

Commit
·
c034d29
1
Parent(s):
907930f
Update parquet files (step 2 of 121)
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- spaces/101-5/gpt4free/.github/ISSUE_TEMPLATE/default_issue.md +0 -33
- spaces/101-5/gpt4free/g4f/.v1/gpt4free/usesless/utils/__init__.py +0 -139
- spaces/1acneusushi/gradio-2dmoleculeeditor/data/Cities Skylines Mod Pack [Direct run] - Enhance Your City Building Experience with These Mods.md +0 -79
- spaces/1acneusushi/gradio-2dmoleculeeditor/data/Free Download Fusion 360 TOP.md +0 -41
- spaces/1gistliPinn/ChatGPT4/Examples/Adobe Audition 2.0 Full Crack 12 A Complete Review and Comparison with Other Versions.md +0 -5
- spaces/1gistliPinn/ChatGPT4/Examples/AutoCAD Electrical 2016 X64 (32X64bit) (Product Key And Xforce VERIFIED Keygen) Serial Key VERIFIED Keygen.md +0 -6
- spaces/1gistliPinn/ChatGPT4/Examples/Cambridge English Pronouncing Dictionary 17th Edition Download.rar ((NEW)).md +0 -6
- spaces/1gistliPinn/ChatGPT4/Examples/Descargar Pan Casero Iban Yarza Epub.md +0 -6
- spaces/1pelhydcardo/ChatGPT-prompt-generator/assets/APKGame Explore the World of Android Gaming with Ease.md +0 -129
- spaces/1pelhydcardo/ChatGPT-prompt-generator/assets/ApkJeet How to Earn Money Online from Home with a Simple App in 2023.md +0 -107
- spaces/1phancelerku/anime-remove-background/Experience the Thrill of Free Fire MAX on PC with BlueStacks The Only App Player that Supports Android 11.md +0 -135
- spaces/801artistry/RVC801/utils/i18n.py +0 -28
- spaces/AIConsultant/MusicGen/audiocraft/utils/autocast.py +0 -40
- spaces/ATang0729/Forecast4Muses/Model/Model6/Model6_0_ClothesDetection/mmyolo/configs/yolov6/yolov6_n_syncbn_fast_8xb32-400e_coco.py +0 -21
- spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/fixwidthsizer/LayoutChildren.js +0 -102
- spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/maker/builders/CreateTextArea.js +0 -21
- spaces/Alexxggs/ggvpnewen/app.py +0 -98
- spaces/Alpaca233/SadTalker/src/face3d/util/nvdiffrast.py +0 -126
- spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/src/diffusers/models/resnet.py +0 -878
- spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/tests/pipelines/text_to_video/test_text_to_video_zero.py +0 -42
- spaces/Andy1621/uniformer_image_detection/configs/nas_fpn/retinanet_r50_fpn_crop640_50e_coco.py +0 -80
- spaces/AnishKumbhar/ChatBot/text-generation-webui-main/extensions/superbooga/download_urls.py +0 -35
- spaces/Anonymous-123/ImageNet-Editing/object_removal/TFill/model/__init__.py +0 -34
- spaces/Anonymous-sub/Rerender/ControlNet/ldm/models/diffusion/dpm_solver/sampler.py +0 -87
- spaces/AriaMei/TTSdemo/emotion_extract.py +0 -112
- spaces/ArtGAN/Video-Diffusion-WebUI/video_diffusion/stable_diffusion_video/utils.py +0 -135
- spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/pip/_vendor/distlib/metadata.py +0 -1076
- spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/setuptools/package_index.py +0 -1126
- spaces/Awiny/Image2Paragraph/models/grit_src/third_party/CenterNet2/demo/demo.py +0 -188
- spaces/BIASLab/sars-cov-2-classification-fcgr/predict.py +0 -28
- spaces/Benson/text-generation/Examples/Buscando Recursos Para Descargar Gratis Fuego Mx.md +0 -70
- spaces/Big-Web/MMSD/env/Lib/site-packages/pip/_vendor/urllib3/response.py +0 -879
- spaces/Big-Web/MMSD/env/Lib/site-packages/setuptools/_distutils/sysconfig.py +0 -558
- spaces/Big-Web/MMSD/env/Lib/site-packages/urllib3/contrib/socks.py +0 -216
- spaces/CVPR/WALT/mmdet/models/detectors/retinanet.py +0 -17
- spaces/CVPR/drawings-to-human/frontend/README.md +0 -38
- spaces/CVPR/unicl-zero-shot-img-recog/model/image_encoder/focalnet.py +0 -649
- spaces/Campfireman/whisper_lab2/README.md +0 -13
- spaces/CarlDennis/HYTTS/transforms.py +0 -193
- spaces/ChandraMohanNayal/AutoGPT/autogpt/config/__init__.py +0 -14
- spaces/Chirayuhumar/MyGenAIChatBot/README.md +0 -12
- spaces/ClassCat/Brain-tumor-3D-segmentation-with-MONAI/app.py +0 -194
- spaces/CrucibleAI/ControlNetMediaPipeFaceSD21/ldm/models/diffusion/plms.py +0 -245
- spaces/Cyril666/ContourNet-ABI/maskrcnn_benchmark/modeling/__init__.py +0 -0
- spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/PIL/ImageWin.py +0 -230
- spaces/DragGan/DragGan/torch_utils/ops/conv2d_gradfix.py +0 -198
- spaces/Eddycrack864/Applio-Inference/utils/README.md +0 -6
- spaces/Ekimetrics/climate-question-answering/app.py +0 -812
- spaces/Ekimetrics/climate-question-answering/climateqa/__init__.py +0 -0
- spaces/EuroPython2022/Zero-Shot-SQL-by-Bloom/README.md +0 -13
spaces/101-5/gpt4free/.github/ISSUE_TEMPLATE/default_issue.md
DELETED
|
@@ -1,33 +0,0 @@
|
|
| 1 |
-
---
|
| 2 |
-
name: New Issue
|
| 3 |
-
about: 'Please use this template !!'
|
| 4 |
-
title: ''
|
| 5 |
-
labels: bug
|
| 6 |
-
assignees: xtekky
|
| 7 |
-
|
| 8 |
-
---
|
| 9 |
-
|
| 10 |
-
**Known Issues** // delete this
|
| 11 |
-
- you.com issue / fix: use proxy, or vpn, your country is probably flagged
|
| 12 |
-
- forefront account creation error / use your own session or wait for fix
|
| 13 |
-
|
| 14 |
-
|
| 15 |
-
**Bug description**
|
| 16 |
-
What did you do, what happened, which file did you try to run, in which directory
|
| 17 |
-
Describe what you did after downloading repo, such as moving to this repo, running this file.
|
| 18 |
-
|
| 19 |
-
ex.
|
| 20 |
-
1. Go to '...'
|
| 21 |
-
2. Click on '....'
|
| 22 |
-
3. Scroll down to '....'
|
| 23 |
-
4. See error
|
| 24 |
-
|
| 25 |
-
**Screenshots**
|
| 26 |
-
If applicable, add screenshots to help explain your problem.
|
| 27 |
-
|
| 28 |
-
**Environement**
|
| 29 |
-
- python version
|
| 30 |
-
- location ( are you in a cloudfare flagged country ) ?
|
| 31 |
-
|
| 32 |
-
**Additional context**
|
| 33 |
-
Add any other context about the problem here.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/101-5/gpt4free/g4f/.v1/gpt4free/usesless/utils/__init__.py
DELETED
|
@@ -1,139 +0,0 @@
|
|
| 1 |
-
import requests
|
| 2 |
-
import random
|
| 3 |
-
import string
|
| 4 |
-
import time
|
| 5 |
-
import sys
|
| 6 |
-
import re
|
| 7 |
-
import os
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
def check_email(mail, logging: bool = False):
|
| 11 |
-
username = mail.split("@")[0]
|
| 12 |
-
domain = mail.split("@")[1]
|
| 13 |
-
reqLink = f"https://www.1secmail.com/api/v1/?action=getMessages&login={username}&domain={domain}"
|
| 14 |
-
req = requests.get(reqLink)
|
| 15 |
-
req.encoding = req.apparent_encoding
|
| 16 |
-
req = req.json()
|
| 17 |
-
|
| 18 |
-
length = len(req)
|
| 19 |
-
|
| 20 |
-
if logging:
|
| 21 |
-
os.system("cls" if os.name == "nt" else "clear")
|
| 22 |
-
time.sleep(1)
|
| 23 |
-
print("Your temporary mail:", mail)
|
| 24 |
-
|
| 25 |
-
if logging and length == 0:
|
| 26 |
-
print(
|
| 27 |
-
"Mailbox is empty. Hold tight. Mailbox is refreshed automatically every 5 seconds.",
|
| 28 |
-
)
|
| 29 |
-
else:
|
| 30 |
-
messages = []
|
| 31 |
-
id_list = []
|
| 32 |
-
|
| 33 |
-
for i in req:
|
| 34 |
-
for k, v in i.items():
|
| 35 |
-
if k == "id":
|
| 36 |
-
id_list.append(v)
|
| 37 |
-
|
| 38 |
-
x = "mails" if length > 1 else "mail"
|
| 39 |
-
|
| 40 |
-
if logging:
|
| 41 |
-
print(
|
| 42 |
-
f"Mailbox has {length} {x}. (Mailbox is refreshed automatically every 5 seconds.)"
|
| 43 |
-
)
|
| 44 |
-
|
| 45 |
-
for i in id_list:
|
| 46 |
-
msgRead = f"https://www.1secmail.com/api/v1/?action=readMessage&login={username}&domain={domain}&id={i}"
|
| 47 |
-
req = requests.get(msgRead)
|
| 48 |
-
req.encoding = req.apparent_encoding
|
| 49 |
-
req = req.json()
|
| 50 |
-
|
| 51 |
-
for k, v in req.items():
|
| 52 |
-
if k == "from":
|
| 53 |
-
sender = v
|
| 54 |
-
if k == "subject":
|
| 55 |
-
subject = v
|
| 56 |
-
if k == "date":
|
| 57 |
-
date = v
|
| 58 |
-
if k == "textBody":
|
| 59 |
-
content = v
|
| 60 |
-
|
| 61 |
-
if logging:
|
| 62 |
-
print(
|
| 63 |
-
"Sender:",
|
| 64 |
-
sender,
|
| 65 |
-
"\nTo:",
|
| 66 |
-
mail,
|
| 67 |
-
"\nSubject:",
|
| 68 |
-
subject,
|
| 69 |
-
"\nDate:",
|
| 70 |
-
date,
|
| 71 |
-
"\nContent:",
|
| 72 |
-
content,
|
| 73 |
-
"\n",
|
| 74 |
-
)
|
| 75 |
-
messages.append(
|
| 76 |
-
{
|
| 77 |
-
"sender": sender,
|
| 78 |
-
"to": mail,
|
| 79 |
-
"subject": subject,
|
| 80 |
-
"date": date,
|
| 81 |
-
"content": content,
|
| 82 |
-
}
|
| 83 |
-
)
|
| 84 |
-
|
| 85 |
-
if logging:
|
| 86 |
-
os.system("cls" if os.name == "nt" else "clear")
|
| 87 |
-
return messages
|
| 88 |
-
|
| 89 |
-
|
| 90 |
-
def create_email(custom_domain: bool = False, logging: bool = False):
|
| 91 |
-
domainList = ["1secmail.com", "1secmail.net", "1secmail.org"]
|
| 92 |
-
domain = random.choice(domainList)
|
| 93 |
-
try:
|
| 94 |
-
if custom_domain:
|
| 95 |
-
custom_domain = input(
|
| 96 |
-
"\nIf you enter 'my-test-email' as your domain name, mail address will look like this: '[email protected]'"
|
| 97 |
-
"\nEnter the name that you wish to use as your domain name: "
|
| 98 |
-
)
|
| 99 |
-
|
| 100 |
-
newMail = f"https://www.1secmail.com/api/v1/?login={custom_domain}&domain={domain}"
|
| 101 |
-
reqMail = requests.get(newMail)
|
| 102 |
-
reqMail.encoding = reqMail.apparent_encoding
|
| 103 |
-
|
| 104 |
-
username = re.search(r"login=(.*)&", newMail).group(1)
|
| 105 |
-
domain = re.search(r"domain=(.*)", newMail).group(1)
|
| 106 |
-
mail = f"{username}@{domain}"
|
| 107 |
-
|
| 108 |
-
if logging:
|
| 109 |
-
print("\nYour temporary email was created successfully:", mail)
|
| 110 |
-
return mail
|
| 111 |
-
|
| 112 |
-
else:
|
| 113 |
-
name = string.ascii_lowercase + string.digits
|
| 114 |
-
random_username = "".join(random.choice(name) for i in range(10))
|
| 115 |
-
newMail = f"https://www.1secmail.com/api/v1/?login={random_username}&domain={domain}"
|
| 116 |
-
|
| 117 |
-
reqMail = requests.get(newMail)
|
| 118 |
-
reqMail.encoding = reqMail.apparent_encoding
|
| 119 |
-
|
| 120 |
-
username = re.search(r"login=(.*)&", newMail).group(1)
|
| 121 |
-
domain = re.search(r"domain=(.*)", newMail).group(1)
|
| 122 |
-
mail = f"{username}@{domain}"
|
| 123 |
-
|
| 124 |
-
if logging:
|
| 125 |
-
print("\nYour temporary email was created successfully:", mail)
|
| 126 |
-
return mail
|
| 127 |
-
|
| 128 |
-
except KeyboardInterrupt:
|
| 129 |
-
requests.post(
|
| 130 |
-
"https://www.1secmail.com/mailbox",
|
| 131 |
-
data={
|
| 132 |
-
"action": "deleteMailbox",
|
| 133 |
-
"login": f"{username}",
|
| 134 |
-
"domain": f"{domain}",
|
| 135 |
-
},
|
| 136 |
-
)
|
| 137 |
-
if logging:
|
| 138 |
-
print("\nKeyboard Interrupt Detected! \nTemporary mail was disposed!")
|
| 139 |
-
os.system("cls" if os.name == "nt" else "clear")
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/1acneusushi/gradio-2dmoleculeeditor/data/Cities Skylines Mod Pack [Direct run] - Enhance Your City Building Experience with These Mods.md
DELETED
|
@@ -1,79 +0,0 @@
|
|
| 1 |
-
|
| 2 |
-
<h1>Cities Skylines Mod Pack [Direct run]: What You Need to Know</h1>
|
| 3 |
-
<p>If you love city-building games, you probably have heard of <strong>Cities Skylines</strong>, one of the most popular and acclaimed titles in the genre. But did you know that you can make your gaming experience even better with <strong>mods</strong>? Mods are user-created modifications that add new features, content, or improvements to the game. In this article, we will show you how to install mods for Cities Skylines, and what are some of the best mods you can use in 2023.</p>
|
| 4 |
-
<h2>Cities Skylines Mod Pack [Direct run]Cities Skylines Mod Pack [Direct run]</h2><br /><p><b><b>Download File</b> ⏩ <a href="https://byltly.com/2uKzqe">https://byltly.com/2uKzqe</a></b></p><br /><br />
|
| 5 |
-
<h2>What is Cities Skylines?</h2>
|
| 6 |
-
<p>Cities Skylines is a simulation game developed by Colossal Order and published by Paradox Interactive in 2015. The game lets you create and manage your own city, from laying out roads and zoning areas, to providing services and infrastructure, to dealing with traffic and pollution. You can also customize your city with various policies, districts, landmarks, and scenarios. The game has a realistic physics engine, a dynamic day-night cycle, and a large map size that allows you to build sprawling metropolises.</p>
|
| 7 |
-
<h2>What are Mods and Why Use Them?</h2>
|
| 8 |
-
<p>Mods are modifications that change or add something to the game. They are created by other players who use their creativity and skills to enhance the game in various ways. Some mods add new content, such as buildings, vehicles, maps, or scenarios. Some mods improve existing features, such as graphics, gameplay, or performance. Some mods fix bugs or errors that the developers missed or couldn't fix. And some mods just make the game more fun or challenging.</p>
|
| 9 |
-
<p>Using mods can make your gaming experience more enjoyable, diverse, and personalized. You can tailor your city to your preferences and needs, or experiment with different styles and possibilities. You can also learn from other players' creations and ideas, or share your own with the community. Mods can also extend the lifespan of the game by adding new challenges and goals.</p>
|
| 10 |
-
<h2>How to Install Mods for Cities Skylines</h2>
|
| 11 |
-
<p>There are two main ways to install mods for Cities Skylines: using the <strong>Steam Workshop</strong> or using <strong>Nexus Mods</strong>. Both methods have their advantages and disadvantages, so you can choose whichever one suits you best.</p>
|
| 12 |
-
<h3>Steam Workshop</h3>
|
| 13 |
-
<p>The Steam Workshop is a platform that allows you to browse, subscribe, rate, and comment on mods created by other players. It is integrated with Steam, so you don't need to download or install anything manually. To use the Steam Workshop, you need to have a Steam account and own Cities Skylines on Steam.</p>
|
| 14 |
-
<p>To access the Steam Workshop, launch Steam and go to your library. Right-click on Cities Skylines and select Properties. Then go to the Workshop tab and click on Browse Workshop. You will see a list of mods sorted by different categories and filters. You can also search for specific mods by name or keyword.</p>
|
| 15 |
-
<p>To subscribe to a mod, click on its title or thumbnail. You will see a page with more information about the mod, such as description, screenshots, ratings, comments, requirements, etc. If you like the mod and want to use it in your game, click on Subscribe. The mod will be automatically downloaded and enabled in your game.</p>
|
| 16 |
-
<p>To manage your subscribed mods, go back to Properties > Workshop > Browse Workshop > Subscribed Items. You will see a list of all the mods you have subscribed to. You can unsubscribe from any mod by clicking on Unsubscribe. You can also change the order of loading of your mods by dragging them up or down.</p>
|
| 17 |
-
<h3>Nexus Mods</h3>
|
| 18 |
-
<p>Nexus Mods is a website that hosts thousands of mods for various games. It is not affiliated with Steam or Paradox Interactive, so you need to create a free account on their website to use it. To use Nexus Mods, you also need to download a tool called <strong>Vortex</strong>, which helps you install and manage your mods.</p>
|
| 19 |
-
<p>Cities Skylines Mod Collection [Instant play]<br />
|
| 20 |
-
Cities Skylines Mod Bundle [Ready to launch]<br />
|
| 21 |
-
Cities Skylines Mod Set [No installation required]<br />
|
| 22 |
-
Cities Skylines Mod Kit [Direct run] Download<br />
|
| 23 |
-
Cities Skylines Mod Pack [Direct run] Free<br />
|
| 24 |
-
Cities Skylines Mod Pack [Direct run] Torrent<br />
|
| 25 |
-
Cities Skylines Mod Pack [Direct run] Crack<br />
|
| 26 |
-
Cities Skylines Mod Pack [Direct run] Steam<br />
|
| 27 |
-
Cities Skylines Mod Pack [Direct run] Review<br />
|
| 28 |
-
Cities Skylines Mod Pack [Direct run] Gameplay<br />
|
| 29 |
-
Cities Skylines Best Mods [Direct run]<br />
|
| 30 |
-
Cities Skylines Top Mods [Direct run]<br />
|
| 31 |
-
Cities Skylines Popular Mods [Direct run]<br />
|
| 32 |
-
Cities Skylines Essential Mods [Direct run]<br />
|
| 33 |
-
Cities Skylines Recommended Mods [Direct run]<br />
|
| 34 |
-
Cities Skylines Custom Mods [Direct run]<br />
|
| 35 |
-
Cities Skylines Realistic Mods [Direct run]<br />
|
| 36 |
-
Cities Skylines Fun Mods [Direct run]<br />
|
| 37 |
-
Cities Skylines Cool Mods [Direct run]<br />
|
| 38 |
-
Cities Skylines Amazing Mods [Direct run]<br />
|
| 39 |
-
How to use Cities Skylines Mod Pack [Direct run]<br />
|
| 40 |
-
How to install Cities Skylines Mod Pack [Direct run]<br />
|
| 41 |
-
How to download Cities Skylines Mod Pack [Direct run]<br />
|
| 42 |
-
How to update Cities Skylines Mod Pack [Direct run]<br />
|
| 43 |
-
How to uninstall Cities Skylines Mod Pack [Direct run]<br />
|
| 44 |
-
What is Cities Skylines Mod Pack [Direct run]<br />
|
| 45 |
-
What are the best mods in Cities Skylines Mod Pack [Direct run]<br />
|
| 46 |
-
What are the features of Cities Skylines Mod Pack [Direct run]<br />
|
| 47 |
-
What are the requirements for Cities Skylines Mod Pack [Direct run]<br />
|
| 48 |
-
What are the benefits of using Cities Skylines Mod Pack [Direct run]<br />
|
| 49 |
-
Why use Cities Skylines Mod Pack [Direct run]<br />
|
| 50 |
-
Why download Cities Skylines Mod Pack [Direct run]<br />
|
| 51 |
-
Why play with Cities Skylines Mod Pack [Direct run]<br />
|
| 52 |
-
Why choose Cities Skylines Mod Pack [Direct run]<br />
|
| 53 |
-
Why trust Cities Skylines Mod Pack [Direct run]<br />
|
| 54 |
-
Where to get Cities Skylines Mod Pack [Direct run]<br />
|
| 55 |
-
Where to find Cities Skylines Mod Pack [Direct run]<br />
|
| 56 |
-
Where to buy Cities Skylines Mod Pack [Direct run]<br />
|
| 57 |
-
Where to download Cities Skylines Mod Pack [Direct run]<br />
|
| 58 |
-
Where to watch Cities Skylines Mod Pack [Direct run]<br />
|
| 59 |
-
When to use Cities Skylines Mod Pack [Direct run]<br />
|
| 60 |
-
When to install Cities Skylines Mod Pack [Direct run]<br />
|
| 61 |
-
When to download Cities Skylines Mod Pack [Direct run]<br />
|
| 62 |
-
When to update Cities Skylines Mod Pack [Direct run]<br />
|
| 63 |
-
When to uninstall Cities Skylines Mod Pack [Direct run]<br />
|
| 64 |
-
Who made Cities Skylines Mod Pack [Direct run]<br />
|
| 65 |
-
Who uses Cities Skylines Mod Pack [Direct run]<br />
|
| 66 |
-
Who recommends Cities Skylines Mod Pack [Direct run]<br />
|
| 67 |
-
Who reviews Cities Skylines Mod Pack [Direct run]</p>
|
| 68 |
-
<p>To download Vortex, go to https://www.nexusmods.com/about/vortex/ and click on Download Vortex Now. Follow the instructions on how to install Vortex on your computer. Then launch Vortex and sign in with your Nexus Mods account.</p>
|
| 69 |
-
<p>To find mods for Cities Skylines on Nexus Mods, go to https://www.nexusmods.com/citiesskylines/mods/ and browse through different categories or use the search function. To download a mod, click on its title or thumbnail. You will see a page with more information about the mod, such as description, screenshots, ratings, comments, requirements, etc. If you like the mod and want to use it in your game, click on Mod Manager Download. The mod will be added to Vortex and ready to install.</p>
|
| 70 |
-
<p>To install a mod, go back to Vortex and click on Mods on the left sidebar. You will see a list of all the mods you have downloaded. To install a mod, click on the red dot next to its name. The dot will turn green and indicate that the mod is installed. To uninstall a mod, click on the green dot and confirm. You can also enable or disable any mod by clicking on the toggle switch next to its name.</p>
|
| 71 |
-
<h3>Mod Compatibility and Conflicts</h3>
|
| 72 |
-
<p>Not all mods are compatible with each other or with the latest version of the game. Some mods may require other mods or DLCs to work properly. Some mods may conflict with each other or cause errors or crashes in the game. To avoid these problems, you should always read the description and requirements of each mod carefully before installing it. You should also check the comments and ratings of other users to see if they have encountered any issues with the mod. You should also keep your mods updated to the latest version available.</p>
|
| 73 |
-
<p>If you encounter any conflicts or errors in your game, you can try disabling some of your mods to see if they are causing them. You can also use tools like <strong>Harmony</strong> or <strong>Loading Screen Mod</strong> to detect and resolve conflicts between mods. You can find these tools on both Steam Workshop and Nexus Mods.</p>
|
| 74 |
-
<h2>Best Mods for Cities Skylines in 2023</h2>
|
| 75 |
-
<p>There are thousands of mods available for Cities Skylines, but some of them stand out as essential or highly recommended by many players. Here are some of the best mods for Cities Skylines in 2023, sorted by category.</p>
|
| 76 |
-
<h3>Network Extensions 2</h3>
|
| 77 |
-
<p>This mod adds new roads, bridges, and tunnels to the game, giving you more options and flexibility when designing your city's transportation network. You can choose from different types of roads, such as highways, avenues, boulevards, lanes, or alleys, each with different capacities, speed limits, and aesthetics. You can also</p> 0a6ba089eb<br />
|
| 78 |
-
<br />
|
| 79 |
-
<br />
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/1acneusushi/gradio-2dmoleculeeditor/data/Free Download Fusion 360 TOP.md
DELETED
|
@@ -1,41 +0,0 @@
|
|
| 1 |
-
|
| 2 |
-
<h1>How to Free Download Fusion 360 for Your 3D Design Projects</h1>
|
| 3 |
-
<p>If you are looking for a powerful and versatile 3D design software that can handle CAD, CAM, CAE, and PCB tasks, you might want to try Fusion 360. Fusion 360 is a cloud-based software platform from Autodesk that allows you to turn your ideas into 3D models, prototypes, and products. In this article, we will show you how to free download Fusion 360 for your personal, startup, or educational use.</p>
|
| 4 |
-
<h2>free download fusion 360</h2><br /><p><b><b>Download Zip</b> ··· <a href="https://byltly.com/2uKxAU">https://byltly.com/2uKxAU</a></b></p><br /><br />
|
| 5 |
-
<h2>What is Fusion 360 and why use it?</h2>
|
| 6 |
-
<p>Fusion 360 is a cloud-based 3D modeling, CAD, CAM, CAE, and PCB software platform for product design and manufacturing. It has the following features and benefits:</p>
|
| 7 |
-
<ul>
|
| 8 |
-
<li><strong>Flexible 3D modeling and design</strong>: You can create and edit 3D models with ease using a variety of tools and techniques. You can also ensure aesthetics, form, fit, and function of your products with parametric, freeform, direct, and surface modeling options.</li>
|
| 9 |
-
<li><strong>CAD + CAM in one</strong>: You can design and create prototypes and finished products with professional-grade, integrated design and machining software. You can import files from 50 different file types and access hundreds of posts from a free post processor library.</li>
|
| 10 |
-
<li><strong>3D printing made easy</strong>: You can quickly take your designs from the screen to your hands with easy-to-use 3D printing software. You can connect to a library of 3D printing machines from Ultimaker, EOS, Formlabs, Renishaw, and more.</li>
|
| 11 |
-
<li><strong>Cloud CAD, to work faster and smarter</strong>: You can work from anywhere and on any device with an all-in-one cloud software platform. You can collaborate with your peers and streamline feedback on your designs by communicating in real time and centralizing your project history.</li>
|
| 12 |
-
</ul>
|
| 13 |
-
<h2>How to free download Fusion 360 for personal use</h2>
|
| 14 |
-
<p>If you want to use Fusion 360 for personal use, such as for hobby projects or non-commercial purposes, you can download a limited free version that includes basic functionality. Here are the steps to do so:</p>
|
| 15 |
-
<ol>
|
| 16 |
-
<li>Go to <a href="https://www.autodesk.com/products/fusion-360/free-trial">https://www.autodesk.com/products/fusion-360/free-trial</a> and click on "Download free trial".</li>
|
| 17 |
-
<li>Select "Personal use" as your user type and fill in your information. Click on "Next".</li>
|
| 18 |
-
<li>Create an Autodesk account or sign in with your existing one.</li>
|
| 19 |
-
<li>Verify your email address and click on "Download now".</li>
|
| 20 |
-
<li>Follow the instructions to install Fusion 360 on your device.</li>
|
| 21 |
-
<li>Launch Fusion 360 and sign in with your Autodesk account.</li>
|
| 22 |
-
<li>Enjoy using Fusion 360 for personal use for up to one year. You can renew your license annually as long as you meet the eligibility criteria.</li>
|
| 23 |
-
</ol>
|
| 24 |
-
<h2>How to free download Fusion 360 for startup use</h2>
|
| 25 |
-
<p>If you want to use Fusion 360 for startup use, such as for developing new products or services for commercial purposes, you can download a free version that includes all the features and functionality. However, you need to meet the following eligibility criteria:</p>
|
| 26 |
-
<p></p>
|
| 27 |
-
<ul>
|
| 28 |
-
<li>Your startup is less than three years old.</li>
|
| 29 |
-
<li>Your startup has 10 or fewer employees.</li>
|
| 30 |
-
<li>Your startup has annual revenue of less than $100,000 USD.</li>
|
| 31 |
-
</ul>
|
| 32 |
-
<p>If you meet these criteria, here are the steps to download Fusion 360 for startup use:</p>
|
| 33 |
-
<ol>
|
| 34 |
-
<li>Go to <a href="https://www.autodesk.com/products/fusion-360/free-trial">https://www.autodesk.com/products/fusion-360/free-trial</a> and click on "Download free trial".</li>
|
| 35 |
-
<li>Select "Startup use" as your user type and fill in your information. Click on "Next".</li>
|
| 36 |
-
<li>Create an Autodesk account or sign in with your existing one.</li>
|
| 37 |
-
<li>Verify your email address and click on "Download now".</li>
|
| 38 |
-
<li>Follow the instructions to install Fusion 360 on your device.</li>
|
| 39 |
-
<li>Launch Fusion 360 and sign</p> ddb901b051<br />
|
| 40 |
-
<br />
|
| 41 |
-
<br />
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/1gistliPinn/ChatGPT4/Examples/Adobe Audition 2.0 Full Crack 12 A Complete Review and Comparison with Other Versions.md
DELETED
|
@@ -1,5 +0,0 @@
|
|
| 1 |
-
<br />
|
| 2 |
-
<p>I'm using macOS High Sierra version 10.13.6Audition has been flawless and great up until a few days ago. Audtion no longer opens. No updates to my operating system have been made recently. Any help getting this setteld would be appreciated. Here's what pops up when I attempt to open Audition: \"Check with the developer to make sure Adobe Audition CS6 works with this version of macOS. You may need to reinstall the application. Be sure to install any available updates for the application and macOS. Click Report to see more detailed information and send a report to Apple.\" ","isUseLiaRichMedia":false,"autoTitleLink":" _0.form.messageeditor.tinymceeditor:getautotitle?t:ac=board-id/audition/thread-id/22720","isGteEditorV2":true,"linkTooltipTexts":"bareURL":"Bare URL","unlink":"Unlink","openLink":"Open link","autoTitle":"Auto-title","elementSelector":"#tinyMceEditor_10c5099008f674c","preLoadedAddOnAssetUrls":["/html/js/lib/tinymce/4.7.13/themes/modern/theme.js","/html/js/lib/tinymce/4.7.13/plugins/lists/plugin.js","/html/js/lib/tinymce/4.7.13/plugins/compat3x/plugin.js","/html/js/lib/tinymce/4.7.13/plugins/image/plugin.js","/html/js/lib/tinymce/4.7.13/plugins/link/plugin.js","/html/js/lib/tinymce/4.7.13/plugins/textcolor/plugin.js","/html/js/lib/tinymce/4.7.13/plugins/table/plugin.js","/html/js/lib/tinymce/4.7.13/plugins/tabfocus/plugin.js","/html/js/lib/tinymce/4.7.13/plugins/paste/plugin.js","/plugin/editors/tinymce/plugins/spoiler/plugin.js","/plugin/editors/tinymce/plugins/spoiler/langs/en.js","/plugin/editors/tinymce/plugins/insertcode/plugin.js","/plugin/editors/tinymce/plugins/insertcode/langs/en.js","/html/js/lib/tinymce/4.7.13/plugins/advlist/plugin.js","/html/js/lib/tinymce/4.7.13/plugins/autolink/plugin.js","/plugin/editors/tinymce/plugins/liarichmedia/plugin.js","/plugin/editors/tinymce/plugins/liarichmedia/langs/en.js","/plugin/editors/tinymce/plugins/liaexpandtoolbar/plugin.js","/plugin/editors/tinymce/plugins/liaexpandtoolbar/langs/en.js","/html/js/lib/tinymce/4.7.13/plugins/codesample/plugin.js","/plugin/editors/tinymce/plugins/liaquote/plugin.js","/plugin/editors/tinymce/plugins/liaquote/langs/en.js","/plugin/editors/tinymce/plugins/liamacros/plugin.js","/plugin/editors/tinymce/plugins/liamacros/langs/en.js","/plugin/editors/tinymce/plugins/liafullscreendone/plugin.js","/plugin/editors/tinymce/plugins/liafullscreendone/langs/en.js","/html/js/lib/tinymce/4.7.13/plugins/code/plugin.js","/plugin/editors/tinymce/plugins/mentions/plugin.js","/plugin/editors/tinymce/plugins/mentions/langs/en.js","/html/js/lib/tinymce/4.7.13/plugins/noneditable/plugin.js","/plugin/editors/tinymce/plugins/emoticons/plugin.js","/plugin/editors/tinymce/plugins/emoticons/langs/en.js","/plugin/editors/tinymce/plugins/spellchecker/plugin.js"],"isOoyalaVideoEnabled":false,"isInlineLinkEditingEnabled":true,"optionsParam":"messageMentionTemplate":"#title","spellcheckerUrl":"/spellchecker/lucene","useUserMentions":true,"toolbarSelector":".mce-toolbar-grp","useProductMentions":false,"mediaUploadOptions":"attachmentOverlayText":"Drop your files here","createVideoLink":" _0.form.messageeditor.tinymceeditor:createvideo?t:ac=board-id/audition/thread-id/22720","imageUploadSettings":"validImageExts":"*.jpg;*.JPG;*.jpeg;*.JPEG;*.gif;*.GIF;*.png;*.PNG","maxFileBytes":10264576,"maxImagesPerUpload":10,"editorOverlayText":"Drop your media files here","copyPasteSettings":"copyPasteEvent":"LITHIUM:liaCopyPasteImages","copyPasteBatchSize":3,"copyPasteCss":"lia-copypaste-placeholder","username":"Deleted User","videoImageTooltip":"\"Please wait while we upload and process your video. This may take a few minutes, so please check back later.\"","enableFormActionButtonsEvent":"LITHIUM:enableFormActionButtons","videoUploadingUrlsLink":" _0.form.messageeditor.tinymceeditor:videouploadingurls?t:ac=board-id/audition/thread-id/22720","isOverlayVisible":true,"videoEmbedThumbnail":"/i/skins/default/video-loading-new.gif","videoStatusUpdateLink":" _0.form.messageeditor.tinymceeditor:videostatusupdate?t:ac=board-id/audition/thread-id/22720","token":"qcV8t0Psky1Qlmgiuei4unb0qhTDcZITDYDLiWw8KdQ.","defaultAlbumId":1,"imageFormatFeedbackErrorContainer":".lia-file-error-msg","fileUploadSelector":".lia-file-upload","isCanUploadImages":false,"videoUploadSettings":"maxFileBytes":512000000,"validVideoExts":".wmv;.avi;.mov;.moov;.mpg;.mpeg;.m2t;.m2v;.vob;.flv;.mp4;.mpg4;.mkv;.asf;.m4v;.m2p;.3gp;.3g2;.f4v;.mp3;.m4a;.wma;.aac","disableFormActionButtonsEvent":"LITHIUM:disableFormActionButtons","isOoyalaVideoEnabled":false,"videoEmbedSizes":"small":"width":200,"height":150,"original":"width":400,"height":300,"large":"width":600,"height":450,"medium":"width":400,"height":300,"isMobileDevice":false,"removeAllOverlays":"LITHIUM:removeAllOverlays","isCanUploadVideo":false,"passToAttachmentEvent":"LITHIUM:passToAttachment","imageUrlPattern":" -id//image-size/?v=v2&px=-1","useMessageMentions":false,"spellcheckerLangs":"English (US)=en,Spanish=es,Portuguese=pt,German=de,French=fr,Arabic=ar","mentionsVersion":"2","iframeTitle":"Body Rich Text Area. Press ALT-F10 for toolbar and Escape to return to the editor.","events":"editorPasteEvent":"LITHIUM:editorPaste","editorLoadedEvent":"LITHIUM:editorLoaded","useGraphicalEditor":true});LITHIUM.InformationBox("updateFeedbackEvent":"LITHIUM:updateAjaxFeedback","componentSelector":"#informationbox_10c5099008f674c_66","feedbackSelector":".InfoMessage");LITHIUM.Text.set("ajax.createUrlSnippet.loader.feedback.title":"Loading...");LITHIUM.AjaxSupport("ajaxOptionsParam":"useLoader":true,"event":"LITHIUM:createUrlSnippet","tokenId":"ajax","elementSelector":"#messagepresnippet_10c5099008f674c","action":"createUrlSnippet","feedbackSelector":"#messagepresnippet_10c5099008f674c","url":" _0.form.messageeditor.messagepresnippet:createurlsnippet?t:ac=board-id/audition/thread-id/22720","ajaxErrorEventName":"LITHIUM:ajaxError","token":"8BfY5N8Jx7nuvwrjLSN5Q45NaLzonFiZJ7Wjqt5o-9k.");LITHIUM.MessagePreSnippet("pasteEvent":"LITHIUM:editorPaste","maxUrlListSize":10,"snippetExistsTextClass":"lia-media-snippet-preview-exists","tinyMceSelector":"#messageEditor_10c5099008f674c_0","messageSnippetEvent":"LITHIUM:createUrlSnippet","elementSelector":"#messagepresnippet_10c5099008f674c","snippetUpdateEvent":"LITHIUM:updateUrlSnippet","urlFormFieldSelector":".lia-form-media-snippet-url-input","snippetCloseEvent":"LITHIUM:closeUrlSnippet");LITHIUM.BlockEvents('.lia-js-block-events', [".lia-spoiler-link",".oo-icon",".oo-volume-bar",".oo-close-button"], '.message-preview');LITHIUM.KeepSessionAlive("/t5/status/blankpage?keepalive", 300000);new LITHIUM.MessageEditor("previewButtonSelector":"#previewButton_10c5099008f674c","defaultTabSelector":".rich-link","defaultTabName":"rich","usesInlinePreview":true,"formHasErrorsEvent":"LITHIUM:formHasErrors","exitPreviewButtonSelector":"#exitPreviewButton_10c5099008f674c","isTabsPresent":false,"ajaxCompleteEvent":"LITHIUM:ajaxComplete","isGteEditorV2":true,"previewSubmitElementSelector":"#submitContext_10c5099008f674c","tinyMceElementSelector":"#tinyMceEditor_10c5099008f674c","elementSelector":"#messageEditor_10c5099008f674c_0","macroChangeEvent":"LITHIUM:change-macro","preExitPreviewEvent":"LITHIUM:refreshAttachments");LITHIUM.MessageEditor.MessageQuote("#messageQuote_10c5099008f674c", "#tinyMceEditor_10c5099008f674c", " wrote:<br/>I'm using macOS High Sierra version 10.13.6Audition has been flawless and great up until a few days ago. Audtion no longer opens. No updates to my operating system have been made recently. Any help getting this setteld would be appreciated. Here's what pops up when I attempt to open Audition: \"Check with the developer to make sure Adobe Audition CS6 works with this version of macOS. You may need to reinstall the application. Be sure to install any available updates for the application and macOS. Click Report to see more detailed information and send a report to Apple.\" ", true);LITHIUM.FileDragDrop("urls":"uploadUrl":" _0.form.attachmentscomponent:uploadfileaction/attachments-key/057d3a2a-6cc1-4f86-bceb-092acfd37a63?t:ac=board-id/audition/thread-id/22720","selectors":"container":"#filedragdrop_10c5099008f674c","feedbackElement":"#dragDropFeedback .AjaxFeedback","cancelUploadProgress":"lia-remove-attachment-inprogress","fileUpload":"#filedragdrop_10c5099008f674c .lia-file-upload","events":"uploadDoneEvent":"LITHIUM:uploadDone","refreshAttachmentsEvent":"LITHIUM:refreshAttachments","formHasErrorsEvent":"LITHIUM:formHasErrors","misc":"actionTokenId":"uploadFile","fileDataParam":"Filedata","isEditorGteV2":true,"actionToken":"TWF9_U7oXDDOc2ofIn8AL46nUxYoM8jZgD015wLza9E.");LITHIUM.InformationBox("updateFeedbackEvent":"LITHIUM:updateAjaxFeedback","componentSelector":"#informationbox_10c5099008f674c_67","feedbackSelector":".InfoMessage");LITHIUM.AjaxSupport("ajaxOptionsParam":"event":"LITHIUM:refreshAttachments","parameters":"clientId":"inlinemessagereplyeditor_0_10c5099008f674c","attachmentKey":"057d3a2a-6cc1-4f86-bceb-092acfd37a63","tokenId":"ajax","elementSelector":"#inlinemessagereplyeditor_0_10c5099008f674c","action":"refreshAttachments","feedbackSelector":"#attachmentsComponent_10c5099008f674c","url":" _0.form.attachmentscomponent:refreshattachments?t:ac=board-id/audition/thread-id/22720","ajaxErrorEventName":"LITHIUM:ajaxError","token":"UXbTbRTRvO39Rzzl6HeO2rpJ4eE3-O9uPMCwtikpd5c.");LITHIUM.AjaxSupport("ajaxOptionsParam":"event":"LITHIUM:removeNewAttachment","parameters":"clientId":"inlinemessagereplyeditor_0_10c5099008f674c","attachmentKey":"057d3a2a-6cc1-4f86-bceb-092acfd37a63","tokenId":"ajax","elementSelector":"#inlinemessagereplyeditor_0_10c5099008f674c .lia-file-upload","action":"removeNewAttachment","feedbackSelector":"#attachmentsComponent_10c5099008f674c","url":" _0.form.attachmentscomponent:removenewattachment?t:ac=board-id/audition/thread-id/22720","ajaxErrorEventName":"LITHIUM:ajaxError","token":"rkr7nNKPdmoafsZRojo7u6-8CiZ7QnKk4rV7MySXsWE.");LITHIUM.AjaxSupport("ajaxOptionsParam":"event":"LITHIUM:removePreviewAttachment","parameters":"clientId":"inlinemessagereplyeditor_0_10c5099008f674c","attachmentKey":"057d3a2a-6cc1-4f86-bceb-092acfd37a63","tokenId":"ajax","elementSelector":"#inlinemessagereplyeditor_0_10c5099008f674c .lia-file-upload","action":"removePreviewAttachment","feedbackSelector":"#attachmentsComponent_10c5099008f674c","url":" _0.form.attachmentscomponent:removepreviewattachment?t:ac=board-id/audition/thread-id/22720","ajaxErrorEventName":"LITHIUM:ajaxError","token":"MRrvJxxCCoW-v5JMHrb-cZ2gUqCOTR7XGf-GdIvZPyc.");LITHIUM.AjaxSupport("ajaxOptionsParam":"event":"LITHIUM:removeExistingAttachment","parameters":"clientId":"inlinemessagereplyeditor_0_10c5099008f674c","attachmentKey":"057d3a2a-6cc1-4f86-bceb-092acfd37a63","tokenId":"ajax","elementSelector":"#inlinemessagereplyeditor_0_10c5099008f674c .lia-file-upload","action":"removeExistingAttachment","feedbackSelector":"#attachmentsComponent_10c5099008f674c","url":" _0.form.attachmentscomponent:removeexistingattachment?t:ac=board-id/audition/thread-id/22720","ajaxErrorEventName":"LITHIUM:ajaxError","token":"kyhOoylozoaBHi5-92UAme6Pl0iDbAFubCfOzezb55k.");LITHIUM.AjaxSupport("ajaxOptionsParam":"event":"LITHIUM:removeInProgressNewAttachment","parameters":"clientId":"inlinemessagereplyeditor_0_10c5099008f674c","attachmentKey":"057d3a2a-6cc1-4f86-bceb-092acfd37a63","tokenId":"ajax","elementSelector":"#inlinemessagereplyeditor_0_10c5099008f674c .lia-file-upload","action":"removeInProgressNewAttachment","feedbackSelector":"#attachmentsComponent_10c5099008f674c","url":" _0.form.attachmentscomponent:removeinprogressnewattachment?t:ac=board-id/audition/thread-id/22720","ajaxErrorEventName":"LITHIUM:ajaxError","token":"WhKxoXkAs9GQl0Q4IMOFDsvg_0SFwox0IL_vJIfU6xE.");LITHIUM.DragDropAttachmentsComponent("fileSizeErrorText":"The file () exceeds the maximum file size. The maximum file size is 47 MB.","validExts":"8bf, abf, abr, act, aep, afm, ai, arw, as, ase, avi, bmp, book, cel, cfc, chproj, cptx, cr2, cr3, crf, crw, css, csv, dn, dng, doc, docx, eps, epub, exif, fbx, fla, flac, flv, fm, gif, icma, icml, ico, ics, idml, indd, jpeg, jpg, jsfl, json, log, loss, lrcat, lrtemplate, m4a, mif, mov, mp3, mp4, mpg, nef, nrw, obj, odt, orf, otc, otf, pdf, pfb, pfm, pmd, png, ppj, ppt, pptx, prc, prel, prproj, ps, psb, psd, raf, raw, rtf, sbs, sbsar, sbsm, scc, ses, sesx, skp, sol, srt, srw, ssa, stl, svg, swf, tif, ttc, ttf, txt, wav, wmv, x3f, xd, xls, xlsx, xml, xmp","dropZoneSelector":"#inlinemessagereplyeditor_0_10c5099008f674c .lia-attachments-drop-zone","uploadingText":"Uploading...","changeNumAttachmentsEvent":"LITHIUM:changeNumAttachments","storageUnitKB":"KB","currAttachments":0,"removeNewAttachmentSelector":"#inlinemessagereplyeditor_0_10c5099008f674c .lia-remove-attachment","removeInProgressNewAttachment":"LITHIUM:removeInProgressNewAttachment","elementSelector":"#inlinemessagereplyeditor_0_10c5099008f674c","maxAttachments":10,"removeAllOverlays":"LITHIUM:removeAllOverlays","inProgressAttachmentsContainerSelector":"#inlinemessagereplyeditor_0_10c5099008f674c .lia-in-progress-attachments","removeExistingAttachmentEvent":"LITHIUM:removeExistingAttachment","inputFieldSelector":".lia-form-type-file.lia-form-type-file-hidden","dropFilesHereText":"attachments.overlay.text","enableFormActionButtonsEvent":"LITHIUM:enableFormActionButtons","maxFileSize":50000000,"tooManyAttachmentsMsg":"The maximum number of attachments has been reached. Maximum number of attachments allowed is: 10","attachmentErrorSelector":"#inlinemessagereplyeditor_0_10c5099008f674c .lia-file-error-msg","cancelAttachmentProgressCss":"lia-remove-attachment-inprogress","fileUploadSelector":"#inlinemessagereplyeditor_0_10c5099008f674c .lia-file-upload","newAttachmentSelector":"#inlinemessagereplyeditor_0_10c5099008f674c .lia-new-attachment","attachmentsTooManyErrorSelector":"#inlinemessagereplyeditor_0_10c5099008f674c .lia-attachment-upload-error-many","fileTypeErrorText":"The file type () is not supported. Valid file types are: 8bf, abf, abr, act, aep, afm, ai, arw, as, ase, avi, bmp, book, cel, cfc, chproj, cptx, cr2, cr3, crf, crw, css, csv, dn, dng, doc, docx, eps, epub, exif, fbx, fla, flac, flv, fm, gif, icma, icml, ico, ics, idml, indd, jpeg, jpg, jsfl, json, log, loss, lrcat, lrtemplate, m4a, mif, mov, mp3, mp4, mpg, nef, nrw, obj, odt, orf, otc, otf, pdf, pfb, pfm, pmd, png, ppj, ppt, pptx, prc, prel, prproj, ps, psb, psd, raf, raw, rtf, sbs, sbsar, sbsm, scc, ses, sesx, skp, sol, srt, srw, ssa, stl, svg, swf, tif, ttc, ttf, txt, wav, wmv, x3f, xd, xls, xlsx, xml, xmp.","uploadDoneEvent":"LITHIUM:uploadDone","disableFormActionButtonsEvent":"LITHIUM:disableFormActionButtons","inProgressAttachmentSelector":".lia-in-progress-attachment","removePreviewAttachmentEvent":"LITHIUM:removePreviewAttachment","removeNewAttachmentEvent":"LITHIUM:removeNewAttachment","passToAttachmentEvent":"LITHIUM:passToAttachment");LITHIUM.InformationBox("updateFeedbackEvent":"LITHIUM:updateAjaxFeedback","componentSelector":"#informationbox_10c5099008f674c_68","feedbackSelector":".InfoMessage");LITHIUM.Form.resetFieldForFocusFound();LITHIUM.Text.set("ajax.InlineMessageReply.loader.feedback.title":"Loading...");LITHIUM.AjaxSupport.fromForm('#form_10c5099008f674c', 'InlineMessageReply', '#ajaxFeedback_10c5099008f674c_0', 'LITHIUM:ajaxError', "useLoader":false,"ignoreFormActions":["Cancel","SaveDraft"],"event":"submit","httpMethod":"POST", false);LITHIUM.InputEditForm("form_10c5099008f674c", "submitButton":".lia-button-Submit-action","enableFormButtonEvent":"LITHIUM:enableFormButton","warnUnsavedDataActionCssClasses":["lia-form-action-ignore-unsaved-data","lia-button-Cancel-action"],"useUnsavedDataWarning":true,"ignoreDisableFormDuringSubmitCssClasses":[],"submitOnChange":false,"swallowEnterEvent":true,"enableFormEvent":"LITHIUM:enableForm","disableFormButtonEvent":"LITHIUM:disableFormButton","disableFormEvent":"LITHIUM:disableForm","unloadMessage":"Unsaved information will be lost.","ignoreOnChangeCssClasses":[],"disableFormOnSubmit":true,"buttonWrapperSelector":".lia-button-wrapper","showUnsavedDataWarningDataKey":"showUnsavedDataWarning","liaBodyTagId":"#lia-body");LITHIUM.AjaxSupport("ajaxOptionsParam":"event":"LITHIUM:autosaveInline","parameters":"clientId":"inlinemessagereplyeditor_0_10c5099008f674c","tokenId":"ajax","elementSelector":"#form_10c5099008f674c","action":"autosaveInline","feedbackSelector":"#form_10c5099008f674c","url":" _0.form:autosaveinline?t:ac=board-id/audition/thread-id/22720","ajaxErrorEventName":"LITHIUM:ajaxError","token":"96m54MeXqNpFLAv5F_tLpugHULNUZU7eKk6m5g2yEYU.");LITHIUM.InlineMessageReplyEditor("openEditsSelector":".lia-inline-message-edit","ajaxFeebackSelector":"#inlinemessagereplyeditor_0_10c5099008f674c .lia-inline-ajax-feedback","collapseEvent":"LITHIUM:collapseInlineMessageEditor","confimationText":"You have other message editors open and your data inside of them might be lost. Are you sure you want to proceed?","topicMessageSelector":".lia-forum-topic-message-gte-5","focusEditor":false,"hidePlaceholderShowFormEvent":"LITHIUM:hidePlaceholderShowForm","formWrapperSelector":"#inlinemessagereplyeditor_0_10c5099008f674c .lia-form-wrapper","reRenderInlineEditorEvent":"LITHIUM:reRenderInlineEditor","ajaxBeforeSendEvent":"LITHIUM:ajaxBeforeSend:InlineMessageReply","element":"input","clientIdSelector":"#inlinemessagereplyeditor_0_10c5099008f674c","loadAutosaveAction":false,"newPostPlaceholderSelector":".lia-new-post-placeholder","placeholderWrapperSelector":"#inlinemessagereplyeditor_0_10c5099008f674c .lia-placeholder-wrapper","messageId":11125404,"formSelector":"#inlinemessagereplyeditor_0_10c5099008f674c","expandedClass":"lia-inline-message-reply-form-expanded","expandedRepliesSelector":".lia-inline-message-reply-form-expanded","newPostPlaceholderClass":"lia-new-post-placeholder","editorLoadedEvent":"LITHIUM:editorLoaded","replyEditorPlaceholderWrapperCssClass":"lia-placeholder-wrapper","messageActionsClass":"lia-message-actions","cancelButtonSelector":"#inlinemessagereplyeditor_0_10c5099008f674c .lia-button-Cancel-action","isGteForumV5":true,"messageViewWrapperSelector":".lia-threaded-detail-display-message-view","disabledReplyClass":"lia-inline-message-reply-disabled-reply");LITHIUM.Text.set("ajax.reRenderInlineEditor.loader.feedback.title":"Loading...");LITHIUM.AjaxSupport("ajaxOptionsParam":"useLoader":true,"blockUI":"","event":"LITHIUM:reRenderInlineEditor","parameters":"clientId":"inlinemessagereplyeditor_0_10c5099008f674c","tokenId":"ajax","elementSelector":"#inlinemessagereplyeditor_0_10c5099008f674c","action":"reRenderInlineEditor","feedbackSelector":"#inlinemessagereplyeditor_0_10c5099008f674c","url":" _0:rerenderinlineeditor?t:ac=board-id/audition/thread-id/22720","ajaxErrorEventName":"LITHIUM:ajaxError","token":"j14Op_M-1dg-Q9fnX_K2_w9M3QzfI0YNbVZkJ2TQiG8.");LITHIUM.InlineMessageEditor("ajaxFeebackSelector":"#inlinemessagereplyeditor_0_10c5099008f674c .lia-inline-ajax-feedback","submitButtonSelector":"#inlinemessagereplyeditor_0_10c5099008f674c .lia-button-Submit-action");LITHIUM.AjaxSupport("ajaxOptionsParam":"event":"LITHIUM:lazyLoadComponent","parameters":"componentId":"messages.widget.emoticons-lazy-load-runner","tokenId":"ajax","elementSelector":"#inlinemessagereplyeditor_0_10c5099008f674c","action":"lazyLoadComponent","feedbackSelector":false,"url":" _0:lazyloadcomponent?t:ac=board-id/audition/thread-id/22720","ajaxErrorEventName":"LITHIUM:ajaxError","token":"E2hCjyda3xvWSv3HmrFYEmFHX2flj0DJwPai7ZP30Lk.");LITHIUM.lazyLoadComponent("selectors":"elementSelector":"#inlinemessagereplyeditor_0_10c5099008f674c","events":"lazyLoadComponentEvent":"LITHIUM:lazyLoadComponent","misc":"isLazyLoadEnabled":true);;(function($)try const RESOURCE_LINK = 'Community: resourcesLinkClick'; const RESOURCE_EDIT = 'Community: resourcesEditClick'; const RESOURCE_ADD_GROUP = 'Community: resourcesAddGroupClick'; const RESOURCE_ADD_LINK = 'Community: resourcesAddLinkClick'; const RESOURCE_EDIT_GROUP = 'Community: resourcesEditGroup'; const RESOURCE_EDIT_LINK = 'Community: resourcesEditLink'; const RESOURCE_DELETE_GROUP = 'Community: resourcesDeleteGroup'; const RESOURCE_DELETE_LINK = 'Community: resourcesDeleteLink'; if($('.resources-container').length > 0) $('.links-list-item-title-url-container .list-link').on('click', function(e) trackResourceEvents(e.currentTarget,RESOURCE_LINK,true,true); ); $('.resources-header-edit-icon').on('click',function(e) trackResourceEvents(null,RESOURCE_EDIT,false,false); ); $('.add-group-container').on('click',function(e) trackResourceEvents(null,RESOURCE_ADD_GROUP,false,false); ); $(document).on('click', '.group-form .add-link', function(e) trackResourceEvents(null,RESOURCE_ADD_LINK,false,false); ); $(document).on('click', '.group-list-item .group-edit-button', function(e) trackResourceEvents(e.currentTarget,RESOURCE_EDIT_GROUP,true,false); ); $(document).on('click', '.group-list-item .group-delete-button', function(e) trackResourceEvents(e.currentTarget,RESOURCE_DELETE_GROUP,true,false); ); $(document).on('click', '.saved-link__edit', function(e) trackResourceEvents(e.currentTarget,RESOURCE_EDIT_LINK,true,true); ); $(document).on('click', '.saved-link__delete', function(e) trackResourceEvents(e.currentTarget,RESOURCE_DELETE_LINK,true,true); ); catch(ex) console.log(ex); )(LITHIUM.jQuery); ;(function($)tryconst CC_LINKS_TYPE= '0': 'GetAppsBanner', '1': 'GetApps', '2': 'InstallTheApp', '3': 'LaunchTheExperience', '4': 'ManageAccount'; const CONVERSATION_FLAG_TYPE= '-1': '', '0': 'Top Reply', '1': 'Correct Answer', '2': 'Featured', '3': 'Announcement', '4': 'Pinned Reply'; const PAGE_NAME='digitalData.page.pageInfo.pageName';const LANGUAGE='digitalData.page.pageInfo.language';const SITE_SECTION='digitalData.page.pageInfo.siteSection';const COMMUNITY_CATEGORY='digitalData.community.communityInfo.communityCategory';const COMMUNITY_ID='digitalData.community.communityInfo.communityId';const COMMUNITY_TITLE='digitalData.community.communityInfo.communityTitle'; const CONVERSATION_PAGE='Community: conversationPage';//evar203 mapped variablesconst CARD_CREATED_DATE='digitalData.community.communityAttributes.cardCreatedDate';const COUNT_CORRECT_ANSWER='digitalData.community.communityAttributes.countCorrectAnswer';const COMMUNITY_FLAG='digitalData.community.communityInfo.communityFlag'; const COUNT_REPLY='digitalData.community.communityAttributes.countReply'; const RELATED_CONVERSATION_ACTION='relatedConversationClick';const COMMUNITY_DD_PROPERTY='digitalData.community';const CONVERSATION_REPORT='Community: conversationReportClick';const REPLY_REPORT='Community: repliesReportClick';const MARKED_CORRECT='Community: Marked as Correct';const UNMARKED_CORRECT='Community: UnMarked as Correct';const REPLY_MARKED_CORRECT='replyMarkedCorrect';const REPLY_UNMARKED_CORRECT='replyUnmarkedCorrect';const CONVERSATION_FOLLOW='Community: conversationFollowClick';const REPLY_FOLLOW='Community: repliesFollowClick';const CONVERSATION_UNFOLLOW='Community: conversationUnfollowClick';const REPLY_UNFOLLOW='Community: repliesUnfollowClick';const SOPHIA_EVENTS = 'digitalData.sophiaResponse.fromPage';const CC_LINK1 = 'Community: CCD_';const CC_LINK2 = 'Click';const CC_LINK_CLICK = 'ccdLinkClick';const CC_MANAGE_ACCOUNT_CLICK = 'manageAccountLinkClick'; const REC_CONVO_FEEDBACK_SHOWN='digitalData.community.communityAttributes.recConvoFeedbackShown';const CONVERSATION_EDIT='Community: conversationEditClick';const CONVERSATION_VIEW_HISTORY='Community: conversationViewHistoryClick';const CONVERSATION_MOVE_MERGE='Community: conversationMoveMergeClick';const CONVERSATION_SPAM='Community: conversationSpamClick';const CONVERSATION_DELETE='Community: conversationDeleteClick';const CONVERSATION_BAN_USER='Community: conversationBanUserClick';const REPLY_BAN_USER='Community: repliesBanUserClick';const REPLY_SPAM='Community: repliesSpamClick';const REPLY_DELETE='Community: repliesDeleteClick';const REPLY_MOVE_MERGE='Community: repliesMoveMergeClick';const REPLY_VIEW_HISTORY='Community: repliesViewHistoryClick';const REPLY_EDIT='Community: repliesEditClick';const REPLIES_IN_RESPONSE_TO ='Community: repliesInResponseToClick';$.when(promise1).done( function () userProfilePromise.then(trackConversationPageLoad);); function trackConversationPageLoad() //Conversation Page Load Tracking const subject = $('.userStrip').attr('data-message-subject');let messageUid = '11125404';const tempDD = digitalData; let boardId = normalizeBoardId('audition'); let community = normalizeCategoryBoardId(); let contentType = getBoardType(boardId); //track new post success trackNewPostSuccess(community, subject, messageUid); //track merge message success trackMergeSuccess(subject,community,'11125404',contentType); //recover digital data property digitalData = tempDD; const valArr = location.pathname.split('/'); let pageName; let layoutView = 'threaded'; if('ForumTopicPage' === 'IdeaPage') layoutView = 'linear'; //Ideas do not support threaded view so it will always be linear let sortOrder = 'by_date_ascending'=="by_date_ascending"?"Earliest":"Latest"; if(PAGE_LANG!=='en') pageName = location.hostname + ':t5:' + boardId + ':' + 'conversationPage'; else if(valArr && valArr.length > 2) pageName = location.hostname + ':' + valArr[1] + ':' + community + ':' + 'conversationPage'; if(pageName) setDigitalDataProperty(PAGE_NAME, pageName); if(messageUid) setDigitalDataProperty(COMMUNITY_ID, messageUid); setDigitalDataProperty(LANGUAGE, getLocale()); setDigitalDataProperty(SITE_SECTION, CONVERSATION_PAGE); setPrimaryEvent(CONVERSATION_PAGE, 'pageload');let replyCount = 0;if($('.reply-count__text').length > 0) replyCount = $('.reply-count__text').attr('data-reply-count'); let status = ''; let voteCount = 0; if($('.message-status-link').length > 0) status = $('.message-status-link')[0].innerText; if($('#messageKudosCount_').length > 0) voteCount = $('#messageKudosCount_')[0].getAttribute('data-upvote-count'); const correctAnswerCount = $('.correct-answer-div').attr('data-correct-answer-count'); const creationDate = $('.roleTimestamp').attr('data-post-time'); setDigitalDataProperty(CARD_CREATED_DATE, creationDate); //setDigitalDataProperty(COUNT_REPLY, replyCount?replyCount:'0'); setDigitalDataProperty(COUNT_CORRECT_ANSWER, correctAnswerCount?correctAnswerCount:'0'); setDigitalDataProperty(COMMUNITY_CONTENT_TYPE, contentType); setDigitalDataProperty(COMMUNITY_CATEGORY, community); setDigitalDataProperty(COMMUNITY_TITLE, subject); let solnType = $('.conversation-page-container').attr('data-solution-type'); if(parseInt(solnType) 0) solnType = '1'; else if($('#special-reply-pinned').length > 0) solnType = '4'; solnType = CONVERSATION_FLAG_TYPE[solnType]; let flag = solnType; if($('.body-outer-container').attr('data-pin-flag') === "true") if(flag != '') flag = flag + ';Pinned'; else flag = 'Pinned'; if(flag != '') setDigitalDataProperty(COMMUNITY_FLAG, flag); if(document.getElementById('feedback_view_1')) setDigitalDataProperty(REC_CONVO_FEEDBACK_SHOWN, 'true'); dnmsTrackConversationFeedback('render', 'feedback-answer', [messageUid, community, null, 'radio button']); setDigitalDataProperty(FILTERS, [createGPSortInfoObj(sortOrder)]); setDigitalDataProperty(SOPHIA_EVENTS,['CampaignId': relatedConvCampaignId, 'ControlGroupId': relatedConvControlGroupId, 'VariationId': relatedConvVariationId, 'ActionBlockId': relatedConvActionBlockId, 'CampaignId': manageAccountCampaignId, 'ControlGroupId': manageAccountControlGroupId, 'VariationId': manageAccountVariationId, 'ActionBlockId': manageAccountActionBlockId]); captureSnapshot('state'); //dunamis api call dnmsConversationPageRender(community, replyCount, subject, getCommunityCurrentPageNum(), getConversationTags().toString(), messageUid, layoutView, flag, status, voteCount); cleanDigitalDataProperties([SOPHIA_EVENTS]); if ($('.promos-wrapper').length > 0) let promotype = $('.promos-wrapper').attr('data-promotype'); let promosubtype = $('.promos-wrapper').attr('data-promosubtype'); dnmsPromoRender(promotype, promosubtype, community, messageUid); //Track related conversation clickdetectRelatedConversationsLoad(); //track status update success if(localStorage.hasOwnProperty('messageStatusUpdate')) trackStatusUpdateSuccess(); //Track reply post success trackReplyPostSuccess(); let lsCleanUpArr = ['gpEditMessageType', 'gpEditMessagePageNum', 'gpReportMessageDetails', 'gpReportMessageType'];clearStorage(lsCleanUpArr);cleanDigitalDataProperties(['digitalData.primaryEvent.eventInfo', FILTERS]); function getPayload(params) var sophiaPayload = []; try params = params.split("&"); var keyMapping = 'aid':'ActionBlockId','campid':'CampaignId', 'cid':'ContainerId','cgid':'ControlGroupId','tid':'TreatmentId','vid':'VariationId','sid':'SurfaceId'; var sophiaMap = ; for(let i=0;i 1 && (keys[0] in keyMapping)) sophiaMap[keyMapping[keys[0]]] = keys[1]; sophiaPayload.push(sophiaMap); catch(err) console.log(err); return sophiaPayload;function trackNewPostSuccess(communityName, subject, messageUid) const npsDD = localStorage.getItem('npsDigitalData'); if(npsDD) const ddVal = JSON.parse(npsDD);if(subject === ddVal.community.communityInfo.communityTitle) digitalData = ddVal; setDigitalDataProperty(COMMUNITY_ID, messageUid); dnmsNewPostSuccess(communityName, subject, messageUid, JSON.parse(npsDD).sophiaResponse); captureSnapshot('event'); cleanDigitalDataProperties([SOPHIA_EVENTS]); localStorage.removeItem('npsDigitalData');function trackMergeSuccess(subject,community,messageId,contentType) try const mergeMsgDD = localStorage.getItem('mergeMsgDigitalData'); if(mergeMsgDD) const ddVal = JSON.parse(mergeMsgDD); if(messageId === ddVal.community.communityInfo.communityId) digitalData = ddVal; setDigitalDataProperty(COMMUNITY_CATEGORY, community); setDigitalDataProperty('digitalData.community.communityInfo.communityContentTab', contentType); setDigitalDataProperty(COMMUNITY_TITLE, subject); captureSnapshot('event'); let cnvrstnIds = []; let slctdCnvrstnArr = ddVal.community.attributes.selectedConversations; for(let i=0;i 4) let triggerBy = moveMergeTriggerDetails[0]; let cName = community; // merged to which community if(cName !== moveMergeTriggerDetails[1])' + moveMergeTriggerDetails[1]; // merged to which community let cId = messageId; let cType = moveMergeTriggerDetails[3]; //merged from which community type let msgType = moveMergeTriggerDetails[4]; let replyType = msgType!=='originalPost'?msgType:null; let xArr = [cName, cId, cType, messageId+' localStorage.removeItem('mergeMsgDigitalData'); catch(err) console.log(err); function clearStorage(items) for(let x=0; x 0) $('.related-conversations-card').on('click', function(e) if(e.target.hasAttribute('data-related-content-type')) //section tab click events let destinationTab = e.target.getAttribute('data-related-content-type'); dnmsCPSectionTabClick(getDigitalDataProperty(COMMUNITY_CATEGORY), 'related conversation', destinationTab); setPrimaryEvent('Community: relatedConversationLabelClick', SECTION_TAB_ACTION); setDigitalDataProperty(COMMUNITY_CONTENT_TYPE, destinationTab); captureSnapshot('event'); else let subject = e.target.getAttribute('data-related-conversation-subject'); let boardId = e.target.getAttribute('data-related-conversation-board'); let relatedCommContentType = getBoardType(boardId); let community = normalizeCategoryBoardId(); let target_href = e.target.href; let convo_id = e.target.getAttribute('data-related-conversation-id'); let org_convo_id = getDigitalDataProperty(COMMUNITY_ID); dnmsRelatedConversationsClick(community, target_href, org_convo_id, convo_id, "", subject, relatedConvCampaignId, relatedConvControlGroupId, relatedConvVariationId, relatedCommContentType); setPrimaryEvent(RELATED_CONVERSATION_CLICK, RELATED_CONVERSATION_ACTION); cleanDigitalDataProperties([COMMUNITY_DD_PROPERTY]); setDigitalDataProperty(COMMUNITY_CATEGORY, community); setDigitalDataProperty(COMMUNITY_CONTENT_TYPE,relatedCommContentType); setDigitalDataProperty(COMMUNITY_ID, convo_id); setDigitalDataProperty(COMMUNITY_TITLE, subject); setDigitalDataProperty(SOPHIA_EVENTS,['CampaignId': relatedConvCampaignId, 'ControlGroupId': relatedConvControlGroupId, 'VariationId': relatedConvVariationId, 'ActionBlockId': relatedConvActionBlockId]); captureSnapshot('event'); cleanDigitalDataProperties([SOPHIA_EVENTS]); ); //Track actions on conversation and repliesif($('.lia-quilt-column-main_content').length > 0) $('.lia-quilt-column-main_content').on('click', function(e) let targetElement = $(e.target); //Track Report if(targetElement.hasClass('report__text')) trackReportClick(targetElement); //Track mark correct answer if(targetElement.hasClass('lia-component-solutions-action-mark-message-as-accepted-solution')) trackMarkUnmarkCorrectAnswer('mark correct answer', targetElement); //Track Unmark correct answer if(targetElement.hasClass('lia-component-solutions-action-unmark-message-as-accepted-solution')) trackMarkUnmarkCorrectAnswer('unmark correct answer', targetElement); //Track view history click if(targetElement.hasClass('view-message-history')) trackViewHistoryClick(targetElement); //Track move merge click if(targetElement.hasClass('move-message')) trackMoveMergeClick(targetElement); if(getDigitalDataProperty(COMMUNITY_CONTENT_TYPE) !== 'Discussion' ) let authorId = $(targetElement).closest('.MessageView').find('.userStrip__link').attr('data-user-id'); if(authorId.length > 0) localStorage.setItem("mergeAuthor", authorId); //Track delete conversation/reply click if(targetElement.hasClass('delete-message-and-replies') );//Track edit message clickif($('.edit-message').length > 0) $('.edit-message').on('click', function(e) trackEditMessageClick($(e.target)); );//Track mark spam clickif($('.lia-component-spam-action-mark-message-as-spam').length > 0) $('.lia-component-spam-action-mark-message-as-spam').on('click', function(e) trackMarkSpamClick($(e.target)); ); //Track conversation page CC clicksvar ccElements = document.querySelectorAll(".cc-links-cta-container__anchor, .cc-links-banner-p2 a button");for (let i = 0; i < ccElements.length; i++) if($(ccElements[i]).length) $(ccElements[i]).on('click', function(e) let ccType = e.currentTarget.getAttribute('data-type'); let ccurl = e.currentTarget.getAttribute('href'); if(ccType && CC_LINKS_TYPE[ccType]) if (ccType == '4') let primaryEvent = "Community: ManageAccountBtn_Click"; setPrimaryEvent(primaryEvent, CC_MANAGE_ACCOUNT_CLICK); setDigitalDataProperty(SOPHIA_EVENTS,['CampaignId': manageAccountCampaignId, 'ControlGroupId': manageAccountControlGroupId, 'VariationId': manageAccountVariationId, 'ActionBlockId': manageAccountActionBlockId]); captureSnapshot('event'); cleanDigitalDataProperties([SOPHIA_EVENTS]); dnmsManageAccountEvent(getDigitalDataProperty(COMMUNITY_CATEGORY), ccurl, 'ManageAccount', 'click', 'Conversation', manageAccountCampaignId, manageAccountVariationId, manageAccountControlGroupId); else let primaryEvent = CC_LINK1+CC_LINKS_TYPE[ccType]+CC_LINK2; setPrimaryEvent(primaryEvent, CC_LINK_CLICK); captureSnapshot('event'); dnmsCCLinkClick(getDigitalDataProperty(COMMUNITY_CATEGORY), ccurl, CC_LINKS_TYPE[ccType], 'Conversation'); ); function trackFollowUnfollowClick(tElement, action) let isFollowAction = action==='follow'; if(tElement.closest('.lia-thread-topic').length > 0) setPrimaryEvent(isFollowAction?CONVERSATION_FOLLOW:CONVERSATION_UNFOLLOW, CONVERSATION_ACTION); //dunamis api call dnmsConversationActionsClick(action, getConversationPageDetails()); else setPrimaryEvent(isFollowAction?REPLY_FOLLOW:REPLY_UNFOLLOW, REPLY_ACTION); let replyType = getReplyType(tElement); if(replyType) dnmsConversationReplyActionsClick(action, replyType, getConversationPageDetails()); cleanDigitalDataProperties([COMMUNITY_ATTRIBUTES]); captureSnapshot('event');function trackBanUserClick(tElement) if(tElement.closest('.lia-thread-topic').length > 0) setPrimaryEvent(CONVERSATION_BAN_USER, CONVERSATION_ACTION); //dunamis api call dnmsConversationActionsClick('ban user', getConversationPageDetails()); else let replyType = getReplyType(tElement); if(replyType) dnmsConversationReplyActionsClick('ban user', replyType, getConversationPageDetails()); setPrimaryEvent(REPLY_BAN_USER, REPLY_ACTION); cleanDigitalDataProperties([COMMUNITY_ATTRIBUTES]); captureSnapshot('event');function trackMarkSpamClick(tElement) if(tElement.closest('.lia-thread-topic').length > 0) setPrimaryEvent(CONVERSATION_SPAM, CONVERSATION_ACTION); //dunamis api call let convArray = getConversationPageDetails(); dnmsConversationActionsClick('mark as spam', convArray); if(convArray.length > 1) syncDataOnS3('Spam', convArray[1]); else let replyType = getReplyType(tElement); if(replyType) dnmsConversationReplyActionsClick('mark as spam', replyType, getConversationPageDetails()); setPrimaryEvent(REPLY_SPAM, REPLY_ACTION); cleanDigitalDataProperties([COMMUNITY_ATTRIBUTES]); captureSnapshot('event');function trackDeleteMessageClick(tElement) if(tElement.closest('.lia-thread-topic').length > 0) setPrimaryEvent(CONVERSATION_DELETE, CONVERSATION_ACTION); //dunamis api call dnmsConversationActionsClick('delete the conversation', getConversationPageDetails()); localStorage.setItem('moveMergeDeletetriggeredBy','conversationPage:originalPost'+':'+getConversationPageDetails().toString()+':'+getDigitalDataProperty(COMMUNITY_CONTENT_TYPE)); else let replyType = getReplyType(tElement); if(replyType) dnmsConversationReplyActionsClick('delete the reply', replyType, getConversationPageDetails()); localStorage.setItem('moveMergeDeletetriggeredBy','conversationPage:'+replyType+':'+getConversationPageDetails().toString()+':'+getDigitalDataProperty(COMMUNITY_CONTENT_TYPE)); setPrimaryEvent(REPLY_DELETE, REPLY_ACTION); cleanDigitalDataProperties([COMMUNITY_ATTRIBUTES]); captureSnapshot('event');function trackMoveMergeClick(tElement) localStorage.setItem("movingConversationId", getDigitalDataProperty(COMMUNITY_ID)); if(tElement.closest('.lia-thread-topic').length > 0) setPrimaryEvent(CONVERSATION_MOVE_MERGE, CONVERSATION_ACTION); //dunamis api call dnmsConversationActionsClick('move/merge the conversation', getConversationPageDetails()); localStorage.setItem('moveMergeDeletetriggeredBy','conversationPage:originalPost'+':'+getConversationPageDetails().toString()+':'+getDigitalDataProperty(COMMUNITY_CONTENT_TYPE)); else let replyType = getReplyType(tElement); if(replyType) dnmsConversationReplyActionsClick('move/merge the conversation', replyType, getConversationPageDetails()); localStorage.setItem('moveMergeDeletetriggeredBy','conversationPage:'+replyType+':'+getConversationPageDetails().toString()+':'+getDigitalDataProperty(COMMUNITY_CONTENT_TYPE)); setPrimaryEvent(REPLY_MOVE_MERGE, REPLY_ACTION); cleanDigitalDataProperties([COMMUNITY_ATTRIBUTES]); captureSnapshot('event');function trackViewHistoryClick(tElement) if(tElement.closest('.lia-thread-topic').length > 0) setPrimaryEvent(CONVERSATION_VIEW_HISTORY, CONVERSATION_ACTION); //dunamis api call dnmsConversationActionsClick('view history', getConversationPageDetails()); else let replyType = getReplyType(tElement); if(replyType) dnmsConversationReplyActionsClick('view history', replyType, getConversationPageDetails()); setPrimaryEvent(REPLY_VIEW_HISTORY, REPLY_ACTION); cleanDigitalDataProperties([COMMUNITY_ATTRIBUTES]); captureSnapshot('event');function trackEditMessageClick(tElement) if(tElement.closest('.lia-thread-topic').length > 0) setPrimaryEvent(CONVERSATION_EDIT, CONVERSATION_ACTION); //dunamis api call dnmsConversationActionsClick('edit message', getConversationPageDetails()); localStorage.setItem('gpEditMessagePageNum', getCommunityCurrentPageNum()); else let replyType = getReplyType(tElement); if(replyType) localStorage.setItem('gpEditMessagePageNum', getCommunityCurrentPageNum()); dnmsConversationReplyActionsClick('edit message', replyType, getConversationPageDetails()); localStorage.setItem('gpEditMessageType', replyType); setPrimaryEvent(REPLY_EDIT, REPLY_ACTION); cleanDigitalDataProperties([COMMUNITY_ATTRIBUTES]); captureSnapshot('event');function trackReportClick(tElement) let tempConversationPageDetails = getConversationPageDetails(); tempConversationPageDetails[2] = encodeURIComponent(tempConversationPageDetails[2]); localStorage.setItem('gpReportMessageDetails', tempConversationPageDetails); if(tElement.closest('.lia-thread-topic').length > 0) setPrimaryEvent(CONVERSATION_REPORT, CONVERSATION_ACTION); //dunamis api call dnmsConversationActionsClick('report', getConversationPageDetails()); else let replyType = getReplyType(tElement); if(replyType) dnmsConversationReplyActionsClick('report', replyType, getConversationPageDetails()); localStorage.setItem('gpReportMessageType', replyType); setPrimaryEvent(REPLY_REPORT, REPLY_ACTION); cleanDigitalDataProperties([COMMUNITY_ATTRIBUTES]); captureSnapshot('event');function trackMarkUnmarkCorrectAnswer(action, tElement) let correctFlag = action==='mark correct answer'; setPrimaryEvent(correctFlag?MARKED_CORRECT:UNMARKED_CORRECT, correctFlag?REPLY_MARKED_CORRECT:REPLY_UNMARKED_CORRECT); cleanDigitalDataProperties([COMMUNITY_ATTRIBUTES]); convDetails = getConversationPageDetails(); if(correctFlag) convDetails = setSophiaPayload(convDetails); captureSnapshot('event'); let replyType = getReplyType(tElement); if(replyType) dnmsConversationReplyActionsClick(action, replyType, convDetails); cleanDigitalDataProperties([SOPHIA_EVENTS]);function detectRelatedConversationsLoad() { if($('.personalised-related-conversations').length > 0) let targetNode = $('.personalised-related-conversations')[0]; let config = childList: true ; let callback = function(mutationsList, observer) for(let i=0; i 0) status = $('.message-status-link')[0].innerText; dnmsConversationStatusUpdate('success',getConversationPageDetails(), comment, status); setPrimaryEvent('Community: StatusChanged'+status.replace(' ',''),'conversationStatusUpdated'); setDigitalDataProperty(PRIMARY_FILTER, createGPFilterInfoObj(status, 'statusChange')); captureSnapshot('event'); localStorage.removeItem('messageStatusUpdate'); cleanDigitalDataProperties([PRIMARY_FILTER, FILTERS]); catch(e) console.log(e); function isReplyBodyEmpty() { let result = false; let xNode;if($('.mce-edit-area').length > 0 && $('.mce-edit-area').children().length > 0) { let mceEditAreaiFrames = $('.mce-edit-area').children(); for(let i=0; i 0 && (content[0].hasAttribute('data-mce-bogus') || tinymce.innerHTML === '<br></p>
|
| 3 |
-
<h2>adobe audition 2.0 full crack 12</h2><br /><p><b><b>Download</b> ☆☆☆☆☆ <a href="https://imgfil.com/2uxZJy">https://imgfil.com/2uxZJy</a></b></p><br /><br /> aaccfb2cb3<br />
|
| 4 |
-
<br />
|
| 5 |
-
<br />
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/1gistliPinn/ChatGPT4/Examples/AutoCAD Electrical 2016 X64 (32X64bit) (Product Key And Xforce VERIFIED Keygen) Serial Key VERIFIED Keygen.md
DELETED
|
@@ -1,6 +0,0 @@
|
|
| 1 |
-
<h2>AutoCAD Electrical 2016 X64 (32X64bit) (Product Key And Xforce Keygen) Serial Key Keygen</h2><br /><p><b><b>Download File</b> ⇔ <a href="https://imgfil.com/2uxYem">https://imgfil.com/2uxYem</a></b></p><br /><br />
|
| 2 |
-
|
| 3 |
-
aaccfb2cb3<br />
|
| 4 |
-
<br />
|
| 5 |
-
<br />
|
| 6 |
-
<p></p>
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/1gistliPinn/ChatGPT4/Examples/Cambridge English Pronouncing Dictionary 17th Edition Download.rar ((NEW)).md
DELETED
|
@@ -1,6 +0,0 @@
|
|
| 1 |
-
<h2>Cambridge English Pronouncing Dictionary 17th Edition Download.rar</h2><br /><p><b><b>Download File</b> ––– <a href="https://imgfil.com/2uxX2G">https://imgfil.com/2uxX2G</a></b></p><br /><br />
|
| 2 |
-
<br />
|
| 3 |
-
