
-import roop.globals
-from roop.typing import Frame, Face
-
-FACE_ANALYSER = None
-THREAD_LOCK = threading.Lock()
-
-
-def get_face_analyser() -> Any:
- global FACE_ANALYSER
-
- with THREAD_LOCK:
- if FACE_ANALYSER is None:
- FACE_ANALYSER = insightface.app.FaceAnalysis(name='buffalo_l', providers=roop.globals.execution_providers)
- FACE_ANALYSER.prepare(ctx_id=0)
- return FACE_ANALYSER
-
-
-def clear_face_analyser() -> Any:
- global FACE_ANALYSER
-
- FACE_ANALYSER = None
-
-
-
-def get_one_face(frame: Frame) -> Any:
- face = get_face_analyser().get(frame)
- try:
- return min(face, key=lambda x: x.bbox[0])
- except ValueError:
- return None
-
-
-def get_many_faces(frame: Frame) -> Optional[List[Face]]:
- try:
- return get_face_analyser().get(frame)
- except ValueError:
- return None
-
-
-def find_similar_face(frame: Frame, reference_face: Face) -> Optional[Face]:
- many_faces = get_many_faces(frame)
- if many_faces:
- for face in many_faces:
- if hasattr(face, 'normed_embedding') and hasattr(reference_face, 'normed_embedding'):
- distance = numpy.sum(numpy.square(face.normed_embedding - reference_face.normed_embedding))
- if distance < roop.globals.similar_face_distance:
- return face
- return None
diff --git a/spaces/AchyuthGamer/OpenGPT-Chat-UI/src/lib/actions/snapScrollToBottom.ts b/spaces/AchyuthGamer/OpenGPT-Chat-UI/src/lib/actions/snapScrollToBottom.ts
deleted file mode 100644
index b22a0648221f6b58853a910fb6286f79574a0246..0000000000000000000000000000000000000000
--- a/spaces/AchyuthGamer/OpenGPT-Chat-UI/src/lib/actions/snapScrollToBottom.ts
+++ /dev/null
@@ -1,54 +0,0 @@
-import { navigating } from "$app/stores";
-import { tick } from "svelte";
-import { get } from "svelte/store";
-
-const detachedOffset = 10;
-
-/**
- * @param node element to snap scroll to bottom
- * @param dependency pass in a dependency to update scroll on changes.
- */
-export const snapScrollToBottom = (node: HTMLElement, dependency: unknown) => {
- let prevScrollValue = node.scrollTop;
- let isDetached = false;
-
- const handleScroll = () => {
- // if user scrolled up, we detach
- if (node.scrollTop < prevScrollValue) {
- isDetached = true;
- }
-
- // if user scrolled back to within 10px of bottom, we reattach
- if (node.scrollTop - (node.scrollHeight - node.clientHeight) >= -detachedOffset) {
- isDetached = false;
- }
-
- prevScrollValue = node.scrollTop;
- };
-
- const updateScroll = async (_options: { force?: boolean } = {}) => {
- const defaultOptions = { force: false };
- const options = { ...defaultOptions, ..._options };
- const { force } = options;
-
- if (!force && isDetached && !get(navigating)) return;
-
- // wait for next tick to ensure that the DOM is updated
- await tick();
-
- node.scrollTo({ top: node.scrollHeight });
- };
-
- node.addEventListener("scroll", handleScroll);
-
- if (dependency) {
- updateScroll({ force: true });
- }
-
- return {
- update: updateScroll,
- destroy: () => {
- node.removeEventListener("scroll", handleScroll);
- },
- };
-};
diff --git a/spaces/AchyuthGamer/OpenGPT/client/css/checkbox.css b/spaces/AchyuthGamer/OpenGPT/client/css/checkbox.css
deleted file mode 100644
index 94955b604ea3fab493a50d740fb29be1a8ef6cd3..0000000000000000000000000000000000000000
--- a/spaces/AchyuthGamer/OpenGPT/client/css/checkbox.css
+++ /dev/null
@@ -1,55 +0,0 @@
-.checkbox input {
- height: 0;
- width: 0;
- display: none;
-}
-
-.checkbox span {
- font-size: 0.875rem;
- color: var(--colour-2);
- margin-left: 4px;
-}
-
-.checkbox label:after {
- content: "";
- position: absolute;
- top: 50%;
- transform: translateY(-50%);
- left: 5px;
- width: 20px;
- height: 20px;
- background: var(--blur-border);
- border-radius: 90px;
- transition: 0.33s;
-}
-
-.checkbox input + label:after,
-.checkbox input:checked + label {
- background: var(--colour-3);
-}
-
-.checkbox input + label,
-.checkbox input:checked + label:after {
- background: var(--blur-border);
-}
-
-.checkbox input:checked + label:after {
- left: calc(100% - 5px - 20px);
-}
-
-@media screen and (max-width: 990px) {
- .checkbox label {
- width: 25px;
- height: 15px;
- }
-
- .checkbox label:after {
- left: 2px;
- width: 10px;
- height: 10px;
- }
-
- .checkbox input:checked + label:after {
- left: calc(100% - 2px - 10px);
- }
-}
diff --git a/spaces/AchyuthGamer/OpenGPT/g4f/Provider/Providers/deprecated/EasyChat.py b/spaces/AchyuthGamer/OpenGPT/g4f/Provider/Providers/deprecated/EasyChat.py
deleted file mode 100644
index ffe9a785a61f17d3b816089165f38dd53e1d7c3f..0000000000000000000000000000000000000000
--- a/spaces/AchyuthGamer/OpenGPT/g4f/Provider/Providers/deprecated/EasyChat.py
+++ /dev/null
@@ -1,111 +0,0 @@
-from __future__ import annotations
-
-import json
-import random
-
-import requests
-
-from ...typing import Any, CreateResult
-from ..base_provider import BaseProvider
-
-
-class EasyChat(BaseProvider):
- url: str = "https://free.easychat.work"
- supports_stream = True
- supports_gpt_35_turbo = True
- working = False
-
- @staticmethod
- def create_completion(
- model: str,
- messages: list[dict[str, str]],
- stream: bool, **kwargs: Any) -> CreateResult:
-
- active_servers = [
- "https://chat10.fastgpt.me",
- "https://chat9.fastgpt.me",
- "https://chat1.fastgpt.me",
- "https://chat2.fastgpt.me",
- "https://chat3.fastgpt.me",
- "https://chat4.fastgpt.me",
- "https://gxos1h1ddt.fastgpt.me"
- ]
-
- server = active_servers[kwargs.get("active_server", random.randint(0, 5))]
- headers = {
- "authority" : f"{server}".replace("https://", ""),
- "accept" : "text/event-stream",
- "accept-language" : "en,fr-FR;q=0.9,fr;q=0.8,es-ES;q=0.7,es;q=0.6,en-US;q=0.5,am;q=0.4,de;q=0.3,fa=0.2",
- "content-type" : "application/json",
- "origin" : f"{server}",
- "referer" : f"{server}/",
- "x-requested-with" : "XMLHttpRequest",
- 'plugins' : '0',
- 'sec-ch-ua' : '"Chromium";v="116", "Not)A;Brand";v="24", "Google Chrome";v="116"',
- 'sec-ch-ua-mobile' : '?0',
- 'sec-ch-ua-platform': '"Windows"',
- 'sec-fetch-dest' : 'empty',
- 'sec-fetch-mode' : 'cors',
- 'sec-fetch-site' : 'same-origin',
- 'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36',
- 'usesearch' : 'false',
- 'x-requested-with' : 'XMLHttpRequest'
- }
-
- json_data = {
- "messages" : messages,
- "stream" : stream,
- "model" : model,
- "temperature" : kwargs.get("temperature", 0.5),
- "presence_penalty" : kwargs.get("presence_penalty", 0),
- "frequency_penalty" : kwargs.get("frequency_penalty", 0),
- "top_p" : kwargs.get("top_p", 1)
- }
-
- session = requests.Session()
- # init cookies from server
- session.get(f"{server}/")
-
- response = session.post(f"{server}/api/openai/v1/chat/completions",
- headers=headers, json=json_data, stream=stream)
-
- if response.status_code == 200:
-
- if stream == False:
- json_data = response.json()
-
- if "choices" in json_data:
- yield json_data["choices"][0]["message"]["content"]
- else:
- raise Exception("No response from server")
-
- else:
-
- for chunk in response.iter_lines():
-
- if b"content" in chunk:
- splitData = chunk.decode().split("data:")
-
- if len(splitData) > 1:
- yield json.loads(splitData[1])["choices"][0]["delta"]["content"]
- else:
- continue
- else:
- raise Exception(f"Error {response.status_code} from server : {response.reason}")
-
-
- @classmethod
- @property
- def params(cls):
- params = [
- ("model", "str"),
- ("messages", "list[dict[str, str]]"),
- ("stream", "bool"),
- ("temperature", "float"),
- ("presence_penalty", "int"),
- ("frequency_penalty", "int"),
- ("top_p", "int"),
- ("active_server", "int"),
- ]
- param = ", ".join([": ".join(p) for p in params])
- return f"g4f.provider.{cls.__name__} supports: ({param})"
diff --git a/spaces/Adapter/T2I-Adapter/app.py b/spaces/Adapter/T2I-Adapter/app.py
deleted file mode 100644
index ff2e874320d8fb065f445e3fb75371ecadd83fe4..0000000000000000000000000000000000000000
--- a/spaces/Adapter/T2I-Adapter/app.py
+++ /dev/null
@@ -1,483 +0,0 @@
-# demo inspired by https://huggingface.co/spaces/lambdalabs/image-mixer-demo
-import argparse
-import copy
-import os
-import shlex
-import subprocess
-from functools import partial
-from itertools import chain
-
-import cv2
-import gradio as gr
-import torch
-from basicsr.utils import tensor2img
-from huggingface_hub import hf_hub_url
-from pytorch_lightning import seed_everything
-from torch import autocast
-
-from ldm.inference_base import (DEFAULT_NEGATIVE_PROMPT, diffusion_inference, get_adapters, get_sd_models)
-from ldm.modules.extra_condition import api
-from ldm.modules.extra_condition.api import (ExtraCondition, get_adapter_feature, get_cond_model)
-import numpy as np
-from ldm.util import read_state_dict
-
-torch.set_grad_enabled(False)
-
-supported_cond_map = ['style', 'color', 'sketch', 'openpose', 'depth', 'canny']
-supported_cond = ['style', 'color', 'sketch', 'sketch', 'openpose', 'depth', 'canny']
-draw_map = gr.Interface(lambda x: x, gr.Image(source="canvas"), gr.Image())
-
-# download the checkpoints
-urls = {
- 'TencentARC/T2I-Adapter': [
- 'models/t2iadapter_keypose_sd14v1.pth', 'models/t2iadapter_color_sd14v1.pth',
- 'models/t2iadapter_openpose_sd14v1.pth', 'models/t2iadapter_seg_sd14v1.pth',
- 'models/t2iadapter_sketch_sd14v1.pth', 'models/t2iadapter_depth_sd14v1.pth',
- 'third-party-models/body_pose_model.pth', "models/t2iadapter_style_sd14v1.pth",
- "models/t2iadapter_canny_sd14v1.pth", 'third-party-models/table5_pidinet.pth',
- "models/t2iadapter_canny_sd15v2.pth", "models/t2iadapter_depth_sd15v2.pth",
- "models/t2iadapter_sketch_sd15v2.pth"
- ],
- 'runwayml/stable-diffusion-v1-5': ['v1-5-pruned-emaonly.ckpt'],
- 'CompVis/stable-diffusion-v-1-4-original':['sd-v1-4.ckpt'],
- 'andite/anything-v4.0': ['anything-v4.0-pruned.ckpt', 'anything-v4.0.vae.pt'],
-}
-
-# download image samples
-torch.hub.download_url_to_file(
- 'https://user-images.githubusercontent.com/52127135/223114920-cae3e723-3683-424a-bebc-0875479f2409.jpg',
- 'cyber_style.jpg')
-torch.hub.download_url_to_file(
- 'https://user-images.githubusercontent.com/52127135/223114946-6ccc127f-cb58-443e-8677-805f5dbaf6f1.png',
- 'sword.png')
-torch.hub.download_url_to_file(
- 'https://user-images.githubusercontent.com/52127135/223121793-20c2ac6a-5a4f-4ff8-88ea-6d007a7959dd.png',
- 'white.png')
-torch.hub.download_url_to_file(
- 'https://user-images.githubusercontent.com/52127135/223127404-4a3748cf-85a6-40f3-af31-a74e206db96e.jpeg',
- 'scream_style.jpeg')
-torch.hub.download_url_to_file(
- 'https://user-images.githubusercontent.com/52127135/223127433-8768913f-9872-4d24-b883-a19a3eb20623.jpg',
- 'motorcycle.jpg')
-
-if os.path.exists('models') == False:
- os.mkdir('models')
-for repo in urls:
- files = urls[repo]
- for file in files:
- url = hf_hub_url(repo, file)
- name_ckp = url.split('/')[-1]
- save_path = os.path.join('models', name_ckp)
- if os.path.exists(save_path) == False:
- subprocess.run(shlex.split(f'wget {url} -O {save_path}'))
-
-# config
-parser = argparse.ArgumentParser()
-parser.add_argument(
- '--sd_ckpt',
- type=str,
- default='models/v1-5-pruned-emaonly.ckpt',
- help='path to checkpoint of stable diffusion model, both .ckpt and .safetensor are supported',
-)
-parser.add_argument(
- '--vae_ckpt',
- type=str,
- default=None,
- help='vae checkpoint, anime SD models usually have seperate vae ckpt that need to be loaded',
-)
-global_opt = parser.parse_args()
-global_opt.config = 'configs/stable-diffusion/sd-v1-inference.yaml'
-for cond_name in supported_cond:
- if cond_name in ['sketch', 'depth', 'canny']:
- setattr(global_opt, f'{cond_name}_adapter_ckpt', f'models/t2iadapter_{cond_name}_sd15v2.pth')
- else:
- setattr(global_opt, f'{cond_name}_adapter_ckpt', f'models/t2iadapter_{cond_name}_sd14v1.pth')
-global_opt.device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
-global_opt.max_resolution = 512 * 512
-global_opt.sampler = 'ddim'
-global_opt.cond_weight = 1.0
-global_opt.C = 4
-global_opt.f = 8
-# adapters and models to processing condition inputs
-adapters = {}
-cond_models = {}
-torch.cuda.empty_cache()
-
-
-def draw_transfer(im1):
- c = im1[:, :, 0:3].astype(np.float32)
- a = im1[:, :, 3:4].astype(np.float32) / 255.0
- im1 = c * a + 255.0 * (1.0 - a)
- im1 = (im1.clip(0, 255)).astype(np.uint8)
-
- return im1
-
-class process:
- def __init__(self):
- self.base_model = 'v1-5-pruned-emaonly.ckpt'
- # stable-diffusion model
- self.sd_model, self.sampler = get_sd_models(global_opt)
-
- def run(self, *args):
- opt = copy.deepcopy(global_opt)
- opt.prompt, opt.neg_prompt, opt.scale, opt.n_samples, opt.seed, opt.steps, opt.resize_short_edge, opt.cond_tau, opt.base_model \
- = args[-9:]
- # check base model
- if opt.base_model!=self.base_model:
- ckpt = os.path.join("models", opt.base_model)
- pl_sd = read_state_dict(ckpt)
- if "state_dict" in pl_sd:
- pl_sd = pl_sd["state_dict"]
- else:
- pl_sd = pl_sd
- self.sd_model.load_state_dict(pl_sd, strict=False)
- del pl_sd
- self.base_model = opt.base_model
- if self.base_model!='v1-5-pruned-emaonly.ckpt' and self.base_model!='sd-v1-4.ckpt':
- vae_sd = torch.load(os.path.join('models', 'anything-v4.0.vae.pt'), map_location="cuda")
- st = vae_sd["state_dict"]
- self.sd_model.first_stage_model.load_state_dict(st, strict=False)
- del st
-
- with torch.inference_mode(), \
- self.sd_model.ema_scope(), \
- autocast('cuda'):
-
- inps = []
- for i in range(0, len(args) - 9, len(supported_cond)):
- inps.append(args[i:i + len(supported_cond)])
-
- conds = []
- activated_conds = []
-
- ims1 = []
- ims2 = []
- for idx, (b, im1, im2, cond_weight) in enumerate(zip(*inps)):
- if b != 'Nothing' and (im1 is not None or im2 is not None):
- if im1 is not None and isinstance(im1,dict):
- im1 = im1['mask']
- im1 = draw_transfer(im1)
-
- if im1 is not None:
- h, w, _ = im1.shape
- else:
- h, w, _ = im2.shape
-
- # resize all the images to the same size
- for idx, (b, im1, im2, cond_weight) in enumerate(zip(*inps)):
- if idx == 0:
- ims1.append(im1)
- ims2.append(im2)
- continue
- if b != 'Nothing':
- if im1 is not None and isinstance(im1,dict):
- im1 = im1['mask']
- im1 = draw_transfer(im1)
- im2 = im1
- cv2.imwrite('sketch.png', im1)
- if im1 is not None:
- im1 = cv2.resize(im1, (w, h), interpolation=cv2.INTER_CUBIC)
- if im2 is not None:
- im2 = cv2.resize(im2, (w, h), interpolation=cv2.INTER_CUBIC)
- ims1.append(im1)
- ims2.append(im2)
-
- for idx, (b, _, _, cond_weight) in enumerate(zip(*inps)):
- cond_name = supported_cond[idx]
- if b == 'Nothing':
- if cond_name in adapters:
- adapters[cond_name]['model'] = adapters[cond_name]['model'].to(opt.device)#.cpu()
- else:
- # print(idx,b)
- activated_conds.append(cond_name)
- if cond_name in adapters:
- adapters[cond_name]['model'] = adapters[cond_name]['model'].to(opt.device)
- else:
- adapters[cond_name] = get_adapters(opt, getattr(ExtraCondition, cond_name))
- adapters[cond_name]['cond_weight'] = cond_weight
-
- process_cond_module = getattr(api, f'get_cond_{cond_name}')
-
- if b == 'Image':
- if cond_name not in cond_models:
- cond_models[cond_name] = get_cond_model(opt, getattr(ExtraCondition, cond_name))
- conds.append(process_cond_module(opt, ims1[idx], 'image', cond_models[cond_name]))
- else:
- if idx == 2: # draw
- conds.append(process_cond_module(opt, (255.-ims2[idx]).astype(np.uint8), cond_name, None))
- else:
- conds.append(process_cond_module(opt, ims2[idx], cond_name, None))
-
- adapter_features, append_to_context = get_adapter_feature(
- conds, [adapters[cond_name] for cond_name in activated_conds])
-
- output_conds = []
- for cond in conds:
- output_conds.append(tensor2img(cond, rgb2bgr=False))
-
- ims = []
- seed_everything(opt.seed)
- for _ in range(opt.n_samples):
- result = diffusion_inference(opt, self.sd_model, self.sampler, adapter_features, append_to_context)
- ims.append(tensor2img(result, rgb2bgr=False))
-
- # Clear GPU memory cache so less likely to OOM
- torch.cuda.empty_cache()
- return ims, output_conds
-
-
-def change_visible(im1, im2, val):
- outputs = {}
- if val == "Image":
- outputs[im1] = gr.update(visible=True)
- outputs[im2] = gr.update(visible=False)
- elif val == "Nothing":
- outputs[im1] = gr.update(visible=False)
- outputs[im2] = gr.update(visible=False)
- else:
- outputs[im1] = gr.update(visible=False)
- outputs[im2] = gr.update(visible=True)
- return outputs
-
-DESCRIPTION = '# [T2I-Adapter](https://github.com/TencentARC/T2I-Adapter)'
-
-DESCRIPTION += f'
Gradio demo for **T2I-Adapter**: [[GitHub]](https://github.com/TencentARC/T2I-Adapter), [[Paper]](https://arxiv.org/abs/2302.08453). If T2I-Adapter is helpful, please help to ⭐ the [Github Repo](https://github.com/TencentARC/T2I-Adapter) and recommend it to your friends 😊
'
-
-DESCRIPTION += f'
For faster inference without waiting in queue, you may duplicate the space and upgrade to GPU in settings.
")
- with gr.Row():
- for cond_name in supported_cond_map[2:6]:
- with gr.Box():
- with gr.Column():
- if cond_name == 'openpose':
- btn1 = gr.Radio(
- choices=["Image", 'pose', "Nothing"],
- label=f"Input type for {cond_name}",
- interactive=True,
- value="Nothing",
- )
- else:
- btn1 = gr.Radio(
- choices=["Image", cond_name, "Nothing"],
- label=f"Input type for {cond_name}",
- interactive=True,
- value="Nothing",
- )
-
- im1 = gr.Image(
- source='upload', label="Image", interactive=True, visible=False, type="numpy")
- im2 = gr.Image(
- source='upload', label=cond_name, interactive=True, visible=False, type="numpy")
- cond_weight = gr.Slider(
- label="Condition weight",
- minimum=0,
- maximum=5,
- step=0.05,
- value=1,
- interactive=True)
-
- fn = partial(change_visible, im1, im2)
- btn1.change(fn=fn, inputs=[btn1], outputs=[im1, im2], queue=False)
- btns.append(btn1)
- ims1.append(im1)
- ims2.append(im2)
- cond_weights.append(cond_weight)
-
- with gr.Column():
- base_model = gr.inputs.Radio(['v1-5-pruned-emaonly.ckpt', 'sd-v1-4.ckpt', 'anything-v4.0-pruned.ckpt'], type="value", default='v1-5-pruned-emaonly.ckpt', label='The base model you want to use. You can try more base models on https://civitai.com/.')
- prompt = gr.Textbox(label="Prompt")
- with gr.Accordion('Advanced options', open=False):
- neg_prompt = gr.Textbox(label="Negative Prompt", value=DEFAULT_NEGATIVE_PROMPT)
- scale = gr.Slider(
- label="Guidance Scale (Classifier free guidance)", value=7.5, minimum=1, maximum=20, step=0.1)
- n_samples = gr.Slider(label="Num samples", value=1, minimum=1, maximum=1, step=1)
- seed = gr.Slider(label="Seed", value=42, minimum=0, maximum=10000, step=1, randomize=True)
- steps = gr.Slider(label="Steps", value=50, minimum=10, maximum=100, step=1)
- resize_short_edge = gr.Slider(label="Image resolution", value=512, minimum=320, maximum=1024, step=1)
- cond_tau = gr.Slider(
- label="timestamp parameter that determines until which step the adapter is applied",
- value=1.0,
- minimum=0.1,
- maximum=1.0,
- step=0.05)
- submit = gr.Button("Generate")
-
- with gr.Box():
- gr.Markdown("
Results
")
- with gr.Column():
- output = gr.Gallery().style(grid=2, height='auto')
- cond = gr.Gallery().style(grid=2, height='auto')
-
- inps = list(chain(btns, ims1, ims2, cond_weights))
-
- inps.extend([prompt, neg_prompt, scale, n_samples, seed, steps, resize_short_edge, cond_tau, base_model])
- submit.click(fn=processer.run, inputs=inps, outputs=[output, cond])
-
- ex = gr.Examples([
- [
- "Image",
- "Nothing",
- "Nothing",
- "Image",
- "Nothing",
- "Nothing",
- "Nothing",
- "cyber_style.jpg",
- "white.png",
- "white.png",
- "sword.png",
- "white.png",
- "white.png",
- "white.png",
- "white.png",
- "white.png",
- "white.png",
- "white.png",
- "white.png",
- "white.png",
- "white.png",
- 1,
- 1,
- 1,
- 1,
- 1,
- 1,
- 1,
- "master sword",
- "longbody, lowres, bad anatomy, bad hands, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality",
- 7.5,
- 1,
- 2500,
- 50,
- 512,
- 1,
- "v1-5-pruned-emaonly.ckpt",
- ],
- [
- "Image",
- "Nothing",
- "Nothing",
- "Image",
- "Nothing",
- "Nothing",
- "Nothing",
- "scream_style.jpeg",
- "white.png",
- "white.png",
- "motorcycle.jpg",
- "white.png",
- "white.png",
- "white.png",
- "white.png",
- "white.png",
- "white.png",
- "white.png",
- "white.png",
- "white.png",
- "white.png",
- 1,
- 1,
- 1,
- 1,
- 1,
- 1,
- 1,
- "motorcycle",
- "longbody, lowres, bad anatomy, bad hands, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality",
- 7.5,
- 1,
- 2500,
- 50,
- 512,
- 1,
- "v1-5-pruned-emaonly.ckpt",
- ],
- ],
- fn=processer.run,
- inputs=inps,
- outputs=[output, cond],
- cache_examples=True)
-
-demo.queue().launch(debug=True, server_name='0.0.0.0')
diff --git a/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/shake/Shake.js b/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/shake/Shake.js
deleted file mode 100644
index ed0e51eb660dd0102ab44c903a414a25df755768..0000000000000000000000000000000000000000
--- a/spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/shake/Shake.js
+++ /dev/null
@@ -1,2 +0,0 @@
-import Shake from '../../../plugins/shakeposition.js';
-export default Shake;
\ No newline at end of file
diff --git a/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/src/diffusers/pipelines/vq_diffusion/pipeline_vq_diffusion.py b/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/src/diffusers/pipelines/vq_diffusion/pipeline_vq_diffusion.py
deleted file mode 100644
index 1abe50a9b6b67485f5b29109dec02b9af0937846..0000000000000000000000000000000000000000
--- a/spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/src/diffusers/pipelines/vq_diffusion/pipeline_vq_diffusion.py
+++ /dev/null
@@ -1,325 +0,0 @@
-# Copyright 2023 Microsoft and The HuggingFace Team. All rights reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-from typing import Callable, List, Optional, Tuple, Union
-
-import torch
-from transformers import CLIPTextModel, CLIPTokenizer
-
-from ...configuration_utils import ConfigMixin, register_to_config
-from ...models import ModelMixin, Transformer2DModel, VQModel
-from ...schedulers import VQDiffusionScheduler
-from ...utils import logging
-from ..pipeline_utils import DiffusionPipeline, ImagePipelineOutput
-
-
-logger = logging.get_logger(__name__) # pylint: disable=invalid-name
-
-
-class LearnedClassifierFreeSamplingEmbeddings(ModelMixin, ConfigMixin):
- """
- Utility class for storing learned text embeddings for classifier free sampling
- """
-
- @register_to_config
- def __init__(self, learnable: bool, hidden_size: Optional[int] = None, length: Optional[int] = None):
- super().__init__()
-
- self.learnable = learnable
-
- if self.learnable:
- assert hidden_size is not None, "learnable=True requires `hidden_size` to be set"
- assert length is not None, "learnable=True requires `length` to be set"
-
- embeddings = torch.zeros(length, hidden_size)
- else:
- embeddings = None
-
- self.embeddings = torch.nn.Parameter(embeddings)
-
-
-class VQDiffusionPipeline(DiffusionPipeline):
- r"""
- Pipeline for text-to-image generation using VQ Diffusion.
-
- This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods
- implemented for all pipelines (downloading, saving, running on a particular device, etc.).
-
- Args:
- vqvae ([`VQModel`]):
- Vector Quantized Variational Auto-Encoder (VAE) model to encode and decode images to and from latent
- representations.
- text_encoder ([`~transformers.CLIPTextModel`]):
- Frozen text-encoder ([clip-vit-base-patch32](https://huggingface.co/openai/clip-vit-base-patch32)).
- tokenizer ([`~transformers.CLIPTokenizer`]):
- A `CLIPTokenizer` to tokenize text.
- transformer ([`Transformer2DModel`]):
- A conditional `Transformer2DModel` to denoise the encoded image latents.
- scheduler ([`VQDiffusionScheduler`]):
- A scheduler to be used in combination with `transformer` to denoise the encoded image latents.
- """
-
- vqvae: VQModel
- text_encoder: CLIPTextModel
- tokenizer: CLIPTokenizer
- transformer: Transformer2DModel
- learned_classifier_free_sampling_embeddings: LearnedClassifierFreeSamplingEmbeddings
- scheduler: VQDiffusionScheduler
-
- def __init__(
- self,
- vqvae: VQModel,
- text_encoder: CLIPTextModel,
- tokenizer: CLIPTokenizer,
- transformer: Transformer2DModel,
- scheduler: VQDiffusionScheduler,
- learned_classifier_free_sampling_embeddings: LearnedClassifierFreeSamplingEmbeddings,
- ):
- super().__init__()
-
- self.register_modules(
- vqvae=vqvae,
- transformer=transformer,
- text_encoder=text_encoder,
- tokenizer=tokenizer,
- scheduler=scheduler,
- learned_classifier_free_sampling_embeddings=learned_classifier_free_sampling_embeddings,
- )
-
- def _encode_prompt(self, prompt, num_images_per_prompt, do_classifier_free_guidance):
- batch_size = len(prompt) if isinstance(prompt, list) else 1
-
- # get prompt text embeddings
- text_inputs = self.tokenizer(
- prompt,
- padding="max_length",
- max_length=self.tokenizer.model_max_length,
- return_tensors="pt",
- )
- text_input_ids = text_inputs.input_ids
-
- if text_input_ids.shape[-1] > self.tokenizer.model_max_length:
- removed_text = self.tokenizer.batch_decode(text_input_ids[:, self.tokenizer.model_max_length :])
- logger.warning(
- "The following part of your input was truncated because CLIP can only handle sequences up to"
- f" {self.tokenizer.model_max_length} tokens: {removed_text}"
- )
- text_input_ids = text_input_ids[:, : self.tokenizer.model_max_length]
- prompt_embeds = self.text_encoder(text_input_ids.to(self.device))[0]
-
- # NOTE: This additional step of normalizing the text embeddings is from VQ-Diffusion.
- # While CLIP does normalize the pooled output of the text transformer when combining
- # the image and text embeddings, CLIP does not directly normalize the last hidden state.
- #
- # CLIP normalizing the pooled output.
- # https://github.com/huggingface/transformers/blob/d92e22d1f28324f513f3080e5c47c071a3916721/src/transformers/models/clip/modeling_clip.py#L1052-L1053
- prompt_embeds = prompt_embeds / prompt_embeds.norm(dim=-1, keepdim=True)
-
- # duplicate text embeddings for each generation per prompt
- prompt_embeds = prompt_embeds.repeat_interleave(num_images_per_prompt, dim=0)
-
- if do_classifier_free_guidance:
- if self.learned_classifier_free_sampling_embeddings.learnable:
- negative_prompt_embeds = self.learned_classifier_free_sampling_embeddings.embeddings
- negative_prompt_embeds = negative_prompt_embeds.unsqueeze(0).repeat(batch_size, 1, 1)
- else:
- uncond_tokens = [""] * batch_size
-
- max_length = text_input_ids.shape[-1]
- uncond_input = self.tokenizer(
- uncond_tokens,
- padding="max_length",
- max_length=max_length,
- truncation=True,
- return_tensors="pt",
- )
- negative_prompt_embeds = self.text_encoder(uncond_input.input_ids.to(self.device))[0]
- # See comment for normalizing text embeddings
- negative_prompt_embeds = negative_prompt_embeds / negative_prompt_embeds.norm(dim=-1, keepdim=True)
-
- # duplicate unconditional embeddings for each generation per prompt, using mps friendly method
- seq_len = negative_prompt_embeds.shape[1]
- negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
- negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
-
- # For classifier free guidance, we need to do two forward passes.
- # Here we concatenate the unconditional and text embeddings into a single batch
- # to avoid doing two forward passes
- prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
-
- return prompt_embeds
-
- @torch.no_grad()
- def __call__(
- self,
- prompt: Union[str, List[str]],
- num_inference_steps: int = 100,
- guidance_scale: float = 5.0,
- truncation_rate: float = 1.0,
- num_images_per_prompt: int = 1,
- generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
- latents: Optional[torch.FloatTensor] = None,
- output_type: Optional[str] = "pil",
- return_dict: bool = True,
- callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
- callback_steps: int = 1,
- ) -> Union[ImagePipelineOutput, Tuple]:
- """
- The call function to the pipeline for generation.
-
- Args:
- prompt (`str` or `List[str]`):
- The prompt or prompts to guide image generation.
- num_inference_steps (`int`, *optional*, defaults to 100):
- The number of denoising steps. More denoising steps usually lead to a higher quality image at the
- expense of slower inference.
- guidance_scale (`float`, *optional*, defaults to 7.5):
- A higher guidance scale value encourages the model to generate images closely linked to the text
- `prompt` at the expense of lower image quality. Guidance scale is enabled when `guidance_scale > 1`.
- truncation_rate (`float`, *optional*, defaults to 1.0 (equivalent to no truncation)):
- Used to "truncate" the predicted classes for x_0 such that the cumulative probability for a pixel is at
- most `truncation_rate`. The lowest probabilities that would increase the cumulative probability above
- `truncation_rate` are set to zero.
- num_images_per_prompt (`int`, *optional*, defaults to 1):
- The number of images to generate per prompt.
- generator (`torch.Generator`, *optional*):
- A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
- generation deterministic.
- latents (`torch.FloatTensor` of shape (batch), *optional*):
- Pre-generated noisy latents sampled from a Gaussian distribution, to be used as inputs for image
- generation. Must be valid embedding indices.If not provided, a latents tensor will be generated of
- completely masked latent pixels.
- output_type (`str`, *optional*, defaults to `"pil"`):
- The output format of the generated image. Choose between `PIL.Image` or `np.array`.
- return_dict (`bool`, *optional*, defaults to `True`):
- Whether or not to return a [`~pipelines.ImagePipelineOutput`] instead of a plain tuple.
- callback (`Callable`, *optional*):
- A function that calls every `callback_steps` steps during inference. The function is called with the
- following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
- callback_steps (`int`, *optional*, defaults to 1):
- The frequency at which the `callback` function is called. If not specified, the callback is called at
- every step.
-
- Returns:
- [`~pipelines.ImagePipelineOutput`] or `tuple`:
- If `return_dict` is `True`, [`~pipelines.ImagePipelineOutput`] is returned, otherwise a `tuple` is
- returned where the first element is a list with the generated images.
- """
- if isinstance(prompt, str):
- batch_size = 1
- elif isinstance(prompt, list):
- batch_size = len(prompt)
- else:
- raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
-
- batch_size = batch_size * num_images_per_prompt
-
- do_classifier_free_guidance = guidance_scale > 1.0
-
- prompt_embeds = self._encode_prompt(prompt, num_images_per_prompt, do_classifier_free_guidance)
-
- if (callback_steps is None) or (
- callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
- ):
- raise ValueError(
- f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
- f" {type(callback_steps)}."
- )
-
- # get the initial completely masked latents unless the user supplied it
-
- latents_shape = (batch_size, self.transformer.num_latent_pixels)
- if latents is None:
- mask_class = self.transformer.num_vector_embeds - 1
- latents = torch.full(latents_shape, mask_class).to(self.device)
- else:
- if latents.shape != latents_shape:
- raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {latents_shape}")
- if (latents < 0).any() or (latents >= self.transformer.num_vector_embeds).any():
- raise ValueError(
- "Unexpected latents value(s). All latents be valid embedding indices i.e. in the range 0,"
- f" {self.transformer.num_vector_embeds - 1} (inclusive)."
- )
- latents = latents.to(self.device)
-
- # set timesteps
- self.scheduler.set_timesteps(num_inference_steps, device=self.device)
-
- timesteps_tensor = self.scheduler.timesteps.to(self.device)
-
- sample = latents
-
- for i, t in enumerate(self.progress_bar(timesteps_tensor)):
- # expand the sample if we are doing classifier free guidance
- latent_model_input = torch.cat([sample] * 2) if do_classifier_free_guidance else sample
-
- # predict the un-noised image
- # model_output == `log_p_x_0`
- model_output = self.transformer(latent_model_input, encoder_hidden_states=prompt_embeds, timestep=t).sample
-
- if do_classifier_free_guidance:
- model_output_uncond, model_output_text = model_output.chunk(2)
- model_output = model_output_uncond + guidance_scale * (model_output_text - model_output_uncond)
- model_output -= torch.logsumexp(model_output, dim=1, keepdim=True)
-
- model_output = self.truncate(model_output, truncation_rate)
-
- # remove `log(0)`'s (`-inf`s)
- model_output = model_output.clamp(-70)
-
- # compute the previous noisy sample x_t -> x_t-1
- sample = self.scheduler.step(model_output, timestep=t, sample=sample, generator=generator).prev_sample
-
- # call the callback, if provided
- if callback is not None and i % callback_steps == 0:
- callback(i, t, sample)
-
- embedding_channels = self.vqvae.config.vq_embed_dim
- embeddings_shape = (batch_size, self.transformer.height, self.transformer.width, embedding_channels)
- embeddings = self.vqvae.quantize.get_codebook_entry(sample, shape=embeddings_shape)
- image = self.vqvae.decode(embeddings, force_not_quantize=True).sample
-
- image = (image / 2 + 0.5).clamp(0, 1)
- image = image.cpu().permute(0, 2, 3, 1).numpy()
-
- if output_type == "pil":
- image = self.numpy_to_pil(image)
-
- if not return_dict:
- return (image,)
-
- return ImagePipelineOutput(images=image)
-
- def truncate(self, log_p_x_0: torch.FloatTensor, truncation_rate: float) -> torch.FloatTensor:
- """
- Truncates `log_p_x_0` such that for each column vector, the total cumulative probability is `truncation_rate`
- The lowest probabilities that would increase the cumulative probability above `truncation_rate` are set to
- zero.
- """
- sorted_log_p_x_0, indices = torch.sort(log_p_x_0, 1, descending=True)
- sorted_p_x_0 = torch.exp(sorted_log_p_x_0)
- keep_mask = sorted_p_x_0.cumsum(dim=1) < truncation_rate
-
- # Ensure that at least the largest probability is not zeroed out
- all_true = torch.full_like(keep_mask[:, 0:1, :], True)
- keep_mask = torch.cat((all_true, keep_mask), dim=1)
- keep_mask = keep_mask[:, :-1, :]
-
- keep_mask = keep_mask.gather(1, indices.argsort(1))
-
- rv = log_p_x_0.clone()
-
- rv[~keep_mask] = -torch.inf # -inf = log(0)
-
- return rv
diff --git a/spaces/Andy1621/uniformer_image_detection/configs/cascade_rpn/crpn_fast_rcnn_r50_caffe_fpn_1x_coco.py b/spaces/Andy1621/uniformer_image_detection/configs/cascade_rpn/crpn_fast_rcnn_r50_caffe_fpn_1x_coco.py
deleted file mode 100644
index 68c57dfb242c6681cda6ead27929d6737c74fc45..0000000000000000000000000000000000000000
--- a/spaces/Andy1621/uniformer_image_detection/configs/cascade_rpn/crpn_fast_rcnn_r50_caffe_fpn_1x_coco.py
+++ /dev/null
@@ -1,75 +0,0 @@
-_base_ = '../fast_rcnn/fast_rcnn_r50_fpn_1x_coco.py'
-model = dict(
- pretrained='open-mmlab://detectron2/resnet50_caffe',
- backbone=dict(
- type='ResNet',
- depth=50,
- num_stages=4,
- out_indices=(0, 1, 2, 3),
- frozen_stages=1,
- norm_cfg=dict(type='BN', requires_grad=False),
- norm_eval=True,
- style='caffe'),
- roi_head=dict(
- bbox_head=dict(
- bbox_coder=dict(target_stds=[0.04, 0.04, 0.08, 0.08]),
- loss_cls=dict(
- type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.5),
- loss_bbox=dict(type='SmoothL1Loss', beta=1.0, loss_weight=1.0))),
- # model training and testing settings
- train_cfg=dict(
- rcnn=dict(
- assigner=dict(
- pos_iou_thr=0.65, neg_iou_thr=0.65, min_pos_iou=0.65),
- sampler=dict(num=256))),
- test_cfg=dict(rcnn=dict(score_thr=1e-3)))
-dataset_type = 'CocoDataset'
-data_root = 'data/coco/'
-img_norm_cfg = dict(
- mean=[103.530, 116.280, 123.675], std=[1.0, 1.0, 1.0], to_rgb=False)
-train_pipeline = [
- dict(type='LoadImageFromFile'),
- dict(type='LoadProposals', num_max_proposals=300),
- dict(type='LoadAnnotations', with_bbox=True),
- dict(type='Resize', img_scale=(1333, 800), keep_ratio=True),
- dict(type='RandomFlip', flip_ratio=0.5),
- dict(type='Normalize', **img_norm_cfg),
- dict(type='Pad', size_divisor=32),
- dict(type='DefaultFormatBundle'),
- dict(type='Collect', keys=['img', 'proposals', 'gt_bboxes', 'gt_labels']),
-]
-test_pipeline = [
- dict(type='LoadImageFromFile'),
- dict(type='LoadProposals', num_max_proposals=300),
- dict(
- type='MultiScaleFlipAug',
- img_scale=(1333, 800),
- flip=False,
- transforms=[
- dict(type='Resize', keep_ratio=True),
- dict(type='RandomFlip'),
- dict(type='Normalize', **img_norm_cfg),
- dict(type='Pad', size_divisor=32),
- dict(type='ImageToTensor', keys=['img']),
- dict(type='ToTensor', keys=['proposals']),
- dict(
- type='ToDataContainer',
- fields=[dict(key='proposals', stack=False)]),
- dict(type='Collect', keys=['img', 'proposals']),
- ])
-]
-data = dict(
- train=dict(
- proposal_file=data_root +
- 'proposals/crpn_r50_caffe_fpn_1x_train2017.pkl',
- pipeline=train_pipeline),
- val=dict(
- proposal_file=data_root +
- 'proposals/crpn_r50_caffe_fpn_1x_val2017.pkl',
- pipeline=test_pipeline),
- test=dict(
- proposal_file=data_root +
- 'proposals/crpn_r50_caffe_fpn_1x_val2017.pkl',
- pipeline=test_pipeline))
-optimizer_config = dict(
- _delete_=True, grad_clip=dict(max_norm=35, norm_type=2))
diff --git a/spaces/AnishKumbhar/ChatBot/text-generation-webui-main/docs/ExLlama.md b/spaces/AnishKumbhar/ChatBot/text-generation-webui-main/docs/ExLlama.md
deleted file mode 100644
index db0ebe63c90cf155e8b550e73a542d560ccb0b54..0000000000000000000000000000000000000000
--- a/spaces/AnishKumbhar/ChatBot/text-generation-webui-main/docs/ExLlama.md
+++ /dev/null
@@ -1,22 +0,0 @@
-# ExLlama
-
-### About
-
-ExLlama is an extremely optimized GPTQ backend for LLaMA models. It features much lower VRAM usage and much higher speeds due to not relying on unoptimized transformers code.
-
-### Usage
-
-Configure text-generation-webui to use exllama via the UI or command line:
- - In the "Model" tab, set "Loader" to "exllama"
- - Specify `--loader exllama` on the command line
-
-### Manual setup
-
-No additional installation steps are necessary since an exllama package is already included in the requirements.txt. If this package fails to install for some reason, you can install it manually by cloning the original repository into your `repositories/` folder:
-
-```
-mkdir repositories
-cd repositories
-git clone https://github.com/turboderp/exllama
-```
-
diff --git a/spaces/AnishKumbhar/ChatBot/text-generation-webui-main/js/switch_tabs.js b/spaces/AnishKumbhar/ChatBot/text-generation-webui-main/js/switch_tabs.js
deleted file mode 100644
index 75d563670dbd7a6d5e1b81eb5d38b025a868c01b..0000000000000000000000000000000000000000
--- a/spaces/AnishKumbhar/ChatBot/text-generation-webui-main/js/switch_tabs.js
+++ /dev/null
@@ -1,59 +0,0 @@
-let chat_tab = document.getElementById("chat-tab");
-let main_parent = chat_tab.parentNode;
-
-function scrollToTop() {
- window.scrollTo({
- top: 0,
- // behavior: 'smooth'
- });
-}
-
-function findButtonsByText(buttonText) {
- const buttons = document.getElementsByTagName("button");
- const matchingButtons = [];
- buttonText = buttonText.trim();
-
- for (let i = 0; i < buttons.length; i++) {
- const button = buttons[i];
- const buttonInnerText = button.textContent.trim();
-
- if (buttonInnerText === buttonText) {
- matchingButtons.push(button);
- }
- }
-
- return matchingButtons;
-}
-
-function switch_to_chat() {
- let chat_tab_button = main_parent.childNodes[0].childNodes[1];
- chat_tab_button.click();
- scrollToTop();
-}
-
-function switch_to_default() {
- let default_tab_button = main_parent.childNodes[0].childNodes[4];
- default_tab_button.click();
- scrollToTop();
-}
-
-function switch_to_notebook() {
- let notebook_tab_button = main_parent.childNodes[0].childNodes[7];
- notebook_tab_button.click();
- findButtonsByText("Raw")[1].click();
- scrollToTop();
-}
-
-function switch_to_generation_parameters() {
- let parameters_tab_button = main_parent.childNodes[0].childNodes[10];
- parameters_tab_button.click();
- findButtonsByText("Generation")[0].click();
- scrollToTop();
-}
-
-function switch_to_character() {
- let parameters_tab_button = main_parent.childNodes[0].childNodes[10];
- parameters_tab_button.click();
- findButtonsByText("Character")[0].click();
- scrollToTop();
-}
diff --git a/spaces/Anonymous-sub/Rerender/ControlNet/ldm/modules/midas/midas/blocks.py b/spaces/Anonymous-sub/Rerender/ControlNet/ldm/modules/midas/midas/blocks.py
deleted file mode 100644
index 2145d18fa98060a618536d9a64fe6589e9be4f78..0000000000000000000000000000000000000000
--- a/spaces/Anonymous-sub/Rerender/ControlNet/ldm/modules/midas/midas/blocks.py
+++ /dev/null
@@ -1,342 +0,0 @@
-import torch
-import torch.nn as nn
-
-from .vit import (
- _make_pretrained_vitb_rn50_384,
- _make_pretrained_vitl16_384,
- _make_pretrained_vitb16_384,
- forward_vit,
-)
-
-def _make_encoder(backbone, features, use_pretrained, groups=1, expand=False, exportable=True, hooks=None, use_vit_only=False, use_readout="ignore",):
- if backbone == "vitl16_384":
- pretrained = _make_pretrained_vitl16_384(
- use_pretrained, hooks=hooks, use_readout=use_readout
- )
- scratch = _make_scratch(
- [256, 512, 1024, 1024], features, groups=groups, expand=expand
- ) # ViT-L/16 - 85.0% Top1 (backbone)
- elif backbone == "vitb_rn50_384":
- pretrained = _make_pretrained_vitb_rn50_384(
- use_pretrained,
- hooks=hooks,
- use_vit_only=use_vit_only,
- use_readout=use_readout,
- )
- scratch = _make_scratch(
- [256, 512, 768, 768], features, groups=groups, expand=expand
- ) # ViT-H/16 - 85.0% Top1 (backbone)
- elif backbone == "vitb16_384":
- pretrained = _make_pretrained_vitb16_384(
- use_pretrained, hooks=hooks, use_readout=use_readout
- )
- scratch = _make_scratch(
- [96, 192, 384, 768], features, groups=groups, expand=expand
- ) # ViT-B/16 - 84.6% Top1 (backbone)
- elif backbone == "resnext101_wsl":
- pretrained = _make_pretrained_resnext101_wsl(use_pretrained)
- scratch = _make_scratch([256, 512, 1024, 2048], features, groups=groups, expand=expand) # efficientnet_lite3
- elif backbone == "efficientnet_lite3":
- pretrained = _make_pretrained_efficientnet_lite3(use_pretrained, exportable=exportable)
- scratch = _make_scratch([32, 48, 136, 384], features, groups=groups, expand=expand) # efficientnet_lite3
- else:
- print(f"Backbone '{backbone}' not implemented")
- assert False
-
- return pretrained, scratch
-
-
-def _make_scratch(in_shape, out_shape, groups=1, expand=False):
- scratch = nn.Module()
-
- out_shape1 = out_shape
- out_shape2 = out_shape
- out_shape3 = out_shape
- out_shape4 = out_shape
- if expand==True:
- out_shape1 = out_shape
- out_shape2 = out_shape*2
- out_shape3 = out_shape*4
- out_shape4 = out_shape*8
-
- scratch.layer1_rn = nn.Conv2d(
- in_shape[0], out_shape1, kernel_size=3, stride=1, padding=1, bias=False, groups=groups
- )
- scratch.layer2_rn = nn.Conv2d(
- in_shape[1], out_shape2, kernel_size=3, stride=1, padding=1, bias=False, groups=groups
- )
- scratch.layer3_rn = nn.Conv2d(
- in_shape[2], out_shape3, kernel_size=3, stride=1, padding=1, bias=False, groups=groups
- )
- scratch.layer4_rn = nn.Conv2d(
- in_shape[3], out_shape4, kernel_size=3, stride=1, padding=1, bias=False, groups=groups
- )
-
- return scratch
-
-
-def _make_pretrained_efficientnet_lite3(use_pretrained, exportable=False):
- efficientnet = torch.hub.load(
- "rwightman/gen-efficientnet-pytorch",
- "tf_efficientnet_lite3",
- pretrained=use_pretrained,
- exportable=exportable
- )
- return _make_efficientnet_backbone(efficientnet)
-
-
-def _make_efficientnet_backbone(effnet):
- pretrained = nn.Module()
-
- pretrained.layer1 = nn.Sequential(
- effnet.conv_stem, effnet.bn1, effnet.act1, *effnet.blocks[0:2]
- )
- pretrained.layer2 = nn.Sequential(*effnet.blocks[2:3])
- pretrained.layer3 = nn.Sequential(*effnet.blocks[3:5])
- pretrained.layer4 = nn.Sequential(*effnet.blocks[5:9])
-
- return pretrained
-
-
-def _make_resnet_backbone(resnet):
- pretrained = nn.Module()
- pretrained.layer1 = nn.Sequential(
- resnet.conv1, resnet.bn1, resnet.relu, resnet.maxpool, resnet.layer1
- )
-
- pretrained.layer2 = resnet.layer2
- pretrained.layer3 = resnet.layer3
- pretrained.layer4 = resnet.layer4
-
- return pretrained
-
-
-def _make_pretrained_resnext101_wsl(use_pretrained):
- resnet = torch.hub.load("facebookresearch/WSL-Images", "resnext101_32x8d_wsl")
- return _make_resnet_backbone(resnet)
-
-
-
-class Interpolate(nn.Module):
- """Interpolation module.
- """
-
- def __init__(self, scale_factor, mode, align_corners=False):
- """Init.
-
- Args:
- scale_factor (float): scaling
- mode (str): interpolation mode
- """
- super(Interpolate, self).__init__()
-
- self.interp = nn.functional.interpolate
- self.scale_factor = scale_factor
- self.mode = mode
- self.align_corners = align_corners
-
- def forward(self, x):
- """Forward pass.
-
- Args:
- x (tensor): input
-
- Returns:
- tensor: interpolated data
- """
-
- x = self.interp(
- x, scale_factor=self.scale_factor, mode=self.mode, align_corners=self.align_corners
- )
-
- return x
-
-
-class ResidualConvUnit(nn.Module):
- """Residual convolution module.
- """
-
- def __init__(self, features):
- """Init.
-
- Args:
- features (int): number of features
- """
- super().__init__()
-
- self.conv1 = nn.Conv2d(
- features, features, kernel_size=3, stride=1, padding=1, bias=True
- )
-
- self.conv2 = nn.Conv2d(
- features, features, kernel_size=3, stride=1, padding=1, bias=True
- )
-
- self.relu = nn.ReLU(inplace=True)
-
- def forward(self, x):
- """Forward pass.
-
- Args:
- x (tensor): input
-
- Returns:
- tensor: output
- """
- out = self.relu(x)
- out = self.conv1(out)
- out = self.relu(out)
- out = self.conv2(out)
-
- return out + x
-
-
-class FeatureFusionBlock(nn.Module):
- """Feature fusion block.
- """
-
- def __init__(self, features):
- """Init.
-
- Args:
- features (int): number of features
- """
- super(FeatureFusionBlock, self).__init__()
-
- self.resConfUnit1 = ResidualConvUnit(features)
- self.resConfUnit2 = ResidualConvUnit(features)
-
- def forward(self, *xs):
- """Forward pass.
-
- Returns:
- tensor: output
- """
- output = xs[0]
-
- if len(xs) == 2:
- output += self.resConfUnit1(xs[1])
-
- output = self.resConfUnit2(output)
-
- output = nn.functional.interpolate(
- output, scale_factor=2, mode="bilinear", align_corners=True
- )
-
- return output
-
-
-
-
-class ResidualConvUnit_custom(nn.Module):
- """Residual convolution module.
- """
-
- def __init__(self, features, activation, bn):
- """Init.
