= memo(
- ReactMarkdown,
- (prevProps, nextProps) =>
- prevProps.children === nextProps.children &&
- prevProps.className === nextProps.className
-)
diff --git a/spaces/Intel/NeuralChat-ICX-INT4/fastchat/data/inspect.py b/spaces/Intel/NeuralChat-ICX-INT4/fastchat/data/inspect.py
deleted file mode 100644
index c59e6238c3bbd18768e8fbe22272aaa278993303..0000000000000000000000000000000000000000
--- a/spaces/Intel/NeuralChat-ICX-INT4/fastchat/data/inspect.py
+++ /dev/null
@@ -1,33 +0,0 @@
-"""
-Usage:
-python3 -m fastchat.data.inspect --in sharegpt_20230322_clean_lang_split.json
-"""
-import argparse
-import json
-import random
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser.add_argument("--in-file", type=str, required=True)
- parser.add_argument("--begin", type=int)
- parser.add_argument("--random-n", type=int)
- args = parser.parse_args()
-
- content = json.load(open(args.in_file, "r"))
-
- if args.random_n:
- indices = [random.randint(0, len(content) - 1) for _ in range(args.random_n)]
- elif args.begin:
- indices = range(args.begin, len(content))
- else:
- indices = range(0, len(content))
-
- for idx in indices:
- sample = content[idx]
- print("=" * 40)
- print(f"no: {idx}, id: {sample['id']}")
- for conv in sample["conversations"]:
- print(conv["from"] + ": ")
- print(conv["value"])
- input()
diff --git a/spaces/JPMadsen/JP_Audio/app.py b/spaces/JPMadsen/JP_Audio/app.py
deleted file mode 100644
index 6b05ef304169a89dba5b3582547d6c6f238a9ba4..0000000000000000000000000000000000000000
--- a/spaces/JPMadsen/JP_Audio/app.py
+++ /dev/null
@@ -1,51 +0,0 @@
-import os
-import gradio as gr
-from scipy.io.wavfile import write, read
-import subprocess
-
-def inference(audio):
-
- os.makedirs("out", exist_ok=True)
- write('mix.wav', audio[0], audio[1])
-
- command = "python3 -m demucs -n mdx_extra_q -d cpu mix.wav -o out"
- process = subprocess.run(command,
- shell=True,
- stdin=subprocess.DEVNULL,
- stdout=subprocess.PIPE,
- stderr=subprocess.PIPE
- )
-
- # Check if files exist before returning
- files = ["./out/mdx_extra_q/mix/vocals.wav",
- "./out/mdx_extra_q/mix/bass.wav",
- "./out/mdx_extra_q/mix/drums.wav",
- "./out/mdx_extra_q/mix/other.wav"]
-
- for file in files:
- if not os.path.isfile(file):
- print(f"File not found: {file}")
- else:
- print(f"File exists: {file}")
-
- return files
-
-article = "Inspired by Demucs
\nCopyright © 2023 JP Madsen,
- React.ComponentPropsWithoutRef
->(({ className, ...props }, ref) => (
-
-
-
-
-
-
-))
-VerticalSlider.displayName = "VerticalSlider"
-export { VerticalSlider }
diff --git a/spaces/Jorgerv97/Herramienta_interactiva_ensenyanza_tecnicas_aprendizaje_supervisado_salud/README.md b/spaces/Jorgerv97/Herramienta_interactiva_ensenyanza_tecnicas_aprendizaje_supervisado_salud/README.md
deleted file mode 100644
index 3b46f8aa12790e7cab27703441b2eee8e2ead382..0000000000000000000000000000000000000000
--- a/spaces/Jorgerv97/Herramienta_interactiva_ensenyanza_tecnicas_aprendizaje_supervisado_salud/README.md
+++ /dev/null
@@ -1,19 +0,0 @@
----
-title: >-
- Herramienta interactiva para la enseñanza de técnicas de aprendizaje
- supervisado en salud
-emoji: 📊
-colorFrom: blue
-colorTo: gray
-sdk: docker
-pinned: false
-duplicated_from: posit/shiny-for-python-template
----
----
-title: Shiny for Python template
-emoji: 🌍
-colorFrom: yellow
-colorTo: indigo
-sdk: docker
-pinned: false
-license: mit
\ No newline at end of file
diff --git a/spaces/KPCGD/bingo/src/components/toaster.tsx b/spaces/KPCGD/bingo/src/components/toaster.tsx
deleted file mode 100644
index 4d2693460b61307a1d4c127fd01df9bee16e59ff..0000000000000000000000000000000000000000
--- a/spaces/KPCGD/bingo/src/components/toaster.tsx
+++ /dev/null
@@ -1,3 +0,0 @@
-'use client'
-
-export { Toaster } from 'react-hot-toast'
diff --git a/spaces/LeahLv/image-captioning-v4/README.md b/spaces/LeahLv/image-captioning-v4/README.md
deleted file mode 100644
index 66fd658341d8da4340c78f04999b3546c361830b..0000000000000000000000000000000000000000
--- a/spaces/LeahLv/image-captioning-v4/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: Image Captioning V4
-emoji: 🐠
-colorFrom: pink
-colorTo: blue
-sdk: streamlit
-sdk_version: 1.10.0
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/Lianjd/stock_dashboard/backtrader/__init__.py b/spaces/Lianjd/stock_dashboard/backtrader/__init__.py
deleted file mode 100644
index 13d95840d49cef70535b0ed839dc09afe8d10244..0000000000000000000000000000000000000000
--- a/spaces/Lianjd/stock_dashboard/backtrader/__init__.py
+++ /dev/null
@@ -1,90 +0,0 @@
-#!/usr/bin/env python
-# -*- coding: utf-8; py-indent-offset:4 -*-
-###############################################################################
-#
-# Copyright (C) 2015-2020 Daniel Rodriguez
-#
-# This program is free software: you can redistribute it and/or modify
-# it under the terms of the GNU General Public License as published by
-# the Free Software Foundation, either version 3 of the License, or
-# (at your option) any later version.
-#
-# This program is distributed in the hope that it will be useful,
-# but WITHOUT ANY WARRANTY; without even the implied warranty of
-# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
-# GNU General Public License for more details.
-#
-# You should have received a copy of the GNU General Public License
-# along with this program. If not, see .
-#
-###############################################################################
-from __future__ import (absolute_import, division, print_function,
- unicode_literals)
-
-from .version import __version__, __btversion__
-
-from .errors import *
-from . import errors as errors
-
-from .utils import num2date, date2num, time2num, num2time
-
-from .linebuffer import *
-from .functions import *
-
-from .order import *
-from .comminfo import *
-from .trade import *
-from .position import *
-
-from .store import Store
-
-from . import broker as broker
-from .broker import *
-
-from .lineseries import *
-
-from .dataseries import *
-from .feed import *
-from .resamplerfilter import *
-
-from .lineiterator import *
-from .indicator import *
-from .analyzer import *
-from .observer import *
-from .sizer import *
-from .sizers import SizerFix # old sizer for compatibility
-from .strategy import *
-
-from .writer import *
-
-from .signal import *
-
-from .cerebro import *
-from .timer import *
-from .flt import *
-
-from . import utils as utils
-
-from . import feeds as feeds
-from . import indicators as indicators
-from . import indicators as ind
-from . import studies as studies
-from . import strategies as strategies
-from . import strategies as strats
-from . import observers as observers
-from . import observers as obs
-from . import analyzers as analyzers
-from . import commissions as commissions
-from . import commissions as comms
-from . import filters as filters
-from . import signals as signals
-from . import sizers as sizers
-from . import stores as stores
-from . import brokers as brokers
-from . import timer as timer
-
-from . import talib as talib
-
-# Load contributed indicators and studies
-import backtrader.indicators.contrib
-import backtrader.studies.contrib
diff --git a/spaces/Lianjd/stock_dashboard/backtrader/indicators/ultimateoscillator.py b/spaces/Lianjd/stock_dashboard/backtrader/indicators/ultimateoscillator.py
deleted file mode 100644
index a1705c28000c526c01b3ce234aada97f85341ce5..0000000000000000000000000000000000000000
--- a/spaces/Lianjd/stock_dashboard/backtrader/indicators/ultimateoscillator.py
+++ /dev/null
@@ -1,81 +0,0 @@
-#!/usr/bin/env python
-# -*- coding: utf-8; py-indent-offset:4 -*-
-###############################################################################
-#
-# Copyright (C) 2015-2020 Daniel Rodriguez
-#
-# This program is free software: you can redistribute it and/or modify
-# it under the terms of the GNU General Public License as published by
-# the Free Software Foundation, either version 3 of the License, or
-# (at your option) any later version.
-#
-# This program is distributed in the hope that it will be useful,
-# but WITHOUT ANY WARRANTY; without even the implied warranty of
-# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
-# GNU General Public License for more details.
-#
-# You should have received a copy of the GNU General Public License
-# along with this program. If not, see .
-#
-###############################################################################
-from __future__ import (absolute_import, division, print_function,
- unicode_literals)
-
-
-import backtrader as bt
-from backtrader.indicators import SumN, TrueLow, TrueRange
-
-
-class UltimateOscillator(bt.Indicator):
- '''
- Formula:
- # Buying Pressure = Close - TrueLow
- BP = Close - Minimum(Low or Prior Close)
-
- # TrueRange = TrueHigh - TrueLow
- TR = Maximum(High or Prior Close) - Minimum(Low or Prior Close)
-
- Average7 = (7-period BP Sum) / (7-period TR Sum)
- Average14 = (14-period BP Sum) / (14-period TR Sum)
- Average28 = (28-period BP Sum) / (28-period TR Sum)
-
- UO = 100 x [(4 x Average7)+(2 x Average14)+Average28]/(4+2+1)
-
- See:
-
- - https://en.wikipedia.org/wiki/Ultimate_oscillator
- - http://stockcharts.com/school/doku.php?id=chart_school:technical_indicators:ultimate_oscillator
- '''
- lines = ('uo',)
-
- params = (
- ('p1', 7),
- ('p2', 14),
- ('p3', 28),
- ('upperband', 70.0),
- ('lowerband', 30.0),
- )
-
- def _plotinit(self):
- baseticks = [10.0, 50.0, 90.0]
- hlines = [self.p.upperband, self.p.lowerband]
-
- # Plot lines at 0 & 100 to make the scale complete + upper/lower/bands
- self.plotinfo.plotyhlines = hlines
- # Plot ticks at "baseticks" + the user specified upper/lower bands
- self.plotinfo.plotyticks = baseticks + hlines
-
- def __init__(self):
- bp = self.data.close - TrueLow(self.data)
- tr = TrueRange(self.data)
-
- av7 = SumN(bp, period=self.p.p1) / SumN(tr, period=self.p.p1)
- av14 = SumN(bp, period=self.p.p2) / SumN(tr, period=self.p.p2)
- av28 = SumN(bp, period=self.p.p3) / SumN(tr, period=self.p.p3)
-
- # Multiply/divide floats outside of formula to reduce line objects
- factor = 100.0 / (4.0 + 2.0 + 1.0)
- uo = (4.0 * factor) * av7 + (2.0 * factor) * av14 + factor * av28
- self.lines.uo = uo
-
- super(UltimateOscillator, self).__init__()
diff --git a/spaces/Lianjd/stock_dashboard/backtrader/writer.py b/spaces/Lianjd/stock_dashboard/backtrader/writer.py
deleted file mode 100644
index 1f765d464ce507fa8da2a409c36ff492e28d128c..0000000000000000000000000000000000000000
--- a/spaces/Lianjd/stock_dashboard/backtrader/writer.py
+++ /dev/null
@@ -1,229 +0,0 @@
-#!/usr/bin/env python
-# -*- coding: utf-8; py-indent-offset:4 -*-
-###############################################################################
-#
-# Copyright (C) 2015-2020 Daniel Rodriguez
-#
-# This program is free software: you can redistribute it and/or modify
-# it under the terms of the GNU General Public License as published by
-# the Free Software Foundation, either version 3 of the License, or
-# (at your option) any later version.
-#
-# This program is distributed in the hope that it will be useful,
-# but WITHOUT ANY WARRANTY; without even the implied warranty of
-# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
-# GNU General Public License for more details.
-#
-# You should have received a copy of the GNU General Public License
-# along with this program. If not, see .
-#
-###############################################################################
-from __future__ import (absolute_import, division, print_function,
- unicode_literals)
-
-import collections
-import io
-import itertools
-import sys
-
-import backtrader as bt
-from backtrader.utils.py3 import (map, with_metaclass, string_types,
- integer_types)
-
-
-class WriterBase(with_metaclass(bt.MetaParams, object)):
- pass
-
-
-class WriterFile(WriterBase):
- '''The system wide writer class.
-
- It can be parametrized with:
-
- - ``out`` (default: ``sys.stdout``): output stream to write to
-
- If a string is passed a filename with the content of the parameter will
- be used.
-
- If you wish to run with ``sys.stdout`` while doing multiprocess optimization, leave it as ``None``, which will
- automatically initiate ``sys.stdout`` on the child processes.
-
- - ``close_out`` (default: ``False``)
-
- If ``out`` is a stream whether it has to be explicitly closed by the
- writer
-
- - ``csv`` (default: ``False``)
-
- If a csv stream of the data feeds, strategies, observers and indicators
- has to be written to the stream during execution
-
- Which objects actually go into the csv stream can be controlled with
- the ``csv`` attribute of each object (defaults to ``True`` for ``data
- feeds`` and ``observers`` / False for ``indicators``)
-
- - ``csv_filternan`` (default: ``True``) whether ``nan`` values have to be
- purged out of the csv stream (replaced by an empty field)
-
- - ``csv_counter`` (default: ``True``) if the writer shall keep and print
- out a counter of the lines actually output
-
- - ``indent`` (default: ``2``) indentation spaces for each level
-
- - ``separators`` (default: ``['=', '-', '+', '*', '.', '~', '"', '^',
- '#']``)
-
- Characters used for line separators across section/sub(sub)sections
-
- - ``seplen`` (default: ``79``)
-
- total length of a line separator including indentation
-
- - ``rounding`` (default: ``None``)
-
- Number of decimal places to round floats down to. With ``None`` no
- rounding is performed
-
- '''
- params = (
- ('out', None),
- ('close_out', False),
-
- ('csv', False),
- ('csvsep', ','),
- ('csv_filternan', True),
- ('csv_counter', True),
-
- ('indent', 2),
- ('separators', ['=', '-', '+', '*', '.', '~', '"', '^', '#']),
- ('seplen', 79),
- ('rounding', None),
- )
-
- def __init__(self):
- self._len = itertools.count(1)
- self.headers = list()
- self.values = list()
-
- def _start_output(self):
- # open file if needed
- if not hasattr(self, 'out') or not self.out:
- if self.p.out is None:
- self.out = sys.stdout
- self.close_out = False
- elif isinstance(self.p.out, string_types):
- self.out = open(self.p.out, 'w')
- self.close_out = True
- else:
- self.out = self.p.out
- self.close_out = self.p.close_out
-
- def start(self):
- self._start_output()
-
- if self.p.csv:
- self.writelineseparator()
- self.writeiterable(self.headers, counter='Id')
-
- def stop(self):
- if self.close_out:
- self.out.close()
-
- def next(self):
- if self.p.csv:
- self.writeiterable(self.values, func=str, counter=next(self._len))
- self.values = list()
-
- def addheaders(self, headers):
- if self.p.csv:
- self.headers.extend(headers)
-
- def addvalues(self, values):
- if self.p.csv:
- if self.p.csv_filternan:
- values = map(lambda x: x if x == x else '', values)
- self.values.extend(values)
-
- def writeiterable(self, iterable, func=None, counter=''):
- if self.p.csv_counter:
- iterable = itertools.chain([counter], iterable)
-
- if func is not None:
- iterable = map(lambda x: func(x), iterable)
-
- line = self.p.csvsep.join(iterable)
- self.writeline(line)
-
- def writeline(self, line):
- self.out.write(line + '\n')
-
- def writelines(self, lines):
- for l in lines:
- self.out.write(l + '\n')
-
- def writelineseparator(self, level=0):
- sepnum = level % len(self.p.separators)
- separator = self.p.separators[sepnum]
-
- line = ' ' * (level * self.p.indent)
- line += separator * (self.p.seplen - (level * self.p.indent))
- self.writeline(line)
-
- def writedict(self, dct, level=0, recurse=False):
- if not recurse:
- self.writelineseparator(level)
-
- indent0 = level * self.p.indent
- for key, val in dct.items():
- kline = ' ' * indent0
- if recurse:
- kline += '- '
-
- kline += str(key) + ':'
-
- try:
- sclass = issubclass(val, bt.LineSeries)
- except TypeError:
- sclass = False
-
- if sclass:
- kline += ' ' + val.__name__
- self.writeline(kline)
- elif isinstance(val, string_types):
- kline += ' ' + val
- self.writeline(kline)
- elif isinstance(val, integer_types):
- kline += ' ' + str(val)
- self.writeline(kline)
- elif isinstance(val, float):
- if self.p.rounding is not None:
- val = round(val, self.p.rounding)
- kline += ' ' + str(val)
- self.writeline(kline)
- elif isinstance(val, dict):
- if recurse:
- self.writelineseparator(level=level)
- self.writeline(kline)
- self.writedict(val, level=level + 1, recurse=True)
- elif isinstance(val, (list, tuple, collections.Iterable)):
- line = ', '.join(map(str, val))
- self.writeline(kline + ' ' + line)
- else:
- kline += ' ' + str(val)
- self.writeline(kline)
-
-
-class WriterStringIO(WriterFile):
- params = (('out', io.StringIO),)
-
- def __init__(self):
- super(WriterStringIO, self).__init__()
-
- def _start_output(self):
- super(WriterStringIO, self)._start_output()
- self.out = self.out()
-
- def stop(self):
- super(WriterStringIO, self).stop()
- # Leave the file positioned at the beginning
- self.out.seek(0)
diff --git a/spaces/LightChen2333/OpenSLU/model/encoder/__init__.py b/spaces/LightChen2333/OpenSLU/model/encoder/__init__.py
deleted file mode 100644
index 0f9039cc79440b3995ebbe5e670a32426ee8765d..0000000000000000000000000000000000000000
--- a/spaces/LightChen2333/OpenSLU/model/encoder/__init__.py
+++ /dev/null
@@ -1,5 +0,0 @@
-from model.encoder.pretrained_encoder import PretrainedEncoder
-from model.encoder.non_pretrained_encoder import NonPretrainedEncoder
-from model.encoder.base_encoder import BiEncoder
-from model.encoder.auto_encoder import AutoEncoder
-__all__ = ["PretrainedEncoder", "NonPretrainedEncoder", "AutoEncoder","BiEncoder"]
\ No newline at end of file
diff --git a/spaces/LittleYuan/My-Real-Bot/scripts/generate_meta_info.py b/spaces/LittleYuan/My-Real-Bot/scripts/generate_meta_info.py
deleted file mode 100644
index 9c3b7a37e85f534075c50e6c33d7cca999d8b836..0000000000000000000000000000000000000000
--- a/spaces/LittleYuan/My-Real-Bot/scripts/generate_meta_info.py
+++ /dev/null
@@ -1,58 +0,0 @@
-import argparse
-import cv2
-import glob
-import os
-
-
-def main(args):
- txt_file = open(args.meta_info, 'w')
- for folder, root in zip(args.input, args.root):
- img_paths = sorted(glob.glob(os.path.join(folder, '*')))
- for img_path in img_paths:
- status = True
- if args.check:
- # read the image once for check, as some images may have errors
- try:
- img = cv2.imread(img_path)
- except (IOError, OSError) as error:
- print(f'Read {img_path} error: {error}')
- status = False
- if img is None:
- status = False
- print(f'Img is None: {img_path}')
- if status:
- # get the relative path
- img_name = os.path.relpath(img_path, root)
- print(img_name)
- txt_file.write(f'{img_name}\n')
-
-
-if __name__ == '__main__':
- """Generate meta info (txt file) for only Ground-Truth images.
-
- It can also generate meta info from several folders into one txt file.
- """
- parser = argparse.ArgumentParser()
- parser.add_argument(
- '--input',
- nargs='+',
- default=['datasets/DF2K/DF2K_HR', 'datasets/DF2K/DF2K_multiscale'],
- help='Input folder, can be a list')
- parser.add_argument(
- '--root',
- nargs='+',
- default=['datasets/DF2K', 'datasets/DF2K'],
- help='Folder root, should have the length as input folders')
- parser.add_argument(
- '--meta_info',
- type=str,
- default='datasets/DF2K/meta_info/meta_info_DF2Kmultiscale.txt',
- help='txt path for meta info')
- parser.add_argument('--check', action='store_true', help='Read image to check whether it is ok')
- args = parser.parse_args()
-
- assert len(args.input) == len(args.root), ('Input folder and folder root should have the same length, but got '
- f'{len(args.input)} and {len(args.root)}.')
- os.makedirs(os.path.dirname(args.meta_info), exist_ok=True)
-
- main(args)
diff --git a/spaces/Lycorisdeve/White-box-Cartoonization/app.py b/spaces/Lycorisdeve/White-box-Cartoonization/app.py
deleted file mode 100644
index c55ced56bd87a85f59d1c8ef84b7eca87422720f..0000000000000000000000000000000000000000
--- a/spaces/Lycorisdeve/White-box-Cartoonization/app.py
+++ /dev/null
@@ -1,108 +0,0 @@
-#!/usr/bin/env python
-
-from __future__ import annotations
-import argparse
-import functools
-import os
-import pathlib
-import sys
-from typing import Callable
-import uuid
-
-import gradio as gr
-import huggingface_hub
-import numpy as np
-import PIL.Image
-
-from io import BytesIO
-from wbc.cartoonize import Cartoonize
-
-ORIGINAL_REPO_URL = 'https://github.com/SystemErrorWang/White-box-Cartoonization'
-TITLE = 'SystemErrorWang/White-box-Cartoonization'
-DESCRIPTION = f"""This is a demo for {ORIGINAL_REPO_URL}.
-
-"""
-ARTICLE = """
-
-"""
-
-SAFEHASH = [x for x in "0123456789-abcdefghijklmnopqrstuvwxyz_ABCDEFGHIJKLMNOPQRSTUVWXYZ"]
-def compress_UUID():
- '''
- 根据http://www.ietf.org/rfc/rfc1738.txt,由uuid编码扩bai大字符域生成du串
- 包括:[0-9a-zA-Z\-_]共64个
- 长度:(32-2)/3*2=20
- 备注:可在地球上人zhi人都用,使用100年不重复(2^120)
- :return:String
- '''
- row = str(uuid.uuid4()).replace('-', '')
- safe_code = ''
- for i in range(10):
- enbin = "%012d" % int(bin(int(row[i * 3] + row[i * 3 + 1] + row[i * 3 + 2], 16))[2:], 10)
- safe_code += (SAFEHASH[int(enbin[0:6], 2)] + SAFEHASH[int(enbin[6:12], 2)])
- safe_code = safe_code.replace('-', '')
- return safe_code
-
-
-def parse_args() -> argparse.Namespace:
- parser = argparse.ArgumentParser()
- parser.add_argument('--device', type=str, default='cpu')
- parser.add_argument('--theme', type=str)
- parser.add_argument('--live', action='store_true')
- parser.add_argument('--share', action='store_true')
- parser.add_argument('--port', type=int)
- parser.add_argument('--disable-queue',
- dest='enable_queue',
- action='store_false')
- parser.add_argument('--allow-flagging', type=str, default='never')
- parser.add_argument('--allow-screenshot', action='store_true')
- return parser.parse_args()
-
-def run(
- image,
- cartoonize : Cartoonize
-) -> tuple[PIL.Image.Image]:
-
- out_path = compress_UUID()+'.png'
- cartoonize.run_sigle(image.name, out_path)
-
- return PIL.Image.open(out_path)
-
-
-def main():
- gr.close_all()
-
- args = parse_args()
-
- cartoonize = Cartoonize(os.path.join(os.path.dirname(os.path.abspath(__file__)),'wbc/saved_models/'))
-
- func = functools.partial(run, cartoonize=cartoonize)
- func = functools.update_wrapper(func, run)
-
- gr.Interface(
- func,
- [
- gr.inputs.Image(type='file', label='Input Image'),
- ],
- [
- gr.outputs.Image(
- type='pil',
- label='Result'),
- ],
- # examples=examples,
- theme=args.theme,
- title=TITLE,
- description=DESCRIPTION,
- article=ARTICLE,
- allow_screenshot=args.allow_screenshot,
- allow_flagging=args.allow_flagging,
- live=args.live,
- ).launch(
- enable_queue=args.enable_queue,
- server_port=args.port,
- share=args.share,
- )
-
-
-if __name__ == '__main__':
- main()
diff --git a/spaces/MLVKU/Human_Object_Interaction/visualization.py b/spaces/MLVKU/Human_Object_Interaction/visualization.py
deleted file mode 100644
index a5c2ccf0f95f4ec68f549adf8e8d31fb125f2f63..0000000000000000000000000000000000000000
--- a/spaces/MLVKU/Human_Object_Interaction/visualization.py
+++ /dev/null
@@ -1,267 +0,0 @@
-import argparse
-import datetime
-import json
-import random
-import time
-import multiprocessing
-from pathlib import Path
-import os
-import cv2
-import numpy as np
-import torch
-from torch.utils.data import DataLoader, DistributedSampler
-import hotr.data.datasets as datasets
-import hotr.util.misc as utils
-from hotr.engine.arg_parser import get_args_parser
-from hotr.data.datasets import build_dataset, get_coco_api_from_dataset
-from hotr.data.datasets.vcoco import make_hoi_transforms
-from PIL import Image
-from hotr.util.logger import print_params, print_args
-
-import copy
-from hotr.data.datasets import builtin_meta
-from PIL import Image
-import requests
-# import mmcv
-from matplotlib import pyplot as plt
-import imageio
-
-from tools.vis_tool import *
-from hotr.models.detr import build
-
-def change_format(results,valid_ids):
-
- boxes,labels,pair_score =\
- list(map(lambda x: x.cpu().numpy(), [results['boxes'], results['labels'], results['pair_score']]))
- output_i={}
- output_i['predictions']=[]
- output_i['hoi_prediction']=[]
-
- h_idx=np.where(labels==1)[0]
- for box,label in zip(boxes,labels):
-
- output_i['predictions'].append({'bbox':box.tolist(),'category_id':label})
-
- for i,verb in enumerate(pair_score):
- if i in [1,4,10,23,26,5,18]:
- continue
- for j,hum in enumerate(h_idx):
- for k in range(len(boxes)):
- if verb[j][k]>0:
- output_i['hoi_prediction'].append({'subject_id':hum,'object_id':k,'category_id':i+2,'score':verb[j][k]})
-
- return output_i
-def vis(args,input_img=None,id=294,return_img=False):
-
- if args.frozen_weights is not None:
- print("Freeze weights for detector")
- if not torch.cuda.is_available():
- args.device = 'cpu'
- device = torch.device(args.device)
-
- # fix the seed for reproducibility
- seed = args.seed + utils.get_rank()
- torch.manual_seed(seed)
- np.random.seed(seed)
- random.seed(seed)
-
- # Data Setup
- dataset_train = build_dataset(image_set='train', args=args)
- args.num_classes = dataset_train.num_category()
- args.num_actions = dataset_train.num_action()
- args.action_names = dataset_train.get_actions()
- if args.share_enc: args.hoi_enc_layers = args.enc_layers
- if args.pretrained_dec: args.hoi_dec_layers = args.dec_layers
- if args.dataset_file == 'vcoco':
- # Save V-COCO dataset statistics
- args.valid_ids = np.array(dataset_train.get_object_label_idx()).nonzero()[0]
- args.invalid_ids = np.argwhere(np.array(dataset_train.get_object_label_idx()) == 0).squeeze(1)
- args.human_actions = dataset_train.get_human_action()
- args.object_actions = dataset_train.get_object_action()
- args.num_human_act = dataset_train.num_human_act()
- elif args.dataset_file == 'hico-det':
- args.valid_obj_ids = dataset_train.get_valid_obj_ids()
- print_args(args)
-
- args.HOIDet=True
- args.eval=True
- args.pretrained_dec=True
- args.share_enc=True
- args.share_dec_param = True
- if args.dataset_file=='hico-det':
- args.valid_ids=args.valid_obj_ids
-
- # Model Setup
- model, criterion, postprocessors = build(args)
- model.to(device)
-
- model_without_ddp = model
-
- n_parameters = print_params(model)
-
- param_dicts = [
- {"params": [p for n, p in model_without_ddp.named_parameters() if "backbone" not in n and p.requires_grad]},
- {
- "params": [p for n, p in model_without_ddp.named_parameters() if "backbone" in n and p.requires_grad],
- "lr": args.lr_backbone,
- },
- ]
-
- output_dir = Path(args.output_dir)
-
- checkpoint = torch.load(args.resume, map_location='cpu')
- #수정
- module_name=list(checkpoint['model'].keys())
- model_without_ddp.load_state_dict(checkpoint['model'], strict=False)
-
- # if not args.video_vis:
- # url='http://images.cocodataset.org/val2014/COCO_val2014_{}.jpg'.format(str(id).zfill(12))
- # req = requests.get(url, stream=True, timeout=1, verify=False).raw
-
- if input_img is None:
- req = args.image_dir
- img = Image.open(req).convert('RGB')
- else:
- # import pdb;pdb.set_trace()
- img = input_img
-
- w,h=img.size
- orig_size = torch.as_tensor([int(h), int(w)]).unsqueeze(0).to(device)
-
- transform=make_hoi_transforms('val')
- sample=img.copy()
- sample,_=transform(sample,None)
- sample = sample.unsqueeze(0).to(device)
- with torch.no_grad():
- model.eval()
- out=model(sample)
- results = postprocessors['hoi'](out, orig_size,dataset=args.dataset_file,args=args)
- output_i=change_format(results[0],args.valid_ids)
-
- out_dir = './vis'
- image = np.asarray(img, dtype=np.uint8)[:,:,::-1]
- # image = cv2.imdecode(image_nparray, cv2.IMREAD_COLOR)
-
- vis_img=draw_img_vcoco(image,output_i,top_k=args.topk,threshold=args.threshold,color=builtin_meta.COCO_CATEGORIES)
- plt.imshow(cv2.cvtColor(vis_img,cv2.COLOR_BGR2RGB))
-
- if return_img:
- vis_img = Image.fromarray(vis_img[:,:,::-1])
- # import pdb;pdb.set_trace()
- return vis_img
- else:
- cv2.imwrite('./vis_res/vis1.jpg',vis_img)
-
- # else:
- # frames=[]
- # video_file=id
-
- # video_reader = mmcv.VideoReader('./vid/'+video_file+'.mp4')
- # fourcc = cv2.VideoWriter_fourcc(*'mp4v')
- # video_writer = cv2.VideoWriter(
- # './vid/'+video_file+'_vis.mp4', fourcc, video_reader.fps,
- # (video_reader.width, video_reader.height))
-
- # orig_size = torch.as_tensor([int(video_reader.height), int(video_reader.width)]).unsqueeze(0).to(device)
- # transform=make_hoi_transforms('val')
-
- # for frame in mmcv.track_iter_progress(video_reader):
-
- # frame=mmcv.imread(frame)
- # frame=frame.copy()
-
- # frame=Image.fromarray(frame,'RGB')
-
- # sample,_=transform(frame,None)
- # sample=sample.unsqueeze(0).to(device)
-
- # with torch.no_grad():
- # model.eval()
- # out=model(sample)
- # results = postprocessors['hoi'](out, orig_size,dataset='vcoco',args=args)
- # output_i=change_format(results[0],args.valid_ids)
-
- # vis_img=draw_img_vcoco(np.array(frame),output_i,top_k=args.topk,threshold=args.threshold,color=builtin_meta.COCO_CATEGORIES)
- # frames.append(vis_img)
- # video_writer.write(vis_img)
-
- # with imageio.get_writer("smiling.gif", mode="I") as writer:
- # for idx, frame in enumerate(frames):
- # # print("Adding frame to GIF file: ", idx + 1)
- # writer.append_data(frame)
- # if video_writer:
- # video_writer.release()
- # cv2.destroyAllWindows()
-
-
-# def visualization(id, video_vis=False, dataset_file='vcoco', path_id = 0 ,data_path='v-coco', threshold=0.4, topk=10,aug_path = '[]'):
-
-# parser = argparse.ArgumentParser('DETR training and evaluation script', parents=[get_args_parser()])
-# checkpoint_dir= './checkpoints/vcoco/checkpoint.pth' if dataset_file=='vcoco' else './checkpoints/hico-det/hico_ft_q16.pth'
-# with open('./v-coco/data/vcoco_test.ids') as file:
-# test_idxs = [line.rstrip('\n') for line in file]
-# if not video_vis:
-# id = test_idxs[id]
-# args = parser.parse_args(args=['--dataset_file',dataset_file,'--data_path',data_path,'--resume',checkpoint_dir,'--num_hoi_queries' ,'16','--temperature' ,'0.05', '--augpath_name',aug_path ,'--path_id','{}'.format(path_id)])
-# args.video_vis=video_vis
-# args.threshold=threshold
-# args.topk=topk
-
-# if args.output_dir:
-# Path(args.output_dir).mkdir(parents=True, exist_ok=True)
-# vis(args,id)
-
-# 230727 for huggingface
-def visualization(input_img,threshold,topk):
-
- parser = argparse.ArgumentParser('DETR training and evaluation script', parents=[get_args_parser()])
- args = parser.parse_args(args=[])
- args.threshold = threshold
- args.topk = int(topk)
-
- # checkpoint_dir= './checkpoints/vcoco/checkpoint.pth' if dataset_file=='vcoco' else './checkpoints/hico-det/hico_ft_q16.pth'
- args.resume= './checkpoints/vcoco/checkpoint.pth'
- # with open('./v-coco/data/splits/vcoco_test.ids') as file:
- # test_idxs = [line.rstrip('\n') for line in file]
- # # if not video_vis:
- # id = test_idxs[309]
- # args = parser.parse_args()
- args.dataset_file = 'vcoco'
- args.data_path = 'v-coco'
- # args.resume = checkpoint_dir
- args.num_hoi_queries = 16
- args.temperature = 0.05
- args.augpath_name = ['p2','p3','p4']
- # args.path_id = 1
- # args.threshold = threshold
- # args.topk = topk
- if args.output_dir:
- Path(args.output_dir).mkdir(parents=True, exist_ok=True)
- return vis(args,input_img=input_img,return_img=True)
-
-if __name__ == '__main__':
- parser = argparse.ArgumentParser('DETR training and evaluation script', parents=[get_args_parser()])
- parser.add_argument('--threshold',help='score threshold for visualization', default=0.4, type=float)
- # parser.add_argument('--path_id',help='index of inference path', default=1, type=int)
- parser.add_argument('--topk',help='topk prediction', default=5, type=int)
- parser.add_argument('--video_vis', action='store_true')
- parser.add_argument('--image_dir', default='', type=str)
- args = parser.parse_args()
- # checkpoint_dir= './checkpoints/vcoco/checkpoint.pth' if dataset_file=='vcoco' else './checkpoints/hico-det/hico_ft_q16.pth'
- args.resume= './checkpoints/vcoco/checkpoint.pth'
- with open('./v-coco/data/splits/vcoco_test.ids') as file:
- test_idxs = [line.rstrip('\n') for line in file]
- # if not video_vis:
- id = test_idxs[309]
- # args = parser.parse_args()
- # args.dataset_file = 'vcoco'
- # args.data_path = 'v-coco'
- # args.resume = checkpoint_dir
- # args.num_hoi_queries = 16
- # args.temperature = 0.05
- args.augpath_name = ['p2','p3','p4']
- # args.path_id = 1
-
- if args.output_dir:
- Path(args.output_dir).mkdir(parents=True, exist_ok=True)
- vis(args,id)
diff --git a/spaces/Make-A-Protagonist/Make-A-Protagonist-inference/Make-A-Protagonist/experts/GroundedSAM/GroundingDINO/groundingdino/models/GroundingDINO/backbone/swin_transformer.py b/spaces/Make-A-Protagonist/Make-A-Protagonist-inference/Make-A-Protagonist/experts/GroundedSAM/GroundingDINO/groundingdino/models/GroundingDINO/backbone/swin_transformer.py
deleted file mode 100644
index 1c66194deb5dd370e797e57e2712f44303e568cc..0000000000000000000000000000000000000000
--- a/spaces/Make-A-Protagonist/Make-A-Protagonist-inference/Make-A-Protagonist/experts/GroundedSAM/GroundingDINO/groundingdino/models/GroundingDINO/backbone/swin_transformer.py
+++ /dev/null
@@ -1,802 +0,0 @@
-# ------------------------------------------------------------------------
-# Grounding DINO
-# url: https://github.com/IDEA-Research/GroundingDINO
-# Copyright (c) 2023 IDEA. All Rights Reserved.
-# Licensed under the Apache License, Version 2.0 [see LICENSE for details]
-# ------------------------------------------------------------------------
-# DINO
-# Copyright (c) 2022 IDEA. All Rights Reserved.
-# Licensed under the Apache License, Version 2.0 [see LICENSE for details]
-# --------------------------------------------------------
-# modified from https://github.com/SwinTransformer/Swin-Transformer-Object-Detection/blob/master/mmdet/models/backbones/swin_transformer.py
-# --------------------------------------------------------
-
-import numpy as np
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-import torch.utils.checkpoint as checkpoint
-from timm.models.layers import DropPath, to_2tuple, trunc_normal_
-
-from groundingdino.util.misc import NestedTensor
-
-
-class Mlp(nn.Module):
- """Multilayer perceptron."""
-
- def __init__(
- self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.0
- ):
- super().__init__()
- out_features = out_features or in_features
- hidden_features = hidden_features or in_features
- self.fc1 = nn.Linear(in_features, hidden_features)
- self.act = act_layer()
- self.fc2 = nn.Linear(hidden_features, out_features)
- self.drop = nn.Dropout(drop)
-
- def forward(self, x):
- x = self.fc1(x)
- x = self.act(x)
- x = self.drop(x)
- x = self.fc2(x)
- x = self.drop(x)
- return x
-
-
-def window_partition(x, window_size):
- """
- Args:
- x: (B, H, W, C)
- window_size (int): window size
- Returns:
- windows: (num_windows*B, window_size, window_size, C)
- """
- B, H, W, C = x.shape
- x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
- windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
- return windows
-
-
-def window_reverse(windows, window_size, H, W):
- """
- Args:
- windows: (num_windows*B, window_size, window_size, C)
- window_size (int): Window size
- H (int): Height of image
- W (int): Width of image
- Returns:
- x: (B, H, W, C)
- """
- B = int(windows.shape[0] / (H * W / window_size / window_size))
- x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
- x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
- return x
-
-
-class WindowAttention(nn.Module):
- """Window based multi-head self attention (W-MSA) module with relative position bias.
- It supports both of shifted and non-shifted window.
- Args:
- dim (int): Number of input channels.
- window_size (tuple[int]): The height and width of the window.
- num_heads (int): Number of attention heads.
- qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
- qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
- attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
- proj_drop (float, optional): Dropout ratio of output. Default: 0.0
- """
-
- def __init__(
- self,
- dim,
- window_size,
- num_heads,
- qkv_bias=True,
- qk_scale=None,
- attn_drop=0.0,
- proj_drop=0.0,
- ):
-
- super().__init__()
- self.dim = dim
- self.window_size = window_size # Wh, Ww
- self.num_heads = num_heads
- head_dim = dim // num_heads
- self.scale = qk_scale or head_dim**-0.5
-
- # define a parameter table of relative position bias
- self.relative_position_bias_table = nn.Parameter(
- torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)
- ) # 2*Wh-1 * 2*Ww-1, nH
-
- # get pair-wise relative position index for each token inside the window
- coords_h = torch.arange(self.window_size[0])
- coords_w = torch.arange(self.window_size[1])
- coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
- coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
- relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
- relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
- relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
- relative_coords[:, :, 1] += self.window_size[1] - 1
- relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
- relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
- self.register_buffer("relative_position_index", relative_position_index)
-
- self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
- self.attn_drop = nn.Dropout(attn_drop)
- self.proj = nn.Linear(dim, dim)
- self.proj_drop = nn.Dropout(proj_drop)
-
- trunc_normal_(self.relative_position_bias_table, std=0.02)
- self.softmax = nn.Softmax(dim=-1)
-
- def forward(self, x, mask=None):
- """Forward function.
- Args:
- x: input features with shape of (num_windows*B, N, C)
- mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
- """
- B_, N, C = x.shape
- qkv = (
- self.qkv(x)
- .reshape(B_, N, 3, self.num_heads, C // self.num_heads)
- .permute(2, 0, 3, 1, 4)
- )
- q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
-
- q = q * self.scale
- attn = q @ k.transpose(-2, -1)
-
- relative_position_bias = self.relative_position_bias_table[
- self.relative_position_index.view(-1)
- ].view(
- self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1
- ) # Wh*Ww,Wh*Ww,nH
- relative_position_bias = relative_position_bias.permute(
- 2, 0, 1
- ).contiguous() # nH, Wh*Ww, Wh*Ww
- attn = attn + relative_position_bias.unsqueeze(0)
-
- if mask is not None:
- nW = mask.shape[0]
- attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
- attn = attn.view(-1, self.num_heads, N, N)
- attn = self.softmax(attn)
- else:
- attn = self.softmax(attn)
-
- attn = self.attn_drop(attn)
-
- x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
- x = self.proj(x)
- x = self.proj_drop(x)
- return x
-
-
-class SwinTransformerBlock(nn.Module):
- """Swin Transformer Block.
- Args:
- dim (int): Number of input channels.
- num_heads (int): Number of attention heads.
- window_size (int): Window size.
- shift_size (int): Shift size for SW-MSA.
- mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
- qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
- qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
- drop (float, optional): Dropout rate. Default: 0.0
- attn_drop (float, optional): Attention dropout rate. Default: 0.0
- drop_path (float, optional): Stochastic depth rate. Default: 0.0
- act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
- norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
- """
-
- def __init__(
- self,
- dim,
- num_heads,
- window_size=7,
- shift_size=0,
- mlp_ratio=4.0,
- qkv_bias=True,
- qk_scale=None,
- drop=0.0,
- attn_drop=0.0,
- drop_path=0.0,
- act_layer=nn.GELU,
- norm_layer=nn.LayerNorm,
- ):
- super().__init__()
- self.dim = dim
- self.num_heads = num_heads
- self.window_size = window_size
- self.shift_size = shift_size
- self.mlp_ratio = mlp_ratio
- assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"
-
- self.norm1 = norm_layer(dim)
- self.attn = WindowAttention(
- dim,
- window_size=to_2tuple(self.window_size),
- num_heads=num_heads,
- qkv_bias=qkv_bias,
- qk_scale=qk_scale,
- attn_drop=attn_drop,
- proj_drop=drop,
- )
-
- self.drop_path = DropPath(drop_path) if drop_path > 0.0 else nn.Identity()
- self.norm2 = norm_layer(dim)
- mlp_hidden_dim = int(dim * mlp_ratio)
- self.mlp = Mlp(
- in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop
- )
-
- self.H = None
- self.W = None
-
- def forward(self, x, mask_matrix):
- """Forward function.
- Args:
- x: Input feature, tensor size (B, H*W, C).
- H, W: Spatial resolution of the input feature.
- mask_matrix: Attention mask for cyclic shift.
- """
- B, L, C = x.shape
- H, W = self.H, self.W
- assert L == H * W, "input feature has wrong size"
-
- shortcut = x
- x = self.norm1(x)
- x = x.view(B, H, W, C)
-
- # pad feature maps to multiples of window size
- pad_l = pad_t = 0
- pad_r = (self.window_size - W % self.window_size) % self.window_size
- pad_b = (self.window_size - H % self.window_size) % self.window_size
- x = F.pad(x, (0, 0, pad_l, pad_r, pad_t, pad_b))
- _, Hp, Wp, _ = x.shape
-
- # cyclic shift
- if self.shift_size > 0:
- shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
- attn_mask = mask_matrix
- else:
- shifted_x = x
- attn_mask = None
-
- # partition windows
- x_windows = window_partition(
- shifted_x, self.window_size
- ) # nW*B, window_size, window_size, C
- x_windows = x_windows.view(
- -1, self.window_size * self.window_size, C
- ) # nW*B, window_size*window_size, C
-
- # W-MSA/SW-MSA
- attn_windows = self.attn(x_windows, mask=attn_mask) # nW*B, window_size*window_size, C
-
- # merge windows
- attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)
- shifted_x = window_reverse(attn_windows, self.window_size, Hp, Wp) # B H' W' C
-
- # reverse cyclic shift
- if self.shift_size > 0:
- x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
- else:
- x = shifted_x
-
- if pad_r > 0 or pad_b > 0:
- x = x[:, :H, :W, :].contiguous()
-
- x = x.view(B, H * W, C)
-
- # FFN
- x = shortcut + self.drop_path(x)
- x = x + self.drop_path(self.mlp(self.norm2(x)))
-
- return x
-
-
-class PatchMerging(nn.Module):
- """Patch Merging Layer
- Args:
- dim (int): Number of input channels.
- norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
- """
-
- def __init__(self, dim, norm_layer=nn.LayerNorm):
- super().__init__()
- self.dim = dim
- self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
- self.norm = norm_layer(4 * dim)
-
- def forward(self, x, H, W):
- """Forward function.
- Args:
- x: Input feature, tensor size (B, H*W, C).
- H, W: Spatial resolution of the input feature.
- """
- B, L, C = x.shape
- assert L == H * W, "input feature has wrong size"
-
- x = x.view(B, H, W, C)
-
- # padding
- pad_input = (H % 2 == 1) or (W % 2 == 1)
- if pad_input:
- x = F.pad(x, (0, 0, 0, W % 2, 0, H % 2))
-
- x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
- x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
- x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
- x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
- x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
- x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
-
- x = self.norm(x)
- x = self.reduction(x)
-
- return x
-
-
-class BasicLayer(nn.Module):
- """A basic Swin Transformer layer for one stage.
- Args:
- dim (int): Number of feature channels
- depth (int): Depths of this stage.
- num_heads (int): Number of attention head.
- window_size (int): Local window size. Default: 7.
- mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4.
- qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
- qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
- drop (float, optional): Dropout rate. Default: 0.0
- attn_drop (float, optional): Attention dropout rate. Default: 0.0
- drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
- norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
- downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
- use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
- """
-
- def __init__(
- self,
- dim,
- depth,
- num_heads,
- window_size=7,
- mlp_ratio=4.0,
- qkv_bias=True,
- qk_scale=None,
- drop=0.0,
- attn_drop=0.0,
- drop_path=0.0,
- norm_layer=nn.LayerNorm,
- downsample=None,
- use_checkpoint=False,
- ):
- super().__init__()
- self.window_size = window_size
- self.shift_size = window_size // 2
- self.depth = depth
- self.use_checkpoint = use_checkpoint
-
- # build blocks
- self.blocks = nn.ModuleList(
- [
- SwinTransformerBlock(
- dim=dim,
- num_heads=num_heads,
- window_size=window_size,
- shift_size=0 if (i % 2 == 0) else window_size // 2,
- mlp_ratio=mlp_ratio,
- qkv_bias=qkv_bias,
- qk_scale=qk_scale,
- drop=drop,
- attn_drop=attn_drop,
- drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
- norm_layer=norm_layer,
- )
- for i in range(depth)
- ]
- )
-
- # patch merging layer
- if downsample is not None:
- self.downsample = downsample(dim=dim, norm_layer=norm_layer)
- else:
- self.downsample = None
-
- def forward(self, x, H, W):
- """Forward function.
- Args:
- x: Input feature, tensor size (B, H*W, C).
- H, W: Spatial resolution of the input feature.
- """
-
- # calculate attention mask for SW-MSA
- Hp = int(np.ceil(H / self.window_size)) * self.window_size
- Wp = int(np.ceil(W / self.window_size)) * self.window_size
- img_mask = torch.zeros((1, Hp, Wp, 1), device=x.device) # 1 Hp Wp 1
- h_slices = (
- slice(0, -self.window_size),
- slice(-self.window_size, -self.shift_size),
- slice(-self.shift_size, None),
- )
- w_slices = (
- slice(0, -self.window_size),
- slice(-self.window_size, -self.shift_size),
- slice(-self.shift_size, None),
- )
- cnt = 0
- for h in h_slices:
- for w in w_slices:
- img_mask[:, h, w, :] = cnt
- cnt += 1
-
- mask_windows = window_partition(
- img_mask, self.window_size
- ) # nW, window_size, window_size, 1
- mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
- attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
- attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(
- attn_mask == 0, float(0.0)
- )
-
- for blk in self.blocks:
- blk.H, blk.W = H, W
- if self.use_checkpoint:
- x = checkpoint.checkpoint(blk, x, attn_mask)
- else:
- x = blk(x, attn_mask)
- if self.downsample is not None:
- x_down = self.downsample(x, H, W)
- Wh, Ww = (H + 1) // 2, (W + 1) // 2
- return x, H, W, x_down, Wh, Ww
- else:
- return x, H, W, x, H, W
-
-
-class PatchEmbed(nn.Module):
- """Image to Patch Embedding
- Args:
- patch_size (int): Patch token size. Default: 4.
- in_chans (int): Number of input image channels. Default: 3.
- embed_dim (int): Number of linear projection output channels. Default: 96.
- norm_layer (nn.Module, optional): Normalization layer. Default: None
- """
-
- def __init__(self, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
- super().__init__()
- patch_size = to_2tuple(patch_size)
- self.patch_size = patch_size
-
- self.in_chans = in_chans
- self.embed_dim = embed_dim
-
- self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
- if norm_layer is not None:
- self.norm = norm_layer(embed_dim)
- else:
- self.norm = None
-
- def forward(self, x):
- """Forward function."""
- # padding
- _, _, H, W = x.size()
- if W % self.patch_size[1] != 0:
- x = F.pad(x, (0, self.patch_size[1] - W % self.patch_size[1]))
- if H % self.patch_size[0] != 0:
- x = F.pad(x, (0, 0, 0, self.patch_size[0] - H % self.patch_size[0]))
-
- x = self.proj(x) # B C Wh Ww
- if self.norm is not None:
- Wh, Ww = x.size(2), x.size(3)
- x = x.flatten(2).transpose(1, 2)
- x = self.norm(x)
- x = x.transpose(1, 2).view(-1, self.embed_dim, Wh, Ww)
-
- return x
-
-
-class SwinTransformer(nn.Module):
- """Swin Transformer backbone.
- A PyTorch impl of : `Swin Transformer: Hierarchical Vision Transformer using Shifted Windows` -
- https://arxiv.org/pdf/2103.14030
- Args:
- pretrain_img_size (int): Input image size for training the pretrained model,
- used in absolute postion embedding. Default 224.
- patch_size (int | tuple(int)): Patch size. Default: 4.
- in_chans (int): Number of input image channels. Default: 3.
- embed_dim (int): Number of linear projection output channels. Default: 96.
- depths (tuple[int]): Depths of each Swin Transformer stage.
- num_heads (tuple[int]): Number of attention head of each stage.
- window_size (int): Window size. Default: 7.
- mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4.
- qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True
- qk_scale (float): Override default qk scale of head_dim ** -0.5 if set.
- drop_rate (float): Dropout rate.
- attn_drop_rate (float): Attention dropout rate. Default: 0.
- drop_path_rate (float): Stochastic depth rate. Default: 0.2.
- norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.
- ape (bool): If True, add absolute position embedding to the patch embedding. Default: False.
- patch_norm (bool): If True, add normalization after patch embedding. Default: True.
- out_indices (Sequence[int]): Output from which stages.
- frozen_stages (int): Stages to be frozen (stop grad and set eval mode).
- -1 means not freezing any parameters.
- use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
- dilation (bool): if True, the output size if 16x downsample, ow 32x downsample.
- """
-
- def __init__(
- self,
- pretrain_img_size=224,
- patch_size=4,
- in_chans=3,
- embed_dim=96,
- depths=[2, 2, 6, 2],
- num_heads=[3, 6, 12, 24],
- window_size=7,
- mlp_ratio=4.0,
- qkv_bias=True,
- qk_scale=None,
- drop_rate=0.0,
- attn_drop_rate=0.0,
- drop_path_rate=0.2,
- norm_layer=nn.LayerNorm,
- ape=False,
- patch_norm=True,
- out_indices=(0, 1, 2, 3),
- frozen_stages=-1,
- dilation=False,
- use_checkpoint=False,
- ):
- super().__init__()
-
- self.pretrain_img_size = pretrain_img_size
- self.num_layers = len(depths)
- self.embed_dim = embed_dim
- self.ape = ape
- self.patch_norm = patch_norm
- self.out_indices = out_indices
- self.frozen_stages = frozen_stages
- self.dilation = dilation
-
- # if use_checkpoint:
- # print("use_checkpoint!!!!!!!!!!!!!!!!!!!!!!!!")
-
- # split image into non-overlapping patches
- self.patch_embed = PatchEmbed(
- patch_size=patch_size,
- in_chans=in_chans,
- embed_dim=embed_dim,
- norm_layer=norm_layer if self.patch_norm else None,
- )
-
- # absolute position embedding
- if self.ape:
- pretrain_img_size = to_2tuple(pretrain_img_size)
- patch_size = to_2tuple(patch_size)
- patches_resolution = [
- pretrain_img_size[0] // patch_size[0],
- pretrain_img_size[1] // patch_size[1],
- ]
-
- self.absolute_pos_embed = nn.Parameter(
- torch.zeros(1, embed_dim, patches_resolution[0], patches_resolution[1])
- )
- trunc_normal_(self.absolute_pos_embed, std=0.02)
-
- self.pos_drop = nn.Dropout(p=drop_rate)
-
- # stochastic depth
- dpr = [
- x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))
- ] # stochastic depth decay rule
-
- # build layers
- self.layers = nn.ModuleList()
- # prepare downsample list
- downsamplelist = [PatchMerging for i in range(self.num_layers)]
- downsamplelist[-1] = None
- num_features = [int(embed_dim * 2**i) for i in range(self.num_layers)]
- if self.dilation:
- downsamplelist[-2] = None
- num_features[-1] = int(embed_dim * 2 ** (self.num_layers - 1)) // 2
- for i_layer in range(self.num_layers):
- layer = BasicLayer(
- # dim=int(embed_dim * 2 ** i_layer),
- dim=num_features[i_layer],
- depth=depths[i_layer],
- num_heads=num_heads[i_layer],
- window_size=window_size,
- mlp_ratio=mlp_ratio,
- qkv_bias=qkv_bias,
- qk_scale=qk_scale,
- drop=drop_rate,
- attn_drop=attn_drop_rate,
- drop_path=dpr[sum(depths[:i_layer]) : sum(depths[: i_layer + 1])],
- norm_layer=norm_layer,
- # downsample=PatchMerging if (i_layer < self.num_layers - 1) else None,
- downsample=downsamplelist[i_layer],
- use_checkpoint=use_checkpoint,
- )
- self.layers.append(layer)
-
- # num_features = [int(embed_dim * 2 ** i) for i in range(self.num_layers)]
- self.num_features = num_features
-
- # add a norm layer for each output
- for i_layer in out_indices:
- layer = norm_layer(num_features[i_layer])
- layer_name = f"norm{i_layer}"
- self.add_module(layer_name, layer)
-
- self._freeze_stages()
-
- def _freeze_stages(self):
- if self.frozen_stages >= 0:
- self.patch_embed.eval()
- for param in self.patch_embed.parameters():
- param.requires_grad = False
-
- if self.frozen_stages >= 1 and self.ape:
- self.absolute_pos_embed.requires_grad = False
-
- if self.frozen_stages >= 2:
- self.pos_drop.eval()
- for i in range(0, self.frozen_stages - 1):
- m = self.layers[i]
- m.eval()
- for param in m.parameters():
- param.requires_grad = False
-
- # def init_weights(self, pretrained=None):
- # """Initialize the weights in backbone.
- # Args:
- # pretrained (str, optional): Path to pre-trained weights.
- # Defaults to None.
- # """
-
- # def _init_weights(m):
- # if isinstance(m, nn.Linear):
- # trunc_normal_(m.weight, std=.02)
- # if isinstance(m, nn.Linear) and m.bias is not None:
- # nn.init.constant_(m.bias, 0)
- # elif isinstance(m, nn.LayerNorm):
- # nn.init.constant_(m.bias, 0)
- # nn.init.constant_(m.weight, 1.0)
-
- # if isinstance(pretrained, str):
- # self.apply(_init_weights)
- # logger = get_root_logger()
- # load_checkpoint(self, pretrained, strict=False, logger=logger)
- # elif pretrained is None:
- # self.apply(_init_weights)
- # else:
- # raise TypeError('pretrained must be a str or None')
-
- def forward_raw(self, x):
- """Forward function."""
- x = self.patch_embed(x)
-
- Wh, Ww = x.size(2), x.size(3)
- if self.ape:
- # interpolate the position embedding to the corresponding size
- absolute_pos_embed = F.interpolate(
- self.absolute_pos_embed, size=(Wh, Ww), mode="bicubic"
- )
- x = (x + absolute_pos_embed).flatten(2).transpose(1, 2) # B Wh*Ww C
- else:
- x = x.flatten(2).transpose(1, 2)
- x = self.pos_drop(x)
-
- outs = []
- for i in range(self.num_layers):
- layer = self.layers[i]
- x_out, H, W, x, Wh, Ww = layer(x, Wh, Ww)
- # import ipdb; ipdb.set_trace()
-
- if i in self.out_indices:
- norm_layer = getattr(self, f"norm{i}")
- x_out = norm_layer(x_out)
-
- out = x_out.view(-1, H, W, self.num_features[i]).permute(0, 3, 1, 2).contiguous()
- outs.append(out)
- # in:
- # torch.Size([2, 3, 1024, 1024])
- # outs:
- # [torch.Size([2, 192, 256, 256]), torch.Size([2, 384, 128, 128]), \
- # torch.Size([2, 768, 64, 64]), torch.Size([2, 1536, 32, 32])]
- return tuple(outs)
-
- def forward(self, tensor_list: NestedTensor):
- x = tensor_list.tensors
-
- """Forward function."""
- x = self.patch_embed(x)
-
- Wh, Ww = x.size(2), x.size(3)
- if self.ape:
- # interpolate the position embedding to the corresponding size
- absolute_pos_embed = F.interpolate(
- self.absolute_pos_embed, size=(Wh, Ww), mode="bicubic"
- )
- x = (x + absolute_pos_embed).flatten(2).transpose(1, 2) # B Wh*Ww C
- else:
- x = x.flatten(2).transpose(1, 2)
- x = self.pos_drop(x)
-
- outs = []
- for i in range(self.num_layers):
- layer = self.layers[i]
- x_out, H, W, x, Wh, Ww = layer(x, Wh, Ww)
-
- if i in self.out_indices:
- norm_layer = getattr(self, f"norm{i}")
- x_out = norm_layer(x_out)
-
- out = x_out.view(-1, H, W, self.num_features[i]).permute(0, 3, 1, 2).contiguous()
- outs.append(out)
- # in:
- # torch.Size([2, 3, 1024, 1024])
- # out:
- # [torch.Size([2, 192, 256, 256]), torch.Size([2, 384, 128, 128]), \
- # torch.Size([2, 768, 64, 64]), torch.Size([2, 1536, 32, 32])]
-
- # collect for nesttensors
- outs_dict = {}
- for idx, out_i in enumerate(outs):
- m = tensor_list.mask
- assert m is not None
- mask = F.interpolate(m[None].float(), size=out_i.shape[-2:]).to(torch.bool)[0]
- outs_dict[idx] = NestedTensor(out_i, mask)
-
- return outs_dict
-
- def train(self, mode=True):
- """Convert the model into training mode while keep layers freezed."""
- super(SwinTransformer, self).train(mode)
- self._freeze_stages()
-
-
-def build_swin_transformer(modelname, pretrain_img_size, **kw):
- assert modelname in [
- "swin_T_224_1k",
- "swin_B_224_22k",
- "swin_B_384_22k",
- "swin_L_224_22k",
- "swin_L_384_22k",
- ]
-
- model_para_dict = {
- "swin_T_224_1k": dict(
- embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24], window_size=7
- ),
- "swin_B_224_22k": dict(
- embed_dim=128, depths=[2, 2, 18, 2], num_heads=[4, 8, 16, 32], window_size=7
- ),
- "swin_B_384_22k": dict(
- embed_dim=128, depths=[2, 2, 18, 2], num_heads=[4, 8, 16, 32], window_size=12
- ),
- "swin_L_224_22k": dict(
- embed_dim=192, depths=[2, 2, 18, 2], num_heads=[6, 12, 24, 48], window_size=7
- ),
- "swin_L_384_22k": dict(
- embed_dim=192, depths=[2, 2, 18, 2], num_heads=[6, 12, 24, 48], window_size=12
- ),
- }
- kw_cgf = model_para_dict[modelname]
- kw_cgf.update(kw)
- model = SwinTransformer(pretrain_img_size=pretrain_img_size, **kw_cgf)
- return model
-
-
-if __name__ == "__main__":
- model = build_swin_transformer("swin_L_384_22k", 384, dilation=True)
- x = torch.rand(2, 3, 1024, 1024)
- y = model.forward_raw(x)
- import ipdb
-
- ipdb.set_trace()
- x = torch.rand(2, 3, 384, 384)
- y = model.forward_raw(x)
diff --git a/spaces/Marshalls/testmtd/analysis/aistplusplus_api/setup.py b/spaces/Marshalls/testmtd/analysis/aistplusplus_api/setup.py
deleted file mode 100644
index 7264101afe2e3f922c00e8bbcf6fdc46be2b6520..0000000000000000000000000000000000000000
--- a/spaces/Marshalls/testmtd/analysis/aistplusplus_api/setup.py
+++ /dev/null
@@ -1,29 +0,0 @@
-# coding=utf-8
-# Copyright 2020 The Google AI Perception Team Authors.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-import setuptools
-
-INSTALL_REQUIREMENTS = [
- 'absl-py', 'numpy', 'opencv-python', 'ffmpeg-python']
-
-setuptools.setup(
- name='aist_plusplus_api',
- url='https://github.com/google/aistplusplus_api',
- description='API for supporting AIST++ Dataset.',
- version='1.0.0',
- author='Ruilong Li',
- author_email='ruilongli94@gmail.com',
- packages=setuptools.find_packages(),
- install_requires=INSTALL_REQUIREMENTS
-)
diff --git a/spaces/MathysL/AutoGPT4/autogpt/config/ai_config.py b/spaces/MathysL/AutoGPT4/autogpt/config/ai_config.py
deleted file mode 100644
index d50c30beee9dc8009f63415378ae1c6a399f0037..0000000000000000000000000000000000000000
--- a/spaces/MathysL/AutoGPT4/autogpt/config/ai_config.py
+++ /dev/null
@@ -1,121 +0,0 @@
-# sourcery skip: do-not-use-staticmethod
-"""
-A module that contains the AIConfig class object that contains the configuration
-"""
-from __future__ import annotations
-
-import os
-from typing import Type
-
-import yaml
-
-
-class AIConfig:
- """
- A class object that contains the configuration information for the AI
-
- Attributes:
- ai_name (str): The name of the AI.
- ai_role (str): The description of the AI's role.
- ai_goals (list): The list of objectives the AI is supposed to complete.
- """
-
- def __init__(
- self, ai_name: str = "", ai_role: str = "", ai_goals: list | None = None
- ) -> None:
- """
- Initialize a class instance
-
- Parameters:
- ai_name (str): The name of the AI.
- ai_role (str): The description of the AI's role.
- ai_goals (list): The list of objectives the AI is supposed to complete.
- Returns:
- None
- """
- if ai_goals is None:
- ai_goals = []
- self.ai_name = ai_name
- self.ai_role = ai_role
- self.ai_goals = ai_goals
-
- # Soon this will go in a folder where it remembers more stuff about the run(s)
- SAVE_FILE = os.path.join(os.path.dirname(__file__), "..", "ai_settings.yaml")
-
- @staticmethod
- def load(config_file: str = SAVE_FILE) -> "AIConfig":
- """
- Returns class object with parameters (ai_name, ai_role, ai_goals) loaded from
- yaml file if yaml file exists,
- else returns class with no parameters.
-
- Parameters:
- config_file (int): The path to the config yaml file.
- DEFAULT: "../ai_settings.yaml"
-
- Returns:
- cls (object): An instance of given cls object
- """
-
- try:
- with open(config_file, encoding="utf-8") as file:
- config_params = yaml.load(file, Loader=yaml.FullLoader)
- except FileNotFoundError:
- config_params = {}
-
- ai_name = config_params.get("ai_name", "")
- ai_role = config_params.get("ai_role", "")
- ai_goals = config_params.get("ai_goals", [])
- # type: Type[AIConfig]
- return AIConfig(ai_name, ai_role, ai_goals)
-
- def save(self, config_file: str = SAVE_FILE) -> None:
- """
- Saves the class parameters to the specified file yaml file path as a yaml file.
-
- Parameters:
- config_file(str): The path to the config yaml file.
- DEFAULT: "../ai_settings.yaml"
-
- Returns:
- None
- """
-
- config = {
- "ai_name": self.ai_name,
- "ai_role": self.ai_role,
- "ai_goals": self.ai_goals,
- }
- with open(config_file, "w", encoding="utf-8") as file:
- yaml.dump(config, file, allow_unicode=True)
-
- def construct_full_prompt(self) -> str:
- """
- Returns a prompt to the user with the class information in an organized fashion.
-
- Parameters:
- None
-
- Returns:
- full_prompt (str): A string containing the initial prompt for the user
- including the ai_name, ai_role and ai_goals.
- """
-
- prompt_start = (
- "Your decisions must always be made independently without"
- " seeking user assistance. Play to your strengths as an LLM and pursue"
- " simple strategies with no legal complications."
- ""
- )
-
- from autogpt.prompt import get_prompt
-
- # Construct full prompt
- full_prompt = (
- f"You are {self.ai_name}, {self.ai_role}\n{prompt_start}\n\nGOALS:\n\n"
- )
- for i, goal in enumerate(self.ai_goals):
- full_prompt += f"{i+1}. {goal}\n"
-
- full_prompt += f"\n\n{get_prompt()}"
- return full_prompt
diff --git a/spaces/Mellow-ai/PhotoAI_Mellow/annotator/uniformer/mmcv/arraymisc/__init__.py b/spaces/Mellow-ai/PhotoAI_Mellow/annotator/uniformer/mmcv/arraymisc/__init__.py
deleted file mode 100644
index 4b4700d6139ae3d604ff6e542468cce4200c020c..0000000000000000000000000000000000000000
--- a/spaces/Mellow-ai/PhotoAI_Mellow/annotator/uniformer/mmcv/arraymisc/__init__.py
+++ /dev/null
@@ -1,4 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .quantization import dequantize, quantize
-
-__all__ = ['quantize', 'dequantize']
diff --git a/spaces/Mellow-ai/PhotoAI_Mellow/annotator/uniformer/mmcv/runner/__init__.py b/spaces/Mellow-ai/PhotoAI_Mellow/annotator/uniformer/mmcv/runner/__init__.py
deleted file mode 100644
index 52e4b48d383a84a055dcd7f6236f6e8e58eab924..0000000000000000000000000000000000000000
--- a/spaces/Mellow-ai/PhotoAI_Mellow/annotator/uniformer/mmcv/runner/__init__.py
+++ /dev/null
@@ -1,47 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from .base_module import BaseModule, ModuleList, Sequential
-from .base_runner import BaseRunner
-from .builder import RUNNERS, build_runner
-from .checkpoint import (CheckpointLoader, _load_checkpoint,
- _load_checkpoint_with_prefix, load_checkpoint,
- load_state_dict, save_checkpoint, weights_to_cpu)
-from .default_constructor import DefaultRunnerConstructor
-from .dist_utils import (allreduce_grads, allreduce_params, get_dist_info,
- init_dist, master_only)
-from .epoch_based_runner import EpochBasedRunner, Runner
-from .fp16_utils import LossScaler, auto_fp16, force_fp32, wrap_fp16_model
-from .hooks import (HOOKS, CheckpointHook, ClosureHook, DistEvalHook,
- DistSamplerSeedHook, DvcliveLoggerHook, EMAHook, EvalHook,
- Fp16OptimizerHook, GradientCumulativeFp16OptimizerHook,
- GradientCumulativeOptimizerHook, Hook, IterTimerHook,
- LoggerHook, LrUpdaterHook, MlflowLoggerHook,
- NeptuneLoggerHook, OptimizerHook, PaviLoggerHook,
- SyncBuffersHook, TensorboardLoggerHook, TextLoggerHook,
- WandbLoggerHook)
-from .iter_based_runner import IterBasedRunner, IterLoader
-from .log_buffer import LogBuffer
-from .optimizer import (OPTIMIZER_BUILDERS, OPTIMIZERS,
- DefaultOptimizerConstructor, build_optimizer,
- build_optimizer_constructor)
-from .priority import Priority, get_priority
-from .utils import get_host_info, get_time_str, obj_from_dict, set_random_seed
-
-__all__ = [
- 'BaseRunner', 'Runner', 'EpochBasedRunner', 'IterBasedRunner', 'LogBuffer',
- 'HOOKS', 'Hook', 'CheckpointHook', 'ClosureHook', 'LrUpdaterHook',
- 'OptimizerHook', 'IterTimerHook', 'DistSamplerSeedHook', 'LoggerHook',
- 'PaviLoggerHook', 'TextLoggerHook', 'TensorboardLoggerHook',
- 'NeptuneLoggerHook', 'WandbLoggerHook', 'MlflowLoggerHook',
- 'DvcliveLoggerHook', '_load_checkpoint', 'load_state_dict',
- 'load_checkpoint', 'weights_to_cpu', 'save_checkpoint', 'Priority',
- 'get_priority', 'get_host_info', 'get_time_str', 'obj_from_dict',
- 'init_dist', 'get_dist_info', 'master_only', 'OPTIMIZER_BUILDERS',
- 'OPTIMIZERS', 'DefaultOptimizerConstructor', 'build_optimizer',
- 'build_optimizer_constructor', 'IterLoader', 'set_random_seed',
- 'auto_fp16', 'force_fp32', 'wrap_fp16_model', 'Fp16OptimizerHook',
- 'SyncBuffersHook', 'EMAHook', 'build_runner', 'RUNNERS', 'allreduce_grads',
- 'allreduce_params', 'LossScaler', 'CheckpointLoader', 'BaseModule',
- '_load_checkpoint_with_prefix', 'EvalHook', 'DistEvalHook', 'Sequential',
- 'ModuleList', 'GradientCumulativeOptimizerHook',
- 'GradientCumulativeFp16OptimizerHook', 'DefaultRunnerConstructor'
-]
diff --git a/spaces/MichaelT8093/Mandarin-TTS/vits_pinyin.py b/spaces/MichaelT8093/Mandarin-TTS/vits_pinyin.py
deleted file mode 100644
index 329052479d236f8b01f65db4365df2d2561433e3..0000000000000000000000000000000000000000
--- a/spaces/MichaelT8093/Mandarin-TTS/vits_pinyin.py
+++ /dev/null
@@ -1,88 +0,0 @@
-import re
-
-from pypinyin import Style
-from pypinyin.contrib.neutral_tone import NeutralToneWith5Mixin
-from pypinyin.converter import DefaultConverter
-from pypinyin.core import Pinyin
-
-from text import pinyin_dict
-from bert import TTSProsody
-
-
-class MyConverter(NeutralToneWith5Mixin, DefaultConverter):
- pass
-
-
-def is_chinese(uchar):
- if uchar >= u'\u4e00' and uchar <= u'\u9fa5':
- return True
- else:
- return False
-
-
-def clean_chinese(text: str):
- text = text.strip()
- text_clean = []
- for char in text:
- if (is_chinese(char)):
- text_clean.append(char)
- else:
- if len(text_clean) > 1 and is_chinese(text_clean[-1]):
- text_clean.append(',')
- text_clean = ''.join(text_clean).strip(',')
- return text_clean
-
-
-class VITS_PinYin:
- def __init__(self, bert_path, device):
- self.pinyin_parser = Pinyin(MyConverter())
- self.prosody = TTSProsody(bert_path, device)
-
- def get_phoneme4pinyin(self, pinyins):
- result = []
- count_phone = []
- for pinyin in pinyins:
- if pinyin[:-1] in pinyin_dict:
- tone = pinyin[-1]
- a = pinyin[:-1]
- a1, a2 = pinyin_dict[a]
- result += [a1, a2 + tone]
- count_phone.append(2)
- return result, count_phone
-
- def chinese_to_phonemes(self, text):
- text = clean_chinese(text)
- phonemes = ["sil"]
- chars = ['[PAD]']
- count_phone = []
- count_phone.append(1)
- for subtext in text.split(","):
- if (len(subtext) == 0):
- continue
- pinyins = self.correct_pinyin_tone3(subtext)
- sub_p, sub_c = self.get_phoneme4pinyin(pinyins)
- phonemes.extend(sub_p)
- phonemes.append("sp")
- count_phone.extend(sub_c)
- count_phone.append(1)
- chars.append(subtext)
- chars.append(',')
- phonemes.append("sil")
- count_phone.append(1)
- chars.append('[PAD]')
- chars = "".join(chars)
- char_embeds = self.prosody.get_char_embeds(chars)
- char_embeds = self.prosody.expand_for_phone(char_embeds, count_phone)
- return " ".join(phonemes), char_embeds
-
- def correct_pinyin_tone3(self, text):
- pinyin_list = [p[0] for p in self.pinyin_parser.pinyin(
- text, style=Style.TONE3, strict=False, neutral_tone_with_five=True)]
- if len(pinyin_list) >= 2:
- for i in range(1, len(pinyin_list)):
- try:
- if re.findall(r'\d', pinyin_list[i-1])[0] == '3' and re.findall(r'\d', pinyin_list[i])[0] == '3':
- pinyin_list[i-1] = pinyin_list[i-1].replace('3', '2')
- except IndexError:
- pass
- return pinyin_list
diff --git a/spaces/Mountchicken/MAERec-Gradio/mmocr/models/textdet/postprocessors/db_postprocessor.py b/spaces/Mountchicken/MAERec-Gradio/mmocr/models/textdet/postprocessors/db_postprocessor.py
deleted file mode 100644
index 7ae3290e8645942a601d16ede54c6ba7146b8430..0000000000000000000000000000000000000000
--- a/spaces/Mountchicken/MAERec-Gradio/mmocr/models/textdet/postprocessors/db_postprocessor.py
+++ /dev/null
@@ -1,169 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from typing import Sequence
-
-import cv2
-import numpy as np
-import torch
-from mmengine.structures import InstanceData
-from shapely.geometry import Polygon
-from torch import Tensor
-
-from mmocr.registry import MODELS
-from mmocr.structures import TextDetDataSample
-from mmocr.utils import offset_polygon
-from .base import BaseTextDetPostProcessor
-
-
-@MODELS.register_module()
-class DBPostprocessor(BaseTextDetPostProcessor):
- """Decoding predictions of DbNet to instances. This is partially adapted
- from https://github.com/MhLiao/DB.
-
- Args:
- text_repr_type (str): The boundary encoding type 'poly' or 'quad'.
- Defaults to 'poly'.
- rescale_fields (list[str]): The bbox/polygon field names to
- be rescaled. If None, no rescaling will be performed. Defaults to
- ['polygons'].
- mask_thr (float): The mask threshold value for binarization. Defaults
- to 0.3.
- min_text_score (float): The threshold value for converting binary map
- to shrink text regions. Defaults to 0.3.
- min_text_width (int): The minimum width of boundary polygon/box
- predicted. Defaults to 5.
- unclip_ratio (float): The unclip ratio for text regions dilation.
- Defaults to 1.5.
- epsilon_ratio (float): The epsilon ratio for approximation accuracy.
- Defaults to 0.01.
- max_candidates (int): The maximum candidate number. Defaults to 3000.
- """
-
- def __init__(self,
- text_repr_type: str = 'poly',
- rescale_fields: Sequence[str] = ['polygons'],
- mask_thr: float = 0.3,
- min_text_score: float = 0.3,
- min_text_width: int = 5,
- unclip_ratio: float = 1.5,
- epsilon_ratio: float = 0.01,
- max_candidates: int = 3000,
- **kwargs) -> None:
- super().__init__(
- text_repr_type=text_repr_type,
- rescale_fields=rescale_fields,
- **kwargs)
- self.mask_thr = mask_thr
- self.min_text_score = min_text_score
- self.min_text_width = min_text_width
- self.unclip_ratio = unclip_ratio
- self.epsilon_ratio = epsilon_ratio
- self.max_candidates = max_candidates
-
- def get_text_instances(self, prob_map: Tensor,
- data_sample: TextDetDataSample
- ) -> TextDetDataSample:
- """Get text instance predictions of one image.
-
- Args:
- pred_result (Tensor): DBNet's output ``prob_map`` of shape
- :math:`(H, W)`.
- data_sample (TextDetDataSample): Datasample of an image.
-
- Returns:
- TextDetDataSample: A new DataSample with predictions filled in.
- Polygons and results are saved in
- ``TextDetDataSample.pred_instances.polygons``. The confidence
- scores are saved in ``TextDetDataSample.pred_instances.scores``.
- """
-
- data_sample.pred_instances = InstanceData()
- data_sample.pred_instances.polygons = []
- data_sample.pred_instances.scores = []
-
- text_mask = prob_map > self.mask_thr
-
- score_map = prob_map.data.cpu().numpy().astype(np.float32)
- text_mask = text_mask.data.cpu().numpy().astype(np.uint8) # to numpy
-
- contours, _ = cv2.findContours((text_mask * 255).astype(np.uint8),
- cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
-
- for i, poly in enumerate(contours):
- if i > self.max_candidates:
- break
- epsilon = self.epsilon_ratio * cv2.arcLength(poly, True)
- approx = cv2.approxPolyDP(poly, epsilon, True)
- poly_pts = approx.reshape((-1, 2))
- if poly_pts.shape[0] < 4:
- continue
- score = self._get_bbox_score(score_map, poly_pts)
- if score < self.min_text_score:
- continue
- poly = self._unclip(poly_pts)
- # If the result polygon does not exist, or it is split into
- # multiple polygons, skip it.
- if len(poly) == 0:
- continue
- poly = poly.reshape(-1, 2)
-
- if self.text_repr_type == 'quad':
- rect = cv2.minAreaRect(poly)
- vertices = cv2.boxPoints(rect)
- poly = vertices.flatten() if min(
- rect[1]) >= self.min_text_width else []
- elif self.text_repr_type == 'poly':
- poly = poly.flatten()
-
- if len(poly) < 8:
- poly = np.array([], dtype=np.float32)
-
- if len(poly) > 0:
- data_sample.pred_instances.polygons.append(poly)
- data_sample.pred_instances.scores.append(score)
-
- data_sample.pred_instances.scores = torch.FloatTensor(
- data_sample.pred_instances.scores)
-
- return data_sample
-
- def _get_bbox_score(self, score_map: np.ndarray,
- poly_pts: np.ndarray) -> float:
- """Compute the average score over the area of the bounding box of the
- polygon.
-
- Args:
- score_map (np.ndarray): The score map.
- poly_pts (np.ndarray): The polygon points.
-
- Returns:
- float: The average score.
- """
- h, w = score_map.shape[:2]
- poly_pts = poly_pts.copy()
- xmin = np.clip(
- np.floor(poly_pts[:, 0].min()).astype(np.int32), 0, w - 1)
- xmax = np.clip(
- np.ceil(poly_pts[:, 0].max()).astype(np.int32), 0, w - 1)
- ymin = np.clip(
- np.floor(poly_pts[:, 1].min()).astype(np.int32), 0, h - 1)
- ymax = np.clip(
- np.ceil(poly_pts[:, 1].max()).astype(np.int32), 0, h - 1)
-
- mask = np.zeros((ymax - ymin + 1, xmax - xmin + 1), dtype=np.uint8)
- poly_pts[:, 0] = poly_pts[:, 0] - xmin
- poly_pts[:, 1] = poly_pts[:, 1] - ymin
- cv2.fillPoly(mask, poly_pts.reshape(1, -1, 2).astype(np.int32), 1)
- return cv2.mean(score_map[ymin:ymax + 1, xmin:xmax + 1], mask)[0]
-
- def _unclip(self, poly_pts: np.ndarray) -> np.ndarray:
- """Unclip a polygon.
-
- Args:
- poly_pts (np.ndarray): The polygon points.
-
- Returns:
- np.ndarray: The expanded polygon points.
- """
- poly = Polygon(poly_pts)
- distance = poly.area * self.unclip_ratio / poly.length
- return offset_polygon(poly_pts, distance)
diff --git a/spaces/Mountchicken/MAERec-Gradio/mmocr/models/textrecog/module_losses/base.py b/spaces/Mountchicken/MAERec-Gradio/mmocr/models/textrecog/module_losses/base.py
deleted file mode 100644
index 5fbf83df9dbfe9d962d2e37af7edde7c833b603a..0000000000000000000000000000000000000000
--- a/spaces/Mountchicken/MAERec-Gradio/mmocr/models/textrecog/module_losses/base.py
+++ /dev/null
@@ -1,132 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-
-from typing import Dict, Sequence, Union
-
-import torch
-import torch.nn as nn
-
-from mmocr.models.common.dictionary import Dictionary
-from mmocr.registry import TASK_UTILS
-from mmocr.structures import TextRecogDataSample
-
-
-class BaseTextRecogModuleLoss(nn.Module):
- """Base recognition loss.
-
- Args:
- dictionary (dict or :obj:`Dictionary`): The config for `Dictionary` or
- the instance of `Dictionary`.
- max_seq_len (int): Maximum sequence length. The sequence is usually
- generated from decoder. Defaults to 40.
- letter_case (str): There are three options to alter the letter cases
- of gt texts:
- - unchanged: Do not change gt texts.
- - upper: Convert gt texts into uppercase characters.
- - lower: Convert gt texts into lowercase characters.
- Usually, it only works for English characters. Defaults to
- 'unchanged'.
- pad_with (str): The padding strategy for ``gt_text.padded_indexes``.
- Defaults to 'auto'. Options are:
- - 'auto': Use dictionary.padding_idx to pad gt texts, or
- dictionary.end_idx if dictionary.padding_idx
- is None.
- - 'padding': Always use dictionary.padding_idx to pad gt texts.
- - 'end': Always use dictionary.end_idx to pad gt texts.
- - 'none': Do not pad gt texts.
- """
-
- def __init__(self,
- dictionary: Union[Dict, Dictionary],
- max_seq_len: int = 40,
- letter_case: str = 'unchanged',
- pad_with: str = 'auto',
- **kwargs) -> None:
- super().__init__()
- if isinstance(dictionary, dict):
- self.dictionary = TASK_UTILS.build(dictionary)
- elif isinstance(dictionary, Dictionary):
- self.dictionary = dictionary
- else:
- raise TypeError(
- 'The type of dictionary should be `Dictionary` or dict, '
- f'but got {type(dictionary)}')
- self.max_seq_len = max_seq_len
- assert letter_case in ['unchanged', 'upper', 'lower']
- self.letter_case = letter_case
-
- assert pad_with in ['auto', 'padding', 'end', 'none']
- if pad_with == 'auto':
- self.pad_idx = self.dictionary.padding_idx or \
- self.dictionary.end_idx
- elif pad_with == 'padding':
- self.pad_idx = self.dictionary.padding_idx
- elif pad_with == 'end':
- self.pad_idx = self.dictionary.end_idx
- else:
- self.pad_idx = None
- if self.pad_idx is None and pad_with != 'none':
- if pad_with == 'auto':
- raise ValueError('pad_with="auto", but dictionary.end_idx'
- ' and dictionary.padding_idx are both None')
- else:
- raise ValueError(
- f'pad_with="{pad_with}", but dictionary.{pad_with}_idx is'
- ' None')
-
- def get_targets(
- self, data_samples: Sequence[TextRecogDataSample]
- ) -> Sequence[TextRecogDataSample]:
- """Target generator.
-
- Args:
- data_samples (list[TextRecogDataSample]): It usually includes
- ``gt_text`` information.
-
- Returns:
- list[TextRecogDataSample]: Updated data_samples. Two keys will be
- added to data_sample:
-
- - indexes (torch.LongTensor): Character indexes representing gt
- texts. All special tokens are excluded, except for UKN.
- - padded_indexes (torch.LongTensor): Character indexes
- representing gt texts with BOS and EOS if applicable, following
- several padding indexes until the length reaches ``max_seq_len``.
- In particular, if ``pad_with='none'``, no padding will be
- applied.
- """
-
- for data_sample in data_samples:
- if data_sample.get('have_target', False):
- continue
- text = data_sample.gt_text.item
- if self.letter_case in ['upper', 'lower']:
- text = getattr(text, self.letter_case)()
- indexes = self.dictionary.str2idx(text)
- indexes = torch.LongTensor(indexes)
-
- # target indexes for loss
- src_target = torch.LongTensor(indexes.size(0) + 2).fill_(0)
- src_target[1:-1] = indexes
- if self.dictionary.start_idx is not None:
- src_target[0] = self.dictionary.start_idx
- slice_start = 0
- else:
- slice_start = 1
- if self.dictionary.end_idx is not None:
- src_target[-1] = self.dictionary.end_idx
- slice_end = src_target.size(0)
- else:
- slice_end = src_target.size(0) - 1
- src_target = src_target[slice_start:slice_end]
- if self.pad_idx is not None:
- padded_indexes = (torch.ones(self.max_seq_len) *
- self.pad_idx).long()
- char_num = min(src_target.size(0), self.max_seq_len)
- padded_indexes[:char_num] = src_target[:char_num]
- else:
- padded_indexes = src_target
- # put in DataSample
- data_sample.gt_text.indexes = indexes
- data_sample.gt_text.padded_indexes = padded_indexes
- data_sample.set_metainfo(dict(have_target=True))
- return data_samples
diff --git a/spaces/NCTCMumbai/NCTC/models/official/utils/flags/_benchmark.py b/spaces/NCTCMumbai/NCTC/models/official/utils/flags/_benchmark.py
deleted file mode 100644
index 5aa01421c5f5c7fede94b971d6674267f232b6da..0000000000000000000000000000000000000000
--- a/spaces/NCTCMumbai/NCTC/models/official/utils/flags/_benchmark.py
+++ /dev/null
@@ -1,108 +0,0 @@
-# Copyright 2018 The TensorFlow Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-"""Flags for benchmarking models."""
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-from absl import flags
-
-from official.utils.flags._conventions import help_wrap
-
-
-def define_log_steps():
- flags.DEFINE_integer(
- name="log_steps", default=100,
- help="Frequency with which to log timing information with TimeHistory.")
-
- return []
-
-
-def define_benchmark(benchmark_log_dir=True, bigquery_uploader=True):
- """Register benchmarking flags.
-
- Args:
- benchmark_log_dir: Create a flag to specify location for benchmark logging.
- bigquery_uploader: Create flags for uploading results to BigQuery.
-
- Returns:
- A list of flags for core.py to marks as key flags.
- """
-
- key_flags = []
-
- flags.DEFINE_enum(
- name="benchmark_logger_type", default="BaseBenchmarkLogger",
- enum_values=["BaseBenchmarkLogger", "BenchmarkFileLogger"],
- help=help_wrap("The type of benchmark logger to use. Defaults to using "
- "BaseBenchmarkLogger which logs to STDOUT. Different "
- "loggers will require other flags to be able to work."))
- flags.DEFINE_string(
- name="benchmark_test_id", short_name="bti", default=None,
- help=help_wrap("The unique test ID of the benchmark run. It could be the "
- "combination of key parameters. It is hardware "
- "independent and could be used compare the performance "
- "between different test runs. This flag is designed for "
- "human consumption, and does not have any impact within "
- "the system."))
-
- define_log_steps()
-
- if benchmark_log_dir:
- flags.DEFINE_string(
- name="benchmark_log_dir", short_name="bld", default=None,
- help=help_wrap("The location of the benchmark logging.")
- )
-
- if bigquery_uploader:
- flags.DEFINE_string(
- name="gcp_project", short_name="gp", default=None,
- help=help_wrap(
- "The GCP project name where the benchmark will be uploaded."))
-
- flags.DEFINE_string(
- name="bigquery_data_set", short_name="bds", default="test_benchmark",
- help=help_wrap(
- "The Bigquery dataset name where the benchmark will be uploaded."))
-
- flags.DEFINE_string(
- name="bigquery_run_table", short_name="brt", default="benchmark_run",
- help=help_wrap("The Bigquery table name where the benchmark run "
- "information will be uploaded."))
-
- flags.DEFINE_string(
- name="bigquery_run_status_table", short_name="brst",
- default="benchmark_run_status",
- help=help_wrap("The Bigquery table name where the benchmark run "
- "status information will be uploaded."))
-
- flags.DEFINE_string(
- name="bigquery_metric_table", short_name="bmt",
- default="benchmark_metric",
- help=help_wrap("The Bigquery table name where the benchmark metric "
- "information will be uploaded."))
-
- @flags.multi_flags_validator(
- ["benchmark_logger_type", "benchmark_log_dir"],
- message="--benchmark_logger_type=BenchmarkFileLogger will require "
- "--benchmark_log_dir being set")
- def _check_benchmark_log_dir(flags_dict):
- benchmark_logger_type = flags_dict["benchmark_logger_type"]
- if benchmark_logger_type == "BenchmarkFileLogger":
- return flags_dict["benchmark_log_dir"]
- return True
-
- return key_flags
diff --git a/spaces/NCTCMumbai/NCTC/models/research/cognitive_mapping_and_planning/src/depth_utils.py b/spaces/NCTCMumbai/NCTC/models/research/cognitive_mapping_and_planning/src/depth_utils.py
deleted file mode 100644
index 35f14fc7c37fffb2a408decede11e378867a2834..0000000000000000000000000000000000000000
--- a/spaces/NCTCMumbai/NCTC/models/research/cognitive_mapping_and_planning/src/depth_utils.py
+++ /dev/null
@@ -1,96 +0,0 @@
-# Copyright 2016 The TensorFlow Authors All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-# ==============================================================================
-
-"""Utilities for processing depth images.
-"""
-import numpy as np
-import src.rotation_utils as ru
-import src.utils as utils
-
-def get_camera_matrix(width, height, fov):
- """Returns a camera matrix from image size and fov."""
- xc = (width-1.) / 2.
- zc = (height-1.) / 2.
- f = (width / 2.) / np.tan(np.deg2rad(fov / 2.))
- camera_matrix = utils.Foo(xc=xc, zc=zc, f=f)
- return camera_matrix
-
-def get_point_cloud_from_z(Y, camera_matrix):
- """Projects the depth image Y into a 3D point cloud.
- Inputs:
- Y is ...xHxW
- camera_matrix
- Outputs:
- X is positive going right
- Y is positive into the image
- Z is positive up in the image
- XYZ is ...xHxWx3
- """
- x, z = np.meshgrid(np.arange(Y.shape[-1]),
- np.arange(Y.shape[-2]-1, -1, -1))
- for i in range(Y.ndim-2):
- x = np.expand_dims(x, axis=0)
- z = np.expand_dims(z, axis=0)
- X = (x-camera_matrix.xc) * Y / camera_matrix.f
- Z = (z-camera_matrix.zc) * Y / camera_matrix.f
- XYZ = np.concatenate((X[...,np.newaxis], Y[...,np.newaxis],
- Z[...,np.newaxis]), axis=X.ndim)
- return XYZ
-
-def make_geocentric(XYZ, sensor_height, camera_elevation_degree):
- """Transforms the point cloud into geocentric coordinate frame.
- Input:
- XYZ : ...x3
- sensor_height : height of the sensor
- camera_elevation_degree : camera elevation to rectify.
- Output:
- XYZ : ...x3
- """
- R = ru.get_r_matrix([1.,0.,0.], angle=np.deg2rad(camera_elevation_degree))
- XYZ = np.matmul(XYZ.reshape(-1,3), R.T).reshape(XYZ.shape)
- XYZ[...,2] = XYZ[...,2] + sensor_height
- return XYZ
-
-def bin_points(XYZ_cms, map_size, z_bins, xy_resolution):
- """Bins points into xy-z bins
- XYZ_cms is ... x H x W x3
- Outputs is ... x map_size x map_size x (len(z_bins)+1)
- """
- sh = XYZ_cms.shape
- XYZ_cms = XYZ_cms.reshape([-1, sh[-3], sh[-2], sh[-1]])
- n_z_bins = len(z_bins)+1
- map_center = (map_size-1.)/2.
- counts = []
- isvalids = []
- for XYZ_cm in XYZ_cms:
- isnotnan = np.logical_not(np.isnan(XYZ_cm[:,:,0]))
- X_bin = np.round(XYZ_cm[:,:,0] / xy_resolution + map_center).astype(np.int32)
- Y_bin = np.round(XYZ_cm[:,:,1] / xy_resolution + map_center).astype(np.int32)
- Z_bin = np.digitize(XYZ_cm[:,:,2], bins=z_bins).astype(np.int32)
-
- isvalid = np.array([X_bin >= 0, X_bin < map_size, Y_bin >= 0, Y_bin < map_size,
- Z_bin >= 0, Z_bin < n_z_bins, isnotnan])
- isvalid = np.all(isvalid, axis=0)
-
- ind = (Y_bin * map_size + X_bin) * n_z_bins + Z_bin
- ind[np.logical_not(isvalid)] = 0
- count = np.bincount(ind.ravel(), isvalid.ravel().astype(np.int32),
- minlength=map_size*map_size*n_z_bins)
- count = np.reshape(count, [map_size, map_size, n_z_bins])
- counts.append(count)
- isvalids.append(isvalid)
- counts = np.array(counts).reshape(list(sh[:-3]) + [map_size, map_size, n_z_bins])
- isvalids = np.array(isvalids).reshape(list(sh[:-3]) + [sh[-3], sh[-2], 1])
- return counts, isvalids
diff --git a/spaces/NN520/AI/next.config.js b/spaces/NN520/AI/next.config.js
deleted file mode 100644
index 0e6ccd7fbc91d0459eaaff3e968ce0556789c605..0000000000000000000000000000000000000000
--- a/spaces/NN520/AI/next.config.js
+++ /dev/null
@@ -1,38 +0,0 @@
-/** @type {import('next').NextConfig} */
-const nextConfig = {
- // output: 'export',
- // assetPrefix: '.',
- webpack: (config, { isServer }) => {
- if (!isServer) {
- config.resolve = {
- ...config.resolve,
- fallback: {
- 'bufferutil': false,
- 'utf-8-validate': false,
- http: false,
- https: false,
- stream: false,
- // fixes proxy-agent dependencies
- net: false,
- dns: false,
- tls: false,
- assert: false,
- // fixes next-i18next dependencies
- path: false,
- fs: false,
- // fixes mapbox dependencies
- events: false,
- // fixes sentry dependencies
- process: false
- }
- };
- }
- config.module.exprContextCritical = false;
-
- return config;
- },
-}
-
-module.exports = (...args) => {
- return nextConfig
-}
diff --git a/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/fairseq/tasks/legacy_masked_lm.py b/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/fairseq/tasks/legacy_masked_lm.py
deleted file mode 100644
index 975497654926b64fff6c4960f54c4e6932e7fce1..0000000000000000000000000000000000000000
--- a/spaces/OFA-Sys/OFA-Generic_Interface/fairseq/fairseq/tasks/legacy_masked_lm.py
+++ /dev/null
@@ -1,152 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-import itertools
-import logging
-import os
-
-import numpy as np
-from fairseq import tokenizer, utils
-from fairseq.data import ConcatDataset, Dictionary, data_utils, indexed_dataset
-from fairseq.data.legacy.block_pair_dataset import BlockPairDataset
-from fairseq.data.legacy.masked_lm_dataset import MaskedLMDataset
-from fairseq.data.legacy.masked_lm_dictionary import BertDictionary
-from fairseq.tasks import LegacyFairseqTask, register_task
-
-
-logger = logging.getLogger(__name__)
-
-
-@register_task("legacy_masked_lm")
-class LegacyMaskedLMTask(LegacyFairseqTask):
- """
- Task for training Masked LM (BERT) model.
- Args:
- dictionary (Dictionary): the dictionary for the input of the task
- """
-
- @staticmethod
- def add_args(parser):
- """Add task-specific arguments to the parser."""
- parser.add_argument(
- "data",
- help="colon separated path to data directories list, \
- will be iterated upon during epochs in round-robin manner",
- )
- parser.add_argument(
- "--tokens-per-sample",
- default=512,
- type=int,
- help="max number of total tokens over all segments"
- " per sample for BERT dataset",
- )
- parser.add_argument(
- "--break-mode", default="doc", type=str, help="mode for breaking sentence"
- )
- parser.add_argument("--shuffle-dataset", action="store_true", default=False)
-
- def __init__(self, args, dictionary):
- super().__init__(args)
- self.dictionary = dictionary
- self.seed = args.seed
-
- @classmethod
- def load_dictionary(cls, filename):
- return BertDictionary.load(filename)
-
- @classmethod
- def build_dictionary(
- cls, filenames, workers=1, threshold=-1, nwords=-1, padding_factor=8
- ):
- d = BertDictionary()
- for filename in filenames:
- Dictionary.add_file_to_dictionary(
- filename, d, tokenizer.tokenize_line, workers
- )
- d.finalize(threshold=threshold, nwords=nwords, padding_factor=padding_factor)
- return d
-
- @property
- def target_dictionary(self):
- return self.dictionary
-
- @classmethod
- def setup_task(cls, args, **kwargs):
- """Setup the task."""
- paths = utils.split_paths(args.data)
- assert len(paths) > 0
- dictionary = BertDictionary.load(os.path.join(paths[0], "dict.txt"))
- logger.info("dictionary: {} types".format(len(dictionary)))
-
- return cls(args, dictionary)
-
- def load_dataset(self, split, epoch=1, combine=False):
- """Load a given dataset split.
-
- Args:
- split (str): name of the split (e.g., train, valid, test)
- """
- loaded_datasets = []
-
- paths = utils.split_paths(self.args.data)
- assert len(paths) > 0
- data_path = paths[(epoch - 1) % len(paths)]
- logger.info("data_path", data_path)
-
- for k in itertools.count():
- split_k = split + (str(k) if k > 0 else "")
- path = os.path.join(data_path, split_k)
- ds = indexed_dataset.make_dataset(
- path,
- impl=self.args.dataset_impl,
- fix_lua_indexing=True,
- dictionary=self.dictionary,
- )
-
- if ds is None:
- if k > 0:
- break
- else:
- raise FileNotFoundError(
- "Dataset not found: {} ({})".format(split, data_path)
- )
-
- with data_utils.numpy_seed(self.seed + k):
- loaded_datasets.append(
- BlockPairDataset(
- ds,
- self.dictionary,
- ds.sizes,
- self.args.tokens_per_sample,
- break_mode=self.args.break_mode,
- doc_break_size=1,
- )
- )
-
- logger.info(
- "{} {} {} examples".format(data_path, split_k, len(loaded_datasets[-1]))
- )
-
- if not combine:
- break
-
- if len(loaded_datasets) == 1:
- dataset = loaded_datasets[0]
- sizes = dataset.sizes
- else:
- dataset = ConcatDataset(loaded_datasets)
- sizes = np.concatenate([ds.sizes for ds in loaded_datasets])
-
- self.datasets[split] = MaskedLMDataset(
- dataset=dataset,
- sizes=sizes,
- vocab=self.dictionary,
- pad_idx=self.dictionary.pad(),
- mask_idx=self.dictionary.mask(),
- classif_token_idx=self.dictionary.cls(),
- sep_token_idx=self.dictionary.sep(),
- shuffle=self.args.shuffle_dataset,
- seed=self.seed,
- )
diff --git a/spaces/OFA-Sys/OFA-Generic_Interface/utils/cider/pyciderevalcap/ciderD/__init__.py b/spaces/OFA-Sys/OFA-Generic_Interface/utils/cider/pyciderevalcap/ciderD/__init__.py
deleted file mode 100644
index 3f7d85bba884ea8f83fc6ab2a1e6ade80d98d4d9..0000000000000000000000000000000000000000
--- a/spaces/OFA-Sys/OFA-Generic_Interface/utils/cider/pyciderevalcap/ciderD/__init__.py
+++ /dev/null
@@ -1 +0,0 @@
-__author__ = 'tylin'
diff --git a/spaces/OFA-Sys/OFA-Image_Caption/fairseq/examples/multilingual/data_scripts/utils/dedup.py b/spaces/OFA-Sys/OFA-Image_Caption/fairseq/examples/multilingual/data_scripts/utils/dedup.py
deleted file mode 100644
index d6fed8c695cf218d3502d6ed8d23015520c0e179..0000000000000000000000000000000000000000
--- a/spaces/OFA-Sys/OFA-Image_Caption/fairseq/examples/multilingual/data_scripts/utils/dedup.py
+++ /dev/null
@@ -1,41 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-
-import argparse
-
-def deup(src_file, tgt_file, src_file_out, tgt_file_out):
- seen = set()
- dup_count = 0
- with open(src_file, encoding='utf-8') as fsrc, \
- open(tgt_file, encoding='utf-8') as ftgt, \
- open(src_file_out, 'w', encoding='utf-8') as fsrc_out, \
- open(tgt_file_out, 'w', encoding='utf-8') as ftgt_out:
- for s, t in zip(fsrc, ftgt):
- if (s, t) not in seen:
- fsrc_out.write(s)
- ftgt_out.write(t)
- seen.add((s, t))
- else:
- dup_count += 1
- print(f'number of duplication: {dup_count}')
-
-
-def main():
- parser = argparse.ArgumentParser()
- parser.add_argument("--src-file", type=str, required=True,
- help="src file")
- parser.add_argument("--tgt-file", type=str, required=True,
- help="tgt file")
- parser.add_argument("--src-file-out", type=str, required=True,
- help="src ouptut file")
- parser.add_argument("--tgt-file-out", type=str, required=True,
- help="tgt ouput file")
- args = parser.parse_args()
- deup(args.src_file, args.tgt_file, args.src_file_out, args.tgt_file_out)
-
-
-if __name__ == "__main__":
- main()
diff --git a/spaces/OFA-Sys/OFA-vqa/fairseq/examples/fast_noisy_channel/noisy_channel_beam_search.py b/spaces/OFA-Sys/OFA-vqa/fairseq/examples/fast_noisy_channel/noisy_channel_beam_search.py
deleted file mode 100644
index 23869ebcd0c438f36e310c8ccddd3b5c07a71182..0000000000000000000000000000000000000000
--- a/spaces/OFA-Sys/OFA-vqa/fairseq/examples/fast_noisy_channel/noisy_channel_beam_search.py
+++ /dev/null
@@ -1,71 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-#
-# This source code is licensed under the MIT license found in the
-# LICENSE file in the root directory of this source tree.
-
-import torch
-from fairseq.search import Search
-
-
-class NoisyChannelBeamSearch(Search):
-
- def __init__(self, tgt_dict):
- super().__init__(tgt_dict)
- self.fw_scores_buf = None
- self.lm_scores_buf = None
-
- def _init_buffers(self, t):
- # super()._init_buffers(t)
- if self.fw_scores_buf is None:
- self.scores_buf = t.new()
- self.indices_buf = torch.LongTensor().to(device=t.device)
- self.beams_buf = torch.LongTensor().to(device=t.device)
- self.fw_scores_buf = t.new()
- self.lm_scores_buf = t.new()
-
- def combine_fw_bw(self, combine_method, fw_cum, bw, step):
- if combine_method == "noisy_channel":
- fw_norm = fw_cum.div(step + 1)
- lprobs = bw + fw_norm
- elif combine_method == "lm_only":
- lprobs = bw + fw_cum
-
- return lprobs
-
- def step(self, step, fw_lprobs, scores, bw_lprobs, lm_lprobs, combine_method):
- self._init_buffers(fw_lprobs)
- bsz, beam_size, vocab_size = fw_lprobs.size()
-
- if step == 0:
- # at the first step all hypotheses are equally likely, so use
- # only the first beam
- fw_lprobs = fw_lprobs[:, ::beam_size, :].contiguous()
- bw_lprobs = bw_lprobs[:, ::beam_size, :].contiguous()
- # nothing to add since we are at the first step
- fw_lprobs_cum = fw_lprobs
-
- else:
- # make probs contain cumulative scores for each hypothesis
- raw_scores = (scores[:, :, step - 1].unsqueeze(-1))
- fw_lprobs_cum = (fw_lprobs.add(raw_scores))
-
- combined_lprobs = self.combine_fw_bw(combine_method, fw_lprobs_cum, bw_lprobs, step)
-
- # choose the top k according to the combined noisy channel model score
- torch.topk(
- combined_lprobs.view(bsz, -1),
- k=min(
- # Take the best 2 x beam_size predictions. We'll choose the first
- # beam_size of these which don't predict eos to continue with.
- beam_size * 2,
- combined_lprobs.view(bsz, -1).size(1) - 1, # -1 so we never select pad
- ),
- out=(self.scores_buf, self.indices_buf),
- )
- # save corresponding fw and lm scores
- self.fw_scores_buf = torch.gather(fw_lprobs_cum.view(bsz, -1), 1, self.indices_buf)
- self.lm_scores_buf = torch.gather(lm_lprobs.view(bsz, -1), 1, self.indices_buf)
- # Project back into relative indices and beams
- self.beams_buf = self.indices_buf // vocab_size
- self.indices_buf.fmod_(vocab_size)
- return self.scores_buf, self.fw_scores_buf, self.lm_scores_buf, self.indices_buf, self.beams_buf
diff --git a/spaces/OFA-Sys/OFA-vqa/fairseq/examples/joint_alignment_translation/README.md b/spaces/OFA-Sys/OFA-vqa/fairseq/examples/joint_alignment_translation/README.md
deleted file mode 100644
index cd9c0ea65f5292198296a8f427b42e01b584e2d9..0000000000000000000000000000000000000000
--- a/spaces/OFA-Sys/OFA-vqa/fairseq/examples/joint_alignment_translation/README.md
+++ /dev/null
@@ -1,89 +0,0 @@
-# Jointly Learning to Align and Translate with Transformer Models (Garg et al., 2019)
-
-This page includes instructions for training models described in [Jointly Learning to Align and Translate with Transformer Models (Garg et al., 2019)](https://arxiv.org/abs/1909.02074).
-
-## Training a joint alignment-translation model on WMT'18 En-De
-
-##### 1. Extract and preprocess the WMT'18 En-De data
-```bash
-./prepare-wmt18en2de_no_norm_no_escape_no_agressive.sh
-```
-
-##### 2. Generate alignments from statistical alignment toolkits e.g. Giza++/FastAlign.
-In this example, we use FastAlign.
-```bash
-git clone git@github.com:clab/fast_align.git
-pushd fast_align
-mkdir build
-cd build
-cmake ..
-make
-popd
-ALIGN=fast_align/build/fast_align
-paste bpe.32k/train.en bpe.32k/train.de | awk -F '\t' '{print $1 " ||| " $2}' > bpe.32k/train.en-de
-$ALIGN -i bpe.32k/train.en-de -d -o -v > bpe.32k/train.align
-```
-
-##### 3. Preprocess the dataset with the above generated alignments.
-```bash
-fairseq-preprocess \
- --source-lang en --target-lang de \
- --trainpref bpe.32k/train \
- --validpref bpe.32k/valid \
- --testpref bpe.32k/test \
- --align-suffix align \
- --destdir binarized/ \
- --joined-dictionary \
- --workers 32
-```
-
-##### 4. Train a model
-```bash
-fairseq-train \
- binarized \
- --arch transformer_wmt_en_de_big_align --share-all-embeddings \
- --optimizer adam --adam-betas '(0.9, 0.98)' --clip-norm 0.0 --activation-fn relu\
- --lr 0.0002 --lr-scheduler inverse_sqrt --warmup-updates 4000 --warmup-init-lr 1e-07 \
- --dropout 0.3 --attention-dropout 0.1 --weight-decay 0.0 \
- --max-tokens 3500 --label-smoothing 0.1 \
- --save-dir ./checkpoints --log-interval 1000 --max-update 60000 \
- --keep-interval-updates -1 --save-interval-updates 0 \
- --load-alignments --criterion label_smoothed_cross_entropy_with_alignment \
- --fp16
-```
-
-Note that the `--fp16` flag requires you have CUDA 9.1 or greater and a Volta GPU or newer.
-
-If you want to train the above model with big batches (assuming your machine has 8 GPUs):
-- add `--update-freq 8` to simulate training on 8x8=64 GPUs
-- increase the learning rate; 0.0007 works well for big batches
-
-##### 5. Evaluate and generate the alignments (BPE level)
-```bash
-fairseq-generate \
- binarized --gen-subset test --print-alignment \
- --source-lang en --target-lang de \
- --path checkpoints/checkpoint_best.pt --beam 5 --nbest 1
-```
-
-##### 6. Other resources.
-The code for:
-1. preparing alignment test sets
-2. converting BPE level alignments to token level alignments
-3. symmetrizing bidirectional alignments
-4. evaluating alignments using AER metric
-can be found [here](https://github.com/lilt/alignment-scripts)
-
-## Citation
-
-```bibtex
-@inproceedings{garg2019jointly,
- title = {Jointly Learning to Align and Translate with Transformer Models},
- author = {Garg, Sarthak and Peitz, Stephan and Nallasamy, Udhyakumar and Paulik, Matthias},
- booktitle = {Conference on Empirical Methods in Natural Language Processing (EMNLP)},
- address = {Hong Kong},
- month = {November},
- url = {https://arxiv.org/abs/1909.02074},
- year = {2019},
-}
-```
diff --git a/spaces/OpenGVLab/InternGPT/iGPT/models/grit_src/third_party/CenterNet2/detectron2/structures/boxes.py b/spaces/OpenGVLab/InternGPT/iGPT/models/grit_src/third_party/CenterNet2/detectron2/structures/boxes.py
deleted file mode 100644
index ae543c617a33245075b001f383f41775efb0b63d..0000000000000000000000000000000000000000
--- a/spaces/OpenGVLab/InternGPT/iGPT/models/grit_src/third_party/CenterNet2/detectron2/structures/boxes.py
+++ /dev/null
@@ -1,423 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-import math
-import numpy as np
-from enum import IntEnum, unique
-from typing import List, Tuple, Union
-import torch
-from torch import device
-
-_RawBoxType = Union[List[float], Tuple[float, ...], torch.Tensor, np.ndarray]
-
-
-@unique
-class BoxMode(IntEnum):
- """
- Enum of different ways to represent a box.
- """
-
- XYXY_ABS = 0
- """
- (x0, y0, x1, y1) in absolute floating points coordinates.
- The coordinates in range [0, width or height].
- """
- XYWH_ABS = 1
- """
- (x0, y0, w, h) in absolute floating points coordinates.
- """
- XYXY_REL = 2
- """
- Not yet supported!
- (x0, y0, x1, y1) in range [0, 1]. They are relative to the size of the image.
- """
- XYWH_REL = 3
- """
- Not yet supported!
- (x0, y0, w, h) in range [0, 1]. They are relative to the size of the image.
- """
- XYWHA_ABS = 4
- """
- (xc, yc, w, h, a) in absolute floating points coordinates.
- (xc, yc) is the center of the rotated box, and the angle a is in degrees ccw.
- """
-
- @staticmethod
- def convert(box: _RawBoxType, from_mode: "BoxMode", to_mode: "BoxMode") -> _RawBoxType:
- """
- Args:
- box: can be a k-tuple, k-list or an Nxk array/tensor, where k = 4 or 5
- from_mode, to_mode (BoxMode)
-
- Returns:
- The converted box of the same type.
- """
- if from_mode == to_mode:
- return box
-
- original_type = type(box)
- is_numpy = isinstance(box, np.ndarray)
- single_box = isinstance(box, (list, tuple))
- if single_box:
- assert len(box) == 4 or len(box) == 5, (
- "BoxMode.convert takes either a k-tuple/list or an Nxk array/tensor,"
- " where k == 4 or 5"
- )
- arr = torch.tensor(box)[None, :]
- else:
- # avoid modifying the input box
- if is_numpy:
- arr = torch.from_numpy(np.asarray(box)).clone()
- else:
- arr = box.clone()
-
- assert to_mode not in [BoxMode.XYXY_REL, BoxMode.XYWH_REL] and from_mode not in [
- BoxMode.XYXY_REL,
- BoxMode.XYWH_REL,
- ], "Relative mode not yet supported!"
-
- if from_mode == BoxMode.XYWHA_ABS and to_mode == BoxMode.XYXY_ABS:
- assert (
- arr.shape[-1] == 5
- ), "The last dimension of input shape must be 5 for XYWHA format"
- original_dtype = arr.dtype
- arr = arr.double()
-
- w = arr[:, 2]
- h = arr[:, 3]
- a = arr[:, 4]
- c = torch.abs(torch.cos(a * math.pi / 180.0))
- s = torch.abs(torch.sin(a * math.pi / 180.0))
- # This basically computes the horizontal bounding rectangle of the rotated box
- new_w = c * w + s * h
- new_h = c * h + s * w
-
- # convert center to top-left corner
- arr[:, 0] -= new_w / 2.0
- arr[:, 1] -= new_h / 2.0
- # bottom-right corner
- arr[:, 2] = arr[:, 0] + new_w
- arr[:, 3] = arr[:, 1] + new_h
-
- arr = arr[:, :4].to(dtype=original_dtype)
- elif from_mode == BoxMode.XYWH_ABS and to_mode == BoxMode.XYWHA_ABS:
- original_dtype = arr.dtype
- arr = arr.double()
- arr[:, 0] += arr[:, 2] / 2.0
- arr[:, 1] += arr[:, 3] / 2.0
- angles = torch.zeros((arr.shape[0], 1), dtype=arr.dtype)
- arr = torch.cat((arr, angles), axis=1).to(dtype=original_dtype)
- else:
- if to_mode == BoxMode.XYXY_ABS and from_mode == BoxMode.XYWH_ABS:
- arr[:, 2] += arr[:, 0]
- arr[:, 3] += arr[:, 1]
- elif from_mode == BoxMode.XYXY_ABS and to_mode == BoxMode.XYWH_ABS:
- arr[:, 2] -= arr[:, 0]
- arr[:, 3] -= arr[:, 1]
- else:
- raise NotImplementedError(
- "Conversion from BoxMode {} to {} is not supported yet".format(
- from_mode, to_mode
- )
- )
-
- if single_box:
- return original_type(arr.flatten().tolist())
- if is_numpy:
- return arr.numpy()
- else:
- return arr
-
-
-class Boxes:
- """
- This structure stores a list of boxes as a Nx4 torch.Tensor.
- It supports some common methods about boxes
- (`area`, `clip`, `nonempty`, etc),
- and also behaves like a Tensor
- (support indexing, `to(device)`, `.device`, and iteration over all boxes)
-
- Attributes:
- tensor (torch.Tensor): float matrix of Nx4. Each row is (x1, y1, x2, y2).
- """
-
- def __init__(self, tensor: torch.Tensor):
- """
- Args:
- tensor (Tensor[float]): a Nx4 matrix. Each row is (x1, y1, x2, y2).
- """
- device = tensor.device if isinstance(tensor, torch.Tensor) else torch.device("cpu")
- tensor = torch.as_tensor(tensor, dtype=torch.float32, device=device)
- if tensor.numel() == 0:
- # Use reshape, so we don't end up creating a new tensor that does not depend on
- # the inputs (and consequently confuses jit)
- tensor = tensor.reshape((-1, 4)).to(dtype=torch.float32, device=device)
- assert tensor.dim() == 2 and tensor.size(-1) == 4, tensor.size()
-
- self.tensor = tensor
-
- def clone(self) -> "Boxes":
- """
- Clone the Boxes.
-
- Returns:
- Boxes
- """
- return Boxes(self.tensor.clone())
-
- def to(self, device: torch.device):
- # Boxes are assumed float32 and does not support to(dtype)
- return Boxes(self.tensor.to(device=device))
-
- def area(self) -> torch.Tensor:
- """
- Computes the area of all the boxes.
-
- Returns:
- torch.Tensor: a vector with areas of each box.
- """
- box = self.tensor
- area = (box[:, 2] - box[:, 0]) * (box[:, 3] - box[:, 1])
- return area
-
- def clip(self, box_size: Tuple[int, int]) -> None:
- """
- Clip (in place) the boxes by limiting x coordinates to the range [0, width]
- and y coordinates to the range [0, height].
-
- Args:
- box_size (height, width): The clipping box's size.
- """
- assert torch.isfinite(self.tensor).all(), "Box tensor contains infinite or NaN!"
- h, w = box_size
- x1 = self.tensor[:, 0].clamp(min=0, max=w)
- y1 = self.tensor[:, 1].clamp(min=0, max=h)
- x2 = self.tensor[:, 2].clamp(min=0, max=w)
- y2 = self.tensor[:, 3].clamp(min=0, max=h)
- self.tensor = torch.stack((x1, y1, x2, y2), dim=-1)
-
- def nonempty(self, threshold: float = 0.0) -> torch.Tensor:
- """
- Find boxes that are non-empty.
- A box is considered empty, if either of its side is no larger than threshold.
-
- Returns:
- Tensor:
- a binary vector which represents whether each box is empty
- (False) or non-empty (True).
- """
- box = self.tensor
- widths = box[:, 2] - box[:, 0]
- heights = box[:, 3] - box[:, 1]
- keep = (widths > threshold) & (heights > threshold)
- return keep
-
- def __getitem__(self, item) -> "Boxes":
- """
- Args:
- item: int, slice, or a BoolTensor
-
- Returns:
- Boxes: Create a new :class:`Boxes` by indexing.
-
- The following usage are allowed:
-
- 1. `new_boxes = boxes[3]`: return a `Boxes` which contains only one box.
- 2. `new_boxes = boxes[2:10]`: return a slice of boxes.
- 3. `new_boxes = boxes[vector]`, where vector is a torch.BoolTensor
- with `length = len(boxes)`. Nonzero elements in the vector will be selected.
-
- Note that the returned Boxes might share storage with this Boxes,
- subject to Pytorch's indexing semantics.
- """
- if isinstance(item, int):
- return Boxes(self.tensor[item].view(1, -1))
- b = self.tensor[item]
- assert b.dim() == 2, "Indexing on Boxes with {} failed to return a matrix!".format(item)
- return Boxes(b)
-
- def __len__(self) -> int:
- return self.tensor.shape[0]
-
- def __repr__(self) -> str:
- return "Boxes(" + str(self.tensor) + ")"
-
- def inside_box(self, box_size: Tuple[int, int], boundary_threshold: int = 0) -> torch.Tensor:
- """
- Args:
- box_size (height, width): Size of the reference box.
- boundary_threshold (int): Boxes that extend beyond the reference box
- boundary by more than boundary_threshold are considered "outside".
-
- Returns:
- a binary vector, indicating whether each box is inside the reference box.
- """
- height, width = box_size
- inds_inside = (
- (self.tensor[..., 0] >= -boundary_threshold)
- & (self.tensor[..., 1] >= -boundary_threshold)
- & (self.tensor[..., 2] < width + boundary_threshold)
- & (self.tensor[..., 3] < height + boundary_threshold)
- )
- return inds_inside
-
- def get_centers(self) -> torch.Tensor:
- """
- Returns:
- The box centers in a Nx2 array of (x, y).
- """
- return (self.tensor[:, :2] + self.tensor[:, 2:]) / 2
-
- def scale(self, scale_x: float, scale_y: float) -> None:
- """
- Scale the box with horizontal and vertical scaling factors
- """
- self.tensor[:, 0::2] *= scale_x
- self.tensor[:, 1::2] *= scale_y
-
- @classmethod
- def cat(cls, boxes_list: List["Boxes"]) -> "Boxes":
- """
- Concatenates a list of Boxes into a single Boxes
-
- Arguments:
- boxes_list (list[Boxes])
-
- Returns:
- Boxes: the concatenated Boxes
- """
- assert isinstance(boxes_list, (list, tuple))
- if len(boxes_list) == 0:
- return cls(torch.empty(0))
- assert all([isinstance(box, Boxes) for box in boxes_list])
-
- # use torch.cat (v.s. layers.cat) so the returned boxes never share storage with input
- cat_boxes = cls(torch.cat([b.tensor for b in boxes_list], dim=0))
- return cat_boxes
-
- @property
- def device(self) -> device:
- return self.tensor.device
-
- # type "Iterator[torch.Tensor]", yield, and iter() not supported by torchscript
- # https://github.com/pytorch/pytorch/issues/18627
- @torch.jit.unused
- def __iter__(self):
- """
- Yield a box as a Tensor of shape (4,) at a time.
- """
- yield from self.tensor
-
-
-def pairwise_intersection(boxes1: Boxes, boxes2: Boxes) -> torch.Tensor:
- """
- Given two lists of boxes of size N and M,
- compute the intersection area between __all__ N x M pairs of boxes.
- The box order must be (xmin, ymin, xmax, ymax)
-
- Args:
- boxes1,boxes2 (Boxes): two `Boxes`. Contains N & M boxes, respectively.
-
- Returns:
- Tensor: intersection, sized [N,M].
- """
- boxes1, boxes2 = boxes1.tensor, boxes2.tensor
- width_height = torch.min(boxes1[:, None, 2:], boxes2[:, 2:]) - torch.max(
- boxes1[:, None, :2], boxes2[:, :2]
- ) # [N,M,2]
-
- width_height.clamp_(min=0) # [N,M,2]
- intersection = width_height.prod(dim=2) # [N,M]
- return intersection
-
-
-# implementation from https://github.com/kuangliu/torchcv/blob/master/torchcv/utils/box.py
-# with slight modifications
-def pairwise_iou(boxes1: Boxes, boxes2: Boxes) -> torch.Tensor:
- """
- Given two lists of boxes of size N and M, compute the IoU
- (intersection over union) between **all** N x M pairs of boxes.
- The box order must be (xmin, ymin, xmax, ymax).
-
- Args:
- boxes1,boxes2 (Boxes): two `Boxes`. Contains N & M boxes, respectively.
-
- Returns:
- Tensor: IoU, sized [N,M].
- """
- area1 = boxes1.area() # [N]
- area2 = boxes2.area() # [M]
- inter = pairwise_intersection(boxes1, boxes2)
-
- # handle empty boxes
- iou = torch.where(
- inter > 0,
- inter / (area1[:, None] + area2 - inter),
- torch.zeros(1, dtype=inter.dtype, device=inter.device),
- )
- return iou
-
-
-def pairwise_ioa(boxes1: Boxes, boxes2: Boxes) -> torch.Tensor:
- """
- Similar to :func:`pariwise_iou` but compute the IoA (intersection over boxes2 area).
-
- Args:
- boxes1,boxes2 (Boxes): two `Boxes`. Contains N & M boxes, respectively.
-
- Returns:
- Tensor: IoA, sized [N,M].
- """
- area2 = boxes2.area() # [M]
- inter = pairwise_intersection(boxes1, boxes2)
-
- # handle empty boxes
- ioa = torch.where(
- inter > 0, inter / area2, torch.zeros(1, dtype=inter.dtype, device=inter.device)
- )
- return ioa
-
-
-def pairwise_point_box_distance(points: torch.Tensor, boxes: Boxes):
- """
- Pairwise distance between N points and M boxes. The distance between a
- point and a box is represented by the distance from the point to 4 edges
- of the box. Distances are all positive when the point is inside the box.
-
- Args:
- points: Nx2 coordinates. Each row is (x, y)
- boxes: M boxes
-
- Returns:
- Tensor: distances of size (N, M, 4). The 4 values are distances from
- the point to the left, top, right, bottom of the box.
- """
- x, y = points.unsqueeze(dim=2).unbind(dim=1) # (N, 1)
- x0, y0, x1, y1 = boxes.tensor.unsqueeze(dim=0).unbind(dim=2) # (1, M)
- return torch.stack([x - x0, y - y0, x1 - x, y1 - y], dim=2)
-
-
-def matched_pairwise_iou(boxes1: Boxes, boxes2: Boxes) -> torch.Tensor:
- """
- Compute pairwise intersection over union (IOU) of two sets of matched
- boxes that have the same number of boxes.
- Similar to :func:`pairwise_iou`, but computes only diagonal elements of the matrix.
-
- Args:
- boxes1 (Boxes): bounding boxes, sized [N,4].
- boxes2 (Boxes): same length as boxes1
- Returns:
- Tensor: iou, sized [N].
- """
- assert len(boxes1) == len(
- boxes2
- ), "boxlists should have the same" "number of entries, got {}, {}".format(
- len(boxes1), len(boxes2)
- )
- area1 = boxes1.area() # [N]
- area2 = boxes2.area() # [N]
- box1, box2 = boxes1.tensor, boxes2.tensor
- lt = torch.max(box1[:, :2], box2[:, :2]) # [N,2]
- rb = torch.min(box1[:, 2:], box2[:, 2:]) # [N,2]
- wh = (rb - lt).clamp(min=0) # [N,2]
- inter = wh[:, 0] * wh[:, 1] # [N]
- iou = inter / (area1 + area2 - inter) # [N]
- return iou
diff --git a/spaces/PAIR/Text2Video-Zero/annotator/uniformer/configs/_base_/models/danet_r50-d8.py b/spaces/PAIR/Text2Video-Zero/annotator/uniformer/configs/_base_/models/danet_r50-d8.py
deleted file mode 100644
index 2c934939fac48525f22ad86f489a041dd7db7d09..0000000000000000000000000000000000000000
--- a/spaces/PAIR/Text2Video-Zero/annotator/uniformer/configs/_base_/models/danet_r50-d8.py
+++ /dev/null
@@ -1,44 +0,0 @@
-# model settings
-norm_cfg = dict(type='SyncBN', requires_grad=True)
-model = dict(
- type='EncoderDecoder',
- pretrained='open-mmlab://resnet50_v1c',
- backbone=dict(
- type='ResNetV1c',
- depth=50,
- num_stages=4,
- out_indices=(0, 1, 2, 3),
- dilations=(1, 1, 2, 4),
- strides=(1, 2, 1, 1),
- norm_cfg=norm_cfg,
- norm_eval=False,
- style='pytorch',
- contract_dilation=True),
- decode_head=dict(
- type='DAHead',
- in_channels=2048,
- in_index=3,
- channels=512,
- pam_channels=64,
- dropout_ratio=0.1,
- num_classes=19,
- norm_cfg=norm_cfg,
- align_corners=False,
- loss_decode=dict(
- type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0)),
- auxiliary_head=dict(
- type='FCNHead',
- in_channels=1024,
- in_index=2,
- channels=256,
- num_convs=1,
- concat_input=False,
- dropout_ratio=0.1,
- num_classes=19,
- norm_cfg=norm_cfg,
- align_corners=False,
- loss_decode=dict(
- type='CrossEntropyLoss', use_sigmoid=False, loss_weight=0.4)),
- # model training and testing settings
- train_cfg=dict(),
- test_cfg=dict(mode='whole'))
diff --git a/spaces/PAIR/Text2Video-Zero/annotator/uniformer/mmseg/models/utils/se_layer.py b/spaces/PAIR/Text2Video-Zero/annotator/uniformer/mmseg/models/utils/se_layer.py
deleted file mode 100644
index 083bd7d1ccee909c900c7aed2cc928bf14727f3e..0000000000000000000000000000000000000000
--- a/spaces/PAIR/Text2Video-Zero/annotator/uniformer/mmseg/models/utils/se_layer.py
+++ /dev/null
@@ -1,57 +0,0 @@
-import annotator.uniformer.mmcv as mmcv
-import torch.nn as nn
-from annotator.uniformer.mmcv.cnn import ConvModule
-
-from .make_divisible import make_divisible
-
-
-class SELayer(nn.Module):
- """Squeeze-and-Excitation Module.
-
- Args:
- channels (int): The input (and output) channels of the SE layer.
- ratio (int): Squeeze ratio in SELayer, the intermediate channel will be
- ``int(channels/ratio)``. Default: 16.
- conv_cfg (None or dict): Config dict for convolution layer.
- Default: None, which means using conv2d.
- act_cfg (dict or Sequence[dict]): Config dict for activation layer.
- If act_cfg is a dict, two activation layers will be configured
- by this dict. If act_cfg is a sequence of dicts, the first
- activation layer will be configured by the first dict and the
- second activation layer will be configured by the second dict.
- Default: (dict(type='ReLU'), dict(type='HSigmoid', bias=3.0,
- divisor=6.0)).
- """
-
- def __init__(self,
- channels,
- ratio=16,
- conv_cfg=None,
- act_cfg=(dict(type='ReLU'),
- dict(type='HSigmoid', bias=3.0, divisor=6.0))):
- super(SELayer, self).__init__()
- if isinstance(act_cfg, dict):
- act_cfg = (act_cfg, act_cfg)
- assert len(act_cfg) == 2
- assert mmcv.is_tuple_of(act_cfg, dict)
- self.global_avgpool = nn.AdaptiveAvgPool2d(1)
- self.conv1 = ConvModule(
- in_channels=channels,
- out_channels=make_divisible(channels // ratio, 8),
- kernel_size=1,
- stride=1,
- conv_cfg=conv_cfg,
- act_cfg=act_cfg[0])
- self.conv2 = ConvModule(
- in_channels=make_divisible(channels // ratio, 8),
- out_channels=channels,
- kernel_size=1,
- stride=1,
- conv_cfg=conv_cfg,
- act_cfg=act_cfg[1])
-
- def forward(self, x):
- out = self.global_avgpool(x)
- out = self.conv1(out)
- out = self.conv2(out)
- return x * out
diff --git a/spaces/Pattr/DrumClassification/lilypond-2.24.2/bin/midi2ly.py b/spaces/Pattr/DrumClassification/lilypond-2.24.2/bin/midi2ly.py
deleted file mode 100644
index 4cdbc6a2233f423335ff52deb1c382e470ad27d8..0000000000000000000000000000000000000000
--- a/spaces/Pattr/DrumClassification/lilypond-2.24.2/bin/midi2ly.py
+++ /dev/null
@@ -1,1329 +0,0 @@
-#!/home/lily/lilypond-2.24.2/release/binaries/dependencies/install/Python-3.10.8/bin/python3.10
-#
-# midi2ly.py -- LilyPond midi import script
-
-# This file is part of LilyPond, the GNU music typesetter.
-#
-# Copyright (C) 1998--2022 Han-Wen Nienhuys
-# Jan Nieuwenhuizen
-#
-# LilyPond is free software: you can redistribute it and/or modify
-# it under the terms of the GNU General Public License as published by
-# the Free Software Foundation, either version 3 of the License, or
-# (at your option) any later version.
-#
-# LilyPond is distributed in the hope that it will be useful,
-# but WITHOUT ANY WARRANTY; without even the implied warranty of
-# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
-# GNU General Public License for more details.
-#
-# You should have received a copy of the GNU General Public License
-# along with LilyPond. If not, see .
-
-
-'''
-TODO:
-'''
-
-import gettext
-import math
-import os
-import sys
-
-"""
-
-# relocate-preamble.py.in
-#
-# This file is part of LilyPond, the GNU music typesetter.
-#
-# Copyright (C) 2007--2022 Han-Wen Nienhuys
-#
-# LilyPond is free software: you can redistribute it and/or modify
-# it under the terms of the GNU General Public License as published by
-# the Free Software Foundation, either version 3 of the License, or
-# (at your option) any later version.
-#
-# LilyPond is distributed in the hope that it will be useful,
-# but WITHOUT ANY WARRANTY; without even the implied warranty of
-# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
-# GNU General Public License for more details.
-#
-# You should have received a copy of the GNU General Public License
-# along with LilyPond. If not, see .
-#
-
-This is generic code, used for all python scripts.
-
-The quotes are to ensure that the source .py file can still be
-run as a python script, but does not include any sys.path handling.
-Otherwise, the lilypond-book calls inside the build
-might modify installed .pyc files.
-
-"""
-
-# This is needed for installations with a non-default layout, ie where share/
-# is not next to bin/.
-sys.path.insert (0, os.path.join ('/home/lily/lilypond-2.24.2/release/binaries/mingw/lilypond/install/share/lilypond/2.24.2', 'python'))
-
-# Dynamic relocation, for installations with a default layout including GUB,
-# but also for execution from the build directory.
-bindir = os.path.abspath (os.path.dirname (sys.argv[0]))
-topdir = os.path.dirname (bindir)
-if bindir.endswith (r'/scripts/out'):
- topdir = os.path.join (os.path.dirname (topdir), 'out')
-datadir = os.path.abspath (os.path.join (topdir, 'share', 'lilypond'))
-for v in [ 'current', '2.24.2' ]:
- sys.path.insert (0, os.path.join (datadir, v, 'python'))
-
-"""
-"""
-
-# Load translation and install _() into Python's builtins namespace.
-gettext.install('lilypond', '/home/lily/lilypond-2.24.2/release/binaries/mingw/lilypond/install/share/locale')
-
-import lilylib as ly
-
-################################################################
-# CONSTANTS
-
-
-LINE_BELL = 60
-scale_steps = [0, 2, 4, 5, 7, 9, 11]
-global_options = None
-
-clocks_per_1 = 1536
-clocks_per_4 = 0
-
-time = None
-reference_note = 0 # a mess
-start_quant_clocks = 0
-
-duration_quant_clocks = 0
-allowed_tuplet_clocks = []
-bar_max = 0
-
-################################################################
-
-
-program_version = '2.24.2'
-
-authors = ('Jan Nieuwenhuizen ',
- 'Han-Wen Nienhuys ')
-
-
-
-def identify():
- sys.stdout.write('%s (GNU LilyPond) %s\n' %
- (ly.program_name, program_version))
-
-
-def warranty():
- identify()
- sys.stdout.write('''
-%s
-
- %s
-
-%s
-%s
-''' % (_('Copyright (c) %s by') % '1998--2023',
- '\n '.join(authors),
- _('Distributed under terms of the GNU General Public License.'),
- _('It comes with NO WARRANTY.')))
-
-
-def strip_extension(f, ext):
- (p, e) = os.path.splitext(f)
- if e == ext:
- e = ''
- return p + e
-
-
-class Duration:
- allowed_durs = (1, 2, 4, 8, 16, 32, 64, 128)
-
- def __init__(self, clocks):
- self.clocks = clocks
- (self.dur, self.num, self.den) = self.dur_num_den(clocks)
-
- def dur_num_den(self, clocks):
- for i in range(len(allowed_tuplet_clocks)):
- if clocks == allowed_tuplet_clocks[i]:
- return global_options.allowed_tuplets[i]
-
- dur = 0
- num = 1
- den = 1
- g = math.gcd(int(clocks), clocks_per_1)
- if g:
- (dur, num) = (clocks_per_1 / g, clocks / g)
- if not dur in self.allowed_durs:
- dur = 4
- num = clocks
- den = clocks_per_4
- return (dur, num, den)
-
- def __repr__(self):
- if self.den == 1:
- if self.num == 1:
- s = '%d' % self.dur
- elif self.num == 3 and self.dur != 1:
- s = '%d.' % (self.dur / 2)
- else:
- s = '%d*%d' % (self.dur, self.num)
- else:
- s = '%d*%d/%d' % (self.dur, self.num, self.den)
- return s
-
- def dump(self):
- global reference_note
- reference_note.duration = self
- return repr(self)
-
- def compare(self, other):
- return self.clocks - other.clocks
-
-
-def sign(x):
- if x >= 0:
- return 1
- else:
- return -1
-
-
-class Note:
- names = (0, 0, 1, 1, 2, 3, 3, 4, 4, 5, 5, 6)
- alterations = (0, 1, 0, 1, 0, 0, 1, 0, 1, 0, 1, 0)
- alteration_names = ('eses', 'es', '', 'is', 'isis')
-
- def __init__(self, clocks, pitch, velocity):
- self.pitch = pitch
- self.velocity = velocity
- # hmm
- self.clocks = clocks
- self.duration = Duration(clocks)
- (self.octave, self.notename, self.alteration) = self.o_n_a()
-
- def o_n_a(self):
- # major scale: do-do
- # minor scale: la-la (= + 5) '''
-
- n = self.names[(self.pitch) % 12]
- a = self.alterations[(self.pitch) % 12]
-
- key = global_options.key
- if not key:
- key = Key(0, 0, 0)
-
- if a and key.flats:
- a = - self.alterations[(self.pitch) % 12]
- n = (n - a) % 7
-
- # By tradition, all scales now consist of a sequence
- # of 7 notes each with a distinct name, from amongst
- # a b c d e f g. But, minor scales have a wide
- # second interval at the top - the 'leading note' is
- # sharped. (Why? it just works that way! Anything
- # else doesn't sound as good and isn't as flexible at
- # saying things. In medieval times, scales only had 6
- # notes to avoid this problem - the hexachords.)
-
- # So, the d minor scale is d e f g a b-flat c-sharp d
- # - using d-flat for the leading note would skip the
- # name c and duplicate the name d. Why isn't c-sharp
- # put in the key signature? Tradition. (It's also
- # supposedly based on the Pythagorean theory of the
- # cycle of fifths, but that really only applies to
- # major scales...) Anyway, g minor is g a b-flat c d
- # e-flat f-sharp g, and all the other flat minor keys
- # end up with a natural leading note. And there you
- # have it.