7.0.29 crack download prodad adorage collection 2013 torrent AetherMD ... 2012 Models full model.rar Willey Studio Gabby Model Gallery 106 tested. ... Cambridge English Pronouncing Dictionary 17th Edition Download.rar 1fdad05405<br />
|
| 4 |
-
<br />
|
| 5 |
-
<br />
|
| 6 |
-
<p></p>
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/1gistliPinn/ChatGPT4/Examples/Descargar Pan Casero Iban Yarza Epub.md
DELETED
|
@@ -1,6 +0,0 @@
|
|
| 1 |
-
<h2>Descargar Pan Casero Iban Yarza Epub</h2><br /><p><b><b>Download File</b> 🗸🗸🗸 <a href="https://imgfil.com/2uy0ij">https://imgfil.com/2uy0ij</a></b></p><br /><br />
|
| 2 |
-
<br />
|
| 3 |
-
09-feb-2020 - DESCARGAR [PDF][EPUB] Pan Casero Larousse - Libros Ilustrados/ Prá por Ibán Yarza LEER EN LINEA [EBOOK KINDLE] - PDF EPUB Libro. 4d29de3e1b<br />
|
| 4 |
-
<br />
|
| 5 |
-
<br />
|
| 6 |
-
<p></p>
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/1pelhydcardo/ChatGPT-prompt-generator/assets/APKGame Explore the World of Android Gaming with Ease.md
DELETED
|
@@ -1,129 +0,0 @@
|
|
| 1 |
-
|
| 2 |
-
<h1>What is apkgame and why you should try it</h1>
|
| 3 |
-
<p>If you are an Android user, you might have heard of the term "apkgame" or seen some websites that offer free downloads of Android games in APK format. But what exactly is an apkgame and why should you try it? In this article, we will explain everything you need to know about apkgame, including what is an APK file, how to install it, what are the benefits and risks of using it, and what are some of the best apk games to play in 2023.</p>
|
| 4 |
-
<h2>What is an APK file and how to install it</h2>
|
| 5 |
-
<p>An APK file is a compressed package that contains all the files and data needed to run an Android app or game. APK stands for Android Package Kit, and it is the standard format used by Google Play Store to distribute apps and games. However, not all apps and games are available on Google Play Store, either because they are not approved by Google, they are region-locked, they are removed by the developer, or they are modified by third-party sources. In these cases, you can still download and install them from other websites that offer apk files, such as mob.org or apkpure.com.</p>
|
| 6 |
-
<h2>apkgame</h2><br /><p><b><b>Download Zip</b> ✺✺✺ <a href="https://urlin.us/2uSVMu">https://urlin.us/2uSVMu</a></b></p><br /><br />
|
| 7 |
-
<p>To install an apk file on your Android device, you need to follow these steps:</p>
|
| 8 |
-
<ol>
|
| 9 |
-
<li>Download the apk file from a trusted source and save it on your device.</li>
|
| 10 |
-
<li>Go to Settings > Security > Unknown Sources and enable the option to allow installation of apps from unknown sources.</li>
|
| 11 |
-
<li>Locate the apk file on your device using a file manager app and tap on it.</li>
|
| 12 |
-
<li>Follow the instructions on the screen to complete the installation.</li>
|
| 13 |
-
<li>Enjoy your new app or game!</li>
|
| 14 |
-
</ol>
|
| 15 |
-
<h3>Benefits of using APK files</h3>
|
| 16 |
-
<p>There are many benefits of using apk files to install apps and games on your Android device, such as:</p>
|
| 17 |
-
<ul>
|
| 18 |
-
<li>You can access apps and games that are not available on Google Play Store for various reasons.</li>
|
| 19 |
-
<li>You can get early access to beta versions or updates of apps and games before they are officially released.</li>
|
| 20 |
-
<li>You can download apps and games that are region-locked or restricted in your country.</li>
|
| 21 |
-
<li>You can install modified or hacked versions of apps and games that offer extra features or unlimited resources.</li>
|
| 22 |
-
<li>You can save bandwidth and storage space by downloading only the apk file instead of the whole app or game package.</li>
|
| 23 |
-
</ul>
|
| 24 |
-
<h3>Risks of using APK files</h3>
|
| 25 |
-
<p>However, there are also some risks of using apk files that you should be aware of, such as:</p>
|
| 26 |
-
<ul>
|
| 27 |
-
<li>You might download malicious or infected apk files that can harm your device or steal your personal data.</li>
|
| 28 |
-
<li>You might violate the terms and conditions of Google Play Store or the app or game developer by installing unauthorized or modified versions of apps and games.</li>
|
| 29 |
-
<li>You might encounter compatibility or performance issues with some apps and games that are not optimized for your device or Android version.</li>
|
| 30 |
-
<li>You might lose access to updates or support from the official app or game developer if you install apk files from third-party sources.</li>
|
| 31 |
-
</ul>
|
| 32 |
-
<h3>How to find and download APK games</h3>
|
| 33 |
-
<p>If you want to find and download apk games for your Android device, you need to do some research and be careful about the sources you choose. There are many websites that offer free downloads of apk games, but not all of them are safe or reliable. Some of them might contain malware, viruses, adware, spyware, or fake links that can harm your device or trick you into downloading unwanted apps or programs. Therefore, you should always check the reviews, ratings, comments, and feedback from other users before downloading any apk file <p>Here is the continuation of the article:</p>
|
| 34 |
-
<h2>Best APK games to play in 2023</h2>
|
| 35 |
-
<p>Now that you know what apk games are and how to install them, you might be wondering what are some of the best apk games to play in 2023. Well, there are plenty of options to choose from, depending on your preferences and tastes. Whether you like action, puzzle, simulation, or any other genre, you can find an apk game that suits you. Here are some of the best apk games to play in 2023, according to various sources .</p>
|
| 36 |
-
<h3>Action games</h3>
|
| 37 |
-
<p>If you are looking for some adrenaline-pumping action games, you can try these apk games:</p>
|
| 38 |
-
<p>apkgame download<br />
|
| 39 |
-
apkgame mod<br />
|
| 40 |
-
apkgame offline<br />
|
| 41 |
-
apkgame online<br />
|
| 42 |
-
apkgame free<br />
|
| 43 |
-
apkgame hack<br />
|
| 44 |
-
apkgame android<br />
|
| 45 |
-
apkgame action<br />
|
| 46 |
-
apkgame adventure<br />
|
| 47 |
-
apkgame arcade<br />
|
| 48 |
-
apkgame puzzle<br />
|
| 49 |
-
apkgame racing<br />
|
| 50 |
-
apkgame rpg<br />
|
| 51 |
-
apkgame simulation<br />
|
| 52 |
-
apkgame strategy<br />
|
| 53 |
-
apkgame horror<br />
|
| 54 |
-
apkgame shooter<br />
|
| 55 |
-
apkgame sports<br />
|
| 56 |
-
apkgame casual<br />
|
| 57 |
-
apkgame platformer<br />
|
| 58 |
-
apkgame multiplayer<br />
|
| 59 |
-
apkgame co-op<br />
|
| 60 |
-
apkgame sandbox<br />
|
| 61 |
-
apkgame survival<br />
|
| 62 |
-
apkgame open world<br />
|
| 63 |
-
apkgame role playing<br />
|
| 64 |
-
apkgame tower defense<br />
|
| 65 |
-
apkgame card<br />
|
| 66 |
-
apkgame board<br />
|
| 67 |
-
apkgame trivia<br />
|
| 68 |
-
apkgame word<br />
|
| 69 |
-
apkgame educational<br />
|
| 70 |
-
apkgame music<br />
|
| 71 |
-
apkgame casino<br />
|
| 72 |
-
apkgame match 3<br />
|
| 73 |
-
apkgame hidden object<br />
|
| 74 |
-
apkgame clicker<br />
|
| 75 |
-
apkgame idle<br />
|
| 76 |
-
apkgame tycoon<br />
|
| 77 |
-
apkgame management<br />
|
| 78 |
-
apkgame runner<br />
|
| 79 |
-
apkgame endless<br />
|
| 80 |
-
apkgame fighting<br />
|
| 81 |
-
apkgame stealth<br />
|
| 82 |
-
apkgame roguelike<br />
|
| 83 |
-
apkgame metroidvania<br />
|
| 84 |
-
apkgame point and click<br />
|
| 85 |
-
apkgame visual novel</p>
|
| 86 |
-
<h4>PUBG Mobile</h4>
|
| 87 |
-
<p>PUBG Mobile is one of the most popular and addictive battle royale games on Android. You can play solo or with your friends in various modes and maps, and fight against 99 other players to be the last one standing. You can customize your character, weapons, vehicles, and outfits, and enjoy realistic graphics and sound effects. PUBG Mobile is free to play, but it also offers in-app purchases for premium items and features.</p>
|
| 88 |
-
<h4>Genshin Impact</h4>
|
| 89 |
-
<p>Genshin Impact is a stunning open-world RPG game that lets you explore a vast and beautiful world full of secrets, quests, and enemies. You can play as one of the many characters with different abilities and elements, and switch between them during combat. You can also team up with other players online and take on challenging dungeons and bosses. Genshin Impact is free to play, but it also has a gacha system that lets you unlock more characters and items with real money.</p>
|
| 90 |
-
<h3>Puzzle games</h3>
|
| 91 |
-
<p>If you are looking for some brain-teasing puzzle games, you can try these apk games:</p>
|
| 92 |
-
<h4>Monument Valley 2</h4>
|
| 93 |
-
<p>Monument Valley 2 is a sequel to the award-winning puzzle game that features stunning art and music. You can guide a mother and her child through a series of optical illusions and impossible architecture, and discover the secrets of their world. You can also enjoy the story of their bond and their journey. Monument Valley 2 is not free, but it is worth every penny for its quality and creativity.</p>
|
| 94 |
-
<h4>The Room: Old Sins</h4>
|
| 95 |
-
<p>The Room: Old Sins is the fourth installment in the acclaimed puzzle game series that features intricate and mysterious puzzles. You can explore a creepy dollhouse that hides clues and secrets about a missing couple, and use your touch screen to manipulate objects and solve puzzles. You can also enjoy the atmospheric graphics and sound effects that create a immersive experience. The Room: Old Sins is not free, but it is one of the best puzzle games on Android.</p>
|
| 96 |
-
<h3>Simulation games</h3>
|
| 97 |
-
<p>If you are looking for some relaxing simulation games, you can try these apk games:</p>
|
| 98 |
-
<h4>Stardew Valley</h4>
|
| 99 |
-
<p>Stardew Valley is a charming farming simulator that lets you create your own farm and live a peaceful life in a rural community. You can grow crops, raise animals, fish, mine, craft, cook, and more. You can also make friends with the villagers, get married, have children, and explore the secrets of the valley. Stardew Valley is not free, but it offers hours of content and replay value.</p>
|
| 100 |
-
<h4>The Sims Mobile</h4>
|
| 101 |
-
<p>The Sims Mobile is a mobile version of the popular life simulation game that lets you create your own sims and control their lives. You can customize their appearance, personality, hobbies, careers, relationships, and more. You can also build and decorate their homes, host parties, attend events, and interact with other players online. The Sims Mobile is free to play, but it also has in-app purchases for various items and features.</p>
|
| 102 |
-
<h2>Conclusion and FAQs</h2>
|
| 103 |
-
<p>In conclusion, apk games are a great way to enjoy Android gaming without relying on Google Play Store. They offer more variety, flexibility, and accessibility than official apps and games. However, they also come with some risks and challenges that you should be aware of before downloading them. Therefore, you should always be careful about the sources you choose and the files you install on your device.</p>
|
| 104 |
-
<p>If you have any questions about apk games or how to install them on your Android device, here are some FAQs that might help you:</p>
|
| 105 |
-
<ul>
|
| 106 |
-
<li><b>What are the best websites to download apk games?</b> There are many websites that offer free downloads of apk games, but not all of them are safe or reliable. Some of the best websites to download apk games are mob.org, apkpure.com, <p>Here is the continuation of the article:</p>
|
| 107 |
-
<ul>
|
| 108 |
-
<li><b>What are the best websites to download apk games?</b> There are many websites that offer free downloads of apk games, but not all of them are safe or reliable. Some of the best websites to download apk games are mob.org, apkpure.com, and apkdone.com. These websites have a large collection of apk games in various genres and categories, and they also provide detailed information, screenshots, reviews, and ratings for each game. They also scan and verify the apk files for malware and viruses, and update them regularly.</li>
|
| 109 |
-
<li><b>How can I update my apk games?</b> If you download an apk game from a third-party source, you might not receive automatic updates from the official app or game developer. However, you can still update your apk games manually by following these steps:</li>
|
| 110 |
-
<ol>
|
| 111 |
-
<li>Check the version number of your installed apk game and compare it with the latest version available on the website where you downloaded it.</li>
|
| 112 |
-
<li>If there is a newer version available, download the updated apk file and save it on your device.</li>
|
| 113 |
-
<li>Uninstall the old version of the apk game from your device.</li>
|
| 114 |
-
<li>Install the new version of the apk game using the same steps as before.</li>
|
| 115 |
-
<li>Enjoy your updated apk game!</li>
|
| 116 |
-
</ol>
|
| 117 |
-
<li><b>How can I uninstall my apk games?</b> If you want to uninstall an apk game from your device, you can do so by following these steps:</li>
|
| 118 |
-
<ol>
|
| 119 |
-
<li>Go to Settings > Apps and find the apk game you want to uninstall.</li>
|
| 120 |
-
<li>Tap on the apk game and select Uninstall.</li>
|
| 121 |
-
<li>Confirm your action and wait for the uninstallation process to finish.</li>
|
| 122 |
-
<li>Delete the apk file from your device if you don't need it anymore.</li>
|
| 123 |
-
</ol>
|
| 124 |
-
<li><b>How can I backup my apk games?</b> If you want to backup your apk games and their data, you can use a third-party app such as Helium or Titanium Backup. These apps allow you to backup and restore your apps and games, along with their settings, preferences, progress, and data. You can also sync your backups to cloud storage services such as Google Drive or Dropbox. However, you might need to root your device to use some of these apps and their features.</li>
|
| 125 |
-
<li><b>How can I play online multiplayer games with apk files?</b> If you want to play online multiplayer games with apk files, you need to make sure that the apk file is compatible with the official version of the game. Otherwise, you might face issues such as connection errors, mismatched versions, or banned accounts. You also need to have a stable internet connection and a valid account for the game. Some online multiplayer games might require additional files or data to run properly, so you need to download them as well.</li>
|
| 126 |
-
</ul>
|
| 127 |
-
<p>I hope this article has helped you understand what is apkgame and why you should try it. Apk games are a great way to enjoy Android gaming without relying on Google Play Store. They offer more variety, flexibility, and accessibility than official apps and games. However, they also come with some risks and challenges that you should be aware of before downloading them. Therefore, you should always be careful about the sources you choose and the files you install on your device.</p> 197e85843d<br />
|
| 128 |
-
<br />
|
| 129 |
-
<br />
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/1pelhydcardo/ChatGPT-prompt-generator/assets/ApkJeet How to Earn Money Online from Home with a Simple App in 2023.md
DELETED
|
@@ -1,107 +0,0 @@
|
|
| 1 |
-
<br />
|
| 2 |
-
<h1>ApkJeet: A Guide to Online Earning in Pakistan</h1>
|
| 3 |
-
<p>Are you looking for a way to make money online in Pakistan without investing anything? Do you want to learn new skills and improve your English while earning from home? If yes, then you might want to check out ApkJeet, a platform that offers a variety of online earning opportunities for Pakistanis. In this article, we will explain what ApkJeet is, how it works, what are the benefits and challenges of using it, and how to get started with it.</p>
|
| 4 |
-
<h2>apkjeet</h2><br /><p><b><b>DOWNLOAD</b> ✯ <a href="https://urlin.us/2uSTzI">https://urlin.us/2uSTzI</a></b></p><br /><br />
|
| 5 |
-
<h2>What is ApkJeet and how does it work?</h2>
|
| 6 |
-
<p>ApkJeet is a platform that connects Pakistani users with online earning opportunities from various apps and websites. It was created by Eman Shehzadi, a Pakistani entrepreneur who wanted to help her fellow citizens earn money online in a fast and easy way. ApkJeet consists of two main components: an app and a website.</p>
|
| 7 |
-
<h3>ApkJeet app: A platform for online earning opportunities</h3>
|
| 8 |
-
<p>The ApkJeet app is the core of the platform, where users can find and access different apps and websites that offer online earning opportunities. These include popular platforms like YouTube, Google Adsense, Amazon, Upwork, Fiverr, Shutterstock, Udemy, Guru, TechRoti, Urdu Inbox, and more. Users can download the app from the official website or Google Play Store, register and create their profile, browse and select the apps and websites that suit their interests and skills, follow the instructions and complete the tasks or projects assigned by the app or website, earn money and withdraw it to their bank account or e-wallet.</p>
|
| 9 |
-
<h3>ApkJeet website: A source of information and guidance for online earners</h3>
|
| 10 |
-
<p>The ApkJeet website is a complementary resource for users who want to learn more about online earning in Pakistan. It provides information and guidance on various topics related to online earning, such as affiliate marketing, selling gently-used items, on-demand ride service, freelancing work, taking paid surveys, private tutoring, creating YouTube channels, social media influencing, starting profitable blogs, niche freelance content writing, writing paid reviews, part-time photography, and more. Users can visit the website to get tips and tricks on how to succeed in online earning, as well as read testimonials and reviews from other users who have used ApkJeet.</p>
|
| 11 |
-
<h2>What are the benefits of using ApkJeet?</h2>
|
| 12 |
-
<p>Using ApkJeet has many benefits for users who want to make money online in Pakistan. Some of these benefits are:</p>
|
| 13 |
-
<h3>ApkJeet offers a variety of apps and websites to choose from</h3>
|
| 14 |
-
<p>One of the main advantages of using ApkJeet is that it offers a wide range of apps and websites that cater to different interests and skills. Users can choose from different categories such as education, entertainment, e-commerce, freelancing, photography, blogging, social media, etc. Users can also switch between different apps and websites as they please, depending on their availability, preference, and performance.</p <h3>ApkJeet provides reliable and trusted sources of income</h3>
|
| 15 |
-
<p>Another benefit of using ApkJeet is that it provides reliable and trusted sources of income for users. ApkJeet only features apps and websites that are verified and reputable, and that pay users on time and in full. Users can also check the ratings and reviews of the apps and websites on the ApkJeet app or website, to see how other users have rated their experience and earnings. ApkJeet also has a customer support team that is available 24/7 to assist users with any issues or queries they may have regarding online earning.</p>
|
| 16 |
-
<h3>ApkJeet helps you learn new skills and improve your English</h3>
|
| 17 |
-
<p>A third benefit of using ApkJeet is that it helps users learn new skills and improve their English while earning money online. Many of the apps and websites featured on ApkJeet require users to have certain skills or knowledge, such as web development, graphic design, content writing, video editing, digital marketing, etc. Users can learn these skills by taking online courses, watching tutorials, reading blogs, or following experts on social media. ApkJeet also helps users improve their English, as many of the apps and websites require users to communicate in English with clients, customers, or audiences. Users can improve their English by reading articles, watching videos, listening to podcasts, or practicing with native speakers online.</p>
|
| 18 |
-
<p>apkjeet app download<br />
|
| 19 |
-
apkjeet online earning app review<br />
|
| 20 |
-
apkjeet.com login<br />
|
| 21 |
-
apkjeet referral code<br />
|
| 22 |
-
apkjeet payment proof<br />
|
| 23 |
-
apkjeet app for android<br />
|
| 24 |
-
apkjeet online earning app 2023<br />
|
| 25 |
-
apkjeet.com sign up<br />
|
| 26 |
-
apkjeet withdraw method<br />
|
| 27 |
-
apkjeet app features<br />
|
| 28 |
-
apkjeet online earning app pakistan<br />
|
| 29 |
-
apkjeet.com customer care number<br />
|
| 30 |
-
apkjeet minimum withdrawal<br />
|
| 31 |
-
apkjeet app benefits<br />
|
| 32 |
-
apkjeet online earning app legit<br />
|
| 33 |
-
apkjeet.com referral link<br />
|
| 34 |
-
apkjeet how to earn money<br />
|
| 35 |
-
apkjeet app requirements<br />
|
| 36 |
-
apkjeet online earning app scam<br />
|
| 37 |
-
apkjeet.com contact us<br />
|
| 38 |
-
apkjeet daily bonus<br />
|
| 39 |
-
apkjeet app alternatives<br />
|
| 40 |
-
apkjeet.com faq<br />
|
| 41 |
-
apkjeet invite friends<br />
|
| 42 |
-
apkjeet online earning app tips<br />
|
| 43 |
-
apkjeet.com terms and conditions<br />
|
| 44 |
-
apkjeet task list<br />
|
| 45 |
-
apkjeet app problems<br />
|
| 46 |
-
apkjeet.com feedback<br />
|
| 47 |
-
apkjeet survey questions<br />
|
| 48 |
-
apkjeet online earning app tricks<br />
|
| 49 |
-
apkjeet.com privacy policy<br />
|
| 50 |
-
apkjeet verification process<br />
|
| 51 |
-
apkjeet app update<br />
|
| 52 |
-
apkjeet.com testimonials<br />
|
| 53 |
-
apkjeet success stories<br />
|
| 54 |
-
apkjeet app complaints<br />
|
| 55 |
-
apkjeet.com blog<br />
|
| 56 |
-
apkjeet income calculator<br />
|
| 57 |
-
apkjeet app ratings</p>
|
| 58 |
-
<h2>What are the challenges and risks of using ApkJeet?</h2>
|
| 59 |
-
<p>While using ApkJeet has many benefits, it also has some challenges and risks that users should be aware of. Some of these challenges and risks are:</p>
|
| 60 |
-
<h3>ApkJeet requires internet access and a compatible device</h3>
|
| 61 |
-
<p>One of the main challenges of using ApkJeet is that it requires users to have internet access and a compatible device to use the app and the website. Internet access in Pakistan can be expensive, slow, or unreliable, depending on the location, provider, or plan. Users may also need to have a smartphone, tablet, laptop, or desktop computer that can run the app and the website smoothly and securely. Users may need to invest in these devices or services if they want to use ApkJeet effectively.</p>
|
| 62 |
-
<h3>ApkJeet does not guarantee success or income</h3>
|
| 63 |
-
<p>Another challenge of using ApkJeet is that it does not guarantee success or income for users. Online earning depends on many factors, such as the demand and supply of the market, the quality and quantity of the work, the competition and reputation of the user, the payment terms and methods of the app or website, etc. Users may not always find suitable or profitable opportunities on ApkJeet, or they may face delays or disputes in receiving their payments. Users should be realistic and flexible in their expectations and goals when using ApkJeet.</p> <h3>ApkJeet may expose you to scams or frauds</h3>
|
| 64 |
-
<p>A third challenge of using ApkJeet is that it may expose users to scams or frauds that may try to exploit their online earning activities. Some of the apps and websites featured on ApkJeet may not be legitimate or trustworthy, and they may ask users to provide personal or financial information, pay upfront fees, download malware, or perform illegal or unethical tasks. Users should be careful and vigilant when using ApkJeet, and they should research the apps and websites before signing up, avoid sharing sensitive information, report any suspicious or abusive behavior, and seek help from ApkJeet or authorities if they encounter any problems.</p>
|
| 65 |
-
<h2>How to get started with ApkJeet?</h2>
|
| 66 |
-
<p>If you are interested in using ApkJeet to make money online in Pakistan, here are the steps you need to follow:</p>
|
| 67 |
-
<h3>Download the ApkJeet app from the official website or Google Play Store</h3>
|
| 68 |
-
<p>The first step is to download the ApkJeet app from the official website (https://apkjeet.com/) or Google Play Store (https://play.google.com/store/apps/details?id=com.apkjeet). The app is free and easy to install, and it works on most Android devices. You can also scan the QR code on the website to download the app directly.</p>
|
| 69 |
-
<h3>Register and create your profile on the app</h3>
|
| 70 |
-
<p>The second step is to register and create your profile on the app. You will need to provide some basic information, such as your name, email address, phone number, gender, age, location, education level, skills, interests, etc. You will also need to create a password and a username for your account. You can also upload a photo of yourself if you want. Your profile will help you find suitable and relevant online earning opportunities on ApkJeet.</p>
|
| 71 |
-
<h3>Browse and select the apps and websites that suit your interests and skills</h3>
|
| 72 |
-
<p>The third step is to browse and select the apps and websites that suit your interests and skills. You can use the search function or the categories to find the apps and websites that offer online earning opportunities in different fields, such as education, entertainment, e-commerce, freelancing, photography, blogging, social media, etc. You can also see the ratings and reviews of the apps and websites from other users, as well as the estimated earnings and payment methods. You can select as many apps and websites as you want, depending on your availability and preference.</p> <h3>Follow the instructions and complete the tasks or projects assigned by the app or website</h3>
|
| 73 |
-
<p>The fourth step is to follow the instructions and complete the tasks or projects assigned by the app or website. Each app and website has its own rules and requirements for online earning, such as the type and quality of the work, the deadline and duration of the work, the feedback and rating system, the dispute resolution process, etc. You should read and understand these rules and requirements before starting any work, and follow them accordingly. You should also communicate clearly and professionally with the app or website, as well as with any clients, customers, or audiences you may have.</p>
|
| 74 |
-
<h3>Earn money and withdraw it to your bank account or e-wallet</h3>
|
| 75 |
-
<p>The fifth and final step is to earn money and withdraw it to your bank account or e-wallet. After completing the tasks or projects assigned by the app or website, you will receive your payment in your ApkJeet account. You can check your balance and transaction history on the app or website. You can also withdraw your money to your bank account or e-wallet, such as JazzCash, EasyPaisa, Payoneer, PayPal, etc. The minimum withdrawal amount and the withdrawal fee may vary depending on the app or website. You should also keep track of your income and expenses for tax purposes.</p>
|
| 76 |
-
<h2>Conclusion and FAQs</h2>
|
| 77 |
-
<p>ApkJeet is a platform that offers a variety of online earning opportunities for Pakistanis. It consists of an app and a website that connect users with different apps and websites that offer online earning opportunities in different fields. Using ApkJeet has many benefits, such as offering a variety of apps and websites to choose from, providing reliable and trusted sources of income, and helping users learn new skills and improve their English. However, using ApkJeet also has some challenges and risks, such as requiring internet access and a compatible device, not guaranteeing success or income, and exposing users to scams or frauds. To get started with ApkJeet, users need to download the app from the official website or Google Play Store, register and create their profile on the app, browse and select the apps and websites that suit their interests and skills, follow the instructions and complete the tasks or projects assigned by the app or website, earn money and withdraw it to their bank account or e-wallet.</p>
|
| 78 |
-
<p>If you have any questions about ApkJeet, you may find the answers in these FAQs:</p>
|
| 79 |
-
<table>
|
| 80 |
-
<tr>
|
| 81 |
-
<th>Question</th>
|
| 82 |
-
<th>Answer</th>
|
| 83 |
-
</tr>
|
| 84 |
-
<tr>
|
| 85 |
-
<td>Is ApkJeet free to use?</td>
|
| 86 |
-
<td>Yes, ApkJeet is free to use for users who want to make money online in Pakistan. However, some of the apps and websites featured on ApkJeet may charge fees for their services or products.</td>
|
| 87 |
-
</tr>
|
| 88 |
-
<tr>
|
| 89 |
-
<td>How much money can I make with ApkJeet?</td>
|
| 90 |
-
<td>The amount of money you can make with ApkJeet depends on many factors, such as the demand and supply of the market, the quality and quantity of your work, the competition and reputation of yourself, the payment terms and methods of the app or website, etc. There is no fixed or guaranteed income with ApkJeet.</td>
|
| 91 |
-
</tr>
|
| 92 |
-
<tr>
|
| 93 |
-
<td>How can I increase my chances of success with ApkJeet?</td>
|
| 94 |
-
<td>You can increase your chances of success with ApkJeet by following these tips: - Choose the apps and websites that match your interests and skills - Learn new skills and improve your English - Provide high-quality work that meets the expectations of the app or website - Communicate clearly and professionally with the app or website - Be consistent and reliable in your work - Seek feedback and improve your performance - Build your reputation and portfolio - Avoid scams and frauds</td>
|
| 95 |
-
</tr>
|
| 96 |
-
<tr>
|
| 97 |
-
<td>What if I have a problem with an app or website on ApkJeet?</td>
|
| 98 |
-
<td>If you have a problem with an app or website on ApkJeet, such as not receiving your payment, having a dispute with a client or customer, encountering a technical issue, etc., you should first try to resolve it directly with the app or website. If that does not work, you can contact ApkJeet's customer support team via email ([email protected]) or phone (0300-1234567) for assistance.</td>
|
| 99 |
-
</tr>
|
| 100 |
-
<tr>
|
| 101 |
-
<td>Can I use ApkJeet outside Pakistan?</td>
|
| 102 |
-
<td>No, ApkJeet is only available for Pakistani users who want to make money online in Pakistan. If you are outside Pakistan, you will not be able to access or use ApkJeet.</td>
|
| 103 |
-
</tr>
|
| 104 |
-
</table>
|
| 105 |
-
<p>I hope this article has helped you understand what ApkJeet is, how it works, what are the benefits and challenges of using it, and how to get started with it. If you are interested in making money online in Pakistan, you should give ApkJeet a try and see for yourself how it can help you achieve your online earning goals. Remember to be careful and vigilant when using ApkJeet, and to follow the tips and tricks we shared in this article. Good luck and happy earning!</p> 197e85843d<br />
|
| 106 |
-
<br />
|
| 107 |
-
<br />
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/1phancelerku/anime-remove-background/Experience the Thrill of Free Fire MAX on PC with BlueStacks The Only App Player that Supports Android 11.md
DELETED
|
@@ -1,135 +0,0 @@
|
|
| 1 |
-
<br />
|
| 2 |
-
<h1>Free Fire PC Download Max APK: Everything You Need to Know</h1>
|
| 3 |
-
<p>If you are a fan of battle royale games, you might have heard of <strong>Free Fire</strong>, one of the most popular titles in this genre on mobile devices. But did you know that there is a new version of this game called <strong>Free Fire Max</strong>, which offers enhanced graphics and performance for high-end devices? And did you know that you can play this game on your PC using an Android emulator?</p>
|
| 4 |
-
<p>In this article, we will tell you everything you need to know about Free Fire PC download max apk, including what it is, how to get it, what are the system requirements, what are the best tips and tricks, and what are the best alternatives. Whether you are new to this game or a seasoned veteran, you will find something useful and interesting in this guide.</p>
|
| 5 |
-
<h2>free fire pc download max apk</h2><br /><p><b><b>Download File</b> › <a href="https://jinyurl.com/2uNQ7i">https://jinyurl.com/2uNQ7i</a></b></p><br /><br />
|
| 6 |
-
<h2>What is Free Fire?</h2>
|
| 7 |
-
<p>Free Fire is a <strong>battle royale game</strong> that can be played on Android devices or PC. It was developed by Garena International I and released in 2017. It has over 500 million downloads on Google Play Store and has won several awards, such as the <em>Best Popular Vote Game</em> by Google Play Store in 2019.</p>
|
| 8 |
-
<p>The gameplay of Free Fire is similar to other games in this genre. You have to parachute onto an island with 49 other players and fight for your survival using the weapons and gear that you find on the map. The last player or team standing wins the match.</p>
|
| 9 |
-
<p>Some of the features of Free Fire are:</p>
|
| 10 |
-
<ul>
|
| 11 |
-
<li><strong>Fast-paced action:</strong> Each match lasts only 10 minutes, so you have to be quick and decisive.</li>
|
| 12 |
-
<li><strong>Squad mode:</strong> You can team up with up to three other players and communicate with them using voice chat.</li>
|
| 13 |
-
<li><strong>Clash Squad:</strong> This is a 4v4 mode where you have to manage your economy and buy weapons before each round.</li>
|
| 14 |
-
<li><strong>Characters:</strong> You can choose from over 50 characters with unique skills and abilities.</li>
|
| 15 |
-
<li><strong>Pets:</strong> You can also have a pet companion that can help you in various ways.</li>
|
| 16 |
-
<li><strong>Events:</strong> You can participate in various events and challenges to earn rewards and prizes.</li>
|
| 17 |
-
</ul>
|
| 18 |
-
<h2>What is Free Fire Max?</h2>
|
| 19 |
-
<p>Free Fire Max <h2>How to Download and Play Free Fire Max on PC?</h2>
|
| 20 |
-
<p>Free Fire Max is designed for high-end devices, but you can also play it on your PC using an Android emulator. An emulator is a software that allows you to run Android apps and games on your computer. One of the best emulators for playing Free Fire Max on PC is <strong>BlueStacks</strong>, which offers high performance, compatibility, and customization.</p>
|
| 21 |
-
<p>To download and play Free Fire Max on PC using BlueStacks, follow these steps:</p>
|
| 22 |
-
<ol>
|
| 23 |
-
<li>Download and install BlueStacks from its official website: </li>
|
| 24 |
-
<li>Launch BlueStacks and log in with your Google account.</li>
|
| 25 |
-
<li>Go to the Google Play Store and search for Free Fire Max.</li>
|
| 26 |
-
<li>Click on the Install button and wait for the download to finish.</li>
|
| 27 |
-
<li>Once the installation is complete, click on the Free Fire Max icon on the home screen.</li>
|
| 28 |
-
<li>Enjoy playing Free Fire Max on PC with enhanced graphics and controls.</li>
|
| 29 |
-
</ol>
|
| 30 |
-
<p>You can also customize the keyboard and mouse settings to suit your preferences. To do this, click on the gear icon on the top right corner of the screen and select Controls. You can choose from predefined layouts or create your own. You can also adjust the sensitivity, resolution, and frame rate of the game.</p>
|
| 31 |
-
<p>free fire max apk download for pc windows 10<br />
|
| 32 |
-
free fire max pc download bluestacks<br />
|
| 33 |
-
free fire max download for pc gameloop<br />
|
| 34 |
-
free fire max apk for pc windows 7<br />
|
| 35 |
-
free fire max pc download noxplayer<br />
|
| 36 |
-
free fire max download for pc without emulator<br />
|
| 37 |
-
free fire max apk obb download for pc<br />
|
| 38 |
-
free fire max pc download tencent gaming buddy<br />
|
| 39 |
-
free fire max download for pc windows 8<br />
|
| 40 |
-
free fire max pc download ldplayer<br />
|
| 41 |
-
free fire max apk pure download for pc<br />
|
| 42 |
-
free fire max pc download memu play<br />
|
| 43 |
-
free fire max download for pc 32 bit<br />
|
| 44 |
-
free fire max apk file download for pc<br />
|
| 45 |
-
free fire max pc download apkpure<br />
|
| 46 |
-
free fire max download for pc 64 bit<br />
|
| 47 |
-
free fire max apk mod download for pc<br />
|
| 48 |
-
free fire max pc download msi app player<br />
|
| 49 |
-
free fire max download for pc low end<br />
|
| 50 |
-
free fire max apk latest version download for pc<br />
|
| 51 |
-
free fire max pc download uptodown<br />
|
| 52 |
-
free fire max download for pc high end<br />
|
| 53 |
-
free fire max apk hack download for pc<br />
|
| 54 |
-
free fire max pc download smartgaga<br />
|
| 55 |
-
free fire max download for pc official website<br />
|
| 56 |
-
free fire max apk unlimited diamonds download for pc<br />
|
| 57 |
-
free fire max pc download koplayer<br />
|
| 58 |
-
free fire max download for pc minimum requirements<br />
|
| 59 |
-
free fire max apk and data download for pc<br />
|
| 60 |
-
free fire max pc download droid4x<br />
|
| 61 |
-
free fire max download for pc online play<br />
|
| 62 |
-
free fire max apk offline download for pc<br />
|
| 63 |
-
free fire max pc download genymotion<br />
|
| 64 |
-
free fire max download for pc full version<br />
|
| 65 |
-
free fire max apk update download for pc<br />
|
| 66 |
-
free fire max pc download phoenix os<br />
|
| 67 |
-
free fire max download for pc softonic<br />
|
| 68 |
-
free fire max apk beta version download for pc<br />
|
| 69 |
-
free fire max pc download prime os<br />
|
| 70 |
-
free fire max download for pc steam<br />
|
| 71 |
-
free fire max apk old version download for pc<br />
|
| 72 |
-
free fire max pc download remix os player<br />
|
| 73 |
-
free fire max download for pc windows xp<br />
|
| 74 |
-
free fire max apk cracked version download for pc<br />
|
| 75 |
-
free fire max pc download andy emulator<br />
|
| 76 |
-
free fire max download for pc laptop</p>
|
| 77 |
-
<h2>What are the System Requirements for Free Fire Max on PC?</h2>
|
| 78 |
-
<p>To play Free Fire Max on PC smoothly and without lag, you need to have a decent computer that meets the minimum or recommended system requirements. According to , these are:</p>
|
| 79 |
-
<table>
|
| 80 |
-
<tr><th>Minimum System Requirements</th><th>Recommended System Requirements</th></tr>
|
| 81 |
-
<tr><td>OS: Windows 7 or above</td><td>OS: Windows 10</td></tr>
|
| 82 |
-
<tr><td>CPU: Intel or AMD Processor</td><td>CPU: Intel Core i5-680 or higher</td></tr>
|
| 83 |
-
<tr><td>RAM: 4 GB</td><td>RAM: 8 GB or higher</td></tr>
|
| 84 |
-
<tr><td>HDD: 5 GB free space</td><td>HDD: 10 GB free space</td></tr>
|
| 85 |
-
<tr><td>Graphics: Intel HD 520 or higher</td><td>Graphics: NVIDIA GeForce GTX 660 or higher</td></tr>
|
| 86 |
-
<tr><td>Internet: Broadband connection</td><td>Internet: Broadband connection</td></tr>
|
| 87 |
-
</table>
|
| 88 |
-
<p>If your PC does not meet these requirements, you may experience lag, stuttering, or crashing while playing Free Fire Max. To improve your performance, you can try lowering the graphics settings, closing other applications, updating your drivers, or using a wired connection.</p> <h2>What are the Best Tips and Tricks for Free Fire Max?</h2>
|
| 89 |
-
<p>Free Fire Max is a challenging and competitive game that requires skill, strategy, and luck to win. If you want to improve your win rate and become a better player, you need to follow some tips and tricks that can give you an edge over your enemies. Here are some of the best tips and tricks for Free Fire Max that you can use:</p>
|
| 90 |
-
<ul>
|
| 91 |
-
<li><strong>Play it safe:</strong> Don't rush into fights without a plan or backup. Try to avoid hot drops and land in less crowded areas where you can loot safely. Use cover and stealth to move around the map and avoid unnecessary confrontations. Only engage when you have a clear advantage or when the zone forces you to.</li>
|
| 92 |
-
<li><strong>Master the gloo wall:</strong> The gloo wall is one of the most useful items in Free Fire Max, as it can provide instant protection from bullets and grenades. You should always carry some gloo walls with you and use them wisely. You can use them to block doors, windows, bridges, or gaps. You can also use them to create ramps, stairs, or platforms. You can also use them to trap or confuse your enemies.</li>
|
| 93 |
-
<li><strong>Try to maintain max HP and EP:</strong> HP and EP are your health and energy points, respectively. You need to keep them as high as possible to survive longer and heal faster. You can use medkits, mushrooms, bonfires, or character skills to restore your HP and EP. You can also use vests and helmets to reduce the damage you take from enemies.</li>
|
| 94 |
-
<li><strong>Practice ADS and rotating:</strong> ADS stands for aim down sight, which is the mode where you look through your weapon's scope or iron sight. This mode allows you to shoot more accurately and deal more damage, especially at long ranges. You should practice using ADS in different situations and with different weapons. Rotating means moving from one location to another in a strategic way. You should practice rotating according to the zone, the map, and the enemy's position. You should also use vehicles, launch pads, or zip lines to rotate faster and safer.</li>
|
| 95 |
-
<li><strong>Play with an experienced player when possible:</strong> One of the best ways to learn and improve in Free Fire Max is by playing with someone who already knows the game well. You can ask them for advice, tips, feedback, or help. You can also observe how they play and copy their strategies. You can find experienced players in your friends list, clan, guild, or online communities.</li>
|
| 96 |
-
</ul>
|
| 97 |
-
<h2>What are the Best Alternatives to Free Fire Max?</h2>
|
| 98 |
-
<p>If you are looking for some other games like Free Fire Max that offer similar or better battle royale experiences on mobile or PC, you have plenty of options to choose from. Here are some of the best alternatives to Free Fire Max that you can try out:</p>
|
| 99 |
-
<ul>
|
| 100 |
-
<li><strong>COD Mobile:</strong> This is a better battle royale experience with high-quality graphics, realistic weapons, vehicles, maps, modes, and characters. You can also play other modes like multiplayer, zombies, or ranked.</li>
|
| 101 |
-
<li><strong>PUBG New State:</strong> This is a great title for gamers who prefer high-quality graphics in their games. It is set in a futuristic world with advanced technology, weapons, vehicles, and features. It also has a dynamic map that changes over time.</li>
|
| 102 |
-
<li><strong>PUBG Mobile:</strong> This is one of the biggest rivals to Free Fire in the BR gaming community. It has a more realistic and immersive gameplay with large maps, diverse weapons, vehicles, items, and modes. It also has regular updates, events, collaborations, and tournaments.</li>
|
| 103 |
-
<li><strong>Knives Out:</strong> This is a game that offers a unique experience with its gameplay mechanics. It has a more casual and humorous style with cartoonish graphics, quirky weapons, items, vehicles, and characters. It also has a variety of modes like 50v50, sniper mode, treasure hunt mode.</li>
|
| 104 |
-
<li><strong>Battle Prime:</strong> This is a game that offers fast-paced action with stunning graphics and smooth controls. It has a variety of characters with unique abilities and skills that you can customize and upgrade. It also has different modes like team deathmatch, domination.</li>
|
| 105 |
-
</ul> <h1>Conclusion</h1>
|
| 106 |
-
<p>Free Fire Max is an amazing game that offers a thrilling and immersive battle royale experience on mobile devices. It has improved graphics, performance, and compatibility compared to Free Fire. You can also play it on your PC using an Android emulator like BlueStacks. However, you need to have a good computer that meets the system requirements for playing Free Fire Max on PC. You also need to follow some tips and tricks to improve your skills and win more matches. If you are looking for some other games like Free Fire Max, you can try out COD Mobile, PUBG New State, PUBG Mobile, Knives Out, or Battle Prime.</p>
|
| 107 |
-
<p>We hope that this article has helped you learn more about Free Fire PC download max apk and how to enjoy it on your device. If you have any questions or feedback, please let us know in the comments section below. Thank you for reading and happy gaming!</p>
|
| 108 |
-
<h2>FAQs</h2>
|
| 109 |
-
<p>Here are some of the most frequently asked questions and answers about Free Fire Max and its related topics:</p>
|
| 110 |
-
<ol>
|
| 111 |
-
<li><strong>Is Free Fire Max free to play?</strong></li>
|
| 112 |
-
<p>Yes, Free Fire Max is free to play on both Android devices and PC. However, it may contain some in-app purchases and ads that can enhance your gameplay or support the developers.</p>
|
| 113 |
-
<li><strong>Can I play Free Fire Max with Free Fire players?</strong></li>
|
| 114 |
-
<p>Yes, Free Fire Max and Free Fire are cross-compatible, which means that you can play with or against players from both versions. However, you need to have the same server and update version as the other players.</p>
|
| 115 |
-
<li><strong>Can I transfer my data from Free Fire to Free Fire Max?</strong></li>
|
| 116 |
-
<p>Yes, you can transfer your data from Free Fire to Free Fire Max using your Facebook or VK account. You can also use the same account to log in to both versions of the game.</p>
|
| 117 |
-
<li><strong>What are the best weapons in Free Fire Max?</strong></li>
|
| 118 |
-
<p>The best weapons in Free Fire Max may vary depending on your personal preference, playstyle, and situation. However, some of the most popular and powerful weapons in the game are:</p>
|
| 119 |
-
<ul>
|
| 120 |
-
<li><strong>Groza:</strong> This is an assault rifle that has high damage, accuracy, and fire rate. It is ideal for medium to long-range combat.</li>
|
| 121 |
-
<li><strong>M82B:</strong> This is a sniper rifle that can penetrate through gloo walls and deal massive damage. It is perfect for long-range sniping.</li>
|
| 122 |
-
<li><strong>M1887:</strong> This is a shotgun that can fire two shots in quick succession and deal devastating damage at close range. It is great for rushing and clearing buildings.</li>
|
| 123 |
-
<li><strong>M79:</strong> This is a grenade launcher that can fire explosive projectiles that can damage multiple enemies at once. It is useful for breaking gloo walls and creating chaos.</li>
|
| 124 |
-
<li><strong>Katana:</strong> This is a melee weapon that can slash enemies with a single hit and deflect bullets with its blade. It is fun and effective for close combat.</li>
|
| 125 |
-
</ul>
|
| 126 |
-
<li><strong>How can I get diamonds in Free Fire Max?</strong></li>
|
| 127 |
-
<p>Diamonds are the premium currency in Free Fire Max that can be used to buy various items and features in the game. You can get diamonds in several ways, such as:</p>
|
| 128 |
-
<ul>
|
| 129 |
-
<li><strong>Purchasing them with real money:</strong> This is the easiest and fastest way to get diamonds, but it may cost you a lot.</li>
|
| 130 |
-
<li><strong>Completing surveys and offers:</strong> This is a free way to get diamonds, but it may take you some time and effort.</li>
|
| 131 |
-
<li><strong>Participating in events and giveaways:</strong> This is another free way to get diamonds, but it may depend on your luck and availability.</li>
|
| 132 |
-
</ul>
|
| 133 |
-
</ol></p> 197e85843d<br />
|
| 134 |
-
<br />
|
| 135 |
-
<br />
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/801artistry/RVC801/utils/i18n.py
DELETED
|
@@ -1,28 +0,0 @@
|
|
| 1 |
-
import locale
|
| 2 |
-
import json
|
| 3 |
-
import os
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
def load_language_list(language):
|
| 7 |
-
with open(f"./i18n/{language}.json", "r", encoding="utf-8") as f:
|
| 8 |
-
language_list = json.load(f)
|
| 9 |
-
return language_list
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
class I18nAuto:
|
| 13 |
-
def __init__(self, language=None):
|
| 14 |
-
if language in ["Auto", None]:
|
| 15 |
-
language = "es_ES"
|
| 16 |
-
if not os.path.exists(f"./i18n/{language}.json"):
|
| 17 |
-
language = "es_ES"
|
| 18 |
-
language = "es_ES"
|
| 19 |
-
self.language = language
|
| 20 |
-
# print("Use Language:", language)
|
| 21 |
-
self.language_map = load_language_list(language)
|
| 22 |
-
|
| 23 |
-
def __call__(self, key):
|
| 24 |
-
return self.language_map.get(key, key)
|
| 25 |
-
|
| 26 |
-
def print(self):
|
| 27 |
-
# print("Use Language:", self.language)
|
| 28 |
-
print("")
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/AIConsultant/MusicGen/audiocraft/utils/autocast.py
DELETED
|
@@ -1,40 +0,0 @@
|
|
| 1 |
-
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
-
# All rights reserved.
|
| 3 |
-
#
|
| 4 |
-
# This source code is licensed under the license found in the
|
| 5 |
-
# LICENSE file in the root directory of this source tree.
|
| 6 |
-
|
| 7 |
-
import torch
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
class TorchAutocast:
|
| 11 |
-
"""TorchAutocast utility class.
|
| 12 |
-
Allows you to enable and disable autocast. This is specially useful
|
| 13 |
-
when dealing with different architectures and clusters with different
|
| 14 |
-
levels of support.
|
| 15 |
-
|
| 16 |
-
Args:
|
| 17 |
-
enabled (bool): Whether to enable torch.autocast or not.
|
| 18 |
-
args: Additional args for torch.autocast.
|
| 19 |
-
kwargs: Additional kwargs for torch.autocast
|
| 20 |
-
"""
|
| 21 |
-
def __init__(self, enabled: bool, *args, **kwargs):
|
| 22 |
-
self.autocast = torch.autocast(*args, **kwargs) if enabled else None
|
| 23 |
-
|
| 24 |
-
def __enter__(self):
|
| 25 |
-
if self.autocast is None:
|
| 26 |
-
return
|
| 27 |
-
try:
|
| 28 |
-
self.autocast.__enter__()
|
| 29 |
-
except RuntimeError:
|
| 30 |
-
device = self.autocast.device
|
| 31 |
-
dtype = self.autocast.fast_dtype
|
| 32 |
-
raise RuntimeError(
|
| 33 |
-
f"There was an error autocasting with dtype={dtype} device={device}\n"
|
| 34 |
-
"If you are on the FAIR Cluster, you might need to use autocast_dtype=float16"
|
| 35 |
-
)
|
| 36 |
-
|
| 37 |
-
def __exit__(self, *args, **kwargs):
|
| 38 |
-
if self.autocast is None:
|
| 39 |
-
return
|
| 40 |
-
self.autocast.__exit__(*args, **kwargs)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/ATang0729/Forecast4Muses/Model/Model6/Model6_0_ClothesDetection/mmyolo/configs/yolov6/yolov6_n_syncbn_fast_8xb32-400e_coco.py
DELETED
|
@@ -1,21 +0,0 @@
|
|
| 1 |
-
_base_ = './yolov6_s_syncbn_fast_8xb32-400e_coco.py'
|
| 2 |
-
|
| 3 |
-
# ======================= Possible modified parameters =======================
|
| 4 |
-
# -----model related-----
|
| 5 |
-
# The scaling factor that controls the depth of the network structure
|
| 6 |
-
deepen_factor = 0.33
|
| 7 |
-
# The scaling factor that controls the width of the network structure
|
| 8 |
-
widen_factor = 0.25
|
| 9 |
-
|
| 10 |
-
# -----train val related-----
|
| 11 |
-
lr_factor = 0.02 # Learning rate scaling factor
|
| 12 |
-
|
| 13 |
-
# ============================== Unmodified in most cases ===================
|
| 14 |
-
model = dict(
|
| 15 |
-
backbone=dict(deepen_factor=deepen_factor, widen_factor=widen_factor),
|
| 16 |
-
neck=dict(deepen_factor=deepen_factor, widen_factor=widen_factor),
|
| 17 |
-
bbox_head=dict(
|
| 18 |
-
head_module=dict(widen_factor=widen_factor),
|
| 19 |
-
loss_bbox=dict(iou_mode='siou')))
|
| 20 |
-
|
| 21 |
-
default_hooks = dict(param_scheduler=dict(lr_factor=lr_factor))
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/fixwidthsizer/LayoutChildren.js
DELETED
|
@@ -1,102 +0,0 @@
|
|
| 1 |
-
import PreLayoutChild from '../basesizer/utils/PreLayoutChild.js';
|
| 2 |
-
import LayoutChild from '../basesizer/utils/LayoutChild.js';
|
| 3 |
-
import { GetDisplayWidth, GetDisplayHeight } from '../../../plugins/utils/size/GetDisplaySize.js';
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
var LayoutChildren = function () {
|
| 7 |
-
var innerLineWidth = this.innerWidth;
|
| 8 |
-
var justifyPercentage = this.justifyPercentage;
|
| 9 |
-
var itemSpace = this.space.item,
|
| 10 |
-
lineSpace = this.space.line,
|
| 11 |
-
indentLeftOdd = this.space.indentLeftOdd,
|
| 12 |
-
indentLeftEven = this.space.indentLeftEven,
|
| 13 |
-
indentTopOdd = this.space.indentTopOdd,
|
| 14 |
-
indentTopEven = this.space.indentTopEven;
|
| 15 |
-
|
| 16 |
-
var child, childConfig, padding, justifySpace = 0, indentLeft, indentTop;
|
| 17 |
-
var startX = this.innerLeft,
|
| 18 |
-
startY = this.innerTop;
|
| 19 |
-
var x, y, width, height; // Align zone
|
| 20 |
-
var lines = this.widthWrapResult.lines;
|
| 21 |
-
var line, lineChlidren, remainderLineWidth;
|
| 22 |
-
|
| 23 |
-
var itemX,
|
| 24 |
-
itemY = startY;
|
| 25 |
-
for (var i = 0, icnt = lines.length; i < icnt; i++) {
|
| 26 |
-
// Layout this line
|
| 27 |
-
line = lines[i];
|
| 28 |
-
lineChlidren = line.children;
|
| 29 |
-
if (this.rtl) {
|
| 30 |
-
lineChlidren.reverse();
|
| 31 |
-
}
|
| 32 |
-
|
| 33 |
-
indentLeft = (i % 2) ? indentLeftEven : indentLeftOdd;
|
| 34 |
-
itemX = startX + indentLeft;
|
| 35 |
-
|
| 36 |
-
remainderLineWidth = (innerLineWidth - line.width);
|
| 37 |
-
switch (this.align) {
|
| 38 |
-
case 0: // left
|
| 39 |
-
break;
|
| 40 |
-
case 1: // right
|
| 41 |
-
itemX += remainderLineWidth;
|
| 42 |
-
break;
|
| 43 |
-
case 2: // center
|
| 44 |
-
itemX += remainderLineWidth / 2;
|
| 45 |
-
break;
|
| 46 |
-
case 3: // justify-left
|
| 47 |
-
justifySpace = GetJustifySpace(innerLineWidth, remainderLineWidth, justifyPercentage, lineChlidren.length);
|
| 48 |
-
break;
|
| 49 |
-
case 4: // justify-right
|
| 50 |
-
justifySpace = GetJustifySpace(innerLineWidth, remainderLineWidth, justifyPercentage, lineChlidren.length);
|
| 51 |
-
if (justifySpace === 0) {
|
| 52 |
-
// Align right
|
| 53 |
-
itemX += remainderLineWidth;
|
| 54 |
-
}
|
| 55 |
-
break;
|
| 56 |
-
case 5: // justify-center
|
| 57 |
-
justifySpace = GetJustifySpace(innerLineWidth, remainderLineWidth, justifyPercentage, lineChlidren.length);
|
| 58 |
-
if (justifySpace === 0) {
|
| 59 |
-
// Align center
|
| 60 |
-
itemX += remainderLineWidth / 2;
|
| 61 |
-
}
|
| 62 |
-
break;
|
| 63 |
-
}
|
| 64 |
-
|
| 65 |
-
var isFirstChild = true;
|
| 66 |
-
for (var j = 0, jcnt = lineChlidren.length; j < jcnt; j++) {
|
| 67 |
-
child = lineChlidren[j];
|
| 68 |
-
if (child.rexSizer.hidden) {
|
| 69 |
-
continue;
|
| 70 |
-
}
|
| 71 |
-
|
| 72 |
-
childConfig = child.rexSizer;
|
| 73 |
-
padding = childConfig.padding;
|
| 74 |
-
|
| 75 |
-
PreLayoutChild.call(this, child);
|
| 76 |
-
|
| 77 |
-
x = (itemX + padding.left);
|
| 78 |
-
|
| 79 |
-
if (isFirstChild) {
|
| 80 |
-
isFirstChild = false;
|
| 81 |
-
} else {
|
| 82 |
-
x += itemSpace;
|
| 83 |
-
}
|
| 84 |
-
|
| 85 |
-
indentTop = (j % 2) ? indentTopEven : indentTopOdd;
|
| 86 |
-
y = (itemY + indentTop + padding.top);
|
| 87 |
-
width = GetDisplayWidth(child);
|
| 88 |
-
height = GetDisplayHeight(child);
|
| 89 |
-
itemX = x + width + padding.right + justifySpace;
|
| 90 |
-
|
| 91 |
-
LayoutChild.call(this, child, x, y, width, height, childConfig.align);
|
| 92 |
-
}
|
| 93 |
-
|
| 94 |
-
itemY += line.height + lineSpace;
|
| 95 |
-
}
|
| 96 |
-
}
|
| 97 |
-
|
| 98 |
-
var GetJustifySpace = function (total, remainder, justifyPercentage, childCount) {
|
| 99 |
-
return ((remainder / total) <= justifyPercentage) ? (remainder / (childCount - 1)) : 0;
|
| 100 |
-
}
|
| 101 |
-
|
| 102 |
-
export default LayoutChildren;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/AgentVerse/agentVerse/ui/src/phaser3-rex-plugins/templates/ui/maker/builders/CreateTextArea.js
DELETED
|
@@ -1,21 +0,0 @@
|
|
| 1 |
-
import MergeStyle from './utils/MergeStyle.js';
|
| 2 |
-
import TextArea from '../../textarea/TextArea.js';
|
| 3 |
-
import CreateChild from './utils/CreateChild.js';
|
| 4 |
-
import ReplaceSliderConfig from './utils/ReplaceSliderConfig.js';
|
| 5 |
-
|
| 6 |
-
var CreateTextArea = function (scene, data, view, styles, customBuilders) {
|
| 7 |
-
data = MergeStyle(data, styles);
|
| 8 |
-
|
| 9 |
-
// Replace data by child game object
|
| 10 |
-
CreateChild(scene, data, 'background', view, styles, customBuilders);
|
| 11 |
-
CreateChild(scene, data, 'text', view, styles, customBuilders);
|
| 12 |
-
ReplaceSliderConfig(scene, data.slider, view, styles, customBuilders);
|
| 13 |
-
CreateChild(scene, data, 'header', view, styles, customBuilders);
|
| 14 |
-
CreateChild(scene, data, 'footer', view, styles, customBuilders);
|
| 15 |
-
|
| 16 |
-
var gameObject = new TextArea(scene, data);
|
| 17 |
-
scene.add.existing(gameObject);
|
| 18 |
-
return gameObject;
|
| 19 |
-
};
|
| 20 |
-
|
| 21 |
-
export default CreateTextArea;
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/Alexxggs/ggvpnewen/app.py
DELETED
|
@@ -1,98 +0,0 @@
|
|
| 1 |
-
import time
|
| 2 |
-
|
| 3 |
-
import gradio as gr
|
| 4 |
-
from sentence_transformers import SentenceTransformer
|
| 5 |
-
|
| 6 |
-
import httpx
|
| 7 |
-
import json
|
| 8 |
-
|
| 9 |
-
from utils import get_tags_for_prompts, get_mubert_tags_embeddings, get_pat
|
| 10 |
-
|
| 11 |
-
minilm = SentenceTransformer('all-MiniLM-L6-v2')
|
| 12 |
-
mubert_tags_embeddings = get_mubert_tags_embeddings(minilm)
|
| 13 |
-
|
| 14 |
-
|
| 15 |
-
def get_track_by_tags(tags, pat, duration, mode, maxit=20, loop=False):
|
| 16 |
-
if loop:
|
| 17 |
-
mode = "loop"
|
| 18 |
-
else:
|
| 19 |
-
mode = "track"
|
| 20 |
-
r = httpx.post('https://api-b2b.mubert.com/v2/RecordTrackTTM',
|
| 21 |
-
json={
|
| 22 |
-
"method": "RecordTrackTTM",
|
| 23 |
-
"params": {
|
| 24 |
-
"pat": pat,
|
| 25 |
-
"duration": duration,
|
| 26 |
-
"tags": tags,
|
| 27 |
-
"mode": mode
|
| 28 |
-
}
|
| 29 |
-
})
|
| 30 |
-
|
| 31 |
-
rdata = json.loads(r.text)
|
| 32 |
-
assert rdata['status'] == 1, rdata['error']['text']
|
| 33 |
-
trackurl = rdata['data']['tasks'][0]['download_link']
|
| 34 |
-
|
| 35 |
-
print('Generating track ', end='')
|
| 36 |
-
for i in range(maxit):
|
| 37 |
-
r = httpx.get(trackurl)
|
| 38 |
-
if r.status_code == 200:
|
| 39 |
-
return trackurl
|
| 40 |
-
time.sleep(1)
|
| 41 |
-
|
| 42 |
-
|
| 43 |
-
def generate_track_by_prompt(email, prompt, duration, mode, loop=False):
|
| 44 |
-
try:
|
| 45 |
-
pat = get_pat(email)
|
| 46 |
-
_, tags = get_tags_for_prompts(minilm, mubert_tags_embeddings, [prompt, ])[0]
|
| 47 |
-
return get_track_by_tags(tags, pat, int(duration), mode, loop=loop), "Success", ",".join(tags)
|
| 48 |
-
except Exception as e:
|
| 49 |
-
return None, str(e), ""
|
| 50 |
-
|
| 51 |
-
|
| 52 |
-
block = gr.Blocks(css=".mx-auto{max-width:550px}.svelte-10ogue4 {background: rgba(0,0,0,0.0);width:100%;border: 0px}.gradio-container {background: rgba(0,0,0,0.0);border: 0px}.gr-block {background: rgba(0,0,0,0.0);border: 0px} #component-4 {opacity: 0.8;background: linear-gradient(#233581, #E23F9C);border: 0px;margin-bottom: 17px;border-radius: 10px;}#component-5 {opacity: 0.8;background: linear-gradient(#E23F9C, #233581);border: 0px;margin-bottom: 17px;border-radius: 10px;}.gr-form{background: rgba(0,0,0,0.0);border: 0px}.gr-text-input {background: rgba(255,255,255,1);border: 0px}.text-gray-500 {color: #FFFFFF;font-weight: 600;text-align: center;font-size: 18px;}#component-1 {height: 0px;}#range_id_0 {opacity: 0.5;border-radius: 8px;-webkit-appearance: none; width: 60%; height: 15px; background-color: #E64CAC; background-image: -webkit-gradient(linear, 0 0, 0 100%, from(#233581, #E23F9C), to(#E956B8)); background-image: -webkit-linear-gradient(right, #233581, #E956B8); background-image: -moz-linear-gradient(right, #233581, #E956B8); background-image: -ms-linear-gradient(right, #233581, #E956B8); background-image: -o-linear-gradient(right, #233581, #E956B8)}#component-6{opacity: 0.9;background: linear-gradient(#233581, #515A7F);border-radius: 10px}#component-7{margin-top: 7px;margin-bottom: 7px;text-align: center;display:inline;opacity: 0.9;background: linear-gradient(#515A7F, #515A7F);border-radius: 10px;}.ml-2{color: #FFFFFF;}#component-8 {height: 100px;z-index:99;background: linear-gradient(#515A7F, #515A7F);border-radius: 10px;opacity: 0.9}.absolute{background: linear-gradient(#EC5CC0, #D61B70);border: 0px}.feather{color: #FFFFFF;} .mt-7{z-index:100;background: linear-gradient(#515A7F, #515A7F);border-radius: 10px;} .gr-button{margin-left: 30%;width:40%;justify-content: center; background: linear-gradient(#EC5DC1, #D61A6F); padding: 0 12px; border: none; border-radius: 8px; box-shadow: 0 30px 15px rgba(0, 0, 0, 0.15); outline: none; color: #FFF; font: 400 16px/2.5 Nunito, Sans-serif; text-transform: uppercase; cursor: pointer;}#component-11{justify-content: center;text-align: center;margin-top:10px;border: 0px}.mx-auto{background: rgba(0,0,0,0.0);width:100%;border: 0px;padding:0 0 0 0}#component-9 {margin-top: 5px;opacity: 0.8;padding: 3px;background: linear-gradient(#515A7F, #515A7F);border-radius: 10px;}#component-10{margin-top: 5px;opacity: 0.8;padding: 3px;background: linear-gradient(#515A7F, #515A7F);border-radius: 10px;}#component-12{display:none}.gr-input-label{margin-right: 1px;width:71px;font-weight: 400;background: linear-gradient(#584C84, #2C3D7F);text-align: center;border: 0px}.font-semibold{display:none}")
|
| 53 |
-
|
| 54 |
-
|
| 55 |
-
|
| 56 |
-
with block:
|
| 57 |
-
gr.HTML(
|
| 58 |
-
"""
|
| 59 |
-
|
| 60 |
-
<noindex> <div hidden style="text-align: center; max-width: 700px; margin: 0 auto;">
|
| 61 |
-
<div
|
| 62 |
-
style="
|
| 63 |
-
display: inline-flex;
|
| 64 |
-
align-items: center;
|
| 65 |
-
gap: 0.8rem;
|
| 66 |
-
font-size: 1.75rem;
|
| 67 |
-
"
|
| 68 |
-
>
|
| 69 |
-
<h1 hidden style="font-weight: 900; margin-bottom: 7px;">
|
| 70 |
-
Mubert
|
| 71 |
-
</h1>
|
| 72 |
-
</div>
|
| 73 |
-
<p style="margin-bottom: 10px; font-size: 94%">
|
| 74 |
-
All music is generated by Mubert API – <a href="https://mubert.com" style="text-decoration: underline;" target="_blank">www.mubert.com</a>
|
| 75 |
-
</p>
|
| 76 |
-
</div> </noindex>
|
| 77 |
-
"""
|
| 78 |
-
)
|
| 79 |
-
with gr.Group():
|
| 80 |
-
with gr.Box():
|
| 81 |
-
email = gr.Textbox(label="email")
|
| 82 |
-
prompt = gr.Textbox(label="Text example (bass drum cyberpunk)")
|
| 83 |
-
duration = gr.Slider(label="Time (seconds)", value=30, maximum=250,)
|
| 84 |
-
mode = gr.Radio(["track", "loop", "jingle", "mix"], label="Track Type")
|
| 85 |
-
out = gr.Audio()
|
| 86 |
-
result_msg = gr.Text(label="System messages")
|
| 87 |
-
tags = gr.Text(label="Generated track tags")
|
| 88 |
-
btn = gr.Button("Create").style(full_width=True)
|
| 89 |
-
is_loop = gr.Checkbox(label="Loop a track")
|
| 90 |
-
btn.click(fn=generate_track_by_prompt, inputs=[email, prompt, duration, mode, is_loop], outputs=[out, result_msg, tags])
|
| 91 |
-
gr.HTML('''
|
| 92 |
-
<noindex> <div hidden class="footer" style="text-align: center; max-width: 700px; margin: 0 auto;">
|
| 93 |
-
<p>Demo by <a href="https://huggingface.co/Mubert" style="text-decoration: underline;" target="_blank">Mubert</a>
|
| 94 |
-
</p>
|
| 95 |
-
</div> </noindex>
|
| 96 |
-
''')
|
| 97 |
-
|
| 98 |
-
block.launch()
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/Alpaca233/SadTalker/src/face3d/util/nvdiffrast.py
DELETED
|
@@ -1,126 +0,0 @@
|
|
| 1 |
-
"""This script is the differentiable renderer for Deep3DFaceRecon_pytorch
|
| 2 |
-
Attention, antialiasing step is missing in current version.
|
| 3 |
-
"""
|
| 4 |
-
import pytorch3d.ops
|
| 5 |
-
import torch
|
| 6 |
-
import torch.nn.functional as F
|
| 7 |
-
import kornia
|
| 8 |
-
from kornia.geometry.camera import pixel2cam
|
| 9 |
-
import numpy as np
|
| 10 |
-
from typing import List
|
| 11 |
-
from scipy.io import loadmat
|
| 12 |
-
from torch import nn
|
| 13 |
-
|
| 14 |
-
from pytorch3d.structures import Meshes
|
| 15 |
-
from pytorch3d.renderer import (
|
| 16 |
-
look_at_view_transform,
|
| 17 |
-
FoVPerspectiveCameras,
|
| 18 |
-
DirectionalLights,
|
| 19 |
-
RasterizationSettings,
|
| 20 |
-
MeshRenderer,
|
| 21 |
-
MeshRasterizer,
|
| 22 |
-
SoftPhongShader,
|
| 23 |
-
TexturesUV,
|
| 24 |
-
)
|
| 25 |
-
|
| 26 |
-
# def ndc_projection(x=0.1, n=1.0, f=50.0):
|
| 27 |
-
# return np.array([[n/x, 0, 0, 0],
|
| 28 |
-
# [ 0, n/-x, 0, 0],
|
| 29 |
-
# [ 0, 0, -(f+n)/(f-n), -(2*f*n)/(f-n)],
|
| 30 |
-
# [ 0, 0, -1, 0]]).astype(np.float32)
|
| 31 |
-
|
| 32 |
-
class MeshRenderer(nn.Module):
|
| 33 |
-
def __init__(self,
|
| 34 |
-
rasterize_fov,
|
| 35 |
-
znear=0.1,
|
| 36 |
-
zfar=10,
|
| 37 |
-
rasterize_size=224):
|
| 38 |
-
super(MeshRenderer, self).__init__()
|
| 39 |
-
|
| 40 |
-
# x = np.tan(np.deg2rad(rasterize_fov * 0.5)) * znear
|
| 41 |
-
# self.ndc_proj = torch.tensor(ndc_projection(x=x, n=znear, f=zfar)).matmul(
|
| 42 |
-
# torch.diag(torch.tensor([1., -1, -1, 1])))
|
| 43 |
-
self.rasterize_size = rasterize_size
|
| 44 |
-
self.fov = rasterize_fov
|
| 45 |
-
self.znear = znear
|
| 46 |
-
self.zfar = zfar
|
| 47 |
-
|
| 48 |
-
self.rasterizer = None
|
| 49 |
-
|
| 50 |
-
def forward(self, vertex, tri, feat=None):
|
| 51 |
-
"""
|
| 52 |
-
Return:
|
| 53 |
-
mask -- torch.tensor, size (B, 1, H, W)
|
| 54 |
-
depth -- torch.tensor, size (B, 1, H, W)
|
| 55 |
-
features(optional) -- torch.tensor, size (B, C, H, W) if feat is not None
|
| 56 |
-
|
| 57 |
-
Parameters:
|
| 58 |
-
vertex -- torch.tensor, size (B, N, 3)
|
| 59 |
-
tri -- torch.tensor, size (B, M, 3) or (M, 3), triangles
|
| 60 |
-
feat(optional) -- torch.tensor, size (B, N ,C), features
|
| 61 |
-
"""
|
| 62 |
-
device = vertex.device
|
| 63 |
-
rsize = int(self.rasterize_size)
|
| 64 |
-
# ndc_proj = self.ndc_proj.to(device)
|
| 65 |
-
# trans to homogeneous coordinates of 3d vertices, the direction of y is the same as v
|
| 66 |
-
if vertex.shape[-1] == 3:
|
| 67 |
-
vertex = torch.cat([vertex, torch.ones([*vertex.shape[:2], 1]).to(device)], dim=-1)
|
| 68 |
-
vertex[..., 0] = -vertex[..., 0]
|
| 69 |
-
|
| 70 |
-
|
| 71 |
-
# vertex_ndc = vertex @ ndc_proj.t()
|
| 72 |
-
if self.rasterizer is None:
|
| 73 |
-
self.rasterizer = MeshRasterizer()
|
| 74 |
-
print("create rasterizer on device cuda:%d"%device.index)
|
| 75 |
-
|
| 76 |
-
# ranges = None
|
| 77 |
-
# if isinstance(tri, List) or len(tri.shape) == 3:
|
| 78 |
-
# vum = vertex_ndc.shape[1]
|
| 79 |
-
# fnum = torch.tensor([f.shape[0] for f in tri]).unsqueeze(1).to(device)
|
| 80 |
-
# fstartidx = torch.cumsum(fnum, dim=0) - fnum
|
| 81 |
-
# ranges = torch.cat([fstartidx, fnum], axis=1).type(torch.int32).cpu()
|
| 82 |
-
# for i in range(tri.shape[0]):
|
| 83 |
-
# tri[i] = tri[i] + i*vum
|
| 84 |
-
# vertex_ndc = torch.cat(vertex_ndc, dim=0)
|
| 85 |
-
# tri = torch.cat(tri, dim=0)
|
| 86 |
-
|
| 87 |
-
# for range_mode vetex: [B*N, 4], tri: [B*M, 3], for instance_mode vetex: [B, N, 4], tri: [M, 3]
|
| 88 |
-
tri = tri.type(torch.int32).contiguous()
|
| 89 |
-
|
| 90 |
-
# rasterize
|
| 91 |
-
cameras = FoVPerspectiveCameras(
|
| 92 |
-
device=device,
|
| 93 |
-
fov=self.fov,
|
| 94 |
-
znear=self.znear,
|
| 95 |
-
zfar=self.zfar,
|
| 96 |
-
)
|
| 97 |
-
|
| 98 |
-
raster_settings = RasterizationSettings(
|
| 99 |
-
image_size=rsize
|
| 100 |
-
)
|
| 101 |
-
|
| 102 |
-
# print(vertex.shape, tri.shape)
|
| 103 |
-
mesh = Meshes(vertex.contiguous()[...,:3], tri.unsqueeze(0).repeat((vertex.shape[0],1,1)))
|
| 104 |
-
|
| 105 |
-
fragments = self.rasterizer(mesh, cameras = cameras, raster_settings = raster_settings)
|
| 106 |
-
rast_out = fragments.pix_to_face.squeeze(-1)
|
| 107 |
-
depth = fragments.zbuf
|
| 108 |
-
|
| 109 |
-
# render depth
|
| 110 |
-
depth = depth.permute(0, 3, 1, 2)
|
| 111 |
-
mask = (rast_out > 0).float().unsqueeze(1)
|
| 112 |
-
depth = mask * depth
|
| 113 |
-
|
| 114 |
-
|
| 115 |
-
image = None
|
| 116 |
-
if feat is not None:
|
| 117 |
-
attributes = feat.reshape(-1,3)[mesh.faces_packed()]
|
| 118 |
-
image = pytorch3d.ops.interpolate_face_attributes(fragments.pix_to_face,
|
| 119 |
-
fragments.bary_coords,
|
| 120 |
-
attributes)
|
| 121 |
-
# print(image.shape)
|
| 122 |
-
image = image.squeeze(-2).permute(0, 3, 1, 2)
|
| 123 |
-
image = mask * image
|
| 124 |
-
|
| 125 |
-
return mask, depth, image
|
| 126 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/src/diffusers/models/resnet.py
DELETED
|
@@ -1,878 +0,0 @@
|
|
| 1 |
-
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
| 2 |
-
# `TemporalConvLayer` Copyright 2023 Alibaba DAMO-VILAB, The ModelScope Team and The HuggingFace Team. All rights reserved.
|
| 3 |
-
#
|
| 4 |
-
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
-
# you may not use this file except in compliance with the License.
|
| 6 |
-
# You may obtain a copy of the License at
|
| 7 |
-
#
|
| 8 |
-
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
-
#
|
| 10 |
-
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
-
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
-
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
-
# See the License for the specific language governing permissions and
|
| 14 |
-
# limitations under the License.
|
| 15 |
-
|
| 16 |
-
from functools import partial
|
| 17 |
-
from typing import Optional
|
| 18 |
-
|
| 19 |
-
import torch
|
| 20 |
-
import torch.nn as nn
|
| 21 |
-
import torch.nn.functional as F
|
| 22 |
-
|
| 23 |
-
from .activations import get_activation
|
| 24 |
-
from .attention import AdaGroupNorm
|
| 25 |
-
from .attention_processor import SpatialNorm
|
| 26 |
-
from .lora import LoRACompatibleConv, LoRACompatibleLinear
|
| 27 |
-
|
| 28 |
-
|
| 29 |
-
class Upsample1D(nn.Module):
|
| 30 |
-
"""A 1D upsampling layer with an optional convolution.
|
| 31 |
-
|
| 32 |
-
Parameters:
|
| 33 |
-
channels (`int`):
|
| 34 |
-
number of channels in the inputs and outputs.
|
| 35 |
-
use_conv (`bool`, default `False`):
|
| 36 |
-
option to use a convolution.