-
- Args:
- features (int): number of features
- """
- super().__init__()
-
- self.bn = bn
-
- self.groups=1
-
- self.conv1 = nn.Conv2d(
- features, features, kernel_size=3, stride=1, padding=1, bias=True, groups=self.groups
- )
-
- self.conv2 = nn.Conv2d(
- features, features, kernel_size=3, stride=1, padding=1, bias=True, groups=self.groups
- )
-
- if self.bn==True:
- self.bn1 = nn.BatchNorm2d(features)
- self.bn2 = nn.BatchNorm2d(features)
-
- self.activation = activation
-
- self.skip_add = nn.quantized.FloatFunctional()
-
- def forward(self, x):
- """Forward pass.
-
- Args:
- x (tensor): input
-
- Returns:
- tensor: output
- """
-
- out = self.activation(x)
- out = self.conv1(out)
- if self.bn==True:
- out = self.bn1(out)
-
- out = self.activation(out)
- out = self.conv2(out)
- if self.bn==True:
- out = self.bn2(out)
-
- if self.groups > 1:
- out = self.conv_merge(out)
-
- return self.skip_add.add(out, x)
-
- # return out + x
-
-
-class FeatureFusionBlock_custom(nn.Module):
- """Feature fusion block.
- """
-
- def __init__(self, features, activation, deconv=False, bn=False, expand=False, align_corners=True):
- """Init.
-
- Args:
- features (int): number of features
- """
- super(FeatureFusionBlock_custom, self).__init__()
-
- self.deconv = deconv
- self.align_corners = align_corners
-
- self.groups=1
-
- self.expand = expand
- out_features = features
- if self.expand==True:
- out_features = features//2
-
- self.out_conv = nn.Conv2d(features, out_features, kernel_size=1, stride=1, padding=0, bias=True, groups=1)
-
- self.resConfUnit1 = ResidualConvUnit_custom(features, activation, bn)
- self.resConfUnit2 = ResidualConvUnit_custom(features, activation, bn)
-
- self.skip_add = nn.quantized.FloatFunctional()
-
- def forward(self, *xs):
- """Forward pass.
-
- Returns:
- tensor: output
- """
- output = xs[0]
-
- if len(xs) == 2:
- res = self.resConfUnit1(xs[1])
- output = self.skip_add.add(output, res)
- # output += res
-
- output = self.resConfUnit2(output)
-
- output = nn.functional.interpolate(
- output, scale_factor=2, mode="bilinear", align_corners=self.align_corners
- )
-
- output = self.out_conv(output)
-
- return output
-
diff --git a/spaces/Arikkod/FoodVisionMini/app.py b/spaces/Arikkod/FoodVisionMini/app.py
deleted file mode 100644
index eae29e16c7c067911a1b2906a99ab36cc62d05b2..0000000000000000000000000000000000000000
--- a/spaces/Arikkod/FoodVisionMini/app.py
+++ /dev/null
@@ -1,51 +0,0 @@
-import gradio as gr
-import os
-import torch
-from model import create_effnetb2_model
-from timeit import default_timer as timer
-from typing import Tuple, Dict
-
-class_names = ['pizza', 'steak', 'sushi']
-effnetb2, effnetb2_transforms = create_effnetb2_model(3, 42)
-# Load save weights:
-effnetb2.load_state_dict(
- torch.load(f='09_pretrained_effnetb2_feature_extractor_pizza_steak_sushi_20_precent.pth',
- map_location=torch.device('cpu')
- )
-)
-
-def predict(img):
- # Start a timer
- start_time = timer()
- # Transform the input image for use wit EffNetB2
- img = effnetb2_transforms(img).unsqueeze(0)
- # Put model into eval mode, make prediction
- effnetb2.eval()
- with torch.inference_mode():
- pred_probs = torch.softmax(effnetb2(img), dim=1)
- # Create a prediction labal and prediction probability dictionary
- pred_labels_and_probs = {class_names[i]:float(pred_probs[0][i]) for i in range(len(class_names))}
- # Calculated pred time
- end_time = timer()
- pred_time = round(end_time - start_time, 4)
- # Return pred dict and pred time
- return pred_labels_and_probs, pred_time
-
-
-title = 'FoodVision Mini 🍕🥩🍣'
-description = 'An [EfficientNetB2 feature extractor](https://pytorch.org/vision/main/models/generated/torchvision.models.efficientnet_b2.html)'
-article = 'Created with Pytorch model deployment'
-example_list = [["./examples/" + file] for file in os.listdir("./examples")]
-
-demo = gr.Interface(fn=predict,
- inputs=gr.Image(type='pil'),
- outputs=[gr.Label(num_top_classes=3, label='Predictions'),
- gr.Number(label='Prediction time (s)')],
- examples=example_list,
- title=title,
- description=description,
- article=article
- )
-
-demo.launch(debug=False,
- share=False)
diff --git a/spaces/Arthur678/vits-uma-genshin-honkai/modules.py b/spaces/Arthur678/vits-uma-genshin-honkai/modules.py
deleted file mode 100644
index 56ea4145eddf19dd330a3a41ab0183efc1686d83..0000000000000000000000000000000000000000
--- a/spaces/Arthur678/vits-uma-genshin-honkai/modules.py
+++ /dev/null
@@ -1,388 +0,0 @@
-import math
-import numpy as np
-import torch
-from torch import nn
-from torch.nn import functional as F
-
-from torch.nn import Conv1d, ConvTranspose1d, AvgPool1d, Conv2d
-from torch.nn.utils import weight_norm, remove_weight_norm
-
-import commons
-from commons import init_weights, get_padding
-from transforms import piecewise_rational_quadratic_transform
-
-
-LRELU_SLOPE = 0.1
-
-
-class LayerNorm(nn.Module):
- def __init__(self, channels, eps=1e-5):
- super().__init__()
- self.channels = channels
- self.eps = eps
-
- self.gamma = nn.Parameter(torch.ones(channels))
- self.beta = nn.Parameter(torch.zeros(channels))
-
- def forward(self, x):
- x = x.transpose(1, -1)
- x = F.layer_norm(x, (self.channels,), self.gamma, self.beta, self.eps)
- return x.transpose(1, -1)
-
-
-class ConvReluNorm(nn.Module):
- def __init__(self, in_channels, hidden_channels, out_channels, kernel_size, n_layers, p_dropout):
- super().__init__()
- self.in_channels = in_channels
- self.hidden_channels = hidden_channels
- self.out_channels = out_channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.p_dropout = p_dropout
- assert n_layers > 1, "Number of layers should be larger than 0."
-
- self.conv_layers = nn.ModuleList()
- self.norm_layers = nn.ModuleList()
- self.conv_layers.append(nn.Conv1d(in_channels, hidden_channels, kernel_size, padding=kernel_size//2))
- self.norm_layers.append(LayerNorm(hidden_channels))
- self.relu_drop = nn.Sequential(
- nn.ReLU(),
- nn.Dropout(p_dropout))
- for _ in range(n_layers-1):
- self.conv_layers.append(nn.Conv1d(hidden_channels, hidden_channels, kernel_size, padding=kernel_size//2))
- self.norm_layers.append(LayerNorm(hidden_channels))
- self.proj = nn.Conv1d(hidden_channels, out_channels, 1)
- self.proj.weight.data.zero_()
- self.proj.bias.data.zero_()
-
- def forward(self, x, x_mask):
- x_org = x
- for i in range(self.n_layers):
- x = self.conv_layers[i](x * x_mask)
- x = self.norm_layers[i](x)
- x = self.relu_drop(x)
- x = x_org + self.proj(x)
- return x * x_mask
-
-
-class DDSConv(nn.Module):
- """
- Dialted and Depth-Separable Convolution
- """
- def __init__(self, channels, kernel_size, n_layers, p_dropout=0.):
- super().__init__()
- self.channels = channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.p_dropout = p_dropout
-
- self.drop = nn.Dropout(p_dropout)
- self.convs_sep = nn.ModuleList()
- self.convs_1x1 = nn.ModuleList()
- self.norms_1 = nn.ModuleList()
- self.norms_2 = nn.ModuleList()
- for i in range(n_layers):
- dilation = kernel_size ** i
- padding = (kernel_size * dilation - dilation) // 2
- self.convs_sep.append(nn.Conv1d(channels, channels, kernel_size,
- groups=channels, dilation=dilation, padding=padding
- ))
- self.convs_1x1.append(nn.Conv1d(channels, channels, 1))
- self.norms_1.append(LayerNorm(channels))
- self.norms_2.append(LayerNorm(channels))
-
- def forward(self, x, x_mask, g=None):
- if g is not None:
- x = x + g
- for i in range(self.n_layers):
- y = self.convs_sep[i](x * x_mask)
- y = self.norms_1[i](y)
- y = F.gelu(y)
- y = self.convs_1x1[i](y)
- y = self.norms_2[i](y)
- y = F.gelu(y)
- y = self.drop(y)
- x = x + y
- return x * x_mask
-
-
-class WN(torch.nn.Module):
- def __init__(self, hidden_channels, kernel_size, dilation_rate, n_layers, gin_channels=0, p_dropout=0):
- super(WN, self).__init__()
- assert(kernel_size % 2 == 1)
- self.hidden_channels =hidden_channels
- self.kernel_size = kernel_size,
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.gin_channels = gin_channels
- self.p_dropout = p_dropout
-
- self.in_layers = torch.nn.ModuleList()
- self.res_skip_layers = torch.nn.ModuleList()
- self.drop = nn.Dropout(p_dropout)
-
- if gin_channels != 0:
- cond_layer = torch.nn.Conv1d(gin_channels, 2*hidden_channels*n_layers, 1)
- self.cond_layer = torch.nn.utils.weight_norm(cond_layer, name='weight')
-
- for i in range(n_layers):
- dilation = dilation_rate ** i
- padding = int((kernel_size * dilation - dilation) / 2)
- in_layer = torch.nn.Conv1d(hidden_channels, 2*hidden_channels, kernel_size,
- dilation=dilation, padding=padding)
- in_layer = torch.nn.utils.weight_norm(in_layer, name='weight')
- self.in_layers.append(in_layer)
-
- # last one is not necessary
- if i < n_layers - 1:
- res_skip_channels = 2 * hidden_channels
- else:
- res_skip_channels = hidden_channels
-
- res_skip_layer = torch.nn.Conv1d(hidden_channels, res_skip_channels, 1)
- res_skip_layer = torch.nn.utils.weight_norm(res_skip_layer, name='weight')
- self.res_skip_layers.append(res_skip_layer)
-
- def forward(self, x, x_mask, g=None, **kwargs):
- output = torch.zeros_like(x)
- n_channels_tensor = torch.IntTensor([self.hidden_channels])
-
- if g is not None:
- g = self.cond_layer(g)
-
- for i in range(self.n_layers):
- x_in = self.in_layers[i](x)
- if g is not None:
- cond_offset = i * 2 * self.hidden_channels
- g_l = g[:,cond_offset:cond_offset+2*self.hidden_channels,:]
- else:
- g_l = torch.zeros_like(x_in)
-
- acts = commons.fused_add_tanh_sigmoid_multiply(
- x_in,
- g_l,
- n_channels_tensor)
- acts = self.drop(acts)
-
- res_skip_acts = self.res_skip_layers[i](acts)
- if i < self.n_layers - 1:
- res_acts = res_skip_acts[:,:self.hidden_channels,:]
- x = (x + res_acts) * x_mask
- output = output + res_skip_acts[:,self.hidden_channels:,:]
- else:
- output = output + res_skip_acts
- return output * x_mask
-
- def remove_weight_norm(self):
- if self.gin_channels != 0:
- torch.nn.utils.remove_weight_norm(self.cond_layer)
- for l in self.in_layers:
- torch.nn.utils.remove_weight_norm(l)
- for l in self.res_skip_layers:
- torch.nn.utils.remove_weight_norm(l)
-
-
-class ResBlock1(torch.nn.Module):
- def __init__(self, channels, kernel_size=3, dilation=(1, 3, 5)):
- super(ResBlock1, self).__init__()
- self.convs1 = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
- padding=get_padding(kernel_size, dilation[0]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
- padding=get_padding(kernel_size, dilation[1]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[2],
- padding=get_padding(kernel_size, dilation[2])))
- ])
- self.convs1.apply(init_weights)
-
- self.convs2 = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1)))
- ])
- self.convs2.apply(init_weights)
-
- def forward(self, x, x_mask=None):
- for c1, c2 in zip(self.convs1, self.convs2):
- xt = F.leaky_relu(x, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c1(xt)
- xt = F.leaky_relu(xt, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c2(xt)
- x = xt + x
- if x_mask is not None:
- x = x * x_mask
- return x
-
- def remove_weight_norm(self):
- for l in self.convs1:
- remove_weight_norm(l)
- for l in self.convs2:
- remove_weight_norm(l)
-
-
-class ResBlock2(torch.nn.Module):
- def __init__(self, channels, kernel_size=3, dilation=(1, 3)):
- super(ResBlock2, self).__init__()
- self.convs = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
- padding=get_padding(kernel_size, dilation[0]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
- padding=get_padding(kernel_size, dilation[1])))
- ])
- self.convs.apply(init_weights)
-
- def forward(self, x, x_mask=None):
- for c in self.convs:
- xt = F.leaky_relu(x, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c(xt)
- x = xt + x
- if x_mask is not None:
- x = x * x_mask
- return x
-
- def remove_weight_norm(self):
- for l in self.convs:
- remove_weight_norm(l)
-
-
-class Log(nn.Module):
- def forward(self, x, x_mask, reverse=False, **kwargs):
- if not reverse:
- y = torch.log(torch.clamp_min(x, 1e-5)) * x_mask
- logdet = torch.sum(-y, [1, 2])
- return y, logdet
- else:
- x = torch.exp(x) * x_mask
- return x
-
-
-class Flip(nn.Module):
- def forward(self, x, *args, reverse=False, **kwargs):
- x = torch.flip(x, [1])
- if not reverse:
- logdet = torch.zeros(x.size(0)).to(dtype=x.dtype, device=x.device)
- return x, logdet
- else:
- return x
-
-
-class ElementwiseAffine(nn.Module):
- def __init__(self, channels):
- super().__init__()
- self.channels = channels
- self.m = nn.Parameter(torch.zeros(channels,1))
- self.logs = nn.Parameter(torch.zeros(channels,1))
-
- def forward(self, x, x_mask, reverse=False, **kwargs):
- if not reverse:
- y = self.m + torch.exp(self.logs) * x
- y = y * x_mask
- logdet = torch.sum(self.logs * x_mask, [1,2])
- return y, logdet
- else:
- x = (x - self.m) * torch.exp(-self.logs) * x_mask
- return x
-
-
-class ResidualCouplingLayer(nn.Module):
- def __init__(self,
- channels,
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- p_dropout=0,
- gin_channels=0,
- mean_only=False):
- assert channels % 2 == 0, "channels should be divisible by 2"
- super().__init__()
- self.channels = channels
- self.hidden_channels = hidden_channels
- self.kernel_size = kernel_size
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.half_channels = channels // 2
- self.mean_only = mean_only
-
- self.pre = nn.Conv1d(self.half_channels, hidden_channels, 1)
- self.enc = WN(hidden_channels, kernel_size, dilation_rate, n_layers, p_dropout=p_dropout, gin_channels=gin_channels)
- self.post = nn.Conv1d(hidden_channels, self.half_channels * (2 - mean_only), 1)
- self.post.weight.data.zero_()
- self.post.bias.data.zero_()
-
- def forward(self, x, x_mask, g=None, reverse=False):
- x0, x1 = torch.split(x, [self.half_channels]*2, 1)
- h = self.pre(x0) * x_mask
- h = self.enc(h, x_mask, g=g)
- stats = self.post(h) * x_mask
- if not self.mean_only:
- m, logs = torch.split(stats, [self.half_channels]*2, 1)
- else:
- m = stats
- logs = torch.zeros_like(m)
-
- if not reverse:
- x1 = m + x1 * torch.exp(logs) * x_mask
- x = torch.cat([x0, x1], 1)
- logdet = torch.sum(logs, [1,2])
- return x, logdet
- else:
- x1 = (x1 - m) * torch.exp(-logs) * x_mask
- x = torch.cat([x0, x1], 1)
- return x
-
-
-class ConvFlow(nn.Module):
- def __init__(self, in_channels, filter_channels, kernel_size, n_layers, num_bins=10, tail_bound=5.0):
- super().__init__()
- self.in_channels = in_channels
- self.filter_channels = filter_channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.num_bins = num_bins
- self.tail_bound = tail_bound
- self.half_channels = in_channels // 2
-
- self.pre = nn.Conv1d(self.half_channels, filter_channels, 1)
- self.convs = DDSConv(filter_channels, kernel_size, n_layers, p_dropout=0.)
- self.proj = nn.Conv1d(filter_channels, self.half_channels * (num_bins * 3 - 1), 1)
- self.proj.weight.data.zero_()
- self.proj.bias.data.zero_()
-
- def forward(self, x, x_mask, g=None, reverse=False):
- x0, x1 = torch.split(x, [self.half_channels]*2, 1)
- h = self.pre(x0)
- h = self.convs(h, x_mask, g=g)
- h = self.proj(h) * x_mask
-
- b, c, t = x0.shape
- h = h.reshape(b, c, -1, t).permute(0, 1, 3, 2) # [b, cx?, t] -> [b, c, t, ?]
-
- unnormalized_widths = h[..., :self.num_bins] / math.sqrt(self.filter_channels)
- unnormalized_heights = h[..., self.num_bins:2*self.num_bins] / math.sqrt(self.filter_channels)
- unnormalized_derivatives = h[..., 2 * self.num_bins:]
-
- x1, logabsdet = piecewise_rational_quadratic_transform(x1,
- unnormalized_widths,
- unnormalized_heights,
- unnormalized_derivatives,
- inverse=reverse,
- tails='linear',
- tail_bound=self.tail_bound
- )
-
- x = torch.cat([x0, x1], 1) * x_mask
- logdet = torch.sum(logabsdet * x_mask, [1,2])
- if not reverse:
- return x, logdet
- else:
- return x
diff --git a/spaces/Arulkumar03/GroundingDINO_SOTA_Zero_Shot_Model/groundingdino/models/GroundingDINO/csrc/MsDeformAttn/ms_deform_attn_cpu.cpp b/spaces/Arulkumar03/GroundingDINO_SOTA_Zero_Shot_Model/groundingdino/models/GroundingDINO/csrc/MsDeformAttn/ms_deform_attn_cpu.cpp
deleted file mode 100644
index 551243fdadfd1682b5dc6628623b67a79b3f6c74..0000000000000000000000000000000000000000
--- a/spaces/Arulkumar03/GroundingDINO_SOTA_Zero_Shot_Model/groundingdino/models/GroundingDINO/csrc/MsDeformAttn/ms_deform_attn_cpu.cpp
+++ /dev/null
@@ -1,43 +0,0 @@
-/*!
-**************************************************************************************************
-* Deformable DETR
-* Copyright (c) 2020 SenseTime. All Rights Reserved.
-* Licensed under the Apache License, Version 2.0 [see LICENSE for details]
-**************************************************************************************************
-* Modified from https://github.com/chengdazhi/Deformable-Convolution-V2-PyTorch/tree/pytorch_1.0.0
-**************************************************************************************************
-*/
-
-#include
-
-#include
-#include
-
-namespace groundingdino {
-
-at::Tensor
-ms_deform_attn_cpu_forward(
- const at::Tensor &value,
- const at::Tensor &spatial_shapes,
- const at::Tensor &level_start_index,
- const at::Tensor &sampling_loc,
- const at::Tensor &attn_weight,
- const int im2col_step)
-{
- AT_ERROR("Not implement on cpu");
-}
-
-std::vector
-ms_deform_attn_cpu_backward(
- const at::Tensor &value,
- const at::Tensor &spatial_shapes,
- const at::Tensor &level_start_index,
- const at::Tensor &sampling_loc,
- const at::Tensor &attn_weight,
- const at::Tensor &grad_output,
- const int im2col_step)
-{
- AT_ERROR("Not implement on cpu");
-}
-
-} // namespace groundingdino
diff --git a/spaces/Ataturk-Chatbot/HuggingFaceChat/README.md b/spaces/Ataturk-Chatbot/HuggingFaceChat/README.md
deleted file mode 100644
index 8013b939f020321c3ade76f59daacead5fcd69e7..0000000000000000000000000000000000000000
--- a/spaces/Ataturk-Chatbot/HuggingFaceChat/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: HuggingFaceChat
-emoji: 🚀
-colorFrom: indigo
-colorTo: red
-sdk: gradio
-sdk_version: 3.50.2
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/pip/_internal/commands/configuration.py b/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/pip/_internal/commands/configuration.py
deleted file mode 100644
index 84b134e490b081d661daf69f98e0b9b1fdddd36f..0000000000000000000000000000000000000000
--- a/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/pip/_internal/commands/configuration.py
+++ /dev/null
@@ -1,282 +0,0 @@
-import logging
-import os
-import subprocess
-from optparse import Values
-from typing import Any, List, Optional
-
-from pip._internal.cli.base_command import Command
-from pip._internal.cli.status_codes import ERROR, SUCCESS
-from pip._internal.configuration import (
- Configuration,
- Kind,
- get_configuration_files,
- kinds,
-)
-from pip._internal.exceptions import PipError
-from pip._internal.utils.logging import indent_log
-from pip._internal.utils.misc import get_prog, write_output
-
-logger = logging.getLogger(__name__)
-
-
-class ConfigurationCommand(Command):
- """
- Manage local and global configuration.
-
- Subcommands:
-
- - list: List the active configuration (or from the file specified)
- - edit: Edit the configuration file in an editor
- - get: Get the value associated with command.option
- - set: Set the command.option=value
- - unset: Unset the value associated with command.option
- - debug: List the configuration files and values defined under them
-
- Configuration keys should be dot separated command and option name,
- with the special prefix "global" affecting any command. For example,
- "pip config set global.index-url https://example.org/" would configure
- the index url for all commands, but "pip config set download.timeout 10"
- would configure a 10 second timeout only for "pip download" commands.
-
- If none of --user, --global and --site are passed, a virtual
- environment configuration file is used if one is active and the file
- exists. Otherwise, all modifications happen to the user file by
- default.
- """
-
- ignore_require_venv = True
- usage = """
- %prog [] list
- %prog [] [--editor ] edit
-
- %prog [] get command.option
- %prog [] set command.option value
- %prog [] unset command.option
- %prog [] debug
- """
-
- def add_options(self) -> None:
- self.cmd_opts.add_option(
- "--editor",
- dest="editor",
- action="store",
- default=None,
- help=(
- "Editor to use to edit the file. Uses VISUAL or EDITOR "
- "environment variables if not provided."
- ),
- )
-
- self.cmd_opts.add_option(
- "--global",
- dest="global_file",
- action="store_true",
- default=False,
- help="Use the system-wide configuration file only",
- )
-
- self.cmd_opts.add_option(
- "--user",
- dest="user_file",
- action="store_true",
- default=False,
- help="Use the user configuration file only",
- )
-
- self.cmd_opts.add_option(
- "--site",
- dest="site_file",
- action="store_true",
- default=False,
- help="Use the current environment configuration file only",
- )
-
- self.parser.insert_option_group(0, self.cmd_opts)
-
- def run(self, options: Values, args: List[str]) -> int:
- handlers = {
- "list": self.list_values,
- "edit": self.open_in_editor,
- "get": self.get_name,
- "set": self.set_name_value,
- "unset": self.unset_name,
- "debug": self.list_config_values,
- }
-
- # Determine action
- if not args or args[0] not in handlers:
- logger.error(
- "Need an action (%s) to perform.",
- ", ".join(sorted(handlers)),
- )
- return ERROR
-
- action = args[0]
-
- # Determine which configuration files are to be loaded
- # Depends on whether the command is modifying.
- try:
- load_only = self._determine_file(
- options, need_value=(action in ["get", "set", "unset", "edit"])
- )
- except PipError as e:
- logger.error(e.args[0])
- return ERROR
-
- # Load a new configuration
- self.configuration = Configuration(
- isolated=options.isolated_mode, load_only=load_only
- )
- self.configuration.load()
-
- # Error handling happens here, not in the action-handlers.
- try:
- handlers[action](options, args[1:])
- except PipError as e:
- logger.error(e.args[0])
- return ERROR
-
- return SUCCESS
-
- def _determine_file(self, options: Values, need_value: bool) -> Optional[Kind]:
- file_options = [
- key
- for key, value in (
- (kinds.USER, options.user_file),
- (kinds.GLOBAL, options.global_file),
- (kinds.SITE, options.site_file),
- )
- if value
- ]
-
- if not file_options:
- if not need_value:
- return None
- # Default to user, unless there's a site file.
- elif any(
- os.path.exists(site_config_file)
- for site_config_file in get_configuration_files()[kinds.SITE]
- ):
- return kinds.SITE
- else:
- return kinds.USER
- elif len(file_options) == 1:
- return file_options[0]
-
- raise PipError(
- "Need exactly one file to operate upon "
- "(--user, --site, --global) to perform."
- )
-
- def list_values(self, options: Values, args: List[str]) -> None:
- self._get_n_args(args, "list", n=0)
-
- for key, value in sorted(self.configuration.items()):
- write_output("%s=%r", key, value)
-
- def get_name(self, options: Values, args: List[str]) -> None:
- key = self._get_n_args(args, "get [name]", n=1)
- value = self.configuration.get_value(key)
-
- write_output("%s", value)
-
- def set_name_value(self, options: Values, args: List[str]) -> None:
- key, value = self._get_n_args(args, "set [name] [value]", n=2)
- self.configuration.set_value(key, value)
-
- self._save_configuration()
-
- def unset_name(self, options: Values, args: List[str]) -> None:
- key = self._get_n_args(args, "unset [name]", n=1)
- self.configuration.unset_value(key)
-
- self._save_configuration()
-
- def list_config_values(self, options: Values, args: List[str]) -> None:
- """List config key-value pairs across different config files"""
- self._get_n_args(args, "debug", n=0)
-
- self.print_env_var_values()
- # Iterate over config files and print if they exist, and the
- # key-value pairs present in them if they do
- for variant, files in sorted(self.configuration.iter_config_files()):
- write_output("%s:", variant)
- for fname in files:
- with indent_log():
- file_exists = os.path.exists(fname)
- write_output("%s, exists: %r", fname, file_exists)
- if file_exists:
- self.print_config_file_values(variant)
-
- def print_config_file_values(self, variant: Kind) -> None:
- """Get key-value pairs from the file of a variant"""
- for name, value in self.configuration.get_values_in_config(variant).items():
- with indent_log():
- write_output("%s: %s", name, value)
-
- def print_env_var_values(self) -> None:
- """Get key-values pairs present as environment variables"""
- write_output("%s:", "env_var")
- with indent_log():
- for key, value in sorted(self.configuration.get_environ_vars()):
- env_var = f"PIP_{key.upper()}"
- write_output("%s=%r", env_var, value)
-
- def open_in_editor(self, options: Values, args: List[str]) -> None:
- editor = self._determine_editor(options)
-
- fname = self.configuration.get_file_to_edit()
- if fname is None:
- raise PipError("Could not determine appropriate file.")
- elif '"' in fname:
- # This shouldn't happen, unless we see a username like that.
- # If that happens, we'd appreciate a pull request fixing this.
- raise PipError(
- f'Can not open an editor for a file name containing "\n{fname}'
- )
-
- try:
- subprocess.check_call(f'{editor} "{fname}"', shell=True)
- except FileNotFoundError as e:
- if not e.filename:
- e.filename = editor
- raise
- except subprocess.CalledProcessError as e:
- raise PipError(
- "Editor Subprocess exited with exit code {}".format(e.returncode)
- )
-
- def _get_n_args(self, args: List[str], example: str, n: int) -> Any:
- """Helper to make sure the command got the right number of arguments"""
- if len(args) != n:
- msg = (
- "Got unexpected number of arguments, expected {}. "
- '(example: "{} config {}")'
- ).format(n, get_prog(), example)
- raise PipError(msg)
-
- if n == 1:
- return args[0]
- else:
- return args
-
- def _save_configuration(self) -> None:
- # We successfully ran a modifying command. Need to save the
- # configuration.
- try:
- self.configuration.save()
- except Exception:
- logger.exception(
- "Unable to save configuration. Please report this as a bug."
- )
- raise PipError("Internal Error.")
-
- def _determine_editor(self, options: Values) -> str:
- if options.editor is not None:
- return options.editor
- elif "VISUAL" in os.environ:
- return os.environ["VISUAL"]
- elif "EDITOR" in os.environ:
- return os.environ["EDITOR"]
- else:
- raise PipError("Could not determine editor to use.")
diff --git a/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/pip/_vendor/requests/certs.py b/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/pip/_vendor/requests/certs.py
deleted file mode 100644
index 38696a1fb3419dd810004d5aec9654e5224042ed..0000000000000000000000000000000000000000
--- a/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/pip/_vendor/requests/certs.py
+++ /dev/null
@@ -1,24 +0,0 @@
-#!/usr/bin/env python
-
-"""
-requests.certs
-~~~~~~~~~~~~~~
-
-This module returns the preferred default CA certificate bundle. There is
-only one — the one from the certifi package.
-
-If you are packaging Requests, e.g., for a Linux distribution or a managed
-environment, you can change the definition of where() to return a separately
-packaged CA bundle.
-"""
-
-import os
-
-if "_PIP_STANDALONE_CERT" not in os.environ:
- from pip._vendor.certifi import where
-else:
- def where():
- return os.environ["_PIP_STANDALONE_CERT"]
-
-if __name__ == "__main__":
- print(where())
diff --git a/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/pkg_resources/_vendor/jaraco/context.py b/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/pkg_resources/_vendor/jaraco/context.py
deleted file mode 100644
index 87a4e3dca299c4201ac50f6ef589dc73f1c45576..0000000000000000000000000000000000000000
--- a/spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/pkg_resources/_vendor/jaraco/context.py
+++ /dev/null
@@ -1,213 +0,0 @@
-import os
-import subprocess
-import contextlib
-import functools
-import tempfile
-import shutil
-import operator
-
-
-@contextlib.contextmanager
-def pushd(dir):
- orig = os.getcwd()
- os.chdir(dir)
- try:
- yield dir
- finally:
- os.chdir(orig)
-
-
-@contextlib.contextmanager
-def tarball_context(url, target_dir=None, runner=None, pushd=pushd):
- """
- Get a tarball, extract it, change to that directory, yield, then
- clean up.
- `runner` is the function to invoke commands.
- `pushd` is a context manager for changing the directory.
- """
- if target_dir is None:
- target_dir = os.path.basename(url).replace('.tar.gz', '').replace('.tgz', '')
- if runner is None:
- runner = functools.partial(subprocess.check_call, shell=True)
- # In the tar command, use --strip-components=1 to strip the first path and
- # then
- # use -C to cause the files to be extracted to {target_dir}. This ensures
- # that we always know where the files were extracted.
- runner('mkdir {target_dir}'.format(**vars()))
- try:
- getter = 'wget {url} -O -'
- extract = 'tar x{compression} --strip-components=1 -C {target_dir}'
- cmd = ' | '.join((getter, extract))
- runner(cmd.format(compression=infer_compression(url), **vars()))
- with pushd(target_dir):
- yield target_dir
- finally:
- runner('rm -Rf {target_dir}'.format(**vars()))
-
-
-def infer_compression(url):
- """
- Given a URL or filename, infer the compression code for tar.
- """
- # cheat and just assume it's the last two characters
- compression_indicator = url[-2:]
- mapping = dict(gz='z', bz='j', xz='J')
- # Assume 'z' (gzip) if no match
- return mapping.get(compression_indicator, 'z')
-
-
-@contextlib.contextmanager
-def temp_dir(remover=shutil.rmtree):
- """
- Create a temporary directory context. Pass a custom remover
- to override the removal behavior.
- """
- temp_dir = tempfile.mkdtemp()
- try:
- yield temp_dir
- finally:
- remover(temp_dir)
-
-
-@contextlib.contextmanager
-def repo_context(url, branch=None, quiet=True, dest_ctx=temp_dir):
- """
- Check out the repo indicated by url.
-
- If dest_ctx is supplied, it should be a context manager
- to yield the target directory for the check out.
- """
- exe = 'git' if 'git' in url else 'hg'
- with dest_ctx() as repo_dir:
- cmd = [exe, 'clone', url, repo_dir]
- if branch:
- cmd.extend(['--branch', branch])
- devnull = open(os.path.devnull, 'w')
- stdout = devnull if quiet else None
- subprocess.check_call(cmd, stdout=stdout)
- yield repo_dir
-
-
-@contextlib.contextmanager
-def null():
- yield
-
-
-class ExceptionTrap:
- """
- A context manager that will catch certain exceptions and provide an
- indication they occurred.
-
- >>> with ExceptionTrap() as trap:
- ... raise Exception()
- >>> bool(trap)
- True
-
- >>> with ExceptionTrap() as trap:
- ... pass
- >>> bool(trap)
- False
-
- >>> with ExceptionTrap(ValueError) as trap:
- ... raise ValueError("1 + 1 is not 3")
- >>> bool(trap)
- True
-
- >>> with ExceptionTrap(ValueError) as trap:
- ... raise Exception()
- Traceback (most recent call last):
- ...
- Exception
-
- >>> bool(trap)
- False
- """
-
- exc_info = None, None, None
-
- def __init__(self, exceptions=(Exception,)):
- self.exceptions = exceptions
-
- def __enter__(self):
- return self
-
- @property
- def type(self):
- return self.exc_info[0]
-
- @property
- def value(self):
- return self.exc_info[1]
-
- @property
- def tb(self):
- return self.exc_info[2]
-
- def __exit__(self, *exc_info):
- type = exc_info[0]
- matches = type and issubclass(type, self.exceptions)
- if matches:
- self.exc_info = exc_info
- return matches
-
- def __bool__(self):
- return bool(self.type)
-
- def raises(self, func, *, _test=bool):
- """
- Wrap func and replace the result with the truth
- value of the trap (True if an exception occurred).
-
- First, give the decorator an alias to support Python 3.8
- Syntax.
-
- >>> raises = ExceptionTrap(ValueError).raises
-
- Now decorate a function that always fails.
-
- >>> @raises
- ... def fail():
- ... raise ValueError('failed')
- >>> fail()
- True
- """
-
- @functools.wraps(func)
- def wrapper(*args, **kwargs):
- with ExceptionTrap(self.exceptions) as trap:
- func(*args, **kwargs)
- return _test(trap)
-
- return wrapper
-
- def passes(self, func):
- """
- Wrap func and replace the result with the truth
- value of the trap (True if no exception).
-
- First, give the decorator an alias to support Python 3.8
- Syntax.
-
- >>> passes = ExceptionTrap(ValueError).passes
-
- Now decorate a function that always fails.
-
- >>> @passes
- ... def fail():
- ... raise ValueError('failed')
-
- >>> fail()
- False
- """
- return self.raises(func, _test=operator.not_)
-
-
-class suppress(contextlib.suppress, contextlib.ContextDecorator):
- """
- A version of contextlib.suppress with decorator support.
-
- >>> @suppress(KeyError)
- ... def key_error():
- ... {}['']
- >>> key_error()
- """
diff --git a/spaces/Awiny/Image2Paragraph/models/grit_src/third_party/CenterNet2/detectron2/utils/video_visualizer.py b/spaces/Awiny/Image2Paragraph/models/grit_src/third_party/CenterNet2/detectron2/utils/video_visualizer.py
deleted file mode 100644
index 9d8a366d3ca78c1824eff62f6fe422542075f055..0000000000000000000000000000000000000000
--- a/spaces/Awiny/Image2Paragraph/models/grit_src/third_party/CenterNet2/detectron2/utils/video_visualizer.py
+++ /dev/null
@@ -1,252 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-import numpy as np
-import pycocotools.mask as mask_util
-
-from detectron2.utils.visualizer import (
- ColorMode,
- Visualizer,
- _create_text_labels,
- _PanopticPrediction,
-)
-
-from .colormap import random_color
-
-
-class _DetectedInstance:
- """
- Used to store data about detected objects in video frame,
- in order to transfer color to objects in the future frames.
-
- Attributes:
- label (int):
- bbox (tuple[float]):
- mask_rle (dict):
- color (tuple[float]): RGB colors in range (0, 1)
- ttl (int): time-to-live for the instance. For example, if ttl=2,
- the instance color can be transferred to objects in the next two frames.
- """
-
- __slots__ = ["label", "bbox", "mask_rle", "color", "ttl"]
-
- def __init__(self, label, bbox, mask_rle, color, ttl):
- self.label = label
- self.bbox = bbox
- self.mask_rle = mask_rle
- self.color = color
- self.ttl = ttl
-
-
-class VideoVisualizer:
- def __init__(self, metadata, instance_mode=ColorMode.IMAGE):
- """
- Args:
- metadata (MetadataCatalog): image metadata.
- """
- self.metadata = metadata
- self._old_instances = []
- assert instance_mode in [
- ColorMode.IMAGE,
- ColorMode.IMAGE_BW,
- ], "Other mode not supported yet."
- self._instance_mode = instance_mode
-
- def draw_instance_predictions(self, frame, predictions):
- """
- Draw instance-level prediction results on an image.
-
- Args:
- frame (ndarray): an RGB image of shape (H, W, C), in the range [0, 255].
- predictions (Instances): the output of an instance detection/segmentation
- model. Following fields will be used to draw:
- "pred_boxes", "pred_classes", "scores", "pred_masks" (or "pred_masks_rle").
-
- Returns:
- output (VisImage): image object with visualizations.
- """
- frame_visualizer = Visualizer(frame, self.metadata)
- num_instances = len(predictions)
- if num_instances == 0:
- return frame_visualizer.output
-
- boxes = predictions.pred_boxes.tensor.numpy() if predictions.has("pred_boxes") else None
- scores = predictions.scores if predictions.has("scores") else None
- classes = predictions.pred_classes.numpy() if predictions.has("pred_classes") else None
- keypoints = predictions.pred_keypoints if predictions.has("pred_keypoints") else None
- colors = predictions.COLOR if predictions.has("COLOR") else [None] * len(predictions)
- durations = predictions.ID_duration if predictions.has("ID_duration") else None
- duration_threshold = self.metadata.get("duration_threshold", 0)
- visibilities = None if durations is None else [x > duration_threshold for x in durations]
-
- if predictions.has("pred_masks"):
- masks = predictions.pred_masks
- # mask IOU is not yet enabled
- # masks_rles = mask_util.encode(np.asarray(masks.permute(1, 2, 0), order="F"))
- # assert len(masks_rles) == num_instances
- else:
- masks = None
-
- detected = [
- _DetectedInstance(classes[i], boxes[i], mask_rle=None, color=colors[i], ttl=8)
- for i in range(num_instances)
- ]
- if not predictions.has("COLOR"):
- colors = self._assign_colors(detected)
-
- labels = _create_text_labels(classes, scores, self.metadata.get("thing_classes", None))
-
- if self._instance_mode == ColorMode.IMAGE_BW:
- # any() returns uint8 tensor
- frame_visualizer.output.reset_image(
- frame_visualizer._create_grayscale_image(
- (masks.any(dim=0) > 0).numpy() if masks is not None else None
- )
- )
- alpha = 0.3
- else:
- alpha = 0.5
-
- labels = (
- None
- if labels is None
- else [y[0] for y in filter(lambda x: x[1], zip(labels, visibilities))]
- ) # noqa
- assigned_colors = (
- None
- if colors is None
- else [y[0] for y in filter(lambda x: x[1], zip(colors, visibilities))]
- ) # noqa
- frame_visualizer.overlay_instances(
- boxes=None if masks is not None else boxes[visibilities], # boxes are a bit distracting
- masks=None if masks is None else masks[visibilities],
- labels=labels,
- keypoints=None if keypoints is None else keypoints[visibilities],
- assigned_colors=assigned_colors,
- alpha=alpha,
- )
-
- return frame_visualizer.output
-
- def draw_sem_seg(self, frame, sem_seg, area_threshold=None):
- """
- Args:
- sem_seg (ndarray or Tensor): semantic segmentation of shape (H, W),
- each value is the integer label.
- area_threshold (Optional[int]): only draw segmentations larger than the threshold
- """
- # don't need to do anything special
- frame_visualizer = Visualizer(frame, self.metadata)
- frame_visualizer.draw_sem_seg(sem_seg, area_threshold=None)
- return frame_visualizer.output
-
- def draw_panoptic_seg_predictions(
- self, frame, panoptic_seg, segments_info, area_threshold=None, alpha=0.5
- ):
- frame_visualizer = Visualizer(frame, self.metadata)
- pred = _PanopticPrediction(panoptic_seg, segments_info, self.metadata)
-
- if self._instance_mode == ColorMode.IMAGE_BW:
- frame_visualizer.output.reset_image(
- frame_visualizer._create_grayscale_image(pred.non_empty_mask())
- )
-
- # draw mask for all semantic segments first i.e. "stuff"
- for mask, sinfo in pred.semantic_masks():
- category_idx = sinfo["category_id"]
- try:
- mask_color = [x / 255 for x in self.metadata.stuff_colors[category_idx]]
- except AttributeError:
- mask_color = None
-
- frame_visualizer.draw_binary_mask(
- mask,
- color=mask_color,
- text=self.metadata.stuff_classes[category_idx],
- alpha=alpha,
- area_threshold=area_threshold,
- )
-
- all_instances = list(pred.instance_masks())
- if len(all_instances) == 0:
- return frame_visualizer.output
- # draw mask for all instances second
- masks, sinfo = list(zip(*all_instances))
- num_instances = len(masks)
- masks_rles = mask_util.encode(
- np.asarray(np.asarray(masks).transpose(1, 2, 0), dtype=np.uint8, order="F")
- )
- assert len(masks_rles) == num_instances
-
- category_ids = [x["category_id"] for x in sinfo]
- detected = [
- _DetectedInstance(category_ids[i], bbox=None, mask_rle=masks_rles[i], color=None, ttl=8)
- for i in range(num_instances)
- ]
- colors = self._assign_colors(detected)
- labels = [self.metadata.thing_classes[k] for k in category_ids]
-
- frame_visualizer.overlay_instances(
- boxes=None,
- masks=masks,
- labels=labels,
- keypoints=None,
- assigned_colors=colors,
- alpha=alpha,
- )
- return frame_visualizer.output
-
- def _assign_colors(self, instances):
- """
- Naive tracking heuristics to assign same color to the same instance,
- will update the internal state of tracked instances.
-
- Returns:
- list[tuple[float]]: list of colors.
- """
-
- # Compute iou with either boxes or masks:
- is_crowd = np.zeros((len(instances),), dtype=np.bool)
- if instances[0].bbox is None:
- assert instances[0].mask_rle is not None
- # use mask iou only when box iou is None
- # because box seems good enough
- rles_old = [x.mask_rle for x in self._old_instances]
- rles_new = [x.mask_rle for x in instances]
- ious = mask_util.iou(rles_old, rles_new, is_crowd)
- threshold = 0.5
- else:
- boxes_old = [x.bbox for x in self._old_instances]
- boxes_new = [x.bbox for x in instances]
- ious = mask_util.iou(boxes_old, boxes_new, is_crowd)
- threshold = 0.6
- if len(ious) == 0:
- ious = np.zeros((len(self._old_instances), len(instances)), dtype="float32")
-
- # Only allow matching instances of the same label:
- for old_idx, old in enumerate(self._old_instances):
- for new_idx, new in enumerate(instances):
- if old.label != new.label:
- ious[old_idx, new_idx] = 0
-
- matched_new_per_old = np.asarray(ious).argmax(axis=1)
- max_iou_per_old = np.asarray(ious).max(axis=1)
-
- # Try to find match for each old instance:
- extra_instances = []
- for idx, inst in enumerate(self._old_instances):
- if max_iou_per_old[idx] > threshold:
- newidx = matched_new_per_old[idx]
- if instances[newidx].color is None:
- instances[newidx].color = inst.color
- continue
- # If an old instance does not match any new instances,
- # keep it for the next frame in case it is just missed by the detector
- inst.ttl -= 1
- if inst.ttl > 0:
- extra_instances.append(inst)
-
- # Assign random color to newly-detected instances:
- for inst in instances:
- if inst.color is None:
- inst.color = random_color(rgb=True, maximum=1)
- self._old_instances = instances[:] + extra_instances
- return [d.color for d in instances]
diff --git a/spaces/Banbri/zcvzcv/LICENCE.md b/spaces/Banbri/zcvzcv/LICENCE.md
deleted file mode 100644
index 537fde8423156f05dc00b52a4fc8eebd451f66e9..0000000000000000000000000000000000000000
--- a/spaces/Banbri/zcvzcv/LICENCE.md
+++ /dev/null
@@ -1,170 +0,0 @@
-Apache License
-==============
-
-_Version 2.0, January 2004_
-_<>_
-
-### Terms and Conditions for use, reproduction, and distribution
-
-#### 1. Definitions
-
-“License” shall mean the terms and conditions for use, reproduction, and
-distribution as defined by Sections 1 through 9 of this document.
-
-“Licensor” shall mean the copyright owner or entity authorized by the copyright
-owner that is granting the License.
-
-“Legal Entity” shall mean the union of the acting entity and all other entities
-that control, are controlled by, or are under common control with that entity.
-For the purposes of this definition, “control” means **(i)** the power, direct or
-indirect, to cause the direction or management of such entity, whether by
-contract or otherwise, or **(ii)** ownership of fifty percent (50%) or more of the
-outstanding shares, or **(iii)** beneficial ownership of such entity.
-
-“You” (or “Your”) shall mean an individual or Legal Entity exercising
-permissions granted by this License.
-
-“Source” form shall mean the preferred form for making modifications, including
-but not limited to software source code, documentation source, and configuration
-files.
-
-“Object” form shall mean any form resulting from mechanical transformation or
-translation of a Source form, including but not limited to compiled object code,
-generated documentation, and conversions to other media types.
-
-“Work” shall mean the work of authorship, whether in Source or Object form, made
-available under the License, as indicated by a copyright notice that is included
-in or attached to the work (an example is provided in the Appendix below).
-
-“Derivative Works” shall mean any work, whether in Source or Object form, that
-is based on (or derived from) the Work and for which the editorial revisions,
-annotations, elaborations, or other modifications represent, as a whole, an
-original work of authorship. For the purposes of this License, Derivative Works
-shall not include works that remain separable from, or merely link (or bind by
-name) to the interfaces of, the Work and Derivative Works thereof.
-
-“Contribution” shall mean any work of authorship, including the original version
-of the Work and any modifications or additions to that Work or Derivative Works
-thereof, that is intentionally submitted to Licensor for inclusion in the Work
-by the copyright owner or by an individual or Legal Entity authorized to submit
-on behalf of the copyright owner. For the purposes of this definition,
-“submitted” means any form of electronic, verbal, or written communication sent
-to the Licensor or its representatives, including but not limited to
-communication on electronic mailing lists, source code control systems, and
-issue tracking systems that are managed by, or on behalf of, the Licensor for
-the purpose of discussing and improving the Work, but excluding communication
-that is conspicuously marked or otherwise designated in writing by the copyright
-owner as “Not a Contribution.”
-
-“Contributor” shall mean Licensor and any individual or Legal Entity on behalf
-of whom a Contribution has been received by Licensor and subsequently
-incorporated within the Work.
-
-#### 2. Grant of Copyright License
-
-Subject to the terms and conditions of this License, each Contributor hereby
-grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free,
-irrevocable copyright license to reproduce, prepare Derivative Works of,
-publicly display, publicly perform, sublicense, and distribute the Work and such
-Derivative Works in Source or Object form.
-
-#### 3. Grant of Patent License
-
-Subject to the terms and conditions of this License, each Contributor hereby
-grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free,
-irrevocable (except as stated in this section) patent license to make, have
-made, use, offer to sell, sell, import, and otherwise transfer the Work, where
-such license applies only to those patent claims licensable by such Contributor
-that are necessarily infringed by their Contribution(s) alone or by combination
-of their Contribution(s) with the Work to which such Contribution(s) was
-submitted. If You institute patent litigation against any entity (including a
-cross-claim or counterclaim in a lawsuit) alleging that the Work or a
-Contribution incorporated within the Work constitutes direct or contributory
-patent infringement, then any patent licenses granted to You under this License
-for that Work shall terminate as of the date such litigation is filed.
-
-#### 4. Redistribution
-
-You may reproduce and distribute copies of the Work or Derivative Works thereof
-in any medium, with or without modifications, and in Source or Object form,
-provided that You meet the following conditions:
-
-* **(a)** You must give any other recipients of the Work or Derivative Works a copy of
-this License; and
-* **(b)** You must cause any modified files to carry prominent notices stating that You
-changed the files; and
-* **(c)** You must retain, in the Source form of any Derivative Works that You distribute,
-all copyright, patent, trademark, and attribution notices from the Source form
-of the Work, excluding those notices that do not pertain to any part of the
-Derivative Works; and
-* **(d)** If the Work includes a “NOTICE” text file as part of its distribution, then any
-Derivative Works that You distribute must include a readable copy of the
-attribution notices contained within such NOTICE file, excluding those notices
-that do not pertain to any part of the Derivative Works, in at least one of the
-following places: within a NOTICE text file distributed as part of the
-Derivative Works; within the Source form or documentation, if provided along
-with the Derivative Works; or, within a display generated by the Derivative
-Works, if and wherever such third-party notices normally appear. The contents of
-the NOTICE file are for informational purposes only and do not modify the
-License. You may add Your own attribution notices within Derivative Works that
-You distribute, alongside or as an addendum to the NOTICE text from the Work,
-provided that such additional attribution notices cannot be construed as
-modifying the License.
-
-You may add Your own copyright statement to Your modifications and may provide
-additional or different license terms and conditions for use, reproduction, or
-distribution of Your modifications, or for any such Derivative Works as a whole,
-provided Your use, reproduction, and distribution of the Work otherwise complies
-with the conditions stated in this License.
-
-#### 5. Submission of Contributions
-
-Unless You explicitly state otherwise, any Contribution intentionally submitted
-for inclusion in the Work by You to the Licensor shall be under the terms and
-conditions of this License, without any additional terms or conditions.
-Notwithstanding the above, nothing herein shall supersede or modify the terms of
-any separate license agreement you may have executed with Licensor regarding
-such Contributions.
-
-#### 6. Trademarks
-
-This License does not grant permission to use the trade names, trademarks,
-service marks, or product names of the Licensor, except as required for
-reasonable and customary use in describing the origin of the Work and
-reproducing the content of the NOTICE file.
-
-#### 7. Disclaimer of Warranty
-
-Unless required by applicable law or agreed to in writing, Licensor provides the
-Work (and each Contributor provides its Contributions) on an “AS IS” BASIS,
-WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied,
-including, without limitation, any warranties or conditions of TITLE,
-NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE. You are
-solely responsible for determining the appropriateness of using or
-redistributing the Work and assume any risks associated with Your exercise of
-permissions under this License.
-
-#### 8. Limitation of Liability
-
-In no event and under no legal theory, whether in tort (including negligence),
-contract, or otherwise, unless required by applicable law (such as deliberate
-and grossly negligent acts) or agreed to in writing, shall any Contributor be
-liable to You for damages, including any direct, indirect, special, incidental,
-or consequential damages of any character arising as a result of this License or
-out of the use or inability to use the Work (including but not limited to
-damages for loss of goodwill, work stoppage, computer failure or malfunction, or
-any and all other commercial damages or losses), even if such Contributor has
-been advised of the possibility of such damages.
-
-#### 9. Accepting Warranty or Additional Liability
-
-While redistributing the Work or Derivative Works thereof, You may choose to
-offer, and charge a fee for, acceptance of support, warranty, indemnity, or
-other liability obligations and/or rights consistent with this License. However,
-in accepting such obligations, You may act only on Your own behalf and on Your
-sole responsibility, not on behalf of any other Contributor, and only if You
-agree to indemnify, defend, and hold each Contributor harmless for any liability
-incurred by, or claims asserted against, such Contributor by reason of your
-accepting any such warranty or additional liability.
-
-_END OF TERMS AND CONDITIONS_
\ No newline at end of file
diff --git a/spaces/Benson/text-generation/Examples/Choque De Clanes Indir Apkcombo.md b/spaces/Benson/text-generation/Examples/Choque De Clanes Indir Apkcombo.md
deleted file mode 100644
index 1cf4d546d9125bbf414cf0ad2aeb5b26ed34d6b2..0000000000000000000000000000000000000000
--- a/spaces/Benson/text-generation/Examples/Choque De Clanes Indir Apkcombo.md
+++ /dev/null
@@ -1,153 +0,0 @@
-
-
Choque de clanes Indir Apkcombo: Cómo descargar y jugar el popular juego de estrategia
-
Si estás buscando un juego de estrategia divertido y adictivo que desafíe tus habilidades y creatividad, deberías probar Clash of Clans. Este juego ha sido uno de los juegos más populares del mundo durante años, con millones de jugadores uniéndose a clanes y compitiendo en guerras épicas. En este artículo, te mostraremos cómo descargar y jugar Clash of Clans desde Apkcombo, un sitio web que ofrece archivos APK gratuitos para juegos y aplicaciones Android. También te daremos algunos consejos y trucos para ayudarte a ganar en este juego.