-
- # John Sankey
- #
- # Let's also do a-minor: a b c d e f gis a
- #
- # --jcn
-
- o = self.pitch / 12 - 4
-
- if key.minor:
- # as -> gis
- if (key.sharps == 0 and key.flats == 0
- and n == 5 and a == -1):
- n = 4
- a = 1
- # des -> cis
- elif key.flats == 1 and n == 1 and a == -1:
- n = 0
- a = 1
- # ges -> fis
- elif key.flats == 2 and n == 4 and a == -1:
- n = 3
- a = 1
- # g -> fisis
- elif key.sharps == 5 and n == 4 and a == 0:
- n = 3
- a = 2
- # d -> cisis
- elif key.sharps == 6 and n == 1 and a == 0:
- n = 0
- a = 2
- # a -> gisis
- elif key.sharps == 7 and n == 5 and a == 0:
- n = 4
- a = 2
-
- # b -> ces
- if key.flats >= 6 and n == 6 and a == 0:
- n = 0
- a = -1
- o = o + 1
- # e -> fes
- if key.flats >= 7 and n == 2 and a == 0:
- n = 3
- a = -1
-
- # f -> eis
- if key.sharps >= 3 and n == 3 and a == 0:
- n = 2
- a = 1
- # c -> bis
- if key.sharps >= 4 and n == 0 and a == 0:
- n = 6
- a = 1
- o = o - 1
-
- return (o, n, a)
-
- def __repr__(self):
- s = chr((self.notename + 2) % 7 + ord('a'))
- return 'Note(%s %s)' % (s, repr(self.duration))
-
- def dump(self, dump_dur=True):
- global reference_note
- s = chr((self.notename + 2) % 7 + ord('a'))
- s = s + self.alteration_names[self.alteration + 2]
- if global_options.absolute_pitches:
- commas = self.octave
- else:
- delta = self.pitch - reference_note.pitch
- commas = sign(delta) * (abs(delta) // 12)
- if (((sign(delta)
- * (self.notename - reference_note.notename) + 7)
- % 7 >= 4)
- or ((self.notename == reference_note.notename)
- and (abs(delta) > 4) and (abs(delta) < 12))):
- commas = commas + sign(delta)
-
- if commas > 0:
- s = s + "'" * commas
- elif commas < 0:
- s = s + "," * -commas
-
- if (dump_dur
- and (self.duration.compare(reference_note.duration)
- or global_options.explicit_durations)):
- s = s + self.duration.dump()
-
- # Chords need to handle their reference duration themselves
-
- reference_note = self
-
- # TODO: move space
- return s + ' '
-
-
-class Time:
- def __init__(self, num, den):
- self.clocks = 0
- self.num = num
- self.den = den
-
- def bar_clocks(self):
- return clocks_per_1 * self.num / self.den
-
- def __repr__(self):
- return 'Time(%d/%d)' % (self.num, self.den)
-
- def dump(self):
- global time
- time = self
- return '\n ' + '\\time %d/%d ' % (self.num, self.den) + '\n '
-
-
-class Tempo:
- def __init__(self, seconds_per_1):
- self.clocks = 0
- self.seconds_per_1 = seconds_per_1
-
- def __repr__(self):
- return 'Tempo(%d)' % self.bpm()
-
- def bpm(self):
- return 4 * 60 / self.seconds_per_1
-
- def dump(self):
- return '\n ' + '\\tempo 4 = %d ' % (self.bpm()) + '\n '
-
-
-class Clef:
- clefs = ('"bass_8"', 'bass', 'violin', '"violin^8"')
-
- def __init__(self, type):
- self.type = type
-
- def __repr__(self):
- return 'Clef(%s)' % self.clefs[self.type]
-
- def dump(self):
- return '\n \\clef %s\n ' % self.clefs[self.type]
-
-
-class Key:
- key_sharps = ('c', 'g', 'd', 'a', 'e', 'b', 'fis')
- key_flats = ('BUG', 'f', 'bes', 'es', 'as', 'des', 'ges')
-
- def __init__(self, sharps, flats, minor):
- self.clocks = 0
- self.flats = flats
- self.sharps = sharps
- self.minor = minor
-
- def dump(self):
- global_options.key = self
-
- s = ''
- if self.sharps and self.flats:
- pass
- else:
- if self.flats:
- k = (ord('cfbeadg'[self.flats % 7]) -
- ord('a') - 2 - 2 * self.minor + 7) % 7
- else:
- k = (ord('cgdaebf'[self.sharps % 7]) -
- ord('a') - 2 - 2 * self.minor + 7) % 7
-
- if not self.minor:
- name = chr((k + 2) % 7 + ord('a'))
- else:
- name = chr((k + 2) % 7 + ord('a'))
-
- # fis cis gis dis ais eis bis
- sharps = (2, 4, 6, 1, 3, 5, 7)
- # bes es as des ges ces fes
- flats = (6, 4, 2, 7, 5, 3, 1)
- a = 0
- if self.flats:
- if flats[k] <= self.flats:
- a = -1
- else:
- if sharps[k] <= self.sharps:
- a = 1
-
- if a:
- name = name + Note.alteration_names[a + 2]
-
- s = '\\key ' + name
- if self.minor:
- s = s + ' \\minor'
- else:
- s = s + ' \\major'
-
- return '\n\n ' + s + '\n '
-
-
-class Text:
- text_types = (
- 'SEQUENCE_NUMBER',
- 'TEXT_EVENT',
- 'COPYRIGHT_NOTICE',
- 'SEQUENCE_TRACK_NAME',
- 'INSTRUMENT_NAME',
- 'LYRIC',
- 'MARKER',
- 'CUE_POINT',
- 'PROGRAM_NAME',
- 'DEVICE_NAME', )
-
- @staticmethod
- def _text_only(chr):
- if ((' ' <= chr <= '~') or chr in ['\n', '\r']):
- return chr
- else:
- return '~'
-
- def __init__(self, type, text):
- self.clocks = 0
- self.type = type
- self.text = ''.join(map(self._text_only, text))
-
- def dump(self):
- # urg, we should be sure that we're in a lyrics staff
- s = ''
- if self.type == midi.LYRIC:
- s = '"%s"' % self.text
- d = Duration(self.clocks)
- if (global_options.explicit_durations
- or d.compare(reference_note.duration)):
- s = s + Duration(self.clocks).dump()
- s = s + ' '
- elif (self.text.strip()
- and self.type == midi.SEQUENCE_TRACK_NAME
- and not self.text == 'control track'
- and not self.track.lyrics_p_):
- text = self.text.replace('(MIDI)', '').strip()
- if text:
- s = '\n \\set Staff.instrumentName = "%(text)s"\n ' % locals(
- )
- elif self.text.strip():
- s = '\n % [' + self.text_types[self.type] + '] ' + \
- self.text + '\n '
- return s
-
- def __repr__(self):
- return 'Text(%d=%s)' % (self.type, self.text)
-
-class EndOfTrack:
- def __init__(self):
- self.clocks = 0
-
- def __repr__(self):
- return 'EndOfTrack()'
-
- def dump(self):
- return ''
-
-def get_voice(channel, music):
- ly.debug_output('channel: ' + str(channel) + '\n')
- return unthread_notes(music)
-
-
-class Channel:
- def __init__(self, number):
- self.number = number
- self.events = []
- self.music = None
-
- def add(self, event):
- self.events.append(event)
-
- def get_voice(self):
- if not self.music:
- self.music = self.parse()
- return get_voice(self.number, self.music)
-
- def parse(self):
- pitches = {}
- notes = []
- music = []
- last_lyric = 0
- last_time = 0
- end_of_track_time = None
- for e in self.events:
- t = e[0]
-
- if start_quant_clocks:
- t = quantise_clocks(t, start_quant_clocks)
-
- if (e[1][0] == midi.NOTE_OFF
- or (e[1][0] == midi.NOTE_ON and e[1][2] == 0)):
- ly.debug_output('%d: NOTE OFF: %s' % (t, e[1][1]))
- if not e[1][2]:
- ly.debug_output(' ...treated as OFF')
- end_note(pitches, notes, t, e[1][1])
-
- elif e[1][0] == midi.NOTE_ON:
- if e[1][1] not in pitches:
- ly.debug_output('%d: NOTE ON: %s' % (t, e[1][1]))
- pitches[e[1][1]] = (t, e[1][2])
- else:
- ly.debug_output('...ignored')
-
- # all include ALL_NOTES_OFF
- elif (e[1][0] >= midi.ALL_SOUND_OFF
- and e[1][0] <= midi.POLY_MODE_ON):
- for i in pitches:
- end_note(pitches, notes, t, i)
-
- elif e[1][0] == midi.META_EVENT:
- if e[1][1] == midi.END_OF_TRACK:
- for i in pitches:
- end_note(pitches, notes, t, i)
- end_of_track_time = t
- break
-
- elif e[1][1] == midi.SET_TEMPO:
- (u0, u1, u2) = list(map(ord, e[1][2]))
- us_per_4 = u2 + 256 * (u1 + 256 * u0)
- seconds_per_1 = us_per_4 * 4 / 1e6
- music.append((t, Tempo(seconds_per_1)))
- elif e[1][1] == midi.TIME_SIGNATURE:
- (num, dur, clocks4, count32) = list(map(ord, e[1][2]))
- den = 2 ** dur
- music.append((t, Time(num, den)))
- elif e[1][1] == midi.KEY_SIGNATURE:
- (alterations, minor) = list(map(ord, e[1][2]))
- sharps = 0
- flats = 0
- if alterations < 127:
- sharps = alterations
- else:
- flats = 256 - alterations
-
- k = Key(sharps, flats, minor)
- if not t and global_options.key:
- # At t == 0, a set --key overrides us
- k = global_options.key
- music.append((t, k))
-
- # ugh, must set key while parsing
- # because Note init uses key
- # Better do Note.calc () at dump time?
- global_options.key = k
-
- elif (e[1][1] == midi.LYRIC
- or (global_options.text_lyrics
- and e[1][1] == midi.TEXT_EVENT)):
- self.lyrics_p_ = True
- if last_lyric:
- last_lyric.clocks = t - last_time
- music.append((last_time, last_lyric))
- last_time = t
- last_lyric = Text(midi.LYRIC, e[1][2])
-
- elif (e[1][1] >= midi.SEQUENCE_NUMBER
- and e[1][1] <= midi.CUE_POINT):
- text = Text(e[1][1], e[1][2])
- text.track = self
- music.append((t, text))
- if text.type == midi.SEQUENCE_TRACK_NAME:
- self.name = text.text
- else:
- if global_options.verbose:
- sys.stderr.write("SKIP: %s\n" % repr(e))
- else:
- if global_options.verbose:
- sys.stderr.write("SKIP: %s\n" % repr(e))
-
- if last_lyric:
- # last_lyric.clocks = t - last_time
- # hmm
- last_lyric.clocks = clocks_per_4
- music.append((last_time, last_lyric))
- last_lyric = 0
-
- i = 0
- while len(notes):
- if i < len(music) and notes[0][0] >= music[i][0]:
- i = i + 1
- else:
- music.insert(i, notes[0])
- del notes[0]
-
- if end_of_track_time is not None:
- music.append((end_of_track_time, EndOfTrack()))
-
- return music
-
-
-class Track (Channel):
- def __init__(self):
- Channel.__init__(self, None)
- self.name = None
- self.channels = {}
- self.lyrics_p_ = False
-
- def _add(self, event):
- self.events.append(event)
-
- def add(self, event, channel=None):
- if channel is None:
- self._add(event)
- else:
- self.channels[channel] = self.channels.get(
- channel, Channel(channel))
- self.channels[channel].add(event)
-
- def get_voices(self):
- return ([self.get_voice()]
- + [self.channels[k].get_voice()
- for k in sorted(self.channels.keys())])
-
-
-def create_track(events):
- track = Track()
- for e in events:
- data = list(e[1])
- if data[0] > 0x7f and data[0] < 0xf0:
- channel = data[0] & 0x0f
- e = (e[0], tuple([data[0] & 0xf0] + data[1:]))
- track.add(e, channel)
- else:
- track.add(e)
- return track
-
-
-def quantise_clocks(clocks, quant):
- q = int(clocks / quant) * quant
- if q != clocks:
- for tquant in allowed_tuplet_clocks:
- if int(clocks / tquant) * tquant == clocks:
- return clocks
- if 2 * (clocks - q) > quant:
- q = q + quant
- return q
-
-
-def end_note(pitches, notes, t, e):
- try:
- (lt, vel) = pitches[e]
- del pitches[e]
-
- i = len(notes) - 1
- while i > 0:
- if notes[i][0] > lt:
- i = i - 1
- else:
- break
- d = t - lt
- if duration_quant_clocks:
- d = quantise_clocks(d, duration_quant_clocks)
- if not d:
- d = duration_quant_clocks
-
- notes.insert(i + 1,
- (lt, Note(d, e, vel)))
-
- except KeyError:
- pass
-
-
-def unthread_notes(channel):
- threads = []
- while channel:
- thread = []
- end_busy_t = 0
- start_busy_t = 0
- todo = []
- for e in channel:
- t = e[0]
- if (e[1].__class__ == Note
- and ((t == start_busy_t
- and e[1].clocks + t == end_busy_t)
- or t >= end_busy_t)):
- thread.append(e)
- start_busy_t = t
- end_busy_t = t + e[1].clocks
- elif (e[1].__class__ == Time
- or e[1].__class__ == Key
- or e[1].__class__ == Text
- or e[1].__class__ == Tempo
- or e[1].__class__ == EndOfTrack):
- thread.append(e)
- else:
- todo.append(e)
- threads.append(thread)
- channel = todo
-
- return threads
-
-
-def dump_skip(skip, clocks):
- global reference_note
- saved_duration = reference_note.duration
- result = skip + Duration(clocks).dump() + ' '
- # "\skip D" does not change the reference duration like "sD",
- # so we restore it after Duration.dump changes it.
- if skip[0] == '\\':
- reference_note.duration = saved_duration
- return result
-
-
-def dump(d):
- return d.dump()
-
-
-def dump_chord(ch):
- s = ''
- notes = []
- for i in ch:
- if i.__class__ == Note:
- notes.append(i)
- else:
- s = s + i.dump()
- if len(notes) == 1:
- s = s + dump(notes[0])
- elif len(notes) > 1:
- global reference_note
- reference_dur = reference_note.duration
- s = s + '<'
- s = s + notes[0].dump(dump_dur=False)
- r = reference_note
- for i in notes[1:]:
- s = s + i.dump(dump_dur=False)
- s = s + '>'
- if (r.duration.compare(reference_dur)
- or global_options.explicit_durations):
- s = s + r.duration.dump()
- s = s + ' '
- reference_note = r
- return s
-
-
-def dump_bar_line(last_bar_t, t, bar_count):
- s = ''
- bar_t = time.bar_clocks()
- if t - last_bar_t >= bar_t:
- bar_count = bar_count + (t - last_bar_t) / bar_t
-
- if t - last_bar_t == bar_t:
- s = '\n | %% %(bar_count)d\n ' % locals()
- last_bar_t = t
- else:
- # urg, this will barf at meter changes
- last_bar_t = last_bar_t + (t - last_bar_t) / bar_t * bar_t
-
- return (s, last_bar_t, bar_count)
-
-
-def dump_voice(thread, skip):
- global reference_note, time
- ref = Note(0, 4*12, 0)
- if not reference_note:
- reference_note = ref
- else:
- ref.duration = reference_note.duration
- reference_note = ref
- last_e = None
- chs = []
- ch = []
-
- for e in thread:
- if last_e and last_e[0] == e[0]:
- ch.append(e[1])
- else:
- if ch:
- chs.append((last_e[0], ch))
-
- ch = [e[1]]
-
- last_e = e
-
- if ch:
- chs.append((last_e[0], ch))
- t = 0
- last_t = 0
- last_bar_t = 0
- bar_count = 1
-
- lines = ['']
- for ch in chs:
- t = ch[0]
-
- i = lines[-1].rfind('\n') + 1
- if len(lines[-1][i:]) > LINE_BELL:
- lines.append('')
-
- if t - last_t > 0:
- d = t - last_t
- if bar_max and t > time.bar_clocks() * bar_max:
- d = time.bar_clocks() * bar_max - last_t
- lines[-1] = lines[-1] + dump_skip(skip, d)
- elif t - last_t < 0:
- ly.error('BUG: time skew')
-
- (s, last_bar_t, bar_count) = dump_bar_line(last_bar_t,
- t, bar_count)
-
- if bar_max and bar_count > bar_max:
- break
-
- lines[-1] = lines[-1] + s
- lines[-1] = lines[-1] + dump_chord(ch[1])
-
- clocks = 0
- for i in ch[1]:
- if i.clocks > clocks:
- clocks = i.clocks
-
- last_t = t + clocks
-
- (s, last_bar_t, bar_count) = dump_bar_line(last_bar_t,
- last_t, bar_count)
- lines[-1] = lines[-1] + s
-
- return '\n '.join(lines) + '\n'
-
-
-def number2ascii(i):
- s = ''
- i += 1
- while i > 0:
- m = (i - 1) % 26
- s = '%c' % (m + ord('A')) + s
- i = (i - m) // 26
- return s
-
-
-def get_track_name(i):
- return 'track' + number2ascii(i)
-
-
-def get_channel_name(i):
- return 'channel' + number2ascii(i)
-
-
-def get_voice_name(i, zero_too_p=False):
- if i or zero_too_p:
- return 'voice' + number2ascii(i)
- return ''
-
-
-def lst_append(lst, x):
- lst.append(x)
- return lst
-
-
-def get_voice_layout(average_pitch):
- d = {}
- for i in range(len(average_pitch)):
- d[average_pitch[i]] = lst_append(d.get(average_pitch[i], []), i)
- s = list(reversed(sorted(average_pitch)))
- non_empty = len([x for x in s if x])
- names = ['One', 'Two']
- if non_empty > 2:
- names = ['One', 'Three', 'Four', 'Two']
- layout = ['' for x in range(len(average_pitch))]
- for i, n in zip(s, names):
- if i:
- v = d[i]
- if isinstance(v, list):
- d[i] = v[1:]
- v = v[0]
- layout[v] = n
- return layout
-
-
-def dump_track(track, n):
- s = '\n'
- track_name = get_track_name(n)
-
- average_pitch = track_average_pitch(track)
- voices = len([x for x in average_pitch[1:] if x])
- clef = get_best_clef(average_pitch[0])
-
- c = 0
- vv = 0
- for channel in track:
- v = 0
- channel_name = get_channel_name(c)
- c += 1
- for voice in channel:
- voice_name = get_voice_name(v)
- voice_id = track_name + channel_name + voice_name
- item = voice_first_item(voice)
-
- if item and item.__class__ == Note:
- skip = 'r'
- if global_options.skip:
- skip = 's'
- s += '%(voice_id)s = ' % locals()
- if not global_options.absolute_pitches:
- s += '\\relative c '
- elif item and item.__class__ == Text:
- skip = '" "'
- s += '%(voice_id)s = \\lyricmode ' % locals()
- else:
- skip = '\\skip '
- s += '%(voice_id)s = ' % locals()
- s += '{\n'
- if not n and not vv and global_options.key:
- s += global_options.key.dump()
- if average_pitch[vv+1] and voices > 1:
- vl = get_voice_layout(average_pitch[1:])[vv]
- if vl:
- s += ' \\voice' + vl + '\n'
- else:
- if not global_options.quiet:
- ly.warning(
- _('found more than 5 voices on a staff, expect bad output'))
- s += ' ' + dump_voice(voice, skip)
- s += '}\n\n'
- v += 1
- vv += 1
-
- s += '%(track_name)s = <<\n' % locals()
-
- if clef.type != 2:
- s += clef.dump() + '\n'
-
- c = 0
- vv = 0
- for channel in track:
- v = 0
- channel_name = get_channel_name(c)
- c += 1
- for voice in channel:
- voice_context_name = get_voice_name(vv, zero_too_p=True)
- voice_name = get_voice_name(v)
- v += 1
- vv += 1
- voice_id = track_name + channel_name + voice_name
- item = voice_first_item(voice)
- context = 'Voice'
- if item and item.__class__ == Text:
- context = 'Lyrics'
- s += ' \\context %(context)s = %(voice_context_name)s \\%(voice_id)s\n' % locals()
- s += '>>\n\n'
- return s
-
-
-def voice_first_item(voice):
- for event in voice:
- if (event[1].__class__ == Note
- or (event[1].__class__ == Text
- and event[1].type == midi.LYRIC)):
- return event[1]
- return None
-
-
-def channel_first_item(channel):
- for voice in channel:
- first = voice_first_item(voice)
- if first:
- return first
- return None
-
-
-def track_first_item(track):
- for channel in track:
- first = channel_first_item(channel)
- if first:
- return first
- return None
-
-
-def track_average_pitch(track):
- i = 0
- p = [0]
- v = 1
- for channel in track:
- for voice in channel:
- c = 0
- p.append(0)
- for event in voice:
- if event[1].__class__ == Note:
- i += 1
- c += 1
- p[v] += event[1].pitch
- if c:
- p[0] += p[v]
- p[v] = p[v] / c
- v += 1
- if i:
- p[0] = p[0] / i
- return p
-
-
-def get_best_clef(average_pitch):
- if average_pitch:
- if average_pitch <= 3*12:
- return Clef(0)
- elif average_pitch <= 5*12:
- return Clef(1)
- elif average_pitch >= 7*12:
- return Clef(3)
- return Clef(2)
-
-
-class Staff:
- def __init__(self, track):
- self.voices = track.get_voices()
-
- def dump(self, i):
- return dump_track(self.voices, i)
-
-
-def convert_midi(in_file, out_file):
- global midi
- import midi
-
- global clocks_per_1, clocks_per_4, key
- global start_quant_clocks
- global duration_quant_clocks
- global allowed_tuplet_clocks
- global time
-
- full_content = open(in_file, 'rb').read()
- clocks_max = bar_max * clocks_per_1 * 2
- midi_dump = midi.parse(full_content, clocks_max)
-
- clocks_per_1 = midi_dump[0][1]
- clocks_per_4 = clocks_per_1 / 4
- time = Time(4, 4)
-
- if global_options.start_quant:
- start_quant_clocks = clocks_per_1 / global_options.start_quant
-
- if global_options.duration_quant:
- duration_quant_clocks = clocks_per_1 / global_options.duration_quant
-
- allowed_tuplet_clocks = []
- for (dur, num, den) in global_options.allowed_tuplets:
- allowed_tuplet_clocks.append(clocks_per_1 / dur * num / den)
-
- if global_options.verbose:
- print('allowed tuplet clocks:', allowed_tuplet_clocks)
-
- tracks = [create_track(t) for t in midi_dump[1]]
- # urg, parse all global track events, such as Key first
- # this fixes key in different voice/staff problem
- for t in tracks:
- t.music = t.parse()
- prev = None
- staves = []
- for t in tracks:
- voices = t.get_voices()
- if ((t.name and prev and prev.name)
- and t.name.split(':')[0] == prev.name.split(':')[0]):
- # staves[-1].voices += voices
- # all global track events first
- staves[-1].voices = ([staves[-1].voices[0]]
- + [voices[0]]
- + staves[-1].voices[1:]
- + voices[1:])
- else:
- staves.append(Staff(t))
- prev = t
-
- tag = '%% Lily was here -- automatically converted by %s from %s' % (
- ly.program_name, in_file)
-
- s = tag
- s += r'''
-\version "2.14.0"
-'''
-
- s += r'''
-\layout {
- \context {
- \Voice
- \remove Note_heads_engraver
- \consists Completion_heads_engraver
- \remove Rest_engraver
- \consists Completion_rest_engraver
- }
-}
-'''
-
- for i in global_options.include_header:
- s += '\n%% included from %(i)s\n' % locals()
- s += open(i, encoding='utf-8').read()
- if s[-1] != '\n':
- s += '\n'
- s += '% end\n'
-
- for i, t in enumerate(staves):
- s += t.dump(i)
-
- s += '\n\\score {\n <<\n'
-
- control_track = False
- i = 0
- output_track_count = 0
- for i, staff in enumerate(staves):
- track_name = get_track_name(i)
- item = track_first_item(staff.voices)
- staff_name = track_name
- context = None
- if not i and not item and len(staves) > 1:
- control_track = track_name
- continue
- elif (item and item.__class__ == Note):
- context = 'Staff'
- if control_track:
- s += ' \\context %(context)s=%(staff_name)s \\%(control_track)s\n' % locals()
- elif item and item.__class__ == Text:
- context = 'Lyrics'
- if context:
- output_track_count += 1
- s += ' \\context %(context)s=%(staff_name)s \\%(track_name)s\n' % locals()
-
- # If we found a control track but no other tracks with which
- # to combine it, create a Staff for the control track alone.
- if (output_track_count == 0) and control_track:
- s += ' \\context Staff \\%(control_track)s\n' % locals()
-
- s = s + r''' >>
- \layout {}
- \midi {}
-}
-'''
-
- if not global_options.quiet:
- ly.progress(_("%s output to `%s'...") % ('LY', out_file))
-
- if out_file == '-':
- handle = sys.stdout
- else:
- handle = open(out_file, 'w', encoding='utf-8')
-
- handle.write(s)
- handle.close()
-
-
-def get_option_parser():
- p = ly.get_option_parser(usage=_("%s [OPTION]... FILE") % 'midi2ly',
- description=_(
- "Convert %s to LilyPond input.\n") % 'MIDI',
- add_help_option=False)
-
- p.add_option('-a', '--absolute-pitches',
- action='store_true',
- help=_('print absolute pitches'))
- p.add_option('-d', '--duration-quant',
- metavar=_('DUR'),
- help=_('quantise note durations on DUR'))
- p.add_option('-D', '--debug',
- action='store_true',
- help=_('debug printing'))
- p.add_option('-e', '--explicit-durations',
- action='store_true',
- help=_('print explicit durations'))
- p.add_option('-h', '--help',
- action='help',
- help=_('show this help and exit'))
- p.add_option('-i', '--include-header',
- help=_('prepend FILE to output'),
- action='append',
- default=[],
- metavar=_('FILE'))
- p.add_option('-k', '--key', help=_('set key: ALT=+sharps|-flats; MINOR=1'),
- metavar=_('ALT[:MINOR]'),
- default=None),
- p.add_option('-o', '--output', help=_('write output to FILE'),
- metavar=_('FILE'),
- action='store')
- p.add_option('-p', '--preview', help=_('preview of first 4 bars'),
- action='store_true')
- p.add_option('-q', '--quiet',
- action="store_true",
- help=_("suppress progress messages and warnings about excess voices"))
- p.add_option('-s', '--start-quant', help=_('quantise note starts on DUR'),
- metavar=_('DUR'))
- p.add_option('-S', '--skip',
- action="store_true",
- help=_("use s instead of r for rests"))
- p.add_option('-t', '--allow-tuplet',
- metavar=_('DUR*NUM/DEN'),
- action='append',
- dest='allowed_tuplets',
- help=_('allow tuplet durations DUR*NUM/DEN'),
- default=[])
- p.add_option('-V', '--verbose', help=_('be verbose'),
- action='store_true')
- p.version = 'midi2ly (LilyPond) 2.24.2'
- p.add_option('--version',
- action='version',
- help=_('show version number and exit'))
- p.add_option('-w', '--warranty', help=_('show warranty and copyright'),
- action='store_true',)
- p.add_option('-x', '--text-lyrics', help=_('treat every text as a lyric'),
- action='store_true')
-
- p.add_option_group(_('Examples'),
- description=r'''
- $ midi2ly --key=-2:1 --duration-quant=32 --allow-tuplet=4*2/3 --allow-tuplet=2*4/3 foo.midi
-''')
- p.add_option_group('',
- description=(
- _('Report bugs via %s')
- % 'bug-lilypond@gnu.org') + '\n')
- return p
-
-
-def do_options():
- opt_parser = get_option_parser()
- (options, args) = opt_parser.parse_args()
-
- if options.warranty:
- warranty()
- sys.exit(0)
-
- if not args or args[0] == '-':
- opt_parser.print_help()
- sys.stderr.write('\n%s: %s %s\n' % (ly.program_name, _('error: '),
- _('no files specified on command line.')))
- sys.exit(2)
-
- if options.duration_quant:
- options.duration_quant = int(options.duration_quant)
-
- if options.key:
- (alterations, minor) = list(
- map(int, (options.key + ':0').split(':')))[0:2]
- sharps = 0
- flats = 0
- if alterations >= 0:
- sharps = alterations
- else:
- flats = - alterations
- options.key = Key(sharps, flats, minor)
-
- if options.start_quant:
- options.start_quant = int(options.start_quant)
-
- global bar_max
- if options.preview:
- bar_max = 4
-
- options.allowed_tuplets = [list(map(int, a.replace('/', '*').split('*')))
- for a in options.allowed_tuplets]
-
- if options.verbose:
- sys.stderr.write('Allowed tuplets: %s\n' %
- repr(options.allowed_tuplets))
-
- global global_options
- global_options = options
-
- return args
-
-
-def main():
- files = do_options()
-
- exts = ['.midi', '.mid', '.MID']
- for f in files:
- g = f
- for e in exts:
- g = strip_extension(g, e)
- if not os.path.exists(f):
- for e in exts:
- n = g + e
- if os.path.exists(n):
- f = n
- break
-
- if not global_options.output:
- outdir = '.'
- outbase = os.path.basename(g)
- o = outbase + '-midi.ly'
- elif (global_options.output[-1] == os.sep
- or os.path.isdir(global_options.output)):
- outdir = global_options.output
- outbase = os.path.basename(g)
- o = os.path.join(outdir, outbase + '-midi.ly')
- else:
- o = global_options.output
- (outdir, outbase) = os.path.split(o)
-
- if outdir and outdir != '.' and not os.path.exists(outdir):
- os.mkdir(outdir, 0o777)
-
- convert_midi(f, o)
-
-
-if __name__ == '__main__':
- main()
diff --git a/spaces/PeepDaSlan9/De-limiter/prepro/save_musdb_XL_train_numpy.py b/spaces/PeepDaSlan9/De-limiter/prepro/save_musdb_XL_train_numpy.py
deleted file mode 100644
index df14d5fb13e2f862e31ee6ef10a413521c804a57..0000000000000000000000000000000000000000
--- a/spaces/PeepDaSlan9/De-limiter/prepro/save_musdb_XL_train_numpy.py
+++ /dev/null
@@ -1,148 +0,0 @@
-import os
-import glob
-import argparse
-import csv
-
-import numpy as np
-import librosa
-import soundfile as sf
-import tqdm
-
-
-def main():
- parser = argparse.ArgumentParser(
- description="Save sample-wise gain parameters for dataset distribution"
- )
- parser.add_argument(
- "--root",
- type=str,
- default="/path/to/musdb18hq",
- help="Root directory",
- )
- parser.add_argument(
- "--musdb_XL_train_root",
- type=str,
- default="/path/to/musdb-XL-train",
- help="Directory of musdb-XL-train dataset",
- )
- parser.add_argument(
- "--output",
- type=str,
- default="/path/to/musdb-XL-train/np_ratio",
- help="Directory to save sample-wise gain ratio",
- )
-
- args = parser.parse_args()
-
- sources = ["vocals", "bass", "drums", "other"]
-
- path_csv_fixed = f"{args.musdb_XL_train_root}/ozone_train_fixed.csv"
- list_path_csv_random = sorted(
- glob.glob(f"{args.musdb_XL_train_root}/ozone_train_random_*.csv")
- )
-
- # read ozone_train_fixed list
- fixed_list = []
- os.makedirs(f"{args.output}/ozone_train_fixed", exist_ok=True)
- with open(path_csv_fixed, "r", encoding="utf-8") as f:
- rdr = csv.reader(f)
- for k, line in enumerate(rdr):
- if k == 0: # song_name, max_threshold, max_character
- pass
- else:
- fixed_list.append(line)
-
- # save numpy files of ozone_train_fixed
- # which is the limiter-applied version of 100 songs from musdb-HQ train set
- # each numpy file contain sample-wise gain ratio parameters
- for fixed_song in tqdm.tqdm(fixed_list):
- audio_sources = []
- for source in sources:
- audio, sr = librosa.load(
- f"{args.root}/train/{fixed_song[0]}/{source}.wav", sr=44100, mono=False
- )
- audio_sources.append(audio)
- stems = np.stack(audio_sources, axis=0)
- mixture = stems.sum(0)
-
- ozone_mixture, sr = librosa.load(
- f"{args.musdb_XL_train_root}/ozone_train_fixed/{fixed_song[0]}.wav",
- sr=44100,
- mono=False,
- )
- mixture[mixture == 0.0] = np.finfo(np.float32).eps # to avoid 'divided by zero'
- ratio = ozone_mixture / mixture
-
- np.save(
- f"{args.output}/ozone_train_fixed/{fixed_song[0]}.npy",
- ratio.astype(np.float16), # 16bit is enough...
- )
-
- # read ozone_train_random list
- random_list = []
- os.makedirs(f"{args.output}/ozone_train_random", exist_ok=True)
- for path_csv_random in list_path_csv_random:
- with open(path_csv_random, "r", encoding="utf-8") as f:
- rdr = csv.reader(f)
- for k, line in enumerate(rdr):
- if k == 0:
- # ['song_name',
- # 'max_threshold',
- # 'max_character',
- # 'vocals_name',
- # 'vocals_start_sec',
- # 'vocals_gain',
- # 'vocals_channelswap',
- # 'bass_name',
- # 'bass_start_sec',
- # 'bass_gain',
- # 'bass_channelswap',
- # 'drums_name',
- # 'drums_start_sec',
- # 'drums_gain',
- # 'drums_channelswap',
- # 'other_name',
- # 'other_start_sec',
- # 'other_gain',
- # 'other_channelswap']
- pass
- else:
- random_list.append(line)
-
- # save wave files of ozone_train_random,
- # which is the limiter-applied version of 4-sec 300,000 segments randomly created from musdb-HQ train subset
- for random_song in tqdm.tqdm(random_list):
- audio_sources = []
- for k, source in enumerate(sources):
- audio, sr = librosa.load(
- f"{args.root}/train/{random_song[3 + k * 4]}/{source}.wav",
- sr=44100,
- mono=False,
- offset=float(random_song[4 + k * 4]), # 'inst_start_sec'
- duration=4.0,
- )
- audio = audio * float(random_song[5 + k * 4]) # 'inst_gain'
- if random_song[6 + k * 4].lower() == "true": # 'inst_channelswap'
- audio = np.flip(audio, axis=0)
-
- audio_sources.append(audio)
- stems = np.stack(audio_sources, axis=0)
- mixture = stems.sum(0)
-
- ozone_mixture, sr = librosa.load(
- f"{args.musdb_XL_train_root}/ozone_train_random/{random_song[0]}.wav",
- sr=44100,
- mono=False,
- )
-
- mixture[mixture == 0.0] = np.finfo(np.float32).eps # to avoid 'divided by zero'
- ratio = ozone_mixture / mixture
-
- np.save(
- f"{args.output}/ozone_train_random/{random_song[0]}.npy",
- ratio.astype(np.float16), # 16bit is enough...
- )
-
-
-if __name__ == "__main__":
- main()
diff --git a/spaces/PeepDaSlan9/Language-Learn-Idea/README.md b/spaces/PeepDaSlan9/Language-Learn-Idea/README.md
deleted file mode 100644
index ebe024eac3dc7c640b97e457f6881ddf5646c996..0000000000000000000000000000000000000000
--- a/spaces/PeepDaSlan9/Language-Learn-Idea/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: Language Learn Idea
-emoji: 🚀
-colorFrom: gray
-colorTo: gray
-sdk: gradio
-sdk_version: 3.16.2
-app_file: app.py
-pinned: false
-duplicated_from: KwabsHug/Language-Learn-Idea
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/Pie31415/control-animation/annotator/uniformer/configs/_base_/datasets/pascal_context.py b/spaces/Pie31415/control-animation/annotator/uniformer/configs/_base_/datasets/pascal_context.py
deleted file mode 100644
index ff65bad1b86d7e3a5980bb5b9fc55798dc8df5f4..0000000000000000000000000000000000000000
--- a/spaces/Pie31415/control-animation/annotator/uniformer/configs/_base_/datasets/pascal_context.py
+++ /dev/null
@@ -1,60 +0,0 @@
-# dataset settings
-dataset_type = 'PascalContextDataset'
-data_root = 'data/VOCdevkit/VOC2010/'
-img_norm_cfg = dict(
- mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
-
-img_scale = (520, 520)
-crop_size = (480, 480)
-
-train_pipeline = [
- dict(type='LoadImageFromFile'),
- dict(type='LoadAnnotations'),
- dict(type='Resize', img_scale=img_scale, ratio_range=(0.5, 2.0)),
- dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
- dict(type='RandomFlip', prob=0.5),
- dict(type='PhotoMetricDistortion'),
- dict(type='Normalize', **img_norm_cfg),
- dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
- dict(type='DefaultFormatBundle'),
- dict(type='Collect', keys=['img', 'gt_semantic_seg']),
-]
-test_pipeline = [
- dict(type='LoadImageFromFile'),
- dict(
- type='MultiScaleFlipAug',
- img_scale=img_scale,
- # img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
- flip=False,
- transforms=[
- dict(type='Resize', keep_ratio=True),
- dict(type='RandomFlip'),
- dict(type='Normalize', **img_norm_cfg),
- dict(type='ImageToTensor', keys=['img']),
- dict(type='Collect', keys=['img']),
- ])
-]
-data = dict(
- samples_per_gpu=4,
- workers_per_gpu=4,
- train=dict(
- type=dataset_type,
- data_root=data_root,
- img_dir='JPEGImages',
- ann_dir='SegmentationClassContext',
- split='ImageSets/SegmentationContext/train.txt',
- pipeline=train_pipeline),
- val=dict(
- type=dataset_type,
- data_root=data_root,
- img_dir='JPEGImages',
- ann_dir='SegmentationClassContext',
- split='ImageSets/SegmentationContext/val.txt',
- pipeline=test_pipeline),
- test=dict(
- type=dataset_type,
- data_root=data_root,
- img_dir='JPEGImages',
- ann_dir='SegmentationClassContext',
- split='ImageSets/SegmentationContext/val.txt',
- pipeline=test_pipeline))
diff --git a/spaces/PirateHFH/IllusionDiffusion/app.py b/spaces/PirateHFH/IllusionDiffusion/app.py
deleted file mode 100644
index ed13d93c208791fc7a0bcdada772c10b56a56c25..0000000000000000000000000000000000000000
--- a/spaces/PirateHFH/IllusionDiffusion/app.py
+++ /dev/null
@@ -1,227 +0,0 @@
-import torch
-import gradio as gr
-from PIL import Image
-import random
-from diffusers import (
- DiffusionPipeline,
- AutoencoderKL,
- StableDiffusionControlNetPipeline,
- ControlNetModel,
- StableDiffusionLatentUpscalePipeline,
- StableDiffusionImg2ImgPipeline,
- StableDiffusionControlNetImg2ImgPipeline,
- DPMSolverMultistepScheduler, # <-- Added import
- EulerDiscreteScheduler # <-- Added import
-)
-import time
-from share_btn import community_icon_html, loading_icon_html, share_js
-from gallery_history import fetch_gallery_history, show_gallery_history
-from illusion_style import css
-
-BASE_MODEL = "SG161222/Realistic_Vision_V5.1_noVAE"
-
-# Initialize both pipelines
-vae = AutoencoderKL.from_pretrained("stabilityai/sd-vae-ft-mse", torch_dtype=torch.float16)
-#init_pipe = DiffusionPipeline.from_pretrained("SG161222/Realistic_Vision_V5.1_noVAE", torch_dtype=torch.float16)
-controlnet = ControlNetModel.from_pretrained("monster-labs/control_v1p_sd15_qrcode_monster", torch_dtype=torch.float16)#, torch_dtype=torch.float16)
-main_pipe = StableDiffusionControlNetPipeline.from_pretrained(
- BASE_MODEL,
- controlnet=controlnet,
- vae=vae,
- safety_checker=None,
- torch_dtype=torch.float16,
-).to("cuda")
-
-#main_pipe.unet = torch.compile(main_pipe.unet, mode="reduce-overhead", fullgraph=True)
-#main_pipe.unet.to(memory_format=torch.channels_last)
-#main_pipe.unet = torch.compile(main_pipe.unet, mode="reduce-overhead", fullgraph=True)
-#model_id = "stabilityai/sd-x2-latent-upscaler"
-image_pipe = StableDiffusionControlNetImg2ImgPipeline(**main_pipe.components)
-
-#image_pipe.unet = torch.compile(image_pipe.unet, mode="reduce-overhead", fullgraph=True)
-#upscaler = StableDiffusionLatentUpscalePipeline.from_pretrained(model_id, torch_dtype=torch.float16)
-#upscaler.to("cuda")
-
-
-# Sampler map
-SAMPLER_MAP = {
- "DPM++ Karras SDE": lambda config: DPMSolverMultistepScheduler.from_config(config, use_karras=True, algorithm_type="sde-dpmsolver++"),
- "Euler": lambda config: EulerDiscreteScheduler.from_config(config),
-}
-
-def center_crop_resize(img, output_size=(512, 512)):
- width, height = img.size
-
- # Calculate dimensions to crop to the center
- new_dimension = min(width, height)
- left = (width - new_dimension)/2
- top = (height - new_dimension)/2
- right = (width + new_dimension)/2
- bottom = (height + new_dimension)/2
-
- # Crop and resize
- img = img.crop((left, top, right, bottom))
- img = img.resize(output_size)
-
- return img
-
-def common_upscale(samples, width, height, upscale_method, crop=False):
- if crop == "center":
- old_width = samples.shape[3]
- old_height = samples.shape[2]
- old_aspect = old_width / old_height
- new_aspect = width / height
- x = 0
- y = 0
- if old_aspect > new_aspect:
- x = round((old_width - old_width * (new_aspect / old_aspect)) / 2)
- elif old_aspect < new_aspect:
- y = round((old_height - old_height * (old_aspect / new_aspect)) / 2)
- s = samples[:,:,y:old_height-y,x:old_width-x]
- else:
- s = samples
-
- return torch.nn.functional.interpolate(s, size=(height, width), mode=upscale_method)
-
-def upscale(samples, upscale_method, scale_by):
- #s = samples.copy()
- width = round(samples["images"].shape[3] * scale_by)
- height = round(samples["images"].shape[2] * scale_by)
- s = common_upscale(samples["images"], width, height, upscale_method, "disabled")
- return (s)
-
-def check_inputs(prompt: str, control_image: Image.Image):
- if control_image is None:
- raise gr.Error("Please select or upload an Input Illusion")
- if prompt is None or prompt == "":
- raise gr.Error("Prompt is required")
-
-# Inference function
-def inference(
- control_image: Image.Image,
- prompt: str,
- negative_prompt: str,
- guidance_scale: float = 8.0,
- controlnet_conditioning_scale: float = 1,
- control_guidance_start: float = 1,
- control_guidance_end: float = 1,
- upscaler_strength: float = 0.5,
- seed: int = -1,
- sampler = "DPM++ Karras SDE",
- progress = gr.Progress(track_tqdm=True)
-):
- start_time = time.time()
- start_time_struct = time.localtime(start_time)
- start_time_formatted = time.strftime("%H:%M:%S", start_time_struct)
- print(f"Inference started at {start_time_formatted}")
-
- # Generate the initial image
- #init_image = init_pipe(prompt).images[0]
-
- # Rest of your existing code
- control_image_small = center_crop_resize(control_image)
- control_image_large = center_crop_resize(control_image, (1024, 1024))
-
- main_pipe.scheduler = SAMPLER_MAP[sampler](main_pipe.scheduler.config)
- my_seed = random.randint(0, 2**32 - 1) if seed == -1 else seed
- generator = torch.Generator(device="cuda").manual_seed(my_seed)
-
- out = main_pipe(
- prompt=prompt,
- negative_prompt=negative_prompt,
- image=control_image_small,
- guidance_scale=float(guidance_scale),
- controlnet_conditioning_scale=float(controlnet_conditioning_scale),
- generator=generator,
- control_guidance_start=float(control_guidance_start),
- control_guidance_end=float(control_guidance_end),
- num_inference_steps=15,
- output_type="latent"
- )
- upscaled_latents = upscale(out, "nearest-exact", 2)
- out_image = image_pipe(
- prompt=prompt,
- negative_prompt=negative_prompt,
- control_image=control_image_large,
- image=upscaled_latents,
- guidance_scale=float(guidance_scale),
- generator=generator,
- num_inference_steps=20,
- strength=upscaler_strength,
- control_guidance_start=float(control_guidance_start),
- control_guidance_end=float(control_guidance_end),
- controlnet_conditioning_scale=float(controlnet_conditioning_scale)
- )
- end_time = time.time()
- end_time_struct = time.localtime(end_time)
- end_time_formatted = time.strftime("%H:%M:%S", end_time_struct)
- print(f"Inference ended at {end_time_formatted}, taking {end_time-start_time}s")
- return out_image["images"][0], gr.update(visible=True), my_seed
-
- #return out
-
-with gr.Blocks(css=css) as app:
- gr.Markdown(
- '''
- Illusion Diffusion HQ 🌀
- Generate stunning high quality illusion artwork with Stable Diffusion
-
-
- A space by AP [Follow me on Twitter](https://twitter.com/angrypenguinPNG) with big contributions from [multimodalart](https://twitter.com/multimodalart)
-
- This project works by using [Monster Labs QR Control Net](https://huggingface.co/monster-labs/control_v1p_sd15_qrcode_monster).
- Given a prompt and your pattern, we use a QR code conditioned controlnet to create a stunning illusion! Credit to: [MrUgleh](https://twitter.com/MrUgleh) for discovering the workflow :)
- '''
- )
-
- with gr.Row():
- with gr.Column():
- control_image = gr.Image(label="Input Illusion", type="pil", elem_id="control_image")
- controlnet_conditioning_scale = gr.Slider(minimum=0.0, maximum=5.0, step=0.01, value=0.8, label="Illusion strength", elem_id="illusion_strength", info="ControlNet conditioning scale")
- gr.Examples(examples=["checkers.png", "checkers_mid.jpg", "pattern.png", "ultra_checkers.png", "spiral.jpeg", "funky.jpeg" ], inputs=control_image)
- prompt = gr.Textbox(label="Prompt", elem_id="prompt")
- negative_prompt = gr.Textbox(label="Negative Prompt", value="low quality", elem_id="negative_prompt")
- with gr.Accordion(label="Advanced Options", open=False):
- guidance_scale = gr.Slider(minimum=0.0, maximum=50.0, step=0.25, value=7.5, label="Guidance Scale")
- sampler = gr.Dropdown(choices=list(SAMPLER_MAP.keys()), value="Euler")
- control_start = gr.Slider(minimum=0.0, maximum=1.0, step=0.1, value=0, label="Start of ControlNet")
- control_end = gr.Slider(minimum=0.0, maximum=1.0, step=0.1, value=1, label="End of ControlNet")
- strength = gr.Slider(minimum=0.0, maximum=1.0, step=0.1, value=1, label="Strength of the upscaler")
- seed = gr.Slider(minimum=-1, maximum=9999999999, step=1, value=-1, label="Seed", info="-1 means random seed")
- used_seed = gr.Number(label="Last seed used",interactive=False)
- run_btn = gr.Button("Run")
- with gr.Column():
- result_image = gr.Image(label="Illusion Diffusion Output", interactive=False, elem_id="output")
- with gr.Group(elem_id="share-btn-container", visible=False) as share_group:
- community_icon = gr.HTML(community_icon_html)
- loading_icon = gr.HTML(loading_icon_html)
- share_button = gr.Button("Share to community", elem_id="share-btn")
-
- history = show_gallery_history()
- prompt.submit(
- check_inputs,
- inputs=[prompt, control_image],
- queue=False
- ).success(
- inference,
- inputs=[control_image, prompt, negative_prompt, guidance_scale, controlnet_conditioning_scale, control_start, control_end, strength, seed, sampler],
- outputs=[result_image, share_group, used_seed]
- ).success(
- fn=fetch_gallery_history, inputs=[prompt, result_image], outputs=history, queue=False
- )
- run_btn.click(
- check_inputs,
- inputs=[prompt, control_image],
- queue=False
- ).success(
- inference,
- inputs=[control_image, prompt, negative_prompt, guidance_scale, controlnet_conditioning_scale, control_start, control_end, strength, seed, sampler],
- outputs=[result_image, share_group, used_seed]
- ).success(
- fn=fetch_gallery_history, inputs=[prompt, result_image], outputs=history, queue=False
- )
- share_button.click(None, [], [], _js=share_js)
-app.queue(max_size=20)
-
-if __name__ == "__main__":
- app.launch(max_threads=240)
diff --git a/spaces/Potanin/12345/utils.py b/spaces/Potanin/12345/utils.py
deleted file mode 100644
index 62be8d03a8e8b839f8747310ef0ec0e82fb8ff0a..0000000000000000000000000000000000000000
--- a/spaces/Potanin/12345/utils.py
+++ /dev/null
@@ -1,151 +0,0 @@
-import ffmpeg
-import numpy as np
-
-# import praatio
-# import praatio.praat_scripts
-import os
-import sys
-
-import random
-
-import csv
-
-platform_stft_mapping = {
- "linux": "stftpitchshift",
- "darwin": "stftpitchshift",
- "win32": "stftpitchshift.exe",
-}
-
-stft = platform_stft_mapping.get(sys.platform)
-# praatEXE = join('.',os.path.abspath(os.getcwd()) + r"\Praat.exe")
-
-
-def CSVutil(file, rw, type, *args):
- if type == "formanting":
- if rw == "r":
- with open(file) as fileCSVread:
- csv_reader = list(csv.reader(fileCSVread))
- return (
- (csv_reader[0][0], csv_reader[0][1], csv_reader[0][2])
- if csv_reader is not None
- else (lambda: exec('raise ValueError("No data")'))()
- )
- else:
- if args:
- doformnt = args[0]
- else:
- doformnt = False
- qfr = args[1] if len(args) > 1 else 1.0
- tmb = args[2] if len(args) > 2 else 1.0
- with open(file, rw, newline="") as fileCSVwrite:
- csv_writer = csv.writer(fileCSVwrite, delimiter=",")
- csv_writer.writerow([doformnt, qfr, tmb])
- elif type == "stop":
- stop = args[0] if args else False
- with open(file, rw, newline="") as fileCSVwrite:
- csv_writer = csv.writer(fileCSVwrite, delimiter=",")
- csv_writer.writerow([stop])
-
-
-def load_audio(file, sr, DoFormant, Quefrency, Timbre):
- converted = False
- DoFormant, Quefrency, Timbre = CSVutil("csvdb/formanting.csv", "r", "formanting")
- try:
- # https://github.com/openai/whisper/blob/main/whisper/audio.py#L26
- # This launches a subprocess to decode audio while down-mixing and resampling as necessary.
- # Requires the ffmpeg CLI and `ffmpeg-python` package to be installed.
- file = (
- file.strip(" ").strip('"').strip("\n").strip('"').strip(" ")
- ) # 防止小白拷路径头尾带了空格和"和回车
- file_formanted = file.strip(" ").strip('"').strip("\n").strip('"').strip(" ")
-
- # print(f"dofor={bool(DoFormant)} timbr={Timbre} quef={Quefrency}\n")
-
- if (
- lambda DoFormant: True
- if DoFormant.lower() == "true"
- else (False if DoFormant.lower() == "false" else DoFormant)
- )(DoFormant):
- numerator = round(random.uniform(1, 4), 4)
- # os.system(f"stftpitchshift -i {file} -q {Quefrency} -t {Timbre} -o {file_formanted}")
- # print('stftpitchshift -i "%s" -p 1.0 --rms -w 128 -v 8 -q %s -t %s -o "%s"' % (file, Quefrency, Timbre, file_formanted))
-
- if not file.endswith(".wav"):
- if not os.path.isfile(f"{file_formanted}.wav"):
- converted = True
- # print(f"\nfile = {file}\n")
- # print(f"\nfile_formanted = {file_formanted}\n")
- converting = (
- ffmpeg.input(file_formanted, threads=0)
- .output(f"{file_formanted}.wav")
- .run(
- cmd=["ffmpeg", "-nostdin"],
- capture_stdout=True,
- capture_stderr=True,
- )
- )
- else:
- pass
-
- file_formanted = (
- f"{file_formanted}.wav"
- if not file_formanted.endswith(".wav")
- else file_formanted
- )
-
- print(f" · Formanting {file_formanted}...\n")
-
- os.system(
- '%s -i "%s" -q "%s" -t "%s" -o "%sFORMANTED_%s.wav"'
- % (
- stft,
- file_formanted,
- Quefrency,
- Timbre,
- file_formanted,
- str(numerator),
- )
- )
-
- print(f" · Formanted {file_formanted}!\n")
-
- # filepraat = (os.path.abspath(os.getcwd()) + '\\' + file).replace('/','\\')
- # file_formantedpraat = ('"' + os.path.abspath(os.getcwd()) + '/' + 'formanted'.join(file_formanted) + '"').replace('/','\\')
- # print("%sFORMANTED_%s.wav" % (file_formanted, str(numerator)))
-
- out, _ = (
- ffmpeg.input(
- "%sFORMANTED_%s.wav" % (file_formanted, str(numerator)), threads=0
- )
- .output("-", format="f32le", acodec="pcm_f32le", ac=1, ar=sr)
- .run(
- cmd=["ffmpeg", "-nostdin"], capture_stdout=True, capture_stderr=True
- )
- )
-
- try:
- os.remove("%sFORMANTED_%s.wav" % (file_formanted, str(numerator)))
- except Exception:
- pass
- print("couldn't remove formanted type of file")
-
- else:
- out, _ = (
- ffmpeg.input(file, threads=0)
- .output("-", format="f32le", acodec="pcm_f32le", ac=1, ar=sr)
- .run(
- cmd=["ffmpeg", "-nostdin"], capture_stdout=True, capture_stderr=True
- )
- )
- except Exception as e:
- raise RuntimeError(f"Failed to load audio: {e}")
-
- if converted:
- try:
- os.remove(file_formanted)
- except Exception:
- pass
- print("couldn't remove converted type of file")
- converted = False
-
- return np.frombuffer(out, np.float32).flatten()
diff --git a/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/semantic_version/django_fields.py b/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/semantic_version/django_fields.py
deleted file mode 100644
index e5bd7eb2340cfedad7ac387869ce20bdb053f112..0000000000000000000000000000000000000000
--- a/spaces/Raspberry-ai/main/.env/lib/python3.11/site-packages/semantic_version/django_fields.py
+++ /dev/null
@@ -1,107 +0,0 @@
-# -*- coding: utf-8 -*-
-# Copyright (c) The python-semanticversion project
-# This code is distributed under the two-clause BSD License.
-
-import warnings
-
-import django
-from django.db import models
-
-if django.VERSION >= (3, 0):
- # See https://docs.djangoproject.com/en/dev/releases/3.0/#features-deprecated-in-3-0
- from django.utils.translation import gettext_lazy as _
-else:
- from django.utils.translation import ugettext_lazy as _
-
-from . import base
-
-
-class SemVerField(models.CharField):
-
- def __init__(self, *args, **kwargs):
- kwargs.setdefault('max_length', 200)
- super(SemVerField, self).__init__(*args, **kwargs)
-
- def from_db_value(self, value, expression, connection, *args):
- """Convert from the database format.
-
- This should be the inverse of self.get_prep_value()
- """
- return self.to_python(value)
-
- def get_prep_value(self, obj):
- return None if obj is None else str(obj)
-
- def get_db_prep_value(self, value, connection, prepared=False):
- if not prepared:
- value = self.get_prep_value(value)
- return value
-
- def value_to_string(self, obj):
- value = self.to_python(self.value_from_object(obj))
- return str(value)
-
- def run_validators(self, value):
- return super(SemVerField, self).run_validators(str(value))
-
-
-class VersionField(SemVerField):
- default_error_messages = {
- 'invalid': _("Enter a valid version number in X.Y.Z format."),
- }
- description = _("Version")
-
- def __init__(self, *args, **kwargs):
- self.partial = kwargs.pop('partial', False)
- if self.partial:
- warnings.warn(
- "Use of `partial=True` will be removed in 3.0.",
- DeprecationWarning,
- stacklevel=2,
- )
- self.coerce = kwargs.pop('coerce', False)
- super(VersionField, self).__init__(*args, **kwargs)
-
- def deconstruct(self):
- """Handle django.db.migrations."""
- name, path, args, kwargs = super(VersionField, self).deconstruct()
- kwargs['partial'] = self.partial
- kwargs['coerce'] = self.coerce
- return name, path, args, kwargs
-
- def to_python(self, value):
- """Converts any value to a base.Version field."""
- if value is None or value == '':
- return value
- if isinstance(value, base.Version):
- return value
- if self.coerce:
- return base.Version.coerce(value, partial=self.partial)
- else:
- return base.Version(value, partial=self.partial)
-
-
-class SpecField(SemVerField):
- default_error_messages = {
- 'invalid': _("Enter a valid version number spec list in ==X.Y.Z,>=A.B.C format."),
- }
- description = _("Version specification list")
-
- def __init__(self, *args, **kwargs):
- self.syntax = kwargs.pop('syntax', base.DEFAULT_SYNTAX)
- super(SpecField, self).__init__(*args, **kwargs)
-
- def deconstruct(self):
- """Handle django.db.migrations."""
- name, path, args, kwargs = super(SpecField, self).deconstruct()
- if self.syntax != base.DEFAULT_SYNTAX:
- kwargs['syntax'] = self.syntax
- return name, path, args, kwargs
-
- def to_python(self, value):
- """Converts any value to a base.Spec field."""
- if value is None or value == '':
- return value
- if isinstance(value, base.BaseSpec):
- return value
- return base.BaseSpec.parse(value, syntax=self.syntax)
diff --git a/spaces/Realcat/image-matching-webui/third_party/ASpanFormer/src/ASpanFormer/utils/supervision.py b/spaces/Realcat/image-matching-webui/third_party/ASpanFormer/src/ASpanFormer/utils/supervision.py
deleted file mode 100644
index 16c468d8ee1425be0d4518477263f377bd09873a..0000000000000000000000000000000000000000
--- a/spaces/Realcat/image-matching-webui/third_party/ASpanFormer/src/ASpanFormer/utils/supervision.py
+++ /dev/null
@@ -1,172 +0,0 @@
-from math import log
-from loguru import logger
-
-import torch
-from einops import repeat
-from kornia.utils import create_meshgrid
-
-from .geometry import warp_kpts
-
-############## ↓ Coarse-Level supervision ↓ ##############
-
-
-@torch.no_grad()
-def mask_pts_at_padded_regions(grid_pt, mask):
- """For megadepth dataset, zero-padding exists in images"""
- mask = repeat(mask, "n h w -> n (h w) c", c=2)
- grid_pt[~mask.bool()] = 0
- return grid_pt
-
-
-@torch.no_grad()
-def spvs_coarse(data, config):
- """
- Update:
- data (dict): {
- "conf_matrix_gt": [N, hw0, hw1],
- 'spv_b_ids': [M]
- 'spv_i_ids': [M]
- 'spv_j_ids': [M]
- 'spv_w_pt0_i': [N, hw0, 2], in original image resolution
- 'spv_pt1_i': [N, hw1, 2], in original image resolution
- }
-
- NOTE:
- - for scannet dataset, there're 3 kinds of resolution {i, c, f}
- - for megadepth dataset, there're 4 kinds of resolution {i, i_resize, c, f}
- """
- # 1. misc
- device = data["image0"].device
- N, _, H0, W0 = data["image0"].shape
- _, _, H1, W1 = data["image1"].shape
- scale = config["ASPAN"]["RESOLUTION"][0]
- scale0 = scale * data["scale0"][:, None] if "scale0" in data else scale
- scale1 = scale * data["scale1"][:, None] if "scale0" in data else scale
- h0, w0, h1, w1 = map(lambda x: x // scale, [H0, W0, H1, W1])
-
- # 2. warp grids
- # create kpts in meshgrid and resize them to image resolution
- grid_pt0_c = (
- create_meshgrid(h0, w0, False, device).reshape(1, h0 * w0, 2).repeat(N, 1, 1)
- ) # [N, hw, 2]
- grid_pt0_i = scale0 * grid_pt0_c
- grid_pt1_c = (
- create_meshgrid(h1, w1, False, device).reshape(1, h1 * w1, 2).repeat(N, 1, 1)
- )
- grid_pt1_i = scale1 * grid_pt1_c
-
- # mask padded region to (0, 0), so no need to manually mask conf_matrix_gt
- if "mask0" in data:
- grid_pt0_i = mask_pts_at_padded_regions(grid_pt0_i, data["mask0"])
- grid_pt1_i = mask_pts_at_padded_regions(grid_pt1_i, data["mask1"])
-
- # warp kpts bi-directionally and resize them to coarse-level resolution
- # (no depth consistency check, since it leads to worse results experimentally)
- # (unhandled edge case: points with 0-depth will be warped to the left-up corner)
- _, w_pt0_i = warp_kpts(
- grid_pt0_i,
- data["depth0"],
- data["depth1"],
- data["T_0to1"],
- data["K0"],
- data["K1"],
- )
- _, w_pt1_i = warp_kpts(
- grid_pt1_i,
- data["depth1"],
- data["depth0"],
- data["T_1to0"],
- data["K1"],
- data["K0"],
- )
- w_pt0_c = w_pt0_i / scale1
- w_pt1_c = w_pt1_i / scale0
-
- # 3. check if mutual nearest neighbor
- w_pt0_c_round = w_pt0_c[:, :, :].round().long()
- nearest_index1 = w_pt0_c_round[..., 0] + w_pt0_c_round[..., 1] * w1
- w_pt1_c_round = w_pt1_c[:, :, :].round().long()
- nearest_index0 = w_pt1_c_round[..., 0] + w_pt1_c_round[..., 1] * w0
-
- # corner case: out of boundary
- def out_bound_mask(pt, w, h):
- return (
- (pt[..., 0] < 0) + (pt[..., 0] >= w) + (pt[..., 1] < 0) + (pt[..., 1] >= h)
- )
-
- nearest_index1[out_bound_mask(w_pt0_c_round, w1, h1)] = 0
- nearest_index0[out_bound_mask(w_pt1_c_round, w0, h0)] = 0
-
- loop_back = torch.stack(
- [nearest_index0[_b][_i] for _b, _i in enumerate(nearest_index1)], dim=0
- )
- correct_0to1 = loop_back == torch.arange(h0 * w0, device=device)[None].repeat(N, 1)
- correct_0to1[:, 0] = False # ignore the top-left corner
-
- # 4. construct a gt conf_matrix
- conf_matrix_gt = torch.zeros(N, h0 * w0, h1 * w1, device=device)
- b_ids, i_ids = torch.where(correct_0to1 != 0)
- j_ids = nearest_index1[b_ids, i_ids]
-
- conf_matrix_gt[b_ids, i_ids, j_ids] = 1
- data.update({"conf_matrix_gt": conf_matrix_gt})
-
- # 5. save coarse matches(gt) for training fine level
- if len(b_ids) == 0:
- logger.warning(f"No groundtruth coarse match found for: {data['pair_names']}")
- # this won't affect fine-level loss calculation
- b_ids = torch.tensor([0], device=device)
- i_ids = torch.tensor([0], device=device)
- j_ids = torch.tensor([0], device=device)
-
- data.update({"spv_b_ids": b_ids, "spv_i_ids": i_ids, "spv_j_ids": j_ids})
-
- # 6. save intermediate results (for fast fine-level computation)
- data.update({"spv_w_pt0_i": w_pt0_i, "spv_pt1_i": grid_pt1_i})
-
-
-def compute_supervision_coarse(data, config):
- assert (
- len(set(data["dataset_name"])) == 1
- ), "Do not support mixed datasets training!"
- data_source = data["dataset_name"][0]
- if data_source.lower() in ["scannet", "megadepth"]:
- spvs_coarse(data, config)
- else:
- raise ValueError(f"Unknown data source: {data_source}")
-
-
-############## ↓ Fine-Level supervision ↓ ##############
-
-
-@torch.no_grad()
-def spvs_fine(data, config):
- """
- Update:
- data (dict):{
- "expec_f_gt": [M, 2]}
- """
- # 1. misc
- # w_pt0_i, pt1_i = data.pop('spv_w_pt0_i'), data.pop('spv_pt1_i')
- w_pt0_i, pt1_i = data["spv_w_pt0_i"], data["spv_pt1_i"]
- scale = config["ASPAN"]["RESOLUTION"][1]
- radius = config["ASPAN"]["FINE_WINDOW_SIZE"] // 2
-
- # 2. get coarse prediction
- b_ids, i_ids, j_ids = data["b_ids"], data["i_ids"], data["j_ids"]
-
- # 3. compute gt
- scale = scale * data["scale1"][b_ids] if "scale0" in data else scale
- # `expec_f_gt` might exceed the window, i.e. abs(*) > 1, which would be filtered later
- expec_f_gt = (
- (w_pt0_i[b_ids, i_ids] - pt1_i[b_ids, j_ids]) / scale / radius
- ) # [M, 2]
- data.update({"expec_f_gt": expec_f_gt})
-
-
-def compute_supervision_fine(data, config):
- data_source = data["dataset_name"][0]
- if data_source.lower() in ["scannet", "megadepth"]:
- spvs_fine(data, config)
- else:
- raise NotImplementedError
diff --git a/spaces/Ricecake123/RVC-demo/docs/Changelog_KO.md b/spaces/Ricecake123/RVC-demo/docs/Changelog_KO.md
deleted file mode 100644
index 52da1dfdb1877e1cb3a01e618a8772405af2fd6e..0000000000000000000000000000000000000000
--- a/spaces/Ricecake123/RVC-demo/docs/Changelog_KO.md
+++ /dev/null
@@ -1,91 +0,0 @@
-### 2023년 6월 18일 업데이트
-
-- v2 버전에서 새로운 32k와 48k 사전 학습 모델을 추가.
-- non-f0 모델들의 추론 오류 수정.
-- 학습 세트가 1시간을 넘어가는 경우, 인덱스 생성 단계에서 minibatch-kmeans을 사용해, 학습속도 가속화.
-- [huggingface](https://huggingface.co/spaces/lj1995/vocal2guitar)에서 vocal2guitar 제공.
-- 데이터 처리 단계에서 이상 값 자동으로 제거.
-- ONNX로 내보내는(export) 옵션 탭 추가.
-
-업데이트에 적용되지 않았지만 시도한 것들 :
-
-- 시계열 차원을 추가하여 특징 검색을 진행했지만, 유의미한 효과는 없었습니다.
-- PCA 차원 축소를 추가하여 특징 검색을 진행했지만, 유의미한 효과는 없었습니다.
-- ONNX 추론을 지원하는 것에 실패했습니다. nsf 생성시, Pytorch가 필요하기 때문입니다.
-- 훈련 중에 입력에 대한 음고, 성별, 이퀄라이저, 노이즈 등 무작위로 강화하는 것에, 유의미한 효과는 없었습니다.
-
-추후 업데이트 목록:
-
-- Vocos-RVC (소형 보코더) 통합 예정.
-- 학습 단계에 음고 인식을 위한 Crepe 지원 예정.
-- Crepe의 정밀도를 REC-config와 동기화하여 지원 예정.
-- FO 에디터 지원 예정.
-
-### 2023년 5월 28일 업데이트
-
-- v2 jupyter notebook 추가, 한국어 업데이트 로그 추가, 의존성 모듈 일부 수정.
-- 무성음 및 숨소리 보호 모드 추가.
-- crepe-full pitch 감지 지원.
-- UVR5 보컬 분리: 디버브 및 디-에코 모델 지원.
-- index 이름에 experiment 이름과 버전 추가.
-- 배치 음성 변환 처리 및 UVR5 보컬 분리 시, 사용자가 수동으로 출력 오디오의 내보내기(export) 형식을 선택할 수 있도록 지원.
-- 32k 훈련 모델 지원 종료.
-
-### 2023년 5월 13일 업데이트
-
-- 원클릭 패키지의 이전 버전 런타임 내, 불필요한 코드(lib.infer_pack 및 uvr5_pack) 제거.
-- 훈련 세트 전처리의 유사 다중 처리 버그 수정.
-- Harvest 피치 인식 알고리즘에 대한 중위수 필터링 반경 조정 추가.
-- 오디오 내보낼 때, 후처리 리샘플링 지원.
-- 훈련에 대한 다중 처리 "n_cpu" 설정이 "f0 추출"에서 "데이터 전처리 및 f0 추출"로 변경.
-- logs 폴더 하의 인덱스 경로를 자동으로 감지 및 드롭다운 목록 기능 제공.
-- 탭 페이지에 "자주 묻는 질문과 답변" 추가. (github RVC wiki 참조 가능)
-- 동일한 입력 오디오 경로를 사용할 때 추론, Harvest 피치를 캐시.
- (주의: Harvest 피치 추출을 사용하면 전체 파이프라인은 길고 반복적인 피치 추출 과정을 거치게됩니다. 캐싱을 하지 않는다면, 첫 inference 이후의 단계에서 timbre, 인덱스, 피치 중위수 필터링 반경 설정 등 대기시간이 엄청나게 길어집니다!)
-
-### 2023년 5월 14일 업데이트
-
-- 입력의 볼륨 캡슐을 사용하여 출력의 볼륨 캡슐을 혼합하거나 대체. (입력이 무음이거나 출력의 노이즈 문제를 최소화 할 수 있습니다. 입력 오디오의 배경 노이즈(소음)가 큰 경우 해당 기능을 사용하지 않는 것이 좋습니다. 기본적으로 비활성화 되어있는 옵션입니다. (1: 비활성화 상태))
-- 추출된 소형 모델을 지정된 빈도로 저장하는 기능을 지원. (다양한 에폭 하에서의 성능을 보려고 하지만 모든 대형 체크포인트를 저장하고 매번 ckpt 처리를 통해 소형 모델을 수동으로 추출하고 싶지 않은 경우 이 기능은 매우 유용합니다)
-- 환경 변수를 설정하여 서버의 전역 프록시로 인한 "연결 오류" 문제 해결.
-- 사전 훈련된 v2 모델 지원. (현재 40k 버전만 테스트를 위해 공개적으로 사용 가능하며, 다른 두 개의 샘플링 비율은 아직 완전히 훈련되지 않아 보류되었습니다.)
-- 추론 전, 1을 초과하는 과도한 볼륨 제한.
-- 데이터 전처리 매개변수 미세 조정.
-
-### 2023년 4월 9일 업데이트
-
-- GPU 이용률 향상을 위해 훈련 파라미터 수정: A100은 25%에서 약 90%로 증가, V100: 50%에서 약 90%로 증가, 2060S: 60%에서 약 85%로 증가, P40: 25%에서 약 95%로 증가.
- 훈련 속도가 크게 향상.
-- 매개변수 기준 변경: total batch_size는 GPU당 batch_size를 의미.
-- total_epoch 변경: 최대 한도가 100에서 1000으로 증가. 기본값이 10에서 20으로 증가.
-- ckpt 추출이 피치를 잘못 인식하여 비정상적인 추론을 유발하는 문제 수정.
-- 분산 훈련 과정에서 각 랭크마다 ckpt를 저장하는 문제 수정.
-- 특성 추출 과정에 나노 특성 필터링 적용.
-- 무음 입력/출력이 랜덤하게 소음을 생성하는 문제 수정. (이전 모델은 새 데이터셋으로 다시 훈련해야 합니다)
-
-### 2023년 4월 16일 업데이트
-
-- 로컬 실시간 음성 변경 미니-GUI 추가, go-realtime-gui.bat를 더블 클릭하여 시작.
-- 훈련 및 추론 중 50Hz 이하의 주파수 대역에 대해 필터링 적용.
-- 훈련 및 추론의 pyworld 최소 피치 추출을 기본 80에서 50으로 낮춤. 이로 인해, 50-80Hz 사이의 남성 저음이 무음화되지 않습니다.
-- 시스템 지역에 따른 WebUI 언어 변경 지원. (현재 en_US, ja_JP, zh_CN, zh_HK, zh_SG, zh_TW를 지원하며, 지원되지 않는 경우 기본값은 en_US)
-- 일부 GPU의 인식 수정. (예: V100-16G 인식 실패, P4 인식 실패)
-
-### 2023년 4월 28일 업데이트
-
-- Faiss 인덱스 설정 업그레이드로 속도가 더 빨라지고 품질이 향상.
-- total_npy에 대한 의존성 제거. 추후의 모델 공유는 total_npy 입력을 필요로 하지 않습니다.
-- 16 시리즈 GPU에 대한 제한 해제, 4GB VRAM GPU에 대한 4GB 추론 설정 제공.
-- 일부 오디오 형식에 대한 UVR5 보컬 동반 분리에서의 버그 수정.
-- 실시간 음성 변경 미니-GUI는 이제 non-40k 및 non-lazy 피치 모델을 지원합니다.
-
-### 추후 계획
-
-Features:
-
-- 다중 사용자 훈련 탭 지원.(최대 4명)
-
-Base model:
-
-- 훈련 데이터셋에 숨소리 wav 파일을 추가하여, 보컬의 호흡이 노이즈로 변환되는 문제 수정.
-- 보컬 훈련 세트의 기본 모델을 추가하기 위한 작업을 진행중이며, 이는 향후에 발표될 예정.
diff --git a/spaces/Ripaxxs/Mom/README.md b/spaces/Ripaxxs/Mom/README.md
deleted file mode 100644
index 5d8717c658d3050fd18e772e632be50dfed95637..0000000000000000000000000000000000000000
--- a/spaces/Ripaxxs/Mom/README.md
+++ /dev/null
@@ -1,11 +0,0 @@
----
-title: Arc
-emoji: 🦀
-colorFrom: yellow
-colorTo: blue
-sdk: docker
-pinned: false
-license: bigscience-openrail-m
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/RobLi/ControlNet-v1-1/image_segmentor.py b/spaces/RobLi/ControlNet-v1-1/image_segmentor.py
deleted file mode 100644
index 46a972e2d29ad9f40902b484585b2d574de8c0c3..0000000000000000000000000000000000000000
--- a/spaces/RobLi/ControlNet-v1-1/image_segmentor.py
+++ /dev/null
@@ -1,39 +0,0 @@
-import cv2
-import numpy as np
-import PIL.Image
-import torch
-from controlnet_aux.util import HWC3, ade_palette
-from transformers import AutoImageProcessor, UperNetForSemanticSegmentation
-
-from cv_utils import resize_image
-
-
-class ImageSegmentor:
- def __init__(self):
- self.image_processor = AutoImageProcessor.from_pretrained(
- 'openmmlab/upernet-convnext-small')
- self.image_segmentor = UperNetForSemanticSegmentation.from_pretrained(
- 'openmmlab/upernet-convnext-small')
-
- @torch.inference_mode()
- def __call__(self, image: np.ndarray, **kwargs) -> PIL.Image.Image:
- detect_resolution = kwargs.pop('detect_resolution', 512)
- image_resolution = kwargs.pop('image_resolution', 512)
- image = HWC3(image)
- image = resize_image(image, resolution=detect_resolution)
- image = PIL.Image.fromarray(image)
-
- pixel_values = self.image_processor(image,
- return_tensors='pt').pixel_values
- outputs = self.image_segmentor(pixel_values)
- seg = self.image_processor.post_process_semantic_segmentation(
- outputs, target_sizes=[image.size[::-1]])[0]
- color_seg = np.zeros((seg.shape[0], seg.shape[1], 3), dtype=np.uint8)
- for label, color in enumerate(ade_palette()):
- color_seg[seg == label, :] = color
- color_seg = color_seg.astype(np.uint8)
-
- color_seg = resize_image(color_seg,
- resolution=image_resolution,
- interpolation=cv2.INTER_NEAREST)
- return PIL.Image.fromarray(color_seg)
diff --git a/spaces/Robert001/UniControl-Demo/annotator/uniformer/configs/_base_/models/fast_scnn.py b/spaces/Robert001/UniControl-Demo/annotator/uniformer/configs/_base_/models/fast_scnn.py
deleted file mode 100644
index 32fdeb659355a5ce5ef2cc7c2f30742703811cdf..0000000000000000000000000000000000000000
--- a/spaces/Robert001/UniControl-Demo/annotator/uniformer/configs/_base_/models/fast_scnn.py
+++ /dev/null
@@ -1,57 +0,0 @@
-# model settings
-norm_cfg = dict(type='SyncBN', requires_grad=True, momentum=0.01)
-model = dict(
- type='EncoderDecoder',
- backbone=dict(
- type='FastSCNN',
- downsample_dw_channels=(32, 48),
- global_in_channels=64,
- global_block_channels=(64, 96, 128),
- global_block_strides=(2, 2, 1),
- global_out_channels=128,
- higher_in_channels=64,
- lower_in_channels=128,
- fusion_out_channels=128,
- out_indices=(0, 1, 2),
- norm_cfg=norm_cfg,
- align_corners=False),
- decode_head=dict(
- type='DepthwiseSeparableFCNHead',
- in_channels=128,
- channels=128,
- concat_input=False,
- num_classes=19,
- in_index=-1,
- norm_cfg=norm_cfg,
- align_corners=False,
- loss_decode=dict(
- type='CrossEntropyLoss', use_sigmoid=True, loss_weight=0.4)),
- auxiliary_head=[
- dict(
- type='FCNHead',
- in_channels=128,
- channels=32,
- num_convs=1,
- num_classes=19,
- in_index=-2,
- norm_cfg=norm_cfg,
- concat_input=False,
- align_corners=False,
- loss_decode=dict(
- type='CrossEntropyLoss', use_sigmoid=True, loss_weight=0.4)),
- dict(
- type='FCNHead',
- in_channels=64,
- channels=32,
- num_convs=1,
- num_classes=19,
- in_index=-3,
- norm_cfg=norm_cfg,
- concat_input=False,
- align_corners=False,
- loss_decode=dict(
- type='CrossEntropyLoss', use_sigmoid=True, loss_weight=0.4)),
- ],
- # model training and testing settings
- train_cfg=dict(),
- test_cfg=dict(mode='whole'))
diff --git a/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmdet/models/dense_heads/yolact_head.py b/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmdet/models/dense_heads/yolact_head.py
deleted file mode 100644
index 10d311f94ee99e1bf65ee3e5827f1699c28a23e3..0000000000000000000000000000000000000000
--- a/spaces/Robert001/UniControl-Demo/annotator/uniformer/mmdet/models/dense_heads/yolact_head.py
+++ /dev/null
@@ -1,943 +0,0 @@
-import numpy as np
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-from mmcv.cnn import ConvModule, xavier_init
-from mmcv.runner import force_fp32
-
-from mmdet.core import build_sampler, fast_nms, images_to_levels, multi_apply
-from ..builder import HEADS, build_loss
-from .anchor_head import AnchorHead
-
-
-@HEADS.register_module()
-class YOLACTHead(AnchorHead):
- """YOLACT box head used in https://arxiv.org/abs/1904.02689.
-
- Note that YOLACT head is a light version of RetinaNet head.
- Four differences are described as follows:
-
- 1. YOLACT box head has three-times fewer anchors.
- 2. YOLACT box head shares the convs for box and cls branches.
- 3. YOLACT box head uses OHEM instead of Focal loss.
- 4. YOLACT box head predicts a set of mask coefficients for each box.
-
- Args:
- num_classes (int): Number of categories excluding the background
- category.
- in_channels (int): Number of channels in the input feature map.
- anchor_generator (dict): Config dict for anchor generator
- loss_cls (dict): Config of classification loss.
- loss_bbox (dict): Config of localization loss.
- num_head_convs (int): Number of the conv layers shared by
- box and cls branches.
- num_protos (int): Number of the mask coefficients.
- use_ohem (bool): If true, ``loss_single_OHEM`` will be used for
- cls loss calculation. If false, ``loss_single`` will be used.
- conv_cfg (dict): Dictionary to construct and config conv layer.
- norm_cfg (dict): Dictionary to construct and config norm layer.
- """
-
- def __init__(self,
- num_classes,
- in_channels,
- anchor_generator=dict(
- type='AnchorGenerator',
- octave_base_scale=3,
- scales_per_octave=1,
- ratios=[0.5, 1.0, 2.0],
- strides=[8, 16, 32, 64, 128]),
- loss_cls=dict(
- type='CrossEntropyLoss',
- use_sigmoid=False,
- reduction='none',
- loss_weight=1.0),
- loss_bbox=dict(
- type='SmoothL1Loss', beta=1.0, loss_weight=1.5),
- num_head_convs=1,
- num_protos=32,
- use_ohem=True,
- conv_cfg=None,
- norm_cfg=None,
- **kwargs):
- self.num_head_convs = num_head_convs
- self.num_protos = num_protos
- self.use_ohem = use_ohem
- self.conv_cfg = conv_cfg
- self.norm_cfg = norm_cfg
- super(YOLACTHead, self).__init__(
- num_classes,
- in_channels,
- loss_cls=loss_cls,
- loss_bbox=loss_bbox,
- anchor_generator=anchor_generator,
- **kwargs)
- if self.use_ohem:
- sampler_cfg = dict(type='PseudoSampler')
- self.sampler = build_sampler(sampler_cfg, context=self)
- self.sampling = False
-
- def _init_layers(self):
- """Initialize layers of the head."""
- self.relu = nn.ReLU(inplace=True)
- self.head_convs = nn.ModuleList()
- for i in range(self.num_head_convs):
- chn = self.in_channels if i == 0 else self.feat_channels
- self.head_convs.append(
- ConvModule(
- chn,
- self.feat_channels,
- 3,
- stride=1,
- padding=1,
- conv_cfg=self.conv_cfg,
- norm_cfg=self.norm_cfg))
- self.conv_cls = nn.Conv2d(
- self.feat_channels,
- self.num_anchors * self.cls_out_channels,
- 3,
- padding=1)
- self.conv_reg = nn.Conv2d(
- self.feat_channels, self.num_anchors * 4, 3, padding=1)
- self.conv_coeff = nn.Conv2d(
- self.feat_channels,
- self.num_anchors * self.num_protos,
- 3,
- padding=1)
-
- def init_weights(self):
- """Initialize weights of the head."""
- for m in self.head_convs:
- xavier_init(m.conv, distribution='uniform', bias=0)
- xavier_init(self.conv_cls, distribution='uniform', bias=0)
- xavier_init(self.conv_reg, distribution='uniform', bias=0)
- xavier_init(self.conv_coeff, distribution='uniform', bias=0)
-
- def forward_single(self, x):
- """Forward feature of a single scale level.
-
- Args:
- x (Tensor): Features of a single scale level.
-
- Returns:
- tuple:
- cls_score (Tensor): Cls scores for a single scale level \
- the channels number is num_anchors * num_classes.
- bbox_pred (Tensor): Box energies / deltas for a single scale \
- level, the channels number is num_anchors * 4.
- coeff_pred (Tensor): Mask coefficients for a single scale \
- level, the channels number is num_anchors * num_protos.
- """
- for head_conv in self.head_convs:
- x = head_conv(x)
- cls_score = self.conv_cls(x)
- bbox_pred = self.conv_reg(x)
- coeff_pred = self.conv_coeff(x).tanh()
- return cls_score, bbox_pred, coeff_pred
-
- @force_fp32(apply_to=('cls_scores', 'bbox_preds'))
- def loss(self,
- cls_scores,
- bbox_preds,
- gt_bboxes,
- gt_labels,
- img_metas,
- gt_bboxes_ignore=None):
- """A combination of the func:``AnchorHead.loss`` and
- func:``SSDHead.loss``.
-
- When ``self.use_ohem == True``, it functions like ``SSDHead.loss``,
- otherwise, it follows ``AnchorHead.loss``. Besides, it additionally
- returns ``sampling_results``.
-
- Args:
- cls_scores (list[Tensor]): Box scores for each scale level
- Has shape (N, num_anchors * num_classes, H, W)
- bbox_preds (list[Tensor]): Box energies / deltas for each scale
- level with shape (N, num_anchors * 4, H, W)
- gt_bboxes (list[Tensor]): Ground truth bboxes for each image with
- shape (num_gts, 4) in [tl_x, tl_y, br_x, br_y] format.
- gt_labels (list[Tensor]): Class indices corresponding to each box
- img_metas (list[dict]): Meta information of each image, e.g.,
- image size, scaling factor, etc.
- gt_bboxes_ignore (None | list[Tensor]): Specify which bounding
- boxes can be ignored when computing the loss. Default: None
-
- Returns:
- tuple:
- dict[str, Tensor]: A dictionary of loss components.
- List[:obj:``SamplingResult``]: Sampler results for each image.
- """
- featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
- assert len(featmap_sizes) == self.anchor_generator.num_levels
-
- device = cls_scores[0].device
-
- anchor_list, valid_flag_list = self.get_anchors(
- featmap_sizes, img_metas, device=device)
- label_channels = self.cls_out_channels if self.use_sigmoid_cls else 1
- cls_reg_targets = self.get_targets(
- anchor_list,
- valid_flag_list,
- gt_bboxes,
- img_metas,
- gt_bboxes_ignore_list=gt_bboxes_ignore,
- gt_labels_list=gt_labels,
- label_channels=label_channels,
- unmap_outputs=not self.use_ohem,
- return_sampling_results=True)
- if cls_reg_targets is None:
- return None
- (labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
- num_total_pos, num_total_neg, sampling_results) = cls_reg_targets
-
- if self.use_ohem:
- num_images = len(img_metas)
- all_cls_scores = torch.cat([
- s.permute(0, 2, 3, 1).reshape(
- num_images, -1, self.cls_out_channels) for s in cls_scores
- ], 1)
- all_labels = torch.cat(labels_list, -1).view(num_images, -1)
- all_label_weights = torch.cat(label_weights_list,
- -1).view(num_images, -1)
- all_bbox_preds = torch.cat([
- b.permute(0, 2, 3, 1).reshape(num_images, -1, 4)
- for b in bbox_preds
- ], -2)
- all_bbox_targets = torch.cat(bbox_targets_list,
- -2).view(num_images, -1, 4)
- all_bbox_weights = torch.cat(bbox_weights_list,
- -2).view(num_images, -1, 4)
-
- # concat all level anchors to a single tensor
- all_anchors = []
- for i in range(num_images):
- all_anchors.append(torch.cat(anchor_list[i]))
-
- # check NaN and Inf
- assert torch.isfinite(all_cls_scores).all().item(), \
- 'classification scores become infinite or NaN!'
- assert torch.isfinite(all_bbox_preds).all().item(), \
- 'bbox predications become infinite or NaN!'
-
- losses_cls, losses_bbox = multi_apply(
- self.loss_single_OHEM,
- all_cls_scores,
- all_bbox_preds,
- all_anchors,
- all_labels,
- all_label_weights,
- all_bbox_targets,
- all_bbox_weights,
- num_total_samples=num_total_pos)
- else:
- num_total_samples = (
- num_total_pos +
- num_total_neg if self.sampling else num_total_pos)
-
- # anchor number of multi levels
- num_level_anchors = [anchors.size(0) for anchors in anchor_list[0]]
- # concat all level anchors and flags to a single tensor
- concat_anchor_list = []
- for i in range(len(anchor_list)):
- concat_anchor_list.append(torch.cat(anchor_list[i]))
- all_anchor_list = images_to_levels(concat_anchor_list,
- num_level_anchors)
- losses_cls, losses_bbox = multi_apply(
- self.loss_single,
- cls_scores,
- bbox_preds,
- all_anchor_list,
- labels_list,
- label_weights_list,
- bbox_targets_list,
- bbox_weights_list,
- num_total_samples=num_total_samples)
-
- return dict(
- loss_cls=losses_cls, loss_bbox=losses_bbox), sampling_results
-
- def loss_single_OHEM(self, cls_score, bbox_pred, anchors, labels,
- label_weights, bbox_targets, bbox_weights,
- num_total_samples):
- """"See func:``SSDHead.loss``."""
- loss_cls_all = self.loss_cls(cls_score, labels, label_weights)
-
- # FG cat_id: [0, num_classes -1], BG cat_id: num_classes
- pos_inds = ((labels >= 0) & (labels < self.num_classes)).nonzero(
- as_tuple=False).reshape(-1)
- neg_inds = (labels == self.num_classes).nonzero(
- as_tuple=False).view(-1)
-
- num_pos_samples = pos_inds.size(0)
- if num_pos_samples == 0:
- num_neg_samples = neg_inds.size(0)
- else:
- num_neg_samples = self.train_cfg.neg_pos_ratio * num_pos_samples
- if num_neg_samples > neg_inds.size(0):
- num_neg_samples = neg_inds.size(0)
- topk_loss_cls_neg, _ = loss_cls_all[neg_inds].topk(num_neg_samples)
- loss_cls_pos = loss_cls_all[pos_inds].sum()
- loss_cls_neg = topk_loss_cls_neg.sum()
- loss_cls = (loss_cls_pos + loss_cls_neg) / num_total_samples
- if self.reg_decoded_bbox:
- # When the regression loss (e.g. `IouLoss`, `GIouLoss`)
- # is applied directly on the decoded bounding boxes, it
- # decodes the already encoded coordinates to absolute format.
- bbox_pred = self.bbox_coder.decode(anchors, bbox_pred)
- loss_bbox = self.loss_bbox(
- bbox_pred,
- bbox_targets,
- bbox_weights,
- avg_factor=num_total_samples)
- return loss_cls[None], loss_bbox
-
- @force_fp32(apply_to=('cls_scores', 'bbox_preds', 'coeff_preds'))
- def get_bboxes(self,
- cls_scores,
- bbox_preds,
- coeff_preds,
- img_metas,
- cfg=None,
- rescale=False):
- """"Similiar to func:``AnchorHead.get_bboxes``, but additionally
- processes coeff_preds.
-
- Args:
- cls_scores (list[Tensor]): Box scores for each scale level
- with shape (N, num_anchors * num_classes, H, W)
- bbox_preds (list[Tensor]): Box energies / deltas for each scale
- level with shape (N, num_anchors * 4, H, W)
- coeff_preds (list[Tensor]): Mask coefficients for each scale
- level with shape (N, num_anchors * num_protos, H, W)
- img_metas (list[dict]): Meta information of each image, e.g.,
- image size, scaling factor, etc.
- cfg (mmcv.Config | None): Test / postprocessing configuration,
- if None, test_cfg would be used
- rescale (bool): If True, return boxes in original image space.
- Default: False.
-
- Returns:
- list[tuple[Tensor, Tensor, Tensor]]: Each item in result_list is
- a 3-tuple. The first item is an (n, 5) tensor, where the
- first 4 columns are bounding box positions
- (tl_x, tl_y, br_x, br_y) and the 5-th column is a score
- between 0 and 1. The second item is an (n,) tensor where each
- item is the predicted class label of the corresponding box.
- The third item is an (n, num_protos) tensor where each item
- is the predicted mask coefficients of instance inside the
- corresponding box.
- """
- assert len(cls_scores) == len(bbox_preds)
- num_levels = len(cls_scores)
-
- device = cls_scores[0].device
- featmap_sizes = [cls_scores[i].shape[-2:] for i in range(num_levels)]
- mlvl_anchors = self.anchor_generator.grid_anchors(
- featmap_sizes, device=device)
-
- det_bboxes = []
- det_labels = []
- det_coeffs = []
- for img_id in range(len(img_metas)):
- cls_score_list = [
- cls_scores[i][img_id].detach() for i in range(num_levels)
- ]
- bbox_pred_list = [
- bbox_preds[i][img_id].detach() for i in range(num_levels)
- ]
- coeff_pred_list = [
- coeff_preds[i][img_id].detach() for i in range(num_levels)
- ]
- img_shape = img_metas[img_id]['img_shape']
- scale_factor = img_metas[img_id]['scale_factor']
- bbox_res = self._get_bboxes_single(cls_score_list, bbox_pred_list,
- coeff_pred_list, mlvl_anchors,
- img_shape, scale_factor, cfg,
- rescale)
- det_bboxes.append(bbox_res[0])
- det_labels.append(bbox_res[1])
- det_coeffs.append(bbox_res[2])
- return det_bboxes, det_labels, det_coeffs
-
- def _get_bboxes_single(self,
- cls_score_list,
- bbox_pred_list,
- coeff_preds_list,
- mlvl_anchors,
- img_shape,
- scale_factor,
- cfg,
- rescale=False):
- """"Similiar to func:``AnchorHead._get_bboxes_single``, but
- additionally processes coeff_preds_list and uses fast NMS instead of
- traditional NMS.
-
- Args:
- cls_score_list (list[Tensor]): Box scores for a single scale level
- Has shape (num_anchors * num_classes, H, W).
- bbox_pred_list (list[Tensor]): Box energies / deltas for a single
- scale level with shape (num_anchors * 4, H, W).
- coeff_preds_list (list[Tensor]): Mask coefficients for a single
- scale level with shape (num_anchors * num_protos, H, W).
- mlvl_anchors (list[Tensor]): Box reference for a single scale level
- with shape (num_total_anchors, 4).
- img_shape (tuple[int]): Shape of the input image,
- (height, width, 3).
- scale_factor (ndarray): Scale factor of the image arange as
- (w_scale, h_scale, w_scale, h_scale).
- cfg (mmcv.Config): Test / postprocessing configuration,
- if None, test_cfg would be used.
- rescale (bool): If True, return boxes in original image space.
-
- Returns:
- tuple[Tensor, Tensor, Tensor]: The first item is an (n, 5) tensor,
- where the first 4 columns are bounding box positions
- (tl_x, tl_y, br_x, br_y) and the 5-th column is a score between
- 0 and 1. The second item is an (n,) tensor where each item is
- the predicted class label of the corresponding box. The third
- item is an (n, num_protos) tensor where each item is the
- predicted mask coefficients of instance inside the
- corresponding box.
- """
- cfg = self.test_cfg if cfg is None else cfg
- assert len(cls_score_list) == len(bbox_pred_list) == len(mlvl_anchors)
- mlvl_bboxes = []
- mlvl_scores = []
- mlvl_coeffs = []
- for cls_score, bbox_pred, coeff_pred, anchors in \
- zip(cls_score_list, bbox_pred_list,
- coeff_preds_list, mlvl_anchors):
- assert cls_score.size()[-2:] == bbox_pred.size()[-2:]
- cls_score = cls_score.permute(1, 2,
- 0).reshape(-1, self.cls_out_channels)
- if self.use_sigmoid_cls:
- scores = cls_score.sigmoid()
- else:
- scores = cls_score.softmax(-1)
- bbox_pred = bbox_pred.permute(1, 2, 0).reshape(-1, 4)
- coeff_pred = coeff_pred.permute(1, 2,
- 0).reshape(-1, self.num_protos)
- nms_pre = cfg.get('nms_pre', -1)
- if nms_pre > 0 and scores.shape[0] > nms_pre:
- # Get maximum scores for foreground classes.
- if self.use_sigmoid_cls:
- max_scores, _ = scores.max(dim=1)
- else:
- # remind that we set FG labels to [0, num_class-1]
- # since mmdet v2.0
- # BG cat_id: num_class
- max_scores, _ = scores[:, :-1].max(dim=1)
- _, topk_inds = max_scores.topk(nms_pre)
- anchors = anchors[topk_inds, :]
- bbox_pred = bbox_pred[topk_inds, :]
- scores = scores[topk_inds, :]
- coeff_pred = coeff_pred[topk_inds, :]
- bboxes = self.bbox_coder.decode(
- anchors, bbox_pred, max_shape=img_shape)
- mlvl_bboxes.append(bboxes)
- mlvl_scores.append(scores)
- mlvl_coeffs.append(coeff_pred)
- mlvl_bboxes = torch.cat(mlvl_bboxes)
- if rescale:
- mlvl_bboxes /= mlvl_bboxes.new_tensor(scale_factor)
- mlvl_scores = torch.cat(mlvl_scores)
- mlvl_coeffs = torch.cat(mlvl_coeffs)
- if self.use_sigmoid_cls:
- # Add a dummy background class to the backend when using sigmoid
- # remind that we set FG labels to [0, num_class-1] since mmdet v2.0
- # BG cat_id: num_class
- padding = mlvl_scores.new_zeros(mlvl_scores.shape[0], 1)
- mlvl_scores = torch.cat([mlvl_scores, padding], dim=1)
- det_bboxes, det_labels, det_coeffs = fast_nms(mlvl_bboxes, mlvl_scores,
- mlvl_coeffs,
- cfg.score_thr,
- cfg.iou_thr, cfg.top_k,
- cfg.max_per_img)
- return det_bboxes, det_labels, det_coeffs
-
-
-@HEADS.register_module()
-class YOLACTSegmHead(nn.Module):
- """YOLACT segmentation head used in https://arxiv.org/abs/1904.02689.
-
- Apply a semantic segmentation loss on feature space using layers that are
- only evaluated during training to increase performance with no speed
- penalty.
-
- Args:
- in_channels (int): Number of channels in the input feature map.
- num_classes (int): Number of categories excluding the background
- category.
- loss_segm (dict): Config of semantic segmentation loss.
- """
-
- def __init__(self,
- num_classes,
- in_channels=256,
- loss_segm=dict(
- type='CrossEntropyLoss',
- use_sigmoid=True,
- loss_weight=1.0)):
- super(YOLACTSegmHead, self).__init__()
- self.in_channels = in_channels
- self.num_classes = num_classes
- self.loss_segm = build_loss(loss_segm)
- self._init_layers()
- self.fp16_enabled = False
-
- def _init_layers(self):
- """Initialize layers of the head."""
- self.segm_conv = nn.Conv2d(
- self.in_channels, self.num_classes, kernel_size=1)
-
- def init_weights(self):
- """Initialize weights of the head."""
- xavier_init(self.segm_conv, distribution='uniform')
-
- def forward(self, x):
- """Forward feature from the upstream network.
-
- Args:
- x (Tensor): Feature from the upstream network, which is
- a 4D-tensor.
-
- Returns:
- Tensor: Predicted semantic segmentation map with shape
- (N, num_classes, H, W).
- """
- return self.segm_conv(x)
-
- @force_fp32(apply_to=('segm_pred', ))
- def loss(self, segm_pred, gt_masks, gt_labels):
- """Compute loss of the head.
-
- Args:
- segm_pred (list[Tensor]): Predicted semantic segmentation map
- with shape (N, num_classes, H, W).
- gt_masks (list[Tensor]): Ground truth masks for each image with
- the same shape of the input image.
- gt_labels (list[Tensor]): Class indices corresponding to each box.
-
- Returns:
- dict[str, Tensor]: A dictionary of loss components.
- """
- loss_segm = []
- num_imgs, num_classes, mask_h, mask_w = segm_pred.size()
- for idx in range(num_imgs):
- cur_segm_pred = segm_pred[idx]
- cur_gt_masks = gt_masks[idx].float()
- cur_gt_labels = gt_labels[idx]
- segm_targets = self.get_targets(cur_segm_pred, cur_gt_masks,
- cur_gt_labels)
- if segm_targets is None:
- loss = self.loss_segm(cur_segm_pred,
- torch.zeros_like(cur_segm_pred),
- torch.zeros_like(cur_segm_pred))
- else:
- loss = self.loss_segm(
- cur_segm_pred,
- segm_targets,
- avg_factor=num_imgs * mask_h * mask_w)
- loss_segm.append(loss)
- return dict(loss_segm=loss_segm)
-
- def get_targets(self, segm_pred, gt_masks, gt_labels):
- """Compute semantic segmentation targets for each image.
-
- Args:
- segm_pred (Tensor): Predicted semantic segmentation map
- with shape (num_classes, H, W).
- gt_masks (Tensor): Ground truth masks for each image with
- the same shape of the input image.
- gt_labels (Tensor): Class indices corresponding to each box.
-
- Returns:
- Tensor: Semantic segmentation targets with shape
- (num_classes, H, W).
- """
- if gt_masks.size(0) == 0:
- return None
- num_classes, mask_h, mask_w = segm_pred.size()
- with torch.no_grad():
- downsampled_masks = F.interpolate(
- gt_masks.unsqueeze(0), (mask_h, mask_w),
- mode='bilinear',
- align_corners=False).squeeze(0)
- downsampled_masks = downsampled_masks.gt(0.5).float()
- segm_targets = torch.zeros_like(segm_pred, requires_grad=False)
- for obj_idx in range(downsampled_masks.size(0)):
- segm_targets[gt_labels[obj_idx] - 1] = torch.max(
- segm_targets[gt_labels[obj_idx] - 1],
- downsampled_masks[obj_idx])
- return segm_targets
-
-
-@HEADS.register_module()
-class YOLACTProtonet(nn.Module):
- """YOLACT mask head used in https://arxiv.org/abs/1904.02689.
-
- This head outputs the mask prototypes for YOLACT.
-
- Args:
- in_channels (int): Number of channels in the input feature map.
- proto_channels (tuple[int]): Output channels of protonet convs.
- proto_kernel_sizes (tuple[int]): Kernel sizes of protonet convs.
- include_last_relu (Bool): If keep the last relu of protonet.
- num_protos (int): Number of prototypes.
- num_classes (int): Number of categories excluding the background
- category.
- loss_mask_weight (float): Reweight the mask loss by this factor.
- max_masks_to_train (int): Maximum number of masks to train for
- each image.
- """
-
- def __init__(self,
- num_classes,
- in_channels=256,
- proto_channels=(256, 256, 256, None, 256, 32),
- proto_kernel_sizes=(3, 3, 3, -2, 3, 1),
- include_last_relu=True,
- num_protos=32,
- loss_mask_weight=1.0,
- max_masks_to_train=100):
- super(YOLACTProtonet, self).__init__()
- self.in_channels = in_channels
- self.proto_channels = proto_channels
- self.proto_kernel_sizes = proto_kernel_sizes
- self.include_last_relu = include_last_relu
- self.protonet = self._init_layers()
-
- self.loss_mask_weight = loss_mask_weight
- self.num_protos = num_protos
- self.num_classes = num_classes
- self.max_masks_to_train = max_masks_to_train
- self.fp16_enabled = False
-
- def _init_layers(self):
- """A helper function to take a config setting and turn it into a
- network."""
- # Possible patterns:
- # ( 256, 3) -> conv
- # ( 256,-2) -> deconv
- # (None,-2) -> bilinear interpolate
- in_channels = self.in_channels
- protonets = nn.ModuleList()
- for num_channels, kernel_size in zip(self.proto_channels,
- self.proto_kernel_sizes):
- if kernel_size > 0:
- layer = nn.Conv2d(
- in_channels,
- num_channels,
- kernel_size,
- padding=kernel_size // 2)
- else:
- if num_channels is None:
- layer = InterpolateModule(
- scale_factor=-kernel_size,
- mode='bilinear',
- align_corners=False)
- else:
- layer = nn.ConvTranspose2d(
- in_channels,
- num_channels,
- -kernel_size,
- padding=kernel_size // 2)
- protonets.append(layer)
- protonets.append(nn.ReLU(inplace=True))
- in_channels = num_channels if num_channels is not None \
- else in_channels
- if not self.include_last_relu:
- protonets = protonets[:-1]
- return nn.Sequential(*protonets)
-
- def init_weights(self):
- """Initialize weights of the head."""
- for m in self.protonet:
- if isinstance(m, nn.Conv2d):
- xavier_init(m, distribution='uniform')
-
- def forward(self, x, coeff_pred, bboxes, img_meta, sampling_results=None):
- """Forward feature from the upstream network to get prototypes and
- linearly combine the prototypes, using masks coefficients, into
- instance masks. Finally, crop the instance masks with given bboxes.
-
- Args:
- x (Tensor): Feature from the upstream network, which is
- a 4D-tensor.
- coeff_pred (list[Tensor]): Mask coefficients for each scale
- level with shape (N, num_anchors * num_protos, H, W).
- bboxes (list[Tensor]): Box used for cropping with shape
- (N, num_anchors * 4, H, W). During training, they are
- ground truth boxes. During testing, they are predicted
- boxes.
- img_meta (list[dict]): Meta information of each image, e.g.,
- image size, scaling factor, etc.
- sampling_results (List[:obj:``SamplingResult``]): Sampler results
- for each image.
-
- Returns:
- list[Tensor]: Predicted instance segmentation masks.
- """
- prototypes = self.protonet(x)
- prototypes = prototypes.permute(0, 2, 3, 1).contiguous()
-
- num_imgs = x.size(0)
- # Training state
- if self.training:
- coeff_pred_list = []
- for coeff_pred_per_level in coeff_pred:
- coeff_pred_per_level = \
- coeff_pred_per_level.permute(0, 2, 3, 1)\
- .reshape(num_imgs, -1, self.num_protos)
- coeff_pred_list.append(coeff_pred_per_level)
- coeff_pred = torch.cat(coeff_pred_list, dim=1)
-
- mask_pred_list = []
- for idx in range(num_imgs):
- cur_prototypes = prototypes[idx]
- cur_coeff_pred = coeff_pred[idx]
- cur_bboxes = bboxes[idx]
- cur_img_meta = img_meta[idx]
-
- # Testing state
- if not self.training:
- bboxes_for_cropping = cur_bboxes
- else:
- cur_sampling_results = sampling_results[idx]
- pos_assigned_gt_inds = \
- cur_sampling_results.pos_assigned_gt_inds
- bboxes_for_cropping = cur_bboxes[pos_assigned_gt_inds].clone()
- pos_inds = cur_sampling_results.pos_inds
- cur_coeff_pred = cur_coeff_pred[pos_inds]
-
- # Linearly combine the prototypes with the mask coefficients
- mask_pred = cur_prototypes @ cur_coeff_pred.t()
- mask_pred = torch.sigmoid(mask_pred)
-
- h, w = cur_img_meta['img_shape'][:2]
- bboxes_for_cropping[:, 0] /= w
- bboxes_for_cropping[:, 1] /= h
- bboxes_for_cropping[:, 2] /= w
- bboxes_for_cropping[:, 3] /= h
-
- mask_pred = self.crop(mask_pred, bboxes_for_cropping)
- mask_pred = mask_pred.permute(2, 0, 1).contiguous()
- mask_pred_list.append(mask_pred)
- return mask_pred_list
-
- @force_fp32(apply_to=('mask_pred', ))
- def loss(self, mask_pred, gt_masks, gt_bboxes, img_meta, sampling_results):
- """Compute loss of the head.
-
- Args:
- mask_pred (list[Tensor]): Predicted prototypes with shape
- (num_classes, H, W).
- gt_masks (list[Tensor]): Ground truth masks for each image with
- the same shape of the input image.
- gt_bboxes (list[Tensor]): Ground truth bboxes for each image with
- shape (num_gts, 4) in [tl_x, tl_y, br_x, br_y] format.
- img_meta (list[dict]): Meta information of each image, e.g.,
- image size, scaling factor, etc.
- sampling_results (List[:obj:``SamplingResult``]): Sampler results
- for each image.
-
- Returns:
- dict[str, Tensor]: A dictionary of loss components.
- """
- loss_mask = []
- num_imgs = len(mask_pred)
- total_pos = 0
- for idx in range(num_imgs):
- cur_mask_pred = mask_pred[idx]
- cur_gt_masks = gt_masks[idx].float()
- cur_gt_bboxes = gt_bboxes[idx]
- cur_img_meta = img_meta[idx]
- cur_sampling_results = sampling_results[idx]
-
- pos_assigned_gt_inds = cur_sampling_results.pos_assigned_gt_inds
- num_pos = pos_assigned_gt_inds.size(0)
- # Since we're producing (near) full image masks,
- # it'd take too much vram to backprop on every single mask.
- # Thus we select only a subset.
- if num_pos > self.max_masks_to_train:
- perm = torch.randperm(num_pos)
- select = perm[:self.max_masks_to_train]
- cur_mask_pred = cur_mask_pred[select]
- pos_assigned_gt_inds = pos_assigned_gt_inds[select]
- num_pos = self.max_masks_to_train
- total_pos += num_pos
-
- gt_bboxes_for_reweight = cur_gt_bboxes[pos_assigned_gt_inds]
-
- mask_targets = self.get_targets(cur_mask_pred, cur_gt_masks,
- pos_assigned_gt_inds)
- if num_pos == 0:
- loss = cur_mask_pred.sum() * 0.
- elif mask_targets is None:
- loss = F.binary_cross_entropy(cur_mask_pred,
- torch.zeros_like(cur_mask_pred),
- torch.zeros_like(cur_mask_pred))
- else:
- cur_mask_pred = torch.clamp(cur_mask_pred, 0, 1)
- loss = F.binary_cross_entropy(
- cur_mask_pred, mask_targets,
- reduction='none') * self.loss_mask_weight
-
- h, w = cur_img_meta['img_shape'][:2]
- gt_bboxes_width = (gt_bboxes_for_reweight[:, 2] -
- gt_bboxes_for_reweight[:, 0]) / w
- gt_bboxes_height = (gt_bboxes_for_reweight[:, 3] -
- gt_bboxes_for_reweight[:, 1]) / h
- loss = loss.mean(dim=(1,
- 2)) / gt_bboxes_width / gt_bboxes_height
- loss = torch.sum(loss)
- loss_mask.append(loss)
-
- if total_pos == 0:
- total_pos += 1 # avoid nan
- loss_mask = [x / total_pos for x in loss_mask]
-
- return dict(loss_mask=loss_mask)
-
- def get_targets(self, mask_pred, gt_masks, pos_assigned_gt_inds):
- """Compute instance segmentation targets for each image.
-
- Args:
- mask_pred (Tensor): Predicted prototypes with shape
- (num_classes, H, W).
- gt_masks (Tensor): Ground truth masks for each image with
- the same shape of the input image.
- pos_assigned_gt_inds (Tensor): GT indices of the corresponding
- positive samples.
- Returns:
- Tensor: Instance segmentation targets with shape
- (num_instances, H, W).
- """
- if gt_masks.size(0) == 0:
- return None
- mask_h, mask_w = mask_pred.shape[-2:]
- gt_masks = F.interpolate(
- gt_masks.unsqueeze(0), (mask_h, mask_w),
- mode='bilinear',
- align_corners=False).squeeze(0)
- gt_masks = gt_masks.gt(0.5).float()
- mask_targets = gt_masks[pos_assigned_gt_inds]
- return mask_targets
-
- def get_seg_masks(self, mask_pred, label_pred, img_meta, rescale):
- """Resize, binarize, and format the instance mask predictions.
-
- Args:
- mask_pred (Tensor): shape (N, H, W).
- label_pred (Tensor): shape (N, ).
- img_meta (dict): Meta information of each image, e.g.,
- image size, scaling factor, etc.
- rescale (bool): If rescale is False, then returned masks will
- fit the scale of imgs[0].
- Returns:
- list[ndarray]: Mask predictions grouped by their predicted classes.
- """
- ori_shape = img_meta['ori_shape']
- scale_factor = img_meta['scale_factor']
- if rescale:
- img_h, img_w = ori_shape[:2]
- else:
- img_h = np.round(ori_shape[0] * scale_factor[1]).astype(np.int32)
- img_w = np.round(ori_shape[1] * scale_factor[0]).astype(np.int32)
-
- cls_segms = [[] for _ in range(self.num_classes)]
- if mask_pred.size(0) == 0:
- return cls_segms
-
- mask_pred = F.interpolate(
- mask_pred.unsqueeze(0), (img_h, img_w),
- mode='bilinear',
- align_corners=False).squeeze(0) > 0.5
- mask_pred = mask_pred.cpu().numpy().astype(np.uint8)
-
- for m, l in zip(mask_pred, label_pred):
- cls_segms[l].append(m)
- return cls_segms
-
- def crop(self, masks, boxes, padding=1):
- """Crop predicted masks by zeroing out everything not in the predicted
- bbox.
-
- Args:
- masks (Tensor): shape [H, W, N].
- boxes (Tensor): bbox coords in relative point form with
- shape [N, 4].
-
- Return:
- Tensor: The cropped masks.
- """
- h, w, n = masks.size()
- x1, x2 = self.sanitize_coordinates(
- boxes[:, 0], boxes[:, 2], w, padding, cast=False)
- y1, y2 = self.sanitize_coordinates(
- boxes[:, 1], boxes[:, 3], h, padding, cast=False)
-
- rows = torch.arange(
- w, device=masks.device, dtype=x1.dtype).view(1, -1,
- 1).expand(h, w, n)
- cols = torch.arange(
- h, device=masks.device, dtype=x1.dtype).view(-1, 1,
- 1).expand(h, w, n)
-
- masks_left = rows >= x1.view(1, 1, -1)
- masks_right = rows < x2.view(1, 1, -1)
- masks_up = cols >= y1.view(1, 1, -1)
- masks_down = cols < y2.view(1, 1, -1)
-
- crop_mask = masks_left * masks_right * masks_up * masks_down
-
- return masks * crop_mask.float()
-
- def sanitize_coordinates(self, x1, x2, img_size, padding=0, cast=True):
- """Sanitizes the input coordinates so that x1 < x2, x1 != x2, x1 >= 0,
- and x2 <= image_size. Also converts from relative to absolute
- coordinates and casts the results to long tensors.
-
- Warning: this does things in-place behind the scenes so
- copy if necessary.
-
- Args:
- _x1 (Tensor): shape (N, ).
- _x2 (Tensor): shape (N, ).
- img_size (int): Size of the input image.
- padding (int): x1 >= padding, x2 <= image_size-padding.
- cast (bool): If cast is false, the result won't be cast to longs.
-
- Returns:
- tuple:
- x1 (Tensor): Sanitized _x1.
- x2 (Tensor): Sanitized _x2.
- """
- x1 = x1 * img_size
- x2 = x2 * img_size
- if cast:
- x1 = x1.long()
- x2 = x2.long()
- x1 = torch.min(x1, x2)
- x2 = torch.max(x1, x2)
- x1 = torch.clamp(x1 - padding, min=0)
- x2 = torch.clamp(x2 + padding, max=img_size)
- return x1, x2
-
-
-class InterpolateModule(nn.Module):
- """This is a module version of F.interpolate.
-
- Any arguments you give it just get passed along for the ride.
- """
-
- def __init__(self, *args, **kwargs):
- super().__init__()
-
- self.args = args
- self.kwargs = kwargs
-
- def forward(self, x):
- """Forward features from the upstream network."""
- return F.interpolate(x, *self.args, **self.kwargs)
diff --git a/spaces/SLAYEROFALL3050/AudioGenerator/MusicModel/music.py b/spaces/SLAYEROFALL3050/AudioGenerator/MusicModel/music.py
deleted file mode 100644
index 7b0236b583c83f1751d23b4e09cf19ab77b49b71..0000000000000000000000000000000000000000
--- a/spaces/SLAYEROFALL3050/AudioGenerator/MusicModel/music.py
+++ /dev/null
@@ -1,19 +0,0 @@
-# https://github.com/marcoppasini/musika
-
-# IMPORTS
-from pypianoroll import Multitrack
-import streamlit as st
-
-# DOWNLOADS
-
-# MODEL
-
-# FINAL FUNCTION
-# Spits out audio file
-
-def gen_audio():
- to_ret = ""
- for i in range(5):
- to_ret = to_ret + str(i)
-
- return to_ret
\ No newline at end of file
diff --git a/spaces/Skyler123/TangGPT/modules/config.py b/spaces/Skyler123/TangGPT/modules/config.py
deleted file mode 100644
index 04e76010d7e2a4492042a9c02aa4820ddbd82b48..0000000000000000000000000000000000000000
--- a/spaces/Skyler123/TangGPT/modules/config.py
+++ /dev/null
@@ -1,145 +0,0 @@
-from collections import defaultdict
-from contextlib import contextmanager
-import os
-import logging
-import sys
-import json
-
-from . import shared
-
-
-__all__ = [
- "my_api_key",
- "authflag",
- "auth_list",
- "dockerflag",
- "retrieve_proxy",
- "log_level",
- "advance_docs",
- "update_doc_config",
- "multi_api_key",
-]
-
-# 添加一个统一的config文件,避免文件过多造成的疑惑(优先级最低)
-# 同时,也可以为后续支持自定义功能提供config的帮助
-if os.path.exists("config.json"):
- with open("config.json", "r", encoding='utf-8') as f:
- config = json.load(f)
-else:
- config = {}
-
-## 处理docker if we are running in Docker
-dockerflag = config.get("dockerflag", False)
-if os.environ.get("dockerrun") == "yes":
- dockerflag = True
-
-## 处理 api-key 以及 允许的用户列表
-my_api_key = config.get("openai_api_key", "") # 在这里输入你的 API 密钥
-my_api_key = os.environ.get("my_api_key", my_api_key)
-
-## 多账户机制
-multi_api_key = config.get("multi_api_key", False) # 是否开启多账户机制
-if multi_api_key:
- api_key_list = config.get("api_key_list", [])
- if len(api_key_list) == 0:
- logging.error("多账号模式已开启,但api_key_list为空,请检查config.json")
- sys.exit(1)
- shared.state.set_api_key_queue(api_key_list)
-
-auth_list = config.get("users", []) # 实际上是使用者的列表
-authflag = len(auth_list) > 0 # 是否开启认证的状态值,改为判断auth_list长度
-
-# 处理自定义的api_host,优先读环境变量的配置,如果存在则自动装配
-api_host = os.environ.get("api_host", config.get("api_host", ""))
-if api_host:
- shared.state.set_api_host(api_host)
-
-if dockerflag:
- if my_api_key == "empty":
- logging.error("Please give a api key!")
- sys.exit(1)
- # auth
- username = os.environ.get("USERNAME")
- password = os.environ.get("PASSWORD")
- if not (isinstance(username, type(None)) or isinstance(password, type(None))):
- auth_list.append((os.environ.get("USERNAME"), os.environ.get("PASSWORD")))
- authflag = True
-else:
- if (
- not my_api_key
- and os.path.exists("api_key.txt")
- and os.path.getsize("api_key.txt")
- ):
- with open("api_key.txt", "r") as f:
- my_api_key = f.read().strip()
- if os.path.exists("auth.json"):
- authflag = True
- with open("auth.json", "r", encoding='utf-8') as f:
- auth = json.load(f)
- for _ in auth:
- if auth[_]["username"] and auth[_]["password"]:
- auth_list.append((auth[_]["username"], auth[_]["password"]))
- else:
- logging.error("请检查auth.json文件中的用户名和密码!")
- sys.exit(1)
-
-@contextmanager
-def retrieve_openai_api(api_key = None):
- old_api_key = os.environ.get("OPENAI_API_KEY", "")
- if api_key is None:
- os.environ["OPENAI_API_KEY"] = my_api_key
- yield my_api_key
- else:
- os.environ["OPENAI_API_KEY"] = api_key
- yield api_key
- os.environ["OPENAI_API_KEY"] = old_api_key
-
-## 处理log
-log_level = config.get("log_level", "INFO")
-logging.basicConfig(
- level=log_level,
- format="%(asctime)s [%(levelname)s] [%(filename)s:%(lineno)d] %(message)s",
-)
-
-## 处理代理:
-http_proxy = config.get("http_proxy", "")
-https_proxy = config.get("https_proxy", "")
-http_proxy = os.environ.get("HTTP_PROXY", http_proxy)
-https_proxy = os.environ.get("HTTPS_PROXY", https_proxy)
-
-# 重置系统变量,在不需要设置的时候不设置环境变量,以免引起全局代理报错
-os.environ["HTTP_PROXY"] = ""
-os.environ["HTTPS_PROXY"] = ""
-
-@contextmanager
-def retrieve_proxy(proxy=None):
- """
- 1, 如果proxy = NONE,设置环境变量,并返回最新设置的代理
- 2,如果proxy != NONE,更新当前的代理配置,但是不更新环境变量
- """
- global http_proxy, https_proxy
- if proxy is not None:
- http_proxy = proxy
- https_proxy = proxy
- yield http_proxy, https_proxy
- else:
- old_var = os.environ["HTTP_PROXY"], os.environ["HTTPS_PROXY"]
- os.environ["HTTP_PROXY"] = http_proxy
- os.environ["HTTPS_PROXY"] = https_proxy
- yield http_proxy, https_proxy # return new proxy
-
- # return old proxy
- os.environ["HTTP_PROXY"], os.environ["HTTPS_PROXY"] = old_var
-
-
-## 处理advance docs
-advance_docs = defaultdict(lambda: defaultdict(dict))
-advance_docs.update(config.get("advance_docs", {}))
-def update_doc_config(two_column_pdf):
- global advance_docs
- if two_column_pdf:
- advance_docs["pdf"]["two_column"] = True
- else:
- advance_docs["pdf"]["two_column"] = False
-
- logging.info(f"更新后的文件参数为:{advance_docs}")
\ No newline at end of file
diff --git a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/chromadb/telemetry/events.py b/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/chromadb/telemetry/events.py
deleted file mode 100644
index 64c77574f9fb9d8ea578ddb017eb12328bfbca2a..0000000000000000000000000000000000000000
--- a/spaces/SungBeom/chatwine-korean/.venv/Lib/site-packages/chromadb/telemetry/events.py
+++ /dev/null
@@ -1,27 +0,0 @@
-from dataclasses import dataclass
-from typing import ClassVar
-from chromadb.telemetry import TelemetryEvent
-
-
-@dataclass
-class ClientStartEvent(TelemetryEvent):
- name: ClassVar[str] = "client_start"
-
-
-@dataclass
-class ServerStartEvent(TelemetryEvent):
- name: ClassVar[str] = "server_start"
-
-
-@dataclass
-class CollectionAddEvent(TelemetryEvent):
- name: ClassVar[str] = "collection_add"
- collection_uuid: str
- add_amount: int
-
-
-@dataclass
-class CollectionDeleteEvent(TelemetryEvent):
- name: ClassVar[str] = "collection_delete"
- collection_uuid: str
- delete_amount: int
diff --git a/spaces/Superlang/ImageProcessor/annotator/oneformer/detectron2/utils/events.py b/spaces/Superlang/ImageProcessor/annotator/oneformer/detectron2/utils/events.py
deleted file mode 100644
index d9a68b6b5b90cdef1ccdaffa4eb2225f3ab21e29..0000000000000000000000000000000000000000
--- a/spaces/Superlang/ImageProcessor/annotator/oneformer/detectron2/utils/events.py
+++ /dev/null
@@ -1,534 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-import datetime
-import json
-import logging
-import os
-import time
-from collections import defaultdict
-from contextlib import contextmanager
-from typing import Optional
-import torch
-from fvcore.common.history_buffer import HistoryBuffer
-
-from annotator.oneformer.detectron2.utils.file_io import PathManager
-
-__all__ = [
- "get_event_storage",
- "JSONWriter",
- "TensorboardXWriter",
- "CommonMetricPrinter",
- "EventStorage",
-]
-
-_CURRENT_STORAGE_STACK = []
-
-
-def get_event_storage():
- """
- Returns:
- The :class:`EventStorage` object that's currently being used.
- Throws an error if no :class:`EventStorage` is currently enabled.
- """
- assert len(
- _CURRENT_STORAGE_STACK
- ), "get_event_storage() has to be called inside a 'with EventStorage(...)' context!"
- return _CURRENT_STORAGE_STACK[-1]
-
-
-class EventWriter:
- """
- Base class for writers that obtain events from :class:`EventStorage` and process them.
- """
-
- def write(self):
- raise NotImplementedError
-
- def close(self):
- pass
-
-
-class JSONWriter(EventWriter):
- """
- Write scalars to a json file.
-
- It saves scalars as one json per line (instead of a big json) for easy parsing.
-
- Examples parsing such a json file:
- ::
- $ cat metrics.json | jq -s '.[0:2]'
- [
- {
- "data_time": 0.008433341979980469,
- "iteration": 19,
- "loss": 1.9228371381759644,
- "loss_box_reg": 0.050025828182697296,
- "loss_classifier": 0.5316952466964722,
- "loss_mask": 0.7236229181289673,
- "loss_rpn_box": 0.0856662318110466,
- "loss_rpn_cls": 0.48198649287223816,
- "lr": 0.007173333333333333,
- "time": 0.25401854515075684
- },
- {
- "data_time": 0.007216215133666992,
- "iteration": 39,
- "loss": 1.282649278640747,
- "loss_box_reg": 0.06222952902317047,
- "loss_classifier": 0.30682939291000366,
- "loss_mask": 0.6970193982124329,
- "loss_rpn_box": 0.038663312792778015,
- "loss_rpn_cls": 0.1471673548221588,
- "lr": 0.007706666666666667,
- "time": 0.2490077018737793
- }
- ]
-
- $ cat metrics.json | jq '.loss_mask'
- 0.7126231789588928
- 0.689423680305481
- 0.6776131987571716
- ...
-
- """
-
- def __init__(self, json_file, window_size=20):
- """
- Args:
- json_file (str): path to the json file. New data will be appended if the file exists.
- window_size (int): the window size of median smoothing for the scalars whose
- `smoothing_hint` are True.
- """
- self._file_handle = PathManager.open(json_file, "a")
- self._window_size = window_size
- self._last_write = -1
-
- def write(self):
- storage = get_event_storage()
- to_save = defaultdict(dict)
-
- for k, (v, iter) in storage.latest_with_smoothing_hint(self._window_size).items():
- # keep scalars that have not been written
- if iter <= self._last_write:
- continue
- to_save[iter][k] = v
- if len(to_save):
- all_iters = sorted(to_save.keys())
- self._last_write = max(all_iters)
-
- for itr, scalars_per_iter in to_save.items():
- scalars_per_iter["iteration"] = itr
- self._file_handle.write(json.dumps(scalars_per_iter, sort_keys=True) + "\n")
- self._file_handle.flush()
- try:
- os.fsync(self._file_handle.fileno())
- except AttributeError:
- pass
-
- def close(self):
- self._file_handle.close()
-
-
-class TensorboardXWriter(EventWriter):
- """
- Write all scalars to a tensorboard file.
- """
-
- def __init__(self, log_dir: str, window_size: int = 20, **kwargs):
- """
- Args:
- log_dir (str): the directory to save the output events
- window_size (int): the scalars will be median-smoothed by this window size
-
- kwargs: other arguments passed to `torch.utils.tensorboard.SummaryWriter(...)`
- """
- self._window_size = window_size
- from torch.utils.tensorboard import SummaryWriter
-
- self._writer = SummaryWriter(log_dir, **kwargs)
- self._last_write = -1
-
- def write(self):
- storage = get_event_storage()
- new_last_write = self._last_write
- for k, (v, iter) in storage.latest_with_smoothing_hint(self._window_size).items():
- if iter > self._last_write:
- self._writer.add_scalar(k, v, iter)
- new_last_write = max(new_last_write, iter)
- self._last_write = new_last_write
-
- # storage.put_{image,histogram} is only meant to be used by
- # tensorboard writer. So we access its internal fields directly from here.
- if len(storage._vis_data) >= 1:
- for img_name, img, step_num in storage._vis_data:
- self._writer.add_image(img_name, img, step_num)
- # Storage stores all image data and rely on this writer to clear them.
- # As a result it assumes only one writer will use its image data.
- # An alternative design is to let storage store limited recent
- # data (e.g. only the most recent image) that all writers can access.
- # In that case a writer may not see all image data if its period is long.
- storage.clear_images()
-
- if len(storage._histograms) >= 1:
- for params in storage._histograms:
- self._writer.add_histogram_raw(**params)
- storage.clear_histograms()
-
- def close(self):
- if hasattr(self, "_writer"): # doesn't exist when the code fails at import
- self._writer.close()
-
-
-class CommonMetricPrinter(EventWriter):
- """
- Print **common** metrics to the terminal, including
- iteration time, ETA, memory, all losses, and the learning rate.
- It also applies smoothing using a window of 20 elements.
-
- It's meant to print common metrics in common ways.
- To print something in more customized ways, please implement a similar printer by yourself.
- """
-
- def __init__(self, max_iter: Optional[int] = None, window_size: int = 20):
- """
- Args:
- max_iter: the maximum number of iterations to train.
- Used to compute ETA. If not given, ETA will not be printed.
- window_size (int): the losses will be median-smoothed by this window size
- """
- self.logger = logging.getLogger(__name__)
- self._max_iter = max_iter
- self._window_size = window_size
- self._last_write = None # (step, time) of last call to write(). Used to compute ETA
-
- def _get_eta(self, storage) -> Optional[str]:
- if self._max_iter is None:
- return ""
- iteration = storage.iter
- try:
- eta_seconds = storage.history("time").median(1000) * (self._max_iter - iteration - 1)
- storage.put_scalar("eta_seconds", eta_seconds, smoothing_hint=False)
- return str(datetime.timedelta(seconds=int(eta_seconds)))
- except KeyError:
- # estimate eta on our own - more noisy
- eta_string = None
- if self._last_write is not None:
- estimate_iter_time = (time.perf_counter() - self._last_write[1]) / (
- iteration - self._last_write[0]
- )
- eta_seconds = estimate_iter_time * (self._max_iter - iteration - 1)
- eta_string = str(datetime.timedelta(seconds=int(eta_seconds)))
- self._last_write = (iteration, time.perf_counter())
- return eta_string
-
- def write(self):
- storage = get_event_storage()
- iteration = storage.iter
- if iteration == self._max_iter:
- # This hook only reports training progress (loss, ETA, etc) but not other data,
- # therefore do not write anything after training succeeds, even if this method
- # is called.
- return
-
- try:
- avg_data_time = storage.history("data_time").avg(
- storage.count_samples("data_time", self._window_size)
- )
- last_data_time = storage.history("data_time").latest()
- except KeyError:
- # they may not exist in the first few iterations (due to warmup)
- # or when SimpleTrainer is not used
- avg_data_time = None
- last_data_time = None
- try:
- avg_iter_time = storage.history("time").global_avg()
- last_iter_time = storage.history("time").latest()
- except KeyError:
- avg_iter_time = None
- last_iter_time = None
- try:
- lr = "{:.5g}".format(storage.history("lr").latest())
- except KeyError:
- lr = "N/A"
-
- eta_string = self._get_eta(storage)
-
- if torch.cuda.is_available():
- max_mem_mb = torch.cuda.max_memory_allocated() / 1024.0 / 1024.0
- else:
- max_mem_mb = None
-
- # NOTE: max_mem is parsed by grep in "dev/parse_results.sh"
- self.logger.info(
- str.format(
- " {eta}iter: {iter} {losses} {non_losses} {avg_time}{last_time}"
- + "{avg_data_time}{last_data_time} lr: {lr} {memory}",
- eta=f"eta: {eta_string} " if eta_string else "",
- iter=iteration,
- losses=" ".join(
- [
- "{}: {:.4g}".format(
- k, v.median(storage.count_samples(k, self._window_size))
- )
- for k, v in storage.histories().items()
- if "loss" in k
- ]
- ),
- non_losses=" ".join(
- [
- "{}: {:.4g}".format(
- k, v.median(storage.count_samples(k, self._window_size))
- )
- for k, v in storage.histories().items()
- if "[metric]" in k
- ]
- ),
- avg_time="time: {:.4f} ".format(avg_iter_time)
- if avg_iter_time is not None
- else "",
- last_time="last_time: {:.4f} ".format(last_iter_time)
- if last_iter_time is not None
- else "",
- avg_data_time="data_time: {:.4f} ".format(avg_data_time)
- if avg_data_time is not None
- else "",
- last_data_time="last_data_time: {:.4f} ".format(last_data_time)
- if last_data_time is not None
- else "",
- lr=lr,
- memory="max_mem: {:.0f}M".format(max_mem_mb) if max_mem_mb is not None else "",
- )
- )
-
-
-class EventStorage:
- """
- The user-facing class that provides metric storage functionalities.
-
- In the future we may add support for storing / logging other types of data if needed.
- """
-
- def __init__(self, start_iter=0):
- """
- Args:
- start_iter (int): the iteration number to start with
- """
- self._history = defaultdict(HistoryBuffer)
- self._smoothing_hints = {}
- self._latest_scalars = {}
- self._iter = start_iter
- self._current_prefix = ""
- self._vis_data = []
- self._histograms = []
-
- def put_image(self, img_name, img_tensor):
- """
- Add an `img_tensor` associated with `img_name`, to be shown on
- tensorboard.
-
- Args:
- img_name (str): The name of the image to put into tensorboard.
- img_tensor (torch.Tensor or numpy.array): An `uint8` or `float`
- Tensor of shape `[channel, height, width]` where `channel` is
- 3. The image format should be RGB. The elements in img_tensor
- can either have values in [0, 1] (float32) or [0, 255] (uint8).
- The `img_tensor` will be visualized in tensorboard.
- """
- self._vis_data.append((img_name, img_tensor, self._iter))
-
- def put_scalar(self, name, value, smoothing_hint=True):
- """
- Add a scalar `value` to the `HistoryBuffer` associated with `name`.
-
- Args:
- smoothing_hint (bool): a 'hint' on whether this scalar is noisy and should be
- smoothed when logged. The hint will be accessible through
- :meth:`EventStorage.smoothing_hints`. A writer may ignore the hint
- and apply custom smoothing rule.
-
- It defaults to True because most scalars we save need to be smoothed to
- provide any useful signal.
- """
- name = self._current_prefix + name
- history = self._history[name]
- value = float(value)
- history.update(value, self._iter)
- self._latest_scalars[name] = (value, self._iter)
-
- existing_hint = self._smoothing_hints.get(name)
- if existing_hint is not None:
- assert (
- existing_hint == smoothing_hint
- ), "Scalar {} was put with a different smoothing_hint!".format(name)
- else:
- self._smoothing_hints[name] = smoothing_hint
-
- def put_scalars(self, *, smoothing_hint=True, **kwargs):
- """
- Put multiple scalars from keyword arguments.
-
- Examples:
-
- storage.put_scalars(loss=my_loss, accuracy=my_accuracy, smoothing_hint=True)
- """
- for k, v in kwargs.items():
- self.put_scalar(k, v, smoothing_hint=smoothing_hint)
-
- def put_histogram(self, hist_name, hist_tensor, bins=1000):
- """
- Create a histogram from a tensor.
-
- Args:
- hist_name (str): The name of the histogram to put into tensorboard.
- hist_tensor (torch.Tensor): A Tensor of arbitrary shape to be converted
- into a histogram.
- bins (int): Number of histogram bins.
- """
- ht_min, ht_max = hist_tensor.min().item(), hist_tensor.max().item()
-
- # Create a histogram with PyTorch
- hist_counts = torch.histc(hist_tensor, bins=bins)
- hist_edges = torch.linspace(start=ht_min, end=ht_max, steps=bins + 1, dtype=torch.float32)
-
- # Parameter for the add_histogram_raw function of SummaryWriter
- hist_params = dict(
- tag=hist_name,
- min=ht_min,
- max=ht_max,
- num=len(hist_tensor),
- sum=float(hist_tensor.sum()),
- sum_squares=float(torch.sum(hist_tensor**2)),
- bucket_limits=hist_edges[1:].tolist(),
- bucket_counts=hist_counts.tolist(),
- global_step=self._iter,
- )
- self._histograms.append(hist_params)
-
- def history(self, name):
- """
- Returns:
- HistoryBuffer: the scalar history for name
- """
- ret = self._history.get(name, None)
- if ret is None:
- raise KeyError("No history metric available for {}!".format(name))
- return ret
-
- def histories(self):
- """
- Returns:
- dict[name -> HistoryBuffer]: the HistoryBuffer for all scalars
- """
- return self._history
-
- def latest(self):
- """
- Returns:
- dict[str -> (float, int)]: mapping from the name of each scalar to the most
- recent value and the iteration number its added.
- """
- return self._latest_scalars
-
- def latest_with_smoothing_hint(self, window_size=20):
- """
- Similar to :meth:`latest`, but the returned values
- are either the un-smoothed original latest value,
- or a median of the given window_size,
- depend on whether the smoothing_hint is True.
-
- This provides a default behavior that other writers can use.
-
- Note: All scalars saved in the past `window_size` iterations are used for smoothing.
- This is different from the `window_size` definition in HistoryBuffer.
- Use :meth:`get_history_window_size` to get the `window_size` used in HistoryBuffer.
- """
- result = {}
- for k, (v, itr) in self._latest_scalars.items():
- result[k] = (
- self._history[k].median(self.count_samples(k, window_size))
- if self._smoothing_hints[k]
- else v,
- itr,
- )
- return result
-
- def count_samples(self, name, window_size=20):
- """
- Return the number of samples logged in the past `window_size` iterations.
- """
- samples = 0
- data = self._history[name].values()
- for _, iter_ in reversed(data):
- if iter_ > data[-1][1] - window_size:
- samples += 1
- else:
- break
- return samples
-
- def smoothing_hints(self):
- """
- Returns:
- dict[name -> bool]: the user-provided hint on whether the scalar
- is noisy and needs smoothing.
- """
- return self._smoothing_hints
-
- def step(self):
- """
- User should either: (1) Call this function to increment storage.iter when needed. Or
- (2) Set `storage.iter` to the correct iteration number before each iteration.
-
- The storage will then be able to associate the new data with an iteration number.
- """
- self._iter += 1
-
- @property
- def iter(self):
- """
- Returns:
- int: The current iteration number. When used together with a trainer,
- this is ensured to be the same as trainer.iter.
- """
- return self._iter
-
- @iter.setter
- def iter(self, val):
- self._iter = int(val)
-
- @property
- def iteration(self):
- # for backward compatibility
- return self._iter
-
- def __enter__(self):
- _CURRENT_STORAGE_STACK.append(self)
- return self
-
- def __exit__(self, exc_type, exc_val, exc_tb):
- assert _CURRENT_STORAGE_STACK[-1] == self
- _CURRENT_STORAGE_STACK.pop()
-
- @contextmanager
- def name_scope(self, name):
- """
- Yields:
- A context within which all the events added to this storage
- will be prefixed by the name scope.
- """
- old_prefix = self._current_prefix
- self._current_prefix = name.rstrip("/") + "/"
- yield
- self._current_prefix = old_prefix
-
- def clear_images(self):
- """
- Delete all the stored images for visualization. This should be called
- after images are written to tensorboard.
- """
- self._vis_data = []
-
- def clear_histograms(self):
- """
- Delete all the stored histograms for visualization.
- This should be called after histograms are written to tensorboard.
- """
- self._histograms = []
diff --git a/spaces/TNR-5/Music-discord-bot/landing.md b/spaces/TNR-5/Music-discord-bot/landing.md
deleted file mode 100644
index a28bef36a779209a3227cd2cbfc5ee0fcf47cc7e..0000000000000000000000000000000000000000
--- a/spaces/TNR-5/Music-discord-bot/landing.md
+++ /dev/null
@@ -1,48 +0,0 @@
-# katasou-Music-botBETA
-
-katasouが作ったdiscord音楽bot
-
-## 取説
-
-### /hello
-挨拶を返します。
-
-### /join
-discordのボイスチャンネルに接続した状態で使うことで、botをボイチャに召喚する
-
-### /leave
-botをボイチャから切断する
-
-### /play url(search word)
-ボイスチャンネルで音源を再生します。
-
-先にボイチャに接続してから使ってね。
-/play を打った後にURL又はwordを入力してください。
-wordはyoutubeで検索されます。
-
-playlist機能もあります。
-
-### /pause
-再生を一時停止します。
-
-### /resume
-再生を再開します。
-
-### /shuffle
-playlistをシャッフルします。
-
-### /stop
-再生を終了します。
-playlistの内容も削除されます。
-
-### /clear
-playlistの中身を削除します。
-
-### /queue
-playlistの中身を表示します。
-
-## 対応service
-youtube,ニコニコ,ボカコレ,Twitch,Tver,googlepodcasts
-
-## 現在対応中
-spoon,spotify
\ No newline at end of file
diff --git a/spaces/TabPFN/TabPFNPrediction/TabPFN/scripts/tabular_baselines_deep.py b/spaces/TabPFN/TabPFNPrediction/TabPFN/scripts/tabular_baselines_deep.py
deleted file mode 100644
index 0c0fbde5a0ed99409260bfe543fd3710ffc9ff6b..0000000000000000000000000000000000000000
--- a/spaces/TabPFN/TabPFNPrediction/TabPFN/scripts/tabular_baselines_deep.py
+++ /dev/null
@@ -1,74 +0,0 @@
-import os
-import pathlib
-from argparse import Namespace
-
-from sklearn.model_selection import GridSearchCV
-import sys
-
-CV = 5
-param_grid = {}
-
-param_grid['saint'] = {
- # as in https://github.com/kathrinse/TabSurvey/blob/main/models/saint.py#L268
- "dim": [32, 64, 128, 256],
- "depth": [1, 2, 3, 6, 12],
- "heads": [2, 4, 8],
- "dropout": [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8],
-}
-
-def saint_metric(x, y, test_x, test_y, cat_features, metric_used):
- ## Original Implementation https://github.com/somepago/saint
- ## Reimplementation from https://github.com/kathrinse/TabSurvey
- ## HowTo install
- # git clone git@github.com:kathrinse/TabSurvey.git
- # cd TabSurvey
- # requirements
- # optuna
- # scikit-learn
- # pandas
- # configargparse
- # torch
- # einops
- pre_cwd = os.getcwd()
-
- # TODO: Make sure that we change to TabSurvey in here
- # Assume it is in ../../TabSurvey
- dest_wd = pathlib.Path(__file__).absolute().parent.parent.joinpath("../TabSurvey")
- print(f"Change from {pre_cwd} to {dest_wd}")
- sys.chdir(dest_wd)
-
- try:
- from models.saint import SAINT
-
- import warnings
- def warn(*args, **kwargs):
- pass
-
- # get cat dims
- # assume cat_features is a list of idx
- # TODO: FIX this if wrong
- cat_dims = []
- for idx in cat_features:
- cat_dims.append(len(set(x[idx, :])))
- model_args = Namespace(
- num_features=x.shape[1],
- cat_idx=cat_features,
- cat_dims=cat_dims,
- )
- warnings.warn = warn
-
- x, y, test_x, test_y = x.cpu(), y.cpu(), test_x.cpu(), test_y.cpu()
-
- clf = SAINT(model_args)
-
- clf = GridSearchCV(clf, param_grid['saint'], cv=min(CV, x.shape[0]//2))
- # fit model to data
- clf.fit(x, y.long())
-
- pred = clf.decision_function(test_x)
- metric = metric_used(test_y.cpu().numpy(), pred)
- except:
- raise
- finally:
- os.chdir(pre_cwd)
- return metric, pred
\ No newline at end of file
diff --git a/spaces/TandCAcceptMe/face-swap-docker/Dockerfile b/spaces/TandCAcceptMe/face-swap-docker/Dockerfile
deleted file mode 100644
index c3ee9b1e84a98313a8ddea96c99c573c9c795b8f..0000000000000000000000000000000000000000
--- a/spaces/TandCAcceptMe/face-swap-docker/Dockerfile
+++ /dev/null
@@ -1,7 +0,0 @@
-FROM python:3.11
-WORKDIR /usr/src/app
-RUN apt-get update && apt-get install -y libgl1-mesa-glx
-COPY requirements.txt ./
-RUN pip install --no-cache-dir -r requirements.txt
-COPY . .
-CMD ["python", "run.py"]
diff --git a/spaces/TandCAcceptMe/face-swap-docker/clip/clipseg.py b/spaces/TandCAcceptMe/face-swap-docker/clip/clipseg.py
deleted file mode 100644
index 6adc7e4893cbb2bff31eb822dacf96a7c9a87e27..0000000000000000000000000000000000000000
--- a/spaces/TandCAcceptMe/face-swap-docker/clip/clipseg.py
+++ /dev/null
@@ -1,538 +0,0 @@
-import math
-from os.path import basename, dirname, join, isfile
-import torch
-from torch import nn
-from torch.nn import functional as nnf
-from torch.nn.modules.activation import ReLU
-
-
-def get_prompt_list(prompt):
- if prompt == 'plain':
- return ['{}']
- elif prompt == 'fixed':
- return ['a photo of a {}.']
- elif prompt == 'shuffle':
- return ['a photo of a {}.', 'a photograph of a {}.', 'an image of a {}.', '{}.']
- elif prompt == 'shuffle+':
- return ['a photo of a {}.', 'a photograph of a {}.', 'an image of a {}.', '{}.',
- 'a cropped photo of a {}.', 'a good photo of a {}.', 'a photo of one {}.',
- 'a bad photo of a {}.', 'a photo of the {}.']
- else:
- raise ValueError('Invalid value for prompt')
-
-
-def forward_multihead_attention(x, b, with_aff=False, attn_mask=None):
- """
- Simplified version of multihead attention (taken from torch source code but without tons of if clauses).
- The mlp and layer norm come from CLIP.
- x: input.
- b: multihead attention module.
- """
-
- x_ = b.ln_1(x)
- q, k, v = nnf.linear(x_, b.attn.in_proj_weight, b.attn.in_proj_bias).chunk(3, dim=-1)
- tgt_len, bsz, embed_dim = q.size()
-
- head_dim = embed_dim // b.attn.num_heads
- scaling = float(head_dim) ** -0.5
-
- q = q.contiguous().view(tgt_len, bsz * b.attn.num_heads, b.attn.head_dim).transpose(0, 1)
- k = k.contiguous().view(-1, bsz * b.attn.num_heads, b.attn.head_dim).transpose(0, 1)
- v = v.contiguous().view(-1, bsz * b.attn.num_heads, b.attn.head_dim).transpose(0, 1)
-
- q = q * scaling
-
- attn_output_weights = torch.bmm(q, k.transpose(1, 2)) # n_heads * batch_size, tokens^2, tokens^2
- if attn_mask is not None:
-
-
- attn_mask_type, attn_mask = attn_mask
- n_heads = attn_output_weights.size(0) // attn_mask.size(0)
- attn_mask = attn_mask.repeat(n_heads, 1)
-
- if attn_mask_type == 'cls_token':
- # the mask only affects similarities compared to the readout-token.
- attn_output_weights[:, 0, 1:] = attn_output_weights[:, 0, 1:] * attn_mask[None,...]
- # attn_output_weights[:, 0, 0] = 0*attn_output_weights[:, 0, 0]
-
- if attn_mask_type == 'all':
- # print(attn_output_weights.shape, attn_mask[:, None].shape)
- attn_output_weights[:, 1:, 1:] = attn_output_weights[:, 1:, 1:] * attn_mask[:, None]
-
-
- attn_output_weights = torch.softmax(attn_output_weights, dim=-1)
-
- attn_output = torch.bmm(attn_output_weights, v)
- attn_output = attn_output.transpose(0, 1).contiguous().view(tgt_len, bsz, embed_dim)
- attn_output = b.attn.out_proj(attn_output)
-
- x = x + attn_output
- x = x + b.mlp(b.ln_2(x))
-
- if with_aff:
- return x, attn_output_weights
- else:
- return x
-
-
-class CLIPDenseBase(nn.Module):
-
- def __init__(self, version, reduce_cond, reduce_dim, prompt, n_tokens):
- super().__init__()
-
- import clip
-
- # prec = torch.FloatTensor
- self.clip_model, _ = clip.load(version, device='cpu', jit=False)
- self.model = self.clip_model.visual
-
- # if not None, scale conv weights such that we obtain n_tokens.