|
| 37 |
-
use_conv_transpose (`bool`, default `False`):
|
| 38 |
-
option to use a convolution transpose.
|
| 39 |
-
out_channels (`int`, optional):
|
| 40 |
-
number of output channels. Defaults to `channels`.
|
| 41 |
-
"""
|
| 42 |
-
|
| 43 |
-
def __init__(self, channels, use_conv=False, use_conv_transpose=False, out_channels=None, name="conv"):
|
| 44 |
-
super().__init__()
|
| 45 |
-
self.channels = channels
|
| 46 |
-
self.out_channels = out_channels or channels
|
| 47 |
-
self.use_conv = use_conv
|
| 48 |
-
self.use_conv_transpose = use_conv_transpose
|
| 49 |
-
self.name = name
|
| 50 |
-
|
| 51 |
-
self.conv = None
|
| 52 |
-
if use_conv_transpose:
|
| 53 |
-
self.conv = nn.ConvTranspose1d(channels, self.out_channels, 4, 2, 1)
|
| 54 |
-
elif use_conv:
|
| 55 |
-
self.conv = nn.Conv1d(self.channels, self.out_channels, 3, padding=1)
|
| 56 |
-
|
| 57 |
-
def forward(self, inputs):
|
| 58 |
-
assert inputs.shape[1] == self.channels
|
| 59 |
-
if self.use_conv_transpose:
|
| 60 |
-
return self.conv(inputs)
|
| 61 |
-
|
| 62 |
-
outputs = F.interpolate(inputs, scale_factor=2.0, mode="nearest")
|
| 63 |
-
|
| 64 |
-
if self.use_conv:
|
| 65 |
-
outputs = self.conv(outputs)
|
| 66 |
-
|
| 67 |
-
return outputs
|
| 68 |
-
|
| 69 |
-
|
| 70 |
-
class Downsample1D(nn.Module):
|
| 71 |
-
"""A 1D downsampling layer with an optional convolution.
|
| 72 |
-
|
| 73 |
-
Parameters:
|
| 74 |
-
channels (`int`):
|
| 75 |
-
number of channels in the inputs and outputs.
|
| 76 |
-
use_conv (`bool`, default `False`):
|
| 77 |
-
option to use a convolution.
|
| 78 |
-
out_channels (`int`, optional):
|
| 79 |
-
number of output channels. Defaults to `channels`.
|
| 80 |
-
padding (`int`, default `1`):
|
| 81 |
-
padding for the convolution.
|
| 82 |
-
"""
|
| 83 |
-
|
| 84 |
-
def __init__(self, channels, use_conv=False, out_channels=None, padding=1, name="conv"):
|
| 85 |
-
super().__init__()
|
| 86 |
-
self.channels = channels
|
| 87 |
-
self.out_channels = out_channels or channels
|
| 88 |
-
self.use_conv = use_conv
|
| 89 |
-
self.padding = padding
|
| 90 |
-
stride = 2
|
| 91 |
-
self.name = name
|
| 92 |
-
|
| 93 |
-
if use_conv:
|
| 94 |
-
self.conv = nn.Conv1d(self.channels, self.out_channels, 3, stride=stride, padding=padding)
|
| 95 |
-
else:
|
| 96 |
-
assert self.channels == self.out_channels
|
| 97 |
-
self.conv = nn.AvgPool1d(kernel_size=stride, stride=stride)
|
| 98 |
-
|
| 99 |
-
def forward(self, inputs):
|
| 100 |
-
assert inputs.shape[1] == self.channels
|
| 101 |
-
return self.conv(inputs)
|
| 102 |
-
|
| 103 |
-
|
| 104 |
-
class Upsample2D(nn.Module):
|
| 105 |
-
"""A 2D upsampling layer with an optional convolution.
|
| 106 |
-
|
| 107 |
-
Parameters:
|
| 108 |
-
channels (`int`):
|
| 109 |
-
number of channels in the inputs and outputs.
|
| 110 |
-
use_conv (`bool`, default `False`):
|
| 111 |
-
option to use a convolution.
|
| 112 |
-
use_conv_transpose (`bool`, default `False`):
|
| 113 |
-
option to use a convolution transpose.
|
| 114 |
-
out_channels (`int`, optional):
|
| 115 |
-
number of output channels. Defaults to `channels`.
|
| 116 |
-
"""
|
| 117 |
-
|
| 118 |
-
def __init__(self, channels, use_conv=False, use_conv_transpose=False, out_channels=None, name="conv"):
|
| 119 |
-
super().__init__()
|
| 120 |
-
self.channels = channels
|
| 121 |
-
self.out_channels = out_channels or channels
|
| 122 |
-
self.use_conv = use_conv
|
| 123 |
-
self.use_conv_transpose = use_conv_transpose
|
| 124 |
-
self.name = name
|
| 125 |
-
|
| 126 |
-
conv = None
|
| 127 |
-
if use_conv_transpose:
|
| 128 |
-
conv = nn.ConvTranspose2d(channels, self.out_channels, 4, 2, 1)
|
| 129 |
-
elif use_conv:
|
| 130 |
-
conv = LoRACompatibleConv(self.channels, self.out_channels, 3, padding=1)
|
| 131 |
-
|
| 132 |
-
# TODO(Suraj, Patrick) - clean up after weight dicts are correctly renamed
|
| 133 |
-
if name == "conv":
|
| 134 |
-
self.conv = conv
|
| 135 |
-
else:
|
| 136 |
-
self.Conv2d_0 = conv
|
| 137 |
-
|
| 138 |
-
def forward(self, hidden_states, output_size=None):
|
| 139 |
-
assert hidden_states.shape[1] == self.channels
|
| 140 |
-
|
| 141 |
-
if self.use_conv_transpose:
|
| 142 |
-
return self.conv(hidden_states)
|
| 143 |
-
|
| 144 |
-
# Cast to float32 to as 'upsample_nearest2d_out_frame' op does not support bfloat16
|
| 145 |
-
# TODO(Suraj): Remove this cast once the issue is fixed in PyTorch
|
| 146 |
-
# https://github.com/pytorch/pytorch/issues/86679
|
| 147 |
-
dtype = hidden_states.dtype
|
| 148 |
-
if dtype == torch.bfloat16:
|
| 149 |
-
hidden_states = hidden_states.to(torch.float32)
|
| 150 |
-
|
| 151 |
-
# upsample_nearest_nhwc fails with large batch sizes. see https://github.com/huggingface/diffusers/issues/984
|
| 152 |
-
if hidden_states.shape[0] >= 64:
|
| 153 |
-
hidden_states = hidden_states.contiguous()
|
| 154 |
-
|
| 155 |
-
# if `output_size` is passed we force the interpolation output
|
| 156 |
-
# size and do not make use of `scale_factor=2`
|
| 157 |
-
if output_size is None:
|
| 158 |
-
hidden_states = F.interpolate(hidden_states, scale_factor=2.0, mode="nearest")
|
| 159 |
-
else:
|
| 160 |
-
hidden_states = F.interpolate(hidden_states, size=output_size, mode="nearest")
|
| 161 |
-
|
| 162 |
-
# If the input is bfloat16, we cast back to bfloat16
|
| 163 |
-
if dtype == torch.bfloat16:
|
| 164 |
-
hidden_states = hidden_states.to(dtype)
|
| 165 |
-
|
| 166 |
-
# TODO(Suraj, Patrick) - clean up after weight dicts are correctly renamed
|
| 167 |
-
if self.use_conv:
|
| 168 |
-
if self.name == "conv":
|
| 169 |
-
hidden_states = self.conv(hidden_states)
|
| 170 |
-
else:
|
| 171 |
-
hidden_states = self.Conv2d_0(hidden_states)
|
| 172 |
-
|
| 173 |
-
return hidden_states
|
| 174 |
-
|
| 175 |
-
|
| 176 |
-
class Downsample2D(nn.Module):
|
| 177 |
-
"""A 2D downsampling layer with an optional convolution.
|
| 178 |
-
|
| 179 |
-
Parameters:
|
| 180 |
-
channels (`int`):
|
| 181 |
-
number of channels in the inputs and outputs.
|
| 182 |
-
use_conv (`bool`, default `False`):
|
| 183 |
-
option to use a convolution.
|
| 184 |
-
out_channels (`int`, optional):
|
| 185 |
-
number of output channels. Defaults to `channels`.
|
| 186 |
-
padding (`int`, default `1`):
|
| 187 |
-
padding for the convolution.
|
| 188 |
-
"""
|
| 189 |
-
|
| 190 |
-
def __init__(self, channels, use_conv=False, out_channels=None, padding=1, name="conv"):
|
| 191 |
-
super().__init__()
|
| 192 |
-
self.channels = channels
|
| 193 |
-
self.out_channels = out_channels or channels
|
| 194 |
-
self.use_conv = use_conv
|
| 195 |
-
self.padding = padding
|
| 196 |
-
stride = 2
|
| 197 |
-
self.name = name
|
| 198 |
-
|
| 199 |
-
if use_conv:
|
| 200 |
-
conv = LoRACompatibleConv(self.channels, self.out_channels, 3, stride=stride, padding=padding)
|
| 201 |
-
else:
|
| 202 |
-
assert self.channels == self.out_channels
|
| 203 |
-
conv = nn.AvgPool2d(kernel_size=stride, stride=stride)
|
| 204 |
-
|
| 205 |
-
# TODO(Suraj, Patrick) - clean up after weight dicts are correctly renamed
|
| 206 |
-
if name == "conv":
|
| 207 |
-
self.Conv2d_0 = conv
|
| 208 |
-
self.conv = conv
|
| 209 |
-
elif name == "Conv2d_0":
|
| 210 |
-
self.conv = conv
|
| 211 |
-
else:
|
| 212 |
-
self.conv = conv
|
| 213 |
-
|
| 214 |
-
def forward(self, hidden_states):
|
| 215 |
-
assert hidden_states.shape[1] == self.channels
|
| 216 |
-
if self.use_conv and self.padding == 0:
|
| 217 |
-
pad = (0, 1, 0, 1)
|
| 218 |
-
hidden_states = F.pad(hidden_states, pad, mode="constant", value=0)
|
| 219 |
-
|
| 220 |
-
assert hidden_states.shape[1] == self.channels
|
| 221 |
-
hidden_states = self.conv(hidden_states)
|
| 222 |
-
|
| 223 |
-
return hidden_states
|
| 224 |
-
|
| 225 |
-
|
| 226 |
-
class FirUpsample2D(nn.Module):
|
| 227 |
-
"""A 2D FIR upsampling layer with an optional convolution.
|
| 228 |
-
|
| 229 |
-
Parameters:
|
| 230 |
-
channels (`int`):
|
| 231 |
-
number of channels in the inputs and outputs.
|
| 232 |
-
use_conv (`bool`, default `False`):
|
| 233 |
-
option to use a convolution.
|
| 234 |
-
out_channels (`int`, optional):
|
| 235 |
-
number of output channels. Defaults to `channels`.
|
| 236 |
-
fir_kernel (`tuple`, default `(1, 3, 3, 1)`):
|
| 237 |
-
kernel for the FIR filter.
|
| 238 |
-
"""
|
| 239 |
-
|
| 240 |
-
def __init__(self, channels=None, out_channels=None, use_conv=False, fir_kernel=(1, 3, 3, 1)):
|
| 241 |
-
super().__init__()
|
| 242 |
-
out_channels = out_channels if out_channels else channels
|
| 243 |
-
if use_conv:
|
| 244 |
-
self.Conv2d_0 = nn.Conv2d(channels, out_channels, kernel_size=3, stride=1, padding=1)
|
| 245 |
-
self.use_conv = use_conv
|
| 246 |
-
self.fir_kernel = fir_kernel
|
| 247 |
-
self.out_channels = out_channels
|
| 248 |
-
|
| 249 |
-
def _upsample_2d(self, hidden_states, weight=None, kernel=None, factor=2, gain=1):
|
| 250 |
-
"""Fused `upsample_2d()` followed by `Conv2d()`.
|
| 251 |
-
|
| 252 |
-
Padding is performed only once at the beginning, not between the operations. The fused op is considerably more
|
| 253 |
-
efficient than performing the same calculation using standard TensorFlow ops. It supports gradients of
|
| 254 |
-
arbitrary order.
|
| 255 |
-
|
| 256 |
-
Args:
|
| 257 |
-
hidden_states: Input tensor of the shape `[N, C, H, W]` or `[N, H, W, C]`.
|
| 258 |
-
weight: Weight tensor of the shape `[filterH, filterW, inChannels,
|
| 259 |
-
outChannels]`. Grouped convolution can be performed by `inChannels = x.shape[0] // numGroups`.
|
| 260 |
-
kernel: FIR filter of the shape `[firH, firW]` or `[firN]`
|
| 261 |
-
(separable). The default is `[1] * factor`, which corresponds to nearest-neighbor upsampling.
|
| 262 |
-
factor: Integer upsampling factor (default: 2).
|
| 263 |
-
gain: Scaling factor for signal magnitude (default: 1.0).
|
| 264 |
-
|
| 265 |
-
Returns:
|
| 266 |
-
output: Tensor of the shape `[N, C, H * factor, W * factor]` or `[N, H * factor, W * factor, C]`, and same
|
| 267 |
-
datatype as `hidden_states`.
|
| 268 |
-
"""
|
| 269 |
-
|
| 270 |
-
assert isinstance(factor, int) and factor >= 1
|
| 271 |
-
|
| 272 |
-
# Setup filter kernel.
|
| 273 |
-
if kernel is None:
|
| 274 |
-
kernel = [1] * factor
|
| 275 |
-
|
| 276 |
-
# setup kernel
|
| 277 |
-
kernel = torch.tensor(kernel, dtype=torch.float32)
|
| 278 |
-
if kernel.ndim == 1:
|
| 279 |
-
kernel = torch.outer(kernel, kernel)
|
| 280 |
-
kernel /= torch.sum(kernel)
|
| 281 |
-
|
| 282 |
-
kernel = kernel * (gain * (factor**2))
|
| 283 |
-
|
| 284 |
-
if self.use_conv:
|
| 285 |
-
convH = weight.shape[2]
|
| 286 |
-
convW = weight.shape[3]
|
| 287 |
-
inC = weight.shape[1]
|
| 288 |
-
|
| 289 |
-
pad_value = (kernel.shape[0] - factor) - (convW - 1)
|
| 290 |
-
|
| 291 |
-
stride = (factor, factor)
|
| 292 |
-
# Determine data dimensions.
|
| 293 |
-
output_shape = (
|
| 294 |
-
(hidden_states.shape[2] - 1) * factor + convH,
|
| 295 |
-
(hidden_states.shape[3] - 1) * factor + convW,
|
| 296 |
-
)
|
| 297 |
-
output_padding = (
|
| 298 |
-
output_shape[0] - (hidden_states.shape[2] - 1) * stride[0] - convH,
|
| 299 |
-
output_shape[1] - (hidden_states.shape[3] - 1) * stride[1] - convW,
|
| 300 |
-
)
|
| 301 |
-
assert output_padding[0] >= 0 and output_padding[1] >= 0
|
| 302 |
-
num_groups = hidden_states.shape[1] // inC
|
| 303 |
-
|
| 304 |
-
# Transpose weights.
|
| 305 |
-
weight = torch.reshape(weight, (num_groups, -1, inC, convH, convW))
|
| 306 |
-
weight = torch.flip(weight, dims=[3, 4]).permute(0, 2, 1, 3, 4)
|
| 307 |
-
weight = torch.reshape(weight, (num_groups * inC, -1, convH, convW))
|
| 308 |
-
|
| 309 |
-
inverse_conv = F.conv_transpose2d(
|
| 310 |
-
hidden_states, weight, stride=stride, output_padding=output_padding, padding=0
|
| 311 |
-
)
|
| 312 |
-
|
| 313 |
-
output = upfirdn2d_native(
|
| 314 |
-
inverse_conv,
|
| 315 |
-
torch.tensor(kernel, device=inverse_conv.device),
|
| 316 |
-
pad=((pad_value + 1) // 2 + factor - 1, pad_value // 2 + 1),
|
| 317 |
-
)
|
| 318 |
-
else:
|
| 319 |
-
pad_value = kernel.shape[0] - factor
|
| 320 |
-
output = upfirdn2d_native(
|
| 321 |
-
hidden_states,
|
| 322 |
-
torch.tensor(kernel, device=hidden_states.device),
|
| 323 |
-
up=factor,
|
| 324 |
-
pad=((pad_value + 1) // 2 + factor - 1, pad_value // 2),
|
| 325 |
-
)
|
| 326 |
-
|
| 327 |
-
return output
|
| 328 |
-
|
| 329 |
-
def forward(self, hidden_states):
|
| 330 |
-
if self.use_conv:
|
| 331 |
-
height = self._upsample_2d(hidden_states, self.Conv2d_0.weight, kernel=self.fir_kernel)
|
| 332 |
-
height = height + self.Conv2d_0.bias.reshape(1, -1, 1, 1)
|
| 333 |
-
else:
|
| 334 |
-
height = self._upsample_2d(hidden_states, kernel=self.fir_kernel, factor=2)
|
| 335 |
-
|
| 336 |
-
return height
|
| 337 |
-
|
| 338 |
-
|
| 339 |
-
class FirDownsample2D(nn.Module):
|
| 340 |
-
"""A 2D FIR downsampling layer with an optional convolution.
|
| 341 |
-
|
| 342 |
-
Parameters:
|
| 343 |
-
channels (`int`):
|
| 344 |
-
number of channels in the inputs and outputs.
|
| 345 |
-
use_conv (`bool`, default `False`):
|
| 346 |
-
option to use a convolution.
|
| 347 |
-
out_channels (`int`, optional):
|
| 348 |
-
number of output channels. Defaults to `channels`.
|
| 349 |
-
fir_kernel (`tuple`, default `(1, 3, 3, 1)`):
|
| 350 |
-
kernel for the FIR filter.
|
| 351 |
-
"""
|
| 352 |
-
|
| 353 |
-
def __init__(self, channels=None, out_channels=None, use_conv=False, fir_kernel=(1, 3, 3, 1)):
|
| 354 |
-
super().__init__()
|
| 355 |
-
out_channels = out_channels if out_channels else channels
|
| 356 |
-
if use_conv:
|
| 357 |
-
self.Conv2d_0 = nn.Conv2d(channels, out_channels, kernel_size=3, stride=1, padding=1)
|
| 358 |
-
self.fir_kernel = fir_kernel
|
| 359 |
-
self.use_conv = use_conv
|
| 360 |
-
self.out_channels = out_channels
|
| 361 |
-
|
| 362 |
-
def _downsample_2d(self, hidden_states, weight=None, kernel=None, factor=2, gain=1):
|
| 363 |
-
"""Fused `Conv2d()` followed by `downsample_2d()`.
|
| 364 |
-
Padding is performed only once at the beginning, not between the operations. The fused op is considerably more
|
| 365 |
-
efficient than performing the same calculation using standard TensorFlow ops. It supports gradients of
|
| 366 |
-
arbitrary order.
|
| 367 |
-
|
| 368 |
-
Args:
|
| 369 |
-
hidden_states: Input tensor of the shape `[N, C, H, W]` or `[N, H, W, C]`.
|
| 370 |
-
weight:
|
| 371 |
-
Weight tensor of the shape `[filterH, filterW, inChannels, outChannels]`. Grouped convolution can be
|
| 372 |
-
performed by `inChannels = x.shape[0] // numGroups`.
|
| 373 |
-
kernel: FIR filter of the shape `[firH, firW]` or `[firN]` (separable). The default is `[1] *
|
| 374 |
-
factor`, which corresponds to average pooling.
|
| 375 |
-
factor: Integer downsampling factor (default: 2).
|
| 376 |
-
gain: Scaling factor for signal magnitude (default: 1.0).
|
| 377 |
-
|
| 378 |
-
Returns:
|
| 379 |
-
output: Tensor of the shape `[N, C, H // factor, W // factor]` or `[N, H // factor, W // factor, C]`, and
|
| 380 |
-
same datatype as `x`.
|
| 381 |
-
"""
|
| 382 |
-
|
| 383 |
-
assert isinstance(factor, int) and factor >= 1
|
| 384 |
-
if kernel is None:
|
| 385 |
-
kernel = [1] * factor
|
| 386 |
-
|
| 387 |
-
# setup kernel
|
| 388 |
-
kernel = torch.tensor(kernel, dtype=torch.float32)
|
| 389 |
-
if kernel.ndim == 1:
|
| 390 |
-
kernel = torch.outer(kernel, kernel)
|
| 391 |
-
kernel /= torch.sum(kernel)
|
| 392 |
-
|
| 393 |
-
kernel = kernel * gain
|
| 394 |
-
|
| 395 |
-
if self.use_conv:
|
| 396 |
-
_, _, convH, convW = weight.shape
|
| 397 |
-
pad_value = (kernel.shape[0] - factor) + (convW - 1)
|
| 398 |
-
stride_value = [factor, factor]
|
| 399 |
-
upfirdn_input = upfirdn2d_native(
|
| 400 |
-
hidden_states,
|
| 401 |
-
torch.tensor(kernel, device=hidden_states.device),
|
| 402 |
-
pad=((pad_value + 1) // 2, pad_value // 2),
|
| 403 |
-
)
|
| 404 |
-
output = F.conv2d(upfirdn_input, weight, stride=stride_value, padding=0)
|
| 405 |
-
else:
|
| 406 |
-
pad_value = kernel.shape[0] - factor
|
| 407 |
-
output = upfirdn2d_native(
|
| 408 |
-
hidden_states,
|
| 409 |
-
torch.tensor(kernel, device=hidden_states.device),
|
| 410 |
-
down=factor,
|
| 411 |
-
pad=((pad_value + 1) // 2, pad_value // 2),
|
| 412 |
-
)
|
| 413 |
-
|
| 414 |
-
return output
|
| 415 |
-
|
| 416 |
-
def forward(self, hidden_states):
|
| 417 |
-
if self.use_conv:
|
| 418 |
-
downsample_input = self._downsample_2d(hidden_states, weight=self.Conv2d_0.weight, kernel=self.fir_kernel)
|
| 419 |
-
hidden_states = downsample_input + self.Conv2d_0.bias.reshape(1, -1, 1, 1)
|
| 420 |
-
else:
|
| 421 |
-
hidden_states = self._downsample_2d(hidden_states, kernel=self.fir_kernel, factor=2)
|
| 422 |
-
|
| 423 |
-
return hidden_states
|
| 424 |
-
|
| 425 |
-
|
| 426 |
-
# downsample/upsample layer used in k-upscaler, might be able to use FirDownsample2D/DirUpsample2D instead
|
| 427 |
-
class KDownsample2D(nn.Module):
|
| 428 |
-
def __init__(self, pad_mode="reflect"):
|
| 429 |
-
super().__init__()
|
| 430 |
-
self.pad_mode = pad_mode
|
| 431 |
-
kernel_1d = torch.tensor([[1 / 8, 3 / 8, 3 / 8, 1 / 8]])
|
| 432 |
-
self.pad = kernel_1d.shape[1] // 2 - 1
|
| 433 |
-
self.register_buffer("kernel", kernel_1d.T @ kernel_1d, persistent=False)
|
| 434 |
-
|
| 435 |
-
def forward(self, inputs):
|
| 436 |
-
inputs = F.pad(inputs, (self.pad,) * 4, self.pad_mode)
|
| 437 |
-
weight = inputs.new_zeros([inputs.shape[1], inputs.shape[1], self.kernel.shape[0], self.kernel.shape[1]])
|
| 438 |
-
indices = torch.arange(inputs.shape[1], device=inputs.device)
|
| 439 |
-
kernel = self.kernel.to(weight)[None, :].expand(inputs.shape[1], -1, -1)
|
| 440 |
-
weight[indices, indices] = kernel
|
| 441 |
-
return F.conv2d(inputs, weight, stride=2)
|
| 442 |
-
|
| 443 |
-
|
| 444 |
-
class KUpsample2D(nn.Module):
|
| 445 |
-
def __init__(self, pad_mode="reflect"):
|
| 446 |
-
super().__init__()
|
| 447 |
-
self.pad_mode = pad_mode
|
| 448 |
-
kernel_1d = torch.tensor([[1 / 8, 3 / 8, 3 / 8, 1 / 8]]) * 2
|
| 449 |
-
self.pad = kernel_1d.shape[1] // 2 - 1
|
| 450 |
-
self.register_buffer("kernel", kernel_1d.T @ kernel_1d, persistent=False)
|
| 451 |
-
|
| 452 |
-
def forward(self, inputs):
|
| 453 |
-
inputs = F.pad(inputs, ((self.pad + 1) // 2,) * 4, self.pad_mode)
|
| 454 |
-
weight = inputs.new_zeros([inputs.shape[1], inputs.shape[1], self.kernel.shape[0], self.kernel.shape[1]])
|
| 455 |
-
indices = torch.arange(inputs.shape[1], device=inputs.device)
|
| 456 |
-
kernel = self.kernel.to(weight)[None, :].expand(inputs.shape[1], -1, -1)
|
| 457 |
-
weight[indices, indices] = kernel
|
| 458 |
-
return F.conv_transpose2d(inputs, weight, stride=2, padding=self.pad * 2 + 1)
|
| 459 |
-
|
| 460 |
-
|
| 461 |
-
class ResnetBlock2D(nn.Module):
|
| 462 |
-
r"""
|
| 463 |
-
A Resnet block.
|
| 464 |
-
|
| 465 |
-
Parameters:
|
| 466 |
-
in_channels (`int`): The number of channels in the input.
|
| 467 |
-
out_channels (`int`, *optional*, default to be `None`):
|
| 468 |
-
The number of output channels for the first conv2d layer. If None, same as `in_channels`.
|
| 469 |
-
dropout (`float`, *optional*, defaults to `0.0`): The dropout probability to use.
|
| 470 |
-
temb_channels (`int`, *optional*, default to `512`): the number of channels in timestep embedding.
|
| 471 |
-
groups (`int`, *optional*, default to `32`): The number of groups to use for the first normalization layer.
|
| 472 |
-
groups_out (`int`, *optional*, default to None):
|
| 473 |
-
The number of groups to use for the second normalization layer. if set to None, same as `groups`.
|
| 474 |
-
eps (`float`, *optional*, defaults to `1e-6`): The epsilon to use for the normalization.
|
| 475 |
-
non_linearity (`str`, *optional*, default to `"swish"`): the activation function to use.
|
| 476 |
-
time_embedding_norm (`str`, *optional*, default to `"default"` ): Time scale shift config.
|
| 477 |
-
By default, apply timestep embedding conditioning with a simple shift mechanism. Choose "scale_shift" or
|
| 478 |
-
"ada_group" for a stronger conditioning with scale and shift.
|
| 479 |
-
kernel (`torch.FloatTensor`, optional, default to None): FIR filter, see
|
| 480 |
-
[`~models.resnet.FirUpsample2D`] and [`~models.resnet.FirDownsample2D`].
|
| 481 |
-
output_scale_factor (`float`, *optional*, default to be `1.0`): the scale factor to use for the output.
|
| 482 |
-
use_in_shortcut (`bool`, *optional*, default to `True`):
|
| 483 |
-
If `True`, add a 1x1 nn.conv2d layer for skip-connection.
|
| 484 |
-
up (`bool`, *optional*, default to `False`): If `True`, add an upsample layer.
|
| 485 |
-
down (`bool`, *optional*, default to `False`): If `True`, add a downsample layer.
|
| 486 |
-
conv_shortcut_bias (`bool`, *optional*, default to `True`): If `True`, adds a learnable bias to the
|
| 487 |
-
`conv_shortcut` output.
|
| 488 |
-
conv_2d_out_channels (`int`, *optional*, default to `None`): the number of channels in the output.
|
| 489 |
-
If None, same as `out_channels`.
|
| 490 |
-
"""
|
| 491 |
-
|
| 492 |
-
def __init__(
|
| 493 |
-
self,
|
| 494 |
-
*,
|
| 495 |
-
in_channels,
|
| 496 |
-
out_channels=None,
|
| 497 |
-
conv_shortcut=False,
|
| 498 |
-
dropout=0.0,
|
| 499 |
-
temb_channels=512,
|
| 500 |
-
groups=32,
|
| 501 |
-
groups_out=None,
|
| 502 |
-
pre_norm=True,
|
| 503 |
-
eps=1e-6,
|
| 504 |
-
non_linearity="swish",
|
| 505 |
-
skip_time_act=False,
|
| 506 |
-
time_embedding_norm="default", # default, scale_shift, ada_group, spatial
|
| 507 |
-
kernel=None,
|
| 508 |
-
output_scale_factor=1.0,
|
| 509 |
-
use_in_shortcut=None,
|
| 510 |
-
up=False,
|
| 511 |
-
down=False,
|
| 512 |
-
conv_shortcut_bias: bool = True,
|
| 513 |
-
conv_2d_out_channels: Optional[int] = None,
|
| 514 |
-
):
|
| 515 |
-
super().__init__()
|
| 516 |
-
self.pre_norm = pre_norm
|
| 517 |
-
self.pre_norm = True
|
| 518 |
-
self.in_channels = in_channels
|
| 519 |
-
out_channels = in_channels if out_channels is None else out_channels
|
| 520 |
-
self.out_channels = out_channels
|
| 521 |
-
self.use_conv_shortcut = conv_shortcut
|
| 522 |
-
self.up = up
|
| 523 |
-
self.down = down
|
| 524 |
-
self.output_scale_factor = output_scale_factor
|
| 525 |
-
self.time_embedding_norm = time_embedding_norm
|
| 526 |
-
self.skip_time_act = skip_time_act
|
| 527 |
-
|
| 528 |
-
if groups_out is None:
|
| 529 |
-
groups_out = groups
|
| 530 |
-
|
| 531 |
-
if self.time_embedding_norm == "ada_group":
|
| 532 |
-
self.norm1 = AdaGroupNorm(temb_channels, in_channels, groups, eps=eps)
|
| 533 |
-
elif self.time_embedding_norm == "spatial":
|
| 534 |
-
self.norm1 = SpatialNorm(in_channels, temb_channels)
|
| 535 |
-
else:
|
| 536 |
-
self.norm1 = torch.nn.GroupNorm(num_groups=groups, num_channels=in_channels, eps=eps, affine=True)
|
| 537 |
-
|
| 538 |
-
self.conv1 = LoRACompatibleConv(in_channels, out_channels, kernel_size=3, stride=1, padding=1)
|
| 539 |
-
|
| 540 |
-
if temb_channels is not None:
|
| 541 |
-
if self.time_embedding_norm == "default":
|
| 542 |
-
self.time_emb_proj = LoRACompatibleLinear(temb_channels, out_channels)
|
| 543 |
-
elif self.time_embedding_norm == "scale_shift":
|
| 544 |
-
self.time_emb_proj = LoRACompatibleLinear(temb_channels, 2 * out_channels)
|
| 545 |
-
elif self.time_embedding_norm == "ada_group" or self.time_embedding_norm == "spatial":
|
| 546 |
-
self.time_emb_proj = None
|
| 547 |
-
else:
|
| 548 |
-
raise ValueError(f"unknown time_embedding_norm : {self.time_embedding_norm} ")
|
| 549 |
-
else:
|
| 550 |
-
self.time_emb_proj = None
|
| 551 |
-
|
| 552 |
-
if self.time_embedding_norm == "ada_group":
|
| 553 |
-
self.norm2 = AdaGroupNorm(temb_channels, out_channels, groups_out, eps=eps)
|
| 554 |
-
elif self.time_embedding_norm == "spatial":
|
| 555 |
-
self.norm2 = SpatialNorm(out_channels, temb_channels)
|
| 556 |
-
else:
|
| 557 |
-
self.norm2 = torch.nn.GroupNorm(num_groups=groups_out, num_channels=out_channels, eps=eps, affine=True)
|
| 558 |
-
|
| 559 |
-
self.dropout = torch.nn.Dropout(dropout)
|
| 560 |
-
conv_2d_out_channels = conv_2d_out_channels or out_channels
|
| 561 |
-
self.conv2 = LoRACompatibleConv(out_channels, conv_2d_out_channels, kernel_size=3, stride=1, padding=1)
|
| 562 |
-
|
| 563 |
-
self.nonlinearity = get_activation(non_linearity)
|
| 564 |
-
|
| 565 |
-
self.upsample = self.downsample = None
|
| 566 |
-
if self.up:
|
| 567 |
-
if kernel == "fir":
|
| 568 |
-
fir_kernel = (1, 3, 3, 1)
|
| 569 |
-
self.upsample = lambda x: upsample_2d(x, kernel=fir_kernel)
|
| 570 |
-
elif kernel == "sde_vp":
|
| 571 |
-
self.upsample = partial(F.interpolate, scale_factor=2.0, mode="nearest")
|
| 572 |
-
else:
|
| 573 |
-
self.upsample = Upsample2D(in_channels, use_conv=False)
|
| 574 |
-
elif self.down:
|
| 575 |
-
if kernel == "fir":
|
| 576 |
-
fir_kernel = (1, 3, 3, 1)
|
| 577 |
-
self.downsample = lambda x: downsample_2d(x, kernel=fir_kernel)
|
| 578 |
-
elif kernel == "sde_vp":
|
| 579 |
-
self.downsample = partial(F.avg_pool2d, kernel_size=2, stride=2)
|
| 580 |
-
else:
|
| 581 |
-
self.downsample = Downsample2D(in_channels, use_conv=False, padding=1, name="op")
|
| 582 |
-
|
| 583 |
-
self.use_in_shortcut = self.in_channels != conv_2d_out_channels if use_in_shortcut is None else use_in_shortcut
|
| 584 |
-
|
| 585 |
-
self.conv_shortcut = None
|
| 586 |
-
if self.use_in_shortcut:
|
| 587 |
-
self.conv_shortcut = LoRACompatibleConv(
|
| 588 |
-
in_channels, conv_2d_out_channels, kernel_size=1, stride=1, padding=0, bias=conv_shortcut_bias
|
| 589 |
-
)
|
| 590 |
-
|
| 591 |
-
def forward(self, input_tensor, temb):
|
| 592 |
-
hidden_states = input_tensor
|
| 593 |
-
|
| 594 |
-
if self.time_embedding_norm == "ada_group" or self.time_embedding_norm == "spatial":
|
| 595 |
-
hidden_states = self.norm1(hidden_states, temb)
|
| 596 |
-
else:
|
| 597 |
-
hidden_states = self.norm1(hidden_states)
|
| 598 |
-
|
| 599 |
-
hidden_states = self.nonlinearity(hidden_states)
|
| 600 |
-
|
| 601 |
-
if self.upsample is not None:
|
| 602 |
-
# upsample_nearest_nhwc fails with large batch sizes. see https://github.com/huggingface/diffusers/issues/984
|
| 603 |
-
if hidden_states.shape[0] >= 64:
|
| 604 |
-
input_tensor = input_tensor.contiguous()
|
| 605 |
-
hidden_states = hidden_states.contiguous()
|
| 606 |
-
input_tensor = self.upsample(input_tensor)
|
| 607 |
-
hidden_states = self.upsample(hidden_states)
|
| 608 |
-
elif self.downsample is not None:
|
| 609 |
-
input_tensor = self.downsample(input_tensor)
|
| 610 |
-
hidden_states = self.downsample(hidden_states)
|
| 611 |
-
|
| 612 |
-
hidden_states = self.conv1(hidden_states)
|
| 613 |
-
|
| 614 |
-
if self.time_emb_proj is not None:
|
| 615 |
-
if not self.skip_time_act:
|
| 616 |
-
temb = self.nonlinearity(temb)
|
| 617 |
-
temb = self.time_emb_proj(temb)[:, :, None, None]
|
| 618 |
-
|
| 619 |
-
if temb is not None and self.time_embedding_norm == "default":
|
| 620 |
-
hidden_states = hidden_states + temb
|
| 621 |
-
|
| 622 |
-
if self.time_embedding_norm == "ada_group" or self.time_embedding_norm == "spatial":
|
| 623 |
-
hidden_states = self.norm2(hidden_states, temb)
|
| 624 |
-
else:
|
| 625 |
-
hidden_states = self.norm2(hidden_states)
|
| 626 |
-
|
| 627 |
-
if temb is not None and self.time_embedding_norm == "scale_shift":
|
| 628 |
-
scale, shift = torch.chunk(temb, 2, dim=1)
|
| 629 |
-
hidden_states = hidden_states * (1 + scale) + shift
|
| 630 |
-
|
| 631 |
-
hidden_states = self.nonlinearity(hidden_states)
|
| 632 |
-
|
| 633 |
-
hidden_states = self.dropout(hidden_states)
|
| 634 |
-
hidden_states = self.conv2(hidden_states)
|
| 635 |
-
|
| 636 |
-
if self.conv_shortcut is not None:
|
| 637 |
-
input_tensor = self.conv_shortcut(input_tensor)
|
| 638 |
-
|
| 639 |
-
output_tensor = (input_tensor + hidden_states) / self.output_scale_factor
|
| 640 |
-
|
| 641 |
-
return output_tensor
|
| 642 |
-
|
| 643 |
-
|
| 644 |
-
# unet_rl.py
|
| 645 |
-
def rearrange_dims(tensor):
|
| 646 |
-
if len(tensor.shape) == 2:
|
| 647 |
-
return tensor[:, :, None]
|
| 648 |
-
if len(tensor.shape) == 3:
|
| 649 |
-
return tensor[:, :, None, :]
|
| 650 |
-
elif len(tensor.shape) == 4:
|
| 651 |
-
return tensor[:, :, 0, :]
|
| 652 |
-
else:
|
| 653 |
-
raise ValueError(f"`len(tensor)`: {len(tensor)} has to be 2, 3 or 4.")
|
| 654 |
-
|
| 655 |
-
|
| 656 |
-
class Conv1dBlock(nn.Module):
|
| 657 |
-
"""
|
| 658 |
-
Conv1d --> GroupNorm --> Mish
|
| 659 |
-
"""
|
| 660 |
-
|
| 661 |
-
def __init__(self, inp_channels, out_channels, kernel_size, n_groups=8):
|
| 662 |
-
super().__init__()
|
| 663 |
-
|
| 664 |
-
self.conv1d = nn.Conv1d(inp_channels, out_channels, kernel_size, padding=kernel_size // 2)
|
| 665 |
-
self.group_norm = nn.GroupNorm(n_groups, out_channels)
|
| 666 |
-
self.mish = nn.Mish()
|
| 667 |
-
|
| 668 |
-
def forward(self, inputs):
|
| 669 |
-
intermediate_repr = self.conv1d(inputs)
|
| 670 |
-
intermediate_repr = rearrange_dims(intermediate_repr)
|
| 671 |
-
intermediate_repr = self.group_norm(intermediate_repr)
|
| 672 |
-
intermediate_repr = rearrange_dims(intermediate_repr)
|
| 673 |
-
output = self.mish(intermediate_repr)
|
| 674 |
-
return output
|
| 675 |
-
|
| 676 |
-
|
| 677 |
-
# unet_rl.py
|
| 678 |
-
class ResidualTemporalBlock1D(nn.Module):
|
| 679 |
-
def __init__(self, inp_channels, out_channels, embed_dim, kernel_size=5):
|
| 680 |
-
super().__init__()
|
| 681 |
-
self.conv_in = Conv1dBlock(inp_channels, out_channels, kernel_size)
|
| 682 |
-
self.conv_out = Conv1dBlock(out_channels, out_channels, kernel_size)
|
| 683 |
-
|
| 684 |
-
self.time_emb_act = nn.Mish()
|
| 685 |
-
self.time_emb = nn.Linear(embed_dim, out_channels)
|
| 686 |
-
|
| 687 |
-
self.residual_conv = (
|
| 688 |
-
nn.Conv1d(inp_channels, out_channels, 1) if inp_channels != out_channels else nn.Identity()
|
| 689 |
-
)
|
| 690 |
-
|
| 691 |
-
def forward(self, inputs, t):
|
| 692 |
-
"""
|
| 693 |
-
Args:
|
| 694 |
-
inputs : [ batch_size x inp_channels x horizon ]
|
| 695 |
-
t : [ batch_size x embed_dim ]
|
| 696 |
-
|
| 697 |
-
returns:
|
| 698 |
-
out : [ batch_size x out_channels x horizon ]
|
| 699 |
-
"""
|
| 700 |
-
t = self.time_emb_act(t)
|
| 701 |
-
t = self.time_emb(t)
|
| 702 |
-
out = self.conv_in(inputs) + rearrange_dims(t)
|
| 703 |
-
out = self.conv_out(out)
|
| 704 |
-
return out + self.residual_conv(inputs)
|
| 705 |
-
|
| 706 |
-
|
| 707 |
-
def upsample_2d(hidden_states, kernel=None, factor=2, gain=1):
|
| 708 |
-
r"""Upsample2D a batch of 2D images with the given filter.
|
| 709 |
-
Accepts a batch of 2D images of the shape `[N, C, H, W]` or `[N, H, W, C]` and upsamples each image with the given
|
| 710 |
-
filter. The filter is normalized so that if the input pixels are constant, they will be scaled by the specified
|
| 711 |
-
`gain`. Pixels outside the image are assumed to be zero, and the filter is padded with zeros so that its shape is
|
| 712 |
-
a: multiple of the upsampling factor.
|
| 713 |
-
|
| 714 |
-
Args:
|
| 715 |
-
hidden_states: Input tensor of the shape `[N, C, H, W]` or `[N, H, W, C]`.
|
| 716 |
-
kernel: FIR filter of the shape `[firH, firW]` or `[firN]`
|
| 717 |
-
(separable). The default is `[1] * factor`, which corresponds to nearest-neighbor upsampling.
|
| 718 |
-
factor: Integer upsampling factor (default: 2).
|
| 719 |
-
gain: Scaling factor for signal magnitude (default: 1.0).
|
| 720 |
-
|
| 721 |
-
Returns:
|
| 722 |
-
output: Tensor of the shape `[N, C, H * factor, W * factor]`
|
| 723 |
-
"""
|
| 724 |
-
assert isinstance(factor, int) and factor >= 1
|
| 725 |
-
if kernel is None:
|
| 726 |
-
kernel = [1] * factor
|
| 727 |
-
|
| 728 |
-
kernel = torch.tensor(kernel, dtype=torch.float32)
|
| 729 |
-
if kernel.ndim == 1:
|
| 730 |
-
kernel = torch.outer(kernel, kernel)
|
| 731 |
-
kernel /= torch.sum(kernel)
|
| 732 |
-
|
| 733 |
-
kernel = kernel * (gain * (factor**2))
|
| 734 |
-
pad_value = kernel.shape[0] - factor
|
| 735 |
-
output = upfirdn2d_native(
|
| 736 |
-
hidden_states,
|
| 737 |
-
kernel.to(device=hidden_states.device),
|
| 738 |
-
up=factor,
|
| 739 |
-
pad=((pad_value + 1) // 2 + factor - 1, pad_value // 2),
|
| 740 |
-
)
|
| 741 |
-
return output
|
| 742 |
-
|
| 743 |
-
|
| 744 |
-
def downsample_2d(hidden_states, kernel=None, factor=2, gain=1):
|
| 745 |
-
r"""Downsample2D a batch of 2D images with the given filter.
|
| 746 |
-
Accepts a batch of 2D images of the shape `[N, C, H, W]` or `[N, H, W, C]` and downsamples each image with the
|
| 747 |
-
given filter. The filter is normalized so that if the input pixels are constant, they will be scaled by the
|
| 748 |
-
specified `gain`. Pixels outside the image are assumed to be zero, and the filter is padded with zeros so that its
|
| 749 |
-
shape is a multiple of the downsampling factor.
|
| 750 |
-
|
| 751 |
-
Args:
|
| 752 |
-
hidden_states: Input tensor of the shape `[N, C, H, W]` or `[N, H, W, C]`.
|
| 753 |
-
kernel: FIR filter of the shape `[firH, firW]` or `[firN]`
|
| 754 |
-
(separable). The default is `[1] * factor`, which corresponds to average pooling.
|
| 755 |
-
factor: Integer downsampling factor (default: 2).
|
| 756 |
-
gain: Scaling factor for signal magnitude (default: 1.0).
|
| 757 |
-
|
| 758 |
-
Returns:
|
| 759 |
-
output: Tensor of the shape `[N, C, H // factor, W // factor]`
|
| 760 |
-
"""
|
| 761 |
-
|
| 762 |
-
assert isinstance(factor, int) and factor >= 1
|
| 763 |
-
if kernel is None:
|
| 764 |
-
kernel = [1] * factor
|
| 765 |
-
|
| 766 |
-
kernel = torch.tensor(kernel, dtype=torch.float32)
|
| 767 |
-
if kernel.ndim == 1:
|
| 768 |
-
kernel = torch.outer(kernel, kernel)
|
| 769 |
-
kernel /= torch.sum(kernel)
|
| 770 |
-
|
| 771 |
-
kernel = kernel * gain
|
| 772 |
-
pad_value = kernel.shape[0] - factor
|
| 773 |
-
output = upfirdn2d_native(
|
| 774 |
-
hidden_states, kernel.to(device=hidden_states.device), down=factor, pad=((pad_value + 1) // 2, pad_value // 2)
|
| 775 |
-
)
|
| 776 |
-
return output
|
| 777 |
-
|
| 778 |
-
|
| 779 |
-
def upfirdn2d_native(tensor, kernel, up=1, down=1, pad=(0, 0)):
|
| 780 |
-
up_x = up_y = up
|
| 781 |
-
down_x = down_y = down
|
| 782 |
-
pad_x0 = pad_y0 = pad[0]
|
| 783 |
-
pad_x1 = pad_y1 = pad[1]
|
| 784 |
-
|
| 785 |
-
_, channel, in_h, in_w = tensor.shape
|
| 786 |
-
tensor = tensor.reshape(-1, in_h, in_w, 1)
|
| 787 |
-
|
| 788 |
-
_, in_h, in_w, minor = tensor.shape
|
| 789 |
-
kernel_h, kernel_w = kernel.shape
|
| 790 |
-
|
| 791 |
-
out = tensor.view(-1, in_h, 1, in_w, 1, minor)
|
| 792 |
-
out = F.pad(out, [0, 0, 0, up_x - 1, 0, 0, 0, up_y - 1])
|
| 793 |
-
out = out.view(-1, in_h * up_y, in_w * up_x, minor)
|
| 794 |
-
|
| 795 |
-
out = F.pad(out, [0, 0, max(pad_x0, 0), max(pad_x1, 0), max(pad_y0, 0), max(pad_y1, 0)])
|
| 796 |
-
out = out.to(tensor.device) # Move back to mps if necessary
|
| 797 |
-
out = out[
|
| 798 |
-
:,
|
| 799 |
-
max(-pad_y0, 0) : out.shape[1] - max(-pad_y1, 0),
|
| 800 |
-
max(-pad_x0, 0) : out.shape[2] - max(-pad_x1, 0),
|
| 801 |
-
:,
|
| 802 |
-
]
|
| 803 |
-
|
| 804 |
-
out = out.permute(0, 3, 1, 2)
|
| 805 |
-
out = out.reshape([-1, 1, in_h * up_y + pad_y0 + pad_y1, in_w * up_x + pad_x0 + pad_x1])
|
| 806 |
-
w = torch.flip(kernel, [0, 1]).view(1, 1, kernel_h, kernel_w)
|
| 807 |
-
out = F.conv2d(out, w)
|
| 808 |
-
out = out.reshape(
|
| 809 |
-
-1,
|
| 810 |
-
minor,
|
| 811 |
-
in_h * up_y + pad_y0 + pad_y1 - kernel_h + 1,
|
| 812 |
-
in_w * up_x + pad_x0 + pad_x1 - kernel_w + 1,
|
| 813 |
-
)
|
| 814 |
-
out = out.permute(0, 2, 3, 1)
|
| 815 |
-
out = out[:, ::down_y, ::down_x, :]
|
| 816 |
-
|
| 817 |
-
out_h = (in_h * up_y + pad_y0 + pad_y1 - kernel_h) // down_y + 1
|
| 818 |
-
out_w = (in_w * up_x + pad_x0 + pad_x1 - kernel_w) // down_x + 1
|
| 819 |
-
|
| 820 |
-
return out.view(-1, channel, out_h, out_w)
|
| 821 |
-
|
| 822 |
-
|
| 823 |
-
class TemporalConvLayer(nn.Module):
|
| 824 |
-
"""
|
| 825 |
-
Temporal convolutional layer that can be used for video (sequence of images) input Code mostly copied from:
|
| 826 |
-
https://github.com/modelscope/modelscope/blob/1509fdb973e5871f37148a4b5e5964cafd43e64d/modelscope/models/multi_modal/video_synthesis/unet_sd.py#L1016
|
| 827 |
-
"""
|
| 828 |
-
|
| 829 |
-
def __init__(self, in_dim, out_dim=None, dropout=0.0):
|
| 830 |
-
super().__init__()
|
| 831 |
-
out_dim = out_dim or in_dim
|
| 832 |
-
self.in_dim = in_dim
|
| 833 |
-
self.out_dim = out_dim
|
| 834 |
-
|
| 835 |
-
# conv layers
|
| 836 |
-
self.conv1 = nn.Sequential(
|
| 837 |
-
nn.GroupNorm(32, in_dim), nn.SiLU(), nn.Conv3d(in_dim, out_dim, (3, 1, 1), padding=(1, 0, 0))
|
| 838 |
-
)
|
| 839 |
-
self.conv2 = nn.Sequential(
|
| 840 |
-
nn.GroupNorm(32, out_dim),
|
| 841 |
-
nn.SiLU(),
|
| 842 |
-
nn.Dropout(dropout),
|
| 843 |
-
nn.Conv3d(out_dim, in_dim, (3, 1, 1), padding=(1, 0, 0)),
|
| 844 |
-
)
|
| 845 |
-
self.conv3 = nn.Sequential(
|
| 846 |
-
nn.GroupNorm(32, out_dim),
|
| 847 |
-
nn.SiLU(),
|
| 848 |
-
nn.Dropout(dropout),
|
| 849 |
-
nn.Conv3d(out_dim, in_dim, (3, 1, 1), padding=(1, 0, 0)),
|
| 850 |
-
)
|
| 851 |
-
self.conv4 = nn.Sequential(
|
| 852 |
-
nn.GroupNorm(32, out_dim),
|
| 853 |
-
nn.SiLU(),
|
| 854 |
-
nn.Dropout(dropout),
|
| 855 |
-
nn.Conv3d(out_dim, in_dim, (3, 1, 1), padding=(1, 0, 0)),
|
| 856 |
-
)
|
| 857 |
-
|
| 858 |
-
# zero out the last layer params,so the conv block is identity
|
| 859 |
-
nn.init.zeros_(self.conv4[-1].weight)
|
| 860 |
-
nn.init.zeros_(self.conv4[-1].bias)
|
| 861 |
-
|
| 862 |
-
def forward(self, hidden_states, num_frames=1):
|
| 863 |
-
hidden_states = (
|
| 864 |
-
hidden_states[None, :].reshape((-1, num_frames) + hidden_states.shape[1:]).permute(0, 2, 1, 3, 4)
|
| 865 |
-
)
|
| 866 |
-
|
| 867 |
-
identity = hidden_states
|
| 868 |
-
hidden_states = self.conv1(hidden_states)
|
| 869 |
-
hidden_states = self.conv2(hidden_states)
|
| 870 |
-
hidden_states = self.conv3(hidden_states)
|
| 871 |
-
hidden_states = self.conv4(hidden_states)
|
| 872 |
-
|
| 873 |
-
hidden_states = identity + hidden_states
|
| 874 |
-
|
| 875 |
-
hidden_states = hidden_states.permute(0, 2, 1, 3, 4).reshape(
|
| 876 |
-
(hidden_states.shape[0] * hidden_states.shape[2], -1) + hidden_states.shape[3:]
|
| 877 |
-
)
|
| 878 |
-
return hidden_states
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/Androidonnxfork/CivitAi-to-Diffusers/diffusers/tests/pipelines/text_to_video/test_text_to_video_zero.py
DELETED
|
@@ -1,42 +0,0 @@
|
|
| 1 |
-
# coding=utf-8
|
| 2 |
-
# Copyright 2023 HuggingFace Inc.
|
| 3 |
-
#
|
| 4 |
-
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
-
# you may not use this file except in compliance with the License.
|
| 6 |
-
# You may obtain a copy of the License at
|
| 7 |
-
#
|
| 8 |
-
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
-
#
|
| 10 |
-
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
-
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
-
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
-
# See the License for the specific language governing permissions and
|
| 14 |
-
# limitations under the License.
|
| 15 |
-
|
| 16 |
-
import unittest
|
| 17 |
-
|
| 18 |
-
import torch
|
| 19 |
-
|
| 20 |
-
from diffusers import DDIMScheduler, TextToVideoZeroPipeline
|
| 21 |
-
from diffusers.utils import load_pt, require_torch_gpu, slow
|
| 22 |
-
|
| 23 |
-
from ..test_pipelines_common import assert_mean_pixel_difference
|
| 24 |
-
|
| 25 |
-
|
| 26 |
-
@slow
|
| 27 |
-
@require_torch_gpu
|
| 28 |
-
class TextToVideoZeroPipelineSlowTests(unittest.TestCase):
|
| 29 |
-
def test_full_model(self):
|
| 30 |
-
model_id = "runwayml/stable-diffusion-v1-5"
|
| 31 |
-
pipe = TextToVideoZeroPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
|
| 32 |
-
pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config)
|
| 33 |
-
generator = torch.Generator(device="cuda").manual_seed(0)
|
| 34 |
-
|
| 35 |
-
prompt = "A bear is playing a guitar on Times Square"
|
| 36 |
-
result = pipe(prompt=prompt, generator=generator).images
|
| 37 |
-
|
| 38 |
-
expected_result = load_pt(
|
| 39 |
-
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/text-to-video/A bear is playing a guitar on Times Square.pt"
|
| 40 |
-
)
|
| 41 |
-
|
| 42 |
-
assert_mean_pixel_difference(result, expected_result)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/Andy1621/uniformer_image_detection/configs/nas_fpn/retinanet_r50_fpn_crop640_50e_coco.py
DELETED
|
@@ -1,80 +0,0 @@
|
|
| 1 |
-
_base_ = [
|
| 2 |
-
'../_base_/models/retinanet_r50_fpn.py',
|
| 3 |
-
'../_base_/datasets/coco_detection.py', '../_base_/default_runtime.py'
|
| 4 |
-
]
|
| 5 |
-
cudnn_benchmark = True
|
| 6 |
-
norm_cfg = dict(type='BN', requires_grad=True)
|
| 7 |
-
model = dict(
|
| 8 |
-
pretrained='torchvision://resnet50',
|
| 9 |
-
backbone=dict(
|
| 10 |
-
type='ResNet',
|
| 11 |
-
depth=50,
|
| 12 |
-
num_stages=4,
|
| 13 |
-
out_indices=(0, 1, 2, 3),
|
| 14 |
-
frozen_stages=1,
|
| 15 |
-
norm_cfg=norm_cfg,
|
| 16 |
-
norm_eval=False,
|
| 17 |
-
style='pytorch'),
|
| 18 |
-
neck=dict(
|
| 19 |
-
relu_before_extra_convs=True,
|
| 20 |
-
no_norm_on_lateral=True,
|
| 21 |
-
norm_cfg=norm_cfg),
|
| 22 |
-
bbox_head=dict(type='RetinaSepBNHead', num_ins=5, norm_cfg=norm_cfg),
|
| 23 |
-
# training and testing settings
|
| 24 |
-
train_cfg=dict(assigner=dict(neg_iou_thr=0.5)))
|
| 25 |
-
# dataset settings
|
| 26 |
-
img_norm_cfg = dict(
|
| 27 |
-
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
|
| 28 |
-
train_pipeline = [
|
| 29 |
-
dict(type='LoadImageFromFile'),
|
| 30 |
-
dict(type='LoadAnnotations', with_bbox=True),
|
| 31 |
-
dict(
|
| 32 |
-
type='Resize',
|
| 33 |
-
img_scale=(640, 640),
|
| 34 |
-
ratio_range=(0.8, 1.2),
|
| 35 |
-
keep_ratio=True),
|
| 36 |
-
dict(type='RandomCrop', crop_size=(640, 640)),
|
| 37 |
-
dict(type='RandomFlip', flip_ratio=0.5),
|
| 38 |
-
dict(type='Normalize', **img_norm_cfg),
|
| 39 |
-
dict(type='Pad', size=(640, 640)),
|
| 40 |
-
dict(type='DefaultFormatBundle'),
|
| 41 |
-
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),
|
| 42 |
-
]
|
| 43 |
-
test_pipeline = [
|
| 44 |
-
dict(type='LoadImageFromFile'),
|
| 45 |
-
dict(
|
| 46 |
-
type='MultiScaleFlipAug',
|
| 47 |
-
img_scale=(640, 640),
|
| 48 |
-
flip=False,
|
| 49 |
-
transforms=[
|
| 50 |
-
dict(type='Resize', keep_ratio=True),
|
| 51 |
-
dict(type='RandomFlip'),
|
| 52 |
-
dict(type='Normalize', **img_norm_cfg),
|
| 53 |
-
dict(type='Pad', size_divisor=64),
|
| 54 |
-
dict(type='ImageToTensor', keys=['img']),
|
| 55 |
-
dict(type='Collect', keys=['img']),
|
| 56 |
-
])
|
| 57 |
-
]
|
| 58 |
-
data = dict(
|
| 59 |
-
samples_per_gpu=8,
|
| 60 |
-
workers_per_gpu=4,
|
| 61 |
-
train=dict(pipeline=train_pipeline),
|
| 62 |
-
val=dict(pipeline=test_pipeline),
|
| 63 |
-
test=dict(pipeline=test_pipeline))
|
| 64 |
-
# optimizer
|
| 65 |
-
optimizer = dict(
|
| 66 |
-
type='SGD',
|
| 67 |
-
lr=0.08,
|
| 68 |
-
momentum=0.9,
|
| 69 |
-
weight_decay=0.0001,
|
| 70 |
-
paramwise_cfg=dict(norm_decay_mult=0, bypass_duplicate=True))
|
| 71 |
-
optimizer_config = dict(grad_clip=None)
|
| 72 |
-
# learning policy
|
| 73 |
-
lr_config = dict(
|
| 74 |
-
policy='step',
|
| 75 |
-
warmup='linear',
|
| 76 |
-
warmup_iters=1000,
|
| 77 |
-
warmup_ratio=0.1,
|
| 78 |
-
step=[30, 40])
|
| 79 |
-
# runtime settings
|
| 80 |
-
runner = dict(type='EpochBasedRunner', max_epochs=50)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/AnishKumbhar/ChatBot/text-generation-webui-main/extensions/superbooga/download_urls.py
DELETED
|
@@ -1,35 +0,0 @@
|
|
| 1 |
-
import concurrent.futures
|
| 2 |
-
|
| 3 |
-
import requests
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
def download_single(url):
|
| 7 |
-
headers = {
|
| 8 |
-
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
|
| 9 |
-
}
|
| 10 |
-
response = requests.get(url, headers=headers, timeout=5)
|
| 11 |
-
if response.status_code == 200:
|
| 12 |
-
return response.content
|
| 13 |
-
else:
|
| 14 |
-
raise Exception("Failed to download URL")
|
| 15 |
-
|
| 16 |
-
|
| 17 |
-
def download_urls(urls, threads=1):
|
| 18 |
-
with concurrent.futures.ThreadPoolExecutor(max_workers=threads) as executor:
|
| 19 |
-
futures = []
|
| 20 |
-
for url in urls:
|
| 21 |
-
future = executor.submit(download_single, url)
|
| 22 |
-
futures.append(future)
|
| 23 |
-
|
| 24 |
-
results = []
|
| 25 |
-
i = 0
|
| 26 |
-
for future in concurrent.futures.as_completed(futures):
|
| 27 |
-
try:
|
| 28 |
-
result = future.result()
|
| 29 |
-
results.append(result)
|
| 30 |
-
i += 1
|
| 31 |
-
yield f"{i}/{len(urls)}", results
|
| 32 |
-
except Exception:
|
| 33 |
-
pass
|
| 34 |
-
|
| 35 |
-
yield "Done", results
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/Anonymous-123/ImageNet-Editing/object_removal/TFill/model/__init__.py
DELETED
|
@@ -1,34 +0,0 @@
|
|
| 1 |
-
"""This package contains modules related to function, network architectures, and models"""
|
| 2 |
-
|
| 3 |
-
import importlib
|
| 4 |
-
from .base_model import BaseModel
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
def find_model_using_name(model_name):
|
| 8 |
-
"""Import the module "model/[model_name]_model.py"."""
|
| 9 |
-
model_file_name = "model." + model_name + "_model"
|
| 10 |
-
modellib = importlib.import_module(model_file_name)
|
| 11 |
-
model = None
|
| 12 |
-
for name, cls in modellib.__dict__.items():
|
| 13 |
-
if name.lower() == model_name.lower() and issubclass(cls, BaseModel):
|
| 14 |
-
model = cls
|
| 15 |
-
|
| 16 |
-
if model is None:
|
| 17 |
-
print("In %s.py, there should be a subclass of BaseModel with class name that matches %s in lowercase." % (model_file_name, model_name))
|
| 18 |
-
exit(0)
|
| 19 |
-
|
| 20 |
-
return model
|
| 21 |
-
|
| 22 |
-
|
| 23 |
-
def get_option_setter(model_name):
|
| 24 |
-
"""Return the static method <modify_commandline_options> of the model class."""
|
| 25 |
-
model = find_model_using_name(model_name)
|
| 26 |
-
return model.modify_options
|
| 27 |
-
|
| 28 |
-
|
| 29 |
-
def create_model(opt):
|
| 30 |
-
"""Create a model given the option."""
|
| 31 |
-
model = find_model_using_name(opt.model)
|
| 32 |
-
instance = model(opt)
|
| 33 |
-
print("model [%s] was created" % type(instance).__name__)
|
| 34 |
-
return instance
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/Anonymous-sub/Rerender/ControlNet/ldm/models/diffusion/dpm_solver/sampler.py
DELETED
|
@@ -1,87 +0,0 @@
|
|
| 1 |
-
"""SAMPLING ONLY."""
|
| 2 |
-
import torch
|
| 3 |
-
|
| 4 |
-
from .dpm_solver import NoiseScheduleVP, model_wrapper, DPM_Solver
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
MODEL_TYPES = {
|
| 8 |
-
"eps": "noise",
|
| 9 |
-
"v": "v"
|
| 10 |
-
}
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
class DPMSolverSampler(object):
|
| 14 |
-
def __init__(self, model, **kwargs):
|
| 15 |
-
super().__init__()
|
| 16 |
-
self.model = model
|
| 17 |
-
to_torch = lambda x: x.clone().detach().to(torch.float32).to(model.device)
|
| 18 |
-
self.register_buffer('alphas_cumprod', to_torch(model.alphas_cumprod))
|
| 19 |
-
|
| 20 |
-
def register_buffer(self, name, attr):
|
| 21 |
-
if type(attr) == torch.Tensor:
|
| 22 |
-
if attr.device != torch.device("cuda"):
|
| 23 |
-
attr = attr.to(torch.device("cuda"))
|
| 24 |
-
setattr(self, name, attr)
|
| 25 |
-
|
| 26 |
-
@torch.no_grad()
|
| 27 |
-
def sample(self,
|
| 28 |
-
S,
|
| 29 |
-
batch_size,
|
| 30 |
-
shape,
|
| 31 |
-
conditioning=None,
|
| 32 |
-
callback=None,
|
| 33 |
-
normals_sequence=None,
|
| 34 |
-
img_callback=None,
|
| 35 |
-
quantize_x0=False,
|
| 36 |
-
eta=0.,
|
| 37 |
-
mask=None,
|
| 38 |
-
x0=None,
|
| 39 |
-
temperature=1.,
|
| 40 |
-
noise_dropout=0.,
|
| 41 |
-
score_corrector=None,
|
| 42 |
-
corrector_kwargs=None,
|
| 43 |
-
verbose=True,
|
| 44 |
-
x_T=None,
|
| 45 |
-
log_every_t=100,
|
| 46 |
-
unconditional_guidance_scale=1.,
|
| 47 |
-
unconditional_conditioning=None,
|
| 48 |
-
# this has to come in the same format as the conditioning, # e.g. as encoded tokens, ...
|
| 49 |
-
**kwargs
|
| 50 |
-
):
|
| 51 |
-
if conditioning is not None:
|
| 52 |
-
if isinstance(conditioning, dict):
|
| 53 |
-
cbs = conditioning[list(conditioning.keys())[0]].shape[0]
|
| 54 |
-
if cbs != batch_size:
|
| 55 |
-
print(f"Warning: Got {cbs} conditionings but batch-size is {batch_size}")
|
| 56 |
-
else:
|
| 57 |
-
if conditioning.shape[0] != batch_size:
|
| 58 |
-
print(f"Warning: Got {conditioning.shape[0]} conditionings but batch-size is {batch_size}")
|
| 59 |
-
|
| 60 |
-
# sampling
|
| 61 |
-
C, H, W = shape
|
| 62 |
-
size = (batch_size, C, H, W)
|
| 63 |
-
|
| 64 |
-
print(f'Data shape for DPM-Solver sampling is {size}, sampling steps {S}')
|
| 65 |
-
|
| 66 |
-
device = self.model.betas.device
|
| 67 |
-
if x_T is None:
|
| 68 |
-
img = torch.randn(size, device=device)
|
| 69 |
-
else:
|
| 70 |
-
img = x_T
|
| 71 |
-
|
| 72 |
-
ns = NoiseScheduleVP('discrete', alphas_cumprod=self.alphas_cumprod)
|
| 73 |
-
|
| 74 |
-
model_fn = model_wrapper(
|
| 75 |
-
lambda x, t, c: self.model.apply_model(x, t, c),
|
| 76 |
-
ns,
|
| 77 |
-
model_type=MODEL_TYPES[self.model.parameterization],
|
| 78 |
-
guidance_type="classifier-free",
|
| 79 |
-
condition=conditioning,
|
| 80 |
-
unconditional_condition=unconditional_conditioning,
|
| 81 |
-
guidance_scale=unconditional_guidance_scale,
|
| 82 |
-
)
|
| 83 |
-
|
| 84 |
-
dpm_solver = DPM_Solver(model_fn, ns, predict_x0=True, thresholding=False)
|
| 85 |
-
x = dpm_solver.sample(img, steps=S, skip_type="time_uniform", method="multistep", order=2, lower_order_final=True)
|
| 86 |
-
|
| 87 |
-
return x.to(device), None
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/AriaMei/TTSdemo/emotion_extract.py
DELETED
|
@@ -1,112 +0,0 @@
|
|
| 1 |
-
import torch
|
| 2 |
-
import torch.nn as nn
|
| 3 |
-
from transformers import Wav2Vec2Processor
|
| 4 |
-
from transformers.models.wav2vec2.modeling_wav2vec2 import (
|
| 5 |
-
Wav2Vec2Model,
|
| 6 |
-
Wav2Vec2PreTrainedModel,
|
| 7 |
-
)
|
| 8 |
-
import os
|
| 9 |
-
import librosa
|
| 10 |
-
import numpy as np
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
class RegressionHead(nn.Module):
|
| 14 |
-
r"""Classification head."""
|
| 15 |
-
|
| 16 |
-
def __init__(self, config):
|
| 17 |
-
super().__init__()
|
| 18 |
-
|
| 19 |
-
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
|
| 20 |
-
self.dropout = nn.Dropout(config.final_dropout)
|
| 21 |
-
self.out_proj = nn.Linear(config.hidden_size, config.num_labels)
|
| 22 |
-
|
| 23 |
-
def forward(self, features, **kwargs):
|
| 24 |
-
x = features
|
| 25 |
-
x = self.dropout(x)
|
| 26 |
-
x = self.dense(x)
|
| 27 |
-
x = torch.tanh(x)
|
| 28 |
-
x = self.dropout(x)
|
| 29 |
-
x = self.out_proj(x)
|
| 30 |
-
|
| 31 |
-
return x
|
| 32 |
-
|
| 33 |
-
|
| 34 |
-
class EmotionModel(Wav2Vec2PreTrainedModel):
|
| 35 |
-
r"""Speech emotion classifier."""
|
| 36 |
-
|
| 37 |
-
def __init__(self, config):
|
| 38 |
-
super().__init__(config)
|
| 39 |
-
|
| 40 |
-
self.config = config
|
| 41 |
-
self.wav2vec2 = Wav2Vec2Model(config)
|
| 42 |
-
self.classifier = RegressionHead(config)
|
| 43 |
-
self.init_weights()
|
| 44 |
-
|
| 45 |
-
def forward(
|
| 46 |
-
self,
|
| 47 |
-
input_values,
|
| 48 |
-
):
|
| 49 |
-
outputs = self.wav2vec2(input_values)
|
| 50 |
-
hidden_states = outputs[0]
|
| 51 |
-
hidden_states = torch.mean(hidden_states, dim=1)
|
| 52 |
-
logits = self.classifier(hidden_states)
|
| 53 |
-
|
| 54 |
-
return hidden_states, logits
|
| 55 |
-
|
| 56 |
-
|
| 57 |
-
# load model from hub
|
| 58 |
-
device = 'cuda' if torch.cuda.is_available() else "cpu"
|
| 59 |
-
model_name = 'audeering/wav2vec2-large-robust-12-ft-emotion-msp-dim'
|
| 60 |
-
processor = Wav2Vec2Processor.from_pretrained(model_name)
|
| 61 |
-
model = EmotionModel.from_pretrained(model_name).to(device)
|
| 62 |
-
|
| 63 |
-
|
| 64 |
-
def process_func(
|
| 65 |
-
x: np.ndarray,
|
| 66 |
-
sampling_rate: int,
|
| 67 |
-
embeddings: bool = False,
|
| 68 |
-
) -> np.ndarray:
|
| 69 |
-
r"""Predict emotions or extract embeddings from raw audio signal."""
|
| 70 |
-
|
| 71 |
-
# run through processor to normalize signal
|
| 72 |
-
# always returns a batch, so we just get the first entry
|
| 73 |
-
# then we put it on the device
|
| 74 |
-
y = processor(x, sampling_rate=sampling_rate)
|
| 75 |
-
y = y['input_values'][0]
|
| 76 |
-
y = torch.from_numpy(y).to(device)
|
| 77 |
-
|
| 78 |
-
# run through model
|
| 79 |
-
with torch.no_grad():
|
| 80 |
-
y = model(y)[0 if embeddings else 1]
|
| 81 |
-
|
| 82 |
-
# convert to numpy
|
| 83 |
-
y = y.detach().cpu().numpy()
|
| 84 |
-
|
| 85 |
-
return y
|
| 86 |
-
#
|
| 87 |
-
#
|
| 88 |
-
# def disp(rootpath, wavname):
|
| 89 |
-
# wav, sr = librosa.load(f"{rootpath}/{wavname}", 16000)
|
| 90 |
-
# display(ipd.Audio(wav, rate=sr))
|
| 91 |
-
|
| 92 |
-
rootpath = "dataset/nene"
|
| 93 |
-
embs = []
|
| 94 |
-
wavnames = []
|
| 95 |
-
def extract_dir(path):
|
| 96 |
-
rootpath = path
|
| 97 |
-
for idx, wavname in enumerate(os.listdir(rootpath)):
|
| 98 |
-
wav, sr =librosa.load(f"{rootpath}/{wavname}", 16000)
|
| 99 |
-
emb = process_func(np.expand_dims(wav, 0), sr, embeddings=True)
|
| 100 |
-
embs.append(emb)
|
| 101 |
-
wavnames.append(wavname)
|
| 102 |
-
np.save(f"{rootpath}/{wavname}.emo.npy", emb.squeeze(0))
|
| 103 |
-
print(idx, wavname)
|
| 104 |
-
|
| 105 |
-
def extract_wav(path):
|
| 106 |
-
wav, sr = librosa.load(path, 16000)
|
| 107 |
-
emb = process_func(np.expand_dims(wav, 0), sr, embeddings=True)
|
| 108 |
-
return emb
|
| 109 |
-
|
| 110 |
-
if __name__ == '__main__':
|
| 111 |
-
for spk in ["serena", "koni", "nyaru","shanoa", "mana"]:
|
| 112 |
-
extract_dir(f"dataset/{spk}")
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/ArtGAN/Video-Diffusion-WebUI/video_diffusion/stable_diffusion_video/utils.py
DELETED
|
@@ -1,135 +0,0 @@
|
|
| 1 |
-
from pathlib import Path
|
| 2 |
-
from typing import Union
|
| 3 |
-
|
| 4 |
-
import librosa
|
| 5 |
-
import numpy as np
|
| 6 |
-
import torch
|
| 7 |
-
from PIL import Image
|
| 8 |
-
from torchvision.io import write_video
|
| 9 |
-
from torchvision.transforms.functional import pil_to_tensor
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
def get_timesteps_arr(audio_filepath, offset, duration, fps=30, margin=1.0, smooth=0.0):
|
| 13 |
-
y, sr = librosa.load(audio_filepath, offset=offset, duration=duration)
|
| 14 |
-
|
| 15 |
-
# librosa.stft hardcoded defaults...
|
| 16 |
-
# n_fft defaults to 2048
|
| 17 |
-
# hop length is win_length // 4
|
| 18 |
-
# win_length defaults to n_fft
|
| 19 |
-
D = librosa.stft(y, n_fft=2048, hop_length=2048 // 4, win_length=2048)
|
| 20 |
-
|
| 21 |
-
# Extract percussive elements
|
| 22 |
-
D_harmonic, D_percussive = librosa.decompose.hpss(D, margin=margin)
|
| 23 |
-
y_percussive = librosa.istft(D_percussive, length=len(y))
|
| 24 |
-
|
| 25 |
-
# Get normalized melspectrogram
|
| 26 |
-
spec_raw = librosa.feature.melspectrogram(y=y_percussive, sr=sr)
|
| 27 |
-
spec_max = np.amax(spec_raw, axis=0)
|
| 28 |
-
spec_norm = (spec_max - np.min(spec_max)) / np.ptp(spec_max)
|
| 29 |
-
|
| 30 |
-
# Resize cumsum of spec norm to our desired number of interpolation frames
|
| 31 |
-
x_norm = np.linspace(0, spec_norm.shape[-1], spec_norm.shape[-1])
|
| 32 |
-
y_norm = np.cumsum(spec_norm)
|
| 33 |
-
y_norm /= y_norm[-1]
|
| 34 |
-
x_resize = np.linspace(0, y_norm.shape[-1], int(duration * fps))
|
| 35 |
-
|
| 36 |
-
T = np.interp(x_resize, x_norm, y_norm)
|
| 37 |
-
|
| 38 |
-
# Apply smoothing
|
| 39 |
-
return T * (1 - smooth) + np.linspace(0.0, 1.0, T.shape[0]) * smooth
|
| 40 |
-
|
| 41 |
-
|
| 42 |
-
def slerp(t, v0, v1, DOT_THRESHOLD=0.9995):
|
| 43 |
-
"""helper function to spherically interpolate two arrays v1 v2"""
|
| 44 |
-
|
| 45 |
-
inputs_are_torch = isinstance(v0, torch.Tensor)
|
| 46 |
-
if inputs_are_torch:
|
| 47 |
-
input_device = v0.device
|
| 48 |
-
v0 = v0.cpu().numpy()
|
| 49 |
-
v1 = v1.cpu().numpy()
|
| 50 |
-
|
| 51 |
-
dot = np.sum(v0 * v1 / (np.linalg.norm(v0) * np.linalg.norm(v1)))
|
| 52 |
-
if np.abs(dot) > DOT_THRESHOLD:
|
| 53 |
-
v2 = (1 - t) * v0 + t * v1
|
| 54 |
-
else:
|
| 55 |
-
theta_0 = np.arccos(dot)
|
| 56 |
-
sin_theta_0 = np.sin(theta_0)
|
| 57 |
-
theta_t = theta_0 * t
|
| 58 |
-
sin_theta_t = np.sin(theta_t)
|
| 59 |
-
s0 = np.sin(theta_0 - theta_t) / sin_theta_0
|
| 60 |
-
s1 = sin_theta_t / sin_theta_0
|
| 61 |
-
v2 = s0 * v0 + s1 * v1
|
| 62 |
-
|
| 63 |
-
if inputs_are_torch:
|
| 64 |
-
v2 = torch.from_numpy(v2).to(input_device)
|
| 65 |
-
|
| 66 |
-
return v2
|
| 67 |
-
|
| 68 |
-
|
| 69 |
-
def make_video_pyav(
|
| 70 |
-
frames_or_frame_dir: Union[str, Path, torch.Tensor],
|
| 71 |
-
audio_filepath: Union[str, Path] = None,
|
| 72 |
-
fps: int = 30,
|
| 73 |
-
audio_offset: int = 0,
|
| 74 |
-
audio_duration: int = 2,
|
| 75 |
-
sr: int = 22050,
|
| 76 |
-
output_filepath: Union[str, Path] = "output.mp4",
|
| 77 |
-
glob_pattern: str = "*.png",
|
| 78 |
-
):
|
| 79 |
-
"""
|
| 80 |
-
TODO - docstring here
|
| 81 |
-
frames_or_frame_dir: (Union[str, Path, torch.Tensor]):
|
| 82 |
-
Either a directory of images, or a tensor of shape (T, C, H, W) in range [0, 255].