-
¿Qué es el Choque de Clanes?
-
Clash of Clans es un juego de estrategia desarrollado por Supercell, una compañía finlandesa que también creó otros juegos de éxito como Clash Royale, Brawl Stars, Boom Beach y Hay Day. En Clash of Clans, puedes construir tu propia aldea, entrenar a tus tropas y unirte o crear un clan con otros jugadores. A continuación, puedes participar en guerras de clanes, donde puedes atacar y defenderte contra otros clanes, o en batallas multijugador, donde puedes asaltar las aldeas de otros jugadores en busca de recursos. También puedes desbloquear y actualizar diferentes tipos de tropas, hechizos y héroes, cada uno con sus propias habilidades y estrategias.
Una breve introducción a las características y la jugabilidad del juego
-
Clash of Clans tiene muchas características que lo convierten en un juego emocionante y diverso. Aquí están algunas de ellas:
-
-
Village: Aquí es donde construyes tu base, que consta de varios edificios, como minas de oro, colectores de elixires, cuarteles, campamentos del ejército, defensas, muros, ayuntamiento, castillo del clan, laboratorio, etc. También puedes personalizar tu pueblo con decoraciones, obstáculos, pieles de héroe y escenarios.
-
-
Hechizos: Estos son los efectos mágicos que puedes usar para apoyar a tus tropas u obstaculizar a tus enemigos en las batallas. Hay diferentes tipos de hechizos, como hechizo de relámpago, hechizo de sanación, hechizo de ira, hechizo de salto, hechizo de congelación, etc. Cada hechizo tiene sus propios efectos y cuesta elixir u elixir oscuro para usar.
-
Héroes: Estas son las unidades especiales que tienen habilidades poderosas y se pueden usar varias veces en batallas. Hay cuatro héroes en el juego: rey bárbaro, reina arquera, gran alcaide y campeón real. Cada héroe tiene su propio nivel que puede actualizar con elixir oscuro o gemas
Los beneficios de descargar Clash of Clans de Apkcombo
-
Apkcombo es un sitio web que ofrece archivos APK gratuitos para juegos y aplicaciones Android. APK significa Android Package Kit, que es el formato de archivo utilizado por Android para distribuir e instalar aplicaciones. Al descargar archivos APK desde Apkcombo, puede disfrutar de algunos beneficios, como:
-
-
Acceso a la última versión: Apkcombo siempre actualiza los archivos APK a la última versión disponible, para que pueda obtener las nuevas características y correcciones de errores para Clash of Clans.
-
Acceso a la versión modded: Apkcombo también proporciona archivos APK modded para algunos juegos y aplicaciones, lo que significa que se han modificado para tener características o ventajas adicionales, como recursos ilimitados, elementos desbloqueados o anuncios eliminados. Sin embargo, tenga cuidado al usar archivos APK modificados, ya que pueden no ser compatibles con el juego original o la aplicación, o pueden violar los términos del servicio.
-
Acceso a la versión bloqueada por región: Apkcombo le permite descargar archivos APK de diferentes regiones, que pueden tener diferentes contenidos o idiomas. Por ejemplo, puedes descargar la versión china de Clash of Clans, que tiene algunas características y eventos exclusivos que no están disponibles en otras regiones.
-
-
-
Sin embargo, también hay algunos riesgos y desventajas de descargar archivos APK de Apkcombo, como:
-
-
Malware o virus potenciales: Apkcombo afirma que todos los archivos APK son escaneados y verificados por el software antivirus, pero todavía hay una posibilidad de que algún código malicioso o software puede estar oculto en los archivos APK. Por lo tanto, siempre debe comprobar el origen y la reputación del archivo APK antes de descargarlo, y utilizar una aplicación antivirus confiable para escanearlo antes de instalarlo.
-
Problemas potenciales de compatibilidad: Apkcombo no garantiza que todos los archivos APK funcionarán en su dispositivo, ya que pueden tener diferentes requisitos o especificaciones. Por lo tanto, siempre debe comprobar la compatibilidad y los requisitos del sistema del archivo APK antes de descargarlo, y hacer una copia de seguridad de sus datos antes de instalarlo.
-
Problemas legales potenciales: Apkcombo no posee ni aloja ninguno de los archivos APK en su sitio web, pero solo proporciona enlaces a otras fuentes. Por lo tanto, siempre debe respetar los derechos de propiedad intelectual y los términos de servicio de los desarrolladores originales y editores de los juegos y aplicaciones. Descargar e instalar archivos APK desde Apkcombo puede violar sus derechos y políticas, y puede resultar en acciones legales o sanciones.
-
-
Por lo tanto, siempre debe ser cuidadoso y responsable al descargar e instalar archivos APK desde Apkcombo. Solo debe descargar archivos APK de fuentes de confianza, y solo para uso personal. También debes evitar usar archivos APK modificados que puedan darte ventajas injustas o dañar a otros jugadores en Clash of Clans.
-
Cómo descargar e instalar Clash of Clans desde Apkcombo
-
Si quieres descargar e instalar Clash of Clans desde Apkcombo, puedes seguir estos pasos:
-
-
Los pasos para descargar el archivo APK desde el sitio web de Apkcombo
Seleccione la versión de Clash of Clans que desea descargar. Puede elegir entre la versión original o la versión modificada.
-
Seleccione la región de Clash of Clans que desea descargar. Puede elegir entre diferentes regiones, como global, China, Japón, etc.
-
Seleccione la arquitectura de su dispositivo. Puede elegir entre armeabi-v7a, arm64-v8a, x86 o x86_x64.
-
Haga clic en el botón "Descargar" y espere a que termine la descarga.
-
-
Los pasos para instalar el archivo APK en su dispositivo Android
-
-
Antes de instalar el archivo APK, asegúrese de que ha habilitado la opción "Fuentes desconocidas" en la configuración del dispositivo. Esto le permitirá instalar aplicaciones desde fuentes distintas de Google Play Store.
-
Localizar el archivo APK descargado en el almacenamiento del dispositivo utilizando una aplicación de administrador de archivos.
-
Toque en el archivo APK y siga las instrucciones en la pantalla para instalarlo.
-
Esperar a que la instalación para completar y lanzar Clash of Clans desde el cajón de la aplicación
Los pasos para actualizar el juego y solucionar cualquier problema
-
-
Para actualizar el juego, puede descargar el último archivo APK de Apkcombo e instalarlo sobre el existente, o puede usar la opción de actualización dentro del juego si está disponible. Siempre debes actualizar el juego para disfrutar de las nuevas características y mejoras.
-
Para solucionar cualquier problema, como fallos, errores o fallas, puede probar algunas de estas soluciones:
-
Borra la caché y los datos del juego desde la configuración de tu dispositivo.
-
Desinstalar y volver a instalar el juego desde Apkcombo.
-
Compruebe su conexión a Internet y asegúrese de que es estable y rápido.
-
Compruebe el almacenamiento del dispositivo y asegúrese de que tiene suficiente espacio para el juego.
-
Póngase en contacto con el equipo de soporte de Supercell desde la configuración del juego o su sitio web para obtener más ayuda.
-
-
-
-
Cómo jugar al choque de clanes y ganar
-
-
Los fundamentos de la construcción de su pueblo y la elevación de su clan
-
Lo primero que tienes que hacer en Clash of Clans es construir tu pueblo y levantar tu clan. Estos son algunos pasos básicos a seguir:
-
-
Comienza construyendo y mejorando tu ayuntamiento, que es el corazón de tu pueblo. Tu nivel de ayuntamiento determina qué edificios y tropas puedes desbloquear y usar.
-
Construya y actualice sus edificios de recursos, como minas de oro, colectores de elixir, almacenes de oro, almacenes de elixir, taladros de elixir oscuro y almacenes de elixir oscuro. Estos edificios le proporcionarán los recursos que necesita para construir y mejorar otros edificios y tropas.
-
Construye y mejora tus edificios de defensa, como cañones, torres de arqueros, morteros, defensas aéreas, torres de magos, teslas ocultas, torres de bombas, torres de infierno, artillería de águilas, etc. Estos edificios protegerán tu pueblo de los ataques enemigos.
-
Construir y mejorar sus paredes, que actuará como una barrera contra las tropas enemigas. También puedes colocar trampas, como bombas, trampas de resorte, bombas de aire, bombas gigantes, minas de aire en busca, trampas de esqueleto, etc. para sorprender y dañar a las tropas enemigas.
-
Construir y mejorar sus edificios del ejército, tales como cuarteles, cuarteles oscuros, campamentos del ejército, fábrica de hechizos, fábrica de hechizos oscuros, taller de asedio, etc. Estos edificios le permitirá entrenar y almacenar sus tropas y hechizos para batallas.
-
Construye y mejora el castillo de tu clan, lo que te permitirá unirte o crear un clan con otros jugadores. También puedes solicitar y donar tropas y hechizos a los miembros de tu clan, que te ayudarán en las batallas.
-
Construir y mejorar sus edificios héroe, tales como el rey bárbaro altar, arquero reina altar, gran guardián altar y campeón real altar. Estos edificios te permitirán desbloquear y usar a los héroes en las batallas.
-
-
-
Siempre debes tratar de equilibrar el desarrollo de tu pueblo, y no descuidar ningún aspecto de él. También debe seguir el pedido de actualización recomendado, que puede encontrar en varias guías y sitios web en línea.
-
Los consejos y trucos para atacar y defender en las guerras de clanes y batallas multijugador
-
Una de las principales atracciones de Clash of Clans son las guerras de clanes y las batallas multijugador, donde puedes poner a prueba tus habilidades y estrategias contra otros jugadores. Aquí hay algunos consejos y trucos para ayudarte a atacar y defender en estos modos:
-
-
Explora a tu enemigo: Antes de atacar, siempre debes explorar la aldea de tu enemigo y analizar su diseño, defensas, trampas, tropas del castillo del clan, héroes, etc. También debes revisar su perfil y ver su historia de ataque y defensa, trofeos, liga, clan, etc. Esto te ayudará a planificar tu ataque y elegir las mejores tropas y hechizos para él.
-
Usa la composición correcta del ejército: Dependiendo de la aldea de tu enemigo y tu estrategia, debes usar la composición correcta del ejército para tu ataque. Debes considerar el costo, tiempo de entrenamiento, espacio de alojamiento, daños, salud, velocidad, rango, preferencia de objetivo, habilidad especial, etc. de cada tropa y hechizo. También debes tener una variedad de tropas y hechizos para lidiar con diferentes situaciones y obstáculos.
-
Usa la técnica de despliegue correcta: Dependiendo de la composición de tu ejército y tu estrategia, debes usar la técnica de despliegue correcta para tu ataque. Debes considerar el tiempo, ubicación, dirección, espaciado, agrupación, canalización, etc. de cada tropa y hechizo. También debes usar las habilidades del héroe y las tropas del castillo del clan sabiamente.
-
-
Practica y aprende: La mejor manera de mejorar tus habilidades de ataque es practicar y aprender de tus propios ataques y los de los demás. Puedes usar la función de desafío amistoso para practicar con tus compañeros de clan o el modo de práctica para aprender algunas estrategias básicas. También puedes ver las repeticiones de tus propios ataques y los de otros para ver qué funcionó y qué no.
-
Diseña tu base: Para defender tu aldea de los ataques enemigos, debes diseñar tu base con cuidado y estratégicamente. Usted debe considerar la disposición, colocación , y la sinergia de cada edificio, pared, trampa, clan de la tropa del castillo, héroe, etc. También debe seguir los principios de diseño de base recomendados, que se pueden encontrar en varias guías y sitios web en línea.
-
Mejora tus defensas: Para defender tu pueblo de los ataques enemigos, debes mejorar tus defensas de forma regular y estratégica. Debe considerar el costo, tiempo, efecto, prioridad, etc. de cada actualización. También debe seguir el pedido de actualización recomendado, que puede encontrar en varias guías y sitios web en línea.
-
Prueba tu base: Para defender tu aldea de los ataques enemigos, debes probar tu base con frecuencia y de manera realista. Puedes usar la función de desafío amigable para probar tu base con tus compañeros de clan o el editor de diseño de base para probar tu base con diferentes escenarios. También puedes ver las repeticiones de ataques enemigos para ver cómo funciona tu base y qué puedes mejorar.
-
-
Los recursos y estrategias para mejorar tus tropas, hechizos y héroes
-
Para tener éxito en Clash of Clans, necesitas mejorar tus tropas, hechizos y héroes constantemente y estratégicamente. Aquí hay algunos recursos y estrategias para ayudarle a hacer eso:
-
-
-
Elixir oscuro: Este es un recurso especial que necesitas para actualizar tus tropas oscuras, hechizos oscuros, héroes y algunos edificios. Puedes obtener elixir oscuro de taladros de elixir oscuro, asaltar aldeas de otros jugadores, completar logros y eventos, abrir carros de botín y cofres de bonificación de estrellas, etc.
-
Gemas: Este es un recurso premium que puede usar para acelerar las actualizaciones, comprar recursos, impulsar edificios, entrenar tropas y hechizos al instante, etc. Puede obtener gemas de eliminar obstáculos, completar logros y eventos, abrir cajas de gemas y carritos de minas de gemas, comprar con dinero real, etc.
-
Base de constructor de oro y elixir: Estos son los recursos que necesita para actualizar sus tropas de base de constructor, edificios y paredes. Puedes obtener oro base constructor y elixir de minas de oro y coleccionistas de elixires, ganar batallas, completar logros y eventos, abrir carritos de botín y cofres de bonificación de estrellas, etc.
-
Gemas de base de constructor: Este es un recurso que puedes usar para acelerar las actualizaciones, comprar recursos, impulsar edificios, etc. en tu base de constructor. Puede obtener gemas base constructor de despejar obstáculos, completar logros y eventos, abrir cajas de gemas y carretas de minas de gemas, comprarlos con dinero real, etc.
-
Artículos mágicos: Estos son artículos especiales que puedes usar para aumentar tu progreso de varias maneras, como aumentar tu producción de recursos, reducir tu tiempo o costo de actualización, mejorar tus tropas o hechizos, etc. Puedes obtener objetos mágicos al completar juegos de clan, alcanzando ciertos niveles de liga, comprándolos con gemas o dinero real, etc.
-
-
-
Conclusión
-
Clash of Clans es un juego que te mantendrá entretenido y comprometido durante horas. Puedes descargarlo y jugarlo desde Apkcombo, un sitio web que ofrece archivos APK gratuitos para juegos y aplicaciones Android. Sin embargo, debe ser cuidadoso y responsable al descargar e instalar archivos APK desde Apkcombo. También debes seguir algunos consejos y trucos para ayudarte a construir tu pueblo, levantar tu clan y ganar en guerras de clanes y batallas multijugador. También debes mejorar tus tropas, hechizos y héroes de forma regular y estratégica. Esperamos que este artículo te haya ayudado a aprender más sobre Clash of Clans indir Apkcombo. ¡Ahora sigue adelante y disfruta del juego!
-
Preguntas frecuentes
-
Q1: ¿Es Clash of Clans libre para jugar?
-
A1: Sí, Clash of Clans es gratis para descargar y jugar. Sin embargo, también ofrece algunas compras opcionales en el juego con dinero real, como gemas, objetos mágicos , u ofertas especiales. Puede desactivar estas compras desde la configuración de su dispositivo si lo desea.
-
Q2: ¿Es seguro descargar Clash of Clans desde Apkcombo?
-
A2: Apkcombo afirma que todos los archivos APK en su sitio web son escaneados y verificados por el software antivirus, pero todavía hay un riesgo de malware o virus. Por lo tanto, siempre debe comprobar el origen y la reputación del archivo APK antes de descargarlo, y utilizar una aplicación antivirus confiable para escanearlo antes de instalarlo. También debe descargar solo archivos APK de fuentes de confianza, y solo para uso personal.
-
Q3: ¿Cómo puedo unirme o crear un clan en Clash of Clans?
-
A3: Para unirte o crear un clan en Clash of Clans, necesitas tener un castillo de clan, que puedes construir después de llegar al nivel 3 del ayuntamiento. Puedes tocar el castillo del clan y elegir la opción de unirte o crear un clan. Puedes buscar clanes por nombre, etiqueta, ubicación, nivel, miembros, etc. o navegar por los clanes recomendados. También puedes invitar o aceptar a otros jugadores para que se unan a tu clan. Puedes chatear, donar, solicitar y luchar con los miembros de tu clan.
-
-
A4: No hay una respuesta definitiva a esta pregunta, ya que diferentes tropas y hechizos pueden funcionar mejor para diferentes situaciones y estrategias. Sin embargo, algunas de las tropas y hechizos más populares y eficaces son:
-
-
-
Tropas
-
Hechizos
-
-
-
Mineros
-
Hechizo de sanación
-
-
-
Jugadores de bolos
-
Hechizo de ira
-
-
-
Jinetes de cerdo
-
Hechizo de congelación
-
-
-
Electro dragones
-
Hechizo de murciélago
-
-
-
Perros de lava
-
Hechizo de prisa
-
-
-
Globos
-
Hechizo de clonación
-
-
-
Golems
-
Hechizo de veneno
-
-
-
Brujas
Hechizo de terremoto
-
-
-
Puedes experimentar con diferentes combinaciones de tropas y hechizos para encontrar los que se adapten a tu estilo y objetivos.
-
Q5: ¿Cómo puedo contactar a Supercell para soporte o retroalimentación?
-
A5: Si tienes algún problema, pregunta o sugerencia con respecto a Clash of Clans, puedes ponerte en contacto con Supercell para obtener apoyo o comentarios. Puedes hacer esto por:
-
-
Tocando en el icono de configuración en el juego y la elección de la "Ayuda y soporte" opción. A continuación, puede examinar las preguntas frecuentes, informar de un problema o enviar un mensaje al equipo de soporte.
-
Visitando el sitio web oficial de Clash of Clans y eligiendo la opción "Contáctenos". Luego puede llenar un formulario con sus datos y consulta.
-
Visitar los foros oficiales de Clash of Clans y publicar su consulta o retroalimentación en la sección correspondiente. También puede interactuar con otros jugadores y moderadores allí.
-
Visitar las páginas oficiales de redes sociales de Clash of Clans, como Facebook, Twitter, Instagram, YouTube, etc. y dejar un comentario o mensaje allí. También puede seguir las últimas noticias y actualizaciones allí.
-
64aa2da5cf
-
-
\ No newline at end of file
diff --git a/spaces/Benson/text-generation/Examples/Descarga De La Aplicacin Comercial Zugacoin.md b/spaces/Benson/text-generation/Examples/Descarga De La Aplicacin Comercial Zugacoin.md
deleted file mode 100644
index 3097d12a474b83ee2976034d56dbcc50d76ad6e0..0000000000000000000000000000000000000000
--- a/spaces/Benson/text-generation/Examples/Descarga De La Aplicacin Comercial Zugacoin.md
+++ /dev/null
@@ -1,138 +0,0 @@
-
-
Descarga de la aplicación comercial Zugacoin: Una guía para principiantes
-
Si usted está buscando una manera de invertir en criptomonedas, activos digitales de comercio, o préstamos de acceso en África, es posible que desee considerar el uso de Zugacoin. Zugacoin es una criptomoneda revolucionaria que tiene como objetivo reconstruir la economía moribunda de África convirtiéndose en la primera moneda en capital y financiación de inversiones. En este artículo, le mostraremos cómo descargar, instalar y usar la aplicación comercial Zugacoin, que es una plataforma segura y conveniente para comprar y vender Zugacoin. También revisaremos las características y beneficios de Zugacoin, así como sus revisiones, calificaciones, pros, contras y comparación con otras criptomonedas. Al final de este artículo, usted tendrá una idea clara de si Zugacoin es una opción de inversión digna para usted o no.
Zugacoin es una criptomoneda que se construye bajo la cadena de bloques Ethereum. Es un token ERC20 con el ticker (SZC); también es negociable en intercambios criptográficos. Este token lanzado a finales de 2020 y es #2672 en el rango de cryptocurrencies en existencia. Al momento de escribir este artículo, Zugacoin cotiza a $47.06 (Coinmarketcap).
-
Zugacoin tiene un suministro máximo que es mucho más limitado que el suministro total de bitcoin. Bitcoin Max. suministro = 21 millones BTC, mientras que Zugacoin Max. suministro = 1 millón SZC. Además, este token tiene la funcionalidad de prueba de apuesta; esto simplemente significa que puedes ganar recompensas apostando o mezclando el token SZC.
-
Zugacoin fue fundada por el Arzobispo Dr. Sam Zuga, un clérigo de la Iglesia Casa de la Alegría, ubicada en Gboko, estado de Benue, Nigeria. Sam Zuga quería una moneda que fomentará el desarrollo económico en África a través de las finanzas descentralizadas. Para lograr este concepto, Zugacoin fue concebido.
-
-
Zugacoin pretende ser una criptomoneda revolucionaria que restaure la economía africana. Quiere cambiar África para siempre haciendo uso de la tecnología blockchain en las economías emergentes de África y más allá. Su objetivo es liberar el potencial creando, ganando, ahorrando y gastando oportunidades en toda África.
-
-
Los usuarios objetivo de Zugacoin son personas subempleadas y desempleadas de África, además de ayudar al gobierno africano en el desarrollo de la economía. Se aconseja a los africanos a tomar ventaja de esta moneda para la libertad financiera, especialmente ya que está en la red Binance SZCB.
-
Algunas de las características y beneficios de usar Zugacoin son:
-
-
Ofrece transacciones rápidas, seguras y de bajo costo a través de las fronteras.
-
Proporciona acceso a préstamos para empresas emergentes y necesidades personales.
Admite múltiples métodos de pago, como transferencia bancaria, pago con tarjeta y dinero móvil.
-
Permite a los usuarios obtener ingresos pasivos mediante la apuesta o la celebración de Zugacoin en sus carteras.
-
Tiene una oferta limitada de 1 millón de SZC, lo que significa que tiene un alto potencial de escasez y demanda.
-
Está respaldado por un fundador de buena reputación y un equipo de expertos en blockchain, finanzas y marketing.
-
Es compatible con la red Ethereum y se puede integrar con otras aplicaciones descentralizadas.
-
-
Cómo descargar e instalar Zugacoin Merchant App
-
Si desea comenzar a usar Zugacoin, tendrá que descargar e instalar la aplicación comercial Zugacoin en su teléfono inteligente. La aplicación está disponible para dispositivos Android e iOS y se puede descargar desde el sitio web oficial o las tiendas de aplicaciones. Estos son los pasos a seguir:
-
Para usuarios de Android
-
-
Ir a la Google Play Store y buscar "Zugacoin Merchant App".
-
Seleccione la aplicación de la lista y toque en "Instalar".
-
Espere a que la aplicación se descargue e instale en su dispositivo.
-
-
-
Para usuarios de iOS
-
-
Ir a la App Store y buscar "Zugacoin Merchant App".
-
Seleccione la aplicación de la lista y toque en "Obtener".
-
Ingresa tu contraseña de Apple ID o usa Touch ID o Face ID para confirmar.
-
Espere a que la aplicación se descargue e instale en su dispositivo.
-
Abra la aplicación y acepte los términos y condiciones.
-
-
Cómo registrarse y verificar su cuenta
-
Después de haber descargado e instalado la aplicación comercial Zugacoin, tendrá que registrarse y verificar su cuenta antes de comenzar a usarla. Estos son los pasos a seguir:
-
-
Abra la aplicación y toque en "Crear cuenta".
-
Ingrese su nombre completo, dirección de correo electrónico, número de teléfono, contraseña y código de referencia (si existe).
-
Toque en "Registrarse" y compruebe su correo electrónico para un enlace de verificación.
-
Haga clic en el enlace para verificar su dirección de correo electrónico y activar su cuenta.
-
Inicie sesión en su cuenta y toque en "Perfil".
-
Seleccione "Verificación" y cargue su documento de identidad (como pasaporte, licencia de conducir o tarjeta de identificación nacional).
Introduzca sus datos personales, como su fecha de nacimiento, sexo, dirección y país.
-
Toque en "Enviar" y espere a que se complete la verificación.
-
Recibirás una notificación cuando tu cuenta esté verificada y lista para usar.
-
-
Cómo comprar y vender Zugacoin en la aplicación
-
Una vez que haya verificado su cuenta, puede comenzar a comprar y vender Zugacoin en la aplicación. Hay tres formas principales de hacer esto: usar la función de escaneo a pago, usar el intercambio P2P y usar la función de intercambio. Estos son los pasos a seguir para cada método:
-
Uso de la función de escaneo a pago
-
Esta función le permite pagar por bienes y servicios con Zugacoin escaneando un código QR. También puedes recibir pagos de otros usuarios generando tu propio código QR. Estos son los pasos a seguir:
-
-
-
Si quieres pagar a alguien, escanea su código QR con tu cámara. Si desea recibir el pago, toque en "Recibir" y mostrar su código QR al pagador.
-
Introduzca la cantidad de Zugacoin que desea enviar o recibir y confirme la transacción.
-
Verá un mensaje de confirmación y un recibo de la transacción.
-
-
Usando el intercambio P2P
-
Esta característica le permite comprar y vender Zugacoin con otros usuarios directamente. Puede elegir entre una lista de ofertas o crear su propia oferta. También puede chatear con el vendedor o el comprador y calificarlos después de la transacción. Estos son los pasos a seguir:
-
-
Abra la aplicación y toque en "P2P Exchange".
-
Si desea comprar Zugacoin, toque en "Comprar". Si desea vender Zugacoin, toque en "Vender".
-
Navegar por la lista de ofertas y seleccionar el que se adapte a sus necesidades. Puede filtrar las ofertas por método de pago, ubicación, precio y calificación.
-
Toque en "Comercio" y chatear con el vendedor o comprador para acordar los términos de la transacción.
-
Siga las instrucciones en la pantalla y complete el pago o transferencia de Zugacoin.
-
Toque en "Confirmar" y espere la confirmación de la otra parte.
-
Verá un mensaje de confirmación y un recibo de la transacción.
-
También puede calificar y revisar al vendedor o comprador después de la transacción.
-
-
Usando la función de intercambio
-
Esta función le permite intercambiar Zugacoin con otras criptomonedas, como Bitcoin, Ethereum, Binance Coin, Tether, etc. Puede elegir entre una lista de monedas admitidas o ingresar una cantidad personalizada. Estos son los pasos a seguir:
-
-
Abra la aplicación y toque en "Intercambiar".
-
Seleccione la moneda que desea intercambiar y la moneda que desea intercambiar.
Introduzca la cantidad de moneda que desea intercambiar o use el control deslizante para ajustar la cantidad.
-
Toque en "Intercambiar ahora" y confirme la transacción.
-
-
-
Comentarios y valoraciones de Zugacoin
-
Zugacoin es una criptomoneda relativamente nueva que aún no ha ganado mucha popularidad o reconocimiento en el espacio criptográfico. Sin embargo, ha recibido algunas críticas y valoraciones de usuarios y expertos que lo han probado o analizado. Estos son algunos de ellos:
-
Pros y contras de Zugacoin
-
Como cualquier otra criptomoneda, Zugacoin tiene sus propios pros y contras que usted debe ser consciente de antes de invertir en ella. Aquí está un resumen de las principales ventajas y desventajas de usar Zugacoin:
-
-
-
Pros
-
Contras
-
-
-
- Ofrece transacciones rápidas, seguras y de bajo costo a través de las fronteras.
-
- Tiene un suministro limitado de 1 millón de SZC, lo que puede limitar su escalabilidad y adopción.
-
-
-
- Proporciona acceso a préstamos para startups de negocios y necesidades personales.
-
- No es ampliamente aceptado o apoyado por comerciantes, bolsas o carteras.
-
-
-
- Permite a los usuarios obtener ingresos pasivos mediante la apuesta o la celebración de Zugacoin en sus carteras.
-
- Es vulnerable a la volatilidad del mercado, la incertidumbre regulatoria y los ciberataques.
-
-
-
- Está respaldado por un fundador de buena reputación y un equipo de expertos en blockchain, finanzas y marketing.
-
- Tiene una baja capitalización de mercado, liquidez y volumen de operaciones.
-
-
-
- Es compatible con la red Ethereum y se puede integrar con otras aplicaciones descentralizadas.
-
- Tiene una baja conciencia, confianza y reputación entre la comunidad criptográfica.
-
-
-
Zugacoin vs otras criptomonedas
-
Zugacoin no es la única criptomoneda que tiene como objetivo empoderar a África y promover la inclusión financiera. Hay otras criptomonedas que tienen objetivos o características similares, como Akoin, KubitX, BitSika, etc. ¿Cómo se compara Zugacoin con ellos? Aquí hay algunos puntos de comparación:
-
-
-
Zugacoin es más compatible con la red Ethereum y sus aplicaciones descentralizadas que otras criptomonedas que utilizan diferentes blockchains o protocolos.
-
Zugacoin tiene una aceptación, soporte y adopción más limitada que otras criptomonedas que tienen más asociaciones, integraciones e intercambios.
-
Zugacoin tiene un gobierno y una visión más centralizados que otras criptomonedas que tienen más participación y retroalimentación de la comunidad.
-
-
Conclusión
-
Zugacoin es una criptomoneda que tiene como objetivo reconstruir la economía de África mediante la concesión de préstamos, pagos e inversiones para las nuevas empresas y las necesidades personales. Es una forma rápida, segura y de bajo costo de realizar transacciones a través de las fronteras y obtener ingresos pasivos al apostar o mantener Zugacoin en su billetera. Está respaldado por un fundador de buena reputación y un equipo de expertos en blockchain, finanzas y marketing. Es compatible con la red Ethereum y puede integrarse con otras aplicaciones descentralizadas.
-
Sin embargo, Zugacoin también tiene algunos inconvenientes que debe considerar antes de invertir en él. Tiene un suministro limitado de 1 millón de SZC, lo que puede limitar su escalabilidad y adopción. No es ampliamente aceptado o apoyado por los comerciantes, intercambios o carteras. Es vulnerable a la volatilidad del mercado, la incertidumbre regulatoria y los ciberataques. Tiene una baja capitalización de mercado, liquidez y volumen de operaciones. Tiene una baja conciencia, confianza y reputación entre la comunidad criptográfica.
-
Si desea probar Zugacoin, tendrá que descargar e instalar la aplicación comercial Zugacoin en su teléfono inteligente. La aplicación es una plataforma segura y conveniente para comprar y vender Zugacoin. Puede utilizar la función de escaneo a pago, el intercambio P2P o la función de intercambio para operar Zugacoin con otros usuarios o criptomonedas. También tendrá que registrarse y verificar su cuenta antes de que pueda comenzar a usar la aplicación.
-
-
Preguntas frecuentes
-
Aquí están algunas de las preguntas y respuestas más frecuentes sobre Zugacoin:
-
-
¿Cuál es el sitio web oficial de Zugacoin?
-
El sitio web oficial de Zugacoin es https://zugacoin.com/ Puede encontrar más información sobre la visión de Zugacoin, misión, hoja de ruta, equipo, socios, noticias, eventos, etc. en el sitio web.
-
¿Dónde puedo comprar Zugacoin?
-
Puedes comprar Zugacoin en la aplicación comercial Zugacoin o en algunos intercambios de criptografía que lo soportan. Algunos de los intercambios que enumeran Zugacoin son BitMart, VinDAX, FinexBox, SatoExchange, etc.
-
¿Cómo puedo ponerme en contacto con Zugacoin?
Puede ponerse en contacto con Zugacoin enviando un correo electrónico a info@zugacoin.com o llamando al +234 811 377 7709. También puedes seguir a Zugacoin en redes sociales, como Facebook, Twitter, Instagram, YouTube, etc.
-
¿Es Zugacoin una estafa?
-
No, Zugacoin no es una estafa. Es una criptomoneda legítima que está registrada y regulada por el gobierno nigeriano. Tiene una visión clara, misión, hoja de ruta, equipo, socios y comunidad. También tiene un libro mayor de blockchain transparente y auditable que registra todas las transacciones y actividades.
-
¿Cómo puedo almacenar Zugacoin?
-
Puede almacenar Zugacoin en la aplicación comercial Zugacoin o en cualquier cartera compatible que soporte tokens ERC20. Algunas de las carteras que puedes usar son Trust Wallet, MetaMask, MyEtherWallet, etc. Siempre debes mantener tus claves y contraseñas privadas seguras.
- 64aa2da5cf
-
-
\ No newline at end of file
diff --git a/spaces/Big-Web/MMSD/env/Lib/site-packages/pip/_internal/req/req_install.py b/spaces/Big-Web/MMSD/env/Lib/site-packages/pip/_internal/req/req_install.py
deleted file mode 100644
index d01b24a918954bd5440c94463369ee7a666aad29..0000000000000000000000000000000000000000
--- a/spaces/Big-Web/MMSD/env/Lib/site-packages/pip/_internal/req/req_install.py
+++ /dev/null
@@ -1,867 +0,0 @@
-# The following comment should be removed at some point in the future.
-# mypy: strict-optional=False
-
-import functools
-import logging
-import os
-import shutil
-import sys
-import uuid
-import zipfile
-from optparse import Values
-from typing import Any, Collection, Dict, Iterable, List, Optional, Sequence, Union
-
-from pip._vendor.packaging.markers import Marker
-from pip._vendor.packaging.requirements import Requirement
-from pip._vendor.packaging.specifiers import SpecifierSet
-from pip._vendor.packaging.utils import canonicalize_name
-from pip._vendor.packaging.version import Version
-from pip._vendor.packaging.version import parse as parse_version
-from pip._vendor.pyproject_hooks import BuildBackendHookCaller
-
-from pip._internal.build_env import BuildEnvironment, NoOpBuildEnvironment
-from pip._internal.exceptions import InstallationError
-from pip._internal.locations import get_scheme
-from pip._internal.metadata import (
- BaseDistribution,
- get_default_environment,
- get_directory_distribution,
- get_wheel_distribution,
-)
-from pip._internal.metadata.base import FilesystemWheel
-from pip._internal.models.direct_url import DirectUrl
-from pip._internal.models.link import Link
-from pip._internal.operations.build.metadata import generate_metadata
-from pip._internal.operations.build.metadata_editable import generate_editable_metadata
-from pip._internal.operations.build.metadata_legacy import (
- generate_metadata as generate_metadata_legacy,
-)
-from pip._internal.operations.install.editable_legacy import (
- install_editable as install_editable_legacy,
-)
-from pip._internal.operations.install.wheel import install_wheel
-from pip._internal.pyproject import load_pyproject_toml, make_pyproject_path
-from pip._internal.req.req_uninstall import UninstallPathSet
-from pip._internal.utils.deprecation import deprecated
-from pip._internal.utils.hashes import Hashes
-from pip._internal.utils.misc import (
- ConfiguredBuildBackendHookCaller,
- ask_path_exists,
- backup_dir,
- display_path,
- hide_url,
- redact_auth_from_url,
-)
-from pip._internal.utils.packaging import safe_extra
-from pip._internal.utils.subprocess import runner_with_spinner_message
-from pip._internal.utils.temp_dir import TempDirectory, tempdir_kinds
-from pip._internal.utils.virtualenv import running_under_virtualenv
-from pip._internal.vcs import vcs
-
-logger = logging.getLogger(__name__)
-
-
-class InstallRequirement:
- """
- Represents something that may be installed later on, may have information
- about where to fetch the relevant requirement and also contains logic for
- installing the said requirement.
- """
-
- def __init__(
- self,
- req: Optional[Requirement],
- comes_from: Optional[Union[str, "InstallRequirement"]],
- editable: bool = False,
- link: Optional[Link] = None,
- markers: Optional[Marker] = None,
- use_pep517: Optional[bool] = None,
- isolated: bool = False,
- *,
- global_options: Optional[List[str]] = None,
- hash_options: Optional[Dict[str, List[str]]] = None,
- config_settings: Optional[Dict[str, Union[str, List[str]]]] = None,
- constraint: bool = False,
- extras: Collection[str] = (),
- user_supplied: bool = False,
- permit_editable_wheels: bool = False,
- ) -> None:
- assert req is None or isinstance(req, Requirement), req
- self.req = req
- self.comes_from = comes_from
- self.constraint = constraint
- self.editable = editable
- self.permit_editable_wheels = permit_editable_wheels
-
- # source_dir is the local directory where the linked requirement is
- # located, or unpacked. In case unpacking is needed, creating and
- # populating source_dir is done by the RequirementPreparer. Note this
- # is not necessarily the directory where pyproject.toml or setup.py is
- # located - that one is obtained via unpacked_source_directory.
- self.source_dir: Optional[str] = None
- if self.editable:
- assert link
- if link.is_file:
- self.source_dir = os.path.normpath(os.path.abspath(link.file_path))
-
- if link is None and req and req.url:
- # PEP 508 URL requirement
- link = Link(req.url)
- self.link = self.original_link = link
-
- # When this InstallRequirement is a wheel obtained from the cache of locally
- # built wheels, this is the source link corresponding to the cache entry, which
- # was used to download and build the cached wheel.
- self.cached_wheel_source_link: Optional[Link] = None
-
- # Information about the location of the artifact that was downloaded . This
- # property is guaranteed to be set in resolver results.
- self.download_info: Optional[DirectUrl] = None
-
- # Path to any downloaded or already-existing package.
- self.local_file_path: Optional[str] = None
- if self.link and self.link.is_file:
- self.local_file_path = self.link.file_path
-
- if extras:
- self.extras = extras
- elif req:
- self.extras = {safe_extra(extra) for extra in req.extras}
- else:
- self.extras = set()
- if markers is None and req:
- markers = req.marker
- self.markers = markers
-
- # This holds the Distribution object if this requirement is already installed.
- self.satisfied_by: Optional[BaseDistribution] = None
- # Whether the installation process should try to uninstall an existing
- # distribution before installing this requirement.
- self.should_reinstall = False
- # Temporary build location
- self._temp_build_dir: Optional[TempDirectory] = None
- # Set to True after successful installation
- self.install_succeeded: Optional[bool] = None
- # Supplied options
- self.global_options = global_options if global_options else []
- self.hash_options = hash_options if hash_options else {}
- self.config_settings = config_settings
- # Set to True after successful preparation of this requirement
- self.prepared = False
- # User supplied requirement are explicitly requested for installation
- # by the user via CLI arguments or requirements files, as opposed to,
- # e.g. dependencies, extras or constraints.
- self.user_supplied = user_supplied
-
- self.isolated = isolated
- self.build_env: BuildEnvironment = NoOpBuildEnvironment()
-
- # For PEP 517, the directory where we request the project metadata
- # gets stored. We need this to pass to build_wheel, so the backend
- # can ensure that the wheel matches the metadata (see the PEP for
- # details).
- self.metadata_directory: Optional[str] = None
-
- # The static build requirements (from pyproject.toml)
- self.pyproject_requires: Optional[List[str]] = None
-
- # Build requirements that we will check are available
- self.requirements_to_check: List[str] = []
-
- # The PEP 517 backend we should use to build the project
- self.pep517_backend: Optional[BuildBackendHookCaller] = None
-
- # Are we using PEP 517 for this requirement?
- # After pyproject.toml has been loaded, the only valid values are True
- # and False. Before loading, None is valid (meaning "use the default").
- # Setting an explicit value before loading pyproject.toml is supported,
- # but after loading this flag should be treated as read only.
- self.use_pep517 = use_pep517
-
- # This requirement needs more preparation before it can be built
- self.needs_more_preparation = False
-
- def __str__(self) -> str:
- if self.req:
- s = str(self.req)
- if self.link:
- s += " from {}".format(redact_auth_from_url(self.link.url))
- elif self.link:
- s = redact_auth_from_url(self.link.url)
- else:
- s = ""
- if self.satisfied_by is not None:
- if self.satisfied_by.location is not None:
- location = display_path(self.satisfied_by.location)
- else:
- location = ""
- s += f" in {location}"
- if self.comes_from:
- if isinstance(self.comes_from, str):
- comes_from: Optional[str] = self.comes_from
- else:
- comes_from = self.comes_from.from_path()
- if comes_from:
- s += f" (from {comes_from})"
- return s
-
- def __repr__(self) -> str:
- return "<{} object: {} editable={!r}>".format(
- self.__class__.__name__, str(self), self.editable
- )
-
- def format_debug(self) -> str:
- """An un-tested helper for getting state, for debugging."""
- attributes = vars(self)
- names = sorted(attributes)
-
- state = ("{}={!r}".format(attr, attributes[attr]) for attr in sorted(names))
- return "<{name} object: {{{state}}}>".format(
- name=self.__class__.__name__,
- state=", ".join(state),
- )
-
- # Things that are valid for all kinds of requirements?
- @property
- def name(self) -> Optional[str]:
- if self.req is None:
- return None
- return self.req.name
-
- @functools.lru_cache() # use cached_property in python 3.8+
- def supports_pyproject_editable(self) -> bool:
- if not self.use_pep517:
- return False
- assert self.pep517_backend
- with self.build_env:
- runner = runner_with_spinner_message(
- "Checking if build backend supports build_editable"
- )
- with self.pep517_backend.subprocess_runner(runner):
- return "build_editable" in self.pep517_backend._supported_features()
-
- @property
- def specifier(self) -> SpecifierSet:
- return self.req.specifier
-
- @property
- def is_pinned(self) -> bool:
- """Return whether I am pinned to an exact version.
-
- For example, some-package==1.2 is pinned; some-package>1.2 is not.
- """
- specifiers = self.specifier
- return len(specifiers) == 1 and next(iter(specifiers)).operator in {"==", "==="}
-
- def match_markers(self, extras_requested: Optional[Iterable[str]] = None) -> bool:
- if not extras_requested:
- # Provide an extra to safely evaluate the markers
- # without matching any extra
- extras_requested = ("",)
- if self.markers is not None:
- return any(
- self.markers.evaluate({"extra": extra}) for extra in extras_requested
- )
- else:
- return True
-
- @property
- def has_hash_options(self) -> bool:
- """Return whether any known-good hashes are specified as options.
-
- These activate --require-hashes mode; hashes specified as part of a
- URL do not.
-
- """
- return bool(self.hash_options)
-
- def hashes(self, trust_internet: bool = True) -> Hashes:
- """Return a hash-comparer that considers my option- and URL-based
- hashes to be known-good.
-
- Hashes in URLs--ones embedded in the requirements file, not ones
- downloaded from an index server--are almost peers with ones from
- flags. They satisfy --require-hashes (whether it was implicitly or
- explicitly activated) but do not activate it. md5 and sha224 are not
- allowed in flags, which should nudge people toward good algos. We
- always OR all hashes together, even ones from URLs.
-
- :param trust_internet: Whether to trust URL-based (#md5=...) hashes
- downloaded from the internet, as by populate_link()
-
- """
- good_hashes = self.hash_options.copy()
- if trust_internet:
- link = self.link
- elif self.original_link and self.user_supplied:
- link = self.original_link
- else:
- link = None
- if link and link.hash:
- good_hashes.setdefault(link.hash_name, []).append(link.hash)
- return Hashes(good_hashes)
-
- def from_path(self) -> Optional[str]:
- """Format a nice indicator to show where this "comes from" """
- if self.req is None:
- return None
- s = str(self.req)
- if self.comes_from:
- if isinstance(self.comes_from, str):
- comes_from = self.comes_from
- else:
- comes_from = self.comes_from.from_path()
- if comes_from:
- s += "->" + comes_from
- return s
-
- def ensure_build_location(
- self, build_dir: str, autodelete: bool, parallel_builds: bool
- ) -> str:
- assert build_dir is not None
- if self._temp_build_dir is not None:
- assert self._temp_build_dir.path
- return self._temp_build_dir.path
- if self.req is None:
- # Some systems have /tmp as a symlink which confuses custom
- # builds (such as numpy). Thus, we ensure that the real path
- # is returned.
- self._temp_build_dir = TempDirectory(
- kind=tempdir_kinds.REQ_BUILD, globally_managed=True
- )
-
- return self._temp_build_dir.path
-
- # This is the only remaining place where we manually determine the path
- # for the temporary directory. It is only needed for editables where
- # it is the value of the --src option.
-
- # When parallel builds are enabled, add a UUID to the build directory
- # name so multiple builds do not interfere with each other.
- dir_name: str = canonicalize_name(self.name)
- if parallel_builds:
- dir_name = f"{dir_name}_{uuid.uuid4().hex}"
-
- # FIXME: Is there a better place to create the build_dir? (hg and bzr
- # need this)
- if not os.path.exists(build_dir):
- logger.debug("Creating directory %s", build_dir)
- os.makedirs(build_dir)
- actual_build_dir = os.path.join(build_dir, dir_name)
- # `None` indicates that we respect the globally-configured deletion
- # settings, which is what we actually want when auto-deleting.
- delete_arg = None if autodelete else False
- return TempDirectory(
- path=actual_build_dir,
- delete=delete_arg,
- kind=tempdir_kinds.REQ_BUILD,
- globally_managed=True,
- ).path
-
- def _set_requirement(self) -> None:
- """Set requirement after generating metadata."""
- assert self.req is None
- assert self.metadata is not None
- assert self.source_dir is not None
-
- # Construct a Requirement object from the generated metadata
- if isinstance(parse_version(self.metadata["Version"]), Version):
- op = "=="
- else:
- op = "==="
-
- self.req = Requirement(
- "".join(
- [
- self.metadata["Name"],
- op,
- self.metadata["Version"],
- ]
- )
- )
-
- def warn_on_mismatching_name(self) -> None:
- metadata_name = canonicalize_name(self.metadata["Name"])
- if canonicalize_name(self.req.name) == metadata_name:
- # Everything is fine.
- return
-
- # If we're here, there's a mismatch. Log a warning about it.
- logger.warning(
- "Generating metadata for package %s "
- "produced metadata for project name %s. Fix your "
- "#egg=%s fragments.",
- self.name,
- metadata_name,
- self.name,
- )
- self.req = Requirement(metadata_name)
-
- def check_if_exists(self, use_user_site: bool) -> None:
- """Find an installed distribution that satisfies or conflicts
- with this requirement, and set self.satisfied_by or
- self.should_reinstall appropriately.
- """
- if self.req is None:
- return
- existing_dist = get_default_environment().get_distribution(self.req.name)
- if not existing_dist:
- return
-
- version_compatible = self.req.specifier.contains(
- existing_dist.version,
- prereleases=True,
- )
- if not version_compatible:
- self.satisfied_by = None
- if use_user_site:
- if existing_dist.in_usersite:
- self.should_reinstall = True
- elif running_under_virtualenv() and existing_dist.in_site_packages:
- raise InstallationError(
- f"Will not install to the user site because it will "
- f"lack sys.path precedence to {existing_dist.raw_name} "
- f"in {existing_dist.location}"
- )
- else:
- self.should_reinstall = True
- else:
- if self.editable:
- self.should_reinstall = True
- # when installing editables, nothing pre-existing should ever
- # satisfy
- self.satisfied_by = None
- else:
- self.satisfied_by = existing_dist
-
- # Things valid for wheels
- @property
- def is_wheel(self) -> bool:
- if not self.link:
- return False
- return self.link.is_wheel
-
- @property
- def is_wheel_from_cache(self) -> bool:
- # When True, it means that this InstallRequirement is a local wheel file in the
- # cache of locally built wheels.
- return self.cached_wheel_source_link is not None
-
- # Things valid for sdists
- @property
- def unpacked_source_directory(self) -> str:
- return os.path.join(
- self.source_dir, self.link and self.link.subdirectory_fragment or ""
- )
-
- @property
- def setup_py_path(self) -> str:
- assert self.source_dir, f"No source dir for {self}"
- setup_py = os.path.join(self.unpacked_source_directory, "setup.py")
-
- return setup_py
-
- @property
- def setup_cfg_path(self) -> str:
- assert self.source_dir, f"No source dir for {self}"
- setup_cfg = os.path.join(self.unpacked_source_directory, "setup.cfg")
-
- return setup_cfg
-
- @property
- def pyproject_toml_path(self) -> str:
- assert self.source_dir, f"No source dir for {self}"
- return make_pyproject_path(self.unpacked_source_directory)
-
- def load_pyproject_toml(self) -> None:
- """Load the pyproject.toml file.
-
- After calling this routine, all of the attributes related to PEP 517
- processing for this requirement have been set. In particular, the
- use_pep517 attribute can be used to determine whether we should
- follow the PEP 517 or legacy (setup.py) code path.
- """
- pyproject_toml_data = load_pyproject_toml(
- self.use_pep517, self.pyproject_toml_path, self.setup_py_path, str(self)
- )
-
- if pyproject_toml_data is None:
- if self.config_settings:
- deprecated(
- reason=f"Config settings are ignored for project {self}.",
- replacement=(
- "to use --use-pep517 or add a "
- "pyproject.toml file to the project"
- ),
- gone_in="23.3",
- )
- self.use_pep517 = False
- return
-
- self.use_pep517 = True
- requires, backend, check, backend_path = pyproject_toml_data
- self.requirements_to_check = check
- self.pyproject_requires = requires
- self.pep517_backend = ConfiguredBuildBackendHookCaller(
- self,
- self.unpacked_source_directory,
- backend,
- backend_path=backend_path,
- )
-
- def isolated_editable_sanity_check(self) -> None:
- """Check that an editable requirement if valid for use with PEP 517/518.
-
- This verifies that an editable that has a pyproject.toml either supports PEP 660
- or as a setup.py or a setup.cfg
- """
- if (
- self.editable
- and self.use_pep517
- and not self.supports_pyproject_editable()
- and not os.path.isfile(self.setup_py_path)
- and not os.path.isfile(self.setup_cfg_path)
- ):
- raise InstallationError(
- f"Project {self} has a 'pyproject.toml' and its build "
- f"backend is missing the 'build_editable' hook. Since it does not "
- f"have a 'setup.py' nor a 'setup.cfg', "
- f"it cannot be installed in editable mode. "
- f"Consider using a build backend that supports PEP 660."
- )
-
- def prepare_metadata(self) -> None:
- """Ensure that project metadata is available.
-
- Under PEP 517 and PEP 660, call the backend hook to prepare the metadata.
- Under legacy processing, call setup.py egg-info.
- """
- assert self.source_dir
- details = self.name or f"from {self.link}"
-
- if self.use_pep517:
- assert self.pep517_backend is not None
- if (
- self.editable
- and self.permit_editable_wheels
- and self.supports_pyproject_editable()
- ):
- self.metadata_directory = generate_editable_metadata(
- build_env=self.build_env,
- backend=self.pep517_backend,
- details=details,
- )
- else:
- self.metadata_directory = generate_metadata(
- build_env=self.build_env,
- backend=self.pep517_backend,
- details=details,
- )
- else:
- self.metadata_directory = generate_metadata_legacy(
- build_env=self.build_env,
- setup_py_path=self.setup_py_path,
- source_dir=self.unpacked_source_directory,
- isolated=self.isolated,
- details=details,
- )
-
- # Act on the newly generated metadata, based on the name and version.
- if not self.name:
- self._set_requirement()
- else:
- self.warn_on_mismatching_name()
-
- self.assert_source_matches_version()
-
- @property
- def metadata(self) -> Any:
- if not hasattr(self, "_metadata"):
- self._metadata = self.get_dist().metadata
-
- return self._metadata
-
- def get_dist(self) -> BaseDistribution:
- if self.metadata_directory:
- return get_directory_distribution(self.metadata_directory)
- elif self.local_file_path and self.is_wheel:
- return get_wheel_distribution(
- FilesystemWheel(self.local_file_path), canonicalize_name(self.name)
- )
- raise AssertionError(
- f"InstallRequirement {self} has no metadata directory and no wheel: "
- f"can't make a distribution."
- )
-
- def assert_source_matches_version(self) -> None:
- assert self.source_dir
- version = self.metadata["version"]
- if self.req.specifier and version not in self.req.specifier:
- logger.warning(
- "Requested %s, but installing version %s",
- self,
- version,
- )
- else:
- logger.debug(
- "Source in %s has version %s, which satisfies requirement %s",
- display_path(self.source_dir),
- version,
- self,
- )
-
- # For both source distributions and editables
- def ensure_has_source_dir(
- self,
- parent_dir: str,
- autodelete: bool = False,
- parallel_builds: bool = False,
- ) -> None:
- """Ensure that a source_dir is set.
-
- This will create a temporary build dir if the name of the requirement
- isn't known yet.
-
- :param parent_dir: The ideal pip parent_dir for the source_dir.
- Generally src_dir for editables and build_dir for sdists.