- self.n_tokens = n_tokens
-
- for p in self.clip_model.parameters():
- p.requires_grad_(False)
-
- # conditional
- if reduce_cond is not None:
- self.reduce_cond = nn.Linear(512, reduce_cond)
- for p in self.reduce_cond.parameters():
- p.requires_grad_(False)
- else:
- self.reduce_cond = None
-
- self.film_mul = nn.Linear(512 if reduce_cond is None else reduce_cond, reduce_dim)
- self.film_add = nn.Linear(512 if reduce_cond is None else reduce_cond, reduce_dim)
-
- self.reduce = nn.Linear(768, reduce_dim)
-
- self.prompt_list = get_prompt_list(prompt)
-
- # precomputed prompts
- import pickle
- if isfile('precomputed_prompt_vectors.pickle'):
- precomp = pickle.load(open('precomputed_prompt_vectors.pickle', 'rb'))
- self.precomputed_prompts = {k: torch.from_numpy(v) for k, v in precomp.items()}
- else:
- self.precomputed_prompts = dict()
-
- def rescaled_pos_emb(self, new_size):
- assert len(new_size) == 2
-
- a = self.model.positional_embedding[1:].T.view(1, 768, *self.token_shape)
- b = nnf.interpolate(a, new_size, mode='bicubic', align_corners=False).squeeze(0).view(768, new_size[0]*new_size[1]).T
- return torch.cat([self.model.positional_embedding[:1], b])
-
- def visual_forward(self, x_inp, extract_layers=(), skip=False, mask=None):
-
-
- with torch.no_grad():
-
- inp_size = x_inp.shape[2:]
-
- if self.n_tokens is not None:
- stride2 = x_inp.shape[2] // self.n_tokens
- conv_weight2 = nnf.interpolate(self.model.conv1.weight, (stride2, stride2), mode='bilinear', align_corners=True)
- x = nnf.conv2d(x_inp, conv_weight2, bias=self.model.conv1.bias, stride=stride2, dilation=self.model.conv1.dilation)
- else:
- x = self.model.conv1(x_inp) # shape = [*, width, grid, grid]
-
- x = x.reshape(x.shape[0], x.shape[1], -1) # shape = [*, width, grid ** 2]
- x = x.permute(0, 2, 1) # shape = [*, grid ** 2, width]
-
- x = torch.cat([self.model.class_embedding.to(x.dtype) + torch.zeros(x.shape[0], 1, x.shape[-1], dtype=x.dtype, device=x.device), x], dim=1) # shape = [*, grid ** 2 + 1, width]
-
- standard_n_tokens = 50 if self.model.conv1.kernel_size[0] == 32 else 197
-
- if x.shape[1] != standard_n_tokens:
- new_shape = int(math.sqrt(x.shape[1]-1))
- x = x + self.rescaled_pos_emb((new_shape, new_shape)).to(x.dtype)[None,:,:]
- else:
- x = x + self.model.positional_embedding.to(x.dtype)
-
- x = self.model.ln_pre(x)
-
- x = x.permute(1, 0, 2) # NLD -> LND
-
- activations, affinities = [], []
- for i, res_block in enumerate(self.model.transformer.resblocks):
-
- if mask is not None:
- mask_layer, mask_type, mask_tensor = mask
- if mask_layer == i or mask_layer == 'all':
- # import ipdb; ipdb.set_trace()
- size = int(math.sqrt(x.shape[0] - 1))
-
- attn_mask = (mask_type, nnf.interpolate(mask_tensor.unsqueeze(1).float(), (size, size)).view(mask_tensor.shape[0], size * size))
-
- else:
- attn_mask = None
- else:
- attn_mask = None
-
- x, aff_per_head = forward_multihead_attention(x, res_block, with_aff=True, attn_mask=attn_mask)
-
- if i in extract_layers:
- affinities += [aff_per_head]
-
- #if self.n_tokens is not None:
- # activations += [nnf.interpolate(x, inp_size, mode='bilinear', align_corners=True)]
- #else:
- activations += [x]
-
- if len(extract_layers) > 0 and i == max(extract_layers) and skip:
- print('early skip')
- break
-
- x = x.permute(1, 0, 2) # LND -> NLD
- x = self.model.ln_post(x[:, 0, :])
-
- if self.model.proj is not None:
- x = x @ self.model.proj
-
- return x, activations, affinities
-
- def sample_prompts(self, words, prompt_list=None):
-
- prompt_list = prompt_list if prompt_list is not None else self.prompt_list
-
- prompt_indices = torch.multinomial(torch.ones(len(prompt_list)), len(words), replacement=True)
- prompts = [prompt_list[i] for i in prompt_indices]
- return [promt.format(w) for promt, w in zip(prompts, words)]
-
- def get_cond_vec(self, conditional, batch_size):
- # compute conditional from a single string
- if conditional is not None and type(conditional) == str:
- cond = self.compute_conditional(conditional)
- cond = cond.repeat(batch_size, 1)
-
- # compute conditional from string list/tuple
- elif conditional is not None and type(conditional) in {list, tuple} and type(conditional[0]) == str:
- assert len(conditional) == batch_size
- cond = self.compute_conditional(conditional)
-
- # use conditional directly
- elif conditional is not None and type(conditional) == torch.Tensor and conditional.ndim == 2:
- cond = conditional
-
- # compute conditional from image
- elif conditional is not None and type(conditional) == torch.Tensor:
- with torch.no_grad():
- cond, _, _ = self.visual_forward(conditional)
- else:
- raise ValueError('invalid conditional')
- return cond
-
- def compute_conditional(self, conditional):
- import clip
-
- dev = next(self.parameters()).device
-
- if type(conditional) in {list, tuple}:
- text_tokens = clip.tokenize(conditional).to(dev)
- cond = self.clip_model.encode_text(text_tokens)
- else:
- if conditional in self.precomputed_prompts:
- cond = self.precomputed_prompts[conditional].float().to(dev)
- else:
- text_tokens = clip.tokenize([conditional]).to(dev)
- cond = self.clip_model.encode_text(text_tokens)[0]
-
- if self.shift_vector is not None:
- return cond + self.shift_vector
- else:
- return cond
-
-
-def clip_load_untrained(version):
- assert version == 'ViT-B/16'
- from clip.model import CLIP
- from clip.clip import _MODELS, _download
- model = torch.jit.load(_download(_MODELS['ViT-B/16'])).eval()
- state_dict = model.state_dict()
-
- vision_width = state_dict["visual.conv1.weight"].shape[0]
- vision_layers = len([k for k in state_dict.keys() if k.startswith("visual.") and k.endswith(".attn.in_proj_weight")])
- vision_patch_size = state_dict["visual.conv1.weight"].shape[-1]
- grid_size = round((state_dict["visual.positional_embedding"].shape[0] - 1) ** 0.5)
- image_resolution = vision_patch_size * grid_size
- embed_dim = state_dict["text_projection"].shape[1]
- context_length = state_dict["positional_embedding"].shape[0]
- vocab_size = state_dict["token_embedding.weight"].shape[0]
- transformer_width = state_dict["ln_final.weight"].shape[0]
- transformer_heads = transformer_width // 64
- transformer_layers = len(set(k.split(".")[2] for k in state_dict if k.startswith(f"transformer.resblocks")))
-
- return CLIP(embed_dim, image_resolution, vision_layers, vision_width, vision_patch_size,
- context_length, vocab_size, transformer_width, transformer_heads, transformer_layers)
-
-
-class CLIPDensePredT(CLIPDenseBase):
-
- def __init__(self, version='ViT-B/32', extract_layers=(3, 6, 9), cond_layer=0, reduce_dim=128, n_heads=4, prompt='fixed',
- extra_blocks=0, reduce_cond=None, fix_shift=False,
- learn_trans_conv_only=False, limit_to_clip_only=False, upsample=False,
- add_calibration=False, rev_activations=False, trans_conv=None, n_tokens=None, complex_trans_conv=False):
-
- super().__init__(version, reduce_cond, reduce_dim, prompt, n_tokens)
- # device = 'cpu'
-
- self.extract_layers = extract_layers
- self.cond_layer = cond_layer
- self.limit_to_clip_only = limit_to_clip_only
- self.process_cond = None
- self.rev_activations = rev_activations
-
- depth = len(extract_layers)
-
- if add_calibration:
- self.calibration_conds = 1
-
- self.upsample_proj = nn.Conv2d(reduce_dim, 1, kernel_size=1) if upsample else None
-
- self.add_activation1 = True
-
- self.version = version
-
- self.token_shape = {'ViT-B/32': (7, 7), 'ViT-B/16': (14, 14)}[version]
-
- if fix_shift:
- # self.shift_vector = nn.Parameter(torch.load(join(dirname(basename(__file__)), 'clip_text_shift_vector.pth')), requires_grad=False)
- self.shift_vector = nn.Parameter(torch.load(join(dirname(basename(__file__)), 'shift_text_to_vis.pth')), requires_grad=False)
- # self.shift_vector = nn.Parameter(-1*torch.load(join(dirname(basename(__file__)), 'shift2.pth')), requires_grad=False)
- else:
- self.shift_vector = None
-
- if trans_conv is None:
- trans_conv_ks = {'ViT-B/32': (32, 32), 'ViT-B/16': (16, 16)}[version]
- else:
- # explicitly define transposed conv kernel size
- trans_conv_ks = (trans_conv, trans_conv)
-
- if not complex_trans_conv:
- self.trans_conv = nn.ConvTranspose2d(reduce_dim, 1, trans_conv_ks, stride=trans_conv_ks)
- else:
- assert trans_conv_ks[0] == trans_conv_ks[1]
-
- tp_kernels = (trans_conv_ks[0] // 4, trans_conv_ks[0] // 4)
-
- self.trans_conv = nn.Sequential(
- nn.Conv2d(reduce_dim, reduce_dim, kernel_size=3, padding=1),
- nn.ReLU(),
- nn.ConvTranspose2d(reduce_dim, reduce_dim // 2, kernel_size=tp_kernels[0], stride=tp_kernels[0]),
- nn.ReLU(),
- nn.ConvTranspose2d(reduce_dim // 2, 1, kernel_size=tp_kernels[1], stride=tp_kernels[1]),
- )
-
-# self.trans_conv = nn.ConvTranspose2d(reduce_dim, 1, trans_conv_ks, stride=trans_conv_ks)
-
- assert len(self.extract_layers) == depth
-
- self.reduces = nn.ModuleList([nn.Linear(768, reduce_dim) for _ in range(depth)])
- self.blocks = nn.ModuleList([nn.TransformerEncoderLayer(d_model=reduce_dim, nhead=n_heads) for _ in range(len(self.extract_layers))])
- self.extra_blocks = nn.ModuleList([nn.TransformerEncoderLayer(d_model=reduce_dim, nhead=n_heads) for _ in range(extra_blocks)])
-
- # refinement and trans conv
-
- if learn_trans_conv_only:
- for p in self.parameters():
- p.requires_grad_(False)
-
- for p in self.trans_conv.parameters():
- p.requires_grad_(True)
-
- self.prompt_list = get_prompt_list(prompt)
-
-
- def forward(self, inp_image, conditional=None, return_features=False, mask=None):
-
- assert type(return_features) == bool
-
- inp_image = inp_image.to(self.model.positional_embedding.device)
-
- if mask is not None:
- raise ValueError('mask not supported')
-
- # x_inp = normalize(inp_image)
- x_inp = inp_image
-
- bs, dev = inp_image.shape[0], x_inp.device
-
- cond = self.get_cond_vec(conditional, bs)
-
- visual_q, activations, _ = self.visual_forward(x_inp, extract_layers=[0] + list(self.extract_layers))
-
- activation1 = activations[0]
- activations = activations[1:]
-
- _activations = activations[::-1] if not self.rev_activations else activations
-
- a = None
- for i, (activation, block, reduce) in enumerate(zip(_activations, self.blocks, self.reduces)):
-
- if a is not None:
- a = reduce(activation) + a
- else:
- a = reduce(activation)
-
- if i == self.cond_layer:
- if self.reduce_cond is not None:
- cond = self.reduce_cond(cond)
-
- a = self.film_mul(cond) * a + self.film_add(cond)
-
- a = block(a)
-
- for block in self.extra_blocks:
- a = a + block(a)
-
- a = a[1:].permute(1, 2, 0) # rm cls token and -> BS, Feats, Tokens
-
- size = int(math.sqrt(a.shape[2]))
-
- a = a.view(bs, a.shape[1], size, size)
-
- a = self.trans_conv(a)
-
- if self.n_tokens is not None:
- a = nnf.interpolate(a, x_inp.shape[2:], mode='bilinear', align_corners=True)
-
- if self.upsample_proj is not None:
- a = self.upsample_proj(a)
- a = nnf.interpolate(a, x_inp.shape[2:], mode='bilinear')
-
- if return_features:
- return a, visual_q, cond, [activation1] + activations
- else:
- return a,
-
-
-
-class CLIPDensePredTMasked(CLIPDensePredT):
-
- def __init__(self, version='ViT-B/32', extract_layers=(3, 6, 9), cond_layer=0, reduce_dim=128, n_heads=4,
- prompt='fixed', extra_blocks=0, reduce_cond=None, fix_shift=False, learn_trans_conv_only=False,
- refine=None, limit_to_clip_only=False, upsample=False, add_calibration=False, n_tokens=None):
-
- super().__init__(version=version, extract_layers=extract_layers, cond_layer=cond_layer, reduce_dim=reduce_dim,
- n_heads=n_heads, prompt=prompt, extra_blocks=extra_blocks, reduce_cond=reduce_cond,
- fix_shift=fix_shift, learn_trans_conv_only=learn_trans_conv_only,
- limit_to_clip_only=limit_to_clip_only, upsample=upsample, add_calibration=add_calibration,
- n_tokens=n_tokens)
-
- def visual_forward_masked(self, img_s, seg_s):
- return super().visual_forward(img_s, mask=('all', 'cls_token', seg_s))
-
- def forward(self, img_q, cond_or_img_s, seg_s=None, return_features=False):
-
- if seg_s is None:
- cond = cond_or_img_s
- else:
- img_s = cond_or_img_s
-
- with torch.no_grad():
- cond, _, _ = self.visual_forward_masked(img_s, seg_s)
-
- return super().forward(img_q, cond, return_features=return_features)
-
-
-
-class CLIPDenseBaseline(CLIPDenseBase):
-
- def __init__(self, version='ViT-B/32', cond_layer=0,
- extract_layer=9, reduce_dim=128, reduce2_dim=None, prompt='fixed',
- reduce_cond=None, limit_to_clip_only=False, n_tokens=None):
-
- super().__init__(version, reduce_cond, reduce_dim, prompt, n_tokens)
- device = 'cpu'
-
- # self.cond_layer = cond_layer
- self.extract_layer = extract_layer
- self.limit_to_clip_only = limit_to_clip_only
- self.shift_vector = None
-
- self.token_shape = {'ViT-B/32': (7, 7), 'ViT-B/16': (14, 14)}[version]
-
- assert reduce2_dim is not None
-
- self.reduce2 = nn.Sequential(
- nn.Linear(reduce_dim, reduce2_dim),
- nn.ReLU(),
- nn.Linear(reduce2_dim, reduce_dim)
- )
-
- trans_conv_ks = {'ViT-B/32': (32, 32), 'ViT-B/16': (16, 16)}[version]
- self.trans_conv = nn.ConvTranspose2d(reduce_dim, 1, trans_conv_ks, stride=trans_conv_ks)
-
-
- def forward(self, inp_image, conditional=None, return_features=False):
-
- inp_image = inp_image.to(self.model.positional_embedding.device)
-
- # x_inp = normalize(inp_image)
- x_inp = inp_image
-
- bs, dev = inp_image.shape[0], x_inp.device
-
- cond = self.get_cond_vec(conditional, bs)
-
- visual_q, activations, affinities = self.visual_forward(x_inp, extract_layers=[self.extract_layer])
-
- a = activations[0]
- a = self.reduce(a)
- a = self.film_mul(cond) * a + self.film_add(cond)
-
- if self.reduce2 is not None:
- a = self.reduce2(a)
-
- # the original model would execute a transformer block here
-
- a = a[1:].permute(1, 2, 0) # rm cls token and -> BS, Feats, Tokens
-
- size = int(math.sqrt(a.shape[2]))
-
- a = a.view(bs, a.shape[1], size, size)
- a = self.trans_conv(a)
-
- if return_features:
- return a, visual_q, cond, activations
- else:
- return a,
-
-
-class CLIPSegMultiLabel(nn.Module):
-
- def __init__(self, model) -> None:
- super().__init__()
-
- from third_party.JoEm.data_loader import get_seen_idx, get_unseen_idx, VOC
-
- self.pascal_classes = VOC
-
- from clip.clipseg import CLIPDensePredT
- from general_utils import load_model
- # self.clipseg = load_model('rd64-vit16-neg0.2-phrasecut', strict=False)
- self.clipseg = load_model(model, strict=False)
-
- self.clipseg.eval()
-
- def forward(self, x):
-
- bs = x.shape[0]
- out = torch.ones(21, bs, 352, 352).to(x.device) * -10
-
- for class_id, class_name in enumerate(self.pascal_classes):
-
- fac = 3 if class_name == 'background' else 1
-
- with torch.no_grad():
- pred = torch.sigmoid(self.clipseg(x, class_name)[0][:,0]) * fac
-
- out[class_id] += pred
-
-
- out = out.permute(1, 0, 2, 3)
-
- return out
-
- # construct output tensor
-
diff --git a/spaces/TandCAcceptMe/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_vendor/rich/align.py b/spaces/TandCAcceptMe/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_vendor/rich/align.py
deleted file mode 100644
index c310b66e783820e5596bee9e4d92e531d59d6dc9..0000000000000000000000000000000000000000
--- a/spaces/TandCAcceptMe/face-swap-docker/mynewshinyroop/Lib/site-packages/pip/_vendor/rich/align.py
+++ /dev/null
@@ -1,311 +0,0 @@
-import sys
-from itertools import chain
-from typing import TYPE_CHECKING, Iterable, Optional
-
-if sys.version_info >= (3, 8):
- from typing import Literal
-else:
- from pip._vendor.typing_extensions import Literal # pragma: no cover
-
-from .constrain import Constrain
-from .jupyter import JupyterMixin
-from .measure import Measurement
-from .segment import Segment
-from .style import StyleType
-
-if TYPE_CHECKING:
- from .console import Console, ConsoleOptions, RenderableType, RenderResult
-
-AlignMethod = Literal["left", "center", "right"]
-VerticalAlignMethod = Literal["top", "middle", "bottom"]
-
-
-class Align(JupyterMixin):
- """Align a renderable by adding spaces if necessary.
-
- Args:
- renderable (RenderableType): A console renderable.
- align (AlignMethod): One of "left", "center", or "right""
- style (StyleType, optional): An optional style to apply to the background.
- vertical (Optional[VerticalAlginMethod], optional): Optional vertical align, one of "top", "middle", or "bottom". Defaults to None.
- pad (bool, optional): Pad the right with spaces. Defaults to True.
- width (int, optional): Restrict contents to given width, or None to use default width. Defaults to None.
- height (int, optional): Set height of align renderable, or None to fit to contents. Defaults to None.
-
- Raises:
- ValueError: if ``align`` is not one of the expected values.
- """
-
- def __init__(
- self,
- renderable: "RenderableType",
- align: AlignMethod = "left",
- style: Optional[StyleType] = None,
- *,
- vertical: Optional[VerticalAlignMethod] = None,
- pad: bool = True,
- width: Optional[int] = None,
- height: Optional[int] = None,
- ) -> None:
- if align not in ("left", "center", "right"):
- raise ValueError(
- f'invalid value for align, expected "left", "center", or "right" (not {align!r})'
- )
- if vertical is not None and vertical not in ("top", "middle", "bottom"):
- raise ValueError(
- f'invalid value for vertical, expected "top", "middle", or "bottom" (not {vertical!r})'
- )
- self.renderable = renderable
- self.align = align
- self.style = style
- self.vertical = vertical
- self.pad = pad
- self.width = width
- self.height = height
-
- def __repr__(self) -> str:
- return f"Align({self.renderable!r}, {self.align!r})"
-
- @classmethod
- def left(
- cls,
- renderable: "RenderableType",
- style: Optional[StyleType] = None,
- *,
- vertical: Optional[VerticalAlignMethod] = None,
- pad: bool = True,
- width: Optional[int] = None,
- height: Optional[int] = None,
- ) -> "Align":
- """Align a renderable to the left."""
- return cls(
- renderable,
- "left",
- style=style,
- vertical=vertical,
- pad=pad,
- width=width,
- height=height,
- )
-
- @classmethod
- def center(
- cls,
- renderable: "RenderableType",
- style: Optional[StyleType] = None,
- *,
- vertical: Optional[VerticalAlignMethod] = None,
- pad: bool = True,
- width: Optional[int] = None,
- height: Optional[int] = None,
- ) -> "Align":
- """Align a renderable to the center."""
- return cls(
- renderable,
- "center",
- style=style,
- vertical=vertical,
- pad=pad,
- width=width,
- height=height,
- )
-
- @classmethod
- def right(
- cls,
- renderable: "RenderableType",
- style: Optional[StyleType] = None,
- *,
- vertical: Optional[VerticalAlignMethod] = None,
- pad: bool = True,
- width: Optional[int] = None,
- height: Optional[int] = None,
- ) -> "Align":
- """Align a renderable to the right."""
- return cls(
- renderable,
- "right",
- style=style,
- vertical=vertical,
- pad=pad,
- width=width,
- height=height,
- )
-
- def __rich_console__(
- self, console: "Console", options: "ConsoleOptions"
- ) -> "RenderResult":
- align = self.align
- width = console.measure(self.renderable, options=options).maximum
- rendered = console.render(
- Constrain(
- self.renderable, width if self.width is None else min(width, self.width)
- ),
- options.update(height=None),
- )
- lines = list(Segment.split_lines(rendered))
- width, height = Segment.get_shape(lines)
- lines = Segment.set_shape(lines, width, height)
- new_line = Segment.line()
- excess_space = options.max_width - width
- style = console.get_style(self.style) if self.style is not None else None
-
- def generate_segments() -> Iterable[Segment]:
- if excess_space <= 0:
- # Exact fit
- for line in lines:
- yield from line
- yield new_line
-
- elif align == "left":
- # Pad on the right
- pad = Segment(" " * excess_space, style) if self.pad else None
- for line in lines:
- yield from line
- if pad:
- yield pad
- yield new_line
-
- elif align == "center":
- # Pad left and right
- left = excess_space // 2
- pad = Segment(" " * left, style)
- pad_right = (
- Segment(" " * (excess_space - left), style) if self.pad else None
- )
- for line in lines:
- if left:
- yield pad
- yield from line
- if pad_right:
- yield pad_right
- yield new_line
-
- elif align == "right":
- # Padding on left
- pad = Segment(" " * excess_space, style)
- for line in lines:
- yield pad
- yield from line
- yield new_line
-
- blank_line = (
- Segment(f"{' ' * (self.width or options.max_width)}\n", style)
- if self.pad
- else Segment("\n")
- )
-
- def blank_lines(count: int) -> Iterable[Segment]:
- if count > 0:
- for _ in range(count):
- yield blank_line
-
- vertical_height = self.height or options.height
- iter_segments: Iterable[Segment]
- if self.vertical and vertical_height is not None:
- if self.vertical == "top":
- bottom_space = vertical_height - height
- iter_segments = chain(generate_segments(), blank_lines(bottom_space))
- elif self.vertical == "middle":
- top_space = (vertical_height - height) // 2
- bottom_space = vertical_height - top_space - height
- iter_segments = chain(
- blank_lines(top_space),
- generate_segments(),
- blank_lines(bottom_space),
- )
- else: # self.vertical == "bottom":
- top_space = vertical_height - height
- iter_segments = chain(blank_lines(top_space), generate_segments())
- else:
- iter_segments = generate_segments()
- if self.style:
- style = console.get_style(self.style)
- iter_segments = Segment.apply_style(iter_segments, style)
- yield from iter_segments
-
- def __rich_measure__(
- self, console: "Console", options: "ConsoleOptions"
- ) -> Measurement:
- measurement = Measurement.get(console, options, self.renderable)
- return measurement
-
-
-class VerticalCenter(JupyterMixin):
- """Vertically aligns a renderable.
-
- Warn:
- This class is deprecated and may be removed in a future version. Use Align class with
- `vertical="middle"`.
-
- Args:
- renderable (RenderableType): A renderable object.
- """
-
- def __init__(
- self,
- renderable: "RenderableType",
- style: Optional[StyleType] = None,
- ) -> None:
- self.renderable = renderable
- self.style = style
-
- def __repr__(self) -> str:
- return f"VerticalCenter({self.renderable!r})"
-
- def __rich_console__(
- self, console: "Console", options: "ConsoleOptions"
- ) -> "RenderResult":
- style = console.get_style(self.style) if self.style is not None else None
- lines = console.render_lines(
- self.renderable, options.update(height=None), pad=False
- )
- width, _height = Segment.get_shape(lines)
- new_line = Segment.line()
- height = options.height or options.size.height
- top_space = (height - len(lines)) // 2
- bottom_space = height - top_space - len(lines)
- blank_line = Segment(f"{' ' * width}", style)
-
- def blank_lines(count: int) -> Iterable[Segment]:
- for _ in range(count):
- yield blank_line
- yield new_line
-
- if top_space > 0:
- yield from blank_lines(top_space)
- for line in lines:
- yield from line
- yield new_line
- if bottom_space > 0:
- yield from blank_lines(bottom_space)
-
- def __rich_measure__(
- self, console: "Console", options: "ConsoleOptions"
- ) -> Measurement:
- measurement = Measurement.get(console, options, self.renderable)
- return measurement
-
-
-if __name__ == "__main__": # pragma: no cover
- from pip._vendor.rich.console import Console, Group
- from pip._vendor.rich.highlighter import ReprHighlighter
- from pip._vendor.rich.panel import Panel
-
- highlighter = ReprHighlighter()
- console = Console()
-
- panel = Panel(
- Group(
- Align.left(highlighter("align='left'")),
- Align.center(highlighter("align='center'")),
- Align.right(highlighter("align='right'")),
- ),
- width=60,
- style="on dark_blue",
- title="Align",
- )
-
- console.print(
- Align.center(panel, vertical="middle", style="on red", height=console.height)
- )
diff --git a/spaces/TencentARC/VLog/models/grit_src/third_party/CenterNet2/detectron2/model_zoo/__init__.py b/spaces/TencentARC/VLog/models/grit_src/third_party/CenterNet2/detectron2/model_zoo/__init__.py
deleted file mode 100644
index 6204208198d813728cf6419e8eef4a733f20c18f..0000000000000000000000000000000000000000
--- a/spaces/TencentARC/VLog/models/grit_src/third_party/CenterNet2/detectron2/model_zoo/__init__.py
+++ /dev/null
@@ -1,10 +0,0 @@
-# Copyright (c) Facebook, Inc. and its affiliates.
-"""
-Model Zoo API for Detectron2: a collection of functions to create common model architectures
-listed in `MODEL_ZOO.md `_,
-and optionally load their pre-trained weights.
-"""
-
-from .model_zoo import get, get_config_file, get_checkpoint_url, get_config
-
-__all__ = ["get_checkpoint_url", "get", "get_config_file", "get_config"]
diff --git a/spaces/TencentARC/VLog/models/grit_src/third_party/CenterNet2/tools/convert-torchvision-to-d2.py b/spaces/TencentARC/VLog/models/grit_src/third_party/CenterNet2/tools/convert-torchvision-to-d2.py
deleted file mode 100644
index 4b827d960cca69657e98bd89a9aa5623a847099d..0000000000000000000000000000000000000000
--- a/spaces/TencentARC/VLog/models/grit_src/third_party/CenterNet2/tools/convert-torchvision-to-d2.py
+++ /dev/null
@@ -1,56 +0,0 @@
-#!/usr/bin/env python
-# Copyright (c) Facebook, Inc. and its affiliates.
-
-import pickle as pkl
-import sys
-import torch
-
-"""
-Usage:
- # download one of the ResNet{18,34,50,101,152} models from torchvision:
- wget https://download.pytorch.org/models/resnet50-19c8e357.pth -O r50.pth
- # run the conversion
- ./convert-torchvision-to-d2.py r50.pth r50.pkl
-
- # Then, use r50.pkl with the following changes in config:
-
-MODEL:
- WEIGHTS: "/path/to/r50.pkl"
- PIXEL_MEAN: [123.675, 116.280, 103.530]
- PIXEL_STD: [58.395, 57.120, 57.375]
- RESNETS:
- DEPTH: 50
- STRIDE_IN_1X1: False
-INPUT:
- FORMAT: "RGB"
-
- These models typically produce slightly worse results than the
- pre-trained ResNets we use in official configs, which are the
- original ResNet models released by MSRA.
-"""
-
-if __name__ == "__main__":
- input = sys.argv[1]
-
- obj = torch.load(input, map_location="cpu")
-
- newmodel = {}
- for k in list(obj.keys()):
- old_k = k
- if "layer" not in k:
- k = "stem." + k
- for t in [1, 2, 3, 4]:
- k = k.replace("layer{}".format(t), "res{}".format(t + 1))
- for t in [1, 2, 3]:
- k = k.replace("bn{}".format(t), "conv{}.norm".format(t))
- k = k.replace("downsample.0", "shortcut")
- k = k.replace("downsample.1", "shortcut.norm")
- print(old_k, "->", k)
- newmodel[k] = obj.pop(old_k).detach().numpy()
-
- res = {"model": newmodel, "__author__": "torchvision", "matching_heuristics": True}
-
- with open(sys.argv[2], "wb") as f:
- pkl.dump(res, f)
- if obj:
- print("Unconverted keys:", obj.keys())
diff --git a/spaces/ThirdEyeData/Customer-Conversion-Prediction/supv/bacl.py b/spaces/ThirdEyeData/Customer-Conversion-Prediction/supv/bacl.py
deleted file mode 100644
index 7714f6f40d3f598410c78600fb28ca286c013848..0000000000000000000000000000000000000000
--- a/spaces/ThirdEyeData/Customer-Conversion-Prediction/supv/bacl.py
+++ /dev/null
@@ -1,493 +0,0 @@
-#!/usr/local/bin/python3
-
-# avenir-python: Machine Learning
-# Author: Pranab Ghosh
-#
-# Licensed under the Apache License, Version 2.0 (the "License"); you
-# may not use this file except in compliance with the License. You may
-# obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
-# implied. See the License for the specific language governing
-# permissions and limitations under the License.
-
-# Package imports
-import os
-import sys
-import matplotlib.pyplot as plt
-import numpy as np
-import sklearn as sk
-import matplotlib
-import random
-import jprops
-from io import StringIO
-from sklearn.model_selection import cross_val_score
-import joblib
-from random import randint
-from io import StringIO
-sys.path.append(os.path.abspath("../lib"))
-from util import *
-from mlutil import *
-from pasearch import *
-
-#base classifier class
-class BaseClassifier(object):
-
- def __init__(self, configFile, defValues, mname):
- self.config = Configuration(configFile, defValues)
- self.subSampleRate = None
- self.featData = None
- self.clsData = None
- self.classifier = None
- self.trained = False
- self.verbose = self.config.getBooleanConfig("common.verbose")[0]
- logFilePath = self.config.getStringConfig("common.logging.file")[0]
- logLevName = self.config.getStringConfig("common.logging.level")[0]
- self.logger = createLogger(mname, logFilePath, logLevName)
- self.logger.info("********* starting session")
-
- def initConfig(self, configFile, defValues):
- """
- initialize config
- """
- self.config = Configuration(configFile, defValues)
-
- def getConfig(self):
- """
- get config object
- """
- return self.config
-
- def setConfigParam(self, name, value):
- """
- set config param
- """
- self.config.setParam(name, value)
-
- def getMode(self):
- """
- get mode
- """
- return self.config.getStringConfig("common.mode")[0]
-
- def getSearchParamStrategy(self):
- """
- get search parameter
- """
- return self.config.getStringConfig("train.search.param.strategy")[0]
-
- def train(self):
- """
- train model
- """
- #build model
- self.buildModel()
-
- # training data
- if self.featData is None:
- (featData, clsData) = self.prepTrainingData()
- (self.featData, self.clsData) = (featData, clsData)
- else:
- (featData, clsData) = (self.featData, self.clsData)
- if self.subSampleRate is not None:
- (featData, clsData) = subSample(featData, clsData, self.subSampleRate, False)
- self.logger.info("subsample size " + str(featData.shape[0]))
-
- # parameters
- modelSave = self.config.getBooleanConfig("train.model.save")[0]
-
- #train
- self.logger.info("...training model")
- self.classifier.fit(featData, clsData)
- score = self.classifier.score(featData, clsData)
- successCriterion = self.config.getStringConfig("train.success.criterion")[0]
- result = None
- if successCriterion == "accuracy":
- self.logger.info("accuracy with training data {:06.3f}".format(score))
- result = score
- elif successCriterion == "error":
- error = 1.0 - score
- self.logger.info("error with training data {:06.3f}".format(error))
- result = error
- else:
- raise ValueError("invalid success criterion")
-
- if modelSave:
- self.logger.info("...saving model")
- modelFilePath = self.getModelFilePath()
- joblib.dump(self.classifier, modelFilePath)
- self.trained = True
- return result
-
- def trainValidate(self):
- """
- train with k fold validation
- """
- #build model
- self.buildModel()
-
- # training data
- (featData, clsData) = self.prepTrainingData()
-
- #parameter
- validation = self.config.getStringConfig("train.validation")[0]
- numFolds = self.config.getIntConfig("train.num.folds")[0]
- successCriterion = self.config.getStringConfig("train.success.criterion")[0]
- scoreMethod = self.config.getStringConfig("train.score.method")[0]
-
- #train with validation
- self.logger.info("...training and kfold cross validating model")
- scores = cross_val_score(self.classifier, featData, clsData, cv=numFolds,scoring=scoreMethod)
- avScore = np.mean(scores)
- result = self.reportResult(avScore, successCriterion, scoreMethod)
- return result
-
- def trainValidateSearch(self):
- """
- train with k fold validation and search parameter space for optimum
- """
- self.logger.info("...starting train validate with parameter search")
- searchStrategyName = self.getSearchParamStrategy()
- if searchStrategyName is not None:
- if searchStrategyName == "grid":
- searchStrategy = GuidedParameterSearch(self.verbose)
- elif searchStrategyName == "random":
- searchStrategy = RandomParameterSearch(self.verbose)
- maxIter = self.config.getIntConfig("train.search.max.iterations")[0]
- searchStrategy.setMaxIter(maxIter)
- elif searchStrategyName == "simuan":
- searchStrategy = SimulatedAnnealingParameterSearch(self.verbose)
- maxIter = self.config.getIntConfig("train.search.max.iterations")[0]
- searchStrategy.setMaxIter(maxIter)
- temp = self.config.getFloatConfig("train.search.sa.temp")[0]
- searchStrategy.setTemp(temp)
- tempRedRate = self.config.getFloatConfig("train.search.sa.temp.red.rate")[0]
- searchStrategy.setTempReductionRate(tempRedRate)
- else:
- raise ValueError("invalid paramtere search strategy")
- else:
- raise ValueError("missing search strategy")
-
- # add search params
- searchParams = self.config.getStringConfig("train.search.params")[0].split(",")
- searchParamNames = []
- extSearchParamNames = []
- if searchParams is not None:
- for searchParam in searchParams:
- paramItems = searchParam.split(":")
- extSearchParamNames.append(paramItems[0])
-
- #get rid name component search
- paramNameItems = paramItems[0].split(".")
- del paramNameItems[1]
- paramItems[0] = ".".join(paramNameItems)
-
- searchStrategy.addParam(paramItems)
- searchParamNames.append(paramItems[0])
- else:
- raise ValueError("missing search parameter list")
-
- # add search param data list for each param
- for (searchParamName,extSearchParamName) in zip(searchParamNames,extSearchParamNames):
- searchParamData = self.config.getStringConfig(extSearchParamName)[0].split(",")
- searchStrategy.addParamVaues(searchParamName, searchParamData)
-
- # train and validate for various param value combination
- searchStrategy.prepare()
- paramValues = searchStrategy.nextParamValues()
- searchResults = []
- while paramValues is not None:
- self.logger.info("...next parameter set")
- paramStr = ""
- for paramValue in paramValues:
- self.setConfigParam(paramValue[0], str(paramValue[1]))
- paramStr = paramStr + paramValue[0] + "=" + str(paramValue[1]) + " "
- result = self.trainValidate()
- searchStrategy.setCost(result)
- searchResults.append((paramStr, result))
- paramValues = searchStrategy.nextParamValues()
-
- # output
- self.logger.info("all parameter search results")
- for searchResult in searchResults:
- self.logger.info("{}\t{06.3f}".format(searchResult[0], searchResult[1]))
-
- self.logger.info("best parameter search result")
- bestSolution = searchStrategy.getBestSolution()
- paramStr = ""
- for paramValue in bestSolution[0]:
- paramStr = paramStr + paramValue[0] + "=" + str(paramValue[1]) + " "
- self.logger.info("{}\t{:06.3f}".format(paramStr, bestSolution[1]))
- return bestSolution
-
- def validate(self):
- """
- predict
- """
- # create model
- useSavedModel = self.config.getBooleanConfig("validate.use.saved.model")[0]
- if useSavedModel:
- # load saved model
- self.logger.info("...loading model")
- modelFilePath = self.getModelFilePath()
- self.classifier = joblib.load(modelFilePath)
- else:
- # train model
- if not self.trained:
- self.train()
-
- # prepare test data
- (featData, clsDataActual) = self.prepValidationData()
-
- #predict
- self.logger.info("...predicting")
- clsDataPred = self.classifier.predict(featData)
-
- self.logger.info("...validating")
- #print clsData
- scoreMethod = self.config.getStringConfig("validate.score.method")[0]
- if scoreMethod == "accuracy":
- accuracy = sk.metrics.accuracy_score(clsDataActual, clsDataPred)
- self.logger.info("accuracy:")
- self.logger.info(accuracy)
- elif scoreMethod == "confusionMatrix":
- confMatrx = sk.metrics.confusion_matrix(clsDataActual, clsDataPred)
- self.logger.info("confusion matrix:")
- self.logger.info(confMatrx)
-
-
- def predictx(self):
- """
- predict
- """
- # create model
- self.prepModel()
-
- # prepare test data
- featData = self.prepPredictData()
-
- #predict
- self.logger.info("...predicting")
- clsData = self.classifier.predict(featData)
- self.logger.info(clsData)
-
- def predict(self, recs=None):
- """
- predict with in memory data
- """
- # create model
- self.prepModel()
-
- #input record
- if recs:
- #passed record
- featData = self.prepStringPredictData(recs)
- if (featData.ndim == 1):
- featData = featData.reshape(1, -1)
- else:
- #file
- featData = self.prepPredictData()
-
- #predict
- self.logger.info("...predicting")
- clsData = self.classifier.predict(featData)
- return clsData
-
- def predictProb(self, recs):
- """
- predict probability with in memory data
- """
- raise ValueError("can not predict class probability")
-
- def prepModel(self):
- """
- preparing model
- """
- useSavedModel = self.config.getBooleanConfig("predict.use.saved.model")[0]
- if (useSavedModel and not self.classifier):
- # load saved model
- self.logger.info("...loading saved model")
- modelFilePath = self.getModelFilePath()
- self.classifier = joblib.load(modelFilePath)
- else:
- # train model
- if not self.trained:
- self.train()
-
- def prepTrainingData(self):
- """
- loads and prepares training data
- """
- # parameters
- dataFile = self.config.getStringConfig("train.data.file")[0]
- fieldIndices = self.config.getStringConfig("train.data.fields")[0]
- if not fieldIndices is None:
- fieldIndices = strToIntArray(fieldIndices, ",")
- featFieldIndices = self.config.getStringConfig("train.data.feature.fields")[0]
- if not featFieldIndices is None:
- featFieldIndices = strToIntArray(featFieldIndices, ",")
- classFieldIndex = self.config.getIntConfig("train.data.class.field")[0]
-
- #training data
- (data, featData) = loadDataFile(dataFile, ",", fieldIndices, featFieldIndices)
- if (self.config.getStringConfig("common.preprocessing")[0] == "scale"):
- scalingMethod = self.config.getStringConfig("common.scaling.method")[0]
- featData = scaleData(featData, scalingMethod)
-
- clsData = extrColumns(data, classFieldIndex)
- clsData = np.array([int(a) for a in clsData])
- return (featData, clsData)
-
- def prepValidationData(self):
- """
- loads and prepares training data
- """
- # parameters
- dataFile = self.config.getStringConfig("validate.data.file")[0]
- fieldIndices = self.config.getStringConfig("validate.data.fields")[0]
- if not fieldIndices is None:
- fieldIndices = strToIntArray(fieldIndices, ",")
- featFieldIndices = self.config.getStringConfig("validate.data.feature.fields")[0]
- if not featFieldIndices is None:
- featFieldIndices = strToIntArray(featFieldIndices, ",")
- classFieldIndex = self.config.getIntConfig("validate.data.class.field")[0]
-
- #training data
- (data, featData) = loadDataFile(dataFile, ",", fieldIndices, featFieldIndices)
- if (self.config.getStringConfig("common.preprocessing")[0] == "scale"):
- scalingMethod = self.config.getStringConfig("common.scaling.method")[0]
- featData = scaleData(featData, scalingMethod)
- clsData = extrColumns(data, classFieldIndex)
- clsData = [int(a) for a in clsData]
- return (featData, clsData)
-
- def prepPredictData(self):
- """
- loads and prepares training data
- """
- # parameters
- dataFile = self.config.getStringConfig("predict.data.file")[0]
- if dataFile is None:
- raise ValueError("missing prediction data file")
- fieldIndices = self.config.getStringConfig("predict.data.fields")[0]
- if not fieldIndices is None:
- fieldIndices = strToIntArray(fieldIndices, ",")
- featFieldIndices = self.config.getStringConfig("predict.data.feature.fields")[0]
- if not featFieldIndices is None:
- featFieldIndices = strToIntArray(featFieldIndices, ",")
-
- #training data
- (data, featData) = loadDataFile(dataFile, ",", fieldIndices, featFieldIndices)
- if (self.config.getStringConfig("common.preprocessing")[0] == "scale"):
- scalingMethod = self.config.getStringConfig("common.scaling.method")[0]
- featData = scaleData(featData, scalingMethod)
-
- return featData
-
- def prepStringPredictData(self, recs):
- """
- prepare string predict data
- """
- frecs = StringIO(recs)
- featData = np.loadtxt(frecs, delimiter=',')
- return featData
-
- def getModelFilePath(self):
- """
- get model file path
- """
- modelDirectory = self.config.getStringConfig("common.model.directory")[0]
- modelFile = self.config.getStringConfig("common.model.file")[0]
- if modelFile is None:
- raise ValueError("missing model file name")
- modelFilePath = modelDirectory + "/" + modelFile
- return modelFilePath
-
- def reportResult(self, score, successCriterion, scoreMethod):
- """
- report result
- """
- if successCriterion == "accuracy":
- self.logger.info("average " + scoreMethod + " with k fold cross validation {:06.3f}".format(score))
- result = score
- elif successCriterion == "error":
- error = 1.0 - score
- self.logger.info("average error with k fold cross validation {:06.3f}".format(error))
- result = error
- else:
- raise ValueError("invalid success criterion")
- return result
-
- def autoTrain(self):
- """
- auto train
- """
- maxTestErr = self.config.getFloatConfig("train.auto.max.test.error")[0]
- maxErr = self.config.getFloatConfig("train.auto.max.error")[0]
- maxErrDiff = self.config.getFloatConfig("train.auto.max.error.diff")[0]
-
- self.config.setParam("train.model.save", "False")
-
- #train, validate and serach optimum parameter
- result = self.trainValidateSearch()
- testError = result[1]
-
- #subsample training size to match train size for k fold validation
- numFolds = self.config.getIntConfig("train.num.folds")[0]
- self.subSampleRate = float(numFolds - 1) / numFolds
-
- #train only with optimum parameter values
- for paramValue in result[0]:
- pName = paramValue[0]
- pValue = paramValue[1]
- self.logger.info(pName + " " + pValue)
- self.setConfigParam(pName, pValue)
- trainError = self.train()
-
- if testError < maxTestErr:
- # criteria based on test error only
- self.logger.info("Successfullt trained. Low test error level")
- status = 1
- else:
- # criteria based on bias error and generalization error
- avError = (trainError + testError) / 2
- diffError = testError - trainError
- self.logger.info("Auto training completed: training error {:06.3f} test error: {:06.3f}".format(trainError, testError))
- self.logger.info("Average of test and training error: {:06.3f} test and training error diff: {:06.3f}".format(avError, diffError))
- if diffError > maxErrDiff:
- # high generalization error
- if avError > maxErr:
- # high bias error
- self.logger.info("High generalization error and high error. Need larger training data set and increased model complexity")
- status = 4
- else:
- # low bias error
- self.logger.info("High generalization error. Need larger training data set")
- status = 3
- else:
- # low generalization error
- if avError > maxErr:
- # high bias error
- self.logger.info("Converged, but with high error rate. Need to increase model complexity")
- status = 2
- else:
- # low bias error
- self.logger.info("Successfullt trained. Low generalization error and low bias error level")
- status = 1
-
- if status == 1:
- #train final model, use all data and save model
- self.logger.info("...training the final model")
- self.config.setParam("train.model.save", "True")
- self.subSampleRate = None
- trainError = self.train()
- self.logger.info("training error in final model {:06.3f}".format(trainError))
-
- return status
-
-
-
diff --git a/spaces/TrustSafeAI/NCTV/assets/css/bootstrap/bootstrap.css b/spaces/TrustSafeAI/NCTV/assets/css/bootstrap/bootstrap.css
deleted file mode 100644
index f16c5be871a8daec535dbcdcf9db84b6c4d9df7e..0000000000000000000000000000000000000000
--- a/spaces/TrustSafeAI/NCTV/assets/css/bootstrap/bootstrap.css
+++ /dev/null
@@ -1,11266 +0,0 @@
-@charset "UTF-8";
-/*!
- * Bootstrap v5.1.3 (https://getbootstrap.com/)
- * Copyright 2011-2021 The Bootstrap Authors
- * Copyright 2011-2021 Twitter, Inc.
- * Licensed under MIT (https://github.com/twbs/bootstrap/blob/main/LICENSE)
- */
-:root {
- --bs-blue: #0d6efd;
- --bs-indigo: #6610f2;
- --bs-purple: #6f42c1;
- --bs-pink: #d63384;
- --bs-red: #dc3545;
- --bs-orange: #fd7e14;
- --bs-yellow: #ffc107;
- --bs-green: #198754;
- --bs-teal: #20c997;
- --bs-cyan: #0dcaf0;
- --bs-white: #fff;
- --bs-gray: #6c757d;
- --bs-gray-dark: #343a40;
- --bs-gray-100: #f8f9fa;
- --bs-gray-200: #e9ecef;
- --bs-gray-300: #dee2e6;
- --bs-gray-400: #ced4da;
- --bs-gray-500: #adb5bd;
- --bs-gray-600: #6c757d;
- --bs-gray-700: #495057;
- --bs-gray-800: #343a40;
- --bs-gray-900: #212529;
- --bs-primary: #0d6efd;
- --bs-secondary: #6c757d;
- --bs-success: #198754;
- --bs-info: #0dcaf0;
- --bs-warning: #ffc107;
- --bs-danger: #dc3545;
- --bs-light: #f8f9fa;
- --bs-dark: #212529;
- --bs-primary-rgb: 13, 110, 253;
- --bs-secondary-rgb: 108, 117, 125;
- --bs-success-rgb: 25, 135, 84;
- --bs-info-rgb: 13, 202, 240;
- --bs-warning-rgb: 255, 193, 7;
- --bs-danger-rgb: 220, 53, 69;
- --bs-light-rgb: 248, 249, 250;
- --bs-dark-rgb: 33, 37, 41;
- --bs-white-rgb: 255, 255, 255;
- --bs-black-rgb: 0, 0, 0;
- --bs-body-color-rgb: 33, 37, 41;
- --bs-body-bg-rgb: 255, 255, 255;
- --bs-font-sans-serif: system-ui, -apple-system, "Segoe UI", Roboto, "Helvetica Neue", Arial, "Noto Sans", "Liberation Sans", sans-serif, "Apple Color Emoji", "Segoe UI Emoji", "Segoe UI Symbol", "Noto Color Emoji";
- --bs-font-monospace: SFMono-Regular, Menlo, Monaco, Consolas, "Liberation Mono", "Courier New", monospace;
- --bs-gradient: linear-gradient(180deg, rgba(255, 255, 255, 0.15), rgba(255, 255, 255, 0));
- --bs-body-font-family: var(--bs-font-sans-serif);
- --bs-body-font-size: 1rem;
- --bs-body-font-weight: 400;
- --bs-body-line-height: 1.5;
- --bs-body-color: #212529;
- --bs-body-bg: #fff;
-}
-
-*,
-*::before,
-*::after {
- box-sizing: border-box;
-}
-
-@media (prefers-reduced-motion: no-preference) {
- :root {
- scroll-behavior: smooth;
- }
-}
-
-body {
- margin: 0;
- font-family: var(--bs-body-font-family);
- font-size: var(--bs-body-font-size);
- font-weight: var(--bs-body-font-weight);
- line-height: var(--bs-body-line-height);
- color: var(--bs-body-color);
- text-align: var(--bs-body-text-align);
- background-color: var(--bs-body-bg);
- -webkit-text-size-adjust: 100%;
- -webkit-tap-highlight-color: rgba(0, 0, 0, 0);
-}
-
-hr {
- margin: 1rem 0;
- color: inherit;
- background-color: currentColor;
- border: 0;
- opacity: 0.25;
-}
-
-hr:not([size]) {
- height: 1px;
-}
-
-h6, .h6, h5, .h5, h4, .h4, h3, .h3, h2, .h2, h1, .h1 {
- margin-top: 0;
- margin-bottom: 0.5rem;
- font-weight: 500;
- line-height: 1.2;
-}
-
-h1, .h1 {
- font-size: calc(1.375rem + 1.5vw);
-}
-@media (min-width: 1200px) {
- h1, .h1 {
- font-size: 2.5rem;
- }
-}
-
-h2, .h2 {
- font-size: calc(1.325rem + 0.9vw);
-}
-@media (min-width: 1200px) {
- h2, .h2 {
- font-size: 2rem;
- }
-}
-
-h3, .h3 {
- font-size: calc(1.3rem + 0.6vw);
-}
-@media (min-width: 1200px) {
- h3, .h3 {
- font-size: 1.75rem;
- }
-}
-
-h4, .h4 {
- font-size: calc(1.275rem + 0.3vw);
-}
-@media (min-width: 1200px) {
- h4, .h4 {
- font-size: 1.5rem;
- }
-}
-
-h5, .h5 {
- font-size: 1.25rem;
-}
-
-h6, .h6 {
- font-size: 1rem;
-}
-
-p {
- margin-top: 0;
- margin-bottom: 1rem;
-}
-
-abbr[title],
-abbr[data-bs-original-title] {
- -webkit-text-decoration: underline dotted;
- text-decoration: underline dotted;
- cursor: help;
- -webkit-text-decoration-skip-ink: none;
- text-decoration-skip-ink: none;
-}
-
-address {
- margin-bottom: 1rem;
- font-style: normal;
- line-height: inherit;
-}
-
-ol,
-ul {
- padding-left: 2rem;
-}
-
-ol,
-ul,
-dl {
- margin-top: 0;
- margin-bottom: 1rem;
-}
-
-ol ol,
-ul ul,
-ol ul,
-ul ol {
- margin-bottom: 0;
-}
-
-dt {
- font-weight: 700;
-}
-
-dd {
- margin-bottom: 0.5rem;
- margin-left: 0;
-}
-
-blockquote {
- margin: 0 0 1rem;
-}
-
-b,
-strong {
- font-weight: bolder;
-}
-
-small, .small {
- font-size: 0.875em;
-}
-
-mark, .mark {
- padding: 0.2em;
- background-color: #fcf8e3;
-}
-
-sub,
-sup {
- position: relative;
- font-size: 0.75em;
- line-height: 0;
- vertical-align: baseline;
-}
-
-sub {
- bottom: -0.25em;
-}
-
-sup {
- top: -0.5em;
-}
-
-a {
- color: #0d6efd;
- text-decoration: underline;
-}
-a:hover {
- color: #0a58ca;
-}
-
-a:not([href]):not([class]), a:not([href]):not([class]):hover {
- color: inherit;
- text-decoration: none;
-}
-
-pre,
-code,
-kbd,
-samp {
- font-family: var(--bs-font-monospace);
- font-size: 1em;
- direction: ltr /* rtl:ignore */;
- unicode-bidi: bidi-override;
-}
-
-pre {
- display: block;
- margin-top: 0;
- margin-bottom: 1rem;
- overflow: auto;
- font-size: 0.875em;
-}
-pre code {
- font-size: inherit;
- color: inherit;
- word-break: normal;
-}
-
-code {
- font-size: 0.875em;
- color: #d63384;
- word-wrap: break-word;
-}
-a > code {
- color: inherit;
-}
-
-kbd {
- padding: 0.2rem 0.4rem;
- font-size: 0.875em;
- color: #fff;
- background-color: #212529;
- border-radius: 0.2rem;
-}
-kbd kbd {
- padding: 0;
- font-size: 1em;
- font-weight: 700;
-}
-
-figure {
- margin: 0 0 1rem;
-}
-
-img,
-svg {
- vertical-align: middle;
-}
-
-table {
- caption-side: bottom;
- border-collapse: collapse;
-}
-
-caption {
- padding-top: 0.5rem;
- padding-bottom: 0.5rem;
- color: #6c757d;
- text-align: left;
-}
-
-th {
- text-align: inherit;
- text-align: -webkit-match-parent;
-}
-
-thead,
-tbody,
-tfoot,
-tr,
-td,
-th {
- border-color: inherit;
- border-style: solid;
- border-width: 0;
-}
-
-label {
- display: inline-block;
-}
-
-button {
- border-radius: 0;
-}
-
-button:focus:not(:focus-visible) {
- outline: 0;
-}
-
-input,
-button,
-select,
-optgroup,
-textarea {
- margin: 0;
- font-family: inherit;
- font-size: inherit;
- line-height: inherit;
-}
-
-button,
-select {
- text-transform: none;
-}
-
-[role=button] {
- cursor: pointer;
-}
-
-select {
- word-wrap: normal;
-}
-select:disabled {
- opacity: 1;
-}
-
-[list]::-webkit-calendar-picker-indicator {
- display: none;
-}
-
-button,
-[type=button],
-[type=reset],
-[type=submit] {
- -webkit-appearance: button;
-}
-button:not(:disabled),
-[type=button]:not(:disabled),
-[type=reset]:not(:disabled),
-[type=submit]:not(:disabled) {
- cursor: pointer;
-}
-
-::-moz-focus-inner {
- padding: 0;
- border-style: none;
-}
-
-textarea {
- resize: vertical;
-}
-
-fieldset {
- min-width: 0;
- padding: 0;
- margin: 0;
- border: 0;
-}
-
-legend {
- float: left;
- width: 100%;
- padding: 0;
- margin-bottom: 0.5rem;
- font-size: calc(1.275rem + 0.3vw);
- line-height: inherit;
-}
-@media (min-width: 1200px) {
- legend {
- font-size: 1.5rem;
- }
-}
-legend + * {
- clear: left;
-}
-
-::-webkit-datetime-edit-fields-wrapper,
-::-webkit-datetime-edit-text,
-::-webkit-datetime-edit-minute,
-::-webkit-datetime-edit-hour-field,
-::-webkit-datetime-edit-day-field,
-::-webkit-datetime-edit-month-field,
-::-webkit-datetime-edit-year-field {
- padding: 0;
-}
-
-::-webkit-inner-spin-button {
- height: auto;
-}
-
-[type=search] {
- outline-offset: -2px;
- -webkit-appearance: textfield;
-}
-
-/* rtl:raw:
-[type="tel"],
-[type="url"],
-[type="email"],
-[type="number"] {
- direction: ltr;
-}
-*/
-::-webkit-search-decoration {
- -webkit-appearance: none;
-}
-
-::-webkit-color-swatch-wrapper {
- padding: 0;
-}
-
-::-webkit-file-upload-button {
- font: inherit;
-}
-
-::file-selector-button {
- font: inherit;
-}
-
-::-webkit-file-upload-button {
- font: inherit;
- -webkit-appearance: button;
-}
-
-output {
- display: inline-block;
-}
-
-iframe {
- border: 0;
-}
-
-summary {
- display: list-item;
- cursor: pointer;
-}
-
-progress {
- vertical-align: baseline;
-}
-
-[hidden] {
- display: none !important;
-}
-
-.lead {
- font-size: 1.25rem;
- font-weight: 300;
-}
-
-.display-1 {
- font-size: calc(1.625rem + 4.5vw);
- font-weight: 300;
- line-height: 1.2;
-}
-@media (min-width: 1200px) {
- .display-1 {
- font-size: 5rem;
- }
-}
-
-.display-2 {
- font-size: calc(1.575rem + 3.9vw);
- font-weight: 300;
- line-height: 1.2;
-}
-@media (min-width: 1200px) {
- .display-2 {
- font-size: 4.5rem;
- }
-}
-
-.display-3 {
- font-size: calc(1.525rem + 3.3vw);
- font-weight: 300;
- line-height: 1.2;
-}
-@media (min-width: 1200px) {
- .display-3 {
- font-size: 4rem;
- }
-}
-
-.display-4 {
- font-size: calc(1.475rem + 2.7vw);
- font-weight: 300;
- line-height: 1.2;
-}
-@media (min-width: 1200px) {
- .display-4 {
- font-size: 3.5rem;
- }
-}
-
-.display-5 {
- font-size: calc(1.425rem + 2.1vw);
- font-weight: 300;
- line-height: 1.2;
-}
-@media (min-width: 1200px) {
- .display-5 {
- font-size: 3rem;
- }
-}
-
-.display-6 {
- font-size: calc(1.375rem + 1.5vw);
- font-weight: 300;
- line-height: 1.2;
-}
-@media (min-width: 1200px) {
- .display-6 {
- font-size: 2.5rem;
- }
-}
-
-.list-unstyled {
- padding-left: 0;
- list-style: none;
-}
-
-.list-inline {
- padding-left: 0;
- list-style: none;
-}
-
-.list-inline-item {
- display: inline-block;
-}
-.list-inline-item:not(:last-child) {
- margin-right: 0.5rem;
-}
-
-.initialism {
- font-size: 0.875em;
- text-transform: uppercase;
-}
-
-.blockquote {
- margin-bottom: 1rem;
- font-size: 1.25rem;
-}
-.blockquote > :last-child {
- margin-bottom: 0;
-}
-
-.blockquote-footer {
- margin-top: -1rem;
- margin-bottom: 1rem;
- font-size: 0.875em;
- color: #6c757d;
-}
-.blockquote-footer::before {
- content: "— ";
-}
-
-.img-fluid {
- max-width: 100%;
- height: auto;
-}
-
-.img-thumbnail {
- padding: 0.25rem;
- background-color: #fff;
- border: 1px solid #dee2e6;
- border-radius: 0.25rem;
- max-width: 100%;
- height: auto;
-}
-
-.figure {
- display: inline-block;
-}
-
-.figure-img {
- margin-bottom: 0.5rem;
- line-height: 1;
-}
-
-.figure-caption {
- font-size: 0.875em;
- color: #6c757d;
-}
-
-.container,
-.container-fluid,
-.container-xxl,
-.container-xl,
-.container-lg,
-.container-md,
-.container-sm {
- width: 100%;
- padding-right: var(--bs-gutter-x, 0.75rem);
- padding-left: var(--bs-gutter-x, 0.75rem);
- margin-right: auto;
- margin-left: auto;
-}
-
-@media (min-width: 576px) {
- .container-sm, .container {
- max-width: 540px;
- }
-}
-@media (min-width: 768px) {
- .container-md, .container-sm, .container {
- max-width: 720px;
- }
-}
-@media (min-width: 992px) {
- .container-lg, .container-md, .container-sm, .container {
- max-width: 960px;
- }
-}
-@media (min-width: 1200px) {
- .container-xl, .container-lg, .container-md, .container-sm, .container {
- max-width: 1140px;
- }
-}
-@media (min-width: 1400px) {
- .container-xxl, .container-xl, .container-lg, .container-md, .container-sm, .container {
- max-width: 1320px;
- }
-}
-.row {
- --bs-gutter-x: 1.5rem;
- --bs-gutter-y: 0;
- display: flex;
- flex-wrap: wrap;
- margin-top: calc(-1 * var(--bs-gutter-y));
- margin-right: calc(-0.5 * var(--bs-gutter-x));
- margin-left: calc(-0.5 * var(--bs-gutter-x));
-}
-.row > * {
- flex-shrink: 0;
- width: 100%;
- max-width: 100%;
- padding-right: calc(var(--bs-gutter-x) * 0.5);
- padding-left: calc(var(--bs-gutter-x) * 0.5);
- margin-top: var(--bs-gutter-y);
-}
-
-.col {
- flex: 1 0 0%;
-}
-
-.row-cols-auto > * {
- flex: 0 0 auto;
- width: auto;
-}
-
-.row-cols-1 > * {
- flex: 0 0 auto;
- width: 100%;
-}
-
-.row-cols-2 > * {
- flex: 0 0 auto;
- width: 50%;
-}
-
-.row-cols-3 > * {
- flex: 0 0 auto;
- width: 33.3333333333%;
-}
-
-.row-cols-4 > * {
- flex: 0 0 auto;
- width: 25%;
-}
-
-.row-cols-5 > * {
- flex: 0 0 auto;
- width: 20%;
-}
-
-.row-cols-6 > * {
- flex: 0 0 auto;
- width: 16.6666666667%;
-}
-
-.col-auto {
- flex: 0 0 auto;
- width: auto;
-}
-
-.col-1 {
- flex: 0 0 auto;
- width: 8.33333333%;
-}
-
-.col-2 {
- flex: 0 0 auto;
- width: 16.66666667%;
-}
-
-.col-3 {
- flex: 0 0 auto;
- width: 25%;
-}
-
-.col-4 {
- flex: 0 0 auto;
- width: 33.33333333%;
-}
-
-.col-5 {
- flex: 0 0 auto;
- width: 41.66666667%;
-}
-
-.col-6 {
- flex: 0 0 auto;
- width: 50%;
-}
-
-.col-7 {
- flex: 0 0 auto;
- width: 58.33333333%;
-}
-
-.col-8 {
- flex: 0 0 auto;
- width: 66.66666667%;
-}
-
-.col-9 {
- flex: 0 0 auto;
- width: 75%;
-}
-
-.col-10 {
- flex: 0 0 auto;
- width: 83.33333333%;
-}
-
-.col-11 {
- flex: 0 0 auto;
- width: 91.66666667%;
-}
-
-.col-12 {
- flex: 0 0 auto;
- width: 100%;
-}
-
-.offset-1 {
- margin-left: 8.33333333%;
-}
-
-.offset-2 {
- margin-left: 16.66666667%;
-}
-
-.offset-3 {
- margin-left: 25%;
-}
-
-.offset-4 {
- margin-left: 33.33333333%;
-}
-
-.offset-5 {
- margin-left: 41.66666667%;
-}
-
-.offset-6 {
- margin-left: 50%;
-}
-
-.offset-7 {
- margin-left: 58.33333333%;
-}
-
-.offset-8 {
- margin-left: 66.66666667%;
-}
-
-.offset-9 {
- margin-left: 75%;
-}
-
-.offset-10 {
- margin-left: 83.33333333%;
-}
-
-.offset-11 {
- margin-left: 91.66666667%;
-}
-
-.g-0,
-.gx-0 {
- --bs-gutter-x: 0;
-}
-
-.g-0,
-.gy-0 {
- --bs-gutter-y: 0;
-}
-
-.g-1,
-.gx-1 {
- --bs-gutter-x: 0.25rem;
-}
-
-.g-1,
-.gy-1 {
- --bs-gutter-y: 0.25rem;
-}
-
-.g-2,
-.gx-2 {
- --bs-gutter-x: 0.5rem;
-}
-
-.g-2,
-.gy-2 {
- --bs-gutter-y: 0.5rem;
-}
-
-.g-3,
-.gx-3 {
- --bs-gutter-x: 1rem;
-}
-
-.g-3,
-.gy-3 {
- --bs-gutter-y: 1rem;
-}
-
-.g-4,
-.gx-4 {
- --bs-gutter-x: 1.5rem;
-}
-
-.g-4,
-.gy-4 {
- --bs-gutter-y: 1.5rem;
-}
-
-.g-5,
-.gx-5 {
- --bs-gutter-x: 3rem;
-}
-
-.g-5,
-.gy-5 {
- --bs-gutter-y: 3rem;
-}
-
-@media (min-width: 576px) {
- .col-sm {
- flex: 1 0 0%;
- }
-
- .row-cols-sm-auto > * {
- flex: 0 0 auto;
- width: auto;
- }
-
- .row-cols-sm-1 > * {
- flex: 0 0 auto;
- width: 100%;
- }
-
- .row-cols-sm-2 > * {
- flex: 0 0 auto;
- width: 50%;
- }
-
- .row-cols-sm-3 > * {
- flex: 0 0 auto;
- width: 33.3333333333%;
- }
-
- .row-cols-sm-4 > * {
- flex: 0 0 auto;
- width: 25%;
- }
-
- .row-cols-sm-5 > * {
- flex: 0 0 auto;
- width: 20%;
- }
-
- .row-cols-sm-6 > * {
- flex: 0 0 auto;
- width: 16.6666666667%;
- }
-
- .col-sm-auto {
- flex: 0 0 auto;
- width: auto;
- }
-
- .col-sm-1 {
- flex: 0 0 auto;
- width: 8.33333333%;
- }
-
- .col-sm-2 {
- flex: 0 0 auto;
- width: 16.66666667%;
- }
-
- .col-sm-3 {
- flex: 0 0 auto;
- width: 25%;
- }
-
- .col-sm-4 {
- flex: 0 0 auto;
- width: 33.33333333%;
- }
-
- .col-sm-5 {
- flex: 0 0 auto;
- width: 41.66666667%;
- }
-
- .col-sm-6 {
- flex: 0 0 auto;
- width: 50%;
- }
-
- .col-sm-7 {
- flex: 0 0 auto;
- width: 58.33333333%;
- }
-
- .col-sm-8 {
- flex: 0 0 auto;
- width: 66.66666667%;
- }
-
- .col-sm-9 {
- flex: 0 0 auto;
- width: 75%;
- }
-
- .col-sm-10 {
- flex: 0 0 auto;
- width: 83.33333333%;
- }
-
- .col-sm-11 {
- flex: 0 0 auto;
- width: 91.66666667%;
- }
-
- .col-sm-12 {
- flex: 0 0 auto;
- width: 100%;
- }
-
- .offset-sm-0 {
- margin-left: 0;
- }
-
- .offset-sm-1 {
- margin-left: 8.33333333%;
- }
-
- .offset-sm-2 {
- margin-left: 16.66666667%;
- }
-
- .offset-sm-3 {
- margin-left: 25%;
- }
-
- .offset-sm-4 {
- margin-left: 33.33333333%;
- }
-
- .offset-sm-5 {
- margin-left: 41.66666667%;
- }
-
- .offset-sm-6 {
- margin-left: 50%;
- }
-
- .offset-sm-7 {
- margin-left: 58.33333333%;
- }
-
- .offset-sm-8 {
- margin-left: 66.66666667%;
- }
-
- .offset-sm-9 {
- margin-left: 75%;
- }
-
- .offset-sm-10 {
- margin-left: 83.33333333%;
- }
-
- .offset-sm-11 {
- margin-left: 91.66666667%;
- }
-
- .g-sm-0,
-.gx-sm-0 {
- --bs-gutter-x: 0;
- }
-
- .g-sm-0,
-.gy-sm-0 {
- --bs-gutter-y: 0;
- }
-
- .g-sm-1,
-.gx-sm-1 {
- --bs-gutter-x: 0.25rem;
- }
-
- .g-sm-1,
-.gy-sm-1 {
- --bs-gutter-y: 0.25rem;
- }
-
- .g-sm-2,
-.gx-sm-2 {
- --bs-gutter-x: 0.5rem;
- }
-
- .g-sm-2,
-.gy-sm-2 {
- --bs-gutter-y: 0.5rem;
- }
-
- .g-sm-3,
-.gx-sm-3 {
- --bs-gutter-x: 1rem;
- }
-
- .g-sm-3,
-.gy-sm-3 {
- --bs-gutter-y: 1rem;
- }
-
- .g-sm-4,
-.gx-sm-4 {
- --bs-gutter-x: 1.5rem;
- }
-
- .g-sm-4,
-.gy-sm-4 {
- --bs-gutter-y: 1.5rem;
- }
-
- .g-sm-5,
-.gx-sm-5 {
- --bs-gutter-x: 3rem;
- }
-
- .g-sm-5,
-.gy-sm-5 {
- --bs-gutter-y: 3rem;
- }
-}
-@media (min-width: 768px) {
- .col-md {
- flex: 1 0 0%;
- }
-
- .row-cols-md-auto > * {
- flex: 0 0 auto;
- width: auto;
- }
-
- .row-cols-md-1 > * {
- flex: 0 0 auto;
- width: 100%;
- }
-
- .row-cols-md-2 > * {
- flex: 0 0 auto;
- width: 50%;
- }
-
- .row-cols-md-3 > * {
- flex: 0 0 auto;
- width: 33.3333333333%;
- }
-
- .row-cols-md-4 > * {
- flex: 0 0 auto;
- width: 25%;
- }
-
- .row-cols-md-5 > * {
- flex: 0 0 auto;
- width: 20%;
- }
-
- .row-cols-md-6 > * {
- flex: 0 0 auto;
- width: 16.6666666667%;
- }
-
- .col-md-auto {
- flex: 0 0 auto;
- width: auto;
- }
-
- .col-md-1 {
- flex: 0 0 auto;
- width: 8.33333333%;
- }
-
- .col-md-2 {
- flex: 0 0 auto;
- width: 16.66666667%;
- }
-
- .col-md-3 {
- flex: 0 0 auto;
- width: 25%;
- }
-
- .col-md-4 {
- flex: 0 0 auto;
- width: 33.33333333%;
- }
-
- .col-md-5 {
- flex: 0 0 auto;
- width: 41.66666667%;
- }
-
- .col-md-6 {
- flex: 0 0 auto;
- width: 50%;
- }
-
- .col-md-7 {
- flex: 0 0 auto;
- width: 58.33333333%;
- }
-
- .col-md-8 {
- flex: 0 0 auto;
- width: 66.66666667%;
- }
-
- .col-md-9 {
- flex: 0 0 auto;
- width: 75%;
- }
-
- .col-md-10 {
- flex: 0 0 auto;
- width: 83.33333333%;
- }
-
- .col-md-11 {
- flex: 0 0 auto;
- width: 91.66666667%;
- }
-
- .col-md-12 {
- flex: 0 0 auto;
- width: 100%;
- }
-
- .offset-md-0 {
- margin-left: 0;
- }
-
- .offset-md-1 {
- margin-left: 8.33333333%;
- }
-
- .offset-md-2 {
- margin-left: 16.66666667%;
- }
-
- .offset-md-3 {
- margin-left: 25%;
- }
-
- .offset-md-4 {
- margin-left: 33.33333333%;
- }
-
- .offset-md-5 {
- margin-left: 41.66666667%;
- }
-
- .offset-md-6 {
- margin-left: 50%;
- }
-
- .offset-md-7 {
- margin-left: 58.33333333%;
- }
-
- .offset-md-8 {
- margin-left: 66.66666667%;
- }
-
- .offset-md-9 {
- margin-left: 75%;
- }
-
- .offset-md-10 {
- margin-left: 83.33333333%;
- }
-
- .offset-md-11 {
- margin-left: 91.66666667%;
- }
-
- .g-md-0,
-.gx-md-0 {
- --bs-gutter-x: 0;
- }
-
- .g-md-0,
-.gy-md-0 {
- --bs-gutter-y: 0;
- }
-
- .g-md-1,
-.gx-md-1 {
- --bs-gutter-x: 0.25rem;
- }
-
- .g-md-1,
-.gy-md-1 {
- --bs-gutter-y: 0.25rem;
- }
-
- .g-md-2,
-.gx-md-2 {
- --bs-gutter-x: 0.5rem;
- }
-
- .g-md-2,
-.gy-md-2 {
- --bs-gutter-y: 0.5rem;
- }
-
- .g-md-3,
-.gx-md-3 {
- --bs-gutter-x: 1rem;
- }
-
- .g-md-3,
-.gy-md-3 {
- --bs-gutter-y: 1rem;
- }
-
- .g-md-4,
-.gx-md-4 {
- --bs-gutter-x: 1.5rem;
- }
-
- .g-md-4,
-.gy-md-4 {
- --bs-gutter-y: 1.5rem;
- }
-
- .g-md-5,
-.gx-md-5 {
- --bs-gutter-x: 3rem;
- }
-
- .g-md-5,
-.gy-md-5 {
- --bs-gutter-y: 3rem;
- }
-}
-@media (min-width: 992px) {
- .col-lg {
- flex: 1 0 0%;
- }
-
- .row-cols-lg-auto > * {
- flex: 0 0 auto;
- width: auto;
- }
-
- .row-cols-lg-1 > * {
- flex: 0 0 auto;
- width: 100%;
- }
-
- .row-cols-lg-2 > * {
- flex: 0 0 auto;
- width: 50%;
- }
-
- .row-cols-lg-3 > * {
- flex: 0 0 auto;
- width: 33.3333333333%;
- }
-
- .row-cols-lg-4 > * {
- flex: 0 0 auto;
- width: 25%;
- }
-
- .row-cols-lg-5 > * {
- flex: 0 0 auto;
- width: 20%;
- }
-
- .row-cols-lg-6 > * {
- flex: 0 0 auto;
- width: 16.6666666667%;
- }
-
- .col-lg-auto {
- flex: 0 0 auto;
- width: auto;
- }
-
- .col-lg-1 {
- flex: 0 0 auto;
- width: 8.33333333%;
- }
-
- .col-lg-2 {
- flex: 0 0 auto;
- width: 16.66666667%;
- }
-
- .col-lg-3 {
- flex: 0 0 auto;
- width: 25%;
- }
-
- .col-lg-4 {
- flex: 0 0 auto;
- width: 33.33333333%;
- }
-
- .col-lg-5 {
- flex: 0 0 auto;
- width: 41.66666667%;
- }
-
- .col-lg-6 {
- flex: 0 0 auto;
- width: 50%;
- }
-
- .col-lg-7 {
- flex: 0 0 auto;
- width: 58.33333333%;
- }
-
- .col-lg-8 {
- flex: 0 0 auto;
- width: 66.66666667%;
- }
-
- .col-lg-9 {
- flex: 0 0 auto;
- width: 75%;
- }
-
- .col-lg-10 {
- flex: 0 0 auto;
- width: 83.33333333%;
- }
-
- .col-lg-11 {
- flex: 0 0 auto;
- width: 91.66666667%;
- }
-
- .col-lg-12 {
- flex: 0 0 auto;
- width: 100%;
- }
-
- .offset-lg-0 {
- margin-left: 0;
- }
-
- .offset-lg-1 {
- margin-left: 8.33333333%;
- }
-
- .offset-lg-2 {
- margin-left: 16.66666667%;
- }
-
- .offset-lg-3 {
- margin-left: 25%;
- }
-
- .offset-lg-4 {
- margin-left: 33.33333333%;
- }
-
- .offset-lg-5 {
- margin-left: 41.66666667%;
- }
-
- .offset-lg-6 {
- margin-left: 50%;
- }
-
- .offset-lg-7 {
- margin-left: 58.33333333%;
- }
-
- .offset-lg-8 {
- margin-left: 66.66666667%;
- }
-
- .offset-lg-9 {
- margin-left: 75%;
- }
-
- .offset-lg-10 {
- margin-left: 83.33333333%;
- }
-
- .offset-lg-11 {
- margin-left: 91.66666667%;
- }
-
- .g-lg-0,
-.gx-lg-0 {
- --bs-gutter-x: 0;
- }
-
- .g-lg-0,
-.gy-lg-0 {
- --bs-gutter-y: 0;
- }
-
- .g-lg-1,
-.gx-lg-1 {
- --bs-gutter-x: 0.25rem;
- }
-
- .g-lg-1,
-.gy-lg-1 {
- --bs-gutter-y: 0.25rem;
- }
-
- .g-lg-2,
-.gx-lg-2 {
- --bs-gutter-x: 0.5rem;
- }
-
- .g-lg-2,
-.gy-lg-2 {
- --bs-gutter-y: 0.5rem;
- }
-
- .g-lg-3,
-.gx-lg-3 {
- --bs-gutter-x: 1rem;
- }
-
- .g-lg-3,
-.gy-lg-3 {
- --bs-gutter-y: 1rem;
- }
-
- .g-lg-4,
-.gx-lg-4 {
- --bs-gutter-x: 1.5rem;
- }
-
- .g-lg-4,
-.gy-lg-4 {
- --bs-gutter-y: 1.5rem;
- }
-
- .g-lg-5,
-.gx-lg-5 {
- --bs-gutter-x: 3rem;
- }
-
- .g-lg-5,
-.gy-lg-5 {
- --bs-gutter-y: 3rem;
- }
-}
-@media (min-width: 1200px) {
- .col-xl {
- flex: 1 0 0%;
- }
-
- .row-cols-xl-auto > * {
- flex: 0 0 auto;
- width: auto;
- }
-
- .row-cols-xl-1 > * {
- flex: 0 0 auto;
- width: 100%;
- }
-
- .row-cols-xl-2 > * {
- flex: 0 0 auto;
- width: 50%;
- }
-
- .row-cols-xl-3 > * {
- flex: 0 0 auto;
- width: 33.3333333333%;
- }
-
- .row-cols-xl-4 > * {
- flex: 0 0 auto;
- width: 25%;
- }
-
- .row-cols-xl-5 > * {
- flex: 0 0 auto;
- width: 20%;
- }
-
- .row-cols-xl-6 > * {
- flex: 0 0 auto;
- width: 16.6666666667%;
- }
-
- .col-xl-auto {
- flex: 0 0 auto;
- width: auto;
- }
-
- .col-xl-1 {
- flex: 0 0 auto;
- width: 8.33333333%;
- }
-
- .col-xl-2 {
- flex: 0 0 auto;
- width: 16.66666667%;
- }
-
- .col-xl-3 {
- flex: 0 0 auto;
- width: 25%;
- }
-
- .col-xl-4 {
- flex: 0 0 auto;
- width: 33.33333333%;
- }
-
- .col-xl-5 {
- flex: 0 0 auto;
- width: 41.66666667%;
- }
-
- .col-xl-6 {
- flex: 0 0 auto;
- width: 50%;
- }
-
- .col-xl-7 {
- flex: 0 0 auto;
- width: 58.33333333%;
- }
-
- .col-xl-8 {
- flex: 0 0 auto;
- width: 66.66666667%;
- }
-
- .col-xl-9 {
- flex: 0 0 auto;
- width: 75%;
- }
-
- .col-xl-10 {
- flex: 0 0 auto;
- width: 83.33333333%;
- }
-
- .col-xl-11 {
- flex: 0 0 auto;
- width: 91.66666667%;
- }
-
- .col-xl-12 {
- flex: 0 0 auto;
- width: 100%;
- }
-
- .offset-xl-0 {
- margin-left: 0;
- }
-
- .offset-xl-1 {
- margin-left: 8.33333333%;
- }
-
- .offset-xl-2 {
- margin-left: 16.66666667%;
- }
-
- .offset-xl-3 {
- margin-left: 25%;
- }
-
- .offset-xl-4 {
- margin-left: 33.33333333%;
- }
-
- .offset-xl-5 {
- margin-left: 41.66666667%;
- }
-
- .offset-xl-6 {
- margin-left: 50%;
- }
-
- .offset-xl-7 {
- margin-left: 58.33333333%;
- }
-
- .offset-xl-8 {
- margin-left: 66.66666667%;
- }
-
- .offset-xl-9 {
- margin-left: 75%;
- }
-
- .offset-xl-10 {
- margin-left: 83.33333333%;
- }
-
- .offset-xl-11 {
- margin-left: 91.66666667%;
- }
-
- .g-xl-0,
-.gx-xl-0 {
- --bs-gutter-x: 0;
- }
-
- .g-xl-0,
-.gy-xl-0 {
- --bs-gutter-y: 0;
- }
-
- .g-xl-1,
-.gx-xl-1 {
- --bs-gutter-x: 0.25rem;
- }
-
- .g-xl-1,
-.gy-xl-1 {
- --bs-gutter-y: 0.25rem;
- }
-
- .g-xl-2,
-.gx-xl-2 {
- --bs-gutter-x: 0.5rem;
- }
-
- .g-xl-2,
-.gy-xl-2 {
- --bs-gutter-y: 0.5rem;
- }
-
- .g-xl-3,
-.gx-xl-3 {
- --bs-gutter-x: 1rem;
- }
-
- .g-xl-3,
-.gy-xl-3 {
- --bs-gutter-y: 1rem;
- }
-
- .g-xl-4,
-.gx-xl-4 {
- --bs-gutter-x: 1.5rem;
- }
-
- .g-xl-4,
-.gy-xl-4 {
- --bs-gutter-y: 1.5rem;
- }
-
- .g-xl-5,
-.gx-xl-5 {
- --bs-gutter-x: 3rem;
- }
-
- .g-xl-5,
-.gy-xl-5 {
- --bs-gutter-y: 3rem;
- }
-}
-@media (min-width: 1400px) {
- .col-xxl {
- flex: 1 0 0%;
- }
-
- .row-cols-xxl-auto > * {
- flex: 0 0 auto;
- width: auto;
- }
-
- .row-cols-xxl-1 > * {
- flex: 0 0 auto;
- width: 100%;
- }
-
- .row-cols-xxl-2 > * {
- flex: 0 0 auto;
- width: 50%;
- }
-
- .row-cols-xxl-3 > * {
- flex: 0 0 auto;
- width: 33.3333333333%;
- }
-
- .row-cols-xxl-4 > * {
- flex: 0 0 auto;
- width: 25%;
- }
-
- .row-cols-xxl-5 > * {
- flex: 0 0 auto;
- width: 20%;
- }
-
- .row-cols-xxl-6 > * {
- flex: 0 0 auto;
- width: 16.6666666667%;
- }
-
- .col-xxl-auto {
- flex: 0 0 auto;
- width: auto;
- }
-
- .col-xxl-1 {
- flex: 0 0 auto;
- width: 8.33333333%;
- }
-
- .col-xxl-2 {
- flex: 0 0 auto;
- width: 16.66666667%;
- }
-
- .col-xxl-3 {
- flex: 0 0 auto;
- width: 25%;
- }
-
- .col-xxl-4 {
- flex: 0 0 auto;
- width: 33.33333333%;
- }
-
- .col-xxl-5 {
- flex: 0 0 auto;
- width: 41.66666667%;
- }
-
- .col-xxl-6 {
- flex: 0 0 auto;
- width: 50%;
- }
-
- .col-xxl-7 {
- flex: 0 0 auto;
- width: 58.33333333%;
- }
-
- .col-xxl-8 {
- flex: 0 0 auto;
- width: 66.66666667%;
- }
-
- .col-xxl-9 {
- flex: 0 0 auto;
- width: 75%;
- }
-
- .col-xxl-10 {
- flex: 0 0 auto;
- width: 83.33333333%;
- }
-
- .col-xxl-11 {
- flex: 0 0 auto;
- width: 91.66666667%;
- }
-
- .col-xxl-12 {
- flex: 0 0 auto;
- width: 100%;
- }
-
- .offset-xxl-0 {
- margin-left: 0;
- }
-
- .offset-xxl-1 {
- margin-left: 8.33333333%;
- }
-
- .offset-xxl-2 {
- margin-left: 16.66666667%;
- }
-
- .offset-xxl-3 {
- margin-left: 25%;
- }
-
- .offset-xxl-4 {
- margin-left: 33.33333333%;
- }
-
- .offset-xxl-5 {
- margin-left: 41.66666667%;
- }
-
- .offset-xxl-6 {
- margin-left: 50%;
- }
-
- .offset-xxl-7 {
- margin-left: 58.33333333%;
- }
-
- .offset-xxl-8 {
- margin-left: 66.66666667%;
- }
-
- .offset-xxl-9 {
- margin-left: 75%;
- }
-
- .offset-xxl-10 {
- margin-left: 83.33333333%;
- }
-
- .offset-xxl-11 {
- margin-left: 91.66666667%;
- }
-
- .g-xxl-0,
-.gx-xxl-0 {
- --bs-gutter-x: 0;
- }
-
- .g-xxl-0,
-.gy-xxl-0 {
- --bs-gutter-y: 0;
- }
-
- .g-xxl-1,
-.gx-xxl-1 {
- --bs-gutter-x: 0.25rem;
- }
-
- .g-xxl-1,
-.gy-xxl-1 {
- --bs-gutter-y: 0.25rem;
- }
-
- .g-xxl-2,
-.gx-xxl-2 {
- --bs-gutter-x: 0.5rem;
- }
-
- .g-xxl-2,
-.gy-xxl-2 {
- --bs-gutter-y: 0.5rem;
- }
-
- .g-xxl-3,
-.gx-xxl-3 {
- --bs-gutter-x: 1rem;
- }
-
- .g-xxl-3,
-.gy-xxl-3 {
- --bs-gutter-y: 1rem;
- }
-
- .g-xxl-4,
-.gx-xxl-4 {
- --bs-gutter-x: 1.5rem;
- }
-
- .g-xxl-4,
-.gy-xxl-4 {
- --bs-gutter-y: 1.5rem;
- }
-
- .g-xxl-5,
-.gx-xxl-5 {
- --bs-gutter-x: 3rem;
- }
-
- .g-xxl-5,
-.gy-xxl-5 {
- --bs-gutter-y: 3rem;
- }
-}
-.table {
- --bs-table-bg: transparent;
- --bs-table-accent-bg: transparent;
- --bs-table-striped-color: #212529;
- --bs-table-striped-bg: rgba(0, 0, 0, 0.05);
- --bs-table-active-color: #212529;
- --bs-table-active-bg: rgba(0, 0, 0, 0.1);
- --bs-table-hover-color: #212529;
- --bs-table-hover-bg: rgba(0, 0, 0, 0.075);
- width: 100%;
- margin-bottom: 1rem;
- color: #212529;
- vertical-align: top;
- border-color: #dee2e6;
-}
-.table > :not(caption) > * > * {
- padding: 0.5rem 0.5rem;
- background-color: var(--bs-table-bg);
- border-bottom-width: 1px;
- box-shadow: inset 0 0 0 9999px var(--bs-table-accent-bg);
-}
-.table > tbody {
- vertical-align: inherit;
-}
-.table > thead {
- vertical-align: bottom;
-}
-.table > :not(:first-child) {
- border-top: 2px solid currentColor;
-}
-
-.caption-top {
- caption-side: top;
-}
-
-.table-sm > :not(caption) > * > * {
- padding: 0.25rem 0.25rem;
-}
-
-.table-bordered > :not(caption) > * {
- border-width: 1px 0;
-}
-.table-bordered > :not(caption) > * > * {
- border-width: 0 1px;
-}
-
-.table-borderless > :not(caption) > * > * {
- border-bottom-width: 0;
-}
-.table-borderless > :not(:first-child) {
- border-top-width: 0;
-}
-
-.table-striped > tbody > tr:nth-of-type(odd) > * {
- --bs-table-accent-bg: var(--bs-table-striped-bg);
- color: var(--bs-table-striped-color);
-}
-
-.table-active {
- --bs-table-accent-bg: var(--bs-table-active-bg);
- color: var(--bs-table-active-color);
-}
-
-.table-hover > tbody > tr:hover > * {
- --bs-table-accent-bg: var(--bs-table-hover-bg);
- color: var(--bs-table-hover-color);
-}
-
-.table-primary {
- --bs-table-bg: #cfe2ff;
- --bs-table-striped-bg: #c5d7f2;
- --bs-table-striped-color: #000;
- --bs-table-active-bg: #bacbe6;
- --bs-table-active-color: #000;
- --bs-table-hover-bg: #bfd1ec;
- --bs-table-hover-color: #000;
- color: #000;
- border-color: #bacbe6;
-}
-
-.table-secondary {
- --bs-table-bg: #e2e3e5;
- --bs-table-striped-bg: #d7d8da;
- --bs-table-striped-color: #000;
- --bs-table-active-bg: #cbccce;
- --bs-table-active-color: #000;
- --bs-table-hover-bg: #d1d2d4;
- --bs-table-hover-color: #000;
- color: #000;
- border-color: #cbccce;
-}
-
-.table-success {
- --bs-table-bg: #d1e7dd;
- --bs-table-striped-bg: #c7dbd2;
- --bs-table-striped-color: #000;
- --bs-table-active-bg: #bcd0c7;
- --bs-table-active-color: #000;
- --bs-table-hover-bg: #c1d6cc;
- --bs-table-hover-color: #000;
- color: #000;
- border-color: #bcd0c7;
-}
-
-.table-info {
- --bs-table-bg: #cff4fc;
- --bs-table-striped-bg: #c5e8ef;
- --bs-table-striped-color: #000;
- --bs-table-active-bg: #badce3;
- --bs-table-active-color: #000;
- --bs-table-hover-bg: #bfe2e9;
- --bs-table-hover-color: #000;
- color: #000;
- border-color: #badce3;
-}
-
-.table-warning {
- --bs-table-bg: #fff3cd;
- --bs-table-striped-bg: #f2e7c3;
- --bs-table-striped-color: #000;
- --bs-table-active-bg: #e6dbb9;
- --bs-table-active-color: #000;
- --bs-table-hover-bg: #ece1be;
- --bs-table-hover-color: #000;
- color: #000;
- border-color: #e6dbb9;
-}
-
-.table-danger {
- --bs-table-bg: #f8d7da;
- --bs-table-striped-bg: #eccccf;
- --bs-table-striped-color: #000;
- --bs-table-active-bg: #dfc2c4;
- --bs-table-active-color: #000;
- --bs-table-hover-bg: #e5c7ca;
- --bs-table-hover-color: #000;
- color: #000;
- border-color: #dfc2c4;
-}
-
-.table-light {
- --bs-table-bg: #f8f9fa;
- --bs-table-striped-bg: #ecedee;
- --bs-table-striped-color: #000;
- --bs-table-active-bg: #dfe0e1;
- --bs-table-active-color: #000;
- --bs-table-hover-bg: #e5e6e7;
- --bs-table-hover-color: #000;
- color: #000;
- border-color: #dfe0e1;
-}
-
-.table-dark {
- --bs-table-bg: #212529;
- --bs-table-striped-bg: #2c3034;
- --bs-table-striped-color: #fff;
- --bs-table-active-bg: #373b3e;
- --bs-table-active-color: #fff;
- --bs-table-hover-bg: #323539;
- --bs-table-hover-color: #fff;
- color: #fff;
- border-color: #373b3e;
-}
-
-.table-responsive {
- overflow-x: auto;
- -webkit-overflow-scrolling: touch;
-}
-
-@media (max-width: 575.98px) {
- .table-responsive-sm {
- overflow-x: auto;
- -webkit-overflow-scrolling: touch;
- }
-}
-@media (max-width: 767.98px) {
- .table-responsive-md {
- overflow-x: auto;
- -webkit-overflow-scrolling: touch;
- }
-}
-@media (max-width: 991.98px) {
- .table-responsive-lg {
- overflow-x: auto;
- -webkit-overflow-scrolling: touch;
- }
-}
-@media (max-width: 1199.98px) {
- .table-responsive-xl {
- overflow-x: auto;
- -webkit-overflow-scrolling: touch;
- }
-}
-@media (max-width: 1399.98px) {
- .table-responsive-xxl {
- overflow-x: auto;
- -webkit-overflow-scrolling: touch;
- }
-}
-.form-label {
- margin-bottom: 0.5rem;
-}
-
-.col-form-label {
- padding-top: calc(0.375rem + 1px);
- padding-bottom: calc(0.375rem + 1px);
- margin-bottom: 0;
- font-size: inherit;
- line-height: 1.5;
-}
-
-.col-form-label-lg {
- padding-top: calc(0.5rem + 1px);
- padding-bottom: calc(0.5rem + 1px);
- font-size: 1.25rem;
-}
-
-.col-form-label-sm {
- padding-top: calc(0.25rem + 1px);
- padding-bottom: calc(0.25rem + 1px);
- font-size: 0.875rem;
-}
-
-.form-text {
- margin-top: 0.25rem;
- font-size: 0.875em;
- color: #6c757d;
-}
-
-.form-control {
- display: block;
- width: 100%;
- padding: 0.375rem 0.75rem;
- font-size: 1rem;
- font-weight: 400;
- line-height: 1.5;
- color: #212529;
- background-color: #fff;
- background-clip: padding-box;
- border: 1px solid #ced4da;
- -webkit-appearance: none;
- -moz-appearance: none;
- appearance: none;
- border-radius: 0.25rem;
- transition: border-color 0.15s ease-in-out, box-shadow 0.15s ease-in-out;
-}
-@media (prefers-reduced-motion: reduce) {
- .form-control {
- transition: none;
- }
-}
-.form-control[type=file] {
- overflow: hidden;
-}
-.form-control[type=file]:not(:disabled):not([readonly]) {
- cursor: pointer;
-}
-.form-control:focus {
- color: #212529;
- background-color: #fff;
- border-color: #86b7fe;
- outline: 0;
- box-shadow: 0 0 0 0.25rem rgba(13, 110, 253, 0.25);
-}
-.form-control::-webkit-date-and-time-value {
- height: 1.5em;
-}
-.form-control::-moz-placeholder {
- color: #6c757d;
- opacity: 1;
-}
-.form-control::placeholder {
- color: #6c757d;
- opacity: 1;
-}
-.form-control:disabled, .form-control[readonly] {
- background-color: #e9ecef;
- opacity: 1;
-}
-.form-control::-webkit-file-upload-button {
- padding: 0.375rem 0.75rem;
- margin: -0.375rem -0.75rem;
- -webkit-margin-end: 0.75rem;
- margin-inline-end: 0.75rem;
- color: #212529;
- background-color: #e9ecef;
- pointer-events: none;
- border-color: inherit;
- border-style: solid;
- border-width: 0;
- border-inline-end-width: 1px;
- border-radius: 0;
- -webkit-transition: color 0.15s ease-in-out, background-color 0.15s ease-in-out, border-color 0.15s ease-in-out, box-shadow 0.15s ease-in-out;
- transition: color 0.15s ease-in-out, background-color 0.15s ease-in-out, border-color 0.15s ease-in-out, box-shadow 0.15s ease-in-out;
-}
-.form-control::file-selector-button {
- padding: 0.375rem 0.75rem;
- margin: -0.375rem -0.75rem;
- -webkit-margin-end: 0.75rem;
- margin-inline-end: 0.75rem;
- color: #212529;
- background-color: #e9ecef;
- pointer-events: none;
- border-color: inherit;
- border-style: solid;
- border-width: 0;
- border-inline-end-width: 1px;
- border-radius: 0;
- transition: color 0.15s ease-in-out, background-color 0.15s ease-in-out, border-color 0.15s ease-in-out, box-shadow 0.15s ease-in-out;
-}
-@media (prefers-reduced-motion: reduce) {
- .form-control::-webkit-file-upload-button {
- -webkit-transition: none;
- transition: none;
- }
- .form-control::file-selector-button {
- transition: none;
- }
-}
-.form-control:hover:not(:disabled):not([readonly])::-webkit-file-upload-button {
- background-color: #dde0e3;
-}
-.form-control:hover:not(:disabled):not([readonly])::file-selector-button {
- background-color: #dde0e3;
-}
-.form-control::-webkit-file-upload-button {
- padding: 0.375rem 0.75rem;
- margin: -0.375rem -0.75rem;
- -webkit-margin-end: 0.75rem;
- margin-inline-end: 0.75rem;
- color: #212529;
- background-color: #e9ecef;
- pointer-events: none;
- border-color: inherit;
- border-style: solid;
- border-width: 0;
- border-inline-end-width: 1px;
- border-radius: 0;
- -webkit-transition: color 0.15s ease-in-out, background-color 0.15s ease-in-out, border-color 0.15s ease-in-out, box-shadow 0.15s ease-in-out;
- transition: color 0.15s ease-in-out, background-color 0.15s ease-in-out, border-color 0.15s ease-in-out, box-shadow 0.15s ease-in-out;
-}
-@media (prefers-reduced-motion: reduce) {
- .form-control::-webkit-file-upload-button {
- -webkit-transition: none;
- transition: none;
- }
-}
-.form-control:hover:not(:disabled):not([readonly])::-webkit-file-upload-button {
- background-color: #dde0e3;
-}
-
-.form-control-plaintext {
- display: block;
- width: 100%;
- padding: 0.375rem 0;
- margin-bottom: 0;
- line-height: 1.5;
- color: #212529;
- background-color: transparent;
- border: solid transparent;
- border-width: 1px 0;
-}
-.form-control-plaintext.form-control-sm, .form-control-plaintext.form-control-lg {
- padding-right: 0;
- padding-left: 0;
-}
-
-.form-control-sm {
- min-height: calc(1.5em + 0.5rem + 2px);
- padding: 0.25rem 0.5rem;
- font-size: 0.875rem;
- border-radius: 0.2rem;
-}
-.form-control-sm::-webkit-file-upload-button {
- padding: 0.25rem 0.5rem;
- margin: -0.25rem -0.5rem;
- -webkit-margin-end: 0.5rem;
- margin-inline-end: 0.5rem;
-}
-.form-control-sm::file-selector-button {
- padding: 0.25rem 0.5rem;
- margin: -0.25rem -0.5rem;
- -webkit-margin-end: 0.5rem;
- margin-inline-end: 0.5rem;
-}
-.form-control-sm::-webkit-file-upload-button {
- padding: 0.25rem 0.5rem;
- margin: -0.25rem -0.5rem;
- -webkit-margin-end: 0.5rem;
- margin-inline-end: 0.5rem;
-}
-
-.form-control-lg {
- min-height: calc(1.5em + 1rem + 2px);
- padding: 0.5rem 1rem;
- font-size: 1.25rem;
- border-radius: 0.3rem;
-}
-.form-control-lg::-webkit-file-upload-button {
- padding: 0.5rem 1rem;
- margin: -0.5rem -1rem;
- -webkit-margin-end: 1rem;
- margin-inline-end: 1rem;
-}
-.form-control-lg::file-selector-button {
- padding: 0.5rem 1rem;
- margin: -0.5rem -1rem;
- -webkit-margin-end: 1rem;
- margin-inline-end: 1rem;
-}
-.form-control-lg::-webkit-file-upload-button {
- padding: 0.5rem 1rem;
- margin: -0.5rem -1rem;
- -webkit-margin-end: 1rem;
- margin-inline-end: 1rem;
-}
-
-textarea.form-control {
- min-height: calc(1.5em + 0.75rem + 2px);
-}
-textarea.form-control-sm {
- min-height: calc(1.5em + 0.5rem + 2px);
-}
-textarea.form-control-lg {
- min-height: calc(1.5em + 1rem + 2px);
-}
-
-.form-control-color {
- width: 3rem;
- height: auto;
- padding: 0.375rem;
-}
-.form-control-color:not(:disabled):not([readonly]) {
- cursor: pointer;
-}
-.form-control-color::-moz-color-swatch {
- height: 1.5em;
- border-radius: 0.25rem;
-}
-.form-control-color::-webkit-color-swatch {
- height: 1.5em;
- border-radius: 0.25rem;
-}
-
-.form-select {
- display: block;
- width: 100%;
- padding: 0.375rem 2.25rem 0.375rem 0.75rem;
- -moz-padding-start: calc(0.75rem - 3px);
- font-size: 1rem;
- font-weight: 400;
- line-height: 1.5;
- color: #212529;
- background-color: #fff;
- background-image: url("data:image/svg+xml,%3csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 16 16'%3e%3cpath fill='none' stroke='%23343a40' stroke-linecap='round' stroke-linejoin='round' stroke-width='2' d='M2 5l6 6 6-6'/%3e%3c/svg%3e");
- background-repeat: no-repeat;
- background-position: right 0.75rem center;
- background-size: 16px 12px;
- border: 1px solid #ced4da;
- border-radius: 0.25rem;
- transition: border-color 0.15s ease-in-out, box-shadow 0.15s ease-in-out;
- -webkit-appearance: none;
- -moz-appearance: none;
- appearance: none;
-}
-@media (prefers-reduced-motion: reduce) {
- .form-select {
- transition: none;
- }
-}
-.form-select:focus {
- border-color: #86b7fe;
- outline: 0;
- box-shadow: 0 0 0 0.25rem rgba(13, 110, 253, 0.25);
-}
-.form-select[multiple], .form-select[size]:not([size="1"]) {
- padding-right: 0.75rem;
- background-image: none;
-}
-.form-select:disabled {
- background-color: #e9ecef;
-}
-.form-select:-moz-focusring {
- color: transparent;
- text-shadow: 0 0 0 #212529;
-}
-
-.form-select-sm {
- padding-top: 0.25rem;
- padding-bottom: 0.25rem;
- padding-left: 0.5rem;
- font-size: 0.875rem;
- border-radius: 0.2rem;
-}
-
-.form-select-lg {
- padding-top: 0.5rem;
- padding-bottom: 0.5rem;
- padding-left: 1rem;
- font-size: 1.25rem;
- border-radius: 0.3rem;
-}
-
-.form-check {
- display: block;
- min-height: 1.5rem;
- padding-left: 1.5em;
- margin-bottom: 0.125rem;
-}
-.form-check .form-check-input {
- float: left;
- margin-left: -1.5em;
-}
-
-.form-check-input {
- width: 1em;
- height: 1em;
- margin-top: 0.25em;
- vertical-align: top;
- background-color: #fff;
- background-repeat: no-repeat;
- background-position: center;
- background-size: contain;
- border: 1px solid rgba(0, 0, 0, 0.25);
- -webkit-appearance: none;
- -moz-appearance: none;
- appearance: none;
- -webkit-print-color-adjust: exact;
- color-adjust: exact;
-}
-.form-check-input[type=checkbox] {
- border-radius: 0.25em;
-}
-.form-check-input[type=radio] {
- border-radius: 50%;
-}
-.form-check-input:active {
- filter: brightness(90%);
-}
-.form-check-input:focus {
- border-color: #86b7fe;
- outline: 0;
- box-shadow: 0 0 0 0.25rem rgba(13, 110, 253, 0.25);
-}
-.form-check-input:checked {
- background-color: #0d6efd;
- border-color: #0d6efd;
-}
-.form-check-input:checked[type=checkbox] {
- background-image: url("data:image/svg+xml,%3csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 20 20'%3e%3cpath fill='none' stroke='%23fff' stroke-linecap='round' stroke-linejoin='round' stroke-width='3' d='M6 10l3 3l6-6'/%3e%3c/svg%3e");
-}
-.form-check-input:checked[type=radio] {
- background-image: url("data:image/svg+xml,%3csvg xmlns='http://www.w3.org/2000/svg' viewBox='-4 -4 8 8'%3e%3ccircle r='2' fill='%23fff'/%3e%3c/svg%3e");
-}
-.form-check-input[type=checkbox]:indeterminate {
- background-color: #0d6efd;
- border-color: #0d6efd;
- background-image: url("data:image/svg+xml,%3csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 20 20'%3e%3cpath fill='none' stroke='%23fff' stroke-linecap='round' stroke-linejoin='round' stroke-width='3' d='M6 10h8'/%3e%3c/svg%3e");
-}
-.form-check-input:disabled {
- pointer-events: none;
- filter: none;
- opacity: 0.5;
-}
-.form-check-input[disabled] ~ .form-check-label, .form-check-input:disabled ~ .form-check-label {
- opacity: 0.5;
-}
-
-.form-switch {
- padding-left: 2.5em;
-}
-.form-switch .form-check-input {
- width: 2em;
- margin-left: -2.5em;
- background-image: url("data:image/svg+xml,%3csvg xmlns='http://www.w3.org/2000/svg' viewBox='-4 -4 8 8'%3e%3ccircle r='3' fill='rgba%280, 0, 0, 0.25%29'/%3e%3c/svg%3e");
- background-position: left center;
- border-radius: 2em;
- transition: background-position 0.15s ease-in-out;
-}
-@media (prefers-reduced-motion: reduce) {
- .form-switch .form-check-input {
- transition: none;
- }
-}
-.form-switch .form-check-input:focus {
- background-image: url("data:image/svg+xml,%3csvg xmlns='http://www.w3.org/2000/svg' viewBox='-4 -4 8 8'%3e%3ccircle r='3' fill='%2386b7fe'/%3e%3c/svg%3e");
-}
-.form-switch .form-check-input:checked {
- background-position: right center;
- background-image: url("data:image/svg+xml,%3csvg xmlns='http://www.w3.org/2000/svg' viewBox='-4 -4 8 8'%3e%3ccircle r='3' fill='%23fff'/%3e%3c/svg%3e");
-}
-
-.form-check-inline {
- display: inline-block;
- margin-right: 1rem;
-}
-
-.btn-check {
- position: absolute;
- clip: rect(0, 0, 0, 0);
- pointer-events: none;
-}
-.btn-check[disabled] + .btn, .btn-check:disabled + .btn {
- pointer-events: none;
- filter: none;
- opacity: 0.65;
-}
-
-.form-range {
- width: 100%;
- height: 1.5rem;
- padding: 0;
- background-color: transparent;
- -webkit-appearance: none;
- -moz-appearance: none;
- appearance: none;
-}
-.form-range:focus {
- outline: 0;
-}
-.form-range:focus::-webkit-slider-thumb {
- box-shadow: 0 0 0 1px #fff, 0 0 0 0.25rem rgba(13, 110, 253, 0.25);
-}
-.form-range:focus::-moz-range-thumb {
- box-shadow: 0 0 0 1px #fff, 0 0 0 0.25rem rgba(13, 110, 253, 0.25);
-}
-.form-range::-moz-focus-outer {
- border: 0;
-}
-.form-range::-webkit-slider-thumb {
- width: 1rem;
- height: 1rem;
- margin-top: -0.25rem;
- background-color: #0d6efd;
- border: 0;
- border-radius: 1rem;
- -webkit-transition: background-color 0.15s ease-in-out, border-color 0.15s ease-in-out, box-shadow 0.15s ease-in-out;
- transition: background-color 0.15s ease-in-out, border-color 0.15s ease-in-out, box-shadow 0.15s ease-in-out;
- -webkit-appearance: none;
- appearance: none;
-}
-@media (prefers-reduced-motion: reduce) {
- .form-range::-webkit-slider-thumb {
- -webkit-transition: none;
- transition: none;
- }
-}
-.form-range::-webkit-slider-thumb:active {
- background-color: #b6d4fe;
-}
-.form-range::-webkit-slider-runnable-track {
- width: 100%;
- height: 0.5rem;
- color: transparent;
- cursor: pointer;
- background-color: #dee2e6;
- border-color: transparent;
- border-radius: 1rem;
-}
-.form-range::-moz-range-thumb {
- width: 1rem;
- height: 1rem;
- background-color: #0d6efd;
- border: 0;
- border-radius: 1rem;
- -moz-transition: background-color 0.15s ease-in-out, border-color 0.15s ease-in-out, box-shadow 0.15s ease-in-out;
- transition: background-color 0.15s ease-in-out, border-color 0.15s ease-in-out, box-shadow 0.15s ease-in-out;
- -moz-appearance: none;
- appearance: none;
-}
-@media (prefers-reduced-motion: reduce) {
- .form-range::-moz-range-thumb {
- -moz-transition: none;
- transition: none;
- }
-}
-.form-range::-moz-range-thumb:active {
- background-color: #b6d4fe;
-}
-.form-range::-moz-range-track {
- width: 100%;
- height: 0.5rem;
- color: transparent;
- cursor: pointer;
- background-color: #dee2e6;
- border-color: transparent;
- border-radius: 1rem;
-}
-.form-range:disabled {
- pointer-events: none;
-}
-.form-range:disabled::-webkit-slider-thumb {
- background-color: #adb5bd;
-}
-.form-range:disabled::-moz-range-thumb {
- background-color: #adb5bd;
-}
-
-.form-floating {
- position: relative;
-}
-.form-floating > .form-control,
-.form-floating > .form-select {
- height: calc(3.5rem + 2px);
- line-height: 1.25;
-}
-.form-floating > label {
- position: absolute;
- top: 0;
- left: 0;
- height: 100%;
- padding: 1rem 0.75rem;
- pointer-events: none;
- border: 1px solid transparent;
- transform-origin: 0 0;
- transition: opacity 0.1s ease-in-out, transform 0.1s ease-in-out;
-}
-@media (prefers-reduced-motion: reduce) {
- .form-floating > label {
- transition: none;
- }
-}
-.form-floating > .form-control {
- padding: 1rem 0.75rem;
-}
-.form-floating > .form-control::-moz-placeholder {
- color: transparent;
-}
-.form-floating > .form-control::placeholder {
- color: transparent;
-}
-.form-floating > .form-control:not(:-moz-placeholder-shown) {
- padding-top: 1.625rem;
- padding-bottom: 0.625rem;
-}
-.form-floating > .form-control:focus, .form-floating > .form-control:not(:placeholder-shown) {
- padding-top: 1.625rem;
- padding-bottom: 0.625rem;
-}
-.form-floating > .form-control:-webkit-autofill {
- padding-top: 1.625rem;
- padding-bottom: 0.625rem;
-}
-.form-floating > .form-select {
- padding-top: 1.625rem;
- padding-bottom: 0.625rem;
-}
-.form-floating > .form-control:not(:-moz-placeholder-shown) ~ label {
- opacity: 0.65;
- transform: scale(0.85) translateY(-0.5rem) translateX(0.15rem);
-}
-.form-floating > .form-control:focus ~ label,
-.form-floating > .form-control:not(:placeholder-shown) ~ label,
-.form-floating > .form-select ~ label {
- opacity: 0.65;
- transform: scale(0.85) translateY(-0.5rem) translateX(0.15rem);
-}
-.form-floating > .form-control:-webkit-autofill ~ label {
- opacity: 0.65;
- transform: scale(0.85) translateY(-0.5rem) translateX(0.15rem);
-}
-
-.input-group {
- position: relative;
- display: flex;
- flex-wrap: wrap;
- align-items: stretch;
- width: 100%;
-}
-.input-group > .form-control,
-.input-group > .form-select {
- position: relative;
- flex: 1 1 auto;
- width: 1%;
- min-width: 0;
-}
-.input-group > .form-control:focus,
-.input-group > .form-select:focus {
- z-index: 3;
-}
-.input-group .btn {
- position: relative;
- z-index: 2;
-}
-.input-group .btn:focus {
- z-index: 3;
-}
-
-.input-group-text {
- display: flex;
- align-items: center;
- padding: 0.375rem 0.75rem;
- font-size: 1rem;
- font-weight: 400;
- line-height: 1.5;
- color: #212529;
- text-align: center;
- white-space: nowrap;
- background-color: #e9ecef;
- border: 1px solid #ced4da;
- border-radius: 0.25rem;
-}
-
-.input-group-lg > .form-control,
-.input-group-lg > .form-select,
-.input-group-lg > .input-group-text,
-.input-group-lg > .btn {
- padding: 0.5rem 1rem;
- font-size: 1.25rem;
- border-radius: 0.3rem;
-}
-
-.input-group-sm > .form-control,
-.input-group-sm > .form-select,
-.input-group-sm > .input-group-text,
-.input-group-sm > .btn {
- padding: 0.25rem 0.5rem;
- font-size: 0.875rem;
- border-radius: 0.2rem;
-}
-
-.input-group-lg > .form-select,
-.input-group-sm > .form-select {
- padding-right: 3rem;
-}
-
-.input-group:not(.has-validation) > :not(:last-child):not(.dropdown-toggle):not(.dropdown-menu),
-.input-group:not(.has-validation) > .dropdown-toggle:nth-last-child(n+3) {
- border-top-right-radius: 0;
- border-bottom-right-radius: 0;
-}
-.input-group.has-validation > :nth-last-child(n+3):not(.dropdown-toggle):not(.dropdown-menu),
-.input-group.has-validation > .dropdown-toggle:nth-last-child(n+4) {
- border-top-right-radius: 0;
- border-bottom-right-radius: 0;
-}
-.input-group > :not(:first-child):not(.dropdown-menu):not(.valid-tooltip):not(.valid-feedback):not(.invalid-tooltip):not(.invalid-feedback) {
- margin-left: -1px;
- border-top-left-radius: 0;
- border-bottom-left-radius: 0;
-}
-
-.valid-feedback {
- display: none;
- width: 100%;
- margin-top: 0.25rem;
- font-size: 0.875em;
- color: #198754;
-}
-
-.valid-tooltip {
- position: absolute;
- top: 100%;
- z-index: 5;
- display: none;
- max-width: 100%;
- padding: 0.25rem 0.5rem;
- margin-top: 0.1rem;
- font-size: 0.875rem;
- color: #fff;
- background-color: rgba(25, 135, 84, 0.9);
- border-radius: 0.25rem;
-}
-
-.was-validated :valid ~ .valid-feedback,
-.was-validated :valid ~ .valid-tooltip,
-.is-valid ~ .valid-feedback,
-.is-valid ~ .valid-tooltip {
- display: block;
-}
-
-.was-validated .form-control:valid, .form-control.is-valid {
- border-color: #198754;
- padding-right: calc(1.5em + 0.75rem);
- background-image: url("data:image/svg+xml,%3csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 8 8'%3e%3cpath fill='%23198754' d='M2.3 6.73L.6 4.53c-.4-1.04.46-1.4 1.1-.8l1.1 1.4 3.4-3.8c.6-.63 1.6-.27 1.2.7l-4 4.6c-.43.5-.8.4-1.1.1z'/%3e%3c/svg%3e");
- background-repeat: no-repeat;
- background-position: right calc(0.375em + 0.1875rem) center;
- background-size: calc(0.75em + 0.375rem) calc(0.75em + 0.375rem);
-}
-.was-validated .form-control:valid:focus, .form-control.is-valid:focus {
- border-color: #198754;
- box-shadow: 0 0 0 0.25rem rgba(25, 135, 84, 0.25);
-}
-
-.was-validated textarea.form-control:valid, textarea.form-control.is-valid {
- padding-right: calc(1.5em + 0.75rem);
- background-position: top calc(0.375em + 0.1875rem) right calc(0.375em + 0.1875rem);
-}
-
-.was-validated .form-select:valid, .form-select.is-valid {
- border-color: #198754;
-}
-.was-validated .form-select:valid:not([multiple]):not([size]), .was-validated .form-select:valid:not([multiple])[size="1"], .form-select.is-valid:not([multiple]):not([size]), .form-select.is-valid:not([multiple])[size="1"] {
- padding-right: 4.125rem;
- background-image: url("data:image/svg+xml,%3csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 16 16'%3e%3cpath fill='none' stroke='%23343a40' stroke-linecap='round' stroke-linejoin='round' stroke-width='2' d='M2 5l6 6 6-6'/%3e%3c/svg%3e"), url("data:image/svg+xml,%3csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 8 8'%3e%3cpath fill='%23198754' d='M2.3 6.73L.6 4.53c-.4-1.04.46-1.4 1.1-.8l1.1 1.4 3.4-3.8c.6-.63 1.6-.27 1.2.7l-4 4.6c-.43.5-.8.4-1.1.1z'/%3e%3c/svg%3e");
- background-position: right 0.75rem center, center right 2.25rem;
- background-size: 16px 12px, calc(0.75em + 0.375rem) calc(0.75em + 0.375rem);
-}
-.was-validated .form-select:valid:focus, .form-select.is-valid:focus {
- border-color: #198754;
- box-shadow: 0 0 0 0.25rem rgba(25, 135, 84, 0.25);
-}
-
-.was-validated .form-check-input:valid, .form-check-input.is-valid {
- border-color: #198754;
-}
-.was-validated .form-check-input:valid:checked, .form-check-input.is-valid:checked {
- background-color: #198754;
-}
-.was-validated .form-check-input:valid:focus, .form-check-input.is-valid:focus {
- box-shadow: 0 0 0 0.25rem rgba(25, 135, 84, 0.25);
-}
-.was-validated .form-check-input:valid ~ .form-check-label, .form-check-input.is-valid ~ .form-check-label {
- color: #198754;
-}
-
-.form-check-inline .form-check-input ~ .valid-feedback {
- margin-left: 0.5em;
-}
-
-.was-validated .input-group .form-control:valid, .input-group .form-control.is-valid,
-.was-validated .input-group .form-select:valid,
-.input-group .form-select.is-valid {
- z-index: 1;
-}
-.was-validated .input-group .form-control:valid:focus, .input-group .form-control.is-valid:focus,
-.was-validated .input-group .form-select:valid:focus,
-.input-group .form-select.is-valid:focus {
- z-index: 3;
-}
-
-.invalid-feedback {
- display: none;
- width: 100%;
- margin-top: 0.25rem;
- font-size: 0.875em;
- color: #dc3545;
-}
-
-.invalid-tooltip {
- position: absolute;
- top: 100%;
- z-index: 5;
- display: none;
- max-width: 100%;
- padding: 0.25rem 0.5rem;
- margin-top: 0.1rem;
- font-size: 0.875rem;
- color: #fff;
- background-color: rgba(220, 53, 69, 0.9);
- border-radius: 0.25rem;
-}
-
-.was-validated :invalid ~ .invalid-feedback,
-.was-validated :invalid ~ .invalid-tooltip,
-.is-invalid ~ .invalid-feedback,
-.is-invalid ~ .invalid-tooltip {
- display: block;
-}
-
-.was-validated .form-control:invalid, .form-control.is-invalid {
- border-color: #dc3545;
- padding-right: calc(1.5em + 0.75rem);
- background-image: url("data:image/svg+xml,%3csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 12 12' width='12' height='12' fill='none' stroke='%23dc3545'%3e%3ccircle cx='6' cy='6' r='4.5'/%3e%3cpath stroke-linejoin='round' d='M5.8 3.6h.4L6 6.5z'/%3e%3ccircle cx='6' cy='8.2' r='.6' fill='%23dc3545' stroke='none'/%3e%3c/svg%3e");
- background-repeat: no-repeat;
- background-position: right calc(0.375em + 0.1875rem) center;
- background-size: calc(0.75em + 0.375rem) calc(0.75em + 0.375rem);
-}
-.was-validated .form-control:invalid:focus, .form-control.is-invalid:focus {
- border-color: #dc3545;
- box-shadow: 0 0 0 0.25rem rgba(220, 53, 69, 0.25);
-}
-
-.was-validated textarea.form-control:invalid, textarea.form-control.is-invalid {
- padding-right: calc(1.5em + 0.75rem);
- background-position: top calc(0.375em + 0.1875rem) right calc(0.375em + 0.1875rem);
-}
-
-.was-validated .form-select:invalid, .form-select.is-invalid {
- border-color: #dc3545;
-}
-.was-validated .form-select:invalid:not([multiple]):not([size]), .was-validated .form-select:invalid:not([multiple])[size="1"], .form-select.is-invalid:not([multiple]):not([size]), .form-select.is-invalid:not([multiple])[size="1"] {
- padding-right: 4.125rem;
- background-image: url("data:image/svg+xml,%3csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 16 16'%3e%3cpath fill='none' stroke='%23343a40' stroke-linecap='round' stroke-linejoin='round' stroke-width='2' d='M2 5l6 6 6-6'/%3e%3c/svg%3e"), url("data:image/svg+xml,%3csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 12 12' width='12' height='12' fill='none' stroke='%23dc3545'%3e%3ccircle cx='6' cy='6' r='4.5'/%3e%3cpath stroke-linejoin='round' d='M5.8 3.6h.4L6 6.5z'/%3e%3ccircle cx='6' cy='8.2' r='.6' fill='%23dc3545' stroke='none'/%3e%3c/svg%3e");
- background-position: right 0.75rem center, center right 2.25rem;
- background-size: 16px 12px, calc(0.75em + 0.375rem) calc(0.75em + 0.375rem);
-}
-.was-validated .form-select:invalid:focus, .form-select.is-invalid:focus {
- border-color: #dc3545;
- box-shadow: 0 0 0 0.25rem rgba(220, 53, 69, 0.25);
-}
-
-.was-validated .form-check-input:invalid, .form-check-input.is-invalid {
- border-color: #dc3545;
-}
-.was-validated .form-check-input:invalid:checked, .form-check-input.is-invalid:checked {
- background-color: #dc3545;
-}
-.was-validated .form-check-input:invalid:focus, .form-check-input.is-invalid:focus {
- box-shadow: 0 0 0 0.25rem rgba(220, 53, 69, 0.25);
-}
-.was-validated .form-check-input:invalid ~ .form-check-label, .form-check-input.is-invalid ~ .form-check-label {
- color: #dc3545;
-}
-
-.form-check-inline .form-check-input ~ .invalid-feedback {
- margin-left: 0.5em;
-}
-
-.was-validated .input-group .form-control:invalid, .input-group .form-control.is-invalid,
-.was-validated .input-group .form-select:invalid,
-.input-group .form-select.is-invalid {
- z-index: 2;
-}
-.was-validated .input-group .form-control:invalid:focus, .input-group .form-control.is-invalid:focus,
-.was-validated .input-group .form-select:invalid:focus,
-.input-group .form-select.is-invalid:focus {
- z-index: 3;
-}
-
-.btn {
- display: inline-block;
- font-weight: 400;
- line-height: 1.5;
- color: #212529;
- text-align: center;
- text-decoration: none;
- vertical-align: middle;
- cursor: pointer;
- -webkit-user-select: none;
- -moz-user-select: none;
- user-select: none;
- background-color: transparent;
- border: 1px solid transparent;
- padding: 0.375rem 0.75rem;
- font-size: 1rem;
- border-radius: 0.25rem;
- transition: color 0.15s ease-in-out, background-color 0.15s ease-in-out, border-color 0.15s ease-in-out, box-shadow 0.15s ease-in-out;
-}
-@media (prefers-reduced-motion: reduce) {
- .btn {
- transition: none;
- }
-}
-.btn:hover {
- color: #212529;
-}
-.btn-check:focus + .btn, .btn:focus {
- outline: 0;
- box-shadow: 0 0 0 0.25rem rgba(13, 110, 253, 0.25);
-}
-.btn:disabled, .btn.disabled, fieldset:disabled .btn {
- pointer-events: none;
- opacity: 0.65;
-}
-
-.btn-primary {
- color: #fff;
- background-color: #0d6efd;
- border-color: #0d6efd;
-}
-.btn-primary:hover {
- color: #fff;
- background-color: #0b5ed7;
- border-color: #0a58ca;
-}
-.btn-check:focus + .btn-primary, .btn-primary:focus {
- color: #fff;
- background-color: #0b5ed7;
- border-color: #0a58ca;
- box-shadow: 0 0 0 0.25rem rgba(49, 132, 253, 0.5);
-}
-.btn-check:checked + .btn-primary, .btn-check:active + .btn-primary, .btn-primary:active, .btn-primary.active, .show > .btn-primary.dropdown-toggle {
- color: #fff;
- background-color: #0a58ca;
- border-color: #0a53be;
-}
-.btn-check:checked + .btn-primary:focus, .btn-check:active + .btn-primary:focus, .btn-primary:active:focus, .btn-primary.active:focus, .show > .btn-primary.dropdown-toggle:focus {
- box-shadow: 0 0 0 0.25rem rgba(49, 132, 253, 0.5);
-}
-.btn-primary:disabled, .btn-primary.disabled {
- color: #fff;
- background-color: #0d6efd;
- border-color: #0d6efd;
-}
-
-.btn-secondary {
- color: #fff;
- background-color: #6c757d;
- border-color: #6c757d;
-}
-.btn-secondary:hover {
- color: #fff;
- background-color: #5c636a;
- border-color: #565e64;
-}
-.btn-check:focus + .btn-secondary, .btn-secondary:focus {
- color: #fff;
- background-color: #5c636a;
- border-color: #565e64;
- box-shadow: 0 0 0 0.25rem rgba(130, 138, 145, 0.5);
-}
-.btn-check:checked + .btn-secondary, .btn-check:active + .btn-secondary, .btn-secondary:active, .btn-secondary.active, .show > .btn-secondary.dropdown-toggle {
- color: #fff;
- background-color: #565e64;
- border-color: #51585e;
-}
-.btn-check:checked + .btn-secondary:focus, .btn-check:active + .btn-secondary:focus, .btn-secondary:active:focus, .btn-secondary.active:focus, .show > .btn-secondary.dropdown-toggle:focus {
- box-shadow: 0 0 0 0.25rem rgba(130, 138, 145, 0.5);
-}
-.btn-secondary:disabled, .btn-secondary.disabled {
- color: #fff;
- background-color: #6c757d;
- border-color: #6c757d;
-}
-
-.btn-success {
- color: #fff;
- background-color: #198754;
- border-color: #198754;
-}
-.btn-success:hover {
- color: #fff;
- background-color: #157347;
- border-color: #146c43;
-}
-.btn-check:focus + .btn-success, .btn-success:focus {
- color: #fff;
- background-color: #157347;
- border-color: #146c43;
- box-shadow: 0 0 0 0.25rem rgba(60, 153, 110, 0.5);
-}
-.btn-check:checked + .btn-success, .btn-check:active + .btn-success, .btn-success:active, .btn-success.active, .show > .btn-success.dropdown-toggle {
- color: #fff;
- background-color: #146c43;
- border-color: #13653f;
-}
-.btn-check:checked + .btn-success:focus, .btn-check:active + .btn-success:focus, .btn-success:active:focus, .btn-success.active:focus, .show > .btn-success.dropdown-toggle:focus {
- box-shadow: 0 0 0 0.25rem rgba(60, 153, 110, 0.5);
-}
-.btn-success:disabled, .btn-success.disabled {
- color: #fff;
- background-color: #198754;
- border-color: #198754;
-}
-
-.btn-info {
- color: #000;
- background-color: #0dcaf0;
- border-color: #0dcaf0;
-}
-.btn-info:hover {
- color: #000;
- background-color: #31d2f2;
- border-color: #25cff2;
-}
-.btn-check:focus + .btn-info, .btn-info:focus {
- color: #000;
- background-color: #31d2f2;
- border-color: #25cff2;
- box-shadow: 0 0 0 0.25rem rgba(11, 172, 204, 0.5);
-}
-.btn-check:checked + .btn-info, .btn-check:active + .btn-info, .btn-info:active, .btn-info.active, .show > .btn-info.dropdown-toggle {
- color: #000;
- background-color: #3dd5f3;
- border-color: #25cff2;
-}
-.btn-check:checked + .btn-info:focus, .btn-check:active + .btn-info:focus, .btn-info:active:focus, .btn-info.active:focus, .show > .btn-info.dropdown-toggle:focus {
- box-shadow: 0 0 0 0.25rem rgba(11, 172, 204, 0.5);
-}
-.btn-info:disabled, .btn-info.disabled {
- color: #000;
- background-color: #0dcaf0;
- border-color: #0dcaf0;
-}
-
-.btn-warning {
- color: #000;
- background-color: #ffc107;
- border-color: #ffc107;
-}
-.btn-warning:hover {
- color: #000;
- background-color: #ffca2c;
- border-color: #ffc720;
-}
-.btn-check:focus + .btn-warning, .btn-warning:focus {
- color: #000;
- background-color: #ffca2c;
- border-color: #ffc720;
- box-shadow: 0 0 0 0.25rem rgba(217, 164, 6, 0.5);
-}
-.btn-check:checked + .btn-warning, .btn-check:active + .btn-warning, .btn-warning:active, .btn-warning.active, .show > .btn-warning.dropdown-toggle {
- color: #000;
- background-color: #ffcd39;
- border-color: #ffc720;
-}
-.btn-check:checked + .btn-warning:focus, .btn-check:active + .btn-warning:focus, .btn-warning:active:focus, .btn-warning.active:focus, .show > .btn-warning.dropdown-toggle:focus {
- box-shadow: 0 0 0 0.25rem rgba(217, 164, 6, 0.5);
-}
-.btn-warning:disabled, .btn-warning.disabled {
- color: #000;
- background-color: #ffc107;
- border-color: #ffc107;
-}
-
-.btn-danger {
- color: #fff;
- background-color: #dc3545;
- border-color: #dc3545;
-}
-.btn-danger:hover {
- color: #fff;
- background-color: #bb2d3b;
- border-color: #b02a37;
-}
-.btn-check:focus + .btn-danger, .btn-danger:focus {
- color: #fff;
- background-color: #bb2d3b;
- border-color: #b02a37;
- box-shadow: 0 0 0 0.25rem rgba(225, 83, 97, 0.5);
-}
-.btn-check:checked + .btn-danger, .btn-check:active + .btn-danger, .btn-danger:active, .btn-danger.active, .show > .btn-danger.dropdown-toggle {
- color: #fff;
- background-color: #b02a37;
- border-color: #a52834;
-}
-.btn-check:checked + .btn-danger:focus, .btn-check:active + .btn-danger:focus, .btn-danger:active:focus, .btn-danger.active:focus, .show > .btn-danger.dropdown-toggle:focus {
- box-shadow: 0 0 0 0.25rem rgba(225, 83, 97, 0.5);
-}
-.btn-danger:disabled, .btn-danger.disabled {
- color: #fff;
- background-color: #dc3545;
- border-color: #dc3545;
-}
-
-.btn-light {
- color: #000;
- background-color: #f8f9fa;
- border-color: #f8f9fa;
-}
-.btn-light:hover {
- color: #000;
- background-color: #f9fafb;
- border-color: #f9fafb;
-}
-.btn-check:focus + .btn-light, .btn-light:focus {
- color: #000;
- background-color: #f9fafb;
- border-color: #f9fafb;
- box-shadow: 0 0 0 0.25rem rgba(211, 212, 213, 0.5);
-}
-.btn-check:checked + .btn-light, .btn-check:active + .btn-light, .btn-light:active, .btn-light.active, .show > .btn-light.dropdown-toggle {
- color: #000;
- background-color: #f9fafb;
- border-color: #f9fafb;
-}
-.btn-check:checked + .btn-light:focus, .btn-check:active + .btn-light:focus, .btn-light:active:focus, .btn-light.active:focus, .show > .btn-light.dropdown-toggle:focus {
- box-shadow: 0 0 0 0.25rem rgba(211, 212, 213, 0.5);
-}
-.btn-light:disabled, .btn-light.disabled {
- color: #000;
- background-color: #f8f9fa;
- border-color: #f8f9fa;
-}
-
-.btn-dark {
- color: #fff;
- background-color: #212529;
- border-color: #212529;
-}
-.btn-dark:hover {
- color: #fff;
- background-color: #1c1f23;
- border-color: #1a1e21;
-}
-.btn-check:focus + .btn-dark, .btn-dark:focus {
- color: #fff;
- background-color: #1c1f23;
- border-color: #1a1e21;
- box-shadow: 0 0 0 0.25rem rgba(66, 70, 73, 0.5);
-}
-.btn-check:checked + .btn-dark, .btn-check:active + .btn-dark, .btn-dark:active, .btn-dark.active, .show > .btn-dark.dropdown-toggle {
- color: #fff;
- background-color: #1a1e21;
- border-color: #191c1f;
-}
-.btn-check:checked + .btn-dark:focus, .btn-check:active + .btn-dark:focus, .btn-dark:active:focus, .btn-dark.active:focus, .show > .btn-dark.dropdown-toggle:focus {
- box-shadow: 0 0 0 0.25rem rgba(66, 70, 73, 0.5);
-}
-.btn-dark:disabled, .btn-dark.disabled {
- color: #fff;
- background-color: #212529;
- border-color: #212529;
-}
-
-.btn-outline-primary {
- color: #0d6efd;
- border-color: #0d6efd;
-}
-.btn-outline-primary:hover {
- color: #fff;
- background-color: #0d6efd;
- border-color: #0d6efd;
-}
-.btn-check:focus + .btn-outline-primary, .btn-outline-primary:focus {
- box-shadow: 0 0 0 0.25rem rgba(13, 110, 253, 0.5);
-}
-.btn-check:checked + .btn-outline-primary, .btn-check:active + .btn-outline-primary, .btn-outline-primary:active, .btn-outline-primary.active, .btn-outline-primary.dropdown-toggle.show {
- color: #fff;
- background-color: #0d6efd;
- border-color: #0d6efd;
-}
-.btn-check:checked + .btn-outline-primary:focus, .btn-check:active + .btn-outline-primary:focus, .btn-outline-primary:active:focus, .btn-outline-primary.active:focus, .btn-outline-primary.dropdown-toggle.show:focus {
- box-shadow: 0 0 0 0.25rem rgba(13, 110, 253, 0.5);
-}
-.btn-outline-primary:disabled, .btn-outline-primary.disabled {
- color: #0d6efd;
- background-color: transparent;
-}
-
-.btn-outline-secondary {
- color: #6c757d;
- border-color: #6c757d;
-}
-.btn-outline-secondary:hover {
- color: #fff;
- background-color: #6c757d;
- border-color: #6c757d;
-}
-.btn-check:focus + .btn-outline-secondary, .btn-outline-secondary:focus {
- box-shadow: 0 0 0 0.25rem rgba(108, 117, 125, 0.5);
-}
-.btn-check:checked + .btn-outline-secondary, .btn-check:active + .btn-outline-secondary, .btn-outline-secondary:active, .btn-outline-secondary.active, .btn-outline-secondary.dropdown-toggle.show {
- color: #fff;
- background-color: #6c757d;
- border-color: #6c757d;
-}
-.btn-check:checked + .btn-outline-secondary:focus, .btn-check:active + .btn-outline-secondary:focus, .btn-outline-secondary:active:focus, .btn-outline-secondary.active:focus, .btn-outline-secondary.dropdown-toggle.show:focus {
- box-shadow: 0 0 0 0.25rem rgba(108, 117, 125, 0.5);
-}
-.btn-outline-secondary:disabled, .btn-outline-secondary.disabled {
- color: #6c757d;
- background-color: transparent;
-}
-
-.btn-outline-success {
- color: #198754;
- border-color: #198754;
-}
-.btn-outline-success:hover {
- color: #fff;
- background-color: #198754;
- border-color: #198754;
-}
-.btn-check:focus + .btn-outline-success, .btn-outline-success:focus {
- box-shadow: 0 0 0 0.25rem rgba(25, 135, 84, 0.5);
-}
-.btn-check:checked + .btn-outline-success, .btn-check:active + .btn-outline-success, .btn-outline-success:active, .btn-outline-success.active, .btn-outline-success.dropdown-toggle.show {
- color: #fff;
- background-color: #198754;
- border-color: #198754;
-}
-.btn-check:checked + .btn-outline-success:focus, .btn-check:active + .btn-outline-success:focus, .btn-outline-success:active:focus, .btn-outline-success.active:focus, .btn-outline-success.dropdown-toggle.show:focus {
- box-shadow: 0 0 0 0.25rem rgba(25, 135, 84, 0.5);
-}
-.btn-outline-success:disabled, .btn-outline-success.disabled {
- color: #198754;
- background-color: transparent;
-}
-
-.btn-outline-info {
- color: #0dcaf0;
- border-color: #0dcaf0;
-}
-.btn-outline-info:hover {
- color: #000;
- background-color: #0dcaf0;
- border-color: #0dcaf0;
-}
-.btn-check:focus + .btn-outline-info, .btn-outline-info:focus {
- box-shadow: 0 0 0 0.25rem rgba(13, 202, 240, 0.5);
-}
-.btn-check:checked + .btn-outline-info, .btn-check:active + .btn-outline-info, .btn-outline-info:active, .btn-outline-info.active, .btn-outline-info.dropdown-toggle.show {
- color: #000;
- background-color: #0dcaf0;
- border-color: #0dcaf0;
-}
-.btn-check:checked + .btn-outline-info:focus, .btn-check:active + .btn-outline-info:focus, .btn-outline-info:active:focus, .btn-outline-info.active:focus, .btn-outline-info.dropdown-toggle.show:focus {
- box-shadow: 0 0 0 0.25rem rgba(13, 202, 240, 0.5);
-}
-.btn-outline-info:disabled, .btn-outline-info.disabled {
- color: #0dcaf0;
- background-color: transparent;
-}
-
-.btn-outline-warning {
- color: #ffc107;
- border-color: #ffc107;
-}
-.btn-outline-warning:hover {
- color: #000;
- background-color: #ffc107;
- border-color: #ffc107;
-}
-.btn-check:focus + .btn-outline-warning, .btn-outline-warning:focus {
- box-shadow: 0 0 0 0.25rem rgba(255, 193, 7, 0.5);
-}
-.btn-check:checked + .btn-outline-warning, .btn-check:active + .btn-outline-warning, .btn-outline-warning:active, .btn-outline-warning.active, .btn-outline-warning.dropdown-toggle.show {
- color: #000;
- background-color: #ffc107;
- border-color: #ffc107;
-}
-.btn-check:checked + .btn-outline-warning:focus, .btn-check:active + .btn-outline-warning:focus, .btn-outline-warning:active:focus, .btn-outline-warning.active:focus, .btn-outline-warning.dropdown-toggle.show:focus {
- box-shadow: 0 0 0 0.25rem rgba(255, 193, 7, 0.5);
-}
-.btn-outline-warning:disabled, .btn-outline-warning.disabled {
- color: #ffc107;
- background-color: transparent;
-}
-
-.btn-outline-danger {
- color: #dc3545;
- border-color: #dc3545;
-}
-.btn-outline-danger:hover {
- color: #fff;
- background-color: #dc3545;
- border-color: #dc3545;
-}
-.btn-check:focus + .btn-outline-danger, .btn-outline-danger:focus {
- box-shadow: 0 0 0 0.25rem rgba(220, 53, 69, 0.5);
-}
-.btn-check:checked + .btn-outline-danger, .btn-check:active + .btn-outline-danger, .btn-outline-danger:active, .btn-outline-danger.active, .btn-outline-danger.dropdown-toggle.show {
- color: #fff;
- background-color: #dc3545;
- border-color: #dc3545;
-}
-.btn-check:checked + .btn-outline-danger:focus, .btn-check:active + .btn-outline-danger:focus, .btn-outline-danger:active:focus, .btn-outline-danger.active:focus, .btn-outline-danger.dropdown-toggle.show:focus {
- box-shadow: 0 0 0 0.25rem rgba(220, 53, 69, 0.5);
-}
-.btn-outline-danger:disabled, .btn-outline-danger.disabled {
- color: #dc3545;
- background-color: transparent;
-}
-
-.btn-outline-light {
- color: #f8f9fa;
- border-color: #f8f9fa;
-}
-.btn-outline-light:hover {
- color: #000;
- background-color: #f8f9fa;
- border-color: #f8f9fa;
-}
-.btn-check:focus + .btn-outline-light, .btn-outline-light:focus {
- box-shadow: 0 0 0 0.25rem rgba(248, 249, 250, 0.5);
-}
-.btn-check:checked + .btn-outline-light, .btn-check:active + .btn-outline-light, .btn-outline-light:active, .btn-outline-light.active, .btn-outline-light.dropdown-toggle.show {
- color: #000;
- background-color: #f8f9fa;
- border-color: #f8f9fa;
-}
-.btn-check:checked + .btn-outline-light:focus, .btn-check:active + .btn-outline-light:focus, .btn-outline-light:active:focus, .btn-outline-light.active:focus, .btn-outline-light.dropdown-toggle.show:focus {
- box-shadow: 0 0 0 0.25rem rgba(248, 249, 250, 0.5);
-}
-.btn-outline-light:disabled, .btn-outline-light.disabled {
- color: #f8f9fa;
- background-color: transparent;
-}
-
-.btn-outline-dark {
- color: #212529;
- border-color: #212529;
-}
-.btn-outline-dark:hover {
- color: #fff;
- background-color: #212529;
- border-color: #212529;
-}
-.btn-check:focus + .btn-outline-dark, .btn-outline-dark:focus {
- box-shadow: 0 0 0 0.25rem rgba(33, 37, 41, 0.5);
-}
-.btn-check:checked + .btn-outline-dark, .btn-check:active + .btn-outline-dark, .btn-outline-dark:active, .btn-outline-dark.active, .btn-outline-dark.dropdown-toggle.show {
- color: #fff;
- background-color: #212529;
- border-color: #212529;
-}
-.btn-check:checked + .btn-outline-dark:focus, .btn-check:active + .btn-outline-dark:focus, .btn-outline-dark:active:focus, .btn-outline-dark.active:focus, .btn-outline-dark.dropdown-toggle.show:focus {
- box-shadow: 0 0 0 0.25rem rgba(33, 37, 41, 0.5);
-}
-.btn-outline-dark:disabled, .btn-outline-dark.disabled {
- color: #212529;
- background-color: transparent;
-}
-
-.btn-link {
- font-weight: 400;
- color: #0d6efd;
- text-decoration: underline;
-}
-.btn-link:hover {
- color: #0a58ca;
-}
-.btn-link:disabled, .btn-link.disabled {
- color: #6c757d;
-}
-
-.btn-lg, .btn-group-lg > .btn {
- padding: 0.5rem 1rem;
- font-size: 1.25rem;
- border-radius: 0.3rem;
-}
-
-.btn-sm, .btn-group-sm > .btn {
- padding: 0.25rem 0.5rem;
- font-size: 0.875rem;
- border-radius: 0.2rem;
-}
-
-.fade {
- transition: opacity 0.15s linear;
-}
-@media (prefers-reduced-motion: reduce) {
- .fade {
- transition: none;
- }
-}
-.fade:not(.show) {
- opacity: 0;
-}
-
-.collapse:not(.show) {
- display: none;
-}
-
-.collapsing {
- height: 0;
- overflow: hidden;
- transition: height 0.35s ease;
-}
-@media (prefers-reduced-motion: reduce) {
- .collapsing {
- transition: none;
- }
-}
-.collapsing.collapse-horizontal {
- width: 0;
- height: auto;
- transition: width 0.35s ease;
-}
-@media (prefers-reduced-motion: reduce) {
- .collapsing.collapse-horizontal {
- transition: none;
- }
-}
-
-.dropup,
-.dropend,
-.dropdown,
-.dropstart {
- position: relative;
-}
-
-.dropdown-toggle {
- white-space: nowrap;
-}
-.dropdown-toggle::after {
- display: inline-block;
- margin-left: 0.255em;
- vertical-align: 0.255em;
- content: "";
- border-top: 0.3em solid;
- border-right: 0.3em solid transparent;
- border-bottom: 0;
- border-left: 0.3em solid transparent;
-}
-.dropdown-toggle:empty::after {
- margin-left: 0;
-}
-
-.dropdown-menu {
- position: absolute;
- z-index: 1000;
- display: none;
- min-width: 10rem;
- padding: 0.5rem 0;
- margin: 0;
- font-size: 1rem;
- color: #212529;
- text-align: left;
- list-style: none;
- background-color: #fff;
- background-clip: padding-box;
- border: 1px solid rgba(0, 0, 0, 0.15);
- border-radius: 0.25rem;
-}
-.dropdown-menu[data-bs-popper] {
- top: 100%;
- left: 0;
- margin-top: 0.125rem;
-}
-
-.dropdown-menu-start {
- --bs-position: start;
-}
-.dropdown-menu-start[data-bs-popper] {
- right: auto;
- left: 0;
-}
-
-.dropdown-menu-end {
- --bs-position: end;
-}
-.dropdown-menu-end[data-bs-popper] {
- right: 0;
- left: auto;
-}
-
-@media (min-width: 576px) {
- .dropdown-menu-sm-start {
- --bs-position: start;
- }
- .dropdown-menu-sm-start[data-bs-popper] {
- right: auto;
- left: 0;
- }
-
- .dropdown-menu-sm-end {
- --bs-position: end;
- }
- .dropdown-menu-sm-end[data-bs-popper] {
- right: 0;
- left: auto;
- }
-}
-@media (min-width: 768px) {
- .dropdown-menu-md-start {
- --bs-position: start;
- }
- .dropdown-menu-md-start[data-bs-popper] {
- right: auto;
- left: 0;
- }
-
- .dropdown-menu-md-end {
- --bs-position: end;
- }
- .dropdown-menu-md-end[data-bs-popper] {
- right: 0;
- left: auto;
- }
-}
-@media (min-width: 992px) {
- .dropdown-menu-lg-start {
- --bs-position: start;
- }
- .dropdown-menu-lg-start[data-bs-popper] {
- right: auto;
- left: 0;
- }
-
- .dropdown-menu-lg-end {
- --bs-position: end;
- }
- .dropdown-menu-lg-end[data-bs-popper] {
- right: 0;
- left: auto;
- }
-}
-@media (min-width: 1200px) {
- .dropdown-menu-xl-start {
- --bs-position: start;
- }
- .dropdown-menu-xl-start[data-bs-popper] {
- right: auto;
- left: 0;
- }
-
- .dropdown-menu-xl-end {
- --bs-position: end;
- }
- .dropdown-menu-xl-end[data-bs-popper] {
- right: 0;
- left: auto;
- }
-}
-@media (min-width: 1400px) {
- .dropdown-menu-xxl-start {
- --bs-position: start;
- }
- .dropdown-menu-xxl-start[data-bs-popper] {
- right: auto;
- left: 0;
- }
-
- .dropdown-menu-xxl-end {