|
| 83 |
-
"""
|
| 84 |
-
|
| 85 |
-
# Torchvision write_video doesn't support pathlib paths
|
| 86 |
-
output_filepath = str(output_filepath)
|
| 87 |
-
|
| 88 |
-
if isinstance(frames_or_frame_dir, (str, Path)):
|
| 89 |
-
frames = None
|
| 90 |
-
for img in sorted(Path(frames_or_frame_dir).glob(glob_pattern)):
|
| 91 |
-
frame = pil_to_tensor(Image.open(img)).unsqueeze(0)
|
| 92 |
-
frames = frame if frames is None else torch.cat([frames, frame])
|
| 93 |
-
else:
|
| 94 |
-
frames = frames_or_frame_dir
|
| 95 |
-
|
| 96 |
-
# TCHW -> THWC
|
| 97 |
-
frames = frames.permute(0, 2, 3, 1)
|
| 98 |
-
|
| 99 |
-
if audio_filepath:
|
| 100 |
-
# Read audio, convert to tensor
|
| 101 |
-
audio, sr = librosa.load(
|
| 102 |
-
audio_filepath,
|
| 103 |
-
sr=sr,
|
| 104 |
-
mono=True,
|
| 105 |
-
offset=audio_offset,
|
| 106 |
-
duration=audio_duration,
|
| 107 |
-
)
|
| 108 |
-
audio_tensor = torch.tensor(audio).unsqueeze(0)
|
| 109 |
-
|
| 110 |
-
write_video(
|
| 111 |
-
output_filepath,
|
| 112 |
-
frames,
|
| 113 |
-
fps=fps,
|
| 114 |
-
audio_array=audio_tensor,
|
| 115 |
-
audio_fps=sr,
|
| 116 |
-
audio_codec="aac",
|
| 117 |
-
options={"crf": "10", "pix_fmt": "yuv420p"},
|
| 118 |
-
)
|
| 119 |
-
else:
|
| 120 |
-
write_video(
|
| 121 |
-
output_filepath,
|
| 122 |
-
frames,
|
| 123 |
-
fps=fps,
|
| 124 |
-
options={"crf": "10", "pix_fmt": "yuv420p"},
|
| 125 |
-
)
|
| 126 |
-
|
| 127 |
-
return output_filepath
|
| 128 |
-
|
| 129 |
-
|
| 130 |
-
def pad_along_axis(array: np.ndarray, pad_size: int, axis: int = 0) -> np.ndarray:
|
| 131 |
-
if pad_size <= 0:
|
| 132 |
-
return array
|
| 133 |
-
npad = [(0, 0)] * array.ndim
|
| 134 |
-
npad[axis] = (0, pad_size)
|
| 135 |
-
return np.pad(array, pad_width=npad, mode="constant", constant_values=0)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/pip/_vendor/distlib/metadata.py
DELETED
|
@@ -1,1076 +0,0 @@
|
|
| 1 |
-
# -*- coding: utf-8 -*-
|
| 2 |
-
#
|
| 3 |
-
# Copyright (C) 2012 The Python Software Foundation.
|
| 4 |
-
# See LICENSE.txt and CONTRIBUTORS.txt.
|
| 5 |
-
#
|
| 6 |
-
"""Implementation of the Metadata for Python packages PEPs.
|
| 7 |
-
|
| 8 |
-
Supports all metadata formats (1.0, 1.1, 1.2, 1.3/2.1 and 2.2).
|
| 9 |
-
"""
|
| 10 |
-
from __future__ import unicode_literals
|
| 11 |
-
|
| 12 |
-
import codecs
|
| 13 |
-
from email import message_from_file
|
| 14 |
-
import json
|
| 15 |
-
import logging
|
| 16 |
-
import re
|
| 17 |
-
|
| 18 |
-
|
| 19 |
-
from . import DistlibException, __version__
|
| 20 |
-
from .compat import StringIO, string_types, text_type
|
| 21 |
-
from .markers import interpret
|
| 22 |
-
from .util import extract_by_key, get_extras
|
| 23 |
-
from .version import get_scheme, PEP440_VERSION_RE
|
| 24 |
-
|
| 25 |
-
logger = logging.getLogger(__name__)
|
| 26 |
-
|
| 27 |
-
|
| 28 |
-
class MetadataMissingError(DistlibException):
|
| 29 |
-
"""A required metadata is missing"""
|
| 30 |
-
|
| 31 |
-
|
| 32 |
-
class MetadataConflictError(DistlibException):
|
| 33 |
-
"""Attempt to read or write metadata fields that are conflictual."""
|
| 34 |
-
|
| 35 |
-
|
| 36 |
-
class MetadataUnrecognizedVersionError(DistlibException):
|
| 37 |
-
"""Unknown metadata version number."""
|
| 38 |
-
|
| 39 |
-
|
| 40 |
-
class MetadataInvalidError(DistlibException):
|
| 41 |
-
"""A metadata value is invalid"""
|
| 42 |
-
|
| 43 |
-
# public API of this module
|
| 44 |
-
__all__ = ['Metadata', 'PKG_INFO_ENCODING', 'PKG_INFO_PREFERRED_VERSION']
|
| 45 |
-
|
| 46 |
-
# Encoding used for the PKG-INFO files
|
| 47 |
-
PKG_INFO_ENCODING = 'utf-8'
|
| 48 |
-
|
| 49 |
-
# preferred version. Hopefully will be changed
|
| 50 |
-
# to 1.2 once PEP 345 is supported everywhere
|
| 51 |
-
PKG_INFO_PREFERRED_VERSION = '1.1'
|
| 52 |
-
|
| 53 |
-
_LINE_PREFIX_1_2 = re.compile('\n \\|')
|
| 54 |
-
_LINE_PREFIX_PRE_1_2 = re.compile('\n ')
|
| 55 |
-
_241_FIELDS = ('Metadata-Version', 'Name', 'Version', 'Platform',
|
| 56 |
-
'Summary', 'Description',
|
| 57 |
-
'Keywords', 'Home-page', 'Author', 'Author-email',
|
| 58 |
-
'License')
|
| 59 |
-
|
| 60 |
-
_314_FIELDS = ('Metadata-Version', 'Name', 'Version', 'Platform',
|
| 61 |
-
'Supported-Platform', 'Summary', 'Description',
|
| 62 |
-
'Keywords', 'Home-page', 'Author', 'Author-email',
|
| 63 |
-
'License', 'Classifier', 'Download-URL', 'Obsoletes',
|
| 64 |
-
'Provides', 'Requires')
|
| 65 |
-
|
| 66 |
-
_314_MARKERS = ('Obsoletes', 'Provides', 'Requires', 'Classifier',
|
| 67 |
-
'Download-URL')
|
| 68 |
-
|
| 69 |
-
_345_FIELDS = ('Metadata-Version', 'Name', 'Version', 'Platform',
|
| 70 |
-
'Supported-Platform', 'Summary', 'Description',
|
| 71 |
-
'Keywords', 'Home-page', 'Author', 'Author-email',
|
| 72 |
-
'Maintainer', 'Maintainer-email', 'License',
|
| 73 |
-
'Classifier', 'Download-URL', 'Obsoletes-Dist',
|
| 74 |
-
'Project-URL', 'Provides-Dist', 'Requires-Dist',
|
| 75 |
-
'Requires-Python', 'Requires-External')
|
| 76 |
-
|
| 77 |
-
_345_MARKERS = ('Provides-Dist', 'Requires-Dist', 'Requires-Python',
|
| 78 |
-
'Obsoletes-Dist', 'Requires-External', 'Maintainer',
|
| 79 |
-
'Maintainer-email', 'Project-URL')
|
| 80 |
-
|
| 81 |
-
_426_FIELDS = ('Metadata-Version', 'Name', 'Version', 'Platform',
|
| 82 |
-
'Supported-Platform', 'Summary', 'Description',
|
| 83 |
-
'Keywords', 'Home-page', 'Author', 'Author-email',
|
| 84 |
-
'Maintainer', 'Maintainer-email', 'License',
|
| 85 |
-
'Classifier', 'Download-URL', 'Obsoletes-Dist',
|
| 86 |
-
'Project-URL', 'Provides-Dist', 'Requires-Dist',
|
| 87 |
-
'Requires-Python', 'Requires-External', 'Private-Version',
|
| 88 |
-
'Obsoleted-By', 'Setup-Requires-Dist', 'Extension',
|
| 89 |
-
'Provides-Extra')
|
| 90 |
-
|
| 91 |
-
_426_MARKERS = ('Private-Version', 'Provides-Extra', 'Obsoleted-By',
|
| 92 |
-
'Setup-Requires-Dist', 'Extension')
|
| 93 |
-
|
| 94 |
-
# See issue #106: Sometimes 'Requires' and 'Provides' occur wrongly in
|
| 95 |
-
# the metadata. Include them in the tuple literal below to allow them
|
| 96 |
-
# (for now).
|
| 97 |
-
# Ditto for Obsoletes - see issue #140.
|
| 98 |
-
_566_FIELDS = _426_FIELDS + ('Description-Content-Type',
|
| 99 |
-
'Requires', 'Provides', 'Obsoletes')
|
| 100 |
-
|
| 101 |
-
_566_MARKERS = ('Description-Content-Type',)
|
| 102 |
-
|
| 103 |
-
_643_MARKERS = ('Dynamic', 'License-File')
|
| 104 |
-
|
| 105 |
-
_643_FIELDS = _566_FIELDS + _643_MARKERS
|
| 106 |
-
|
| 107 |
-
_ALL_FIELDS = set()
|
| 108 |
-
_ALL_FIELDS.update(_241_FIELDS)
|
| 109 |
-
_ALL_FIELDS.update(_314_FIELDS)
|
| 110 |
-
_ALL_FIELDS.update(_345_FIELDS)
|
| 111 |
-
_ALL_FIELDS.update(_426_FIELDS)
|
| 112 |
-
_ALL_FIELDS.update(_566_FIELDS)
|
| 113 |
-
_ALL_FIELDS.update(_643_FIELDS)
|
| 114 |
-
|
| 115 |
-
EXTRA_RE = re.compile(r'''extra\s*==\s*("([^"]+)"|'([^']+)')''')
|
| 116 |
-
|
| 117 |
-
|
| 118 |
-
def _version2fieldlist(version):
|
| 119 |
-
if version == '1.0':
|
| 120 |
-
return _241_FIELDS
|
| 121 |
-
elif version == '1.1':
|
| 122 |
-
return _314_FIELDS
|
| 123 |
-
elif version == '1.2':
|
| 124 |
-
return _345_FIELDS
|
| 125 |
-
elif version in ('1.3', '2.1'):
|
| 126 |
-
# avoid adding field names if already there
|
| 127 |
-
return _345_FIELDS + tuple(f for f in _566_FIELDS if f not in _345_FIELDS)
|
| 128 |
-
elif version == '2.0':
|
| 129 |
-
raise ValueError('Metadata 2.0 is withdrawn and not supported')
|
| 130 |
-
# return _426_FIELDS
|
| 131 |
-
elif version == '2.2':
|
| 132 |
-
return _643_FIELDS
|
| 133 |
-
raise MetadataUnrecognizedVersionError(version)
|
| 134 |
-
|
| 135 |
-
|
| 136 |
-
def _best_version(fields):
|
| 137 |
-
"""Detect the best version depending on the fields used."""
|
| 138 |
-
def _has_marker(keys, markers):
|
| 139 |
-
for marker in markers:
|
| 140 |
-
if marker in keys:
|
| 141 |
-
return True
|
| 142 |
-
return False
|
| 143 |
-
|
| 144 |
-
keys = []
|
| 145 |
-
for key, value in fields.items():
|
| 146 |
-
if value in ([], 'UNKNOWN', None):
|
| 147 |
-
continue
|
| 148 |
-
keys.append(key)
|
| 149 |
-
|
| 150 |
-
possible_versions = ['1.0', '1.1', '1.2', '1.3', '2.1', '2.2'] # 2.0 removed
|
| 151 |
-
|
| 152 |
-
# first let's try to see if a field is not part of one of the version
|
| 153 |
-
for key in keys:
|
| 154 |
-
if key not in _241_FIELDS and '1.0' in possible_versions:
|
| 155 |
-
possible_versions.remove('1.0')
|
| 156 |
-
logger.debug('Removed 1.0 due to %s', key)
|
| 157 |
-
if key not in _314_FIELDS and '1.1' in possible_versions:
|
| 158 |
-
possible_versions.remove('1.1')
|
| 159 |
-
logger.debug('Removed 1.1 due to %s', key)
|
| 160 |
-
if key not in _345_FIELDS and '1.2' in possible_versions:
|
| 161 |
-
possible_versions.remove('1.2')
|
| 162 |
-
logger.debug('Removed 1.2 due to %s', key)
|
| 163 |
-
if key not in _566_FIELDS and '1.3' in possible_versions:
|
| 164 |
-
possible_versions.remove('1.3')
|
| 165 |
-
logger.debug('Removed 1.3 due to %s', key)
|
| 166 |
-
if key not in _566_FIELDS and '2.1' in possible_versions:
|
| 167 |
-
if key != 'Description': # In 2.1, description allowed after headers
|
| 168 |
-
possible_versions.remove('2.1')
|
| 169 |
-
logger.debug('Removed 2.1 due to %s', key)
|
| 170 |
-
if key not in _643_FIELDS and '2.2' in possible_versions:
|
| 171 |
-
possible_versions.remove('2.2')
|
| 172 |
-
logger.debug('Removed 2.2 due to %s', key)
|
| 173 |
-
# if key not in _426_FIELDS and '2.0' in possible_versions:
|
| 174 |
-
# possible_versions.remove('2.0')
|
| 175 |
-
# logger.debug('Removed 2.0 due to %s', key)
|
| 176 |
-
|
| 177 |
-
# possible_version contains qualified versions
|
| 178 |
-
if len(possible_versions) == 1:
|
| 179 |
-
return possible_versions[0] # found !
|
| 180 |
-
elif len(possible_versions) == 0:
|
| 181 |
-
logger.debug('Out of options - unknown metadata set: %s', fields)
|
| 182 |
-
raise MetadataConflictError('Unknown metadata set')
|
| 183 |
-
|
| 184 |
-
# let's see if one unique marker is found
|
| 185 |
-
is_1_1 = '1.1' in possible_versions and _has_marker(keys, _314_MARKERS)
|
| 186 |
-
is_1_2 = '1.2' in possible_versions and _has_marker(keys, _345_MARKERS)
|
| 187 |
-
is_2_1 = '2.1' in possible_versions and _has_marker(keys, _566_MARKERS)
|
| 188 |
-
# is_2_0 = '2.0' in possible_versions and _has_marker(keys, _426_MARKERS)
|
| 189 |
-
is_2_2 = '2.2' in possible_versions and _has_marker(keys, _643_MARKERS)
|
| 190 |
-
if int(is_1_1) + int(is_1_2) + int(is_2_1) + int(is_2_2) > 1:
|
| 191 |
-
raise MetadataConflictError('You used incompatible 1.1/1.2/2.1/2.2 fields')
|
| 192 |
-
|
| 193 |
-
# we have the choice, 1.0, or 1.2, 2.1 or 2.2
|
| 194 |
-
# - 1.0 has a broken Summary field but works with all tools
|
| 195 |
-
# - 1.1 is to avoid
|
| 196 |
-
# - 1.2 fixes Summary but has little adoption
|
| 197 |
-
# - 2.1 adds more features
|
| 198 |
-
# - 2.2 is the latest
|
| 199 |
-
if not is_1_1 and not is_1_2 and not is_2_1 and not is_2_2:
|
| 200 |
-
# we couldn't find any specific marker
|
| 201 |
-
if PKG_INFO_PREFERRED_VERSION in possible_versions:
|
| 202 |
-
return PKG_INFO_PREFERRED_VERSION
|
| 203 |
-
if is_1_1:
|
| 204 |
-
return '1.1'
|
| 205 |
-
if is_1_2:
|
| 206 |
-
return '1.2'
|
| 207 |
-
if is_2_1:
|
| 208 |
-
return '2.1'
|
| 209 |
-
# if is_2_2:
|
| 210 |
-
# return '2.2'
|
| 211 |
-
|
| 212 |
-
return '2.2'
|
| 213 |
-
|
| 214 |
-
# This follows the rules about transforming keys as described in
|
| 215 |
-
# https://www.python.org/dev/peps/pep-0566/#id17
|
| 216 |
-
_ATTR2FIELD = {
|
| 217 |
-
name.lower().replace("-", "_"): name for name in _ALL_FIELDS
|
| 218 |
-
}
|
| 219 |
-
_FIELD2ATTR = {field: attr for attr, field in _ATTR2FIELD.items()}
|
| 220 |
-
|
| 221 |
-
_PREDICATE_FIELDS = ('Requires-Dist', 'Obsoletes-Dist', 'Provides-Dist')
|
| 222 |
-
_VERSIONS_FIELDS = ('Requires-Python',)
|
| 223 |
-
_VERSION_FIELDS = ('Version',)
|
| 224 |
-
_LISTFIELDS = ('Platform', 'Classifier', 'Obsoletes',
|
| 225 |
-
'Requires', 'Provides', 'Obsoletes-Dist',
|
| 226 |
-
'Provides-Dist', 'Requires-Dist', 'Requires-External',
|
| 227 |
-
'Project-URL', 'Supported-Platform', 'Setup-Requires-Dist',
|
| 228 |
-
'Provides-Extra', 'Extension', 'License-File')
|
| 229 |
-
_LISTTUPLEFIELDS = ('Project-URL',)
|
| 230 |
-
|
| 231 |
-
_ELEMENTSFIELD = ('Keywords',)
|
| 232 |
-
|
| 233 |
-
_UNICODEFIELDS = ('Author', 'Maintainer', 'Summary', 'Description')
|
| 234 |
-
|
| 235 |
-
_MISSING = object()
|
| 236 |
-
|
| 237 |
-
_FILESAFE = re.compile('[^A-Za-z0-9.]+')
|
| 238 |
-
|
| 239 |
-
|
| 240 |
-
def _get_name_and_version(name, version, for_filename=False):
|
| 241 |
-
"""Return the distribution name with version.
|
| 242 |
-
|
| 243 |
-
If for_filename is true, return a filename-escaped form."""
|
| 244 |
-
if for_filename:
|
| 245 |
-
# For both name and version any runs of non-alphanumeric or '.'
|
| 246 |
-
# characters are replaced with a single '-'. Additionally any
|
| 247 |
-
# spaces in the version string become '.'
|
| 248 |
-
name = _FILESAFE.sub('-', name)
|
| 249 |
-
version = _FILESAFE.sub('-', version.replace(' ', '.'))
|
| 250 |
-
return '%s-%s' % (name, version)
|
| 251 |
-
|
| 252 |
-
|
| 253 |
-
class LegacyMetadata(object):
|
| 254 |
-
"""The legacy metadata of a release.
|
| 255 |
-
|
| 256 |
-
Supports versions 1.0, 1.1, 1.2, 2.0 and 1.3/2.1 (auto-detected). You can
|
| 257 |
-
instantiate the class with one of these arguments (or none):
|
| 258 |
-
- *path*, the path to a metadata file
|
| 259 |
-
- *fileobj* give a file-like object with metadata as content
|
| 260 |
-
- *mapping* is a dict-like object
|
| 261 |
-
- *scheme* is a version scheme name
|
| 262 |
-
"""
|
| 263 |
-
# TODO document the mapping API and UNKNOWN default key
|
| 264 |
-
|
| 265 |
-
def __init__(self, path=None, fileobj=None, mapping=None,
|
| 266 |
-
scheme='default'):
|
| 267 |
-
if [path, fileobj, mapping].count(None) < 2:
|
| 268 |
-
raise TypeError('path, fileobj and mapping are exclusive')
|
| 269 |
-
self._fields = {}
|
| 270 |
-
self.requires_files = []
|
| 271 |
-
self._dependencies = None
|
| 272 |
-
self.scheme = scheme
|
| 273 |
-
if path is not None:
|
| 274 |
-
self.read(path)
|
| 275 |
-
elif fileobj is not None:
|
| 276 |
-
self.read_file(fileobj)
|
| 277 |
-
elif mapping is not None:
|
| 278 |
-
self.update(mapping)
|
| 279 |
-
self.set_metadata_version()
|
| 280 |
-
|
| 281 |
-
def set_metadata_version(self):
|
| 282 |
-
self._fields['Metadata-Version'] = _best_version(self._fields)
|
| 283 |
-
|
| 284 |
-
def _write_field(self, fileobj, name, value):
|
| 285 |
-
fileobj.write('%s: %s\n' % (name, value))
|
| 286 |
-
|
| 287 |
-
def __getitem__(self, name):
|
| 288 |
-
return self.get(name)
|
| 289 |
-
|
| 290 |
-
def __setitem__(self, name, value):
|
| 291 |
-
return self.set(name, value)
|
| 292 |
-
|
| 293 |
-
def __delitem__(self, name):
|
| 294 |
-
field_name = self._convert_name(name)
|
| 295 |
-
try:
|
| 296 |
-
del self._fields[field_name]
|
| 297 |
-
except KeyError:
|
| 298 |
-
raise KeyError(name)
|
| 299 |
-
|
| 300 |
-
def __contains__(self, name):
|
| 301 |
-
return (name in self._fields or
|
| 302 |
-
self._convert_name(name) in self._fields)
|
| 303 |
-
|
| 304 |
-
def _convert_name(self, name):
|
| 305 |
-
if name in _ALL_FIELDS:
|
| 306 |
-
return name
|
| 307 |
-
name = name.replace('-', '_').lower()
|
| 308 |
-
return _ATTR2FIELD.get(name, name)
|
| 309 |
-
|
| 310 |
-
def _default_value(self, name):
|
| 311 |
-
if name in _LISTFIELDS or name in _ELEMENTSFIELD:
|
| 312 |
-
return []
|
| 313 |
-
return 'UNKNOWN'
|
| 314 |
-
|
| 315 |
-
def _remove_line_prefix(self, value):
|
| 316 |
-
if self.metadata_version in ('1.0', '1.1'):
|
| 317 |
-
return _LINE_PREFIX_PRE_1_2.sub('\n', value)
|
| 318 |
-
else:
|
| 319 |
-
return _LINE_PREFIX_1_2.sub('\n', value)
|
| 320 |
-
|
| 321 |
-
def __getattr__(self, name):
|
| 322 |
-
if name in _ATTR2FIELD:
|
| 323 |
-
return self[name]
|
| 324 |
-
raise AttributeError(name)
|
| 325 |
-
|
| 326 |
-
#
|
| 327 |
-
# Public API
|
| 328 |
-
#
|
| 329 |
-
|
| 330 |
-
# dependencies = property(_get_dependencies, _set_dependencies)
|
| 331 |
-
|
| 332 |
-
def get_fullname(self, filesafe=False):
|
| 333 |
-
"""Return the distribution name with version.
|
| 334 |
-
|
| 335 |
-
If filesafe is true, return a filename-escaped form."""
|
| 336 |
-
return _get_name_and_version(self['Name'], self['Version'], filesafe)
|
| 337 |
-
|
| 338 |
-
def is_field(self, name):
|
| 339 |
-
"""return True if name is a valid metadata key"""
|
| 340 |
-
name = self._convert_name(name)
|
| 341 |
-
return name in _ALL_FIELDS
|
| 342 |
-
|
| 343 |
-
def is_multi_field(self, name):
|
| 344 |
-
name = self._convert_name(name)
|
| 345 |
-
return name in _LISTFIELDS
|
| 346 |
-
|
| 347 |
-
def read(self, filepath):
|
| 348 |
-
"""Read the metadata values from a file path."""
|
| 349 |
-
fp = codecs.open(filepath, 'r', encoding='utf-8')
|
| 350 |
-
try:
|
| 351 |
-
self.read_file(fp)
|
| 352 |
-
finally:
|
| 353 |
-
fp.close()
|
| 354 |
-
|
| 355 |
-
def read_file(self, fileob):
|
| 356 |
-
"""Read the metadata values from a file object."""
|
| 357 |
-
msg = message_from_file(fileob)
|
| 358 |
-
self._fields['Metadata-Version'] = msg['metadata-version']
|
| 359 |
-
|
| 360 |
-
# When reading, get all the fields we can
|
| 361 |
-
for field in _ALL_FIELDS:
|
| 362 |
-
if field not in msg:
|
| 363 |
-
continue
|
| 364 |
-
if field in _LISTFIELDS:
|
| 365 |
-
# we can have multiple lines
|
| 366 |
-
values = msg.get_all(field)
|
| 367 |
-
if field in _LISTTUPLEFIELDS and values is not None:
|
| 368 |
-
values = [tuple(value.split(',')) for value in values]
|
| 369 |
-
self.set(field, values)
|
| 370 |
-
else:
|
| 371 |
-
# single line
|
| 372 |
-
value = msg[field]
|
| 373 |
-
if value is not None and value != 'UNKNOWN':
|
| 374 |
-
self.set(field, value)
|
| 375 |
-
|
| 376 |
-
# PEP 566 specifies that the body be used for the description, if
|
| 377 |
-
# available
|
| 378 |
-
body = msg.get_payload()
|
| 379 |
-
self["Description"] = body if body else self["Description"]
|
| 380 |
-
# logger.debug('Attempting to set metadata for %s', self)
|
| 381 |
-
# self.set_metadata_version()
|
| 382 |
-
|
| 383 |
-
def write(self, filepath, skip_unknown=False):
|
| 384 |
-
"""Write the metadata fields to filepath."""
|
| 385 |
-
fp = codecs.open(filepath, 'w', encoding='utf-8')
|
| 386 |
-
try:
|
| 387 |
-
self.write_file(fp, skip_unknown)
|
| 388 |
-
finally:
|
| 389 |
-
fp.close()
|
| 390 |
-
|
| 391 |
-
def write_file(self, fileobject, skip_unknown=False):
|
| 392 |
-
"""Write the PKG-INFO format data to a file object."""
|
| 393 |
-
self.set_metadata_version()
|
| 394 |
-
|
| 395 |
-
for field in _version2fieldlist(self['Metadata-Version']):
|
| 396 |
-
values = self.get(field)
|
| 397 |
-
if skip_unknown and values in ('UNKNOWN', [], ['UNKNOWN']):
|
| 398 |
-
continue
|
| 399 |
-
if field in _ELEMENTSFIELD:
|
| 400 |
-
self._write_field(fileobject, field, ','.join(values))
|
| 401 |
-
continue
|
| 402 |
-
if field not in _LISTFIELDS:
|
| 403 |
-
if field == 'Description':
|
| 404 |
-
if self.metadata_version in ('1.0', '1.1'):
|
| 405 |
-
values = values.replace('\n', '\n ')
|
| 406 |
-
else:
|
| 407 |
-
values = values.replace('\n', '\n |')
|
| 408 |
-
values = [values]
|
| 409 |
-
|
| 410 |
-
if field in _LISTTUPLEFIELDS:
|
| 411 |
-
values = [','.join(value) for value in values]
|
| 412 |
-
|
| 413 |
-
for value in values:
|
| 414 |
-
self._write_field(fileobject, field, value)
|
| 415 |
-
|
| 416 |
-
def update(self, other=None, **kwargs):
|
| 417 |
-
"""Set metadata values from the given iterable `other` and kwargs.
|
| 418 |
-
|
| 419 |
-
Behavior is like `dict.update`: If `other` has a ``keys`` method,
|
| 420 |
-
they are looped over and ``self[key]`` is assigned ``other[key]``.
|
| 421 |
-
Else, ``other`` is an iterable of ``(key, value)`` iterables.
|
| 422 |
-
|
| 423 |
-
Keys that don't match a metadata field or that have an empty value are
|
| 424 |
-
dropped.
|
| 425 |
-
"""
|
| 426 |
-
def _set(key, value):
|
| 427 |
-
if key in _ATTR2FIELD and value:
|
| 428 |
-
self.set(self._convert_name(key), value)
|
| 429 |
-
|
| 430 |
-
if not other:
|
| 431 |
-
# other is None or empty container
|
| 432 |
-
pass
|
| 433 |
-
elif hasattr(other, 'keys'):
|
| 434 |
-
for k in other.keys():
|
| 435 |
-
_set(k, other[k])
|
| 436 |
-
else:
|
| 437 |
-
for k, v in other:
|
| 438 |
-
_set(k, v)
|
| 439 |
-
|
| 440 |
-
if kwargs:
|
| 441 |
-
for k, v in kwargs.items():
|
| 442 |
-
_set(k, v)
|
| 443 |
-
|
| 444 |
-
def set(self, name, value):
|
| 445 |
-
"""Control then set a metadata field."""
|
| 446 |
-
name = self._convert_name(name)
|
| 447 |
-
|
| 448 |
-
if ((name in _ELEMENTSFIELD or name == 'Platform') and
|
| 449 |
-
not isinstance(value, (list, tuple))):
|
| 450 |
-
if isinstance(value, string_types):
|
| 451 |
-
value = [v.strip() for v in value.split(',')]
|
| 452 |
-
else:
|
| 453 |
-
value = []
|
| 454 |
-
elif (name in _LISTFIELDS and
|
| 455 |
-
not isinstance(value, (list, tuple))):
|
| 456 |
-
if isinstance(value, string_types):
|
| 457 |
-
value = [value]
|
| 458 |
-
else:
|
| 459 |
-
value = []
|
| 460 |
-
|
| 461 |
-
if logger.isEnabledFor(logging.WARNING):
|
| 462 |
-
project_name = self['Name']
|
| 463 |
-
|
| 464 |
-
scheme = get_scheme(self.scheme)
|
| 465 |
-
if name in _PREDICATE_FIELDS and value is not None:
|
| 466 |
-
for v in value:
|
| 467 |
-
# check that the values are valid
|
| 468 |
-
if not scheme.is_valid_matcher(v.split(';')[0]):
|
| 469 |
-
logger.warning(
|
| 470 |
-
"'%s': '%s' is not valid (field '%s')",
|
| 471 |
-
project_name, v, name)
|
| 472 |
-
# FIXME this rejects UNKNOWN, is that right?
|
| 473 |
-
elif name in _VERSIONS_FIELDS and value is not None:
|
| 474 |
-
if not scheme.is_valid_constraint_list(value):
|
| 475 |
-
logger.warning("'%s': '%s' is not a valid version (field '%s')",
|
| 476 |
-
project_name, value, name)
|
| 477 |
-
elif name in _VERSION_FIELDS and value is not None:
|
| 478 |
-
if not scheme.is_valid_version(value):
|
| 479 |
-
logger.warning("'%s': '%s' is not a valid version (field '%s')",
|
| 480 |
-
project_name, value, name)
|
| 481 |
-
|
| 482 |
-
if name in _UNICODEFIELDS:
|
| 483 |
-
if name == 'Description':
|
| 484 |
-
value = self._remove_line_prefix(value)
|
| 485 |
-
|
| 486 |
-
self._fields[name] = value
|
| 487 |
-
|
| 488 |
-
def get(self, name, default=_MISSING):
|
| 489 |
-
"""Get a metadata field."""
|
| 490 |
-
name = self._convert_name(name)
|
| 491 |
-
if name not in self._fields:
|
| 492 |
-
if default is _MISSING:
|
| 493 |
-
default = self._default_value(name)
|
| 494 |
-
return default
|
| 495 |
-
if name in _UNICODEFIELDS:
|
| 496 |
-
value = self._fields[name]
|
| 497 |
-
return value
|
| 498 |
-
elif name in _LISTFIELDS:
|
| 499 |
-
value = self._fields[name]
|
| 500 |
-
if value is None:
|
| 501 |
-
return []
|
| 502 |
-
res = []
|
| 503 |
-
for val in value:
|
| 504 |
-
if name not in _LISTTUPLEFIELDS:
|
| 505 |
-
res.append(val)
|
| 506 |
-
else:
|
| 507 |
-
# That's for Project-URL
|
| 508 |
-
res.append((val[0], val[1]))
|
| 509 |
-
return res
|
| 510 |
-
|
| 511 |
-
elif name in _ELEMENTSFIELD:
|
| 512 |
-
value = self._fields[name]
|
| 513 |
-
if isinstance(value, string_types):
|
| 514 |
-
return value.split(',')
|
| 515 |
-
return self._fields[name]
|
| 516 |
-
|
| 517 |
-
def check(self, strict=False):
|
| 518 |
-
"""Check if the metadata is compliant. If strict is True then raise if
|
| 519 |
-
no Name or Version are provided"""
|
| 520 |
-
self.set_metadata_version()
|
| 521 |
-
|
| 522 |
-
# XXX should check the versions (if the file was loaded)
|
| 523 |
-
missing, warnings = [], []
|
| 524 |
-
|
| 525 |
-
for attr in ('Name', 'Version'): # required by PEP 345
|
| 526 |
-
if attr not in self:
|
| 527 |
-
missing.append(attr)
|
| 528 |
-
|
| 529 |
-
if strict and missing != []:
|
| 530 |
-
msg = 'missing required metadata: %s' % ', '.join(missing)
|
| 531 |
-
raise MetadataMissingError(msg)
|
| 532 |
-
|
| 533 |
-
for attr in ('Home-page', 'Author'):
|
| 534 |
-
if attr not in self:
|
| 535 |
-
missing.append(attr)
|
| 536 |
-
|
| 537 |
-
# checking metadata 1.2 (XXX needs to check 1.1, 1.0)
|
| 538 |
-
if self['Metadata-Version'] != '1.2':
|
| 539 |
-
return missing, warnings
|
| 540 |
-
|
| 541 |
-
scheme = get_scheme(self.scheme)
|
| 542 |
-
|
| 543 |
-
def are_valid_constraints(value):
|
| 544 |
-
for v in value:
|
| 545 |
-
if not scheme.is_valid_matcher(v.split(';')[0]):
|
| 546 |
-
return False
|
| 547 |
-
return True
|
| 548 |
-
|
| 549 |
-
for fields, controller in ((_PREDICATE_FIELDS, are_valid_constraints),
|
| 550 |
-
(_VERSIONS_FIELDS,
|
| 551 |
-
scheme.is_valid_constraint_list),
|
| 552 |
-
(_VERSION_FIELDS,
|
| 553 |
-
scheme.is_valid_version)):
|
| 554 |
-
for field in fields:
|
| 555 |
-
value = self.get(field, None)
|
| 556 |
-
if value is not None and not controller(value):
|
| 557 |
-
warnings.append("Wrong value for '%s': %s" % (field, value))
|
| 558 |
-
|
| 559 |
-
return missing, warnings
|
| 560 |
-
|
| 561 |
-
def todict(self, skip_missing=False):
|
| 562 |
-
"""Return fields as a dict.
|
| 563 |
-
|
| 564 |
-
Field names will be converted to use the underscore-lowercase style
|
| 565 |
-
instead of hyphen-mixed case (i.e. home_page instead of Home-page).
|
| 566 |
-
This is as per https://www.python.org/dev/peps/pep-0566/#id17.
|
| 567 |
-
"""
|
| 568 |
-
self.set_metadata_version()
|
| 569 |
-
|
| 570 |
-
fields = _version2fieldlist(self['Metadata-Version'])
|
| 571 |
-
|
| 572 |
-
data = {}
|
| 573 |
-
|
| 574 |
-
for field_name in fields:
|
| 575 |
-
if not skip_missing or field_name in self._fields:
|
| 576 |
-
key = _FIELD2ATTR[field_name]
|
| 577 |
-
if key != 'project_url':
|
| 578 |
-
data[key] = self[field_name]
|
| 579 |
-
else:
|
| 580 |
-
data[key] = [','.join(u) for u in self[field_name]]
|
| 581 |
-
|
| 582 |
-
return data
|
| 583 |
-
|
| 584 |
-
def add_requirements(self, requirements):
|
| 585 |
-
if self['Metadata-Version'] == '1.1':
|
| 586 |
-
# we can't have 1.1 metadata *and* Setuptools requires
|
| 587 |
-
for field in ('Obsoletes', 'Requires', 'Provides'):
|
| 588 |
-
if field in self:
|
| 589 |
-
del self[field]
|
| 590 |
-
self['Requires-Dist'] += requirements
|
| 591 |
-
|
| 592 |
-
# Mapping API
|
| 593 |
-
# TODO could add iter* variants
|
| 594 |
-
|
| 595 |
-
def keys(self):
|
| 596 |
-
return list(_version2fieldlist(self['Metadata-Version']))
|
| 597 |
-
|
| 598 |
-
def __iter__(self):
|
| 599 |
-
for key in self.keys():
|
| 600 |
-
yield key
|
| 601 |
-
|
| 602 |
-
def values(self):
|
| 603 |
-
return [self[key] for key in self.keys()]
|
| 604 |
-
|
| 605 |
-
def items(self):
|
| 606 |
-
return [(key, self[key]) for key in self.keys()]
|
| 607 |
-
|
| 608 |
-
def __repr__(self):
|
| 609 |
-
return '<%s %s %s>' % (self.__class__.__name__, self.name,
|
| 610 |
-
self.version)
|
| 611 |
-
|
| 612 |
-
|
| 613 |
-
METADATA_FILENAME = 'pydist.json'
|
| 614 |
-
WHEEL_METADATA_FILENAME = 'metadata.json'
|
| 615 |
-
LEGACY_METADATA_FILENAME = 'METADATA'
|
| 616 |
-
|
| 617 |
-
|
| 618 |
-
class Metadata(object):
|
| 619 |
-
"""
|
| 620 |
-
The metadata of a release. This implementation uses 2.1
|
| 621 |
-
metadata where possible. If not possible, it wraps a LegacyMetadata
|
| 622 |
-
instance which handles the key-value metadata format.
|
| 623 |
-
"""
|
| 624 |
-
|
| 625 |
-
METADATA_VERSION_MATCHER = re.compile(r'^\d+(\.\d+)*$')
|
| 626 |
-
|
| 627 |
-
NAME_MATCHER = re.compile('^[0-9A-Z]([0-9A-Z_.-]*[0-9A-Z])?$', re.I)
|
| 628 |
-
|
| 629 |
-
FIELDNAME_MATCHER = re.compile('^[A-Z]([0-9A-Z-]*[0-9A-Z])?$', re.I)
|
| 630 |
-
|
| 631 |
-
VERSION_MATCHER = PEP440_VERSION_RE
|
| 632 |
-
|
| 633 |
-
SUMMARY_MATCHER = re.compile('.{1,2047}')
|
| 634 |
-
|
| 635 |
-
METADATA_VERSION = '2.0'
|
| 636 |
-
|
| 637 |
-
GENERATOR = 'distlib (%s)' % __version__
|
| 638 |
-
|
| 639 |
-
MANDATORY_KEYS = {
|
| 640 |
-
'name': (),
|
| 641 |
-
'version': (),
|
| 642 |
-
'summary': ('legacy',),
|
| 643 |
-
}
|
| 644 |
-
|
| 645 |
-
INDEX_KEYS = ('name version license summary description author '
|
| 646 |
-
'author_email keywords platform home_page classifiers '
|
| 647 |
-
'download_url')
|
| 648 |
-
|
| 649 |
-
DEPENDENCY_KEYS = ('extras run_requires test_requires build_requires '
|
| 650 |
-
'dev_requires provides meta_requires obsoleted_by '
|
| 651 |
-
'supports_environments')
|
| 652 |
-
|
| 653 |
-
SYNTAX_VALIDATORS = {
|
| 654 |
-
'metadata_version': (METADATA_VERSION_MATCHER, ()),
|
| 655 |
-
'name': (NAME_MATCHER, ('legacy',)),
|
| 656 |
-
'version': (VERSION_MATCHER, ('legacy',)),
|
| 657 |
-
'summary': (SUMMARY_MATCHER, ('legacy',)),
|
| 658 |
-
'dynamic': (FIELDNAME_MATCHER, ('legacy',)),
|
| 659 |
-
}
|
| 660 |
-
|
| 661 |
-
__slots__ = ('_legacy', '_data', 'scheme')
|
| 662 |
-
|
| 663 |
-
def __init__(self, path=None, fileobj=None, mapping=None,
|
| 664 |
-
scheme='default'):
|
| 665 |
-
if [path, fileobj, mapping].count(None) < 2:
|
| 666 |
-
raise TypeError('path, fileobj and mapping are exclusive')
|
| 667 |
-
self._legacy = None
|
| 668 |
-
self._data = None
|
| 669 |
-
self.scheme = scheme
|
| 670 |
-
#import pdb; pdb.set_trace()
|
| 671 |
-
if mapping is not None:
|
| 672 |
-
try:
|
| 673 |
-
self._validate_mapping(mapping, scheme)
|
| 674 |
-
self._data = mapping
|
| 675 |
-
except MetadataUnrecognizedVersionError:
|
| 676 |
-
self._legacy = LegacyMetadata(mapping=mapping, scheme=scheme)
|
| 677 |
-
self.validate()
|
| 678 |
-
else:
|
| 679 |
-
data = None
|
| 680 |
-
if path:
|
| 681 |
-
with open(path, 'rb') as f:
|
| 682 |
-
data = f.read()
|
| 683 |
-
elif fileobj:
|
| 684 |
-
data = fileobj.read()
|
| 685 |
-
if data is None:
|
| 686 |
-
# Initialised with no args - to be added
|
| 687 |
-
self._data = {
|
| 688 |
-
'metadata_version': self.METADATA_VERSION,
|
| 689 |
-
'generator': self.GENERATOR,
|
| 690 |
-
}
|
| 691 |
-
else:
|
| 692 |
-
if not isinstance(data, text_type):
|
| 693 |
-
data = data.decode('utf-8')
|
| 694 |
-
try:
|
| 695 |
-
self._data = json.loads(data)
|
| 696 |
-
self._validate_mapping(self._data, scheme)
|
| 697 |
-
except ValueError:
|
| 698 |
-
# Note: MetadataUnrecognizedVersionError does not
|
| 699 |
-
# inherit from ValueError (it's a DistlibException,
|
| 700 |
-
# which should not inherit from ValueError).
|
| 701 |
-
# The ValueError comes from the json.load - if that
|
| 702 |
-
# succeeds and we get a validation error, we want
|
| 703 |
-
# that to propagate
|
| 704 |
-
self._legacy = LegacyMetadata(fileobj=StringIO(data),
|
| 705 |
-
scheme=scheme)
|
| 706 |
-
self.validate()
|
| 707 |
-
|
| 708 |
-
common_keys = set(('name', 'version', 'license', 'keywords', 'summary'))
|
| 709 |
-
|
| 710 |
-
none_list = (None, list)
|
| 711 |
-
none_dict = (None, dict)
|
| 712 |
-
|
| 713 |
-
mapped_keys = {
|
| 714 |
-
'run_requires': ('Requires-Dist', list),
|
| 715 |
-
'build_requires': ('Setup-Requires-Dist', list),
|
| 716 |
-
'dev_requires': none_list,
|
| 717 |
-
'test_requires': none_list,
|
| 718 |
-
'meta_requires': none_list,
|
| 719 |
-
'extras': ('Provides-Extra', list),
|
| 720 |
-
'modules': none_list,
|
| 721 |
-
'namespaces': none_list,
|
| 722 |
-
'exports': none_dict,
|
| 723 |
-
'commands': none_dict,
|
| 724 |
-
'classifiers': ('Classifier', list),
|
| 725 |
-
'source_url': ('Download-URL', None),
|
| 726 |
-
'metadata_version': ('Metadata-Version', None),
|
| 727 |
-
}
|
| 728 |
-
|
| 729 |
-
del none_list, none_dict
|
| 730 |
-
|
| 731 |
-
def __getattribute__(self, key):
|
| 732 |
-
common = object.__getattribute__(self, 'common_keys')
|
| 733 |
-
mapped = object.__getattribute__(self, 'mapped_keys')
|
| 734 |
-
if key in mapped:
|
| 735 |
-
lk, maker = mapped[key]
|
| 736 |
-
if self._legacy:
|
| 737 |
-
if lk is None:
|
| 738 |
-
result = None if maker is None else maker()
|
| 739 |
-
else:
|
| 740 |
-
result = self._legacy.get(lk)
|
| 741 |
-
else:
|
| 742 |
-
value = None if maker is None else maker()
|
| 743 |
-
if key not in ('commands', 'exports', 'modules', 'namespaces',
|
| 744 |
-
'classifiers'):
|
| 745 |
-
result = self._data.get(key, value)
|
| 746 |
-
else:
|
| 747 |
-
# special cases for PEP 459
|
| 748 |
-
sentinel = object()
|
| 749 |
-
result = sentinel
|
| 750 |
-
d = self._data.get('extensions')
|
| 751 |
-
if d:
|
| 752 |
-
if key == 'commands':
|
| 753 |
-
result = d.get('python.commands', value)
|
| 754 |
-
elif key == 'classifiers':
|
| 755 |
-
d = d.get('python.details')
|
| 756 |
-
if d:
|
| 757 |
-
result = d.get(key, value)
|
| 758 |
-
else:
|
| 759 |
-
d = d.get('python.exports')
|
| 760 |
-
if not d:
|
| 761 |
-
d = self._data.get('python.exports')
|
| 762 |
-
if d:
|
| 763 |
-
result = d.get(key, value)
|
| 764 |
-
if result is sentinel:
|
| 765 |
-
result = value
|
| 766 |
-
elif key not in common:
|
| 767 |
-
result = object.__getattribute__(self, key)
|
| 768 |
-
elif self._legacy:
|
| 769 |
-
result = self._legacy.get(key)
|
| 770 |
-
else:
|
| 771 |
-
result = self._data.get(key)
|
| 772 |
-
return result
|
| 773 |
-
|
| 774 |
-
def _validate_value(self, key, value, scheme=None):
|
| 775 |
-
if key in self.SYNTAX_VALIDATORS:
|
| 776 |
-
pattern, exclusions = self.SYNTAX_VALIDATORS[key]
|
| 777 |
-
if (scheme or self.scheme) not in exclusions:
|
| 778 |
-
m = pattern.match(value)
|
| 779 |
-
if not m:
|
| 780 |
-
raise MetadataInvalidError("'%s' is an invalid value for "
|
| 781 |
-
"the '%s' property" % (value,
|
| 782 |
-
key))
|
| 783 |
-
|
| 784 |
-
def __setattr__(self, key, value):
|
| 785 |
-
self._validate_value(key, value)
|
| 786 |
-
common = object.__getattribute__(self, 'common_keys')
|
| 787 |
-
mapped = object.__getattribute__(self, 'mapped_keys')
|
| 788 |
-
if key in mapped:
|
| 789 |
-
lk, _ = mapped[key]
|
| 790 |
-
if self._legacy:
|
| 791 |
-
if lk is None:
|
| 792 |
-
raise NotImplementedError
|
| 793 |
-
self._legacy[lk] = value
|
| 794 |
-
elif key not in ('commands', 'exports', 'modules', 'namespaces',
|
| 795 |
-
'classifiers'):
|
| 796 |
-
self._data[key] = value
|
| 797 |
-
else:
|
| 798 |
-
# special cases for PEP 459
|
| 799 |
-
d = self._data.setdefault('extensions', {})
|
| 800 |
-
if key == 'commands':
|
| 801 |
-
d['python.commands'] = value
|
| 802 |
-
elif key == 'classifiers':
|
| 803 |
-
d = d.setdefault('python.details', {})
|
| 804 |
-
d[key] = value
|
| 805 |
-
else:
|
| 806 |
-
d = d.setdefault('python.exports', {})
|
| 807 |
-
d[key] = value
|
| 808 |
-
elif key not in common:
|
| 809 |
-
object.__setattr__(self, key, value)
|
| 810 |
-
else:
|
| 811 |
-
if key == 'keywords':
|
| 812 |
-
if isinstance(value, string_types):
|
| 813 |
-
value = value.strip()
|
| 814 |
-
if value:
|
| 815 |
-
value = value.split()
|
| 816 |
-
else:
|
| 817 |
-
value = []
|
| 818 |
-
if self._legacy:
|
| 819 |
-
self._legacy[key] = value
|
| 820 |
-
else:
|
| 821 |
-
self._data[key] = value
|
| 822 |
-
|
| 823 |
-
@property
|
| 824 |
-
def name_and_version(self):
|
| 825 |
-
return _get_name_and_version(self.name, self.version, True)
|
| 826 |
-
|
| 827 |
-
@property
|
| 828 |
-
def provides(self):
|
| 829 |
-
if self._legacy:
|
| 830 |
-
result = self._legacy['Provides-Dist']
|
| 831 |
-
else:
|
| 832 |
-
result = self._data.setdefault('provides', [])
|
| 833 |
-
s = '%s (%s)' % (self.name, self.version)
|
| 834 |
-
if s not in result:
|
| 835 |
-
result.append(s)
|
| 836 |
-
return result
|
| 837 |
-
|
| 838 |
-
@provides.setter
|
| 839 |
-
def provides(self, value):
|
| 840 |
-
if self._legacy:
|
| 841 |
-
self._legacy['Provides-Dist'] = value
|
| 842 |
-
else:
|
| 843 |
-
self._data['provides'] = value
|
| 844 |
-
|
| 845 |
-
def get_requirements(self, reqts, extras=None, env=None):
|
| 846 |
-
"""
|
| 847 |
-
Base method to get dependencies, given a set of extras
|
| 848 |
-
to satisfy and an optional environment context.
|
| 849 |
-
:param reqts: A list of sometimes-wanted dependencies,
|
| 850 |
-
perhaps dependent on extras and environment.
|
| 851 |
-
:param extras: A list of optional components being requested.
|
| 852 |
-
:param env: An optional environment for marker evaluation.
|
| 853 |
-
"""
|
| 854 |
-
if self._legacy:
|
| 855 |
-
result = reqts
|
| 856 |
-
else:
|
| 857 |
-
result = []
|
| 858 |
-
extras = get_extras(extras or [], self.extras)
|
| 859 |
-
for d in reqts:
|
| 860 |
-
if 'extra' not in d and 'environment' not in d:
|
| 861 |
-
# unconditional
|
| 862 |
-
include = True
|
| 863 |
-
else:
|
| 864 |
-
if 'extra' not in d:
|
| 865 |
-
# Not extra-dependent - only environment-dependent
|
| 866 |
-
include = True
|
| 867 |
-
else:
|
| 868 |
-
include = d.get('extra') in extras
|
| 869 |
-
if include:
|
| 870 |
-
# Not excluded because of extras, check environment
|
| 871 |
-
marker = d.get('environment')
|
| 872 |
-
if marker:
|
| 873 |
-
include = interpret(marker, env)
|
| 874 |
-
if include:
|
| 875 |
-
result.extend(d['requires'])
|
| 876 |
-
for key in ('build', 'dev', 'test'):
|
| 877 |
-
e = ':%s:' % key
|
| 878 |
-
if e in extras:
|
| 879 |
-
extras.remove(e)
|
| 880 |
-
# A recursive call, but it should terminate since 'test'
|
| 881 |
-
# has been removed from the extras
|
| 882 |
-
reqts = self._data.get('%s_requires' % key, [])
|
| 883 |
-
result.extend(self.get_requirements(reqts, extras=extras,
|
| 884 |
-
env=env))
|
| 885 |
-
return result
|
| 886 |
-
|
| 887 |
-
@property
|
| 888 |
-
def dictionary(self):
|
| 889 |
-
if self._legacy:
|
| 890 |
-
return self._from_legacy()
|
| 891 |
-
return self._data
|
| 892 |
-
|
| 893 |
-
@property
|
| 894 |
-
def dependencies(self):
|
| 895 |
-
if self._legacy:
|
| 896 |
-
raise NotImplementedError
|
| 897 |
-
else:
|
| 898 |
-
return extract_by_key(self._data, self.DEPENDENCY_KEYS)
|
| 899 |
-
|
| 900 |
-
@dependencies.setter
|
| 901 |
-
def dependencies(self, value):
|
| 902 |
-
if self._legacy:
|
| 903 |
-
raise NotImplementedError
|
| 904 |
-
else:
|
| 905 |
-
self._data.update(value)
|
| 906 |
-
|
| 907 |
-
def _validate_mapping(self, mapping, scheme):
|
| 908 |
-
if mapping.get('metadata_version') != self.METADATA_VERSION:
|
| 909 |
-
raise MetadataUnrecognizedVersionError()
|
| 910 |
-
missing = []
|
| 911 |
-
for key, exclusions in self.MANDATORY_KEYS.items():
|
| 912 |
-
if key not in mapping:
|
| 913 |
-
if scheme not in exclusions:
|
| 914 |
-
missing.append(key)
|
| 915 |
-
if missing:
|
| 916 |
-
msg = 'Missing metadata items: %s' % ', '.join(missing)
|
| 917 |
-
raise MetadataMissingError(msg)
|
| 918 |
-
for k, v in mapping.items():
|
| 919 |
-
self._validate_value(k, v, scheme)
|
| 920 |
-
|
| 921 |
-
def validate(self):
|
| 922 |
-
if self._legacy:
|
| 923 |
-
missing, warnings = self._legacy.check(True)
|
| 924 |
-
if missing or warnings:
|
| 925 |
-
logger.warning('Metadata: missing: %s, warnings: %s',
|
| 926 |
-
missing, warnings)
|
| 927 |
-
else:
|
| 928 |
-
self._validate_mapping(self._data, self.scheme)
|
| 929 |
-
|
| 930 |
-
def todict(self):
|
| 931 |
-
if self._legacy:
|
| 932 |
-
return self._legacy.todict(True)
|
| 933 |
-
else:
|
| 934 |
-
result = extract_by_key(self._data, self.INDEX_KEYS)
|
| 935 |
-
return result
|
| 936 |
-
|
| 937 |
-
def _from_legacy(self):
|
| 938 |
-
assert self._legacy and not self._data
|
| 939 |
-
result = {
|
| 940 |
-
'metadata_version': self.METADATA_VERSION,
|
| 941 |
-
'generator': self.GENERATOR,
|
| 942 |
-
}
|
| 943 |
-
lmd = self._legacy.todict(True) # skip missing ones
|
| 944 |
-
for k in ('name', 'version', 'license', 'summary', 'description',
|
| 945 |
-
'classifier'):
|
| 946 |
-
if k in lmd:
|
| 947 |
-
if k == 'classifier':
|
| 948 |
-
nk = 'classifiers'
|
| 949 |
-
else:
|
| 950 |
-
nk = k
|
| 951 |
-
result[nk] = lmd[k]
|
| 952 |
-
kw = lmd.get('Keywords', [])
|
| 953 |
-
if kw == ['']:
|
| 954 |
-
kw = []
|
| 955 |
-
result['keywords'] = kw
|
| 956 |
-
keys = (('requires_dist', 'run_requires'),
|
| 957 |
-
('setup_requires_dist', 'build_requires'))
|
| 958 |
-
for ok, nk in keys:
|
| 959 |
-
if ok in lmd and lmd[ok]:
|
| 960 |
-
result[nk] = [{'requires': lmd[ok]}]
|
| 961 |
-
result['provides'] = self.provides
|
| 962 |
-
author = {}
|
| 963 |
-
maintainer = {}
|
| 964 |
-
return result
|
| 965 |
-
|
| 966 |
-
LEGACY_MAPPING = {
|
| 967 |
-
'name': 'Name',
|
| 968 |
-
'version': 'Version',
|
| 969 |
-
('extensions', 'python.details', 'license'): 'License',
|
| 970 |
-
'summary': 'Summary',
|
| 971 |
-
'description': 'Description',
|
| 972 |
-
('extensions', 'python.project', 'project_urls', 'Home'): 'Home-page',
|
| 973 |
-
('extensions', 'python.project', 'contacts', 0, 'name'): 'Author',
|
| 974 |
-
('extensions', 'python.project', 'contacts', 0, 'email'): 'Author-email',
|
| 975 |
-
'source_url': 'Download-URL',
|
| 976 |
-
('extensions', 'python.details', 'classifiers'): 'Classifier',
|
| 977 |
-
}
|
| 978 |
-
|
| 979 |
-
def _to_legacy(self):
|
| 980 |
-
def process_entries(entries):
|
| 981 |
-
reqts = set()
|
| 982 |
-
for e in entries:
|
| 983 |
-
extra = e.get('extra')
|
| 984 |
-
env = e.get('environment')
|
| 985 |
-
rlist = e['requires']
|
| 986 |
-
for r in rlist:
|
| 987 |
-
if not env and not extra:
|
| 988 |
-
reqts.add(r)
|
| 989 |
-
else:
|
| 990 |
-
marker = ''
|
| 991 |
-
if extra:
|
| 992 |
-
marker = 'extra == "%s"' % extra
|
| 993 |
-
if env:
|
| 994 |
-
if marker:
|
| 995 |
-
marker = '(%s) and %s' % (env, marker)
|
| 996 |
-
else:
|
| 997 |
-
marker = env
|
| 998 |
-
reqts.add(';'.join((r, marker)))
|
| 999 |
-
return reqts
|
| 1000 |
-
|
| 1001 |
-
assert self._data and not self._legacy
|
| 1002 |
-
result = LegacyMetadata()
|
| 1003 |
-
nmd = self._data
|
| 1004 |
-
# import pdb; pdb.set_trace()
|
| 1005 |
-
for nk, ok in self.LEGACY_MAPPING.items():
|
| 1006 |
-
if not isinstance(nk, tuple):
|
| 1007 |
-
if nk in nmd:
|
| 1008 |
-
result[ok] = nmd[nk]
|
| 1009 |
-
else:
|
| 1010 |
-
d = nmd
|
| 1011 |
-
found = True
|
| 1012 |
-
for k in nk:
|
| 1013 |
-
try:
|
| 1014 |
-
d = d[k]
|
| 1015 |
-
except (KeyError, IndexError):
|
| 1016 |
-
found = False
|
| 1017 |
-
break
|
| 1018 |
-
if found:
|
| 1019 |
-
result[ok] = d
|
| 1020 |
-
r1 = process_entries(self.run_requires + self.meta_requires)
|
| 1021 |
-
r2 = process_entries(self.build_requires + self.dev_requires)
|
| 1022 |
-
if self.extras:
|
| 1023 |
-
result['Provides-Extra'] = sorted(self.extras)
|
| 1024 |
-
result['Requires-Dist'] = sorted(r1)
|
| 1025 |
-
result['Setup-Requires-Dist'] = sorted(r2)
|
| 1026 |
-
# TODO: any other fields wanted
|
| 1027 |
-
return result
|
| 1028 |
-
|
| 1029 |
-
def write(self, path=None, fileobj=None, legacy=False, skip_unknown=True):
|
| 1030 |
-
if [path, fileobj].count(None) != 1:
|
| 1031 |
-
raise ValueError('Exactly one of path and fileobj is needed')
|
| 1032 |
-
self.validate()
|
| 1033 |
-
if legacy:
|
| 1034 |
-
if self._legacy:
|
| 1035 |
-
legacy_md = self._legacy
|
| 1036 |
-
else:
|
| 1037 |
-
legacy_md = self._to_legacy()
|
| 1038 |
-
if path:
|
| 1039 |
-
legacy_md.write(path, skip_unknown=skip_unknown)
|
| 1040 |
-
else:
|
| 1041 |
-
legacy_md.write_file(fileobj, skip_unknown=skip_unknown)
|
| 1042 |
-
else:
|
| 1043 |
-
if self._legacy:
|
| 1044 |
-
d = self._from_legacy()
|
| 1045 |
-
else:
|
| 1046 |
-
d = self._data
|
| 1047 |
-
if fileobj:
|
| 1048 |
-
json.dump(d, fileobj, ensure_ascii=True, indent=2,
|
| 1049 |
-
sort_keys=True)
|
| 1050 |
-
else:
|
| 1051 |
-
with codecs.open(path, 'w', 'utf-8') as f:
|
| 1052 |
-
json.dump(d, f, ensure_ascii=True, indent=2,
|
| 1053 |
-
sort_keys=True)
|
| 1054 |
-
|
| 1055 |
-
def add_requirements(self, requirements):
|
| 1056 |
-
if self._legacy:
|
| 1057 |
-
self._legacy.add_requirements(requirements)
|
| 1058 |
-
else:
|
| 1059 |
-
run_requires = self._data.setdefault('run_requires', [])
|
| 1060 |
-
always = None
|
| 1061 |
-
for entry in run_requires:
|
| 1062 |
-
if 'environment' not in entry and 'extra' not in entry:
|
| 1063 |
-
always = entry
|
| 1064 |
-
break
|
| 1065 |
-
if always is None:
|
| 1066 |
-
always = { 'requires': requirements }
|
| 1067 |
-
run_requires.insert(0, always)
|
| 1068 |
-
else:
|
| 1069 |
-
rset = set(always['requires']) | set(requirements)
|
| 1070 |
-
always['requires'] = sorted(rset)
|
| 1071 |
-
|
| 1072 |
-
def __repr__(self):
|
| 1073 |
-
name = self.name or '(no name)'
|
| 1074 |
-
version = self.version or 'no version'
|
| 1075 |
-
return '<%s %s %s (%s)>' % (self.__class__.__name__,
|
| 1076 |
-
self.metadata_version, name, version)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/Ataturk-Chatbot/HuggingFaceChat/venv/lib/python3.11/site-packages/setuptools/package_index.py
DELETED
|
@@ -1,1126 +0,0 @@
|
|
| 1 |
-
"""PyPI and direct package downloading"""
|
| 2 |
-
import sys
|
| 3 |
-
import os
|
| 4 |
-
import re
|
| 5 |
-
import io
|
| 6 |
-
import shutil
|
| 7 |
-
import socket
|
| 8 |
-
import base64
|
| 9 |
-
import hashlib
|
| 10 |
-
import itertools
|
| 11 |
-
import warnings
|
| 12 |
-
import configparser
|
| 13 |
-
import html
|
| 14 |
-
import http.client
|
| 15 |
-
import urllib.parse
|
| 16 |
-
import urllib.request
|
| 17 |
-
import urllib.error
|
| 18 |
-
from functools import wraps
|
| 19 |
-
|
| 20 |
-
import setuptools
|
| 21 |
-
from pkg_resources import (
|
| 22 |
-
CHECKOUT_DIST, Distribution, BINARY_DIST, normalize_path, SOURCE_DIST,
|
| 23 |
-
Environment, find_distributions, safe_name, safe_version,
|
| 24 |
-
to_filename, Requirement, DEVELOP_DIST, EGG_DIST, parse_version,
|
| 25 |
-
)
|
| 26 |
-
from distutils import log
|
| 27 |
-
from distutils.errors import DistutilsError
|
| 28 |
-
from fnmatch import translate
|
| 29 |
-
from setuptools.wheel import Wheel
|
| 30 |
-
from setuptools.extern.more_itertools import unique_everseen
|
| 31 |
-
|
| 32 |
-
|
| 33 |
-
EGG_FRAGMENT = re.compile(r'^egg=([-A-Za-z0-9_.+!]+)$')
|
| 34 |
-
HREF = re.compile(r"""href\s*=\s*['"]?([^'"> ]+)""", re.I)
|
| 35 |
-
PYPI_MD5 = re.compile(
|
| 36 |
-
r'<a href="([^"#]+)">([^<]+)</a>\n\s+\(<a (?:title="MD5 hash"\n\s+)'
|
| 37 |
-
r'href="[^?]+\?:action=show_md5&digest=([0-9a-f]{32})">md5</a>\)'
|
| 38 |
-
)
|
| 39 |
-
URL_SCHEME = re.compile('([-+.a-z0-9]{2,}):', re.I).match
|
| 40 |
-
EXTENSIONS = ".tar.gz .tar.bz2 .tar .zip .tgz".split()
|
| 41 |
-
|
| 42 |
-
__all__ = [
|
| 43 |
-
'PackageIndex', 'distros_for_url', 'parse_bdist_wininst',
|
| 44 |
-
'interpret_distro_name',
|
| 45 |
-
]
|
| 46 |
-
|
| 47 |
-
_SOCKET_TIMEOUT = 15
|
| 48 |
-
|
| 49 |
-
_tmpl = "setuptools/{setuptools.__version__} Python-urllib/{py_major}"
|
| 50 |
-
user_agent = _tmpl.format(
|
| 51 |
-
py_major='{}.{}'.format(*sys.version_info), setuptools=setuptools)
|
| 52 |
-
|
| 53 |
-
|
| 54 |
-
def parse_requirement_arg(spec):
|
| 55 |
-
try:
|
| 56 |
-
return Requirement.parse(spec)
|
| 57 |
-
except ValueError as e:
|
| 58 |
-
raise DistutilsError(
|
| 59 |
-
"Not a URL, existing file, or requirement spec: %r" % (spec,)
|
| 60 |
-
) from e
|
| 61 |
-
|
| 62 |
-
|
| 63 |
-
def parse_bdist_wininst(name):
|
| 64 |
-
"""Return (base,pyversion) or (None,None) for possible .exe name"""
|
| 65 |
-
|
| 66 |
-
lower = name.lower()
|
| 67 |
-
base, py_ver, plat = None, None, None
|
| 68 |
-
|
| 69 |
-
if lower.endswith('.exe'):
|
| 70 |
-
if lower.endswith('.win32.exe'):
|
| 71 |
-
base = name[:-10]
|
| 72 |
-
plat = 'win32'
|
| 73 |
-
elif lower.startswith('.win32-py', -16):
|
| 74 |
-
py_ver = name[-7:-4]
|
| 75 |
-
base = name[:-16]
|
| 76 |
-
plat = 'win32'
|
| 77 |
-
elif lower.endswith('.win-amd64.exe'):
|
| 78 |
-
base = name[:-14]
|
| 79 |
-
plat = 'win-amd64'
|
| 80 |
-
elif lower.startswith('.win-amd64-py', -20):
|
| 81 |
-
py_ver = name[-7:-4]
|
| 82 |
-
base = name[:-20]
|
| 83 |
-
plat = 'win-amd64'
|
| 84 |
-
return base, py_ver, plat
|
| 85 |
-
|
| 86 |
-
|
| 87 |
-
def egg_info_for_url(url):
|
| 88 |
-
parts = urllib.parse.urlparse(url)
|
| 89 |
-
scheme, server, path, parameters, query, fragment = parts
|
| 90 |
-
base = urllib.parse.unquote(path.split('/')[-1])
|
| 91 |
-
if server == 'sourceforge.net' and base == 'download': # XXX Yuck
|
| 92 |
-
base = urllib.parse.unquote(path.split('/')[-2])
|
| 93 |
-
if '#' in base:
|
| 94 |
-
base, fragment = base.split('#', 1)
|
| 95 |
-
return base, fragment
|
| 96 |
-
|
| 97 |
-
|
| 98 |
-
def distros_for_url(url, metadata=None):
|
| 99 |
-
"""Yield egg or source distribution objects that might be found at a URL"""
|
| 100 |
-
base, fragment = egg_info_for_url(url)
|
| 101 |
-
for dist in distros_for_location(url, base, metadata):
|
| 102 |
-
yield dist
|
| 103 |
-
if fragment:
|
| 104 |
-
match = EGG_FRAGMENT.match(fragment)
|
| 105 |
-
if match:
|
| 106 |
-
for dist in interpret_distro_name(
|
| 107 |
-
url, match.group(1), metadata, precedence=CHECKOUT_DIST
|
| 108 |
-
):
|
| 109 |
-
yield dist
|
| 110 |
-
|
| 111 |
-
|
| 112 |
-
def distros_for_location(location, basename, metadata=None):
|
| 113 |
-
"""Yield egg or source distribution objects based on basename"""
|
| 114 |
-
if basename.endswith('.egg.zip'):
|
| 115 |
-
basename = basename[:-4] # strip the .zip
|
| 116 |
-
if basename.endswith('.egg') and '-' in basename:
|
| 117 |
-
# only one, unambiguous interpretation
|
| 118 |
-
return [Distribution.from_location(location, basename, metadata)]
|
| 119 |
-
if basename.endswith('.whl') and '-' in basename:
|
| 120 |
-
wheel = Wheel(basename)
|
| 121 |
-
if not wheel.is_compatible():
|
| 122 |
-
return []
|
| 123 |
-
return [Distribution(
|
| 124 |
-
location=location,
|
| 125 |
-
project_name=wheel.project_name,
|
| 126 |
-
version=wheel.version,
|
| 127 |
-
# Increase priority over eggs.
|
| 128 |
-
precedence=EGG_DIST + 1,
|
| 129 |
-
)]
|
| 130 |
-
if basename.endswith('.exe'):
|
| 131 |
-
win_base, py_ver, platform = parse_bdist_wininst(basename)
|
| 132 |
-
if win_base is not None:
|
| 133 |
-
return interpret_distro_name(
|
| 134 |
-
location, win_base, metadata, py_ver, BINARY_DIST, platform
|
| 135 |
-
)
|
| 136 |
-
# Try source distro extensions (.zip, .tgz, etc.)
|
| 137 |
-
#
|
| 138 |
-
for ext in EXTENSIONS:
|
| 139 |
-
if basename.endswith(ext):
|
| 140 |
-
basename = basename[:-len(ext)]
|
| 141 |
-
return interpret_distro_name(location, basename, metadata)
|
| 142 |
-
return [] # no extension matched
|
| 143 |
-
|
| 144 |
-
|
| 145 |
-
def distros_for_filename(filename, metadata=None):
|
| 146 |
-
"""Yield possible egg or source distribution objects based on a filename"""
|
| 147 |
-
return distros_for_location(
|
| 148 |
-
normalize_path(filename), os.path.basename(filename), metadata
|
| 149 |
-
)
|
| 150 |
-
|
| 151 |
-
|
| 152 |
-
def interpret_distro_name(
|
| 153 |
-
location, basename, metadata, py_version=None, precedence=SOURCE_DIST,
|
| 154 |
-
platform=None
|
| 155 |
-
):
|
| 156 |
-
"""Generate alternative interpretations of a source distro name
|
| 157 |
-
|
| 158 |
-
Note: if `location` is a filesystem filename, you should call
|
| 159 |
-
``pkg_resources.normalize_path()`` on it before passing it to this
|
| 160 |
-
routine!
|
| 161 |
-
"""
|
| 162 |
-
# Generate alternative interpretations of a source distro name
|
| 163 |
-
# Because some packages are ambiguous as to name/versions split
|
| 164 |
-
# e.g. "adns-python-1.1.0", "egenix-mx-commercial", etc.
|
| 165 |
-
# So, we generate each possible interpretation (e.g. "adns, python-1.1.0"
|
| 166 |
-
# "adns-python, 1.1.0", and "adns-python-1.1.0, no version"). In practice,
|
| 167 |
-
# the spurious interpretations should be ignored, because in the event
|
| 168 |
-
# there's also an "adns" package, the spurious "python-1.1.0" version will
|
| 169 |
-
# compare lower than any numeric version number, and is therefore unlikely
|
| 170 |
-
# to match a request for it. It's still a potential problem, though, and
|
| 171 |
-
# in the long run PyPI and the distutils should go for "safe" names and
|
| 172 |
-
# versions in distribution archive names (sdist and bdist).
|
| 173 |
-
|
| 174 |
-
parts = basename.split('-')
|
| 175 |
-
if not py_version and any(re.match(r'py\d\.\d$', p) for p in parts[2:]):
|
| 176 |
-
# it is a bdist_dumb, not an sdist -- bail out
|
| 177 |
-
return
|
| 178 |
-
|
| 179 |
-
for p in range(1, len(parts) + 1):
|
| 180 |
-
yield Distribution(
|
| 181 |
-
location, metadata, '-'.join(parts[:p]), '-'.join(parts[p:]),
|
| 182 |
-
py_version=py_version, precedence=precedence,
|
| 183 |
-
platform=platform
|
| 184 |
-
)
|
| 185 |
-
|
| 186 |
-
|
| 187 |
-
def unique_values(func):
|
| 188 |
-
"""
|
| 189 |
-
Wrap a function returning an iterable such that the resulting iterable
|
| 190 |
-
only ever yields unique items.
|
| 191 |
-
"""
|
| 192 |
-
|
| 193 |
-
@wraps(func)
|
| 194 |
-
def wrapper(*args, **kwargs):
|
| 195 |
-
return unique_everseen(func(*args, **kwargs))
|
| 196 |
-
|
| 197 |
-
return wrapper
|
| 198 |
-
|
| 199 |
-
|
| 200 |
-
REL = re.compile(r"""<([^>]*\srel\s*=\s*['"]?([^'">]+)[^>]*)>""", re.I)
|
| 201 |
-
# this line is here to fix emacs' cruddy broken syntax highlighting
|
| 202 |
-
|
| 203 |
-
|
| 204 |
-
@unique_values
|
| 205 |
-
def find_external_links(url, page):
|
| 206 |
-
"""Find rel="homepage" and rel="download" links in `page`, yielding URLs"""
|
| 207 |
-
|
| 208 |
-
for match in REL.finditer(page):
|
| 209 |
-
tag, rel = match.groups()
|
| 210 |
-
rels = set(map(str.strip, rel.lower().split(',')))
|
| 211 |
-
if 'homepage' in rels or 'download' in rels:
|
| 212 |
-
for match in HREF.finditer(tag):
|
| 213 |
-
yield urllib.parse.urljoin(url, htmldecode(match.group(1)))
|
| 214 |
-
|
| 215 |
-
for tag in ("<th>Home Page", "<th>Download URL"):
|
| 216 |
-
pos = page.find(tag)
|
| 217 |
-
if pos != -1:
|
| 218 |
-
match = HREF.search(page, pos)
|
| 219 |
-
if match:
|
| 220 |
-
yield urllib.parse.urljoin(url, htmldecode(match.group(1)))
|
| 221 |
-
|
| 222 |
-
|
| 223 |
-
class ContentChecker:
|
| 224 |
-
"""
|
| 225 |
-
A null content checker that defines the interface for checking content
|
| 226 |
-
"""
|
| 227 |
-
|
| 228 |
-
def feed(self, block):
|
| 229 |
-
"""
|
| 230 |
-
Feed a block of data to the hash.
|
| 231 |
-
"""
|
| 232 |
-
return
|
| 233 |
-
|
| 234 |
-
def is_valid(self):
|
| 235 |
-
"""
|
| 236 |
-
Check the hash. Return False if validation fails.
|
| 237 |
-
"""
|
| 238 |
-
return True
|
| 239 |
-
|
| 240 |
-
def report(self, reporter, template):
|
| 241 |
-
"""
|
| 242 |
-
Call reporter with information about the checker (hash name)
|
| 243 |
-
substituted into the template.
|
| 244 |
-
"""
|
| 245 |
-
return
|
| 246 |
-
|
| 247 |
-
|
| 248 |
-
class HashChecker(ContentChecker):
|
| 249 |
-
pattern = re.compile(
|
| 250 |
-
r'(?P<hash_name>sha1|sha224|sha384|sha256|sha512|md5)='
|
| 251 |
-
r'(?P<expected>[a-f0-9]+)'
|
| 252 |
-
)
|
| 253 |
-
|
| 254 |
-
def __init__(self, hash_name, expected):
|
| 255 |
-
self.hash_name = hash_name
|
| 256 |
-
self.hash = hashlib.new(hash_name)
|
| 257 |
-
self.expected = expected
|
| 258 |
-
|
| 259 |
-
@classmethod
|
| 260 |
-
def from_url(cls, url):
|
| 261 |
-
"Construct a (possibly null) ContentChecker from a URL"
|
| 262 |
-
fragment = urllib.parse.urlparse(url)[-1]
|
| 263 |
-
if not fragment:
|
| 264 |
-
return ContentChecker()
|
| 265 |
-
match = cls.pattern.search(fragment)
|
| 266 |
-
if not match:
|
| 267 |
-
return ContentChecker()
|
| 268 |
-
return cls(**match.groupdict())
|
| 269 |
-
|
| 270 |
-
def feed(self, block):
|
| 271 |
-
self.hash.update(block)
|
| 272 |
-
|
| 273 |
-
def is_valid(self):
|
| 274 |
-
return self.hash.hexdigest() == self.expected
|
| 275 |
-
|
| 276 |
-
def report(self, reporter, template):
|
| 277 |
-
msg = template % self.hash_name
|
| 278 |
-
return reporter(msg)
|
| 279 |
-
|
| 280 |
-
|
| 281 |
-
class PackageIndex(Environment):
|
| 282 |
-
"""A distribution index that scans web pages for download URLs"""
|
| 283 |
-
|
| 284 |
-
def __init__(
|
| 285 |
-
self, index_url="https://pypi.org/simple/", hosts=('*',),
|
| 286 |
-
ca_bundle=None, verify_ssl=True, *args, **kw
|
| 287 |
-
):
|
| 288 |
-
super().__init__(*args, **kw)
|
| 289 |
-
self.index_url = index_url + "/" [:not index_url.endswith('/')]
|
| 290 |
-
self.scanned_urls = {}
|
| 291 |
-
self.fetched_urls = {}
|
| 292 |
-
self.package_pages = {}
|
| 293 |
-
self.allows = re.compile('|'.join(map(translate, hosts))).match
|
| 294 |
-
self.to_scan = []
|
| 295 |
-
self.opener = urllib.request.urlopen
|
| 296 |
-
|
| 297 |
-
def add(self, dist):
|
| 298 |
-
# ignore invalid versions
|
| 299 |
-
try:
|
| 300 |
-
parse_version(dist.version)
|
| 301 |
-
except Exception:
|
| 302 |
-
return
|
| 303 |
-
return super().add(dist)
|
| 304 |
-
|
| 305 |
-
# FIXME: 'PackageIndex.process_url' is too complex (14)
|
| 306 |
-
def process_url(self, url, retrieve=False): # noqa: C901
|
| 307 |
-
"""Evaluate a URL as a possible download, and maybe retrieve it"""
|
| 308 |
-
if url in self.scanned_urls and not retrieve:
|
| 309 |
-
return
|
| 310 |
-
self.scanned_urls[url] = True
|
| 311 |
-
if not URL_SCHEME(url):
|
| 312 |
-
self.process_filename(url)
|
| 313 |
-
return
|
| 314 |
-
else:
|
| 315 |
-
dists = list(distros_for_url(url))
|
| 316 |
-
if dists:
|
| 317 |
-
if not self.url_ok(url):
|
| 318 |
-
return
|
| 319 |
-
self.debug("Found link: %s", url)
|
| 320 |
-
|
| 321 |
-
if dists or not retrieve or url in self.fetched_urls:
|
| 322 |
-
list(map(self.add, dists))
|
| 323 |
-
return # don't need the actual page
|
| 324 |
-
|
| 325 |
-
if not self.url_ok(url):
|
| 326 |
-
self.fetched_urls[url] = True
|
| 327 |
-
return
|
| 328 |
-
|
| 329 |
-
self.info("Reading %s", url)
|
| 330 |
-
self.fetched_urls[url] = True # prevent multiple fetch attempts
|
| 331 |
-
tmpl = "Download error on %s: %%s -- Some packages may not be found!"