- :return: self.source_dir
- """
- if self.source_dir is None:
- self.source_dir = self.ensure_build_location(
- parent_dir,
- autodelete=autodelete,
- parallel_builds=parallel_builds,
- )
-
- # For editable installations
- def update_editable(self) -> None:
- if not self.link:
- logger.debug(
- "Cannot update repository at %s; repository location is unknown",
- self.source_dir,
- )
- return
- assert self.editable
- assert self.source_dir
- if self.link.scheme == "file":
- # Static paths don't get updated
- return
- vcs_backend = vcs.get_backend_for_scheme(self.link.scheme)
- # Editable requirements are validated in Requirement constructors.
- # So here, if it's neither a path nor a valid VCS URL, it's a bug.
- assert vcs_backend, f"Unsupported VCS URL {self.link.url}"
- hidden_url = hide_url(self.link.url)
- vcs_backend.obtain(self.source_dir, url=hidden_url, verbosity=0)
-
- # Top-level Actions
- def uninstall(
- self, auto_confirm: bool = False, verbose: bool = False
- ) -> Optional[UninstallPathSet]:
- """
- Uninstall the distribution currently satisfying this requirement.
-
- Prompts before removing or modifying files unless
- ``auto_confirm`` is True.
-
- Refuses to delete or modify files outside of ``sys.prefix`` -
- thus uninstallation within a virtual environment can only
- modify that virtual environment, even if the virtualenv is
- linked to global site-packages.
-
- """
- assert self.req
- dist = get_default_environment().get_distribution(self.req.name)
- if not dist:
- logger.warning("Skipping %s as it is not installed.", self.name)
- return None
- logger.info("Found existing installation: %s", dist)
-
- uninstalled_pathset = UninstallPathSet.from_dist(dist)
- uninstalled_pathset.remove(auto_confirm, verbose)
- return uninstalled_pathset
-
- def _get_archive_name(self, path: str, parentdir: str, rootdir: str) -> str:
- def _clean_zip_name(name: str, prefix: str) -> str:
- assert name.startswith(
- prefix + os.path.sep
- ), f"name {name!r} doesn't start with prefix {prefix!r}"
- name = name[len(prefix) + 1 :]
- name = name.replace(os.path.sep, "/")
- return name
-
- path = os.path.join(parentdir, path)
- name = _clean_zip_name(path, rootdir)
- return self.name + "/" + name
-
- def archive(self, build_dir: Optional[str]) -> None:
- """Saves archive to provided build_dir.
-
- Used for saving downloaded VCS requirements as part of `pip download`.
- """
- assert self.source_dir
- if build_dir is None:
- return
-
- create_archive = True
- archive_name = "{}-{}.zip".format(self.name, self.metadata["version"])
- archive_path = os.path.join(build_dir, archive_name)
-
- if os.path.exists(archive_path):
- response = ask_path_exists(
- "The file {} exists. (i)gnore, (w)ipe, "
- "(b)ackup, (a)bort ".format(display_path(archive_path)),
- ("i", "w", "b", "a"),
- )
- if response == "i":
- create_archive = False
- elif response == "w":
- logger.warning("Deleting %s", display_path(archive_path))
- os.remove(archive_path)
- elif response == "b":
- dest_file = backup_dir(archive_path)
- logger.warning(
- "Backing up %s to %s",
- display_path(archive_path),
- display_path(dest_file),
- )
- shutil.move(archive_path, dest_file)
- elif response == "a":
- sys.exit(-1)
-
- if not create_archive:
- return
-
- zip_output = zipfile.ZipFile(
- archive_path,
- "w",
- zipfile.ZIP_DEFLATED,
- allowZip64=True,
- )
- with zip_output:
- dir = os.path.normcase(os.path.abspath(self.unpacked_source_directory))
- for dirpath, dirnames, filenames in os.walk(dir):
- for dirname in dirnames:
- dir_arcname = self._get_archive_name(
- dirname,
- parentdir=dirpath,
- rootdir=dir,
- )
- zipdir = zipfile.ZipInfo(dir_arcname + "/")
- zipdir.external_attr = 0x1ED << 16 # 0o755
- zip_output.writestr(zipdir, "")
- for filename in filenames:
- file_arcname = self._get_archive_name(
- filename,
- parentdir=dirpath,
- rootdir=dir,
- )
- filename = os.path.join(dirpath, filename)
- zip_output.write(filename, file_arcname)
-
- logger.info("Saved %s", display_path(archive_path))
-
- def install(
- self,
- global_options: Optional[Sequence[str]] = None,
- root: Optional[str] = None,
- home: Optional[str] = None,
- prefix: Optional[str] = None,
- warn_script_location: bool = True,
- use_user_site: bool = False,
- pycompile: bool = True,
- ) -> None:
- scheme = get_scheme(
- self.name,
- user=use_user_site,
- home=home,
- root=root,
- isolated=self.isolated,
- prefix=prefix,
- )
-
- if self.editable and not self.is_wheel:
- install_editable_legacy(
- global_options=global_options if global_options is not None else [],
- prefix=prefix,
- home=home,
- use_user_site=use_user_site,
- name=self.name,
- setup_py_path=self.setup_py_path,
- isolated=self.isolated,
- build_env=self.build_env,
- unpacked_source_directory=self.unpacked_source_directory,
- )
- self.install_succeeded = True
- return
-
- assert self.is_wheel
- assert self.local_file_path
-
- install_wheel(
- self.name,
- self.local_file_path,
- scheme=scheme,
- req_description=str(self.req),
- pycompile=pycompile,
- warn_script_location=warn_script_location,
- direct_url=self.download_info if self.original_link else None,
- requested=self.user_supplied,
- )
- self.install_succeeded = True
-
-
-def check_invalid_constraint_type(req: InstallRequirement) -> str:
- # Check for unsupported forms
- problem = ""
- if not req.name:
- problem = "Unnamed requirements are not allowed as constraints"
- elif req.editable:
- problem = "Editable requirements are not allowed as constraints"
- elif req.extras:
- problem = "Constraints cannot have extras"
-
- if problem:
- deprecated(
- reason=(
- "Constraints are only allowed to take the form of a package "
- "name and a version specifier. Other forms were originally "
- "permitted as an accident of the implementation, but were "
- "undocumented. The new implementation of the resolver no "
- "longer supports these forms."
- ),
- replacement="replacing the constraint with a requirement",
- # No plan yet for when the new resolver becomes default
- gone_in=None,
- issue=8210,
- )
-
- return problem
-
-
-def _has_option(options: Values, reqs: List[InstallRequirement], option: str) -> bool:
- if getattr(options, option, None):
- return True
- for req in reqs:
- if getattr(req, option, None):
- return True
- return False
-
-
-def check_legacy_setup_py_options(
- options: Values,
- reqs: List[InstallRequirement],
-) -> None:
- has_build_options = _has_option(options, reqs, "build_options")
- has_global_options = _has_option(options, reqs, "global_options")
- if has_build_options or has_global_options:
- deprecated(
- reason="--build-option and --global-option are deprecated.",
- issue=11859,
- replacement="to use --config-settings",
- gone_in="23.3",
- )
- logger.warning(
- "Implying --no-binary=:all: due to the presence of "
- "--build-option / --global-option. "
- )
- options.format_control.disallow_binaries()
diff --git a/spaces/Big-Web/MMSD/env/Lib/site-packages/pip/_vendor/pygments/util.py b/spaces/Big-Web/MMSD/env/Lib/site-packages/pip/_vendor/pygments/util.py
deleted file mode 100644
index 8032962dc994bd2b62e98f02016c88d0994e2f58..0000000000000000000000000000000000000000
--- a/spaces/Big-Web/MMSD/env/Lib/site-packages/pip/_vendor/pygments/util.py
+++ /dev/null
@@ -1,308 +0,0 @@
-"""
- pygments.util
- ~~~~~~~~~~~~~
-
- Utility functions.
-
- :copyright: Copyright 2006-2022 by the Pygments team, see AUTHORS.
- :license: BSD, see LICENSE for details.
-"""
-
-import re
-from io import TextIOWrapper
-
-
-split_path_re = re.compile(r'[/\\ ]')
-doctype_lookup_re = re.compile(r'''
- ]*>
-''', re.DOTALL | re.MULTILINE | re.VERBOSE)
-tag_re = re.compile(r'<(.+?)(\s.*?)?>.*?',
- re.IGNORECASE | re.DOTALL | re.MULTILINE)
-xml_decl_re = re.compile(r'\s*<\?xml[^>]*\?>', re.I)
-
-
-class ClassNotFound(ValueError):
- """Raised if one of the lookup functions didn't find a matching class."""
-
-
-class OptionError(Exception):
- pass
-
-
-def get_choice_opt(options, optname, allowed, default=None, normcase=False):
- string = options.get(optname, default)
- if normcase:
- string = string.lower()
- if string not in allowed:
- raise OptionError('Value for option %s must be one of %s' %
- (optname, ', '.join(map(str, allowed))))
- return string
-
-
-def get_bool_opt(options, optname, default=None):
- string = options.get(optname, default)
- if isinstance(string, bool):
- return string
- elif isinstance(string, int):
- return bool(string)
- elif not isinstance(string, str):
- raise OptionError('Invalid type %r for option %s; use '
- '1/0, yes/no, true/false, on/off' % (
- string, optname))
- elif string.lower() in ('1', 'yes', 'true', 'on'):
- return True
- elif string.lower() in ('0', 'no', 'false', 'off'):
- return False
- else:
- raise OptionError('Invalid value %r for option %s; use '
- '1/0, yes/no, true/false, on/off' % (
- string, optname))
-
-
-def get_int_opt(options, optname, default=None):
- string = options.get(optname, default)
- try:
- return int(string)
- except TypeError:
- raise OptionError('Invalid type %r for option %s; you '
- 'must give an integer value' % (
- string, optname))
- except ValueError:
- raise OptionError('Invalid value %r for option %s; you '
- 'must give an integer value' % (
- string, optname))
-
-
-def get_list_opt(options, optname, default=None):
- val = options.get(optname, default)
- if isinstance(val, str):
- return val.split()
- elif isinstance(val, (list, tuple)):
- return list(val)
- else:
- raise OptionError('Invalid type %r for option %s; you '
- 'must give a list value' % (
- val, optname))
-
-
-def docstring_headline(obj):
- if not obj.__doc__:
- return ''
- res = []
- for line in obj.__doc__.strip().splitlines():
- if line.strip():
- res.append(" " + line.strip())
- else:
- break
- return ''.join(res).lstrip()
-
-
-def make_analysator(f):
- """Return a static text analyser function that returns float values."""
- def text_analyse(text):
- try:
- rv = f(text)
- except Exception:
- return 0.0
- if not rv:
- return 0.0
- try:
- return min(1.0, max(0.0, float(rv)))
- except (ValueError, TypeError):
- return 0.0
- text_analyse.__doc__ = f.__doc__
- return staticmethod(text_analyse)
-
-
-def shebang_matches(text, regex):
- r"""Check if the given regular expression matches the last part of the
- shebang if one exists.
-
- >>> from pygments.util import shebang_matches
- >>> shebang_matches('#!/usr/bin/env python', r'python(2\.\d)?')
- True
- >>> shebang_matches('#!/usr/bin/python2.4', r'python(2\.\d)?')
- True
- >>> shebang_matches('#!/usr/bin/python-ruby', r'python(2\.\d)?')
- False
- >>> shebang_matches('#!/usr/bin/python/ruby', r'python(2\.\d)?')
- False
- >>> shebang_matches('#!/usr/bin/startsomethingwith python',
- ... r'python(2\.\d)?')
- True
-
- It also checks for common windows executable file extensions::
-
- >>> shebang_matches('#!C:\\Python2.4\\Python.exe', r'python(2\.\d)?')
- True
-
- Parameters (``'-f'`` or ``'--foo'`` are ignored so ``'perl'`` does
- the same as ``'perl -e'``)
-
- Note that this method automatically searches the whole string (eg:
- the regular expression is wrapped in ``'^$'``)
- """
- index = text.find('\n')
- if index >= 0:
- first_line = text[:index].lower()
- else:
- first_line = text.lower()
- if first_line.startswith('#!'):
- try:
- found = [x for x in split_path_re.split(first_line[2:].strip())
- if x and not x.startswith('-')][-1]
- except IndexError:
- return False
- regex = re.compile(r'^%s(\.(exe|cmd|bat|bin))?$' % regex, re.IGNORECASE)
- if regex.search(found) is not None:
- return True
- return False
-
-
-def doctype_matches(text, regex):
- """Check if the doctype matches a regular expression (if present).
-
- Note that this method only checks the first part of a DOCTYPE.
- eg: 'html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"'
- """
- m = doctype_lookup_re.search(text)
- if m is None:
- return False
- doctype = m.group(1)
- return re.compile(regex, re.I).match(doctype.strip()) is not None
-
-
-def html_doctype_matches(text):
- """Check if the file looks like it has a html doctype."""
- return doctype_matches(text, r'html')
-
-
-_looks_like_xml_cache = {}
-
-
-def looks_like_xml(text):
- """Check if a doctype exists or if we have some tags."""
- if xml_decl_re.match(text):
- return True
- key = hash(text)
- try:
- return _looks_like_xml_cache[key]
- except KeyError:
- m = doctype_lookup_re.search(text)
- if m is not None:
- return True
- rv = tag_re.search(text[:1000]) is not None
- _looks_like_xml_cache[key] = rv
- return rv
-
-
-def surrogatepair(c):
- """Given a unicode character code with length greater than 16 bits,
- return the two 16 bit surrogate pair.
- """
- # From example D28 of:
- # http://www.unicode.org/book/ch03.pdf
- return (0xd7c0 + (c >> 10), (0xdc00 + (c & 0x3ff)))
-
-
-def format_lines(var_name, seq, raw=False, indent_level=0):
- """Formats a sequence of strings for output."""
- lines = []
- base_indent = ' ' * indent_level * 4
- inner_indent = ' ' * (indent_level + 1) * 4
- lines.append(base_indent + var_name + ' = (')
- if raw:
- # These should be preformatted reprs of, say, tuples.
- for i in seq:
- lines.append(inner_indent + i + ',')
- else:
- for i in seq:
- # Force use of single quotes
- r = repr(i + '"')
- lines.append(inner_indent + r[:-2] + r[-1] + ',')
- lines.append(base_indent + ')')
- return '\n'.join(lines)
-
-
-def duplicates_removed(it, already_seen=()):
- """
- Returns a list with duplicates removed from the iterable `it`.
-
- Order is preserved.
- """
- lst = []
- seen = set()
- for i in it:
- if i in seen or i in already_seen:
- continue
- lst.append(i)
- seen.add(i)
- return lst
-
-
-class Future:
- """Generic class to defer some work.
-
- Handled specially in RegexLexerMeta, to support regex string construction at
- first use.
- """
- def get(self):
- raise NotImplementedError
-
-
-def guess_decode(text):
- """Decode *text* with guessed encoding.
-
- First try UTF-8; this should fail for non-UTF-8 encodings.
- Then try the preferred locale encoding.
- Fall back to latin-1, which always works.
- """
- try:
- text = text.decode('utf-8')
- return text, 'utf-8'
- except UnicodeDecodeError:
- try:
- import locale
- prefencoding = locale.getpreferredencoding()
- text = text.decode()
- return text, prefencoding
- except (UnicodeDecodeError, LookupError):
- text = text.decode('latin1')
- return text, 'latin1'
-
-
-def guess_decode_from_terminal(text, term):
- """Decode *text* coming from terminal *term*.
-
- First try the terminal encoding, if given.
- Then try UTF-8. Then try the preferred locale encoding.
- Fall back to latin-1, which always works.
- """
- if getattr(term, 'encoding', None):
- try:
- text = text.decode(term.encoding)
- except UnicodeDecodeError:
- pass
- else:
- return text, term.encoding
- return guess_decode(text)
-
-
-def terminal_encoding(term):
- """Return our best guess of encoding for the given *term*."""
- if getattr(term, 'encoding', None):
- return term.encoding
- import locale
- return locale.getpreferredencoding()
-
-
-class UnclosingTextIOWrapper(TextIOWrapper):
- # Don't close underlying buffer on destruction.
- def close(self):
- self.flush()
diff --git a/spaces/Big-Web/MMSD/env/Lib/site-packages/setuptools/_distutils/dep_util.py b/spaces/Big-Web/MMSD/env/Lib/site-packages/setuptools/_distutils/dep_util.py
deleted file mode 100644
index db1fa01996ce0d47cd7f070c53b085926440d377..0000000000000000000000000000000000000000
--- a/spaces/Big-Web/MMSD/env/Lib/site-packages/setuptools/_distutils/dep_util.py
+++ /dev/null
@@ -1,96 +0,0 @@
-"""distutils.dep_util
-
-Utility functions for simple, timestamp-based dependency of files
-and groups of files; also, function based entirely on such
-timestamp dependency analysis."""
-
-import os
-from distutils.errors import DistutilsFileError
-
-
-def newer(source, target):
- """Return true if 'source' exists and is more recently modified than
- 'target', or if 'source' exists and 'target' doesn't. Return false if
- both exist and 'target' is the same age or younger than 'source'.
- Raise DistutilsFileError if 'source' does not exist.
- """
- if not os.path.exists(source):
- raise DistutilsFileError("file '%s' does not exist" % os.path.abspath(source))
- if not os.path.exists(target):
- return 1
-
- from stat import ST_MTIME
-
- mtime1 = os.stat(source)[ST_MTIME]
- mtime2 = os.stat(target)[ST_MTIME]
-
- return mtime1 > mtime2
-
-
-# newer ()
-
-
-def newer_pairwise(sources, targets):
- """Walk two filename lists in parallel, testing if each source is newer
- than its corresponding target. Return a pair of lists (sources,
- targets) where source is newer than target, according to the semantics
- of 'newer()'.
- """
- if len(sources) != len(targets):
- raise ValueError("'sources' and 'targets' must be same length")
-
- # build a pair of lists (sources, targets) where source is newer
- n_sources = []
- n_targets = []
- for i in range(len(sources)):
- if newer(sources[i], targets[i]):
- n_sources.append(sources[i])
- n_targets.append(targets[i])
-
- return (n_sources, n_targets)
-
-
-# newer_pairwise ()
-
-
-def newer_group(sources, target, missing='error'):
- """Return true if 'target' is out-of-date with respect to any file
- listed in 'sources'. In other words, if 'target' exists and is newer
- than every file in 'sources', return false; otherwise return true.
- 'missing' controls what we do when a source file is missing; the
- default ("error") is to blow up with an OSError from inside 'stat()';
- if it is "ignore", we silently drop any missing source files; if it is
- "newer", any missing source files make us assume that 'target' is
- out-of-date (this is handy in "dry-run" mode: it'll make you pretend to
- carry out commands that wouldn't work because inputs are missing, but
- that doesn't matter because you're not actually going to run the
- commands).
- """
- # If the target doesn't even exist, then it's definitely out-of-date.
- if not os.path.exists(target):
- return 1
-
- # Otherwise we have to find out the hard way: if *any* source file
- # is more recent than 'target', then 'target' is out-of-date and
- # we can immediately return true. If we fall through to the end
- # of the loop, then 'target' is up-to-date and we return false.
- from stat import ST_MTIME
-
- target_mtime = os.stat(target)[ST_MTIME]
- for source in sources:
- if not os.path.exists(source):
- if missing == 'error': # blow up when we stat() the file
- pass
- elif missing == 'ignore': # missing source dropped from
- continue # target's dependency list
- elif missing == 'newer': # missing source means target is
- return 1 # out-of-date
-
- source_mtime = os.stat(source)[ST_MTIME]
- if source_mtime > target_mtime:
- return 1
- else:
- return 0
-
-
-# newer_group ()
diff --git a/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/detectron2/layers/csrc/nms_rotated/nms_rotated.h b/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/detectron2/layers/csrc/nms_rotated/nms_rotated.h
deleted file mode 100644
index f0dd981745a5a2b97b44d4d232a131e9255c02fe..0000000000000000000000000000000000000000
--- a/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/detectron2/layers/csrc/nms_rotated/nms_rotated.h
+++ /dev/null
@@ -1,38 +0,0 @@
-// Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
-#pragma once
-#include
-
-namespace detectron2 {
-
-at::Tensor nms_rotated_cpu(
- const at::Tensor& dets,
- const at::Tensor& scores,
- const float iou_threshold);
-
-#ifdef WITH_CUDA
-at::Tensor nms_rotated_cuda(
- const at::Tensor& dets,
- const at::Tensor& scores,
- const float iou_threshold);
-#endif
-
-// Interface for Python
-// inline is needed to prevent multiple function definitions when this header is
-// included by different cpps
-inline at::Tensor nms_rotated(
- const at::Tensor& dets,
- const at::Tensor& scores,
- const float iou_threshold) {
- assert(dets.device().is_cuda() == scores.device().is_cuda());
- if (dets.device().is_cuda()) {
-#ifdef WITH_CUDA
- return nms_rotated_cuda(dets, scores, iou_threshold);
-#else
- AT_ERROR("Not compiled with GPU support");
-#endif
- }
-
- return nms_rotated_cpu(dets, scores, iou_threshold);
-}
-
-} // namespace detectron2
diff --git a/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/projects/TensorMask/tensormask/layers/swap_align2nat.py b/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/projects/TensorMask/tensormask/layers/swap_align2nat.py
deleted file mode 100644
index a72c98a968577eff2302d75e4cb41620e4ecf582..0000000000000000000000000000000000000000
--- a/spaces/CVPR/Dual-Key_Backdoor_Attacks/datagen/detectron2/projects/TensorMask/tensormask/layers/swap_align2nat.py
+++ /dev/null
@@ -1,61 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
-from torch import nn
-from torch.autograd import Function
-from torch.autograd.function import once_differentiable
-
-from tensormask import _C
-
-
-class _SwapAlign2Nat(Function):
- @staticmethod
- def forward(ctx, X, lambda_val, pad_val):
- ctx.lambda_val = lambda_val
- ctx.input_shape = X.size()
-
- Y = _C.swap_align2nat_forward(X, lambda_val, pad_val)
- return Y
-
- @staticmethod
- @once_differentiable
- def backward(ctx, gY):
- lambda_val = ctx.lambda_val
- bs, ch, h, w = ctx.input_shape
-
- gX = _C.swap_align2nat_backward(gY, lambda_val, bs, ch, h, w)
-
- return gX, None, None
-
-
-swap_align2nat = _SwapAlign2Nat.apply
-
-
-class SwapAlign2Nat(nn.Module):
- """
- The op `SwapAlign2Nat` described in https://arxiv.org/abs/1903.12174.
- Given an input tensor that predicts masks of shape (N, C=VxU, H, W),
- apply the op, it will return masks of shape (N, V'xU', H', W') where
- the unit lengths of (V, U) and (H, W) are swapped, and the mask representation
- is transformed from aligned to natural.
- Args:
- lambda_val (int): the relative unit length ratio between (V, U) and (H, W),
- as we always have larger unit lengths for (V, U) than (H, W),
- lambda_val is always >= 1.
- pad_val (float): padding value for the values falling outside of the input
- tensor, default set to -6 as sigmoid(-6) is ~0, indicating
- that is no masks outside of the tensor.
- """
-
- def __init__(self, lambda_val, pad_val=-6.0):
- super(SwapAlign2Nat, self).__init__()
- self.lambda_val = lambda_val
- self.pad_val = pad_val
-
- def forward(self, X):
- return swap_align2nat(X, self.lambda_val, self.pad_val)
-
- def __repr__(self):
- tmpstr = self.__class__.__name__ + "("
- tmpstr += "lambda_val=" + str(self.lambda_val)
- tmpstr += ", pad_val=" + str(self.pad_val)
- tmpstr += ")"
- return tmpstr
diff --git a/spaces/CVPR/MonoScene/monoscene/.ipynb_checkpoints/modules-checkpoint.py b/spaces/CVPR/MonoScene/monoscene/.ipynb_checkpoints/modules-checkpoint.py
deleted file mode 100644
index 3e8bf875ccd6dffb51bb5acb25f0302fe0032d6c..0000000000000000000000000000000000000000
--- a/spaces/CVPR/MonoScene/monoscene/.ipynb_checkpoints/modules-checkpoint.py
+++ /dev/null
@@ -1,194 +0,0 @@
-import torch
-import torch.nn as nn
-from monoscene.DDR import Bottleneck3D
-
-
-class ASPP(nn.Module):
- """
- ASPP 3D
- Adapt from https://github.com/cv-rits/LMSCNet/blob/main/LMSCNet/models/LMSCNet.py#L7
- """
-
- def __init__(self, planes, dilations_conv_list):
- super().__init__()
-
- # ASPP Block
- self.conv_list = dilations_conv_list
- self.conv1 = nn.ModuleList(
- [
- nn.Conv3d(
- planes, planes, kernel_size=3, padding=dil, dilation=dil, bias=False
- )
- for dil in dilations_conv_list
- ]
- )
- self.bn1 = nn.ModuleList(
- [nn.BatchNorm3d(planes) for dil in dilations_conv_list]
- )
- self.conv2 = nn.ModuleList(
- [
- nn.Conv3d(
- planes, planes, kernel_size=3, padding=dil, dilation=dil, bias=False
- )
- for dil in dilations_conv_list
- ]
- )
- self.bn2 = nn.ModuleList(
- [nn.BatchNorm3d(planes) for dil in dilations_conv_list]
- )
- self.relu = nn.ReLU()
-
- def forward(self, x_in):
-
- y = self.bn2[0](self.conv2[0](self.relu(self.bn1[0](self.conv1[0](x_in)))))
- for i in range(1, len(self.conv_list)):
- y += self.bn2[i](self.conv2[i](self.relu(self.bn1[i](self.conv1[i](x_in)))))
- x_in = self.relu(y + x_in) # modified
-
- return x_in
-
-
-class SegmentationHead(nn.Module):
- """
- 3D Segmentation heads to retrieve semantic segmentation at each scale.
- Formed by Dim expansion, Conv3D, ASPP block, Conv3D.
- Taken from https://github.com/cv-rits/LMSCNet/blob/main/LMSCNet/models/LMSCNet.py#L7
- """
-
- def __init__(self, inplanes, planes, nbr_classes, dilations_conv_list):
- super().__init__()
-
- # First convolution
- self.conv0 = nn.Conv3d(inplanes, planes, kernel_size=3, padding=1, stride=1)
-
- # ASPP Block
- self.conv_list = dilations_conv_list
- self.conv1 = nn.ModuleList(
- [
- nn.Conv3d(
- planes, planes, kernel_size=3, padding=dil, dilation=dil, bias=False
- )
- for dil in dilations_conv_list
- ]
- )
- self.bn1 = nn.ModuleList(
- [nn.BatchNorm3d(planes) for dil in dilations_conv_list]
- )
- self.conv2 = nn.ModuleList(
- [
- nn.Conv3d(
- planes, planes, kernel_size=3, padding=dil, dilation=dil, bias=False
- )
- for dil in dilations_conv_list
- ]
- )
- self.bn2 = nn.ModuleList(
- [nn.BatchNorm3d(planes) for dil in dilations_conv_list]
- )
- self.relu = nn.ReLU()
-
- self.conv_classes = nn.Conv3d(
- planes, nbr_classes, kernel_size=3, padding=1, stride=1
- )
-
- def forward(self, x_in):
-
- # Convolution to go from inplanes to planes features...
- x_in = self.relu(self.conv0(x_in))
-
- y = self.bn2[0](self.conv2[0](self.relu(self.bn1[0](self.conv1[0](x_in)))))
- for i in range(1, len(self.conv_list)):
- y += self.bn2[i](self.conv2[i](self.relu(self.bn1[i](self.conv1[i](x_in)))))
- x_in = self.relu(y + x_in) # modified
-
- x_in = self.conv_classes(x_in)
-
- return x_in
-
-
-class ProcessKitti(nn.Module):
- def __init__(self, feature, norm_layer, bn_momentum, dilations=[1, 2, 3]):
- super(Process, self).__init__()
- self.main = nn.Sequential(
- *[
- Bottleneck3D(
- feature,
- feature // 4,
- bn_momentum=bn_momentum,
- norm_layer=norm_layer,
- dilation=[i, i, i],
- )
- for i in dilations
- ]
- )
-
- def forward(self, x):
- return self.main(x)
-
-
-class Process(nn.Module):
- def __init__(self, feature, norm_layer, bn_momentum, dilations=[1, 2, 3]):
- super(Process, self).__init__()
- self.main = nn.Sequential(
- *[
- Bottleneck3D(
- feature,
- feature // 4,
- bn_momentum=bn_momentum,
- norm_layer=norm_layer,
- dilation=[i, i, i],
- )
- for i in dilations
- ]
- )
-
- def forward(self, x):
- return self.main(x)
-
-
-class Upsample(nn.Module):
- def __init__(self, in_channels, out_channels, norm_layer, bn_momentum):
- super(Upsample, self).__init__()
- self.main = nn.Sequential(
- nn.ConvTranspose3d(
- in_channels,
- out_channels,
- kernel_size=3,
- stride=2,
- padding=1,
- dilation=1,
- output_padding=1,
- ),
- norm_layer(out_channels, momentum=bn_momentum),
- nn.ReLU(),
- )
-
- def forward(self, x):
- return self.main(x)
-
-
-class Downsample(nn.Module):
- def __init__(self, feature, norm_layer, bn_momentum, expansion=8):
- super(Downsample, self).__init__()
- self.main = Bottleneck3D(
- feature,
- feature // 4,
- bn_momentum=bn_momentum,
- expansion=expansion,
- stride=2,
- downsample=nn.Sequential(
- nn.AvgPool3d(kernel_size=2, stride=2),
- nn.Conv3d(
- feature,
- int(feature * expansion / 4),
- kernel_size=1,
- stride=1,
- bias=False,
- ),
- norm_layer(int(feature * expansion / 4), momentum=bn_momentum),
- ),
- norm_layer=norm_layer,
- )
-
- def forward(self, x):
- return self.main(x)
diff --git a/spaces/CVPR/WALT/mmdet/datasets/xml_style.py b/spaces/CVPR/WALT/mmdet/datasets/xml_style.py
deleted file mode 100644
index 71069488b0f6da3b37e588228f44460ce5f00679..0000000000000000000000000000000000000000
--- a/spaces/CVPR/WALT/mmdet/datasets/xml_style.py
+++ /dev/null
@@ -1,170 +0,0 @@
-import os.path as osp
-import xml.etree.ElementTree as ET
-
-import mmcv
-import numpy as np
-from PIL import Image
-
-from .builder import DATASETS
-from .custom import CustomDataset
-
-
-@DATASETS.register_module()
-class XMLDataset(CustomDataset):
- """XML dataset for detection.
-
- Args:
- min_size (int | float, optional): The minimum size of bounding
- boxes in the images. If the size of a bounding box is less than
- ``min_size``, it would be add to ignored field.
- """
-
- def __init__(self, min_size=None, **kwargs):
- assert self.CLASSES or kwargs.get(
- 'classes', None), 'CLASSES in `XMLDataset` can not be None.'
- super(XMLDataset, self).__init__(**kwargs)
- self.cat2label = {cat: i for i, cat in enumerate(self.CLASSES)}
- self.min_size = min_size
-
- def load_annotations(self, ann_file):
- """Load annotation from XML style ann_file.
-
- Args:
- ann_file (str): Path of XML file.
-
- Returns:
- list[dict]: Annotation info from XML file.
- """
-
- data_infos = []
- img_ids = mmcv.list_from_file(ann_file)
- for img_id in img_ids:
- filename = f'JPEGImages/{img_id}.jpg'
- xml_path = osp.join(self.img_prefix, 'Annotations',
- f'{img_id}.xml')
- tree = ET.parse(xml_path)
- root = tree.getroot()
- size = root.find('size')
- if size is not None:
- width = int(size.find('width').text)
- height = int(size.find('height').text)
- else:
- img_path = osp.join(self.img_prefix, 'JPEGImages',
- '{}.jpg'.format(img_id))
- img = Image.open(img_path)
- width, height = img.size
- data_infos.append(
- dict(id=img_id, filename=filename, width=width, height=height))
-
- return data_infos
-
- def _filter_imgs(self, min_size=32):
- """Filter images too small or without annotation."""
- valid_inds = []
- for i, img_info in enumerate(self.data_infos):
- if min(img_info['width'], img_info['height']) < min_size:
- continue
- if self.filter_empty_gt:
- img_id = img_info['id']
- xml_path = osp.join(self.img_prefix, 'Annotations',
- f'{img_id}.xml')
- tree = ET.parse(xml_path)
- root = tree.getroot()
- for obj in root.findall('object'):
- name = obj.find('name').text
- if name in self.CLASSES:
- valid_inds.append(i)
- break
- else:
- valid_inds.append(i)
- return valid_inds
-
- def get_ann_info(self, idx):
- """Get annotation from XML file by index.
-
- Args:
- idx (int): Index of data.
-
- Returns:
- dict: Annotation info of specified index.
- """
-
- img_id = self.data_infos[idx]['id']
- xml_path = osp.join(self.img_prefix, 'Annotations', f'{img_id}.xml')
- tree = ET.parse(xml_path)
- root = tree.getroot()
- bboxes = []
- labels = []
- bboxes_ignore = []
- labels_ignore = []
- for obj in root.findall('object'):
- name = obj.find('name').text
- if name not in self.CLASSES:
- continue
- label = self.cat2label[name]
- difficult = obj.find('difficult')
- difficult = 0 if difficult is None else int(difficult.text)
- bnd_box = obj.find('bndbox')
- # TODO: check whether it is necessary to use int
- # Coordinates may be float type
- bbox = [
- int(float(bnd_box.find('xmin').text)),
- int(float(bnd_box.find('ymin').text)),
- int(float(bnd_box.find('xmax').text)),
- int(float(bnd_box.find('ymax').text))
- ]
- ignore = False
- if self.min_size:
- assert not self.test_mode
- w = bbox[2] - bbox[0]
- h = bbox[3] - bbox[1]
- if w < self.min_size or h < self.min_size:
- ignore = True
- if difficult or ignore:
- bboxes_ignore.append(bbox)
- labels_ignore.append(label)
- else:
- bboxes.append(bbox)
- labels.append(label)
- if not bboxes:
- bboxes = np.zeros((0, 4))
- labels = np.zeros((0, ))
- else:
- bboxes = np.array(bboxes, ndmin=2) - 1
- labels = np.array(labels)
- if not bboxes_ignore:
- bboxes_ignore = np.zeros((0, 4))
- labels_ignore = np.zeros((0, ))
- else:
- bboxes_ignore = np.array(bboxes_ignore, ndmin=2) - 1
- labels_ignore = np.array(labels_ignore)
- ann = dict(
- bboxes=bboxes.astype(np.float32),
- labels=labels.astype(np.int64),
- bboxes_ignore=bboxes_ignore.astype(np.float32),
- labels_ignore=labels_ignore.astype(np.int64))
- return ann
-
- def get_cat_ids(self, idx):
- """Get category ids in XML file by index.
-
- Args:
- idx (int): Index of data.
-
- Returns:
- list[int]: All categories in the image of specified index.
- """
-
- cat_ids = []
- img_id = self.data_infos[idx]['id']
- xml_path = osp.join(self.img_prefix, 'Annotations', f'{img_id}.xml')
- tree = ET.parse(xml_path)
- root = tree.getroot()
- for obj in root.findall('object'):
- name = obj.find('name').text
- if name not in self.CLASSES:
- continue
- label = self.cat2label[name]
- cat_ids.append(label)
-
- return cat_ids
diff --git a/spaces/Caoyunkang/Segment-Any-Anomaly/utils/__init__.py b/spaces/Caoyunkang/Segment-Any-Anomaly/utils/__init__.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/ChandraMohanNayal/AutoGPT/ui/app.py b/spaces/ChandraMohanNayal/AutoGPT/ui/app.py
deleted file mode 100644
index d7dbd31e901969d090292215935bdbc3d9d75e37..0000000000000000000000000000000000000000
--- a/spaces/ChandraMohanNayal/AutoGPT/ui/app.py
+++ /dev/null
@@ -1,145 +0,0 @@
-import gradio as gr
-import utils
-from api import AutoAPI, get_openai_api_key
-import os, shutil
-import json
-
-FILE_DIR = os.path.dirname(os.path.abspath(__file__))
-OUTPUT_DIR = os.path.join(os.path.dirname(FILE_DIR), "auto_gpt_workspace")
-if not os.path.exists(OUTPUT_DIR):
- os.mkdir(OUTPUT_DIR)
-
-CSS = """
-#chatbot {font-family: monospace;}
-#files .generating {display: none;}
-#files .min {min-height: 0px;}
-"""
-
-with gr.Blocks(css=CSS) as app:
- with gr.Column() as setup_pane:
- gr.Markdown(f"""# Auto-GPT
- 1. Duplicate this Space: This will **NOT** work without duplication!
- 2. Enter your OpenAI API Key below.
- """)
- with gr.Row():
- open_ai_key = gr.Textbox(
- value=get_openai_api_key(),
- label="OpenAI API Key",
- type="password",
- )
- gr.Markdown(
- "3. Fill the values below, then click 'Start'. There are example values you can load at the bottom of this page."
- )
- with gr.Row():
- ai_name = gr.Textbox(label="AI Name", placeholder="e.g. Entrepreneur-GPT")
- ai_role = gr.Textbox(
- label="AI Role",
- placeholder="e.g. an AI designed to autonomously develop and run businesses with the sole goal of increasing your net worth.",
- )
- top_5_goals = gr.Dataframe(
- row_count=(5, "fixed"),
- col_count=(1, "fixed"),
- headers=["AI Goals - Enter up to 5"],
- type="array"
- )
- start_btn = gr.Button("Start", variant="primary")
- with open(os.path.join(FILE_DIR, "examples.json"), "r") as f:
- example_values = json.load(f)
- gr.Examples(
- example_values,
- [ai_name, ai_role, top_5_goals],
- )
- with gr.Column(visible=False) as main_pane:
- with gr.Row():
- with gr.Column(scale=2):
- chatbot = gr.Chatbot(elem_id="chatbot")
- with gr.Row():
- yes_btn = gr.Button("Yes", variant="primary", interactive=False)
- consecutive_yes = gr.Slider(
- 1, 10, 1, step=1, label="Consecutive Yes", interactive=False
- )
- custom_response = gr.Textbox(
- label="Custom Response",
- placeholder="Press 'Enter' to Submit.",
- interactive=False,
- )
- with gr.Column(scale=1):
- gr.HTML(
- lambda: f"""
- Generated Files
-
{utils.format_directory(OUTPUT_DIR)}
- """, every=3, elem_id="files"
- )
- download_btn = gr.Button("Download All Files")
-
- chat_history = gr.State([[None, None]])
- api = gr.State(None)
-
- def start(open_ai_key, ai_name, ai_role, top_5_goals):
- auto_api = AutoAPI(open_ai_key, ai_name, ai_role, top_5_goals)
- return gr.Column.update(visible=False), gr.Column.update(visible=True), auto_api
-
- def bot_response(chat, api):
- messages = []
- for message in api.get_chatbot_response():
- messages.append(message)
- chat[-1][1] = "\n".join(messages) + "..."
- yield chat
- chat[-1][1] = "\n".join(messages)
- yield chat
-
- def send_message(count, chat, api, message="Y"):
- if message != "Y":
- count = 1
- for i in range(count):
- chat.append([message, None])
- yield chat, count - i
- api.send_message(message)
- for updated_chat in bot_response(chat, api):
- yield updated_chat, count - i
-
- def activate_inputs():
- return {
- yes_btn: gr.Button.update(interactive=True),
- consecutive_yes: gr.Slider.update(interactive=True),
- custom_response: gr.Textbox.update(interactive=True),
- }
-
- def deactivate_inputs():
- return {
- yes_btn: gr.Button.update(interactive=False),
- consecutive_yes: gr.Slider.update(interactive=False),
- custom_response: gr.Textbox.update(interactive=False),
- }
-
- start_btn.click(
- start,
- [open_ai_key, ai_name, ai_role, top_5_goals],
- [setup_pane, main_pane, api],
- ).then(bot_response, [chat_history, api], chatbot).then(
- activate_inputs, None, [yes_btn, consecutive_yes, custom_response]
- )
-
- yes_btn.click(
- deactivate_inputs, None, [yes_btn, consecutive_yes, custom_response]
- ).then(
- send_message, [consecutive_yes, chat_history, api], [chatbot, consecutive_yes]
- ).then(
- activate_inputs, None, [yes_btn, consecutive_yes, custom_response]
- )
- custom_response.submit(
- deactivate_inputs, None, [yes_btn, consecutive_yes, custom_response]
- ).then(
- send_message,
- [consecutive_yes, chat_history, api, custom_response],
- [chatbot, consecutive_yes],
- ).then(
- activate_inputs, None, [yes_btn, consecutive_yes, custom_response]
- )
-
- def download_all_files():
- shutil.make_archive("outputs", "zip", OUTPUT_DIR)
-
- download_btn.click(download_all_files).then(None, _js=utils.DOWNLOAD_OUTPUTS_JS)
-
-app.queue(concurrency_count=20).launch(file_directories=[OUTPUT_DIR])
diff --git a/spaces/ChrisPreston/diff-svc_minato_aqua/utils/__init__.py b/spaces/ChrisPreston/diff-svc_minato_aqua/utils/__init__.py
deleted file mode 100644
index edd05b1cbcf86d489ce395ab90e50587c7bef4c6..0000000000000000000000000000000000000000
--- a/spaces/ChrisPreston/diff-svc_minato_aqua/utils/__init__.py
+++ /dev/null
@@ -1,250 +0,0 @@
-import glob
-import logging
-import re
-import time
-from collections import defaultdict
-import os
-import sys
-import shutil
-import types
-import numpy as np
-import torch
-import torch.nn.functional as F
-import torch.distributed as dist
-from torch import nn
-
-
-def tensors_to_scalars(metrics):
- new_metrics = {}
- for k, v in metrics.items():
- if isinstance(v, torch.Tensor):
- v = v.item()
- if type(v) is dict:
- v = tensors_to_scalars(v)
- new_metrics[k] = v
- return new_metrics
-
-
-class AvgrageMeter(object):
-
- def __init__(self):
- self.reset()
-
- def reset(self):
- self.avg = 0
- self.sum = 0
- self.cnt = 0
-
- def update(self, val, n=1):
- self.sum += val * n
- self.cnt += n
- self.avg = self.sum / self.cnt
-
-
-def collate_1d(values, pad_idx=0, left_pad=False, shift_right=False, max_len=None, shift_id=1):
- """Convert a list of 1d tensors into a padded 2d tensor."""
- size = max(v.size(0) for v in values) if max_len is None else max_len
- res = values[0].new(len(values), size).fill_(pad_idx)
-
- def copy_tensor(src, dst):
- assert dst.numel() == src.numel()
- if shift_right:
- dst[1:] = src[:-1]
- dst[0] = shift_id
- else:
- dst.copy_(src)
-
- for i, v in enumerate(values):
- copy_tensor(v, res[i][size - len(v):] if left_pad else res[i][:len(v)])
- return res
-
-
-def collate_2d(values, pad_idx=0, left_pad=False, shift_right=False, max_len=None):
- """Convert a list of 2d tensors into a padded 3d tensor."""
- size = max(v.size(0) for v in values) if max_len is None else max_len
- res = values[0].new(len(values), size, values[0].shape[1]).fill_(pad_idx)
-
- def copy_tensor(src, dst):
- assert dst.numel() == src.numel()
- if shift_right:
- dst[1:] = src[:-1]
- else:
- dst.copy_(src)
-
- for i, v in enumerate(values):
- copy_tensor(v, res[i][size - len(v):] if left_pad else res[i][:len(v)])
- return res
-
-
-def _is_batch_full(batch, num_tokens, max_tokens, max_sentences):
- if len(batch) == 0:
- return 0
- if len(batch) == max_sentences:
- return 1
- if num_tokens > max_tokens:
- return 1
- return 0
-
-
-def batch_by_size(
- indices, num_tokens_fn, max_tokens=None, max_sentences=None,
- required_batch_size_multiple=1, distributed=False
-):
- """
- Yield mini-batches of indices bucketed by size. Batches may contain
- sequences of different lengths.
-
- Args:
- indices (List[int]): ordered list of dataset indices
- num_tokens_fn (callable): function that returns the number of tokens at
- a given index
- max_tokens (int, optional): max number of tokens in each batch
- (default: None).
- max_sentences (int, optional): max number of sentences in each
- batch (default: None).
- required_batch_size_multiple (int, optional): require batch size to
- be a multiple of N (default: 1).
- """
- max_tokens = max_tokens if max_tokens is not None else sys.maxsize
- max_sentences = max_sentences if max_sentences is not None else sys.maxsize
- bsz_mult = required_batch_size_multiple
-
- if isinstance(indices, types.GeneratorType):
- indices = np.fromiter(indices, dtype=np.int64, count=-1)
-
- sample_len = 0
- sample_lens = []
- batch = []
- batches = []
- for i in range(len(indices)):
- idx = indices[i]
- num_tokens = num_tokens_fn(idx)
- sample_lens.append(num_tokens)
- sample_len = max(sample_len, num_tokens)
- assert sample_len <= max_tokens, (
- "sentence at index {} of size {} exceeds max_tokens "
- "limit of {}!".format(idx, sample_len, max_tokens)
- )
- num_tokens = (len(batch) + 1) * sample_len
-
- if _is_batch_full(batch, num_tokens, max_tokens, max_sentences):
- mod_len = max(
- bsz_mult * (len(batch) // bsz_mult),
- len(batch) % bsz_mult,
- )
- batches.append(batch[:mod_len])
- batch = batch[mod_len:]
- sample_lens = sample_lens[mod_len:]
- sample_len = max(sample_lens) if len(sample_lens) > 0 else 0
- batch.append(idx)
- if len(batch) > 0:
- batches.append(batch)
- return batches
-
-
-def make_positions(tensor, padding_idx):
- """Replace non-padding symbols with their position numbers.
-
- Position numbers begin at padding_idx+1. Padding symbols are ignored.
- """
- # The series of casts and type-conversions here are carefully
- # balanced to both work with ONNX export and XLA. In particular XLA
- # prefers ints, cumsum defaults to output longs, and ONNX doesn't know
- # how to handle the dtype kwarg in cumsum.
- mask = tensor.ne(padding_idx).int()
- return (
- torch.cumsum(mask, dim=1).type_as(mask) * mask
- ).long() + padding_idx
-
-
-def softmax(x, dim):
- return F.softmax(x, dim=dim, dtype=torch.float32)
-
-
-def unpack_dict_to_list(samples):
- samples_ = []
- bsz = samples.get('outputs').size(0)
- for i in range(bsz):
- res = {}
- for k, v in samples.items():
- try:
- res[k] = v[i]
- except:
- pass
- samples_.append(res)
- return samples_
-
-
-def load_ckpt(cur_model, ckpt_base_dir, prefix_in_ckpt='model', force=True, strict=True):
- if os.path.isfile(ckpt_base_dir):
- base_dir = os.path.dirname(ckpt_base_dir)
- checkpoint_path = [ckpt_base_dir]
- else:
- base_dir = ckpt_base_dir
- checkpoint_path = sorted(glob.glob(f'{base_dir}/model_ckpt_steps_*.ckpt'), key=
- lambda x: int(re.findall(f'{base_dir}/model_ckpt_steps_(\d+).ckpt', x.replace('\\','/'))[0]))
- if len(checkpoint_path) > 0:
- checkpoint_path = checkpoint_path[-1]
- state_dict = torch.load(checkpoint_path, map_location="cpu")["state_dict"]
- state_dict = {k[len(prefix_in_ckpt) + 1:]: v for k, v in state_dict.items()
- if k.startswith(f'{prefix_in_ckpt}.')}
- if not strict:
- cur_model_state_dict = cur_model.state_dict()
- unmatched_keys = []
- for key, param in state_dict.items():
- if key in cur_model_state_dict:
- new_param = cur_model_state_dict[key]
- if new_param.shape != param.shape:
- unmatched_keys.append(key)
- print("| Unmatched keys: ", key, new_param.shape, param.shape)
- for key in unmatched_keys:
- del state_dict[key]
- cur_model.load_state_dict(state_dict, strict=strict)
- print(f"| load '{prefix_in_ckpt}' from '{checkpoint_path}'.")
- else:
- e_msg = f"| ckpt not found in {base_dir}."