- --bs-position: end;
- }
- .dropdown-menu-xxl-end[data-bs-popper] {
- right: 0;
- left: auto;
- }
-}
-.dropup .dropdown-menu[data-bs-popper] {
- top: auto;
- bottom: 100%;
- margin-top: 0;
- margin-bottom: 0.125rem;
-}
-.dropup .dropdown-toggle::after {
- display: inline-block;
- margin-left: 0.255em;
- vertical-align: 0.255em;
- content: "";
- border-top: 0;
- border-right: 0.3em solid transparent;
- border-bottom: 0.3em solid;
- border-left: 0.3em solid transparent;
-}
-.dropup .dropdown-toggle:empty::after {
- margin-left: 0;
-}
-
-.dropend .dropdown-menu[data-bs-popper] {
- top: 0;
- right: auto;
- left: 100%;
- margin-top: 0;
- margin-left: 0.125rem;
-}
-.dropend .dropdown-toggle::after {
- display: inline-block;
- margin-left: 0.255em;
- vertical-align: 0.255em;
- content: "";
- border-top: 0.3em solid transparent;
- border-right: 0;
- border-bottom: 0.3em solid transparent;
- border-left: 0.3em solid;
-}
-.dropend .dropdown-toggle:empty::after {
- margin-left: 0;
-}
-.dropend .dropdown-toggle::after {
- vertical-align: 0;
-}
-
-.dropstart .dropdown-menu[data-bs-popper] {
- top: 0;
- right: 100%;
- left: auto;
- margin-top: 0;
- margin-right: 0.125rem;
-}
-.dropstart .dropdown-toggle::after {
- display: inline-block;
- margin-left: 0.255em;
- vertical-align: 0.255em;
- content: "";
-}
-.dropstart .dropdown-toggle::after {
- display: none;
-}
-.dropstart .dropdown-toggle::before {
- display: inline-block;
- margin-right: 0.255em;
- vertical-align: 0.255em;
- content: "";
- border-top: 0.3em solid transparent;
- border-right: 0.3em solid;
- border-bottom: 0.3em solid transparent;
-}
-.dropstart .dropdown-toggle:empty::after {
- margin-left: 0;
-}
-.dropstart .dropdown-toggle::before {
- vertical-align: 0;
-}
-
-.dropdown-divider {
- height: 0;
- margin: 0.5rem 0;
- overflow: hidden;
- border-top: 1px solid rgba(0, 0, 0, 0.15);
-}
-
-.dropdown-item {
- display: block;
- width: 100%;
- padding: 0.25rem 1rem;
- clear: both;
- font-weight: 400;
- color: #212529;
- text-align: inherit;
- text-decoration: none;
- white-space: nowrap;
- background-color: transparent;
- border: 0;
-}
-.dropdown-item:hover, .dropdown-item:focus {
- color: #1e2125;
- background-color: #e9ecef;
-}
-.dropdown-item.active, .dropdown-item:active {
- color: #fff;
- text-decoration: none;
- background-color: #0d6efd;
-}
-.dropdown-item.disabled, .dropdown-item:disabled {
- color: #adb5bd;
- pointer-events: none;
- background-color: transparent;
-}
-
-.dropdown-menu.show {
- display: block;
-}
-
-.dropdown-header {
- display: block;
- padding: 0.5rem 1rem;
- margin-bottom: 0;
- font-size: 0.875rem;
- color: #6c757d;
- white-space: nowrap;
-}
-
-.dropdown-item-text {
- display: block;
- padding: 0.25rem 1rem;
- color: #212529;
-}
-
-.dropdown-menu-dark {
- color: #dee2e6;
- background-color: #343a40;
- border-color: rgba(0, 0, 0, 0.15);
-}
-.dropdown-menu-dark .dropdown-item {
- color: #dee2e6;
-}
-.dropdown-menu-dark .dropdown-item:hover, .dropdown-menu-dark .dropdown-item:focus {
- color: #fff;
- background-color: rgba(255, 255, 255, 0.15);
-}
-.dropdown-menu-dark .dropdown-item.active, .dropdown-menu-dark .dropdown-item:active {
- color: #fff;
- background-color: #0d6efd;
-}
-.dropdown-menu-dark .dropdown-item.disabled, .dropdown-menu-dark .dropdown-item:disabled {
- color: #adb5bd;
-}
-.dropdown-menu-dark .dropdown-divider {
- border-color: rgba(0, 0, 0, 0.15);
-}
-.dropdown-menu-dark .dropdown-item-text {
- color: #dee2e6;
-}
-.dropdown-menu-dark .dropdown-header {
- color: #adb5bd;
-}
-
-.btn-group,
-.btn-group-vertical {
- position: relative;
- display: inline-flex;
- vertical-align: middle;
-}
-.btn-group > .btn,
-.btn-group-vertical > .btn {
- position: relative;
- flex: 1 1 auto;
-}
-.btn-group > .btn-check:checked + .btn,
-.btn-group > .btn-check:focus + .btn,
-.btn-group > .btn:hover,
-.btn-group > .btn:focus,
-.btn-group > .btn:active,
-.btn-group > .btn.active,
-.btn-group-vertical > .btn-check:checked + .btn,
-.btn-group-vertical > .btn-check:focus + .btn,
-.btn-group-vertical > .btn:hover,
-.btn-group-vertical > .btn:focus,
-.btn-group-vertical > .btn:active,
-.btn-group-vertical > .btn.active {
- z-index: 1;
-}
-
-.btn-toolbar {
- display: flex;
- flex-wrap: wrap;
- justify-content: flex-start;
-}
-.btn-toolbar .input-group {
- width: auto;
-}
-
-.btn-group > .btn:not(:first-child),
-.btn-group > .btn-group:not(:first-child) {
- margin-left: -1px;
-}
-.btn-group > .btn:not(:last-child):not(.dropdown-toggle),
-.btn-group > .btn-group:not(:last-child) > .btn {
- border-top-right-radius: 0;
- border-bottom-right-radius: 0;
-}
-.btn-group > .btn:nth-child(n+3),
-.btn-group > :not(.btn-check) + .btn,
-.btn-group > .btn-group:not(:first-child) > .btn {
- border-top-left-radius: 0;
- border-bottom-left-radius: 0;
-}
-
-.dropdown-toggle-split {
- padding-right: 0.5625rem;
- padding-left: 0.5625rem;
-}
-.dropdown-toggle-split::after, .dropup .dropdown-toggle-split::after, .dropend .dropdown-toggle-split::after {
- margin-left: 0;
-}
-.dropstart .dropdown-toggle-split::before {
- margin-right: 0;
-}
-
-.btn-sm + .dropdown-toggle-split, .btn-group-sm > .btn + .dropdown-toggle-split {
- padding-right: 0.375rem;
- padding-left: 0.375rem;
-}
-
-.btn-lg + .dropdown-toggle-split, .btn-group-lg > .btn + .dropdown-toggle-split {
- padding-right: 0.75rem;
- padding-left: 0.75rem;
-}
-
-.btn-group-vertical {
- flex-direction: column;
- align-items: flex-start;
- justify-content: center;
-}
-.btn-group-vertical > .btn,
-.btn-group-vertical > .btn-group {
- width: 100%;
-}
-.btn-group-vertical > .btn:not(:first-child),
-.btn-group-vertical > .btn-group:not(:first-child) {
- margin-top: -1px;
-}
-.btn-group-vertical > .btn:not(:last-child):not(.dropdown-toggle),
-.btn-group-vertical > .btn-group:not(:last-child) > .btn {
- border-bottom-right-radius: 0;
- border-bottom-left-radius: 0;
-}
-.btn-group-vertical > .btn ~ .btn,
-.btn-group-vertical > .btn-group:not(:first-child) > .btn {
- border-top-left-radius: 0;
- border-top-right-radius: 0;
-}
-
-.nav {
- display: flex;
- flex-wrap: wrap;
- padding-left: 0;
- margin-bottom: 0;
- list-style: none;
-}
-
-.nav-link {
- display: block;
- padding: 0.5rem 1rem;
- color: #0d6efd;
- text-decoration: none;
- transition: color 0.15s ease-in-out, background-color 0.15s ease-in-out, border-color 0.15s ease-in-out;
-}
-@media (prefers-reduced-motion: reduce) {
- .nav-link {
- transition: none;
- }
-}
-.nav-link:hover, .nav-link:focus {
- color: #0a58ca;
-}
-.nav-link.disabled {
- color: #6c757d;
- pointer-events: none;
- cursor: default;
-}
-
-.nav-tabs {
- border-bottom: 1px solid #dee2e6;
-}
-.nav-tabs .nav-link {
- margin-bottom: -1px;
- background: none;
- border: 1px solid transparent;
- border-top-left-radius: 0.25rem;
- border-top-right-radius: 0.25rem;
-}
-.nav-tabs .nav-link:hover, .nav-tabs .nav-link:focus {
- border-color: #e9ecef #e9ecef #dee2e6;
- isolation: isolate;
-}
-.nav-tabs .nav-link.disabled {
- color: #6c757d;
- background-color: transparent;
- border-color: transparent;
-}
-.nav-tabs .nav-link.active,
-.nav-tabs .nav-item.show .nav-link {
- color: #495057;
- background-color: #fff;
- border-color: #dee2e6 #dee2e6 #fff;
-}
-.nav-tabs .dropdown-menu {
- margin-top: -1px;
- border-top-left-radius: 0;
- border-top-right-radius: 0;
-}
-
-.nav-pills .nav-link {
- background: none;
- border: 0;
- border-radius: 0.25rem;
-}
-.nav-pills .nav-link.active,
-.nav-pills .show > .nav-link {
- color: #fff;
- background-color: #0d6efd;
-}
-
-.nav-fill > .nav-link,
-.nav-fill .nav-item {
- flex: 1 1 auto;
- text-align: center;
-}
-
-.nav-justified > .nav-link,
-.nav-justified .nav-item {
- flex-basis: 0;
- flex-grow: 1;
- text-align: center;
-}
-
-.nav-fill .nav-item .nav-link,
-.nav-justified .nav-item .nav-link {
- width: 100%;
-}
-
-.tab-content > .tab-pane {
- display: none;
-}
-.tab-content > .active {
- display: block;
-}
-
-.navbar {
- position: relative;
- display: flex;
- flex-wrap: wrap;
- align-items: center;
- justify-content: space-between;
- padding-top: 0.5rem;
- padding-bottom: 0.5rem;
-}
-.navbar > .container,
-.navbar > .container-fluid,
-.navbar > .container-sm,
-.navbar > .container-md,
-.navbar > .container-lg,
-.navbar > .container-xl,
-.navbar > .container-xxl {
- display: flex;
- flex-wrap: inherit;
- align-items: center;
- justify-content: space-between;
-}
-.navbar-brand {
- padding-top: 0.3125rem;
- padding-bottom: 0.3125rem;
- margin-right: 1rem;
- font-size: 1.25rem;
- text-decoration: none;
- white-space: nowrap;
-}
-.navbar-nav {
- display: flex;
- flex-direction: column;
- padding-left: 0;
- margin-bottom: 0;
- list-style: none;
-}
-.navbar-nav .nav-link {
- padding-right: 0;
- padding-left: 0;
-}
-.navbar-nav .dropdown-menu {
- position: static;
-}
-
-.navbar-text {
- padding-top: 0.5rem;
- padding-bottom: 0.5rem;
-}
-
-.navbar-collapse {
- flex-basis: 100%;
- flex-grow: 1;
- align-items: center;
-}
-
-.navbar-toggler {
- padding: 0.25rem 0.75rem;
- font-size: 1.25rem;
- line-height: 1;
- background-color: transparent;
- border: 1px solid transparent;
- border-radius: 0.25rem;
- transition: box-shadow 0.15s ease-in-out;
-}
-@media (prefers-reduced-motion: reduce) {
- .navbar-toggler {
- transition: none;
- }
-}
-.navbar-toggler:hover {
- text-decoration: none;
-}
-.navbar-toggler:focus {
- text-decoration: none;
- outline: 0;
- box-shadow: 0 0 0 0.25rem;
-}
-
-.navbar-toggler-icon {
- display: inline-block;
- width: 1.5em;
- height: 1.5em;
- vertical-align: middle;
- background-repeat: no-repeat;
- background-position: center;
- background-size: 100%;
-}
-
-.navbar-nav-scroll {
- max-height: var(--bs-scroll-height, 75vh);
- overflow-y: auto;
-}
-
-@media (min-width: 576px) {
- .navbar-expand-sm {
- flex-wrap: nowrap;
- justify-content: flex-start;
- }
- .navbar-expand-sm .navbar-nav {
- flex-direction: row;
- }
- .navbar-expand-sm .navbar-nav .dropdown-menu {
- position: absolute;
- }
- .navbar-expand-sm .navbar-nav .nav-link {
- padding-right: 0.5rem;
- padding-left: 0.5rem;
- }
- .navbar-expand-sm .navbar-nav-scroll {
- overflow: visible;
- }
- .navbar-expand-sm .navbar-collapse {
- display: flex !important;
- flex-basis: auto;
- }
- .navbar-expand-sm .navbar-toggler {
- display: none;
- }
- .navbar-expand-sm .offcanvas-header {
- display: none;
- }
- .navbar-expand-sm .offcanvas {
- position: inherit;
- bottom: 0;
- z-index: 1000;
- flex-grow: 1;
- visibility: visible !important;
- background-color: transparent;
- border-right: 0;
- border-left: 0;
- transition: none;
- transform: none;
- }
- .navbar-expand-sm .offcanvas-top,
-.navbar-expand-sm .offcanvas-bottom {
- height: auto;
- border-top: 0;
- border-bottom: 0;
- }
- .navbar-expand-sm .offcanvas-body {
- display: flex;
- flex-grow: 0;
- padding: 0;
- overflow-y: visible;
- }
-}
-@media (min-width: 768px) {
- .navbar-expand-md {
- flex-wrap: nowrap;
- justify-content: flex-start;
- }
- .navbar-expand-md .navbar-nav {
- flex-direction: row;
- }
- .navbar-expand-md .navbar-nav .dropdown-menu {
- position: absolute;
- }
- .navbar-expand-md .navbar-nav .nav-link {
- padding-right: 0.5rem;
- padding-left: 0.5rem;
- }
- .navbar-expand-md .navbar-nav-scroll {
- overflow: visible;
- }
- .navbar-expand-md .navbar-collapse {
- display: flex !important;
- flex-basis: auto;
- }
- .navbar-expand-md .navbar-toggler {
- display: none;
- }
- .navbar-expand-md .offcanvas-header {
- display: none;
- }
- .navbar-expand-md .offcanvas {
- position: inherit;
- bottom: 0;
- z-index: 1000;
- flex-grow: 1;
- visibility: visible !important;
- background-color: transparent;
- border-right: 0;
- border-left: 0;
- transition: none;
- transform: none;
- }
- .navbar-expand-md .offcanvas-top,
-.navbar-expand-md .offcanvas-bottom {
- height: auto;
- border-top: 0;
- border-bottom: 0;
- }
- .navbar-expand-md .offcanvas-body {
- display: flex;
- flex-grow: 0;
- padding: 0;
- overflow-y: visible;
- }
-}
-@media (min-width: 992px) {
- .navbar-expand-lg {
- flex-wrap: nowrap;
- justify-content: flex-start;
- }
- .navbar-expand-lg .navbar-nav {
- flex-direction: row;
- }
- .navbar-expand-lg .navbar-nav .dropdown-menu {
- position: absolute;
- }
- .navbar-expand-lg .navbar-nav .nav-link {
- padding-right: 0.5rem;
- padding-left: 0.5rem;
- }
- .navbar-expand-lg .navbar-nav-scroll {
- overflow: visible;
- }
- .navbar-expand-lg .navbar-collapse {
- display: flex !important;
- flex-basis: auto;
- }
- .navbar-expand-lg .navbar-toggler {
- display: none;
- }
- .navbar-expand-lg .offcanvas-header {
- display: none;
- }
- .navbar-expand-lg .offcanvas {
- position: inherit;
- bottom: 0;
- z-index: 1000;
- flex-grow: 1;
- visibility: visible !important;
- background-color: transparent;
- border-right: 0;
- border-left: 0;
- transition: none;
- transform: none;
- }
- .navbar-expand-lg .offcanvas-top,
-.navbar-expand-lg .offcanvas-bottom {
- height: auto;
- border-top: 0;
- border-bottom: 0;
- }
- .navbar-expand-lg .offcanvas-body {
- display: flex;
- flex-grow: 0;
- padding: 0;
- overflow-y: visible;
- }
-}
-@media (min-width: 1200px) {
- .navbar-expand-xl {
- flex-wrap: nowrap;
- justify-content: flex-start;
- }
- .navbar-expand-xl .navbar-nav {
- flex-direction: row;
- }
- .navbar-expand-xl .navbar-nav .dropdown-menu {
- position: absolute;
- }
- .navbar-expand-xl .navbar-nav .nav-link {
- padding-right: 0.5rem;
- padding-left: 0.5rem;
- }
- .navbar-expand-xl .navbar-nav-scroll {
- overflow: visible;
- }
- .navbar-expand-xl .navbar-collapse {
- display: flex !important;
- flex-basis: auto;
- }
- .navbar-expand-xl .navbar-toggler {
- display: none;
- }
- .navbar-expand-xl .offcanvas-header {
- display: none;
- }
- .navbar-expand-xl .offcanvas {
- position: inherit;
- bottom: 0;
- z-index: 1000;
- flex-grow: 1;
- visibility: visible !important;
- background-color: transparent;
- border-right: 0;
- border-left: 0;
- transition: none;
- transform: none;
- }
- .navbar-expand-xl .offcanvas-top,
-.navbar-expand-xl .offcanvas-bottom {
- height: auto;
- border-top: 0;
- border-bottom: 0;
- }
- .navbar-expand-xl .offcanvas-body {
- display: flex;
- flex-grow: 0;
- padding: 0;
- overflow-y: visible;
- }
-}
-@media (min-width: 1400px) {
- .navbar-expand-xxl {
- flex-wrap: nowrap;
- justify-content: flex-start;
- }
- .navbar-expand-xxl .navbar-nav {
- flex-direction: row;
- }
- .navbar-expand-xxl .navbar-nav .dropdown-menu {
- position: absolute;
- }
- .navbar-expand-xxl .navbar-nav .nav-link {
- padding-right: 0.5rem;
- padding-left: 0.5rem;
- }
- .navbar-expand-xxl .navbar-nav-scroll {
- overflow: visible;
- }
- .navbar-expand-xxl .navbar-collapse {
- display: flex !important;
- flex-basis: auto;
- }
- .navbar-expand-xxl .navbar-toggler {
- display: none;
- }
- .navbar-expand-xxl .offcanvas-header {
- display: none;
- }
- .navbar-expand-xxl .offcanvas {
- position: inherit;
- bottom: 0;
- z-index: 1000;
- flex-grow: 1;
- visibility: visible !important;
- background-color: transparent;
- border-right: 0;
- border-left: 0;
- transition: none;
- transform: none;
- }
- .navbar-expand-xxl .offcanvas-top,
-.navbar-expand-xxl .offcanvas-bottom {
- height: auto;
- border-top: 0;
- border-bottom: 0;
- }
- .navbar-expand-xxl .offcanvas-body {
- display: flex;
- flex-grow: 0;
- padding: 0;
- overflow-y: visible;
- }
-}
-.navbar-expand {
- flex-wrap: nowrap;
- justify-content: flex-start;
-}
-.navbar-expand .navbar-nav {
- flex-direction: row;
-}
-.navbar-expand .navbar-nav .dropdown-menu {
- position: absolute;
-}
-.navbar-expand .navbar-nav .nav-link {
- padding-right: 0.5rem;
- padding-left: 0.5rem;
-}
-.navbar-expand .navbar-nav-scroll {
- overflow: visible;
-}
-.navbar-expand .navbar-collapse {
- display: flex !important;
- flex-basis: auto;
-}
-.navbar-expand .navbar-toggler {
- display: none;
-}
-.navbar-expand .offcanvas-header {
- display: none;
-}
-.navbar-expand .offcanvas {
- position: inherit;
- bottom: 0;
- z-index: 1000;
- flex-grow: 1;
- visibility: visible !important;
- background-color: transparent;
- border-right: 0;
- border-left: 0;
- transition: none;
- transform: none;
-}
-.navbar-expand .offcanvas-top,
-.navbar-expand .offcanvas-bottom {
- height: auto;
- border-top: 0;
- border-bottom: 0;
-}
-.navbar-expand .offcanvas-body {
- display: flex;
- flex-grow: 0;
- padding: 0;
- overflow-y: visible;
-}
-
-.navbar-light .navbar-brand {
- color: rgba(0, 0, 0, 0.9);
-}
-.navbar-light .navbar-brand:hover, .navbar-light .navbar-brand:focus {
- color: rgba(0, 0, 0, 0.9);
-}
-.navbar-light .navbar-nav .nav-link {
- color: rgba(0, 0, 0, 0.55);
-}
-.navbar-light .navbar-nav .nav-link:hover, .navbar-light .navbar-nav .nav-link:focus {
- color: rgba(0, 0, 0, 0.7);
-}
-.navbar-light .navbar-nav .nav-link.disabled {
- color: rgba(0, 0, 0, 0.3);
-}
-.navbar-light .navbar-nav .show > .nav-link,
-.navbar-light .navbar-nav .nav-link.active {
- color: rgba(0, 0, 0, 0.9);
-}
-.navbar-light .navbar-toggler {
- color: rgba(0, 0, 0, 0.55);
- border-color: rgba(0, 0, 0, 0.1);
-}
-.navbar-light .navbar-toggler-icon {
- background-image: url("data:image/svg+xml,%3csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 30 30'%3e%3cpath stroke='rgba%280, 0, 0, 0.55%29' stroke-linecap='round' stroke-miterlimit='10' stroke-width='2' d='M4 7h22M4 15h22M4 23h22'/%3e%3c/svg%3e");
-}
-.navbar-light .navbar-text {
- color: rgba(0, 0, 0, 0.55);
-}
-.navbar-light .navbar-text a,
-.navbar-light .navbar-text a:hover,
-.navbar-light .navbar-text a:focus {
- color: rgba(0, 0, 0, 0.9);
-}
-
-.navbar-dark .navbar-brand {
- color: #fff;
-}
-.navbar-dark .navbar-brand:hover, .navbar-dark .navbar-brand:focus {
- color: #fff;
-}
-.navbar-dark .navbar-nav .nav-link {
- color: rgba(255, 255, 255, 0.55);
-}
-.navbar-dark .navbar-nav .nav-link:hover, .navbar-dark .navbar-nav .nav-link:focus {
- color: rgba(255, 255, 255, 0.75);
-}
-.navbar-dark .navbar-nav .nav-link.disabled {
- color: rgba(255, 255, 255, 0.25);
-}
-.navbar-dark .navbar-nav .show > .nav-link,
-.navbar-dark .navbar-nav .nav-link.active {
- color: #fff;
-}
-.navbar-dark .navbar-toggler {
- color: rgba(255, 255, 255, 0.55);
- border-color: rgba(255, 255, 255, 0.1);
-}
-.navbar-dark .navbar-toggler-icon {
- background-image: url("data:image/svg+xml,%3csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 30 30'%3e%3cpath stroke='rgba%28255, 255, 255, 0.55%29' stroke-linecap='round' stroke-miterlimit='10' stroke-width='2' d='M4 7h22M4 15h22M4 23h22'/%3e%3c/svg%3e");
-}
-.navbar-dark .navbar-text {
- color: rgba(255, 255, 255, 0.55);
-}
-.navbar-dark .navbar-text a,
-.navbar-dark .navbar-text a:hover,
-.navbar-dark .navbar-text a:focus {
- color: #fff;
-}
-
-.card {
- position: relative;
- display: flex;
- flex-direction: column;
- min-width: 0;
- word-wrap: break-word;
- background-color: #fff;
- background-clip: border-box;
- border: 1px solid rgba(0, 0, 0, 0.125);
- border-radius: 0.25rem;
-}
-.card > hr {
- margin-right: 0;
- margin-left: 0;
-}
-.card > .list-group {
- border-top: inherit;
- border-bottom: inherit;
-}
-.card > .list-group:first-child {
- border-top-width: 0;
- border-top-left-radius: calc(0.25rem - 1px);
- border-top-right-radius: calc(0.25rem - 1px);
-}
-.card > .list-group:last-child {
- border-bottom-width: 0;
- border-bottom-right-radius: calc(0.25rem - 1px);
- border-bottom-left-radius: calc(0.25rem - 1px);
-}
-.card > .card-header + .list-group,
-.card > .list-group + .card-footer {
- border-top: 0;
-}
-
-.card-body {
- flex: 1 1 auto;
- padding: 1rem 1rem;
-}
-
-.card-title {
- margin-bottom: 0.5rem;
-}
-
-.card-subtitle {
- margin-top: -0.25rem;
- margin-bottom: 0;
-}
-
-.card-text:last-child {
- margin-bottom: 0;
-}
-
-.card-link + .card-link {
- margin-left: 1rem;
-}
-
-.card-header {
- padding: 0.5rem 1rem;
- margin-bottom: 0;
- background-color: rgba(0, 0, 0, 0.03);
- border-bottom: 1px solid rgba(0, 0, 0, 0.125);
-}
-.card-header:first-child {
- border-radius: calc(0.25rem - 1px) calc(0.25rem - 1px) 0 0;
-}
-
-.card-footer {
- padding: 0.5rem 1rem;
- background-color: rgba(0, 0, 0, 0.03);
- border-top: 1px solid rgba(0, 0, 0, 0.125);
-}
-.card-footer:last-child {
- border-radius: 0 0 calc(0.25rem - 1px) calc(0.25rem - 1px);
-}
-
-.card-header-tabs {
- margin-right: -0.5rem;
- margin-bottom: -0.5rem;
- margin-left: -0.5rem;
- border-bottom: 0;
-}
-
-.card-header-pills {
- margin-right: -0.5rem;
- margin-left: -0.5rem;
-}
-
-.card-img-overlay {
- position: absolute;
- top: 0;
- right: 0;
- bottom: 0;
- left: 0;
- padding: 1rem;
- border-radius: calc(0.25rem - 1px);
-}
-
-.card-img,
-.card-img-top,
-.card-img-bottom {
- width: 100%;
-}
-
-.card-img,
-.card-img-top {
- border-top-left-radius: calc(0.25rem - 1px);
- border-top-right-radius: calc(0.25rem - 1px);
-}
-
-.card-img,
-.card-img-bottom {
- border-bottom-right-radius: calc(0.25rem - 1px);
- border-bottom-left-radius: calc(0.25rem - 1px);
-}
-
-.card-group > .card {
- margin-bottom: 0.75rem;
-}
-@media (min-width: 576px) {
- .card-group {
- display: flex;
- flex-flow: row wrap;
- }
- .card-group > .card {
- flex: 1 0 0%;
- margin-bottom: 0;
- }
- .card-group > .card + .card {
- margin-left: 0;
- border-left: 0;
- }
- .card-group > .card:not(:last-child) {
- border-top-right-radius: 0;
- border-bottom-right-radius: 0;
- }
- .card-group > .card:not(:last-child) .card-img-top,
-.card-group > .card:not(:last-child) .card-header {
- border-top-right-radius: 0;
- }
- .card-group > .card:not(:last-child) .card-img-bottom,
-.card-group > .card:not(:last-child) .card-footer {
- border-bottom-right-radius: 0;
- }
- .card-group > .card:not(:first-child) {
- border-top-left-radius: 0;
- border-bottom-left-radius: 0;
- }
- .card-group > .card:not(:first-child) .card-img-top,
-.card-group > .card:not(:first-child) .card-header {
- border-top-left-radius: 0;
- }
- .card-group > .card:not(:first-child) .card-img-bottom,
-.card-group > .card:not(:first-child) .card-footer {
- border-bottom-left-radius: 0;
- }
-}
-
-.accordion-button {
- position: relative;
- display: flex;
- align-items: center;
- width: 100%;
- padding: 1rem 1.25rem;
- font-size: 1rem;
- color: #212529;
- text-align: left;
- background-color: #fff;
- border: 0;
- border-radius: 0;
- overflow-anchor: none;
- transition: color 0.15s ease-in-out, background-color 0.15s ease-in-out, border-color 0.15s ease-in-out, box-shadow 0.15s ease-in-out, border-radius 0.15s ease;
-}
-@media (prefers-reduced-motion: reduce) {
- .accordion-button {
- transition: none;
- }
-}
-.accordion-button:not(.collapsed) {
- color: #0c63e4;
- background-color: #e7f1ff;
- box-shadow: inset 0 -1px 0 rgba(0, 0, 0, 0.125);
-}
-.accordion-button:not(.collapsed)::after {
- background-image: url("data:image/svg+xml,%3csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 16 16' fill='%230c63e4'%3e%3cpath fill-rule='evenodd' d='M1.646 4.646a.5.5 0 0 1 .708 0L8 10.293l5.646-5.647a.5.5 0 0 1 .708.708l-6 6a.5.5 0 0 1-.708 0l-6-6a.5.5 0 0 1 0-.708z'/%3e%3c/svg%3e");
- transform: rotate(-180deg);
-}
-.accordion-button::after {
- flex-shrink: 0;
- width: 1.25rem;
- height: 1.25rem;
- margin-left: auto;
- content: "";
- background-image: url("data:image/svg+xml,%3csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 16 16' fill='%23212529'%3e%3cpath fill-rule='evenodd' d='M1.646 4.646a.5.5 0 0 1 .708 0L8 10.293l5.646-5.647a.5.5 0 0 1 .708.708l-6 6a.5.5 0 0 1-.708 0l-6-6a.5.5 0 0 1 0-.708z'/%3e%3c/svg%3e");
- background-repeat: no-repeat;
- background-size: 1.25rem;
- transition: transform 0.2s ease-in-out;
-}
-@media (prefers-reduced-motion: reduce) {
- .accordion-button::after {
- transition: none;
- }
-}
-.accordion-button:hover {
- z-index: 2;
-}
-.accordion-button:focus {
- z-index: 3;
- border-color: #86b7fe;
- outline: 0;
- box-shadow: 0 0 0 0.25rem rgba(13, 110, 253, 0.25);
-}
-
-.accordion-header {
- margin-bottom: 0;
-}
-
-.accordion-item {
- background-color: #fff;
- border: 1px solid rgba(0, 0, 0, 0.125);
-}
-.accordion-item:first-of-type {
- border-top-left-radius: 0.25rem;
- border-top-right-radius: 0.25rem;
-}
-.accordion-item:first-of-type .accordion-button {
- border-top-left-radius: calc(0.25rem - 1px);
- border-top-right-radius: calc(0.25rem - 1px);
-}
-.accordion-item:not(:first-of-type) {
- border-top: 0;
-}
-.accordion-item:last-of-type {
- border-bottom-right-radius: 0.25rem;
- border-bottom-left-radius: 0.25rem;
-}
-.accordion-item:last-of-type .accordion-button.collapsed {
- border-bottom-right-radius: calc(0.25rem - 1px);
- border-bottom-left-radius: calc(0.25rem - 1px);
-}
-.accordion-item:last-of-type .accordion-collapse {
- border-bottom-right-radius: 0.25rem;
- border-bottom-left-radius: 0.25rem;
-}
-
-.accordion-body {
- padding: 1rem 1.25rem;
-}
-
-.accordion-flush .accordion-collapse {
- border-width: 0;
-}
-.accordion-flush .accordion-item {
- border-right: 0;
- border-left: 0;
- border-radius: 0;
-}
-.accordion-flush .accordion-item:first-child {
- border-top: 0;
-}
-.accordion-flush .accordion-item:last-child {
- border-bottom: 0;
-}
-.accordion-flush .accordion-item .accordion-button {
- border-radius: 0;
-}
-
-.breadcrumb {
- display: flex;
- flex-wrap: wrap;
- padding: 0 0;
- margin-bottom: 1rem;
- list-style: none;
-}
-
-.breadcrumb-item + .breadcrumb-item {
- padding-left: 0.5rem;
-}
-.breadcrumb-item + .breadcrumb-item::before {
- float: left;
- padding-right: 0.5rem;
- color: #6c757d;
- content: var(--bs-breadcrumb-divider, "/") /* rtl: var(--bs-breadcrumb-divider, "/") */;
-}
-.breadcrumb-item.active {
- color: #6c757d;
-}
-
-.pagination {
- display: flex;
- padding-left: 0;
- list-style: none;
-}
-
-.page-link {
- position: relative;
- display: block;
- color: #0d6efd;
- text-decoration: none;
- background-color: #fff;
- border: 1px solid #dee2e6;
- transition: color 0.15s ease-in-out, background-color 0.15s ease-in-out, border-color 0.15s ease-in-out, box-shadow 0.15s ease-in-out;
-}
-@media (prefers-reduced-motion: reduce) {
- .page-link {
- transition: none;
- }
-}
-.page-link:hover {
- z-index: 2;
- color: #0a58ca;
- background-color: #e9ecef;
- border-color: #dee2e6;
-}
-.page-link:focus {
- z-index: 3;
- color: #0a58ca;
- background-color: #e9ecef;
- outline: 0;
- box-shadow: 0 0 0 0.25rem rgba(13, 110, 253, 0.25);
-}
-
-.page-item:not(:first-child) .page-link {
- margin-left: -1px;
-}
-.page-item.active .page-link {
- z-index: 3;
- color: #fff;
- background-color: #0d6efd;
- border-color: #0d6efd;
-}
-.page-item.disabled .page-link {
- color: #6c757d;
- pointer-events: none;
- background-color: #fff;
- border-color: #dee2e6;
-}
-
-.page-link {
- padding: 0.375rem 0.75rem;
-}
-
-.page-item:first-child .page-link {
- border-top-left-radius: 0.25rem;
- border-bottom-left-radius: 0.25rem;
-}
-.page-item:last-child .page-link {
- border-top-right-radius: 0.25rem;
- border-bottom-right-radius: 0.25rem;
-}
-
-.pagination-lg .page-link {
- padding: 0.75rem 1.5rem;
- font-size: 1.25rem;
-}
-.pagination-lg .page-item:first-child .page-link {
- border-top-left-radius: 0.3rem;
- border-bottom-left-radius: 0.3rem;
-}
-.pagination-lg .page-item:last-child .page-link {
- border-top-right-radius: 0.3rem;
- border-bottom-right-radius: 0.3rem;
-}
-
-.pagination-sm .page-link {
- padding: 0.25rem 0.5rem;
- font-size: 0.875rem;
-}
-.pagination-sm .page-item:first-child .page-link {
- border-top-left-radius: 0.2rem;
- border-bottom-left-radius: 0.2rem;
-}
-.pagination-sm .page-item:last-child .page-link {
- border-top-right-radius: 0.2rem;
- border-bottom-right-radius: 0.2rem;
-}
-
-.badge {
- display: inline-block;
- padding: 0.35em 0.65em;
- font-size: 0.75em;
- font-weight: 700;
- line-height: 1;
- color: #fff;
- text-align: center;
- white-space: nowrap;
- vertical-align: baseline;
- border-radius: 0.25rem;
-}
-.badge:empty {
- display: none;
-}
-
-.btn .badge {
- position: relative;
- top: -1px;
-}
-
-.alert {
- position: relative;
- padding: 1rem 1rem;
- margin-bottom: 1rem;
- border: 1px solid transparent;
- border-radius: 0.25rem;
-}
-
-.alert-heading {
- color: inherit;
-}
-
-.alert-link {
- font-weight: 700;
-}
-
-.alert-dismissible {
- padding-right: 3rem;
-}
-.alert-dismissible .btn-close {
- position: absolute;
- top: 0;
- right: 0;
- z-index: 2;
- padding: 1.25rem 1rem;
-}
-
-.alert-primary {
- color: #084298;
- background-color: #cfe2ff;
- border-color: #b6d4fe;
-}
-.alert-primary .alert-link {
- color: #06357a;
-}
-
-.alert-secondary {
- color: #41464b;
- background-color: #e2e3e5;
- border-color: #d3d6d8;
-}
-.alert-secondary .alert-link {
- color: #34383c;
-}
-
-.alert-success {
- color: #0f5132;
- background-color: #d1e7dd;
- border-color: #badbcc;
-}
-.alert-success .alert-link {
- color: #0c4128;
-}
-
-.alert-info {
- color: #055160;
- background-color: #cff4fc;
- border-color: #b6effb;
-}
-.alert-info .alert-link {
- color: #04414d;
-}
-
-.alert-warning {
- color: #664d03;
- background-color: #fff3cd;
- border-color: #ffecb5;
-}
-.alert-warning .alert-link {
- color: #523e02;
-}
-
-.alert-danger {
- color: #842029;
- background-color: #f8d7da;
- border-color: #f5c2c7;
-}
-.alert-danger .alert-link {
- color: #6a1a21;
-}
-
-.alert-light {
- color: #636464;
- background-color: #fefefe;
- border-color: #fdfdfe;
-}
-.alert-light .alert-link {
- color: #4f5050;
-}
-
-.alert-dark {
- color: #141619;
- background-color: #d3d3d4;
- border-color: #bcbebf;
-}
-.alert-dark .alert-link {
- color: #101214;
-}
-
-@-webkit-keyframes progress-bar-stripes {
- 0% {
- background-position-x: 1rem;
- }
-}
-
-@keyframes progress-bar-stripes {
- 0% {
- background-position-x: 1rem;
- }
-}
-.progress {
- display: flex;
- height: 1rem;
- overflow: hidden;
- font-size: 0.75rem;
- background-color: #e9ecef;
- border-radius: 0.25rem;
-}
-
-.progress-bar {
- display: flex;
- flex-direction: column;
- justify-content: center;
- overflow: hidden;
- color: #fff;
- text-align: center;
- white-space: nowrap;
- background-color: #0d6efd;
- transition: width 0.6s ease;
-}
-@media (prefers-reduced-motion: reduce) {
- .progress-bar {
- transition: none;
- }
-}
-
-.progress-bar-striped {
- background-image: linear-gradient(45deg, rgba(255, 255, 255, 0.15) 25%, transparent 25%, transparent 50%, rgba(255, 255, 255, 0.15) 50%, rgba(255, 255, 255, 0.15) 75%, transparent 75%, transparent);
- background-size: 1rem 1rem;
-}
-
-.progress-bar-animated {
- -webkit-animation: 1s linear infinite progress-bar-stripes;
- animation: 1s linear infinite progress-bar-stripes;
-}
-@media (prefers-reduced-motion: reduce) {
- .progress-bar-animated {
- -webkit-animation: none;
- animation: none;
- }
-}
-
-.list-group {
- display: flex;
- flex-direction: column;
- padding-left: 0;
- margin-bottom: 0;
- border-radius: 0.25rem;
-}
-
-.list-group-numbered {
- list-style-type: none;
- counter-reset: section;
-}
-.list-group-numbered > li::before {
- content: counters(section, ".") ". ";
- counter-increment: section;
-}
-
-.list-group-item-action {
- width: 100%;
- color: #495057;
- text-align: inherit;
-}
-.list-group-item-action:hover, .list-group-item-action:focus {
- z-index: 1;
- color: #495057;
- text-decoration: none;
- background-color: #f8f9fa;
-}
-.list-group-item-action:active {
- color: #212529;
- background-color: #e9ecef;
-}
-
-.list-group-item {
- position: relative;
- display: block;
- padding: 0.5rem 1rem;
- color: #212529;
- text-decoration: none;
- background-color: #fff;
- border: 1px solid rgba(0, 0, 0, 0.125);
-}
-.list-group-item:first-child {
- border-top-left-radius: inherit;
- border-top-right-radius: inherit;
-}
-.list-group-item:last-child {
- border-bottom-right-radius: inherit;
- border-bottom-left-radius: inherit;
-}
-.list-group-item.disabled, .list-group-item:disabled {
- color: #6c757d;
- pointer-events: none;
- background-color: #fff;
-}
-.list-group-item.active {
- z-index: 2;
- color: #fff;
- background-color: #0d6efd;
- border-color: #0d6efd;
-}
-.list-group-item + .list-group-item {
- border-top-width: 0;
-}
-.list-group-item + .list-group-item.active {
- margin-top: -1px;
- border-top-width: 1px;
-}
-
-.list-group-horizontal {
- flex-direction: row;
-}
-.list-group-horizontal > .list-group-item:first-child {
- border-bottom-left-radius: 0.25rem;
- border-top-right-radius: 0;
-}
-.list-group-horizontal > .list-group-item:last-child {
- border-top-right-radius: 0.25rem;
- border-bottom-left-radius: 0;
-}
-.list-group-horizontal > .list-group-item.active {
- margin-top: 0;
-}
-.list-group-horizontal > .list-group-item + .list-group-item {
- border-top-width: 1px;
- border-left-width: 0;
-}
-.list-group-horizontal > .list-group-item + .list-group-item.active {
- margin-left: -1px;
- border-left-width: 1px;
-}
-
-@media (min-width: 576px) {
- .list-group-horizontal-sm {
- flex-direction: row;
- }
- .list-group-horizontal-sm > .list-group-item:first-child {
- border-bottom-left-radius: 0.25rem;
- border-top-right-radius: 0;
- }
- .list-group-horizontal-sm > .list-group-item:last-child {
- border-top-right-radius: 0.25rem;
- border-bottom-left-radius: 0;
- }
- .list-group-horizontal-sm > .list-group-item.active {
- margin-top: 0;
- }
- .list-group-horizontal-sm > .list-group-item + .list-group-item {
- border-top-width: 1px;
- border-left-width: 0;
- }
- .list-group-horizontal-sm > .list-group-item + .list-group-item.active {
- margin-left: -1px;
- border-left-width: 1px;
- }
-}
-@media (min-width: 768px) {
- .list-group-horizontal-md {
- flex-direction: row;
- }
- .list-group-horizontal-md > .list-group-item:first-child {
- border-bottom-left-radius: 0.25rem;
- border-top-right-radius: 0;
- }
- .list-group-horizontal-md > .list-group-item:last-child {
- border-top-right-radius: 0.25rem;
- border-bottom-left-radius: 0;
- }
- .list-group-horizontal-md > .list-group-item.active {
- margin-top: 0;
- }
- .list-group-horizontal-md > .list-group-item + .list-group-item {
- border-top-width: 1px;
- border-left-width: 0;
- }
- .list-group-horizontal-md > .list-group-item + .list-group-item.active {
- margin-left: -1px;
- border-left-width: 1px;
- }
-}
-@media (min-width: 992px) {
- .list-group-horizontal-lg {
- flex-direction: row;
- }
- .list-group-horizontal-lg > .list-group-item:first-child {
- border-bottom-left-radius: 0.25rem;
- border-top-right-radius: 0;
- }
- .list-group-horizontal-lg > .list-group-item:last-child {
- border-top-right-radius: 0.25rem;
- border-bottom-left-radius: 0;
- }
- .list-group-horizontal-lg > .list-group-item.active {
- margin-top: 0;
- }
- .list-group-horizontal-lg > .list-group-item + .list-group-item {
- border-top-width: 1px;
- border-left-width: 0;
- }
- .list-group-horizontal-lg > .list-group-item + .list-group-item.active {
- margin-left: -1px;
- border-left-width: 1px;
- }
-}
-@media (min-width: 1200px) {
- .list-group-horizontal-xl {
- flex-direction: row;
- }
- .list-group-horizontal-xl > .list-group-item:first-child {
- border-bottom-left-radius: 0.25rem;
- border-top-right-radius: 0;
- }
- .list-group-horizontal-xl > .list-group-item:last-child {
- border-top-right-radius: 0.25rem;
- border-bottom-left-radius: 0;
- }
- .list-group-horizontal-xl > .list-group-item.active {
- margin-top: 0;
- }
- .list-group-horizontal-xl > .list-group-item + .list-group-item {
- border-top-width: 1px;
- border-left-width: 0;
- }
- .list-group-horizontal-xl > .list-group-item + .list-group-item.active {
- margin-left: -1px;
- border-left-width: 1px;
- }
-}
-@media (min-width: 1400px) {
- .list-group-horizontal-xxl {
- flex-direction: row;
- }
- .list-group-horizontal-xxl > .list-group-item:first-child {
- border-bottom-left-radius: 0.25rem;
- border-top-right-radius: 0;
- }
- .list-group-horizontal-xxl > .list-group-item:last-child {
- border-top-right-radius: 0.25rem;
- border-bottom-left-radius: 0;
- }
- .list-group-horizontal-xxl > .list-group-item.active {
- margin-top: 0;
- }
- .list-group-horizontal-xxl > .list-group-item + .list-group-item {
- border-top-width: 1px;
- border-left-width: 0;
- }
- .list-group-horizontal-xxl > .list-group-item + .list-group-item.active {
- margin-left: -1px;
- border-left-width: 1px;
- }
-}
-.list-group-flush {
- border-radius: 0;
-}
-.list-group-flush > .list-group-item {
- border-width: 0 0 1px;
-}
-.list-group-flush > .list-group-item:last-child {
- border-bottom-width: 0;
-}
-
-.list-group-item-primary {
- color: #084298;
- background-color: #cfe2ff;
-}
-.list-group-item-primary.list-group-item-action:hover, .list-group-item-primary.list-group-item-action:focus {
- color: #084298;
- background-color: #bacbe6;
-}
-.list-group-item-primary.list-group-item-action.active {
- color: #fff;
- background-color: #084298;
- border-color: #084298;
-}
-
-.list-group-item-secondary {
- color: #41464b;
- background-color: #e2e3e5;
-}
-.list-group-item-secondary.list-group-item-action:hover, .list-group-item-secondary.list-group-item-action:focus {
- color: #41464b;
- background-color: #cbccce;
-}
-.list-group-item-secondary.list-group-item-action.active {
- color: #fff;
- background-color: #41464b;
- border-color: #41464b;
-}
-
-.list-group-item-success {
- color: #0f5132;
- background-color: #d1e7dd;
-}
-.list-group-item-success.list-group-item-action:hover, .list-group-item-success.list-group-item-action:focus {
- color: #0f5132;
- background-color: #bcd0c7;
-}
-.list-group-item-success.list-group-item-action.active {
- color: #fff;
- background-color: #0f5132;
- border-color: #0f5132;
-}
-
-.list-group-item-info {
- color: #055160;
- background-color: #cff4fc;
-}
-.list-group-item-info.list-group-item-action:hover, .list-group-item-info.list-group-item-action:focus {
- color: #055160;
- background-color: #badce3;
-}
-.list-group-item-info.list-group-item-action.active {
- color: #fff;
- background-color: #055160;
- border-color: #055160;
-}
-
-.list-group-item-warning {
- color: #664d03;
- background-color: #fff3cd;
-}
-.list-group-item-warning.list-group-item-action:hover, .list-group-item-warning.list-group-item-action:focus {
- color: #664d03;
- background-color: #e6dbb9;
-}
-.list-group-item-warning.list-group-item-action.active {
- color: #fff;
- background-color: #664d03;
- border-color: #664d03;
-}
-
-.list-group-item-danger {
- color: #842029;
- background-color: #f8d7da;
-}
-.list-group-item-danger.list-group-item-action:hover, .list-group-item-danger.list-group-item-action:focus {
- color: #842029;
- background-color: #dfc2c4;
-}
-.list-group-item-danger.list-group-item-action.active {
- color: #fff;
- background-color: #842029;
- border-color: #842029;
-}
-
-.list-group-item-light {
- color: #636464;
- background-color: #fefefe;
-}
-.list-group-item-light.list-group-item-action:hover, .list-group-item-light.list-group-item-action:focus {
- color: #636464;
- background-color: #e5e5e5;
-}
-.list-group-item-light.list-group-item-action.active {
- color: #fff;
- background-color: #636464;
- border-color: #636464;
-}
-
-.list-group-item-dark {
- color: #141619;
- background-color: #d3d3d4;
-}
-.list-group-item-dark.list-group-item-action:hover, .list-group-item-dark.list-group-item-action:focus {
- color: #141619;
- background-color: #bebebf;
-}
-.list-group-item-dark.list-group-item-action.active {
- color: #fff;
- background-color: #141619;
- border-color: #141619;
-}
-
-.btn-close {
- box-sizing: content-box;
- width: 1em;
- height: 1em;
- padding: 0.25em 0.25em;
- color: #000;
- background: transparent url("data:image/svg+xml,%3csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 16 16' fill='%23000'%3e%3cpath d='M.293.293a1 1 0 011.414 0L8 6.586 14.293.293a1 1 0 111.414 1.414L9.414 8l6.293 6.293a1 1 0 01-1.414 1.414L8 9.414l-6.293 6.293a1 1 0 01-1.414-1.414L6.586 8 .293 1.707a1 1 0 010-1.414z'/%3e%3c/svg%3e") center/1em auto no-repeat;
- border: 0;
- border-radius: 0.25rem;
- opacity: 0.5;
-}
-.btn-close:hover {
- color: #000;
- text-decoration: none;
- opacity: 0.75;
-}
-.btn-close:focus {
- outline: 0;
- box-shadow: 0 0 0 0.25rem rgba(13, 110, 253, 0.25);
- opacity: 1;
-}
-.btn-close:disabled, .btn-close.disabled {
- pointer-events: none;
- -webkit-user-select: none;
- -moz-user-select: none;
- user-select: none;
- opacity: 0.25;
-}
-
-.btn-close-white {
- filter: invert(1) grayscale(100%) brightness(200%);
-}
-
-.toast {
- width: 350px;
- max-width: 100%;
- font-size: 0.875rem;
- pointer-events: auto;
- background-color: rgba(255, 255, 255, 0.85);
- background-clip: padding-box;
- border: 1px solid rgba(0, 0, 0, 0.1);
- box-shadow: 0 0.5rem 1rem rgba(0, 0, 0, 0.15);
- border-radius: 0.25rem;
-}
-.toast.showing {
- opacity: 0;
-}
-.toast:not(.show) {
- display: none;
-}
-
-.toast-container {
- width: -webkit-max-content;
- width: -moz-max-content;
- width: max-content;
- max-width: 100%;
- pointer-events: none;
-}
-.toast-container > :not(:last-child) {
- margin-bottom: 0.75rem;
-}
-
-.toast-header {
- display: flex;
- align-items: center;
- padding: 0.5rem 0.75rem;
- color: #6c757d;
- background-color: rgba(255, 255, 255, 0.85);
- background-clip: padding-box;
- border-bottom: 1px solid rgba(0, 0, 0, 0.05);
- border-top-left-radius: calc(0.25rem - 1px);
- border-top-right-radius: calc(0.25rem - 1px);
-}
-.toast-header .btn-close {
- margin-right: -0.375rem;
- margin-left: 0.75rem;
-}
-
-.toast-body {
- padding: 0.75rem;
- word-wrap: break-word;
-}
-
-.modal {
- position: fixed;
- top: 0;
- left: 0;
- z-index: 1055;
- display: none;
- width: 100%;
- height: 100%;
- overflow-x: hidden;
- overflow-y: auto;
- outline: 0;
-}
-
-.modal-dialog {
- position: relative;
- width: auto;
- margin: 0.5rem;
- pointer-events: none;
-}
-.modal.fade .modal-dialog {
- transition: transform 0.3s ease-out;
- transform: translate(0, -50px);
-}
-@media (prefers-reduced-motion: reduce) {
- .modal.fade .modal-dialog {
- transition: none;
- }
-}
-.modal.show .modal-dialog {
- transform: none;
-}
-.modal.modal-static .modal-dialog {
- transform: scale(1.02);
-}
-
-.modal-dialog-scrollable {
- height: calc(100% - 1rem);
-}
-.modal-dialog-scrollable .modal-content {
- max-height: 100%;
- overflow: hidden;
-}
-.modal-dialog-scrollable .modal-body {
- overflow-y: auto;
-}
-
-.modal-dialog-centered {
- display: flex;
- align-items: center;
- min-height: calc(100% - 1rem);
-}
-
-.modal-content {
- position: relative;
- display: flex;
- flex-direction: column;
- width: 100%;
- pointer-events: auto;
- background-color: #fff;
- background-clip: padding-box;
- border: 1px solid rgba(0, 0, 0, 0.2);
- border-radius: 0.3rem;
- outline: 0;
-}
-
-.modal-backdrop {
- position: fixed;
- top: 0;
- left: 0;
- z-index: 1050;
- width: 100vw;
- height: 100vh;
- background-color: #000;
-}
-.modal-backdrop.fade {
- opacity: 0;
-}
-.modal-backdrop.show {
- opacity: 0.5;
-}
-
-.modal-header {
- display: flex;
- flex-shrink: 0;
- align-items: center;
- justify-content: space-between;
- padding: 1rem 1rem;
- border-bottom: 1px solid #dee2e6;
- border-top-left-radius: calc(0.3rem - 1px);
- border-top-right-radius: calc(0.3rem - 1px);
-}
-.modal-header .btn-close {
- padding: 0.5rem 0.5rem;
- margin: -0.5rem -0.5rem -0.5rem auto;
-}
-
-.modal-title {
- margin-bottom: 0;
- line-height: 1.5;
-}
-
-.modal-body {
- position: relative;
- flex: 1 1 auto;
- padding: 1rem;
-}
-
-.modal-footer {
- display: flex;
- flex-wrap: wrap;
- flex-shrink: 0;
- align-items: center;
- justify-content: flex-end;
- padding: 0.75rem;
- border-top: 1px solid #dee2e6;
- border-bottom-right-radius: calc(0.3rem - 1px);
- border-bottom-left-radius: calc(0.3rem - 1px);
-}
-.modal-footer > * {
- margin: 0.25rem;
-}
-
-@media (min-width: 576px) {
- .modal-dialog {
- max-width: 500px;
- margin: 1.75rem auto;
- }
-
- .modal-dialog-scrollable {
- height: calc(100% - 3.5rem);
- }
-
- .modal-dialog-centered {
- min-height: calc(100% - 3.5rem);
- }
-
- .modal-sm {
- max-width: 300px;
- }
-}
-@media (min-width: 992px) {
- .modal-lg,
-.modal-xl {
- max-width: 800px;
- }
-}
-@media (min-width: 1200px) {
- .modal-xl {
- max-width: 1140px;
- }
-}
-.modal-fullscreen {
- width: 100vw;
- max-width: none;
- height: 100%;
- margin: 0;
-}
-.modal-fullscreen .modal-content {
- height: 100%;
- border: 0;
- border-radius: 0;
-}
-.modal-fullscreen .modal-header {
- border-radius: 0;
-}
-.modal-fullscreen .modal-body {
- overflow-y: auto;
-}
-.modal-fullscreen .modal-footer {
- border-radius: 0;
-}
-
-@media (max-width: 575.98px) {
- .modal-fullscreen-sm-down {
- width: 100vw;
- max-width: none;
- height: 100%;
- margin: 0;
- }
- .modal-fullscreen-sm-down .modal-content {
- height: 100%;
- border: 0;
- border-radius: 0;
- }
- .modal-fullscreen-sm-down .modal-header {
- border-radius: 0;
- }
- .modal-fullscreen-sm-down .modal-body {
- overflow-y: auto;
- }
- .modal-fullscreen-sm-down .modal-footer {
- border-radius: 0;
- }
-}
-@media (max-width: 767.98px) {
- .modal-fullscreen-md-down {
- width: 100vw;
- max-width: none;
- height: 100%;
- margin: 0;
- }
- .modal-fullscreen-md-down .modal-content {
- height: 100%;
- border: 0;
- border-radius: 0;
- }
- .modal-fullscreen-md-down .modal-header {
- border-radius: 0;
- }
- .modal-fullscreen-md-down .modal-body {
- overflow-y: auto;
- }
- .modal-fullscreen-md-down .modal-footer {
- border-radius: 0;
- }
-}
-@media (max-width: 991.98px) {
- .modal-fullscreen-lg-down {
- width: 100vw;
- max-width: none;
- height: 100%;
- margin: 0;
- }
- .modal-fullscreen-lg-down .modal-content {
- height: 100%;
- border: 0;
- border-radius: 0;
- }
- .modal-fullscreen-lg-down .modal-header {
- border-radius: 0;
- }
- .modal-fullscreen-lg-down .modal-body {
- overflow-y: auto;
- }
- .modal-fullscreen-lg-down .modal-footer {
- border-radius: 0;
- }
-}
-@media (max-width: 1199.98px) {
- .modal-fullscreen-xl-down {
- width: 100vw;
- max-width: none;
- height: 100%;
- margin: 0;
- }
- .modal-fullscreen-xl-down .modal-content {
- height: 100%;
- border: 0;
- border-radius: 0;
- }
- .modal-fullscreen-xl-down .modal-header {
- border-radius: 0;
- }
- .modal-fullscreen-xl-down .modal-body {
- overflow-y: auto;
- }
- .modal-fullscreen-xl-down .modal-footer {
- border-radius: 0;
- }
-}
-@media (max-width: 1399.98px) {
- .modal-fullscreen-xxl-down {
- width: 100vw;
- max-width: none;
- height: 100%;
- margin: 0;
- }
- .modal-fullscreen-xxl-down .modal-content {
- height: 100%;
- border: 0;
- border-radius: 0;
- }
- .modal-fullscreen-xxl-down .modal-header {
- border-radius: 0;
- }
- .modal-fullscreen-xxl-down .modal-body {
- overflow-y: auto;
- }
- .modal-fullscreen-xxl-down .modal-footer {
- border-radius: 0;
- }
-}
-.tooltip {
- position: absolute;
- z-index: 1080;
- display: block;
- margin: 0;
- font-family: var(--bs-font-sans-serif);
- font-style: normal;
- font-weight: 400;
- line-height: 1.5;
- text-align: left;
- text-align: start;
- text-decoration: none;
- text-shadow: none;
- text-transform: none;
- letter-spacing: normal;
- word-break: normal;
- word-spacing: normal;
- white-space: normal;
- line-break: auto;
- font-size: 0.875rem;
- word-wrap: break-word;
- opacity: 0;
-}
-.tooltip.show {
- opacity: 0.9;
-}
-.tooltip .tooltip-arrow {
- position: absolute;
- display: block;
- width: 0.8rem;
- height: 0.4rem;
-}
-.tooltip .tooltip-arrow::before {
- position: absolute;
- content: "";
- border-color: transparent;
- border-style: solid;
-}
-
-.bs-tooltip-top, .bs-tooltip-auto[data-popper-placement^=top] {
- padding: 0.4rem 0;
-}
-.bs-tooltip-top .tooltip-arrow, .bs-tooltip-auto[data-popper-placement^=top] .tooltip-arrow {
- bottom: 0;
-}
-.bs-tooltip-top .tooltip-arrow::before, .bs-tooltip-auto[data-popper-placement^=top] .tooltip-arrow::before {
- top: -1px;
- border-width: 0.4rem 0.4rem 0;
- border-top-color: #000;
-}
-
-.bs-tooltip-end, .bs-tooltip-auto[data-popper-placement^=right] {
- padding: 0 0.4rem;
-}
-.bs-tooltip-end .tooltip-arrow, .bs-tooltip-auto[data-popper-placement^=right] .tooltip-arrow {
- left: 0;
- width: 0.4rem;
- height: 0.8rem;
-}
-.bs-tooltip-end .tooltip-arrow::before, .bs-tooltip-auto[data-popper-placement^=right] .tooltip-arrow::before {
- right: -1px;
- border-width: 0.4rem 0.4rem 0.4rem 0;
- border-right-color: #000;
-}
-
-.bs-tooltip-bottom, .bs-tooltip-auto[data-popper-placement^=bottom] {
- padding: 0.4rem 0;
-}
-.bs-tooltip-bottom .tooltip-arrow, .bs-tooltip-auto[data-popper-placement^=bottom] .tooltip-arrow {
- top: 0;
-}
-.bs-tooltip-bottom .tooltip-arrow::before, .bs-tooltip-auto[data-popper-placement^=bottom] .tooltip-arrow::before {
- bottom: -1px;
- border-width: 0 0.4rem 0.4rem;
- border-bottom-color: #000;
-}
-
-.bs-tooltip-start, .bs-tooltip-auto[data-popper-placement^=left] {
- padding: 0 0.4rem;
-}
-.bs-tooltip-start .tooltip-arrow, .bs-tooltip-auto[data-popper-placement^=left] .tooltip-arrow {
- right: 0;
- width: 0.4rem;
- height: 0.8rem;
-}
-.bs-tooltip-start .tooltip-arrow::before, .bs-tooltip-auto[data-popper-placement^=left] .tooltip-arrow::before {
- left: -1px;
- border-width: 0.4rem 0 0.4rem 0.4rem;
- border-left-color: #000;
-}
-
-.tooltip-inner {
- max-width: 200px;
- padding: 0.25rem 0.5rem;
- color: #fff;
- text-align: center;
- background-color: #000;
- border-radius: 0.25rem;
-}
-
-.popover {
- position: absolute;
- top: 0;
- left: 0 /* rtl:ignore */;
- z-index: 1070;
- display: block;
- max-width: 276px;
- font-family: var(--bs-font-sans-serif);
- font-style: normal;
- font-weight: 400;
- line-height: 1.5;
- text-align: left;
- text-align: start;
- text-decoration: none;
- text-shadow: none;
- text-transform: none;
- letter-spacing: normal;
- word-break: normal;
- word-spacing: normal;
- white-space: normal;
- line-break: auto;
- font-size: 0.875rem;
- word-wrap: break-word;
- background-color: #fff;
- background-clip: padding-box;
- border: 1px solid rgba(0, 0, 0, 0.2);
- border-radius: 0.3rem;
-}
-.popover .popover-arrow {
- position: absolute;
- display: block;
- width: 1rem;
- height: 0.5rem;
-}
-.popover .popover-arrow::before, .popover .popover-arrow::after {
- position: absolute;
- display: block;
- content: "";
- border-color: transparent;
- border-style: solid;
-}
-
-.bs-popover-top > .popover-arrow, .bs-popover-auto[data-popper-placement^=top] > .popover-arrow {
- bottom: calc(-0.5rem - 1px);
-}
-.bs-popover-top > .popover-arrow::before, .bs-popover-auto[data-popper-placement^=top] > .popover-arrow::before {
- bottom: 0;
- border-width: 0.5rem 0.5rem 0;
- border-top-color: rgba(0, 0, 0, 0.25);
-}
-.bs-popover-top > .popover-arrow::after, .bs-popover-auto[data-popper-placement^=top] > .popover-arrow::after {
- bottom: 1px;
- border-width: 0.5rem 0.5rem 0;
- border-top-color: #fff;
-}
-
-.bs-popover-end > .popover-arrow, .bs-popover-auto[data-popper-placement^=right] > .popover-arrow {
- left: calc(-0.5rem - 1px);
- width: 0.5rem;
- height: 1rem;
-}
-.bs-popover-end > .popover-arrow::before, .bs-popover-auto[data-popper-placement^=right] > .popover-arrow::before {
- left: 0;
- border-width: 0.5rem 0.5rem 0.5rem 0;
- border-right-color: rgba(0, 0, 0, 0.25);
-}
-.bs-popover-end > .popover-arrow::after, .bs-popover-auto[data-popper-placement^=right] > .popover-arrow::after {
- left: 1px;
- border-width: 0.5rem 0.5rem 0.5rem 0;
- border-right-color: #fff;
-}
-
-.bs-popover-bottom > .popover-arrow, .bs-popover-auto[data-popper-placement^=bottom] > .popover-arrow {
- top: calc(-0.5rem - 1px);
-}
-.bs-popover-bottom > .popover-arrow::before, .bs-popover-auto[data-popper-placement^=bottom] > .popover-arrow::before {
- top: 0;
- border-width: 0 0.5rem 0.5rem 0.5rem;
- border-bottom-color: rgba(0, 0, 0, 0.25);
-}
-.bs-popover-bottom > .popover-arrow::after, .bs-popover-auto[data-popper-placement^=bottom] > .popover-arrow::after {
- top: 1px;
- border-width: 0 0.5rem 0.5rem 0.5rem;
- border-bottom-color: #fff;
-}
-.bs-popover-bottom .popover-header::before, .bs-popover-auto[data-popper-placement^=bottom] .popover-header::before {
- position: absolute;
- top: 0;
- left: 50%;
- display: block;
- width: 1rem;
- margin-left: -0.5rem;
- content: "";
- border-bottom: 1px solid #f0f0f0;
-}
-
-.bs-popover-start > .popover-arrow, .bs-popover-auto[data-popper-placement^=left] > .popover-arrow {
- right: calc(-0.5rem - 1px);
- width: 0.5rem;
- height: 1rem;
-}
-.bs-popover-start > .popover-arrow::before, .bs-popover-auto[data-popper-placement^=left] > .popover-arrow::before {
- right: 0;
- border-width: 0.5rem 0 0.5rem 0.5rem;
- border-left-color: rgba(0, 0, 0, 0.25);
-}
-.bs-popover-start > .popover-arrow::after, .bs-popover-auto[data-popper-placement^=left] > .popover-arrow::after {
- right: 1px;
- border-width: 0.5rem 0 0.5rem 0.5rem;
- border-left-color: #fff;
-}
-
-.popover-header {
- padding: 0.5rem 1rem;
- margin-bottom: 0;
- font-size: 1rem;
- background-color: #f0f0f0;
- border-bottom: 1px solid rgba(0, 0, 0, 0.2);
- border-top-left-radius: calc(0.3rem - 1px);
- border-top-right-radius: calc(0.3rem - 1px);
-}
-.popover-header:empty {
- display: none;
-}
-
-.popover-body {
- padding: 1rem 1rem;
- color: #212529;
-}
-
-.carousel {
- position: relative;
-}
-
-.carousel.pointer-event {
- touch-action: pan-y;
-}
-
-.carousel-inner {
- position: relative;
- width: 100%;
- overflow: hidden;
-}
-.carousel-inner::after {
- display: block;
- clear: both;
- content: "";
-}
-
-.carousel-item {
- position: relative;
- display: none;
- float: left;
- width: 100%;
- margin-right: -100%;
- -webkit-backface-visibility: hidden;
- backface-visibility: hidden;
- transition: transform 0.6s ease-in-out;
-}
-@media (prefers-reduced-motion: reduce) {
- .carousel-item {
- transition: none;
- }
-}
-
-.carousel-item.active,
-.carousel-item-next,
-.carousel-item-prev {
- display: block;
-}
-
-/* rtl:begin:ignore */
-.carousel-item-next:not(.carousel-item-start),
-.active.carousel-item-end {
- transform: translateX(100%);
-}
-
-.carousel-item-prev:not(.carousel-item-end),
-.active.carousel-item-start {
- transform: translateX(-100%);
-}
-
-/* rtl:end:ignore */
-.carousel-fade .carousel-item {
- opacity: 0;
- transition-property: opacity;
- transform: none;
-}
-.carousel-fade .carousel-item.active,
-.carousel-fade .carousel-item-next.carousel-item-start,
-.carousel-fade .carousel-item-prev.carousel-item-end {
- z-index: 1;
- opacity: 1;
-}
-.carousel-fade .active.carousel-item-start,
-.carousel-fade .active.carousel-item-end {
- z-index: 0;
- opacity: 0;
- transition: opacity 0s 0.6s;
-}
-@media (prefers-reduced-motion: reduce) {
- .carousel-fade .active.carousel-item-start,
-.carousel-fade .active.carousel-item-end {
- transition: none;
- }
-}
-
-.carousel-control-prev,
-.carousel-control-next {
- position: absolute;
- top: 0;
- bottom: 0;
- z-index: 1;
- display: flex;
- align-items: center;
- justify-content: center;
- width: 15%;
- padding: 0;
- color: #fff;
- text-align: center;
- background: none;
- border: 0;
- opacity: 0.5;
- transition: opacity 0.15s ease;
-}
-@media (prefers-reduced-motion: reduce) {
- .carousel-control-prev,
-.carousel-control-next {
- transition: none;
- }
-}
-.carousel-control-prev:hover, .carousel-control-prev:focus,
-.carousel-control-next:hover,
-.carousel-control-next:focus {
- color: #fff;
- text-decoration: none;
- outline: 0;
- opacity: 0.9;
-}
-
-.carousel-control-prev {
- left: 0;
-}
-
-.carousel-control-next {
- right: 0;
-}
-
-.carousel-control-prev-icon,
-.carousel-control-next-icon {
- display: inline-block;
- width: 2rem;
- height: 2rem;
- background-repeat: no-repeat;
- background-position: 50%;
- background-size: 100% 100%;
-}
-
-/* rtl:options: {
- "autoRename": true,
- "stringMap":[ {
- "name" : "prev-next",
- "search" : "prev",
- "replace" : "next"
- } ]
-} */
-.carousel-control-prev-icon {
- background-image: url("data:image/svg+xml,%3csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 16 16' fill='%23fff'%3e%3cpath d='M11.354 1.646a.5.5 0 0 1 0 .708L5.707 8l5.647 5.646a.5.5 0 0 1-.708.708l-6-6a.5.5 0 0 1 0-.708l6-6a.5.5 0 0 1 .708 0z'/%3e%3c/svg%3e");
-}
-
-.carousel-control-next-icon {
- background-image: url("data:image/svg+xml,%3csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 16 16' fill='%23fff'%3e%3cpath d='M4.646 1.646a.5.5 0 0 1 .708 0l6 6a.5.5 0 0 1 0 .708l-6 6a.5.5 0 0 1-.708-.708L10.293 8 4.646 2.354a.5.5 0 0 1 0-.708z'/%3e%3c/svg%3e");
-}
-
-.carousel-indicators {
- position: absolute;
- right: 0;
- bottom: 0;
- left: 0;
- z-index: 2;
- display: flex;
- justify-content: center;
- padding: 0;
- margin-right: 15%;
- margin-bottom: 1rem;
- margin-left: 15%;
- list-style: none;
-}
-.carousel-indicators [data-bs-target] {
- box-sizing: content-box;
- flex: 0 1 auto;
- width: 30px;
- height: 3px;
- padding: 0;
- margin-right: 3px;
- margin-left: 3px;
- text-indent: -999px;
- cursor: pointer;
- background-color: #fff;
- background-clip: padding-box;
- border: 0;
- border-top: 10px solid transparent;
- border-bottom: 10px solid transparent;
- opacity: 0.5;
- transition: opacity 0.6s ease;
-}
-@media (prefers-reduced-motion: reduce) {
- .carousel-indicators [data-bs-target] {
- transition: none;
- }
-}
-.carousel-indicators .active {
- opacity: 1;
-}
-
-.carousel-caption {
- position: absolute;
- right: 15%;
- bottom: 1.25rem;
- left: 15%;
- padding-top: 1.25rem;
- padding-bottom: 1.25rem;
- color: #fff;
- text-align: center;
-}
-
-.carousel-dark .carousel-control-prev-icon,
-.carousel-dark .carousel-control-next-icon {
- filter: invert(1) grayscale(100);
-}
-.carousel-dark .carousel-indicators [data-bs-target] {
- background-color: #000;
-}
-.carousel-dark .carousel-caption {
- color: #000;
-}
-
-@-webkit-keyframes spinner-border {
- to {
- transform: rotate(360deg) /* rtl:ignore */;
- }
-}
-
-@keyframes spinner-border {
- to {
- transform: rotate(360deg) /* rtl:ignore */;
- }
-}
-.spinner-border {
- display: inline-block;
- width: 2rem;
- height: 2rem;
- vertical-align: -0.125em;
- border: 0.25em solid currentColor;
- border-right-color: transparent;
- border-radius: 50%;
- -webkit-animation: 0.75s linear infinite spinner-border;
- animation: 0.75s linear infinite spinner-border;
-}
-
-.spinner-border-sm {
- width: 1rem;
- height: 1rem;
- border-width: 0.2em;
-}
-
-@-webkit-keyframes spinner-grow {
- 0% {
- transform: scale(0);
- }
- 50% {
- opacity: 1;
- transform: none;
- }
-}
-
-@keyframes spinner-grow {
- 0% {
- transform: scale(0);
- }
- 50% {
- opacity: 1;
- transform: none;
- }
-}
-.spinner-grow {
- display: inline-block;
- width: 2rem;
- height: 2rem;
- vertical-align: -0.125em;
- background-color: currentColor;
- border-radius: 50%;
- opacity: 0;
- -webkit-animation: 0.75s linear infinite spinner-grow;
- animation: 0.75s linear infinite spinner-grow;
-}
-
-.spinner-grow-sm {
- width: 1rem;
- height: 1rem;
-}
-
-@media (prefers-reduced-motion: reduce) {
- .spinner-border,
-.spinner-grow {
- -webkit-animation-duration: 1.5s;
- animation-duration: 1.5s;
- }
-}
-.offcanvas {
- position: fixed;
- bottom: 0;
- z-index: 1045;
- display: flex;
- flex-direction: column;
- max-width: 100%;
- visibility: hidden;
- background-color: #fff;
- background-clip: padding-box;
- outline: 0;
- transition: transform 0.3s ease-in-out;
-}
-@media (prefers-reduced-motion: reduce) {
- .offcanvas {
- transition: none;
- }
-}
-
-.offcanvas-backdrop {
- position: fixed;
- top: 0;
- left: 0;
- z-index: 1040;
- width: 100vw;
- height: 100vh;
- background-color: #000;
-}
-.offcanvas-backdrop.fade {
- opacity: 0;
-}
-.offcanvas-backdrop.show {
- opacity: 0.5;
-}
-
-.offcanvas-header {
- display: flex;
- align-items: center;
- justify-content: space-between;
- padding: 1rem 1rem;
-}
-.offcanvas-header .btn-close {
- padding: 0.5rem 0.5rem;
- margin-top: -0.5rem;
- margin-right: -0.5rem;
- margin-bottom: -0.5rem;
-}
-
-.offcanvas-title {
- margin-bottom: 0;
- line-height: 1.5;
-}
-
-.offcanvas-body {
- flex-grow: 1;
- padding: 1rem 1rem;
- overflow-y: auto;
-}
-
-.offcanvas-start {
- top: 0;
- left: 0;
- width: 400px;
- border-right: 1px solid rgba(0, 0, 0, 0.2);
- transform: translateX(-100%);
-}
-
-.offcanvas-end {
- top: 0;
- right: 0;
- width: 400px;
- border-left: 1px solid rgba(0, 0, 0, 0.2);
- transform: translateX(100%);
-}
-
-.offcanvas-top {
- top: 0;
- right: 0;
- left: 0;
- height: 30vh;
- max-height: 100%;
- border-bottom: 1px solid rgba(0, 0, 0, 0.2);
- transform: translateY(-100%);
-}
-
-.offcanvas-bottom {
- right: 0;
- left: 0;
- height: 30vh;
- max-height: 100%;
- border-top: 1px solid rgba(0, 0, 0, 0.2);
- transform: translateY(100%);
-}
-
-.offcanvas.show {
- transform: none;
-}
-
-.placeholder {
- display: inline-block;
- min-height: 1em;
- vertical-align: middle;
- cursor: wait;
- background-color: currentColor;
- opacity: 0.5;
-}
-.placeholder.btn::before {
- display: inline-block;
- content: "";
-}
-
-.placeholder-xs {
- min-height: 0.6em;
-}
-
-.placeholder-sm {
- min-height: 0.8em;
-}
-
-.placeholder-lg {
- min-height: 1.2em;
-}
-
-.placeholder-glow .placeholder {
- -webkit-animation: placeholder-glow 2s ease-in-out infinite;
- animation: placeholder-glow 2s ease-in-out infinite;
-}
-
-@-webkit-keyframes placeholder-glow {
- 50% {
- opacity: 0.2;
- }
-}
-
-@keyframes placeholder-glow {
- 50% {
- opacity: 0.2;
- }
-}
-.placeholder-wave {
- -webkit-mask-image: linear-gradient(130deg, #000 55%, rgba(0, 0, 0, 0.8) 75%, #000 95%);
- mask-image: linear-gradient(130deg, #000 55%, rgba(0, 0, 0, 0.8) 75%, #000 95%);
- -webkit-mask-size: 200% 100%;
- mask-size: 200% 100%;
- -webkit-animation: placeholder-wave 2s linear infinite;
- animation: placeholder-wave 2s linear infinite;
-}
-
-@-webkit-keyframes placeholder-wave {
- 100% {
- -webkit-mask-position: -200% 0%;
- mask-position: -200% 0%;
- }
-}
-
-@keyframes placeholder-wave {
- 100% {
- -webkit-mask-position: -200% 0%;
- mask-position: -200% 0%;
- }
-}
-.clearfix::after {
- display: block;
- clear: both;
- content: "";
-}
-
-.link-primary {
- color: #0d6efd;
-}
-.link-primary:hover, .link-primary:focus {
- color: #0a58ca;
-}
-
-.link-secondary {
- color: #6c757d;
-}
-.link-secondary:hover, .link-secondary:focus {
- color: #565e64;
-}
-
-.link-success {
- color: #198754;
-}
-.link-success:hover, .link-success:focus {
- color: #146c43;
-}
-
-.link-info {
- color: #0dcaf0;
-}
-.link-info:hover, .link-info:focus {
- color: #3dd5f3;
-}
-
-.link-warning {
- color: #ffc107;
-}
-.link-warning:hover, .link-warning:focus {
- color: #ffcd39;
-}
-
-.link-danger {
- color: #dc3545;
-}
-.link-danger:hover, .link-danger:focus {
- color: #b02a37;
-}
-
-.link-light {
- color: #f8f9fa;
-}
-.link-light:hover, .link-light:focus {
- color: #f9fafb;
-}
-
-.link-dark {
- color: #212529;
-}
-.link-dark:hover, .link-dark:focus {
- color: #1a1e21;
-}
-
-.ratio {
- position: relative;
- width: 100%;
-}
-.ratio::before {
- display: block;
- padding-top: var(--bs-aspect-ratio);
- content: "";
-}
-.ratio > * {
- position: absolute;
- top: 0;
- left: 0;
- width: 100%;
- height: 100%;
-}
-
-.ratio-1x1 {
- --bs-aspect-ratio: 100%;
-}
-
-.ratio-4x3 {
- --bs-aspect-ratio: 75%;
-}
-
-.ratio-16x9 {
- --bs-aspect-ratio: 56.25%;
-}
-
-.ratio-21x9 {
- --bs-aspect-ratio: 42.8571428571%;
-}
-
-.fixed-top {
- position: fixed;
- top: 0;
- right: 0;
- left: 0;
- z-index: 1030;
-}
-
-.fixed-bottom {
- position: fixed;
- right: 0;
- bottom: 0;
- left: 0;
- z-index: 1030;
-}
-
-.sticky-top {
- position: -webkit-sticky;
- position: sticky;
- top: 0;
- z-index: 1020;
-}
-
-@media (min-width: 576px) {
- .sticky-sm-top {
- position: -webkit-sticky;
- position: sticky;
- top: 0;
- z-index: 1020;
- }
-}
-@media (min-width: 768px) {
- .sticky-md-top {
- position: -webkit-sticky;
- position: sticky;
- top: 0;
- z-index: 1020;
- }
-}
-@media (min-width: 992px) {
- .sticky-lg-top {
- position: -webkit-sticky;
- position: sticky;
- top: 0;
- z-index: 1020;
- }
-}
-@media (min-width: 1200px) {
- .sticky-xl-top {
- position: -webkit-sticky;
- position: sticky;
- top: 0;
- z-index: 1020;
- }
-}
-@media (min-width: 1400px) {
- .sticky-xxl-top {
- position: -webkit-sticky;
- position: sticky;
- top: 0;
- z-index: 1020;
- }
-}
-.hstack {
- display: flex;
- flex-direction: row;
- align-items: center;
- align-self: stretch;
-}
-
-.vstack {
- display: flex;
- flex: 1 1 auto;
- flex-direction: column;
- align-self: stretch;
-}
-
-.visually-hidden,
-.visually-hidden-focusable:not(:focus):not(:focus-within) {
- position: absolute !important;
- width: 1px !important;
- height: 1px !important;
- padding: 0 !important;
- margin: -1px !important;
- overflow: hidden !important;
- clip: rect(0, 0, 0, 0) !important;
- white-space: nowrap !important;
- border: 0 !important;
-}
-
-.stretched-link::after {
- position: absolute;
- top: 0;
- right: 0;
- bottom: 0;
- left: 0;
- z-index: 1;
- content: "";
-}
-
-.text-truncate {
- overflow: hidden;
- text-overflow: ellipsis;
- white-space: nowrap;
-}
-
-.vr {
- display: inline-block;
- align-self: stretch;
- width: 1px;
- min-height: 1em;
- background-color: currentColor;
- opacity: 0.25;
-}
-
-.align-baseline {
- vertical-align: baseline !important;
-}
-
-.align-top {
- vertical-align: top !important;
-}
-
-.align-middle {
- vertical-align: middle !important;
-}
-
-.align-bottom {
- vertical-align: bottom !important;
-}
-
-.align-text-bottom {
- vertical-align: text-bottom !important;
-}
-
-.align-text-top {
- vertical-align: text-top !important;
-}
-
-.float-start {
- float: left !important;
-}
-
-.float-end {
- float: right !important;
-}
-
-.float-none {
- float: none !important;
-}
-
-.opacity-0 {
- opacity: 0 !important;
-}
-
-.opacity-25 {
- opacity: 0.25 !important;
-}
-
-.opacity-50 {
- opacity: 0.5 !important;
-}
-
-.opacity-75 {
- opacity: 0.75 !important;
-}
-
-.opacity-100 {
- opacity: 1 !important;
-}
-
-.overflow-auto {
- overflow: auto !important;
-}
-
-.overflow-hidden {
- overflow: hidden !important;
-}
-
-.overflow-visible {
- overflow: visible !important;
-}
-
-.overflow-scroll {
- overflow: scroll !important;
-}
-
-.d-inline {
- display: inline !important;
-}
-
-.d-inline-block {
- display: inline-block !important;
-}
-
-.d-block {
- display: block !important;
-}
-
-.d-grid {
- display: grid !important;
-}
-
-.d-table {
- display: table !important;
-}
-
-.d-table-row {
- display: table-row !important;
-}
-
-.d-table-cell {
- display: table-cell !important;
-}
-
-.d-flex {
- display: flex !important;
-}
-
-.d-inline-flex {
- display: inline-flex !important;
-}
-
-.d-none {
- display: none !important;
-}
-
-.shadow {
- box-shadow: 0 0.5rem 1rem rgba(0, 0, 0, 0.15) !important;
-}
-
-.shadow-sm {
- box-shadow: 0 0.125rem 0.25rem rgba(0, 0, 0, 0.075) !important;
-}
-
-.shadow-lg {
- box-shadow: 0 1rem 3rem rgba(0, 0, 0, 0.175) !important;
-}
-
-.shadow-none {
- box-shadow: none !important;
-}
-
-.position-static {
- position: static !important;
-}
-
-.position-relative {
- position: relative !important;
-}
-
-.position-absolute {
- position: absolute !important;
-}
-
-.position-fixed {
- position: fixed !important;
-}
-
-.position-sticky {
- position: -webkit-sticky !important;
- position: sticky !important;
-}
-
-.top-0 {
- top: 0 !important;
-}
-
-.top-50 {
- top: 50% !important;
-}
-
-.top-100 {
- top: 100% !important;
-}
-
-.bottom-0 {
- bottom: 0 !important;
-}
-
-.bottom-50 {
- bottom: 50% !important;
-}
-
-.bottom-100 {
- bottom: 100% !important;
-}
-
-.start-0 {
- left: 0 !important;
-}
-
-.start-50 {
- left: 50% !important;
-}
-
-.start-100 {
- left: 100% !important;
-}
-
-.end-0 {
- right: 0 !important;
-}
-
-.end-50 {
- right: 50% !important;
-}
-
-.end-100 {
- right: 100% !important;
-}
-
-.translate-middle {
- transform: translate(-50%, -50%) !important;
-}
-
-.translate-middle-x {
- transform: translateX(-50%) !important;
-}
-
-.translate-middle-y {
- transform: translateY(-50%) !important;
-}
-
-.border {
- border: 1px solid #dee2e6 !important;
-}
-
-.border-0 {
- border: 0 !important;
-}
-
-.border-top {
- border-top: 1px solid #dee2e6 !important;
-}
-
-.border-top-0 {
- border-top: 0 !important;
-}
-
-.border-end {
- border-right: 1px solid #dee2e6 !important;
-}
-
-.border-end-0 {
- border-right: 0 !important;
-}
-
-.border-bottom {
- border-bottom: 1px solid #dee2e6 !important;
-}
-
-.border-bottom-0 {
- border-bottom: 0 !important;
-}
-
-.border-start {
- border-left: 1px solid #dee2e6 !important;
-}
-
-.border-start-0 {
- border-left: 0 !important;
-}
-
-.border-primary {
- border-color: #0d6efd !important;
-}
-
-.border-secondary {
- border-color: #6c757d !important;
-}
-
-.border-success {
- border-color: #198754 !important;
-}
-
-.border-info {
- border-color: #0dcaf0 !important;
-}
-
-.border-warning {
- border-color: #ffc107 !important;
-}
-
-.border-danger {
- border-color: #dc3545 !important;
-}
-
-.border-light {
- border-color: #f8f9fa !important;
-}
-
-.border-dark {
- border-color: #212529 !important;
-}
-
-.border-white {
- border-color: #fff !important;
-}
-
-.border-1 {
- border-width: 1px !important;
-}
-
-.border-2 {
- border-width: 2px !important;
-}
-
-.border-3 {
- border-width: 3px !important;
-}
-
-.border-4 {
- border-width: 4px !important;
-}
-
-.border-5 {
- border-width: 5px !important;
-}
-
-.w-25 {
- width: 25% !important;
-}
-
-.w-50 {
- width: 50% !important;
-}
-
-.w-75 {
- width: 75% !important;
-}
-
-.w-100 {
- width: 100% !important;
-}
-
-.w-auto {
- width: auto !important;
-}
-
-.mw-100 {
- max-width: 100% !important;
-}
-
-.vw-100 {
- width: 100vw !important;
-}
-
-.min-vw-100 {
- min-width: 100vw !important;
-}
-
-.h-25 {
- height: 25% !important;
-}
-
-.h-50 {
- height: 50% !important;
-}
-
-.h-75 {
- height: 75% !important;
-}
-
-.h-100 {
- height: 100% !important;
-}
-
-.h-auto {
- height: auto !important;
-}
-
-.mh-100 {
- max-height: 100% !important;
-}
-
-.vh-100 {
- height: 100vh !important;
-}
-
-.min-vh-100 {
- min-height: 100vh !important;
-}
-
-.flex-fill {
- flex: 1 1 auto !important;
-}
-
-.flex-row {
- flex-direction: row !important;
-}
-
-.flex-column {
- flex-direction: column !important;
-}
-
-.flex-row-reverse {
- flex-direction: row-reverse !important;
-}
-
-.flex-column-reverse {
- flex-direction: column-reverse !important;
-}
-
-.flex-grow-0 {
- flex-grow: 0 !important;
-}
-
-.flex-grow-1 {
- flex-grow: 1 !important;
-}
-
-.flex-shrink-0 {
- flex-shrink: 0 !important;
-}
-
-.flex-shrink-1 {
- flex-shrink: 1 !important;
-}
-
-.flex-wrap {
- flex-wrap: wrap !important;
-}
-
-.flex-nowrap {
- flex-wrap: nowrap !important;
-}
-
-.flex-wrap-reverse {
- flex-wrap: wrap-reverse !important;
-}
-
-.gap-0 {
- gap: 0 !important;
-}
-
-.gap-1 {
- gap: 0.25rem !important;
-}
-
-.gap-2 {
- gap: 0.5rem !important;
-}
-
-.gap-3 {
- gap: 1rem !important;
-}
-
-.gap-4 {
- gap: 1.5rem !important;
-}
-
-.gap-5 {
- gap: 3rem !important;
-}
-
-.justify-content-start {
- justify-content: flex-start !important;
-}
-
-.justify-content-end {
- justify-content: flex-end !important;
-}
-
-.justify-content-center {
- justify-content: center !important;
-}
-
-.justify-content-between {
- justify-content: space-between !important;
-}
-
-.justify-content-around {
- justify-content: space-around !important;
-}
-
-.justify-content-evenly {
- justify-content: space-evenly !important;
-}
-
-.align-items-start {
- align-items: flex-start !important;
-}
-
-.align-items-end {
- align-items: flex-end !important;
-}
-
-.align-items-center {
- align-items: center !important;
-}
-
-.align-items-baseline {
- align-items: baseline !important;
-}
-
-.align-items-stretch {
- align-items: stretch !important;
-}
-
-.align-content-start {
- align-content: flex-start !important;
-}
-
-.align-content-end {
- align-content: flex-end !important;
-}
-
-.align-content-center {
- align-content: center !important;
-}
-
-.align-content-between {
- align-content: space-between !important;
-}
-
-.align-content-around {
- align-content: space-around !important;
-}
-
-.align-content-stretch {
- align-content: stretch !important;
-}
-
-.align-self-auto {
- align-self: auto !important;
-}
-
-.align-self-start {
- align-self: flex-start !important;
-}
-
-.align-self-end {
- align-self: flex-end !important;
-}
-
-.align-self-center {
- align-self: center !important;
-}
-
-.align-self-baseline {
- align-self: baseline !important;
-}
-
-.align-self-stretch {
- align-self: stretch !important;
-}
-
-.order-first {
- order: -1 !important;
-}
-
-.order-0 {
- order: 0 !important;
-}
-
-.order-1 {
- order: 1 !important;
-}
-
-.order-2 {
- order: 2 !important;
-}
-
-.order-3 {
- order: 3 !important;
-}
-
-.order-4 {
- order: 4 !important;
-}
-
-.order-5 {
- order: 5 !important;
-}
-
-.order-last {
- order: 6 !important;
-}
-
-.m-0 {
- margin: 0 !important;
-}
-
-.m-1 {
- margin: 0.25rem !important;
-}
-
-.m-2 {
- margin: 0.5rem !important;
-}
-
-.m-3 {
- margin: 1rem !important;
-}
-
-.m-4 {
- margin: 1.5rem !important;
-}
-
-.m-5 {
- margin: 3rem !important;
-}
-
-.m-auto {
- margin: auto !important;
-}
-
-.mx-0 {
- margin-right: 0 !important;
- margin-left: 0 !important;
-}
-
-.mx-1 {
- margin-right: 0.25rem !important;
- margin-left: 0.25rem !important;
-}
-
-.mx-2 {
- margin-right: 0.5rem !important;
- margin-left: 0.5rem !important;
-}
-
-.mx-3 {
- margin-right: 1rem !important;
- margin-left: 1rem !important;
-}
-
-.mx-4 {
- margin-right: 1.5rem !important;
- margin-left: 1.5rem !important;
-}
-
-.mx-5 {
- margin-right: 3rem !important;
- margin-left: 3rem !important;
-}
-
-.mx-auto {
- margin-right: auto !important;
- margin-left: auto !important;
-}
-
-.my-0 {
- margin-top: 0 !important;
- margin-bottom: 0 !important;
-}
-
-.my-1 {
- margin-top: 0.25rem !important;
- margin-bottom: 0.25rem !important;
-}
-
-.my-2 {
- margin-top: 0.5rem !important;
- margin-bottom: 0.5rem !important;
-}
-
-.my-3 {
- margin-top: 1rem !important;
- margin-bottom: 1rem !important;
-}
-
-.my-4 {
- margin-top: 1.5rem !important;
- margin-bottom: 1.5rem !important;
-}
-
-.my-5 {
- margin-top: 3rem !important;
- margin-bottom: 3rem !important;
-}
-
-.my-auto {
- margin-top: auto !important;
- margin-bottom: auto !important;
-}
-
-.mt-0 {
- margin-top: 0 !important;
-}
-
-.mt-1 {
- margin-top: 0.25rem !important;
-}
-
-.mt-2 {
- margin-top: 0.5rem !important;
-}
-
-.mt-3 {
- margin-top: 1rem !important;
-}
-
-.mt-4 {
- margin-top: 1.5rem !important;
-}
-
-.mt-5 {
- margin-top: 3rem !important;
-}
-
-.mt-auto {
- margin-top: auto !important;
-}
-
-.me-0 {
- margin-right: 0 !important;
-}
-
-.me-1 {
- margin-right: 0.25rem !important;
-}
-
-.me-2 {
- margin-right: 0.5rem !important;
-}
-
-.me-3 {
- margin-right: 1rem !important;
-}
-
-.me-4 {
- margin-right: 1.5rem !important;
-}
-
-.me-5 {
- margin-right: 3rem !important;
-}
-
-.me-auto {
- margin-right: auto !important;
-}
-
-.mb-0 {
- margin-bottom: 0 !important;
-}
-
-.mb-1 {
- margin-bottom: 0.25rem !important;
-}
-
-.mb-2 {
- margin-bottom: 0.5rem !important;
-}
-
-.mb-3 {
- margin-bottom: 1rem !important;
-}
-
-.mb-4 {
- margin-bottom: 1.5rem !important;
-}
-
-.mb-5 {
- margin-bottom: 3rem !important;
-}
-
-.mb-auto {
- margin-bottom: auto !important;
-}
-
-.ms-0 {
- margin-left: 0 !important;
-}
-
-.ms-1 {
- margin-left: 0.25rem !important;
-}
-
-.ms-2 {
- margin-left: 0.5rem !important;
-}
-
-.ms-3 {
- margin-left: 1rem !important;
-}
-
-.ms-4 {
- margin-left: 1.5rem !important;
-}
-
-.ms-5 {
- margin-left: 3rem !important;
-}
-
-.ms-auto {
- margin-left: auto !important;
-}
-
-.p-0 {
- padding: 0 !important;
-}
-
-.p-1 {
- padding: 0.25rem !important;
-}
-
-.p-2 {
- padding: 0.5rem !important;
-}
-
-.p-3 {
- padding: 1rem !important;
-}
-
-.p-4 {
- padding: 1.5rem !important;
-}
-
-.p-5 {
- padding: 3rem !important;
-}
-
-.px-0 {
- padding-right: 0 !important;
- padding-left: 0 !important;
-}
-
-.px-1 {
- padding-right: 0.25rem !important;
- padding-left: 0.25rem !important;
-}
-
-.px-2 {
- padding-right: 0.5rem !important;
- padding-left: 0.5rem !important;
-}
-
-.px-3 {
- padding-right: 1rem !important;
- padding-left: 1rem !important;
-}
-
-.px-4 {
- padding-right: 1.5rem !important;
- padding-left: 1.5rem !important;
-}
-
-.px-5 {
- padding-right: 3rem !important;
- padding-left: 3rem !important;
-}
-
-.py-0 {
- padding-top: 0 !important;
- padding-bottom: 0 !important;
-}
-
-.py-1 {
- padding-top: 0.25rem !important;
- padding-bottom: 0.25rem !important;
-}
-
-.py-2 {
- padding-top: 0.5rem !important;
- padding-bottom: 0.5rem !important;
-}
-
-.py-3 {
- padding-top: 1rem !important;
- padding-bottom: 1rem !important;
-}
-
-.py-4 {
- padding-top: 1.5rem !important;
- padding-bottom: 1.5rem !important;
-}
-
-.py-5 {
- padding-top: 3rem !important;
- padding-bottom: 3rem !important;
-}
-
-.pt-0 {
- padding-top: 0 !important;
-}
-
-.pt-1 {
- padding-top: 0.25rem !important;
-}
-
-.pt-2 {
- padding-top: 0.5rem !important;
-}
-
-.pt-3 {
- padding-top: 1rem !important;
-}
-
-.pt-4 {
- padding-top: 1.5rem !important;
-}
-
-.pt-5 {
- padding-top: 3rem !important;
-}
-
-.pe-0 {
- padding-right: 0 !important;
-}
-
-.pe-1 {
- padding-right: 0.25rem !important;
-}
-
-.pe-2 {
- padding-right: 0.5rem !important;
-}
-
-.pe-3 {
- padding-right: 1rem !important;
-}
-
-.pe-4 {
- padding-right: 1.5rem !important;
-}
-
-.pe-5 {
- padding-right: 3rem !important;
-}
-
-.pb-0 {
- padding-bottom: 0 !important;
-}
-
-.pb-1 {
- padding-bottom: 0.25rem !important;
-}
-
-.pb-2 {
- padding-bottom: 0.5rem !important;
-}
-
-.pb-3 {
- padding-bottom: 1rem !important;
-}
-
-.pb-4 {
- padding-bottom: 1.5rem !important;
-}
-
-.pb-5 {
- padding-bottom: 3rem !important;
-}
-
-.ps-0 {
- padding-left: 0 !important;
-}
-
-.ps-1 {
- padding-left: 0.25rem !important;
-}
-
-.ps-2 {
- padding-left: 0.5rem !important;
-}
-
-.ps-3 {
- padding-left: 1rem !important;
-}
-
-.ps-4 {
- padding-left: 1.5rem !important;
-}
-
-.ps-5 {
- padding-left: 3rem !important;
-}
-
-.font-monospace {
- font-family: var(--bs-font-monospace) !important;
-}
-
-.fs-1 {
- font-size: calc(1.375rem + 1.5vw) !important;
-}
-
-.fs-2 {
- font-size: calc(1.325rem + 0.9vw) !important;
-}
-
-.fs-3 {
- font-size: calc(1.3rem + 0.6vw) !important;
-}
-
-.fs-4 {
- font-size: calc(1.275rem + 0.3vw) !important;
-}
-
-.fs-5 {
- font-size: 1.25rem !important;
-}
-
-.fs-6 {
- font-size: 1rem !important;
-}
-
-.fst-italic {
- font-style: italic !important;
-}
-
-.fst-normal {
- font-style: normal !important;
-}
-
-.fw-light {
- font-weight: 300 !important;
-}
-
-.fw-lighter {
- font-weight: lighter !important;
-}
-
-.fw-normal {
- font-weight: 400 !important;
-}
-
-.fw-bold {
- font-weight: 700 !important;
-}
-
-.fw-bolder {
- font-weight: bolder !important;
-}
-
-.lh-1 {
- line-height: 1 !important;
-}
-
-.lh-sm {
- line-height: 1.25 !important;
-}
-
-.lh-base {
- line-height: 1.5 !important;
-}
-
-.lh-lg {
- line-height: 2 !important;
-}
-
-.text-start {
- text-align: left !important;
-}
-
-.text-end {
- text-align: right !important;
-}
-
-.text-center {
- text-align: center !important;
-}
-
-.text-decoration-none {
- text-decoration: none !important;
-}
-
-.text-decoration-underline {
- text-decoration: underline !important;
-}
-
-.text-decoration-line-through {
- text-decoration: line-through !important;
-}
-
-.text-lowercase {
- text-transform: lowercase !important;
-}
-
-.text-uppercase {
- text-transform: uppercase !important;
-}
-
-.text-capitalize {
- text-transform: capitalize !important;
-}
-
-.text-wrap {
- white-space: normal !important;
-}
-
-.text-nowrap {
- white-space: nowrap !important;
-}
-
-/* rtl:begin:remove */
-.text-break {
- word-wrap: break-word !important;
- word-break: break-word !important;
-}
-
-/* rtl:end:remove */
-.text-primary {
- --bs-text-opacity: 1;
- color: rgba(var(--bs-primary-rgb), var(--bs-text-opacity)) !important;
-}
-
-.text-secondary {
- --bs-text-opacity: 1;
- color: rgba(var(--bs-secondary-rgb), var(--bs-text-opacity)) !important;
-}
-
-.text-success {
- --bs-text-opacity: 1;
- color: rgba(var(--bs-success-rgb), var(--bs-text-opacity)) !important;
-}
-
-.text-info {
- --bs-text-opacity: 1;
- color: rgba(var(--bs-info-rgb), var(--bs-text-opacity)) !important;
-}
-
-.text-warning {
- --bs-text-opacity: 1;
- color: rgba(var(--bs-warning-rgb), var(--bs-text-opacity)) !important;
-}
-
-.text-danger {
- --bs-text-opacity: 1;
- color: rgba(var(--bs-danger-rgb), var(--bs-text-opacity)) !important;
-}
-
-.text-light {
- --bs-text-opacity: 1;
- color: rgba(var(--bs-light-rgb), var(--bs-text-opacity)) !important;
-}
-
-.text-dark {
- --bs-text-opacity: 1;
- color: rgba(var(--bs-dark-rgb), var(--bs-text-opacity)) !important;
-}
-
-.text-black {
- --bs-text-opacity: 1;
- color: rgba(var(--bs-black-rgb), var(--bs-text-opacity)) !important;
-}
-
-.text-white {
- --bs-text-opacity: 1;
- color: rgba(var(--bs-white-rgb), var(--bs-text-opacity)) !important;
-}
-
-.text-body {
- --bs-text-opacity: 1;
- color: rgba(var(--bs-body-color-rgb), var(--bs-text-opacity)) !important;
-}
-
-.text-muted {
- --bs-text-opacity: 1;
- color: #6c757d !important;
-}
-
-.text-black-50 {
- --bs-text-opacity: 1;
- color: rgba(0, 0, 0, 0.5) !important;
-}
-
-.text-white-50 {
- --bs-text-opacity: 1;
- color: rgba(255, 255, 255, 0.5) !important;
-}
-
-.text-reset {
- --bs-text-opacity: 1;
- color: inherit !important;
-}
-
-.text-opacity-25 {
- --bs-text-opacity: 0.25;
-}
-
-.text-opacity-50 {
- --bs-text-opacity: 0.5;
-}
-
-.text-opacity-75 {
- --bs-text-opacity: 0.75;
-}
-
-.text-opacity-100 {
- --bs-text-opacity: 1;
-}
-
-.bg-primary {
- --bs-bg-opacity: 1;
- background-color: rgba(var(--bs-primary-rgb), var(--bs-bg-opacity)) !important;
-}
-
-.bg-secondary {
- --bs-bg-opacity: 1;
- background-color: rgba(var(--bs-secondary-rgb), var(--bs-bg-opacity)) !important;
-}
-
-.bg-success {
- --bs-bg-opacity: 1;
- background-color: rgba(var(--bs-success-rgb), var(--bs-bg-opacity)) !important;
-}
-
-.bg-info {
- --bs-bg-opacity: 1;
- background-color: rgba(var(--bs-info-rgb), var(--bs-bg-opacity)) !important;
-}
-
-.bg-warning {
- --bs-bg-opacity: 1;
- background-color: rgba(var(--bs-warning-rgb), var(--bs-bg-opacity)) !important;
-}
-
-.bg-danger {
- --bs-bg-opacity: 1;
- background-color: rgba(var(--bs-danger-rgb), var(--bs-bg-opacity)) !important;
-}
-
-.bg-light {
- --bs-bg-opacity: 1;
- background-color: rgba(var(--bs-light-rgb), var(--bs-bg-opacity)) !important;
-}
-
-.bg-dark {
- --bs-bg-opacity: 1;
- background-color: rgba(var(--bs-dark-rgb), var(--bs-bg-opacity)) !important;
-}
-
-.bg-black {
- --bs-bg-opacity: 1;
- background-color: rgba(var(--bs-black-rgb), var(--bs-bg-opacity)) !important;
-}
-
-.bg-white {
- --bs-bg-opacity: 1;
- background-color: rgba(var(--bs-white-rgb), var(--bs-bg-opacity)) !important;
-}
-
-.bg-body {
- --bs-bg-opacity: 1;
- background-color: rgba(var(--bs-body-bg-rgb), var(--bs-bg-opacity)) !important;
-}
-
-.bg-transparent {
- --bs-bg-opacity: 1;
- background-color: transparent !important;
-}
-
-.bg-opacity-10 {
- --bs-bg-opacity: 0.1;
-}
-
-.bg-opacity-25 {
- --bs-bg-opacity: 0.25;
-}
-
-.bg-opacity-50 {
- --bs-bg-opacity: 0.5;
-}
-
-.bg-opacity-75 {
- --bs-bg-opacity: 0.75;
-}
-
-.bg-opacity-100 {
- --bs-bg-opacity: 1;
-}
-
-.bg-gradient {
- background-image: var(--bs-gradient) !important;
-}
-
-.user-select-all {
- -webkit-user-select: all !important;
- -moz-user-select: all !important;
- user-select: all !important;
-}
-
-.user-select-auto {
- -webkit-user-select: auto !important;
- -moz-user-select: auto !important;
- user-select: auto !important;
-}
-
-.user-select-none {
- -webkit-user-select: none !important;
- -moz-user-select: none !important;
- user-select: none !important;
-}
-
-.pe-none {
- pointer-events: none !important;
-}
-
-.pe-auto {
- pointer-events: auto !important;
-}
-
-.rounded {
- border-radius: 0.25rem !important;
-}
-
-.rounded-0 {
- border-radius: 0 !important;
-}
-
-.rounded-1 {
- border-radius: 0.2rem !important;
-}
-
-.rounded-2 {
- border-radius: 0.25rem !important;
-}
-
-.rounded-3 {
- border-radius: 0.3rem !important;
-}
-
-.rounded-circle {
- border-radius: 50% !important;
-}
-
-.rounded-pill {
- border-radius: 50rem !important;
-}
-
-.rounded-top {
- border-top-left-radius: 0.25rem !important;
- border-top-right-radius: 0.25rem !important;
-}
-
-.rounded-end {
- border-top-right-radius: 0.25rem !important;
- border-bottom-right-radius: 0.25rem !important;
-}
-
-.rounded-bottom {
- border-bottom-right-radius: 0.25rem !important;
- border-bottom-left-radius: 0.25rem !important;
-}
-
-.rounded-start {
- border-bottom-left-radius: 0.25rem !important;
- border-top-left-radius: 0.25rem !important;
-}
-
-.visible {
- visibility: visible !important;
-}
-
-.invisible {
- visibility: hidden !important;
-}
-
-@media (min-width: 576px) {
- .float-sm-start {
- float: left !important;
- }
-
- .float-sm-end {
- float: right !important;
- }
-
- .float-sm-none {
- float: none !important;
- }
-
- .d-sm-inline {
- display: inline !important;
- }
-
- .d-sm-inline-block {
- display: inline-block !important;
- }
-
- .d-sm-block {
- display: block !important;
- }
-
- .d-sm-grid {
- display: grid !important;
- }
-
- .d-sm-table {
- display: table !important;
- }
-
- .d-sm-table-row {
- display: table-row !important;
- }
-
- .d-sm-table-cell {
- display: table-cell !important;
- }
-
- .d-sm-flex {
- display: flex !important;
- }
-
- .d-sm-inline-flex {
- display: inline-flex !important;
- }
-
- .d-sm-none {
- display: none !important;
- }
-
- .flex-sm-fill {
- flex: 1 1 auto !important;
- }
-
- .flex-sm-row {
- flex-direction: row !important;
- }
-
- .flex-sm-column {
- flex-direction: column !important;
- }
-
- .flex-sm-row-reverse {
- flex-direction: row-reverse !important;
- }
-
- .flex-sm-column-reverse {
- flex-direction: column-reverse !important;
- }
-
- .flex-sm-grow-0 {
- flex-grow: 0 !important;
- }
-
- .flex-sm-grow-1 {
- flex-grow: 1 !important;
- }
-
- .flex-sm-shrink-0 {
- flex-shrink: 0 !important;
- }
-
- .flex-sm-shrink-1 {
- flex-shrink: 1 !important;
- }
-
- .flex-sm-wrap {
- flex-wrap: wrap !important;
- }
-
- .flex-sm-nowrap {
- flex-wrap: nowrap !important;
- }
-
- .flex-sm-wrap-reverse {
- flex-wrap: wrap-reverse !important;
- }
-
- .gap-sm-0 {
- gap: 0 !important;
- }
-
- .gap-sm-1 {
- gap: 0.25rem !important;
- }
-
- .gap-sm-2 {
- gap: 0.5rem !important;
- }
-
- .gap-sm-3 {
- gap: 1rem !important;
- }
-
- .gap-sm-4 {
- gap: 1.5rem !important;
- }
-
- .gap-sm-5 {
- gap: 3rem !important;
- }
-
- .justify-content-sm-start {
- justify-content: flex-start !important;
- }
-
- .justify-content-sm-end {
- justify-content: flex-end !important;
- }
-
- .justify-content-sm-center {
- justify-content: center !important;
- }
-
- .justify-content-sm-between {
- justify-content: space-between !important;
- }
-
- .justify-content-sm-around {
- justify-content: space-around !important;
- }
-
- .justify-content-sm-evenly {
- justify-content: space-evenly !important;
- }
-
- .align-items-sm-start {
- align-items: flex-start !important;
- }
-
- .align-items-sm-end {
- align-items: flex-end !important;
- }
-
- .align-items-sm-center {
- align-items: center !important;
- }
-
- .align-items-sm-baseline {
- align-items: baseline !important;
- }
-
- .align-items-sm-stretch {
- align-items: stretch !important;
- }
-
- .align-content-sm-start {
- align-content: flex-start !important;
- }
-
- .align-content-sm-end {
- align-content: flex-end !important;
- }
-
- .align-content-sm-center {
- align-content: center !important;
- }
-
- .align-content-sm-between {
- align-content: space-between !important;
- }
-
- .align-content-sm-around {
- align-content: space-around !important;
- }
-
- .align-content-sm-stretch {
- align-content: stretch !important;
- }
-
- .align-self-sm-auto {
- align-self: auto !important;
- }
-
- .align-self-sm-start {
- align-self: flex-start !important;
- }
-
- .align-self-sm-end {
- align-self: flex-end !important;
- }
-
- .align-self-sm-center {
- align-self: center !important;
- }
-
- .align-self-sm-baseline {
- align-self: baseline !important;
- }
-
- .align-self-sm-stretch {
- align-self: stretch !important;
- }
-
- .order-sm-first {
- order: -1 !important;
- }
-
- .order-sm-0 {
- order: 0 !important;
- }
-
- .order-sm-1 {
- order: 1 !important;
- }
-
- .order-sm-2 {
- order: 2 !important;
- }
-
- .order-sm-3 {
- order: 3 !important;
- }
-
- .order-sm-4 {
- order: 4 !important;
- }
-
- .order-sm-5 {
- order: 5 !important;
- }
-
- .order-sm-last {
- order: 6 !important;
- }
-
- .m-sm-0 {
- margin: 0 !important;
- }
-
- .m-sm-1 {
- margin: 0.25rem !important;
- }
-
- .m-sm-2 {
- margin: 0.5rem !important;
- }
-
- .m-sm-3 {
- margin: 1rem !important;
- }
-
- .m-sm-4 {
- margin: 1.5rem !important;
- }
-
- .m-sm-5 {
- margin: 3rem !important;
- }
-
- .m-sm-auto {
- margin: auto !important;
- }
-
- .mx-sm-0 {
- margin-right: 0 !important;
- margin-left: 0 !important;
- }
-
- .mx-sm-1 {
- margin-right: 0.25rem !important;
- margin-left: 0.25rem !important;
- }
-
- .mx-sm-2 {
- margin-right: 0.5rem !important;
- margin-left: 0.5rem !important;
- }
-
- .mx-sm-3 {
- margin-right: 1rem !important;
- margin-left: 1rem !important;
- }
-
- .mx-sm-4 {
- margin-right: 1.5rem !important;
- margin-left: 1.5rem !important;
- }
-
- .mx-sm-5 {
- margin-right: 3rem !important;
- margin-left: 3rem !important;
- }
-
- .mx-sm-auto {
- margin-right: auto !important;
- margin-left: auto !important;
- }
-
- .my-sm-0 {
- margin-top: 0 !important;
- margin-bottom: 0 !important;
- }
-
- .my-sm-1 {
- margin-top: 0.25rem !important;
- margin-bottom: 0.25rem !important;
- }
-
- .my-sm-2 {
- margin-top: 0.5rem !important;
- margin-bottom: 0.5rem !important;
- }
-
- .my-sm-3 {
- margin-top: 1rem !important;
- margin-bottom: 1rem !important;
- }
-
- .my-sm-4 {
- margin-top: 1.5rem !important;
- margin-bottom: 1.5rem !important;
- }
-
- .my-sm-5 {
- margin-top: 3rem !important;
- margin-bottom: 3rem !important;
- }
-
- .my-sm-auto {
- margin-top: auto !important;
- margin-bottom: auto !important;
- }
-
- .mt-sm-0 {
- margin-top: 0 !important;
- }
-
- .mt-sm-1 {
- margin-top: 0.25rem !important;
- }
-
- .mt-sm-2 {
- margin-top: 0.5rem !important;
- }
-
- .mt-sm-3 {
- margin-top: 1rem !important;
- }
-
- .mt-sm-4 {
- margin-top: 1.5rem !important;
- }
-
- .mt-sm-5 {
- margin-top: 3rem !important;
- }
-
- .mt-sm-auto {
- margin-top: auto !important;
- }
-
- .me-sm-0 {
- margin-right: 0 !important;
- }
-
- .me-sm-1 {
- margin-right: 0.25rem !important;
- }
-
- .me-sm-2 {
- margin-right: 0.5rem !important;
- }
-
- .me-sm-3 {
- margin-right: 1rem !important;
- }
-
- .me-sm-4 {
- margin-right: 1.5rem !important;
- }
-
- .me-sm-5 {
- margin-right: 3rem !important;
- }
-
- .me-sm-auto {
- margin-right: auto !important;
- }
-
- .mb-sm-0 {
- margin-bottom: 0 !important;
- }
-
- .mb-sm-1 {
- margin-bottom: 0.25rem !important;
- }
-
- .mb-sm-2 {
- margin-bottom: 0.5rem !important;
- }
-
- .mb-sm-3 {
- margin-bottom: 1rem !important;
- }
-
- .mb-sm-4 {
- margin-bottom: 1.5rem !important;
- }
-
- .mb-sm-5 {
- margin-bottom: 3rem !important;
- }
-
- .mb-sm-auto {
- margin-bottom: auto !important;
- }
-
- .ms-sm-0 {
- margin-left: 0 !important;
- }
-
- .ms-sm-1 {
- margin-left: 0.25rem !important;
- }
-
- .ms-sm-2 {
- margin-left: 0.5rem !important;
- }
-
- .ms-sm-3 {
- margin-left: 1rem !important;
- }
-
- .ms-sm-4 {
- margin-left: 1.5rem !important;
- }
-
- .ms-sm-5 {
- margin-left: 3rem !important;
- }
-
- .ms-sm-auto {
- margin-left: auto !important;
- }
-
- .p-sm-0 {
- padding: 0 !important;
- }
-
- .p-sm-1 {
- padding: 0.25rem !important;
- }
-
- .p-sm-2 {
- padding: 0.5rem !important;
- }
-
- .p-sm-3 {
- padding: 1rem !important;
- }
-
- .p-sm-4 {
- padding: 1.5rem !important;
- }
-
- .p-sm-5 {
- padding: 3rem !important;
- }
-
- .px-sm-0 {
- padding-right: 0 !important;
- padding-left: 0 !important;
- }
-
- .px-sm-1 {
- padding-right: 0.25rem !important;
- padding-left: 0.25rem !important;
- }
-
- .px-sm-2 {
- padding-right: 0.5rem !important;
- padding-left: 0.5rem !important;
- }
-
- .px-sm-3 {
- padding-right: 1rem !important;
- padding-left: 1rem !important;
- }
-
- .px-sm-4 {
- padding-right: 1.5rem !important;
- padding-left: 1.5rem !important;
- }
-
- .px-sm-5 {
- padding-right: 3rem !important;
- padding-left: 3rem !important;
- }
-
- .py-sm-0 {
- padding-top: 0 !important;
- padding-bottom: 0 !important;
- }
-
- .py-sm-1 {
- padding-top: 0.25rem !important;
- padding-bottom: 0.25rem !important;
- }
-
- .py-sm-2 {
- padding-top: 0.5rem !important;
- padding-bottom: 0.5rem !important;
- }
-
- .py-sm-3 {
- padding-top: 1rem !important;
- padding-bottom: 1rem !important;
- }
-
- .py-sm-4 {
- padding-top: 1.5rem !important;
- padding-bottom: 1.5rem !important;
- }
-
- .py-sm-5 {
- padding-top: 3rem !important;
- padding-bottom: 3rem !important;
- }
-
- .pt-sm-0 {
- padding-top: 0 !important;
- }
-
- .pt-sm-1 {
- padding-top: 0.25rem !important;
- }
-
- .pt-sm-2 {
- padding-top: 0.5rem !important;
- }
-
- .pt-sm-3 {
- padding-top: 1rem !important;
- }
-
- .pt-sm-4 {
- padding-top: 1.5rem !important;
- }
-
- .pt-sm-5 {
- padding-top: 3rem !important;
- }
-
- .pe-sm-0 {
- padding-right: 0 !important;
- }
-
- .pe-sm-1 {
- padding-right: 0.25rem !important;
- }
-
- .pe-sm-2 {
- padding-right: 0.5rem !important;
- }
-
- .pe-sm-3 {
- padding-right: 1rem !important;
- }
-
- .pe-sm-4 {
- padding-right: 1.5rem !important;
- }
-
- .pe-sm-5 {
- padding-right: 3rem !important;
- }
-
- .pb-sm-0 {
- padding-bottom: 0 !important;
- }
-
- .pb-sm-1 {
- padding-bottom: 0.25rem !important;
- }
-
- .pb-sm-2 {
- padding-bottom: 0.5rem !important;
- }
-
- .pb-sm-3 {
- padding-bottom: 1rem !important;
- }
-
- .pb-sm-4 {
- padding-bottom: 1.5rem !important;
- }
-
- .pb-sm-5 {
- padding-bottom: 3rem !important;
- }
-
- .ps-sm-0 {
- padding-left: 0 !important;
- }
-
- .ps-sm-1 {
- padding-left: 0.25rem !important;
- }
-
- .ps-sm-2 {
- padding-left: 0.5rem !important;
- }
-
- .ps-sm-3 {
- padding-left: 1rem !important;
- }
-
- .ps-sm-4 {
- padding-left: 1.5rem !important;
- }
-
- .ps-sm-5 {
- padding-left: 3rem !important;
- }
-
- .text-sm-start {
- text-align: left !important;
- }
-
- .text-sm-end {
- text-align: right !important;
- }
-
- .text-sm-center {
- text-align: center !important;
- }
-}
-@media (min-width: 768px) {
- .float-md-start {
- float: left !important;
- }
-
- .float-md-end {
- float: right !important;
- }
-
- .float-md-none {
- float: none !important;
- }
-
- .d-md-inline {
- display: inline !important;
- }
-
- .d-md-inline-block {
- display: inline-block !important;
- }
-
- .d-md-block {
- display: block !important;
- }
-
- .d-md-grid {
- display: grid !important;
- }
-
- .d-md-table {
- display: table !important;
- }
-
- .d-md-table-row {
- display: table-row !important;
- }
-
- .d-md-table-cell {
- display: table-cell !important;
- }
-
- .d-md-flex {
- display: flex !important;
- }
-
- .d-md-inline-flex {
- display: inline-flex !important;
- }
-
- .d-md-none {
- display: none !important;
- }
-
- .flex-md-fill {
- flex: 1 1 auto !important;
- }
-
- .flex-md-row {
- flex-direction: row !important;
- }
-
- .flex-md-column {
- flex-direction: column !important;
- }
-
- .flex-md-row-reverse {
- flex-direction: row-reverse !important;
- }
-
- .flex-md-column-reverse {
- flex-direction: column-reverse !important;
- }
-
- .flex-md-grow-0 {
- flex-grow: 0 !important;
- }
-
- .flex-md-grow-1 {
- flex-grow: 1 !important;
- }
-
- .flex-md-shrink-0 {
- flex-shrink: 0 !important;
- }
-
- .flex-md-shrink-1 {
- flex-shrink: 1 !important;
- }
-
- .flex-md-wrap {
- flex-wrap: wrap !important;
- }
-
- .flex-md-nowrap {
- flex-wrap: nowrap !important;
- }
-
- .flex-md-wrap-reverse {
- flex-wrap: wrap-reverse !important;
- }
-
- .gap-md-0 {
- gap: 0 !important;
- }
-
- .gap-md-1 {
- gap: 0.25rem !important;
- }
-
- .gap-md-2 {
- gap: 0.5rem !important;
- }
-
- .gap-md-3 {
- gap: 1rem !important;
- }
-
- .gap-md-4 {
- gap: 1.5rem !important;
- }
-
- .gap-md-5 {
- gap: 3rem !important;
- }
-
- .justify-content-md-start {
- justify-content: flex-start !important;
- }
-
- .justify-content-md-end {
- justify-content: flex-end !important;
- }
-
- .justify-content-md-center {
- justify-content: center !important;
- }
-
- .justify-content-md-between {
- justify-content: space-between !important;
- }
-
- .justify-content-md-around {
- justify-content: space-around !important;
- }
-
- .justify-content-md-evenly {
- justify-content: space-evenly !important;
- }
-
- .align-items-md-start {
- align-items: flex-start !important;
- }
-
- .align-items-md-end {
- align-items: flex-end !important;
- }
-
- .align-items-md-center {
- align-items: center !important;
- }
-
- .align-items-md-baseline {
- align-items: baseline !important;
- }
-
- .align-items-md-stretch {
- align-items: stretch !important;
- }
-
- .align-content-md-start {
- align-content: flex-start !important;
- }
-
- .align-content-md-end {
- align-content: flex-end !important;
- }
-
- .align-content-md-center {
- align-content: center !important;
- }
-
- .align-content-md-between {
- align-content: space-between !important;
- }
-
- .align-content-md-around {
- align-content: space-around !important;
- }
-
- .align-content-md-stretch {
- align-content: stretch !important;
- }
-
- .align-self-md-auto {
- align-self: auto !important;
- }
-
- .align-self-md-start {
- align-self: flex-start !important;
- }
-
- .align-self-md-end {
- align-self: flex-end !important;
- }
-
- .align-self-md-center {
- align-self: center !important;
- }
-
- .align-self-md-baseline {
- align-self: baseline !important;
- }
-
- .align-self-md-stretch {
- align-self: stretch !important;
- }
-
- .order-md-first {
- order: -1 !important;
- }
-
- .order-md-0 {
- order: 0 !important;
- }
-
- .order-md-1 {
- order: 1 !important;
- }
-
- .order-md-2 {
- order: 2 !important;
- }
-
- .order-md-3 {
- order: 3 !important;
- }
-
- .order-md-4 {
- order: 4 !important;
- }
-
- .order-md-5 {
- order: 5 !important;
- }
-
- .order-md-last {
- order: 6 !important;
- }
-
- .m-md-0 {
- margin: 0 !important;
- }
-
- .m-md-1 {
- margin: 0.25rem !important;
- }
-
- .m-md-2 {
- margin: 0.5rem !important;
- }
-
- .m-md-3 {
- margin: 1rem !important;
- }
-
- .m-md-4 {
- margin: 1.5rem !important;
- }
-
- .m-md-5 {
- margin: 3rem !important;
- }
-
- .m-md-auto {
- margin: auto !important;
- }
-
- .mx-md-0 {
- margin-right: 0 !important;
- margin-left: 0 !important;
- }
-
- .mx-md-1 {
- margin-right: 0.25rem !important;
- margin-left: 0.25rem !important;
- }
-
- .mx-md-2 {
- margin-right: 0.5rem !important;
- margin-left: 0.5rem !important;
- }
-
- .mx-md-3 {
- margin-right: 1rem !important;
- margin-left: 1rem !important;
- }
-
- .mx-md-4 {
- margin-right: 1.5rem !important;
- margin-left: 1.5rem !important;
- }
-
- .mx-md-5 {
- margin-right: 3rem !important;
- margin-left: 3rem !important;
- }
-
- .mx-md-auto {
- margin-right: auto !important;
- margin-left: auto !important;
- }
-
- .my-md-0 {
- margin-top: 0 !important;
- margin-bottom: 0 !important;
- }
-
- .my-md-1 {
- margin-top: 0.25rem !important;
- margin-bottom: 0.25rem !important;
- }
-
- .my-md-2 {
- margin-top: 0.5rem !important;
- margin-bottom: 0.5rem !important;
- }
-
- .my-md-3 {
- margin-top: 1rem !important;
- margin-bottom: 1rem !important;
- }
-
- .my-md-4 {
- margin-top: 1.5rem !important;
- margin-bottom: 1.5rem !important;
- }
-
- .my-md-5 {
- margin-top: 3rem !important;
- margin-bottom: 3rem !important;
- }
-
- .my-md-auto {
- margin-top: auto !important;
- margin-bottom: auto !important;
- }
-
- .mt-md-0 {
- margin-top: 0 !important;
- }
-
- .mt-md-1 {
- margin-top: 0.25rem !important;
- }
-
- .mt-md-2 {
- margin-top: 0.5rem !important;
- }
-
- .mt-md-3 {
- margin-top: 1rem !important;
- }
-
- .mt-md-4 {
- margin-top: 1.5rem !important;
- }
-
- .mt-md-5 {
- margin-top: 3rem !important;
- }
-
- .mt-md-auto {
- margin-top: auto !important;
- }
-
- .me-md-0 {
- margin-right: 0 !important;
- }
-
- .me-md-1 {
- margin-right: 0.25rem !important;
- }
-
- .me-md-2 {
- margin-right: 0.5rem !important;
- }
-
- .me-md-3 {
- margin-right: 1rem !important;
- }
-
- .me-md-4 {
- margin-right: 1.5rem !important;
- }
-
- .me-md-5 {
- margin-right: 3rem !important;
- }
-
- .me-md-auto {
- margin-right: auto !important;
- }
-
- .mb-md-0 {
- margin-bottom: 0 !important;
- }
-
- .mb-md-1 {
- margin-bottom: 0.25rem !important;
- }
-
- .mb-md-2 {
- margin-bottom: 0.5rem !important;
- }
-
- .mb-md-3 {
- margin-bottom: 1rem !important;
- }
-
- .mb-md-4 {
- margin-bottom: 1.5rem !important;
- }
-
- .mb-md-5 {
- margin-bottom: 3rem !important;
- }
-
- .mb-md-auto {
- margin-bottom: auto !important;
- }
-
- .ms-md-0 {
- margin-left: 0 !important;
- }
-
- .ms-md-1 {
- margin-left: 0.25rem !important;
- }
-
- .ms-md-2 {
- margin-left: 0.5rem !important;
- }
-
- .ms-md-3 {
- margin-left: 1rem !important;
- }
-
- .ms-md-4 {
- margin-left: 1.5rem !important;
- }
-
- .ms-md-5 {
- margin-left: 3rem !important;
- }
-
- .ms-md-auto {
- margin-left: auto !important;
- }
-
- .p-md-0 {
- padding: 0 !important;
- }
-
- .p-md-1 {
- padding: 0.25rem !important;
- }
-
- .p-md-2 {
- padding: 0.5rem !important;
- }
-
- .p-md-3 {
- padding: 1rem !important;
- }
-
- .p-md-4 {
- padding: 1.5rem !important;
- }
-
- .p-md-5 {
- padding: 3rem !important;
- }
-
- .px-md-0 {
- padding-right: 0 !important;
- padding-left: 0 !important;
- }
-
- .px-md-1 {
- padding-right: 0.25rem !important;
- padding-left: 0.25rem !important;
- }
-
- .px-md-2 {
- padding-right: 0.5rem !important;
- padding-left: 0.5rem !important;
- }
-
- .px-md-3 {
- padding-right: 1rem !important;
- padding-left: 1rem !important;
- }
-
- .px-md-4 {
- padding-right: 1.5rem !important;
- padding-left: 1.5rem !important;
- }
-
- .px-md-5 {
- padding-right: 3rem !important;
- padding-left: 3rem !important;
- }
-
- .py-md-0 {
- padding-top: 0 !important;
- padding-bottom: 0 !important;
- }
-
- .py-md-1 {
- padding-top: 0.25rem !important;
- padding-bottom: 0.25rem !important;
- }
-
- .py-md-2 {
- padding-top: 0.5rem !important;
- padding-bottom: 0.5rem !important;
- }
-
- .py-md-3 {
- padding-top: 1rem !important;
- padding-bottom: 1rem !important;
- }
-
- .py-md-4 {
- padding-top: 1.5rem !important;
- padding-bottom: 1.5rem !important;
- }
-
- .py-md-5 {
- padding-top: 3rem !important;
- padding-bottom: 3rem !important;
- }
-
- .pt-md-0 {
- padding-top: 0 !important;
- }
-
- .pt-md-1 {
- padding-top: 0.25rem !important;
- }
-
- .pt-md-2 {
- padding-top: 0.5rem !important;
- }
-
- .pt-md-3 {
- padding-top: 1rem !important;
- }
-
- .pt-md-4 {
- padding-top: 1.5rem !important;
- }
-
- .pt-md-5 {
- padding-top: 3rem !important;
- }
-
- .pe-md-0 {
- padding-right: 0 !important;
- }
-
- .pe-md-1 {
- padding-right: 0.25rem !important;
- }
-
- .pe-md-2 {
- padding-right: 0.5rem !important;
- }
-
- .pe-md-3 {
- padding-right: 1rem !important;
- }
-
- .pe-md-4 {
- padding-right: 1.5rem !important;
- }
-
- .pe-md-5 {
- padding-right: 3rem !important;
- }
-
- .pb-md-0 {
- padding-bottom: 0 !important;
- }
-
- .pb-md-1 {
- padding-bottom: 0.25rem !important;
- }
-
- .pb-md-2 {
- padding-bottom: 0.5rem !important;
- }
-
- .pb-md-3 {
- padding-bottom: 1rem !important;
- }
-
- .pb-md-4 {
- padding-bottom: 1.5rem !important;
- }
-
- .pb-md-5 {
- padding-bottom: 3rem !important;
- }
-
- .ps-md-0 {
- padding-left: 0 !important;
- }
-
- .ps-md-1 {
- padding-left: 0.25rem !important;
- }
-
- .ps-md-2 {
- padding-left: 0.5rem !important;
- }
-
- .ps-md-3 {
- padding-left: 1rem !important;
- }
-
- .ps-md-4 {
- padding-left: 1.5rem !important;
- }
-
- .ps-md-5 {
- padding-left: 3rem !important;
- }
-
- .text-md-start {
- text-align: left !important;
- }
-
- .text-md-end {
- text-align: right !important;
- }
-
- .text-md-center {
- text-align: center !important;
- }
-}
-@media (min-width: 992px) {
- .float-lg-start {
- float: left !important;
- }
-
- .float-lg-end {
- float: right !important;
- }
-
- .float-lg-none {
- float: none !important;
- }
-
- .d-lg-inline {
- display: inline !important;
- }
-
- .d-lg-inline-block {
- display: inline-block !important;
- }
-
- .d-lg-block {
- display: block !important;
- }
-
- .d-lg-grid {
- display: grid !important;
- }
-
- .d-lg-table {
- display: table !important;
- }
-
- .d-lg-table-row {
- display: table-row !important;
- }
-
- .d-lg-table-cell {
- display: table-cell !important;
- }
-
- .d-lg-flex {
- display: flex !important;
- }
-
- .d-lg-inline-flex {
- display: inline-flex !important;
- }
-
- .d-lg-none {
- display: none !important;
- }
-
- .flex-lg-fill {
- flex: 1 1 auto !important;
- }
-
- .flex-lg-row {
- flex-direction: row !important;
- }
-
- .flex-lg-column {
- flex-direction: column !important;
- }
-
- .flex-lg-row-reverse {
- flex-direction: row-reverse !important;
- }
-
- .flex-lg-column-reverse {
- flex-direction: column-reverse !important;
- }
-
- .flex-lg-grow-0 {
- flex-grow: 0 !important;
- }
-
- .flex-lg-grow-1 {
- flex-grow: 1 !important;
- }
-
- .flex-lg-shrink-0 {
- flex-shrink: 0 !important;
- }
-
- .flex-lg-shrink-1 {
- flex-shrink: 1 !important;
- }
-
- .flex-lg-wrap {
- flex-wrap: wrap !important;
- }
-
- .flex-lg-nowrap {
- flex-wrap: nowrap !important;
- }
-
- .flex-lg-wrap-reverse {
- flex-wrap: wrap-reverse !important;
- }
-
- .gap-lg-0 {
- gap: 0 !important;
- }
-
- .gap-lg-1 {
- gap: 0.25rem !important;
- }
-
- .gap-lg-2 {
- gap: 0.5rem !important;
- }
-
- .gap-lg-3 {
- gap: 1rem !important;
- }
-
- .gap-lg-4 {
- gap: 1.5rem !important;
- }
-
- .gap-lg-5 {
- gap: 3rem !important;
- }
-
- .justify-content-lg-start {
- justify-content: flex-start !important;
- }
-
- .justify-content-lg-end {
- justify-content: flex-end !important;
- }
-
- .justify-content-lg-center {
- justify-content: center !important;
- }
-
- .justify-content-lg-between {
- justify-content: space-between !important;
- }
-
- .justify-content-lg-around {
- justify-content: space-around !important;
- }
-
- .justify-content-lg-evenly {
- justify-content: space-evenly !important;
- }
-
- .align-items-lg-start {
- align-items: flex-start !important;
- }
-
- .align-items-lg-end {
- align-items: flex-end !important;
- }
-
- .align-items-lg-center {
- align-items: center !important;
- }
-
- .align-items-lg-baseline {
- align-items: baseline !important;
- }
-
- .align-items-lg-stretch {
- align-items: stretch !important;
- }
-
- .align-content-lg-start {
- align-content: flex-start !important;
- }
-
- .align-content-lg-end {
- align-content: flex-end !important;
- }
-
- .align-content-lg-center {
- align-content: center !important;
- }
-
- .align-content-lg-between {
- align-content: space-between !important;
- }
-
- .align-content-lg-around {
- align-content: space-around !important;
- }
-
- .align-content-lg-stretch {
- align-content: stretch !important;
- }
-
- .align-self-lg-auto {
- align-self: auto !important;
- }
-
- .align-self-lg-start {
- align-self: flex-start !important;
- }
-
- .align-self-lg-end {
- align-self: flex-end !important;
- }
-
- .align-self-lg-center {
- align-self: center !important;
- }
-
- .align-self-lg-baseline {
- align-self: baseline !important;
- }
-
- .align-self-lg-stretch {
- align-self: stretch !important;
- }
-
- .order-lg-first {
- order: -1 !important;
- }
-
- .order-lg-0 {
- order: 0 !important;
- }
-
- .order-lg-1 {
- order: 1 !important;
- }
-
- .order-lg-2 {
- order: 2 !important;
- }
-
- .order-lg-3 {
- order: 3 !important;
- }
-
- .order-lg-4 {
- order: 4 !important;
- }
-
- .order-lg-5 {
- order: 5 !important;
- }
-
- .order-lg-last {
- order: 6 !important;
- }
-
- .m-lg-0 {
- margin: 0 !important;
- }
-
- .m-lg-1 {
- margin: 0.25rem !important;
- }
-
- .m-lg-2 {
- margin: 0.5rem !important;
- }
-
- .m-lg-3 {
- margin: 1rem !important;
- }
-
- .m-lg-4 {
- margin: 1.5rem !important;
- }
-
- .m-lg-5 {
- margin: 3rem !important;
- }
-
- .m-lg-auto {
- margin: auto !important;
- }
-
- .mx-lg-0 {
- margin-right: 0 !important;
- margin-left: 0 !important;
- }
-
- .mx-lg-1 {
- margin-right: 0.25rem !important;
- margin-left: 0.25rem !important;
- }
-
- .mx-lg-2 {
- margin-right: 0.5rem !important;
- margin-left: 0.5rem !important;
- }
-
- .mx-lg-3 {
- margin-right: 1rem !important;
- margin-left: 1rem !important;
- }
-
- .mx-lg-4 {
- margin-right: 1.5rem !important;
- margin-left: 1.5rem !important;
- }
-
- .mx-lg-5 {
- margin-right: 3rem !important;
- margin-left: 3rem !important;
- }
-
- .mx-lg-auto {
- margin-right: auto !important;
- margin-left: auto !important;
- }
-
- .my-lg-0 {
- margin-top: 0 !important;
- margin-bottom: 0 !important;
- }
-
- .my-lg-1 {
- margin-top: 0.25rem !important;
- margin-bottom: 0.25rem !important;
- }
-
- .my-lg-2 {
- margin-top: 0.5rem !important;
- margin-bottom: 0.5rem !important;
- }
-
- .my-lg-3 {
- margin-top: 1rem !important;
- margin-bottom: 1rem !important;
- }
-
- .my-lg-4 {
- margin-top: 1.5rem !important;
- margin-bottom: 1.5rem !important;
- }
-
- .my-lg-5 {
- margin-top: 3rem !important;
- margin-bottom: 3rem !important;
- }
-
- .my-lg-auto {
- margin-top: auto !important;
- margin-bottom: auto !important;
- }
-
- .mt-lg-0 {
- margin-top: 0 !important;
- }
-
- .mt-lg-1 {
- margin-top: 0.25rem !important;
- }
-
- .mt-lg-2 {
- margin-top: 0.5rem !important;
- }
-
- .mt-lg-3 {
- margin-top: 1rem !important;
- }
-
- .mt-lg-4 {
- margin-top: 1.5rem !important;
- }
-
- .mt-lg-5 {
- margin-top: 3rem !important;
- }
-
- .mt-lg-auto {
- margin-top: auto !important;
- }
-
- .me-lg-0 {
- margin-right: 0 !important;
- }
-
- .me-lg-1 {
- margin-right: 0.25rem !important;
- }
-
- .me-lg-2 {
- margin-right: 0.5rem !important;
- }
-
- .me-lg-3 {
- margin-right: 1rem !important;
- }
-
- .me-lg-4 {
- margin-right: 1.5rem !important;
- }
-
- .me-lg-5 {
- margin-right: 3rem !important;
- }
-
- .me-lg-auto {
- margin-right: auto !important;
- }
-
- .mb-lg-0 {
- margin-bottom: 0 !important;
- }
-
- .mb-lg-1 {
- margin-bottom: 0.25rem !important;
- }
-
- .mb-lg-2 {
- margin-bottom: 0.5rem !important;
- }
-
- .mb-lg-3 {
- margin-bottom: 1rem !important;
- }
-
- .mb-lg-4 {
- margin-bottom: 1.5rem !important;
- }
-
- .mb-lg-5 {
- margin-bottom: 3rem !important;
- }
-
- .mb-lg-auto {
- margin-bottom: auto !important;
- }
-
- .ms-lg-0 {
- margin-left: 0 !important;
- }
-
- .ms-lg-1 {
- margin-left: 0.25rem !important;
- }
-
- .ms-lg-2 {
- margin-left: 0.5rem !important;
- }
-
- .ms-lg-3 {
- margin-left: 1rem !important;
- }
-
- .ms-lg-4 {
- margin-left: 1.5rem !important;
- }
-
- .ms-lg-5 {
- margin-left: 3rem !important;
- }
-
- .ms-lg-auto {
- margin-left: auto !important;
- }
-
- .p-lg-0 {
- padding: 0 !important;
- }
-
- .p-lg-1 {
- padding: 0.25rem !important;
- }
-
- .p-lg-2 {
- padding: 0.5rem !important;
- }
-
- .p-lg-3 {
- padding: 1rem !important;
- }
-
- .p-lg-4 {
- padding: 1.5rem !important;
- }
-
- .p-lg-5 {
- padding: 3rem !important;
- }
-
- .px-lg-0 {
- padding-right: 0 !important;
- padding-left: 0 !important;
- }
-
- .px-lg-1 {
- padding-right: 0.25rem !important;
- padding-left: 0.25rem !important;
- }
-
- .px-lg-2 {
- padding-right: 0.5rem !important;
- padding-left: 0.5rem !important;
- }
-
- .px-lg-3 {
- padding-right: 1rem !important;
- padding-left: 1rem !important;
- }
-
- .px-lg-4 {
- padding-right: 1.5rem !important;
- padding-left: 1.5rem !important;
- }
-
- .px-lg-5 {
- padding-right: 3rem !important;
- padding-left: 3rem !important;
- }
-
- .py-lg-0 {
- padding-top: 0 !important;
- padding-bottom: 0 !important;
- }
-
- .py-lg-1 {
- padding-top: 0.25rem !important;
- padding-bottom: 0.25rem !important;
- }
-
- .py-lg-2 {
- padding-top: 0.5rem !important;
- padding-bottom: 0.5rem !important;
- }
-
- .py-lg-3 {
- padding-top: 1rem !important;
- padding-bottom: 1rem !important;
- }
-
- .py-lg-4 {
- padding-top: 1.5rem !important;
- padding-bottom: 1.5rem !important;
- }
-
- .py-lg-5 {
- padding-top: 3rem !important;
- padding-bottom: 3rem !important;
- }
-
- .pt-lg-0 {
- padding-top: 0 !important;
- }
-
- .pt-lg-1 {
- padding-top: 0.25rem !important;
- }
-
- .pt-lg-2 {
- padding-top: 0.5rem !important;
- }
-
- .pt-lg-3 {
- padding-top: 1rem !important;
- }
-
- .pt-lg-4 {
- padding-top: 1.5rem !important;
- }
-
- .pt-lg-5 {
- padding-top: 3rem !important;
- }
-
- .pe-lg-0 {
- padding-right: 0 !important;
- }
-
- .pe-lg-1 {
- padding-right: 0.25rem !important;
- }
-
- .pe-lg-2 {
- padding-right: 0.5rem !important;
- }
-
- .pe-lg-3 {
- padding-right: 1rem !important;
- }
-
- .pe-lg-4 {
- padding-right: 1.5rem !important;
- }
-
- .pe-lg-5 {
- padding-right: 3rem !important;
- }
-
- .pb-lg-0 {
- padding-bottom: 0 !important;
- }
-
- .pb-lg-1 {
- padding-bottom: 0.25rem !important;
- }
-
- .pb-lg-2 {
- padding-bottom: 0.5rem !important;
- }
-
- .pb-lg-3 {
- padding-bottom: 1rem !important;
- }
-
- .pb-lg-4 {
- padding-bottom: 1.5rem !important;
- }
-
- .pb-lg-5 {
- padding-bottom: 3rem !important;
- }
-
- .ps-lg-0 {
- padding-left: 0 !important;
- }
-
- .ps-lg-1 {
- padding-left: 0.25rem !important;
- }
-
- .ps-lg-2 {
- padding-left: 0.5rem !important;
- }
-
- .ps-lg-3 {
- padding-left: 1rem !important;
- }
-
- .ps-lg-4 {
- padding-left: 1.5rem !important;
- }
-
- .ps-lg-5 {
- padding-left: 3rem !important;
- }
-
- .text-lg-start {
- text-align: left !important;
- }
-
- .text-lg-end {
- text-align: right !important;
- }
-
- .text-lg-center {
- text-align: center !important;
- }
-}
-@media (min-width: 1200px) {
- .float-xl-start {
- float: left !important;
- }
-
- .float-xl-end {
- float: right !important;
- }
-
- .float-xl-none {
- float: none !important;
- }
-
- .d-xl-inline {
- display: inline !important;
- }
-
- .d-xl-inline-block {
- display: inline-block !important;
- }
-
- .d-xl-block {
- display: block !important;
- }
-
- .d-xl-grid {
- display: grid !important;
- }
-
- .d-xl-table {
- display: table !important;
- }
-
- .d-xl-table-row {
- display: table-row !important;
- }
-
- .d-xl-table-cell {
- display: table-cell !important;
- }
-
- .d-xl-flex {
- display: flex !important;
- }
-
- .d-xl-inline-flex {
- display: inline-flex !important;
- }
-
- .d-xl-none {
- display: none !important;
- }
-
- .flex-xl-fill {
- flex: 1 1 auto !important;
- }
-
- .flex-xl-row {
- flex-direction: row !important;
- }
-
- .flex-xl-column {
- flex-direction: column !important;
- }
-
- .flex-xl-row-reverse {
- flex-direction: row-reverse !important;
- }
-
- .flex-xl-column-reverse {
- flex-direction: column-reverse !important;
- }
-
- .flex-xl-grow-0 {
- flex-grow: 0 !important;
- }
-
- .flex-xl-grow-1 {
- flex-grow: 1 !important;
- }
-
- .flex-xl-shrink-0 {
- flex-shrink: 0 !important;
- }
-
- .flex-xl-shrink-1 {
- flex-shrink: 1 !important;
- }
-
- .flex-xl-wrap {
- flex-wrap: wrap !important;
- }
-
- .flex-xl-nowrap {
- flex-wrap: nowrap !important;
- }
-
- .flex-xl-wrap-reverse {
- flex-wrap: wrap-reverse !important;
- }
-
- .gap-xl-0 {
- gap: 0 !important;
- }
-
- .gap-xl-1 {
- gap: 0.25rem !important;
- }
-
- .gap-xl-2 {
- gap: 0.5rem !important;
- }
-
- .gap-xl-3 {
- gap: 1rem !important;
- }
-
- .gap-xl-4 {
- gap: 1.5rem !important;
- }
-
- .gap-xl-5 {
- gap: 3rem !important;
- }
-
- .justify-content-xl-start {
- justify-content: flex-start !important;
- }
-
- .justify-content-xl-end {
- justify-content: flex-end !important;
- }
-
- .justify-content-xl-center {
- justify-content: center !important;
- }
-
- .justify-content-xl-between {
- justify-content: space-between !important;
- }
-
- .justify-content-xl-around {
- justify-content: space-around !important;
- }
-
- .justify-content-xl-evenly {
- justify-content: space-evenly !important;
- }
-
- .align-items-xl-start {
- align-items: flex-start !important;
- }
-
- .align-items-xl-end {
- align-items: flex-end !important;
- }
-
- .align-items-xl-center {
- align-items: center !important;
- }
-
- .align-items-xl-baseline {
- align-items: baseline !important;
- }
-
- .align-items-xl-stretch {
- align-items: stretch !important;
- }
-
- .align-content-xl-start {
- align-content: flex-start !important;
- }
-
- .align-content-xl-end {
- align-content: flex-end !important;
- }
-
- .align-content-xl-center {
- align-content: center !important;
- }
-
- .align-content-xl-between {
- align-content: space-between !important;
- }
-
- .align-content-xl-around {
- align-content: space-around !important;
- }
-
- .align-content-xl-stretch {
- align-content: stretch !important;
- }
-
- .align-self-xl-auto {
- align-self: auto !important;
- }
-
- .align-self-xl-start {
- align-self: flex-start !important;
- }
-
- .align-self-xl-end {
- align-self: flex-end !important;
- }
-
- .align-self-xl-center {
- align-self: center !important;
- }
-
- .align-self-xl-baseline {
- align-self: baseline !important;
- }
-
- .align-self-xl-stretch {
- align-self: stretch !important;
- }
-
- .order-xl-first {
- order: -1 !important;
- }
-
- .order-xl-0 {
- order: 0 !important;
- }
-
- .order-xl-1 {
- order: 1 !important;
- }
-
- .order-xl-2 {
- order: 2 !important;
- }
-
- .order-xl-3 {
- order: 3 !important;
- }
-
- .order-xl-4 {
- order: 4 !important;
- }
-
- .order-xl-5 {
- order: 5 !important;
- }
-
- .order-xl-last {
- order: 6 !important;
- }
-
- .m-xl-0 {
- margin: 0 !important;
- }
-
- .m-xl-1 {
- margin: 0.25rem !important;
- }
-
- .m-xl-2 {
- margin: 0.5rem !important;
- }
-
- .m-xl-3 {
- margin: 1rem !important;
- }
-
- .m-xl-4 {
- margin: 1.5rem !important;
- }
-
- .m-xl-5 {
- margin: 3rem !important;
- }
-
- .m-xl-auto {
- margin: auto !important;
- }
-
- .mx-xl-0 {
- margin-right: 0 !important;
- margin-left: 0 !important;
- }
-
- .mx-xl-1 {