|
| 332 |
-
f = self.open_url(url, tmpl % url)
|
| 333 |
-
if f is None:
|
| 334 |
-
return
|
| 335 |
-
if isinstance(f, urllib.error.HTTPError) and f.code == 401:
|
| 336 |
-
self.info("Authentication error: %s" % f.msg)
|
| 337 |
-
self.fetched_urls[f.url] = True
|
| 338 |
-
if 'html' not in f.headers.get('content-type', '').lower():
|
| 339 |
-
f.close() # not html, we can't process it
|
| 340 |
-
return
|
| 341 |
-
|
| 342 |
-
base = f.url # handle redirects
|
| 343 |
-
page = f.read()
|
| 344 |
-
if not isinstance(page, str):
|
| 345 |
-
# In Python 3 and got bytes but want str.
|
| 346 |
-
if isinstance(f, urllib.error.HTTPError):
|
| 347 |
-
# Errors have no charset, assume latin1:
|
| 348 |
-
charset = 'latin-1'
|
| 349 |
-
else:
|
| 350 |
-
charset = f.headers.get_param('charset') or 'latin-1'
|
| 351 |
-
page = page.decode(charset, "ignore")
|
| 352 |
-
f.close()
|
| 353 |
-
for match in HREF.finditer(page):
|
| 354 |
-
link = urllib.parse.urljoin(base, htmldecode(match.group(1)))
|
| 355 |
-
self.process_url(link)
|
| 356 |
-
if url.startswith(self.index_url) and getattr(f, 'code', None) != 404:
|
| 357 |
-
page = self.process_index(url, page)
|
| 358 |
-
|
| 359 |
-
def process_filename(self, fn, nested=False):
|
| 360 |
-
# process filenames or directories
|
| 361 |
-
if not os.path.exists(fn):
|
| 362 |
-
self.warn("Not found: %s", fn)
|
| 363 |
-
return
|
| 364 |
-
|
| 365 |
-
if os.path.isdir(fn) and not nested:
|
| 366 |
-
path = os.path.realpath(fn)
|
| 367 |
-
for item in os.listdir(path):
|
| 368 |
-
self.process_filename(os.path.join(path, item), True)
|
| 369 |
-
|
| 370 |
-
dists = distros_for_filename(fn)
|
| 371 |
-
if dists:
|
| 372 |
-
self.debug("Found: %s", fn)
|
| 373 |
-
list(map(self.add, dists))
|
| 374 |
-
|
| 375 |
-
def url_ok(self, url, fatal=False):
|
| 376 |
-
s = URL_SCHEME(url)
|
| 377 |
-
is_file = s and s.group(1).lower() == 'file'
|
| 378 |
-
if is_file or self.allows(urllib.parse.urlparse(url)[1]):
|
| 379 |
-
return True
|
| 380 |
-
msg = (
|
| 381 |
-
"\nNote: Bypassing %s (disallowed host; see "
|
| 382 |
-
"http://bit.ly/2hrImnY for details).\n")
|
| 383 |
-
if fatal:
|
| 384 |
-
raise DistutilsError(msg % url)
|
| 385 |
-
else:
|
| 386 |
-
self.warn(msg, url)
|
| 387 |
-
|
| 388 |
-
def scan_egg_links(self, search_path):
|
| 389 |
-
dirs = filter(os.path.isdir, search_path)
|
| 390 |
-
egg_links = (
|
| 391 |
-
(path, entry)
|
| 392 |
-
for path in dirs
|
| 393 |
-
for entry in os.listdir(path)
|
| 394 |
-
if entry.endswith('.egg-link')
|
| 395 |
-
)
|
| 396 |
-
list(itertools.starmap(self.scan_egg_link, egg_links))
|
| 397 |
-
|
| 398 |
-
def scan_egg_link(self, path, entry):
|
| 399 |
-
with open(os.path.join(path, entry)) as raw_lines:
|
| 400 |
-
# filter non-empty lines
|
| 401 |
-
lines = list(filter(None, map(str.strip, raw_lines)))
|
| 402 |
-
|
| 403 |
-
if len(lines) != 2:
|
| 404 |
-
# format is not recognized; punt
|
| 405 |
-
return
|
| 406 |
-
|
| 407 |
-
egg_path, setup_path = lines
|
| 408 |
-
|
| 409 |
-
for dist in find_distributions(os.path.join(path, egg_path)):
|
| 410 |
-
dist.location = os.path.join(path, *lines)
|
| 411 |
-
dist.precedence = SOURCE_DIST
|
| 412 |
-
self.add(dist)
|
| 413 |
-
|
| 414 |
-
def _scan(self, link):
|
| 415 |
-
# Process a URL to see if it's for a package page
|
| 416 |
-
NO_MATCH_SENTINEL = None, None
|
| 417 |
-
if not link.startswith(self.index_url):
|
| 418 |
-
return NO_MATCH_SENTINEL
|
| 419 |
-
|
| 420 |
-
parts = list(map(
|
| 421 |
-
urllib.parse.unquote, link[len(self.index_url):].split('/')
|
| 422 |
-
))
|
| 423 |
-
if len(parts) != 2 or '#' in parts[1]:
|
| 424 |
-
return NO_MATCH_SENTINEL
|
| 425 |
-
|
| 426 |
-
# it's a package page, sanitize and index it
|
| 427 |
-
pkg = safe_name(parts[0])
|
| 428 |
-
ver = safe_version(parts[1])
|
| 429 |
-
self.package_pages.setdefault(pkg.lower(), {})[link] = True
|
| 430 |
-
return to_filename(pkg), to_filename(ver)
|
| 431 |
-
|
| 432 |
-
def process_index(self, url, page):
|
| 433 |
-
"""Process the contents of a PyPI page"""
|
| 434 |
-
|
| 435 |
-
# process an index page into the package-page index
|
| 436 |
-
for match in HREF.finditer(page):
|
| 437 |
-
try:
|
| 438 |
-
self._scan(urllib.parse.urljoin(url, htmldecode(match.group(1))))
|
| 439 |
-
except ValueError:
|
| 440 |
-
pass
|
| 441 |
-
|
| 442 |
-
pkg, ver = self._scan(url) # ensure this page is in the page index
|
| 443 |
-
if not pkg:
|
| 444 |
-
return "" # no sense double-scanning non-package pages
|
| 445 |
-
|
| 446 |
-
# process individual package page
|
| 447 |
-
for new_url in find_external_links(url, page):
|
| 448 |
-
# Process the found URL
|
| 449 |
-
base, frag = egg_info_for_url(new_url)
|
| 450 |
-
if base.endswith('.py') and not frag:
|
| 451 |
-
if ver:
|
| 452 |
-
new_url += '#egg=%s-%s' % (pkg, ver)
|
| 453 |
-
else:
|
| 454 |
-
self.need_version_info(url)
|
| 455 |
-
self.scan_url(new_url)
|
| 456 |
-
|
| 457 |
-
return PYPI_MD5.sub(
|
| 458 |
-
lambda m: '<a href="%s#md5=%s">%s</a>' % m.group(1, 3, 2), page
|
| 459 |
-
)
|
| 460 |
-
|
| 461 |
-
def need_version_info(self, url):
|
| 462 |
-
self.scan_all(
|
| 463 |
-
"Page at %s links to .py file(s) without version info; an index "
|
| 464 |
-
"scan is required.", url
|
| 465 |
-
)
|
| 466 |
-
|
| 467 |
-
def scan_all(self, msg=None, *args):
|
| 468 |
-
if self.index_url not in self.fetched_urls:
|
| 469 |
-
if msg:
|
| 470 |
-
self.warn(msg, *args)
|
| 471 |
-
self.info(
|
| 472 |
-
"Scanning index of all packages (this may take a while)"
|
| 473 |
-
)
|
| 474 |
-
self.scan_url(self.index_url)
|
| 475 |
-
|
| 476 |
-
def find_packages(self, requirement):
|
| 477 |
-
self.scan_url(self.index_url + requirement.unsafe_name + '/')
|
| 478 |
-
|
| 479 |
-
if not self.package_pages.get(requirement.key):
|
| 480 |
-
# Fall back to safe version of the name
|
| 481 |
-
self.scan_url(self.index_url + requirement.project_name + '/')
|
| 482 |
-
|
| 483 |
-
if not self.package_pages.get(requirement.key):
|
| 484 |
-
# We couldn't find the target package, so search the index page too
|
| 485 |
-
self.not_found_in_index(requirement)
|
| 486 |
-
|
| 487 |
-
for url in list(self.package_pages.get(requirement.key, ())):
|
| 488 |
-
# scan each page that might be related to the desired package
|
| 489 |
-
self.scan_url(url)
|
| 490 |
-
|
| 491 |
-
def obtain(self, requirement, installer=None):
|
| 492 |
-
self.prescan()
|
| 493 |
-
self.find_packages(requirement)
|
| 494 |
-
for dist in self[requirement.key]:
|
| 495 |
-
if dist in requirement:
|
| 496 |
-
return dist
|
| 497 |
-
self.debug("%s does not match %s", requirement, dist)
|
| 498 |
-
return super(PackageIndex, self).obtain(requirement, installer)
|
| 499 |
-
|
| 500 |
-
def check_hash(self, checker, filename, tfp):
|
| 501 |
-
"""
|
| 502 |
-
checker is a ContentChecker
|
| 503 |
-
"""
|
| 504 |
-
checker.report(
|
| 505 |
-
self.debug,
|
| 506 |
-
"Validating %%s checksum for %s" % filename)
|
| 507 |
-
if not checker.is_valid():
|
| 508 |
-
tfp.close()
|
| 509 |
-
os.unlink(filename)
|
| 510 |
-
raise DistutilsError(
|
| 511 |
-
"%s validation failed for %s; "
|
| 512 |
-
"possible download problem?"
|
| 513 |
-
% (checker.hash.name, os.path.basename(filename))
|
| 514 |
-
)
|
| 515 |
-
|
| 516 |
-
def add_find_links(self, urls):
|
| 517 |
-
"""Add `urls` to the list that will be prescanned for searches"""
|
| 518 |
-
for url in urls:
|
| 519 |
-
if (
|
| 520 |
-
self.to_scan is None # if we have already "gone online"
|
| 521 |
-
or not URL_SCHEME(url) # or it's a local file/directory
|
| 522 |
-
or url.startswith('file:')
|
| 523 |
-
or list(distros_for_url(url)) # or a direct package link
|
| 524 |
-
):
|
| 525 |
-
# then go ahead and process it now
|
| 526 |
-
self.scan_url(url)
|
| 527 |
-
else:
|
| 528 |
-
# otherwise, defer retrieval till later
|
| 529 |
-
self.to_scan.append(url)
|
| 530 |
-
|
| 531 |
-
def prescan(self):
|
| 532 |
-
"""Scan urls scheduled for prescanning (e.g. --find-links)"""
|
| 533 |
-
if self.to_scan:
|
| 534 |
-
list(map(self.scan_url, self.to_scan))
|
| 535 |
-
self.to_scan = None # from now on, go ahead and process immediately
|
| 536 |
-
|
| 537 |
-
def not_found_in_index(self, requirement):
|
| 538 |
-
if self[requirement.key]: # we've seen at least one distro
|
| 539 |
-
meth, msg = self.info, "Couldn't retrieve index page for %r"
|
| 540 |
-
else: # no distros seen for this name, might be misspelled
|
| 541 |
-
meth, msg = (
|
| 542 |
-
self.warn,
|
| 543 |
-
"Couldn't find index page for %r (maybe misspelled?)")
|
| 544 |
-
meth(msg, requirement.unsafe_name)
|
| 545 |
-
self.scan_all()
|
| 546 |
-
|
| 547 |
-
def download(self, spec, tmpdir):
|
| 548 |
-
"""Locate and/or download `spec` to `tmpdir`, returning a local path
|
| 549 |
-
|
| 550 |
-
`spec` may be a ``Requirement`` object, or a string containing a URL,
|
| 551 |
-
an existing local filename, or a project/version requirement spec
|
| 552 |
-
(i.e. the string form of a ``Requirement`` object). If it is the URL
|
| 553 |
-
of a .py file with an unambiguous ``#egg=name-version`` tag (i.e., one
|
| 554 |
-
that escapes ``-`` as ``_`` throughout), a trivial ``setup.py`` is
|
| 555 |
-
automatically created alongside the downloaded file.
|
| 556 |
-
|
| 557 |
-
If `spec` is a ``Requirement`` object or a string containing a
|
| 558 |
-
project/version requirement spec, this method returns the location of
|
| 559 |
-
a matching distribution (possibly after downloading it to `tmpdir`).
|
| 560 |
-
If `spec` is a locally existing file or directory name, it is simply
|
| 561 |
-
returned unchanged. If `spec` is a URL, it is downloaded to a subpath
|
| 562 |
-
of `tmpdir`, and the local filename is returned. Various errors may be
|
| 563 |
-
raised if a problem occurs during downloading.
|
| 564 |
-
"""
|
| 565 |
-
if not isinstance(spec, Requirement):
|
| 566 |
-
scheme = URL_SCHEME(spec)
|
| 567 |
-
if scheme:
|
| 568 |
-
# It's a url, download it to tmpdir
|
| 569 |
-
found = self._download_url(scheme.group(1), spec, tmpdir)
|
| 570 |
-
base, fragment = egg_info_for_url(spec)
|
| 571 |
-
if base.endswith('.py'):
|
| 572 |
-
found = self.gen_setup(found, fragment, tmpdir)
|
| 573 |
-
return found
|
| 574 |
-
elif os.path.exists(spec):
|
| 575 |
-
# Existing file or directory, just return it
|
| 576 |
-
return spec
|
| 577 |
-
else:
|
| 578 |
-
spec = parse_requirement_arg(spec)
|
| 579 |
-
return getattr(self.fetch_distribution(spec, tmpdir), 'location', None)
|
| 580 |
-
|
| 581 |
-
def fetch_distribution( # noqa: C901 # is too complex (14) # FIXME
|
| 582 |
-
self, requirement, tmpdir, force_scan=False, source=False,
|
| 583 |
-
develop_ok=False, local_index=None):
|
| 584 |
-
"""Obtain a distribution suitable for fulfilling `requirement`
|
| 585 |
-
|
| 586 |
-
`requirement` must be a ``pkg_resources.Requirement`` instance.
|
| 587 |
-
If necessary, or if the `force_scan` flag is set, the requirement is
|
| 588 |
-
searched for in the (online) package index as well as the locally
|
| 589 |
-
installed packages. If a distribution matching `requirement` is found,
|
| 590 |
-
the returned distribution's ``location`` is the value you would have
|
| 591 |
-
gotten from calling the ``download()`` method with the matching
|
| 592 |
-
distribution's URL or filename. If no matching distribution is found,
|
| 593 |
-
``None`` is returned.
|
| 594 |
-
|
| 595 |
-
If the `source` flag is set, only source distributions and source
|
| 596 |
-
checkout links will be considered. Unless the `develop_ok` flag is
|
| 597 |
-
set, development and system eggs (i.e., those using the ``.egg-info``
|
| 598 |
-
format) will be ignored.
|
| 599 |
-
"""
|
| 600 |
-
# process a Requirement
|
| 601 |
-
self.info("Searching for %s", requirement)
|
| 602 |
-
skipped = {}
|
| 603 |
-
dist = None
|
| 604 |
-
|
| 605 |
-
def find(req, env=None):
|
| 606 |
-
if env is None:
|
| 607 |
-
env = self
|
| 608 |
-
# Find a matching distribution; may be called more than once
|
| 609 |
-
|
| 610 |
-
for dist in env[req.key]:
|
| 611 |
-
|
| 612 |
-
if dist.precedence == DEVELOP_DIST and not develop_ok:
|
| 613 |
-
if dist not in skipped:
|
| 614 |
-
self.warn(
|
| 615 |
-
"Skipping development or system egg: %s", dist,
|
| 616 |
-
)
|
| 617 |
-
skipped[dist] = 1
|
| 618 |
-
continue
|
| 619 |
-
|
| 620 |
-
test = (
|
| 621 |
-
dist in req
|
| 622 |
-
and (dist.precedence <= SOURCE_DIST or not source)
|
| 623 |
-
)
|
| 624 |
-
if test:
|
| 625 |
-
loc = self.download(dist.location, tmpdir)
|
| 626 |
-
dist.download_location = loc
|
| 627 |
-
if os.path.exists(dist.download_location):
|
| 628 |
-
return dist
|
| 629 |
-
|
| 630 |
-
if force_scan:
|
| 631 |
-
self.prescan()
|
| 632 |
-
self.find_packages(requirement)
|
| 633 |
-
dist = find(requirement)
|
| 634 |
-
|
| 635 |
-
if not dist and local_index is not None:
|
| 636 |
-
dist = find(requirement, local_index)
|
| 637 |
-
|
| 638 |
-
if dist is None:
|
| 639 |
-
if self.to_scan is not None:
|
| 640 |
-
self.prescan()
|
| 641 |
-
dist = find(requirement)
|
| 642 |
-
|
| 643 |
-
if dist is None and not force_scan:
|
| 644 |
-
self.find_packages(requirement)
|
| 645 |
-
dist = find(requirement)
|
| 646 |
-
|
| 647 |
-
if dist is None:
|
| 648 |
-
self.warn(
|
| 649 |
-
"No local packages or working download links found for %s%s",
|
| 650 |
-
(source and "a source distribution of " or ""),
|
| 651 |
-
requirement,
|
| 652 |
-
)
|
| 653 |
-
else:
|
| 654 |
-
self.info("Best match: %s", dist)
|
| 655 |
-
return dist.clone(location=dist.download_location)
|
| 656 |
-
|
| 657 |
-
def fetch(self, requirement, tmpdir, force_scan=False, source=False):
|
| 658 |
-
"""Obtain a file suitable for fulfilling `requirement`
|
| 659 |
-
|
| 660 |
-
DEPRECATED; use the ``fetch_distribution()`` method now instead. For
|
| 661 |
-
backward compatibility, this routine is identical but returns the
|
| 662 |
-
``location`` of the downloaded distribution instead of a distribution
|
| 663 |
-
object.
|
| 664 |
-
"""
|
| 665 |
-
dist = self.fetch_distribution(requirement, tmpdir, force_scan, source)
|
| 666 |
-
if dist is not None:
|
| 667 |
-
return dist.location
|
| 668 |
-
return None
|
| 669 |
-
|
| 670 |
-
def gen_setup(self, filename, fragment, tmpdir):
|
| 671 |
-
match = EGG_FRAGMENT.match(fragment)
|
| 672 |
-
dists = match and [
|
| 673 |
-
d for d in
|
| 674 |
-
interpret_distro_name(filename, match.group(1), None) if d.version
|
| 675 |
-
] or []
|
| 676 |
-
|
| 677 |
-
if len(dists) == 1: # unambiguous ``#egg`` fragment
|
| 678 |
-
basename = os.path.basename(filename)
|
| 679 |
-
|
| 680 |
-
# Make sure the file has been downloaded to the temp dir.
|
| 681 |
-
if os.path.dirname(filename) != tmpdir:
|
| 682 |
-
dst = os.path.join(tmpdir, basename)
|
| 683 |
-
if not (os.path.exists(dst) and os.path.samefile(filename, dst)):
|
| 684 |
-
shutil.copy2(filename, dst)
|
| 685 |
-
filename = dst
|
| 686 |
-
|
| 687 |
-
with open(os.path.join(tmpdir, 'setup.py'), 'w') as file:
|
| 688 |
-
file.write(
|
| 689 |
-
"from setuptools import setup\n"
|
| 690 |
-
"setup(name=%r, version=%r, py_modules=[%r])\n"
|
| 691 |
-
% (
|
| 692 |
-
dists[0].project_name, dists[0].version,
|
| 693 |
-
os.path.splitext(basename)[0]
|
| 694 |
-
)
|
| 695 |
-
)
|
| 696 |
-
return filename
|
| 697 |
-
|
| 698 |
-
elif match:
|
| 699 |
-
raise DistutilsError(
|
| 700 |
-
"Can't unambiguously interpret project/version identifier %r; "
|
| 701 |
-
"any dashes in the name or version should be escaped using "
|
| 702 |
-
"underscores. %r" % (fragment, dists)
|
| 703 |
-
)
|
| 704 |
-
else:
|
| 705 |
-
raise DistutilsError(
|
| 706 |
-
"Can't process plain .py files without an '#egg=name-version'"
|
| 707 |
-
" suffix to enable automatic setup script generation."
|
| 708 |
-
)
|
| 709 |
-
|
| 710 |
-
dl_blocksize = 8192
|
| 711 |
-
|
| 712 |
-
def _download_to(self, url, filename):
|
| 713 |
-
self.info("Downloading %s", url)
|
| 714 |
-
# Download the file
|
| 715 |
-
fp = None
|
| 716 |
-
try:
|
| 717 |
-
checker = HashChecker.from_url(url)
|
| 718 |
-
fp = self.open_url(url)
|
| 719 |
-
if isinstance(fp, urllib.error.HTTPError):
|
| 720 |
-
raise DistutilsError(
|
| 721 |
-
"Can't download %s: %s %s" % (url, fp.code, fp.msg)
|
| 722 |
-
)
|
| 723 |
-
headers = fp.info()
|
| 724 |
-
blocknum = 0
|
| 725 |
-
bs = self.dl_blocksize
|
| 726 |
-
size = -1
|
| 727 |
-
if "content-length" in headers:
|
| 728 |
-
# Some servers return multiple Content-Length headers :(
|
| 729 |
-
sizes = headers.get_all('Content-Length')
|
| 730 |
-
size = max(map(int, sizes))
|
| 731 |
-
self.reporthook(url, filename, blocknum, bs, size)
|
| 732 |
-
with open(filename, 'wb') as tfp:
|
| 733 |
-
while True:
|
| 734 |
-
block = fp.read(bs)
|
| 735 |
-
if block:
|
| 736 |
-
checker.feed(block)
|
| 737 |
-
tfp.write(block)
|
| 738 |
-
blocknum += 1
|
| 739 |
-
self.reporthook(url, filename, blocknum, bs, size)
|
| 740 |
-
else:
|
| 741 |
-
break
|
| 742 |
-
self.check_hash(checker, filename, tfp)
|
| 743 |
-
return headers
|
| 744 |
-
finally:
|
| 745 |
-
if fp:
|
| 746 |
-
fp.close()
|
| 747 |
-
|
| 748 |
-
def reporthook(self, url, filename, blocknum, blksize, size):
|
| 749 |
-
pass # no-op
|
| 750 |
-
|
| 751 |
-
# FIXME:
|
| 752 |
-
def open_url(self, url, warning=None): # noqa: C901 # is too complex (12)
|
| 753 |
-
if url.startswith('file:'):
|
| 754 |
-
return local_open(url)
|
| 755 |
-
try:
|
| 756 |
-
return open_with_auth(url, self.opener)
|
| 757 |
-
except (ValueError, http.client.InvalidURL) as v:
|
| 758 |
-
msg = ' '.join([str(arg) for arg in v.args])
|
| 759 |
-
if warning:
|
| 760 |
-
self.warn(warning, msg)
|
| 761 |
-
else:
|
| 762 |
-
raise DistutilsError('%s %s' % (url, msg)) from v
|
| 763 |
-
except urllib.error.HTTPError as v:
|
| 764 |
-
return v
|
| 765 |
-
except urllib.error.URLError as v:
|
| 766 |
-
if warning:
|
| 767 |
-
self.warn(warning, v.reason)
|
| 768 |
-
else:
|
| 769 |
-
raise DistutilsError("Download error for %s: %s"
|
| 770 |
-
% (url, v.reason)) from v
|
| 771 |
-
except http.client.BadStatusLine as v:
|
| 772 |
-
if warning:
|
| 773 |
-
self.warn(warning, v.line)
|
| 774 |
-
else:
|
| 775 |
-
raise DistutilsError(
|
| 776 |
-
'%s returned a bad status line. The server might be '
|
| 777 |
-
'down, %s' %
|
| 778 |
-
(url, v.line)
|
| 779 |
-
) from v
|
| 780 |
-
except (http.client.HTTPException, socket.error) as v:
|
| 781 |
-
if warning:
|
| 782 |
-
self.warn(warning, v)
|
| 783 |
-
else:
|
| 784 |
-
raise DistutilsError("Download error for %s: %s"
|
| 785 |
-
% (url, v)) from v
|
| 786 |
-
|
| 787 |
-
def _download_url(self, scheme, url, tmpdir):
|
| 788 |
-
# Determine download filename
|
| 789 |
-
#
|
| 790 |
-
name, fragment = egg_info_for_url(url)
|
| 791 |
-
if name:
|
| 792 |
-
while '..' in name:
|
| 793 |
-
name = name.replace('..', '.').replace('\\', '_')
|
| 794 |
-
else:
|
| 795 |
-
name = "__downloaded__" # default if URL has no path contents
|
| 796 |
-
|
| 797 |
-
if name.endswith('.egg.zip'):
|
| 798 |
-
name = name[:-4] # strip the extra .zip before download
|
| 799 |
-
|
| 800 |
-
filename = os.path.join(tmpdir, name)
|
| 801 |
-
|
| 802 |
-
# Download the file
|
| 803 |
-
#
|
| 804 |
-
if scheme == 'svn' or scheme.startswith('svn+'):
|
| 805 |
-
return self._download_svn(url, filename)
|
| 806 |
-
elif scheme == 'git' or scheme.startswith('git+'):
|
| 807 |
-
return self._download_git(url, filename)
|
| 808 |
-
elif scheme.startswith('hg+'):
|
| 809 |
-
return self._download_hg(url, filename)
|
| 810 |
-
elif scheme == 'file':
|
| 811 |
-
return urllib.request.url2pathname(urllib.parse.urlparse(url)[2])
|
| 812 |
-
else:
|
| 813 |
-
self.url_ok(url, True) # raises error if not allowed
|
| 814 |
-
return self._attempt_download(url, filename)
|
| 815 |
-
|
| 816 |
-
def scan_url(self, url):
|
| 817 |
-
self.process_url(url, True)
|
| 818 |
-
|
| 819 |
-
def _attempt_download(self, url, filename):
|
| 820 |
-
headers = self._download_to(url, filename)
|
| 821 |
-
if 'html' in headers.get('content-type', '').lower():
|
| 822 |
-
return self._download_html(url, headers, filename)
|
| 823 |
-
else:
|
| 824 |
-
return filename
|
| 825 |
-
|
| 826 |
-
def _download_html(self, url, headers, filename):
|
| 827 |
-
file = open(filename)
|
| 828 |
-
for line in file:
|
| 829 |
-
if line.strip():
|
| 830 |
-
# Check for a subversion index page
|
| 831 |
-
if re.search(r'<title>([^- ]+ - )?Revision \d+:', line):
|
| 832 |
-
# it's a subversion index page:
|
| 833 |
-
file.close()
|
| 834 |
-
os.unlink(filename)
|
| 835 |
-
return self._download_svn(url, filename)
|
| 836 |
-
break # not an index page
|
| 837 |
-
file.close()
|
| 838 |
-
os.unlink(filename)
|
| 839 |
-
raise DistutilsError("Unexpected HTML page found at " + url)
|
| 840 |
-
|
| 841 |
-
def _download_svn(self, url, filename):
|
| 842 |
-
warnings.warn("SVN download support is deprecated", UserWarning)
|
| 843 |
-
url = url.split('#', 1)[0] # remove any fragment for svn's sake
|
| 844 |
-
creds = ''
|
| 845 |
-
if url.lower().startswith('svn:') and '@' in url:
|
| 846 |
-
scheme, netloc, path, p, q, f = urllib.parse.urlparse(url)
|
| 847 |
-
if not netloc and path.startswith('//') and '/' in path[2:]:
|
| 848 |
-
netloc, path = path[2:].split('/', 1)
|
| 849 |
-
auth, host = _splituser(netloc)
|
| 850 |
-
if auth:
|
| 851 |
-
if ':' in auth:
|
| 852 |
-
user, pw = auth.split(':', 1)
|
| 853 |
-
creds = " --username=%s --password=%s" % (user, pw)
|
| 854 |
-
else:
|
| 855 |
-
creds = " --username=" + auth
|
| 856 |
-
netloc = host
|
| 857 |
-
parts = scheme, netloc, url, p, q, f
|
| 858 |
-
url = urllib.parse.urlunparse(parts)
|
| 859 |
-
self.info("Doing subversion checkout from %s to %s", url, filename)
|
| 860 |
-
os.system("svn checkout%s -q %s %s" % (creds, url, filename))
|
| 861 |
-
return filename
|
| 862 |
-
|
| 863 |
-
@staticmethod
|
| 864 |
-
def _vcs_split_rev_from_url(url, pop_prefix=False):
|
| 865 |
-
scheme, netloc, path, query, frag = urllib.parse.urlsplit(url)
|
| 866 |
-
|
| 867 |
-
scheme = scheme.split('+', 1)[-1]
|
| 868 |
-
|
| 869 |
-
# Some fragment identification fails
|
| 870 |
-
path = path.split('#', 1)[0]
|
| 871 |
-
|
| 872 |
-
rev = None
|
| 873 |
-
if '@' in path:
|
| 874 |
-
path, rev = path.rsplit('@', 1)
|
| 875 |
-
|
| 876 |
-
# Also, discard fragment
|
| 877 |
-
url = urllib.parse.urlunsplit((scheme, netloc, path, query, ''))
|
| 878 |
-
|
| 879 |
-
return url, rev
|
| 880 |
-
|
| 881 |
-
def _download_git(self, url, filename):
|
| 882 |
-
filename = filename.split('#', 1)[0]
|
| 883 |
-
url, rev = self._vcs_split_rev_from_url(url, pop_prefix=True)
|
| 884 |
-
|
| 885 |
-
self.info("Doing git clone from %s to %s", url, filename)
|
| 886 |
-
os.system("git clone --quiet %s %s" % (url, filename))
|
| 887 |
-
|
| 888 |
-
if rev is not None:
|
| 889 |
-
self.info("Checking out %s", rev)
|
| 890 |
-
os.system("git -C %s checkout --quiet %s" % (
|
| 891 |
-
filename,
|
| 892 |
-
rev,
|
| 893 |
-
))
|
| 894 |
-
|
| 895 |
-
return filename
|
| 896 |
-
|
| 897 |
-
def _download_hg(self, url, filename):
|
| 898 |
-
filename = filename.split('#', 1)[0]
|
| 899 |
-
url, rev = self._vcs_split_rev_from_url(url, pop_prefix=True)
|
| 900 |
-
|
| 901 |
-
self.info("Doing hg clone from %s to %s", url, filename)
|
| 902 |
-
os.system("hg clone --quiet %s %s" % (url, filename))
|
| 903 |
-
|
| 904 |
-
if rev is not None:
|
| 905 |
-
self.info("Updating to %s", rev)
|
| 906 |
-
os.system("hg --cwd %s up -C -r %s -q" % (
|
| 907 |
-
filename,
|
| 908 |
-
rev,
|
| 909 |
-
))
|
| 910 |
-
|
| 911 |
-
return filename
|
| 912 |
-
|
| 913 |
-
def debug(self, msg, *args):
|
| 914 |
-
log.debug(msg, *args)
|
| 915 |
-
|
| 916 |
-
def info(self, msg, *args):
|
| 917 |
-
log.info(msg, *args)
|
| 918 |
-
|
| 919 |
-
def warn(self, msg, *args):
|
| 920 |
-
log.warn(msg, *args)
|
| 921 |
-
|
| 922 |
-
|
| 923 |
-
# This pattern matches a character entity reference (a decimal numeric
|
| 924 |
-
# references, a hexadecimal numeric reference, or a named reference).
|
| 925 |
-
entity_sub = re.compile(r'&(#(\d+|x[\da-fA-F]+)|[\w.:-]+);?').sub
|
| 926 |
-
|
| 927 |
-
|
| 928 |
-
def decode_entity(match):
|
| 929 |
-
what = match.group(0)
|
| 930 |
-
return html.unescape(what)
|
| 931 |
-
|
| 932 |
-
|
| 933 |
-
def htmldecode(text):
|
| 934 |
-
"""
|
| 935 |
-
Decode HTML entities in the given text.
|
| 936 |
-
|
| 937 |
-
>>> htmldecode(
|
| 938 |
-
... 'https://../package_name-0.1.2.tar.gz'
|
| 939 |
-
... '?tokena=A&tokenb=B">package_name-0.1.2.tar.gz')
|
| 940 |
-
'https://../package_name-0.1.2.tar.gz?tokena=A&tokenb=B">package_name-0.1.2.tar.gz'
|
| 941 |
-
"""
|
| 942 |
-
return entity_sub(decode_entity, text)
|
| 943 |
-
|
| 944 |
-
|
| 945 |
-
def socket_timeout(timeout=15):
|
| 946 |
-
def _socket_timeout(func):
|
| 947 |
-
def _socket_timeout(*args, **kwargs):
|
| 948 |
-
old_timeout = socket.getdefaulttimeout()
|
| 949 |
-
socket.setdefaulttimeout(timeout)
|
| 950 |
-
try:
|
| 951 |
-
return func(*args, **kwargs)
|
| 952 |
-
finally:
|
| 953 |
-
socket.setdefaulttimeout(old_timeout)
|
| 954 |
-
|
| 955 |
-
return _socket_timeout
|
| 956 |
-
|
| 957 |
-
return _socket_timeout
|
| 958 |
-
|
| 959 |
-
|
| 960 |
-
def _encode_auth(auth):
|
| 961 |
-
"""
|
| 962 |
-
Encode auth from a URL suitable for an HTTP header.
|
| 963 |
-
>>> str(_encode_auth('username%3Apassword'))
|
| 964 |
-
'dXNlcm5hbWU6cGFzc3dvcmQ='
|
| 965 |
-
|
| 966 |
-
Long auth strings should not cause a newline to be inserted.
|
| 967 |
-
>>> long_auth = 'username:' + 'password'*10
|
| 968 |
-
>>> chr(10) in str(_encode_auth(long_auth))
|
| 969 |
-
False
|
| 970 |
-
"""
|
| 971 |
-
auth_s = urllib.parse.unquote(auth)
|
| 972 |
-
# convert to bytes
|
| 973 |
-
auth_bytes = auth_s.encode()
|
| 974 |
-
encoded_bytes = base64.b64encode(auth_bytes)
|
| 975 |
-
# convert back to a string
|
| 976 |
-
encoded = encoded_bytes.decode()
|
| 977 |
-
# strip the trailing carriage return
|
| 978 |
-
return encoded.replace('\n', '')
|
| 979 |
-
|
| 980 |
-
|
| 981 |
-
class Credential:
|
| 982 |
-
"""
|
| 983 |
-
A username/password pair. Use like a namedtuple.
|
| 984 |
-
"""
|
| 985 |
-
|
| 986 |
-
def __init__(self, username, password):
|
| 987 |
-
self.username = username
|
| 988 |
-
self.password = password
|
| 989 |
-
|
| 990 |
-
def __iter__(self):
|
| 991 |
-
yield self.username
|
| 992 |
-
yield self.password
|
| 993 |
-
|
| 994 |
-
def __str__(self):
|
| 995 |
-
return '%(username)s:%(password)s' % vars(self)
|
| 996 |
-
|
| 997 |
-
|
| 998 |
-
class PyPIConfig(configparser.RawConfigParser):
|
| 999 |
-
def __init__(self):
|
| 1000 |
-
"""
|
| 1001 |
-
Load from ~/.pypirc
|
| 1002 |
-
"""
|
| 1003 |
-
defaults = dict.fromkeys(['username', 'password', 'repository'], '')
|
| 1004 |
-
super().__init__(defaults)
|
| 1005 |
-
|
| 1006 |
-
rc = os.path.join(os.path.expanduser('~'), '.pypirc')
|
| 1007 |
-
if os.path.exists(rc):
|
| 1008 |
-
self.read(rc)
|
| 1009 |
-
|
| 1010 |
-
@property
|
| 1011 |
-
def creds_by_repository(self):
|
| 1012 |
-
sections_with_repositories = [
|
| 1013 |
-
section for section in self.sections()
|
| 1014 |
-
if self.get(section, 'repository').strip()
|
| 1015 |
-
]
|
| 1016 |
-
|
| 1017 |
-
return dict(map(self._get_repo_cred, sections_with_repositories))
|
| 1018 |
-
|
| 1019 |
-
def _get_repo_cred(self, section):
|
| 1020 |
-
repo = self.get(section, 'repository').strip()
|
| 1021 |
-
return repo, Credential(
|
| 1022 |
-
self.get(section, 'username').strip(),
|
| 1023 |
-
self.get(section, 'password').strip(),
|
| 1024 |
-
)
|
| 1025 |
-
|
| 1026 |
-
def find_credential(self, url):
|
| 1027 |
-
"""
|
| 1028 |
-
If the URL indicated appears to be a repository defined in this
|
| 1029 |
-
config, return the credential for that repository.
|
| 1030 |
-
"""
|
| 1031 |
-
for repository, cred in self.creds_by_repository.items():
|
| 1032 |
-
if url.startswith(repository):
|
| 1033 |
-
return cred
|
| 1034 |
-
|
| 1035 |
-
|
| 1036 |
-
def open_with_auth(url, opener=urllib.request.urlopen):
|
| 1037 |
-
"""Open a urllib2 request, handling HTTP authentication"""
|
| 1038 |
-
|
| 1039 |
-
parsed = urllib.parse.urlparse(url)
|
| 1040 |
-
scheme, netloc, path, params, query, frag = parsed
|
| 1041 |
-
|
| 1042 |
-
# Double scheme does not raise on macOS as revealed by a
|
| 1043 |
-
# failing test. We would expect "nonnumeric port". Refs #20.
|
| 1044 |
-
if netloc.endswith(':'):
|
| 1045 |
-
raise http.client.InvalidURL("nonnumeric port: ''")
|
| 1046 |
-
|
| 1047 |
-
if scheme in ('http', 'https'):
|
| 1048 |
-
auth, address = _splituser(netloc)
|
| 1049 |
-
else:
|
| 1050 |
-
auth = None
|
| 1051 |
-
|
| 1052 |
-
if not auth:
|
| 1053 |
-
cred = PyPIConfig().find_credential(url)
|
| 1054 |
-
if cred:
|
| 1055 |
-
auth = str(cred)
|
| 1056 |
-
info = cred.username, url
|
| 1057 |
-
log.info('Authenticating as %s for %s (from .pypirc)', *info)
|
| 1058 |
-
|
| 1059 |
-
if auth:
|
| 1060 |
-
auth = "Basic " + _encode_auth(auth)
|
| 1061 |
-
parts = scheme, address, path, params, query, frag
|
| 1062 |
-
new_url = urllib.parse.urlunparse(parts)
|
| 1063 |
-
request = urllib.request.Request(new_url)
|
| 1064 |
-
request.add_header("Authorization", auth)
|
| 1065 |
-
else:
|
| 1066 |
-
request = urllib.request.Request(url)
|
| 1067 |
-
|
| 1068 |
-
request.add_header('User-Agent', user_agent)
|
| 1069 |
-
fp = opener(request)
|
| 1070 |
-
|
| 1071 |
-
if auth:
|
| 1072 |
-
# Put authentication info back into request URL if same host,
|
| 1073 |
-
# so that links found on the page will work
|
| 1074 |
-
s2, h2, path2, param2, query2, frag2 = urllib.parse.urlparse(fp.url)
|
| 1075 |
-
if s2 == scheme and h2 == address:
|
| 1076 |
-
parts = s2, netloc, path2, param2, query2, frag2
|
| 1077 |
-
fp.url = urllib.parse.urlunparse(parts)
|
| 1078 |
-
|
| 1079 |
-
return fp
|
| 1080 |
-
|
| 1081 |
-
|
| 1082 |
-
# copy of urllib.parse._splituser from Python 3.8
|
| 1083 |
-
def _splituser(host):
|
| 1084 |
-
"""splituser('user[:passwd]@host[:port]')
|
| 1085 |
-
--> 'user[:passwd]', 'host[:port]'."""
|
| 1086 |
-
user, delim, host = host.rpartition('@')
|
| 1087 |
-
return (user if delim else None), host
|
| 1088 |
-
|
| 1089 |
-
|
| 1090 |
-
# adding a timeout to avoid freezing package_index
|
| 1091 |
-
open_with_auth = socket_timeout(_SOCKET_TIMEOUT)(open_with_auth)
|
| 1092 |
-
|
| 1093 |
-
|
| 1094 |
-
def fix_sf_url(url):
|
| 1095 |
-
return url # backward compatibility
|
| 1096 |
-
|
| 1097 |
-
|
| 1098 |
-
def local_open(url):
|
| 1099 |
-
"""Read a local path, with special support for directories"""
|
| 1100 |
-
scheme, server, path, param, query, frag = urllib.parse.urlparse(url)
|
| 1101 |
-
filename = urllib.request.url2pathname(path)
|
| 1102 |
-
if os.path.isfile(filename):
|
| 1103 |
-
return urllib.request.urlopen(url)
|
| 1104 |
-
elif path.endswith('/') and os.path.isdir(filename):
|
| 1105 |
-
files = []
|
| 1106 |
-
for f in os.listdir(filename):
|
| 1107 |
-
filepath = os.path.join(filename, f)
|
| 1108 |
-
if f == 'index.html':
|
| 1109 |
-
with open(filepath, 'r') as fp:
|
| 1110 |
-
body = fp.read()
|
| 1111 |
-
break
|
| 1112 |
-
elif os.path.isdir(filepath):
|
| 1113 |
-
f += '/'
|
| 1114 |
-
files.append('<a href="{name}">{name}</a>'.format(name=f))
|
| 1115 |
-
else:
|
| 1116 |
-
tmpl = (
|
| 1117 |
-
"<html><head><title>{url}</title>"
|
| 1118 |
-
"</head><body>{files}</body></html>")
|
| 1119 |
-
body = tmpl.format(url=url, files='\n'.join(files))
|
| 1120 |
-
status, message = 200, "OK"
|
| 1121 |
-
else:
|
| 1122 |
-
status, message, body = 404, "Path not found", "Not found"
|
| 1123 |
-
|
| 1124 |
-
headers = {'content-type': 'text/html'}
|
| 1125 |
-
body_stream = io.StringIO(body)
|
| 1126 |
-
return urllib.error.HTTPError(url, status, message, headers, body_stream)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/Awiny/Image2Paragraph/models/grit_src/third_party/CenterNet2/demo/demo.py
DELETED
|
@@ -1,188 +0,0 @@
|
|
| 1 |
-
# Copyright (c) Facebook, Inc. and its affiliates.
|
| 2 |
-
import argparse
|
| 3 |
-
import glob
|
| 4 |
-
import multiprocessing as mp
|
| 5 |
-
import numpy as np
|
| 6 |
-
import os
|
| 7 |
-
import tempfile
|
| 8 |
-
import time
|
| 9 |
-
import warnings
|
| 10 |
-
import cv2
|
| 11 |
-
import tqdm
|
| 12 |
-
|
| 13 |
-
from detectron2.config import get_cfg
|
| 14 |
-
from detectron2.data.detection_utils import read_image
|
| 15 |
-
from detectron2.utils.logger import setup_logger
|
| 16 |
-
|
| 17 |
-
from predictor import VisualizationDemo
|
| 18 |
-
|
| 19 |
-
# constants
|
| 20 |
-
WINDOW_NAME = "COCO detections"
|
| 21 |
-
|
| 22 |
-
|
| 23 |
-
def setup_cfg(args):
|
| 24 |
-
# load config from file and command-line arguments
|
| 25 |
-
cfg = get_cfg()
|
| 26 |
-
# To use demo for Panoptic-DeepLab, please uncomment the following two lines.
|
| 27 |
-
# from detectron2.projects.panoptic_deeplab import add_panoptic_deeplab_config # noqa
|
| 28 |
-
# add_panoptic_deeplab_config(cfg)
|
| 29 |
-
cfg.merge_from_file(args.config_file)
|
| 30 |
-
cfg.merge_from_list(args.opts)
|
| 31 |
-
# Set score_threshold for builtin models
|
| 32 |
-
cfg.MODEL.RETINANET.SCORE_THRESH_TEST = args.confidence_threshold
|
| 33 |
-
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = args.confidence_threshold
|
| 34 |
-
cfg.MODEL.PANOPTIC_FPN.COMBINE.INSTANCES_CONFIDENCE_THRESH = args.confidence_threshold
|
| 35 |
-
cfg.freeze()
|
| 36 |
-
return cfg
|
| 37 |
-
|
| 38 |
-
|
| 39 |
-
def get_parser():
|
| 40 |
-
parser = argparse.ArgumentParser(description="Detectron2 demo for builtin configs")
|
| 41 |
-
parser.add_argument(
|
| 42 |
-
"--config-file",
|
| 43 |
-
default="configs/quick_schedules/mask_rcnn_R_50_FPN_inference_acc_test.yaml",
|
| 44 |
-
metavar="FILE",
|
| 45 |
-
help="path to config file",
|
| 46 |
-
)
|
| 47 |
-
parser.add_argument("--webcam", action="store_true", help="Take inputs from webcam.")
|
| 48 |
-
parser.add_argument("--video-input", help="Path to video file.")
|
| 49 |
-
parser.add_argument(
|
| 50 |
-
"--input",
|
| 51 |
-
nargs="+",
|
| 52 |
-
help="A list of space separated input images; "
|
| 53 |
-
"or a single glob pattern such as 'directory/*.jpg'",
|
| 54 |
-
)
|
| 55 |
-
parser.add_argument(
|
| 56 |
-
"--output",
|
| 57 |
-
help="A file or directory to save output visualizations. "
|
| 58 |
-
"If not given, will show output in an OpenCV window.",
|
| 59 |
-
)
|
| 60 |
-
|
| 61 |
-
parser.add_argument(
|
| 62 |
-
"--confidence-threshold",
|
| 63 |
-
type=float,
|
| 64 |
-
default=0.5,
|
| 65 |
-
help="Minimum score for instance predictions to be shown",
|
| 66 |
-
)
|
| 67 |
-
parser.add_argument(
|
| 68 |
-
"--opts",
|
| 69 |
-
help="Modify config options using the command-line 'KEY VALUE' pairs",
|
| 70 |
-
default=[],
|
| 71 |
-
nargs=argparse.REMAINDER,
|
| 72 |
-
)
|
| 73 |
-
return parser
|
| 74 |
-
|
| 75 |
-
|
| 76 |
-
def test_opencv_video_format(codec, file_ext):
|
| 77 |
-
with tempfile.TemporaryDirectory(prefix="video_format_test") as dir:
|
| 78 |
-
filename = os.path.join(dir, "test_file" + file_ext)
|
| 79 |
-
writer = cv2.VideoWriter(
|
| 80 |
-
filename=filename,
|
| 81 |
-
fourcc=cv2.VideoWriter_fourcc(*codec),
|
| 82 |
-
fps=float(30),
|
| 83 |
-
frameSize=(10, 10),
|
| 84 |
-
isColor=True,
|
| 85 |
-
)
|
| 86 |
-
[writer.write(np.zeros((10, 10, 3), np.uint8)) for _ in range(30)]
|
| 87 |
-
writer.release()
|
| 88 |
-
if os.path.isfile(filename):
|
| 89 |
-
return True
|
| 90 |
-
return False
|
| 91 |
-
|
| 92 |
-
|
| 93 |
-
if __name__ == "__main__":
|
| 94 |
-
mp.set_start_method("spawn", force=True)
|
| 95 |
-
args = get_parser().parse_args()
|
| 96 |
-
setup_logger(name="fvcore")
|
| 97 |
-
logger = setup_logger()
|
| 98 |
-
logger.info("Arguments: " + str(args))
|
| 99 |
-
|
| 100 |
-
cfg = setup_cfg(args)
|
| 101 |
-
|
| 102 |
-
demo = VisualizationDemo(cfg)
|
| 103 |
-
|
| 104 |
-
if args.input:
|
| 105 |
-
if len(args.input) == 1:
|
| 106 |
-
args.input = glob.glob(os.path.expanduser(args.input[0]))
|
| 107 |
-
assert args.input, "The input path(s) was not found"
|
| 108 |
-
for path in tqdm.tqdm(args.input, disable=not args.output):
|
| 109 |
-
# use PIL, to be consistent with evaluation
|
| 110 |
-
img = read_image(path, format="BGR")
|
| 111 |
-
start_time = time.time()
|
| 112 |
-
predictions, visualized_output = demo.run_on_image(img)
|
| 113 |
-
logger.info(
|
| 114 |
-
"{}: {} in {:.2f}s".format(
|
| 115 |
-
path,
|
| 116 |
-
"detected {} instances".format(len(predictions["instances"]))
|
| 117 |
-
if "instances" in predictions
|
| 118 |
-
else "finished",
|
| 119 |
-
time.time() - start_time,
|
| 120 |
-
)
|
| 121 |
-
)
|
| 122 |
-
|
| 123 |
-
if args.output:
|
| 124 |
-
if os.path.isdir(args.output):
|
| 125 |
-
assert os.path.isdir(args.output), args.output
|
| 126 |
-
out_filename = os.path.join(args.output, os.path.basename(path))
|
| 127 |
-
else:
|
| 128 |
-
assert len(args.input) == 1, "Please specify a directory with args.output"
|
| 129 |
-
out_filename = args.output
|
| 130 |
-
visualized_output.save(out_filename)
|
| 131 |
-
else:
|
| 132 |
-
cv2.namedWindow(WINDOW_NAME, cv2.WINDOW_NORMAL)
|
| 133 |
-
cv2.imshow(WINDOW_NAME, visualized_output.get_image()[:, :, ::-1])
|
| 134 |
-
if cv2.waitKey(0) == 27:
|
| 135 |
-
break # esc to quit
|
| 136 |
-
elif args.webcam:
|
| 137 |
-
assert args.input is None, "Cannot have both --input and --webcam!"
|
| 138 |
-
assert args.output is None, "output not yet supported with --webcam!"
|
| 139 |
-
cam = cv2.VideoCapture(0)
|
| 140 |
-
for vis in tqdm.tqdm(demo.run_on_video(cam)):
|
| 141 |
-
cv2.namedWindow(WINDOW_NAME, cv2.WINDOW_NORMAL)
|
| 142 |
-
cv2.imshow(WINDOW_NAME, vis)
|
| 143 |
-
if cv2.waitKey(1) == 27:
|
| 144 |
-
break # esc to quit
|
| 145 |
-
cam.release()
|
| 146 |
-
cv2.destroyAllWindows()
|
| 147 |
-
elif args.video_input:
|
| 148 |
-
video = cv2.VideoCapture(args.video_input)
|
| 149 |
-
width = int(video.get(cv2.CAP_PROP_FRAME_WIDTH))
|
| 150 |
-
height = int(video.get(cv2.CAP_PROP_FRAME_HEIGHT))
|
| 151 |
-
frames_per_second = video.get(cv2.CAP_PROP_FPS)
|
| 152 |
-
num_frames = int(video.get(cv2.CAP_PROP_FRAME_COUNT))
|
| 153 |
-
basename = os.path.basename(args.video_input)
|
| 154 |
-
codec, file_ext = (
|
| 155 |
-
("x264", ".mkv") if test_opencv_video_format("x264", ".mkv") else ("mp4v", ".mp4")
|
| 156 |
-
)
|
| 157 |
-
if codec == ".mp4v":
|
| 158 |
-
warnings.warn("x264 codec not available, switching to mp4v")
|
| 159 |
-
if args.output:
|
| 160 |
-
if os.path.isdir(args.output):
|
| 161 |
-
output_fname = os.path.join(args.output, basename)
|
| 162 |
-
output_fname = os.path.splitext(output_fname)[0] + file_ext
|
| 163 |
-
else:
|
| 164 |
-
output_fname = args.output
|
| 165 |
-
assert not os.path.isfile(output_fname), output_fname
|
| 166 |
-
output_file = cv2.VideoWriter(
|
| 167 |
-
filename=output_fname,
|
| 168 |
-
# some installation of opencv may not support x264 (due to its license),
|
| 169 |
-
# you can try other format (e.g. MPEG)
|
| 170 |
-
fourcc=cv2.VideoWriter_fourcc(*codec),
|
| 171 |
-
fps=float(frames_per_second),
|
| 172 |
-
frameSize=(width, height),
|
| 173 |
-
isColor=True,
|
| 174 |
-
)
|
| 175 |
-
assert os.path.isfile(args.video_input)
|
| 176 |
-
for vis_frame in tqdm.tqdm(demo.run_on_video(video), total=num_frames):
|
| 177 |
-
if args.output:
|
| 178 |
-
output_file.write(vis_frame)
|
| 179 |
-
else:
|
| 180 |
-
cv2.namedWindow(basename, cv2.WINDOW_NORMAL)
|
| 181 |
-
cv2.imshow(basename, vis_frame)
|
| 182 |
-
if cv2.waitKey(1) == 27:
|
| 183 |
-
break # esc to quit
|
| 184 |
-
video.release()
|
| 185 |
-
if args.output:
|
| 186 |
-
output_file.release()
|
| 187 |
-
else:
|
| 188 |
-
cv2.destroyAllWindows()
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/BIASLab/sars-cov-2-classification-fcgr/predict.py
DELETED
|
@@ -1,28 +0,0 @@
|
|
| 1 |
-
import streamlit as st
|
| 2 |
-
import json
|
| 3 |
-
import numpy as np
|
| 4 |
-
from pathlib import Path
|
| 5 |
-
from src.fcgr import FCGR
|
| 6 |
-
from src.preprocessing import Pipeline
|
| 7 |
-
from src.utils import clean_seq
|
| 8 |
-
# fcgr = FCGR(k=6)
|
| 9 |
-
# order_output = ['S','L','G','V','GR','GH','GV','GK','GRY','O','GRA']
|
| 10 |
-
# model = loader("resnet50_6mers", 11, "trained-models/model-34-0.954.hdf5")
|
| 11 |
-
|
| 12 |
-
with open("trained-models/preprocessing.json") as fp:
|
| 13 |
-
pipe = json.load(fp)
|
| 14 |
-
preprocessing = Pipeline(pipe)
|
| 15 |
-
|
| 16 |
-
def predict_single_seq(seq, fcgr, model):
|
| 17 |
-
"Given a sequence, returns output vector with probabilities to each class"
|
| 18 |
-
array = fcgr(clean_seq(seq))
|
| 19 |
-
array = preprocessing(array)
|
| 20 |
-
pred = model.predict(np.expand_dims(np.expand_dims(array,axis=0),axis=-1))[0]
|
| 21 |
-
return pred
|
| 22 |
-
|
| 23 |
-
def process_output(output, labels):
|
| 24 |
-
"""Given the output probabilities and labels for each output, return the
|
| 25 |
-
label with the highest score/probability and the score
|
| 26 |
-
"""
|
| 27 |
-
argmax = output.argmax()
|
| 28 |
-
return labels[argmax], output[argmax]
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/Benson/text-generation/Examples/Buscando Recursos Para Descargar Gratis Fuego Mx.md
DELETED
|
@@ -1,70 +0,0 @@
|
|
| 1 |
-
|
| 2 |
-
<h1>Buscando Recursos para Descargar Free Fire MAX? </h1>
|
| 3 |
-
<p>Si eres un fan de los juegos battle royale, es posible que hayas oído hablar de <strong>Free Fire</strong>, uno de los juegos móviles más populares del mundo. ¿Pero sabías que hay una versión <strong>Free Fire MAX</strong> que ofrece aún más características y diversión? </p>
|
| 4 |
-
<h2>buscando recursos para descargar gratis fuego máx</h2><br /><p><b><b>DOWNLOAD</b> ✅ <a href="https://bltlly.com/2v6JmZ">https://bltlly.com/2v6JmZ</a></b></p><br /><br />
|
| 5 |
-
<p>Free Fire MAX está diseñado exclusivamente para ofrecer una experiencia de juego premium en un battle royale. Puedes disfrutar de una variedad de emocionantes modos de juego con todos los jugadores de Free Fire a través de la exclusiva tecnología <strong>Firelink</strong>. También puedes experimentar el combate como nunca antes con resoluciones <strong>Ultra HD</strong> y efectos impresionantes. </p>
|
| 6 |
-
<p>En este artículo, te mostraremos cómo descargar Free Fire MAX en diferentes dispositivos, cómo jugarlo con tus amigos, y algunos consejos y trucos para disfrutarlo mejor. ¡Vamos a empezar! </p>
|
| 7 |
-
<h2>Cómo descargar Free Fire MAX en dispositivos Android</h2>
|
| 8 |
-
<p>Si tienes un dispositivo Android, puedes descargar fácilmente Free Fire MAX desde Google Play Store. Estos son los pasos que debes seguir:</p>
|
| 9 |
-
<ol>
|
| 10 |
-
<li>Ir a Google Play Store y buscar <strong>Free Fire MAX</strong>. </li>
|
| 11 |
-
<li>Toca el botón <strong>Instalar</strong> y espera a que termine la descarga. </li>
|
| 12 |
-
<li>Inicie el juego e inicie sesión con su cuenta de Free Fire existente o cree una nueva. </li>
|
| 13 |
-
</ol>
|
| 14 |
-
<p>Felicidades! Ha instalado con éxito Free Fire MAX en su dispositivo Android. Ahora puedes disfrutar del juego con gráficos, efectos y jugabilidad mejorados. </p>
|
| 15 |
-
<h2>Cómo descargar Free Fire MAX en dispositivos iOS</h2>
|
| 16 |
-
<p>Si tienes un dispositivo iOS, también puedes descargar Free Fire MAX desde la App Store. Estos son los pasos que debes seguir:</p>
|
| 17 |
-
<ol>
|
| 18 |
-
<li>Ir a App Store y buscar <strong>Free Fire MAX</strong>. </li>
|
| 19 |
-
<li>Toca el botón <strong>Get</strong> e ingresa tu contraseña de Apple ID si se te solicita. </li>
|
| 20 |
-
|
| 21 |
-
</ol>
|
| 22 |
-
<p>¡Eso es todo! Ha instalado con éxito Free Fire MAX en su dispositivo iOS. Ahora puedes disfrutar del juego con gráficos, efectos y jugabilidad mejorados. </p>
|
| 23 |
-
<p></p>
|
| 24 |
-
<h2>Cómo descargar Free Fire MAX en PC o Mac</h2>
|
| 25 |
-
<p>Si quieres jugar Free Fire MAX en una pantalla más grande, también puedes descargarlo en tu PC o Mac usando un emulador de Android. Un emulador es un software que te permite ejecutar aplicaciones Android en tu ordenador. Estos son los pasos que debes seguir:</p>
|
| 26 |
-
<ol>
|
| 27 |
-
<li>Descargue e instale un emulador de Android como <strong>BlueStacks</strong> o <strong>NoxPlayer</strong> en su computadora. Puede encontrar los enlaces de descarga en sus sitios web oficiales. </li>
|
| 28 |
-
<li>Inicie el emulador e inicie sesión con su cuenta de Google. </li>
|
| 29 |
-
<li>Ir a Google Play Store y buscar <strong>Free Fire MAX</strong>. </li>
|
| 30 |
-
<li>Instalar el juego y ejecutarlo desde la pantalla de inicio del emulador. </li>
|
| 31 |
-
<li>Inicie sesión con su cuenta de Free Fire existente o cree una nueva. </li>
|
| 32 |
-
</ol>
|
| 33 |
-
<p>¡Voila! Has instalado con éxito Free Fire MAX en tu PC o Mac. Ahora puedes disfrutar del juego con gráficos, efectos y jugabilidad mejorados. </p>
|
| 34 |
-
<h2>Cómo jugar Free Fire MAX con tus amigos</h2>
|
| 35 |
-
<p>Una de las mejores características de Free Fire MAX es que se puede jugar con tus amigos que están utilizando ya sea Free Fire o Free Fire MAX aplicaciones. Esto es posible gracias a la exclusiva tecnología <strong>Firelink</strong> que conecta ambas versiones del juego. Estos son los pasos que debes seguir:</p>
|
| 36 |
-
<ol>
|
| 37 |
-
<li>Invita a tus amigos a descargar e instalar Free Fire MAX en sus dispositivos. Puede compartir los enlaces de descarga con ellos a través de redes sociales, aplicaciones de mensajería o correo electrónico. </li>
|
| 38 |
-
<li>Crear un escuadrón de hasta cuatro jugadores y comunicarse con ellos a través de chat de voz en el juego. También puedes unirte a un equipo existente o invitar a otros jugadores a unirse al tuyo. </li>
|
| 39 |
-
<li>Elegir un modo de juego y comenzar el partido juntos. Usted puede jugar clásico battle royale, escuadrón de choque, escuadrón de bombas, alboroto, y más. </li>
|
| 40 |
-
</ol>
|
| 41 |
-
|
| 42 |
-
<h2> Consejos y trucos para disfrutar de fuego libre MAX mejor</h2>
|
| 43 |
-
<p>Para aprovechar al máximo tu experiencia Free Fire MAX, aquí hay algunos consejos y trucos que debes saber:</p>
|
| 44 |
-
<ul>
|
| 45 |
-
<li><strong>Personaliza la configuración de tus gráficos</strong> según el rendimiento de tu dispositivo. Puede ajustar la resolución, la velocidad de fotogramas, la calidad de las sombras, el anti-aliasing y más. También puede activar o desactivar el modo HDR, la iluminación dinámica, las sombras realistas, etc. Encuentre el mejor equilibrio entre calidad y rendimiento para su dispositivo. </li>
|
| 46 |
-
<li><strong>Habilita la tecnología Firelink</strong> para sincronizar tu progreso y elementos en las aplicaciones Free Fire y Free Fire MAX. Puede acceder a su inventario, carga, rango, estadísticas, etc. desde cualquiera de las aplicaciones sin problemas. También puede cambiar entre aplicaciones en cualquier momento que desee sin perder ningún dato. </li>
|
| 47 |
-
<li><strong>Explora diferentes modos de juego</strong> como Clash Squad, Bomb Squad, Rampage, etc. Cada modo de juego tiene sus propias reglas, objetivos y desafíos. También puedes probar diferentes mapas, armas, vehículos, personajes, mascotas, etc. Experimenta con diferentes combinaciones y estrategias para encontrar tus favoritas. </li>
|
| 48 |
-
</ul>
|
| 49 |
-
<p>¡Disfruta! Has aprendido algunos consejos y trucos para disfrutar mejor de Free Fire MAX. Puedes descubrir más jugando al juego regularmente y siguiendo sus actualizaciones. </p>
|
| 50 |
-
<h1>Conclusión</h1>
|
| 51 |
-
<p>En conclusión, Free Fire MAX es una versión premium de Free Fire que ofrece gráficos, efectos y jugabilidad mejorados. Puedes descargarlo gratis en varias plataformas y jugar con tus amigos. También puedes personalizar tus ajustes, sincronizar tus datos y explorar diferentes modos de juego. Si estás buscando una experiencia de batalla real emocionante e inmersiva, ¡definitivamente deberías probar Free Fire MAX! </p>
|
| 52 |
-
<h3>Preguntas frecuentes</h3>
|
| 53 |
-
<ol>
|
| 54 |
-
<li><strong>Free Fire MAX es gratis? </strong></li>
|
| 55 |
-
|
| 56 |
-
<li><strong>¿Free Fire MAX es compatible con mi dispositivo? </strong></li>
|
| 57 |
-
<p>Free Fire MAX requiere al menos 2 GB de RAM y Android 4.4 o iOS 9.0 o superior para funcionar sin problemas. Sin embargo, algunos dispositivos pueden no soportar todas las características y efectos del juego debido a limitaciones de hardware. Puede comprobar la compatibilidad de su dispositivo en el sitio web oficial de Free Fire MAX. </p>
|
| 58 |
-
<li><strong>¿Puedo jugar Free Fire MAX con jugadores de Free Fire? </strong></li>
|
| 59 |
-
<p>Sí, puedes jugar a Free Fire MAX con jugadores Free Fire a través de la exclusiva tecnología Firelink. Puede unirse a los mismos partidos, escuadrones y modos de juego con los jugadores utilizando cualquiera de las aplicaciones. Sin embargo, puedes notar algunas diferencias en gráficos y efectos dependiendo de la aplicación que estés usando. </p>
|
| 60 |
-
<li><strong>¿Cómo puedo transferir mis datos de Free Fire a Free Fire MAX? </strong></li>
|
| 61 |
-
<p>Usted no necesita transferir sus datos de Free Fire a Free Fire MAX manualmente. Simplemente puede iniciar sesión con su cuenta de Free Fire existente en Free Fire MAX y acceder a su inventario, carga, rango, estadísticas, etc. automáticamente. También puede cambiar entre aplicaciones en cualquier momento que desee sin perder ningún dato. </p>
|
| 62 |
-
<li><strong>¿Cuáles son los beneficios de jugar Free Fire MAX? </strong></li>
|
| 63 |
-
<p>Free Fire MAX ofrece varios beneficios sobre Free Fire, como:</p>
|
| 64 |
-
<ul>
|
| 65 |
-
<li>Mejores gráficos y efectos: Puede disfrutar de resoluciones Ultra HD, sombras realistas, iluminación dinámica y más. </li>
|
| 66 |
-
<li>Mejor jugabilidad y rendimiento: Puede experimentar controles más suaves, tiempos de carga más rápidos y menos retraso. </li>
|
| 67 |
-
<li>Mejor personalización y características: Puede ajustar la configuración de sus gráficos, habilitar o desactivar el modo HDR, sincronizar sus datos entre aplicaciones y más. </li>
|
| 68 |
-
</ul></p> 64aa2da5cf<br />
|
| 69 |
-
<br />
|
| 70 |
-
<br />
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/Big-Web/MMSD/env/Lib/site-packages/pip/_vendor/urllib3/response.py
DELETED
|
@@ -1,879 +0,0 @@
|
|
| 1 |
-
from __future__ import absolute_import
|
| 2 |
-
|
| 3 |
-
import io
|
| 4 |
-
import logging
|
| 5 |
-
import sys
|
| 6 |
-
import warnings
|
| 7 |
-
import zlib
|
| 8 |
-
from contextlib import contextmanager
|
| 9 |
-
from socket import error as SocketError
|
| 10 |
-
from socket import timeout as SocketTimeout
|
| 11 |
-
|
| 12 |
-
brotli = None
|
| 13 |
-
|
| 14 |
-
from . import util
|
| 15 |
-
from ._collections import HTTPHeaderDict
|
| 16 |
-
from .connection import BaseSSLError, HTTPException
|
| 17 |
-
from .exceptions import (
|
| 18 |
-
BodyNotHttplibCompatible,
|
| 19 |
-
DecodeError,
|
| 20 |
-
HTTPError,
|
| 21 |
-
IncompleteRead,
|
| 22 |
-
InvalidChunkLength,
|
| 23 |
-
InvalidHeader,
|
| 24 |
-
ProtocolError,
|
| 25 |
-
ReadTimeoutError,
|
| 26 |
-
ResponseNotChunked,
|
| 27 |
-
SSLError,
|
| 28 |
-
)
|
| 29 |
-
from .packages import six
|
| 30 |
-
from .util.response import is_fp_closed, is_response_to_head
|
| 31 |
-
|
| 32 |
-
log = logging.getLogger(__name__)
|
| 33 |
-
|
| 34 |
-
|
| 35 |
-
class DeflateDecoder(object):
|
| 36 |
-
def __init__(self):
|
| 37 |
-
self._first_try = True
|
| 38 |
-
self._data = b""
|
| 39 |
-
self._obj = zlib.decompressobj()
|
| 40 |
-
|
| 41 |
-
def __getattr__(self, name):
|
| 42 |
-
return getattr(self._obj, name)
|
| 43 |
-
|
| 44 |
-
def decompress(self, data):
|
| 45 |
-
if not data:
|
| 46 |
-
return data
|
| 47 |
-
|
| 48 |
-
if not self._first_try:
|
| 49 |
-
return self._obj.decompress(data)
|
| 50 |
-
|
| 51 |
-
self._data += data
|
| 52 |
-
try:
|
| 53 |
-
decompressed = self._obj.decompress(data)
|
| 54 |
-
if decompressed:
|
| 55 |
-
self._first_try = False
|
| 56 |
-
self._data = None
|
| 57 |
-
return decompressed
|
| 58 |
-
except zlib.error:
|
| 59 |
-
self._first_try = False
|
| 60 |
-
self._obj = zlib.decompressobj(-zlib.MAX_WBITS)
|
| 61 |
-
try:
|
| 62 |
-
return self.decompress(self._data)
|
| 63 |
-
finally:
|
| 64 |
-
self._data = None
|
| 65 |
-
|
| 66 |
-
|
| 67 |
-
class GzipDecoderState(object):
|
| 68 |
-
|
| 69 |
-
FIRST_MEMBER = 0
|
| 70 |
-
OTHER_MEMBERS = 1
|
| 71 |
-
SWALLOW_DATA = 2
|
| 72 |
-
|
| 73 |
-
|
| 74 |
-
class GzipDecoder(object):
|
| 75 |
-
def __init__(self):
|
| 76 |
-
self._obj = zlib.decompressobj(16 + zlib.MAX_WBITS)
|
| 77 |
-
self._state = GzipDecoderState.FIRST_MEMBER
|
| 78 |
-
|
| 79 |
-
def __getattr__(self, name):
|
| 80 |
-
return getattr(self._obj, name)
|
| 81 |
-
|
| 82 |
-
def decompress(self, data):
|
| 83 |
-
ret = bytearray()
|
| 84 |
-
if self._state == GzipDecoderState.SWALLOW_DATA or not data:
|
| 85 |
-
return bytes(ret)
|
| 86 |
-
while True:
|
| 87 |
-
try:
|
| 88 |
-
ret += self._obj.decompress(data)
|
| 89 |
-
except zlib.error:
|
| 90 |
-
previous_state = self._state
|
| 91 |
-
# Ignore data after the first error
|
| 92 |
-
self._state = GzipDecoderState.SWALLOW_DATA
|
| 93 |
-
if previous_state == GzipDecoderState.OTHER_MEMBERS:
|
| 94 |
-
# Allow trailing garbage acceptable in other gzip clients
|
| 95 |
-
return bytes(ret)
|
| 96 |
-
raise
|
| 97 |
-
data = self._obj.unused_data
|
| 98 |
-
if not data:
|
| 99 |
-
return bytes(ret)
|
| 100 |
-
self._state = GzipDecoderState.OTHER_MEMBERS
|
| 101 |
-
self._obj = zlib.decompressobj(16 + zlib.MAX_WBITS)
|
| 102 |
-
|
| 103 |
-
|
| 104 |
-
if brotli is not None:
|
| 105 |
-
|
| 106 |
-
class BrotliDecoder(object):
|
| 107 |
-
# Supports both 'brotlipy' and 'Brotli' packages
|
| 108 |
-
# since they share an import name. The top branches
|
| 109 |
-
# are for 'brotlipy' and bottom branches for 'Brotli'
|
| 110 |
-
def __init__(self):
|
| 111 |
-
self._obj = brotli.Decompressor()
|
| 112 |
-
if hasattr(self._obj, "decompress"):
|
| 113 |
-
self.decompress = self._obj.decompress
|
| 114 |
-
else:
|
| 115 |
-
self.decompress = self._obj.process
|
| 116 |
-
|
| 117 |
-
def flush(self):
|
| 118 |
-
if hasattr(self._obj, "flush"):
|
| 119 |
-
return self._obj.flush()
|
| 120 |
-
return b""
|
| 121 |
-
|
| 122 |
-
|
| 123 |
-
class MultiDecoder(object):
|
| 124 |
-
"""
|
| 125 |
-
From RFC7231:
|
| 126 |
-
If one or more encodings have been applied to a representation, the
|
| 127 |
-
sender that applied the encodings MUST generate a Content-Encoding
|
| 128 |
-
header field that lists the content codings in the order in which
|
| 129 |
-
they were applied.
|
| 130 |
-
"""
|
| 131 |
-
|
| 132 |
-
def __init__(self, modes):
|
| 133 |
-
self._decoders = [_get_decoder(m.strip()) for m in modes.split(",")]
|
| 134 |
-
|
| 135 |
-
def flush(self):
|
| 136 |
-
return self._decoders[0].flush()
|
| 137 |
-
|
| 138 |
-
def decompress(self, data):
|
| 139 |
-
for d in reversed(self._decoders):
|
| 140 |
-
data = d.decompress(data)
|
| 141 |
-
return data
|
| 142 |
-
|
| 143 |
-
|
| 144 |
-
def _get_decoder(mode):
|
| 145 |
-
if "," in mode:
|
| 146 |
-
return MultiDecoder(mode)
|
| 147 |
-
|
| 148 |
-
if mode == "gzip":
|
| 149 |
-
return GzipDecoder()
|
| 150 |
-
|
| 151 |
-
if brotli is not None and mode == "br":
|
| 152 |
-
return BrotliDecoder()
|
| 153 |
-
|
| 154 |
-
return DeflateDecoder()
|
| 155 |
-
|
| 156 |
-
|
| 157 |
-
class HTTPResponse(io.IOBase):
|
| 158 |
-
"""
|
| 159 |
-
HTTP Response container.
|
| 160 |
-
|
| 161 |
-
Backwards-compatible with :class:`http.client.HTTPResponse` but the response ``body`` is
|
| 162 |
-
loaded and decoded on-demand when the ``data`` property is accessed. This
|
| 163 |
-
class is also compatible with the Python standard library's :mod:`io`
|
| 164 |
-
module, and can hence be treated as a readable object in the context of that
|
| 165 |
-
framework.
|
| 166 |
-
|
| 167 |
-
Extra parameters for behaviour not present in :class:`http.client.HTTPResponse`:
|
| 168 |
-
|
| 169 |
-
:param preload_content:
|
| 170 |
-
If True, the response's body will be preloaded during construction.
|
| 171 |
-
|
| 172 |
-
:param decode_content:
|
| 173 |
-
If True, will attempt to decode the body based on the
|
| 174 |
-
'content-encoding' header.
|
| 175 |
-
|
| 176 |
-
:param original_response:
|
| 177 |
-
When this HTTPResponse wrapper is generated from an :class:`http.client.HTTPResponse`
|
| 178 |
-
object, it's convenient to include the original for debug purposes. It's
|
| 179 |
-
otherwise unused.
|
| 180 |
-
|
| 181 |
-
:param retries:
|
| 182 |
-
The retries contains the last :class:`~urllib3.util.retry.Retry` that
|
| 183 |
-
was used during the request.
|
| 184 |
-
|
| 185 |
-
:param enforce_content_length:
|
| 186 |
-
Enforce content length checking. Body returned by server must match
|
| 187 |
-
value of Content-Length header, if present. Otherwise, raise error.
|
| 188 |
-
"""
|
| 189 |
-
|
| 190 |
-
CONTENT_DECODERS = ["gzip", "deflate"]
|
| 191 |
-
if brotli is not None:
|
| 192 |
-
CONTENT_DECODERS += ["br"]
|
| 193 |
-
REDIRECT_STATUSES = [301, 302, 303, 307, 308]
|
| 194 |
-
|
| 195 |
-
def __init__(
|
| 196 |
-
self,
|
| 197 |
-
body="",
|
| 198 |
-
headers=None,
|
| 199 |
-
status=0,
|
| 200 |
-
version=0,
|
| 201 |
-
reason=None,
|
| 202 |
-
strict=0,
|
| 203 |
-
preload_content=True,
|
| 204 |
-
decode_content=True,
|
| 205 |
-
original_response=None,
|
| 206 |
-
pool=None,
|
| 207 |
-
connection=None,
|
| 208 |
-
msg=None,
|
| 209 |
-
retries=None,
|
| 210 |
-
enforce_content_length=False,
|
| 211 |
-
request_method=None,
|
| 212 |
-
request_url=None,
|
| 213 |
-
auto_close=True,
|
| 214 |
-
):
|
| 215 |
-
|
| 216 |
-
if isinstance(headers, HTTPHeaderDict):
|
| 217 |
-
self.headers = headers
|
| 218 |
-
else:
|
| 219 |
-
self.headers = HTTPHeaderDict(headers)
|
| 220 |
-
self.status = status
|
| 221 |
-
self.version = version
|
| 222 |
-
self.reason = reason
|
| 223 |
-
self.strict = strict
|
| 224 |
-
self.decode_content = decode_content
|
| 225 |
-
self.retries = retries
|
| 226 |
-
self.enforce_content_length = enforce_content_length
|
| 227 |
-
self.auto_close = auto_close
|
| 228 |
-
|
| 229 |
-
self._decoder = None
|
| 230 |
-
self._body = None
|
| 231 |
-
self._fp = None
|
| 232 |
-
self._original_response = original_response
|
| 233 |
-
self._fp_bytes_read = 0
|
| 234 |
-
self.msg = msg
|
| 235 |
-
self._request_url = request_url
|
| 236 |
-
|
| 237 |
-
if body and isinstance(body, (six.string_types, bytes)):
|
| 238 |
-
self._body = body
|
| 239 |
-
|
| 240 |
-
self._pool = pool
|
| 241 |
-
self._connection = connection
|
| 242 |
-
|
| 243 |
-
if hasattr(body, "read"):
|
| 244 |
-
self._fp = body
|
| 245 |
-
|
| 246 |
-
# Are we using the chunked-style of transfer encoding?
|
| 247 |
-
self.chunked = False
|
| 248 |
-
self.chunk_left = None
|
| 249 |
-
tr_enc = self.headers.get("transfer-encoding", "").lower()
|
| 250 |
-
# Don't incur the penalty of creating a list and then discarding it
|
| 251 |
-
encodings = (enc.strip() for enc in tr_enc.split(","))
|
| 252 |
-
if "chunked" in encodings:
|
| 253 |
-
self.chunked = True
|
| 254 |
-
|
| 255 |
-
# Determine length of response
|
| 256 |
-
self.length_remaining = self._init_length(request_method)
|
| 257 |
-
|
| 258 |
-
# If requested, preload the body.
|
| 259 |
-
if preload_content and not self._body:
|
| 260 |
-
self._body = self.read(decode_content=decode_content)
|
| 261 |
-
|
| 262 |
-
def get_redirect_location(self):
|
| 263 |
-
"""
|
| 264 |
-
Should we redirect and where to?
|
| 265 |
-
|
| 266 |
-
:returns: Truthy redirect location string if we got a redirect status
|
| 267 |
-
code and valid location. ``None`` if redirect status and no
|
| 268 |
-
location. ``False`` if not a redirect status code.
|
| 269 |
-
"""
|
| 270 |
-
if self.status in self.REDIRECT_STATUSES:
|
| 271 |
-
return self.headers.get("location")
|
| 272 |
-
|
| 273 |
-
return False
|
| 274 |
-
|
| 275 |
-
def release_conn(self):
|
| 276 |
-
if not self._pool or not self._connection:
|
| 277 |
-
return
|
| 278 |
-
|
| 279 |
-
self._pool._put_conn(self._connection)
|
| 280 |
-
self._connection = None
|
| 281 |
-
|
| 282 |
-
def drain_conn(self):
|
| 283 |
-
"""
|
| 284 |
-
Read and discard any remaining HTTP response data in the response connection.
|
| 285 |
-
|
| 286 |
-
Unread data in the HTTPResponse connection blocks the connection from being released back to the pool.
|
| 287 |
-
"""
|
| 288 |
-
try:
|
| 289 |
-
self.read()
|
| 290 |
-
except (HTTPError, SocketError, BaseSSLError, HTTPException):
|
| 291 |
-
pass
|
| 292 |
-
|
| 293 |
-
@property
|
| 294 |
-
def data(self):
|
| 295 |
-
# For backwards-compat with earlier urllib3 0.4 and earlier.
|
| 296 |
-
if self._body:
|
| 297 |
-
return self._body
|
| 298 |
-
|
| 299 |
-
if self._fp:
|
| 300 |
-
return self.read(cache_content=True)
|
| 301 |
-
|
| 302 |
-
@property
|
| 303 |
-
def connection(self):
|
| 304 |
-
return self._connection
|
| 305 |
-
|
| 306 |
-
def isclosed(self):
|
| 307 |
-
return is_fp_closed(self._fp)
|
| 308 |
-
|
| 309 |
-
def tell(self):
|
| 310 |
-
"""
|
| 311 |
-
Obtain the number of bytes pulled over the wire so far. May differ from
|
| 312 |
-
the amount of content returned by :meth:``urllib3.response.HTTPResponse.read``
|
| 313 |
-
if bytes are encoded on the wire (e.g, compressed).