- if force:
- assert False, e_msg
- else:
- print(e_msg)
-
-
-def remove_padding(x, padding_idx=0):
- if x is None:
- return None
- assert len(x.shape) in [1, 2]
- if len(x.shape) == 2: # [T, H]
- return x[np.abs(x).sum(-1) != padding_idx]
- elif len(x.shape) == 1: # [T]
- return x[x != padding_idx]
-
-
-class Timer:
- timer_map = {}
-
- def __init__(self, name, print_time=False):
- if name not in Timer.timer_map:
- Timer.timer_map[name] = 0
- self.name = name
- self.print_time = print_time
-
- def __enter__(self):
- self.t = time.time()
-
- def __exit__(self, exc_type, exc_val, exc_tb):
- Timer.timer_map[self.name] += time.time() - self.t
- if self.print_time:
- print(self.name, Timer.timer_map[self.name])
-
-
-def print_arch(model, model_name='model'):
- #print(f"| {model_name} Arch: ", model)
- num_params(model, model_name=model_name)
-
-
-def num_params(model, print_out=True, model_name="model"):
- parameters = filter(lambda p: p.requires_grad, model.parameters())
- parameters = sum([np.prod(p.size()) for p in parameters]) / 1_000_000
- if print_out:
- print(f'| {model_name} Trainable Parameters: %.3fM' % parameters)
- return parameters
diff --git a/spaces/CikeyQI/Yunzai/Yunzai/lib/listener/listener.js b/spaces/CikeyQI/Yunzai/Yunzai/lib/listener/listener.js
deleted file mode 100644
index 644f7a1bb5ee78279807bce45a6733f333274b74..0000000000000000000000000000000000000000
--- a/spaces/CikeyQI/Yunzai/Yunzai/lib/listener/listener.js
+++ /dev/null
@@ -1,16 +0,0 @@
-import PluginsLoader from '../plugins/loader.js'
-
-export default class EventListener {
- /**
- * 事件监听
- * @param data.prefix 事件名称前缀
- * @param data.event 监听的事件
- * @param data.once 是否只监听一次
- */
- constructor (data) {
- this.prefix = data.prefix || ''
- this.event = data.event
- this.once = data.once || false
- this.plugins = PluginsLoader
- }
-}
\ No newline at end of file
diff --git a/spaces/CofAI/chat/g4f/Provider/Providers/Forefront.py b/spaces/CofAI/chat/g4f/Provider/Providers/Forefront.py
deleted file mode 100644
index e7e89831cc4ec6dc37ea094d9828a7582e981ff1..0000000000000000000000000000000000000000
--- a/spaces/CofAI/chat/g4f/Provider/Providers/Forefront.py
+++ /dev/null
@@ -1,30 +0,0 @@
-import os
-import json
-import requests
-from ...typing import sha256, Dict, get_type_hints
-
-url = 'https://forefront.com'
-model = ['gpt-3.5-turbo']
-supports_stream = True
-needs_auth = False
-
-def _create_completion(model: str, messages: list, stream: bool, **kwargs):
- json_data = {
- 'text': messages[-1]['content'],
- 'action': 'noauth',
- 'id': '',
- 'parentId': '',
- 'workspaceId': '',
- 'messagePersona': '607e41fe-95be-497e-8e97-010a59b2e2c0',
- 'model': 'gpt-4',
- 'messages': messages[:-1] if len(messages) > 1 else [],
- 'internetMode': 'auto'
- }
- response = requests.post( 'https://streaming.tenant-forefront-default.knative.chi.coreweave.com/free-chat',
- json=json_data, stream=True)
- for token in response.iter_lines():
- if b'delta' in token:
- token = json.loads(token.decode().split('data: ')[1])['delta']
- yield (token)
-params = f'g4f.Providers.{os.path.basename(__file__)[:-3]} supports: ' + \
- '(%s)' % ', '.join([f"{name}: {get_type_hints(_create_completion)[name].__name__}" for name in _create_completion.__code__.co_varnames[:_create_completion.__code__.co_argcount]])
\ No newline at end of file
diff --git a/spaces/CuraAlizm/stabilityai-stable-diffusion-xl-base-1.0/app.py b/spaces/CuraAlizm/stabilityai-stable-diffusion-xl-base-1.0/app.py
deleted file mode 100644
index 9520517f687cf7229ddfab9d8c5f8af7f76b0bd4..0000000000000000000000000000000000000000
--- a/spaces/CuraAlizm/stabilityai-stable-diffusion-xl-base-1.0/app.py
+++ /dev/null
@@ -1,3 +0,0 @@
-import gradio as gr
-
-gr.Interface.load("models/stabilityai/stable-diffusion-xl-base-1.0").launch()
\ No newline at end of file
diff --git a/spaces/Cvandi/remake/tests/test_model.py b/spaces/Cvandi/remake/tests/test_model.py
deleted file mode 100644
index c20bb1d56ed20222e929e9c94026f6ea383c6026..0000000000000000000000000000000000000000
--- a/spaces/Cvandi/remake/tests/test_model.py
+++ /dev/null
@@ -1,126 +0,0 @@
-import torch
-import yaml
-from basicsr.archs.rrdbnet_arch import RRDBNet
-from basicsr.data.paired_image_dataset import PairedImageDataset
-from basicsr.losses.losses import GANLoss, L1Loss, PerceptualLoss
-
-from realesrgan.archs.discriminator_arch import UNetDiscriminatorSN
-from realesrgan.models.realesrgan_model import RealESRGANModel
-from realesrgan.models.realesrnet_model import RealESRNetModel
-
-
-def test_realesrnet_model():
- with open('tests/data/test_realesrnet_model.yml', mode='r') as f:
- opt = yaml.load(f, Loader=yaml.FullLoader)
-
- # build model
- model = RealESRNetModel(opt)
- # test attributes
- assert model.__class__.__name__ == 'RealESRNetModel'
- assert isinstance(model.net_g, RRDBNet)
- assert isinstance(model.cri_pix, L1Loss)
- assert isinstance(model.optimizers[0], torch.optim.Adam)
-
- # prepare data
- gt = torch.rand((1, 3, 32, 32), dtype=torch.float32)
- kernel1 = torch.rand((1, 5, 5), dtype=torch.float32)
- kernel2 = torch.rand((1, 5, 5), dtype=torch.float32)
- sinc_kernel = torch.rand((1, 5, 5), dtype=torch.float32)
- data = dict(gt=gt, kernel1=kernel1, kernel2=kernel2, sinc_kernel=sinc_kernel)
- model.feed_data(data)
- # check dequeue
- model.feed_data(data)
- # check data shape
- assert model.lq.shape == (1, 3, 8, 8)
- assert model.gt.shape == (1, 3, 32, 32)
-
- # change probability to test if-else
- model.opt['gaussian_noise_prob'] = 0
- model.opt['gray_noise_prob'] = 0
- model.opt['second_blur_prob'] = 0
- model.opt['gaussian_noise_prob2'] = 0
- model.opt['gray_noise_prob2'] = 0
- model.feed_data(data)
- # check data shape
- assert model.lq.shape == (1, 3, 8, 8)
- assert model.gt.shape == (1, 3, 32, 32)
-
- # ----------------- test nondist_validation -------------------- #
- # construct dataloader
- dataset_opt = dict(
- name='Demo',
- dataroot_gt='tests/data/gt',
- dataroot_lq='tests/data/lq',
- io_backend=dict(type='disk'),
- scale=4,
- phase='val')
- dataset = PairedImageDataset(dataset_opt)
- dataloader = torch.utils.data.DataLoader(dataset=dataset, batch_size=1, shuffle=False, num_workers=0)
- assert model.is_train is True
- model.nondist_validation(dataloader, 1, None, False)
- assert model.is_train is True
-
-
-def test_realesrgan_model():
- with open('tests/data/test_realesrgan_model.yml', mode='r') as f:
- opt = yaml.load(f, Loader=yaml.FullLoader)
-
- # build model
- model = RealESRGANModel(opt)
- # test attributes
- assert model.__class__.__name__ == 'RealESRGANModel'
- assert isinstance(model.net_g, RRDBNet) # generator
- assert isinstance(model.net_d, UNetDiscriminatorSN) # discriminator
- assert isinstance(model.cri_pix, L1Loss)
- assert isinstance(model.cri_perceptual, PerceptualLoss)
- assert isinstance(model.cri_gan, GANLoss)
- assert isinstance(model.optimizers[0], torch.optim.Adam)
- assert isinstance(model.optimizers[1], torch.optim.Adam)
-
- # prepare data
- gt = torch.rand((1, 3, 32, 32), dtype=torch.float32)
- kernel1 = torch.rand((1, 5, 5), dtype=torch.float32)
- kernel2 = torch.rand((1, 5, 5), dtype=torch.float32)
- sinc_kernel = torch.rand((1, 5, 5), dtype=torch.float32)
- data = dict(gt=gt, kernel1=kernel1, kernel2=kernel2, sinc_kernel=sinc_kernel)
- model.feed_data(data)
- # check dequeue
- model.feed_data(data)
- # check data shape
- assert model.lq.shape == (1, 3, 8, 8)
- assert model.gt.shape == (1, 3, 32, 32)
-
- # change probability to test if-else
- model.opt['gaussian_noise_prob'] = 0
- model.opt['gray_noise_prob'] = 0
- model.opt['second_blur_prob'] = 0
- model.opt['gaussian_noise_prob2'] = 0
- model.opt['gray_noise_prob2'] = 0
- model.feed_data(data)
- # check data shape
- assert model.lq.shape == (1, 3, 8, 8)
- assert model.gt.shape == (1, 3, 32, 32)
-
- # ----------------- test nondist_validation -------------------- #
- # construct dataloader
- dataset_opt = dict(
- name='Demo',
- dataroot_gt='tests/data/gt',
- dataroot_lq='tests/data/lq',
- io_backend=dict(type='disk'),
- scale=4,
- phase='val')
- dataset = PairedImageDataset(dataset_opt)
- dataloader = torch.utils.data.DataLoader(dataset=dataset, batch_size=1, shuffle=False, num_workers=0)
- assert model.is_train is True
- model.nondist_validation(dataloader, 1, None, False)
- assert model.is_train is True
-
- # ----------------- test optimize_parameters -------------------- #
- model.feed_data(data)
- model.optimize_parameters(1)
- assert model.output.shape == (1, 3, 32, 32)
- assert isinstance(model.log_dict, dict)
- # check returned keys
- expected_keys = ['l_g_pix', 'l_g_percep', 'l_g_gan', 'l_d_real', 'out_d_real', 'l_d_fake', 'out_d_fake']
- assert set(expected_keys).issubset(set(model.log_dict.keys()))
diff --git a/spaces/Cyril666/ContourNet-ABI/maskrcnn_benchmark/solver/build.py b/spaces/Cyril666/ContourNet-ABI/maskrcnn_benchmark/solver/build.py
deleted file mode 100644
index 865a4ec8d1b3d996b0618e3b2b77bd1b44acfa96..0000000000000000000000000000000000000000
--- a/spaces/Cyril666/ContourNet-ABI/maskrcnn_benchmark/solver/build.py
+++ /dev/null
@@ -1,31 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
-import torch
-
-from .lr_scheduler import WarmupMultiStepLR
-
-
-def make_optimizer(cfg, model):
- params = []
- for key, value in model.named_parameters():
- if not value.requires_grad:
- continue
- lr = cfg.SOLVER.BASE_LR
- weight_decay = cfg.SOLVER.WEIGHT_DECAY
- if "bias" in key:
- lr = cfg.SOLVER.BASE_LR * cfg.SOLVER.BIAS_LR_FACTOR
- weight_decay = cfg.SOLVER.WEIGHT_DECAY_BIAS
- params += [{"params": [value], "lr": lr, "weight_decay": weight_decay}]
-
- optimizer = torch.optim.SGD(params, lr, momentum=cfg.SOLVER.MOMENTUM)
- return optimizer
-
-
-def make_lr_scheduler(cfg, optimizer):
- return WarmupMultiStepLR(
- optimizer,
- cfg.SOLVER.STEPS,
- cfg.SOLVER.GAMMA,
- warmup_factor=cfg.SOLVER.WARMUP_FACTOR,
- warmup_iters=cfg.SOLVER.WARMUP_ITERS,
- warmup_method=cfg.SOLVER.WARMUP_METHOD,
- )
diff --git a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/attr/filters.py b/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/attr/filters.py
deleted file mode 100644
index a1e40c98db853aa375ab0b24559e0559f91e6152..0000000000000000000000000000000000000000
--- a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/attr/filters.py
+++ /dev/null
@@ -1,66 +0,0 @@
-# SPDX-License-Identifier: MIT
-
-"""
-Commonly useful filters for `attr.asdict`.
-"""
-
-from ._make import Attribute
-
-
-def _split_what(what):
- """
- Returns a tuple of `frozenset`s of classes and attributes.
- """
- return (
- frozenset(cls for cls in what if isinstance(cls, type)),
- frozenset(cls for cls in what if isinstance(cls, str)),
- frozenset(cls for cls in what if isinstance(cls, Attribute)),
- )
-
-
-def include(*what):
- """
- Include *what*.
-
- :param what: What to include.
- :type what: `list` of classes `type`, field names `str` or
- `attrs.Attribute`\\ s
-
- :rtype: `callable`
-
- .. versionchanged:: 23.1.0 Accept strings with field names.
- """
- cls, names, attrs = _split_what(what)
-
- def include_(attribute, value):
- return (
- value.__class__ in cls
- or attribute.name in names
- or attribute in attrs
- )
-
- return include_
-
-
-def exclude(*what):
- """
- Exclude *what*.
-
- :param what: What to exclude.
- :type what: `list` of classes `type`, field names `str` or
- `attrs.Attribute`\\ s.
-
- :rtype: `callable`
-
- .. versionchanged:: 23.3.0 Accept field name string as input argument
- """
- cls, names, attrs = _split_what(what)
-
- def exclude_(attribute, value):
- return not (
- value.__class__ in cls
- or attribute.name in names
- or attribute in attrs
- )
-
- return exclude_
diff --git a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/fontTools/misc/psLib.py b/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/fontTools/misc/psLib.py
deleted file mode 100644
index 1e0408ce9c16f9a784f53ef1d17af88b0ab65647..0000000000000000000000000000000000000000
--- a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/fontTools/misc/psLib.py
+++ /dev/null
@@ -1,399 +0,0 @@
-from fontTools.misc.textTools import bytechr, byteord, bytesjoin, tobytes, tostr
-from fontTools.misc import eexec
-from .psOperators import (
- PSOperators,
- ps_StandardEncoding,
- ps_array,
- ps_boolean,
- ps_dict,
- ps_integer,
- ps_literal,
- ps_mark,
- ps_name,
- ps_operator,
- ps_procedure,
- ps_procmark,
- ps_real,
- ps_string,
-)
-import re
-from collections.abc import Callable
-from string import whitespace
-import logging
-
-
-log = logging.getLogger(__name__)
-
-ps_special = b"()<>[]{}%" # / is one too, but we take care of that one differently
-
-skipwhiteRE = re.compile(bytesjoin([b"[", whitespace, b"]*"]))
-endofthingPat = bytesjoin([b"[^][(){}<>/%", whitespace, b"]*"])
-endofthingRE = re.compile(endofthingPat)
-commentRE = re.compile(b"%[^\n\r]*")
-
-# XXX This not entirely correct as it doesn't allow *nested* embedded parens:
-stringPat = rb"""
- \(
- (
- (
- [^()]* \ [()]
- )
- |
- (
- [^()]* \( [^()]* \)
- )
- )*
- [^()]*
- \)
-"""
-stringPat = b"".join(stringPat.split())
-stringRE = re.compile(stringPat)
-
-hexstringRE = re.compile(bytesjoin([b"<[", whitespace, b"0-9A-Fa-f]*>"]))
-
-
-class PSTokenError(Exception):
- pass
-
-
-class PSError(Exception):
- pass
-
-
-class PSTokenizer(object):
- def __init__(self, buf=b"", encoding="ascii"):
- # Force self.buf to be a byte string
- buf = tobytes(buf)
- self.buf = buf
- self.len = len(buf)
- self.pos = 0
- self.closed = False
- self.encoding = encoding
-
- def read(self, n=-1):
- """Read at most 'n' bytes from the buffer, or less if the read
- hits EOF before obtaining 'n' bytes.
- If 'n' is negative or omitted, read all data until EOF is reached.
- """
- if self.closed:
- raise ValueError("I/O operation on closed file")
- if n is None or n < 0:
- newpos = self.len
- else:
- newpos = min(self.pos + n, self.len)
- r = self.buf[self.pos : newpos]
- self.pos = newpos
- return r
-
- def close(self):
- if not self.closed:
- self.closed = True
- del self.buf, self.pos
-
- def getnexttoken(
- self,
- # localize some stuff, for performance
- len=len,
- ps_special=ps_special,
- stringmatch=stringRE.match,
- hexstringmatch=hexstringRE.match,
- commentmatch=commentRE.match,
- endmatch=endofthingRE.match,
- ):
-
- self.skipwhite()
- if self.pos >= self.len:
- return None, None
- pos = self.pos
- buf = self.buf
- char = bytechr(byteord(buf[pos]))
- if char in ps_special:
- if char in b"{}[]":
- tokentype = "do_special"
- token = char
- elif char == b"%":
- tokentype = "do_comment"
- _, nextpos = commentmatch(buf, pos).span()
- token = buf[pos:nextpos]
- elif char == b"(":
- tokentype = "do_string"
- m = stringmatch(buf, pos)
- if m is None:
- raise PSTokenError("bad string at character %d" % pos)
- _, nextpos = m.span()
- token = buf[pos:nextpos]
- elif char == b"<":
- tokentype = "do_hexstring"
- m = hexstringmatch(buf, pos)
- if m is None:
- raise PSTokenError("bad hexstring at character %d" % pos)
- _, nextpos = m.span()
- token = buf[pos:nextpos]
- else:
- raise PSTokenError("bad token at character %d" % pos)
- else:
- if char == b"/":
- tokentype = "do_literal"
- m = endmatch(buf, pos + 1)
- else:
- tokentype = ""
- m = endmatch(buf, pos)
- if m is None:
- raise PSTokenError("bad token at character %d" % pos)
- _, nextpos = m.span()
- token = buf[pos:nextpos]
- self.pos = pos + len(token)
- token = tostr(token, encoding=self.encoding)
- return tokentype, token
-
- def skipwhite(self, whitematch=skipwhiteRE.match):
- _, nextpos = whitematch(self.buf, self.pos).span()
- self.pos = nextpos
-
- def starteexec(self):
- self.pos = self.pos + 1
- self.dirtybuf = self.buf[self.pos :]
- self.buf, R = eexec.decrypt(self.dirtybuf, 55665)
- self.len = len(self.buf)
- self.pos = 4
-
- def stopeexec(self):
- if not hasattr(self, "dirtybuf"):
- return
- self.buf = self.dirtybuf
- del self.dirtybuf
-
-
-class PSInterpreter(PSOperators):
- def __init__(self, encoding="ascii"):
- systemdict = {}
- userdict = {}
- self.encoding = encoding
- self.dictstack = [systemdict, userdict]
- self.stack = []
- self.proclevel = 0
- self.procmark = ps_procmark()
- self.fillsystemdict()
-
- def fillsystemdict(self):
- systemdict = self.dictstack[0]
- systemdict["["] = systemdict["mark"] = self.mark = ps_mark()
- systemdict["]"] = ps_operator("]", self.do_makearray)
- systemdict["true"] = ps_boolean(1)
- systemdict["false"] = ps_boolean(0)
- systemdict["StandardEncoding"] = ps_array(ps_StandardEncoding)
- systemdict["FontDirectory"] = ps_dict({})
- self.suckoperators(systemdict, self.__class__)
-
- def suckoperators(self, systemdict, klass):
- for name in dir(klass):
- attr = getattr(self, name)
- if isinstance(attr, Callable) and name[:3] == "ps_":
- name = name[3:]
- systemdict[name] = ps_operator(name, attr)
- for baseclass in klass.__bases__:
- self.suckoperators(systemdict, baseclass)
-
- def interpret(self, data, getattr=getattr):
- tokenizer = self.tokenizer = PSTokenizer(data, self.encoding)
- getnexttoken = tokenizer.getnexttoken
- do_token = self.do_token
- handle_object = self.handle_object
- try:
- while 1:
- tokentype, token = getnexttoken()
- if not token:
- break
- if tokentype:
- handler = getattr(self, tokentype)
- object = handler(token)
- else:
- object = do_token(token)
- if object is not None:
- handle_object(object)
- tokenizer.close()
- self.tokenizer = None
- except:
- if self.tokenizer is not None:
- log.debug(
- "ps error:\n"
- "- - - - - - -\n"
- "%s\n"
- ">>>\n"
- "%s\n"
- "- - - - - - -",
- self.tokenizer.buf[self.tokenizer.pos - 50 : self.tokenizer.pos],
- self.tokenizer.buf[self.tokenizer.pos : self.tokenizer.pos + 50],
- )
- raise
-
- def handle_object(self, object):
- if not (self.proclevel or object.literal or object.type == "proceduretype"):
- if object.type != "operatortype":
- object = self.resolve_name(object.value)
- if object.literal:
- self.push(object)
- else:
- if object.type == "proceduretype":
- self.call_procedure(object)
- else:
- object.function()
- else:
- self.push(object)
-
- def call_procedure(self, proc):
- handle_object = self.handle_object
- for item in proc.value:
- handle_object(item)
-
- def resolve_name(self, name):
- dictstack = self.dictstack
- for i in range(len(dictstack) - 1, -1, -1):
- if name in dictstack[i]:
- return dictstack[i][name]
- raise PSError("name error: " + str(name))
-
- def do_token(
- self,
- token,
- int=int,
- float=float,
- ps_name=ps_name,
- ps_integer=ps_integer,
- ps_real=ps_real,
- ):
- try:
- num = int(token)
- except (ValueError, OverflowError):
- try:
- num = float(token)
- except (ValueError, OverflowError):
- if "#" in token:
- hashpos = token.find("#")
- try:
- base = int(token[:hashpos])
- num = int(token[hashpos + 1 :], base)
- except (ValueError, OverflowError):
- return ps_name(token)
- else:
- return ps_integer(num)
- else:
- return ps_name(token)
- else:
- return ps_real(num)
- else:
- return ps_integer(num)
-
- def do_comment(self, token):
- pass
-
- def do_literal(self, token):
- return ps_literal(token[1:])
-
- def do_string(self, token):
- return ps_string(token[1:-1])
-
- def do_hexstring(self, token):
- hexStr = "".join(token[1:-1].split())
- if len(hexStr) % 2:
- hexStr = hexStr + "0"
- cleanstr = []
- for i in range(0, len(hexStr), 2):
- cleanstr.append(chr(int(hexStr[i : i + 2], 16)))
- cleanstr = "".join(cleanstr)
- return ps_string(cleanstr)
-
- def do_special(self, token):
- if token == "{":
- self.proclevel = self.proclevel + 1
- return self.procmark
- elif token == "}":
- proc = []
- while 1:
- topobject = self.pop()
- if topobject == self.procmark:
- break
- proc.append(topobject)
- self.proclevel = self.proclevel - 1
- proc.reverse()
- return ps_procedure(proc)
- elif token == "[":
- return self.mark
- elif token == "]":
- return ps_name("]")
- else:
- raise PSTokenError("huh?")
-
- def push(self, object):
- self.stack.append(object)
-
- def pop(self, *types):
- stack = self.stack
- if not stack:
- raise PSError("stack underflow")
- object = stack[-1]
- if types:
- if object.type not in types:
- raise PSError(
- "typecheck, expected %s, found %s" % (repr(types), object.type)
- )
- del stack[-1]
- return object
-
- def do_makearray(self):
- array = []
- while 1:
- topobject = self.pop()
- if topobject == self.mark:
- break
- array.append(topobject)
- array.reverse()
- self.push(ps_array(array))
-
- def close(self):
- """Remove circular references."""
- del self.stack
- del self.dictstack
-
-
-def unpack_item(item):
- tp = type(item.value)
- if tp == dict:
- newitem = {}
- for key, value in item.value.items():
- newitem[key] = unpack_item(value)
- elif tp == list:
- newitem = [None] * len(item.value)
- for i in range(len(item.value)):
- newitem[i] = unpack_item(item.value[i])
- if item.type == "proceduretype":
- newitem = tuple(newitem)
- else:
- newitem = item.value
- return newitem
-
-
-def suckfont(data, encoding="ascii"):
- m = re.search(rb"/FontName\s+/([^ \t\n\r]+)\s+def", data)
- if m:
- fontName = m.group(1)
- fontName = fontName.decode()
- else:
- fontName = None
- interpreter = PSInterpreter(encoding=encoding)
- interpreter.interpret(
- b"/Helvetica 4 dict dup /Encoding StandardEncoding put definefont pop"
- )
- interpreter.interpret(data)
- fontdir = interpreter.dictstack[0]["FontDirectory"].value
- if fontName in fontdir:
- rawfont = fontdir[fontName]
- else:
- # fall back, in case fontName wasn't found
- fontNames = list(fontdir.keys())
- if len(fontNames) > 1:
- fontNames.remove("Helvetica")
- fontNames.sort()
- rawfont = fontdir[fontNames[0]]
- interpreter.close()
- return unpack_item(rawfont)
diff --git a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/gradio/templates/cdn/assets/Textbox-1f11d244.js b/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/gradio/templates/cdn/assets/Textbox-1f11d244.js
deleted file mode 100644
index 5a2cc70aeb07b058aa75ea95ee899f841ca7e0fa..0000000000000000000000000000000000000000
--- a/spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/gradio/templates/cdn/assets/Textbox-1f11d244.js
+++ /dev/null
@@ -1,2 +0,0 @@
-import{S as ue,e as fe,s as _e,N as z,k as H,O as ee,K as h,U as te,p as y,o as K,M as ge,u as Y,v,y as Z,z as k,A as p,x as L,B as ke,am as we,P as ve,R as ye,a7 as le,h as D,ap as N,aj as pe,Q as g,X as Te,a1 as G,m as oe,n as X,Z as qe,$ as Ee,ak as m,j as ie,t as ne,F as M,E as Be,ae as Ne,q as ze,r as Ce}from"./index-1d65707a.js";/* empty css */import{f as Se,B as je}from"./Button-f155035a.js";import{B as De}from"./BlockTitle-dee077e8.js";import{C as He,a as Ke}from"./Copy-9f1657c4.js";function Le(l){let e;return{c(){e=ve(l[3])},m(t,a){y(t,e,a)},p(t,a){a[0]&8&&ye(e,t[3])},d(t){t&&p(e)}}}function Ue(l){let e,t,a,n,i,u,d,c,r=l[6]&&l[10]&&se(l);return{c(){r&&r.c(),e=ee(),t=z("textarea"),h(t,"data-testid","textbox"),h(t,"class","scroll-hide svelte-1kcgrqr"),h(t,"dir",a=l[11]?"rtl":"ltr"),h(t,"placeholder",l[2]),h(t,"rows",l[1]),t.disabled=l[5],h(t,"style",n=l[12]?"text-align: "+l[12]:"")},m(s,o){r&&r.m(s,o),y(s,e,o),y(s,t,o),N(t,l[0]),l[28](t),u=!0,d||(c=[pe(i=l[19].call(null,t,l[0])),g(t,"input",l[27]),g(t,"keypress",l[18]),g(t,"blur",l[15]),g(t,"select",l[17])],d=!0)},p(s,o){s[6]&&s[10]?r?(r.p(s,o),o[0]&1088&&k(r,1)):(r=se(s),r.c(),k(r,1),r.m(e.parentNode,e)):r&&(Y(),v(r,1,1,()=>{r=null}),Z()),(!u||o[0]&2048&&a!==(a=s[11]?"rtl":"ltr"))&&h(t,"dir",a),(!u||o[0]&4)&&h(t,"placeholder",s[2]),(!u||o[0]&2)&&h(t,"rows",s[1]),(!u||o[0]&32)&&(t.disabled=s[5]),(!u||o[0]&4096&&n!==(n=s[12]?"text-align: "+s[12]:""))&&h(t,"style",n),i&&Te(i.update)&&o[0]&1&&i.update.call(null,s[0]),o[0]&1&&N(t,s[0])},i(s){u||(k(r),u=!0)},o(s){v(r),u=!1},d(s){s&&(p(e),p(t)),r&&r.d(s),l[28](null),d=!1,G(c)}}}function Ae(l){let e;function t(i,u){if(i[9]==="text")return Qe;if(i[9]==="password")return Pe;if(i[9]==="email")return Oe}let a=t(l),n=a&&a(l);return{c(){n&&n.c(),e=oe()},m(i,u){n&&n.m(i,u),y(i,e,u)},p(i,u){a===(a=t(i))&&n?n.p(i,u):(n&&n.d(1),n=a&&a(i),n&&(n.c(),n.m(e.parentNode,e)))},i:X,o:X,d(i){i&&p(e),n&&n.d(i)}}}function se(l){let e,t,a,n;const i=[Me,Fe],u=[];function d(c,r){return c[14]?0:1}return e=d(l),t=u[e]=i[e](l),{c(){t.c(),a=oe()},m(c,r){u[e].m(c,r),y(c,a,r),n=!0},p(c,r){let s=e;e=d(c),e===s?u[e].p(c,r):(Y(),v(u[s],1,1,()=>{u[s]=null}),Z(),t=u[e],t?t.p(c,r):(t=u[e]=i[e](c),t.c()),k(t,1),t.m(a.parentNode,a))},i(c){n||(k(t),n=!0)},o(c){v(t),n=!1},d(c){c&&p(a),u[e].d(c)}}}function Fe(l){let e,t,a,n,i;return t=new He({}),{c(){e=z("button"),H(t.$$.fragment),h(e,"class","copy-text svelte-1kcgrqr")},m(u,d){y(u,e,d),K(t,e,null),a=!0,n||(i=g(e,"click",l[16]),n=!0)},p:X,i(u){a||(k(t.$$.fragment,u),a=!0)},o(u){v(t.$$.fragment,u),a=!1},d(u){u&&p(e),L(t),n=!1,i()}}}function Me(l){let e,t,a,n;return t=new Ke({}),{c(){e=z("button"),H(t.$$.fragment),h(e,"class","svelte-1kcgrqr")},m(i,u){y(i,e,u),K(t,e,null),n=!0},p:X,i(i){n||(k(t.$$.fragment,i),i&&(a||qe(()=>{a=Ee(e,Se,{duration:300}),a.start()})),n=!0)},o(i){v(t.$$.fragment,i),n=!1},d(i){i&&p(e),L(t)}}}function Oe(l){let e,t,a;return{c(){e=z("input"),h(e,"data-testid","textbox"),h(e,"type","email"),h(e,"class","scroll-hide svelte-1kcgrqr"),h(e,"placeholder",l[2]),e.disabled=l[5],h(e,"autocomplete","email")},m(n,i){y(n,e,i),N(e,l[0]),l[26](e),t||(a=[g(e,"input",l[25]),g(e,"keypress",l[18]),g(e,"blur",l[15]),g(e,"select",l[17])],t=!0)},p(n,i){i[0]&4&&h(e,"placeholder",n[2]),i[0]&32&&(e.disabled=n[5]),i[0]&1&&e.value!==n[0]&&N(e,n[0])},d(n){n&&p(e),l[26](null),t=!1,G(a)}}}function Pe(l){let e,t,a;return{c(){e=z("input"),h(e,"data-testid","password"),h(e,"type","password"),h(e,"class","scroll-hide svelte-1kcgrqr"),h(e,"placeholder",l[2]),e.disabled=l[5],h(e,"autocomplete","")},m(n,i){y(n,e,i),N(e,l[0]),l[24](e),t||(a=[g(e,"input",l[23]),g(e,"keypress",l[18]),g(e,"blur",l[15]),g(e,"select",l[17])],t=!0)},p(n,i){i[0]&4&&h(e,"placeholder",n[2]),i[0]&32&&(e.disabled=n[5]),i[0]&1&&e.value!==n[0]&&N(e,n[0])},d(n){n&&p(e),l[24](null),t=!1,G(a)}}}function Qe(l){let e,t,a,n,i;return{c(){e=z("input"),h(e,"data-testid","textbox"),h(e,"type","text"),h(e,"class","scroll-hide svelte-1kcgrqr"),h(e,"dir",t=l[11]?"rtl":"ltr"),h(e,"placeholder",l[2]),e.disabled=l[5],h(e,"style",a=l[12]?"text-align: "+l[12]:"")},m(u,d){y(u,e,d),N(e,l[0]),l[22](e),n||(i=[g(e,"input",l[21]),g(e,"keypress",l[18]),g(e,"blur",l[15]),g(e,"select",l[17])],n=!0)},p(u,d){d[0]&2048&&t!==(t=u[11]?"rtl":"ltr")&&h(e,"dir",t),d[0]&4&&h(e,"placeholder",u[2]),d[0]&32&&(e.disabled=u[5]),d[0]&4096&&a!==(a=u[12]?"text-align: "+u[12]:"")&&h(e,"style",a),d[0]&1&&e.value!==u[0]&&N(e,u[0])},d(u){u&&p(e),l[22](null),n=!1,G(i)}}}function Re(l){let e,t,a,n,i,u;t=new De({props:{show_label:l[6],info:l[4],$$slots:{default:[Le]},$$scope:{ctx:l}}});const d=[Ae,Ue],c=[];function r(s,o){return s[1]===1&&s[8]===1?0:1}return n=r(l),i=c[n]=d[n](l),{c(){e=z("label"),H(t.$$.fragment),a=ee(),i.c(),h(e,"class","svelte-1kcgrqr"),te(e,"container",l[7])},m(s,o){y(s,e,o),K(t,e,null),ge(e,a),c[n].m(e,null),u=!0},p(s,o){const b={};o[0]&64&&(b.show_label=s[6]),o[0]&16&&(b.info=s[4]),o[0]&8|o[1]&8&&(b.$$scope={dirty:o,ctx:s}),t.$set(b);let q=n;n=r(s),n===q?c[n].p(s,o):(Y(),v(c[q],1,1,()=>{c[q]=null}),Z(),i=c[n],i?i.p(s,o):(i=c[n]=d[n](s),i.c()),k(i,1),i.m(e,null)),(!u||o[0]&128)&&te(e,"container",s[7])},i(s){u||(k(t.$$.fragment,s),k(i),u=!0)},o(s){v(t.$$.fragment,s),v(i),u=!1},d(s){s&&p(e),L(t),c[n].d()}}}function Xe(l,e,t){let{value:a=""}=e,{value_is_output:n=!1}=e,{lines:i=1}=e,{placeholder:u="Type here..."}=e,{label:d}=e,{info:c=void 0}=e,{disabled:r=!1}=e,{show_label:s=!0}=e,{container:o=!0}=e,{max_lines:b}=e,{type:q="text"}=e,{show_copy_button:U=!1}=e,{rtl:A=!1}=e,{text_align:F=void 0}=e,w,C=!1,S;const T=ke();function O(){T("change",a),n||T("input")}we(()=>{t(20,n=!1)});function P(){T("blur")}async function I(){"clipboard"in navigator&&(await navigator.clipboard.writeText(a),J())}function J(){t(14,C=!0),S&&clearTimeout(S),S=setTimeout(()=>{t(14,C=!1)},1e3)}function V(_){const E=_.target,Q=E.value,B=[E.selectionStart,E.selectionEnd];T("select",{value:Q.substring(...B),index:B})}async function W(_){await le(),(_.key==="Enter"&&_.shiftKey&&i>1||_.key==="Enter"&&!_.shiftKey&&i===1&&b>=1)&&(_.preventDefault(),T("submit"))}async function j(_){if(await le(),i===b||!o)return;let E=b===void 0?!1:b===void 0?21*11:21*(b+1),Q=21*(i+1);const B=_.target;B.style.height="1px";let R;E&&B.scrollHeight>E?R=E:B.scrollHeight_.removeEventListener("input",j)}}function $(){a=this.value,t(0,a)}function f(_){D[_?"unshift":"push"](()=>{w=_,t(13,w)})}function re(){a=this.value,t(0,a)}function ce(_){D[_?"unshift":"push"](()=>{w=_,t(13,w)})}function he(){a=this.value,t(0,a)}function be(_){D[_?"unshift":"push"](()=>{w=_,t(13,w)})}function de(){a=this.value,t(0,a)}function me(_){D[_?"unshift":"push"](()=>{w=_,t(13,w)})}return l.$$set=_=>{"value"in _&&t(0,a=_.value),"value_is_output"in _&&t(20,n=_.value_is_output),"lines"in _&&t(1,i=_.lines),"placeholder"in _&&t(2,u=_.placeholder),"label"in _&&t(3,d=_.label),"info"in _&&t(4,c=_.info),"disabled"in _&&t(5,r=_.disabled),"show_label"in _&&t(6,s=_.show_label),"container"in _&&t(7,o=_.container),"max_lines"in _&&t(8,b=_.max_lines),"type"in _&&t(9,q=_.type),"show_copy_button"in _&&t(10,U=_.show_copy_button),"rtl"in _&&t(11,A=_.rtl),"text_align"in _&&t(12,F=_.text_align)},l.$$.update=()=>{l.$$.dirty[0]&8451&&w&&i!==b&&j({target:w}),l.$$.dirty[0]&1&&O()},[a,i,u,d,c,r,s,o,b,q,U,A,F,w,C,P,I,V,W,x,n,$,f,re,ce,he,be,de,me]}let Ye=class extends ue{constructor(e){super(),fe(this,e,Xe,Re,_e,{value:0,value_is_output:20,lines:1,placeholder:2,label:3,info:4,disabled:5,show_label:6,container:7,max_lines:8,type:9,show_copy_button:10,rtl:11,text_align:12},null,[-1,-1])}};function ae(l){let e,t;const a=[l[16]];let n={};for(let i=0;iie(t,"value",d)),D.push(()=>ie(t,"value_is_output",c)),t.$on("change",l[22]),t.$on("input",l[23]),t.$on("submit",l[24]),t.$on("blur",l[25]),t.$on("select",l[26]),{c(){u&&u.c(),e=ee(),H(t.$$.fragment)},m(s,o){u&&u.m(s,o),y(s,e,o),K(t,s,o),i=!0},p(s,o){s[16]?u?(u.p(s,o),o&65536&&k(u,1)):(u=ae(s),u.c(),k(u,1),u.m(e.parentNode,e)):u&&(Y(),v(u,1,1,()=>{u=null}),Z());const b={};o&4&&(b.label=s[2]),o&8&&(b.info=s[3]),o&512&&(b.show_label=s[9]),o&128&&(b.lines=s[7]),o&2048&&(b.type=s[11]),o&262144&&(b.rtl=s[18]),o&524288&&(b.text_align=s[19]),o&132224&&(b.max_lines=!s[10]&&s[17]==="static"?s[7]+1:s[10]),o&256&&(b.placeholder=s[8]),o&32768&&(b.show_copy_button=s[15]),o&4096&&(b.container=s[12]),o&131072&&(b.disabled=s[17]==="static"),!a&&o&1&&(a=!0,b.value=s[0],ne(()=>a=!1)),!n&&o&2&&(n=!0,b.value_is_output=s[1],ne(()=>n=!1)),t.$set(b)},i(s){i||(k(u),k(t.$$.fragment,s),i=!0)},o(s){v(u),v(t.$$.fragment,s),i=!1},d(s){s&&p(e),u&&u.d(s),L(t,s)}}}function Ge(l){let e,t;return e=new je({props:{visible:l[6],elem_id:l[4],elem_classes:l[5],scale:l[13],min_width:l[14],allow_overflow:!1,padding:l[12],$$slots:{default:[Ze]},$$scope:{ctx:l}}}),{c(){H(e.$$.fragment)},m(a,n){K(e,a,n),t=!0},p(a,[n]){const i={};n&64&&(i.visible=a[6]),n&16&&(i.elem_id=a[4]),n&32&&(i.elem_classes=a[5]),n&8192&&(i.scale=a[13]),n&16384&&(i.min_width=a[14]),n&4096&&(i.padding=a[12]),n&135241615&&(i.$$scope={dirty:n,ctx:a}),e.$set(i)},i(a){t||(k(e.$$.fragment,a),t=!0)},o(a){v(e.$$.fragment,a),t=!1},d(a){L(e,a)}}}function Ie(l,e,t){let{label:a="Textbox"}=e,{info:n=void 0}=e,{elem_id:i=""}=e,{elem_classes:u=[]}=e,{visible:d=!0}=e,{value:c=""}=e,{lines:r}=e,{placeholder:s=""}=e,{show_label:o}=e,{max_lines:b}=e,{type:q="text"}=e,{container:U=!0}=e,{scale:A=null}=e,{min_width:F=void 0}=e,{show_copy_button:w=!1}=e,{loading_status:C=void 0}=e,{mode:S}=e,{value_is_output:T=!1}=e,{rtl:O=!1}=e,{text_align:P=void 0}=e;function I(f){c=f,t(0,c)}function J(f){T=f,t(1,T)}function V(f){M.call(this,l,f)}function W(f){M.call(this,l,f)}function j(f){M.call(this,l,f)}function x(f){M.call(this,l,f)}function $(f){M.call(this,l,f)}return l.$$set=f=>{"label"in f&&t(2,a=f.label),"info"in f&&t(3,n=f.info),"elem_id"in f&&t(4,i=f.elem_id),"elem_classes"in f&&t(5,u=f.elem_classes),"visible"in f&&t(6,d=f.visible),"value"in f&&t(0,c=f.value),"lines"in f&&t(7,r=f.lines),"placeholder"in f&&t(8,s=f.placeholder),"show_label"in f&&t(9,o=f.show_label),"max_lines"in f&&t(10,b=f.max_lines),"type"in f&&t(11,q=f.type),"container"in f&&t(12,U=f.container),"scale"in f&&t(13,A=f.scale),"min_width"in f&&t(14,F=f.min_width),"show_copy_button"in f&&t(15,w=f.show_copy_button),"loading_status"in f&&t(16,C=f.loading_status),"mode"in f&&t(17,S=f.mode),"value_is_output"in f&&t(1,T=f.value_is_output),"rtl"in f&&t(18,O=f.rtl),"text_align"in f&&t(19,P=f.text_align)},[c,T,a,n,i,u,d,r,s,o,b,q,U,A,F,w,C,S,O,P,I,J,V,W,j,x,$]}class tt extends ue{constructor(e){super(),fe(this,e,Ie,Ge,_e,{label:2,info:3,elem_id:4,elem_classes:5,visible:6,value:0,lines:7,placeholder:8,show_label:9,max_lines:10,type:11,container:12,scale:13,min_width:14,show_copy_button:15,loading_status:16,mode:17,value_is_output:1,rtl:18,text_align:19})}get label(){return this.$$.ctx[2]}set label(e){this.$$set({label:e}),m()}get info(){return this.$$.ctx[3]}set info(e){this.$$set({info:e}),m()}get elem_id(){return this.$$.ctx[4]}set elem_id(e){this.$$set({elem_id:e}),m()}get elem_classes(){return this.$$.ctx[5]}set elem_classes(e){this.$$set({elem_classes:e}),m()}get visible(){return this.$$.ctx[6]}set visible(e){this.$$set({visible:e}),m()}get value(){return this.$$.ctx[0]}set value(e){this.$$set({value:e}),m()}get lines(){return this.$$.ctx[7]}set lines(e){this.$$set({lines:e}),m()}get placeholder(){return this.$$.ctx[8]}set placeholder(e){this.$$set({placeholder:e}),m()}get show_label(){return this.$$.ctx[9]}set show_label(e){this.$$set({show_label:e}),m()}get max_lines(){return this.$$.ctx[10]}set max_lines(e){this.$$set({max_lines:e}),m()}get type(){return this.$$.ctx[11]}set type(e){this.$$set({type:e}),m()}get container(){return this.$$.ctx[12]}set container(e){this.$$set({container:e}),m()}get scale(){return this.$$.ctx[13]}set scale(e){this.$$set({scale:e}),m()}get min_width(){return this.$$.ctx[14]}set min_width(e){this.$$set({min_width:e}),m()}get show_copy_button(){return this.$$.ctx[15]}set show_copy_button(e){this.$$set({show_copy_button:e}),m()}get loading_status(){return this.$$.ctx[16]}set loading_status(e){this.$$set({loading_status:e}),m()}get mode(){return this.$$.ctx[17]}set mode(e){this.$$set({mode:e}),m()}get value_is_output(){return this.$$.ctx[1]}set value_is_output(e){this.$$set({value_is_output:e}),m()}get rtl(){return this.$$.ctx[18]}set rtl(e){this.$$set({rtl:e}),m()}get text_align(){return this.$$.ctx[19]}set text_align(e){this.$$set({text_align:e}),m()}}export{tt as T};
-//# sourceMappingURL=Textbox-1f11d244.js.map
diff --git a/spaces/Dagfinn1962/CPU/README.md b/spaces/Dagfinn1962/CPU/README.md
deleted file mode 100644
index 305b17c26e6cf9097d8ed11927e463c17017fa49..0000000000000000000000000000000000000000
--- a/spaces/Dagfinn1962/CPU/README.md
+++ /dev/null
@@ -1,14 +0,0 @@
----
-title: SD 2.1 CPU
-emoji: 🐢
-colorFrom: green
-colorTo: indigo
-sdk: gradio
-sdk_version: 3.23.0
-app_file: app.py
-pinned: false
-license: mit
-duplicated_from: Manjushri/SD-2.1-CPU
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
\ No newline at end of file
diff --git a/spaces/DaleChen/AutoGPT/autogpt/memory/no_memory.py b/spaces/DaleChen/AutoGPT/autogpt/memory/no_memory.py
deleted file mode 100644
index 0371e96ae89f5eb88dae019a66351a229596ed7a..0000000000000000000000000000000000000000
--- a/spaces/DaleChen/AutoGPT/autogpt/memory/no_memory.py
+++ /dev/null
@@ -1,73 +0,0 @@
-"""A class that does not store any data. This is the default memory provider."""
-from __future__ import annotations
-
-from typing import Any
-
-from autogpt.memory.base import MemoryProviderSingleton
-
-
-class NoMemory(MemoryProviderSingleton):
- """
- A class that does not store any data. This is the default memory provider.
- """
-
- def __init__(self, cfg):
- """
- Initializes the NoMemory provider.
-
- Args:
- cfg: The config object.
-
- Returns: None
- """
- pass
-
- def add(self, data: str) -> str:
- """
- Adds a data point to the memory. No action is taken in NoMemory.
-
- Args:
- data: The data to add.
-
- Returns: An empty string.
- """
- return ""
-
- def get(self, data: str) -> list[Any] | None:
- """
- Gets the data from the memory that is most relevant to the given data.
- NoMemory always returns None.
-
- Args:
- data: The data to compare to.
-
- Returns: None
- """
- return None
-
- def clear(self) -> str:
- """
- Clears the memory. No action is taken in NoMemory.
-
- Returns: An empty string.
- """
- return ""
-
- def get_relevant(self, data: str, num_relevant: int = 5) -> list[Any] | None:
- """
- Returns all the data in the memory that is relevant to the given data.
- NoMemory always returns None.
-
- Args:
- data: The data to compare to.
- num_relevant: The number of relevant data to return.
-
- Returns: None
- """
- return None
-
- def get_stats(self):
- """
- Returns: An empty dictionary as there are no stats in NoMemory.
- """
- return {}
diff --git a/spaces/Dao3/chatwithdocs/embeddings.py b/spaces/Dao3/chatwithdocs/embeddings.py
deleted file mode 100644
index d7596d473dd2539e182058296e1f8844c0a37a22..0000000000000000000000000000000000000000
--- a/spaces/Dao3/chatwithdocs/embeddings.py
+++ /dev/null
@@ -1,115 +0,0 @@
-"""Wrapper around OpenAI embedding models."""
-from typing import Any, Dict, List, Optional
-
-from pydantic import BaseModel, Extra, root_validator
-
-from langchain.embeddings.base import Embeddings
-from langchain.utils import get_from_dict_or_env
-
-from tenacity import (
- retry,
- retry_if_exception_type,
- stop_after_attempt,
- wait_exponential,
-)
-from openai.error import Timeout, APIError, APIConnectionError, RateLimitError
-
-
-class OpenAIEmbeddings(BaseModel, Embeddings):
- """Wrapper around OpenAI embedding models.
- To use, you should have the ``openai`` python package installed, and the
- environment variable ``OPENAI_API_KEY`` set with your API key or pass it
- as a named parameter to the constructor.
- Example:
- .. code-block:: python
- from langchain.embeddings import OpenAIEmbeddings
- openai = OpenAIEmbeddings(openai_api_key="my-api-key")
- """
-
- client: Any #: :meta private:
- document_model_name: str = "text-embedding-ada-002"
- query_model_name: str = "text-embedding-ada-002"
- openai_api_key: Optional[str] = None
-
- class Config:
- """Configuration for this pydantic object."""
-
- extra = Extra.forbid
-
- # TODO: deprecate this
- @root_validator(pre=True, allow_reuse=True)
- def get_model_names(cls, values: Dict) -> Dict:
- """Get model names from just old model name."""
- if "model_name" in values:
- if "document_model_name" in values:
- raise ValueError(
- "Both `model_name` and `document_model_name` were provided, "
- "but only one should be."
- )
- if "query_model_name" in values:
- raise ValueError(
- "Both `model_name` and `query_model_name` were provided, "
- "but only one should be."
- )
- model_name = values.pop("model_name")
- values["document_model_name"] = f"text-search-{model_name}-doc-001"
- values["query_model_name"] = f"text-search-{model_name}-query-001"
- return values
-
- @root_validator(allow_reuse=True)
- def validate_environment(cls, values: Dict) -> Dict:
- """Validate that api key and python package exists in environment."""
- openai_api_key = get_from_dict_or_env(
- values, "openai_api_key", "OPENAI_API_KEY"
- )
- try:
- import openai
-
- openai.api_key = openai_api_key
- values["client"] = openai.Embedding
- except ImportError:
- raise ValueError(
- "Could not import openai python package. "
- "Please it install it with `pip install openai`."
- )
- return values
-
- @retry(
- reraise=True,
- stop=stop_after_attempt(100),
- wait=wait_exponential(multiplier=1, min=10, max=60),
- retry=(
- retry_if_exception_type(Timeout)
- | retry_if_exception_type(APIError)
- | retry_if_exception_type(APIConnectionError)
- | retry_if_exception_type(RateLimitError)
- ),
- )
- def _embedding_func(self, text: str, *, engine: str) -> List[float]:
- """Call out to OpenAI's embedding endpoint with exponential backoff."""
- # replace newlines, which can negatively affect performance.
- text = text.replace("\n", " ")
- return self.client.create(input=[text], engine=engine)["data"][0]["embedding"]
-
- def embed_documents(self, texts: List[str]) -> List[List[float]]:
- """Call out to OpenAI's embedding endpoint for embedding search docs.
- Args:
- texts: The list of texts to embed.
- Returns:
- List of embeddings, one for each text.
- """
- responses = [
- self._embedding_func(text, engine=self.document_model_name)
- for text in texts
- ]
- return responses
-
- def embed_query(self, text: str) -> List[float]:
- """Call out to OpenAI's embedding endpoint for embedding query text.
- Args:
- text: The text to embed.
- Returns:
- Embeddings for the text.
- """
- embedding = self._embedding_func(text, engine=self.query_model_name)
- return embedding
\ No newline at end of file
diff --git a/spaces/Demosthene-OR/avr23-cds-translation/tabs/intro.py b/spaces/Demosthene-OR/avr23-cds-translation/tabs/intro.py
deleted file mode 100644
index b5cb350304ce0dc171c9346c50a9eeda25426a0f..0000000000000000000000000000000000000000
--- a/spaces/Demosthene-OR/avr23-cds-translation/tabs/intro.py
+++ /dev/null
@@ -1,55 +0,0 @@
-import streamlit as st
-
-
-
-title = "Système de traduction adapté aux lunettes connectées"
-sidebar_name = "Introduction"
-
-
-def run():
-
- # TODO: choose between one of these GIFs
- # st.image("https://dst-studio-template.s3.eu-west-3.amazonaws.com/1.gif")
- # st.image("https://dst-studio-template.s3.eu-west-3.amazonaws.com/2.gif")
- # st.image("https://dst-studio-template.s3.eu-west-3.amazonaws.com/3.gif")
- # st.image("assets/tough-communication.gif",use_column_width=True)
- st.image("https://media.tenor.com/pfOeAfytY98AAAAC/miss-honey-glasses-off.gif",use_column_width=True)
- st.title(title)
-
- st.markdown("--------------------------------------------------------")
-
- st.header("**Contexte**")
-
- st.markdown(
- """
- Les personnes malentendantes souffrent d’un problème auditif et se trouvent donc dans l’incapacité de communiquer aisément avec autrui.
- Par ailleurs, toute personne se trouvant dans un pays étranger dont il ne connaît pas la langue se trouve dans la situation d’une personne malentendante.
- Les lunettes connectées sont dotées de la technologie de reconnaissance vocale avec des algorithmes de deep learning en intelligence artificielle.
- Elles permettent de localiser la voix d’un interlocuteur puis d’afficher sur les verres la transcription textuelle en temps réel. A partir de cette transcription, il est possible d’:red[**afficher la traduction dans la langue du porteur de ces lunettes**].
-
- """
- )
- st.header("**Objectifs**")
-
- st.markdown(
- """
- L’objectif de ce projet est d’adapter un système de traduction au projet de lunettes connectées. Le système implémenté par ces lunettes permet de localiser, de transcrire la voix d’un interlocuteur et d’afficher la transcription sur des lunettes connectées.
- Dans ce projet, notre groupe implémentera un :red[**système de traduction**] qui élargira l’utilisation de ces lunettes à un public plus vaste et permettra à deux individus ne pratiquant pas la même langue de pouvoir communiquer aisément.
- Ce projet concentrera ses efforts sur l'implémentation d’un système de traduction plutôt que sur la reconnaissance vocale. Celle-ci nous sera fournie.
-
- Il nous faut prendre en considération quelques contraintes d’usages final, et voir si nous pourrons les respecter :
-
- - Traduction en temps réel d’un dialogue oral -> optimisation sur la rapidité
- - Dialogue courant sans expertise particulière (champs sémantique généraliste)
- - Prise en compte de la vitesse de lecture de chacun, la traduction doit être synthétique et conserver l’idée clé sans biais. (tout public et/ou design inclusif)
-
- Il est souhaitable que le système puisse rapidement :red[**identifier si les phrases fournies sont exprimées dans une des langues connues**] par le système de traduction, et si c’est le cas, :red[**laquelle**].
- De plus, si le système de reconnaissance vocale n’est pas fiable, il est souhaitable de corriger la phrase en fonction des mots environnants ou des phrases préalablement entendues.
- Lors de la traduction, nous prendrons en compte le contexte défini par la phrase précédente ainsi que par le contexte des phrases préalablement traduites.
- Nous évaluerons la qualité de nos résultats en les comparant avec des systèmes performants tels que “[Google translate](https://translate.google.fr/)” et “[Deepl](https://www.deepl.com/translator)”.
- Enfin, si le temps, nos compétences et les datasets existants, le permettent, nous intégreront une langue originale, non proposée par ces systèmes, telle qu’une langue régionale ou de l’argot.
-
- Le projet est enregistré sur [Github](https://github.com/DataScientest-Studio/AVR23_CDS_Reco_vocale/tree/main)
-
- """
- )
\ No newline at end of file
diff --git a/spaces/Dinoking/Guccio-AI-Designer/netdissect/upsegmodel/__init__.py b/spaces/Dinoking/Guccio-AI-Designer/netdissect/upsegmodel/__init__.py
deleted file mode 100644
index 76b40a0a36bc2976f185dbdc344c5a7c09b65920..0000000000000000000000000000000000000000
--- a/spaces/Dinoking/Guccio-AI-Designer/netdissect/upsegmodel/__init__.py
+++ /dev/null
@@ -1 +0,0 @@
-from .models import ModelBuilder, SegmentationModule
diff --git a/spaces/Dipl0/Dipl0-pepe-diffuser/app.py b/spaces/Dipl0/Dipl0-pepe-diffuser/app.py
deleted file mode 100644
index 4c2da02a033d91ee480f2844f58ce46439f97c3b..0000000000000000000000000000000000000000
--- a/spaces/Dipl0/Dipl0-pepe-diffuser/app.py
+++ /dev/null
@@ -1,3 +0,0 @@
-import gradio as gr
-
-gr.Interface.load("models/Dipl0/pepe-diffuser").launch()
\ No newline at end of file
diff --git a/spaces/Djacon/emotion_detection/static/index.html b/spaces/Djacon/emotion_detection/static/index.html
deleted file mode 100644
index 6e00a4e98607a67667f978489218067a5532abe2..0000000000000000000000000000000000000000
--- a/spaces/Djacon/emotion_detection/static/index.html
+++ /dev/null
@@ -1,348 +0,0 @@
-
-
-
-
-
-
-
- Text2Feature | Homepage
-
-
-
-
-
-
-
-
-
-
-
- – your gateway to the world of text processing and analysis! Our tools empower you to
- easily and swiftly process textual information from any source, be it files, web pages, or text data. We provide
- you with powerful instruments to search for and extract key 'features' within text, aiding you in extracting
- valuable insights and making informed decisions.