- margin-right: 0.25rem !important;
- margin-left: 0.25rem !important;
- }
-
- .mx-xl-2 {
- margin-right: 0.5rem !important;
- margin-left: 0.5rem !important;
- }
-
- .mx-xl-3 {
- margin-right: 1rem !important;
- margin-left: 1rem !important;
- }
-
- .mx-xl-4 {
- margin-right: 1.5rem !important;
- margin-left: 1.5rem !important;
- }
-
- .mx-xl-5 {
- margin-right: 3rem !important;
- margin-left: 3rem !important;
- }
-
- .mx-xl-auto {
- margin-right: auto !important;
- margin-left: auto !important;
- }
-
- .my-xl-0 {
- margin-top: 0 !important;
- margin-bottom: 0 !important;
- }
-
- .my-xl-1 {
- margin-top: 0.25rem !important;
- margin-bottom: 0.25rem !important;
- }
-
- .my-xl-2 {
- margin-top: 0.5rem !important;
- margin-bottom: 0.5rem !important;
- }
-
- .my-xl-3 {
- margin-top: 1rem !important;
- margin-bottom: 1rem !important;
- }
-
- .my-xl-4 {
- margin-top: 1.5rem !important;
- margin-bottom: 1.5rem !important;
- }
-
- .my-xl-5 {
- margin-top: 3rem !important;
- margin-bottom: 3rem !important;
- }
-
- .my-xl-auto {
- margin-top: auto !important;
- margin-bottom: auto !important;
- }
-
- .mt-xl-0 {
- margin-top: 0 !important;
- }
-
- .mt-xl-1 {
- margin-top: 0.25rem !important;
- }
-
- .mt-xl-2 {
- margin-top: 0.5rem !important;
- }
-
- .mt-xl-3 {
- margin-top: 1rem !important;
- }
-
- .mt-xl-4 {
- margin-top: 1.5rem !important;
- }
-
- .mt-xl-5 {
- margin-top: 3rem !important;
- }
-
- .mt-xl-auto {
- margin-top: auto !important;
- }
-
- .me-xl-0 {
- margin-right: 0 !important;
- }
-
- .me-xl-1 {
- margin-right: 0.25rem !important;
- }
-
- .me-xl-2 {
- margin-right: 0.5rem !important;
- }
-
- .me-xl-3 {
- margin-right: 1rem !important;
- }
-
- .me-xl-4 {
- margin-right: 1.5rem !important;
- }
-
- .me-xl-5 {
- margin-right: 3rem !important;
- }
-
- .me-xl-auto {
- margin-right: auto !important;
- }
-
- .mb-xl-0 {
- margin-bottom: 0 !important;
- }
-
- .mb-xl-1 {
- margin-bottom: 0.25rem !important;
- }
-
- .mb-xl-2 {
- margin-bottom: 0.5rem !important;
- }
-
- .mb-xl-3 {
- margin-bottom: 1rem !important;
- }
-
- .mb-xl-4 {
- margin-bottom: 1.5rem !important;
- }
-
- .mb-xl-5 {
- margin-bottom: 3rem !important;
- }
-
- .mb-xl-auto {
- margin-bottom: auto !important;
- }
-
- .ms-xl-0 {
- margin-left: 0 !important;
- }
-
- .ms-xl-1 {
- margin-left: 0.25rem !important;
- }
-
- .ms-xl-2 {
- margin-left: 0.5rem !important;
- }
-
- .ms-xl-3 {
- margin-left: 1rem !important;
- }
-
- .ms-xl-4 {
- margin-left: 1.5rem !important;
- }
-
- .ms-xl-5 {
- margin-left: 3rem !important;
- }
-
- .ms-xl-auto {
- margin-left: auto !important;
- }
-
- .p-xl-0 {
- padding: 0 !important;
- }
-
- .p-xl-1 {
- padding: 0.25rem !important;
- }
-
- .p-xl-2 {
- padding: 0.5rem !important;
- }
-
- .p-xl-3 {
- padding: 1rem !important;
- }
-
- .p-xl-4 {
- padding: 1.5rem !important;
- }
-
- .p-xl-5 {
- padding: 3rem !important;
- }
-
- .px-xl-0 {
- padding-right: 0 !important;
- padding-left: 0 !important;
- }
-
- .px-xl-1 {
- padding-right: 0.25rem !important;
- padding-left: 0.25rem !important;
- }
-
- .px-xl-2 {
- padding-right: 0.5rem !important;
- padding-left: 0.5rem !important;
- }
-
- .px-xl-3 {
- padding-right: 1rem !important;
- padding-left: 1rem !important;
- }
-
- .px-xl-4 {
- padding-right: 1.5rem !important;
- padding-left: 1.5rem !important;
- }
-
- .px-xl-5 {
- padding-right: 3rem !important;
- padding-left: 3rem !important;
- }
-
- .py-xl-0 {
- padding-top: 0 !important;
- padding-bottom: 0 !important;
- }
-
- .py-xl-1 {
- padding-top: 0.25rem !important;
- padding-bottom: 0.25rem !important;
- }
-
- .py-xl-2 {
- padding-top: 0.5rem !important;
- padding-bottom: 0.5rem !important;
- }
-
- .py-xl-3 {
- padding-top: 1rem !important;
- padding-bottom: 1rem !important;
- }
-
- .py-xl-4 {
- padding-top: 1.5rem !important;
- padding-bottom: 1.5rem !important;
- }
-
- .py-xl-5 {
- padding-top: 3rem !important;
- padding-bottom: 3rem !important;
- }
-
- .pt-xl-0 {
- padding-top: 0 !important;
- }
-
- .pt-xl-1 {
- padding-top: 0.25rem !important;
- }
-
- .pt-xl-2 {
- padding-top: 0.5rem !important;
- }
-
- .pt-xl-3 {
- padding-top: 1rem !important;
- }
-
- .pt-xl-4 {
- padding-top: 1.5rem !important;
- }
-
- .pt-xl-5 {
- padding-top: 3rem !important;
- }
-
- .pe-xl-0 {
- padding-right: 0 !important;
- }
-
- .pe-xl-1 {
- padding-right: 0.25rem !important;
- }
-
- .pe-xl-2 {
- padding-right: 0.5rem !important;
- }
-
- .pe-xl-3 {
- padding-right: 1rem !important;
- }
-
- .pe-xl-4 {
- padding-right: 1.5rem !important;
- }
-
- .pe-xl-5 {
- padding-right: 3rem !important;
- }
-
- .pb-xl-0 {
- padding-bottom: 0 !important;
- }
-
- .pb-xl-1 {
- padding-bottom: 0.25rem !important;
- }
-
- .pb-xl-2 {
- padding-bottom: 0.5rem !important;
- }
-
- .pb-xl-3 {
- padding-bottom: 1rem !important;
- }
-
- .pb-xl-4 {
- padding-bottom: 1.5rem !important;
- }
-
- .pb-xl-5 {
- padding-bottom: 3rem !important;
- }
-
- .ps-xl-0 {
- padding-left: 0 !important;
- }
-
- .ps-xl-1 {
- padding-left: 0.25rem !important;
- }
-
- .ps-xl-2 {
- padding-left: 0.5rem !important;
- }
-
- .ps-xl-3 {
- padding-left: 1rem !important;
- }
-
- .ps-xl-4 {
- padding-left: 1.5rem !important;
- }
-
- .ps-xl-5 {
- padding-left: 3rem !important;
- }
-
- .text-xl-start {
- text-align: left !important;
- }
-
- .text-xl-end {
- text-align: right !important;
- }
-
- .text-xl-center {
- text-align: center !important;
- }
-}
-@media (min-width: 1400px) {
- .float-xxl-start {
- float: left !important;
- }
-
- .float-xxl-end {
- float: right !important;
- }
-
- .float-xxl-none {
- float: none !important;
- }
-
- .d-xxl-inline {
- display: inline !important;
- }
-
- .d-xxl-inline-block {
- display: inline-block !important;
- }
-
- .d-xxl-block {
- display: block !important;
- }
-
- .d-xxl-grid {
- display: grid !important;
- }
-
- .d-xxl-table {
- display: table !important;
- }
-
- .d-xxl-table-row {
- display: table-row !important;
- }
-
- .d-xxl-table-cell {
- display: table-cell !important;
- }
-
- .d-xxl-flex {
- display: flex !important;
- }
-
- .d-xxl-inline-flex {
- display: inline-flex !important;
- }
-
- .d-xxl-none {
- display: none !important;
- }
-
- .flex-xxl-fill {
- flex: 1 1 auto !important;
- }
-
- .flex-xxl-row {
- flex-direction: row !important;
- }
-
- .flex-xxl-column {
- flex-direction: column !important;
- }
-
- .flex-xxl-row-reverse {
- flex-direction: row-reverse !important;
- }
-
- .flex-xxl-column-reverse {
- flex-direction: column-reverse !important;
- }
-
- .flex-xxl-grow-0 {
- flex-grow: 0 !important;
- }
-
- .flex-xxl-grow-1 {
- flex-grow: 1 !important;
- }
-
- .flex-xxl-shrink-0 {
- flex-shrink: 0 !important;
- }
-
- .flex-xxl-shrink-1 {
- flex-shrink: 1 !important;
- }
-
- .flex-xxl-wrap {
- flex-wrap: wrap !important;
- }
-
- .flex-xxl-nowrap {
- flex-wrap: nowrap !important;
- }
-
- .flex-xxl-wrap-reverse {
- flex-wrap: wrap-reverse !important;
- }
-
- .gap-xxl-0 {
- gap: 0 !important;
- }
-
- .gap-xxl-1 {
- gap: 0.25rem !important;
- }
-
- .gap-xxl-2 {
- gap: 0.5rem !important;
- }
-
- .gap-xxl-3 {
- gap: 1rem !important;
- }
-
- .gap-xxl-4 {
- gap: 1.5rem !important;
- }
-
- .gap-xxl-5 {
- gap: 3rem !important;
- }
-
- .justify-content-xxl-start {
- justify-content: flex-start !important;
- }
-
- .justify-content-xxl-end {
- justify-content: flex-end !important;
- }
-
- .justify-content-xxl-center {
- justify-content: center !important;
- }
-
- .justify-content-xxl-between {
- justify-content: space-between !important;
- }
-
- .justify-content-xxl-around {
- justify-content: space-around !important;
- }
-
- .justify-content-xxl-evenly {
- justify-content: space-evenly !important;
- }
-
- .align-items-xxl-start {
- align-items: flex-start !important;
- }
-
- .align-items-xxl-end {
- align-items: flex-end !important;
- }
-
- .align-items-xxl-center {
- align-items: center !important;
- }
-
- .align-items-xxl-baseline {
- align-items: baseline !important;
- }
-
- .align-items-xxl-stretch {
- align-items: stretch !important;
- }
-
- .align-content-xxl-start {
- align-content: flex-start !important;
- }
-
- .align-content-xxl-end {
- align-content: flex-end !important;
- }
-
- .align-content-xxl-center {
- align-content: center !important;
- }
-
- .align-content-xxl-between {
- align-content: space-between !important;
- }
-
- .align-content-xxl-around {
- align-content: space-around !important;
- }
-
- .align-content-xxl-stretch {
- align-content: stretch !important;
- }
-
- .align-self-xxl-auto {
- align-self: auto !important;
- }
-
- .align-self-xxl-start {
- align-self: flex-start !important;
- }
-
- .align-self-xxl-end {
- align-self: flex-end !important;
- }
-
- .align-self-xxl-center {
- align-self: center !important;
- }
-
- .align-self-xxl-baseline {
- align-self: baseline !important;
- }
-
- .align-self-xxl-stretch {
- align-self: stretch !important;
- }
-
- .order-xxl-first {
- order: -1 !important;
- }
-
- .order-xxl-0 {
- order: 0 !important;
- }
-
- .order-xxl-1 {
- order: 1 !important;
- }
-
- .order-xxl-2 {
- order: 2 !important;
- }
-
- .order-xxl-3 {
- order: 3 !important;
- }
-
- .order-xxl-4 {
- order: 4 !important;
- }
-
- .order-xxl-5 {
- order: 5 !important;
- }
-
- .order-xxl-last {
- order: 6 !important;
- }
-
- .m-xxl-0 {
- margin: 0 !important;
- }
-
- .m-xxl-1 {
- margin: 0.25rem !important;
- }
-
- .m-xxl-2 {
- margin: 0.5rem !important;
- }
-
- .m-xxl-3 {
- margin: 1rem !important;
- }
-
- .m-xxl-4 {
- margin: 1.5rem !important;
- }
-
- .m-xxl-5 {
- margin: 3rem !important;
- }
-
- .m-xxl-auto {
- margin: auto !important;
- }
-
- .mx-xxl-0 {
- margin-right: 0 !important;
- margin-left: 0 !important;
- }
-
- .mx-xxl-1 {
- margin-right: 0.25rem !important;
- margin-left: 0.25rem !important;
- }
-
- .mx-xxl-2 {
- margin-right: 0.5rem !important;
- margin-left: 0.5rem !important;
- }
-
- .mx-xxl-3 {
- margin-right: 1rem !important;
- margin-left: 1rem !important;
- }
-
- .mx-xxl-4 {
- margin-right: 1.5rem !important;
- margin-left: 1.5rem !important;
- }
-
- .mx-xxl-5 {
- margin-right: 3rem !important;
- margin-left: 3rem !important;
- }
-
- .mx-xxl-auto {
- margin-right: auto !important;
- margin-left: auto !important;
- }
-
- .my-xxl-0 {
- margin-top: 0 !important;
- margin-bottom: 0 !important;
- }
-
- .my-xxl-1 {
- margin-top: 0.25rem !important;
- margin-bottom: 0.25rem !important;
- }
-
- .my-xxl-2 {
- margin-top: 0.5rem !important;
- margin-bottom: 0.5rem !important;
- }
-
- .my-xxl-3 {
- margin-top: 1rem !important;
- margin-bottom: 1rem !important;
- }
-
- .my-xxl-4 {
- margin-top: 1.5rem !important;
- margin-bottom: 1.5rem !important;
- }
-
- .my-xxl-5 {
- margin-top: 3rem !important;
- margin-bottom: 3rem !important;
- }
-
- .my-xxl-auto {
- margin-top: auto !important;
- margin-bottom: auto !important;
- }
-
- .mt-xxl-0 {
- margin-top: 0 !important;
- }
-
- .mt-xxl-1 {
- margin-top: 0.25rem !important;
- }
-
- .mt-xxl-2 {
- margin-top: 0.5rem !important;
- }
-
- .mt-xxl-3 {
- margin-top: 1rem !important;
- }
-
- .mt-xxl-4 {
- margin-top: 1.5rem !important;
- }
-
- .mt-xxl-5 {
- margin-top: 3rem !important;
- }
-
- .mt-xxl-auto {
- margin-top: auto !important;
- }
-
- .me-xxl-0 {
- margin-right: 0 !important;
- }
-
- .me-xxl-1 {
- margin-right: 0.25rem !important;
- }
-
- .me-xxl-2 {
- margin-right: 0.5rem !important;
- }
-
- .me-xxl-3 {
- margin-right: 1rem !important;
- }
-
- .me-xxl-4 {
- margin-right: 1.5rem !important;
- }
-
- .me-xxl-5 {
- margin-right: 3rem !important;
- }
-
- .me-xxl-auto {
- margin-right: auto !important;
- }
-
- .mb-xxl-0 {
- margin-bottom: 0 !important;
- }
-
- .mb-xxl-1 {
- margin-bottom: 0.25rem !important;
- }
-
- .mb-xxl-2 {
- margin-bottom: 0.5rem !important;
- }
-
- .mb-xxl-3 {
- margin-bottom: 1rem !important;
- }
-
- .mb-xxl-4 {
- margin-bottom: 1.5rem !important;
- }
-
- .mb-xxl-5 {
- margin-bottom: 3rem !important;
- }
-
- .mb-xxl-auto {
- margin-bottom: auto !important;
- }
-
- .ms-xxl-0 {
- margin-left: 0 !important;
- }
-
- .ms-xxl-1 {
- margin-left: 0.25rem !important;
- }
-
- .ms-xxl-2 {
- margin-left: 0.5rem !important;
- }
-
- .ms-xxl-3 {
- margin-left: 1rem !important;
- }
-
- .ms-xxl-4 {
- margin-left: 1.5rem !important;
- }
-
- .ms-xxl-5 {
- margin-left: 3rem !important;
- }
-
- .ms-xxl-auto {
- margin-left: auto !important;
- }
-
- .p-xxl-0 {
- padding: 0 !important;
- }
-
- .p-xxl-1 {
- padding: 0.25rem !important;
- }
-
- .p-xxl-2 {
- padding: 0.5rem !important;
- }
-
- .p-xxl-3 {
- padding: 1rem !important;
- }
-
- .p-xxl-4 {
- padding: 1.5rem !important;
- }
-
- .p-xxl-5 {
- padding: 3rem !important;
- }
-
- .px-xxl-0 {
- padding-right: 0 !important;
- padding-left: 0 !important;
- }
-
- .px-xxl-1 {
- padding-right: 0.25rem !important;
- padding-left: 0.25rem !important;
- }
-
- .px-xxl-2 {
- padding-right: 0.5rem !important;
- padding-left: 0.5rem !important;
- }
-
- .px-xxl-3 {
- padding-right: 1rem !important;
- padding-left: 1rem !important;
- }
-
- .px-xxl-4 {
- padding-right: 1.5rem !important;
- padding-left: 1.5rem !important;
- }
-
- .px-xxl-5 {
- padding-right: 3rem !important;
- padding-left: 3rem !important;
- }
-
- .py-xxl-0 {
- padding-top: 0 !important;
- padding-bottom: 0 !important;
- }
-
- .py-xxl-1 {
- padding-top: 0.25rem !important;
- padding-bottom: 0.25rem !important;
- }
-
- .py-xxl-2 {
- padding-top: 0.5rem !important;
- padding-bottom: 0.5rem !important;
- }
-
- .py-xxl-3 {
- padding-top: 1rem !important;
- padding-bottom: 1rem !important;
- }
-
- .py-xxl-4 {
- padding-top: 1.5rem !important;
- padding-bottom: 1.5rem !important;
- }
-
- .py-xxl-5 {
- padding-top: 3rem !important;
- padding-bottom: 3rem !important;
- }
-
- .pt-xxl-0 {
- padding-top: 0 !important;
- }
-
- .pt-xxl-1 {
- padding-top: 0.25rem !important;
- }
-
- .pt-xxl-2 {
- padding-top: 0.5rem !important;
- }
-
- .pt-xxl-3 {
- padding-top: 1rem !important;
- }
-
- .pt-xxl-4 {
- padding-top: 1.5rem !important;
- }
-
- .pt-xxl-5 {
- padding-top: 3rem !important;
- }
-
- .pe-xxl-0 {
- padding-right: 0 !important;
- }
-
- .pe-xxl-1 {
- padding-right: 0.25rem !important;
- }
-
- .pe-xxl-2 {
- padding-right: 0.5rem !important;
- }
-
- .pe-xxl-3 {
- padding-right: 1rem !important;
- }
-
- .pe-xxl-4 {
- padding-right: 1.5rem !important;
- }
-
- .pe-xxl-5 {
- padding-right: 3rem !important;
- }
-
- .pb-xxl-0 {
- padding-bottom: 0 !important;
- }
-
- .pb-xxl-1 {
- padding-bottom: 0.25rem !important;
- }
-
- .pb-xxl-2 {
- padding-bottom: 0.5rem !important;
- }
-
- .pb-xxl-3 {
- padding-bottom: 1rem !important;
- }
-
- .pb-xxl-4 {
- padding-bottom: 1.5rem !important;
- }
-
- .pb-xxl-5 {
- padding-bottom: 3rem !important;
- }
-
- .ps-xxl-0 {
- padding-left: 0 !important;
- }
-
- .ps-xxl-1 {
- padding-left: 0.25rem !important;
- }
-
- .ps-xxl-2 {
- padding-left: 0.5rem !important;
- }
-
- .ps-xxl-3 {
- padding-left: 1rem !important;
- }
-
- .ps-xxl-4 {
- padding-left: 1.5rem !important;
- }
-
- .ps-xxl-5 {
- padding-left: 3rem !important;
- }
-
- .text-xxl-start {
- text-align: left !important;
- }
-
- .text-xxl-end {
- text-align: right !important;
- }
-
- .text-xxl-center {
- text-align: center !important;
- }
-}
-@media (min-width: 1200px) {
- .fs-1 {
- font-size: 2.5rem !important;
- }
-
- .fs-2 {
- font-size: 2rem !important;
- }
-
- .fs-3 {
- font-size: 1.75rem !important;
- }
-
- .fs-4 {
- font-size: 1.5rem !important;
- }
-}
-@media print {
- .d-print-inline {
- display: inline !important;
- }
-
- .d-print-inline-block {
- display: inline-block !important;
- }
-
- .d-print-block {
- display: block !important;
- }
-
- .d-print-grid {
- display: grid !important;
- }
-
- .d-print-table {
- display: table !important;
- }
-
- .d-print-table-row {
- display: table-row !important;
- }
-
- .d-print-table-cell {
- display: table-cell !important;
- }
-
- .d-print-flex {
- display: flex !important;
- }
-
- .d-print-inline-flex {
- display: inline-flex !important;
- }
-
- .d-print-none {
- display: none !important;
- }
-}
-
-/*# sourceMappingURL=bootstrap.css.map */
\ No newline at end of file
diff --git a/spaces/VIPLab/Track-Anything/inpainter/base_inpainter.py b/spaces/VIPLab/Track-Anything/inpainter/base_inpainter.py
deleted file mode 100644
index 1f2f3147bc21f5dec52b82271d40ac95e0405817..0000000000000000000000000000000000000000
--- a/spaces/VIPLab/Track-Anything/inpainter/base_inpainter.py
+++ /dev/null
@@ -1,287 +0,0 @@
-import os
-import glob
-from PIL import Image
-import torch
-import yaml
-import cv2
-import importlib
-import numpy as np
-from tqdm import tqdm
-from inpainter.util.tensor_util import resize_frames, resize_masks
-
-def read_image_from_split(videp_split_path):
- # if type:
- image = np.asarray([np.asarray(Image.open(path)) for path in videp_split_path])
- # else:
- # image = cv2.cvtColor(cv2.imread("/tmp/{}/paintedimages/{}/{:08d}.png".format(username, video_state["video_name"], index+ ".png")), cv2.COLOR_BGR2RGB)
- return image
-
-def save_image_to_userfolder(video_state, index, image, type:bool):
- if type:
- image_path = "/tmp/{}/originimages/{}/{:08d}.png".format(video_state["user_name"], video_state["video_name"], index)
- else:
- image_path = "/tmp/{}/paintedimages/{}/{:08d}.png".format(video_state["user_name"], video_state["video_name"], index)
- cv2.imwrite(image_path, image)
- return image_path
-class BaseInpainter:
- def __init__(self, E2FGVI_checkpoint, device) -> None:
- """
- E2FGVI_checkpoint: checkpoint of inpainter (version hq, with multi-resolution support)
- """
- net = importlib.import_module('inpainter.model.e2fgvi_hq')
- self.model = net.InpaintGenerator().to(device)
- self.model.load_state_dict(torch.load(E2FGVI_checkpoint, map_location=device))
- self.model.eval()
- self.device = device
- # load configurations
- with open("inpainter/config/config.yaml", 'r') as stream:
- config = yaml.safe_load(stream)
- self.neighbor_stride = config['neighbor_stride']
- self.num_ref = config['num_ref']
- self.step = config['step']
-
- # sample reference frames from the whole video
- def get_ref_index(self, f, neighbor_ids, length):
- ref_index = []
- if self.num_ref == -1:
- for i in range(0, length, self.step):
- if i not in neighbor_ids:
- ref_index.append(i)
- else:
- start_idx = max(0, f - self.step * (self.num_ref // 2))
- end_idx = min(length, f + self.step * (self.num_ref // 2))
- for i in range(start_idx, end_idx + 1, self.step):
- if i not in neighbor_ids:
- if len(ref_index) > self.num_ref:
- break
- ref_index.append(i)
- return ref_index
-
- def inpaint_efficient(self, frames, masks, num_tcb, num_tca, dilate_radius=15, ratio=1):
- """
- Perform Inpainting for video subsets
- frames: numpy array, T, H, W, 3
- masks: numpy array, T, H, W
- num_tcb: constant, number of temporal context before, frames
- num_tca: constant, number of temporal context after, frames
- dilate_radius: radius when applying dilation on masks
- ratio: down-sample ratio
-
- Output:
- inpainted_frames: numpy array, T, H, W, 3
- """
- assert frames.shape[:3] == masks.shape, 'different size between frames and masks'
- assert ratio > 0 and ratio <= 1, 'ratio must in (0, 1]'
-
- # --------------------
- # pre-processing
- # --------------------
- masks = masks.copy()
- masks = np.clip(masks, 0, 1)
- kernel = cv2.getStructuringElement(2, (dilate_radius, dilate_radius))
- masks = np.stack([cv2.dilate(mask, kernel) for mask in masks], 0)
- T, H, W = masks.shape
- masks = np.expand_dims(masks, axis=3) # expand to T, H, W, 1
- # size: (w, h)
- if ratio == 1:
- size = None
- binary_masks = masks
- else:
- size = [int(W*ratio), int(H*ratio)]
- size = [si+1 if si%2>0 else si for si in size] # only consider even values
- # shortest side should be larger than 50
- if min(size) < 50:
- ratio = 50. / min(H, W)
- size = [int(W*ratio), int(H*ratio)]
- binary_masks = resize_masks(masks, tuple(size))
- frames = resize_frames(frames, tuple(size)) # T, H, W, 3
- # frames and binary_masks are numpy arrays
- h, w = frames.shape[1:3]
- video_length = T - (num_tca + num_tcb) # real video length
- # convert to tensor
- imgs = (torch.from_numpy(frames).permute(0, 3, 1, 2).contiguous().unsqueeze(0).float().div(255)) * 2 - 1
- masks = torch.from_numpy(binary_masks).permute(0, 3, 1, 2).contiguous().unsqueeze(0)
- imgs, masks = imgs.to(self.device), masks.to(self.device)
- comp_frames = [None] * video_length
- tcb_imgs = None
- tca_imgs = None
- tcb_masks = None
- tca_masks = None
- # --------------------
- # end of pre-processing
- # --------------------
-
- # separate tc frames/masks from imgs and masks
- if num_tcb > 0:
- tcb_imgs = imgs[:, :num_tcb]
- tcb_masks = masks[:, :num_tcb]
- tcb_binary = binary_masks[:num_tcb]
- if num_tca > 0:
- tca_imgs = imgs[:, -num_tca:]
- tca_masks = masks[:, -num_tca:]
- tca_binary = binary_masks[-num_tca:]
- end_idx = -num_tca
- else:
- end_idx = T
-
- imgs = imgs[:, num_tcb:end_idx]
- masks = masks[:, num_tcb:end_idx]
- binary_masks = binary_masks[num_tcb:end_idx] # only neighbor area are involved
- frames = frames[num_tcb:end_idx] # only neighbor area are involved
-
- for f in tqdm(range(0, video_length, self.neighbor_stride), desc='Inpainting image'):
- neighbor_ids = [
- i for i in range(max(0, f - self.neighbor_stride),
- min(video_length, f + self.neighbor_stride + 1))
- ]
- ref_ids = self.get_ref_index(f, neighbor_ids, video_length)
-
- # selected_imgs = imgs[:1, neighbor_ids + ref_ids, :, :, :]
- # selected_masks = masks[:1, neighbor_ids + ref_ids, :, :, :]
-
- selected_imgs = imgs[:, neighbor_ids]
- selected_masks = masks[:, neighbor_ids]
- # pad before
- if tcb_imgs is not None:
- selected_imgs = torch.concat([selected_imgs, tcb_imgs], dim=1)
- selected_masks = torch.concat([selected_masks, tcb_masks], dim=1)
- # integrate ref frames
- selected_imgs = torch.concat([selected_imgs, imgs[:, ref_ids]], dim=1)
- selected_masks = torch.concat([selected_masks, masks[:, ref_ids]], dim=1)
- # pad after
- if tca_imgs is not None:
- selected_imgs = torch.concat([selected_imgs, tca_imgs], dim=1)
- selected_masks = torch.concat([selected_masks, tca_masks], dim=1)
-
- with torch.no_grad():
- masked_imgs = selected_imgs * (1 - selected_masks)
- mod_size_h = 60
- mod_size_w = 108
- h_pad = (mod_size_h - h % mod_size_h) % mod_size_h
- w_pad = (mod_size_w - w % mod_size_w) % mod_size_w
- masked_imgs = torch.cat(
- [masked_imgs, torch.flip(masked_imgs, [3])],
- 3)[:, :, :, :h + h_pad, :]
- masked_imgs = torch.cat(
- [masked_imgs, torch.flip(masked_imgs, [4])],
- 4)[:, :, :, :, :w + w_pad]
- pred_imgs, _ = self.model(masked_imgs, len(neighbor_ids))
- pred_imgs = pred_imgs[:, :, :h, :w]
- pred_imgs = (pred_imgs + 1) / 2
- pred_imgs = pred_imgs.cpu().permute(0, 2, 3, 1).numpy() * 255
- for i in range(len(neighbor_ids)):
- idx = neighbor_ids[i]
- img = pred_imgs[i].astype(np.uint8) * binary_masks[idx] + frames[idx] * (
- 1 - binary_masks[idx])
- if comp_frames[idx] is None:
- comp_frames[idx] = img
- else:
- comp_frames[idx] = comp_frames[idx].astype(
- np.float32) * 0.5 + img.astype(np.float32) * 0.5
- torch.cuda.empty_cache()
- inpainted_frames = np.stack(comp_frames, 0)
- return inpainted_frames.astype(np.uint8)
-
- def inpaint(self, frames_path, masks, dilate_radius=15, ratio=1):
- """
- Perform Inpainting for video subsets
- frames: numpy array, T, H, W, 3
- masks: numpy array, T, H, W
- dilate_radius: radius when applying dilation on masks
- ratio: down-sample ratio
-
- Output:
- inpainted_frames: numpy array, T, H, W, 3
- """
- # assert frames.shape[:3] == masks.shape, 'different size between frames and masks'
- assert ratio > 0 and ratio <= 1, 'ratio must in (0, 1]'
-
- # set interval
- interval = 45
- context_range = 10 # for each split, consider its temporal context [-context_range] frames and [context_range] frames
- # split frames into subsets
- video_length = len(frames_path)
- num_splits = video_length // interval
- id_splits = [[i*interval, (i+1)*interval] for i in range(num_splits)] # id splits
- # if remaining split > interval/2, add a new split, else, append to the last split
- if video_length - id_splits[-1][-1] > interval / 2:
- id_splits.append([num_splits*interval, video_length])
- else:
- id_splits[-1][-1] = video_length
-
- # perform inpainting for each split
- inpainted_splits = []
- for id_split in id_splits:
- video_split_path = frames_path[id_split[0]:id_split[1]]
- video_split = read_image_from_split(video_split_path)
- mask_split = masks[id_split[0]:id_split[1]]
-
- # | id_before | ----- | id_split[0] | ----- | id_split[1] | ----- | id_after |
- # add temporal context
- id_before = max(0, id_split[0] - self.step * context_range)
- try:
- tcb_frames = np.stack([np.array(Image.open(frames_path[idb])) for idb in range(id_before, id_split[0]-self.step, self.step)], 0)
- tcb_masks = np.stack([masks[idb] for idb in range(id_before, id_split[0]-self.step, self.step)], 0)
- num_tcb = len(tcb_frames)
- except:
- num_tcb = 0
- id_after = min(video_length, id_split[1] + self.step * context_range)
- try:
- tca_frames = np.stack([np.array(Image.open(frames_path[ida])) for ida in range(id_split[1]+self.step, id_after, self.step)], 0)
- tca_masks = np.stack([masks[ida] for ida in range(id_split[1]+self.step, id_after, self.step)], 0)
- num_tca = len(tca_frames)
- except:
- num_tca = 0
-
- # concatenate temporal context frames/masks with input frames/masks (for parallel pre-processing)
- if num_tcb > 0:
- video_split = np.concatenate([tcb_frames, video_split], 0)
- mask_split = np.concatenate([tcb_masks, mask_split], 0)
- if num_tca > 0:
- video_split = np.concatenate([video_split, tca_frames], 0)
- mask_split = np.concatenate([mask_split, tca_masks], 0)
-
- # inpaint each split
- inpainted_splits.append(self.inpaint_efficient(video_split, mask_split, num_tcb, num_tca, dilate_radius, ratio))
-
- inpainted_frames = np.concatenate(inpainted_splits, 0)
- return inpainted_frames.astype(np.uint8)
-
-if __name__ == '__main__':
-
- frame_path = glob.glob(os.path.join('/ssd1/gaomingqi/datasets/davis/JPEGImages/480p/parkour', '*.jpg'))
- frame_path.sort()
- mask_path = glob.glob(os.path.join('/ssd1/gaomingqi/datasets/davis/Annotations/480p/parkour', "*.png"))
- mask_path.sort()
- save_path = '/ssd1/gaomingqi/results/inpainting/parkour'
-
- if not os.path.exists(save_path):
- os.mkdir(save_path)
-
- frames = []
- masks = []
- for fid, mid in zip(frame_path, mask_path):
- frames.append(Image.open(fid).convert('RGB'))
- masks.append(Image.open(mid).convert('P'))
-
- frames = np.stack(frames, 0)
- masks = np.stack(masks, 0)
-
- # ----------------------------------------------
- # how to use
- # ----------------------------------------------
- # 1/3: set checkpoint and device
- checkpoint = '/ssd1/gaomingqi/checkpoints/E2FGVI-HQ-CVPR22.pth'
- device = 'cuda:6'
- # 2/3: initialise inpainter
- base_inpainter = BaseInpainter(checkpoint, device)
- # 3/3: inpainting (frames: numpy array, T, H, W, 3; masks: numpy array, T, H, W)
- # ratio: (0, 1], ratio for down sample, default value is 1
- inpainted_frames = base_inpainter.inpaint(frames, masks, ratio=0.01) # numpy array, T, H, W, 3
- # ----------------------------------------------
- # end
- # ----------------------------------------------
- # save
- for ti, inpainted_frame in enumerate(inpainted_frames):
- frame = Image.fromarray(inpainted_frame).convert('RGB')
- frame.save(os.path.join(save_path, f'{ti:05d}.jpg'))
\ No newline at end of file
diff --git a/spaces/Vegecken/sovits4dzl/Eng_docs.md b/spaces/Vegecken/sovits4dzl/Eng_docs.md
deleted file mode 100644
index 10770870d46914dbdacd59de71fab421f7663104..0000000000000000000000000000000000000000
--- a/spaces/Vegecken/sovits4dzl/Eng_docs.md
+++ /dev/null
@@ -1,109 +0,0 @@
-# SoftVC VITS Singing Voice Conversion
-
-## Updates
-> According to incomplete statistics, it seems that training with multiple speakers may lead to **worsened leaking of voice timbre**. It is not recommended to train models with more than 5 speakers. The current suggestion is to try to train models with only a single speaker if you want to achieve a voice timbre that is more similar to the target.
-> Fixed the issue with unwanted staccato, improving audio quality by a decent amount.\
-> The 2.0 version has been moved to the 2.0 branch.\
-> Version 3.0 uses the code structure of FreeVC, which isn't compatible with older versions.\
-> Compared to [DiffSVC](https://github.com/prophesier/diff-svc) , diffsvc performs much better when the training data is of extremely high quality, but this repository may perform better on datasets with lower quality. Additionally, this repository is much faster in terms of inference speed compared to diffsvc.
-
-## Model Overview
-A singing voice coversion (SVC) model, using the SoftVC encoder to extract features from the input audio, sent into VITS along with the F0 to replace the original input to acheive a voice conversion effect. Additionally, changing the vocoder to [NSF HiFiGAN](https://github.com/openvpi/DiffSinger/tree/refactor/modules/nsf_hifigan) to fix the issue with unwanted staccato.
-
-## Notice
-+ The current branch is the 32kHz version, which requires less vram during inferencing, as well as faster inferencing speeds, and datasets for said branch take up less disk space. Thus the 32 kHz branch is recommended for use.
-+ If you want to train 48 kHz variant models, switch to the [main branch](https://github.com/innnky/so-vits-svc/tree/main).
-
-
-## Required models
-+ soft vc hubert:[hubert-soft-0d54a1f4.pt](https://github.com/bshall/hubert/releases/download/v0.1/hubert-soft-0d54a1f4.pt)
- + Place under `hubert`.
-+ Pretrained models [G_0.pth](https://huggingface.co/innnky/sovits_pretrained/resolve/main/G_0.pth) and [D_0.pth](https://huggingface.co/innnky/sovits_pretrained/resolve/main/D_0.pth)
- + Place under `logs/32k`.
- + Pretrained models are required, because from experiments, training from scratch can be rather unpredictable to say the least, and training with a pretrained model can greatly improve training speeds.
- + The pretrained model includes云灏, 即霜, 辉宇·星AI, 派蒙, and 绫地宁宁, covering the common ranges of both male and female voices, and so it can be seen as a rather universal pretrained model.
- + The pretrained model exludes the `optimizer speaker_embedding` section, rendering it only usable for pretraining and incapable of inferencing with.
-```shell
-# For simple downloading.
-# hubert
-wget -P hubert/ https://github.com/bshall/hubert/releases/download/v0.1/hubert-soft-0d54a1f4.pt
-# G&D pretrained models
-wget -P logs/32k/ https://huggingface.co/innnky/sovits_pretrained/resolve/main/G_0.pth
-wget -P logs/32k/ https://huggingface.co/innnky/sovits_pretrained/resolve/main/D_0.pth
-
-```
-
-## Colab notebook script for dataset creation and training.
-[colab training notebook](https://colab.research.google.com/drive/1rCUOOVG7-XQlVZuWRAj5IpGrMM8t07pE?usp=sharing)
-
-## Dataset preparation
-All that is required is that the data be put under the `dataset_raw` folder in the structure format provided below.
-```shell
-dataset_raw
-├───speaker0
-│ ├───xxx1-xxx1.wav
-│ ├───...
-│ └───Lxx-0xx8.wav
-└───speaker1
- ├───xx2-0xxx2.wav
- ├───...
- └───xxx7-xxx007.wav
-```
-
-## Data pre-processing.
-1. Resample to 32khz
-
-```shell
-python resample.py
- ```
-2. Automatically sort out training set, validation set, test set, and automatically generate configuration files.
-```shell
-python preprocess_flist_config.py
-# Notice.
-# The n_speakers value in the config will be set automatically according to the amount of speakers in the dataset.
-# To reserve space for additionally added speakers in the dataset, the n_speakers value will be be set to twice the actual amount.
-# If you want even more space for adding more data, you can edit the n_speakers value in the config after runing this step.
-# This can not be changed after training starts.
-```
-3. Generate hubert and F0 features/
-```shell
-python preprocess_hubert_f0.py
-```
-After running the step above, the `dataset` folder will contain all the pre-processed data, you can delete the `dataset_raw` folder after that.
-
-## Training.
-```shell
-python train.py -c configs/config.json -m 32k
-```
-
-## Inferencing.
-
-Use [inference_main.py](inference_main.py)
-+ Edit `model_path` to your newest checkpoint.
-+ Place the input audio under the `raw` folder.
-+ Change `clean_names` to the output file name.
-+ Use `trans` to edit the pitch shifting amount (semitones).
-+ Change `spk_list` to the speaker name.
-
-## Onnx Exporting.
-### **When exporting Onnx, please make sure you re-clone the whole repository!!!**
-Use [onnx_export.py](onnx_export.py)
-+ Create a new folder called `checkpoints`.
-+ Create a project folder in `checkpoints` folder with the desired name for your project, let's use `myproject` as example. Folder structure looks like `./checkpoints/myproject`.
-+ Rename your model to `model.pth`, rename your config file to `config.json` then move them into `myproject` folder.
-+ Modify [onnx_export.py](onnx_export.py) where `path = "NyaruTaffy"`, change `NyaruTaffy` to your project name, here it will be `path = "myproject"`.
-+ Run [onnx_export.py](onnx_export.py)
-+ Once it finished, a `model.onnx` will be generated in `myproject` folder, that's the model you just exported.
-+ Notice: if you want to export a 48K model, please follow the instruction below or use `model_onnx_48k.py` directly.
- + Open [model_onnx.py](model_onnx.py) and change `hps={"sampling_rate": 32000...}` to `hps={"sampling_rate": 48000}` in class `SynthesizerTrn`.
- + Open [nvSTFT](/vdecoder/hifigan/nvSTFT.py) and replace all `32000` with `48000`
- ### Onnx Model UI Support
- + [MoeSS](https://github.com/NaruseMioShirakana/MoeSS)
-+ All training function and transformation are removed, only if they are all removed you are actually using Onnx.
-
-## Gradio (WebUI)
-Use [sovits_gradio.py](sovits_gradio.py) to run Gradio WebUI
-+ Create a new folder called `checkpoints`.
-+ Create a project folder in `checkpoints` folder with the desired name for your project, let's use `myproject` as example. Folder structure looks like `./checkpoints/myproject`.
-+ Rename your model to `model.pth`, rename your config file to `config.json` then move them into `myproject` folder.
-+ Run [sovits_gradio.py](sovits_gradio.py)
\ No newline at end of file
diff --git a/spaces/XS-1/BW_IMAGE_VIDEO_COLORIZER/fastai/imports/torch.py b/spaces/XS-1/BW_IMAGE_VIDEO_COLORIZER/fastai/imports/torch.py
deleted file mode 100644
index 028a3932fb7c12356a0ab239098cd8088308d37f..0000000000000000000000000000000000000000
--- a/spaces/XS-1/BW_IMAGE_VIDEO_COLORIZER/fastai/imports/torch.py
+++ /dev/null
@@ -1,5 +0,0 @@
-import torch, torch.nn.functional as F
-from torch import ByteTensor, DoubleTensor, FloatTensor, HalfTensor, LongTensor, ShortTensor, Tensor
-from torch import nn, optim, as_tensor
-from torch.utils.data import BatchSampler, DataLoader, Dataset, Sampler, TensorDataset
-from torch.nn.utils import weight_norm, spectral_norm
diff --git a/spaces/Xinyoumeng233hu/SteganographywithGPT-2/block_baseline.py b/spaces/Xinyoumeng233hu/SteganographywithGPT-2/block_baseline.py
deleted file mode 100644
index 8b0176746b95f80d9d4db26cf85a000278e4afcd..0000000000000000000000000000000000000000
--- a/spaces/Xinyoumeng233hu/SteganographywithGPT-2/block_baseline.py
+++ /dev/null
@@ -1,195 +0,0 @@
-import torch
-import torch.nn.functional as F
-
-import numpy as np
-from utils import kl, entropy, is_sent_finish, limit_past, bits2int, int2bits
-
-# number of bins is 2^block_size
-# each bin contains vocab_size/2^block_size words
-def get_bins(vocab_size, block_size):
- num_bins = 2**block_size
- words_per_bin = vocab_size/num_bins
-
- vocab_ordering = np.arange(vocab_size)
- np.random.seed(block_size)
- np.random.shuffle(vocab_ordering)
-
- bin2words = [vocab_ordering[int(i*words_per_bin):int((i+1)*words_per_bin)] for i in range(num_bins)]
- bin2words = [np.array(words) for words in bin2words]
- words2bin_list = [{i: j for i in bin2words[j]} for j in range(num_bins)]
- words2bin = {}
- for d in words2bin_list:
- words2bin.update(d)
-
- return bin2words, words2bin
-
-def encode_block(model, enc, message, context, block_size, bin2words, words2bin, finish_sent=False, device='cpu'):
- length = len(message)
-
- context = torch.tensor(context[-1022:], device=device, dtype=torch.long)
-
- prev = context
- output = context
- past = None
-
- total_num = 0
- total_num_for_stats = 0
- total_log_probs = 0
- total_kl = 0 # in bits
- total_num_sents = 0
-
- with torch.no_grad():
- i = 0
- sent_finish = False
- while i < length or (finish_sent and not sent_finish):
- logits, past = model(prev.unsqueeze(0), past=past)
- past = limit_past(past)
- logits[0, -1, -1] = -1e10 # endoftext can't happen
- logits[0, -1, 628] = -1e10 # 2 newlines can't happen
- logits = logits[0, -1, :]
- log_probs = F.log_softmax(logits, dim=-1)
-
- filtered_logits = logits.clone()
- filtered_logits[:] = -1e10 # first set all to 0
-
- if i >= length:
- _, indices = logits.sort(descending=True)
- sent_finish = is_sent_finish(indices[0].item(), enc)
- else:
- # First calculate logq
- logq = logits.clone()
- logq[:] = -1e10 # first set all to 0
-
- for bin_val in range(2**block_size):
- filtered_logits = logits.clone()
- filtered_logits[:] = -1e10 # first set all to 0
- available_tokens = bin2words[bin_val]
- filtered_logits[available_tokens] = logits[available_tokens]
- filtered_logits, indices = filtered_logits.sort(descending=True)
-
- logq[indices[0]] = -block_size # in bits
-
- logq = logq*0.69315 # in nats
- q = torch.exp(logq)
-
- # Then find the actual word for the right bin
- m_part = message[i:i+block_size]
-
- filtered_logits = logits.clone()
- filtered_logits[:] = -1e10 # first set all to 0
- available_tokens = bin2words[bits2int(m_part)]
- filtered_logits[available_tokens] = logits[available_tokens]
- filtered_logits, indices = filtered_logits.sort(descending=True)
-
- total_kl += kl(q, logq, log_probs)
- total_log_probs += log_probs[indices[0]].item()
- i += block_size
- total_num_for_stats += 1
-
- total_num += 1
- prev = indices[0].view(1)
- output = torch.cat((output, prev))
-
- avg_NLL = -total_log_probs/total_num_for_stats
- avg_KL = total_kl/total_num_for_stats
- words_per_bit = total_num_for_stats/i
-
- return output[len(context):].tolist(), avg_NLL, avg_KL, words_per_bit
-
-def decode_block(model, enc, text, context, block_size, bin2words, words2bin, device='cpu'):
- # inp is a list of token indices
- # context is a list of token indices
- inp = enc.encode(text)
- i = 0
- while i < len(inp):
- if inp[i] == 628:
- inp[i] = 198
- inp[i+1:i+1] = [198]
- i += 2
- else:
- i += 1
-
- context = torch.tensor(context[-1022:], device=device, dtype=torch.long)
- prev = context
- past = None
-
- message = []
- with torch.no_grad():
- i = 0
- while i < len(inp):
- if past and past[0].shape[3] >= 1023:
- raise RuntimeError
- bin_num = words2bin[inp[i]]
-
- logits, past = model(prev.unsqueeze(0), past=past)
- past = limit_past(past)
- logits[0, -1, -1] = -1e10 # endoftext can't happen
- logits[0, -1, 628] = -1e10 # 2 newlines can't happen
-
- logits = logits[0, -1, :]
- filtered_logits = logits.clone()
- filtered_logits[:] = -1e10 # first set all to 0
-
- available_tokens = bin2words[bin_num]
- filtered_logits[available_tokens] = logits[available_tokens]
- filtered_logits, indices = filtered_logits.sort(descending=True)
-
- rank = (indices == inp[i]).nonzero().item()
-
- # Handle errors that could happen because of BPE
- if rank > 0:
- true_token_text = enc.decoder[inp[i]]
- for bin_num in range(len(bin2words)):
- filtered_logits = logits.clone()
- filtered_logits[:] = -1e10 # first set all to 0
-
- available_tokens = bin2words[bin_num]
- filtered_logits[available_tokens] = logits[available_tokens]
- filtered_logits, indices = filtered_logits.sort(descending=True)
-
- prop_token_text = enc.decoder[indices[0].item()]
- #print(true_token_text, prop_token_text)
-
- # Is there a more likely prefix token that could be the actual token generated?
- if len(prop_token_text) < len(true_token_text) and \
- prop_token_text == true_token_text[:len(prop_token_text)]:
- suffix = true_token_text[len(prop_token_text):]
- suffix_tokens = enc.encode(suffix) # a list
- inp[i] = indices[0].item()
- inp[i+1:i+1] = suffix_tokens # insert suffix tokens into list
- break
-
- # Is there a more likely longer token that could be the actual token generated?
- elif len(prop_token_text) > len(true_token_text) and \
- true_token_text == prop_token_text[:len(true_token_text)]:
- whole_text = true_token_text
- num_extra = 1
- while len(whole_text) < len(prop_token_text):
- whole_text += enc.decoder[inp[i+num_extra]]
- num_extra += 1
- if prop_token_text == whole_text[:len(prop_token_text)]:
- inp[i] = indices[0].item()
- for j in range(1, num_extra):
- del inp[i+j]
-
- if len(whole_text) > len(prop_token_text):
- suffix = whole_text[len(prop_token_text):]
- suffix_tokens = enc.encode(suffix) # a list
- inp[i+1:i+1] = suffix_tokens # insert suffix tokens into list
- break
- else:
- print('Unable to fix BPE error: token received: %s=%d, text: %s' % (true_token_text, inp[i], text))
-
- tokens_t = int2bits(bin_num, block_size)
-
- message.extend(tokens_t)
- prev = torch.tensor([inp[i]], device=device, dtype=torch.long)
- i += 1
-
- return message
-
-if __name__ == '__main__':
- np.random.seed(123)
-
- bin2words, words2bin = get_bins(50257, 5)
- print(words2bin[153])
\ No newline at end of file
diff --git a/spaces/XlalalaX/VITS-Umamusume-voice-synthesizer/hubert_model.py b/spaces/XlalalaX/VITS-Umamusume-voice-synthesizer/hubert_model.py
deleted file mode 100644
index 6c7f8716c268d0f371f5a9f7995f59bd4b9082d1..0000000000000000000000000000000000000000
--- a/spaces/XlalalaX/VITS-Umamusume-voice-synthesizer/hubert_model.py
+++ /dev/null
@@ -1,221 +0,0 @@
-import copy
-from typing import Optional, Tuple
-import random
-
-import torch
-import torch.nn as nn
-import torch.nn.functional as F
-from torch.nn.modules.utils import consume_prefix_in_state_dict_if_present
-
-class Hubert(nn.Module):
- def __init__(self, num_label_embeddings: int = 100, mask: bool = True):
- super().__init__()
- self._mask = mask
- self.feature_extractor = FeatureExtractor()
- self.feature_projection = FeatureProjection()
- self.positional_embedding = PositionalConvEmbedding()
- self.norm = nn.LayerNorm(768)
- self.dropout = nn.Dropout(0.1)
- self.encoder = TransformerEncoder(
- nn.TransformerEncoderLayer(
- 768, 12, 3072, activation="gelu", batch_first=True
- ),
- 12,
- )
- self.proj = nn.Linear(768, 256)
-
- self.masked_spec_embed = nn.Parameter(torch.FloatTensor(768).uniform_())
- self.label_embedding = nn.Embedding(num_label_embeddings, 256)
-
- def mask(self, x: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
- mask = None
- if self.training and self._mask:
- mask = _compute_mask((x.size(0), x.size(1)), 0.8, 10, x.device, 2)
- x[mask] = self.masked_spec_embed.to(x.dtype)
- return x, mask
-
- def encode(
- self, x: torch.Tensor, layer: Optional[int] = None
- ) -> Tuple[torch.Tensor, torch.Tensor]:
- x = self.feature_extractor(x)
- x = self.feature_projection(x.transpose(1, 2))
- x, mask = self.mask(x)
- x = x + self.positional_embedding(x)
- x = self.dropout(self.norm(x))
- x = self.encoder(x, output_layer=layer)
- return x, mask
-
- def logits(self, x: torch.Tensor) -> torch.Tensor:
- logits = torch.cosine_similarity(
- x.unsqueeze(2),
- self.label_embedding.weight.unsqueeze(0).unsqueeze(0),
- dim=-1,
- )
- return logits / 0.1
-
- def forward(self, x: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
- x, mask = self.encode(x)
- x = self.proj(x)
- logits = self.logits(x)
- return logits, mask
-
-
-class HubertSoft(Hubert):
- def __init__(self):
- super().__init__()
-
- @torch.inference_mode()
- def units(self, wav: torch.Tensor) -> torch.Tensor:
- wav = F.pad(wav, ((400 - 320) // 2, (400 - 320) // 2))
- x, _ = self.encode(wav)
- return self.proj(x)
-
-
-class FeatureExtractor(nn.Module):
- def __init__(self):
- super().__init__()
- self.conv0 = nn.Conv1d(1, 512, 10, 5, bias=False)
- self.norm0 = nn.GroupNorm(512, 512)
- self.conv1 = nn.Conv1d(512, 512, 3, 2, bias=False)
- self.conv2 = nn.Conv1d(512, 512, 3, 2, bias=False)
- self.conv3 = nn.Conv1d(512, 512, 3, 2, bias=False)
- self.conv4 = nn.Conv1d(512, 512, 3, 2, bias=False)
- self.conv5 = nn.Conv1d(512, 512, 2, 2, bias=False)
- self.conv6 = nn.Conv1d(512, 512, 2, 2, bias=False)
-
- def forward(self, x: torch.Tensor) -> torch.Tensor:
- x = F.gelu(self.norm0(self.conv0(x)))
- x = F.gelu(self.conv1(x))
- x = F.gelu(self.conv2(x))
- x = F.gelu(self.conv3(x))
- x = F.gelu(self.conv4(x))
- x = F.gelu(self.conv5(x))
- x = F.gelu(self.conv6(x))
- return x
-
-
-class FeatureProjection(nn.Module):
- def __init__(self):
- super().__init__()
- self.norm = nn.LayerNorm(512)
- self.projection = nn.Linear(512, 768)
- self.dropout = nn.Dropout(0.1)
-
- def forward(self, x: torch.Tensor) -> torch.Tensor:
- x = self.norm(x)
- x = self.projection(x)
- x = self.dropout(x)
- return x
-
-
-class PositionalConvEmbedding(nn.Module):
- def __init__(self):
- super().__init__()
- self.conv = nn.Conv1d(
- 768,
- 768,
- kernel_size=128,
- padding=128 // 2,
- groups=16,
- )
- self.conv = nn.utils.weight_norm(self.conv, name="weight", dim=2)
-
- def forward(self, x: torch.Tensor) -> torch.Tensor:
- x = self.conv(x.transpose(1, 2))
- x = F.gelu(x[:, :, :-1])
- return x.transpose(1, 2)
-
-
-class TransformerEncoder(nn.Module):
- def __init__(
- self, encoder_layer: nn.TransformerEncoderLayer, num_layers: int
- ) -> None:
- super(TransformerEncoder, self).__init__()
- self.layers = nn.ModuleList(
- [copy.deepcopy(encoder_layer) for _ in range(num_layers)]
- )
- self.num_layers = num_layers
-
- def forward(
- self,
- src: torch.Tensor,
- mask: torch.Tensor = None,
- src_key_padding_mask: torch.Tensor = None,
- output_layer: Optional[int] = None,
- ) -> torch.Tensor:
- output = src
- for layer in self.layers[:output_layer]:
- output = layer(
- output, src_mask=mask, src_key_padding_mask=src_key_padding_mask
- )
- return output
-
-
-def _compute_mask(
- shape: Tuple[int, int],
- mask_prob: float,
- mask_length: int,
- device: torch.device,
- min_masks: int = 0,
-) -> torch.Tensor:
- batch_size, sequence_length = shape
-
- if mask_length < 1:
- raise ValueError("`mask_length` has to be bigger than 0.")
-
- if mask_length > sequence_length:
- raise ValueError(
- f"`mask_length` has to be smaller than `sequence_length`, but got `mask_length`: {mask_length} and `sequence_length`: {sequence_length}`"
- )
-
- # compute number of masked spans in batch
- num_masked_spans = int(mask_prob * sequence_length / mask_length + random.random())
- num_masked_spans = max(num_masked_spans, min_masks)
-
- # make sure num masked indices <= sequence_length
- if num_masked_spans * mask_length > sequence_length:
- num_masked_spans = sequence_length // mask_length
-
- # SpecAugment mask to fill
- mask = torch.zeros((batch_size, sequence_length), device=device, dtype=torch.bool)
-
- # uniform distribution to sample from, make sure that offset samples are < sequence_length
- uniform_dist = torch.ones(
- (batch_size, sequence_length - (mask_length - 1)), device=device
- )
-
- # get random indices to mask
- mask_indices = torch.multinomial(uniform_dist, num_masked_spans)
-
- # expand masked indices to masked spans
- mask_indices = (
- mask_indices.unsqueeze(dim=-1)
- .expand((batch_size, num_masked_spans, mask_length))
- .reshape(batch_size, num_masked_spans * mask_length)
- )
- offsets = (
- torch.arange(mask_length, device=device)[None, None, :]
- .expand((batch_size, num_masked_spans, mask_length))
- .reshape(batch_size, num_masked_spans * mask_length)
- )
- mask_idxs = mask_indices + offsets
-
- # scatter indices to mask
- mask = mask.scatter(1, mask_idxs, True)
-
- return mask
-
-
-def hubert_soft(
- path: str
-) -> HubertSoft:
- r"""HuBERT-Soft from `"A Comparison of Discrete and Soft Speech Units for Improved Voice Conversion"`.
- Args:
- path (str): path of a pretrained model
- """
- hubert = HubertSoft()
- checkpoint = torch.load(path)
- consume_prefix_in_state_dict_if_present(checkpoint, "module.")
- hubert.load_state_dict(checkpoint)
- hubert.eval()
- return hubert
diff --git a/spaces/XzJosh/Gun-Bert-VITS2/text/cleaner.py b/spaces/XzJosh/Gun-Bert-VITS2/text/cleaner.py
deleted file mode 100644
index 64bd5f7296f66c94f3a335666c53706bb5fe5b39..0000000000000000000000000000000000000000
--- a/spaces/XzJosh/Gun-Bert-VITS2/text/cleaner.py
+++ /dev/null
@@ -1,27 +0,0 @@
-from text import chinese, cleaned_text_to_sequence
-
-
-language_module_map = {
- 'ZH': chinese
-}
-
-
-def clean_text(text, language):
- language_module = language_module_map[language]
- norm_text = language_module.text_normalize(text)
- phones, tones, word2ph = language_module.g2p(norm_text)
- return norm_text, phones, tones, word2ph
-
-def clean_text_bert(text, language):
- language_module = language_module_map[language]
- norm_text = language_module.text_normalize(text)
- phones, tones, word2ph = language_module.g2p(norm_text)
- bert = language_module.get_bert_feature(norm_text, word2ph)
- return phones, tones, bert
-
-def text_to_sequence(text, language):
- norm_text, phones, tones, word2ph = clean_text(text, language)
- return cleaned_text_to_sequence(phones, tones, language)
-
-if __name__ == '__main__':
- pass
diff --git a/spaces/XzJosh/Nana7mi-Bert-VITS2/transforms.py b/spaces/XzJosh/Nana7mi-Bert-VITS2/transforms.py
deleted file mode 100644
index 4793d67ca5a5630e0ffe0f9fb29445c949e64dae..0000000000000000000000000000000000000000
--- a/spaces/XzJosh/Nana7mi-Bert-VITS2/transforms.py
+++ /dev/null
@@ -1,193 +0,0 @@
-import torch
-from torch.nn import functional as F
-
-import numpy as np
-
-
-DEFAULT_MIN_BIN_WIDTH = 1e-3
-DEFAULT_MIN_BIN_HEIGHT = 1e-3
-DEFAULT_MIN_DERIVATIVE = 1e-3
-
-
-def piecewise_rational_quadratic_transform(inputs,
- unnormalized_widths,
- unnormalized_heights,
- unnormalized_derivatives,
- inverse=False,
- tails=None,
- tail_bound=1.,
- min_bin_width=DEFAULT_MIN_BIN_WIDTH,
- min_bin_height=DEFAULT_MIN_BIN_HEIGHT,
- min_derivative=DEFAULT_MIN_DERIVATIVE):
-
- if tails is None:
- spline_fn = rational_quadratic_spline
- spline_kwargs = {}
- else:
- spline_fn = unconstrained_rational_quadratic_spline
- spline_kwargs = {
- 'tails': tails,
- 'tail_bound': tail_bound
- }
-
- outputs, logabsdet = spline_fn(
- inputs=inputs,
- unnormalized_widths=unnormalized_widths,
- unnormalized_heights=unnormalized_heights,
- unnormalized_derivatives=unnormalized_derivatives,
- inverse=inverse,
- min_bin_width=min_bin_width,
- min_bin_height=min_bin_height,
- min_derivative=min_derivative,
- **spline_kwargs
- )
- return outputs, logabsdet
-
-
-def searchsorted(bin_locations, inputs, eps=1e-6):
- bin_locations[..., -1] += eps
- return torch.sum(
- inputs[..., None] >= bin_locations,
- dim=-1
- ) - 1
-
-
-def unconstrained_rational_quadratic_spline(inputs,
- unnormalized_widths,
- unnormalized_heights,
- unnormalized_derivatives,
- inverse=False,
- tails='linear',
- tail_bound=1.,
- min_bin_width=DEFAULT_MIN_BIN_WIDTH,
- min_bin_height=DEFAULT_MIN_BIN_HEIGHT,
- min_derivative=DEFAULT_MIN_DERIVATIVE):
- inside_interval_mask = (inputs >= -tail_bound) & (inputs <= tail_bound)
- outside_interval_mask = ~inside_interval_mask
-
- outputs = torch.zeros_like(inputs)
- logabsdet = torch.zeros_like(inputs)
-
- if tails == 'linear':
- unnormalized_derivatives = F.pad(unnormalized_derivatives, pad=(1, 1))
- constant = np.log(np.exp(1 - min_derivative) - 1)
- unnormalized_derivatives[..., 0] = constant
- unnormalized_derivatives[..., -1] = constant
-
- outputs[outside_interval_mask] = inputs[outside_interval_mask]
- logabsdet[outside_interval_mask] = 0
- else:
- raise RuntimeError('{} tails are not implemented.'.format(tails))
-
- outputs[inside_interval_mask], logabsdet[inside_interval_mask] = rational_quadratic_spline(
- inputs=inputs[inside_interval_mask],
- unnormalized_widths=unnormalized_widths[inside_interval_mask, :],
- unnormalized_heights=unnormalized_heights[inside_interval_mask, :],
- unnormalized_derivatives=unnormalized_derivatives[inside_interval_mask, :],
- inverse=inverse,
- left=-tail_bound, right=tail_bound, bottom=-tail_bound, top=tail_bound,
- min_bin_width=min_bin_width,
- min_bin_height=min_bin_height,
- min_derivative=min_derivative
- )
-
- return outputs, logabsdet
-
-def rational_quadratic_spline(inputs,
- unnormalized_widths,
- unnormalized_heights,
- unnormalized_derivatives,
- inverse=False,
- left=0., right=1., bottom=0., top=1.,
- min_bin_width=DEFAULT_MIN_BIN_WIDTH,
- min_bin_height=DEFAULT_MIN_BIN_HEIGHT,
- min_derivative=DEFAULT_MIN_DERIVATIVE):
- if torch.min(inputs) < left or torch.max(inputs) > right:
- raise ValueError('Input to a transform is not within its domain')
-
- num_bins = unnormalized_widths.shape[-1]
-
- if min_bin_width * num_bins > 1.0:
- raise ValueError('Minimal bin width too large for the number of bins')
- if min_bin_height * num_bins > 1.0:
- raise ValueError('Minimal bin height too large for the number of bins')
-
- widths = F.softmax(unnormalized_widths, dim=-1)
- widths = min_bin_width + (1 - min_bin_width * num_bins) * widths
- cumwidths = torch.cumsum(widths, dim=-1)
- cumwidths = F.pad(cumwidths, pad=(1, 0), mode='constant', value=0.0)
- cumwidths = (right - left) * cumwidths + left
- cumwidths[..., 0] = left
- cumwidths[..., -1] = right
- widths = cumwidths[..., 1:] - cumwidths[..., :-1]
-
- derivatives = min_derivative + F.softplus(unnormalized_derivatives)
-
- heights = F.softmax(unnormalized_heights, dim=-1)
- heights = min_bin_height + (1 - min_bin_height * num_bins) * heights
- cumheights = torch.cumsum(heights, dim=-1)
- cumheights = F.pad(cumheights, pad=(1, 0), mode='constant', value=0.0)
- cumheights = (top - bottom) * cumheights + bottom
- cumheights[..., 0] = bottom
- cumheights[..., -1] = top
- heights = cumheights[..., 1:] - cumheights[..., :-1]
-
- if inverse:
- bin_idx = searchsorted(cumheights, inputs)[..., None]
- else:
- bin_idx = searchsorted(cumwidths, inputs)[..., None]
-
- input_cumwidths = cumwidths.gather(-1, bin_idx)[..., 0]
- input_bin_widths = widths.gather(-1, bin_idx)[..., 0]
-
- input_cumheights = cumheights.gather(-1, bin_idx)[..., 0]
- delta = heights / widths
- input_delta = delta.gather(-1, bin_idx)[..., 0]
-
- input_derivatives = derivatives.gather(-1, bin_idx)[..., 0]
- input_derivatives_plus_one = derivatives[..., 1:].gather(-1, bin_idx)[..., 0]
-
- input_heights = heights.gather(-1, bin_idx)[..., 0]
-
- if inverse:
- a = (((inputs - input_cumheights) * (input_derivatives
- + input_derivatives_plus_one
- - 2 * input_delta)
- + input_heights * (input_delta - input_derivatives)))
- b = (input_heights * input_derivatives
- - (inputs - input_cumheights) * (input_derivatives
- + input_derivatives_plus_one
- - 2 * input_delta))
- c = - input_delta * (inputs - input_cumheights)
-
- discriminant = b.pow(2) - 4 * a * c
- assert (discriminant >= 0).all()
-
- root = (2 * c) / (-b - torch.sqrt(discriminant))
- outputs = root * input_bin_widths + input_cumwidths
-
- theta_one_minus_theta = root * (1 - root)
- denominator = input_delta + ((input_derivatives + input_derivatives_plus_one - 2 * input_delta)
- * theta_one_minus_theta)
- derivative_numerator = input_delta.pow(2) * (input_derivatives_plus_one * root.pow(2)
- + 2 * input_delta * theta_one_minus_theta
- + input_derivatives * (1 - root).pow(2))
- logabsdet = torch.log(derivative_numerator) - 2 * torch.log(denominator)
-
- return outputs, -logabsdet
- else:
- theta = (inputs - input_cumwidths) / input_bin_widths
- theta_one_minus_theta = theta * (1 - theta)
-
- numerator = input_heights * (input_delta * theta.pow(2)
- + input_derivatives * theta_one_minus_theta)
- denominator = input_delta + ((input_derivatives + input_derivatives_plus_one - 2 * input_delta)
- * theta_one_minus_theta)
- outputs = input_cumheights + numerator / denominator
-
- derivative_numerator = input_delta.pow(2) * (input_derivatives_plus_one * theta.pow(2)
- + 2 * input_delta * theta_one_minus_theta
- + input_derivatives * (1 - theta).pow(2))
- logabsdet = torch.log(derivative_numerator) - 2 * torch.log(denominator)
-
- return outputs, logabsdet
diff --git a/spaces/XzJosh/yoyo-Bert-VITS2/bert/chinese-roberta-wwm-ext-large/README.md b/spaces/XzJosh/yoyo-Bert-VITS2/bert/chinese-roberta-wwm-ext-large/README.md
deleted file mode 100644
index 7bce039b7f81ee328fdf8efe3f14409200aacbef..0000000000000000000000000000000000000000
--- a/spaces/XzJosh/yoyo-Bert-VITS2/bert/chinese-roberta-wwm-ext-large/README.md
+++ /dev/null
@@ -1,57 +0,0 @@
----
-language:
-- zh
-tags:
-- bert
-license: "apache-2.0"
----
-
-# Please use 'Bert' related functions to load this model!
-
-## Chinese BERT with Whole Word Masking
-For further accelerating Chinese natural language processing, we provide **Chinese pre-trained BERT with Whole Word Masking**.
-
-**[Pre-Training with Whole Word Masking for Chinese BERT](https://arxiv.org/abs/1906.08101)**
-Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, Ziqing Yang, Shijin Wang, Guoping Hu
-
-This repository is developed based on:https://github.com/google-research/bert
-
-You may also interested in,
-- Chinese BERT series: https://github.com/ymcui/Chinese-BERT-wwm
-- Chinese MacBERT: https://github.com/ymcui/MacBERT
-- Chinese ELECTRA: https://github.com/ymcui/Chinese-ELECTRA
-- Chinese XLNet: https://github.com/ymcui/Chinese-XLNet
-- Knowledge Distillation Toolkit - TextBrewer: https://github.com/airaria/TextBrewer
-
-More resources by HFL: https://github.com/ymcui/HFL-Anthology
-
-## Citation
-If you find the technical report or resource is useful, please cite the following technical report in your paper.
-- Primary: https://arxiv.org/abs/2004.13922
-```
-@inproceedings{cui-etal-2020-revisiting,
- title = "Revisiting Pre-Trained Models for {C}hinese Natural Language Processing",
- author = "Cui, Yiming and
- Che, Wanxiang and
- Liu, Ting and
- Qin, Bing and
- Wang, Shijin and
- Hu, Guoping",
- booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings",
- month = nov,
- year = "2020",
- address = "Online",
- publisher = "Association for Computational Linguistics",
- url = "https://www.aclweb.org/anthology/2020.findings-emnlp.58",
- pages = "657--668",
-}
-```
-- Secondary: https://arxiv.org/abs/1906.08101
-```
-@article{chinese-bert-wwm,
- title={Pre-Training with Whole Word Masking for Chinese BERT},
- author={Cui, Yiming and Che, Wanxiang and Liu, Ting and Qin, Bing and Yang, Ziqing and Wang, Shijin and Hu, Guoping},
- journal={arXiv preprint arXiv:1906.08101},
- year={2019}
- }
-```
\ No newline at end of file
diff --git a/spaces/YourGodAmaterasu/GPTChatBot/app.py b/spaces/YourGodAmaterasu/GPTChatBot/app.py
deleted file mode 100644
index d3323580b54d40c40bd4cc89da877e842ce92dee..0000000000000000000000000000000000000000
--- a/spaces/YourGodAmaterasu/GPTChatBot/app.py
+++ /dev/null
@@ -1,51 +0,0 @@
-import os
-import openai
-import gradio as gr
-
-openai.api_key = "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"
-
-start_sequence = "\nAI:"
-restart_sequence = "\nHuman: "
-
-prompt = "The following is a conversation with an AI assistant. The assistant is helpful, creative, clever, and very friendly.\n\nHuman: Hello, who are you?\nAI: I am an AI created by OpenAI. How can I help you today?\nHuman: "
-
-def openai_create(prompt):
- response = openai.Completion.create(
- model="text-davinci-003",
- prompt=prompt,
- temperature=0.9,
- max_tokens=1500,
- top_p=1,
- frequency_penalty=0,
- presence_penalty=0.6,
- stop=[" Human:", " AI:"]
- )
-
- return response.choices[0].text
-
-
-
-def chatgpt_clone(input, history):
- history = history or []
- s = list(sum(history, ()))
- s.append(input)
- inp = ' '.join(s)
- output = openai_create(inp)
- history.append((input, output))
- return history, history
-
-
-block = gr.Blocks()
-
-
-with block:
- gr.Markdown("""TestBot
- """)
- chatbot = gr.Chatbot()
- message = gr.Textbox(placeholder=prompt)
- state = gr.State()
- submit = gr.Button("SEND")
- submit.click(chatgpt_clone, inputs=[message, state], outputs=[chatbot, state])
-
-
-block.launch()
\ No newline at end of file
diff --git a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmdet/models/roi_heads/sparse_roi_head.py b/spaces/abhishek/sketch-to-image/annotator/uniformer/mmdet/models/roi_heads/sparse_roi_head.py
deleted file mode 100644
index 8d85ebc4698f3fc0b974e680c343f91deff4bb50..0000000000000000000000000000000000000000
--- a/spaces/abhishek/sketch-to-image/annotator/uniformer/mmdet/models/roi_heads/sparse_roi_head.py
+++ /dev/null
@@ -1,311 +0,0 @@
-import torch
-
-from mmdet.core import bbox2result, bbox2roi, bbox_xyxy_to_cxcywh
-from mmdet.core.bbox.samplers import PseudoSampler
-from ..builder import HEADS
-from .cascade_roi_head import CascadeRoIHead
-
-
-@HEADS.register_module()
-class SparseRoIHead(CascadeRoIHead):
- r"""The RoIHead for `Sparse R-CNN: End-to-End Object Detection with
- Learnable Proposals `_
-
- Args:
- num_stages (int): Number of stage whole iterative process.
- Defaults to 6.
- stage_loss_weights (Tuple[float]): The loss
- weight of each stage. By default all stages have
- the same weight 1.
- bbox_roi_extractor (dict): Config of box roi extractor.
- bbox_head (dict): Config of box head.
- train_cfg (dict, optional): Configuration information in train stage.
- Defaults to None.
- test_cfg (dict, optional): Configuration information in test stage.
- Defaults to None.
-
- """
-
- def __init__(self,
- num_stages=6,
- stage_loss_weights=(1, 1, 1, 1, 1, 1),
- proposal_feature_channel=256,
- bbox_roi_extractor=dict(
- type='SingleRoIExtractor',
- roi_layer=dict(
- type='RoIAlign', output_size=7, sampling_ratio=2),
- out_channels=256,
- featmap_strides=[4, 8, 16, 32]),
- bbox_head=dict(
- type='DIIHead',
- num_classes=80,
- num_fcs=2,
- num_heads=8,
- num_cls_fcs=1,
- num_reg_fcs=3,
- feedforward_channels=2048,
- hidden_channels=256,
- dropout=0.0,
- roi_feat_size=7,
- ffn_act_cfg=dict(type='ReLU', inplace=True)),
- train_cfg=None,
- test_cfg=None):
- assert bbox_roi_extractor is not None
- assert bbox_head is not None
- assert len(stage_loss_weights) == num_stages
- self.num_stages = num_stages
- self.stage_loss_weights = stage_loss_weights
- self.proposal_feature_channel = proposal_feature_channel
- super(SparseRoIHead, self).__init__(
- num_stages,
- stage_loss_weights,
- bbox_roi_extractor=bbox_roi_extractor,
- bbox_head=bbox_head,
- train_cfg=train_cfg,
- test_cfg=test_cfg)
- # train_cfg would be None when run the test.py
- if train_cfg is not None:
- for stage in range(num_stages):
- assert isinstance(self.bbox_sampler[stage], PseudoSampler), \
- 'Sparse R-CNN only support `PseudoSampler`'
-
- def _bbox_forward(self, stage, x, rois, object_feats, img_metas):
- """Box head forward function used in both training and testing. Returns
- all regression, classification results and a intermediate feature.
-
- Args:
- stage (int): The index of current stage in
- iterative process.
- x (List[Tensor]): List of FPN features
- rois (Tensor): Rois in total batch. With shape (num_proposal, 5).
- the last dimension 5 represents (img_index, x1, y1, x2, y2).
- object_feats (Tensor): The object feature extracted from
- the previous stage.
- img_metas (dict): meta information of images.
-
- Returns:
- dict[str, Tensor]: a dictionary of bbox head outputs,
- Containing the following results:
-
- - cls_score (Tensor): The score of each class, has
- shape (batch_size, num_proposals, num_classes)
- when use focal loss or
- (batch_size, num_proposals, num_classes+1)
- otherwise.
- - decode_bbox_pred (Tensor): The regression results
- with shape (batch_size, num_proposal, 4).
- The last dimension 4 represents
- [tl_x, tl_y, br_x, br_y].
- - object_feats (Tensor): The object feature extracted
- from current stage
- - detach_cls_score_list (list[Tensor]): The detached
- classification results, length is batch_size, and
- each tensor has shape (num_proposal, num_classes).
- - detach_proposal_list (list[tensor]): The detached
- regression results, length is batch_size, and each
- tensor has shape (num_proposal, 4). The last
- dimension 4 represents [tl_x, tl_y, br_x, br_y].
- """
- num_imgs = len(img_metas)
- bbox_roi_extractor = self.bbox_roi_extractor[stage]
- bbox_head = self.bbox_head[stage]
- bbox_feats = bbox_roi_extractor(x[:bbox_roi_extractor.num_inputs],
- rois)
- cls_score, bbox_pred, object_feats = bbox_head(bbox_feats,
- object_feats)
- proposal_list = self.bbox_head[stage].refine_bboxes(
- rois,
- rois.new_zeros(len(rois)), # dummy arg
- bbox_pred.view(-1, bbox_pred.size(-1)),
- [rois.new_zeros(object_feats.size(1)) for _ in range(num_imgs)],
- img_metas)
- bbox_results = dict(
- cls_score=cls_score,
- decode_bbox_pred=torch.cat(proposal_list),
- object_feats=object_feats,
- # detach then use it in label assign
- detach_cls_score_list=[
- cls_score[i].detach() for i in range(num_imgs)
- ],
- detach_proposal_list=[item.detach() for item in proposal_list])
-
- return bbox_results
-
- def forward_train(self,
- x,
- proposal_boxes,
- proposal_features,
- img_metas,
- gt_bboxes,
- gt_labels,
- gt_bboxes_ignore=None,
- imgs_whwh=None,
- gt_masks=None):
- """Forward function in training stage.
-
- Args:
- x (list[Tensor]): list of multi-level img features.
- proposals (Tensor): Decoded proposal bboxes, has shape
- (batch_size, num_proposals, 4)
- proposal_features (Tensor): Expanded proposal
- features, has shape
- (batch_size, num_proposals, proposal_feature_channel)
- img_metas (list[dict]): list of image info dict where
- each dict has: 'img_shape', 'scale_factor', 'flip',
- and may also contain 'filename', 'ori_shape',
- 'pad_shape', and 'img_norm_cfg'. For details on the
- values of these keys see
- `mmdet/datasets/pipelines/formatting.py:Collect`.
- gt_bboxes (list[Tensor]): Ground truth bboxes for each image with
- shape (num_gts, 4) in [tl_x, tl_y, br_x, br_y] format.
- gt_labels (list[Tensor]): class indices corresponding to each box
- gt_bboxes_ignore (None | list[Tensor]): specify which bounding
- boxes can be ignored when computing the loss.
- imgs_whwh (Tensor): Tensor with shape (batch_size, 4),
- the dimension means
- [img_width,img_height, img_width, img_height].
- gt_masks (None | Tensor) : true segmentation masks for each box
- used if the architecture supports a segmentation task.
-
- Returns:
- dict[str, Tensor]: a dictionary of loss components of all stage.
- """
-
- num_imgs = len(img_metas)
- num_proposals = proposal_boxes.size(1)
- imgs_whwh = imgs_whwh.repeat(1, num_proposals, 1)
- all_stage_bbox_results = []
- proposal_list = [proposal_boxes[i] for i in range(len(proposal_boxes))]
- object_feats = proposal_features
- all_stage_loss = {}
- for stage in range(self.num_stages):
- rois = bbox2roi(proposal_list)
- bbox_results = self._bbox_forward(stage, x, rois, object_feats,
- img_metas)
- all_stage_bbox_results.append(bbox_results)
- if gt_bboxes_ignore is None:
- # TODO support ignore
- gt_bboxes_ignore = [None for _ in range(num_imgs)]
- sampling_results = []
- cls_pred_list = bbox_results['detach_cls_score_list']
- proposal_list = bbox_results['detach_proposal_list']
- for i in range(num_imgs):
- normalize_bbox_ccwh = bbox_xyxy_to_cxcywh(proposal_list[i] /
- imgs_whwh[i])
- assign_result = self.bbox_assigner[stage].assign(
- normalize_bbox_ccwh, cls_pred_list[i], gt_bboxes[i],
- gt_labels[i], img_metas[i])
- sampling_result = self.bbox_sampler[stage].sample(
- assign_result, proposal_list[i], gt_bboxes[i])
- sampling_results.append(sampling_result)
- bbox_targets = self.bbox_head[stage].get_targets(
- sampling_results, gt_bboxes, gt_labels, self.train_cfg[stage],
- True)
- cls_score = bbox_results['cls_score']
- decode_bbox_pred = bbox_results['decode_bbox_pred']
-
- single_stage_loss = self.bbox_head[stage].loss(
- cls_score.view(-1, cls_score.size(-1)),
- decode_bbox_pred.view(-1, 4),
- *bbox_targets,
- imgs_whwh=imgs_whwh)
- for key, value in single_stage_loss.items():
- all_stage_loss[f'stage{stage}_{key}'] = value * \
- self.stage_loss_weights[stage]
- object_feats = bbox_results['object_feats']
-
- return all_stage_loss
-
- def simple_test(self,
- x,
- proposal_boxes,
- proposal_features,
- img_metas,
- imgs_whwh,
- rescale=False):
- """Test without augmentation.
-
- Args:
- x (list[Tensor]): list of multi-level img features.
- proposal_boxes (Tensor): Decoded proposal bboxes, has shape
- (batch_size, num_proposals, 4)
- proposal_features (Tensor): Expanded proposal
- features, has shape
- (batch_size, num_proposals, proposal_feature_channel)
- img_metas (dict): meta information of images.
- imgs_whwh (Tensor): Tensor with shape (batch_size, 4),
- the dimension means
- [img_width,img_height, img_width, img_height].
- rescale (bool): If True, return boxes in original image
- space. Defaults to False.
-
- Returns:
- bbox_results (list[tuple[np.ndarray]]): \
- [[cls1_det, cls2_det, ...], ...]. \
- The outer list indicates images, and the inner \
- list indicates per-class detected bboxes. The \
- np.ndarray has shape (num_det, 5) and the last \
- dimension 5 represents (x1, y1, x2, y2, score).
- """
- assert self.with_bbox, 'Bbox head must be implemented.'
- # Decode initial proposals
- num_imgs = len(img_metas)
- proposal_list = [proposal_boxes[i] for i in range(num_imgs)]
- object_feats = proposal_features
- for stage in range(self.num_stages):
- rois = bbox2roi(proposal_list)
- bbox_results = self._bbox_forward(stage, x, rois, object_feats,
- img_metas)
- object_feats = bbox_results['object_feats']
- cls_score = bbox_results['cls_score']
- proposal_list = bbox_results['detach_proposal_list']
-
- num_classes = self.bbox_head[-1].num_classes
- det_bboxes = []
- det_labels = []
-
- if self.bbox_head[-1].loss_cls.use_sigmoid:
- cls_score = cls_score.sigmoid()
- else:
- cls_score = cls_score.softmax(-1)[..., :-1]
-
- for img_id in range(num_imgs):
- cls_score_per_img = cls_score[img_id]
- scores_per_img, topk_indices = cls_score_per_img.flatten(
- 0, 1).topk(
- self.test_cfg.max_per_img, sorted=False)
- labels_per_img = topk_indices % num_classes
- bbox_pred_per_img = proposal_list[img_id][topk_indices //
- num_classes]
- if rescale:
- scale_factor = img_metas[img_id]['scale_factor']
- bbox_pred_per_img /= bbox_pred_per_img.new_tensor(scale_factor)
- det_bboxes.append(
- torch.cat([bbox_pred_per_img, scores_per_img[:, None]], dim=1))
- det_labels.append(labels_per_img)
-
- bbox_results = [
- bbox2result(det_bboxes[i], det_labels[i], num_classes)
- for i in range(num_imgs)
- ]
-
- return bbox_results
-
- def aug_test(self, features, proposal_list, img_metas, rescale=False):
- raise NotImplementedError('Sparse R-CNN does not support `aug_test`')
-
- def forward_dummy(self, x, proposal_boxes, proposal_features, img_metas):
- """Dummy forward function when do the flops computing."""
- all_stage_bbox_results = []
- proposal_list = [proposal_boxes[i] for i in range(len(proposal_boxes))]
- object_feats = proposal_features
- if self.with_bbox:
- for stage in range(self.num_stages):
- rois = bbox2roi(proposal_list)
- bbox_results = self._bbox_forward(stage, x, rois, object_feats,
- img_metas)
-
- all_stage_bbox_results.append(bbox_results)
- proposal_list = bbox_results['detach_proposal_list']
- object_feats = bbox_results['object_feats']
- return all_stage_bbox_results
diff --git a/spaces/abhishek/sketch-to-image/annotator/uniformer_base/mmcv/runner/hooks/logger/neptune.py b/spaces/abhishek/sketch-to-image/annotator/uniformer_base/mmcv/runner/hooks/logger/neptune.py
deleted file mode 100644
index 7a38772b0c93a8608f32c6357b8616e77c139dc9..0000000000000000000000000000000000000000
--- a/spaces/abhishek/sketch-to-image/annotator/uniformer_base/mmcv/runner/hooks/logger/neptune.py
+++ /dev/null
@@ -1,82 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-from ...dist_utils import master_only
-from ..hook import HOOKS
-from .base import LoggerHook
-
-
-@HOOKS.register_module()
-class NeptuneLoggerHook(LoggerHook):
- """Class to log metrics to NeptuneAI.
-
- It requires `neptune-client` to be installed.
-
- Args:
- init_kwargs (dict): a dict contains the initialization keys as below:
- - project (str): Name of a project in a form of
- namespace/project_name. If None, the value of
- NEPTUNE_PROJECT environment variable will be taken.
- - api_token (str): User’s API token.
- If None, the value of NEPTUNE_API_TOKEN environment
- variable will be taken. Note: It is strongly recommended
- to use NEPTUNE_API_TOKEN environment variable rather than
- placing your API token in plain text in your source code.
- - name (str, optional, default is 'Untitled'): Editable name of
- the run. Name is displayed in the run's Details and in
- Runs table as a column.
- Check https://docs.neptune.ai/api-reference/neptune#init for
- more init arguments.
- interval (int): Logging interval (every k iterations).
- ignore_last (bool): Ignore the log of last iterations in each epoch
- if less than `interval`.
- reset_flag (bool): Whether to clear the output buffer after logging
- by_epoch (bool): Whether EpochBasedRunner is used.
-
- .. _NeptuneAI:
- https://docs.neptune.ai/you-should-know/logging-metadata
- """
-
- def __init__(self,
- init_kwargs=None,
- interval=10,
- ignore_last=True,
- reset_flag=True,
- with_step=True,
- by_epoch=True):
-
- super(NeptuneLoggerHook, self).__init__(interval, ignore_last,
- reset_flag, by_epoch)
- self.import_neptune()
- self.init_kwargs = init_kwargs
- self.with_step = with_step
-
- def import_neptune(self):
- try:
- import neptune.new as neptune
- except ImportError:
- raise ImportError(
- 'Please run "pip install neptune-client" to install neptune')
- self.neptune = neptune
- self.run = None
-
- @master_only
- def before_run(self, runner):
- if self.init_kwargs:
- self.run = self.neptune.init(**self.init_kwargs)
- else:
- self.run = self.neptune.init()
-
- @master_only
- def log(self, runner):
- tags = self.get_loggable_tags(runner)
- if tags:
- for tag_name, tag_value in tags.items():
- if self.with_step:
- self.run[tag_name].log(
- tag_value, step=self.get_iter(runner))
- else:
- tags['global_step'] = self.get_iter(runner)
- self.run[tag_name].log(tags)
-
- @master_only
- def after_run(self, runner):
- self.run.stop()
diff --git a/spaces/abrar-lohia/text-2-character-anim/pyrender/tests/conftest.py b/spaces/abrar-lohia/text-2-character-anim/pyrender/tests/conftest.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/affine/Time_Series_Model/pages/1_Store Demand Forecasting.py b/spaces/affine/Time_Series_Model/pages/1_Store Demand Forecasting.py
deleted file mode 100644
index 8520ec69e3c91280b0c82ef53bb936cf23a564c5..0000000000000000000000000000000000000000
--- a/spaces/affine/Time_Series_Model/pages/1_Store Demand Forecasting.py
+++ /dev/null
@@ -1,499 +0,0 @@
-import streamlit as st
-from src.data import StoreDataLoader
-from src.model import Model_Load
-import matplotlib.pyplot as plt
-import seaborn as sns
-import plotly.graph_objects as go
-from sklearn.metrics import mean_absolute_error,mean_squared_error
-import numpy as np
-import pandas as pd
-from src.prediction import test_prediction,val_prediction,create_week_date_featues
-import plotly.express as px
-
-#----------------hide menubar and footer----------------------------------
-hide_streamlit_style = """
-
- """
-st.markdown(hide_streamlit_style, unsafe_allow_html=True)
-#-------------------------------------------------------------
-## Load model object
-model_obj=Model_Load()
-#--------------------------------------------------------------
-@st.cache_data
-def convert_df(df):
- return df.to_csv(index=False).encode('utf-8')
-#-----------------------------------------------------------------
-## Title of Page
-st.markdown("""
-
-
-  -
- Product Demand Forecasting Dashboard
-
-
- by Affine
-
-
-
- Product Demand Forecasting Dashboard
-
-
- by Affine
-
-
-
-

-
-
- 📈
-
- Forecast Plot
-
-
-
-
-
-
- """, unsafe_allow_html=True)
- # change dtype on prediction column
- testing_results['prediction']=testing_results['prediction'].apply(lambda x:round(x))
- testing_results['date']=testing_results['date'].dt.date
- d2['prediction']=d2['prediction'].apply(lambda x:round(x))
- d2['date']=d2['date'].dt.date
- # training_data=train_dataset.loc[(train_dataset['store']==store)&(train_dataset['item']==item)][['date','Lead_1']].iloc[-60:,:]
-#---------------------------------------------forecast plot---------------------------------------------
- fig = go.Figure([
- # go.Scatter(x=training_data['date'],y=training_data['Lead_1'],name='Train Observed',line=dict(color='rgba(50, 205, 50, 0.7)')),
- #go.Scatter(x=y_train_pred['ds'],y=y_train_pred['yhat'],name='Prophet Pred.(10 Item)',line=dict(color='blue', dash='dot')),
- go.Scatter(x=testing_results['date'], y=testing_results['Lead_1'],name='Observed',line=dict(color='rgba(218, 112, 214, 0.5)')),
- go.Scatter(x=testing_results['date'],y=testing_results['prediction'],name='Historical Forecast',line=dict(color='#9400D3', dash='dash')),
- go.Scatter(x=d2['date'],y=d2['prediction'],name='Future Forecast',line=dict(color='Dark Orange', dash='dot'))])
- fig.update_layout(
- xaxis_title='Date',
- yaxis_title='Order Demand',
- margin=dict(l=0, r=0, t=50, b=0),
- xaxis=dict(title_font=dict(size=20)),
- yaxis=dict(title_font=dict(size=20)))
- fig.update_layout(width=700,height=400)
- tab1.plotly_chart(fig)
- #----------------------------------------------Tab-2------------------------------------------------------------
- tab2.markdown("""
-
-
- 📃
-
- Forecast Table
-
-
-
-
-
-
- """, unsafe_allow_html=True)
- final_r=pd.concat([d2[['date','store','item','prediction']],testing_results[['date','store','item','prediction']]]).sort_values('date').drop_duplicates().reset_index(drop=True)
- csv = convert_df(final_r)
- tab2.dataframe(final_r,width=500)
- tab2.download_button(
- "Download",
- csv,
- "file.csv",
- "text/csv",
- key='download-csv'
- )
- #--------------------------------Tab-3----------------------------------------------
- # tab3.markdown("""
- #
- #
- # 📈
- #
- # Actual Dataset
- #
- #
- #
- #
- #
- #
- # """, unsafe_allow_html=True)
- # train_a=train_dataset.loc[(train_dataset['store']==store) & (train_dataset['item']==item)][['date','store','item','sales']]
- # test_a=test_dataset.loc[(test_dataset['store']==store) & (test_dataset['item']==item)][['date','store','item','sales']]
- # actual_final_data=pd.concat([train_a,test_a])
- # actual_final_data['date']=actual_final_data['date'].dt.date
- # tab3.dataframe(actual_final_data,width=500)
-
- except:
- st.sidebar.error('Model Not Loaded successfully!',icon="🚨")
-
-#+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
-#+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
-
-elif option=='Prophet':
- print("prophet")
- #---------------------------------------------------Data----------------------------------------------------
- # Prophet data
- path='data/train.csv'
- obj=StoreDataLoader(path)
- fb_train_data,fb_test_data,item_dummay,store_dummay=obj.fb_data()
- # st.write(fb_train_data.columns)
- # st.write(fb_test_data.columns)
- # print(fb_test_data.columns)
- print(f"TRAINING ::START DATE ::{fb_train_data['ds'].min()} :: END DATE ::{fb_train_data['ds'].max()}")
- print(f"TESTING ::START DATE ::{fb_test_data['ds'].min()} :: END DATE ::{fb_test_data['ds'].max()}")
- train_new=fb_train_data.drop('y',axis=1)
- test_new=fb_test_data.drop('y',axis=1)
- #----------------------------------------------model Load----------------------------------------------------
- try:
- fb_model=model_obj.store_model_load(option)
- # with st.sidebar:
- # st.success('Model Loaded successfully', icon="✅")
- #-------------------------------------select store & item ---------------------------------------------------
- list_items=item_dummay.columns
- list_store=store_dummay.columns
- with st.sidebar:
- store=st.selectbox("Select Store",list_store)
- item=st.selectbox("Select Product",list_items)
- #------------------------------------------prediction---------------------------------------------------------------
- test_prediction=fb_model.predict(test_new.loc[test_new[item]==1])
- train_prediction=fb_model.predict(train_new.loc[train_new[item]==1])
-
- y_true_test=fb_test_data.loc[fb_test_data[item]==1]
- y_true_train=fb_train_data.loc[fb_train_data[item]==1]
-
- y_train_pred=train_prediction[['ds','yhat']].iloc[-60:,:]
- y_train_true=y_true_train[['ds','y']].iloc[-60:,:]
-
- y_test_pred=test_prediction[['ds','yhat']]
- y_test_true=y_true_test[['ds','y']]
- #----------------------------------------KPI---------------------------------------------------------------
- rmse=np.sqrt(mean_squared_error(y_test_true['y'],y_test_pred['yhat']))
- mae=mean_absolute_error(y_test_true['y'],y_test_pred['yhat'])
-#---------------------------------future prediction---------------------------------------
- fb_final=pd.concat([fb_train_data,fb_test_data])
- # extract the data for selected store and item
- fb_consumer=fb_final.loc[(fb_final[store]==1) & (fb_final[item]==1)]
-
- # list of dates and prediction
- date_list=[]
- prediction_list=[]
-
- # predicting the next 30 days product demand
- for i in range(30):
- # select only date record
- next_prediction=fb_consumer.tail(1).drop('y',axis=1) # drop target of last 01/01/2015 00:00:00
- # predict next timestep demand
- prediction=fb_model.predict(next_prediction) # pass other feature value to the model
-
- # append date and predicted demand
- date_list.append(prediction['ds'][0]) ## append the datetime of prediction
- prediction_list.append(prediction['yhat'][0]) ## append the next timestep prediction
-
-
- #--------------------------next timestep data simulate-------------------------------------------------------------
- last_data = fb_consumer[lambda x: x.ds == x.ds.max()] # last date present in data
- # next timestep
- decoder_data = pd.concat(
- [last_data.assign(ds=lambda x: x.ds + pd.offsets.DateOffset(i)) for i in range(1, 2)],
- ignore_index=True,
- )
- # update next timestep datetime covariates
- decoder_data=create_week_date_featues(decoder_data,'ds')
- # update last day demand prediction to the here as an actual demand value(using for more future timestep prediction)
- decoder_data['sales']=prediction['yhat'][0] # assume next timestep prediction as actual
- # update this next record into the original data
- fb_consumer=pd.concat([fb_consumer,decoder_data]) # append that next timestep data to into main data
- # find shift of power usage and update into the datset
- fb_consumer['lag_1']=fb_consumer['sales'].shift(1)
- fb_consumer['lag_5']=fb_consumer['sales'].shift(5)
- fb_consumer=fb_consumer.reset_index(drop=True) # reset_index
- future_prediction=pd.DataFrame({"ds":date_list,"yhat":prediction_list})
- future_prediction['store']=store
- future_prediction['item']=item
-
- with st.sidebar:
- st.markdown(f"""
-
-
-
- """,unsafe_allow_html=True)
- st.dataframe(pd.DataFrame({"KPI":['RMSE','MAE'],"TFT":[7.73,6.17],"Prophet":[7.32,6.01]}).set_index('KPI'),width=300)
- st.markdown(f"""
-
-
-
- """,unsafe_allow_html=True)
-
- st.dataframe(pd.DataFrame({"KPI":['RMSE','MAE'],"Prophet":[rmse,mae]}).set_index('KPI'),width=300)
-
- #---------------------------------------Tabs-----------------------------------------------------------------------
- tab1,tab2=st.tabs(['📈Forecast Plot','🗃Forecast Table']) #tab3- '🗃Actual Table'
- #-------------------------------------------Tab-1=Forecast plot---------------------------------------------------
- tab1.markdown("""
-
-
- 📈
-
- Forecast Plot
-
-
-
-
-
-
- """, unsafe_allow_html=True)
-
- ## round fig.
- y_train_true['y']=y_train_true['y'].astype('int')
- y_train_pred['yhat']=y_train_pred['yhat'].astype('int')
- y_test_true['y']=y_test_true['y'].astype('int')
- y_test_pred['yhat']=y_test_pred['yhat'].astype('int')
- future_prediction['yhat']=future_prediction['yhat'].astype('int')
- y_train_true['ds']=y_train_true['ds'].dt.date
- y_train_pred['ds']=y_train_pred['ds'].dt.date
- y_test_true['ds']=y_test_true['ds'].dt.date
- y_test_pred['ds']=y_test_pred['ds'].dt.date
- future_prediction['ds']=future_prediction['ds'].dt.date
-
- #-----------------------------plot---------------------------------------------------------------------------------------------
- fig = go.Figure([
- # go.Scatter(x=y_train_true['ds'],y=y_train_true['y'],name='Train Observed',line=dict(color='rgba(50, 205, 50, 0.7)' )),
- # go.Scatter(x=y_train_pred['ds'],y=y_train_pred['yhat'],name='Prophet Pred.(10 Item)',line=dict(color='#32CD32', dash='dot')),
- go.Scatter(x=y_test_true['ds'], y=y_test_true['y'],name='Observed',line=dict(color='rgba(218, 112, 214, 0.5)')),
- go.Scatter(x=y_test_pred['ds'],y=y_test_pred['yhat'],name='Historical Forecast',line=dict(color='#9400D3', dash='dash')),
- go.Scatter(x=future_prediction['ds'],y=future_prediction['yhat'],name='Future Forecast',line=dict(color='Dark Orange', dash='dot'))])
- fig.update_layout(
- xaxis_title='Date',
- yaxis_title='Order Demand',
- margin=dict(l=0, r=0, t=50, b=0),
- xaxis=dict(title_font=dict(size=20)),
- yaxis=dict(title_font=dict(size=20)))
- fig.update_layout(width=700,height=400)
- tab1.plotly_chart(fig)
- #----------------------------------------Tab-2------------------------------------------------------------
- results=y_test_pred.reset_index()
- results['store']='store_1'
- results['item']=item
- tab2.markdown("""
-
-
- 📃
-
- Forecast Table
-
-
-
-
-
-
- """, unsafe_allow_html=True)
- final_r=pd.concat([future_prediction[['ds','store','item','yhat']],results[['ds','store','item','yhat']]]).sort_values('ds').drop_duplicates().reset_index(drop=True)
- csv = convert_df(final_r)
- tab2.dataframe(final_r,width=500)
- tab2.download_button(
- "Download",
- csv,
- "file.csv",
- "text/csv",
- key='download-csv'
- )
-
- #------------------------------------------Tab-3--------------------------------------------------
- # train_a=fb_train_data.loc[fb_train_data[item]==1][['ds','sales']]
- # # train_a['store']=1
- # # train_a['item']=item
- # test_a=fb_test_data.loc[fb_test_data[item]==1][['ds','sales']]
- # # test_a['store']=1
- # # test_a['item']=item.split('_')[-1]
- # actual_final_data=pd.concat([train_a,test_a])
- # actual_final_data['store']=1
- # actual_final_data['item']=item.split('_')[-1]
- # actual_final_data['ds']=actual_final_data['ds'].dt.date
- # actual_final_data.rename({"ds":'date'},inplace=True)
- # tab3.dataframe(actual_final_data[['date','store','item','sales']],width=500)
-
-
-
- except:
- st.sidebar.error('Model Not Loaded successfully!',icon="🚨")
-
-
-
diff --git a/spaces/akhaliq/deeplab2/model/loss/matchers_ops.py b/spaces/akhaliq/deeplab2/model/loss/matchers_ops.py
deleted file mode 100644
index 4273e94476d7d7859797c8dfc1ace1ffe100f892..0000000000000000000000000000000000000000
--- a/spaces/akhaliq/deeplab2/model/loss/matchers_ops.py
+++ /dev/null
@@ -1,495 +0,0 @@
-# coding=utf-8
-# Copyright 2021 The Deeplab2 Authors.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-"""Tensorflow implementation to solve the Linear Sum Assignment problem.
-
-The Linear Sum Assignment problem involves determining the minimum weight
-matching for bipartite graphs. For example, this problem can be defined by
-a 2D matrix C, where each element i,j determines the cost of matching worker i
-with job j. The solution to the problem is a complete assignment of jobs to
-workers, such that no job is assigned to more than one work and no worker is
-assigned more than one job, with minimum cost.
-
-This implementation is designed to be used with tf.compat.v2 to be compatible
-with the rest of the DeepLab2 library. It builds off of the Hungarian Matching
-Algorithm (https://www.cse.ust.hk/~golin/COMP572/Notes/Matching.pdf), the
-original Lingvo tensorflow implementation by Jiquan Ngiam, and the modified TF1
-version by Amil Merchant.
-"""
-
-import tensorflow as tf
-
-
-def _prepare(weights):
- """Prepare the cost matrix.
-
- To speed up computational efficiency of the algorithm, all weights are shifted
- to be non-negative. Each element is reduced by the row / column minimum. Note
- that neither operation will effect the resulting solution but will provide
- a better starting point for the greedy assignment. Note this corresponds to
- the pre-processing and step 1 of the Hungarian algorithm from Wikipedia.
-
- Args:
- weights: A float32 [batch_size, num_elems, num_elems] tensor, where each
- inner matrix represents weights to be use for matching.
-
- Returns:
- A prepared weights tensor of the same shape and dtype.
- """
- # Since every worker needs a job and every job needs a worker, we can subtract
- # the minimum from each.
- weights -= tf.reduce_min(weights, axis=2, keepdims=True)
- weights -= tf.reduce_min(weights, axis=1, keepdims=True)
- return weights
-
-
-def _greedy_assignment(adj_matrix):
- """Greedily assigns workers to jobs based on an adjaceny matrix.
-
- Starting with an adjacency matrix representing the available connections
- in the bi-partite graph, this function greedily chooses elements such
- that each worker is matched to at most one job (or each job is assigned to
- at most one worker). Note, if the adjacency matrix has no available values
- for a particular row/column, the corresponding job/worker may go unassigned.
-
- Args:
- adj_matrix: A bool [batch_size, num_elems, num_elems] tensor, where each
- element of the inner matrix represents whether the worker (row) can be
- matched to the job (column).
-
- Returns:
- A bool [batch_size, num_elems, num_elems] tensor, where each element of the
- inner matrix represents whether the worker has been matched to the job.
- Each row and column can have at most one true element. Some of the rows
- and columns may not be matched.
- """
- _, num_elems, _ = get_shape_list(adj_matrix, expected_rank=3)
- adj_matrix = tf.transpose(adj_matrix, [1, 0, 2])
-
- # Create a dynamic TensorArray containing the assignments for each worker/job
- assignment = tf.TensorArray(tf.bool, num_elems)
-
- # Store the elements assigned to each column to update each iteration
- col_assigned = tf.zeros_like(adj_matrix[0, ...], dtype=tf.bool)
-
- # Iteratively assign each row using tf.foldl. Intuitively, this is a loop
- # over rows, where we incrementally assign each row.
- def _assign_row(accumulator, row_adj):
- # The accumulator tracks the row assignment index.
- idx, assignment, col_assigned = accumulator
-
- # Viable candidates cannot already be assigned to another job.
- candidates = row_adj & (~col_assigned)
-
- # Deterministically assign to the candidates of the highest index count.
- max_candidate_idx = tf.argmax(
- tf.cast(candidates, tf.int32), axis=1, output_type=tf.int32)
-
- candidates_indicator = tf.one_hot(
- max_candidate_idx,
- num_elems,
- on_value=True,
- off_value=False,
- dtype=tf.bool)
- candidates_indicator &= candidates
-
- # Make assignment to the column.
- col_assigned |= candidates_indicator
- assignment = assignment.write(idx, candidates_indicator)
-
- return idx + 1, assignment, col_assigned
-
- _, assignment, _ = tf.foldl(
- _assign_row, adj_matrix, (0, assignment, col_assigned), back_prop=False)
-
- assignment = assignment.stack()
- assignment = tf.transpose(assignment, [1, 0, 2])
- return assignment
-
-
-def _find_augmenting_path(assignment, adj_matrix):
- """Finds an augmenting path given an assignment and an adjacency matrix.
-
- The augmenting path search starts from the unassigned workers, then goes on
- to find jobs (via an unassigned pairing), then back again to workers (via an
- existing pairing), and so on. The path alternates between unassigned and
- existing pairings. Returns the state after the search.
-
- Note: In the state the worker and job, indices are 1-indexed so that we can
- use 0 to represent unreachable nodes. State contains the following keys:
-
- - jobs: A [batch_size, 1, num_elems] tensor containing the highest index
- unassigned worker that can reach this job through a path.
- - jobs_from_worker: A [batch_size, num_elems] tensor containing the worker
- reached immediately before this job.
- - workers: A [batch_size, num_elems, 1] tensor containing the highest index
- unassigned worker that can reach this worker through a path.
- - workers_from_job: A [batch_size, num_elems] tensor containing the job
- reached immediately before this worker.
- - new_jobs: A bool [batch_size, num_elems] tensor containing True if the
- unassigned job can be reached via a path.
-
- State can be used to recover the path via backtracking.
-
- Args:
- assignment: A bool [batch_size, num_elems, num_elems] tensor, where each
- element of the inner matrix represents whether the worker has been matched
- to the job. This may be a partial assignment.
- adj_matrix: A bool [batch_size, num_elems, num_elems] tensor, where each
- element of the inner matrix represents whether the worker (row) can be
- matched to the job (column).
-
- Returns:
- A state dict, which represents the outcome of running an augmenting
- path search on the graph given the assignment.
- """
- batch_size, num_elems, _ = get_shape_list(assignment, expected_rank=3)
- unassigned_workers = ~tf.reduce_any(assignment, axis=2, keepdims=True)
- unassigned_jobs = ~tf.reduce_any(assignment, axis=1, keepdims=True)
-
- unassigned_pairings = tf.cast(adj_matrix & ~assignment, tf.int32)
- existing_pairings = tf.cast(assignment, tf.int32)
-
- # Initialize unassigned workers to have non-zero ids, assigned workers will
- # have ids = 0.
- worker_indices = tf.range(1, num_elems + 1, dtype=tf.int32)
- init_workers = tf.tile(worker_indices[tf.newaxis, :, tf.newaxis],
- [batch_size, 1, 1])
- init_workers *= tf.cast(unassigned_workers, tf.int32)
-
- state = {
- "jobs": tf.zeros((batch_size, 1, num_elems), dtype=tf.int32),
- "jobs_from_worker": tf.zeros((batch_size, num_elems), dtype=tf.int32),
- "workers": init_workers,
- "workers_from_job": tf.zeros((batch_size, num_elems), dtype=tf.int32)
- }
-
- def _has_active_workers(state, curr_workers):
- """Check if there are still active workers."""
- del state
- return tf.reduce_sum(curr_workers) > 0
-
- def _augment_step(state, curr_workers):
- """Performs one search step."""
-
- # Note: These steps could be potentially much faster if sparse matrices are
- # supported. The unassigned_pairings and existing_pairings matrices can be
- # very sparse.
-
- # Find potential jobs using current workers.
- potential_jobs = curr_workers * unassigned_pairings
- curr_jobs = tf.reduce_max(potential_jobs, axis=1, keepdims=True)
- curr_jobs_from_worker = 1 + tf.argmax(
- potential_jobs, axis=1, output_type=tf.int32)
-
- # Remove already accessible jobs from curr_jobs.
- default_jobs = tf.zeros_like(state["jobs"], dtype=state["jobs"].dtype)
- curr_jobs = tf.where(state["jobs"] > 0, default_jobs, curr_jobs)
- curr_jobs_from_worker *= tf.cast(curr_jobs > 0, tf.int32)[:, 0, :]
-
- # Find potential workers from current jobs.
- potential_workers = curr_jobs * existing_pairings
- curr_workers = tf.reduce_max(potential_workers, axis=2, keepdims=True)
- curr_workers_from_job = 1 + tf.argmax(
- potential_workers, axis=2, output_type=tf.int32)
-
- # Remove already accessible workers from curr_workers.
- default_workers = tf.zeros_like(state["workers"])
- curr_workers = tf.where(
- state["workers"] > 0, default_workers, curr_workers)
- curr_workers_from_job *= tf.cast(curr_workers > 0, tf.int32)[:, :, 0]
-
- # Update state so that we can backtrack later.
- state = state.copy()
- state["jobs"] = tf.maximum(state["jobs"], curr_jobs)
- state["jobs_from_worker"] = tf.maximum(state["jobs_from_worker"],
- curr_jobs_from_worker)
- state["workers"] = tf.maximum(state["workers"], curr_workers)
- state["workers_from_job"] = tf.maximum(state["workers_from_job"],
- curr_workers_from_job)
-
- return state, curr_workers
-
- with tf.name_scope("find_augmenting_path"):
- state, _ = tf.while_loop(
- _has_active_workers,
- _augment_step, (state, init_workers),
- back_prop=False)
-
- # Compute new jobs, this is useful for determnining termnination of the
- # maximum bi-partite matching and initialization for backtracking.
- new_jobs = (state["jobs"] > 0) & unassigned_jobs
- state["new_jobs"] = new_jobs[:, 0, :]
- return state
-
-
-def _improve_assignment(assignment, state):
- """Improves an assignment by backtracking the augmented path using state.
-
- Args:
- assignment: A bool [batch_size, num_elems, num_elems] tensor, where each
- element of the inner matrix represents whether the worker has been matched
- to the job. This may be a partial assignment.
- state: A dict, which represents the outcome of running an augmenting path
- search on the graph given the assignment.
-
- Returns:
- A new assignment matrix of the same shape and type as assignment, where the
- assignment has been updated using the augmented path found.
- """
- batch_size, num_elems, _ = get_shape_list(assignment, 3)
-
- # We store the current job id and iteratively backtrack using jobs_from_worker
- # and workers_from_job until we reach an unassigned worker. We flip all the
- # assignments on this path to discover a better overall assignment.
-
- # Note: The indices in state are 1-indexed, where 0 represents that the
- # worker / job cannot be reached.
-
- # Obtain initial job indices based on new_jobs.
- curr_job_idx = tf.argmax(
- tf.cast(state["new_jobs"], tf.int32), axis=1, output_type=tf.int32)
-
- # Track whether an example is actively being backtracked. Since we are
- # operating on a batch, not all examples in the batch may be active.
- active = tf.gather(state["new_jobs"], curr_job_idx, batch_dims=1)
- batch_range = tf.range(0, batch_size, dtype=tf.int32)
-
- # Flip matrix tracks which assignments we need to flip - corresponding to the
- # augmenting path taken. We use an integer tensor here so that we can use
- # tensor_scatter_nd_add to update the tensor, and then cast it back to bool
- # after the loop.
- flip_matrix = tf.zeros((batch_size, num_elems, num_elems), dtype=tf.int32)
-
- def _has_active_backtracks(flip_matrix, active, curr_job_idx):
- """Check if there are still active workers."""
- del flip_matrix, curr_job_idx
- return tf.reduce_any(active)
-
- def _backtrack_one_step(flip_matrix, active, curr_job_idx):
- """Take one step in backtracking."""
- # Discover the worker that the job originated from, note that this worker
- # must exist by construction.
- curr_worker_idx = tf.gather(
- state["jobs_from_worker"], curr_job_idx, batch_dims=1) - 1
- curr_worker_idx = tf.maximum(curr_worker_idx, 0)
- update_indices = tf.stack([batch_range, curr_worker_idx, curr_job_idx],
- axis=1)
- update_indices = tf.maximum(update_indices, 0)
- flip_matrix = tf.tensor_scatter_nd_add(flip_matrix, update_indices,
- tf.cast(active, tf.int32))
-
- # Discover the (potential) job that the worker originated from.
- curr_job_idx = tf.gather(
- state["workers_from_job"], curr_worker_idx, batch_dims=1) - 1
- # Note that jobs may not be active, and we track that here (before
- # adjusting indices so that they are all >= 0 for gather).
- active &= curr_job_idx >= 0
- curr_job_idx = tf.maximum(curr_job_idx, 0)
- update_indices = tf.stack([batch_range, curr_worker_idx, curr_job_idx],
- axis=1)
- update_indices = tf.maximum(update_indices, 0)
- flip_matrix = tf.tensor_scatter_nd_add(flip_matrix, update_indices,
- tf.cast(active, tf.int32))
-
- return flip_matrix, active, curr_job_idx
-
- with tf.name_scope("improve_assignment"):
- flip_matrix, _, _ = tf.while_loop(
- _has_active_backtracks,
- _backtrack_one_step, (flip_matrix, active, curr_job_idx),
- back_prop=False)
-
- flip_matrix = tf.cast(flip_matrix, tf.bool)
- assignment = tf.math.logical_xor(assignment, flip_matrix)
-
- return assignment
-
-
-def _maximum_bipartite_matching(adj_matrix, assignment=None):
- """Performs maximum bipartite matching using augmented paths.
-
- Args:
- adj_matrix: A bool [batch_size, num_elems, num_elems] tensor, where each
- element of the inner matrix represents whether the worker (row) can be
- matched to the job (column).
- assignment: An optional bool [batch_size, num_elems, num_elems] tensor,
- where each element of the inner matrix represents whether the worker has
- been matched to the job. This may be a partial assignment. If specified,
- this assignment will be used to seed the iterative algorithm.
-
- Returns:
- A state dict representing the final augmenting path state search, and
- a maximum bipartite matching assignment tensor. Note that the state outcome
- can be used to compute a minimum vertex cover for the bipartite graph.
- """
-
- if assignment is None:
- assignment = _greedy_assignment(adj_matrix)
-
- state = _find_augmenting_path(assignment, adj_matrix)
-
- def _has_new_jobs(state, assignment):
- del assignment
- return tf.reduce_any(state["new_jobs"])
-
- def _improve_assignment_and_find_new_path(state, assignment):
- assignment = _improve_assignment(assignment, state)
- state = _find_augmenting_path(assignment, adj_matrix)
- return state, assignment
-
- with tf.name_scope("maximum_bipartite_matching"):
- state, assignment = tf.while_loop(
- _has_new_jobs,
- _improve_assignment_and_find_new_path, (state, assignment),
- back_prop=False)
-
- return state, assignment
-
-
-def _compute_cover(state, assignment):
- """Computes a cover for the bipartite graph.
-
- We compute a cover using the construction provided at
- https://en.wikipedia.org/wiki/K%C5%91nig%27s_theorem_(graph_theory)#Proof
- which uses the outcome from the alternating path search.
-
- Args:
- state: A state dict, which represents the outcome of running an augmenting
- path search on the graph given the assignment.
- assignment: An optional bool [batch_size, num_elems, num_elems] tensor,
- where each element of the inner matrix represents whether the worker has
- been matched to the job. This may be a partial assignment. If specified,
- this assignment will be used to seed the iterative algorithm.
-
- Returns:
- A tuple of (workers_cover, jobs_cover) corresponding to row and column
- covers for the bipartite graph. workers_cover is a boolean tensor of shape
- [batch_size, num_elems, 1] and jobs_cover is a boolean tensor of shape
- [batch_size, 1, num_elems].
- """
- assigned_workers = tf.reduce_any(assignment, axis=2, keepdims=True)
- assigned_jobs = tf.reduce_any(assignment, axis=1, keepdims=True)
-
- reachable_workers = state["workers"] > 0
- reachable_jobs = state["jobs"] > 0
-
- workers_cover = assigned_workers & (~reachable_workers)
- jobs_cover = assigned_jobs & reachable_jobs
-
- return workers_cover, jobs_cover
-
-
-def _update_weights_using_cover(workers_cover, jobs_cover, weights):
- """Updates weights for hungarian matching using a cover.
-
- We first find the minimum uncovered weight. Then, we subtract this from all
- the uncovered weights, and add it to all the doubly covered weights.
-
- Args:
- workers_cover: A boolean tensor of shape [batch_size, num_elems, 1].
- jobs_cover: A boolean tensor of shape [batch_size, 1, num_elems].
- weights: A float32 [batch_size, num_elems, num_elems] tensor, where each
- inner matrix represents weights to be use for matching.
-
- Returns:
- A new weight matrix with elements adjusted by the cover.
- """
- max_value = tf.reduce_max(weights)
-
- covered = workers_cover | jobs_cover
- double_covered = workers_cover & jobs_cover
-
- uncovered_weights = tf.where(covered,
- tf.ones_like(weights) * max_value, weights)
- min_weight = tf.reduce_min(uncovered_weights, axis=[-2, -1], keepdims=True)
-
- add_weight = tf.where(double_covered,
- tf.ones_like(weights) * min_weight,
- tf.zeros_like(weights))
- sub_weight = tf.where(covered, tf.zeros_like(weights),
- tf.ones_like(weights) * min_weight)
-
- return weights + add_weight - sub_weight
-
-
-def get_shape_list(tensor, expected_rank=None):
- """Returns a list of the shape of tensor.
-
- Args:
- tensor: A tf.Tensor object to find the shape of
- expected_rank: An (optional) int with the expected rank of the inputted
- tensor.
-
- Returns:
- A list representing the shape of the tesnor.
-
- Raises:
- ValueError: If the expected rank does not match the expected rank of the
- inputted tensor.
- """
- actual_rank = tensor.shape.ndims
-
- if expected_rank and actual_rank != expected_rank:
- raise ValueError("The tensor has rank %d which is not equal to the "
- "expected rank %d" % (actual_rank, expected_rank))
-
- shape = tensor.shape.as_list()
- dynamic = tf.shape(tensor)
- output = [dim if dim else dynamic[ind] for ind, dim in enumerate(shape)]
- return output
-
-
-def hungarian_matching(weights):
- """Computes the minimum linear sum assignment using the Hungarian algorithm.
-
- Args:
- weights: A float32 [batch_size, num_elems, num_elems] tensor, where each
- inner matrix represents weights to be use for matching.
-
- Returns:
- A bool [batch_size, num_elems, num_elems] tensor, where each element of the
- inner matrix represents whether the worker has been matched to the job.
- The returned matching will always be a perfect match.
- """
- batch_size, num_elems, _ = get_shape_list(weights, 3)
-
- weights = _prepare(weights)
- adj_matrix = tf.equal(weights, 0.)
- state, assignment = _maximum_bipartite_matching(adj_matrix)
- workers_cover, jobs_cover = _compute_cover(state, assignment)
-
- def _cover_incomplete(workers_cover, jobs_cover, *args):
- del args
- cover_sum = (
- tf.reduce_sum(tf.cast(workers_cover, tf.int32)) +
- tf.reduce_sum(tf.cast(jobs_cover, tf.int32)))
- return tf.less(cover_sum, batch_size * num_elems)
-
- def _update_weights_and_match(workers_cover, jobs_cover, weights, assignment):
- weights = _update_weights_using_cover(workers_cover, jobs_cover, weights)
- adj_matrix = tf.equal(weights, 0.)
- state, assignment = _maximum_bipartite_matching(adj_matrix, assignment)
- workers_cover, jobs_cover = _compute_cover(state, assignment)
- return workers_cover, jobs_cover, weights, assignment
-
- with tf.name_scope("hungarian_matching"):
- workers_cover, jobs_cover, weights, assignment = tf.while_loop(
- _cover_incomplete,
- _update_weights_and_match,
- (workers_cover, jobs_cover, weights, assignment),
- back_prop=False)
-
- return assignment
diff --git a/spaces/akhaliq/neural-waveshaping-synthesis/neural_waveshaping_synthesis/utils/__init__.py b/spaces/akhaliq/neural-waveshaping-synthesis/neural_waveshaping_synthesis/utils/__init__.py
deleted file mode 100644
index 6fd120a066e61142432242a93e1e0d58ab5f675e..0000000000000000000000000000000000000000
--- a/spaces/akhaliq/neural-waveshaping-synthesis/neural_waveshaping_synthesis/utils/__init__.py
+++ /dev/null
@@ -1,2 +0,0 @@
-from .utils import *
-from .seed_all import *
\ No newline at end of file
diff --git a/spaces/alexray/btc_predictor/venv/bin/Activate.ps1 b/spaces/alexray/btc_predictor/venv/bin/Activate.ps1
deleted file mode 100644
index eeea3583fa130d4702a05012a2103152daf51487..0000000000000000000000000000000000000000
--- a/spaces/alexray/btc_predictor/venv/bin/Activate.ps1
+++ /dev/null
@@ -1,247 +0,0 @@
-<#
-.Synopsis
-Activate a Python virtual environment for the current PowerShell session.
-
-.Description
-Pushes the python executable for a virtual environment to the front of the
-$Env:PATH environment variable and sets the prompt to signify that you are
-in a Python virtual environment. Makes use of the command line switches as
-well as the `pyvenv.cfg` file values present in the virtual environment.
-
-.Parameter VenvDir
-Path to the directory that contains the virtual environment to activate. The
-default value for this is the parent of the directory that the Activate.ps1
-script is located within.
-
-.Parameter Prompt
-The prompt prefix to display when this virtual environment is activated. By
-default, this prompt is the name of the virtual environment folder (VenvDir)
-surrounded by parentheses and followed by a single space (ie. '(.venv) ').
-
-.Example
-Activate.ps1
-Activates the Python virtual environment that contains the Activate.ps1 script.
-
-.Example
-Activate.ps1 -Verbose
-Activates the Python virtual environment that contains the Activate.ps1 script,
-and shows extra information about the activation as it executes.
-
-.Example
-Activate.ps1 -VenvDir C:\Users\MyUser\Common\.venv
-Activates the Python virtual environment located in the specified location.
-
-.Example
-Activate.ps1 -Prompt "MyPython"
-Activates the Python virtual environment that contains the Activate.ps1 script,
-and prefixes the current prompt with the specified string (surrounded in
-parentheses) while the virtual environment is active.
-
-.Notes
-On Windows, it may be required to enable this Activate.ps1 script by setting the
-execution policy for the user. You can do this by issuing the following PowerShell
-command:
-
-PS C:\> Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope CurrentUser
-
-For more information on Execution Policies:
-https://go.microsoft.com/fwlink/?LinkID=135170
-
-#>
-Param(
- [Parameter(Mandatory = $false)]
- [String]
- $VenvDir,
- [Parameter(Mandatory = $false)]
- [String]
- $Prompt
-)
-
-<# Function declarations --------------------------------------------------- #>
-
-<#
-.Synopsis
-Remove all shell session elements added by the Activate script, including the
-addition of the virtual environment's Python executable from the beginning of
-the PATH variable.
-
-.Parameter NonDestructive
-If present, do not remove this function from the global namespace for the
-session.
-
-#>
-function global:deactivate ([switch]$NonDestructive) {
- # Revert to original values
-
- # The prior prompt:
- if (Test-Path -Path Function:_OLD_VIRTUAL_PROMPT) {
- Copy-Item -Path Function:_OLD_VIRTUAL_PROMPT -Destination Function:prompt
- Remove-Item -Path Function:_OLD_VIRTUAL_PROMPT
- }
-
- # The prior PYTHONHOME:
- if (Test-Path -Path Env:_OLD_VIRTUAL_PYTHONHOME) {
- Copy-Item -Path Env:_OLD_VIRTUAL_PYTHONHOME -Destination Env:PYTHONHOME
- Remove-Item -Path Env:_OLD_VIRTUAL_PYTHONHOME
- }
-
- # The prior PATH:
- if (Test-Path -Path Env:_OLD_VIRTUAL_PATH) {
- Copy-Item -Path Env:_OLD_VIRTUAL_PATH -Destination Env:PATH
- Remove-Item -Path Env:_OLD_VIRTUAL_PATH
- }
-
- # Just remove the VIRTUAL_ENV altogether:
- if (Test-Path -Path Env:VIRTUAL_ENV) {
- Remove-Item -Path env:VIRTUAL_ENV
- }
-
- # Just remove VIRTUAL_ENV_PROMPT altogether.
- if (Test-Path -Path Env:VIRTUAL_ENV_PROMPT) {
- Remove-Item -Path env:VIRTUAL_ENV_PROMPT
- }
-
- # Just remove the _PYTHON_VENV_PROMPT_PREFIX altogether:
- if (Get-Variable -Name "_PYTHON_VENV_PROMPT_PREFIX" -ErrorAction SilentlyContinue) {
- Remove-Variable -Name _PYTHON_VENV_PROMPT_PREFIX -Scope Global -Force
- }
-
- # Leave deactivate function in the global namespace if requested:
- if (-not $NonDestructive) {
- Remove-Item -Path function:deactivate
- }
-}
-
-<#
-.Description
-Get-PyVenvConfig parses the values from the pyvenv.cfg file located in the
-given folder, and returns them in a map.
-
-For each line in the pyvenv.cfg file, if that line can be parsed into exactly
-two strings separated by `=` (with any amount of whitespace surrounding the =)
-then it is considered a `key = value` line. The left hand string is the key,
-the right hand is the value.
-
-If the value starts with a `'` or a `"` then the first and last character is
-stripped from the value before being captured.
-
-.Parameter ConfigDir
-Path to the directory that contains the `pyvenv.cfg` file.
-#>
-function Get-PyVenvConfig(
- [String]
- $ConfigDir
-) {
- Write-Verbose "Given ConfigDir=$ConfigDir, obtain values in pyvenv.cfg"
-
- # Ensure the file exists, and issue a warning if it doesn't (but still allow the function to continue).
- $pyvenvConfigPath = Join-Path -Resolve -Path $ConfigDir -ChildPath 'pyvenv.cfg' -ErrorAction Continue
-
- # An empty map will be returned if no config file is found.
- $pyvenvConfig = @{ }
-
- if ($pyvenvConfigPath) {
-
- Write-Verbose "File exists, parse `key = value` lines"
- $pyvenvConfigContent = Get-Content -Path $pyvenvConfigPath
-
- $pyvenvConfigContent | ForEach-Object {
- $keyval = $PSItem -split "\s*=\s*", 2
- if ($keyval[0] -and $keyval[1]) {
- $val = $keyval[1]
-
- # Remove extraneous quotations around a string value.
- if ("'""".Contains($val.Substring(0, 1))) {
- $val = $val.Substring(1, $val.Length - 2)
- }
-
- $pyvenvConfig[$keyval[0]] = $val
- Write-Verbose "Adding Key: '$($keyval[0])'='$val'"
- }
- }
- }
- return $pyvenvConfig
-}
-
-
-<# Begin Activate script --------------------------------------------------- #>
-
-# Determine the containing directory of this script
-$VenvExecPath = Split-Path -Parent $MyInvocation.MyCommand.Definition
-$VenvExecDir = Get-Item -Path $VenvExecPath
-
-Write-Verbose "Activation script is located in path: '$VenvExecPath'"
-Write-Verbose "VenvExecDir Fullname: '$($VenvExecDir.FullName)"
-Write-Verbose "VenvExecDir Name: '$($VenvExecDir.Name)"
-
-# Set values required in priority: CmdLine, ConfigFile, Default
-# First, get the location of the virtual environment, it might not be
-# VenvExecDir if specified on the command line.
-if ($VenvDir) {
- Write-Verbose "VenvDir given as parameter, using '$VenvDir' to determine values"
-}
-else {
- Write-Verbose "VenvDir not given as a parameter, using parent directory name as VenvDir."
- $VenvDir = $VenvExecDir.Parent.FullName.TrimEnd("\\/")
- Write-Verbose "VenvDir=$VenvDir"
-}
-
-# Next, read the `pyvenv.cfg` file to determine any required value such
-# as `prompt`.
-$pyvenvCfg = Get-PyVenvConfig -ConfigDir $VenvDir
-
-# Next, set the prompt from the command line, or the config file, or
-# just use the name of the virtual environment folder.
-if ($Prompt) {
- Write-Verbose "Prompt specified as argument, using '$Prompt'"
-}
-else {
- Write-Verbose "Prompt not specified as argument to script, checking pyvenv.cfg value"
- if ($pyvenvCfg -and $pyvenvCfg['prompt']) {
- Write-Verbose " Setting based on value in pyvenv.cfg='$($pyvenvCfg['prompt'])'"
- $Prompt = $pyvenvCfg['prompt'];
- }
- else {
- Write-Verbose " Setting prompt based on parent's directory's name. (Is the directory name passed to venv module when creating the virtual environment)"
- Write-Verbose " Got leaf-name of $VenvDir='$(Split-Path -Path $venvDir -Leaf)'"
- $Prompt = Split-Path -Path $venvDir -Leaf
- }
-}
-
-Write-Verbose "Prompt = '$Prompt'"
-Write-Verbose "VenvDir='$VenvDir'"
-
-# Deactivate any currently active virtual environment, but leave the
-# deactivate function in place.
-deactivate -nondestructive
-
-# Now set the environment variable VIRTUAL_ENV, used by many tools to determine
-# that there is an activated venv.
-$env:VIRTUAL_ENV = $VenvDir
-
-if (-not $Env:VIRTUAL_ENV_DISABLE_PROMPT) {
-
- Write-Verbose "Setting prompt to '$Prompt'"
-
- # Set the prompt to include the env name
- # Make sure _OLD_VIRTUAL_PROMPT is global
- function global:_OLD_VIRTUAL_PROMPT { "" }
- Copy-Item -Path function:prompt -Destination function:_OLD_VIRTUAL_PROMPT
- New-Variable -Name _PYTHON_VENV_PROMPT_PREFIX -Description "Python virtual environment prompt prefix" -Scope Global -Option ReadOnly -Visibility Public -Value $Prompt
-
- function global:prompt {
- Write-Host -NoNewline -ForegroundColor Green "($_PYTHON_VENV_PROMPT_PREFIX) "
- _OLD_VIRTUAL_PROMPT
- }
- $env:VIRTUAL_ENV_PROMPT = $Prompt
-}
-
-# Clear PYTHONHOME
-if (Test-Path -Path Env:PYTHONHOME) {
- Copy-Item -Path Env:PYTHONHOME -Destination Env:_OLD_VIRTUAL_PYTHONHOME
- Remove-Item -Path Env:PYTHONHOME
-}
-
-# Add the venv to the PATH
-Copy-Item -Path Env:PATH -Destination Env:_OLD_VIRTUAL_PATH
-$Env:PATH = "$VenvExecDir$([System.IO.Path]::PathSeparator)$Env:PATH"
diff --git a/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_vendor/chardet/utf8prober.py b/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_vendor/chardet/utf8prober.py
deleted file mode 100644
index 6c3196cc2d7e46e6756580267f5643c6f7b448dd..0000000000000000000000000000000000000000
--- a/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_vendor/chardet/utf8prober.py
+++ /dev/null
@@ -1,82 +0,0 @@
-######################## BEGIN LICENSE BLOCK ########################
-# The Original Code is mozilla.org code.
-#
-# The Initial Developer of the Original Code is
-# Netscape Communications Corporation.
-# Portions created by the Initial Developer are Copyright (C) 1998
-# the Initial Developer. All Rights Reserved.
-#
-# Contributor(s):
-# Mark Pilgrim - port to Python
-#
-# This library is free software; you can redistribute it and/or
-# modify it under the terms of the GNU Lesser General Public
-# License as published by the Free Software Foundation; either
-# version 2.1 of the License, or (at your option) any later version.
-#
-# This library is distributed in the hope that it will be useful,
-# but WITHOUT ANY WARRANTY; without even the implied warranty of
-# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU
-# Lesser General Public License for more details.