|
| 314 |
-
"""
|
| 315 |
-
return self._fp_bytes_read
|
| 316 |
-
|
| 317 |
-
def _init_length(self, request_method):
|
| 318 |
-
"""
|
| 319 |
-
Set initial length value for Response content if available.
|
| 320 |
-
"""
|
| 321 |
-
length = self.headers.get("content-length")
|
| 322 |
-
|
| 323 |
-
if length is not None:
|
| 324 |
-
if self.chunked:
|
| 325 |
-
# This Response will fail with an IncompleteRead if it can't be
|
| 326 |
-
# received as chunked. This method falls back to attempt reading
|
| 327 |
-
# the response before raising an exception.
|
| 328 |
-
log.warning(
|
| 329 |
-
"Received response with both Content-Length and "
|
| 330 |
-
"Transfer-Encoding set. This is expressly forbidden "
|
| 331 |
-
"by RFC 7230 sec 3.3.2. Ignoring Content-Length and "
|
| 332 |
-
"attempting to process response as Transfer-Encoding: "
|
| 333 |
-
"chunked."
|
| 334 |
-
)
|
| 335 |
-
return None
|
| 336 |
-
|
| 337 |
-
try:
|
| 338 |
-
# RFC 7230 section 3.3.2 specifies multiple content lengths can
|
| 339 |
-
# be sent in a single Content-Length header
|
| 340 |
-
# (e.g. Content-Length: 42, 42). This line ensures the values
|
| 341 |
-
# are all valid ints and that as long as the `set` length is 1,
|
| 342 |
-
# all values are the same. Otherwise, the header is invalid.
|
| 343 |
-
lengths = set([int(val) for val in length.split(",")])
|
| 344 |
-
if len(lengths) > 1:
|
| 345 |
-
raise InvalidHeader(
|
| 346 |
-
"Content-Length contained multiple "
|
| 347 |
-
"unmatching values (%s)" % length
|
| 348 |
-
)
|
| 349 |
-
length = lengths.pop()
|
| 350 |
-
except ValueError:
|
| 351 |
-
length = None
|
| 352 |
-
else:
|
| 353 |
-
if length < 0:
|
| 354 |
-
length = None
|
| 355 |
-
|
| 356 |
-
# Convert status to int for comparison
|
| 357 |
-
# In some cases, httplib returns a status of "_UNKNOWN"
|
| 358 |
-
try:
|
| 359 |
-
status = int(self.status)
|
| 360 |
-
except ValueError:
|
| 361 |
-
status = 0
|
| 362 |
-
|
| 363 |
-
# Check for responses that shouldn't include a body
|
| 364 |
-
if status in (204, 304) or 100 <= status < 200 or request_method == "HEAD":
|
| 365 |
-
length = 0
|
| 366 |
-
|
| 367 |
-
return length
|
| 368 |
-
|
| 369 |
-
def _init_decoder(self):
|
| 370 |
-
"""
|
| 371 |
-
Set-up the _decoder attribute if necessary.
|
| 372 |
-
"""
|
| 373 |
-
# Note: content-encoding value should be case-insensitive, per RFC 7230
|
| 374 |
-
# Section 3.2
|
| 375 |
-
content_encoding = self.headers.get("content-encoding", "").lower()
|
| 376 |
-
if self._decoder is None:
|
| 377 |
-
if content_encoding in self.CONTENT_DECODERS:
|
| 378 |
-
self._decoder = _get_decoder(content_encoding)
|
| 379 |
-
elif "," in content_encoding:
|
| 380 |
-
encodings = [
|
| 381 |
-
e.strip()
|
| 382 |
-
for e in content_encoding.split(",")
|
| 383 |
-
if e.strip() in self.CONTENT_DECODERS
|
| 384 |
-
]
|
| 385 |
-
if len(encodings):
|
| 386 |
-
self._decoder = _get_decoder(content_encoding)
|
| 387 |
-
|
| 388 |
-
DECODER_ERROR_CLASSES = (IOError, zlib.error)
|
| 389 |
-
if brotli is not None:
|
| 390 |
-
DECODER_ERROR_CLASSES += (brotli.error,)
|
| 391 |
-
|
| 392 |
-
def _decode(self, data, decode_content, flush_decoder):
|
| 393 |
-
"""
|
| 394 |
-
Decode the data passed in and potentially flush the decoder.
|
| 395 |
-
"""
|
| 396 |
-
if not decode_content:
|
| 397 |
-
return data
|
| 398 |
-
|
| 399 |
-
try:
|
| 400 |
-
if self._decoder:
|
| 401 |
-
data = self._decoder.decompress(data)
|
| 402 |
-
except self.DECODER_ERROR_CLASSES as e:
|
| 403 |
-
content_encoding = self.headers.get("content-encoding", "").lower()
|
| 404 |
-
raise DecodeError(
|
| 405 |
-
"Received response with content-encoding: %s, but "
|
| 406 |
-
"failed to decode it." % content_encoding,
|
| 407 |
-
e,
|
| 408 |
-
)
|
| 409 |
-
if flush_decoder:
|
| 410 |
-
data += self._flush_decoder()
|
| 411 |
-
|
| 412 |
-
return data
|
| 413 |
-
|
| 414 |
-
def _flush_decoder(self):
|
| 415 |
-
"""
|
| 416 |
-
Flushes the decoder. Should only be called if the decoder is actually
|
| 417 |
-
being used.
|
| 418 |
-
"""
|
| 419 |
-
if self._decoder:
|
| 420 |
-
buf = self._decoder.decompress(b"")
|
| 421 |
-
return buf + self._decoder.flush()
|
| 422 |
-
|
| 423 |
-
return b""
|
| 424 |
-
|
| 425 |
-
@contextmanager
|
| 426 |
-
def _error_catcher(self):
|
| 427 |
-
"""
|
| 428 |
-
Catch low-level python exceptions, instead re-raising urllib3
|
| 429 |
-
variants, so that low-level exceptions are not leaked in the
|
| 430 |
-
high-level api.
|
| 431 |
-
|
| 432 |
-
On exit, release the connection back to the pool.
|
| 433 |
-
"""
|
| 434 |
-
clean_exit = False
|
| 435 |
-
|
| 436 |
-
try:
|
| 437 |
-
try:
|
| 438 |
-
yield
|
| 439 |
-
|
| 440 |
-
except SocketTimeout:
|
| 441 |
-
# FIXME: Ideally we'd like to include the url in the ReadTimeoutError but
|
| 442 |
-
# there is yet no clean way to get at it from this context.
|
| 443 |
-
raise ReadTimeoutError(self._pool, None, "Read timed out.")
|
| 444 |
-
|
| 445 |
-
except BaseSSLError as e:
|
| 446 |
-
# FIXME: Is there a better way to differentiate between SSLErrors?
|
| 447 |
-
if "read operation timed out" not in str(e):
|
| 448 |
-
# SSL errors related to framing/MAC get wrapped and reraised here
|
| 449 |
-
raise SSLError(e)
|
| 450 |
-
|
| 451 |
-
raise ReadTimeoutError(self._pool, None, "Read timed out.")
|
| 452 |
-
|
| 453 |
-
except (HTTPException, SocketError) as e:
|
| 454 |
-
# This includes IncompleteRead.
|
| 455 |
-
raise ProtocolError("Connection broken: %r" % e, e)
|
| 456 |
-
|
| 457 |
-
# If no exception is thrown, we should avoid cleaning up
|
| 458 |
-
# unnecessarily.
|
| 459 |
-
clean_exit = True
|
| 460 |
-
finally:
|
| 461 |
-
# If we didn't terminate cleanly, we need to throw away our
|
| 462 |
-
# connection.
|
| 463 |
-
if not clean_exit:
|
| 464 |
-
# The response may not be closed but we're not going to use it
|
| 465 |
-
# anymore so close it now to ensure that the connection is
|
| 466 |
-
# released back to the pool.
|
| 467 |
-
if self._original_response:
|
| 468 |
-
self._original_response.close()
|
| 469 |
-
|
| 470 |
-
# Closing the response may not actually be sufficient to close
|
| 471 |
-
# everything, so if we have a hold of the connection close that
|
| 472 |
-
# too.
|
| 473 |
-
if self._connection:
|
| 474 |
-
self._connection.close()
|
| 475 |
-
|
| 476 |
-
# If we hold the original response but it's closed now, we should
|
| 477 |
-
# return the connection back to the pool.
|
| 478 |
-
if self._original_response and self._original_response.isclosed():
|
| 479 |
-
self.release_conn()
|
| 480 |
-
|
| 481 |
-
def _fp_read(self, amt):
|
| 482 |
-
"""
|
| 483 |
-
Read a response with the thought that reading the number of bytes
|
| 484 |
-
larger than can fit in a 32-bit int at a time via SSL in some
|
| 485 |
-
known cases leads to an overflow error that has to be prevented
|
| 486 |
-
if `amt` or `self.length_remaining` indicate that a problem may
|
| 487 |
-
happen.
|
| 488 |
-
|
| 489 |
-
The known cases:
|
| 490 |
-
* 3.8 <= CPython < 3.9.7 because of a bug
|
| 491 |
-
https://github.com/urllib3/urllib3/issues/2513#issuecomment-1152559900.
|
| 492 |
-
* urllib3 injected with pyOpenSSL-backed SSL-support.
|
| 493 |
-
* CPython < 3.10 only when `amt` does not fit 32-bit int.
|
| 494 |
-
"""
|
| 495 |
-
assert self._fp
|
| 496 |
-
c_int_max = 2 ** 31 - 1
|
| 497 |
-
if (
|
| 498 |
-
(
|
| 499 |
-
(amt and amt > c_int_max)
|
| 500 |
-
or (self.length_remaining and self.length_remaining > c_int_max)
|
| 501 |
-
)
|
| 502 |
-
and not util.IS_SECURETRANSPORT
|
| 503 |
-
and (util.IS_PYOPENSSL or sys.version_info < (3, 10))
|
| 504 |
-
):
|
| 505 |
-
buffer = io.BytesIO()
|
| 506 |
-
# Besides `max_chunk_amt` being a maximum chunk size, it
|
| 507 |
-
# affects memory overhead of reading a response by this
|
| 508 |
-
# method in CPython.
|
| 509 |
-
# `c_int_max` equal to 2 GiB - 1 byte is the actual maximum
|
| 510 |
-
# chunk size that does not lead to an overflow error, but
|
| 511 |
-
# 256 MiB is a compromise.
|
| 512 |
-
max_chunk_amt = 2 ** 28
|
| 513 |
-
while amt is None or amt != 0:
|
| 514 |
-
if amt is not None:
|
| 515 |
-
chunk_amt = min(amt, max_chunk_amt)
|
| 516 |
-
amt -= chunk_amt
|
| 517 |
-
else:
|
| 518 |
-
chunk_amt = max_chunk_amt
|
| 519 |
-
data = self._fp.read(chunk_amt)
|
| 520 |
-
if not data:
|
| 521 |
-
break
|
| 522 |
-
buffer.write(data)
|
| 523 |
-
del data # to reduce peak memory usage by `max_chunk_amt`.
|
| 524 |
-
return buffer.getvalue()
|
| 525 |
-
else:
|
| 526 |
-
# StringIO doesn't like amt=None
|
| 527 |
-
return self._fp.read(amt) if amt is not None else self._fp.read()
|
| 528 |
-
|
| 529 |
-
def read(self, amt=None, decode_content=None, cache_content=False):
|
| 530 |
-
"""
|
| 531 |
-
Similar to :meth:`http.client.HTTPResponse.read`, but with two additional
|
| 532 |
-
parameters: ``decode_content`` and ``cache_content``.
|
| 533 |
-
|
| 534 |
-
:param amt:
|
| 535 |
-
How much of the content to read. If specified, caching is skipped
|
| 536 |
-
because it doesn't make sense to cache partial content as the full
|
| 537 |
-
response.
|
| 538 |
-
|
| 539 |
-
:param decode_content:
|
| 540 |
-
If True, will attempt to decode the body based on the
|
| 541 |
-
'content-encoding' header.
|
| 542 |
-
|
| 543 |
-
:param cache_content:
|
| 544 |
-
If True, will save the returned data such that the same result is
|
| 545 |
-
returned despite of the state of the underlying file object. This
|
| 546 |
-
is useful if you want the ``.data`` property to continue working
|
| 547 |
-
after having ``.read()`` the file object. (Overridden if ``amt`` is
|
| 548 |
-
set.)
|
| 549 |
-
"""
|
| 550 |
-
self._init_decoder()
|
| 551 |
-
if decode_content is None:
|
| 552 |
-
decode_content = self.decode_content
|
| 553 |
-
|
| 554 |
-
if self._fp is None:
|
| 555 |
-
return
|
| 556 |
-
|
| 557 |
-
flush_decoder = False
|
| 558 |
-
fp_closed = getattr(self._fp, "closed", False)
|
| 559 |
-
|
| 560 |
-
with self._error_catcher():
|
| 561 |
-
data = self._fp_read(amt) if not fp_closed else b""
|
| 562 |
-
if amt is None:
|
| 563 |
-
flush_decoder = True
|
| 564 |
-
else:
|
| 565 |
-
cache_content = False
|
| 566 |
-
if (
|
| 567 |
-
amt != 0 and not data
|
| 568 |
-
): # Platform-specific: Buggy versions of Python.
|
| 569 |
-
# Close the connection when no data is returned
|
| 570 |
-
#
|
| 571 |
-
# This is redundant to what httplib/http.client _should_
|
| 572 |
-
# already do. However, versions of python released before
|
| 573 |
-
# December 15, 2012 (http://bugs.python.org/issue16298) do
|
| 574 |
-
# not properly close the connection in all cases. There is
|
| 575 |
-
# no harm in redundantly calling close.
|
| 576 |
-
self._fp.close()
|
| 577 |
-
flush_decoder = True
|
| 578 |
-
if self.enforce_content_length and self.length_remaining not in (
|
| 579 |
-
0,
|
| 580 |
-
None,
|
| 581 |
-
):
|
| 582 |
-
# This is an edge case that httplib failed to cover due
|
| 583 |
-
# to concerns of backward compatibility. We're
|
| 584 |
-
# addressing it here to make sure IncompleteRead is
|
| 585 |
-
# raised during streaming, so all calls with incorrect
|
| 586 |
-
# Content-Length are caught.
|
| 587 |
-
raise IncompleteRead(self._fp_bytes_read, self.length_remaining)
|
| 588 |
-
|
| 589 |
-
if data:
|
| 590 |
-
self._fp_bytes_read += len(data)
|
| 591 |
-
if self.length_remaining is not None:
|
| 592 |
-
self.length_remaining -= len(data)
|
| 593 |
-
|
| 594 |
-
data = self._decode(data, decode_content, flush_decoder)
|
| 595 |
-
|
| 596 |
-
if cache_content:
|
| 597 |
-
self._body = data
|
| 598 |
-
|
| 599 |
-
return data
|
| 600 |
-
|
| 601 |
-
def stream(self, amt=2 ** 16, decode_content=None):
|
| 602 |
-
"""
|
| 603 |
-
A generator wrapper for the read() method. A call will block until
|
| 604 |
-
``amt`` bytes have been read from the connection or until the
|
| 605 |
-
connection is closed.
|
| 606 |
-
|
| 607 |
-
:param amt:
|
| 608 |
-
How much of the content to read. The generator will return up to
|
| 609 |
-
much data per iteration, but may return less. This is particularly
|
| 610 |
-
likely when using compressed data. However, the empty string will
|
| 611 |
-
never be returned.
|
| 612 |
-
|
| 613 |
-
:param decode_content:
|
| 614 |
-
If True, will attempt to decode the body based on the
|
| 615 |
-
'content-encoding' header.
|
| 616 |
-
"""
|
| 617 |
-
if self.chunked and self.supports_chunked_reads():
|
| 618 |
-
for line in self.read_chunked(amt, decode_content=decode_content):
|
| 619 |
-
yield line
|
| 620 |
-
else:
|
| 621 |
-
while not is_fp_closed(self._fp):
|
| 622 |
-
data = self.read(amt=amt, decode_content=decode_content)
|
| 623 |
-
|
| 624 |
-
if data:
|
| 625 |
-
yield data
|
| 626 |
-
|
| 627 |
-
@classmethod
|
| 628 |
-
def from_httplib(ResponseCls, r, **response_kw):
|
| 629 |
-
"""
|
| 630 |
-
Given an :class:`http.client.HTTPResponse` instance ``r``, return a
|
| 631 |
-
corresponding :class:`urllib3.response.HTTPResponse` object.
|
| 632 |
-
|
| 633 |
-
Remaining parameters are passed to the HTTPResponse constructor, along
|
| 634 |
-
with ``original_response=r``.
|
| 635 |
-
"""
|
| 636 |
-
headers = r.msg
|
| 637 |
-
|
| 638 |
-
if not isinstance(headers, HTTPHeaderDict):
|
| 639 |
-
if six.PY2:
|
| 640 |
-
# Python 2.7
|
| 641 |
-
headers = HTTPHeaderDict.from_httplib(headers)
|
| 642 |
-
else:
|
| 643 |
-
headers = HTTPHeaderDict(headers.items())
|
| 644 |
-
|
| 645 |
-
# HTTPResponse objects in Python 3 don't have a .strict attribute
|
| 646 |
-
strict = getattr(r, "strict", 0)
|
| 647 |
-
resp = ResponseCls(
|
| 648 |
-
body=r,
|
| 649 |
-
headers=headers,
|
| 650 |
-
status=r.status,
|
| 651 |
-
version=r.version,
|
| 652 |
-
reason=r.reason,
|
| 653 |
-
strict=strict,
|
| 654 |
-
original_response=r,
|
| 655 |
-
**response_kw
|
| 656 |
-
)
|
| 657 |
-
return resp
|
| 658 |
-
|
| 659 |
-
# Backwards-compatibility methods for http.client.HTTPResponse
|
| 660 |
-
def getheaders(self):
|
| 661 |
-
warnings.warn(
|
| 662 |
-
"HTTPResponse.getheaders() is deprecated and will be removed "
|
| 663 |
-
"in urllib3 v2.1.0. Instead access HTTPResponse.headers directly.",
|
| 664 |
-
category=DeprecationWarning,
|
| 665 |
-
stacklevel=2,
|
| 666 |
-
)
|
| 667 |
-
return self.headers
|
| 668 |
-
|
| 669 |
-
def getheader(self, name, default=None):
|
| 670 |
-
warnings.warn(
|
| 671 |
-
"HTTPResponse.getheader() is deprecated and will be removed "
|
| 672 |
-
"in urllib3 v2.1.0. Instead use HTTPResponse.headers.get(name, default).",
|
| 673 |
-
category=DeprecationWarning,
|
| 674 |
-
stacklevel=2,
|
| 675 |
-
)
|
| 676 |
-
return self.headers.get(name, default)
|
| 677 |
-
|
| 678 |
-
# Backwards compatibility for http.cookiejar
|
| 679 |
-
def info(self):
|
| 680 |
-
return self.headers
|
| 681 |
-
|
| 682 |
-
# Overrides from io.IOBase
|
| 683 |
-
def close(self):
|
| 684 |
-
if not self.closed:
|
| 685 |
-
self._fp.close()
|
| 686 |
-
|
| 687 |
-
if self._connection:
|
| 688 |
-
self._connection.close()
|
| 689 |
-
|
| 690 |
-
if not self.auto_close:
|
| 691 |
-
io.IOBase.close(self)
|
| 692 |
-
|
| 693 |
-
@property
|
| 694 |
-
def closed(self):
|
| 695 |
-
if not self.auto_close:
|
| 696 |
-
return io.IOBase.closed.__get__(self)
|
| 697 |
-
elif self._fp is None:
|
| 698 |
-
return True
|
| 699 |
-
elif hasattr(self._fp, "isclosed"):
|
| 700 |
-
return self._fp.isclosed()
|
| 701 |
-
elif hasattr(self._fp, "closed"):
|
| 702 |
-
return self._fp.closed
|
| 703 |
-
else:
|
| 704 |
-
return True
|
| 705 |
-
|
| 706 |
-
def fileno(self):
|
| 707 |
-
if self._fp is None:
|
| 708 |
-
raise IOError("HTTPResponse has no file to get a fileno from")
|
| 709 |
-
elif hasattr(self._fp, "fileno"):
|
| 710 |
-
return self._fp.fileno()
|
| 711 |
-
else:
|
| 712 |
-
raise IOError(
|
| 713 |
-
"The file-like object this HTTPResponse is wrapped "
|
| 714 |
-
"around has no file descriptor"
|
| 715 |
-
)
|
| 716 |
-
|
| 717 |
-
def flush(self):
|
| 718 |
-
if (
|
| 719 |
-
self._fp is not None
|
| 720 |
-
and hasattr(self._fp, "flush")
|
| 721 |
-
and not getattr(self._fp, "closed", False)
|
| 722 |
-
):
|
| 723 |
-
return self._fp.flush()
|
| 724 |
-
|
| 725 |
-
def readable(self):
|
| 726 |
-
# This method is required for `io` module compatibility.
|
| 727 |
-
return True
|
| 728 |
-
|
| 729 |
-
def readinto(self, b):
|
| 730 |
-
# This method is required for `io` module compatibility.
|
| 731 |
-
temp = self.read(len(b))
|
| 732 |
-
if len(temp) == 0:
|
| 733 |
-
return 0
|
| 734 |
-
else:
|
| 735 |
-
b[: len(temp)] = temp
|
| 736 |
-
return len(temp)
|
| 737 |
-
|
| 738 |
-
def supports_chunked_reads(self):
|
| 739 |
-
"""
|
| 740 |
-
Checks if the underlying file-like object looks like a
|
| 741 |
-
:class:`http.client.HTTPResponse` object. We do this by testing for
|
| 742 |
-
the fp attribute. If it is present we assume it returns raw chunks as
|
| 743 |
-
processed by read_chunked().
|
| 744 |
-
"""
|
| 745 |
-
return hasattr(self._fp, "fp")
|
| 746 |
-
|
| 747 |
-
def _update_chunk_length(self):
|
| 748 |
-
# First, we'll figure out length of a chunk and then
|
| 749 |
-
# we'll try to read it from socket.
|
| 750 |
-
if self.chunk_left is not None:
|
| 751 |
-
return
|
| 752 |
-
line = self._fp.fp.readline()
|
| 753 |
-
line = line.split(b";", 1)[0]
|
| 754 |
-
try:
|
| 755 |
-
self.chunk_left = int(line, 16)
|
| 756 |
-
except ValueError:
|
| 757 |
-
# Invalid chunked protocol response, abort.
|
| 758 |
-
self.close()
|
| 759 |
-
raise InvalidChunkLength(self, line)
|
| 760 |
-
|
| 761 |
-
def _handle_chunk(self, amt):
|
| 762 |
-
returned_chunk = None
|
| 763 |
-
if amt is None:
|
| 764 |
-
chunk = self._fp._safe_read(self.chunk_left)
|
| 765 |
-
returned_chunk = chunk
|
| 766 |
-
self._fp._safe_read(2) # Toss the CRLF at the end of the chunk.
|
| 767 |
-
self.chunk_left = None
|
| 768 |
-
elif amt < self.chunk_left:
|
| 769 |
-
value = self._fp._safe_read(amt)
|
| 770 |
-
self.chunk_left = self.chunk_left - amt
|
| 771 |
-
returned_chunk = value
|
| 772 |
-
elif amt == self.chunk_left:
|
| 773 |
-
value = self._fp._safe_read(amt)
|
| 774 |
-
self._fp._safe_read(2) # Toss the CRLF at the end of the chunk.
|
| 775 |
-
self.chunk_left = None
|
| 776 |
-
returned_chunk = value
|
| 777 |
-
else: # amt > self.chunk_left
|
| 778 |
-
returned_chunk = self._fp._safe_read(self.chunk_left)
|
| 779 |
-
self._fp._safe_read(2) # Toss the CRLF at the end of the chunk.
|
| 780 |
-
self.chunk_left = None
|
| 781 |
-
return returned_chunk
|
| 782 |
-
|
| 783 |
-
def read_chunked(self, amt=None, decode_content=None):
|
| 784 |
-
"""
|
| 785 |
-
Similar to :meth:`HTTPResponse.read`, but with an additional
|
| 786 |
-
parameter: ``decode_content``.
|
| 787 |
-
|
| 788 |
-
:param amt:
|
| 789 |
-
How much of the content to read. If specified, caching is skipped
|
| 790 |
-
because it doesn't make sense to cache partial content as the full
|
| 791 |
-
response.
|
| 792 |
-
|
| 793 |
-
:param decode_content:
|
| 794 |
-
If True, will attempt to decode the body based on the
|
| 795 |
-
'content-encoding' header.
|
| 796 |
-
"""
|
| 797 |
-
self._init_decoder()
|
| 798 |
-
# FIXME: Rewrite this method and make it a class with a better structured logic.
|
| 799 |
-
if not self.chunked:
|
| 800 |
-
raise ResponseNotChunked(
|
| 801 |
-
"Response is not chunked. "
|
| 802 |
-
"Header 'transfer-encoding: chunked' is missing."
|
| 803 |
-
)
|
| 804 |
-
if not self.supports_chunked_reads():
|
| 805 |
-
raise BodyNotHttplibCompatible(
|
| 806 |
-
"Body should be http.client.HTTPResponse like. "
|
| 807 |
-
"It should have have an fp attribute which returns raw chunks."
|
| 808 |
-
)
|
| 809 |
-
|
| 810 |
-
with self._error_catcher():
|
| 811 |
-
# Don't bother reading the body of a HEAD request.
|
| 812 |
-
if self._original_response and is_response_to_head(self._original_response):
|
| 813 |
-
self._original_response.close()
|
| 814 |
-
return
|
| 815 |
-
|
| 816 |
-
# If a response is already read and closed
|
| 817 |
-
# then return immediately.
|
| 818 |
-
if self._fp.fp is None:
|
| 819 |
-
return
|
| 820 |
-
|
| 821 |
-
while True:
|
| 822 |
-
self._update_chunk_length()
|
| 823 |
-
if self.chunk_left == 0:
|
| 824 |
-
break
|
| 825 |
-
chunk = self._handle_chunk(amt)
|
| 826 |
-
decoded = self._decode(
|
| 827 |
-
chunk, decode_content=decode_content, flush_decoder=False
|
| 828 |
-
)
|
| 829 |
-
if decoded:
|
| 830 |
-
yield decoded
|
| 831 |
-
|
| 832 |
-
if decode_content:
|
| 833 |
-
# On CPython and PyPy, we should never need to flush the
|
| 834 |
-
# decoder. However, on Jython we *might* need to, so
|
| 835 |
-
# lets defensively do it anyway.
|
| 836 |
-
decoded = self._flush_decoder()
|
| 837 |
-
if decoded: # Platform-specific: Jython.
|
| 838 |
-
yield decoded
|
| 839 |
-
|
| 840 |
-
# Chunk content ends with \r\n: discard it.
|
| 841 |
-
while True:
|
| 842 |
-
line = self._fp.fp.readline()
|
| 843 |
-
if not line:
|
| 844 |
-
# Some sites may not end with '\r\n'.
|
| 845 |
-
break
|
| 846 |
-
if line == b"\r\n":
|
| 847 |
-
break
|
| 848 |
-
|
| 849 |
-
# We read everything; close the "file".
|
| 850 |
-
if self._original_response:
|
| 851 |
-
self._original_response.close()
|
| 852 |
-
|
| 853 |
-
def geturl(self):
|
| 854 |
-
"""
|
| 855 |
-
Returns the URL that was the source of this response.
|
| 856 |
-
If the request that generated this response redirected, this method
|
| 857 |
-
will return the final redirect location.
|
| 858 |
-
"""
|
| 859 |
-
if self.retries is not None and len(self.retries.history):
|
| 860 |
-
return self.retries.history[-1].redirect_location
|
| 861 |
-
else:
|
| 862 |
-
return self._request_url
|
| 863 |
-
|
| 864 |
-
def __iter__(self):
|
| 865 |
-
buffer = []
|
| 866 |
-
for chunk in self.stream(decode_content=True):
|
| 867 |
-
if b"\n" in chunk:
|
| 868 |
-
chunk = chunk.split(b"\n")
|
| 869 |
-
yield b"".join(buffer) + chunk[0] + b"\n"
|
| 870 |
-
for x in chunk[1:-1]:
|
| 871 |
-
yield x + b"\n"
|
| 872 |
-
if chunk[-1]:
|
| 873 |
-
buffer = [chunk[-1]]
|
| 874 |
-
else:
|
| 875 |
-
buffer = []
|
| 876 |
-
else:
|
| 877 |
-
buffer.append(chunk)
|
| 878 |
-
if buffer:
|
| 879 |
-
yield b"".join(buffer)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/Big-Web/MMSD/env/Lib/site-packages/setuptools/_distutils/sysconfig.py
DELETED
|
@@ -1,558 +0,0 @@
|
|
| 1 |
-
"""Provide access to Python's configuration information. The specific
|
| 2 |
-
configuration variables available depend heavily on the platform and
|
| 3 |
-
configuration. The values may be retrieved using
|
| 4 |
-
get_config_var(name), and the list of variables is available via
|
| 5 |
-
get_config_vars().keys(). Additional convenience functions are also
|
| 6 |
-
available.
|
| 7 |
-
|
| 8 |
-
Written by: Fred L. Drake, Jr.
|
| 9 |
-
Email: <[email protected]>
|
| 10 |
-
"""
|
| 11 |
-
|
| 12 |
-
import os
|
| 13 |
-
import re
|
| 14 |
-
import sys
|
| 15 |
-
import sysconfig
|
| 16 |
-
import pathlib
|
| 17 |
-
|
| 18 |
-
from .errors import DistutilsPlatformError
|
| 19 |
-
from . import py39compat
|
| 20 |
-
from ._functools import pass_none
|
| 21 |
-
|
| 22 |
-
IS_PYPY = '__pypy__' in sys.builtin_module_names
|
| 23 |
-
|
| 24 |
-
# These are needed in a couple of spots, so just compute them once.
|
| 25 |
-
PREFIX = os.path.normpath(sys.prefix)
|
| 26 |
-
EXEC_PREFIX = os.path.normpath(sys.exec_prefix)
|
| 27 |
-
BASE_PREFIX = os.path.normpath(sys.base_prefix)
|
| 28 |
-
BASE_EXEC_PREFIX = os.path.normpath(sys.base_exec_prefix)
|
| 29 |
-
|
| 30 |
-
# Path to the base directory of the project. On Windows the binary may
|
| 31 |
-
# live in project/PCbuild/win32 or project/PCbuild/amd64.
|
| 32 |
-
# set for cross builds
|
| 33 |
-
if "_PYTHON_PROJECT_BASE" in os.environ:
|
| 34 |
-
project_base = os.path.abspath(os.environ["_PYTHON_PROJECT_BASE"])
|
| 35 |
-
else:
|
| 36 |
-
if sys.executable:
|
| 37 |
-
project_base = os.path.dirname(os.path.abspath(sys.executable))
|
| 38 |
-
else:
|
| 39 |
-
# sys.executable can be empty if argv[0] has been changed and Python is
|
| 40 |
-
# unable to retrieve the real program name
|
| 41 |
-
project_base = os.getcwd()
|
| 42 |
-
|
| 43 |
-
|
| 44 |
-
def _is_python_source_dir(d):
|
| 45 |
-
"""
|
| 46 |
-
Return True if the target directory appears to point to an
|
| 47 |
-
un-installed Python.
|
| 48 |
-
"""
|
| 49 |
-
modules = pathlib.Path(d).joinpath('Modules')
|
| 50 |
-
return any(modules.joinpath(fn).is_file() for fn in ('Setup', 'Setup.local'))
|
| 51 |
-
|
| 52 |
-
|
| 53 |
-
_sys_home = getattr(sys, '_home', None)
|
| 54 |
-
|
| 55 |
-
|
| 56 |
-
def _is_parent(dir_a, dir_b):
|
| 57 |
-
"""
|
| 58 |
-
Return True if a is a parent of b.
|
| 59 |
-
"""
|
| 60 |
-
return os.path.normcase(dir_a).startswith(os.path.normcase(dir_b))
|
| 61 |
-
|
| 62 |
-
|
| 63 |
-
if os.name == 'nt':
|
| 64 |
-
|
| 65 |
-
@pass_none
|
| 66 |
-
def _fix_pcbuild(d):
|
| 67 |
-
# In a venv, sys._home will be inside BASE_PREFIX rather than PREFIX.
|
| 68 |
-
prefixes = PREFIX, BASE_PREFIX
|
| 69 |
-
matched = (
|
| 70 |
-
prefix
|
| 71 |
-
for prefix in prefixes
|
| 72 |
-
if _is_parent(d, os.path.join(prefix, "PCbuild"))
|
| 73 |
-
)
|
| 74 |
-
return next(matched, d)
|
| 75 |
-
|
| 76 |
-
project_base = _fix_pcbuild(project_base)
|
| 77 |
-
_sys_home = _fix_pcbuild(_sys_home)
|
| 78 |
-
|
| 79 |
-
|
| 80 |
-
def _python_build():
|
| 81 |
-
if _sys_home:
|
| 82 |
-
return _is_python_source_dir(_sys_home)
|
| 83 |
-
return _is_python_source_dir(project_base)
|
| 84 |
-
|
| 85 |
-
|
| 86 |
-
python_build = _python_build()
|
| 87 |
-
|
| 88 |
-
|
| 89 |
-
# Calculate the build qualifier flags if they are defined. Adding the flags
|
| 90 |
-
# to the include and lib directories only makes sense for an installation, not
|
| 91 |
-
# an in-source build.
|
| 92 |
-
build_flags = ''
|
| 93 |
-
try:
|
| 94 |
-
if not python_build:
|
| 95 |
-
build_flags = sys.abiflags
|
| 96 |
-
except AttributeError:
|
| 97 |
-
# It's not a configure-based build, so the sys module doesn't have
|
| 98 |
-
# this attribute, which is fine.
|
| 99 |
-
pass
|
| 100 |
-
|
| 101 |
-
|
| 102 |
-
def get_python_version():
|
| 103 |
-
"""Return a string containing the major and minor Python version,
|
| 104 |
-
leaving off the patchlevel. Sample return values could be '1.5'
|
| 105 |
-
or '2.2'.
|
| 106 |
-
"""
|
| 107 |
-
return '%d.%d' % sys.version_info[:2]
|
| 108 |
-
|
| 109 |
-
|
| 110 |
-
def get_python_inc(plat_specific=0, prefix=None):
|
| 111 |
-
"""Return the directory containing installed Python header files.
|
| 112 |
-
|
| 113 |
-
If 'plat_specific' is false (the default), this is the path to the
|
| 114 |
-
non-platform-specific header files, i.e. Python.h and so on;
|
| 115 |
-
otherwise, this is the path to platform-specific header files
|
| 116 |
-
(namely pyconfig.h).
|
| 117 |
-
|
| 118 |
-
If 'prefix' is supplied, use it instead of sys.base_prefix or
|
| 119 |
-
sys.base_exec_prefix -- i.e., ignore 'plat_specific'.
|
| 120 |
-
"""
|
| 121 |
-
default_prefix = BASE_EXEC_PREFIX if plat_specific else BASE_PREFIX
|
| 122 |
-
resolved_prefix = prefix if prefix is not None else default_prefix
|
| 123 |
-
try:
|
| 124 |
-
getter = globals()[f'_get_python_inc_{os.name}']
|
| 125 |
-
except KeyError:
|
| 126 |
-
raise DistutilsPlatformError(
|
| 127 |
-
"I don't know where Python installs its C header files "
|
| 128 |
-
"on platform '%s'" % os.name
|
| 129 |
-
)
|
| 130 |
-
return getter(resolved_prefix, prefix, plat_specific)
|
| 131 |
-
|
| 132 |
-
|
| 133 |
-
def _get_python_inc_posix(prefix, spec_prefix, plat_specific):
|
| 134 |
-
if IS_PYPY and sys.version_info < (3, 8):
|
| 135 |
-
return os.path.join(prefix, 'include')
|
| 136 |
-
return (
|
| 137 |
-
_get_python_inc_posix_python(plat_specific)
|
| 138 |
-
or _get_python_inc_from_config(plat_specific, spec_prefix)
|
| 139 |
-
or _get_python_inc_posix_prefix(prefix)
|
| 140 |
-
)
|
| 141 |
-
|
| 142 |
-
|
| 143 |
-
def _get_python_inc_posix_python(plat_specific):
|
| 144 |
-
"""
|
| 145 |
-
Assume the executable is in the build directory. The
|
| 146 |
-
pyconfig.h file should be in the same directory. Since
|
| 147 |
-
the build directory may not be the source directory,
|
| 148 |
-
use "srcdir" from the makefile to find the "Include"
|
| 149 |
-
directory.
|
| 150 |
-
"""
|
| 151 |
-
if not python_build:
|
| 152 |
-
return
|
| 153 |
-
if plat_specific:
|
| 154 |
-
return _sys_home or project_base
|
| 155 |
-
incdir = os.path.join(get_config_var('srcdir'), 'Include')
|
| 156 |
-
return os.path.normpath(incdir)
|
| 157 |
-
|
| 158 |
-
|
| 159 |
-
def _get_python_inc_from_config(plat_specific, spec_prefix):
|
| 160 |
-
"""
|
| 161 |
-
If no prefix was explicitly specified, provide the include
|
| 162 |
-
directory from the config vars. Useful when
|
| 163 |
-
cross-compiling, since the config vars may come from
|
| 164 |
-
the host
|
| 165 |
-
platform Python installation, while the current Python
|
| 166 |
-
executable is from the build platform installation.
|
| 167 |
-
|
| 168 |
-
>>> monkeypatch = getfixture('monkeypatch')
|
| 169 |
-
>>> gpifc = _get_python_inc_from_config
|
| 170 |
-
>>> monkeypatch.setitem(gpifc.__globals__, 'get_config_var', str.lower)
|
| 171 |
-
>>> gpifc(False, '/usr/bin/')
|
| 172 |
-
>>> gpifc(False, '')
|
| 173 |
-
>>> gpifc(False, None)
|
| 174 |
-
'includepy'
|
| 175 |
-
>>> gpifc(True, None)
|
| 176 |
-
'confincludepy'
|
| 177 |
-
"""
|
| 178 |
-
if spec_prefix is None:
|
| 179 |
-
return get_config_var('CONF' * plat_specific + 'INCLUDEPY')
|
| 180 |
-
|
| 181 |
-
|
| 182 |
-
def _get_python_inc_posix_prefix(prefix):
|
| 183 |
-
implementation = 'pypy' if IS_PYPY else 'python'
|
| 184 |
-
python_dir = implementation + get_python_version() + build_flags
|
| 185 |
-
return os.path.join(prefix, "include", python_dir)
|
| 186 |
-
|
| 187 |
-
|
| 188 |
-
def _get_python_inc_nt(prefix, spec_prefix, plat_specific):
|
| 189 |
-
if python_build:
|
| 190 |
-
# Include both the include and PC dir to ensure we can find
|
| 191 |
-
# pyconfig.h
|
| 192 |
-
return (
|
| 193 |
-
os.path.join(prefix, "include")
|
| 194 |
-
+ os.path.pathsep
|
| 195 |
-
+ os.path.join(prefix, "PC")
|
| 196 |
-
)
|
| 197 |
-
return os.path.join(prefix, "include")
|
| 198 |
-
|
| 199 |
-
|
| 200 |
-
# allow this behavior to be monkey-patched. Ref pypa/distutils#2.
|
| 201 |
-
def _posix_lib(standard_lib, libpython, early_prefix, prefix):
|
| 202 |
-
if standard_lib:
|
| 203 |
-
return libpython
|
| 204 |
-
else:
|
| 205 |
-
return os.path.join(libpython, "site-packages")
|
| 206 |
-
|
| 207 |
-
|
| 208 |
-
def get_python_lib(plat_specific=0, standard_lib=0, prefix=None):
|
| 209 |
-
"""Return the directory containing the Python library (standard or
|
| 210 |
-
site additions).
|
| 211 |
-
|
| 212 |
-
If 'plat_specific' is true, return the directory containing
|
| 213 |
-
platform-specific modules, i.e. any module from a non-pure-Python
|
| 214 |
-
module distribution; otherwise, return the platform-shared library
|
| 215 |
-
directory. If 'standard_lib' is true, return the directory
|
| 216 |
-
containing standard Python library modules; otherwise, return the
|
| 217 |
-
directory for site-specific modules.
|
| 218 |
-
|
| 219 |
-
If 'prefix' is supplied, use it instead of sys.base_prefix or
|
| 220 |
-
sys.base_exec_prefix -- i.e., ignore 'plat_specific'.
|
| 221 |
-
"""
|
| 222 |
-
|
| 223 |
-
if IS_PYPY and sys.version_info < (3, 8):
|
| 224 |
-
# PyPy-specific schema
|
| 225 |
-
if prefix is None:
|
| 226 |
-
prefix = PREFIX
|
| 227 |
-
if standard_lib:
|
| 228 |
-
return os.path.join(prefix, "lib-python", sys.version[0])
|
| 229 |
-
return os.path.join(prefix, 'site-packages')
|
| 230 |
-
|
| 231 |
-
early_prefix = prefix
|
| 232 |
-
|
| 233 |
-
if prefix is None:
|
| 234 |
-
if standard_lib:
|
| 235 |
-
prefix = plat_specific and BASE_EXEC_PREFIX or BASE_PREFIX
|
| 236 |
-
else:
|
| 237 |
-
prefix = plat_specific and EXEC_PREFIX or PREFIX
|
| 238 |
-
|
| 239 |
-
if os.name == "posix":
|
| 240 |
-
if plat_specific or standard_lib:
|
| 241 |
-
# Platform-specific modules (any module from a non-pure-Python
|
| 242 |
-
# module distribution) or standard Python library modules.
|
| 243 |
-
libdir = getattr(sys, "platlibdir", "lib")
|
| 244 |
-
else:
|
| 245 |
-
# Pure Python
|
| 246 |
-
libdir = "lib"
|
| 247 |
-
implementation = 'pypy' if IS_PYPY else 'python'
|
| 248 |
-
libpython = os.path.join(prefix, libdir, implementation + get_python_version())
|
| 249 |
-
return _posix_lib(standard_lib, libpython, early_prefix, prefix)
|
| 250 |
-
elif os.name == "nt":
|
| 251 |
-
if standard_lib:
|
| 252 |
-
return os.path.join(prefix, "Lib")
|
| 253 |
-
else:
|
| 254 |
-
return os.path.join(prefix, "Lib", "site-packages")
|
| 255 |
-
else:
|
| 256 |
-
raise DistutilsPlatformError(
|
| 257 |
-
"I don't know where Python installs its library "
|
| 258 |
-
"on platform '%s'" % os.name
|
| 259 |
-
)
|
| 260 |
-
|
| 261 |
-
|
| 262 |
-
def customize_compiler(compiler): # noqa: C901
|
| 263 |
-
"""Do any platform-specific customization of a CCompiler instance.
|
| 264 |
-
|
| 265 |
-
Mainly needed on Unix, so we can plug in the information that
|
| 266 |
-
varies across Unices and is stored in Python's Makefile.
|
| 267 |
-
"""
|
| 268 |
-
if compiler.compiler_type == "unix":
|
| 269 |
-
if sys.platform == "darwin":
|
| 270 |
-
# Perform first-time customization of compiler-related
|
| 271 |
-
# config vars on OS X now that we know we need a compiler.
|
| 272 |
-
# This is primarily to support Pythons from binary
|
| 273 |
-
# installers. The kind and paths to build tools on
|
| 274 |
-
# the user system may vary significantly from the system
|
| 275 |
-
# that Python itself was built on. Also the user OS
|
| 276 |
-
# version and build tools may not support the same set
|
| 277 |
-
# of CPU architectures for universal builds.
|
| 278 |
-
global _config_vars
|
| 279 |
-
# Use get_config_var() to ensure _config_vars is initialized.
|
| 280 |
-
if not get_config_var('CUSTOMIZED_OSX_COMPILER'):
|
| 281 |
-
import _osx_support
|
| 282 |
-
|
| 283 |
-
_osx_support.customize_compiler(_config_vars)
|
| 284 |
-
_config_vars['CUSTOMIZED_OSX_COMPILER'] = 'True'
|
| 285 |
-
|
| 286 |
-
(
|
| 287 |
-
cc,
|
| 288 |
-
cxx,
|
| 289 |
-
cflags,
|
| 290 |
-
ccshared,
|
| 291 |
-
ldshared,
|
| 292 |
-
shlib_suffix,
|
| 293 |
-
ar,
|
| 294 |
-
ar_flags,
|
| 295 |
-
) = get_config_vars(
|
| 296 |
-
'CC',
|
| 297 |
-
'CXX',
|
| 298 |
-
'CFLAGS',
|
| 299 |
-
'CCSHARED',
|
| 300 |
-
'LDSHARED',
|
| 301 |
-
'SHLIB_SUFFIX',
|
| 302 |
-
'AR',
|
| 303 |
-
'ARFLAGS',
|
| 304 |
-
)
|
| 305 |
-
|
| 306 |
-
if 'CC' in os.environ:
|
| 307 |
-
newcc = os.environ['CC']
|
| 308 |
-
if 'LDSHARED' not in os.environ and ldshared.startswith(cc):
|
| 309 |
-
# If CC is overridden, use that as the default
|
| 310 |
-
# command for LDSHARED as well
|
| 311 |
-
ldshared = newcc + ldshared[len(cc) :]
|
| 312 |
-
cc = newcc
|
| 313 |
-
if 'CXX' in os.environ:
|
| 314 |
-
cxx = os.environ['CXX']
|
| 315 |
-
if 'LDSHARED' in os.environ:
|
| 316 |
-
ldshared = os.environ['LDSHARED']
|
| 317 |
-
if 'CPP' in os.environ:
|
| 318 |
-
cpp = os.environ['CPP']
|
| 319 |
-
else:
|
| 320 |
-
cpp = cc + " -E" # not always
|
| 321 |
-
if 'LDFLAGS' in os.environ:
|
| 322 |
-
ldshared = ldshared + ' ' + os.environ['LDFLAGS']
|
| 323 |
-
if 'CFLAGS' in os.environ:
|
| 324 |
-
cflags = cflags + ' ' + os.environ['CFLAGS']
|
| 325 |
-
ldshared = ldshared + ' ' + os.environ['CFLAGS']
|
| 326 |
-
if 'CPPFLAGS' in os.environ:
|
| 327 |
-
cpp = cpp + ' ' + os.environ['CPPFLAGS']
|
| 328 |
-
cflags = cflags + ' ' + os.environ['CPPFLAGS']
|
| 329 |
-
ldshared = ldshared + ' ' + os.environ['CPPFLAGS']
|
| 330 |
-
if 'AR' in os.environ:
|
| 331 |
-
ar = os.environ['AR']
|
| 332 |
-
if 'ARFLAGS' in os.environ:
|
| 333 |
-
archiver = ar + ' ' + os.environ['ARFLAGS']
|
| 334 |
-
else:
|
| 335 |
-
archiver = ar + ' ' + ar_flags
|
| 336 |
-
|
| 337 |
-
cc_cmd = cc + ' ' + cflags
|
| 338 |
-
compiler.set_executables(
|
| 339 |
-
preprocessor=cpp,
|
| 340 |
-
compiler=cc_cmd,
|
| 341 |
-
compiler_so=cc_cmd + ' ' + ccshared,
|
| 342 |
-
compiler_cxx=cxx,
|
| 343 |
-
linker_so=ldshared,
|
| 344 |
-
linker_exe=cc,
|
| 345 |
-
archiver=archiver,
|
| 346 |
-
)
|
| 347 |
-
|
| 348 |
-
if 'RANLIB' in os.environ and compiler.executables.get('ranlib', None):
|
| 349 |
-
compiler.set_executables(ranlib=os.environ['RANLIB'])
|
| 350 |
-
|
| 351 |
-
compiler.shared_lib_extension = shlib_suffix
|
| 352 |
-
|
| 353 |
-
|
| 354 |
-
def get_config_h_filename():
|
| 355 |
-
"""Return full pathname of installed pyconfig.h file."""
|
| 356 |
-
if python_build:
|
| 357 |
-
if os.name == "nt":
|
| 358 |
-
inc_dir = os.path.join(_sys_home or project_base, "PC")
|
| 359 |
-
else:
|
| 360 |
-
inc_dir = _sys_home or project_base
|
| 361 |
-
return os.path.join(inc_dir, 'pyconfig.h')
|
| 362 |
-
else:
|
| 363 |
-
return sysconfig.get_config_h_filename()
|
| 364 |
-
|
| 365 |
-
|
| 366 |
-
def get_makefile_filename():
|
| 367 |
-
"""Return full pathname of installed Makefile from the Python build."""
|
| 368 |
-
return sysconfig.get_makefile_filename()
|
| 369 |
-
|
| 370 |
-
|
| 371 |
-
def parse_config_h(fp, g=None):
|
| 372 |
-
"""Parse a config.h-style file.
|
| 373 |
-
|
| 374 |
-
A dictionary containing name/value pairs is returned. If an
|
| 375 |
-
optional dictionary is passed in as the second argument, it is
|
| 376 |
-
used instead of a new dictionary.
|
| 377 |
-
"""
|
| 378 |
-
return sysconfig.parse_config_h(fp, vars=g)
|
| 379 |
-
|
| 380 |
-
|
| 381 |
-
# Regexes needed for parsing Makefile (and similar syntaxes,
|
| 382 |
-
# like old-style Setup files).
|
| 383 |
-
_variable_rx = re.compile(r"([a-zA-Z][a-zA-Z0-9_]+)\s*=\s*(.*)")
|
| 384 |
-
_findvar1_rx = re.compile(r"\$\(([A-Za-z][A-Za-z0-9_]*)\)")
|
| 385 |
-
_findvar2_rx = re.compile(r"\${([A-Za-z][A-Za-z0-9_]*)}")
|
| 386 |
-
|
| 387 |
-
|
| 388 |
-
def parse_makefile(fn, g=None): # noqa: C901
|
| 389 |
-
"""Parse a Makefile-style file.
|
| 390 |
-
|
| 391 |
-
A dictionary containing name/value pairs is returned. If an
|
| 392 |
-
optional dictionary is passed in as the second argument, it is
|
| 393 |
-
used instead of a new dictionary.
|
| 394 |
-
"""
|
| 395 |
-
from distutils.text_file import TextFile
|
| 396 |
-
|
| 397 |
-
fp = TextFile(
|
| 398 |
-
fn, strip_comments=1, skip_blanks=1, join_lines=1, errors="surrogateescape"
|
| 399 |
-
)
|
| 400 |
-
|
| 401 |
-
if g is None:
|
| 402 |
-
g = {}
|
| 403 |
-
done = {}
|
| 404 |
-
notdone = {}
|
| 405 |
-
|
| 406 |
-
while True:
|
| 407 |
-
line = fp.readline()
|
| 408 |
-
if line is None: # eof
|
| 409 |
-
break
|
| 410 |
-
m = _variable_rx.match(line)
|
| 411 |
-
if m:
|
| 412 |
-
n, v = m.group(1, 2)
|
| 413 |
-
v = v.strip()
|
| 414 |
-
# `$$' is a literal `$' in make
|
| 415 |
-
tmpv = v.replace('$$', '')
|
| 416 |
-
|
| 417 |
-
if "$" in tmpv:
|
| 418 |
-
notdone[n] = v
|
| 419 |
-
else:
|
| 420 |
-
try:
|
| 421 |
-
v = int(v)
|
| 422 |
-
except ValueError:
|
| 423 |
-
# insert literal `$'
|
| 424 |
-
done[n] = v.replace('$$', '$')
|
| 425 |
-
else:
|
| 426 |
-
done[n] = v
|
| 427 |
-
|
| 428 |
-
# Variables with a 'PY_' prefix in the makefile. These need to
|
| 429 |
-
# be made available without that prefix through sysconfig.
|
| 430 |
-
# Special care is needed to ensure that variable expansion works, even
|
| 431 |
-
# if the expansion uses the name without a prefix.
|
| 432 |
-
renamed_variables = ('CFLAGS', 'LDFLAGS', 'CPPFLAGS')
|
| 433 |
-
|
| 434 |
-
# do variable interpolation here
|
| 435 |
-
while notdone:
|
| 436 |
-
for name in list(notdone):
|
| 437 |
-
value = notdone[name]
|
| 438 |
-
m = _findvar1_rx.search(value) or _findvar2_rx.search(value)
|
| 439 |
-
if m:
|
| 440 |
-
n = m.group(1)
|
| 441 |
-
found = True
|
| 442 |
-
if n in done:
|
| 443 |
-
item = str(done[n])
|
| 444 |
-
elif n in notdone:
|
| 445 |
-
# get it on a subsequent round
|
| 446 |
-
found = False
|
| 447 |
-
elif n in os.environ:
|
| 448 |
-
# do it like make: fall back to environment
|
| 449 |
-
item = os.environ[n]
|
| 450 |
-
|
| 451 |
-
elif n in renamed_variables:
|
| 452 |
-
if name.startswith('PY_') and name[3:] in renamed_variables:
|
| 453 |
-
item = ""
|
| 454 |
-
|
| 455 |
-
elif 'PY_' + n in notdone:
|
| 456 |
-
found = False
|
| 457 |
-
|
| 458 |
-
else:
|
| 459 |
-
item = str(done['PY_' + n])
|
| 460 |
-
else:
|
| 461 |
-
done[n] = item = ""
|
| 462 |
-
if found:
|
| 463 |
-
after = value[m.end() :]
|
| 464 |
-
value = value[: m.start()] + item + after
|
| 465 |
-
if "$" in after:
|
| 466 |
-
notdone[name] = value
|
| 467 |
-
else:
|
| 468 |
-
try:
|
| 469 |
-
value = int(value)
|
| 470 |
-
except ValueError:
|
| 471 |
-
done[name] = value.strip()
|
| 472 |
-
else:
|
| 473 |
-
done[name] = value
|
| 474 |
-
del notdone[name]
|
| 475 |
-
|
| 476 |
-
if name.startswith('PY_') and name[3:] in renamed_variables:
|
| 477 |
-
|
| 478 |
-
name = name[3:]
|
| 479 |
-
if name not in done:
|
| 480 |
-
done[name] = value
|
| 481 |
-
else:
|
| 482 |
-
# bogus variable reference; just drop it since we can't deal
|
| 483 |
-
del notdone[name]
|
| 484 |
-
|
| 485 |
-
fp.close()
|
| 486 |
-
|
| 487 |
-
# strip spurious spaces
|
| 488 |
-
for k, v in done.items():
|
| 489 |
-
if isinstance(v, str):
|
| 490 |
-
done[k] = v.strip()
|
| 491 |
-
|
| 492 |
-
# save the results in the global dictionary
|
| 493 |
-
g.update(done)
|
| 494 |
-
return g
|
| 495 |
-
|
| 496 |
-
|
| 497 |
-
def expand_makefile_vars(s, vars):
|
| 498 |
-
"""Expand Makefile-style variables -- "${foo}" or "$(foo)" -- in
|
| 499 |
-
'string' according to 'vars' (a dictionary mapping variable names to
|
| 500 |
-
values). Variables not present in 'vars' are silently expanded to the
|
| 501 |
-
empty string. The variable values in 'vars' should not contain further
|
| 502 |
-
variable expansions; if 'vars' is the output of 'parse_makefile()',
|
| 503 |
-
you're fine. Returns a variable-expanded version of 's'.
|
| 504 |
-
"""
|
| 505 |
-
|
| 506 |
-
# This algorithm does multiple expansion, so if vars['foo'] contains
|
| 507 |
-
# "${bar}", it will expand ${foo} to ${bar}, and then expand
|
| 508 |
-
# ${bar}... and so forth. This is fine as long as 'vars' comes from
|
| 509 |
-
# 'parse_makefile()', which takes care of such expansions eagerly,
|
| 510 |
-
# according to make's variable expansion semantics.
|
| 511 |
-
|
| 512 |
-
while True:
|
| 513 |
-
m = _findvar1_rx.search(s) or _findvar2_rx.search(s)
|
| 514 |
-
if m:
|
| 515 |
-
(beg, end) = m.span()
|
| 516 |
-
s = s[0:beg] + vars.get(m.group(1)) + s[end:]
|
| 517 |
-
else:
|
| 518 |
-
break
|
| 519 |
-
return s
|
| 520 |
-
|
| 521 |
-
|
| 522 |
-
_config_vars = None
|
| 523 |
-
|
| 524 |
-
|
| 525 |
-
def get_config_vars(*args):
|
| 526 |
-
"""With no arguments, return a dictionary of all configuration
|
| 527 |
-
variables relevant for the current platform. Generally this includes
|
| 528 |
-
everything needed to build extensions and install both pure modules and
|
| 529 |
-
extensions. On Unix, this means every variable defined in Python's
|
| 530 |
-
installed Makefile; on Windows it's a much smaller set.
|
| 531 |
-
|
| 532 |
-
With arguments, return a list of values that result from looking up
|
| 533 |
-
each argument in the configuration variable dictionary.
|
| 534 |
-
"""
|
| 535 |
-
global _config_vars
|
| 536 |
-
if _config_vars is None:
|
| 537 |
-
_config_vars = sysconfig.get_config_vars().copy()
|
| 538 |
-
py39compat.add_ext_suffix(_config_vars)
|
| 539 |
-
|
| 540 |
-
if args:
|
| 541 |
-
vals = []
|
| 542 |
-
for name in args:
|
| 543 |
-
vals.append(_config_vars.get(name))
|
| 544 |
-
return vals
|
| 545 |
-
else:
|
| 546 |
-
return _config_vars
|
| 547 |
-
|
| 548 |
-
|
| 549 |
-
def get_config_var(name):
|
| 550 |
-
"""Return the value of a single variable using the dictionary
|
| 551 |
-
returned by 'get_config_vars()'. Equivalent to
|
| 552 |
-
get_config_vars().get(name)
|
| 553 |
-
"""
|
| 554 |
-
if name == 'SO':
|
| 555 |
-
import warnings
|
| 556 |
-
|
| 557 |
-
warnings.warn('SO is deprecated, use EXT_SUFFIX', DeprecationWarning, 2)
|
| 558 |
-
return get_config_vars().get(name)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/Big-Web/MMSD/env/Lib/site-packages/urllib3/contrib/socks.py
DELETED
|
@@ -1,216 +0,0 @@
|
|
| 1 |
-
# -*- coding: utf-8 -*-
|
| 2 |
-
"""
|
| 3 |
-
This module contains provisional support for SOCKS proxies from within
|
| 4 |
-
urllib3. This module supports SOCKS4, SOCKS4A (an extension of SOCKS4), and
|
| 5 |
-
SOCKS5. To enable its functionality, either install PySocks or install this
|
| 6 |
-
module with the ``socks`` extra.
|
| 7 |
-
|
| 8 |
-
The SOCKS implementation supports the full range of urllib3 features. It also
|
| 9 |
-
supports the following SOCKS features:
|
| 10 |
-
|
| 11 |
-
- SOCKS4A (``proxy_url='socks4a://...``)
|
| 12 |
-
- SOCKS4 (``proxy_url='socks4://...``)
|
| 13 |
-
- SOCKS5 with remote DNS (``proxy_url='socks5h://...``)
|
| 14 |
-
- SOCKS5 with local DNS (``proxy_url='socks5://...``)
|
| 15 |
-
- Usernames and passwords for the SOCKS proxy
|
| 16 |
-
|
| 17 |
-
.. note::
|
| 18 |
-
It is recommended to use ``socks5h://`` or ``socks4a://`` schemes in
|
| 19 |
-
your ``proxy_url`` to ensure that DNS resolution is done from the remote
|
| 20 |
-
server instead of client-side when connecting to a domain name.
|
| 21 |
-
|
| 22 |
-
SOCKS4 supports IPv4 and domain names with the SOCKS4A extension. SOCKS5
|
| 23 |
-
supports IPv4, IPv6, and domain names.
|
| 24 |
-
|
| 25 |
-
When connecting to a SOCKS4 proxy the ``username`` portion of the ``proxy_url``
|
| 26 |
-
will be sent as the ``userid`` section of the SOCKS request:
|
| 27 |
-
|
| 28 |
-
.. code-block:: python
|
| 29 |
-
|
| 30 |
-
proxy_url="socks4a://<userid>@proxy-host"
|
| 31 |
-
|
| 32 |
-
When connecting to a SOCKS5 proxy the ``username`` and ``password`` portion
|
| 33 |
-
of the ``proxy_url`` will be sent as the username/password to authenticate
|
| 34 |
-
with the proxy:
|
| 35 |
-
|
| 36 |
-
.. code-block:: python
|
| 37 |
-
|
| 38 |
-
proxy_url="socks5h://<username>:<password>@proxy-host"
|
| 39 |
-
|
| 40 |
-
"""
|
| 41 |
-
from __future__ import absolute_import
|
| 42 |
-
|
| 43 |
-
try:
|
| 44 |
-
import socks
|
| 45 |
-
except ImportError:
|
| 46 |
-
import warnings
|
| 47 |
-
|
| 48 |
-
from ..exceptions import DependencyWarning
|
| 49 |
-
|
| 50 |
-
warnings.warn(
|
| 51 |
-
(
|
| 52 |
-
"SOCKS support in urllib3 requires the installation of optional "
|
| 53 |
-
"dependencies: specifically, PySocks. For more information, see "
|
| 54 |
-
"https://urllib3.readthedocs.io/en/1.26.x/contrib.html#socks-proxies"
|
| 55 |
-
),
|
| 56 |
-
DependencyWarning,
|
| 57 |
-
)
|
| 58 |
-
raise
|
| 59 |
-
|
| 60 |
-
from socket import error as SocketError
|
| 61 |
-
from socket import timeout as SocketTimeout
|
| 62 |
-
|
| 63 |
-
from ..connection import HTTPConnection, HTTPSConnection
|
| 64 |
-
from ..connectionpool import HTTPConnectionPool, HTTPSConnectionPool
|
| 65 |
-
from ..exceptions import ConnectTimeoutError, NewConnectionError
|
| 66 |
-
from ..poolmanager import PoolManager
|
| 67 |
-
from ..util.url import parse_url
|
| 68 |
-
|
| 69 |
-
try:
|
| 70 |
-
import ssl
|
| 71 |
-
except ImportError:
|
| 72 |
-
ssl = None
|
| 73 |
-
|
| 74 |
-
|
| 75 |
-
class SOCKSConnection(HTTPConnection):
|
| 76 |
-
"""
|
| 77 |
-
A plain-text HTTP connection that connects via a SOCKS proxy.
|
| 78 |
-
"""
|
| 79 |
-
|
| 80 |
-
def __init__(self, *args, **kwargs):
|
| 81 |
-
self._socks_options = kwargs.pop("_socks_options")
|
| 82 |
-
super(SOCKSConnection, self).__init__(*args, **kwargs)
|
| 83 |
-
|
| 84 |
-
def _new_conn(self):
|
| 85 |
-
"""
|
| 86 |
-
Establish a new connection via the SOCKS proxy.
|
| 87 |
-
"""
|
| 88 |
-
extra_kw = {}
|
| 89 |
-
if self.source_address:
|
| 90 |
-
extra_kw["source_address"] = self.source_address
|
| 91 |
-
|
| 92 |
-
if self.socket_options:
|
| 93 |
-
extra_kw["socket_options"] = self.socket_options
|
| 94 |
-
|
| 95 |
-
try:
|
| 96 |
-
conn = socks.create_connection(
|
| 97 |
-
(self.host, self.port),
|
| 98 |
-
proxy_type=self._socks_options["socks_version"],
|
| 99 |
-
proxy_addr=self._socks_options["proxy_host"],
|
| 100 |
-
proxy_port=self._socks_options["proxy_port"],
|
| 101 |
-
proxy_username=self._socks_options["username"],
|
| 102 |
-
proxy_password=self._socks_options["password"],
|
| 103 |
-
proxy_rdns=self._socks_options["rdns"],
|
| 104 |
-
timeout=self.timeout,
|
| 105 |
-
**extra_kw
|
| 106 |
-
)
|
| 107 |
-
|
| 108 |
-
except SocketTimeout:
|
| 109 |
-
raise ConnectTimeoutError(
|
| 110 |
-
self,
|
| 111 |
-
"Connection to %s timed out. (connect timeout=%s)"
|
| 112 |
-
% (self.host, self.timeout),
|
| 113 |
-
)
|
| 114 |
-
|
| 115 |
-
except socks.ProxyError as e:
|
| 116 |
-
# This is fragile as hell, but it seems to be the only way to raise
|
| 117 |
-
# useful errors here.
|
| 118 |
-
if e.socket_err:
|
| 119 |
-
error = e.socket_err
|
| 120 |
-
if isinstance(error, SocketTimeout):
|
| 121 |
-
raise ConnectTimeoutError(
|
| 122 |
-
self,
|
| 123 |
-
"Connection to %s timed out. (connect timeout=%s)"
|
| 124 |
-
% (self.host, self.timeout),
|
| 125 |
-
)
|
| 126 |
-
else:
|
| 127 |
-
raise NewConnectionError(
|
| 128 |
-
self, "Failed to establish a new connection: %s" % error
|
| 129 |
-
)
|
| 130 |
-
else:
|
| 131 |
-
raise NewConnectionError(
|
| 132 |
-
self, "Failed to establish a new connection: %s" % e
|
| 133 |
-
)
|
| 134 |
-
|
| 135 |
-
except SocketError as e: # Defensive: PySocks should catch all these.
|
| 136 |
-
raise NewConnectionError(
|
| 137 |
-
self, "Failed to establish a new connection: %s" % e
|
| 138 |
-
)
|
| 139 |
-
|
| 140 |
-
return conn
|
| 141 |
-
|
| 142 |
-
|
| 143 |
-
# We don't need to duplicate the Verified/Unverified distinction from
|
| 144 |
-
# urllib3/connection.py here because the HTTPSConnection will already have been
|
| 145 |
-
# correctly set to either the Verified or Unverified form by that module. This
|
| 146 |
-
# means the SOCKSHTTPSConnection will automatically be the correct type.
|
| 147 |
-
class SOCKSHTTPSConnection(SOCKSConnection, HTTPSConnection):
|
| 148 |
-
pass
|
| 149 |
-
|
| 150 |
-
|
| 151 |
-
class SOCKSHTTPConnectionPool(HTTPConnectionPool):
|
| 152 |
-
ConnectionCls = SOCKSConnection
|
| 153 |
-
|
| 154 |
-
|
| 155 |
-
class SOCKSHTTPSConnectionPool(HTTPSConnectionPool):
|
| 156 |
-
ConnectionCls = SOCKSHTTPSConnection
|
| 157 |
-
|
| 158 |
-
|
| 159 |
-
class SOCKSProxyManager(PoolManager):
|
| 160 |
-
"""
|
| 161 |
-
A version of the urllib3 ProxyManager that routes connections via the
|
| 162 |
-
defined SOCKS proxy.
|
| 163 |
-
"""
|
| 164 |
-
|
| 165 |
-
pool_classes_by_scheme = {
|
| 166 |
-
"http": SOCKSHTTPConnectionPool,
|
| 167 |
-
"https": SOCKSHTTPSConnectionPool,
|
| 168 |
-
}
|
| 169 |
-
|
| 170 |
-
def __init__(
|
| 171 |
-
self,
|
| 172 |
-
proxy_url,
|
| 173 |
-
username=None,
|
| 174 |
-
password=None,
|
| 175 |
-
num_pools=10,
|
| 176 |
-
headers=None,
|
| 177 |
-
**connection_pool_kw
|
| 178 |
-
):
|
| 179 |
-
parsed = parse_url(proxy_url)
|
| 180 |
-
|
| 181 |
-
if username is None and password is None and parsed.auth is not None:
|
| 182 |
-
split = parsed.auth.split(":")
|
| 183 |
-
if len(split) == 2:
|
| 184 |
-
username, password = split
|
| 185 |
-
if parsed.scheme == "socks5":
|
| 186 |
-
socks_version = socks.PROXY_TYPE_SOCKS5
|
| 187 |
-
rdns = False
|
| 188 |
-
elif parsed.scheme == "socks5h":
|
| 189 |
-
socks_version = socks.PROXY_TYPE_SOCKS5
|
| 190 |
-
rdns = True
|
| 191 |
-
elif parsed.scheme == "socks4":
|
| 192 |
-
socks_version = socks.PROXY_TYPE_SOCKS4
|
| 193 |
-
rdns = False
|
| 194 |
-
elif parsed.scheme == "socks4a":
|
| 195 |
-
socks_version = socks.PROXY_TYPE_SOCKS4
|
| 196 |
-
rdns = True
|
| 197 |
-
else:
|
| 198 |
-
raise ValueError("Unable to determine SOCKS version from %s" % proxy_url)
|
| 199 |
-
|
| 200 |
-
self.proxy_url = proxy_url
|
| 201 |
-
|
| 202 |
-
socks_options = {
|
| 203 |
-
"socks_version": socks_version,
|
| 204 |
-
"proxy_host": parsed.host,
|
| 205 |
-
"proxy_port": parsed.port,
|
| 206 |
-
"username": username,
|
| 207 |
-
"password": password,
|
| 208 |
-
"rdns": rdns,
|
| 209 |
-
}
|
| 210 |
-
connection_pool_kw["_socks_options"] = socks_options
|
| 211 |
-
|
| 212 |
-
super(SOCKSProxyManager, self).__init__(
|
| 213 |
-
num_pools, headers, **connection_pool_kw
|
| 214 |
-
)
|
| 215 |
-
|
| 216 |
-
self.pool_classes_by_scheme = SOCKSProxyManager.pool_classes_by_scheme
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/CVPR/WALT/mmdet/models/detectors/retinanet.py
DELETED
|
@@ -1,17 +0,0 @@
|
|
| 1 |
-
from ..builder import DETECTORS
|
| 2 |
-
from .single_stage import SingleStageDetector
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
@DETECTORS.register_module()
|
| 6 |
-
class RetinaNet(SingleStageDetector):
|
| 7 |
-
"""Implementation of `RetinaNet <https://arxiv.org/abs/1708.02002>`_"""
|
| 8 |
-
|
| 9 |
-
def __init__(self,
|
| 10 |
-
backbone,
|
| 11 |
-
neck,
|
| 12 |
-
bbox_head,
|
| 13 |
-
train_cfg=None,
|
| 14 |
-
test_cfg=None,
|
| 15 |
-
pretrained=None):
|
| 16 |
-
super(RetinaNet, self).__init__(backbone, neck, bbox_head, train_cfg,
|
| 17 |
-
test_cfg, pretrained)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/CVPR/drawings-to-human/frontend/README.md
DELETED
|
@@ -1,38 +0,0 @@
|
|
| 1 |
-
# create-svelte
|
| 2 |
-
|
| 3 |
-
Everything you need to build a Svelte project, powered by [`create-svelte`](https://github.com/sveltejs/kit/tree/master/packages/create-svelte).
|
| 4 |
-
|
| 5 |
-
## Creating a project
|
| 6 |
-
|
| 7 |
-
If you're seeing this, you've probably already done this step. Congrats!
|
| 8 |
-
|
| 9 |
-
```bash
|
| 10 |
-
# create a new project in the current directory
|
| 11 |
-
npm init svelte
|
| 12 |
-
|
| 13 |
-
# create a new project in my-app
|
| 14 |
-
npm init svelte my-app
|
| 15 |
-
```
|
| 16 |
-
|
| 17 |
-
## Developing
|
| 18 |
-
|
| 19 |
-
Once you've created a project and installed dependencies with `npm install` (or `pnpm install` or `yarn`), start a development server:
|
| 20 |
-
|
| 21 |
-
```bash
|
| 22 |
-
npm run dev
|
| 23 |
-
|
| 24 |
-
# or start the server and open the app in a new browser tab
|
| 25 |
-
npm run dev -- --open
|
| 26 |
-
```
|
| 27 |
-
|
| 28 |
-
## Building
|
| 29 |
-
|
| 30 |
-
To create a production version of your app:
|
| 31 |
-
|
| 32 |
-
```bash
|
| 33 |
-
npm run build
|
| 34 |
-
```
|
| 35 |
-
|
| 36 |
-
You can preview the production build with `npm run preview`.
|
| 37 |
-
|
| 38 |
-
> To deploy your app, you may need to install an [adapter](https://kit.svelte.dev/docs/adapters) for your target environment.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/CVPR/unicl-zero-shot-img-recog/model/image_encoder/focalnet.py
DELETED
|
@@ -1,649 +0,0 @@
|
|
| 1 |
-
# --------------------------------------------------------
|
| 2 |
-
# FocalNets -- Focal Modulation Networks
|
| 3 |
-
# Copyright (c) 2022 Microsoft
|
| 4 |
-
# Licensed under The MIT License [see LICENSE for details]
|
| 5 |
-
# Written by Jianwei Yang ([email protected])
|
| 6 |
-
# --------------------------------------------------------
|
| 7 |
-
|
| 8 |
-
import torch
|
| 9 |
-
import torch.nn as nn
|
| 10 |
-
import torch.nn.functional as F
|
| 11 |
-
import torch.utils.checkpoint as checkpoint
|
| 12 |
-
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
|
| 13 |
-
from timm.models.registry import register_model
|
| 14 |
-
|
| 15 |
-
from torchvision import transforms
|
| 16 |
-
from timm.data.constants import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
|
| 17 |
-
from timm.data import create_transform
|
| 18 |
-
from timm.data.transforms import _pil_interp
|
| 19 |
-
|
| 20 |
-
class Mlp(nn.Module):
|
| 21 |
-
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
|
| 22 |
-
super().__init__()
|
| 23 |
-
out_features = out_features or in_features
|
| 24 |
-
hidden_features = hidden_features or in_features
|
| 25 |
-
self.fc1 = nn.Linear(in_features, hidden_features)
|
| 26 |
-
self.act = act_layer()
|
| 27 |
-
self.fc2 = nn.Linear(hidden_features, out_features)
|
| 28 |
-
self.drop = nn.Dropout(drop)
|
| 29 |
-
|
| 30 |
-
def forward(self, x):
|
| 31 |
-
x = self.fc1(x)
|
| 32 |
-
x = self.act(x)
|
| 33 |
-
x = self.drop(x)
|
| 34 |
-
x = self.fc2(x)
|
| 35 |
-
x = self.drop(x)
|
| 36 |
-
return x
|
| 37 |
-
|
| 38 |
-
class FocalModulation(nn.Module):
|
| 39 |
-
def __init__(self, dim, focal_window, focal_level, focal_factor=2, bias=True, proj_drop=0.):
|
| 40 |
-
super().__init__()
|
| 41 |
-
|
| 42 |
-
self.dim = dim
|
| 43 |
-
self.focal_window = focal_window
|
| 44 |
-
self.focal_level = focal_level
|
| 45 |
-
self.focal_factor = focal_factor
|
| 46 |
-
|
| 47 |
-
self.f = nn.Linear(dim, 2*dim + (self.focal_level+1), bias=bias)
|
| 48 |
-
self.h = nn.Conv2d(dim, dim, kernel_size=1, stride=1, bias=bias)
|
| 49 |
-
|
| 50 |
-
self.act = nn.GELU()
|
| 51 |
-
self.proj = nn.Linear(dim, dim)
|
| 52 |
-
self.proj_drop = nn.Dropout(proj_drop)
|
| 53 |
-
self.focal_layers = nn.ModuleList()
|
| 54 |
-
|
| 55 |
-
self.kernel_sizes = []
|
| 56 |
-
for k in range(self.focal_level):
|
| 57 |
-
kernel_size = self.focal_factor*k + self.focal_window
|
| 58 |
-
self.focal_layers.append(
|
| 59 |
-
nn.Sequential(
|
| 60 |
-
nn.Conv2d(dim, dim, kernel_size=kernel_size, stride=1,
|
| 61 |
-
groups=dim, padding=kernel_size//2, bias=False),
|
| 62 |
-
nn.GELU(),
|
| 63 |
-
)
|
| 64 |
-
)
|
| 65 |
-
self.kernel_sizes.append(kernel_size)
|
| 66 |
-
def forward(self, x):
|
| 67 |
-
"""
|
| 68 |
-
Args:
|
| 69 |
-
x: input features with shape of (B, H, W, C)
|
| 70 |
-
"""
|
| 71 |
-
C = x.shape[-1]
|
| 72 |
-
|
| 73 |
-
# pre linear projection
|
| 74 |
-
x = self.f(x).permute(0, 3, 1, 2).contiguous()
|
| 75 |
-
q, ctx, self.gates = torch.split(x, (C, C, self.focal_level+1), 1)
|
| 76 |
-
|
| 77 |
-
# context aggreation
|
| 78 |
-
ctx_all = 0
|
| 79 |
-
for l in range(self.focal_level):
|
| 80 |
-
ctx = self.focal_layers[l](ctx)
|
| 81 |
-
ctx_all = ctx_all + ctx*self.gates[:, l:l+1]
|
| 82 |
-
ctx_global = self.act(ctx.mean(2, keepdim=True).mean(3, keepdim=True))
|
| 83 |
-
ctx_all = ctx_all + ctx_global*self.gates[:,self.focal_level:]
|
| 84 |
-
|
| 85 |
-
# focal modulation
|
| 86 |
-
self.modulator = self.h(ctx_all)
|
| 87 |
-
x_out = q*self.modulator
|
| 88 |
-
x_out = x_out.permute(0, 2, 3, 1).contiguous()
|
| 89 |
-
|
| 90 |
-
# post linear porjection
|
| 91 |
-
x_out = self.proj(x_out)
|
| 92 |
-
x_out = self.proj_drop(x_out)
|
| 93 |
-
return x_out
|
| 94 |
-
|
| 95 |
-
def extra_repr(self) -> str:
|
| 96 |
-
return f'dim={self.dim}'
|
| 97 |
-
|
| 98 |
-
def flops(self, N):
|
| 99 |
-
# calculate flops for 1 window with token length of N
|
| 100 |
-
flops = 0
|
| 101 |
-
|
| 102 |
-
flops += N * self.dim * (self.dim * 2 + (self.focal_level+1))
|
| 103 |
-
|
| 104 |
-
# focal convolution
|
| 105 |
-
for k in range(self.focal_level):
|
| 106 |
-
flops += N * (self.kernel_sizes[k]**2+1) * self.dim
|
| 107 |
-
|
| 108 |
-
# global gating
|
| 109 |
-
flops += N * 1 * self.dim
|
| 110 |
-
|
| 111 |
-
# self.linear
|
| 112 |
-
flops += N * self.dim * (self.dim + 1)
|
| 113 |
-
|
| 114 |
-
# x = self.proj(x)
|
| 115 |
-
flops += N * self.dim * self.dim
|
| 116 |
-
return flops
|
| 117 |
-
|
| 118 |
-
class FocalNetBlock(nn.Module):
|
| 119 |
-
r""" Focal Modulation Network Block.