-
-
- With Text2Feature, you can:
-
-
-
Import and analyze text files in various formats.
-
Search for and highlight important features within text for further exploration.
-
Structure and organize your textual content for more effective analysis.
-
Utilize a range of tools and methods for text processing and knowledge extraction.
-
-
- Join Text2Feature and transform text into valuable knowledge effortlessly. Get started now and bring your
- research and analytical ideas to life!
-
-
-
-
-
-
-
-
-
-
-
-
-
\ No newline at end of file
diff --git a/spaces/DragGan/DragGan-Inversion/stylegan_human/training_scripts/sg3/train.py b/spaces/DragGan/DragGan-Inversion/stylegan_human/training_scripts/sg3/train.py
deleted file mode 100644
index afc4c934c6944b4333efa38a025f14888c67c59d..0000000000000000000000000000000000000000
--- a/spaces/DragGan/DragGan-Inversion/stylegan_human/training_scripts/sg3/train.py
+++ /dev/null
@@ -1,325 +0,0 @@
-# Copyright (c) SenseTime Research. All rights reserved.
-
-# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
-#
-# NVIDIA CORPORATION and its licensors retain all intellectual property
-# and proprietary rights in and to this software, related documentation
-# and any modifications thereto. Any use, reproduction, disclosure or
-# distribution of this software and related documentation without an express
-# license agreement from NVIDIA CORPORATION is strictly prohibited.
-
-"""Train a GAN using the techniques described in the paper
-"Alias-Free Generative Adversarial Networks"."""
-
-import os
-import click
-import re
-import json
-import tempfile
-import torch
-
-import dnnlib
-from training import training_loop
-from metrics import metric_main
-from torch_utils import training_stats
-from torch_utils import custom_ops
-import ast
-# ----------------------------------------------------------------------------
-
-
-def subprocess_fn(rank, c, temp_dir):
- dnnlib.util.Logger(file_name=os.path.join(
- c.run_dir, 'log.txt'), file_mode='a', should_flush=True)
-
- # Init torch.distributed.
- if c.num_gpus > 1:
- init_file = os.path.abspath(os.path.join(
- temp_dir, '.torch_distributed_init'))
- if os.name == 'nt':
- init_method = 'file:///' + init_file.replace('\\', '/')
- torch.distributed.init_process_group(
- backend='gloo', init_method=init_method, rank=rank, world_size=c.num_gpus)
- else:
- init_method = f'file://{init_file}'
- torch.distributed.init_process_group(
- backend='nccl', init_method=init_method, rank=rank, world_size=c.num_gpus)
-
- # Init torch_utils.
- sync_device = torch.device('cuda', rank) if c.num_gpus > 1 else None
- training_stats.init_multiprocessing(rank=rank, sync_device=sync_device)
- if rank != 0:
- custom_ops.verbosity = 'none'
-
- # Execute training loop.
- training_loop.training_loop(rank=rank, **c)
-
-# ----------------------------------------------------------------------------
-
-
-def launch_training(c, desc, outdir, dry_run):
- dnnlib.util.Logger(should_flush=True)
-
- # Pick output directory.
- prev_run_dirs = []
- if os.path.isdir(outdir):
- prev_run_dirs = [x for x in os.listdir(
- outdir) if os.path.isdir(os.path.join(outdir, x))]
- prev_run_ids = [re.match(r'^\d+', x) for x in prev_run_dirs]
- prev_run_ids = [int(x.group()) for x in prev_run_ids if x is not None]
- cur_run_id = max(prev_run_ids, default=-1) + 1
- c.run_dir = os.path.join(outdir, f'{cur_run_id:05d}-{desc}')
- assert not os.path.exists(c.run_dir)
-
- # Print options.
- print()
- print('Training options:')
- print(json.dumps(c, indent=2))
- print()
- print(f'Output directory: {c.run_dir}')
- print(f'Number of GPUs: {c.num_gpus}')
- print(f'Batch size: {c.batch_size} images')
- print(f'Training duration: {c.total_kimg} kimg')
- print(f'Dataset path: {c.training_set_kwargs.path}')
- print(f'Dataset size: {c.training_set_kwargs.max_size} images')
- print(f'Dataset resolution: {c.training_set_kwargs.resolution}')
- print(f'Dataset labels: {c.training_set_kwargs.use_labels}')
- print(f'Dataset x-flips: {c.training_set_kwargs.xflip}')
- print()
-
- # Dry run?
- if dry_run:
- print('Dry run; exiting.')
- return
-
- # Create output directory.
- print('Creating output directory...')
- os.makedirs(c.run_dir)
- with open(os.path.join(c.run_dir, 'training_options.json'), 'wt') as f:
- json.dump(c, f, indent=2)
-
- # Launch processes.
- print('Launching processes...')
- torch.multiprocessing.set_start_method('spawn')
- with tempfile.TemporaryDirectory() as temp_dir:
- if c.num_gpus == 1:
- subprocess_fn(rank=0, c=c, temp_dir=temp_dir)
- else:
- torch.multiprocessing.spawn(
- fn=subprocess_fn, args=(c, temp_dir), nprocs=c.num_gpus)
-
-# ----------------------------------------------------------------------------
-
-
-def init_dataset_kwargs(data, square=False):
- # dataset
-
- try:
- dataset_kwargs = dnnlib.EasyDict(class_name='training.dataset.ImageFolderDataset',
- path=data, use_labels=True, max_size=None, xflip=False, square=square)
- # Subclass of training.dataset.Dataset.
- dataset_obj = dnnlib.util.construct_class_by_name(**dataset_kwargs)
- # Be explicit about resolution.
- dataset_kwargs.resolution = dataset_obj.resolution
- # Be explicit about labels.
- dataset_kwargs.use_labels = dataset_obj.has_labels
- # Be explicit about dataset size.
- dataset_kwargs.max_size = len(dataset_obj)
- return dataset_kwargs, dataset_obj.name
- except IOError as err:
- raise click.ClickException(f'--data: {err}')
-
- print("out of dataset")
-# ----------------------------------------------------------------------------
-
-
-def parse_comma_separated_list(s):
- if isinstance(s, list):
- return s
- if s is None or s.lower() == 'none' or s == '':
- return []
- return s.split(',')
-
-# ----------------------------------------------------------------------------
-
-
-@click.command()
-# Required.
-@click.option('--outdir', help='Where to save the results', metavar='DIR', required=True)
-@click.option('--cfg', help='Base configuration', type=click.Choice(['stylegan3-t', 'stylegan3-r', 'stylegan2']), required=True)
-@click.option('--data', help='Training data', metavar='PATH', required=True)
-@click.option('--gpus', help='Number of GPUs to use', metavar='INT', type=click.IntRange(min=1), required=True)
-@click.option('--batch', help='Total batch size', metavar='INT', type=click.IntRange(min=1), required=True)
-@click.option('--gamma', help='R1 regularization weight', metavar='FLOAT', type=click.FloatRange(min=0), required=True)
-@click.option('--square', help='True for square, False for rectangle', type=bool, metavar='BOOL', default=False)
-# Optional features.
-@click.option('--cond', help='Train conditional model', metavar='BOOL', type=bool, default=False, show_default=True)
-@click.option('--mirror', help='Enable dataset x-flips', metavar='BOOL', type=bool, default=False, show_default=True)
-@click.option('--aug', help='Augmentation mode', type=click.Choice(['noaug', 'ada', 'fixed']), default='ada', show_default=True)
-@click.option('--resume', help='Resume from given network pickle', metavar='[PATH|URL]', type=str)
-@click.option('--freezed', help='Freeze first layers of D', metavar='INT', type=click.IntRange(min=0), default=0, show_default=True)
-# Misc hyperparameters.
-@click.option('--p', help='Probability for --aug=fixed', metavar='FLOAT', type=click.FloatRange(min=0, max=1), default=0.2, show_default=True)
-@click.option('--target', help='Target value for --aug=ada', metavar='FLOAT', type=click.FloatRange(min=0, max=1), default=0.6, show_default=True)
-@click.option('--batch-gpu', help='Limit batch size per GPU', metavar='INT', type=click.IntRange(min=1))
-@click.option('--cbase', help='Capacity multiplier', metavar='INT', type=click.IntRange(min=1), default=32768, show_default=True)
-@click.option('--cmax', help='Max. feature maps', metavar='INT', type=click.IntRange(min=1), default=512, show_default=True)
-@click.option('--glr', help='G learning rate [default: varies]', metavar='FLOAT', type=click.FloatRange(min=0))
-@click.option('--dlr', help='D learning rate', metavar='FLOAT', type=click.FloatRange(min=0), default=0.002, show_default=True)
-@click.option('--map-depth', help='Mapping network depth [default: varies]', metavar='INT', type=click.IntRange(min=1))
-@click.option('--mbstd-group', help='Minibatch std group size', metavar='INT', type=click.IntRange(min=1), default=4, show_default=True)
-# Misc settings.
-@click.option('--desc', help='String to include in result dir name', metavar='STR', type=str)
-@click.option('--metrics', help='Quality metrics', metavar='[NAME|A,B,C|none]', type=parse_comma_separated_list, default='fid50k_full', show_default=True)
-@click.option('--kimg', help='Total training duration', metavar='KIMG', type=click.IntRange(min=1), default=25000, show_default=True)
-@click.option('--tick', help='How often to print progress', metavar='KIMG', type=click.IntRange(min=1), default=4, show_default=True)
-@click.option('--snap', help='How often to save snapshots', metavar='TICKS', type=click.IntRange(min=1), default=50, show_default=True)
-@click.option('--seed', help='Random seed', metavar='INT', type=click.IntRange(min=0), default=0, show_default=True)
-@click.option('--fp32', help='Disable mixed-precision', metavar='BOOL', type=bool, default=False, show_default=True)
-@click.option('--nobench', help='Disable cuDNN benchmarking', metavar='BOOL', type=bool, default=False, show_default=True)
-@click.option('--workers', help='DataLoader worker processes', metavar='INT', type=click.IntRange(min=1), default=3, show_default=True)
-@click.option('-n', '--dry-run', help='Print training options and exit', is_flag=True)
-def main(**kwargs):
- """Train a GAN using the techniques described in the paper
- "Alias-Free Generative Adversarial Networks".
-
- Examples:
-
- \b
- # Train StyleGAN3-T for AFHQv2 using 8 GPUs.
- python train.py --outdir=~/training-runs --cfg=stylegan3-t --data=~/datasets/afhqv2-512x512.zip \\
- --gpus=8 --batch=32 --gamma=8.2 --mirror=1
-
- \b
- # Fine-tune StyleGAN3-R for MetFaces-U using 1 GPU, starting from the pre-trained FFHQ-U pickle.
- python train.py --outdir=~/training-runs --cfg=stylegan3-r --data=~/datasets/metfacesu-1024x1024.zip \\
- --gpus=8 --batch=32 --gamma=6.6 --mirror=1 --kimg=5000 --snap=5 \\
- --resume=https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/stylegan3-r-ffhqu-1024x1024.pkl
-
- \b
- # Train StyleGAN2 for FFHQ at 1024x1024 resolution using 8 GPUs.
- python train.py --outdir=~/training-runs --cfg=stylegan2 --data=~/datasets/ffhq-1024x1024.zip \\
- --gpus=8 --batch=32 --gamma=10 --mirror=1 --aug=noaug
- """
-
- # Initialize config.
- opts = dnnlib.EasyDict(kwargs) # Command line arguments.
- c = dnnlib.EasyDict() # Main config dict.
- print('---- square: ', opts.square)
- c.G_kwargs = dnnlib.EasyDict(
- class_name=None, z_dim=512, w_dim=512, mapping_kwargs=dnnlib.EasyDict(), square=opts.square)
- c.D_kwargs = dnnlib.EasyDict(class_name='training.networks_stylegan2.Discriminator', block_kwargs=dnnlib.EasyDict(
- ), mapping_kwargs=dnnlib.EasyDict(), epilogue_kwargs=dnnlib.EasyDict(), square=opts.square)
- c.G_opt_kwargs = dnnlib.EasyDict(
- class_name='torch.optim.Adam', betas=[0, 0.99], eps=1e-8)
- c.D_opt_kwargs = dnnlib.EasyDict(
- class_name='torch.optim.Adam', betas=[0, 0.99], eps=1e-8)
- c.loss_kwargs = dnnlib.EasyDict(class_name='training.loss.StyleGAN2Loss')
- c.data_loader_kwargs = dnnlib.EasyDict(pin_memory=True, prefetch_factor=2)
-
- # Training set.
- c.training_set_kwargs, dataset_name = init_dataset_kwargs(
- data=opts.data, square=opts.square)
- if opts.cond and not c.training_set_kwargs.use_labels:
- raise click.ClickException(
- '--cond=True requires labels specified in dataset.json')
- c.training_set_kwargs.use_labels = opts.cond
- c.training_set_kwargs.xflip = opts.mirror
-
- # Hyperparameters & settings.
- c.num_gpus = opts.gpus
- c.batch_size = opts.batch
- c.batch_gpu = opts.batch_gpu or opts.batch // opts.gpus
- c.G_kwargs.channel_base = c.D_kwargs.channel_base = opts.cbase
- c.G_kwargs.channel_max = c.D_kwargs.channel_max = opts.cmax
- c.G_kwargs.mapping_kwargs.num_layers = (
- 8 if opts.cfg == 'stylegan2' else 2) if opts.map_depth is None else opts.map_depth
- c.D_kwargs.block_kwargs.freeze_layers = opts.freezed
- c.D_kwargs.epilogue_kwargs.mbstd_group_size = opts.mbstd_group
- c.loss_kwargs.r1_gamma = opts.gamma
- c.G_opt_kwargs.lr = (
- 0.002 if opts.cfg == 'stylegan2' else 0.0025) if opts.glr is None else opts.glr
- c.D_opt_kwargs.lr = opts.dlr
- c.metrics = opts.metrics
- c.total_kimg = opts.kimg
- c.kimg_per_tick = opts.tick
- c.image_snapshot_ticks = c.network_snapshot_ticks = opts.snap
- c.random_seed = c.training_set_kwargs.random_seed = opts.seed
- c.data_loader_kwargs.num_workers = opts.workers
-
- # Sanity checks.
- if c.batch_size % c.num_gpus != 0:
- raise click.ClickException('--batch must be a multiple of --gpus')
- if c.batch_size % (c.num_gpus * c.batch_gpu) != 0:
- raise click.ClickException(
- '--batch must be a multiple of --gpus times --batch-gpu')
- if c.batch_gpu < c.D_kwargs.epilogue_kwargs.mbstd_group_size:
- raise click.ClickException(
- '--batch-gpu cannot be smaller than --mbstd')
- if any(not metric_main.is_valid_metric(metric) for metric in c.metrics):
- raise click.ClickException('\n'.join(
- ['--metrics can only contain the following values:'] + metric_main.list_valid_metrics()))
-
- # Base configuration.
- c.ema_kimg = c.batch_size * 10 / 32
- if opts.cfg == 'stylegan2':
- c.G_kwargs.class_name = 'training.networks_stylegan2.Generator'
- # Enable style mixing regularization.
- c.loss_kwargs.style_mixing_prob = 0.9
- c.loss_kwargs.pl_weight = 2 # Enable path length regularization.
- c.G_reg_interval = 4 # Enable lazy regularization for G.
- # Speed up training by using regular convolutions instead of grouped convolutions.
- c.G_kwargs.fused_modconv_default = 'inference_only'
- # Speed up path length regularization by skipping gradient computation wrt. conv2d weights.
- c.loss_kwargs.pl_no_weight_grad = True
- else:
- c.G_kwargs.class_name = 'training.networks_stylegan3.Generator'
- c.G_kwargs.magnitude_ema_beta = 0.5 ** (c.batch_size / (20 * 1e3))
- if opts.cfg == 'stylegan3-r':
- c.G_kwargs.conv_kernel = 1 # Use 1x1 convolutions.
- c.G_kwargs.channel_base *= 2 # Double the number of feature maps.
- c.G_kwargs.channel_max *= 2
- # Use radially symmetric downsampling filters.
- c.G_kwargs.use_radial_filters = True
- # Blur the images seen by the discriminator.
- c.loss_kwargs.blur_init_sigma = 10
- # Fade out the blur during the first N kimg.
- c.loss_kwargs.blur_fade_kimg = c.batch_size * 200 / 32
-
- # Augmentation.
- if opts.aug != 'noaug':
- c.augment_kwargs = dnnlib.EasyDict(class_name='training.augment.AugmentPipe', xflip=1, rotate90=1, xint=1,
- scale=1, rotate=1, aniso=1, xfrac=1, brightness=1, contrast=1, lumaflip=1, hue=1, saturation=1)
- if opts.aug == 'ada':
- c.ada_target = opts.target
- if opts.aug == 'fixed':
- c.augment_p = opts.p
-
- # Resume.
- if opts.resume is not None:
- c.resume_pkl = opts.resume
- c.ada_kimg = 100 # Make ADA react faster at the beginning.
- c.ema_rampup = None # Disable EMA rampup.
- c.loss_kwargs.blur_init_sigma = 0 # Disable blur rampup.
-
- # Performance-related toggles.
- if opts.fp32:
- c.G_kwargs.num_fp16_res = c.D_kwargs.num_fp16_res = 0
- c.G_kwargs.conv_clamp = c.D_kwargs.conv_clamp = None
- if opts.nobench:
- c.cudnn_benchmark = False
-
- # Description string.
- desc = f'{opts.cfg:s}-{dataset_name:s}-gpus{c.num_gpus:d}-batch{c.batch_size:d}-gamma{c.loss_kwargs.r1_gamma:g}'
- if opts.desc is not None:
- desc += f'-{opts.desc}'
-
- # Launch.
- launch_training(c=c, desc=desc, outdir=opts.outdir, dry_run=opts.dry_run)
-
-# ----------------------------------------------------------------------------
-
-
-if __name__ == "__main__":
- main() # pylint: disable=no-value-for-parameter
-
-# ----------------------------------------------------------------------------
diff --git a/spaces/ECCV2022/bytetrack/exps/example/mot/yolox_x_ablation.py b/spaces/ECCV2022/bytetrack/exps/example/mot/yolox_x_ablation.py
deleted file mode 100644
index 6afb771555419b1166adfdce8489303ae912c9fc..0000000000000000000000000000000000000000
--- a/spaces/ECCV2022/bytetrack/exps/example/mot/yolox_x_ablation.py
+++ /dev/null
@@ -1,138 +0,0 @@
-# encoding: utf-8
-import os
-import random
-import torch
-import torch.nn as nn
-import torch.distributed as dist
-
-from yolox.exp import Exp as MyExp
-from yolox.data import get_yolox_datadir
-
-class Exp(MyExp):
- def __init__(self):
- super(Exp, self).__init__()
- self.num_classes = 1
- self.depth = 1.33
- self.width = 1.25
- self.exp_name = os.path.split(os.path.realpath(__file__))[1].split(".")[0]
- self.train_ann = "train.json"
- self.val_ann = "val_half.json"
- self.input_size = (800, 1440)
- self.test_size = (800, 1440)
- self.random_size = (18, 32)
- self.max_epoch = 80
- self.print_interval = 20
- self.eval_interval = 5
- self.test_conf = 0.1
- self.nmsthre = 0.7
- self.no_aug_epochs = 10
- self.basic_lr_per_img = 0.001 / 64.0
- self.warmup_epochs = 1
-
- def get_data_loader(self, batch_size, is_distributed, no_aug=False):
- from yolox.data import (
- MOTDataset,
- TrainTransform,
- YoloBatchSampler,
- DataLoader,
- InfiniteSampler,
- MosaicDetection,
- )
-
- dataset = MOTDataset(
- data_dir=os.path.join(get_yolox_datadir(), "mix_mot_ch"),
- json_file=self.train_ann,
- name='',
- img_size=self.input_size,
- preproc=TrainTransform(
- rgb_means=(0.485, 0.456, 0.406),
- std=(0.229, 0.224, 0.225),
- max_labels=500,
- ),
- )
-
- dataset = MosaicDetection(
- dataset,
- mosaic=not no_aug,
- img_size=self.input_size,
- preproc=TrainTransform(
- rgb_means=(0.485, 0.456, 0.406),
- std=(0.229, 0.224, 0.225),
- max_labels=1000,
- ),
- degrees=self.degrees,
- translate=self.translate,
- scale=self.scale,
- shear=self.shear,
- perspective=self.perspective,
- enable_mixup=self.enable_mixup,
- )
-
- self.dataset = dataset
-
- if is_distributed:
- batch_size = batch_size // dist.get_world_size()
-
- sampler = InfiniteSampler(
- len(self.dataset), seed=self.seed if self.seed else 0
- )
-
- batch_sampler = YoloBatchSampler(
- sampler=sampler,
- batch_size=batch_size,
- drop_last=False,
- input_dimension=self.input_size,
- mosaic=not no_aug,
- )
-
- dataloader_kwargs = {"num_workers": self.data_num_workers, "pin_memory": True}
- dataloader_kwargs["batch_sampler"] = batch_sampler
- train_loader = DataLoader(self.dataset, **dataloader_kwargs)
-
- return train_loader
-
- def get_eval_loader(self, batch_size, is_distributed, testdev=False):
- from yolox.data import MOTDataset, ValTransform
-
- valdataset = MOTDataset(
- data_dir=os.path.join(get_yolox_datadir(), "mot"),
- json_file=self.val_ann,
- img_size=self.test_size,
- name='train',
- preproc=ValTransform(
- rgb_means=(0.485, 0.456, 0.406),
- std=(0.229, 0.224, 0.225),
- ),
- )
-
- if is_distributed:
- batch_size = batch_size // dist.get_world_size()
- sampler = torch.utils.data.distributed.DistributedSampler(
- valdataset, shuffle=False
- )
- else:
- sampler = torch.utils.data.SequentialSampler(valdataset)
-
- dataloader_kwargs = {
- "num_workers": self.data_num_workers,
- "pin_memory": True,
- "sampler": sampler,
- }
- dataloader_kwargs["batch_size"] = batch_size
- val_loader = torch.utils.data.DataLoader(valdataset, **dataloader_kwargs)
-
- return val_loader
-
- def get_evaluator(self, batch_size, is_distributed, testdev=False):
- from yolox.evaluators import COCOEvaluator
-
- val_loader = self.get_eval_loader(batch_size, is_distributed, testdev=testdev)
- evaluator = COCOEvaluator(
- dataloader=val_loader,
- img_size=self.test_size,
- confthre=self.test_conf,
- nmsthre=self.nmsthre,
- num_classes=self.num_classes,
- testdev=testdev,
- )
- return evaluator
diff --git a/spaces/EronSamez/RVC_HFmeu/lib/infer_pack/modules/F0Predictor/PMF0Predictor.py b/spaces/EronSamez/RVC_HFmeu/lib/infer_pack/modules/F0Predictor/PMF0Predictor.py
deleted file mode 100644
index b2c592527a5966e6f8e79e8c52dc5b414246dcc6..0000000000000000000000000000000000000000
--- a/spaces/EronSamez/RVC_HFmeu/lib/infer_pack/modules/F0Predictor/PMF0Predictor.py
+++ /dev/null
@@ -1,97 +0,0 @@
-from lib.infer_pack.modules.F0Predictor.F0Predictor import F0Predictor
-import parselmouth
-import numpy as np
-
-
-class PMF0Predictor(F0Predictor):
- def __init__(self, hop_length=512, f0_min=50, f0_max=1100, sampling_rate=44100):
- self.hop_length = hop_length
- self.f0_min = f0_min
- self.f0_max = f0_max
- self.sampling_rate = sampling_rate
-
- def interpolate_f0(self, f0):
- """
- 对F0进行插值处理
- """
-
- data = np.reshape(f0, (f0.size, 1))
-
- vuv_vector = np.zeros((data.size, 1), dtype=np.float32)
- vuv_vector[data > 0.0] = 1.0
- vuv_vector[data <= 0.0] = 0.0
-
- ip_data = data
-
- frame_number = data.size
- last_value = 0.0
- for i in range(frame_number):
- if data[i] <= 0.0:
- j = i + 1
- for j in range(i + 1, frame_number):
- if data[j] > 0.0:
- break
- if j < frame_number - 1:
- if last_value > 0.0:
- step = (data[j] - data[i - 1]) / float(j - i)
- for k in range(i, j):
- ip_data[k] = data[i - 1] + step * (k - i + 1)
- else:
- for k in range(i, j):
- ip_data[k] = data[j]
- else:
- for k in range(i, frame_number):
- ip_data[k] = last_value
- else:
- ip_data[i] = data[i] # 这里可能存在一个没有必要的拷贝
- last_value = data[i]
-
- return ip_data[:, 0], vuv_vector[:, 0]
-
- def compute_f0(self, wav, p_len=None):
- x = wav
- if p_len is None:
- p_len = x.shape[0] // self.hop_length
- else:
- assert abs(p_len - x.shape[0] // self.hop_length) < 4, "pad length error"
- time_step = self.hop_length / self.sampling_rate * 1000
- f0 = (
- parselmouth.Sound(x, self.sampling_rate)
- .to_pitch_ac(
- time_step=time_step / 1000,
- voicing_threshold=0.6,
- pitch_floor=self.f0_min,
- pitch_ceiling=self.f0_max,
- )
- .selected_array["frequency"]
- )
-
- pad_size = (p_len - len(f0) + 1) // 2
- if pad_size > 0 or p_len - len(f0) - pad_size > 0:
- f0 = np.pad(f0, [[pad_size, p_len - len(f0) - pad_size]], mode="constant")
- f0, uv = self.interpolate_f0(f0)
- return f0
-
- def compute_f0_uv(self, wav, p_len=None):
- x = wav
- if p_len is None:
- p_len = x.shape[0] // self.hop_length
- else:
- assert abs(p_len - x.shape[0] // self.hop_length) < 4, "pad length error"
- time_step = self.hop_length / self.sampling_rate * 1000
- f0 = (
- parselmouth.Sound(x, self.sampling_rate)
- .to_pitch_ac(
- time_step=time_step / 1000,
- voicing_threshold=0.6,
- pitch_floor=self.f0_min,
- pitch_ceiling=self.f0_max,
- )
- .selected_array["frequency"]
- )
-
- pad_size = (p_len - len(f0) + 1) // 2
- if pad_size > 0 or p_len - len(f0) - pad_size > 0:
- f0 = np.pad(f0, [[pad_size, p_len - len(f0) - pad_size]], mode="constant")
- f0, uv = self.interpolate_f0(f0)
- return f0, uv
diff --git a/spaces/EsoCode/text-generation-webui/extensions/superbooga/download_urls.py b/spaces/EsoCode/text-generation-webui/extensions/superbooga/download_urls.py
deleted file mode 100644
index efe300d28393e4550f241808073f04c98fb33ace..0000000000000000000000000000000000000000
--- a/spaces/EsoCode/text-generation-webui/extensions/superbooga/download_urls.py
+++ /dev/null
@@ -1,32 +0,0 @@
-import concurrent.futures
-
-import requests
-
-
-def download_single(url):
- response = requests.get(url, timeout=5)
- if response.status_code == 200:
- return response.content
- else:
- raise Exception("Failed to download URL")
-
-
-def download_urls(urls, threads=1):
- with concurrent.futures.ThreadPoolExecutor(max_workers=threads) as executor:
- futures = []
- for url in urls:
- future = executor.submit(download_single, url)
- futures.append(future)
-
- results = []
- i = 0
- for future in concurrent.futures.as_completed(futures):
- try:
- result = future.result()
- results.append(result)
- i += 1
- yield f"{i}/{len(urls)}", results
- except Exception:
- pass
-
- yield "Done", results
diff --git a/spaces/EuroPython2022/mmocr-demo/configs/_base_/recog_pipelines/seg_pipeline.py b/spaces/EuroPython2022/mmocr-demo/configs/_base_/recog_pipelines/seg_pipeline.py
deleted file mode 100644
index 378474dfb5341ec93e73bb61047c43ba72d5e127..0000000000000000000000000000000000000000
--- a/spaces/EuroPython2022/mmocr-demo/configs/_base_/recog_pipelines/seg_pipeline.py
+++ /dev/null
@@ -1,66 +0,0 @@
-img_norm_cfg = dict(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
-
-gt_label_convertor = dict(
- type='SegConvertor', dict_type='DICT36', with_unknown=True, lower=True)
-
-train_pipeline = [
- dict(type='LoadImageFromFile'),
- dict(
- type='RandomPaddingOCR',
- max_ratio=[0.15, 0.2, 0.15, 0.2],
- box_type='char_quads'),
- dict(type='OpencvToPil'),
- dict(
- type='RandomRotateImageBox',
- min_angle=-17,
- max_angle=17,
- box_type='char_quads'),
- dict(type='PilToOpencv'),
- dict(
- type='ResizeOCR',
- height=64,
- min_width=64,
- max_width=512,
- keep_aspect_ratio=True),
- dict(
- type='OCRSegTargets',
- label_convertor=gt_label_convertor,
- box_type='char_quads'),
- dict(type='RandomRotateTextDet', rotate_ratio=0.5, max_angle=15),
- dict(type='ColorJitter', brightness=0.4, contrast=0.4, saturation=0.4),
- dict(type='ToTensorOCR'),
- dict(type='FancyPCA'),
- dict(type='NormalizeOCR', **img_norm_cfg),
- dict(
- type='CustomFormatBundle',
- keys=['gt_kernels'],
- visualize=dict(flag=False, boundary_key=None),
- call_super=False),
- dict(
- type='Collect',
- keys=['img', 'gt_kernels'],
- meta_keys=['filename', 'ori_shape', 'resize_shape'])
-]
-
-test_img_norm_cfg = dict(
- mean=[x * 255 for x in img_norm_cfg['mean']],
- std=[x * 255 for x in img_norm_cfg['std']])
-
-test_pipeline = [
- dict(type='LoadImageFromFile'),
- dict(
- type='ResizeOCR',
- height=64,
- min_width=64,
- max_width=None,
- keep_aspect_ratio=True),
- dict(type='Normalize', **test_img_norm_cfg),
- dict(type='DefaultFormatBundle'),
- dict(
- type='Collect',
- keys=['img'],
- meta_keys=[
- 'filename', 'resize_shape', 'img_norm_cfg', 'ori_filename',
- 'img_shape', 'ori_shape'
- ])
-]
diff --git a/spaces/Falah/female/app.py b/spaces/Falah/female/app.py
deleted file mode 100644
index 53c83b218c0f6e27ff2ec10315b591568660598a..0000000000000000000000000000000000000000
--- a/spaces/Falah/female/app.py
+++ /dev/null
@@ -1,35 +0,0 @@
-import random
-import yaml
-import gradio as gr
-
-def generate_text():
- input_data = get_options('female.yaml')
- command = input_data['command']
- for key in input_data.keys():
- if key != 'command':
- command = command.replace(f'[{key}]', input_data[key][random.randint(0, len(input_data[key]) - 1)])
- return command
-
-def get_options(file_path):
- with open(file_path, 'r') as file:
- options = yaml.load(file, Loader=yaml.FullLoader)
- return options
-
-iface = gr.Interface(
- fn=generate_text,
- inputs=None,
- outputs=gr.outputs.Textbox(label="Generated Text"),
- title="Beautiful Female AI Generator Prompts",
- description="Generates a random text prompt for a female by AI ",
- allow_flagging=False,
- theme="compact",
- examples=[
- ["Generate"],
- ["Generate"],
- ["Generate"]
- ],
- # Add image to the interface
- #image="https://iraqprogrammer.files.wordpress.com/2023/03/00045-3227812873.png?w=1400&h="
-)
-
-iface.launch()
diff --git a/spaces/Faridmaruf/RVCV2MODEL/lib/infer_pack/modules.py b/spaces/Faridmaruf/RVCV2MODEL/lib/infer_pack/modules.py
deleted file mode 100644
index c83289df7c79a4810dacd15c050148544ba0b6a9..0000000000000000000000000000000000000000
--- a/spaces/Faridmaruf/RVCV2MODEL/lib/infer_pack/modules.py
+++ /dev/null
@@ -1,522 +0,0 @@
-import copy
-import math
-import numpy as np
-import scipy
-import torch
-from torch import nn
-from torch.nn import functional as F
-
-from torch.nn import Conv1d, ConvTranspose1d, AvgPool1d, Conv2d
-from torch.nn.utils import weight_norm, remove_weight_norm
-
-from lib.infer_pack import commons
-from lib.infer_pack.commons import init_weights, get_padding
-from lib.infer_pack.transforms import piecewise_rational_quadratic_transform
-
-
-LRELU_SLOPE = 0.1
-
-
-class LayerNorm(nn.Module):
- def __init__(self, channels, eps=1e-5):
- super().__init__()
- self.channels = channels
- self.eps = eps
-
- self.gamma = nn.Parameter(torch.ones(channels))
- self.beta = nn.Parameter(torch.zeros(channels))
-
- def forward(self, x):
- x = x.transpose(1, -1)
- x = F.layer_norm(x, (self.channels,), self.gamma, self.beta, self.eps)
- return x.transpose(1, -1)
-
-
-class ConvReluNorm(nn.Module):
- def __init__(
- self,
- in_channels,
- hidden_channels,
- out_channels,
- kernel_size,
- n_layers,
- p_dropout,
- ):
- super().__init__()
- self.in_channels = in_channels
- self.hidden_channels = hidden_channels
- self.out_channels = out_channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.p_dropout = p_dropout
- assert n_layers > 1, "Number of layers should be larger than 0."
-
- self.conv_layers = nn.ModuleList()
- self.norm_layers = nn.ModuleList()
- self.conv_layers.append(
- nn.Conv1d(
- in_channels, hidden_channels, kernel_size, padding=kernel_size // 2
- )
- )
- self.norm_layers.append(LayerNorm(hidden_channels))
- self.relu_drop = nn.Sequential(nn.ReLU(), nn.Dropout(p_dropout))
- for _ in range(n_layers - 1):
- self.conv_layers.append(
- nn.Conv1d(
- hidden_channels,
- hidden_channels,
- kernel_size,
- padding=kernel_size // 2,
- )
- )
- self.norm_layers.append(LayerNorm(hidden_channels))
- self.proj = nn.Conv1d(hidden_channels, out_channels, 1)
- self.proj.weight.data.zero_()
- self.proj.bias.data.zero_()
-
- def forward(self, x, x_mask):
- x_org = x
- for i in range(self.n_layers):
- x = self.conv_layers[i](x * x_mask)
- x = self.norm_layers[i](x)
- x = self.relu_drop(x)
- x = x_org + self.proj(x)
- return x * x_mask
-
-
-class DDSConv(nn.Module):
- """
- Dialted and Depth-Separable Convolution
- """
-
- def __init__(self, channels, kernel_size, n_layers, p_dropout=0.0):
- super().__init__()
- self.channels = channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.p_dropout = p_dropout
-
- self.drop = nn.Dropout(p_dropout)
- self.convs_sep = nn.ModuleList()
- self.convs_1x1 = nn.ModuleList()
- self.norms_1 = nn.ModuleList()
- self.norms_2 = nn.ModuleList()
- for i in range(n_layers):
- dilation = kernel_size**i
- padding = (kernel_size * dilation - dilation) // 2
- self.convs_sep.append(
- nn.Conv1d(
- channels,
- channels,
- kernel_size,
- groups=channels,
- dilation=dilation,
- padding=padding,
- )
- )
- self.convs_1x1.append(nn.Conv1d(channels, channels, 1))
- self.norms_1.append(LayerNorm(channels))
- self.norms_2.append(LayerNorm(channels))
-
- def forward(self, x, x_mask, g=None):
- if g is not None:
- x = x + g
- for i in range(self.n_layers):
- y = self.convs_sep[i](x * x_mask)
- y = self.norms_1[i](y)
- y = F.gelu(y)
- y = self.convs_1x1[i](y)
- y = self.norms_2[i](y)
- y = F.gelu(y)
- y = self.drop(y)
- x = x + y
- return x * x_mask
-
-
-class WN(torch.nn.Module):
- def __init__(
- self,
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- gin_channels=0,
- p_dropout=0,
- ):
- super(WN, self).__init__()
- assert kernel_size % 2 == 1
- self.hidden_channels = hidden_channels
- self.kernel_size = (kernel_size,)
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.gin_channels = gin_channels
- self.p_dropout = p_dropout
-
- self.in_layers = torch.nn.ModuleList()
- self.res_skip_layers = torch.nn.ModuleList()
- self.drop = nn.Dropout(p_dropout)
-
- if gin_channels != 0:
- cond_layer = torch.nn.Conv1d(
- gin_channels, 2 * hidden_channels * n_layers, 1
- )
- self.cond_layer = torch.nn.utils.weight_norm(cond_layer, name="weight")
-
- for i in range(n_layers):
- dilation = dilation_rate**i
- padding = int((kernel_size * dilation - dilation) / 2)
- in_layer = torch.nn.Conv1d(
- hidden_channels,
- 2 * hidden_channels,
- kernel_size,
- dilation=dilation,
- padding=padding,
- )
- in_layer = torch.nn.utils.weight_norm(in_layer, name="weight")
- self.in_layers.append(in_layer)
-
- # last one is not necessary
- if i < n_layers - 1:
- res_skip_channels = 2 * hidden_channels
- else:
- res_skip_channels = hidden_channels
-
- res_skip_layer = torch.nn.Conv1d(hidden_channels, res_skip_channels, 1)
- res_skip_layer = torch.nn.utils.weight_norm(res_skip_layer, name="weight")
- self.res_skip_layers.append(res_skip_layer)
-
- def forward(self, x, x_mask, g=None, **kwargs):
- output = torch.zeros_like(x)
- n_channels_tensor = torch.IntTensor([self.hidden_channels])
-
- if g is not None:
- g = self.cond_layer(g)
-
- for i in range(self.n_layers):
- x_in = self.in_layers[i](x)
- if g is not None:
- cond_offset = i * 2 * self.hidden_channels
- g_l = g[:, cond_offset : cond_offset + 2 * self.hidden_channels, :]
- else:
- g_l = torch.zeros_like(x_in)
-
- acts = commons.fused_add_tanh_sigmoid_multiply(x_in, g_l, n_channels_tensor)
- acts = self.drop(acts)
-
- res_skip_acts = self.res_skip_layers[i](acts)
- if i < self.n_layers - 1:
- res_acts = res_skip_acts[:, : self.hidden_channels, :]
- x = (x + res_acts) * x_mask
- output = output + res_skip_acts[:, self.hidden_channels :, :]
- else:
- output = output + res_skip_acts
- return output * x_mask
-
- def remove_weight_norm(self):
- if self.gin_channels != 0:
- torch.nn.utils.remove_weight_norm(self.cond_layer)
- for l in self.in_layers:
- torch.nn.utils.remove_weight_norm(l)
- for l in self.res_skip_layers:
- torch.nn.utils.remove_weight_norm(l)
-
-
-class ResBlock1(torch.nn.Module):
- def __init__(self, channels, kernel_size=3, dilation=(1, 3, 5)):
- super(ResBlock1, self).__init__()
- self.convs1 = nn.ModuleList(
- [
- weight_norm(
- Conv1d(
- channels,
- channels,
- kernel_size,
- 1,
- dilation=dilation[0],
- padding=get_padding(kernel_size, dilation[0]),
- )
- ),
- weight_norm(
- Conv1d(
- channels,
- channels,
- kernel_size,
- 1,
- dilation=dilation[1],
- padding=get_padding(kernel_size, dilation[1]),
- )
- ),
- weight_norm(
- Conv1d(
- channels,
- channels,
- kernel_size,
- 1,
- dilation=dilation[2],
- padding=get_padding(kernel_size, dilation[2]),
- )
- ),
- ]
- )
- self.convs1.apply(init_weights)
-
- self.convs2 = nn.ModuleList(
- [
- weight_norm(
- Conv1d(
- channels,
- channels,
- kernel_size,
- 1,
- dilation=1,
- padding=get_padding(kernel_size, 1),
- )
- ),
- weight_norm(
- Conv1d(
- channels,
- channels,
- kernel_size,
- 1,
- dilation=1,
- padding=get_padding(kernel_size, 1),
- )
- ),
- weight_norm(
- Conv1d(
- channels,
- channels,
- kernel_size,
- 1,
- dilation=1,
- padding=get_padding(kernel_size, 1),
- )
- ),
- ]
- )
- self.convs2.apply(init_weights)
-
- def forward(self, x, x_mask=None):
- for c1, c2 in zip(self.convs1, self.convs2):
- xt = F.leaky_relu(x, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c1(xt)
- xt = F.leaky_relu(xt, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c2(xt)
- x = xt + x
- if x_mask is not None:
- x = x * x_mask
- return x
-
- def remove_weight_norm(self):
- for l in self.convs1:
- remove_weight_norm(l)
- for l in self.convs2:
- remove_weight_norm(l)
-
-
-class ResBlock2(torch.nn.Module):
- def __init__(self, channels, kernel_size=3, dilation=(1, 3)):
- super(ResBlock2, self).__init__()
- self.convs = nn.ModuleList(
- [
- weight_norm(
- Conv1d(
- channels,
- channels,
- kernel_size,
- 1,
- dilation=dilation[0],
- padding=get_padding(kernel_size, dilation[0]),
- )
- ),
- weight_norm(
- Conv1d(
- channels,
- channels,
- kernel_size,
- 1,
- dilation=dilation[1],
- padding=get_padding(kernel_size, dilation[1]),
- )
- ),
- ]
- )
- self.convs.apply(init_weights)
-
- def forward(self, x, x_mask=None):
- for c in self.convs:
- xt = F.leaky_relu(x, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c(xt)
- x = xt + x
- if x_mask is not None:
- x = x * x_mask
- return x
-
- def remove_weight_norm(self):
- for l in self.convs:
- remove_weight_norm(l)
-
-
-class Log(nn.Module):
- def forward(self, x, x_mask, reverse=False, **kwargs):
- if not reverse:
- y = torch.log(torch.clamp_min(x, 1e-5)) * x_mask
- logdet = torch.sum(-y, [1, 2])
- return y, logdet
- else:
- x = torch.exp(x) * x_mask
- return x
-
-
-class Flip(nn.Module):
- def forward(self, x, *args, reverse=False, **kwargs):
- x = torch.flip(x, [1])
- if not reverse:
- logdet = torch.zeros(x.size(0)).to(dtype=x.dtype, device=x.device)
- return x, logdet
- else:
- return x
-
-
-class ElementwiseAffine(nn.Module):
- def __init__(self, channels):
- super().__init__()
- self.channels = channels
- self.m = nn.Parameter(torch.zeros(channels, 1))
- self.logs = nn.Parameter(torch.zeros(channels, 1))
-
- def forward(self, x, x_mask, reverse=False, **kwargs):
- if not reverse:
- y = self.m + torch.exp(self.logs) * x
- y = y * x_mask
- logdet = torch.sum(self.logs * x_mask, [1, 2])
- return y, logdet
- else:
- x = (x - self.m) * torch.exp(-self.logs) * x_mask
- return x
-
-
-class ResidualCouplingLayer(nn.Module):
- def __init__(
- self,
- channels,
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- p_dropout=0,
- gin_channels=0,
- mean_only=False,
- ):
- assert channels % 2 == 0, "channels should be divisible by 2"
- super().__init__()
- self.channels = channels
- self.hidden_channels = hidden_channels
- self.kernel_size = kernel_size
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.half_channels = channels // 2
- self.mean_only = mean_only
-
- self.pre = nn.Conv1d(self.half_channels, hidden_channels, 1)
- self.enc = WN(
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- p_dropout=p_dropout,
- gin_channels=gin_channels,
- )
- self.post = nn.Conv1d(hidden_channels, self.half_channels * (2 - mean_only), 1)
- self.post.weight.data.zero_()
- self.post.bias.data.zero_()
-
- def forward(self, x, x_mask, g=None, reverse=False):
- x0, x1 = torch.split(x, [self.half_channels] * 2, 1)
- h = self.pre(x0) * x_mask
- h = self.enc(h, x_mask, g=g)
- stats = self.post(h) * x_mask
- if not self.mean_only:
- m, logs = torch.split(stats, [self.half_channels] * 2, 1)
- else:
- m = stats
- logs = torch.zeros_like(m)
-
- if not reverse:
- x1 = m + x1 * torch.exp(logs) * x_mask
- x = torch.cat([x0, x1], 1)
- logdet = torch.sum(logs, [1, 2])
- return x, logdet
- else:
- x1 = (x1 - m) * torch.exp(-logs) * x_mask
- x = torch.cat([x0, x1], 1)
- return x
-
- def remove_weight_norm(self):
- self.enc.remove_weight_norm()
-
-
-class ConvFlow(nn.Module):
- def __init__(
- self,
- in_channels,
- filter_channels,
- kernel_size,
- n_layers,
- num_bins=10,
- tail_bound=5.0,
- ):
- super().__init__()
- self.in_channels = in_channels
- self.filter_channels = filter_channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.num_bins = num_bins
- self.tail_bound = tail_bound
- self.half_channels = in_channels // 2
-
- self.pre = nn.Conv1d(self.half_channels, filter_channels, 1)
- self.convs = DDSConv(filter_channels, kernel_size, n_layers, p_dropout=0.0)
- self.proj = nn.Conv1d(
- filter_channels, self.half_channels * (num_bins * 3 - 1), 1
- )
- self.proj.weight.data.zero_()
- self.proj.bias.data.zero_()
-
- def forward(self, x, x_mask, g=None, reverse=False):
- x0, x1 = torch.split(x, [self.half_channels] * 2, 1)
- h = self.pre(x0)
- h = self.convs(h, x_mask, g=g)
- h = self.proj(h) * x_mask
-
- b, c, t = x0.shape
- h = h.reshape(b, c, -1, t).permute(0, 1, 3, 2) # [b, cx?, t] -> [b, c, t, ?]
-
- unnormalized_widths = h[..., : self.num_bins] / math.sqrt(self.filter_channels)
- unnormalized_heights = h[..., self.num_bins : 2 * self.num_bins] / math.sqrt(
- self.filter_channels
- )
- unnormalized_derivatives = h[..., 2 * self.num_bins :]
-
- x1, logabsdet = piecewise_rational_quadratic_transform(
- x1,
- unnormalized_widths,
- unnormalized_heights,
- unnormalized_derivatives,
- inverse=reverse,
- tails="linear",
- tail_bound=self.tail_bound,
- )
-
- x = torch.cat([x0, x1], 1) * x_mask
- logdet = torch.sum(logabsdet * x_mask, [1, 2])
- if not reverse:
- return x, logdet
- else:
- return x
diff --git a/spaces/Fernando22/freegpt-webui/g4f/Provider/Providers/hteyun.py b/spaces/Fernando22/freegpt-webui/g4f/Provider/Providers/hteyun.py
deleted file mode 100644
index a6eba7c00331d720afb47215e818f5900d4aedcf..0000000000000000000000000000000000000000
--- a/spaces/Fernando22/freegpt-webui/g4f/Provider/Providers/hteyun.py
+++ /dev/null
@@ -1,34 +0,0 @@
-import requests
-import os
-import json
-from ...typing import sha256, Dict, get_type_hints
-
-url = 'https://hteyun.com'
-model = ['gpt-3.5-turbo', 'gpt-3.5-turbo-16k', 'gpt-3.5-turbo-16k-0613', 'gpt-3.5-turbo-0613']
-supports_stream = True
-needs_auth = False
-
-def _create_completion(model: str, messages: list, stream: bool, temperature: float = 0.7, **kwargs):
- headers = {
- 'Content-Type': 'application/json',
- 'Accept': 'application/json, text/plain, */*',
- 'Accept-Language': 'ru-RU,ru;q=0.9,en-US;q=0.8,en;q=0.7,ja;q=0.6,zh-TW;q=0.5,zh;q=0.4',
- 'Origin': 'https://hteyun.com',
- 'Referer': 'https://hteyun.com/chat/',
- }
- data = {
- 'messages': messages,
- 'model': model,
- 'systemMessage': 'You are ChatGPT, a large language model trained by OpenAI. Follow the user\'s instructions carefully. Respond using russian language.',
- 'temperature': 0.7,
- 'presence_penalty': 0,
- }
- response = requests.post(url + '/api/chat-stream', json=data, headers=headers, stream=True)
- print(response.json())
-
- # Извлечение текста из response
- return response.json()['text']
-
-
-params = f'g4f.Providers.{os.path.basename(__file__)[:-3]} supports: ' + \
- '(%s)' % ', '.join([f"{name}: {get_type_hints(_create_completion)[name].__name__}" for name in _create_completion.__code__.co_varnames[:_create_completion.__code__.co_argcount]])
diff --git a/spaces/Fisharp/starcoder-playground/src/utils.py b/spaces/Fisharp/starcoder-playground/src/utils.py
deleted file mode 100644
index 767c5da57dc769cd1830f2ffdbccd7548e5f9c87..0000000000000000000000000000000000000000
--- a/spaces/Fisharp/starcoder-playground/src/utils.py
+++ /dev/null
@@ -1,97 +0,0 @@
-import os
-from typing import List
-from urllib.parse import urljoin
-
-from settings import (
- DEFAULT_HUGGINGFACE_MODELS_API_BASE_URL,
- STATIC_PATH,
-)
-
-def masked(value: str, n_shown: int, length: int = None) -> str:
- """Returns a string with the first and last n_shown characters
- and the middle of the string replaced with '*'
-
- Args:
- value (str): The string to mask
- n_shown (int): The number of characters to show at the beginning and end of the string
- length (int, optional): The length of the string. If not given, it will be calculated as the length of the value. Defaults to None.
-
- Returns:
- str: The masked string
- """
- l = length or len(value)
- return value[0:n_shown] + '*'*(length-2*n_shown) + value[-n_shown:]
-
-
-def ofuscated(value: str) -> str:
- """Returns a string with the first and last 4 characters
- and the middle of the string replaced with '*'
-
- Args:
- value (str): The string to mask
-
- Returns:
- str: The masked string
- """
- return masked(value, 4, len(value)//2)
-
-
-def preview(label:str, value: str, ofuscate=False):
- """Print the variable name and its value in a nice way.
- If ofuscate is True, it will ofuscate the value
-
- Args:
- variable_name (str): The name of the variable to print
- ofuscate (bool, optional): If True, it will ofuscate the value. Defaults to False.
- """
- str_value = ofuscated(str(value)) if ofuscate else str(value)
- print(f"{label} = {str_value}")
-
-def get_url_from_env_or_default_path(env_name: str, api_path: str) -> str:
- """Takes an url from the env variable (given the env name)
- or combines with urljoin the default models base url
- with the default path (given the path name)
-
- Args:
- env_name (str): The name of the environment variable to check
- api_path (str): The default path to use if the environment variable is not set
-
- Returns:
- str: The url to use
- """
- return os.environ.get(env_name) or urljoin(
- DEFAULT_HUGGINGFACE_MODELS_API_BASE_URL, api_path
- )
-
-def get_file_as_string(file_name, path=STATIC_PATH) -> str:
- """Loads the content of a file given its name
- and returns all of its lines as a single string
- if a file path is given, it will be used
- instead of the default static path (from settings)
-
- Args:
- file_name (_type_): The name of the file to load.
- path (str, optional): The path to the file. Defaults to the current directory.
-
- Returns:
- str: The content of the file as a single string
- """
- with open(os.path.join(path, file_name), mode='r', encoding='UTF-8') as f:
- return f.read()
-
-
-def get_sections(string: str, delimiter: str, up_to: int = None) -> List[str]:
- """Splits a string into sections given a delimiter
-
- Args:
- string (str): The string to split
- delimiter (str): The delimiter to use
- up_to (int, optional): The maximum number of sections to return.