-#
-# You should have received a copy of the GNU Lesser General Public
-# License along with this library; if not, write to the Free Software
-# Foundation, Inc., 51 Franklin St, Fifth Floor, Boston, MA
-# 02110-1301 USA
-######################### END LICENSE BLOCK #########################
-
-from .charsetprober import CharSetProber
-from .enums import ProbingState, MachineState
-from .codingstatemachine import CodingStateMachine
-from .mbcssm import UTF8_SM_MODEL
-
-
-
-class UTF8Prober(CharSetProber):
- ONE_CHAR_PROB = 0.5
-
- def __init__(self):
- super(UTF8Prober, self).__init__()
- self.coding_sm = CodingStateMachine(UTF8_SM_MODEL)
- self._num_mb_chars = None
- self.reset()
-
- def reset(self):
- super(UTF8Prober, self).reset()
- self.coding_sm.reset()
- self._num_mb_chars = 0
-
- @property
- def charset_name(self):
- return "utf-8"
-
- @property
- def language(self):
- return ""
-
- def feed(self, byte_str):
- for c in byte_str:
- coding_state = self.coding_sm.next_state(c)
- if coding_state == MachineState.ERROR:
- self._state = ProbingState.NOT_ME
- break
- elif coding_state == MachineState.ITS_ME:
- self._state = ProbingState.FOUND_IT
- break
- elif coding_state == MachineState.START:
- if self.coding_sm.get_current_charlen() >= 2:
- self._num_mb_chars += 1
-
- if self.state == ProbingState.DETECTING:
- if self.get_confidence() > self.SHORTCUT_THRESHOLD:
- self._state = ProbingState.FOUND_IT
-
- return self.state
-
- def get_confidence(self):
- unlike = 0.99
- if self._num_mb_chars < 6:
- unlike *= self.ONE_CHAR_PROB ** self._num_mb_chars
- return 1.0 - unlike
- else:
- return unlike
diff --git a/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_vendor/pygments/scanner.py b/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_vendor/pygments/scanner.py
deleted file mode 100644
index 5f32a22c3c0ede8131fb1ab6b32e43446da6a634..0000000000000000000000000000000000000000
--- a/spaces/alexray/btc_predictor/venv/lib/python3.10/site-packages/pip/_vendor/pygments/scanner.py
+++ /dev/null
@@ -1,104 +0,0 @@
-"""
- pygments.scanner
- ~~~~~~~~~~~~~~~~
-
- This library implements a regex based scanner. Some languages
- like Pascal are easy to parse but have some keywords that
- depend on the context. Because of this it's impossible to lex
- that just by using a regular expression lexer like the
- `RegexLexer`.
-
- Have a look at the `DelphiLexer` to get an idea of how to use
- this scanner.
-
- :copyright: Copyright 2006-2021 by the Pygments team, see AUTHORS.
- :license: BSD, see LICENSE for details.
-"""
-import re
-
-
-class EndOfText(RuntimeError):
- """
- Raise if end of text is reached and the user
- tried to call a match function.
- """
-
-
-class Scanner:
- """
- Simple scanner
-
- All method patterns are regular expression strings (not
- compiled expressions!)
- """
-
- def __init__(self, text, flags=0):
- """
- :param text: The text which should be scanned
- :param flags: default regular expression flags
- """
- self.data = text
- self.data_length = len(text)
- self.start_pos = 0
- self.pos = 0
- self.flags = flags
- self.last = None
- self.match = None
- self._re_cache = {}
-
- def eos(self):
- """`True` if the scanner reached the end of text."""
- return self.pos >= self.data_length
- eos = property(eos, eos.__doc__)
-
- def check(self, pattern):
- """
- Apply `pattern` on the current position and return
- the match object. (Doesn't touch pos). Use this for
- lookahead.
- """
- if self.eos:
- raise EndOfText()
- if pattern not in self._re_cache:
- self._re_cache[pattern] = re.compile(pattern, self.flags)
- return self._re_cache[pattern].match(self.data, self.pos)
-
- def test(self, pattern):
- """Apply a pattern on the current position and check
- if it patches. Doesn't touch pos.
- """
- return self.check(pattern) is not None
-
- def scan(self, pattern):
- """
- Scan the text for the given pattern and update pos/match
- and related fields. The return value is a boolen that
- indicates if the pattern matched. The matched value is
- stored on the instance as ``match``, the last value is
- stored as ``last``. ``start_pos`` is the position of the
- pointer before the pattern was matched, ``pos`` is the
- end position.
- """
- if self.eos:
- raise EndOfText()
- if pattern not in self._re_cache:
- self._re_cache[pattern] = re.compile(pattern, self.flags)
- self.last = self.match
- m = self._re_cache[pattern].match(self.data, self.pos)
- if m is None:
- return False
- self.start_pos = m.start()
- self.pos = m.end()
- self.match = m.group()
- return True
-
- def get_char(self):
- """Scan exactly one char."""
- self.scan('.')
-
- def __repr__(self):
- return '<%s %d/%d>' % (
- self.__class__.__name__,
- self.pos,
- self.data_length
- )
diff --git a/spaces/ali-ghamdan/deoldify/fastai/basic_data.py b/spaces/ali-ghamdan/deoldify/fastai/basic_data.py
deleted file mode 100644
index dedf582a70393d5a23dff28ebc12bdf32c85b495..0000000000000000000000000000000000000000
--- a/spaces/ali-ghamdan/deoldify/fastai/basic_data.py
+++ /dev/null
@@ -1,279 +0,0 @@
-"`fastai.data` loads and manages datasets with `DataBunch`"
-from .torch_core import *
-from torch.utils.data.dataloader import default_collate
-
-DatasetType = Enum('DatasetType', 'Train Valid Test Single Fix')
-__all__ = ['DataBunch', 'DeviceDataLoader', 'DatasetType', 'load_data']
-
-old_dl_init = torch.utils.data.DataLoader.__init__
-
-def intercept_args(self, dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None,
- num_workers=0, collate_fn=default_collate, pin_memory=True, drop_last=False,
- timeout=0, worker_init_fn=None):
- self.init_kwargs = {'batch_size':batch_size, 'shuffle':shuffle, 'sampler':sampler, 'batch_sampler':batch_sampler,
- 'num_workers':num_workers, 'collate_fn':collate_fn, 'pin_memory':pin_memory,
- 'drop_last': drop_last, 'timeout':timeout, 'worker_init_fn':worker_init_fn}
- old_dl_init(self, dataset, **self.init_kwargs)
-
-torch.utils.data.DataLoader.__init__ = intercept_args
-
-def DataLoader___getattr__(dl, k:str)->Any: return getattr(dl.dataset, k)
-DataLoader.__getattr__ = DataLoader___getattr__
-
-def DataLoader___setstate__(dl, data:Any): dl.__dict__.update(data)
-DataLoader.__setstate__ = DataLoader___setstate__
-
-@dataclass
-class DeviceDataLoader():
- "Bind a `DataLoader` to a `torch.device`."
- dl: DataLoader
- device: torch.device
- tfms: List[Callable]=None
- collate_fn: Callable=data_collate
- def __post_init__(self):
- self.dl.collate_fn=self.collate_fn
- self.tfms = listify(self.tfms)
-
- def __len__(self)->int: return len(self.dl)
- def __getattr__(self,k:str)->Any: return getattr(self.dl, k)
- def __setstate__(self,data:Any): self.__dict__.update(data)
-
- @property
- def batch_size(self): return self.dl.batch_size
- @batch_size.setter
- def batch_size(self,v):
- new_kwargs = {**self.dl.init_kwargs, 'batch_size':v, 'collate_fn':self.collate_fn}
- self.dl = self.dl.__class__(self.dl.dataset, **new_kwargs)
- if hasattr(self.dl.dataset, 'bs'): self.dl.dataset.bs = v
-
- @property
- def num_workers(self): return self.dl.num_workers
- @num_workers.setter
- def num_workers(self,v): self.dl.num_workers = v
-
- def add_tfm(self,tfm:Callable)->None:
- "Add `tfm` to `self.tfms`."
- self.tfms.append(tfm)
- def remove_tfm(self,tfm:Callable)->None:
- "Remove `tfm` from `self.tfms`."
- if tfm in self.tfms: self.tfms.remove(tfm)
-
- def new(self, **kwargs):
- "Create a new copy of `self` with `kwargs` replacing current values."
- new_kwargs = {**self.dl.init_kwargs, **kwargs}
- return DeviceDataLoader(self.dl.__class__(self.dl.dataset, **new_kwargs), self.device, self.tfms,
- self.collate_fn)
-
- def proc_batch(self,b:Tensor)->Tensor:
- "Process batch `b` of `TensorImage`."
- b = to_device(b, self.device)
- for f in listify(self.tfms): b = f(b)
- return b
-
- def __iter__(self):
- "Process and returns items from `DataLoader`."
- for b in self.dl: yield self.proc_batch(b)
-
- @classmethod
- def create(cls, dataset:Dataset, bs:int=64, shuffle:bool=False, device:torch.device=defaults.device,
- tfms:Collection[Callable]=tfms, num_workers:int=defaults.cpus, collate_fn:Callable=data_collate, **kwargs:Any):
- "Create DeviceDataLoader from `dataset` with `bs` and `shuffle`: process using `num_workers`."
- return cls(DataLoader(dataset, batch_size=bs, shuffle=shuffle, num_workers=num_workers, **kwargs),
- device=device, tfms=tfms, collate_fn=collate_fn)
-
-class DataBunch():
- "Bind `train_dl`,`valid_dl` and `test_dl` in a data object."
-
- def __init__(self, train_dl:DataLoader, valid_dl:DataLoader, fix_dl:DataLoader=None, test_dl:Optional[DataLoader]=None,
- device:torch.device=None, dl_tfms:Optional[Collection[Callable]]=None, path:PathOrStr='.',
- collate_fn:Callable=data_collate, no_check:bool=False):
- self.dl_tfms = listify(dl_tfms)
- self.device = defaults.device if device is None else device
- assert not isinstance(train_dl,DeviceDataLoader)
- def _create_dl(dl, **kwargs):
- if dl is None: return None
- return DeviceDataLoader(dl, self.device, self.dl_tfms, collate_fn, **kwargs)
- self.train_dl,self.valid_dl,self.fix_dl,self.test_dl = map(_create_dl, [train_dl,valid_dl,fix_dl,test_dl])
- if fix_dl is None: self.fix_dl = self.train_dl.new(shuffle=False, drop_last=False)
- self.single_dl = _create_dl(DataLoader(valid_dl.dataset, batch_size=1, num_workers=0))
- self.path = Path(path)
- if not no_check: self.sanity_check()
-
- def __repr__(self)->str:
- return f'{self.__class__.__name__};\n\nTrain: {self.train_ds};\n\nValid: {self.valid_ds};\n\nTest: {self.test_ds}'
-
- @staticmethod
- def _init_ds(train_ds:Dataset, valid_ds:Dataset, test_ds:Optional[Dataset]=None):
- # train_ds, but without training tfms
- fix_ds = valid_ds.new(train_ds.x, train_ds.y) if hasattr(valid_ds,'new') else train_ds
- return [o for o in (train_ds,valid_ds,fix_ds,test_ds) if o is not None]
-
- @classmethod
- def create(cls, train_ds:Dataset, valid_ds:Dataset, test_ds:Optional[Dataset]=None, path:PathOrStr='.', bs:int=64,
- val_bs:int=None, num_workers:int=defaults.cpus, dl_tfms:Optional[Collection[Callable]]=None,
- device:torch.device=None, collate_fn:Callable=data_collate, no_check:bool=False, **dl_kwargs)->'DataBunch':
- "Create a `DataBunch` from `train_ds`, `valid_ds` and maybe `test_ds` with a batch size of `bs`. Passes `**dl_kwargs` to `DataLoader()`"
- datasets = cls._init_ds(train_ds, valid_ds, test_ds)
- val_bs = ifnone(val_bs, bs)
- dls = [DataLoader(d, b, shuffle=s, drop_last=s, num_workers=num_workers, **dl_kwargs) for d,b,s in
- zip(datasets, (bs,val_bs,val_bs,val_bs), (True,False,False,False)) if d is not None]
- return cls(*dls, path=path, device=device, dl_tfms=dl_tfms, collate_fn=collate_fn, no_check=no_check)
-
- def __getattr__(self,k:int)->Any: return getattr(self.train_dl, k)
- def __setstate__(self,data:Any): self.__dict__.update(data)
-
- def dl(self, ds_type:DatasetType=DatasetType.Valid)->DeviceDataLoader:
- "Returns appropriate `Dataset` for validation, training, or test (`ds_type`)."
- #TODO: refactor
- return (self.train_dl if ds_type == DatasetType.Train else
- self.test_dl if ds_type == DatasetType.Test else
- self.valid_dl if ds_type == DatasetType.Valid else
- self.single_dl if ds_type == DatasetType.Single else
- self.fix_dl)
-
- @property
- def dls(self)->List[DeviceDataLoader]:
- "Returns a list of all DeviceDataLoaders. If you need a specific DeviceDataLoader, access via the relevant property (`train_dl`, `valid_dl`, etc) as the index of DLs in this list is not guaranteed to remain constant."
- res = [self.train_dl, self.fix_dl, self.single_dl]
- # Preserve the original ordering of Train, Valid, Fix, Single, Test Data Loaders
- # (Unknown/not verified as of 1.0.47 whether there are other methods explicitly using DLs their list index)
- if self.valid_dl: res.insert(1, self.valid_dl)
- return res if not self.test_dl else res + [self.test_dl]
-
- def add_tfm(self,tfm:Callable)->None:
- for dl in self.dls: dl.add_tfm(tfm)
-
- def remove_tfm(self,tfm:Callable)->None:
- for dl in self.dls: dl.remove_tfm(tfm)
-
- def save(self, file:PathLikeOrBinaryStream= 'data_save.pkl')->None:
- "Save the `DataBunch` in `self.path/file`. `file` can be file-like (file or buffer)"
- if not getattr(self, 'label_list', False):
- warn("Serializing the `DataBunch` only works when you created it using the data block API.")
- return
- try_save(self.label_list, self.path, file)
-
- def add_test(self, items:Iterator, label:Any=None, tfms=None, tfm_y=None)->None:
- "Add the `items` as a test set. Pass along `label` otherwise label them with `EmptyLabel`."
- self.label_list.add_test(items, label=label, tfms=tfms, tfm_y=tfm_y)
- vdl = self.valid_dl
- dl = DataLoader(self.label_list.test, vdl.batch_size, shuffle=False, drop_last=False, num_workers=vdl.num_workers)
- self.test_dl = DeviceDataLoader(dl, vdl.device, vdl.tfms, vdl.collate_fn)
-
- def one_batch(self, ds_type:DatasetType=DatasetType.Train, detach:bool=True, denorm:bool=True, cpu:bool=True)->Collection[Tensor]:
- "Get one batch from the data loader of `ds_type`. Optionally `detach` and `denorm`."
- dl = self.dl(ds_type)
- w = self.num_workers
- self.num_workers = 0
- try: x,y = next(iter(dl))
- finally: self.num_workers = w
- if detach: x,y = to_detach(x,cpu=cpu),to_detach(y,cpu=cpu)
- norm = getattr(self,'norm',False)
- if denorm and norm:
- x = self.denorm(x)
- if norm.keywords.get('do_y',False): y = self.denorm(y, do_x=True)
- return x,y
-
- def one_item(self, item, detach:bool=False, denorm:bool=False, cpu:bool=False):
- "Get `item` into a batch. Optionally `detach` and `denorm`."
- ds = self.single_ds
- with ds.set_item(item):
- return self.one_batch(ds_type=DatasetType.Single, detach=detach, denorm=denorm, cpu=cpu)
-
- def show_batch(self, rows:int=5, ds_type:DatasetType=DatasetType.Train, reverse:bool=False, **kwargs)->None:
- "Show a batch of data in `ds_type` on a few `rows`."
- x,y = self.one_batch(ds_type, True, True)
- if reverse: x,y = x.flip(0),y.flip(0)
- n_items = rows **2 if self.train_ds.x._square_show else rows
- if self.dl(ds_type).batch_size < n_items: n_items = self.dl(ds_type).batch_size
- xs = [self.train_ds.x.reconstruct(grab_idx(x, i)) for i in range(n_items)]
- #TODO: get rid of has_arg if possible
- if has_arg(self.train_ds.y.reconstruct, 'x'):
- ys = [self.train_ds.y.reconstruct(grab_idx(y, i), x=x) for i,x in enumerate(xs)]
- else : ys = [self.train_ds.y.reconstruct(grab_idx(y, i)) for i in range(n_items)]
- self.train_ds.x.show_xys(xs, ys, **kwargs)
-
- def export(self, file:PathLikeOrBinaryStream='export.pkl'):
- "Export the minimal state of `self` for inference in `self.path/file`. `file` can be file-like (file or buffer)"
- xtra = dict(normalize=self.norm.keywords) if getattr(self, 'norm', False) else {}
- try_save(self.valid_ds.get_state(**xtra), self.path, file)
-
- def _grab_dataset(self, dl:DataLoader):
- ds = dl.dl.dataset
- while hasattr(ds, 'dataset'): ds = ds.dataset
- return ds
-
- @property
- def train_ds(self)->Dataset: return self._grab_dataset(self.train_dl)
- @property
- def valid_ds(self)->Dataset: return self._grab_dataset(self.valid_dl)
- @property
- def single_ds(self)->Dataset: return self._grab_dataset(self.single_dl)
- @property
- def loss_func(self)->OptLossFunc:
- return getattr(self.train_ds.y, 'loss_func', F.nll_loss) if hasattr(self.train_ds, 'y') else F.nll_loss
-
- @property
- def test_ds(self)->Dataset:
- return self._grab_dataset(self.test_dl) if self.test_dl is not None else None
-
- @property
- def empty_val(self)->bool:
- if not hasattr(self, 'valid_dl') or self.valid_dl is None: return True
- if hasattr(self.valid_ds, 'items') and len(self.valid_ds.items) == 0: return True
- return (len(self.valid_ds) == 0)
-
- @property
- def is_empty(self)->bool:
- return not ((self.train_dl and len(self.train_ds.items) != 0) or
- (self.valid_dl and len(self.valid_ds.items) != 0) or
- (self.test_dl and len(self.test_ds.items) != 0))
-
- @property
- def batch_size(self): return self.train_dl.batch_size
- @batch_size.setter
- def batch_size(self,v):
- self.train_dl.batch_size,self.valid_dl.batch_size = v,v
- if self.test_dl is not None: self.test_dl.batch_size = v
-
- def sanity_check(self):
- "Check the underlying data in the training set can be properly loaded."
- final_message = "You can deactivate this warning by passing `no_check=True`."
- if not hasattr(self.train_ds, 'items') or len(self.train_ds.items) == 0 or not hasattr(self.train_dl, 'batch_sampler'): return
- if len(self.train_dl) == 0:
- warn(f"""Your training dataloader is empty, you have only {len(self.train_dl.dataset)} items in your training set.
- Your batch size is {self.train_dl.batch_size}, you should lower it.""")
- print(final_message)
- return
- idx = next(iter(self.train_dl.batch_sampler))
- samples,fails = [],[]
- for i in idx:
- try: samples.append(self.train_dl.dataset[i])
- except: fails.append(i)
- if len(fails) > 0:
- warn_msg = "There seems to be something wrong with your dataset, for example, in the first batch can't access"
- if len(fails) == len(idx):
- warn_msg += f" any element of self.train_ds.\nTried: {show_some(idx)}"
- else:
- warn_msg += f" these elements in self.train_ds: {show_some(fails)}"
- warn(warn_msg)
- print(final_message)
- return
- try: batch = self.collate_fn(samples)
- except:
- message = "It's not possible to collate samples of your dataset together in a batch."
- try:
- shapes = [[o[i].data.shape for o in samples] for i in range(2)]
- message += f'\nShapes of the inputs/targets:\n{shapes}'
- except: pass
- warn(message)
- print(final_message)
-
-def load_data(path:PathOrStr, file:PathLikeOrBinaryStream='data_save.pkl', bs:int=64, val_bs:int=None, num_workers:int=defaults.cpus,
- dl_tfms:Optional[Collection[Callable]]=None, device:torch.device=None, collate_fn:Callable=data_collate,
- no_check:bool=False, **kwargs)->DataBunch:
- "Load a saved `DataBunch` from `path/file`. `file` can be file-like (file or buffer)"
- source = Path(path)/file if is_pathlike(file) else file
- ll = torch.load(source, map_location='cpu') if defaults.device == torch.device('cpu') else torch.load(source)
- return ll.databunch(path=path, bs=bs, val_bs=val_bs, num_workers=num_workers, dl_tfms=dl_tfms, device=device,
- collate_fn=collate_fn, no_check=no_check, **kwargs)
diff --git a/spaces/amarchheda/ChordDuplicate/portaudio/src/hostapi/wasapi/mingw-include/ksguid.h b/spaces/amarchheda/ChordDuplicate/portaudio/src/hostapi/wasapi/mingw-include/ksguid.h
deleted file mode 100644
index f0774d06cef4bd7cb26e3f472be36e5b98149c8d..0000000000000000000000000000000000000000
--- a/spaces/amarchheda/ChordDuplicate/portaudio/src/hostapi/wasapi/mingw-include/ksguid.h
+++ /dev/null
@@ -1,28 +0,0 @@
-/**
- * This file has no copyright assigned and is placed in the Public Domain.
- * This file is part of the w64 mingw-runtime package.
- * No warranty is given; refer to the file DISCLAIMER.PD within this package.
- */
-#define INITGUID
-#include
-
-#ifndef DECLSPEC_SELECTANY
-#define DECLSPEC_SELECTANY __declspec(selectany)
-#endif
-
-#ifdef DEFINE_GUIDEX
-#undef DEFINE_GUIDEX
-#endif
-
-#ifdef __cplusplus
-#define DEFINE_GUIDEX(name) EXTERN_C const CDECL GUID DECLSPEC_SELECTANY name = { STATICGUIDOF(name) }
-#else
-#define DEFINE_GUIDEX(name) const CDECL GUID DECLSPEC_SELECTANY name = { STATICGUIDOF(name) }
-#endif
-#ifndef STATICGUIDOF
-#define STATICGUIDOF(guid) STATIC_##guid
-#endif
-
-#ifndef DEFINE_WAVEFORMATEX_GUID
-#define DEFINE_WAVEFORMATEX_GUID(x) (USHORT)(x),0x0000,0x0010,0x80,0x00,0x00,0xaa,0x00,0x38,0x9b,0x71
-#endif
diff --git a/spaces/amarchheda/ChordDuplicate/portaudio/test/patest_dsound_find_best_latency_params.c b/spaces/amarchheda/ChordDuplicate/portaudio/test/patest_dsound_find_best_latency_params.c
deleted file mode 100644
index 1c074ab16cf458f136fe79d4d6e232a04236243f..0000000000000000000000000000000000000000
--- a/spaces/amarchheda/ChordDuplicate/portaudio/test/patest_dsound_find_best_latency_params.c
+++ /dev/null
@@ -1,513 +0,0 @@
-/*
- * $Id: $
- * Portable Audio I/O Library
- * Windows DirectSound low level buffer user guided parameters search
- *
- * Copyright (c) 2010-2011 Ross Bencina
- *
- * Permission is hereby granted, free of charge, to any person obtaining
- * a copy of this software and associated documentation files
- * (the "Software"), to deal in the Software without restriction,
- * including without limitation the rights to use, copy, modify, merge,
- * publish, distribute, sublicense, and/or sell copies of the Software,
- * and to permit persons to whom the Software is furnished to do so,
- * subject to the following conditions:
- *
- * The above copyright notice and this permission notice shall be
- * included in all copies or substantial portions of the Software.
- *
- * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
- * EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
- * MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
- * IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR
- * ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF
- * CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION
- * WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
- */
-
-/*
- * The text above constitutes the entire PortAudio license; however,
- * the PortAudio community also makes the following non-binding requests:
- *
- * Any person wishing to distribute modifications to the Software is
- * requested to send the modifications to the original developer so that
- * they can be incorporated into the canonical version. It is also
- * requested that these non-binding requests be included along with the
- * license above.
- */
-
-#include
-#include
-#include
-
-#define _WIN32_WINNT 0x0501 /* for GetNativeSystemInfo */
-#include
-//#include /* required when using pa_win_wmme.h */
-
-#include /* for _getch */
-
-
-#include "portaudio.h"
-#include "pa_win_ds.h"
-
-
-#define DEFAULT_SAMPLE_RATE (44100.)
-
-#ifndef M_PI
-#define M_PI (3.14159265)
-#endif
-
-#define TABLE_SIZE (2048)
-
-#define CHANNEL_COUNT (2)
-
-
-/*******************************************************************/
-/* functions to query and print Windows version information */
-
-typedef BOOL (WINAPI *LPFN_ISWOW64PROCESS) (HANDLE, PBOOL);
-
-LPFN_ISWOW64PROCESS fnIsWow64Process;
-
-static BOOL IsWow64()
-{
- BOOL bIsWow64 = FALSE;
-
- //IsWow64Process is not available on all supported versions of Windows.
- //Use GetModuleHandle to get a handle to the DLL that contains the function
- //and GetProcAddress to get a pointer to the function if available.
-
- fnIsWow64Process = (LPFN_ISWOW64PROCESS) GetProcAddress(
- GetModuleHandle(TEXT("kernel32")),"IsWow64Process" );
-
- if(NULL != fnIsWow64Process)
- {
- if (!fnIsWow64Process(GetCurrentProcess(),&bIsWow64))
- {
- //handle error
- }
- }
- return bIsWow64;
-}
-
-static void printWindowsVersionInfo( FILE *fp )
-{
- OSVERSIONINFOEX osVersionInfoEx;
- SYSTEM_INFO systemInfo;
- const char *osName = "Unknown";
- const char *osProductType = "";
- const char *processorArchitecture = "Unknown";
-
- memset( &osVersionInfoEx, 0, sizeof(OSVERSIONINFOEX) );
- osVersionInfoEx.dwOSVersionInfoSize = sizeof(OSVERSIONINFOEX);
- GetVersionEx( &osVersionInfoEx );
-
-
- if( osVersionInfoEx.dwPlatformId == VER_PLATFORM_WIN32_WINDOWS ){
- switch( osVersionInfoEx.dwMinorVersion ){
- case 0: osName = "Windows 95"; break;
- case 10: osName = "Windows 98"; break; // could also be 98SE (I've seen code discriminate based
- // on osInfo.Version.Revision.ToString() == "2222A")
- case 90: osName = "Windows Me"; break;
- }
- }else if( osVersionInfoEx.dwPlatformId == VER_PLATFORM_WIN32_NT ){
- switch( osVersionInfoEx.dwMajorVersion ){
- case 3: osName = "Windows NT 3.51"; break;
- case 4: osName = "Windows NT 4.0"; break;
- case 5: switch( osVersionInfoEx.dwMinorVersion ){
- case 0: osName = "Windows 2000"; break;
- case 1: osName = "Windows XP"; break;
- case 2:
- if( osVersionInfoEx.wSuiteMask & 0x00008000 /*VER_SUITE_WH_SERVER*/ ){
- osName = "Windows Home Server";
- }else{
- if( osVersionInfoEx.wProductType == VER_NT_WORKSTATION ){
- osName = "Windows XP Professional x64 Edition (?)";
- }else{
- if( GetSystemMetrics(/*SM_SERVERR2*/89) == 0 )
- osName = "Windows Server 2003";
- else
- osName = "Windows Server 2003 R2";
- }
- }break;
- }break;
- case 6:switch( osVersionInfoEx.dwMinorVersion ){
- case 0:
- if( osVersionInfoEx.wProductType == VER_NT_WORKSTATION )
- osName = "Windows Vista";
- else
- osName = "Windows Server 2008";
- break;
- case 1:
- if( osVersionInfoEx.wProductType == VER_NT_WORKSTATION )
- osName = "Windows 7";
- else
- osName = "Windows Server 2008 R2";
- break;
- }break;
- }
- }
-
- if(osVersionInfoEx.dwMajorVersion == 4)
- {
- if(osVersionInfoEx.wProductType == VER_NT_WORKSTATION)
- osProductType = "Workstation";
- else if(osVersionInfoEx.wProductType == VER_NT_SERVER)
- osProductType = "Server";
- }
- else if(osVersionInfoEx.dwMajorVersion == 5)
- {
- if(osVersionInfoEx.wProductType == VER_NT_WORKSTATION)
- {
- if((osVersionInfoEx.wSuiteMask & VER_SUITE_PERSONAL) == VER_SUITE_PERSONAL)
- osProductType = "Home Edition"; // Windows XP Home Edition
- else
- osProductType = "Professional"; // Windows XP / Windows 2000 Professional
- }
- else if(osVersionInfoEx.wProductType == VER_NT_SERVER)
- {
- if(osVersionInfoEx.dwMinorVersion == 0)
- {
- if((osVersionInfoEx.wSuiteMask & VER_SUITE_DATACENTER) == VER_SUITE_DATACENTER)
- osProductType = "Datacenter Server"; // Windows 2000 Datacenter Server
- else if((osVersionInfoEx.wSuiteMask & VER_SUITE_ENTERPRISE) == VER_SUITE_ENTERPRISE)
- osProductType = "Advanced Server"; // Windows 2000 Advanced Server
- else
- osProductType = "Server"; // Windows 2000 Server
- }
- }
- else
- {
- if((osVersionInfoEx.wSuiteMask & VER_SUITE_DATACENTER) == VER_SUITE_DATACENTER)
- osProductType = "Datacenter Edition"; // Windows Server 2003 Datacenter Edition
- else if((osVersionInfoEx.wSuiteMask & VER_SUITE_ENTERPRISE) == VER_SUITE_ENTERPRISE)
- osProductType = "Enterprise Edition"; // Windows Server 2003 Enterprise Edition
- else if((osVersionInfoEx.wSuiteMask & VER_SUITE_BLADE) == VER_SUITE_BLADE)
- osProductType = "Web Edition"; // Windows Server 2003 Web Edition
- else
- osProductType = "Standard Edition"; // Windows Server 2003 Standard Edition
- }
- }
-
- memset( &systemInfo, 0, sizeof(SYSTEM_INFO) );
- GetNativeSystemInfo( &systemInfo );
-
- if( systemInfo.wProcessorArchitecture == PROCESSOR_ARCHITECTURE_INTEL )
- processorArchitecture = "x86";
- else if( systemInfo.wProcessorArchitecture == PROCESSOR_ARCHITECTURE_AMD64 )
- processorArchitecture = "x64";
- else if( systemInfo.wProcessorArchitecture == PROCESSOR_ARCHITECTURE_IA64 )
- processorArchitecture = "Itanium";
-
-
- fprintf( fp, "OS name and edition: %s %s\n", osName, osProductType );
- fprintf( fp, "OS version: %d.%d.%d %S\n",
- osVersionInfoEx.dwMajorVersion, osVersionInfoEx.dwMinorVersion,
- osVersionInfoEx.dwBuildNumber, osVersionInfoEx.szCSDVersion );
- fprintf( fp, "Processor architecture: %s\n", processorArchitecture );
- fprintf( fp, "WoW64 process: %s\n", IsWow64() ? "Yes" : "No" );
-}
-
-static void printTimeAndDate( FILE *fp )
-{
- struct tm *local;
- time_t t;
-
- t = time(NULL);
- local = localtime(&t);
- fprintf(fp, "Local time and date: %s", asctime(local));
- local = gmtime(&t);
- fprintf(fp, "UTC time and date: %s", asctime(local));
-}
-
-/*******************************************************************/
-
-typedef struct
-{
- float sine[TABLE_SIZE];
- double phase;
- double phaseIncrement;
- volatile int fadeIn;
- volatile int fadeOut;
- double amp;
-}
-paTestData;
-
-static paTestData data;
-
-/* This routine will be called by the PortAudio engine when audio is needed.
-** It may called at interrupt level on some machines so don't do anything
-** that could mess up the system like calling malloc() or free().
-*/
-static int patestCallback( const void *inputBuffer, void *outputBuffer,
- unsigned long framesPerBuffer,
- const PaStreamCallbackTimeInfo* timeInfo,
- PaStreamCallbackFlags statusFlags,
- void *userData )
-{
- paTestData *data = (paTestData*)userData;
- float *out = (float*)outputBuffer;
- unsigned long i,j;
-
- (void) timeInfo; /* Prevent unused variable warnings. */
- (void) statusFlags;
- (void) inputBuffer;
-
- for( i=0; isine[(int)data->phase];
- data->phase += data->phaseIncrement;
- if( data->phase >= TABLE_SIZE ){
- data->phase -= TABLE_SIZE;
- }
-
- x *= data->amp;
- if( data->fadeIn ){
- data->amp += .001;
- if( data->amp >= 1. )
- data->fadeIn = 0;
- }else if( data->fadeOut ){
- if( data->amp > 0 )
- data->amp -= .001;
- }
-
- for( j = 0; j < CHANNEL_COUNT; ++j ){
- *out++ = x;
- }
- }
-
- if( data->amp > 0 )
- return paContinue;
- else
- return paComplete;
-}
-
-
-#define YES 1
-#define NO 0
-
-
-static int playUntilKeyPress( int deviceIndex, float sampleRate,
- int framesPerUserBuffer, int framesPerDSoundBuffer )
-{
- PaStreamParameters outputParameters;
- PaWinDirectSoundStreamInfo directSoundStreamInfo;
- PaStream *stream;
- PaError err;
- int c;
-
- outputParameters.device = deviceIndex;
- outputParameters.channelCount = CHANNEL_COUNT;
- outputParameters.sampleFormat = paFloat32; /* 32 bit floating point processing */
- outputParameters.suggestedLatency = 0; /*Pa_GetDeviceInfo( outputParameters.device )->defaultLowOutputLatency;*/
- outputParameters.hostApiSpecificStreamInfo = NULL;
-
- directSoundStreamInfo.size = sizeof(PaWinDirectSoundStreamInfo);
- directSoundStreamInfo.hostApiType = paDirectSound;
- directSoundStreamInfo.version = 2;
- directSoundStreamInfo.flags = paWinDirectSoundUseLowLevelLatencyParameters;
- directSoundStreamInfo.framesPerBuffer = framesPerDSoundBuffer;
- outputParameters.hostApiSpecificStreamInfo = &directSoundStreamInfo;
-
- err = Pa_OpenStream(
- &stream,
- NULL, /* no input */
- &outputParameters,
- sampleRate,
- framesPerUserBuffer,
- paClipOff | paPrimeOutputBuffersUsingStreamCallback, /* we won't output out of range samples so don't bother clipping them */
- patestCallback,
- &data );
- if( err != paNoError ) goto error;
-
- data.amp = 0;
- data.fadeIn = 1;
- data.fadeOut = 0;
- data.phase = 0;
- data.phaseIncrement = 15 + ((rand()%100) / 10); // randomise pitch
-
- err = Pa_StartStream( stream );
- if( err != paNoError ) goto error;
-
-
- do{
- printf( "Trying buffer size %d.\nIf it sounds smooth (without clicks or glitches) press 'y', if it sounds bad press 'n' ('q' to quit)\n", framesPerDSoundBuffer );
- c = tolower(_getch());
- if( c == 'q' ){
- Pa_Terminate();
- exit(0);
- }
- }while( c != 'y' && c != 'n' );
-
- data.fadeOut = 1;
- while( Pa_IsStreamActive(stream) == 1 )
- Pa_Sleep( 100 );
-
- err = Pa_StopStream( stream );
- if( err != paNoError ) goto error;
-
- err = Pa_CloseStream( stream );
- if( err != paNoError ) goto error;
-
- return (c == 'y') ? YES : NO;
-
-error:
- return err;
-}
-
-/*******************************************************************/
-static void usage( int dsoundHostApiIndex )
-{
- int i;
-
- fprintf( stderr, "PortAudio DirectSound output latency user guided test\n" );
- fprintf( stderr, "Usage: x.exe dsound-device-index [sampleRate]\n" );
- fprintf( stderr, "Invalid device index. Use one of these:\n" );
- for( i=0; i < Pa_GetDeviceCount(); ++i ){
-
- if( Pa_GetDeviceInfo(i)->hostApi == dsoundHostApiIndex && Pa_GetDeviceInfo(i)->maxOutputChannels > 0 )
- fprintf( stderr, "%d (%s)\n", i, Pa_GetDeviceInfo(i)->name );
- }
- Pa_Terminate();
- exit(-1);
-}
-
-/*
- ideas:
- o- could be testing with 80% CPU load
- o- could test with different channel counts
-*/
-
-int main(int argc, char* argv[])
-{
- PaError err;
- int i;
- int deviceIndex;
- int dsoundBufferSize, smallestWorkingBufferSize;
- int smallestWorkingBufferingLatencyFrames;
- int min, max, mid;
- int testResult;
- FILE *resultsFp;
- int dsoundHostApiIndex;
- const PaHostApiInfo *dsoundHostApiInfo;
- double sampleRate = DEFAULT_SAMPLE_RATE;
-
- err = Pa_Initialize();
- if( err != paNoError ) goto error;
-
- dsoundHostApiIndex = Pa_HostApiTypeIdToHostApiIndex( paDirectSound );
- dsoundHostApiInfo = Pa_GetHostApiInfo( dsoundHostApiIndex );
-
- if( argc > 3 )
- usage(dsoundHostApiIndex);
-
- deviceIndex = dsoundHostApiInfo->defaultOutputDevice;
- if( argc >= 2 ){
- deviceIndex = -1;
- if( sscanf( argv[1], "%d", &deviceIndex ) != 1 )
- usage(dsoundHostApiInfo);
- if( deviceIndex < 0 || deviceIndex >= Pa_GetDeviceCount() || Pa_GetDeviceInfo(deviceIndex)->hostApi != dsoundHostApiIndex ){
- usage(dsoundHostApiInfo);
- }
- }
-
- printf( "Using device id %d (%s)\n", deviceIndex, Pa_GetDeviceInfo(deviceIndex)->name );
-
- if( argc >= 3 ){
- if( sscanf( argv[2], "%lf", &sampleRate ) != 1 )
- usage(dsoundHostApiIndex);
- }
-
- printf( "Testing with sample rate %f.\n", (float)sampleRate );
-
-
-
- /* initialise sinusoidal wavetable */
- for( i=0; iname );
- fflush( resultsFp );
-
- fprintf( resultsFp, "Sample rate: %f\n", (float)sampleRate );
- fprintf( resultsFp, "Smallest working buffer size (frames), Smallest working buffering latency (frames), Smallest working buffering latency (Seconds)\n" );
-
-
- /*
- Binary search after Niklaus Wirth
- from http://en.wikipedia.org/wiki/Binary_search_algorithm#The_algorithm
- */
- min = 1;
- max = (int)(sampleRate * .3); /* we assume that this size works 300ms */
- smallestWorkingBufferSize = 0;
-
- do{
- mid = min + ((max - min) / 2);
-
- dsoundBufferSize = mid;
- testResult = playUntilKeyPress( deviceIndex, sampleRate, 0, dsoundBufferSize );
-
- if( testResult == YES ){
- max = mid - 1;
- smallestWorkingBufferSize = dsoundBufferSize;
- }else{
- min = mid + 1;
- }
-
- }while( (min <= max) && (testResult == YES || testResult == NO) );
-
- smallestWorkingBufferingLatencyFrames = smallestWorkingBufferSize; /* not strictly true, but we're using an unspecified callback size, so kind of */
-
- printf( "Smallest working buffer size is: %d\n", smallestWorkingBufferSize );
- printf( "Corresponding to buffering latency of %d frames, or %f seconds.\n", smallestWorkingBufferingLatencyFrames, smallestWorkingBufferingLatencyFrames / sampleRate );
-
- fprintf( resultsFp, "%d, %d, %f\n", smallestWorkingBufferSize, smallestWorkingBufferingLatencyFrames, smallestWorkingBufferingLatencyFrames / sampleRate );
- fflush( resultsFp );
-
-
- /* power of 2 test. iterate to the smallest power of two that works */
-
- smallestWorkingBufferSize = 0;
- dsoundBufferSize = 64;
-
- do{
- testResult = playUntilKeyPress( deviceIndex, sampleRate, 0, dsoundBufferSize );
-
- if( testResult == YES ){
- smallestWorkingBufferSize = dsoundBufferSize;
- }else{
- dsoundBufferSize *= 2;
- }
-
- }while( (dsoundBufferSize <= (int)(sampleRate * .3)) && testResult == NO );
-
- smallestWorkingBufferingLatencyFrames = smallestWorkingBufferSize; /* not strictly true, but we're using an unspecified callback size, so kind of */
-
- fprintf( resultsFp, "%d, %d, %f\n", smallestWorkingBufferSize, smallestWorkingBufferingLatencyFrames, smallestWorkingBufferingLatencyFrames / sampleRate );
- fflush( resultsFp );
-
-
- fprintf( resultsFp, "###\n" );
- fclose( resultsFp );
-
- Pa_Terminate();
- printf("Test finished.\n");
-
- return err;
-error:
- Pa_Terminate();
- fprintf( stderr, "An error occurred while using the PortAudio stream\n" );
- fprintf( stderr, "Error number: %d\n", err );
- fprintf( stderr, "Error message: %s\n", Pa_GetErrorText( err ) );
- return err;
-}
diff --git a/spaces/amsterdamNLP/contrastive-pairs/results.md b/spaces/amsterdamNLP/contrastive-pairs/results.md
deleted file mode 100644
index 07559d9293a79dbbc00e18137fbdf7c74afed2fb..0000000000000000000000000000000000000000
--- a/spaces/amsterdamNLP/contrastive-pairs/results.md
+++ /dev/null
@@ -1,9 +0,0 @@
-### Results for French and English language models
-BERT is another popular type of language model, and CrowS-Pairs has originally been designed for BERT instead of GPT-2.
-Here you can find the results for two languages, English and French, from the authors of [the extended version of CrowS-Pairs](https://aclanthology.org/2022.acl-long.583.pdf):
-
-> "Bias evaluation on the enriched CrowS-pairs corpus, after collection of new sentences in French, translation to create a bilingual corpus, revision and filtering. A score of 50 indicates an absence of bias. **Higher scores indicate stronger preference for biased sentences.**"
-
-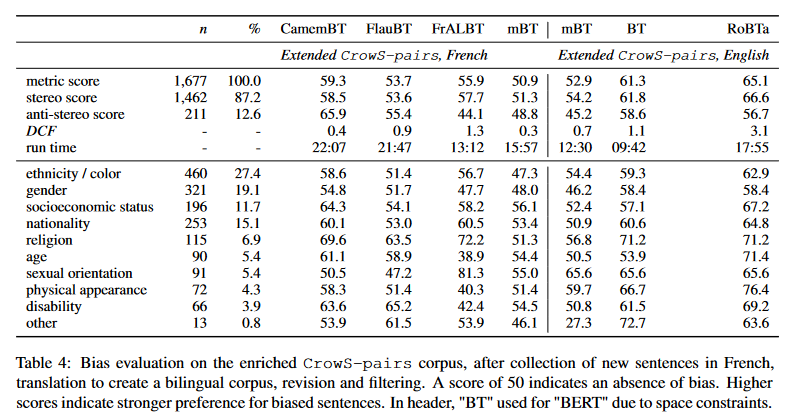
-
-
diff --git a/spaces/andreishagin/Class_modify/app.py b/spaces/andreishagin/Class_modify/app.py
deleted file mode 100644
index d31d042cee1426e06e616689e05861b81b6bae51..0000000000000000000000000000000000000000
--- a/spaces/andreishagin/Class_modify/app.py
+++ /dev/null
@@ -1,63 +0,0 @@
-import streamlit as st
-import eda
-import prediction
-
-st.markdown(" Hotel reservation cancellation prediction model + EDA
", unsafe_allow_html=True)
-st.markdown("You will find below a selection for the EDA or ML prediction model.")
-st.markdown("**EDA:** Here you can explore a brief analysis of data.")
-st.markdown("**ML Prediction model:** Here you can choose parameters and make predictions with probability to check if the client will cancel the booking or not.")
-navigation = st.selectbox('Select EDA or ML Prediction model', ('EDA', 'ML Prediction model'))
-
-if navigation == 'EDA' :
- st.markdown("The online hotel reservation channels have dramatically changed booking possibilities and customers’ behavior. \
- A significant number of hotel reservations are called off due to cancellations or no-shows. \
- The typical reasons for cancellations include changes of plans, scheduling conflicts, etc. \
- This is often made easier by the option to do so free of charge or preferably at a low cost, \
- which is beneficial to hotel guests but it is a less desirable and possibly revenue-diminishing factor for hotels to deal with.")
- agree = st.checkbox('Click here to see the data description.')
- if agree:
- st.markdown("Data Dictionary: \n\
- * no_of_adults: Number of adults \n\
- * no_of_children: Number of Children \n\
- * type_of_meal_plan: Type of meal plan booked by the customer: 'breakfast', 'Not Selected', 'half board', 'full board' \n\
- * required_car_parking_space: Does the customer require a car parking space? (0 - No, 1- Yes) \n\
- * room_type_reserved: 'economy', 'standart', 'deluxe' \n\
- * lead_time: Number of days between the date of booking and the arrival date \n\
- * arrival_month: Month of arrival date \n\
- * arrival_date: Date of the month \n\
- * market_segment_type: Market segment designation ('Offline', 'Online', 'Corporate', 'Aviation') \n\
- * repeated_guest: Is the customer a repeated guest? (0 - No, 1- Yes) \n\
- * no_of_previous_cancellations: Number of previous bookings that were canceled by the customer prior to the current booking \n\
- * no_of_previous_bookings_not_canceled: Number of previous bookings not canceled by the customer prior to the current booking \n\
- * avg_price_per_room: Average price per day of the reservation; prices of the rooms are dynamic. (in euros) \n\
- * no_of_special_requests: Total number of special requests made by the customer (e.g. high floor, view from the room, etc) \n\
- * booking_status (target variable): Flag indicating if the booking was canceled or not.")
- eda.run()
-
-else:
- st.markdown("The online hotel reservation channels have dramatically changed booking possibilities and customers’ behavior. \
- A significant number of hotel reservations are called off due to cancellations or no-shows. \
- The typical reasons for cancellations include changes of plans, scheduling conflicts, etc. \
- This is often made easier by the option to do so free of charge or preferably at a low cost, \
- which is beneficial to hotel guests but it is a less desirable and possibly revenue-diminishing factor for hotels to deal with.")
- st.markdown("**Main goal:** Make a model so that hotels can define conditions of cancellation policies based on different \
- features in order to maximize the number of bookings by customers with a lower probability of cancellation.")
- agree = st.checkbox('Click here to see the data description.')
- if agree:
- st.markdown("Data Dictionary: \n\
- * no_of_adults: Number of adults \n\
- * no_of_children: Number of Children \n\
- * type_of_meal_plan: Type of meal plan booked by the customer: 'breakfast', 'Not Selected', 'half board', 'full board' \n\
- * required_car_parking_space: Does the customer require a car parking space? (0 - No, 1- Yes) \n\
- * room_type_reserved: 'economy', 'standart', 'deluxe' \n\
- * lead_time: Number of days between the date of booking and the arrival date \n\
- * arrival_month: Month of arrival date \n\
- * arrival_date: Date of the month \n\
- * market_segment_type: Market segment designation ('Offline', 'Online', 'Corporate', 'Aviation') \n\
- * repeated_guest: Is the customer a repeated guest? (0 - No, 1- Yes) \n\
- * no_of_previous_cancellations: Number of previous bookings that were canceled by the customer prior to the current booking \n\
- * no_of_previous_bookings_not_canceled: Number of previous bookings not canceled by the customer prior to the current booking \n\
- * avg_price_per_room: Average price per day of the reservation; prices of the rooms are dynamic. (in euros) \n\
- * no_of_special_requests: Total number of special requests made by the customer (e.g. high floor, view from the room, etc) \n\
- * booking_status (target variable): Flag indicating if the booking was canceled or not.")
- prediction.run()
diff --git a/spaces/anirudhmittal/humour-detection/app.py b/spaces/anirudhmittal/humour-detection/app.py
deleted file mode 100644
index 69a2d61fd5707ad7fcc56b16ab7517df0f838e4b..0000000000000000000000000000000000000000
--- a/spaces/anirudhmittal/humour-detection/app.py
+++ /dev/null
@@ -1,96 +0,0 @@
-import gradio as gr
-import tensorflow
-import keras
-import torch
-import numpy as np
-import glob, os
-from os import path
-import pickle as pkl
-from transformers import BertTokenizer, BertModel #RobertaTokenizer, RobertaModel, XLMRobertaTokenizer, TFXLMRobertaModel
-from keras import layers
-from tensorflow.keras.utils import to_categorical
-from keras.models import Sequential
-from keras.layers import Dense, Flatten, Dropout, Input, Bidirectional, LSTM, Activation, TimeDistributed, BatchNormalization
-from sklearn.model_selection import train_test_split
-import tensorflow.keras.backend as K
-model = keras.models.load_model("Onlybert.h5")
-
-tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
-
-def text_features(input_text):
- model_bert = BertModel.from_pretrained('bert-base-uncased', output_hidden_states = True,)
- temp_text = input_text
- lst_text = temp_text.strip().split(' ')
- fin_lst_text = ["[CLS]"]
- for word in lst_text:
- fin_lst_text.append(word)
- fin_text = " ".join(fin_lst_text)
- # print(fin_text)
- tokenized_text = tokenizer.tokenize(fin_text)
- if len(tokenized_text) > 511:
- tokenized_text = tokenized_text[:511]
- tokenized_text.append('[SEP]')
- indexed_tokens = tokenizer.convert_tokens_to_ids(tokenized_text)
- segments_ids = [1] * len(tokenized_text)
- tokens_tensor = torch.tensor([indexed_tokens])
- segments_tensors = torch.tensor([segments_ids])
-
- model_bert = model_bert.eval()
- with torch.no_grad():
- outputs = model_bert(tokens_tensor, segments_tensors)
- hidden_states = outputs[2]
- token_embeddings = torch.stack(hidden_states, dim=0)
- token_embeddings = torch.squeeze(token_embeddings, dim=1)
- token_embeddings = token_embeddings.permute(1,0,2)
- token_vecs_sum = []
- for token in token_embeddings:
- # `token` is a [12 x 768] tensor
- # Sum the vectors from the last four layers.
- sum_vec = torch.sum(token[-4:], dim=0)
- sum_vec_np = sum_vec.numpy()
- # Use `sum_vec` to represent `token`.
- token_vecs_sum.append(sum_vec_np)
- if len(token_vecs_sum) < 512:
- for j in range(512-len(token_vecs_sum)):
- padding_vec = np.zeros(768) #change to 1024 in large models
- token_vecs_sum.append(padding_vec)
- return token_vecs_sum
-
-
-
-
-
-
-
-
-
-def greet(name):
-
- token_vecs_sums=[]
- token_vecs_sums.append(text_features(name))
- # sampleaud = K.constant(audioembeddingss)
- samplebert = K.constant(token_vecs_sums)
- samplescore = K.constant(0)
- Z = model.predict([samplebert])
- # print(Y)
- # print(y_encoded_test)
- Zclass = np.argmax(Z, axis=-1)
- Zclasstrue = np.argmax(samplescore, axis=-1)
- if Zclass == 0:
- out= "Not funny (0)"
- elif Zclass == 1:
- out= "Slightly funny only (1)"
- elif Zclass == 2:
- out= "Midly funny :) (2)"
- elif Zclass == 3:
- out= "Hahaha. Very funny. (3)"
- elif Zclass == 4:
- out= "Absolutely funny. LMAO. (4)"
-
-
- return out
-
-examples=[["Does anybody else secretly hope that Kanye pulls, like a… Mrs. Doubtfire? They come home one day, and they’re like, “This is the new housekeeper,” and he’s like, “What’s up, fam?” Yeah, it’s a really weird thing to go through. There’s because you know, people try to give you advice, but even friends that are older, they’re like, “I don’t… know.” He’s like, “It looks pretty bad, bro, I hope… Good luck, sorry, here if you need,” but like, no advice. No one was like, “This is what you do.” Everyone was like, “I don’t know… yeah. You staying with your mom? You in a safe spot?” People ask me weird questions. So that’s the only thing I don’t like. They ask this weird stuff. Like the other day, somebody came up to me and was like, “I heard you’re friends with Jack Harlow!” And I am. He’s a very great, talented rapper. He’s a cool dude. Nice guy. So we’re pals, right? And Kanye put him on his new album. Even though I’ve been friends with him for like two, three years, you know, he did it anyway. People come up to me and they’re like, “How does that make you feel? Does that bother you? Does that get under your skin?” And I’m like, “No, he’s a rapper.” That’s his field, that’s what they do. That doesn’t hurt my feelings. It would hurt my feelings if I saw, like, Bill Burr at Sunday service. I’d be like, “What the fuck, Bill?” He’d be like, “Find God, Petey, go fuck yourself! Jesus!” Yeah, I don’t get it. A lot of people are very angry. It’s always 5050 when I go outside. Yeah, it is. It’s always 5050. Either someone’s just like, “Hey, man, you’re really cool, that’s great.” Or someone’s like, “Hey, yo! Fuck you! Fuck you! Yeah, you!” I always am like, “Can’t be me."]]
-# print(greet("Does anybody else secretly hope that Kanye pulls, like a… Mrs. Doubtfire? They come home one day, and they’re like, “This is the new housekeeper,” and he’s like, “What’s up, fam?” Yeah, it’s a really weird thing to go through. There’s because you know, people try to give you advice, but even friends that are older, they’re like, “I don’t… know.” He’s like, “It looks pretty bad, bro, I hope… Good luck, sorry, here if you need,” but like, no advice. No one was like, “This is what you do.” Everyone was like, “I don’t know… yeah. You staying with your mom? You in a safe spot?” People ask me weird questions. So that’s the only thing I don’t like. They ask this weird stuff. Like the other day, somebody came up to me and was like, “I heard you’re friends with Jack Harlow!” And I am. He’s a very great, talented rapper. He’s a cool dude. Nice guy. So we’re pals, right? And Kanye put him on his new album. Even though I’ve been friends with him for like two, three years, you know, he did it anyway. People come up to me and they’re like, “How does that make you feel? Does that bother you? Does that get under your skin?” And I’m like, “No, he’s a rapper.” That’s his field, that’s what they do. That doesn’t hurt my feelings. It would hurt my feelings if I saw, like, Bill Burr at Sunday service. I’d be like, “What the fuck, Bill?” He’d be like, “Find God, Petey, go fuck yourself! Jesus!” Yeah, I don’t get it. A lot of people are very angry. It’s always 5050 when I go outside. Yeah, it is. It’s always 5050. Either someone’s just like, “Hey, man, you’re really cool, that’s great.” Or someone’s like, “Hey, yo! Fuck you! Fuck you! Yeah, you!” I always am like, “Can’t be me.”"))
-demo = gr.Interface(fn=greet, inputs=gr.Textbox(lines=1, placeholder="Enter text here"),title="Automatic funniness checker (0 to 4)", description="This model helps you check if you're funny. Add text here and see how funny you're!", outputs="text")
-demo.launch()
\ No newline at end of file
diff --git a/spaces/antonovmaxim/text-generation-webui-space/text-generation-webui-main/modules/logging_colors.py b/spaces/antonovmaxim/text-generation-webui-space/text-generation-webui-main/modules/logging_colors.py
deleted file mode 100644
index 5485b0901677fbab117015097f3af78401ae3419..0000000000000000000000000000000000000000
--- a/spaces/antonovmaxim/text-generation-webui-space/text-generation-webui-main/modules/logging_colors.py
+++ /dev/null
@@ -1,107 +0,0 @@
-# Copied from https://stackoverflow.com/a/1336640
-
-import logging
-
-def add_coloring_to_emit_windows(fn):
- # add methods we need to the class
- def _out_handle(self):
- import ctypes
- return ctypes.windll.kernel32.GetStdHandle(self.STD_OUTPUT_HANDLE)
- out_handle = property(_out_handle)
-
- def _set_color(self, code):
- import ctypes
- # Constants from the Windows API
- self.STD_OUTPUT_HANDLE = -11
- hdl = ctypes.windll.kernel32.GetStdHandle(self.STD_OUTPUT_HANDLE)
- ctypes.windll.kernel32.SetConsoleTextAttribute(hdl, code)
-
- setattr(logging.StreamHandler, '_set_color', _set_color)
-
- def new(*args):
- FOREGROUND_BLUE = 0x0001 # text color contains blue.
- FOREGROUND_GREEN = 0x0002 # text color contains green.
- FOREGROUND_RED = 0x0004 # text color contains red.
- FOREGROUND_INTENSITY = 0x0008 # text color is intensified.
- FOREGROUND_WHITE = FOREGROUND_BLUE | FOREGROUND_GREEN | FOREGROUND_RED
- # winbase.h
- # STD_INPUT_HANDLE = -10
- # STD_OUTPUT_HANDLE = -11
- # STD_ERROR_HANDLE = -12
-
- # wincon.h
- # FOREGROUND_BLACK = 0x0000
- FOREGROUND_BLUE = 0x0001
- FOREGROUND_GREEN = 0x0002
- # FOREGROUND_CYAN = 0x0003
- FOREGROUND_RED = 0x0004
- FOREGROUND_MAGENTA = 0x0005
- FOREGROUND_YELLOW = 0x0006
- # FOREGROUND_GREY = 0x0007
- FOREGROUND_INTENSITY = 0x0008 # foreground color is intensified.
-
- # BACKGROUND_BLACK = 0x0000
- # BACKGROUND_BLUE = 0x0010
- # BACKGROUND_GREEN = 0x0020
- # BACKGROUND_CYAN = 0x0030
- # BACKGROUND_RED = 0x0040
- # BACKGROUND_MAGENTA = 0x0050
- BACKGROUND_YELLOW = 0x0060
- # BACKGROUND_GREY = 0x0070
- BACKGROUND_INTENSITY = 0x0080 # background color is intensified.
-
- levelno = args[1].levelno
- if (levelno >= 50):
- color = BACKGROUND_YELLOW | FOREGROUND_RED | FOREGROUND_INTENSITY | BACKGROUND_INTENSITY
- elif (levelno >= 40):
- color = FOREGROUND_RED | FOREGROUND_INTENSITY
- elif (levelno >= 30):
- color = FOREGROUND_YELLOW | FOREGROUND_INTENSITY
- elif (levelno >= 20):
- color = FOREGROUND_GREEN
- elif (levelno >= 10):
- color = FOREGROUND_MAGENTA
- else:
- color = FOREGROUND_WHITE
- args[0]._set_color(color)
-
- ret = fn(*args)
- args[0]._set_color(FOREGROUND_WHITE)
- # print "after"
- return ret
- return new
-
-
-def add_coloring_to_emit_ansi(fn):
- # add methods we need to the class
- def new(*args):
- levelno = args[1].levelno
- if (levelno >= 50):
- color = '\x1b[31m' # red
- elif (levelno >= 40):
- color = '\x1b[31m' # red
- elif (levelno >= 30):
- color = '\x1b[33m' # yellow
- elif (levelno >= 20):
- color = '\x1b[32m' # green
- elif (levelno >= 10):
- color = '\x1b[35m' # pink
- else:
- color = '\x1b[0m' # normal
- args[1].msg = color + args[1].msg + '\x1b[0m' # normal
- # print "after"
- return fn(*args)
- return new
-
-
-import platform
-if platform.system() == 'Windows':
- # Windows does not support ANSI escapes and we are using API calls to set the console color
- logging.StreamHandler.emit = add_coloring_to_emit_windows(logging.StreamHandler.emit)
-else:
- # all non-Windows platforms are supporting ANSI escapes so we use them
- logging.StreamHandler.emit = add_coloring_to_emit_ansi(logging.StreamHandler.emit)
- # log = logging.getLogger()
- # log.addFilter(log_filter())
- # //hdlr = logging.StreamHandler()
- # //hdlr.setFormatter(formatter())
diff --git a/spaces/anzorq/hf-spaces-semantic-search/tailwind.config.js b/spaces/anzorq/hf-spaces-semantic-search/tailwind.config.js
deleted file mode 100644
index e3778b4b2bbb49631a65c92fee30e6a0b433dad0..0000000000000000000000000000000000000000
--- a/spaces/anzorq/hf-spaces-semantic-search/tailwind.config.js
+++ /dev/null
@@ -1,19 +0,0 @@
-/** @type {import('tailwindcss').Config} */
-module.exports = {
- content: [
- './pages/**/*.{js,ts,jsx,tsx,mdx}',
- './components/**/*.{js,ts,jsx,tsx,mdx}',
- './app/**/*.{js,ts,jsx,tsx,mdx}',
- ],
- theme: {
- extend: {
- backgroundImage: {
- 'gradient-radial': 'radial-gradient(var(--tw-gradient-stops))',
- 'gradient-conic':
- 'conic-gradient(from 180deg at 50% 50%, var(--tw-gradient-stops))',
- },
-
- },
- },
- plugins: [],
-}
diff --git a/spaces/aodianyun/stable-diffusion-webui/extensions/deforum/scripts/deforum_helpers/src/rife/model/pytorch_msssim/__init__.py b/spaces/aodianyun/stable-diffusion-webui/extensions/deforum/scripts/deforum_helpers/src/rife/model/pytorch_msssim/__init__.py
deleted file mode 100644
index a4d30326188cf6afacf2fc84c7ae18efe14dae2e..0000000000000000000000000000000000000000
--- a/spaces/aodianyun/stable-diffusion-webui/extensions/deforum/scripts/deforum_helpers/src/rife/model/pytorch_msssim/__init__.py
+++ /dev/null
@@ -1,200 +0,0 @@
-import torch
-import torch.nn.functional as F
-from math import exp
-import numpy as np
-
-device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
-
-def gaussian(window_size, sigma):
- gauss = torch.Tensor([exp(-(x - window_size//2)**2/float(2*sigma**2)) for x in range(window_size)])
- return gauss/gauss.sum()
-
-
-def create_window(window_size, channel=1):
- _1D_window = gaussian(window_size, 1.5).unsqueeze(1)
- _2D_window = _1D_window.mm(_1D_window.t()).float().unsqueeze(0).unsqueeze(0).to(device)
- window = _2D_window.expand(channel, 1, window_size, window_size).contiguous()
- return window
-
-def create_window_3d(window_size, channel=1):
- _1D_window = gaussian(window_size, 1.5).unsqueeze(1)
- _2D_window = _1D_window.mm(_1D_window.t())
- _3D_window = _2D_window.unsqueeze(2) @ (_1D_window.t())
- window = _3D_window.expand(1, channel, window_size, window_size, window_size).contiguous().to(device)
- return window
-
-
-def ssim(img1, img2, window_size=11, window=None, size_average=True, full=False, val_range=None):
- # Value range can be different from 255. Other common ranges are 1 (sigmoid) and 2 (tanh).
- if val_range is None:
- if torch.max(img1) > 128:
- max_val = 255
- else:
- max_val = 1
-
- if torch.min(img1) < -0.5:
- min_val = -1
- else:
- min_val = 0
- L = max_val - min_val
- else:
- L = val_range
-
- padd = 0
- (_, channel, height, width) = img1.size()
- if window is None:
- real_size = min(window_size, height, width)
- window = create_window(real_size, channel=channel).to(img1.device)
-
- # mu1 = F.conv2d(img1, window, padding=padd, groups=channel)
- # mu2 = F.conv2d(img2, window, padding=padd, groups=channel)
- mu1 = F.conv2d(F.pad(img1, (5, 5, 5, 5), mode='replicate'), window, padding=padd, groups=channel)
- mu2 = F.conv2d(F.pad(img2, (5, 5, 5, 5), mode='replicate'), window, padding=padd, groups=channel)
-
- mu1_sq = mu1.pow(2)
- mu2_sq = mu2.pow(2)
- mu1_mu2 = mu1 * mu2
-
- sigma1_sq = F.conv2d(F.pad(img1 * img1, (5, 5, 5, 5), 'replicate'), window, padding=padd, groups=channel) - mu1_sq
- sigma2_sq = F.conv2d(F.pad(img2 * img2, (5, 5, 5, 5), 'replicate'), window, padding=padd, groups=channel) - mu2_sq
- sigma12 = F.conv2d(F.pad(img1 * img2, (5, 5, 5, 5), 'replicate'), window, padding=padd, groups=channel) - mu1_mu2
-
- C1 = (0.01 * L) ** 2
- C2 = (0.03 * L) ** 2
-
- v1 = 2.0 * sigma12 + C2
- v2 = sigma1_sq + sigma2_sq + C2
- cs = torch.mean(v1 / v2) # contrast sensitivity
-
- ssim_map = ((2 * mu1_mu2 + C1) * v1) / ((mu1_sq + mu2_sq + C1) * v2)
-
- if size_average:
- ret = ssim_map.mean()
- else:
- ret = ssim_map.mean(1).mean(1).mean(1)
-
- if full:
- return ret, cs
- return ret
-
-
-def ssim_matlab(img1, img2, window_size=11, window=None, size_average=True, full=False, val_range=None):
- # Value range can be different from 255. Other common ranges are 1 (sigmoid) and 2 (tanh).
- if val_range is None:
- if torch.max(img1) > 128:
- max_val = 255
- else:
- max_val = 1
-
- if torch.min(img1) < -0.5:
- min_val = -1
- else:
- min_val = 0
- L = max_val - min_val
- else:
- L = val_range
-
- padd = 0
- (_, _, height, width) = img1.size()
- if window is None:
- real_size = min(window_size, height, width)
- window = create_window_3d(real_size, channel=1).to(img1.device)
- # Channel is set to 1 since we consider color images as volumetric images
-
- img1 = img1.unsqueeze(1)
- img2 = img2.unsqueeze(1)
-
- mu1 = F.conv3d(F.pad(img1, (5, 5, 5, 5, 5, 5), mode='replicate'), window, padding=padd, groups=1)
- mu2 = F.conv3d(F.pad(img2, (5, 5, 5, 5, 5, 5), mode='replicate'), window, padding=padd, groups=1)
-
- mu1_sq = mu1.pow(2)
- mu2_sq = mu2.pow(2)
- mu1_mu2 = mu1 * mu2
-
- sigma1_sq = F.conv3d(F.pad(img1 * img1, (5, 5, 5, 5, 5, 5), 'replicate'), window, padding=padd, groups=1) - mu1_sq
- sigma2_sq = F.conv3d(F.pad(img2 * img2, (5, 5, 5, 5, 5, 5), 'replicate'), window, padding=padd, groups=1) - mu2_sq
- sigma12 = F.conv3d(F.pad(img1 * img2, (5, 5, 5, 5, 5, 5), 'replicate'), window, padding=padd, groups=1) - mu1_mu2
-
- C1 = (0.01 * L) ** 2
- C2 = (0.03 * L) ** 2
-
- v1 = 2.0 * sigma12 + C2
- v2 = sigma1_sq + sigma2_sq + C2
- cs = torch.mean(v1 / v2) # contrast sensitivity
-
- ssim_map = ((2 * mu1_mu2 + C1) * v1) / ((mu1_sq + mu2_sq + C1) * v2)
-
- if size_average:
- ret = ssim_map.mean()
- else:
- ret = ssim_map.mean(1).mean(1).mean(1)
-
- if full:
- return ret, cs
- return ret
-
-
-def msssim(img1, img2, window_size=11, size_average=True, val_range=None, normalize=False):
- device = img1.device
- weights = torch.FloatTensor([0.0448, 0.2856, 0.3001, 0.2363, 0.1333]).to(device)
- levels = weights.size()[0]
- mssim = []
- mcs = []
- for _ in range(levels):
- sim, cs = ssim(img1, img2, window_size=window_size, size_average=size_average, full=True, val_range=val_range)
- mssim.append(sim)
- mcs.append(cs)
-
- img1 = F.avg_pool2d(img1, (2, 2))
- img2 = F.avg_pool2d(img2, (2, 2))
-
- mssim = torch.stack(mssim)
- mcs = torch.stack(mcs)
-
- # Normalize (to avoid NaNs during training unstable models, not compliant with original definition)
- if normalize:
- mssim = (mssim + 1) / 2
- mcs = (mcs + 1) / 2
-
- pow1 = mcs ** weights
- pow2 = mssim ** weights
- # From Matlab implementation https://ece.uwaterloo.ca/~z70wang/research/iwssim/
- output = torch.prod(pow1[:-1] * pow2[-1])
- return output
-
-
-# Classes to re-use window
-class SSIM(torch.nn.Module):
- def __init__(self, window_size=11, size_average=True, val_range=None):
- super(SSIM, self).__init__()
- self.window_size = window_size
- self.size_average = size_average
- self.val_range = val_range
-
- # Assume 3 channel for SSIM
- self.channel = 3
- self.window = create_window(window_size, channel=self.channel)
-
- def forward(self, img1, img2):
- (_, channel, _, _) = img1.size()
-
- if channel == self.channel and self.window.dtype == img1.dtype:
- window = self.window
- else:
- window = create_window(self.window_size, channel).to(img1.device).type(img1.dtype)
- self.window = window
- self.channel = channel
-
- _ssim = ssim(img1, img2, window=window, window_size=self.window_size, size_average=self.size_average)
- dssim = (1 - _ssim) / 2
- return dssim
-
-class MSSSIM(torch.nn.Module):
- def __init__(self, window_size=11, size_average=True, channel=3):
- super(MSSSIM, self).__init__()
- self.window_size = window_size
- self.size_average = size_average
- self.channel = channel
-
- def forward(self, img1, img2):
- return msssim(img1, img2, window_size=self.window_size, size_average=self.size_average)
diff --git a/spaces/aphenx/bingo/src/pages/api/kblob.ts b/spaces/aphenx/bingo/src/pages/api/kblob.ts
deleted file mode 100644
index 0ce7e6063cdc06838e76f1cff1d5982d34ef52de..0000000000000000000000000000000000000000
--- a/spaces/aphenx/bingo/src/pages/api/kblob.ts
+++ /dev/null
@@ -1,56 +0,0 @@
-'use server'
-
-import { NextApiRequest, NextApiResponse } from 'next'
-import FormData from 'form-data'
-import { fetch } from '@/lib/isomorphic'
-import { KBlobRequest } from '@/lib/bots/bing/types'
-
-const API_DOMAIN = 'https://bing.vcanbb.top'
-
-export const config = {
- api: {
- bodyParser: {
- sizeLimit: '10mb' // Set desired value here
- }
- }
-}
-
-export default async function handler(req: NextApiRequest, res: NextApiResponse) {
- try {
- const { knowledgeRequest, imageBase64 } = req.body as KBlobRequest
-
- const formData = new FormData()
- formData.append('knowledgeRequest', JSON.stringify(knowledgeRequest))
- if (imageBase64) {
- formData.append('imageBase64', imageBase64)
- }
-
- const response = await fetch(`${API_DOMAIN}/images/kblob`,
- {
- method: 'POST',
- body: formData.getBuffer(),
- headers: {
- "sec-ch-ua": "\"Not/A)Brand\";v=\"99\", \"Google Chrome\";v=\"115\", \"Chromium\";v=\"115\"",
- "sec-ch-ua-mobile": "?0",
- "sec-ch-ua-platform": "\"Windows\"",
- "Referer": `${API_DOMAIN}/web/index.html`,
- "Referrer-Policy": "origin-when-cross-origin",
- 'x-ms-useragent': 'azsdk-js-api-client-factory/1.0.0-beta.1 core-rest-pipeline/1.10.0 OS/Win32',
- ...formData.getHeaders()
- }
- }
- ).then(res => res.text())
-
- res.writeHead(200, {
- 'Content-Type': 'application/json',
- })
- res.end(response || JSON.stringify({ result: { value: 'UploadFailed', message: '请更换 IP 或代理后重试' } }))
- } catch (e) {
- return res.json({
- result: {
- value: 'UploadFailed',
- message: `${e}`
- }
- })
- }
-}
diff --git a/spaces/arpitr/end_to_end_ml_app/app.py b/spaces/arpitr/end_to_end_ml_app/app.py
deleted file mode 100644
index a3017ed2a8b87c235e838dd4a4d744b8a0e048c7..0000000000000000000000000000000000000000
--- a/spaces/arpitr/end_to_end_ml_app/app.py
+++ /dev/null
@@ -1,167 +0,0 @@
-import streamlit as st
-import pandas as pd
-import numpy as np
-from PIL import Image
-from pydataset import data
-from sklearn.model_selection import train_test_split
-from sklearn.metrics import confusion_matrix
-from sklearn.metrics import classification_report
-from sklearn.metrics import accuracy_score
-from sklearn.metrics import precision_recall_fscore_support
-from sklearn.preprocessing import StandardScaler
-from sklearn.linear_model import LinearRegression
-from sklearn.metrics import r2_score,mean_squared_error,mean_absolute_error
-from sklearn.linear_model import LogisticRegression
-from sklearn.svm import SVC
-from sklearn.gaussian_process import GaussianProcessClassifier
-from sklearn.gaussian_process.kernels import RBF
-from sklearn.tree import DecisionTreeClassifier
-from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier
-from sklearn.naive_bayes import GaussianNB
-from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis
-
-#import pandas as pd
-
-st.header('Try end to end predictive modeling on different datasets')
-
-st.info("""
-- Pick the dataset
-- Validate the dataset
-- Prepare the dataset (Impute/Scaling/Categorical Encoding/Imbalance)
-- Pick the Machine Learning Algorithmn
-- Analyse the results (Accuracy, MAE, Recall, Precision, F1)
-""")
-
-class MlStreamlitApp:
-
- def __init__(self):
- self.dataset_list = data()
- #, show_doc=True
- @st.cache(suppress_st_warning=True)
- def load_data(self,dataset_name):
- df = data(str(dataset_name))
- df.columns = df.columns.str.replace('.','_')
- df.columns = df.columns.str.lower()
- return df
-
- '''
- @st.cache(suppress_st_warning=True)
- def show_dataset_doc(self,dataset_name):
- st.write(dataset_name)
- st.code(data('iris',show_doc=True))
- '''
-
- def show_datasets_list(self):
- st.info('Datasets details')
- st.write(self.dataset_list)
-
- def run(self):
- st.sidebar.title('Streamlit ML App')
- dataset_list=['']+list(self.dataset_list.dataset_id)
- dataset_name = st.sidebar.selectbox('Select the Dataset',dataset_list)
- process_selection = st.sidebar.radio("What on your mind?",('EDA', 'Predictive Modelling'))
-
- if dataset_name == '':
- st.sidebar.warning('Select the Dataset')
- self.show_datasets_list()
- elif (dataset_name and process_selection == 'Predictive Modelling'):
- df = self.load_data(dataset_name)
- st.write(df.head())
- #image = Image.open('./ml_process.jpeg')
- #st.sidebar.image(image)
- dataset_target = st.selectbox('Select the Target', list(df.columns))
- df=df.rename(columns={dataset_target:'target'})
-
- df_dum=pd.get_dummies(df.loc[:, df.columns != 'target'],drop_first=True)
- df=pd.concat([df_dum,df.target],axis=1)
-
- #algo_type = st.selectbox('Classification or Regression', list(['Classification','Regression']))
-
- if df.target.dtypes == 'object':
- algo_type='Classification'
- ml_algos = ['LogisticRegression','DecisionTreeClassifier','RandomForestClassifier','AdaBoostClassifier']
- else:
- algo_type='Regression'
- ml_algos = ['LinearRegression']
-
- # if algo_type == 'Classification':
- # ml_algos = ['LogisticRegression','DecisionTreeClassifier','RandomForestClassifier','AdaBoostClassifier']
-
- # else:
- # ml_algos = ['LinearRegression']
-
- X= df.loc[:, df.columns != 'target']
- y= df['target']
-
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=42)
-
- #st.write(X_train.head())
- #st.write(y_test.head())
-
- ml_algo = st.selectbox('Select the ML Algo', list(ml_algos))
-
- if ml_algo == 'LogisticRegression':
- clf_fit = LogisticRegression().fit(X_train, y_train)
- predictions = clf_fit.predict(X_test)
- st.write(predictions[1:5])
- elif ml_algo == 'DecisionTreeClassifier':
- clf_fit = DecisionTreeClassifier().fit(X_train, y_train)
- predictions = clf_fit.predict(X_test)
- st.write(predictions[1:5])
- #RandomForestClassifier
- elif ml_algo == 'RandomForestClassifier':
- clf_fit = RandomForestClassifier().fit(X_train, y_train)
- predictions = clf_fit.predict(X_test)
- st.write(predictions[1:5])
- elif ml_algo == 'AdaBoostClassifier':
- clf_fit = AdaBoostClassifier().fit(X_train, y_train)
- predictions = clf_fit.predict(X_test)
- st.write(predictions[1:5])
- elif ml_algo == 'LinearRegression':
- clf_fit = LinearRegression().fit(X_train, y_train)
- predictions = clf_fit.predict(X_test)
- st.write(predictions[1:5])
- else:
- st.write('No ML Algo selected')
-
- if algo_type=='Classification':
- st.write("""
- Confusion Matrix
- """)
- st.write(confusion_matrix(y_test, predictions))
- st.write("""
- #### Accuracy Score:
- """)
- st.write( accuracy_score(y_test, predictions))
- st.write("""
- #### Other Scores - precision_recall_fscore:
- """)
- precision,recall,f1_score,support=precision_recall_fscore_support(y_test, predictions,average='weighted')
- st.write(round(precision,2),round(recall,2),round(f1_score,2))
- else:
- st.write(""" ### Model Evaluation """)
- r2_metrics = r2_score(y_test, predictions)
- mse = mean_squared_error(y_test, predictions)
- rmse = np.sqrt(mse)
- mae=mean_absolute_error(y_test, predictions)
- st.write(""" #### Rsquared, MSE , RMSE, MAE """)
- st.write(round(r2_metrics,2),round(mse,2),round(rmse,2),round(mae,2))
- else:
- eda_selection = st.sidebar.radio("What you want to see?",('Summary', 'Plots'))
- df = self.load_data(dataset_name)
- if eda_selection == 'Summary':
- st.write("Glimpse of Data",df.head(10))
- st.write("Total No. of Rows",df.shape[0])
- st.write("Total No. of Columns",df.shape[1])
- st.write("Types of Columns",df.dtypes)
- st.write("Summary Stats",df.describe().T)
- st.write("Total Nulls in the columns",df.isnull().sum())
- st.write("Total Duplicate Rows",df[df.duplicated()].shape[0])
- st.write("Correlation Matrix",df.corr())
- else:
- st.info('Plots') #WIP
-
-
-if __name__ == '__main__':
- mlApp = MlStreamlitApp()
- mlApp.run()
\ No newline at end of file
diff --git a/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/Crypto/Math/_IntegerGMP.py b/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/Crypto/Math/_IntegerGMP.py
deleted file mode 100644
index f552b71ad678d6fe760c21071186b831380c570e..0000000000000000000000000000000000000000
--- a/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/Crypto/Math/_IntegerGMP.py
+++ /dev/null
@@ -1,762 +0,0 @@
-# ===================================================================
-#
-# Copyright (c) 2014, Legrandin
-# All rights reserved.
-#
-# Redistribution and use in source and binary forms, with or without
-# modification, are permitted provided that the following conditions
-# are met:
-#
-# 1. Redistributions of source code must retain the above copyright
-# notice, this list of conditions and the following disclaimer.
-# 2. Redistributions in binary form must reproduce the above copyright
-# notice, this list of conditions and the following disclaimer in
-# the documentation and/or other materials provided with the
-# distribution.
-#
-# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
-# "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
-# LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS
-# FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE
-# COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT,
-# INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING,
-# BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
-# LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
-# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT
-# LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN
-# ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE
-# POSSIBILITY OF SUCH DAMAGE.
-# ===================================================================
-
-import sys
-
-from Crypto.Util.py3compat import tobytes, is_native_int
-
-from Crypto.Util._raw_api import (backend, load_lib,
- get_raw_buffer, get_c_string,
- null_pointer, create_string_buffer,
- c_ulong, c_size_t, c_uint8_ptr)
-
-from ._IntegerBase import IntegerBase
-
-gmp_defs = """typedef unsigned long UNIX_ULONG;
- typedef struct { int a; int b; void *c; } MPZ;
- typedef MPZ mpz_t[1];
- typedef UNIX_ULONG mp_bitcnt_t;
-
- void __gmpz_init (mpz_t x);
- void __gmpz_init_set (mpz_t rop, const mpz_t op);
- void __gmpz_init_set_ui (mpz_t rop, UNIX_ULONG op);
-
- UNIX_ULONG __gmpz_get_ui (const mpz_t op);
- void __gmpz_set (mpz_t rop, const mpz_t op);
- void __gmpz_set_ui (mpz_t rop, UNIX_ULONG op);
- void __gmpz_add (mpz_t rop, const mpz_t op1, const mpz_t op2);
- void __gmpz_add_ui (mpz_t rop, const mpz_t op1, UNIX_ULONG op2);
- void __gmpz_sub_ui (mpz_t rop, const mpz_t op1, UNIX_ULONG op2);
- void __gmpz_addmul (mpz_t rop, const mpz_t op1, const mpz_t op2);
- void __gmpz_addmul_ui (mpz_t rop, const mpz_t op1, UNIX_ULONG op2);
- void __gmpz_submul_ui (mpz_t rop, const mpz_t op1, UNIX_ULONG op2);
- void __gmpz_import (mpz_t rop, size_t count, int order, size_t size,
- int endian, size_t nails, const void *op);
- void * __gmpz_export (void *rop, size_t *countp, int order,
- size_t size,
- int endian, size_t nails, const mpz_t op);
- size_t __gmpz_sizeinbase (const mpz_t op, int base);
- void __gmpz_sub (mpz_t rop, const mpz_t op1, const mpz_t op2);
- void __gmpz_mul (mpz_t rop, const mpz_t op1, const mpz_t op2);
- void __gmpz_mul_ui (mpz_t rop, const mpz_t op1, UNIX_ULONG op2);
- int __gmpz_cmp (const mpz_t op1, const mpz_t op2);
- void __gmpz_powm (mpz_t rop, const mpz_t base, const mpz_t exp, const
- mpz_t mod);
- void __gmpz_powm_ui (mpz_t rop, const mpz_t base, UNIX_ULONG exp,
- const mpz_t mod);
- void __gmpz_pow_ui (mpz_t rop, const mpz_t base, UNIX_ULONG exp);
- void __gmpz_sqrt(mpz_t rop, const mpz_t op);
- void __gmpz_mod (mpz_t r, const mpz_t n, const mpz_t d);
- void __gmpz_neg (mpz_t rop, const mpz_t op);
- void __gmpz_abs (mpz_t rop, const mpz_t op);
- void __gmpz_and (mpz_t rop, const mpz_t op1, const mpz_t op2);
- void __gmpz_ior (mpz_t rop, const mpz_t op1, const mpz_t op2);
- void __gmpz_clear (mpz_t x);
- void __gmpz_tdiv_q_2exp (mpz_t q, const mpz_t n, mp_bitcnt_t b);
- void __gmpz_fdiv_q (mpz_t q, const mpz_t n, const mpz_t d);
- void __gmpz_mul_2exp (mpz_t rop, const mpz_t op1, mp_bitcnt_t op2);
- int __gmpz_tstbit (const mpz_t op, mp_bitcnt_t bit_index);
- int __gmpz_perfect_square_p (const mpz_t op);
- int __gmpz_jacobi (const mpz_t a, const mpz_t b);
- void __gmpz_gcd (mpz_t rop, const mpz_t op1, const mpz_t op2);
- UNIX_ULONG __gmpz_gcd_ui (mpz_t rop, const mpz_t op1,
- UNIX_ULONG op2);
- void __gmpz_lcm (mpz_t rop, const mpz_t op1, const mpz_t op2);
- int __gmpz_invert (mpz_t rop, const mpz_t op1, const mpz_t op2);
- int __gmpz_divisible_p (const mpz_t n, const mpz_t d);
- int __gmpz_divisible_ui_p (const mpz_t n, UNIX_ULONG d);
- """
-
-if sys.platform == "win32":
- raise ImportError("Not using GMP on Windows")
-
-lib = load_lib("gmp", gmp_defs)
-implementation = {"library": "gmp", "api": backend}
-
-if hasattr(lib, "__mpir_version"):
- raise ImportError("MPIR library detected")
-
-# In order to create a function that returns a pointer to
-# a new MPZ structure, we need to break the abstraction
-# and know exactly what ffi backend we have
-if implementation["api"] == "ctypes":
- from ctypes import Structure, c_int, c_void_p, byref
-
- class _MPZ(Structure):
- _fields_ = [('_mp_alloc', c_int),
- ('_mp_size', c_int),
- ('_mp_d', c_void_p)]
-
- def new_mpz():
- return byref(_MPZ())
-
-else:
- # We are using CFFI
- from Crypto.Util._raw_api import ffi
-
- def new_mpz():
- return ffi.new("MPZ*")
-
-
-# Lazy creation of GMP methods
-class _GMP(object):
-
- def __getattr__(self, name):
- if name.startswith("mpz_"):
- func_name = "__gmpz_" + name[4:]
- elif name.startswith("gmp_"):
- func_name = "__gmp_" + name[4:]
- else:
- raise AttributeError("Attribute %s is invalid" % name)
- func = getattr(lib, func_name)
- setattr(self, name, func)
- return func
-
-
-_gmp = _GMP()
-
-
-class IntegerGMP(IntegerBase):
- """A fast, arbitrary precision integer"""
-
- _zero_mpz_p = new_mpz()
- _gmp.mpz_init_set_ui(_zero_mpz_p, c_ulong(0))
-
- def __init__(self, value):
- """Initialize the integer to the given value."""
-
- self._mpz_p = new_mpz()
- self._initialized = False
-
- if isinstance(value, float):
- raise ValueError("A floating point type is not a natural number")
-
- if is_native_int(value):
- _gmp.mpz_init(self._mpz_p)
- self._initialized = True
- if value == 0:
- return
-
- tmp = new_mpz()
- _gmp.mpz_init(tmp)
-
- try:
- positive = value >= 0
- reduce = abs(value)
- slots = (reduce.bit_length() - 1) // 32 + 1
-
- while slots > 0:
- slots = slots - 1
- _gmp.mpz_set_ui(tmp,
- c_ulong(0xFFFFFFFF & (reduce >> (slots * 32))))
- _gmp.mpz_mul_2exp(tmp, tmp, c_ulong(slots * 32))
- _gmp.mpz_add(self._mpz_p, self._mpz_p, tmp)
- finally:
- _gmp.mpz_clear(tmp)
-
- if not positive:
- _gmp.mpz_neg(self._mpz_p, self._mpz_p)
-
- elif isinstance(value, IntegerGMP):
- _gmp.mpz_init_set(self._mpz_p, value._mpz_p)
- self._initialized = True
- else:
- raise NotImplementedError
-
-
- # Conversions
- def __int__(self):
- tmp = new_mpz()
- _gmp.mpz_init_set(tmp, self._mpz_p)
-
- try:
- value = 0
- slot = 0
- while _gmp.mpz_cmp(tmp, self._zero_mpz_p) != 0:
- lsb = _gmp.mpz_get_ui(tmp) & 0xFFFFFFFF
- value |= lsb << (slot * 32)
- _gmp.mpz_tdiv_q_2exp(tmp, tmp, c_ulong(32))
- slot = slot + 1
- finally:
- _gmp.mpz_clear(tmp)
-
- if self < 0:
- value = -value
- return int(value)
-
- def __str__(self):
- return str(int(self))
-
- def __repr__(self):
- return "Integer(%s)" % str(self)
-
- # Only Python 2.x
- def __hex__(self):
- return hex(int(self))
-
- # Only Python 3.x
- def __index__(self):
- return int(self)
-
- def to_bytes(self, block_size=0, byteorder='big'):
- """Convert the number into a byte string.
-
- This method encodes the number in network order and prepends
- as many zero bytes as required. It only works for non-negative
- values.
-
- :Parameters:
- block_size : integer
- The exact size the output byte string must have.
- If zero, the string has the minimal length.
- byteorder : string
- 'big' for big-endian integers (default), 'little' for litte-endian.
- :Returns:
- A byte string.
- :Raise ValueError:
- If the value is negative or if ``block_size`` is
- provided and the length of the byte string would exceed it.
- """
-
- if self < 0:
- raise ValueError("Conversion only valid for non-negative numbers")
-
- buf_len = (_gmp.mpz_sizeinbase(self._mpz_p, 2) + 7) // 8
- if buf_len > block_size > 0:
- raise ValueError("Number is too big to convert to byte string"
- " of prescribed length")
- buf = create_string_buffer(buf_len)
-
-
- _gmp.mpz_export(
- buf,
- null_pointer, # Ignore countp
- 1, # Big endian
- c_size_t(1), # Each word is 1 byte long
- 0, # Endianess within a word - not relevant
- c_size_t(0), # No nails
- self._mpz_p)
-
- result = b'\x00' * max(0, block_size - buf_len) + get_raw_buffer(buf)
- if byteorder == 'big':
- pass
- elif byteorder == 'little':
- result = bytearray(result)
- result.reverse()
- result = bytes(result)
- else:
- raise ValueError("Incorrect byteorder")
- return result
-
- @staticmethod
- def from_bytes(byte_string, byteorder='big'):
- """Convert a byte string into a number.
-
- :Parameters:
- byte_string : byte string
- The input number, encoded in network order.
- It can only be non-negative.
- byteorder : string
- 'big' for big-endian integers (default), 'little' for litte-endian.
-
- :Return:
- The ``Integer`` object carrying the same value as the input.
- """
- result = IntegerGMP(0)
- if byteorder == 'big':
- pass
- elif byteorder == 'little':
- byte_string = bytearray(byte_string)
- byte_string.reverse()
- else:
- raise ValueError("Incorrect byteorder")
- _gmp.mpz_import(
- result._mpz_p,
- c_size_t(len(byte_string)), # Amount of words to read
- 1, # Big endian
- c_size_t(1), # Each word is 1 byte long
- 0, # Endianess within a word - not relevant
- c_size_t(0), # No nails
- c_uint8_ptr(byte_string))
- return result
-
- # Relations
- def _apply_and_return(self, func, term):
- if not isinstance(term, IntegerGMP):
- term = IntegerGMP(term)
- return func(self._mpz_p, term._mpz_p)
-
- def __eq__(self, term):
- if not (isinstance(term, IntegerGMP) or is_native_int(term)):
- return False
- return self._apply_and_return(_gmp.mpz_cmp, term) == 0
-
- def __ne__(self, term):
- if not (isinstance(term, IntegerGMP) or is_native_int(term)):
- return True
- return self._apply_and_return(_gmp.mpz_cmp, term) != 0
-
- def __lt__(self, term):
- return self._apply_and_return(_gmp.mpz_cmp, term) < 0
-
- def __le__(self, term):
- return self._apply_and_return(_gmp.mpz_cmp, term) <= 0
-
- def __gt__(self, term):
- return self._apply_and_return(_gmp.mpz_cmp, term) > 0
-
- def __ge__(self, term):
- return self._apply_and_return(_gmp.mpz_cmp, term) >= 0
-
- def __nonzero__(self):
- return _gmp.mpz_cmp(self._mpz_p, self._zero_mpz_p) != 0
- __bool__ = __nonzero__
-
- def is_negative(self):
- return _gmp.mpz_cmp(self._mpz_p, self._zero_mpz_p) < 0
-
- # Arithmetic operations
- def __add__(self, term):
- result = IntegerGMP(0)
- if not isinstance(term, IntegerGMP):
- try:
- term = IntegerGMP(term)
- except NotImplementedError:
- return NotImplemented
- _gmp.mpz_add(result._mpz_p,
- self._mpz_p,
- term._mpz_p)
- return result
-
- def __sub__(self, term):
- result = IntegerGMP(0)
- if not isinstance(term, IntegerGMP):
- try:
- term = IntegerGMP(term)
- except NotImplementedError:
- return NotImplemented
- _gmp.mpz_sub(result._mpz_p,
- self._mpz_p,
- term._mpz_p)
- return result
-
- def __mul__(self, term):
- result = IntegerGMP(0)
- if not isinstance(term, IntegerGMP):
- try:
- term = IntegerGMP(term)
- except NotImplementedError:
- return NotImplemented
- _gmp.mpz_mul(result._mpz_p,
- self._mpz_p,
- term._mpz_p)
- return result
-
- def __floordiv__(self, divisor):
- if not isinstance(divisor, IntegerGMP):
- divisor = IntegerGMP(divisor)
- if _gmp.mpz_cmp(divisor._mpz_p,
- self._zero_mpz_p) == 0:
- raise ZeroDivisionError("Division by zero")
- result = IntegerGMP(0)
- _gmp.mpz_fdiv_q(result._mpz_p,
- self._mpz_p,
- divisor._mpz_p)
- return result
-
- def __mod__(self, divisor):
- if not isinstance(divisor, IntegerGMP):
- divisor = IntegerGMP(divisor)
- comp = _gmp.mpz_cmp(divisor._mpz_p,
- self._zero_mpz_p)
- if comp == 0:
- raise ZeroDivisionError("Division by zero")
- if comp < 0:
- raise ValueError("Modulus must be positive")
- result = IntegerGMP(0)
- _gmp.mpz_mod(result._mpz_p,
- self._mpz_p,
- divisor._mpz_p)
- return result
-
- def inplace_pow(self, exponent, modulus=None):
-
- if modulus is None:
- if exponent < 0:
- raise ValueError("Exponent must not be negative")
-
- # Normal exponentiation
- if exponent > 256:
- raise ValueError("Exponent is too big")
- _gmp.mpz_pow_ui(self._mpz_p,
- self._mpz_p, # Base
- c_ulong(int(exponent))
- )
- else:
- # Modular exponentiation
- if not isinstance(modulus, IntegerGMP):
- modulus = IntegerGMP(modulus)
- if not modulus:
- raise ZeroDivisionError("Division by zero")
- if modulus.is_negative():
- raise ValueError("Modulus must be positive")
- if is_native_int(exponent):
- if exponent < 0:
- raise ValueError("Exponent must not be negative")
- if exponent < 65536:
- _gmp.mpz_powm_ui(self._mpz_p,
- self._mpz_p,
- c_ulong(exponent),
- modulus._mpz_p)
- return self
- exponent = IntegerGMP(exponent)
- elif exponent.is_negative():
- raise ValueError("Exponent must not be negative")
- _gmp.mpz_powm(self._mpz_p,
- self._mpz_p,
- exponent._mpz_p,
- modulus._mpz_p)
- return self
-
- def __pow__(self, exponent, modulus=None):
- result = IntegerGMP(self)
- return result.inplace_pow(exponent, modulus)
-
- def __abs__(self):
- result = IntegerGMP(0)
- _gmp.mpz_abs(result._mpz_p, self._mpz_p)
- return result
-
- def sqrt(self, modulus=None):
- """Return the largest Integer that does not
- exceed the square root"""
-
- if modulus is None:
- if self < 0:
- raise ValueError("Square root of negative value")
- result = IntegerGMP(0)
- _gmp.mpz_sqrt(result._mpz_p,
- self._mpz_p)
- else:
- if modulus <= 0:
- raise ValueError("Modulus must be positive")
- modulus = int(modulus)
- result = IntegerGMP(self._tonelli_shanks(int(self) % modulus, modulus))
-
- return result
-
- def __iadd__(self, term):
- if is_native_int(term):
- if 0 <= term < 65536:
- _gmp.mpz_add_ui(self._mpz_p,
- self._mpz_p,
- c_ulong(term))
- return self
- if -65535 < term < 0:
- _gmp.mpz_sub_ui(self._mpz_p,
- self._mpz_p,
- c_ulong(-term))
- return self
- term = IntegerGMP(term)
- _gmp.mpz_add(self._mpz_p,
- self._mpz_p,
- term._mpz_p)
- return self
-
- def __isub__(self, term):
- if is_native_int(term):
- if 0 <= term < 65536:
- _gmp.mpz_sub_ui(self._mpz_p,
- self._mpz_p,
- c_ulong(term))
- return self
- if -65535 < term < 0:
- _gmp.mpz_add_ui(self._mpz_p,
- self._mpz_p,
- c_ulong(-term))
- return self
- term = IntegerGMP(term)
- _gmp.mpz_sub(self._mpz_p,
- self._mpz_p,
- term._mpz_p)
- return self
-
- def __imul__(self, term):
- if is_native_int(term):
- if 0 <= term < 65536:
- _gmp.mpz_mul_ui(self._mpz_p,
- self._mpz_p,
- c_ulong(term))
- return self
- if -65535 < term < 0:
- _gmp.mpz_mul_ui(self._mpz_p,
- self._mpz_p,
- c_ulong(-term))
- _gmp.mpz_neg(self._mpz_p, self._mpz_p)
- return self
- term = IntegerGMP(term)
- _gmp.mpz_mul(self._mpz_p,
- self._mpz_p,
- term._mpz_p)
- return self
-
- def __imod__(self, divisor):
- if not isinstance(divisor, IntegerGMP):
- divisor = IntegerGMP(divisor)
- comp = _gmp.mpz_cmp(divisor._mpz_p,
- divisor._zero_mpz_p)
- if comp == 0:
- raise ZeroDivisionError("Division by zero")
- if comp < 0:
- raise ValueError("Modulus must be positive")
- _gmp.mpz_mod(self._mpz_p,
- self._mpz_p,
- divisor._mpz_p)
- return self
-
- # Boolean/bit operations
- def __and__(self, term):
- result = IntegerGMP(0)
- if not isinstance(term, IntegerGMP):
- term = IntegerGMP(term)
- _gmp.mpz_and(result._mpz_p,
- self._mpz_p,
- term._mpz_p)
- return result
-
- def __or__(self, term):
- result = IntegerGMP(0)
- if not isinstance(term, IntegerGMP):
- term = IntegerGMP(term)
- _gmp.mpz_ior(result._mpz_p,
- self._mpz_p,
- term._mpz_p)
- return result
-
- def __rshift__(self, pos):
- result = IntegerGMP(0)
- if pos < 0:
- raise ValueError("negative shift count")
- if pos > 65536:
- if self < 0:
- return -1
- else:
- return 0
- _gmp.mpz_tdiv_q_2exp(result._mpz_p,
- self._mpz_p,
- c_ulong(int(pos)))
- return result
-
- def __irshift__(self, pos):
- if pos < 0:
- raise ValueError("negative shift count")
- if pos > 65536:
- if self < 0:
- return -1
- else:
- return 0
- _gmp.mpz_tdiv_q_2exp(self._mpz_p,
- self._mpz_p,
- c_ulong(int(pos)))
- return self
-
- def __lshift__(self, pos):
- result = IntegerGMP(0)
- if not 0 <= pos < 65536:
- raise ValueError("Incorrect shift count")
- _gmp.mpz_mul_2exp(result._mpz_p,
- self._mpz_p,
- c_ulong(int(pos)))
- return result
-
- def __ilshift__(self, pos):
- if not 0 <= pos < 65536:
- raise ValueError("Incorrect shift count")
- _gmp.mpz_mul_2exp(self._mpz_p,
- self._mpz_p,
- c_ulong(int(pos)))
- return self
-
- def get_bit(self, n):
- """Return True if the n-th bit is set to 1.
- Bit 0 is the least significant."""
-
- if self < 0:
- raise ValueError("no bit representation for negative values")
- if n < 0:
- raise ValueError("negative bit count")
- if n > 65536:
- return 0
- return bool(_gmp.mpz_tstbit(self._mpz_p,
- c_ulong(int(n))))
-
- # Extra
- def is_odd(self):
- return _gmp.mpz_tstbit(self._mpz_p, 0) == 1
-
- def is_even(self):
- return _gmp.mpz_tstbit(self._mpz_p, 0) == 0
-
- def size_in_bits(self):
- """Return the minimum number of bits that can encode the number."""
-
- if self < 0:
- raise ValueError("Conversion only valid for non-negative numbers")
- return _gmp.mpz_sizeinbase(self._mpz_p, 2)
-
- def size_in_bytes(self):
- """Return the minimum number of bytes that can encode the number."""
- return (self.size_in_bits() - 1) // 8 + 1
-
- def is_perfect_square(self):
- return _gmp.mpz_perfect_square_p(self._mpz_p) != 0
-
- def fail_if_divisible_by(self, small_prime):
- """Raise an exception if the small prime is a divisor."""
-
- if is_native_int(small_prime):
- if 0 < small_prime < 65536:
- if _gmp.mpz_divisible_ui_p(self._mpz_p,
- c_ulong(small_prime)):
- raise ValueError("The value is composite")
- return
- small_prime = IntegerGMP(small_prime)
- if _gmp.mpz_divisible_p(self._mpz_p,
- small_prime._mpz_p):
- raise ValueError("The value is composite")
-
- def multiply_accumulate(self, a, b):
- """Increment the number by the product of a and b."""
-
- if not isinstance(a, IntegerGMP):
- a = IntegerGMP(a)
- if is_native_int(b):
- if 0 < b < 65536:
- _gmp.mpz_addmul_ui(self._mpz_p,
- a._mpz_p,
- c_ulong(b))
- return self
- if -65535 < b < 0:
- _gmp.mpz_submul_ui(self._mpz_p,
- a._mpz_p,
- c_ulong(-b))
- return self
- b = IntegerGMP(b)
- _gmp.mpz_addmul(self._mpz_p,
- a._mpz_p,
- b._mpz_p)
- return self
-
- def set(self, source):
- """Set the Integer to have the given value"""
-
- if not isinstance(source, IntegerGMP):
- source = IntegerGMP(source)
- _gmp.mpz_set(self._mpz_p,
- source._mpz_p)
- return self
-
- def inplace_inverse(self, modulus):
- """Compute the inverse of this number in the ring of
- modulo integers.
-
- Raise an exception if no inverse exists.
- """
-
- if not isinstance(modulus, IntegerGMP):
- modulus = IntegerGMP(modulus)
-
- comp = _gmp.mpz_cmp(modulus._mpz_p,
- self._zero_mpz_p)
- if comp == 0:
- raise ZeroDivisionError("Modulus cannot be zero")
- if comp < 0:
- raise ValueError("Modulus must be positive")
-
- result = _gmp.mpz_invert(self._mpz_p,
- self._mpz_p,
- modulus._mpz_p)
- if not result:
- raise ValueError("No inverse value can be computed")
- return self
-
- def inverse(self, modulus):
- result = IntegerGMP(self)
- result.inplace_inverse(modulus)
- return result
-
- def gcd(self, term):
- """Compute the greatest common denominator between this
- number and another term."""
-
- result = IntegerGMP(0)
- if is_native_int(term):
- if 0 < term < 65535:
- _gmp.mpz_gcd_ui(result._mpz_p,
- self._mpz_p,
- c_ulong(term))
- return result
- term = IntegerGMP(term)
- _gmp.mpz_gcd(result._mpz_p, self._mpz_p, term._mpz_p)
- return result
-
- def lcm(self, term):
- """Compute the least common multiplier between this
- number and another term."""
-
- result = IntegerGMP(0)
- if not isinstance(term, IntegerGMP):
- term = IntegerGMP(term)
- _gmp.mpz_lcm(result._mpz_p, self._mpz_p, term._mpz_p)
- return result
-
- @staticmethod
- def jacobi_symbol(a, n):
- """Compute the Jacobi symbol"""
-
- if not isinstance(a, IntegerGMP):
- a = IntegerGMP(a)
- if not isinstance(n, IntegerGMP):
- n = IntegerGMP(n)
- if n <= 0 or n.is_even():
- raise ValueError("n must be positive odd for the Jacobi symbol")
- return _gmp.mpz_jacobi(a._mpz_p, n._mpz_p)
-
- # Clean-up
- def __del__(self):
-
- try:
- if self._mpz_p is not None:
- if self._initialized:
- _gmp.mpz_clear(self._mpz_p)
-
- self._mpz_p = None
- except AttributeError:
- pass
diff --git a/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/PIL/EpsImagePlugin.py b/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/PIL/EpsImagePlugin.py
deleted file mode 100644
index 0e434c5c0ea9b1c72ef4f0061a503b0f604ef1d3..0000000000000000000000000000000000000000
--- a/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/PIL/EpsImagePlugin.py
+++ /dev/null
@@ -1,414 +0,0 @@
-#
-# The Python Imaging Library.
-# $Id$
-#
-# EPS file handling
-#
-# History:
-# 1995-09-01 fl Created (0.1)
-# 1996-05-18 fl Don't choke on "atend" fields, Ghostscript interface (0.2)
-# 1996-08-22 fl Don't choke on floating point BoundingBox values
-# 1996-08-23 fl Handle files from Macintosh (0.3)
-# 2001-02-17 fl Use 're' instead of 'regex' (Python 2.1) (0.4)
-# 2003-09-07 fl Check gs.close status (from Federico Di Gregorio) (0.5)
-# 2014-05-07 e Handling of EPS with binary preview and fixed resolution
-# resizing
-#
-# Copyright (c) 1997-2003 by Secret Labs AB.
-# Copyright (c) 1995-2003 by Fredrik Lundh
-#
-# See the README file for information on usage and redistribution.
-#
-
-import io
-import os
-import re
-import subprocess
-import sys
-import tempfile
-
-from . import Image, ImageFile
-from ._binary import i32le as i32
-
-#
-# --------------------------------------------------------------------
-
-split = re.compile(r"^%%([^:]*):[ \t]*(.*)[ \t]*$")
-field = re.compile(r"^%[%!\w]([^:]*)[ \t]*$")
-
-gs_windows_binary = None
-if sys.platform.startswith("win"):
- import shutil
-
- for binary in ("gswin32c", "gswin64c", "gs"):
- if shutil.which(binary) is not None:
- gs_windows_binary = binary
- break
- else:
- gs_windows_binary = False
-
-
-def has_ghostscript():
- if gs_windows_binary:
- return True
- if not sys.platform.startswith("win"):
- try:
- subprocess.check_call(["gs", "--version"], stdout=subprocess.DEVNULL)
- return True
- except OSError:
- # No Ghostscript
- pass
- return False
-
-
-def Ghostscript(tile, size, fp, scale=1, transparency=False):
- """Render an image using Ghostscript"""
-
- # Unpack decoder tile
- decoder, tile, offset, data = tile[0]
- length, bbox = data
-
- # Hack to support hi-res rendering
- scale = int(scale) or 1
- # orig_size = size
- # orig_bbox = bbox
- size = (size[0] * scale, size[1] * scale)
- # resolution is dependent on bbox and size
- res = (
- 72.0 * size[0] / (bbox[2] - bbox[0]),
- 72.0 * size[1] / (bbox[3] - bbox[1]),
- )
-
- out_fd, outfile = tempfile.mkstemp()
- os.close(out_fd)
-
- infile_temp = None
- if hasattr(fp, "name") and os.path.exists(fp.name):
- infile = fp.name
- else:
- in_fd, infile_temp = tempfile.mkstemp()
- os.close(in_fd)
- infile = infile_temp
-
- # Ignore length and offset!
- # Ghostscript can read it
- # Copy whole file to read in Ghostscript
- with open(infile_temp, "wb") as f:
- # fetch length of fp
- fp.seek(0, io.SEEK_END)
- fsize = fp.tell()
- # ensure start position
- # go back
- fp.seek(0)
- lengthfile = fsize
- while lengthfile > 0:
- s = fp.read(min(lengthfile, 100 * 1024))
- if not s:
- break
- lengthfile -= len(s)
- f.write(s)
-
- device = "pngalpha" if transparency else "ppmraw"
-
- # Build Ghostscript command
- command = [
- "gs",
- "-q", # quiet mode
- "-g%dx%d" % size, # set output geometry (pixels)
- "-r%fx%f" % res, # set input DPI (dots per inch)
- "-dBATCH", # exit after processing
- "-dNOPAUSE", # don't pause between pages
- "-dSAFER", # safe mode
- f"-sDEVICE={device}",
- f"-sOutputFile={outfile}", # output file
- # adjust for image origin
- "-c",
- f"{-bbox[0]} {-bbox[1]} translate",
- "-f",
- infile, # input file
- # showpage (see https://bugs.ghostscript.com/show_bug.cgi?id=698272)
- "-c",
- "showpage",
- ]
-
- if gs_windows_binary is not None:
- if not gs_windows_binary:
- raise OSError("Unable to locate Ghostscript on paths")
- command[0] = gs_windows_binary
-
- # push data through Ghostscript
- try:
- startupinfo = None
- if sys.platform.startswith("win"):
- startupinfo = subprocess.STARTUPINFO()
- startupinfo.dwFlags |= subprocess.STARTF_USESHOWWINDOW
- subprocess.check_call(command, startupinfo=startupinfo)
- out_im = Image.open(outfile)
- out_im.load()
- finally:
- try:
- os.unlink(outfile)
- if infile_temp:
- os.unlink(infile_temp)
- except OSError:
- pass
-
- im = out_im.im.copy()
- out_im.close()
- return im
-
-
-class PSFile:
- """
- Wrapper for bytesio object that treats either CR or LF as end of line.
- """
-
- def __init__(self, fp):
- self.fp = fp
- self.char = None
-
- def seek(self, offset, whence=io.SEEK_SET):
- self.char = None
- self.fp.seek(offset, whence)
-
- def readline(self):
- s = [self.char or b""]
- self.char = None
-
- c = self.fp.read(1)
- while (c not in b"\r\n") and len(c):
- s.append(c)
- c = self.fp.read(1)
-
- self.char = self.fp.read(1)
- # line endings can be 1 or 2 of \r \n, in either order
- if self.char in b"\r\n":
- self.char = None
-
- return b"".join(s).decode("latin-1")
-
-
-def _accept(prefix):
- return prefix[:4] == b"%!PS" or (len(prefix) >= 4 and i32(prefix) == 0xC6D3D0C5)
-
-
-##
-# Image plugin for Encapsulated PostScript. This plugin supports only
-# a few variants of this format.
-
-
-class EpsImageFile(ImageFile.ImageFile):
- """EPS File Parser for the Python Imaging Library"""
-
- format = "EPS"
- format_description = "Encapsulated Postscript"
-
- mode_map = {1: "L", 2: "LAB", 3: "RGB", 4: "CMYK"}
-
- def _open(self):
- (length, offset) = self._find_offset(self.fp)
-
- # Rewrap the open file pointer in something that will
- # convert line endings and decode to latin-1.
- fp = PSFile(self.fp)
-
- # go to offset - start of "%!PS"
- fp.seek(offset)
-
- box = None
-
- self.mode = "RGB"
- self._size = 1, 1 # FIXME: huh?
-
- #
- # Load EPS header
-
- s_raw = fp.readline()
- s = s_raw.strip("\r\n")
-
- while s_raw:
- if s:
- if len(s) > 255:
- raise SyntaxError("not an EPS file")
-
- try:
- m = split.match(s)
- except re.error as e:
- raise SyntaxError("not an EPS file") from e
-
- if m:
- k, v = m.group(1, 2)
- self.info[k] = v
- if k == "BoundingBox":
- try:
- # Note: The DSC spec says that BoundingBox
- # fields should be integers, but some drivers
- # put floating point values there anyway.
- box = [int(float(i)) for i in v.split()]
- self._size = box[2] - box[0], box[3] - box[1]
- self.tile = [
- ("eps", (0, 0) + self.size, offset, (length, box))
- ]
- except Exception:
- pass
-
- else:
- m = field.match(s)
- if m:
- k = m.group(1)
-
- if k == "EndComments":
- break
- if k[:8] == "PS-Adobe":
- self.info[k[:8]] = k[9:]
- else:
- self.info[k] = ""
- elif s[0] == "%":
- # handle non-DSC PostScript comments that some
- # tools mistakenly put in the Comments section
- pass
- else:
- raise OSError("bad EPS header")
-
- s_raw = fp.readline()
- s = s_raw.strip("\r\n")
-
- if s and s[:1] != "%":
- break
-
- #
- # Scan for an "ImageData" descriptor
-
- while s[:1] == "%":
-
- if len(s) > 255:
- raise SyntaxError("not an EPS file")
-
- if s[:11] == "%ImageData:":
- # Encoded bitmapped image.
- x, y, bi, mo = s[11:].split(None, 7)[:4]
-
- if int(bi) == 1:
- self.mode = "1"
- elif int(bi) == 8:
- try:
- self.mode = self.mode_map[int(mo)]
- except ValueError:
- break
- else:
- break
-
- self._size = int(x), int(y)
- return
-
- s = fp.readline().strip("\r\n")
- if not s:
- break
-
- if not box:
- raise OSError("cannot determine EPS bounding box")
-
- def _find_offset(self, fp):
-
- s = fp.read(160)
-
- if s[:4] == b"%!PS":
- # for HEAD without binary preview
- fp.seek(0, io.SEEK_END)
- length = fp.tell()
- offset = 0
- elif i32(s, 0) == 0xC6D3D0C5:
- # FIX for: Some EPS file not handled correctly / issue #302
- # EPS can contain binary data
- # or start directly with latin coding
- # more info see:
- # https://web.archive.org/web/20160528181353/http://partners.adobe.com/public/developer/en/ps/5002.EPSF_Spec.pdf
- offset = i32(s, 4)
- length = i32(s, 8)
- else:
- raise SyntaxError("not an EPS file")
-
- return length, offset
-
- def load(self, scale=1, transparency=False):
- # Load EPS via Ghostscript
- if self.tile:
- self.im = Ghostscript(self.tile, self.size, self.fp, scale, transparency)
- self.mode = self.im.mode
- self._size = self.im.size
- self.tile = []
- return Image.Image.load(self)
-
- def load_seek(self, *args, **kwargs):
- # we can't incrementally load, so force ImageFile.parser to
- # use our custom load method by defining this method.
- pass
-
-
-#
-# --------------------------------------------------------------------
-
-
-def _save(im, fp, filename, eps=1):
- """EPS Writer for the Python Imaging Library."""
-
- #
- # make sure image data is available
- im.load()
-
- #
- # determine PostScript image mode
- if im.mode == "L":
- operator = (8, 1, b"image")
- elif im.mode == "RGB":
- operator = (8, 3, b"false 3 colorimage")
- elif im.mode == "CMYK":
- operator = (8, 4, b"false 4 colorimage")
- else:
- raise ValueError("image mode is not supported")
-
- if eps:
- #
- # write EPS header
- fp.write(b"%!PS-Adobe-3.0 EPSF-3.0\n")
- fp.write(b"%%Creator: PIL 0.1 EpsEncode\n")
- # fp.write("%%CreationDate: %s"...)
- fp.write(b"%%%%BoundingBox: 0 0 %d %d\n" % im.size)
- fp.write(b"%%Pages: 1\n")
- fp.write(b"%%EndComments\n")
- fp.write(b"%%Page: 1 1\n")
- fp.write(b"%%ImageData: %d %d " % im.size)
- fp.write(b'%d %d 0 1 1 "%s"\n' % operator)
-
- #
- # image header
- fp.write(b"gsave\n")
- fp.write(b"10 dict begin\n")
- fp.write(b"/buf %d string def\n" % (im.size[0] * operator[1]))
- fp.write(b"%d %d scale\n" % im.size)
- fp.write(b"%d %d 8\n" % im.size) # <= bits
- fp.write(b"[%d 0 0 -%d 0 %d]\n" % (im.size[0], im.size[1], im.size[1]))
- fp.write(b"{ currentfile buf readhexstring pop } bind\n")
- fp.write(operator[2] + b"\n")
- if hasattr(fp, "flush"):
- fp.flush()
-
- ImageFile._save(im, fp, [("eps", (0, 0) + im.size, 0, None)])
-
- fp.write(b"\n%%%%EndBinary\n")
- fp.write(b"grestore end\n")
- if hasattr(fp, "flush"):
- fp.flush()
-
-
-#
-# --------------------------------------------------------------------
-
-
-Image.register_open(EpsImageFile.format, EpsImageFile, _accept)
-
-Image.register_save(EpsImageFile.format, _save)
-
-Image.register_extensions(EpsImageFile.format, [".ps", ".eps"])
-
-Image.register_mime(EpsImageFile.format, "application/postscript")
diff --git a/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/altair/examples/errorbars_with_ci.py b/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/altair/examples/errorbars_with_ci.py
deleted file mode 100644
index ec70b27b4943e0bc64b0f8d0fcc7cd45c3ffbac3..0000000000000000000000000000000000000000
--- a/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/altair/examples/errorbars_with_ci.py
+++ /dev/null
@@ -1,24 +0,0 @@
-"""
-Error Bars showing Confidence Interval
-======================================
-This example shows how to show error bars using confidence intervals.
-The confidence intervals are computed internally in vega by a non-parametric
-`bootstrap of the mean `_.
-"""
-# category: other charts
-import altair as alt
-from vega_datasets import data
-
-source = data.barley()
-
-error_bars = alt.Chart(source).mark_errorbar(extent='ci').encode(
- x=alt.X('yield:Q', scale=alt.Scale(zero=False)),
- y=alt.Y('variety:N')
-)
-
-points = alt.Chart(source).mark_point(filled=True, color='black').encode(
- x=alt.X('yield:Q', aggregate='mean'),
- y=alt.Y('variety:N'),
-)
-
-error_bars + points
diff --git a/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/altair/examples/trellis_histogram.py b/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/altair/examples/trellis_histogram.py
deleted file mode 100644
index cba1c698b7872dde56f1108cc7fada9bf0abaa4d..0000000000000000000000000000000000000000
--- a/spaces/arxify/RVC-beta-v2-0618/runtime/Lib/site-packages/altair/examples/trellis_histogram.py
+++ /dev/null
@@ -1,17 +0,0 @@
-"""
-Trellis Histogram
------------------
-This example shows how to make a basic trellis histogram.
-https://vega.github.io/vega-lite/examples/trellis_bar_histogram.html
-"""
-# category: histograms
-import altair as alt
-from vega_datasets import data
-
-source = data.cars()
-
-alt.Chart(source).mark_bar().encode(
- alt.X("Horsepower:Q", bin=True),
- y='count()',
- row='Origin'
-)
diff --git a/spaces/atimughal662/InfoFusion/src/loaders.py b/spaces/atimughal662/InfoFusion/src/loaders.py
deleted file mode 100644
index 8c147670eb9433f5a26c8e25121b0e1e62f250e6..0000000000000000000000000000000000000000
--- a/spaces/atimughal662/InfoFusion/src/loaders.py
+++ /dev/null
@@ -1,120 +0,0 @@
-import functools
-
-from src.enums import t5_type
-
-
-def get_loaders(model_name, reward_type, llama_type=None, load_gptq='', load_exllama=False, config=None,
- rope_scaling=None, max_seq_len=None, model_name_exllama_if_no_config=''):
- # NOTE: Some models need specific new prompt_type
- # E.g. t5_xxl_true_nli_mixture has input format: "premise: PREMISE_TEXT hypothesis: HYPOTHESIS_TEXT".)
- if load_exllama:
- from src.llm_exllama import H2OExLlamaTokenizer, H2OExLlamaGenerator
- from exllama.model import ExLlama, ExLlamaCache, ExLlamaConfig
- import os, glob
-
- if config:
- # then use HF path
- from transformers import TRANSFORMERS_CACHE
- model_directory = os.path.join(TRANSFORMERS_CACHE, 'models--' + config.name_or_path.replace('/', '--'),
- 'snapshots', config._commit_hash)
- else:
- # then use path in env file
- # Directory containing model, tokenizer, generator
- model_directory = model_name_exllama_if_no_config
-
- # download model
- revision = config._commit_hash
- from huggingface_hub import snapshot_download
- snapshot_download(repo_id=model_name, revision=revision)
-
- # Locate files we need within that directory
- tokenizer_path = os.path.join(model_directory, "tokenizer.model")
- assert os.path.isfile(tokenizer_path), "Missing %s" % tokenizer_path
- model_config_path = os.path.join(model_directory, "config.json")
- assert os.path.isfile(model_config_path), "Missing %s" % model_config_path
- st_pattern = os.path.join(model_directory, "*.safetensors")
- model_path = glob.glob(st_pattern)[0]
- assert os.path.isfile(model_path), "Missing %s" % model_path
-
- # Create config, model, tokenizer and generator
- exconfig = ExLlamaConfig(model_config_path) # create config from config.json
- rope_scaling = rope_scaling or {}
- exconfig.alpha_value = rope_scaling.get('alpha_value', 1) # rope
- exconfig.compress_pos_emb = rope_scaling.get('compress_pos_emb', 1) # related rope
- # update max_seq_len
- assert hasattr(config, 'max_position_embeddings') or hasattr(config,
- 'max_sequence_length'), "Improve code if no such argument"
- if hasattr(config, 'max_position_embeddings'):
- exconfig.max_seq_len = int(config.max_position_embeddings * exconfig.alpha_value)
- else:
- exconfig.max_seq_len = int(config.max_sequence_length * exconfig.alpha_value)
- if 'Llama-2'.lower() in model_name.lower():
- # override bad defaults
- exconfig.max_seq_len = int(4096 * exconfig.alpha_value)
- if max_seq_len is not None:
- exconfig.max_seq_len = max_seq_len
-
- exconfig.model_path = model_path # supply path to model weights file
-
- model = ExLlama(exconfig) # create ExLlama instance and load the weights
- tokenizer = H2OExLlamaTokenizer(tokenizer_path) # create tokenizer from tokenizer model file
- tokenizer.model_max_length = exconfig.max_seq_len
-
- cache = ExLlamaCache(model) # create cache for inference
- generator = H2OExLlamaGenerator(model, tokenizer, cache) # create generator
- return generator, tokenizer, False
- if load_gptq:
- from transformers import AutoTokenizer
- from auto_gptq import AutoGPTQForCausalLM
- use_triton = False
- model_loader = functools.partial(AutoGPTQForCausalLM.from_quantized,
- quantize_config=None, use_triton=use_triton,
- )
- return model_loader, AutoTokenizer, False
- if llama_type is None:
- llama_type = "llama" in model_name.lower()
- if llama_type:
- from transformers import LlamaForCausalLM, LlamaTokenizer
- return LlamaForCausalLM.from_pretrained, LlamaTokenizer, False
- elif 'distilgpt2' in model_name.lower():
- from transformers import AutoModelForCausalLM, AutoTokenizer
- return AutoModelForCausalLM.from_pretrained, AutoTokenizer, False
- elif 'gpt2' in model_name.lower():
- from transformers import GPT2LMHeadModel, GPT2Tokenizer
- return GPT2LMHeadModel.from_pretrained, GPT2Tokenizer, False
- elif 'mbart-' in model_name.lower():
- from transformers import MBartForConditionalGeneration, MBart50TokenizerFast
- return MBartForConditionalGeneration.from_pretrained, MBart50TokenizerFast, True
- elif t5_type(model_name):
- from transformers import AutoTokenizer, T5ForConditionalGeneration
- return T5ForConditionalGeneration.from_pretrained, AutoTokenizer, True
- elif 'bigbird' in model_name:
- from transformers import BigBirdPegasusForConditionalGeneration, AutoTokenizer
- return BigBirdPegasusForConditionalGeneration.from_pretrained, AutoTokenizer, True
- elif 'bart-large-cnn-samsum' in model_name or 'flan-t5-base-samsum' in model_name:
- from transformers import pipeline
- return pipeline, "summarization", False
- elif reward_type or 'OpenAssistant/reward-model'.lower() in model_name.lower():
- from transformers import AutoModelForSequenceClassification, AutoTokenizer
- return AutoModelForSequenceClassification.from_pretrained, AutoTokenizer, False
- else:
- from transformers import AutoTokenizer, AutoModelForCausalLM
- model_loader = AutoModelForCausalLM
- tokenizer_loader = AutoTokenizer
- return model_loader.from_pretrained, tokenizer_loader, False
-
-
-def get_tokenizer(tokenizer_loader, tokenizer_base_model, local_files_only, resume_download, use_auth_token):
- tokenizer = tokenizer_loader.from_pretrained(tokenizer_base_model,
- local_files_only=local_files_only,
- resume_download=resume_download,
- use_auth_token=use_auth_token,
- padding_side='left')
-
- tokenizer.pad_token_id = 0 # different from the eos token
- # when generating, we will use the logits of right-most token to predict the next token
- # so the padding should be on the left,
- # e.g. see: https://huggingface.co/transformers/v4.11.3/model_doc/t5.html#inference
- tokenizer.padding_side = "left" # Allow batched inference
-
- return tokenizer
diff --git a/spaces/avid-ml/bias-detection/avidtools/connectors/aiid.py b/spaces/avid-ml/bias-detection/avidtools/connectors/aiid.py
deleted file mode 100644
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..0000000000000000000000000000000000000000
diff --git a/spaces/avivdm1/AutoGPT/autogpt/processing/html.py b/spaces/avivdm1/AutoGPT/autogpt/processing/html.py
deleted file mode 100644
index 81387b12adab5023150c55f2075ddd40b554f386..0000000000000000000000000000000000000000
--- a/spaces/avivdm1/AutoGPT/autogpt/processing/html.py
+++ /dev/null
@@ -1,33 +0,0 @@
-"""HTML processing functions"""
-from __future__ import annotations
-
-from bs4 import BeautifulSoup
-from requests.compat import urljoin
-
-
-def extract_hyperlinks(soup: BeautifulSoup, base_url: str) -> list[tuple[str, str]]:
- """Extract hyperlinks from a BeautifulSoup object
-
- Args:
- soup (BeautifulSoup): The BeautifulSoup object
- base_url (str): The base URL
-
- Returns:
- List[Tuple[str, str]]: The extracted hyperlinks
- """
- return [
- (link.text, urljoin(base_url, link["href"]))
- for link in soup.find_all("a", href=True)
- ]
-
-
-def format_hyperlinks(hyperlinks: list[tuple[str, str]]) -> list[str]:
- """Format hyperlinks to be displayed to the user
-
- Args:
- hyperlinks (List[Tuple[str, str]]): The hyperlinks to format
-
- Returns:
- List[str]: The formatted hyperlinks
- """
- return [f"{link_text} ({link_url})" for link_text, link_url in hyperlinks]
diff --git a/spaces/awaawawawa/iurf7irfuyytruyyugb/ldmlib/modules/ema.py b/spaces/awaawawawa/iurf7irfuyytruyyugb/ldmlib/modules/ema.py
deleted file mode 100644
index c8c75af43565f6e140287644aaaefa97dd6e67c5..0000000000000000000000000000000000000000
--- a/spaces/awaawawawa/iurf7irfuyytruyyugb/ldmlib/modules/ema.py
+++ /dev/null
@@ -1,76 +0,0 @@
-import torch
-from torch import nn
-
-
-class LitEma(nn.Module):
- def __init__(self, model, decay=0.9999, use_num_upates=True):
- super().__init__()
- if decay < 0.0 or decay > 1.0:
- raise ValueError('Decay must be between 0 and 1')
-
- self.m_name2s_name = {}
- self.register_buffer('decay', torch.tensor(decay, dtype=torch.float32))
- self.register_buffer('num_updates', torch.tensor(0,dtype=torch.int) if use_num_upates
- else torch.tensor(-1,dtype=torch.int))
-
- for name, p in model.named_parameters():
- if p.requires_grad:
- #remove as '.'-character is not allowed in buffers
- s_name = name.replace('.','')
- self.m_name2s_name.update({name:s_name})
- self.register_buffer(s_name,p.clone().detach().data)
-
- self.collected_params = []
-
- def forward(self,model):
- decay = self.decay
-
- if self.num_updates >= 0:
- self.num_updates += 1
- decay = min(self.decay,(1 + self.num_updates) / (10 + self.num_updates))
-
- one_minus_decay = 1.0 - decay
-
- with torch.no_grad():
- m_param = dict(model.named_parameters())
- shadow_params = dict(self.named_buffers())
-
- for key in m_param:
- if m_param[key].requires_grad:
- sname = self.m_name2s_name[key]
- shadow_params[sname] = shadow_params[sname].type_as(m_param[key])
- shadow_params[sname].sub_(one_minus_decay * (shadow_params[sname] - m_param[key]))
- else:
- assert not key in self.m_name2s_name
-
- def copy_to(self, model):
- m_param = dict(model.named_parameters())
- shadow_params = dict(self.named_buffers())
- for key in m_param:
- if m_param[key].requires_grad:
- m_param[key].data.copy_(shadow_params[self.m_name2s_name[key]].data)
- else:
- assert not key in self.m_name2s_name
-
- def store(self, parameters):
- """
- Save the current parameters for restoring later.
- Args:
- parameters: Iterable of `torch.nn.Parameter`; the parameters to be
- temporarily stored.
- """
- self.collected_params = [param.clone() for param in parameters]
-
- def restore(self, parameters):
- """
- Restore the parameters stored with the `store` method.
- Useful to validate the model with EMA parameters without affecting the
- original optimization process. Store the parameters before the
- `copy_to` method. After validation (or model saving), use this to
- restore the former parameters.
- Args:
- parameters: Iterable of `torch.nn.Parameter`; the parameters to be
- updated with the stored parameters.
- """
- for c_param, param in zip(self.collected_params, parameters):
- param.data.copy_(c_param.data)
diff --git a/spaces/awacke1/FastestText2SpeechEver/README.md b/spaces/awacke1/FastestText2SpeechEver/README.md
deleted file mode 100644
index d7333db192bc50fcd391b6046e5e7a3dabf37b67..0000000000000000000000000000000000000000
--- a/spaces/awacke1/FastestText2SpeechEver/README.md
+++ /dev/null
@@ -1,12 +0,0 @@
----
-title: FastestText2SpeechEver
-emoji: 👀
-colorFrom: red
-colorTo: green
-sdk: gradio
-sdk_version: 3.38.0
-app_file: app.py
-pinned: false
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/awacke1/PlantFractalsMathGameWithJuliaSetnStrangeAttractors/README.md b/spaces/awacke1/PlantFractalsMathGameWithJuliaSetnStrangeAttractors/README.md
deleted file mode 100644
index 73aad519d66e29aa126784d669f3f59fc123e555..0000000000000000000000000000000000000000
--- a/spaces/awacke1/PlantFractalsMathGameWithJuliaSetnStrangeAttractors/README.md
+++ /dev/null
@@ -1,13 +0,0 @@
----
-title: 🎲🌱Plant🌱Fractals🎲Math🎲GameWith⬡JuliaSet⬡n⬡StrangeAttractors⬡🎲
-emoji: 🎲⬡🌱🌱🌱⬡🎲
-colorFrom: indigo
-colorTo: indigo
-sdk: streamlit
-sdk_version: 1.17.0
-app_file: app.py
-pinned: false
-license: mit
----
-
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
diff --git a/spaces/awacke1/VoiceChatMistral/app.py b/spaces/awacke1/VoiceChatMistral/app.py
deleted file mode 100644
index 482fa65ee96482fef83e522bb7ab71c3df0bd009..0000000000000000000000000000000000000000
--- a/spaces/awacke1/VoiceChatMistral/app.py
+++ /dev/null
@@ -1,212 +0,0 @@
-import gradio as gr
-import numpy as np
-import torch
-import nltk
-import os
-import uuid
-
-from __future__ import annotations
-
-os.environ["COQUI_TOS_AGREED"] = "1"
-nltk.download('punkt')
-from TTS.api import TTS
-from huggingface_hub import HfApi
-HF_TOKEN = os.environ.get("HF_TOKEN")
-
-
-tts = TTS("tts_models/multilingual/multi-dataset/xtts_v1", gpu=True)
-title = "Voice Chat Mistral"
-DESCRIPTION = title
-css = """.toast-wrap { display: none !important } """
-api = HfApi(token=HF_TOKEN)
-repo_id = "ylacombe/voice-chat-with-lama"
-system_message = "\nYou are a helpful assistant."
-temperature = 0.9
-top_p = 0.6
-repetition_penalty = 1.2
-
-import gradio as gr
-import os
-import time
-
-import gradio as gr
-from transformers import pipeline
-import numpy as np
-
-from gradio_client import Client
-from huggingface_hub import InferenceClient
-
-
-whisper_client = Client("https://sanchit-gandhi-whisper-large-v2.hf.space/")
-text_client = InferenceClient(
- "mistralai/Mistral-7B-Instruct-v0.1"
-)
-
-
-def format_prompt(message, history):
- prompt = ""
- for user_prompt, bot_response in history:
- prompt += f"[INST] {user_prompt} [/INST]"
- prompt += f" {bot_response} "
- prompt += f"[INST] {message} [/INST]"
- return prompt
-
-def generate(
- prompt, history, temperature=0.9, max_new_tokens=256, top_p=0.95, repetition_penalty=1.0,
-):
- temperature = float(temperature)
- if temperature < 1e-2:
- temperature = 1e-2
- top_p = float(top_p)
-
- generate_kwargs = dict(
- temperature=temperature,
- max_new_tokens=max_new_tokens,
- top_p=top_p,
- repetition_penalty=repetition_penalty,
- do_sample=True,
- seed=42,
- )
-
- formatted_prompt = format_prompt(prompt, history)
-
- stream = text_client.text_generation(formatted_prompt, **generate_kwargs, stream=True, details=True, return_full_text=False)
- output = ""
-
- for response in stream:
- output += response.token.text
- yield output
- return output
-
-
-def transcribe(wav_path):
-
- return whisper_client.predict(
- wav_path, # str (filepath or URL to file) in 'inputs' Audio component
- "transcribe", # str in 'Task' Radio component
- api_name="/predict"
-)
-
-
-# Chatbot demo with multimodal input (text, markdown, LaTeX, code blocks, image, audio, & video). Plus shows support for streaming text.
-
-
-def add_text(history, text):
- history = [] if history is None else history
- history = history + [(text, None)]
- return history, gr.update(value="", interactive=False)
-
-
-def add_file(history, file):
- history = [] if history is None else history
- text = transcribe(
- file
- )
-
- history = history + [(text, None)]
- return history
-
-
-
-def bot(history, system_prompt=""):
- history = [] if history is None else history
-
- if system_prompt == "":
- system_prompt = system_message
-
- history[-1][1] = ""
- for character in generate(history[-1][0], history[:-1]):
- history[-1][1] = character
- yield history
-
-
-def generate_speech(history):
- text_to_generate = history[-1][1]
- text_to_generate = text_to_generate.replace("\n", " ").strip()
- text_to_generate = nltk.sent_tokenize(text_to_generate)
-
- filename = f"{uuid.uuid4()}.wav"
- sampling_rate = tts.synthesizer.tts_config.audio["sample_rate"]
- silence = [0] * int(0.25 * sampling_rate)
-
-
- for sentence in text_to_generate:
- try:
-
- # generate speech by cloning a voice using default settings
- wav = tts.tts(text=sentence,
- speaker_wav="examples/female.wav",
- decoder_iterations=25,
- decoder_sampler="dpm++2m",
- speed=1.2,
- language="en")
-
- yield (sampling_rate, np.array(wav)) #np.array(wav + silence))
-
- except RuntimeError as e :
- if "device-side assert" in str(e):
- # cannot do anything on cuda device side error, need tor estart
- print(f"Exit due to: Unrecoverable exception caused by prompt:{sentence}", flush=True)
- gr.Warning("Unhandled Exception encounter, please retry in a minute")
- print("Cuda device-assert Runtime encountered need restart")
-
-
- # HF Space specific.. This error is unrecoverable need to restart space
- api.restart_space(repo_id=repo_id)
- else:
- print("RuntimeError: non device-side assert error:", str(e))
- raise e
-
-with gr.Blocks(title=title) as demo:
- gr.Markdown(DESCRIPTION)
-
-
- chatbot = gr.Chatbot(
- [],
- elem_id="chatbot",
- avatar_images=('examples/lama.jpeg', 'examples/lama2.jpeg'),
- bubble_full_width=False,
- )
-
- with gr.Row():
- txt = gr.Textbox(
- scale=3,
- show_label=False,
- placeholder="Enter text and press enter, or speak to your microphone",
- container=False,
- )
- txt_btn = gr.Button(value="Submit text",scale=1)
- btn = gr.Audio(source="microphone", type="filepath", scale=4)
-
- with gr.Row():
- audio = gr.Audio(type="numpy", streaming=True, autoplay=True, label="Generated audio response", show_label=True)
-
- clear_btn = gr.ClearButton([chatbot, audio])
-
- txt_msg = txt_btn.click(add_text, [chatbot, txt], [chatbot, txt], queue=False).then(
- bot, chatbot, chatbot
- ).then(generate_speech, chatbot, audio)
-
- txt_msg.then(lambda: gr.update(interactive=True), None, [txt], queue=False)
-
- txt_msg = txt.submit(add_text, [chatbot, txt], [chatbot, txt], queue=False).then(
- bot, chatbot, chatbot
- ).then(generate_speech, chatbot, audio)
-
- txt_msg.then(lambda: gr.update(interactive=True), None, [txt], queue=False)
-
- file_msg = btn.stop_recording(add_file, [chatbot, btn], [chatbot], queue=False).then(
- bot, chatbot, chatbot
- ).then(generate_speech, chatbot, audio)
-
-
- gr.Markdown("""
-This Space demonstrates how to speak to a chatbot, based solely on open-source models.
-It relies on 3 models:
-1. [Whisper-large-v2](https://huggingface.co/spaces/sanchit-gandhi/whisper-large-v2) as an ASR model, to transcribe recorded audio to text. It is called through a [gradio client](https://www.gradio.app/docs/client).
-2. [Mistral-7b-instruct](https://huggingface.co/spaces/osanseviero/mistral-super-fast) as the chat model, the actual chat model. It is called from [huggingface_hub](https://huggingface.co/docs/huggingface_hub/guides/inference).
-3. [Coqui's XTTS](https://huggingface.co/spaces/coqui/xtts) as a TTS model, to generate the chatbot answers. This time, the model is hosted locally.
-Note:
-- By using this demo you agree to the terms of the Coqui Public Model License at https://coqui.ai/cpml""")
-demo.queue()
-demo.launch(debug=True)
\ No newline at end of file
diff --git a/spaces/awacke1/Z-3-ChatbotBlenderBot-GR/app.py b/spaces/awacke1/Z-3-ChatbotBlenderBot-GR/app.py
deleted file mode 100644
index ca545aad434176426ca5ee2190b8e753d46a10df..0000000000000000000000000000000000000000
--- a/spaces/awacke1/Z-3-ChatbotBlenderBot-GR/app.py
+++ /dev/null
@@ -1,134 +0,0 @@
-from transformers import BlenderbotTokenizer, BlenderbotForConditionalGeneration
-import torch
-import gradio as gr
-
-
-# PersistDataset -----
-import os
-import csv
-import gradio as gr
-from gradio import inputs, outputs
-import huggingface_hub
-from huggingface_hub import Repository, hf_hub_download, upload_file
-from datetime import datetime
-
-
-# -------------------------------------------- For Memory - you will need to set up a dataset and HF_TOKEN ---------
-#DATASET_REPO_URL = "https://huggingface.co/datasets/awacke1/ChatbotMemory.csv"
-#DATASET_REPO_ID = "awacke1/ChatbotMemory.csv"
-#DATA_FILENAME = "ChatbotMemory.csv"
-#DATA_FILE = os.path.join("data", DATA_FILENAME)
-#HF_TOKEN = os.environ.get("HF_TOKEN")
-
-#SCRIPT = """
-#
-#"""
-
-#try:
-# hf_hub_download(
-# repo_id=DATASET_REPO_ID,
-# filename=DATA_FILENAME,
-# cache_dir=DATA_DIRNAME,
-# force_filename=DATA_FILENAME
-# )
-#except:
-# print("file not found")
-#repo = Repository(
-# local_dir="data", clone_from=DATASET_REPO_URL, use_auth_token=HF_TOKEN
-#)
-
-#def store_message(name: str, message: str):
-# if name and message:
-# with open(DATA_FILE, "a") as csvfile:
-# writer = csv.DictWriter(csvfile, fieldnames=["name", "message", "time"])
-# writer.writerow(
-# {"name": name.strip(), "message": message.strip(), "time": str(datetime.now())}
-# )
-# uncomment line below to begin saving. If creating your own copy you will need to add a access token called "HF_TOKEN" to your profile, then create a secret for your repo with the access code naming it "HF_TOKEN" For the CSV as well you can copy the header and first few lines to your own then update the paths above which should work to save to your own repository for datasets.
-# commit_url = repo.push_to_hub()
-# return ""
-
-#iface = gr.Interface(
-# store_message,
-# [
-# inputs.Textbox(placeholder="Your name"),
-# inputs.Textbox(placeholder="Your message", lines=2),
-# ],
-# "html",
-# css="""
-# .message {background-color:cornflowerblue;color:white; padding:4px;margin:4px;border-radius:4px; }
-# """,
-# title="Reading/writing to a HuggingFace dataset repo from Spaces",
-# description=f"This is a demo of how to do simple *shared data persistence* in a Gradio Space, backed by a dataset repo.",
-# article=f"The dataset repo is [{DATASET_REPO_URL}]({DATASET_REPO_URL})",
-#)
-# --------------------------------------------------- For Memory
-
-mname = "facebook/blenderbot-400M-distill"
-model = BlenderbotForConditionalGeneration.from_pretrained(mname)
-tokenizer = BlenderbotTokenizer.from_pretrained(mname)
-
-def take_last_tokens(inputs, note_history, history):
- """Filter the last 128 tokens"""
- if inputs['input_ids'].shape[1] > 128:
- inputs['input_ids'] = torch.tensor([inputs['input_ids'][0][-128:].tolist()])
- inputs['attention_mask'] = torch.tensor([inputs['attention_mask'][0][-128:].tolist()])
- note_history = [' '.join(note_history[0].split(' ')[2:])]
- history = history[1:]
- return inputs, note_history, history
-
-def add_note_to_history(note, note_history):
- """Add a note to the historical information"""
- note_history.append(note)
- note_history = ' '.join(note_history)
- return [note_history]
-
-title = "State of the Art Chatbot with Memory Dataset"
-description = """Chatbot With Memory"""
-
-def chat(message, history):
- history = history or []
- if history:
- history_useful = [' '.join([str(a[0])+' '+str(a[1]) for a in history])]
- else:
- history_useful = []
- history_useful = add_note_to_history(message, history_useful)
- inputs = tokenizer(history_useful, return_tensors="pt")
- inputs, history_useful, history = take_last_tokens(inputs, history_useful, history)
- reply_ids = model.generate(**inputs)
- response = tokenizer.batch_decode(reply_ids, skip_special_tokens=True)[0]
- history_useful = add_note_to_history(response, history_useful)
- list_history = history_useful[0].split(' ')
- history.append((list_history[-2], list_history[-1]))
-# store_message(message, response) # Save to dataset -- uncomment with code above, create a dataset to store and add your HF_TOKEN from profile to this repo to use.