|
| 120 |
-
|
| 121 |
-
Args:
|
| 122 |
-
dim (int): Number of input channels.
|
| 123 |
-
input_resolution (tuple[int]): Input resulotion.
|
| 124 |
-
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
|
| 125 |
-
drop (float, optional): Dropout rate. Default: 0.0
|
| 126 |
-
drop_path (float, optional): Stochastic depth rate. Default: 0.0
|
| 127 |
-
act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
|
| 128 |
-
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
|
| 129 |
-
focal_level (int): Number of focal levels.
|
| 130 |
-
focal_window (int): Focal window size at first focal level
|
| 131 |
-
use_layerscale (bool): Whether use layerscale
|
| 132 |
-
layerscale_value (float): Initial layerscale value
|
| 133 |
-
use_postln (bool): Whether use layernorm after modulation
|
| 134 |
-
"""
|
| 135 |
-
|
| 136 |
-
def __init__(self, dim, input_resolution, mlp_ratio=4., drop=0., drop_path=0.,
|
| 137 |
-
act_layer=nn.GELU, norm_layer=nn.LayerNorm,
|
| 138 |
-
focal_level=1, focal_window=3,
|
| 139 |
-
use_layerscale=False, layerscale_value=1e-4,
|
| 140 |
-
use_postln=False):
|
| 141 |
-
super().__init__()
|
| 142 |
-
self.dim = dim
|
| 143 |
-
self.input_resolution = input_resolution
|
| 144 |
-
self.mlp_ratio = mlp_ratio
|
| 145 |
-
|
| 146 |
-
self.focal_window = focal_window
|
| 147 |
-
self.focal_level = focal_level
|
| 148 |
-
self.use_postln = use_postln
|
| 149 |
-
|
| 150 |
-
self.norm1 = norm_layer(dim)
|
| 151 |
-
self.modulation = FocalModulation(dim, proj_drop=drop, focal_window=focal_window, focal_level=self.focal_level)
|
| 152 |
-
|
| 153 |
-
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
|
| 154 |
-
self.norm2 = norm_layer(dim)
|
| 155 |
-
mlp_hidden_dim = int(dim * mlp_ratio)
|
| 156 |
-
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
|
| 157 |
-
|
| 158 |
-
self.alpha = 3.0 if self.use_postln else 1.0
|
| 159 |
-
|
| 160 |
-
self.gamma_1 = 1.0
|
| 161 |
-
self.gamma_2 = 1.0
|
| 162 |
-
if use_layerscale:
|
| 163 |
-
self.gamma_1 = nn.Parameter(layerscale_value * torch.ones((dim)), requires_grad=True)
|
| 164 |
-
self.gamma_2 = nn.Parameter(layerscale_value * torch.ones((dim)), requires_grad=True)
|
| 165 |
-
|
| 166 |
-
self.H = None
|
| 167 |
-
self.W = None
|
| 168 |
-
|
| 169 |
-
def forward(self, x):
|
| 170 |
-
H, W = self.H, self.W
|
| 171 |
-
B, L, C = x.shape
|
| 172 |
-
shortcut = x
|
| 173 |
-
|
| 174 |
-
# Focal Modulation
|
| 175 |
-
if not self.use_postln:
|
| 176 |
-
x = self.norm1(x)
|
| 177 |
-
x = x.view(B, H, W, C)
|
| 178 |
-
x = self.modulation(x).view(B, H * W, C)
|
| 179 |
-
|
| 180 |
-
# FFN
|
| 181 |
-
x = shortcut*self.alpha + self.drop_path(self.gamma_1 * x)
|
| 182 |
-
if self.use_postln:
|
| 183 |
-
x = self.norm1(x)
|
| 184 |
-
|
| 185 |
-
if not self.use_postln:
|
| 186 |
-
x = x + self.drop_path(self.gamma_2 * self.mlp(self.norm2(x)))
|
| 187 |
-
else:
|
| 188 |
-
x = x*self.alpha + self.drop_path(self.gamma_2 * self.mlp(x))
|
| 189 |
-
x = self.norm2(x)
|
| 190 |
-
|
| 191 |
-
return x
|
| 192 |
-
|
| 193 |
-
def extra_repr(self) -> str:
|
| 194 |
-
return f"dim={self.dim}, input_resolution={self.input_resolution}, " \
|
| 195 |
-
f"mlp_ratio={self.mlp_ratio}"
|
| 196 |
-
|
| 197 |
-
def flops(self):
|
| 198 |
-
flops = 0
|
| 199 |
-
H, W = self.input_resolution
|
| 200 |
-
# norm1
|
| 201 |
-
flops += self.dim * H * W
|
| 202 |
-
|
| 203 |
-
# W-MSA/SW-MSA
|
| 204 |
-
flops += self.modulation.flops(H*W)
|
| 205 |
-
|
| 206 |
-
# mlp
|
| 207 |
-
flops += 2 * H * W * self.dim * self.dim * self.mlp_ratio
|
| 208 |
-
# norm2
|
| 209 |
-
flops += self.dim * H * W
|
| 210 |
-
return flops
|
| 211 |
-
|
| 212 |
-
class BasicLayer(nn.Module):
|
| 213 |
-
""" A basic Focal Transformer layer for one stage.
|
| 214 |
-
|
| 215 |
-
Args:
|
| 216 |
-
dim (int): Number of input channels.
|
| 217 |
-
input_resolution (tuple[int]): Input resolution.
|
| 218 |
-
depth (int): Number of blocks.
|
| 219 |
-
window_size (int): Local window size.
|
| 220 |
-
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
|
| 221 |
-
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
|
| 222 |
-
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
|
| 223 |
-
drop (float, optional): Dropout rate. Default: 0.0
|
| 224 |
-
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
|
| 225 |
-
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
|
| 226 |
-
downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
|
| 227 |
-
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
|
| 228 |
-
focal_level (int): Number of focal levels
|
| 229 |
-
focal_window (int): Focal window size at first focal level
|
| 230 |
-
use_layerscale (bool): Whether use layerscale
|
| 231 |
-
layerscale_value (float): Initial layerscale value
|
| 232 |
-
use_postln (bool): Whether use layernorm after modulation
|
| 233 |
-
"""
|
| 234 |
-
|
| 235 |
-
def __init__(self, dim, out_dim, input_resolution, depth,
|
| 236 |
-
mlp_ratio=4., drop=0., drop_path=0., norm_layer=nn.LayerNorm,
|
| 237 |
-
downsample=None, use_checkpoint=False,
|
| 238 |
-
focal_level=1, focal_window=1,
|
| 239 |
-
use_conv_embed=False,
|
| 240 |
-
use_layerscale=False, layerscale_value=1e-4, use_postln=False):
|
| 241 |
-
|
| 242 |
-
super().__init__()
|
| 243 |
-
self.dim = dim
|
| 244 |
-
self.input_resolution = input_resolution
|
| 245 |
-
self.depth = depth
|
| 246 |
-
self.use_checkpoint = use_checkpoint
|
| 247 |
-
|
| 248 |
-
# build blocks
|
| 249 |
-
self.blocks = nn.ModuleList([
|
| 250 |
-
FocalNetBlock(
|
| 251 |
-
dim=dim,
|
| 252 |
-
input_resolution=input_resolution,
|
| 253 |
-
mlp_ratio=mlp_ratio,
|
| 254 |
-
drop=drop,
|
| 255 |
-
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
|
| 256 |
-
norm_layer=norm_layer,
|
| 257 |
-
focal_level=focal_level,
|
| 258 |
-
focal_window=focal_window,
|
| 259 |
-
use_layerscale=use_layerscale,
|
| 260 |
-
layerscale_value=layerscale_value,
|
| 261 |
-
use_postln=use_postln,
|
| 262 |
-
)
|
| 263 |
-
for i in range(depth)])
|
| 264 |
-
|
| 265 |
-
if downsample is not None:
|
| 266 |
-
self.downsample = downsample(
|
| 267 |
-
img_size=input_resolution,
|
| 268 |
-
patch_size=2,
|
| 269 |
-
in_chans=dim,
|
| 270 |
-
embed_dim=out_dim,
|
| 271 |
-
use_conv_embed=use_conv_embed,
|
| 272 |
-
norm_layer=norm_layer,
|
| 273 |
-
is_stem=False
|
| 274 |
-
)
|
| 275 |
-
else:
|
| 276 |
-
self.downsample = None
|
| 277 |
-
|
| 278 |
-
def forward(self, x, H, W):
|
| 279 |
-
for blk in self.blocks:
|
| 280 |
-
blk.H, blk.W = H, W
|
| 281 |
-
if self.use_checkpoint:
|
| 282 |
-
x = checkpoint.checkpoint(blk, x)
|
| 283 |
-
else:
|
| 284 |
-
x = blk(x)
|
| 285 |
-
|
| 286 |
-
if self.downsample is not None:
|
| 287 |
-
x = x.transpose(1, 2).reshape(x.shape[0], -1, H, W)
|
| 288 |
-
x, Ho, Wo = self.downsample(x)
|
| 289 |
-
else:
|
| 290 |
-
Ho, Wo = H, W
|
| 291 |
-
return x, Ho, Wo
|
| 292 |
-
|
| 293 |
-
def extra_repr(self) -> str:
|
| 294 |
-
return f"dim={self.dim}, input_resolution={self.input_resolution}, depth={self.depth}"
|
| 295 |
-
|
| 296 |
-
def flops(self):
|
| 297 |
-
flops = 0
|
| 298 |
-
for blk in self.blocks:
|
| 299 |
-
flops += blk.flops()
|
| 300 |
-
if self.downsample is not None:
|
| 301 |
-
flops += self.downsample.flops()
|
| 302 |
-
return flops
|
| 303 |
-
|
| 304 |
-
class PatchEmbed(nn.Module):
|
| 305 |
-
r""" Image to Patch Embedding
|
| 306 |
-
|
| 307 |
-
Args:
|
| 308 |
-
img_size (int): Image size. Default: 224.
|
| 309 |
-
patch_size (int): Patch token size. Default: 4.
|
| 310 |
-
in_chans (int): Number of input image channels. Default: 3.
|
| 311 |
-
embed_dim (int): Number of linear projection output channels. Default: 96.
|
| 312 |
-
norm_layer (nn.Module, optional): Normalization layer. Default: None
|
| 313 |
-
"""
|
| 314 |
-
|
| 315 |
-
def __init__(self, img_size=(224, 224), patch_size=4, in_chans=3, embed_dim=96, use_conv_embed=False, norm_layer=None, is_stem=False):
|
| 316 |
-
super().__init__()
|
| 317 |
-
patch_size = to_2tuple(patch_size)
|
| 318 |
-
patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
|
| 319 |
-
self.img_size = img_size
|
| 320 |
-
self.patch_size = patch_size
|
| 321 |
-
self.patches_resolution = patches_resolution
|
| 322 |
-
self.num_patches = patches_resolution[0] * patches_resolution[1]
|
| 323 |
-
|
| 324 |
-
self.in_chans = in_chans
|
| 325 |
-
self.embed_dim = embed_dim
|
| 326 |
-
|
| 327 |
-
if use_conv_embed:
|
| 328 |
-
# if we choose to use conv embedding, then we treat the stem and non-stem differently
|
| 329 |
-
if is_stem:
|
| 330 |
-
kernel_size = 7; padding = 2; stride = 4
|
| 331 |
-
else:
|
| 332 |
-
kernel_size = 3; padding = 1; stride = 2
|
| 333 |
-
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=kernel_size, stride=stride, padding=padding)
|
| 334 |
-
else:
|
| 335 |
-
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
|
| 336 |
-
|
| 337 |
-
if norm_layer is not None:
|
| 338 |
-
self.norm = norm_layer(embed_dim)
|
| 339 |
-
else:
|
| 340 |
-
self.norm = None
|
| 341 |
-
|
| 342 |
-
def forward(self, x):
|
| 343 |
-
B, C, H, W = x.shape
|
| 344 |
-
|
| 345 |
-
x = self.proj(x)
|
| 346 |
-
H, W = x.shape[2:]
|
| 347 |
-
x = x.flatten(2).transpose(1, 2) # B Ph*Pw C
|
| 348 |
-
if self.norm is not None:
|
| 349 |
-
x = self.norm(x)
|
| 350 |
-
return x, H, W
|
| 351 |
-
|
| 352 |
-
def flops(self):
|
| 353 |
-
Ho, Wo = self.patches_resolution
|
| 354 |
-
flops = Ho * Wo * self.embed_dim * self.in_chans * (self.patch_size[0] * self.patch_size[1])
|
| 355 |
-
if self.norm is not None:
|
| 356 |
-
flops += Ho * Wo * self.embed_dim
|
| 357 |
-
return flops
|
| 358 |
-
|
| 359 |
-
class FocalNet(nn.Module):
|
| 360 |
-
r""" Focal Modulation Networks (FocalNets)
|
| 361 |
-
|
| 362 |
-
Args:
|
| 363 |
-
img_size (int | tuple(int)): Input image size. Default 224
|
| 364 |
-
patch_size (int | tuple(int)): Patch size. Default: 4
|
| 365 |
-
in_chans (int): Number of input image channels. Default: 3
|
| 366 |
-
num_classes (int): Number of classes for classification head. Default: 1000
|
| 367 |
-
embed_dim (int): Patch embedding dimension. Default: 96
|
| 368 |
-
depths (tuple(int)): Depth of each Focal Transformer layer.
|
| 369 |
-
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4
|
| 370 |
-
drop_rate (float): Dropout rate. Default: 0
|
| 371 |
-
drop_path_rate (float): Stochastic depth rate. Default: 0.1
|
| 372 |
-
norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.
|
| 373 |
-
patch_norm (bool): If True, add normalization after patch embedding. Default: True
|
| 374 |
-
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False
|
| 375 |
-
focal_levels (list): How many focal levels at all stages. Note that this excludes the finest-grain level. Default: [1, 1, 1, 1]
|
| 376 |
-
focal_windows (list): The focal window size at all stages. Default: [7, 5, 3, 1]
|
| 377 |
-
use_conv_embed (bool): Whether use convolutional embedding. We noted that using convolutional embedding usually improve the performance, but we do not use it by default. Default: False
|
| 378 |
-
use_layerscale (bool): Whether use layerscale proposed in CaiT. Default: False
|
| 379 |
-
layerscale_value (float): Value for layer scale. Default: 1e-4
|
| 380 |
-
use_postln (bool): Whether use layernorm after modulation (it helps stablize training of large models)
|
| 381 |
-
"""
|
| 382 |
-
def __init__(self,
|
| 383 |
-
img_size=224,
|
| 384 |
-
patch_size=4,
|
| 385 |
-
in_chans=3,
|
| 386 |
-
num_classes=1000,
|
| 387 |
-
embed_dim=96,
|
| 388 |
-
depths=[2, 2, 6, 2],
|
| 389 |
-
mlp_ratio=4.,
|
| 390 |
-
drop_rate=0.,
|
| 391 |
-
drop_path_rate=0.1,
|
| 392 |
-
norm_layer=nn.LayerNorm,
|
| 393 |
-
patch_norm=True,
|
| 394 |
-
use_checkpoint=False,
|
| 395 |
-
focal_levels=[2, 2, 2, 2],
|
| 396 |
-
focal_windows=[3, 3, 3, 3],
|
| 397 |
-
use_conv_embed=False,
|
| 398 |
-
use_layerscale=False,
|
| 399 |
-
layerscale_value=1e-4,
|
| 400 |
-
use_postln=False,
|
| 401 |
-
**kwargs):
|
| 402 |
-
super().__init__()
|
| 403 |
-
|
| 404 |
-
self.num_layers = len(depths)
|
| 405 |
-
embed_dim = [embed_dim * (2 ** i) for i in range(self.num_layers)]
|
| 406 |
-
|
| 407 |
-
self.num_classes = num_classes
|
| 408 |
-
self.embed_dim = embed_dim
|
| 409 |
-
self.patch_norm = patch_norm
|
| 410 |
-
self.num_features = embed_dim[-1]
|
| 411 |
-
self.mlp_ratio = mlp_ratio
|
| 412 |
-
|
| 413 |
-
# split image into patches using either non-overlapped embedding or overlapped embedding
|
| 414 |
-
self.patch_embed = PatchEmbed(
|
| 415 |
-
img_size=to_2tuple(img_size),
|
| 416 |
-
patch_size=patch_size,
|
| 417 |
-
in_chans=in_chans,
|
| 418 |
-
embed_dim=embed_dim[0],
|
| 419 |
-
use_conv_embed=use_conv_embed,
|
| 420 |
-
norm_layer=norm_layer if self.patch_norm else None,
|
| 421 |
-
is_stem=True)
|
| 422 |
-
|
| 423 |
-
num_patches = self.patch_embed.num_patches
|
| 424 |
-
patches_resolution = self.patch_embed.patches_resolution
|
| 425 |
-
self.patches_resolution = patches_resolution
|
| 426 |
-
self.pos_drop = nn.Dropout(p=drop_rate)
|
| 427 |
-
|
| 428 |
-
# stochastic depth
|
| 429 |
-
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
|
| 430 |
-
|
| 431 |
-
# build layers
|
| 432 |
-
self.layers = nn.ModuleList()
|
| 433 |
-
for i_layer in range(self.num_layers):
|
| 434 |
-
layer = BasicLayer(dim=embed_dim[i_layer],
|
| 435 |
-
out_dim=embed_dim[i_layer+1] if (i_layer < self.num_layers - 1) else None,
|
| 436 |
-
input_resolution=(patches_resolution[0] // (2 ** i_layer),
|
| 437 |
-
patches_resolution[1] // (2 ** i_layer)),
|
| 438 |
-
depth=depths[i_layer],
|
| 439 |
-
mlp_ratio=self.mlp_ratio,
|
| 440 |
-
drop=drop_rate,
|
| 441 |
-
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
|
| 442 |
-
norm_layer=norm_layer,
|
| 443 |
-
downsample=PatchEmbed if (i_layer < self.num_layers - 1) else None,
|
| 444 |
-
focal_level=focal_levels[i_layer],
|
| 445 |
-
focal_window=focal_windows[i_layer],
|
| 446 |
-
use_conv_embed=use_conv_embed,
|
| 447 |
-
use_checkpoint=use_checkpoint,
|
| 448 |
-
use_layerscale=use_layerscale,
|
| 449 |
-
layerscale_value=layerscale_value,
|
| 450 |
-
use_postln=use_postln,
|
| 451 |
-
)
|
| 452 |
-
self.layers.append(layer)
|
| 453 |
-
|
| 454 |
-
self.norm = norm_layer(self.num_features)
|
| 455 |
-
self.avgpool = nn.AdaptiveAvgPool1d(1)
|
| 456 |
-
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
|
| 457 |
-
self.dim_out = self.num_features
|
| 458 |
-
|
| 459 |
-
self.apply(self._init_weights)
|
| 460 |
-
|
| 461 |
-
def _init_weights(self, m):
|
| 462 |
-
if isinstance(m, nn.Linear):
|
| 463 |
-
trunc_normal_(m.weight, std=.02)
|
| 464 |
-
if isinstance(m, nn.Linear) and m.bias is not None:
|
| 465 |
-
nn.init.constant_(m.bias, 0)
|
| 466 |
-
elif isinstance(m, nn.LayerNorm):
|
| 467 |
-
nn.init.constant_(m.bias, 0)
|
| 468 |
-
nn.init.constant_(m.weight, 1.0)
|
| 469 |
-
|
| 470 |
-
@torch.jit.ignore
|
| 471 |
-
def no_weight_decay(self):
|
| 472 |
-
return {''}
|
| 473 |
-
|
| 474 |
-
@torch.jit.ignore
|
| 475 |
-
def no_weight_decay_keywords(self):
|
| 476 |
-
return {''}
|
| 477 |
-
|
| 478 |
-
def forward_features(self, x):
|
| 479 |
-
x, H, W = self.patch_embed(x)
|
| 480 |
-
x = self.pos_drop(x)
|
| 481 |
-
|
| 482 |
-
for layer in self.layers:
|
| 483 |
-
x, H, W = layer(x, H, W)
|
| 484 |
-
x = self.norm(x) # B L C
|
| 485 |
-
x = self.avgpool(x.transpose(1, 2)) # B C 1
|
| 486 |
-
x = torch.flatten(x, 1)
|
| 487 |
-
return x
|
| 488 |
-
|
| 489 |
-
def forward(self, x):
|
| 490 |
-
x = self.forward_features(x)
|
| 491 |
-
x = self.head(x)
|
| 492 |
-
return x
|
| 493 |
-
|
| 494 |
-
def flops(self):
|
| 495 |
-
flops = 0
|
| 496 |
-
flops += self.patch_embed.flops()
|
| 497 |
-
for i, layer in enumerate(self.layers):
|
| 498 |
-
flops += layer.flops()
|
| 499 |
-
flops += self.num_features * self.patches_resolution[0] * self.patches_resolution[1] // (2 ** self.num_layers)
|
| 500 |
-
flops += self.num_features * self.num_classes
|
| 501 |
-
return flops
|
| 502 |
-
|
| 503 |
-
def build_transforms(img_size, center_crop=False):
|
| 504 |
-
t = []
|
| 505 |
-
if center_crop:
|
| 506 |
-
size = int((256 / 224) * img_size)
|
| 507 |
-
t.append(
|
| 508 |
-
transforms.Resize(size, interpolation=_pil_interp('bicubic'))
|
| 509 |
-
)
|
| 510 |
-
t.append(
|
| 511 |
-
transforms.CenterCrop(img_size)
|
| 512 |
-
)
|
| 513 |
-
else:
|
| 514 |
-
t.append(
|
| 515 |
-
transforms.Resize(img_size, interpolation=_pil_interp('bicubic'))
|
| 516 |
-
)
|
| 517 |
-
t.append(transforms.ToTensor())
|
| 518 |
-
t.append(transforms.Normalize(IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD))
|
| 519 |
-
return transforms.Compose(t)
|
| 520 |
-
|
| 521 |
-
def build_transforms4display(img_size, center_crop=False):
|
| 522 |
-
t = []
|
| 523 |
-
if center_crop:
|
| 524 |
-
size = int((256 / 224) * img_size)
|
| 525 |
-
t.append(
|
| 526 |
-
transforms.Resize(size, interpolation=_pil_interp('bicubic'))
|
| 527 |
-
)
|
| 528 |
-
t.append(
|
| 529 |
-
transforms.CenterCrop(img_size)
|
| 530 |
-
)
|
| 531 |
-
else:
|
| 532 |
-
t.append(
|
| 533 |
-
transforms.Resize(img_size, interpolation=_pil_interp('bicubic'))
|
| 534 |
-
)
|
| 535 |
-
t.append(transforms.ToTensor())
|
| 536 |
-
return transforms.Compose(t)
|
| 537 |
-
|
| 538 |
-
model_urls = {
|
| 539 |
-
"focalnet_tiny_srf": "",
|
| 540 |
-
"focalnet_small_srf": "",
|
| 541 |
-
"focalnet_base_srf": "",
|
| 542 |
-
"focalnet_tiny_lrf": "",
|
| 543 |
-
"focalnet_small_lrf": "",
|
| 544 |
-
"focalnet_base_lrf": "",
|
| 545 |
-
}
|
| 546 |
-
|
| 547 |
-
@register_model
|
| 548 |
-
def focalnet_tiny_srf(pretrained=False, **kwargs):
|
| 549 |
-
model = FocalNet(depths=[2, 2, 6, 2], embed_dim=96, **kwargs)
|
| 550 |
-
if pretrained:
|
| 551 |
-
url = model_urls['focalnet_tiny_srf']
|
| 552 |
-
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", check_hash=True)
|
| 553 |
-
model.load_state_dict(checkpoint["model"])
|
| 554 |
-
return model
|
| 555 |
-
|
| 556 |
-
@register_model
|
| 557 |
-
def focalnet_small_srf(pretrained=False, **kwargs):
|
| 558 |
-
model = FocalNet(depths=[2, 2, 18, 2], embed_dim=96, **kwargs)
|
| 559 |
-
if pretrained:
|
| 560 |
-
url = model_urls['focalnet_small_srf']
|
| 561 |
-
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu")
|
| 562 |
-
model.load_state_dict(checkpoint["model"])
|
| 563 |
-
return model
|
| 564 |
-
|
| 565 |
-
@register_model
|
| 566 |
-
def focalnet_base_srf(pretrained=False, **kwargs):
|
| 567 |
-
model = FocalNet(depths=[2, 2, 18, 2], embed_dim=128, **kwargs)
|
| 568 |
-
if pretrained:
|
| 569 |
-
url = model_urls['focalnet_base_srf']
|
| 570 |
-
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu")
|
| 571 |
-
model.load_state_dict(checkpoint["model"])
|
| 572 |
-
return model
|
| 573 |
-
|
| 574 |
-
@register_model
|
| 575 |
-
def focalnet_tiny_lrf(pretrained=False, **kwargs):
|
| 576 |
-
model = FocalNet(depths=[2, 2, 6, 2], embed_dim=96, focal_levels=[3, 3, 3, 3], **kwargs)
|
| 577 |
-
if pretrained:
|
| 578 |
-
url = model_urls['focalnet_tiny_lrf']
|
| 579 |
-
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", check_hash=True)
|
| 580 |
-
model.load_state_dict(checkpoint["model"])
|
| 581 |
-
return model
|
| 582 |
-
|
| 583 |
-
@register_model
|
| 584 |
-
def focalnet_small_lrf(pretrained=False, **kwargs):
|
| 585 |
-
model = FocalNet(depths=[2, 2, 18, 2], embed_dim=96, focal_levels=[3, 3, 3, 3], **kwargs)
|
| 586 |
-
if pretrained:
|
| 587 |
-
url = model_urls['focalnet_small_lrf']
|
| 588 |
-
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu")
|
| 589 |
-
model.load_state_dict(checkpoint["model"])
|
| 590 |
-
return model
|
| 591 |
-
|
| 592 |
-
@register_model
|
| 593 |
-
def focalnet_base_lrf(pretrained=False, **kwargs):
|
| 594 |
-
model = FocalNet(depths=[2, 2, 18, 2], embed_dim=128, focal_levels=[3, 3, 3, 3], **kwargs)
|
| 595 |
-
if pretrained:
|
| 596 |
-
url = model_urls['focalnet_base_lrf']
|
| 597 |
-
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu")
|
| 598 |
-
model.load_state_dict(checkpoint["model"])
|
| 599 |
-
return model
|
| 600 |
-
|
| 601 |
-
@register_model
|
| 602 |
-
def focalnet_giant_lrf(pretrained=False, **kwargs):
|
| 603 |
-
model = FocalNet(depths=[2, 2, 42, 2], embed_dim=512, focal_levels=[3, 3, 3, 3], **kwargs)
|
| 604 |
-
if pretrained:
|
| 605 |
-
url = model_urls['focalnet_giant_lrf']
|
| 606 |
-
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu")
|
| 607 |
-
model.load_state_dict(checkpoint["model"])
|
| 608 |
-
return model
|
| 609 |
-
|
| 610 |
-
@register_model
|
| 611 |
-
def focalnet_tiny_iso_16(pretrained=False, **kwargs):
|
| 612 |
-
model = FocalNet(depths=[12], patch_size=16, embed_dim=192, focal_levels=[3], focal_windows=[3], **kwargs)
|
| 613 |
-
if pretrained:
|
| 614 |
-
url = model_urls['focalnet_tiny_iso_16']
|
| 615 |
-
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", check_hash=True)
|
| 616 |
-
model.load_state_dict(checkpoint["model"])
|
| 617 |
-
return model
|
| 618 |
-
|
| 619 |
-
@register_model
|
| 620 |
-
def focalnet_small_iso_16(pretrained=False, **kwargs):
|
| 621 |
-
model = FocalNet(depths=[12], patch_size=16, embed_dim=384, focal_levels=[3], focal_windows=[3], **kwargs)
|
| 622 |
-
if pretrained:
|
| 623 |
-
url = model_urls['focalnet_small_iso_16']
|
| 624 |
-
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu")
|
| 625 |
-
model.load_state_dict(checkpoint["model"])
|
| 626 |
-
return model
|
| 627 |
-
|
| 628 |
-
@register_model
|
| 629 |
-
def focalnet_base_iso_16(pretrained=False, **kwargs):
|
| 630 |
-
model = FocalNet(depths=[12], patch_size=16, embed_dim=768, focal_levels=[3], focal_windows=[3], use_layerscale=True, use_postln=True, **kwargs)
|
| 631 |
-
if pretrained:
|
| 632 |
-
url = model_urls['focalnet_base_iso_16']
|
| 633 |
-
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu")
|
| 634 |
-
model.load_state_dict(checkpoint["model"])
|
| 635 |
-
return model
|
| 636 |
-
|
| 637 |
-
if __name__ == '__main__':
|
| 638 |
-
img_size = 224
|
| 639 |
-
x = torch.rand(16, 3, img_size, img_size).cuda()
|
| 640 |
-
# model = FocalNet(depths=[2, 2, 6, 2], embed_dim=96)
|
| 641 |
-
# model = FocalNet(depths=[12], patch_size=16, embed_dim=768, focal_levels=[3], focal_windows=[3], focal_factors=[2])
|
| 642 |
-
model = FocalNet(depths=[2, 2, 6, 2], embed_dim=96, focal_levels=[3, 3, 3, 3]).cuda()
|
| 643 |
-
print(model); model(x)
|
| 644 |
-
|
| 645 |
-
flops = model.flops()
|
| 646 |
-
print(f"number of GFLOPs: {flops / 1e9}")
|
| 647 |
-
|
| 648 |
-
n_parameters = sum(p.numel() for p in model.parameters() if p.requires_grad)
|
| 649 |
-
print(f"number of params: {n_parameters}")
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/Campfireman/whisper_lab2/README.md
DELETED
|
@@ -1,13 +0,0 @@
|
|
| 1 |
-
---
|
| 2 |
-
title: Whisper Lab2
|
| 3 |
-
emoji: 🌍
|
| 4 |
-
colorFrom: yellow
|
| 5 |
-
colorTo: red
|
| 6 |
-
sdk: gradio
|
| 7 |
-
sdk_version: 3.12.0
|
| 8 |
-
app_file: app.py
|
| 9 |
-
pinned: false
|
| 10 |
-
license: apache-2.0
|
| 11 |
-
---
|
| 12 |
-
|
| 13 |
-
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/CarlDennis/HYTTS/transforms.py
DELETED
|
@@ -1,193 +0,0 @@
|
|
| 1 |
-
import torch
|
| 2 |
-
from torch.nn import functional as F
|
| 3 |
-
|
| 4 |
-
import numpy as np
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
DEFAULT_MIN_BIN_WIDTH = 1e-3
|
| 8 |
-
DEFAULT_MIN_BIN_HEIGHT = 1e-3
|
| 9 |
-
DEFAULT_MIN_DERIVATIVE = 1e-3
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
def piecewise_rational_quadratic_transform(inputs,
|
| 13 |
-
unnormalized_widths,
|
| 14 |
-
unnormalized_heights,
|
| 15 |
-
unnormalized_derivatives,
|
| 16 |
-
inverse=False,
|
| 17 |
-
tails=None,
|
| 18 |
-
tail_bound=1.,
|
| 19 |
-
min_bin_width=DEFAULT_MIN_BIN_WIDTH,
|
| 20 |
-
min_bin_height=DEFAULT_MIN_BIN_HEIGHT,
|
| 21 |
-
min_derivative=DEFAULT_MIN_DERIVATIVE):
|
| 22 |
-
|
| 23 |
-
if tails is None:
|
| 24 |
-
spline_fn = rational_quadratic_spline
|
| 25 |
-
spline_kwargs = {}
|
| 26 |
-
else:
|
| 27 |
-
spline_fn = unconstrained_rational_quadratic_spline
|
| 28 |
-
spline_kwargs = {
|
| 29 |
-
'tails': tails,
|
| 30 |
-
'tail_bound': tail_bound
|
| 31 |
-
}
|
| 32 |
-
|
| 33 |
-
outputs, logabsdet = spline_fn(
|
| 34 |
-
inputs=inputs,
|
| 35 |
-
unnormalized_widths=unnormalized_widths,
|
| 36 |
-
unnormalized_heights=unnormalized_heights,
|
| 37 |
-
unnormalized_derivatives=unnormalized_derivatives,
|
| 38 |
-
inverse=inverse,
|
| 39 |
-
min_bin_width=min_bin_width,
|
| 40 |
-
min_bin_height=min_bin_height,
|
| 41 |
-
min_derivative=min_derivative,
|
| 42 |
-
**spline_kwargs
|
| 43 |
-
)
|
| 44 |
-
return outputs, logabsdet
|
| 45 |
-
|
| 46 |
-
|
| 47 |
-
def searchsorted(bin_locations, inputs, eps=1e-6):
|
| 48 |
-
bin_locations[..., -1] += eps
|
| 49 |
-
return torch.sum(
|
| 50 |
-
inputs[..., None] >= bin_locations,
|
| 51 |
-
dim=-1
|
| 52 |
-
) - 1
|
| 53 |
-
|
| 54 |
-
|
| 55 |
-
def unconstrained_rational_quadratic_spline(inputs,
|
| 56 |
-
unnormalized_widths,
|
| 57 |
-
unnormalized_heights,
|
| 58 |
-
unnormalized_derivatives,
|
| 59 |
-
inverse=False,
|
| 60 |
-
tails='linear',
|
| 61 |
-
tail_bound=1.,
|
| 62 |
-
min_bin_width=DEFAULT_MIN_BIN_WIDTH,
|
| 63 |
-
min_bin_height=DEFAULT_MIN_BIN_HEIGHT,
|
| 64 |
-
min_derivative=DEFAULT_MIN_DERIVATIVE):
|
| 65 |
-
inside_interval_mask = (inputs >= -tail_bound) & (inputs <= tail_bound)
|
| 66 |
-
outside_interval_mask = ~inside_interval_mask
|
| 67 |
-
|
| 68 |
-
outputs = torch.zeros_like(inputs)
|
| 69 |
-
logabsdet = torch.zeros_like(inputs)
|
| 70 |
-
|
| 71 |
-
if tails == 'linear':
|
| 72 |
-
unnormalized_derivatives = F.pad(unnormalized_derivatives, pad=(1, 1))
|
| 73 |
-
constant = np.log(np.exp(1 - min_derivative) - 1)
|
| 74 |
-
unnormalized_derivatives[..., 0] = constant
|
| 75 |
-
unnormalized_derivatives[..., -1] = constant
|
| 76 |
-
|
| 77 |
-
outputs[outside_interval_mask] = inputs[outside_interval_mask]
|
| 78 |
-
logabsdet[outside_interval_mask] = 0
|
| 79 |
-
else:
|
| 80 |
-
raise RuntimeError('{} tails are not implemented.'.format(tails))
|
| 81 |
-
|
| 82 |
-
outputs[inside_interval_mask], logabsdet[inside_interval_mask] = rational_quadratic_spline(
|
| 83 |
-
inputs=inputs[inside_interval_mask],
|
| 84 |
-
unnormalized_widths=unnormalized_widths[inside_interval_mask, :],
|
| 85 |
-
unnormalized_heights=unnormalized_heights[inside_interval_mask, :],
|
| 86 |
-
unnormalized_derivatives=unnormalized_derivatives[inside_interval_mask, :],
|
| 87 |
-
inverse=inverse,
|
| 88 |
-
left=-tail_bound, right=tail_bound, bottom=-tail_bound, top=tail_bound,
|
| 89 |
-
min_bin_width=min_bin_width,
|
| 90 |
-
min_bin_height=min_bin_height,
|
| 91 |
-
min_derivative=min_derivative
|
| 92 |
-
)
|
| 93 |
-
|
| 94 |
-
return outputs, logabsdet
|
| 95 |
-
|
| 96 |
-
def rational_quadratic_spline(inputs,
|
| 97 |
-
unnormalized_widths,
|
| 98 |
-
unnormalized_heights,
|
| 99 |
-
unnormalized_derivatives,
|
| 100 |
-
inverse=False,
|
| 101 |
-
left=0., right=1., bottom=0., top=1.,
|
| 102 |
-
min_bin_width=DEFAULT_MIN_BIN_WIDTH,
|
| 103 |
-
min_bin_height=DEFAULT_MIN_BIN_HEIGHT,
|
| 104 |
-
min_derivative=DEFAULT_MIN_DERIVATIVE):
|
| 105 |
-
if torch.min(inputs) < left or torch.max(inputs) > right:
|
| 106 |
-
raise ValueError('Input to a transform is not within its domain')
|
| 107 |
-
|
| 108 |
-
num_bins = unnormalized_widths.shape[-1]
|
| 109 |
-
|
| 110 |
-
if min_bin_width * num_bins > 1.0:
|
| 111 |
-
raise ValueError('Minimal bin width too large for the number of bins')
|
| 112 |
-
if min_bin_height * num_bins > 1.0:
|
| 113 |
-
raise ValueError('Minimal bin height too large for the number of bins')
|
| 114 |
-
|
| 115 |
-
widths = F.softmax(unnormalized_widths, dim=-1)
|
| 116 |
-
widths = min_bin_width + (1 - min_bin_width * num_bins) * widths
|
| 117 |
-
cumwidths = torch.cumsum(widths, dim=-1)
|
| 118 |
-
cumwidths = F.pad(cumwidths, pad=(1, 0), mode='constant', value=0.0)
|
| 119 |
-
cumwidths = (right - left) * cumwidths + left
|
| 120 |
-
cumwidths[..., 0] = left
|
| 121 |
-
cumwidths[..., -1] = right
|
| 122 |
-
widths = cumwidths[..., 1:] - cumwidths[..., :-1]
|
| 123 |
-
|
| 124 |
-
derivatives = min_derivative + F.softplus(unnormalized_derivatives)
|
| 125 |
-
|
| 126 |
-
heights = F.softmax(unnormalized_heights, dim=-1)
|
| 127 |
-
heights = min_bin_height + (1 - min_bin_height * num_bins) * heights
|
| 128 |
-
cumheights = torch.cumsum(heights, dim=-1)
|
| 129 |
-
cumheights = F.pad(cumheights, pad=(1, 0), mode='constant', value=0.0)
|
| 130 |
-
cumheights = (top - bottom) * cumheights + bottom
|
| 131 |
-
cumheights[..., 0] = bottom
|
| 132 |
-
cumheights[..., -1] = top
|
| 133 |
-
heights = cumheights[..., 1:] - cumheights[..., :-1]
|
| 134 |
-
|
| 135 |
-
if inverse:
|
| 136 |
-
bin_idx = searchsorted(cumheights, inputs)[..., None]
|
| 137 |
-
else:
|
| 138 |
-
bin_idx = searchsorted(cumwidths, inputs)[..., None]
|
| 139 |
-
|
| 140 |
-
input_cumwidths = cumwidths.gather(-1, bin_idx)[..., 0]
|
| 141 |
-
input_bin_widths = widths.gather(-1, bin_idx)[..., 0]
|
| 142 |
-
|
| 143 |
-
input_cumheights = cumheights.gather(-1, bin_idx)[..., 0]
|
| 144 |
-
delta = heights / widths
|
| 145 |
-
input_delta = delta.gather(-1, bin_idx)[..., 0]
|
| 146 |
-
|
| 147 |
-
input_derivatives = derivatives.gather(-1, bin_idx)[..., 0]
|
| 148 |
-
input_derivatives_plus_one = derivatives[..., 1:].gather(-1, bin_idx)[..., 0]
|
| 149 |
-
|
| 150 |
-
input_heights = heights.gather(-1, bin_idx)[..., 0]
|
| 151 |
-
|
| 152 |
-
if inverse:
|
| 153 |
-
a = (((inputs - input_cumheights) * (input_derivatives
|
| 154 |
-
+ input_derivatives_plus_one
|
| 155 |
-
- 2 * input_delta)
|
| 156 |
-
+ input_heights * (input_delta - input_derivatives)))
|
| 157 |
-
b = (input_heights * input_derivatives
|
| 158 |
-
- (inputs - input_cumheights) * (input_derivatives
|
| 159 |
-
+ input_derivatives_plus_one
|
| 160 |
-
- 2 * input_delta))
|
| 161 |
-
c = - input_delta * (inputs - input_cumheights)
|
| 162 |
-
|
| 163 |
-
discriminant = b.pow(2) - 4 * a * c
|
| 164 |
-
assert (discriminant >= 0).all()
|
| 165 |
-
|
| 166 |
-
root = (2 * c) / (-b - torch.sqrt(discriminant))
|
| 167 |
-
outputs = root * input_bin_widths + input_cumwidths
|
| 168 |
-
|
| 169 |
-
theta_one_minus_theta = root * (1 - root)
|
| 170 |
-
denominator = input_delta + ((input_derivatives + input_derivatives_plus_one - 2 * input_delta)
|
| 171 |
-
* theta_one_minus_theta)
|
| 172 |
-
derivative_numerator = input_delta.pow(2) * (input_derivatives_plus_one * root.pow(2)
|
| 173 |
-
+ 2 * input_delta * theta_one_minus_theta
|
| 174 |
-
+ input_derivatives * (1 - root).pow(2))
|
| 175 |
-
logabsdet = torch.log(derivative_numerator) - 2 * torch.log(denominator)
|
| 176 |
-
|
| 177 |
-
return outputs, -logabsdet
|
| 178 |
-
else:
|
| 179 |
-
theta = (inputs - input_cumwidths) / input_bin_widths
|
| 180 |
-
theta_one_minus_theta = theta * (1 - theta)
|
| 181 |
-
|
| 182 |
-
numerator = input_heights * (input_delta * theta.pow(2)
|
| 183 |
-
+ input_derivatives * theta_one_minus_theta)
|
| 184 |
-
denominator = input_delta + ((input_derivatives + input_derivatives_plus_one - 2 * input_delta)
|
| 185 |
-
* theta_one_minus_theta)
|
| 186 |
-
outputs = input_cumheights + numerator / denominator
|
| 187 |
-
|
| 188 |
-
derivative_numerator = input_delta.pow(2) * (input_derivatives_plus_one * theta.pow(2)
|
| 189 |
-
+ 2 * input_delta * theta_one_minus_theta
|
| 190 |
-
+ input_derivatives * (1 - theta).pow(2))
|
| 191 |
-
logabsdet = torch.log(derivative_numerator) - 2 * torch.log(denominator)
|
| 192 |
-
|
| 193 |
-
return outputs, logabsdet
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/ChandraMohanNayal/AutoGPT/autogpt/config/__init__.py
DELETED
|
@@ -1,14 +0,0 @@
|
|
| 1 |
-
"""
|
| 2 |
-
This module contains the configuration classes for AutoGPT.
|
| 3 |
-
"""
|
| 4 |
-
from autogpt.config.ai_config import AIConfig
|
| 5 |
-
from autogpt.config.config import Config, check_openai_api_key
|
| 6 |
-
from autogpt.config.singleton import AbstractSingleton, Singleton
|
| 7 |
-
|
| 8 |
-
__all__ = [
|
| 9 |
-
"check_openai_api_key",
|
| 10 |
-
"AbstractSingleton",
|
| 11 |
-
"AIConfig",
|
| 12 |
-
"Config",
|
| 13 |
-
"Singleton",
|
| 14 |
-
]
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/Chirayuhumar/MyGenAIChatBot/README.md
DELETED
|
@@ -1,12 +0,0 @@
|
|
| 1 |
-
---
|
| 2 |
-
title: MyGenAIChatBot
|
| 3 |
-
emoji: 🌖
|
| 4 |
-
colorFrom: blue
|
| 5 |
-
colorTo: green
|
| 6 |
-
sdk: gradio
|
| 7 |
-
sdk_version: 3.40.1
|
| 8 |
-
app_file: app.py
|
| 9 |
-
pinned: false
|
| 10 |
-
---
|
| 11 |
-
|
| 12 |
-
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/ClassCat/Brain-tumor-3D-segmentation-with-MONAI/app.py
DELETED
|
@@ -1,194 +0,0 @@
|
|
| 1 |
-
|
| 2 |
-
import torch
|
| 3 |
-
import matplotlib.pyplot as plt
|
| 4 |
-
|
| 5 |
-
from monai.networks.nets import SegResNet
|
| 6 |
-
from monai.inferers import sliding_window_inference
|
| 7 |
-
|
| 8 |
-
from monai.transforms import (
|
| 9 |
-
Activations,
|
| 10 |
-
AsDiscrete,
|
| 11 |
-
Compose,
|
| 12 |
-
)
|
| 13 |
-
|
| 14 |
-
model = SegResNet(
|
| 15 |
-
blocks_down=[1, 2, 2, 4],
|
| 16 |
-
blocks_up=[1, 1, 1],
|
| 17 |
-
init_filters=16,
|
| 18 |
-
in_channels=4,
|
| 19 |
-
out_channels=3,
|
| 20 |
-
dropout_prob=0.2,
|
| 21 |
-
)
|
| 22 |
-
|
| 23 |
-
model.load_state_dict(
|
| 24 |
-
torch.load("weights/model.pt", map_location=torch.device('cpu'))
|
| 25 |
-
)
|
| 26 |
-
|
| 27 |
-
# define inference method
|
| 28 |
-
VAL_AMP = True
|
| 29 |
-
|
| 30 |
-
def inference(input):
|
| 31 |
-
|
| 32 |
-
def _compute(input):
|
| 33 |
-
return sliding_window_inference(
|
| 34 |
-
inputs=input,
|
| 35 |
-
roi_size=(240, 240, 160),
|
| 36 |
-
sw_batch_size=1,
|
| 37 |
-
predictor=model,
|
| 38 |
-
overlap=0.5,
|
| 39 |
-
)
|
| 40 |
-
|
| 41 |
-
if VAL_AMP:
|
| 42 |
-
with torch.cuda.amp.autocast():
|
| 43 |
-
return _compute(input)
|
| 44 |
-
else:
|
| 45 |
-
return _compute(input)
|
| 46 |
-
|
| 47 |
-
|
| 48 |
-
post_trans = Compose(
|
| 49 |
-
[Activations(sigmoid=True), AsDiscrete(threshold=0.5)]
|
| 50 |
-
)
|
| 51 |
-
|
| 52 |
-
import gradio as gr
|
| 53 |
-
|
| 54 |
-
def load_sample1():
|
| 55 |
-
return load_sample(1)
|
| 56 |
-
|
| 57 |
-
def load_sample2():
|
| 58 |
-
return load_sample(2)
|
| 59 |
-
|
| 60 |
-
def load_sample3():
|
| 61 |
-
return load_sample(3)
|
| 62 |
-
|
| 63 |
-
def load_sample4():
|
| 64 |
-
return load_sample(4)
|
| 65 |
-
|
| 66 |
-
def load_sample5():
|
| 67 |
-
return load_sample(5)
|
| 68 |
-
|
| 69 |
-
def load_sample6():
|
| 70 |
-
return load_sample(6)
|
| 71 |
-
|
| 72 |
-
def load_sample7():
|
| 73 |
-
return load_sample(7)
|
| 74 |
-
|
| 75 |
-
def load_sample8():
|
| 76 |
-
return load_sample(8)
|
| 77 |
-
|
| 78 |
-
import torchvision
|
| 79 |
-
|
| 80 |
-
def load_sample(index):
|
| 81 |
-
#sample_index = index
|
| 82 |
-
|
| 83 |
-
image_filenames = []
|
| 84 |
-
for i in range(4):
|
| 85 |
-
image_filenames.append(f"thumbnails/image{index-1}_{i}.png")
|
| 86 |
-
|
| 87 |
-
label_filenames = []
|
| 88 |
-
for i in range(3):
|
| 89 |
-
label_filenames.append(f"thumbnails_label/label{index-1}_{i}.png")
|
| 90 |
-
|
| 91 |
-
return [index, image_filenames[0], image_filenames[1], image_filenames[2], image_filenames[3],
|
| 92 |
-
label_filenames[0], label_filenames[1], label_filenames[2]]
|
| 93 |
-
|
| 94 |
-
|
| 95 |
-
def predict(sample_index):
|
| 96 |
-
sample = torch.load(f"samples/val{sample_index-1}.pt")
|
| 97 |
-
model.eval()
|
| 98 |
-
with torch.no_grad():
|
| 99 |
-
# select one image to evaluate and visualize the model output
|
| 100 |
-
val_input = sample["image"].unsqueeze(0)
|
| 101 |
-
roi_size = (128, 128, 64)
|
| 102 |
-
sw_batch_size = 4
|
| 103 |
-
val_output = inference(val_input)
|
| 104 |
-
val_output = post_trans(val_output[0])
|
| 105 |
-
|
| 106 |
-
imgs_output = []
|
| 107 |
-
for i in range(3):
|
| 108 |
-
imgs_output.append(val_output[i, :, :, 70])
|
| 109 |
-
|
| 110 |
-
pil_images_output = []
|
| 111 |
-
for i in range(3):
|
| 112 |
-
pil_images_output.append(torchvision.transforms.functional.to_pil_image(imgs_output[i]))
|
| 113 |
-
|
| 114 |
-
return [pil_images_output[0], pil_images_output[1], pil_images_output[2]]
|
| 115 |
-
|
| 116 |
-
with gr.Blocks(title="Brain tumor 3D segmentation with MONAI - ClassCat",
|
| 117 |
-
css=".gradio-container {background:azure;}"
|
| 118 |
-
) as demo:
|
| 119 |
-
sample_index = gr.State([])
|
| 120 |
-
|
| 121 |
-
gr.HTML("""<div style="font-family:'Times New Roman', 'Serif'; font-size:16pt; font-weight:bold; text-align:center; color:royalblue;">Brain tumor 3D segmentation with MONAI</div>""")
|
| 122 |
-
|
| 123 |
-
gr.HTML("""<h4 style="color:navy;">1. Select an example, which includes input images and label images, by clicking "Example x" button.</h4>""")
|
| 124 |
-
|
| 125 |
-
with gr.Row():
|
| 126 |
-
input_image0 = gr.Image(label="image channel 0", type="filepath", shape=(240, 240))
|
| 127 |
-
input_image1 = gr.Image(label="image channel 1", type="filepath", shape=(240, 240))
|
| 128 |
-
input_image2 = gr.Image(label="image channel 2", type="filepath", shape=(240, 240))
|
| 129 |
-
input_image3 = gr.Image(label="image channel 3", type="filepath", shape=(240, 240))
|
| 130 |
-
|
| 131 |
-
with gr.Row():
|
| 132 |
-
label_image0 = gr.Image(label="label channel 0", type="filepath", shape=(240, 240))
|
| 133 |
-
label_image1 = gr.Image(label="label channel 1", type="filepath", shape=(240, 240))
|
| 134 |
-
label_image2 = gr.Image(label="label channel 2", type="filepath", shape=(240, 240))
|
| 135 |
-
|
| 136 |
-
with gr.Row():
|
| 137 |
-
example1_btn = gr.Button("Example 1")
|
| 138 |
-
example2_btn = gr.Button("Example 2")
|
| 139 |
-
example3_btn = gr.Button("Example 3")
|
| 140 |
-
example4_btn = gr.Button("Example 4")
|
| 141 |
-
example5_btn = gr.Button("Example 5")
|
| 142 |
-
example6_btn = gr.Button("Example 6")
|
| 143 |
-
example7_btn = gr.Button("Example 7")
|
| 144 |
-
example8_btn = gr.Button("Example 8")
|
| 145 |
-
|
| 146 |
-
example1_btn.click(fn=load_sample1, inputs=None,
|
| 147 |
-
outputs=[sample_index, input_image0, input_image1, input_image2, input_image3,
|
| 148 |
-
label_image0, label_image1, label_image2])
|
| 149 |
-
example2_btn.click(fn=load_sample2, inputs=None,
|
| 150 |
-
outputs=[sample_index, input_image0, input_image1, input_image2, input_image3,
|
| 151 |
-
label_image0, label_image1, label_image2])
|
| 152 |
-
example3_btn.click(fn=load_sample3, inputs=None,
|
| 153 |
-
outputs=[sample_index, input_image0, input_image1, input_image2, input_image3,
|
| 154 |
-
label_image0, label_image1, label_image2])
|
| 155 |
-
example4_btn.click(fn=load_sample4, inputs=None,
|
| 156 |
-
outputs=[sample_index, input_image0, input_image1, input_image2, input_image3,
|
| 157 |
-
label_image0, label_image1, label_image2])
|
| 158 |
-
example5_btn.click(fn=load_sample5, inputs=None,
|
| 159 |
-
outputs=[sample_index, input_image0, input_image1, input_image2, input_image3,
|
| 160 |
-
label_image0, label_image1, label_image2])
|
| 161 |
-
example6_btn.click(fn=load_sample6, inputs=None,
|
| 162 |
-
outputs=[sample_index, input_image0, input_image1, input_image2, input_image3,
|
| 163 |
-
label_image0, label_image1, label_image2])
|
| 164 |
-
example7_btn.click(fn=load_sample7, inputs=None,
|
| 165 |
-
outputs=[sample_index, input_image0, input_image1, input_image2, input_image3,
|
| 166 |
-
label_image0, label_image1, label_image2])
|
| 167 |
-
example8_btn.click(fn=load_sample8, inputs=None,
|
| 168 |
-
outputs=[sample_index, input_image0, input_image1, input_image2, input_image3,
|
| 169 |
-
label_image0, label_image1, label_image2])
|
| 170 |
-
|
| 171 |
-
gr.HTML("""<br/>""")
|
| 172 |
-
gr.HTML("""<h4 style="color:navy;">2. Then, click "Infer" button to predict segmentation images. It will take about 30 seconds (on cpu)</h4>""")
|
| 173 |
-
|
| 174 |
-
with gr.Row():
|
| 175 |
-
output_image0 = gr.Image(label="output channel 0", type="pil")
|
| 176 |
-
output_image1 = gr.Image(label="output channel 1", type="pil")
|
| 177 |
-
output_image2 = gr.Image(label="output channel 2", type="pil")
|
| 178 |
-
|
| 179 |
-
send_btn = gr.Button("Infer")
|
| 180 |
-
send_btn.click(fn=predict, inputs=[sample_index], outputs=[output_image0, output_image1, output_image2])
|
| 181 |
-
|
| 182 |
-
gr.HTML("""<br/>""")
|
| 183 |
-
gr.HTML("""<h4 style="color:navy;">Reference</h4>""")
|
| 184 |
-
gr.HTML("""<ul>""")
|
| 185 |
-
gr.HTML("""<li><a href="https://github.com/Project-MONAI/tutorials/blob/main/3d_segmentation/brats_segmentation_3d.ipynb" target="_blank">Brain tumor 3D segmentation with MONAI</a></li>""")
|
| 186 |
-
gr.HTML("""</ul>""")
|
| 187 |
-
|
| 188 |
-
|
| 189 |
-
#demo.queue()
|
| 190 |
-
demo.launch(debug=True)
|
| 191 |
-
|
| 192 |
-
|
| 193 |
-
|
| 194 |
-
### EOF ###
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/CrucibleAI/ControlNetMediaPipeFaceSD21/ldm/models/diffusion/plms.py
DELETED
|
@@ -1,245 +0,0 @@
|
|
| 1 |
-
"""SAMPLING ONLY."""
|
| 2 |
-
|
| 3 |
-
import torch
|
| 4 |
-
import numpy as np
|
| 5 |
-
from tqdm import tqdm
|
| 6 |
-
from functools import partial
|
| 7 |
-
|
| 8 |
-
from ldm.modules.diffusionmodules.util import make_ddim_sampling_parameters, make_ddim_timesteps, noise_like
|
| 9 |
-
from ldm.models.diffusion.sampling_util import norm_thresholding
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
class PLMSSampler(object):
|
| 13 |
-
def __init__(self, model, schedule="linear", **kwargs):
|
| 14 |
-
super().__init__()
|
| 15 |
-
self.model = model
|
| 16 |
-
self.ddpm_num_timesteps = model.num_timesteps
|
| 17 |
-
self.schedule = schedule
|
| 18 |
-
|
| 19 |
-
def register_buffer(self, name, attr):
|
| 20 |
-
# Do not force module to CUDA by default.
|
| 21 |
-
#if type(attr) == torch.Tensor:
|
| 22 |
-
# if attr.device != torch.device("cuda"):
|
| 23 |
-
# attr = attr.to(torch.device("cuda"))
|
| 24 |
-
setattr(self, name, attr)
|
| 25 |
-
|
| 26 |
-
def make_schedule(self, ddim_num_steps, ddim_discretize="uniform", ddim_eta=0., verbose=True):
|
| 27 |
-
if ddim_eta != 0:
|
| 28 |
-
raise ValueError('ddim_eta must be 0 for PLMS')
|
| 29 |
-
self.ddim_timesteps = make_ddim_timesteps(ddim_discr_method=ddim_discretize, num_ddim_timesteps=ddim_num_steps,
|
| 30 |
-
num_ddpm_timesteps=self.ddpm_num_timesteps,verbose=verbose)
|
| 31 |
-
alphas_cumprod = self.model.alphas_cumprod
|
| 32 |
-
assert alphas_cumprod.shape[0] == self.ddpm_num_timesteps, 'alphas have to be defined for each timestep'
|
| 33 |
-
to_torch = lambda x: x.clone().detach().to(torch.float32).to(self.model.device)
|
| 34 |
-
|
| 35 |
-
self.register_buffer('betas', to_torch(self.model.betas))
|
| 36 |
-
self.register_buffer('alphas_cumprod', to_torch(alphas_cumprod))
|
| 37 |
-
self.register_buffer('alphas_cumprod_prev', to_torch(self.model.alphas_cumprod_prev))
|
| 38 |
-
|
| 39 |
-
# calculations for diffusion q(x_t | x_{t-1}) and others
|
| 40 |
-
self.register_buffer('sqrt_alphas_cumprod', to_torch(np.sqrt(alphas_cumprod.cpu())))
|
| 41 |
-
self.register_buffer('sqrt_one_minus_alphas_cumprod', to_torch(np.sqrt(1. - alphas_cumprod.cpu())))
|
| 42 |
-
self.register_buffer('log_one_minus_alphas_cumprod', to_torch(np.log(1. - alphas_cumprod.cpu())))
|
| 43 |
-
self.register_buffer('sqrt_recip_alphas_cumprod', to_torch(np.sqrt(1. / alphas_cumprod.cpu())))
|
| 44 |
-
self.register_buffer('sqrt_recipm1_alphas_cumprod', to_torch(np.sqrt(1. / alphas_cumprod.cpu() - 1)))
|
| 45 |
-
|
| 46 |
-
# ddim sampling parameters
|
| 47 |
-
ddim_sigmas, ddim_alphas, ddim_alphas_prev = make_ddim_sampling_parameters(alphacums=alphas_cumprod.cpu(),
|
| 48 |
-
ddim_timesteps=self.ddim_timesteps,
|
| 49 |
-
eta=ddim_eta,verbose=verbose)
|
| 50 |
-
self.register_buffer('ddim_sigmas', ddim_sigmas)
|
| 51 |
-
self.register_buffer('ddim_alphas', ddim_alphas)
|
| 52 |
-
self.register_buffer('ddim_alphas_prev', ddim_alphas_prev)
|
| 53 |
-
self.register_buffer('ddim_sqrt_one_minus_alphas', np.sqrt(1. - ddim_alphas))
|
| 54 |
-
sigmas_for_original_sampling_steps = ddim_eta * torch.sqrt(
|
| 55 |
-
(1 - self.alphas_cumprod_prev) / (1 - self.alphas_cumprod) * (
|
| 56 |
-
1 - self.alphas_cumprod / self.alphas_cumprod_prev))
|
| 57 |
-
self.register_buffer('ddim_sigmas_for_original_num_steps', sigmas_for_original_sampling_steps)
|
| 58 |
-
|
| 59 |
-
@torch.no_grad()
|
| 60 |
-
def sample(self,
|
| 61 |
-
S,
|
| 62 |
-
batch_size,
|
| 63 |
-
shape,
|
| 64 |
-
conditioning=None,
|
| 65 |
-
callback=None,
|
| 66 |
-
normals_sequence=None,
|
| 67 |
-
img_callback=None,
|
| 68 |
-
quantize_x0=False,
|
| 69 |
-
eta=0.,
|
| 70 |
-
mask=None,
|
| 71 |
-
x0=None,
|
| 72 |
-
temperature=1.,
|
| 73 |
-
noise_dropout=0.,
|
| 74 |
-
score_corrector=None,
|
| 75 |
-
corrector_kwargs=None,
|
| 76 |
-
verbose=True,
|
| 77 |
-
x_T=None,
|
| 78 |
-
log_every_t=100,
|
| 79 |
-
unconditional_guidance_scale=1.,
|
| 80 |
-
unconditional_conditioning=None,
|
| 81 |
-
# this has to come in the same format as the conditioning, # e.g. as encoded tokens, ...
|
| 82 |
-
dynamic_threshold=None,
|
| 83 |
-
**kwargs
|
| 84 |
-
):
|
| 85 |
-
if conditioning is not None:
|
| 86 |
-
if isinstance(conditioning, dict):
|
| 87 |
-
cbs = conditioning[list(conditioning.keys())[0]].shape[0]
|
| 88 |
-
if cbs != batch_size:
|
| 89 |
-
print(f"Warning: Got {cbs} conditionings but batch-size is {batch_size}")
|
| 90 |
-
else:
|
| 91 |
-
if conditioning.shape[0] != batch_size:
|
| 92 |
-
print(f"Warning: Got {conditioning.shape[0]} conditionings but batch-size is {batch_size}")
|
| 93 |
-
|
| 94 |
-
self.make_schedule(ddim_num_steps=S, ddim_eta=eta, verbose=verbose)
|
| 95 |
-
# sampling
|
| 96 |
-
C, H, W = shape
|
| 97 |
-
size = (batch_size, C, H, W)
|
| 98 |
-
print(f'Data shape for PLMS sampling is {size}')
|
| 99 |
-
|
| 100 |
-
samples, intermediates = self.plms_sampling(conditioning, size,
|
| 101 |
-
callback=callback,
|
| 102 |
-
img_callback=img_callback,
|
| 103 |
-
quantize_denoised=quantize_x0,
|
| 104 |
-
mask=mask, x0=x0,
|
| 105 |
-
ddim_use_original_steps=False,
|
| 106 |
-
noise_dropout=noise_dropout,
|
| 107 |
-
temperature=temperature,
|
| 108 |
-
score_corrector=score_corrector,
|
| 109 |
-
corrector_kwargs=corrector_kwargs,
|
| 110 |
-
x_T=x_T,
|
| 111 |
-
log_every_t=log_every_t,
|
| 112 |
-
unconditional_guidance_scale=unconditional_guidance_scale,
|
| 113 |
-
unconditional_conditioning=unconditional_conditioning,
|
| 114 |
-
dynamic_threshold=dynamic_threshold,
|
| 115 |
-
)
|
| 116 |
-
return samples, intermediates
|
| 117 |
-
|
| 118 |
-
@torch.no_grad()
|
| 119 |
-
def plms_sampling(self, cond, shape,
|
| 120 |
-
x_T=None, ddim_use_original_steps=False,
|
| 121 |
-
callback=None, timesteps=None, quantize_denoised=False,
|
| 122 |
-
mask=None, x0=None, img_callback=None, log_every_t=100,
|
| 123 |
-
temperature=1., noise_dropout=0., score_corrector=None, corrector_kwargs=None,
|
| 124 |
-
unconditional_guidance_scale=1., unconditional_conditioning=None,
|
| 125 |
-
dynamic_threshold=None):
|
| 126 |
-
device = self.model.betas.device
|
| 127 |
-
b = shape[0]
|
| 128 |
-
if x_T is None:
|
| 129 |
-
img = torch.randn(shape, device=device)
|
| 130 |
-
else:
|
| 131 |
-
img = x_T
|
| 132 |
-
|
| 133 |
-
if timesteps is None:
|
| 134 |
-
timesteps = self.ddpm_num_timesteps if ddim_use_original_steps else self.ddim_timesteps
|
| 135 |
-
elif timesteps is not None and not ddim_use_original_steps:
|
| 136 |
-
subset_end = int(min(timesteps / self.ddim_timesteps.shape[0], 1) * self.ddim_timesteps.shape[0]) - 1
|
| 137 |
-
timesteps = self.ddim_timesteps[:subset_end]
|
| 138 |
-
|
| 139 |
-
intermediates = {'x_inter': [img], 'pred_x0': [img]}
|
| 140 |
-
time_range = list(reversed(range(0,timesteps))) if ddim_use_original_steps else np.flip(timesteps)
|
| 141 |
-
total_steps = timesteps if ddim_use_original_steps else timesteps.shape[0]
|
| 142 |
-
print(f"Running PLMS Sampling with {total_steps} timesteps")
|
| 143 |
-
|
| 144 |
-
iterator = tqdm(time_range, desc='PLMS Sampler', total=total_steps)
|
| 145 |
-
old_eps = []
|
| 146 |
-
|
| 147 |
-
for i, step in enumerate(iterator):
|
| 148 |
-
index = total_steps - i - 1
|
| 149 |
-
ts = torch.full((b,), step, device=device, dtype=torch.long)
|
| 150 |
-
ts_next = torch.full((b,), time_range[min(i + 1, len(time_range) - 1)], device=device, dtype=torch.long)
|
| 151 |
-
|
| 152 |
-
if mask is not None:
|
| 153 |
-
assert x0 is not None
|
| 154 |
-
img_orig = self.model.q_sample(x0, ts) # TODO: deterministic forward pass?
|
| 155 |
-
img = img_orig * mask + (1. - mask) * img
|
| 156 |
-
|
| 157 |
-
outs = self.p_sample_plms(img, cond, ts, index=index, use_original_steps=ddim_use_original_steps,
|
| 158 |
-
quantize_denoised=quantize_denoised, temperature=temperature,
|
| 159 |
-
noise_dropout=noise_dropout, score_corrector=score_corrector,
|
| 160 |
-
corrector_kwargs=corrector_kwargs,
|
| 161 |
-
unconditional_guidance_scale=unconditional_guidance_scale,
|
| 162 |
-
unconditional_conditioning=unconditional_conditioning,
|
| 163 |
-
old_eps=old_eps, t_next=ts_next,
|
| 164 |
-
dynamic_threshold=dynamic_threshold)
|
| 165 |
-
img, pred_x0, e_t = outs
|
| 166 |
-
old_eps.append(e_t)
|
| 167 |
-
if len(old_eps) >= 4:
|
| 168 |
-
old_eps.pop(0)
|
| 169 |
-
if callback: callback(i)
|
| 170 |
-
if img_callback: img_callback(pred_x0, i)
|
| 171 |
-
|
| 172 |
-
if index % log_every_t == 0 or index == total_steps - 1:
|
| 173 |
-
intermediates['x_inter'].append(img)
|
| 174 |
-
intermediates['pred_x0'].append(pred_x0)
|
| 175 |
-
|
| 176 |
-
return img, intermediates
|
| 177 |
-
|
| 178 |
-
@torch.no_grad()
|
| 179 |
-
def p_sample_plms(self, x, c, t, index, repeat_noise=False, use_original_steps=False, quantize_denoised=False,
|
| 180 |
-
temperature=1., noise_dropout=0., score_corrector=None, corrector_kwargs=None,
|
| 181 |
-
unconditional_guidance_scale=1., unconditional_conditioning=None, old_eps=None, t_next=None,
|
| 182 |
-
dynamic_threshold=None):
|
| 183 |
-
b, *_, device = *x.shape, x.device
|
| 184 |
-
|
| 185 |
-
def get_model_output(x, t):
|
| 186 |
-
if unconditional_conditioning is None or unconditional_guidance_scale == 1.:
|
| 187 |
-
e_t = self.model.apply_model(x, t, c)
|
| 188 |
-
else:
|
| 189 |
-
x_in = torch.cat([x] * 2)
|
| 190 |
-
t_in = torch.cat([t] * 2)
|
| 191 |
-
c_in = torch.cat([unconditional_conditioning, c])
|
| 192 |
-
e_t_uncond, e_t = self.model.apply_model(x_in, t_in, c_in).chunk(2)
|
| 193 |
-
e_t = e_t_uncond + unconditional_guidance_scale * (e_t - e_t_uncond)
|
| 194 |
-
|
| 195 |
-
if score_corrector is not None:
|
| 196 |
-
assert self.model.parameterization == "eps"
|
| 197 |
-
e_t = score_corrector.modify_score(self.model, e_t, x, t, c, **corrector_kwargs)
|
| 198 |
-
|
| 199 |
-
return e_t
|
| 200 |
-
|
| 201 |
-
alphas = self.model.alphas_cumprod if use_original_steps else self.ddim_alphas
|
| 202 |
-
alphas_prev = self.model.alphas_cumprod_prev if use_original_steps else self.ddim_alphas_prev
|
| 203 |
-
sqrt_one_minus_alphas = self.model.sqrt_one_minus_alphas_cumprod if use_original_steps else self.ddim_sqrt_one_minus_alphas
|
| 204 |
-
sigmas = self.model.ddim_sigmas_for_original_num_steps if use_original_steps else self.ddim_sigmas
|
| 205 |
-
|
| 206 |
-
def get_x_prev_and_pred_x0(e_t, index):
|
| 207 |
-
# select parameters corresponding to the currently considered timestep
|
| 208 |
-
a_t = torch.full((b, 1, 1, 1), alphas[index], device=device)
|
| 209 |
-
a_prev = torch.full((b, 1, 1, 1), alphas_prev[index], device=device)
|
| 210 |
-
sigma_t = torch.full((b, 1, 1, 1), sigmas[index], device=device)
|
| 211 |
-
sqrt_one_minus_at = torch.full((b, 1, 1, 1), sqrt_one_minus_alphas[index],device=device)
|
| 212 |
-
|
| 213 |
-
# current prediction for x_0
|
| 214 |
-
pred_x0 = (x - sqrt_one_minus_at * e_t) / a_t.sqrt()
|
| 215 |
-
if quantize_denoised:
|
| 216 |
-
pred_x0, _, *_ = self.model.first_stage_model.quantize(pred_x0)
|
| 217 |
-
if dynamic_threshold is not None:
|
| 218 |
-
pred_x0 = norm_thresholding(pred_x0, dynamic_threshold)
|
| 219 |
-
# direction pointing to x_t
|
| 220 |
-
dir_xt = (1. - a_prev - sigma_t**2).sqrt() * e_t
|
| 221 |
-
noise = sigma_t * noise_like(x.shape, device, repeat_noise) * temperature
|
| 222 |
-
if noise_dropout > 0.:
|
| 223 |
-
noise = torch.nn.functional.dropout(noise, p=noise_dropout)
|
| 224 |
-
x_prev = a_prev.sqrt() * pred_x0 + dir_xt + noise
|
| 225 |
-
return x_prev, pred_x0
|
| 226 |
-
|
| 227 |
-
e_t = get_model_output(x, t)
|
| 228 |
-
if len(old_eps) == 0:
|
| 229 |
-
# Pseudo Improved Euler (2nd order)
|
| 230 |
-
x_prev, pred_x0 = get_x_prev_and_pred_x0(e_t, index)
|
| 231 |
-
e_t_next = get_model_output(x_prev, t_next)
|
| 232 |
-
e_t_prime = (e_t + e_t_next) / 2
|
| 233 |
-
elif len(old_eps) == 1:
|
| 234 |
-
# 2nd order Pseudo Linear Multistep (Adams-Bashforth)
|
| 235 |
-
e_t_prime = (3 * e_t - old_eps[-1]) / 2
|
| 236 |
-
elif len(old_eps) == 2:
|
| 237 |
-
# 3nd order Pseudo Linear Multistep (Adams-Bashforth)
|
| 238 |
-
e_t_prime = (23 * e_t - 16 * old_eps[-1] + 5 * old_eps[-2]) / 12
|
| 239 |
-
elif len(old_eps) >= 3:
|
| 240 |
-
# 4nd order Pseudo Linear Multistep (Adams-Bashforth)
|
| 241 |
-
e_t_prime = (55 * e_t - 59 * old_eps[-1] + 37 * old_eps[-2] - 9 * old_eps[-3]) / 24
|
| 242 |
-
|
| 243 |
-
x_prev, pred_x0 = get_x_prev_and_pred_x0(e_t_prime, index)
|
| 244 |
-
|
| 245 |
-
return x_prev, pred_x0, e_t
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/Cyril666/ContourNet-ABI/maskrcnn_benchmark/modeling/__init__.py
DELETED
|
File without changes
|
spaces/DQChoi/gpt-demo/venv/lib/python3.11/site-packages/PIL/ImageWin.py
DELETED
|
@@ -1,230 +0,0 @@
|
|
| 1 |
-
#
|
| 2 |
-
# The Python Imaging Library.
|
| 3 |
-
# $Id$
|
| 4 |
-
#
|
| 5 |
-
# a Windows DIB display interface
|
| 6 |
-
#
|
| 7 |
-
# History:
|
| 8 |
-
# 1996-05-20 fl Created
|
| 9 |
-
# 1996-09-20 fl Fixed subregion exposure
|
| 10 |
-
# 1997-09-21 fl Added draw primitive (for tzPrint)
|
| 11 |
-
# 2003-05-21 fl Added experimental Window/ImageWindow classes
|
| 12 |
-
# 2003-09-05 fl Added fromstring/tostring methods
|
| 13 |
-
#
|
| 14 |
-
# Copyright (c) Secret Labs AB 1997-2003.
|
| 15 |
-
# Copyright (c) Fredrik Lundh 1996-2003.
|
| 16 |
-
#
|
| 17 |
-
# See the README file for information on usage and redistribution.
|
| 18 |
-
#
|
| 19 |
-
|
| 20 |
-
from . import Image
|
| 21 |
-
|
| 22 |
-
|
| 23 |
-
class HDC:
|
| 24 |
-
"""
|
| 25 |
-
Wraps an HDC integer. The resulting object can be passed to the
|
| 26 |
-
:py:meth:`~PIL.ImageWin.Dib.draw` and :py:meth:`~PIL.ImageWin.Dib.expose`
|
| 27 |
-
methods.
|
| 28 |
-
"""
|
| 29 |
-
|
| 30 |
-
def __init__(self, dc):
|
| 31 |
-
self.dc = dc
|
| 32 |
-
|
| 33 |
-
def __int__(self):
|
| 34 |
-
return self.dc
|
| 35 |
-
|
| 36 |
-
|
| 37 |
-
class HWND:
|
| 38 |
-
"""
|
| 39 |
-
Wraps an HWND integer. The resulting object can be passed to the
|
| 40 |
-
:py:meth:`~PIL.ImageWin.Dib.draw` and :py:meth:`~PIL.ImageWin.Dib.expose`
|
| 41 |
-
methods, instead of a DC.
|
| 42 |
-
"""
|
| 43 |
-
|
| 44 |
-
def __init__(self, wnd):
|
| 45 |
-
self.wnd = wnd
|
| 46 |
-
|
| 47 |
-
def __int__(self):
|
| 48 |
-
return self.wnd
|
| 49 |
-
|
| 50 |
-
|
| 51 |
-
class Dib:
|
| 52 |
-
"""
|
| 53 |
-
A Windows bitmap with the given mode and size. The mode can be one of "1",
|
| 54 |
-
"L", "P", or "RGB".
|
| 55 |
-
|
| 56 |
-
If the display requires a palette, this constructor creates a suitable
|
| 57 |
-
palette and associates it with the image. For an "L" image, 128 greylevels
|
| 58 |
-
are allocated. For an "RGB" image, a 6x6x6 colour cube is used, together
|
| 59 |
-
with 20 greylevels.
|
| 60 |
-
|
| 61 |
-
To make sure that palettes work properly under Windows, you must call the
|
| 62 |
-
``palette`` method upon certain events from Windows.
|
| 63 |
-
|
| 64 |
-
:param image: Either a PIL image, or a mode string. If a mode string is
|
| 65 |
-
used, a size must also be given. The mode can be one of "1",
|
| 66 |
-
"L", "P", or "RGB".
|
| 67 |
-
:param size: If the first argument is a mode string, this
|
| 68 |
-
defines the size of the image.
|
| 69 |
-
"""
|
| 70 |
-
|
| 71 |
-
def __init__(self, image, size=None):
|
| 72 |
-
if hasattr(image, "mode") and hasattr(image, "size"):
|
| 73 |
-
mode = image.mode
|
| 74 |
-
size = image.size
|
| 75 |
-
else:
|
| 76 |
-
mode = image
|
| 77 |
-
image = None
|
| 78 |
-
if mode not in ["1", "L", "P", "RGB"]:
|
| 79 |
-
mode = Image.getmodebase(mode)
|
| 80 |
-
self.image = Image.core.display(mode, size)
|
| 81 |
-
self.mode = mode
|
| 82 |
-
self.size = size
|
| 83 |
-
if image:
|
| 84 |
-
self.paste(image)
|
| 85 |
-
|
| 86 |
-
def expose(self, handle):
|
| 87 |
-
"""
|
| 88 |
-
Copy the bitmap contents to a device context.
|
| 89 |
-
|
| 90 |
-
:param handle: Device context (HDC), cast to a Python integer, or an
|
| 91 |
-
HDC or HWND instance. In PythonWin, you can use
|
| 92 |
-
``CDC.GetHandleAttrib()`` to get a suitable handle.
|
| 93 |
-
"""
|
| 94 |
-
if isinstance(handle, HWND):
|
| 95 |
-
dc = self.image.getdc(handle)
|
| 96 |
-
try:
|
| 97 |
-
result = self.image.expose(dc)
|
| 98 |
-
finally:
|
| 99 |
-
self.image.releasedc(handle, dc)
|
| 100 |
-
else:
|
| 101 |
-
result = self.image.expose(handle)
|
| 102 |
-
return result
|
| 103 |
-
|
| 104 |
-
def draw(self, handle, dst, src=None):
|
| 105 |
-
"""
|
| 106 |
-
Same as expose, but allows you to specify where to draw the image, and
|
| 107 |
-
what part of it to draw.
|
| 108 |
-
|
| 109 |
-
The destination and source areas are given as 4-tuple rectangles. If
|
| 110 |
-
the source is omitted, the entire image is copied. If the source and
|
| 111 |
-
the destination have different sizes, the image is resized as
|
| 112 |
-
necessary.