- Defaults to None (which means all sections)
-
- Returns:
- List[str]: The list of sections (up to the given limit, if any provided)
- """
- return [section.strip()
- for section in string.split(delimiter)
- if (section and not section.isspace())][:up_to]
diff --git a/spaces/Flyingpotato42/gpt4all-tweaked/app.py b/spaces/Flyingpotato42/gpt4all-tweaked/app.py
deleted file mode 100644
index 158da3c08dddf7469a9549786c2a39a822a08f6b..0000000000000000000000000000000000000000
--- a/spaces/Flyingpotato42/gpt4all-tweaked/app.py
+++ /dev/null
@@ -1,17 +0,0 @@
-import gradio as gr
-import os
-import base64
-encrypted = "ZWRjNjE1NjZhNTVkZmVkOGI5MzA0Y2JiMmJlNzE0NWQ2YTllMjQ2MTg2YTc0MzMyZTE4NzRkNzEzMmVjMTEzZg=="
-base64_bytes = encrypted.encode('ascii')
-message_bytes = base64.b64decode(base64_bytes)
-os.environ["SERPAPI_API_KEY"] = message_bytes.decode('ascii')
-from langchain.agents import load_tools
-from langchain.agents import initialize_agent
-from langchain.llms import GPT4All
-model_path = "./ggml-gpt4all-j-v1.3-groovy.bin"
-llm = GPT4All(model=model_path)
-agent = initialize_agent(llm, agent="zero-shot-react-description", verbose=False)
-def greet(prompt):
- return agent.run(prompt)
-iface = gr.Interface(fn=greet, inputs="text", outputs="text")
-iface.launch()
\ No newline at end of file
diff --git a/spaces/FrankZxShen/vits-fast-finetuning-pcr/utils.py b/spaces/FrankZxShen/vits-fast-finetuning-pcr/utils.py
deleted file mode 100644
index a91f9eb2df9f2b097431432753212eb440f93020..0000000000000000000000000000000000000000
--- a/spaces/FrankZxShen/vits-fast-finetuning-pcr/utils.py
+++ /dev/null
@@ -1,399 +0,0 @@
-import os
-import glob
-import sys
-import argparse
-import logging
-import json
-import subprocess
-import numpy as np
-from scipy.io.wavfile import read
-import torch
-import regex as re
-
-MATPLOTLIB_FLAG = False
-
-logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
-logger = logging
-
-
-
-zh_pattern = re.compile(r'[\u4e00-\u9fa5]')
-en_pattern = re.compile(r'[a-zA-Z]')
-jp_pattern = re.compile(r'[\u3040-\u30ff\u31f0-\u31ff]')
-kr_pattern = re.compile(r'[\uac00-\ud7af\u1100-\u11ff\u3130-\u318f\ua960-\ua97f]')
-num_pattern=re.compile(r'[0-9]')
-comma=r"(?<=[.。!!??;;,,、::'\"‘“”’()()《》「」~——])" #向前匹配但固定长度
-tags={'ZH':'[ZH]','EN':'[EN]','JP':'[JA]','KR':'[KR]'}
-
-def tag_cjke(text):
- '''为中英日韩加tag,中日正则分不开,故先分句分离中日再识别,以应对大部分情况'''
- sentences = re.split(r"([.。!!??;;,,、::'\"‘“”’()()【】《》「」~——]+ *(?![0-9]))", text) #分句,排除小数点
- sentences.append("")
- sentences = ["".join(i) for i in zip(sentences[0::2],sentences[1::2])]
- # print(sentences)
- prev_lang=None
- tagged_text = ""
- for s in sentences:
- #全为符号跳过
- nu = re.sub(r'[\s\p{P}]+', '', s, flags=re.U).strip()
- if len(nu)==0:
- continue
- s = re.sub(r'[()()《》「」【】‘“”’]+', '', s)
- jp=re.findall(jp_pattern, s)
- #本句含日语字符判断为日语
- if len(jp)>0:
- prev_lang,tagged_jke=tag_jke(s,prev_lang)
- tagged_text +=tagged_jke
- else:
- prev_lang,tagged_cke=tag_cke(s,prev_lang)
- tagged_text +=tagged_cke
- return tagged_text
-
-def tag_jke(text,prev_sentence=None):
- '''为英日韩加tag'''
- # 初始化标记变量
- tagged_text = ""
- prev_lang = None
- tagged=0
- # 遍历文本
- for char in text:
- # 判断当前字符属于哪种语言
- if jp_pattern.match(char):
- lang = "JP"
- elif zh_pattern.match(char):
- lang = "JP"
- elif kr_pattern.match(char):
- lang = "KR"
- elif en_pattern.match(char):
- lang = "EN"
- # elif num_pattern.match(char):
- # lang = prev_sentence
- else:
- lang = None
- tagged_text += char
- continue
- # 如果当前语言与上一个语言不同,就添加标记
- if lang != prev_lang:
- tagged=1
- if prev_lang==None: # 开头
- tagged_text =tags[lang]+tagged_text
- else:
- tagged_text =tagged_text+tags[prev_lang]+tags[lang]
-
- # 重置标记变量
- prev_lang = lang
-
- # 添加当前字符到标记文本中
- tagged_text += char
-
- # 在最后一个语言的结尾添加对应的标记
- if prev_lang:
- tagged_text += tags[prev_lang]
- if not tagged:
- prev_lang=prev_sentence
- tagged_text =tags[prev_lang]+tagged_text+tags[prev_lang]
-
- return prev_lang,tagged_text
-
-def tag_cke(text,prev_sentence=None):
- '''为中英韩加tag'''
- # 初始化标记变量
- tagged_text = ""
- prev_lang = None
- # 是否全略过未标签
- tagged=0
-
- # 遍历文本
- for char in text:
- # 判断当前字符属于哪种语言
- if zh_pattern.match(char):
- lang = "ZH"
- elif kr_pattern.match(char):
- lang = "KR"
- elif en_pattern.match(char):
- lang = "EN"
- # elif num_pattern.match(char):
- # lang = prev_sentence
- else:
- # 略过
- lang = None
- tagged_text += char
- continue
-
- # 如果当前语言与上一个语言不同,添加标记
- if lang != prev_lang:
- tagged=1
- if prev_lang==None: # 开头
- tagged_text =tags[lang]+tagged_text
- else:
- tagged_text =tagged_text+tags[prev_lang]+tags[lang]
-
- # 重置标记变量
- prev_lang = lang
-
- # 添加当前字符到标记文本中
- tagged_text += char
-
- # 在最后一个语言的结尾添加对应的标记
- if prev_lang:
- tagged_text += tags[prev_lang]
- # 未标签则继承上一句标签
- if tagged==0:
- prev_lang=prev_sentence
- tagged_text =tags[prev_lang]+tagged_text+tags[prev_lang]
- return prev_lang,tagged_text
-
-
-def load_checkpoint(checkpoint_path, model, optimizer=None, drop_speaker_emb=False):
- assert os.path.isfile(checkpoint_path)
- checkpoint_dict = torch.load(checkpoint_path, map_location='cpu')
- iteration = checkpoint_dict['iteration']
- learning_rate = checkpoint_dict['learning_rate']
- if optimizer is not None:
- optimizer.load_state_dict(checkpoint_dict['optimizer'])
- saved_state_dict = checkpoint_dict['model']
- if hasattr(model, 'module'):
- state_dict = model.module.state_dict()
- else:
- state_dict = model.state_dict()
- new_state_dict = {}
- for k, v in state_dict.items():
- try:
- if k == 'emb_g.weight':
- if drop_speaker_emb:
- new_state_dict[k] = v
- continue
- v[:saved_state_dict[k].shape[0], :] = saved_state_dict[k]
- new_state_dict[k] = v
- else:
- new_state_dict[k] = saved_state_dict[k]
- except:
- logger.info("%s is not in the checkpoint" % k)
- new_state_dict[k] = v
- if hasattr(model, 'module'):
- model.module.load_state_dict(new_state_dict)
- else:
- model.load_state_dict(new_state_dict)
- logger.info("Loaded checkpoint '{}' (iteration {})".format(
- checkpoint_path, iteration))
- return model, optimizer, learning_rate, iteration
-
-
-def save_checkpoint(model, optimizer, learning_rate, iteration, checkpoint_path):
- logger.info("Saving model and optimizer state at iteration {} to {}".format(
- iteration, checkpoint_path))
- if hasattr(model, 'module'):
- state_dict = model.module.state_dict()
- else:
- state_dict = model.state_dict()
- torch.save({'model': state_dict,
- 'iteration': iteration,
- 'optimizer': optimizer.state_dict() if optimizer is not None else None,
- 'learning_rate': learning_rate}, checkpoint_path)
-
-
-def summarize(writer, global_step, scalars={}, histograms={}, images={}, audios={}, audio_sampling_rate=22050):
- for k, v in scalars.items():
- writer.add_scalar(k, v, global_step)
- for k, v in histograms.items():
- writer.add_histogram(k, v, global_step)
- for k, v in images.items():
- writer.add_image(k, v, global_step, dataformats='HWC')
- for k, v in audios.items():
- writer.add_audio(k, v, global_step, audio_sampling_rate)
-
-
-def latest_checkpoint_path(dir_path, regex="G_*.pth"):
- f_list = glob.glob(os.path.join(dir_path, regex))
- f_list.sort(key=lambda f: int("".join(filter(str.isdigit, f))))
- x = f_list[-1]
- print(x)
- return x
-
-
-def plot_spectrogram_to_numpy(spectrogram):
- global MATPLOTLIB_FLAG
- if not MATPLOTLIB_FLAG:
- import matplotlib
- matplotlib.use("Agg")
- MATPLOTLIB_FLAG = True
- mpl_logger = logging.getLogger('matplotlib')
- mpl_logger.setLevel(logging.WARNING)
- import matplotlib.pylab as plt
- import numpy as np
-
- fig, ax = plt.subplots(figsize=(10, 2))
- im = ax.imshow(spectrogram, aspect="auto", origin="lower",
- interpolation='none')
- plt.colorbar(im, ax=ax)
- plt.xlabel("Frames")
- plt.ylabel("Channels")
- plt.tight_layout()
-
- fig.canvas.draw()
- data = np.fromstring(fig.canvas.tostring_rgb(), dtype=np.uint8, sep='')
- data = data.reshape(fig.canvas.get_width_height()[::-1] + (3,))
- plt.close()
- return data
-
-
-def plot_alignment_to_numpy(alignment, info=None):
- global MATPLOTLIB_FLAG
- if not MATPLOTLIB_FLAG:
- import matplotlib
- matplotlib.use("Agg")
- MATPLOTLIB_FLAG = True
- mpl_logger = logging.getLogger('matplotlib')
- mpl_logger.setLevel(logging.WARNING)
- import matplotlib.pylab as plt
- import numpy as np
-
- fig, ax = plt.subplots(figsize=(6, 4))
- im = ax.imshow(alignment.transpose(), aspect='auto', origin='lower',
- interpolation='none')
- fig.colorbar(im, ax=ax)
- xlabel = 'Decoder timestep'
- if info is not None:
- xlabel += '\n\n' + info
- plt.xlabel(xlabel)
- plt.ylabel('Encoder timestep')
- plt.tight_layout()
-
- fig.canvas.draw()
- data = np.fromstring(fig.canvas.tostring_rgb(), dtype=np.uint8, sep='')
- data = data.reshape(fig.canvas.get_width_height()[::-1] + (3,))
- plt.close()
- return data
-
-
-def load_wav_to_torch(full_path):
- sampling_rate, data = read(full_path)
- return torch.FloatTensor(data.astype(np.float32)), sampling_rate
-
-
-def load_filepaths_and_text(filename, split="|"):
- with open(filename, encoding='utf-8') as f:
- filepaths_and_text = [line.strip().split(split) for line in f]
- return filepaths_and_text
-
-
-def get_hparams(init=True):
- parser = argparse.ArgumentParser()
- parser.add_argument('-c', '--config', type=str, default="./configs/modified_finetune_speaker.json",
- help='JSON file for configuration')
- parser.add_argument('-m', '--model', type=str, default="pretrained_models",
- help='Model name')
- parser.add_argument('-n', '--max_epochs', type=int, default=50,
- help='finetune epochs')
- parser.add_argument('--drop_speaker_embed', type=bool, default=False, help='whether to drop existing characters')
-
- args = parser.parse_args()
- model_dir = os.path.join("./", args.model)
-
- if not os.path.exists(model_dir):
- os.makedirs(model_dir)
-
- config_path = args.config
- config_save_path = os.path.join(model_dir, "config.json")
- if init:
- with open(config_path, "r") as f:
- data = f.read()
- with open(config_save_path, "w") as f:
- f.write(data)
- else:
- with open(config_save_path, "r") as f:
- data = f.read()
- config = json.loads(data)
-
- hparams = HParams(**config)
- hparams.model_dir = model_dir
- hparams.max_epochs = args.max_epochs
- hparams.drop_speaker_embed = args.drop_speaker_embed
- return hparams
-
-
-def get_hparams_from_dir(model_dir):
- config_save_path = os.path.join(model_dir, "config.json")
- with open(config_save_path, "r") as f:
- data = f.read()
- config = json.loads(data)
-
- hparams = HParams(**config)
- hparams.model_dir = model_dir
- return hparams
-
-
-def get_hparams_from_file(config_path):
- with open(config_path, "r", encoding="utf-8") as f:
- data = f.read()
- config = json.loads(data)
-
- hparams = HParams(**config)
- return hparams
-
-
-def check_git_hash(model_dir):
- source_dir = os.path.dirname(os.path.realpath(__file__))
- if not os.path.exists(os.path.join(source_dir, ".git")):
- logger.warn("{} is not a git repository, therefore hash value comparison will be ignored.".format(
- source_dir
- ))
- return
-
- cur_hash = subprocess.getoutput("git rev-parse HEAD")
-
- path = os.path.join(model_dir, "githash")
- if os.path.exists(path):
- saved_hash = open(path).read()
- if saved_hash != cur_hash:
- logger.warn("git hash values are different. {}(saved) != {}(current)".format(
- saved_hash[:8], cur_hash[:8]))
- else:
- open(path, "w").write(cur_hash)
-
-
-def get_logger(model_dir, filename="train.log"):
- global logger
- logger = logging.getLogger(os.path.basename(model_dir))
- logger.setLevel(logging.DEBUG)
-
- formatter = logging.Formatter("%(asctime)s\t%(name)s\t%(levelname)s\t%(message)s")
- if not os.path.exists(model_dir):
- os.makedirs(model_dir)
- h = logging.FileHandler(os.path.join(model_dir, filename))
- h.setLevel(logging.DEBUG)
- h.setFormatter(formatter)
- logger.addHandler(h)
- return logger
-
-
-class HParams():
- def __init__(self, **kwargs):
- for k, v in kwargs.items():
- if type(v) == dict:
- v = HParams(**v)
- self[k] = v
-
- def keys(self):
- return self.__dict__.keys()
-
- def items(self):
- return self.__dict__.items()
-
- def values(self):
- return self.__dict__.values()
-
- def __len__(self):
- return len(self.__dict__)
-
- def __getitem__(self, key):
- return getattr(self, key)
-
- def __setitem__(self, key, value):
- return setattr(self, key, value)
-
- def __contains__(self, key):
- return key in self.__dict__
-
- def __repr__(self):
- return self.__dict__.__repr__()
\ No newline at end of file
diff --git a/spaces/FridaZuley/RVC_HFKawaii/demucs/utils.py b/spaces/FridaZuley/RVC_HFKawaii/demucs/utils.py
deleted file mode 100644
index 4364184059b1afe3c8379c77793a8e76dccf9699..0000000000000000000000000000000000000000
--- a/spaces/FridaZuley/RVC_HFKawaii/demucs/utils.py
+++ /dev/null
@@ -1,323 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-# All rights reserved.
-#
-# This source code is licensed under the license found in the
-# LICENSE file in the root directory of this source tree.
-
-import errno
-import functools
-import hashlib
-import inspect
-import io
-import os
-import random
-import socket
-import tempfile
-import warnings
-import zlib
-from contextlib import contextmanager
-
-from diffq import UniformQuantizer, DiffQuantizer
-import torch as th
-import tqdm
-from torch import distributed
-from torch.nn import functional as F
-
-
-def center_trim(tensor, reference):
- """
- Center trim `tensor` with respect to `reference`, along the last dimension.
- `reference` can also be a number, representing the length to trim to.
- If the size difference != 0 mod 2, the extra sample is removed on the right side.
- """
- if hasattr(reference, "size"):
- reference = reference.size(-1)
- delta = tensor.size(-1) - reference
- if delta < 0:
- raise ValueError("tensor must be larger than reference. " f"Delta is {delta}.")
- if delta:
- tensor = tensor[..., delta // 2:-(delta - delta // 2)]
- return tensor
-
-
-def average_metric(metric, count=1.):
- """
- Average `metric` which should be a float across all hosts. `count` should be
- the weight for this particular host (i.e. number of examples).
- """
- metric = th.tensor([count, count * metric], dtype=th.float32, device='cuda')
- distributed.all_reduce(metric, op=distributed.ReduceOp.SUM)
- return metric[1].item() / metric[0].item()
-
-
-def free_port(host='', low=20000, high=40000):
- """
- Return a port number that is most likely free.
- This could suffer from a race condition although
- it should be quite rare.
- """
- sock = socket.socket()
- while True:
- port = random.randint(low, high)
- try:
- sock.bind((host, port))
- except OSError as error:
- if error.errno == errno.EADDRINUSE:
- continue
- raise
- return port
-
-
-def sizeof_fmt(num, suffix='B'):
- """
- Given `num` bytes, return human readable size.
- Taken from https://stackoverflow.com/a/1094933
- """
- for unit in ['', 'Ki', 'Mi', 'Gi', 'Ti', 'Pi', 'Ei', 'Zi']:
- if abs(num) < 1024.0:
- return "%3.1f%s%s" % (num, unit, suffix)
- num /= 1024.0
- return "%.1f%s%s" % (num, 'Yi', suffix)
-
-
-def human_seconds(seconds, display='.2f'):
- """
- Given `seconds` seconds, return human readable duration.
- """
- value = seconds * 1e6
- ratios = [1e3, 1e3, 60, 60, 24]
- names = ['us', 'ms', 's', 'min', 'hrs', 'days']
- last = names.pop(0)
- for name, ratio in zip(names, ratios):
- if value / ratio < 0.3:
- break
- value /= ratio
- last = name
- return f"{format(value, display)} {last}"
-
-
-class TensorChunk:
- def __init__(self, tensor, offset=0, length=None):
- total_length = tensor.shape[-1]
- assert offset >= 0
- assert offset < total_length
-
- if length is None:
- length = total_length - offset
- else:
- length = min(total_length - offset, length)
-
- self.tensor = tensor
- self.offset = offset
- self.length = length
- self.device = tensor.device
-
- @property
- def shape(self):
- shape = list(self.tensor.shape)
- shape[-1] = self.length
- return shape
-
- def padded(self, target_length):
- delta = target_length - self.length
- total_length = self.tensor.shape[-1]
- assert delta >= 0
-
- start = self.offset - delta // 2
- end = start + target_length
-
- correct_start = max(0, start)
- correct_end = min(total_length, end)
-
- pad_left = correct_start - start
- pad_right = end - correct_end
-
- out = F.pad(self.tensor[..., correct_start:correct_end], (pad_left, pad_right))
- assert out.shape[-1] == target_length
- return out
-
-
-def tensor_chunk(tensor_or_chunk):
- if isinstance(tensor_or_chunk, TensorChunk):
- return tensor_or_chunk
- else:
- assert isinstance(tensor_or_chunk, th.Tensor)
- return TensorChunk(tensor_or_chunk)
-
-
-def apply_model(model, mix, shifts=None, split=False,
- overlap=0.25, transition_power=1., progress=False):
- """
- Apply model to a given mixture.
-
- Args:
- shifts (int): if > 0, will shift in time `mix` by a random amount between 0 and 0.5 sec
- and apply the oppositve shift to the output. This is repeated `shifts` time and
- all predictions are averaged. This effectively makes the model time equivariant
- and improves SDR by up to 0.2 points.
- split (bool): if True, the input will be broken down in 8 seconds extracts
- and predictions will be performed individually on each and concatenated.
- Useful for model with large memory footprint like Tasnet.
- progress (bool): if True, show a progress bar (requires split=True)
- """
- assert transition_power >= 1, "transition_power < 1 leads to weird behavior."
- device = mix.device
- channels, length = mix.shape
- if split:
- out = th.zeros(len(model.sources), channels, length, device=device)
- sum_weight = th.zeros(length, device=device)
- segment = model.segment_length
- stride = int((1 - overlap) * segment)
- offsets = range(0, length, stride)
- scale = stride / model.samplerate
- if progress:
- offsets = tqdm.tqdm(offsets, unit_scale=scale, ncols=120, unit='seconds')
- # We start from a triangle shaped weight, with maximal weight in the middle
- # of the segment. Then we normalize and take to the power `transition_power`.
- # Large values of transition power will lead to sharper transitions.
- weight = th.cat([th.arange(1, segment // 2 + 1),
- th.arange(segment - segment // 2, 0, -1)]).to(device)
- assert len(weight) == segment
- # If the overlap < 50%, this will translate to linear transition when
- # transition_power is 1.
- weight = (weight / weight.max())**transition_power
- for offset in offsets:
- chunk = TensorChunk(mix, offset, segment)
- chunk_out = apply_model(model, chunk, shifts=shifts)
- chunk_length = chunk_out.shape[-1]
- out[..., offset:offset + segment] += weight[:chunk_length] * chunk_out
- sum_weight[offset:offset + segment] += weight[:chunk_length]
- offset += segment
- assert sum_weight.min() > 0
- out /= sum_weight
- return out
- elif shifts:
- max_shift = int(0.5 * model.samplerate)
- mix = tensor_chunk(mix)
- padded_mix = mix.padded(length + 2 * max_shift)
- out = 0
- for _ in range(shifts):
- offset = random.randint(0, max_shift)
- shifted = TensorChunk(padded_mix, offset, length + max_shift - offset)
- shifted_out = apply_model(model, shifted)
- out += shifted_out[..., max_shift - offset:]
- out /= shifts
- return out
- else:
- valid_length = model.valid_length(length)
- mix = tensor_chunk(mix)
- padded_mix = mix.padded(valid_length)
- with th.no_grad():
- out = model(padded_mix.unsqueeze(0))[0]
- return center_trim(out, length)
-
-
-@contextmanager
-def temp_filenames(count, delete=True):
- names = []
- try:
- for _ in range(count):
- names.append(tempfile.NamedTemporaryFile(delete=False).name)
- yield names
- finally:
- if delete:
- for name in names:
- os.unlink(name)
-
-
-def get_quantizer(model, args, optimizer=None):
- quantizer = None
- if args.diffq:
- quantizer = DiffQuantizer(
- model, min_size=args.q_min_size, group_size=8)
- if optimizer is not None:
- quantizer.setup_optimizer(optimizer)
- elif args.qat:
- quantizer = UniformQuantizer(
- model, bits=args.qat, min_size=args.q_min_size)
- return quantizer
-
-
-def load_model(path, strict=False):
- with warnings.catch_warnings():
- warnings.simplefilter("ignore")
- load_from = path
- package = th.load(load_from, 'cpu')
-
- klass = package["klass"]
- args = package["args"]
- kwargs = package["kwargs"]
-
- if strict:
- model = klass(*args, **kwargs)
- else:
- sig = inspect.signature(klass)
- for key in list(kwargs):
- if key not in sig.parameters:
- warnings.warn("Dropping inexistant parameter " + key)
- del kwargs[key]
- model = klass(*args, **kwargs)
-
- state = package["state"]
- training_args = package["training_args"]
- quantizer = get_quantizer(model, training_args)
-
- set_state(model, quantizer, state)
- return model
-
-
-def get_state(model, quantizer):
- if quantizer is None:
- state = {k: p.data.to('cpu') for k, p in model.state_dict().items()}
- else:
- state = quantizer.get_quantized_state()
- buf = io.BytesIO()
- th.save(state, buf)
- state = {'compressed': zlib.compress(buf.getvalue())}
- return state
-
-
-def set_state(model, quantizer, state):
- if quantizer is None:
- model.load_state_dict(state)
- else:
- buf = io.BytesIO(zlib.decompress(state["compressed"]))
- state = th.load(buf, "cpu")
- quantizer.restore_quantized_state(state)
-
- return state
-
-
-def save_state(state, path):
- buf = io.BytesIO()
- th.save(state, buf)
- sig = hashlib.sha256(buf.getvalue()).hexdigest()[:8]
-
- path = path.parent / (path.stem + "-" + sig + path.suffix)
- path.write_bytes(buf.getvalue())
-
-
-def save_model(model, quantizer, training_args, path):
- args, kwargs = model._init_args_kwargs
- klass = model.__class__
-
- state = get_state(model, quantizer)
-
- save_to = path
- package = {
- 'klass': klass,
- 'args': args,
- 'kwargs': kwargs,
- 'state': state,
- 'training_args': training_args,
- }
- th.save(package, save_to)
-
-
-def capture_init(init):
- @functools.wraps(init)
- def __init__(self, *args, **kwargs):
- self._init_args_kwargs = (args, kwargs)
- init(self, *args, **kwargs)
-
- return __init__
diff --git a/spaces/FridaZuley/RVC_HFKawaii/infer/lib/uvr5_pack/utils.py b/spaces/FridaZuley/RVC_HFKawaii/infer/lib/uvr5_pack/utils.py
deleted file mode 100644
index f4805cdb25e7c50611412a19340ad525d1251d7b..0000000000000000000000000000000000000000
--- a/spaces/FridaZuley/RVC_HFKawaii/infer/lib/uvr5_pack/utils.py
+++ /dev/null
@@ -1,121 +0,0 @@
-import json
-
-import numpy as np
-import torch
-from tqdm import tqdm
-
-
-def load_data(file_name: str = "./infer/lib/uvr5_pack/name_params.json") -> dict:
- with open(file_name, "r") as f:
- data = json.load(f)
-
- return data
-
-
-def make_padding(width, cropsize, offset):
- left = offset
- roi_size = cropsize - left * 2
- if roi_size == 0:
- roi_size = cropsize
- right = roi_size - (width % roi_size) + left
-
- return left, right, roi_size
-
-
-def inference(X_spec, device, model, aggressiveness, data):
- """
- data : dic configs
- """
-
- def _execute(
- X_mag_pad, roi_size, n_window, device, model, aggressiveness, is_half=True
- ):
- model.eval()
- with torch.no_grad():
- preds = []
-
- iterations = [n_window]
-
- total_iterations = sum(iterations)
- for i in tqdm(range(n_window)):
- start = i * roi_size
- X_mag_window = X_mag_pad[
- None, :, :, start : start + data["window_size"]
- ]
- X_mag_window = torch.from_numpy(X_mag_window)
- if is_half:
- X_mag_window = X_mag_window.half()
- X_mag_window = X_mag_window.to(device)
-
- pred = model.predict(X_mag_window, aggressiveness)
-
- pred = pred.detach().cpu().numpy()
- preds.append(pred[0])
-
- pred = np.concatenate(preds, axis=2)
- return pred
-
- def preprocess(X_spec):
- X_mag = np.abs(X_spec)
- X_phase = np.angle(X_spec)
-
- return X_mag, X_phase
-
- X_mag, X_phase = preprocess(X_spec)
-
- coef = X_mag.max()
- X_mag_pre = X_mag / coef
-
- n_frame = X_mag_pre.shape[2]
- pad_l, pad_r, roi_size = make_padding(n_frame, data["window_size"], model.offset)
- n_window = int(np.ceil(n_frame / roi_size))
-
- X_mag_pad = np.pad(X_mag_pre, ((0, 0), (0, 0), (pad_l, pad_r)), mode="constant")
-
- if list(model.state_dict().values())[0].dtype == torch.float16:
- is_half = True
- else:
- is_half = False
- pred = _execute(
- X_mag_pad, roi_size, n_window, device, model, aggressiveness, is_half
- )
- pred = pred[:, :, :n_frame]
-
- if data["tta"]:
- pad_l += roi_size // 2
- pad_r += roi_size // 2
- n_window += 1
-
- X_mag_pad = np.pad(X_mag_pre, ((0, 0), (0, 0), (pad_l, pad_r)), mode="constant")
-
- pred_tta = _execute(
- X_mag_pad, roi_size, n_window, device, model, aggressiveness, is_half
- )
- pred_tta = pred_tta[:, :, roi_size // 2 :]
- pred_tta = pred_tta[:, :, :n_frame]
-
- return (pred + pred_tta) * 0.5 * coef, X_mag, np.exp(1.0j * X_phase)
- else:
- return pred * coef, X_mag, np.exp(1.0j * X_phase)
-
-
-def _get_name_params(model_path, model_hash):
- data = load_data()
- flag = False
- ModelName = model_path
- for type in list(data):
- for model in list(data[type][0]):
- for i in range(len(data[type][0][model])):
- if str(data[type][0][model][i]["hash_name"]) == model_hash:
- flag = True
- elif str(data[type][0][model][i]["hash_name"]) in ModelName:
- flag = True
-
- if flag:
- model_params_auto = data[type][0][model][i]["model_params"]
- param_name_auto = data[type][0][model][i]["param_name"]
- if type == "equivalent":
- return param_name_auto, model_params_auto
- else:
- flag = False
- return param_name_auto, model_params_auto
diff --git a/spaces/GXSA/bingo/src/components/user-menu.tsx b/spaces/GXSA/bingo/src/components/user-menu.tsx
deleted file mode 100644
index 9bd1edc9cf9f39b63629b021f0c1186b1a7c1341..0000000000000000000000000000000000000000
--- a/spaces/GXSA/bingo/src/components/user-menu.tsx
+++ /dev/null
@@ -1,113 +0,0 @@
-'use client'
-
-import { useEffect, useState } from 'react'
-import Image from 'next/image'
-import { toast } from 'react-hot-toast'
-import { Button } from '@/components/ui/button'
-import pkg from '../../package.json'
-import {
- DropdownMenu,
- DropdownMenuContent,
- DropdownMenuItem,
- DropdownMenuSeparator,
- DropdownMenuTrigger
-} from '@/components/ui/dropdown-menu'
-import { IconCopy, IconExternalLink, IconGitHub } from '@/components/ui/icons'
-import SettingIcon from '@/assets/images/settings.svg'
-import { useCopyToClipboard } from '@/lib/hooks/use-copy-to-clipboard'
-
-export function UserMenu() {
- const [host, setHost] = useState('')
- const { isCopied, copyToClipboard } = useCopyToClipboard({ timeout: 2000 })
- useEffect(() => {
- setHost(location.host)
- }, [])
-
- useEffect(() => {
- if (isCopied) {
- toast.success('复制成功')
- }
- }, [isCopied])
- return (
-
 -
-  -
- 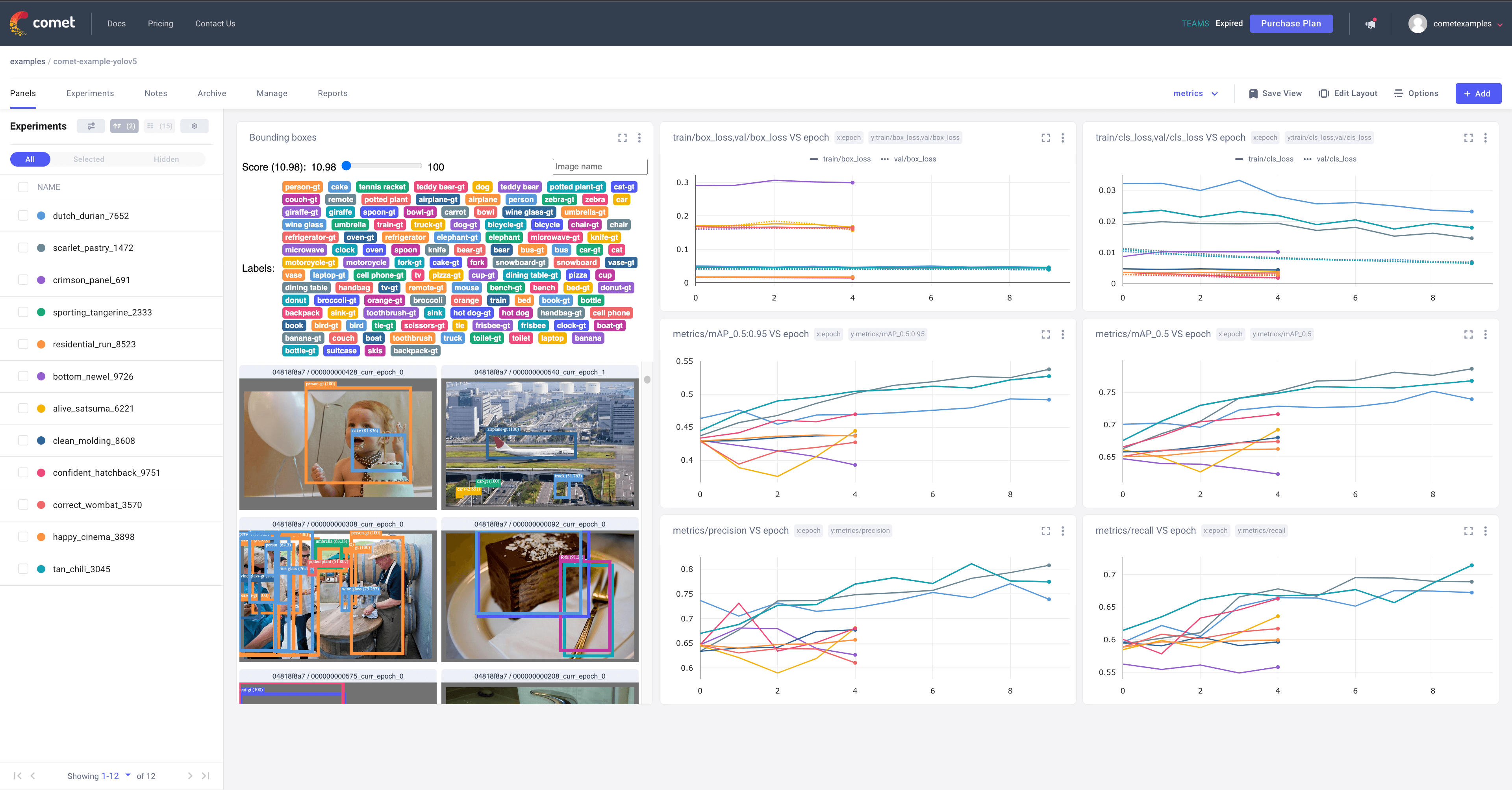 -
-# Try out an Example!
-Check out an example of a [completed run here](https://www.comet.com/examples/comet-example-yolov5/a0e29e0e9b984e4a822db2a62d0cb357?experiment-tab=chart&showOutliers=true&smoothing=0&transformY=smoothing&xAxis=step&ref=yolov5&utm_source=yolov5&utm_medium=affilliate&utm_campaign=yolov5_comet_integration)
-
-Or better yet, try it out yourself in this Colab Notebook
-
-[](https://colab.research.google.com/drive/1RG0WOQyxlDlo5Km8GogJpIEJlg_5lyYO?usp=sharing)
-
-# Log automatically
-
-By default, Comet will log the following items
-
-## Metrics
-- Box Loss, Object Loss, Classification Loss for the training and validation data
-- mAP_0.5, mAP_0.5:0.95 metrics for the validation data.
-- Precision and Recall for the validation data
-
-## Parameters
-
-- Model Hyperparameters
-- All parameters passed through the command line options
-
-## Visualizations
-
-- Confusion Matrix of the model predictions on the validation data
-- Plots for the PR and F1 curves across all classes
-- Correlogram of the Class Labels
-
-# Configure Comet Logging
-
-Comet can be configured to log additional data either through command line flags passed to the training script
-or through environment variables.
-
-```shell
-export COMET_MODE=online # Set whether to run Comet in 'online' or 'offline' mode. Defaults to online
-export COMET_MODEL_NAME=
-
-# Try out an Example!
-Check out an example of a [completed run here](https://www.comet.com/examples/comet-example-yolov5/a0e29e0e9b984e4a822db2a62d0cb357?experiment-tab=chart&showOutliers=true&smoothing=0&transformY=smoothing&xAxis=step&ref=yolov5&utm_source=yolov5&utm_medium=affilliate&utm_campaign=yolov5_comet_integration)
-
-Or better yet, try it out yourself in this Colab Notebook
-
-[](https://colab.research.google.com/drive/1RG0WOQyxlDlo5Km8GogJpIEJlg_5lyYO?usp=sharing)
-
-# Log automatically
-
-By default, Comet will log the following items
-
-## Metrics
-- Box Loss, Object Loss, Classification Loss for the training and validation data
-- mAP_0.5, mAP_0.5:0.95 metrics for the validation data.
-- Precision and Recall for the validation data
-
-## Parameters
-
-- Model Hyperparameters
-- All parameters passed through the command line options
-
-## Visualizations
-
-- Confusion Matrix of the model predictions on the validation data
-- Plots for the PR and F1 curves across all classes
-- Correlogram of the Class Labels
-
-# Configure Comet Logging
-
-Comet can be configured to log additional data either through command line flags passed to the training script
-or through environment variables.
-
-```shell
-export COMET_MODE=online # Set whether to run Comet in 'online' or 'offline' mode. Defaults to online
-export COMET_MODEL_NAME= -
-You can preview the data directly in the Comet UI.
-
-
-You can preview the data directly in the Comet UI.
- -
-Artifacts are versioned and also support adding metadata about the dataset. Comet will automatically log the metadata from your dataset `yaml` file
-
-
-Artifacts are versioned and also support adding metadata about the dataset. Comet will automatically log the metadata from your dataset `yaml` file
-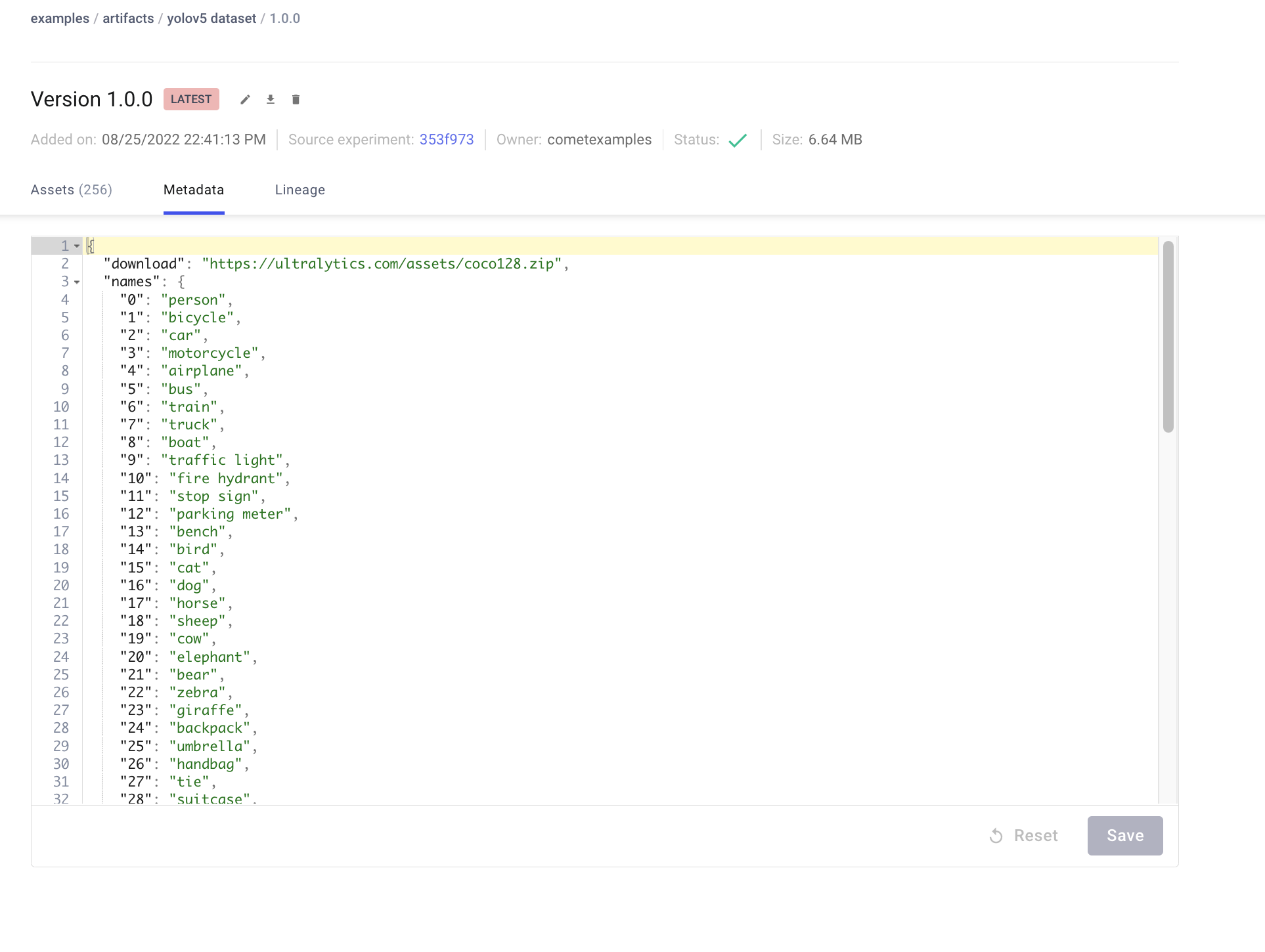 -
-### Using a saved Artifact
-
-If you would like to use a dataset from Comet Artifacts, set the `path` variable in your dataset `yaml` file to point to the following Artifact resource URL.
-
-```
-# contents of artifact.yaml file
-path: "comet://
-
-### Using a saved Artifact
-
-If you would like to use a dataset from Comet Artifacts, set the `path` variable in your dataset `yaml` file to point to the following Artifact resource URL.
-
-```
-# contents of artifact.yaml file
-path: "comet:// -
-## Resuming a Training Run
-
-If your training run is interrupted for any reason, e.g. disrupted internet connection, you can resume the run using the `resume` flag and the Comet Run Path.
-
-The Run Path has the following format `comet://
-
-## Resuming a Training Run
-
-If your training run is interrupted for any reason, e.g. disrupted internet connection, you can resume the run using the `resume` flag and the Comet Run Path.
-
-The Run Path has the following format `comet://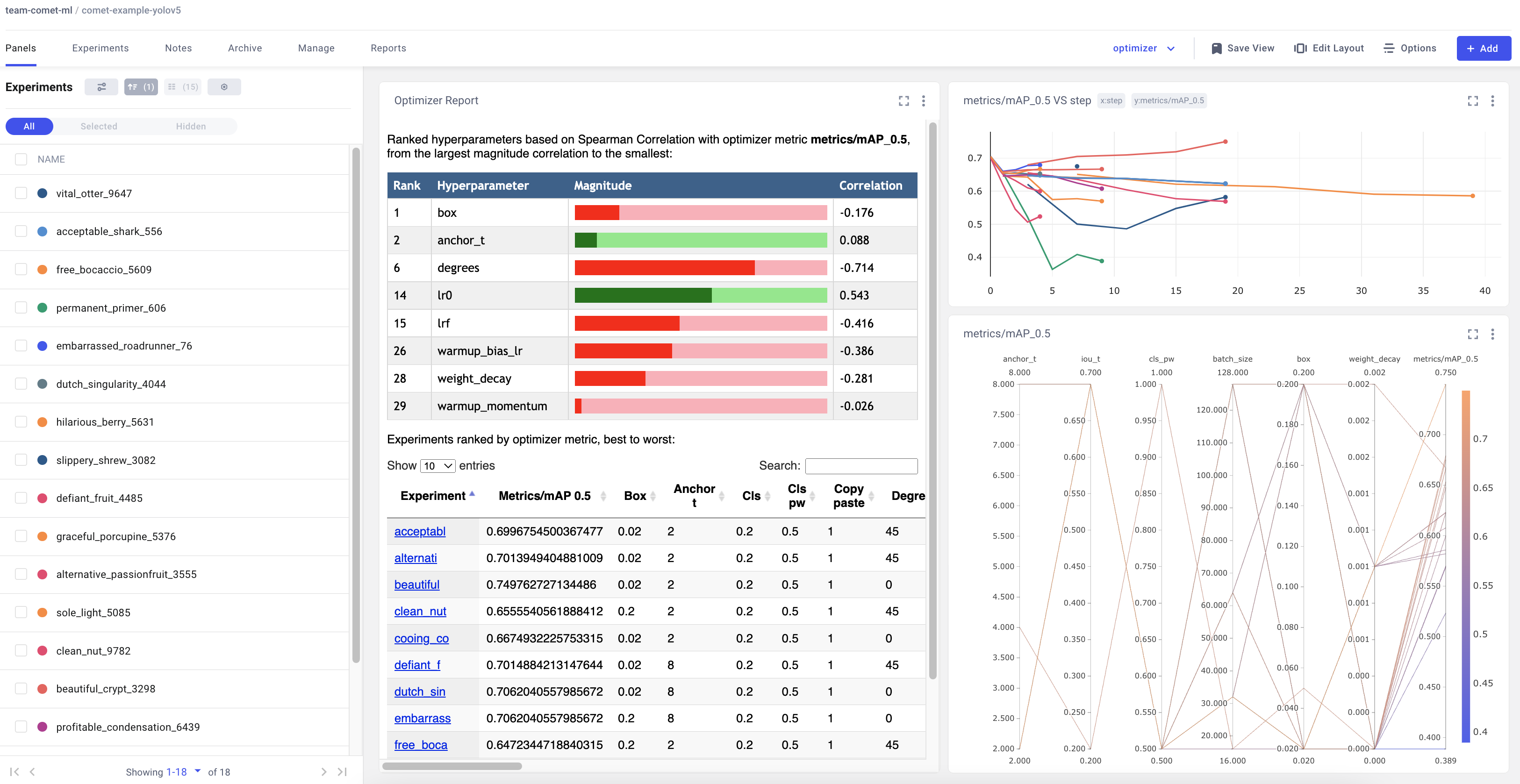 diff --git a/spaces/Illumotion/Koboldcpp/examples/chat-13B.sh b/spaces/Illumotion/Koboldcpp/examples/chat-13B.sh
deleted file mode 100644
index 35c089d57d253ae828322f550f08f102f1aed59d..0000000000000000000000000000000000000000
--- a/spaces/Illumotion/Koboldcpp/examples/chat-13B.sh
+++ /dev/null
@@ -1,41 +0,0 @@
-#!/bin/bash
-
-set -e
-
-cd "$(dirname "$0")/.." || exit
-
-MODEL="${MODEL:-./models/13B/ggml-model-q4_0.bin}"
-PROMPT_TEMPLATE=${PROMPT_TEMPLATE:-./prompts/chat.txt}
-USER_NAME="${USER_NAME:-USER}"
-AI_NAME="${AI_NAME:-ChatLLaMa}"
-
-# Adjust to the number of CPU cores you want to use.
-N_THREAD="${N_THREAD:-8}"
-# Number of tokens to predict (made it larger than default because we want a long interaction)
-N_PREDICTS="${N_PREDICTS:-2048}"
-
-# Note: you can also override the generation options by specifying them on the command line:
-# For example, override the context size by doing: ./chatLLaMa --ctx_size 1024
-GEN_OPTIONS="${GEN_OPTIONS:---ctx_size 2048 --temp 0.7 --top_k 40 --top_p 0.5 --repeat_last_n 256 --batch_size 1024 --repeat_penalty 1.17647}"
-
-DATE_TIME=$(date +%H:%M)
-DATE_YEAR=$(date +%Y)
-
-PROMPT_FILE=$(mktemp -t llamacpp_prompt.XXXXXXX.txt)
-
-sed -e "s/\[\[USER_NAME\]\]/$USER_NAME/g" \
- -e "s/\[\[AI_NAME\]\]/$AI_NAME/g" \
- -e "s/\[\[DATE_TIME\]\]/$DATE_TIME/g" \
- -e "s/\[\[DATE_YEAR\]\]/$DATE_YEAR/g" \
- $PROMPT_TEMPLATE > $PROMPT_FILE
-
-# shellcheck disable=SC2086 # Intended splitting of GEN_OPTIONS
-./main $GEN_OPTIONS \
- --model "$MODEL" \
- --threads "$N_THREAD" \
- --n_predict "$N_PREDICTS" \
- --color --interactive \
- --file ${PROMPT_FILE} \
- --reverse-prompt "${USER_NAME}:" \
- --in-prefix ' ' \
- "$@"
diff --git a/spaces/Ilzhabimantara/rvc-Blue-archives/lib/infer_pack/modules/F0Predictor/PMF0Predictor.py b/spaces/Ilzhabimantara/rvc-Blue-archives/lib/infer_pack/modules/F0Predictor/PMF0Predictor.py
deleted file mode 100644
index b2c592527a5966e6f8e79e8c52dc5b414246dcc6..0000000000000000000000000000000000000000
--- a/spaces/Ilzhabimantara/rvc-Blue-archives/lib/infer_pack/modules/F0Predictor/PMF0Predictor.py
+++ /dev/null
@@ -1,97 +0,0 @@
-from lib.infer_pack.modules.F0Predictor.F0Predictor import F0Predictor
-import parselmouth
-import numpy as np
-
-
-class PMF0Predictor(F0Predictor):
- def __init__(self, hop_length=512, f0_min=50, f0_max=1100, sampling_rate=44100):
- self.hop_length = hop_length
- self.f0_min = f0_min
- self.f0_max = f0_max
- self.sampling_rate = sampling_rate
-
- def interpolate_f0(self, f0):
- """
- 对F0进行插值处理
- """
-
- data = np.reshape(f0, (f0.size, 1))
-
- vuv_vector = np.zeros((data.size, 1), dtype=np.float32)
- vuv_vector[data > 0.0] = 1.0
- vuv_vector[data <= 0.0] = 0.0
-
- ip_data = data
-
- frame_number = data.size
- last_value = 0.0
- for i in range(frame_number):
- if data[i] <= 0.0:
- j = i + 1
- for j in range(i + 1, frame_number):
- if data[j] > 0.0:
- break
- if j < frame_number - 1:
- if last_value > 0.0:
- step = (data[j] - data[i - 1]) / float(j - i)
- for k in range(i, j):
- ip_data[k] = data[i - 1] + step * (k - i + 1)
- else:
- for k in range(i, j):
- ip_data[k] = data[j]
- else:
- for k in range(i, frame_number):
- ip_data[k] = last_value
- else:
- ip_data[i] = data[i] # 这里可能存在一个没有必要的拷贝
- last_value = data[i]
-
- return ip_data[:, 0], vuv_vector[:, 0]
-
- def compute_f0(self, wav, p_len=None):
- x = wav
- if p_len is None:
- p_len = x.shape[0] // self.hop_length
- else:
- assert abs(p_len - x.shape[0] // self.hop_length) < 4, "pad length error"
- time_step = self.hop_length / self.sampling_rate * 1000
- f0 = (
- parselmouth.Sound(x, self.sampling_rate)
- .to_pitch_ac(
- time_step=time_step / 1000,
- voicing_threshold=0.6,
- pitch_floor=self.f0_min,
- pitch_ceiling=self.f0_max,
- )
- .selected_array["frequency"]
- )
-
- pad_size = (p_len - len(f0) + 1) // 2
- if pad_size > 0 or p_len - len(f0) - pad_size > 0:
- f0 = np.pad(f0, [[pad_size, p_len - len(f0) - pad_size]], mode="constant")
- f0, uv = self.interpolate_f0(f0)
- return f0
-
- def compute_f0_uv(self, wav, p_len=None):
- x = wav
- if p_len is None:
- p_len = x.shape[0] // self.hop_length
- else:
- assert abs(p_len - x.shape[0] // self.hop_length) < 4, "pad length error"
- time_step = self.hop_length / self.sampling_rate * 1000
- f0 = (
- parselmouth.Sound(x, self.sampling_rate)
- .to_pitch_ac(
- time_step=time_step / 1000,
- voicing_threshold=0.6,
- pitch_floor=self.f0_min,
- pitch_ceiling=self.f0_max,
- )
- .selected_array["frequency"]
- )
-
- pad_size = (p_len - len(f0) + 1) // 2
- if pad_size > 0 or p_len - len(f0) - pad_size > 0:
- f0 = np.pad(f0, [[pad_size, p_len - len(f0) - pad_size]], mode="constant")
- f0, uv = self.interpolate_f0(f0)
- return f0, uv
diff --git a/spaces/Ivanrs/batch-image-bg-remover/README.md b/spaces/Ivanrs/batch-image-bg-remover/README.md
deleted file mode 100644
index 14f8e4e5a6bf277b00946fe3bb07c8dd6a34cbce..0000000000000000000000000000000000000000
--- a/spaces/Ivanrs/batch-image-bg-remover/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Batch Image Bg Remover
-emoji: ⚡
-colorFrom: gray
-colorTo: green
-sdk: gradio
-sdk_version: 3.1.1
-app_file: app.py
-pinned: false
-license: apache-2.0
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/JUNGU/SuperGlue-Image-Matching/models/utils.py b/spaces/JUNGU/SuperGlue-Image-Matching/models/utils.py
deleted file mode 100644
index 1a506ec988df122539319398e78233b0afec15bb..0000000000000000000000000000000000000000
--- a/spaces/JUNGU/SuperGlue-Image-Matching/models/utils.py
+++ /dev/null
@@ -1,567 +0,0 @@
-# %BANNER_BEGIN%
-# ---------------------------------------------------------------------
-# %COPYRIGHT_BEGIN%
-#
-# Magic Leap, Inc. ("COMPANY") CONFIDENTIAL
-#
-# Unpublished Copyright (c) 2020
-# Magic Leap, Inc., All Rights Reserved.