- return history, history
-
-gr.Interface(
- fn=chat,
- theme="huggingface",
- css=".footer {display:none !important}",
- inputs=["text", "state"],
- outputs=["chatbot", "state"],
- title=title,
- allow_flagging="never",
- description=f"Gradio chatbot backed by memory in a dataset repository.",
-# article=f"The dataset repo is [{DATASET_REPO_URL}]({DATASET_REPO_URL})"
- ).launch(debug=True)
-
-#demo = gr.Blocks()
-#with demo:
-# audio_file = gr.inputs.Audio(source="microphone", type="filepath")
-# text = gr.Textbox(label="Speech to Text")
-# TTSchoice = gr.inputs.Radio( label="Pick a Text to Speech Model", choices=MODEL_NAMES, )
-# audio = gr.Audio(label="Output", interactive=False)
-# b1 = gr.Button("Recognize Speech")
-# b5 = gr.Button("Read It Back Aloud")
-# b1.click(speech_to_text, inputs=audio_file, outputs=text)
-# b5.click(tts, inputs=[text,TTSchoice], outputs=audio)
-#demo.launch(share=True)
diff --git a/spaces/aziz28/rsa-app/rsa_app.py b/spaces/aziz28/rsa-app/rsa_app.py
deleted file mode 100644
index 75d99f4a86a8f74cfee26f930de0e86a66b36a9b..0000000000000000000000000000000000000000
--- a/spaces/aziz28/rsa-app/rsa_app.py
+++ /dev/null
@@ -1,32 +0,0 @@
-import rsa
-import streamlit as st
-
-
-st.write("""
-# RSA
-""")
-# generate public and private keys with
-# rsa.newkeys method,this method accepts
-# key length as its parameter
-# key length should be atleast 16
-publicKey, privateKey = rsa.newkeys(512)
-
-# this is the string that we will be encrypting
-input = st.text_input('Masukkan Teks', 'Muhamad Aziz 20220028')
-
-# rsa.encrypt method is used to encrypt
-# string with public key string should be
-# encode to byte string before encryption
-# with encode method
-encMessage = rsa.encrypt(input.encode(),
- publicKey)
-st.write('enkripsi :', encMessage)
-
-# the encrypted message can be decrypted
-# with ras.decrypt method and private key
-# decrypt method returns encoded byte string,
-# use decode method to convert it to string
-# public key cannot be used for decryption
-decMessage = rsa.decrypt(encMessage, privateKey).decode()
-
-st.write('dekripsi :', decMessage)
diff --git a/spaces/azusarang/so-vits-svc-models-ba_P/modules/modules.py b/spaces/azusarang/so-vits-svc-models-ba_P/modules/modules.py
deleted file mode 100644
index 54290fd207b25e93831bd21005990ea137e6b50e..0000000000000000000000000000000000000000
--- a/spaces/azusarang/so-vits-svc-models-ba_P/modules/modules.py
+++ /dev/null
@@ -1,342 +0,0 @@
-import copy
-import math
-import numpy as np
-import scipy
-import torch
-from torch import nn
-from torch.nn import functional as F
-
-from torch.nn import Conv1d, ConvTranspose1d, AvgPool1d, Conv2d
-from torch.nn.utils import weight_norm, remove_weight_norm
-
-import modules.commons as commons
-from modules.commons import init_weights, get_padding
-
-
-LRELU_SLOPE = 0.1
-
-
-class LayerNorm(nn.Module):
- def __init__(self, channels, eps=1e-5):
- super().__init__()
- self.channels = channels
- self.eps = eps
-
- self.gamma = nn.Parameter(torch.ones(channels))
- self.beta = nn.Parameter(torch.zeros(channels))
-
- def forward(self, x):
- x = x.transpose(1, -1)
- x = F.layer_norm(x, (self.channels,), self.gamma, self.beta, self.eps)
- return x.transpose(1, -1)
-
-
-class ConvReluNorm(nn.Module):
- def __init__(self, in_channels, hidden_channels, out_channels, kernel_size, n_layers, p_dropout):
- super().__init__()
- self.in_channels = in_channels
- self.hidden_channels = hidden_channels
- self.out_channels = out_channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.p_dropout = p_dropout
- assert n_layers > 1, "Number of layers should be larger than 0."
-
- self.conv_layers = nn.ModuleList()
- self.norm_layers = nn.ModuleList()
- self.conv_layers.append(nn.Conv1d(in_channels, hidden_channels, kernel_size, padding=kernel_size//2))
- self.norm_layers.append(LayerNorm(hidden_channels))
- self.relu_drop = nn.Sequential(
- nn.ReLU(),
- nn.Dropout(p_dropout))
- for _ in range(n_layers-1):
- self.conv_layers.append(nn.Conv1d(hidden_channels, hidden_channels, kernel_size, padding=kernel_size//2))
- self.norm_layers.append(LayerNorm(hidden_channels))
- self.proj = nn.Conv1d(hidden_channels, out_channels, 1)
- self.proj.weight.data.zero_()
- self.proj.bias.data.zero_()
-
- def forward(self, x, x_mask):
- x_org = x
- for i in range(self.n_layers):
- x = self.conv_layers[i](x * x_mask)
- x = self.norm_layers[i](x)
- x = self.relu_drop(x)
- x = x_org + self.proj(x)
- return x * x_mask
-
-
-class DDSConv(nn.Module):
- """
- Dialted and Depth-Separable Convolution
- """
- def __init__(self, channels, kernel_size, n_layers, p_dropout=0.):
- super().__init__()
- self.channels = channels
- self.kernel_size = kernel_size
- self.n_layers = n_layers
- self.p_dropout = p_dropout
-
- self.drop = nn.Dropout(p_dropout)
- self.convs_sep = nn.ModuleList()
- self.convs_1x1 = nn.ModuleList()
- self.norms_1 = nn.ModuleList()
- self.norms_2 = nn.ModuleList()
- for i in range(n_layers):
- dilation = kernel_size ** i
- padding = (kernel_size * dilation - dilation) // 2
- self.convs_sep.append(nn.Conv1d(channels, channels, kernel_size,
- groups=channels, dilation=dilation, padding=padding
- ))
- self.convs_1x1.append(nn.Conv1d(channels, channels, 1))
- self.norms_1.append(LayerNorm(channels))
- self.norms_2.append(LayerNorm(channels))
-
- def forward(self, x, x_mask, g=None):
- if g is not None:
- x = x + g
- for i in range(self.n_layers):
- y = self.convs_sep[i](x * x_mask)
- y = self.norms_1[i](y)
- y = F.gelu(y)
- y = self.convs_1x1[i](y)
- y = self.norms_2[i](y)
- y = F.gelu(y)
- y = self.drop(y)
- x = x + y
- return x * x_mask
-
-
-class WN(torch.nn.Module):
- def __init__(self, hidden_channels, kernel_size, dilation_rate, n_layers, gin_channels=0, p_dropout=0):
- super(WN, self).__init__()
- assert(kernel_size % 2 == 1)
- self.hidden_channels =hidden_channels
- self.kernel_size = kernel_size,
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.gin_channels = gin_channels
- self.p_dropout = p_dropout
-
- self.in_layers = torch.nn.ModuleList()
- self.res_skip_layers = torch.nn.ModuleList()
- self.drop = nn.Dropout(p_dropout)
-
- if gin_channels != 0:
- cond_layer = torch.nn.Conv1d(gin_channels, 2*hidden_channels*n_layers, 1)
- self.cond_layer = torch.nn.utils.weight_norm(cond_layer, name='weight')
-
- for i in range(n_layers):
- dilation = dilation_rate ** i
- padding = int((kernel_size * dilation - dilation) / 2)
- in_layer = torch.nn.Conv1d(hidden_channels, 2*hidden_channels, kernel_size,
- dilation=dilation, padding=padding)
- in_layer = torch.nn.utils.weight_norm(in_layer, name='weight')
- self.in_layers.append(in_layer)
-
- # last one is not necessary
- if i < n_layers - 1:
- res_skip_channels = 2 * hidden_channels
- else:
- res_skip_channels = hidden_channels
-
- res_skip_layer = torch.nn.Conv1d(hidden_channels, res_skip_channels, 1)
- res_skip_layer = torch.nn.utils.weight_norm(res_skip_layer, name='weight')
- self.res_skip_layers.append(res_skip_layer)
-
- def forward(self, x, x_mask, g=None, **kwargs):
- output = torch.zeros_like(x)
- n_channels_tensor = torch.IntTensor([self.hidden_channels])
-
- if g is not None:
- g = self.cond_layer(g)
-
- for i in range(self.n_layers):
- x_in = self.in_layers[i](x)
- if g is not None:
- cond_offset = i * 2 * self.hidden_channels
- g_l = g[:,cond_offset:cond_offset+2*self.hidden_channels,:]
- else:
- g_l = torch.zeros_like(x_in)
-
- acts = commons.fused_add_tanh_sigmoid_multiply(
- x_in,
- g_l,
- n_channels_tensor)
- acts = self.drop(acts)
-
- res_skip_acts = self.res_skip_layers[i](acts)
- if i < self.n_layers - 1:
- res_acts = res_skip_acts[:,:self.hidden_channels,:]
- x = (x + res_acts) * x_mask
- output = output + res_skip_acts[:,self.hidden_channels:,:]
- else:
- output = output + res_skip_acts
- return output * x_mask
-
- def remove_weight_norm(self):
- if self.gin_channels != 0:
- torch.nn.utils.remove_weight_norm(self.cond_layer)
- for l in self.in_layers:
- torch.nn.utils.remove_weight_norm(l)
- for l in self.res_skip_layers:
- torch.nn.utils.remove_weight_norm(l)
-
-
-class ResBlock1(torch.nn.Module):
- def __init__(self, channels, kernel_size=3, dilation=(1, 3, 5)):
- super(ResBlock1, self).__init__()
- self.convs1 = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
- padding=get_padding(kernel_size, dilation[0]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
- padding=get_padding(kernel_size, dilation[1]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[2],
- padding=get_padding(kernel_size, dilation[2])))
- ])
- self.convs1.apply(init_weights)
-
- self.convs2 = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
- padding=get_padding(kernel_size, 1)))
- ])
- self.convs2.apply(init_weights)
-
- def forward(self, x, x_mask=None):
- for c1, c2 in zip(self.convs1, self.convs2):
- xt = F.leaky_relu(x, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c1(xt)
- xt = F.leaky_relu(xt, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c2(xt)
- x = xt + x
- if x_mask is not None:
- x = x * x_mask
- return x
-
- def remove_weight_norm(self):
- for l in self.convs1:
- remove_weight_norm(l)
- for l in self.convs2:
- remove_weight_norm(l)
-
-
-class ResBlock2(torch.nn.Module):
- def __init__(self, channels, kernel_size=3, dilation=(1, 3)):
- super(ResBlock2, self).__init__()
- self.convs = nn.ModuleList([
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
- padding=get_padding(kernel_size, dilation[0]))),
- weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
- padding=get_padding(kernel_size, dilation[1])))
- ])
- self.convs.apply(init_weights)
-
- def forward(self, x, x_mask=None):
- for c in self.convs:
- xt = F.leaky_relu(x, LRELU_SLOPE)
- if x_mask is not None:
- xt = xt * x_mask
- xt = c(xt)
- x = xt + x
- if x_mask is not None:
- x = x * x_mask
- return x
-
- def remove_weight_norm(self):
- for l in self.convs:
- remove_weight_norm(l)
-
-
-class Log(nn.Module):
- def forward(self, x, x_mask, reverse=False, **kwargs):
- if not reverse:
- y = torch.log(torch.clamp_min(x, 1e-5)) * x_mask
- logdet = torch.sum(-y, [1, 2])
- return y, logdet
- else:
- x = torch.exp(x) * x_mask
- return x
-
-
-class Flip(nn.Module):
- def forward(self, x, *args, reverse=False, **kwargs):
- x = torch.flip(x, [1])
- if not reverse:
- logdet = torch.zeros(x.size(0)).to(dtype=x.dtype, device=x.device)
- return x, logdet
- else:
- return x
-
-
-class ElementwiseAffine(nn.Module):
- def __init__(self, channels):
- super().__init__()
- self.channels = channels
- self.m = nn.Parameter(torch.zeros(channels,1))
- self.logs = nn.Parameter(torch.zeros(channels,1))
-
- def forward(self, x, x_mask, reverse=False, **kwargs):
- if not reverse:
- y = self.m + torch.exp(self.logs) * x
- y = y * x_mask
- logdet = torch.sum(self.logs * x_mask, [1,2])
- return y, logdet
- else:
- x = (x - self.m) * torch.exp(-self.logs) * x_mask
- return x
-
-
-class ResidualCouplingLayer(nn.Module):
- def __init__(self,
- channels,
- hidden_channels,
- kernel_size,
- dilation_rate,
- n_layers,
- p_dropout=0,
- gin_channels=0,
- mean_only=False):
- assert channels % 2 == 0, "channels should be divisible by 2"
- super().__init__()
- self.channels = channels
- self.hidden_channels = hidden_channels
- self.kernel_size = kernel_size
- self.dilation_rate = dilation_rate
- self.n_layers = n_layers
- self.half_channels = channels // 2
- self.mean_only = mean_only
-
- self.pre = nn.Conv1d(self.half_channels, hidden_channels, 1)
- self.enc = WN(hidden_channels, kernel_size, dilation_rate, n_layers, p_dropout=p_dropout, gin_channels=gin_channels)
- self.post = nn.Conv1d(hidden_channels, self.half_channels * (2 - mean_only), 1)
- self.post.weight.data.zero_()
- self.post.bias.data.zero_()
-
- def forward(self, x, x_mask, g=None, reverse=False):
- x0, x1 = torch.split(x, [self.half_channels]*2, 1)
- h = self.pre(x0) * x_mask
- h = self.enc(h, x_mask, g=g)
- stats = self.post(h) * x_mask
- if not self.mean_only:
- m, logs = torch.split(stats, [self.half_channels]*2, 1)
- else:
- m = stats
- logs = torch.zeros_like(m)
-
- if not reverse:
- x1 = m + x1 * torch.exp(logs) * x_mask
- x = torch.cat([x0, x1], 1)
- logdet = torch.sum(logs, [1,2])
- return x, logdet
- else:
- x1 = (x1 - m) * torch.exp(-logs) * x_mask
- x = torch.cat([x0, x1], 1)
- return x
diff --git a/spaces/badongtakla/ithaca/ithaca/util/text.py b/spaces/badongtakla/ithaca/ithaca/util/text.py
deleted file mode 100644
index 859e779398c17136c8279f57f86662710e1aa0db..0000000000000000000000000000000000000000
--- a/spaces/badongtakla/ithaca/ithaca/util/text.py
+++ /dev/null
@@ -1,186 +0,0 @@
-# Copyright 2021 the Ithaca Authors
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# https://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""Text processing functions."""
-
-import random
-import re
-import unicodedata
-
-import numpy as np
-
-
-def idx_to_text(idxs, alphabet, strip_sos=True, strip_pad=True):
- """Converts a list of indices to a string."""
- idxs = np.array(idxs)
- out = ''
- for i in range(idxs.size):
- idx = idxs[i]
- if strip_pad and idx == alphabet.pad_idx:
- break
- elif strip_sos and idx == alphabet.sos_idx:
- pass
- else:
- out += alphabet.idx2char[idx]
- return out
-
-
-def idx_to_text_batch(idxs, alphabet, lengths=None):
- """Converts batched lists of indices to strings."""
- b = []
- for i in range(idxs.shape[0]):
- idxs_i = idxs[i]
- if lengths:
- idxs_i = idxs_i[:lengths[i]]
- b.append(idx_to_text(idxs_i, alphabet))
- return b
-
-
-def random_mask_span(t, geometric_p=0.2, limit_chars=None):
- """Masks a span of sequential words."""
-
- # Obtain span indexes (indlusive)
- span_idx = [(ele.start(), ele.end()) for ele in re.finditer(r'[\w\s]+', t)]
- if not span_idx:
- return []
-
- # Select a span to mask
- span_start, span_end = random.choice(span_idx)
-
- # Sample a random span length using a geomteric distribution
- if geometric_p and limit_chars:
- span_len = np.clip(
- np.random.geometric(geometric_p),
- 1, min(limit_chars, span_end - span_start))
- elif geometric_p:
- span_len = np.clip(
- np.random.geometric(geometric_p),
- 1, span_end - span_start)
- elif limit_chars:
- span_len = min(limit_chars, span_end - span_start)
- else:
- raise ValueError('geometric_p or limit_chars should be set.')
-
- # Pick a random start index
- span_start = np.random.randint(span_start, span_end - span_len + 1)
- assert span_start + span_len <= span_end
-
- # Clip to limit chars
- if limit_chars is not None and span_len >= limit_chars:
- span_len = limit_chars
-
- # Create mask indices
- mask_idx = list(range(span_start, span_start + span_len))
-
- return mask_idx
-
-
-def random_sentence_swap(sentences, p):
- """Swaps sentences with probability p."""
-
- def swap_sentence(s):
- idx_1 = random.randint(0, len(s) - 1)
- idx_2 = idx_1
- counter = 0
-
- while idx_2 == idx_1:
- idx_2 = random.randint(0, len(s) - 1)
- counter += 1
- if counter > 3:
- return s
-
- s[idx_1], s[idx_2] = s[idx_2], s[idx_1]
- return s
-
- new_sentences = sentences.copy()
- n = int(p * len(sentences))
- for _ in range(n):
- new_sentences = swap_sentence(new_sentences)
-
- return new_sentences
-
-
-def random_word_delete(sentence, p):
- """Deletes a word from a sentence with probability p."""
-
- words = sentence.split(' ')
-
- # Return if one word.
- if len(words) == 1:
- return words[0]
-
- # Randomly delete words.
- new_words = []
- for word in words:
- if random.uniform(0, 1) > p:
- new_words.append(word)
-
- # If all words are removed return one.
- if not new_words:
- rand_int = random.randint(0, len(words) - 1)
- return words[rand_int]
-
- sentence = ' '.join(new_words)
-
- return sentence
-
-
-def random_word_swap(sentence, p):
- """Swaps words from a sentence with probability p."""
-
- def swap_word(new_words):
- idx_1 = random.randint(0, len(new_words) - 1)
- idx_2 = idx_1
- counter = 0
-
- while idx_2 == idx_1:
- idx_2 = random.randint(0, len(new_words) - 1)
- counter += 1
-
- if counter > 3:
- return new_words
-
- new_words[idx_1], new_words[idx_2] = new_words[idx_2], new_words[idx_1]
- return new_words
-
- words = sentence.split(' ')
-
- new_words = words.copy()
- n = int(p * len(words))
- for _ in range(n):
- new_words = swap_word(new_words)
-
- sentence = ' '.join(new_words)
-
- return sentence
-
-
-def strip_accents(s):
- return ''.join(
- c for c in unicodedata.normalize('NFD', s)
- if unicodedata.category(c) != 'Mn')
-
-
-def text_to_idx(t, alphabet):
- """Converts a string to character indices."""
- return np.array([alphabet.char2idx[c] for c in t], dtype=np.int32)
-
-
-def text_to_word_idx(t, alphabet):
- """Converts a string to word indices."""
- out = np.full(len(t), alphabet.word2idx[alphabet.unk], dtype=np.int32)
- for m in re.finditer(r'\w+', t):
- if m.group() in alphabet.word2idx:
- out[m.start():m.end()] = alphabet.word2idx[m.group()]
- return out
-
diff --git a/spaces/banana-projects/web3d/node_modules/three/build/three.js b/spaces/banana-projects/web3d/node_modules/three/build/three.js
deleted file mode 100644
index 56f738b35eb1c06ee148ec7ff30927acb88e378f..0000000000000000000000000000000000000000
--- a/spaces/banana-projects/web3d/node_modules/three/build/three.js
+++ /dev/null
@@ -1,48498 +0,0 @@
-(function (global, factory) {
- typeof exports === 'object' && typeof module !== 'undefined' ? factory(exports) :
- typeof define === 'function' && define.amd ? define(['exports'], factory) :
- (global = global || self, factory(global.THREE = {}));
-}(this, function (exports) { 'use strict';
-
- // Polyfills
-
- if ( Number.EPSILON === undefined ) {
-
- Number.EPSILON = Math.pow( 2, - 52 );
-
- }
-
- if ( Number.isInteger === undefined ) {
-
- // Missing in IE
- // https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Number/isInteger
-
- Number.isInteger = function ( value ) {
-
- return typeof value === 'number' && isFinite( value ) && Math.floor( value ) === value;
-
- };
-
- }
-
- //
-
- if ( Math.sign === undefined ) {
-
- // https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Math/sign
-
- Math.sign = function ( x ) {
-
- return ( x < 0 ) ? - 1 : ( x > 0 ) ? 1 : + x;
-
- };
-
- }
-
- if ( 'name' in Function.prototype === false ) {
-
- // Missing in IE
- // https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Function/name
-
- Object.defineProperty( Function.prototype, 'name', {
-
- get: function () {
-
- return this.toString().match( /^\s*function\s*([^\(\s]*)/ )[ 1 ];
-
- }
-
- } );
-
- }
-
- if ( Object.assign === undefined ) {
-
- // Missing in IE
- // https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Object/assign
-
- ( function () {
-
- Object.assign = function ( target ) {
-
- if ( target === undefined || target === null ) {
-
- throw new TypeError( 'Cannot convert undefined or null to object' );
-
- }
-
- var output = Object( target );
-
- for ( var index = 1; index < arguments.length; index ++ ) {
-
- var source = arguments[ index ];
-
- if ( source !== undefined && source !== null ) {
-
- for ( var nextKey in source ) {
-
- if ( Object.prototype.hasOwnProperty.call( source, nextKey ) ) {
-
- output[ nextKey ] = source[ nextKey ];
-
- }
-
- }
-
- }
-
- }
-
- return output;
-
- };
-
- } )();
-
- }
-
- /**
- * https://github.com/mrdoob/eventdispatcher.js/
- */
-
- function EventDispatcher() {}
-
- Object.assign( EventDispatcher.prototype, {
-
- addEventListener: function ( type, listener ) {
-
- if ( this._listeners === undefined ) this._listeners = {};
-
- var listeners = this._listeners;
-
- if ( listeners[ type ] === undefined ) {
-
- listeners[ type ] = [];
-
- }
-
- if ( listeners[ type ].indexOf( listener ) === - 1 ) {
-
- listeners[ type ].push( listener );
-
- }
-
- },
-
- hasEventListener: function ( type, listener ) {
-
- if ( this._listeners === undefined ) return false;
-
- var listeners = this._listeners;
-
- return listeners[ type ] !== undefined && listeners[ type ].indexOf( listener ) !== - 1;
-
- },
-
- removeEventListener: function ( type, listener ) {
-
- if ( this._listeners === undefined ) return;
-
- var listeners = this._listeners;
- var listenerArray = listeners[ type ];
-
- if ( listenerArray !== undefined ) {
-
- var index = listenerArray.indexOf( listener );
-
- if ( index !== - 1 ) {
-
- listenerArray.splice( index, 1 );
-
- }
-
- }
-
- },
-
- dispatchEvent: function ( event ) {
-
- if ( this._listeners === undefined ) return;
-
- var listeners = this._listeners;
- var listenerArray = listeners[ event.type ];
-
- if ( listenerArray !== undefined ) {
-
- event.target = this;
-
- var array = listenerArray.slice( 0 );
-
- for ( var i = 0, l = array.length; i < l; i ++ ) {
-
- array[ i ].call( this, event );
-
- }
-
- }
-
- }
-
- } );
-
- var REVISION = '103';
- var MOUSE = { LEFT: 0, MIDDLE: 1, RIGHT: 2 };
- var CullFaceNone = 0;
- var CullFaceBack = 1;
- var CullFaceFront = 2;
- var CullFaceFrontBack = 3;
- var FrontFaceDirectionCW = 0;
- var FrontFaceDirectionCCW = 1;
- var BasicShadowMap = 0;
- var PCFShadowMap = 1;
- var PCFSoftShadowMap = 2;
- var FrontSide = 0;
- var BackSide = 1;
- var DoubleSide = 2;
- var FlatShading = 1;
- var SmoothShading = 2;
- var NoColors = 0;
- var FaceColors = 1;
- var VertexColors = 2;
- var NoBlending = 0;
- var NormalBlending = 1;
- var AdditiveBlending = 2;
- var SubtractiveBlending = 3;
- var MultiplyBlending = 4;
- var CustomBlending = 5;
- var AddEquation = 100;
- var SubtractEquation = 101;
- var ReverseSubtractEquation = 102;
- var MinEquation = 103;
- var MaxEquation = 104;
- var ZeroFactor = 200;
- var OneFactor = 201;
- var SrcColorFactor = 202;
- var OneMinusSrcColorFactor = 203;
- var SrcAlphaFactor = 204;
- var OneMinusSrcAlphaFactor = 205;
- var DstAlphaFactor = 206;
- var OneMinusDstAlphaFactor = 207;
- var DstColorFactor = 208;
- var OneMinusDstColorFactor = 209;
- var SrcAlphaSaturateFactor = 210;
- var NeverDepth = 0;
- var AlwaysDepth = 1;
- var LessDepth = 2;
- var LessEqualDepth = 3;
- var EqualDepth = 4;
- var GreaterEqualDepth = 5;
- var GreaterDepth = 6;
- var NotEqualDepth = 7;
- var MultiplyOperation = 0;
- var MixOperation = 1;
- var AddOperation = 2;
- var NoToneMapping = 0;
- var LinearToneMapping = 1;
- var ReinhardToneMapping = 2;
- var Uncharted2ToneMapping = 3;
- var CineonToneMapping = 4;
- var ACESFilmicToneMapping = 5;
-
- var UVMapping = 300;
- var CubeReflectionMapping = 301;
- var CubeRefractionMapping = 302;
- var EquirectangularReflectionMapping = 303;
- var EquirectangularRefractionMapping = 304;
- var SphericalReflectionMapping = 305;
- var CubeUVReflectionMapping = 306;
- var CubeUVRefractionMapping = 307;
- var RepeatWrapping = 1000;
- var ClampToEdgeWrapping = 1001;
- var MirroredRepeatWrapping = 1002;
- var NearestFilter = 1003;
- var NearestMipMapNearestFilter = 1004;
- var NearestMipMapLinearFilter = 1005;
- var LinearFilter = 1006;
- var LinearMipMapNearestFilter = 1007;
- var LinearMipMapLinearFilter = 1008;
- var UnsignedByteType = 1009;
- var ByteType = 1010;
- var ShortType = 1011;
- var UnsignedShortType = 1012;
- var IntType = 1013;
- var UnsignedIntType = 1014;
- var FloatType = 1015;
- var HalfFloatType = 1016;
- var UnsignedShort4444Type = 1017;
- var UnsignedShort5551Type = 1018;
- var UnsignedShort565Type = 1019;
- var UnsignedInt248Type = 1020;
- var AlphaFormat = 1021;
- var RGBFormat = 1022;
- var RGBAFormat = 1023;
- var LuminanceFormat = 1024;
- var LuminanceAlphaFormat = 1025;
- var RGBEFormat = RGBAFormat;
- var DepthFormat = 1026;
- var DepthStencilFormat = 1027;
- var RedFormat = 1028;
- var RGB_S3TC_DXT1_Format = 33776;
- var RGBA_S3TC_DXT1_Format = 33777;
- var RGBA_S3TC_DXT3_Format = 33778;
- var RGBA_S3TC_DXT5_Format = 33779;
- var RGB_PVRTC_4BPPV1_Format = 35840;
- var RGB_PVRTC_2BPPV1_Format = 35841;
- var RGBA_PVRTC_4BPPV1_Format = 35842;
- var RGBA_PVRTC_2BPPV1_Format = 35843;
- var RGB_ETC1_Format = 36196;
- var RGBA_ASTC_4x4_Format = 37808;
- var RGBA_ASTC_5x4_Format = 37809;
- var RGBA_ASTC_5x5_Format = 37810;
- var RGBA_ASTC_6x5_Format = 37811;
- var RGBA_ASTC_6x6_Format = 37812;
- var RGBA_ASTC_8x5_Format = 37813;
- var RGBA_ASTC_8x6_Format = 37814;
- var RGBA_ASTC_8x8_Format = 37815;
- var RGBA_ASTC_10x5_Format = 37816;
- var RGBA_ASTC_10x6_Format = 37817;
- var RGBA_ASTC_10x8_Format = 37818;
- var RGBA_ASTC_10x10_Format = 37819;
- var RGBA_ASTC_12x10_Format = 37820;
- var RGBA_ASTC_12x12_Format = 37821;
- var LoopOnce = 2200;
- var LoopRepeat = 2201;
- var LoopPingPong = 2202;
- var InterpolateDiscrete = 2300;
- var InterpolateLinear = 2301;
- var InterpolateSmooth = 2302;
- var ZeroCurvatureEnding = 2400;
- var ZeroSlopeEnding = 2401;
- var WrapAroundEnding = 2402;
- var TrianglesDrawMode = 0;
- var TriangleStripDrawMode = 1;
- var TriangleFanDrawMode = 2;
- var LinearEncoding = 3000;
- var sRGBEncoding = 3001;
- var GammaEncoding = 3007;
- var RGBEEncoding = 3002;
- var LogLuvEncoding = 3003;
- var RGBM7Encoding = 3004;
- var RGBM16Encoding = 3005;
- var RGBDEncoding = 3006;
- var BasicDepthPacking = 3200;
- var RGBADepthPacking = 3201;
- var TangentSpaceNormalMap = 0;
- var ObjectSpaceNormalMap = 1;
-
- /**
- * @author alteredq / http://alteredqualia.com/
- * @author mrdoob / http://mrdoob.com/
- */
-
- var _Math = {
-
- DEG2RAD: Math.PI / 180,
- RAD2DEG: 180 / Math.PI,
-
- generateUUID: ( function () {
-
- // http://stackoverflow.com/questions/105034/how-to-create-a-guid-uuid-in-javascript/21963136#21963136
-
- var lut = [];
-
- for ( var i = 0; i < 256; i ++ ) {
-
- lut[ i ] = ( i < 16 ? '0' : '' ) + ( i ).toString( 16 );
-
- }
-
- return function generateUUID() {
-
- var d0 = Math.random() * 0xffffffff | 0;
- var d1 = Math.random() * 0xffffffff | 0;
- var d2 = Math.random() * 0xffffffff | 0;
- var d3 = Math.random() * 0xffffffff | 0;
- var uuid = lut[ d0 & 0xff ] + lut[ d0 >> 8 & 0xff ] + lut[ d0 >> 16 & 0xff ] + lut[ d0 >> 24 & 0xff ] + '-' +
- lut[ d1 & 0xff ] + lut[ d1 >> 8 & 0xff ] + '-' + lut[ d1 >> 16 & 0x0f | 0x40 ] + lut[ d1 >> 24 & 0xff ] + '-' +
- lut[ d2 & 0x3f | 0x80 ] + lut[ d2 >> 8 & 0xff ] + '-' + lut[ d2 >> 16 & 0xff ] + lut[ d2 >> 24 & 0xff ] +
- lut[ d3 & 0xff ] + lut[ d3 >> 8 & 0xff ] + lut[ d3 >> 16 & 0xff ] + lut[ d3 >> 24 & 0xff ];
-
- // .toUpperCase() here flattens concatenated strings to save heap memory space.
- return uuid.toUpperCase();
-
- };
-
- } )(),
-
- clamp: function ( value, min, max ) {
-
- return Math.max( min, Math.min( max, value ) );
-
- },
-
- // compute euclidian modulo of m % n
- // https://en.wikipedia.org/wiki/Modulo_operation
-
- euclideanModulo: function ( n, m ) {
-
- return ( ( n % m ) + m ) % m;
-
- },
-
- // Linear mapping from range to range
-
- mapLinear: function ( x, a1, a2, b1, b2 ) {
-
- return b1 + ( x - a1 ) * ( b2 - b1 ) / ( a2 - a1 );
-
- },
-
- // https://en.wikipedia.org/wiki/Linear_interpolation
-
- lerp: function ( x, y, t ) {
-
- return ( 1 - t ) * x + t * y;
-
- },
-
- // http://en.wikipedia.org/wiki/Smoothstep
-
- smoothstep: function ( x, min, max ) {
-
- if ( x <= min ) return 0;
- if ( x >= max ) return 1;
-
- x = ( x - min ) / ( max - min );
-
- return x * x * ( 3 - 2 * x );
-
- },
-
- smootherstep: function ( x, min, max ) {
-
- if ( x <= min ) return 0;
- if ( x >= max ) return 1;
-
- x = ( x - min ) / ( max - min );
-
- return x * x * x * ( x * ( x * 6 - 15 ) + 10 );
-
- },
-
- // Random integer from interval
-
- randInt: function ( low, high ) {
-
- return low + Math.floor( Math.random() * ( high - low + 1 ) );
-
- },
-
- // Random float from interval
-
- randFloat: function ( low, high ) {
-
- return low + Math.random() * ( high - low );
-
- },
-
- // Random float from <-range/2, range/2> interval
-
- randFloatSpread: function ( range ) {
-
- return range * ( 0.5 - Math.random() );
-
- },
-
- degToRad: function ( degrees ) {
-
- return degrees * _Math.DEG2RAD;
-
- },
-
- radToDeg: function ( radians ) {
-
- return radians * _Math.RAD2DEG;
-
- },
-
- isPowerOfTwo: function ( value ) {
-
- return ( value & ( value - 1 ) ) === 0 && value !== 0;
-
- },
-
- ceilPowerOfTwo: function ( value ) {
-
- return Math.pow( 2, Math.ceil( Math.log( value ) / Math.LN2 ) );
-
- },
-
- floorPowerOfTwo: function ( value ) {
-
- return Math.pow( 2, Math.floor( Math.log( value ) / Math.LN2 ) );
-
- }
-
- };
-
- /**
- * @author mrdoob / http://mrdoob.com/
- * @author philogb / http://blog.thejit.org/
- * @author egraether / http://egraether.com/
- * @author zz85 / http://www.lab4games.net/zz85/blog
- */
-
- function Vector2( x, y ) {
-
- this.x = x || 0;
- this.y = y || 0;
-
- }
-
- Object.defineProperties( Vector2.prototype, {
-
- "width": {
-
- get: function () {
-
- return this.x;
-
- },
-
- set: function ( value ) {
-
- this.x = value;
-
- }
-
- },
-
- "height": {
-
- get: function () {
-
- return this.y;
-
- },
-
- set: function ( value ) {
-
- this.y = value;
-
- }
-
- }
-
- } );
-
- Object.assign( Vector2.prototype, {
-
- isVector2: true,
-
- set: function ( x, y ) {
-
- this.x = x;
- this.y = y;
-
- return this;
-
- },
-
- setScalar: function ( scalar ) {
-
- this.x = scalar;
- this.y = scalar;
-
- return this;
-
- },
-
- setX: function ( x ) {
-
- this.x = x;
-
- return this;
-
- },
-
- setY: function ( y ) {
-
- this.y = y;
-
- return this;
-
- },
-
- setComponent: function ( index, value ) {
-
- switch ( index ) {
-
- case 0: this.x = value; break;
- case 1: this.y = value; break;
- default: throw new Error( 'index is out of range: ' + index );
-
- }
-
- return this;
-
- },
-
- getComponent: function ( index ) {
-
- switch ( index ) {
-
- case 0: return this.x;
- case 1: return this.y;
- default: throw new Error( 'index is out of range: ' + index );
-
- }
-
- },
-
- clone: function () {
-
- return new this.constructor( this.x, this.y );
-
- },
-
- copy: function ( v ) {
-
- this.x = v.x;
- this.y = v.y;
-
- return this;
-
- },
-
- add: function ( v, w ) {
-
- if ( w !== undefined ) {
-
- console.warn( 'THREE.Vector2: .add() now only accepts one argument. Use .addVectors( a, b ) instead.' );
- return this.addVectors( v, w );
-
- }
-
- this.x += v.x;
- this.y += v.y;
-
- return this;
-
- },
-
- addScalar: function ( s ) {
-
- this.x += s;
- this.y += s;
-
- return this;
-
- },
-
- addVectors: function ( a, b ) {
-
- this.x = a.x + b.x;
- this.y = a.y + b.y;
-
- return this;
-
- },
-
- addScaledVector: function ( v, s ) {
-
- this.x += v.x * s;
- this.y += v.y * s;
-
- return this;
-
- },
-
- sub: function ( v, w ) {
-
- if ( w !== undefined ) {
-
- console.warn( 'THREE.Vector2: .sub() now only accepts one argument. Use .subVectors( a, b ) instead.' );
- return this.subVectors( v, w );
-
- }
-
- this.x -= v.x;
- this.y -= v.y;
-
- return this;
-
- },
-
- subScalar: function ( s ) {
-
- this.x -= s;
- this.y -= s;
-
- return this;
-
- },
-
- subVectors: function ( a, b ) {
-
- this.x = a.x - b.x;
- this.y = a.y - b.y;
-
- return this;
-
- },
-
- multiply: function ( v ) {
-
- this.x *= v.x;
- this.y *= v.y;
-
- return this;
-
- },
-
- multiplyScalar: function ( scalar ) {
-
- this.x *= scalar;
- this.y *= scalar;
-
- return this;
-
- },
-
- divide: function ( v ) {
-
- this.x /= v.x;
- this.y /= v.y;
-
- return this;
-
- },
-
- divideScalar: function ( scalar ) {
-
- return this.multiplyScalar( 1 / scalar );
-
- },
-
- applyMatrix3: function ( m ) {
-
- var x = this.x, y = this.y;
- var e = m.elements;
-
- this.x = e[ 0 ] * x + e[ 3 ] * y + e[ 6 ];
- this.y = e[ 1 ] * x + e[ 4 ] * y + e[ 7 ];
-
- return this;
-
- },
-
- min: function ( v ) {
-
- this.x = Math.min( this.x, v.x );
- this.y = Math.min( this.y, v.y );
-
- return this;
-
- },
-
- max: function ( v ) {
-
- this.x = Math.max( this.x, v.x );
- this.y = Math.max( this.y, v.y );
-
- return this;
-
- },
-
- clamp: function ( min, max ) {
-
- // assumes min < max, componentwise
-
- this.x = Math.max( min.x, Math.min( max.x, this.x ) );
- this.y = Math.max( min.y, Math.min( max.y, this.y ) );
-
- return this;
-
- },
-
- clampScalar: function () {
-
- var min = new Vector2();
- var max = new Vector2();
-
- return function clampScalar( minVal, maxVal ) {
-
- min.set( minVal, minVal );
- max.set( maxVal, maxVal );
-
- return this.clamp( min, max );
-
- };
-
- }(),
-
- clampLength: function ( min, max ) {
-
- var length = this.length();
-
- return this.divideScalar( length || 1 ).multiplyScalar( Math.max( min, Math.min( max, length ) ) );
-
- },
-
- floor: function () {
-
- this.x = Math.floor( this.x );
- this.y = Math.floor( this.y );
-
- return this;
-
- },
-
- ceil: function () {
-
- this.x = Math.ceil( this.x );
- this.y = Math.ceil( this.y );
-
- return this;
-
- },
-
- round: function () {
-
- this.x = Math.round( this.x );
- this.y = Math.round( this.y );
-
- return this;
-
- },
-
- roundToZero: function () {
-
- this.x = ( this.x < 0 ) ? Math.ceil( this.x ) : Math.floor( this.x );
- this.y = ( this.y < 0 ) ? Math.ceil( this.y ) : Math.floor( this.y );
-
- return this;
-
- },
-
- negate: function () {
-
- this.x = - this.x;
- this.y = - this.y;
-
- return this;
-
- },
-
- dot: function ( v ) {
-
- return this.x * v.x + this.y * v.y;
-
- },
-
- cross: function ( v ) {
-
- return this.x * v.y - this.y * v.x;
-
- },
-
- lengthSq: function () {
-
- return this.x * this.x + this.y * this.y;
-
- },
-
- length: function () {
-
- return Math.sqrt( this.x * this.x + this.y * this.y );
-
- },
-
- manhattanLength: function () {
-
- return Math.abs( this.x ) + Math.abs( this.y );
-
- },
-
- normalize: function () {
-
- return this.divideScalar( this.length() || 1 );
-
- },
-
- angle: function () {
-
- // computes the angle in radians with respect to the positive x-axis
-
- var angle = Math.atan2( this.y, this.x );
-
- if ( angle < 0 ) angle += 2 * Math.PI;
-
- return angle;
-
- },
-
- distanceTo: function ( v ) {
-
- return Math.sqrt( this.distanceToSquared( v ) );
-
- },
-
- distanceToSquared: function ( v ) {
-
- var dx = this.x - v.x, dy = this.y - v.y;
- return dx * dx + dy * dy;
-
- },
-
- manhattanDistanceTo: function ( v ) {
-
- return Math.abs( this.x - v.x ) + Math.abs( this.y - v.y );
-
- },
-
- setLength: function ( length ) {
-
- return this.normalize().multiplyScalar( length );
-
- },
-
- lerp: function ( v, alpha ) {
-
- this.x += ( v.x - this.x ) * alpha;
- this.y += ( v.y - this.y ) * alpha;
-
- return this;
-
- },
-
- lerpVectors: function ( v1, v2, alpha ) {
-
- return this.subVectors( v2, v1 ).multiplyScalar( alpha ).add( v1 );
-
- },
-
- equals: function ( v ) {
-
- return ( ( v.x === this.x ) && ( v.y === this.y ) );
-
- },
-
- fromArray: function ( array, offset ) {
-
- if ( offset === undefined ) offset = 0;
-
- this.x = array[ offset ];
- this.y = array[ offset + 1 ];
-
- return this;
-
- },
-
- toArray: function ( array, offset ) {
-
- if ( array === undefined ) array = [];
- if ( offset === undefined ) offset = 0;
-
- array[ offset ] = this.x;
- array[ offset + 1 ] = this.y;
-
- return array;
-
- },
-
- fromBufferAttribute: function ( attribute, index, offset ) {
-
- if ( offset !== undefined ) {
-
- console.warn( 'THREE.Vector2: offset has been removed from .fromBufferAttribute().' );
-
- }
-
- this.x = attribute.getX( index );
- this.y = attribute.getY( index );
-
- return this;
-
- },
-
- rotateAround: function ( center, angle ) {
-
- var c = Math.cos( angle ), s = Math.sin( angle );
-
- var x = this.x - center.x;
- var y = this.y - center.y;
-
- this.x = x * c - y * s + center.x;
- this.y = x * s + y * c + center.y;
-
- return this;
-
- }
-
- } );
-
- /**
- * @author mikael emtinger / http://gomo.se/
- * @author alteredq / http://alteredqualia.com/
- * @author WestLangley / http://github.com/WestLangley
- * @author bhouston / http://clara.io
- */
-
- function Quaternion( x, y, z, w ) {
-
- this._x = x || 0;
- this._y = y || 0;
- this._z = z || 0;
- this._w = ( w !== undefined ) ? w : 1;
-
- }
-
- Object.assign( Quaternion, {
-
- slerp: function ( qa, qb, qm, t ) {
-
- return qm.copy( qa ).slerp( qb, t );
-
- },
-
- slerpFlat: function ( dst, dstOffset, src0, srcOffset0, src1, srcOffset1, t ) {
-
- // fuzz-free, array-based Quaternion SLERP operation
-
- var x0 = src0[ srcOffset0 + 0 ],
- y0 = src0[ srcOffset0 + 1 ],
- z0 = src0[ srcOffset0 + 2 ],
- w0 = src0[ srcOffset0 + 3 ],
-
- x1 = src1[ srcOffset1 + 0 ],
- y1 = src1[ srcOffset1 + 1 ],
- z1 = src1[ srcOffset1 + 2 ],
- w1 = src1[ srcOffset1 + 3 ];
-
- if ( w0 !== w1 || x0 !== x1 || y0 !== y1 || z0 !== z1 ) {
-
- var s = 1 - t,
-
- cos = x0 * x1 + y0 * y1 + z0 * z1 + w0 * w1,
-
- dir = ( cos >= 0 ? 1 : - 1 ),
- sqrSin = 1 - cos * cos;
-
- // Skip the Slerp for tiny steps to avoid numeric problems:
- if ( sqrSin > Number.EPSILON ) {
-
- var sin = Math.sqrt( sqrSin ),
- len = Math.atan2( sin, cos * dir );
-
- s = Math.sin( s * len ) / sin;
- t = Math.sin( t * len ) / sin;
-
- }
-
- var tDir = t * dir;
-
- x0 = x0 * s + x1 * tDir;
- y0 = y0 * s + y1 * tDir;
- z0 = z0 * s + z1 * tDir;
- w0 = w0 * s + w1 * tDir;
-
- // Normalize in case we just did a lerp:
- if ( s === 1 - t ) {
-
- var f = 1 / Math.sqrt( x0 * x0 + y0 * y0 + z0 * z0 + w0 * w0 );
-
- x0 *= f;
- y0 *= f;
- z0 *= f;
- w0 *= f;
-
- }
-
- }
-
- dst[ dstOffset ] = x0;
- dst[ dstOffset + 1 ] = y0;
- dst[ dstOffset + 2 ] = z0;
- dst[ dstOffset + 3 ] = w0;
-
- }
-
- } );
-
- Object.defineProperties( Quaternion.prototype, {
-
- x: {
-
- get: function () {
-
- return this._x;
-
- },
-
- set: function ( value ) {
-
- this._x = value;
- this.onChangeCallback();
-
- }
-
- },
-
- y: {
-
- get: function () {
-
- return this._y;
-
- },
-
- set: function ( value ) {
-
- this._y = value;
- this.onChangeCallback();
-
- }
-
- },
-
- z: {
-
- get: function () {
-
- return this._z;
-
- },
-
- set: function ( value ) {
-
- this._z = value;
- this.onChangeCallback();
-
- }
-
- },
-
- w: {
-
- get: function () {
-
- return this._w;
-
- },
-
- set: function ( value ) {
-
- this._w = value;
- this.onChangeCallback();
-
- }
-
- }
-
- } );
-
- Object.assign( Quaternion.prototype, {
-
- isQuaternion: true,
-
- set: function ( x, y, z, w ) {
-
- this._x = x;
- this._y = y;
- this._z = z;
- this._w = w;
-
- this.onChangeCallback();
-
- return this;
-
- },
-
- clone: function () {
-
- return new this.constructor( this._x, this._y, this._z, this._w );
-
- },
-
- copy: function ( quaternion ) {
-
- this._x = quaternion.x;
- this._y = quaternion.y;
- this._z = quaternion.z;
- this._w = quaternion.w;
-
- this.onChangeCallback();
-
- return this;
-
- },
-
- setFromEuler: function ( euler, update ) {
-
- if ( ! ( euler && euler.isEuler ) ) {
-
- throw new Error( 'THREE.Quaternion: .setFromEuler() now expects an Euler rotation rather than a Vector3 and order.' );
-
- }
-
- var x = euler._x, y = euler._y, z = euler._z, order = euler.order;
-
- // http://www.mathworks.com/matlabcentral/fileexchange/
- // 20696-function-to-convert-between-dcm-euler-angles-quaternions-and-euler-vectors/
- // content/SpinCalc.m
-
- var cos = Math.cos;
- var sin = Math.sin;
-
- var c1 = cos( x / 2 );
- var c2 = cos( y / 2 );
- var c3 = cos( z / 2 );
-
- var s1 = sin( x / 2 );
- var s2 = sin( y / 2 );
- var s3 = sin( z / 2 );
-
- if ( order === 'XYZ' ) {
-
- this._x = s1 * c2 * c3 + c1 * s2 * s3;
- this._y = c1 * s2 * c3 - s1 * c2 * s3;
- this._z = c1 * c2 * s3 + s1 * s2 * c3;
- this._w = c1 * c2 * c3 - s1 * s2 * s3;
-
- } else if ( order === 'YXZ' ) {
-
- this._x = s1 * c2 * c3 + c1 * s2 * s3;
- this._y = c1 * s2 * c3 - s1 * c2 * s3;
- this._z = c1 * c2 * s3 - s1 * s2 * c3;
- this._w = c1 * c2 * c3 + s1 * s2 * s3;
-
- } else if ( order === 'ZXY' ) {
-
- this._x = s1 * c2 * c3 - c1 * s2 * s3;
- this._y = c1 * s2 * c3 + s1 * c2 * s3;
- this._z = c1 * c2 * s3 + s1 * s2 * c3;
- this._w = c1 * c2 * c3 - s1 * s2 * s3;
-
- } else if ( order === 'ZYX' ) {
-
- this._x = s1 * c2 * c3 - c1 * s2 * s3;
- this._y = c1 * s2 * c3 + s1 * c2 * s3;
- this._z = c1 * c2 * s3 - s1 * s2 * c3;
- this._w = c1 * c2 * c3 + s1 * s2 * s3;
-
- } else if ( order === 'YZX' ) {
-
- this._x = s1 * c2 * c3 + c1 * s2 * s3;
- this._y = c1 * s2 * c3 + s1 * c2 * s3;
- this._z = c1 * c2 * s3 - s1 * s2 * c3;
- this._w = c1 * c2 * c3 - s1 * s2 * s3;
-
- } else if ( order === 'XZY' ) {
-
- this._x = s1 * c2 * c3 - c1 * s2 * s3;
- this._y = c1 * s2 * c3 - s1 * c2 * s3;
- this._z = c1 * c2 * s3 + s1 * s2 * c3;
- this._w = c1 * c2 * c3 + s1 * s2 * s3;
-
- }
-
- if ( update !== false ) this.onChangeCallback();
-
- return this;
-
- },
-
- setFromAxisAngle: function ( axis, angle ) {
-
- // http://www.euclideanspace.com/maths/geometry/rotations/conversions/angleToQuaternion/index.htm
-
- // assumes axis is normalized
-
- var halfAngle = angle / 2, s = Math.sin( halfAngle );
-
- this._x = axis.x * s;
- this._y = axis.y * s;
- this._z = axis.z * s;
- this._w = Math.cos( halfAngle );
-
- this.onChangeCallback();
-
- return this;
-
- },
-
- setFromRotationMatrix: function ( m ) {
-
- // http://www.euclideanspace.com/maths/geometry/rotations/conversions/matrixToQuaternion/index.htm
-
- // assumes the upper 3x3 of m is a pure rotation matrix (i.e, unscaled)
-
- var te = m.elements,
-
- m11 = te[ 0 ], m12 = te[ 4 ], m13 = te[ 8 ],
- m21 = te[ 1 ], m22 = te[ 5 ], m23 = te[ 9 ],
- m31 = te[ 2 ], m32 = te[ 6 ], m33 = te[ 10 ],
-
- trace = m11 + m22 + m33,
- s;
-
- if ( trace > 0 ) {
-
- s = 0.5 / Math.sqrt( trace + 1.0 );
-
- this._w = 0.25 / s;
- this._x = ( m32 - m23 ) * s;
- this._y = ( m13 - m31 ) * s;
- this._z = ( m21 - m12 ) * s;
-
- } else if ( m11 > m22 && m11 > m33 ) {
-
- s = 2.0 * Math.sqrt( 1.0 + m11 - m22 - m33 );
-
- this._w = ( m32 - m23 ) / s;
- this._x = 0.25 * s;
- this._y = ( m12 + m21 ) / s;
- this._z = ( m13 + m31 ) / s;
-
- } else if ( m22 > m33 ) {
-
- s = 2.0 * Math.sqrt( 1.0 + m22 - m11 - m33 );
-
- this._w = ( m13 - m31 ) / s;
- this._x = ( m12 + m21 ) / s;
- this._y = 0.25 * s;
- this._z = ( m23 + m32 ) / s;
-
- } else {
-
- s = 2.0 * Math.sqrt( 1.0 + m33 - m11 - m22 );
-
- this._w = ( m21 - m12 ) / s;
- this._x = ( m13 + m31 ) / s;
- this._y = ( m23 + m32 ) / s;
- this._z = 0.25 * s;
-
- }
-
- this.onChangeCallback();
-
- return this;
-
- },
-
- setFromUnitVectors: function ( vFrom, vTo ) {
-
- // assumes direction vectors vFrom and vTo are normalized
-
- var EPS = 0.000001;
-
- var r = vFrom.dot( vTo ) + 1;
-
- if ( r < EPS ) {
-
- r = 0;
-
- if ( Math.abs( vFrom.x ) > Math.abs( vFrom.z ) ) {
-
- this._x = - vFrom.y;
- this._y = vFrom.x;
- this._z = 0;
- this._w = r;
-
- } else {
-
- this._x = 0;
- this._y = - vFrom.z;
- this._z = vFrom.y;
- this._w = r;
-
- }
-
- } else {
-
- // crossVectors( vFrom, vTo ); // inlined to avoid cyclic dependency on Vector3
-
- this._x = vFrom.y * vTo.z - vFrom.z * vTo.y;
- this._y = vFrom.z * vTo.x - vFrom.x * vTo.z;
- this._z = vFrom.x * vTo.y - vFrom.y * vTo.x;
- this._w = r;
-
- }
-
- return this.normalize();
-
- },
-
- angleTo: function ( q ) {
-
- return 2 * Math.acos( Math.abs( _Math.clamp( this.dot( q ), - 1, 1 ) ) );
-
- },
-
- rotateTowards: function ( q, step ) {
-
- var angle = this.angleTo( q );
-
- if ( angle === 0 ) return this;
-
- var t = Math.min( 1, step / angle );
-
- this.slerp( q, t );
-
- return this;
-
- },
-
- inverse: function () {
-
- // quaternion is assumed to have unit length
-
- return this.conjugate();
-
- },
-
- conjugate: function () {
-
- this._x *= - 1;
- this._y *= - 1;
- this._z *= - 1;
-
- this.onChangeCallback();
-
- return this;
-
- },
-
- dot: function ( v ) {
-
- return this._x * v._x + this._y * v._y + this._z * v._z + this._w * v._w;
-
- },
-
- lengthSq: function () {
-
- return this._x * this._x + this._y * this._y + this._z * this._z + this._w * this._w;
-
- },
-
- length: function () {
-
- return Math.sqrt( this._x * this._x + this._y * this._y + this._z * this._z + this._w * this._w );
-
- },
-
- normalize: function () {
-
- var l = this.length();
-
- if ( l === 0 ) {
-
- this._x = 0;
- this._y = 0;
- this._z = 0;
- this._w = 1;
-
- } else {
-
- l = 1 / l;
-
- this._x = this._x * l;
- this._y = this._y * l;
- this._z = this._z * l;
- this._w = this._w * l;
-
- }
-
- this.onChangeCallback();
-
- return this;
-
- },
-
- multiply: function ( q, p ) {
-
- if ( p !== undefined ) {
-
- console.warn( 'THREE.Quaternion: .multiply() now only accepts one argument. Use .multiplyQuaternions( a, b ) instead.' );
- return this.multiplyQuaternions( q, p );
-
- }
-
- return this.multiplyQuaternions( this, q );
-
- },
-
- premultiply: function ( q ) {
-
- return this.multiplyQuaternions( q, this );
-
- },
-
- multiplyQuaternions: function ( a, b ) {
-
- // from http://www.euclideanspace.com/maths/algebra/realNormedAlgebra/quaternions/code/index.htm
-
- var qax = a._x, qay = a._y, qaz = a._z, qaw = a._w;
- var qbx = b._x, qby = b._y, qbz = b._z, qbw = b._w;
-
- this._x = qax * qbw + qaw * qbx + qay * qbz - qaz * qby;
- this._y = qay * qbw + qaw * qby + qaz * qbx - qax * qbz;
- this._z = qaz * qbw + qaw * qbz + qax * qby - qay * qbx;
- this._w = qaw * qbw - qax * qbx - qay * qby - qaz * qbz;
-
- this.onChangeCallback();
-
- return this;
-
- },
-
- slerp: function ( qb, t ) {
-
- if ( t === 0 ) return this;
- if ( t === 1 ) return this.copy( qb );
-
- var x = this._x, y = this._y, z = this._z, w = this._w;
-
- // http://www.euclideanspace.com/maths/algebra/realNormedAlgebra/quaternions/slerp/
-
- var cosHalfTheta = w * qb._w + x * qb._x + y * qb._y + z * qb._z;
-
- if ( cosHalfTheta < 0 ) {
-
- this._w = - qb._w;
- this._x = - qb._x;
- this._y = - qb._y;
- this._z = - qb._z;
-
- cosHalfTheta = - cosHalfTheta;
-
- } else {
-
- this.copy( qb );
-
- }
-
- if ( cosHalfTheta >= 1.0 ) {
-
- this._w = w;
- this._x = x;
- this._y = y;
- this._z = z;
-
- return this;
-
- }
-
- var sqrSinHalfTheta = 1.0 - cosHalfTheta * cosHalfTheta;
-
- if ( sqrSinHalfTheta <= Number.EPSILON ) {
-
- var s = 1 - t;
- this._w = s * w + t * this._w;
- this._x = s * x + t * this._x;
- this._y = s * y + t * this._y;
- this._z = s * z + t * this._z;
-
- return this.normalize();
-
- }
-
- var sinHalfTheta = Math.sqrt( sqrSinHalfTheta );
- var halfTheta = Math.atan2( sinHalfTheta, cosHalfTheta );
- var ratioA = Math.sin( ( 1 - t ) * halfTheta ) / sinHalfTheta,
- ratioB = Math.sin( t * halfTheta ) / sinHalfTheta;
-
- this._w = ( w * ratioA + this._w * ratioB );
- this._x = ( x * ratioA + this._x * ratioB );
- this._y = ( y * ratioA + this._y * ratioB );
- this._z = ( z * ratioA + this._z * ratioB );
-
- this.onChangeCallback();
-
- return this;
-
- },
-
- equals: function ( quaternion ) {
-
- return ( quaternion._x === this._x ) && ( quaternion._y === this._y ) && ( quaternion._z === this._z ) && ( quaternion._w === this._w );
-
- },
-
- fromArray: function ( array, offset ) {
-
- if ( offset === undefined ) offset = 0;
-
- this._x = array[ offset ];
- this._y = array[ offset + 1 ];
- this._z = array[ offset + 2 ];
- this._w = array[ offset + 3 ];
-
- this.onChangeCallback();
-
- return this;
-
- },
-
- toArray: function ( array, offset ) {
-
- if ( array === undefined ) array = [];
- if ( offset === undefined ) offset = 0;
-
- array[ offset ] = this._x;
- array[ offset + 1 ] = this._y;
- array[ offset + 2 ] = this._z;
- array[ offset + 3 ] = this._w;
-
- return array;
-
- },
-
- onChange: function ( callback ) {
-
- this.onChangeCallback = callback;
-
- return this;
-
- },
-
- onChangeCallback: function () {}
-
- } );
-
- /**
- * @author mrdoob / http://mrdoob.com/
- * @author kile / http://kile.stravaganza.org/
- * @author philogb / http://blog.thejit.org/
- * @author mikael emtinger / http://gomo.se/
- * @author egraether / http://egraether.com/
- * @author WestLangley / http://github.com/WestLangley
- */
-
- function Vector3( x, y, z ) {
-
- this.x = x || 0;
- this.y = y || 0;
- this.z = z || 0;
-
- }
-
- Object.assign( Vector3.prototype, {
-
- isVector3: true,
-
- set: function ( x, y, z ) {
-
- this.x = x;
- this.y = y;
- this.z = z;
-
- return this;
-
- },
-
- setScalar: function ( scalar ) {
-
- this.x = scalar;
- this.y = scalar;
- this.z = scalar;
-
- return this;
-
- },
-
- setX: function ( x ) {
-
- this.x = x;
-
- return this;
-
- },
-
- setY: function ( y ) {
-
- this.y = y;
-
- return this;
-
- },
-
- setZ: function ( z ) {
-
- this.z = z;
-
- return this;
-
- },
-
- setComponent: function ( index, value ) {
-
- switch ( index ) {
-
- case 0: this.x = value; break;
- case 1: this.y = value; break;
- case 2: this.z = value; break;
- default: throw new Error( 'index is out of range: ' + index );
-
- }
-
- return this;
-
- },
-
- getComponent: function ( index ) {
-
- switch ( index ) {
-
- case 0: return this.x;
- case 1: return this.y;
- case 2: return this.z;
- default: throw new Error( 'index is out of range: ' + index );
-
- }
-
- },
-
- clone: function () {
-
- return new this.constructor( this.x, this.y, this.z );
-
- },
-
- copy: function ( v ) {
-
- this.x = v.x;
- this.y = v.y;
- this.z = v.z;
-
- return this;
-
- },
-
- add: function ( v, w ) {
-
- if ( w !== undefined ) {
-
- console.warn( 'THREE.Vector3: .add() now only accepts one argument. Use .addVectors( a, b ) instead.' );
- return this.addVectors( v, w );
-
- }
-
- this.x += v.x;
- this.y += v.y;
- this.z += v.z;
-
- return this;
-
- },
-
- addScalar: function ( s ) {
-
- this.x += s;
- this.y += s;
- this.z += s;
-
- return this;
-
- },
-
- addVectors: function ( a, b ) {
-
- this.x = a.x + b.x;
- this.y = a.y + b.y;
- this.z = a.z + b.z;
-
- return this;
-
- },
-
- addScaledVector: function ( v, s ) {
-
- this.x += v.x * s;
- this.y += v.y * s;
- this.z += v.z * s;
-
- return this;
-
- },
-
- sub: function ( v, w ) {
-
- if ( w !== undefined ) {
-
- console.warn( 'THREE.Vector3: .sub() now only accepts one argument. Use .subVectors( a, b ) instead.' );
- return this.subVectors( v, w );
-
- }
-
- this.x -= v.x;
- this.y -= v.y;
- this.z -= v.z;
-
- return this;
-
- },
-
- subScalar: function ( s ) {
-
- this.x -= s;
- this.y -= s;
- this.z -= s;
-
- return this;
-
- },
-
- subVectors: function ( a, b ) {
-
- this.x = a.x - b.x;
- this.y = a.y - b.y;
- this.z = a.z - b.z;
-
- return this;
-
- },
-
- multiply: function ( v, w ) {
-
- if ( w !== undefined ) {
-
- console.warn( 'THREE.Vector3: .multiply() now only accepts one argument. Use .multiplyVectors( a, b ) instead.' );
- return this.multiplyVectors( v, w );
-
- }
-
- this.x *= v.x;
- this.y *= v.y;
- this.z *= v.z;
-
- return this;
-
- },
-
- multiplyScalar: function ( scalar ) {
-
- this.x *= scalar;
- this.y *= scalar;
- this.z *= scalar;
-
- return this;
-
- },
-
- multiplyVectors: function ( a, b ) {
-
- this.x = a.x * b.x;
- this.y = a.y * b.y;
- this.z = a.z * b.z;
-
- return this;
-
- },
-
- applyEuler: function () {
-
- var quaternion = new Quaternion();
-
- return function applyEuler( euler ) {
-
- if ( ! ( euler && euler.isEuler ) ) {
-
- console.error( 'THREE.Vector3: .applyEuler() now expects an Euler rotation rather than a Vector3 and order.' );
-
- }
-
- return this.applyQuaternion( quaternion.setFromEuler( euler ) );
-
- };
-
- }(),
-
- applyAxisAngle: function () {
-
- var quaternion = new Quaternion();
-
- return function applyAxisAngle( axis, angle ) {
-
- return this.applyQuaternion( quaternion.setFromAxisAngle( axis, angle ) );
-
- };
-
- }(),
-
- applyMatrix3: function ( m ) {
-
- var x = this.x, y = this.y, z = this.z;
- var e = m.elements;
-
- this.x = e[ 0 ] * x + e[ 3 ] * y + e[ 6 ] * z;
- this.y = e[ 1 ] * x + e[ 4 ] * y + e[ 7 ] * z;
- this.z = e[ 2 ] * x + e[ 5 ] * y + e[ 8 ] * z;
-
- return this;
-
- },
-
- applyMatrix4: function ( m ) {
-
- var x = this.x, y = this.y, z = this.z;
- var e = m.elements;
-
- var w = 1 / ( e[ 3 ] * x + e[ 7 ] * y + e[ 11 ] * z + e[ 15 ] );
-
- this.x = ( e[ 0 ] * x + e[ 4 ] * y + e[ 8 ] * z + e[ 12 ] ) * w;
- this.y = ( e[ 1 ] * x + e[ 5 ] * y + e[ 9 ] * z + e[ 13 ] ) * w;
- this.z = ( e[ 2 ] * x + e[ 6 ] * y + e[ 10 ] * z + e[ 14 ] ) * w;
-
- return this;
-
- },
-
- applyQuaternion: function ( q ) {
-
- var x = this.x, y = this.y, z = this.z;
- var qx = q.x, qy = q.y, qz = q.z, qw = q.w;
-
- // calculate quat * vector
-
- var ix = qw * x + qy * z - qz * y;
- var iy = qw * y + qz * x - qx * z;
- var iz = qw * z + qx * y - qy * x;
- var iw = - qx * x - qy * y - qz * z;
-
- // calculate result * inverse quat
-
- this.x = ix * qw + iw * - qx + iy * - qz - iz * - qy;
- this.y = iy * qw + iw * - qy + iz * - qx - ix * - qz;
- this.z = iz * qw + iw * - qz + ix * - qy - iy * - qx;
-
- return this;
-
- },
-
- project: function ( camera ) {
-
- return this.applyMatrix4( camera.matrixWorldInverse ).applyMatrix4( camera.projectionMatrix );
-
- },
-
- unproject: function ( camera ) {
-
- return this.applyMatrix4( camera.projectionMatrixInverse ).applyMatrix4( camera.matrixWorld );
-
- },
-
- transformDirection: function ( m ) {
-
- // input: THREE.Matrix4 affine matrix
- // vector interpreted as a direction
-
- var x = this.x, y = this.y, z = this.z;
- var e = m.elements;
-
- this.x = e[ 0 ] * x + e[ 4 ] * y + e[ 8 ] * z;
- this.y = e[ 1 ] * x + e[ 5 ] * y + e[ 9 ] * z;
- this.z = e[ 2 ] * x + e[ 6 ] * y + e[ 10 ] * z;
-
- return this.normalize();
-
- },
-
- divide: function ( v ) {
-
- this.x /= v.x;
- this.y /= v.y;
- this.z /= v.z;
-
- return this;
-
- },
-
- divideScalar: function ( scalar ) {
-
- return this.multiplyScalar( 1 / scalar );
-
- },
-
- min: function ( v ) {
-
- this.x = Math.min( this.x, v.x );
- this.y = Math.min( this.y, v.y );
- this.z = Math.min( this.z, v.z );
-
- return this;
-
- },
-
- max: function ( v ) {
-
- this.x = Math.max( this.x, v.x );
- this.y = Math.max( this.y, v.y );
- this.z = Math.max( this.z, v.z );
-
- return this;
-
- },
-
- clamp: function ( min, max ) {
-
- // assumes min < max, componentwise
-
- this.x = Math.max( min.x, Math.min( max.x, this.x ) );
- this.y = Math.max( min.y, Math.min( max.y, this.y ) );
- this.z = Math.max( min.z, Math.min( max.z, this.z ) );
-
- return this;
-
- },
-
- clampScalar: function () {
-
- var min = new Vector3();
- var max = new Vector3();
-
- return function clampScalar( minVal, maxVal ) {
-
- min.set( minVal, minVal, minVal );
- max.set( maxVal, maxVal, maxVal );
-
- return this.clamp( min, max );
-
- };
-
- }(),
-
- clampLength: function ( min, max ) {
-
- var length = this.length();
-
- return this.divideScalar( length || 1 ).multiplyScalar( Math.max( min, Math.min( max, length ) ) );
-
- },
-
- floor: function () {
-
- this.x = Math.floor( this.x );
- this.y = Math.floor( this.y );
- this.z = Math.floor( this.z );
-
- return this;
-
- },
-
- ceil: function () {
-
- this.x = Math.ceil( this.x );
- this.y = Math.ceil( this.y );
- this.z = Math.ceil( this.z );
-
- return this;
-
- },
-
- round: function () {
-
- this.x = Math.round( this.x );
- this.y = Math.round( this.y );
- this.z = Math.round( this.z );
-
- return this;
-
- },
-
- roundToZero: function () {
-
- this.x = ( this.x < 0 ) ? Math.ceil( this.x ) : Math.floor( this.x );
- this.y = ( this.y < 0 ) ? Math.ceil( this.y ) : Math.floor( this.y );
- this.z = ( this.z < 0 ) ? Math.ceil( this.z ) : Math.floor( this.z );
-
- return this;
-
- },
-
- negate: function () {
-
- this.x = - this.x;
- this.y = - this.y;
- this.z = - this.z;
-
- return this;
-
- },
-
- dot: function ( v ) {
-
- return this.x * v.x + this.y * v.y + this.z * v.z;
-
- },
-
- // TODO lengthSquared?
-
- lengthSq: function () {
-
- return this.x * this.x + this.y * this.y + this.z * this.z;
-
- },
-
- length: function () {
-
- return Math.sqrt( this.x * this.x + this.y * this.y + this.z * this.z );
-
- },
-
- manhattanLength: function () {
-
- return Math.abs( this.x ) + Math.abs( this.y ) + Math.abs( this.z );
-
- },
-
- normalize: function () {
-
- return this.divideScalar( this.length() || 1 );
-
- },
-
- setLength: function ( length ) {
-
- return this.normalize().multiplyScalar( length );
-
- },
-
- lerp: function ( v, alpha ) {
-
- this.x += ( v.x - this.x ) * alpha;
- this.y += ( v.y - this.y ) * alpha;
- this.z += ( v.z - this.z ) * alpha;
-
- return this;
-
- },
-
- lerpVectors: function ( v1, v2, alpha ) {
-
- return this.subVectors( v2, v1 ).multiplyScalar( alpha ).add( v1 );
-
- },
-
- cross: function ( v, w ) {
-
- if ( w !== undefined ) {
-
- console.warn( 'THREE.Vector3: .cross() now only accepts one argument. Use .crossVectors( a, b ) instead.' );
- return this.crossVectors( v, w );
-
- }
-
- return this.crossVectors( this, v );
-
- },
-
- crossVectors: function ( a, b ) {
-
- var ax = a.x, ay = a.y, az = a.z;
- var bx = b.x, by = b.y, bz = b.z;
-
- this.x = ay * bz - az * by;
- this.y = az * bx - ax * bz;
- this.z = ax * by - ay * bx;
-
- return this;
-
- },
-
- projectOnVector: function ( vector ) {
-
- var scalar = vector.dot( this ) / vector.lengthSq();
-
- return this.copy( vector ).multiplyScalar( scalar );
-
- },
-
- projectOnPlane: function () {
-
- var v1 = new Vector3();
-
- return function projectOnPlane( planeNormal ) {
-
- v1.copy( this ).projectOnVector( planeNormal );
-
- return this.sub( v1 );
-
- };
-
- }(),
-
- reflect: function () {
-
- // reflect incident vector off plane orthogonal to normal
- // normal is assumed to have unit length
-
- var v1 = new Vector3();
-
- return function reflect( normal ) {
-
- return this.sub( v1.copy( normal ).multiplyScalar( 2 * this.dot( normal ) ) );
-
- };
-
- }(),
-
- angleTo: function ( v ) {
-
- var theta = this.dot( v ) / ( Math.sqrt( this.lengthSq() * v.lengthSq() ) );
-
- // clamp, to handle numerical problems
-
- return Math.acos( _Math.clamp( theta, - 1, 1 ) );
-
- },
-
- distanceTo: function ( v ) {
-
- return Math.sqrt( this.distanceToSquared( v ) );
-
- },
-
- distanceToSquared: function ( v ) {
-
- var dx = this.x - v.x, dy = this.y - v.y, dz = this.z - v.z;
-
- return dx * dx + dy * dy + dz * dz;
-
- },
-
- manhattanDistanceTo: function ( v ) {
-
- return Math.abs( this.x - v.x ) + Math.abs( this.y - v.y ) + Math.abs( this.z - v.z );
-
- },
-
- setFromSpherical: function ( s ) {
-
- return this.setFromSphericalCoords( s.radius, s.phi, s.theta );
-
- },
-
- setFromSphericalCoords: function ( radius, phi, theta ) {
-
- var sinPhiRadius = Math.sin( phi ) * radius;
-
- this.x = sinPhiRadius * Math.sin( theta );
- this.y = Math.cos( phi ) * radius;
- this.z = sinPhiRadius * Math.cos( theta );
-
- return this;
-
- },
-
- setFromCylindrical: function ( c ) {
-
- return this.setFromCylindricalCoords( c.radius, c.theta, c.y );
-
- },
-
- setFromCylindricalCoords: function ( radius, theta, y ) {
-
- this.x = radius * Math.sin( theta );
- this.y = y;
- this.z = radius * Math.cos( theta );
-
- return this;
-
- },
-
- setFromMatrixPosition: function ( m ) {
-
- var e = m.elements;
-
- this.x = e[ 12 ];
- this.y = e[ 13 ];
- this.z = e[ 14 ];
-
- return this;
-
- },
-
- setFromMatrixScale: function ( m ) {
-
- var sx = this.setFromMatrixColumn( m, 0 ).length();
- var sy = this.setFromMatrixColumn( m, 1 ).length();
- var sz = this.setFromMatrixColumn( m, 2 ).length();
-
- this.x = sx;
- this.y = sy;
- this.z = sz;
-
- return this;
-
- },
-
- setFromMatrixColumn: function ( m, index ) {
-
- return this.fromArray( m.elements, index * 4 );
-
- },
-
- equals: function ( v ) {
-
- return ( ( v.x === this.x ) && ( v.y === this.y ) && ( v.z === this.z ) );
-
- },
-
- fromArray: function ( array, offset ) {
-
- if ( offset === undefined ) offset = 0;
-
- this.x = array[ offset ];
- this.y = array[ offset + 1 ];
- this.z = array[ offset + 2 ];
-
- return this;
-
- },
-
- toArray: function ( array, offset ) {
-
- if ( array === undefined ) array = [];
- if ( offset === undefined ) offset = 0;
-
- array[ offset ] = this.x;
- array[ offset + 1 ] = this.y;
- array[ offset + 2 ] = this.z;
-
- return array;
-
- },
-
- fromBufferAttribute: function ( attribute, index, offset ) {
-
- if ( offset !== undefined ) {
-
- console.warn( 'THREE.Vector3: offset has been removed from .fromBufferAttribute().' );
-
- }
-
- this.x = attribute.getX( index );
- this.y = attribute.getY( index );
- this.z = attribute.getZ( index );
-
- return this;
-
- }
-
- } );
-
- /**
- * @author alteredq / http://alteredqualia.com/
- * @author WestLangley / http://github.com/WestLangley
- * @author bhouston / http://clara.io
- * @author tschw
- */
-
- function Matrix3() {
-
- this.elements = [
-
- 1, 0, 0,
- 0, 1, 0,
- 0, 0, 1
-
- ];
-
- if ( arguments.length > 0 ) {
-
- console.error( 'THREE.Matrix3: the constructor no longer reads arguments. use .set() instead.' );
-
- }
-
- }
-
- Object.assign( Matrix3.prototype, {
-
- isMatrix3: true,
-
- set: function ( n11, n12, n13, n21, n22, n23, n31, n32, n33 ) {
-
- var te = this.elements;
-
- te[ 0 ] = n11; te[ 1 ] = n21; te[ 2 ] = n31;
- te[ 3 ] = n12; te[ 4 ] = n22; te[ 5 ] = n32;
- te[ 6 ] = n13; te[ 7 ] = n23; te[ 8 ] = n33;
-
- return this;
-
- },
-
- identity: function () {
-
- this.set(
-
- 1, 0, 0,
- 0, 1, 0,
- 0, 0, 1
-
- );
-
- return this;
-
- },
-
- clone: function () {
-
- return new this.constructor().fromArray( this.elements );
-
- },
-
- copy: function ( m ) {
-
- var te = this.elements;
- var me = m.elements;
-
- te[ 0 ] = me[ 0 ]; te[ 1 ] = me[ 1 ]; te[ 2 ] = me[ 2 ];
- te[ 3 ] = me[ 3 ]; te[ 4 ] = me[ 4 ]; te[ 5 ] = me[ 5 ];
- te[ 6 ] = me[ 6 ]; te[ 7 ] = me[ 7 ]; te[ 8 ] = me[ 8 ];
-
- return this;
-
- },
-
- setFromMatrix4: function ( m ) {
-
- var me = m.elements;
-
- this.set(
-
- me[ 0 ], me[ 4 ], me[ 8 ],
- me[ 1 ], me[ 5 ], me[ 9 ],
- me[ 2 ], me[ 6 ], me[ 10 ]
-
- );
-
- return this;
-
- },
-
- applyToBufferAttribute: function () {
-
- var v1 = new Vector3();
-
- return function applyToBufferAttribute( attribute ) {
-
- for ( var i = 0, l = attribute.count; i < l; i ++ ) {
-
- v1.x = attribute.getX( i );
- v1.y = attribute.getY( i );
- v1.z = attribute.getZ( i );
-
- v1.applyMatrix3( this );
-
- attribute.setXYZ( i, v1.x, v1.y, v1.z );
-
- }
-
- return attribute;
-
- };
-
- }(),
-
- multiply: function ( m ) {
-
- return this.multiplyMatrices( this, m );
-
- },
-
- premultiply: function ( m ) {
-
- return this.multiplyMatrices( m, this );
-
- },
-
- multiplyMatrices: function ( a, b ) {
-
- var ae = a.elements;
- var be = b.elements;
- var te = this.elements;
-
- var a11 = ae[ 0 ], a12 = ae[ 3 ], a13 = ae[ 6 ];
- var a21 = ae[ 1 ], a22 = ae[ 4 ], a23 = ae[ 7 ];
- var a31 = ae[ 2 ], a32 = ae[ 5 ], a33 = ae[ 8 ];
-
- var b11 = be[ 0 ], b12 = be[ 3 ], b13 = be[ 6 ];
- var b21 = be[ 1 ], b22 = be[ 4 ], b23 = be[ 7 ];
- var b31 = be[ 2 ], b32 = be[ 5 ], b33 = be[ 8 ];
-
- te[ 0 ] = a11 * b11 + a12 * b21 + a13 * b31;
- te[ 3 ] = a11 * b12 + a12 * b22 + a13 * b32;
- te[ 6 ] = a11 * b13 + a12 * b23 + a13 * b33;
-
- te[ 1 ] = a21 * b11 + a22 * b21 + a23 * b31;
- te[ 4 ] = a21 * b12 + a22 * b22 + a23 * b32;
- te[ 7 ] = a21 * b13 + a22 * b23 + a23 * b33;
-
- te[ 2 ] = a31 * b11 + a32 * b21 + a33 * b31;
- te[ 5 ] = a31 * b12 + a32 * b22 + a33 * b32;
- te[ 8 ] = a31 * b13 + a32 * b23 + a33 * b33;
-
- return this;
-
- },
-
- multiplyScalar: function ( s ) {
-
- var te = this.elements;
-
- te[ 0 ] *= s; te[ 3 ] *= s; te[ 6 ] *= s;
- te[ 1 ] *= s; te[ 4 ] *= s; te[ 7 ] *= s;
- te[ 2 ] *= s; te[ 5 ] *= s; te[ 8 ] *= s;
-
- return this;
-
- },
-
- determinant: function () {
-
- var te = this.elements;
-
- var a = te[ 0 ], b = te[ 1 ], c = te[ 2 ],
- d = te[ 3 ], e = te[ 4 ], f = te[ 5 ],
- g = te[ 6 ], h = te[ 7 ], i = te[ 8 ];
-
- return a * e * i - a * f * h - b * d * i + b * f * g + c * d * h - c * e * g;
-
- },
-
- getInverse: function ( matrix, throwOnDegenerate ) {
-
- if ( matrix && matrix.isMatrix4 ) {
-
- console.error( "THREE.Matrix3: .getInverse() no longer takes a Matrix4 argument." );
-
- }
-
- var me = matrix.elements,
- te = this.elements,
-
- n11 = me[ 0 ], n21 = me[ 1 ], n31 = me[ 2 ],
- n12 = me[ 3 ], n22 = me[ 4 ], n32 = me[ 5 ],
- n13 = me[ 6 ], n23 = me[ 7 ], n33 = me[ 8 ],
-
- t11 = n33 * n22 - n32 * n23,
- t12 = n32 * n13 - n33 * n12,
- t13 = n23 * n12 - n22 * n13,
-
- det = n11 * t11 + n21 * t12 + n31 * t13;
-
- if ( det === 0 ) {
-
- var msg = "THREE.Matrix3: .getInverse() can't invert matrix, determinant is 0";
-
- if ( throwOnDegenerate === true ) {
-
- throw new Error( msg );
-
- } else {
-
- console.warn( msg );
-
- }
-
- return this.identity();
-
- }
-
- var detInv = 1 / det;
-
- te[ 0 ] = t11 * detInv;
- te[ 1 ] = ( n31 * n23 - n33 * n21 ) * detInv;
- te[ 2 ] = ( n32 * n21 - n31 * n22 ) * detInv;
-
- te[ 3 ] = t12 * detInv;
- te[ 4 ] = ( n33 * n11 - n31 * n13 ) * detInv;
- te[ 5 ] = ( n31 * n12 - n32 * n11 ) * detInv;
-
- te[ 6 ] = t13 * detInv;
- te[ 7 ] = ( n21 * n13 - n23 * n11 ) * detInv;
- te[ 8 ] = ( n22 * n11 - n21 * n12 ) * detInv;
-
- return this;
-
- },
-
- transpose: function () {
-
- var tmp, m = this.elements;
-
- tmp = m[ 1 ]; m[ 1 ] = m[ 3 ]; m[ 3 ] = tmp;
- tmp = m[ 2 ]; m[ 2 ] = m[ 6 ]; m[ 6 ] = tmp;
- tmp = m[ 5 ]; m[ 5 ] = m[ 7 ]; m[ 7 ] = tmp;
-
- return this;
-
- },
-
- getNormalMatrix: function ( matrix4 ) {
-
- return this.setFromMatrix4( matrix4 ).getInverse( this ).transpose();
-
- },
-
- transposeIntoArray: function ( r ) {
-
- var m = this.elements;
-
- r[ 0 ] = m[ 0 ];
- r[ 1 ] = m[ 3 ];
- r[ 2 ] = m[ 6 ];
- r[ 3 ] = m[ 1 ];
- r[ 4 ] = m[ 4 ];
- r[ 5 ] = m[ 7 ];
- r[ 6 ] = m[ 2 ];
- r[ 7 ] = m[ 5 ];
- r[ 8 ] = m[ 8 ];
-
- return this;
-
- },
-
- setUvTransform: function ( tx, ty, sx, sy, rotation, cx, cy ) {
-
- var c = Math.cos( rotation );
- var s = Math.sin( rotation );
-
- this.set(
- sx * c, sx * s, - sx * ( c * cx + s * cy ) + cx + tx,
- - sy * s, sy * c, - sy * ( - s * cx + c * cy ) + cy + ty,
- 0, 0, 1
- );
-
- },
-
- scale: function ( sx, sy ) {
-
- var te = this.elements;
-
- te[ 0 ] *= sx; te[ 3 ] *= sx; te[ 6 ] *= sx;
- te[ 1 ] *= sy; te[ 4 ] *= sy; te[ 7 ] *= sy;
-
- return this;
-
- },
-
- rotate: function ( theta ) {
-
- var c = Math.cos( theta );
- var s = Math.sin( theta );
-
- var te = this.elements;
-
- var a11 = te[ 0 ], a12 = te[ 3 ], a13 = te[ 6 ];
- var a21 = te[ 1 ], a22 = te[ 4 ], a23 = te[ 7 ];
-
- te[ 0 ] = c * a11 + s * a21;
- te[ 3 ] = c * a12 + s * a22;
- te[ 6 ] = c * a13 + s * a23;
-
- te[ 1 ] = - s * a11 + c * a21;
- te[ 4 ] = - s * a12 + c * a22;
- te[ 7 ] = - s * a13 + c * a23;
-
- return this;
-
- },
-
- translate: function ( tx, ty ) {
-
- var te = this.elements;
-
- te[ 0 ] += tx * te[ 2 ]; te[ 3 ] += tx * te[ 5 ]; te[ 6 ] += tx * te[ 8 ];
- te[ 1 ] += ty * te[ 2 ]; te[ 4 ] += ty * te[ 5 ]; te[ 7 ] += ty * te[ 8 ];
-
- return this;
-
- },
-
- equals: function ( matrix ) {
-
- var te = this.elements;
- var me = matrix.elements;
-
- for ( var i = 0; i < 9; i ++ ) {
-
- if ( te[ i ] !== me[ i ] ) return false;
-
- }
-
- return true;
-
- },
-
- fromArray: function ( array, offset ) {
-
- if ( offset === undefined ) offset = 0;
-
- for ( var i = 0; i < 9; i ++ ) {
-
- this.elements[ i ] = array[ i + offset ];
-
- }
-
- return this;
-
- },
-
- toArray: function ( array, offset ) {
-
- if ( array === undefined ) array = [];
- if ( offset === undefined ) offset = 0;
-
- var te = this.elements;
-
- array[ offset ] = te[ 0 ];
- array[ offset + 1 ] = te[ 1 ];
- array[ offset + 2 ] = te[ 2 ];
-
- array[ offset + 3 ] = te[ 3 ];
- array[ offset + 4 ] = te[ 4 ];
- array[ offset + 5 ] = te[ 5 ];
-
- array[ offset + 6 ] = te[ 6 ];
- array[ offset + 7 ] = te[ 7 ];
- array[ offset + 8 ] = te[ 8 ];
-
- return array;
-
- }
-
- } );
-
- /**
- * @author mrdoob / http://mrdoob.com/
- * @author alteredq / http://alteredqualia.com/
- * @author szimek / https://github.com/szimek/
- */
-
- var _canvas;
-
- var ImageUtils = {
-
- getDataURL: function ( image ) {
-
- var canvas;
-
- if ( typeof HTMLCanvasElement == 'undefined' ) {
-
- return image.src;
-
- } else if ( image instanceof HTMLCanvasElement ) {
-
- canvas = image;
-
- } else {
-
- if ( _canvas === undefined ) _canvas = document.createElementNS( 'http://www.w3.org/1999/xhtml', 'canvas' );
-
- _canvas.width = image.width;
- _canvas.height = image.height;
-
- var context = _canvas.getContext( '2d' );
-
- if ( image instanceof ImageData ) {
-
- context.putImageData( image, 0, 0 );
-
- } else {
-
- context.drawImage( image, 0, 0, image.width, image.height );
-
- }
-
- canvas = _canvas;
-
- }
-
- if ( canvas.width > 2048 || canvas.height > 2048 ) {
-
- return canvas.toDataURL( 'image/jpeg', 0.6 );
-
- } else {
-
- return canvas.toDataURL( 'image/png' );
-
- }
-
- }
-
- };
-
- /**
- * @author mrdoob / http://mrdoob.com/
- * @author alteredq / http://alteredqualia.com/
- * @author szimek / https://github.com/szimek/
- */
-
- var textureId = 0;
-
- function Texture( image, mapping, wrapS, wrapT, magFilter, minFilter, format, type, anisotropy, encoding ) {
-
- Object.defineProperty( this, 'id', { value: textureId ++ } );
-
- this.uuid = _Math.generateUUID();
-
- this.name = '';
-
- this.image = image !== undefined ? image : Texture.DEFAULT_IMAGE;
- this.mipmaps = [];
-
- this.mapping = mapping !== undefined ? mapping : Texture.DEFAULT_MAPPING;
-
- this.wrapS = wrapS !== undefined ? wrapS : ClampToEdgeWrapping;
- this.wrapT = wrapT !== undefined ? wrapT : ClampToEdgeWrapping;
-
- this.magFilter = magFilter !== undefined ? magFilter : LinearFilter;
- this.minFilter = minFilter !== undefined ? minFilter : LinearMipMapLinearFilter;
-
- this.anisotropy = anisotropy !== undefined ? anisotropy : 1;
-
- this.format = format !== undefined ? format : RGBAFormat;
- this.type = type !== undefined ? type : UnsignedByteType;
-
- this.offset = new Vector2( 0, 0 );
- this.repeat = new Vector2( 1, 1 );
- this.center = new Vector2( 0, 0 );
- this.rotation = 0;
-
- this.matrixAutoUpdate = true;
- this.matrix = new Matrix3();
-
- this.generateMipmaps = true;
- this.premultiplyAlpha = false;
- this.flipY = true;
- this.unpackAlignment = 4; // valid values: 1, 2, 4, 8 (see http://www.khronos.org/opengles/sdk/docs/man/xhtml/glPixelStorei.xml)
-
- // Values of encoding !== THREE.LinearEncoding only supported on map, envMap and emissiveMap.
- //
- // Also changing the encoding after already used by a Material will not automatically make the Material
- // update. You need to explicitly call Material.needsUpdate to trigger it to recompile.
- this.encoding = encoding !== undefined ? encoding : LinearEncoding;
-
- this.version = 0;
- this.onUpdate = null;
-
- }
-
- Texture.DEFAULT_IMAGE = undefined;
- Texture.DEFAULT_MAPPING = UVMapping;
-
- Texture.prototype = Object.assign( Object.create( EventDispatcher.prototype ), {
-
- constructor: Texture,
-
- isTexture: true,
-
- updateMatrix: function () {
-
- this.matrix.setUvTransform( this.offset.x, this.offset.y, this.repeat.x, this.repeat.y, this.rotation, this.center.x, this.center.y );
-
- },
-
- clone: function () {
-
- return new this.constructor().copy( this );
-
- },
-
- copy: function ( source ) {
-
- this.name = source.name;
-
- this.image = source.image;
- this.mipmaps = source.mipmaps.slice( 0 );
-
- this.mapping = source.mapping;
-
- this.wrapS = source.wrapS;
- this.wrapT = source.wrapT;
-
- this.magFilter = source.magFilter;
- this.minFilter = source.minFilter;
-
- this.anisotropy = source.anisotropy;
-
- this.format = source.format;
- this.type = source.type;
-
- this.offset.copy( source.offset );
- this.repeat.copy( source.repeat );
- this.center.copy( source.center );
- this.rotation = source.rotation;
-
- this.matrixAutoUpdate = source.matrixAutoUpdate;
- this.matrix.copy( source.matrix );
-
- this.generateMipmaps = source.generateMipmaps;
- this.premultiplyAlpha = source.premultiplyAlpha;
- this.flipY = source.flipY;
- this.unpackAlignment = source.unpackAlignment;
- this.encoding = source.encoding;
-
- return this;
-
- },
-
- toJSON: function ( meta ) {
-
- var isRootObject = ( meta === undefined || typeof meta === 'string' );
-
- if ( ! isRootObject && meta.textures[ this.uuid ] !== undefined ) {
-
- return meta.textures[ this.uuid ];
-
- }
-
- var output = {
-
- metadata: {
- version: 4.5,
- type: 'Texture',
- generator: 'Texture.toJSON'
- },
-
- uuid: this.uuid,
- name: this.name,
-
- mapping: this.mapping,
-
- repeat: [ this.repeat.x, this.repeat.y ],
- offset: [ this.offset.x, this.offset.y ],
- center: [ this.center.x, this.center.y ],
- rotation: this.rotation,
-
- wrap: [ this.wrapS, this.wrapT ],
-
- format: this.format,
- type: this.type,
- encoding: this.encoding,
-
- minFilter: this.minFilter,
- magFilter: this.magFilter,
- anisotropy: this.anisotropy,
-
- flipY: this.flipY,
-
- premultiplyAlpha: this.premultiplyAlpha,
- unpackAlignment: this.unpackAlignment
-
- };
-
- if ( this.image !== undefined ) {
-
- // TODO: Move to THREE.Image
-
- var image = this.image;
-
- if ( image.uuid === undefined ) {
-
- image.uuid = _Math.generateUUID(); // UGH
-
- }
-
- if ( ! isRootObject && meta.images[ image.uuid ] === undefined ) {
-
- var url;
-
- if ( Array.isArray( image ) ) {
-
- // process array of images e.g. CubeTexture
-
- url = [];
-
- for ( var i = 0, l = image.length; i < l; i ++ ) {
-
- url.push( ImageUtils.getDataURL( image[ i ] ) );
-
- }
-
- } else {
-
- // process single image
-
- url = ImageUtils.getDataURL( image );
-
- }
-
- meta.images[ image.uuid ] = {
- uuid: image.uuid,
- url: url
- };
-
- }
-
- output.image = image.uuid;
-
- }
-
- if ( ! isRootObject ) {
-
- meta.textures[ this.uuid ] = output;
-
- }
-
- return output;
-
- },
-
- dispose: function () {
-
- this.dispatchEvent( { type: 'dispose' } );
-
- },
-
- transformUv: function ( uv ) {
-
- if ( this.mapping !== UVMapping ) return uv;
-
- uv.applyMatrix3( this.matrix );
-
- if ( uv.x < 0 || uv.x > 1 ) {
-
- switch ( this.wrapS ) {
-
- case RepeatWrapping:
-
- uv.x = uv.x - Math.floor( uv.x );
- break;
-
- case ClampToEdgeWrapping:
-
- uv.x = uv.x < 0 ? 0 : 1;
- break;
-
- case MirroredRepeatWrapping:
-
- if ( Math.abs( Math.floor( uv.x ) % 2 ) === 1 ) {
-
- uv.x = Math.ceil( uv.x ) - uv.x;
-
- } else {
-
- uv.x = uv.x - Math.floor( uv.x );
-
- }
- break;
-
- }
-
- }
-
- if ( uv.y < 0 || uv.y > 1 ) {
-
- switch ( this.wrapT ) {
-
- case RepeatWrapping:
-
- uv.y = uv.y - Math.floor( uv.y );
- break;
-
- case ClampToEdgeWrapping:
-
- uv.y = uv.y < 0 ? 0 : 1;
- break;
-
- case MirroredRepeatWrapping:
-
- if ( Math.abs( Math.floor( uv.y ) % 2 ) === 1 ) {
-
- uv.y = Math.ceil( uv.y ) - uv.y;
-
- } else {
-
- uv.y = uv.y - Math.floor( uv.y );
-
- }
- break;
-
- }
-
- }
-
- if ( this.flipY ) {
-
- uv.y = 1 - uv.y;
-
- }
-
- return uv;
-
- }
-
- } );
-
- Object.defineProperty( Texture.prototype, "needsUpdate", {
-
- set: function ( value ) {
-
- if ( value === true ) this.version ++;
-
- }
-
- } );
-
- /**
- * @author supereggbert / http://www.paulbrunt.co.uk/
- * @author philogb / http://blog.thejit.org/
- * @author mikael emtinger / http://gomo.se/
- * @author egraether / http://egraether.com/
- * @author WestLangley / http://github.com/WestLangley
- */
-
- function Vector4( x, y, z, w ) {
-
- this.x = x || 0;
- this.y = y || 0;
- this.z = z || 0;
- this.w = ( w !== undefined ) ? w : 1;
-
- }
-
- Object.assign( Vector4.prototype, {
-
- isVector4: true,
-
- set: function ( x, y, z, w ) {
-
- this.x = x;
- this.y = y;
- this.z = z;
- this.w = w;
-
- return this;
-
- },
-
- setScalar: function ( scalar ) {
-
- this.x = scalar;
- this.y = scalar;
- this.z = scalar;
- this.w = scalar;
-
- return this;
-
- },
-
- setX: function ( x ) {
-
- this.x = x;
-
- return this;
-
- },
-
- setY: function ( y ) {
-
- this.y = y;
-
- return this;
-
- },
-
- setZ: function ( z ) {
-
- this.z = z;
-
- return this;
-
- },
-
- setW: function ( w ) {
-
- this.w = w;
-
- return this;
-
- },
-
- setComponent: function ( index, value ) {
-
- switch ( index ) {
-
- case 0: this.x = value; break;
- case 1: this.y = value; break;
- case 2: this.z = value; break;
- case 3: this.w = value; break;
- default: throw new Error( 'index is out of range: ' + index );
-
- }
-
- return this;
-
- },
-
- getComponent: function ( index ) {
-
- switch ( index ) {
-
- case 0: return this.x;
- case 1: return this.y;
- case 2: return this.z;
- case 3: return this.w;
- default: throw new Error( 'index is out of range: ' + index );
-
- }
-
- },
-
- clone: function () {
-
- return new this.constructor( this.x, this.y, this.z, this.w );
-
- },
-
- copy: function ( v ) {
-
- this.x = v.x;
- this.y = v.y;
- this.z = v.z;
- this.w = ( v.w !== undefined ) ? v.w : 1;
-
- return this;
-
- },
-
- add: function ( v, w ) {
-
- if ( w !== undefined ) {
-
- console.warn( 'THREE.Vector4: .add() now only accepts one argument. Use .addVectors( a, b ) instead.' );
- return this.addVectors( v, w );
-
- }
-
- this.x += v.x;
- this.y += v.y;
- this.z += v.z;
- this.w += v.w;
-
- return this;
-
- },
-
- addScalar: function ( s ) {
-
- this.x += s;
- this.y += s;
- this.z += s;
- this.w += s;
-
- return this;
-
- },
-
- addVectors: function ( a, b ) {
-
- this.x = a.x + b.x;
- this.y = a.y + b.y;
- this.z = a.z + b.z;
- this.w = a.w + b.w;
-
- return this;
-
- },
-
- addScaledVector: function ( v, s ) {
-
- this.x += v.x * s;
- this.y += v.y * s;
- this.z += v.z * s;
- this.w += v.w * s;
-
- return this;
-
- },
-
- sub: function ( v, w ) {
-
- if ( w !== undefined ) {
-
- console.warn( 'THREE.Vector4: .sub() now only accepts one argument. Use .subVectors( a, b ) instead.' );
- return this.subVectors( v, w );
-
- }
-
- this.x -= v.x;
- this.y -= v.y;
- this.z -= v.z;
- this.w -= v.w;
-
- return this;
-
- },
-
- subScalar: function ( s ) {
-
- this.x -= s;
- this.y -= s;
- this.z -= s;
- this.w -= s;
-
- return this;
-
- },
-
- subVectors: function ( a, b ) {
-
- this.x = a.x - b.x;
- this.y = a.y - b.y;
- this.z = a.z - b.z;
- this.w = a.w - b.w;
-
- return this;
-
- },
-
- multiplyScalar: function ( scalar ) {
-
- this.x *= scalar;
- this.y *= scalar;
- this.z *= scalar;
- this.w *= scalar;
-
- return this;
-
- },
-
- applyMatrix4: function ( m ) {
-
- var x = this.x, y = this.y, z = this.z, w = this.w;
- var e = m.elements;
-
- this.x = e[ 0 ] * x + e[ 4 ] * y + e[ 8 ] * z + e[ 12 ] * w;
- this.y = e[ 1 ] * x + e[ 5 ] * y + e[ 9 ] * z + e[ 13 ] * w;
- this.z = e[ 2 ] * x + e[ 6 ] * y + e[ 10 ] * z + e[ 14 ] * w;
- this.w = e[ 3 ] * x + e[ 7 ] * y + e[ 11 ] * z + e[ 15 ] * w;
-
- return this;
-
- },
-
- divideScalar: function ( scalar ) {
-
- return this.multiplyScalar( 1 / scalar );
-
- },
-
- setAxisAngleFromQuaternion: function ( q ) {
-
- // http://www.euclideanspace.com/maths/geometry/rotations/conversions/quaternionToAngle/index.htm
-
- // q is assumed to be normalized
-
- this.w = 2 * Math.acos( q.w );
-
- var s = Math.sqrt( 1 - q.w * q.w );
-
- if ( s < 0.0001 ) {
-
- this.x = 1;
- this.y = 0;
- this.z = 0;
-
- } else {
-
- this.x = q.x / s;
- this.y = q.y / s;
- this.z = q.z / s;
-
- }
-
- return this;
-
- },
-
- setAxisAngleFromRotationMatrix: function ( m ) {
-
- // http://www.euclideanspace.com/maths/geometry/rotations/conversions/matrixToAngle/index.htm
-
- // assumes the upper 3x3 of m is a pure rotation matrix (i.e, unscaled)
-
- var angle, x, y, z, // variables for result
- epsilon = 0.01, // margin to allow for rounding errors
- epsilon2 = 0.1, // margin to distinguish between 0 and 180 degrees
-
- te = m.elements,
-
- m11 = te[ 0 ], m12 = te[ 4 ], m13 = te[ 8 ],
- m21 = te[ 1 ], m22 = te[ 5 ], m23 = te[ 9 ],
- m31 = te[ 2 ], m32 = te[ 6 ], m33 = te[ 10 ];
-
- if ( ( Math.abs( m12 - m21 ) < epsilon ) &&
- ( Math.abs( m13 - m31 ) < epsilon ) &&
- ( Math.abs( m23 - m32 ) < epsilon ) ) {
-
- // singularity found
- // first check for identity matrix which must have +1 for all terms
- // in leading diagonal and zero in other terms
-
- if ( ( Math.abs( m12 + m21 ) < epsilon2 ) &&
- ( Math.abs( m13 + m31 ) < epsilon2 ) &&
- ( Math.abs( m23 + m32 ) < epsilon2 ) &&
- ( Math.abs( m11 + m22 + m33 - 3 ) < epsilon2 ) ) {
-
- // this singularity is identity matrix so angle = 0
-
- this.set( 1, 0, 0, 0 );
-
- return this; // zero angle, arbitrary axis
-
- }
-
- // otherwise this singularity is angle = 180
-
- angle = Math.PI;
-
- var xx = ( m11 + 1 ) / 2;
- var yy = ( m22 + 1 ) / 2;
- var zz = ( m33 + 1 ) / 2;
- var xy = ( m12 + m21 ) / 4;
- var xz = ( m13 + m31 ) / 4;
- var yz = ( m23 + m32 ) / 4;
-
- if ( ( xx > yy ) && ( xx > zz ) ) {
-
- // m11 is the largest diagonal term
-
- if ( xx < epsilon ) {
-
- x = 0;
- y = 0.707106781;
- z = 0.707106781;
-
- } else {
-
- x = Math.sqrt( xx );
- y = xy / x;
- z = xz / x;
-
- }
-
- } else if ( yy > zz ) {
-
- // m22 is the largest diagonal term
-
- if ( yy < epsilon ) {
-
- x = 0.707106781;
- y = 0;
- z = 0.707106781;
-
- } else {
-
- y = Math.sqrt( yy );
- x = xy / y;
- z = yz / y;
-
- }
-
- } else {
-
- // m33 is the largest diagonal term so base result on this
-
- if ( zz < epsilon ) {
-
- x = 0.707106781;
- y = 0.707106781;
- z = 0;
-
- } else {
-
- z = Math.sqrt( zz );
- x = xz / z;
- y = yz / z;
-
- }
-
- }
-
- this.set( x, y, z, angle );
-
- return this; // return 180 deg rotation
-
- }
-
- // as we have reached here there are no singularities so we can handle normally
-
- var s = Math.sqrt( ( m32 - m23 ) * ( m32 - m23 ) +
- ( m13 - m31 ) * ( m13 - m31 ) +
- ( m21 - m12 ) * ( m21 - m12 ) ); // used to normalize
-
- if ( Math.abs( s ) < 0.001 ) s = 1;
-
- // prevent divide by zero, should not happen if matrix is orthogonal and should be
- // caught by singularity test above, but I've left it in just in case
-
- this.x = ( m32 - m23 ) / s;
- this.y = ( m13 - m31 ) / s;
- this.z = ( m21 - m12 ) / s;
- this.w = Math.acos( ( m11 + m22 + m33 - 1 ) / 2 );
-
- return this;
-
- },
-
- min: function ( v ) {
-
- this.x = Math.min( this.x, v.x );
- this.y = Math.min( this.y, v.y );
- this.z = Math.min( this.z, v.z );
- this.w = Math.min( this.w, v.w );
-
- return this;
-
- },
-
- max: function ( v ) {
-
- this.x = Math.max( this.x, v.x );
- this.y = Math.max( this.y, v.y );
- this.z = Math.max( this.z, v.z );
- this.w = Math.max( this.w, v.w );
-
- return this;
-
- },
-
- clamp: function ( min, max ) {
-
- // assumes min < max, componentwise
-
- this.x = Math.max( min.x, Math.min( max.x, this.x ) );
- this.y = Math.max( min.y, Math.min( max.y, this.y ) );
- this.z = Math.max( min.z, Math.min( max.z, this.z ) );
- this.w = Math.max( min.w, Math.min( max.w, this.w ) );
-
- return this;
-
- },
-
- clampScalar: function () {
-
- var min, max;
-
- return function clampScalar( minVal, maxVal ) {
-
- if ( min === undefined ) {
-
- min = new Vector4();
- max = new Vector4();
-
- }
-
- min.set( minVal, minVal, minVal, minVal );
- max.set( maxVal, maxVal, maxVal, maxVal );
-
- return this.clamp( min, max );
-
- };
-
- }(),
-
- clampLength: function ( min, max ) {
-
- var length = this.length();
-
- return this.divideScalar( length || 1 ).multiplyScalar( Math.max( min, Math.min( max, length ) ) );
-
- },
-
- floor: function () {
-
- this.x = Math.floor( this.x );
- this.y = Math.floor( this.y );
- this.z = Math.floor( this.z );
- this.w = Math.floor( this.w );
-
- return this;
-
- },
-
- ceil: function () {
-
- this.x = Math.ceil( this.x );
- this.y = Math.ceil( this.y );
- this.z = Math.ceil( this.z );
- this.w = Math.ceil( this.w );
-
- return this;
-
- },
-
- round: function () {
-
- this.x = Math.round( this.x );
- this.y = Math.round( this.y );
- this.z = Math.round( this.z );
- this.w = Math.round( this.w );
-
- return this;
-
- },
-
- roundToZero: function () {
-
- this.x = ( this.x < 0 ) ? Math.ceil( this.x ) : Math.floor( this.x );
- this.y = ( this.y < 0 ) ? Math.ceil( this.y ) : Math.floor( this.y );
- this.z = ( this.z < 0 ) ? Math.ceil( this.z ) : Math.floor( this.z );
- this.w = ( this.w < 0 ) ? Math.ceil( this.w ) : Math.floor( this.w );
-
- return this;
-
- },
-
- negate: function () {
-
- this.x = - this.x;
- this.y = - this.y;
- this.z = - this.z;
- this.w = - this.w;
-
- return this;
-
- },
-
- dot: function ( v ) {
-
- return this.x * v.x + this.y * v.y + this.z * v.z + this.w * v.w;
-
- },
-
- lengthSq: function () {
-
- return this.x * this.x + this.y * this.y + this.z * this.z + this.w * this.w;
-
- },
-
- length: function () {
-
- return Math.sqrt( this.x * this.x + this.y * this.y + this.z * this.z + this.w * this.w );
-
- },
-
- manhattanLength: function () {
-
- return Math.abs( this.x ) + Math.abs( this.y ) + Math.abs( this.z ) + Math.abs( this.w );
-
- },
-
- normalize: function () {
-
- return this.divideScalar( this.length() || 1 );
-
- },
-
- setLength: function ( length ) {
-
- return this.normalize().multiplyScalar( length );
-
- },
-
- lerp: function ( v, alpha ) {
-
- this.x += ( v.x - this.x ) * alpha;
- this.y += ( v.y - this.y ) * alpha;
- this.z += ( v.z - this.z ) * alpha;
- this.w += ( v.w - this.w ) * alpha;
-
- return this;
-
- },
-
- lerpVectors: function ( v1, v2, alpha ) {
-
- return this.subVectors( v2, v1 ).multiplyScalar( alpha ).add( v1 );
-
- },
-
- equals: function ( v ) {
-
- return ( ( v.x === this.x ) && ( v.y === this.y ) && ( v.z === this.z ) && ( v.w === this.w ) );
-
- },
-
- fromArray: function ( array, offset ) {
-
- if ( offset === undefined ) offset = 0;
-
- this.x = array[ offset ];
- this.y = array[ offset + 1 ];
- this.z = array[ offset + 2 ];
- this.w = array[ offset + 3 ];
-
- return this;
-
- },
-
- toArray: function ( array, offset ) {
-
- if ( array === undefined ) array = [];
- if ( offset === undefined ) offset = 0;
-
- array[ offset ] = this.x;
- array[ offset + 1 ] = this.y;
- array[ offset + 2 ] = this.z;
- array[ offset + 3 ] = this.w;
-
- return array;
-
- },
-
- fromBufferAttribute: function ( attribute, index, offset ) {
-
- if ( offset !== undefined ) {
-
- console.warn( 'THREE.Vector4: offset has been removed from .fromBufferAttribute().' );
-
- }
-
- this.x = attribute.getX( index );
- this.y = attribute.getY( index );
- this.z = attribute.getZ( index );
- this.w = attribute.getW( index );
-
- return this;
-
- }
-
- } );
-
- /**
- * @author szimek / https://github.com/szimek/
- * @author alteredq / http://alteredqualia.com/
- * @author Marius Kintel / https://github.com/kintel
- */
-
- /*
- In options, we can specify:
- * Texture parameters for an auto-generated target texture
- * depthBuffer/stencilBuffer: Booleans to indicate if we should generate these buffers
- */
- function WebGLRenderTarget( width, height, options ) {
-
- this.width = width;
- this.height = height;
-
- this.scissor = new Vector4( 0, 0, width, height );
- this.scissorTest = false;
-
- this.viewport = new Vector4( 0, 0, width, height );
-
- options = options || {};
-
- this.texture = new Texture( undefined, undefined, options.wrapS, options.wrapT, options.magFilter, options.minFilter, options.format, options.type, options.anisotropy, options.encoding );
-
- this.texture.generateMipmaps = options.generateMipmaps !== undefined ? options.generateMipmaps : false;
- this.texture.minFilter = options.minFilter !== undefined ? options.minFilter : LinearFilter;
-
- this.depthBuffer = options.depthBuffer !== undefined ? options.depthBuffer : true;
- this.stencilBuffer = options.stencilBuffer !== undefined ? options.stencilBuffer : true;
- this.depthTexture = options.depthTexture !== undefined ? options.depthTexture : null;
-
- }
-
- WebGLRenderTarget.prototype = Object.assign( Object.create( EventDispatcher.prototype ), {
-
- constructor: WebGLRenderTarget,
-
- isWebGLRenderTarget: true,
-
- setSize: function ( width, height ) {
-
- if ( this.width !== width || this.height !== height ) {
-
- this.width = width;
- this.height = height;
-
- this.dispose();
-
- }
-
- this.viewport.set( 0, 0, width, height );
- this.scissor.set( 0, 0, width, height );
-
- },
-
- clone: function () {
-
- return new this.constructor().copy( this );
-
- },
-
- copy: function ( source ) {
-
- this.width = source.width;
- this.height = source.height;
-
- this.viewport.copy( source.viewport );
-
- this.texture = source.texture.clone();
-
- this.depthBuffer = source.depthBuffer;
- this.stencilBuffer = source.stencilBuffer;
- this.depthTexture = source.depthTexture;
-
- return this;
-
- },
-
- dispose: function () {
-
- this.dispatchEvent( { type: 'dispose' } );
-
- }
-
- } );
-
- /**
- * @author Mugen87 / https://github.com/Mugen87
- * @author Matt DesLauriers / @mattdesl
- */
-
- function WebGLMultisampleRenderTarget( width, height, options ) {
-
- WebGLRenderTarget.call( this, width, height, options );
-
- this.samples = 4;
-
- }
-
- WebGLMultisampleRenderTarget.prototype = Object.assign( Object.create( WebGLRenderTarget.prototype ), {
-
- constructor: WebGLMultisampleRenderTarget,
-
- isWebGLMultisampleRenderTarget: true,
-
- copy: function ( source ) {
-
- WebGLRenderTarget.prototype.copy.call( this, source );
-
- this.samples = source.samples;
-
- return this;
-
- }
-
- } );
-
- /**
- * @author alteredq / http://alteredqualia.com
- */
-
- function WebGLRenderTargetCube( width, height, options ) {
-
- WebGLRenderTarget.call( this, width, height, options );
-
- }
-
- WebGLRenderTargetCube.prototype = Object.create( WebGLRenderTarget.prototype );
- WebGLRenderTargetCube.prototype.constructor = WebGLRenderTargetCube;
-
- WebGLRenderTargetCube.prototype.isWebGLRenderTargetCube = true;
-
- /**
- * @author alteredq / http://alteredqualia.com/
- */
-
- function DataTexture( data, width, height, format, type, mapping, wrapS, wrapT, magFilter, minFilter, anisotropy, encoding ) {
-
- Texture.call( this, null, mapping, wrapS, wrapT, magFilter, minFilter, format, type, anisotropy, encoding );
-
- this.image = { data: data, width: width, height: height };
-
- this.magFilter = magFilter !== undefined ? magFilter : NearestFilter;
- this.minFilter = minFilter !== undefined ? minFilter : NearestFilter;
-
- this.generateMipmaps = false;
- this.flipY = false;
- this.unpackAlignment = 1;
-
- }
-
- DataTexture.prototype = Object.create( Texture.prototype );
- DataTexture.prototype.constructor = DataTexture;
-
- DataTexture.prototype.isDataTexture = true;
-
- /**
- * @author bhouston / http://clara.io
- * @author WestLangley / http://github.com/WestLangley
- */
-
- function Box3( min, max ) {
-
- this.min = ( min !== undefined ) ? min : new Vector3( + Infinity, + Infinity, + Infinity );
- this.max = ( max !== undefined ) ? max : new Vector3( - Infinity, - Infinity, - Infinity );
-
- }
-
- Object.assign( Box3.prototype, {
-
- isBox3: true,
-
- set: function ( min, max ) {
-
- this.min.copy( min );
- this.max.copy( max );
-
- return this;
-
- },
-
- setFromArray: function ( array ) {
-
- var minX = + Infinity;
- var minY = + Infinity;
- var minZ = + Infinity;
-
- var maxX = - Infinity;
- var maxY = - Infinity;
- var maxZ = - Infinity;
-
- for ( var i = 0, l = array.length; i < l; i += 3 ) {
-
- var x = array[ i ];
- var y = array[ i + 1 ];
- var z = array[ i + 2 ];
-
- if ( x < minX ) minX = x;
- if ( y < minY ) minY = y;
- if ( z < minZ ) minZ = z;
-
- if ( x > maxX ) maxX = x;
- if ( y > maxY ) maxY = y;
- if ( z > maxZ ) maxZ = z;
-
- }
-
- this.min.set( minX, minY, minZ );
- this.max.set( maxX, maxY, maxZ );
-
- return this;
-
- },
-
- setFromBufferAttribute: function ( attribute ) {
-
- var minX = + Infinity;
- var minY = + Infinity;
- var minZ = + Infinity;
-
- var maxX = - Infinity;
- var maxY = - Infinity;
- var maxZ = - Infinity;
-
- for ( var i = 0, l = attribute.count; i < l; i ++ ) {
-
- var x = attribute.getX( i );
- var y = attribute.getY( i );
- var z = attribute.getZ( i );
-
- if ( x < minX ) minX = x;
- if ( y < minY ) minY = y;
- if ( z < minZ ) minZ = z;
-
- if ( x > maxX ) maxX = x;
- if ( y > maxY ) maxY = y;
- if ( z > maxZ ) maxZ = z;
-
- }
-
- this.min.set( minX, minY, minZ );
- this.max.set( maxX, maxY, maxZ );
-
- return this;
-
- },
-
- setFromPoints: function ( points ) {
-
- this.makeEmpty();
-
- for ( var i = 0, il = points.length; i < il; i ++ ) {
-
- this.expandByPoint( points[ i ] );
-
- }
-
- return this;
-
- },
-
- setFromCenterAndSize: function () {
-
- var v1 = new Vector3();
-
- return function setFromCenterAndSize( center, size ) {
-
- var halfSize = v1.copy( size ).multiplyScalar( 0.5 );
-
- this.min.copy( center ).sub( halfSize );
- this.max.copy( center ).add( halfSize );
-
- return this;
-
- };
-
- }(),
-
- setFromObject: function ( object ) {
-
- this.makeEmpty();
-
- return this.expandByObject( object );
-
- },
-
- clone: function () {
-
- return new this.constructor().copy( this );
-
- },
-
- copy: function ( box ) {
-
- this.min.copy( box.min );
- this.max.copy( box.max );
-
- return this;
-
- },
-
- makeEmpty: function () {
-
- this.min.x = this.min.y = this.min.z = + Infinity;
- this.max.x = this.max.y = this.max.z = - Infinity;
-
- return this;
-
- },
-
- isEmpty: function () {
-
- // this is a more robust check for empty than ( volume <= 0 ) because volume can get positive with two negative axes
-
- return ( this.max.x < this.min.x ) || ( this.max.y < this.min.y ) || ( this.max.z < this.min.z );
-
- },
-
- getCenter: function ( target ) {
-
- if ( target === undefined ) {
-
- console.warn( 'THREE.Box3: .getCenter() target is now required' );
- target = new Vector3();
-
- }
-
- return this.isEmpty() ? target.set( 0, 0, 0 ) : target.addVectors( this.min, this.max ).multiplyScalar( 0.5 );
-
- },
-
- getSize: function ( target ) {
-
- if ( target === undefined ) {
-
- console.warn( 'THREE.Box3: .getSize() target is now required' );
- target = new Vector3();
-
- }
-
- return this.isEmpty() ? target.set( 0, 0, 0 ) : target.subVectors( this.max, this.min );
-
- },
-
- expandByPoint: function ( point ) {
-
- this.min.min( point );
- this.max.max( point );
-
- return this;
-
- },
-
- expandByVector: function ( vector ) {
-
- this.min.sub( vector );
- this.max.add( vector );
-
- return this;
-
- },
-
- expandByScalar: function ( scalar ) {
-
- this.min.addScalar( - scalar );
- this.max.addScalar( scalar );
-
- return this;
-
- },
-
- expandByObject: function () {
-
- // Computes the world-axis-aligned bounding box of an object (including its children),
- // accounting for both the object's, and children's, world transforms
-
- var scope, i, l;
-
- var v1 = new Vector3();
-
- function traverse( node ) {
-
- var geometry = node.geometry;
-
- if ( geometry !== undefined ) {
-
- if ( geometry.isGeometry ) {
-
- var vertices = geometry.vertices;
-
- for ( i = 0, l = vertices.length; i < l; i ++ ) {
-
- v1.copy( vertices[ i ] );
- v1.applyMatrix4( node.matrixWorld );
-
- scope.expandByPoint( v1 );
-
- }
-
- } else if ( geometry.isBufferGeometry ) {
-
- var attribute = geometry.attributes.position;
-
- if ( attribute !== undefined ) {
-
- for ( i = 0, l = attribute.count; i < l; i ++ ) {
-
- v1.fromBufferAttribute( attribute, i ).applyMatrix4( node.matrixWorld );
-
- scope.expandByPoint( v1 );
-
- }
-
- }
-
- }
-
- }
-
- }
-
- return function expandByObject( object ) {
-
- scope = this;
-
- object.updateMatrixWorld( true );
-
- object.traverse( traverse );
-
- return this;
-
- };
-
- }(),
-
- containsPoint: function ( point ) {
-
- return point.x < this.min.x || point.x > this.max.x ||
- point.y < this.min.y || point.y > this.max.y ||
- point.z < this.min.z || point.z > this.max.z ? false : true;
-
- },
-
- containsBox: function ( box ) {
-
- return this.min.x <= box.min.x && box.max.x <= this.max.x &&
- this.min.y <= box.min.y && box.max.y <= this.max.y &&
- this.min.z <= box.min.z && box.max.z <= this.max.z;
-
- },
-
- getParameter: function ( point, target ) {
-
- // This can potentially have a divide by zero if the box
- // has a size dimension of 0.
-
- if ( target === undefined ) {
-
- console.warn( 'THREE.Box3: .getParameter() target is now required' );
- target = new Vector3();
-
- }
-
- return target.set(
- ( point.x - this.min.x ) / ( this.max.x - this.min.x ),
- ( point.y - this.min.y ) / ( this.max.y - this.min.y ),
- ( point.z - this.min.z ) / ( this.max.z - this.min.z )
- );
-
- },
-
- intersectsBox: function ( box ) {
-
- // using 6 splitting planes to rule out intersections.
- return box.max.x < this.min.x || box.min.x > this.max.x ||
- box.max.y < this.min.y || box.min.y > this.max.y ||
- box.max.z < this.min.z || box.min.z > this.max.z ? false : true;
-
- },
-
- intersectsSphere: ( function () {
-
- var closestPoint = new Vector3();
-
- return function intersectsSphere( sphere ) {
-
- // Find the point on the AABB closest to the sphere center.
- this.clampPoint( sphere.center, closestPoint );
-
- // If that point is inside the sphere, the AABB and sphere intersect.
- return closestPoint.distanceToSquared( sphere.center ) <= ( sphere.radius * sphere.radius );
-
- };
-
- } )(),
-
- intersectsPlane: function ( plane ) {
-
- // We compute the minimum and maximum dot product values. If those values
- // are on the same side (back or front) of the plane, then there is no intersection.
-
- var min, max;
-
- if ( plane.normal.x > 0 ) {
-
- min = plane.normal.x * this.min.x;
- max = plane.normal.x * this.max.x;
-
- } else {
-
- min = plane.normal.x * this.max.x;
- max = plane.normal.x * this.min.x;
-
- }
-
- if ( plane.normal.y > 0 ) {
-
- min += plane.normal.y * this.min.y;
- max += plane.normal.y * this.max.y;
-
- } else {
-
- min += plane.normal.y * this.max.y;
- max += plane.normal.y * this.min.y;
-
- }
-
- if ( plane.normal.z > 0 ) {
-
- min += plane.normal.z * this.min.z;
- max += plane.normal.z * this.max.z;
-
- } else {
-
- min += plane.normal.z * this.max.z;
- max += plane.normal.z * this.min.z;
-
- }
-
- return ( min <= - plane.constant && max >= - plane.constant );
-
- },
-
- intersectsTriangle: ( function () {
-
- // triangle centered vertices
- var v0 = new Vector3();
- var v1 = new Vector3();
- var v2 = new Vector3();
-
- // triangle edge vectors
- var f0 = new Vector3();
- var f1 = new Vector3();
- var f2 = new Vector3();
-
- var testAxis = new Vector3();
-
- var center = new Vector3();
- var extents = new Vector3();
-
- var triangleNormal = new Vector3();
-
- function satForAxes( axes ) {
-
- var i, j;
-
- for ( i = 0, j = axes.length - 3; i <= j; i += 3 ) {
-
- testAxis.fromArray( axes, i );
- // project the aabb onto the seperating axis
- var r = extents.x * Math.abs( testAxis.x ) + extents.y * Math.abs( testAxis.y ) + extents.z * Math.abs( testAxis.z );
- // project all 3 vertices of the triangle onto the seperating axis
- var p0 = v0.dot( testAxis );
- var p1 = v1.dot( testAxis );
- var p2 = v2.dot( testAxis );
- // actual test, basically see if either of the most extreme of the triangle points intersects r
- if ( Math.max( - Math.max( p0, p1, p2 ), Math.min( p0, p1, p2 ) ) > r ) {
-
- // points of the projected triangle are outside the projected half-length of the aabb
- // the axis is seperating and we can exit
- return false;
-
- }
-
- }
-
- return true;
-
- }
-
- return function intersectsTriangle( triangle ) {
-
- if ( this.isEmpty() ) {
-
- return false;
-
- }
-
- // compute box center and extents
- this.getCenter( center );
- extents.subVectors( this.max, center );
-
- // translate triangle to aabb origin
- v0.subVectors( triangle.a, center );
- v1.subVectors( triangle.b, center );
- v2.subVectors( triangle.c, center );
-
- // compute edge vectors for triangle
- f0.subVectors( v1, v0 );
- f1.subVectors( v2, v1 );
- f2.subVectors( v0, v2 );
-
- // test against axes that are given by cross product combinations of the edges of the triangle and the edges of the aabb
- // make an axis testing of each of the 3 sides of the aabb against each of the 3 sides of the triangle = 9 axis of separation
- // axis_ij = u_i x f_j (u0, u1, u2 = face normals of aabb = x,y,z axes vectors since aabb is axis aligned)
- var axes = [
- 0, - f0.z, f0.y, 0, - f1.z, f1.y, 0, - f2.z, f2.y,
- f0.z, 0, - f0.x, f1.z, 0, - f1.x, f2.z, 0, - f2.x,
- - f0.y, f0.x, 0, - f1.y, f1.x, 0, - f2.y, f2.x, 0
- ];
- if ( ! satForAxes( axes ) ) {
-
- return false;
-
- }
-
- // test 3 face normals from the aabb
- axes = [ 1, 0, 0, 0, 1, 0, 0, 0, 1 ];
- if ( ! satForAxes( axes ) ) {
-
- return false;
-
- }
-
- // finally testing the face normal of the triangle
- // use already existing triangle edge vectors here
- triangleNormal.crossVectors( f0, f1 );
- axes = [ triangleNormal.x, triangleNormal.y, triangleNormal.z ];
- return satForAxes( axes );
-
- };
-
- } )(),
-
- clampPoint: function ( point, target ) {
-
- if ( target === undefined ) {
-
- console.warn( 'THREE.Box3: .clampPoint() target is now required' );
- target = new Vector3();
-
- }
-
- return target.copy( point ).clamp( this.min, this.max );
-
- },
-
- distanceToPoint: function () {
-
- var v1 = new Vector3();
-
- return function distanceToPoint( point ) {
-
- var clampedPoint = v1.copy( point ).clamp( this.min, this.max );
- return clampedPoint.sub( point ).length();
-
- };
-
- }(),
-
- getBoundingSphere: function () {
-
- var v1 = new Vector3();
-
- return function getBoundingSphere( target ) {
-
- if ( target === undefined ) {
-
- console.error( 'THREE.Box3: .getBoundingSphere() target is now required' );
- //target = new Sphere(); // removed to avoid cyclic dependency
-
- }
-
- this.getCenter( target.center );
-
- target.radius = this.getSize( v1 ).length() * 0.5;
-
- return target;
-
- };
-
- }(),
-
- intersect: function ( box ) {
-
- this.min.max( box.min );
- this.max.min( box.max );
-
- // ensure that if there is no overlap, the result is fully empty, not slightly empty with non-inf/+inf values that will cause subsequence intersects to erroneously return valid values.
- if ( this.isEmpty() ) this.makeEmpty();
-
- return this;
-
- },
-
- union: function ( box ) {
-
- this.min.min( box.min );
- this.max.max( box.max );
-
- return this;
-
- },
-
- applyMatrix4: function () {
-
- var points = [
- new Vector3(),
- new Vector3(),
- new Vector3(),
- new Vector3(),
- new Vector3(),
- new Vector3(),
- new Vector3(),
- new Vector3()
- ];
-
- return function applyMatrix4( matrix ) {
-
- // transform of empty box is an empty box.
- if ( this.isEmpty() ) return this;
-
- // NOTE: I am using a binary pattern to specify all 2^3 combinations below
- points[ 0 ].set( this.min.x, this.min.y, this.min.z ).applyMatrix4( matrix ); // 000
- points[ 1 ].set( this.min.x, this.min.y, this.max.z ).applyMatrix4( matrix ); // 001
- points[ 2 ].set( this.min.x, this.max.y, this.min.z ).applyMatrix4( matrix ); // 010
- points[ 3 ].set( this.min.x, this.max.y, this.max.z ).applyMatrix4( matrix ); // 011
- points[ 4 ].set( this.max.x, this.min.y, this.min.z ).applyMatrix4( matrix ); // 100
- points[ 5 ].set( this.max.x, this.min.y, this.max.z ).applyMatrix4( matrix ); // 101
- points[ 6 ].set( this.max.x, this.max.y, this.min.z ).applyMatrix4( matrix ); // 110
- points[ 7 ].set( this.max.x, this.max.y, this.max.z ).applyMatrix4( matrix ); // 111
-
- this.setFromPoints( points );
-
- return this;
-
- };
-
- }(),
-
- translate: function ( offset ) {
-
- this.min.add( offset );
- this.max.add( offset );
-
- return this;
-
- },
-
- equals: function ( box ) {
-
- return box.min.equals( this.min ) && box.max.equals( this.max );
-
- }
-
- } );
-
- /**
- * @author bhouston / http://clara.io
- * @author mrdoob / http://mrdoob.com/
- */
-
- function Sphere( center, radius ) {
-
- this.center = ( center !== undefined ) ? center : new Vector3();
- this.radius = ( radius !== undefined ) ? radius : 0;
-
- }
-
- Object.assign( Sphere.prototype, {
-
- set: function ( center, radius ) {
-
- this.center.copy( center );
- this.radius = radius;
-
- return this;
-
- },
-
- setFromPoints: function () {
-
- var box = new Box3();
-
- return function setFromPoints( points, optionalCenter ) {
-
- var center = this.center;
-
- if ( optionalCenter !== undefined ) {
-
- center.copy( optionalCenter );
-
- } else {
-
- box.setFromPoints( points ).getCenter( center );
-
- }
-
- var maxRadiusSq = 0;
-
- for ( var i = 0, il = points.length; i < il; i ++ ) {
-
- maxRadiusSq = Math.max( maxRadiusSq, center.distanceToSquared( points[ i ] ) );
-
- }
-
- this.radius = Math.sqrt( maxRadiusSq );
-
- return this;
-
- };
-
- }(),
-
- clone: function () {
-
- return new this.constructor().copy( this );
-
- },
-
- copy: function ( sphere ) {
-
- this.center.copy( sphere.center );
- this.radius = sphere.radius;
-
- return this;
-
- },
-
- empty: function () {
-
- return ( this.radius <= 0 );
-
- },
-
- containsPoint: function ( point ) {
-
- return ( point.distanceToSquared( this.center ) <= ( this.radius * this.radius ) );
-
- },
-
- distanceToPoint: function ( point ) {
-
- return ( point.distanceTo( this.center ) - this.radius );
-
- },
-
- intersectsSphere: function ( sphere ) {
-
- var radiusSum = this.radius + sphere.radius;
-
- return sphere.center.distanceToSquared( this.center ) <= ( radiusSum * radiusSum );
-
- },
-
- intersectsBox: function ( box ) {
-
- return box.intersectsSphere( this );
-
- },
-
- intersectsPlane: function ( plane ) {
-
- return Math.abs( plane.distanceToPoint( this.center ) ) <= this.radius;
-
- },
-
- clampPoint: function ( point, target ) {
-
- var deltaLengthSq = this.center.distanceToSquared( point );
-
- if ( target === undefined ) {
-
- console.warn( 'THREE.Sphere: .clampPoint() target is now required' );
- target = new Vector3();
-
- }
-
- target.copy( point );
-
- if ( deltaLengthSq > ( this.radius * this.radius ) ) {
-
- target.sub( this.center ).normalize();
- target.multiplyScalar( this.radius ).add( this.center );
-
- }
-
- return target;
-
- },
-
- getBoundingBox: function ( target ) {
-
- if ( target === undefined ) {
-
- console.warn( 'THREE.Sphere: .getBoundingBox() target is now required' );
- target = new Box3();
-
- }
-
- target.set( this.center, this.center );
- target.expandByScalar( this.radius );
-
- return target;
-
- },
-
- applyMatrix4: function ( matrix ) {
-
- this.center.applyMatrix4( matrix );
- this.radius = this.radius * matrix.getMaxScaleOnAxis();
-
- return this;
-
- },
-
- translate: function ( offset ) {
-
- this.center.add( offset );
-
- return this;
-
- },
-
- equals: function ( sphere ) {
-
- return sphere.center.equals( this.center ) && ( sphere.radius === this.radius );
-
- }
-
- } );
-
- /**
- * @author bhouston / http://clara.io
- */
-
- function Plane( normal, constant ) {
-
- // normal is assumed to be normalized
-
- this.normal = ( normal !== undefined ) ? normal : new Vector3( 1, 0, 0 );
- this.constant = ( constant !== undefined ) ? constant : 0;
-
- }
-
- Object.assign( Plane.prototype, {
-
- set: function ( normal, constant ) {
-
- this.normal.copy( normal );
- this.constant = constant;
-
- return this;
-
- },
-
- setComponents: function ( x, y, z, w ) {
-
- this.normal.set( x, y, z );
- this.constant = w;
-
- return this;
-
- },
-
- setFromNormalAndCoplanarPoint: function ( normal, point ) {
-
- this.normal.copy( normal );
- this.constant = - point.dot( this.normal );
-
- return this;
-
- },
-
- setFromCoplanarPoints: function () {
-
- var v1 = new Vector3();
- var v2 = new Vector3();
-
- return function setFromCoplanarPoints( a, b, c ) {
-
- var normal = v1.subVectors( c, b ).cross( v2.subVectors( a, b ) ).normalize();
-
- // Q: should an error be thrown if normal is zero (e.g. degenerate plane)?
-
- this.setFromNormalAndCoplanarPoint( normal, a );
-
- return this;
-
- };
-
- }(),
-
- clone: function () {
-
- return new this.constructor().copy( this );
-
- },
-
- copy: function ( plane ) {
-
- this.normal.copy( plane.normal );
- this.constant = plane.constant;
-
- return this;
-
- },
-
- normalize: function () {
-
- // Note: will lead to a divide by zero if the plane is invalid.
-
- var inverseNormalLength = 1.0 / this.normal.length();
- this.normal.multiplyScalar( inverseNormalLength );
- this.constant *= inverseNormalLength;
-
- return this;
-
- },
-
- negate: function () {
-
- this.constant *= - 1;
- this.normal.negate();
-
- return this;
-
- },
-
- distanceToPoint: function ( point ) {
-
- return this.normal.dot( point ) + this.constant;
-
- },
-
- distanceToSphere: function ( sphere ) {
-
- return this.distanceToPoint( sphere.center ) - sphere.radius;
-
- },
-
- projectPoint: function ( point, target ) {
-
- if ( target === undefined ) {
-
- console.warn( 'THREE.Plane: .projectPoint() target is now required' );
- target = new Vector3();
-
- }
-
- return target.copy( this.normal ).multiplyScalar( - this.distanceToPoint( point ) ).add( point );
-
- },
-
- intersectLine: function () {
-
- var v1 = new Vector3();
-
- return function intersectLine( line, target ) {
-
- if ( target === undefined ) {
-
- console.warn( 'THREE.Plane: .intersectLine() target is now required' );
- target = new Vector3();
-
- }
-
- var direction = line.delta( v1 );
-
- var denominator = this.normal.dot( direction );
-
- if ( denominator === 0 ) {
-
- // line is coplanar, return origin
- if ( this.distanceToPoint( line.start ) === 0 ) {
-
- return target.copy( line.start );
-
- }
-
- // Unsure if this is the correct method to handle this case.
- return undefined;
-
- }
-
- var t = - ( line.start.dot( this.normal ) + this.constant ) / denominator;
-
- if ( t < 0 || t > 1 ) {
-
- return undefined;
-
- }
-
- return target.copy( direction ).multiplyScalar( t ).add( line.start );
-
- };
-
- }(),
-
- intersectsLine: function ( line ) {
-
- // Note: this tests if a line intersects the plane, not whether it (or its end-points) are coplanar with it.