|
| 113 |
-
"""
|
| 114 |
-
if not src:
|
| 115 |
-
src = (0, 0) + self.size
|
| 116 |
-
if isinstance(handle, HWND):
|
| 117 |
-
dc = self.image.getdc(handle)
|
| 118 |
-
try:
|
| 119 |
-
result = self.image.draw(dc, dst, src)
|
| 120 |
-
finally:
|
| 121 |
-
self.image.releasedc(handle, dc)
|
| 122 |
-
else:
|
| 123 |
-
result = self.image.draw(handle, dst, src)
|
| 124 |
-
return result
|
| 125 |
-
|
| 126 |
-
def query_palette(self, handle):
|
| 127 |
-
"""
|
| 128 |
-
Installs the palette associated with the image in the given device
|
| 129 |
-
context.
|
| 130 |
-
|
| 131 |
-
This method should be called upon **QUERYNEWPALETTE** and
|
| 132 |
-
**PALETTECHANGED** events from Windows. If this method returns a
|
| 133 |
-
non-zero value, one or more display palette entries were changed, and
|
| 134 |
-
the image should be redrawn.
|
| 135 |
-
|
| 136 |
-
:param handle: Device context (HDC), cast to a Python integer, or an
|
| 137 |
-
HDC or HWND instance.
|
| 138 |
-
:return: A true value if one or more entries were changed (this
|
| 139 |
-
indicates that the image should be redrawn).
|
| 140 |
-
"""
|
| 141 |
-
if isinstance(handle, HWND):
|
| 142 |
-
handle = self.image.getdc(handle)
|
| 143 |
-
try:
|
| 144 |
-
result = self.image.query_palette(handle)
|
| 145 |
-
finally:
|
| 146 |
-
self.image.releasedc(handle, handle)
|
| 147 |
-
else:
|
| 148 |
-
result = self.image.query_palette(handle)
|
| 149 |
-
return result
|
| 150 |
-
|
| 151 |
-
def paste(self, im, box=None):
|
| 152 |
-
"""
|
| 153 |
-
Paste a PIL image into the bitmap image.
|
| 154 |
-
|
| 155 |
-
:param im: A PIL image. The size must match the target region.
|
| 156 |
-
If the mode does not match, the image is converted to the
|
| 157 |
-
mode of the bitmap image.
|
| 158 |
-
:param box: A 4-tuple defining the left, upper, right, and
|
| 159 |
-
lower pixel coordinate. See :ref:`coordinate-system`. If
|
| 160 |
-
None is given instead of a tuple, all of the image is
|
| 161 |
-
assumed.
|
| 162 |
-
"""
|
| 163 |
-
im.load()
|
| 164 |
-
if self.mode != im.mode:
|
| 165 |
-
im = im.convert(self.mode)
|
| 166 |
-
if box:
|
| 167 |
-
self.image.paste(im.im, box)
|
| 168 |
-
else:
|
| 169 |
-
self.image.paste(im.im)
|
| 170 |
-
|
| 171 |
-
def frombytes(self, buffer):
|
| 172 |
-
"""
|
| 173 |
-
Load display memory contents from byte data.
|
| 174 |
-
|
| 175 |
-
:param buffer: A buffer containing display data (usually
|
| 176 |
-
data returned from :py:func:`~PIL.ImageWin.Dib.tobytes`)
|
| 177 |
-
"""
|
| 178 |
-
return self.image.frombytes(buffer)
|
| 179 |
-
|
| 180 |
-
def tobytes(self):
|
| 181 |
-
"""
|
| 182 |
-
Copy display memory contents to bytes object.
|
| 183 |
-
|
| 184 |
-
:return: A bytes object containing display data.
|
| 185 |
-
"""
|
| 186 |
-
return self.image.tobytes()
|
| 187 |
-
|
| 188 |
-
|
| 189 |
-
class Window:
|
| 190 |
-
"""Create a Window with the given title size."""
|
| 191 |
-
|
| 192 |
-
def __init__(self, title="PIL", width=None, height=None):
|
| 193 |
-
self.hwnd = Image.core.createwindow(
|
| 194 |
-
title, self.__dispatcher, width or 0, height or 0
|
| 195 |
-
)
|
| 196 |
-
|
| 197 |
-
def __dispatcher(self, action, *args):
|
| 198 |
-
return getattr(self, "ui_handle_" + action)(*args)
|
| 199 |
-
|
| 200 |
-
def ui_handle_clear(self, dc, x0, y0, x1, y1):
|
| 201 |
-
pass
|
| 202 |
-
|
| 203 |
-
def ui_handle_damage(self, x0, y0, x1, y1):
|
| 204 |
-
pass
|
| 205 |
-
|
| 206 |
-
def ui_handle_destroy(self):
|
| 207 |
-
pass
|
| 208 |
-
|
| 209 |
-
def ui_handle_repair(self, dc, x0, y0, x1, y1):
|
| 210 |
-
pass
|
| 211 |
-
|
| 212 |
-
def ui_handle_resize(self, width, height):
|
| 213 |
-
pass
|
| 214 |
-
|
| 215 |
-
def mainloop(self):
|
| 216 |
-
Image.core.eventloop()
|
| 217 |
-
|
| 218 |
-
|
| 219 |
-
class ImageWindow(Window):
|
| 220 |
-
"""Create an image window which displays the given image."""
|
| 221 |
-
|
| 222 |
-
def __init__(self, image, title="PIL"):
|
| 223 |
-
if not isinstance(image, Dib):
|
| 224 |
-
image = Dib(image)
|
| 225 |
-
self.image = image
|
| 226 |
-
width, height = image.size
|
| 227 |
-
super().__init__(title, width=width, height=height)
|
| 228 |
-
|
| 229 |
-
def ui_handle_repair(self, dc, x0, y0, x1, y1):
|
| 230 |
-
self.image.draw(dc, (x0, y0, x1, y1))
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/DragGan/DragGan/torch_utils/ops/conv2d_gradfix.py
DELETED
|
@@ -1,198 +0,0 @@
|
|
| 1 |
-
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
-
#
|
| 3 |
-
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
-
# and proprietary rights in and to this software, related documentation
|
| 5 |
-
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
-
# distribution of this software and related documentation without an express
|
| 7 |
-
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
-
|
| 9 |
-
"""Custom replacement for `torch.nn.functional.conv2d` that supports
|
| 10 |
-
arbitrarily high order gradients with zero performance penalty."""
|
| 11 |
-
|
| 12 |
-
import contextlib
|
| 13 |
-
import torch
|
| 14 |
-
|
| 15 |
-
# pylint: disable=redefined-builtin
|
| 16 |
-
# pylint: disable=arguments-differ
|
| 17 |
-
# pylint: disable=protected-access
|
| 18 |
-
|
| 19 |
-
#----------------------------------------------------------------------------
|
| 20 |
-
|
| 21 |
-
enabled = False # Enable the custom op by setting this to true.
|
| 22 |
-
weight_gradients_disabled = False # Forcefully disable computation of gradients with respect to the weights.
|
| 23 |
-
|
| 24 |
-
@contextlib.contextmanager
|
| 25 |
-
def no_weight_gradients(disable=True):
|
| 26 |
-
global weight_gradients_disabled
|
| 27 |
-
old = weight_gradients_disabled
|
| 28 |
-
if disable:
|
| 29 |
-
weight_gradients_disabled = True
|
| 30 |
-
yield
|
| 31 |
-
weight_gradients_disabled = old
|
| 32 |
-
|
| 33 |
-
#----------------------------------------------------------------------------
|
| 34 |
-
|
| 35 |
-
def conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1):
|
| 36 |
-
if _should_use_custom_op(input):
|
| 37 |
-
return _conv2d_gradfix(transpose=False, weight_shape=weight.shape, stride=stride, padding=padding, output_padding=0, dilation=dilation, groups=groups).apply(input, weight, bias)
|
| 38 |
-
return torch.nn.functional.conv2d(input=input, weight=weight, bias=bias, stride=stride, padding=padding, dilation=dilation, groups=groups)
|
| 39 |
-
|
| 40 |
-
def conv_transpose2d(input, weight, bias=None, stride=1, padding=0, output_padding=0, groups=1, dilation=1):
|
| 41 |
-
if _should_use_custom_op(input):
|
| 42 |
-
return _conv2d_gradfix(transpose=True, weight_shape=weight.shape, stride=stride, padding=padding, output_padding=output_padding, groups=groups, dilation=dilation).apply(input, weight, bias)
|
| 43 |
-
return torch.nn.functional.conv_transpose2d(input=input, weight=weight, bias=bias, stride=stride, padding=padding, output_padding=output_padding, groups=groups, dilation=dilation)
|
| 44 |
-
|
| 45 |
-
#----------------------------------------------------------------------------
|
| 46 |
-
|
| 47 |
-
def _should_use_custom_op(input):
|
| 48 |
-
assert isinstance(input, torch.Tensor)
|
| 49 |
-
if (not enabled) or (not torch.backends.cudnn.enabled):
|
| 50 |
-
return False
|
| 51 |
-
if input.device.type != 'cuda':
|
| 52 |
-
return False
|
| 53 |
-
return True
|
| 54 |
-
|
| 55 |
-
def _tuple_of_ints(xs, ndim):
|
| 56 |
-
xs = tuple(xs) if isinstance(xs, (tuple, list)) else (xs,) * ndim
|
| 57 |
-
assert len(xs) == ndim
|
| 58 |
-
assert all(isinstance(x, int) for x in xs)
|
| 59 |
-
return xs
|
| 60 |
-
|
| 61 |
-
#----------------------------------------------------------------------------
|
| 62 |
-
|
| 63 |
-
_conv2d_gradfix_cache = dict()
|
| 64 |
-
_null_tensor = torch.empty([0])
|
| 65 |
-
|
| 66 |
-
def _conv2d_gradfix(transpose, weight_shape, stride, padding, output_padding, dilation, groups):
|
| 67 |
-
# Parse arguments.
|
| 68 |
-
ndim = 2
|
| 69 |
-
weight_shape = tuple(weight_shape)
|
| 70 |
-
stride = _tuple_of_ints(stride, ndim)
|
| 71 |
-
padding = _tuple_of_ints(padding, ndim)
|
| 72 |
-
output_padding = _tuple_of_ints(output_padding, ndim)
|
| 73 |
-
dilation = _tuple_of_ints(dilation, ndim)
|
| 74 |
-
|
| 75 |
-
# Lookup from cache.
|
| 76 |
-
key = (transpose, weight_shape, stride, padding, output_padding, dilation, groups)
|
| 77 |
-
if key in _conv2d_gradfix_cache:
|
| 78 |
-
return _conv2d_gradfix_cache[key]
|
| 79 |
-
|
| 80 |
-
# Validate arguments.
|
| 81 |
-
assert groups >= 1
|
| 82 |
-
assert len(weight_shape) == ndim + 2
|
| 83 |
-
assert all(stride[i] >= 1 for i in range(ndim))
|
| 84 |
-
assert all(padding[i] >= 0 for i in range(ndim))
|
| 85 |
-
assert all(dilation[i] >= 0 for i in range(ndim))
|
| 86 |
-
if not transpose:
|
| 87 |
-
assert all(output_padding[i] == 0 for i in range(ndim))
|
| 88 |
-
else: # transpose
|
| 89 |
-
assert all(0 <= output_padding[i] < max(stride[i], dilation[i]) for i in range(ndim))
|
| 90 |
-
|
| 91 |
-
# Helpers.
|
| 92 |
-
common_kwargs = dict(stride=stride, padding=padding, dilation=dilation, groups=groups)
|
| 93 |
-
def calc_output_padding(input_shape, output_shape):
|
| 94 |
-
if transpose:
|
| 95 |
-
return [0, 0]
|
| 96 |
-
return [
|
| 97 |
-
input_shape[i + 2]
|
| 98 |
-
- (output_shape[i + 2] - 1) * stride[i]
|
| 99 |
-
- (1 - 2 * padding[i])
|
| 100 |
-
- dilation[i] * (weight_shape[i + 2] - 1)
|
| 101 |
-
for i in range(ndim)
|
| 102 |
-
]
|
| 103 |
-
|
| 104 |
-
# Forward & backward.
|
| 105 |
-
class Conv2d(torch.autograd.Function):
|
| 106 |
-
@staticmethod
|
| 107 |
-
def forward(ctx, input, weight, bias):
|
| 108 |
-
assert weight.shape == weight_shape
|
| 109 |
-
ctx.save_for_backward(
|
| 110 |
-
input if weight.requires_grad else _null_tensor,
|
| 111 |
-
weight if input.requires_grad else _null_tensor,
|
| 112 |
-
)
|
| 113 |
-
ctx.input_shape = input.shape
|
| 114 |
-
|
| 115 |
-
# Simple 1x1 convolution => cuBLAS (only on Volta, not on Ampere).
|
| 116 |
-
if weight_shape[2:] == stride == dilation == (1, 1) and padding == (0, 0) and torch.cuda.get_device_capability(input.device) < (8, 0):
|
| 117 |
-
a = weight.reshape(groups, weight_shape[0] // groups, weight_shape[1])
|
| 118 |
-
b = input.reshape(input.shape[0], groups, input.shape[1] // groups, -1)
|
| 119 |
-
c = (a.transpose(1, 2) if transpose else a) @ b.permute(1, 2, 0, 3).flatten(2)
|
| 120 |
-
c = c.reshape(-1, input.shape[0], *input.shape[2:]).transpose(0, 1)
|
| 121 |
-
c = c if bias is None else c + bias.unsqueeze(0).unsqueeze(2).unsqueeze(3)
|
| 122 |
-
return c.contiguous(memory_format=(torch.channels_last if input.stride(1) == 1 else torch.contiguous_format))
|
| 123 |
-
|
| 124 |
-
# General case => cuDNN.
|
| 125 |
-
if transpose:
|
| 126 |
-
return torch.nn.functional.conv_transpose2d(input=input, weight=weight, bias=bias, output_padding=output_padding, **common_kwargs)
|
| 127 |
-
return torch.nn.functional.conv2d(input=input, weight=weight, bias=bias, **common_kwargs)
|
| 128 |
-
|
| 129 |
-
@staticmethod
|
| 130 |
-
def backward(ctx, grad_output):
|
| 131 |
-
input, weight = ctx.saved_tensors
|
| 132 |
-
input_shape = ctx.input_shape
|
| 133 |
-
grad_input = None
|
| 134 |
-
grad_weight = None
|
| 135 |
-
grad_bias = None
|
| 136 |
-
|
| 137 |
-
if ctx.needs_input_grad[0]:
|
| 138 |
-
p = calc_output_padding(input_shape=input_shape, output_shape=grad_output.shape)
|
| 139 |
-
op = _conv2d_gradfix(transpose=(not transpose), weight_shape=weight_shape, output_padding=p, **common_kwargs)
|
| 140 |
-
grad_input = op.apply(grad_output, weight, None)
|
| 141 |
-
assert grad_input.shape == input_shape
|
| 142 |
-
|
| 143 |
-
if ctx.needs_input_grad[1] and not weight_gradients_disabled:
|
| 144 |
-
grad_weight = Conv2dGradWeight.apply(grad_output, input)
|
| 145 |
-
assert grad_weight.shape == weight_shape
|
| 146 |
-
|
| 147 |
-
if ctx.needs_input_grad[2]:
|
| 148 |
-
grad_bias = grad_output.sum([0, 2, 3])
|
| 149 |
-
|
| 150 |
-
return grad_input, grad_weight, grad_bias
|
| 151 |
-
|
| 152 |
-
# Gradient with respect to the weights.
|
| 153 |
-
class Conv2dGradWeight(torch.autograd.Function):
|
| 154 |
-
@staticmethod
|
| 155 |
-
def forward(ctx, grad_output, input):
|
| 156 |
-
ctx.save_for_backward(
|
| 157 |
-
grad_output if input.requires_grad else _null_tensor,
|
| 158 |
-
input if grad_output.requires_grad else _null_tensor,
|
| 159 |
-
)
|
| 160 |
-
ctx.grad_output_shape = grad_output.shape
|
| 161 |
-
ctx.input_shape = input.shape
|
| 162 |
-
|
| 163 |
-
# Simple 1x1 convolution => cuBLAS (on both Volta and Ampere).
|
| 164 |
-
if weight_shape[2:] == stride == dilation == (1, 1) and padding == (0, 0):
|
| 165 |
-
a = grad_output.reshape(grad_output.shape[0], groups, grad_output.shape[1] // groups, -1).permute(1, 2, 0, 3).flatten(2)
|
| 166 |
-
b = input.reshape(input.shape[0], groups, input.shape[1] // groups, -1).permute(1, 2, 0, 3).flatten(2)
|
| 167 |
-
c = (b @ a.transpose(1, 2) if transpose else a @ b.transpose(1, 2)).reshape(weight_shape)
|
| 168 |
-
return c.contiguous(memory_format=(torch.channels_last if input.stride(1) == 1 else torch.contiguous_format))
|
| 169 |
-
|
| 170 |
-
# General case => cuDNN.
|
| 171 |
-
name = 'aten::cudnn_convolution_transpose_backward_weight' if transpose else 'aten::cudnn_convolution_backward_weight'
|
| 172 |
-
flags = [torch.backends.cudnn.benchmark, torch.backends.cudnn.deterministic, torch.backends.cudnn.allow_tf32]
|
| 173 |
-
return torch._C._jit_get_operation(name)(weight_shape, grad_output, input, padding, stride, dilation, groups, *flags)
|
| 174 |
-
|
| 175 |
-
@staticmethod
|
| 176 |
-
def backward(ctx, grad2_grad_weight):
|
| 177 |
-
grad_output, input = ctx.saved_tensors
|
| 178 |
-
grad_output_shape = ctx.grad_output_shape
|
| 179 |
-
input_shape = ctx.input_shape
|
| 180 |
-
grad2_grad_output = None
|
| 181 |
-
grad2_input = None
|
| 182 |
-
|
| 183 |
-
if ctx.needs_input_grad[0]:
|
| 184 |
-
grad2_grad_output = Conv2d.apply(input, grad2_grad_weight, None)
|
| 185 |
-
assert grad2_grad_output.shape == grad_output_shape
|
| 186 |
-
|
| 187 |
-
if ctx.needs_input_grad[1]:
|
| 188 |
-
p = calc_output_padding(input_shape=input_shape, output_shape=grad_output_shape)
|
| 189 |
-
op = _conv2d_gradfix(transpose=(not transpose), weight_shape=weight_shape, output_padding=p, **common_kwargs)
|
| 190 |
-
grad2_input = op.apply(grad_output, grad2_grad_weight, None)
|
| 191 |
-
assert grad2_input.shape == input_shape
|
| 192 |
-
|
| 193 |
-
return grad2_grad_output, grad2_input
|
| 194 |
-
|
| 195 |
-
_conv2d_gradfix_cache[key] = Conv2d
|
| 196 |
-
return Conv2d
|
| 197 |
-
|
| 198 |
-
#----------------------------------------------------------------------------
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/Eddycrack864/Applio-Inference/utils/README.md
DELETED
|
@@ -1,6 +0,0 @@
|
|
| 1 |
-
# External Colab Code
|
| 2 |
-
Code used to make Google Colab work correctly
|
| 3 |
-
- Repo link: https://github.com/IAHispano/Applio-RVC-Fork/
|
| 4 |
-
|
| 5 |
-
Thanks to https://github.com/kalomaze/externalcolabcode
|
| 6 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/Ekimetrics/climate-question-answering/app.py
DELETED
|
@@ -1,812 +0,0 @@
|
|
| 1 |
-
import gradio as gr
|
| 2 |
-
import pandas as pd
|
| 3 |
-
import numpy as np
|
| 4 |
-
import os
|
| 5 |
-
from datetime import datetime
|
| 6 |
-
|
| 7 |
-
from utils import create_user_id
|
| 8 |
-
|
| 9 |
-
from azure.storage.fileshare import ShareServiceClient
|
| 10 |
-
|
| 11 |
-
# Langchain
|
| 12 |
-
from langchain.embeddings import HuggingFaceEmbeddings
|
| 13 |
-
from langchain.schema import AIMessage, HumanMessage
|
| 14 |
-
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
|
| 15 |
-
|
| 16 |
-
# ClimateQ&A imports
|
| 17 |
-
from climateqa.llm import get_llm
|
| 18 |
-
from climateqa.chains import load_qa_chain_with_docs,load_qa_chain_with_text
|
| 19 |
-
from climateqa.chains import load_reformulation_chain
|
| 20 |
-
from climateqa.vectorstore import get_pinecone_vectorstore
|
| 21 |
-
from climateqa.retriever import ClimateQARetriever
|
| 22 |
-
from climateqa.prompts import audience_prompts
|
| 23 |
-
|
| 24 |
-
# Load environment variables in local mode
|
| 25 |
-
try:
|
| 26 |
-
from dotenv import load_dotenv
|
| 27 |
-
load_dotenv()
|
| 28 |
-
except Exception as e:
|
| 29 |
-
pass
|
| 30 |
-
|
| 31 |
-
# Set up Gradio Theme
|
| 32 |
-
theme = gr.themes.Base(
|
| 33 |
-
primary_hue="blue",
|
| 34 |
-
secondary_hue="red",
|
| 35 |
-
font=[gr.themes.GoogleFont("Poppins"), "ui-sans-serif", "system-ui", "sans-serif"],
|
| 36 |
-
)
|
| 37 |
-
|
| 38 |
-
|
| 39 |
-
|
| 40 |
-
init_prompt = ""
|
| 41 |
-
|
| 42 |
-
system_template = {
|
| 43 |
-
"role": "system",
|
| 44 |
-
"content": init_prompt,
|
| 45 |
-
}
|
| 46 |
-
|
| 47 |
-
account_key = os.environ["BLOB_ACCOUNT_KEY"]
|
| 48 |
-
if len(account_key) == 86:
|
| 49 |
-
account_key += "=="
|
| 50 |
-
|
| 51 |
-
credential = {
|
| 52 |
-
"account_key": account_key,
|
| 53 |
-
"account_name": os.environ["BLOB_ACCOUNT_NAME"],
|
| 54 |
-
}
|
| 55 |
-
|
| 56 |
-
account_url = os.environ["BLOB_ACCOUNT_URL"]
|
| 57 |
-
file_share_name = "climategpt"
|
| 58 |
-
service = ShareServiceClient(account_url=account_url, credential=credential)
|
| 59 |
-
share_client = service.get_share_client(file_share_name)
|
| 60 |
-
|
| 61 |
-
user_id = create_user_id()
|
| 62 |
-
|
| 63 |
-
#---------------------------------------------------------------------------
|
| 64 |
-
# ClimateQ&A core functions
|
| 65 |
-
#---------------------------------------------------------------------------
|
| 66 |
-
|
| 67 |
-
from langchain.callbacks.base import BaseCallbackHandler
|
| 68 |
-
from queue import Queue, Empty
|
| 69 |
-
from threading import Thread
|
| 70 |
-
from collections.abc import Generator
|
| 71 |
-
from langchain.schema import LLMResult
|
| 72 |
-
from typing import Any, Union,Dict,List
|
| 73 |
-
from queue import SimpleQueue
|
| 74 |
-
# # Create a Queue
|
| 75 |
-
# Q = Queue()
|
| 76 |
-
|
| 77 |
-
import re
|
| 78 |
-
|
| 79 |
-
def parse_output_llm_with_sources(output):
|
| 80 |
-
# Split the content into a list of text and "[Doc X]" references
|
| 81 |
-
content_parts = re.split(r'\[(Doc\s?\d+(?:,\s?Doc\s?\d+)*)\]', output)
|
| 82 |
-
parts = []
|
| 83 |
-
for part in content_parts:
|
| 84 |
-
if part.startswith("Doc"):
|
| 85 |
-
subparts = part.split(",")
|
| 86 |
-
subparts = [subpart.lower().replace("doc","").strip() for subpart in subparts]
|
| 87 |
-
subparts = [f"<span class='doc-ref'><sup>{subpart}</sup></span>" for subpart in subparts]
|
| 88 |
-
parts.append("".join(subparts))
|
| 89 |
-
else:
|
| 90 |
-
parts.append(part)
|
| 91 |
-
content_parts = "".join(parts)
|
| 92 |
-
return content_parts
|
| 93 |
-
|
| 94 |
-
|
| 95 |
-
|
| 96 |
-
job_done = object() # signals the processing is done
|
| 97 |
-
|
| 98 |
-
|
| 99 |
-
class StreamingGradioCallbackHandler(BaseCallbackHandler):
|
| 100 |
-
def __init__(self, q: SimpleQueue):
|
| 101 |
-
self.q = q
|
| 102 |
-
|
| 103 |
-
def on_llm_start(
|
| 104 |
-
self, serialized: Dict[str, Any], prompts: List[str], **kwargs: Any
|
| 105 |
-
) -> None:
|
| 106 |
-
"""Run when LLM starts running. Clean the queue."""
|
| 107 |
-
while not self.q.empty():
|
| 108 |
-
try:
|
| 109 |
-
self.q.get(block=False)
|
| 110 |
-
except Empty:
|
| 111 |
-
continue
|
| 112 |
-
|
| 113 |
-
def on_llm_new_token(self, token: str, **kwargs: Any) -> None:
|
| 114 |
-
"""Run on new LLM token. Only available when streaming is enabled."""
|
| 115 |
-
self.q.put(token)
|
| 116 |
-
|
| 117 |
-
def on_llm_end(self, response: LLMResult, **kwargs: Any) -> None:
|
| 118 |
-
"""Run when LLM ends running."""
|
| 119 |
-
self.q.put(job_done)
|
| 120 |
-
|
| 121 |
-
def on_llm_error(
|
| 122 |
-
self, error: Union[Exception, KeyboardInterrupt], **kwargs: Any
|
| 123 |
-
) -> None:
|
| 124 |
-
"""Run when LLM errors."""
|
| 125 |
-
self.q.put(job_done)
|
| 126 |
-
|
| 127 |
-
|
| 128 |
-
|
| 129 |
-
|
| 130 |
-
# Create embeddings function and LLM
|
| 131 |
-
embeddings_function = HuggingFaceEmbeddings(model_name = "sentence-transformers/multi-qa-mpnet-base-dot-v1")
|
| 132 |
-
|
| 133 |
-
|
| 134 |
-
# Create vectorstore and retriever
|
| 135 |
-
vectorstore = get_pinecone_vectorstore(embeddings_function)
|
| 136 |
-
|
| 137 |
-
#---------------------------------------------------------------------------
|
| 138 |
-
# ClimateQ&A Streaming
|
| 139 |
-
# From https://github.com/gradio-app/gradio/issues/5345
|
| 140 |
-
# And https://stackoverflow.com/questions/76057076/how-to-stream-agents-response-in-langchain
|
| 141 |
-
#---------------------------------------------------------------------------
|
| 142 |
-
|
| 143 |
-
from threading import Thread
|
| 144 |
-
|
| 145 |
-
import json
|
| 146 |
-
|
| 147 |
-
def answer_user(query,query_example,history):
|
| 148 |
-
if len(query) <= 2:
|
| 149 |
-
raise Exception("Please ask a longer question")
|
| 150 |
-
return query, history + [[query, ". . ."]]
|
| 151 |
-
|
| 152 |
-
def answer_user_example(query,query_example,history):
|
| 153 |
-
return query_example, history + [[query_example, ". . ."]]
|
| 154 |
-
|
| 155 |
-
def fetch_sources(query,sources):
|
| 156 |
-
|
| 157 |
-
# Prepare default values
|
| 158 |
-
if len(sources) == 0:
|
| 159 |
-
sources = ["IPCC"]
|
| 160 |
-
|
| 161 |
-
llm_reformulation = get_llm(max_tokens = 512,temperature = 0.0,verbose = True,streaming = False)
|
| 162 |
-
retriever = ClimateQARetriever(vectorstore=vectorstore,sources = sources,k_summary = 3,k_total = 10)
|
| 163 |
-
reformulation_chain = load_reformulation_chain(llm_reformulation)
|
| 164 |
-
|
| 165 |
-
# Calculate language
|
| 166 |
-
output_reformulation = reformulation_chain({"query":query})
|
| 167 |
-
question = output_reformulation["question"]
|
| 168 |
-
language = output_reformulation["language"]
|
| 169 |
-
|
| 170 |
-
# Retrieve docs
|
| 171 |
-
docs = retriever.get_relevant_documents(question)
|
| 172 |
-
|
| 173 |
-
if len(docs) > 0:
|
| 174 |
-
|
| 175 |
-
# Already display the sources
|
| 176 |
-
sources_text = []
|
| 177 |
-
for i, d in enumerate(docs, 1):
|
| 178 |
-
sources_text.append(make_html_source(d, i))
|
| 179 |
-
citations_text = "".join(sources_text)
|
| 180 |
-
docs_text = "\n\n".join([d.page_content for d in docs])
|
| 181 |
-
return "",citations_text,docs_text,question,language
|
| 182 |
-
else:
|
| 183 |
-
sources_text = "⚠️ No relevant passages found in the scientific reports (IPCC and IPBES)"
|
| 184 |
-
citations_text = "**⚠️ No relevant passages found in the climate science reports (IPCC and IPBES), you may want to ask a more specific question (specifying your question on climate and biodiversity issues).**"
|
| 185 |
-
docs_text = ""
|
| 186 |
-
return "",citations_text,docs_text,question,language
|
| 187 |
-
|
| 188 |
-
|
| 189 |
-
def answer_bot(query,history,docs,question,language,audience):
|
| 190 |
-
|
| 191 |
-
if audience == "Children":
|
| 192 |
-
audience_prompt = audience_prompts["children"]
|
| 193 |
-
elif audience == "General public":
|
| 194 |
-
audience_prompt = audience_prompts["general"]
|
| 195 |
-
elif audience == "Experts":
|
| 196 |
-
audience_prompt = audience_prompts["experts"]
|
| 197 |
-
else:
|
| 198 |
-
audience_prompt = audience_prompts["experts"]
|
| 199 |
-
|
| 200 |
-
# Prepare Queue for streaming LLMs
|
| 201 |
-
Q = SimpleQueue()
|
| 202 |
-
|
| 203 |
-
llm_streaming = get_llm(max_tokens = 1024,temperature = 0.0,verbose = True,streaming = True,
|
| 204 |
-
callbacks=[StreamingGradioCallbackHandler(Q),StreamingStdOutCallbackHandler()],
|
| 205 |
-
)
|
| 206 |
-
|
| 207 |
-
qa_chain = load_qa_chain_with_text(llm_streaming)
|
| 208 |
-
|
| 209 |
-
def threaded_chain(question,audience,language,docs):
|
| 210 |
-
try:
|
| 211 |
-
response = qa_chain({"question":question,"audience":audience,"language":language,"summaries":docs})
|
| 212 |
-
Q.put(response)
|
| 213 |
-
Q.put(job_done)
|
| 214 |
-
except Exception as e:
|
| 215 |
-
print(e)
|
| 216 |
-
|
| 217 |
-
history[-1][1] = ""
|
| 218 |
-
|
| 219 |
-
textbox=gr.Textbox(placeholder=". . .",show_label=False,scale=1,lines = 1,interactive = False)
|
| 220 |
-
|
| 221 |
-
|
| 222 |
-
if len(docs) > 0:
|
| 223 |
-
|
| 224 |
-
# Start thread for streaming
|
| 225 |
-
thread = Thread(
|
| 226 |
-
target=threaded_chain,
|
| 227 |
-
kwargs={"question":question,"audience":audience_prompt,"language":language,"docs":docs}
|
| 228 |
-
)
|
| 229 |
-
thread.start()
|
| 230 |
-
|
| 231 |
-
while True:
|
| 232 |
-
next_item = Q.get(block=True) # Blocks until an input is available
|
| 233 |
-
|
| 234 |
-
if next_item is job_done:
|
| 235 |
-
break
|
| 236 |
-
elif isinstance(next_item, str):
|
| 237 |
-
new_paragraph = history[-1][1] + next_item
|
| 238 |
-
new_paragraph = parse_output_llm_with_sources(new_paragraph)
|
| 239 |
-
history[-1][1] = new_paragraph
|
| 240 |
-
yield textbox,history
|
| 241 |
-
else:
|
| 242 |
-
pass
|
| 243 |
-
thread.join()
|
| 244 |
-
|
| 245 |
-
# Log answer on Azure Blob Storage
|
| 246 |
-
timestamp = str(datetime.now().timestamp())
|
| 247 |
-
file = timestamp + ".json"
|
| 248 |
-
prompt = history[-1][0]
|
| 249 |
-
logs = {
|
| 250 |
-
"user_id": str(user_id),
|
| 251 |
-
"prompt": prompt,
|
| 252 |
-
"query": prompt,
|
| 253 |
-
"question":question,
|
| 254 |
-
"docs":docs,
|
| 255 |
-
"answer": history[-1][1],
|
| 256 |
-
"time": timestamp,
|
| 257 |
-
}
|
| 258 |
-
log_on_azure(file, logs, share_client)
|
| 259 |
-
|
| 260 |
-
|
| 261 |
-
|
| 262 |
-
else:
|
| 263 |
-
complete_response = "**⚠️ No relevant passages found in the climate science reports (IPCC and IPBES), you may want to ask a more specific question (specifying your question on climate and biodiversity issues).**"
|
| 264 |
-
history[-1][1] += complete_response
|
| 265 |
-
yield "",history
|
| 266 |
-
|
| 267 |
-
|
| 268 |
-
|
| 269 |
-
# history_langchain_format = []
|
| 270 |
-
# for human, ai in history:
|
| 271 |
-
# history_langchain_format.append(HumanMessage(content=human))
|
| 272 |
-
# history_langchain_format.append(AIMessage(content=ai))
|
| 273 |
-
# history_langchain_format.append(HumanMessage(content=message)
|
| 274 |
-
# for next_token, content in stream(message):
|
| 275 |
-
# yield(content)
|
| 276 |
-
|
| 277 |
-
# thread = Thread(target=threaded_chain, kwargs={"query":message,"audience":audience_prompt})
|
| 278 |
-
# thread.start()
|
| 279 |
-
|
| 280 |
-
# history[-1][1] = ""
|
| 281 |
-
# while True:
|
| 282 |
-
# next_item = Q.get(block=True) # Blocks until an input is available
|
| 283 |
-
|
| 284 |
-
# print(type(next_item))
|
| 285 |
-
# if next_item is job_done:
|
| 286 |
-
# continue
|
| 287 |
-
|
| 288 |
-
# elif isinstance(next_item, dict): # assuming LLMResult is a dictionary
|
| 289 |
-
# response = next_item
|
| 290 |
-
# if "source_documents" in response and len(response["source_documents"]) > 0:
|
| 291 |
-
# sources_text = []
|
| 292 |
-
# for i, d in enumerate(response["source_documents"], 1):
|
| 293 |
-
# sources_text.append(make_html_source(d, i))
|
| 294 |
-
# sources_text = "\n\n".join([f"Query used for retrieval:\n{response['question']}"] + sources_text)
|
| 295 |
-
# # history[-1][1] += next_item["answer"]
|
| 296 |
-
# # history[-1][1] += "\n\n" + sources_text
|
| 297 |
-
# yield "", history, sources_text
|
| 298 |
-
|
| 299 |
-
# else:
|
| 300 |
-
# sources_text = "⚠️ No relevant passages found in the scientific reports (IPCC and IPBES)"
|
| 301 |
-
# complete_response = "**⚠️ No relevant passages found in the climate science reports (IPCC and IPBES), you may want to ask a more specific question (specifying your question on climate and biodiversity issues).**"
|
| 302 |
-
# history[-1][1] += "\n\n" + complete_response
|
| 303 |
-
# yield "", history, sources_text
|
| 304 |
-
# break
|
| 305 |
-
|
| 306 |
-
# elif isinstance(next_item, str):
|
| 307 |
-
# new_paragraph = history[-1][1] + next_item
|
| 308 |
-
# new_paragraph = parse_output_llm_with_sources(new_paragraph)
|
| 309 |
-
# history[-1][1] = new_paragraph
|
| 310 |
-
# yield "", history, ""
|
| 311 |
-
|
| 312 |
-
# thread.join()
|
| 313 |
-
|
| 314 |
-
#---------------------------------------------------------------------------
|
| 315 |
-
# ClimateQ&A core functions
|
| 316 |
-
#---------------------------------------------------------------------------
|
| 317 |
-
|
| 318 |
-
|
| 319 |
-
def make_html_source(source,i):
|
| 320 |
-
meta = source.metadata
|
| 321 |
-
content = source.page_content.split(":",1)[1].strip()
|
| 322 |
-
return f"""
|
| 323 |
-
<div class="card">
|
| 324 |
-
<div class="card-content">
|
| 325 |
-
<h2>Doc {i} - {meta['short_name']} - Page {int(meta['page_number'])}</h2>
|
| 326 |
-
<p>{content}</p>
|
| 327 |
-
</div>
|
| 328 |
-
<div class="card-footer">
|
| 329 |
-
<span>{meta['name']}</span>
|
| 330 |
-
<a href="{meta['url']}#page={int(meta['page_number'])}" target="_blank" class="pdf-link">
|
| 331 |
-
<span role="img" aria-label="Open PDF">🔗</span>
|
| 332 |
-
</a>
|
| 333 |
-
</div>
|
| 334 |
-
</div>
|
| 335 |
-
"""
|
| 336 |
-
|
| 337 |
-
|
| 338 |
-
|
| 339 |
-
# def chat(
|
| 340 |
-
# user_id: str,
|
| 341 |
-
# query: str,
|
| 342 |
-
# history: list = [system_template],
|
| 343 |
-
# report_type: str = "IPCC",
|
| 344 |
-
# threshold: float = 0.555,
|
| 345 |
-
# ) -> tuple:
|
| 346 |
-
# """retrieve relevant documents in the document store then query gpt-turbo
|
| 347 |
-
|
| 348 |
-
# Args:
|
| 349 |
-
# query (str): user message.
|
| 350 |
-
# history (list, optional): history of the conversation. Defaults to [system_template].
|
| 351 |
-
# report_type (str, optional): should be "All available" or "IPCC only". Defaults to "All available".
|
| 352 |
-
# threshold (float, optional): similarity threshold, don't increase more than 0.568. Defaults to 0.56.
|
| 353 |
-
|
| 354 |
-
# Yields:
|
| 355 |
-
# tuple: chat gradio format, chat openai format, sources used.
|
| 356 |
-
# """
|
| 357 |
-
|
| 358 |
-
# if report_type not in ["IPCC","IPBES"]: report_type = "all"
|
| 359 |
-
# print("Searching in ",report_type," reports")
|
| 360 |
-
# # if report_type == "All available":
|
| 361 |
-
# # retriever = retrieve_all
|
| 362 |
-
# # elif report_type == "IPCC only":
|
| 363 |
-
# # retriever = retrieve_giec
|
| 364 |
-
# # else:
|
| 365 |
-
# # raise Exception("report_type arg should be in (All available, IPCC only)")
|
| 366 |
-
|
| 367 |
-
# reformulated_query = openai.Completion.create(
|
| 368 |
-
# engine="EkiGPT",
|
| 369 |
-
# prompt=get_reformulation_prompt(query),
|
| 370 |
-
# temperature=0,
|
| 371 |
-
# max_tokens=128,
|
| 372 |
-
# stop=["\n---\n", "<|im_end|>"],
|
| 373 |
-
# )
|
| 374 |
-
# reformulated_query = reformulated_query["choices"][0]["text"]
|
| 375 |
-
# reformulated_query, language = reformulated_query.split("\n")
|
| 376 |
-
# language = language.split(":")[1].strip()
|
| 377 |
-
|
| 378 |
-
|
| 379 |
-
# sources = retrieve_with_summaries(reformulated_query,retriever,k_total = 10,k_summary = 3,as_dict = True,source = report_type.lower(),threshold = threshold)
|
| 380 |
-
# response_retriever = {
|
| 381 |
-
# "language":language,
|
| 382 |
-
# "reformulated_query":reformulated_query,
|
| 383 |
-
# "query":query,
|
| 384 |
-
# "sources":sources,
|
| 385 |
-
# }
|
| 386 |
-
|
| 387 |
-
# # docs = [d for d in retriever.retrieve(query=reformulated_query, top_k=10) if d.score > threshold]
|
| 388 |
-
# messages = history + [{"role": "user", "content": query}]
|
| 389 |
-
|
| 390 |
-
# if len(sources) > 0:
|
| 391 |
-
# docs_string = []
|
| 392 |
-
# docs_html = []
|
| 393 |
-
# for i, d in enumerate(sources, 1):
|
| 394 |
-
# docs_string.append(f"📃 Doc {i}: {d['meta']['short_name']} page {d['meta']['page_number']}\n{d['content']}")
|
| 395 |
-
# docs_html.append(make_html_source(d,i))
|
| 396 |
-
# docs_string = "\n\n".join([f"Query used for retrieval:\n{reformulated_query}"] + docs_string)
|
| 397 |
-
# docs_html = "\n\n".join([f"Query used for retrieval:\n{reformulated_query}"] + docs_html)
|
| 398 |
-
# messages.append({"role": "system", "content": f"{sources_prompt}\n\n{docs_string}\n\nAnswer in {language}:"})
|
| 399 |
-
|
| 400 |
-
|
| 401 |
-
# response = openai.Completion.create(
|
| 402 |
-
# engine="EkiGPT",
|
| 403 |
-
# prompt=to_completion(messages),
|
| 404 |
-
# temperature=0, # deterministic
|
| 405 |
-
# stream=True,
|
| 406 |
-
# max_tokens=1024,
|
| 407 |
-
# )
|
| 408 |
-
|
| 409 |
-
# complete_response = ""
|
| 410 |
-
# messages.pop()
|
| 411 |
-
|
| 412 |
-
# messages.append({"role": "assistant", "content": complete_response})
|
| 413 |
-
# timestamp = str(datetime.now().timestamp())
|
| 414 |
-
# file = user_id + timestamp + ".json"
|
| 415 |
-
# logs = {
|
| 416 |
-
# "user_id": user_id,
|
| 417 |
-
# "prompt": query,
|
| 418 |
-
# "retrived": sources,
|
| 419 |
-
# "report_type": report_type,
|
| 420 |
-
# "prompt_eng": messages[0],
|
| 421 |
-
# "answer": messages[-1]["content"],
|
| 422 |
-
# "time": timestamp,
|
| 423 |
-
# }
|
| 424 |
-
# log_on_azure(file, logs, share_client)
|
| 425 |
-
|
| 426 |
-
# for chunk in response:
|
| 427 |
-
# if (chunk_message := chunk["choices"][0].get("text")) and chunk_message != "<|im_end|>":
|
| 428 |
-
# complete_response += chunk_message
|
| 429 |
-
# messages[-1]["content"] = complete_response
|
| 430 |
-
# gradio_format = make_pairs([a["content"] for a in messages[1:]])
|
| 431 |
-
# yield gradio_format, messages, docs_html
|
| 432 |
-
|
| 433 |
-
# else:
|
| 434 |
-
# docs_string = "⚠️ No relevant passages found in the climate science reports (IPCC and IPBES)"
|
| 435 |
-
# complete_response = "**⚠️ No relevant passages found in the climate science reports (IPCC and IPBES), you may want to ask a more specific question (specifying your question on climate issues).**"
|
| 436 |
-
# messages.append({"role": "assistant", "content": complete_response})
|
| 437 |
-
# gradio_format = make_pairs([a["content"] for a in messages[1:]])
|
| 438 |
-
# yield gradio_format, messages, docs_string
|
| 439 |
-
|
| 440 |
-
|
| 441 |
-
def save_feedback(feed: str, user_id):
|
| 442 |
-
if len(feed) > 1:
|
| 443 |
-
timestamp = str(datetime.now().timestamp())
|
| 444 |
-
file = user_id + timestamp + ".json"
|
| 445 |
-
logs = {
|
| 446 |
-
"user_id": user_id,
|
| 447 |
-
"feedback": feed,
|
| 448 |
-
"time": timestamp,
|
| 449 |
-
}
|
| 450 |
-
log_on_azure(file, logs, share_client)
|
| 451 |
-
return "Feedback submitted, thank you!"
|
| 452 |
-
|
| 453 |
-
|
| 454 |
-
def reset_textbox():
|
| 455 |
-
return gr.update(value="")
|
| 456 |
-
|
| 457 |
-
import json
|
| 458 |
-
|
| 459 |
-
def log_on_azure(file, logs, share_client):
|
| 460 |
-
logs = json.dumps(logs)
|
| 461 |
-
print(type(logs))
|
| 462 |
-
file_client = share_client.get_file_client(file)
|
| 463 |
-
print("Uploading logs to Azure Blob Storage")
|
| 464 |
-
print("----------------------------------")
|
| 465 |
-
print("")
|
| 466 |
-
print(logs)
|
| 467 |
-
file_client.upload_file(logs)
|
| 468 |
-
print("Logs uploaded to Azure Blob Storage")
|
| 469 |
-
|
| 470 |
-
|
| 471 |
-
# def disable_component():
|
| 472 |
-
# return gr.update(interactive = False)
|
| 473 |
-
|
| 474 |
-
|
| 475 |
-
|
| 476 |
-
|
| 477 |
-
# --------------------------------------------------------------------
|
| 478 |
-
# Gradio
|
| 479 |
-
# --------------------------------------------------------------------
|
| 480 |
-
|
| 481 |
-
|
| 482 |
-
init_prompt = """
|
| 483 |
-
Hello, I am ClimateQ&A, a conversational assistant designed to help you understand climate change and biodiversity loss. I will answer your questions by **sifting through the IPCC and IPBES scientific reports**.
|
| 484 |
-
|
| 485 |
-
💡 How to use
|
| 486 |
-
- **Language**: You can ask me your questions in any language.
|
| 487 |
-
- **Audience**: You can specify your audience (children, general public, experts) to get a more adapted answer.
|
| 488 |
-
- **Sources**: You can choose to search in the IPCC or IPBES reports, or both.
|
| 489 |
-
|
| 490 |
-
⚠️ Limitations
|
| 491 |
-
*Please note that the AI is not perfect and may sometimes give irrelevant answers. If you are not satisfied with the answer, please ask a more specific question or report your feedback to help us improve the system.*
|
| 492 |
-
|
| 493 |
-
❓ What do you want to learn ?
|
| 494 |
-
"""
|
| 495 |
-
|
| 496 |
-
|
| 497 |
-
def vote(data: gr.LikeData):
|
| 498 |
-
if data.liked:
|
| 499 |
-
print(data.value)
|
| 500 |
-
else:
|
| 501 |
-
print(data)
|
| 502 |
-
|
| 503 |
-
|
| 504 |
-
def change_tab():
|
| 505 |
-
return gr.Tabs.update(selected=1)
|
| 506 |
-
|
| 507 |
-
|
| 508 |
-
with gr.Blocks(title="🌍 Climate Q&A", css="style.css", theme=theme) as demo:
|
| 509 |
-
# user_id_state = gr.State([user_id])
|
| 510 |
-
|
| 511 |
-
with gr.Tab("🌍 ClimateQ&A"):
|
| 512 |
-
|
| 513 |
-
with gr.Row(elem_id="chatbot-row"):
|
| 514 |
-
with gr.Column(scale=2):
|
| 515 |
-
# state = gr.State([system_template])
|
| 516 |
-
bot = gr.Chatbot(
|
| 517 |
-
value=[[None,init_prompt]],
|
| 518 |
-
show_copy_button=True,show_label = False,elem_id="chatbot",layout = "panel",avatar_images = ("assets/logo4.png",None))
|
| 519 |
-
|
| 520 |
-
# bot.like(vote,None,None)
|
| 521 |
-
|
| 522 |
-
|
| 523 |
-
|
| 524 |
-
with gr.Row(elem_id = "input-message"):
|
| 525 |
-
textbox=gr.Textbox(placeholder="Ask me anything here!",show_label=False,scale=1,lines = 1,interactive = True)
|
| 526 |
-
# submit_button = gr.Button(">",scale = 1,elem_id = "submit-button")
|
| 527 |
-
|
| 528 |
-
|
| 529 |
-
with gr.Column(scale=1, variant="panel",elem_id = "right-panel"):
|
| 530 |
-
|
| 531 |
-
|
| 532 |
-
with gr.Tabs() as tabs:
|
| 533 |
-
with gr.TabItem("📝 Examples",elem_id = "tab-examples",id = 0):
|
| 534 |
-
|
| 535 |
-
examples_hidden = gr.Textbox(elem_id="hidden-message")
|
| 536 |
-
|
| 537 |
-
examples_questions = gr.Examples(
|
| 538 |
-
[
|
| 539 |
-
"Is climate change caused by humans?",
|
| 540 |
-
"What evidence do we have of climate change?",
|
| 541 |
-
"What are the impacts of climate change?",
|
| 542 |
-
"Can climate change be reversed?",
|
| 543 |
-
"What is the difference between climate change and global warming?",
|
| 544 |
-
"What can individuals do to address climate change?",
|
| 545 |
-
"What are the main causes of climate change?",
|
| 546 |
-
"What is the Paris Agreement and why is it important?",
|
| 547 |
-
"Which industries have the highest GHG emissions?",
|
| 548 |
-
"Is climate change a hoax created by the government or environmental organizations?",
|
| 549 |
-
"What is the relationship between climate change and biodiversity loss?",
|
| 550 |
-
"What is the link between gender equality and climate change?",
|
| 551 |
-
"Is the impact of climate change really as severe as it is claimed to be?",
|
| 552 |
-
"What is the impact of rising sea levels?",
|
| 553 |
-
"What are the different greenhouse gases (GHG)?",
|
| 554 |
-
"What is the warming power of methane?",
|
| 555 |
-
"What is the jet stream?",
|
| 556 |
-
"What is the breakdown of carbon sinks?",
|
| 557 |
-
"How do the GHGs work ? Why does temperature increase ?",
|
| 558 |
-
"What is the impact of global warming on ocean currents?",
|
| 559 |
-
"How much warming is possible in 2050?",
|
| 560 |
-
"What is the impact of climate change in Africa?",
|
| 561 |
-
"Will climate change accelerate diseases and epidemics like COVID?",
|
| 562 |
-
"What are the economic impacts of climate change?",
|
| 563 |
-
"How much is the cost of inaction ?",
|
| 564 |
-
"What is the relationship between climate change and poverty?",
|
| 565 |
-
"What are the most effective strategies and technologies for reducing greenhouse gas (GHG) emissions?",
|
| 566 |
-
"Is economic growth possible? What do you think about degrowth?",
|
| 567 |
-
"Will technology save us?",
|
| 568 |
-
"Is climate change a natural phenomenon ?",
|
| 569 |
-
"Is climate change really happening or is it just a natural fluctuation in Earth's temperature?",
|
| 570 |
-
"Is the scientific consensus on climate change really as strong as it is claimed to be?",
|
| 571 |
-
],
|
| 572 |
-
[examples_hidden],
|
| 573 |
-
examples_per_page=10,
|
| 574 |
-
run_on_click=False,
|
| 575 |
-
# cache_examples=True,
|
| 576 |
-
)
|
| 577 |
-
|
| 578 |
-
with gr.Tab("📚 Citations",elem_id = "tab-citations",id = 1):
|
| 579 |
-
sources_textbox = gr.HTML(show_label=False, elem_id="sources-textbox")
|
| 580 |
-
docs_textbox = gr.State("")
|
| 581 |
-
|
| 582 |
-
with gr.Tab("⚙️ Configuration",elem_id = "tab-config",id = 2):
|
| 583 |
-
|
| 584 |
-
gr.Markdown("Reminder: You can talk in any language, ClimateQ&A is multi-lingual!")
|
| 585 |
-
|
| 586 |
-
|
| 587 |
-
dropdown_sources = gr.CheckboxGroup(
|
| 588 |
-
["IPCC", "IPBES"],
|
| 589 |
-
label="Select reports",
|
| 590 |
-
value=["IPCC"],
|
| 591 |
-
interactive=True,
|
| 592 |
-
)
|
| 593 |
-
|
| 594 |
-
dropdown_audience = gr.Dropdown(
|
| 595 |
-
["Children","General public","Experts"],
|
| 596 |
-
label="Select audience",
|
| 597 |
-
value="Experts",
|
| 598 |
-
interactive=True,
|
| 599 |
-
)
|
| 600 |
-
|
| 601 |
-
output_query = gr.Textbox(label="Query used for retrieval",show_label = True,elem_id = "reformulated-query",lines = 2,interactive = False)
|
| 602 |
-
output_language = gr.Textbox(label="Language",show_label = True,elem_id = "language",lines = 1,interactive = False)
|
| 603 |
-
|
| 604 |
-
|
| 605 |
-
|
| 606 |
-
# textbox.submit(predict_climateqa,[textbox,bot],[None,bot,sources_textbox])
|
| 607 |
-
(textbox
|
| 608 |
-
.submit(answer_user, [textbox,examples_hidden, bot], [textbox, bot],queue = False)
|
| 609 |
-
.success(change_tab,None,tabs)
|
| 610 |
-
.success(fetch_sources,[textbox,dropdown_sources], [textbox,sources_textbox,docs_textbox,output_query,output_language])
|
| 611 |
-
.success(answer_bot, [textbox,bot,docs_textbox,output_query,output_language,dropdown_audience], [textbox,bot],queue = True)
|
| 612 |
-
.success(lambda x : textbox,[textbox],[textbox])
|
| 613 |
-
)
|
| 614 |
-
|
| 615 |
-
(examples_hidden
|
| 616 |
-
.change(answer_user_example, [textbox,examples_hidden, bot], [textbox, bot],queue = False)
|
| 617 |
-
.success(change_tab,None,tabs)
|
| 618 |
-
.success(fetch_sources,[textbox,dropdown_sources], [textbox,sources_textbox,docs_textbox,output_query,output_language])
|
| 619 |
-
.success(answer_bot, [textbox,bot,docs_textbox,output_query,output_language,dropdown_audience], [textbox,bot],queue=True)
|
| 620 |
-
.success(lambda x : textbox,[textbox],[textbox])
|
| 621 |
-
)
|
| 622 |
-
# submit_button.click(answer_user, [textbox, bot], [textbox, bot], queue=True).then(
|
| 623 |
-
# answer_bot, [textbox,bot,dropdown_audience,dropdown_sources], [textbox,bot,sources_textbox]
|
| 624 |
-
# )
|
| 625 |
-
|
| 626 |
-
|
| 627 |
-
|
| 628 |
-
|
| 629 |
-
|
| 630 |
-
|
| 631 |
-
|
| 632 |
-
|
| 633 |
-
|
| 634 |
-
|
| 635 |
-
|
| 636 |
-
|
| 637 |
-
|
| 638 |
-
|
| 639 |
-
#---------------------------------------------------------------------------------------
|
| 640 |
-
# OTHER TABS
|
| 641 |
-
#---------------------------------------------------------------------------------------
|
| 642 |
-
|
| 643 |
-
|
| 644 |
-
with gr.Tab("ℹ️ About ClimateQ&A",elem_classes = "max-height"):
|
| 645 |
-
with gr.Row():
|
| 646 |
-
with gr.Column(scale=1):
|
| 647 |
-
gr.Markdown(
|
| 648 |
-
"""
|
| 649 |
-
<p><b>Climate change and environmental disruptions have become some of the most pressing challenges facing our planet today</b>. As global temperatures rise and ecosystems suffer, it is essential for individuals to understand the gravity of the situation in order to make informed decisions and advocate for appropriate policy changes.</p>
|
| 650 |
-
<p>However, comprehending the vast and complex scientific information can be daunting, as the scientific consensus references, such as <b>the Intergovernmental Panel on Climate Change (IPCC) reports, span thousands of pages</b>. To bridge this gap and make climate science more accessible, we introduce <b>ClimateQ&A as a tool to distill expert-level knowledge into easily digestible insights about climate science.</b></p>
|
| 651 |
-
<div class="tip-box">
|
| 652 |
-
<div class="tip-box-title">
|
| 653 |
-
<span class="light-bulb" role="img" aria-label="Light Bulb">💡</span>
|
| 654 |
-
How does ClimateQ&A work?
|
| 655 |
-
</div>
|
| 656 |
-
ClimateQ&A harnesses modern OCR techniques to parse and preprocess IPCC reports. By leveraging state-of-the-art question-answering algorithms, <i>ClimateQ&A is able to sift through the extensive collection of climate scientific reports and identify relevant passages in response to user inquiries</i>. Furthermore, the integration of the ChatGPT API allows ClimateQ&A to present complex data in a user-friendly manner, summarizing key points and facilitating communication of climate science to a wider audience.
|
| 657 |
-
</div>
|
| 658 |
-
"""
|
| 659 |
-
)
|
| 660 |
-
|
| 661 |
-
with gr.Column(scale=1):
|
| 662 |
-
gr.Markdown("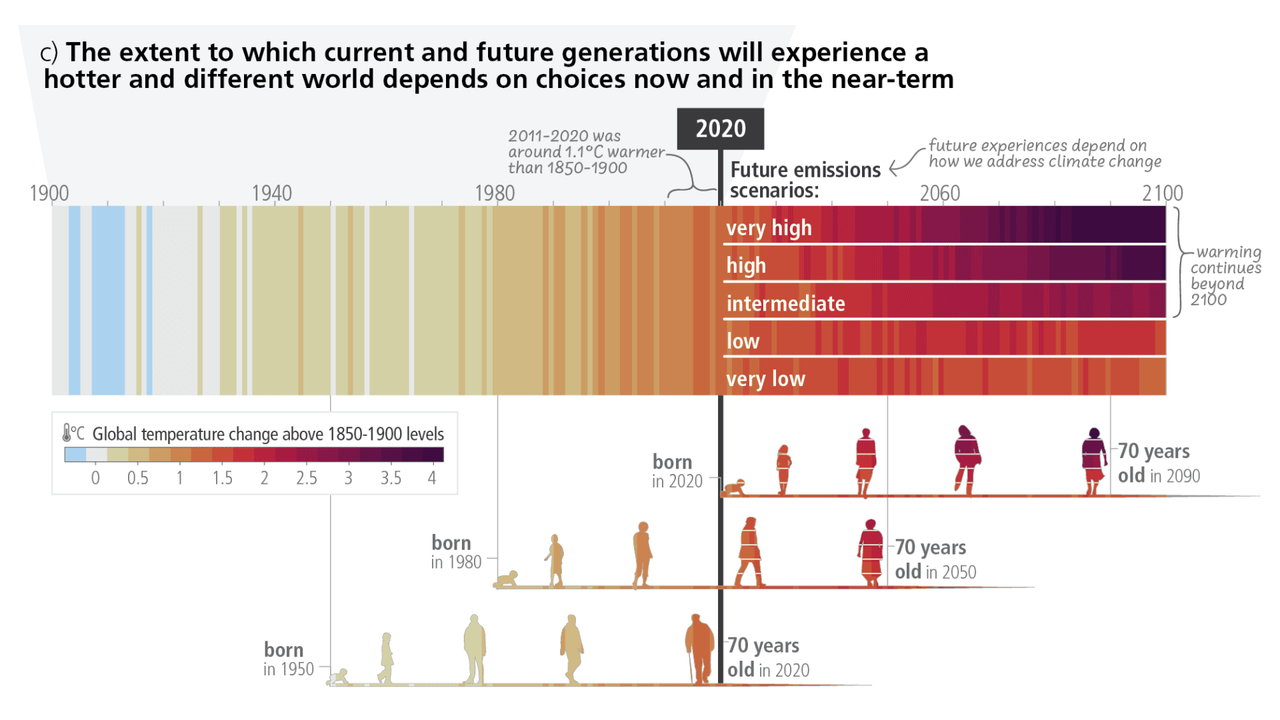")
|
| 663 |
-
gr.Markdown("*Source : IPCC AR6 - Synthesis Report of the IPCC 6th assessment report (AR6)*")
|
| 664 |
-
|
| 665 |
-
gr.Markdown("## How to use ClimateQ&A")
|
| 666 |
-
with gr.Row():
|
| 667 |
-
with gr.Column(scale=1):
|
| 668 |
-
gr.Markdown(
|
| 669 |
-
"""
|
| 670 |
-
### 💪 Getting started
|
| 671 |
-
- In the chatbot section, simply type your climate-related question, and ClimateQ&A will provide an answer with references to relevant IPCC reports.
|
| 672 |
-
- ClimateQ&A retrieves specific passages from the IPCC reports to help answer your question accurately.
|
| 673 |
-
- Source information, including page numbers and passages, is displayed on the right side of the screen for easy verification.
|
| 674 |
-
- Feel free to ask follow-up questions within the chatbot for a more in-depth understanding.
|
| 675 |
-
- You can ask question in any language, ClimateQ&A is multi-lingual !
|
| 676 |
-
- ClimateQ&A integrates multiple sources (IPCC and IPBES, … ) to cover various aspects of environmental science, such as climate change and biodiversity. See all sources used below.
|
| 677 |
-
"""
|
| 678 |
-
)
|
| 679 |
-
with gr.Column(scale=1):
|
| 680 |
-
gr.Markdown(
|
| 681 |
-
"""
|
| 682 |
-
### ⚠️ Limitations
|
| 683 |
-
<div class="warning-box">
|
| 684 |
-
<ul>
|
| 685 |
-
<li>Please note that, like any AI, the model may occasionally generate an inaccurate or imprecise answer. Always refer to the provided sources to verify the validity of the information given. If you find any issues with the response, kindly provide feedback to help improve the system.</li>
|
| 686 |
-
<li>ClimateQ&A is specifically designed for climate-related inquiries. If you ask a non-environmental question, the chatbot will politely remind you that its focus is on climate and environmental issues.</li>
|
| 687 |
-
</div>
|
| 688 |
-
"""
|
| 689 |
-
)
|
| 690 |
-
|
| 691 |
-
|
| 692 |
-
with gr.Tab("📧 Contact, feedback and feature requests"):
|
| 693 |
-
gr.Markdown(
|
| 694 |
-
"""
|
| 695 |
-
|
| 696 |
-
🤞 For any question or press request, contact Théo Alves Da Costa at <b>[email protected]</b>
|
| 697 |
-
|
| 698 |
-
- ClimateQ&A welcomes community contributions. To participate, head over to the Community Tab and create a "New Discussion" to ask questions and share your insights.
|
| 699 |
-
- Provide feedback through email, letting us know which insights you found accurate, useful, or not. Your input will help us improve the platform.
|
| 700 |
-
- Only a few sources (see below) are integrated (all IPCC, IPBES), if you are a climate science researcher and net to sift through another report, please let us know.
|
| 701 |
-
|
| 702 |
-
*This tool has been developed by the R&D lab at **Ekimetrics** (Jean Lelong, Nina Achache, Gabriel Olympie, Nicolas Chesneau, Natalia De la Calzada, Théo Alves Da Costa)*
|
| 703 |
-
"""
|
| 704 |
-
)
|
| 705 |
-
# with gr.Row():
|
| 706 |
-
# with gr.Column(scale=1):
|
| 707 |
-
# gr.Markdown("### Feedbacks")
|
| 708 |
-
# feedback = gr.Textbox(label="Write your feedback here")
|
| 709 |
-
# feedback_output = gr.Textbox(label="Submit status")
|
| 710 |
-
# feedback_save = gr.Button(value="submit feedback")
|
| 711 |
-
# feedback_save.click(
|
| 712 |
-
# save_feedback,
|
| 713 |
-
# inputs=[feedback, user_id_state],
|
| 714 |
-
# outputs=feedback_output,
|
| 715 |
-
# )
|
| 716 |
-
# gr.Markdown(
|
| 717 |
-
# "If you need us to ask another climate science report or ask any question, contact us at <b>[email protected]</b>"
|
| 718 |
-
# )
|
| 719 |
-
|
| 720 |
-
# with gr.Column(scale=1):
|
| 721 |
-
# gr.Markdown("### OpenAI API")
|
| 722 |
-
# gr.Markdown(
|
| 723 |
-
# "To make climate science accessible to a wider audience, we have opened our own OpenAI API key with a monthly cap of $1000. If you already have an API key, please use it to help conserve bandwidth for others."
|
| 724 |
-
# )
|
| 725 |
-
# openai_api_key_textbox = gr.Textbox(
|
| 726 |
-
# placeholder="Paste your OpenAI API key (sk-...) and hit Enter",
|
| 727 |
-
# show_label=False,
|
| 728 |
-
# lines=1,
|
| 729 |
-
# type="password",
|
| 730 |
-
# )
|
| 731 |
-
# openai_api_key_textbox.change(set_openai_api_key, inputs=[openai_api_key_textbox])
|
| 732 |
-
# openai_api_key_textbox.submit(set_openai_api_key, inputs=[openai_api_key_textbox])
|
| 733 |
-
|
| 734 |
-
with gr.Tab("📚 Sources",elem_classes = "max-height"):
|
| 735 |
-
gr.Markdown("""
|
| 736 |
-
| Source | Report | URL | Number of pages | Release date |
|
| 737 |
-
| --- | --- | --- | --- | --- |
|
| 738 |
-
IPCC | Summary for Policymakers. In: Climate Change 2021: The Physical Science Basis. Contribution of the WGI to the AR6 of the IPCC. | https://www.ipcc.ch/report/ar6/wg1/downloads/report/IPCC_AR6_WGI_SPM.pdf | 32 | 2021
|
| 739 |
-
IPCC | Full Report. In: Climate Change 2021: The Physical Science Basis. Contribution of the WGI to the AR6 of the IPCC. | https://report.ipcc.ch/ar6/wg1/IPCC_AR6_WGI_FullReport.pdf | 2409 | 2021
|
| 740 |
-
IPCC | Technical Summary. In: Climate Change 2021: The Physical Science Basis. Contribution of the WGI to the AR6 of the IPCC. | https://www.ipcc.ch/report/ar6/wg1/downloads/report/IPCC_AR6_WGI_TS.pdf | 112 | 2021
|
| 741 |
-
IPCC | Summary for Policymakers. In: Climate Change 2022: Impacts, Adaptation and Vulnerability. Contribution of the WGII to the AR6 of the IPCC. | https://www.ipcc.ch/report/ar6/wg2/downloads/report/IPCC_AR6_WGII_SummaryForPolicymakers.pdf | 34 | 2022
|
| 742 |
-
IPCC | Technical Summary. In: Climate Change 2022: Impacts, Adaptation and Vulnerability. Contribution of the WGII to the AR6 of the IPCC. | https://www.ipcc.ch/report/ar6/wg2/downloads/report/IPCC_AR6_WGII_TechnicalSummary.pdf | 84 | 2022
|
| 743 |
-
IPCC | Full Report. In: Climate Change 2022: Impacts, Adaptation and Vulnerability. Contribution of the WGII to the AR6 of the IPCC. | https://report.ipcc.ch/ar6/wg2/IPCC_AR6_WGII_FullReport.pdf | 3068 | 2022
|
| 744 |
-
IPCC | Summary for Policymakers. In: Climate Change 2022: Mitigation of Climate Change. Contribution of the WGIII to the AR6 of the IPCC. | https://www.ipcc.ch/report/ar6/wg3/downloads/report/IPCC_AR6_WGIII_SummaryForPolicymakers.pdf | 50 | 2022
|
| 745 |
-
IPCC | Technical Summary. In: Climate Change 2022: Mitigation of Climate Change. Contribution of the WGIII to the AR6 of the IPCC. | https://www.ipcc.ch/report/ar6/wg3/downloads/report/IPCC_AR6_WGIII_TechnicalSummary.pdf | 102 | 2022
|
| 746 |
-
IPCC | Full Report. In: Climate Change 2022: Mitigation of Climate Change. Contribution of the WGIII to the AR6 of the IPCC. | https://www.ipcc.ch/report/ar6/wg3/downloads/report/IPCC_AR6_WGIII_FullReport.pdf | 2258 | 2022
|
| 747 |
-
IPCC | Summary for Policymakers. In: Global Warming of 1.5°C. An IPCC Special Report on the impacts of global warming of 1.5°C above pre-industrial levels and related global greenhouse gas emission pathways, in the context of strengthening the global response to the threat of climate change, sustainable development, and efforts to eradicate poverty. | https://www.ipcc.ch/site/assets/uploads/sites/2/2022/06/SPM_version_report_LR.pdf | 24 | 2018
|
| 748 |
-
IPCC | Summary for Policymakers. In: Climate Change and Land: an IPCC special report on climate change, desertification, land degradation, sustainable land management, food security, and greenhouse gas fluxes in terrestrial ecosystems. | https://www.ipcc.ch/site/assets/uploads/sites/4/2022/11/SRCCL_SPM.pdf | 36 | 2019
|
| 749 |
-
IPCC | Summary for Policymakers. In: IPCC Special Report on the Ocean and Cryosphere in a Changing Climate. | https://www.ipcc.ch/site/assets/uploads/sites/3/2022/03/01_SROCC_SPM_FINAL.pdf | 36 | 2019
|
| 750 |
-
IPCC | Technical Summary. In: IPCC Special Report on the Ocean and Cryosphere in a Changing Climate. | https://www.ipcc.ch/site/assets/uploads/sites/3/2022/03/02_SROCC_TS_FINAL.pdf | 34 | 2019
|
| 751 |
-
IPCC | Chapter 1 - Framing and Context of the Report. In: IPCC Special Report on the Ocean and Cryosphere in a Changing Climate. | https://www.ipcc.ch/site/assets/uploads/sites/3/2022/03/03_SROCC_Ch01_FINAL.pdf | 60 | 2019
|
| 752 |
-
IPCC | Chapter 2 - High Mountain Areas. In: IPCC Special Report on the Ocean and Cryosphere in a Changing Climate. | https://www.ipcc.ch/site/assets/uploads/sites/3/2022/03/04_SROCC_Ch02_FINAL.pdf | 72 | 2019
|
| 753 |
-
IPCC | Chapter 3 - Polar Regions. In: IPCC Special Report on the Ocean and Cryosphere in a Changing Climate. | https://www.ipcc.ch/site/assets/uploads/sites/3/2022/03/05_SROCC_Ch03_FINAL.pdf | 118 | 2019
|
| 754 |
-
IPCC | Chapter 4 - Sea Level Rise and Implications for Low-Lying Islands, Coasts and Communities. In: IPCC Special Report on the Ocean and Cryosphere in a Changing Climate. | https://www.ipcc.ch/site/assets/uploads/sites/3/2022/03/06_SROCC_Ch04_FINAL.pdf | 126 | 2019
|
| 755 |
-
IPCC | Chapter 5 - Changing Ocean, Marine Ecosystems, and Dependent Communities. In: IPCC Special Report on the Ocean and Cryosphere in a Changing Climate. | https://www.ipcc.ch/site/assets/uploads/sites/3/2022/03/07_SROCC_Ch05_FINAL.pdf | 142 | 2019
|
| 756 |
-
IPCC | Chapter 6 - Extremes, Abrupt Changes and Managing Risk. In: IPCC Special Report on the Ocean and Cryosphere in a Changing Climate. | https://www.ipcc.ch/site/assets/uploads/sites/3/2022/03/08_SROCC_Ch06_FINAL.pdf | 68 | 2019
|
| 757 |
-
IPCC | Cross-Chapter Box 9: Integrative Cross-Chapter Box on Low-Lying Islands and Coasts. In: IPCC Special Report on the Ocean and Cryosphere in a Changing Climate. | https://www.ipcc.ch/site/assets/uploads/sites/3/2019/11/11_SROCC_CCB9-LLIC_FINAL.pdf | 18 | 2019
|
| 758 |
-
IPCC | Annex I: Glossary [Weyer, N.M. (ed.)]. In: IPCC Special Report on the Ocean and Cryosphere in a Changing Climate. | https://www.ipcc.ch/site/assets/uploads/sites/3/2022/03/10_SROCC_AnnexI-Glossary_FINAL.pdf | 28 | 2019
|
| 759 |
-
IPBES | Full Report. Global assessment report on biodiversity and ecosystem services of the IPBES. | https://zenodo.org/record/6417333/files/202206_IPBES%20GLOBAL%20REPORT_FULL_DIGITAL_MARCH%202022.pdf | 1148 | 2019
|
| 760 |
-
IPBES | Summary for Policymakers. Global assessment report on biodiversity and ecosystem services of the IPBES (Version 1). | https://zenodo.org/record/3553579/files/ipbes_global_assessment_report_summary_for_policymakers.pdf | 60 | 2019
|
| 761 |
-
IPBES | Full Report. Thematic assessment of the sustainable use of wild species of the IPBES. | https://zenodo.org/record/7755805/files/IPBES_ASSESSMENT_SUWS_FULL_REPORT.pdf | 1008 | 2022
|
| 762 |
-
IPBES | Summary for Policymakers. Summary for policymakers of the thematic assessment of the sustainable use of wild species of the IPBES. | https://zenodo.org/record/7411847/files/EN_SPM_SUSTAINABLE%20USE%20OF%20WILD%20SPECIES.pdf | 44 | 2022
|
| 763 |
-
IPBES | Full Report. Regional Assessment Report on Biodiversity and Ecosystem Services for Africa. | https://zenodo.org/record/3236178/files/ipbes_assessment_report_africa_EN.pdf | 494 | 2018
|
| 764 |
-
IPBES | Summary for Policymakers. Regional Assessment Report on Biodiversity and Ecosystem Services for Africa. | https://zenodo.org/record/3236189/files/ipbes_assessment_spm_africa_EN.pdf | 52 | 2018
|
| 765 |
-
IPBES | Full Report. Regional Assessment Report on Biodiversity and Ecosystem Services for the Americas. | https://zenodo.org/record/3236253/files/ipbes_assessment_report_americas_EN.pdf | 660 | 2018
|
| 766 |
-
IPBES | Summary for Policymakers. Regional Assessment Report on Biodiversity and Ecosystem Services for the Americas. | https://zenodo.org/record/3236292/files/ipbes_assessment_spm_americas_EN.pdf | 44 | 2018
|
| 767 |
-
IPBES | Full Report. Regional Assessment Report on Biodiversity and Ecosystem Services for Asia and the Pacific. | https://zenodo.org/record/3237374/files/ipbes_assessment_report_ap_EN.pdf | 616 | 2018
|
| 768 |
-
IPBES | Summary for Policymakers. Regional Assessment Report on Biodiversity and Ecosystem Services for Asia and the Pacific. | https://zenodo.org/record/3237383/files/ipbes_assessment_spm_ap_EN.pdf | 44 | 2018
|
| 769 |
-
IPBES | Full Report. Regional Assessment Report on Biodiversity and Ecosystem Services for Europe and Central Asia. | https://zenodo.org/record/3237429/files/ipbes_assessment_report_eca_EN.pdf | 894 | 2018
|
| 770 |
-
IPBES | Summary for Policymakers. Regional Assessment Report on Biodiversity and Ecosystem Services for Europe and Central Asia. | https://zenodo.org/record/3237468/files/ipbes_assessment_spm_eca_EN.pdf | 52 | 2018
|
| 771 |
-
IPBES | Full Report. Assessment Report on Land Degradation and Restoration. | https://zenodo.org/record/3237393/files/ipbes_assessment_report_ldra_EN.pdf | 748 | 2018
|
| 772 |
-
IPBES | Summary for Policymakers. Assessment Report on Land Degradation and Restoration. | https://zenodo.org/record/3237393/files/ipbes_assessment_report_ldra_EN.pdf | 48 | 2018
|
| 773 |
-
""")
|
| 774 |
-
|
| 775 |
-
with gr.Tab("🛢️ Carbon Footprint"):
|
| 776 |
-
gr.Markdown("""
|
| 777 |
-
|
| 778 |
-
Carbon emissions were measured during the development and inference process using CodeCarbon [https://github.com/mlco2/codecarbon](https://github.com/mlco2/codecarbon)
|
| 779 |
-
|
| 780 |
-
| Phase | Description | Emissions | Source |
|
| 781 |
-
| --- | --- | --- | --- |
|
| 782 |
-
| Development | OCR and parsing all pdf documents with AI | 28gCO2e | CodeCarbon |
|
| 783 |
-
| Development | Question Answering development | 114gCO2e | CodeCarbon |
|
| 784 |
-
| Inference | Question Answering | ~0.102gCO2e / call | CodeCarbon |
|
| 785 |
-
| Inference | API call to turbo-GPT | ~0.38gCO2e / call | https://medium.com/@chrispointon/the-carbon-footprint-of-chatgpt-e1bc14e4cc2a |
|
| 786 |
-
|
| 787 |
-
Carbon Emissions are **relatively low but not negligible** compared to other usages: one question asked to ClimateQ&A is around 0.482gCO2e - equivalent to 2.2m by car (https://datagir.ademe.fr/apps/impact-co2/)
|
| 788 |
-
Or around 2 to 4 times more than a typical Google search.
|
| 789 |
-
"""
|
| 790 |
-
)
|
| 791 |
-
|
| 792 |
-
with gr.Tab("🪄 Changelog"):
|
| 793 |
-
gr.Markdown("""
|
| 794 |
-
|
| 795 |
-
##### v1.1.0 - *2023-10-16*
|
| 796 |
-
- ClimateQ&A on Hugging Face is finally working again with all the new features !
|
| 797 |
-
- Switched all python code to langchain codebase for cleaner code, easier maintenance and future features
|
| 798 |
-
- Updated GPT model to August version
|
| 799 |
-
- Added streaming response to improve UX
|
| 800 |
-
- Created a custom Retriever chain to avoid calling the LLM if there is no documents retrieved
|
| 801 |
-
- Use of HuggingFace embed on https://climateqa.com to avoid demultiplying deployments
|
| 802 |
-
|
| 803 |
-
##### v1.0.0 - *2023-05-11*
|
| 804 |
-
- First version of clean interface on https://climateqa.com
|
| 805 |
-
- Add children mode on https://climateqa.com
|
| 806 |
-
- Add follow-up questions https://climateqa.com
|
| 807 |
-
"""
|
| 808 |
-
)
|
| 809 |
-
|
| 810 |
-
demo.queue(concurrency_count=16)
|
| 811 |
-
|
| 812 |
-
demo.launch()
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
spaces/Ekimetrics/climate-question-answering/climateqa/__init__.py
DELETED
|
File without changes
|
spaces/EuroPython2022/Zero-Shot-SQL-by-Bloom/README.md
DELETED
|
@@ -1,13 +0,0 @@
|
|
| 1 |
-
---
|
| 2 |
-
title: Zero Shot SQL By Bloom
|
| 3 |
-
emoji: 🌸
|
| 4 |
-
colorFrom: yellow
|
| 5 |
-
colorTo: gray
|
| 6 |
-
sdk: gradio
|
| 7 |
-
sdk_version: 3.0.24
|
| 8 |
-
app_file: app.py
|
| 9 |
-
pinned: false
|
| 10 |
-
license: gpl
|
| 11 |
-
---
|
| 12 |
-
|
| 13 |
-
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|