-#
-# NOTICE: All information contained herein is, and remains the property
-# of COMPANY. The intellectual and technical concepts contained herein
-# are proprietary to COMPANY and may be covered by U.S. and Foreign
-# Patents, patents in process, and are protected by trade secret or
-# copyright law. Dissemination of this information or reproduction of
-# this material is strictly forbidden unless prior written permission is
-# obtained from COMPANY. Access to the source code contained herein is
-# hereby forbidden to anyone except current COMPANY employees, managers
-# or contractors who have executed Confidentiality and Non-disclosure
-# agreements explicitly covering such access.
-#
-# The copyright notice above does not evidence any actual or intended
-# publication or disclosure of this source code, which includes
-# information that is confidential and/or proprietary, and is a trade
-# secret, of COMPANY. ANY REPRODUCTION, MODIFICATION, DISTRIBUTION,
-# PUBLIC PERFORMANCE, OR PUBLIC DISPLAY OF OR THROUGH USE OF THIS
-# SOURCE CODE WITHOUT THE EXPRESS WRITTEN CONSENT OF COMPANY IS
-# STRICTLY PROHIBITED, AND IN VIOLATION OF APPLICABLE LAWS AND
-# INTERNATIONAL TREATIES. THE RECEIPT OR POSSESSION OF THIS SOURCE
-# CODE AND/OR RELATED INFORMATION DOES NOT CONVEY OR IMPLY ANY RIGHTS
-# TO REPRODUCE, DISCLOSE OR DISTRIBUTE ITS CONTENTS, OR TO MANUFACTURE,
-# USE, OR SELL ANYTHING THAT IT MAY DESCRIBE, IN WHOLE OR IN PART.
-#
-# %COPYRIGHT_END%
-# ----------------------------------------------------------------------
-# %AUTHORS_BEGIN%
-#
-# Originating Authors: Paul-Edouard Sarlin
-# Daniel DeTone
-# Tomasz Malisiewicz
-#
-# %AUTHORS_END%
-# --------------------------------------------------------------------*/
-# %BANNER_END%
-
-from pathlib import Path
-import time
-from collections import OrderedDict
-from threading import Thread
-import numpy as np
-import cv2
-import torch
-import matplotlib.pyplot as plt
-import matplotlib
-matplotlib.use('Agg')
-
-
-class AverageTimer:
- """ Class to help manage printing simple timing of code execution. """
-
- def __init__(self, smoothing=0.3, newline=False):
- self.smoothing = smoothing
- self.newline = newline
- self.times = OrderedDict()
- self.will_print = OrderedDict()
- self.reset()
-
- def reset(self):
- now = time.time()
- self.start = now
- self.last_time = now
- for name in self.will_print:
- self.will_print[name] = False
-
- def update(self, name='default'):
- now = time.time()
- dt = now - self.last_time
- if name in self.times:
- dt = self.smoothing * dt + (1 - self.smoothing) * self.times[name]
- self.times[name] = dt
- self.will_print[name] = True
- self.last_time = now
-
- def print(self, text='Timer'):
- total = 0.
- print('[{}]'.format(text), end=' ')
- for key in self.times:
- val = self.times[key]
- if self.will_print[key]:
- print('%s=%.3f' % (key, val), end=' ')
- total += val
- print('total=%.3f sec {%.1f FPS}' % (total, 1./total), end=' ')
- if self.newline:
- print(flush=True)
- else:
- print(end='\r', flush=True)
- self.reset()
-
-
-class VideoStreamer:
- """ Class to help process image streams. Four types of possible inputs:"
- 1.) USB Webcam.
- 2.) An IP camera
- 3.) A directory of images (files in directory matching 'image_glob').
- 4.) A video file, such as an .mp4 or .avi file.
- """
- def __init__(self, basedir, resize, skip, image_glob, max_length=1000000):
- self._ip_grabbed = False
- self._ip_running = False
- self._ip_camera = False
- self._ip_image = None
- self._ip_index = 0
- self.cap = []
- self.camera = True
- self.video_file = False
- self.listing = []
- self.resize = resize
- self.interp = cv2.INTER_AREA
- self.i = 0
- self.skip = skip
- self.max_length = max_length
- if isinstance(basedir, int) or basedir.isdigit():
- print('==> Processing USB webcam input: {}'.format(basedir))
- self.cap = cv2.VideoCapture(int(basedir))
- self.listing = range(0, self.max_length)
- elif basedir.startswith(('http', 'rtsp')):
- print('==> Processing IP camera input: {}'.format(basedir))
- self.cap = cv2.VideoCapture(basedir)
- self.start_ip_camera_thread()
- self._ip_camera = True
- self.listing = range(0, self.max_length)
- elif Path(basedir).is_dir():
- print('==> Processing image directory input: {}'.format(basedir))
- self.listing = list(Path(basedir).glob(image_glob[0]))
- for j in range(1, len(image_glob)):
- image_path = list(Path(basedir).glob(image_glob[j]))
- self.listing = self.listing + image_path
- self.listing.sort()
- self.listing = self.listing[::self.skip]
- self.max_length = np.min([self.max_length, len(self.listing)])
- if self.max_length == 0:
- raise IOError('No images found (maybe bad \'image_glob\' ?)')
- self.listing = self.listing[:self.max_length]
- self.camera = False
- elif Path(basedir).exists():
- print('==> Processing video input: {}'.format(basedir))
- self.cap = cv2.VideoCapture(basedir)
- self.cap.set(cv2.CAP_PROP_BUFFERSIZE, 1)
- num_frames = int(self.cap.get(cv2.CAP_PROP_FRAME_COUNT))
- self.listing = range(0, num_frames)
- self.listing = self.listing[::self.skip]
- self.video_file = True
- self.max_length = np.min([self.max_length, len(self.listing)])
- self.listing = self.listing[:self.max_length]
- else:
- raise ValueError('VideoStreamer input \"{}\" not recognized.'.format(basedir))
- if self.camera and not self.cap.isOpened():
- raise IOError('Could not read camera')
-
- def load_image(self, impath):
- """ Read image as grayscale and resize to img_size.
- Inputs
- impath: Path to input image.
- Returns
- grayim: uint8 numpy array sized H x W.
- """
- grayim = cv2.imread(impath, 0)
- if grayim is None:
- raise Exception('Error reading image %s' % impath)
- w, h = grayim.shape[1], grayim.shape[0]
- w_new, h_new = process_resize(w, h, self.resize)
- grayim = cv2.resize(
- grayim, (w_new, h_new), interpolation=self.interp)
- return grayim
-
- def next_frame(self):
- """ Return the next frame, and increment internal counter.
- Returns
- image: Next H x W image.
- status: True or False depending whether image was loaded.
- """
-
- if self.i == self.max_length:
- return (None, False)
- if self.camera:
-
- if self._ip_camera:
- #Wait for first image, making sure we haven't exited
- while self._ip_grabbed is False and self._ip_exited is False:
- time.sleep(.001)
-
- ret, image = self._ip_grabbed, self._ip_image.copy()
- if ret is False:
- self._ip_running = False
- else:
- ret, image = self.cap.read()
- if ret is False:
- print('VideoStreamer: Cannot get image from camera')
- return (None, False)
- w, h = image.shape[1], image.shape[0]
- if self.video_file:
- self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.listing[self.i])
-
- w_new, h_new = process_resize(w, h, self.resize)
- image = cv2.resize(image, (w_new, h_new),
- interpolation=self.interp)
- image = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
- else:
- image_file = str(self.listing[self.i])
- image = self.load_image(image_file)
- self.i = self.i + 1
- return (image, True)
-
- def start_ip_camera_thread(self):
- self._ip_thread = Thread(target=self.update_ip_camera, args=())
- self._ip_running = True
- self._ip_thread.start()
- self._ip_exited = False
- return self
-
- def update_ip_camera(self):
- while self._ip_running:
- ret, img = self.cap.read()
- if ret is False:
- self._ip_running = False
- self._ip_exited = True
- self._ip_grabbed = False
- return
-
- self._ip_image = img
- self._ip_grabbed = ret
- self._ip_index += 1
- #print('IPCAMERA THREAD got frame {}'.format(self._ip_index))
-
-
- def cleanup(self):
- self._ip_running = False
-
-# --- PREPROCESSING ---
-
-def process_resize(w, h, resize):
- assert(len(resize) > 0 and len(resize) <= 2)
- if len(resize) == 1 and resize[0] > -1:
- scale = resize[0] / max(h, w)
- w_new, h_new = int(round(w*scale)), int(round(h*scale))
- elif len(resize) == 1 and resize[0] == -1:
- w_new, h_new = w, h
- else: # len(resize) == 2:
- w_new, h_new = resize[0], resize[1]
-
- # Issue warning if resolution is too small or too large.
- if max(w_new, h_new) < 160:
- print('Warning: input resolution is very small, results may vary')
- elif max(w_new, h_new) > 2000:
- print('Warning: input resolution is very large, results may vary')
-
- return w_new, h_new
-
-
-def frame2tensor(frame, device):
- return torch.from_numpy(frame/255.).float()[None, None].to(device)
-
-
-def read_image(path, device, resize, rotation, resize_float):
- image = cv2.imread(str(path), cv2.IMREAD_GRAYSCALE)
- if image is None:
- return None, None, None
- w, h = image.shape[1], image.shape[0]
- w_new, h_new = process_resize(w, h, resize)
- scales = (float(w) / float(w_new), float(h) / float(h_new))
-
- if resize_float:
- image = cv2.resize(image.astype('float32'), (w_new, h_new))
- else:
- image = cv2.resize(image, (w_new, h_new)).astype('float32')
-
- if rotation != 0:
- image = np.rot90(image, k=rotation)
- if rotation % 2:
- scales = scales[::-1]
-
- inp = frame2tensor(image, device)
- return image, inp, scales
-
-def process_image(image, device, resize, rotation, resize_float):
- image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
- if image is None:
- return None, None, None
- w, h = image.shape[1], image.shape[0]
- w_new, h_new = process_resize(w, h, resize)
- scales = (float(w) / float(w_new), float(h) / float(h_new))
-
- if resize_float:
- image = cv2.resize(image.astype('float32'), (w_new, h_new))
- else:
- image = cv2.resize(image, (w_new, h_new)).astype('float32')
-
- if rotation != 0:
- image = np.rot90(image, k=rotation)
- if rotation % 2:
- scales = scales[::-1]
-
- inp = frame2tensor(image, device)
- return image, inp, scales
-
-# --- GEOMETRY ---
-
-
-def estimate_pose(kpts0, kpts1, K0, K1, thresh, conf=0.99999):
- if len(kpts0) < 5:
- return None
-
- f_mean = np.mean([K0[0, 0], K1[1, 1], K0[0, 0], K1[1, 1]])
- norm_thresh = thresh / f_mean
-
- kpts0 = (kpts0 - K0[[0, 1], [2, 2]][None]) / K0[[0, 1], [0, 1]][None]
- kpts1 = (kpts1 - K1[[0, 1], [2, 2]][None]) / K1[[0, 1], [0, 1]][None]
-
- E, mask = cv2.findEssentialMat(
- kpts0, kpts1, np.eye(3), threshold=norm_thresh, prob=conf,
- method=cv2.RANSAC)
-
- assert E is not None
-
- best_num_inliers = 0
- ret = None
- for _E in np.split(E, len(E) / 3):
- n, R, t, _ = cv2.recoverPose(
- _E, kpts0, kpts1, np.eye(3), 1e9, mask=mask)
- if n > best_num_inliers:
- best_num_inliers = n
- ret = (R, t[:, 0], mask.ravel() > 0)
- return ret
-
-
-def rotate_intrinsics(K, image_shape, rot):
- """image_shape is the shape of the image after rotation"""
- assert rot <= 3
- h, w = image_shape[:2][::-1 if (rot % 2) else 1]
- fx, fy, cx, cy = K[0, 0], K[1, 1], K[0, 2], K[1, 2]
- rot = rot % 4
- if rot == 1:
- return np.array([[fy, 0., cy],
- [0., fx, w-1-cx],
- [0., 0., 1.]], dtype=K.dtype)
- elif rot == 2:
- return np.array([[fx, 0., w-1-cx],
- [0., fy, h-1-cy],
- [0., 0., 1.]], dtype=K.dtype)
- else: # if rot == 3:
- return np.array([[fy, 0., h-1-cy],
- [0., fx, cx],
- [0., 0., 1.]], dtype=K.dtype)
-
-
-def rotate_pose_inplane(i_T_w, rot):
- rotation_matrices = [
- np.array([[np.cos(r), -np.sin(r), 0., 0.],
- [np.sin(r), np.cos(r), 0., 0.],
- [0., 0., 1., 0.],
- [0., 0., 0., 1.]], dtype=np.float32)
- for r in [np.deg2rad(d) for d in (0, 270, 180, 90)]
- ]
- return np.dot(rotation_matrices[rot], i_T_w)
-
-
-def scale_intrinsics(K, scales):
- scales = np.diag([1./scales[0], 1./scales[1], 1.])
- return np.dot(scales, K)
-
-
-def to_homogeneous(points):
- return np.concatenate([points, np.ones_like(points[:, :1])], axis=-1)
-
-
-def compute_epipolar_error(kpts0, kpts1, T_0to1, K0, K1):
- kpts0 = (kpts0 - K0[[0, 1], [2, 2]][None]) / K0[[0, 1], [0, 1]][None]
- kpts1 = (kpts1 - K1[[0, 1], [2, 2]][None]) / K1[[0, 1], [0, 1]][None]
- kpts0 = to_homogeneous(kpts0)
- kpts1 = to_homogeneous(kpts1)
-
- t0, t1, t2 = T_0to1[:3, 3]
- t_skew = np.array([
- [0, -t2, t1],
- [t2, 0, -t0],
- [-t1, t0, 0]
- ])
- E = t_skew @ T_0to1[:3, :3]
-
- Ep0 = kpts0 @ E.T # N x 3
- p1Ep0 = np.sum(kpts1 * Ep0, -1) # N
- Etp1 = kpts1 @ E # N x 3
- d = p1Ep0**2 * (1.0 / (Ep0[:, 0]**2 + Ep0[:, 1]**2)
- + 1.0 / (Etp1[:, 0]**2 + Etp1[:, 1]**2))
- return d
-
-
-def angle_error_mat(R1, R2):
- cos = (np.trace(np.dot(R1.T, R2)) - 1) / 2
- cos = np.clip(cos, -1., 1.) # numercial errors can make it out of bounds
- return np.rad2deg(np.abs(np.arccos(cos)))
-
-
-def angle_error_vec(v1, v2):
- n = np.linalg.norm(v1) * np.linalg.norm(v2)
- return np.rad2deg(np.arccos(np.clip(np.dot(v1, v2) / n, -1.0, 1.0)))
-
-
-def compute_pose_error(T_0to1, R, t):
- R_gt = T_0to1[:3, :3]
- t_gt = T_0to1[:3, 3]
- error_t = angle_error_vec(t, t_gt)
- error_t = np.minimum(error_t, 180 - error_t) # ambiguity of E estimation
- error_R = angle_error_mat(R, R_gt)
- return error_t, error_R
-
-
-def pose_auc(errors, thresholds):
- sort_idx = np.argsort(errors)
- errors = np.array(errors.copy())[sort_idx]
- recall = (np.arange(len(errors)) + 1) / len(errors)
- errors = np.r_[0., errors]
- recall = np.r_[0., recall]
- aucs = []
- for t in thresholds:
- last_index = np.searchsorted(errors, t)
- r = np.r_[recall[:last_index], recall[last_index-1]]
- e = np.r_[errors[:last_index], t]
- aucs.append(np.trapz(r, x=e)/t)
- return aucs
-
-
-# --- VISUALIZATION ---
-
-
-def plot_image_pair(imgs, dpi=100, size=6, pad=.5):
- n = len(imgs)
- assert n == 2, 'number of images must be two'
- figsize = (size*n, size*3/4) if size is not None else None
- _, ax = plt.subplots(1, n, figsize=figsize, dpi=dpi)
- for i in range(n):
- ax[i].imshow(imgs[i], cmap=plt.get_cmap('gray'), vmin=0, vmax=255)
- ax[i].get_yaxis().set_ticks([])
- ax[i].get_xaxis().set_ticks([])
- for spine in ax[i].spines.values(): # remove frame
- spine.set_visible(False)
- plt.tight_layout(pad=pad)
-
-
-def plot_keypoints(kpts0, kpts1, color='w', ps=2):
- ax = plt.gcf().axes
- ax[0].scatter(kpts0[:, 0], kpts0[:, 1], c=color, s=ps)
- ax[1].scatter(kpts1[:, 0], kpts1[:, 1], c=color, s=ps)
-
-
-def plot_matches(kpts0, kpts1, color, lw=1.5, ps=4):
- fig = plt.gcf()
- ax = fig.axes
- fig.canvas.draw()
-
- transFigure = fig.transFigure.inverted()
- fkpts0 = transFigure.transform(ax[0].transData.transform(kpts0))
- fkpts1 = transFigure.transform(ax[1].transData.transform(kpts1))
-
- fig.lines = [matplotlib.lines.Line2D(
- (fkpts0[i, 0], fkpts1[i, 0]), (fkpts0[i, 1], fkpts1[i, 1]), zorder=1,
- transform=fig.transFigure, c=color[i], linewidth=lw)
- for i in range(len(kpts0))]
- ax[0].scatter(kpts0[:, 0], kpts0[:, 1], c=color, s=ps)
- ax[1].scatter(kpts1[:, 0], kpts1[:, 1], c=color, s=ps)
-
-
-def make_matching_plot(image0, image1, kpts0, kpts1, mkpts0, mkpts1,
- color, text, path, show_keypoints=False,
- fast_viz=False, opencv_display=False,
- opencv_title='matches', small_text=[]):
-
- if fast_viz:
- make_matching_plot_fast(image0, image1, kpts0, kpts1, mkpts0, mkpts1,
- color, text, path, show_keypoints, 10,
- opencv_display, opencv_title, small_text)
- return
-
- plot_image_pair([image0, image1])
- if show_keypoints:
- plot_keypoints(kpts0, kpts1, color='k', ps=4)
- plot_keypoints(kpts0, kpts1, color='w', ps=2)
- plot_matches(mkpts0, mkpts1, color)
-
- fig = plt.gcf()
- txt_color = 'k' if image0[:100, :150].mean() > 200 else 'w'
- fig.text(
- 0.01, 0.99, '\n'.join(text), transform=fig.axes[0].transAxes,
- fontsize=15, va='top', ha='left', color=txt_color)
-
- txt_color = 'k' if image0[-100:, :150].mean() > 200 else 'w'
- fig.text(
- 0.01, 0.01, '\n'.join(small_text), transform=fig.axes[0].transAxes,
- fontsize=5, va='bottom', ha='left', color=txt_color)
-
- plt.savefig(str(path), bbox_inches='tight', pad_inches=0)
- plt.close()
-
-
-def make_matching_plot_fast(image0, image1, kpts0, kpts1, mkpts0,
- mkpts1, color, text, path=None,
- show_keypoints=False, margin=10,
- opencv_display=False, opencv_title='',
- small_text=[]):
- H0, W0 = image0.shape
- H1, W1 = image1.shape
- H, W = max(H0, H1), W0 + W1 + margin
-
- out = 255*np.ones((H, W), np.uint8)
- out[:H0, :W0] = image0
- out[:H1, W0+margin:] = image1
- out = np.stack([out]*3, -1)
-
- if show_keypoints:
- kpts0, kpts1 = np.round(kpts0).astype(int), np.round(kpts1).astype(int)
- white = (255, 255, 255)
- black = (0, 0, 0)
- for x, y in kpts0:
- cv2.circle(out, (x, y), 2, black, -1, lineType=cv2.LINE_AA)
- cv2.circle(out, (x, y), 1, white, -1, lineType=cv2.LINE_AA)
- for x, y in kpts1:
- cv2.circle(out, (x + margin + W0, y), 2, black, -1,
- lineType=cv2.LINE_AA)
- cv2.circle(out, (x + margin + W0, y), 1, white, -1,
- lineType=cv2.LINE_AA)
-
- mkpts0, mkpts1 = np.round(mkpts0).astype(int), np.round(mkpts1).astype(int)
- color = (np.array(color[:, :3])*255).astype(int)[:, ::-1]
- for (x0, y0), (x1, y1), c in zip(mkpts0, mkpts1, color):
- c = c.tolist()
- cv2.line(out, (x0, y0), (x1 + margin + W0, y1),
- color=c, thickness=1, lineType=cv2.LINE_AA)
- # display line end-points as circles
- cv2.circle(out, (x0, y0), 2, c, -1, lineType=cv2.LINE_AA)
- cv2.circle(out, (x1 + margin + W0, y1), 2, c, -1,
- lineType=cv2.LINE_AA)
-
- # Scale factor for consistent visualization across scales.
- sc = min(H / 640., 2.0)
-
- # Big text.
- Ht = int(30 * sc) # text height
- txt_color_fg = (255, 255, 255)
- txt_color_bg = (0, 0, 0)
- for i, t in enumerate(text):
- cv2.putText(out, t, (int(8*sc), Ht*(i+1)), cv2.FONT_HERSHEY_DUPLEX,
- 1.0*sc, txt_color_bg, 2, cv2.LINE_AA)
- cv2.putText(out, t, (int(8*sc), Ht*(i+1)), cv2.FONT_HERSHEY_DUPLEX,
- 1.0*sc, txt_color_fg, 1, cv2.LINE_AA)
-
- # Small text.
- Ht = int(18 * sc) # text height
- for i, t in enumerate(reversed(small_text)):
- cv2.putText(out, t, (int(8*sc), int(H-Ht*(i+.6))), cv2.FONT_HERSHEY_DUPLEX,
- 0.5*sc, txt_color_bg, 2, cv2.LINE_AA)
- cv2.putText(out, t, (int(8*sc), int(H-Ht*(i+.6))), cv2.FONT_HERSHEY_DUPLEX,
- 0.5*sc, txt_color_fg, 1, cv2.LINE_AA)
- return out
-
-
-def error_colormap(x):
- return np.clip(
- np.stack([2-x*2, x*2, np.zeros_like(x), np.ones_like(x)], -1), 0, 1)
diff --git a/spaces/Jason1112/ML-GUI/readme.md b/spaces/Jason1112/ML-GUI/readme.md
deleted file mode 100644
index fafdf1e2a871a4f7b318dd0b81936fb2a9bdaf0b..0000000000000000000000000000000000000000
--- a/spaces/Jason1112/ML-GUI/readme.md
+++ /dev/null
@@ -1,10 +0,0 @@
----
-title: ML-GUI
-app_file: app.py
-sdk: gradio
-sdk_version: 3.35.2
----
-Hướng dẫn chạy:
-
diff --git a/spaces/Illumotion/Koboldcpp/examples/chat-13B.sh b/spaces/Illumotion/Koboldcpp/examples/chat-13B.sh
deleted file mode 100644
index 35c089d57d253ae828322f550f08f102f1aed59d..0000000000000000000000000000000000000000
--- a/spaces/Illumotion/Koboldcpp/examples/chat-13B.sh
+++ /dev/null
@@ -1,41 +0,0 @@
-#!/bin/bash
-
-set -e
-
-cd "$(dirname "$0")/.." || exit
-
-MODEL="${MODEL:-./models/13B/ggml-model-q4_0.bin}"
-PROMPT_TEMPLATE=${PROMPT_TEMPLATE:-./prompts/chat.txt}
-USER_NAME="${USER_NAME:-USER}"
-AI_NAME="${AI_NAME:-ChatLLaMa}"
-
-# Adjust to the number of CPU cores you want to use.
-N_THREAD="${N_THREAD:-8}"
-# Number of tokens to predict (made it larger than default because we want a long interaction)
-N_PREDICTS="${N_PREDICTS:-2048}"
-
-# Note: you can also override the generation options by specifying them on the command line:
-# For example, override the context size by doing: ./chatLLaMa --ctx_size 1024
-GEN_OPTIONS="${GEN_OPTIONS:---ctx_size 2048 --temp 0.7 --top_k 40 --top_p 0.5 --repeat_last_n 256 --batch_size 1024 --repeat_penalty 1.17647}"
-
-DATE_TIME=$(date +%H:%M)
-DATE_YEAR=$(date +%Y)
-
-PROMPT_FILE=$(mktemp -t llamacpp_prompt.XXXXXXX.txt)
-
-sed -e "s/\[\[USER_NAME\]\]/$USER_NAME/g" \
- -e "s/\[\[AI_NAME\]\]/$AI_NAME/g" \
- -e "s/\[\[DATE_TIME\]\]/$DATE_TIME/g" \
- -e "s/\[\[DATE_YEAR\]\]/$DATE_YEAR/g" \
- $PROMPT_TEMPLATE > $PROMPT_FILE
-
-# shellcheck disable=SC2086 # Intended splitting of GEN_OPTIONS
-./main $GEN_OPTIONS \
- --model "$MODEL" \
- --threads "$N_THREAD" \
- --n_predict "$N_PREDICTS" \
- --color --interactive \
- --file ${PROMPT_FILE} \
- --reverse-prompt "${USER_NAME}:" \
- --in-prefix ' ' \
- "$@"
diff --git a/spaces/Ilzhabimantara/rvc-Blue-archives/lib/infer_pack/modules/F0Predictor/PMF0Predictor.py b/spaces/Ilzhabimantara/rvc-Blue-archives/lib/infer_pack/modules/F0Predictor/PMF0Predictor.py
deleted file mode 100644
index b2c592527a5966e6f8e79e8c52dc5b414246dcc6..0000000000000000000000000000000000000000
--- a/spaces/Ilzhabimantara/rvc-Blue-archives/lib/infer_pack/modules/F0Predictor/PMF0Predictor.py
+++ /dev/null
@@ -1,97 +0,0 @@
-from lib.infer_pack.modules.F0Predictor.F0Predictor import F0Predictor
-import parselmouth
-import numpy as np
-
-
-class PMF0Predictor(F0Predictor):
- def __init__(self, hop_length=512, f0_min=50, f0_max=1100, sampling_rate=44100):
- self.hop_length = hop_length
- self.f0_min = f0_min
- self.f0_max = f0_max
- self.sampling_rate = sampling_rate
-
- def interpolate_f0(self, f0):
- """
- 对F0进行插值处理
- """
-
- data = np.reshape(f0, (f0.size, 1))
-
- vuv_vector = np.zeros((data.size, 1), dtype=np.float32)
- vuv_vector[data > 0.0] = 1.0
- vuv_vector[data <= 0.0] = 0.0
-
- ip_data = data
-
- frame_number = data.size
- last_value = 0.0
- for i in range(frame_number):
- if data[i] <= 0.0:
- j = i + 1
- for j in range(i + 1, frame_number):
- if data[j] > 0.0:
- break
- if j < frame_number - 1:
- if last_value > 0.0:
- step = (data[j] - data[i - 1]) / float(j - i)
- for k in range(i, j):
- ip_data[k] = data[i - 1] + step * (k - i + 1)
- else:
- for k in range(i, j):
- ip_data[k] = data[j]
- else:
- for k in range(i, frame_number):
- ip_data[k] = last_value
- else:
- ip_data[i] = data[i] # 这里可能存在一个没有必要的拷贝
- last_value = data[i]
-
- return ip_data[:, 0], vuv_vector[:, 0]
-
- def compute_f0(self, wav, p_len=None):
- x = wav
- if p_len is None:
- p_len = x.shape[0] // self.hop_length
- else:
- assert abs(p_len - x.shape[0] // self.hop_length) < 4, "pad length error"
- time_step = self.hop_length / self.sampling_rate * 1000
- f0 = (
- parselmouth.Sound(x, self.sampling_rate)
- .to_pitch_ac(
- time_step=time_step / 1000,
- voicing_threshold=0.6,
- pitch_floor=self.f0_min,
- pitch_ceiling=self.f0_max,
- )
- .selected_array["frequency"]
- )
-
- pad_size = (p_len - len(f0) + 1) // 2
- if pad_size > 0 or p_len - len(f0) - pad_size > 0:
- f0 = np.pad(f0, [[pad_size, p_len - len(f0) - pad_size]], mode="constant")
- f0, uv = self.interpolate_f0(f0)
- return f0
-
- def compute_f0_uv(self, wav, p_len=None):
- x = wav
- if p_len is None:
- p_len = x.shape[0] // self.hop_length
- else:
- assert abs(p_len - x.shape[0] // self.hop_length) < 4, "pad length error"
- time_step = self.hop_length / self.sampling_rate * 1000
- f0 = (
- parselmouth.Sound(x, self.sampling_rate)
- .to_pitch_ac(
- time_step=time_step / 1000,
- voicing_threshold=0.6,
- pitch_floor=self.f0_min,
- pitch_ceiling=self.f0_max,
- )
- .selected_array["frequency"]
- )
-
- pad_size = (p_len - len(f0) + 1) // 2
- if pad_size > 0 or p_len - len(f0) - pad_size > 0:
- f0 = np.pad(f0, [[pad_size, p_len - len(f0) - pad_size]], mode="constant")
- f0, uv = self.interpolate_f0(f0)
- return f0, uv
diff --git a/spaces/Ivanrs/batch-image-bg-remover/README.md b/spaces/Ivanrs/batch-image-bg-remover/README.md
deleted file mode 100644
index 14f8e4e5a6bf277b00946fe3bb07c8dd6a34cbce..0000000000000000000000000000000000000000
--- a/spaces/Ivanrs/batch-image-bg-remover/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Batch Image Bg Remover
-emoji: ⚡
-colorFrom: gray
-colorTo: green
-sdk: gradio
-sdk_version: 3.1.1
-app_file: app.py
-pinned: false
-license: apache-2.0
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/JUNGU/SuperGlue-Image-Matching/models/utils.py b/spaces/JUNGU/SuperGlue-Image-Matching/models/utils.py
deleted file mode 100644
index 1a506ec988df122539319398e78233b0afec15bb..0000000000000000000000000000000000000000
--- a/spaces/JUNGU/SuperGlue-Image-Matching/models/utils.py
+++ /dev/null
@@ -1,567 +0,0 @@
-# %BANNER_BEGIN%
-# ---------------------------------------------------------------------
-# %COPYRIGHT_BEGIN%
-#
-# Magic Leap, Inc. ("COMPANY") CONFIDENTIAL
-#
-# Unpublished Copyright (c) 2020
-# Magic Leap, Inc., All Rights Reserved.
-#
-# NOTICE: All information contained herein is, and remains the property
-# of COMPANY. The intellectual and technical concepts contained herein
-# are proprietary to COMPANY and may be covered by U.S. and Foreign
-# Patents, patents in process, and are protected by trade secret or
-# copyright law. Dissemination of this information or reproduction of
-# this material is strictly forbidden unless prior written permission is
-# obtained from COMPANY. Access to the source code contained herein is
-# hereby forbidden to anyone except current COMPANY employees, managers
-# or contractors who have executed Confidentiality and Non-disclosure
-# agreements explicitly covering such access.
-#
-# The copyright notice above does not evidence any actual or intended
-# publication or disclosure of this source code, which includes
-# information that is confidential and/or proprietary, and is a trade
-# secret, of COMPANY. ANY REPRODUCTION, MODIFICATION, DISTRIBUTION,
-# PUBLIC PERFORMANCE, OR PUBLIC DISPLAY OF OR THROUGH USE OF THIS
-# SOURCE CODE WITHOUT THE EXPRESS WRITTEN CONSENT OF COMPANY IS
-# STRICTLY PROHIBITED, AND IN VIOLATION OF APPLICABLE LAWS AND
-# INTERNATIONAL TREATIES. THE RECEIPT OR POSSESSION OF THIS SOURCE
-# CODE AND/OR RELATED INFORMATION DOES NOT CONVEY OR IMPLY ANY RIGHTS
-# TO REPRODUCE, DISCLOSE OR DISTRIBUTE ITS CONTENTS, OR TO MANUFACTURE,
-# USE, OR SELL ANYTHING THAT IT MAY DESCRIBE, IN WHOLE OR IN PART.
-#
-# %COPYRIGHT_END%
-# ----------------------------------------------------------------------
-# %AUTHORS_BEGIN%
-#
-# Originating Authors: Paul-Edouard Sarlin
-# Daniel DeTone
-# Tomasz Malisiewicz
-#
-# %AUTHORS_END%
-# --------------------------------------------------------------------*/
-# %BANNER_END%
-
-from pathlib import Path
-import time
-from collections import OrderedDict
-from threading import Thread
-import numpy as np
-import cv2
-import torch
-import matplotlib.pyplot as plt
-import matplotlib
-matplotlib.use('Agg')
-
-
-class AverageTimer:
- """ Class to help manage printing simple timing of code execution. """
-
- def __init__(self, smoothing=0.3, newline=False):
- self.smoothing = smoothing
- self.newline = newline
- self.times = OrderedDict()
- self.will_print = OrderedDict()
- self.reset()
-
- def reset(self):
- now = time.time()
- self.start = now
- self.last_time = now
- for name in self.will_print:
- self.will_print[name] = False
-
- def update(self, name='default'):
- now = time.time()
- dt = now - self.last_time
- if name in self.times:
- dt = self.smoothing * dt + (1 - self.smoothing) * self.times[name]
- self.times[name] = dt
- self.will_print[name] = True
- self.last_time = now
-
- def print(self, text='Timer'):
- total = 0.
- print('[{}]'.format(text), end=' ')
- for key in self.times:
- val = self.times[key]
- if self.will_print[key]:
- print('%s=%.3f' % (key, val), end=' ')
- total += val
- print('total=%.3f sec {%.1f FPS}' % (total, 1./total), end=' ')
- if self.newline:
- print(flush=True)
- else:
- print(end='\r', flush=True)
- self.reset()
-
-
-class VideoStreamer:
- """ Class to help process image streams. Four types of possible inputs:"
- 1.) USB Webcam.
- 2.) An IP camera
- 3.) A directory of images (files in directory matching 'image_glob').
- 4.) A video file, such as an .mp4 or .avi file.
- """
- def __init__(self, basedir, resize, skip, image_glob, max_length=1000000):
- self._ip_grabbed = False
- self._ip_running = False
- self._ip_camera = False
- self._ip_image = None
- self._ip_index = 0
- self.cap = []
- self.camera = True
- self.video_file = False
- self.listing = []
- self.resize = resize
- self.interp = cv2.INTER_AREA
- self.i = 0
- self.skip = skip
- self.max_length = max_length
- if isinstance(basedir, int) or basedir.isdigit():
- print('==> Processing USB webcam input: {}'.format(basedir))
- self.cap = cv2.VideoCapture(int(basedir))
- self.listing = range(0, self.max_length)
- elif basedir.startswith(('http', 'rtsp')):
- print('==> Processing IP camera input: {}'.format(basedir))
- self.cap = cv2.VideoCapture(basedir)
- self.start_ip_camera_thread()
- self._ip_camera = True
- self.listing = range(0, self.max_length)
- elif Path(basedir).is_dir():
- print('==> Processing image directory input: {}'.format(basedir))
- self.listing = list(Path(basedir).glob(image_glob[0]))
- for j in range(1, len(image_glob)):
- image_path = list(Path(basedir).glob(image_glob[j]))
- self.listing = self.listing + image_path
- self.listing.sort()
- self.listing = self.listing[::self.skip]
- self.max_length = np.min([self.max_length, len(self.listing)])
- if self.max_length == 0:
- raise IOError('No images found (maybe bad \'image_glob\' ?)')
- self.listing = self.listing[:self.max_length]
- self.camera = False
- elif Path(basedir).exists():
- print('==> Processing video input: {}'.format(basedir))
- self.cap = cv2.VideoCapture(basedir)
- self.cap.set(cv2.CAP_PROP_BUFFERSIZE, 1)
- num_frames = int(self.cap.get(cv2.CAP_PROP_FRAME_COUNT))
- self.listing = range(0, num_frames)
- self.listing = self.listing[::self.skip]
- self.video_file = True
- self.max_length = np.min([self.max_length, len(self.listing)])
- self.listing = self.listing[:self.max_length]
- else:
- raise ValueError('VideoStreamer input \"{}\" not recognized.'.format(basedir))
- if self.camera and not self.cap.isOpened():
- raise IOError('Could not read camera')
-
- def load_image(self, impath):
- """ Read image as grayscale and resize to img_size.
- Inputs
- impath: Path to input image.
- Returns
- grayim: uint8 numpy array sized H x W.
- """
- grayim = cv2.imread(impath, 0)
- if grayim is None:
- raise Exception('Error reading image %s' % impath)
- w, h = grayim.shape[1], grayim.shape[0]
- w_new, h_new = process_resize(w, h, self.resize)
- grayim = cv2.resize(
- grayim, (w_new, h_new), interpolation=self.interp)
- return grayim
-
- def next_frame(self):
- """ Return the next frame, and increment internal counter.
- Returns
- image: Next H x W image.
- status: True or False depending whether image was loaded.
- """
-
- if self.i == self.max_length:
- return (None, False)
- if self.camera:
-
- if self._ip_camera:
- #Wait for first image, making sure we haven't exited
- while self._ip_grabbed is False and self._ip_exited is False:
- time.sleep(.001)
-
- ret, image = self._ip_grabbed, self._ip_image.copy()
- if ret is False:
- self._ip_running = False
- else:
- ret, image = self.cap.read()
- if ret is False:
- print('VideoStreamer: Cannot get image from camera')
- return (None, False)
- w, h = image.shape[1], image.shape[0]
- if self.video_file:
- self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.listing[self.i])
-
- w_new, h_new = process_resize(w, h, self.resize)
- image = cv2.resize(image, (w_new, h_new),
- interpolation=self.interp)
- image = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
- else:
- image_file = str(self.listing[self.i])
- image = self.load_image(image_file)
- self.i = self.i + 1
- return (image, True)
-
- def start_ip_camera_thread(self):
- self._ip_thread = Thread(target=self.update_ip_camera, args=())
- self._ip_running = True
- self._ip_thread.start()
- self._ip_exited = False
- return self
-
- def update_ip_camera(self):
- while self._ip_running:
- ret, img = self.cap.read()
- if ret is False:
- self._ip_running = False
- self._ip_exited = True
- self._ip_grabbed = False
- return
-
- self._ip_image = img
- self._ip_grabbed = ret
- self._ip_index += 1
- #print('IPCAMERA THREAD got frame {}'.format(self._ip_index))
-
-
- def cleanup(self):
- self._ip_running = False
-
-# --- PREPROCESSING ---
-
-def process_resize(w, h, resize):
- assert(len(resize) > 0 and len(resize) <= 2)
- if len(resize) == 1 and resize[0] > -1:
- scale = resize[0] / max(h, w)
- w_new, h_new = int(round(w*scale)), int(round(h*scale))
- elif len(resize) == 1 and resize[0] == -1:
- w_new, h_new = w, h
- else: # len(resize) == 2:
- w_new, h_new = resize[0], resize[1]
-
- # Issue warning if resolution is too small or too large.
- if max(w_new, h_new) < 160:
- print('Warning: input resolution is very small, results may vary')
- elif max(w_new, h_new) > 2000:
- print('Warning: input resolution is very large, results may vary')
-
- return w_new, h_new
-
-
-def frame2tensor(frame, device):
- return torch.from_numpy(frame/255.).float()[None, None].to(device)
-
-
-def read_image(path, device, resize, rotation, resize_float):
- image = cv2.imread(str(path), cv2.IMREAD_GRAYSCALE)
- if image is None:
- return None, None, None
- w, h = image.shape[1], image.shape[0]
- w_new, h_new = process_resize(w, h, resize)
- scales = (float(w) / float(w_new), float(h) / float(h_new))
-
- if resize_float:
- image = cv2.resize(image.astype('float32'), (w_new, h_new))
- else:
- image = cv2.resize(image, (w_new, h_new)).astype('float32')
-
- if rotation != 0:
- image = np.rot90(image, k=rotation)
- if rotation % 2:
- scales = scales[::-1]
-
- inp = frame2tensor(image, device)
- return image, inp, scales
-
-def process_image(image, device, resize, rotation, resize_float):
- image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
- if image is None:
- return None, None, None
- w, h = image.shape[1], image.shape[0]
- w_new, h_new = process_resize(w, h, resize)
- scales = (float(w) / float(w_new), float(h) / float(h_new))
-
- if resize_float:
- image = cv2.resize(image.astype('float32'), (w_new, h_new))
- else:
- image = cv2.resize(image, (w_new, h_new)).astype('float32')
-
- if rotation != 0:
- image = np.rot90(image, k=rotation)
- if rotation % 2:
- scales = scales[::-1]
-
- inp = frame2tensor(image, device)
- return image, inp, scales
-
-# --- GEOMETRY ---
-
-
-def estimate_pose(kpts0, kpts1, K0, K1, thresh, conf=0.99999):
- if len(kpts0) < 5:
- return None
-
- f_mean = np.mean([K0[0, 0], K1[1, 1], K0[0, 0], K1[1, 1]])
- norm_thresh = thresh / f_mean
-
- kpts0 = (kpts0 - K0[[0, 1], [2, 2]][None]) / K0[[0, 1], [0, 1]][None]
- kpts1 = (kpts1 - K1[[0, 1], [2, 2]][None]) / K1[[0, 1], [0, 1]][None]
-
- E, mask = cv2.findEssentialMat(
- kpts0, kpts1, np.eye(3), threshold=norm_thresh, prob=conf,
- method=cv2.RANSAC)
-
- assert E is not None
-
- best_num_inliers = 0
- ret = None
- for _E in np.split(E, len(E) / 3):
- n, R, t, _ = cv2.recoverPose(
- _E, kpts0, kpts1, np.eye(3), 1e9, mask=mask)
- if n > best_num_inliers:
- best_num_inliers = n
- ret = (R, t[:, 0], mask.ravel() > 0)
- return ret
-
-
-def rotate_intrinsics(K, image_shape, rot):
- """image_shape is the shape of the image after rotation"""
- assert rot <= 3
- h, w = image_shape[:2][::-1 if (rot % 2) else 1]
- fx, fy, cx, cy = K[0, 0], K[1, 1], K[0, 2], K[1, 2]
- rot = rot % 4
- if rot == 1:
- return np.array([[fy, 0., cy],
- [0., fx, w-1-cx],
- [0., 0., 1.]], dtype=K.dtype)
- elif rot == 2:
- return np.array([[fx, 0., w-1-cx],
- [0., fy, h-1-cy],
- [0., 0., 1.]], dtype=K.dtype)
- else: # if rot == 3:
- return np.array([[fy, 0., h-1-cy],
- [0., fx, cx],
- [0., 0., 1.]], dtype=K.dtype)
-
-
-def rotate_pose_inplane(i_T_w, rot):
- rotation_matrices = [
- np.array([[np.cos(r), -np.sin(r), 0., 0.],
- [np.sin(r), np.cos(r), 0., 0.],
- [0., 0., 1., 0.],
- [0., 0., 0., 1.]], dtype=np.float32)
- for r in [np.deg2rad(d) for d in (0, 270, 180, 90)]
- ]
- return np.dot(rotation_matrices[rot], i_T_w)
-
-
-def scale_intrinsics(K, scales):
- scales = np.diag([1./scales[0], 1./scales[1], 1.])
- return np.dot(scales, K)
-
-
-def to_homogeneous(points):
- return np.concatenate([points, np.ones_like(points[:, :1])], axis=-1)
-
-
-def compute_epipolar_error(kpts0, kpts1, T_0to1, K0, K1):
- kpts0 = (kpts0 - K0[[0, 1], [2, 2]][None]) / K0[[0, 1], [0, 1]][None]
- kpts1 = (kpts1 - K1[[0, 1], [2, 2]][None]) / K1[[0, 1], [0, 1]][None]
- kpts0 = to_homogeneous(kpts0)
- kpts1 = to_homogeneous(kpts1)
-
- t0, t1, t2 = T_0to1[:3, 3]
- t_skew = np.array([
- [0, -t2, t1],
- [t2, 0, -t0],
- [-t1, t0, 0]
- ])
- E = t_skew @ T_0to1[:3, :3]
-
- Ep0 = kpts0 @ E.T # N x 3
- p1Ep0 = np.sum(kpts1 * Ep0, -1) # N
- Etp1 = kpts1 @ E # N x 3
- d = p1Ep0**2 * (1.0 / (Ep0[:, 0]**2 + Ep0[:, 1]**2)
- + 1.0 / (Etp1[:, 0]**2 + Etp1[:, 1]**2))
- return d
-
-
-def angle_error_mat(R1, R2):
- cos = (np.trace(np.dot(R1.T, R2)) - 1) / 2
- cos = np.clip(cos, -1., 1.) # numercial errors can make it out of bounds
- return np.rad2deg(np.abs(np.arccos(cos)))
-
-
-def angle_error_vec(v1, v2):
- n = np.linalg.norm(v1) * np.linalg.norm(v2)
- return np.rad2deg(np.arccos(np.clip(np.dot(v1, v2) / n, -1.0, 1.0)))
-
-
-def compute_pose_error(T_0to1, R, t):
- R_gt = T_0to1[:3, :3]
- t_gt = T_0to1[:3, 3]
- error_t = angle_error_vec(t, t_gt)
- error_t = np.minimum(error_t, 180 - error_t) # ambiguity of E estimation
- error_R = angle_error_mat(R, R_gt)
- return error_t, error_R
-
-
-def pose_auc(errors, thresholds):
- sort_idx = np.argsort(errors)
- errors = np.array(errors.copy())[sort_idx]
- recall = (np.arange(len(errors)) + 1) / len(errors)
- errors = np.r_[0., errors]
- recall = np.r_[0., recall]
- aucs = []
- for t in thresholds:
- last_index = np.searchsorted(errors, t)
- r = np.r_[recall[:last_index], recall[last_index-1]]
- e = np.r_[errors[:last_index], t]
- aucs.append(np.trapz(r, x=e)/t)
- return aucs
-
-
-# --- VISUALIZATION ---
-
-
-def plot_image_pair(imgs, dpi=100, size=6, pad=.5):
- n = len(imgs)
- assert n == 2, 'number of images must be two'
- figsize = (size*n, size*3/4) if size is not None else None
- _, ax = plt.subplots(1, n, figsize=figsize, dpi=dpi)
- for i in range(n):
- ax[i].imshow(imgs[i], cmap=plt.get_cmap('gray'), vmin=0, vmax=255)
- ax[i].get_yaxis().set_ticks([])
- ax[i].get_xaxis().set_ticks([])
- for spine in ax[i].spines.values(): # remove frame
- spine.set_visible(False)
- plt.tight_layout(pad=pad)
-
-
-def plot_keypoints(kpts0, kpts1, color='w', ps=2):
- ax = plt.gcf().axes
- ax[0].scatter(kpts0[:, 0], kpts0[:, 1], c=color, s=ps)
- ax[1].scatter(kpts1[:, 0], kpts1[:, 1], c=color, s=ps)
-
-
-def plot_matches(kpts0, kpts1, color, lw=1.5, ps=4):
- fig = plt.gcf()
- ax = fig.axes
- fig.canvas.draw()
-
- transFigure = fig.transFigure.inverted()
- fkpts0 = transFigure.transform(ax[0].transData.transform(kpts0))
- fkpts1 = transFigure.transform(ax[1].transData.transform(kpts1))
-
- fig.lines = [matplotlib.lines.Line2D(
- (fkpts0[i, 0], fkpts1[i, 0]), (fkpts0[i, 1], fkpts1[i, 1]), zorder=1,
- transform=fig.transFigure, c=color[i], linewidth=lw)
- for i in range(len(kpts0))]
- ax[0].scatter(kpts0[:, 0], kpts0[:, 1], c=color, s=ps)
- ax[1].scatter(kpts1[:, 0], kpts1[:, 1], c=color, s=ps)
-
-
-def make_matching_plot(image0, image1, kpts0, kpts1, mkpts0, mkpts1,
- color, text, path, show_keypoints=False,
- fast_viz=False, opencv_display=False,
- opencv_title='matches', small_text=[]):
-
- if fast_viz:
- make_matching_plot_fast(image0, image1, kpts0, kpts1, mkpts0, mkpts1,
- color, text, path, show_keypoints, 10,
- opencv_display, opencv_title, small_text)
- return
-
- plot_image_pair([image0, image1])
- if show_keypoints:
- plot_keypoints(kpts0, kpts1, color='k', ps=4)
- plot_keypoints(kpts0, kpts1, color='w', ps=2)
- plot_matches(mkpts0, mkpts1, color)
-
- fig = plt.gcf()
- txt_color = 'k' if image0[:100, :150].mean() > 200 else 'w'
- fig.text(
- 0.01, 0.99, '\n'.join(text), transform=fig.axes[0].transAxes,
- fontsize=15, va='top', ha='left', color=txt_color)
-
- txt_color = 'k' if image0[-100:, :150].mean() > 200 else 'w'
- fig.text(
- 0.01, 0.01, '\n'.join(small_text), transform=fig.axes[0].transAxes,
- fontsize=5, va='bottom', ha='left', color=txt_color)
-
- plt.savefig(str(path), bbox_inches='tight', pad_inches=0)
- plt.close()
-
-
-def make_matching_plot_fast(image0, image1, kpts0, kpts1, mkpts0,
- mkpts1, color, text, path=None,
- show_keypoints=False, margin=10,
- opencv_display=False, opencv_title='',
- small_text=[]):
- H0, W0 = image0.shape
- H1, W1 = image1.shape
- H, W = max(H0, H1), W0 + W1 + margin
-
- out = 255*np.ones((H, W), np.uint8)
- out[:H0, :W0] = image0
- out[:H1, W0+margin:] = image1
- out = np.stack([out]*3, -1)
-
- if show_keypoints:
- kpts0, kpts1 = np.round(kpts0).astype(int), np.round(kpts1).astype(int)
- white = (255, 255, 255)
- black = (0, 0, 0)
- for x, y in kpts0:
- cv2.circle(out, (x, y), 2, black, -1, lineType=cv2.LINE_AA)
- cv2.circle(out, (x, y), 1, white, -1, lineType=cv2.LINE_AA)
- for x, y in kpts1:
- cv2.circle(out, (x + margin + W0, y), 2, black, -1,
- lineType=cv2.LINE_AA)
- cv2.circle(out, (x + margin + W0, y), 1, white, -1,
- lineType=cv2.LINE_AA)
-
- mkpts0, mkpts1 = np.round(mkpts0).astype(int), np.round(mkpts1).astype(int)
- color = (np.array(color[:, :3])*255).astype(int)[:, ::-1]
- for (x0, y0), (x1, y1), c in zip(mkpts0, mkpts1, color):
- c = c.tolist()
- cv2.line(out, (x0, y0), (x1 + margin + W0, y1),
- color=c, thickness=1, lineType=cv2.LINE_AA)
- # display line end-points as circles
- cv2.circle(out, (x0, y0), 2, c, -1, lineType=cv2.LINE_AA)
- cv2.circle(out, (x1 + margin + W0, y1), 2, c, -1,
- lineType=cv2.LINE_AA)
-
- # Scale factor for consistent visualization across scales.
- sc = min(H / 640., 2.0)
-
- # Big text.
- Ht = int(30 * sc) # text height
- txt_color_fg = (255, 255, 255)
- txt_color_bg = (0, 0, 0)
- for i, t in enumerate(text):
- cv2.putText(out, t, (int(8*sc), Ht*(i+1)), cv2.FONT_HERSHEY_DUPLEX,
- 1.0*sc, txt_color_bg, 2, cv2.LINE_AA)
- cv2.putText(out, t, (int(8*sc), Ht*(i+1)), cv2.FONT_HERSHEY_DUPLEX,
- 1.0*sc, txt_color_fg, 1, cv2.LINE_AA)
-
- # Small text.
- Ht = int(18 * sc) # text height
- for i, t in enumerate(reversed(small_text)):
- cv2.putText(out, t, (int(8*sc), int(H-Ht*(i+.6))), cv2.FONT_HERSHEY_DUPLEX,
- 0.5*sc, txt_color_bg, 2, cv2.LINE_AA)
- cv2.putText(out, t, (int(8*sc), int(H-Ht*(i+.6))), cv2.FONT_HERSHEY_DUPLEX,
- 0.5*sc, txt_color_fg, 1, cv2.LINE_AA)
- return out
-
-
-def error_colormap(x):
- return np.clip(
- np.stack([2-x*2, x*2, np.zeros_like(x), np.ones_like(x)], -1), 0, 1)
diff --git a/spaces/Jason1112/ML-GUI/readme.md b/spaces/Jason1112/ML-GUI/readme.md
deleted file mode 100644
index fafdf1e2a871a4f7b318dd0b81936fb2a9bdaf0b..0000000000000000000000000000000000000000
--- a/spaces/Jason1112/ML-GUI/readme.md
+++ /dev/null
@@ -1,10 +0,0 @@
----
-title: ML-GUI
-app_file: app.py
-sdk: gradio
-sdk_version: 3.35.2
----
-Hướng dẫn chạy:
-