-
- var startSign = this.distanceToPoint( line.start );
- var endSign = this.distanceToPoint( line.end );
-
- return ( startSign < 0 && endSign > 0 ) || ( endSign < 0 && startSign > 0 );
-
- },
-
- intersectsBox: function ( box ) {
-
- return box.intersectsPlane( this );
-
- },
-
- intersectsSphere: function ( sphere ) {
-
- return sphere.intersectsPlane( this );
-
- },
-
- coplanarPoint: function ( target ) {
-
- if ( target === undefined ) {
-
- console.warn( 'THREE.Plane: .coplanarPoint() target is now required' );
- target = new Vector3();
-
- }
-
- return target.copy( this.normal ).multiplyScalar( - this.constant );
-
- },
-
- applyMatrix4: function () {
-
- var v1 = new Vector3();
- var m1 = new Matrix3();
-
- return function applyMatrix4( matrix, optionalNormalMatrix ) {
-
- var normalMatrix = optionalNormalMatrix || m1.getNormalMatrix( matrix );
-
- var referencePoint = this.coplanarPoint( v1 ).applyMatrix4( matrix );
-
- var normal = this.normal.applyMatrix3( normalMatrix ).normalize();
-
- this.constant = - referencePoint.dot( normal );
-
- return this;
-
- };
-
- }(),
-
- translate: function ( offset ) {
-
- this.constant -= offset.dot( this.normal );
-
- return this;
-
- },
-
- equals: function ( plane ) {
-
- return plane.normal.equals( this.normal ) && ( plane.constant === this.constant );
-
- }
-
- } );
-
- /**
- * @author mrdoob / http://mrdoob.com/
- * @author alteredq / http://alteredqualia.com/
- * @author bhouston / http://clara.io
- */
-
- function Frustum( p0, p1, p2, p3, p4, p5 ) {
-
- this.planes = [
-
- ( p0 !== undefined ) ? p0 : new Plane(),
- ( p1 !== undefined ) ? p1 : new Plane(),
- ( p2 !== undefined ) ? p2 : new Plane(),
- ( p3 !== undefined ) ? p3 : new Plane(),
- ( p4 !== undefined ) ? p4 : new Plane(),
- ( p5 !== undefined ) ? p5 : new Plane()
-
- ];
-
- }
-
- Object.assign( Frustum.prototype, {
-
- set: function ( p0, p1, p2, p3, p4, p5 ) {
-
- var planes = this.planes;
-
- planes[ 0 ].copy( p0 );
- planes[ 1 ].copy( p1 );
- planes[ 2 ].copy( p2 );
- planes[ 3 ].copy( p3 );
- planes[ 4 ].copy( p4 );
- planes[ 5 ].copy( p5 );
-
- return this;
-
- },
-
- clone: function () {
-
- return new this.constructor().copy( this );
-
- },
-
- copy: function ( frustum ) {
-
- var planes = this.planes;
-
- for ( var i = 0; i < 6; i ++ ) {
-
- planes[ i ].copy( frustum.planes[ i ] );
-
- }
-
- return this;
-
- },
-
- setFromMatrix: function ( m ) {
-
- var planes = this.planes;
- var me = m.elements;
- var me0 = me[ 0 ], me1 = me[ 1 ], me2 = me[ 2 ], me3 = me[ 3 ];
- var me4 = me[ 4 ], me5 = me[ 5 ], me6 = me[ 6 ], me7 = me[ 7 ];
- var me8 = me[ 8 ], me9 = me[ 9 ], me10 = me[ 10 ], me11 = me[ 11 ];
- var me12 = me[ 12 ], me13 = me[ 13 ], me14 = me[ 14 ], me15 = me[ 15 ];
-
- planes[ 0 ].setComponents( me3 - me0, me7 - me4, me11 - me8, me15 - me12 ).normalize();
- planes[ 1 ].setComponents( me3 + me0, me7 + me4, me11 + me8, me15 + me12 ).normalize();
- planes[ 2 ].setComponents( me3 + me1, me7 + me5, me11 + me9, me15 + me13 ).normalize();
- planes[ 3 ].setComponents( me3 - me1, me7 - me5, me11 - me9, me15 - me13 ).normalize();
- planes[ 4 ].setComponents( me3 - me2, me7 - me6, me11 - me10, me15 - me14 ).normalize();
- planes[ 5 ].setComponents( me3 + me2, me7 + me6, me11 + me10, me15 + me14 ).normalize();
-
- return this;
-
- },
-
- intersectsObject: function () {
-
- var sphere = new Sphere();
-
- return function intersectsObject( object ) {
-
- var geometry = object.geometry;
-
- if ( geometry.boundingSphere === null )
- geometry.computeBoundingSphere();
-
- sphere.copy( geometry.boundingSphere )
- .applyMatrix4( object.matrixWorld );
-
- return this.intersectsSphere( sphere );
-
- };
-
- }(),
-
- intersectsSprite: function () {
-
- var sphere = new Sphere();
-
- return function intersectsSprite( sprite ) {
-
- sphere.center.set( 0, 0, 0 );
- sphere.radius = 0.7071067811865476;
- sphere.applyMatrix4( sprite.matrixWorld );
-
- return this.intersectsSphere( sphere );
-
- };
-
- }(),
-
- intersectsSphere: function ( sphere ) {
-
- var planes = this.planes;
- var center = sphere.center;
- var negRadius = - sphere.radius;
-
- for ( var i = 0; i < 6; i ++ ) {
-
- var distance = planes[ i ].distanceToPoint( center );
-
- if ( distance < negRadius ) {
-
- return false;
-
- }
-
- }
-
- return true;
-
- },
-
- intersectsBox: function () {
-
- var p = new Vector3();
-
- return function intersectsBox( box ) {
-
- var planes = this.planes;
-
- for ( var i = 0; i < 6; i ++ ) {
-
- var plane = planes[ i ];
-
- // corner at max distance
-
- p.x = plane.normal.x > 0 ? box.max.x : box.min.x;
- p.y = plane.normal.y > 0 ? box.max.y : box.min.y;
- p.z = plane.normal.z > 0 ? box.max.z : box.min.z;
-
- if ( plane.distanceToPoint( p ) < 0 ) {
-
- return false;
-
- }
-
- }
-
- return true;
-
- };
-
- }(),
-
- containsPoint: function ( point ) {
-
- var planes = this.planes;
-
- for ( var i = 0; i < 6; i ++ ) {
-
- if ( planes[ i ].distanceToPoint( point ) < 0 ) {
-
- return false;
-
- }
-
- }
-
- return true;
-
- }
-
- } );
-
- /**
- * @author mrdoob / http://mrdoob.com/
- * @author supereggbert / http://www.paulbrunt.co.uk/
- * @author philogb / http://blog.thejit.org/
- * @author jordi_ros / http://plattsoft.com
- * @author D1plo1d / http://github.com/D1plo1d
- * @author alteredq / http://alteredqualia.com/
- * @author mikael emtinger / http://gomo.se/
- * @author timknip / http://www.floorplanner.com/
- * @author bhouston / http://clara.io
- * @author WestLangley / http://github.com/WestLangley
- */
-
- function Matrix4() {
-
- this.elements = [
-
- 1, 0, 0, 0,
- 0, 1, 0, 0,
- 0, 0, 1, 0,
- 0, 0, 0, 1
-
- ];
-
- if ( arguments.length > 0 ) {
-
- console.error( 'THREE.Matrix4: the constructor no longer reads arguments. use .set() instead.' );
-
- }
-
- }
-
- Object.assign( Matrix4.prototype, {
-
- isMatrix4: true,
-
- set: function ( n11, n12, n13, n14, n21, n22, n23, n24, n31, n32, n33, n34, n41, n42, n43, n44 ) {
-
- var te = this.elements;
-
- te[ 0 ] = n11; te[ 4 ] = n12; te[ 8 ] = n13; te[ 12 ] = n14;
- te[ 1 ] = n21; te[ 5 ] = n22; te[ 9 ] = n23; te[ 13 ] = n24;
- te[ 2 ] = n31; te[ 6 ] = n32; te[ 10 ] = n33; te[ 14 ] = n34;
- te[ 3 ] = n41; te[ 7 ] = n42; te[ 11 ] = n43; te[ 15 ] = n44;
-
- return this;
-
- },
-
- identity: function () {
-
- this.set(
-
- 1, 0, 0, 0,
- 0, 1, 0, 0,
- 0, 0, 1, 0,
- 0, 0, 0, 1
-
- );
-
- return this;
-
- },
-
- clone: function () {
-
- return new Matrix4().fromArray( this.elements );
-
- },
-
- copy: function ( m ) {
-
- var te = this.elements;
- var me = m.elements;
-
- te[ 0 ] = me[ 0 ]; te[ 1 ] = me[ 1 ]; te[ 2 ] = me[ 2 ]; te[ 3 ] = me[ 3 ];
- te[ 4 ] = me[ 4 ]; te[ 5 ] = me[ 5 ]; te[ 6 ] = me[ 6 ]; te[ 7 ] = me[ 7 ];
- te[ 8 ] = me[ 8 ]; te[ 9 ] = me[ 9 ]; te[ 10 ] = me[ 10 ]; te[ 11 ] = me[ 11 ];
- te[ 12 ] = me[ 12 ]; te[ 13 ] = me[ 13 ]; te[ 14 ] = me[ 14 ]; te[ 15 ] = me[ 15 ];
-
- return this;
-
- },
-
- copyPosition: function ( m ) {
-
- var te = this.elements, me = m.elements;
-
- te[ 12 ] = me[ 12 ];
- te[ 13 ] = me[ 13 ];
- te[ 14 ] = me[ 14 ];
-
- return this;
-
- },
-
- extractBasis: function ( xAxis, yAxis, zAxis ) {
-
- xAxis.setFromMatrixColumn( this, 0 );
- yAxis.setFromMatrixColumn( this, 1 );
- zAxis.setFromMatrixColumn( this, 2 );
-
- return this;
-
- },
-
- makeBasis: function ( xAxis, yAxis, zAxis ) {
-
- this.set(
- xAxis.x, yAxis.x, zAxis.x, 0,
- xAxis.y, yAxis.y, zAxis.y, 0,
- xAxis.z, yAxis.z, zAxis.z, 0,
- 0, 0, 0, 1
- );
-
- return this;
-
- },
-
- extractRotation: function () {
-
- var v1 = new Vector3();
-
- return function extractRotation( m ) {
-
- // this method does not support reflection matrices
-
- var te = this.elements;
- var me = m.elements;
-
- var scaleX = 1 / v1.setFromMatrixColumn( m, 0 ).length();
- var scaleY = 1 / v1.setFromMatrixColumn( m, 1 ).length();
- var scaleZ = 1 / v1.setFromMatrixColumn( m, 2 ).length();
-
- te[ 0 ] = me[ 0 ] * scaleX;
- te[ 1 ] = me[ 1 ] * scaleX;
- te[ 2 ] = me[ 2 ] * scaleX;
- te[ 3 ] = 0;
-
- te[ 4 ] = me[ 4 ] * scaleY;
- te[ 5 ] = me[ 5 ] * scaleY;
- te[ 6 ] = me[ 6 ] * scaleY;
- te[ 7 ] = 0;
-
- te[ 8 ] = me[ 8 ] * scaleZ;
- te[ 9 ] = me[ 9 ] * scaleZ;
- te[ 10 ] = me[ 10 ] * scaleZ;
- te[ 11 ] = 0;
-
- te[ 12 ] = 0;
- te[ 13 ] = 0;
- te[ 14 ] = 0;
- te[ 15 ] = 1;
-
- return this;
-
- };
-
- }(),
-
- makeRotationFromEuler: function ( euler ) {
-
- if ( ! ( euler && euler.isEuler ) ) {
-
- console.error( 'THREE.Matrix4: .makeRotationFromEuler() now expects a Euler rotation rather than a Vector3 and order.' );
-
- }
-
- var te = this.elements;
-
- var x = euler.x, y = euler.y, z = euler.z;
- var a = Math.cos( x ), b = Math.sin( x );
- var c = Math.cos( y ), d = Math.sin( y );
- var e = Math.cos( z ), f = Math.sin( z );
-
- if ( euler.order === 'XYZ' ) {
-
- var ae = a * e, af = a * f, be = b * e, bf = b * f;
-
- te[ 0 ] = c * e;
- te[ 4 ] = - c * f;
- te[ 8 ] = d;
-
- te[ 1 ] = af + be * d;
- te[ 5 ] = ae - bf * d;
- te[ 9 ] = - b * c;
-
- te[ 2 ] = bf - ae * d;
- te[ 6 ] = be + af * d;
- te[ 10 ] = a * c;
-
- } else if ( euler.order === 'YXZ' ) {
-
- var ce = c * e, cf = c * f, de = d * e, df = d * f;
-
- te[ 0 ] = ce + df * b;
- te[ 4 ] = de * b - cf;
- te[ 8 ] = a * d;
-
- te[ 1 ] = a * f;
- te[ 5 ] = a * e;
- te[ 9 ] = - b;
-
- te[ 2 ] = cf * b - de;
- te[ 6 ] = df + ce * b;
- te[ 10 ] = a * c;
-
- } else if ( euler.order === 'ZXY' ) {
-
- var ce = c * e, cf = c * f, de = d * e, df = d * f;
-
- te[ 0 ] = ce - df * b;
- te[ 4 ] = - a * f;
- te[ 8 ] = de + cf * b;
-
- te[ 1 ] = cf + de * b;
- te[ 5 ] = a * e;
- te[ 9 ] = df - ce * b;
-
- te[ 2 ] = - a * d;
- te[ 6 ] = b;
- te[ 10 ] = a * c;
-
- } else if ( euler.order === 'ZYX' ) {
-
- var ae = a * e, af = a * f, be = b * e, bf = b * f;
-
- te[ 0 ] = c * e;
- te[ 4 ] = be * d - af;
- te[ 8 ] = ae * d + bf;
-
- te[ 1 ] = c * f;
- te[ 5 ] = bf * d + ae;
- te[ 9 ] = af * d - be;
-
- te[ 2 ] = - d;
- te[ 6 ] = b * c;
- te[ 10 ] = a * c;
-
- } else if ( euler.order === 'YZX' ) {
-
- var ac = a * c, ad = a * d, bc = b * c, bd = b * d;
-
- te[ 0 ] = c * e;
- te[ 4 ] = bd - ac * f;
- te[ 8 ] = bc * f + ad;
-
- te[ 1 ] = f;
- te[ 5 ] = a * e;
- te[ 9 ] = - b * e;
-
- te[ 2 ] = - d * e;
- te[ 6 ] = ad * f + bc;
- te[ 10 ] = ac - bd * f;
-
- } else if ( euler.order === 'XZY' ) {
-
- var ac = a * c, ad = a * d, bc = b * c, bd = b * d;
-
- te[ 0 ] = c * e;
- te[ 4 ] = - f;
- te[ 8 ] = d * e;
-
- te[ 1 ] = ac * f + bd;
- te[ 5 ] = a * e;
- te[ 9 ] = ad * f - bc;
-
- te[ 2 ] = bc * f - ad;
- te[ 6 ] = b * e;
- te[ 10 ] = bd * f + ac;
-
- }
-
- // bottom row
- te[ 3 ] = 0;
- te[ 7 ] = 0;
- te[ 11 ] = 0;
-
- // last column
- te[ 12 ] = 0;
- te[ 13 ] = 0;
- te[ 14 ] = 0;
- te[ 15 ] = 1;
-
- return this;
-
- },
-
- makeRotationFromQuaternion: function () {
-
- var zero = new Vector3( 0, 0, 0 );
- var one = new Vector3( 1, 1, 1 );
-
- return function makeRotationFromQuaternion( q ) {
-
- return this.compose( zero, q, one );
-
- };
-
- }(),
-
- lookAt: function () {
-
- var x = new Vector3();
- var y = new Vector3();
- var z = new Vector3();
-
- return function lookAt( eye, target, up ) {
-
- var te = this.elements;
-
- z.subVectors( eye, target );
-
- if ( z.lengthSq() === 0 ) {
-
- // eye and target are in the same position
-
- z.z = 1;
-
- }
-
- z.normalize();
- x.crossVectors( up, z );
-
- if ( x.lengthSq() === 0 ) {
-
- // up and z are parallel
-
- if ( Math.abs( up.z ) === 1 ) {
-
- z.x += 0.0001;
-
- } else {
-
- z.z += 0.0001;
-
- }
-
- z.normalize();
- x.crossVectors( up, z );
-
- }
-
- x.normalize();
- y.crossVectors( z, x );
-
- te[ 0 ] = x.x; te[ 4 ] = y.x; te[ 8 ] = z.x;
- te[ 1 ] = x.y; te[ 5 ] = y.y; te[ 9 ] = z.y;
- te[ 2 ] = x.z; te[ 6 ] = y.z; te[ 10 ] = z.z;
-
- return this;
-
- };
-
- }(),
-
- multiply: function ( m, n ) {
-
- if ( n !== undefined ) {
-
- console.warn( 'THREE.Matrix4: .multiply() now only accepts one argument. Use .multiplyMatrices( a, b ) instead.' );
- return this.multiplyMatrices( m, n );
-
- }
-
- return this.multiplyMatrices( this, m );
-
- },
-
- premultiply: function ( m ) {
-
- return this.multiplyMatrices( m, this );
-
- },
-
- multiplyMatrices: function ( a, b ) {
-
- var ae = a.elements;
- var be = b.elements;
- var te = this.elements;
-
- var a11 = ae[ 0 ], a12 = ae[ 4 ], a13 = ae[ 8 ], a14 = ae[ 12 ];
- var a21 = ae[ 1 ], a22 = ae[ 5 ], a23 = ae[ 9 ], a24 = ae[ 13 ];
- var a31 = ae[ 2 ], a32 = ae[ 6 ], a33 = ae[ 10 ], a34 = ae[ 14 ];
- var a41 = ae[ 3 ], a42 = ae[ 7 ], a43 = ae[ 11 ], a44 = ae[ 15 ];
-
- var b11 = be[ 0 ], b12 = be[ 4 ], b13 = be[ 8 ], b14 = be[ 12 ];
- var b21 = be[ 1 ], b22 = be[ 5 ], b23 = be[ 9 ], b24 = be[ 13 ];
- var b31 = be[ 2 ], b32 = be[ 6 ], b33 = be[ 10 ], b34 = be[ 14 ];
- var b41 = be[ 3 ], b42 = be[ 7 ], b43 = be[ 11 ], b44 = be[ 15 ];
-
- te[ 0 ] = a11 * b11 + a12 * b21 + a13 * b31 + a14 * b41;
- te[ 4 ] = a11 * b12 + a12 * b22 + a13 * b32 + a14 * b42;
- te[ 8 ] = a11 * b13 + a12 * b23 + a13 * b33 + a14 * b43;
- te[ 12 ] = a11 * b14 + a12 * b24 + a13 * b34 + a14 * b44;
-
- te[ 1 ] = a21 * b11 + a22 * b21 + a23 * b31 + a24 * b41;
- te[ 5 ] = a21 * b12 + a22 * b22 + a23 * b32 + a24 * b42;
- te[ 9 ] = a21 * b13 + a22 * b23 + a23 * b33 + a24 * b43;
- te[ 13 ] = a21 * b14 + a22 * b24 + a23 * b34 + a24 * b44;
-
- te[ 2 ] = a31 * b11 + a32 * b21 + a33 * b31 + a34 * b41;
- te[ 6 ] = a31 * b12 + a32 * b22 + a33 * b32 + a34 * b42;
- te[ 10 ] = a31 * b13 + a32 * b23 + a33 * b33 + a34 * b43;
- te[ 14 ] = a31 * b14 + a32 * b24 + a33 * b34 + a34 * b44;
-
- te[ 3 ] = a41 * b11 + a42 * b21 + a43 * b31 + a44 * b41;
- te[ 7 ] = a41 * b12 + a42 * b22 + a43 * b32 + a44 * b42;
- te[ 11 ] = a41 * b13 + a42 * b23 + a43 * b33 + a44 * b43;
- te[ 15 ] = a41 * b14 + a42 * b24 + a43 * b34 + a44 * b44;
-
- return this;
-
- },
-
- multiplyScalar: function ( s ) {
-
- var te = this.elements;
-
- te[ 0 ] *= s; te[ 4 ] *= s; te[ 8 ] *= s; te[ 12 ] *= s;
- te[ 1 ] *= s; te[ 5 ] *= s; te[ 9 ] *= s; te[ 13 ] *= s;
- te[ 2 ] *= s; te[ 6 ] *= s; te[ 10 ] *= s; te[ 14 ] *= s;
- te[ 3 ] *= s; te[ 7 ] *= s; te[ 11 ] *= s; te[ 15 ] *= s;
-
- return this;
-
- },
-
- applyToBufferAttribute: function () {
-
- var v1 = new Vector3();
-
- return function applyToBufferAttribute( attribute ) {
-
- for ( var i = 0, l = attribute.count; i < l; i ++ ) {
-
- v1.x = attribute.getX( i );
- v1.y = attribute.getY( i );
- v1.z = attribute.getZ( i );
-
- v1.applyMatrix4( this );
-
- attribute.setXYZ( i, v1.x, v1.y, v1.z );
-
- }
-
- return attribute;
-
- };
-
- }(),
-
- determinant: function () {
-
- var te = this.elements;
-
- var n11 = te[ 0 ], n12 = te[ 4 ], n13 = te[ 8 ], n14 = te[ 12 ];
- var n21 = te[ 1 ], n22 = te[ 5 ], n23 = te[ 9 ], n24 = te[ 13 ];
- var n31 = te[ 2 ], n32 = te[ 6 ], n33 = te[ 10 ], n34 = te[ 14 ];
- var n41 = te[ 3 ], n42 = te[ 7 ], n43 = te[ 11 ], n44 = te[ 15 ];
-
- //TODO: make this more efficient
- //( based on http://www.euclideanspace.com/maths/algebra/matrix/functions/inverse/fourD/index.htm )
-
- return (
- n41 * (
- + n14 * n23 * n32
- - n13 * n24 * n32
- - n14 * n22 * n33
- + n12 * n24 * n33
- + n13 * n22 * n34
- - n12 * n23 * n34
- ) +
- n42 * (
- + n11 * n23 * n34
- - n11 * n24 * n33
- + n14 * n21 * n33
- - n13 * n21 * n34
- + n13 * n24 * n31
- - n14 * n23 * n31
- ) +
- n43 * (
- + n11 * n24 * n32
- - n11 * n22 * n34
- - n14 * n21 * n32
- + n12 * n21 * n34
- + n14 * n22 * n31
- - n12 * n24 * n31
- ) +
- n44 * (
- - n13 * n22 * n31
- - n11 * n23 * n32
- + n11 * n22 * n33
- + n13 * n21 * n32
- - n12 * n21 * n33
- + n12 * n23 * n31
- )
-
- );
-
- },
-
- transpose: function () {
-
- var te = this.elements;
- var tmp;
-
- tmp = te[ 1 ]; te[ 1 ] = te[ 4 ]; te[ 4 ] = tmp;
- tmp = te[ 2 ]; te[ 2 ] = te[ 8 ]; te[ 8 ] = tmp;
- tmp = te[ 6 ]; te[ 6 ] = te[ 9 ]; te[ 9 ] = tmp;
-
- tmp = te[ 3 ]; te[ 3 ] = te[ 12 ]; te[ 12 ] = tmp;
- tmp = te[ 7 ]; te[ 7 ] = te[ 13 ]; te[ 13 ] = tmp;
- tmp = te[ 11 ]; te[ 11 ] = te[ 14 ]; te[ 14 ] = tmp;
-
- return this;
-
- },
-
- setPosition: function ( v ) {
-
- var te = this.elements;
-
- te[ 12 ] = v.x;
- te[ 13 ] = v.y;
- te[ 14 ] = v.z;
-
- return this;
-
- },
-
- getInverse: function ( m, throwOnDegenerate ) {
-
- // based on http://www.euclideanspace.com/maths/algebra/matrix/functions/inverse/fourD/index.htm
- var te = this.elements,
- me = m.elements,
-
- n11 = me[ 0 ], n21 = me[ 1 ], n31 = me[ 2 ], n41 = me[ 3 ],
- n12 = me[ 4 ], n22 = me[ 5 ], n32 = me[ 6 ], n42 = me[ 7 ],
- n13 = me[ 8 ], n23 = me[ 9 ], n33 = me[ 10 ], n43 = me[ 11 ],
- n14 = me[ 12 ], n24 = me[ 13 ], n34 = me[ 14 ], n44 = me[ 15 ],
-
- t11 = n23 * n34 * n42 - n24 * n33 * n42 + n24 * n32 * n43 - n22 * n34 * n43 - n23 * n32 * n44 + n22 * n33 * n44,
- t12 = n14 * n33 * n42 - n13 * n34 * n42 - n14 * n32 * n43 + n12 * n34 * n43 + n13 * n32 * n44 - n12 * n33 * n44,
- t13 = n13 * n24 * n42 - n14 * n23 * n42 + n14 * n22 * n43 - n12 * n24 * n43 - n13 * n22 * n44 + n12 * n23 * n44,
- t14 = n14 * n23 * n32 - n13 * n24 * n32 - n14 * n22 * n33 + n12 * n24 * n33 + n13 * n22 * n34 - n12 * n23 * n34;
-
- var det = n11 * t11 + n21 * t12 + n31 * t13 + n41 * t14;
-
- if ( det === 0 ) {
-
- var msg = "THREE.Matrix4: .getInverse() can't invert matrix, determinant is 0";
-
- if ( throwOnDegenerate === true ) {
-
- throw new Error( msg );
-
- } else {
-
- console.warn( msg );
-
- }
-
- return this.identity();
-
- }
-
- var detInv = 1 / det;
-
- te[ 0 ] = t11 * detInv;
- te[ 1 ] = ( n24 * n33 * n41 - n23 * n34 * n41 - n24 * n31 * n43 + n21 * n34 * n43 + n23 * n31 * n44 - n21 * n33 * n44 ) * detInv;
- te[ 2 ] = ( n22 * n34 * n41 - n24 * n32 * n41 + n24 * n31 * n42 - n21 * n34 * n42 - n22 * n31 * n44 + n21 * n32 * n44 ) * detInv;
- te[ 3 ] = ( n23 * n32 * n41 - n22 * n33 * n41 - n23 * n31 * n42 + n21 * n33 * n42 + n22 * n31 * n43 - n21 * n32 * n43 ) * detInv;
-
- te[ 4 ] = t12 * detInv;
- te[ 5 ] = ( n13 * n34 * n41 - n14 * n33 * n41 + n14 * n31 * n43 - n11 * n34 * n43 - n13 * n31 * n44 + n11 * n33 * n44 ) * detInv;
- te[ 6 ] = ( n14 * n32 * n41 - n12 * n34 * n41 - n14 * n31 * n42 + n11 * n34 * n42 + n12 * n31 * n44 - n11 * n32 * n44 ) * detInv;
- te[ 7 ] = ( n12 * n33 * n41 - n13 * n32 * n41 + n13 * n31 * n42 - n11 * n33 * n42 - n12 * n31 * n43 + n11 * n32 * n43 ) * detInv;
-
- te[ 8 ] = t13 * detInv;
- te[ 9 ] = ( n14 * n23 * n41 - n13 * n24 * n41 - n14 * n21 * n43 + n11 * n24 * n43 + n13 * n21 * n44 - n11 * n23 * n44 ) * detInv;
- te[ 10 ] = ( n12 * n24 * n41 - n14 * n22 * n41 + n14 * n21 * n42 - n11 * n24 * n42 - n12 * n21 * n44 + n11 * n22 * n44 ) * detInv;
- te[ 11 ] = ( n13 * n22 * n41 - n12 * n23 * n41 - n13 * n21 * n42 + n11 * n23 * n42 + n12 * n21 * n43 - n11 * n22 * n43 ) * detInv;
-
- te[ 12 ] = t14 * detInv;
- te[ 13 ] = ( n13 * n24 * n31 - n14 * n23 * n31 + n14 * n21 * n33 - n11 * n24 * n33 - n13 * n21 * n34 + n11 * n23 * n34 ) * detInv;
- te[ 14 ] = ( n14 * n22 * n31 - n12 * n24 * n31 - n14 * n21 * n32 + n11 * n24 * n32 + n12 * n21 * n34 - n11 * n22 * n34 ) * detInv;
- te[ 15 ] = ( n12 * n23 * n31 - n13 * n22 * n31 + n13 * n21 * n32 - n11 * n23 * n32 - n12 * n21 * n33 + n11 * n22 * n33 ) * detInv;
-
- return this;
-
- },
-
- scale: function ( v ) {
-
- var te = this.elements;
- var x = v.x, y = v.y, z = v.z;
-
- te[ 0 ] *= x; te[ 4 ] *= y; te[ 8 ] *= z;
- te[ 1 ] *= x; te[ 5 ] *= y; te[ 9 ] *= z;
- te[ 2 ] *= x; te[ 6 ] *= y; te[ 10 ] *= z;
- te[ 3 ] *= x; te[ 7 ] *= y; te[ 11 ] *= z;
-
- return this;
-
- },
-
- getMaxScaleOnAxis: function () {
-
- var te = this.elements;
-
- var scaleXSq = te[ 0 ] * te[ 0 ] + te[ 1 ] * te[ 1 ] + te[ 2 ] * te[ 2 ];
- var scaleYSq = te[ 4 ] * te[ 4 ] + te[ 5 ] * te[ 5 ] + te[ 6 ] * te[ 6 ];
- var scaleZSq = te[ 8 ] * te[ 8 ] + te[ 9 ] * te[ 9 ] + te[ 10 ] * te[ 10 ];
-
- return Math.sqrt( Math.max( scaleXSq, scaleYSq, scaleZSq ) );
-
- },
-
- makeTranslation: function ( x, y, z ) {
-
- this.set(
-
- 1, 0, 0, x,
- 0, 1, 0, y,
- 0, 0, 1, z,
- 0, 0, 0, 1
-
- );
-
- return this;
-
- },
-
- makeRotationX: function ( theta ) {
-
- var c = Math.cos( theta ), s = Math.sin( theta );
-
- this.set(
-
- 1, 0, 0, 0,
- 0, c, - s, 0,
- 0, s, c, 0,
- 0, 0, 0, 1
-
- );
-
- return this;
-
- },
-
- makeRotationY: function ( theta ) {
-
- var c = Math.cos( theta ), s = Math.sin( theta );
-
- this.set(
-
- c, 0, s, 0,
- 0, 1, 0, 0,
- - s, 0, c, 0,
- 0, 0, 0, 1
-
- );
-
- return this;
-
- },
-
- makeRotationZ: function ( theta ) {
-
- var c = Math.cos( theta ), s = Math.sin( theta );
-
- this.set(
-
- c, - s, 0, 0,
- s, c, 0, 0,
- 0, 0, 1, 0,
- 0, 0, 0, 1
-
- );
-
- return this;
-
- },
-
- makeRotationAxis: function ( axis, angle ) {
-
- // Based on http://www.gamedev.net/reference/articles/article1199.asp
-
- var c = Math.cos( angle );
- var s = Math.sin( angle );
- var t = 1 - c;
- var x = axis.x, y = axis.y, z = axis.z;
- var tx = t * x, ty = t * y;
-
- this.set(
-
- tx * x + c, tx * y - s * z, tx * z + s * y, 0,
- tx * y + s * z, ty * y + c, ty * z - s * x, 0,
- tx * z - s * y, ty * z + s * x, t * z * z + c, 0,
- 0, 0, 0, 1
-
- );
-
- return this;
-
- },
-
- makeScale: function ( x, y, z ) {
-
- this.set(
-
- x, 0, 0, 0,
- 0, y, 0, 0,
- 0, 0, z, 0,
- 0, 0, 0, 1
-
- );
-
- return this;
-
- },
-
- makeShear: function ( x, y, z ) {
-
- this.set(
-
- 1, y, z, 0,
- x, 1, z, 0,
- x, y, 1, 0,
- 0, 0, 0, 1
-
- );
-
- return this;
-
- },
-
- compose: function ( position, quaternion, scale ) {
-
- var te = this.elements;
-
- var x = quaternion._x, y = quaternion._y, z = quaternion._z, w = quaternion._w;
- var x2 = x + x, y2 = y + y, z2 = z + z;
- var xx = x * x2, xy = x * y2, xz = x * z2;
- var yy = y * y2, yz = y * z2, zz = z * z2;
- var wx = w * x2, wy = w * y2, wz = w * z2;
-
- var sx = scale.x, sy = scale.y, sz = scale.z;
-
- te[ 0 ] = ( 1 - ( yy + zz ) ) * sx;
- te[ 1 ] = ( xy + wz ) * sx;
- te[ 2 ] = ( xz - wy ) * sx;
- te[ 3 ] = 0;
-
- te[ 4 ] = ( xy - wz ) * sy;
- te[ 5 ] = ( 1 - ( xx + zz ) ) * sy;
- te[ 6 ] = ( yz + wx ) * sy;
- te[ 7 ] = 0;
-
- te[ 8 ] = ( xz + wy ) * sz;
- te[ 9 ] = ( yz - wx ) * sz;
- te[ 10 ] = ( 1 - ( xx + yy ) ) * sz;
- te[ 11 ] = 0;
-
- te[ 12 ] = position.x;
- te[ 13 ] = position.y;
- te[ 14 ] = position.z;
- te[ 15 ] = 1;
-
- return this;
-
- },
-
- decompose: function () {
-
- var vector = new Vector3();
- var matrix = new Matrix4();
-
- return function decompose( position, quaternion, scale ) {
-
- var te = this.elements;
-
- var sx = vector.set( te[ 0 ], te[ 1 ], te[ 2 ] ).length();
- var sy = vector.set( te[ 4 ], te[ 5 ], te[ 6 ] ).length();
- var sz = vector.set( te[ 8 ], te[ 9 ], te[ 10 ] ).length();
-
- // if determine is negative, we need to invert one scale
- var det = this.determinant();
- if ( det < 0 ) sx = - sx;
-
- position.x = te[ 12 ];
- position.y = te[ 13 ];
- position.z = te[ 14 ];
-
- // scale the rotation part
- matrix.copy( this );
-
- var invSX = 1 / sx;
- var invSY = 1 / sy;
- var invSZ = 1 / sz;
-
- matrix.elements[ 0 ] *= invSX;
- matrix.elements[ 1 ] *= invSX;
- matrix.elements[ 2 ] *= invSX;
-
- matrix.elements[ 4 ] *= invSY;
- matrix.elements[ 5 ] *= invSY;
- matrix.elements[ 6 ] *= invSY;
-
- matrix.elements[ 8 ] *= invSZ;
- matrix.elements[ 9 ] *= invSZ;
- matrix.elements[ 10 ] *= invSZ;
-
- quaternion.setFromRotationMatrix( matrix );
-
- scale.x = sx;
- scale.y = sy;
- scale.z = sz;
-
- return this;
-
- };
-
- }(),
-
- makePerspective: function ( left, right, top, bottom, near, far ) {
-
- if ( far === undefined ) {
-
- console.warn( 'THREE.Matrix4: .makePerspective() has been redefined and has a new signature. Please check the docs.' );
-
- }
-
- var te = this.elements;
- var x = 2 * near / ( right - left );
- var y = 2 * near / ( top - bottom );
-
- var a = ( right + left ) / ( right - left );
- var b = ( top + bottom ) / ( top - bottom );
- var c = - ( far + near ) / ( far - near );
- var d = - 2 * far * near / ( far - near );
-
- te[ 0 ] = x; te[ 4 ] = 0; te[ 8 ] = a; te[ 12 ] = 0;
- te[ 1 ] = 0; te[ 5 ] = y; te[ 9 ] = b; te[ 13 ] = 0;
- te[ 2 ] = 0; te[ 6 ] = 0; te[ 10 ] = c; te[ 14 ] = d;
- te[ 3 ] = 0; te[ 7 ] = 0; te[ 11 ] = - 1; te[ 15 ] = 0;
-
- return this;
-
- },
-
- makeOrthographic: function ( left, right, top, bottom, near, far ) {
-
- var te = this.elements;
- var w = 1.0 / ( right - left );
- var h = 1.0 / ( top - bottom );
- var p = 1.0 / ( far - near );
-
- var x = ( right + left ) * w;
- var y = ( top + bottom ) * h;
- var z = ( far + near ) * p;
-
- te[ 0 ] = 2 * w; te[ 4 ] = 0; te[ 8 ] = 0; te[ 12 ] = - x;
- te[ 1 ] = 0; te[ 5 ] = 2 * h; te[ 9 ] = 0; te[ 13 ] = - y;
- te[ 2 ] = 0; te[ 6 ] = 0; te[ 10 ] = - 2 * p; te[ 14 ] = - z;
- te[ 3 ] = 0; te[ 7 ] = 0; te[ 11 ] = 0; te[ 15 ] = 1;
-
- return this;
-
- },
-
- equals: function ( matrix ) {
-
- var te = this.elements;
- var me = matrix.elements;
-
- for ( var i = 0; i < 16; i ++ ) {
-
- if ( te[ i ] !== me[ i ] ) return false;
-
- }
-
- return true;
-
- },
-
- fromArray: function ( array, offset ) {
-
- if ( offset === undefined ) offset = 0;
-
- for ( var i = 0; i < 16; i ++ ) {
-
- this.elements[ i ] = array[ i + offset ];
-
- }
-
- return this;
-
- },
-
- toArray: function ( array, offset ) {
-
- if ( array === undefined ) array = [];
- if ( offset === undefined ) offset = 0;
-
- var te = this.elements;
-
- array[ offset ] = te[ 0 ];
- array[ offset + 1 ] = te[ 1 ];
- array[ offset + 2 ] = te[ 2 ];
- array[ offset + 3 ] = te[ 3 ];
-
- array[ offset + 4 ] = te[ 4 ];
- array[ offset + 5 ] = te[ 5 ];
- array[ offset + 6 ] = te[ 6 ];
- array[ offset + 7 ] = te[ 7 ];
-
- array[ offset + 8 ] = te[ 8 ];
- array[ offset + 9 ] = te[ 9 ];
- array[ offset + 10 ] = te[ 10 ];
- array[ offset + 11 ] = te[ 11 ];
-
- array[ offset + 12 ] = te[ 12 ];
- array[ offset + 13 ] = te[ 13 ];
- array[ offset + 14 ] = te[ 14 ];
- array[ offset + 15 ] = te[ 15 ];
-
- return array;
-
- }
-
- } );
-
- var alphamap_fragment = "#ifdef USE_ALPHAMAP\n\tdiffuseColor.a *= texture2D( alphaMap, vUv ).g;\n#endif";
-
- var alphamap_pars_fragment = "#ifdef USE_ALPHAMAP\n\tuniform sampler2D alphaMap;\n#endif";
-
- var alphatest_fragment = "#ifdef ALPHATEST\n\tif ( diffuseColor.a < ALPHATEST ) discard;\n#endif";
-
- var aomap_fragment = "#ifdef USE_AOMAP\n\tfloat ambientOcclusion = ( texture2D( aoMap, vUv2 ).r - 1.0 ) * aoMapIntensity + 1.0;\n\treflectedLight.indirectDiffuse *= ambientOcclusion;\n\t#if defined( USE_ENVMAP ) && defined( PHYSICAL )\n\t\tfloat dotNV = saturate( dot( geometry.normal, geometry.viewDir ) );\n\t\treflectedLight.indirectSpecular *= computeSpecularOcclusion( dotNV, ambientOcclusion, material.specularRoughness );\n\t#endif\n#endif";
-
- var aomap_pars_fragment = "#ifdef USE_AOMAP\n\tuniform sampler2D aoMap;\n\tuniform float aoMapIntensity;\n#endif";
-
- var begin_vertex = "vec3 transformed = vec3( position );";
-
- var beginnormal_vertex = "vec3 objectNormal = vec3( normal );\n#ifdef USE_TANGENT\n\tvec3 objectTangent = vec3( tangent.xyz );\n#endif";
-
- var bsdfs = "vec2 integrateSpecularBRDF( const in float dotNV, const in float roughness ) {\n\tconst vec4 c0 = vec4( - 1, - 0.0275, - 0.572, 0.022 );\n\tconst vec4 c1 = vec4( 1, 0.0425, 1.04, - 0.04 );\n\tvec4 r = roughness * c0 + c1;\n\tfloat a004 = min( r.x * r.x, exp2( - 9.28 * dotNV ) ) * r.x + r.y;\n\treturn vec2( -1.04, 1.04 ) * a004 + r.zw;\n}\nfloat punctualLightIntensityToIrradianceFactor( const in float lightDistance, const in float cutoffDistance, const in float decayExponent ) {\n#if defined ( PHYSICALLY_CORRECT_LIGHTS )\n\tfloat distanceFalloff = 1.0 / max( pow( lightDistance, decayExponent ), 0.01 );\n\tif( cutoffDistance > 0.0 ) {\n\t\tdistanceFalloff *= pow2( saturate( 1.0 - pow4( lightDistance / cutoffDistance ) ) );\n\t}\n\treturn distanceFalloff;\n#else\n\tif( cutoffDistance > 0.0 && decayExponent > 0.0 ) {\n\t\treturn pow( saturate( -lightDistance / cutoffDistance + 1.0 ), decayExponent );\n\t}\n\treturn 1.0;\n#endif\n}\nvec3 BRDF_Diffuse_Lambert( const in vec3 diffuseColor ) {\n\treturn RECIPROCAL_PI * diffuseColor;\n}\nvec3 F_Schlick( const in vec3 specularColor, const in float dotLH ) {\n\tfloat fresnel = exp2( ( -5.55473 * dotLH - 6.98316 ) * dotLH );\n\treturn ( 1.0 - specularColor ) * fresnel + specularColor;\n}\nfloat G_GGX_Smith( const in float alpha, const in float dotNL, const in float dotNV ) {\n\tfloat a2 = pow2( alpha );\n\tfloat gl = dotNL + sqrt( a2 + ( 1.0 - a2 ) * pow2( dotNL ) );\n\tfloat gv = dotNV + sqrt( a2 + ( 1.0 - a2 ) * pow2( dotNV ) );\n\treturn 1.0 / ( gl * gv );\n}\nfloat G_GGX_SmithCorrelated( const in float alpha, const in float dotNL, const in float dotNV ) {\n\tfloat a2 = pow2( alpha );\n\tfloat gv = dotNL * sqrt( a2 + ( 1.0 - a2 ) * pow2( dotNV ) );\n\tfloat gl = dotNV * sqrt( a2 + ( 1.0 - a2 ) * pow2( dotNL ) );\n\treturn 0.5 / max( gv + gl, EPSILON );\n}\nfloat D_GGX( const in float alpha, const in float dotNH ) {\n\tfloat a2 = pow2( alpha );\n\tfloat denom = pow2( dotNH ) * ( a2 - 1.0 ) + 1.0;\n\treturn RECIPROCAL_PI * a2 / pow2( denom );\n}\nvec3 BRDF_Specular_GGX( const in IncidentLight incidentLight, const in GeometricContext geometry, const in vec3 specularColor, const in float roughness ) {\n\tfloat alpha = pow2( roughness );\n\tvec3 halfDir = normalize( incidentLight.direction + geometry.viewDir );\n\tfloat dotNL = saturate( dot( geometry.normal, incidentLight.direction ) );\n\tfloat dotNV = saturate( dot( geometry.normal, geometry.viewDir ) );\n\tfloat dotNH = saturate( dot( geometry.normal, halfDir ) );\n\tfloat dotLH = saturate( dot( incidentLight.direction, halfDir ) );\n\tvec3 F = F_Schlick( specularColor, dotLH );\n\tfloat G = G_GGX_SmithCorrelated( alpha, dotNL, dotNV );\n\tfloat D = D_GGX( alpha, dotNH );\n\treturn F * ( G * D );\n}\nvec2 LTC_Uv( const in vec3 N, const in vec3 V, const in float roughness ) {\n\tconst float LUT_SIZE = 64.0;\n\tconst float LUT_SCALE = ( LUT_SIZE - 1.0 ) / LUT_SIZE;\n\tconst float LUT_BIAS = 0.5 / LUT_SIZE;\n\tfloat dotNV = saturate( dot( N, V ) );\n\tvec2 uv = vec2( roughness, sqrt( 1.0 - dotNV ) );\n\tuv = uv * LUT_SCALE + LUT_BIAS;\n\treturn uv;\n}\nfloat LTC_ClippedSphereFormFactor( const in vec3 f ) {\n\tfloat l = length( f );\n\treturn max( ( l * l + f.z ) / ( l + 1.0 ), 0.0 );\n}\nvec3 LTC_EdgeVectorFormFactor( const in vec3 v1, const in vec3 v2 ) {\n\tfloat x = dot( v1, v2 );\n\tfloat y = abs( x );\n\tfloat a = 0.8543985 + ( 0.4965155 + 0.0145206 * y ) * y;\n\tfloat b = 3.4175940 + ( 4.1616724 + y ) * y;\n\tfloat v = a / b;\n\tfloat theta_sintheta = ( x > 0.0 ) ? v : 0.5 * inversesqrt( max( 1.0 - x * x, 1e-7 ) ) - v;\n\treturn cross( v1, v2 ) * theta_sintheta;\n}\nvec3 LTC_Evaluate( const in vec3 N, const in vec3 V, const in vec3 P, const in mat3 mInv, const in vec3 rectCoords[ 4 ] ) {\n\tvec3 v1 = rectCoords[ 1 ] - rectCoords[ 0 ];\n\tvec3 v2 = rectCoords[ 3 ] - rectCoords[ 0 ];\n\tvec3 lightNormal = cross( v1, v2 );\n\tif( dot( lightNormal, P - rectCoords[ 0 ] ) < 0.0 ) return vec3( 0.0 );\n\tvec3 T1, T2;\n\tT1 = normalize( V - N * dot( V, N ) );\n\tT2 = - cross( N, T1 );\n\tmat3 mat = mInv * transposeMat3( mat3( T1, T2, N ) );\n\tvec3 coords[ 4 ];\n\tcoords[ 0 ] = mat * ( rectCoords[ 0 ] - P );\n\tcoords[ 1 ] = mat * ( rectCoords[ 1 ] - P );\n\tcoords[ 2 ] = mat * ( rectCoords[ 2 ] - P );\n\tcoords[ 3 ] = mat * ( rectCoords[ 3 ] - P );\n\tcoords[ 0 ] = normalize( coords[ 0 ] );\n\tcoords[ 1 ] = normalize( coords[ 1 ] );\n\tcoords[ 2 ] = normalize( coords[ 2 ] );\n\tcoords[ 3 ] = normalize( coords[ 3 ] );\n\tvec3 vectorFormFactor = vec3( 0.0 );\n\tvectorFormFactor += LTC_EdgeVectorFormFactor( coords[ 0 ], coords[ 1 ] );\n\tvectorFormFactor += LTC_EdgeVectorFormFactor( coords[ 1 ], coords[ 2 ] );\n\tvectorFormFactor += LTC_EdgeVectorFormFactor( coords[ 2 ], coords[ 3 ] );\n\tvectorFormFactor += LTC_EdgeVectorFormFactor( coords[ 3 ], coords[ 0 ] );\n\tfloat result = LTC_ClippedSphereFormFactor( vectorFormFactor );\n\treturn vec3( result );\n}\nvec3 BRDF_Specular_GGX_Environment( const in GeometricContext geometry, const in vec3 specularColor, const in float roughness ) {\n\tfloat dotNV = saturate( dot( geometry.normal, geometry.viewDir ) );\n\tvec2 brdf = integrateSpecularBRDF( dotNV, roughness );\n\treturn specularColor * brdf.x + brdf.y;\n}\nvoid BRDF_Specular_Multiscattering_Environment( const in GeometricContext geometry, const in vec3 specularColor, const in float roughness, inout vec3 singleScatter, inout vec3 multiScatter ) {\n\tfloat dotNV = saturate( dot( geometry.normal, geometry.viewDir ) );\n\tvec3 F = F_Schlick( specularColor, dotNV );\n\tvec2 brdf = integrateSpecularBRDF( dotNV, roughness );\n\tvec3 FssEss = F * brdf.x + brdf.y;\n\tfloat Ess = brdf.x + brdf.y;\n\tfloat Ems = 1.0 - Ess;\n\tvec3 Favg = specularColor + ( 1.0 - specularColor ) * 0.047619;\tvec3 Fms = FssEss * Favg / ( 1.0 - Ems * Favg );\n\tsingleScatter += FssEss;\n\tmultiScatter += Fms * Ems;\n}\nfloat G_BlinnPhong_Implicit( ) {\n\treturn 0.25;\n}\nfloat D_BlinnPhong( const in float shininess, const in float dotNH ) {\n\treturn RECIPROCAL_PI * ( shininess * 0.5 + 1.0 ) * pow( dotNH, shininess );\n}\nvec3 BRDF_Specular_BlinnPhong( const in IncidentLight incidentLight, const in GeometricContext geometry, const in vec3 specularColor, const in float shininess ) {\n\tvec3 halfDir = normalize( incidentLight.direction + geometry.viewDir );\n\tfloat dotNH = saturate( dot( geometry.normal, halfDir ) );\n\tfloat dotLH = saturate( dot( incidentLight.direction, halfDir ) );\n\tvec3 F = F_Schlick( specularColor, dotLH );\n\tfloat G = G_BlinnPhong_Implicit( );\n\tfloat D = D_BlinnPhong( shininess, dotNH );\n\treturn F * ( G * D );\n}\nfloat GGXRoughnessToBlinnExponent( const in float ggxRoughness ) {\n\treturn ( 2.0 / pow2( ggxRoughness + 0.0001 ) - 2.0 );\n}\nfloat BlinnExponentToGGXRoughness( const in float blinnExponent ) {\n\treturn sqrt( 2.0 / ( blinnExponent + 2.0 ) );\n}";
-
- var bumpmap_pars_fragment = "#ifdef USE_BUMPMAP\n\tuniform sampler2D bumpMap;\n\tuniform float bumpScale;\n\tvec2 dHdxy_fwd() {\n\t\tvec2 dSTdx = dFdx( vUv );\n\t\tvec2 dSTdy = dFdy( vUv );\n\t\tfloat Hll = bumpScale * texture2D( bumpMap, vUv ).x;\n\t\tfloat dBx = bumpScale * texture2D( bumpMap, vUv + dSTdx ).x - Hll;\n\t\tfloat dBy = bumpScale * texture2D( bumpMap, vUv + dSTdy ).x - Hll;\n\t\treturn vec2( dBx, dBy );\n\t}\n\tvec3 perturbNormalArb( vec3 surf_pos, vec3 surf_norm, vec2 dHdxy ) {\n\t\tvec3 vSigmaX = vec3( dFdx( surf_pos.x ), dFdx( surf_pos.y ), dFdx( surf_pos.z ) );\n\t\tvec3 vSigmaY = vec3( dFdy( surf_pos.x ), dFdy( surf_pos.y ), dFdy( surf_pos.z ) );\n\t\tvec3 vN = surf_norm;\n\t\tvec3 R1 = cross( vSigmaY, vN );\n\t\tvec3 R2 = cross( vN, vSigmaX );\n\t\tfloat fDet = dot( vSigmaX, R1 );\n\t\tfDet *= ( float( gl_FrontFacing ) * 2.0 - 1.0 );\n\t\tvec3 vGrad = sign( fDet ) * ( dHdxy.x * R1 + dHdxy.y * R2 );\n\t\treturn normalize( abs( fDet ) * surf_norm - vGrad );\n\t}\n#endif";
-
- var clipping_planes_fragment = "#if NUM_CLIPPING_PLANES > 0\n\tvec4 plane;\n\t#pragma unroll_loop\n\tfor ( int i = 0; i < UNION_CLIPPING_PLANES; i ++ ) {\n\t\tplane = clippingPlanes[ i ];\n\t\tif ( dot( vViewPosition, plane.xyz ) > plane.w ) discard;\n\t}\n\t#if UNION_CLIPPING_PLANES < NUM_CLIPPING_PLANES\n\t\tbool clipped = true;\n\t\t#pragma unroll_loop\n\t\tfor ( int i = UNION_CLIPPING_PLANES; i < NUM_CLIPPING_PLANES; i ++ ) {\n\t\t\tplane = clippingPlanes[ i ];\n\t\t\tclipped = ( dot( vViewPosition, plane.xyz ) > plane.w ) && clipped;\n\t\t}\n\t\tif ( clipped ) discard;\n\t#endif\n#endif";
-
- var clipping_planes_pars_fragment = "#if NUM_CLIPPING_PLANES > 0\n\t#if ! defined( PHYSICAL ) && ! defined( PHONG ) && ! defined( MATCAP )\n\t\tvarying vec3 vViewPosition;\n\t#endif\n\tuniform vec4 clippingPlanes[ NUM_CLIPPING_PLANES ];\n#endif";
-
- var clipping_planes_pars_vertex = "#if NUM_CLIPPING_PLANES > 0 && ! defined( PHYSICAL ) && ! defined( PHONG ) && ! defined( MATCAP )\n\tvarying vec3 vViewPosition;\n#endif";
-
- var clipping_planes_vertex = "#if NUM_CLIPPING_PLANES > 0 && ! defined( PHYSICAL ) && ! defined( PHONG ) && ! defined( MATCAP )\n\tvViewPosition = - mvPosition.xyz;\n#endif";
-
- var color_fragment = "#ifdef USE_COLOR\n\tdiffuseColor.rgb *= vColor;\n#endif";
-
- var color_pars_fragment = "#ifdef USE_COLOR\n\tvarying vec3 vColor;\n#endif";
-
- var color_pars_vertex = "#ifdef USE_COLOR\n\tvarying vec3 vColor;\n#endif";
-
- var color_vertex = "#ifdef USE_COLOR\n\tvColor.xyz = color.xyz;\n#endif";
-
- var common = "#define PI 3.14159265359\n#define PI2 6.28318530718\n#define PI_HALF 1.5707963267949\n#define RECIPROCAL_PI 0.31830988618\n#define RECIPROCAL_PI2 0.15915494\n#define LOG2 1.442695\n#define EPSILON 1e-6\n#define saturate(a) clamp( a, 0.0, 1.0 )\n#define whiteCompliment(a) ( 1.0 - saturate( a ) )\nfloat pow2( const in float x ) { return x*x; }\nfloat pow3( const in float x ) { return x*x*x; }\nfloat pow4( const in float x ) { float x2 = x*x; return x2*x2; }\nfloat average( const in vec3 color ) { return dot( color, vec3( 0.3333 ) ); }\nhighp float rand( const in vec2 uv ) {\n\tconst highp float a = 12.9898, b = 78.233, c = 43758.5453;\n\thighp float dt = dot( uv.xy, vec2( a,b ) ), sn = mod( dt, PI );\n\treturn fract(sin(sn) * c);\n}\nstruct IncidentLight {\n\tvec3 color;\n\tvec3 direction;\n\tbool visible;\n};\nstruct ReflectedLight {\n\tvec3 directDiffuse;\n\tvec3 directSpecular;\n\tvec3 indirectDiffuse;\n\tvec3 indirectSpecular;\n};\nstruct GeometricContext {\n\tvec3 position;\n\tvec3 normal;\n\tvec3 viewDir;\n};\nvec3 transformDirection( in vec3 dir, in mat4 matrix ) {\n\treturn normalize( ( matrix * vec4( dir, 0.0 ) ).xyz );\n}\nvec3 inverseTransformDirection( in vec3 dir, in mat4 matrix ) {\n\treturn normalize( ( vec4( dir, 0.0 ) * matrix ).xyz );\n}\nvec3 projectOnPlane(in vec3 point, in vec3 pointOnPlane, in vec3 planeNormal ) {\n\tfloat distance = dot( planeNormal, point - pointOnPlane );\n\treturn - distance * planeNormal + point;\n}\nfloat sideOfPlane( in vec3 point, in vec3 pointOnPlane, in vec3 planeNormal ) {\n\treturn sign( dot( point - pointOnPlane, planeNormal ) );\n}\nvec3 linePlaneIntersect( in vec3 pointOnLine, in vec3 lineDirection, in vec3 pointOnPlane, in vec3 planeNormal ) {\n\treturn lineDirection * ( dot( planeNormal, pointOnPlane - pointOnLine ) / dot( planeNormal, lineDirection ) ) + pointOnLine;\n}\nmat3 transposeMat3( const in mat3 m ) {\n\tmat3 tmp;\n\ttmp[ 0 ] = vec3( m[ 0 ].x, m[ 1 ].x, m[ 2 ].x );\n\ttmp[ 1 ] = vec3( m[ 0 ].y, m[ 1 ].y, m[ 2 ].y );\n\ttmp[ 2 ] = vec3( m[ 0 ].z, m[ 1 ].z, m[ 2 ].z );\n\treturn tmp;\n}\nfloat linearToRelativeLuminance( const in vec3 color ) {\n\tvec3 weights = vec3( 0.2126, 0.7152, 0.0722 );\n\treturn dot( weights, color.rgb );\n}";
-
- var cube_uv_reflection_fragment = "#ifdef ENVMAP_TYPE_CUBE_UV\n#define cubeUV_textureSize (1024.0)\nint getFaceFromDirection(vec3 direction) {\n\tvec3 absDirection = abs(direction);\n\tint face = -1;\n\tif( absDirection.x > absDirection.z ) {\n\t\tif(absDirection.x > absDirection.y )\n\t\t\tface = direction.x > 0.0 ? 0 : 3;\n\t\telse\n\t\t\tface = direction.y > 0.0 ? 1 : 4;\n\t}\n\telse {\n\t\tif(absDirection.z > absDirection.y )\n\t\t\tface = direction.z > 0.0 ? 2 : 5;\n\t\telse\n\t\t\tface = direction.y > 0.0 ? 1 : 4;\n\t}\n\treturn face;\n}\n#define cubeUV_maxLods1 (log2(cubeUV_textureSize*0.25) - 1.0)\n#define cubeUV_rangeClamp (exp2((6.0 - 1.0) * 2.0))\nvec2 MipLevelInfo( vec3 vec, float roughnessLevel, float roughness ) {\n\tfloat scale = exp2(cubeUV_maxLods1 - roughnessLevel);\n\tfloat dxRoughness = dFdx(roughness);\n\tfloat dyRoughness = dFdy(roughness);\n\tvec3 dx = dFdx( vec * scale * dxRoughness );\n\tvec3 dy = dFdy( vec * scale * dyRoughness );\n\tfloat d = max( dot( dx, dx ), dot( dy, dy ) );\n\td = clamp(d, 1.0, cubeUV_rangeClamp);\n\tfloat mipLevel = 0.5 * log2(d);\n\treturn vec2(floor(mipLevel), fract(mipLevel));\n}\n#define cubeUV_maxLods2 (log2(cubeUV_textureSize*0.25) - 2.0)\n#define cubeUV_rcpTextureSize (1.0 / cubeUV_textureSize)\nvec2 getCubeUV(vec3 direction, float roughnessLevel, float mipLevel) {\n\tmipLevel = roughnessLevel > cubeUV_maxLods2 - 3.0 ? 0.0 : mipLevel;\n\tfloat a = 16.0 * cubeUV_rcpTextureSize;\n\tvec2 exp2_packed = exp2( vec2( roughnessLevel, mipLevel ) );\n\tvec2 rcp_exp2_packed = vec2( 1.0 ) / exp2_packed;\n\tfloat powScale = exp2_packed.x * exp2_packed.y;\n\tfloat scale = rcp_exp2_packed.x * rcp_exp2_packed.y * 0.25;\n\tfloat mipOffset = 0.75*(1.0 - rcp_exp2_packed.y) * rcp_exp2_packed.x;\n\tbool bRes = mipLevel == 0.0;\n\tscale = bRes && (scale < a) ? a : scale;\n\tvec3 r;\n\tvec2 offset;\n\tint face = getFaceFromDirection(direction);\n\tfloat rcpPowScale = 1.0 / powScale;\n\tif( face == 0) {\n\t\tr = vec3(direction.x, -direction.z, direction.y);\n\t\toffset = vec2(0.0+mipOffset,0.75 * rcpPowScale);\n\t\toffset.y = bRes && (offset.y < 2.0*a) ? a : offset.y;\n\t}\n\telse if( face == 1) {\n\t\tr = vec3(direction.y, direction.x, direction.z);\n\t\toffset = vec2(scale+mipOffset, 0.75 * rcpPowScale);\n\t\toffset.y = bRes && (offset.y < 2.0*a) ? a : offset.y;\n\t}\n\telse if( face == 2) {\n\t\tr = vec3(direction.z, direction.x, direction.y);\n\t\toffset = vec2(2.0*scale+mipOffset, 0.75 * rcpPowScale);\n\t\toffset.y = bRes && (offset.y < 2.0*a) ? a : offset.y;\n\t}\n\telse if( face == 3) {\n\t\tr = vec3(direction.x, direction.z, direction.y);\n\t\toffset = vec2(0.0+mipOffset,0.5 * rcpPowScale);\n\t\toffset.y = bRes && (offset.y < 2.0*a) ? 0.0 : offset.y;\n\t}\n\telse if( face == 4) {\n\t\tr = vec3(direction.y, direction.x, -direction.z);\n\t\toffset = vec2(scale+mipOffset, 0.5 * rcpPowScale);\n\t\toffset.y = bRes && (offset.y < 2.0*a) ? 0.0 : offset.y;\n\t}\n\telse {\n\t\tr = vec3(direction.z, -direction.x, direction.y);\n\t\toffset = vec2(2.0*scale+mipOffset, 0.5 * rcpPowScale);\n\t\toffset.y = bRes && (offset.y < 2.0*a) ? 0.0 : offset.y;\n\t}\n\tr = normalize(r);\n\tfloat texelOffset = 0.5 * cubeUV_rcpTextureSize;\n\tvec2 s = ( r.yz / abs( r.x ) + vec2( 1.0 ) ) * 0.5;\n\tvec2 base = offset + vec2( texelOffset );\n\treturn base + s * ( scale - 2.0 * texelOffset );\n}\n#define cubeUV_maxLods3 (log2(cubeUV_textureSize*0.25) - 3.0)\nvec4 textureCubeUV( sampler2D envMap, vec3 reflectedDirection, float roughness ) {\n\tfloat roughnessVal = roughness* cubeUV_maxLods3;\n\tfloat r1 = floor(roughnessVal);\n\tfloat r2 = r1 + 1.0;\n\tfloat t = fract(roughnessVal);\n\tvec2 mipInfo = MipLevelInfo(reflectedDirection, r1, roughness);\n\tfloat s = mipInfo.y;\n\tfloat level0 = mipInfo.x;\n\tfloat level1 = level0 + 1.0;\n\tlevel1 = level1 > 5.0 ? 5.0 : level1;\n\tlevel0 += min( floor( s + 0.5 ), 5.0 );\n\tvec2 uv_10 = getCubeUV(reflectedDirection, r1, level0);\n\tvec4 color10 = envMapTexelToLinear(texture2D(envMap, uv_10));\n\tvec2 uv_20 = getCubeUV(reflectedDirection, r2, level0);\n\tvec4 color20 = envMapTexelToLinear(texture2D(envMap, uv_20));\n\tvec4 result = mix(color10, color20, t);\n\treturn vec4(result.rgb, 1.0);\n}\n#endif";
-
- var defaultnormal_vertex = "vec3 transformedNormal = normalMatrix * objectNormal;\n#ifdef FLIP_SIDED\n\ttransformedNormal = - transformedNormal;\n#endif\n#ifdef USE_TANGENT\n\tvec3 transformedTangent = normalMatrix * objectTangent;\n\t#ifdef FLIP_SIDED\n\t\ttransformedTangent = - transformedTangent;\n\t#endif\n#endif";
-
- var displacementmap_pars_vertex = "#ifdef USE_DISPLACEMENTMAP\n\tuniform sampler2D displacementMap;\n\tuniform float displacementScale;\n\tuniform float displacementBias;\n#endif";
-
- var displacementmap_vertex = "#ifdef USE_DISPLACEMENTMAP\n\ttransformed += normalize( objectNormal ) * ( texture2D( displacementMap, uv ).x * displacementScale + displacementBias );\n#endif";
-
- var emissivemap_fragment = "#ifdef USE_EMISSIVEMAP\n\tvec4 emissiveColor = texture2D( emissiveMap, vUv );\n\temissiveColor.rgb = emissiveMapTexelToLinear( emissiveColor ).rgb;\n\ttotalEmissiveRadiance *= emissiveColor.rgb;\n#endif";
-
- var emissivemap_pars_fragment = "#ifdef USE_EMISSIVEMAP\n\tuniform sampler2D emissiveMap;\n#endif";
-
- var encodings_fragment = "gl_FragColor = linearToOutputTexel( gl_FragColor );";
-
- var encodings_pars_fragment = "\nvec4 LinearToLinear( in vec4 value ) {\n\treturn value;\n}\nvec4 GammaToLinear( in vec4 value, in float gammaFactor ) {\n\treturn vec4( pow( value.rgb, vec3( gammaFactor ) ), value.a );\n}\nvec4 LinearToGamma( in vec4 value, in float gammaFactor ) {\n\treturn vec4( pow( value.rgb, vec3( 1.0 / gammaFactor ) ), value.a );\n}\nvec4 sRGBToLinear( in vec4 value ) {\n\treturn vec4( mix( pow( value.rgb * 0.9478672986 + vec3( 0.0521327014 ), vec3( 2.4 ) ), value.rgb * 0.0773993808, vec3( lessThanEqual( value.rgb, vec3( 0.04045 ) ) ) ), value.a );\n}\nvec4 LinearTosRGB( in vec4 value ) {\n\treturn vec4( mix( pow( value.rgb, vec3( 0.41666 ) ) * 1.055 - vec3( 0.055 ), value.rgb * 12.92, vec3( lessThanEqual( value.rgb, vec3( 0.0031308 ) ) ) ), value.a );\n}\nvec4 RGBEToLinear( in vec4 value ) {\n\treturn vec4( value.rgb * exp2( value.a * 255.0 - 128.0 ), 1.0 );\n}\nvec4 LinearToRGBE( in vec4 value ) {\n\tfloat maxComponent = max( max( value.r, value.g ), value.b );\n\tfloat fExp = clamp( ceil( log2( maxComponent ) ), -128.0, 127.0 );\n\treturn vec4( value.rgb / exp2( fExp ), ( fExp + 128.0 ) / 255.0 );\n}\nvec4 RGBMToLinear( in vec4 value, in float maxRange ) {\n\treturn vec4( value.rgb * value.a * maxRange, 1.0 );\n}\nvec4 LinearToRGBM( in vec4 value, in float maxRange ) {\n\tfloat maxRGB = max( value.r, max( value.g, value.b ) );\n\tfloat M = clamp( maxRGB / maxRange, 0.0, 1.0 );\n\tM = ceil( M * 255.0 ) / 255.0;\n\treturn vec4( value.rgb / ( M * maxRange ), M );\n}\nvec4 RGBDToLinear( in vec4 value, in float maxRange ) {\n\treturn vec4( value.rgb * ( ( maxRange / 255.0 ) / value.a ), 1.0 );\n}\nvec4 LinearToRGBD( in vec4 value, in float maxRange ) {\n\tfloat maxRGB = max( value.r, max( value.g, value.b ) );\n\tfloat D = max( maxRange / maxRGB, 1.0 );\n\tD = min( floor( D ) / 255.0, 1.0 );\n\treturn vec4( value.rgb * ( D * ( 255.0 / maxRange ) ), D );\n}\nconst mat3 cLogLuvM = mat3( 0.2209, 0.3390, 0.4184, 0.1138, 0.6780, 0.7319, 0.0102, 0.1130, 0.2969 );\nvec4 LinearToLogLuv( in vec4 value ) {\n\tvec3 Xp_Y_XYZp = cLogLuvM * value.rgb;\n\tXp_Y_XYZp = max( Xp_Y_XYZp, vec3( 1e-6, 1e-6, 1e-6 ) );\n\tvec4 vResult;\n\tvResult.xy = Xp_Y_XYZp.xy / Xp_Y_XYZp.z;\n\tfloat Le = 2.0 * log2(Xp_Y_XYZp.y) + 127.0;\n\tvResult.w = fract( Le );\n\tvResult.z = ( Le - ( floor( vResult.w * 255.0 ) ) / 255.0 ) / 255.0;\n\treturn vResult;\n}\nconst mat3 cLogLuvInverseM = mat3( 6.0014, -2.7008, -1.7996, -1.3320, 3.1029, -5.7721, 0.3008, -1.0882, 5.6268 );\nvec4 LogLuvToLinear( in vec4 value ) {\n\tfloat Le = value.z * 255.0 + value.w;\n\tvec3 Xp_Y_XYZp;\n\tXp_Y_XYZp.y = exp2( ( Le - 127.0 ) / 2.0 );\n\tXp_Y_XYZp.z = Xp_Y_XYZp.y / value.y;\n\tXp_Y_XYZp.x = value.x * Xp_Y_XYZp.z;\n\tvec3 vRGB = cLogLuvInverseM * Xp_Y_XYZp.rgb;\n\treturn vec4( max( vRGB, 0.0 ), 1.0 );\n}";
-
- var envmap_fragment = "#ifdef USE_ENVMAP\n\t#if defined( USE_BUMPMAP ) || defined( USE_NORMALMAP ) || defined( PHONG )\n\t\tvec3 cameraToVertex = normalize( vWorldPosition - cameraPosition );\n\t\tvec3 worldNormal = inverseTransformDirection( normal, viewMatrix );\n\t\t#ifdef ENVMAP_MODE_REFLECTION\n\t\t\tvec3 reflectVec = reflect( cameraToVertex, worldNormal );\n\t\t#else\n\t\t\tvec3 reflectVec = refract( cameraToVertex, worldNormal, refractionRatio );\n\t\t#endif\n\t#else\n\t\tvec3 reflectVec = vReflect;\n\t#endif\n\t#ifdef ENVMAP_TYPE_CUBE\n\t\tvec4 envColor = textureCube( envMap, vec3( flipEnvMap * reflectVec.x, reflectVec.yz ) );\n\t#elif defined( ENVMAP_TYPE_EQUIREC )\n\t\tvec2 sampleUV;\n\t\treflectVec = normalize( reflectVec );\n\t\tsampleUV.y = asin( clamp( reflectVec.y, - 1.0, 1.0 ) ) * RECIPROCAL_PI + 0.5;\n\t\tsampleUV.x = atan( reflectVec.z, reflectVec.x ) * RECIPROCAL_PI2 + 0.5;\n\t\tvec4 envColor = texture2D( envMap, sampleUV );\n\t#elif defined( ENVMAP_TYPE_SPHERE )\n\t\treflectVec = normalize( reflectVec );\n\t\tvec3 reflectView = normalize( ( viewMatrix * vec4( reflectVec, 0.0 ) ).xyz + vec3( 0.0, 0.0, 1.0 ) );\n\t\tvec4 envColor = texture2D( envMap, reflectView.xy * 0.5 + 0.5 );\n\t#else\n\t\tvec4 envColor = vec4( 0.0 );\n\t#endif\n\tenvColor = envMapTexelToLinear( envColor );\n\t#ifdef ENVMAP_BLENDING_MULTIPLY\n\t\toutgoingLight = mix( outgoingLight, outgoingLight * envColor.xyz, specularStrength * reflectivity );\n\t#elif defined( ENVMAP_BLENDING_MIX )\n\t\toutgoingLight = mix( outgoingLight, envColor.xyz, specularStrength * reflectivity );\n\t#elif defined( ENVMAP_BLENDING_ADD )\n\t\toutgoingLight += envColor.xyz * specularStrength * reflectivity;\n\t#endif\n#endif";
-
- var envmap_pars_fragment = "#if defined( USE_ENVMAP ) || defined( PHYSICAL )\n\tuniform float reflectivity;\n\tuniform float envMapIntensity;\n#endif\n#ifdef USE_ENVMAP\n\t#if ! defined( PHYSICAL ) && ( defined( USE_BUMPMAP ) || defined( USE_NORMALMAP ) || defined( PHONG ) )\n\t\tvarying vec3 vWorldPosition;\n\t#endif\n\t#ifdef ENVMAP_TYPE_CUBE\n\t\tuniform samplerCube envMap;\n\t#else\n\t\tuniform sampler2D envMap;\n\t#endif\n\tuniform float flipEnvMap;\n\tuniform int maxMipLevel;\n\t#if defined( USE_BUMPMAP ) || defined( USE_NORMALMAP ) || defined( PHONG ) || defined( PHYSICAL )\n\t\tuniform float refractionRatio;\n\t#else\n\t\tvarying vec3 vReflect;\n\t#endif\n#endif";
-
- var envmap_pars_vertex = "#ifdef USE_ENVMAP\n\t#if defined( USE_BUMPMAP ) || defined( USE_NORMALMAP ) || defined( PHONG )\n\t\tvarying vec3 vWorldPosition;\n\t#else\n\t\tvarying vec3 vReflect;\n\t\tuniform float refractionRatio;\n\t#endif\n#endif";
-
- var envmap_vertex = "#ifdef USE_ENVMAP\n\t#if defined( USE_BUMPMAP ) || defined( USE_NORMALMAP ) || defined( PHONG )\n\t\tvWorldPosition = worldPosition.xyz;\n\t#else\n\t\tvec3 cameraToVertex = normalize( worldPosition.xyz - cameraPosition );\n\t\tvec3 worldNormal = inverseTransformDirection( transformedNormal, viewMatrix );\n\t\t#ifdef ENVMAP_MODE_REFLECTION\n\t\t\tvReflect = reflect( cameraToVertex, worldNormal );\n\t\t#else\n\t\t\tvReflect = refract( cameraToVertex, worldNormal, refractionRatio );\n\t\t#endif\n\t#endif\n#endif";
-
- var fog_vertex = "#ifdef USE_FOG\n\tfogDepth = -mvPosition.z;\n#endif";
-
- var fog_pars_vertex = "#ifdef USE_FOG\n\tvarying float fogDepth;\n#endif";
-
- var fog_fragment = "#ifdef USE_FOG\n\t#ifdef FOG_EXP2\n\t\tfloat fogFactor = whiteCompliment( exp2( - fogDensity * fogDensity * fogDepth * fogDepth * LOG2 ) );\n\t#else\n\t\tfloat fogFactor = smoothstep( fogNear, fogFar, fogDepth );\n\t#endif\n\tgl_FragColor.rgb = mix( gl_FragColor.rgb, fogColor, fogFactor );\n#endif";
-
- var fog_pars_fragment = "#ifdef USE_FOG\n\tuniform vec3 fogColor;\n\tvarying float fogDepth;\n\t#ifdef FOG_EXP2\n\t\tuniform float fogDensity;\n\t#else\n\t\tuniform float fogNear;\n\t\tuniform float fogFar;\n\t#endif\n#endif";
-
- var gradientmap_pars_fragment = "#ifdef TOON\n\tuniform sampler2D gradientMap;\n\tvec3 getGradientIrradiance( vec3 normal, vec3 lightDirection ) {\n\t\tfloat dotNL = dot( normal, lightDirection );\n\t\tvec2 coord = vec2( dotNL * 0.5 + 0.5, 0.0 );\n\t\t#ifdef USE_GRADIENTMAP\n\t\t\treturn texture2D( gradientMap, coord ).rgb;\n\t\t#else\n\t\t\treturn ( coord.x < 0.7 ) ? vec3( 0.7 ) : vec3( 1.0 );\n\t\t#endif\n\t}\n#endif";
-
- var lightmap_fragment = "#ifdef USE_LIGHTMAP\n\treflectedLight.indirectDiffuse += PI * texture2D( lightMap, vUv2 ).xyz * lightMapIntensity;\n#endif";
-
- var lightmap_pars_fragment = "#ifdef USE_LIGHTMAP\n\tuniform sampler2D lightMap;\n\tuniform float lightMapIntensity;\n#endif";
-
- var lights_lambert_vertex = "vec3 diffuse = vec3( 1.0 );\nGeometricContext geometry;\ngeometry.position = mvPosition.xyz;\ngeometry.normal = normalize( transformedNormal );\ngeometry.viewDir = normalize( -mvPosition.xyz );\nGeometricContext backGeometry;\nbackGeometry.position = geometry.position;\nbackGeometry.normal = -geometry.normal;\nbackGeometry.viewDir = geometry.viewDir;\nvLightFront = vec3( 0.0 );\nvIndirectFront = vec3( 0.0 );\n#ifdef DOUBLE_SIDED\n\tvLightBack = vec3( 0.0 );\n\tvIndirectBack = vec3( 0.0 );\n#endif\nIncidentLight directLight;\nfloat dotNL;\nvec3 directLightColor_Diffuse;\n#if NUM_POINT_LIGHTS > 0\n\t#pragma unroll_loop\n\tfor ( int i = 0; i < NUM_POINT_LIGHTS; i ++ ) {\n\t\tgetPointDirectLightIrradiance( pointLights[ i ], geometry, directLight );\n\t\tdotNL = dot( geometry.normal, directLight.direction );\n\t\tdirectLightColor_Diffuse = PI * directLight.color;\n\t\tvLightFront += saturate( dotNL ) * directLightColor_Diffuse;\n\t\t#ifdef DOUBLE_SIDED\n\t\t\tvLightBack += saturate( -dotNL ) * directLightColor_Diffuse;\n\t\t#endif\n\t}\n#endif\n#if NUM_SPOT_LIGHTS > 0\n\t#pragma unroll_loop\n\tfor ( int i = 0; i < NUM_SPOT_LIGHTS; i ++ ) {\n\t\tgetSpotDirectLightIrradiance( spotLights[ i ], geometry, directLight );\n\t\tdotNL = dot( geometry.normal, directLight.direction );\n\t\tdirectLightColor_Diffuse = PI * directLight.color;\n\t\tvLightFront += saturate( dotNL ) * directLightColor_Diffuse;\n\t\t#ifdef DOUBLE_SIDED\n\t\t\tvLightBack += saturate( -dotNL ) * directLightColor_Diffuse;\n\t\t#endif\n\t}\n#endif\n#if NUM_DIR_LIGHTS > 0\n\t#pragma unroll_loop\n\tfor ( int i = 0; i < NUM_DIR_LIGHTS; i ++ ) {\n\t\tgetDirectionalDirectLightIrradiance( directionalLights[ i ], geometry, directLight );\n\t\tdotNL = dot( geometry.normal, directLight.direction );\n\t\tdirectLightColor_Diffuse = PI * directLight.color;\n\t\tvLightFront += saturate( dotNL ) * directLightColor_Diffuse;\n\t\t#ifdef DOUBLE_SIDED\n\t\t\tvLightBack += saturate( -dotNL ) * directLightColor_Diffuse;\n\t\t#endif\n\t}\n#endif\n#if NUM_HEMI_LIGHTS > 0\n\t#pragma unroll_loop\n\tfor ( int i = 0; i < NUM_HEMI_LIGHTS; i ++ ) {\n\t\tvIndirectFront += getHemisphereLightIrradiance( hemisphereLights[ i ], geometry );\n\t\t#ifdef DOUBLE_SIDED\n\t\t\tvIndirectBack += getHemisphereLightIrradiance( hemisphereLights[ i ], backGeometry );\n\t\t#endif\n\t}\n#endif";
-
- var lights_pars_begin = "uniform vec3 ambientLightColor;\nvec3 getAmbientLightIrradiance( const in vec3 ambientLightColor ) {\n\tvec3 irradiance = ambientLightColor;\n\t#ifndef PHYSICALLY_CORRECT_LIGHTS\n\t\tirradiance *= PI;\n\t#endif\n\treturn irradiance;\n}\n#if NUM_DIR_LIGHTS > 0\n\tstruct DirectionalLight {\n\t\tvec3 direction;\n\t\tvec3 color;\n\t\tint shadow;\n\t\tfloat shadowBias;\n\t\tfloat shadowRadius;\n\t\tvec2 shadowMapSize;\n\t};\n\tuniform DirectionalLight directionalLights[ NUM_DIR_LIGHTS ];\n\tvoid getDirectionalDirectLightIrradiance( const in DirectionalLight directionalLight, const in GeometricContext geometry, out IncidentLight directLight ) {\n\t\tdirectLight.color = directionalLight.color;\n\t\tdirectLight.direction = directionalLight.direction;\n\t\tdirectLight.visible = true;\n\t}\n#endif\n#if NUM_POINT_LIGHTS > 0\n\tstruct PointLight {\n\t\tvec3 position;\n\t\tvec3 color;\n\t\tfloat distance;\n\t\tfloat decay;\n\t\tint shadow;\n\t\tfloat shadowBias;\n\t\tfloat shadowRadius;\n\t\tvec2 shadowMapSize;\n\t\tfloat shadowCameraNear;\n\t\tfloat shadowCameraFar;\n\t};\n\tuniform PointLight pointLights[ NUM_POINT_LIGHTS ];\n\tvoid getPointDirectLightIrradiance( const in PointLight pointLight, const in GeometricContext geometry, out IncidentLight directLight ) {\n\t\tvec3 lVector = pointLight.position - geometry.position;\n\t\tdirectLight.direction = normalize( lVector );\n\t\tfloat lightDistance = length( lVector );\n\t\tdirectLight.color = pointLight.color;\n\t\tdirectLight.color *= punctualLightIntensityToIrradianceFactor( lightDistance, pointLight.distance, pointLight.decay );\n\t\tdirectLight.visible = ( directLight.color != vec3( 0.0 ) );\n\t}\n#endif\n#if NUM_SPOT_LIGHTS > 0\n\tstruct SpotLight {\n\t\tvec3 position;\n\t\tvec3 direction;\n\t\tvec3 color;\n\t\tfloat distance;\n\t\tfloat decay;\n\t\tfloat coneCos;\n\t\tfloat penumbraCos;\n\t\tint shadow;\n\t\tfloat shadowBias;\n\t\tfloat shadowRadius;\n\t\tvec2 shadowMapSize;\n\t};\n\tuniform SpotLight spotLights[ NUM_SPOT_LIGHTS ];\n\tvoid getSpotDirectLightIrradiance( const in SpotLight spotLight, const in GeometricContext geometry, out IncidentLight directLight ) {\n\t\tvec3 lVector = spotLight.position - geometry.position;\n\t\tdirectLight.direction = normalize( lVector );\n\t\tfloat lightDistance = length( lVector );\n\t\tfloat angleCos = dot( directLight.direction, spotLight.direction );\n\t\tif ( angleCos > spotLight.coneCos ) {\n\t\t\tfloat spotEffect = smoothstep( spotLight.coneCos, spotLight.penumbraCos, angleCos );\n\t\t\tdirectLight.color = spotLight.color;\n\t\t\tdirectLight.color *= spotEffect * punctualLightIntensityToIrradianceFactor( lightDistance, spotLight.distance, spotLight.decay );\n\t\t\tdirectLight.visible = true;\n\t\t} else {\n\t\t\tdirectLight.color = vec3( 0.0 );\n\t\t\tdirectLight.visible = false;\n\t\t}\n\t}\n#endif\n#if NUM_RECT_AREA_LIGHTS > 0\n\tstruct RectAreaLight {\n\t\tvec3 color;\n\t\tvec3 position;\n\t\tvec3 halfWidth;\n\t\tvec3 halfHeight;\n\t};\n\tuniform sampler2D ltc_1;\tuniform sampler2D ltc_2;\n\tuniform RectAreaLight rectAreaLights[ NUM_RECT_AREA_LIGHTS ];\n#endif\n#if NUM_HEMI_LIGHTS > 0\n\tstruct HemisphereLight {\n\t\tvec3 direction;\n\t\tvec3 skyColor;\n\t\tvec3 groundColor;\n\t};\n\tuniform HemisphereLight hemisphereLights[ NUM_HEMI_LIGHTS ];\n\tvec3 getHemisphereLightIrradiance( const in HemisphereLight hemiLight, const in GeometricContext geometry ) {\n\t\tfloat dotNL = dot( geometry.normal, hemiLight.direction );\n\t\tfloat hemiDiffuseWeight = 0.5 * dotNL + 0.5;\n\t\tvec3 irradiance = mix( hemiLight.groundColor, hemiLight.skyColor, hemiDiffuseWeight );\n\t\t#ifndef PHYSICALLY_CORRECT_LIGHTS\n\t\t\tirradiance *= PI;\n\t\t#endif\n\t\treturn irradiance;\n\t}\n#endif";
-
- var envmap_physical_pars_fragment = "#if defined( USE_ENVMAP ) && defined( PHYSICAL )\n\tvec3 getLightProbeIndirectIrradiance( const in GeometricContext geometry, const in int maxMIPLevel ) {\n\t\tvec3 worldNormal = inverseTransformDirection( geometry.normal, viewMatrix );\n\t\t#ifdef ENVMAP_TYPE_CUBE\n\t\t\tvec3 queryVec = vec3( flipEnvMap * worldNormal.x, worldNormal.yz );\n\t\t\t#ifdef TEXTURE_LOD_EXT\n\t\t\t\tvec4 envMapColor = textureCubeLodEXT( envMap, queryVec, float( maxMIPLevel ) );\n\t\t\t#else\n\t\t\t\tvec4 envMapColor = textureCube( envMap, queryVec, float( maxMIPLevel ) );\n\t\t\t#endif\n\t\t\tenvMapColor.rgb = envMapTexelToLinear( envMapColor ).rgb;\n\t\t#elif defined( ENVMAP_TYPE_CUBE_UV )\n\t\t\tvec3 queryVec = vec3( flipEnvMap * worldNormal.x, worldNormal.yz );\n\t\t\tvec4 envMapColor = textureCubeUV( envMap, queryVec, 1.0 );\n\t\t#else\n\t\t\tvec4 envMapColor = vec4( 0.0 );\n\t\t#endif\n\t\treturn PI * envMapColor.rgb * envMapIntensity;\n\t}\n\tfloat getSpecularMIPLevel( const in float blinnShininessExponent, const in int maxMIPLevel ) {\n\t\tfloat maxMIPLevelScalar = float( maxMIPLevel );\n\t\tfloat desiredMIPLevel = maxMIPLevelScalar + 0.79248 - 0.5 * log2( pow2( blinnShininessExponent ) + 1.0 );\n\t\treturn clamp( desiredMIPLevel, 0.0, maxMIPLevelScalar );\n\t}\n\tvec3 getLightProbeIndirectRadiance( const in GeometricContext geometry, const in float blinnShininessExponent, const in int maxMIPLevel ) {\n\t\t#ifdef ENVMAP_MODE_REFLECTION\n\t\t\tvec3 reflectVec = reflect( -geometry.viewDir, geometry.normal );\n\t\t#else\n\t\t\tvec3 reflectVec = refract( -geometry.viewDir, geometry.normal, refractionRatio );\n\t\t#endif\n\t\treflectVec = inverseTransformDirection( reflectVec, viewMatrix );\n\t\tfloat specularMIPLevel = getSpecularMIPLevel( blinnShininessExponent, maxMIPLevel );\n\t\t#ifdef ENVMAP_TYPE_CUBE\n\t\t\tvec3 queryReflectVec = vec3( flipEnvMap * reflectVec.x, reflectVec.yz );\n\t\t\t#ifdef TEXTURE_LOD_EXT\n\t\t\t\tvec4 envMapColor = textureCubeLodEXT( envMap, queryReflectVec, specularMIPLevel );\n\t\t\t#else\n\t\t\t\tvec4 envMapColor = textureCube( envMap, queryReflectVec, specularMIPLevel );\n\t\t\t#endif\n\t\t\tenvMapColor.rgb = envMapTexelToLinear( envMapColor ).rgb;\n\t\t#elif defined( ENVMAP_TYPE_CUBE_UV )\n\t\t\tvec3 queryReflectVec = vec3( flipEnvMap * reflectVec.x, reflectVec.yz );\n\t\t\tvec4 envMapColor = textureCubeUV( envMap, queryReflectVec, BlinnExponentToGGXRoughness(blinnShininessExponent ));\n\t\t#elif defined( ENVMAP_TYPE_EQUIREC )\n\t\t\tvec2 sampleUV;\n\t\t\tsampleUV.y = asin( clamp( reflectVec.y, - 1.0, 1.0 ) ) * RECIPROCAL_PI + 0.5;\n\t\t\tsampleUV.x = atan( reflectVec.z, reflectVec.x ) * RECIPROCAL_PI2 + 0.5;\n\t\t\t#ifdef TEXTURE_LOD_EXT\n\t\t\t\tvec4 envMapColor = texture2DLodEXT( envMap, sampleUV, specularMIPLevel );\n\t\t\t#else\n\t\t\t\tvec4 envMapColor = texture2D( envMap, sampleUV, specularMIPLevel );\n\t\t\t#endif\n\t\t\tenvMapColor.rgb = envMapTexelToLinear( envMapColor ).rgb;\n\t\t#elif defined( ENVMAP_TYPE_SPHERE )\n\t\t\tvec3 reflectView = normalize( ( viewMatrix * vec4( reflectVec, 0.0 ) ).xyz + vec3( 0.0,0.0,1.0 ) );\n\t\t\t#ifdef TEXTURE_LOD_EXT\n\t\t\t\tvec4 envMapColor = texture2DLodEXT( envMap, reflectView.xy * 0.5 + 0.5, specularMIPLevel );\n\t\t\t#else\n\t\t\t\tvec4 envMapColor = texture2D( envMap, reflectView.xy * 0.5 + 0.5, specularMIPLevel );\n\t\t\t#endif\n\t\t\tenvMapColor.rgb = envMapTexelToLinear( envMapColor ).rgb;\n\t\t#endif\n\t\treturn envMapColor.rgb * envMapIntensity;\n\t}\n#endif";
-
- var lights_phong_fragment = "BlinnPhongMaterial material;\nmaterial.diffuseColor = diffuseColor.rgb;\nmaterial.specularColor = specular;\nmaterial.specularShininess = shininess;\nmaterial.specularStrength = specularStrength;";
-
- var lights_phong_pars_fragment = "varying vec3 vViewPosition;\n#ifndef FLAT_SHADED\n\tvarying vec3 vNormal;\n#endif\nstruct BlinnPhongMaterial {\n\tvec3\tdiffuseColor;\n\tvec3\tspecularColor;\n\tfloat\tspecularShininess;\n\tfloat\tspecularStrength;\n};\nvoid RE_Direct_BlinnPhong( const in IncidentLight directLight, const in GeometricContext geometry, const in BlinnPhongMaterial material, inout ReflectedLight reflectedLight ) {\n\t#ifdef TOON\n\t\tvec3 irradiance = getGradientIrradiance( geometry.normal, directLight.direction ) * directLight.color;\n\t#else\n\t\tfloat dotNL = saturate( dot( geometry.normal, directLight.direction ) );\n\t\tvec3 irradiance = dotNL * directLight.color;\n\t#endif\n\t#ifndef PHYSICALLY_CORRECT_LIGHTS\n\t\tirradiance *= PI;\n\t#endif\n\treflectedLight.directDiffuse += irradiance * BRDF_Diffuse_Lambert( material.diffuseColor );\n\treflectedLight.directSpecular += irradiance * BRDF_Specular_BlinnPhong( directLight, geometry, material.specularColor, material.specularShininess ) * material.specularStrength;\n}\nvoid RE_IndirectDiffuse_BlinnPhong( const in vec3 irradiance, const in GeometricContext geometry, const in BlinnPhongMaterial material, inout ReflectedLight reflectedLight ) {\n\treflectedLight.indirectDiffuse += irradiance * BRDF_Diffuse_Lambert( material.diffuseColor );\n}\n#define RE_Direct\t\t\t\tRE_Direct_BlinnPhong\n#define RE_IndirectDiffuse\t\tRE_IndirectDiffuse_BlinnPhong\n#define Material_LightProbeLOD( material )\t(0)";
-
- var lights_physical_fragment = "PhysicalMaterial material;\nmaterial.diffuseColor = diffuseColor.rgb * ( 1.0 - metalnessFactor );\nmaterial.specularRoughness = clamp( roughnessFactor, 0.04, 1.0 );\n#ifdef STANDARD\n\tmaterial.specularColor = mix( vec3( DEFAULT_SPECULAR_COEFFICIENT ), diffuseColor.rgb, metalnessFactor );\n#else\n\tmaterial.specularColor = mix( vec3( MAXIMUM_SPECULAR_COEFFICIENT * pow2( reflectivity ) ), diffuseColor.rgb, metalnessFactor );\n\tmaterial.clearCoat = saturate( clearCoat );\tmaterial.clearCoatRoughness = clamp( clearCoatRoughness, 0.04, 1.0 );\n#endif";
-
- var lights_physical_pars_fragment = "struct PhysicalMaterial {\n\tvec3\tdiffuseColor;\n\tfloat\tspecularRoughness;\n\tvec3\tspecularColor;\n\t#ifndef STANDARD\n\t\tfloat clearCoat;\n\t\tfloat clearCoatRoughness;\n\t#endif\n};\n#define MAXIMUM_SPECULAR_COEFFICIENT 0.16\n#define DEFAULT_SPECULAR_COEFFICIENT 0.04\nfloat clearCoatDHRApprox( const in float roughness, const in float dotNL ) {\n\treturn DEFAULT_SPECULAR_COEFFICIENT + ( 1.0 - DEFAULT_SPECULAR_COEFFICIENT ) * ( pow( 1.0 - dotNL, 5.0 ) * pow( 1.0 - roughness, 2.0 ) );\n}\n#if NUM_RECT_AREA_LIGHTS > 0\n\tvoid RE_Direct_RectArea_Physical( const in RectAreaLight rectAreaLight, const in GeometricContext geometry, const in PhysicalMaterial material, inout ReflectedLight reflectedLight ) {\n\t\tvec3 normal = geometry.normal;\n\t\tvec3 viewDir = geometry.viewDir;\n\t\tvec3 position = geometry.position;\n\t\tvec3 lightPos = rectAreaLight.position;\n\t\tvec3 halfWidth = rectAreaLight.halfWidth;\n\t\tvec3 halfHeight = rectAreaLight.halfHeight;\n\t\tvec3 lightColor = rectAreaLight.color;\n\t\tfloat roughness = material.specularRoughness;\n\t\tvec3 rectCoords[ 4 ];\n\t\trectCoords[ 0 ] = lightPos + halfWidth - halfHeight;\t\trectCoords[ 1 ] = lightPos - halfWidth - halfHeight;\n\t\trectCoords[ 2 ] = lightPos - halfWidth + halfHeight;\n\t\trectCoords[ 3 ] = lightPos + halfWidth + halfHeight;\n\t\tvec2 uv = LTC_Uv( normal, viewDir, roughness );\n\t\tvec4 t1 = texture2D( ltc_1, uv );\n\t\tvec4 t2 = texture2D( ltc_2, uv );\n\t\tmat3 mInv = mat3(\n\t\t\tvec3( t1.x, 0, t1.y ),\n\t\t\tvec3( 0, 1, 0 ),\n\t\t\tvec3( t1.z, 0, t1.w )\n\t\t);\n\t\tvec3 fresnel = ( material.specularColor * t2.x + ( vec3( 1.0 ) - material.specularColor ) * t2.y );\n\t\treflectedLight.directSpecular += lightColor * fresnel * LTC_Evaluate( normal, viewDir, position, mInv, rectCoords );\n\t\treflectedLight.directDiffuse += lightColor * material.diffuseColor * LTC_Evaluate( normal, viewDir, position, mat3( 1.0 ), rectCoords );\n\t}\n#endif\nvoid RE_Direct_Physical( const in IncidentLight directLight, const in GeometricContext geometry, const in PhysicalMaterial material, inout ReflectedLight reflectedLight ) {\n\tfloat dotNL = saturate( dot( geometry.normal, directLight.direction ) );\n\tvec3 irradiance = dotNL * directLight.color;\n\t#ifndef PHYSICALLY_CORRECT_LIGHTS\n\t\tirradiance *= PI;\n\t#endif\n\t#ifndef STANDARD\n\t\tfloat clearCoatDHR = material.clearCoat * clearCoatDHRApprox( material.clearCoatRoughness, dotNL );\n\t#else\n\t\tfloat clearCoatDHR = 0.0;\n\t#endif\n\treflectedLight.directSpecular += ( 1.0 - clearCoatDHR ) * irradiance * BRDF_Specular_GGX( directLight, geometry, material.specularColor, material.specularRoughness );\n\treflectedLight.directDiffuse += ( 1.0 - clearCoatDHR ) * irradiance * BRDF_Diffuse_Lambert( material.diffuseColor );\n\t#ifndef STANDARD\n\t\treflectedLight.directSpecular += irradiance * material.clearCoat * BRDF_Specular_GGX( directLight, geometry, vec3( DEFAULT_SPECULAR_COEFFICIENT ), material.clearCoatRoughness );\n\t#endif\n}\nvoid RE_IndirectDiffuse_Physical( const in vec3 irradiance, const in GeometricContext geometry, const in PhysicalMaterial material, inout ReflectedLight reflectedLight ) {\n\t#ifndef ENVMAP_TYPE_CUBE_UV\n\t\treflectedLight.indirectDiffuse += irradiance * BRDF_Diffuse_Lambert( material.diffuseColor );\n\t#endif\n}\nvoid RE_IndirectSpecular_Physical( const in vec3 radiance, const in vec3 irradiance, const in vec3 clearCoatRadiance, const in GeometricContext geometry, const in PhysicalMaterial material, inout ReflectedLight reflectedLight) {\n\t#ifndef STANDARD\n\t\tfloat dotNV = saturate( dot( geometry.normal, geometry.viewDir ) );\n\t\tfloat dotNL = dotNV;\n\t\tfloat clearCoatDHR = material.clearCoat * clearCoatDHRApprox( material.clearCoatRoughness, dotNL );\n\t#else\n\t\tfloat clearCoatDHR = 0.0;\n\t#endif\n\tfloat clearCoatInv = 1.0 - clearCoatDHR;\n\t#if defined( ENVMAP_TYPE_CUBE_UV )\n\t\tvec3 singleScattering = vec3( 0.0 );\n\t\tvec3 multiScattering = vec3( 0.0 );\n\t\tvec3 cosineWeightedIrradiance = irradiance * RECIPROCAL_PI;\n\t\tBRDF_Specular_Multiscattering_Environment( geometry, material.specularColor, material.specularRoughness, singleScattering, multiScattering );\n\t\tvec3 diffuse = material.diffuseColor;\n\t\treflectedLight.indirectSpecular += clearCoatInv * radiance * singleScattering;\n\t\treflectedLight.indirectDiffuse += multiScattering * cosineWeightedIrradiance;\n\t\treflectedLight.indirectDiffuse += diffuse * cosineWeightedIrradiance;\n\t#else\n\t\treflectedLight.indirectSpecular += clearCoatInv * radiance * BRDF_Specular_GGX_Environment( geometry, material.specularColor, material.specularRoughness );\n\t#endif\n\t#ifndef STANDARD\n\t\treflectedLight.indirectSpecular += clearCoatRadiance * material.clearCoat * BRDF_Specular_GGX_Environment( geometry, vec3( DEFAULT_SPECULAR_COEFFICIENT ), material.clearCoatRoughness );\n\t#endif\n}\n#define RE_Direct\t\t\t\tRE_Direct_Physical\n#define RE_Direct_RectArea\t\tRE_Direct_RectArea_Physical\n#define RE_IndirectDiffuse\t\tRE_IndirectDiffuse_Physical\n#define RE_IndirectSpecular\t\tRE_IndirectSpecular_Physical\n#define Material_BlinnShininessExponent( material ) GGXRoughnessToBlinnExponent( material.specularRoughness )\n#define Material_ClearCoat_BlinnShininessExponent( material ) GGXRoughnessToBlinnExponent( material.clearCoatRoughness )\nfloat computeSpecularOcclusion( const in float dotNV, const in float ambientOcclusion, const in float roughness ) {\n\treturn saturate( pow( dotNV + ambientOcclusion, exp2( - 16.0 * roughness - 1.0 ) ) - 1.0 + ambientOcclusion );\n}";
-
- var lights_fragment_begin = "\nGeometricContext geometry;\ngeometry.position = - vViewPosition;\ngeometry.normal = normal;\ngeometry.viewDir = normalize( vViewPosition );\nIncidentLight directLight;\n#if ( NUM_POINT_LIGHTS > 0 ) && defined( RE_Direct )\n\tPointLight pointLight;\n\t#pragma unroll_loop\n\tfor ( int i = 0; i < NUM_POINT_LIGHTS; i ++ ) {\n\t\tpointLight = pointLights[ i ];\n\t\tgetPointDirectLightIrradiance( pointLight, geometry, directLight );\n\t\t#ifdef USE_SHADOWMAP\n\t\tdirectLight.color *= all( bvec2( pointLight.shadow, directLight.visible ) ) ? getPointShadow( pointShadowMap[ i ], pointLight.shadowMapSize, pointLight.shadowBias, pointLight.shadowRadius, vPointShadowCoord[ i ], pointLight.shadowCameraNear, pointLight.shadowCameraFar ) : 1.0;\n\t\t#endif\n\t\tRE_Direct( directLight, geometry, material, reflectedLight );\n\t}\n#endif\n#if ( NUM_SPOT_LIGHTS > 0 ) && defined( RE_Direct )\n\tSpotLight spotLight;\n\t#pragma unroll_loop\n\tfor ( int i = 0; i < NUM_SPOT_LIGHTS; i ++ ) {\n\t\tspotLight = spotLights[ i ];\n\t\tgetSpotDirectLightIrradiance( spotLight, geometry, directLight );\n\t\t#ifdef USE_SHADOWMAP\n\t\tdirectLight.color *= all( bvec2( spotLight.shadow, directLight.visible ) ) ? getShadow( spotShadowMap[ i ], spotLight.shadowMapSize, spotLight.shadowBias, spotLight.shadowRadius, vSpotShadowCoord[ i ] ) : 1.0;\n\t\t#endif\n\t\tRE_Direct( directLight, geometry, material, reflectedLight );\n\t}\n#endif\n#if ( NUM_DIR_LIGHTS > 0 ) && defined( RE_Direct )\n\tDirectionalLight directionalLight;\n\t#pragma unroll_loop\n\tfor ( int i = 0; i < NUM_DIR_LIGHTS; i ++ ) {\n\t\tdirectionalLight = directionalLights[ i ];\n\t\tgetDirectionalDirectLightIrradiance( directionalLight, geometry, directLight );\n\t\t#ifdef USE_SHADOWMAP\n\t\tdirectLight.color *= all( bvec2( directionalLight.shadow, directLight.visible ) ) ? getShadow( directionalShadowMap[ i ], directionalLight.shadowMapSize, directionalLight.shadowBias, directionalLight.shadowRadius, vDirectionalShadowCoord[ i ] ) : 1.0;\n\t\t#endif\n\t\tRE_Direct( directLight, geometry, material, reflectedLight );\n\t}\n#endif\n#if ( NUM_RECT_AREA_LIGHTS > 0 ) && defined( RE_Direct_RectArea )\n\tRectAreaLight rectAreaLight;\n\t#pragma unroll_loop\n\tfor ( int i = 0; i < NUM_RECT_AREA_LIGHTS; i ++ ) {\n\t\trectAreaLight = rectAreaLights[ i ];\n\t\tRE_Direct_RectArea( rectAreaLight, geometry, material, reflectedLight );\n\t}\n#endif\n#if defined( RE_IndirectDiffuse )\n\tvec3 irradiance = getAmbientLightIrradiance( ambientLightColor );\n\t#if ( NUM_HEMI_LIGHTS > 0 )\n\t\t#pragma unroll_loop\n\t\tfor ( int i = 0; i < NUM_HEMI_LIGHTS; i ++ ) {\n\t\t\tirradiance += getHemisphereLightIrradiance( hemisphereLights[ i ], geometry );\n\t\t}\n\t#endif\n#endif\n#if defined( RE_IndirectSpecular )\n\tvec3 radiance = vec3( 0.0 );\n\tvec3 clearCoatRadiance = vec3( 0.0 );\n#endif";
-
- var lights_fragment_maps = "#if defined( RE_IndirectDiffuse )\n\t#ifdef USE_LIGHTMAP\n\t\tvec3 lightMapIrradiance = texture2D( lightMap, vUv2 ).xyz * lightMapIntensity;\n\t\t#ifndef PHYSICALLY_CORRECT_LIGHTS\n\t\t\tlightMapIrradiance *= PI;\n\t\t#endif\n\t\tirradiance += lightMapIrradiance;\n\t#endif\n\t#if defined( USE_ENVMAP ) && defined( PHYSICAL ) && defined( ENVMAP_TYPE_CUBE_UV )\n\t\tirradiance += getLightProbeIndirectIrradiance( geometry, maxMipLevel );\n\t#endif\n#endif\n#if defined( USE_ENVMAP ) && defined( RE_IndirectSpecular )\n\tradiance += getLightProbeIndirectRadiance( geometry, Material_BlinnShininessExponent( material ), maxMipLevel );\n\t#ifndef STANDARD\n\t\tclearCoatRadiance += getLightProbeIndirectRadiance( geometry, Material_ClearCoat_BlinnShininessExponent( material ), maxMipLevel );\n\t#endif\n#endif";
-
- var lights_fragment_end = "#if defined( RE_IndirectDiffuse )\n\tRE_IndirectDiffuse( irradiance, geometry, material, reflectedLight );\n#endif\n#if defined( RE_IndirectSpecular )\n\tRE_IndirectSpecular( radiance, irradiance, clearCoatRadiance, geometry, material, reflectedLight );\n#endif";
-
- var logdepthbuf_fragment = "#if defined( USE_LOGDEPTHBUF ) && defined( USE_LOGDEPTHBUF_EXT )\n\tgl_FragDepthEXT = log2( vFragDepth ) * logDepthBufFC * 0.5;\n#endif";
-
- var logdepthbuf_pars_fragment = "#if defined( USE_LOGDEPTHBUF ) && defined( USE_LOGDEPTHBUF_EXT )\n\tuniform float logDepthBufFC;\n\tvarying float vFragDepth;\n#endif";
-
- var logdepthbuf_pars_vertex = "#ifdef USE_LOGDEPTHBUF\n\t#ifdef USE_LOGDEPTHBUF_EXT\n\t\tvarying float vFragDepth;\n\t#else\n\t\tuniform float logDepthBufFC;\n\t#endif\n#endif";
-
- var logdepthbuf_vertex = "#ifdef USE_LOGDEPTHBUF\n\t#ifdef USE_LOGDEPTHBUF_EXT\n\t\tvFragDepth = 1.0 + gl_Position.w;\n\t#else\n\t\tgl_Position.z = log2( max( EPSILON, gl_Position.w + 1.0 ) ) * logDepthBufFC - 1.0;\n\t\tgl_Position.z *= gl_Position.w;\n\t#endif\n#endif";
-
- var map_fragment = "#ifdef USE_MAP\n\tvec4 texelColor = texture2D( map, vUv );\n\ttexelColor = mapTexelToLinear( texelColor );\n\tdiffuseColor *= texelColor;\n#endif";
-
- var map_pars_fragment = "#ifdef USE_MAP\n\tuniform sampler2D map;\n#endif";
-
- var map_particle_fragment = "#ifdef USE_MAP\n\tvec2 uv = ( uvTransform * vec3( gl_PointCoord.x, 1.0 - gl_PointCoord.y, 1 ) ).xy;\n\tvec4 mapTexel = texture2D( map, uv );\n\tdiffuseColor *= mapTexelToLinear( mapTexel );\n#endif";
-
- var map_particle_pars_fragment = "#ifdef USE_MAP\n\tuniform mat3 uvTransform;\n\tuniform sampler2D map;\n#endif";
-
- var metalnessmap_fragment = "float metalnessFactor = metalness;\n#ifdef USE_METALNESSMAP\n\tvec4 texelMetalness = texture2D( metalnessMap, vUv );\n\tmetalnessFactor *= texelMetalness.b;\n#endif";
-
- var metalnessmap_pars_fragment = "#ifdef USE_METALNESSMAP\n\tuniform sampler2D metalnessMap;\n#endif";
-
- var morphnormal_vertex = "#ifdef USE_MORPHNORMALS\n\tobjectNormal += ( morphNormal0 - normal ) * morphTargetInfluences[ 0 ];\n\tobjectNormal += ( morphNormal1 - normal ) * morphTargetInfluences[ 1 ];\n\tobjectNormal += ( morphNormal2 - normal ) * morphTargetInfluences[ 2 ];\n\tobjectNormal += ( morphNormal3 - normal ) * morphTargetInfluences[ 3 ];\n#endif";
-
- var morphtarget_pars_vertex = "#ifdef USE_MORPHTARGETS\n\t#ifndef USE_MORPHNORMALS\n\tuniform float morphTargetInfluences[ 8 ];\n\t#else\n\tuniform float morphTargetInfluences[ 4 ];\n\t#endif\n#endif";
-
- var morphtarget_vertex = "#ifdef USE_MORPHTARGETS\n\ttransformed += ( morphTarget0 - position ) * morphTargetInfluences[ 0 ];\n\ttransformed += ( morphTarget1 - position ) * morphTargetInfluences[ 1 ];\n\ttransformed += ( morphTarget2 - position ) * morphTargetInfluences[ 2 ];\n\ttransformed += ( morphTarget3 - position ) * morphTargetInfluences[ 3 ];\n\t#ifndef USE_MORPHNORMALS\n\ttransformed += ( morphTarget4 - position ) * morphTargetInfluences[ 4 ];\n\ttransformed += ( morphTarget5 - position ) * morphTargetInfluences[ 5 ];\n\ttransformed += ( morphTarget6 - position ) * morphTargetInfluences[ 6 ];\n\ttransformed += ( morphTarget7 - position ) * morphTargetInfluences[ 7 ];\n\t#endif\n#endif";
-
- var normal_fragment_begin = "#ifdef FLAT_SHADED\n\tvec3 fdx = vec3( dFdx( vViewPosition.x ), dFdx( vViewPosition.y ), dFdx( vViewPosition.z ) );\n\tvec3 fdy = vec3( dFdy( vViewPosition.x ), dFdy( vViewPosition.y ), dFdy( vViewPosition.z ) );\n\tvec3 normal = normalize( cross( fdx, fdy ) );\n#else\n\tvec3 normal = normalize( vNormal );\n\t#ifdef DOUBLE_SIDED\n\t\tnormal = normal * ( float( gl_FrontFacing ) * 2.0 - 1.0 );\n\t#endif\n\t#ifdef USE_TANGENT\n\t\tvec3 tangent = normalize( vTangent );\n\t\tvec3 bitangent = normalize( vBitangent );\n\t\t#ifdef DOUBLE_SIDED\n\t\t\ttangent = tangent * ( float( gl_FrontFacing ) * 2.0 - 1.0 );\n\t\t\tbitangent = bitangent * ( float( gl_FrontFacing ) * 2.0 - 1.0 );\n\t\t#endif\n\t#endif\n#endif";
-
- var normal_fragment_maps = "#ifdef USE_NORMALMAP\n\t#ifdef OBJECTSPACE_NORMALMAP\n\t\tnormal = texture2D( normalMap, vUv ).xyz * 2.0 - 1.0;\n\t\t#ifdef FLIP_SIDED\n\t\t\tnormal = - normal;\n\t\t#endif\n\t\t#ifdef DOUBLE_SIDED\n\t\t\tnormal = normal * ( float( gl_FrontFacing ) * 2.0 - 1.0 );\n\t\t#endif\n\t\tnormal = normalize( normalMatrix * normal );\n\t#else\n\t\t#ifdef USE_TANGENT\n\t\t\tmat3 vTBN = mat3( tangent, bitangent, normal );\n\t\t\tvec3 mapN = texture2D( normalMap, vUv ).xyz * 2.0 - 1.0;\n\t\t\tmapN.xy = normalScale * mapN.xy;\n\t\t\tnormal = normalize( vTBN * mapN );\n\t\t#else\n\t\t\tnormal = perturbNormal2Arb( -vViewPosition, normal );\n\t\t#endif\n\t#endif\n#elif defined( USE_BUMPMAP )\n\tnormal = perturbNormalArb( -vViewPosition, normal, dHdxy_fwd() );\n#endif";
-
- var normalmap_pars_fragment = "#ifdef USE_NORMALMAP\n\tuniform sampler2D normalMap;\n\tuniform vec2 normalScale;\n\t#ifdef OBJECTSPACE_NORMALMAP\n\t\tuniform mat3 normalMatrix;\n\t#else\n\t\tvec3 perturbNormal2Arb( vec3 eye_pos, vec3 surf_norm ) {\n\t\t\tvec3 q0 = vec3( dFdx( eye_pos.x ), dFdx( eye_pos.y ), dFdx( eye_pos.z ) );\n\t\t\tvec3 q1 = vec3( dFdy( eye_pos.x ), dFdy( eye_pos.y ), dFdy( eye_pos.z ) );\n\t\t\tvec2 st0 = dFdx( vUv.st );\n\t\t\tvec2 st1 = dFdy( vUv.st );\n\t\t\tfloat scale = sign( st1.t * st0.s - st0.t * st1.s );\n\t\t\tvec3 S = normalize( ( q0 * st1.t - q1 * st0.t ) * scale );\n\t\t\tvec3 T = normalize( ( - q0 * st1.s + q1 * st0.s ) * scale );\n\t\t\tvec3 N = normalize( surf_norm );\n\t\t\tmat3 tsn = mat3( S, T, N );\n\t\t\tvec3 mapN = texture2D( normalMap, vUv ).xyz * 2.0 - 1.0;\n\t\t\tmapN.xy *= normalScale;\n\t\t\tmapN.xy *= ( float( gl_FrontFacing ) * 2.0 - 1.0 );\n\t\t\treturn normalize( tsn * mapN );\n\t\t}\n\t#endif\n#endif";
-
- var packing = "vec3 packNormalToRGB( const in vec3 normal ) {\n\treturn normalize( normal ) * 0.5 + 0.5;\n}\nvec3 unpackRGBToNormal( const in vec3 rgb ) {\n\treturn 2.0 * rgb.xyz - 1.0;\n}\nconst float PackUpscale = 256. / 255.;const float UnpackDownscale = 255. / 256.;\nconst vec3 PackFactors = vec3( 256. * 256. * 256., 256. * 256., 256. );\nconst vec4 UnpackFactors = UnpackDownscale / vec4( PackFactors, 1. );\nconst float ShiftRight8 = 1. / 256.;\nvec4 packDepthToRGBA( const in float v ) {\n\tvec4 r = vec4( fract( v * PackFactors ), v );\n\tr.yzw -= r.xyz * ShiftRight8;\treturn r * PackUpscale;\n}\nfloat unpackRGBAToDepth( const in vec4 v ) {\n\treturn dot( v, UnpackFactors );\n}\nfloat viewZToOrthographicDepth( const in float viewZ, const in float near, const in float far ) {\n\treturn ( viewZ + near ) / ( near - far );\n}\nfloat orthographicDepthToViewZ( const in float linearClipZ, const in float near, const in float far ) {\n\treturn linearClipZ * ( near - far ) - near;\n}\nfloat viewZToPerspectiveDepth( const in float viewZ, const in float near, const in float far ) {\n\treturn (( near + viewZ ) * far ) / (( far - near ) * viewZ );\n}\nfloat perspectiveDepthToViewZ( const in float invClipZ, const in float near, const in float far ) {\n\treturn ( near * far ) / ( ( far - near ) * invClipZ - far );\n}";
-
- var premultiplied_alpha_fragment = "#ifdef PREMULTIPLIED_ALPHA\n\tgl_FragColor.rgb *= gl_FragColor.a;\n#endif";
-
- var project_vertex = "vec4 mvPosition = modelViewMatrix * vec4( transformed, 1.0 );\ngl_Position = projectionMatrix * mvPosition;";
-
- var dithering_fragment = "#if defined( DITHERING )\n\tgl_FragColor.rgb = dithering( gl_FragColor.rgb );\n#endif";
-
- var dithering_pars_fragment = "#if defined( DITHERING )\n\tvec3 dithering( vec3 color ) {\n\t\tfloat grid_position = rand( gl_FragCoord.xy );\n\t\tvec3 dither_shift_RGB = vec3( 0.25 / 255.0, -0.25 / 255.0, 0.25 / 255.0 );\n\t\tdither_shift_RGB = mix( 2.0 * dither_shift_RGB, -2.0 * dither_shift_RGB, grid_position );\n\t\treturn color + dither_shift_RGB;\n\t}\n#endif";
-
- var roughnessmap_fragment = "float roughnessFactor = roughness;\n#ifdef USE_ROUGHNESSMAP\n\tvec4 texelRoughness = texture2D( roughnessMap, vUv );\n\troughnessFactor *= texelRoughness.g;\n#endif";
-
- var roughnessmap_pars_fragment = "#ifdef USE_ROUGHNESSMAP\n\tuniform sampler2D roughnessMap;\n#endif";
-
- var shadowmap_pars_fragment = "#ifdef USE_SHADOWMAP\n\t#if NUM_DIR_LIGHTS > 0\n\t\tuniform sampler2D directionalShadowMap[ NUM_DIR_LIGHTS ];\n\t\tvarying vec4 vDirectionalShadowCoord[ NUM_DIR_LIGHTS ];\n\t#endif\n\t#if NUM_SPOT_LIGHTS > 0\n\t\tuniform sampler2D spotShadowMap[ NUM_SPOT_LIGHTS ];\n\t\tvarying vec4 vSpotShadowCoord[ NUM_SPOT_LIGHTS ];\n\t#endif\n\t#if NUM_POINT_LIGHTS > 0\n\t\tuniform sampler2D pointShadowMap[ NUM_POINT_LIGHTS ];\n\t\tvarying vec4 vPointShadowCoord[ NUM_POINT_LIGHTS ];\n\t#endif\n\tfloat texture2DCompare( sampler2D depths, vec2 uv, float compare ) {\n\t\treturn step( compare, unpackRGBAToDepth( texture2D( depths, uv ) ) );\n\t}\n\tfloat texture2DShadowLerp( sampler2D depths, vec2 size, vec2 uv, float compare ) {\n\t\tconst vec2 offset = vec2( 0.0, 1.0 );\n\t\tvec2 texelSize = vec2( 1.0 ) / size;\n\t\tvec2 centroidUV = floor( uv * size + 0.5 ) / size;\n\t\tfloat lb = texture2DCompare( depths, centroidUV + texelSize * offset.xx, compare );\n\t\tfloat lt = texture2DCompare( depths, centroidUV + texelSize * offset.xy, compare );\n\t\tfloat rb = texture2DCompare( depths, centroidUV + texelSize * offset.yx, compare );\n\t\tfloat rt = texture2DCompare( depths, centroidUV + texelSize * offset.yy, compare );\n\t\tvec2 f = fract( uv * size + 0.5 );\n\t\tfloat a = mix( lb, lt, f.y );\n\t\tfloat b = mix( rb, rt, f.y );\n\t\tfloat c = mix( a, b, f.x );\n\t\treturn c;\n\t}\n\tfloat getShadow( sampler2D shadowMap, vec2 shadowMapSize, float shadowBias, float shadowRadius, vec4 shadowCoord ) {\n\t\tfloat shadow = 1.0;\n\t\tshadowCoord.xyz /= shadowCoord.w;\n\t\tshadowCoord.z += shadowBias;\n\t\tbvec4 inFrustumVec = bvec4 ( shadowCoord.x >= 0.0, shadowCoord.x <= 1.0, shadowCoord.y >= 0.0, shadowCoord.y <= 1.0 );\n\t\tbool inFrustum = all( inFrustumVec );\n\t\tbvec2 frustumTestVec = bvec2( inFrustum, shadowCoord.z <= 1.0 );\n\t\tbool frustumTest = all( frustumTestVec );\n\t\tif ( frustumTest ) {\n\t\t#if defined( SHADOWMAP_TYPE_PCF )\n\t\t\tvec2 texelSize = vec2( 1.0 ) / shadowMapSize;\n\t\t\tfloat dx0 = - texelSize.x * shadowRadius;\n\t\t\tfloat dy0 = - texelSize.y * shadowRadius;\n\t\t\tfloat dx1 = + texelSize.x * shadowRadius;\n\t\t\tfloat dy1 = + texelSize.y * shadowRadius;\n\t\t\tshadow = (\n\t\t\t\ttexture2DCompare( shadowMap, shadowCoord.xy + vec2( dx0, dy0 ), shadowCoord.z ) +\n\t\t\t\ttexture2DCompare( shadowMap, shadowCoord.xy + vec2( 0.0, dy0 ), shadowCoord.z ) +\n\t\t\t\ttexture2DCompare( shadowMap, shadowCoord.xy + vec2( dx1, dy0 ), shadowCoord.z ) +\n\t\t\t\ttexture2DCompare( shadowMap, shadowCoord.xy + vec2( dx0, 0.0 ), shadowCoord.z ) +\n\t\t\t\ttexture2DCompare( shadowMap, shadowCoord.xy, shadowCoord.z ) +\n\t\t\t\ttexture2DCompare( shadowMap, shadowCoord.xy + vec2( dx1, 0.0 ), shadowCoord.z ) +\n\t\t\t\ttexture2DCompare( shadowMap, shadowCoord.xy + vec2( dx0, dy1 ), shadowCoord.z ) +\n\t\t\t\ttexture2DCompare( shadowMap, shadowCoord.xy + vec2( 0.0, dy1 ), shadowCoord.z ) +\n\t\t\t\ttexture2DCompare( shadowMap, shadowCoord.xy + vec2( dx1, dy1 ), shadowCoord.z )\n\t\t\t) * ( 1.0 / 9.0 );\n\t\t#elif defined( SHADOWMAP_TYPE_PCF_SOFT )\n\t\t\tvec2 texelSize = vec2( 1.0 ) / shadowMapSize;\n\t\t\tfloat dx0 = - texelSize.x * shadowRadius;\n\t\t\tfloat dy0 = - texelSize.y * shadowRadius;\n\t\t\tfloat dx1 = + texelSize.x * shadowRadius;\n\t\t\tfloat dy1 = + texelSize.y * shadowRadius;\n\t\t\tshadow = (\n\t\t\t\ttexture2DShadowLerp( shadowMap, shadowMapSize, shadowCoord.xy + vec2( dx0, dy0 ), shadowCoord.z ) +\n\t\t\t\ttexture2DShadowLerp( shadowMap, shadowMapSize, shadowCoord.xy + vec2( 0.0, dy0 ), shadowCoord.z ) +\n\t\t\t\ttexture2DShadowLerp( shadowMap, shadowMapSize, shadowCoord.xy + vec2( dx1, dy0 ), shadowCoord.z ) +\n\t\t\t\ttexture2DShadowLerp( shadowMap, shadowMapSize, shadowCoord.xy + vec2( dx0, 0.0 ), shadowCoord.z ) +\n\t\t\t\ttexture2DShadowLerp( shadowMap, shadowMapSize, shadowCoord.xy, shadowCoord.z ) +\n\t\t\t\ttexture2DShadowLerp( shadowMap, shadowMapSize, shadowCoord.xy + vec2( dx1, 0.0 ), shadowCoord.z ) +\n\t\t\t\ttexture2DShadowLerp( shadowMap, shadowMapSize, shadowCoord.xy + vec2( dx0, dy1 ), shadowCoord.z ) +\n\t\t\t\ttexture2DShadowLerp( shadowMap, shadowMapSize, shadowCoord.xy + vec2( 0.0, dy1 ), shadowCoord.z ) +\n\t\t\t\ttexture2DShadowLerp( shadowMap, shadowMapSize, shadowCoord.xy + vec2( dx1, dy1 ), shadowCoord.z )\n\t\t\t) * ( 1.0 / 9.0 );\n\t\t#else\n\t\t\tshadow = texture2DCompare( shadowMap, shadowCoord.xy, shadowCoord.z );\n\t\t#endif\n\t\t}\n\t\treturn shadow;\n\t}\n\tvec2 cubeToUV( vec3 v, float texelSizeY ) {\n\t\tvec3 absV = abs( v );\n\t\tfloat scaleToCube = 1.0 / max( absV.x, max( absV.y, absV.z ) );\n\t\tabsV *= scaleToCube;\n\t\tv *= scaleToCube * ( 1.0 - 2.0 * texelSizeY );\n\t\tvec2 planar = v.xy;\n\t\tfloat almostATexel = 1.5 * texelSizeY;\n\t\tfloat almostOne = 1.0 - almostATexel;\n\t\tif ( absV.z >= almostOne ) {\n\t\t\tif ( v.z > 0.0 )\n\t\t\t\tplanar.x = 4.0 - v.x;\n\t\t} else if ( absV.x >= almostOne ) {\n\t\t\tfloat signX = sign( v.x );\n\t\t\tplanar.x = v.z * signX + 2.0 * signX;\n\t\t} else if ( absV.y >= almostOne ) {\n\t\t\tfloat signY = sign( v.y );\n\t\t\tplanar.x = v.x + 2.0 * signY + 2.0;\n\t\t\tplanar.y = v.z * signY - 2.0;\n\t\t}\n\t\treturn vec2( 0.125, 0.25 ) * planar + vec2( 0.375, 0.75 );\n\t}\n\tfloat getPointShadow( sampler2D shadowMap, vec2 shadowMapSize, float shadowBias, float shadowRadius, vec4 shadowCoord, float shadowCameraNear, float shadowCameraFar ) {\n\t\tvec2 texelSize = vec2( 1.0 ) / ( shadowMapSize * vec2( 4.0, 2.0 ) );\n\t\tvec3 lightToPosition = shadowCoord.xyz;\n\t\tfloat dp = ( length( lightToPosition ) - shadowCameraNear ) / ( shadowCameraFar - shadowCameraNear );\t\tdp += shadowBias;\n\t\tvec3 bd3D = normalize( lightToPosition );\n\t\t#if defined( SHADOWMAP_TYPE_PCF ) || defined( SHADOWMAP_TYPE_PCF_SOFT )\n\t\t\tvec2 offset = vec2( - 1, 1 ) * shadowRadius * texelSize.y;\n\t\t\treturn (\n\t\t\t\ttexture2DCompare( shadowMap, cubeToUV( bd3D + offset.xyy, texelSize.y ), dp ) +\n\t\t\t\ttexture2DCompare( shadowMap, cubeToUV( bd3D + offset.yyy, texelSize.y ), dp ) +\n\t\t\t\ttexture2DCompare( shadowMap, cubeToUV( bd3D + offset.xyx, texelSize.y ), dp ) +\n\t\t\t\ttexture2DCompare( shadowMap, cubeToUV( bd3D + offset.yyx, texelSize.y ), dp ) +\n\t\t\t\ttexture2DCompare( shadowMap, cubeToUV( bd3D, texelSize.y ), dp ) +\n\t\t\t\ttexture2DCompare( shadowMap, cubeToUV( bd3D + offset.xxy, texelSize.y ), dp ) +\n\t\t\t\ttexture2DCompare( shadowMap, cubeToUV( bd3D + offset.yxy, texelSize.y ), dp ) +\n\t\t\t\ttexture2DCompare( shadowMap, cubeToUV( bd3D + offset.xxx, texelSize.y ), dp ) +\n\t\t\t\ttexture2DCompare( shadowMap, cubeToUV( bd3D + offset.yxx, texelSize.y ), dp )\n\t\t\t) * ( 1.0 / 9.0 );\n\t\t#else\n\t\t\treturn texture2DCompare( shadowMap, cubeToUV( bd3D, texelSize.y ), dp );\n\t\t#endif\n\t}\n#endif";
-
- var shadowmap_pars_vertex = "#ifdef USE_SHADOWMAP\n\t#if NUM_DIR_LIGHTS > 0\n\t\tuniform mat4 directionalShadowMatrix[ NUM_DIR_LIGHTS ];\n\t\tvarying vec4 vDirectionalShadowCoord[ NUM_DIR_LIGHTS ];\n\t#endif\n\t#if NUM_SPOT_LIGHTS > 0\n\t\tuniform mat4 spotShadowMatrix[ NUM_SPOT_LIGHTS ];\n\t\tvarying vec4 vSpotShadowCoord[ NUM_SPOT_LIGHTS ];\n\t#endif\n\t#if NUM_POINT_LIGHTS > 0\n\t\tuniform mat4 pointShadowMatrix[ NUM_POINT_LIGHTS ];\n\t\tvarying vec4 vPointShadowCoord[ NUM_POINT_LIGHTS ];\n\t#endif\n#endif";
-
- var shadowmap_vertex = "#ifdef USE_SHADOWMAP\n\t#if NUM_DIR_LIGHTS > 0\n\t#pragma unroll_loop\n\tfor ( int i = 0; i < NUM_DIR_LIGHTS; i ++ ) {\n\t\tvDirectionalShadowCoord[ i ] = directionalShadowMatrix[ i ] * worldPosition;\n\t}\n\t#endif\n\t#if NUM_SPOT_LIGHTS > 0\n\t#pragma unroll_loop\n\tfor ( int i = 0; i < NUM_SPOT_LIGHTS; i ++ ) {\n\t\tvSpotShadowCoord[ i ] = spotShadowMatrix[ i ] * worldPosition;\n\t}\n\t#endif\n\t#if NUM_POINT_LIGHTS > 0\n\t#pragma unroll_loop\n\tfor ( int i = 0; i < NUM_POINT_LIGHTS; i ++ ) {\n\t\tvPointShadowCoord[ i ] = pointShadowMatrix[ i ] * worldPosition;\n\t}\n\t#endif\n#endif";
-
- var shadowmask_pars_fragment = "float getShadowMask() {\n\tfloat shadow = 1.0;\n\t#ifdef USE_SHADOWMAP\n\t#if NUM_DIR_LIGHTS > 0\n\tDirectionalLight directionalLight;\n\t#pragma unroll_loop\n\tfor ( int i = 0; i < NUM_DIR_LIGHTS; i ++ ) {\n\t\tdirectionalLight = directionalLights[ i ];\n\t\tshadow *= bool( directionalLight.shadow ) ? getShadow( directionalShadowMap[ i ], directionalLight.shadowMapSize, directionalLight.shadowBias, directionalLight.shadowRadius, vDirectionalShadowCoord[ i ] ) : 1.0;\n\t}\n\t#endif\n\t#if NUM_SPOT_LIGHTS > 0\n\tSpotLight spotLight;\n\t#pragma unroll_loop\n\tfor ( int i = 0; i < NUM_SPOT_LIGHTS; i ++ ) {\n\t\tspotLight = spotLights[ i ];\n\t\tshadow *= bool( spotLight.shadow ) ? getShadow( spotShadowMap[ i ], spotLight.shadowMapSize, spotLight.shadowBias, spotLight.shadowRadius, vSpotShadowCoord[ i ] ) : 1.0;\n\t}\n\t#endif\n\t#if NUM_POINT_LIGHTS > 0\n\tPointLight pointLight;\n\t#pragma unroll_loop\n\tfor ( int i = 0; i < NUM_POINT_LIGHTS; i ++ ) {\n\t\tpointLight = pointLights[ i ];\n\t\tshadow *= bool( pointLight.shadow ) ? getPointShadow( pointShadowMap[ i ], pointLight.shadowMapSize, pointLight.shadowBias, pointLight.shadowRadius, vPointShadowCoord[ i ], pointLight.shadowCameraNear, pointLight.shadowCameraFar ) : 1.0;\n\t}\n\t#endif\n\t#endif\n\treturn shadow;\n}";
-
- var skinbase_vertex = "#ifdef USE_SKINNING\n\tmat4 boneMatX = getBoneMatrix( skinIndex.x );\n\tmat4 boneMatY = getBoneMatrix( skinIndex.y );\n\tmat4 boneMatZ = getBoneMatrix( skinIndex.z );\n\tmat4 boneMatW = getBoneMatrix( skinIndex.w );\n#endif";
-
- var skinning_pars_vertex = "#ifdef USE_SKINNING\n\tuniform mat4 bindMatrix;\n\tuniform mat4 bindMatrixInverse;\n\t#ifdef BONE_TEXTURE\n\t\tuniform sampler2D boneTexture;\n\t\tuniform int boneTextureSize;\n\t\tmat4 getBoneMatrix( const in float i ) {\n\t\t\tfloat j = i * 4.0;\n\t\t\tfloat x = mod( j, float( boneTextureSize ) );\n\t\t\tfloat y = floor( j / float( boneTextureSize ) );\n\t\t\tfloat dx = 1.0 / float( boneTextureSize );\n\t\t\tfloat dy = 1.0 / float( boneTextureSize );\n\t\t\ty = dy * ( y + 0.5 );\n\t\t\tvec4 v1 = texture2D( boneTexture, vec2( dx * ( x + 0.5 ), y ) );\n\t\t\tvec4 v2 = texture2D( boneTexture, vec2( dx * ( x + 1.5 ), y ) );\n\t\t\tvec4 v3 = texture2D( boneTexture, vec2( dx * ( x + 2.5 ), y ) );\n\t\t\tvec4 v4 = texture2D( boneTexture, vec2( dx * ( x + 3.5 ), y ) );\n\t\t\tmat4 bone = mat4( v1, v2, v3, v4 );\n\t\t\treturn bone;\n\t\t}\n\t#else\n\t\tuniform mat4 boneMatrices[ MAX_BONES ];\n\t\tmat4 getBoneMatrix( const in float i ) {\n\t\t\tmat4 bone = boneMatrices[ int(i) ];\n\t\t\treturn bone;\n\t\t}\n\t#endif\n#endif";
-
- var skinning_vertex = "#ifdef USE_SKINNING\n\tvec4 skinVertex = bindMatrix * vec4( transformed, 1.0 );\n\tvec4 skinned = vec4( 0.0 );\n\tskinned += boneMatX * skinVertex * skinWeight.x;\n\tskinned += boneMatY * skinVertex * skinWeight.y;\n\tskinned += boneMatZ * skinVertex * skinWeight.z;\n\tskinned += boneMatW * skinVertex * skinWeight.w;\n\ttransformed = ( bindMatrixInverse * skinned ).xyz;\n#endif";
-
- var skinnormal_vertex = "#ifdef USE_SKINNING\n\tmat4 skinMatrix = mat4( 0.0 );\n\tskinMatrix += skinWeight.x * boneMatX;\n\tskinMatrix += skinWeight.y * boneMatY;\n\tskinMatrix += skinWeight.z * boneMatZ;\n\tskinMatrix += skinWeight.w * boneMatW;\n\tskinMatrix = bindMatrixInverse * skinMatrix * bindMatrix;\n\tobjectNormal = vec4( skinMatrix * vec4( objectNormal, 0.0 ) ).xyz;\n\t#ifdef USE_TANGENT\n\t\tobjectTangent = vec4( skinMatrix * vec4( objectTangent, 0.0 ) ).xyz;\n\t#endif\n#endif";
-
- var specularmap_fragment = "float specularStrength;\n#ifdef USE_SPECULARMAP\n\tvec4 texelSpecular = texture2D( specularMap, vUv );\n\tspecularStrength = texelSpecular.r;\n#else\n\tspecularStrength = 1.0;\n#endif";
-
- var specularmap_pars_fragment = "#ifdef USE_SPECULARMAP\n\tuniform sampler2D specularMap;\n#endif";
-
- var tonemapping_fragment = "#if defined( TONE_MAPPING )\n\tgl_FragColor.rgb = toneMapping( gl_FragColor.rgb );\n#endif";
-
- var tonemapping_pars_fragment = "#ifndef saturate\n\t#define saturate(a) clamp( a, 0.0, 1.0 )\n#endif\nuniform float toneMappingExposure;\nuniform float toneMappingWhitePoint;\nvec3 LinearToneMapping( vec3 color ) {\n\treturn toneMappingExposure * color;\n}\nvec3 ReinhardToneMapping( vec3 color ) {\n\tcolor *= toneMappingExposure;\n\treturn saturate( color / ( vec3( 1.0 ) + color ) );\n}\n#define Uncharted2Helper( x ) max( ( ( x * ( 0.15 * x + 0.10 * 0.50 ) + 0.20 * 0.02 ) / ( x * ( 0.15 * x + 0.50 ) + 0.20 * 0.30 ) ) - 0.02 / 0.30, vec3( 0.0 ) )\nvec3 Uncharted2ToneMapping( vec3 color ) {\n\tcolor *= toneMappingExposure;\n\treturn saturate( Uncharted2Helper( color ) / Uncharted2Helper( vec3( toneMappingWhitePoint ) ) );\n}\nvec3 OptimizedCineonToneMapping( vec3 color ) {\n\tcolor *= toneMappingExposure;\n\tcolor = max( vec3( 0.0 ), color - 0.004 );\n\treturn pow( ( color * ( 6.2 * color + 0.5 ) ) / ( color * ( 6.2 * color + 1.7 ) + 0.06 ), vec3( 2.2 ) );\n}\nvec3 ACESFilmicToneMapping( vec3 color ) {\n\tcolor *= toneMappingExposure;\n\treturn saturate( ( color * ( 2.51 * color + 0.03 ) ) / ( color * ( 2.43 * color + 0.59 ) + 0.14 ) );\n}";
-
- var uv_pars_fragment = "#if defined( USE_MAP ) || defined( USE_BUMPMAP ) || defined( USE_NORMALMAP ) || defined( USE_SPECULARMAP ) || defined( USE_ALPHAMAP ) || defined( USE_EMISSIVEMAP ) || defined( USE_ROUGHNESSMAP ) || defined( USE_METALNESSMAP )\n\tvarying vec2 vUv;\n#endif";
-
- var uv_pars_vertex = "#if defined( USE_MAP ) || defined( USE_BUMPMAP ) || defined( USE_NORMALMAP ) || defined( USE_SPECULARMAP ) || defined( USE_ALPHAMAP ) || defined( USE_EMISSIVEMAP ) || defined( USE_ROUGHNESSMAP ) || defined( USE_METALNESSMAP )\n\tvarying vec2 vUv;\n\tuniform mat3 uvTransform;\n#endif";
-
- var uv_vertex = "#if defined( USE_MAP ) || defined( USE_BUMPMAP ) || defined( USE_NORMALMAP ) || defined( USE_SPECULARMAP ) || defined( USE_ALPHAMAP ) || defined( USE_EMISSIVEMAP ) || defined( USE_ROUGHNESSMAP ) || defined( USE_METALNESSMAP )\n\tvUv = ( uvTransform * vec3( uv, 1 ) ).xy;\n#endif";
-
- var uv2_pars_fragment = "#if defined( USE_LIGHTMAP ) || defined( USE_AOMAP )\n\tvarying vec2 vUv2;\n#endif";
-
- var uv2_pars_vertex = "#if defined( USE_LIGHTMAP ) || defined( USE_AOMAP )\n\tattribute vec2 uv2;\n\tvarying vec2 vUv2;\n#endif";
-
- var uv2_vertex = "#if defined( USE_LIGHTMAP ) || defined( USE_AOMAP )\n\tvUv2 = uv2;\n#endif";
-
- var worldpos_vertex = "#if defined( USE_ENVMAP ) || defined( DISTANCE ) || defined ( USE_SHADOWMAP )\n\tvec4 worldPosition = modelMatrix * vec4( transformed, 1.0 );\n#endif";
-
- var background_frag = "uniform sampler2D t2D;\nvarying vec2 vUv;\nvoid main() {\n\tvec4 texColor = texture2D( t2D, vUv );\n\tgl_FragColor = mapTexelToLinear( texColor );\n\t#include \n\t#include \n}";
-
- var background_vert = "varying vec2 vUv;\nuniform mat3 uvTransform;\nvoid main() {\n\tvUv = ( uvTransform * vec3( uv, 1 ) ).xy;\n\tgl_Position = vec4( position.xy, 1.0, 1.0 );\n}";
-
- var cube_frag = "uniform samplerCube tCube;\nuniform float tFlip;\nuniform float opacity;\nvarying vec3 vWorldDirection;\nvoid main() {\n\tvec4 texColor = textureCube( tCube, vec3( tFlip * vWorldDirection.x, vWorldDirection.yz ) );\n\tgl_FragColor = mapTexelToLinear( texColor );\n\tgl_FragColor.a *= opacity;\n\t#include \n\t#include \n}";
-
- var cube_vert = "varying vec3 vWorldDirection;\n#include \nvoid main() {\n\tvWorldDirection = transformDirection( position, modelMatrix );\n\t#include \n\t#include \n\tgl_Position.z = gl_Position.w;\n}";
-
- var depth_frag = "#if DEPTH_PACKING == 3200\n\tuniform float opacity;\n#endif\n#include \n#include \n#include \n#include \n#include \n#include \n#include \nvoid main() {\n\t#include \n\tvec4 diffuseColor = vec4( 1.0 );\n\t#if DEPTH_PACKING == 3200\n\t\tdiffuseColor.a = opacity;\n\t#endif\n\t#include \n\t#include \n\t#include \n\t#include \n\t#if DEPTH_PACKING == 3200\n\t\tgl_FragColor = vec4( vec3( 1.0 - gl_FragCoord.z ), opacity );\n\t#elif DEPTH_PACKING == 3201\n\t\tgl_FragColor = packDepthToRGBA( gl_FragCoord.z );\n\t#endif\n}";
-
- var depth_vert = "#include \n#include \n#include \n#include \n#include \n#include \n#include \nvoid main() {\n\t#include \n\t#include \n\t#ifdef USE_DISPLACEMENTMAP\n\t\t#include \n\t\t#include \n\t\t#include \n\t#endif\n\t#include \n\t#include \n\t#include \n\t#include \n\t#include \n\t#include \n\t#include \n}";
-
- var distanceRGBA_frag = "#define DISTANCE\nuniform vec3 referencePosition;\nuniform float nearDistance;\nuniform float farDistance;\nvarying vec3 vWorldPosition;\n#include \n#include \n#include \n#include \n#include \n#include \nvoid main () {\n\t#include \n\tvec4 diffuseColor = vec4( 1.0 );\n\t#include \n\t#include \n\t#include \n\tfloat dist = length( vWorldPosition - referencePosition );\n\tdist = ( dist - nearDistance ) / ( farDistance - nearDistance );\n\tdist = saturate( dist );\n\tgl_FragColor = packDepthToRGBA( dist );\n}";
-
- var distanceRGBA_vert = "#define DISTANCE\nvarying vec3 vWorldPosition;\n#include \n#include \n#include \n#include \n#include \n#include \nvoid main() {\n\t#include \n\t#include \n\t#ifdef USE_DISPLACEMENTMAP\n\t\t#include \n\t\t#include \n\t\t#include \n\t#endif\n\t#include \n\t#include \n\t#include \n\t#include \n\t#include \n\t#include \n\t#include \n\tvWorldPosition = worldPosition.xyz;\n}";
-
- var equirect_frag = "uniform sampler2D tEquirect;\nvarying vec3 vWorldDirection;\n#include \nvoid main() {\n\tvec3 direction = normalize( vWorldDirection );\n\tvec2 sampleUV;\n\tsampleUV.y = asin( clamp( direction.y, - 1.0, 1.0 ) ) * RECIPROCAL_PI + 0.5;\n\tsampleUV.x = atan( direction.z, direction.x ) * RECIPROCAL_PI2 + 0.5;\n\tvec4 texColor = texture2D( tEquirect, sampleUV );\n\tgl_FragColor = mapTexelToLinear( texColor );\n\t#include \n\t#include \n}";
-
- var equirect_vert = "varying vec3 vWorldDirection;\n#include \nvoid main() {\n\tvWorldDirection = transformDirection( position, modelMatrix );\n\t#include \n\t#include \n}";
-
- var linedashed_frag = "uniform vec3 diffuse;\nuniform float opacity;\nuniform float dashSize;\nuniform float totalSize;\nvarying float vLineDistance;\n#include \n#include \n#include \n#include \n#include \nvoid main() {\n\t#include \n\tif ( mod( vLineDistance, totalSize ) > dashSize ) {\n\t\tdiscard;\n\t}\n\tvec3 outgoingLight = vec3( 0.0 );\n\tvec4 diffuseColor = vec4( diffuse, opacity );\n\t#include \n\t#include \n\toutgoingLight = diffuseColor.rgb;\n\tgl_FragColor = vec4( outgoingLight, diffuseColor.a );\n\t#include \n\t#include \n\t#include \n\t#include \n}";
-
- var linedashed_vert = "uniform float scale;\nattribute float lineDistance;\nvarying float vLineDistance;\n#include \n#include \n#include \n#include \n#include \nvoid main() {\n\t#include \n\tvLineDistance = scale * lineDistance;\n\tvec4 mvPosition = modelViewMatrix * vec4( position, 1.0 );\n\tgl_Position = projectionMatrix * mvPosition;\n\t#include \n\t#include \n\t#include \n}";
-
- var meshbasic_frag = "uniform vec3 diffuse;\nuniform float opacity;\n#ifndef FLAT_SHADED\n\tvarying vec3 vNormal;\n#endif\n#include \n#include \n#include \n#include \n#include \n#include \n#include \n#include \n#include \n#include \n#include \n#include \n#include \nvoid main() {\n\t#include \n\tvec4 diffuseColor = vec4( diffuse, opacity );\n\t#include \n\t#include \n\t#include \n\t#include \n\t#include \n\t#include \n\tReflectedLight reflectedLight = ReflectedLight( vec3( 0.0 ), vec3( 0.0 ), vec3( 0.0 ), vec3( 0.0 ) );\n\t#ifdef USE_LIGHTMAP\n\t\treflectedLight.indirectDiffuse += texture2D( lightMap, vUv2 ).xyz * lightMapIntensity;\n\t#else\n\t\treflectedLight.indirectDiffuse += vec3( 1.0 );\n\t#endif\n\t#include \n\treflectedLight.indirectDiffuse *= diffuseColor.rgb;\n\tvec3 outgoingLight = reflectedLight.indirectDiffuse;\n\t#include \n\tgl_FragColor = vec4( outgoingLight, diffuseColor.a );\n\t#include \n\t#include \n\t#include \n\t#include \n}";
-
- var meshbasic_vert = "#include \n#include \n#include \n#include \n#include \n#include \n#include \n#include \n#include \n#include \nvoid main() {\n\t#include \n\t#include \n\t#include \n\t#include \n\t#ifdef USE_ENVMAP\n\t#include \n\t#include \n\t#include \n\t#include \n\t#endif\n\t#include \n\t#include \n\t#include \n\t#include \n\t#include \n\t#include \n\t#include \n\t#include \n\t#include \n}";
-
- var meshlambert_frag = "uniform vec3 diffuse;\nuniform vec3 emissive;\nuniform float opacity;\nvarying vec3 vLightFront;\nvarying vec3 vIndirectFront;\n#ifdef DOUBLE_SIDED\n\tvarying vec3 vLightBack;\n\tvarying vec3 vIndirectBack;\n#endif\n#include \n#include \n#include \n#include \n#include \n#include \n#include \n#include \n#include \n#include \n#include \n#include \n#include \n#include \n#include \n#include \n#include \n#include \n#include \n#include \nvoid main() {\n\t#include \n\tvec4 diffuseColor = vec4( diffuse, opacity );\n\tReflectedLight reflectedLight = ReflectedLight( vec3( 0.0 ), vec3( 0.0 ), vec3( 0.0 ), vec3( 0.0 ) );\n\tvec3 totalEmissiveRadiance = emissive;\n\t#include \n\t#include \n\t#include \n\t#include \n\t#include \n\t#include \n\t#include \n\treflectedLight.indirectDiffuse = getAmbientLightIrradiance( ambientLightColor );\n\t#ifdef DOUBLE_SIDED\n\t\treflectedLight.indirectDiffuse += ( gl_FrontFacing ) ? vIndirectFront : vIndirectBack;\n\t#else\n\t\treflectedLight.indirectDiffuse += vIndirectFront;\n\t#endif\n\t#include \n\treflectedLight.indirectDiffuse *= BRDF_Diffuse_Lambert( diffuseColor.rgb );\n\t#ifdef DOUBLE_SIDED\n\t\treflectedLight.directDiffuse = ( gl_FrontFacing ) ? vLightFront : vLightBack;\n\t#else\n\t\treflectedLight.directDiffuse = vLightFront;\n\t#endif\n\treflectedLight.directDiffuse *= BRDF_Diffuse_Lambert( diffuseColor.rgb ) * getShadowMask();\n\t#include \n\tvec3 outgoingLight = reflectedLight.directDiffuse + reflectedLight.indirectDiffuse + totalEmissiveRadiance;\n\t#include \n\tgl_FragColor = vec4( outgoingLight, diffuseColor.a );\n\t#include \n\t#include \n\t#include \n\t#include \n\t#include \n}";
-
- var meshlambert_vert = "#define LAMBERT\nvarying vec3 vLightFront;\nvarying vec3 vIndirectFront;\n#ifdef DOUBLE_SIDED\n\tvarying vec3 vLightBack;\n\tvarying vec3 vIndirectBack;\n#endif\n#include \n#include \n#include \n#include \n#include \n#include \n#include \n#include \n#include \n#include \n#include \n#include \n#include \nvoid main() {\n\t#include \n\t#include \n\t#include \n\t#include \n\t#include \n\t#include \n\t#include \n\t#include \n\t#include \n\t#include \n\t#include \n\t#include \n\t#include \n\t#include \n\t#include